/


























































































































































































































































































































Text
Томас Эрл
Ваджид Хаттак
Пол Булер
ОСНОВЫ
BIG DATA
концепции, алгоритмы и технологии
«Этот текст обязателен
к прочтению для всех
в современном бизнесе»
- Peter Woodhull, CEO, Modus21
«Единственная книга, которая
четко описывает и связывает
концепции Big Data
с полезностью для бизнеса»
- Dr. Christopher Starr, PhD
«Просто это лучшая книга
о больших данных на рынке»
- Sam Roslam, Cascadian IT Group
«... один из самых современных
подходов, которые я видел
по основам больших данных»
- Joshua М. Davis, PhD
Balance
Business
Books
EFFICIENT
Information
Technologies
Thomas Erl,
Wajid Khattak,
Paul Buhler
Big Data Fundamentals
Concepts, Drivers & Techniques
PRENTICE
HALL
ServiceTech
Ot® PRESS
Томас Эрл,
Ваджид Хатта к,
Пол Булер
Основы Big Data
Концепции, алгоритмы и технологии
Balance
Business
Books
УДК 004.6
АЗЭ79
Настоящее печатное издание защищено авторским правом. Никакая часть
данной книги не может быть воспроизведена в какой бы то ни было форме без
письменного разрешения владельцев авторских прав. Прежде чем произвести
любое копирование, сохранение в поисковой системе, распространение
или передачу в любой форме или любыми средствами (электронными,
механическими, в виде записи или другими), следует получить разрешение
от издателя или, в соответствующих случаях, лицензию, предоставляющую
право копирования.
Права на перевод и печать получены ООО «Баланс Бизнес Букс» по соглашению
с издательством PRENTICE HALL (USA)
All rights reserved. No part of this book may be reproduced or transmitted in any form or
by any means, electronic or mechanical, including photocopying, recording or by any
information storage retrieval system, without permission from Pearson Education,Inc.
RUSSIAN language edition published by BALANCE BUSINESS BOOKS. Ltd., Copyright © 2018.
АЗ Э 79 Основи Big Data: Концепци, алгоритми та технолоп“|/Пер.з англ. Анаклия Гладуна;
За наук.ред. Опекая Найди. — Днпро: «Баланс Б1знес Букс», 2018. - 320 с.
«Основи Big Data: концепци, алгоритми та технолоп!» забезпечують прагматичне та
серйозне занурення у сферу великих даних. Популярний IT-автор Томас Ерл та його
команда чпко пояснюють ключов! концепци, теор1Ю та терм!нолопю великих даних,
а також фундаментальн! технологи та методи. Весь матер!ал книги тюструеться
прикладами з практики та численними просгими д!аграмами.
Книга издана при содействии Efficient Information Technologies.
ISBN 0134291077 Pearson Education, Inc. (USA) © 2016 Prentice Hall
ISBN 978-966-415-062-7 Баланс Бизнес Букс (Днепр)
© 2018 «Баланс Бизнес Буко
7
Вступительное слово
«В жизни все меняется быстро и живо», — озвучил когда-то
очевидную и простую вещь в «Мертвых душах» Николай Ва¬
сильевич Гоголь. Наверное, даже он не подозревал, насколько
быстро и живо будет меняться мир через каких-то двести лет.
Да что там двести! Полный демонтаж и перестройка челове¬
ческого сознания стремительными темпами происходит в
последние 10-15 лет. Мы переместились в виртуальный мир.
Образование, покупки, счета, личная жизнь... Неужели здесь
проходит большая часть нашего времени? И что за всем этим
стоит: неминуемый прогресс, выгода и расчет больших кор¬
пораций или стремление людей к удобству и максимально¬
му упрощению всех жизненно значимых процессов? Одно
известно точно: Интернет покорил мир, вовлек миллиарды
людей, технологий, приборов, машин. И объемы ежесекунд¬
но накапливаемой информации неумолимо возрастают.
Неудивительно, что такой глобальный процесс заинтриговал
ученых, которые нарекли всю эту вакханалию с неуемным
нагромождением данных Big Data. Для достоверности уточ¬
ним: термин «Big Data» впервые ввел аналитик Даг Ланей в
2001 году. В своей работе он писал: «Большие данные — это
огромный массив информации, который увеличивается с
перманентно возрастающей скоростью и имеет большое
разнообразие форматов. Это ценный ресурс, требующий
новаторских подходов анализа и обработки. А уж если пра¬
вильно извлечь из него пользу — появляются безграничные
возможности для оптимизации процессов и понимания их
сути». Другими словами, главная цель всех усилий в этом на¬
правлении — попытаться эффективно обрабатывать масси¬
вы разнородной информации и извлекать из них пользу.
Несколько лет назад сеть магазинов Target прославилась од¬
ним интересным случаем. Аналитики компании стали при¬
менять инновационные методы обработки данных о своих
8
покупателях. Информация о клиентах, которую они собира¬
ли, позволяла составлять такие прогнозы потребительского
поведения, которые со стороны выглядели почти как магия.
Target начала адаптировать машинное обучение для анализа
потребительского поведения. Алгоритмы анализировали, ка¬
ким образом и под воздействием каких факторов менялись
предпочтения клиентов, и делали соответствующие прогно¬
зы следующих покупок. На основании этих прогнозов компа¬
ния «подкидывала» в почтовый ящик клиентам специальные
предложения, которые должны были выстрелить в нужное
время и попасть в руки нужному человеку, угадав именно
его потребность. В начале 2012 года вспыхнул скандал: отец
12-летней девочки пожаловался руководству магазина на то,
что его дочери присылают информационные буклеты с то¬
варами для беременных женщин. А когда торговая сеть уже
принесла публичные извинения, выяснилось, что школьни¬
ца на самом деле оказалась беременной. Алгоритм «засек»
перемены в покупательском поведении девочки, которые
косвенно указывали на ее беременность. Так доморощенный
метод анализа хаотичной информации дал неожиданно точ¬
ный результат. Позже Target все же признали, что этот факт
был случайным совпадением. Но это вовсе не свидетельству¬
ет о ложности применяемых методов. Просто на том этапе
они были несовершенны и давали много осечек.
Данная книга более подробно расскажет о причинах возник¬
новения новых подходов к хранению и обработке данных с
учетом их растущих объемов и форматов, позволит читате¬
лям лучше понимать технические и технологические про¬
цессы, которые стоят у истоков больших данных.
Приятного прочтения!
Алексей Найда,
сооснователь и генеральный директор компании
«Эффективные информационные технологии»
Моей семье и друзьям.
— Томас Эрл
Я посвящаю эту книгу моим дочерям
Хади и Ареше, моей жене Наташе
и моим родителям.
— Ваджид Хаттак
Я благодарю свою жену и семью
за их терпение и за то, что мирились
с моей занятостью на протяжении
многих лет.
Я высоко ценю всех студентов и коллег,
которым я имел честь преподавать
и у которых я учился.
От Иоанна 3:16,2 от Петра 1:5-8
— Пол Булер,
доктор философии
10
Краткое содержание
Часть I
Основы больших данных
Глава 1 Понимание больших данных 25
Глава 2 Бизнес мотивация и стимулы для перехода
к обработке больших данных 61
Глава 3 Переход к большим данным и вопросы
планирования 85
Глава 4 Корпоративные технологии и Business
Intelligence для больших данных 125
Часть 11
Хранение и анализ больших данных
Глава 5 Концепции хранения больших данных 147
Глава 6 Концепции обработки больших данных 179
Глава 7 Технологии хранения больших данных 215
Глава 8 Основные методы анализа больших данных 261
11
Содержание
Благодарности 19
Сервис для читателей 20
Часть I
Основы больших данных
Глава 1
Понимание больших данных 25
Концепты и терминология 28
Наборы данных 28
Анализ данных 29
Аналитика данных 29
Дескриптивная аналитика 32
Диагностическая аналитика 32
Прогностическая аналитика 34
Прескриптивная аналитика 36
Business Intelligence (Bl) ► 37
Ключевые показатели эффективности (KPI) 38
Характеристики больших данных 39
Объем 40
Скорость 41
Многообразие 42
12
Достоверность 42
Ценность 43
Различные типы данных 44
Структурированные данные 46
Неструктурированные данные 46
Слабоструктурированные данные 47
Метаданные 48
История исследования конкретного случая 49
История компании 49
Техническая инфраструктура и среда автоматизации 50
Бизнес-цели и препятствия 52
Пример из практики 55
Идентификация характеристик данных 57
Объем 58
Скорость 58
Многообразие 59
Достоверность 59
Ценность 59
Идентификация типов данных 60
Глава 2
Бизнес-мотивация и стимулы
для перехода к обработке больших данных 61
Динамика рынка 63
Бизнес-архитектура 66
Управление бизнес-процессами 70
Информационно-коммуникационные технологии 72
Аналитика данных и наука о данных 73
Цифровизация 73
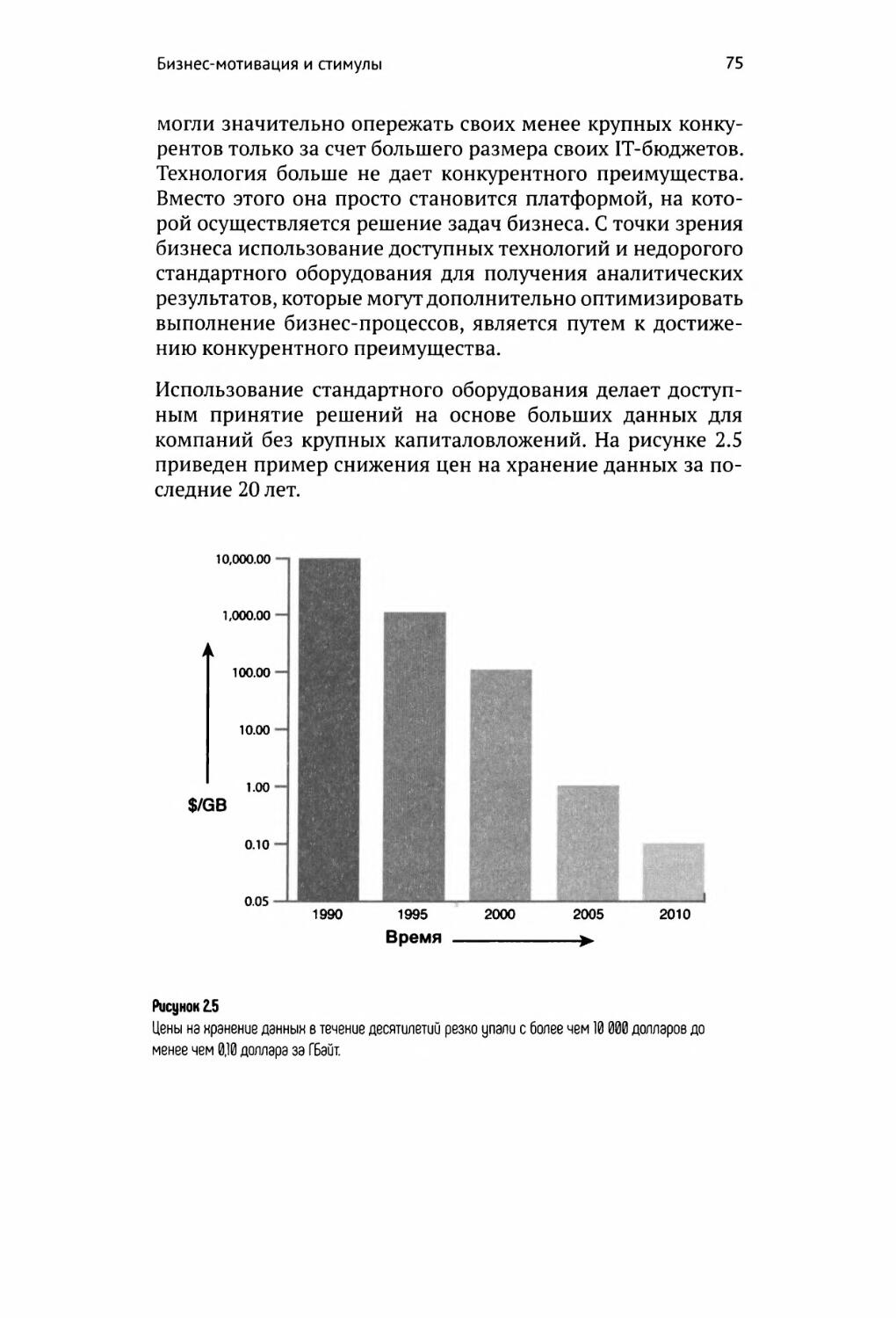
Доступные технологии и стандартные аппаратные средства 74
Социальные сети 76
Сообщества и устройства,
связанные коммуникационными сетями 76
13
Облачные вычисления 77
Интернет Всего (1оЕ) 79
Примеры из практики 81
Глава 3
Переход к большим данным
и вопросы планирования 85
Организационные предпосылки 88
Приобретение данных 88
Конфиденциальность 89
Безопасность 90
Происхождение 90
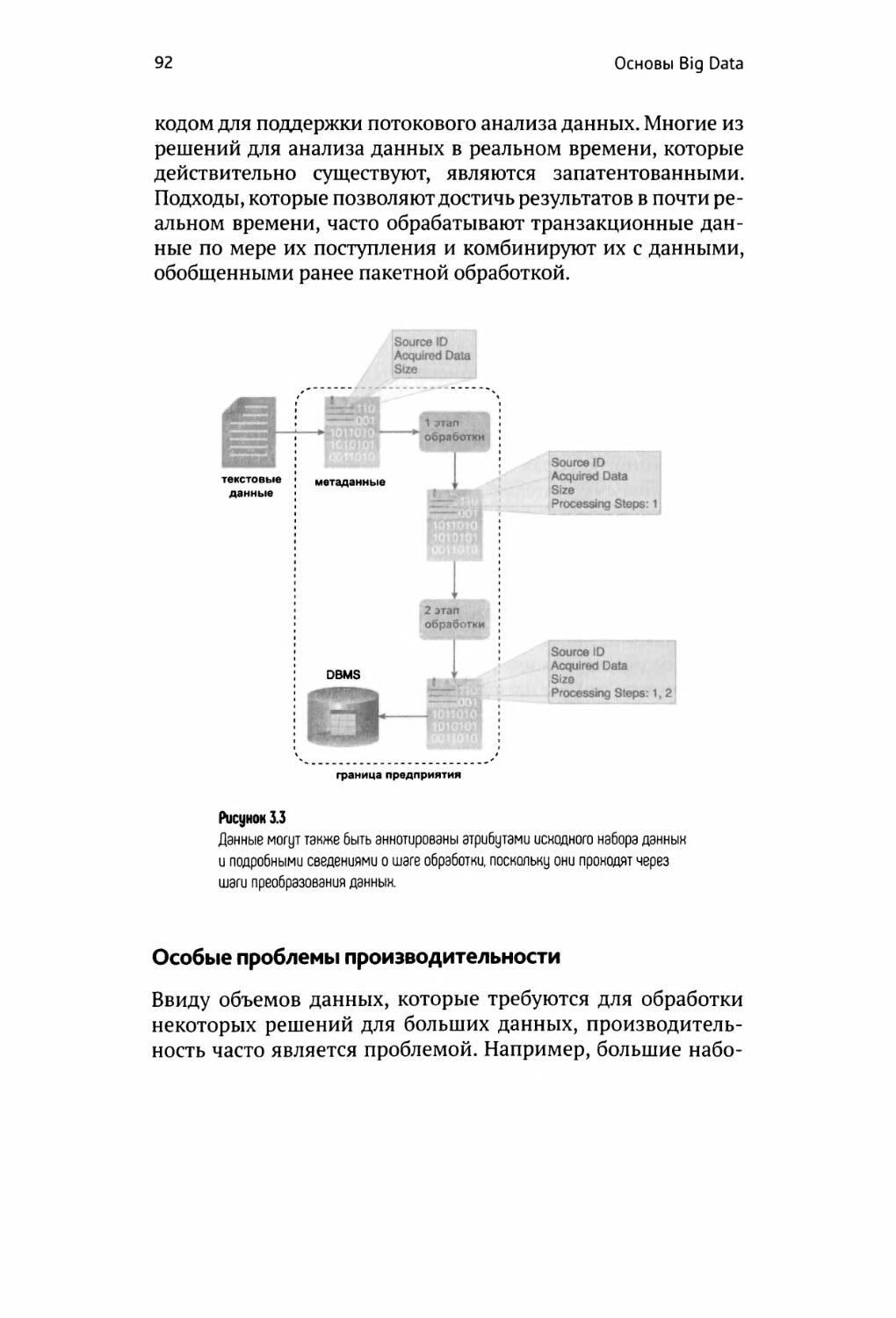
Ограничения поддержки в реальном времени 91
Особые проблемы производительности 92
Особые требования к руководству 93
Методология 94
Облака 94
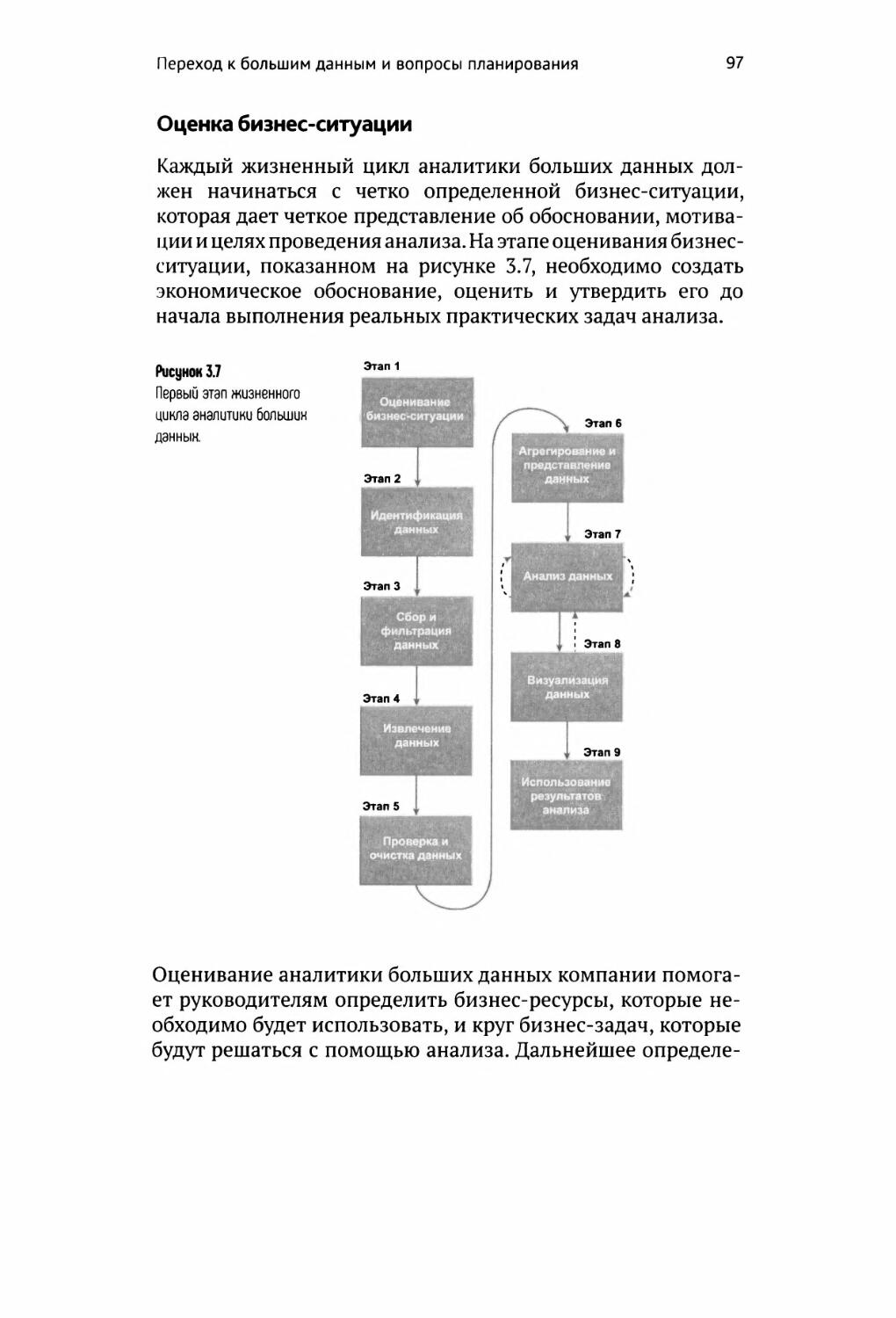
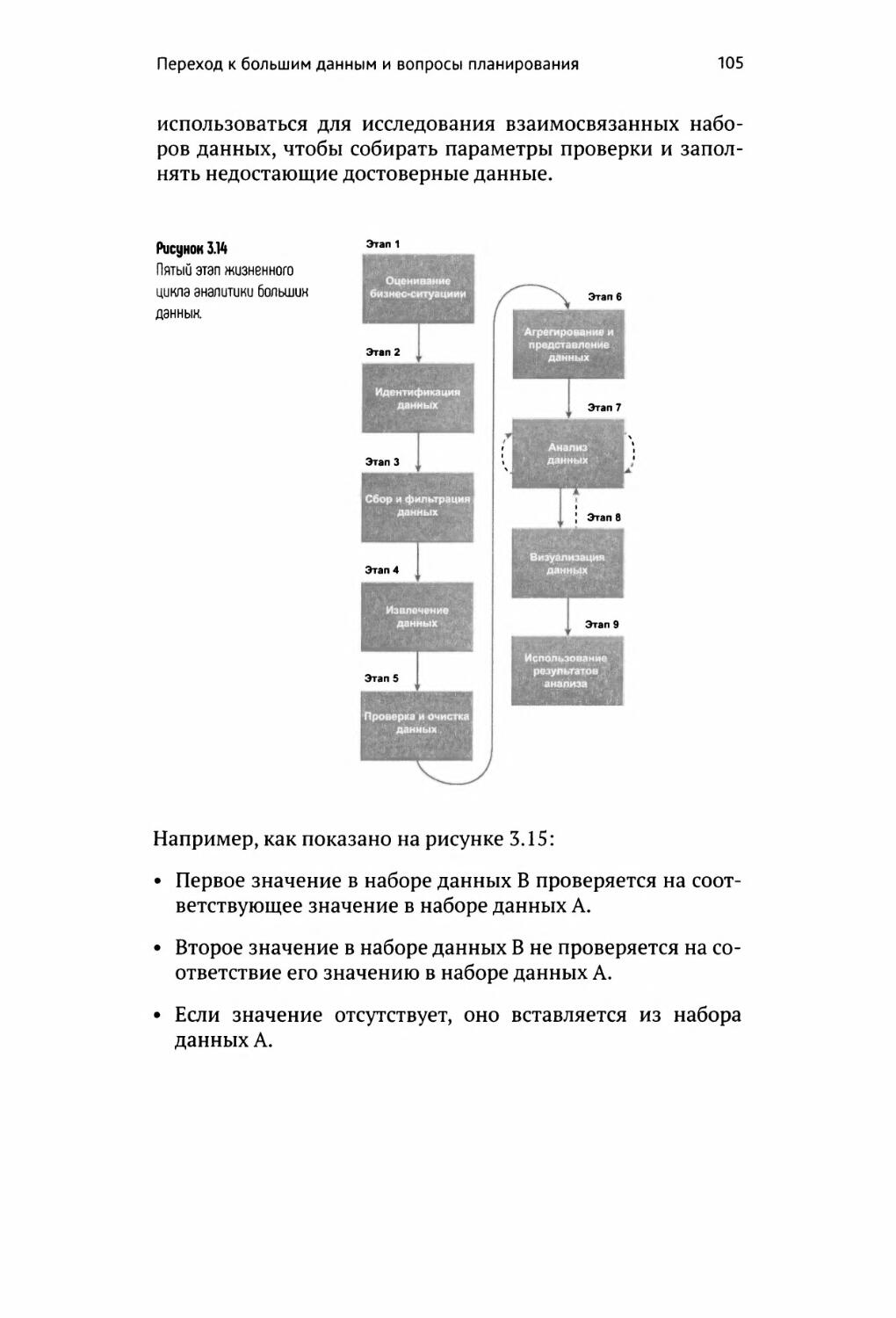
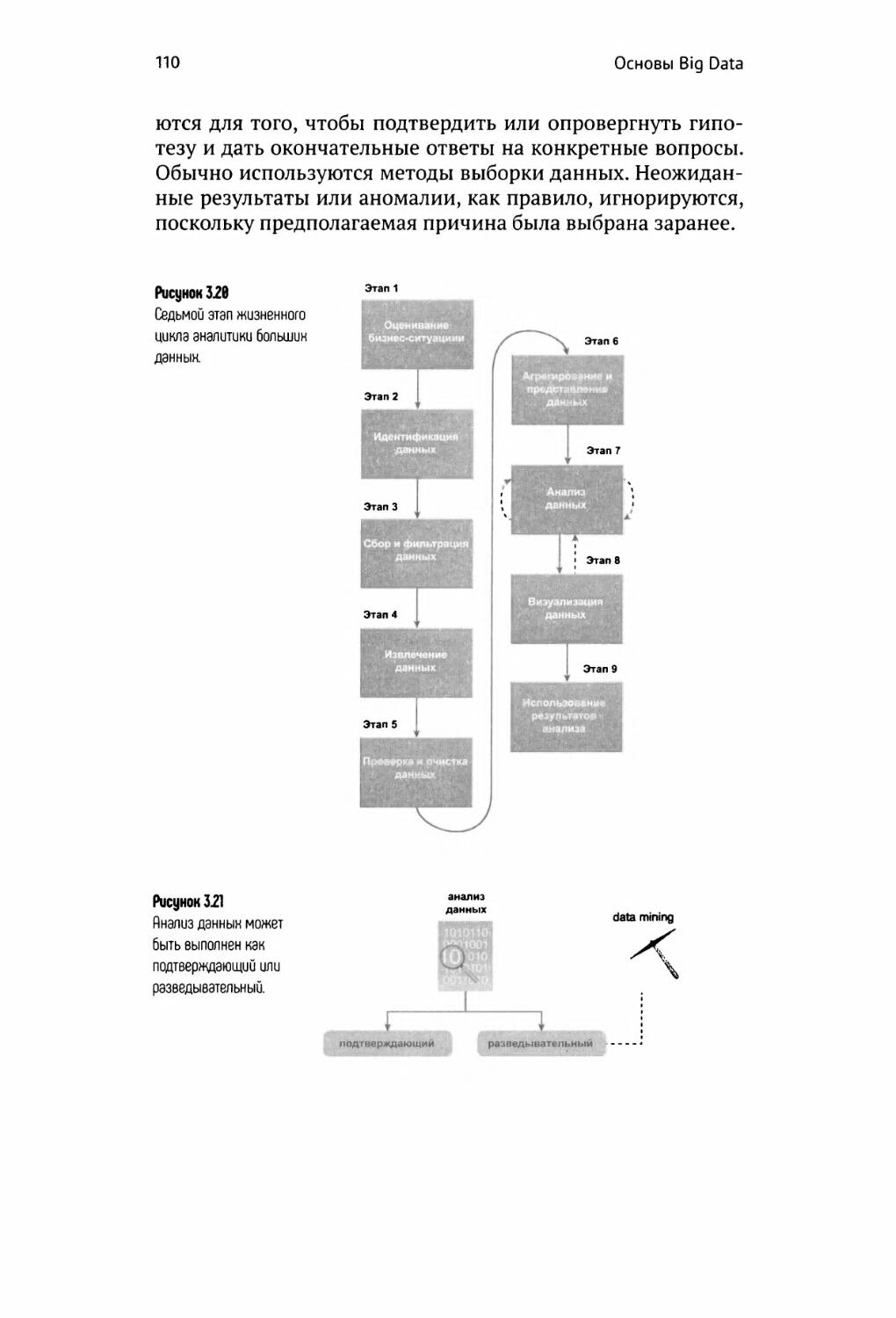
Жизненный цикл аналитики больших данных 95
Оценка бизнес-ситуации 97
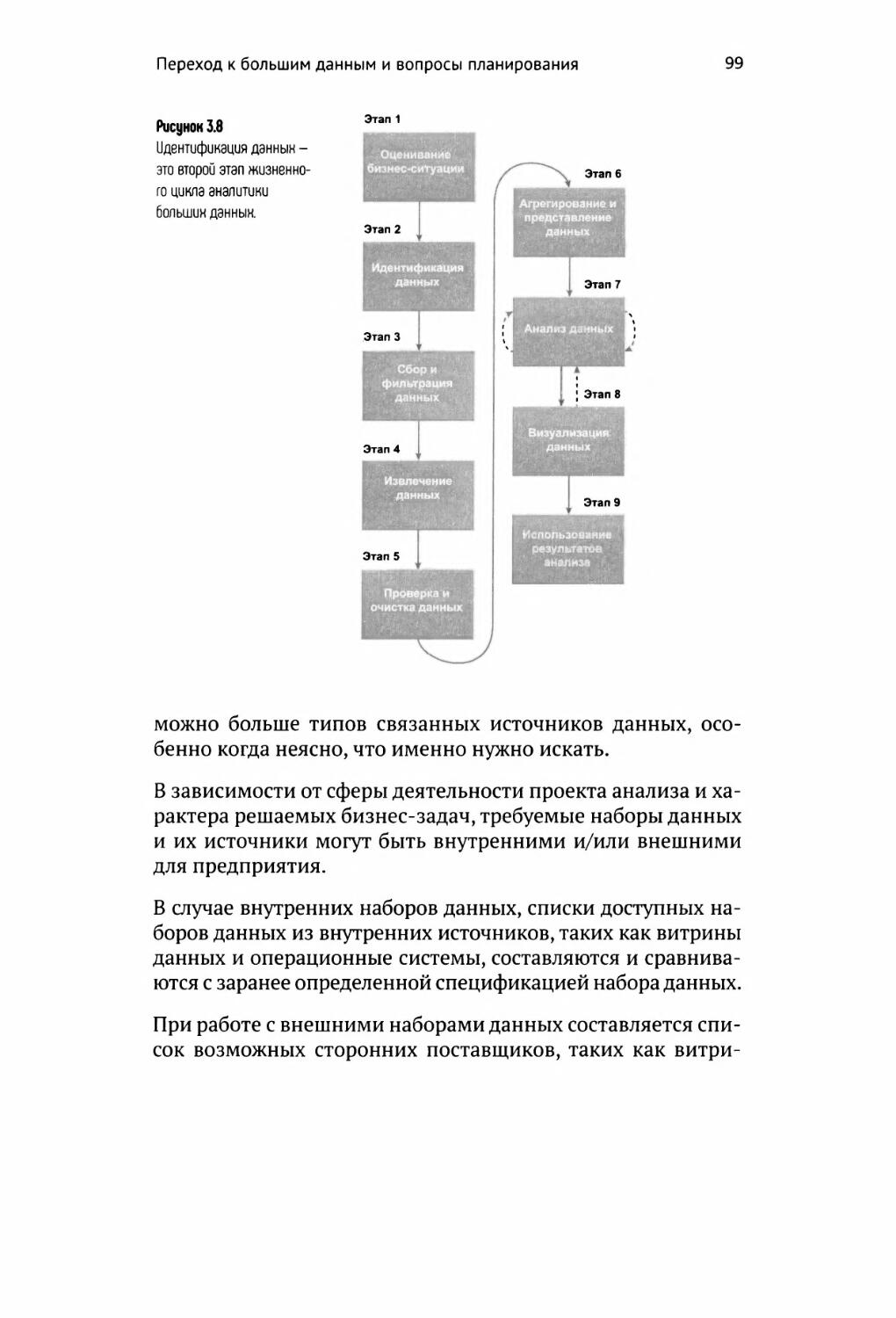
Идентификация данных 98
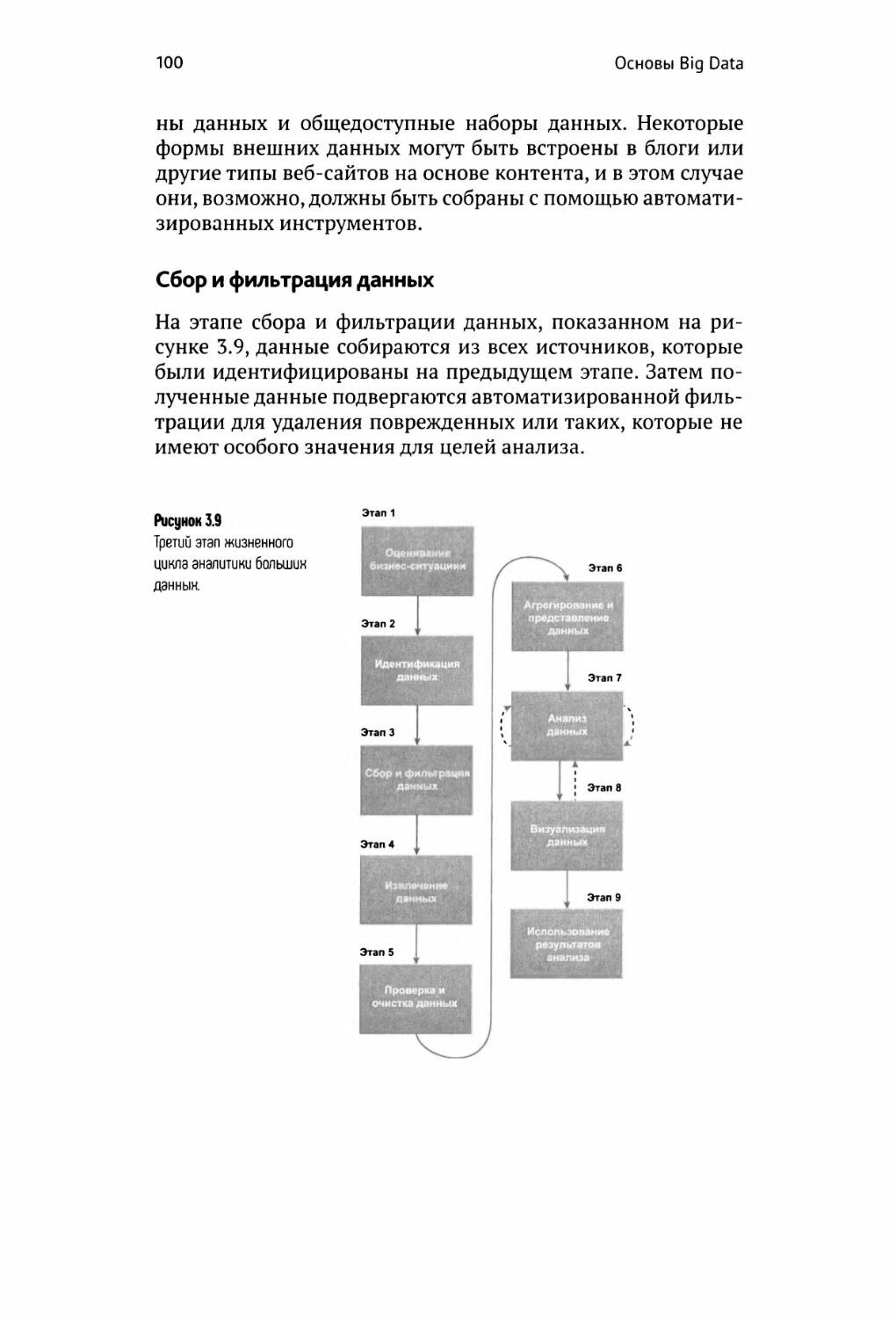
Сбор и фильтрация данных 100
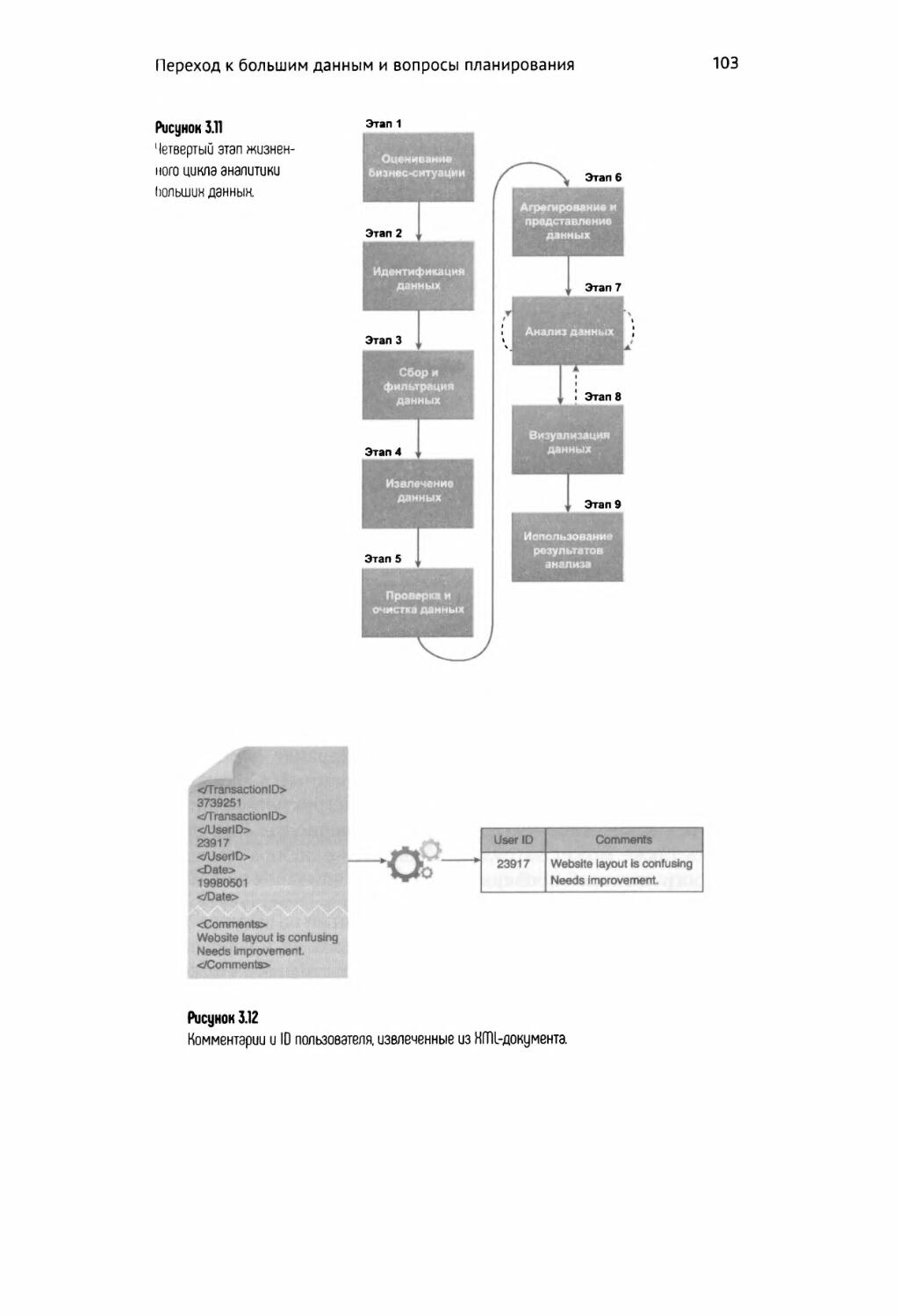
Извлечение данных 102
Проверка и очистка данных 104
Агрегирование и представление данных 106
Анализ данных 109
Визуализация данных 111
Использование результатов анализа 112
Пример из практики » 114
Жизненный цикл аналитики больших данных 118
Оценка бизнес-ситуации 118
Идентификация данных 120
Сбор и фильтрация данных 120
Извлечение данных 121
14
Проверка и очистка данных 121
Агрегирование и представление данных 122
Анализ данных 122
Визуализация данных 123
Использование результатов анализа 123
Глава 4
Корпоративные технологии
и Business Intelligence для больших данных 125
Обработка транзакций в реальном времени (OLTP) 127
Аналитическая обработка в реальном времени (OLAP) 128
Извлечение, преобразование и загрузка (ETL) 129
Хранилища данных 130
Витрины данных 131
Традиционный BI 131
Специализированные отчеты 132
Информационные панели 132
BI для больших данных 133
Традиционная визуализация данных 136
Визуализация данных при обработке больших данных 136
Пример из практики 138
Корпоративные технологии 138
Business Intelligence для больших данных 139
Часть II: Хранение и анализ больших данных
Глава 5
Концепции хранения больших данных 147
Кластеры 149
Файловые системы и распределенные файловые системы 150
NoSQL 151
Шардинг 152
15
Репликация 154
Режим репликации «ведущий-ведомый» 155
Режим репликации «одноранговый» 158
Шардинг и репликация 161
Объединение шардинга и репликации
в режиме «ведущий-ведомый» 162
Объединение шардинга и репликации
в режиме «одноранговый» 164
Теорема САР 165
ACID 168
BASE 173
Пример из практики 176
Глава 6
Концепции обработки больших данных 173
Параллельная обработка данных 181
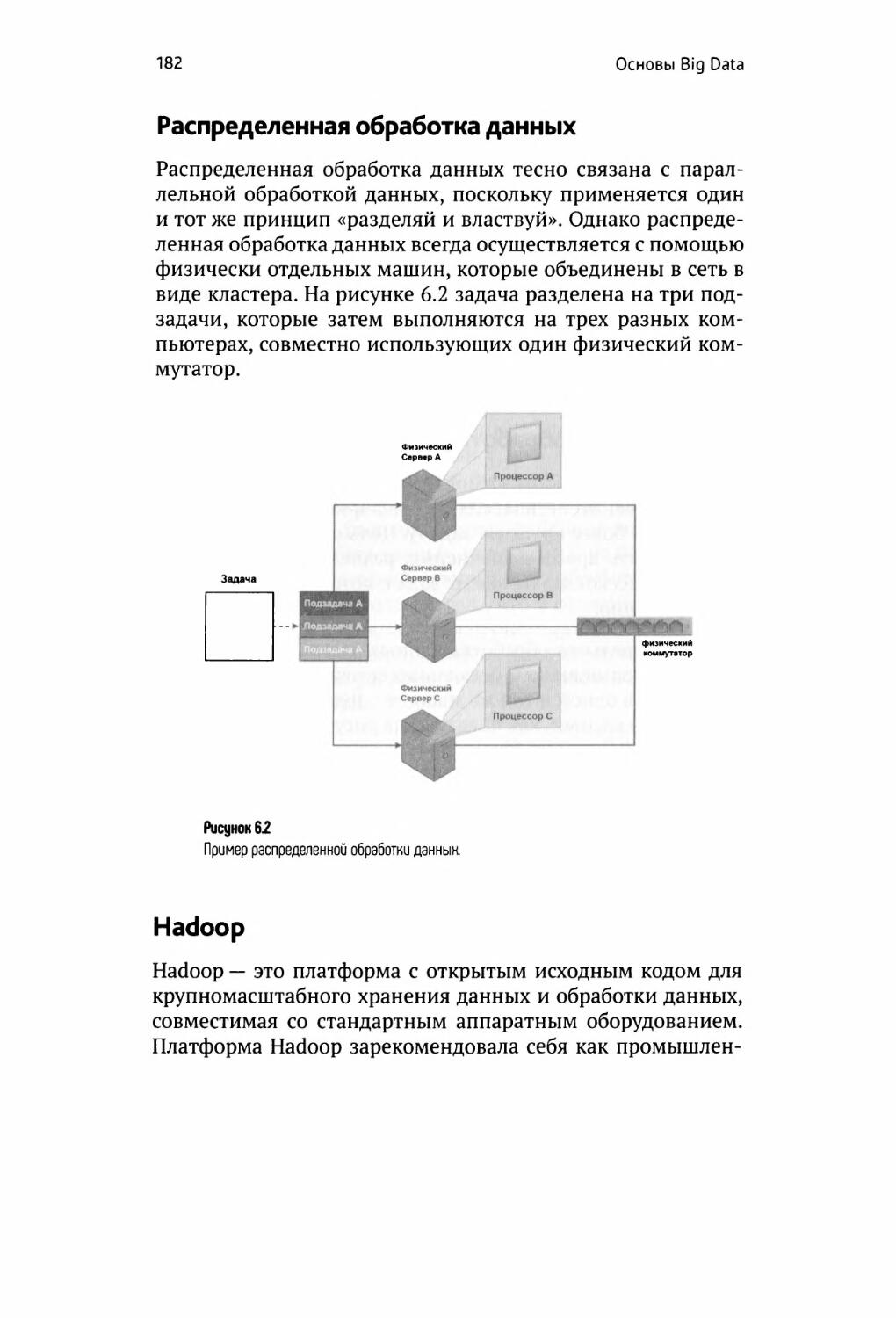
Распределенная обработка данных 182
Hadoop 182
Обработка рабочих заданий 183
Пакетная обработка 184
Транзакционная обработка 185
Кластер 186
Обработка в пакетном режиме 187
Пакетная обработка с помощью MapReduce 187
Задачи Мар и Reduce 189
Мар 189
Объединение 191
Разбиение , 192
Перетасовка и сортировка 194
Reduce 195
Простой пример MapReduce 196
Интерпретация алгоритмов MapReduce 197
Обработка в режиме реального времени 201
16
Объем, согласованность, скорость (ОСС) 202
Обработка потока событий 207
Обработка сложных событий 207
Обработка больших данных
в режиме реального времени и ОСС 208
Обработка больших данных
в реальном времени и MapReduce 209
Пример из практики 210
Обработка рабочих заданий 211
Обработка в пакетном режиме 211
Обработка в реальном времени 213
Глава 7
Технологии хранения больших данных 215
Дисковые устройства хранения 218
Распределенные файловые системы 218
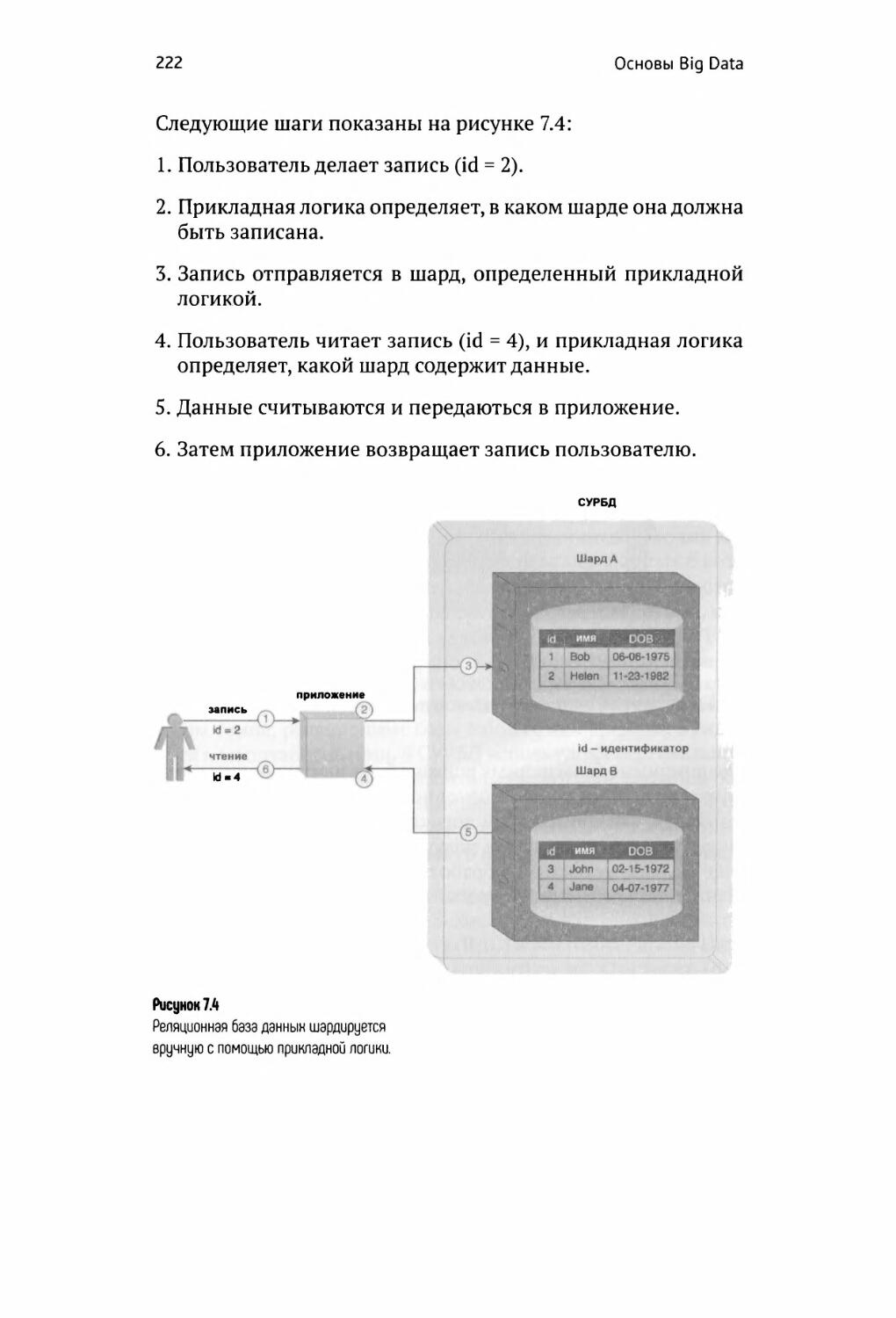
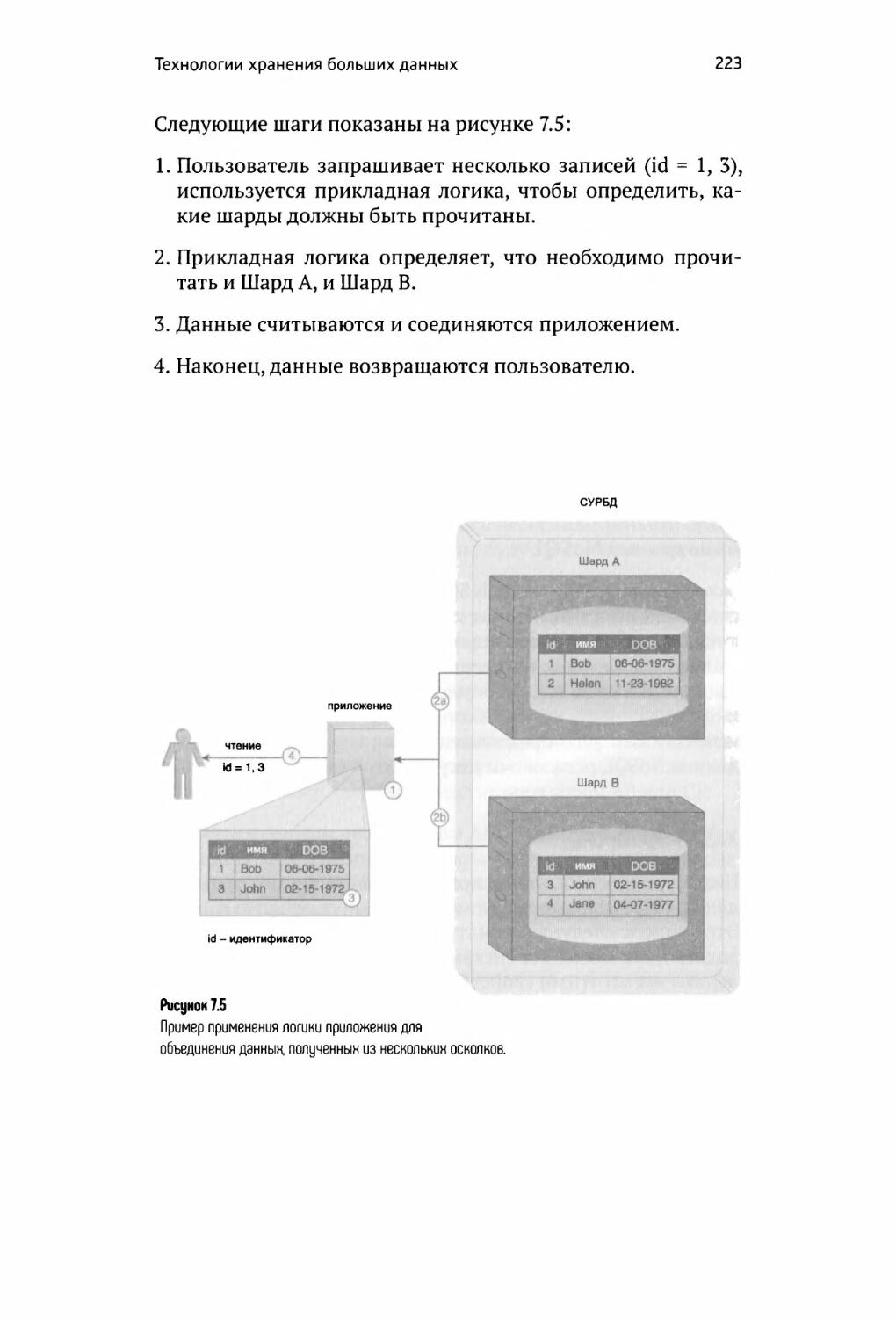
СУРБД баз данных 220
Базы данных NoSQL 224
Характеристики 224
Логическое обоснование 226
Объем 227
Скорость 227
Многообразие 227
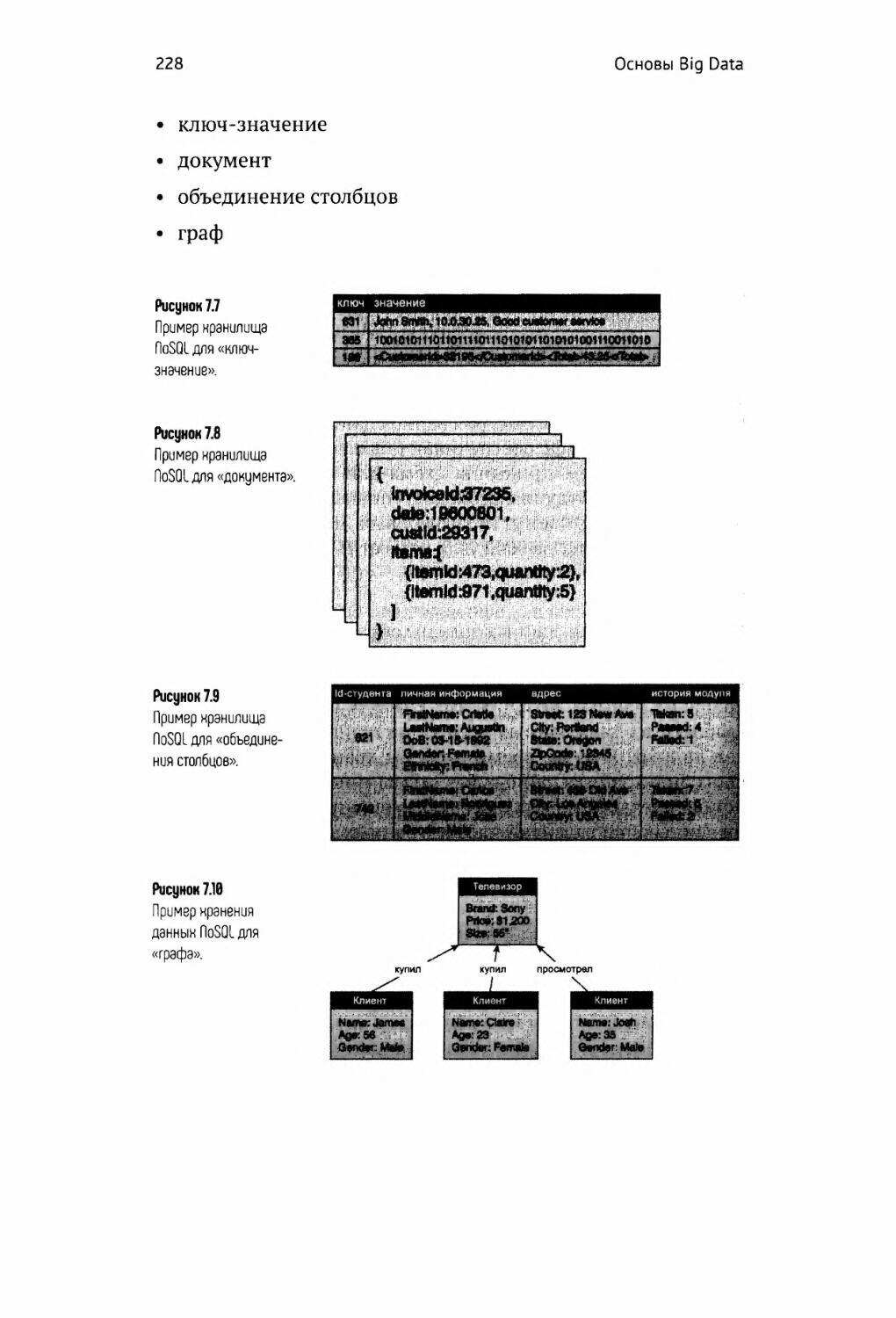
Типы 227
Ключ-значение 229
Документ 231
Объединение столбцов 233
Граф 236
Базы данных NewSQL 238
Системы хранения в оперативной памяти 239
In-Memory Data Grid 244
Сквозное чтение 248
Сквозная запись 249
17
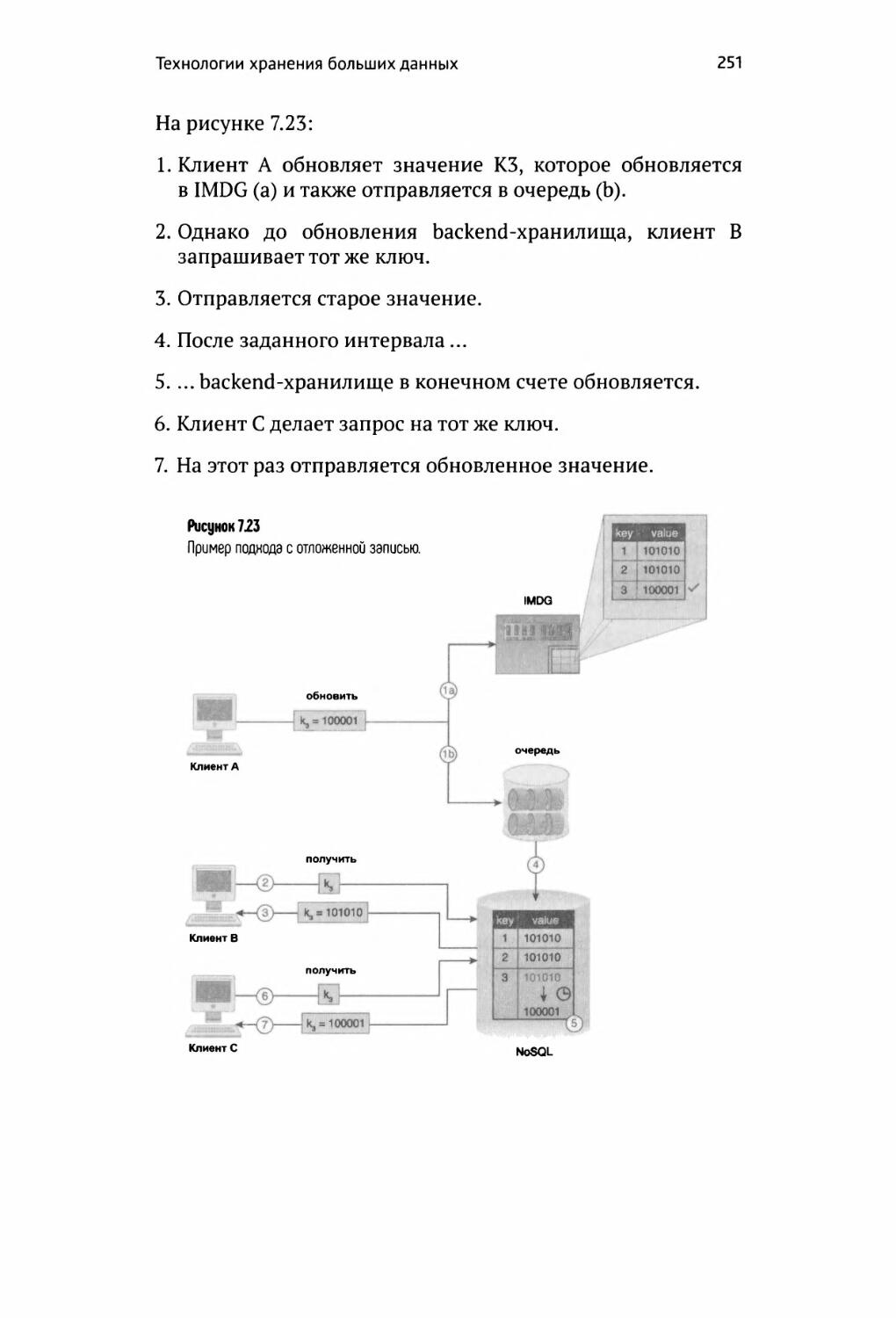
Отложенная запись 250
Обновление 252
In-Memory Databases 254
Пример из практики 258
Глава 8
Основные методы анализа больших данных 261
Количественный анализ 264
Качественный анализ 265
Data Mining 265
Статистический анализ 266
А/В-тестирование 267
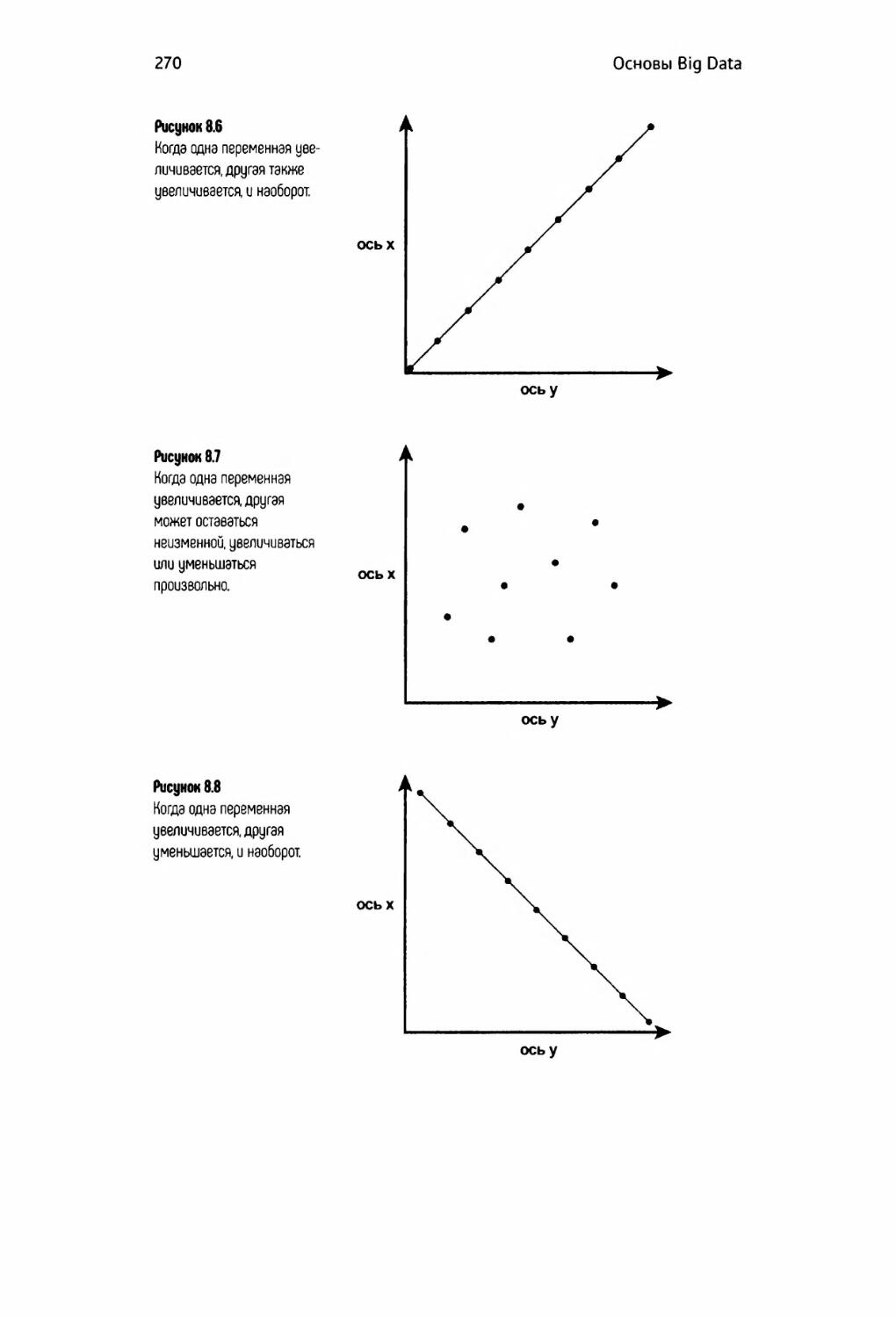
Корреляция 268
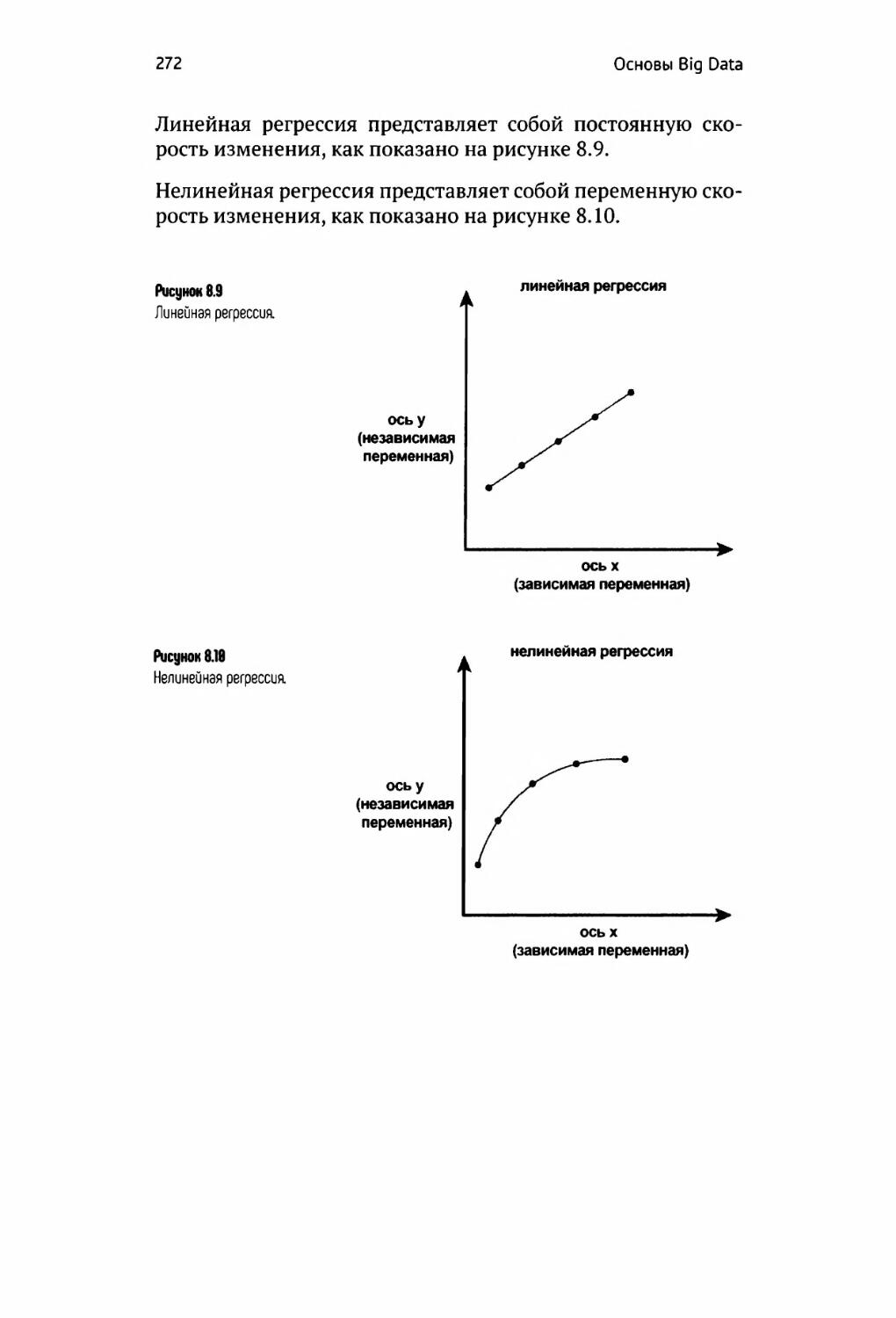
Регрессия 271
Машинное обучение 273
Классификация (машинное обучение с учителем) 274
Кластеризация (машинное обучение без учителя) 276
Обнаружение выбросов 276
Фильтрация 278
Семантический анализ 280
Обработка естественного языка 281
Обработка текста 282
Анализ эмоциональной окраски высказываний 284
Визуальный анализ 285
Цветные карты 286
Временные ряды 288
Сетевые графы 289
Сопоставление пространственных данных 291
Примеры из практики 293
Корреляция 294
Регрессия 294
Временной ряд 294
Кластеризация 295
18
Классификация 295
Приложение А
Заключение на основе примеров
ИЗ ПраКТИКИ 297
Об авторах 301
Томас Эрл 301
Ваджид Хаттак 301
Пол Бюлер 302
Предметный указатель 303
19
Благодарности
В алфавитном порядке по фамилии:
• Allen Afuah, Ross School of Business, University of Michigan
• Thomas Davenport, Babson College
• Hugh Dubberly, Dubberly Design Office
• Joe Gollner, Gnostyx Research Inc.
• Dominic Greenwood, Whitestein Technologies
• Gareth Morgan, The Schulich School of Business, York
University
• Peter Morville, Semantic Studios
• Michael Porter, The Institute for Strategy and Competitiveness,
Harvard Business School
• Mark von Rosing, LEADing Practice
• Jeanne Ross, Center for Information Systems Research, MIT
Sloan School of Management
• Jim Sinur, Flueresque
• John Sterman, MIT System Dynamics Group, MIT Sloan School
of Management
Особая благодарность исследовательским и конструктор¬
ским коллективам Arcitura Education и Big Data Science
School, разработавшим учебные модули для сертифициро¬
ванных специалистов в области больших данных (BDSCP),
на которых основана эта книга.
20
Сервис для читателей
Зарегистрируйте свой экземпляр «Основы больших данных»
на informit.com для получения удобного доступа к загруз¬
кам, обновлениям и исправлениям по мере их появления.
Чтобы начать процесс регистрации, перейдите на страницу
informit.com/register и войдите в систему или создайте учет¬
ную запись.
* Введите ISBN книги, 4286456214581 и нажмите «Отпра¬
вить». Как только процесс будет завершен, вы найдете лю¬
бой доступный бонусный контент в разделе «Зарегистриро¬
ванные продукты».
* Не забудьте поставить галочку в случае, если вы хотели бы
получать от нас эксклюзивные скидки на будущие издания
этой книги.
Основы больших данных
Глава 1 Понятие больших данных
Глава 2 Экономическая мотивация и стимулы для
перехода к обработке больших данных
Глава 3 Переход к большим данным и вопросы
планирования
Глава 4 Корпоративные технологии и Business
Intelligence для больших данных
22
Большие данные могут изменять характер бизнеса. Фак¬
тически существует множество компаний, деятельность
которых основывается на их способности генерировать
идеи, которые могут предоставить только большие данные.
В первых главах этой книги рассматриваются основы боль¬
ших данных, в первую очередь с точки зрения бизнеса. Пред¬
приятиям необходимо понять, что большие данные — это не
только технология, но и способ продвижения организации с
помощью технологий.
Часть I имеет следующую структуру:
• Глава 1 дает представление о ключевых понятиях и тер¬
минологии, которые определяют саму суть больших
данных, а также о потенциале, который они содержат,
чтобы оправдать ожидания при решении сложных бизнес-
задач. Объясняются разнообразные характеристики, ко¬
торые позволяют различать наборы больших данных,
а также определяются разные типы данных и технологии
их анализа.
• Глава 2 ориентирована на то, чтобы ответить на вопрос:
почему компании должны быть мотивированы к внедре¬
нию систем обработки больших данных вследствие фун¬
даментальных изменений на рынке и в мире бизнеса?
Большие данные не являются технологией, связанной с
трансформацией бизнеса; однако они позволяют вне¬
23
дрить инновации внутри предприятия при условии, что
последнее действует на основе полученных знаний.
• В главе 3 говорится о том, что большие данные — это не
просто «традиционный бизнес», и что решение об исполь¬
зовании больших данных должно учитывать рассмотрение
множества факторов бизнеса и технологий. Это подчерки¬
вает тот факт, что большие данные открывают для пред¬
приятия факторы воздействия внешних данных, которые
должны регулироваться и управляться. Так же, как и жиз¬
ненный цикл аналитики больших данных устанавливает
особые требования к обработке данных.
• В главе 4 рассматриваются современные подходы к хра¬
нилищу корпоративных данных и Business Intelligence.
Затем эта тема детализируется, чтобы показать, что хра¬
нение больших данных и ресурсы для их анализа могут
использоваться в связке с инструментами корпоратив¬
ного мониторинга производительности для увеличения
аналитических возможностей предприятия и углубления
выводов, полученных при обработке данных, предостав¬
ляемых Business Intelligence.
Правильно используемые большие данные являются частью
стратегической инициативы, основанной на предположении
о том, что внутренние данные (полученные внутри бизнеса)
не дают всех ответов. Другими словами, большие данные —
это не просто проблемы управления данными, которые мож¬
но решить с помощью технологии. Речь идет о бизнес-про-
блемах, решения которых обеспечиваются технологиями,
которые могут поддерживать анализ наборов больших дан¬
ных. По этой причине бизнес-ориентированные рассуждения
в части I создают основу для тематики, ориентированной на
технологии и описанной в части II.
25
Глава 1
Понимание больших
данных
Концепты и терминология\
Характеристики больших данных "Ч'--...
Различные типы данных^/ / i
Введение в исследование конкретных слу4аёр из практики
К
&
•К
26
Большие данные представляют собой сферу деятельности,
направленную на анализ, обработку и хранение больших
коллекций данных, которые часто генерируются разрознен¬
ными источниками. Решения и методы для больших данных
становятся востребованными тогда, когда традиционные
методы анализа данных, технологии их обработки и хране¬
ния оказываются недостаточными. Если более конкретно, то
большим данным присущи специфические особенности, та¬
кие как объединение разнообразных несвязанных наборов
данных, обработка больших объемов неструктурированных
данных и выявление скрытой информации в оперативном
режиме, без задержек.
Несмотря на то что большие данные появились как новая
дисциплина, изначально они развивались в течение многих
лет. Управление большими массивами данных и их анализ
были многолетней проблемой — начиная от трудоемких под¬
ходов к ранним переписям населения до актуарной науки по
вычислению страховых взносов. Эти два направления стали
причиной развития науки о больших данных.
В дополнение к традиционным аналитическим подходам,
основанным на статистике, большие данные добавляют
новые методы, усиленные вычислительными ресурсами и
подходами к выполнению аналитических алгоритмов. Та¬
кие изменения очень важны, поскольку наборы данных
продолжают увеличиваться в размерах, становясь все более
разнообразными, сложными и ориентированными на не¬
Понимание больших данных
27
прерывный поток. В то время как статистические подходы
использовались для приблизительных показателей чис¬
ленности населения с помощью выборки, как в библейские
времена, достижения в области вычислительной науки по¬
зволили обрабатывать наборы данных целиком, делая не¬
нужными такие выборки.
Анализ больших наборов данных является междисциплинар¬
ной задачей, которая сочетает в себе математику, статистику,
компьютерные науки и специальные знания предметной об¬
ласти. Такая смесь навыков и точек зрения привела к некото¬
рой путанице относительно того, что включает в себя область
больших данных и их анализ. Следовательно, ответ будет за¬
висеть от точки зрения того, кто отвечает на этот вопрос. Гра¬
ницы того, что представляет собой проблема больших данных,
также варьируются из-за изменяющихся и совершенствую¬
щихся перспектив программного обеспечения и технологий
аппаратного обеспечения. Это связано с тем, что определение
больших данных учитывает влияние их характеристик на ар¬
хитектуру самой среды обработки. Тридцать лет назад один
гигабайт данных мог бы быть проблемой больших данных и
требовать специальных целенаправленных вычислительных
ресурсов. Теперь гигабайты данных — обычное явление, они
могут быть легко переданы, обработаны и сохранены на кли-
енториентированных устройствах.
Данные внутри сред больших данных, как правило, нака¬
пливаются благодаря сбору данных внутри предприятия с
помощью приложений, датчиков и внешних источников.
Данные, обработанные с помощью методов решений для
больших данных, могут использоваться непосредственно
корпоративными приложениями или переправляться в хра¬
нилище для улучшения существующих данных.
Результаты, полученные при обработке больших данных,
могут привести к широкому спектру выгод и преимуществ,
таких как:
операционная оптимизация
28
Основы Big Data
• новые знания для выполнения поставленных заданий
• выявление новых рынков
• точные прогнозы
• обнаружение неисправностей и мошенничества
• более детализированные факты
• совершенствование процесса принятия решений
• научные открытия
Несомненно, применимость и потенциальные выгоды от
больших данных очень широкие. Тем не менее, здесь суще¬
ствует множество проблем, которые необходимо учитывать
при выборе подходов аналитики больших данных. Эти про¬
блемы должны быть понятны и взвешены с учетом ожидае¬
мых преимуществ, чтобы получить обоснованные решения
и планы. Более подробно эти темы рассматриваются во вто¬
рой части книги.
Концепты и терминология
В качестве отправной точки мы должны определить и по¬
нять некоторые фундаментальные концепты и термины.
Наборы данных
Коллекции или группы связанных данных обычно называ¬
ются наборами данных. Каждую группу или элемент группы
(единицу данных) разделяет один и тот же набор атрибутов
или свойств, как и все остальные в этом же наборе данных.
Некоторыми примерами наборов данных служат:
• твиты, сохраненные в файле
• коллекция графических файлов в каталоге
• строки, извлечение из таблицы базы данных, сохранен¬
ные в файле формата CSV
Понимание больших данных
29
• исторические погодные наблюдения, сохраненные как
XML-файлы
На рисунке 1.1 показаны три набора данных, основанные на
трех различных форматах данных.
Рисунок 1.1
Наборы данный могут
нанодиться в различный
форматах.
Наборы данных
Данные Реляционные Графические
XML данные данные
Анализ данных
Анализ данных представляет собой процесс исследования
данных для поиска фактов, отношений, шаблонов, идей
и/или тенденций. Общая цель анализа данных заключается
в том, чтобы поддерживать принятие более обоснованных ре¬
шений. Простым примером анализа данных является анализ
данных по продаже мороженого с целью определить, каким об¬
разом количество проданных рожков связано со среднесуточ¬
ной температурой воздуха. Результаты такого анализа могли
бы стать обоснованием для решения о количестве мороженого,
которое магазин должен заказать в зависимости от прогноза
погоды. Выполнение анализа данных
помогает установить закономерности
и взаимосвязи между анализируемы¬
ми данными. На рисунке 1.2 показано
изображение символа, обозначающе¬
го процесс анализа данных.
Рисунок12
Символ, который
используется для
обозначения анализа
данный.
Аналитика данных
Аналитика данных — это более ши¬
рокий термин, который охватывает и
сам анализ данных. Аналитика дан¬
30
Основы Big Data
ных является дисциплиной, которая охватывает управление
полным жизненным циклом данных, а именно сбор, очист¬
ку, организацию, хранение, анализ и регулирование данных.
Термин включает в себя разработку методов анализа, науч¬
ных методик, а также автоматизированных инструментов.
В средах больших данных для аналитики были разработаны
методы, позволяющие проводить анализ с помощью хорошо
масштабируемых распределенных технологий и механиз¬
мов, способных к анализу больших объемов данных, посту¬
пающих из различных источников. На рисунке 1.3 показано
изображение символа, используемого для обозначения ана¬
литики данных.
Рисунок 13
Символ, который
используется для
обозначения аналитики
данный.
Обычно жизненный цикл аналитики боль¬
ших данных включает идентификацию,
доставку, подготовку и анализ больших
объемов «сырых», неструктурированных
данных, с целью извлечения полезной и
значимой информации, которая может слу¬
жить в качестве входных данных для опре¬
деления моделей, улучшения существую¬
щих корпоративных данных и выполнения
крупномасштабных поисковых запросов.
Различные виды организаций по-разному
используют инструменты и методы ана¬
литики данных. Например, возьмем такие
три сектора:
• В средах, ориентированных на бизнес, результаты анали¬
тики данных могут снизить эксплуатационные расходы и
облегчить принятие стратегических решений.
• В научной сфере аналитика данных может помочь опреде¬
лить причину явления для улучшения точности прогнозов.
• В средах, базирующихся на сервисах, таких как органи¬
зации общественного сектора, аналитика данных может
помочь усилить акцент на предоставлении высококаче¬
ственных услуг при низких затратах.
Понимание больших данных
31
Аналитика данных дает возможность принимать решения
на основе данных с привлечением научной поддержки та¬
ким образом, чтобы эти решения могли основываться на
фактических данных, а не на прошлом опыте или одной
только интуиции.
Существуют четыре основные категории аналитики, кото¬
рые различаются производимыми результатами:
• дескриптивная аналитика
• диагностическая аналитика
• прогностическая аналитика
• прескриптивная аналитика
Различные типы аналитики усиливают разные методы и ал¬
горитмы анализа. Под этим подразумевается, что могут су¬
ществовать различные требования к данным, их хранению
и обработке в целях облегчения предоставления множества
разных типов аналитических результатов. Рисунок 1.4 ил¬
люстрирует реальную картину, когда генерирование высо¬
козначимых аналитических результатов увеличивает слож¬
ность и стоимость аналитической среды.
Рисунок 1.4
Важность и сложность
увеличиваются от
дескриптивной до
прескриптивной
аналитики.
высокая
средняя
низкая
32
Основы Big Data
Дескриптивная аналитика
Дескриптивная аналитика используется для поиска ответов
на вопросы о событиях, которые уже произошли. Эта форма
аналитики согласовывает данные с контекстом для генери¬
рования информации.
Приведем примеры вопросов:
• Каким был объем продаж за последние 12 месяцев?
• Сколько звонков поступило в службу поддержки, упоря¬
доченных по категориям серьезности и географическому
расположению?
• Какова ежемесячная комиссия, заработанная каждым
агентом по продажам?
По оценкам, 80 % сгенерированных результатов аналитики
являются дескриптивными по своей природе. Ориентиро¬
ванная на смысловую полезность, дескриптивная аналитика
обеспечивается с наименьшими затратами и требует отно¬
сительного базового набора навыков.
Дескриптивная аналитика часто выполняется с помощью
специальных отчетов или информационных панелей, как по¬
казано на рисунке 1.5. Отчеты обычно статичны по своей при¬
роде и отображают исторические данные, которые представ¬
лены в форме таблиц или диаграмм. Запросы выполняются
в рабочих хранилищах данных внутри предприятия, напри¬
мер, в системе управления взаимоотношениями с клиентами
(Customer Relationship Management — CRM) или планирования
ресурсов предприятия (Enterprise Resource Planning — ERP).
Диагностическая аналитика
Диагностическая аналитика направлена на то, чтобы опре¬
делить причину произошедшего события, используя вопро¬
сы, которые фокусируются на причинах этого события. Цель
Понимание больших данных
33
Рисунок 1.5
Рабочие системы,
изображенные слевд
задействуются с помощью
инструментов дескриптивной
аналитики для создания
отчетов или информацион¬
ный панелей, изображенным
справа.
панели
этого типа аналитики — определить, какая информация от¬
носится к данному явлению, чтобы дать возможность отве¬
тить на вопросы о том, почему это произошло.
К таким вопросам относятся:
• Почему продажи 02 были меньше, чем продажи 01?
• Почему в службу поддержки поступило больше звонков из
восточного региона, чем из западного?
• Почему увеличилось число повторных госпитализаций
пациентов за последние три месяца?
Диагностическая аналитика дает большую значимость, чем
дескриптивная, но требует более продвинутого набора на¬
выков. Обычно диагностическая аналитика требует сбора
данных из различных источников и хранения их в структу¬
ре, которая подвергается детальному анализу и свертыва¬
нию, как показано на рисунке 1.6.
Результаты диагностической аналитики могут быть просмо¬
трены с помощью инструментов интерактивной визуализа¬
ции, которые позволяют пользователям определять тенден¬
34
Основы Big Data
ции и шаблоны. Выполнение запросов здесь значительно
сложнее, чем в дескриптивной аналитике, и выполняются
они на многомерных данных, содержащихся в системах ана¬
литической обработки.
Рисунок 16
Диагностическая
аналитика может
обеспечить данные,
которые поднодят
для ик более
детального изучения
и свертывания.
свертывание
Прогностическая аналитика
Прогностическая аналитика проводится с целью определить
результат события, которое может произойти в будущем. С
помощью прогностической аналитики информация усили¬
вается смысловым содержанием. Интенсивность и значи¬
мость ассоциативных связей формируют основу моделей,
которые используются для создания будущих прогнозов на
основе прошлых событий.
Важно учитывать, что у моделей, которые используются для
прогностической аналитики, существуют неявные зависи¬
мости от условий, в которых происходили прошлые собы¬
тия. Если лежащие в основе причины изменяются, то и мо¬
дели прогнозирования должны быть откорректированы.
Вопросы обычно формулируются с использованием обосно¬
вания «Что, если...», например:
• Какова вероятность невозвращения клиентом кредита,
если пропущен ежемесячный платеж?
Понимание больших данных
35
• Каков процент эффективности лечения пациента, если
вместо препарата А будет использоваться препарат В?
• Если клиент приобрел продукты А и В, каковы шансы, что
он также купит продукт С?
Прогностическая аналитика призвана предсказать исход
события, при этом прогнозы делаются на основе шаблонов,
тенденций и исключений, найденных в исторических и те¬
кущих данных. Это может привести к выявлению как рисков,
так и возможностей.
Такой вид аналитики предполагает использование боль¬
ших наборов данных, внутренних и внешних, и различных
методов анализа этих данных. Эта аналитика обеспечивает
высокую значимость результатов и требует еще более совер¬
шенного набора навыков, чем дескриптивная и прогности¬
ческая. Как правило, инструменты прогностической анали¬
тики используют лежащие в их основе абстрактные способы
решения статистических сложных и запутанных тонкостей,
предоставляя удобные для пользователя внешние интер¬
фейсы, как показано на рисунке 1.7.
Рисунок 1.7
инструменты
прогностической
аналитики могут
предоставить удобные
для пользователя
внешние интерфейсы.
OLAP
текстовые
данные
аналитика
п рогностическая
аналитика
36
Основы Big Data
Прескриптивная аналитика
Прескриптивная аналитика основывается на результатах
прогностической аналитики, предписывая меры, которые
должны быть предприняты. Акцент делается не только на том,
какому предписанному варианту лучше всего следовать, но и
почему. Другими словами, прескриптивная аналитика дает
результаты, на основе которых можно делать выводы, по¬
скольку они встраивают элементы ситуативного понимания.
Таким образом, этот вид аналитики может быть использо¬
ван для получения преимуществ или снижения риска.
Вопросы могут иметь следующий вид:
• Какой из трех препаратов обеспечивает наилучшие результаты?
• Когда наилучше время для проведения определенной акции?
Прескриптивная аналитика представляет большую значи¬
мость, чем любые другие виды аналитики, и, соответствен¬
но, требует самого продвинутого набора навыков, а также
специализированного программного обеспечения и инстру¬
ментов. Благодаря ей рассчитываются различные результа¬
ты и предлагается оптимальный курс действий для каждого
из них. Такая тактика переходит от пояснений к консульта¬
циям и может включать в себя моделирование различных
сценариев.
Этот вид аналитики охватывает внутренние данные одно¬
временно с внешними. Внутренние данные могут включать
в себя текущие и исторические данные о продажах, инфор¬
мацию о клиентах, данные о продуктах и бизнес-правила.
Внешние же могут содержать данные из социальных сетей,
прогнозы погоды и демографические данные, подготовлен¬
ные правительством. Прескриптивная аналитика предпола¬
гает использование бизнес-правил и больших объемов вну¬
тренних и внешних данных для моделирования результатов
и прописывает оптимальный план действий, как показано
на рисунке 1.8.
Понимание больших данных
37
Рисунок 1.8
Прескриптивная аналитика
включает в себя использование
бизнес-прэвил и внутренний
и/или внешний данный для
проведения глубокого анализа
бизнес-
правила
аналитика прескриптивная
текстовые
данные
аналитика
Business Intelligence (Bl)
BI позволяет организации получить представление о произ¬
водительности предприятия путем анализа данных, создан¬
ных бизнес-процессами и информационными системами.
Результаты анализа могут использоваться руководством для
управления бизнесом с целью устранения выявленных про¬
блем или повышения эффективности работы организации.
BI применяет аналитику к большим объемам данных в мас¬
штабах всего предприятия, которые обычно консолидиру¬
ются в хранилище корпоративных данных для выполнения
аналитических запросов.
Как показано на рисунке 1.9, результат BI может отображать¬
ся на информационной панели, которая позволяет менед¬
жерам получать и анализировать результаты и, возможно,
уточнять аналитические запросы для дальнейшего исследо¬
вания данных.
38
Основы Big Data
Рисунок 1.9
Bl можно использозать
для усовершенствования
бизнес-приложений,
консолидации данный
в нранилищан данный
и анализа запросов
с помощью информаци¬
онной панели.
хранилища
данных
панель
Ключевые показатели эффективности (KPI)
KPI — это показатель, который может использоваться для
оценивания успеха в конкретном бизнес-контексте. KPI свя¬
заны с общими стратегическими целями и задачами пред¬
приятия. Они часто используются для выявления проблем
эффективности бизнеса и демонстрации соответствия нор¬
мативным требованиям. Таким образом, KPI выступают в
качестве количественных ориентиров для измерения кон¬
кретного аспекта общей эффективности бизнеса. KPI часто
отображаются посредством информационной панели KPI,
как показано на рисунке 1.10. Информационная панель объ¬
единяет отображение нескольких KPI и сравнивает факти¬
ческие измерения с пороговыми значениями, по которым
определяется допустимый диапазон значений KPI.
Рисунок 1.10
информационная панель
KPI выступает в качестве
центрального ориентира
для оценивания эффек¬
тивности бизнеса.
информационная панель KPI
Понимание больших данных
39
Характеристики больших данных
Для того чтобы набор данных можно было считать больши¬
ми данными, он должен обладать одной или несколькими
характеристиками, которые обеспечивают адаптацию его к
проектному решению и архитектуре аналитической среды.
Большинство этих характеристик данных были первона¬
чально определены Дугом Лейни в начале 2001 года, когда
он опубликовал свою статью, описывающую влияние объе¬
ма, скорости и многообразия данных электронной коммер¬
ции на хранилища данных предприятия. К этому списку
была добавлена достоверность для расчета более низкого
отношения сигнал/шум неструктурированных данных по
сравнению со структурированными источниками данных.
В конечном счете, цель заключается в проведении анализа
данных таким образом, чтобы высококачественные резуль¬
таты предоставлялись своевременно, что обеспечит опти¬
мальную значимость для предприятия.
В этом разделе рассматриваются пять характеристик боль¬
ших данных, которые можно использовать для дифферен¬
циации данных, классифицированных как «большие», из
других форм. Пять свойств больших данных, показанных на
рисунке 1.11, которые обычно называют как «Пять V»:
• объем
• скорость
• многообразие
• достоверность
• ценность
л МНОГО-
скооость образие досто’
скорость г верность
объем
ценность
Рисунок 111
«Пять V» больший данный.
40
Основы Big Data
Объем
Предполагаемый объем данных, который обрабатывается
решениями для больших данных, является существенным и
постоянно растущим. Большие объемы данных накладыва¬
ют различные требования по хранению и обработке данных,
а также к дополнительной подготовке данных, к процессам
сопровождения и управления. На рисунке 1.12 визуально
представлен большой объем данных, которые ежедневно
создаются организациями и пользователями по всему миру.
Рисунок 1.12
Организации и пользователи
по всему миру создают
более 2,5 ЕВ [экзабайтов)
данный в день. В качестве
сравнения: в настоящее
время библиотека Конгресса
США содержит более 300 ТВ
(терабайтов) данный.
5 миллиардов DVDs
2.5 экзабайт
65,000 DVDs
300 терабайт
Типичные источники данных, которые отвечают за генера¬
цию больших объемов данных, могут включать в себя:
• онлайн-транзакции, такие как розничные точки продаж и
банкинг
• научные и исследовательские эксперименты, такие как
большой адронный коллайдер и атакамский большой ан¬
тенный телескоп миллиметрового/субмиллиметрового
диапазона
• сенсоры, такие как GPS-сенсоры, RFID, смарт-счетчики и
телематика
социальные сети, такие как Facebook и Twitter
Понимание больших данных
41
Скорость
В средах с большими данными последние могут поступать с
высокими скоростями, и при этом огромные массивы дан¬
ных могут накапливаться за очень короткие промежутки
времени. С точки зрения предприятия скорость передачи
данных преобразуется в количество времени, которое тре¬
буется для обработки данных после их поступления в преде¬
лы предприятия. Решение проблемы быстрого притока дан¬
ных требует от предприятия разработки гибких и доступных
решений обработки данных и соответствующих условий для
их хранения.
В зависимости от источника данных скорость может быть не
всегда высокой. Например, изображения сканирования МРТ
генерируются не так часто, как записи в журнале веб-сер¬
вера с высоким трафиком. Как показано на рисунке 1.13,
скорость передачи данных рассматривается в перспективе,
если учитывать, что за минуту могут быть легко созданы
следующие объемы данных: 350 тысяч твитов, 300 часов ви¬
деоматериалов, загруженных на YouTube, 171 миллион элек¬
тронных писем и 330 гигабайт данных от сенсоров реактив¬
ного двигателя.
Рисунок 1.13
Примеры высокоскоростным
наборов большим данным,
производимым каждую
минуту, включают в себя
твиты, видеоматериалы,
электронные письма и гига¬
байты данным, генерируемым
реактивным двигателем.
350,000
ТВИТОВ
171 мипллион
электоронных
писем
300 часов
видиоматериалов
60
секунд
330
гигабайт
42
Основы Big Data
Многообразие
Многообразие данных касается множества форматов и ти¬
пов данных, которые должны поддерживаться решениями
для больших данных. Многообразие данных создает про¬
блемы для предприятий с точки зрения интеграции данных,
их трансформации, обработки и хранения. На рисунке 1.14
показано визуальное представление многообразия данных,
которое включает в себя структурированные данные в фор¬
ме финансовых транзакций, слабоструктурированные дан¬
ные в виде электронных писем и неструктурированные дан¬
ные в виде изображений.
структурированные
данные
Рисунок 1.14
Примеры широкого многообразия наборов больший данный, такик как структурированные,
текстовые, графические, видео- аудио-, НШ1- JSOD-, сенсорные данные и метаданные.
Достоверность
Достоверность касается качества или точности данных. Дан¬
ные, которые попадают в среду больших данных, необходимо
оценивать по качеству, что может послужить поводом для обра¬
ботки данных с целью устранить ошибочные данные и шумы. В
отношении достоверности данные могут быть частью сигнала
или шума набора данных. Шум — это данные, которые не могут
быть преобразованы в информацию и, следовательно, не име¬
ют ценности, тогда как сигналы имеют ценность и приводят к
значимой информации. Данные с высоким отношением сиг-
нал/шум имеют большую достоверность, чем данные с более
низким отношением. Данные, которые получены из контро¬
лируемых источников, например, через онлайн-регистрацию
клиентов, как правило, содержат меньше шума, чем данные,
Понимание больших данных
43
полученные через неконтролируемые источники, такие как
сообщения в блогах. Таким образом, отношение сигнал/шум в
данных зависит от источника данных и его типа.
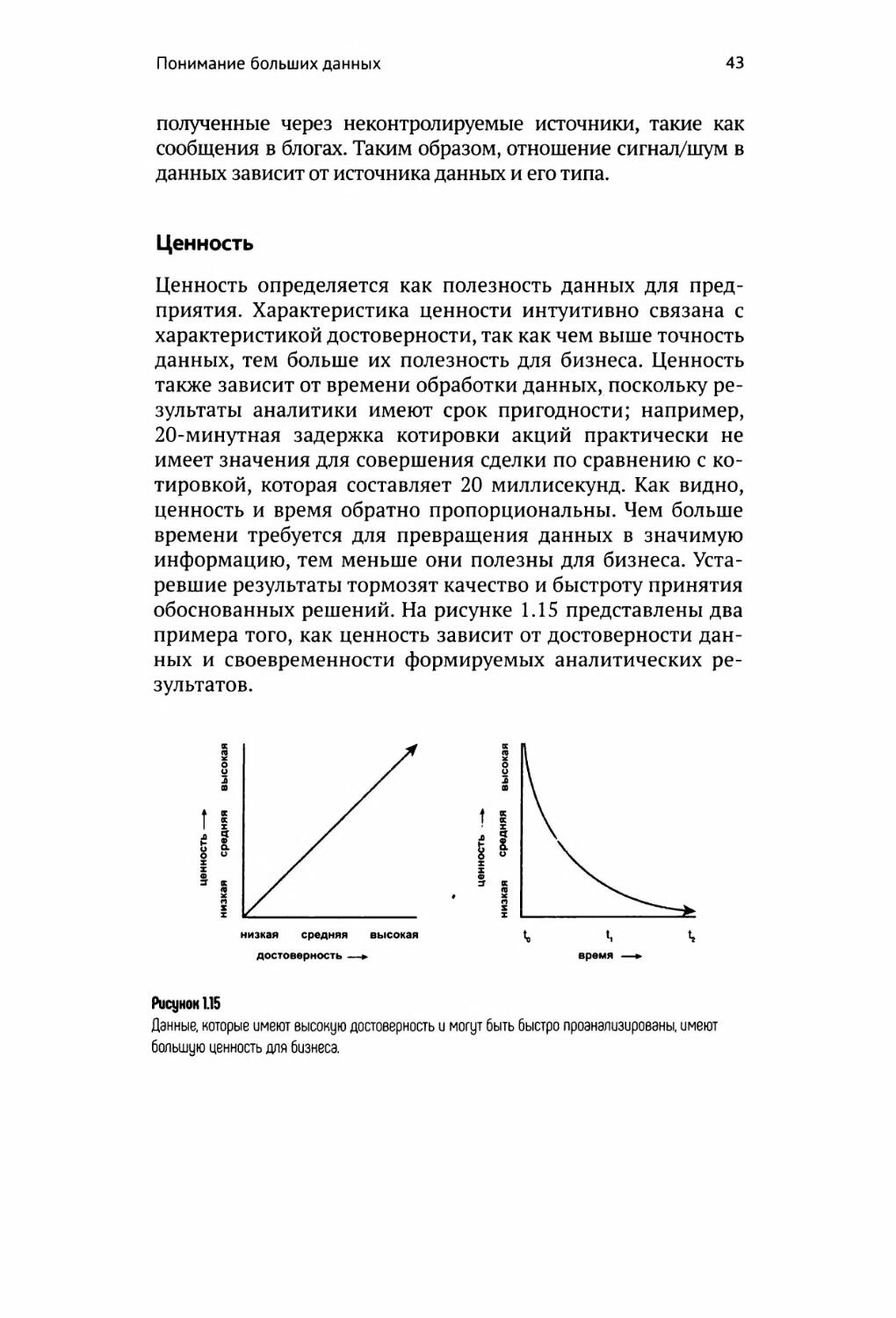
Ценность
Ценность определяется как полезность данных для пред¬
приятия. Характеристика ценности интуитивно связана с
характеристикой достоверности, так как чем выше точность
данных, тем больше их полезность для бизнеса. Ценность
также зависит от времени обработки данных, поскольку ре¬
зультаты аналитики имеют срок пригодности; например,
20-минутная задержка котировки акций практически не
имеет значения для совершения сделки по сравнению с ко¬
тировкой, которая составляет 20 миллисекунд. Как видно,
ценность и время обратно пропорциональны. Чем больше
времени требуется для превращения данных в значимую
информацию, тем меньше они полезны для бизнеса. Уста¬
ревшие результаты тормозят качество и быстроту принятия
обоснованных решений. На рисунке 1.15 представлены два
примера того, как ценность зависит от достоверности дан¬
ных и своевременности формируемых аналитических ре¬
зультатов.
Рисунок 115
Данные, которые имеют высокую достоверность и могут быть быстро проанализированы, имеют
большую ценность для бизнеса
44
Основы Big Data
Помимо достоверности и времени на ценность влияют сле¬
дующие вопросы, связанные с жизненным циклом:
• Насколько хорошо данные были сохранены?
• Были ли значимые атрибуты данных удалены во время
очистки данных?
• Корректно ли задаются вопросы при анализе данных?
• В точности ли переданы результаты анализа соответству¬
ющим лицам, принимающим решения?
Различные типы данных
Данные, которые обрабатываются решениями для больших
данных, могут быть созданы человеком или генерироваться
автоматически, хотя в конечном итоге обязанность получе¬
ния аналитических результатов ложится на машины. Дан¬
ные, созданные человеком, являются результатом взаимо¬
действия человека с системами, такими как онлайн-сервисы
и цифровые устройства. На рисунке 1.16 приведены приме¬
ры созданных человеком данных.
Рисунок 116
Примеры данным, созданным
человеком, включают в себя
социальные сети, сообщения
в блогам, электронные письма
обмен фотографиями и обмен
сообщениями.
Машинные данные генерируются программными средства¬
ми и аппаратными устройствами в ответ на события реаль¬
ного мира. Например, файл журнала фиксирует решение об
авторизации, принятое службой безопасности, а система
Понимание больших данных
45
точек продаж создает транзакции сравнения с запасами то¬
варов, чтобы отразить объем товаров, приобретенных кли¬
ентами. С точки зрения перспективы развития аппаратных
средств примером автоматически генерируемых данных
могла бы послужить информация, передаваемая многочис¬
ленными сенсорами сотового телефона, которые могут со¬
общать и о местоположении, и об уровне сигнала сотовой
связи. На рисунке 1.17 показано представление различных
типов данных, сгенерированных машинами.
Рисунок 1.17
Примеры данный, сгенери¬
рованный машинами, вклю¬
чают в себя веб-журналы,
сенсорные данные, данные
телеметрии, смарт-счетчиков
и данные об использовании
устройства.
текстовые
данные
сенсорные
данные
,|2, 359]
GPS-данные
XML-данные
Итак, созданные человеком и сгенерированные машинами дан¬
ные могут поступать из различных источников и представляться
в различных форматах или типах. В этом разделе рассматривает¬
ся множество типов данных, которые обрабатываются решения¬
ми для больших данных. Основными типами данных являются:
• структурированные данные
• неструктурированные данные
• слабоструктурированные данные
44
Основы Big Data
Помимо достоверности и времени на ценность влияют сле¬
дующие вопросы, связанные с жизненным циклом:
• Насколько хорошо данные были сохранены?
• Были ли значимые атрибуты данных удалены во время
очистки данных?
• Корректно ли задаются вопросы при анализе данных?
• В точности ли переданы результаты анализа соответству¬
ющим лицам, принимающим решения?
Различные типы данных
Данные, которые обрабатываются решениями для больших
данных, могут быть созданы человеком или генерироваться
автоматически, хотя в конечном итоге обязанность получе¬
ния аналитических результатов ложится на машины. Дан¬
ные, созданные человеком, являются результатом взаимо¬
действия человека с системами, такими как онлайн-сервисы
и цифровые устройства. На рисунке 1.16 приведены приме¬
ры созданных человеком данных.
Рисунок 1.16
Примеры данный, созданный
человеком, включают в себя
социальные сети, сообщения
в блоган, электронные письма
обмен фотографиями и обмен
сообщениями.
Машинные данные генерируются программными средства¬
ми и аппаратными устройствами в ответ на события реаль¬
ного мира. Например, файл журнала фиксирует решение об
авторизации, принятое службой безопасности, а система
Понимание больших данных
45
точек продаж создает транзакции сравнения с запасами то¬
варов, чтобы отразить объем товаров, приобретенных кли¬
ентами. С точки зрения перспективы развития аппаратных
средств примером автоматически генерируемых данных
могла бы послужить информация, передаваемая многочис¬
ленными сенсорами сотового телефона, которые могут со¬
общать и о местоположении, и об уровне сигнала сотовой
связи. На рисунке 1.17 показано представление различных
типов данных, сгенерированных машинами.
Рисунок 1.17
Примеры данный, сгенери¬
рованный машинами, вклю¬
чают в себя веб-журналы,
сенсорные данные, данные
телеметрии, смарт-счетчиков
и данные об использовании
устройства.
текстовые
данные
Итак, созданные человеком и сгенерированные машинами дан¬
ные могут поступать из различных источников и представляться
в различных форматах или типах. В этом разделе рассматривает¬
ся множество типов данных, которые обрабатываются решения¬
ми для больших данных. Основными типами данных являются:
• структурированные данные
• неструктурированные данные
• слабоструктурированные данные
46
Основы Big Data
Эти типы данных относятся к данным внутренней организа¬
ции и иногда называются форматами данных. Помимо этих
трех основных типов еще одним важным типом данных в
средах больших данных являются метаданные. Рассмотрим
каждый тип данных по очереди.
Структурированные данные
Структурированные данные соответ¬
ствуют моделям или схемам данных и
часто хранятся в табличных формах.
Они использюется для фиксации отно¬
шений между различными объектами
и поэтому чаще всего хранятся в ре¬
ляционных базах данных. Структури¬
рованные данные часто генерируются
корпоративными приложениями и ин¬
формационными системами, такими
как системы ERP и CRM. Из-за обилия
Рисунок 1.18
Символ для обозначения
структурированный данный,
сонрэненнын в табличной
форме.
инструментов и баз данных, которые поддерживают структу¬
рированные данные, они редко нуждаются в особых подходах
к обработке или хранению. Примерами такого типа данных
являются банковские операции, счета-фактуры и записи кли¬
ентов. На рисунке 1.18 показан символ, который использует¬
ся для представления структурированных данных.
Неструктурированные данные
Данные, которые не соответствуют моделям или схемам
данных, называются неструктурированными данными. Счи¬
тается, что неструктурированные данные составляют 80 %
данных любого предприятия. Неструктурированные данные
имеют более быстрый темп роста, чем структурированные.
На рисунке 1.19 показаны некоторые общие типы неструк¬
турированных данных. Эта форма данных является либо
текстовой, либо бинарной и зачастую передается посред¬
ством файлов, которые являются автономными и нереляци-
Понимание больших данных
47
онными. Текстовый файл может вмещать содержимое раз¬
личных твитов или постов в блогах. Бинарные файлы чаще
представляют собой мультимедийные файлы, содержащие
изображения, аудио- или видеоданные. Технически и тек¬
стовые, и бинарные файлы имеют структуру, определенную
самим форматом файла, но этот аспект игнорируется, а по¬
нятие неструктурированное™ относится к формату данных,
которые содержит сам файл.
Рисунок 1.19
Видео, графические
и аудиофайлы являются
типами неструктуриро¬
ванный данный.
видео
графические аудио
файлы
Обычно для обработки и хранения неструктурированных
данных требуется специализированная логика. Например,
для воспроизведения видеофайла важно наличие правиль¬
ного кодека. Неструктурированные данные нельзя напря¬
мую обработать или запросить с помощью SQL. Если их
необходимо хранить в реляционной базе данных, то они со¬
храняются в таблице как большие бинарные объекты (Binary
Large Object — BLOB). Кроме того, база данных NoSQL явля¬
ется нереляционной базой данных, которая может исполь¬
зоваться для хранения неструктурированных данных вме¬
сте со структурированными.
Слабоструктурированные данные
Слабоструктурированные данные имеют определенный
уровень структуры и согласованности, но не являются реля¬
ционными по своей природе. Они являются иерархически¬
ми или основанными на графах. Такого рода данные обычно
хранятся в файлах, содержащих текст. Например, на рисунке
1.20 показано, что файлы XML и JSON являются распростра¬
ненными формами слабоструктурированных данных. Ввиду
48
Основы Big Data
текстовой природы этих данных и их соответствия опреде¬
ленному уровню структуры они обрабатываются легче, чем
неструктурированные данные.
Рисунок 120
НГП1-, JSOfl- и сенсорные
денные являются
слэбоструктурированными.
XML- JSON- сенсорные
данные данные данные
Примеры общих источников слабоструктурированных дан¬
ных включают файлы электронной системы документо¬
оборота (EDI), электронные таблицы, RSS-каналы и данные
от сенсоров. Слабоструктурированные данные часто имеют
специальные требования к предварительной обработке и
хранению, особенно если основной формат не является тек¬
стовым. Примером предварительной обработки слабострук¬
турированных данных может быть проверка допустимости
XML-файла с целью гарантирования соответствия его опре¬
делению схемы.
Метаданные
Метаданные предоставляют информацию о
характеристиках и структуре набора данных.
Этот тип данных в основном генерируется ма¬
шинами и может присоединяться к данным.
Отслеживание метаданных имеет ключевое
значение при обработке больших данных,
их хранении и анализе, поскольку они пре¬
доставляют информацию о происхождении
данных и их источнике во время обработки.
Примеры метаданных включают в себя:
Рисунок 121
Символ для обозначе¬
ния метаданных.
XML-теги, указывающие автора и дату
создания документа
Понимание больших данных
49
• атрибуты, указывающие размер и разрешение файла циф¬
ровой фотографии
Решения для больших данных полагаются на метаданные,
особенно при обработке слабоструктурированных и не¬
структурированных данных. На рисунке 1.21 показан сим¬
вол для обозначения метаданных.
История исследования конкретного случая
«Гарантирование страхования» (Ensure to Insure, ETI) — ве¬
дущая страховая компания, которая предоставляет широ¬
кий спектр страховых программ в области здравоохранения,
строительства, морского и авиационного секторов для своей
25-миллионной базы клиентов по всему миру. Компания на¬
считывает около 5 тысяч сотрудников и производит годовой
доход более 350 миллионов долларов США.
История компании
50 лет назад компания ETI начала свою деятельность в качестве
эксклюзивного поставщика в сфере медицинского страхова¬
ния. В результате многочисленных приобретений за послед¬
ние 30 лет ETI расширила свои услуги, включив программы по
страхованию имущества и страхования от несчастных случаев
в строительном, морском и авиационном секторах.
Каждый из четырех секторов состоит из основной группы
специализированных и опытных агентов, страховых стати¬
стов, агентов по страхованию и специалистов по обработке
страховых заявок.
Агенты приносят доход компании, продавая полисы, в то
время как страховые статисты отвечают за оценивание сте¬
пени риска, придумывают новые страховые проекты и пе¬
ресматривают действующие проекты. Страховые статисты
также выполняют анализ «Что, если...» и используют инфор¬
мационные панели и сбалансированные системы показа¬
50
Основы Big Data
телей для сценариев оценивания. Агенты по страхованию
оценивают новые заявки на страхование и принимают ре¬
шения о сумме страховых выплат. Специалисты по обработ¬
ке страховых заявок расследуют претензии, предъявляемые
к страховому полису, и приходят к урегулированию расчет¬
ной суммы для держателя страхового полиса.
Некоторые из ключевых отделов в ETI охватывают зада¬
чи андеррайтинга (подписание договоров о страхования),
урегулирования претензий, обслуживания клиентов, юри¬
дические, маркетинговые, кадровые ресурсы, отделы бух¬
галтерии и IT-специалистов. Как предполагаемые, так и
существующие клиенты, как правило, обращаются в отдел
обслуживания клиентов ETI по телефону, но за последние
несколько лет значительно увеличилось количество обраще¬
ний по электронной почте и социальным сетям.
ETI стремится отличать себя, предоставляя конкурентную
политику и премиальное обслуживание клиентов, которая
не заканчивается, как только политика была продана.
ETI стремится поднять свой уровень путем предоставления
конкурентоспособных полисов и VIP обслуживания клиен¬
там, которое не заканчивается после продажи страхового
полиса. Руководство компании полагает, что это поможет
в повышении уровня привлечения и удержания клиентов.
ETI в значительной степени полагается на своих страховых
статистов, работающих над созданием страховых проектов,
которые отражают потребности своих клиентов.
Техническая инфраструктура и среда автоматизации
IT-среда ETI состоит из комбинации клиент-серверных и
мэйнфреймовых платформ, которые поддерживают выпол¬
нение ряда систем, в том числе для котирования полисов и
управления полисами, управления заявками, оценивания
рисков, управления документооборотом биллинга, плани¬
рования ресурсов предприятия (ERP) и управления взаимо¬
отношениями с клиентами (CRM).
Понимание больших данных
51
Система котирования полисов используются для создания
новых страховых проектов и предоставления котировок
потенциальным клиентам. Она интегрирована с веб-сай¬
том и порталом обслуживания клиентов, чтобы посетители
веб-сайта и агенты по обслуживанию клиентов имели воз¬
можности получить страховые котировки. Система управ¬
ления страховыми полисами обрабатывает все аспекты
управления жизненным циклом полиса, включая выпуск,
обновление, замену и отмену полиса. Система управления
заявками имеет дело с обработкой страховых случаев.
Заявка регистрируется, когда держатель страхового полиса
составляет отчет, и затем передается специалисту по стра¬
ховым заявкам, который анализирует заявку с учетом име¬
ющейся информации, что была представлена при подаче
заявки, а также справочной информации, полученной из
различных внутренних и внешних источников. На основе
проанализированной информации, заявка будет урегулиро¬
вана в соответствии с определенным набором бизнес-пра-
вил. Система оценивания риска используется страховыми
статистами для оценивания любого потенциального ри¬
ска, например, как шторм или наводнение, который может
привести к подаче страховых заявок держателями полисов.
Система оценивания рисков позволяет оценивать риски на
основе вероятности, что включает в себя выполнение раз¬
личных математических и статистических моделей.
Система управления документами выступает в качестве
центрального репозитория для всех видов документов, в
том числе полисов, заявок, отсканированных документов и
корреспонденции клиентов. Биллинговая система отслежи¬
вает инкассо страховых взносов клиентов, а также создает
различные напоминания для клиентов, которые пропустили
свой платеж через почтовое и электронное письмо. ERP-си¬
стема используется для повседневной работы ETI, включая
управление человеческими ресурсами и учетными и запи¬
сями. CRM-система фиксирует все аспекты коммуникации
с клиентами по телефону, электронной и обычной почте, а
52
Основы Big Data
также предоставляет портал анентам call-центра для работы
с запросами клиентов. Кроме того, это позволяет маркетин¬
говой команде создавать, запускать маркетинговые кампа¬
нии и управлять ними. Данные из этих операционных си¬
стем экспортируются в корпоративное хранилище данных
(Enterprise Data Warehouse — EDW), которое используется
для формирования отчетов для финансового анализа и ана¬
лиза эффективности. EDW также используется при создании
отчетов для различных регулирующих органов, чтобы гене¬
рировать постоянное соответствие нормативным требова¬
ниям.
Бизнес-цели и препятствия
За последние несколько десятилетий рентабельность ком¬
пании снизилась. Был сформирован комитет, состоящий
из старших руководителей, для расследования и предо¬
ставления рекомендаций. Выводы комитета показали, что
основной причиной ухудшения финансового положения
компании является увеличение количества мошеннических
заявок и связанных с ними выплат, а также что совершае¬
мое мошенничество стало сложноорганизованным и трудно
распознаваемым, поскольку и сами мошенники стали более
изощренными и организованными. Помимо прямых денеж¬
ных потерь, расходы на обработку мошеннических заявок
приводят к косвенным убыткам.
Другим фактором, влияющим на снижение доходов, являет¬
ся значительное увеличение числа катастроф, таких как на¬
воднения, штормы и эпидемии, что в свою очередь привело
к увеличению количества неподдельных заявок дорогого
класса. Дальнейшие причины снижения доходов включают
в себя отток клиентов из-за медленной обработки заявок и
страховые проекты, которые больше не соответствуют по¬
требностям клиентов. Последнее слабое звено обнаружи¬
лось с появлением технически продвинутых конкурентов,
которые начали использовать средства телематики для пре¬
доставления персонализированных полисов.
Понимание больших данных
53
Комитет отмечает, что частота внесения изменений в дей¬
ствующие и новые правила в последнее время возросла. К
сожалению, компания не торопилась реагировать и не была
способна обеспечить беспрепятственное и непрерывное со¬
блюдение установленных требований. Из-за этих недостат¬
ков ETI вынуждена была платить крупные штрафы.
Комитет так же отметил, что еще одна причина ухудшения
финансовой результативности компании заключается в том,
что и создание страховых проектов, и подписание полисов
проходит без тщательного оценивания рисков. Это приве¬
ло к установлению некорректных сумм взносов и увеличе¬
нию выплат, которые значительно превышают ожидаемые.
В настоящее время недостача между собранными взносами
и произведенными выплатами компенсируется прибылью
от инвестиций. Однако это решение не является долгосроч¬
ным, так как снижает прибыль от инвестиций. Кроме того,
страховые проекты, как правило, основаны на опыте стра¬
ховых статистов и анализе населения в целом, в результате
чего страховые проекты распространяются только на группу
клиентов среднего класса. Клиенты, чьи обстоятельства от¬
личаются от обстоятельств группы клиентов среднего клас¬
са, не заинтересованы в таких страховых проектах.
Основываясь на выводах комитета, директорами ETI уста¬
навливаются следующие стратегические цели:
1. Снизить потери путем а) улучшения качества оценива¬
ния рисков и максимального снижения рисков, которые
применяются как при создании страховых проектов, так
и при отборе новых заявок на момент разработки полиса;
б) внедрения упреждающей системы по мониторингу ка¬
тастроф, которая уменьшит количество потенциальных
заявок, связанных с бедствиями; и в) выявления мошен¬
нических заявок.
2. Снизить потери клиентов и улучшить удержание клиен¬
тов путем а) быстрого урегулирования заявок и б) предо¬
ставления персонализированных и конкурентоспособ-
54
Основы Big Data
вых полисов на основе индивидуальных обстоятельств, а
не только демографического обобщения.
3. Обеспечивать и поддерживать полное соответствие нор¬
мативным требованиям в любое время, используя усовер¬
шенствованные методы управления рисками, которые
смогут лучше предсказывать риски, поскольку большин¬
ство правил требуют точного знания рисков для гарантии
их соблюдения.
После консультаций с командой IT-специалистов комитет ре¬
комендовал принять стратегию, ориентированную на данные,
с расширенной аналитикой, которая будет применяться для
многих бизнес-функций таким образом, чтобы в различных
бизнес-процессах учитывались соответствующие как внутрен¬
ние, так и внешние данные. Таким образом, решения могут
основываться на фактах, а не только на опыте и интуиции. В
частности, внимание акцентируется на необходимости допол¬
нения больших объемов структурированных данных больши¬
ми объемами неструктурированных данных для поддержки
выполнения глубинного и своевременного анализа данных.
Комитет выяснил у команды IT-специалистов, имеются ли
какие-либо существующие препятствия, которые могут по¬
мешать осуществлению вышеупомянутой стратегии. Ко¬
манде IT-специалистов напомнили о финансовых ограни¬
чениях, в которых она должна действовать. В ответ на это
команда подготовила технико-экономическое обоснование,
в котором подчеркнула следующие препятствия:
• Получение, хранение и обработка неструктурированных
данных из внутренних и внешних источников данных — в
настоящее время сохраняются и обрабатываются только
структурированные данные, поскольку существующие
технологии не поддерживают хранение и обработку не¬
структурированных данных.
• Своевременная обработка больших объемов данных — хотя
EDW используется для создания отчетов на основе исто¬
Понимание больших данных 55
рических данных, объем обработанных данных нельзя
классифицировать как большой, и для генерации отчетов
требуется много времени.
• Обработка нескольких типов данных и комбинирование
структурированных данных с неструктурированными дан¬
ными — производится множество типов неструктуриро¬
ванных данных, таких как текстовые документы и жур¬
налы call-центра, которые в настоящее время не могут
обрабатываться из-за их неструктурированного характе¬
ра. Кроме того, структурированные данные используются
изолированно для всех видов анализа.
Команда IT-специалистов завершила формирование своих
рекомендаций следующим выводом: ETI должна применять
большие данные в качестве основного средства преодоле¬
ния этих препятствий для достижения поставленных целей.
ПРИМЕР ИЗ ПРАКТИКИ
Хотя ETI и выбрала большие данные для реализации сво¬
их стратегических целей в качестве текущей установки,
но поскольку ETI не имеет никаких собственных навы¬
ков работы с большими данными, то ей приходится вы¬
бирать между наймом консультантов по большим дан¬
ным и отправкой команды собственных ГГ-специалистов
на обучающие курсы по большим данным. Был выбран
последний вариант. Тем не менее, только старшие члены
команды IT-специалистов были отправлены на обучение
с ожиданием рентабельного и долгосрочного предложе¬
ния, когда обученные члены команды станут постоян¬
ным собственным ресурсом ‘по управлению большими
данными, с которым в любое время можно проконсуль¬
тироваться, а так же получить возможность дальнейшего
обучения младших членов команды, тем самым улучшая
корпоративные навыки работы с большими данными.
56 Основы Big Data
Пройдя тренинг по большим данным, обученные члены
команды подчеркнули необходимость наличия обще¬
го словаря терминов, чтобы вся команда была на одной
волне при обсуждении вопросов о больших данных. Был
принят подход, основанный на примерах. При обсужде¬
нии проблемы наборов данных оказалось, что некоторые
связанные наборы данных, на которые указывают чле¬
ны команды, включают в себя заявки, полисы, котировки
риска, данные профиля клиента и данные переписи. Не¬
смотря на то, что концепции анализа данных и аналитики
данных быстро осваиваются, некоторые члены команды,
у которых нет большого опыта в сфере бизнес-деятель-
ности, испытывают затруднения при понимании BI и
создания соответствующих KPI. Один из обученных чле¬
нов команды IT-специалистов объясняет BI, используя
в качестве примера процесс ежемесячного создания от¬
четов для оценивания эффективности за предыдущий
месяц. Этот процесс включает в себя импорт данных из
операционных систем в EDW и генерирование KPI, таких
как проданные полисы и поданные, обработанные, при¬
нятые и отклоненные заявки, которые отображаются на
мониторах различных информационных панелей и кар¬
тах сбалансированных систем показателей.
В терминах аналитики ETI использует как дескриптивную,
так и диагностическую аналитику. Дескриптивная анали¬
тика охватывает запросы системы управления полисами
для определения количества продаваемых полисов каж¬
дый день, запросы системы управления заявками, чтобы
выяснить количество ежедневно подаваемых заявок и
запросы биллинговой системы, чтобы выяснить, сколько
клиентов не получили своих премиальных выплат.
Диагностическая аналитика выполняется в рамках раз¬
личных действий BI, таких как выполнение запросов для
предоставления ответов на вопросы, например, почему
цель продаж прошлого месяца не была достигнута. Она
Понимание больших данных
57
включает в себя выполнение операций детализации и
разбивки продаж по типу и местоположению так, что¬
бы можно было определить, какие позиции показывали
низкие результаты для определенных типов полисов.
В настоящее время ETI не использует ни прогностиче¬
скую, ни прескриптивную аналитику. Однако использо¬
вание больших данных позволит ей выполнять эти типы
аналитики, поскольку появится возможность использо¬
вать неструктурированные данные, которые в сочетании
со структурированными данными предоставляют цен¬
ный ресурс для поддержки этих типов аналитики. ETI
решила внедрять эти два типа аналитики постепенно,
сначала используя прогностическую, а затем медлен¬
но наращивая свои возможности для реализации прес¬
криптивной аналитики.
На данном этапе ETI планирует использовать прогности¬
ческую аналитику для достижения своих целей. Напри¬
мер, прогностическая аналитика включает в себя обна¬
ружение фальсифицированных заявок, предсказывая,
какая из заявок будет мошеннической, а в случае кли¬
ентских нарушений, предсказывать, какие из клиентов
вероятнее всего будут недобросовестными. В будущем
ожидается, что с помощью прескриптивной аналитики
ETI сможет еще больше повысить реализацию своих це¬
лей. Например, прескриптивная аналитика может пред¬
писывать правильную сумму премии с учетом всех фак¬
торов риска или может устанавливать оптимальный курс
действий для смягчения претензий в случае форс-мажо-
ров, таких как наводнения или штормы.
Идентификация характеристик данных
Члены команды IT-специалистов намерены оценить
различные наборы данных, созданные в пределах ETI,
а также любые другие данные сгенерированные за пре¬
58 Основы Big Data
делами ETI, но которые могут представлять интерес для
компании в контексте характеристик объема, скорости,
многообразия, достоверности и ценности. Члены коман¬
ды выбирают каждую характеристику поочередно и об¬
суждают, как различные наборы данных проявляют себя
через эту характеристику.
Объем
Команда отмечает, что внутри компании генерируется
большое количество транзакционных данных в резуль¬
тате обработки заявок, продажи новых полисов и изме¬
нений в существующих полисах. Тем не менее, быстрое
обсуждение показывает, что большие объемы неструкту¬
рированных данных, и внутри и за пределами компании,
могут оказаться полезными на пути достижения целей
ETI. Эти данные включают в себя медицинские справки,
документы, предоставленные клиентами во время пода¬
чи заявления на страхование, опись имущества, данные
о транспортных средствах, данные социальных сетей и
данные о погоде.
Скорость
Что касается потока данных, то некоторые данные имеют
низкую скорость (например, данные представления зая¬
вок и оформленных новых полисов). Однако такие дан¬
ные, как журналы веб-серверов и страховые котировки,
являются данными с высокой скоростью. Глядя за преде¬
лы компании, члены команды IT-специалистов ожидают,
что данные социальных сетей и данные о погоде могут
накапливаться быстрыми темпами. Кроме того, ожида¬
ется, что для управления катастрофическими рисками и
обнаружения сфальсифицированных заявок данные не¬
обходимо обрабатывать достаточно быстро для миними¬
зации потерь.
Понимание больших данных
59
Многообразие
Для достижения своих целей ETI потребуется исполь¬
зовать ряд наборов данных, которые включают в себя
медицинские записи, данные полисов, данные заявок,
данные о котировках, данные социальных сетей, записи
агента call-центра, записи специалиста по страховым ис¬
кам, фотографии инцидентов, прогнозы погоды, данные
переписи, журналы веб-серверов и электронные письма.
Достоверность
Выборка данных, взятая из рабочих систем и EDW, де¬
монстрирует признаки высокой достоверности. Команда
IT-специалистов мотивирует это проверками данных,
которые выполняются на многих этапах, включая про¬
верку во время ввода данных, проверку в различных
точках, когда приложение обрабатывает данные, напри¬
мер, проверка вводимых значений на функциональном
уровне и проверка, выполняемая базой данных, когда
данные сохранены. Выходя за границы ETI, исследова¬
ние нескольких выборок, взятых из социальных сетей и
погодных сводок, демонстрирует дальнейшее снижение
достоверности, указывая на то, что такие данные требу¬
ют более глубокого уровня проверки и очистки, чтобы
сделать их достоверными.
Ценность
Что касается характеристики ценности, то все члены ко¬
манды IT-специалистов согласны с тем, что им необхо¬
димо извлечь максимальную выгоду из доступных набо¬
ров данных, гарантируя, что наборы данных хранятся в
их первоначальной форме и что к ним применяют пра¬
вильный вид аналитики.
60 Основы Big Data
Идентификация типов данных
Члены команды IT-специалистов осуществили категори¬
зацию различных наборов данных, которые были иден¬
тифицированы к настоящему моменту, и составили сле¬
дующий список:
• Структурированные данные: данные полиса, данные
заявки, данные из профиля клиента и данные о коти¬
ровках.
• Неструктурированные данные: данные из социальных
сетей, документы по страховым заявкам, записи аген¬
та call-центра, записи специалиста по страховым заяв¬
кам и фотографии инцидентов.
• Слабоструктурированные данные: медицинские кар¬
ты, данные профиля клиентов, метеорологические
сводки погоды, данные переписи населения, журналы
веб-серверов и электронные письма.
Метаданные представляют собой новую концепцию для
группы, поскольку существующие процедуры управле¬
ния данными ETI не создают и не добавляют какие-либо
метаданные. Кроме того, существующие методы обра¬
ботки данных не учитывают никаких метаданных, даже
если они присутствовали. Одна из причин, отмеченая
командой IT-специалистов, заключается в том, что в на¬
стоящее время почти все данные, которые хранятся и об¬
рабатываются, структурированы по своей природе и про¬
дуцируются самой компанией. Следовательно, истоки и
характеристики данных неявно известны. После некото¬
рого рассмотрения члены команды понимают, что для
структурированных данных и словарей данных наличие
последних обновленных временных меток и столбцов
userid в разных таблицах реляционной базы данных мо¬
гут использоваться в качестве формы метаданных.
.61
Глава 2
Бизнес-мотивация
и стимулы для перехода
к обработке больших
данных
Динамика рынка
Бизнес-архитектура
Управление бизнес-процессами
Информационные и коммуникационные технологии
Интернет Всего
62
Сегодня для многих организаций приемлемо, чтобы биз¬
нес был спроектирован так же, как и его технология. Та¬
кая смена тактики в перспективе отразится на расширении
области архитектуры предприятия, которая раньше была
тесно связана с технологической архитектурой, но теперь
включает в себя и бизнес-архитектуру. Несмотря на то что
компании по-прежнему рассматриваются с точки зрения
механистических систем, когда управление и контроль пе¬
редаются от руководителей к менеджерам, а затем и к ве¬
дущим сотрудникам, цикл обратной связи, основанной на
взаимосвязанных и скоординированных вычисленииях,
обеспечивает более глубокое понимание эффективности
принятия управленческих решений.
Такой цикл от принятия решения к действию, измерению
и оцениванию результатов создает возможности для ком¬
пании по непрерывной оптимизации своей деятельности.
Фактически, механистический вид руководства вытесняет
более органичный, который управляет бизнесом, основыва¬
ясь на своей способности преобразовывать данные в знания
и проникновение в сущность задачи. Одна из проблем такой
перспективы заключается в том, что традиционно предпри¬
ятиями управляют, основываясь почти исключительно на
собственных внутренних данных, которые хранятся в ин¬
формационных системах. Однако компании понимают, что
этого недостаточно для реализации бизнес-моделей на рын¬
ке, который скорее напоминает экологическую систему. Та¬
Бизнес-мотивация и стимулы
63
ким образом, организациям необходимо получать данные
извне, чтобы напрямую обнаруживать факторы, которые
влияют на их прибыльность. Использование таких внешних
данных чаще всего приводит к созданию таких наборов, как
«большие данные».
В этой главе мы рассмотрим бизнес-мотивации и стимулы
для внедрения решений и технологий больших данных. Вне¬
дрение больших данных представляет собой объединение
нескольких направлений, в том числе динамику рынка, по¬
нимание и формализм бизнес-архитектуры (ВА), осознание
того, что способность бизнеса приносить прибыль непосред¬
ственно связано с управлением процессами предприятия
(Business Process Management — BPM), инновациями в обла¬
сти информационно-коммуникационных технологий (ИКТ)
и, наконец, Интернетом всего (Internet of Everything — IoE).
Каждая из этих тем будет последовательно рассмотрена.
Динамика рынка
В последнее время наметился фундаментальный сдвиг в
том, как компании оценивают себя и рынок.
За последние 15 лет произошли два больших изменения на
фондовом рынке: первым был взлет мыльного пузыря дот¬
комов в 2000 году, а вторым — глобальный спад, начавший¬
ся в 2008 году. В каждом случае компании защищали свои
позиции и работали над улучшением своей эффективности
и результативности для стабилизации рентабельности за
счет снижения затрат. И это, конечно же, нормально. Когда
клиентов мало, сокращение расходов часто приводит к под¬
держанию корпоративной прибыли. В этой среде компании
проводят проекты трансформации, чтобы улучшить свои
корпоративные процессы для достижения экономии.
По мере того как мировая экономики начала выходить из
кризиса, компании стали ориентироваться на внешний мир,
стремясь найти новых клиентов и не позволять существую¬
щим клиентам уходить к конкурентам. Достигнуто это было
64
Основы Big Data
Дэвенпорт (Davenport) и Прусак
(Prusak) предоставили обще¬
принятые рабочие опреде¬
ления данных, информации
и знаний в своей книге «Ра¬
ботающие знания» (Working
Knowledge). Согласно авторам,
«данные — это набор дискрет¬
ных, объективных фактов о
событиях». В контексте бизне¬
са эти события являются дей¬
ствиями, которые происходят
в рамках бизнес-процессов и
информационных систем орга¬
низации, — они представляют
собой генерирование, модифи¬
кацию и завершение работы,
связанной с предприятиями
(например, обновление зака¬
зов, отгрузок, уведомлений и
адресов клиентов). Эти собы¬
тия являются отражением ре¬
альной деятельности, которая
представлена в реляционных
хранилищах данных корпо¬
ративных информационных
систем. Дэвенпорт и Прусак
дополнительно определяют ин¬
формацию как «данные, кото¬
рые имеют значение». Это кон¬
текстуализированные данные,
необходимые для обеспечения
коммуникации; они доставля¬
ют сообщение и информируют
получателя— будь то человек
или система. Затем информа¬
ция обогащается благодаря
опыту и интуиции в генериро¬
вании знаний. Авторы утвер¬
ждают, что «знание — это ди¬
намически изменяемая смесь
сформировавшегося опыта,
ценностей, контекстной ин¬
формации и экспертного мне¬
ния, которая обеспечивает ос¬
нову для оценки и объединения
нового опыта и информации».
за счет предоставления но¬
вых продуктов и услуг и ак¬
центирования внимания
клиентов на более выгод¬
ных предложениях. Это уже
совершенно другой рыноч¬
ный цикл, ориентирован¬
ный на сокращение расхо¬
дов, поскольку речь идет не
о преобразовании, а об ин¬
новациях. Инновации дают
компании надежду найти
новые способы достижения
конкурентного преимуще¬
ства на рынке и, как след¬
ствие, увеличения доходов.
Мировая экономика может
проходить через периоды
неопределенности ввиду раз¬
личных факторов. Мы в це¬
лом согласны, что экономи¬
ки основных развитых стран
мира в настоящее время не¬
разрывно связаны; другими
словами, они образуют си¬
стему систем. Аналогичным
образом, мировые компании
меняют свою точку зрения
относительно своей иден¬
тичности и независимости,
поскольку они признают, что
также переплетены в слож¬
ной сети продуктов и услуг.
По этой же причине компа¬
нии должны расширять свою
деятельность по Business
Бизнес-мотивация и стимулы
65
Intelligence за пределы ретроспективного анализа вну¬
тренней информации, извлеченной из корпоративных ин¬
формационных систем. Они должны открыться внешним
источникам данных, чтобы осмыслить состояние рынка и
определить свое место в нем.
Признание того, что внешние данные привносят дополни¬
тельный контекст в их внутренние данные, позволяет кор¬
порации с большей легкостью продвигаться вверх по цепоч¬
ке аналитических значений от оценки прошедших событий
до способности с легкостью предвидеть будущие события.
Благодаря соответствующему инструменту, который под¬
держивает возможности сложного моделирования, компа¬
ния может развивать аналитические результаты, которые
обеспечивают методику долгосрочного прогнозирования. В
этом случае инструмент помогает преодолеть разрыв меж¬
ду знаниями и мудростью, а также предоставляет консуль¬
тативные аналитические результаты. В этом сила больших
данных, которые обогащают корпоративную перспективу
за пределами интроспекции, из которого компания может
только сделать заключение о состояние рынка, чтобы пози¬
ционировать себя на этом рынке.
Переход от оценки прошедших событий к форсайту (методи¬
ке долгосрочного прогнозирования) можно понять через при¬
зму пирамиды DIKW, изображенной на рисунке 2.1. Обратите
внимание, что на этом рисунке в верхней части треугольника
мудрость отображается как эскиз, который иллюстрирует, что
она существует, но обычно не генерируется с помощью си¬
стем ICT. Вместо этого специалисты представляют проникно¬
вение в сущность и опыт в рамках доступных знаний, чтобы
их можно было интегрировать для формирования мудрости.
Генерирование мудрости посредством технических средств
быстро переходит в философскую дискуссию, которая выхо¬
дит за рамки тематики этой книги. В бизнес-средах техно¬
логии используются для поддержки управления знаниями, а
персонал ответственен за реализацию своей компетентности
и мудрости, чтобы действовать соответственно.
66
Основы Big Data
Мудрость
заданное понимание
превращается в
долгосрочное
прогнозирование
Знания
проникновение
в сущность
заданный смысл
превращается в
Информацию
заданный контекст
превращается в
Данные
оценивание
прошедших
событий
л
§
X
ф
События
Рисунок 2.1
Пирамида DIKQJ показывает, как данные могут быть обогащены контекстом для создания инфор¬
мации, информация может быть наполнена смыслом для создания знаний, а знания могут быть
интегрированы для формирования мудрости.
Бизнес-архитектура
В течение последнего десятилетия наблюдается осознание
того, что слишком часто корпоративная архитектура пред¬
приятия является просто недальновидным представлением
ее технологической архитектуры. Стремясь отобрать власть
у цитадели ИТ, бизнес-архитектура появилась как допол¬
нительная дисциплина. Стратегическая цель состоит в том,
чтобы архитектура предприятия представляла собой сба¬
лансированное представление между бизнесом и техноло¬
гической архитектурой. Бизнес-архитектура обеспечивает
средства проектирования или конкретизации проекта. Биз¬
нес-архитектура позволяет организации согласовывать свое
стратегическое видение с его базовым исполнением, будь
то технические ресурсы или человеческий капитал. Таким
образом, бизнес-архитектура включает в себя связи от аб¬
страктных концептов, таких как бизнес-миссии, видения,
стратегии и цели, до более конкретных, таких как бизнес-
Бизнес-мотивация и стимулы
67
услуги, организационные структуры, ключевые показатели
эффективности и прикладные сервисы.
Эти связи очень важны, потому что они обеспечивают реко¬
мендации согласовать бизнес и его информационные техно¬
логии. Общепризнанным является мнение о том, что бизнес
функционирует как многоуровневая система: верхний уро¬
вень — это стратегический уровень, занимаемый руководи¬
телями высшего звена и консультативными группами; сред¬
ний уровень — это тактический или менеджерский уровень,
который стремится управлять организацией в соответствии
со стратегией; и нижний уровень — это операционный уро¬
вень, на котором бизнес выполняет основные процессы и
создает выгодные предложения для своих клиентов. Эти
три уровня часто демонстрируют определенную степень
независимости друг от друга, но цели и задачи каждого из
них часто определяются уровнем выше, иными словами,
движутся сверху вниз. С точки зрения мониторинга комму¬
никационные потоки передачи движутся вверх по потоку
или снизу вверх через набор исходных параметров и пока¬
зателей. Мониторинг активности бизнеса на операционном
уровне формирует показатели эффективности (Performance
Indicators — PI) и метрики, как для услуг, так и для процес¬
сов. Они агрегируются для создания ключевых показателей
эффективности (KPI), используемых на тактическом уровне.
Эти KPI могут на стратегическом уровне быть согласованы с
критическими факторами успеха (Critical Success Factors —
CSF), которые, в свою очередь, помогают оценить прогресс
на пути достижения стратегических целей и задач.
Большие данные связаны с бизнес-архитектурой на каждом
из организационных уровней, как это показано на рисун¬
ке 2.2. Большие данные улучшают ценность, поскольку они
обеспечивают дополнительный контекст за счет интеграции
внешних перспектив, чтобы помочь преобразовать данные в
информацию и позволить сгенерировать знания из инфор¬
мации. Например, на операционном уровне генерируются
метрики, которые просто сообщают о том, что происходит
68
Основы Big Data
в бизнесе. По сути, идет преобразование данных с помощью
бизнес-концепций и контекста для получения информации.
На тактическом уровне эта информация может быть про¬
анализирована через призму корпоративной эффективно¬
сти, чтобы ответить на вопросы о том, как работает бизнес.
Другими словами, придать ценность информации. Эта ин¬
формация может быть дополнительно усовершенствована,
чтобы ответить на вопросы о том, почему бизнес остается
работать на том уровне, на котором он находится. Когда
стратегический уровень вооружен этими знаниями, он мо¬
жет обеспечить глубокое проникновение в суть и дать отве¬
ты на вопросы о том, какая стратегия должна быть изменена
или принята для исправления или повышения производи¬
тельности.
Мудрость
(знают,
Стратегический _ «почему»)
(CSF)
4 Знания
_ „ (знают, «как»)
Тактический
(KPI)
f Информация
(знают, «что»)
Операционный <—
(Pl/метрики)
Данные
(ничего не знают)
t
События
Рисунок 22
Пирамида DIKUJ иллюстрирует ориентирование на стратегический, тактический и
операционный уровни компании.
Как и в любой многоуровневой системе, не все уровни из¬
меняются с одинаковой скоростью. В случае коммерческо¬
го предприятия стратегический уровень является наименее
Ьизнес-мотивация и стимулы
69
переменчивым уровнем, а операционный уровень — наи¬
более переменчивым уровнем. Менее изменяемые уровни
обеспечивают стабильность и главное направление для бо¬
лее изменяемых уровней. В традиционных организацион¬
ных иерархиях уровень менеджеров отвечает за руководство
операционным уровнем в соответствии со стратегией, со¬
зданной исполнительной командой. Ввиду этого различия в
скорости изменения можно представить, что три уровня от¬
вечают за реализацию стратегии, функционирование бизне¬
са и выполнение процессов соответственно. Каждый из этих
уровней опирается на различные метрики (исходные пара¬
метры и показатели) и меры, представленные с помощью
различных функций визуализации и отчетности. Например,
стратегический уровень может основываться на сбаланси¬
рованных системах показателей, тактический уровень — на
KPI и производительности корпорации, а операционный
уровень— на визуализации выполняющихся бизнес-про-
цессов и их статусов.
Представленный на рисунке 2.3 вариант диаграммы, соз¬
данный Джо Гольнером (Joe Gollner) в его блоге «Анатомия
знания», показывает, как организация может связывать и
выравнивать свои организационные уровни путем созда¬
ния благоприятного цикла через контур обратной связи. С
правой стороны пирамиды стратегический уровень откли¬
кается на применение суждения или мнения путем при¬
нятия решений относительно корпоративной стратегии,
политики, целей и задач, которые сообщаются в качестве
требований для тактического уровня. Тактический уровень,
в свою очередь, использует эти знания для формирования
приоритетов и действий, соответствующих главному на¬
правлению корпорации. Действия позволяют согласовывать
активность бизнеса на операционном уровне. Это, в свою
очередь, должно приводить к заметным изменениям, как в
опыте внутренних заинтересованных сторон, так и внешних
клиентов по мере предоставления и потребления ими биз-
нес-услуг. Изменения или результаты должны появляться и
отображаться в данных в виде измененных PI, которые затем
70
Основы Big Data
агрегируются в KPI. Напомним, что KPI — это метрики, кото¬
рые могут быть связаны с критическими факторами успеха,
информирующие руководящий состав о том, корректно ли
работают их стратегии. Со временем привнесение суждений
и действий в цикл стратегического и тактического уровней
будет способствовать совершенствованию предоставления
бизнес-услуг.
Мудрость
Стратегический Суждения
(CSF) * * (Ограничения)
f Знания X
□папИМ y
Тактический (KPI) . Действие
—► —► (Согласование)
Информация |
Операционный Опыт
(Pl/метрики) (Результат)
Данные
t
События
Рисунок 2.3
Создание благоприятного цикла для выравнивания организации по уровням
посредством контура обратной связи.
Управление бизнес-процессами
Компании предоставляют услуги клиентам и другим за¬
интересованным сторонам посредством выполнения сво¬
их бизнес-процессов. Бизнес-процесс представляет собой
описание того, как выполняется работа в организации. Он
описывает все связанные с работой виды действий и их вза¬
имоотношений, согласованных с организационными субъ¬
ектами и ресурсами, ответственными за их проведение.
Взаимоотношения между действиями могут быть времен¬
нозависимыми; например, действие А выполняется перед
действием В. Отношения также могут описывать, имеет ли
выполняемое действие условный характер, основывается на
Ьизнес-мотивация и стимулы
71
результатах или условиях, порождаемых другими действия-
ми или через обнаружение событий, генерируемых вне са¬
мого бизнес-процесса.
Управление бизнес-процессами применяет технологии вы¬
сокого уровня для улучшения корпоративного результата.
Системы управления бизнес-процессами (Business Process
Management Systems — BPMS) предоставляют разработчикам
программного обеспечения модельно-управляемую плат¬
форму, которая становится средой разработки бизнес-при-
ложений (Business Application Development Environment —
BADE). Бизнес-приложение должно выступать посредником
между людьми и другими ресурсами, задействованными в
технологиях, выполняться в соответствии с корпоративной
политикой и гарантировать справедливое распределение
работы между сотрудниками. В BADE модели бизнес-про-
цессов объединяются с моделями организационных ролей и
структур, объектами бизнес-деятельности и их отношения¬
ми, бизнес-правилами и пользовательскими интерфейсами.
Среда разработки объединяет эти модели вместе для созда¬
ния бизнес-приложения, которое мониторит и управляет
рабочим процессом, а также обеспечивает управление ра¬
бочей нагрузкой. Все это происходит в исполняемой среде,
которая обеспечивает соблюдение корпоративной политики
и безопасности, а также управление состоянием для долго¬
срочных бизнес-процессов. Состояние отдельного процесса
или всех процессов может быть опрошено и визуализирова¬
но посредством мониторинга бизнес-активности (Business
Activity Monitoring — ВАМ).
Когда BPM комбинируется с BPMS, процессы могут выпол¬
няться целенаправленно. Цели связаны с фрагментами про¬
цесса, которые динамически выбираются и собираются во
время выполнения в соответствии с оценкой этих целей.
Если использовать сочетание аналитических результатов
от больших данных и целевого поведения, то выполнение
процесса может стать адаптивным к рынку и реагировать
на условия окружающей среды. Простой пример: процесс
72
Основы Big Data
контакта с клиентом включает в себя фрагменты процессов,
которые позволяют коммуницировать посредством теле¬
фонной связи, электронной почты, текстового сообщения и
традиционной почты. В начале выбор методов взаимодей¬
ствия с клиентом не считается важным, и они выбираются
случайным образом. Тем не менее, проводится внутренний
анализ для оценивания эффективности метода взаимодей¬
ствия с клиентом с помощью статистического анализа ско¬
рости отклика клиентов.
Результаты этого анализа будут привязаны к цели, от кото¬
рой зависит выбор метода взаимодействия с клиентом, и
когда определяется явное предпочтение, то весовой коэф¬
фициент изменяется в пользу того способа связи с клиен¬
том, который показывает наилучший результат.
Более детальный анализ может включать кластеризацию
клиентов, которая позволяет отнести отдельных клиентов
к группам, где одним из параметров кластера является ме¬
тод взаимодействия с клиентом. В этом случае с клиентами
можно будет контактировать самым эффективным спосо¬
бом, что предоставляет новые возможности для индивиду¬
ального целевого маркетинга.
И нформационно-
коммуникационные технологии
В этом разделе рассматриваются следующие разработки
ICT, которые ускорили темпы внедрения больших данных
на предприятиях:
• аналитика данных и наука о данных;
• цифровизация;
• доступная технология и стандартные аппаратные средства;
социальные сети;
Бизнес-мотивация и стимулы
73
• сообщества и устройства, связанные коммуникационными
сетями;
• облачные вычисления.
Аналитика данных и наука о данных
Предприятия занимаются сбором, накоплением, хранени¬
ем, проверкой и обработкой растущих объемов данных. Это
происходит из-за стремления поиска новых идей, которые
могли бы стимулировать более эффективное и результатив¬
ное ведение деятельности, дать менеджерам возможность
активно управлять бизнесом и позволить руководителям
компании более точно формулировать и оценивать свои
стратегические инициативы.
В конечном счете, предприятия ищут новые способы обрете¬
ния конкурентного преимущества. Таким образом, возросла
потребность в методах и технологиях, которые помогли бы
извлекать ценную информацию и знания. Вычислительные
методы, статистические методы и технология информаци¬
онных хранилищ продвинулись настолько, что они слились
воедино и каждый из них привносит свои специфические
методы и инструменты, которые позволяют выполнять ана¬
лиз больших данных.
Высокий уровень развития практики этих областей стиму¬
лировал и позволил реализовать главную часть функцио¬
нальных возможностей, ожидаемых от современных реше¬
ний для больших данных, сред и платформ.
Цифровизация
Для многих предприятий цифровые средства заменили фи¬
зические средства в качестве фактического обмена данны¬
ми и механизма доставки.
Использование цифровых артефактов экономит время и за¬
траты, так как их распространение поддерживается глобаль¬
74
Основы Big Data
ной, существовавшей ранее инфраструктурой Интернета. По
мере того как потребители подключаются к бизнесу посред¬
ством своего взаимодействия с цифровыми эквивалентны¬
ми заменами, это приводит к возможности сбора дополни¬
тельных «вторичных» данных; например, предлагая клиенту
оставить контакты для обратной связи, заполнить анкету или
просто предоставить средство для показа релевантного ре¬
кламного объявления и отслеживания его рейтинга кликов.
Сбор вторичных данных важен для предприятий, поскольку
их анализ может обеспечить персонифицированный марке¬
тинг, автоматические рекомендации и разработку оптимизи¬
рованных характеристик продукта. На рисунке 2.4 визуально
представлены примеры цифровизации.
Рисунок 2.4
Примеры цифровизации
включают онлайн-банкинг,
телевидение по требова¬
нию и потоковое видео.
счета
Доступные технологии
и стандартные аппаратные средства
Технологии, способные хранить и обрабатывать большое ко¬
личество разнообразных данных, становятся все более до¬
ступными. Кроме того, решения для больших данных часто
используют программное обеспечение с открытым исход¬
ным кодом, которое выполняется на стандартных аппарат¬
ных средствах, что дополнительно снижает затраты. Ком¬
бинирование стандартного оборудования и программного
обеспечения с открытым исходным кодом практически лик¬
видировало преимущество крупных предприятий, которые
Бизнес-мотивация и стимулы
75
могли значительно опережать своих менее крупных конку¬
рентов только за счет большего размера своих 1Т-бюджетов.
Технология больше не дает конкурентного преимущества.
Вместо этого она просто становится платформой, на кото¬
рой осуществляется решение задач бизнеса. С точки зрения
бизнеса использование доступных технологий и недорогого
стандартного оборудования для получения аналитических
результатов, которые могут дополнительно оптимизировать
выполнение бизнес-процессов, является путем к достиже¬
нию конкурентного преимущества.
Использование стандартного оборудования делает доступ¬
ным принятие решений на основе больших данных для
компаний без крупных капиталовложений. На рисунке 2.5
приведен пример снижения цен на хранение данных за по¬
следние 20 лет.
Рисунок 25
Цены нэ нрэнение данный в течение десятилетий резко упали с более чем 10 000 долларов до
менее чем 0,10 доллара за Гбайт.
76
Основы Big Data
Социальные сети
Появление социальных сетей позволило клиентам получать
обратную связь в режиме, близком к реальному времени,
через открытые и общедоступные среды передачи данных.
Это вынудило предприятия учитывать отзывы клиентов о
своих услугах и предложениях в стратегическом планирова¬
нии. В результате компании сохраняют все больше данных о
взаимодействии с клиентами в своих системах управления
взаимоотношениями с клиентами (CRM), а также собирают
отзывы, жалобы и благодарности клиентов в социальных
сетях. Эта информация является исходным материалом для
алгоритмов анализа больших данных, которые выявляют
мнение клиента в попытке обеспечить более высокий уро¬
вень обслуживания, увеличить продажи, предоставить це¬
ленаправленный маркетинг и даже создать новые продукты
и услуги. Компании поняли, что деятельность по продвиже¬
нию брендов больше не управляется только внутренней мар¬
кетинговой активностью. Вместо этого бренды продуктов и
корпоративная репутация создаются совместно компанией
и ее клиентами. По этой причине предприятия все больше
заинтересованы в использование общедоступных наборов
данных из социальных сетей и других внешних источников
данных.
Сообщества и устройства,
связанные коммуникационными сетями
Расширение охвата сети Интернет, распространение сото¬
вой связи и сетей Wi-Fi позволило увеличить число людей и
их устройств в виртуальных сообществах. В сочетании с рас¬
пространением подключенных к Интернету сенсоров основа
Интернета Вещей (1оТ) — обширная коллекция интеллекту¬
альных, подключенных к Интернету устройств. Как показа¬
но на рисунке 2.6, это, в свою очередь, привело к значитель¬
ному увеличению количества доступных потоков данных. В
то время как некоторые потоки являются общедоступными,
другие потоки направляются непосредственно в корпора¬
Бизнес-мотивация и стимулы
77
ции для анализа. Например, на основе исполнения догово¬
ров по меджменту, связанных с тяжелым оборудованием,
используемым в горнодобывающей промышленности, уда¬
лось стимулировать оптимальную работу профилактиче¬
ского и прогностического обслуживания, чтобы уменьшить
необходимость простоев и избежать простоев, связанных с
внеплановым корректирующим обслуживанием. Это требу¬
ет детального анализа показаний сенсоров, генерируемых
оборудованием для раннего обнаружения проблем, которые
могут быть устранены с помощью упреждающего планиро¬
вания мероприятий по техническому обслуживанию.
Рисунок 2.6
Сообщества и устройства, связанные коммуникационными сетями, включают
в себя телевизионную аппаратуру, переносные компьютеры, RFID, нолодильники,
GPS-устройства, мобильные устройства и смарт счетчики.
Облачные вычисления
Прогресс в облачных вычислениях привел к созданию сред,
способных обеспечивать высокомасштабируемые 1Т-ресур-
сы по требованию, которые можно арендовать с помощью
моделей оплаты по мере использования. У предприятий
есть возможность использовать сервисы инфраструктуры,
хранения и обработки данных, предоставляемые этими сре¬
дами, для создания масштабируемых решений для больших
данных, которые могут выполнять широкомасштабные за¬
78
Основы Big Data
дачи обработки. Несмотря на то, что традиционно эти сре¬
ды считаются выведенными за пределы компании и обычно
они изображаются символом облака, компании также ис¬
пользуют программное обеспечение управления облаками
для создания в удаленных облаках более эффективного ис¬
пользования существующих инфраструктур с помощью вир¬
туализации. В любом случае способность облака динамиче¬
ски масштабироваться в зависимости от нагрузки позволяет
создавать устойчивые аналитические среды, которые мак¬
симизируют эффективное использование ресурсов ИКТ.
На рисунке 2.7 показан пример того, как облачная среда
может использоваться для возможностей ее масштабирова¬
ния при выполнении задач обработки больших данных. Тот
факт, что удаленные облачные ИТ-ресурсы можно арендо¬
вать, существенно сокращает необходимые предваритель¬
ные инвестиции в проекты больших данных.
Рисунок 27
Облако может использоваться для выполнения анализа данный по запросу
в конце каждого месяца или для горизонтального масштабирования при
увеличении нагрузки.
Бизнес-мотивация и стимулы
79
Это имеет смысл для предприятий уже использующих облач¬
ные вычисления, чтобы повторно задействовать облако для
инициатив по использованию больших данных, поскольку:
• персонал уже обладает необходимыми навыками облач¬
ных вычислений;
• исходные данные уже присутствуют в облаке.
Миграция в облако логична для предприятий, планирую¬
щих использовать аналитику на наборах данных, которые
доступны через витрины данных, так как многие витрины
данных делают свои наборы доступными в облачной среде,
например Amazon S3.
Проще говоря, облачные вычисления могут обеспечить три
основных компонента, необходимых для решений больших
данных: внешние наборы данных, возможности масштаби¬
руемой обработки и большие объемы хранилища данных.
Интернет Всего (1оЕ)
Процесс слияния достижений в области информационных
и коммуникационных технологий, динамики рынка, биз-
нес-архитектуры и управления бизнес-процессами, способ¬
ствуют развитию того, что сейчас известно как Интернет
Всего (Internet of Everything или IoE). 1оЕ комбинирует сер¬
висы, предоставляемые интеллектуальными устройствами
Интернета Вещей (Internet of Things — 1оТ), подключенными
к сети с бизнес-процессами, имеющими ясную цель, и ко¬
торые обладают способностью предоставлять уникальные и
различные ценные предложения.
Это является платформой для инноваций, которая позво¬
ляет создавать новые продукты и услуги, а также новые
источники доходов для компаний. Большие данные являют¬
ся основой для IoE. Большие данные являются сердцем IoE.
Сообщества и устройства, связанные коммуникационными
сетями, что работают на доступных технологиях и аппарат¬
80
Основы Big Data
ных средствах, передают потоки цифровых данных, кото¬
рые подвержены аналитическим процессам, размещенным
в средах с гибкими облачными вычислениями.
Результаты анализа могут дать представление о том, как
много ценной информации было сгенерировано текущим
процессом и должен ли процесс активно искать возможно¬
сти для дальнейшей оптимизации.
Компании, ориентированные на 1оЕ, могут использовать
большие данные для создания и оптимизации технологи¬
ческих процессов, и предлагать их третьим сторонам в ка¬
честве внешних бизнес-процессов. Как было установлено в
Манифесте бизнес-процессов под редакцией Роджера Берл-
тона (Roger Burlton, 2011), бизнес-процессы организации
являются источником для формирования результатов, име¬
ющих ценность для клиентов и других заинтересованных
сторон. В сочетании с анализом потоковых данных и поль¬
зовательского контекста возможность адаптировать выпол¬
нение этих процессов для согласования с целями клиента
станет ключевым отличием корпораций в будущем.
Примером области, которая извлекла выгоду от 1оЕ, является
точное сельское хозяйство, и ведущие позиции здесь зани¬
мают традиционные производители сельскохозяйственного
оборудования.
При объединении в систему систем, GPS-управляемых трак¬
торов, сенсоров влажности и удобрения в полевых условиях,
сенсоров полива по мере необходимости, внесения удобре¬
ний, системы применения пестицидов и оборудования для
посева с системой регулирования нормы высева, можно уве¬
личить производительность полевых работ с минимальны¬
ми затратами. Точное земледелие позволяет использовать
альтернативные подходы к сельскому хозяйству, которые
бросают вызов промышленным монокультурным фермам.
С помощью 1оЕ небольшие фермы могут конкурировать за
счет использования разнообразия сельскохозяйственных
культур и экологически чувствительных методов. Помимо
Бизнес-мотивация и стимулы
81
наличия подключенного интеллектуального сельскохозяй-
ственного оборудования, анализ больших данных и данных
полевых сенсоров может управлять системой поддержки
принятия решений для помощи фермерам и их машинам
для получения оптимальных урожаев.
ПРИМЕРЫ ИЗ ПРАКТИКИ
Комитет старших менеджеров ETI исследовал ухудшение
финансового положения компании и понял, что многие
из текущих проблем корпорации могли бы быть обнару¬
жены ранее. Если бы руководство на тактическом уровне
было более осведомленным, оно могло бы предпринять
активные действия, чтобы избежать некоторых потерь.
Отсутствие своевременного предупреждения объясня¬
лось тем, что ETI не осознавало изменения динамики
рынка. Новые конкуренты, используя передовые техно¬
логии для обработки заявок и определения выплат, на¬
рушили равновесие рынка и заняли долю в бизнесе ETI.
В то же время, отсутствие у компании системы для обна¬
ружения сложных прецедентов мошенничеств было ис¬
пользовано недобросовестными клиентами и, возмож¬
но, даже организованной преступностью.
Команда высшего руководства сообщила о своих ре¬
зультатах команде исполнительного руководства. Впо¬
следствии, в свете предыдущих установленных страте¬
гических целей, вводится новый набор корпоративных
и инновационных приоритетов. Эти инициативы будут
использоваться для направления и сопровождения кор¬
поративных ресурсов на решения, которые повысят спо¬
собности ETI к увеличению прибыли.
Принимая во внимание изменения, вводятся дисципли¬
ны управления бизнес-процессами для документирова¬
ния, анализа и улучшения обработки заявок. Затем эти
модели бизнес-процессов будут использоваться систе¬
82
Основы Big Data
мой управления бизнес-процессами (BPMS), которая, по
сути, является основой для автоматизации процессов,
чтобы обеспечить последовательное и контролируемое
выполнение процесса. Это поможет ETI продемонстри¬
ровать соблюдение нормативных требований. Дополни¬
тельным преимуществом использования BPMS является
то, что отслеживание заявок, обработанных системой,
включает информацию о том, какие сотрудники об¬
служивали эту заявку. Несмотря на то что не было под¬
тверждений, есть подозрение, что некоторая часть обра¬
ботанных мошеннических заявок может быть отслежена
сотрудниками, которые подрывают внутреннюю систе¬
му ручного управления, определенную корпоративной
политикой. Другими словами, BPMS позволит не только
расширить возможности для удовлетворения внешних
нормативных требований, но и обеспечит соблюдение
стандартных рабочих процедур и методов работы в рам¬
ках ETI.
Оценивание рисков и обнаружение мошенничества бу¬
дут расширены благодаря применению инновационных
технологий по обработке больших данных, которые по¬
зволят получить аналитические результаты для управ¬
ления процессом принятия решений на основе данных.
Результаты оценивания риска помогут страховым ста¬
тистам уменьшить свою зависимость от интуиции, пре¬
доставив им сгенерированные метрики оценки степени
риска. Кроме того, выводы о возможности обнаружения
мошенничества будут включены в автоматизированный
рабочий процесс обработки заявок. Результаты по обна¬
ружению мошенничества также будут использоваться
для направления сомнительных заявок опытным специ¬
алистам по страховым выплатам. А они, в свою очередь,
смогут более тщательно оценивать характер заявки от¬
носительно ответственности по заявкам ETI и вероят¬
ность того, что заявка действительно является мошен¬
нической.
Бизнес-мотивация и стимулы
83
Со временем эта ручная обработка может привести к
большей автоматизации, поскольку решения специали¬
стов по страховым выплатам отслеживаются BPMS и мо¬
гут использоваться для создания обучающего комплекса
о заявках, которые включают решение о том, было или не
было заявки признанной мошеннической. Эти обучающие
комплексы расширят возможности ETI при выполнении
прогностической аналитики, так как наборы данных могут
быть использованы автоматическим классификатором.
Разумеется, руководители также понимают, что они
были не в состоянии постоянно оптимизировать опе¬
рации ETI, потому что они недостаточно улучшали дан¬
ные для генерирования знаний. Причина этого связана
с отсутствием понимания бизнес-архитектуры. В целом,
руководители понимают, что они обрабатывали каждое
статистическое измерение как ключевой показатель эф¬
фективности (KPI). Это привело к появлению множества
анализов, но поскольку в них не доставало предметно¬
го акцента, они не давали потенциальной ценности.
С осознанием того, что KPI являются показателями более
высокого уровня и их меньше по количеству, было лег¬
ко согласоваться с несколькими показателями, которые
должны контролироваться на тактическом уровне.
Кроме того, руководители всегда испытывали затрудне¬
ния при согласовании выполнения бизнес-процессов со
стратегическим исполнением. Отчасти это было вызвано
отсутствием определения критических факторов успеха
(Critical Success Factors — CSF). Стратегические цели и за¬
дачи должны оцениваться как CSF, а не KPI. Внедрение
CSF помогло ETI связать и согласовать стратегический,
тактический и операционный уровни их бизнеса. Испол¬
нительные и управленческие команды будут вниматель¬
но следить за их новой инициативой в области измере¬
ния и оценивания в стремлении оценить преимущества,
которые она предоставит в течение следующего квартала.
84 Основы Big Data
Окончательное решение было принято руководством
ETI. Это решение создало новую организационную роль,
отвечающую за управление инновациями. Руководители
поняли, что компания стала слишком интроспективной.
Погрязнув в работе по управлению четырьмя линиями
страховых продуктов, команда не смогла понять, что
рынок меняется. Группа была удивлена, узнав о пользе
больших данных, а также современных инструментов и
технологий для аналитики данных.
Аналогично, хотя они оцифровали свой электронный
биллинг и широко использовали технологии сканиро¬
вания для обработки заявок, они не предполагали, что
использование клиентами технологий смартфона может
привести к появлению новых каналов цифровой инфор¬
мации, которые могут еще больше упростить обработку
заявок. Хотя руководители не считают, что они в состо¬
янии внедрить облачные технологии на уровне инфра¬
структуры, они рассмотрели возможности использова¬
ния внешнего программного обеспечения в качестве
провайдера сервисов для снижения эксплуатационных
расходов, связанных с управлением их взаимоотноше¬
ниями с клиентами.
При этом команды исполнительного и руководящего
звена считают, что они решают организационные во¬
просы по согласованию, предлагают уместный план для
внедрения дисциплин и технологий управления биз-
нес-процессами и успешно применяют большие данные,
что позволит увеличить их способность чувствовать ры¬
нок и, следовательно, лучше адаптироваться к изменяю¬
щимся условиям.
Переход
к большим данным
и вопросы планирования
Организационные предпосылки
Приобретение данных
Конфиденциальность
Безопасность
Происхождение
Ограничения поддержки в реальном времени
Особые проблемы производительности
Особые требования к руководству
Методология
Облака
Жизненный цикл аналитики больших данных
86
Инициативы относительно больших данных носят стра¬
тегический характер и должны быть ориентированы
на бизнес. Переход к большим данным может быть транс¬
формационным, но чаще всего является инновационным.
Трансформационная деятельность, как правило, представ¬
ляет собой работу с низким уровнем риска, направленную
на повышение эффективности и результативности. Иннова¬
ции же требуют изменения мышления, потому что они кар¬
динально изменяют структуру бизнеса как в его продуктах,
услугах, так и в организации. Такова сила перехода к боль¬
шим данным; она может позволить такие виды изменений.
Управление инновациями требует осторожности — слишком
много контролирующих сил могут задавить инициативу и
ослабить результаты, а недостаток контроля может превра¬
тить проект с наилучшими замыслами в научный экспери¬
мент, который никогда не принесет обещанных результатов.
Именно на этой основе в главе 3 рассматривается переход к
большим данным и вопросы планирования.
Учитывая характер больших данных и их аналитическую
силу, следует обратить внимание на множество проблем,
которые необходимо рассмотреть и спланировать в пер¬
вую очередь. Например, с внедрением какой-либо новой
технологии необходимо решить проблему обеспечения ее
средствами в соответствии с существующими корпоратив¬
ными стандартами. Проблемы, связанные с отслеживанием
происхождения набора данных от их доставки до их исполь-
Переход к большим данным и вопросы планирования
87
зования, часто являются следствием новых требований к
организациям. Необходимо планировать управление кон¬
фиденциальностью составляющих компонентов, данные
которых обрабатываются или чьи идентификационные дан¬
ные выявляются аналитическими процессами.
Большие данные даже открывают дополнительные воз¬
можности для рассмотрения перехода от локальных сред и
в удаленные, масштабируемые среды, размещенные в об¬
лаке. Большие данные также открывают дополнительные
возможности для планирования перемещения от локальных
сред к удаленно-настраиваемым, масштабируемым средам,
которые размещаются в облаке.
На самом деле все вышеупомянутые соображения требуют
от организаций одобрения и обеспечения ряда особых про¬
цессов руководства и платформы принятия решений для
того, чтобы гарантировать, что ответственные стороны по¬
нимают природу больших данных, последствия перехода к
ним и требования к управлению ними.
В пределах организации переход к большим данным изменя¬
ет подход к выполнению бизнес-аналитики. По этой причине
в этой главе представлен жизненный цикл аналитики боль¬
ших данных. Жизненный цикл начинается с создания биз-
нес-модели для проекта больших данных и заканчивается
тем, что аналитические результаты развертываются в орга¬
низации для получения максимальной ценности. Существу¬
ет ряд промежуточных этапов, которые организуют шаги по
идентификации, приобретению, фильтрации, извлечению,
очистке и агрегированию данных. Все это необходимо прово¬
дить до начала анализа. Для выполнения этого жизненного
цикла требуются новые компетенции, которые должны быть
разработаны или позаимствованы для организации.
Как показано ранее, при переходе к большим данным, по¬
является много вещей, которые необходимо принимать во
внимание. В этой главе описываются основные потенциаль¬
ные проблемы и соображения.
88
Основы Big Data
Организационные предпосылки
Платформы для больших данных не являются решениями
«под ключ». Для того чтобы при анализе данных и анали¬
тике создавалась ценная информация, предприятиям необ¬
ходимо иметь системы управления данными и платформы
управления большими данными. Также необходимы контро¬
лирующие процессы и достаточный набор навыков для тех,
кто будет нести ответственность за внедрение, настройку,
наполнение и использование решений для больших данных.
Кроме того, необходимо оценить качество данных, предна¬
значенных для обработки решений для больших данных.
Устаревшие, недопустимые, или плохо идентифицирован¬
ные данные приведут к некачественным исходным данным,
которые, независимо от того, насколько хорошим было ре¬
шение для больших данных, будет продолжать производить
результаты низкого качества. Время жизни среды больших
данных также должно планироваться. Также необходимо
разработать перспективный план для гарантии того, что лю¬
бое необходимое расширение или дополнение среды плани¬
ровалось в соответствии с требованиями предприятия.
Приобретение данных
Приобретение самих законченных решений для больших
данных может быть экономичным благодаря наличию плат¬
форм и инструментов с открытым исходным кодом, а также
возможностей для использования стандартных аппаратных
средств. Однако для получения внешних данных по-преж¬
нему могут потребоваться значительные финансовые затра¬
ты. Природа бизнеса может сделать внешние данные очень
ценными. Чем больше объем и разнообразие данных, кото¬
рые можно предоставить, тем выше шансы найти скрытые
идеи из шаблонов.
Внешние источники данных включают в себя правитель¬
ственные источники и коммерческие витрины. Данные,
предоставляемые правительством (например, картографи¬
Переход к большим данным и вопросы планирования
89
ческие), могут быть бесплатными. Тем не менее, большин¬
ство релевантных коммерческих данных необходимо будет
приобрести, что может подразумевать дальнейшие затраты
на подписку на эти данные, чтобы обеспечить доставку об¬
новлений для подготовленных наборов данных.
Конфиденциальность
Выполнение аналитической обработки данных может рас¬
крыть конфиденциальную информацию об организации или
частных лицах. Даже анализируя отдельные наборы данных,
которые содержат, казалось бы, безвредную информацию,
можно раскрыть личную информацию при совместном анали¬
зе наборов данных. Это может привести к преднамеренному
или непреднамеренному нарушению конфиденциальности.
Решение этих проблем конфиденциальности требует пони¬
мания природы накапливаемых данных и соответствующих
правил конфиденциальности информации, а также специ¬
альных методов для маркировки и деперсонализации (ма¬
скирования) данных. Например, телеметрические данные,
такие как GPS-журнал автомобиля или данные смарт-счет-
чиков, собранные за продолжительный период времени,
могут показать местоположение и поведение человека, как
показано на рисунке 3.1.
Джон 27 лет
женат
двое детей
живет в Нью-Йорке
заказывает пиццу по
понедельникам
читает документальные романы
Рисунок 3.1
информация, полученная на основе выполняемой аналитики
по графическим файлам, реляционным данным и текстовым
данным, используется для создания профиля Джона.
i J
графические
файлы
90
Основы Big Data
Безопасность
Некоторым компонентам решений для больших данных не
хватает надежности традиционных сред корпоративных ре¬
шений, когда дело доходит до контроля доступа и защиты
данных. Защита больших данных предполагает обеспечение
достаточной защиты для сетей передачи данных и репози¬
ториев с помощью механизмов аутентификации и автори¬
зации.
Безопасность больших данных также предусматривает уста¬
новление уровней доступа к данным для различных катего¬
рий пользователей. Например, в отличие от традиционных
систем управления реляционными базами данных, базы
данных NoSQL, как правило, не предоставляют надежных
встроенных механизмов безопасности. Вместо этого они
полагаются на простые API-интерфейсы на основе HTTP, в
котором данные передаются в незашифрованном виде, что
делает данные уязвимыми к сетевым атакам, как показано
на рисунке 3.2.
Рисунок 32
Базы данный AoSDl могут быть уязвимыми перед сетевыми атаками.
Происхождение
Происхождение относится к информации об источнике
данных и о том, как они будут обработаны. Информация о
происхождении помогает определять подлинность и каче¬
ство данных, что может использоваться для целей аудита.
Переход к большим данным и вопросы планирования
91
Поддержка происхождения для большого объема данных,
который был получен, объединен и прошел через несколько
этапов обработки, может быть сложной задачей. На разных
этапах жизненного цикла аналитики, данные будут нахо¬
диться в разных состояниях из-за того, что они могут пе¬
редаваться, обрабатываться или храниться. Эти состояния
соответствуют понятиям «данные в движении», «данные в
использовании» и «данные в состоянии покоя». Важно отме¬
тить, что всякий раз, когда большие данные изменяют свое
состояние, они должны инициировать сбор информации о
происхождении, которая записывается как метаданные.
Когда данные попадают в аналитическую среду, запись их
происхождения может быть инициализирована записью
информации, которая фиксирует историю жизни данных.
В конечном счете, целью получения происхождения явля¬
ется возможность аргументирования полученных анали¬
тических результатов, зная происхождение данных, и ана¬
лиз шагов или алгоритмов используемых для обработки
данных, которые привели к имеющемуся результату. Ин¬
формация о происхождении имеет важное значение для
понимания ценности аналитического результата. Подобно
научным исследованиям, если результаты нельзя оправдать
и повторить, они не заслуживают доверия. Когда информа¬
ция о происхождении регистрируется на пути к получению
аналитических результатов, как показано на рисунке 3.3,
результаты могут быть более надежными и, следовательно,
использоваться с уверенностью.
Ограничения поддержки в реальном времени
Информационные панели и другие приложения, которые за¬
прашивают потоковую передачу данных и оповещений, часто
требуют передачи данных в режиме реального времени или
почти реального времени. Многие решения и инструменты
для больших данных с открытым исходным кодом ориенти¬
рованы на пакетную обработку; однако появилось новое по¬
коление инструментальных средств с открытым исходным
92
Основы Big Data
кодом для поддержки потокового анализа данных. Многие из
решений для анализа данных в реальном времени, которые
действительно существуют, являются запатентованными.
Подходы, которые позволяют достичь результатов в почти ре¬
альном времени, часто обрабатывают транзакционные дан¬
ные по мере их поступления и комбинируют их с данными,
обобщенными ранее пакетной обработкой.
текстовые
данные
Source ID
Acquired Data
Size
2 этап •
обработки ;
Source ID
Acquired Data
Size
Processing Steps: 1
DRMS
граница предприятия
Рисунок 3.3
Данные могут также быть аннотированы атрибутами иснодного набора данный
и подробными сведениями о шаге обработки, поскольку они проводят через
шаги преобразования данный.
Source ID
Acquired Data
Size
Processing Steps: 1,2
Особые проблемы производительности
Ввиду объемов данных, которые требуются для обработки
некоторых решений для больших данных, производитель¬
ность часто является проблемой. Например, большие набо-
Переход к большим данным и вопросы планирования
93
ры данных в сочетании со сложными алгоритмами поиска
могут привести к увеличению времени обработки запросов.
Другая проблема производительности связана с пропускной
способностью сети. При увеличении объема данных время
передачи единицы данных может превышать фактическое
время обработки, как показано на рисунке 3.4.
Рисунок 3.4
Передача 1 петабайта данный через
1-гигабитное 1АП-соединение с про¬
пускной способностью 80% займет
приблизительно 2750 часов
1 петабайт
1 петабайт
t, -^= 2,750 часов
Особые требования к руководству
Решения для больших данных имеют доступ к данным и гене¬
рируют данные, которые становятся активами компании. Не¬
обходима структура руководства, которая обеспечивала бы то,
что сами данные и среда решения регулировались, стандарти¬
зировались и эволюционировали контролируемым образом.
Примеры того, что может охватывать структура руководства
большими данными, включают:
• стандартизацию того, как тегируются данные и как мета¬
данные используются для тегирования
• политики, которые регулируют тип приобретенных внеш¬
них данных
• политики в отношении обеспечения конфиденциально¬
сти данных и анонимности (обезличивания) данных
• политики для архивирования источников данных и ре¬
зультатов анализа
• политики, устанавливающие рекомендации по очистке и
фильтрации данных
94
Основы Big Data
Методология
Требуется методология для управления как потоками дан¬
ных, так и решениями для больших данных. Необходимо
рассмотреть способ создания цикла обратной связи для воз¬
можности подвергнуть уже обработанные данные повторной
обработке, как показано на рисунке 3.5. Например, можно
использовать итеративный подход, чтобы бизнес-персонал
мог периодически предоставлять обратную связь IT-персо¬
налу. Каждый цикл обратной связи дает возможности для
доработки системы путем изменения процедур подготовки
или анализа данных.
Рисунок 15
Кэждое повторение может
помочь в тонкой нэстройке
этапов обработки, алгоритмов
и моделей данный для повы¬
шения точности результатов
и эффективности бизнеса
персонал
получение
данных
бизнес-
персонал
обработка
данных
визуализация
данных
анализ
данных
Облака
Как уже упоминалось в главе 2, помимо всего прочего, об¬
лака предоставляют удаленные среды, которые могут содер¬
жать IT-инфраструктуру для широкомасштабного хранения
и обработки информации. Независимо от того, пользуется
ли организация облачной средой, переход к среде больших
данных может потребовать, чтобы часть или вся эта среда
размещалась в облаке. Например, предприятие, которое
установило свою CRM-систему в облаке, решает, нужно ли
Переход к большим данным и вопросы планирования
95
добавить решение для больших данных в ту же облачную
среду, чтобы выполнить аналитику CRM на данных. Затем
эти данные, которые находится в пределах границ предпри¬
ятия, могут совместно использоваться с первичной средой
больших данных.
Общие обоснования для включения облачной среды в под¬
держку решения для работы с большими данными включают:
• неадекватные внутренние аппаратные ресурсы
• недоступны предварительные капиталовложения для за¬
купки систем
• проект должен быть изолирован от остальной части биз¬
неса, чтобы не влиять на существующие бизнес-процессы;
• инициативы больших данных являются апробированием
концепции
• наборы данных, которые необходимо обработать, уже яв¬
ляются резидентами облака
• достигаются пределы доступных вычислительных ресур¬
сов и ресурсов хранения, используемых внутри компании
для решений больших данных
Жизненный цикл аналитики больших данных
Анализ больших данных отличается от традиционного
анализа данных в первую очередь ввиду характеристик
обрабатываемых данных, таких как объем, скорость и раз¬
нообразие. Для удовлетворения различных требований к
выполнению анализа больших данных необходима поэтап¬
ная методология для организации действий и задач, связан¬
ных с приобретением, обработкой, анализом и повторным
использованием данных. В следующих разделах рассматри¬
вается конкретный жизненный цикл аналитики данных,
который организует и обеспечивает выполнение задач и
действий, связанных с анализом больших данных. С точки
96
Основы Big Data
зрения внедрения больших данных и перспективного пла¬
нирования важно, чтобы в дополнение к жизненному циклу
учитывались вопросы обучения, образования, оснащения и
кадрового укомплектования персонала команды аналитики
данных.
Жизненный цикл аналитики больших данных можно разде¬
лить на следующие девять этапов, как показано на рисунке 3.6:
1. Оценивание
бизнес-ситуации
2. Идентификация данных
3. Сбор и фильтрация
данных
4. Извлечение данных
5. Проверка и очистка
данных
6. Агрегирование
и представление данных
7. Анализ данных
8. Визуализация данных
9. Использование
результатов анализа
Этап 1
Рисунок 3.6
Девять этапов жизненного цикла аналитики
больший данный.
Переход к большим данным и вопросы планирования
97
Оценка бизнес-ситуации
Каждый жизненный цикл аналитики больших данных дол¬
жен начинаться с четко определенной бизнес-ситуации,
которая дает четкое представление об обосновании, мотива¬
ции и целях проведения анализа. На этапе оценивания бизнес-
ситуации, показанном на рисунке 3.7, необходимо создать
экономическое обоснование, оценить и утвердить его до
начала выполнения реальных практических задач анализа.
Рисунок 3.7
Первый этап жизненного
цикла аналитики больший
данный
Этап 1
Оценивание аналитики больших данных компании помога¬
ет руководителям определить бизнес-ресурсы, которые не¬
обходимо будет использовать, и круг бизнес-задач, которые
будут решаться с помощью анализа. Дальнейшее определе¬
98
Основы Big Data
ние KPI на этом этапе может помочь определить критерии
оценки и руководство для оценивания результатов анали¬
тики. Если KPI не являются легкодоступными, необходимо
приложить усилия для достижения целей аналитического
проекта SMART, который расшифровывается (побуквенно)
как конкретность, измеримость, достижимость, актуаль¬
ность и своевременность.
На основе бизнес-требований, описанных на этапе биз-
нес-ситуации, можно определить действительно ли про¬
блемы бизнеса рассматриваются как проблемы больших
данных. Для того, чтобы квалифицироваться как проблема
больших данных, бизнес-задача должна быть непосред¬
ственно связана с одной или несколькими характеристика¬
ми больших данных такими, как объем, скорость или много¬
образие.
Отметим также, что еще одним результатом этого этапа яв¬
ляется определение базового бюджета, необходимого для
выполнения проекта анализа. Все необходимые затраты, на
инструменты, оборудование и обучение, должны быть про¬
считаны заранее, чтобы предполагаемые инвестиции можно
было сопоставить с ожидаемыми выгодами от достижения
целей. Первоначальные итерации жизненного цикла ана¬
литики больших данных потребуют больше авансовых ин¬
вестиций в технологии, продукты и обучение для больших
данных по сравнению с поздними итерациями, где ранние
инвестиции могут быть повторно использованы.
Идентификация данных
Этап идентификации данных, показанный на рисунке 3.8,
посвящен определению наборов данных, необходимых для
аналитических проектов и их источников.
Выявление более широкого спектра источников данных
может увеличить вероятность обнаружения скрытых зако¬
номерностей и корреляций. Например, чтобы дать анали¬
тическое заключение, может быть полезно определить как
Переход к большим данным и вопросы планирования
99
Рисунок 3.8
идентификация данный -
это второй этап жизненно¬
го цикла аналитики
больший данный.
Этап 1
Оценивание
бизнес-сиУуации
Этап 2
+
Идентификация
данных
Этап 3
Сбор и
фильтрация
данных
Этап 4 |
Извлечение
данных
Этап 5 |
Проверка и
очистка данных
Агрегирование и
представление
данных
можно больше типов связанных источников данных, осо¬
бенно когда неясно, что именно нужно искать.
В зависимости от сферы деятельности проекта анализа и ха¬
рактера решаемых бизнес-задач, требуемые наборы данных
и их источники могут быть внутренними и/или внешними
для предприятия.
В случае внутренних наборов данных, списки доступных на¬
боров данных из внутренних источников, таких как витрины
данных и операционные системы, составляются и сравнива¬
ются с заранее определенной спецификацией набора данных.
При работе с внешними наборами данных составляется спи¬
сок возможных сторонних поставщиков, таких как витри¬
100
Основы Big Data
ны данных и общедоступные наборы данных. Некоторые
формы внешних данных могут быть встроены в блоги или
другие типы веб-сайтов на основе контента, и в этом случае
они, возможно, должны быть собраны с помощью автомати¬
зированных инструментов.
Сбор и фильтрация данных
На этапе сбора и фильтрации данных, показанном на ри¬
сунке 3.9, данные собираются из всех источников, которые
были идентифицированы на предыдущем этапе. Затем по¬
лученные данные подвергаются автоматизированной филь¬
трации для удаления поврежденных или таких, которые не
имеют особого значения для целей анализа.
Рисунок 3.9
Третий этап жизненного
цикла аналитики больший
данный.
Этап 1
Переход к большим данным и вопросы планирования
101
В зависимости от типа источника данные могут поступать
как набор файлов, например, данные, приобретенные у сто¬
роннего поставщика, или могут потребовать интеграции
API, например, с Twitter. Во многих случаях, особенно в слу¬
чае внешних неструктурированных данных, некоторые или
большинство полученных данных могут быть нерелевантны¬
ми (шумом) и могут быть отброшены в процессе фильтрации.
Данные, классифицированные как «искаженные», могут
включать записи с отсутствующими или бессмысленными
значениями или недопустимыми типами данных. Данные,
отфильтрованные для одного анализа, могут быть значи¬
мыми для другого типа анализа. Поэтому рекомендуется
сохранить точную копию исходного набора данных перед
началом фильтрации. Чтобы свести к минимуму требуемое
пространство для хранения, точная копия может быть сжата.
Необходимо сохранить как внутренние, так и внешние данные
после генерирования или использования внутри компании.
Для пакетной аналитики эти данные сохраняются на диске пе¬
ред началом анализа. В случае аналитики в реальном времени
данные сначала анализируются, а затем сохраняются на диске.
Рисунок 3.10
Метаданные добавляются к данным
из внутренний и внешний источников.
102
Основы Big Data
Как показано на рисунке 3.10, метаданные могут быть до¬
бавлены посредством системы автоматического управления
и контроля к данным из внутренних и внешних источников
данных для улучшения классификации и запросов. При¬
меры добавленных метаданных включают в себя размер и
структуру набора данных, информацию об источнике, дату
и время создания или сбора, а также ориентированную на
конкретный язык информацию. Очень важно, чтобы мета¬
данные были машиночитаемыми и передавались далее на
последующие этапы анализа. Это помогает поддерживать
происхождение данных на протяжении всего жизненного
цикла аналитики больших данных, что помогает устанавли¬
вать и сохранить точность и качество данных.
Извлечение данных
Некоторые данные, идентифицированные как входные
данные для анализа, могут поступать в формате, несовме¬
стимом с решением для работы с большими данными. Не¬
обходимость обращаться к несопоставимым типам данных
более вероятна при работе с данными из внешних источни¬
ков. Этап жизненного цикла извлечения данных, показан¬
ный на рисунке 3.11, предназначен для извлечения несопо¬
ставимых данных и преобразования их в формат, который
базовое решение для больших данных может использовать в
целях анализа данных.
Необходимая степень извлечения и преобразования зависят от
типов аналитики и возможностей решения для больших дан¬
ных. Например, извлечение обязательных полей из текстовых
данных с разделителями, таких как файлы журнала веб-серве¬
ра, может не понадобиться, если базовые решения для боль¬
ших данных уже могут напрямую обрабатывать эти файлы.
Аналогично, извлечение текста для аналитики текста, ко¬
торый требует сканирования всех документов, упрощается,
если базовое решение для больших данных может напрямую
читать документ в его собственном формате.
Переход к большим данным и вопросы планирования
103
Рисунок 3.11
Четвертый этап жизнен¬
ного цикла аналитики
больший данным.
Этап 1
Оценивание
бизнес «ситуации
Этап 6
Этап 2
Агрегирование и
представление
данных
Идентификация
данных
Этап 7
Этап 3
Анализ данных
Сбор и
фильтрация
данных
! Этап 8
Визуализация
данных
Этап 4
Извлечение
данных
Этап 9
Этап 5
Использование
результатов
анализа
</TransactionlD>
3739251
</TransactionlD>
</UserlD>
23917
</UserlD>
<Date>
19980501
</Date>
User ID
Comments
23917
Website layout is confusing
Needs improvement.
<Comments>
Website layout is confusing
Needs improvement.
</Comments>
Рисунок 3.12
Комментарии и ID пользователя, извлеченные из КПП-документа
104
Основы Big Data
Рисунок 3.12 иллюстрирует извлечение комментариев и
идентификаторов пользователей, встроенных в XML-доку-
мент, без необходимости дальнейшего преобразования.
На рисунке 3.13 показано извлечение координат широты и
долготы пользователя из одного единого поля JSON.
Дальнейшее преобразование необходимо для разделения
данных на два отдельных поля, как того требует решение
для больших данных.
{
userid: 29317
name: John Doe
uri: www.arcitura.com
descriptton: education
location: 37.76, -122.42
}
User 10
Latitude
Longitude
23917
37.75
-122.42
Рисунок 3.13
идентификатор и координаты пользователя извлекаются из единого поля JSOH.
Проверка и очистка данных
Неправильные данные могут искажать и фальсифицировать
результаты анализа. В отличие от традиционных корпора¬
тивных данных, где структура данных заранее определена
и данные предварительно проверены, данные вводимые в
анализ больших данных могут быть неструктурированны¬
ми, без каких-либо указаний на достоверность. Эта слож¬
ность также может затруднить получение набора подходя¬
щих ограничений проверки.
Этап проверки и очистки данных, показанный на рисунке 3.14,
предназначен для создания зачастую сложных правил про¬
верки и удаления любых известных недопустимых данных.
Решения для больших данных часто получают избыточные
данные в разных наборах данных. Эта избыточность может
Переход к большим данным и вопросы планирования
105
использоваться для исследования взаимосвязанных набо¬
ров данных, чтобы собирать параметры проверки и запол¬
нять недостающие достоверные данные.
Рисунок 3.14
Пятый этап жизненного
цикла аналитики больший
данный.
Этап 1
Например, как показано на рисунке 3.15:
• Первое значение в наборе данных В проверяется на соот¬
ветствующее значение в наборе данных А.
• Второе значение в наборе данных В не проверяется на со¬
ответствие его значению в наборе данных А.
• Если значение отсутствует, оно вставляется из набора
данных А.
106
Основы Big Data
Рисунок 3.15
Проверка данный может использоваться для проверки взаимосвязанный
наборов данный, чтобы восполнить недостающие достоверные данные.
Для пакетной аналитики проверка данных и их очистка мо¬
гут быть выполнены с помощью автономной операции ETL.
Для аналитики в реальном времени требуется более сложная
система внутренней памяти для проверки и очистки данных
по мере их поступления из источника. Происхождение мо¬
жет играть важную роль в определении точности и качества
сомнительных данных. Данные, которые кажутся недопу¬
стимыми, могут по-прежнему иметь значимость, поскольку
они могут скрывать закономерности и тенденции, как пока¬
зано на рисунке 3.16.
Рисунок 3.16
Наличие неправильный данный
приводит к появлению резкий выбросов.
Несмотря на то что данные выглядят как
неправильные, они могут указывать на
новый шаблон.
Агрегирование и представление данных
Данные могут быть распределены по нескольким наборам
данных, требуя объединения наборов данных через об¬
щие поля, например дату или идентификатор (ID). В дру¬
гих случаях одни и те же поля данных могут отображаться
в нескольких наборах данных, таких как дата рождения.
Переход к большим данным и вопросы планирования
107
В любом случае, требуется метод свертки данных или необходимо
определить набор данных, представляющий правильное значение.
Этап агрегирования и представления данных, показанный на ри¬
сунке 3.17, предназначен для интеграции нескольких наборов дан¬
ных вместе для достижения унифицированного представления.
Рисунок 3.17
Шестой этап жизнен¬
ного цикла аналитики
больший данный.
Этап 1
Выполнение этого этапа может осложниться из-за различий в:
• структуре данных — хотя формат данных может быть од¬
ним и тем же, модель структуры данных может отличаться
• семантике— значение, отмеченное по-разному в двух
разных наборах данных, может означать одно и то же, на¬
пример «surname (фамилия)» и «last name (фамилия)»
108
Основы Big Data
Большие объемы, обрабатываемые решениями для больших
данных, могут сделать агрегирование данных долговремен¬
ным и трудоемким. Согласование этих различий может по¬
требовать сложной логики, которая выполняется автомати¬
чески без вмешательства человека.
На этом этапе необходимо учитывать требования к будуще¬
му анализу данных для возможности повторного использо¬
вания данных. Независимо от того, требуется или нет агреги¬
рование данных, важно понимать, что одни и те же данные
могут храниться в разных формах. Одна форма может лучше
подходить для определенного типа анализа, чем другая. На¬
пример, данные, хранящиеся как BLOB, будут малопригод¬
ны, если анализ требует доступа к отдельным полям данных.
Структура данных, стандартизованная решениями для боль¬
ших данных, может выступать в качестве общего знаменате¬
ля, который может использоваться для целого ряда методов
анализа и проектов. Для этого может потребоваться созда¬
ние центрального репозитория стандартного анализа, тако¬
го как база данных NoSQL, показанного на рисунке 3.18.
Рисунок 3.18
Простой пример
агрегирования данный,
где два набора данный
агрегируются вместе,
используя поле Id
На рисунке 3.19 показан один и тот же фрагмент данных,
хранящийся в двух разных форматах. Набор данных А со¬
держит требуемый фрагмент данных, но он является частью
BLOB, который не всегда доступен для запросов. Набор дан¬
ных В содержит тот же фрагмент данных, организованных в
виде хранящихся столбцов, что позволяет запрашивать ка¬
ждое поле по отдельности.
Переход к большим данным и вопросы планирования
109
Рисунок 3.19
Набор данный А и В
можно комбинировать
для создания стандар¬
тизированной структуры
данный с помощью
решения для больший
данный.
Анализ данных
Этап анализа данных, показанный на рисунке 3.20, посвящен
выполнению фактической задачи анализа, которая обычно
включает в себя один или несколько типов аналитики. Этот
этап может быть итеративным по своей природе, особенно
если анализ данных является разведывательным — в этом
случае анализ повторяется до тех пор, пока не будет обна¬
ружен соответствующий шаблон или корреляция. Подход к
разведывательному анализу будет кратко объясняться вме¬
сте с конфирмационным (подтверждающим) анализом.
В зависимости от типа требуемого аналитического резуль¬
тата этот этап может быть таким же простым, как запрос к
набору данных, чтобы вычислить агрегирование для сравне¬
ния. С другой стороны, это может быть столь же сложным,
как комбинирование интеллектуального анализа данных и
сложных методов статистического анализа для обнаруже¬
ния закономерностей и аномалий, или для создания стати¬
стической или математической модели, описывающей вза¬
имосвязи между переменными.
Анализ данных может быть классифицирован как подтверж¬
дающий или разведывательный анализ, последний из кото¬
рых связан с data mining, как показано на рисунке 3.21.
Подтверждающий анализ данных является дедуктивным
подходом, при котором причина исследуемого явления
предлагается заранее. Предлагаемая причина или предпо¬
ложение называется гипотезой. Затем данные анализиру-
110
Основы Big Data
ются для того, чтобы подтвердить или опровергнуть гипо¬
тезу и дать окончательные ответы на конкретные вопросы.
Обычно используются методы выборки данных. Неожидан¬
ные результаты или аномалии, как правило, игнорируются,
поскольку предполагаемая причина была выбрана заранее.
Рисунок 320
Седьмой этап жизненного
цикла аналитики больший
данный.
Этап 1
Рисунок 321
Анализ данный может
быть выполнен как
подтверждающий или
разведывательный.
анализ
данных
подтверждающий разведывательный
data mining
Переход к большим данным и вопросы планирования
111
Разведывательный анализ данных представляет собой ин¬
дуктивный подход, который тесно связан с data mining. Ни
одна из гипотез или предположений не генерируются зара¬
нее. Вместо этого данные анализируются посредством ана¬
лиза для развития понимания причины этого явления. Хотя
анализ может и не давать окончательных ответов, этот ме¬
тод обеспечивает общее направление, которое может поспо¬
собствовать обнаружению закономерностей или аномалий.
Визуализация данных
Способность анализировать огромные объемы данных и
находить полезные идеи не имеет большого значения, если
единственными, кто может интерпретировать результаты,
являются аналитики.
Рисунок 322
Восьмой этап жизненного
цикла аналитики больший
данный.
Этап 1
112
Основы Big Data
Этап визуализации данных, показанный на рисунке 3.22,
посвящен использованию методов визуализации данных
и инструментам графического представления результатов
анализа для их эффективной интерпретации бизнес-поль-
зователями.
Бизнес-пользователи должны быть в состоянии понять ре¬
зультаты для того, чтобы получить значение из анализа и впо¬
следствии иметь возможность предоставлять обратную связь,
как показано пунктирной линией, от этапа 8 обратно к этапу 7.
Результаты завершения этапа визуализации данных предо¬
ставляют пользователям возможность выполнять визуальный
анализ, которые дает возможность находить ответы на вопро¬
сы, которые еще не сформулированы пользователями. Мето¬
ды визуального анализа рассматриваются далее в этой книге.
Те же результаты могут быть представлены несколькими
различными способами, которые могут влиять на интер¬
претацию результатов. Следовательно, важно использовать
наиболее подходящий метод визуализации, сохраняя в кон¬
тексте предметную область бизнеса.
Еще один аспект, который следует иметь в виду, заключается
в том, что предоставление метода перехода к сравнительно
простой статистике имеет решающее значение для понима¬
ния пользователями того, как были сгенерированы сверну¬
тые или агрегированные результаты.
Использование результатов анализа
После получения результатов анализа, предоставляемых
бизнес-пользователям для поддержки принятия бизнес-ре-
шений, таких как информационные панели, могут быть до¬
полнительные возможности для использования результатов
анализа. Этап использования результатов анализа, показан¬
ный на рисунке 3.23, посвящен определению того, как и где
обрабатываемые аналитические данные могут быть в даль¬
нейшем использованы.
Переход к большим данным и вопросы планирования
113
Рисунок 323
Девятый этап жизненного
цикла аналитики больший
данный.
Этап 1
В зависимости от характера анализируемых проблем, резуль¬
таты анализа могут быть «моделями», что воплощают новые
идеи и понимание о природе закономерностей и взаимосвя¬
зей, которые существуют в анализируемых данных. Модель
может выглядеть как математическое уравнение или набор
правил. Модели могут использоваться для улучшения логики
бизнес-процессов и прикладных систем, и могут служить ос¬
новой новой системы или программного обеспечения.
Общие области, которые изучаются на этом этапе, включают
в себя следующее:
• входные данные для корпоративных систем — результаты
анализа данных могут автоматически или вручную вво¬
диться непосредственно в корпоративные системы для
114
Основы Big Data
повышения и оптимизации их поведения и производи¬
тельности. Например, данные интернет-магазина могут
быть обработаны с использованием анализа результатов
по клиентам, что повлияет на то, как он сгенерирует ре¬
комендации по продукту. Новые модели могут исполь¬
зоваться для улучшения логики программирования в су¬
ществующих корпоративных системах или стать основой
для новых систем
• оптимизация бизнес-процессов — определенные шабло¬
ны, корреляции и аномалии, обнаруженные при анализе
данных, используются для уточнения бизнес-процессов.
Примером является объединение маршрутов транспор¬
тировки как часть процесса цепочки поставок. Модели
также могут привести к возможности улучшения логики
бизнес-процессов
• предупреждения — результаты анализа данных могут ис¬
пользоваться в качестве входных данных для существу¬
ющих предупреждений или служить основой для новых
предупреждений. Например, предупреждения могут быть
созданы, чтобы информировать пользователей по элек¬
тронной почте или в SMS-сообщении о событии, которое
требует от них принятия корректирующих мер
ПРИМЕР ИЗ ПРАКТИКИ
Большинство команд IT-специалистов ETI убеждены, что
большие данные — это волшебная палочка, которая решит
все их текущие проблемы. Однако обученные IT-специа¬
листы отмечают, что внедрение больших данных — это
далеко не то же самое, что внедрение технологической
платформы. Скорее всего, для гарантии успешного вне¬
дрения больших данных сначала придется рассмотреть
ряд факторов. Поэтому для обеспечения полного пони¬
мания влияния факторов, связанных с бизнесом, коман¬
Переход к большим данным и вопросы планирования
115
да IT-специалистов совместно с бизнес-менеджерами
составляет технико-экономическое обоснование. Привле¬
чение бизнес-персонала на таком раннем этапе будет спо¬
собствовать созданию среды, которая уменьшает разрыв
между предполагаемыми ожиданиями руководства и тем,
что IT-специалисты действительно могут предоставить.
Существует глубокое понимание того, что внедрение
больших данных ориентировано на бизнес и поможет
ETI в достижении ее целей. Возможности больших дан¬
ных для хранения и обработки больших объемов не¬
структурированных данных и объединения нескольких
наборов данных помогут ETI понять риски. Компания
надеется, что в результате она сможет свести к миниму¬
му свои потери, признавая только менее рискованных
претендентов в качестве своих клиентов. Аналогичным
образом, ETI прогнозирует, что способность исследовать
неструктурированные данные о поведении клиента и
обнаружение аномалии его поведения будет способство¬
вать дальнейшему снижению потерь, поскольку мошен¬
нические заявки могут быть сразу отклонены.
Решение о подготовке команды IT-специалистов в обла¬
сти больших данных повысило готовность Е'П к их вне¬
дрению. Команда полагает, что теперь у нее есть базовый
набор навыков, необходимых для реализации инициати¬
вы больших данных. Ранее выявленные и классифициро¬
ванные данные позволяют команде занять твердую пози¬
цию для принятия решений о необходимых технологиях.
Так же участие в управлении бизнесом на ранних стадиях
обеспечило понимание, которое позволит ей предвидеть
будущие изменения, необходимые для поддержания ме¬
ханизма принятия решений для больших данных в соот¬
ветствии с любыми возникающими бизнес-требованиями.
На этом предварительном этапе было выявлено только
несколько внешних источников данных, таких как соци¬
116 Основы Big Data
альные сети и данные переписи населения. Выделение
достаточного бюджета для сбора данных от сторонних
поставщиков данных, согласуется персоналом компа¬
нии. Что касается конфиденциальности, бизнес-поль-
зователи относятся немного настороженно к тому, что
получение дополнительных данных о клиентах может
вызвать недоверие клиентов. Однако считается, что для
получения согласия и доверия клиентов может быть вве¬
дена система поощрений, например, снижение страхо¬
вых взносов. При рассмотрении вопросов безопасности
команда IT-специалистов отмечает потребность в до¬
полнительных усилиях по разработке, чтобы гарантиро¬
вать наличия основанных на ролях стандартных средств
управления доступом к данным, хранящимся в среде
решений больших данных. Это особенно актуально для
баз данных с открытым исходным кодом, которые будут
содержать не реляционные данные.
Хотя бизнес-пользователи в восторге от возможности
выполнять глубокую аналитику за счет использования
неструктурированных данных, они задаются вопросом
о степени доверия к результатам, поскольку для анализа
использовались и данные независимых источников дан¬
ных. Команда IT-специалистов является ответственной
за то, что будет адаптирована платформа для добавления
и обновления метаданных относительно каждого набо¬
ра данных, который хранится и обрабатывается так, что
постоянно поддерживается его происхождение, а резуль¬
таты обработки можно отследить вплоть до исходных
источников данных.
Сегодняшние цели ETI включают в себя сокращение вре¬
мени, которое требуется для удовлетворения заявок и
выявления мошеннических заявок. Для достижения этих
целей потребуется решение, которое обеспечит своевре¬
менность результатов. Однако, предполагается, что в ре¬
альном времени анализа данных не требуется. Команда
Переход к большим данным и вопросы планирования
117
IT-специалистов полагает, что эти цели могут быть удов¬
летворены путем разработки пакетного решения для
больших данных, использующего технологию больших
данных с открытым исходным кодом.
Текущая IT-инфраструктура ETI состоит из сравнительно
старых сетевых стандартов. Точно так же спецификации
большинства серверов, такие как скорость процессо¬
ра, объем диска и скорость вращения диска, указывают,
что они не способны обеспечить оптимальную произ¬
водительность обработки данных. Поэтому было приня¬
то решение о необходимости обновить существующую
IT-инфраструктуру до того, как будет спроектировано и
построено решение для больших данных.
Команды как бизнес-менеджеров, так и 1Т-специалистов
убеждены, что для управления платформой больших
данных требуется не только стандартизировать исполь¬
зование разрозненных источников данных, но и полно¬
стью соблюдать любые правила конфиденциальности
данных. Кроме того, из-за бизнес-направленности ана¬
лиза данных и гарантии получения значимых резуль¬
татов анализа было принято решение о необходимости
применения итеративного подхода к анализу данных,
который включает в себя бизнес-персонал из соответ¬
ствующего отдела. Например, в сценарии «повышения
лояльности клиентов», объединение маркетинга и сбыта
может быть включено в процесс анализа данных прямо
из набора данных так, что выбираются только соответ¬
ствующие атрибуты этих наборов данных. Позже коман¬
да бизнес-менеджеров может предоставить полезную
обратную связь с точки зрения интерпретации и приме¬
нимости результатов анализа.
Что касается «облачных» вычислений, команда IT-специ¬
алистов отмечает, что ни одна из ее систем, в настоящее
время не размещена в облаке и что команда не обладает
118 Основы Big Data
навыками, связанными с облаком. Эти факты наряду с
проблемами конфиденциальности данных привели к
тому, что команда IT-специалистов приняла решение о
создании решения для больших данных на месте. Группа
отмечает, что они оставят возможность облачного хостин¬
га открытой, поскольку есть некоторые предположения,
что в будущем их внутренняя CRM-система может быть
заменена на облачное решение, как сервис SaaS для CRM.
Жизненный цикл аналитики больших данных
Большие данные компании ETI достигли той стадии,
когда команда IT-специалистов обладает необходимы¬
ми навыками, и руководство убеждено в потенциальных
выгодах, при которых решение для больших данных мо¬
жет обеспечить поддержку’ целей компании. Совет ди¬
ректоров пожелал увидеть большие данные в действии. В
ответ на это команда IT-специалистов в сотрудничестве
с бизнес-персоналом возглавила первый проект ETI по
большим данным. После тщательного процесса оцени¬
вания была выбрана задача «Выявление мошеннических
заявок» в качестве первого решения для больших дан¬
ных. Затем команда использует поэтапный подход, опи¬
санный в жизненном цикле аналитики больших данных,
для достижения этой цели.
Оценка бизнес-ситуации
Проведение анализа больших данных для «выявле¬
ния мошеннических заявок» напрямую соответствует
уменьшению денежных потерь и, следовательно, предо¬
ставлению полной поддержки бизнесу. Несмотря на то,
что мошенничество происходит во всех четырех бизнес-
секторах ETI, в интересах упрощения анализа масштаб
анализа больших данных ограничивается выявлением
мошенничества в строительном секторе.
Переход к большим данным и вопросы планирования
119
ETI предоставляет строительное и имущественное стра¬
хование как для коммунальных, так и для коммерческих
клиентов. Хотя страховое мошенничество может быть
и случайным, и организованным, случайное мошен¬
ничество в виде лжи и преувеличения составляет боль¬
шинство случаев. Для оценивания успешности решения
больших данных для обнаружения мошенничества, од¬
ним из установленных KPI является сокращение мошен¬
нических заявок на 15 %.
Принимая во внимание бюджет, команда решает, что их
наибольшие расходы будут связаны с созданием новой
инфраструктуры, подходящей для создания среды реше¬
ний для больших данных. Они понимают, что будут ис¬
пользоваться технологии с открытым исходным кодом
для поддержки пакетной обработки и, следовательно,
не считают, что для программных средств необходимы
большие начальные инвестиции.
Однако при рассмотрении расширенного жизненно¬
го цикла аналитики больших данных члены команды
осознали, что им следует планировать бюджет с учетом
затрат для приобретения дополнительных качествен¬
ных данных и программных средств для их очистки, а
также новых технологий визуализации данных. После
учета этих расходов анализ рентабельности показывает,
что, инвестируя в решения для больших данных, можно
вернуть затраты увеличенными в несколько раз, если
удастся достичь целевых показателей KPI, выявляющих
мошенничество. В результате этого анализа команда
полагает, что существует сильная аргументация для ис¬
пользования больших данных в расширенном анализе
данных.
120 Основы Big Data
Идентификация данных
Определен ряд внутренних и внешних наборов данных.
Внутренние данные включают в себя данные полисов,
документы заявлений о страховании, данные о заявках,
записи специалиста по страховым заявкам, фотогра¬
фии инцидентов, заметки и электронные письма агента
call-центра. Внешние данные включают данные в соци¬
альных сетях (например, Twitter), метеорологические от¬
четы, географические (GIS) данные и данные переписи
населения. Почти все наборы данных предоставляются с
периодом пятилетней давности. Данные о заявке состо¬
ят из исторических данных заявки, которые охватывают
несколько полей, одно из которых указывает, была заяв¬
ка мошеннической или законной.
Сбор и фильтрация данных
Сведения о полисе получены из системы администриро¬
вания полисами, данные заявок, фотографии инцидентов
и записи специалистов по страховым заявкам получены
из системы управления заявками, а документы заявле¬
ний о страховании — из системы управления докумен¬
тами. В настоящее время в данных заявок содержатся за¬
писи специалистов по страховым заявкам. Поэтому для
их извлечения используется отдельный процесс. Записи
и электронные письма агентов call-центра поступают из
CRM-системы.
Остальные наборы данных поступают от сторонних по¬
ставщиков данных. Сжатая копия исходной версии всех
наборов данных хранится на диске. С точки зрения пер¬
спектив происхождения для фиксации происхождения
каждого набора данных отслеживаются следующие ме¬
таданные: наименование, источник, размер, формат,
контрольная сумма, дата и количество записей набора
данных. Быстрая проверка качества данных каналов
Переход к большим данным и вопросы планирования
121
Twitter и сообщений о прогнозе погоды показывает, что
около четырех-пяти процентов их записей поврежде¬
ны. Следовательно, для удаления поврежденных записей
создаются два рабочих места для фильтрации пакетных
данных.
Извлечение данных
Команда IT-специалистов отмечает, что некоторые из
наборов данных должны быть предварительно обрабо¬
таны для извлечения необходимых полей. Например,
набор данных твитов находится в формате JSON. Для
того, чтобы иметь возможность анализировать твиты,
идентификаторы пользователей, метки времени и текст
твитов, данные необходимо извлечь и преобразовать в
табличную форму. Кроме того, набор данных прогно¬
за погоды поступает в иерархическом формате (XML),
а в табличной форме извлекаются и сохраняются такие
поля, как временная метка, температурный прогноз,
прогнозы скорости ветра, направления ветра, снегопа¬
дов и наводнений.
Проверка и очистка данных
Чтобы снизить затраты, ETI в настоящее время исполь¬
зует бесплатные версии метеорологических данных и
наборы данных переписи, что не гарантирует 100 % точ¬
ность. В результате, эти наборы данных должны быть
проверены и очищены. Основываясь на опубликованной
информации в поле, команда может проверить извле¬
ченное поле на опечатки и любые неправильные данные,
а также проверить типы данных и диапазоны проверки.
Правило утверждает, что запись не будет удалена, если
она содержит какой-либо значимый уровень информа¬
ции, хотя некоторые из ее полей и могут содержать недо¬
пустимые данные.
122 Основы Big Data
Агрегирование и представление данных
Для содержательного анализа данных было решено объ¬
единить данные полисов, данные заявок и примечания
агентов call-центров в единый набор данных, который
является табличным по своему характеру, и где на ка¬
ждое поле можно ссылаться через запрос данных. Счи¬
тается, что это поможет не только с текущей задачей
анализа данных для выявления мошеннических заявок,
но также поможет с другими задачами анализа данных,
такими как оценивание риска и оперативное быстрое
уре!улирование заявок. Результирующий набор данных
сохраняется в базе данных NoSQL.
Анализ данных
На этом этапе команда IT-специалистов привлекает
специалистов по анализу данных, поскольку сама она не
обладает нужным набором навыков для анализа данных
в целях выявления мошеннических заявок. Чтобы иметь
возможность обнаруживать мошеннические транзакции,
сначала необходимо проанализировать характер мошен¬
нических заявок для определения, какие характеристики
отличают мошеннические заявки от законных. Для это¬
го используется разведывательный метод анализа дан¬
ных. В рамках этого анализа применяется ряд методов,
некоторые из которых рассматриваются в Главе 8. Этот
этап повторяется несколько раз, поскольку результаты,
полученные после первого прохода, не являются доста¬
точно убедительными для понимания того, что отличает
мошеннические заявки от правомерных заявок. В рам¬
ках этого процесса, атрибуты, которые не указывают на
мошеннические заявки, отбрасываются, в то время как
атрибуты, которые имеют непосредственное отношение,
сохраняются или добавляются.
Переход к большим данным и вопросы планирования
123
Визуализация данных
Команда обнаружила некоторые интересные результа¬
ты, и теперь ей необходимо передать их страховым ста¬
тистам, ведущим специалистам по страховке и специа¬
листам по страховым заявкам. Используются различные
методы визуализации, включая гистограммы, линейные
диаграммы и диаграммы разброса данных. Диаграммы
разброса данных используются для анализа групп мо¬
шеннических и законных заявок с учетом различных
факторов, таких как возраст клиента, возраст полиса, ко¬
личество предъявленных заявок и стоимость заявки.
Использование результатов анализа
Основываясь на результатах анализа данных, специа¬
листы по оцениванию и принятию рисков на страхо¬
вание и урегулированию претензий пользователей по
страхованию уже сформировали понимание характера
мошеннических заявок. Однако для того, чтобы полу¬
чить ощутимые выгоды от этого анализа данных, должна
быть сгенерирована модель, основанная на технологии
машинного обучения, которая затем включается в суще¬
ствующую систему обработки заявок, чтобы выявить мо¬
шеннические заявки. Применяемый метод машинного
обучения будет рассмотрен в главе 8.
124
125
Глава 4
Корпоративные
технологии
и Business Intelligence
для больших данных
Обработка транзакций в реальном времени (OLTP)
Аналитическая обработка в реальном времени (OLAP) •
Извлечение, преобразование и загрузка/ЕТЕ) / -
/7 / \ . 7 ’
Хранилища данных , ,z Z
Витрины данных : ' ’ /
Традиционный BI
/7 \ х / z ■ • i \
BI для больших данных, .-Х<ч
126
Как сказано в главе 2, на предприятии, созданном в виде
многоуровневой системы, стратегический уровень огра¬
ничивает тактический уровень, который в свою очередь
руководит операционным уровнем. Слаженность работы
уровней поддерживается с помощью метрик и показателей
производительности, которые обеспечивает операционный
уровень с пониманием сущности того, как выполняются
его процессы. Эти измерения агрегированы и расширены
за счет дополнительных значений полученных на основе
KPI, благодаря чему менеджеры тактического уровня могут
оценить корпоративную производительность, или деятель¬
ность бизнеса. При этом KPI связаны с другими измерения¬
ми и соглашениями, которые используются для оценивания
критических факторов успеха. В конечном итоге эта после¬
довательность улучшений соответствует преобразованию
данных в информацию, информации в знания и знаний
в мудрость.
В этой главе обсуждаются корпоративные технологии, кото¬
рые поддерживают это преобразование. Данные хранятся в
пределах операционного уровня информационных систем
организации. Кроме того, структура базы данных усилена
запросами для генерирования информации. Высшую сту¬
пень иерархии аналитики занимают аналитические систе¬
мы обработки. Эти системы усиливают многомерные струк¬
туры для того, чтобы отвечать на более сложные запросы и
обеспечивать более глубокое понимание операций бизнеса.
Корпоративные технологии и Business Intelligence
127
В более широком масштабе, данные собираются со всего
предприятия и складируются в хранилище данных. Именно
из этих хранилищ данных руководство получает сведения о
более широкой корпоративной производительности и KPI.
Эта глава затрагивает следующие темы:
• Обработка транзакций в реальном времени (OLTP)
• Аналитическая обработка в реальном времени (OLAP)
• Извлечение, преобразование и загрузка (ETL)
• Хранилища данных
• Витрины данных
• Традиционный BI
Обработка транзакций в реальном времени (OLTP)
OLTP — система программного обеспечения, которая обраба¬
тывает данные, представленные в виде транзакций. Термин
«онлайновая транзакция» относится к выполнению действия
в режиме реального времени и не требует пакетного представ¬
ления данных. OLTP системы хранят нормализованные рабо¬
чие данные. Эти данные являются общедоступным источни¬
ком структурированных данных и служат в качестве входных
данных для многих аналитических процессов. Результаты
анализа больших данных могут использоваться для улучше¬
ния данных OLTP, хранящихся в основных реляционных базах
данных. OLTP системы, например, система для ведения роз¬
ничной торговли, выполняют бизнес-процессы для поддерж¬
ки корпоративных операций. Как показано на рисунке 4.1,
они выполняют транзакции с реляционной базой данных.
Запросы, поддерживаемые OLTP системами, состоят из про¬
стых операций вставки, удаления и обновления с временем
отклика длительностью менее одной секунды. Примеры
включают систему резервирования билетов, банкинг и си¬
стемы для ведения розничной торговли.
128
Основы Big Data
Рисунок 4.1
OLTP системы выполняют
простые операции баз
данный, обеспечивая
время отклика длитель¬
ностью менее одной
секунды.
бизнес- быстрые простые реляционная
процессы запросы СУБД
Аналитическая обработка в реальном времени (OLAP)
Системы аналитической обработки в реальном времени
(OLAP) используются для обработки запросов анализа дан¬
ных. Системы OLAP являются неотъемлемой частью процес¬
сов Business Intelligence, интеллектуального анализа данных и
машинного обучения. Они имеют отношения к большим дан¬
ным в том, что могут служить как источником данных, так и
приемником данных, способным их накоплять. OLAP исполь¬
зуются в диагностических, прогностических и прескриптив¬
ных аналитиках. Как показано на рисунке 4.2, OLAP-системы
выполняют сложные запросы с длительным временем вы¬
полнения к многомерной базе данных, структура которой оп¬
тимизирована для реализации продвинутой аналитики.
OLAP-системы хранят исторические данные, которые агре¬
гированы и денормализованы, для поддерживания возмож¬
ности быстрого создания отчетов. Кроме того, они использу¬
ют базы данных, в которых хранятся исторические данные
в многомерных структурах, и могут ответить на сложные
запросы, основанные на отношениях между многочислен¬
ными аспектами данных.
Рисунок 42
использование OLAP-
системами многомерный
баз данный.
анализ
данных
сложные запросы
с длительным
временем
СУБД
Корпоративные технологии и Business Intelligence
129
Извлечение, преобразование и загрузка (ETL)
Извлечение, преобразование и загрузка (ETL) — это процесс
загрузки данных из исходной системы в целевую систему.
Исходной системой может быть база данных, плоский файл
или приложение. Точно так же целевой системой может быть
база данных или некоторая другая система хранения.
ETL представляет главную операцию, посредством которой
хранилища данных накапливают данные. Решение Big Data
выполняет набор функций ETL для преобразования данных
различных типов. На рисунке 4.3 показано, что запраши¬
ваемые данные сначала обнаруживают или извлекают из
источников, после чего фрагменты видоизменяются или
трансформируются путем применения правил. И, наконец,
данные вставляются или загружаются в целевую систему.
Рисунок 4Л
Процесс ETL может извлекать данные из несколькин источников
и преобразовать ин для загрузки в одну целевую систему.
130
Основы Big Data
Хранилища данных
Хранилище данных является центральным репозиторием,
имеющим масштаб корпорации, состоящий из историче¬
ских и текущих данных. Хранилища данных интенсивно
используются BI для выполнения различных аналитических
запросов, и они, как правило, имеют интерфейс с системой
OLAP для поддержки многомерных аналитических запро¬
сов, как показано на рисунке 4.4.
Рисунок 4.4
Пакетные задания
периодически загружают
данные в нранилище
данный из операционный
систем, такин как ERR
eRm и scm.
СУБД OLAP
хранилище данных
CRM
Данные, имеющие отношение к нескольким бизнес-объек-
там, из разных операционных систем, периодически извле¬
каются, проверяются на достоверность, трансформируют¬
ся и консолидируются в единую денормализованную базу
данных. При периодическом сборе данных со всех концов
корпорации, объем данных, содержавшихся в определен¬
ном хранилище данных, будет продолжать увеличиваться.
Со временем это приводит к замедлению времени откли¬
ка на запросы при выполнении задач анализа данных. Для
устранения этого недостатка, хранилища данных, как пра¬
вило, содержат оптимизированные базы данных, называе¬
мые аналитическими базами данных для обработки отчетов
и задач анализа данных. Аналитическая база данных может
существовать как в качестве отдельной СУБД, так и в виде
базы данных OLAP.
Корпоративные технологии и Business Intelligence
131
Витрины данных
Витрина данных представляет собой подмножество данных,
хранящихся в хранилище данных, которые обычно относит¬
ся к отделу, подразделению или конкретной области бизне¬
са. Хранилища данных могут иметь несколько витрин дан¬
ных. Как показано на рисунке 4.5, собираются все данные в
масштабе предприятия и затем извлекаются бизнес-сущно-
сти. Проблемно-ориентированные объекты сохраняются в
хранилищах данных, благодаря процессу ETL.
OLTP
Рисунок 4.5
Единственный вариант «адекватности» нранилища данным базируется на очищенным данным,
что является необмодимым условием для точным и безошибочным отчетов, как показано
в правой части рисунка.
корпоративное хранилище данных
витрина финансовых" 1 финансовый
Традиционный BI
Традиционный Business Intelligence главным образом ис¬
пользует дескриптивную и диагностическую аналитики,
чтобы предоставить информацию об исторических и те¬
кущих событиях. Он не является «интеллектуальным», по¬
132
Основы Big Data
скольку дает ответы только на правильно сформулирован¬
ные вопросы. Правильная формулировка вопросов требует
понимания проблем бизнеса, его доходов и проблем данных
непосредственно. BI дает информацию относительно раз¬
личных KPI при помощи:
• специализированных отчетов
• информационных панелей
Специализированные отчеты
Специализированная отчетность— это процесс, который
предусматривает ручную обработку данных для создания
выполняемых под заказ индивидуальных отчетов, как по¬
казано на рисунке 4.6. Основное внимание в специализи¬
рованном отчете обычно уделяется конкретной области
бизнеса, например, маркетингу или управлению цепочками
поставок. Созданные пользовательские отчеты являются де¬
тализированными и часто имеют табличный характер.
Рисунок 4.6
источники данный OLAP и
OLTP могут быть использо¬
ваны программно-инстру¬
ментальными средствами
Business Intelligence как для
специализированный отчетов,
так и для информационный
панелей.
OLTP
Информационные панели
Информационные панели управления обеспечивают це¬
лостное представление о ключевых областях бизнеса. Ин¬
формация, отображаемая на информационных панелях,
генерируется с периодическими интервалами в реальном
времени или в почти реальном времени. Представление
Корпоративные технологии и Business Intelligence
133
данных на информационных панелях носит графический
характер, используя гистограммы, круговые диаграммы и
панели средств измерений, как показано на рисунке 4.7.
Рисунок 4.7
Программно-инструмен¬
тальные средства Business
Intelligence используют OLAP
и OLTP для отображения
информации на информаци¬
онный панелян.
програмно- информационная
инструментальные панель
средства
Как уже объяснялось ранее, хранилища данных и витри¬
ны данных содержат консолидированную и проверенную
информацию об организационных структурах всей корпо¬
рации. Традиционные BI не могут эффективно функцио¬
нировать без витрин данных, поскольку они содержат оп¬
тимизированные и сегрегированные данные, которые BI
требует для целей отчетности. Без витрин данных необхо¬
димо было бы каждый раз извлекать данные из хранилища с
помощью процесса ETL в рабочем порядке, когда требуется
выполнить запрос. Это увеличило бы время и затраты на вы¬
полнение запросов и создание отчетов.
Традиционный BI использует хранилища данных и витри¬
ны данных для отчетности и анализа данных, поскольку они
позволяют выполнять запросы по сложному анализу дан¬
ных с множественными объединениями и агрегированиями
данных, как показано на рисунке 4.8.
BI для больших данных
Business Intelligence для больших данных основывается на
традиционном BI, путем прямого действия на очищенные
консолидированные данные всей корпорации в хранилище
данных и комбинирования их с полуструктурированными и
134
Основы Big Data
неструктурированными источниками данных. Он включает
в себя как предиктивную, так и прескриптивную аналитики,
чтобы облегчить развитие понимание эффективности биз¬
неса в рамках всей корпорации.
корпоративное хранилище данных
Рисунок 4.8
Пример традиционного Business Intelligence.
В то время как традиционные BI-анализы, как правило, со¬
риентированы на отдельные бизнес-процессах, В1-анализ
больших данных фокусируется на множественных биз¬
нес-процессах одновременно. Это помогает выявлять зако¬
номерности и аномалии в более широком масштабе внутри
корпорации. Это также приводит к отысканию данных пу¬
тем выявления новых знаний и информации, которая ранее
отсутствовала или была неизвестна.
Business Intelligence для больших данных требует анализа
неструктурированных, полуструктурированных и структу¬
рированных данных, которые постоянно находятся в храни¬
лище данных корпорации. Для этого требуется хранилище
данных «следующего поколения», в котором используются
Корпоративные технологии и Business Intelligence
135
новые функции и технологии для хранения очищенных дан¬
ных, поступающих из разных источников, в единственном
однотипном формате данных. Объединение традиционного
хранилища данных с этими новыми технологиями приво¬
дит к созданию гибридного хранилища данных.
Это хранилище действует как единообразный и централь¬
ный репозиторий структурированных, полуструктурирован-
ных и неструктурированных данных, который может предо¬
ставить программно-инструментальным средствам Business
Intelligence для больших данных все необходимые данные. Это
избавляет от необходимости того, чтобы программно-инстру¬
ментальные средства Business Intelligence для больших данных
подключались к множественным источникам данных для по¬
лучения или доступа к данным. На рисунке 4.9 хранилище дан¬
ных следующего поколения устанавливает стандартизованный
уровень доступа к данным для различных источников данных.
Рисунок 4.9
Нранилище данный
следующего поколения.
136
Основы Big Data
Традиционная визуализация данных
Визуализация данных — это метод, посредством которого
аналитические результаты представляются в графическом
виде с использованием таких элементов, как диаграммы,
карты, сетки данных, инфографики и предупреждающие
оповещения. Графическое представление данных может
облегчить понимание отчетов, просматривать тенденции
и устанавливать шаблоны.
Традиционная визуализация данных обеспечивает в ос¬
новном статические диаграммы и графики в отчетах и ин¬
формационных панелях, тогда как современные средства
визуализации данных являются интерактивными и могут
предоставлять как итоговые, так и детальные представле¬
ния данных. Они призваны помочь людям, которым не хва¬
тает статистических и/или математических навыков, лучше
понять аналитические результаты, не прибегая к электрон¬
ным таблицам.
Традиционные средства визуализации данных запраши¬
вают данные из реляционных баз данных, OLAP-систем,
хранилищ данных и электронных таблиц, чтобы предста¬
вить результаты как дескриптивной, так и диагностической
аналитики.
Визуализация данных при обработке больших данных
Для решений с большими данными требуются инструмен¬
ты визуализации данных, которые могут легко подклю¬
чаться к структурированным, полуструктурированным и
неструктурированным источникам данных и в дальней¬
шем способны обрабатывать миллионы записей данных.
Средства визуализации данных для решений с большими
данными обычно используют аналитические технологии в
памяти, которые уменьшают задержку, обычно связанную
с традиционными инструментами визуализации данных
на дисках.
Корпоративные технологии и Business Intelligence
137
Продвинутые инструментальные средства визуализации
данных для решений с большими данными включают в
себя предиктивную и прескриптивную аналитики данных и
функции преобразования данных. Эти инструменты устра¬
няют необходимость в методах предварительной обработ¬
ки данных, таких как ETL. Эти инструментальные средства
также предоставляют возможность прямого подключения
к структурированным, полуструктурированным и неструк¬
турированным источникам данных. В рамках решений для
больших данных продвинутые инструментальные средства
визуализации данных могут объединять структурирован¬
ные и неструктурированные данные, хранящиеся в памяти
для быстрого доступа к данным. Запросы и статистические
формулы могут быть тогда применены как часть различ¬
ных задач анализа данных для просмотра данных в удоб¬
ном для пользователя формате, например, на информаци¬
онной панели.
Общие функции инструментальных средств для визуализа¬
ции, используемые в больших данных:
• агрегирование— обеспечивает целостное и суммарное
представление данных в разных контекстах;
• углубленный уровень детализации — позволяет подробный
просмотр интересующих данных, сосредоточив внимание
на подмножестве данных из сводного представления;
• фильтрация — помогает сосредоточиться на определен¬
ном наборе данных, отфильтровывая данные, не пред¬
ставляющие непосредственного интереса;
• сводная таблица — группирует данные по нескольким ка¬
тегориям, чтобы показать промежуточные результаты и
итоговые значения;
• анализ «Что, если...» — позволяет визуализировать группу
результатов, позволяя динамически изменять связанные
факторы.
138
Основы Big Data
ПРИМЕР ИЗ ПРАКТИКИ
Корпоративные технологии
ETI использует OLTP практически во всех бизнес-функ-
циях. Его политика котировок, администрирование по¬
литик, управления заявками, биллинг, планирования
ресурсов предприятия (ERP) и систем управления взаи¬
моотношениями с клиентами (CRM) — все они основаны
на OLTP. Пример использования OLTP в ETI возникает
всякий раз, когда появляется новая заявка, поскольку
это приводит к созданию новой записи в таблице заявок,
находящейся в реляционной базе данных, которая ис¬
пользуется системой управления заявками. Аналогично,
когда заявка обрабатывается специалистом по обработ¬
ке страховых заявок, ее статус изменяется от поданной к
принятой и от принятой к обрабатываемой и, наконец,
обрабатывается посредством простых операций обнов¬
ления базы данных.
EDW заполняется еженедельно, используя набор опера¬
ций ETL, которые включают операции извлечения дан¬
ных из таблиц в реляционных базах данных, используя
операционные системы, проверку и преобразование
данных, и загрузку их в базу данных EDW. Данные, из¬
влеченные из операционных систем, представлены в
неструктурированном двумерном формате файла, кото¬
рый сначала импортируется в промежуточную базу дан¬
ных, где он преобразуется путем выполнения различных
сценариев. Один процесс ETL, который касается данных
клиента, запускает приложение нескольких правил для
проверки данных, одним из которых является подтверж¬
дение того, что у каждого клиента есть поля как имени,
так и фамилии, заполненные релевантными символа¬
ми. Кроме того, как часть одного и того же процесса ETL,
первые две строки адреса объединяются вместе.
Корпоративные технологии и Business Intelligence
139
EDW включает в себя систему OL.AP, в которой данные
хранятся в виде кубов, которые позволяют выполнять
различные запросы отчетов. Например, куб полиса со¬
стоит из начислений проданных полисов (таблица фак¬
тов) и данных о местоположении, типе и времени (таблиц
измерений). Аналитики выполняют запросы на разных
кубах в рамках деятельности по Business Intelligence (BI).
Для обеспечения безопасности и быстрого ответа на за¬
просы, EDW дополнительно содержит две витрины дан¬
ных. Одна из них состоит из данных о заявках и полисах,
которые используются экспертами-статистиками стра¬
хового учреждения и юридической группой для различ¬
ных анализов данных, включая оценку риска и обеспе¬
чение соответствия нормативным требованиям. Вторая
содержит данные о продажах, которые используются от¬
делом продаж для мониторинга продаж и определения
будущих стратегий продаж.
Business Intelligence для больших данных
Как известно, ETI в настоящее время использует BI, ко¬
торый попадает в категорию традиционных BI. Единая
информационная панель, используемая отделом про¬
даж, отображает различные ключевые показатели эф¬
фективности (KPI), связанные с полисами, посредством
различных диаграмм, например, разбивку проданных
полисов по типу, региону и стоимости, а также полисы,
срок действия которых истекает каждый месяц. Различ¬
ные информационные панели информируют страховых
агентов об их текущих действиях, таких как заработан¬
ные комиссионные и действительно ли они движутся в
направлении к достижению своих ежемесячных целей.
Обе эти информационные панели передают данные из
витрины данных продаж.
140
Основы Big Data
В call-центре табло предоставляет важную статистику,
связанную с ежедневными операциями центра, такими
как количество вызовов в очереди, среднее время ожида¬
ния, количество прерванных вызовов и вызовы по типу.
Этот табло получает данные непосредственно из реляци¬
онной базы данных CRM с помощью BI приложения, кото¬
рое предоставляет простой пользовательский интерфейс
для построения различных SQL-запросов, которые пери¬
одически выполняются для получения запрашиваемых
KPI. При этом команда юристов и экспертов-статистов
страховой компании генерируют некоторые специали¬
зированные отчеты, которые напоминают электронную
таблицу. Некоторые из этих отчетов направляются в ре¬
гулирующие органы в рамках обеспечения постоянного
соответствия нормативным требованиям.
ETI считает, что внедрение BI для больших данных в зна¬
чительной степени поможет в достижении его стратеги¬
ческих целей. Например, подключение социальных се¬
тей вместе с комментариями агентов call-центра может
обеспечить лучшее понимание причин отказа клиента
от услуг страховой компании. Точно так же законность
поданного иска может быть установлена быстрее тогда,
когда ценная информация может быть собрана из доку¬
ментов, представленных на момент приобретения поли¬
са и используя перекрестные ссылки на данные рассма¬
триваемой заявки. Эта информация затем может быть
сопоставлена с аналогичными заявками с целью обнару¬
жения мошенничества.
Что касается визуализации данных, то инструменталь¬
ные средства BI, используемые аналитиками, в насто¬
ящее время работают только со структурированными
данными. С точки зрения сложности и простоты исполь¬
зования большинство из этих инструментальных средств
предоставляют функции «указать-и-щелкнуть», что дает
возможность использовать мастер настройки, или мож¬
Корпоративные технологии и Business Intelligence
141
но выбрать вручную необходимые поля из соответствую¬
щих таблиц, отображаемых графически, для создания за¬
просов к базе данных. Результаты запроса затем можно
отобразить, выбирая соответствующие диаграммы и гра¬
фики. Конечным результатом является информацион¬
ная панель, на которой отображаются различные ста¬
тистические данные. На информационной панели мож¬
но дополнительно настроить параметры фильтрации,
агрегации и детализации. Примером этого может быть
пользователь, который кликает на изображении еже¬
квартальной диаграммы продаж и получает изображе¬
ние помесячной разбивки показателей продаж. Хотя ин¬
формационная панель, которая обеспечивает функцию
анализа «что-если», в настоящее время не поддержива¬
ется, но имея одну из них, она позволит экспертам-ста¬
тистам страховой компании быстро определить различ¬
ные уровни риска путем изменения соответствующих
факторов риска.
143
Часть II
Хранение и анализ
больших данных
Глава 5 Концепции хранения больших данных
Глава 6 Концепции обработки больших данных
Глава 7 Технологии хранения больших данных
Глава 8 Методы анализа больших данных
144
Основы Big Data
Как было показано в первой части книги, движущими сила¬
ми внедрения больших данных являются как бизнес, так и
технологии. Во второй половине этой книги, основной ак¬
цент смещен от обеспечения высокоуровневого понимания
больших данных и его последствий для бизнеса к освеще¬
нию ключевых понятий, связанных с двумя основными про¬
блемами больших данных: хранением и анализом.
Часть II имеет следующую структуру:
• В главе 5 рассматриваются ключевые концепции, связан¬
ные с хранением массивов данных для больших данных.
Эти концепции информируют читателя о том, что хране¬
ние больших данных имеет радикально отличающиеся
характеристики, от технологии хранения в реляционных
базах данных, присущих традиционным информацион¬
ным системам для бизнеса.
• Глава 6 дает представление о том, как обрабатываются мас-;
сивы больших данных, используя возможности распреде¬
ленной и параллельной обработки. Это, в свою очередь^'
иллюстрируется рассмотрением платформы MapReduce;
которая показывает, как она использует подход «разделяй'
и властвуй» для эффективной обработки массивов боль¬
ших данных.
• Глава 7 расширяет задачу хранения, показывая, как кон¬
цепции из главы 5 реализованы с учетом различных осо¬
бенностей технологий базы данных NoSQL. Здесь допол¬
нительно исследуются требования режимов пакетной
обработки и обработки в реальном времени с точки зре¬
ния возможностей хранения на диске и в памяти.
• В главе 8 речь идет о введении в пространство методов
анализа больших данных. Анализ больших данных ис¬
пользует статистические подходы для количественного
и качественного анализа, в то время как вычислительные
подходы используются для интеллектуального анализа
данных и машинного обучения.
Хранение и анализ больших данных
145
Технологические концепции, описанные во второй части,
являются важными для лидеров бизнеса и технологий, а так¬
же для лиц, принимающих решения, которые будут призва¬
ны оценить экономическое обоснование внедрения боль¬
ших данных на своих предприятиях.
147
Глава 5
Концепции хранения
больших данных
Кластеры
Файловые системы и распределенные файловые системы
NoSQL \ "д\
Шардинг . у .■ кх
| \ I " '
Репликация < /.
Шардинг и репликация ’
САР теорема «.
ACID - . х //
BASE . X Г
148
Данные, полученные из внешних источников, часто бы¬
вают не в том формате или не в той структуре, которые
могут быть непосредственно обработаны. Чтобы преодолеть
эти несовместимости и подготовить данные для хранения и
обработки, необходимо выполнить преобразование сырых
данных. Преобразование данных включает в себя шаги по
фильтрации, очистке и другим способам подготовки данных
для их последующего анализа. С точки зрения хранения, ко¬
пия данных сначала сохраняется в ее первоначальном фор¬
мате, и затем преобразованные данные нужно сохранить
снова. Как правило, хранение требуется каждый раз, когда
происходит следующее:
• получен внешний массив данных или внутренние данные
будут использоваться в среде обработки больших данных
• при выполнении действий с данными для того, чтобы их
можно было использовать для анализа данных
• при обработке данных посредством применения ETL, или
когда сгенерирован результат при выполнении аналити¬
ческой операции
Из-за необходимости хранения массивов данных большого
объема, часто в нескольких экземплярах, были созданы ин¬
новационные стратегии хранения и технологии для дости¬
жения экономичных и масштабируемых решений по хране¬
нию данных. Для того, чтобы понять основные механизмы
Концепции хранения больших данных
149
технологии хранения больших данных, в этой главе пред¬
ставлены следующие темы:
• кластеры
• файловые системы и распределенные файловые системы
• NoSQL
• шардинг
• репликация
• САР теорема
• ACID
• BASE
Кластеры
При вычислении кластер представляет собой тесно свя¬
занную совокупность серверов или узлов. Эти серверы, как
правило, имеют одинаковую аппаратную спецификацию и
соединены вместе через сеть для работы в качестве единого
блока, как показано на рисунке 5.1. Каждый узел в кластере
имеет свои собственные выделенные ресурсы, такие как па¬
мять, процессор и жесткий диск. Кластер может выполнять
задачу, разбивая ее на мелкие кусочки и распределяя их вы¬
полнение на разных компьютерах, принадлежащих кластеру.
150
Основы Big Data
Файловые системы
и распределенные файловые системы
Файловая система — это способ хранения
и организации данных на запоминающих
устройствах, таких как флэш-накопители,
DVD-диски и жесткие диски. Файл — это не¬
делимая единица хранения, используемая
файловой системой для хранения данных.
Файловая система обеспечивает логическое
Рисунок 52
Обозначение,
используемое для
представления
файловой системы.
представление данных, хранящихся на запо¬
минающем устройстве, и представляет его
в виде древовидной структуры каталогов и
файлов, как показано на рисунке 5.2. Опера¬
ционные системы используют файловые си¬
стемы для хранения и считывания данных
по поручению приложений. Каждая операционная система
поддерживает одну или несколько файловых систем, напри¬
мер NTFS в Microsoft Windows и ext в Linux.
Распределенная файловая система — файловая система, ко¬
торая может хранить большие файлы, распределенные по
узлам кластера, как показано на рисунке 5.3. Для клиента
файлы выглядят как локальные объекты; однако это толь¬
ко логическое представление, так как физически файлы
Рисунок 5.3
Обозначение,
используемое для
представления
распределенный
файловый систем.
Концепции хранения больших данных
151
распределены по всему кластеру. Эти локальные отобража¬
емые элементы представлены благодаря распределенной
файловой системе, которая позволяет осуществлять доступ
к файлам из разнообразных мест. Примерами могут быть
файловая система Google (GFS) и распределенная файловая
система Hadoop (HDFS).
Рисунок 5.4
База данный типа
AoSQl может
обеспечиваться RPI-
или SQL-подобным
интерфейсом запроса.
SQL-подобный
NoSQL
База данных типа NoSQL является не реляционной базой
данных, которая отличается высокой масштабируемостью,
отказоустойчивостью и разработана специально для хра¬
нения полуструктурированных и неструктурированных
данных. База данных типа NoSQL зачастую снабжается ин¬
терфейсом запроса, основанным на API, который может
вызваться из приложения. База данных типа NoSQL также
поддерживает языки запросов отличные от структуриро¬
ванного языка запросов SQL, поскольку SQL был разработан
для запроса только структурированных данных, хранящихся
в реляционной базе данных. Как пример, база данных типа
NoSQL, которая оптимизирована для хранения XML-файлов,
часто использует XQuery в качестве языка запросов. Таким
же образом, база данных типа NoSQL, разработанная для
152
Основы Big Data
хранения RDF данных будет использовать язык SPARQL для
запроса отношений, которые она содержит. Как утвержда¬
ют многие, существуют некоторые базы данных типа NoSQL,
которые также снабжаются SQL-подобным интерфейсом за¬
проса, как показано на рисунке 5.4.
Шардинг
Шардинг— это процесс горизонтального разделения боль¬
шого массива данных на коллекцию меньших, которые яв¬
ляются более управляемыми и называются шардами. Шарды
распределены среди множества узлов, где узел — это сервер
или компьютер (рисунок 5.5). Каждый шард хранится на от¬
дельном узле, и каждый узел ответственен только за данные,
хранящиеся на нем. Каждый сегмент совместно использует
одну и ту же логическую структуру в базе данных, и все вме¬
сте шарды представляют собой полный набор данных.
Рисунок 55
Пример разбиения, где массив данный распределяется между узлами А и 6,
в результате чего получается шард А и шард В соответственно.
Концепции хранения больших данных
153
Шардинг часто является прозрачным для клиента, однако
это не является обязательным требованием. Шардинг позво¬
ляет распределять нагрузки по обработке между нескольки¬
ми узлами для достижения горизонтальной масштабируе¬
мости.
Горизонтальное масштабирование — это способ увеличения
производительности системы за счет добавления аналогич¬
ных или более мощных ресурсов наряду с существующими
ресурсами. Поскольку каждый узел отвечает только за часть
всего массива данных, то при этом время чтения/записи
значительно улучшается.
Рисунок 5.6 иллюстрирует, как работает сегментирование на
практике:
DBMS
Узел А
2
чтение/
запись
Узел В
Сегмент В
чтение/
запись
Рисунок 5.6
Пример сегментирования, где данные извлекаются из обоин узлов Р и В.
Сегмент А
И
name
DOB |
гг
Bob
■ 06-06-19751
: 2
Helen
j 11-23-1982 J
чтение
John I 02-15-1972 i
4 Jane 04-07-1977
154
Основы Big Data
1. Каждый сегмент может независимо обслуживать опера¬
ции чтения и записи для определенного подмножества
данных, за которые он отвечает.
2. В зависимости от запроса данные могут быть выбраны из
обоих сегментов.
Преимуществом шардинга является то, что оно обеспечи¬
вает частичную отказоустойчивость к сбоям. В случае сбоя
узла, только данные хранящиеся на этом узле подвержены
влиянию. Что касается разбиения данных, то необходимо
учитывать шаблоны запросов, чтобы сами сегменты не ста¬
новились узкими местами производительности.
Например, запросы, требующие данные из нескольких сег¬
ментов, накладывают ограничение на производительность.
Локальное размещение данных позволяет хранить общедо¬
ступные данные, расположенные в одном сегменте, и помога¬
ет противостоять таким проблемам с производительностью.
Репликация
Репликация хранит множество копий наборов данных, из¬
вестных как «реплики», на нескольких узлах (рисунок 5.7).
Репликация обеспечивает масштабируемость и доступность
благодаря тому факту, что одни и те же данные реплициру¬
ются на разных узлах. При этом также достигается отказоу¬
стойчивость, поскольку избыточность данных гарантирует,
что данные не будут потеряны в случае, когда отдельный
узел выходит из строя. Для реализации репликации исполь¬
зуются два разных метода:
• ведущий-ведомый
• равный к равному (пиринговый)
Концепции хранения больших данных
155
Рисунок 5.7
Пример репликации, где набор данным реплицируется в узел А и узел 8,
в результате получается реплика А и реплика В.
Режим репликации «ведущий-ведомый»
Во время однонаправленного режима репликации «веду¬
щий-ведомый» узлы размещаются в конфигурации веду¬
щий-ведомый, и все данные записываются в главный узел.
После сохранения данные реплицируются на несколько под¬
чиненных узлов. Все внешние запросы на запись, включая
вставку, обновление и удаление данных, происходят на глав¬
ном узле, в то время, как запросы на чтение могут выпол¬
няться любым подчиненным узлом. На рисунке 5.8 управле¬
ние записью осуществляется главным узлом, и данные могут
считываться либо с ведомого узла А, либо с ведомого узла В.
156
Основы Big Data
Режим однонаправленной репликации «ведущий-ведо¬
мый» идеально подходит для чтения интенсивных загрузок
в большей степени, чем для записи интенсивных загрузок,
поскольку растущие требования к чтению могут управлять¬
ся посредством горизонтального масштабирования через
добавление дополнительных ведомых узлов.
СУБД
Рисунок 5.8
Пример однонаправленного режима репликации «ведущий-ведомый», где ведущий узел А
является одноточечным контактом для всен функций записи, а данные могут считываться
с ведомого узла А и с ведомого узла 8.
Записи являются согласованными, поскольку все записи ко¬
ординируются главным узлом. Это означает, что произво¬
дительность записи будет ухудшаться по мере увеличения
Концепции хранения больших данных
157
объема записи. Если ведущий узел выйдет из строя, то чте¬
ние по-прежнему будет возможным через любой из ведомых
узлов.
Ведомый узел может быть сконфигурирован как резервный
узел для ведущего узла. И в случае сбоя основного узла за¬
пись не будет поддерживаться до тех пор, пока ведущий узел
не будет восстановлен.
Ведущий узел восстанавливается либо из резервной копии
ведущего узла, либо из подчиненных узлов выбирается но¬
вый ведущий узел. Одна из проблем, связанных с однона¬
правленным режимом репликации «ведущий-ведомый»,—
это несогласованность чтения, что может быть проблемой,
если ведомый узел читается до обновления ведущего, кото¬
рый его копирует.
Для обеспечения согласованности чтения, там может быть
реализована система голосования в том случае, если чтение
объявлено согласованным, а большинство ведомых узлов
содержат одну и ту же версию записи. Для внедрения такой
системы голосования требуется надежный и быстрый меха¬
низм обмена данными между ведомыми узлами.
Рисунок 5.9 иллюстрирует сценарий, в котором возникает
несогласованность чтения.
1. Пользователь А обновляет данные.
2. Данные копируются на ведомый узел А ведущим узлом.
3. Перед копированием данных на ведомый узел В, пользо¬
ватель В пытается прочитать данные из ведомого узла В,
что приводит к несогласованному считыванию.
4. В конечном итоге данные станут согласованными, когда
ведомый узел В будет обновлен ведущим узлом.
158
Основы Big Data
СУБД
Рисунок 5.9
Пример однонаправленного режима репликации «ведущий-ведомый», когда происнодит
несогласованность чтения.
Режим репликации «одноранговый»
При репликации в режиме «одноранговый» все узлы рабо¬
тают на одном уровне. Другими словами, между узлами нет
отношения «ведущий-ведомый». Каждый узел, известный как
одноранговый узел, в равной степени способен обрабатывать
операции чтения и записи. Каждая запись копируется во все
одноранговые узлы, как показано на рисунке 5.10.
Одноранговая репликация подвержена ошибкам записи, воз¬
никающим в результате одновременного обновления одних и
Концепции хранения больших данных
159
Реплика С
Реплика А
Одноранговый узел А
Одноранговый узел В
Одноранговый узел С
га • name 1 DOB
СУБД
Рисунок 5.10
Данные для записи копируются а одноранговые узлы А, В и С одновременно. Данные считываются
с однорангового узла А, но ин также можно считывать с однорангового узла В или узла С.
1 j Rob
2 ( Helen
3 j John
06-06-1975
11-23-1982
Реплика В
Helen 11-23-1962
V Jobn : 02-15-1972
4 | Jane 04-07-1977
тех же данных несколькими одноранговыми узлами. Эту про¬
блему можно решить путем реализации либо пессимистиче¬
ской, либо оптимистической стратегии распараллеливания.
• Пессимистический параллелизм представляет собой упре¬
ждающую стратегию, которая предотвращает несогласован¬
ность. Она использует блокировки для гарантии того, что
только одно обновление на запись может происходить одно¬
временно. Однако это наносит ущерб доступности, посколь¬
ку обновляемая запись базы данных остается недоступной
до тех пор, пока не будут освобождены все блокировки.
• Оптимистичный параллелизм — это реактивная страте¬
гия, которая не использует блокировки. Вместо этого она
допускает несогласованность, предполагая, что в конеч¬
ном итоге согласованность будет достигнута после того,
как все обновления распространятся.
При оптимистичном параллелизме одноранговые узлы мо¬
гут оставаться несогласованными в течение некоторого пе¬
160
Основы Big Data
риода времени, прежде чем достигнут согласованности. Од¬
нако база данных остается доступной, поскольку блокировка
не задействована. Подобно режиму однонаправленной ре¬
пликации «ведущий-ведомый», чтение может быть несогла¬
сованным в течение периода времени, когда некоторые из
одноранговых узлов завершили свои обновления, в то время
как другие еще выполняют свои обновления. Тем не менее,
чтение в конечном итоге становится согласованным, когда
обновления были выполнены для всех одноранговых узлов.
Для обеспечения согласованности чтения, там может быть
реализована система голосования в том случае, если чтение
объявлено согласованным, а большинство одноранговых уз¬
лов содержат одну и ту же версию записи. Как отмечалось
ранее, внедрение такой системы голосования требует на¬
дежного и быстрого механизма обмена данными между од¬
норанговыми узлами.
Рисунок 5.11. демонстрирует сценарий, когда происходит
несогласованное чтение
1. Пользователь А обновляет данные.
2. а) Данные копируются в одноранговый узел А.
б) Данные копируются в одноранговый узел В.
3. Прежде чем данные будут скопированы в одноранговый
узел С, пользователь В может попытаться прочитать дан¬
ные из однорангового узла С, что приведет к несогласо¬
ванному чтению.
4. В конечном итоге данные будут обновлены на одноран¬
говом узле С, и база данных снова станет согласованной.
Концепции хранения больших данных
161
СУБД
Рисунок 5.11
Пример одноранговой репликации, когда происнодит несогласованное чтение.
Шардинг и репликация
Для улучшения ограниченной отказоустойчивостии, обе¬
спечиваемую с помощью использования приемов шардин-
га, а также для получения дополнительных преимуществ от
повышенной доступности и масштабируемости реплика¬
ции, можно комбинировать как шардинг, так и репликацию,
как показано на рисунке 5.12.
В этом разделе рассматриваются следующие комбинации:
• шардинг и репликация в режиме «ведущий-ведомый»
• шардинг и репликация в режиме «одноранговый»
162
Основы Big Data
Рисунок 5.12
Сравнение шардинга и
репликации, показывающее,
как набор данный распреде¬
ляется между двумя узлами
с разными подводами.
Шардинг
Узел А
Репликация
Узел А
Узел В
Узел В
Объединение шардинга и репликации
в режиме «ведущий-ведомый»
Когда шардинг объединяется с репликацией в режиме «ве¬
дущий-ведомый», то несколько шардов становятся ведомы¬
ми одного ведущего, а сам ведущий также является шардом.
Концепции хранения больших данных
163
Хотя это приводит к появлению нескольких ведущих, одним
ведомым шардом может управлять только один ведущий
шард.
Согласованность записи поддерживается ведущим шар¬
дом. Однако, если ведущий шард становится нерабочим или
происходит перебой в работе сети, то это влияет на отказо¬
устойчивость в отношении операций записи. Реплики шар-
дов хранятся на нескольких ведомых узлах для обеспечения
масштабируемости и отказоустойчивости для операций
чтения. На рисунке 5.13:
• каждый узел может действовать как ведущий и как ведо¬
мый для разных шардов
• операции записи (id = 2) в шард А регулируются узлом А,
так как он является ведущим для шарда А
• узел А реплицирует данные (id = 2) в узел В, который явля¬
ется ведомым для шарда А
• операции чтения (id = 4) могут обслуживаться напрямую
либо узлом В, либо узлом С, поскольку каждый из них содер¬
жит шард В
СУБД
Рисунок 5.13
Пример показывающий объединение шардинга и репликации в режиме «ведущий-ведомый».
164
Основы Big Data
Объединение шардинга и репликации
в режиме «одноранговый»
Когда шардинг объединяется с репликацией в режиме «од¬
норанговый», каждый шард реплицируется нескольким од¬
норанговым узлам, и каждый одноранговый узел отвечает
только за подмножество из общего массива данных. В сово¬
купности это помогает повысить масштабируемость и отка¬
зоустойчивость. Поскольку в этом процессе нет ведущего, то
нет и единственной точки сбоя и поддерживается при этом
отказоустойчивость как для операций чтения, так и опера¬
ций записи. На рисунке 5.14:
• каждый узел содержит копии двух разных шардов
• операции записи (id = 3) реплицируют как на узел А, так и
на узел С (одноранговые), поскольку они отвечают за шард С
• операции чтения (id = 6) могут обслуживаться либо узлом
В, либо узлом С, поскольку каждый из них содержит шард В
СУБД
Рисунок 5.14
Пример объединения шардинга и репликации в режиме «одноранговый».
Концепции хранения больших данных
165
Теорема САР
Теорема о согласованности, доступности и устойчивости при
разделении (САР), также известная как теорема Брюера, вы¬
ражает тройное ограничение, связанное с распределенными
системами баз данных. Она утверждает, что распределенная
система баз данных, работающая в кластере, может обеспе¬
чить только два из следующих трех свойств:
• Согласованность— чтение данных из любого узла при¬
водит к таким же данным, находящимся на нескольких
узлах (рисунок 5.15).
• Доступность. Запрос на чтение/запись всегда будет под¬
твержден в виде успеха или отказа (рисунок 5.16).
• Устойчивость при разделении. Система базы данных может
быть отказоустойчивой при сбоях обмена данными в про¬
цессе разделения кластера на несколько хранилищ данных
и при этом может обслуживать запросы чтения/записи
(рисунок 5.16).
DBMS
чтение
Й3 = 49
чтение
Рисунок 5.15
Согласованность: все три пользователя получают одинаковые значения для суммы столбца даже
если три разный узла обслуживают операцию чтения значения.
166
Основы Big Data
СУБД
Рисунок 5.16
Доступность и устойчивость при разделении: в случае нарушения обмена данными запросы от
обоин пользователей все еще обслуживаются [1,2). Однако у пользователя В запись не выполняется,
так как запись с id = 3 не была скопирована в одноранговый узел С. Пользователь своевременно
был уведомлен (3) о том, что обновление не удалось.
Последующие сценарии демонстрируют, почему одновре¬
менно могут поддерживаться только два из трех свойств те¬
оремы САР. Чтобы помочь этой дискуссии, на рисунке 5.17
представлена диаграмма Венна, показывающая зоны пере¬
крытия между согласованностью, доступностью и устойчи¬
востью при разделении.
Если требуются согласованность (С) и доступность (А), то до¬
ступные узлы должны связываться для обеспечения согла¬
сованности (С). Поэтому блочное разбиение (Р) невозможно.
Если требуются согласованность (С) и блочное разбиение
(Р), то узлы не могут оставаться доступными (А), поскольку
узлы станут недоступными при достижении состояния со¬
гласованности (С). Если требуются доступность (А) и блочное
разбиение (Р), то согласованность (С) невозможна из-за тре¬
бования к обмену данными между узлами. Таким образом,
база данных может оставаться доступной (А), но с некоторы¬
ми противоречивыми исходами.
Концепции хранения больших данных
167
с+д
согласованность доступность
С+Д+У
невозможно
С+У Д+У
устойчивость
при разделении
Рисунок 5.17
Диаграмма Венна с обобщением теоремы CAR
В распределенной базе данных масштабируемость и отка¬
зоустойчивость могут быть улучшены с помощью дополни¬
тельных узлов, несмотря на проблемы с согласованностью
(С). Добавление узлов может также вызвать потерю доступ¬
ности (А) из-за задержки, вызванной увеличением обмена
данными между узлами.
Системы распределенных баз данных не могут быть на 100 %
отказоустойчивыми к разделению (Р). Несмотря на то, что
перебои с обменом данными являются редкими и времен¬
ными, устойчивость к разделению (Р) всегда должна под¬
держиваться распределенной базой данных; поэтому САР
обычно является решением между выбором С + Р или А + Р.
Требования к системе продиктуют, какое из решений будет
выбрано.
168
Основы Big Data
ACID
ACID — это принцип проектирования базы данных, связан¬
ный с управлением транзакциями. Это аббревиатура, обо¬
значающая:
• атомарность
• согласованность
• изолированность
• долговечность
ACID — это стиль управления транзакциями, который задей¬
ствует пессимистичные элементы управления параллелиз¬
мом доступа для обеспечения согласованности, поддержи¬
ваемой путем применения блокировок записей. ACID — это
традиционный подход к управлению транзакциями базы
данных, так как он используется системами управления ре¬
ляционными базами данных.
Атомарность гарантирует, что все операции будут всегда
успешно выполнены или вообще не выполнены через сбои.
Иными словами, не существует частичных транзакций. На
рисунке 5.18 показаны следующие шаги:
1. Пользователь пытается обновить три записи, которые
являются частью транзакции.
2. Две записи успешно обновляются до возникновения сбоя.
3. В результате база данных аннулирует любые частичные
последствия выполнения транзакции и возвращает систе¬
му в прежнее состояние.
Согласованность гарантирует, что база данных будет всегда
оставаться в непротиворечивом состоянии, гарантируя, что
только данные, которые соответствуют ограничениям схе¬
мы базы данных, могут быть записаны в базу данных. Таким
образом, база данных, которая находится в согласованном
состоянии, останется в согласованном состоянии и после
успешной транзакции.
Концепции хранения больших данных
169
Реляционная СУБД
Рисунок 5.18
Пример свойства атомарности принципа ACID является здесь очевидным.
Реляционная СУБД
Рисунок 5.19
Пример согласованности ACIQ
На рисунке 5.19:
1. Пользователь пытается обновить столбец общей суммы
таблицы, который имеет тип float (числа с плавающей запя¬
той) со значением varchar.
170
Основы Big Data
2. База данных применяет свою проверку правильности и
отклоняет это обновление, потому что это значение нару¬
шает условия проверки ограничений для столбца суммы.
Изолированность гарантирует, что результаты транзакции не
будут видны другим операциям, пока она не будет завершена.
Реляционная СУБД
Рисунок 528
Пример свойстве изолированности ACIO.
На рисунке 5.20:
1. Пользователь А пытается обновить две записи, которые
являются частью транзакции.
2. База данных успешно обновляет первую запись.
3. Однако, прежде чем он сможет обновить вторую запись,
пользователь В попытается также обновить ту же запись.
База данных не разрешает обновление пользователю В до
тех пор, пока обновление пользователя А не завершится
Концепции хранения больших данных
171
успешно или не будет выполнено полностью. Это проис¬
ходит потому, что запись с ids блокируется базой данных
до завершения транзакции.
Долговечность гарантирует, что результаты операции бу¬
дут постоянными. Другими словами, как только транзакция
была выполнена ее нельзя отменить. Это происходит неза¬
висимо от сбоя системы.
На рисунке 5.21:
1. Пользователь обновляет запись, которая является частью
транзакции.
2. База данных успешно обновляет запись.
3. Сразу после этого обновления происходит сбой питания.
База данных сохраняет свое состояние, пока отсутствует
питание.
4. Питание возобновляется.
5. База данных обслуживает запись в соответствии с послед¬
ним обновлением по запросу пользователя.
На рисунке 5.22 показаны результаты применения принци¬
па ACID:
1. Пользователь А пытается обновить запись, которая явля¬
ется частью транзакции.
2. База данных проверяет значение и успешно применяет
обновление.
3. После успешного завершения транзакции, когда пользо¬
ватели В и С запрашивают одну и ту же запись, база данных
предоставляет обновленное значение для обоих пользова¬
телей.
172
Основы Big Data
Рисунок 521
Яарактеристика долговечности ACIDL
I ,
id 2 = 83 выборка
id 2 = 83 обновление
Рисунок 522
Принцип ACID
приводит к согласо¬
ванному поведению
базы данный.
реляционная СУБД
Концепции хранения больших данных
173
BASE
BASE является принципом проектирования баз данных на
основе теоремы САР и максимального использования кон¬
цепций систем баз данных, которые используют распреде¬
ленную технологию. BASE расшифровывается как:
• совершенно доступны
• мягкое состояние
• случайная согласованность
Когда база данных поддерживает BASE, то это способствует
доступности благодаря согласованности. Другими словами,
база данных А+Р с точки зрения САР. В сущности, BASE ис¬
пользует оптимистичные элементы управления паралле¬
лизмом, ослабляя сильные ограничения согласованности,
определяемые свойствами ACID.
СУБД
Рисунок 523
Пользователь А и пользователь В получают данные, несмотря на та
что база данный разбивается на фрагменты в результате сбоя сети.
174
Основы Big Data
Если база данных «совершенно доступна», эта база данных
всегда будет подтверждать запрос клиента, либо в форме
запрашиваемых данных, либо через уведомление об успеш-
ном/неудачном выполнении.
На рисунке 5.23 база данных «совершенно доступна», даже
при том, что она оказалась разбитой на фрагменты в резуль¬
тате сбоя в сети.
«Мягкое состояние» означает, что база данных может нахо¬
диться в несогласованном состоянии при выполнении чте¬
ния данных; таким образом, результаты могут измениться,
если снова запросить те же самые данные. Это связано с тем,
что данные могут быть обновлены для обеспечения согласо¬
ванности, даже если пользователь не записал их в базу дан¬
ных между двумя чтениями. Это свойство тесно связано со
случайной согласованностью.
id - идентификатор
Рисунок 524
Пример свойства
«мягкого состояния»
BASE показан здесь.
СУБД
На рисунке 5.24:
1. Пользователь А обновляет запись на одноранговом узле А.
2. До того, как другие одноранговые узлы обновлятся, поль¬
зователь В запрашивает ту же запись у однорангового узла С.
Концепции хранения больших данных
175
3. Теперь база данных находится в гибком состоянии, и уста¬
ревшие данные возвращаются пользователю В.
Случайная согласованность — это состояние, при котором
считывания разными клиентами сразу после записи в базу
данных, могут не вернуть согласованных результатов. База
данных достигает согласованности только после того, как
изменения были распространены на все узлы. Пока база
данных находится в процессе достижения состояния окон¬
чательной согласованности, она будет в мягком состоянии.
На рисунке 5.25:
1. Пользователь А обновляет запись.
2. Запись только что обновилась в одноранговый узел А, но
до того, как другие одноранговые узлы могут быть обнов¬
лены, пользователь В запрашивает ту же самую запись.
3. Теперь база данных находится в мягком состоянии. Уста¬
ревшие данные возвращаются пользователю В от одно¬
рангового узла С.
4. Однако согласованность в конечном итоге достигается, и
пользователь С получает правильное значение.
8
§
с
S
§
СУБД
Id - идентификатор
Одноранговый узел А
Рисунок 525
Пример свойства
случайной согласо¬
ванности BASE
176
Основы Big Data
BASE делает упор на более непосредственной согласован¬
ности, в отличие от ACID, что обеспечивает немедленную
согласованность за счет доступности из-за блокировки за¬
писей. Этот мягкий подход к согласованности позволяет
BASE совмещать базы данных для обслуживания нескольких
клиентов без задержки хотя и выдают несогласованные ре¬
зультаты. Таким образом, BASE-совместимые базы данных
не являются полезными для транзакционных систем, где от¬
сутствие согласованности является проблемой.
ПРИМЕР ИЗ ПРАКТИКИ
IT-среда ETI в настоящее время используют операцион¬
ные системы Linux и Windows. Следовательно, использу¬
ются как файловая система ext, так и файловая система
NTFS. Веб-серверы и некоторые серверы приложений ис¬
пользуют ext, в то время как остальные серверы прило¬
жений, серверы баз данных и конечные пользователи на¬
строены на использование NTFS. Сетевое хранилище NAS,
сконфигурированное с использованием RAID 5, также
используется для отказоустойчивого хранения докумен¬
тов. Хотя IT-команда знакома с файловыми системами,
понятия кластера, распределенной файловой системы и
NoSQL являются новыми для группы. Тем не менее, после
обсуждения с обученными IT-специалистами, вся группа
сможет понять эти концепции и технологии.
Текущее IT-пространство ETI полностью состоит из реля¬
ционных баз данных, в которых используется принцип
проектирования базы данных ACID. IT-группа не пони¬
мает принцип BASE и с трудом понимает теорему САР.
Некоторые члены команды не уверены в необходимо¬
сти и важности этих концепций в отношении хранили¬
ща наборов данных больших данных. Ознакомившись с
этим, обученные IT-специалисты стараются уменьшить
Концепции хранения больших данных
177
путаницу членов команды, объясняя, что эти концеп¬
ции применимы только для хранения огромных объемов
данных, распределенных специальным способом в кла¬
стере. Кластеры стали очевидным выбором для хранения
очень большого объема данных из-за их способности
поддерживать линейную масштабируемость путем гори¬
зонтального масштабирования.
Так как кластеры состоят из узлов, соединенных сетью,
то неизбежны сбои при обмене данными, которые соз¬
дают накопители данных или разбиения кластера. Для
решения проблем разбивки данных вводятся принцип
BASE и теорема САР.
Далее объясняется, что любая база данных, следующая за
принципом BASE, становится более быстро реагирующей
на запросы своих клиентам, хотя считываемые данные
могут быть несогласованными по сравнению с базой дан¬
ных, которая следует принципу ACID. Через понимание
принципа BASE, IT-специалисты более легко уясняют, по¬
чему база данных, реализованная в кластере, должна вы¬
бирать между согласованностью и доступностью.
Хотя ни одна из существующих реляционных баз данных
не использует шардинг, почти все они реплицируются для
аварийного восстановления и оперативной отчетности.
Чтобы лучше понять концепции шардирования и репли¬
кации, IT-команда проходит через тестовые задания для
уяснения, как эти концепции могут быть применены к
данным страховых котировок, поскольку большое количе¬
ство котировок создается и становятся быстродоступны¬
ми. При шардировании команда полагает, что использова¬
ние типовой (страховой сектор — здоровье, строительство,
морской транспорт и авиация) страховой квоты в качестве
критерия для шарда, создаст сбалансированный набор
данных на нескольких узлах, поскольку запросы в основ¬
ном выполняются в рамках одного и того же страхового
сектора и межсекторные запросы встречаются редко.
178
Что касается репликации, то команда выступает в пользу
выбора базы данных NoSQL, которая реализует страте¬
гию репликации одноранговой сети. Причина такого ре¬
шения в том, что страховые котировки создаются и из¬
влекаются довольно часто, но редко обновляются.
Следовательно, вероятность получения несогласованной
записи низкая. Учитывая это, команда поддерживает
производительность чтения/записи через согласован¬
ность, выбирая одноранговую репликацию.
Концепции обработк
больших данных
Параллельная обработка данных
Распределенная обработка данных
Hadoop
Обработка рабочих заданий
Кластер
Обработка в пакетном режиме
Обработка в режиме реального времени
180
Потребность в обработке больших объемов данных явля¬
ется не нова. При рассмотрении взаимосвязи между хра¬
нилищем данных и связанными с ним витринами данных
становится ясно, что разбиение большого набора данных на
меньший может ускорить обработку. Наборы больших дан¬
ных, хранящиеся в распределенных файловых системах или
в распределенной базе данных, уже разбиты на более мелкие
наборы данных. Разгадкой к пониманию обработки больших
данных является понимание того, что в отличие от центра¬
лизованной обработки, которая происходит в традиционной
реляционной базе данных, большие данные часто обрабаты¬
ваются параллельно распределенным образом в том месте, в
котором они хранятся.
Конечно, не все большие данные являются пакетно-обра-
батываемыми. Некоторым данным присуща характеристи¬
ка скорости и они вливаются в упорядоченный во времени
поток данных. Аналитика больших данных также имеет ре¬
шения по обработке для этого типа данных. Благодаря ис¬
пользованию архитектур хранения данных во внутренней
памяти, приобретает смысл подробного информирования
о ситуации с данными. Важным принципом, который на¬
кладывает ограничения на потоковую обработку больших
данных, называется принцип скорости, согласованности и
объема (SCV). Этот принцип подробно описан в данной главе.
Концепции обработки больших данных
181
Для дальнейшего обсуждения вопросов обработки больших
данных каждая из следующих концепций будет рассмотрена
поочередно:
• параллельная обработка данных
• распределенная обработка данных
• Hadoop
• обработка рабочих заданий
• кластер
Параллельная обработка данных
Параллельная обработка данных предполагает одновремен¬
ное выполнение нескольких подзадач, которые совместно
составляют более крупную задачу. Цель состоит в том, что¬
бы сократить время выполнения, разделив одну большую
задачу на несколько меньших задач, которые выполняются
одновременно.
Хотя параллельная обработка данных может быть осущест¬
влена с использованием нескольких сетевых машин, ее чаще
реализуют в одной и той же машине с несколькими процес¬
сорами или ядрами, как показано на рисунке 6.1.
Задача
Рисунок 6.1
Задача может быть разделена на три подзадачи, которые выполняются
параллельно на трен разный процессоран в той же машине.
182
Основы Big Data
Распределенная обработка данных
Распределенная обработка данных тесно связана с парал¬
лельной обработкой данных, поскольку применяется один
и тот же принцип «разделяй и властвуй». Однако распреде¬
ленная обработка данных всегда осуществляется с помощью
физически отдельных машин, которые объединены в сеть в
виде кластера. На рисунке 6.2 задача разделена на три под¬
задачи, которые затем выполняются на трех разных ком¬
пьютерах, совместно использующих один физический ком¬
мутатор.
Задача
Рисунок 62
Пример распределенной обработки данный.
Hadoop
Hadoop — это платформа с открытым исходным кодом для
крупномасштабного хранения данных и обработки данных,
совместимая со стандартным аппаратным оборудованием.
Платформа Hadoop зарекомендовала себя как промышлен¬
Концепции обработки больших данных
183
ная платформа де-факто для современных решений для
больших данных. Она может использоваться в качестве меха¬
низма ETL или в качестве машины аналитики для обработки
больших объемов структурированных, полуструктурирован-
ных и неструктурированных данных. С точки зрения анали¬
за Hadoop реализует инфраструктуру обработки MapReduce.
На рисунке 6.3 показаны некоторые особенности Hadoop.
Hadoop
Рисунок 6.3
Hadoop - это универсальная платформа, которая обеспечивает как возможности
обработки, так и нранения.
Обработка рабочих заданий
Рабочее задание для обработки больших данных определя¬
ется как количеством, так и характером данных, которые
обрабатываются в течение определенного периода времени.
Рабочие задания обычно делятся на два типа:
• пакетные
транзакционные
184
Основы Big Data
Пакетная обработка
Пакетная обработка, также известная как автономная обра¬
ботка, включает обработку данных в пакетах и, как прави¬
ло, накладывает задержки, что, в свою очередь, приводит к
ответам с высокими задержками. Пакетная обработка зада¬
ний обычно вовлекает большие объемы данных с последо¬
вательным чтением/записью и состоит из групп запросов на
чтение или запись.
Запросы могут быть сложными и включать несколько свя¬
зей. Системы OLAP обычно обрабатывают рабочие задания
в пакетах. Стратегические BI и аналитика ориентированы
на пакетную обработку, поскольку они требуют задач интен¬
сивного чтения и вовлекают большие объемы данных. Как
показано на рисунке 6.4, пакетное рабочее задание содер¬
жит сгруппированные операции чтения/записи, которые
используют большой объем данных, могут содержать слож¬
ные связи и обеспечивают ответы с высокой задержкой.
УДАЛЕНИЕ
Рисунок 6.4
Пакетное рабочее задание может включать в себя групповые
операции чтения/записи для IASERT, SELECT, UPDATE и DELETE
Концепции обработки больших данных
185
Транзакционная обработка
Транзакционная обработка также известна как онлайн-об¬
работка. Транзакционная обработка рабочего задания при¬
держивается подхода, при котором данные обрабатываются
в интерактивном режиме без задержек, что приводит к отве¬
там с низким уровнем задержки. Транзакционные рабочие
задания включают небольшие объемы данных с произволь¬
ным обращением к памяти за считываниями и записями.
OLTP и операционные системы, которые, как правило, ис¬
пользуют интенсивно операции записи, подпадают под эту
категорию. Хотя такие рабочие задания содержат сочетание
запросов на чтение и запись, они, как правило, более интен¬
сивно используют операцию записи, чем операцию чтения.
Транзакционные рабочие задания включают в себя опера¬
ции чтения/записи с произвольным обращением к памяти,
которые вовлекают меньшее количество соединений, чем
Business Intelligence и рабочие задания для отчетов. Учи¬
тывая их онлайн характер и операционную значимость для
предприятия, они требуют реакции откликов с низким уров¬
нем задержки и с меньшим размером данных, как показано
на рисунке 6.5.
УДАЛЕНИЕ
Рисунок 6.5
Транзакционные рабочие задания имеют небольшое количество
соединений и более низкие задержки отклика чем рабочие
задания для пакетной обработки.
186
Основы Big Data
Кластер
Точно так же, как кластеры обеспечивают необходимую
поддержку при создании горизонтально масштабируемых
решений для хранения, кластеры также обеспечивают ме¬
ханизм, позволяющий распределенную обработку данных с
линейной масштабируемостью.
Поскольку кластеры обладают высокой масштабируемостью,
они обеспечивают идеальную среду для обработки больших
данных, поскольку большие наборы данных можно разде¬
лить на более мелкие наборы данных, а затем обрабатывать
их параллельно распределенным способом. При использо¬
вании кластера наборы больших данных могут обрабаты¬
ваться как в пакетном режиме, так и в режиме реального
времени (рисунок 6.6). В идеальном случае кластер будет
состоять из недорогих серийно выпускаемых узлов обору¬
дования, которые в совокупности обеспечивают возросшую
вычислительную мощность.
потоковые данные
Щ
данные
для пакетной
обработки ;
кластер
Рисунок 6.6
Кластер может использоваться для поддержки пакетной обработки больший
массивов данный и обработки потоковый данный в режиме реального времени.
Дополнительным преимуществом кластеров является то,
что они обеспечивают изначальную избыточность и отказо¬
устойчивость, поскольку состоят из физически разделенных
Концепции обработки больших данных
187
узлов. Избыточность и отказоустойчивость позволяют гибко
выполнять обработку и анализ в случае сбоя в сети или узле.
Ввиду изменений требований к обработке, предъявляемых
в среде больших данных, использование инфраструктурных
сервисов, развернутых в облаке, или уже существующих го¬
товых аналитических сред в качестве основы кластера, яв¬
ляется разумным из-за их эластичности и модели оплаты за
использование вычислений.
Обработка в пакетном режиме
В пакетном режиме данные обрабатываются в автономном ре¬
жиме пакетами, а время отклика может варьироваться от не¬
скольких минут до нескольких часов. Кроме того, данные долж¬
ны быть сохранены на диске, прежде чем они будут обработаны.
Пакетный режим обычно включает в себя обработку ряда
наборов больших данных либо по одному, либо вместе, в ос¬
новном, учитывая объем и различные характеристики набо¬
ров больших данных.
Большая часть обработки больших данных выполняется в
пакетном режиме. Он относительно прост, прост в настрой¬
ке и дешевле по сравнению с режимом реального времени.
Стратегический BI, интеллектуальная и предсказательная
аналитика и операции ETL обычно ориентированы на па¬
кетную обработку.
Пакетная обработка с помощью MapReduce
MapReduce — широко используемая реализация инфра¬
структуры пакетной обработки. Она хорошо масштаби¬
рована и надежна и базируется на принципе «разделяй и
властвуй», который обеспечивает встроенную отказоустой¬
чивость и избыточность.
Она разделяет большую проблему на совокупность неболь¬
ших проблем, каждая из которых может быть быстро решена.
188
Основы Big Data
MapReduce имеет истоки как в распреде¬
ленных, так и в параллельных вычислениях.
MapReduce — пакетно-ориентированный
процессор (рисунок 6.7), используемый
для обработки больших наборов данных с
использованием параллельной обработки,
развернутой на кластерах серийного ком¬
пьютерного оборудования.
Рисунои 6.7
Символ, используемый
для представления
модуля обработки.
MapReduce не требует, чтобы входные данные соответство¬
вали какой-либо конкретной модели данных. Поэтому его
можно использовать для обработки наборов данных без схе¬
мы. Набор данных разбивается на несколько меньших фраг¬
ментов, и операции выполняются для каждого фрагмента
независимо и параллельно. Результаты всех операций затем
суммируются для получения решения. Из-за накладных рас¬
ходов по координации, затраченных на управление задани¬
ем, процессор обработки MapReduce обычно поддерживает
только пакетные рабочие задания, поскольку эта работа не
будет иметь низкого уровня задержки. MapReduce базирует¬
ся на исследовательском научном документе Google по этой
теме, опубликованном в начале 2000 года.
Процессор обработки MapReduce работает иначе по сравне¬
нию с традиционной парадигмой обработки данных. Тради¬
ционно обработка данных требует перемещения данных из
узла хранения в узел обработки, который выполняет алго¬
ритм обработки данных. Этот подход отлично работает для
небольших наборов данных; однако в случае с большими
наборами данных перемещение данных может повлечь за
собой больше накладных расходов, чем фактическая обра¬
ботка данных.
В MapReduce алгоритм обработки данных взамен этого сам
перемещается в узлы, которые хранят данные. Алгоритм об¬
работки данных выполняется параллельно на этих узлах, тем
самым устраняя необходимость переноса данных в первую
очередь. Это не только сохраняет пропускную способность
сети, но и также приводит к значительному сокращению
Концепции обработки больших данных
189
времени обработки больших наборов данных, поскольку па¬
раллельная обработка меньших фрагментов данных выпол¬
няется намного быстрее.
Задачи Мар и Reduce
Каждое выполнение обработки процессором MapReduce
известно как рабочее задание MapReduce. Каждое задание
MapReduce состоит из задачи шар и задачи reduce, и каждая
задача состоит из нескольких этапов. На рисунке 6.8 пока¬
заны задача тар и задача reduce, а также отдельные этапы.
Задачи Мар:
Задачи Reduce:
• map
• перетасовка и сортировка
объединение
reduce
(факультативно)
• разбиение
Рисунок 6.8
иллюстрация задания
(TlapReduce с указанными
этапами тар.
задача тар
задача reduce 1
Мар
Первый шаг MapReduce известен как тар, во время которо¬
го файл набора данных разбивается на несколько меньших
разбивок. Для каждой разбивки проводится детальный ана¬
лиз его составных записей как пары «ключ-значение». Клю¬
чом обычно является порядковый номер записи, а значени¬
ем является фактическая запись.
190
Основы Big Data
Проанализированные пары «ключ-значение» для каждой
разбивки затем отправляются к функции тар или к преоб¬
разователю данных (mapper), с одной функцией преобразо¬
вания на каждую разбивку. Функция тар выполняет логику,
определяемую пользователем. Каждая разбивка обычно со¬
держит несколько пар «ключ-значение», и функция преоб¬
разования (mapper) выполняется один раз для каждой пары
«ключ-значение» в разбивке.
Процесс mapper обрабатывает каждую пару «ключ-значе¬
ние» в соответствии с логикой, определяемой пользователем
и затем генерирует пару «ключ-значение» как его результат.
Результирующий выходной ключ может либо совпадать с
ключом входа, либо значением подстроки для входного зна¬
чения, либо другим сериализуемым объектом, определяе¬
мым пользователем.
Аналогично, выходное значение может либо совпадать с
входным значением, либо значением подстроки для входно¬
го значения, либо другим сериализуемым объектом, опреде¬
ляемым пользователем.
Когда все записи разбивки были обработаны, выходом яв¬
ляется список пар «ключ-значение», где для одного и того
же ключа могут существовать несколько пар «ключ-значе¬
ние». Следует отметить, что для входной пары «ключ-зна¬
чение» mapper не может создавать никакой выходной пары
«ключ-значение» (фильтрация) или может генерировать
несколько пар «ключ-значение» (демультиплексирование).
Первый шаг тар можно кратко сформулировать при помо¬
щи уравнения, показанного на рисунке 6.9.
Рисунок 6.9
Подведение итогов
Концепции обработки больших данных
191
Объединение
Как правило, выход функции тар подается непосредствен¬
но на обработку функции reduce. Однако задачи тар и
reduce как правило выполняются на разных узлах. Это тре¬
бует перемещения данных между блоками mapper и reduce.
Это перемещение данных может потреблять много ценной
пропускной способности и непосредственно влияет на за¬
держку обработки.
При использовании больших наборов данных время, за¬
трачиваемое на перемещение данных между этапами тар
и reduce, может превысить фактическое время обработки,
затрачиваемое на выполнение задач тар и reduce. По этой
причине процессор обработки MapReduce предоставляет
необязательную функцию объединение (combine), кото¬
рая суммирует данные с выходов преобразователей дан¬
ных (mapper’s) до того, как они будут обработаны функцией
reduce. Рисунок 6.10 иллюстрирует консолидацию выхода из
стадии тар на этапе объединения.
Combiner (модуль объединения) — это, по существу, функ¬
ция модуля reduce, которая локально группирует выходные
данные модулей mapper на том же самом узле, что и модуль
mapper. Функция модуля reduce может использоваться как
функция модуля combine, или может быть использована как
функция, определенная пользователем. Процессор обработки
Рисунок 6.1В
Этап объединения группы
вынодов после этапа тар.
задача тар
задача reduce
192
Основы Big Data
MapReduce объединяет все значения для заданного клю¬
ча из выходного файла модуля mapper, создавая несколько
пар «ключ-значение» в качестве входных данных для моду¬
ля combine, где ключ не повторяется и значение существует
как список всех соответствующих значений для этого ключа.
Этап модуля combine является только стадией оптимизации,
и поэтому он может даже не вызываться процессором обра¬
ботки MapReduce.
Например, функция модуля combine будет работать для на¬
хождения наибольшего или наименьшего числа, но не будет
работать для нахождения среднего значения всех чисел, по¬
скольку она работает только с подмножеством данных. Ста¬
дию объединения (combine) можно кратко сформулировать
при помощи уравнения, показанного на рисунке 6.11.
Рисунок 6.11
Краткое изложение
этапа объединения.
index
Разбиение
Во время этапа разбиения, если задействовано более чем
один модуль reduce, модуль разбиения разделяет выход с
модуля mapper или модуля combiner (если он указан и вызы¬
вается обработчиком MapReduce) в разбиения между экзем¬
плярами модуля reducer. Количество разбивок будет равно
количеству модулей reducer. На рисунке 6.12 показан этап
разбиения, который назначает выходы от этапа объедине¬
ния до конкретных модулей reducer.
Хотя каждая разбивка содержит несколько пар «ключ-зна¬
чение», все записи для определенного ключа назначают¬
ся одной и той же самой разбивке. Процессор обработки
MapReduce гарантирует случайное и справедливое распреде¬
ление между модулями reduce, одновременно удостоверяясь,
Концепции обработки больших данных
193
Рисунок 6.12
Этап разбиения назначает
еынод из задачи тар в
задачу reduce.
что все одинаковые ключи для нескольких модулей mapper
заканчиваются одним и тем же экземпляром модуля reduce.
В зависимости от характера рабочего задания некоторые
модули reducer иногда могут получать большее количество
пар «ключ-значение» по сравнению с другими. В результате
такой неравномерной нагрузки некоторые модули reducer
будут завершать задание раньше других. В целом, это яв¬
ление менее эффективно и приводит к увеличению време¬
ни выполнения задания, в отличие от того когда бы работа
была равномерно распределена между модулями reducer.
Это можно исправить, путем настройки логики разбиения,
с целью гарантирования справедливого распределения пар
«ключ-значение».
Функция разбиения является последним этапом задачи
тар. Она возвращает указатель модуля reducer, которому
должна быть отправлена конкретная разбивка. Этап разбие¬
ния можно кратко сформулировать при помощи уравнения,
показанного на рисунке 6.13.
Рисунок 6.13
Краткое изложение
этапа разбиения.
(Мг)
index
194
Основы Big Data
Перетасовка и сортировка
На первом этапе задачи reduce, выходы от всех разбивок ко¬
пируются для всех узлов сети, на которых выполняется за¬
дача reduce. Это известно как операция перетасовки. Список
«ключ-значение» на выходе каждой из разбивок может со¬
держать один и тот же ключ несколько раз.
Затем процессор обработки MapReduce автоматически груп¬
пирует и сортирует пары «ключ-значение» согласно данным
о ключах так, чтобы результат содержал отсортированный
список всех входных ключей и их значений с одинаковыми
ключами, появляющимися вместе. Способ группировки и
сортировки ключей можно настраивать.
Такое объединение создает одну пару «ключ-значение» для
каждой группы, где ключ — это ключ группы, а значение —
список всех значений группы. Этот этап можно свести к
уравнению на рисунке 6.14.
Рисунок 6.14
Краткое изложение
этапа перетасовки
и сортирования.
Рисунок 6.15
Во время этапа
перетасовки и
сортирования данные
копируются по сети
в узлы, выполняющие
задачу reduce,
и сортируются
по ключу.
объеди- раз- перетасовка «Инга
та₽ нение биение и сортирование геоисе
задача reduce
задача тар
Концепции обработки больших данных
195
I la рисунке 6.15 показано гипотетическое задание MapReduce,
которое выполняет этап перетасовки и сортирования для
задачи reduce.
Reduce
Reduce — это заключительный этап задачи reduce. В зависи¬
мости от логики, определяемой пользователем, специфици¬
рованной в функции reduce (блок reducer), reducer будет либо
обрабатывать свой вход, либо выдаст результат без внесения
каких-либо изменений. В любом случае для каждой пары
«ключ-значение», которую получает reducer, обрабатывает¬
ся список значений, хранящихся в области значений пары, и
считывается другая пара «ключ-значение».
Результирующий ключ может либо совпадать с ключом вхо¬
да, либо значением подстроки из входного значения, либо с
другим сериализуемым объектом, определяемым пользова¬
телем. Выходное значение может либо совпадать с входным
значением, либо значением подстроки из входного значе¬
ния, либо с другим сериализуемым объектом, определяе¬
мым пользователем.
Обратите внимание, что так же, как и mapper, для входной
пары «ключ-значение» reducer может не создавать выход¬
ную пару «ключ-значение» (фильтрация) или может гене¬
рировать несколько пар «ключ-значение» (демультиплек¬
сирование). Выходной сигнал из модуля reducer, который
является парой «ключ-значение», затем записывается в виде
отдельного файла — по одному файлу на каждый reducer.
Это показано на рисунке 6.16, в котором освещается этап
reduce для задачи reduce. Чтобы просмотреть весь результат
рабочего задания MapReduce, должны быть объединены все
части файла.
Количество модулей reducer можно настраивать. Также мо¬
жет выполняться рабочее задание MapReduce без модуля
reducer, например, при выполнении фильтрации.
196
Основы Big Data
Рисунок 6.16
Этап reduce является
последним этапом
задачи reduce.
задача тар
задача reduce <
Обратите внимание, что сигнатура результата (типы «ключ-зна¬
чение») функции тар должна соответствовать значению
входной (типа «ключ-значение») функции reduce/combine.
Этап reduce может быть представлен с помощью уравнения
на рисунке 6.17.
Рисунок 6.17
Сводная информация об
этапе reduce.
Простой пример MapReduce
На рисунке 6.18 представлены следующие этапы:
1. Входной файл (sales.txt) разделяется на два разбиения.
2. Две задачи тар, выполняемые на двух разных узлах,
узле А и узле В, извлекают данные о продуктах и их ко¬
личествах из записей соответствующих разбиений парал¬
лельно. Результатом каждой функции тар является пара
«ключ-значение», где данные о продуктах являются клю¬
чом, а их количество — значением.
Концепции обработки больших данных
197
3. Затем модуль объединения (combiner) выполняет локаль¬
ное суммирование количества продуктов.
4. Поскольку существует только одна задача reduce, то разде¬
ление не выполняется.
5. Выходные данные из двух задач тар затем копируются в
третий узел, узел С, который запускает этап перетасовки в
рамках задачи reduce.
6. Стадия сортировки затем группирует все количества од¬
ного и того же продукта вместе в виде списка.
7. Как и модуль объединения (combiner), функция reduce
суммирует количества каждого уникального продукта для
получения результата.
Узел С
Узел А
Я
Рисунок 6.18
Пример (TlapReduce в действии.
Интерпретация алгоритмов MapReduce
В отличие от традиционных моделей программирования
MapReduce следует своей собственной модели программиро¬
вания. Чтобы понять, как алгоритмы могут быть спроектиро¬
198
Основы Big Data
ваны или адаптированы к этой модели программирования,
сначала необходимо изучить принцип ее проектирования.
Как описано выше, MapReduce работает по принципу «раз¬
деляй и властвуй». Однако важно понять семантику этого
принципа в контексте MapReduce.
Принцип «разделяй и властвуй» обычно достигается с ис¬
пользованием одного из следующих подходов:
Параллелизм задач. Параллелизм задач относится к распа¬
раллеливанию обработки данных путем разделения зада¬
чи на подзадачи и запуска каждой подзадачи на отдельном
процессоре, как правило, на отдельном узле в кластере (ри¬
сунок 6.19). Каждая подзадача обычно выполняет разные ал¬
горитмы, с собственной копией одних и тех же данных или
с различными данными, используя их в качестве своего вхо¬
да, параллельно. Как правило, выходные данные от несколь¬
ких подзадач объединяются для получения окончательного
набора результатов.
Рисунок 6.19
Задача разбивается на две пол
подзадачу А и подзадачу В, кот
затем выполняются на двун ра
узлан с использованием одног
же набора данный.
задача
Концепции обработки больших данных
199
Параллелизм данных. Параллелизм данных относится к рас¬
параллеливанию обработки данных путем разделения набо¬
ра данных на несколько наборов данных и параллельной об¬
работки каждого набора данных (рисунок 6.20). Поднаборы
данных распределены по нескольким узлам и все они обра¬
батываются с использованием одного и того же алгоритма.
Как правило, выходные данные из каждого обработанного
поднабора данных объединяются вместе, для получения
окончательного набора результатов.
набор данных
id
1 I
74
"ут
3 |
85
4
52
и
Рисунок 620
Набор данный разделяется на два
поднабора данный поднэбор данный
А о поднабор данный В, которые затем
обрабатываются на двун разный узлан,
используя одну о ту же функцию.
Поднабор данных А
id
величина
1J
74 1
~2|
29
id
величина i
3
85
~~4™
52
В средах с большими данными одна и та же задача, как пра¬
вило, должна выполняться повторно с разными блоками
данных, где полный набор данных распределяется по не¬
скольким узлам из-за его большого размера. MapReduce ре¬
шает это требование, используя подход параллелизма дан¬
ных, когда данные разделяются на разбиения. Каждое такое
разбиение затем обрабатывается своим экземпляром функ¬
200
Основы Big Data
ции map, которая содержит ту же самую логику обработки,
что и другие функции тар.
Большинство традиционных разработок алгоритмов следу¬
ет из последовательного подхода, когда операции над дан¬
ными выполняются одна за другой таким образом, что по¬
следующая операция зависит от предыдущей операции.
В MapReduce операции разделяются между функциями тар
и reduce. Задачи тар и reduce выполняются независимо друг
от друга и, в свою очередь, изолируются друг от друга. Кроме
того, каждый экземпляр функции тар или reduce выполня¬
ется независимо от других экземпляров.
Сигнатуры функций в традиционной разработке алгорит¬
мов, как правило, не ограничены. В MapReduce сигнатуры
функций тар и reduce являются ограничеными набором пар
«ключ-значение». Это единственный способ, с помощью ко¬
торого функция тар может связываться с функцией reduce.
Помимо этого, логика в функции тар будет зависеть от того,
как проанализированы записи, что зависит, в свою очередь
от того, что представляет собой логический блок данных в
наборе данных.
Например, каждая строка в тек¬
стовом файле обычно представ¬
ляет собой одну запись. Однако
может случиться так, что набор
из двух или более строк факти¬
чески представляет собой одну
запись (рисунок 6.21). Кроме
того, логика в функции reduce
зависит от выхода функции
тар, в частности, какие клю¬
чи были выбраны из функции тар, так как функция reduce
получает уникальный ключ с консолидированным списком
всех его значений. Следует отметить, что в некоторых сце¬
нариях, таких как извлечение текста, функция reduce может
не потребоваться.
Адресная строка 1
Адресная строка 2 ► Адрес
Индекс
Рисунок 621
Экземпляр когда три строки
составляют одну запись.
Концепции обработки больших данных
201
Основные соображения при разработке алгоритма
MapReduce можно резюмировать следующим образом:
• использование относительно упрощенной алгоритмиче¬
ской логики таким образом, чтобы требуемый результат
можно было получить, применяя одну и ту же логику к
различным частям набора данных параллельно и затем
агрегировать результаты каким-либо образом
• доступность к набору данных, находящихся в распре¬
деленном виде, которые разделены на части по всему
кластеру таким образом, чтобы несколько функций тар
могли обрабатывать различные подмножества наборов
данных параллельно
• понимание структуры данных в наборе данных так, чтобы
можно было выбрать осмысленный блок данных (одну запись)
• разделение алгоритмической логики между функциями
тар и reduce так, чтобы логика в функции тар не зави¬
села от полного набора данных, так как данные доступны
только в рамках одного разбиения
• порождение корректного ключа функцией тар вместе
со всеми требуемыми данными в качестве значений, по¬
скольку логика функции reduce может обрабатывать толь¬
ко те значения, которые были сгенерированы в качестве
части пар «ключ-значение» функцией тар
• порождение корректного ключа функцией reduce вместе
с требуемыми данными в качестве значений, потому, что
результат от каждой функции reduce становится оконча¬
тельным результатом алгоритма MapReduce
Обработка в режиме реального времени
В режиме реального времени данные обрабатываются в опе¬
ративной памяти по мере их предоставления до того, как они
сохраняются на диске. Время отклика обычно составляет от
202
Основы Big Data
одной секунды до минуты. Режим реального времени зависит
от характеристики скорости для больших наборов данных.
В рамках обработки больших данных, обработка в реальном
масштабе времени называется также обработкой события
или обработкой потока, поскольку данные либо поступают
непрерывно (поток), либо с интервалами (событие). Величи¬
на отдельного события/потока обычно мала по размеру, но
их непрерывный характер приводит к очень большим набо¬
рам данных.
Другой связанный термин, интерактивный режим, относит¬
ся к категории реального времени. Интерактивный режим
обычно касается обработки запросов в реальном масштабе
времени. Оперативные BI/аналитика обычно выполняются
в режиме реального времени.
Фундаментальный принцип, связанный с обработкой боль¬
ших данных, называется принципом объема, согласованно¬
сти и скорости (ОСС). Он рассматривается одним из первых,
поскольку он устанавливает некоторые базовые ограниче¬
ния на обработку, которые большей частию влияют на ре¬
жим обработки в реальном времени.
Объем, согласованность, скорость (ОСС)
В то время, как теорема САР в основном связана с распре¬
деленным хранением данных, принцип ОСС (рисунок 6.22)
связан с распределенной обработкой данных. Принцип
утверждает, что распределенная система обработки данных
может быть разработана для поддержки только двух из сле¬
дующих трех требований.
• Скорость. Скорость определяет, как быстро данные могут
быть обработаны после их создания. В случае аналитики в
реальном времени данные обрабатываются сравнительно
быстрее, чем при аналитике с пакетной обработкой. Как
правило, в первом случае исключается время, затрачивав-
Концепции обработки больших данных
203
мое на сбор данных, и все внимание фокусируется только
на фактической обработке данных, такой как формирова¬
ние статистики или выполнение алгоритма.
• Согласованность. Согласованность относится к корректно¬
сти и точности результатов. Результаты считаются кор¬
ректными, если они близки к правильному значению, и
точны, если близки друг к другу. Более согласованная си¬
стема будет использовать все доступные данные, что при¬
ведет к высокой корректности и точности по сравнению с
менее согласованной системой, которая использует мето¬
ды выборок, что может привести к снижению корректно¬
сти с приемлемым уровнем точности.
• Объем. Объем ссылается на количество данных, которые
могут быть обработаны. Характеристики скорости больших
данных приводят к быстро растущим наборам данных, что
в результате приводит к огромным объемам данных, кото¬
рые необходимо обрабатывать распределенным образом.
Обработка таких объемных данных во всей их полноте без
обеспечения скорости и согласованности невозможна.
Если требуются скорость (S) и согласованность (С), то невоз¬
можно обработать большие объемы данных (V), потому что
большие объемы данных снижают скорость обработки дан¬
ных. Если требуется согласованность (С) и обработка больших
объемов данных (V), то невозможно обрабатывать данные на
высокой скорости (S), поскольку для достижения высокой ско¬
рости обработки данных требуются меньшие объемы данных.
Если требуется обработка большого объема (V) в сочетании с
высокой скоростью (S) обработки данных, то обработанные
результаты не будут согласованными (С), поскольку высоко¬
скоростная обработка больших объемов данных включает в
себя выборку данных, что может снизить согласованность.
Следует отметить, что выбор двух из трех поддерживаемых
параметров полностью зависит от системных требований
среды анализа.
204
Основы Big Data
скорость согласованность
С + С
С + С + О
невозможно
С+О С+О
объем
Рисунок 622
Эта диаграмма Венна
резюмирует принцип ОСС.
В средах с большими данными максимальный объем данных
является обязательным для проведения глубинного анализа,
такого как идентификация шаблонов. Следовательно, отказ
от объема (V) ради скорости (S) и согласованности (С) долж¬
ны быть тщательно спланированы, поскольку данные могут
потребоваться еще для пакетной обработки, чтобы получить
более полные сведения.
В случае обработки больших данных, исходя из того, что по¬
теря данных (V) неприемлема, традиционно система анали¬
за данных в реальном времени будет либо S + V, либо С + V, в
зависимости от того, являются ли предпочтительными ско¬
рость (S) или согласованные результаты (С).
Концепции обработки больших данных
205
Обработка больших данных в режиме реального времени
обычно относится к аналитике в реальном времени или
близком к реальному времени.
Данные обрабатываются по мере их поступления в пределах
предприятия без завышенной задержки.
Вместо того, чтобы изначально хранить данные на диске,
например, в базе данных, данные сначала обрабатываются в
памяти, а затем сохраняются на диске для дальнейшего ис¬
пользования или архивирования. Этот подход является про¬
тивоположностью к режиму пакетной обработки, где дан¬
ные сначала сохраняются на диске, а затем обрабатываются,
что может повлечь за собой значительные задержки.
Для анализа больших данных в реальном масштабе време¬
ни требуется использование устройств хранения данных в
оперативной памяти (IMDG или IMDB). После того, как дан¬
ные будут сохранены в памяти, они могут быть обработаны
в режиме реального времени без каких-либо задержек вво¬
да-вывода жесткого диска. Обработка в реальном времени
может включать в себя вычисление простой статистики, вы¬
полнение сложных алгоритмов или обновление состояния
данных в оперативной памяти в результате изменения, об¬
наруженного в некоторой метрике.
Для расширенного анализа данных, данные в оперативной
памяти можно комбинировать с ранее обработанными па¬
кетами данных или денормализованными данными, за¬
груженными с устройств хранения на диске. Это помогает
добиться обработки данных в реальном масштабе времени,
поскольку наборы данных могут быть объединены в памяти.
Хотя обработка больших данных в реальном масштабе вре¬
мени традиционно относится к прибывающим новым дан¬
ным, она также может включать в себя выполнение запросов
к ранее сохраненным данным, которые требуют интерак¬
тивного ответа.
206
Основы Big Data
После обработки данных, результаты обработки могут быть
опубликованы для заинтересованных потребителей. Это
может произойти в реальном масштабе времени с помощью
приложения информационной панели или Web-приложе¬
ния, которое обеспечивает обновления в реальном времени
для пользователя.
В зависимости от требований к системе, обработанные дан¬
ные вместе с необработанными входными данными могут
быть выгружены на дисковое хранилище для последующего
комплексного анализа пакетных данных.
На рисунке 6.23 показаны следующие шаги:
1. Потоковые данные поступают в систему передачи данных.
2. Затем они синхронно сохраняются в оперативной памяти
(а) и во внешнем запоминающем устройстве (б).
3. После этого используется процессор обработки для обра¬
ботки данных в реальном масштабе времени.
4. И наконец, результаты поступают на информационную
панель для оперативного анализа.
система процессор информационная
передачи данных оперативная обработки данных панель
устройство памяти
Рисунок 623
Пример обработки данный а реальном масштабе времени в среде больший данный.
Существуют две важные концепции, связанные с обработ¬
кой больших данных в реальном масштабе времени:
Обработка потока событий (ESP)
Обработка сложных событий (СЕР)
Концепции обработки больших данных
207
Обработка потока событий
Во время обработки потока событий непрерывно анализиру¬
ется входящий поток событий, обычно из одного источника
и упорядоченный по времени. Анализ может выполняться
с помощью простых запросов или применения алгоритмов,
базирующихся в основном на формуле. Анализ проводится
в оперативной памяти до сохранения событий на дисковом
запоминающем устройстве.
Другие источники данных (резидентные данные) также мо¬
гут быть включены в анализ для выполнения более точной
аналитики. Результаты обработки могут поступать на ин¬
формационную панель или могут выступать в качестве триг¬
гера для другого приложения, выполняющего предваритель¬
но сконфигурированные действия, или для последующего
анализа. Обработка потока событий фокусируется больше на
скорости, чем на сложности; операция, которая будет выпол¬
нена, сравнительно проста, чтобы ускорить выполнение.
Обработка сложных событий
В ходе обработки сложных событий одновременно и в реаль¬
ном масштабе времени анализируется ряд событий, которые
часто поступают из разрозненных источников и поступают в
разные временные интервалы, для выявления закономерно¬
стей и инициирования действий. Применяются алгоритмы,
основанные на правилах и статистические методы, с учетом
бизнес-логики и контекста процесса для обнаружения слож¬
ных шаблонов событий со сквозной функциональностью.
Обработка сложных событий уделяет больше внимания
сложности, предоставляя многофункциональную аналити¬
ку. Однако в результате скорость выполнения может быть
снижена. В общем, обработка сложных событий считается
надмножеством обработки потока событий, и часто резуль¬
тат обработки потока событий приводит к генерации синте¬
зируемых событий, которые могут быть использованы для
обработки сложных событий.
208
Основы Big Data
Обработка больших данных
в режиме реального времени и ОСС
При проектировании системы обработки больших данных в
реальном времени необходимо иметь в виду принцип ОСС. В
свете этого принципа рассмотрим систему обработки боль¬
ших данных в реальном времени и в почти реальном време¬
ни. Для сценариев как с жестким реальным временем, так и
близким к реальному времени предполагается, что потеря
данных является недопустимым; другими словами, требует¬
ся обработка больших объемов данных (V) для обеих систем.
Обратите внимание, что требование о том, что потеря данных
не должна происходить, не означает, что все данные будут об¬
рабатываться в реальном времени. Скорее, это означает, что
система фиксирует все входные данные и, что данные всегда
сохраняются на диске, либо непосредственно записываются
в дисковое хранилище, либо косвенно на диск, служащий в
качестве вспомогательного уровня для оперативной памяти.
В случае системы с жестким реальным временем требуется
быстрый ответ (S), поэтому согласованность (С) будет на¬
рушена, если данные большой объемности (V) необходимо
обрабатывать в памяти. Этот сценарий потребует исполь¬
зования методов выборки или аппроксимации, что в свою
очередь приводит к менее точным результатам, но своевре¬
менно и с терпимой точностью.
В случае системы, близкой к реальному времени, требуется
достаточно быстрая реакция (S), поэтому согласованность
(С) может быть гарантирована, если данные большой объ¬
емности (V) необходимо обрабатывать в памяти. Результаты
будут более точными по сравнению с системой с жестким
реальным временем, поскольку полный набор данных мож¬
но использовать вместо отбора выборок или использования
методов приближения.
Таким образом, в контексте обработки больших данных си¬
стема с жестким реальным временем требует компромисса
Концепции обработки больших данных
209
в отношении согласованности (С) для гарантирования бы¬
строго ответа (S), в то время как система, близкая к реально¬
му времени, может пойти на компромисс со скоростью (S),
чтобы гарантировать согласованные результаты (С).
Обработка больших данных
в реальном времени и MapReduce
MapReduce обычно не подходит для обработки больших дан¬
ных в реальном времени. Для этого есть несколько причин,
не последней из которых является объем затрат, связан¬
ных с созданием рабочего задания и координацией работы
MapReduce. MapReduce предназначен для пакетной обработ¬
ки больших объемов данных, которые были сохранены на
диске. MapReduce не может обрабатывать данные с опреде¬
ленным шагом, а может обрабатывать только полные набо¬
ры данных. Поэтому MapReduce требует, чтобы все входные
данные были полностью доступны до начала выполнения
задания обработки данных. Это противоречит требованиям
к обработке данных в реальном времени, поскольку обра¬
ботка в реальном времени вовлекает данные, которые часто
являются неполными и непрерывно поступают посредством
потока данных.
Кроме того, с MapReduce задача reduce обычно не может на¬
чаться до завершения всех задач тар. Во-первых, результат
задачи тар сохраняется локально на каждом узле, который
выполняет функцию тар. Затем результат тар копируется
по узлах сети, которые выполняют функцию reduce, вводя
задержку обработки. Аналогично, результаты одного моду¬
ля reducer не могут быть напрямую поданы на вход другого
модуля reducer, а скорее всего, результаты должны быть пе¬
реданы сначала модулю mapper в следующем рабочем зада¬
нии MapReduce.
Как было продемонстрировано, MapReduce как правило не
пригоден для обработки в реальном времени, особенно ког¬
да присутствуют жесткие ограничения реального времени.
210 Основы Big Data
Существуют, однако, некоторые стратегии, которые могут
позволить использовать MapReduce в сценариях обработ¬
ки больших данных в режиме реального времени. Одна из
стратегий заключается в использовании оперативной памя¬
ти для хранения данных, которые используются в качестве
входных данных для интерактивных запросов, состоящих из
рабочих заданий MapReduce.
В качестве альтернативы, могут быть развернуты рабочие
задания микропакетов MapReduce, которые сконфигури¬
рованы для работы со сравнительно небольшими набора¬
ми данных с частотными интервалами, например, каждые
пятнадцать минут. Другой подход заключается в непрерыв¬
ном выполнении рабочих заданий MapReduce для наборов
данных на уровне диска для создания материализованных
представлений, которые затем могут быть объединены с не¬
большими объемами результатов анализа, полученных из
вновь поступающих в оперативную память потоковых дан¬
ных, для интерактивной обработки запросов.
Учитывая доминирующее положение смарт устройств и кор¬
поративных устремлений для более активного привлечения
клиентов, совершенствование возможностей обработки
больших данных в реальном масштабе времени происходит
очень быстро. Несколько проектов Apache с открытым ис¬
ходным кодом, в частности Spark, Storm и Tez, обеспечивают
реальные возможности обработки больших данных в реаль¬
ном времени и являются фундаментом нового поколения
решений для обработки в реальном масштабе времени.
ПРИМЕР ИЗ ПРАКТИКИ
Большинство рабочих информационных систем ETI ис¬
пользуют архитектуру клиент-сервер и n-уровневые ар¬
хитектуры. После инвентаризации IT-систем, компания
определяет, что ни одна из систем не использует распре¬
деленную обработку данных. Вместо этого данные, ко¬
онцепции обработки больших данных
211
торые необходимо обрабатывать, либо принимаются от
клиента, либо извлекаются из базы данных, а затем об¬
рабатываются одной машиной.
Хотя в текущей модели обработки данных не использу¬
ется распределенная обработка данных, некоторые из
разработчиков программного обеспечения согласны с
тем, что модель параллельной обработки данных на ма¬
шинном уровне используется в некоторой степени. Их
объяснение основывается на том факте, что некоторые
из их высокопроизводительных пользовательских при¬
ложений используют многопоточность, позволяющую
разделить работу по обработке данных для выполнения
на нескольких ядрах, имеющихся на серверах в стойке.
Обработка рабочих заданий
ГГ-команда подразумевает транзакционные и пакетные
рабочие задания, поскольку оба рабочих задания в на¬
стоящее время подтверждают обработку данных в ETI
IT-среды. Действующие системы, такие как управление
претензиями и биллинг, проявляют транзакционную
нагрузку, включающую в себя транзакции базы данных,
совместимые с ACID. С другой стороны, заполненность
EDW посредством действий ETL и BI представляет собой
пакетное рабочее задание.
Обработка в пакетном режиме
Будучи новичками в технологиях больших данных,
IT-специалисты выбирают поэтапный подход при пер¬
вой реализации пакетной обработки данных. Как только
команда наберет достаточный опыт, она может перейти к
реализации обработки данных в реальном масштабе вре¬
мени. Чтобы понять концепцию платформы MapReduce,
IT-команда отбирает сценарий, где может быть приме¬
нен MapReduce, и выполняет интеллектуальную задачу.
212
Основы Big Data
Сотрудники отмечают, что одной из задач, которая долж¬
на выполняться на регулярной основе и, которая зани¬
мает много времени, является поиск расположения наи¬
более популярных страховых продуктов.
Популярность страхового продукта определяется путем
выяснения, сколько раз просматривалась соответству¬
ющая страница этого продукта. Web-сервер создает за¬
пись (строку текста с разделенным запятыми набором
полей) в файле журнала всякий раз, когда запрашивается
Web-страница. Среди других полей журнал Web-сервера
содержит IP-адрес посетителя сайта, который запросил
Web-страницу, время, когда Web-страница была запро¬
шена, и имя страницы. Имя страницы соответствует на¬
званию страхового продукта, который интересует посе¬
тителя сайта. В настоящее время журналы Web-сервера
импортируются из всех Web-серверов в реляционную
базу данных. Затем выполняется SOL-запрос для того,
чтобы получить список имен страниц вместе с количе¬
ством просмотров страниц. Импорт журнальных файлов
и выполнение SOL-запроса занимает много времени.
Для того чтобы получить значение количества просмо¬
тров страниц с помощью MapReduce, IT-команда ис¬
пользует следующий подход. На этапе тар для каждой
входной строки текста, имя страницы извлекается и уста¬
навливается как выходной ключ, а числовое значение 1
является значением. На стадии reduce все входные зна¬
чения (список из набора 1) для одиночного ввода ключа
(имя страницы) просто суммируются с использованием
цикла, чтобы получить общее количество просмотров
страниц. Результат этапа reduce состоит из имени стра¬
ницы в качестве ключа и общего количества просмотров
страниц в качестве значения. Чтобы сделать обработку
более эффективной, обученные IT-специалисты инфор¬
мируют остальную группу, что объединяющий модуль
combiner может использоваться для выполнения точно
Концепции обработки больших данных
213
такой же логики, как и модуль reducer. Тем не менее, ре¬
зультат от модуля combiner будет содержать промежу¬
точный итог подсчета количества просмотров страниц.
Таким образом, в модуле reducer, несмотря на то, что
логика для получения общего количества просмотров
страниц остается неизменной, вместо получения списка
«единиц» (значения) для каждого имени страницы (клю¬
ча), список входных значений будет состоять из проме¬
жуточного итога от каждого таррег-модуля.
Обработка в реальном времени
IT-команда возлагает надежды, что модель обработки
потока событий может использоваться для выполнения
анализа эмоциональной окраски высказываний в Twitter
в реальном времени для того, чтобы найти причины не¬
удовлетворенности клиентов.
214
215
Глава 7
Технологии хранения
больших данных
Дисковые системы хранения
Системы хранения в оперативной памяти х
216
Стечением времени технологии хранения продолжают
развиваться, перемещаясь с внутренних серверов во
внешнюю сеть. Сегодняшний импульс к развитию конвер¬
гентной архитектуры возвращает задачи вычисления, хра¬
нения, организации памяти и сети к исходному состоянию,
когда архитектура может управляться по единому принци¬
пу. Среди этих перемен необходимость хранить большие
данные радикально изменила реляционное, ориентирован¬
ное на базы данных представление, как это было признано
ICT-компаниями, начиная с конца 1980-х годов. Суть в том,
что реляционная технология попросту не масштабируется,
для поддержки больших объемов данных. Не говоря уже о
том, что компании могут приобрести подлинную ценность
благодаря обработке слабоструктурированных и неструк¬
турированных данных, которые в большинстве случаев не¬
совместимы с реляционными подходами. Большие данные
раздвинули границы хранения к единому представлению
доступной памяти и кластера дискового хранилища. Если
требуется больше места для хранения, то горизонтальное
масштабирование позволяет расширить кластер за счет
добавления большего количества узлов. Тот факт, что это
одинаково справедливо как для памяти, так и для дисковых
устройств, важен, поскольку инновационные подходы пре¬
доставляют аналитику в реальном времени через использо¬
вание системы хранения внутренней памяти. Даже пакет¬
ная обработка ускорилась благодаря производительности
217
твердотельных накопителей (SSD), которые становятся ме¬
нее дорогими.
В этой главе мы дадим более глубокий анализ использования
устройств хранения для больших данных как дисковых (on-
disk) запоминающих устройств, так и оперативной памяти
(in-memory). Будут рассмотрены темы от простых понятий
распределенных файловых систем для хранения плоских
файлов до систем хранения NoSQL для неструктурирован¬
ных и слабоструктурированных данных. В частности, объяс¬
няются различные варианты технологий баз данных NoSQL
и их соответствующее использование. Последняя важная
тема главы — оперативная память, которая облегчает обра¬
ботку потоковых данных и может хранить базы данных це¬
ликом. Эти технологии позволяют перейти от традиционной
дисковой, пакетной обработки к внутренней работе в режи¬
ме реального времени.
218
Основы Big Data
Дисковые системы хранения
Дисковое хранилище обычно использует недорогие жест¬
кие диски для долговременного хранения данных. Дисковое
хранилище может быть реализовано с помощью распреде¬
ленной файловой системы или базы данных, как показано
на рисунке 7.1.
распределенная файловая система
SQL-подобная NoSQL
база данных
Рисунок 7.1
Дисковое хранилище может быть реализовано с помощью распределенной
файловой системы или базы данных.
API
Распределенные файловые системы
Распределенные файловые системы, как и любая файловая
система, не зависят от хранимых данных и поэтому поддер¬
живают хранение данных без схемы. В общем случае рас¬
пределенная файловая система системы хранения данных
обеспечивает встроенную избыточность и высокую доступ¬
ность путем копирования данных в несколько локальных
местоположений посредством репликации.
Системы хранения, реализованные с помощью распреде¬
ленной файловой системы, обеспечивают простой, быстрый
доступ к хранилищу данных, которое может сохранять боль¬
шие наборы данных, нереляционные по своей природе, как
Технологии хранения больших данных
219
слабоструктурированные и неструктурированные данные.
Хотя они и базируются на простых механизмах блокировки
файлов для управления параллелизмом, они предоставляют
возможность быстрого чтения/записи с учетом скоростной
характеристики для больших данных.
Распределенная файловая система не подходит для набо¬
ров данных с большим количеством мелких файлов, так как
приводит к активизации чрезмерной поисковой активности
на диске, тем самым замедляя общий доступ к данным. Кро¬
ме того, при обработке нескольких файлов меньшего разме¬
ра возникают дополнительные накладные затраты, так как
специализированные процессы обычно генерируются про¬
цессором обработки во время выполнения обработки каж¬
дого файла до того, как результаты будут синхронизированы
по всему кластеру.
Из-за этих ограничений распределенные файловые систе¬
мы лучше всего работают с меньшим количеством файлов
большего размера, доступ к которым осуществляется по¬
следовательно. Несколько файлов небольшого размера, как
правило, объединяются в один файл для обеспечения опти¬
мального хранения и обработки. Это позволяет повысить
производительность распределенных файловых систем при
доступе к данным в потоковом режиме без случайного чте¬
ния и записи (рисунок 7.2).
распределенная файловая система
Рисунок 12
Распределенная файловая система' получающая доступ к данным в потоковом режиме без
случайного чтения и записи.
220
Основы Big Data
Распределенная файловая система подходит для хранения
больших наборов необработанных данных или для архиви¬
рования наборов данных. Кроме того, она обеспечивает воз¬
можность недорогого хранения больших объемов данных,
которые должны оставаться доступными в сети (online), в
течение длительного периода времени. Это связано с тем,
что дисковые накопители могут просто быть добавлены в
кластер без необходимости выгружать данные в автоном¬
ное (offline) хранилище данных, например, такое как ленты.
Следует отметить, что распределенные файловые системы
не предоставляют возможность поиска по содержимому
файлов в качестве стандартной встроенной возможности.
СУРБД
Системы управления реляционными базами данных
(СУРБД) хороши для обработки транзакционных рабочих за¬
даний с использованием небольших объемов данных с воз¬
можностью произвольного чтения/записи. СУРБД являются
ACID-совместимыми, и, соблюдая это соответствие, они, как
правило, ограничены одним узлом. По этой причине СУРБД
не дают встроенной избыточности и отказоустойчивости.
Для обработки больших объемов данных, поступающих в бы¬
стром темпе, реляционные базы данных, как правило, нужда¬
ются в масштабировании. В СУРБД используется вертикальное
масштабирование, а не горизонтальное, которое является бо¬
лее дорогостоящей и революционной стратегией масштабиро¬
вания. Это делает СУРБД менее подходящими для долгосроч¬
ного хранения данных, которые со временем накапливаются.
Обратите внимание, что некоторые реляционные базы дан¬
ных, например IBM DB2 pureScale, Sybase ASE Cluster Edition,
Oracle Real Application Clusters (RAC) и Microsoft Parallel Data
Warehouse (PDW), способны запускаться на кластерах (ри¬
сунок 7.3). Однако эти кластеры баз данных по-прежнему
используют общую память, которая может действовать как
единственная точка отказа.
Технологии хранения больших данных
221
кластерная СУРБД
Рисунок 7.3
В кластерной рациональной базе данный используется арнитектура общей памяти, которая является
потенциально уязвимой точкой отказа, что влияет на доступность базы данный.
Реляционные базы данных должны быть шардированы вруч¬
ную, с использованием в основном прикладной логики. Это
означает, что прикладной логике необходимо знать, какой
шард запрашивать, чтобы получить требуемые данные. Это
еще больше усложняет обработку данных, когда требуются
данные из нескольких шардов.
222
Основы Big Data
Следующие шаги показаны на рисунке 7.4:
1. Пользователь делает запись (id = 2).
2. Прикладная логика определяет, в каком шарде она должна
быть записана.
3. Запись отправляется в шард, определенный прикладной
логикой.
4. Пользователь читает запись (id = 4), и прикладная логика
определяет, какой шард содержит данные.
5. Данные считываются и передаються в приложение.
6. Затем приложение возвращает запись пользователю.
СУРБД
Рисунок 7.4
Реляционная база данный шардируется
вручную с помощью прикладной логики.
Технологии хранения больших данных
223
Следующие шаги показаны на рисунке 7.5:
1. Пользователь запрашивает несколько записей (id = 1, 3),
используется прикладная логика, чтобы определить, ка¬
кие шарды должны быть прочитаны.
2. Прикладная логика определяет, что необходимо прочи¬
тать и Шард А, и Шард В.
3. Данные считываются и соединяются приложением.
4. Наконец, данные возвращаются пользователю.
Рисунок 7.5
Пример применения логики приложения для
объединения данный, полученный из несколькин осколков.
СУРБД
Шард А
224
Основы Big Data
Реляционные базы данных, как правило, требуют данных
для привязки к схеме. В результате хранение слабострукту¬
рированных и неструктурированных данных, схемы кото¬
рых не являются реляционными, не поддерживается непо¬
средственно. Более того, соответствие схемы реляционной
базы данных подтверждается во время ввода или обновле¬
ния данных, проверкой данных на ограничения схемы. Это
приводит к накладным затратам, которые создают задержку.
Эта задержка делает реляционные базы данных не подхо¬
дящими для хранения высокоскоростных данных, которым
требуется высоконадежное устройство хранения баз данных
с высокой скоростью записи. В результате из-за недостат¬
ков, традиционная СУРБД обычно не используется в каче¬
стве основной системы хранения в среде решений для боль¬
ших данных.
Базы данных NoSQL
Базы данных NoSQL (Not-only SQL) отно¬
сятся к технологиям, которые использу¬
ются для разработки нереляционных баз
данных следующего поколения, обла¬
дающих высокой масштабируемостью
и отказоустойчивостью. Обозначение,
используемое для представления баз
данных NoSQL, показано на рисунке 7.6.
базы данных NoSQL
Рисунок 7.6
Обозначение, которое
используется для представления
базы данный OoSQL
Характеристики
Ниже приведен список основных свойств систем хранения
данных NoSQL, которые отличают их от стандартных СУБД.
Этот список следует рассматривать только как общее руко¬
водство, так как не все системы хранения данных NoSQL об¬
ладают всеми этими свойствами.
• Модель данных без схемы — данные могут существовать в
своей необработанной форме.
Технологии хранения больших данных
225
• Горизонтальное, а не вертикальное масштабирование —
для получения дополнительного хранилища с базой дан¬
ных NoSQL можно добавить дополнительные узлы, вме¬
сто замены существующего узла более совершенным, с
лучшими характеристиками/большей вместимостью.
• Высокая доступность— строится на основе кластерных
технологий, которые обеспечивают встроенную отказоу¬
стойчивость.
• Снижение эксплуатационных расходов — многие базы дан¬
ных NoSQL построены на платформах с открытым исход¬
ным кодом без каких-либо затрат на лицензирование.
Поэтому они могут быть развернуты на стандартном ап¬
паратном обеспечении.
• Потенциальная согласованность— данные читаются на
нескольких узлах, но могут быть несогласованными сразу
после записи. Однако все узлы будут в конечном итоге в
согласованном состоянии.
• BASE, без ACID— BASE-соответствие требует, чтобы база
данных поддерживала высокую доступность в случае сбоя
сети/узла, при этом не обязательно, чтобы база данных на¬
ходилась в согласованном состоянии при каждом обновле¬
нии. База данных может быть в гибком/несогласованном
состоянии, пока она в конечном итоге не достигнет согла¬
сованности. В результате, учитывая теорему САР, системы
хранения NoSQL обычно представляют собой АР или СР.
• Доступ к данным посредством API—доступ к данным, как
правило, поддерживается с помощью запросов на основе
API, включая API REST, в то время как некоторые реали¬
зации также могут предоставить возможность SQL-подоб¬
ных запросов.
• Автоматический шардинг и репликация — для поддержки
горизонтального масштабирования и обеспечения вы¬
сокой доступности в системах хранения данных NoSQL
автоматически используются методы шардирования и
226
Основы Big Data
репликации, когда набор данных разбивается горизон¬
тально, а затем копируется на несколько узлов.
• Интегрированное кэширование— устраняет необходи¬
мость в стороннем уровне распределенного кэширования,
таком как Memcached.
• Распределенная поддержка запросов — системы хранения
данных NoSQL поддерживают согласованное поведение
запросов в нескольких шардах.
• Многовариантная персистентность— использование хра¬
нилища NoSQL не требует отказа от традиционных СУРБД.
На самом деле, они обе могут использоваться одновремен¬
но, тем самым поддерживая многовариантную персистент¬
ность, которая представляет собой подход для хранения
данных с использованием различных видов технологий
хранения в рамках одной архитектуры решения. Это подхо¬
дит при разработке систем, требующих структурированных,
а также слабо/неструктурированных данных.
• Ориентирование на агрегирование — в отличие от реляци¬
онных баз данных, которые наиболее эффективно рабо¬
тают с полностью нормализованными данными, системы
хранения NoSQL хранят денормализованные агрегиро¬
ванные данные (объект, содержащий соединенные, чаще
вложенные, данные для объекта), тем самым устраняя
необходимость в объединении и масштабном сопостав¬
лении между объектами прикладного уровня и данными,
хранящимися в базе данных. Однако есть одно исключе¬
ние, состоящее в том, что графовые базы данных (вводи¬
мые в ближайшее время) не являются агрегированными.
Логическое обоснование
Появление систем хранения данных NoSQL можно в первую
очередь объяснить объемами, скоростью и разнообразием
наборов больших данных.
Технологии хранения больших данных
227
Объем
Требование к хранению постоянно растущих объемов дан¬
ных позволяет использовать базы данных, обладающие вы¬
сокой масштабируемостью, при этом снижая затраты для
поддержания конкурентоспособности бизнеса. Системы
хранения данных NoSQL удовлетворяют этому требованию,
предоставляя возможности масштабирования при исполь¬
зовании недорогих обслуживающих серверов.
Скорость
Быстрый приток данных требует наличия баз данных с воз¬
можностью доступа к быстрой записи данных. Системы хра¬
нения данных NoSQL обеспечивают быструю запись данных
с использованием принципа схема-для-чтения, а не схе-
ма-для-записи. Будучи высокодоступными, системы хране¬
ния данных NoSQL могут гарантировать, что задержка запи¬
си не возникнет из-за сбоя узла или сети.
Многообразие
Системы хранения данных должны обрабатывать различные
форматы данных, включая документы, электронные письма,
изображения и видео, а также неполные данные. Системы
хранения данных NoSQL могут хранить различные формы
слабоструктурированных и неструктурированных форма¬
тов данных. В то же время системы хранения базы NoSQL
способны хранить данные без схемы и неполные данные с
дополнительной возможностью изменения схемы как моде¬
ли данных при развитии наборов данных. Другими словами,
базы данных NoSQL поддерживают эволюцию схемы.
Типы
Как показано на рисунках 7.7-7.10, системы хранения дан¬
ных базы NoSQL в основном можно разделить на четыре
типа в зависимости от способа хранения данных:
228
Основы Big Data
• ключ-значение
• документ
• объединение столбцов
• граф
Рисунок 7.7
Пример нранилища
floSQl для «ключ-
значение».
ключ значение
—— —
1001010111011011110111010101мкношиюиюю |
Рисунок 7.8
Пример нранилища
HoSOl для «документа».
Рисунок 7.9
Пример нранилища
RoSQL для «объедине¬
ния столбцов».
Рисунок 7.10
Пример нранения
данный AoSOl для
«графа».
Технологии хранения больших данных
229
Ключ-значение
Системы хранения данных типа «ключ-значение» сохраня¬
ют данные как пару из ключа и значения и действуют как
хеш-таблицы. Таблица представляет собой список значений,
где каждое значение идентифицируется ключом. Это значе¬
ние неявное для базы данных и обычно хранится как BLOB.
Сохраненное значение может быть любой совокупностью,
начиная от данных датчика и заканчивая видео.
Поиск значения может быть выполнен только с помощью
ключей, так как база данных не учитывает детали храни¬
мой совокупности. Частичное обновление невозможно.
Обновление представляет собой операцию удаления или
вставки.
Обычно система хранения «ключ-значение» не поддержи¬
вают никаких индексов, поэтому записи выполняются до¬
вольно быстро. Основываясь на простой модели хранения,
системы хранения «ключ-значение» являются высокомас¬
штабируемыми.
Поскольку ключи являются единственным средством извле¬
чения данных, обычно ключ добавляется с типом сохраняе¬
мого значения для легкого извлечения данных. Примером
является 123_sensorl.
Чтобы обеспечить некоторую структуру хранимых данных,
большинство систем хранения ключ-значение предостав¬
ляет коллекции или блоки (например, таблицы), в которых
могут быть организованы пары ключ-значение. Одна кол¬
лекция может содержать несколько форматов данных, как
показано на рисунке 7.11. Некоторые реализации поддер¬
живают сжатие значений для уменьшения занимаемого
пространства. Однако, это приводит к задержке во время
чтения, так как сначала данные должны быть распакованы
перед возвратом пользователю.
230
Основы Big Data
Рисунок 7.11
Пример данным, организованный в пары «ключ-значение».
Системы хранения «ключ-значение» подходит для случаев,
когда:
• требуется хранилище для неструктурированных данных
• требуется высокая эффективность чтения/записи
• значение полностью идентифицируется только одним
ключом
• значение — автономный объект, не зависящий от других
значений
• значения имеют сравнительно простую структуру или яв¬
ляются бинарными
• шаблоны запросов просты, и включают в себя только опе¬
рации вставки, выбора и удаления
• к сохраненным значениям обращаются на прикладном
уровне
Системы хранения данных «ключ-значение» не целесоо¬
бразны, если:
• приложениям требуется выполнить поиск или фильтра¬
цию данных с использованием атрибутов хранимого зна¬
чения
• существуют взаимосвязи между различными записями
пары «ключ-значение»
• значения группы ключей должны обновляться в одной
транзакции
Технологии хранения больших данных
231
• несколько ключей требуют преобразования (обращения)
за одну операцию
• требуется согласованность схемы для разных значений
• требуется обновление отдельных атрибутов значения
Примерами систем хранения «ключ-значение» являются
Riak, Redis и Amazon Dynamo DB.
Документ
Системы хранения «документов» также хранят данные как
пары с ключом и значением. Однако, в отличие от систем
хранения «ключ-значение», хранимое значение — это до¬
кумент, который можно запросить из базы данных. Эти до¬
кументы могут иметь сложную разветвленную структуру,
такую как счета-фактуры, показанные на рисунке 7.12. Доку¬
менты можно кодировать, используя схему кодирования на
основе текста, такую как XML или JSON, или используя схему
двоичного кодирования, такую как BSON (Binary JSON).
счет-фактура
invoice ld:37235,
date 19600801,
custld:29317,
iteme:(
{ttemkl;473,quantity:2},
{itemld.971,quantity 5}
J
I ключ значение
527 {lnvolceld.37235.dato:19600801 .custld-29317,items.[{itornld 473.quantity:2}.{itemld.971 ,quantity:5}]}
439 {invoiceld:37236.date. 19600201,custld.24663,items:[{itemld.471 .quantity 5},{itcmld:345,quantrty.1}]}
814 (mvoiceld 37237,date. 19601201,custld:45824,items:{(rtemld 493.quantity:1).{rtemld 123,quantity 1}]}
651 {invoiceld.37238,date-19601001,custld:34589.items:[{itemld:56l .quantity:3}.{i1emld 176.quantity 9}]}
Рисунок 7.12
JSOn в системе хранения документов.
Подобно системам хранения «ключ-значение», большин¬
ство систем хранения «документов» предоставляют коллек¬
ции или блоки (например, таблицы), в которых могут быть
организованы пары «ключ-значение». Основные различия
между системами хранения «документов» и системами хра¬
нения «ключ-значение» следующие:
232
Основы Big Data
• системы хранения «документов» осведомлены о значении
• сохраненное значение самостоятельно описывается;
схема может быть выведена из структуры значения или
включена в значение ссылкой на схему документа
• операция выбора может ссылаться на поле внутри агреги¬
рованного значения
• операция выбора может получить часть агрегированного
значения
• поддерживаются частичные обновления; поэтому агреги¬
рованное подмножество может быть обновлено
• как правило, поддерживаются индексы, которые ускоря¬
ют поиск
Каждый документ может иметь альтернативную схему; поэ¬
тому возможно хранение разных типов документов в одной
и той же коллекции или блоке. Дополнительные поля могут
добавляться в документ после начальной вставки, тем са¬
мым обеспечивая гибкую поддержку схемы.
Следует отметить, что системы хранения «документов» не
ограничиваются хранением данных, которые встречаются в
форме реальных документов, таких как XML-файл, но их так¬
же могут использоваться для хранения любого агрегата, кото¬
рый состоит из набора полей с плоской или вложенной схемой.
Рассмотрим рисунок 7.12, на котором показаны документы
JSON, которые хранятся в базе данных документов NoSQL.
Система хранения документов является целесообразной, когда:
• хранятся слабоструктурированные документо-ориенти¬
рованные данные, содержащие плоскую или разветвлен¬
ную схему
• эволюция схемы является требованием, из-за неизвест¬
ности или вероятности изменения структуры документа
Технологии хранения больших данных
233
• приложения требуют частичного обновления агрегата
данных, сохраненного как документ
• поисковые запросы должны выполняться в разных полях
документов
• объекты домена, такие как клиенты, хранятся в форме се¬
риализованного объекта
• шаблоны запросов включают операции вставки, выбора,
обновления и удаления
Система хранения документов является нецелесообразной, когда:
• необходимо обновить несколько документов в рамках од¬
ной транзакции
• выполняются операции, требующие объединения несколь¬
ких документов или хранения нормализованных данных
• необходимо применение схемы для достижения согласо¬
ванного проектирования запросов, так как структура доку¬
мента может меняться между последовательными выполне¬
ниями запросов, что потребует реструктуризации запроса
• хранимое значение не является самостоятельно описыва¬
емым и не имеет ссылки на схему
• данные должны храниться в двоичном коде
Примеры систем хранения документов включают MongoDB,
CouchDB и Terrastore.
Объединение столбцов
Системы хранения данных семейства объединения столбцов
хранят данные так же, как традиционные СУРБД, но связан¬
ные столбцы сгруппированы в одной строке, что приводит к
образованию объединения столбцов (рисунок 7.13). Каждый
столбец может быть коллекцией связанных столбцов, так
называемый сверхстолбец.
234
Основы Big Data
объединение столбцов
1 ld-студента
личная информация
адрес
история модулей
821
FlrstName: Cristie
LastName: Augustin
DoB: 03-15-1992
Gender. Female
Ethnicity: French
Street: 123 New Ave
City: Portland
State: Oregon
ZipCode: 12345
Country: USA
Taken: 5
Passed:4
Failed: 1
742
FirstName: Carlos
LastName Rodriguez
MiddleName: Jose
Gender: Male
Street: 456 Ok! Ave
City: Los Angeles
Country: USA
Taken:7
Passed:5
Failed: 2
Рисунок 7.13
Выделенные столбцы описывают функцию гибкой скемы, поддерживаемую
базами данный объединения столбцов, где каждая сторона может иметь
различный набор столбцов.
Каждый сверхстолбец может содержать произвольное число
связанных столбцов, которые обычно извлекаются или об¬
новляются как единое целое. Каждая строка состоит из не¬
скольких объединений столбцов, и может иметь различные
наборы столбцов, тем самым показывая гибкую поддержку
схемы. Каждая строка идентифицируется с помощью клю¬
чевой строки.
Системы хранения объединения столбцов обеспечивают
быстрый доступ к данным с возможностью произвольного
чтения/записи. Они хранят разные объединения столбцов в
отдельных физических файлах, что улучшает скорость реак¬
ции на запросы, так как поиск производится только по объ¬
единениям столбцов.
Некоторые системы хранения объединения столбцов пре¬
доставляют поддержку для избирательного сжатия объеди¬
нения столбцов. Оставляя доступными для поиска несжатые
объединения столбцов можно сделать запросы быстрее, так
как искомый столбец не должен распаковываться для по¬
иска. Большинство реализаций поддерживают управление
Технологии хранения больших данных
235
версиями данных, в то время как некоторые поддерживают
определение срока хранения для столбца данных. Когда срок
хранения данных истекает, они удаляются автоматически.
Использовать системы хранения объединения столбцов це¬
лесообразно, когда:
• необходима возможность произвольного чтения/записи в
реальном масштабе времени, и хранимые данные имеют
определенную структуру
• данные представляют собой табличную структуру, где ка¬
ждая строка состоит из большого числа столбцов и суще¬
ствуют вложенные группы взаимосвязанных данных
• требуется поддержка развития схемы, поскольку объеди¬
нения столбцов могут быть добавлены или удалены без
каких-либо простоев системы
• к некоторым полям, чаще всего, обращаются вместе, и по¬
иск должен выполнятся с использованием значений полей
• требуется эффективное использование хранилища дан¬
ных, когда данные состоят из редко заполненных строк,
так как базы данных объединения столбцов распределя¬
ют только пространство памяти, если имеется в наличии
столбец для строки. Если столбца нет, пространство не вы¬
деляется
• шаблоны запросов включают в себя операции вставки,
выбора, обновления и удаления
Системы хранения объединения столбцов нецелесообразны,
когда:
• требуется реляционный доступ к данным, например, объ¬
единение
• требуется поддержка ACID транзакций
двоичные данные должны сохранятся
236
Основы Big Data
• должны выполняться SQL-совместимые запросы
• шаблоны запросов, могут часто меняться, поскольку они
могут инициировать соответствующую реструктуризацию
расположения объединения столбцов
Примеры систем хранения объединения столбцов включают
в себя Cassandra, HBase и Amazon SimpleDB.
Граф
Графовые системы хранения используются для хранения
взаимосвязанных объектов. В отличие от других систем хра¬
нения NoSQL, где акцент делается на структуру объектов,
графовые системы хранения делают упор на сохранение
связей между объектами (рисунок 7.14).
Категория
Name: Electronics
Total Products: 350
Клиент
купил
Name: James
Age: 56
Gender: Male
содержит
содержит содержит
I Телевизор
DVD-
проигрыватель
Brand: Sony
Price: $1,200
Size: 55"
Brand. LG
Price: $300
купил просмотрел купил
домашний кинотеатр
Клиент
Name: Claire
Age: 23
Gender: Female
V
просмотрел
Клиент
Клиент
Name: Josh
Name: Anna
Age: 35
Gender: Male
Age: 42
Gender: Female
просмотрел
Тостер
Brand: Bosch
Price: $50
содержит
Brand: Samsung
Price: $1,200
купил
Клиент
Name: Cados
Age: 37
Gender: Male
купил просмотрел просмотрел
I
Чайник
Кофеварка
Brand: Kenwood
Price: $75
содержит содержит
Brand: Delonghi
Price: $250
Capacity: 1 liter
Рисунок 7.14
Графовые системы
«ранения сонраняют
объекты и ин отношения.
Категория
Name: Kitchen Appliances
Total Products: 520
i
Технологии хранения больших данных
237
Объекты хранятся в виде узлов (не путать с узлами кластера)
и также называются вершинами, в то время как связи между
объектами сохраняются как ребра. На языке реляционных
баз каждый узел можно рассматривать как единую строку,
а ребром обозначать связь.
Узлы могут иметь более одного типа связей посредством не¬
скольких ребер. Каждый узел может содержать данные атри¬
бутов в виде пар «ключ-значение», например, как узел клиен¬
та с атрибутами идентификатора личности, имени и возраста.
Каждое ребро может иметь свои собственные данные атри¬
бутов в виде пар «ключ-значение», которые могут исполь¬
зоваться для дальнейшей фильтрации результатов запро¬
са. Наличие нескольких ребер аналогично определению
нескольких внешних ключей в реляционной базе данных;
однако не для каждого узла требуется наличие одинаковых
ребер. Запросы, как правило, предполагают выявление вза¬
имосвязанных узлов на основе атрибутов узлов и/или атри¬
бутов ребер, обычно называемых узлами обхода. Задавая
направление обхода узла, ребра могут быть однонаправлен¬
ными или двунаправленными. Как правило, устройства хра¬
нения графов обеспечивают согласованность через соответ¬
ствие ACID.
Степень полезности устройства хранения графов зависит от
количества и типов ребер, образованных между узлами. Чем
больше число ребер и их разнообразие, тем разнообразнее
типы запросов, которые система может обрабатывать. Поэ¬
тому так важно всесторонне охватить все типы отношений,
которые существуют между узлами. Это справедливо не
только для существующих сценариев использования, но и
для анализа данных.
Графовые системы хранения обычно позволяют добавлять
новые типы узлов без внесения изменений в базу данных.
Это также позволяет определять дополнительные связи
между узлами по мере появления новых типов отношений
или узлов в базе данных.
238
Основы Big Data
Графовые системы хранения целесообразны, когда:
• необходимо хранить взаимосвязанные объекты
• запрос объектов основывается на типе отношений между
ними, а не на атрибутах объектов
• осуществляется поиск группы взаимосвязанных объектов
• осуществляется поиск расстояний между объектами с точки
зрения расстояния обхода узла
• выполняется интеллектуальный анализ данных с целью
поиска закономерностей
Графовые системы хранения неприемлемы, если:
• необходимы обновления для большого числа атрибутов
узлов или атрибутов ребер, поскольку это связано с поис¬
ком узлов или ребер, что является дорогостоящей опера¬
цией по сравнению с выполнением обходов узлов
• объекты имеют большое количество атрибутов или вло¬
женных данных — лучше всего хранить легкие объекты
в графовых системах хранения, сохраняя остальные дан¬
ные атрибутов в отдельной неграфовой системе хранения
данных NoSQL
• требуется хранилище двоичных данных
• запросы, основанные на выборе атрибутов узла/ребра, до¬
минируют над запросами обхода узлов
Примеры включают в себя Neo4J, Infinite Graph и OrientDB.
Базы данных NewSQL
Системы хранения данных NoSQL являются хорошо масшта¬
бируемыми, доступными, отказоустойчивыми и быстродей¬
ствующими для операций чтения/записи. Тем не менее, они
не обеспечивают такой же поддержки для обработки тран¬
Технологии хранения больших данных
239
закций и согласованности, какую демонстрируют СУРБД,
совместимые с ACID. Следуя модели BASE, устройства хра¬
нения NoSQL обеспечивают случайную согласованность, а
не немедленную согласованность. Поэтому они будут нахо¬
диться в состоянии наибольшей уязвимости при достиже¬
нии состояния случайной согласованности. В результате они
не подходят для использования в реализации крупномас¬
штабных систем обработки транзакций.
Системы хранения NewSQL сочетают в себе свойства ACID
СУРБД с масштабируемостью и отказоустойчивостью, ко¬
торые предлагают системы хранения NoSQL. Базы данных
NewSQL обычно поддерживают SQL-совместимый синтак¬
сис для описания данных и операций манипулирования
данными, и они часто используют логическую реляционную
модель данных для хранения данных.
Базы данных NewSQL могут использоваться для разработ¬
ки OLTP-систем с очень большим объемом транзакций,
например, для банковской системы. Они также могут ис¬
пользоваться для аналитики в реальном масштабе времени,
например, оперативной аналитики, поскольку некоторые
реализации используют внутреннюю память.
По сравнению с NoSQL, системы хранения NewSQL обеспе¬
чивает более простой переход от традиционных СУРБД к
масштабируемым базам данных благодаря поддержке SQL.
Примеры баз данных NewSQL включают в себя VoltDB,
NuoDB и InnoDB.
Системы хранения в оперативной памяти
В предыдущем разделе были представлены системы хране¬
ния на дисках и их различные типы в качестве основного
средства для хранения данных. Этот раздел основывается на
этих знаниях, представляя хранение в оперативной памяти
как средство, обеспечивающее возможности для высокопро¬
изводительного и усовершенствованного хранения данных.
240
Основы Big Data
Системы хранения в оперативной памяти обычно исполь¬
зуют ОЗУ, главную память компьютера, в качестве своего
основного носителя, чтобы обеспечить быстрый доступ к
данным. Увеличение емкости и снижение стоимости ОЗУ в
сочетании с увеличением скорости чтения/записи твердо¬
тельных жестких дисков, позволило разработать эффектив¬
ные решения для хранения данных в оперативной памяти.
Хранение данных в оперативной памяти устраняет задерж¬
ку дискового ввода/вывода и время передачи данных между
основной памятью и жестким диском. Это общее сокраще¬
ние задержки чтения/записи данных значительно ускоряет
обработку данных. Емкость оперативной памяти хранения
данных может быть значительно увеличена за счет горизон¬
тального масштабирования кластера, на котором размеща¬
ется система хранения в оперативной памяти.
Память всего кластера позволяет хранить большие объемы
данных, в том числе наборы больших данных, доступ к кото¬
рым можно получить значительно быстрее, если сравнивать
с дисковыми системами хранения. Это значительно сокра¬
щает общее время выполнения аналитики больших данных,
что позволяет выполнять аналитику в реальном времени.
оперативная
память
На рисунке 7.15 показан символ, который пред¬
ставляет собой оперативную память. На рисун¬
ке 7.16 приводится сравнение времени доступа
между устройствами оперативной памяти и
дисковыми устройствами хранения. Верхняя
часть рисунка показывает, что последовательное чтение 1 МБ
данных из оперативной памяти занимает около 0,25 мс. Нижняя
половина рисунка показывает, что чтение такого же объема дан¬
ных с дискового устройства хранения занимает около 20 мс. Это
показывает, что чтение данных из оперативной памяти в 80 раз
быстрее, чем с дискового устройства хранения. Обратите внима¬
ние на то, что предполагается, что время передачи сетевых дан¬
ных одинаково для этих двух сценариев, и поэтому оно было ис¬
ключено из времени считывания.
Технологии хранения больших данных
241
оперативная
дисковое устройство
хранения
Рисунок 7.16
Оперативная память в 80 раз быстрее при передаче данный, чем дисковые
устройства нранения.
Системы хранения в оперативной памяти позволяют выпол¬
нять аналитику в памяти, то есть путем выполнения запро¬
сов к данным, хранящимся в памяти, а не на диске. Выпол¬
нение аналитики в оперативной памяти позволяет ускорить
операционную аналитику и BI посредством быстрого вы¬
полнения запросов и алгоритмов.
В первую очередь, оперативная память позволяет ощутить
быстрый приток данных в среде больших данных (характе¬
ристика скорости), предоставляя среду хранения данных,
которая создает ощущение реального времени.
Оперативная память для больших данных реализуется в
кластере, обеспечивая высокую доступность и избыточность
данных. Таким образом, горизонтальной масштабируемо¬
сти можно достигнуть путем простого добавления большего
количества узлов или памяти. Если сравнивать с дисковым
устройством хранения, оперативная память намного доро¬
же из-за более высокой стоимости памяти по сравнению с
дисковым устройством хранения.
Хотя 64-разрядная машина может использовать 16 экзабайт
оперативной памяти, из-за физических ограничений маши¬
ны, таких как количество слотов памяти, реально установлен¬
242
Основы Big Data
ная память значительно меньшая. Для горизонтального мас¬
штабирования, добавление большего объема памяти является
не простым делом, также, как и добавление узлов, которые
требуются в случае достижения предела памяти для каждого
узла. Все это увеличивает затраты на хранение данных.
Помимо дороговизны, оперативная память не предоставля¬
ет такого же уровня поддержки для длительного хранения
данных. Ценовой фактор дополнительно влияет на достижи¬
мую емкость оперативной памяти, по сравнению с дисковым
устройством хранения. Следовательно, в оперативной памя¬
ти всегда хранятся только самая актуальная и свежая инфор¬
мация или данные, имеющие наибольшую значимость, тогда
как устаревшие данные заменяются более новыми и более
свежими данными.
В зависимости от реализации, оперативная память может
поддерживать хранение без схемы или хранение со схемой.
Хранилище без схемы осуществляется посредством сохра¬
нения данных на основе «ключ-значения».
Оперативная память является актуальной, когда:
• данные поступают в быстром темпе и требуют аналитики
в реальном времени или обработки потока событий
• требуется непрерывная или постоянная выполняющаяся
аналитика, как например, BI и операционная аналитика
• необходимо выполнить интерактивную обработку запро¬
сов и визуализацию данных в реальном времени, включая
анализ данных «что-если» и операций развертки
• требуется один и тот же набор данных для нескольких за¬
даний обработки данных
• выполняется анализ данных, так как не требуется переза¬
гружать с диска один и тот же набор данных, если алго¬
ритм изменяется
Технологии хранения больших данных
243
• обработка данных предполагает итерационный доступ к
одному набору данных, например, выполнение алгорит¬
мов, базирующихся на графах
• разработка решений для больших данных с малыми за¬
держками и поддержкой ACID транзакций
Оперативная память не является актуальной, когда:
• обработка данных состоит из пакетной обработки
• в течение длительного времени необходимо хранить
очень большие объемы данных во внутренней памяти для
проведения глубокого анализа данных
• выполняется стратегический BI или исторический анализ,
который предполагает доступ к очень большим объемам
данных и включает в себя пакетную обработку данных
• наборы данных чрезвычайно велики и не помещаются в
доступную память
• выполняется переход от традиционного анализа данных к
анализу больших данных, поскольку использование опе¬
ративной памяти может потребовать дополнительных на¬
выков и в том числе сложной настройки
• предприятие имеет ограниченный бюджет, так как уста¬
новка оперативной памяти может потребовать обновле¬
ния узлов, что можно сделать либо путем замены узла,
либо путем добавления большего объема ОЗУ
Устройства оперативной памяти могут реализовываться как:
• In-Memory Data Grid (IMDG)
• In-Memory Database (IMDB)
Хотя обе эти технологии используют память в качестве основ¬
ного носителя данных, однако то, что делает их отличными,
заключается в способе хранения данных в памяти. Далее будут
рассмотрены основные особенности каждой из этих технологий.
244
Основы Big Data
In-Memory Data Grid
IMDG хранит данные в виде пар «ключ-зна¬
чение» среди множества узлов, где ключи и
значения могут быть любыми бизнес-объ-
ектами или прикладными данными в се¬
риализованной форме. Это поддерживает
хранение данных без учета схемы за счет
хранения слабо/неструктурированных дан¬
ных. Доступ к данным обычно осуществля¬
ется через API-интерфейсы. Символ, кото¬
рый используется для отображения IMDG,
показан на рисунке 7.17.
IMDG
Oto
is
Рисунок 7.17
Символ, что использу¬
ется для представле¬
ния imoG.
На рисунке 7.18:
1. Изображение (a), XML данные (Ь) и объект покупателя (с)
сначала сериализуются с использованием механизма се¬
риализации.
2. Затем они сохраняются как пары «ключ-значение» в IMDG.
3. Клиент запрашивает объект покупателя с помощью соот¬
ветствующего ключа.
4. Затем 1МБСвозвращает значение в сериализованной форме.
5. Затем клиент использует механизм сериализации, чтобы
десериализовать значения для получения объекта поку¬
пателя...
6.... с целью управлять объектом покупателя.
Узлы в IMDG поддерживают синхронизацию и в совокуп¬
ности обеспечивают высокую доступность, отказоустойчи¬
вость и согласованность. По сравнению с подходом NoSQL,
для обеспечения согласованности IMDG поддерживают не¬
медленную согласованность.
По сравнению с IMDB для реляционных баз данных (что бу¬
дут рассмотрены ниже), 1МОСобеспечивают более быстрый
Технологии хранения больших данных
245
покупатель (объект)
Рисунок 7.18
Устройство «ранения IfTIDG.
IMDG
key
value
1
0101010
2
1010101
3
1010101
image
customer (object)
customer (object)
доступ к данным, поскольку они хранят нереляционные
данные как объекты. Следовательно, в отличие от IMDB, объ¬
ектно-реляционное отображение не требуется, и клиенты
могут работать непосредственно с конкретными объектами
домена.
Горизонтальное масштабирование IMDG, реализует разбие¬
ние и репликацию данных, а так же дальнейшую поддержку
доступности за счет репликации данных, по меньшей мере,
на одном дополнительном узле. В случае сбоя в работе ма¬
шины, IMDG автоматически воссоздают утраченные копии
данных из реплики в рамках процесса восстановления.
IMDG активно используются для аналитики в реальном мас¬
штабе времени, поскольку поддерживают обработку слож¬
ных событий (СЕР) с помощью модели обмена сообщения¬
ми для публикации и подписки. Это достигается с помощью
функции, называемой непрерывным запросом, которая так¬
же известна как активный запрос, где фильтр для события
(-ий), представляющего интерес, регистрируется в IMDG.
Затем IMDG непрерывно оценивает фильтр и каждый раз,
когда фильтр выполняется в результате операций вставки/
246
Основы Big Data
обновления/удаления, подписанные клиенты информи¬
руются (рисунок 7.19). Уведомления отправляются асин¬
хронно, как события об изменениях, такие как добавленные,
удаленные и обновленные события, с информацией о парах
«ключ-значение», например, старые и новые значения.
клиент
Рисунок 7.19
IfDDG нранит цены на акции, где ключ - это символ акции, а значение - цена
акций (отображается как текст для удобства чтения). Клиент выдает непрерыв¬
ный запрос (ключ = SSfllF) (1), который зарегистрирован в IITIDG (2). Когда курс
акций для фонда SSALF изменяется (3), обновленное событие отправляется
клиенту подписчику, который имеет различные сведения о событии (4).
С точки зрения функциональности, IMDG сродни распреде¬
ленному кэшу, поскольку оба обеспечивают доступ, осно¬
ванный на памяти, к часто используемым данным. Однако,
в отличие от распределенного кэша, IMDG обеспечивает
встроенную поддержку репликации и высокой доступности.
Механизмы обработки в реальном времени могут исполь¬
зовать IMDG, где высокоскоростные данные сохраняются в
Технологии хранения больших данных
247
IMDG по мере их поступления и обрабатываются до сохра¬
нения на дисковом устройстве хранения или данные с дис¬
кового устройства хранения копируются в IMDG. Это на по¬
рядок ускоряет обработку данных и увеличивает повторное
использование данных в случае, когда несколько заданий
или итеративных алгоритмов работают с одними и теми
же данными. IMDG могут также поддерживать MapReduce
в оперативной памяти, что помогает уменьшить задержку
обработки MapReduce на диске, особенно когда одну и ту же
задачу нужно выполнить несколько раз.
IMDG также могут быть развернуты в облачной среде, где
они предоставляют гибкую среду хранения данных, которая
может автоматически масштабироваться по мере увеличе¬
ния или уменьшения производительности или потребности
в хранилище, как показано на рисунке 7.20.
KPDG, развернутая в облаке, автоматически масштабируется по мере увеличения
спроса на крэнение данный.
IMDG могут быть добавлены к существующим решениям
для больших данных, введя их между существующим диско¬
вым устройством хранения и приложением обработки дан¬
248
Основы Big Data
ных. Однако это введение обычно требует изменения кода
приложения для реализации API IMDG.
Обратите внимание, что некоторые реализации IMDG также
могут предоставлять ограниченную или полную поддержку
SQL.
В качестве примеров можно привести In-Memory Data Fabric,
Hazelcast и Oracle Coherence.
В среде решений для больших данных, IMDG часто разверты¬
ваются вместе с дисковыми устройствами хранения, которые
выступают в качестве backend-хранилища. Это достигается с
помощью следующих подходов, которые могут комбиниро¬
ваться по мере необходимости для поддержки производи¬
тельности чтения/записи, согласованности и простоты:
• сквозное чтение (от начала до конца)
• сквозная запись
• отложенная запись
• обновление
Сквозное чтение
Если запрашиваемое значение для ключа не найдено в
IMDG, оно синхронно считывается с дискового backend-хра¬
нилища, такого как база данных. После успешного считыва¬
ния с дискового backend-хранилища пара «ключ-значение»
доставляется в IMDG, и запрашиваемое значение возвраща¬
ется клиенту. Любые последующие запросы на тот же ключ
в дальнейшем обслуживаются IMDG напрямую, а не через
backend-хранилище. Несмотря на то, что это простой подход,
его синхронная природа может привести к задержке чтения.
На рисунке 7.21 приведен пример метода сквозного чтения,
в котором клиент А пытается прочитать ключ КЗ (1), кото¬
рый в настоящее время не существует в IMDG. Следователь¬
но, он считывается из backend-хранилища (2) и доставляется
Технологии хранения больших данных
249
в IMDG (3) перед отправкой клиенту А (4). Последующий за¬
прос для того же ключа клиентом В (5) будет обслуживается
непосредственно IMDG (6).
Рисунок 721
Пример использования IITIDG с методом сквозного чтения
key
value I
1
0101010
1010101
1010101
NoSQL
Сквозная запись
Любая запись (вставка/обновление/удаление) в IMDG запи¬
сывается синхронно в режиме транзакции на backend дис¬
ковое устройство хранения, такое как база данных. Если
происходит сбой при записи на backend дисковом устрой¬
стве хранения, происходит откат обновления IMDG. Из-за
этой транзакционной природы, согласованность данных
достигается непосредственно между двумя хранилищами
данных. Однако эта поддержка транзакций обеспечивается
за счет задержки записи, поскольку любая операция записи
считается завершенной только тогда, когда получена обрат¬
ная связь (успеха/неудачи записи) из backend-хранилища
(рисунок 7.22).
250
Основы Big Data
клиент
успех
—<D—
kj = 1010101 -
добавить
key value
10101010
2 1010101
NoSQL
key
value I
1
0101010
2
101610Т
3
1010101
Рисунок 722
Клиент вводит новую пару «ключ-значение» (КЗ, V3), которая доставляется как в IITIDG (1а), так и в
backend-нранилище (lb) транзакционным способом. После успешного добавления данный в KTIDG
(2а) и в backend-крэнилище (2Ь) клиенту сообщают, что данные были успешно добавлены (3).
Отложенная запись
Любая запись в IMDG записывается асинхронно в пакетном ре¬
жиме на дисковое backend-хранилище, такое как база данных.
Очередь обычно помещается между IMDG и дисковым
backend-хранилищем для отслеживания необходимых из¬
менений в дисковом backend-хранилище. Эта очередь мо¬
жет быть сконфигурирована для записи данных в дисковое
backend-хранилище с различными интервалами.
Асинхронная природа увеличивает как скорость записи
(операция записи считается завершенной, как только она
записана в IMDG), так и скорость чтения (данные могут счи¬
тываться из IMDG, как только они записаны в IMDG), а так же
масштабируемость/доступность в целом.
Однако асинхронная природа вносит несогласованность до
тех пор, пока backend-хранилище не обновится в заданном
интервале.
Технологии хранения больших данных
251
На рисунке 7.23:
1. Клиент А обновляет значение КЗ, которое обновляется
в IMDG (а) и также отправляется в очередь (Ь).
2. Однако до обновления backend-хранилища, клиент В
запрашивает тот же ключ.
3. Отправляется старое значение.
4. После заданного интервала...
5.... backend-хранилище в конечном счете обновляется.
6. Клиент С делает запрос на тот же ключ.
7. На этот раз отправляется обновленное значение.
Рисунок 723
Пример поднодз с отложенной записью.
Клиент С
NoSQL
key
value ,
1
101010
Zj
101010
3 '
100001
252
Основы Big Data
Обновление
Обновление — это активный подход, при котором любые
часто запрашиваемые значения автоматически, асинхрон¬
но обновляются в IMDG, при условии, что к значению обра¬
щаются до истечения срока его действия, в соответствие с
настройками IMDG. Если доступ к значению осуществляется
после истечения его срока действия, значение, как и в режи¬
ме чтения, синхронно считывается из внутреннего храни¬
лища и обновляется в IMDG перед возвратом клиенту.
Из-за его асинхронной и продвинутой природы, этот под¬
ход помогает достичь лучшей производительности чтения и
особенно полезен, когда к одним и тем же значениям часто
обращаются или обращается большое число клиентов.
По сравнению с методом сквозного чтения, когда значение
передается из IMDG до истечения его срока действия, несо¬
гласованность данных между IMDG и backend-хранилищем
минимизируется, поскольку значения обновляются до исте¬
чения срока их действия.
На рисунке 7.24:
1. Клиент А запрашивает КЗ до истечения срока его действия.
2. Текущее значение возвращается из IMDG.
3. Значение обновляется из backend-хранилища.
4. Затем значение асинхронно обновляется в IMDG.
5. По истечению заданного времени пара «ключ-значение»
будет удалена из IMDG.
6. Теперь клиент В делает запрос на КЗ.
7. Поскольку ключ не существует в IMDG, он синхронно за¬
прашивается из backend-хранилища...
8.... и обновляется.
9. 9. Затем значение возвращается клиенту В.
Технологии хранения больших данных
253
получить
IMDG
получить
Клиент В
NoSQL
key value
1 101010
2 101010
3 ; 10001
Клиент А
Рисунок 724
Пример irnDG, что использует
подвод обновления.
Система хранения данных IMDG подходящая, когда:
• данные должны быть легкодоступны в виде объектов с
минимальной задержкой
• хранящиеся данные нереляционные по своей природе,
такие как слабоструктурированные и неструктурирован¬
ные данные
• добавление поддержки в реальном масштабе времени
существующему решению для больших данных, в настоя¬
щее время использующего дисковое хранилище
• существующую систему хранения нельзя заменить, но
можно изменить уровень доступа к данным
• масштабируемость важнее реляционного хранилища;
хотя IMDG более масштабируемые, чем IMDB (IMDB яв¬
ляются функционально полными базами данных), они не
поддерживают реляционные хранилища
Примеры систем хранения IMDG включают: Hazelcast,
Infinispan, Pivotal GemFire и Gigaspaces ХАР.
254
Основы Big Data
In-Memory Databases
IMDB — это система хранения в оператив¬
ной памяти, которая использует техноло¬
гии баз данных и усиливает производи¬
тельность ОЗУ для преодоления проблем с
задержкой во время выполнения, которые
характерны для дисковых систем хранения.
Символ для представления IMDB показан
на рисунке 7.25.
На рисунке 7.26:
IMDB
1111
Рисунок 725
Символ, используемый
для представления
ИЛОВ.
(1 В
П
1. Реляционный набор данных хранится в
IMDB.
2. Клиент запрашивает запись о покупателе (id = 2) через SQL.
3. Затем соответствующая запись покупателя возвращается
в IMDB, которая непосредственно управляет клиентом,
без необходимости какой-либо десериализации.
Технологии хранения больших данных
255
IMDB может быть реляционной по своей природе (реляци¬
онная IMDB) для хранения структурированных данных, или
может использовать технологию NoSQL (нереляционная
IMDB) для хранения слабоструктурированных и неструкту¬
рированных данных.
В отличие от IMDG, которые обычно обеспечивают доступ
к данным через API-интерфейсы, реляционные IMDB ис¬
пользуют более привычный язык SQL, что упрощает рабо¬
ту аналитикам или ученым, не обладающим продвинутыми
навыками программирования. NoSQL основанные на IMDB
обычно предоставляют доступ через API-интерфейсы, кото¬
рые могут быть такими ж простыми, как операции put (по¬
местить), get (получить) и delete (удалить). В зависимости
от базовой реализации, некоторые IMDB являются горизон¬
тально масштабированными, в то время как другие могут
быть вертикально масштабированными, для достижения
высокой масштабируемости.
Не все реализации IMDB непосредственно поддерживают
устойчивость к внешним факторам, но вместо этого исполь¬
зуют различные стратегии для обеспечения устойчивости к
сбоям в работе системы или повреждению памяти. Эти стра¬
тегии включают следующее:
• Использование энергонезависимого ОЗУ (NVRAM) для
постоянного хранения данных.
• Журналы транзакций базы данных можно периодически
хранить на энергонезависимых носителях, например, на
жестком диске.
• Файлы снимков, фиксирующих состояние базы данных в
определенный момент времени, сохраняются на диске.
• IMDB может использовать шардинг и репликацию для
поддержки повышения доступности и надежности, как
замену устойчивости.
• IMDB может использоваться в сочетании с дисковыми
системами хранения, такими как базы данных NoSQL и
СУРБД для долговременного хранения.
256
Основы Big Data
Как и IMDG, IMDB также может поддерживать функцию
непрерывного запроса, когда фильтр в форме запроса на
данные, представляющие интерес, регистрируется в IMDB.
Затем IMDB непрерывно выполняет запрос итерационным
способом. Всякий раз, когда результат запроса изменяется
в результате операций вставки/обновления/удаления, под¬
писанным клиентам асинхронно сообщают, отправляя из¬
менения в виде событий, таких как добавленные, удаленные
и обновленные события, с информацией о значениях записи,
таких как старые и новые значения.
На рисунке 7.27 IMDB хранит значения температуры для
различных сенсоров. Отображаются следующие шаги:
1. Клиент выдает непрерывный запрос (select * from sensors
where temperature > 75).
2. Запрос регистрируется в IMDB.
3. Когда температура для любого сенсора превышает 75...
4.... обновленное событие отправляется клиенту-подписчи¬
ку, который имеет различные сведения о событии.
Рисунок 726
Приводится пример нранилища IITIDB.
сконфигурированного для непрерывного запроса
Технологии хранения больших данных
257
IMDB активно используются в аналитике реального време¬
ни, а также в дальнейшем могут использоваться для раз¬
работки приложений с низкой задержкой, требующих пол¬
ной поддержки ACID-транзакций (реляционная IMDB). По
сравнению с IMDG, IMDB обеспечивают простоту настройки
систем хранения в оперативной памяти, поскольку IMDB
обычно не требуют дисковой системы хранения.
Введение IMDB в существующее решение для больших дан¬
ных обычно требует замены существующих дисковых систем
хранения, в том числе и любые СУРБД, если они используют¬
ся. В случае замены СУРБД реляционной IMDB, практически
не потребуется или потребуется незначительное изменение
в коде приложения из-за поддержки SQL, предоставляемой
реляционной IMDB. Однако при замене СУРБД на IMDB
NoSQL может потребоваться изменение кода из-за необхо¬
димости реализации в NoSQL API-интерфейса для IMDB.
При замене дисковой системы хранения базы данных NoSQL
на реляционную IMDB, часто требуется изменение кода для
установки доступа основанного на SQL. Однако при замене
дисковой системы хранения базы данных NoSQL на IMDB
NoSQL изменение кода может потребоваться в связи с вне¬
дрением новых API-интерфейсов.
Реляционные IMDB, как правило, менее масштабируемы,
чем IMDG, поскольку реляционные IMDB должны поддержи¬
вать распределенные запросы и транзакции в кластере. Для
некоторых реализаций IMDB может быть полезно масшта¬
бирование, оно поможет устранить задержку, возникающую
при выполнении запросов и транзакций в среде масштаби¬
рования.
Примерами могут служить Aerospike, MemSQL, Altibase HDB,
extreme DB и Pivotal GemFireXD.
Система хранения данных IMDB является подходящей, если:
• реляционные данные необходимо сохранять в памяти с
поддержкой ACID;
258 Основы Big Data
• необходимо дополнение функции поддержки реального
времени к существующему решению для больших дан¬
ных, которое в настоящее время использует дисковую си¬
стему хранения;
• существующие дисковые системы хранения могут быть
заменены эквивалентными технологиями систем хране¬
ния в оператиивной памяти;
• необходима минимизация изменений на уровне доступа к
данным из кода приложения, например, когда приложение
состоит из уровня доступа к данным, основанного на SQL;
• реляционное хранилище является более важным, чем
масштабируемость.
ПРИМЕР ИЗ ПРАКТИКИ
Команда IT-специалистов ETI оценили использование
различных технологий хранения больших данных для
обеспечения хранения различных наборов данных, ука¬
занных в главе 1. Следуя стратегии по обработке данных,
команда решила внедрить технологии дисковых систем
хранения для обеспечения пакетной обработки данных
и включения в них технологии хранения данных с под¬
держкой обработки данных в реальном масштабе вре¬
мени. Команда определила, что ей необходимо исполь¬
зовать комбинацию распределенной файловой системы
и базы данных NoSOL для хранения разнообразных ис¬
ходных наборов данных, созданных как внутри ETI, так
и за ее пределами, а так же для хранения обработанных
данных.
Любой линейный текстовый набор данных, такой как
файлы журнала веб-сервера, где запись представляется
разграниченной строкой текста и набора данных, может
Технологии хранения больших данных 259
обрабатываться потоковым способом (записи обрабаты¬
ваются одна за другой без необходимости произвольного
обращения к определенным записям), и храниться в рас¬
пределенной файловой системе Hadoop (HDFS).
Фотографии инцидентов занимают большой объем па¬
мяти и в настоящее время хранятся в реляционных ба¬
зах данных в виде BLOB с идентификатором, который
соответствует ID инцидента. Поскольку эти фотографии
являются данными в двоичном коде и доступ к ним мож¬
но получить только через их идентификаторы, команда
ГГ-специалистов полагают, что эффективней использо¬
вать базу данных с «ключ-значением». Это позволит обе¬
спечить недорогой способ для хранения фотографий ин¬
цидентов и освободит место в реляционной базе данных.
Документация базы данных NoSOL будет использоваться
для хранения иерархических данных, включая данные
Twitter (JSON), данные о погоде (XML), заметки агента
call-центра (XML), примечания специалиста по страхо¬
вым заявкам (XML), медицинские записи (записи, совме¬
стимые с HL7 в XML) и электронные письма (XML).
Когда одновременно существует естественное группиро¬
вание полей и необходим быстрый доступ к связанным
полям, данные сохраняются в базе данных NoSOL семей¬
ства объединения столбцов. Например, данные профиля
клиента состоят из персональных данных клиента, адре¬
са и интересов, а также поля текущей стратегии поведе¬
ния, каждое из которых состоит из нескольких полей. С
другой стороны, обработанные твиты и метеорологиче¬
ские данные также могут храниться в базе данных объ¬
единения столбцов, поскольку обработанные данные
должны быть в табличной форме, из которой к отдель¬
ным полям могут обратиться различные аналитические
запросы.
261
Глава 8
Основные методы
анализа
больших данных
Количественный анализ
f..
Качественный анализ
/
Сбор данных
Г
Статистический анализ
л
Машинное обучение
Семантический анализ
Визуальный анализ
262
Анализ больших данных сочетает
традиционные методы статисти¬
ческого анализа данных с вычисли¬
тельными методами. Статистическая
выборка из совокупности является
идеальной, когда доступен весь набор
данных, и такое условие типично для
традиционных сценариев пакетной
обработки. Однако большие данные
могут перейти от пакетной обработ¬
ки к обработке в реальном време¬
ни из-за необходимости понимать
смысл потоковых данных. В случае
потоковых данных наборы данных
накапливаются с течением времени,
и данные упорядочиваются во вре¬
мени. В потоковых данных акцент
делается на своевременную обработ¬
ку, так как аналитические результаты
имеют срок годности. Независимо от
того, является ли это распознавание
возможности продажи, которая выте¬
кает из текущего контекста клиента,
или обнаружением аномальных ус¬
ловий в производственной среде, что
требуют вмешательства для защиты
оборудования или обеспечения каче¬
В 2003 году Уильям Агре-
сти (William Agresti) при¬
знал переход к вычис¬
лительным принципам
и выступил за создание
новой вычислительной
дисциплины под назва¬
нием Информатика От¬
крытий. Взгляд Агрести
на эту область предпо¬
лагал композицию. Дру¬
гими словами, он считал,
что информатика откры¬
тий представляет собой
синтез следующих об¬
ластей: распознавание
образов (интеллектуаль¬
ный анализ данных - data
mining); искусственный
интеллект (машинное
обу-чение); обработка
документов и текстов
(семантическая обработ¬
ка); управление базами
данных и хранилищами,
а также извлечение ин¬
формации. Дальновид¬
ное понимание Агрести
в отношении важности
и широты вычислитель¬
ных подходов к анализу
данных, и его внимание
к этим вопросам только
усиливалось с течением
времени и появлением
науки о данных как дис¬
циплины.
Основные методы анализа больших данных
263
ства продукта, существенное значение имеет время, а также
актуальность аналитического результата.
В любом быстро меняющемся пространстве, таком как боль¬
шие данные, всегда существуют возможности для иннова¬
ций. Примером этого является вопрос о том, как наилучшим
образом сочетать статистические и вычислительные подхо¬
ды для данной аналитической задачи. Статистические мето¬
ды широко используются для разведочного анализа данных,
после чего могут применяться вычислительные методы,
которые используют информацию, извлеченную из резуль¬
татов статистического анализа набора данных. Переход от
пакетной обработки к обработке в реальном времени пред¬
ставляет еще одну трудность, поскольку методы обработки
в реальном времени должны использовать эффективные в
плане вычисления алгоритмы.
Еще одна трудность заключается в спо¬
собе сбалансировать точность аналити¬
ческого результата с временем выпол¬
нения алгоритма. Во многих случаях
аппроксимация может быть достаточ¬
ной и доступной. С точки зрения пер¬
спективных направлений хранения
Рисунок 8.1
Символ, используемый для
представления анализа
данный.
многоуровневые системы для хранения
данных, использующие ОЗУ, твердо¬
тельные накопители и жесткие диски,
обеспечат гибкость в краткосрочной
перспективе и возможность анализа в
реальном времени с долгосрочным и
экономически эффективным хранилищем. В долгосрочной
перспективе организации предстоит работать с механизмом
анализа больших данных по двух направлениях: обрабаты¬
вать потоковые данные по мере их поступления и выполнять
пакетный анализ этих данных по мере их накопления, для
выявления шаблонов и тенденций. (Символ, используемый
для представления анализа данных, показан на рисунке 8.1).
264
Основы Big Data
Эта глава начинается с описания следующих основных ти¬
пов анализа данных:
• количественного анализа
• качественного анализа
• Data Mining (интеллектуального анализа данных)
• статистического анализа
• машинного обучения
• семантического анализа
• визуального анализа
Количественный анализ
Количественный анализ — это метод анализа данных, кото¬
рый фокусируется на определении количественных законо¬
мерностей и корреляций, найденных в данных. Основанный
на статистических методах, этот метод предполагает анализ
большого количества наблюдений из набора данных. По¬
скольку размер выборки большой, результаты могут приме¬
няться обобщенно ко всему набору данных. На рисунке 8.2
показан тот факт, что количественный анализ дает числовые
результаты.
Рисунок 82
Результат количественного
анализа имеет числовой
нарактер.
числовые
результаты
Результаты количественного анализа носят абсолютный
характер и поэтому могут использоваться для численных
сравнений. Например, количественный анализ по продажам
Основные методы анализа больших данных
265
мороженого может обнаружить, что увеличение температу¬
ры на 5 градусов увеличивает продажи мороженого на 15 %.
Качественный анализ
Качественный анализ — это метод анализа данных, кото¬
рый фокусируется на описании различных качеств данных
с использованием слов. Он предполагает анализ меньшей
выборки, но более основательнее, по сравнению с количе¬
ственным анализом данных. Такие результаты анализа не
могут быть обобщены на весь набор данных из-за неболь¬
шого размера выборки. Их также нельзя численно измерить
или использовать для числовых сравнений. Например, ка¬
чественный анализ по продажам мороженого может пока¬
зать, что показатели продаж в мае были не такими высоки¬
ми, как в июне. Результаты анализа указывают только на то,
что цифры «не так высоки, как», и не дают количественной
разницы. Результатом качественного анализа является опи¬
сание отношения с использованием слов, как показано на
рисунке 8.3.
Рисунок 8.3
Результаты качественного
анализа носят описательный
характер и не могут быть
обобщены для всего набора
данный.
анализ
результаты
Data Mining
Data Mining (интеллектуальный анализ данных), известен
также как обнаружение данных, представляет собой специ¬
ализированную форму анализа данных, предназначенную
для больших наборов данных. В связи с анализом больших
данных, Data Mining обычно относится к автоматизирован¬
ным, основанным на программном обеспечении методам,
266
Основы Big Data
которые просеивают массивные наборы данных для выяв¬
ления закономерностей и тенденций.
В частности, это предполагает извлече¬
ние скрытых или неизвестных шабло¬
нов в данных с целью идентификации
ранее неизвестных закономерностей.
Data Mining является основой для про¬
гностической аналитики и Business
Intelligence (BI). Символ, используе¬
мый для представления Data Mining,
показан на рисунке 8.4.
Рисунок 8.4
Символ, используемый для
представления Data (Dining.
Статистический анализ
Статистический анализ использует статистические методы,
основанные на математических формулах в качестве сред¬
ства для анализа данных. Статистический анализ чаще всего
является количественным, но может быть и качественным.
Этот тип анализа обычно используется для описания набо¬
ров данных посредством итогового обобщения, например,
предоставление среднего значения, медианы или метода
статистики, связанных с набором данных. Также он может
использоваться для определения моделей и отношений вну¬
три набора данных, таких как регрессия и корреляция.
В этом разделе описываются следующие виды статистиче¬
ского анализа:
• А/В-тестирование
• корреляция
регрессия
Основные методы анализа больших данных
267
А/В-тестирование
А/В-тестирование, также известное как сплит-тестирова¬
ние или тестирование с помощью «ведра», сравнивает две
версии элемента для определения, какая из них является
более совершенной на основе предопределенной метрики.
Элемент может представлять целый ряд вещей. Например,
это может быть контент, такой как веб-страница или пред¬
ложение продукта или услуги, например, в виде цены на
электронные товары. Текущая версия элемента называется
контрольной версией, тогда как измененная версия назы¬
вается расчетной. Обе версии одновременно подвергаются
эксперименту. Наблюдения записываются для определения,
какая версия является более успешной.
Хотя А/В-тестирование может быть реализовано практиче¬
ски для любой области, чаще всего оно используется в мар¬
кетинге. Как правило, цель состоит в том, чтобы оценивать
поведение человека для возможности увеличения продаж.
Например, чтобы определить наилучшее расположение объ¬
явления для мороженого на веб-сайте компании А, исполь¬
зуются две разные версии объявления. Версия А является
уже существующим объявлением (контрольная), в то время
как в Версии В расположение слегка изменилось (расчетная).
Затем обе версии одновременно показываются различным
пользователям:
• Версия А — группе А
• Версия В — группе В
Анализ результатов показывает, что версия В для объявления
привела к увеличению продаж по сравнению с версией А.
В других областях, таких как научные, где целью может быть
простое наблюдение, такая версия работает лучше для улуч¬
шения процесса или продукта. На рисунке 8.5 приведен при¬
мер A/В-тестирования для двух разных версий электронных
писем, отправленных одновременно.
268
Основы Big Data
Электронное
письмо А
Электронное
письмо В
Рисунок 8.5
Две разные версии электронный писем рассылаются одновременно
в рэмкан маркетинговой кампании, чтобы узнать, какой вариант
привлекает больше потенциальный клиентов.
Примеры вопросов могут включать в себя:
• Является ли новый препарат лучше, чем старый?
• Клиенты лучше реагируют на рекламные объявления, от¬
правленные по электронной или по обычной почте?
• Является ли вновь созданный дизайн главной страницы
Web-сайта источником генерирования большего количе¬
ства трафика от пользователей?
Корреляция
Корреляция — это метод анализа, используемый для опреде¬
ления, того, связаны ли две переменные друг с другом. Если
окажется, что они связаны между собой, следующим шагом
будет определение их отношений. Например, значение пе¬
ременной А увеличивается всякий раз, когда увеличивается
значение переменной В. Нас может заинтересовать также
определение того, насколько тесно связаны переменные А
и В, а значит, мы также можем проанализировать, в какой
степени переменная В увеличивается по отношению к уве¬
личению переменной А.
Использование корреляции помогает развить понимание
набора данных и найти отношения, которые могут помочь
Основные методы анализа больших данных
269
в объяснении явлений. Поэтому корреляция обычно исполь¬
зуется для Data Mining, где определение взаимосвязей меж¬
ду переменными в наборе данных приводит к обнаружению
закономерностей и аномалий. А это в свою очередь раскры¬
вает природу набора данных или причину явления.
Когда две переменные считаются коррелированными, они
выравниваются на основе линейной зависимости. Это озна¬
чает, что когда одна переменная изменяется, другая пере¬
менная также изменяется пропорционально и постоянно.
Корреляция выражается в виде десятичного числа от -1 до
+ 1, которое называется коэффициентом корреляции. Сте¬
пень отношения изменяется от сильной к слабой при пере¬
ходе от -1 к 0 или +1 к 0.
На рисунке 8.6 показана корреляция +1, которая свидетель¬
ствует о наличии сильной положительной связи между дву¬
мя переменными.
На рисунке 8.7 показана корреляция 0, которая свидетель¬
ствует о том, что не существует взаимосвязи между двумя
переменными.
На рисунке 8.8 корреляция -1 указывает на сильную отрица¬
тельную связь между двумя переменными.
Например, менеджеры считают, что магазину мороженого
необходим больший запасе мороженого в жаркие дни, но
не знают, на сколько же больше запасов нужно. Чтобы опре¬
делить, действительно ли существует связь между темпера¬
турой и продажами мороженого, аналитики сначала при¬
меняют корреляцию к количеству проданного мороженого
и зафиксированным показаниям температуры. Значение
+0,75 свидетельствует о наличии сильной взаимосвязи меж¬
ду ними. Эта связь показывает, что с повышением темпера¬
туры продается больше мороженого.
27Q
Основы Big Data
Рисунок 8.7
Когда одна переменная
увеличивается, другая
может оставаться
неизменной, увеличиваться
или уменьшаться
произвольно.
Рисунок 8.6
Когда одна переменная уве¬
личивается, другая также
увеличивается, и наоборот.
Рисунок 8.8
Когда одна переменная
увеличивается, другая
уменьшается, и наоборот.
ось у
Основные методы анализа больших данных
271
Далее приводятся примеры вопросов, при корреляции:
• Влияет ли удаленность от моря на температуру в городе?
• Ученики, с хорошей успеваемость в младшей школе, имеют
такую же хорошую успеваемость в средней школе?
• В какой мере ожирение связано с перееданием ?
Регрессия
Аналитический метод регрессии исследует, как связана за¬
висимая переменная с независимой переменной в наборе
данных. Как пример, регрессия может помочь определить
тип отношений между температурой, независимой пере¬
менной, и урожайностью культур, зависимой переменной.
Применение этого метода помогает определить, как зна¬
чения зависимой переменной изменяется относительно
изменений в значении независимой переменной. Когда,
например, увеличивается независимая переменная, зависи¬
мая переменная также увеличивается? Если да, увеличение
линейное или нелинейное?
Например, чтобы определить, сколько дополнительных за¬
пасов необходимо иметь каждому магазину мороженого,
аналитики применяют регрессию, указывая температурные
значения. Эти значения основаны на прогнозе погоды в ка¬
честве независимой переменной и количестве продаваемо¬
го мороженого в качестве зависимой переменной. Аналити¬
ки обнаруживают, что для каждого повышения температуры
на 5 градусов необходимо 15 % дополнительных запасов.
Одновременно можно протестировать несколько независи¬
мых переменных. Однако в таких случаях изменяться может
только одна независимая переменная, в то время как другие
остаются неизменными. Регрессия может помочь лучше по¬
нять явление, и почему оно произошло. А также она может
использоваться для прогнозирования значений зависимой
переменной.
272
Основы Big Data
Линейная регрессия представляет собой постоянную ско¬
рость изменения, как показано на рисунке 8.9.
Нелинейная регрессия представляет собой переменную ско¬
рость изменения, как показано на рисунке 8.10.
Рисунок 8.9
Линейная регрессия.
Рисунок 8.10
Нелинейная регрессия
Основные методы анализа больших данных
273
Примеры вопросов могут включать в себя:
• Какая будет температура в городе, находящемся в 250 ми¬
лях от моря?
• Какими будут оценки ученика, что учится в средней школе,
основываясь на его оценках в начальной школе?
• Каковы шансы, что человек будет страдать ожирением, ос¬
новываясь на количестве потребляемой пищи?
Регрессия и корреляция имеют ряд важных отличий. Корре¬
ляция не предполагает причинности. Изменение значения
одной переменной может не отвечать за изменение зна¬
чения второй переменной, хотя оба значения могут изме¬
няться с одинаковой скоростью. Это может произойти из-за
неизвестной третьей переменной, известной как искажаю¬
щий фактор. Корреляция предполагает, что обе переменные
независимы.
С другой стороны, регрессия применима к переменным, ко¬
торые ранее были определены как зависимые и независимые
переменные, и подразумевает, что между этими переменны¬
ми существует определенная степень причинности. Причин¬
но-следственная связь может быть прямой или косвенной.
В больших данных сначала может применяться корреляция,
для обнаружения существования связи. Затем может быть
применена регрессия для дальнейшего изучения взаимос¬
вязи и прогнозирования значений зависимой переменной
на основе известных значений независимой переменной.
Машинное обучение
Люди хорошо разбираются в шаблонах и отношениях вну¬
три данных. К сожалению, мы не можем обработать большие
объемы данных очень быстро. Машины, с другой стороны,
очень искусны в быстрой обработке больших объемов дан¬
ных, но только тогда, когда знают как.
274
Основы Big Data
Если знания человека сочетать со скоростью обработки ма¬
шины, то последние смогут обрабатывать большие объемы
данных, без особого вмешательства человека. Это и является
основной концепцией машинного обучения.
В этом разделе изучается машинное обучение и его взаи¬
мосвязь с Data Mining посредством освещения следующих
типов методов машинного обучения:
• Классификация
• Кластеризация
• Обнаружение выбросов
• Фильтрация
Классификация (машинное обучение с учителем)
Классификация — это метод обучения с учителем, при ко¬
тором данные классифицируются на релевантные, заранее
исследованные категории. Он состоит из двух этапов:
1. Система получает обучающие данные, которые уже клас¬
сифицированы или промаркированы, для возможности
развития понимания различных категорий.
2. Система получает неизвестные, но аналогичные данные
для классификации, и на основании понимания, которое
она получила из обучающих данных, алгоритм классифи¬
цирует немаркированные данные.
Общим применением этого метода является фильтрация
спама электронной почты. Обратите внимание, что класси¬
фикация может проводиться по двум или более категориям.
В упрощенном процессе классификации машина получает
промаркированные данные во время обучения, что позво¬
ляет лучше понять классификацию, как показано на рисунке
8.11. Затем машина получает немаркированные данные, ко¬
торые она классифицирует сама.
Основные методы анализа больших данных
275
Рисунок 8.11
Машинное обучение может
использоваться для авто¬
матической классификации
наборов данных
Например, банк хочет выяснить, какой из его клиентов, веро¬
ятнее всего, не выполнит своих обязательств по кредитным
платежам. Основываясь на исторических данных, составля¬
ется обучающий набор данных, который содержит марки¬
рованные примеры клиентов, что ранее выполнили или не
выполнили свои платежные обязательства. Эти обучающие
данные передаются в алгоритм классификации, который ис¬
пользуется для развития понимания «хороших» и «плохих»
клиентов. Наконец, вводятся новые данные немаркирован¬
ных клиентов, чтобы выяснить, принадлежит ли данный
клиент к категории, не выполняющей своих обязательств.
Примеры вопросов могут быть следующими:
• Следует ли принять или отклонить заявку претендента
на выдачу кредитной карты на основании других принятых
или отклоненных заявок?
• Является ли томат фруктом или овощем, основываясь на
известных примерах фруктов и овощей?
• Результаты клинических испытаний для пациентов свиде¬
тельствуют об угрозе сердечного приступа?
276
Основы Big Data
Кластеризация (машинное обучение без учителя)
Кластеризация — это метод обучения без учителя, при кото¬
ром данные делятся на разные группы, так что данные в ка¬
ждой группе имеют схожие свойства. Не требуется никакого
предварительного изучения требуемых категорий. Вместо
этого категории генерируются неявно на основе группиро¬
вания данных. Способ группирования данных зависит от
типа используемого алгоритма. Каждый алгоритм исполь¬
зует различную технику для определения кластеров.
Кластеризация обычно используется в Data Mining для полу¬
чения представления о свойствах заданного набора данных.
После разработки такого понимания классификация может
использоваться для более точного прогнозирования подоб¬
ных, но новых или ненаблюдаемых данных.
Кластеризация может применяться для категоризации неиз¬
вестных документов и персонализированных маркетинго¬
вых кампаний, группируя клиентов со схожим поведением.
Точечный график дает наглядное представление кластеров
на рисунке 8.12.
Рисунок 8.12
Точечный график суммирует
результаты кластеризации.
Например, банк хочет представить своим существующим
клиентам ряд новых финансовых продуктов на основе про¬
филей клиентов, которые он имеет в своих отчетах. Анали¬
Основные методы анализа больших данных
277
тики категоризируют клиентов по нескольким группам с
помощью кластеризации. Затем каждой группе представ¬
ляют один или несколько финансовых продуктов, наиболее
подходящих для характеристик общего профиля группы.
Примеры вопросов могут включать в себя:
• Сколько существует различных видов деревьев, основываясь
на сходстве между деревьями?
• Сколько существует групп клиентов, основываясь на исто¬
рии аналогичных покупок?
• Какие различные группы вирусов, основываясь на их харак¬
теристиках?
Обнаружение выбросов
Обнаружение выбросов — это процесс поиска данных, кото¬
рые существенно отличаются от других данных в заданном
наборе данных или несовместимы с ними. Этот метод ма¬
шинного обучения используется для выявления аномалий,
патологий и отклонений, которые могут быть полезны, на¬
пример, возможности или невыгоды, такие как риски.
Обнаружение выбросов тесно связано с концепцией класси¬
фикации и кластеризации, хотя алгоритмы и сосредоточены
на поиске аномальных значений. Процесс может основы¬
ваться либо на контролируемом, либо на неконтролируемом
обучении. Приложения для обнаружения выбросов вклю¬
чают обнаружение мошенничества, медицинскую диагно¬
стику, анализ сетевых данных и анализ данных датчиков.
Точечный график визуально выделяет данные, которые яв¬
ляются выбросами, как показано на рисунке 8.13.
Например, чтобы выяснить, является ли транзакция мошен¬
нической, команда IT-специалистов банка строит систему,
использующую метод обнаружения выбросов, основанный
на обучении с учителем. Сначала набор известных мошен-
276
Основы Big Data
Кластеризация (машинное обучение без учителя)
Кластеризация — это метод обучения без учителя, при кото¬
ром данные делятся на разные группы, так что данные в ка¬
ждой группе имеют схожие свойства. Не требуется никакого
предварительного изучения требуемых категорий. Вместо
этого категории генерируются неявно на основе группиро¬
вания данных. Способ группирования данных зависит от
типа используемого алгоритма. Каждый алгоритм исполь¬
зует различную технику для определения кластеров.
Кластеризация обычно используется в Data Mining для полу¬
чения представления о свойствах заданного набора данных.
После разработки такого понимания классификация может
использоваться для более точного прогнозирования подоб¬
ных, но новых или ненаблюдаемых данных.
Кластеризация может применяться для категоризации неиз¬
вестных документов и персонализированных маркетинго¬
вых кампаний, группируя клиентов со схожим поведением.
Точечный график дает наглядное представление кластеров
на рисунке 8.12.
Рисунок 8.12
Точечный график суммирует
результаты кластеризации.
Например, банк хочет представить своим существующим
клиентам ряд новых финансовых продуктов на основе про¬
филей клиентов, которые он имеет в своих отчетах. Анали¬
Основные методы анализа больших данных
277
тики категоризируют клиентов по нескольким группам с
помощью кластеризации. Затем каждой группе представ¬
ляют один или несколько финансовых продуктов, наиболее
подходящих для характеристик общего профиля группы.
Примеры вопросов могут включать в себя:
• Сколько существует различных видов деревьев, основываясь
на сходстве между деревьями?
• Сколько существует групп клиентов, основываясь на исто¬
рии аналогичных покупок?
• Какие различные группы вирусов, основываясь на их харак¬
теристиках?
Обнаружение выбросов
Обнаружение выбросов — это процесс поиска данных, кото¬
рые существенно отличаются от других данных в заданном
наборе данных или несовместимы с ними. Этот метод ма¬
шинного обучения используется для выявления аномалий,
патологий и отклонений, которые могут быть полезны, на¬
пример, возможности или невыгоды, такие как риски.
Обнаружение выбросов тесно связано с концепцией класси¬
фикации и кластеризации, хотя алгоритмы и сосредоточены
на поиске аномальных значений. Процесс может основы¬
ваться либо на контролируемом, либо на неконтролируемом
обучении. Приложения для обнаружения выбросов вклю¬
чают обнаружение мошенничества, медицинскую диагно¬
стику, анализ сетевых данных и анализ данных датчиков.
Точечный график визуально выделяет данные, которые яв¬
ляются выбросами, как показано на рисунке 8.13.
Например, чтобы выяснить, является ли транзакция мошен¬
нической, команда IT-специалистов банка строит систему,
использующую метод обнаружения выбросов, основанный
на обучении с учителем. Сначала набор известных мошен-
278
Основы Big Data
Рисунок 8.13
Выделение выброса не
точечном графике.
ось у
нических транзакций подается в алгоритм обнаружения вы¬
бросов. Затем после обучения системы неизвестные тран¬
закции подаются в алгоритм обнаружения выброса, чтобы
предсказать, являются ли они мошенническими или нет.
Примеры вопросов могут включать в себя следующее:
• Является ли спортсмен тем, кто использовал допинговые
препараты?
• Имеются ли неправильно идентифицированные фрукты и
овощи в учебном наборе данных, который используется для
задачи классификации?
• Существует ли особый штамм вируса, который не реагиру¬
ет на лекарства?
Фильтрация
Фильтрация — это автоматизированный процесс поиска ре¬
левантных элементов из совокупности всех элементов. Эле¬
менты могут быть отфильтрованы либо на основе собствен¬
ного поведения пользователя, либо путем сопоставления
поведения нескольких пользователей. Фильтрация обычно
применяется с помощью следующих двух подходов:
Основные методы анализа больших данных
279
• коллаборативной фильтрации
• фильтрации на основе контента
Широко распространённым средством для осуществления
фильтрации, является использование рекомендационных
систем. Коллаборативная фильтрация — это метод фильтра¬
ции элементов, основанный на взаимодействии или слиянии
предыдущих действий пользователя с поведением других.
Предыдущее поведение исследуемого пользователя, в том
числе и его предпочтения, рейтинги, истории покупок и мно¬
гое другое, взаимодействуют с поведением подобных поль¬
зователей. Основываясь на сходстве поведения пользовате¬
лей, элементы фильтруются для исследуемого пользователя.
Коллаборативная фильтрация основана исключительно
на сходстве между поведением пользователей. Для точной
фильтрации элементов требуется большое количество дан¬
ных о поведении пользователей. Это является примером
применения закона больших чисел.
Фильтрация на основе контента — это метод фильтрации
элементов, сфокусированный на сходстве между пользова¬
телями и элементами. Профиль пользователя создается на
основе предыдущего поведения пользователя, например,
его предпочтений, оценок и истории покупок. Сходства, вы¬
явленные между профилем пользователя и атрибутами раз¬
личных элементов, приводит к элементам, которые филь¬
труются для пользователя. В противовес коллаборативной
фильтрации, фильтрация на основе контента предназна¬
чена исключительно для индивидуальных предпочтений
пользователя и не требует данных о других пользователях.
Рекомендационная система предсказывает предпочтения
пользователя и формирует соответствующие предложения
для пользователя. Предложения обычно касаются рекомен¬
дации элементов, таких как фильмы, книги, веб-страницы и
люди. Рекомендационная система обычно использует либо
коллаборативную фильтрацию, либо фильтрацию на основе
280
Основы Big Data
контента для генерирования своих предложений. Она также
может основываться на гибриде из коллаборативной филь¬
трации и фильтрации на основе контента для настройки
точности и эффективности генерируемых предложений.
Например, чтобы реализовать возможности перекрест¬
ных продаж, банк строит рекомендационную систему, ис¬
пользующую фильтрацию на основе контента. На основе
найденных совпадений между финансовыми продуктами,
приобретенными клиентами, и свойствами аналогичных
финансовых продуктов рекомендационная система авто¬
матизирует предложения для потенциальных финансовых
продуктов, в которых клиенты также могут быть заинтере¬
сованы.
Примеры вопросов могут включать в себя:
• Как можно отображать только те новостные статьи, ко¬
торые интересуют пользователя?
• Какие места для отдыха можно порекомендовать, основы¬
ваясь на истории путешествий отдыхающего?
• Каких других новых пользователей можно предложить в ка¬
честве друзей на основе текущего профиля пользователя?
Семантический анализ
Фрагмент текста или речевые данные могут иметь разные
значения в разных контекстах, тогда как полное предложе¬
ние может сохранить свое значение, даже если имеет разную
структуру. Для того, чтобы машины могли извлекать значи¬
мую информацию, текстовые и речевые данные должны по¬
ниматься машинами так же, как и людьми. Семантический
анализ представляет собой практический метод извлечения
значимой информации из текстовых и речевых данных.
В этом разделе описываются следующие типы семантиче¬
ского анализа:
Основные методы анализа больших данных
281
• Обработка естественного языка
• Обработка текста
• Анализ эмоциональной окраски высказываний
Обработка естественного языка
(Natural Language Processing)
Обработка естественного языка — это способность компью¬
тера понимать человеческую речь и текст, как это делают
люди. Это позволяет компьютерам выполнять множество
полезных задач, таких как поиск по всему тексту.
Например, чтобы повысить качество обслуживания клиен¬
тов, компания по производству мороженого использует об¬
работку естественного языка для преобразования звонков
клиентов в текстовые данные, которые затем анализируют¬
ся с целью выявления причин неудовлетворенности клиен¬
тов, которые часто повторяются.
Вместо жесткого кодирования требуемых правил обучения
применяется машинное обучение либо с учителем, либо без
учителя, для развития понимания компьютером естествен¬
ного языка. В целом, чем больше данных для обучения есть в
распоряжении компьютера, тем правильнее он сможет рас¬
шифровать текст и речь человека.
Обработка естественного языка охватывает как распозна¬
вание текста, так и распознавание речи. При распознавании
речи система пытается осмыслить слова, а затем выполнить
действие, например, цитировать их в текст.
Примеры вопросов могут быть следующими:
• Как может быть разработана автоматизированная си¬
стема обмена телефонными звонками, которая способна
распознавать правильные добавочные номера на основе сло¬
весного разговора с вызывающим абонентом?
282
Основы Big Data
• Как можно автоматически идентифицировать граммати¬
ческие ошибки?
• Как спроектировать систему, которая сможет правильно
понимать различные акценты английского языка?
Обработка текста
Неструктурированный текст, как правило, гораздо сложнее
анализировать и искать по сравнению со структурирован¬
ным текстом. Обработка текста — это специализированный
анализ текста посредством применения Data Mining (ин¬
теллектуального анализа данных), машинного обучения и
методов обработки естественного языка для извлечения
ценных знаний из неструктурированного текста. Текстовая
аналитика обеспечивает возможность исследования текста,
а не просто его поиск.
Полезные сведения из текстовых данных можно получить,
помогая компаниям развить понимание информации, со¬
держащейся в тексте большого объема. В качестве продол¬
жения предыдущего примера с NLP, цитируемые текстовые
данные далее анализируются с использованием текстовой
аналитики для извлечения осмысленной информации об
общих причинах недовольства клиентов.
Основным принципом обработки текста является превра¬
щение неструктурированного текста в данные, которые
можно искать и анализировать. По мере увеличения коли¬
чества оцифрованных документов, электронных писем, со¬
общений в социальных сетях и файлов журналов компаниям
все чаще приходится использовать любые ценные сведения,
которые можно извлечь из этих форм слабоструктурирован¬
ных и неструктурированных данных. Анализ только лишь
операционных (структурированных) данных может приве¬
сти к тому, что предприятия упустят возможности экономии
или расширения бизнеса, особенно те, что ориентированы
на клиентов.
Основные методы анализа больших данных
283
Приложения включают в себя классификацию и поиск доку¬
ментов, а также построение всеобъемлющего представления
о клиенте путем извлечения информации из системы CRM.
Обработка текста обычно состоит из двух шагов:
1. Анализ текста в документах для извлечения следующих
сущностей:
• Именованные объекты — личность, группа, место,
компания
• Объекты на основе шаблонов — номер социального
страхования, почтовый индекс
• Концепты — абстрактное представление объекта
• Факты — взаимосвязь между объектами
2. Категоризация документов с использованием этих из¬
влеченных объектов и фактов.
Извлеченная информация может использоваться для вы¬
полнения контекстно-зависимого поиска объектов, в за¬
висимости от типа отношений, который существует между
этими объектами. На рисунке 8.14 показано упрощенное
представление анализа текста.
документы
ИМЯ
адрес
сайта
город
страна
номер
телефона
—
2ZZZZZ
——
Рисунок 8.14
Объекты извлекаются из текстовый файлов, используя семантические правила
структурированные таким образом, чтобы ин можно было найти.
284
Основы Big Data
Примеры вопросов могут включать в себя следующее:
• Как можно классифицировать веб-сайты, основываясь на
содержании их веб-страниц?
• Как можно найти книги с содержанием, которое имеет от¬
ношение к теме изучения?
• Как можно определить контракты, содержащие конфиден¬
циальную информацию о компании?
Анализ эмоциональной окраски высказываний
Анализ эмоциональной окраски высказываний — это
специализированная форма анализа текста, которая фоку¬
сируется на определении предвзятости или эмоций отдель¬
ных лиц. Этот вид анализа определяет отношение автора
текста, анализируя текст в контексте естественного языка.
Анализ эмоциональной окраски высказываний не только
предоставляет информацию о том, что чувствуют люди, но
и интенсивность их чувств. Эта информация в дальнейшем
может интегрироваться в процесс принятия решений. Об¬
щие приложения для анализа эмоциональной окраски вы¬
сказываний охватывают выявление удовлетворенности или
неудовлетворенности клиентов на ранних этапах успеха или
неудачи продукта или выявление новых тенденций.
Например, компания по производству мороженого хоте¬
ла бы узнать, какие из ее вкусов мороженого больше всего
нравятся детям. Сами по себе данные о продажах не предо¬
ставляют эту информацию, поскольку дети, потребляющие
мороженое, необязательно являются покупателями мо¬
роженого. Анализ эмоциональной окраски высказываний
применяется к архиву клиентских отзывов, оставленных
на веб-сайте компании по производству мороженого, для
извлечения информации, которая касается предпочтения
детей к определенным вкусам мороженого по сравнению с
другими вкусами.
Основные методы анализа больших данных
285
Примерами вопросов могут служить:
• Как можно измерить реакцию клиентов на новую упаковку
продукта?
• Какой участник является вероятным победителем в песен¬
ном конкурсе?
• Может ли отток клиентов определяться комментариями
в социальных сетях?
Визуальный анализ
Визуальный анализ является формой анализа данных, кото¬
рая содержит графическое представление данных для обе¬
спечения или улучшения их визуального восприятия. Ос¬
новываясь на предположении, что людям проще и быстрее
понять и сделать выводы из графиков, чем из текстов, визу¬
альный анализ действует как инструмент обнаружения зна¬
ний в области больших данных.
Цель заключается в использовании графических представ¬
лений для более глубокого понимания анализируемых дан¬
ных. В частности, это помогает выявлять и подчеркивать
скрытые закономерности, корреляции и аномалии. Визу¬
альный анализ также непосредственно связан с пробным
анализом данных, поскольку он подходит с разных сторон к
формулированию вопросов.
В этом разделе описываются следующие типы визуального
анализа:
• Цветовые карты
• Временные ряды
• Сетевые графики
• Сопоставление пространственных данных
286
Основы Big Data
Цветовые карты
Цветовые карты представляют собой эффективный визуаль¬
ный метод анализа для выражения шаблонов, композиции
данных посредством отношений часть-целое и географиче¬
ского распределения данных. Они также облегчают выявле¬
ние области интересов и обнаружение экстремальных (вы-
соких/низких) значений в наборе данных.
Например, для того чтобы определить регионы самых вы¬
соких и низких продаж мороженого, данные о продажах
формируются с помощью использования цветовой карты.
Зеленый используется для выделения наиболее эффектив¬
ных регионов, в то время как красный используется для вы¬
деления наименее эффективных регионов.
Сама цветовая карта представляет собой визуальное цве¬
товое представление значений данных. Каждому значению
присваивается цвет в соответствии с его типом или диапа¬
зоном, в который он попадает. Например, цветовая карта
может присваивать значения 0-3 красному цвету, 4-6 — жел¬
тому (янтарному) и 7-10 — зеленому.
Цветовая карта может быть в виде диаграммы или карты.
Диаграмма представляет собой матрицу значений, в кото¬
рой каждая ячейка имеет цветовое кодирование в соответ¬
ствии со значением, как показано на рисунке 8.15. Она так¬
же может представлять иерархические значения с помощью
цветных вложенных прямоугольников.
На рисунке 8.16 карта представляет собой географическую
меру, с помощью которой различные регионы выделяются
цветом или заштриховываются в соответствии с опреде¬
ленной темой. Вместо того, чтобы окрашивать или заштри¬
ховывать весь регион, карта может быть наложена слоем,
состоящим из наборов цветных/заштрихованных точек, от¬
носящихся к различным областям, или цветных/заштрихо¬
ванных контуров, представляющих различные области.
Основные методы анализа больших данных
287
Рисунок 8.15
Диаграмма цветовой карты, отображающая продажи трен подразделений
компании в течение шести месяцев.
показатели продаж среди штатов США за 2013 год
■ $1ООт<
■ $50т - $1ООт
| $25т - $50т
Ц $5т - $25т
□ $5т>
Рисунок 8.16
Цветовая карта показателей
продаж в США за 2013 год
Примеры вопросов могут быть следующими:
• Как можно визуально определить какие-либо закономерно¬
сти, связанные с выбросами углекислого газа в больших ко¬
личествах в городах по всему миру?
• Как можно увидеть существование каких-либо закономер¬
ностей различных видов рака по отношению к различным
этническим группам?
• Как можно проанализировать футболистов в соответ¬
ствии с их достоинствами и недостатками?
288
Основы Big Data
Временные ряды
Графики временных рядов позволяют анализировать дан¬
ные, которые записываются через определенные интерва¬
лы времени. Этот тип анализа использует временные ряды,
которые представляют собой упорядоченный по времени
набор значений, записанных через регулярные интервалы
времени. Примером может служить временной ряд, содер¬
жащий данные о продажах, которые учитываются в конце
каждого месяца.
Анализ временных рядов помогает выявить закономерно¬
сти в данных, зависящих от времени. После идентификации
шаблон можно экстраполировать для будущих прогнозов.
Например, для определения моделей сезонных продаж, еже¬
месячные показатели продаж мороженого представляются в
виде временного ряда, что также помогает прогнозировать
показатели продаж в следующем сезоне.
Обычно анализ временных рядов используется для прогно¬
зирования через определение долгосрочных тенденций, пе¬
риодических сезонных моделей и нерегулярных кратковре¬
менных отклонений в наборе данных. В отличие от других
видов анализа анализ временных рядов всегда включает
время в качестве сравнительной переменной, и собранные
данные всегда зависят от времени.
График временного ряда обычно выражается через линей¬
ный график, со временем, нанесенным на ось х, и значением
записанных данных, нанесенным на ось у, как показано на
рисунке 8.17.
Временной ряд, представленный на рисунке 8.17, охваты¬
вает семь лет. Равномерно расположенные пики к концу
каждого года показывают периодические сезонные модели,
например рождественские продажи. Пунктирные красные
круги обозначают кратковременные нерегулярные отклоне¬
ния. Синяя линия показывает восходящий тренд, указываю¬
щий на увеличение продаж.
Основные методы анализа больших данных
289
временной ряд продаж
1990 1991 1992 1993 1994 1995 1996
Рисунок 8.17
Линейный график, демонстрирующий временные ряды продаж
с 1990 по 1996 года.
Примеры вопросов могут включать:
• Какой урожай следует ожидать фермеру исходя из истори¬
ческих данных по урожайности?
• Каков ожидаемый прирост населения в ближайшие 5лет?
• Является текущее снижение продаж единичным случаем
или оно происходит регулярно?
Сетевые графы
В контексте визуального анализа сетевой граф отображает
взаимосвязанный набор объектов. Субъектом может быть
человек, группа, или некоторый другой объект из бизнес-до-
мена, например продукт. Объекты могут быть связаны друг с
другом напрямую или косвенно. Некоторые соединения мо¬
гут быть только односторонними, так что обход в обратном
направлении невозможен.
Сетевой анализ — это метод, который фокусируется на ана¬
лизе отношений между объектами в сети. Он включает в
себя построение объектов в виде узлов и связей, таких как
290
Основы Big Data
ребра между узлами. Существуют специализированные раз¬
новидности сетевого анализа, в том числе:
• оптимизация маршрута
• анализ социальных сетей
• прогнозирование распространения, такое как распро¬
странение инфекционной болезни
Ниже приведен простой пример применения сетевого анали¬
за для оптимизации маршрута на основе продаж мороженого.
Некоторые менеджеры магазина мороженого жалуются на
проблему времени, которое требуется грузовикам доставки
для проезда между центральным складом и магазинами в
отдаленных районах. В более жаркие дни мороженое, до¬
ставляемое с центрального склада в отдаленные магазины,
тает и уже не может быть продано. Сетевой анализ исполь¬
зуется для поиска кратчайших маршрутов между централь¬
ным складом и удаленными хранилищами, чтобы миними¬
зировать продолжительность доставок.
Рассмотрим график социальной сети на рисунке 8.18 для
простого примера анализа социальной сети:
Рисунок 8.18
Пример социального сетевого графа.
Katie Carlos Joseph
Основные методы анализа больших данных
291
• У Джона много друзей, в то время как у Элис только один друг.
• Результаты анализа социальных сетей показывают, что
Элис, скорее всего, подружится с Джоном и Кэти, посколь¬
ку у них есть общий друг по имени Оливер.
Примеры вопросов могут включать:
• Как можно определить агента влияния среди большой груп¬
пы пользователей?
• Связаны ли два человека друг с другом через длинную цепочку
родословной?
• Как я могу определить закономерности взаимодействия
между очень большим числом взаимодействий белка?
Сопоставление пространственных данных
Пространственные или геопространственные данные обычно
используются для определения географического местоположе¬
ния отдельных объектов, которые затем могут сопоставляться.
Анализ пространственных данных сфокусирован на анализе
геолокационных данных для поиска различных географиче¬
ских взаимосвязей и закономерностей между объектами.
Пространственные данные обрабатываются через геогра¬
фическую информационную систему (ГИС), которая отобра¬
жает пространственные данные на карте, в основном, ис¬
пользуя координаты долготы и широты. ГИС предоставляет
инструментарий, который позволяет осуществлять интерак¬
тивное исследование пространственных данных, например,
измерение расстояния между двумя точками, или опреде¬
ление области вокруг точки в виде окружности с заданным
расстоянием на основе радиуса. Благодаря постоянно расту¬
щей доступности данных на основе определения их место¬
положения, таких как данные сенсоров и социальных сетей,
пространственные данные могут быть проанализированы
для получения информации о местоположении.
292
Основы Big Data
Например, в рамках корпоративной экспансии планируется
открытие новых магазинов мороженого. Существует требо¬
вание о том, чтобы два магазина не находиться на расстоя¬
нии менее 5 километров друг от друга, для предотвращения
конкуренции магазинов друг с другом. Пространственные
данные используются для построения существующих ма¬
газинов и определения оптимального местоположения для
новых магазинов не менее чем в 5 километрах от существу¬
ющих магазинов.
Приложения для анализа пространственных данных вклю¬
чают операционную и логистическую оптимизацию, эколо¬
гические науки и планирование инфраструктуры. Данные,
используемые в качестве входных для анализа простран¬
ственных данных, могут содержать точные местоположе¬
ния, такие как долгота и широта, или информацию, необхо¬
димую для расчета местоположений, например, почтовые
индексы или IP-адреса.
Кроме того, анализ пространственных данных может ис¬
пользоваться для определения числа объектов, которые по¬
падают в определенный радиус другого объекта. Например,
супермаркет использует анализ пространственных данных
для целевого маркетинга, как показано на рисунке 8.19. Ме¬
стоположения извлекаются из сообщений пользователей в
социальных сетях, а персонализированные предложения до¬
ставляются в реальном времени в зависимости от близости
пользователя к магазину.
Примеры вопросов могут быть следующими:
• Сколько зданий будет затронуто из-за проекта расшире¬
ния дороги?
• Как далеко должны ездить клиенты, чтобы добраться до
супермаркета?
• 1де находятся высокие и низкие концентрации определен¬
ных минералов основываясь на добыче из разных мест вы¬
бранного района?
Основные методы анализа больших данных
293
Oliver
fi/p купил 1 Q/f"
У h Joe забрал1 и /
Timothy -w пустой «
James
Рисунок 8.19
Анализ пространственный данный может использоваться для целевого маркетинга
ПРИМЕРЫ ИЗ ПРАКТИКИ
В настоящее время ETI используются как количественные,
так и качественные анализы. Страховые статисты выпол¬
няют количественный анализ посредством применения
различных статистических методов, таких как вероятность,
среднее значение, стандартное отклонение и распределе¬
ния для оценки рисков. С другой стороны, качественный
анализ проводится на этапе подписания страховых доку¬
ментов (андеррайтинга), где подробно проверяется един¬
ственное приложение для получения представления об
уровне риска — низком, среднем или высоком. Затем на
этапе оценивания заявок анализирует поданную заявку,
чтобы получить представление о том, является ли она мо¬
шеннической. В настоящее время аналитики ETI не прово¬
дят никакого серьезного интеллектуального анализа дан¬
ных. Вместо этого большинство их усилий направлено на
выполнение BI с использованием данных EDW.
294
Основы Big Data
Команда IT-специалистов и аналитики применяют ряд ме¬
тодов анализа в попытке выявить мошеннические транзак¬
ции на этапе анализа данных, как части жизненного цикла
больших данных. Здесь представлены некоторые из приме¬
няемых методов.
Корреляция
Отмечается, что множество мошеннических страховых зая¬
вок появляется сразу после покупки полиса. Чтобы убедиться
в этом, применяется корреляция между сроком действия по¬
лиса и количеством мошеннических заявок. Результат -0,80
показывает, что существует связь между двумя переменны¬
ми: количество мошеннических заявок уменьшается по мере
истечения строка действия полиса.
Регрессия
Основываясь на этом открытии, аналитики хотят узнать,
сколько мошеннических заявок подано на основе срока
действия полиса, поскольку эта информация поможет им
определить вероятность того, является ли мошеннической
или нет поданная заявка. Следовательно, метод регрессии
применяется с учетом срока действия полиса в качестве не¬
зависимой переменной и количества мошеннических зая¬
вок в качестве зависимой переменной.
Временной ряд
Аналитики хотят выяснить, зависят ли мошеннические
заявки от времени. Особенно они заинтересованы в
выявлении каких-либо конкретных периодов времени,
в течение которых число мошеннических заявок уве¬
личивается. Временной ряд необоснованных заявок за
последние пять лет формируется на основе ряда мо¬
шеннических заявок, которые вычислялись для каждой
недели. Визуальный анализ графика временных рядов
показывает сезонную тенденцию, который указывает,
Основные методы анализа больших данных 295
что количество мошеннических заявок возрастает перед
праздниками и ближе к концу лета. Эти результаты сви¬
детельствуют о том, что либо клиенты предъявляют лож¬
ные заявки для получения денег на период отпуска, либо
обновляют свою электронику и другие товары после
праздника, сообщая о повреждении или краже старой.
Также обнаружилось несколько кратковременных нере¬
гулярных отклонений, которые, при детальном рассмо¬
трении, оказываются связанными с такими катастрофа¬
ми, как наводнения и штормы. Долгосрочная тенденция
предполагает, что, вероятно, число мошеннических зая¬
вок будет расти в будущем.
Кластеризация
Хотя все мошеннические заявки бывают разными, анали¬
тики заинтересованы в том, чтобы выяснить, существуют
ли какие-либо сходства между мошенническими заявками.
Метод кластеризации используется для группирования раз¬
личных мошеннических заявок на основе ряда атрибутов,
таких как возраст клиента, срок действия полиса, пол, число
предыдущих заявок и частота их подачи.
Классификация
Во время применения этапа анализа результатов метод
классификации используется для разработки модели, ко¬
торая сможет отличать законную заявку от мошеннической
заявки. Для этого модель сначала обучается с использо¬
ванием истории набора заявок, в котором каждая заявка
промаркирована как законная или мошенническая. После
обучения модель переводится в оперативный режим, когда
вновь поданные, немаркированные заявки классифициру¬
ются как мошеннические или законные.
2S7
Приложение А
Заключение на основе
примеров из практики
298
ETI успешно разработала решение для обнаружения «мо¬
шеннических заявок», что дало команде 1Т-специалистов
возможность получить опыт и уверенность в области хране¬
ния и анализа больших данных. Что еще более важно, они
поняли, что они достигли лишь части одной из ключевых
задач, поставленной высшим руководством. Остаются еще
проекты, которые призваны: улучшить оценивание риска
для приложений по новым полисам; проводить управление
катастрофами для уменьшения количества заявок, связан¬
ных с бедствием; уменьшить отток клиентов, за счет предо¬
ставления более эффективного урегулирования платежей и
персонифицированной политики и, наконец, добиться пол¬
ного соответствия нормативным требованиям.
Зная, что «успех порождает успех», менеджер корпоратив¬
ных инноваций, работающий с приоритетным портфелем
проектов, информирует команду IT-специалистов о том,
что в дальнейшем они будут решать текущие проблемы эф¬
фективности, которые привели к медленной обработке за¬
явок. В то время как команда IT-специалистов была занята
изучением больших данных для внедрения решений для
обнаружения мошенничества, менеджер по инновациям
задействовал группу бизнес-аналитиков для документиро¬
вания и анализа бизнес-процессов обработки заявок. Эти
модели процессов будут использоваться для управления ав¬
томатизацией, которая будет реализована с помощью BPMS.
Менеджер по инновациям выбрал этот подход в качестве
Заключение на основе примеров из практики
299
следующей цели, потому что компания хочет получить мак¬
симальную ценность из модели для обнаружения мошенни¬
чества. Это будет достигнуто, когда эти преимущества будут
получены на основе платформы автоматизации процессов.
В дальнейшем это позволит собирать обучающие данные,
которые могут способствовать постепенному совершен¬
ствованию машинного алгоритма обучения с учителем, что
ведет к классификации заявок как законных, так и мошен¬
нических.
Другим преимуществом внедрения процессов автомати¬
зации является стандартизация самой работы. Если все
эксперты по рассмотрению заявок вынуждены следовать
одинаковым процедурам обработки, отклонения в обслу¬
живании клиентов должны снизиться, и это может помочь
клиентам ETI достичь большей уверенности в правильности
обработки их заявок. Хотя это является косвенным преиму¬
ществом, следует признать тот факт, что именно благодаря
выполнению бизнес-процессов клиенты ETI будут воспри¬
нимать значимость своих отношений с ETI. Хотя сама BPMS
не является инициативой больших данных, она будет гене¬
рировать огромное количество данных, связанных с такими
вещами, как непрерывное время процесса, время ожидания
отдельных действий и пропускная способность отдельных
сотрудников, обрабатывающих претензии. Эти данные мо¬
гут быть собраны и добыты для интересных отношений,
особенно в сочетании с данными о клиентах. Было бы по¬
лезно знать, сопоставляются ли коэффициенты корреляции
клиентов со временем обработки заявок для отказа клиен¬
там. Если это так, то может быть разработана регрессионная
модель для прогнозирования того, какие клиенты рискуют
оказаться в беде, и с ними может связаться заранее персонал
службы поддержки.
ETI видит улучшение своей повседневной деятельности
путем создания эффективного цикла управленческих дей¬
ствий, сопровождаемого измерением и анализом реакции
организации. Исполнительная команда считает полезным
300
рассматривать организацию не как машину, а как организм.
Эта перспектива позволила сместить парадигму, которая
стимулирует не только более глубокую аналитику внутрен¬
них данных, но и осознание необходимости включения
внешних данных. Обычно ETI приходилось смущенно при¬
знавать, что в основном они управляли своим бизнесом по
описательной аналитике из OLTP-систем. Теперь более ши¬
рокие перспективы аналитики и Business Intelligence позво¬
ляют более эффективно использовать их возможности EDW
и OLAP. На самом деле, способность ETI исследовать свою
клиентскую базу в морской, авиационной и коммерческой
сферах бизнеса позволила организации определить, что
есть много клиентов, которые имеют отдельные полисы для
лодок, самолетов и элитной недвижимости высокого клас¬
са. Уже только это единственное понимание открыло новые
маркетинговые стратегии и возможности для увеличения
объемов продаж.
Более того, будущее ETI выглядит более ярким, посколь¬
ку компания принимает решения, основанные на данных.
Теперь, когда ее бизнес получил преимущество от диагно¬
стической и прогностическое аналитики, организация рас¬
сматривает способы использования прескриптивной ана¬
литики для достижения целей предотвращения рисков.
Способность ETI в постепенном переходе к большим дан¬
ным и их использование в качестве средства улучшения со¬
гласованности между бизнесом и IT, принесла невероятные
преимущества. Исполнительная команда ETI согласилась с
тем, что большие данные — это грандиозное начинание, и
они ожидают, что их акционеры посчитают так же, когда ETI
вернет былой уровень своей доходности.
301
Об авторах
Томас Эрл
Томас Эрл является самым продаваемым автором в обла¬
сти IT, основателем Arcitura Education и редактором серии
Service Technology Series издательства Prentice Hall от Тома¬
са Эрла. Насчитывая более 200 000 экземпляров в печатном
виде по всему миру, его книги стали международными бе¬
стселлерами и были официально одобрены старшими чле¬
нами крупнейших IT-организаций, таких как IBM, Microsoft,
Oracle, Intel, Accenture, IEEE, HL7, MITER, SAP, CISCO, HP
и многими другими. В качестве генерального директора
Arcitura Education Inc, Томас руководил разработкой учебных
программ для признанных во всем мире программ серти¬
фикации аккредитованных сертифицированных специали¬
стов по крупным наукам (BDSCP), Cloud Certified Professional
(ССР) и SOA Certified Professional (SOACP), которые создали
серию официальных, независимых от поставщиков серти¬
фикатов, и их получили тысячи IT-специалистов по всему
миру. Томас объездил более 20 стран в качестве докладчи¬
ка и инструктора. Более 100 статей и интервью Томаса были
опубликованы в многочисленных публикациях, включая
The Wall Street Journal и CIO Magazine.
Ваджид Хаттак
Ваджид Хаттак является исследователем и тренером по
большим данным в Arcitura Education Inc. Его области ин¬
302
тересов включают в себя разработку и архитектуру крупных
данных, науку о данных, машинное обучение, аналитику и
SOA. Он имеет обширный опыт в разработке программного
обеспечения на платформе .NET и в областях решений для
Business Intelligence и ГИС.
Ваджид окончил магистратуру по программному обеспече¬
нию и безопасности с отличием в Бирмингемском город¬
ском университете в 2008 году. До этого в 2003 году он полу¬
чил степень бакалавра в области разработки программного
обеспечения в Бирмингемском городском университете с
признанием высшей степени. Он имеет сертификаты MCAD
& MCTS (Microsoft), SOA Architect, Big Data Scientist, Big Data
Engineer и Big Data Consultant (Arcitura).
Пол Бюлер
Доктор Пол Бюлер — опытный профессионал, который работал
в коммерческой, правительственной и академической среде.
Он является уважаемым исследователем, практиком и препо¬
давателем концепций, технологий и методологий внедрения
сервис-ориентированных вычислений. Его работа в XaaS
естественным образом распространяется на облака, большие
данные и области IoE. Недавняя работа доктора Бюлера была
сосредоточена на уменьшения разрыва между бизнес-стра-
тегией и исполнительным процессом за счет использования
гибких принципов проектирования и целевого исполнения.
В качестве главного ученого в Modus21 доктор Бюлер отве¬
чает за согласование корпоративной стратегии с новыми
тенденциями в бизнес-архитектуре и структурах процессов.
Он также имеет степень профессора в колледже в Чарльсто¬
не, где преподает в аспирантуре, а также читает курсы по
информатике для студентов. Доктор Бюлер получил доктор¬
скую степень в области вычислительной техники в Универ¬
ситете Южной Каролины. Также он имеет степень магистра
компьютерных наук в Университете Джона Хопкинса и сте¬
пень бакалавра компьютерных наук в Citadel.
303
Предметный указатель
А
A/В тестирование, 267
проектирование базы
данных на основе
ACID, 168
сбор данных (жизнен¬
ный цикл аналитики
больших данных), 95
активный запрос, 245
доступные технологии
как бизнес-мотивация
для больших данных, 74
агрегирование данных
(жизненный цикл
аналитики больших
данных), 95
разработка алгоритма
в MapReduce, 144,183
анализ. См. анализ
данных
аналитика. См. анали¬
тика данных
архитектура. См. биз¬
нес-архитектура
В
BADE (среда разработ¬
ки бизнес-приложе-
ний), 71
BASE проектирование
баз данных, 173
с MapReduce, 183
этап объединения, 191
принцип «разделяй и
властвуй», 198
этап разбиения, 192
этап перетасовки и
сортирования, 195
BI (Business
Intelligence) 37
динамика рынка, 63
специализированные
отчеты, 152
информационные панели,
152
большие данные
жизненный цикл анали¬
тики, 95
этап сбора и фильтрации
данных, 100
этап агрегирования и
представления данных, 107
этап анализа данных, 109
этап извлечения данных,
102
этап идентификации
данных, 98
этап проверки и очистки
данных, 104
этап визуализации дан¬
ных, 111
этап использования ре¬
зультатов анализа, 112
обработка. См. обработка
данных
типы данных (форматы
данных), 44
метаданные, 48
полуструктурированные
данные, 155
структурированные
данные, 46
неструктурированные
данные, 46
большие данные в BI
(Business Intelligence), 131
BPM (управление биз-
нес-процессами), 63
BPMS (система управ¬
ления бизнес-процес-
сами), 71
среда разработки
бизнес-приложений
(BADE), 71
бизнес-архитектура, 66
этап оценивания биз-
нес-ситуации (жизнен¬
ный цикл аналитики
больших данных), 95
Business Intelligence
(BI). См. BI (Business
Intelligence)
Бизнес-мотивация и
стимулы
бизнес-архитектура, 66
управление бизнес-про-
цессами (ВРМ), 63
информационные и
коммуникационные
технологии (ICT), 72
доступные технологии, 74
облачные вычисления, 77
цифровизация, 75
Интернет Всего (1оЕ), 79
динамика рынка, 63
управление бизнес-про-
цессами (ВРМ), 63
системы управления
бизнес-процессами
(BPMS), 71
С
САР (согласованность,
доступность и устойчи¬
вость при разбиении)
теорема, 165
Пример из практики,
ETI (гарантирование
страхования)
основы, 176
жизненный цикл анали¬
тики больших данных, 95
большие данные для BI
(Business Intelligence),
131
характеристики больших
данных, 39
бизнес-мотивация и
стимулы, 61
304
СЕР (обработка слож¬
ных событий ), 206
очистка данных (жиз¬
ненный цикл аналити¬
ки больших данных), 95
облачные вычисления, 77
кластеризация, 276
кластеры, 149
для СУРБД, 220
коллаборативная
фильтрация, 279
хранилище NoSQL для
объединения столбцов,
151
этап объединения
(MapReduce), 187
обработка сложных
событий (СЕР), 206
согласованность
в проектировании баз дан¬
ных на основе ACID, 168
в проектировании баз дан¬
ных на основе BASE, 173
в САР-теореме, 165
в SCV-принципе, 180
теорема согласован¬
ности, доступности
и устойчивости при
разбиении (САР), 165
непрерывный запрос, 256
корреляция, 268
D
информационная
панель, 38,139
данных
определение, 38
в DIKW пирамиде, 66,68
этап сбора и фильтра¬
ции данных (жизнен¬
ный цикл аналитики
больших данных), 95
этап агрегирования и
представления данных
(жизненный цикл
аналитики больших
данных), 95
анализ данных
data mining, 265
определение, 265
кластеризация, 276
фильтрация, 278
обнаружение выбросов, 277
качественный анализ,
265
количественный анализ,
264
поддержка реального
времени, 91
методы статистического
анализа, 266
A/В тестирование, 267
методы визуального
анализа, 285
цветовые карты, 285
сетевые графы, 289
сопоставление простран¬
ственных данных, 291
временные ряды, 288
этап анализа данных
(жизненный цикл
аналитики больших
данных), 95
аналитика данных
как бизнес-мотивация
для больших данных, 29
определение, 29
дескриптивные аналити¬
ки, определение, 32
диагностические анали¬
тики, определение, 32
технологии предприятия
витрины данных, 131
хранилища данных, 130
ETL (извлечение, преобра¬
зование и загрузка), 129
OLAP (аналитическая
обработка в реальном
времени), 128
OLTP (обработка
транзакций в реальном
времени), 127
жизненный цикл, 95
этап сбора и фильтрации
данных, 100
этап агрегирования и пред¬
ставления данных, 107
этап анализа данных, 109
этап извлечения данных, 102
этап идентификации
данных, 98
этап проверки и очистки
данных, 104
этап визуализации дан¬
ных, 111
этап использования ре¬
зультатов анализа, 112
базы данных
NewSQL, 238
NoSQL, 151
СУРБД, 220
обнаружение данных,
265
этап извлечения дан¬
ных (жизненный цикл
аналитики больших
данных), 95
форматы данных, 44
метаданные, 48
полуструктурированные
данные, 133
структурированные
данные, 46
неструктурированные
данные, 46
этап идентификации
данных (жизненный
цикл аналитики боль¬
ших данных), 95, 98
витрины данных, 131
data mining, 265
параллелизм данных, 199
обработка данных, 183
пакетная обработка, 184
с MapReduce, 187
кластеры, 149
распределенная обработ¬
ка данных, 182
Hadoop, 182
параллельная обработка
данных, 181
режим реального време¬
ни^!
СЕР (обработка сложных
событий ), 206
ESP (обработка потока
событий), 207
MapReduce, 187
SCV принцип (скорость,
согласованность, объем),
180
обработка транзакций, 127
рабочие задания, 183
сбор данных, 265
этап проверки и очистки
данных (жизненный
305
цикл аналитики боль¬
ших данных), 95
этап визуализации
данных (жизненный
цикл аналитики боль¬
ших данных), 95
больших данных в BI, 95
хранилища данных, 130
дескриптивные ана¬
литики
определение, 32
диагностические ана¬
литики
определение, 32
цифровизация как
бизнес-мотивация для
больших данных, 73
DIKW пирамида, 66,68
распределенная обра¬
ботка данных, 182
распределенная фай¬
ловая система, 150
принцип «разделяй и
властвуй» (MapReduce),
187
документ в хранилище
NoSQL, 151
долговечность при
проектировании баз
данных на основе
ACID, 168
Е
ребра (в графах NoSQL
хранилища), 151
гарантирование стра¬
хования (ETI) пример
из практики. См.
пример из практики,
ETI (гарантирование
страхования)
корпоративные техно¬
логии для аналитики
витрины данных, 131
хранилища данных, 130
ETL (извлечение, преоб¬
разование и загрузка), 129
OLAP (аналитическая
обработка в реальном
времени), 128
OLTP (обработка
транзакций в реальном
времени), 127
ESP (обработка потока
событий), 207
ETI (гарантирование
страхования) при¬
мер из практики. См.
пример из практики,
ETI (гарантирование
страхования)
ETL (извлечение,
преобразование и
загрузка), 129
пример оценки бизне¬
са (жизненный цикл
аналитики больших
данных), 95
обработка событий.
См. режим реального
времени
обработка потока
событий (ESP), 207
случайная согласован¬
ность при проектиро¬
вании баз данных на
основе BASE, 225
разведывательный
анализ, 109
извлечение данных
(жизненный цикл
аналитики больших
данных), 95
извлечение, преоб¬
разование и загрузка
(ETL), 129
F
отказоустойчивость в
кластерах, 154
цикл обратной связи
в бизнес-архитектуре,
62,94
файловые системы, 150
фильтрация данных
(жизненный цикл
аналитики больших
данных), 95
G-H
географические
информационные
системы (GIS), 120
структура руководства,
93
графическое пред¬
ставление данных. См.
методы визуального
анализа
граф NoSQL хранили¬
ща, 151
Hadoop, 182
цветовые карты, 285
горизонтальное мас¬
штабирование, 153, 245
ICT (информационные
и коммуникационные
технологии), 72
доступные технологии, 74
облачные вычисления, 77
цифровизация, 73
идентификация дан¬
ных (жизненный цикл
аналитики больших
данных), 95
информация
в DIKW пирамиде, 66,68
информационные и
коммуникационные
технологии (ICT). См. ICT
интерактивный ре¬
жим, 202
Интернет Вещей (lol), 76
Интернет Всего (1оЕ),
как бизнес-мотивация
для больших данных, 79
изоляция при проекти¬
ровании баз данных на
основе ACID, 168
J-K
рабочие задания
(MapReduce), 187
306
ключ-значение в
NoSQL памяти, 151
знание
определение, 64
в DIKW пирамиде, 66,68
KPIs (ключевые пока¬
затели эффективно¬
сти), 67
L-M
задержка в СУРБД, 220
линейная регрессия, 272
машинное обучение, 273
кластеризация, 276
фильтрация,278
обнаружение выбросов,
277
тактический уровень,
69,126
MapReduce, 187
этап map (MapReduce),
187
задачи шар
(MapReduce), 187
память. См. устройства
хранения внутренней
памяти
метаданные
в этапе сбора и фильтра¬
ции данных (жизненный
цикл аналитики больших
данных), 95
N
обработка естествен¬
ного языка, 281
сетевые графы, 289
NewSQL, 238
узлы (в графе NoSQL
хранилища), 151
нелинейная регрессия,
272
NoSQL, 151
О
Автономная обра¬
ботка. См. пакетная
обработка
OLAP (аналитическая
обработка в реальном
времени), 128
OLTP (обработка тран¬
закций в реальном
времени), 127
устройства хранения
на дисках
базы данных
NewSQL, 238
NoSQL, 151
аналитическая об¬
работка в реальном
времени (OLAP), 128
обработка в реальном
времени, 128
обработка транзакций
в реальном времени
(OLTP), 127
обнаружение выбросов,
277
р
параллельная обработка
данных, 181
этап разбиения
(MapReduce), 187
устойчивость при раз¬
биении в САР теореме,
165
одноранговая реплика¬
ция, 158
производительность
KPIs. См. KPIs (ключевые
показатели эффектив¬
ности)
шардинг, 161
Жизненный цикл анали¬
тики больших данных, 95
этап сбора и фильтрации
данных, 100
этап агрегирования и
представления данных, 107
этап анализа данных, 109
этап извлечения данных, 102
этап идентификации
данных, 98
этап проверки и очистки
данных, 104
этап визуализации дан¬
ных, 111
этап использования ре¬
зультатов анализа, 112
облачные вычисления,
77
структура руководства, 93
поддержка реального
времени в анализе дан¬
ных, 91
обработка. См. обра¬
ботка данных
0-R
качественный анализ,
265
количественный анализ,
264
СУРБД (системы управ¬
ления реляционными
базами данных), 220
метод сквозного чте¬
ния (IMDGs), 248
режим реального вре¬
мени, 91
СЕР (обработка сложных
событий), 206
ESP (обработка потоков
событий), 207
MapReduce, 187
SCV принцип (скорость,
согласованность, объем),
180
поддержка реального
времени при анализе
данных, 91
согласование данных
(жизненный цикл
аналитики больших
данных), 95
этап reduce
(MapReduce), 187
задачи reduce
(MapReduce), 187
метод обновления
(IMDGs), 248
307
регрессия, 271
корреляция, 268
системы управления
реляционными базами
данных (СУРБД), 220
репликация, 154
объединение с шардин-
гом, 161
репликация в режиме «ве¬
дущий - ведомый», 155
одноранговая репликация,
158
ведущий-ведомый, 155
одноранговый, 158
результаты анализа, ис¬
пользование (жизнен¬
ный цикл аналитики
больших данных), 95
$
схемы в СУРБД, 220
SCV-принцип (ско¬
рость, согласованность,
объем), 180
анализ эмоциональной
окраски высказываний,
284
шардинг, 161
объединение с реплика¬
цией, 161
репликация в режиме»ве-
дущий-ведомый», 155
одноранговая репликация,
158
этап перетасовки
и сортирования
(MapReduce), 187
отношение сигнал/
шум, определение, 39
сопоставление про¬
странственных данных,
291
скорость в SCV прин¬
ципе, 180
сплит-тестирование, 267
статистический анализ,
266
A/В тестирование, 267
корреляция, 268
регрессия, 271
устройства хранения
данных
хранение в оперативной
памяти, 239
IMDGs, 248
Хранение надиске, 101
технологии хранения
проектирование баз дан¬
ных на основе ACID, 168
САР теорема, 165
кластеры, 149
базы данных NoSQL, 151
репликация, 154
репликация в режиме
«ведущий-ведомый», 155
одноранговая репликация,
158
шардинг, 161
объединение с репликацией,
161
обработка потоков.
См. режим реального
времени структуриро¬
ванные
машинное обучение с
учителем, 274
т
временные ряды, 288
традиционный BI
(Business Intelligence),
131
специализированные
отчеты, 132
информационная па¬
нель, 139
обработка транзакций,
127
U-V
неструктурированные
данные
определение, 46
машинное обучение
без учителя, 273
этап использования
результатов анализа
(жизненный цикл
аналитики больших
данных), 95
проверка правильно¬
сти данных (жизнен¬
ный цикл аналитики
больших данных), 95
ценность
определение, 43
многообразие
пример из практики, 26
определение, 59, 227
в NoSQL, 151
скорость
определение,227
хранение в оперативной
памяти, 239
в NoSQL, 151
режим реального време¬
ни, 91
достоверность
определение, 42
вертикальное масшта¬
бирование, 220
методы визуального
анализа, 285
цветовые карты, 285
сетевые графы, 289
сопоставление простран¬
ственных данных, 291
временные ряды, 288
визуализация данных
(жизненный цикл
аналитики больших
данных), 95
объем
определение, 227
в NoSQL, 151
в SCV принципе, 180
неструктурированные
данные
определение, 46
машинное обучение
без учителя, 273
использование этапа
анализа результатов
(жизненный цикл ана¬
литики данных), 95
валидация данных
(жизненный цикл ана¬
литики данных), 95
ценность
определение, 43
многообразие
308
определение, 59,227
в NoSQL, 151
скорость
определение, 227
хранение в оперативной
памяти, 239
в NoSQL, 151
режим реального време¬
ни^!
достоверность
определение, 42
вертикальное масшта¬
бирование, 220
методы визуального
анализа, 285
цветовые карты, 285
сетевые графики, 285
временные ряды, 288
визуализация данных
(жизненный цикл
аналитики больших
данных), 95
объем
определение, 40
в NoSQL, 151
в принципе SCV, 180
W-X-Y-Z
анализ «Что, если...» в
инструментах визуали¬
зации данных, 34
рабочие задания (обра¬
ботка данных)
пакетная обработка, 184
с MapReduce, 187
обработка транзакций,
127
метод с отложенной
записью (IMDG), 244
метод сквозной записи
(IMDG), 244
EFFICIENT
Information
Technologies
Трансформируйте свою компанию вместе
с «Эффективными информационными технологиями»
Make your business data-driven!
©
Конструируем — эффективное создание
потоков данных
Управляем — ускорение ERP и BI систем
Исследуем — оптимизация хранилищ
данных и инфраструктуры данных
Оптимизируем — ускорение доступа
к данным и снижение ИТ затрат
Защищаем — защищенные данные
для защищенного бизнеса
360° — управление поведенческим
опытом и удовлетворенностью клиентов
20+ эффективных решений в портфеле
50+ успешных проектов в СНГ и Европе
V +38 044 594 8018
9 ул. Елены Телигы, 6, Киев, Украина, 04112
& info@it-efficient.com
а it-efficient.com
„ мармите Enter
поиска и нажми
Balance
Business
BooKs
bbb.com.ua
Если вы хотите усовершенствовать
ваши личные навыки или ускорить
движение по карьерной лестнице, стать
более эффективным руководителем
или более квалифицированным
специалистом, открыть новые
возможности или просто получить
вдохновение для работы, наши книги
помогут вам в этом.
Каждый знает, что хорошая книга —
это не только удовольствие, но и
польза, а приносить пользу обществу,
в котором живешь, — долг каждого,
кто имеет такую возможность. Именно
поэтому наша команда выбрала своим
делом издательский бизнес.
Специализация издательства «Баланс
Бизнес Букс» — качественная деловая
литература. На сегодняшний день наш
ассортимент составляет более 150
наименований деловой литературы.
Мы надеемся, что наши книги станут
незаменимыми помощниками
и неизменными спутниками
в динамичном мире бизнеса.
Узнайте больше о нашем издательстве
bbb.com.ua
Виртуальные
миллиарды
. J2 ппп названием «биткоин»
375В
н^фрова
ВиртУ альные
миллиарда11
длгм ПЛ
стоявшие
НОВИНКИ
помпы была представлена миру
Автор
млйшмазд
ХИППИ
корп.
icmmrm.
КНИГА ВI
ШЙ1„ и
АШНЖАМЕВ И аГМАЯЯРОВАЛА
ишАНыделмк»
Издательский
бизнес изнутри
Корпорация хиипи
Майкл Классен
2758
1598
Оцифрованный
.менеджмент
Business I n telligence
для ТОПов
Владимир Савчук
375%
Майкл Классен
«Офисный Лайфхак» — это сборник советов
и практических рекомендаций, следуя которым вы
сможете повысить эффективность работы и увеличить
количество свободного времени.
Эта книга поможет в организации рабочих
процессов и решении ежедневных задач, таких как
работа с почтой, документами, общение с клиентами,
начальством и подчиненными, звонки и совещания.
офисный лайфхак
Партнерские услуги от издательства «Баланс Бизнес Букс»
• брендирование суперобложек с вашим логотипом(от
разработки дизайна до готового продукта);
• реклама в книгах нашего издательства (рекламные паке¬
ты, в зависимости от ваших потребностей);
• формирование корпоративной библиотеки (по изда¬
тельской цене);
• корпоративные подарки (подборка книг под тематику
вашего бизнеса).
Формирование корпоративной библиотеки
Корпоративная библиотека — это центр профессиональ¬
ных знаний, который всегда находится под рукой.
В современном деловом мире профессиональное само¬
обучение сотрудников компании является одним из ее
главных стратегических ресурсов. Именно поэтому мно¬
гие украинские компании приходят к пониманию необхо¬
димости создания собственных корпоративных библио¬
тек.
Услуга «Корпоративная библиотека» предполагает две
основные формы комплектования:
• Разовое комплектование библиотеки «под ключ»;
• Периодическое доукомплектование библиотеки книж¬
ными новинками издательства.
ilSSxS
ii
1 шИ
Эрик Гейсингер
Виртуальные
миллиарды
ГбНИИу
Bfe
наркобарон
и близнецы
из Лиги плюща,
стоявшие
за взлетом
Биткоина
Balance
Business
Books A
1
f
4
Татьяна Верба
Издательский бизнес изнутри
От рукописи к бестселлеру:
пошаговое руководство по подготовке книги к печати,
производству и продвижению
Профессиональные советы от издательства
деловой литературы «Баланс Бизнес Букс»
Business
«Баланс Бизнес Букс»
первое в Украине специализированное издательство деловой литературы
основано в 2000 году
мы выпускаем качественную деловую литературу
книги для бизнеса
тщательно отобранные на лучших международных выставках
наша продукция — это ваш помощник в ведении бизнеса
от рекламы до финансов
от маркетинга до управления персоналом
мы выпустили более
350
наименований книг
каждой из которых искренне гордимся
Среди книг, вышедших под маркой «Баланс Бизнес Букс» — лучшая деловая литература украинских авторов,
а также переводные книги ведущих мировых издательств: American Society for Quality (USA), Berrett-Koehler
Publishers, Inc. (USA), Copenhagen Business School Press (Denmark), Kogan Page (UK), Palgrave Macmillan (UK),
Pearson Education Limited (UK), Thomson Learning. В ассортименте издательства - мировые бестселлеры, такие,
как «Сбалансированная система показателей Balance Scorecard», Караоке-капитализм» и одна из семи наиболее
важных книг, вышедших в 2016 году по версии журнала "Inc." «Виртуальные миллиарды. Биткоин» и серия книг
библиотеки Уортонской бизнес-школы Wharton School Publishing.
«Основы Big Data: концепции, алгоритмы и технологии» обеспечивают прагматичное и
серьезное введение в область больших данных. Популярный ИТ-автор Томас Эрл
и его команда четко объясняют ключевые концепции, теорию и терминологию Big Data,
а также фундаментальные технологии и методы. Весь охват материала книги поддер¬
живается примерами из практики и многочисленными простыми диаграммами.
Наукове видання
Томас Ерл
Основи Big Data: кон цеп цн, алгоритми та технологи
Роайською мовою.
Переклад Анатол|‘й Гладун
Науковий редактор Олекай Найда
Редактор В1ктор Луюн
Верстка Олександр Тараненко
Дизайн обкладинки Олександр Тараненко
В|дпов1дальний за випуск Тетяна Верба
П«дписано до друку 19.04.2018. Формат 60x90 1/16
Наклад 1000 прим.
ТО В «Баланс Б|знес Букс»,
9 вул. Андр5я Фабра, 4, м. Джпро, УкраТна, 49070
% +380(56)370-30-44
в info@bbb.com.ua
А bbb.com.ua
П bbbpublish ing
Св|доцтво ДК №2070 в<д 21.01.2005р.
В1ддруковано у ТОВ «Фактор-Друк»
9 вул. Саратовська, 51, м. Харюв, УкраТна, 61030
Замовлення № 3104
Книга «Основы Big Data» - это серьезное практическое введе¬
ние в область больших данных. Популярный ИТ-автор Томас Эрл
и его команда доступно объясняют ключевые концепции,
теорию и терминологию Big Data, а также фундаментальные
технологии и методы. Материалы книги подробно проиллю¬
стрированы примерами из практики и многочисленными
простыми диаграммами.
Эта книга содержит:
• открытие фундаментальных концепций Big Data и того,
что отличает эту технологию от предыдущих форм анализа
данных и науки о данных;
• понимание бизнес-мотиваций и стимулов, связанных с адаптацией
к большим данным для оперативного улучшения за счет инноваций;
• планирование стратегических, бизнес-мотивированных инициатив
на основе больших данных;
• рассмотрение таких вопросов, как управление данными,
руководство и безопасность;
• «Пять V» - свойства наборов данных: объем, скорость, разнообразие,
достоверность и ценность;
• объяснение отношений больших данных с OLTP, OLAP, ETL,
хранилищами данных и витринами данных;
• объяснение работы с большими данными в структурированных,
неструктурированных, полуструктурированных форматах
и форматах метаданных;
• увеличение ценности за счет интеграции ресурсов больших данных
с мониторингом эффективности бизнеса;
• понимание того, как большие данные используют распределенную
и параллельную обработку;
• использование NoSOL и других технологий для удовлетворения
различных требований к обработке больших данных;
• использование статистических подходов для количественного
и качественного анализа;
• применение методов вычислительного анализа,
включая машинное обучение.
9 49070, Украина
Днепр, ул. Андрея Фабра, 4
а info@bbb.com.ua
bbbpublishing
4 820092 " 000513
+380(56)370-30-44
+380 (44) 393-26-20
А bbb.com.ua
ISBN 978-966-415-062-7
Баланс Бизнес Букс © 2018