/






































































































































Author: Растригин Л.А.
Tags: регулирование и управление машинами, процессами случайный поиск специфика этапы истории предрассудки
Year: 1978




Text
АКАДЕМИЯ НАУК СССР
НАУЧНЫЙ СОВЕТ ПО КОМПЛЕКСНОЙ ПРОБЛЕМЕ
«КИБЕРНЕТИКА*
MJ UII II
II
Выпуск 33
ПРОБЛЕМЫ СЛУЧАЙНОГО ПОИСКА
(Под редакцией Л. А. Растригина)
МрСКВА 1978
Сборник подготовлен Научным советом
по комплексной проблеме «Кибернетика» АН СССР.
117333, Москва, В-333, ул. Вавилова, 40, телефон 135-40-71
РЕДАКЦИОННАЯ КОЛЛЕГИЯ:
Д. т. н. С. И. Самойленко (председатель),
д. т. н. Е. В. Маркова (зам. председателя),
к. ф. н. С. С. Масчан (зам. председателя),
В. Г. Левадный (ответственный секретарь), д. т. н. В. М. Ахутин,
к. г.-м. н. Г. Г. Воробьев, д. т. н. Ю. Г. Дадаев,
д. ф.-м. н. Ю. И. Журавлев, чл.-корр. АН СССР Д. Е. Охоцимокийг
д. т. н. Д. А. Поспелов, д. т. н. И. В. Прангишвили,
чл.-корр. АН СССР А. Г. Спиркин, д. т. н. И. С. Уколов,
Э. В. Ханина, чл.-корр. АН СССР Я. 3. Цыпкин
В подготовке сборника принимали участие Л. А. Растригин,
П. Л. Мороз, А. И. Жданок, Г. С. Тapaceнко
(g) Научный совет по комплексна проблеме «Кибернетика»
АН СССР, 1978
УДК 62-506
СЛУЧАЙНЫЙ ПОИСК—СПЕЦИФИКА,
ЭТАПЫ ИСТОРИИ И ПРЕДРАССУДКИ
Л. А, Растригин
(Рига)
Случайный -поиск как МёТОД рекуррентной оптимизации
сложных систем возник сравнительно недавно — в начале
шестидесятых годов [1]. За немногим более чем полтора
десятилетия своей истории случайный поиск стал мощным
вычислительным средством, позволяющим решать сложнейшие задачи,
выдвигаемые наукой и народным хозяйством. Сейчас пожалуй уже
ни у кого нет сомнений б правомочности стохастических
процедур поиска и существовании задач, где такой подход более
целесообразен с различных точек зрения, чем детерминиррванные
алгоритмы поиска. Это оказалось возможным прежде всего в
связи с успешным решением ряда важных прикладных задач
(в основном из области оптимального проектирования сложных
систем современной техники), которые не удавалось решить,
другими методами, теоретическими результатами, с помощыо
которых показана большая эффективность случайного поиска
по сравнению с известными детерминированными процедурами,
и очевидными перспективами, которые открываются с
использованием элемента случайности в процессе -поиска (особенно по
преодолению приславутого «проклятия -размерности»).
ОСОБЕННОСТИ СЛУЧАЙНОГО ПОИСКА
Остановимся коротко на основных особенностях случайного
поиска, отличающих его от известных детерминированных
процедур оптимизации.
Случайный поиск как метод оптимизации получил
наибольшее применение при решении задач математического
программирования
Q(X)-+mm, (1)
1*
3
.[Si
где Х = (хи .. .,л:л) — вектор оптимизируемых параметров;
Q (X) — скалярная функция, значения которой могут
определяться случайной ошибкой; 5 —заданное множество допустимых
значений оптимизируемых параметров, которое определяется
системой равенств и неравенств:
g.(X) = 0, / = 1,...,т<л;
(*)>0, У = 1 Л. W
Задача математического программирования заключается
в отыскании решения X*, обладающего свойствами
Q(X*)=minQ(X) (3)
Известные методы решения приведенной задачи
существенным образом связаны с видом и свойствами функций Q(X)y
gi(X) и hj(X). Среди этих методов значительное место
занимают поисковые методы, суть которых сводится к
построению последовательности состояний
Х0-»Хг-+Х2-+ ... ^XN^ ..., (4)
где каждое последующее состояние должно быть в
определенном смысле лучше предыдушего. Алгоритм поиска определяет
способ перехода от одного состояния к другому:
XN = F[Xi9 Q(Xi)9 f = W-l,..., N-q]. (5)
Здесь q — глубина памяти алгоритма (иначе говоря, алгоритм
поиска является q-m^TOBUu). Функция (а в общем случае
оператор) F целиком определяет алгоритм поиска. Под F
подразумевается правило, инструкция, предписание, в соответствии с
которым следует действовать при данной предистории поиска
глубиной q.
Если оператор F детерминированный, то поиск называют
регулярным (детерминированным). Если же оператор случайный,
то поиск называют случайным (стохастическим).
Обозначим FQ — регулярный, a Fx— случайный операторы
поиска, где \ — символ случайного оператора. Для простоты
будем рассматривать операторы, которые могут быть
представлены в виде функций. Это не снизит значительно общности
рассмотрения. Алгоритм случайного поиска при этом записывается
в виде
X„=Ft[X„-u Q(**-i), W„-x] =
=/[х„_ь Q(**-i), w^-i.q, (6)
где / — функция, и^лг-i — вектор предистории поиска (в
простейшем случае q — шагового поиска):
4
То обстоятельство, что при £=0, т. е. в отсутствие элемента
случайности поиск приобретает детерминированный характер,
позволяет сделать первое и очевидное утверждение, что любой
регулярный метод поиска является частным случаем (при £ = 0)
некоторого множества случайных алгоритмов случайного
поиска.
Приведем пример. Градиентный метод поиска
A^ = *Ar-i-agradQ(*Ar-i), (7)
где оценка градиента имеет вид
gr ad Q {Х„-г) = у {Q (ЛГлг-i + gex) -
-Q(**-i), .. .,Q(*W-i + *^-Q(**-i)} (8)
(er i-й орт), является частным случаем, по крайней мере,
двух алгоритмов случайного поиска.
Первый алгоритм
XN = XN_X - a grad Q (AV-i) + «• (9)
где I —единичный случайный /г-мерный вектор. Это известный
градиентный алгоритм случайного поиска [3,4]. Второй
алгоритм имеет вид (7), но оценки градиента вычисляются
по формуле
grad Q (*„_0 =
_ V [Q (Х„-г + get + /!<)-<? (^)](gg< + /fr)
^ l**i + /!ilf * ( )
Здесь ^ — /-я реализация единичного случайного вектора. При
/ = 0 оба алгоритма вырождаются в градиентный алгоритм
поиска (7).
Таким образом, случайный поиск является естественным
расширением, продолжением и обобщением известных регулярных
методов поиска.
Другой особенностью случайного поиска, которая открывает
широкие возможности для его эффективного применения,
является использование оператора случайного шага g в качестве
стохастической модели сложных регулярных операторов
отыскания направлений поиска в пространстве оптимизируемых
параметров {X}.
Например, один из алгоритмов случайного поиска с
линейной тактикой (случайного спуска):
fog при ДО„>0; п
&XN+i = ^Xn при ±Qn < о У11)
является стохастической моделью алгоритма наискорейшего
спуска
5
„ iagtauQ(XN) при AQ//>0; .
Л*"+1 = (ДХ„ при AQ„<0, (12>
в которой вектор £ моделирует оценку градиента grad Q.
Любопытно, что подобную «оценку» нельзя даже назвать грубой,
так как ее стохастические свойства не напоминают свойств
оцениваемого градиента. Однако, несмотря на это, алгоритм (11)
не только работоспособен, но в ряде случаев и более
эффективен, чем алгоритм (12). Это показано в работе [5].
Здесь оператор случайного шага £ заменяет громоздкий
оператор оценки градиента, например, по формуле (8). Если
плотность распределения случайного вектора | выродится в дельта-
функцию вида
/>(!) = § (T-gradQ), (13)
то алгоритм случайного спуска (11) сведется к частному
случаю— алгоритму наискорейшего спуска (12).
Следующей особенностью случайного поиска, выгодно
отличающей его от регулярных методов, является его глобальность,
проявляющаяся прежде всего в локальных алгоритмах
случайного поиска, не предназначенных для отыскания глобального
экстремума. Так, алгоритм случайного спуска (11) может «айти
глобальный экстремум, а регулярный алгоритм наискорейшего
спуска в принципе не допускает такой возможности, поскольку
он построен для отыскания локального экстремума.
Таким образом, глобальность алгоритмов случайного поиска
является как бы «премией» за использование случайности и
что-то вроде «бесплатного приложения» к алгоритму. Это
обстоятельство особенно важно при оптимизации объектов с
неизвестной структурой, когда нет полной уверенности в одноэкст-
ремальности задачи и возможно (хотя и не ожидается) наличие
нескольких экстремумов. Использование в таком случае методов
глобального поиска было бы «неразумной» расточительностью.
Методы локального случайного поиска здесь наиболее прием-
лимы, так как они эффективно решают локальную задачу и
могут в принципе решить глобальную, если таковая будет иметь
место. Это обеспечивает случайному поиску своеобразную
психологическую надежность, которую очень ценят программисты.
Алгоритмическая простота случайного поиска делает его
привлекательным в первую очередь для потребителей. Опыт
показывает, что известные алгоритмы случайного поиска
являются лишь «канвой», на которой пользователь в каждом
конкретном случае «вышивает узоры» новых алгоритмов,
отражающих не только его вкусы и наклонности, что нельзя не
учитывать, но и специфику оптимизируемого объекта. Последнее
создает реальную основу для реализации известного
принципа— алгоритм должен конструироваться «под объект».
6
Наконец алгоритмическая простота случайного поиска
обуславливает простоту его аппаратурной реализации. Это не
только дает возможность строить простые, компактные и надежные
оптимизаторы с неограниченным числом оптимизируемых
параметров [6], но и позволяет довольно просто организовать их
оптимальный синтез на ЦВМ [7].
Теперь рассмотрим этапы истории случайного поиска.
Начнем с предыстории.
ПРЕДЫСТОРИЯ СЛУЧАЙНОГО ПОИСКА
Случайный поиск в процессах оптимизации имеет
предысторию, которой являются методы планирования экспериментов,
Монте-Карло, смешанные стратегии, «шумовая» идентификация,
гомеостат и усилитель умственных способностей. Рассмотрим их
коротко, тем более, что случайный поиск в своем развитии
опирается на эти вехи, о чем будет сказано ниже.
РАНДОМИЗАЦИЯ в процессах планирования
экспериментов вводится при необходимости осреднить результат по
ситуациям при наличии систематического дрейфа или
коррелированных помех. При этом случайный выбор порядка экспериментов
гарантирует несмещенность получаемых оценок параметров
модели объекта.
Здесь случайность играет роль смешивающего фактора,
позволяющего отфильтровать неизвестный систематический фактор.
МЕТОД МОНТЕ-КАРЛО сводится к оценке интеграла
I = \f{X)dX (14)
с помощью случайных точек (испытаний) Хи ..., Хм имеющих
распределение плотности вероятностей р (X), обладающей
свойствами:
р(Х)>0 для X£Q и \p(X)dX = 0
€1
Монте —Карловская оценка интеграла (14) имеет вид:
причем она обладает следующими ценными свойствами
состоятельности и несмещенности:
Y\mIN = I\ MIN = Iy
где М — оператор математического ожидания.
Преимущество этой оценки интеграла (14) по сравнению с
вычисленной по регулярной сетке проявляется с ростом
размерности области QczR71. Так при /г^З точность Монте-Карлов-
7
ской оценки в среднем превышает регулярную [8]. Любопытно,
что аналогичная оценка (п^З) определяет зону преимуществ,
случайного поиска по сравнению с градиентным по критерию
быстродействия [2].
В методе Монте-Карло случайность играет роль механизма,,
гарантирующего сколь угодно плотное размещение точек в
заданной области. Спецификой этой оценки, отличающей ее от
регулярной, является возможность ее реализации при любом ЛГ
(в том числе и при N=1, что широко используется в та.к
называемых рандомизированных алгоритмах оптимизации, о
которых будет сказано ниже).
СМЕШАННАЯ СТРАТЕГИЯ в матричных играх с
платежной матрицей в (#, у), когда решается задача максимизации
среднего выигрыша, заключается в вероятностном взвешивании
своих чистых стратегий Si,..., Sm:
т / т \
где pi — вероятность выбора /-й стратегии St. При отсутствии
седловой точки у матрицы в (л:, у), т. е. при
max min b (л:, у) Ф min max b (jc, у)
x у ух
смешанная стратегия является оптимальной. Это показано фон-
Нейманом еще в 1928 г. [9]. В данном случае смешение
стратегий связано не столько максимизацией выигрыша, сколько с
минимизацией проигрыша. Случай здесь не дает возможности
противнику много выиграть, и играет роль «дымовой завесы».
При отсутствии активности противника решение всегда
лежит в области чистых стратегий (смешение возможно, если
число таких оптимальных стратегий больше единицы. Однако оно
не необходимо).
ШУМОВАЯ ИДЕНТИФИКАЦИЯ динамических объектов
опирается на известное соотношение свертки между
автокорреляционной функцией входа Kxx(t) и взаимно-корреляционной
функцией входа и выхода Kxy(t) линейной динамической
системы
оо
Kxy(t) = \g(%)Kxx(t-t)<K
О
с весовой функцией g(t). Для идентификации этой функции
достаточно на вход объекта подать белый шум,
автокорреляционная функция которого является дельта-функция. В этом
случае, как легко заметить, взаимокорреляционная функция с
точностью до постоянного коэффициента будет совпадать с весовой
функцией объекта g(t). Здесь случайность позволяет как бы
«прощупать» динамику объекта на всех частотах. Она модели-
8
рует нереальное «всечастотное» возмущение стохастическим
образом.
ГОМЕОСТАТ предложенный Эшби [11] в 1946 г.
представляет собой линейную динамическую систему, которая в случае
неустойчивости изменяет свои параметры случайным образом
до тех пор пока не «айдет их устойчивую комбинацию, после
чего параметры не меняются. Управление гомеостата
Чг-"
где Y—-вектор переменных, изменяющихся в пределах: ||Г||<а*
А—матрица параметров, которая изменяется во времени
следующим образом:
при \\У\\-=а
при \\У\\^а9 к '
Мл "'
где S—случайная матрица, ||-||—знак нормы, которая .может
выбираться различным образом. Как легко заметить, (16)
является по сути дела алгоритмом случайного поиска с линейной
тактикой, который для случая оптимизации записывается в
виде (11).
В гомеостате случайность играет роль «всех
возможностей», что гарантирует ему отыскание устойчивой комбинации
параметров. Существенно, чтобы вероятность этого события не
была бы слишком малой. В противном случае алгоритм (3)
естественно неэффективен, как и всякий другой алгоритм
случайного поиска. Это обстоятельство четко определяет требование
к любому стохастическому алгоритму: вероятность удачного
шага не должна быть малой.
Алгоритм УСИЛИТЕЛЯ УМСТВЕННЫХ СПОСОБНОСТЕЙ
Эшби [12] по сути дела повторяет идею гомеостата и так же
эксплуатирует идею случайности как источника всех
возможностей.
И, наконец, важнейшим этапом предистории было
предложение А. А. Красовского использовать случайные модулирующие
сигналы для экстремального регулирования с применением
синхронного детектора.
Таким образом предистория случайного поиска связана с
использованием категории случайности для достижения
позитивных целей, исключая решение задачи оптимизации. С
предложения решать задачи оптимизации применяя элемент
случайности [1] и начинается история случайного поиска.
Эту историю условно можно подразделить на следующие
этапы
1. Эвристический этап
2. Этап рандомизации
3. Этап адаптации
9
ЭВРИСТИЧЕСКИЙ ЭТАП (1960—1970)
Этот этап характеризуется бурным процессом создания
огромного числа различных алгоритмов случайного поиска.
Интенсивность развития этого этапа напоминает прарыв огромной
силы. Трудно сказать, чем был вызван этот прорыв. Скорее
всего он был связан с неожиданным раскрытием больших
возможностей случайного поиска (СП), где обнаружились
факторы различного рода. А именно:
1. факторы простоты;
2. алгоритмические факторы;
3. бионические факторы;
4. психологические факторы.
Рассмотрим коротко основные из них.
ФАКТОРЫ ПРОСТОТЫ определяют несомненное
преимущество случайных процедур поиска по сравнению с
детерминированными:
1) Простота выбора случайного направления в алгоритмах.
2) Простота учета ограничений (нарушение ограничений
классифицируется как неудачный шаг со всеми необходимыми
последствиями — обратный шаг, адаптация длины шага,
адаптация распределения случайного шага и т. д.).
3) Простата учета предистории СП, которая отражается в
вероятностных свойствах случайного шага (самообучение)
[13].
4) Простота эвристического синтеза алгоритмов СП.
(Например при затруднениях следует вводить случайный шаг).
5) Простота программирования СП. (Опыт показывает, что
программы СП всегда оказываются значительно проще и
короче программ регулярных методов поиска).
АЛГОРИТМИЧЕСКИЕ ФАКТОРЫ определяют
качественную специфику алгоритмов случайного поиска:
1. Нечувствительность СП ко всякого рода ловушкам
(например, седловым точкам оптимизируемой функции).
2. Увеличение частоты циклов поиска по сравнению с
регулярными методами (так на п пробных шагов одного цикла
градиентного поиска приходится в среднем два случайных шага,
образующих цикл случайного поиска.).
3. Повышенное быстродействие случайного поиска (так если
регулярные алгоритмы обеспечивают продвижение к цели со
•скоростью обратнопропорциональной ra-раэмерности объекта,
то случайный поиск имеет скорость (1/Уга). Причем
преимущество случайного поиска с ростом размерности
оптимизируемой системы проявляются все в большей степени.
4. Сочетаемость случайного поиска с детерминированными
процедурами. (Так 1на базе случайного поиска могут быть
объединены любые регулярные алгоритмы, например, путем их
вероятностного взвешивания [14]).
30
'5. Иерархическая структура алгоритма случайного поиска,
которая позволяет довольно просто создавать на их базе
пакеты программ оптимизации [15].
БИОНИЧЕСКИЕ ФАКТОРЫ связывают алгоритмы
случайного поиска с биологическими системами управления на
различных уровнях, что позволяет широко пользоваться
аналогиями при синтезе алгоритмов случайного поиска [16]. Укажем на
уровни биологической организации, которые уже дали
возможность синтезировать эффективные алгоритмы случайного поиска:
1. Нейронный уровень, моделирование которого позволило
создать матричный случайный поиск [17], являющийся
стохастическим аналогом известного метода вращающихся
координат Розенброка.
2. Поведенческий уровень, моделирующий поведение животных
в неизвестной среде, дал возможность синтезировать
эффективные методы структурной адаптации случайного поиска
[18].
3. Популяционный уровень, моделирующий процессы эволюции,
эффективно использован для создания большего числа
алгоритмов случайного поиска, среди которых упомянем [19, 20].
4. Психологический уровень связан с моделированием
различных тактик поведения, что породило целый спектр
алгоритмов случайного поиска. Принцип «удовольствия»,
заставляющий повторять успешные действия отражен в алгоритмах
случайного поиска с линейной тактикой [21]. Он моделирует
работу подсознания. Случайный поиск с нелинейной
тактикой, позволяющий исправлять ошибки, моделирует принцип
«неудовольствия» и по сути дела является модификацией
метода проб и ошибок.
Все указанные факторы способствовали интенсивному
эвристическому синтезу алгоритмов случайного поиска и их
применению для решения сложных оптимизационных задач, которые
не удавалось решить другими методами. Эти обстоятельства
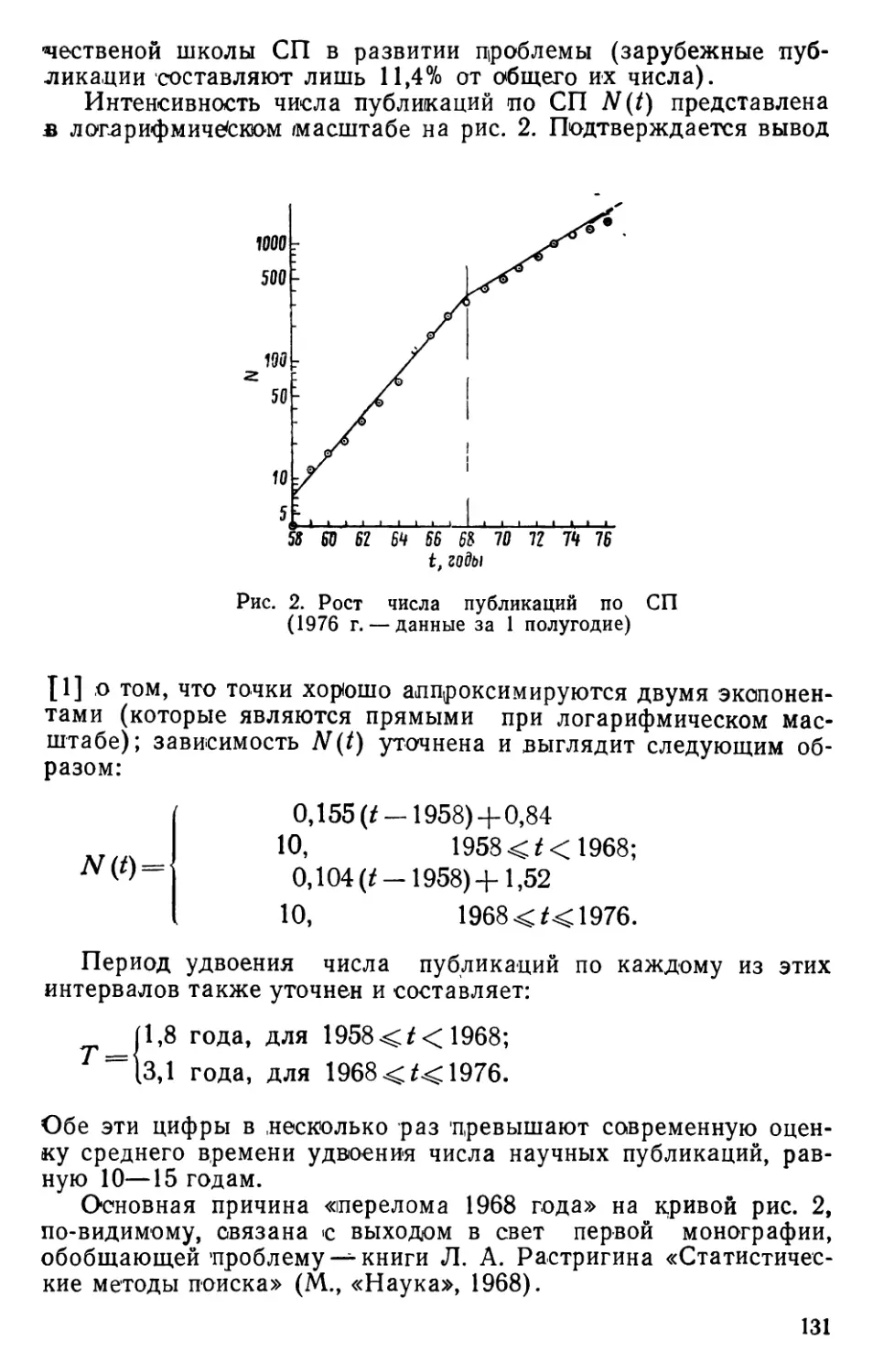
отразились в большем числе публикаций. Показано, что
интенсивность появления работ по случайному поиску в этот период
была максимальной (период удвоения числа публикаций была
равна 1,8 года по сравнению с 10—15 годами по науке в целом
[22]).
Теоретическое осмысливание результатов эвристического
этапа привело к обобщению, связанному с идеей рандомизации,
ла базе которой удалось обобщить эвристические алгоритмы.
ЭТАП РАНДОМИЗАЦИИ (1970—1975)
Идея рандомизации опирается на локальное представление
•минимизируемой функции Q(x) в локально-осредненном виде
123]:
11
где p(.) —весовая функция, заданная аналитически.
Конструкция этого осреднения позволяет определять градиент функции
Q(X) путем прямого дифференцирования:
4Q'(X) = lQ{X)vp(X-Y)dT9
где V —знак градиента. Оценку этого интеграла удобнее всего
делать методом Монте-Карло, т. е. воспользоваться (15):
VQ (x) = lfZ J(Y7) »
где Yt — независимые случайные вектора, генерированные в
соответствии с плотностью распределения p(Y).
Любопытно, что эту оценку можно сделать по одному
эксперименту, т. е. при N = \. Полученную оценку теперь
можно использовать, например, для оптимизации градиентным
методом [24]:
XM = Xk-wQ'{Xk)
как легко заметить, получаем алгоритм случайного поиска, где
случайность вошла при оценке градиента по Монте-Карло. Это
и есть рандомизация, которую в даином случае точнее назвать
«Монтекарлизацией».
В общем случае, взвешивание имеет статистический характер
Q'(X)=SQ(Y)p(Y/X)dY9
где p(Y/X) —условная плотность распределения У в районе X.
Оно получило наименование рандомизированного сглаживания
[25]. Различные виды условного распределения p(Y/X) приводят
к различным алгоритмам поиска. Так нормальное распределение
дает случайный поиск с парными пробами, а равномерное —
метод Кифера-Вольфовица. Как видно, идея рандомизированного
сглаживания явилась эффективным средством объединения
различных алгоритмов поиска. Особенно привлекательна она для
решения дискретных задач, когда множество {X} конечно. В этом
случае удается организовать поиск на базе указанного
рандомизированного сглаживания. В общем случае он оказывается
случайным.
Этап рандомизации очень много дал в понимании места
процессов случайного поиска среди других процессов принятия
решений. Случайный поиск оказался прямым следствием
смешанных стратегий, в то время как регулярные методы порождается
чистыми стратегиями.
12
ЭТАП АДАПТАЦИИ (1975—...)
Этот новый этап развития случайного поиска
характеризуется пониманием, что нельзя априори выбирать адекватный
объекту алгоритм поиска. Более того, для достаточно сложных
объектов такого всюду оптимального алгоритма и не существует.
Алгоритм поиска должен адаптироваться к каждой конкретной
ситуации, сложившейся в объекте в процессе поиска. При этом
процесс адаптации затрагивает как структуру S алгоритма
поиска А, так и его параметры Cs: A = <S, Cs>.
Рассмотрим оба вида адаптации.
1. Параметрическая адаптация (S = const, Cs=var в
алгоритмах случайного поиска обычно затрагивает длину рабочего
шага, объем накопления и распределения случайного шага. При
этом адаптация позволяет увеличить скорость сходимости
процесса случайного поиска, сделать его более надежным и т. д.
2. Структурная адаптация (S-var), S б fi, где й —
множество допустимых структур), связана как с изменением структуры,
так и ее параметров. Здесь возможны два случая [26]:
а) Множество возможных структур конечно: Q= {Si, ..., Sh}.
Эта задача эквивалентна работе с k алгоритмами поиска,
причем адаптация сводится к организации перехода с одного
алгоритма .на другой. Это по сути дела задача о £-руком бандите,
эффективного решения который для случая поиска еще не
найдено, хотя и имеются интересные попытки [27].
б) Множество Q — бесконечно. В этом случае задачу можно
параметризировать.
Очень эффективно в задачах структурной адаптации
применение идей эволюционного моделирования [28] и биологической
эволюции. Последняя уже была использована при адаптации
коллектива оптимизирующих автоматов [19, 29].
Этап адаптации еще не кончился и трудно сказать когда это
произойдет. Ясно одно, что успешность использования
алгоритмов случайного поиска при оптимизации сложных объектов
целиком зависит от его адаптивных свойств.
Работа по созданию эффективных алгоритмов структурной
адаптации только еще началась. Трудность этой задачи никак
нельзя преуменьшать. Для ее решения понадобится привлечь
не только классические методы типа теории статистических
решений, но и новые методы типа искусственного интеллекта.
ПРЕДРАССУДКИ
Широкому распространению случайного поиска часто
препятствуют всякого рода предрассудки, связанные с его
вероятностным характером. Рассмотрим некоторые из них.
1. ПСИХОЛОГИЧЕСКИЙ ПРЕДРАССУДОК связаи с
интуитивным представлением об оптимальности неслучайного
поведения. Он опирается на стремление минимизировать неопре-
13
деленность в процессах принятия решений. Очевидно, что в
достаточно сложных ситуациях снять полностью неопределенность
не удается и решение фактически рандомизируется
неизвестными факторами, влияние которых значительно. Именно поэтому
человек столь неохотно идет на преднамеренную
рандомизацию— ведь она вводит неопределенность, которая и создает
психологический дискомфорт при использовании
рандомизированных правил принятия решения даже при отсутствии
активного противника.
2. ВЕРОЯТНОСТНЫЙ ПРЕДРАССУДОК опирается на
довольно поверхностное соображение о том, что используя
стохастические алгоритмы поиска случайно можно и не решить
поставленную задачу. Действительно, если число шагов поиска
мало и строго ограничено, всегда существует конечная
вероятность того, что задача не будет решена. Но эта вероятность
достаточно мала (порядка 2~N, где N— число шагов поиска) и
легко учитывается при необходимости получения надежных
решений.
3. МАТЕМАТИЧЕСКИЙ ПРЕДРАССУДОК связан с
известным положением теории статистических решений о том, что
минимум функционала потерь достигается на чистых
стратегиях поведения, откуда делается вывод о том, что
детерминированное поведение всегда оптимально, коль скоро задан
критерий потерь. Имеются эффективные попытки построить
детерминированные алгоритмы поиска экстремума, опираясь на
это положение [30]. Естественно, что этот путь приводит к
регулярным алгоритмам.
Однако для того, чтобы воспользоваться этим положением
в задачах оптимизации необходимо иметь полное описание (в
том числе и вероятностное) поведения объекта в зоне, где
принимается решение. Но задачи оптимизации и отличаются тем,
что для их решения нет надобности в полном или
приближенном описании объекта — в процессе поиска может не
создаваться никаких моделей. Это обстоятельство и позволяет считать,
что многошаговый стохастический процесс поиска с точки
зрения простоты его реализации и быстродействия является в
сложных ситуациях более удобной конструкцией, чем любой из
регулярных методов.
ОРГВОПРОСЫ ПРОБЛЕМЫ СЛУЧАЙНОГО ПОИСКА
В конце 1970 г. при Совете по комплексной проблеме
«Кибернетика» была образована комиссия по проблеме случайного
поиска. В эту комиссию вошли представители от различных
научно-исследовательских и учебных организаций страны, где
систематически ведутся исследования по теории и приложениям
случайного поиска. Комиссия организует проведения
симпозиумов и рабочих совещаний, готовит ежегодник «Проблемы слу-
14
чайного поиска» (изд-во «Зинатне» в Риге уже выпустило
5 типографских сборников по 15 авт. листов каждый), издаег
библиографию по проблеме и проблемные записки [31—34].
Ежегодно комиссией проводятся узкие рабочие совещания,
посвященные различным аспектам случайного поиска. Всего
проведено одиннадцать таких совещаний по следующим темам:
ноябрь 1971 (Рига)—«Проблемная записка»
май 1972 (Харьков)—«Проблемная записка»
октябрь 1972 (Цакхадзор, Армения) — «Тестовые функции»
апрель 1973 (Рига) —«Проблемная записка»
октябрь 1973 (Ташкент)—«Случайный поиск в задачах
оптимального проектирования» [35]
март 1974 (Йошкар-Ола) — «Проблема подготовки
кадров» [36]
сентябрь 1974 (Харьков)—«Биологические аспекты
случайного поиска» [37]
октябрь 1975 (Таллин) — «Адаптация в процессах
случайного поиска»
июнь 1976 (Днепропетровск)—«Учет ограничений в
процессах случайного поиска».
декабрь 1976 (Агверан, Армения)—«Тестовые задачи и
методика тестирования алгоритмов СП».
апрель 1977 (Самарканд)—«Распознавание в процессах
поиска».
ЛИТЕРАТУРА
1. Растригин Л. А. Экстремальное регулирование методом случайного
поиска. — «Автоматика и телемеханика», I960, № 9.
2. Растригин Л. А. Сходимость метода случайного поиска при
экстремальном регулировании многсшараметрических систем. — «Автоматика и
телемеханика», ,1963, №11.
3. Юдин Д. Б. Методы качественного анализа сложных систем. П.—
«Изв. АН СССР», «Техническая кибернетика», 1966, № 1.
4. Хасьминский Р. 3. Применение случайного поиска в задачах
оптимизации и опознания. — «Проблемы передачи информации», 1965,
№ 3
5. Николаев Е. Г. Случайный и градиентный выбор направлений спуска в
алгоритмах оптимизации.— В кн.: «Проблемы случайного поиска». М., 1973,
6. Растригин Л. А., Сытенко Л. В. Многоканальные статистические
оптимизаторы. М., «Энергия», 1973.
7. Н икиф op oiB а Н. Е. О выборе оптимальных значений параметров
оптимизаторов. — В кн.: «Проблемы случайного поиска», вып. 3, Рига,
«Зинатне», 1974, стр. 265-^27i2.
8. С о б о ль И. М. Численные методы Монте-Карло. М., «Наука», 1973.
9. Нейман Д ж. Фон, Морге нштерн О. Теория игр и
экономическое поведение. Пер. с англ. М., «Наука», 1970.
10. Растригин Л. А. Статистические методы поиска. М., «Наука», 1968.
11. Эшби У. Росс. Конструкция мозга. М., ИЛ, 1962.
12. Эшби У. Росс. Схема усилителя мыслительных способностей. — В кн.:
«Автоматы». М., ИЛ, 1955.
13. Растригин Л. А. Случайный поиск в задачах оптимизации
многопараметрических систем. Рига, «Зинатне», 1965.
15-
14. Golinski I. Adaptacyny system optymalizacji nieliniowej. Pzace Ins.
Maszyn Matematycznych. 1975, 3.
15. Тарасеико Г. С. Пакет программ безусловной оптимизации. — В кн.:
«Проблемы случайного поиска», вып. 6. Рига, «Зинатне», .1977.
16. «Бионические аспекты случайного поиска» (ло материалам совещания).
«Информационные материалы: кибернетика», АН СССР, -вып. 1 (83), М.,
1975, стр. в—11.
17. Гринченко С. Н., Растригин Л. А. Алгоритмы матричного
случайного поиска. — В кн.: «Проблемы случайного поиска», вып. 5. Рига,
«Зинатне», 1976.
18. Короп В. Ф. Метод случайного спуска. — В кн.: «Проблемы
случайного поиска», вып. б. Рига, «Зинатне», 1976.
19. Нейм арк Ю. И. Автоматная оптимизация. — «Радиофизика», 1972, № 7.
20. Половинкин А. И. Алгоритмы поиска глобального экстремума при
проектировании инженерных конструкций. — «Автоматика и
вычислительная техника», 1970, № 2.
21. Растригин Л. А. Случайный поиск с линейной тактикой. Рига,
«Зинатне», 1971.
22. Гринченко С. Н. Еще раз о динамике публикаций ло случайному
поиску. (Ом. наст. об.).
23. Юдин Д. Б. Методы количественного анализа сложных систем. — П.
«Изв. АН CCGP», «Техническая кибернетика», 1966, № 1.
24. А н т о н о в Е. Г., К а т о в н и к В. Я. Фильтрация и сглаживание в
задачах поиска экстремума функций 'многих переменных. — «Автоматика и
вычислительная техника», 1970, № 6, стр. 53—60.
25. Цыпкин Я. 3. Сглаженные рандомизированные функционалы и.
алгоритмы в теории адаптации и обучения. — «Автоматика и телемеханика»,
1971, Хя 8.
26. Растригин Л. А. Структурная адаптация алгоритмов случайного
поиска.— В кн.: «Проблемы случайного поиска», вып. 5, Рига, «Зинатне»,
1976.
27. Я'блонский А. И. Рандомизированные стратегии в адаптивных
процессах двуальтернативного выбора. — «Автоматика и вычислительная
техника», 1977, № -I.
2-8. Фогель Л., Оуэне А., У о л ш М. Искусственный интелект и
эволюционное моделирование. Пер. с англ. М., «Мир», 1969.
29. My х ни В. И., Н е им а рк Ю. И., Р о н и н Е. И. Автоматная
оптимизация с эволюционной адаптацией. — В <ш.: «Проблемы случайного поиска»,
вып. 2. Рига, «Зинатне», 1973, стр. 83—98.
30. М о цк у с И. Б. Об оптимальных методах поиска экстремума. — В сб.:
«Вопросы кибернетики. Проблемы случайного поиска». М., 1973.
31. «Теория и применение случайного поиска». Библиография. Рига, 1972.
Ш. «Случайный поиск. (Теория и применение)». Библиография. Рига, 1973.
33. «Проблемы случайного поиска». (Проблемная записка). Проект. Рига,
«Зинатне», 1972.
34. Растригин Л. А. Методы случайного поиска. Предварительная
публикация. М. 1977.
35. Растригин Л. А., К а ми лов М. М. Проблемы случайного поиска.
«Информационные материалы: Кибернетика», АН СССР, вып. 3(76). М.,
1974, стр. 3—8.
36. Растригин Л. А., Т р а х тенб е рг <В. С. Рабочее совещание по
случайному поиску ,(лодготовка кадров). — «Информационные материалы:
Кибернетика», АН СССР, вып. 6i(78). M., 1974, стр. 13—14.
37. Растригин Л. А., Короп В. Ф. Биологические аспекты случайного
поиска. (По материалам совещания). — «Информационные материалы:
Кибернетика», АН GGCP, вып. 1 (83). М., 1976, стр. 8—41.
38. Растригин Л. А., Григоренко В. П. Адаптация случайного
поиска. (Материалы научных совещаний). «Информационные материалы:
Кибернетика», АН СССР, Вып. 4(92), М., 1976, стр. 27—30
16
УДК 62-506
ИНФОРМАЦИОННО-СТАТИСТИЧЕСКИЕ
АЛГОРИТМЫ ДЛЯ РЕШЕНИЯ
МНОГОЭКСТРЕМАЛЬНЫХ ЗАДАЧ
Р. Г. Стронгин
(Горький)
В последние годы расширился круг исследований,
посвященных созданию в том или ином смысле оптимальных
алгоритмов для отыскания экстремума функций (см., например, [1—7]).
При таких подходах, берущих начало от работы [8], вместо
внесения извне достаточно определенной схемы алгоритма с
последующим ее изучением, ставится задача выведения
численного метода из некоторой математической постановки,
включающей формальные предположения о классе функций,
содержащем оптимизируемую функцию, и некоторый критерий
эффективности вычислительного процесса, связывающий результаты
вычислений с оценками точности отыскания экстремума (два
обзора, посвященные таким подходам, опубликованы в
[9,10]).
Создание новых методов путем выведения оптимальных
алгоритмов предполагает наличие достаточно удобного
математического аппарата исследования, позволяющего эффективно
строить оценки экстремума по значениям оптимизируемой
функции, вычисленным в некоторых точках области
определения. Эти вопросы успешно решаются для выпуклых и
унимодальных одномерных функций [2, 8]. Однако для
многоэкстремальных функций, удовлетворяющих условию Липшица,
построение таких оценок в общем случае связано с
решением трудных задач теории покрытий [1, 4]. При
вероятностных предположениях об оптимизируемой
многоэкстремальной функции (см., например, [9, 10]) оценки экстремума
определяются через трудновычислимые интегралы по
соответствующим вероятностным мерам. Поэтому для получения
достаточно простых алгоритмов оптимизации прибегают к
приближенному построению покрытий [11], к приближенному
интегрированию [12], к замене оценок экстремума другими более или
менее естественными критериями, допускающими более простое
вычисление (например, [3, 5]). В некоторых случаях [13]
удается построить оптимальный алгоритм, не прибегая к упомянутым
выше упрощениям, однако в описание такого алгоритма входит
параметр (например, константа Липшица), который должен
быть задан априорно. Трудности априорного задания константы
можно гюеадоЯ&гь Приоетнув к уточнению принятой априорной
оценки в ходе решения задачи, но это приводит к тому, что тео-
17
ретическая многошаговая оптимальность алгоритма не
реализуется.
Поэтому выведение оптимального при тех или иных
предположениях метода следует рассматривать лишь как первый шаг,
который целесообразно дополнить изучением построенного
алгоритма оптимизации с традиционных позиций (вопросы
сходимости, скорости сходимости, устойчивости и т. п.). Ниже
описываются некоторые результаты такого «двухшагового»
рассмотрения для алгоритмов многоэкстремальной оптимизации,
построенных в рамках информационно-статистического подхода
(это описание является продолжением обзора [10]).
ВЕРОЯТНОСТНОЕ ОПИСАНИЕ И ОЦЕНКИ ЭКСТРЕМУМА
Для выведения оценок экстремума из вероятностных
представлений о множестве функций, содержащем оптимизируемую
функцию, в [14] предлагается следующая формальная схема.
Рассматривается задача отыскания абсолютного минимума
действительной функции ср на конечной сетке в некоторой
области евклидова пространства. Если занумеровать узлы сетки по
i от 0 до п (т. е. i g/= {0, 1,...,га}), то множество всех
функций отождествимо с п+1—мерным пространством Rn+i,
поскольку любая функция ср определяется /г+1-м значением
ф(0),..., ф(/г). Принимается, что априорные свойства
оптимизируемой функции заданы с помощью непрерывной
положительной плотности /(ф) на пространстве Rn¥i.
Допускается возможность вычисления значений функции в
узлах сетки / (эта операция названа испытанием), причем, в.
формальное рассмотрение входит лишь результат z
(вещественное число) испытания в точке i£lf который описывается как
реализация случайной величины с условной функцией
распределения вероятностей ^(г/ф). При этом рассматривается два
важных случая. В первом случае, эта функция может быть
задана условной положительной плотностью г|>г(2/ф)
распределения вероятностей, что можно интерпретировать как испытания
при наличии случайных помех, ибо повторные реализации
испытания с одним и тем же индексом i с вероятностью 1 будут
различны. Во втором случае,
иг / , ч J0' *<*<')•
т. е. исход г с вероятностью 1 совпадает со значением
функции в точке испытания (испытания без помех).
Вводится понятие дополнительной информации uk о
минимизируемой функции как множество пар
">Л = {(*„ z,):0<s<£},
18
соответствующих индексам iSJ для которых известны
результаты испытаний zs, и определяются априорные т](а) и
апостериорные т; (а/шЛ) вероятности того, что абсолютный минимум
достигается в узле а, т. е. функция <рбФа, где
Фа = {?6/?rt+1 :(v/e/\«) ? (0 > ?'(«)}•
Эти вероятности можно использовать для описания процесса
отыскания экстремума по мере накопления дополнительной
информации (!>А, однако они являются трудновычислимыми,
поскольку определяются через интегралы от плотностей по
областям достаточно сложного вида, например
Фа
и непосредственное использование этих вероятностей приведет
к громоздким методам, включающим операцию численного
интегрирования в пространствах существенно высокой
размерности (порядка числа п узлов сетки /).
Для преодоления вычислительных трудностей предлагается
аппроксимировать вероятности т)(а/©л) более просто
вычислимыми оценками £(а/соО, Для построения которых формально
задается разложение плотности f (cp)
/<?)=2/(*/«ж«). о)
ag/
При этом оценки £(а/о>л) определяются путем интегрирования
по всему пространству, что (в силу простоты области
интегрирования), например, для конкретных типов плотностей /(ср) из
работ [15, 16], позволяет получить аналитические выражения
для Ц*/<»к).
Доказано, что, если плотности /(у/а) зависят от
вещественного параметра с>0 таким образом, что
11m J /c(<p/a)d<p = lf ae/, (2)
то (с вероятностью 1)
11т|5(а/(ол) —ч(а/<ол)| = 0, аб/,
причем, аналогичное утверждение справедливо и для априорных
распределений |(а) и т](а) (т. е. £(а) в (1) можно
интерпретировать как априориое распределение для расположения
экстремума). По существу, условие (2) выделяет некоторый класс
вероятностных описаний, для которых построение
вероятностных оценок абсолютного экстремума удается упростить
(заметим, что для конкретных типов плотностей /(<р) из [15, 16],
представленных разложением (1), условие (2) выполняется).
2*
19
АПРИОРНАЯ ИНФОРМАЦИЯ И СВОЙСТВА АЛГОРИТМОВ
В работах [15—17] построены аналитические выражения
вероятностных оценок £(а/(о&) экстремума для трех классов
одномерных многоэкстремальных задач (минимизация при
вычислениях значений функции без помех; минимизация при
вычислениях с помехами; минимизация без помех при заданном
значении функции в точке абсолютного минимума) и
предложены пошагово-оптимальные алгоритмы, основанные на
использовании этих оценок (см. также [18]). Полученные результаты,
если их рассматривать в плане зависимости алгоритма от
априорных предположений, позволяют делать некоторые
интересные выводы.
Функционирование алгоритмов при минимизации
действительной функции ф(х) в отрезке [а, Ь] вещественной оси можно
описать как последовательное применение отображений
xk=--Gk(x\ ...,**-i; z°, ...,^"1), Л = 1,2
сопоставляющих функции у(х) последовательность точек {xk},
в которых вычисляются значения этой функции (результаты
вычислений обозначены через zk). В [19] показано, что
предельные точки последовательности {xh} для алгоритма из [15]
необходимо локально-оптимальны (если ц>(х) есть Липшицевая
функция). То есть последовательность {xh} не является всюду
плотной в области определения [а, 6], если функция отлична от
константы. Аналогичным свойством обладает
последовательность {xh} для алгоритма из [17], если функция ср(х)
мажорируется некоторым конусом с основанием в точке корня [20].
При минимизации с помехами для алгоритма из [18]
справедливо, что относительное число испытаний, попадающих в
фиксированную точку области определения, достигает максимума
в точке абсолютного минимума и экспоненциально спадает по
мере возрастания значений функции [21].
Для сравнения отметим, что алгоритмы [5, 12] порождают
(случай испытаний без помех) всюду плотные
последовательности в области определения, причем, одно из важных
различий априорных предположений, из которых выведены методы
[15—18], с одной стороны, и методы [5, 12], с другой стороны,
:qctoht в том, что, в первом случае, математические ожидания
первых разностей функции считаются отличными от нуля
(функция «не похожа» на константу), а, во втором случае, они
предполагаются нулевыми (функция — реализация винеровского
процесса). .
Однако, предположение, что математическое ожидание
первых разностей функции отлично от нуля, приводит к тому, что
абсолютное значение этого математического ожидания
становится параметром метода, подлежащим оценке в ходе решения
20
задачи [15, 19], в отличие от алгоритмов [5, 12], которые
также содержат параметры, но оценки этих параметров
несущественны для асимптотической сходимости к минимальному
значению функции. В этом отношении алгоритмы [15, 19] ближе
к методам [1, 3, 11], в которых необходима оценка константы
Липшица.
Исходные предположения, из которых выводится алгоритм
[17], отличаются от модели, использованной при построении
метода [15], по существу, лишь условием, что значение
функции в искомой точке абсолютного минимума задано. Это
дополнительное условие не только приводит к другому
алгоритму, но этот новый алгоритм уже не содержит параметров
исходной модели, подлежащих оценке.
В работах [22, 23] изучается вопрос об условиях, при
которых скорость сходимости алгоритма [15, 19] к глобальному
экстремуму, начиная с некоторого шага становится близкой к
геометрической, т. е. алгоритм автоматически переходит к
уточнению точки минимума со скоростью, характерной для
локальных методов, хотя правила выполнения итераций в
процессе решения задачи остаются неизменными (и для них
справедливо утверждение о сходимости к абсолютному экстремуму).
Установлено, что такая сходимость возможна, если функция в
некоторой окрестности точки х* экстремума имеет вид <р(х)~
~ К\х—х*\у где К—константа Липшица функции. В случае,
когда функция является гладкой в окрестности абсолютного
минимума, почти геометрическая сходимость не достижима.
В [24] эти результаты используются для ускорения сходимости
в других классах задач путем преобразования функции,
обеспечивающего выполнение условий почти геометрической
сходимости.
Показательно, что условие почти геометрической сходимости
имеет вид, подобный предположению о поведении
математического ожидания функции в окрестности минимума,
содержащемуся в модели [15], на которой основан обсуждаемый
алгоритм, т. е. быстрая сходимость возможна тогда, когда
априорные предположения выполняются достаточно полно.
Таким образом, существенные свойства алгоритмов,
построенных как оптимальные методы, определяются характером
некоторых основных предположений, входящих в априорное
описание класса функций, содержащего оптимизируемую
функцию. Это обстоятельство иллюстрирует возможности такого
подхода для построения эффективных алгоритмов.
Вопросы программной реализации рассмотренных выше
методов и сравнение их с другими алгоритмами обсуждаются
в [25].
21
ЛИТЕРАТУРА
1. Сухарев А. Г. Оптимальный поиск экстремума. М., МГУ, 1975.
2. Ч е рн о уськ о Ф. Л. Об оптимальном поиске минимума выпуклых
функций* — «Журнал вычисл. матем. и матем. физ.», 1970, т. 10, № 6,
стр, 1355—1366.
3. Данилин Ю. М. Оценка эффективности одного алгоритма отыскания
абсолютного минимума. — «Журнал вычисл. матем. и матем. физ.», 1971,
т. 11, Ко 4, стр. 1026^—И0Э1.
4. Иванов В. iB, Об оптимальных алгоритмах минимизации функций
некоторый, классов.— «Кибернетика», 19712^ IN? 4, стр, 3(1—94.
5. К u s h n е г. Н. A new Method of Locating the Maximum point of an
Arbitrary Multipeak Curve in the Presence of Noise. — Trans. ASME, Ser. D,
J. Basic Eng., 1964, v. 86, № 1, pp. 97—106.
6. Неймарк Ю. <И., Стронгин Р. Г. Информационный подход к
задаче поиска экстремума функции. — «Изв. АН СССР», «Техническая
кибернетика»», 1$66, № 1, стр. 17—26.
7. М оцк у с И. -Б. О байесовых методах поиска экстремума. —
«Автоматика и вычислительная техника», 19712, № 3, стр. 53—62.
8. К i e f е г J. Sequential Minimax Search for a Maximum. — «Proc. Amer.
Math. Soc.», 1953, v. 4, № 3, pp. 50i2->506.
9. Mo цк,у с И. Б. Об оптимальных методах поиска экстремума. —
«Вопросы кибернетики. Проблемы случайного поиска». Мм 1973/
10. Стронгин Р. Г. 'Информационно-статистический подход к построению
алгоритмов поиска глобального экстремума. — «Вопросы кибернетики.
Проблемы случайного поиска». М., .1973.
11. Евтушенко Ю. Г. Численный метод поиска глобального экстремума
функций (перебор на неравномерной сетке). — «Журнал .вычисл. матем. и
матем. физ.», 1971, т. 11, № 6, стр. '1390—1403.
12. Жилинскас А. Г. Одношаговый байесовский метод поиска экстремума
функций одной переменной. — «Кибернетика», 1975, № 1, стр. 139—144.
13. Сухарев А. Г. Наилучшие стратегии последовательного поиска
экстремума.— «Журнал вычисл. матем. и матем. физ.», 1972, т. 12, № 1,
стр. 35—50.
14. Стронгин Р. Г. О вероятностной оценке экстремума в
многоэкстремальных задачах. — В кн.: «Проблемы случайного поиска», вып. 5.
Рига, «Зинатне», 1976.
15.. С тр он г и н Р. Т\ Вы'бор испытаний и условие остановки в одномерном
глобальном поиске. — «Изв. высш. учебн. завед.», «Радиофизика», 1971,
т. /14, № 3, стр. 432—440.
16. Стронгин Р. Г. Информанионный метод многоэкстремальной
минимизации при измерениях с помехами. — «Изв. .АН СССР», «Техническая
кибернетика», 1969, № 6, стр. 118—126.
17. Стронгин Р. Г. Вероятностный подход к задаче определения корня
функции. — «Журнал вычисл. матем. и матем. физ.», 1972, т. 12, № 1,
стр. 3—13.
18. Стр он гин Р. Г. Алгоритмы для поиска абсолютного минимума. — В кн.:
«Задачи статистической оптимизации». Рига, «Зинатне», 1971.
19. Стронгин Р. Г. О сходимости одного алгоритма поиска глобального
экстремума. — «Изв. АН СССР», «Техническая кибернетика», 1973, №4,
стр. 10—16.
20. Стронгин Р. Г. Информационно-статистический метод решения-систем
нелинейных уравнений. — В кн.: «(Проблемы случайного поиска», вып. 4.
Рига, сЗинатне», '1975.
21. Стронгин Р. Г. Оценка сходимости помехоустойчивого алгоритма
глобального поиска. — В кн.: «Проблемы случайного поиска», вып. 6. Рига,
«Зинатне», «1977 (в печати).
22. Стронгин Р. Г. Монотонные алгоритмы многоэкстремальной олтими*
22
зации. 11-й Всесоюзный семи.нар «Численные иметоды нелинейного праграм-
мирова/ния». Харьков, 1976.
23. Стронгин Р. Г. О монотонной сходимости алгоритма глобального
поиска. — В кн. «Динамика систем», вып. 4. «Горький, Изд. ГГУ,
1976.
24. С Tip о нгин Р. Г. Простой алгоритм поиска глобального экстремума
функций .нескольких переменных и его использование в задаче
аппроксимации функций.—«сИзв. высш. учебн. завад.», «Радиофизика», 1972, т. 15,
№ 7, стр. 1077—«1084.
25. Г р и ш а г и н В. А., Стронгин Р. Г. Алгоритмы и программы
глобального поиска. — В кн.: «Автоматизированное оптимальное проектирование
инженерных объектов и технологических (Процессов». Горький, Изд. ГГУ,
J 974.
УДК 62-506
ОПТИМИЗИРУЮЩИЕ СЛУЧАЙНЫЕ ПРОЦЕССА
С НЕПРЕРЫВНЫМ ВРЕМЕНАМ
КАК ИДЕАЛЬНЫЙ МОДЕЛИ АЛГОРИТМОВ
СТОХАСТИЧЕСКОЙ ОПТИМИЗАЦИИ
Л. Л. Мороз, А. П. Коростелев
(Москва)
1. Введение. Под алгоритмами стохастической оптимизации
в настоящей работе мы понимаем практически реализуемые
дискретные алгоритмы, осуществляющие поиск экстремума той
или иной функции цели, и работающие в обстановке случайных
помех. Ниже, в примерах, мы рассматриваем рекуррентные
стохастические алгоритмы, представляющие собой цепи Маркова.
Однако, общие рассуждения, относящиеся к полезности
изучения процессов с непрерывным временем, могут быть отнесены
к более широкому классу дискретных процедур, например — к
дискретным процедурам «с памятью» (или с «накоплением»).
Огромное количество практически реализуемых алгоритмов
приводит к необходимости внесения некоторого
упорядочивания. Постановка такой задачи и частичное ее разрешение
содержатся для не стохастических алгоритмов в монографии
Э. Полака [1]'. Следуя этой работе, мы так же вводим понятие
принципиального алгоритма (ПА), однако вкладываем в это
понятие иное содержание.
ПА мы будем называть случайный процесс с непрерывным
временем, траектории которого осуществляют оптимизацию
заданной функций цели, и который в некотором смысле является
идеальной моделью для изучения определенных свойств
алгоритмов стохастической оптимизации. Сам ПА может быть
практически принципиально не реализуемым (например, — это
диффузионный процесс, траектории которого имеют бесконечную
скорость).
23
Приведенное определение ПА не претендует на формальную
полноту. Ниже мы попытаемся раскрыть его содержание на
ряде примеров.
Смысл введения ПА состоит в следующем: очень часто один
и тот же ПА допускает различную практическую реализацию в
виде алгоритмов стохастической оптимизации. Тем самым ПА
вводит упорядочивание в практически реализуемые алгоритмы:
алгоритмы, приближающие один и тот же ПА, попадают в один
класс.
Здесь сразу же необходимо отметить наличие
определенного субъективного момента в выборе ПА, однако польза
подобного подхода кажется несомненной.
Отметим, что под оптимизирующими процессами с
непрерывным временем мы понимаем не процессы оптимизации,
допускающие непрерывную во времени реализацию, например, в
аналоговых устройствах. Подобные процессы сами требуют
значительных сил на изучение их поведения [2, 3].
Мы вводим ПА, как некоторые более простые для
изучения, а часто — просто хорошо изученные, случайные процессы,
такие, например, как решения стохастических
дифференциальных уравнений [4, 5, 6].
Из известных авторам работ, в которых в той или иной
форме предлагается рассматривать идеальные модели отметим
здесь работу Л. Льюнга [7], где указано на необходимость
изучения обыкновенных дифференциальных уравнений,
описывающих поведение «незашумленных» траекторий, и работу Дере-
вицкого и Фрадкова [8], где содержится та же идея, а, кроме
того, изучаются и «зашумленные» траектории, представляющие
собой решение стохастического уравнения Ито.
Авторы также развивали этот подход на ряде конкретных
примеров [9, 10, И].
2. Ограничиваясь рекуррентными алгоритмами
стохастической оптимизации, можно определить ПА как марковские
процессы с непрерывным временем. В числе основных преимуществ
исследования ПА можно указать следующие:
— существует достаточно развитая теория подобных
процессов;
— существует мощный математический аппарат для
изучения этих процессов (стохастические дифференциальные
уравнения, краевые задачи, интегральные уравнения и т. д.);
— развитие существующего математического аппарата
позволяет, как правило, разрешить те специфические
теоретические вопросы, которые возникают при рассмотрении
марковских процессов в качестве процессов оптимизации;
— возможность получения качественных результатов,
поскольку поведение оптимизирующих процессов с непрерывным
временем лучше поддается эвристическому исследованию,
нежели поведение более сложных дискретных алгоритмов;
24
— возможность получения количественных оценок для ПАГ
(например, — дисперсий, времен достижения окрестности
экстремума и т. д.), которые затем могут быть использованы при
практических вычислениях.
3. В настоящем разделе мы проиллюстрируем предыдущие
рассуждения на ряде конкретных примеров.
Пример 1. Условия сходимости.
Рассмотрим дискретный и непрерывный алгоритмы
стохастической аппроксимации (Кифера—Вольфовица) [6]
х^-хл=±[У£*^^ (1)
dX {t)=^- Г/(*(0 + г(0)-/(Х(0--с(0) +
+o(t,X(t))wt]dt, (2>
где ап, сп\ a(t), c(t)— соответственно последовательности и
функции рабочих и пробных шагов; /(л:) —функция цели; Ел —
дискретный «шум» (последовательность независимых случайных
величин) Mln=0; Dtn=\\ wt—«белый шум»; сл(л:), o(t,x) —
интенсивности «шумов».
При некоторых условиях на функции f(x) и a(t, х) для
сходимости с вероятностью 1 процедур (1) и (2) AOCTaT04HOv
выполнения соответственно следующих условий [6J:
2ая=оо; ^j-f< + °o; 2аЛ< + °°;
л=1 *ШЩ сп п=\
(3)
\a{t)dt= + oo; \^Ldt< + oo; $ a(t).C(t)dt< + оо. (4>
о о к ' о
Исторически подобные достаточные условия сходимости
первыми были изучены для дискретных процедур [12]. Однако,
если бы были известны условия (4), то они по аналогии
наводили бы на мысль о справедливости условий (3). Подобные
рассуждения оказались полезными при решении следующей
задачи: найти условия необходимые и достаточные для
сходимости процедур (1) и (2). При определенных предположениях
на функции в правых частях (1) и (2) эти условия выглядят так:
оо оо
2#rt=00> для любого Х>0 2 ал-ехр{ —Хс^/ал}< оо; (5)
ОО
§ a(t)dt = оо, для любого Х>0
о
? (6)
\ a(t).exp {-\-c2(t)/a(t)} < оо.
о
25
Справедливость условий (6) срйвййтёлЬно лёгкб Мря^т быть
получка Ш осн№аний результатов раббт [13— 14]\ Услоййе
<5) быйю выМсано1 по аналогии. Оно оказалось спрайёД^йй^Гм,
но доказательство его существенно сложнее.
Пример 2. AcrfMhTOtHqecrtoe поведение процедуры Роббин-
са —Монро:
*яц - ~*п = \ {R (хп) + о (хп) • 6Я); (7)
dX(t)=±(R(X(t)) + c(X(t))wt)dt, (8)
где R(x) = B-(x — xQ) + 0(\x — xQ\); В — пбСтояннагя матрица.
При некоторых условиях случайные векторы уп = \Пь хп и
y(t) = Yt X(t) имеет асимптотически нормальные
распределения: Этот факт в непрерывном случае доказать Шюго npoiiie,
чем й дискретном (см. главу 6 книги [6]).
В непрерывном случае можно изучить асимптотическое
поведение процедур при другой зависимости рабочего Шага ot
времени (см. [15]). Так для процедуры
dX{t) = ±{-s\gnX{t) + wt\di
случайная величина Y(t) = ty -X (t) имеет асимптотически
«двухстороннее» показательное распределение. Оказывается, что для
соответствующей дискретной процедуры
*п+1 - *п = -г: I - Sign Xn + У
случайная величина уп = п>у-хп имеет также невырожденное
предельное распределение, но уже зависящее от характера
«шума» %п.
Пример 3. Процедуры оптимизации в условиях ограничений.
Отражение по направлению внутренней нормали. Пусть D —
область с кусочно гладкой границей. Рассмотрим два процесса
оптимизации с непрерывным временем:
dXt = -([S7f{Xt) + Wt]dt; (9)
dXt = [a(t)4ftft) + ^o{t, Xt)wt]dt (10)
с отражением по направлению внутренней нормали к границе Г
области D. Здесь т>0 малый параметр; wt — винеровский
процесс; f(x) o(t,x); a(t), c(t) — те же функции, что и в (2).
Можно доказать, что при малых т с вероятностью близкой
к 1 траектории (9) следуют вдоль траектории системы
dYt=4f<Xt)dt, (И)
.26
тде
~f(, b(v/W' xeD;
' * '~~ (проекции 4f{x) на границу Г при х$Т,
и процесс (9) имеет инвариантную меру ц (х) (стационарное при
i->oo распределение), определяемую формулой
1х (х) = const -exp {^~^}, (12)
которая при уг+Q является б-образной мерой, сосредоточенной
в точке глобального максимума (если он единственный)
функции f(x).
Для процесса (10) можно доказать сходимость его к точке
максимума функции f(x) в D либо к точке условного
максимума /(х).на границе Г при выполнении условий типа (6).
При построении дискретной процедуры оптимизации в
условиях ограничений в зависимости от целей, стоящих перед
исследователем, можно использовать в качестве идеальных моделей
как (9), так и (10). В первом случае дискретная процедура —
процедура с малым> неубывающим во времени рабочим шагом у:
*1ил —*n = T-lV/Si) + T«[, (13)
аппроксимирующая на границе Г отражение по направлению
внутренней нормали. Аппроксимацию отражения можно
производить различными способами, например, как в [11]. От
процедуры (13) естественно ожидать приближения на конечных
временах системы (11) и- наличия стационарного распределения,
которое, вообще говоря, отлично от (12) при разных «шумах»
в (13), но должно «сосредотачиваться» в точках максимума /(*).
Непрерывная модель (10) приводит при том или ином
приближении нормального отражения к процедуре стохастической
аппроксимации типа (1), но действующей в условиях
ограничений. По аналогии условия сходимости должны иметь вид (5).
Пример 4. Процедуры оптимизации в условиях ограничений.
Отражение по направлению поля, вырождающегося в
касательное. Пусть на границе гладкой области D определено поле 1(х)9
вырождающееся в касательное и терпящее разрыв в отдельных
точках. Особую точку О касания назовем притягивающей, если,
в некоторой окрестности О поле 1(х) направлено к этой точке.
Пусть f(x) —дифференцируемая функция цели. Пусть поле 1(х)
сконструировано так, что его притягивающие точки совпадают
с точками условного максимума f(x) на границе Г. Рассмотрим
два процесса оптимизации с непрерывным временем:
dXt = b(JCt)dt+c(Xt)dwt, (14)
где о(х)от (л:) — невырожденная матрица диффузии; Ь (^ —
произвольное поле в области D\
2?
dXt = a(t)v/(Xt)dt+^o(t, Xt)dwt (15)
с отражением по направлению поля 1(х) на границе Г [16].
Процесс (14)—однородный по времени, а в (15) входят
функции a(t) и c(t), стремящиеся к нулю при t-+oo.
Процесс (14) сходится с вероятностью 1 к одной из
притягивающих точек на границе за конечное в среднем время [16].
Процесс (15) сходится либо к одной из притягивающих точек
на границе, либо к точке максимума f(x) в области D. Эти
факты объясняются следующим образом: вырождающееся в
касательное поле обладает свойством «подталкивать»
поисковую траекторию к особой точке.
Для нахождения максимума f(x), который apriori находится
на границе можно использовать дискретный аналог процедуры
(14), аппроксимируя отражение по направлению поля 1(х). От
дискретной процедуры естественно ожидать сходимость (в
определенном смысле) за конечное в среднем число шагов.
Дискретный аналог процедуры (15) предназначен для нахождения
максимума f(x) вне зависимости от его положения.
Пример 5. Асимптотика стохастических процедур
оптимизации в условиях ограничений.
Рассмотрим дискретную процедуру
*rt+i —~Хп = <*п [ V/ (хп) + у, (16>
если xn£D — заданная область с гладкой границей Г. Если же
лся+1(ЕО, то осуществляем «зеркальное» отражение относительна
границы Г. Идеальной моделью процедуры (16) будет процесс
с нормальным отражением от границы Г, удовлетворяющий
уравнению
dXt = a(t).[S7f(Xt)dt + dwt]. (17>
Если О —точка условного максимума f(x) на границе Г, то
скорость сходимости (17) в касательном направлении a~lt2(t),
а в направлении нормали — аг1 (t), если только || V/(0) |j =^0-
Та же скорость сходимости имеет место и для процедуры (16),.
(см. пример 3).
4. В связи с изложенным выше авторам кажется
целесообразным следующий подход к конструированию алгоритмов
стохастической оптимизации:
4.1. Строится (если это возможно!) идеальная модель (ПА)
в виде оптимизирующего случайного процесса с непрерывным-,
временем, обладающего определенными требуемыми
свойствами.
4.2. Идеальная модель исследуется методами теории
случайных процессов.
4.3. Практически реализуемые алгоритмы стохастической оп-
28
тимизации конструируются как дискретные алгоритмы,
сохраняющие в определенном смысле требуемые свойства ПА.
4.4. Исследуются особенности поведения сконструированных
дискретных алгоритмов по сравнению с поведением ПА.
Следует указать, что построение ПА возможно,
по-видимому, далеко не всегда. Например, в предложенную схему не
вписываются задачи дискретного программирования.
5. Вопросы синтеза дискретных алгоритмов.
При использовании предлагаемого подхода синтез
алгоритмов, обладающих желаемыми свойствами, можно разбить на
2 этапа: структурный и параметрический. Структурный
синтез осуществляется на уровне выбора ПА. В
зависимости от исходной информации определяется класс
оптимизирующих случайных процессов с непрерывным временем,
которые могут выступать в качестве ПА в конкретной задаче.
Параметрический синтез состоит в выборе параметров
дискретного алгоритма с тем, чтобы приближались желаемые свойства
ПА (поведение внутри области' допустимого изменения
параметров или на границе, асимптотическое поведение или
поведение на конечном отрезке времени и т. д.).
Пример 6. Ставится задача найти глобальный максимум f(x)
в области D в обстановке случайных помех. Априорная
информация: существуют два близких по величине локальных
максимума: один — в подобласти D\^D, другой — на участке Г
границы dD\ причем наибольший из них является глобальным
максимумом. Задано ограничение на число возможных
«замеров» функции f(x).
Структурный синтез. Выбираем дискретный аналог
алгоритма (15), который предназначен для поиска максимума как
внутри области, так и на границе.
Параметрический синтез. Алгоритм работает дважды: с
начальной точкой из Z?! и Г. Закон убывания рабочих и пробных
шагов и число шагов осуществляем так, чтобы каждый из
максимумов был определен с одной и той же точностью,
диктуемой ограничениями на число проводимых «замеров» функции
f(x). При этом пользуемся результатами об асимптотическом
поведении алгоритма в окрестности каждого из максимумов.
ЛИТЕРАТУРА
1. Пола-к Э. Численные методы оптимизации. Единый -подход. М., «Мир»,
1974.
2. D г i m 1 М., Nedoma I. Stochastic Approximation for Continuous
Random Processes. — «Trans. II Prague Conf. on Inform. Theory, Stat. Decision
Funct. and Random Proc», Prague, 1960, pp. 145—158.
3. S a k г i s о n D. I. A Continuous Kiefer-Wolfowitz Procedure for Random
Processes. — «Ann. Math. Stat.», 1964, 35, pp. 590—599.
4. Кушнер Г. Дж. Стохастическая устойчивость и управление. М., «Мир»,
1969.
29
5. Хасьминский Р. 3. Устойчивость дифференциальных уравнений при«
случайных возмущениях их параметров. М., «Наука», 1969.
6. Невельсон М. Б., Хась минский Р. 3. Стохастическая
аппроксимация и «рекуррентное оценивание. М., «Наука», 1972.
7. L j u n g L. Convergence of Recursive Stochastic Algorithms, Report 7403. —
«Division of Automatic Control», Lund Inst, of Technology, 11974.
8. Деревицкий Д. П., Фрадков А. Л. Две модели для анализа
динамики алгоритмов адаптации. — «Автоматика и телемеханика», 1974, № 1,.
стр. 67—75.
9. М о р о з П. А. О связи диффузионных процессов с отражением с
процедурами стохастической оптимизации. — В об.: «Автоматизированные
системы управления в нефтяной и газовой промышленности». М., «Недра»,»
1976, 11в—»1<23.
10. Мороз П. А., Ко росте лев А. П. О нахождении условного
экстремума методом случайного -поиска. — «Автоматика и вычислительная тех- -
ника», 1971, № 2, стр. 36—40.
11. Мороз П. А., Кор ос теле в А. Л. О /принципе конструирования
процедур стохастической оптимизации в условиях ограничений. — «Автомата- -
ка и .вычислительная техника», Ш76, № 3.
12. В 1 u m I. R. Approximation method which converge with probability one,
Ann. Math. Stat. 25, 2 1(1954), 382-^386.
13. Вент цель А. Д., Фрейд л ин М. И. О малых случайных
возмущениях динамических систем. — «Успехи математических наук», 1970, т. 25,.
вып. 1, стр. 3—55.
14. Вентцель А. Д. Грубые предельные теоремы о больших уклонениях
для марковских случайных процессов I. — «Теория вероятности и ее
применение», 1976, т. 21, вып. 2, стр. 235—26(2.
15. Хась-минский Р. 3. О поведении процессов стохастической
аппроксимации для больших значений времени. — «Проблемы передачи
информации», 1973, т. 8, вып. 1.
16. Малютов М. Б. О краевой задаче Пуанкаре. — «Трзнш Московского-
матем. общества, 1969, т. 20, стр. 173—204.
УДК 62-506
О МЕТОДАХ ПОИСКА ЭКСТРЕМУМА
С НАИМЕНЬШЕЙ СРЕДНЕЙ ПОГРЕШНОСТЬЮ
Я. Б. Моцкус
(Вильнюс)
1. ВВЕДЕНИЕ
Многие известные методы поиска точки минимума
унимодальных функций многих переменных основаны на идее
квадратичной аппроксимации.
Многоэкстремальные задачи нередко оказываются столь
сложными, что на минимизируемую функцию целесообразно
смотреть как на реализацию некоторой случайной функции.
В таком случае оптимальным методом можно назвать такой
метод поиска, который минимизирует среднее отклонение от
искомой точки.
30
2. ФОРМУЛИРОВКА ЗАДАЧИ
Пусть минимизируемая функция f(x, со) является
реализацией некоторой случайной функции ср(х), где хвАаЯт9 со 6Й-
Здесь со — элементарное событие — неизвестный нам индекс
реализации.
Предположим, что статистические характеристики
случайной функции ф(#) заданы системой конечномерных функций
распределения
FXlt...,xn(yu ...,Уп) = Р{^/(хь <»)<yh i = l л},
л=1,2,..., (1).
где Р — априорная вероятность события
(»:/(Л|,»)<й, * = 1,...,я}. (1а)*
Наблюдением назовем вычисление значения функции в
точке xt. Результаты п наблюдений представим в виде вектора
««^(TW Т(4 хи...,хп) (2)
Решающим правилом назовем измеримую вектор-функцию
d = (du .. .,dn), компоненты которой определяют зависимость
Л+ 1-ого наблюдения от вектора zn, т. е.
хп+г = dn (zn) = *я+1 (d, со). (3)
Оптимальным или байесовым методом поиска назовем такое
решающее правило rf°, которое минимизирует среднее
отклонение от минимума, т. е. соответствует услорию
minAf[{(p(^+1)-cp0}, (4).
а
где <? (XN+i)=f($N+i (d, <*>), со) — значение функции / в точке
окончательного рещения Xn+u а 9о = 1п1/(х*®У- При доста-
х£А
точно общих предположениях [1], [2[, [3] рещение задачи (4)
существует и может быть получено из системы рекуррентных
уравнений
uN(zN)=min M{<?(x)/zN}y
х£А
ип_.х(гп_х)=т\пМ{ип(?п_.и cp(4 *)IZn-x) n=N,...,2 (5)
х£А
и0=т\пМиг(<?(х)ух),
х£А
где М {vXxDIzn} — условное математическое ожидание
случайной величины <?(х) относительно случайного вектора гдг.
Уравнения (5) остаются без изменений, и в случае «зашум-
ленных измерений» когда при фиксированном х&А наблюдаем
сумму
♦ C*i)—?(*i)+4i.
31
где Y]i — «шум» — независимые случайные величины с нулевым
математическим ожиданием и конечной дисперсией. При этих
условиях случайный вектор zn имеет вид
гп = (У(хг), ...,<К*Я), хи .-,хп), я = 1, ...,ЛГ
3. ИЛЛЮСТРАТИВНЫЙ ПРИМЕР
? (*)=/(*, <о) = (Х — со)2,
Априорная плотность вероятности —
/7((о) = ^-, если coge.
Из уравнений (5) следует, что оптимальная точка первого
наблюдения —
хг= ±1,
а точка оптимального решения —
( 1—Кт(1), еслил:1 = 1,
•*2~~(-1+}Лр(-1), если jc1= —1.
4. УСЛОВИЯ СХОДИМОСТИ
Согласно условию (4), байесовый метод поиска зависит от
того, каким будет задано априорное распределение
вероятностей Р. Поэтому для обоснования байесовых методов поиска
экстремума необходимо выяснить вопрос, каким требованиям
должно удовлетворять априорное распределение Р, чтобы
решающее правило d°, определяемое уравнениями (5), при
большом N обеспечило сходимость к минимуму любой непрерывной
функции. Ответ дает теорема I.
Перед тем как сформулировать эту теорему, введем
следующие обозначения:
гп = гя(х,<»,(1)=*т1п\\х — Х1\\ = \\х — хцХ)\\9
ККп
-А(сп) = {лг:11тгя = 5,5>0Э хвА],
П-*-оо
В(и) = {х:1\тгп = 0, х£А},
П-*-оо
Fx (У1гп) — функция условного распределения случайной
величины <р(«*) относительного случайного вектора zn.
f /,,\_- I0» если У<У*>
г»\У) — \\9 если у>ул,
32
Теорема 1. Пусть: 1) Л —компакт; 2) /(л:, со) —непрерывные
функции х; 3) условные математические ожидания в
уравнениях (5) непрерывны 4) существуют априорные плотности
вероятностей РХ19...,хп(Уи ••-, Уп)>0\ 5) VxgZJ (со), 8>0 Я/г5, что
\Fx(y\*n)-F*(y)\<b n>n6
и
Fxi(y/zn)—F(ii(y)=Oy / = 1,..., п;
6) Vjc'gA (со), у£% 38 = 8 {х'у) > 0 независимо от /г, что
Fx(y/zn)>b; 7) функция и (со) = sup |Un(zn)\ равномерно
интегрируема по Fx (ylzn)\ 8) М | ср01< оо, тогда
Нт|/(л:лг+1(^, со), со) —тт/(л:, со)|=0, VcogS,
TV—оо jr£4
где d°— решающее правило, соответствующее системе (5),
когда условные математические ожидания для всех zn
вычисляются с помощью формулы условных плотностей.
Теорема I означает, что при соблюдении условий 1)—8)
последовательность решающих правил, соответствующих
уравнению (5), гарантирует сходимость к минимуму для любой
непрерывной функции при N-+oo. При конечном N байесовый
метод d° обеспечивает наименьшее среднее отклонение от
минимума.
Большинство условий теоремы I легко проверяется,
несколько сложнее проверка условия 6); для марковских процессов
условие 6) выполняется.
5. ОДНОШАГОВЫЕ МЕТОДЫ
Решить нелинейные уравнения многомерного динамического
программирования (5) трудно. Поэтому в практических
вычислениях в основном применяются различные приближенные
подходы. Одним из них является одношаговый метод, когда на
каждом шаге предполагается, что следующее наблюдение будет
последним, т. е.
Яя_1 (*„-.!) = т1пЛ1 {«! («я-ь •*> ?(*)/a«_i} л=1» — • N,
х£А
где
u*n(zn) = mlnM [<f(x)lzn). (6)
х£А
Оказывается, что в условиях теоремы I решающее правило,
соответствующее условиям (6), также обеспечивает сходимость
к минимуму любой непрерывной функции.
3—6065
33
6. СЛУЧАЙ ОГРАНИЧЕННОЙ ПАМЯТИ
Другим способом приближенного решения уравнений (5)
является ограничение «памяти». Предполагается, что можно
«запомнить» результаты не более No наблюдений [1]. Случай,,
когда Л/о=1, рассмотрен в [53. В этом случае-байесовбе
решающее правило оказывается близким к одному из наиболее
известных вариантов случайного поиска [6]: следующее
наблюдение должно быть расположено на сфере, центром которой
является точка наиболее успешного наблюдения. Отличие бай-
есового метода в случае рассмотренном в [5], от методов
случайного поиска [6] заключается в том, что радиус сферы
нефиксируется заранее, а вычисляется по результатам
наблюдений согласно рекурентным уравнениям. В случае ограниченной
памяти сходимость к минимуму не гарантируется.
7. ВЫБОР АПРИОРНОЙ ФУНКЦИИ РАСПРЕДЕЛЕНИЯ
Априорное вероятностное пространство (Р, a, Q), где Р —
вероятностная мера на сг-алгебре, сг порожденной
цилиндрическими множествами (2), Q — множество подлежащих
рассмотрению функций заданных на Лс=/?п, по существу является
некоторой статистической моделью рассматриваемой
оптимизационной задачи. Эта модель определяет не только набор
возможных функций, но и вероятность их появления. Следовательно
удачный выбор функции априорного распределения (1)
является тем единственным рычагом, при помощи которого байесовые
методы поиска можно приспосабливать к требованиям того или
иного класса оптимизационных задач.
В соответствии с условием 2 теоремы 1 ограничимся
рассмотрением непрерывных функций. Для простоты будем считать,
что они заданы на /^-мерном кубе [ — 1, 1]. Одним из наиболее
слабых, но сохраняющих непрерывность реализаций требований
к функциям априорного распределения является независимость,
приращений Де1,..., е (х1,..., хт), определяемых рекуррентными,
формулами
Де.еДл:1,..., Хт) = Ьв%, (х\ *2 + s2,..., Хт) — ДеЛ*1,..., Хт)>
V.-.e^*1,..., ^) = Д81,...,ет_1(х1,..., *» + ej|l)-
-Де.......^*1,..., #"), (7)
где аг'6 I — 1, 1], £*>0, / = 1,..., т.
Легко видеть, что приращения, заданные формулами (7)„
являются разностными аналогами m-тых производных.
34
Известно [10], что из непрерывности реализаций и
независимости приращений следует, что конечномерные функции
распределения обязаны быть гауссовыми. Другим естественным
условием является требование стационарности, т. е.
однородности (независимость от сдвигов).
Нетрудно убедиться, что все указанные требования
(непрерывность, независимость приращений * и стационарность
соблюдаются для гауссового поля, с математическим ожидани-
ем [I и ковариационной функцией
/r,A_(,n(i--!^r*1).
/ = 1
(8)
где *}, л^6[—1, 1].
Для лучшего понимания этого случайного поля
ковариационную функцию (8) представим в виде
где xt, /=1,..., 2т есть координаты вершин куба [—1, 1],
т
KxfyM-flLiVti (Ю)
fining — xlr xlk — *{), если xl} > x\ xlk>x\
^г_"|тах(л^ —x\, xlk — xj), если xl. <x\ x\ <x[- I11'
Следовательно в случае jx = 0 на случайное поле,
определяемое условием (8), можно смотреть как на сумму независимых
винеровских полей с началами координат в вершинах куба
[—1, 1]. В одномерном случае эта сумма двух независимых
винеровских процессов; начало первого из них в точке —1, а
начало второго — в точке +1, причем второй процесс протекает в
обратном направлении.
Так можно определять функции априорного распределения
с точностью до нескольких параметров, в данном случае это
всего лишь два параметра \i и а2.
Для статистической оценки этих параметров можно провести
некоторое число М дополнительных наблюдений. Координаты
этих наблюдений удобно выбрать по закону равной вероятности
на А. Оценки для \х и а2 найдем методом максимального
правдоподобия. В нашем случае функция правдоподобия
Z,(|x,c2) = lng(2>, с2), (12)
где
3*
35
-w
g(z\v-, °2) =
здесь
Zt=<f(X,)-
2=(РЗД).
= (2*o2)
>ZM) '
21 2e 2e*5rs-i5 (i3)
Из (12) (13) получаем, что
10*. o»)=-^ln2it-^.lno»-lln|S|—5Jr5rS-»i. (14)
Из условия максимума функции Z,(|i, с2) по ц и о2 следует,
что оценки максимального правдоподобия для ji и о2
выражаются следующими формулами
^=ж2 р^;р<**) (15)
и
Л=1
Ж Л1
1
fl2=i22' 2 pj/x/*» (16)
• 1 ь ■ * k
где г; =<p(.£y) — ц и pj1^ —элемент матрицы 2"1
*ЛЛ
Исследовалась также функция апприорного распределения,
соответствующая гауссовому случайному полю с независящими
от х математическим ожиданием ja, дисперсией с2 и
корреляционной функцией
Р,.,ь = * (17>
где Сг, t=l,..., m масштабы. Эта функция привлекла внимание
тем, что в одномерном случае она соответствует марковскому
процессу. К сожалению, вопрос нахождения несмещенных
оценок для неизвестных параметров ц, а2 и cif i=l,...,m весьма
сложен.
8. СОЧЕТАНИЕ БАЙЕСОВЫХ МЕТОДОВ ПОИСКА
С МЕТОДАМИ ЛОКАЛЬНОГО СПУСКА
Такие общие статистические свойства реализации случайных
полей, рассмотренных в предыдущем параграфе, как
независимость приращений или марковость вполне согласуются с
нашими априорными представлениями об общем «глобальном»
поведении минимизируемых функций. Этого к сожалению, нельзя
36
сказать о некоторых характеристиках локального поведения
реализаций. Известно например, что реализация винеровских
процессов не дифференцируемы почти во всех точках. Сказанное
делает весьма сомнительным адекватность статистических
моделей типа (8) или (17) при рассмотрении коротких
интерзалов. Именно локальной неадекватностью статистических
моделей типа (8) или (17) и можно объяснить то снижение
эффективности байесовых методов, которые нередко наблюдаются
на завершающих стадиях поиска экстремума, когда
наблюдения в основном производятся в непосредственной близости от
лучших найденных точек и расстояния между наблюдениями
приближаются к нулю.
Поэтому полезно было бы своевременно обнаружить такие
области, в которых, в связи с уменьшением расстояния между
соседними наблюдениями, глобальная статистическая модель
перестает быть адекватной. В таких областях целесообразнее
пользоваться квадратичной аппроксимацией минимизируемых
функций, которая хорошо зарекомендовала себя при решении
многих задач локальной оптимизации. Кроме того, в ряде
случаев поиск следует прекратить, до того, как будет израсходован
весь запас наблюдений, если вероятность нахождения
минимума оказывается не менее заданного уровня значимости.
Указанные вопросы изучались для одномерного случая, когда в
качестве глобальной статистической модели был принят вине-
ровский процесс [11]. Использовалось следующее эмпирически
найденное условие для обнаружения интервалов локальной
неадекватности. Если на £-ом шаге для некоторого 4, 4^4^
=^&—3, выполняется условие
v(x*k-l)>4(Xlk)* '* = ** —2,...,/*,
и
?(*«*)<?(■***+*)' ik = lk,---Jk + 2> О8)
где Xik, ik = \, .. .,k упорядоченные по возрастанию точки
вычислений, то (xik-2, Х1к+ъ) считается интервалом локальной
неадекватности модели. Обоснованием этого условия является
то, что для винеровского процесса при данных xik, ik = lk —
—2, ...,/Л + 2 вероятность выполнения неравенств (18) меньше
0.016, в то же время, неравенства (18) могут быть объяснены,
предполагая унимодальность у(х) в интервале (л:/Л_2, */Л+2).
Поэтому предлагается, обнаружив интервал (а:/л-2, -К/^+з)»
«локальный минимум в нем вычислить с точностью е при помощи
локальной оптимизации. Поиск прекращается, если или рк><*
или израсходован запас наблюдений. Здесь ри вероятность
нахождения минимума с точностью е>0, а а — уровень
значимости. Величина е определяется точностью локального поиска,
а вероятность рь. вычисляется по несложным формулам [И].
37
9. ЗАВИСИМОСТЬ ЭФФЕКТИВНОСТИ БАЙЕСОВОГО МЕТОДА
ПОИСКА ЭКСТРЕМУМА ОТ АПРИОРНОГО РАСПРЕДЕЛЕНИЯ
Ввиду относительной свободы выбора априорных
распределений представляет интерес вопрос о средней погрешности
байесовых методов поиска в случае, когда для минимизации
реализаций некоторого случайного поля применяется байесовый
метод, построенный на основании другого априорного
распределения. Вопрос исследован в [12] для случая когда реализация
стационарного марковского процесса минимизировалась
используя байесовый метод, построенный в предположении, что
процесс винеровский. В качестве контроля те же реализации,
минимизированы при помощи байесового метода,
соответствующего исследуемому стационарному марковскому процессу.
В обоих случаях применялись одношаговые методы.
Рассматривалось 100 реализаций марковского процесса на интервале
[0, 1] с нулевым средним, единичной дисперсией и
корреляционной функцией
-с\хь-хА
Л1Лj
В случае использования истинной (марковской) модели
значения параметров предполагались известными. В случае
ложной (винеровской) модели значения параметров
оценивались по выборке.
В результате оказалось, что несмотря на заметное
расхождение априорных распределений (винеровский процесс даже йе
является стационарным) средняя погрешность байесовых
алгоритмов, построенных по истинной и, ложной статистической
модели, отличаются незначительно. Это указывает на
относительно слабую зависимость эффективности байесовых методов от
принятого для их построения априорного распределения.
10. НЕКОТОРЫЕ ПРИМЕНЕНИЯ
Байесовые методы поиска экстремума функций многих
перемен ных, построенные в соответствии с априорным
распределением типа (17), использовались для решения
многоэкстремальной задачи о максимизации апостериорной вероятности
моментов изменения статистических характеристик случайных
сигналов [8]. Для этой задачи проведено сравнение байесовых
методов с методом Монте—Карло. Байесовые методы
применялись также для планирования экстремальных экспериментов
по созданию термостойких пластмасс [9].
Байесовые методы поиска экстремума для решения
одномерных задач в случае винеровской модели применялись для
оптимизации спиральной малодиспергирующей линии задержки
38
видеоимпульсов [13]. В этой задаче минимизировалась
выпуклая функция, заданная на невыпуклой области. Минимизация
осуществлялась одномерным байесовым методом по отдельным
случайно выбранным направлениям. Ограничения учитывались
лри помощи штрафной функции.
ЛИТЕРАТУРА
1. Моцкус И. Б. О байесовых методах поиска экстремума. — «Автоматика
и вычислительная техника», 1972, № 3.
2. Mockus J. The Bayes Methods for Seeking the Extremal. Point. — «Ky-
bernetes», il974, v. 3, pp. 103—108.
.3. M о с k u s J. On Bayesian Methods of Optimization. — «Towards Global
Optimization». North-Holland, Amsterdam, 1975.
4. Шал тяни с В. Р. Об одном методе многоэкстремальной оптимизации.—
«Автоматика и вычислительная техника», .1971, № 3.
5. Жилинскас А. Г., Моцкус И. Б. Об одном байесовом методе
поиска минимума. — «Автоматика и вычислительная техника», 1972, № 3.
6. Растригин Л. А. Стохастические методы поиска. М., «Наука»,
1968.
7. Жилинскас А. Г. Одношашвый 'байесовский метод поиска экстремума
функций одной переменной. — «Кибернетика», № 1.
■8. Телькснис Л. А., Шалтянис В. Р. Применение одного метода
многоэкстремальной оптимизации к задачам определения изменений
свойств случайных сигналов. — «Тезисы докладов V 'Всесоюзной
конференции по экстремальным задачам». Горький, '1971.
9. Алишаускас А. В., Л и пек и с А. Л., Масюлис А. Н., Шалтя-
н и с В. Р. 'Применение многоэкстремальной оптимизации при
планировании экспериментов по созданию термостойких полимерных
композиций. — В кн.: «Случайный поиск экстремума». Киев, «'Наукова думка»,
1974.
J0. Катка у екайте А. И. Случайные поля с независимыми
приращениями.— «Литовский математический сборник», 1972, №4, стр. 75—£5.
11. Ж и лин с к ас А. Г. Метод одномерной многоэкстремальной
оптимизации. — «Изв. АН СССР», «Техническая кибернетика», 1976, № 4.
.12. Жилинскас А. |Г., Тимофеев Л. Л. О зависимости эффективности
байесовского метода поиска экстремума от априорного распределения. —
«Материалы 1-го Всесоюзного семинара по численным методам
нелинейного программирования». Киев, «Наукова думка», 1976.
А 3. Ж и л и н с к а с А. Г., Я к у ч ё н и с А. А. Оптимизация конструкций
спиральной малодиспергирующей линии задержки видеоимпульсов. —
«Труды АН Лит. ССР», 1976, серия Б, т. 1 (86).
39
УДК 62-506
ИССЛЕДОВАНИЕ УСЛОВИЙ СХОДИМОСТИ
РЕЛАКСАЦИОННЫХ АЛГОРИТМОВ
СЛУЧАЙНОГО ПОИСКА
Г. С. Тарасенко
(Рига)
В данной работе рассматривается новый подход к
исследованию релаксационных алгоритмов случайного поиска. Под
алгоритмами случайного поиска [1] подразумеваются
итеративные методы нахождения минимума функций многих
переменных, которые на каждой итерации используют реализацию
случайного вектора £* с функцией распределения Flk(x).
Каждый конкретный алгоритм определяется прежде всего правилом
использования последовательности случайных векторов {£&}.
Поскольку при создании методов оптимизации необходимо
учитывать, что они должны реализовываться на ЭВМ, то такие
правила записываются в виде одного или нескольких
рекуррентных соотношений.
Примером могут служить следующие:
xk+i — xk~ak 2cl ^k {'
Xk+i = x* + Xi{x*>tk)tk, (2)
(1, если Q(x + y)<Q(x)
где Xl(x, y) = [0^ если Q{x + y)>Q(xy д^-Я^минимизи-
руемая функция; {%}, {1л} —последовательности случайных
векторов, распределенных соответственно на единичной сфере
и сферах радиуса {ak}\ {ck} — числовая последовательность.
Соотношение (1) выделяет класс методов, называемых
алгоритмами «с парной пробой» [2], а соотношение (2) является
обобщением алгоритма случайного поиска «с пересчетом» [2], [3].
В общем виде класс алгоритмов случайного поиска
определяет рекуррентное соотношение вида
**=^(*оЛ, ...Л-0, (3>
где {yIrk} —некоторая последовательность операторов; £0, ...
..., £*_i — случайные вектора с функциями распределения
^бо» • • •»^4*-i * Однако полностью правила типа (3) не
определяют алгоритмы случайного поиска.
Требуется также задание в явной либо неявной форме
некоторой последовательности операторов {Фл}, которые
начальной точке поиска х0, реализациям у0, ..., yk_x случайных век-
40
торов £0, .. .,E*_i, функциям распределения Z7^, .. .,Fi ставят
в соответствие следующую функцию распределения Fik, то есть
ри = ф* (*о. % - • ■■ Ун-и Fu* • • -*FU-i)' (4
Операторы ФЛ могут быть как детерминированные, так и)
стохастические. В первом случае запись (4) эквивалентна
следующей
Flk=*®k(Xo* Уо>-> Ун-и ?0>
так как по х0, у0> F^ определяется F^, затем по х0, у0, ух>
F\t—F\% и так далее.
В смысле соотношений (3) и (4) уточним понятие
адаптивного алгоритма.
Будем считать, что алгоритм случайного поиска вида (3)
не адаптивный, если оператор Фк зависит только от номера к
и текущей точки xk> то есть
^* = ф* (•**)•
В противном случае алгоритм называется адаптивным. Если
операторы Фк и ЧГЛ одинаковы на всех итерациях: ФЛ = Ф,
ЧГЛ==ЧГ, то метод задаваемый соотношением (3) —(4) назовем
стационарным алгоритмом, порожденным операторами Ф и lF.
Примером стационарного неадаптивного метода является
алгоритм случайного спуска [4], в котором
Xk+i = Xk + a(*k*tk)tk (5>
Fik—Fv*
где 5Л, I* —случайные векторы, равномерно распределенные па
единичной сфере S = {c:||c|| = l}, а функция а(х,у)
определяется из условия
Q (х + а (х, у) у) = min Q (х + \у). (6>
Алгоритм «с парными пробами» (1), в котором параметры akr
ck изменяются, например, по закону
аь = Т> сь=т$3я> F^k=F4*
является примером неадаптивного нестационарного метода.
В алгоритме «с пересчетом» (2) с адаптацией рабочего шага
а [5], в котором
(bakJ если Q(*a)<Q(*a-i)
а^ = Ьа„ если Q(**) = Q(«**-i)
41
функция Fg получается в результате применения оператора Ф
•к функции Fiki, векторам xk_x и укшЛ\
ЛЛС*) = ф(*А-ь Ук-и Fik_t (х)) = Zi (хк_и yk-i)Fzk-1(lTlx)+
+ 0 -Xi (Xk-u y*-i))Fik_t (Ч1*)
Поэтому, согласно определению этот метод является
стационарным адаптивным алгоритмом. В случае, когда
(Ti(£)a*, если Q(xk)<Q(xkJ)
а*+1—1Т2(А)аЛэ если Q(xk) = Q(xk__l)y
где Yi(*)> 72(k) —некоторые детерминированные функции от к,
алгоритм вида (2) является адаптивным нестационарным
методом.
Основным методом исследования сходимости алгоритмов
вида (3) до последнего времени является вероятностный
аналог прямого метода Ляпунова [6]. Однако основное
предположение этого метода — марковость последовательности {xh} не
выполняется для адаптивных алгоритмов.
Поэтому необходим новый подход к исследованию
итеративных процедур статистической оптимизации.
Пусть ^ — пространство функций распределений. Обозначим
пару (х, F) через z и Rnxfr = Z. Тогда соотношения (3) —(4)
определяют некоторое случайное блуждание в Z.
Алгоритмам случайного поиска, траектории {xk} которых
сходятся в том или ином вероятностном смысле к множеству
экстремумов X* функции Q, соответствуют определенные типы
блужданий zk в Z.
Для выделения особого рода случайных движений в Z
введем понятие г — возвратного множества.
Определение [8]. Множество Dx(zZ назовем е-возвратным
в DaZ, если Dxf]D^0, и для любых к0>0 существует е>0
такое, что
lim Р{{<о:гл(ш)еА} nBD{k<t)}> eP {BD(k0)}y (7)
£-*оо
где
BD(k0) = {u:zk(u)£D для всех k>k}.
Множество Во(к0) — это совокупность траекторий {zk},
которые не выходят из D. Поэтому условие (7) означает, что
траектории, которые начиная с момента времени k0
содержатся в D, с положительной вероятностью пересекаются с
множеством Dx за конечное время. В [8] показано, что вероятность
любого конечного числа таких пересечений больше 0.
Введем функцию v:Q(zRn->R\ обладающую следующими
свойствами: 1) v(x)>0; 2) v(x)>v(y), если Q(a;)<Q(*/) и v(x)*=v(y),
если Q(x)=Q(y). Здесь Q:GczRn->Rl минимизируемая функция.
-42
Рассмотрим частный вид уравнения (3):
*4 = ЧГ(*м, 5М) (8)
и определим следующую вероятность
41 (*. Р) = />(»:*(*(*, $ («))) -z>(x)<P}
Функция r\i(zy P) является вероятностью события,
означающего, что уменьшение функции v на А-той итерации будет не
меньше, чем (J при условии, что xk=x и /Г^=7Г6.
В рамках введенных понятий можно сформулировать
достаточные условия сходимости для следующего класса
алгоритмов оптимизации типа (8):
•*А = *А-1+Х2(*Л-1. *А-Ь 0)5Л_ь (9)
где
v /*. и п\-11*если Q(x+y)<Q(x) и х+у£°
Ъ\х*У*и) — ^ если Q(.*-f */)>Q(.k), либо x + yW.
Здесь Q:GczRn^Rl минимизируемая функция, G — допустимая
область поиска. Класс алгоритмов (9) есть обобщение схемы (2)
методов безусловной оптимизации типа «с пересчетом». На
каждой итерации методов (9) минимизируемая функция Q не
возрастает, т. е. эти алгоритмы являются релаксационными [7].
На множество функций распределений f также введем
ограничение. Потребуем существование измеримого оператора
ЧГ', действующего из Rn+m в Rn такого, что случайный
вектор 6, использующийся в итеративном процессе (9) на А-той
итерации однозначно представлен в виде
е = чг'(ЧМ). (Ю)
где ^ — независимые случайные векторы, имеющие одинаковую
для всех k функцию распределения, ЛбЛс/?т.
Следовательно функции распределения F% , порожденные
последовательностью операторов Фл, параметризованы. Чтобы
это подчеркнуть будем записывать
Также зависимость (4) в данном случае можно представить
в виде
Ак = Ф'к(х0,у0, ...,У*-ь A), ...,Ak-i). (И)
Под множеством Z в этом случае будем понимать GxA
43
т. е. 2 = (jc, Л), а вероятность r\i(z,$) имеет вид:
4i (*. P) = 4i С*. Д Р) = Я {«>:х + 6А(о>)бО,
В качестве функции г> выберем разность
где Q* —нижняя грань функции Q на множестве G.
Следующая лемма приводит важное свойство
е—возвратных множеств, на основе которого будут сформулированы
достаточные условия сходимости алгоритмов вида (9) —(11).
Лемма [8]. Пусть
1) z0eDaZ- x0eG;
2) существует множество DxaZ является е-возвратным в Dy
то есть выполнено условие (7);
3) существует £<0 такое, что inf r\i(z, P)>0
Тогда последовательность {zk}> порожденная рекуррентными
соотношениями (9), (11) при условии (10) почти наверное (п. н.)
за конечное время выходит из множества D.
Введем множество
Q (8) = {х:х&\ Q* + 8<Q(jc)<Q(х0)}
Тогда из результата леммы следует
Теорема 1. [8] Пусть:
1) *06С;
2) существует множество AgZ, являющееся е—возвратным
в G(b)xRm при любом 86(0, v(x0)
3) Для каждого 8g(0,v(Xq)) существует р=Р(8)<0 такое, что
inf 4i(«,P)>0. (12)
zGDtr\G(b)XRn
Тогда последовательность Q(xk)9 порожденная
соотношением (9)—(11) при условии (10) сходится почти наверное к
наименьшему значению Q* функции Q на множестве G.
Следствие 1. Если дополнительно к условиям теоремы 1
множества {^:Q(x)<const; x$G} компактны, то
последовательность {xk} сходится почти наверное к множеству X*, где
X* — множество минимумов функции Q на множестве G.
Для стационарных не адаптивных алгоритмов функция
распределения случайной величины %k полностью определяется
44
точкой х. Поэтому функция *yj1 (z, Р) зависит только от х #
Обозначим ее в этом случае через цг (х, Р).
Следствие 2. Пусть последовательность {xk} порождена
стационарным не адаптивным алгоритмом вида (9), для
произвольного Що, v (х0)) существует Р<0 такое, что
inf
xQ3^)y]i(X^)>0.
Тогда для произвольной начальной точки x0£G
Согласно теореме 1 для доказательства сходимости
отдельных алгоритмов типа (9) достаточно определить существование
множества Du являющего е—возвратным для всех G(tyXRm>
а также выполнение условия (12).
Прежде, чем приступать к рассмотрению конкретных
алгоритмов вида (9), введем класс случайных векторов S [3].
Вектора этого класса
1) распределены по единичной сфере S = {c:||c|| = l};
2) на А-том шаге итеративного алгоритма типа (9)
однозначно представимы в виде
е=чг0(й.«). (13)
где ^о — измеримое отображение; Й —независимые векторы,
равномерно распределенные на единичной сфере; а принадлежит
компактному множеству A°aRm (условие (13) означает, что
класс векторов S параметризован);
3) имеют положительную плотность
Pl(c)=P(c>*)*
которая непрерывна на 5х^°.
Иллюстрацией применения теоремы 1 служит установление
факта сходимости для обобщения алгоритма случайного спуска
(5), в котором векторы Ik принадлежат классу S. В этом
случае в качестве притягивающего множества достаточно выбрать
RnXA°.
Условие (12) выполняются, если минимизируемая функция Q
непрерывна и множества {х : Q(x) ^const}—ограничены.
Следовательно справедлива
Теорема 2 [8]. Пусть функция Q : Rn^R\ непрерывна и
множества {х: Q(x)<const} ограничены. Тогда
последовательность {хк}у порожденная соотношениями (5), где \ъ 6 S,
сходится почти наверное к множеству минимумов X* функции Q.
В работах [4], [7], [9] получены оценки скорости
сходимости алгоритмов случайного спуска на классах дважды диф-
45
ференцируемых функций. Теорема 2 устанавливает сходимость
обобщения этого метода на более широком классе
минимизируемых функций. Но поскольку нахождение минимума на
прямой является самостоятельной задачей, то полученный
результат представляет в основном методический и теоретический
интерес.
Более интересным является применение результата
теоремы 1 для исследования алгоритмов типа (9) в которых
*а = я*Ча. (14)
Ti(*)*A-b если Q(xk^)<Q(xk_2)
ak_u если Q(xk_l) = Q(xk_2), н° Q(**-i)<
ab = \ <Qt**-,-i) (15)
b(k)ak_u если Q (**_i = Q (*-2) и Q(*M) =
= Q(**-,-i),
где для всех k т^бЗ, Ti(*)> 1» 0 < Тг (*) < 1 э s>\.
Введем функцию
dG(x)= max I| -x: — у ||.
{y:y£G; Q(y)<Q(x)}
Для алгоритмов вида (9), (14), (15) притягивающими будут
[3], [8] множества вида
Rn X {об/?1: аб[?1 (х), ср2 (х)\, xeRn} X Д°,
где функции 9ь ?2:С/с/?л^/?1 удовлетворяют условиям:
0<?iW<T2W<rfGW
0< Нтср^лг^); lim cp2(л:Л)<dG(х) при ^$X*
Лтд-*»* *k-*x
<?i(x) = <p2(x) = 0 при хб^*.
Прежде, чем уточнить ограничения в выборе параметров.
Ъ(к) и Ъ(к) введем классы функций Г, Г(/?,Е) и Тг (S).
Определение [3]. Функция Q:Rn->Rl принадлежит классу
Г, если выполнены следующие условия:
A. Функция непрерывна.
B. Функция унимодальна, т. е. имеется единственное одно-
связное множество минимумов X*.
C. Множества {x:Q(a:)< const} ограничены.
Д. В каждой окрестности U(x) произвольной точки х$Х*
содержатся точки у и z такие, что
Q(y)<Q(x)<Q(z).
46
Это условие' означает, что функция Q не имеет локальных,
максимумов и у поверхности равного уровня не существует
«усиков» и «площадок» размерности я.
Замечание. В класс Т входят также и недифференцируемые
невыпуклые функции.
Для введения подклассов 7^(2) и Т(р, Е) класса 7\
определим вероятность удачного шага т](а, х, а)
7j(a, х, а)= . J p(cya)dsc,
{c:Q(x+ac)<Q(x)}
dsc~элемент сферы S = {c:||c || = 1}.
Определение [3]. Функция Q из класса Т принадлежит
подклассу Т(р> 3),, если для каждого §6(0, z> (д:0)) inf lim
(х, а)£С(б)хЛ0 J^o
т](a, л:, а)>р.
Определение [З]. Функция QgT принадлежит подклассу
Тг (Е), если для всех 86(0, v (x0)) inf lim tj (a, jc, a) > 0.
(jrfa)gO(6)xA» 5^0
Из определения классов Г (/7, S) и Тг (Е) вытекает, что для
всех р>0
Г(р,Е)сГ1(Е).
Следующее утверждение показывает, каким может быть-
класс функций Г (1/2, Е).
Утверждение [3]. Пусть функция Q:Rn->Rl удовлетворяет
условиям:
1) функция унимодальна и ограничена снизу;
2) функция непрерывно дифференцируема;
3) градиент функции Q'(х) = 0 только тогда, когда х£Х*\
множества {x:Q(x)<const} ограничены.
Для плотности распределения /?(с, а) случайных векторов
\\з E и любого вектора g=£0 выполняется равенство:
J p(c9a)dsc = ±. (16)
{c:(c,g)>0}
Тогда Qer(l/2, S).
Замечание. Требованию (16) удовлетворяет, в частности,,
случайный вектор равномерно распределенный по поверхности
/г-мерной сферы, а также проекция на единичную сферу
вектора, равномерно распределенного в /г-мерном кубе, либо на его
поверхности.
Если выполнено условие (16), то примером не выпуклой
функции из класса Г (1/2, Е) служит так называемый «банан
Розенброка»:
47
Q (x)=100 (x2 - x\f + (1 - x,)2.
Примером недифференцируемой функции из класса Т1(Е)
при /1=2 является
Q(jc)H*i| + *«.
Рассмотрим случай, когда область G совпадает с 7?л. Тогда
справедливы следующие два утверждения
Теорема 3. [3] Пусть Q=X"; QeT(p, 3);
ti(*)=ti>1; тз(А)=т2<1;
TfT|-">i-
Тогда последовательность {xk}, порожденная соотношениями
(9), (14), (15) сходится почти наверное к множеству X*.
Теорема 4. [3] Пусть G=Rn\ <2£ГХ(Щ\
Т2(А)=Т2<1; 07)
где fi:^,_>'^1 монотонно возрастающая дифференцируемая
функция, такая, что
Ъ (*)-><»; (18)
Тогда последовательность {xk}, порожденная соотношениями
{9), (14), (15) сходится почти наверное к множеству X*.
Замечание. В качестве TiC*) можно выбрать, например,
Т1<л:) = 1п(л:).
Если область С не совпадает со всем пространством, то
результат о сходимости последовательности 1хп} к X*
получен для выпуклых непрерывных функций Q, заданных на
выпуклом допустимом множестве G = {л:: g^ (лс) < 0, / = 1, ..., г}.
Теорема 5. [8] Пусть Q, g^:/?*-*/?1; / = 1, ..., г
—непрерывные выпуклые функции.
Множества {х: x^Q\ Q (х) < const} ограничены;
{*:£,(*)<(), i = \, . ..,r}^0;
коэффициенты^ (k) и f2 (&) удовлетворяют условиям (17)—(19).
Тогда последовательность {xk}, порожденная
соотношениями (9), (14), (15) сходится почти наверное к множеству X*.
В работах [10] — [11] на квадратичных функциях
определялась оптимальная, в смысле наибольшего уменьшения невязки,
величина рабочего шага для алгоритма типа (9), (14). На
каждой итерации этого метода случайные векторы независимы и
равномерно распределены на поверхности единичной сферы.
48
Оказалось, что асимптотическая по п оптимальная величина а
ле зависит от степени овражности минимизируемой функции и
соответствует постоянной вероятности удачного шага равной
0,27. Согласно [11] при применении процедуры изменения
шага (15) с постоянными коэффициентами 71 и 72 вероятность
удачи т|(а, х) колеблется около значения /?, определяемом из
соотношения YipY21~p=l. Выбрав /7 = 0.27 получаем алгоритм,
близкий к оптимальному.
Этот результат подтверждает целесообразность применения
алгоритмов изменения величины а вида (15).
В приведенных выше алгоритмах адаптивно изменяется
величина шага а. На плотность распределения векторов щ
наложено не жесткое ограничение: щ£Е, причем метод изменения
щ на факт сходимости алгоритма поиска не влияет. Поэтому
можно создавать различные эвристические методы типа (9),
<14), (15) с адаптацией плотности распределения. В работе
£12] предложен один из таких алгоритмов.
В заключении автор выражает благодарность В. Т. Стоян-
деву и Е. С. Усачеву за внимание к работе.
ЛИТЕРАТУРА
1. Случайный поиск (Теория и применение). Библиография.
Рига, 1973, 76 с.
2. Растригин Л. А. Статистические методы поиска. М., «Наука», 1968,
376 1с.
3. Тарасенко Г. С. Сходимость релаксационных алгоритмов случайного
'поиска типа «с пересчетом»». — «Проблемы случайного поиска», вып. 6,
Рига, «Зинатне», .1977 i(b печати).
4. Николаев Е. Г. О скорейшем спуске, основанном на методе
случайного Gm — (градиента. — «Автоматика и вычислительная техника», № 3,
1970, Рига, с. 40—46.
5. Растр иг и н Л. А., Тарасенко Г. С. Об одном алгоритме
случайного поиска. — «Проблемы случайного поиска», «вып. 3, Рига, «Зинатне»,
1974, 108-НМ2.
6. Поляк Б. Т. Сходимость и скорость сходимости итеративных
стохастических алгоритмов 1. Общий случай. — «Автоматика и телемеханика»,
№ 12, 1976, с. 83—94.
7. Карманов В. Г. Математическое программирование. М., 1975, 272.
8. Тарасенко Г. С. Исследование релаксационных алгоритмов случайного
поиска общего вида. — «Проблемы случайного поиска», вып. 7. Рига,
«Зинатне», 1978, (в печати).
9. Ш о р Н. 3., Щ е п а к и н М. Б. Об оценке скорости метода случайного
поиска. — «Кибернетика», № 4, 1974, с. 65—58.
10. S с h u m е г М., S t e i g 1 u t z К. Adaptive step size random search. —
«IEEE Trans. Autom. Control», 1968, ЛЗ, № 3, 270-4276 p.
11. Тарасенко Г. С. Исследование адаптивного алгоритма случайного
поиска. — «Проблемы случайного поиска», вып. 5. Рига, «Зинатне», 1976,
119—'124.
12. Тарасенко Г. С. Построение релаксационных алгоритмов поиска с
адаптацией плотности распределения случайных векторов. — «Проблемы
случайного поиска», вып. 7. Рига, «Зинатне», 1978 (в печати).
4-6065
49
УДК 62-506
ПРОЦЕДУРА РЕЛАКСАЦИИ
СТОХАСТИЧЕСКИХ АЛГОРИТМОВ i
ОПТИМИЗАЦИИ И ВОПРОСЫ СХОДИМОСТИ
А. И. Жданок
(Рига)
Существует довольно большой класс алгоритмов
оптимизации, называемых релаксационными. Они отличаются тем, что
на каждом шаге значение минимизируемого функционала не
возрастает. С точки зрения исследователя такие алгоритмы
удобны тем, что при доказательстве их сходимости достаточна
показать лишь существование в минимизирующей
последовательности такой подпоследовательности, которая сходится к
точке минимума. Не менее широк и класс алгоритмов, не
являющихся релаксационными. Для доказательства их
сходимости уже недостаточно показать существование сходящейся
подпоследовательности. Однако в большинстве используемых
ныне схемах доказательств выделение сходящейся
подпоследовательности является обязательным промежуточным этапом.
А наибольшие трудности возникают при логическом переходе от
сходимости подпоследовательности к сходимости всей
минимизирующей последовательности. Обусловлено это спецификой
метода функций Ляпунова явно или неявно используемого при
доказательствах сходимости алгоритмов. Обрисованная
ситуация является чисто технической стороной разбираемого здесь
вопроса. Существуют и объективные отличия между
релаксационными и нерелаксационными алгоритмами. А именно,
нерелаксационный алгоритм может сходиться на некотором
классе минимизируемых функционалов и не сходиться на более
широком классе, но при работе на этом более широком классе
порождаемая им минимизирующая последовательность может
содержать сходящуюся подпоследовательность. Такой ситуации
для релаксационных алгоритмов не возникает.
Рассмотрим теперь следующую процедуру. Не вмешиваясь
в работу произвольного алгоритма, будем дополнительно
фиксировать только те точки в порождаемой им минимизирующей
последовательности, которые приводят к уменьшению
значения минимизируемого функционала (по сравнению с
предыдущей таким же образом фиксированной точкой). Образование
такой параллельной исходной минимизирующей
последовательности естественно назвать процедурой релаксации алгоритма,
оптимизации. Тут же заметим, что построение релаксации не
требует дополнительных вычислений функционала, а говоря
языком программиста; на каждом шаге использует лишь одна
50
сравнение и одно пересвоение. Другими словами затраты
машинного времени практически не возрастают.
Что может дать процедура релаксации? Если исходный
алгоритм сходится на некотором классе функционалов, то,
очевидно, и его релаксация будет сходящейся. Легко проверить
также и то, что если исходный алгоритм порождает
минимизирующую последовательность, в которой содержится
сходящаяся подпоследовательность, то его релаксация будет сходящаяся.
Возможности релаксации в случае детерминированных
алгоритмов (и без помех) указанной ситуацией, в основном, и
исчерпываются. Однако, если порождаемая алгоритмом
минимизирующая последовательность является стохастической (алгоритмы
случайного поиска или произвольные алгоритмы в обстановке
помех), то при релаксации возникает гораздо более сложная
ситуация и наблюдаются интересные эффекты. Оказывается,
что релаксированный алгоритм будет сходиться почти
наверное (п. н.) даже и в том случае, когда исходная
минимизирующая последовательность не сходится сама и не содержит
сходящейся по произвольным фиксированным моментам времени
подпоследовательности. Требуется лишь, чтобы существовала
сходящаяся в некотором смысле подпоследовательность,
которая определяется по случайным моментам времени. В частности,
релаксирование алгоритма, сходящегося в вероятностном смысле
слабо, например по вероятности, делает его сходящимся п. н.
При естественных дополнительных условиях (например,
детерминированность начальной точки) релаксация гарантирует
сходимость алгоритма в среднем, среднем квадратическом и,
вообще, в произвольном пространстве Lh (пространство
случайных величин, к-ая степень модуля которых интегрируема).
Таким образом, установление необходимых и достаточных
условий сходимости релаксированных, а также собственно
релаксационных алгоритмов связано с изучением специальных
стохастических последовательностей, которые названы здесь
г-последовательностями. Что касается скорости сходимости ре-
лаксированного алгоритма, то она может только возрасти по
сравнению с исходным. Кроме того, в рамках развиваемого
метода предлагается специальный прием для оценивания скорости
сходимости релаксаций.
К предыстории предлагаемой здесь практической процедуры
релаксации и математического метода ее исследования следует
отнести многочисленные работы различных авторов,
посвященные собственно релаксационным методам. Поведение
алгоритма случайного перебора, необходимые и достаточные условия
сходимости которого устанавливаются здесь как пример
применения предлагаемого метода, ранее изучалось в частном
случае в работе [1]. В указанной работе содержится утверждение
о том, что случайный перебор на сфере с равномерным
законом распределения проб сходится (по распределению) к точке
4*
51
максимума максимизируемого функционала на сфере. Кроме
того в [1] высказано важное утверждение о том, что
наложение ограниченной помехи при измерении максимизируемого
функционала в случайном переборе на сфере не влияет на факт
его сходимости. Как будет видно из приведенных ниже
результатов оба утверждения действительно верны, а наложение
ограниченной помехи при некоторых условиях не изменяет факта
сходимости и для более широкого класса релаксационных
процессов.
Ниже приводятся только основные результаты, касающиеся
процедуры релаксации. Подробное изложение разбираемых
здесь вопросов, а также все доказательства и примеры можно
найти в работах [2] и [3].
Рассмотрим последовательность случайных величин {*/*(<»))},
(t= 1, 2,...), определенных на вероятностном пространстве
(Q, Л, Р) и п. н. ограниченных снизу неслучайным числом у*.
Определение 1. Последовательность {#*(со)}, */*(*>) ^?#* п. н.,
назовем г-последовательностью, если существует
последовательность случайных целых чисел {ti((o)} (i=l, 2,...) таких,
что
P{lim^(u))(«>) = ^}-1.
/-►оо
Отметим, что из того что {yt(^)} является
г-последовательностью, еще не следует, что она содержит какую-либо
обычную (по детерминированным моментам времени)
подпоследовательность {#//(<*>)}, сходящуюся к у*, однако обратное
верно. В частности, если #/(<*>)->#* в любом вероятностном
смысле, то {_*//(<*>)}— /"-последовательность. Далее нам
понадобится следующая эквивалентная форма приведенного
определения: {г/Д^)}, */*(«>)> #*, является /--последовательностью,
если для любого е>0 и для последовательности множеств
{At (е)}, At(е) = {u)g2 : 3* (а>)< t, ytw (а))<у* + е}, выполняется
Р (At (е)) -> 1 при t -> оо.
Произвольный алгоритм S минимизации функционалов
Q:Rn-^R1 стохастический, или детерминированный,
символически запишем в виде xt{™) = S(-), 2 = 1,2, ..., где точкой
обозначена любая группа аргументов, используемых
алгоритмом S для нахождения 2-ого приближения хДсо) к множеству
минимумов AT* функционала Q. При фиксированном Q
минимизирующую последовательность {xt (о))}, порождаемую
алгоритмом 5, будем отождествлять с самим алгоритмом S.
Пусть в Rn задана некоторая метрика р, ?(х, у) = \\х — у\\.
Обозначим Г класс функционалов Q: Rn->R1, Q(x)>Q*> — оо,
имеющих в Rn непустое ограниченное множество минимумов
X* и непрерывных в X*. Символом Г обозначим подкласс Г
52
такой, что для любого е>0 существует такое о>0, что при
р (х, X*) = inf р (х, у)>г выполняется Q (х) > Q* + <*-
У£Х*
Определение 2. Последовательность {zt (o>)} будем
называть релаксацией алгоритма {xt(u>)}, если для любого wgQ и
/ = 1,2,...
- («л = {х*+х (а)) при Q(*<+1 (а))) <Q (г< W
*"+1 к > \zt (а)) при Q (*,f, (аз» > Q (г, (а)))
Теорема 1. Пусть задан произвольный алгоритм 5 и
функционал (?6Г. Для сходимости п.н. релаксации {£,(«>)}
алгоритма S к множеству минимумов Л"* функционала Q
необходимо и достаточно выполнения любого из следующих
трех условий:
а) {p(.X;((i>), X*)} — г-последовательность;
б) [Q (xt (о)))} — г-последовательность;
если Q дифференцируем, его градиент \7Q(x) обращается
в ноль на X* и только на X*, (| VQ(•)||€Г, то
в) (II VQ (xt (со)) ||} — г-последовательность.
Если в теореме 1 потребовать лишь Qgr и ||VQ(-)I|GI\ то
условия а), б) или в) будут необходимыми и достаточными
условиями сходимости п.н. релаксации по функционалу, т.е.
Q(г,(а>))->Q* п.н. Если дополнительно при некоторых k и i
выполнено Ж |Q (*,(«>)) |*< oo, то релаксация сходится по
функционалу и в Lk. Отметим, что условия теоремы 1_будут
выполнены, если для произвольного S и некоторого Q6r
справедливо limp (я, (<*>), Х*) = 0 п.н. или limQ(xt (w)) = Q* п.н.
t-t-oo t-+oo
или lim||vQ(^(o)))|| = 0 п.н. при ||VQ(-)ll6r.
Теорема 1 дает условия, при которых гарантируется, что
релаксация сделает «плохой»» алгоритм «хорошим».
Рассмотрим теперь задачу, в некотором смысле обратную. Пусть
алгоритм 5 уже является релаксационным. Чтобы найти условия
его сходимости, можно попытаться установить г-свойства его
самого. А можно и построить такой нерелаксационный
алгоритм, релаксация которого совпадает с исходным. Применяя к
такому «предалгоритму» теорему 1 можно установить условия
сходимости исходного алгоритма. «Предалгоритм» может быть
существенно проще исходного. Именно при помощи такого
приема найдены необходимые и достаточные условия сходимости
алгоритма случайного перебора (приведены ниже).
Если исходный алгоритм не сходится, а его релаксация
сходится, то сравнивать их скорости сходимости не приходится.
В том же случае, когда и сам алгоритм и его релаксация
сходятся по функционалу в некотором Lk, имеет место следующее
53
легко проверяемое неравенство: M\Q(zt((u))—Q*|fe^
^M|Q(xt((o))—Q*|\ /=1, 2,..., т. е. скорость сходимости
при релаксации может только возрасти. Построив для
последовательности {Q(2f((o))} последовательность определенных выше
множеств {4f(e)} можно установить точную оценку скорости
сходимости релаксации {^(<о)} по функционалу в Lk
Af|Q(^H)-Q*|* = Je*rfP(A/(e)), < = l,2f....
Обратимся теперь к конкретному стохастическому
алгоритму оптимизации — случайному перебору [4]^ Для нахождения
множества минимумов X* функционала Q 6 Г в некоторой
области DczR71, на каждом шаге t случайно выбирается точка в
D — реализация случайного вектора t,t (все £* независимы) с
функцией распределения Л(-)- Фиксируются только те точки,
которые приводят к уменьшению значения Q. Такой алгоритм,
очевидно, является релаксационным. Воспользовавшись
изложенным методом нетрудно установить, что для сходимости
алгоритма к множеству X* п. н. необходимо и достаточно чтобы
для любого е>0 выполнялось
оо
t=\
где и(Х*9 е) — е — окрестность множества X* в Rn. В частности,
если D ограничена и все ^ распределены равномерно в Z), или
D = Rn и все £f распределены одинаково нормально (с
произвольным центром), то алгоритм случайного перебора сходится
п. н. Оценки скорости сходимости алгоритма случайного
перебора приведены в [2].
Все вышеизложенное относится лишь к случаю отсутствия
помех. Поведение релаксаций в обстановке помех будет
несколько иным. Однако, и здесь при некоторых условиях будет
гарантироваться сходимость п. н. релаксированного
алгоритма, если даже исходный алгоритм не сходится. Приведем лишь
следующий, частный случай полученного в [3] результата.
Теорема 2. Пусть QQT, алгоритм 5 такой, что в {xt(^)}
существует сходящаяся к X* п. н. подпоследовательность
{xt. (u))}, при каждом t значение функционала Я(х((т))
измеряется с аддитивной помехой С, (<*>), все С,(и>) независимы и
одинаково распределены на произвольном ограниченном
интервале. Тогда релаксация алгоритма 5 сходится п. н. к X*.
В заключение отметим, что релаксирование произвольного
алгоритма в практических задачах всегда целесообразно, так
как эта процедура приводит лишь к расширению класса
функционалов, на которых алгоритм сходится п. н. и к повышению
скорости его сходимости. С другой стороны, развитый в [2]
54
аппарат /"-последовательностей является удобным
инструментом теоретического исследования вопросов сходимости
различных алгоритмов оптимизации.
ЛИТЕРАТУРА
1. Вайс-б орд 3. М., Растр и г ин Л. А., Рубинштейн Я. С.
Сходимость алгоритма случайного поиска по наилучшей пробе. — АВТ, 1973,
№ 1, с. 40—45.
2. Ждан о к А. И. Релаксация стохастических алгоритмов оптимизации
при отсутствии помех. — «Проблемы случайного поиска», вып. 7. Рига,
«З'инатне», (в печати).
3. Ж д а н о к А. И. Релаксация стохастических алгоритмов оптимизации в
обстановке помех. — «Проблемы случайного поиска», вып. 7. Рига, «Зи-
натне», (в печати).
4. Растр и пин Л. А. Статистические методы поиска. М., «Наука», 1968,
376 с.
УДК 62-506
АВТОМАТНЫЕ МОДЕЛИ ПОИСКА ЭКСТРЕМУМА
Л. А. Растригин, К. К. Puna
(Рига)
Идея представления алгоритмов поисковой оптимизации в
виде конечного автомата впервые была сформулирована в
1967 г. [1, 2] для алгоритмов случайного поиска. В этом же
году в работе [3] была показана возможность использования
вероятностных автоматов для решения задачи
многопараметрической оптимизации. Сначала оба направления развивались
независимо. Первое из них исследовалось в работах [4—6] и его
можно условно назвать «Случайный поиск, как вероятностный
автомат». Второе направление исследовалось в работах [7—16]
и его иногда называют «Вероятностный автомат, как случайный
поиск». Затем было обнаружено [17—18], что оба направления
представляют собой разные ветви одного и того же дерева —
автоматной стохастической оптимизации. Была также
обнаружена [19] автоматная интерпретация детерминированных
алгоритмов поисковой оптимизации. Далее изложим основные
результаты исследования автоматных моделей поисковой
оптимизации.
Рассматривается задача определения минимума функции
многих переменных Q(Ar) = Q(x1,..., хп). Необходимо найти
точку X*=(x*v..., х*п), где
Q(X*)=minQ(X). (1)
XQRn
55
Предполагается, что Q(X) вычисляется с ошибкой:
Q'(*) = Q(*)+e(0), (2>
где е(а) нормально распределенное случайное число с
математическим ожиданием М[е] = 0 и дисперсией £>[е] = с2.
Алгоритмы поиска, рассматриваемые ниже, имеют следующий
вид, [1,20]. Из исходной точки XN делаются k случайные или
детерминированные пробные шаги &Х§\..., AATj^} и
определяется значение функции Qx(XN + bLX$),..., (^{Xh + LX)!}))^
Затем, используя результаты пробных шагов из состояния Х^
в соответствии с выбранным алгоритмом поиска делается
рабочий шаг kXN\
Хи+\ = Хн-\-кХьг (3)
Самообучение в процессе поиска вводится следующим образом
[1]. Направление рабочего шага кХ^ задается при помощи
условной вероятности
p(LXN) = p(L\XWN) (4>
Вектор памяти W изменяется от шага к шагу рекуррентным
образом
WN+l = ^f{WN9 &XN, AQ„), (5)
где <!> детерминированная или случайная функция.
Конечно-автоматное представление требует, чтобы вектор
шага &Х и вектор памяти W принимали значения из конечных,
множеств: ДЛГб{ДЛГ<'">}, У=1,..., ъ\ W£{WW}, / = 1,...,/тг. Для
группы алгоритмов без самообучения автомат поиска
определяется следующим образом [4 — 6, 17]. Состояние автомата
совпадает с его выходом и равно пробному ^Х^ или
рабочему &XN шагам. Входом автомата является знак приращения:
оптимизируемой функции, т. е.
(1, если AQ„>0;
*-sgnAQ„=={0f если AQ^<0f (6)
где kQ'N = Q' (XN) — Q' (XN-i). Переходная функция автомата
задается двумя стохастическими матрицами Л0==!|^)Ц Для
с = 0 и Аг --= || a}J> || для с=\.
Алгоритмы поиска с самообучением имеют следующее
автоматное представление [17, 18, 21]: состоянием автомата
является вектор памяти W', выходом является вектор шага &ХГ
вход определяется формулой (6). Выходную функцию автомата
задает формула (4), а переходную функцию формула (5).
Оптимизируемая функция Q' (X) определяет внешнюю среду, с
которой взаимодействует автомат. Внешняя среда задается,
вероятностями штрафов Sj действий автомата.
56
5/ = Вер(с = 1|Д* = ДХ</>) = 1[1+ф(^-)]> (7>
где
bQ<n = Q(X + bX(»)-Q{X), у = 1,..., V,
г
Ф (г) = -т= \ в d£ — интеграл вероятностей.
f о
Различные автоматные алгоритмы поиска представлены в
табл. 1. Наиболее общий автомат поиска получаем, в случае
алгоритмов поиска с самообучением, когда формулы (4) и (5)
представляют условные вероятности [17, 18]. Переходная
функция автомата тогда записывается в виде набора стохастических
матриц, элементы которых зависят от выхода AX{j) автомата на
предыдущем шаге и от входа с автомата на текущем шаге, т. е.
ЛДАЛ-О) Н|/$>(/) ||, <8)'
где p$(J) вероятность перехода из /-го состояния в k-oe
состояние: с=0, 1; /=1,..м v. Выходную функцию автомата
можно задать стохастической матрицей
Т = Ш1 (9)
где qtj — вероятность появления у автомата выхода AXW при
его нахождении в состоянии W{i).
Из этой общей схемы автомата поиска можно получить
различные известные автоматы (алгоритмы), поиска. Если
элементы матрицы АС(АХ{^) только 0 и 1, то имеем алгоритм
случайного поиска с покоординатным самообучением [1, 17, 18, 22—
25]. Если элементы матрицы АС(АХ{^) не зависят от выхода
автомата AX{i\ /=1, ..., vy а элементы матрицы Т равны 0 и 1, то
имеем алгоритм оптимизации коллективом независимых
вероятностных автоматов [2, 17, 18]. Когда элементы матриц АС(АХ{^)
не зависят от АХ{^ и равны 0 и 1, то имеем упрощенный
алгоритм покоординатного самообучения, что эквивалентно
коллективу оптимизирующих автоматов с детерминированными
переходами и случайными выходами [17, 21].
Алгоритмы покоординатного самообучения характеризуются
тем, что переходная функция ty(WN, AXNt AQN') автомата
детерминированная, а выходная функция p(AX\WN) случайная.
В алгоритме оптимизации коллективом независимых
вероятностных автоматов переходная функция ty(WN, AXN, AQN')
случайная и не зависит от выхода автомата AXN, а выходная функция
p(AX\WN) детерминированная. Оба эти алгоритмы
представляют разные направления случайного поиска. Сопоставление
работы случайного поиска с покоординатным самообучением и
коллектива оптимизирующих автоматов показывает их большую
общность с точки зрения конечного результата [8, 10]. Однако
автоматные модели этих алгоритмов .не гомоморфны [26], т. е.
как автоматы они не эквивалентны.
57"
00
Переходная функция
1
2
3
4
5
6
7
8
9
10
Случайный поиск с
покоординатным
самообучением
Случайный поиск с
упрощенным
покоординатным самообучением
Коллектив
оптимизирующих независимых
автоматов
Случайный поиск с
возвратом
Детерминированный
аналог случайного
поиска с возвратом
Случайный спуск
Гаусса-Зейделя
Последовательный
градиент
Параллельный градиент
Наискорейший спуск
WN+1 = $(WN. sgnAQ^, ДА-„)
WN+1 = q{WN, sgn\Q'N)
WN+l = p(WN\ sgn AQN)
WN = AXf
'TV
WN=AXN
WN=&X„
wn=axn
wn=axn
W0v = A*at
Здесь i|) и F—детерминирование функции, a p'(WN | sgnAQ'N),
роятностей.
Таблица 1
Выходная функция
p(AXN = p(AX\WN)
p(AXN = p(AX\WN)
AXN = F(WN)
&XN+1 = p(&X\sgn&Q'N)
&XN+l = ф (ДЛ^, sgn AQ'N)
^XN+i = P(^\sgaAQ'N)
Аллг+1 = i> (л*лг. sgn AQ'N)
bXN+\ = $(bXN, sgnAQ^)
AXN+1 = q(&XN, sgnAQ'N)
ДА'ЛГ+1 = 1|)(ДА-ЛГ, sgnAQ^)
p (Д X\ sgn Д Q'N) и p(AX\WN) —плотности ве-
Функционирование автомата (8), (9), в случайной среде (7)
описывается цепью Маркова с матрицей переходных
вероятностей [17, 18]
V
Л= ^i[(l-Sj)QU)A0^XU))i.SjQ(j)A1^XU% (Ш)
1-1
;где Q(у) — диагональная матрица порядка тХт:
QUh
qlfOO...O
О q2jO...O
О OO...qmJ
.Sj — определяется формулой (7). Если вероятности штрафов
дейЪтвий автомата Sj (/=1, ..., v) постоянны (оптимизируемая
функция Q(X) линейна с аддитивной помехой), то цепь
Маркова (10) однородная. В случае эргодичности этой цепи можно
найти ее предельные вероятности />=(рь ..., рт), которые
определяют предельные свойства автомата поиска.
До настоящего времени были рассмотрены только автоматы,
для которых элементы матриц переходных вероятностей (8) не
зависят от выходов автомата AXW. Результаты исследевания
поведения таких автоматов в стационарных и простейших
марковских случайных средах с двумя состояниями изложены в
"монографиях [27, 28]. Следовательно, исследование поведения
автомата (8) в случайных средах представляет интерес не
только для теории поисковой оптимизации, но также и для теории
коллективного поведения автоматов.
Использование автоматных моделей для описания алгоритмов
поисковой оптимизации позволяет получить не только
конкретные расчетные формулы, но и исследовать общие свойства
процесса поиска. Получены следующие общие результаты. Процесс
покоординатного самообучения при случайном поиске
представляет собой эргодическую марковскую цепь, если число d,
ограничивающее изменение координат w\ вектора памяти И^(|а^|=^
<£Zd, t=l, ..., п) удовлетворяет условию 0<d<l. При d=\ эта
цепь Маркова не эргодическая, т. е. предельные вероятности
вектора W зависят от его начального состояния W0 [17]. Если
вектор памяти W в процессе самообучения поиска изменяется
ло формуле
WN+l = WN-bsgn{AQN'HXN)\ 0<б^1,
то среднее предельное приращение Л1[Д<3] оптимизируемой
функции Q(X) в случае отсутствия помехи при вычислении
Q(X)9 т. е. при е(а)=0 не зависит от параметра б (скорости
изменения вектора W). В случае присутствия помехи при
вычислении Q(X), т. е. когда в формуле (2) &(а)Ф0, то величина
>M[AQ] больше тогда, когда величина параметра б «меньше [17].
59
Процесс самообучения поиска с использованием упрощенно*
го алгоритма покоординатного самообучения
WN+i = WN—esgnAQj/sgnlF* 0<б^1,
представляет собой неэргодическую марковскую цепь [17, 21].
Процесс самообучения поиска при оптимизации коллективом
независимых вероятностных автоматов представляет собой эр*
годическую марковскую цепь для любых значений параметра
г (0<г<1), где г — переходная вероятность из одного
состояния в другое автоматов, образующих коллектив [8, 10, 11, 17].
Существенным обстоятельством в процессах оптимизации
является то, чтобы хотя при бесконечном числе шагов поиска
(#->оо) был достигнут экстремум оптимизируемой функции
Q(X). Достижение экстремума в процессе поиска гарантируется
нерастекаемостью процесса поиска, т. е. свойством процесса
поиска не удаляться от точки экстремума функции Q(X). В
работе [29], используя условия .нерастекаемости марковского
процесса [30], найдены достаточные условия нерастекаемости
автоматного случайного поиска. Существование коллектива
вероятностных автоматов, в пределе (Л^-^оо) имеющей
целесообразное поведение в составной марковской среде, показано в
работе [31]. Эффективно работающие адаптивные коллективы
оптимизирующих автоматов предложены и исследованы
моделированием .на ЦВМ в работах [9, 12, 16, 32]. В работе [33]
вероятностный автомат определяется как дискретный случайный
процесс и там же предлагается исследовать алгоритмы
случайного поиска с использованием таких автоматов.
Изложенный автоматный подход позволяет синтезировать
оптимальные автоматы поиска [17]. Задача синтеза
оптимального автомата поиска заключается в определении таких матриц
переходных вероятностей автомата и матрицы выходных
вероятностей, при которых автомат поиска с максимальной скоростью
оптимизирует заданную функцию. Задача синтеза оптимального
автомата поиска решается путем нахождения предельных
вероятностей цепи Маркова (10) и последующей оптимизацией
некоторого функционала, оценивающего скорость процесса
оптимизации.
В классе алгоритмов случайного поиска с автоматным
самообучением построен оптимальный алгоритм для оптимизации*
одномерных (т=\) и двумерных (п = 2) кусочно-линейных
функций Q(X). При п=1 оптимальным является
детерминированный автомат поиска, а при п = 2 — вероятностный автомат
[17, 34] с матрицами переходных вероятностей
110 0 0
0 1 0 0
0 0 1 0
| 0 0 0 1
г лН
10 0 1 01
0 0 0 1
10 0 0
0 1 0 0
60
т=
и матрицей выходных вероятностей
А А _!_ А
16 16 16 16
А А А 1
16 16 16 16
А А А А
16 16 16 16
А А А А
16 16 16 16
Рассмотрим автоматные модели для класса алгоритмов
поиска без самообучения. Эти алгоритмы характеризуются тем, что
выбор текущего шага поиска зависит только от знака
приращения оптимизируемой функции AQ' на текущем шаге поиска,
и не зависит от предыстории поиска. К этому классу
принадлежат, например, следующие алгоритмы: случайный поиск с
возвратом, случайный спуск, Гаусса — Зейделя, градиента,
наискорейшего спуска [1, 17]. Выходная функция (4) автомата для
таких алгоритмов поиска совпадает с его переходной функцией
и имеет вид
p(LXN)=p(liX\sgnLQ„-l)
Пусть вероятности штрафов 5
(И)
j постоянны, т. е. случайная
(Q (X) аппроксимируется линейной
среда (7) стационарная
функцией).
Пусть автомат поиска делает только рабочие шаги и его
матрицы переходов имеют вид
Л0 = Г; Л = |1||, (12)
где / — единичная матрица (mXtn)\ m — количество состояний
автомата. Такой автомат поиска описывает алгоритм случайного
спуска, в соответствии с которым после удачного шага
продолжается спуск в том же направлении, а после неудачного шага
выбирается новое случайное направление спуска равновероятно
по всем направлениям [17, 19]. Функционирование этого
автомата в стационарной случайной среде описывается цепью
Маркова, которая для всех значений Sj¥=0 эргодическая. Ее
предельные вероятности равны
W(J§£) •'-1---л
(13)
Предполагая, что множество направлений спуска совпадает с
множеством положительных и отрицательных направлений
координатных осей (пг = 2п), имеем следующую формулу для
вычисления среднего приращения оптимизируемой функции на
одном шаге
61
*1«а-Й£)"!(.Ь-Ь)'
(14)
где
Sj =
т[1+Ф18
!-ф«
, j = 1,..., /г;
, y = Ai+l,.. .,2л,
ay —направляющие косинусы вектора градиента функции Q(X).
Пусть матрицы переходов автомата поиска имеют вид
10 1,1 т
Aq— 1» ^i —
1
1 0
где 1\ — единичная матрица порядка ((т— 1) X (т— 1)). Такой
автомат поиска описывает метод Гаусса — Зайделя, в
соответствии с которым после удачного шага продолжается спуск по
той же координате, а после неудачного шага переходит к спуску
по следующей координате [17, 19]. Функционирование этого
автомата в стационарной случайной среде описывается цепью
Маркова, которая эргодическая при <т=^0. Ее предельные
вероятности определяются формулой (13), а среднее приращение
оптимизируемой функции формулой (14). Следовательно, при
а=^0 предельные свойства алгоритма Гаусса — Зайделя
совпадают с предельными свойствами алгоритма случайного спуска.
Показано, что автомат (12) является оптимальным в классе
автоматов поиска, состояния которых совпадают с выходами
[17].
Аналогичные формулы для определения предельных
вероятностей цепи Маркова и среднего приращения оптимизируемой
функции Q(X) получены и для алгоритмов случайного поиска
с возвратом, детерминированного аналога алгоритма с
возвратом, алгоритмов последовательного и параллельного градиентов
и алгоритма наискорейшего спуска [17, 19].
Рассмотрим поведение вероятностных автоматов поиска,,
задаваемых формулой (11), в нестационарных случайных
средах. Пусть нестационарная случайная среда задается функцией
Q«>(*)=Se'(y)*i'
(16)
* = 1
вектор коэффициентов которой a<'*> = (ajy), ..., a{nJ)) (вектор
градиента функции) является случайным, принимающим
значения из конечного множества. Предполагается, что мощности
множеств состояний случайного вектора olU) и состояний LXW
автомата поиска одинаковы (т=2п) и, что удовлетворяются
условию [38,39]:
olW=£lXW, ...,a<«> = A*(»>; (17)
62
АЛЧН-Ю^—АЛЧ'), / = 1,...,я.
Вероятность штрафа i-того действия автомата поиска при
нахождении оптимизируемой функции Q<'> (X) в у-ое состояние
определяется формулой
S|y, = Bep(c = l|AX = AX('), Q = Q(»(X)) =
»(')м (18>
-4[-+*ет
где AQy°—приращение оптимизируемой функции при
нахождении ее градиента в /-ом состоянии и при смещении в
пространстве параметров {X) по i-му направлению.
Поведение автоматов в простейших марковских случайных
средах рассмотрено в работах [27, 28, 31]. В работе [35]
показана целесообразность поведения детерминированного автомата
с линейной тактикой и двумя состояниями в марковской
случайной среде с двумя состояниями, переходные вероятности которой
зависят от состояния, в которой находится автомат, т. е. в среде,
которая описывается неоднородной цепью Маркова. Однако для
моделирования поведения оптимизируемых функций
различных классов, более удобно выбрать нестационарные
случайные среды более общего вида. Определим такие среды. Пусть
переходы среды из одних состояний в другие описываются цепью
Маркова с матрицей переходных вероятностей щ (/=1, ..., тх),
зависящей от двух последующих состояний автомата поиска:
*1=*(Л)=
х<'>
11
*(/>
хО , . ..хО
при /(ДХ^Д^л^Н/г (19)
Здесь /(ДЛ^, AA^-i), функция, определяющая выбор
нестационарной случайной среды из заданного наОора сред и
принимающая конечное число значений, т. е. /(ДЛлг» Д-^лг-Об
6{/ь • •-»//7ix}, где N номер такта работы автомата (номер
шага поиска). В работе [35] рассмотренная нестационарная
случайная среда получается из случайной среды (19) при
/ (Д^лг, ДХдг-1)=/ (kXN)=fl (l = \, 2). Далее конкретизируем
случайную среду (19) следующим образом [36 — 39]:
*г
■JV
при ЬХиФ—кХм-и
чН1*ЙМ1 при bxN=-bXN-u
(20)
где N — номер шага поиска. Это означает, что матрица хг
описывает изменение среды при изменении, как состояний
автомата ДАТ, так и времени ЛГ, а х2 — изменение среды при
постоянном состоянии автомата кХ и изменении только
времени N.
63
Обозначим через Л0 = ||Р^Н и А\ = \\Ъм II (*> * = 1, ..., т)
матрицы переходов автомата поиска при нештрафе (с = 0)
и штрафе (£ = 1) соответственно. Поведение автомата поиска
зависит от состояния случайной среды. В фиксированной
случайной среде QU) (X) оно описывается цепью Маркова
с матрицей переходных вероятностей
AU) = \\aWl
где
^-PiikO-^^Ti*^. /,A,7 = l,...,m. (21)
Поведение нестационарной случайной среды в свою очередь
зависит от состояния, в котором находится автомат поиска.
Для фиксированного состояния kX(i) автомата оно описывается
цепью Маркова с матрицей переходных вероятностей
Д(|> = |
°у*
где
*(0
6/А
(0-^W^+a^xjy, при i<n;
lO-^W^+e^,^. при />*
У, k, / = 1, . ..,/ГС.
(22)
Будем говорить, что система поиск — объект находится в
состоянии (/, у), если автомат поиска находится в состоянии
&X{i\ а объект в состоянии Q{J)(X). Можно показать, что
тогда система поиск — объект описывается однородной цепью
Маркова с матрицей переходных вероятностей
A = \\Ti*\\,
где
Т,
ik~
/т(1) а(*>
(m) g(0
Л/Ле
ml
dik
(/71) *(*)
^лглг
/, £=1, . . ., /Я.
(23)
Исследование поведения автомата поиска в нестационарной
случайной среде (20) сводится к исследованию однородной
цепи Маркова (23). Если цепь Маркова (23) эргодическая, то
существуют ее предельные вероятности:
Р = (р[», ..., р\т«\ р?>,..., р\т*\ ..., /><•>,.. •, р***). (24)
Предельные вероятности р\^ являются функциями переходных
вероятностей автомата р£Л, ^ik (/, £ = 1, ..., т) и переходных
вероятностей среды *$, х<2> (у, Л=1, -.., т*)
р\»=р\]) (Pa, ti*; *}У> *#; *,(/))« (25)
64
Функционирование автомата А в нестационарной случайной
среде оценивается некоторым функционалом от параметров
среды и автомата:
/=/(^,Ti*;^,.^,;sp). (26)
В качестве функционала (26) можно выбрать, например, сред
ний штраф автомата, среднее приращение оптимизируемой
функции и другие величины, характеризующие работу системы
поиска. Задача построения оптимального автомата для
нестационарной случайной среды (20) заключается в нахождении
таких переходных вероятностей р/Л, -\ik (/, & = 1, ..., т) автомата
Л, при которых функционал (26) принимает экстремальное
значение, т. е.
/* = extr/i
*lk*4lk
'i*.Ti*;*JV.^^iy))-
(27)
Таким образом, задача построения автомата, оптимально
действующего в нестационарной случайной среде (20), сводится
к нахождению предельных вероятностей цепи Маркова (23)
и последующего решения экстремальной задачи (27).
Пусть матрицы (20) имеют вид
8 1—8 0 0...0 01
0
1-80...0 0
х2 =
1-8 0 0
1 0 0...0 0
0 1 0...0 0
0 0 0...0 1
0...0 8
при ИХыф-Ь.Хы_1
при LXN=-LXN_l
(28)
(29)
Здесь б — параметр, определяющий скорость изменения
нестационарной случайной среды (0^б^1). При 6 = 1 случайная
среда стационарная.
Эта среда представляет собой модели различных функций,
которые могут описать реальные задачи оптимизации. Матрица
(28) описывает изменение оптимизируемой функции Q(X) при
изменении ее аргумента X. При б, близком к единице функция
изменяется медленно, а при б, близком к нулю она изменяется
быстро. Таким образом, при помощи матрицы (28) можно
моделировать функции с различными свойствами. Матрица (29)
оставляет оптимизируемую функцию без изменения. Это
соответствует тому, что при возврате в процессе поиска в
предыдущее состояние значение оптимизируемой функции не изменяется.
Рассматривая в качестве функционала'(25) средний штраф
действий автомата поиска
5—6065
65
7=2I>'y)sH\ (30)
для нестационарной случайной среды (28) — (29) получен
следующий оптимальный автомат поиска [38, 39].
При 0,5<8<1:
Лп =
При 0<8<0,5:
Ао =
11 0 0 01
0 1 0 0
1 0 0 1 0
|| 0 0 0 1|
, Л =
10 1 0 01
0 0 10
0 0 0 1
11 0 0 о)
(31)
10 1 0 01
0 0 10
0 0 0 1
||1 0 0 0
\ Al\
11 0 0 Oil
0 1 0 0
0 0 1 0
10 0 0 1|.
(32>
Из матриц (31) и (32) следует, что при оптимизации
медленно меняющихся объектов 0,5<6<1 после удачного шага поиска
следующий шаг необходимо делать в том же направлении, а
после неудачного шага поиска следует переходить к
оптимизации по следующей координате. Это соответствует известному
алгоритму Гаусса — Зейделя. При оптимизации быстро
меняющихся объектов 0<6<0,5 после удачного шага поиска следует
переходить к оптимизации по следующей координате, а после
неудачного шага поиска необходимо делать шаг в том же
направлении, т. е. ожидать перехода объекта в это состояние. При
6 = 0,5 можно пользоваться как первым, так и вторым
алгоритмом оптимизации. Оптимальный автомат поиска для
нестационарной случайной среды (28) — (29) построен также для случая,,
когда не выполняются условия (17). Вместо выполнения
условия (17) требуется, чтобы случайные направления градиента
оптимизируемой функции Q^](X) совпадали с положительными
и отрицательными направлениями координатных осей Х{ (i =
= 1, ..., п), и чтобы смещения AX{i) (i=l, ..., т) в
пространстве {X} были направлены по вершинам п — мерного гиперкуба.
В качестве функционала (26) выбрано среднее приращение
оптимизируемой функции Qij)(X) (на одном шаге поиска:
тх т
МIAQ] =2 2 < ЬХтР\'\ grad QU) (X) > ,
/=11=1
(33>
где скобки < , > обозначают скалярное произведение
векторов.
В этих условиях получен следующий оптимальный автомат
поиска [17, 36, 37].
66
При 2/3-
п 6—
При
<8<1:
11 00 01
0 10 0
0 0 10
|0 0 0 1
>
щ— <8<т
л,=
10 0 1 01
0 0 0 1
10 0 0
10 1 0 о||
(34)
Ап =
2-6
4(1-6)
О
2—36
4(1-6)
О
О
2-6
4(1-6)
О
2—36
4(1-6)
2—36
4(1-6)
О
2-6
4(1-6)
О
О
2—36
4(1-6)
О
2-6
4(1-6)
и,=
10 0 1 Oil
0 0 0 1
10 0 0
|0 1 0 о|
(35)
При 0<8<
б-Уб
ю
Л =
О
3-26
8(1-6)
1 — 26
3—26 1—26 3—26
8(1—6) 4(1—6) 8(1—6)
q 3-26 1-26
3—26
О
3-26
8(1 — 6) 4(1 — 6) 8(1—6)
8(1-6) 4(1 — 6)
3-26
4(1-6) 8(1-6)
3—26 1 — 26
8(1-6)
О
u=
10 0 1 Oil
0 0 0 1
10 00
|о 1 оо|
(36)
Следовательно, для рассмотренной ситуации, при .оптимизации
медленно изменяющихся объектов оптимальным является
детерминированный автомат поиска, а при оптимизации быстро
изменяющихся объектов — вероятностный автомат поиска.
Пусть переходная матрица случайной среды (19) имеющей
два состояния, зависит только от текущего состояния AXN
автомата поиска [35, 40], т. е.
1-8, 8t
х,=х(ДХ(1)) =
*2 = *(ДХ(2)) =
(37)
I ^2 * — ^2 |
У]2 1—^2 1
Оптимальный автомат поиска строим в классе автоматов,
задаваемых переходными матрицами:
л=
р 1-р
1-р р
т 1-т
1—т т
(38)
5*
67
Качество функционирования построэнного автомата поиска
будем оценивать по величине среднего штрафа действий
автомата (по формуле (30)). В перечисленных условиях оптимальным
является автомат со следующими матрицами переходных
вероятностей [40].
1 0
0 1
Ах =
(39)
т 1-т
1-7 Т
где 0<7< 1.
Следовательно, для нестационарной случайной среды (37)
так же как для стационарной случайной среды (7)
оптимальным является алгоритм случайного спуска.
ЛИТЕРАТУРА
1. Растригин Л. А. Статистические методы поиска. М., «Наука», 1968.
2. Растригин Л. А. Случайный поиск как стохастический автомат. —
В кн.: «Проблемы статистической оптимизации». Рига, «Зинатне», 1968,
стр. 5—'14.
3. Ней марк Ю. И., Г р иг о,р емко В. П., Рапопорт А. Н. Об
оптимизации и опознания.— «Проблемы передачи информации», 1965, № 3.
тами. — «Ученые записки НИИ ЛМК ГГУ им. Лобачевского». Горький,
1967, стр. 148—166 (Ротапринт).
4. Растр и гни Л. А., Рипа iK. К. Представление случайного поиска в
качестве стохастического автомата. — В кн.: «Задача статистической
оптимизации». Рига, «Зинатне», 1971, стр. 3—13.
5. Р и п а К. К. Случайный поиск экстремума многомерного объекта как
стохастический автомат. — В кн.: «Задачи статистической оптимизации».
Рига, «Зинатне», 1971, стр. 16—30.
6. Растригин Л. А., Рипа К. К. Статистический поиск как
вероятностный автомат. — «Автоматика и вычислительная техника», Рига, 1971,
№ 1, стр. 64)—55.
7. Г р и г о р е « к о В. П., Н е й м а р к Ю. И., Рапопорт А. Н.
Оптимизация коллективом независимых автоматов и игры автоматов. — «Изв. высш.
учебн. завед.», «Радиофизика», 1968, № 7, стр. 1019—1027.
в. Рипа К. К. Сравнение статистических свойств оптимизирующих
автоматов и случайного поиска.—В кн.: «Вопросы кибернетики и
вычислительной математики», вып. 28. Ташкент, 1969, стр. 168—177.
9. Григоренко 'В. П., Не им а р.к Ю. И., Рапопорт А. П. Об одной
гомеостатической модели оптимизации. — В кн.: «Вопросы кибернетики и
вычислительной математики», вып. 28. Ташкент, 1969, стр. 151—159.
10. Рипа К. К. Некоторые статистические свойства оптимизирующих
автоматов и случайного поиска. — «Автоматика и вычислительная техника»,
1970, № 3, стр. 28—Q2.
11. Григоренко Б. П., Рапопорт А. П. К теории поиска коллективом
•независимых автоматов. — «Изв. высш. учебн. завед.», «Радиофизика»,
1970, № 11, стр. 1726—1735.
12. Григоренко В. П., Неймарк Ю. И., Рапопорт А. Н., Ро-
нин Е. И. Оптимизация коллективом независимых автоматов с
адаптацией.— В кн.: «Задачи статистической оптимизации». Рига, «Зинатне»,
.1971, стр. 31—43.
13. Г р иго р е нко В. П., Неймарк Ю. И., Рапопорт А. Н.,
Ронян Е. И. Коллектив независимых стохастических автоматов как
поисковая оптимизационная система. — «Изв. высш. учебн. завед.»,
«Радиофизика», 1072, № 3, стр. 366—375.
68
14. Гр и горен ко В. П., Неймарк Ю. И., Мухии В. И.,
Рапопорт А. Н., Ронин Е. И. Оптимизация коллективом независимых
стохастических автоматов структуры игрового автомата. — «Автоматика и
вычислительная техника», 1972, № 2, стр. 41—60.
15. Н е й м а р к Ю. И. Автоматная оптимизация. — «Изв. высш. учебж за-
вед.», «Радиофизика», 1972, JST? 7, стр. 967—971.
16. Мухин В. И., Неймарк Ю. И., Ронин Е. И. Автоматная
оптимизация с эволюционной адаптацией. — В кн.: «.Проблемы случайного
поиска», вьоп. 2. Рига, «Зинатне», 1973, стр. 83—97.
17. Р а с т р и г и н Л. А., Р и п а К. К. Автоматная теория случайного
поиска. Рига, «Зинатне», 1973.
18. Рипа К. К. Алгоритмы самообучения при случайном поиске как
вероятностные автоматы. — В кн.: «Проблемы случайного поиска», вып. 2.
Рига, «Зинатне», 1973, стр. 99—ili26.
19. Растригин Л. А., Рипа К. К. Детерминированные методы поиска
как конечные автоматы. — В кн.: «Проблемы случайного поиска», вып. 2.
Рига, «Зинатне», 1973, стр. 51—81.
20. «Теория и применение случайного поиска». Под общей редакцией
Л. А. Растригина. Рига, «Зинатне», «1969.
21. Рипа К. К. Свойства системы оптимизации коллективом независимых
автоматов со случайными выходами.—-В кн.: «Проблемы случайного
поиска», вьгп. 3. Рига, «Зинатне», 1974, стр. 27—41.
22. Растригин Л. А., Рипа К. К. Моделирование обучения при
экстремальном регулировании мнссапараметрических систем методом
случайного поиска. — «Автоматика», Киев, 1964, № 5, стр. 55—63.
23. Растригин Л. А., Рипа К. К. Применение цепей Маркова к описанию
и исследованию динамики покоординатного обучения при статистической
оптимизации многопараметричеоких систем. — В кн.: «Методы
статистической оптимизации». Рига, «Зинатне», 1968, стр. 1131—il48.
24. Рипа К. К. Динамика покоординатного обучения при статистической
оптимизации в обстановке помех. — «Автоматика и вычислительная
техника», 1967, № 3, стр. 26—31.
25. Рипа К. К. Динамика покоординатного обучения с малой
интенсивностью при статистической оптимизации в обстановке помех. — В кн.:
«Проблемы статистической оптимизации». Рига, «Зинатне», 1968,
стр. 51—62.
26. Рипа К. К. Об эквивалентности алгоритмов самообучения при
случайном поиске. — В кн.: «Проблемы случайного поиска», вып. 4. Рига,
«Зинатне», 1975, стр. 66—84.
27. Цетлин М. Л. Исследование по теории автоматов и моделированию
биологических систем. М., «Наука», '1969.
28. Варшавский В. И. Коллективное поведение автоматов. М., «Наука»,
1973.
29. Мухин В. И., Неймарк Ю. И., Ронин Е. И. О нерастекаемости
случайного автоматного поиска.—В кн.: «Проблемы случайного поиска»,
вып. 3. Рига, «Зинатне», 1974, стр. 9—ч16.
30. Не й м а р к Ю. И. О нерастекаемости марковских процессов. — В кн.:
«Теория колебаний, прикладная математика и кибернетика». «Ученые
записки НИИ ПМК ГТУ им. Лобачевского». Горький, 1973, стр. 4—14.
31. Неймарк Ю. И., Ронин Е. И., Мухин Е. И. О «некоторых
структурах целесообразного поведения в изменяющихся средах.--В кн.:
«Проблемы случайного поиска», вып. 4. Рига, «Зинатне», 1975, стр. 18—31.
32. Неймарк Ю. И., Ронин Е. И., Мухин В. И. Автоматный
оптимизатор с адаптацией.—В кн.: «Теория колебаний, прикладная математика
и кибернетика». «Ученые записки НИИ ПМК Г.ГУ им. Н. И.
Лобачевского». Горький, il973, стр. 28—37.
33. М а й б а у м Г., М ю л м а н н П., Н и х т В. Стохастический автомат н ме-
69
тод случайного поиска. — В кн.: «Проблемы случайного поиска», вып. 3.
Рига, «Зинатне», 1974, стр. 17—126.
34. Рипа К. К. Синтез оптимальных алгоритмов в классе алгоритмов
случайного поиска с автоматным самообучением. — В кн.: «Проблемы
случайного поиска», вып. 3. Рига, «Зинатне», Ш74, стр. 42—66.
35. Т s u j i H., M d z u m о t о М., Т о у о d a J., T a n a k а К. An Automation
in the Nonstationary Random Environment. — «Inf. Sci.», Apr. 1973, v. 6,
№ 2, pp. 123—142.
36. Pa стриг и н Л. А., Рипа К. К. Синтез оптимальных алгоритмов в
классе алгоритмов дискретно распределенного случайного поиска для
Марковских объектов оптимизации. — «Автоматика и вычислительная
техника», 1971, № 6, стр. <16-Ч22.
37. Рипа К. К. Оптимальные алгоритмы дискретно распределенного
случайного поиска.—iB кн.: «Проблемы случайного поиска», вып. 1. Рига,
«Зинатне», 1972, стр. .19—(44.
38. Р и п а .К. К. Построение оптимальных алгоритмов в классе
некоординатных алгоритмов поиска для Марковских объектов оптимизации. — В кн.:
«Проблемы случайного поиска», вып. 5. Рига, «Зинатне», 1976, стр.
97—112.
39. Растр и г ин Л. А., Рипа 'К. К. Оптимальные автоматные алгоритмы
поиска в нестационарных случайных средах. — В кн.: «Проблемы
случайного поиска», вып. 6. Рига, «Зинатне», 11977 '(в печати).
4Q. Рипа К. К. Синтез оптимального автомата, действующего в
нестационарной случайной среде. — В кн.: «Проблемы случайного поиска», вып. 6.
Рига, «Зинатне» 1977 '.(в печати).
УДК 62-506
О НЕИРОБИОНИЧЕСКИХ АЛГОРИТМАХ
МАТРИЧНОГО СЛУЧАЙНОГО ПОИСКА
С. Н. Гринченко
(Ростов-на-Дону)
Проблема разработки алгоритмов статистической
оптимизации (случайного поиска) является, как известно, весьма
актуальной. Для синтеза таких алгоритмов, наряду с
эвристическими методами, в последнее время все шире привлекаются и
бионические подходы. Такие подходы интересны в теоретическом
плане и вполне оправдывают себя на практике, ибо дают
возможность воспользоваться в области технической кибернетики
теми высоко эффективными управляющими и
оптимизирующими механизмами, которые выработала живая природа .за многие
и многие миллионы «итераций» своей эволюции [1].
Ниже кратко излагаются основные этапы синтеза метода
«матричного» случайного поиска, разработанного на основе
привлечения нейробионического подхода, .который использует
полученные биологами в самое последнее время сведения о
функционировании нервной клетки.
70
МОДЕЛИРОВАНИЕ НЕЙРОННЫХ СЕТЕЙ
ИЗ ДИНАМИЧЕСКИХ И ОПТИМИЗИРУЮЩИХСЯ НЕЙРОНОВ
<,+i)_JA(J+1)*(J) —*(S+1)» ПРИ
х ~~ \0, при
0)
Рассмотрим особенности функционирования одной простой
модели сети динамических нейронов (оди,н такт дискретного
времени), связанных по схеме полного графа («полной сети»),
т. е. «каждый с каждым». Пусть х= (хи ..., хп) —-вектор
сигналов в сети (мгновенных частот импульсаций нейронов); s —
номер такта дискретного времени; А=||а^|| — квадратная
матрица весов связей между .нейронами (ее строки аг- представляют
собой векторы коэффициентов чувствительности входов i-x
нейронов); h — вектор порогов (нейронов: h=(hu ..., hn).
Тогда для полной сети динамических нейронов справедливо:
ACH-Djd*) — А<»+и>0;
A(*+i)jc(s)_A(s+i)<o.
Представим матрицу А в виде суммы единичной и
«дополнительной» матриц:
k = I + R. (2)
С учетом этого выражения (1) перепишется следующим
образом:
х (*+п =
(xW + Ris+VxW —.¥*+"> при x0» + #(*+i>jc<s) — А<*+*)>();
= 10, при jc^+/?^+1U-^-A^+1)<0. (3)
Структурная схема итеративного процесса в полной сети
динамических .нейронов может быть изображена, по аналогии с [2],
следующим образом:
Рис. 1
Д—дискретный интегратор, =ф—векторы, д^—матрицы
Как легко видно, все особенности указанного итеративного
процесса определяются выбором двух независимых параметров
J} и А.
На основании анализа результатов нейроцитохимических и
нейрофизиологических экспериментов, проведенных в последнее
время кандидатом биологических наук С. Л. Загускиным, нами
была предложена модель «оптимизирующегося нейрона» или
«оптрона» [3—5], в которой выбор параметров щ и hi (i —
.номер оптрона в сети) осуществляется с памощью блоков соответ-
71
ственно много- и одноканального экстремального регулирования
(оптимизации). Эти оптимизационные механизмы осуществляют
поиск таких значений а{ и hiy которые доставляли бы минимум
некоторому функционалу, зависящему либо от внутренних
параметров нейрона Сг(ф(Яг, Лг), *г), либо задаваемому извне
С{*(х) —как это происходит в одном из вариантов модели
оптрона — «d-модификации».
Для i-то оптрона, являющегося составной частью полной
сети, можно записать итеративные законы изменения
параметров:
(4)
dht
где: а и p— матрицы коэффициентов поисковых итеративных
процессов; ^ — символ «оценки» градиента (частной
производной), которая производится оптимизаторами по тому или
иному способу. Отметим, что независимые параметры а{ и hb
влияют на значения соответствующих переменных в сети: xt =
= xi(ahhi).
Введем оператор «матрицирования» М —оператор,
преобразующий нексторый вектор z = (zu ..., zk,..., zm) в диагональную
матрицу с элементами Zkk = zk, а также обратный к нему
оператор М""1, преобразующий некоторую диагональную матрицу
Z в вектор-столбец z с элементами zk = Zkk. Введем, кроме
того, оператор «матричный градиент» вида Wa= U—Л-
Обозначим Т операцию транспонирования матрицы.
Тогда для оптронной сети можно записать аналогично (4):
A(*+i) = л<*> _ ai(s+1)(Wl [MC (хЩ}Т\
д(*+1) = Д(в)-р{«+») .м-1 {(Mv„) [MC (.*<*>)]};
причем х = х(А, К).
Итеративный процесс изменения матрицы межнейронных
связей А запишем в форме итеративного процесса изменения
дополнительной матрицы R, т. е. с учетом выражения (2):
R<*H) = Rw _ тГ^!). {w^ [S\C (jc<5>)]}t.
Структурная схема итеративного процесса в полной сети
оптимизирующихся нейронов может быть изображена следующим
образом (рис. 2).
В нейрофизиологических экспериментах часто наблюдается
ситуация, когда группа соседних, тесно связанных между собой
нейронов, расположенных в области ветвления одного
афферентного волокна, работает синхронно, образуя «агрегат» или
«ансамбль» нейронов. В терминах d-модификации модели
72
I
1
31
Рис. 2
оптрон.ной сети такая группа неиро-нов может рассматриваться
как полная сеть, а сигнал, приходящий по афферентному
волокну на каждый из нейронов сети — как общая для всех
нейронов скалярная целевая функция q(x), заменяющая в этом
случае векторную целевую функцию С*(х). Это приводит к
упрощению выражений, описывающих функционирование
поисковых оптимизационных процессов в такой сети:
(5>
A(5+i)==A(s)_a^+i) .WAq(x) либо
R(^i) = R(^)-t^+1).Wr^(jc);
Л(5+1> = h(S) _ p^+n. ^hq (jc).
Итак, в сетях оптимизирующихся нейронов итеративные
процессы изменения переменных и параметров организованы в два
этапа: итеративно связанные между собой реализации вектора
сигналов в сети х выбираются в зависимости от итеративных
же (причем .независимых и происходящих параллельно)
процессов оптимизации параметров сети A(R) и h.
Анализ поведения микроструктурных образований в
реальном нейроне и некоторые другие данные позволяют сделать
вывод о характере алгоритмов итеративных поисковых процессов
изменения параметров оптронной сети. Они, несомненно,
относятся к классу алгоритмов случайного поиска, в которых выбор
оценок градиента ^q и матричного градиента W<7, а также
выбор коэффициентов итеративных процессов а (у) и 0,
осуществляются с помощью случайного варьирования поисковых
параметров A(R) и Л.
73
МОДЕЛЬ ОПТРОННОИ СЕТИ КАК АНАЛОГ АЛГОРИТМА
МАТРИЧНОЙ ПОИСКОВОЙ ОПТИМИЗАЦИИ
Проанализируем теперь особенности поведения сети
оптимизирующихся нейронов с целью выявления возможности
использования какого-либо варианта алгоритма ее функционирования
для решения типовой задачи поиска экстремума .некоторой
многомерной функции: min Q(x).
х£Х
Для этой цели рассмотрим наиболее простой вариант модели
оптрон-ной сети — ее d-модификацию (5). Введем очевидное
обобщение процессов (1), (3)—расширим область
существования вектора на все пространство (т. е. снимем условие
положительности частот). Тогда:
(Xis+v = А^+^х^ — A<*+!>;
А(*и> = А<*> - a3(s+1) - WAQ (je <*>);
[й<*-и> = АО — $*1) • VAQ (jcW).
или
(X{S+1) = X(S) + R(S+1)^(e) __ £<S+1) ; a).
R(s+D = ^(s)_T(^).w^Q(^)); 6). (6)
[*<•+!> = *(*) - ^s+1) • v„Q (*<«>). в).
Структурная схема итеративного процесса (6), который
можно назвать матрично-векторным процессом параметрической
поисковой оптимизации, представлена на рис. 3:
Рис. 3
Известно, что итеративный процесс поисковой оптимизации
общего вида записывается следующим образом [2]:
*<*+!> =*<*> —D<*+l) • VQ (*<*>),
где: D — коэффициент итерации.
(7)
74
Сравним его с полученным нами ранее двухэтапным
итеративным процессом матрично-векторного поиска (6), для чего
перепишем .выражение (6) в разностной форме:
jAjcW^rm-DjcW _й<*+1>; а).
AR(*) = -Ti,+l)-WRQ(^)); б). (8)
[АЛ <*> = - pc*+i>. vAQ (*(,)). в).
Члены, стоящие в правой части (8а), представляют собой
полное смещение вектора х в направлении минимума функции
•Q(jc). Ввиду того, что в это выражение входят два
независимых поисковых параметра R и А, представим общее
приращение Дх на s-том шаге как сумму приращений,
обусловленных изменениями поисковой матрицы R и поискового
вектора k: Ax<*) = Ajc[f)+^i,)- Легко видно, что: Axr =
= {AR}jc; Ахл = ДА. (9)
Подставив в (9) значения AR и ДА из (8), получим
окончательно рекуррентную форму итеративного процесса матрично-
векторного поиска:
Xis+i) = x(s)- [T^+i>. W/?Q(*<*))] jc<*> - pj*+«. v„Q (*<*>). (10)
Сравнение выражений (7) и (10) позволяет прийти -к
выводу, что последнее является обобщением процесса (7) на случай
комбинированного матрично-векторного процесса оптимизации.
Принятие матрицы R равной нулю (т. е. А = 1) приводит к ну-
левому значению оператора W(-) и, таким образом, сводит
процесс (10) к виду (7).
АЛГОРИТМЫ МАТРИЧНО-ВЕКТОРНОЙ ^
СЛУЧАЙНОЙ ОПТИМИЗАЦИИ
Выше уже говорилось о том, что определенные
биологические соображения указывают на вероятностный, случайный
характер процессов оптимизации -в оптроне (оптронной сети).
Следовательно, и в процедурах (6), (8), построенных как их
аналоги, соответствующие алгоритмы также следует выбрать
случайными. Реализация процедур (6 6, в) как процедур
случайного поиска .состоит в то.м, что величины поисковой матрицы R
и поискового вектора h выбираются случайными: R = ∈ Л =
= k2S (где: ku k2 — некоторые коэффициенты), причем в
простейшем случае стро,ки случайной матрицы Яг=(ягь . ••> тип) и
случайный вектор 5=(gi, ..., £п) принимаются равномерно
распределенными по поверхности единичного /г-мерного
гиперкуба.
Целенаправленность поиска может быть обеспечена,
например, выбором величин поисковых параметров аналогично
{8 6, в):
75
AR(,+i) = _w(*+i). wnQ (*<*>);
ДА(^+1)= — (МЕС+1)). VaQ(^(5));
при этом х = х(к, Е).
Подставляя эти выражения непосредственно в (8а), полу*
чим процесс, аналогичный процессу (10), но отличающийся
конкретизацией вида коэффициентов итерации Тз и Рз-
jc(*+D=rjc(*) —[icC+^.WrtQtJcOMjcW— (MS^+^-VeQ (*<*>).
Целенаправленность поиска может быть достигнута и
другими способами, например выбором величин поисковых
параметров согласно выражениям:
<x(s+l) = X(s) + R{s+l)x(s) _£(*).
R(H-U = | ^ при g (JC(,+D) > Q (*<*>);
L(#4n iS(*+1)* ПРИ Q(^+1,XQ(^);
l*(* )==l 0, при Q(x«+V)>Q(x&).
Структурная схема итеративного процесса матрично-вектор-
наго случайного поиска, организованного согласно последнему
выражению, может быть представлена следующим образом:
(5*1)
Рис. 4
ЗАКЛЮЧЕНИЕ
Подытоживая все вышеизложенное, сформулируем два
основных нейробионических положения, использованных нами в
процессе синтеза алгоритмов матричного случайного поиска:
1) специфический характер итеративного функционирования
моделей нейронных сетей, содержащих оператор линейного
преобразования А:
Особенность их поведения заключается ,в том, что изменение
вектора переменных сети х осуществляется не только измене-
нием вектора порогов нейронов Л, суммирующимся с х> но и
76
изменением матрицы весов связей в сети А — матрицы
коэффициентов чувствительности входов нейронов — умножающейся
на х.
2) поисковый характер регуляторных процессов, происходящих в
нервной клетке, и в частности — процессов оптимизации
энергетики, трофики и функции в нейроне. Эта важнейшая их
особенность выявлена в последнее время с помощью тонких нейроци-
тохимических и нейрофизиологических экспериментов; именно
она позволила обосновать введение в модель нейрона
механизмов типа одно- и многоканальных экстремальных регуляторов
(оптимизаторов), работающих по методу случайного поиска.
Взаимодействие .между этими алгоритмическими механизмами
и структурными связями, существующими в нейроне, и дали
нам возможность синтезировать алгоритмы, названные
алгоритмами матричного и матрично-векторного случайного поиска
[6-8].
Каждый из перечисленных фактов в отдельности
представляет лишь определенный теоретический интерес; взятые же
вместе, они послужили основой практически важной
бионической разработки — позволили совершить переход от результатов,
полученных биологами — через кибернетическую модель — к
технико-кибернетической системе. Таким образом, нейробионичес-
кий подход облегчил процесс синтеза алгоритмов матричного
■случайного поиска, позволил при их создании использовать
термины, результаты и наглядные представления, полученные
при моделировании нервной клетки, а также дал возможность
заменить -произвольные эвристические посылки некоторыми
вполне определенными, обоснованными биологами положениями.
Дальнейшее развитие указанного подхода, несомненно, даст
возможность выдвинуть новые идеи в области технической
кибернетики, и в частности — в теории случайного поиска.
ЛИТЕРАТУРА
1. Растригин Л. А. Случайный поиск — проблемы, пути и перспективы.
В кн.: «Вопросы кибернетики. Проблемы случайного поиска». М., 1973,
стр. 3—17.
2. Ц ы п к и н Я. 3. Адаптация и обучение в автоматических системах. М.,
«Наука», 1908.
3. Гринченко С. Н., Загускин С. Л., Загускина Л. Д. Модель
оптимизации энергетики нейрона. — В кн.: «Проблемы бионики», вып. 15.
Харьков, изд. ХГУ, стр. 71—$0.
4. Коган А. Б., Гринченко С. Н., Загускин С. Л. Устройство для
■моделирования нервной клетки. Авт. свидетельство СССР № 494752 с
приоритетом от 27.05.74 — «Открытия, изобретения, промышленные
образцы, товарные знаки», 1975, № 45, стр. 146.
5. Гринченко С. 1Н., Загускин С. Л. Моделирование функционально-
топохимических механизмов нейрона с использованием алгоритмов
поисковой оптимизации. — В сб.: «Математическая теория биологических
процессов». Калининград, 1976, стр. 383—н386.
77
6. Гринченко С. 'Н., Растригин Л. А. О матричном случайном
поиске.— «Автоматика и вычислительная техника», 1977, № 1, стр. 48—51.
7. Гринченко С. Н., Растр иг и н Л. А. Алгоритм матричного
случайного поиска.—В сб.: «Проблемы случайного шоиска», вып. .5. Рига, «Зи-
натне», 1976, стр. 167—1-84.
8. Гринченко С. Н. Синтез и анализ алгоритмов матричного случайного»
поиска. Автореферат диссертации «а соиок. уч. ст. канд. техн. наук. Киевг
УДК 62.506
АДАПТАЦИЯ И КАЧЕСТВЕННАЯ ТЕОРИЯ
ПРОЦЕССОВ
Е. С. Усачев
(Москва)
В этой статье делается попытка определить предмет теории
адаптации и выяснить ее связь с качественной теорией
процессов.
Процесс есть множество всех его историй, т. е. множество
всевозможных его траекторий Х-0000= (... хп ... Хо ... хп .. .)-
Назовем ее со — асимптотическим с (а — асимптотическим)
свойством траектории A"_oo°° любое свойство, не зависящее от
произвольной полутраектории Х_(Х>Г1=( хп) (от
полутраектории Хп°°=(хп ). Назовем простой ячейкой множества
Гт всех траекторий, обладающих одинаковыми ос- и
©-асимптотическими свойствами. Попросту говоря, траектории, попавшие
в одну Ть имеют одинаковое бесконечно далекое прошлое и
одинаковое бесконечно далекое будущее и отличаются друг от
друга только переходными режимами. Ячейкой назо-вем любое
объединение простых ячеек. Элементарной ячейкой назовем
простую ячейку, не содержащую собственных ячеек.
Элементарными ячейками являются неподвижные точки, циклы,
сепаратрисы, эргодические множества. Простыми ячейками являются
«естественные» объединения элементарных ячеек, например,,
инвариантные многообразия, содержащие в себе более одной
ячейки. Ячейками являются некоторые типы окрестностей
инвариантных множеств.
Фазовым портретом процесса называется схема разбиения
множества траекторий процесса на элементарные ячейки, т. е.
перечень элементарных ячеек с указанием их взаимного
расположения относительно друг друга.
Качественная теория процессов изучает типы ячеек, их
взаимное расположение и перестройку три непрерывном изменении
параметров, определяющих процесс.
78
О процессах можно говорить на разных математических
языках, и разные языки по-разному пригодны к разным
ситуациям. Язык фазовых портретов удобен при обсуждении
поведения процесса на бесконечном интервале времени. Однако он
совершенно не пригоден в начальной стадии, при создании
моделей процесса. Модели процесса естественнее всего описывать
в локальных и инфинитизимальных терминах, указав связь
предыдущего значения процесса с последующим. Для процессов с
дискретным временем такая связь обычно задается
рекуррентными уравнениями xn+i=f(xni n) и переходными функциями
Р(пу х, п+\у В). Если функция Ы » ) процесса *n+i=M*n, n)
является гладкой или хотя бы непрерывной, то рассмотрев
процесс #n+i =/2(^71, п) на конечном интервале времени с
достаточно близкими начальными условиями и при достаточно
близкой к функции /г, мы можем не заметить существенной разницы
между процессами xn+i=fi(xn, n+\). Если же для нас важно,
чтобы процессы xn+\=fi(xni n+\) были бы сходимыми и
близкими на бесконечном интервале времени, то для этого
необходимо и достаточно, чтобы фазовые портреты у процессов были
бы близки и подобны, т. е. чтобы ячейки первого процесса были
бы близко расположены к схожим с ними ячейками второго
процесса и чтобы фазовый портрет одного процесса можно было
бы отобразить в фазовый портрет другого процесса
взаимнооднозначным отображением Ф, мало отличающимся от
тождественного (иными словами sup р(Ф(я), *)<е, т. е. Ф недалеко
я
отодвигает образ Ф(х) от прообраза х и поэтому процессы
xn+i=fi(xnt n) £=1,2 и в целом малозаметно отличаются один
от другого).
Качественная теория детерминированных процессов изучает
типы ячеек и фазовых портретов процессов и их перестройки
при непрерывных изменениях параметров процессов, т. е. при
переходе от f\ и Д, где Д- мало отличаются одна от другой.
Качественная теория дискретных процессов xn+i=f(xn, n) и
процессов, описываемых дифференциальными уравнениями х' =
=f(x, t) по существу одинакова в том смысле, что здесь
имеются одинаковые типы ячеек и портретов, одинаковые типы
перестроек портретов и ячеек при непрерывном изменении
функций /. Поэтому при обсуждении какой-либо проблемы, связанной
с процессами, за модельный пример можно брать те процессы,
которые проще для обсуждения, а по существу ничем не
отличаются от самих общих типов процессов. Поэтому в
дальнейшем речь идет о процессах с дискретным временем.
Выше говорилось о качественной теории детерминированных
процессов. Однако все проблемы, стоящие в качественной теории
детерминированных процессов, возникают и в теории случайных
процессов. При этом наиболее естественно, видимо,
рассматривать проблемы качественной теории для случайно возмущенных
детерминированных процессов, ибо такие процессы объединяют
79
в себе своеобразие детерминированных и со своеобразием
случайных процессов и, естественно, ожидать, что здесь будут
весьма разнообразные ячейки и их перестройки, при изменении
параметров. Моделью случайно возмущенного
детерминированного процесса являются случайные динамические системы
jcn+i=f(xn, п> со), которые переходят из хп в xn+\=f(xny п, о) с
вероятностью р(со, п, хп). Случайные динамические системы
являются дискретными аналогами стохастических урав-нений
x'=f(x,tt(u) и обобщением дискретных процессов xn+\=f{xn> n).
Управляемой случайной динамической системой называется
марковская цепь xn+i=f(xnt иПу пу со), переходящая под
действием управления ип из хп в xn+i=f(xn, иПу п, со) с вероятностью
р((о, /г, хп, ип).
В дальнейшем под управляемым процессом будем
подразумевать управляемые случайные динамические системы.
Если какой-то объект / известен не полностью, то
математически это все равно, что точно известно .некоторое множество В
объектов, из которого выбран /. Под управлением в условиях
неопределенности понимают управление .неполностью известным
процессом. Поэтому математически задача управления в
условиях неопределенности формулируется как задача управления
процессом, про который известно, что он принадлежит точно
известному классу В.
Любой способ управления можно представить в виде
управляемого процесса (автомата) (фЬ ф2):
tt/i+l=<Pl(tt/i, 2/i *п* П, а>) (срх)
2/1+1 = ¥2 (Ял. 2Л> ■*/» ">, а>) (<р2),
где ип — управление, zn — состояние управляющего, хп —
состояние управляемого процесса.
Возьмем управляемый процесс xn+i=f(xn,un,n, <*>),
подключим к нему управляющий процесс и получим «обычный»
процесс (/ь <рь <р2):
Xn^l=f(Xn, tln, П, о)) (/)
Ял+1 = <Р1(Яя. Zn, Хп, /Z, <о) (срО
2я+1=<Р2(Я/1, 2Я, Хп, /Z, <о) Ы-
Все, что можно сказать о процессах управления, о их типах,
целях и результатах, все это может и должно выражаться в
терминах процесса (<pi, ф2), класса В и в терминах траекторий
составных процессов (/, фЬ ф2). И если мы хотим понять смысл
проблем адаптации, то нам следует обсуждать все в этих
терминах.
В общем случае было бы неправильно говорить только о
целях управления и об оптимальности управления. Не менее
естественной задачей управления является исследование методов
управления, которые не являются оптимальными и даже не дости-
80
гают цели управления. Примером управляющей системы, не
достигающей цели управления, является стохастическая модель
обучения, предложенная в [1]. Эта модель хорошо описывает
динамику ошибок при образовании условного рефлекса и
показывает полное согласие с экспериментом ,на тех классах
управляемых процессов, в которых модель не достигает цели.
Если говорить совсем точно, то эта модель не в состоянии
оптимально угадывать, какой из п сигналов R\ ..., Rn
появится на выходе устройства, выдающего сигнал Ri с
вероятностью Pi. Метод стохастической аппроксимации <в этом случае
стал бы с вероятностью 1 называть тот Ru для которого Р{ =
= maxPfc. Стохастическая модель обучения подобно всем живым
k
организмам в таких экспериментах в конце концов начинает
называть каждую Ri с вероятностью его появления Рг\
Учитывая общую концепцию условных рефлексов [2], этому факту
можно дать следующее истолкование. Сложные системы
обладают «физической» и «информационной» инерционностью и они
не могут быстро перестраиваться на новый режим работы и
управления. Поэтому они вынуждены прогнозировать будущие
ситуации и настраиваться на них заранее. Здесь возможны
ошибки двух типов. Первая ошибка — приготовиться к тому,
чего не случится, вторая ошибка — не подготовиться к тому, что
произойдет. Живые организмы, видимо, предпочитают не делать
ошибок второго типа и поэтому их поведение не является
оптимальным в некоторых ситуациях. Конечно, можно было бы в
каждом случае придумать искусственную цель или
искусственный критерий, дающий управление оптимальным. Но в
действительности часто приходится иметь дело с хорошей управляющей
системой, не достигающей цели управления. Поэтому в общем
случае надо рассматривать цели и результаты управления.
Естественно полагать, что цели и результаты управления
образуют а-алгебру F в пространстве историй управления, т. е. в
пространстве траекторий процесса y_ro~ = *-~<x>-ttoo00.2oo0°.
После этих предварительных замечаний попытаемся
сформулировать предмет теории адаптации. Это необходимо сделать
хотя бы потому, что -в этом вопросе существует большое
разногласие в мнениях, а главное, здесь имеется много путанных
высказываний, искажающих идею адаптации в глазах
специалистов по теории управления.
Например, один автор, давно пропагандирующий
теорию адаптации, утверждает: «Характерной особенностью
адаптивных систем, как средства управления, как
средства «принятия решения», отличающей их от процедур
математической статистики, является следующее. Статистические
выводы непременно сопровождаются ошибками (одного или
двух родов), вероятности которых положительны. Напротив,
«решения» адаптивных систем, принимаемые через конечное
время безошибочны».
6—6065 81
Выше уже говорилось, что управляющие системы, в том
числе и адаптивные, могут вообще не достигнуть цели и не принять
правильного решения. Далее мы увидим, что цели адаптации
обычно не достижимы за конечное время, хотя
адаптивная система очень быстро может начать вести себя
так, будто бы цель адаптации достигнута. Но самое
то главное, конечно, в том, что математическая
статистика в тех случаях, когда она может быть успешно
применена, дает результаты, во всяком случае на худшие, чем
теория адаптации. И если в математической статистике неизбежны
ошибки при принятии решений, то это вытекает из самой
природы вещей. Принципиально невозможно по конечному числу
случайных наблюдений (т. е. за конечное время) принять
безошибочное решение. Понимание этого факта и вынудило
статистиков ввести определение ошибок разного рода.
В чем же специфика процесса адаптации? Для ответа на
этот вопрос, прежде всего выясним возможные цели и
результаты адаптации, т. е. определим а-алгебру F целей и результатов
адаптации как процесса управления. Для этого подключим
адаптивную систему к управляемому процессу и дадим ей
возможность «адаптироваться», а потому подключим ее к другому
управляемому процессу. Естественно ожидать, что адаптивная
система «приспособится» и к этому процессу. И так, сколько бы
раз мы не меняли управляемость процесса, давая адаптивной
системе время для обучения, она не утратит своей способности
переучиваться и приспосабливаться.
Таким образом, цели и результаты адаптации не зависят
от любого конечного числа замен управляемого процесса. На
языке историй управления, т. е. на языке траекторий
процесса управления это означает, что цели и результаты
управления не зависят от любого начального куска траектории. Но
тогда а-алгебра целей и результатов управления определяется
совершенно однозначно. Это есть а-алгебра со-асимптотических
событий. Таким образом, цели и результаты адаптации есть
(о-асимптотические события ib пространстве траекторий процесса
управления. Это вытекает из одного только интуитивного
определения адаптации, как процесса управления, 'на окончательный
результат которого не влияет любое конечное число замен
управляемых .процессов, лишь бы в конце концов последний, не
заменяемый процесс был один и тот же.
Этим адаптация отличается от традиционных задач
математической статистики, в которых существует момент
окончательного и бесповоротного решения, после которого уже ничего
изменить нельзя. Типичной задачей классической статистики
является задача стрельбы самонаводящейся ракетой.
Предполагается, что если такой ракетой произведен выстрел, то она
должна быть рано или поздно взорвана. Момент взрыва есть
момент окончательного решения. В каждом конкретном случае
82
классическая статистика не гарантирует правильности решения,
но она гарантирует, что предлагаемая ей .процедура является
наилучшей процедурой при ее массовом использовании, т. е. при
многократной стрельбе.
Типичной задачей адаптации является задача стабилизации
неизвестного управляемого процесса (fa)£B в неизвестной
области Gay зависящей от стабилизируемого процесса.
Стабилизирован (fa) в области Ga, адаптивная система будет получать
наименьший штраф или будет с наибольшим успехом решать
какие-то другие проблемы. Как правило, со-асимптотические
события не достижимы за конечное время. Так траектории
дифференциальных управлений и гладких отображений xn+\=f(xn) не
достигают за конечное время неподвижных точек. В противном
случае нарушилась бы теорема единственности, утверждающая,
что через каждую точку X проходит единственная траектория
процесса. Хотя процесс стабилизации экслоненциально быстро
загоняет систему в любую окрестность неподвижной точки Х*9 он
тем не менее не вводит систему в саму точку X* за конечное
время. Аналогичное явление имеет место в случайно
возмущенных процессах, т. е. в теории стохастических дифференциальных
уравнений и в теории случайных динамических систем. Поэтому
исследование случайно возмущенных процессов ведется без
использования классической теоремы Деблина, с привлечением
новых методов — теории стохастических функций Ляпунова,
теории мартингалов и т. д. Таким образом, адаптивная система
достигает целей и результатов адаптации, как правило, «на
бесконечности», но .при этом может очень быстро достигнуть
«малой окрестности цели».
Подводя итоги всем проделанным рассуждениям, можно было
бы сказать, что теория адаптации есть теория управления в
условиях неопределенности на бесконечном интервале времени с
целями и результатами, образующими со-алгебру F^ со-асимпто-
тических событий в' пространстве историй управления. Однако
такое определение не совсем точно, хотя бы потому, что
управлением на бесконечном интервале времени с со-асимптотически-
ми целями занимается и теория оптимальных статистических
решений [4]. Чтобы понять отличие теории адаптации от теории
оптимальных статистических решений, следует
проанализировать сам термин неопределенность. Неопределенность бывает по
крайней мере двух типов. Неопределенность первого типа —
«неопределенность из-за незнания». Неопределенность второго
типа — «неопределенность из-за сложности». Теория
оптимальных статистических решений имеет дело с неопределенностью
первого типа, игнорирует «неопределенность из-за сложности»
и связанные с ней трудности. Типичным примером
неопределенности из-за сложности является задача численной оптимизации
известной функции и задача игры в шахматы.
Разыскивая оптимум какой-либо известной ему функции
6*
83
f(x) вычислитель обычно использует итерационную процедуру
хп+1 = ч>(хп, f(xn))> которая по локальным наблюдениям
значений f(xn) функции позволяет приблизиться к ее экстремальному
значению. Используя управляющую систему *п+1=<р(л;п, ип)
вычислитель ведет себя так, будто бы ему «неизвестна»
оптимизируемая функция и он может только наблюдать ее отдельные
локальные значения.
Другим примером задачи на неопределенность из-за
сложности является игра в шахматы. С точки зрения теории,
пренебрегающей вычислительными трудностями, игра в шахматы не
представляет собой серьезной проблемы. Если же учесть
неопределенность из-за сложности, то игра в шахматы становится
непостижимым искусством, граничащим с мистикой. Примитивно
♦рассуждая, автоматизацию игры в шахматы можно осуществить
двумя способами. Первый способ — обычный перебор всех
вариантов. Второй способ — построить на всех позициях z
оценочную функцию f(z) так, чтобы игрок, улучшающий с точки
зрения f(z) свою позицию на каждом шаге в конце концов
выигрывал бы партию. Такую функцию можно построить, перебрав все
вариации игры. Оба пути невозможны и поэтому непонятно,
как вообще можно делать правильно первые ходы, на которых
закладывается основа будущей победы.
М. М. Ботвинник высказывает в [4] много интересных
соображений об игре в шахматы, как о процессе управления
сложной системой. В частности, он предлагает ввести
многоуровневое управление игрой, определив для каждого уровня свои
задачи и цели. Его предложение, выражаясь языком физиологов,
порождает новую проблему — проблему интеграции — проблему
декомпозиции управления на уровни и проблему правил
соперничества «за конечный путь». Если наделить отдельные фигуры
личными целями, то между ними сразу же возникнет
соперничество за право первой достигнуть личной цели, аналогичное
соперничеству рефлексов «за конечный п^ть». При этом одни
фигуры, будут подобно рефлексам, стремиться подавить другие
фигуры того же цвета, т. е. заставить их уступить ход,
освободить место, пожертвовать собой и т. п.
Так борьба с неопределенностью из-за сложности заставляет
производить декомпозицию целей и систем управления, вводить
принципы интеграции, строить оценочные функции и т. д. и
т. п. При этом может оказаться, что неопределенность из-за
сложности не позволяет сразу найти правильные принципы
интеграции, правильную декомпозицию, правильную оценочную
функцию. Теория адаптации предлагает синтезировать все
необходимые структуры в процессе самого управления. Грубо
говоря, в «классической теории» сначала вводится класс В
управляемых процессов xn+\=ft{xn, иПу /г, со), потом синтезируется
управляющая система (фь фг):
84
2/|+1=<Р2(ЯЛ» ^я> Хп, П, о>) (ф2)
а потом начинается процесс управления (/Y, ерь ?г)- В теории
адаптации управляющая система (<рь ср2) считается неизвестной
и синтезируется в процессе управления. Поэтому процесс
адаптации описывается системой (/Y, Фь Ф2> Фз):
Xn+l=fy(X„ Un, П, <о) (Д)
Ия+1=Ф1(«я. «я. Уя. ХП9 П, ш) (фх)
2я+1=Ф2(>я> 2я> </я> -*я> ^, ш) (Ф2)
Уп+\ = Фг(ип, гп, уп, хп, п, со) (Ф3)
При этом предполагается, что существует такое //*, что
Ф! (л:, и, z, у*, я, и) = у1 (и, г, х, п, со) (?1)
*2 {и, z, у*, х, п, со) = <р2(и, г, л:, л, со) (<р2)
Если целью «классической» системы (/ , срь ср2) было со-асимп-
тотическое событие 2у, то целью адаптивной системы (/ , Фи
Ф2,ФЪ) является ш-асимптотическое событие Q ХУ*-
Таким образом, дели адаптивной системы, управляющей
процессом (/т) в общем случае шире, чем дели «классической
системы», управляющей с «той же целью» в тех же условиях, тем
же процессом. Адаптивное управление пытается одолеть
неопределенность из-за сложности посредством «простых»
итерационных процедур, образующих в совокупности сложную
итерационную процедуру нахождения «корня» итерационного
уравнения. Этот «корень» есть система управления и со-асимптоти-
ческое событие.
Анализ целей и результатов адаптации всегда сводится к
исследованию о)-асимптотических событий историй обучения.
Можно было бы подумать, что для теории адаптации
достаточно уметь находить <о-асимптотические события и вероятности
их появления. Однако это не так. Вспомним концепцию
М. Л. Цетлина о безадресном управлении [6]. По этой
концепции верхний уровень управления не посылает специфической
информации, адресованной индивидуальной подсистеме нижнего
уровня, а всего лишь меняет правила «игры» между
подсистемами, а подсистемы адаптируются к игре, преследуя личные
цели. При такой интерпретации управления верхнему уровню
нет смысла менять управляющий сигнал раньше, чем
закончится процесс адаптации на нижнем уровне. Таким образом, «один
такт работы верхнего уровня есть бесконечная история
адаптации на нижнем уровне». Поэтому единицей информации для
верхнего уровня будет ячейка фазового портрета процесса
адаптации на нижнем уровне. При этом ос-асимптотические
85
свойства ячейки укажут, от чего отучился нижний уровень, а
со-асимптотические свойства укажут, чему он научился.
Подводя итоги, можно сказать, что теория адаптации самым
тесным образом связана с качественной теорией процессов, как
детерминированных, так и случайных.
Вернемся теперь к проблемам качественной теории
процессов и посмотрим, как можно вычислять вероятности со-асимпто-
тических событий.
Пусть марковская t(t) цепь на X задана переходной
функцией Р(п, jc, /z+1, В), определяющей условную верюятность
попадания из точки jc, в которой находилась система в момент
п в множество В к моменту /г+1. Переходная функция
определяет линейные операторы PJJ+1 в пространстве мер ^ и
измеримых функций / по формулам Р*+1р = {Р(п, х, /г + 1, B)dp(x)
и ря+1/=СЯ(/г, jc, /г+1, dy)f(y). Каждая переходная функция
определяет, кроме того, семейство Рх п вероятностных мер на
траекториях х™. Эти меры определяют вероятности
всевозможных событий в пространстве траекторий х% при условии, что
в момент п траектории проходят через точку х. Каждый
целевой функционал Ф(х<^оо^ от траектории х™ж, могущий
появиться в проблемах адаптации, должен быть непременно измеримым
относительно с-алгебры ш-асимптотических событий F^.
Используя предложения V22 [7], можно устанозить связь между Яя+1,
рх.п и ф(*-оо)-
Формула /п(х) = {Ф(х™оо)(1Рх п (х%) устанавливает
взаимооднозначное соответствие между /^-измеримыми
функционалами Ф и последовательностями /п измеримых функций на X так,
что /я = Pn+ifn+i и Для любой вероятности Р почти
наверное Нт/Я(ЕЯ) = Ф при л->оо.
В частности, если Ф(д:+~) есть характеристическая
функция события Л, то /г(х) есть вероятность достижения А для
траекторий, прохЪдящих через точку х в момент п. В том
случае, когда алгебра F^ состоит из конечного числа d
элементов, в F^ можно выбрать такие Ег ...Ed, которые не
пересекаются, а их суммы порождают всю F^. Тогда определены
вероятности рп(х, Ek) = ^xk(*-<„)dPxn(x~), где х,г —
характеристическая функция множества Ek. При этом любой
/^-измеримый функционал Ф(д:!!00) есть линейная комбинация
d
Pn(x,Ek) и ^р(х, Ek) = 1, т. е. с вероятностью 1 непременно
наступит одно из («-асимптотических событий F^.
86
Если цепь Z(t) однородна, то Р* х = Рп ситуация
значительно упрощается и проясняется в случае конечной алгебры F^
аз-асимптотических событий. Для детерминированного процесса
конечность алгебры («-асимптотических событий эквивалентна
тому, что есть конечное число d предельных циклов
jci = (xn - • • xip) K которым «притягиваются» все остальные
траектории. В частности, некоторые из циклов лг; = (л;п. . .х1р )
могут быть не устойчивы. Тогда к такому циклу «притягивает^
ся» только он сам.
Движение по циклу x-t может происходить только в
определенной А-фазе. Точка движется в А-фазе, если в момент
npi она находится в состоянии xik. Аналогично притяжение к
циклу xt тоже может происходить в определенной &-фазе, т. е.
конец хп полутраектории х* притягивается к частице,
движущейся по циклу xt в А-фазэ. Если же траектория не просто
наматывается на цикл, а даже входит в него за конечноз
число шагов, то притяжение в А-фазе эквивалентно вхождению в
цикл через £-е состояние xik. Используя вольность речи,
можно сказать, что траектория, наматывающаяся на предельный
цикл в А-фазе, входит в этот предельный цикл на
бесконечности через состояние xik.
В случае общей марковской цепи, имеющей конечную
алгебру асимптотических событий, ситуация несколько сложнее.
В простейшем случае состояния xik цикла заменяются
циклическими подклассами Eik, являющимися подмножествами X.
В случае «классических» марковских цепей каждая
траектория за конечнее число шагов входит в циклический класс
Et = i U Е1к\ через некоторый циклический подкласс Eih и
начинает размешиваться в Е{ в &-фазе, переходя на каждом
шаге последовательно из Eik в Eik+X и из Eip в Еп.
В случайных динамических системах наблюдается обычно
-аналогичная картина, но с той разницей, что траектории не
входят в Ei за конечное время, а всего лишь притягиваются с
вероятностью 1 к одному из циклов в определенной &-фазе.
Видимо, можно построить экзотические примеры, когда существуют
циклические классы и вместе с тем траектории не
притягиваются к ним, а проводят основную массу времени в малых
окрестностях, вращаясь в определенной &-фазе.
И, наконец, в общем случае, элементы Eik конечной а-алгеб-
ры о)-асимптотических событий в пространстве траекторий
вообще не обязаны принадлежать множеству X.
Учитывая все эти интуитивные соображения, вернемся к
строгим фактам.
87
В [7] показано, что если цепь стационарна, а а-алгебра Fo*
ш-асимптотических событий конечна, то в /\>о можно выбрать
элементы Eik таким образом, что оператор Р будет
периодически переставлять функции р(х, Eik) = }tikdPx>n переводя
p{x,Eik) в р(х, Eiyk+i) и p(x,Eip.) в р(х,Еп), где х/* —
характеристическая функция Eik.
Таким образом, последовательность /я=Я2+1/л+ь
порождаемая со-асимптотическим функционалом Ф = уш в данном
случае превращается в последовательность рп, в которой рп
является одной из функций р (л:, Eik) причем, если рп = р (х, Е(Л)У
то /?л+1 (х) = р (х, Eit2)... Pn+pi-i =Р (х, EiPi), pn+Pl=P (*, £„)...
и т. д.
Пусть теперь Elk — множество, на котором функция р(х, Eik)
равна 1, тогда с вероятностью 1 оператор Р переводит точки
множества Eik в точки множества Eitk+i ...Eip. в Ёп. Если бы
оператор Р не переводил бы точки таким образом, что
функция p(x,Elk) не равнялась бы 1 на Eik. Таким образом, если
есть измеримое множество, на котором p(x,Eik) равно 1, та
есть циклический класс Ёп ... EiPi «отправляясь из которого»-
цепь с вероятностью 1 получает ш-асимптотические события
Ец ... EiPl и который она никогда не покидает. Поэтому Eik.
можно считать подмножеством Elk.
Предположим теперь, что каждая функция p(x,Eik)
непрерывна и равна 1 на множестве EikQX, а алгебра Foo
содержит более одного элемента. Тогда множества Eik замкнуты
и почти каждая траектория притягивается к какому-нибудь
циклу Ei = (En ... Eip) в какой-нибудь £-фазе.
Доказательство: В силу того, что существует хотя бы два
равных множества Eik функции pik, должны быть различные
и принимать значения, равные 1 на одном Eik и равные 0 на
всех остальных Ё]г В силу непрерывности этих функций*,
каждая pik должна принимать значения, близкие к 1 в малой
е-окрестности S(Eik, e) множества Eik и значения, близкие к О
в достаточно малой е-окрестности 5 (Ejn e) остальных множеств
Ejr Функция pik порождает периодическую последовательность
Pik, Ppik • • • PNPik • • • • Почти каждая траектория xf должна
иметь предел вдоль этой последовательности, т. е. должен
существовать
f = limfn(xn) при п-+оо,
где fn=PnPik- Этот предел будет равен 1, если осуществится
^-асимптотическое событие Eik и 0 в случае осуществления
88
какого-то другого ш-асимптотического события. Будем полагать,
что на траектории х™ осуществляется ^-асимптотическое
событие Et. Тогда, начиная с некоторого jV>0, все fN(x/v)>
>1—8. В силу непрерывности функций pik(x) неравенства
/лг (хлг) > 1 — 8 для достаточно малых 8 возможно только
в очень малой е-окрестности множества Ё{ и, кроме того, при
условии, что точки XN переходят из е-окрестности Eik в е-ок-
рестность Eltk+U повторяя переход pik в pitk+l = Pplk в
последовательности fi ... fN ... . Таким образом, сходимость
/n(xn) к 1 эквивалентна тому, что траектория X™
притягивается к множеству Е{, наматываясь на «цикл» Ё1=фп ... Ё1р)
в определенной £-фазе. Ввиду того, что какое-нибудь
(«-асимптотическое событие Et произойдет с вероятностью 1,
для почти каждой траектории X™ существует такая
последовательность /ы{х)> вдоль которой /n(xn) стремится к 1.
Поэтому почти каждая траектория притягивается к некоторому
«циклу» Et в некоторой Л-фазе.
Доказанное утверждение дает новый критерий устойчивости и
сходимости траекторий почти .наверное. Однако, это
утверждение не указывает нам никаких способов, позволяющих доказать
непрерывность функций р(ху Eik).
В некоторых случаях здесь могут помочь эргодические
теоремы для операторов. При некоторых дополнительных условиях
на Р, которые трудно охватить одним критерием,
последовательность операторов Р вырождается при п-^оэ в периодическую
последовательность Qn, ядро Q(xt /г, В) которой имеет вид:
d k=m=pl
Q (X, П, В) =2 2 Р (•*• Elk) V-im (В).
i=\ k-\-m=n(moupi)
k=m=l
Здесь p (xy Eik) — вероятность притягивания траектории, выхо-
дящей из л: к «циклу» Eik ... Elp. в £-фазе, v*ik —
распределение на Eik.
При более сильных предположениях можно показать, что-
Рп сходится Qn в слабой метрике L со скоростью ел, т. е.
существует такая последовательность ея, что L(Pn, Qn)<en,
где вл>0 и ел->0 при п-+оо.
Скажем, что траектория X™ лежит вел—воронке цикла
El = (Ei.i ... EiPi), если X™ притягивается к этому циклу в
некоторой £-фазе так, что расстояние от Хп до
соответствующего Eik меньше вл.
оо
Если L(Pn,Qn)<zn, то к моменту п только 2^ek траекто-
рий не лежат в гп—воронках циклов Et.
89^
Доказательство. Неравенства L (Pn, Qn) < еЛ означают,
ъ частности, что
Q(x,n,Eik)^P(x,n,S(Elkts)) + sn<Q(x,n,S(S(Elk,sn),tn)+
+ 2*a = Q(x,n,Elk) + 2*k,
где S(2,e) есть б — окрестность множества 2, а 2 есть
замыкание 2. Эти неравенства означают, что вне Ел-воронок всех
циклов в момент п лежит не более чем 2ел траекторий.
Поэтому на всем промежутке времени от п и до оо вне
оо
ел-воронок лежит не более чем 2^ел траекторий.
Заметим, что во многих интересных случаях (например, в
-стохастической модели обучения) еп = Сап, где а£(0,1). Иными
словами, во многих случаях наматывание на цикл происходит
экспоненциально быстро.
Подводя итоги, можно сказать, что асимптотические свойства
последовательности операторов Рп часто содержат в себе
глобальную информацию о фазовом портрете марковского процесса.
Заменяя случайную динамическую систему xn+\=f\(xnf со)
близкой случайной динамической системой xn+i=f2(xnt со), мы
вместе с тем заменяем один переходной оператор другим,
близким к исходному в том или ином смысле. Если такая замена не
изменит числа собственных векторов и не сильно изменит их
структуру, то со-асимптотические свойства этих двух систем
различаются незначительно. В таком случае мы можем сказать,
"что случайная динамическая система (f\) является структурно
устойчивой (грубой). Наблюдая изменения в структуре
собственных векторов переходного оператора при изменении
параметров марковской цепи, в некоторых случаях можно
обнаружить бифуркационные значения параметров, кардинально
меняющих структуру (о-асимптотических свойств.
Язык теории операторов является только одним из
возможных языков исследования глобальных со-асимптотических свойств
случайно возмущенных процессов. В задачу данной статьи не
входит обсуждение всех имеющихся здесь проблем и подходов.
В статье была сделана попытка определить предмет теории
адаптации, выяснить ее связь с качественной теорией цроцессов
и в самых общих чертах показать, что философия качественной
теории детерминированных процессов во всех своих аспектах
может быть распространена на случайно возмущенные процессы.
Конкретные примеры будут рассмотрены в другой работе.
Автор выражает свою искреннюю признательность
Л. А. Растригину, А. И. Жданку и Г. С. Тарасенко за
критические высказывания, способствовавшие уяснению некоторых
вопросов, обсуждаемых в статье.
•90
ЛИТЕРАТУРА
1. Буш Р. и Мостеллер Ф. Стохастическая модель обучаемости. М.,
Физматгиз, 1962.
"2. Анохин П. К. Биология условного рефлекса. М. «Наука», 1970.
3. Г р о о т М. Д е. Оптимальные статистические решения. М., «Мир»,
•1974.
4. Ботвинник М. М. О кибернетической цели игры. М., «Сов. радио»,
1975.
5. Шерригтон Ч. Интегральная деятельность нервной системы. Л.,
«Наука», 1969.
6. Цетлин М. Л. Исследования по теории автоматов и «моделированию
биологических систем. М., «Наука», 1969.
7. Неве. Математические основы теории вероятностей. М., «Мир», 1969.
УДК 62-506
О СЛУЧАЙНОМ ПОИСКЕ
В МНОГОКРИТЕРИАЛЬНЫХ ЗАДАЧАХ
А. И. Каплинский, А. С. Красненкер
(Воронеж, Москва)
ВВЕДЕНИЕ
Вопросы принятия наилучших (оптимальных) решений стали
б настоящее время весьма актуальными в технике, экономике,
военном деле и других областях человеческой деятельности.
Решение этих вопросов заключается обычно в построении
математической модели, количественно описывающей способы
действий (стратегии, допустимые решения и т. п.) и
соответствующие им результаты, выборе критериев эффективности и, наконец,
определении понятия оптимальных решений и отыскании их
подходящими вычислительными методами.
Наиболее естественным представляется понятие
оптимальности, состоящее в требовании максимизации (минимизации)
некоторой скалярной функции, определенной на множестве
допустимых решений. Однако далеко не всегда »на практике
удается сформулировать ту или иную задачу принятия наилучшего
решения в виде задачи скалярной оптимизации. Гораздо легче
бывает указать несколько скалярных функций, увеличение
(уменьшение) значений которых составляет цель
рассматриваемой задачи. При этом задачи о выборе наилучшего с точки
зрения указанных критериев решения, получили название
многокритериальных задач или задач векторной оптимизации [1—5].
Этим задачам в последнее время уделяется много внимания в
91
литературе по различной тематике. При этом часто вместо
вектора критериев используют некоторую их свертку, т. е. такой
единый критерий, который как-то учитывает необходимость
оптимизации по частным критериям. Достоинства и недостатки
такого «априорного свертывания» подробно изучены в работах
[1—3, 6]. Наряду с этим все чаще появляются работы, где
развивается иной подход, отличительной особенностью которого
является участие в процессе оптимизации лица, принимающего
решения (ЛПР). Настоящая работа посвящена именно этому
подходу. Мы выделим в рамках этого подхода большую группу
методов, называемых человеко-машинными цроцедурами. Суть
этих методов состоит в следующем.
Лицу, принимающему решения, последовательно
предлагаются результаты от использования тех или иных стратегий,
которые ЛПР оценивает согласно вопросам, интересующим
исследователя. Информация, поступающая при этом от ЛПР,
используется исследователем для выбора другой, лучшей стратегии.
Так переходя от одной стратегии к другой, лучшей с точки
зрения лица, принимающего решения, процедура обеспечивает
сходимость к оптимальному решению.
Человеко-машинные процедуры различаются тем, в каком
виде от ЛПР поступает информация о качестве тех или иных
решений. Кроме того, отличительной чертой такой процедуры
является правило, по которому исследователь (на основе
поступающей информации) перестраивает решения.
Обсуждаемый подход является сравнительно молодым,
однако уже имеются небольшие обзоры соответствующей
литературы, например [3].
Большинство существующих человеко-машинных процедур
носит детерминированный характер, в том смысле, что от лица,
принимающего решения требуется точная, непротиворечивая
информация, а роль исследователя ограничивается подстройкой
под эту информацию.
На практике, однако, трудно обеспечить такие условия. Как
цравило, для успешного решения необходимо дать возможность
для обучения как самому исследователю, так и лицу, црини-
мающему решения. Такое обучение непременно должно
допускать неточности, а возможно и грубые просчеты со стороны
ЛПР. Наличие таких «помех» должно как-то учитываться
исследователем .при построении алгоритмов диалога.
С учетом сделанных замечаний нам представляется
целесообразным обратить внимание на интенсивно развивающиеся в
последнее время методы адаптации и обучения в
оптимизационных задачах [7].
В настоящей статье мы рассматриваем некоторые
возможные способы применения адаптивных методов к задаче
векторной оптимизации.
92
1. РАНДОМИЗАЦИЯ И СГЛАЖИВАНИЕ
В МНОГОКРИТЕРИАЛЬНЫХ ЗАДАЧАХ
Согласно [8—10] решение задачи векторной оптимизации
представляет собой процесс преодоления неопределенности
специального вида, а именно неопределенности в выборе критерия
оптимальности. Как и другие неопределенности, такие как
негладкость функций цели и ограничений в оптимизационных
-задачах, дискретность множества решений, наличие помех,
неопределенность в выборе критерия не дает возможности
использовать классические методы оптимизации, например градиентный
метод. Тем не менее, задачи с указанными трудностями
исследуются уже давно и для их решения разработаны
многочисленные методы, .преодолевающие описанные неопределенности. Од-
ним из подходов к решению «плохих» задач» является
рандомизация переменных и сглаживание рассматриваемых функций.
В [8] приводится обширная литература, в которой этот подход
применяется для решения самых разных математических задач.
Мы рассмотрим здесь в общих чертах как рандомизация и
сглаживание применяются для решения много критериальных
задач.
Вначале [6, 8, 10—12] многокритериальные задачи
формулируются в виде задачи стохастической оптимизации
I = M{<b{M{F\fx{y{V))4 /2(У(10),...
...,/m(t/(lO)]},Z}}->min, (1)
v
где V — случайный вектор, реализации которого являются
числовыми признаками решений, на которых оцределены
показатели качества исследуемой системы f\(y), Ыу),.--, fm(y)> F —
количественная характеристика результата использования
решения y(V)t M{} — математическое ожидание этого результата,
которое в дальнейшем будет предлагаться для обсуждения
ЛПР, Ф — некоторая скалярная функция, строго монотонная
по предпочтениям ЛПР. Относительно такой функции, точнее
относительно М{Ф(-, Z)} (случайный вектор Z характеризует
неуверенность лица, принимающего решения), предполагается
лишь существование. Соответствующие условия являются не
слишком стеснительными и приведены например в [6].
Для решения задачи (1) в работах [12—14] предлагается
метод локальных улучшений, состоящий в построении
вероятностных итеративных алгоритмов изменения случайного вектора
Уп, сходящегося в том или ином смысле к решению V* задачи
(1). Основным моментом этого метода является выбор
случайного направления движения Sn в точке Vn~l для перехода в
следующую точку
Vn = T{V"-\C\Sn), (2)
93
где Т—оператор движения, Сп — случайный вектор параметров
алгоритма. Простейшим примером оператора Т служит
Т (Vn'\ Cn, Sn) = Vn~l - С* - Sn. (3)
Другие примеры имеются в [9, 13].
Та или иная конкретная форма выражения (2)
подставляется в минимизируемый функционал из (1), после чего этот
функционал варьируется в форме (2). При этом вариацией служит
как раз случайный вектор движения Sn. Этот последний
выбирается из условия локального улучшения, которое получается
в результате вариации и имеет вид
M{(v,S»)}<0, (4),
где через V обозначена главная линейная часть функционала Г
из (1). Подробный вывод условия локального улучшения
приведен в [12, 15].
Для выполнения условия (4) необходимо знать различные
свойства функции Ф. В частности, как правило, бывает нужен:
градиент этой функции или какое-либо его приближение.
Информация об этих свойствах в задаче векторной оптимизации:
поступает от лица, цринимающего решения в виде ответов на
вопросы исследователя. Эти вопросы могут быть самыми
различными, например:
а) «Какой из двух результатов более цредпочтителен
Z7 l/i (У (^ [«])),...,/»(У (^1я]))1 или
FI/, (У (V* [«])),..., fm (у (V» [«]))] Ъ
б) «Значение какого из показателей f\(y(V[n])), ...
... , fm(y(V[n])) является наименее удовлетворительным?»
в) «Назовите гп\ штук наименее удовлетворительных
значений показателей из /ь /г,..., fm»-
Если использовать в диалоге с ЛПР лишь один какой-либо
вопрос, то мы получим с учетом (3) вполне определенный
псевдоградиентный алгоритм [16], где в качестве направления
движения выбран вектор Sn из условия (4), в котором градиент V
приближенно определен по ответу на соответствующий вопрос.
Примеры таких алгоритмов приведены в [8, 11]. Так, если
m
y(V) = 2irgm2ixM{fv(y)}y (5)
У
и от лица, принимающего решения поступают указания о том,
какие из показателей fj(y) следует в первую очергедь.
94
улучшить (скажем увеличить), то алгоритм изменения
случайной величины V выглядит следующим образом
рпг1 + спрг}
PJ=■ j xlcn j , У —1.2 m,
(6>
где pj с номерами, отвечающими наиболее важным в момент
п показателям, выбраны больше остальных р". Параллельно-
этому алгоритму определяются решения
1[п] = 1[п-1] + спV/vim (/ [/г-1]), (7>
где V [/г] — реализация случайной величины V на /г-ом шаге-
Здесь ЛПР реагирует на сами значения показателей
Л(У[п-Ц) /я.(У[л-1]). т. е.
F\fi fm] = {fi /«Ь (8)
Перейдем теперь к рассмотрению водроса о повышении
скорости работы алгоритмов векторной оптимизации.
2. ОБУЧЕНИЕ В ЗАДАЧАХ ВЕКТОРНОЙ ОПТИМИЗАЦИИ
Использование одного и того же вопроса в процессе
решения дриводит к алгоритмам, медленно сходящимся к оптимуму.
Представляется естественным «ак-то учитывать тот опыт,
который ЛПР накапливает во время диалога. Желание учесть
такой опыт привело к созданию многоуровневых [17] или
обучаемых алгоритмов [8, 10, 15]. Основной принцип построения
таких алгоритмов состоит в следующем. Параметры Сп,
входящие в выражение (2) (кроме них вводится [15]
дополнительный вектор обучения), остаются неопределенными при
выведении условия локального улучшения (4). При этом выбранный,
вектор движения Sn, очевидно, не зависит от этих параметров,,
то есть Sn=Sn(Cn). После определения Sn(Cn) в основной
функционал подставляется выражение
Vn = T(V*-\ О, Sn(C")) (9)
и этот функционал варьируется в точке по некоторому правилу
С^1 = ТХ(С\ С^+1), (10)
которое и определяет корректирующий алгоритм или алгоритм
второго уровня. Вектор движения здесь также определяется из
условия локального улучшения. Явный вид таких условий
приведен в [15].
В обычных алгоритмах случайного поиска в качестве
параметров выступают длина шага, дисперсия случайного
направления движения и другие. В алгоритмах векторной оптимизации
95
специфическим является например параметр, характеризующий
сложность вопросов, задаваемых ЛПР. В [15] этот параметр
вводится следующим образом.
Пусть для простоты имеются лишь два критерия /ь /2. Из
(6) видно, что для полного одределения алгоритма необходимо
выбрать числа pjn, /=1, 2,..., т. Этот выбор можно
осуществить задавая вопросы:
Вх «Какой из показателей важнее?» (Ответ: «f\»).
В2 «Считаете ли Вы, что если показателю /г нужно уделять
основное внимание на А раз больше (то есть увеличить частоту
его "появления в алгоритме (7) на А раз), то показателю fs
следует уделять основное внимание не менее чем на 2А раз
больше?» (Ответ: «нет»).
В «Считаете ли Вы, что если показателю /г нужно уделять
основное внимание на А раз больше, то показателю /s — не ме-
4
нее чем на -^ А раз больше?» (Ответ: «да»).
Количество таких вопросов и определяет меру трудности для
лица, принимающего решения. Формально такой параметр
равен числу отрезков, на которые дихотомией разбивается
множество точек
Р={(Ри Рг) :Рь Р2>0, pi + p2=l}. ' (И)
Вывод и обсуждение условия локального улучшения для этого
случая приведен в [15].
3. СТАБИЛЬНЫЕ АГЛОРИТМЫ ВЕКТОРНОЙ ОПТИМИЗАЦИИ
Как уже отмечалось, информация от лица, принимающего
решения, как правило, поступает с большими неточностями.
Последние связаны с неуверенностью, недостаточной
компетентностью, необъективностью, а порой и злонамеренностью
реального ЛПР. Возможны также случаи, когда достоверная
информация искажается вследствие независящих от ЛПР причин.
В таких ситуациях оказывается полезным следующий подход,
основанный на использовании в процессе диалога объективной
априорной информации об оптимальном решении. Этот .подход
представляет собой применение своего рода «адаптивного
метода максимального правдоподобия», изложенного в [18], к
многокритериальным задачам (соответствующая статья находится
в печати в журнале «Экономика и математические методы»).
Предположим, что существует оптимальное с точки зрения
ЛПР решение #*. Ему соответствуют олтимальные значения
показателей fi(y*)=f i*,...9 /m(y*)=/m*. Если бы удалось как
либо описать предпочтения ЛПР., то задача определения у*
свелась бы к отысканию минимального (максимального)
элемента на множестве допустимых решений Y—{y). Именно так
и поступают при аксиоматическом подходе к векторной оптими-
96
зации [2, 19]. Рассматриваемый подход предполагает лишь
следующую информацию. Лицо, принимающее решения должно
сообщать (безусловно с ошибкой) отклонения значений от
желаемых значений fj(y). При этом */* определится из системы
уравнений
ЛГ{/у(У)-/*)2=0' 7=1.2 т9 (12)
где осреднение проводится как раз по ошибкам в информации
Система (12) заменяется системой оптимизационных задач.
M{(fj(y)-fy}-»min, / = 1,2,...,/и (13)
у
причем вместо квадрата может быть выбрана любая функция F
с единственным глобальным минимумом в нуле. Выбор такой
функции существенно влияет на используемый далее алгоритм
т
I[n] = /ln-l\-lm2F'{fj(nn-s]-rjW)9 (14)
где fj*[n]—реализация случайной величины /Д сообщаемая
лицом, принимающем решения на n-ом шаге. В
рассматриваемом подходе предлагается осуществлять такой выбор на основе
имеющейся априорной информации о характере случайностей
Различные типы такой информации и соответствующие
алгоритмы приведены в [18] и в статье, отмеченной'*. Также
приведены результаты экспериментов, .показывающие значительное
преимущество в скорости сходимости алгоритмов,
использующих объективную априорную информацию.
ЗАКЛЮЧЕНИЕ
В заключение отметим некоторые перспективы
использования развиваемого адаптивного подхода к многокритериальным
задачам.
Авторами рассматривался ряд конкретных задач векторной
оптимизации, таких, как выбор оптимальной
последовательности обслуживания программ вычислительной системой по
критериям— приоритет и общее время обслуживания, выбор
оптимального правила посадки самолетов по критериям — время
опоздания, .ценность груза, запас горючего, выбор правила
продажи билетов на самолеты с учетом равномерности загрузки
рейсов и возможно меньшего числа отказов пассажирам [6, 12].
Разработанные алгоритмы использовались для решения
сложных задач математического программирования. При этом
считалось, что эти задачи являются векторными с показателями,
7—6065
97
совпадающими с функцией цели и функциями ограничений.
Рандомизация позволила преодолеть трудности, связанные с
большим числом нелинейных ограничений. Решение таких задач
адаптивными методами с участием лиц, принимающих решения
представляется весьма эффективным при создании различных
систем автоматического проектирования. В таких системах чаще
всего оптимальные проекты выбираются после длительных
диалогов с конструкторами. Адаптивные методы позволяют сделать
эти диалоги более направленными и также позволят повысить
скорость сходимости к оптимальному результату. Простота
используемых при этом алгоритмов дает возможность составить
стандартные црограммы диалога, что особенно важно при
работе на ЭВМ.
ЛИТЕРАТУРА
1. Борисов В. И. Проблемы 'векторной оптимизации.—IB кн.:
«Исследование операций». М., «Наука», 1972.
2. Озерной В. М. 'Принятие решений. (Обзор). — «Автоматика и
телемеханика», il971, № 11.
3. Ларичев О. И. Человеко-машинные процедуры принятия решений.—
«Автоматика и телемеханика», 1971, № .12.
4. Подиновский В. В., Лебедев Б. В., Стырикович Р. С. Задача-
оптимизации по упорядоченной совокупности критериев. — «Экономика и
математические методы», il97il, т. 7, вып. 4.
5. Гермейер Ю. Б. Введение в теорию исследования операций. М.,
«Наука», 1973.
6. Красненкер А. С. Задачи и методы векторной оптимизации. — В сб.:
«Измерения, контроль, -автоматизация», 1975, № 1.
7. Цыпкин Я- 3. Основы теории обучающихся систем. М., «Наука», 1970.
8. Каплинский А. И., Красненкер А. С, Цыпкин Я. 3.
Рандомизация и сглаживание в задачах и алгоритмах адаптации. — «Автоматика
и телемеханика», 1974, № 6.
9. Цыпкин Я. 3. Адаптивные методы выбора решений в условиях
неопределенности. — «Автоматика и телемеханика», 1976, № 4.
10. Кандинский А. И., >Кр а с н е н к е р А. С. О формировании
многоуровневых алгоритмов стохастической оптимизации. — «Автоматика и
вычислительная техника», 1977, № 4. *
11. Красненкер А. С. Рандомизация и сглаживание в задачах векторной
оптимизации. — «Автоматика и телемеханика», 1976, № 3.
12. Капли .некий А. И., Красненкер А. С. О формировании
алгоритмов стохастической оптимизации. Препринт НЭП АН УССР 74—14—АСУ.
Донецк, 1973.
13. Каплинский А. И., Красненкер А. С. О способах локальных
улучшений в задачах стахастической оптимизации.—В об. «Вопросы
оптимального программирования б производственных задачах», НИЭИ В ГУ.
Воронеж, 1973.
14. Цыпкин Я. 3., iKan ли некий А. И., Красненкер А. С. Методы
локальных улучшений в задачах стохастической оптимизации.— «Изв.
АН СССР. Техническая кибернетика», 1973, № 6.
15. Каплинский А. И., Красненкер А. С. О многокритериальном
подходе к формированию многоуровневых алгоритмов стохастической
оптимизации.— «Автоматика и (вычислительная техника», 1975, № 4.
16. Поляк Б. Т., Цыпкин Я. 3. Псевдоградиентные алгоритмы обучения:
адаптации. — «Автоматика и телемеханика», 1973, № 3.
98
17. Растр иг ии Л. А. Статистические (методы поиска. М., «Наука», 1,968.
18. Цыпки н Я. 3. Оптимизация в условиях •неопределенности. — «Доклады
АН ОССР», 1976, т. 228, № 6.
19. К'Р ас н е н,ке,р А. С. О поведении системы с (несколькими
показателями. — «Труды математического факультета ВГУ», Воронеж, 1972, Вып. 3.
УДК 62-506
АДАПТАЦИЯ В МОДЕЛИ ЭВОЛЮЦИОННОГО ПРОЦЕССА
В. Эбелинг, Р. Файстель
(Росток)
1. ВВЕДЕНИЕ
Изучение процессов адаптации на разных уровнях
представляет интерес для моделирования поведения сложных систем
[1]. Цель настоящей работы состоит в том, чтобы показать,
что поведение системы последовательностей со свойством
самовоспроизведения при условии отбора может служить примером
эволюционных процессов. Исследование таких систем
представляет интерес именно для моделирования процессов
самоорганизации биополимеров [2]. Алгоритм эволюционной адаптации
[3] определяется взаимодействием динамических процессов
конкуренции и процессов случайного поиска [4].
Рассмотрим систему из п элементов. Структура каждого
элемента определяется последовательностью X различных еди:
ниц с общей длиной цепи v, т. е. определенный элемент можно
представить в виде
i={zlz2 ... zv} (l)
zn = au a2, ...,a%
Для определенности можно себе представить, что эти
последовательности моделируют линейные биополимеры, например,
нуклеиновые кислоты (^ = 4) или белки (Х = 20). Число всех
различных последовательностей длины v представляет
N = \v (2)
Отсюда вытекает огромная структурная и информационная
емкость элементов рассматриваемой системы, которая,
например, в случае Х = 4 и v=1000 определяется гигантским числом
ЛГ=41обо«10600. (3)
Фактически в результате случайной сборки не может
возникнуть определенная последовательность. Как показал Эйген [2],
введение правил отбора значительно ускоряет процесс
формирования определенных последовательностей.
7*
99
2. КИНЕТИКА ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Введем следующие предположения, которые характеризуют
класс рассматриваемых моделей:
а) последовательности самовоспроизводятся в случайные
моменты времени tu t2, tz,... Средняя частота (продуктивность)
самовоспроизведения вида i пропорциональна числу этих
последовательностей Xi(t) в системе;
;' в) система разбавляется со скоростью (—k0Xi)t таким
образом, что суммарное число видов в системе остается постоянным
по времени. ^
п = 2 Xi(t) = const, (4)
i
где сумма распространяется по всем последовательностям;
с) в процессе репродукции могут редко возникать
случайные ошибочные копии, которые могут воспроизводиться дальше.
Кинетические уравнения процесса имеют вид стохастических
дифференциальных уравнений типа
-jfxi(t) = ei(t)xl(t)-kQ(t)xi(t) +
+ 2М')-М0-М')-М')1 (5)
у
где et (t) — частота репродукции, qtj (t) — матрица перехода
Отметим, что при условии (4) ошибочная репродукция
является переходом. Случайные функции e^t) и gtj(t) отличны
dt нуля только ь дискретные моменты времени и имеют вид
М0=2*1*)8('-'*); (6)
k
fi/(0-2!'&,8('-<»>
к
Из условия постоянства числа всех частиц следует
£*-^2*'W=2mo*iW-mo2*<w=o (7)
mo-<*(o>4?2*'<o*i(o
Можно переходить к динамическим уравнениям для средних
значений по ансамблю
Х^Хг, Я,-вг, Qi,=l4 (8)
Введем отклонения от средних
bx^iXi-Xfo te, = (*,-£,) (9)
100
Тогда получим путем усреднения исходных уравнений (5):
dt
xt(t)={EAt- <е))xl+2al}Xj+Mt2>
(10)
j
<*>-42*/*/
j
Множитель Qi имеет значение вероятности правильного
копирования цепочки и Вторые моменты Л^(2) можно в первом
приближении не учитывать. В приближении первых моментов
стационарное распределение видов определяется нелинейными
алгебраическими уравнениями
EiQiXi+%GlkXk = ±2EkXkXi (»)
к k
В случае отсутствия мутации Glk=0, Q, = l устойчивое
стационарное решение имеет вид
Хт = п для вида Ет->Е^
Xt = 0 для видов i=£m
Р оль показателя качества адаптационного процесса
случае играет продуктивность Ek. Выигрывает вид
большой продуктивностью. Для достаточно низкой
мутации находим в первом приближении
(12)
В ЭТОМ
с самой
частоты
г—['-££*]
(13)
Ei
Отсюда вытекает, что с ростом частоты мутации G^ шансы
выживания вида / уменьшаются. С другой стороны, при отсутствии
мутации Gi;=0, Qi=l процесс отбора быстро достигает
состояния победы вида т, которое описывается уравнением (12).
Такой экстремум процесса адаптации был бы бесполезен для
дальнейшей эволюции. Оптимальная эволюция происходит, если
частота мутации достаточно мала для того, чтобы обеспечить
выживание Хт&п и с другой стороны настолько велика, чтобы
обеспечить достаточно мутантов.
В дальнейшем ограничимся случаем, когда мутации
происходят достаточно редко. Тогда исходное уравнение (5) можно
заменить уравнением [5].
101
+21М')*/(о-ы')-м')1 (14)
<£>=т2Е***(<) (15)
k
В интервалах между переходами, которые происходят
в дискретные моменты времени tu t2, t3,... уравнения (14—15)
решаются точно. Например, находим для 0</<^
/Л д *|(0)СХР(Д|О
*,w~a2**<o)cxP<iw) (16)
В результате перехода в момент ^ число видов меняется
дискретно, так что
xi(t1) = xi(tl-0) + Axi (17)
Отсюда находим решение в следующем интервале
xM=n*i(il)CXPlBiii-il)] 08)
для t1<ct<t2.
Аналогично находим решение для всех интервалов [5].
Очевидно продуктивность Ei играет роль показателя качества в
определенном интервале, и выигрывает вид, который имеет самое
большое значение показателя качества. Однако, в каждом
интервале отбор начинается снова, потому что возникают новые
виды, которые принимают участие в конкуренции.
Таким, образом, алгоритм адаптации состоит из двух
элементов, которые тесно связаны друг с другом;
1) Динамический процесс конкуренции видов. Поставленная
цель этого процесса состоит в достижении состояния, где
доминирует последовательность (вид) с максимальным показателем
качества.
2) Стохастический процесс появления новых
последовательностей (видов), который представляет случайный поиск более
превосходящих видов.
3. ЧИСЛЕННЫЕ ПРИМЕРЫ
Рассмотрим сначала последовательность чисел (Х=10)
Zft = 0, 1,2, ... 9
Для определенности предполагаем, что длина цепочек v=12,
так что в игре принимают участие 1012 последовательностей.
В качестве показателя £г- мы произвольно берем число
102
E{=Oy Z1Z2Z3... Z\2
которое всегда меньше единицы. Рассмотрим некоторые
примеры
/ = {35790.. .6}, Я, = 0,35790.. .6
/ = {28405.. .3}, £, = 0,28405.. .3
/ = {99999.. .9}, Я,=0,99999.. .9
Очевидно последний пример имеет максимальное значение
показателя качества.
Правила мутации: в случайные моменты времени t\, i2, ...
(Д/«10) возникают Axs случайных последовательностей S =
= {ZiZ2..., Zl2} где (Axjn) =0,01.
Процесс моделируется на вычислительной машине [6].
Между мутациями система следует уравнениям типа (16) и (18).
Рис. 1. Первая реализация эволюционного
процесса с крупными мутациями
Рис. 2. Вторая реализация того же самого
процесса
Рис. 1—2 показывают две реализации временной эволюции
системы с начальными условиями:
Х((0) = 0,25п / = {340 154... 7}
Xj(0)=0,25n j = {260248... 1}
103
Xt(0)=025n / = {180445 9}
Xk(0) = 0,25n £ = {100178 3}
На рисунках показаны только первые три буквы
последовательностей. Примеры показывают, что индивидуальный путь
эволюции системы совершенно случаен, но процесс протекает с
необходимостью в направлении еще
более выгодных
последовательностей. Эволюционное дерево
системы (рис. 3) имеет довольно простой
вид. Все пути как будто сходятся к
наиболее выгодной
последовательности {999... 9}. Через любой путь
можно в принципе достигать этой
цели, но фактически этот процесс
неисчерпаемый, потому, что всегда
есть еще более выгодные виды в
запасе и реализация
последовательности {999... 9} можно ожидать
только через несколько тысяч лет
машинного времени. Простая
структура дерева эволюции данной
модели связана с тем, что мутации имеют
крупный характер. По каждой
мутации структура последовательности:
сильно меняется а, следовательно^
меняется и показатель качества.
Следующая модель [6] характеризуется мелкими мутациями,,
и вследствии этого возникает сложное дерево эволюции с
сильным ветвлением. Последовательности этой игры имеют длину
I^v^20 и состоят из единиц Л, Б, С, D. Рассмотрим
некоторые примеры
i = {B), Ei = \n2
J = {D), E, = ln4
k = 0AC)y £* = 1п9
1 = {DACB}, Ez = lnll
m={BDADBB}, Яш = 1п0,5
Алгоритм вычисления ценности W и показателя качества
Е = \п W задан в таблице 1. Первые буквы A,B,CtD
получают ценность W=l,2, 3, 4, потом ценность изменяется по
правилам таблицы 1 в зависимости от того, какая буква
стоит за предыдущей буквой. Номер позиции р первой буквы
определенной пары в последовательности определяет
множитель q по правилу
q=p для /7 = 1—9
q={p — 6)/2 для р = 10—19
Рис. 3. Возможные пути
эволюционного процесса
104
Для последовательности {BDADBB} получаем, например*
ценность
Г = (2+2+1)44-1=?
Таблица 1. Алгоритм вычисления ценности
AAW:=W CAW:=W/3
ABW:=W CBW:=W + q/3
ACW:=W+\ CCW:=W
ADW:=Wlq CDW:=W/3
BAW: =W+q/2\DAW: =W+4lq
BBW: =W DBW: =W/A
BCW: =Wl2 \DCW: =W + ql4
BDW:=W+2 \DDW:=W
Правила мутации: последовательность пишется формально в
виде OBDADBBO
Любой знак заменяется через О, А, В, С или D. Появление
нуля в середине означает, что копирование на этом месте
кончается так, что правая часть последовательности больше не
учитывается.
В процессе мутации длина цепочки может увеличиваться или
уменьшаться или отдельные позиции последовательности могут
изменяться. Процесс мутации может повторяться мгновенно
несколько раз. Между мутациями система развивается по законам
типа (16) и (18). При всех процессах число частиц /г=2А^
100 700
t
Рис. 4. Процесс репликации
последовательностей букв при условии, что редко
возникают мелкие мутации
сохраняется. Интервал между мутациями Д*»1. Рис. 4—5
показывают конкретные реализации игры с начальным условием
ХА (0) = *в (0) = Хс (0) = XD (0) = 0,25/г
Во втором примере (рис. 6) частота мутации в три раза больше.
105,
x 50
Рис. 5. Процесс репликации последовательностей
букв при условии, что более часто возникают
мелкие мутации
*
15
^л
С».
2
и
:* 10
5
BDACBACBD
t
BDACBACB
t
ВВАСВАС ,
ВВАСВА '
-I*
02М
ВАВМВАС \ ВАСЖВО
ВАВдАСВА ВАСВАСВО f
/ ВАСВАСВ /
ВСВВАСВА ^ВАСВВСВ
сшит васввс
^ ^ВАСВВ
BABD BF
щв /
—вс- ъ'
Рис. 6. Эволюционное дерево для кинетики
цепочек букв до длины V = 9
Дерево эволюции (множество всех возможных путей) сильно
ветвится с нарастанием длины цепочек. Индивидуальный путь
каждой реализации имеет случайный характер, но процесс
адаптации всегда протекает с необходимостью в направлении
возрастания показателя качества. Отметим, что система при каждой
реализации находится в определенной ветви дерева и может
достигать только относительного максимума показателя
качества. Переход между отдельными ветвями дерева весьма
невероятен, потому, что в данной игре мутации имеют мелкий характер.
106
Таким образом» процесс адаптации для ветвящихся процессов
имеет особенности. История системы качественно определяет
возможные пути дальнейшей эволюции и исключает фактически
-большой класс эозможных путей. Законный характер носит
только стремление системы двигаться выше по ветвям
эволюционного дерева. Вопрос нахождения абсолютного максимума
теряет смысл вследствие возрастающего ветвления. Возможно
такая модель может служить примером для моделирований
более реальных эволюционных процессов.
ЛИТЕРАТУРА
:1. Растригин Л. А. Проблема адаптации в технике, биологии -и
социологии.— В юн.: «Адаптивные системы», вып. 1. Рита, ,1972.
'2. Э й г е н М. Самоорганизация материи и эволюция биологических
макромолекул. М., «Мир», 1973.
3. М аур инь А. М. Адаитациогенез как путь достижения потребного
будущего.— В кн.: «Адаптивные системы», вып. 1, Рига, 1972.
4. Рас три г ин Л. А. Случайный поиск в процессах адаптации. Рига, 1973.
5. Е b е 1 i n g W. Strukturbilclurig bei irreversiblen Prozessen. Leipzig, Teubner-
Verlag, ,1975.
6. Ebeling W., Feistel R. Studia biophysica 1974, 43, № 2—3.
УДК 62-506
СЛУЧАЙНЫЙ ПОИСК В СИСТЕМАХ
ОПТИМАЛЬНОГО ПРОЕКТИРОВАНИЯ
В. С. Трахтенберг, В. К. Иванов,
Ю. Н, Новоселов, Г. Д. Пешатов
(г. Йошкар-Ола)
А. РОЛЬ МАТЕМАТИЧЕСКИХ МЕТОДОВ
ОПТИМИЗАЦИИ В САПР
Автоматизированное проектирование технических объектов,
особенно на начальных этапах, связано с проведением
структурных и параметрических исследований вариантов. При этом все
ютчетливее наблюдается тенденция выполнять эти исследования
путем решения экстремальных задач с различными
критериями качества, ограничениями, исходными данными, на основе
результатов которых проектировщик принимает окончательные
решения.
Дискуссии о роли оптимизации в системах
автоматизированного проектирования (САПР) продолжаются, однако
постепенно начинает преобладать следующая точка зрения.
107
1. Бесспорно, что САПР — это не набор оптимизационных
задач, но САПР без оптимизации — это «дорогостоящая
игрушка». Основная задача систем — не только выполнять прямые
расчеты предложенных проектировщиком вариантов объекта, но-
и предлагать оптимальные по различным критериям варианты
решений.
2. Оптимизация в САПР — это способ исследования
возможности создания объекта, удовлетворяющего техническому
заданию, предложенному извне или улучшенному самой системой^
3. Оптимизация в САПР с применением метода управляемых
ограничений позволяет указывать кратчайшие пути создания
объектов с перспективными техническими характеристиками,
т. е. является инструментом технического прогнозирования »
разработки рациональных программ развития техники.
4. Оптимизация при решении комплексных задач
предварительного проектирования — главный путь повышения качества
создаваемых изделий.
5. Оптимизация на множестве критериев качества
направлена на поиск компромиссных решений, который иногда ошибочно
представляют как отрицание оптимизации.
6. Оптимизация в процессе исследования экстремальной
области позволяет обоснованно учитывать неформализованные
требования к проектируемому объекту.
7. Оптимизация открывает новые возможности повышения
квалификации проектировщиков, накопления ими объективно
правильного опыта, устранения практики принятия
субъективных решений.
8. К оптимизации в человеко-машинном режиме следует
относиться с осторожностью, поскольку она приводит к
качественным решениям только при правильном распределении
функций между человеком и автоматом.
Б. ТРЕБОВАНИЯ К МЕТОДАМ ОПТИМИЗАЦИИ,
ВКЛЮЧАЕМЫМ В САПР
Методы оптимизации, включенные в систему
автоматизированного проектирования, попадают, образно выражаясь, в
условия серийного производства. Здесь исключены возможности
математического анализа специфики предложенной задачи,
доработки метода оптимизации, выяснения причин
неудовлетворительной сходимости и т. п. Проектировщик должен создавать
технические объекты, а не заниматься исследованиями
численных методов оптимизации. Поэтому в оптимизационные блоки
САПР допустимо включать методы, удовлетворяющие
требованиям: 1) универсальности, 2) адаптивности, 3) надежности,
4) быстродействия.
Детализация этих требований означает, что методы
оптимизации должны:
108
— быть применимы к широкому классу задач;
— выявлять специфику предложенной задачи и при
необходимости изменять свою структуру и параметры;
— с высокой надежностью находить бассейн глобального
экстремума;
— находить решение задачи в течение разумного периода
-времени.
Они должны эффективно работать:
— в обстановке большого числа различных функциональных
ограничений;
— при малых размерах допустимой области, в том числе
многосвязной;
— при отсутствии допустимой области (в этом случае
проектировщику должны указываться рациональные пути
корректировки задачи);
— в пространствах высокой размерности, одновременно
содержащих дискретные и непрерывные переменные;
— в смешанных задачах одновременной оптимизации в
конечномерном и функциональном пространствах;
— в обстановке сложных рельефов поверхности критерия
качества;
— в обстановке вычислительных погрешностей и других
ломех.
Разработка метода, удовлетворяющего всем перечисленным
требованиям, является, по мнению большинства специалистов,
неразрешимой задачей. При создании оптимизационного блока
САПР авторы исходят из концепции, что задачи в системе будут
решаться коллективом последовательно или циклически
работающих методов. Основная задача — выбрать априори
последовательность методов, гарантирующих с высокой надежностью
{пусть с неминимально возможной трудоемкостью!) отыскание
решения предложенной задачи из множества характерных для
данной предметной области.
В. МЕТОДЫ СЛУЧАЙНОГО ПОИСКА,
ВКЛЮЧЕННЫЕ В ОПТИМИЗАЦИОННЫЙ БЛОК САПР
Сравнение различных численных методов оптимизации,
проведенное в процессе решения ряда практических задач
проектирования, позволило сделать объективный .вывод о
предпочтительности методов случайного поиска, а также их комбинаций
между собой и с другими (детерминированными) методами.
Учитывалась не только (и не столько) трудоемкость поиска
экстремума, но и такие факторы, как возможность решения
задачи без предварительного анализа ее специфики, надежность
отыскания решения в серии экспериментов, простота
применения стандартной программы оптимизации и другие указанные в
предыдущем разделе требования.
109
Основу разрабатываемого оптимизационного блока
составляют следующие программы методов, в той или иной степени*
основанных на идеях случайного поиска [1, 2]:
1) программы поиска глобального экстремума,
разработанные под руководством А. И. Половинкина [3, 4J;
2) программа поиска минимума коллективом независимых'
автоматов (алгоритм «Харьков»), разработанная под
руководством В. Ф. Коропа [5];
3) программа комбинированного алгоритма статистического
поиска, разработанная под руководством А. П. Тунакова [6];
4) программы комбинированных алгоритмов случайного
поиска, разработанные под руководством В. С. Трахтенберга
[7-91-
В стадии завершения исследований находится программа
поиска экстремума с помощью алгоритма «Случайный луч»,,
разработанного Ю. Н. Новоселовым. Алгоритм предназначен
для поиска глобального экстремума в обстановке сложных огра-
ничений.
Г. КРАТКАЯ ХАРАКТЕРИСТИКА НЕКОТОРЫХ
РЕШЕННЫХ ЗАДАЧ
Указанные выше (под номером 4) программы
комбинированных алгоритмов случайного поиска проверены на решении
следующих задач.
1. Задача поиска оптимальных аэродинамических форм типа
профиля крыла (плоская задача) и типа крыла
(пространственная задача) [10]. Текущие формы тел строились на классе
алгебраических функций, описывающих части контура (или
поверхности) между характерными точками.
Исследования, проведенные на различных математических
моделях процесса аэродинамического обтекания, показали, что
комбинированные алгоритмы случайного поиска надежно
приводят в окрестность экстремума, однако не позволяют достигнуть
высокой точности решения за разумное число шагов. Более
экономно с точки зрения потерь на поиск переключаться в
окрестности экстремума на детерминированные методы [11].
2. Задача поиска оптимальных параметров системы
автоматического управления (САУ) заданной структуры по критерию
минимума времени регулирования при ряде дополнительных
ограничений (на величину перерегулирования, время
срабатывания и др.)- Исследования проводились при различных критериях
качества, наборах ограничений и структурных схемах САУ.
Полученные результаты подтверждают надежность поисковой
процедуры.
3. Задача поиска реализуемого технического задания,
наименее уклоняющегося от желаемого (на примере САУ).
Спецификой этой задачи является то, что она сводится к двум вло-
110
женным друг в друга процессам оптимизации: во внутреннем
цикле решается задача оптимизации параметре* САУ пб
заданному критерию и ограничениям на остальные выходные
характеристики, а во внешнем цикле делается один очередной шаг
изменения ограничений в желаемом направлении. Из-за
высокой вычислительной трудоемкости этой задачи пока нельзя дать
определенные заключения о сходимости внешнего цикла
оптимизации. Окончательные выводы о целесообразности решения
подобных задач можно будет сделать в ближайшее время после
организации их решения на цифро-аналоговом комплексе.
4. Задача поиска оптимального управления динамическим
объектом, которая сводится к задаче математического
программирования. Здесь случайный поиск (как и другие, известные
нам методы) дал хотя и обнадеживающие результаты, но пока
не надежные при серийном решении.
Подводя итоги, следует сделать вывод, что проблема
создания оптимизационных блоков, в которых случайный поиск
заслуженно займет достойное место, требует к себе неослабного
внимания.
ЛИТЕРАТУРА
1. Ра стриг ии Л. А. Статистические методы поиска. М., «Наука», 1968.
2. Растригин Л. А. Системы экстремального управления. М., «Наука»,
1974.
3. П о лов ин кии А. И. Алгоритм поиска глобального экстремума при
проектировании инженерных конструкций. — «Автоматика и
.вычислительная техника», Рига, .1970, № 2.
4. Меркурьев В. В., Молдавский М. А. Комплекс программ поиска
глобального экстремума. — В об. «Математическое обеспечение АСУП».
Москва — Горький, >197б, стр. 13.3— 135.
5. К о р о и В. Ф. Локально-глобальный поиск коллективом автоматов
Буша—Мюстеллера.— «Автоматика и вычислительная техника», ,(Рига),
1975, № 2.
6. Тунаков А. П., Дроздов Ю. В. Комбинированный алгоритм
статистического поиска.—В об. «Автоматизированное оптимальное
проектирование инженерных объектов и технологических процессов», вып. 1.
Горький, Изд. ГГУ, 1974.
7. Трахтен(берг В. С. Поисковая и бешоисковая настройка модели
динамического объекта. — «Автоматика и вычислительная техника», (Рига).
1968, № 2.
8. Новоселов Ю. Н., Попов П. Н., Тр ахтен'б е рог В. С.
Самонастройка модели динамического объекта методом случайного поиска. —
В сб. «Алгоритмы и программы случайного поиска». Рига, «Зинатне»,
1969.
9. Р я к и н а Л. М., ТрахтенбергВ. С. Комбинированный метод
случайного поиска. — В сб.: «VI 'Всесоюзная конференция по экстремальным
задачам и их приложениям», ч. II. Таллин, 1973.
10. П о л о в и н к и н А. И., Т р а х т е н б е р г В. С и др. Алгоритмы
оптимизации проектных решений. М., «Энергия», 1976.
11. Химмельблау Д. Прикладное нелинейное программирование. М.,
«Мир», 1975.
Ill
О ПРОБЛЕМАХ РАЗВИТИЯ НАБРОСОВЫХ
И УСКОРЕННЫХ С ПСЕВДООБРАЩЕНИЯМИ
СТАТИСТИЧЕСКИХ АЛГОРИТМОВ ОПТИМИЗАЦИИ
В. Я. Мелешко
1. ВВЕДЕНИЕ
Как и в [1], в данной работе будут обсуждены на
содержательном уровне, а также намечены пути создания и указаны
возникающие при этом проблемы, для некоторых важных в
настоящее время направлений развития новых эффективных
алгоритмов оптимизации, включая решения родственных задач
отыскания корней многомерных функций при наличии помех. При
этом существенно использован опыт практической эксплуатации
известных детерминированных и статистических методов
оптимизации [2—11]. Естественно, что определяющим в
формировании этого опыта был класс решаемых задач, который
ограничивался задачами, возникающими при идентификации
нелинейных моделей в технических и физических системах [12]. Эти
задачи были, как правило, существенно нелинейными и плохо
обусловленными, несмотря на сравнительно небольшую
размерность. С другой сторону, в данной заметке делается обзор
работ проводимых по численным методам математического
программирования в Лаборатории проблем оптимизации и
исследования операций Харьковского государственного университета.
Первое из обсуждаемых ниже направлений развития методов
оптимизации — это создание эффективных набросовых методов
определения экстремумов. Актуальность его объясняется
следующим.
Почти во всех руководствах по численным методам
оптимизации, прекрасно написанных как на строго математическом [2—
7], так и на содержательном [8, 9, 13] уровне, предлагаются и
исследуются, главным образом, методы для гладко-выпуклых
(возможно недифференцируемых) задач, т. е. локальные методы.
Большинство практических задач, например, особенно при
идентификации нелинейных моделей, являются невыпуклыми, более
того — многоэкстремальными. Поэтому необходимы локально-
глобальные алгоритмы, частично обсужденные в [9, 13] при
описании многоэкстремальных методов случайного поиска.
В данной работе такие методы названы набросовыми, в отличие
от локальных, которые являются поисковыми. В набросовых
алгоритмах реализуется идея глобального наброса начальных
условий, которые должны «равномерно» покрыть область
поиска. Затем с этих начальных условий идет запуск локального
112
поиска экстремума, с последующим выделением более узкой
области поиска для повторения этой процедуры.
Качественно можно охарактеризовать набросовые
алгоритмы— как алгоритмы, работающие по «избыточной
информации». По существу в них допускается возможность дублирования
спусков в одну и ту же точку экстремума, особенно, когда
минимизируемая функция окажется выпуклой в исследуемой
окрестности поиска. Избыточность вычислений преднамеренно
вводится, чтобы увеличить надежность поиска глобального
минимума. Такой прием хорошо известен в технике при построении
высоко надежных систем из ненадежных элементов, где он стал
уже классическим.
Второе обсуждаемое направление связано с созданием новых
статистических методов оптимизации с использованием
оптимальных линейных оценок, полученных на основе теории
псевдообратных операторов [14—15]. При этом существенно
используются замечательные свойства псевдообратных операторов и
рекуррентные соотношения для вычисления псевдорешений [16].
В ускоренных статистических алгоритмах с псевдообращением
[17, 18] при реализации на ЭВМ важное значение имеет
введение регуляризации для получения устойчивых псевдообращений
[19—22] и тем самым устойчивых к возмущениям оптимальных
оценок.
Ускоренные алгоритмы с псевдообращением (иначе говоря,
методы псевдообратных операторов [19, 23]) в статистических
задачах являются асимптотически оптимальными [24, 25], т. е.
асимптотически в них достигается нижняя грань в неравенстве
Рао — Крамера для оценки корня градиента в окрестности
минимума. Отметим, что предварительные численные
исследования предложенных методов с псевдообращением действительно
показали на отдельных тестовых функциях лучшие результаты,
чем известные методы стохастической аппроксимации [26]. При
этом рассматривались следующие задачи:
а) статистической оптимизации,
б) многоэкстремальной оптимизации,
в) динамической оптимизации [18,27],
г) статистической оптимизации овражных функций.
Практический опыт показывает, что даже при решнии опти-
мизационых задач из определенной узкой области (например,
идентификации моделей в ядерной физике, или системах нераз-
рушающего контроля интегральных схем) невозможно одним
универсальным алгоритмом решить весь набор предъявляемых
этой областью задач. Необходимо иметь значительное число
методов, обладающих различными полезными свойствами. Еще
лучше иметь возможностью компилировать в диалоговом
режиме требуемые эффективные алгоритмы в процессе счета,
учитывая выясненные свойства решаемой задачи. Такая
возможность реализуется пакетами программ, содержащими алгоритмы
8—6065
113
оптимизации, основные принципы реализации которых
системами программирования низшего уровня, указаны в
заключительном параграфе данной работы. При этом использованы
результаты [28].
2. НАБРОСОВЫЕ АЛГОРИТМЫ ОПТИМИЗАЦИИ
Чтобы лучше оттенить схему построения набросавых
алгоритмов, рассмотрим построение конкретных метода вложенных
симплексов и метода случайного наброса, принадлежащих к
этому классу алгоритмов. В .первом методе происходит
детерминированный наброс, а во втором — статистический. Но в обоих
методах ведется локальный спуск, из набрасываемых точек, и
адаптивное уменьшение области поиска.
Итак, пусть в Rm требуется минимизировать функцию f(x),
x£Rm. Известно [29], что в m-мерном евклидовом пространстве
Rm строки матрицы.
kxk2 ... km_xkn
— R\k2... km_xk„
Mx = \
0 0 ...-R^K
0 0 ... 0 -R
т/
где
#t-V 27Г+7У
ki=V2i{i + \)' 1 = 1*-* т,
являются вершинами с центром в начале координат и со
стороной единица и радиусами Rmi km — описанной и вписанной
соответственно сферы.
Введем матрицу
М2=-рМи (1)
которая также задает симплекс, со стороной только равной р.
Определим параметр р так, чтобы
Р/?ш = тт||л:, —г/у||2 = Г, *, j = 1,..., tn+\\ P<2; (2)
tj
где jc£ — вершины первого симплекса Мх, #у —вершины второго
симплекса М2.
Так как
т—1 т-\
Г-р22*?+(р*«-/?*)2=р22а2,+(р*я-/?|Я)2 =
р2т + т—2р
— 2(jii + 1) '
114
то из (2) следует значение оптимального р в (1), которое
составляет
р = ^ ПРИ w<4, p = 2 при ту А.
Ясно, что симплекс Мх вложен при ту 2 в симплекс Af2,
чем и объясняется название метода.
Таким образом, в качестве первоначального наброса
используем N = 2т^-3 точек, определяемых строками матрицы М =
[МЛ
= \М21, где 0—нулевая строка, соответствующая центру сим-
\0 /
плекса. При этом все точки из М лежат в описывающем
шаре радиуса
^ = №т="ъУ 2(т + \) ПРИ 4>т>2'
b=mVn^h) при^>4.
Теперь сформулируем метод вложенных симплексов в
предположении, что область поиска Х0 (точнее начальных точек
поиска минимума) задается совокупностью неравенств
^о• «^w^Xi^x<ii £ = l,..., m*
Тогда: 1) проводится масштабирование области Х0 до
области
Z0: —1<2,-<1;
2) в области Z0 радиусом Rx = \ строятся точки М; их
N =2т + 3 штук;
3) из всех этих точек делается локальный спуск, в
результате чего получаем N локальных минимумов;
4) выделяется т<Л/\<N локальных минимумов {х\, л:*, ...
• ••» -л'* jj
5) определяется
jcjj>= min х{„ х&)= max xi*'
/=l,...,Wi j=l,...tNt
которые задают новую область поиска
A\:x{J><jc,<jc#>, * = 1,..., т\
6) поиск повторяется с пункта 1.
Останов происходит, когда область Х\ описывается шаром
радиуса е (е>0), либо N локальных минимумов совпадают с
предыдущими локальными минимумами.
Из описания данного алгоритма видно, что метод вложенных
симплексов особенно эффективен, когда многоэкстремальная
функция вблизи уровня и окрестности глобального минимума
«* 115
многоэкстремальна, а выше некоторого уровня является
выпуклой. Именно такие функции характерны, например, для
различных невязок, типа квадратичных, возникающих в
нелинейном методе наименьших квадратов. Локальный поиск позволяет
сузить область поиска до существенно многоэкстремальной
области.
Перейдем к описанию статистических набросовых методов.
В отличие от предыдущего детерминированного наброса, в этих
методах исходные точки в области Х0 формируются путем
статистического моделирования случайных [9, 13], либо, что
более эффективно, но более трудоемко, псевдослучайных
последовательностей [30]. При этом остается главная особенность
набросовых алгоритмов — это адаптивное сужение области
наброса Xi в процессе поиска.
Перечислим основные проблемы развития набросовых
алгоритмов.
1. Необходимо создать экономичные детерминированные и
случайные схемы наброса.
2. Требуется развить гибкие способы адаптивного сужения
области поиска.
3. Выделить путем проведения аналитических и в
особенности численных исследований на ЭВМ классы задач и функций,
для которых эффективны набросовые методы.
4. Построить различные схемы изменения метрики для
глобального наброса (аналогично, как в локальных алгоритмах
[31] производится изменение метрики в направлении разности
градиентов).
5. Создать математические классы минимизируемых
функций, для которых сходится данный метод в детерминированном
или вероятностном смысле.
3. УСКОРЕННЫЕ СТАТИСТИЧЕСКИЕ АЛГОРИТМЫ
С ИСПОЛЬЗОВАНИЕМ ПСЕВДООБРАЩЕНИЙ
Предположим, что требуется минимизировать функцию f(x),
когда при каждом вычислении f(xl) в точке xlQRm действуют
статистические помехи. Тогда оценка градиента fn в точке хп,
вычисленная по отдельным реализациям f(xl) будет также
случайной и иметь некоторую дисперсионную матрицу К- Если
предположить, что
f(x)=±(Ax,x) + (B,x), (3)
где А —положительно определенная матрица, Ь — некоторый
вектор из Rm, то задача отыскания минимума функции (3)
может вестись путем вычисления неизвестных А и b по
реализациям оценок градиентов /п. В свою очередь эта задача пол-
116
ностыо сводится к оценке неизвестной матрицы б по
реализациям—строкам y&Rm в следующей модели:
где Ж —среднее, D— дисперсионная матрица,
/С—положительно определенная симметричная матрица, Х£ — положительные
числа.
Обозначим rt = {jfx: у\: ... : #), А] = (а\: ^ : ... : ^), В* -
транспонированную матрицу для 5 и введем оптимальную
линейную оценку [14] 6 для неизвестной матрицы б размерности
пХт. Для заданной матрицы D = (d}j)izl'""™ определим
вектор-столбец (dx)*2i=D{v)* получаемый как
т. е. путем расположения снизу очередного правого столбца
матрицы D.
При сделанных предположениях оптимальная линейная
оценка б, имеет вид
^ = (А)АТ1А,ТА*А71У0 A^dlag^b X2f ...Д<), (4)
и вычисляется по рекуррентным формулам
е, = §ы + МИ-*А-1). (5)
где 1) если a/=aji_1=^0, то
S^a^aJ)-!, T/ = PiTm. r^P.rwPJ + ^MJ, Р, = /-5Л, (6)
2) если af = 0, то
Si=ri_la\{\i + alri^a*iy\ ъ = Ъ-и ri = (/-sia/)r^1; (7)
flo =0, r0 = 0, 70 = / —единичная матрица /zXw.
Дисперсионная матрица оптимальной линейной оценки есть
D(blv)) = (K*rt), (8)
где г/ = (А*Л~1А/)+ рекуррентно находится по формулам (5) —
(7), (K®rt) — кронекеро произведение матриц [32].
Матрица достоверности вектора bjv) есть
где 1т — единичная матрица размерности тХт.
Формулы (5) — (7) задают дискретный фильтр,
составляющим которого (формула (7)) является фильтр Калмана—Бью-
си. Применяя этот фильтр к реализациям функции, получаем
возможность оптимально оценивать градиент, а применяя к
лоследним — возможность находить неизвестные матрицу А и
вектор Ъ в модели (3). Если А и Ь вычислены достаточно
точно, то искомый минимум f(x) будет х^=А'хЬ.
117
Именно такая идея реализуется в ускоренных
статистических методах оптимизации с адаптивной моделью. Если
исходная функция f(x) неквадратичная, то производится ее
аппроксимация квадратичной и уже к этой аппроксимации
применяется изложенный подход.
Данные алгоритмы особенно эффективны, когда
минимизируемая функция в области поиска Х0 близка к квадратичной^
либо к квазиквадратичной вида
/ (х) = 1 (Ауг (х)9 уг (х)) + (6, у2 (*)), (9>
где Л —квадратная положительно определенная матрица
тхХтъ b*2Rm\ Уг(х), Уъ(х) — некоторые заданные функции от
переменной х, x£Rm.
Производная квазиквадратичной функции (9) есть
Г(х) = у[*хАУ1(х) + у'2*хЬ,
, (dyxj(x) y-l.....mt
где Ухх = [—Щ-)М9...9Я -якобиан, t = l, 2.
Предполагая, что
Mfn = yimxAy(x) + y2x(x)b, Df'n = Kn
и учитывая, что элементы А и Ь входят линейно в равенства
для среднего, замечаем, что полностью применим оптимальный'
фильтр (5) — (7).
Тем самым получаем статистический вариант
«криволинейного» квазиньютоновского метода, который обобщает методы,
описанные в [17, 18].
Перечислим основные проблемы развития ускоренных
статистических методов с адаптивной моделью, получаемых на
основе использования псевдообратных операторов.
1. Создание регуляризованных оптимальных рекуррентных
оценок. Приведенные оптимальные оценки (5) — (7) являются
эффективными, когда выполняются все сделанные в них
предположения. На практике эти предположения нарушаются, ввиду
наличия погрешностей вычислений, ошибок различных
аппроксимаций, неопределенности в описании помех. Это приводит к
расходимости оптимальных оценок на задачах существенной
размерности даже в случае квадратичных функций f(x). Это
свойство известно, как расходимость фильтров Калмана—Бью-
си [8, 33, 34]. Поэтому необходимы устойчивые к
возмущениям рекуррентные фильтры типа (5) — (7). И уже построенные
на их основе методы оптимизации будут эффективнее
предложенных в [17—19].
2. Применение управляемых последовательных оценок.
Когда аппроксимация минимизируемой функции f(x) достаточно
118
точна выражениями (3), (9), и помехи, действующие на
оценку градиента хорошо изучены, тогда появляется возможность в
процессе поиска выбирать точки, дающие максимальную
точность при оценке неизвестных А и 6.
Такая задача выбора оптимальных точек сводится к задаче
последовательного оптимального планирования экспериментов
[35, 36]. При этом успешно можно использовать процедуры
компромиссного планирования [37].
3. Создание статистических методов с адаптивной моделью
для условных экстремальных задач. Предложенные в [17—19]
схемы методов с псевдообращениями ограничены безусловными
экстремальными задачами. Использование теории Lg —
псевдообратных операторов и развитых на их основе теорем
декомпозиции псевдообращенных операторов, позволяет создать
указанные безусловные методы на экстремальные задачи с
ограничениями (возможно операторными), задаваемыми в виде
равенств. Интерес представляет распространить эти методы и на
экстремальные задачи с ограничениями, включающими
неравенства.
Требуется продолжить исследования, начатые в [26] по
численному исследованию ускоренных алгоритмов статистической
оптимизации, использующих псевдообращения.
4. О ПРИНЦИПАХ СОЗДАНИЯ ПАКЕТОВ
ПРИКЛАДНЫХ ПРОГРАММ АЛГОРИТМОВ
ОПТИМИЗАЦИИ
Различают два основных принципа создания пакетов
программ модульный [28] и библиотечный [38].
Модульный принцип включает создание монитора и набора
основных модулей алгоритмов. Модули обычно выделяются по
вычислению:
1) направления поиска,
2) шага,
3) разностных оценок градиентов,
4) статистических оценок градиентов,
5) формирования матриц изменения метрики,
6) тестовых функций,
7) правил останова,
8) схем наброса начальных условий.
Монитор является управляющей программой,
компилирующей модули. Реализуется путем директивного формирования
алгоритма и адаптивного. При директивном формировании
используется таблица (матрица, граф) соответствий
«характеристики задачи» — «набор модулей». При адаптивном — эти
связи случайные и задаются вероятностями, которые
формируются, либо в процессе поиска, либо исходя из опыта
решения задач определенного класса.
119
Модульный принцип особенно полезен при работе с
дисплеями в режиме диалога.
Библиотечный принцип эффективен при одноразовом
решении экстремальных задач с известными свойствами. Требует
выработки единых паспортных данных для всех алгоритмов с
тем, чтобы максимально обеспечить удобство использования их
потребителем.
ЛИТЕРАТУРА
1. Мелешко В. И., Растригин Л. А. Состояние и проблемы развития
случайного поиска. — В сб. «Случайный поиск экстремума». Киев,
«Наумова думка», 1974, стр. 5—16.
2. Ф и а к ко А., М а к - К oip м ик Г. Нелинейное программирование.
Методы последовательной безусловной минимизации. М., «Мир», 1972.
3. Е р м о л ь е в Ю. М. Методы стохастического программирования. М.,
«Наука», 1976.
4. О р т е г а Д ж., Реййболдт В. Итерационные методы решения
нелинейных систем уравнений со многими неизвестными. М., «Мир», 1975.
5. Юди.н Д. Б. Математические методы управления ib условиях неполной
информации. М., «Сов. радио», il974.
6. Пшеничный Б. Н., Данилин Ю. М. Численные методы в
экстремальных задачах. М., «Наука», 1975.
7. Неве лье он М. Б., Хасьминекий Р. 3. Стохастическая
аппроксимация и рекуррентное оценивание. М., «(Наука», 1972.
8. Цы'пкин Я. 3. Основы теории обучающихся систем. М., «Наука»,.
1970.
9. Растригин Л. А. Системы экстремального управления. М., «Наука»,.
1974.
10. Мелешко В. И. Градиентные методы оптимизации с памятью. — «Изв.
АН СССР», «Техническая -кибернетика», 1973, № 1.
11. Мелешко В. -И., П е с и н а Р. И. Алгоритм оптимизации многошаговым-
методом статистического квазиградиента. — В кн.: «Проблемы случайного
поиска», зьш. 4, Рига, «Зинатне», 1974, стр. il56—170.
12. Мелешко В. И., Моги л я некий !В. Е., Назырова В. П., Лер-
нер И. У. Численные методы идентификации динамических (моделей на
основе регрессионного анализа. Препринт 76—29, ИК АН УССР, Киев,
1976, стр. 3—29.
13. Растригин Л. А. Статистические методы поиска. М., «Наука», 1968.
14. Мелешко В. И. Рекуррентное статистическое оценивание на основе
nce-вд о обратных операторо-в. — «Автоматика и телемеханика», 1976, № 8Г
стр. -101—110.
15. Мелешко В. И. Оптимальное оценивание с (псевдообращением в
задачах фильтрации и наблюдаемости линейных систем. — «Автоматика и
телемеханика», 1976, № 10, стр. 101—-Ю8.
16. Мелешко iB. И. Псевдообратные операторы и рекуррентное вычисление
псевдорешений в гильбертовых пространствах.«Сибирский
математический журнал», 1978, № 2.
17. Мелешко В. И. Ускореннные статистические методы оптимизации с
адаптивной моделью. — «Автоматика и вычислительная техника», 1976,
№ 4, стр. 35—42.
18. Мелешко В. И. Статистические алгоритмы оптимизации с адаптацией
модели по разностям оценок градиентов. — «Автоматика и
вычислительная техника», 1977, № 1.
19. Мелешко В. И. Численные методы безусловной оптимизации с
использованием псевдообращений. — В сб.: «Численные методы нелинейного
120
программирования». Тезисы И-го Всесоюзного семинара, АН СССР—MB
ССО СССР, Харьков, 1976, стр. 14^23.
20. Мелешко В. И. Об .устойчивом рекуррентном псевдообращении
вырожденных и плохо обусловленных матриц. — В сб.: «Численные методы
нелинейного программирования». Киев, «Наукова думка», 1976, стр. 53—67.
21. Мелешко В. И., Лесина Р. И., Башмакова Т. И.
Экспериментальное исследование регуляризованных рекуррентных псевдообращений
матриц. — В сб.: «Численные методы нелинейного программирования».
Киев, «Наукова думка», 1976, стр. 68—79.
22. Мелешко В. И. Устойчивое к возмущениям лсевдообращение
замкнутых операторов. — «Журнал вычислительной математики и
математической физики», 1977, № 5.
23. Мелешко В. И. Методы псевдообратных операторов определения сед-
ловых точек. — В сб.: «Численные методы нелинейного программирования».
Киев, «Наукова думка», 1976, стр. 27—32.
24. Н е в е л ь с о н М. Б., X а с ь >м и н с к и й Р. 3. Адаптивная процедура
Роббинса—Монро. — «Автоматика и телемеханика», 1973, № 10, стр. 71—83.
25. Поляк Б. Т., Цыпкин Я. 3. Потенциальные возможности адаптации.—
«Вопросы кибернетики. Адаптивные системы» (труды II Ленинградского
симпозиума «Теория адаптивных систем»). М., 1976.
26. Мелешко В. И., Назырова В. П., Пес и на Р. И. Численное
исследование статистических алгоритмов одноэкстремальной и
многоэкстремальной оптимизации с адаптивной моделью. — Препринт 77—, ИК АН
УССР, Киев, 1977.
27. Мелешко В. -И. Динамическая оптимизация методом обобщенных ква-
зиградиентов. — «Кибернетика», 1975, N? 3, стр. 73—79.
28. Мелешко В. И., П е с и н а Р. И. Разработка пакета программ
безусловной оптимизации на модульном принципе. — «Управляющие системы и
машины», (Киев), № 2, 1977.
29. Горский В. Г., Бродский В. 3. О симплекс планах первого
порядка и связанных с ними планах второго порядка. — В кн.: «Новые
идеи в планировании экспериментов». М., «Наука», 1960, стр. 59—117.
30. Соболь И. М. Численные методы Монте-Карло. М., «Наука», 1973.
31. Шор Н. 3. О скорости сходимости обобщенного градиентного спуска.—
«Кибернетика», 1968, № 3.
32. Маркус М., Мин к X. Обзор по теории матриц и матричных неравенств.
М., «Наука», 1972.
33. Л и п ц е р Р. Ш., Ширяев А. Н. Статистика случайных процессов. М.,
«Наука», 1974.
34. Р я б о в а - О р е ш к о в а А. П. Об устойчивости фильтров Калмана. —
«Изв. АН СССР», «Техническая кибернетика», 11970, № б.
35. К i e i e r J. General equivalence theory for optimum disigns (approximate
theory). — «The Ann. of Stat.», -1974, v. 2, № 5, pp. #49—£79.
36. Ф е д о р о в В. В. Теория оптимального эксперимента. М., «Наука»,
1971.
37. Мелешко В. И., Дольберг О. М. Компромиссное статистическое
планирование экспериментов по нескольким критериям. — «Автоматика и
вычислительная техника», 1976, № '2, стр. 39--44.
38. Брябрин В. М., Евтушенко Ю. Г., Семовский С. В. Диалоговая
система оптимизации.—В сб.: «Численные методы нелинейного
программирования». Тезисы Н-го Всесоюзного семинара, АН СССР—MB ССО
СССР. Харьков, 1976, стр. 3—7.
9—6065
121
УДК 62-506-
К ПРОБЛЕМЕ ПОСТРОЕНИЯ ПАКЕТОВ
ПРОГРАММ ОПТИМИЗАЦИИ
В. П. Григоренко
(Таллин)
Эффективность использования современной вычислительной
техники в значительной степени зависит от темпов разработки
и внедрения новых алгоритмов и программ. В связи с этим в>
последнее время большое развитие получает создание пакетов
прикладных программ (ППП).
Под пакетом обычно понимают совокупность программ,
ориентированных на решение определенного класса задач.
Современные пакеты включают: ведущую программу — монитор,
процессор с входного языка, набор программных модулей, набор
обслуживающих программ [1].
Увеличение производительности программирования с
применением пакетов прикладных программ базируется на
переложении все более разнообразных функций по реализации
программ от человека к машине. Наконец, только применение
пакетов программ позволит объединить и сохранить наиболее
ценную часть прикладного программного обеспечения ЭВМ.
В настоящей работе исследуется проблема построения
пакетов прикладных программ решения оптимизационных задач.
Формулируются основные требования, которым должны
удовлетворять современные пакеты, дается классификация
пакетов, которая иллюстрируется описанием пяти конкретных
пакетов программ оптимизации.
Трудности решения общей задачи нелинейного
программирования общеизвестны, они в основном связаны с «проклятием
размерности», многоэкстремальностью, стохастичностью и т. д.
Отсутствие общей теории и универсальных методов, а также
необходимость решения огромного количества практических
оптимизационных задач ведет к быстрому росту числа
разрабатываемых эвристических алгоритмов и приемов поиска экстремума.
Однако бессистемное накопление различных методов и
алгоритмов не решает существа проблемы. Каждая новая
практическая задача ставит проектировщика перед дилеммой: либо
пытаться отыскать в массе программ нужную, либо, исходя из
знания физических особенностей оптимизируемого объекта,
попытаться разработать еще один, но свой алгоритм и
соответствующую программу.
Одним из возможных путей решения указанной проблемы
является, по-видимому, разработка на единой концептуальной
122
основе пакетов прикладных программ решения
оптимизационных задач.
При- всем разнообразии различных подходов к созданию
пакетов прикладных программ решения задач оптимизации
современные пакеты должны удовлетворять ряду требований,
обеспечивающих пользователя пакета возможностью, во-первых,
простого выбора алгоритма для решения конкретной задачи
оптимизации, и, во-вторых, возможностью ставить свою задачу
на ЭВМ при минимальном знании приемов программирования.
Это возможно лишь в том случае, когда задается не программа
решения задачи, а ее языковая модель — содержательное
описание задачи на проблемно-ориентированном языке.
Следующим очень важным требованием к пакету программ решения
экстремальных задач является обеспечение в нем помимо
автоматического режима решения задачи без вмешательства
человека, также интерактивного, предполагающего возможность
оперативного взаимодействия пользователя с ЭВМ на любом
этапе выбора оптимального решения. Особый эффект
диалоговый режим дает при решении плохо формализуемых задач, где
необходимы опыт и интуиция специалиста.
Как уже указывалось выше пакет прикладных программ
состоит из программных .модулей, образующих тело пакета, и
управляющей программы или монитора пакета. С точки зрения
архитектуры пакета, т. е. его внутренней организации и способа
общения с ним пользователя, пакеты можно разделить на два
класса, — пакеты организованные по библиотечному принципу
и пакеты с автоматической генерацией [2]. В первом случае
пользователю представляется либо возможность с помощью
специальных средств обратиться из своей программы к любому
модулю или цепочке модулей библиотеки, либо задать в
управляющей программе один из заранее предусмотренных путей
расчета — последовательности вычислительных модулей. В
пакетах с автоматической генерацией программа решения задачи
генерируется по содержательному описанию задачи: описание
задачи транслируется с проблемно-ориентированного языка
высокого уровня на внутренний язык пакета, приобретая вид
программы решения задачи. Необходимыми составными
частями такого пакета являются входной язык высокого уровня и
соответствующий транслятор.
Несмотря на то, что в настоящее время разработано уже
достаточно много пакетов прикладных программ различного
назначения как у нас, так и за рубежом (смотри библиографию
в [3]), публикаций о работах по созданию пакетов программ
оптимизации имеется пока крайне мало.
Пакеты прикладных программ оказались наиболее
подходящей формой исполнения программного обеспечения систем
автоматизированного проектирования САПР [4]. Развитие работ
по САПР послужило толчком к созданию пакетов прикладных
9*
123
программ для решения задач оптимизации, так как большинство
инженерных задач схемотехнического проектирования
математически могут быть сформулированы как задачи нелинейной
оптимизации.
Одной из первых работ, в которой был описан программный
комплекс, в основном удовлетворяющий перечисленным выше
требованиям к пакетам программ, является [5]. В работе
описана система автоматизации процесса принятия оптимальных
решений САППОР, которая позволяет решать задачи
оптимального проектирования электронных схем как в пакетном режиме,
так и в режиме диалогового взаимодействия «человек — ЭВМ».
Программное обеспечение системы, выполненное в виде пакета
программ, включает в себя внешний язык описания структуры
и компонентов схемы, язык общения, позволяющий в
естественном для разработчика электронных схем виде формулировать
задачи исследования, транслятор, переводящий поставленную
задачу во внутренний язык ЭВМ и подготавливающий ее к
пакетной обработке, набор сервисных программ, позволяющих
получать результаты в наглядной форме.
Следует отметить, что в пакетах программ оптимизации,
выполненных как программное обеспечение САПР, на единой
методологической основе решаются все этапы выработки
оптимального проектного решения: автоматическое составление
вычислительной модели оптимизируемого объекта по информации
о его структуре, математическая формулировка задачи
оптимизации и численное решение сформулированной задачи одним из
методов поисковой оптимизации.
Модуль «Метод» системы САППОР содержит достаточно
большое число различных методов поисковой оптимизации,
позволяющих эффективно решать широкий класс задач
нелинейного программирования.
Для задач глобальной оптимизации в САППОР
использовался модифицированный метод случайного поиска с
направляющим конусом.
Что касается алгоритмов случайного поиска, то они
оказались очень удобными для реализации в пакетах программ
оптимизации. В [6] разработан пакет прикладных программ
статистической оптимизации для задач машинного проектирования
силовых полупроводниковых приборов. В первой очереди
пакета реализовано шесть различных алгоритмов случайного поиска:
алгоритм с пересчетом, статистический градиент, с парными
пробами, направляющий конус, Gm — градиент и метод
сопряженных градиентов.
Пакет построен по библиотечному принципу, теля пакета
имеет модульную структуру. Поскольку шаговые алгоритмы
случайного поиска модульны по своей природе, то выделение в
отдельные программные модули алгоритма выбора направления
спуска, величины шага, проверки критерия останова, критерия
124
переключения с алгоритма »на алгоритм и др., позволило в
управляющей программе пакета реализовать широкую гамму
различных вариантов использования упомянутых выше
алгоритмов случайного поиска для задач многопараметрической
оптимизации.
Пакет прикладных программ с автоматической генерацией
изложен в работе [7]. Основу пакета составляют несколько
алгоритмов случайного поиска, которые аналогично [6]
разбиваются на ряд модулей, используемых в различных алгоритмах.
Из этих модулей с помощью системы генерации собирается
Фортран — программа, настроенная по параметрам еще до
счета, причем в .момент сборки задается режим генерации,
определяющий те модули, которые .войдут в конструируемую
программу. Применение различных режимов генерации позволяет
собирать из одних и тех же модулей различные программы. Гибкая
организация банка модулей позволила свести переключение с
одного метода минимизации на другой или же модификацию
алгоритма к изменению режимов генерации.
Программные модули пакета написаны на языке МАКФОР
[8].
Проведенное экспериментальное решение пакетом большого
числа тестовых задач при различных режимах управления
показало его высокую эффективность.
В [9] разработан пакет программ ВЕКТОР-1,
предназначенный для решения одного класса задач дискретной оптимизации.
Пакет снабжен проблем,но-ориентированным языком высокого
уровня и автоматической генерацией. Монитор пакета состоит
из следующих основных программных блоков:
АДМИНИСТРАТОРА— головной управляющей программы;
ИНТЕРПРЕТАТОРА—совокупности программ, выполняющих интерпретацию и
обработку .предложений входного языка; ПЛАНИРОВЩИКА —
программы, осуществляющей планирование, т. е. построение
схемы вычислительного процесса с указанием необходимых
модулей и последовательности их выполнения для получения
решения поставленной задачи. Среди других программных
блоков монитора отметим БЛОК НАКОПЛЕНИЯ ОПЫТА
—программу, выполняющую накопление статистических данных о
работе пакета, таких, например, как частота использования тех
или иных модулей в системе, определение наиболее часто
решаемых задач, время, затрачиваемое системой на различных этапах
ее работы или время работы отдельных модулей и др.
В заключение краткого обзора пакетов црограмм
оптимизации рассмотрим особенности подхода и принципы, положенные
в основу разрабатываемого в НИИ ТЭЗ им. М. И. Калинина
(г. Таллин) программного обеспечения САПР
электротехнических устройств, реализуемого в виде пакетов прикладных
программ [10].
125
Предварительно отметим, что, как правило, мониторы
пакетов разрабатываются специалистами той предметной области,
где намечается использование пакета, поэтому на качестве
пакетов сказывается нехватка опыта системного
программирования. В связи с этим при разработке пакетов нами
использовалась инструментальная система программирования ПРИЗ [11],
которая специально предназначена для создания пакетов
программ.
При использовании инструментальной системы
программирования отпадает 'необходимость три разработке каждого
пакета создавать свою мониторную систему. Тело пакета создается
при помощи двух программ системы ПРИЗ: конструктора
языка и транслятора программ. Конструктор языка обрабатывает
описания синтаксиса и части семантики входного языка пакета,
а транслятор, как правило, является частью стандартного
матобеспечения ЭВМ, он используется для перевода программ,
включаемых в тело пакета.
Монитором пакета является организующая программа
системы ПРИЗ, которая разделена на три части: транслятор задач,
планировщик и компилятор. Транслятор задач переводит
входной текст задачи на внутренний язык, используя описание
синтаксиса языка и модель предметной области. Планировщик
составляет алгоритм решения задачи, то есть определяет
последовательность применяемых модулей (программ), используя
модель предметной области и описание задачи на внутреннем
языке. Компилятор выдает полностью готовую программу
решения задачи. Планировщик и компилятор вместе образуют
генератор, который по описанию задачи составляет рабочую
программу решения задачи.
Наличие в системе ПРИЗ базового семантически
расширяемого язьгка УТОПИСТ [12] позволяет просто создавать входные
проблемно-ориентированные языки конкретных пакетов.
Рассмотрим теперь диалоговую систему принятия
оптимальных решений ДИСПОР, предназначенную для решения на ЭВМ
задач оптимального проектирования электротехнических
устройств (силовых диодов и тиристоров, силовых агрегатов,
предохранителей, автоматических выключателей). Программное
обеспечение ДИСПОР выполнено в виде нескольких пакетов
прикладных программ, объединенных в рамках ПРИЗ-а в
интегрированную систему совместимых пакетов [13].
Следуя [14], процесс проектирования в ДИСПОР
представляется как двухэтапный автоматизированный процесс принятия
оптимальных решений: этап формализации целей
проектирования и этап оптимизации. В связи с таким разделением процесса
проектирования на два самостоятельных этапа программное
обеспечение ДИСПОР построено в виде
проблемно-ориентированных пакетов, рассчитанных на пользователей
непрограммистов, для этапа формализации целей и процедурно-ориентиро-
126
.ванного пакета, рассчитанного на специалиста по решению
оптимизационных задач, для этапа оптимизации.
Программное обеспечение задач первого этапа включает
пакеты программ, реализующие математические модели
электротехнических устройств, пакет «Статистика» [15] и пакет
«Формализация», предназначенный для свертывания критериев
в задачах векторной оптимизации.
На этапе формализации при помощи перечисленных пакетов
решается задача переложения технического задания с языка
описания объекта на язык, понятный ЭВМ. На этом этапе
проектировщик через дисплей осуществляет проведение на
модели проектируемого изделия многократных, многовариантных
просчетов и оперативного анализа результатов с целью выбора
критерия оптимизации, как правило, в многокритериальной
постановке, задания оптимизируемых параметров и ограничений,
определяющих область допустимых решений.
Диалог проектировщика с ЭВМ ведется на
проблемно-ориентированных языках ,пакетов, результатом является
-скомпилированная программа, вычисляющая критерий качества и
ограничения в общей задаче нелинейного программирования, к которой
^сводится задача оптимального проектирования.
Рассмотрим теперь процедурно-ориентированную часть
программного обеспечения ДИСПОР, предназначенную для
решения сформулированной на предыдущем этапе задачи
нелинейного программирования.
Эта часть выполнена в виде пакета программ библиотечного
типа, особенностями пакета является, во-первых, инициируемый
ЭВМ диалог через дисплей с использованием техники выбора
меню [16], и, во-вторых, наличие «самообучения» ,в .процессе
функционирования -системы «пользователь-ЭВМ». Имеется в
виду включение в состав пакета программы
формально-логического анализа ситуаций и их закрепления в памяти машины,
что позволяет прогнозировать действия пользователя в процессе
решения задачи оптимизации. В ходе такого «самообучения» в
зависимости от периода «повторяемости аналогичных ситуаций
ЭВМ выступает уже в качестве советчика при выборе
алгоритмов оптимизации, параметров алгоритмов и др., выдавая им
статистически достоверную характеристику и тем самым
дополняя интуицию и опыт пользователя. Заметим, что такое
«самообучение» возможно как в режиме нормальной эксплуатации
пакета, так и при решении тестовых задач.
Блочная структура пакета обеспечивает ему большую
гибкость и универсальность. Опишем некоторые основные блоки
пакета.
Блок алгоритмов оптимизации, имеет модульное -строение,
открыт для расширения новыми алгоритмами. В первой очереди
пакета реализованы следующие алгоритмы оптимизации:
алгоритмы случайного поиска, взятые из пакета [6], информацион-
127
но-статистический алгоритм глобального поиска [17], алгоритм
глобальной оптимизации с использованием стохастических
обучаемых автоматов [18], а также ряд алгоритмов градиентного
типа. В состав блока входит также каталог алгоритмов,
состоящий из списка описаний и «лицевых счетов» алгоритмов. Блок,
прерывания обеспечивает прерывание работы алгоритма в
соответствии с заданными заранее условиями или в любой момент
работы 'по желанию пользователя, а также выдачу
промежуточных результатов. Блок редактирования позволяет
корректировать ход решения задачи оптимизации. Блок
формально-логического анализа «лицевых счетов» алгоритмов обеспечивает
режим «самообучения» либо в ходе неоднократного решения
практических задач оптимизации, либо в ходе тренировочного
решения тестовых задач. К услугам пользователя имеются
также следующие сервисные программные модули: модуль печати
на АЦЭП промежуточных и конечных результатов поиска в^
различных форматах, модуль вывода ,на экран дисплея
динамики изменения во времени оптимизируемого критерия, модуль-
выдачи результатов сканирования критерия по любой
переменной в табличной или графической форме на АЦПУ или
дисплей, модуль расчета координат точек изолиний критерия с
выводом изолиний на | плоттер.
Разработанный пакет программ обеспечил пользователю
системы ДИСПОР возможность активного участия во всех этапах,
поиска оптимального решения, от выбора алгоритма
оптимизации и настройки его параметров, до принятия окончательное
решения о том, что найденный оптимум удовлетворяет всем
требованиям, предъявляемым к проектируемому объекту.
ЛИТЕРАТУРА
1. Та-мм Б. Г., Ты угу Э. X. О создании проблемно-ориентированного
программного обеспечения. — «Кибернетика», 11975, № 4.
2. Та'мм Б. Г., Ты угу Э. X. Пакеты с генерацией программ.— Тезисы до-
•кладов 'международной (конференции «Структура и организация пакетов-
программ». Тбилиси, 1976, стр. 14—16.
3. 3 и з и н М. Н., Загадский Б. А., Темное в а Т. А., Яр о слав-
це'ва Л. Н. Автоматизация реакторных расчетов. М., Атомиздат, 1974.
4. «Руководящие методические материалы .по созданию программного
обеспечения систем автоматизации проектных, конструкторских и
технологических разработок в отраслях промышленности и строительства»,
Редакция 0-,1975, ВЦ АН СССР, 1975.
5. Бати ще'в Д. И. и др. САППОР—система автоматизации процесса
принятия оптимальные решений.—iB сб.: «Кибернетические системы
автоматизации проектирования». М., МД НТП, 1973. стр. 31—42.
6. Тарасенко Г. С. Пакет программ безусловной оптимизации. — В сб.:
«Проблемы случайного поиска», вып. 6. Рига, «Зинатне», Ш77.
7. «Пакет минимизации. Алгоритмы и програм1Мы», вып. 1. Под общей ред.
Т. Л. Рудневой. iM., Изд-во МГУ, 1975. стр. 5-^53.
8. Арушанян О. Б., Гайсарян С. Е., Кабанов М. И. МАКФОРг
Язык описания .макромодулей Генератора программ. — «Вычислительные*
128
методы и программирование», вып. XXII. Сб. работ ВЦ МГУ. М., 1974„
стр. 12—26.
9. Гуля ни цк и й Л. Ф., Касишицкая М. Ф.; Сер гиен к о И. В.,
С т и р а н к а А. И., Х*и л ь ч е н к о В. И. Пакет программ ВЕКТОР-1. —
«Программирование», 1976, № 2, стр. 42—54.
10. Тыугу Э. X., Григоренко В. П. Принципы построения пакетов
прикладных (пропра-м-м машинного проектирования. — «Автоматизация
проектирования сложных систем», выл. 2. Минск, 1976.
11. Кахро М. И., Мяннисалу М. А., Саан Ю. П., Тыугу Э. X.
Система программирования ПРИЗ. — «Програрмирование», 1976, № 1,
стр. 38—46.
12. Мяннисалу М. А., Тыугу Э. X. Язык описания задач УТОПИСТ.—
«Управляющие системы и машины», 1974, № 1, стр. 60—-&4.
13. Григоренко В. П., Ре б а не Л. А., Сотников а Н. С. Вопросы
интеграции пакетов прикладных программ. — Тезисы докладов
международной конференции «Структура и организация пакетов программ».
Тбилиси, 1976. стр. 143—146.
14. Батищев Д. И. Системный подход к задачам машинного
проектирования радиоэлектронных схем. — В об.: «Автоматизированное
оптимальное проектирование инженерных объектов и технологических процессов»,
ч. II. Горький, 1974. стр. 11—18.
16. Григоренко В. П., Мяннисалу М. А., Ре бане Л. А. Пакет
прикладных программ по математической статистике. Ротапринт ЭК «Бит».
Таллин, 1975.
16. Мартин Дж. Системный анализ передачи данных, ч. I. M., «Мир»,
1.975.
17. Стронгин Р. Г. Алгоритмы для поиска а)бсолютного минимума. — В сб.:
«Задачи статистической оптимизации». Рига, 197,1. стр. 51—6в.
18. Б руне Е. Д., Григоренко В. П., Юле-гин Ю. Н. Автоматные
модели адаптивных систем управления и оптимизации. — В об.: «Проблемы
случайного поиска», вып. 6. Рига, «Зинатне», '1977.
УДК 62-506
ЕЩЕ РАЗ О ДИНАМИКЕ ПУБЛИКАЦИИ
ПО ПРОБЛЕМЕ СЛУЧАЙНОГО ПОИСКА
С. Н. Гринченко
(Ростов-на-Дону)
Интенсивное развитие в последние годы исследований по
теории и приложениям случайного поиска (СП) ставит задачу
оценки характеристик этого процесса и перспектив дальнейшей
разработки проблемы. Одним из методов науковедческого
анализа актуальности научных направлений является изучение
скорости роста числа 'публикаций. Применительно к проблеме СП
такой анализ был недавно проведен Л. А. Растригиным в [1]
на основе данных второй библиографии по СП [2],
включающей работы, опубликованные до середины 1973 г.
12^
Библиография [3], составленная автором и являющаяся
продолжением [2], с одной стороны, содержит работы,
опубликованные с 1973 до середины 1976 г., а с другой — значительное
число работ за 1958—1972 гг., по различным причинам лропу-
щенные в [2]. Количество последних (204 работы) составило
ровно одну треть от числа соответствующих работ (612),
включенных в [2]; общее же число работ по СП, включенных в
библиографии, увеличилось на 86,7%. Такое расширение списка
позволяет повторить анализ, проведенный в [1], с целью
уточнения и проверки основных выводов.
п
200
180
160
то
120
60 \-
Ч)
б)
kvrdll
Vt 16
58 60 62 64 66 66 70 TL
t, годы
Рис. 1. Число публикаций по проблеме СП по
годам (1976 г. — полугодие):
а — общее число работ по проблеме; б — в том числе
работы на иностранных языках
Гистограмма роста числа публикаций по годам (рис. 1, а)
подтверждает вывод об экспоненциальном росте этой величины.
Некоторое снижение ординаты в 1974—1975 гг., безусловно,
объя-сняется значительной задержкой (1—1,5 г) публикации
рефератов работ в реферативных журналах, вследствие чего в
библиографию 'пока не вошли многочисленные исследования по
приложениям СП, публикуемые в отраслевых и ведомственных
изданиях.
Гистограмма, изображенная на рис. 1,6, показывает динамику
роста числа публикаций .по СП за рубежом. Необходимо
отметить, что нам известны далеко не все такие работы — в этом
убеждает простое сопоставление списка защищенных
диссертаций и опубликованных статей (последнее, кстати, справедливо
и для отечественных работ). Тем не менее, указанная
гистограмма позволяет сделать, по-крайней мере, два вывода: во-лер-
вых, отметить общую тенденцию нарастания числа зарубежных
публикаций по СП, и, во-вторых, — доминирующая роль оте-
i30
■чественой школы СП в развитии проблемы (зарубежные
публикации составляют лишь 11,4% от общего их числа).
Интенсивность числа публикаций по СП N(t) представлена
в логарифмическом /масштабе на рис. 2. Подтверждается вывод
60 62 54 66 6$ 10 П 74 76
t, годы
Рис. 2. Рост числа публикаций по СП
(1976 г.— данные за 1 полугодие)
II] .о том, что точки хорюшо аппроксимируются двумя
экспонентами (которые являются прямыми при логарифмическом
масштабе); зависимость N(t) уточнена и выглядит следующим
образом:
#(*)=
0,155 (*-1958) + 0,84
10, 1958<*<1968;
0,104 (*-1958) +1,52
10, 1968 <*< 1976.
Период удвоения числа публикаций по каждому из этих
интервалов также уточнен и составляет:
■-&
1,8 года, для 1958 </< 1968;
1 года, для 1968 <*< 1976.
Обе эти цифры в .несколько раз превышают современную
оценку среднего времени удвоения числа научных публикаций,
равную 10—15 годам.
Основная причина «перелома 1968 года» на кривой рис. 2,
по-видимому, связана >с выходом в свет первой монографии,
обобщающей 'проблему—- книги Л. А. Растригина
«Статистические методы поиска» (М., «Наука», 1968).
131
Продолжающийся до настоящего времени экспоненциальный
рост числа публикаций по СП, без заметных признаков
перехода на логистическую кривую, свидетельствует, что с одной
стороны, далеко не все теоретические проблемы СП исследованы, а,
с другой, — что границы «сферы» приложений СП еще не
достигнуты. СП, успешно решая современные многопараметричес-
кие задачи, завоевывает себе все новые и новые области
применения, демонстрируя высокую эффективность работы при
чрезвычайной простоте реализации и не имея себе в этом
равных конкурентов.
Дальнейший анализ работ, включенных в [2] и в
библиографию [3], позволяет выявить структуру авторских
коллективов и относительный вклад, внесенный различными авторами в
разработку проблемы СП. Так, из общего числа 916 авторов
600 чел. (или 65,5%) имеют по одной работе по этой тематике,
Рис. 3. Соотношение
количества авторов,
имеющих одну, две либо три
и более работ по СП
106 чел. (или 11,6%) —по две, и 210 чел. (или 22,9%) —по три
и более работ (см. рис. 3).
Таким образом, основное ядро исследователей проблемы СП
и его «приложений составляет 200—250 чел., в том числе 150—
200 чел. в СССР. На рис. 4 приведена гистограмма .количества
работ у авторов, внесших наибольший вклад в развитие
проблемы СП и имеющих свыше 15 публикаций.
Всего этими восемнадцатью авторами (1,9% общего
количества авторов) опубликовано 565 работ, что составляет 44,8%
публикаций по СП на русском языке и 39,7% общего количества
публикаций по проблеме.
Эти цифры еще раз указывают на ведущую роль советских
ученых в разработке и .применении современного эффективного
средства поиска оптимальных решений самых различных
проблем — метода случайного поиска.
132
Рис. 4. Количество публикаций
основных авторов работ по СП
Предполагаемый комиссией по случайному поиску в
будущем выпуск новых дополнений к библиографии но СП лозволит
вновь вернуться к анализу развития этого научного
направления.
ЛИТЕРАТУРА
1. Растригин Л. А. Динамика публикаций по проблеме случайного поиска
(вместо предисловия).—В кн.: «Проблемы случайного поиска», вып. 4.
Рига, «Зинатне», 11976, сггр. 3—6.
2. «Случайный поиск. Систематический указатель литературы». Рига, 1973.
3. Г р и н ч е н к о С. Н. Библиография по проблеме случайного поиска. —
приложение к кн.: Растригин Л. А. Методы случайного поиска (препринт).
М., Научный Совет по кибернетике, 1977, стр. 26—89.
СОДЕРЖАН ИЕ
Растригин Л. А. Случайный поиск — специфика, этапы истории и пред*
рассудки 3^
Стронгин Р. Г. Информационно-статистические алгоритмы для решения
многоэкстремальных задач IT
Мороз П. А., Коростелев А. Я. Оптимизирующие случайные процессы
с непрерывным временем как идеальные модели алгоритмов
стохастической оптимизации 23:
Моцкус Я. Б. О методах поиска экстремума с наименьшей средней
погрешностью 301
Тарасенко Г. С. Исследование условий сходимости релаксационных
алгоритмов случайного поиска 40'
Жданок А. Я. Процедура релаксации стохастических алгоритмов
оптимизации и вопросы сходимости 50'
Растригин Л. A., Puna К К. Автоматные модели поиска экстремума 55
Гринченко С. Н. О нейробионических алгоритмах матричного
случайного поиска 70
Усачев Е. С. Адаптация и качественная теория процессов ... 78
Каплияокий А. Я., Красненке-р Л. С. О случайном поиске в
многокритериальных задачах 91
Эбелинг В., Файстель Р. Адаптация в модели эволюционного процесса 99
Трахтенберг В. С, Иванов В. К, Новоселов Ю. Я., Пешатов Г. Д.
Случайный поиск в системах оптимального проектирования . .107
Мелешко В. Я. О проблемах развития набросовых и ускоренных с
псевдообращениями статистических алгоритмов оптимизации . . 112
Григоренко В. П. К проблеме построения пакетов программ
оптимизации 122
Гринченко С. Я. Еще раз о динамике публикаций по проблеме
случайного поиска 129
Технический редактор Л. Я. Савельева
Сдано в набор 15/VII-1977 г. Подписано в печать 21/Х-1977 г. Т—17699 Формат 60X90Vie
Печ. л. 8,5 Уч.-изд. л. 8,49 Тираж 1000 экз. Цена 42 коп. Заказ 6065
Производственно-издательский комбинат ВИНИТИ, Люберцы, Октябрьский проспект, 403
АКАДЕМИЯ НАУК СССР
НАУЧНЫЙ СОВЕТ ПО КОМПЛЕКСНОЙ ПРОБЛЕМЕ
„КИБЕРНЕТИКА"
ШЕПНИ!
Выпуск 33
ПРОБЛЕМЫ СЛУЧАЙНОГО ПОИСКА
МОСКВА 1978