/











































































































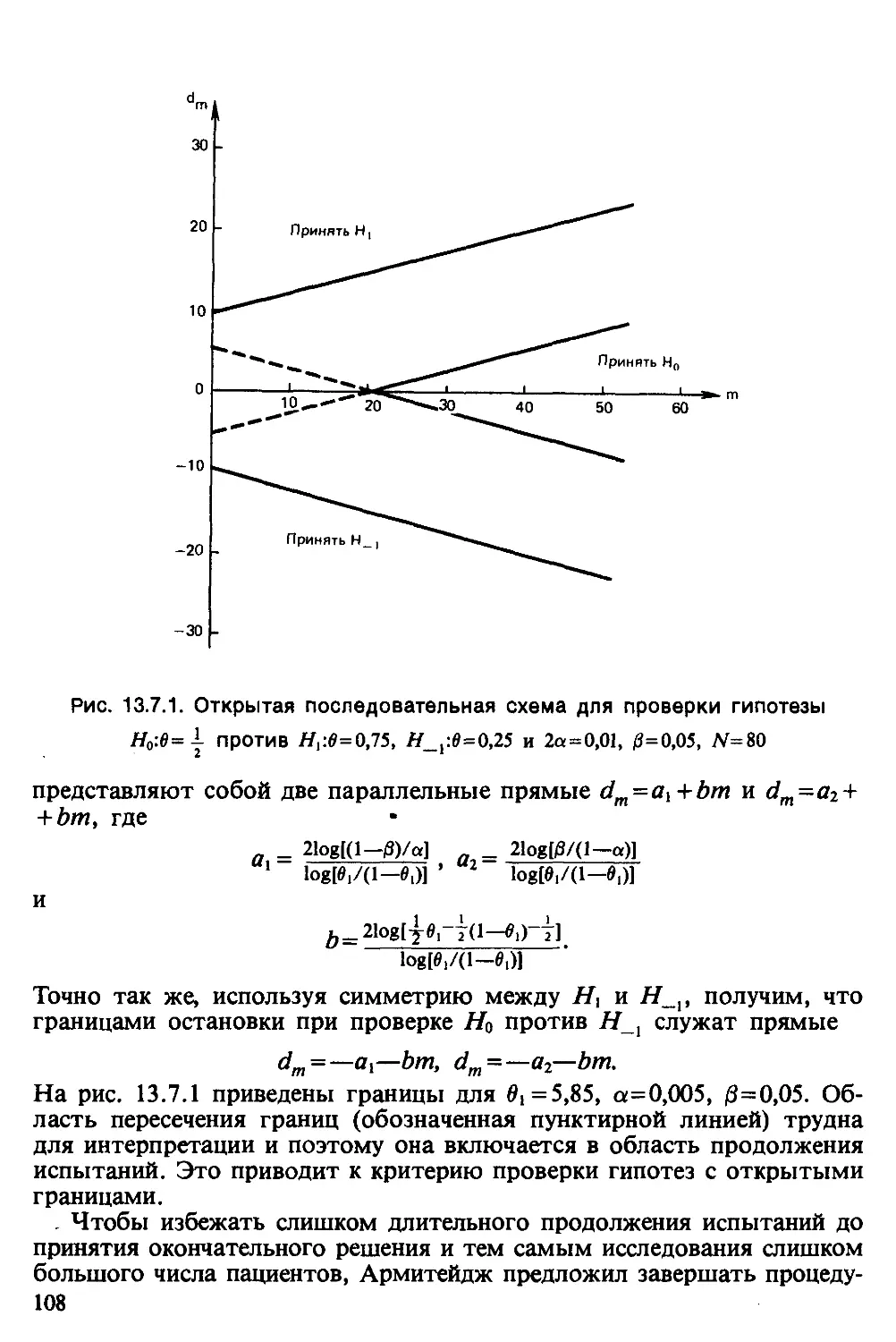




































































































































































































































































































































































































































Text
СПРАВОЧНИК
ПО ПРИКЛАДНОЙ
СТАТИСТИКЕ
HANDBOOK
OF APPLICABLE
MATHEMATICS
Chief Editor: Waiter Ledermann
Volume VI: Statistics
PART В
Edited by Emlyn Lloyd
University of Lancaster
A Wiley-lnterscience Publication
JOHN WILEY & SONS
Chichester-New York-Brisbane-Toronto-Singap
СПРАВОЧНИК
ПО ПРИКЛАДНОЙ
СТАТИСТИКЕ
Под редакцией Э. Ллойда, У. Ледермана
ТОМ 2
Перевод с английского
под редакцией С.А.Айвазяна и Ю.Н.Тюрина
МОСКВА
’’ФИНАНСЫ И СТАТИСТИКА”
1990
ББК 16.2.9
С74
0702000000 — 024
010(01)-90
110-89
ISBN 5-279-00246-1 (Т. 2, рус.) ©1984 by John Wiley & Sons Ltd.
ISBN 5-279-00244-5
ISBN 0-471-90272-1 (англ.)
© Перевод на русский язык, предисло
вие, «Финансы и статистика», 1990
Глава 11
ЛИНЕЙНЫЕ МОДЕЛИ I
11.1. ОПИСАНИЕ МОДЕЛИ
Одна из задач науки состоит в изучении отношений между пере-
менными. Простейшим из отношений является линейное, которое со-
стоит в том, что возрастание значения одной из переменных на
единицу измерения обязательно влечет за собой изменение другой пе-
ременной на соответствующую постоянную величину. Если бы изме-
рения переменных были абсолютно точными и вполне доступными, в
статистическом анализе не было бы особой необходимости. Но так
как измерения подвержены ошибкам и обладают определенной стои-
мостью, то изучение отношений между переменными проводится в ус-
ловиях неопределенности и приближенности. Статистическая теория
линейных моделей — область прикладной математики, развитие кото-
рой стимулировалось потребностями ученых, работающих в области
экономики, биологии и во многих других областях. Начало теории ли-
нейной регрессии было положено Гальтоном в процессе изучения про-
блем наследственности. Методы дисперсионного анализа [см. гл. 8]
появились в 20-х годах нашего столетия в связи с исследованиями, на-
правленными на повышение урожайности сельскохозяйственных куль-
тур. Лог-линейные модели, применяемые в количественном анализе и
для обработки качественных данных медицинской и социальной стати-
стики, были развиты в 60-х годах. Все перечисленные виды анализа
основаны на теории обобщенных линейных моделей.
Конструкция линейной модели есть некоторая попытка описать ли-
нейные отношения в условиях неопределенности. Эта конструкция
включает несколько компонентов.
Обозначим переменные через Y, х2, ...» хр, и пусть мы хотим
выбрать оптимальную линейную комбинацию переменных х{, х2, ...,
хр (объясняющих переменных) для наилучшей аппроксимации К
Спецификация линейной модели включает:
1) функцию плотности вероятности для У;
2) параметр этой функции плотности, который линейно зависит от
Xi, х2, ..., хр (линейный предиктор);
3) набор наблюдений над переменными (данные);
4) выборочную модель для наблюдения.
Спецификация функции плотности и линейный предиктор опреде-
ляют вероятностную модель для Y. Если бы оптимальная линейная
комбинация объясняющих переменных стала известной, то статисти-
ческая работа была бы завершена, а модель оказалась бы готовой для
использования. Однако обычно данные 3) и способ, которым они бы-
ли собраны, предоставляют только возможность сформулировать 4),
средство оценить линейный предиктор и проверить предположения,
сделанные относительно функции плотности и ее связи с линейным
предиктором.
Когда вероятностная модель полностью известна, она может быть
применена для нескольких целей: для предсказания наиболее вероятно-
го значения или интервалов значений для Y при заданных значениях
Xi, х2, ...» хр; для оценки относительного влияния одной из этих пере-
менных, скажем Xi на У; для определения комбинаций значений объяс-
няющих переменных, которые дают возрастание величины У на
некоторое фиксированное значение по отношению к среднему значе-
нию У; для сравнения отношения между У и некоторым подмноже-
ством объясняющих переменных с отношением для другого подмно-
жества объясняющих переменных.
Когда модель определена по наблюдаемым данным посредством
предположений, оценок, тестирований и проверок [ см. гл. 1], она мо-
жет служить также сжатым описанием данных и сглаженной их верси-
ей, где случайные выбросы подавлены.
Вероятностная модель описана в разделе 11.1, а ее база данных —
в разделе 11.2. Дальнейшее рассмотрение моделей для регрессионного,
дисперсионного и ковариационного анализа содержится в разделе
11.3, а таблицы сопряженности обсуждаются в разделе 11.4. Методы
статистического вывода, основанные на функции правдоподобия [см.
раздел 6.2.1], и аналогичные методы анализа обобщенных моделей яв-
ляются наиболее распространенными. К методу наименьших квадра-
тов, описанному в гл. 8, мы снова вернемся в разделе 12.1, а
выборочные свойства оценок будут обсуждаться в разделе 12.2. Изу-
чение этих проблем нам поможет в разделе 12.3 при анализе функции
правдоподобия для линейной модели. Основная направленность гл. И
— приложения, в то время как гл. 12 посвящена в основном теории.
В настоящей главе сделана попытка сконцентрировать внимание на
запросах и возможностях ученого-практика. Абстрактные математиче-
ские рассуждения представлены в сокращенном виде, а численные при-
меры служат для пояснений. Понятия вектора и векторного про-
странства введены в анализ линейных моделей, что обеспечивает до-
статочно мощный подход. Преимущество этого подхода состоит в
том, что он позволяет унифицировать работу с моделями регрессион-
ного, дисперсионного и ковариационного анализа, а также анализа
таблиц сопряженностей, кратко описать модели в терминах вектор-
ных подпространств, избежать сложных формул, основанных на коор-
динатных обозначениях. Этот подход связывает линейные модели с
многомерным анализом [см. гл. 16, 17], анализом временных рядов
[см. гл. 18], планированием экспериментов [см. гл. 9].
Необходимые сведения из линейной алгебры содержатся в разделах
11.1.1 и 11.3.1.
Приведенные численные примеры иллюстрируют доказательства.
Они не претендуют служить рецептами. Поскольку многие методы
приводят к итеративным вычислительным процедурам, ожидается,
что читатель имеет доступ к соответствующему программному обес-
печению. Многие обозначения и выбор материала о линейных моде-
лях связаны со статистическим пакетом GLIM [см. Baker and Nelder
(1978)].
11.1.1. ЭЛЕМЕНТЫ ЛИНЕЙНОЙ АЛГЕБРЫ
Понятия линейной алгебры [см. I, гл. 5] имеют естественное при-
менение в теории линейных статистических моделей. Они служат
«языком» как для описания линейной модели, так и для теоретическо-
го описания численных задач оценивания. Важнейшими понятиями яв-
ляются векторное сложение и умножение на скаляр, векторное
пространство и подпространство, преобразования и проекции, внут-
реннее (скалярное) произведение и нормы. Дополнительные понятия,
которые необходимы статистикам, не очень знакомым с линейной ал-
геброй, — индикаторные векторы и поточечное умножение для описа-
ния факторных моделей [см. раздел 9.8].
Векторы. Точка на линии может быть представлена числом, т. е.
х. Точка на плоскости может быть определена упорядоченной парой
чисел (Xi, х2). Точка в трехмерном пространстве может быть представ-
лена как тройка чисел (хь х2, х3). Другими словами, (хь х2, ..., хп)
определяет точку в л-мерном пространстве. Графическое же представ-
ление возможно только для л^З.
• <ХцХ2)
(Хи Х21 х3)
г
Х1
тН
Определение 11.1.1. Вектор в п-мерном пространстве Вектор
в «-мерном пространстве есть упорядоченная последовательность
х = (%1, х2, ...» хп) действительных чисел, которые называются коор-
динатами вектора х. (Векторы записываются столбцами, но из сооб-
ражений полиграфического удобства мы иногда представляем их в
виде строк.)
Предположим, что возраст, рост, вес и коэффициент интеллекту-
ального развития ребенка — 7 лет, 1,10 м, 35 кг и 122 IQ соответ-
ственно. Эти характеристики могут быть представлены как точка (7,
1,10, 35, 122) в четырехмерном пространстве. Конструкции такого ти-
па, однако, в линейных моделях используются не часто. Более распро-
страненной является следующая конструкция. Предположим, возраст
четверых детей — 7, 5, 6 и 5 лет. Эти данные могут быть представле-
ны как точка с координатами (7, 5, 6, 5) в четырехмерном про-
странстве.
Векторное сложение и умножение на скаляр осуществляются непо-
средственно.
Сложение Пусть х = (хь х2, ..., хп) и у = (уъ у2, ...» уп).
Тогда х + у = (Xi + х2 + у2....хп + уп).
Умножение на скаляр. Пусть х = (хь х2, ..., хп) и а есть действи-
тельное число. Тогда вектор ох задается в виде
оХ = (aXi, «Хг, •••, охп).
Приведенные ниже диаграммы иллюстрируют эти операции.
Векторное пространство. Векторы в «-мерном пространстве удов-
летворяют некоторым правилам, основанным на операциях сложения
и умножения на скаляр. Любое множество векторов, удовлетворя-
ющее этим правилам, образует векторное пространство. Если х, у и
Z — произвольные векторы из векторного пространства V, а а и /3 —
скаляры, то
X + у € V,
X + у = у + X,
(X + у) + Z = X + (у + Z),
х + О = X,
х — х + О,
аХ € V,
(а0)Х = а(0Х),
1 • X = X,
(а + /3)* = ах + /Зх,
а(Х + у) = аХ + ау.
Скалярное произведение*. Понятие скалярного произведения явля-
ется алгебраическим эквивалентом геометрических понятий длины и
угла. Обычное скалярное произведение векторов х и у в «-мерном
пространстве определяется как [х, у] = хху\ + Хгу2 + ... +х„у„.
Итак, если х = (—2, 3, 1) и у = (1, 0, 4), то [х, у] = 2 х 1 + 3 х 0 +
+ 1 х 4 = 2. Укажем важное свойство скалярного произведения:
симметрия: [х, у] = [у, х],
линейность: Пх» У + = JX’ + ^х’
I [х, ay] = а [X, у],
положительность: [х, х] > 0; [х, х] = 0; х = О
для любых векторов х, у, z в «-мерном пространстве.
Норма. Норма вектора соответствует геометрическому понятию
длины. Если х = (хь х2.....хл) — вектор в «-мерном пространстве,
то норма х есть неотрицательная величина, определяемая
||х|| = [X, Х]1/2 = (Х^ + Х2 + — +*п)1/2-
Так как [х, х] > 0, норма — всегда действительное число.
Рисунок показывает,
почему норма
соответствует длине
вектора
* В оригинале употребляется термин inner product, которому соответствует термин
внутреннее произведение Мы используем в переводе более распространенный в совет-
ской литературе термин скалярное произведение — Примеч. пер.
9
Например, пусть х = (2, 3). Тогда х| | = (22 + 32)1/2 = уТЗ. Анало-
гично если X = (—2, 3, 1), то ||х|| = ((—2)2 + З2 + 12)1/2 = V14.
Единичный (нормированный) вектор. Вектор х называется единич-
ным, если его норма ||х|| = 1. Если х — произвольный вектор, отлич-
ный от нулевого 0 = (0,0,...,0), то ||х||~’х — единичный вектор.
Замечание. Несколько опережая изложение, укажем, что корреляци-
онные и регрессионные коэффициенты весьма просто выражаются в
терминах скалярных произведений. Пусть х и у — два вектора наблю-
дений (измеренных относительно среднего). Тогда выборочный коэф-
фициент корреляции для переменных х и у есть
[х, у]
||Х|| ||У|Г
а простой коэффициент регрессии у на X есть
[X, у]
Цх||2
Индикаторные векторы. Индикаторным вектором называется век-
тор, координаты которого принимают только значения 0 или 1. На-
пример, в шестимерном пространстве индикаторными будут векторы
(1, 1,0, 1, 0, 0) и (0, 0, 0, 1, 1, 0). Нулевой вектор 0 = (0, 0, ..., 0)
и вектор из единиц 1 = (1, 1, ..., 1) являются индикаторными вектора-
ми. Важное подмножество составляют нормированные индикаторные
векторы. В шестимерном пространстве ими будут
= (1, 0, 0, 0, 0, 0), е2 = (0, 1, 0, 0, 0, 0) ..., е6 = (0, 0, 0, 0, 1).
Здесь [еь 61] = 1 и [eb е2] = 0. Очень важно, что любой вектор х мо-
жет быть записан в виде линейной комбинации векторов е. Так,
х = (xi, х2, ..., х6) = Х161 + х2е2 + ... +х6е6.
Покоординатное (поточечное) умножение. Пусть х и у — векторы
в л-мерном пространстве. Определим вектор как
ху = (х^, Х2У2, ..., х„у„).
Координаты вектора ху получаются перемножением соответствую-
щих координат векторов х и у. Ясно, что
ху = ух, Х1 = X, х(у + z) = ху + XZ
и что [X, у 1] = [X, у]. Если а и b — индикаторные векторы, то вектор
ab также будет индикаторным. Последнее свойство является основной
причиной для введения покоординатного умножения.
Замечание. Покоординатное умножение не следует путать с точеч-
ным умножением, а.Ь, которое используется в аналитической декарто-
вой геометрии, кинематике и т. п. Последнее совпадает с нашим
скалярным произведением.
11.1.2. БИНОМИАЛЬНАЯ ЛОГИСТИЧЕСКАЯ МОДЕЛЬ
Летальная доза лекарства оценивается по наблюдению за смертель-
ными исходами в группах мышей, которым введены различные дозы
препарата (см. раздел 6.6). Пусть х обозначает дозу инъекции, а р(х) —
вероятность смерти мыши при заданной дозе х единиц. Каждому
10
члену одной из групп, со-
стоящей из пяти мышей, _____
было введено х единиц ле- I
карства. Пусть Y обозна- р х I
чает число погибших в s'
этой группе мышей. Если .s'''
наблюдение над какой-ли-
5о мышью не зависит от -----------------о ~
наблюдения за другими, ---►х
то, используя биномиаль-
ное распределение, полу-
чаем
Рис. 11.1.1. Логистическая функция
P(Y=y)=( у)р(хУ(1—р(х))5~У для у=0, 1, ..., 5.
Правдоподобным вариантом для кривой смертности р(х) является ло-
гистическая функция [см. II, раздел 11.10, а также Owen (1962), табли-
цы — G]
р(х) = ехр(—1 + Зх)/(1 +ехр(—1 + Зх)).
Эта кривая представлена на рис. 11.1.1. Используя логарифмирование,
можно получить выражение
log [р(х)/(1—р(*))] = — 1 + Зх,
линейное по х и принадлежащее к нашей категории линейных моделей.
Возможность применения логистической модели может быть про-
иллюстрирована с помощью ответов на следующие вопросы. Чему
равна вероятность смерти мыши при х=0?
р(0) = е-//(1+е~/)-0,269.
Чему равна вероятность смерти пяти мышей при дозе х=1?
Р( У= 5)= (5 )р(1)5(1—р(1))5-5 =р(1)5 = [е-1+V(1 + е~1+3)]5 = (0,881)5=0,530.
Какая доза х соответствует значению р(х) = 1/2?
log [1/2(1—1/2)]=0= —1 + Зх, откуда х=1/3.
Предположим, 50 мышам введена доза х=1/3 и 100 мышам — доза
х=0. Сколько мышей погибнет?
50р( 1/3) +100р(0) = 25,0 + 26,9 = 51,9.
11.1.3. ОБЩАЯ ЛИНЕЙНАЯ МОДЕЛЬ
Простой пример с биномиальной логистической кривой дает пред-
ставление о вероятностной структуре линейной модели и о том, для
чего она может применяться.
Основной интерес заключается в выявлении связи между перемен-
ной Y, зависимой переменной, и другой переменной или набором пере-
менных Xi, х2, ..., хр, известных как объясняющие переменные.
Зависимая переменная Y есть случайная переменная с функцией плот-
ности вероятности /, которая, по предположению, является членом
11
экспоненциального семейства плотностей [см. раздел 1.4.2] и зависит
самое большее от двух параметров: т] — линейного предиктора и ф —
«мешающего» параметра. Функция плотности может быть записана
как
где линейный предиктор представляет собой линейную комбинацию
объясняющих переменных х2> ..., хр, т. е.
V = 01*1 + @1X2 + ... + РрХр, (11.1.1)
а ф — константа, не зависящая от объясняющих переменных. Предпо-
лагается, что имеется функциональная зависимость (функция связи)
между ожидаемым значением зависимой переменной EY и линейным
предиктором
V = g(EY). (11.1.2)
Функция g известна как функция связи.
В примере с биномиальной логистической моделью Y — число
смертей в группе из пяти мышей; имеется одна объясняющая перемен-
ная х, доза лекарства; функция плотности для Y биномиальная и явля-
ется членом экспоненциального семейства. Линейный предиктор есть
7} = —1 + Зх. Мешающий параметр отсутствует, а функция связи
log [EY/(5—EY)] = т}.
В этом примере все составляющие части (плотность, функция свя-
зи, предиктор) рассматриваются как известные, и модель готова для
использования. В реальной ситуации, когда относительно зависимости
между зависимой переменной и объясняющими переменными доступ-
на лишь информация, содержащаяся в п наблюдениях над переменны-
ми, вероятностная структура неизвестна, она может даже не
существовать. В теории линейных моделей мы идем на некоторый
компромисс и предполагаем, что функция f (у\т],ф) известна с точнос-
тью до параметров 31, /32, ...» (Зр и ф.
Хотя такое предположение может быть ошибочным, оно очень
удобно на практике. Знание ситуации (контекста), порождающей дан-
ные, обычно позволяет сделать выбор функций плотности и связи от-
носительно безошибочным, в то время как свобода в подборе
подходящих значений параметров обеспечивает гибкость в приложе-
нии модели к различным совокупностям данных. В примере с биноми-
ально-логистической моделью это означает, что параметры а и 0 в
линейном предикторе 7i = a+@x оцениваются из данных. С другой сто-
роны, структура модели не меняется.
Анализ «доза—смертность» с применением другой функции связи
проведен в разделе 6.6. В этом случае зависимой переменной Y соот-
ветствует случайная переменная Rj, индуцированная числом насеко-
мых Гу, погибших в группе из лу насекомых при применении дозы
инсектицида на j-ъл уровне [см. табл. 6.6.1]. Снова имеется одна объ-
ясняющая переменная — log(*y), где х — назначенная доза инсектици-
да. Мешающий параметр отсутствует, функцией плотности зависи-
12
мой переменной R будет Bin (лу, тгу), где тгу = Ф(а + 0Xj). [Здесь через
Ф обозначена стандартная нормальная функция распределения, так
что
Ф(м) = (гтг)-1^ ехР (~ -У2) М
Линейный предиктор есть rj = а + /Зху, а функция связи
g [Е (RJ)] = т,
задается как
Е (Rj) = njirj = nj Ф (а + /Зху).
Итак,
a + ffxj = ф-'[1£(Яу)}.
(Здесь Ф-1 обозначает функцию, обратную кФ.)
11.1.4. МОДЕЛЬ С НОРМАЛЬНОЙ ФУНКЦИЕЙ ПЛОТНОСТИ
И ТОЖДЕСТВЕННОЙ ФУНКЦИЕЙ СВЯЗИ (Normal-Identity Model)
Объем (volume) древесины, который может быть получен из неко-
торого дерева, зависит от его высоты (height) и радиуса (radius) ство-
ла. Если бы ствол представлял собой идеальный цилиндр, то мы бы
имели vol= ?r(radius)2(height) и log vol=log(%) + 21og(radius)+log(height).
Правая часть равенства является линейным предиктором. Положим
Xi = l, x2 = log(radius) и x3 = log (height) и запишем
7j = log (тг) xi+2x2+x3.
Существуют две возможности для выбора функции плотности объ-
ема: либо предположить, что измеряемый объем Y имеет нормальное
распределение со средним значением EY, определяемым как
log EY=rj,
либо предположить, что переменная У-log (измеренный объем) рас-
пределена нормально со средним значением
При отсутствии ддполнительной информации предпочтем послед-
нее предположение по следующим соображениям. Объем может быть
только положительной величиной, в то же время как нормальная слу-
чайная величина может принимать и положительные, и отрицатель-
ные значения. Кроме того, дисперсия величины объема скорее всего
возрастает с увеличением размеров дерева, дисперсия же логарифма
от объема может быть более стабильной.
Итак, предполагается, что функция плотности для Y= измеренный
log (volume) будет
ЛУ^,Ф) = (2тгФГ1/2ехр [—-А- (у — ц)2/ф],
13
где n=EY — среднее значение log (volume) и ф = уаг(У) — параметр
масштаба. Линейный предиктор есть
7/ = /3,Х1 + /32Х2 + /?Л (/31 = 10g7T,/32 = 2,/33 = 1),
а функция связи является тождественной функцией
£(У) = д=т?.
При заданных значениях /315 /32, /З3 и ф модель готова для примене-
ния. Например, мы хотим узнать 95%-ный доверительный интервал
для log (volume), когда х} = 1, x2 = log 10 и x3 = log 2. Используя введен-
ные ранее значения для /Зн /32, /?з и положив </> = 0,5, получим
At = log(7r) + 21og 10+log 2 = 6,443.
Требование Р [ —у < ф~'/2 (Y— ц) < у] = 0,95 дает 7=1,96. Итак,
95%-ный доверительный интервал есть центрированный интервал
д ± 1,96 ф1/2 =6,443 + 1,96 V0,5 = (5,06, 8,93)
[см. раздел 4.1.3].
11.1.5. ЛИНЕЙНЫЙ ПРЕДИКТОР И ФУНКЦИЯ СВЯЗИ
Линейный предиктор играет ключевую роль в теории и приложени-
ях линейных моделей. Отношение между зависимыми и объясняющи-
ми переменными определено посредством лишь линейного
предиктора. Это одна из объединяющих тем в теории линейных моде-
лей. Значения х{, х2, ..., хр определяют значение предиктора q, кото-
рое в свою очередь определяет плотность Y и тем самым
относительные вероятности различных значений Y. Схематически
X), х2, ..., хр — Г] — f -* Y.
Предиктор задается равенством
7? = /31xl+/32x2+... + /3px;7,
где /31, /32, ..., 0р — фиксированные параметры. Важно отметить, что:
а) все объясняющие переменные являются количественными; поэ-
тому если используются неколичественные переменные (например,
цвет), они должны быть предварительно перекодированы в числовые
коды;
б) объясняющие переменные являются количественно взаимо-
заменяемыми; например, если 7? = 3 + 4х2+Хз, то возрастание х2 на одну
единицу эквивалентно возрастанию х3 на четыре единицы. В этом
смысле переменные могут быть заменены друг другом;
в) коэффициенты /Зь /32, .., /3^ в линейном предикторе могут интер-
претироваться как частные производные
дх. = дхг = дхр = ®р'
Это означает, что если значение Xj возрастает точно на одну единицу,
в то время как остальные переменные сохраняют свои значения, ли-
14
нейный предиктор изменяется на единиц. (Это может быть как ре-
алистичной интерпретацией, так и нереалистичной. В примере с объе-
мом древесины, если радиус ствола дерева увеличивается, то,
вероятно, возрастает и его высота.)
Ожидаемое значение Y связано с линейным предиктором у посред-
ством функции связи g(EY) = i}. В некоторых случаях известны естест-
венные кандидаты на роль g, в других выбор может быть более или
менее произвольным. В регрессионном, дисперсионном и ковариаци-
онном анализе естественным кандидатом является тождественная
функция, а при анализе таблиц сопряженностей — логарифм.
Интересным примером является экспоненциальное распределение
[см. II, раздел 11.2]. Оно иногда используется, когда зависимая пере-
менная представляет собой «время жизни» некоторого наблюдения.
Если плотность Y есть
/(у) = — е~у^,у > 0, ц > О,
м
то ЕУ= д. Двумя кандидатами является тождественная функция EY- у
и обратная с l/EY=i?. В первом случае среднее время жизни линейно
зависит от объясняющей переменной. Во втором средний темп смерти
есть линейная функция объясняющей переменной. Оба предположения
осмысленны, хотя они имеют недостаток, заключающийся в том, что
левая часть уравнений связи должна быть положительной, в то время
как правая может принимать и отрицательные значения. (По этой
причине на практике часто применяют функцию связи вида
log (EY)= v.)
Функцию связи не следует путать с преобразованием зависимой пе-
ременной. Другими словами, модель, в которой Y имеет плотность f
с g(EY) = i], — не то же самое, что модель, в которой g(Y) имеет плот-
ность f и Eg(Y)=t]. Эти модели могут даже не быть близкими друг к
другу.
11.1.6. ФУНКЦИЯ ПЛОТНОСТИ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТИ
Предполагается, что функция плотности для Y принадлежит семей-
ству плотностей вида
ЛУ^,Ф) = ехр { ~^(9у — Ь(0)) + с(у,ф)}_ (11.1.3)
Это семейство входит в экспоненциальное семейство плотностей (см.
раздел 3.4.2]. Плотности семейства зависят от двух параметров:
«естественного» параметра 9 и «мешающего» параметра масштаба ф
от некоторых функций а, b и с. Приведем несколько известных
примеров:
нормальная плотность:
(2тг)~1/2 о ~'ехр — (у — ц)2/2о2-
= ехр [—т(уу~ ^-ц2) — — viog 27ГН tCM- П’ Разлел Н.4.3];
/т2 7 7<т2 7
15
в
пуассоновское распределе-
ние:
f
0 9
Х1, х2,..., X --------*• Л <------► М = EY
f
4
var (Y) -«-------ф
= ехр [у log д — д —
— log у!]
(см. II, раздел 5.4];
экспоненциальная плот-
ность:
= ехр {—у/ц — log/ij
[см. II, раздел 11.2];
+ к log(l —p) + log (£)]
Рис. 11.1.2. Параметрическая структура
для экспоненциального семейства
биномиальное распределение:
(J)M1 —Р)к~у = ехр [у log
[см. II, раздел 5.2.2].
Значение экспоненциального семейства определяется двумя фактора-
ми. Оно включает важнейшие плотности, используемые в практиче-
ских приложениях, такие, как перечисленные выше, и является
достаточно общим, чтобы служить основой для теоретических рас-
смотрений. Классический регрессионный и дисперсионный анализ, а
также анализ таблиц сопряженностей построены именно на этом. Для
каждого из них линейный предиктор есть tj = /3iXi + (32х2 + ... + РрХр. В
регрессионном анализе х являются непрерывными, в то время как в
дисперсионном анализе и анализе таблиц сопряженностей они пред-
ставляют собой индикаторные (бинарные) переменные. В регрессион-
ном и дисперсионном анализе плотность нормальна, а функция связи
между n=EY и 17 тождественна. В анализе таблиц сопряженностей
плотность пуассоновская, а функция связи логарифмическая.
Структура отношения между этими параметрами для экспоненци-
ального семейства функций представлена в виде диаграммы на рис.
11.1.2.
Отношения между в и ц и между rj и д определяются взаимно одно-
значно, первое — с помощью функции плотности, второе — с по-
мощью функции связи. Дисперсия зависимой переменной Y зависит от
ожидаемого значения д и параметра масштаба ф, если последний при-
сутствует.
11.1.7. ФУНКЦИЯ ПРАВДОПОДОБИЯ ДЛЯ ЭКСПОНЕНЦИАЛЬНОГО
СЕМЕЙСТВА
Метод максимального правдоподобия обеспечивает статистиков
весьма общей и адекватной теорией статистического вывода. В част-
ности, на его основе может быть построена методология для оценива-
ния параметров (подгонка модели) (см. гл. 6] и проверки гипотез
(выбор модели) [см. гл.5]. Этот подход основан на анализе правдо-
подобия (или логарифма правдоподобия [см. раздел 6.2.1]), связанно-
ю с одним наблюдением. Когда мы имеем дело только с оценкой па-
раметра 6, а не ф, в случае экспоненциального семейства (11.1.3)
функция правдоподобия в рассматривается как функция только одного
параметра:
Х(0) = log/ty 10,ф)=const +[9у—Ь(в)] (11.1.4)
<?(</>)
хотя ее значение обычно зависит также и от ф. Проблемы оценивания,
связанные с наличием параметра ф, будут обсуждаться отдельно.
Основной интерес для статистики заключается в том, чтобы знать,
в какой степени действуют объясняющие переменные посредством
функции г} на зависимую переменную Y. Поведение функции правдопо-
добия в зависимости от изменения линейного предиктора может быть
сформулировано в виде следующего важного результата:
dv var(y) dr,
и
(11.1.6)
dr,2 var( У) Wy v 7
Аналитические выражения для производной и кривизны функции
правдоподобия имеют простой вид в терминах величин у—д, var Y и
производной dp/dr]. Функция правдоподобия для полной выборки с
помощью этих выражений обычно обладает свойством единственнос-
ти решения уравнений правдоподобия [см. пример 6.2.6], а так как
кривизна всегда отрицательна, то это решение будет максимумом [см.
раздел 6.2.2]. Поскольку приведенные результаты верны для всех
плотностей из экспоненциального семейства, это позволяет применять
один и тот же вычислительный алгоритм для решения соответствую-
щих уравнений правдоподобия.
Докажем эти результаты в предположении, что выполняются два
классических свойства функции правдоподобия:
[см. (6.2.10) и (6.2.11)].
Дифференцирование лог-линейной функции (11.1.4) дает
(Д = у-Ь (0) и сРХ = _ Ь^в)
(16 ' а(<Ь) М2 а(<Ь)
Используя первое свойство, получаем р=ЕХ=Ь(0). Второе свойство
дает var (У) = Ь"(в)а(ф) и, следовательно,
du _ уаг(У)
d6 ~ <?(</>)
17
Правило дифференцирования сложных функций позволяет полу-
чить равенства
dX dX dd de de dp
= PI = - - •
dr)----------------------de dq-dr)-dp dr)
Подставляя сюда выражения для dX/df) и dO/d^, получаем результат
(11.1.5), т. е. выражение для d\/dr). Результат (11.1.6) может быть по-
лучен из равенства Ed2\/drf-= — E(dX/drj)2 или с помощью повторного
применения правила дифференцирования сложной функции:
сРХ _ сРХ / de У dx d2e
drj2 ~ de2 + dq2 '
11.1.8. ПРИМЕР С БИНОМИАЛЬНО-ЛОГИСТИЧЕСКОЙ МОДЕЛЬЮ
В примере о смертности мышей [см. раздел 11.1.2] естественный
кандидат для линейной модели имеет следующие компоненты:
п.р.в.: = f(y\p) = ( у) ру{\~рУ~у, (р=р(х)),
линейный предиктор: т] = а+&х,
функцию связи: i? = log(p/(l—(/?)).
Следовательно,
1) n=EY=5p, уаг(У) = 5р(1—р),
2) p = eV(l +е’’) и d/i/dif)=var(Y),
поскольку
5di)/dp. = d [log р—log(l—p)}/dp=\/p+\/{\—р)=\/р(\—р) = 5/уаг(У).
Окончательно
dX
dq
У—H
var(Y)
= У—*=У—5р
dr)
и
Е =--------------5— (^)2 = — уаг(У) = — 5р(1—р).
dv уаг(У) dr) v 7 ^7
Используя равенства
получаем
ЭХ , . ЭХ . ч
-г- = о—д) и — = о—Ii)x.
да др
Заметим, что кривизна максимальна, когда var(Y) имеет наибольшее
значение. Это будет при р=1/2, так что максимальная информация
получается из эксперимента при тех значениях х, для которых р=1/2.
11.2. ПОДГОНКА МОДЕЛЕЙ ПО ДАННЫМ
11.2.1. СТРУКТУРА ДАННЫХ
Структура линейной модели строго следует из структуры данных.
Массив данных должен иметь следующий вид. Для каждой из t=l, 2,
..., п различных единиц (объектов) одинаковой природы измерены
значения некоторой зависимой переменной и р объясняющих перемен-
ных. Данные организуются в виде прямоугольного массива, каждая
строка которого соответствует единице (объекту), а каждый столбец
— переменной.
Массив данных имеет следующий вид:
Переменная t У хг X р
Объект 1 *11 Ххг xip
2 Уг *2! Х22 х1р
п Уп xnl Хп2 хпр
Такой массив может быть рассмотрен либо как множество вектор-
столбцов у, Xi, ..., хр с компонентами у = (у/) и Xj = (x/.), либо как мат-
рица данных (у i X) с Х=(х/у). Этот массив имеет п(р+1) элементов.
Многие наборы данных выходят за рамки этой структуры. Такими
будут, например, массивы данных с пропущенными значениями, мас-
сивы с несколькими зависимыми-переменными и массивы без зависи-
мой переменной, которые используются в многомерном статистиче-
ском анализе. Предположение об однородности объектов также явля-
ется некоторым ограничением. Из однородности следует, что резуль-
тат анализа данных не должен зависеть от перестановки строк
таблицы. Это условие, в частности, исключает из рассмотрения вре-
менные ряды, где важен порядок наблюдений, и данные, где объекты
имеют различные веса. Это имеет место при анализе стратифициро-
ванных выборок. Исключается также и случай, когда объекты разби-
ваются на несколько кластеров.
Результаты анализа не должны зависеть и от перестановки объяс-
няющих переменных. Порядок столбцов в матрице данных не должен
добавлять какую-нибудь значимую информацию.
Поскольку эти ограничения достаточно серьезны, тем более неожи-
данными являются мощность и гибкость приложений теории линей-
ных моделей.
Параметрическая структура линейной модели проявляется следую-
щим образом. Для каждого объекта ожидаемое значение зависимой
переменной EYt задается выражением
19
или в векторной записи
£Y=/z«t; = ^iXi+/32Х24- ••• +$дХр.
Как ожидаемое значение М/, так и значение линейного предиктора
т?г зависит от номера t. Однако коэффициенты /Зь (32, ..., /Зр одинако-
вы для всех объектов. Подгонка модели эквивалентна оцениванию
этих параметров и параметра ф.
Параметр масштаба ф не зависит от t, но теория легко может
быть распространена на случай такой зависимости с помощью взве-
шивания, т. е. при замене ф на ф/w,, где wt — известные веса. Это
позволяет включить и случай нормально распределенной зависимой
переменной, которая в действительности есть усредненное значение wt
независимых наблюдений. Такое расширение теории до некоторой сте-
пени позволяет снять ограничения, связанные с требованием однород-
ности объектов в матрице данных.
11.2.2. ФУНКЦИЯ ПРАВДОПОДОБИЯ И ЕЕ МАКСИМУМ
Два простейших предположения относительно получения данных
состоят в том, что, во-первых, каждый объект получается случайным
выбором из некоторой генеральной совокупности и, во-вторых, при
наблюдаемых значениях объясняющих переменных п наблюдений за-
висимой переменной статистически независимы. Выборка, удовлетво-
ряющая этим условиям, является репрезентативной для совокупности.
Из соображений симметрии все объекты рассматриваются в процеду-
ре вывода с одинаковыми весами. Эти два предположения о случай-
ности выбора и независимости наблюдений обусловливают
аддитивность функции логарифмического правдоподобия
^Мч^Ф),
где X(i7z,</>) — лог-правдоподобие одного наблюдения из экспоненци-
ального семейства, определенного в (11.1.4).
Дифференцируя по получаем
ЗХ = ЭХ(г)(,ф) дт){ _
d/3j t drjt d0j
Определим вектор V X и диагональную матрицу Н следующим
образом:
VX= . H = diag С^’)
diit dr)2t
Поскольку
-X
Wj tJ’
20
первую и вторую производные от X(i?,0) можно записать в виде
и
где [♦, •] — обычное скалярное зроизведение. Эти уравнения следует
отметить за их простоту и общность одновременно.
Значение 0, доставляющее максимальное значение, является реше-
нием уравнения
[VX,xy]=0, j=l, 2, .... р,
для которого матрица размера рхр с элементами [ху, HxJ отрица-
тельно определена. Для решения этого уравнения может быть испо-
льзован итеративный алгоритм взвешенного метода наименьших
квадратов. Он обсуждается в разделе 12.3.5. Так как Н диагональна,
решение будет точкой максимума, если все элементы Н отрицатель-
ны. Это обычная ситуация для линейных моделей с плотностями из
экспоненциального семейства.
При наличии решений уравнений правдоподобия Д вектор подог-
нанных значений д может быть получен как
где i/=^iXi + (e2X2+ ... +£рХр.
Пример. Биномиально-логистическая модель. Имеются данные о
числе смертей (у) в шести группах из пяти мышей. Мышам из одной
группы была введена одинаковая доза препарата (х). Массив данных:
Переменные У 1 X
Объекты t=l 1 1 0
2 0 1 2
3 2 1 4
4 4 1 6
5 3 1 8
п-(у 6 4 1 10
Модель:
линейный предиктор: i] = a+fix,
функция связи: д = 5р и р=^/(1+^),
так что — =5р(1—/>) = уаг(У),
dii
п.р.в. Y : Bin (5, />);
21
лог-правдоподобие:
X(?j) =>’log£>+(5—>’)log(l—p) + const.
dX у—p dp
----------= r-----— = у—§pt
d-ц var( Y) d-ц
уравнения правдоподобия:
/ Pa
[VX,l]=0=EO>-5p,)-l= Ejz-5Ep, = 14-5 +
t 1 + e
ga+20 ga+100 ч
]_|_g« + 2(3 + + l-|_e«+10/3 /’
[ V X,x] = 0 L(yt—5pt)xt = E у pc — 5 E ppct =
/ pa + 20 «+10(3 .
= 96—5 ( +... + e—~Гпд 10)
v l + e“+2£ l-l-e“+iO0 ''
Решение: a~—1,974, /3 = 0,359 (проверяется подстановкой).
Подогнанные значения получаются из формулы
Д, = 5Д = 5е“+Ч /(1+е)“+Ч,
что дает Д=(0,61, 1,11, 1,84, 2,72, 3,55, 4,17).
В данном случае нет необходимости в рассмотрении гессиана
[ху, Нх^] полностью, чтобы проверить, является ли данное решение
максимумом. Легко видеть, что
ут = = - -~г = ~ var<r> < 0,
dr)z dr) d-ц
и, таким образом, элементы матрицы Н всегда отрицательны.
11.2.3. ДЕВИАЦИ°
О том, насколько хорошо модель описывает данные, можно су-
дить по расхождению между вектором наблюдаемых значений у и
вектором подогнанных значений д. Существуют различные способы
измерить это расхождение. Поскольку мы используем метод макси-
мального правдоподобия, подходящей для нас мерой является макси-
мизированная тест-статистика логарифма отношения правдоподо-
бия (LLRTS), сконструированная на основе следующих соображений
[см. раздел 5.5].
Модели с большим количеством объясняющих переменных до-
лжны дать подогнанные значения, которые лучше аппроксимируют
исходные данные. В экстремальном случае, включая в линейный пре-
диктор столько переменных, сколько имеется объектов, получим ли-
нейную модель, точно воспроизводящую данные. Эта так называемая
насыщенная модель, S, имеет свойство
Д (5) = У-
22
Обозначим модель, включающую только часть объясняющих пере-
менных, через М, а соответствующее ей подогнанное значение — че-
рез Д (М).
Девиация модели М определяется как
у dev(Ai)=X(«S),W-X«i(AO, Ф).
Максимизированное значение лог-максимума правдоподобия X мо-
жет только возрастать с ростом числа переменных, включенных в М
из S. Чем ближе девиация к нулю, тем ближе Д (М) к у.
Примеры:
Нормальная плотность N(^,</>)
с тождественной связью
Пуассоновское распределение Р(ц)
с логарифмической связью
Биномиальное распределение Bin(Zr,p)
с логистической связью
Девиация
2 Еу( logrr /Д,
+ (к—y,)log(fc—yt}/{k—
Для данных о смертности мышей с использованием биномиально-
логистической модели имеем:
dev(M) = 2 [1 -blog (l/0,61) + 41og(4/4,39) +... +
+ 41og(4/4,17) + log(l/0,83)] = 4,519.
В примере с нормальной плотностью девиация есть сумма квадра-
тов, и анализ девиации является обобщением техники дисперсионного
анализа. Этот пример показывает также, что в том случае, когда име-
ется параметр ф, его роль не совпадает с ролью g. В этом случае деви-
ация может быть использована для оценки ф.
Девиация играет большую роль в процедурах подгонки моделей.
а) Она является суммирующей статистикой для суждения об адек-
ватности подгонки частной (ненасыщенной) модели, а ее выборочное
распределение позволяет построить тест для проверки качества
подгонки.
б) С другой стороны, приравнивание девиации к ее ожидаемому
значению может быть использовано для получения оценки мешающе-
го параметра ф. Конечно, невозможно обеспечить а) и б) одно-
временно.
в) Сравнение девиаций — основа теста отношения правдоподобия
для проверки гипотезы, может ли быть включена в набор или исклю-
чена из него одна или несколько объясняющих переменных.
г) Этот тест может применяться для подбора наилучшего подмно-
жества объясняющих переменных из некоторого исходного.
23
В предположении, что М — истинная модель, выборочное распре-
деление девиации dev(M) есть хи-квадрат [см. раздел 2.5.4, п. а)] с чис-
лом степеней свободы df(M) = « — число объясняющих переменных в
М.
Для примера о смертности мышей
dev (АД ~ х2(6—2) = х2(4)
и наблюдаемое значение 4,52 незначимо на 5 %-ном уровне, что указы-
вает на осмысленность подгонки.
11.2.4. РЕГРЕССИЯ, ПРОХОДЯЩАЯ ЧЕРЕЗ НАЧАЛО КООРДИНАТ
Модель регрессии, которая проходит через начало координат, не
часто полезна на практике, но она дает простую аналитическую иллю-
страцию для предыдущего обсуждения. Рассмотрим пример:
Данные:
у —2 —3 2 5 8 п = 5
х —2—1012
Модель:
п.р.в. Y: нормальная, среднее д, дисперсия ф, ф не известна,
линейный предиктор: ^t=Eyt = f)t, функция связи = /3 не из-
вестно,
лог-правдоподобие: Х(0) = YXogf(y^=
t
= Д— log 27ГФ----х-Ф~'(У( — £х,)2) =
= — i°s 27г</> — Л— ^2’
Z t
уравнение правдоподобия: Е(уг — &xt)xt = 0,
/
так что
3 = Е xtyt / Е х2( =
= (—2—2+... + 8,2)/(—22+... + 22) = 28/10 = 2,8,
подогнанные значения: у = 2,8л;
остатки:
у —5,6 —2,8 0,0 2,8 5,6
у—у 3,6 —0,2 2,0 2,2 2,4
24
график:
Девиация:
X (S) = — у п log 2тсф =
= XG3) = — 4- п log 2тгф — 1 Цу( — yt)2 =
L Лф t
1 , n , 27,6 , 27,6
= - — n log 2тгф — — = dev (0) = — .
2 20 ф
Отметим некоторые особенности в этом анализе. Задача максима-
лизации функции правдоподобия свелась к задаче наименьших квадра-
тов, т. е. минимизации Е (yt—(3xt)2 = Е y2t—2(3 Ех^ + Р2 Lxt. Девиа-
ция шкалирована делением на ф, что является прямым следствием
предположения о нормальности плотности. Приравнивая девиацию к
ее ожидаемому значению (числу степеней свободы), получим оценку
ф = 27,6/(5—1) = 6,90. Рассмотрение графика остатков приводит к
мысли, что лучшей подгонки можно было бы добиться с помощью
VI = а + (3х{.
11.2.5. РАЗЛОЖЕНИЕ ДЕВИАЦИИ
Чтобы увидеть, можно ли удалить некоторую объясняющую пере-
менную из модели без значимого сокращения прогностической силы
модели, можно подогнать модель дважды — с этой переменной (М)
25
и без нее (N). Разница девиаций будет статистикой для суждения о
включении этой переменной в модель. Снова обратимся к примеру с
биномиально-логистической моделью. Экспериментатор хочет прове-
рить эффект дозы (х) препарата относительно смертности (у).
Модель:
п.р.в. Y М = М : т] = : Bin (5, р), р - eV(l +е^,
а + (3х, N : г] — а.
Результат X У у{М) dev(Af) Девиация ы: 0 2 4 6 8 10 1 0 2 4 3 4 0,6 1,1 1,8 2,7 3,6 4,2 2,3 2,3 2,3 2,3 2,3 2,3 = 4,52 dev(TV)-12,98 для более сложной модели dev(M) меньше, чем для
dev(TV), как и должно быть. Оценка значимости величины этого сокра-
щения требует знания выборочного распределения. Аппроксимация
распределения отношения правдоподобия для больших выборок дает
следующее: если N является истинной моделью (нулевая модель) и N
содержится в М («загнездована»), то разность dev(N)—dev(Af) имеет
распределение х2 с df(7V)—df(Af) степенями свободы (где df(AZ) равно
числу степеней свободы для N и т. д.). Более того, эта разность рас-
пределена независимо от dev(Af). В нашем случае dev(TV)—
dev(M) = 8,46. При гипотезе /3 = 0 это реализация х2-распределенной
случайной величины с 2—1 = 1 степенями свободы и уровень значимос-
ти для нее около 0,004. Итак, гипотеза /3=0 значимо несостоятельна
[см. табл. 5.2.1].
В случае данных с нормальной функцией плотности асимптотиче-
ский результат для больших выборок относительно распределения
разности девиаций будет точным для выборок любого объема, но не-
обходима некоторая его модификация в связи с наличием парамет-
ра ф. Проиллюстрируем это на примере с регрессией, проходящей че-
рез начало координат.
Данные:
У -2
х —2
—3 2 5 8
— 10 12
Матрица перекрестных произведений:
и = 5, Ех, = 0,
Ех^ = 10, Ех^ = 28,
Еу| = 106.
Модель:
п.р.в. для Y: N(/z,0),
тождественная функция связи: ц = т],
линейный предиктор: М : т] = а+[3х, N : т] = а.
26
Лог-отношение правдоподобиг.:
Х = const---—- Е(У/ —
t
Уравнения правдоподобия для М:
Е (у, — а — (3xt) = О,
Е (yt — а — I3xt)xt = 0.
Решение:
а = ^ySxt х) = 28.. =28
V Е (х-ху 10
„.V (М) = ± Е (у, - ММ)У = 1 5,6,
ф ф
df (М) = 3.
Уравнения правдоподобия для TV:
s (yt — О').
Решение:
а = У( = 2*
“д’
dev (М = т Е (У, - Д,(М)2 = т 86-°-
ф ф
df (TV) = 4.
Параметр масштаба ф оценивается с помощью приравнивания де-
виацт и для большей модели к ее математическому ожиданию. Так как
мат' матическое ожидание для х2-случайной величины есть просто чис-
ло степеней свободы, получаем
ф = 5,6/3 = 1,87.
Тест для проверки гипотезы /3=0 будет тогда следующим:
F = ф-1 [dev (TV) — dev (M)]/[df (TV) — df(M)].
Эта статистика является отношением двух независимых х2-распреде-
ленных случайных величин и, следовательно, подчиняется F-распреде-
лению. Результаты анализа могут быть сведены в таблицу анализа
девиаций:
Источник Число степеней свободы Девиация Средняя девиация F
М—N регрессия 1 81,4 81,4 43,61
м остаток 3 5,6 1,87
N полная 4 86,0
27
Наблюдаемое значение F расположено между 1%-ным значением
(34,1) и 0,1%-ным значением (167) для F{^-распределения, и, следова-
тельно, уровень значимости, соответствующий нулевой гипотезе, так-
же лежит в этих пределах. Поэтому результат проверки гипотезы
можно считать высокозначимым. Гипотеза явно несостоятельна.
11.3. СПЕЦИФИКАЦИЯ И ОТБОР МОДЕЛЕЙ
11.3.1. ПОДПРОСТРАНСТВА
Линейные комбинации. Пусть хь х2, ..., хр — векторы в л-мерном
пространстве [см. определение 11.1.1] и аь а2, ар — скаляры (дей-
ствительные числа), тогда
Ы ] X] 4- СХ2Х2 4-... 4" QipXp
есть линейная комбинация от xi} х2, ..., хр.
Примеры:
1) 2X1+х2—7х3,Х]+х3, а]Х]-1-а3х3 — это все линейные комбинации
Х1, х2, х3;
2) в шестимерном пространстве любой вектор а = (а1^а2, ..., а6) мо-
жет быть записан как линейная комбинация шести единичных индика-
торных векторов 6], е2, ..., е6;
3) линейный предиктор есть линейная комбинация объясняющих
векторов.
Оболочка. Оболочкой span (х1} х2, ..., хр) называется множество
всех линейных комбинаций векторов хь х2, ..., хр. Любой вектор в
этом множестве может быть записан в виде + ... + ос^р для неко-
торых «1, а2, ..., ар.
Примеры:
1) в шестимерном пространстве два первых единичных индикатор-
ных вектора будут et = (1,0,...,0) и е2 = (0,1,...,0). Любой вектор из
span (6i,е2) может быть записан в виде (аь «2, ..., 0), но в то же время
span (6i, е2) не содержит вектора (0,0,...,0,1). Нулевой вектор принад-
лежит к span (е1} е2);
2) чтобы определить, включен ли объясняющий вектор в подгоняе-
мую модель, достаточно проверить, принадлежит ли линейный пре-
диктор span (хь х2, ...» хр_!) или span (хь х2, ..., хр).
Подпространства. Пусть через S обозначено подмножество векто-
ров в n-мерном пространстве. Предположим, что Si и s2 принадле-
жат S. Тогда S будет подпространством, если a) Si+S2 принадле-
жит S и б) aSi принадлежит S.
Пример. В трехмерном пространстве оболочка S=span (бь е2) есть
подпространство, поскольку если Si = «16! 4-«2е2 и s2 = /3ie1 + 132е2, то
Sl+S2 = (a14-|81)e14-(a24-i82)e2 — линейная комбинация et и 62, также
принадлежащая S. Аналогично «51 = (««1)61 4-(аа2)е2 лежит в S. Итак,
S представляет собой подпространство. Геометрически это плоскость,
28
которая проходит через начало координат под прямым углом к треть-
ей оси. Вообще легко видеть, что оболочка span (х1} х2, ..., хр) всегда
является подпространством.
Размерность. Размерность подпространства S будем обозначать
как dim(S). Размерность есть минимальное число векторов, необходи-
мых для того, чтобы построить оболочку для S. В трехмерном про-
странстве dim(span(e|} е2,))=2, dim(span(ei, е2, е3)) = 3, dim(span(l, е1}
е2> <-3)) = 3.
Сумма двух подпространств. Пусть и 52 — два подпростран-
ства. Суммой S=Si+S2 будет множество векторов S, которые могут
быть записаны в виде s = s, + s2, где sx€Si и S2€S2. Легко видеть, что
сумма S — также подпространство. Приведем некоторые примеры.
1) Если Si=span(eb е2, е3) и S2=span(e2, е3, е4), то Si +S2 = span(6i,
е2, е3, е4) (в/ — здесь индикаторные векторы в шестимерном про-
странстве). Заметим, что dim(S! + S2)^dimSi +dimS2.
2) Вообще, если Si=span(x1} х2, ..., хр) и S2 = span(Zi, z2, ..., z^), то
S1+S2 = span(xb ..., xp, г,, ..., zq).
Произведение подпространств. Пусть Si и S2 — два подпростран-
ства. Их произведением S=S,*S2 называется оболочка векторов S, ко-
торые могут быть представлены в виде покоординатного
(поточечного) произведения векторов S = SiS2, где SitSi и S2€S2 [см.
раздел 11.1.1]. В частности, если Si=span(Xi, х2, ..., хр) и S2 = span(zb
z2, ..., z^), то их произведение Si*S2 = span(XiZi, XiZ2, ..., *tzq, x2zb ...,
x2z„, ..., XpZ^). Например, если Si=span(eb e2) и S2 = span(e2, e3), to
Si*S2=span(e2), так как eie2=6ie3=e2e3=0, a e2=e2©2. Аналогично, ес-
ли в четырехмерном пространстве рассмотреть векторы а( =(1,1,0,0),
а2 = (0,0,1,1), bi = (1,0,1,0) и Ь2 = (0,1,0,1) и определить A = span(ai, а2) и
2?=span(bi, Ь2), то /4*S=span(ei, е2, е3, е4). Чтобы увидеть это, отме-
тим, что ei = aibi, 62=aib2, 63 = a2bi, б4 = а2Ь2.
Множество S векторов s = SiS2, где Si^SiH S2€S2, вообще говоря, не
является подпространством. Снова рассмотрим пример для четырех-
мерного пространства с ?4 = span(ai, а2) и B=span(bi, Ь2). Тогда
©1 = a1bi и е4 = а2Ь2, так что et и е4 могут быть записаны в виде
произведений. Однако 6i+e4=(l ,0,0,1). С другой стороны, (а|Э1+ а2а2)х
х (/3ХЬ1 + /?2Ь2) = а 1 0 1 е 1 + ац32е2 + а201в3 + и отсутствует решение,
такое, чтобы ai0i = l, ai02=O, ce23i=0, а202 = 1.
11.3.2. ФОРМУЛЫ МОДЕЛЕЙ ДЛЯ ЛИНЕЙНОГО ПРЕДИКТОРА
Линейный предиктор представляет собой линейную комбинацию
предикторных переменных вида tj = /3iXi+02х2 +... + /Зрхр. Для дальней-
шего чрезвычайно полезно иметь более сжатую запись для линейного
предиктора, в частности такую, где в явном виде отсутствуют коэф-
29
фициенты. В качестве такой записи можно принять
г] е span (хь х2, хр),
где span(-) генерирует подпространство всех возможных линейных
комбинаций заданных векторов.
Спецификация т] = а+(3х, или в векторной форме 7i = al + (3x, испо-
льзуемая в биномиально-логистической модели, для данных о смерт-
ности мышей может быть записана как
г} е span (1, х).
Иногда связь между ожидаемым числом смертей EY и дозой х мо-
жет иметь более сложный вид. Возможная разумная процедура улуч-
шить подгонку данных состоит в расширении модели за счет
включения члена, квадратичного по х, т. е. нужно подгонять
т] е span (1, х, х2),
где х2 = [х2]. Сравнение девиаций для этих двух моделей дает тест
для проверки нелинейности.
Дальнейшее упрощение формул может быть получено за счет испо-
льзования X, если положить X = span(l, х) и X2 = span(l, х2). (Такое
использование прописных латинских букв отличается от их стандарт-
ного применения в статистике, когда X обозначает случайную величи-
ну.) Рассмотренная выше квадратичная модель может тогда быть
записана в виде
т] € X + X2.
Вообще, если Xj = span(l, ху), модель вида т] = /301 ч-+ ... + £рхр
эквивалентна т) е Х{+Х2 +...+Хр. Причина, по которой требуется,
чтобы 1 € Xj, связана с возможным наличием индикаторных перемен-
ных, которые появятся позднее. Введенные обозначения проясняют
взгляд на линейные модели как на подпространства, к которым при-
надлежат линейные предикторы.
Стандартные модели
Простая линейная регрессия Квадратичная регрессия Полиномиальная регрессия Регрессия через начало координат Регрессия с двумя переменными Множественная регрессия г) € X 7) $Х + X2 7) € X + X2 + ... + Хк 7) € span (х) 7) € Xf + Х2 7) € Х{ + Х2 + ... + X
Пример. Регрессия с двумя переменными. Вернемся к примеру с де-
ревьями и объемом древесины. Пусть у—вектор log (volume), X!—век-
тор log(radius) и х2—вектор log(height). Тогда линейный предиктор для
множества «идеальных» деревьев будет
г) = log 7г1 + 2хх 4- х2.
30
Чтобы проверить, насколько адекватно эти коэффициенты позволяют
описать наши данные, оценим у € Xi + Х2 и сравним оцененные коэф-
фициенты 0О, 01, 02 с log%, 2 и 1. Может возникнуть вопрос: если бы
между радиусом (radius) и высотой (height) имелась точная корреляци-
онная связь, так что знание радиуса однозначно определяло бы высо-
ту, то модель у Xi была бы информативна так же, как модель
17 € Х2 или как модель ?? € Х{ + Х2? Какая из этих моделей даст на-
илучший предиктор, когда радиус и высота не полностью коррели-
рованы?
Этот пример приводит к рассмотрению диаграммы для четырех
моделей:
Связывающие линии указывают, какое из подпространств вложено
в другое. На практике подобные диаграммы дают удобную форму
представления оцененных моделей.
С ростом числа переменных эти диаграммы быстро становятся
сложными. Диаграмма
Xj +х2 +х3
представляет все подмодели для линейного предиктора с тремя пере-
менными.
Число степеней свободы, ассоциированное с некоторой моделью
М, есть просто H-dim(M), где dim(M) — минимальное число векторов,
требуемое для span(M).
11.3.3. МОДЕЛИ С КАЧЕСТВЕННЫМИ ДАННЫМИ
Линейные модели объясняют значения зависимой переменной по-
средством линейной комбинации объясняющих переменных (линейно-
го предиктора). Предположим, мы заинтересованы в выяснении связи
между весом и ростом детей школьного возраста. Априорно такая
связь зависит от пола ребенка, так что модель должна учитывать это
31
обстоятельство. Сначала рассмотрим трудности, связанные с понима-
нием смысла линейной комбинации типа 0,25 height + 1,6 sex, так как
пол (sex) в отличие от роста (height) не может быть измерен в коли-
чественной шкале.
Фактор. Количественная переменная, которая принимает конечное
число нечисловых значений, будет называться фактором, а ее значе-
ния называются уровнями. Итак, пол — фактор с двумя уровнями
(мужской и женский). Аналогично если деревья классифицировать по
видам, то вид является фактором, имеющим столько уровней, сколько
существует видов.
Различие между факторами и количественными переменными
обычно достаточно очевидно. Однако бывают переменные, занимаю-
щие некоторое промежуточное положение. Например, если рост грубо
определить как низкий, средний и высокий, то его можно рассматри-
вать либо как фактор, либо как количественную переменную со значе-
нием, например, —1, 0, 1.
Предположим, что А — фактор с четырьмя уровнями, обозначен-
ными как Ль Л2, А3, А4, а В и С — факторы с двумя уровнями Blt
В2 и С], С2. Каждый объект принимает один и только один уровень
каждого фактора. Пусть п = 6 и часть массива данных содержит сле-
дующую информацию:
Объект А В с
1 ^2 Вг Cl
2 At в2 С2
3 At в2 Cl'
4 А2 Bi С2
5 Аа Bi Cl
6 Ау Bl С2
Эта информация может быть представлена с помощью индикаторных
векторов:
Объект а, а2 аэ а4 ь, ь; с, Сг
1 0 1 0 0 0 1 1 0
2 1 0 0 0 0 1 0 1
3 1 0 0 0 0 1 1 0
4 0 1 0 0 1 0 0 1
5 0 0 0 1 1 0 1 0
6 0 0 1 0 1 0 0 1
32
Индикаторный вектор 8i есть индикатор уровня At у фактора А, кото-
рый наблюдается у второго и третьего объектов. С помощью индика-
торного вектора с2 указывается, что уровень С2 фактора С
наблюдается у объектов 2, 4, 6.
В этом контексте индикаторные векторы удовлетворяют некото-
рым очевидным правилам.
В нашем примере
81+82 + 83 + 84 = 1, bi + Ь2 = 1, С!+с2 = 1.
Кроме того, покоординатное умножение двух индикаторных векторов
для одного и того же фактора есть нулевой вектор
8i82=0, а3а4=0, bib2=0, С1С2=0.
Результат покоординатного произведения двух индикаторных векто-
ров от различных факторов указывает уровни обоих факторов и сам
является индикаторным вектором. Например, вектор
а2Ь2 = (1,0,0,0,0,0)
указывает, что только первый объект имеет уровень А2 для А и уро-
вень В2 для В. Аналогично а2Ь2С! указывает объекты с уровнями Л2,
В2 и Ci соответствующих факторов. Скалярное произведение [1, • ] да-
ет число объектов для каждого уровня. Так [1, а2]=2 и [1, а2Ь2] = 1.
Более формально пусть А — фактор с I уровнями и ав а2, ..., az
— соответствующие им индикаторные векторы. Аналогично опреде-
лим фактор В с числом уровней J и индикаторные векторы Ьь Ь2, ...,
Ь7. Тогда легко проверить, что
Е а, = 1, Е Ь, = 1,
а также ' 7
аа,- far если z = *'»
11 10, если i i',
Е 8,-b^b,-, Е a,by = a,.
Линейный предиктор. Мы имеем теперь достаточный формальный
аппарат, чтобы вернуться к моделям, содержащим качественные дан-
ные. Предположим, что было обследовано шесть детей, из которых
три девочки, каждая весом в 40 кг, и три мальчика, каждый весом в
45 кг. Если А — фактор пола, то он имеет два индикаторных вектора:
Э] для девочек с компонентами Si =(1,1,1,0,0,0) и а2 для мальчиков с
компонентами а2=(0,0,0,1,1,1). Положив
rj=40ai + 45а2,
получим вектор (40, 40, 40, 45, 45, 45), который воспроизводит веса
как для девочек, так и для мальчиков. Здесь линейный предиктор
представляет собой линейную комбинацию индикаторных векторов
в] и а2.
Этот пример дает представление о том, как можно работать с про-
извольными факторами. Прибегнем теперь к небольшой модифика-
ции, упрощающей дальнейшее рассмотрение. Линейный предиктор в
этом примере может быть представлен также в виде линейной ком-
бинации 1 и а2:
17=40 1 + 5а2 .
33
Коэффициент при 1 равен значению предиктора на первом уровне Л
(девочки). Коэффициент индикаторного вектора а2 определяет теперь
различие между значениями предиктора на первом и втором уровнях.
Здесь 1) € span(l, а2).
Вообще, если А — фактор с I уровнями, интересной является мо-
дель, для которой предиктор г? € span(l, а2, а3, ..., az). Например, для
сравнения урожайности четырех различных сортов картофеля может
быть предложен предиктор
г? = 20 1 + 2а2 — ,4а3 + а4.
Тогда урожайность для первого сорта будет 20, для воторого — 22,
для третьего — 16, для четвертого — 21. Если бы различий между
сортами не было и урожайность для всех сортов была бы 20, то
ц = 20 1 + 0а2 + 0а3 + 0а4 = 20 1,
так что rj € span(l).
Проверка различий между уровнями фактора А эквивалентна срав-
нению моделей rj € span(l, а2, ..., ay) и у € span(l).
Символ А обозначает фактор (качественную переменную). Без за-
труднений его можно использовать и для обозначения подпростран-
ства, порожденного соответствующими индикаторными векторами:
А = span(l, а2, а3, .... а/).
Это позволяет ссылаться на соответствующее подпространство, избе-
гая громоздкого перечисления образующих его векторов. Также без
каких-либо затруднений будем использовать l = span[l],
11.3.4. ДВА ФАКТОРА: ГЛАВНЫЕ ЭФФЕКТЫ И ВЗАИМОДЕЙСТВИЕ
Начнем с простого примера. Предположим, фактор А представля-
ет два сорта картофеля, а фактор В — два типа удобрений. Пусть ис-
тинная урожайность картофеля р=т) измерена при четырех различных
условиях, определяемых факторами, и получены следующие ре-
зультаты:
Удобрение в, «2
Сорт А, 20 22
у42 25 27
Эта таблица преобразуется в следующую с индикаторными век-
торами:
п 1 а2 ь2 а2Ь2
20 1 0 0 0
22 1 0 1 0
25 1 1 0 0
27 1 1 1 1
34
Линейный предиктор определяется как
17 — 20 1 + 5Я2 + 2Ь2.
Важное свойство приведенного набора данных состоит в том, что по-
вышение урожайности, обусловленное выбором сорта Л2, по сравне-
нию с Ль одно и то же независимо от выбора типа удобрения —
#1(25—20=5) или В2(27—22 = 5). Аналогично повышение урожайности,
обусловленное применением удобрения В2 вместо Blf одно и то же для
обоих сортов (22—20 = 2=27—25). Это дает основание говорить об эф-
фекте сорта без упоминания об используемом удобрении и об эффекте
удобрения без ссылки на сорт.
Рассмотрим альтернативный пример с таблицей следующих
данных:
Удобрение В, Вг
Сорт At 20 22
Аг 25 26
Здесь линейный предиктор
= 20 1 + 5а2 + 2Ь2 — 1а2Ь2.
Различие урожайности между сортами здесь составляет 5 для В] и 4
для В2; различие для удобрений — 2 для Л! и 1 для Л2. Итак, величи-
на различия, обусловленная сортом, зависит от удобрения, и наобо-
рот. Второй пример демонстрирует взаимодействие между факторами
А и В в противоположность первому. В терминах линейного предик-
тора взаимодействие между А и В имеет место, если предиктор вклю-
чает покоординатное произведение векторов вида ab. Для двух
уровней >l = span(l, а2) и B=span(l, b2), так что Л+В=8рап(1, а2, Ь2)
и >l*B=span(l, а2> Ь2> а2Ь2). Линейный предиктор в первом примере
т/ = 20 1 + 5а2 + 2Ь2 есть линейная комбинация 1, а2 и Ь2 и, следова-
тельно, у € А+В. Линейный предиктор для второго примера есть ли-
нейная комбинация 1, а2>Ь2 и а2Ь2, поэтому rj € А*В.
Вообще для двух факторов А и В мы говорим, что взаимодействие
отсутствует, если у € А + В. Модель г? € А + В мы назовем моделью
главных эффектов, а модель ij € А*В — моделью главных эффектов
с взаимодействиями [см. раздел 9.8.1]. Рис. 11.3.1 иллюстрирует по-
нятие взаимодействия.
При отсутствии взаимодействия существует возможность эконом-
ного описания набора данных. Это означает, что индикаторные векто-
ры вида а,Ьу, служащие для указания наблюдений с уровнями Л,- и Bj,
не являются необходимыми для описания поведения линейного пре-
диктора. Наличие взаимодействия существенно усложняет получение
выводов относительно данных.
35
а) Взаимодействия нет,
линии параллельны
Рис. 11.3.1. Иллюстрация понятия «взаимодействие»
б) Взаимодействие,
линии не параллельны
Проверка отсутствия взаимодействия эквивалентна сравнению ка-
чества подгонки моделей € А*В и у € А+В. Заметим, что
А+В С А*В и в А*В имеются векторы, не содержащиеся в Л+Д На-
помним, что
А + В = span(l,a2,...,aj,b2,...,b7)
и
= span(l,a2,...,aj,b2,...,b7,a2b2,...,aTb7).
11.3.5. ДВУХФАКТОРНАЯ МОДЕЛЬ ДВУХВХОДОВОЙ МОДЕЛИ
ДИСПЕРСИОННОГО АНАЛИЗА
Пример, рассмотренный здесь, иллюстрирует приложение линей-
ных моделей к анализу планирования экспериментов. В теории линей-
ных моделей многое было стимулировано развитием эксперименталь-
ного подхода в сельском хозяйстве и медицине.
Следующий эксперимент был спланирован для исследования влия-
ния сульфатов на урожайность пшеницы. Рандомизированный блоч-
ный план состоит из шести блоков, каждый из которых содержит
четыре делянки [см. пример 9.7.1]. Каждому из четырех уровней обра-
ботки удобрением (А — без удобрения, В=20 фунтов, С=40 фунтов,
Z>=60 фунтов) соответствовала одна делянка внутри каждого блока.
Данные об урожайности приведены в следующей таблице:
Урожайность пшеницы в рандомизированном блочном эксперименте
Блок 1 2 3 4 5 6
Участок 17,1(77) 17.5(B) 15,304) 13,104) 14,0(0 20,5(0
18,6(0 19,3(0 19,5(0 18,0(0 12,6(0 16.5(B)
17,1(B) 19,7(0 21,6(0 15,1(0 13,104) 15,404)
13,304) 14,4(Л) 19.9(B) 15.9(B) 16.0(B) 18,2(0
36
Основная идея плана состоит в получении шести измерений на каж-
дую обработку, которые не подвержены [см. раздел 9.9] влиянию раз-
личий между блоками (последние могли бы быть представлены
различиями в типах почвы или сортах пшеницы). Для этих данных
естественным кандидатом для модели является предположение, что
урожайность Y распределена N(/t, ф) с тождественной функцией связи
среднего и линейного предиктора. Объясняющие переменные являют-
ся индикаторными векторами для обработок и индикаторны-
ми векторами для блоков bi,b2,...,b6. Массив данных содержит 24
элемента. Очевидный выбор для линейного предиктора — д € Т+В.
Чтобы это увидеть, обозначим через д,у ожидаемый урожай для z-й
обработки в J-м блоке. Если бы различие между обработками или
между блоками отсутствовало, то величина цу была бы постоянной,
скажем X, для всех 24 элементов. Эквивалентными спецификациями
являются
д,у = Х, или д=Х1, или д € span(l).
Если же различие между блоками существует (что вероятно по причи-
не блокирования [см. раздел 9.3]), то цу может зависеть от J. Пусть
X.j — добавочный эффект на урожайность, обусловленный у'-м бло-
ком. Тогда fiy-\+X.j или, что эквивалентно,
д=Х1 + ЕХу by, или д € span(l,bb...,b6), или д € В .
Если имеются различия в обработке, X,-, то
д,у = Х+Х;-. + Х.у , или д = Х1 + SXf.tj-b EXyby, или д € Т+В.
Таким образом, предполагается, что взаимодействие между блоками и
обработками отсутствует, т. е. эффект блокирования и эффект обра-
ботки аддитивны.
Детали процедуры оценивания опускаются. Заметим только, что
подогнанные величины для моделей непосредственно задаются с
помощью
~ У у
И
p.y(T+B)=yi +у—у. • .
Для проверки влияния обработок вычисляются величины
dev(B)= ± = 88,23/0
и I
dev(T+BJ = -I £[>-,,—ЩТ+Bj? = 30,29/0.
Предположение аддитивности эффектов обработки и блоков явля-
ется важным для дальнейшего анализа, когда ф может быть исключе-
на только приравниванием dev(T+B) к величине ее степеней свободы
(df(T+B) = 24—(1 + 3 + 5) = 15, так что ф = 30,29/15 = 2,02). Модель, ко-
торая содержит все взаимодействия обработок и блоков, равно как
37
и неизвестный параметр масштаба, будет неидентифицируемой. Что-
бы увидеть это, заметим, что модель со взаимодействиями Т*В содер-
жит 6-4=24=1-1-4—1+6—1 + (4—1)(6—1) индикаторных вектора. Но
имеется только 24 результата наблюдения. Так как число параметров
равно числу наблюдений, Д(Т*В) = у, модель Т*В является насыщенной
моделью. Следовательно, df(T*B) = O, и не остается степеней свободы,
чтобы получить оценку для ф. Если подозревается наличие взаимо-
действия между блоками и обработками, то это должно быть учтено
на стадии планирования введением повторных комбинаций обработ-
ка-блок.
В условиях аддитивности ф=2,02. Тестовая статистика для провер-
ки различий, обусловленных обработками, есть
г [dev(B)-dev(7+B)]/3 57,94/3 п
г = ----------------- = ------ = y,jo.
ф 2,02
Это отношение имеет F-распределение с 3 и 15 степенями свободы и
значимо на 5%-ном уровне (9,56 > 3,29)’ Ясно, что различие, обуслов-
ленное обработками, отсутствует.
Более систематическое представление результатов дано с помощью
графика девиаций и таблицы дисперсионного анализа (ANOVA).
Дерево девиаций
Т + В
(30,29, 15)
(155,02, 23)
Таблица ANOVA
Источник дисперсии Число степеней свободы Сумма квадратов Средний квадрат F
Обработки Т 3 57,94 19,31 9,56
Блоки В 5 66,79 13,36
Остаток 15 30,29 2,02
В целом 23 155,02
Исследование этих данных и моделей можно было бы продолжить
для проверки отдельных уровней обработки и изучения соответствую-
38
щих остатков. (Из некоторых соображений следует, что эффект обра-
ботки мог бы быть аппроксимирован квадратичной функцией; уро-
жайность растет скачками, начиная с А, достигает максимума на
уровне С, а затем слегка падает; урожайность участка, обработанного
на уровне С в блоке 5, кажется слишком малой, на что указывают и
вычисления остатков у—Д(Т+В).)
Сбалансированность. Девиации для моделей 1, Т, В, Т+В даны в
дереве девиаций. В этом эксперименте они удовлетворяют равенству
dev(l)—dev(7)=57,94= dev(B)—dev (7+В),
так что девиация, относящаяся к обработкам, одна и та же независи-
мо от того, были ли блоки выровнены. Это свойство есть следствие
сбалансированности плана эксперимента и модели, используемой для
анализа. На стадии планирования эксперимента каждая обработка бы-
ла приписана точно один раз каждому блоку. Аддитивная модель
Т+В и предположение, что каждое наблюдение имеет одинаковую дис-
персию, вместе обусловливают сбалансированность модели.
11.3.6. ФАКТОРНАЯ МОДЕЛЬ ДЛЯ КРОСС-КЛАССИФИЦИРОВАННЫХ ДАННЫХ
Информативным представлением массива данных, в котором объ-
ясняющими переменными являются факторы, будет таблица кросс-
классификации для уровней факторов. Приведем два примера.
Курение и пол
(курящие) Вг (некурящие)
At (девочки) 10 40
Л 2 (мальчики) 45 25
Длина ящериц по видам и регионам
В, (вид 1) Вг (вид 2)
А) (север) 15,2 17,7
А г (юг) 16,3 18,6
Структура этих таблиц идентична, что ведет к подгонке моделей,
имеющих один и тот же линейный предиктор. Однако сначала обсу-
дим различия между примерами.
Заметим, что имеется неопределенность относительно размера
массива данных в примере о курильщиках. Могло быть четыре на-
блюдения для четырех клеток таблицы, а могло быть и 120 наблюде-
ний, соответствующих 120 подросткам. В другом примере данные о
длине ящериц сбалансированы. Для каждой клетки таблицы имеется
точно одна ящерица и четыре объекта (единицы).
Второе различие состоит в выборе вероятностной модели для за-
висимой переменной. Число подростков, попадающих в некоторую
ячейку, есть зависимая переменная для первого примера. Правдопо-
добной моделью является мультиномиальное распределение [см. II,
раздел 6.4] с параметрами £=120 и вероятностями, приписанными для
этих четырех ячеек. Альтернативой, хотя в некотором смысле и экви-
валентной, является пуассоновская функция плотности [см. II, раздел
5.4]. Обе эти модели дискретны и не имеют неизвестного параметра
масштаба. Для другой таблицы длина ящерицы представляет собой
непрерывную переменную, и разумно выбрать нормальную плотность
[см. II, раздел 11.4], которая зависит от параметра масштаба.
Еще одно различие связано с выбором подходящей шкалы измере-
ний. Вопрос, закономерный для таблицы «Курение и пол», состоит в
том, является ли отношение курильщиков к некурящим одинаковым
для обоих полов, т. е. значимо ли отличается отношение 10/40 от 45/25.
Для данных о ящерицах логичен вопрос, одинаково ли региональное
различие в длине для обоих видов, т. е. значимо ли различие разно-
стей 16,3—15,2 и 18,6—17,7. В предыдущем примере естественная
шкала вычислений мультипликативная, в то время как в последнем —
аддитивная.
Последнее различие может быть устранено переходом к логариф-
мической шкале в примере «курильщики—пол». Тогда будут сравни-
ваться величины (loglO—log40) и (log45—log25). Сравнение имеет
такую же аддитивную структуру, как и в примере с ящерицами. Заме-
тим, что (loglO—log40)—(log45—log25) = (loglO—log45)—(log40—log25),
так что вопрос о равенстве пропорций курильщиков и некурящих для
обоих полов имеет тот же ответ, что и вопрос, одинаково ли соотно-
шение девочек и мальчиков среди курильщиков и некурящих. Линей-
ный предиктор для обоих примеров имеет вид
t] = XI4- авг + + уЯгЬг-
И в том и в другом случаях проверяется равенство у=0. Пример «ку-
рильщики—пол» имел логарифмическую функцию связи log(/x) = ту, в то
время как примеру с длиной ящериц соответствует тождественная
функция связи. Но в обоих примерах небезынтересно выяснить, суще-
ствует ли взаимодействие, для чего проводится сравнение модели
q е А*В с q € А+В. Диаграмма моделей для линейного предиктора в
случае двух факторов имеет следующий вид:
А * В
А + В
40
Л и В — факторы, обеспечивающие кросс-классификацию данных.
Сравнение моделей г|€Л*Ви17€Л4-В является тестом для выявления
взаимодействия: имеется ли связь между полом и курением; имеется
ли различие между видами ящериц, обусловленное регионами? При
сравнении у £ А+В с 17 € А проверяется различие между уровнями В
на каждом уровне А : равно ли число курящих числу некурящих среди
мальчиков и девочек; имеют ли виды ящериц одинаковую длину на се-
вере и на юге? Сравнение rj € В с г? € 1 позволяет определить различие
между уровнями В в целом: равно ли число курящих числу некурящих
независимо от пола; является ли длина разных видов ящериц одинако-
вой независимо от региона?
При выборе модели для сравнения необходимы внимание и осто-
рожность. Так, в примере «курильщики — пол» реальный интерес
представляет только сравнение А * В с А + В, в то время как в при-
мере с ящерицами интересно только сравнение А + В, А и В.
Введенные здесь обозначения позволяют легко ссылаться на раз-
личные модели. В частности, нам не нужно указывать число уровней
у факторов. Та же иерархия моделей пригодна и в случае пяти видов
ящериц и четырех регионов. Эти обозначения легко распространить и
на ситуацию с тремя факторами. Пусть мы имеем наблюдения с тре-
мя факторами. Тогда двухвходовая таблица заменяется трехвходовой:
Данные Бартлетта о черенках слив
Время посадки Длина черенка Условия (С)
(Я) (5)
прижился погиб
Тотчас ДЛИННЫЙ 156 84
короткий 107 133
Весной длинный 84 156
короткий 31 209
Приведем иерархию факторных моделей, подходящих для трехфак-
торной таблицы кросс-классификации с факторами А, В, С.
Диаграмма иерархии моделей для трех факторов
Трехвходовое взаимодействие
Двухвходовое взаимодействие
А*В+В*С
А*В+С
А*В
Главные эффекты
А+В
а'
41
Другие модели могут быть получены при перестановке букв
А, В и С.
В целом имеется одна модель, содержащая все трехвходовые взаи-
модействия, т. е. индикаторные векторы для одновременной специфи-
кации уровней для А, В и С fa,byCp, десять моделей с двухвходовыми
взаимодействиями, но без трехвходовых, семь моделей с простыми
главными эффектами и одну модель с некоторым постоянным зна-
чением.
Решение, какую из моделей выбрать для оценки, зависит от спосо-
ба получения данных, априорного знания о возможных зависимостях,
цели, для которой используется модель, и простоты содержательной
интерпретации модели. Для иллюстрации сложности интерпретации,
связанной с трехфакторной моделью, предположим, что известно су-
ществование связей между А и С. Таким образом, моделью будет
rj € А*С, и она не будет редуцироваться к у € А + С. При этом из воз-
можных объяснений такого взаимодействия можно было бы предпо-
лагать, что если значение В поддерживается постоянным, то это
взаимодействие исчезает. В этом случае любая из моделей г/ € А*В*С
и ij€ Л*2?+2?*С+С*Л должна редуцироваться к г? € А*В+В*С.
Количество факторных моделей растет с увеличением числа факто-
ров. Читатель может попытаться построить диаграмму моделей для
четырех факторов.
11.3.7. СМЕШАННЫЕ МОДЕЛИ
Определенный интерес представляют модели, у которых линейный
предиктор содержит как количественные, так и качественные перемен-
ные. Множество таких моделей включает модели, возникающие в ко-
вариационном анализе, а также модели для проверки однородности
линий регрессии, оцененных для нескольких групп.
Если X представляет собой модель, порожденную количественным
вектором х, и А — модель, порожденная индикаторными векторами
фактора А, то
A +Ar=span(l,a2,...,a/,x)
и
А ♦ Х= span(l ,а2,‘... ,а/,х,а2х,... ,а/х)
Это два основных члена (термина) для описания смешанных моделей.
В эквивалентных координатных обозначениях линейный предиктор
для i-ro уровня фактора А может быть записан как если
т) € А+Х, и aj + fijX, если у 6 А*Х.
Ковариационный анализ может быть просто объяснен в этих обо-
значениях с помощью примера. Обратимся снова к рандомизирован-
ному блочному эксперименту для проверки влияния удобрений, Т, на
урожайность пшеницы [см. раздел 11.3.5]. По существу, проверка ги-
потезы об отсутствии различий между обработками (дозами удобре-
ний) сводится к подгонке моделей у € В (В — блоки) и € Т+В и
42
Рис. 11.3.2. Пояснение к ковариационному анализу: две обработки
(□, О) на шести единицах
последующему сравнению величины сокращения девиации с табулиро-
ванными значениями значимостей (хотя имеется некоторое осложне-
ние, связанное с оценкой параметра масштаба ф). Предположим
теперь, что, кроме урожайности, у, наблюдалось и число всходов, х,
на 24 делянках. Так как рост числа всходов должен, вообще говоря,
вести к некоторому повышению урожайности, эта переменная могла
бы оказать определенное влияние на выводы из эксперимента, в осо-
бенности если число всходов коррелировало с дозой удобрения. Тогда
сравнение В с Т+ В будет смещенным. Главная цель ковариационного
анализа состоит в учете этого смещения (даже если число всходов и
не коррелирован© с уровнями удобрения, ковариационный анализ поз-
воляет построить более мощный тест, поскольку дает более эффектив-
ную оценку для ф).
Идея ковариационного анализа состоит в уточнении предиктора с
использованием разности -q—(Зх и в сравнении оценок у—(Зх € В и т/—
—/Зх € Т+В. Когда значение /3 неизвестно, это сравнение эквивалентно
сравнению оценок для q € В+Х и -q € Т+В+Х.
Несколько идеализированный рис. 11.3.2 иллюстрирует мотивацию
для применения моделей ковариационного анализа. В ситуациях, изо-
браженных на рис. а) и б), вывод относительно значимости эффекта
обработки будет различным в зависимости от того, учитывалось ли
число всходов. Сравнение оценок модели В и Т+ В указывает на значи-
мость Т для а) и незначимость Т для б). В то же время сравнение оце-
нок В+Х и Т+В+Х приводит к противоположному заклю-
43
чению. Только в ситуации, изображенной на рис. в), где распределение
х одинаково для обеих обработок, указанные сравнения приводят к за-
ключению о значимости эффекта обработки.
Аналогично проверка однородности линий регрессии, или, более
общее, линейных предикторов, так же просто описывается с помощью
введенных обозначений. В ранее рассмотренном примере о смертнос-
ти мышей (У) в зависимости от дозы (х) препарата применялась бино-
миально-логистическая модель. Распределение Y было Bin (5, р),
p=eV(l+e,>) и т] = (х+/3х. Предположим теперь, что группы однополы.
Тогда возможно, что препарат на самцов и самок действует по-разно-
му, т. е. нужно проверить, необходимо ли использовать T} = cti+/3ix
для самок, а t] = q!2 + (32x для самцов. Если S — фактор пола, то это
сводится к сравнению моделей
ту € S*X, ту € S+X, ту € X.
Сравнение девиаций для S*X и S+X дает нам тест для проверки па-
раллельности линий регрессии. Если они параллельны, то далее про-
веряется равенство свободных членов. Если они совпадают, то эти
прямые идентичны.
11.3.8. ФАКТОРЫ С УПОРЯДОЧЕННЫМИ УРОВНЯМИ
Факторы с упорядоченными уровнями пригодны для более деталь-
ного анализа. Рандомизированный блочный эксперимент из раздела
11.3.5, относящийся к изучению влияния уровня удобрения на урожай-
ность пшеницы, служит достаточно хорошим примером. Двухфактор-
ная модель с главным эффектом может быть записана как
liy^X+Xj + Tj или ц е в+т,
где 7j — эффект /-го уровня удобрения на ожидаемый урожай дгу, a Xj
— блоковый эффект. Уровни удобрения — хг =0, х2=20, х3=40, х4=60.
Для квадратичной модели имеем
fiy = X+Xj+ (3xL+ух2.
Три параметра т2, т3, т4 (3=4—1, размерность оболочки Г) сокраща-
ются до двух, соответствующих линейной и квадратичной компонен-
там эффекта обработки (дозы удобрения). Квадратичная модель для
урожайности позволяет получить аппроксимацию положения максиму-
ма урожайности; приравнивая дц/дх= (3+2ух к нулю, имеем х=—&/2у.
Пусть х = Ex/а,, х2= Е х^а, и Af=span(l,x), Ar2=span(l,x2). Тогда ква-
дратичная модель может быть записана в виде ц € В+Х+Х2.
Некоторой альтернативой будет служить применение линейной ком-
поненты фактора обработки, х, для проверки наличия взаимодейст-
вия блоков и обработок. План эксперимента был составлен так, что-
бы каждая обработка применялась только один раз в каждом блоке.
Когда повторения отсутствуют, невозможно получить разделенную
оценку ошибки. Очевидно, взаимодействие 7*В смешано с оценива-
44
нием параметра масштаба ф. Однако можно проверить, варьируется
ли компонента Т от блока к блоку, т. е. имеется ли некоторое взаимо-
действие вида (линейная компонента 7)*Д Это может быть достигну-
то сравнением девиации для модели
Ну= X+\j+Ti+0или +Т+ В* АГ
с девиацией модели и € В+Т.
Проверка наличия взаимодействия и квадратичной модели для
главного эффекта обработки может быть проведена одновременно пу-
тем сравнения моделей, приведенных на диаграмме:
в+т+в*х
10df
В+Т
15df
В+В*Х+Х*
lldf
В+Х+Х2
16df
Заметим, что эта диаграмма могла бы быть более полной при вклю-
чении взаимодействия (квадратичное Т)*В, т. е. члена В*Х2.
С большей общностью пусть А — фактор с I уровнями и его /-му
уровню соответствует величина х,. Положим теперь х^ = Ех^а;-, где х{
— некоторая величина, соответствующая /-му уровню А. Определим
к-ю компоненту А как А* = span (1,х*). Если величины х; различны,
то А можно представить в виде
А=Х+Х2 +...+Х1~1,
т. е. А разлагается на линейную, квадратичную и т. д. компоненты.
Для равноотстоящих значений х, (х,=/) легко сконструировать ортого-
нальные полиномы, взяв линейные комбинации [см. раздел
11.3.1]: Zo = l, Zi= лин. комб. (l»Xi), z2= лин. комб. (1,хьх2) и т. д.
так, чтобы Zo,zb... были ортогональны.
Пример. Пусть п=6 и А имеет три уровня, 1=3, с индикаторными
векторами аьа2,аз и значениями Xi = l, х2=2, х3 = 3. Тогда
а, а2 а, 1 х, х2 z, z, z2
10 0 1111—11
10 0 1111—11
0101241 0—2
0 10 12 4 1 0—2
0 0 1 1 3 9 1 1 1
0 0 1 1 3 9 1 1 1
45
Легко проверить, что АГ1+Л2=8рап(1,хьх2)=Л = span(l,a2,a3). Следует
заметить, что, хотя уровни некоторого фактора могут быть упорядо-
чены, возможность однозначного присвоения числовых значений его
уровням не является однозначной. Так острота зрения может быть
низкой, средней, высокой. Для этих уровней значения —1, 0, 1 ничем
не хуже, чем —1, 0, 100. Существуют методы подгонки моделей со
значениями уровней, относительно которых предполагается только
ранжирование (xi<x2<x3), но они слишком сложны для обсуждения
здесь.
11.4. ТАБЛИЦЫ СОПРЯЖЕННОСТЕЙ
11.4.1. ВЫБОРОЧНЫЕ МОДЕЛИ ДЛЯ ТАБЛИЦ СОПРЯЖЕННОСТЕЙ
Таблицы сопряженностей представляют собой подходящую форму
суммаризации массива данных, когда зависимая и объясняющая пере-
менные являются индикаторными векторами. Пусть Л, есть z-й уро-
вень А иуй=1, если t € Ait и Уц=0 в противном случае, так что у, _
индикаторный вектор для Л,-. Тогда сумма yi+ дает число объектов из
массива данных с уровнем Л,. Одновходовая таблица сопряженностей
есть просто таблица итогов:
Я, Аг Л, Итог
J1 + У2 + п
Двухвходовая таблица конструируется с помощью индикаторных
векторов Уу, получаемых поточечным умножением векторов у, для Л,-
и уj для В/У,уУ,У7). так что Уу7 = 1, если t € Л,- и t 6 Bj. Элементами в
этой таблице будут величины уу+. В качестве примера приведем сле-
дующие таблицы:
I-2 = J в2
Л, Уи + У,2 +
У2,+ У 22 +
Курящие Некурящие
Девочки 10 40
Мальчики 45 25
л = 120
Трех- и многовходовые таблицы определяются очевидным образом.
Когда имеется более одной зависимой переменной, таблицы сопря-
женностей строго следовало бы отнести к области многомерного ана-
лиза [см. гл. 6]. Однако поскольку такое расширение связано только
46
с индикаторными векторами, можно рассматривать их и в рамках раз-
витой здесь концепции, применяя некоторую перекодировку массива
данных. В примере «курящие — пол» исходный массив содержал 120
строк и каждая строка соответствовала подростку. В новом массиве,
представленном в табл. 11.4.1, каждый объект соответствует одной из
клеток таблицы сопряженностей «Курение и пол».
Такое преобразование существенно сокращает объем данных, но
при предположении о линейности модели это не приводит к потере
информации.
Таблица 11.4.1. Преобразование массива данных
Исходные объекты G в S -S Новые объекты У G в S -S
1 0 1 1 0 1 10 1 0 1 0
2 1 0 0 1 2 40 1 0 0 1
• - - • • 3 45 0 1 1 0
л = 120 1 0 0 1 Л=4 25 0 1 0 1 '
Старый массив может быть реконструирован из нового, за исключе-
нием порядка строк, что несущественно при условии, если массив дан-
ных допускает перестановку строк. В статистической терминологии
суммы индикаторов в клетках являются достаточными статистиками
[см. раздел 3.4].
Вектор сумм в клетках У=(У1»У2,•••»>%) теперь образует зависимую пе-
ременную, но, к сожалению, его компоненты не являются независимо
распределенными, так как сумма yt равна п, количеству объектов в ис-
ходном массиве. Однако в то же время у имеет условное пуассоновское
распределение, для которого, к счастью, процедура подгонки подходящей
модели идентична процедуре подгонки для выборки из независимого пу-
ассоновского распределения, пока условие соблюдается.
Мы получим этот результат, рассматривая простой выбор из
мультиномиального распределения, т. е. предполагая, что исходные
объекты с номерами /=1,2,...,л независимо распределены и каждый из
них имеет одинаковый набор вероятностей р\,рг,...,рк попадания в
одну из к клеток. Хорошо известный результат, основанный на стан-
дартной теории распределений, состоит в том, что распределение ко-
личеств объектов, попавших в клетки Уг,---У^ будет мультино-
миальным с параметрами п=у + и Pijh,...,pk [см. раздел 2.9]. Дру-
гой стандартный результат состоит в том, что если каждая из незави-
симых случайных величин у, (/=1,2,...,Л) имеет распределение
Пуассона с параметром (/=1,2,...Л) и если у+=Уъ+Уг +.............+Ук
и д + = Д] +д2 +...+д^, то У + имеет пуассоновское распределение с парат
47
метром (д + )[см. табл. 2.4.1]; условное распределение множества сумм
в клетках У1ПРИ Условии, что значение у+ -п, будет мульти-
номиальным с параметрами (п\ +,...,^Л/ц+) [см. раздел 2.9]. Сле-
довательно, мультиномиальное распределение сумм в клетках может
рассматриваться как условное пуассоновское.
Дальше можно показать, что функция плотности объединенного
распределения ji^2,---«yjt может быть записана как отношение пуассо-
новских плотностей, так что лог-правдоподобие задается выражением
Х(/?1 ,Рг, • •. ,Рк)=\р(пр} ,пр2,... ,прк)—\р{п),
где \р — функция лог-правдоподобия для совместного пуассоновского
распределения при предположении о независимости, а Хр — лог-прав-
доподобие для одной пуассоновской случайной величины. Член Хр(п) не
зависит функционально от вероятностей ръРг,...,рк, поэтому вывод от-
носительно них будет основан только на \ip. А это равносильно экви-
валентному предположению, что У\Уг,...ук являются независимыми
пуассоновскими величинами со средними npitnp2,...,npk.
Имеются другие выборочные схемы для таблиц сопряженностей,
т. е. различные способы выбора объектов. Все они приводят к процеду-
ре вывода, основанной на функции правдоподобия для пуассоновского
распределения. Одной из наиболее важных схем является product-
мультиномиальная. Она имеет много приложений и особенно часто ис-
пользуется в клинических исследованиях для анализа ретроспективных
и проспективных экспериментов. Простой пример проспективного пла-
на возникает, когда индивиды (объекты) распределяются в группу с об-
работкой и контрольную группу. Обе группы поддерживаются в одних
и тех же клинических условиях и наблюдается состояние входящих в
них объектов (болен — не болен). Результирующей двухвходовой таб-
лицей будет следующая:
ЯДболен) Я2(не болен) Итого
Л)(с обработкой) Уп У12 У1 +
Л2(без обработки) У21 Угг Уг +
Здесь у++ -п и к—4. Заметим, что здесь число индивидов в каждой из
групп фиксировано с самого начала и анализ должен проводиться с уче-
том заданных фиксированных значений yi+ и у2+. Выход индивидов из
эксперимента не допускается. В этом эксперименте А рассматривается
как объясняющий фактор (фактор обработки, экзогенный фактор),
а В известен как фактор отклика.
Легко видеть, что такая модель является расширением простой
мультиномиальной модели для двух мультиномиальных (фактически
биномиальных, так как имеются только два уровня у фактора от-
48
клика В). Функцией лог-правдоподобия будет
X(P1 \,Pi2,P2i ,Ргг) = ХфО1 +Р11 ь У1 +P2|i)—Хр(У1 + ) +
+ Х/р(Уг+Р\ 12, У г +Рг12)—Хр(у2+),
где рф =Р(В,|Л1),Р2|1 =Р(В2|Л1) и т. д. — условные вероятности, так
что 11 +р2)1 = 1 и Р1|2+р2|2 = 1.
Итак, лог-линейная функция правдоподобия свелась к той же фор-
ме, что и прежде, но подчинена дополнительным ограничениям
У+ + (Ри+р12)=У1 + ,У+ + (Р21+Р22)=У2+- Следовательно, здесь можно ис-
пользовать способы подгонки, как для таблицы с распределением Пу-
ассона в условиях независимости, но с учетом ограничений на па-
раметры.
Заслуживает внимания факт, что на практике возникают выборки,
точно подчиняющиеся распределению Пуассона. Как пример приведем
количество соединений между абонентами в телефонной сети. Это
случайная величина, которая может хорошо описываться пуассонов-
ским распределением. Это обусловлено характеризацией пуассоновско-
го распределения как распределения частоты «редких» событий.
Двухвходовая квадратная таблица классификации соединений по ис-
1 очнику и приемнику вызова и представляющая число сделанных со-
единений будет таблицей сопряженностей.
11.4.2. МОДЕЛИ НЕЗАВИСИМОСТИ ДЛЯ ЛИНЕЙНОГО ПРЕДИКТОРА
Говорят, что факторы А и В независимы, если и только если веро-
ятность классификации объекта одновременно к Z-му условию А и у-му
условию В равна произведению
Р(Т tAjV. Tt Bj) = P(J € А-)Р(Т € Bj)
для всех i и j, или в эквивалентной записи ру=р,+р +j, или с очевид-
ными сокращениями Р(А Q В)=Р(А)Р(В).
Исходный массив данных был редуцирован к двухвходовой табли-
це сопряженностей с IJ клетками с числом объектов уу в клетке
и EYy-npy. Если А и В независимы, то
EYy=npi+p+J.
Для логарифмической функции связи линейный предиктор есть
Чу = \ogEYy = logzz + logp/+ + log/? +j,
или в векторной форме
Ч=log/? 1 + Elogp; + а, + S log/? +jbj.
Итак, ч -- линейная комбинация индикаторных векторов для уровней
А и В, dj и Ь/ принадлежат подпространству А + В. Основываясь на
предыдущих определениях, можно сказать, что факторы А и В явля-
ются независимыми, если и только если ч € А+В. Тот факт, что
7/-logET 6 А+В, при условии независимости определяет важность лог-
линейных моделей.
49
Пример. Приведенная таблица ожидаемых частот указывает на не-
зависимость, линейный предиктор принадлежит А+В.
Я, Вг
^1 32 8
^2 16 4
Клетки ч = 5 1 + -1«2 + —2Ь2
1 5 1 0 0
2 3 1 0 1
3 4 1 1 0
4 2 1 1 1
Для удобства логарифмы взяты по основанию 2.
Оба фактора были рассмотрены как факторы отклика. Теперь
предположим, что фактор В фиксирован, т. е. число nj наблюдений с
уровнем Bj фиксировано заранее. Частоты в двухвходовой таблице
должны удовлетворять условию
а ожидаемое значение частот задается выражением
EYjj^rijPi^,
где рм — условная вероятность наблюдения /-го уровня А при усло-
вии, что уровень фактора В есть Bj.
Эквивалентное определение независимости А и В состоит в том,
что условная вероятность А при заданном значении В равна марги-
нальной вероятности А, т. е. Р(Л|В)=Р(Л) или Рф=Л+- Подходящей
моделью независимости для математического ожидания частоты в
случае фиксированного фактора будет тогда
EYy—rijP^.
Это снова эквивалентно условию г/ € А л-В, в чем легко убедиться,
взяв логарифм.
В примере «курильщики—пол», рассмотренном в разделе 11.3.6,
двухвходовая таблица сопряженностей классифицирует 120 подростков
по комбинациям пола и по отношению к курению. Курильщиков нам-
ного больше среди мальчиков, и отношение перекрестных произведе-
ний срг=10-25/40-45=0,139 существенно отличается от единицы.
Формально подгонка модели для проверки независимости состоит в
следующем.
Модель:
п.р.в. Y: условная пуассоновская при условии п = 120,
логарифмическая связь: i/=log(2jY),
линейный предиктор при условии независимости: у € А+В
Подогнанные значения: детали опускаются, за исключением заме-
чания, что
+В)=Л+У+/У+ + •
50
Данные и подогнанные значения представлены в следующей
таблице:
Девочки Мальчики Курят Не курят
10(22,9) 45(32,1) 40(27,1) 25(37,9) п = 120
Девиация:
беу(Л + В)=2( 101og(10/22,9) +... + 25log(25/37,9)) = 24,23, df(A + В) = 1.
Уровень значимости для значения девиации будет вне 0,1%-ного зна-
чения и, следовательно, очень мало вероятно, что курение и пол
независимы. Гипотеза о независимости значимо несостоятельна.
Логарифм отношения перекрестных произведений в таблицах
2x2. Тот факт, что условие у € A + B=span(l,a2,b2) эквивалентно ус-
ловию независимости, может быть использован для введения неко-
торой меры зависимости (ассоциации). Если факторы зависимы, то
€ A *B=span(l,a2,b2,a2b2), и коэффициент при члене, описывающем
взаимодействие, может рассматриваться как мера зависимости, кото-
рая известна как логарифм отношения кросс-произведений. Запишем
это следующим образом: коэффициент при а2Ь2 равен:
, , EY„EYn ,
Л22—Л21—Л12 +Ли = log -------- = log
ЕГ12£У21
РчР22
P12P2I
11.4.3. МОДЕЛИ НЕЗАВИСИМОСТИ ДЛЯ ТРЕХВХОДОВЫХ ТАБЛИЦ
Модели независимости для трех факторов существенно более инте-
ресны, чем для двух, поскольку взаимоотношения между тремя фак-
торами более разнообразны.
Определим следующие типы независимости между тремя фактора-
ми-откликами А, В и С.
Определение 11.4.1. Л и в попарно независимы, если Р(А Q В) =
= Р(А)Р(В); А, В и С взаимно независимы, если Р(Лр|ВР|С) =
= Р(А)Р(В)Р(Су, А и В условно независимы при заданном С, если
Р(АГ}В\С)=Р(А\С)Р(В\С).
Из этих определений непосредственно следует, что взаимозависи-
мость А, ВиС необходимо влечет попарную независимость для всех
пар факторов, но попарная независимость, вообще говоря, не влечет
взаимонезависимости. Аналогично условная независимость А и В при
фиксированном С не влечет попарной независимости Л и В и на-
оборот.
В прикладных работах часто интересно выяснить, может ли на-
блюдаемая зависимость между Л и В объясняться С, если Л и В
условно независимы при фиксировании уровней С.
Приведем численный пример, иллюстрирующий условную незави-
симость:
А х! AxBIC, ЛхВ|С2
35 25 25 15 15 5 15 5 20 20 10 10
п = 100 ^=40 П2 = 60
Этот пример показывает, что зависимость между А и В, наблюдае-
мая в маргинальной таблице, Ах В, может быть объяснена с по-
мощью трехвходовой таблицы, включающей фактор С, даже в случае,
когда для любого уровня С факторы А и В условно независимы.
Между моделями независимости и лог-линейными моделями име-
ется прямое соответствие, как, например, в следующей таблице:
Вероятностные модели для Р(А П В П С) Линейная модель
(1) \/ик 1
(2) P(A)/JK А
(3) Р(А)Р(В)Р(С) А+В+С
(4) Р(А Q В)Р(С) А*В+С
(5) Р(А\С)Р(В\С)Р(С) А *С+В*С
(6) ч А *В+В*С+С*А
(7) Р(СИ П В)Р(А)Р(В) ч
(8) Р(А п в n Q А*В*С
(9) (7) (6)
Первые две модели соответствуют равновероятности и имеют не-
большое практическое значение. Взаимозависимости соответствует
модель (3), в условной независимости — модель (5). Модель (6) не яв-
ляется трехвходовой, однако она включает все двухфакторные взаимо-
действия. Для нее невозможно привести в замкнутой форме
выражения в терминах вероятностей. Для двухвходовой таблицы со-
пряженностей, получаемой агрегацией по фактору С, лог-линейной
моделью для (7) будет А + В. Насыщенной моделью будет (8), а мо-
дель (9) получена на основе равенства Р(А Q В Q С)=Р(С\А Q В)Р(А Q В)
при дополнительном предположении, что Р(А (^\В)=Р(А)Р(В), как и в
модели (7), в то время как лог-линейная модель для Р(С\А Q В) зада-
на посредством (6)
52
11.4.4. ФАКТОРЫ ОТКЛИКА И ОБРАБОТКИ
Анализ моделей зависит от контекста, определяемого данными.
Так же, как в регрессионном анализе отсутствуют формальные прави-
ла для определения, какие объясняющие переменные включать в ли-
нейный предиктор, в анализе таблиц сопряженностей не существует
формальных правил относительно того, какие таблицы необходимо
выделять. На самом деле из-за многомерности ситуация для таблиц
сопряженностей является более сложной. Некоторые упрощения, вы-
текающие из разбиения факторов на факторы отклика и обработок,
были описаны выше. Мы будем рассматривать ситуацию только с
одним фактором отклика.
В следующем примере трехвходовой таблицы гибель сливовых че-
ренков М есть фактор отклика, а время посадки Т и длина L — факто-
ры их обработки.
Таблица сопряженностей с данными о черенках слив
L т м Итого
прижился погиб
Длинный Тотчас 156 84 240
Весной 84 156 240
Короткий Тотчас 107 133 240
Весной 31 209 240
Одна из моделей для этой таблицы включает следующие компо-
ненты: распределение Bin(240,p,y), логит-функцию связи [см. раздел
2.7.3, п. г.], ЕУ/у=240р/у. Эквивалентно может рассматриваться и мо-
дель условного пуассоновского распределения при фиксированной сум-
ме маргинальных частот, равной 240, т. е. модель с пуассоновской
плотностью и логарифмической функцией связи. Линейный предиктор
у] должен принадлежать L*T, чтобы удовлетворять ограничениям на
маргинальные «астоты. Модель содержит М, чтобы учесть полную
вероятность приживания черенка и взаимодействия между М и L, Т
для исследования зависимости гибели от длины черенка и от времени
посадки. Разумными моделями для подгонки являются:
L*T+M
L*T+M*L L*T+M*T
L*T+M*(L+T)
L*T+M*L*T
Девиации, df
(151,0, 3)
(105,2, 2) (53,4, 2)
(2,29, 1)
(0, 0)
53
Анализ приведенной иерархии моделей показывает, что модель с
трехфакторным взаимодействием не обеспечивает хорошей подгонки
(девиация=2,29, df=l), из чего можно заключить, что гибель черенков
зависит и от их длины, и от времени. Однако эти два фактора не да-
ют каталитического эффекта, т. е. отсутствует дополнительный рост
гибели, обусловленный одновременным действием сроков посадки и
использованием более длинных черенков.
11.5. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Подход к линейным моделям, развитый здесь, базируется на
статье: Nelder J.A., Wedderborn R.W. (1972). Generalised
Linear Models, J. Roy. Statist. Soc. A. 135, 370—384.
Соответствующую литературу см. также в разделе 12.4. Руковод-
ство по использованию пакета GLIM содержится в работе: Baker
R.J., Nelder J. (1978). The GLIM System, Release 3, N. A. G.
Глава 12
ЛИНЕЙНЫЕ МОДЕЛИ II
Во введении к гл. 11 было дано краткое описание проблем, изло-
женных в настоящей главе, и говорилось о ее связи с гл.11.
12.1. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
12.1.1. ОСНОВНЫЕ ИДЕИ, ПОЛОЖЕННЫЕ В ОСНОВУ МЕТОДА
НАИМЕНЬШИХ КВАДРАТОВ
С помощью метода наименьших квадратов [см. разделы 3.5.2,
3.5.5, гл. 8 и 10] можно решить задачу проведения «наилучшей» пря-
мой линии через совокупность точек (хь у,),...,(хп, у„). Сначала рас-
смотрим прямую вида у=@х, которая проходит через начало
координат и полностью определяется параметром /3.
За расстояние между точкой на плоскости (xt, у() и нашей прямой
возьмем отклонение по вертикали, т. е. £>t=yt—&xt [см. рис. 12.1.1].
Очевидно, что чем меньше это отклонение, тем лучше подогнана (по-
добрана) прямая. Совокупной мерой расхождения между точками и
прямой служит сумма квадратов 8* + 8* + ... + 8*. Метод наимень-
ших квадратов заключается в выборе такой прямой, которая миними-
зирует эту величину.
В «-мерном векторном пространстве [см. раздел 11.1.1], если обо-
значить у = (уь Уг, — ,Уп), х = (Хь хг,...,хп) и € = (8ь 82,...,8„) = у —
—/Зх, сумма квадратов запишется в виде ||£||2= ||у—/Зх|(. Пусть b —
значение /3, которое минимизирует. |у—/Зх|2, тогда вектор у = 6х есть
вектор расчетных (подогнанных) значений. Дальнейшее исследование
и обсуждение метода наименьших квадратов требует введения поня-
тия ортогональных векторов.
Определение 12.1.1. Ортогональность векторов. Векторы х и у,
принадлежащие «-мерному пространству, называются ортогональны-
ми (обозначим как х±у), если их скалярное призведение равно нулю,
т. е.
(х,у)=0.
55
Рис. 12.1.1. Типичная наблюдаемая точка (xt, yt), «подогнанная» точка (xt, (ixt) и
отклонение 8,
Теперь вновь обратимся к задаче минимизации суммы квадратов
|| у—Зх ||2. Можно показать, что (3=Ь минимизирует эту величину тог-
да и только тогда, когда
у—&х±х, т. е. 6=(у, х) (х, х)-1. (а)
При этом
у = (у,х)(х,
Легко проверить, что в этом случае
у—у±у и (у, х) = (у, х). (б)
Верны также соотношения
II у 12=(у, X)2 И X И -2 = Ь(у, х), I у 12= I у II2+ II у—у 112. (в)
Наконец, введем еще одну важную характеристику линейной модели:
* = (У, у)/(||у II • ||У) = II У II/||у II- (и)
Таким образом, как следует из (а), значение (3 тогда и только тогда
минимизирует величину |у—/?х||2, когда вектор отклонений у—0х
ортогонален вектору х. Часто условие минимизации (у—/Зх, х) = 0 на-
зывается нормальным уравнением.
Если b удовлетворяет нормальному уравнению, то оно минимизи-
рует сумму квадратов. Доказательство этого утверждения приводится
в следующем разделе.
Результаты (а) и (б), касающиеся коэффициента b и вектора расчет-
ных значений у, следуют непосредственно из соотношения (у—
—Ьх,х)=0. Сумма квадратов, соответствующая подогнанной прямой,
равна || У ||2. Выражения (в) следуют непосредственно из соотношений
(а). Разложение суммы квадратов | у ||2 на составляющие в (в) полу-
чится, если записать у = у + (у—у) и учесть, что члены последней сум-
56
мы ортогональны друг другу — это в свою очередь следует из (б). Ко-
эффициент множественной корреляции R определяется как коэффици-
ент корреляции между вектором у и вектором значений у. Можно
показать, что его квадрат равен отношению соответствующих сумм
квадратов [см. (г)].
Рассмотрим следующий пример.
Пример 12.1.1. Метод наименьших квадратов для построения
прямой, проходящей через начало координат. Данные таковы:
У —32148
X —2—10 1 2
Соответствующие суммы квадратов и перекрестных произведений сле-
дующие:
(х,х) (X, у) 10 24
(У,х) (У. У) 24 94
Оценка метода наименьших квадратов
Ь= (у, х) (х, х)-1 =24/*10=2,4.
Таким образом, подогнанная прямая имеет вид у=2,4х.
Расчетные значения:
у | —4,8 —2,4 0,0 2,4 4,8
Сумма квадратов и ее разложение:
11у12=94, || у || 2=(2,4)24=57,6,
II У-У II 2= IIУI 2 - II У II2 = 94—57,6 = 36,4.
Квадрат коэффициента множественной корреляции:
Д2=57,6/94=61,3%.
12.1.2. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ НА ПЛОСКОСТИ
Представление векторов, в виде точек «-мерного пространства поз-
воляет глубже понять суть метода наименьших квадратов. При л=2
соответствущие векторы у=(_Уь Уг) и x=(xb х2) изображаются точка-
ми на плоскости. Вектор /Зх коллинеарен вектору х. Как следует из
рис. 12.1.2, значение /3, минимизирующее расстояние от у до /Зх, равно
значению Ь, для которого вектор у—Ь*. ортогонален вектору х.
57
Вторая координата
Рис. 12.1.2. Геометрическое представление векторов в n-мерном пространстве.
Вектор Ьх ортогонален проекции у на х, отклонение у—дх перпендикулярно х
Рис. 12.1.3. Ортогональная проекция
Ь* и неортогональная проекция
(д+6)х
Рис. 12.1.4. Тенью вектора у от сол-
нечных лучей, падающих ортого-
нально span(x), будет вектор у
Для доказательства, что условие у—£х±х является необходимым
и достаточным для того, чтобы значение ||у—/?х|2 было равно мини-
муму || у—6хЦ2, дадим приращение 8, а именно рассмотрим Ь+8 [рис.
12.1.3]. Тогда
||у—(Ы- 6)х j2 - I у - Ьх II 2= -26(у-г>х, х) -ь 521 х Ц2.
Допустим, b минимизирует сумму квадратов |у—/Зх||2. Тогда правая
часть последнего выражения является неотрицательной квадратичной
функцией от 8 с положительным коэффициентом при 82. Один из ее
корней равен нулю, поэтому второй корень тоже должен быть равен
нулю. Таким образом, коэффициент при 6 равен нулю, т. е. (у—
—Ьх,х)=О. Если же b удовлетворяет нормальному уравнению, то пра-
58
вая часть рассматриваемого выра-
жения будет неотрицательной, по-
этому это значение b определяет
минимум суммы квадратов.
Геометрически вектор у можно
представить себе проекцией векто-
ра у на линейное подпространство,
натянутое на вектор х [см. раздел
11.3.1]. Если направление солнеч-
ных лучей ортогонально вектору
х, то у будет тенью вектора у
[рис. 12.1.4]. Из такой интерпрета-
ции у, в частности, следует, что
у=у.
Доказательство. По опре-
делению
у=(у,х) (x,x)-1x=Z?x.
Рис. 12.1.5. Теорема Пифагора для
заштрихованного треугольника при-
водит к разложению суммы квадра-
тов: || у || 2= II у II2 + II у—у I2
Поэтому
у= (у, X) (X, Х)-‘Х = (ЬХ, X) (х, Х)-'Х =
= Z?(x, х) (х, x)-lx=Z>x=y.
Проекция является ортогональной, поскольку у—у ±у. Геометрически
разложение суммы квадратов следует из теоремы Пифагора [рис.
12.1.5, рассматривается заштрихованный треугольник].
12.1.3. МЕТОД МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ
ДЛЯ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
Если выборочное распределение является нормальным, то оценка
метода наименьших квадратов совпадает с оценкой метода макси-
мального правдоподобия. Действительно, логарифм функции правдо-
подобия [см. примеры 6.2.4 и 6.5.1] для независимой случайной
выборки у,, Уг,...,уп, где у, имеет нормальное распределение с мате-
матическим ожиданием = и дисперсией ф, равен:
Х(д) = const—Г (у—11,)2/2ф =
= const— || у—д || 2/2ф= const— ||у—/Зх || 2/2ф.
Таким образом, в этом случае максимум функции правдоподобия со-
ответствует минимуму суммы квадратов [см. раздел 3.5.5]. Дифферен-
цирование дает
= /?xz)xz/0=(y—bx, х)/ф.
59
Поэтому ЭХ/d/3=О приводит к нормальному уравнению (у—£х, х)=0.
Оценка м равна расчетному значению у.
Отклонение (deviation) для соответствующей модели равно:
dev = 2[X(y)—Х(д)]= I у-д 12/ф,
а отклонение, отвечающее нулевой гипотезе д=0, равно:
dev = 2[Х(у)—Х(0)] = || у || 2/ф.
Таким образом, разложение суммы квадратов соответствует разложе-
нию логарифма функции плотности.
12.1.4. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ В СЛУЧАЕ ДВУХ
ОБЪЯСНЯЮЩИХ ПЕРЕМЕННЫХ
Теория метода наименьших квадратов легко обобщается на ситуа-
цию с р объясняющими переменными, однако общий случай может
быть удачно продемонстрирован для р = 2. Доказательства примерно
те же, что и в случае, когда р = 1.
Значения bi, b2 минимизируют сумму квадратов ||у—0jXi—/?2х2||2
тогда и только тогда, когда
у—djXj—d2x±xi,x2,
т. е. когда bi и Ь2 являются решениями системы уравнений
Z>l(x1,xy)+Z>2(x2,x/) = (y, Ху), >1,2.
При этом
У = Ь^+Ь2*2, у—у±у,
(У,Х1) = (у,Х1), (У,х2) = (у, х2)
и
IIУ II2 = У) + *2(Х2, у)
II у II2 = 1у!2+1у-у112-
Коэффициент корреляции определяется так же, как и ранее:
R= IIУ II / IIУII •
Условия ортогональности приводят к системе нормальных уравнений:
' 0=(у—Ь, хг--Ь2х2,х1)=(у „ Х1)—bj(х,, х()—Ь2(х2, xj,
I 0 = (у—Z>tX;—/>2х2,х2) = (у, х2)—Z>i(X), х2)—/>2(х2, х2).
60
Решением этой системы является пара чисел Ьх, Ьг, которая может
быть найдена по формуле:
(Xi, х2)
(х2, х2)
(Xi, у)
(Х2, у)
Пример 12.1.2. Метод наименьших квадратов в двухпараметриче-
ском случае. Имеются следующие данные:
У —3 2—14 8
к —2—10 1 2
X 1 1—41 1
Оценки метода наименьших квадратов:
Подогнанная модель:
y=2,4Xi +0,75х2.
Пример 12.1.3. Парная линейная регрессия. Для того чтобы оце-
нить параметры а и 13 модели простой линейной регресии
Vt = ot+I3xt + E>(, t=l,2,...,n,
положим X] =1, х2 = х. Тогда
(1, 1) = л, (1, х) = Ехр fx,x)=ExJ.
Оценками метода наименьших квадратов будут
bi п Ex, — 1 ЪУ,
ь2 ex;
Положим
61
b = (Xxtyt—n-l£xt Ey,)/(E^—«“’(Ex,)2).
Тогда предыдущая запись может быть упрощена:
Ьх LxitLyt—LxtLxtyt
= (лЕ^-(Ех/)2)->
b2 J [_ nLxtyt—LxtLyt
У—Ьх~
b
Подогнанная прямая имеет вид ^=У + b(x—Т); она проходит через
«центр тяжести» (Г, У); тангенс угла ее наклона равен:
b=L(xt—T) (yt—У)/£(х(—Т)2.
Доказательство эквивалентности системы нормальных уравнений и
задачи минимизации суммы квадратов полностью аналогично доказа-
тельству в случае, когдар=Л. Напомним, что оценки метода наимень-
ших квадратов Ьх и Ь2 получены в результате решения системы
нормальных уравнений с помощью обращения матрицы. Вектор от-
клонений у—у ортогонален вектору расчетных значений у, что, как и
прежде, ведет к разложению суммы квадратов.
В случае когда р=2, в отличие от одномерной ситуации существует
возможность разложения суммы квадратов || у ||2 на составляющие,
отвечающие Xi и х2. Рассмотрим рис. 12.1.6. Он нарисован в плоскос-
ти, натянутой на векторы Xi и х2. Этой плоскости принадлежит также
вектор у. Насколько значение | у ||2 обусловлено вектором Xi и на-
сколько оно обусловлено вектором х2? Для того чтобы ответить на
эти вопросы, необходимо более детально рассмотреть проблему под-
гонки регрессионного уравнения, а также ввести дополнительные обо-
значения.
Обозначим через у(хЭ вектор расчетных значений у при минимиза-
ции || у—3iX,||; очевидно, что у (xj принадлежит линейному подпро-
странству, натянутому на вектор х,, [пишем y(X])6span(Xi)].
Аналогично у (x2)6span(x2). Пусть у(х1} х2) — вектор расчетных значе-
ний у, полученный при минимизации суммы квадратов fly——3iXt—З2Х2Ц2
одновременно по 31 и 32. Таким образом у (хь x2)6span(Xi, х2), т. е.
линейному подпространству размерности 2, натянутому на векторы Xi
и х2. Выкладки упрощаются, если скалярное произведение (хн х2)=0.
62
Ортогональный случай
/х,, х2)=0. Здесь
У(х., х2)=у(х.)+у(х2),
||У(х1,х2)|2=||У(Х1)|2+
-ЬIУ (Х2) Р-
Рис. 12.1.6. Вектор у лежит в плоскости, на-
тянутой на векторы Xj и х2
(у—Z>]X], х,)=0, откуда следует, что
Проще всего доказать эти
результаты, заметив, что
нормальным уравнением
для Ь\ будет уравнение
y€span(Xi). Аналогично уравнение (у—х,—d2x2, Xi)=0 ведет к то-
му, что y€span(x,, х2). Однако если (х,, х2)=0, то оба уравнения при-
водят к одному и тому же значению поэтому у(х,, х2)=Ь1х1+Ь2х2 =
= У(Х1)+Ь2х2. Аналогичные рассуждения применимы и для коэф-
фициента Ь2, откуда следует, что у (х,, х2)=у (Xi)+y (х2). Для доказа-
тельства второго равенства достаточно заметить, что при Xi ± х2 име-
ем у(х,)±у(х2). Последнее, в частности, приводит к разложению
суммы квадратов на составляющие:
|у|2=|у-у(х,, х2)Р + |у(х,)р+ |у(х2)I2.
Пример 12.1.4. Подгонка в условиях ортогонального плана. Возь-
мем данные из примера 12.1.1. Матрица скалярных произведений
равна:
(XuXj) (Xi, х2) (х1}у)
(х2, х2) (х2, у)
(У, У)
10 0
20
24
15
94
Сумма квадратов ||ур=94. Далее нетрудно проверить:
|у(х», х2)р= | у р=(у, М1+Мг)=ЫУ> Х!)+Ь2(у,х2)=
= (2,4)-24+(0,75)45 = 57,6+11,25=68,85,
||У (х,) || 2=Ьх(у, Xi)=242/10=57,6, |у (х2) || 2=д2(у, х2)=152/20=11,25,
| у—у р=94—68,85=25,15.
Разложение суммы квадратов (СК) представлено в следующей
таблице:
Источник Степень свободы Сумма квадратов
СК, обусловленная хх 1 57,60
СК, обусловленная хг 1 11,25
СК, обусловленная х1 и х2 2 68,85
СК остаточная 3 25,15
СК общая 5 94,0
63
Рис 12.1.7. В случае б) существуют два спосо-
ба разложения вектора подогнанных значе-
ний у(х,,х2): 1) у (х,, х2)=у (х,)+у (е2),
2) у(х,, хг)=у(е!)+у(х2)
12.1.5. НЕОРТОГОНАЛЬНЫЙ
СЛУЧАЙ
Если Xi и х2 неортого-
нальны, т. е. (Xi, х2)^0,
то интерпретация разложе-
ния суммы квадратов при-
водит к определенным
затруднениям, связанным
с тем,_ что сумма квадра-
тов | у (х,, х2)||2 не может
быть единственным обра-
зом разбита на сумму ква-
дратов, обусловленную
изолированным влиянием
факторов Xi и х2. На рис.
12.1.7 иллюстрируется по-
добная неоднозначность.
Таким образом, вместо
предыдущего разложения
можно предложить разло-
жение следующего вида:
У(Х1, х2) = у (х,)+у (е2)-
= у(е,)+у(х2),
||У(Х1, х2)||2=||у(Х1)||2+
+ II 9(61)112= I у (eJH 2+
+ IIУ (х2) 12.
Векторы Xi и х2 [см. рис.
12.1.7] могут быть преоб-
разованы в пару ортого-
нальных векторов: вектор
X] оставляем без измене-
ния, а вектор х2 заменяем
на вектор е2=х2—(х2, х2) (х,, xJ-'Xi— перпендикуляр, опущенный из
вектора х2 на вектор X, [см. рис. 12.1.7,6,1)]. Аналогично можно рас-
смотреть пару ортогональных векторов х2 и ei=x,—(хь х2) (х2, х2)~'х2
— перпендикуляр, опущенный из вектора Xi на вектор х2 [см. рис.
12.1.7.6,2)]. Результаты, полученные выше для ортогонального слу-
чая, позволяют теперь предложить два разбиения для суммы квадра-
тов. Эти разложения имеют следующую интерпретацию. Общая
сумма квадратов | у (Xi, х2)Ц2, полученная в результате подгонки у но
64
Xi и x2, может быть разбита на части: первая обусловлена подгонкой
по одному лишь Хь а вторая — подгонкой оставшейся части у по х2.
Аналогично общую сумму квадратов можно разложить на сумму ква-
дратов, обусловленную х2, и сумму квадратов, обусловленную подгон-
кой остатка у по хь Формальное доказательство данного разложения
следует из ортогональности (Х|, е2)=0 (легко видеть, что е2 — вектор
остатков при подгонке х2 к X]). Нетрудно также показать, что вектор
у (Xi, х2) совпадает с вектором у(хн е2).
Пример 12.1.5. Метод наименьших квадратов в неортогоналъном
случае. Данные представляют собой некоторую модификацию данных
из предыдущего примера. Матрица скалярных произведений имеет
вид
(ХьХО (х,,х2) (Хь у) 10 8 24
(Х2, х2) (Х2, у) = 20 15
(У, У) 94 •
Суммы квадратов:
II У II 2 = 94; ||у (Х1) 11 2=(2,4)-24 = 57,6; ||у (х2) Ц 2 = (0,75)-15 = 11,25.
Оценка методом наименьших квадратов:
10
Сумма квадратов:
||у(х., х2) Ц 2= d](y, xj + МУ» х2)= [24, 15]
8
20
24
15
8
= 2,65(24) +—31 • (15)=63,60—5,10=58,90.
Разложение суммы квадратов представлено в следующей таблице:
Источник Степень свободы Сумма квадратов Источник Степень свободы Сумма квадратов
СК, обусловленная хх СК, обусловленная х2 при данном Xj 1 1 57,60 1,30 СК, обусловленная х2 при данном х, Х1 1 1 47,65 11,25
СК, обусловленная Xj и х2 СК остаточная 2 58,90 35,10 СК, обусловленная Xj и х2 2 58,90 35,10
СК общая 94 94
65
Результат разложения суммы квадратов для обоих примеров мо-
жет быть представлен схемой:
Пример 12.1.4 (ортогональный случай)
Одновременная подгонка по и х2
25,15^
Подгонка по Подгонка по х2
36,40 82,25
Нет подгонки
Пример 12.1.5 (неортогональный
случай)
Одновременная подгонка по хх и х2
35,10
Подгонка по х, Подгонка по х2
/82,25
Нет подгонки
94,00
94,00
При изменении (х,, х2) значения коэффициентов Ьх и Ь2 также меняют-
ся. В приведенном примере значение Ь2 изменилось с 0,75 (при
(х,, х2)=0) на —0,34; при этом у коэффициента изменился даже знак.
В этой связи интерпретировать коэффициент модели необходимо с
большой осторожностью, поскольку он зависит от значений других
объясняющих переменных.
Сумма квадратов, объясняемая присутствием х( и х2, уже не яв-
ляется суммой квадратов, объясняемых изолированно х( и х2. Как
правило, последняя будет меньше первой*; так, в нашем примере
58,90 <68,85.
При возрастании величины (Xj, х2) матрица
(х., х.) (Xi, х2)
(х2, X]) (х2, х2)
может стать вырожденной. В этом случае вектор х2 линейно зависит
от вектора х(; говорят, что X] и х2 коллинеарны. Коэффициент корре-
ляции между X] и х2 тогда равен единице, и одна переменная без поте-
ри информации может быть удалена из анализа. На практике более
распространен случай, когда корреляция между Х1И х2 близка к 1, хотя
в точности и не равна ей**. Здесь дополнительные трудности вызыва-
ют вопросы, что значит близки к 1 и когда одна переменная может
быть удалена из анализа?
*Это будет иметь место, если векторы Xj и х2 образуют острый угол. — Примеч.
пер.
••Точнее, здесь необходимо говорить о косинусе угла между векторами, а не о (коэф-
фициенте) корреляции, поскольку рассматриваемые переменные х, и х2 не центрирова-
ны. — Примеч. пер.
66
12.1.6. ОБОБЩЕНИЯ НА СЛУЧАЙ НЕСКОЛЬКИХ ОБЪЯСНЯЮЩИХ
ПЕРЕМЕННЫХ
Решение задачи минимизации суммы квадратов очевидным обра-
зом обобщается на случай нескольких объясняющих переменных р.
Ситуации, когда р=\ и р=2, были рассмотрены выше. В общем слу-
чае нормальные уравнения вытекают из условия ортогональности:
у—b2*2...— bpXpLXt, *2,...,*р.
Если векторы х, ортогональны друг другу, то решением будет
/>у = (у, Ху)||ХуЦ~2, как при р=1. В общем же случае для нахождения
bif b2,...,bp необходимо решить систему р линейных уравнений с р
неизвестными, что требует обращения соответствующей матрицы.
Сумму квадратов || у (Xi, х2,... ,хр) ||2, обусловленную объясняемы-
ми переменными, можно разбить следующим образом. Допустим, пе-
ременные упорядочены как х,, х2,...,хр. Положим
®1 = хь
е2=х2—хдео,
е3=х3—x3(ei)—х3(е2),
ер=хр-хр(е1)-хр(е2)-...-хр(ер_1).
Новые переменные попарно ортогональны*, поэтому
IIУ(х., х2,...,хр)р=||у(е1)р+ ||у(е2)|| + ... + ||у(ер)р.
Значение ||у(ву)р можно интерпретировать как сумму квадратов,
обусловленную Ху, с поправкой на х,, х2,...,Ху_р На практике основ-
ное затруднение при такой интерпретации состоит в аргументирован-
ном выборе порядка объясняющих переменных из всех возможных
упорядочений.
Вектором расчетных значений будет линейная комбинация векто-
ров Х|, х2,...,хр, а именно
у (Xi, x2,...,xp) = Z?1x1 + ft2x2+ ... + bp*p.
При желании этот вектор можно представить как линейную комбина-
цию попарно ортогональных переменных et, е2,...,ер. Коэффициен-
* Заметим, что вектор е2 есть перпендикуляр, опущенный из конца вектора х2 на век-
тор Xl е3 есть перпендикуляр, опущенный из конца вектора х3 на плоскость векторов
(х,, х2),..., вектор ер есть перпендикуляр, опущенный из конца вектора хр на линейное
подпространство, порожденное р—1 векторами X,, х2,...,х . — Примеч. пер.
67
ты при х,, х2,..., и, в частности, при хр в обоих случаях, естественно,
должны совпасть. Но вектор еу- является линейной комбинацией
Xi, х2,...,Ху, поэтому только е„ зависит от хр. В силу совпадения ко-
эффициентов при ер и Хр в обеих линейных комбинациях получаем
^=(У,ер) (ер, ер)-‘,
где
ер=хр—хр(х,, х2,...,Хр_,).
В этом выражении коэффициент Ьр в аналитическом виде выражается
через вектор у и вектор отклонений, представляющий собой вектор
хр с поправкой на все остальные объясняющие переменные. Такая
форма записи удобна для исследования теоретических свойств оценок
метода наименьших квадратов.
12.2. ВЫБОРОЧНЫЕ СВОЙСТВА
12.2.1. ТЕОРИЯ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
Собранные в этом разделе результаты необходимы для построения
выборочных распределений [см. раздел 2.2] оценок метода наимень-
ших квадратов, подогнанных значений зависимых переменных, откло-
нений и компонент в разложении суммы квадратов при условии, что
исходная генеральная совокупность нормально распределена.
В дальнейшем будем пользоваться следующими обозначениями:
N(/4, ф) — нормальное распределение с математическим ожидани-
ем ц и дисперсией ф [см. раздел 1.4.2, где дисперсия обозначена через
а2. Обозначение N(/t, ф), использованное здесь, всюду заменяется на
N(/t, у/ф) или N(/t, <т)];
Х2(к, X) — нецентральное распределение х2 с к степенями свободы
(с.с.) и параметром нецентральности X [см. раздел 2.8.1];
F(kx, к2) — F-распределение со степенями свободы ki и к2,
t(k) — распределение Стьюдента с к степенями свободы.
Мы имеем следующие результаты:
1. Если z~N(g, ф), то:
а) az+с-№(ац+с, а2ф) [см. раздел 2.5.1];
б) г2/ф ~ х2(1, д2/2ф) [см. раздел 2.8.1].
2. Если Zi и zi имеют двумерное нормальное распределение [см.
раздел 13.4.6], то
a) Zi +z2 ~ N;
б) Zi и Z2 независимы тогда и только тогда, когда cov(zi, Zz)=O
[см. II, теорема 13.4.1].
3. Если Zi~N(/4], ФО, Z2~N(/i2, ф2), zi и Zi независимы, то:
68
a) Zi+z2 ~ N(/i|+д2, Ф1 + Ф2) [см. раздел 2.5.3,a)];
6) z2+z|~ Х2(2,4~(д* + М2))» если 0i = l = 02 [см. раздел 2.8.1].
4. а) Если z\ ~ x2(kx, XJ, z21~xi{k2i\2) и z2, z22 независимы, то
z2 +z2 ~ X2(*i + £2, Xi + X2) [см. раздел 2.8.1];
б) если z] ~ x2(Aj, XJ, z2 ~ x2(k, X) и z2=z2+z2, причем z\ и z\ неза-
висимы, то z2~x2(^—^i> X—XJ.
5. а) Если zi ~ N(g, ф), z\/Ф ~ x2(^> 0). причем z2 и z\ независимы,
то £1/2(Zi—д)/Z2~ t(k) следует распределению Стьюдента с к степе-
нями свободы;
б) если z2 ~ х2(^1> 0)» z\ ~ х2(к2, 0), причем z\ и z\ независимы, то
z2£2/z2Aj ~F(kXt к2)> т. е. следует F-распределению с к, и к2 степеня-
ми свободы.
Применение этих результатов покажем на примере линейной нор-
мальной модели, в которой предполагается, что значения объясняе-
мой переменной у,, у2,...,уп независимы и извлечены из нормальной
генеральной совокупности со средними соответственно дь р.2,...,цп и
общей дисперсией ф. Составим вектор у= {yXi y2T--,ynY Тогда для
любого фиксированного вектора г [см. раздел 2.5.3,а)]
(Г, y)~N((r, д), 011Г IP)
и [см. раздел 2.5.4,а)]
0_|(У> У) ~ Х2(п, ||д||2/2ф).
Первое утверждение следует из приведенных выше результатов 1а) и
За), поскольку (г, у} = т\ух +г2у2 + ... +гпуп — линейная комбинация
нормальных величин. Второе утверждение следует из 36), поскольку
0"‘(У, У) = Ф~'(У2х+У22 + ... +^)-
12.2.2. ПЕРВЫЕ И ВТОРЫЕ МОМЕНТЫ
Наша ближайшая задача — получение формул для математическо-
го ожидания и дисперсии оценок метода наименьших квадратов при
условии, что первые два момента распределения выборки Ух, у2,...,уп
известны. А именно будем предполагать, что имеют место следую-
щие соотношения:
г z ч ( 0, если Г # t,
£>, = д,, cov (.у,, v )= ]
С 0, если t' = t,
69
где t=l ,2,...,п. Эквивалентно в векторной форме это может быть пе-
реписано так:
Еу = ц, cov ((Г, у) (S, у)) = ф(г, S),
где векторы г и S, имеющие размерность п, фиксированы (не-
случайны)*.
Это стандартная система предположений относительной линейной
модели с нормальными ошибками. Основная задача — получить вы-
ражение для дисперсий и ковариаций вектора коэффициентов Ь, найти
векторы расчетных значений у, отклонений у—у, а также математи-
ческие ~ ожидания^ компонент разложения суммы квадратов
II У II2 = II У II2 + II У —У II2• Случаи, когда р- 1 и р=2 рассматриваются от-
дельно; основное внимание уделяется результатам; доказательства по
возможности коротки. Приведенные выше условия позволяют найти
первые два момента линейной формы (г, у);
E(r, y)-(r, м), var (г, у)=ф || г ||2.
12.2.3. ОДНА ОБЪЯСНЯЮЩАЯ ПЕРЕМЕННАЯ
Модель: р=1, Ey = /t=/3x (х^О),
cov((r,y), (s,y)) = 0(r,s),
У2, ••• ,Уп независимы, каждое имеет нормальное распределение.
Среднее и дисперсия оценки Ь:
Eb = $, var (Z?) = ф || X || ~2.
Доказательство: как следует из раздела 12.1.1,
Z?=(x, у)/|| х ||-2.
Как следует из раздела 12.2.1,
Е(х, у) = (х, Д)=/?(х, х)=01 х II2,
var(x, у) = ф(х, х).
Теорема Гаусса—Маркова. Оценка метода наименьших квадратов
имеет минимальную дисперсию в классе всех линейных несмещенных
оценок параметра (3 [ср. с разделом 8.2].
Доказательство. Пусть (а, у) — какая-либо оценка параметра у.
Она линейна по у, причем
* Последняя запись превращается в предыдущую, если в качестве г взять вектор, в
котором на /-м месте стоит 1, а остальные координаты вектора равны нулю. Аналогич-
но надо выбрать второй вектор S, в нем единица стоит на месте t'. — Примеч. пер.,
70
£Ya,y)=(a,>)=/?(a,x).
В силу ее несмещенности отсюда следует, что (а,х) = 1. Далее,
var(a, у)=Ф(а, а)>ф(а,х)2/(х, х) = 0||х|-2,
что является следствием неравенства Коши—Шварца [см. IV, раздел
21.2.4]. Замечаем, что неравенство превращается в равенство при
а = ||х||~2х, т. е. в случае оценки наименьших квадратов*.
Нормальность Ь. Поскольку оценка b линейна по у, она имеет нор-
мальное распределение с математическим ожиданием и дисперсией,
представленными выше (это свойство оценки используется при пост-
роении доверительного интервала для параметра /3).
Пример. Пусть (у, х) = 200, (X, х) = 400, а ф=4,
Ь=200/400 = 0,5, var(Z>)=4/400=10-2.
Поскольку (Z?—/3) var~1/2(Z>) ~ N(0,l), 95%-ным доверительным интер-
валом для (3 будет 0,5 ± 1,96-10-’=(0,304; 0,696) [см. пример 4.2.1].
Подогнанные значения у. Имеем следующие результаты**:
у)=(г, д), cov((r, у), (s, у)) = Ф(г, х) (х, s)/1 х ||-2.
Доказательство. По определению у = дх, поэтому (г, у) = д(г, х).
Для доказательства теперь достаточно воспользоваться результатами,
приведенными выше.
Пример. Для того чтобы найти дисперсию расчетного значения
при г=1, положим r=ai = (1,0,...,0). Тогда л = (аь у) и var(yi)=0x*/
U
t = 1 '
Отклонения. Имеем
£(г, У—У)=0, cov((r, у—у), (s, у—у)) = Ф((г, s)—(г, х) (х, s)/1 х ||-2).
Доказательство. Как следует из приведенных выше формул,
cov((r, у), (s, у))= cov((r, у), (х, у)) (s, х)/1| х j-2 =
* Как мог заметить читатель, при доказательстве теоремы не требуется нормаль-
ность распределения уг Если же считать, что нормально распределены, то можно
доказать более сильный результат: оценка метода наименьших квадратов будет иметь
минимальную дисперсию в классе всех несмещенных (линейных и нелинейных) оценок
параметра 0. — Примеч. пер.
“ Другими словами, Е’у1 = |3х/, cov(yp у .)=0xf.x./1| х |2. — Примеч. пер.
71
= 0(r, X) (S, X)/|| X |-2 =
=cov((r, y), (s,y)).
Отсюда разность между левой и правой частями равна:
cov((r, у—у), (s,y))=O.
Поэтому
cov(r, у-у), (S, у—у))= cov((r, у), (S, у))-cov((r, у), (S, у)).
Для окончательного доказательства необходимо воспользоваться при-
веденными формулами для ковариаций скалярных произведений.
Пример. Дисперсия отклонения при /=1 равна:
var(yj—у!) = ф(1—х^/Ех^)-
Нормальность подогнанных значений и отклонений. Поскольку
(г, у) и (S, у—у) являются линейными функциями вектора у, коорди-
наты которого нормально распределены, расчетные значения и откло-
нения также имеют нормальное распределение. Более того, поскольку
последние не коррелируют, расчетные значения и отклонения неза-
висимы.
Пример. Для того чтобы проверить, что значение У1—У1 слишком
велико для рассматриваемой линейной модели, вычислим (yi —
—У1)/ф’/2(1—х\/Ех]У/1 и проверим, принадлежит ли это значение
интервалу (—1,96, 1,96).
Дисперсионный анализ. Каждое слагаемое в разложении суммы
квадратов (СК) имеет нецентральное распределение %2 со скалярным
множителем ф:
Источник Сумма квадратов Степень свободы Параметр нецентральности
СК, обусловленная х СК остаточная СК общая ф-* |у Г Ф~' II у-УII2 Ф-Чу I2 1 п— 1 п ||лр/20 = ^||хр/20 0 И2/2ф
Поскольку (г, у) и (S, у—у) независимы при любых г и S, || у ||2 и
II У—У II2 также независимы (доказательство опускаем).
Математическое ожидание нецентральной переменной %2 равно чис-
лу степеней свободы плюс удвоенный параметр нецентральности, [см.
раздел 2.8.1], поэтому Е| у 12=ф+(Р || х ||2. Отсюда несмещенной оцен-
72
кой для ф будет
Ф = \\У~У \\2/(п—1).
Пример. Допустим
(X, X) (Х,у) 400 200 , п = 5.
(У. У) 120
Тогда
II у || 2=b2 II х II 2=(Xj у)21| х ||-2 = (200)2400-' = 100.
Таблица дисперсионного анализа будет иметь вид:
Источник Степень свободы Сумма квадратов Оценка Г-отношение
СК, обусловленная х 1 100 100 20
СК остаточная 4 20 ф=5
СК общая 5 120
Поскольку 5%-ной точкой распределения F (1,4) является 7,71 <20,
можно утверждать, что уменьшение суммы квадратов, обусловленное
х, значимо.
12.2.4. ДВЕ ОРТОГОНАЛЬНЫЕ ОБЪЯСНЯЮЩИЕ ПЕРЕМЕННЫЕ
В целях простоты удобно рассмотреть сначала ситуацию, когда пе-
ременные ортогональны, а затем и общий случай. Доказательства для
приведенных результатов опускаем.
Модель:
р=2, £y=/4=j31x1+j32x2, (xls х2)=0,
cov((r, у), (S, У))=0(Г, S) для любых Г и S.
Ji, У2,-’-,Уп независимы и одинаково распределены по нормально-
му закону.
Оценки метода наименьших квадратов:
bi=(*x,y) ||х1||-2, 62=(х2, у) || х21|-2.
73
При этом
bt =
Z?2 02
var(Z?i)
cov(Z>) =
cov(Z>ls b2)
var(Z>2)
0
11*2 ||-2
причем bi и b2 независимы и одинаково распределены. Теорема Гаус-
са—Маркова означает, что оценки метода наименьших квадратов Ь{ и
Ь2 имеют минимальные дисперсии в классе всех линейных несмещен-
ных оценок.
Подогнанные значения и отклонения. Вектор расчетных значений
в ортогональном случае представим в виде у = у(хн х2) = у(х1) + у(х2).
При этом
Е(Г, У) = (г, д) и Е(г,у—у)=0 для всех г,
cov((r, у), (S,y))=0((r,x1)|(x1 || -2(X,, s) + (r, х2) II х2||-2(X2, S)),
COV((r, У), (S, у — у)) = 0, cov((r, у —У) (S, у — y)) = cov((r, У), (S, у)) —
—cov((r,y), (s, у)).
Все фигурирующие здесь линейные комбинации векторов у и у—у
нормально распределены.
Дисперсионный анализ. Каждое слагаемое в разложении суммы
квадратов имеет нецентральное распределение %2, масштабированное
дисперсией ф:
Источник Сумма квадратов Степень свободы Параметр нецентральное™
СК, обусловленная х, СК, обусловленная х2 СК, обусловленная х,, х2 СК остаточная СК общая И у(х,) II2 И У(х2)В2 1 У(Х1, х2)р II у-у 1!2 ЙУII2 1 1 2 п—2 п 02вх,р/2ф 02 IJ х2 Ц 2/2ф Ы12/2</> 0 |д||2/2</>
74
Суммы квадратов первых двух строчек таблицы независимы между
собой и независимы от остаточной суммы квадратов. Несмещенная
оценка ф равна: ф = | у — у 12/(п—2).
Пример 12.2.1. Две ортогональные объясняющие переменные. Вер-
немся к численному примеру из раздела 12.1.4.
Данные: л=10, матрица скалярных произведений
(ХпхО (Х!,Хг) U1, J) 10 0 24
(х2, х2) (х2, J) — 20 15
(У, У) 94
первое наблюдение: (ylt xtl, х12) = (2,1; 1; 2).
Модель: Ey=0lxl ±02х2, var(.yr) = 0.
Требуется найти доверительный интервал для 0]—02, оценку для ф,
провести дисперсионный анализ для проверки гипотезы 02=0, постро-
ить доверительный интервал для отклонения, соответствующего пер-
вому наблюдению.
Доверительный интервал для —02. Обратимся к Ь{—Ь2 и при
этом заметим, что var(Z?i—Z?2)= var(Z?,)—2cov(bb b2)+ var(b2).
Имеем:
Z?, =24/10=2,4, Ь2 = 15/20=0,75, b,—b2 = 2,4—0,75= 1,65,
var(Z>!—Z>2) = ф(10‘+ 2(0)+ 20')”0,l 5ф.
Поэтому доверительным интервалом будет 1,65 ± 1,96-(0,15ф)1/2. На-
пример, если Ф = 3, то этот интервал будет равен (0,34, 2, 96)*.
Оценка ф. По приведенной выше формуле
0 = || у—у ||2/(и—2) = 2,515/8 = 3,14.
Модифицированный доверительный интервал равен: 1,65 ±
±2,31 Vo, 15-3,14 =(0,07, 3, 21), где 2,31 — пороговое значение /-ста-
тистики распределения Стьюдента с 8 степенями свободы [см. прило-
жение 5]**.
* Предлагаемый доверительный интервал имеет 95%-ный коэффициент доверия,
т. е. вероятность накрытия этим интервалом истинного значения /?,—4г равна 0,95; зна-
чение 1,96 находится из таблицы нормального распределения. — Примеч. пер.
** Отличие от предыдущего доверительного интервала состоит в том, что здесь ф
оценивается (истинное значение ф неизвестно), поэтому необходимо обращаться к таб-
лицам Z-распределения. В первом же случае ф считалось известным, поэтому надо было
обращаться к таблице нормального распределения. — Примеч. пер.
75
Дисперсионный анализ для проверки гипотезы /32~0
Источник Степень свободы Сумма квадратов Оценка F-отношение
СК, обусловленная х. 1 57,6
СК, обусловленная хг 1 11,25 11,25 3,58
СК остаточная 8 25,15 ф = 3,14
СК общая 10 94
Поскольку при 5%-ном уровне значимости критическое значение F
(1, 8), равное 5,32, превосходит полученное 3,58, мы заключаем, что
гипотеза /32=О принимается. Это означает, что фактор х2 в нашей мо-
дели может быть опущен.
Отклонения. Расчетное значение у при х( = 1, хг=2 равно у =2,4+
+0,75-2 = 3,9. Поэтому первое отклонение равно: 2,1—3,9 =—1,8. Да-
лее находим
var (у—у t) = var (yt)—var (у t) =
= ф—ф (12/10+0+22/20)=0,7ф.
Если ф = 3, то интервал (—1,8 ± 1,96(0,7-3)|/2) = (—3,64, 1,04) включает
0, поэтому нет причин считать первое отклонение резко выделя-
ющимся.
12.2.5. НЕОРТОГОНАЛЬНЫЕ ОБЪЯСНЯЮЩИЕ ПЕРЕМЕННЫЕ
При переходе от ортогональных переменных к неортогональным
меняется несколько важных результатов. В частности, оценки метода
наименьших квадратов становятся коррелированными. Это означает,
что процедура построения доверительных интервалов для коэффици-
ентов должна быть изменена. Необходимы определенные модифика-
ции и в других случаях. Сумма квадратов || у |2 теперь может быть
представлена на основе X] и х2 не единственным образом, поэтому при
проверке гипотезы /32=О следует учитывать, включен ли в модель фак-
тор X]. Необходимые изменения проиллюстрируем на примере.
Данные: п =10, матрица скалярных произведений
(Х,,Х,) (Xi,X2) (Х1, у) 10 8 24
(х2, х2) (Х2, у) = 20 15
(У, У) 94
первое наблюдение: ^1=2,1; х( = 1; х2=2.
76
Модель: р = 2, Еу = 11=&1*1 + /32х2,
cov((r, у), (s, у))=ф(г, s),
У1, У2,---,Уп независимы и распределены по нормальному закону.
Необходимо построить доверительный интервал для 31—/32, найти
оценку для ф, проверить гипотезу об исключении фактора х2, найти
отклонение при /=1.
Оценки метода наименьших квадратов. Их получаем, решая систе-
му нормальных уравнений, т. е.
откуда
где е^х,—(х,, х2)|х2|-'х2, е2= ||х21 —(х2, хО||Xj Ц-'Xi — отклоне-
ния в регресии х, на х2 и соответственно х2 на хь
Вычисляем:
(у,е,)=(Х|, У)—(х,, х2)|х2|-'(х2, у)=24—8-15/20=18,0,
(у,е2)=(х2, у)—(х2, х,) | х, |-'(х,, у)=15—8-24/10=— 4,2,
Iв, | г= |х, 12-(х,, х2)21 х |-’= 10-82/20 = 6,8,
| в212= I х21 2-(х2, х,)2 IX, 1-2=20-82/10= 13,6.
Таким образом,
2,647
—0,309
Первые два момента оценок Ь} и Ъ2 равны:
77
Е
bi
var(bi) cov(Z?i,Z?!)
var(Z?2)
(xbXi) (Xi,x2)
(x2, x2)
—0,06
0,07
где r=(x,, x2) |i X] ||-11| x21|-1 = 8/10-20=0,566. Отсюда
var(Z?i—b2)=var(Z?,)—2cov(Z?ls Z?2) + var(Z?2)=
= 0(0,15+0,12 + 0,07)=0,340.
Доверительным 95°7о-ным интервалом для /3]—(32 будет 2,34 ±
±1,96 VO,34 0 =(0,36, 4, 32), при 0 = 3. В результате корреляции меж-
ду х, и х2 эффективность оценок уменьшилась (дисперсии увеличи-
лись). Например, если (х,, х2) изменяется от 0 до 8, то var(Z?i) изменя-
ется от 0,100 до 0,150.
Расчетные значения и отклонения. Теперь
y = y(Xi, х2) = Ь1х1 +Ь2х2(^у(х,) + у(х2)) =
= у(х1) + у(е2) = у(е1)+у(х2).
Моменты расчетных значений и отклонений есть:
E(r,y) = (r,g), Е(г,у—у) = 0,
cov((r, у), (s, у))=0((r, xj, (г, х2))
S)
cov((r,y), (s, у-у))=0,
cov((r, у—у), (S, У—y)) = cov((r, у), (S, У))—cov((r, У), (S, у))
для любых Г и S.
Таким образом, изменения коснулись лишь вторых моментов расчет-
ных значений.
78
При Xi = l, х2 = 2 у i =2,647—2,309=2,029,
var(yi)=0(l, 2)
10
8
8
20
=0,67 ф
и
var(yi—У1) = Ф—0,670=0,330.
Если 0 = 3, то значение Ji очень близко к >>1=2,1.
Дисперсионный анализ. Все слагаемые в разложении суммы ква-
дратов с точностью до множителя 0 имеют нецентральное распреде-
ление %2:
Источник Сумма квадратов Степень свободы Параметр нецентральности
СК, обусловленная х{ 1 У(х.) ||2 1 (11дР— |32е2р)/2ф
СК, обусловленная х2
с поправкой на х. Я у(в2)к2 1 02|е2Р/2Ф
СК, обусловленная х, и х2 |У(Хн х2)Р 2 1дР/2ф
СК остаточная | у—у(х,, Х2)Р п—2 0
СК общая |у I2 п |дР/20
Слагаемые общей суммы квадратов независимы друг от друга, а так-
же от остаточной суммы квадратов. Несмещенной оценкой 0 является
0=11у-у112/(«-2).
Критерий для проверки предположения, что х2 может быть исклю-
чен из модели, — это критерий для проверки гипотезы 02=О. С этой
целью построим таблицу, следуя рассуждениям из раздела 12.1.5:
Источник Степень свободы Сумма квадратов Опенка F-отношение
СК, обусловленная одним х. 1 57,60
СК, обусловленная х2
с поправкой на х. 1 1,3 1,3 0,296
СК остаточная 8 35,10 ф=4,38
СК общая 10 94
Поскольку F-отношение меньше 1, гипотеза 02=0 принимается (х2
можно исключить из модели).
79
12.3. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
И ФУНКЦИЯ ПРАВДОПОДОБИЯ
12.3.1. ВЗВЕШЕННЫЙ МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
Допустим, что. исходное распределение yt является нормальным с
дисперсией $/wt (а не ф, как в обычном случае, веса известны). Что-
бы учесть разницу в информации, которую несет каждое наблюдение,
для нахождения оценки необходимо минимизировать взвешенную сум-
му квадратов отклонений. Взвешенный метод наименьших квадратов,
как показано ниже, будет использован при аппроксимации п.р.в. экспо-
ненциального распределения.
Обобщения, связанные с применением взвешенного метода на-
именьших квадратов, тривиальны. Определим скалярное произведение
по формуле
(X, y)w = WlXiyi + W2X2y2+ ... + ™пхпУп>
где для всех /=1,...,л. Рассмотрим теперь задачу минимизации
|У—Alw=(y—А» У—A)w’ гдед=0х или + /32х2.
Все алгебраические результаты из раздела 12.1 при этом сохраняют
свою силу с заменой скалярного произведения (.,.) на (.,.)w.
В частности, для р=1 нормальное уравнение будет иметь вид
(У—У. x)w=°,
откуда Ь=(х, y)w/|| х || w- Разложение суммы квадратов принимает
вид
II у U= II у II V II у-у U-
Пример. Данные:
У
—32148
х
—2—10 1 2
W 112 2 0
Как видим, наблюдения 3 и 4 имеют удвоенный вес по сравнению с
1 и 2, тогда как наблюдения 5 вообще следует исключить из анализа.
Матрица скалярных произведений будет следующей:
80
(x,x)w (x,y)w
7 12
(y,y)w
47
откуда b= 12/7= 1,7.
Очевидным образом на случай взвешивания обобщаются все
остальные результаты из раздела 12.1. Аналогично находится и оцен-
ка взвешенного метода наименьших квадратов двух или большего чис-
ла объясняющих переменных, при этом обычное скалярное произве-
дение необходимо заменить на взвешенное.
Точно так же обобщаются на случай взвешенного метода наимень-
ших квадратов выборочные свойства оценок, если условия относи-
тельно вторых моментов заменить на
cov((r, y)w, (s, y)w) = </>(r,s)w.
Для того чтобы убедиться в том, что это условие эквивалентно усло-
вию чаху{ = ф/ wt, достаточно положить r=s = (l, 0,...,0); тогда
COV(W!^1, W1JI) = w;var(ji) = 0
Последнее условие гарантирует, что оценка взвешенного метода
наименьших квадратов является несмещенной и имеет минимальную
дисперсию в классе всех линейных несмещенных оценок. Все выбороч-
ные свойства также остаются верными, если ylt у2,-..,Уп независимы
и нормально распределены с дисперсией wr>0 для любого t. Если
для некоторого t имеем wz=0, то происходит потеря одной степени
свободы, а все остальные результаты сохраняются.
Следует, однако, заметить, что для большинства распределений,
принадлежащих экспоненциальному семейству, дисперсия wt является
функцией среднего /х,, т. е. w = w(ji), что, разумеется, приводит к
определенным трудностям.
Пример. Пусть Еу = ц=(3х=уат(у). Положим = т. е. мы до-
пускаем некоторую вольность в обозначении w(/4) = 0-'x~'. Тогда*
iy-/*Uw=riy-MU-’ = riy.U-. + /3||x|J-.-2(y,x)x-..
Это выражение достигает минимума при
ь= (IУII х-./1X |
* Необходимо предположить, что xt>Q. — Примеч. пер.
£1
и оно уже нелинейно по у. Для р> 1 не существует аналитического ре-
шения соответствующей оптимизационной задачи. К счастью, имеется
итеративный алгоритм решения подобных задач, который будет рас-
смотрен ниже.
12.3.2. АППРОКСИМАЦИЯ ФУНКЦИИ ПРАВДОПОДОБИЯ
ОБОБЩЕННЫХ ЛИНЕЙНЫХ МОДЕЛЕЙ
В этом и в следующих разделах излагаются основы применения
итеративно-взвешенного метода наименьших квадратов для максими-
зации функции правдоподобия обобщенной линейной модели.
Напомним сначала вывод системы нормальных уравнений для
взвешенного метода наименьших квадратов. Обозначим через
М=’span(Xi, х2,...,х„) линейное подпространство, натянутое на век-
торы Xi, Х2,...,Хд. Пусть deAf и дбЛ/, тогда д+ScteAf для любого ве-
щественного 5. Далее можно записать следующее тождество:
||у—(д+М)Ц-1у-д 1Й = 5(У-Д, d)w + ^||dU.
Вектор д будет вектором расчетных значений для взвешенного метода
наименьших квадратов, если левая часть окажется неотрицательной
при jjL — p,. Правая часть неотрицательна для любого 6 тогда и только
тогда, когда коэффициент при 6 равен нулю. Отсюда система нор-
мальных уравнений взвешенного метода наименьших квадратов имеет
вид (у—д, d)w=0 для любого deAf, т. е. (у—д, xz)=0 для z = l,2,...,p.
Основная идея заключается в аппроксимации логарифма функции
правдоподобия обобщенной линейной модели выражением, аналогич-
ным правой части предыдущего соотношения.
Как следует из раздела 11.2.1, каждое наблюдение у имеет п.р.в. f
и математическое ожидание д Линейный предиктор т/ связан с ц функ-
циональной зависимостью у(ц) = г]. Логарифм функции правдоподобия
имеет вид Х(ту)= log(y |т/, ф), производная которой по г) есть
d\ — У—Д dh р d2X _ 1 / dji \2
dr) ~ var(y) drj ’ 21 dr]2 ~ var(y) \ dr) J •
Вместо аргумента г) в целях устранения нелинейности перейдем к ц.
Для этого введем переменную
Z=v + (y—fl)
dr)
du
Очевидно, что
Ez=r), var(z)= var(y)f Y
dfi'
82
Заменяя у—д, приходим к
d\ _ z—17 г d2X _ 1
dr] ~ var(z) ’ L dr]2 var(z) '
Разложение логарифма функции плотности в ряд Тейлора до чле-
нов второго порядка тогда будет иметь вид
X(rj+ bd)=*X(r]) + dd <ar$ — Т var(z) •
(На самом деле коэффициент при 62 должен быть равен d2X/dr]2, а не
Ed2\/dr]2, но это различие не существенно.)
Поскольку наблюдения в выборке независимы, логарифм функции
плотности по всей выборке будет равен сумме индивидуальных
значений:
X(^=EX(r]t).
Таким образом, на основе разложения в ряд Тейлора можно записать:
X(,+«d)-X(4) = a(z-ч, d)w—4-«4dli,
где веса в скалярном произведении берутся равными
w, = l/var(zf).
12.3.3. ПРИМЕР: МОДЕЛЬ НЕЗАВИСИМОСТИ
Допустим, в таблице сопряженности 2x2, классифицированной по
двум факторам А и В, наблюдение у^, соответствующее клетке таб-
лицы (/, J), имеет распределение Пуассона с математическим ожи-
данием
^EyirnPij = npi+p+j
[см. раздел 11.4.1]. Линейный предиктор 17,у = logEy,- в векторном ви-
де может быть записан как
= (log д) 1 + Е (logp +) а; + Е (logp ) Ь.,
I I J J
т. е. А+В= span(3],...,а7, bi,...,b7). Логарифм функции правдопо-
добия одного наблюдения равен:
83
х (л) = — М+У log Д—log у!
Его произведение по rj имеет вид
d\ . . d2\
~^Г = ~е+У> ~сф =
Подставив z=i}+{y—ii)di]/dfi=i)+yeri—1 вместо у, получим
Х(т/ + 6б7)—Х(т7) = dd(z—т1)е^—-y(6d)2e,>.
Тогда для совместной функции правдоподобия
х(ч+6d >—х (Ч> = a(d, z-,)w—is | d | *,
где wt = e^‘.
В этом примере вторая производная не зависит от у. Уравнения
правдоподобия для этого примера могут быть решены точно:
(d,z—jy)w=(d,у—д)=Еб70(у0—д0), й€А+В.
Положим d^S/M+B. Приравнивая полученное выражение к нулю,
получим
откуда nl+=yi+, аналогично n+j=y+£. Поскольку = д+у/д++,
оценками максимального правдоподобия будут Hjj=yi+y+j/y++.
12.3.4. ПРИМЕР С ЭКСПОНЕНЦИАЛЬНЫМ РАСПРЕДЕЛЕНИЕМ
Допустим, что наблюдения имеют экспоненциальное распределе-
ние, т. е. п.р.в. имеет вид
/(^|д)=ехр(—у/ц—logM), ^>0.
При этом Еу=ц, уагу=д2. Допустим, функция связи равна logji=??,
т. е. ц=е^, dn/dij = e1t, а линейный предиктор имеет вид т? = /2х. Лога-
рифм п.р.в. тогда равен:
• Здесь плюс означает, что по замещенному индексу произведено усреднение. — При-
меч. пер.
84
Х(т))=—ye
а производные равны:
dX
Нт/
d2X „ i
w = ~ye 1 Е\~^} = -1-
Положим
z=n+(y—-fy- =т?+(7в-”—1).
Тогда
= ye~ 1>— 1
dX . , d2X . , .
= (Z-ч), = -l-(z-4).
Разложение в ряд Тейлора по d=x приводит к
X(4+Sx)-X(4)=6x(z->I)-y(«^)!(1+z->>).
Суммированием по 7=1,2,..., л приходим к
Х(|;+5х)—X(q)= 6(Х, Z—ц)—~р52(Х, X)—~^-б2(Х2, Z—4),
где скалярное произведение имеет постоянные веса.
Нормальное уравнение имеет вид (x,z—^)=0 или в координатной
форме
Е xt (z — ^xt (yt e~t3x<— 1)=0.
Относительно 0 это уравнение не может быть решено аналитически,
в следующем разделе приводится итеративная процедура решения.
Допустим, при неограниченном увеличении объема выборки нео-
граниченно увеличивается (х,х). Тогда
(х2, z-4)/(x, х)=Ex,2(z,-4()/Ex,2 — 0
по закону больших чисел. Отсюда следует, что соответствующий член
в разложении Тейлора может быть опущен.
85
12.3.5. ИТЕРАТИВНАЯ ПРОЦЕДУРА
Аппроксимация логарифма функции правдоподобия выборки экспо-
ненциального семейства, как было установлено ранее, имеет вид
X(,+6d)-X(,) = 6(z-4, d)w—j- 62|d С-
Для стационарной точки
(Z—г], d)w = 0 при 1) = т/ для всех dcAf.
Поскольку коэффициент при 52 отрицателен, эта стационарная точка
будет точкой максимума. Поскольку этот коэффициент всегда отрица-
телен, все стационарные точки являются точками максимума. Однако
для гладкой функции точки максимума должны перемежаться точками
минимума. Поэтому в данном случае максимум единствен. Приведен-
ные аргументы, однако, достаточно уязвимы, поскольку в рассужде-
ниях игнорируются члены разложения в ряд Тейлора, начиная со
второй производной d2\/d^2. В этой связи свойства единственности и
существования можно рассматривать лишь как правдоподобное.
Алгоритм нахождения оценок максимального правдоподобия обоб-
щенных линейных моделей является итеративным. Обозначим далее
z(tj) через Z, тогда итеративная процедура будет иметь следующий
вид:
1) выберем т?0;
2) вычислим z(tjo) и w(i?o);
3) решим систему (z(i?0)—-i?i, d)w(4o) = O, где d=Xi, х2,...,хр, отно-
сительно тц;
4) положим = и если сходимость не достигнута*, вернемся к
шагу 2.
Заметим, что в пункте 3 представлена система нормальных уравне-
ний взвешенного метода наименьших квадратов. Так, при р=2 для ре-
шения упомянутой системы необходимо сначала решить систему
относительно Ьх и Ь2:
(XbXi)w (XbX2)w bx (X.,z)w
(X2,X2)W _ _ь2 _ _ (x2,z)w
где w=w(7jo) и z=z(i?0), а затем положить + 62х2.
* Достижимость сходимости можно проверить, например, с помощью неравенства
Hi—Чо| гДе £ — достаточно малое положительное число (допуск). — Примеч. пер.
86
Каждая итерация алгоритма требует обращения матрицы рхр,
вычисления векторов z и W и матрицы скалярных произведений
(X;, Xy)w. Описанный метод называется итеративно-взвешенным ме-
тодом наименьших квадратов*.
12.3.6. АСИМПТОТИЧЕСКАЯ ТЕОРИЯ
Выборочные свойства оценок линейных моделей в условиях нор-
мального распределения были установлены в разделе 12.2. К сожале-
нию, для обобщенных линейных моделей, т. е. в условиях
распределения отклонений, отличного от нормального, подобной тео-
рии для конечных объемов выборок не существует. Здесь в лучшем
случае, при больших объемах выборок, можно воспользоваться лишь
приближениями, основанными на ассимптотической теории оценок
максимального правдоподобия [см. раздел 6.2.5,а)].
Напомним, что логарифм функции правдоподобия линейной моде-
ли с произвольным распределением отклонений может быть прибли-
женно записан как
d)„—|-«4d, d)„,
где d€span(Af), причем
и
w= w(t/)= l/var(z)
зависят от неизвестного параметра у. Нетрудно показать, что для ли-
нейной модели с нормально распределенными отклонениями и разны-
ми дисперсиями (взвешенный метод наименьших квадратов)
приближенное равенство превращается в точное. Для этой модели z—
—7j = y—д и поэтому (Z—Т), d)w = (y—д, d)w. Поскольку по условию
вектор у нормально распределен, последняя величина также нормаль-
но распределена. Это замечание позволяет получить для данной моде-
ли точные распределения оценок.
В общем случае величина (z—ij, d)w = E/(z/—iqt)dtwt при условии,
что zt независимо распределены, будет иметь асимптотически-
нормальное распределение, что следует из хорошо известной цент-
ральной предельной теоремы. Отсюда можно получить асимптотиче-
ское выборочное распределение для оценки /3 параметра & и других
необходимых статистик. Они будут такими же, как и для взвешенной
нормальной модели.
* В книге П. Хьюбера «Робастность в статистике» (М.: Мир, 1984) приводятся усло-
вия сходимости этого алгоритма. — Примеч. пер.
87
Вернемся к разделу 12.3.4, где рассматривался пример с экспонен-
циальным распределением. Для этого случая р=1, ri = (3x, причем /3
находится из уравнения
Ездехр(—^xt) = Lx(.
Значение /3 может быть найдено, например, итеративно-взвешенным
методом наименьших квадратов по формуле
3=(Х, Х)-‘(Х, Z),
где z=z(tj) = 17 +уе~~^—1.. Асимптотическое распределение оценки 3 со-
впадает с распределением случайной величины (х, х)'(х, z0), где ко-
ординаты вектора z0 независимы и одинаково распределены.
Асимптотическая теория выборочных распределений оценок обес-
печивает достаточно хорошие результаты в большинстве практиче-
ских ситуаций. Однако поскольку эти результаты не являются
точными, некоторые важные задачи остаются нерешенными, напри-
мер, задачи адекватного анализа отклонений в произвольной обоб-
щенной линейной модели.
12.4. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Для более детального изучения типа моделей, обсуждаемых в гл.
11 и 12, в частности, модели доза — эффект [см. раздел 11.1.3], сове-
туем книгу [Finney (1971)]. Прекрасный обзор по линейным моделям
читатель найдет в работах [Fraser (1979); Graybill (1976) — С]. Иссле-
дованию специальных проблем, связанных с таблицами сопряженнос-
ти, посвящена работа: Bishop Y., Fienberg S., Holland P.
(1975). Discrete Multivariate Analysis, MIT Press.
Finney D. J. (1971). Probit Analysis. Third edn., Cambridge University Press.
Fraser D. A. S. (1979). Inference and Linear Models, McGraw-Hill.
Глава 13
ПОСЛЕДОВАТЕЛЬНЫЙ АНАЛИЗ
ВВЕДЕНИЕ
Рассмотрим схему выборочного контроля [см. пример 1.2.1 и раз-
дел 5.12.1] в случае, когда изделия (например, электрические лампоч-
ки) упакованы в партии по 100 штук и вся партия бракуется, если в
партии найдется по меньшей мере пять неисправных, и принимается,
если число неисправных элементов не превышает четырех.
В схеме выборки заданного объема проверяются все 100 элементов,
и партия бракуется, если в конце проверки обнаруживается пять или
более неисправных изделий. В последовательной выборочной схеме,
наоборот, изделия проверяются одно за другим, и проверка прекраща-
ется, когда обнаружено либо 5 неисправных, либо 96 исправных. Яс-
но, что последовательная выборочная схема более эффективна, чем
схема выборки заданного объема, поскольку, возможно, не потребует-
ся проверять все 100 изделий.
Если в партии, состоящей из 100 изделий, содержится 12 неисправ-
ных, то объем выборки при последовательной выборочной схеме бу-
дет целым числом от 5 (если все первые пять изделий — неисправны)
до 93 (если все оставшиеся 7 изделий неисправны). Объем выборки за-
висит от порядка, в котором проверяются изделия, и является случай-
ной величиной. В данной ситуации получается безусловная экономия в
числе изделий, которые нужно проверить, чтобы принять окончатель-
ное решение относительно всей партии.
Чтобы продемонстрировать другое свойство последовательной вы-
борочной схемы, рассмотрим эксперимент по определению прочности
стеклянных труб.
Металлические шарики фиксированного размера и веса бросают с
различной высоты на стеклянную трубу до тех пор, пока труба не раз-
рушится, и записывают, на какой высоте произошло разрушение. Та-
кой эксперимент целесообразно проводить по последовательной схеме,
а не по плану, при котором производятся полные серии испытаний на
произвольно выбранной высоте (схема выборки фиксированного объ-
ема), поскольку разумно проводить пробы одну за другой. Если при
падении с определенной высоты разрушения не произошло, то шарик
бросают с большей высоты и т. д. до тех пор, пока труба не разру-
шится. При таком плане эксперимента результат предыдущего испы-
тания определяет уровень, на котором проводится следующее.
89
Процедуры последовательной выборки, в которых, как в первом
примере, задается только правило остановки, обычно называются по-
следовательным анализом. Процедуры, в которых задаются как пра-
вило остановки, так и правило выбора следующего элемента (второй
пример), называются последовательным планированием эксперимен-
та. Эта глава посвящена последовательному анализу.
Очевидные преимущества последовательной выборочной схемы
перед эквивалентной схемой выборки фиксированного объема не озна-
чают, что последовательную схему нужно использовать во всех случа-
ях. Последовательная выборочная схема более эффективна, когда
наблюдения естественно проводить по очереди, одно за другим, как,
например, на фабричном конвейере. Она менее эффективна по сравне-
нию со схемой выборки конечного объема, если для получения резуль-
татов каждого отдельного опыта требуется длительное время,
например в сельскохозяйственных исследованиях.
13.1. ПОСЛЕДОВАТЕЛЬНАЯ ПРОВЕРКА ГИПОТЕЗ
В предыдущих главах выводы относительно неизвестных парамет-
ров генеральной совокупности или распределения вероятностей, опи-
сывающего эту генеральную совокупность, основывались на
случайной выборке фиксированного объема. Предположим, что после-
довательная выборка извлекается из генеральной совокупности, при-
чем в каждый момент времени производится не более одного
наблюдения и после получения результата наблюдения принимается
решение — либо прекратить процесс выбора и использовать имеющу-
юся выборку и соответствующие ей значения статистик для получения
выводов относительно параметров, либо продолжить выбор и произ-
вести следующее наблюдение. При таком способе действий процедура
выбора прекращается, как только получена достаточная информация
относительно неизвестных параметров.
Как показано в разделе 5.12, основанный на выборках фиксирован-
ного объема критерий Неймана—Пирсона для проверки двух гипотез
Но и Hi определяется заданием множества значений выбранной стати-
стики, в котором гипотеза отвергается и принимается гипотеза Но.
Это множество называется критическим множеством критерия или
областью отклонения Но. Для отыскания критического множества
фиксируется максимальный уровень значимости а (т. е. величина
ошибки I рода) и выбирается критерий с наименьшим значением
ошибки II рода & (т. е. наибольшей мощностью 1—/3). Таким образом,
в критериях, основанных на выборках фиксированного объема, фикси-
руется уровень значимости а и объем выборки п, а 0 минимизируется.
При последовательных критериях проверки гипотез процесс выбо-
ра прекращается, когда выборка содержит достаточно информации,
чтобы принять или отклонить гипотезу Но. Если информации недо-
статочно, делается еще одно наблюдение. Таким образом, при последо-
90
вательной проверке гипотез текущие выборочные значения могут по-
пасть в одну из трех областей: область принятия и область отклоне-
ния, как и в случае выборки фиксированного объема, а кроме того, и
в область продолжения, когда необходимо продолжать наблюдения.
При определении этих трех областей фиксируется значение а и значе-
ние /3 (т. е. максимальной желаемой ошибки II рода), а объем выбор-
ки п является случайной величиной.
13.1.1. ОПЕРАТИВНАЯ ХАРАКТЕРИСТИКА
Предположим, что наблюдения х2>... извлечены из генеральной
совокупности, соответствующей распределению вероятностей с неиз-
вестным параметром 0, и что заданы три вышеописанные области.
Тем самым определен последовательный критерий. Исчерпывающей
характеристикой критерия, основанного на выборке фиксированного
объема, является его функция мощности, которая задает вероятность
отклонения Но как функцию параметра в. Для последовательного кри-
терия используется оперативная характеристика (О.Х) Р(0\ которая
описывает вероятность принятия Но в зависимости от 0. (Функция
мощности [см. раздел 5.12.2] равна 1—Р(0)). Если и основная гипотеза
Но, и альтернативная Hi простые: Но‘.0 = 0о и Hx'.0 = 0i (0!>0О) [ср. с
разделом 5.2.1, в)], то
Р(0о) = (1-а) и P(0i)^(3.
13.1.2. ОЖИДАЕМЫЙ ОБЪЕМ ВЫБОРКИ
Поскольку при последовательной проверке гипотез объем выборки
является случайной величиной, интересно определить его математиче-
ское ожидание. Сравнение последовательных критериев с критериями,
основанными на выборках фиксированного объема, должно базиро-
ваться на ожидаемом объеме выборки, а не на наборе фактических
значений объемов выборок для какого-нибудь конкретного множества
наблюдений.
Ожидаемый объем выборки является функцией истинного значения
параметра. Например, если обе гипотезы простые, как и раньше, а ис-
тинное значение 0 близко к (0o + 0i)/2, то ожидаемый объем выборки
будет больше, чем в случае, когда |0—0J мало по сравнению с |0—0О|.
Ожидаемый объем выборки часто называют средним числом наблюде-
ний (Average Sample Number (ASN)).
13.1.3. ПРИМЕРЫ СХЕМ ВЫБОРОЧНОГО КОНТРОЛЯ
В двух следующих схемах выборочного контроля предполагается,
что доля 0 неисправных изделий в партии неизвестна и каждое изделие
в партии либо неисправно, либо исправно. Требуется принять или за-
браковать партию на основании последовательной выборки изделий.
91
Считается, что па^ггия состоит из большого числа изделий п и что на-
блюдения независимы.
Пример 13.1.1. Простая последовательная выборка (Вальд). За-
фиксируем целое число nQ, такое, что если первые л0 изделий исправ-
ны, выбор прекращается и партия принимается. Если для некоторого
объема выборки т-е изделие неисправно, то партия бракуется.
И пусть гипотезы — Но: принять партию, Нх: забраковать партию.
Вычислим оперативную характеристику Р(9\ Вероятность принять
Но, если доля неисправных изделий равна 0, равна вероятности того,
что первые п0 изделий исправны. Отсюда Р(9)-(1—0)п°. Заметим, что
Р(0) = 1 (все изделия в партии исправны) и Р(1)=0 (все изделия неис-
правны). Функцию Р(6) можно изобразить при О<0<1. Она одновре-
менно является О X для схемы с фиксированным объемом выборки п0
[см. рис. 5.12.1].
В описанной последовательной схеме объем выборки N будет равен
п, где 1^л^и0—1, если последнее изделие неисправно, и равен п0
только в случае, когда все первые (п0—1) изделий исправны. Поэтому
ожидаемый объем выборки E(N\0) [см. раздел 1.4.2] задается ра-
венством л _]
E(N\0) = Е mP(N=m) + noP(N=no),
ff! = l
где
P(N=m)=(l—l^w^no—1,
P(7V=n0)=(l—Я)"0-1-
Величину E(7V|0) также можно изобразить как функцию 0 при О<0< 1.
Подробное рассмотрение этого примера можно найти в работе
[Wald (I960)].
Пример 13.1.2. Последовательный выбор с ограниченным объе-
мом выборки. Рассмотрим модификацию предыдущего примера.
Пусть максимальный объем выборки равен и выбор прекращается,
а партия бракуется, если среди первых пх изделий будет обнаружено
с<>1) или более неисправных, причем Л] и с фиксированы. Партия
принимается, если среди первых пх изделий не менее пх—с+1 ис-
правных.
О X этой схемы равна вероятности того, что найдется (с—1) или
менее неисправных изделий среди первых пх, если доля неисправных
изделий равна 0:
Р(0)= Eof?)041—0)л'-г.
И опять Р(0)=1, Р(1)=0 и Р(0) можно изобразить как функцию от 0 на
интервале 0^0^ 1. Следует отметить, что эта ОХ совпадает с ОХ
критерия, основанного на выборке фиксированного объема пх.
Чтобы вычислить ожидаемый объем выборки, все партии следует
разбить на принимаемые и бракуемые. Для бракуемых партий вероят-
ность прекратить испытания при N=m равна вероятности того, что
92
с-е неисправное изделие совпадает с т-м обследованным:
P,(N=m) = (mc“'i>(l- »Г~С,
m = c,
Для принимаемых партий положим 5=frii—с+1). Тогда вероятность
решения «принять» при N=m равна вероятности того, что 5-е исправ-
ное изделие совпадает с т-м обследованным*:
Pa(N^m)=(mc-\)(l-0y№"-s, m=s, s+1.и,.
Тогда я» т
E(N\e)= £tmP/N=m)+ ZmP„(N=m).
Подробности анализа этой схемы можно найти в работе [Wetherill
(1966)].
13.2. ПОСЛЕДОВАТЕЛЬНЫЙ КРИТЕРИЙ ОТНОШЕНИЯ
ВЕРОЯТНОСТЕЙ (ПКОВ)
Рассмотрим последовательную случайную выборку хь х2,... из рас-
пределения вероятностей, зависящего от одного неизвестного пара-
метра в. Наблюдения будем считать независимыми. Пусть значение
функции плотности вероятности в точке х равно f(x; &). Требуется про-
верить простую гипотезу Н0:9=90 против простой альтернативы
Н}:в-0} [см. раздел 5.2.1 в) и г)]. Наилучший (наиболее мощный) кри-
терий, основанный на выборке заданного объема п, с уровнем значи-
мости а, как следует из леммы Неймана—Пирсона [см. раздел 5.12.2],
основан на отношении правдоподобия
X = П
п ™ f(xM ‘
Гипотеза Но отвергается, если Хп>к, где значение константы к под-
бирается так, что вероятность ошибки I рода равна: Р(\п>к\0о)-а.
В последовательном критерии отношения вероятностей (ПКОВ),
введенном Вальдом [см. Wald (1947)] для проверки двух гипотез, так-
же используется отношение правдоподобия. Фиксируются значения ве-
роятности ошибки I рода а и вероятности ошибки II рода /3- Отсюда
находят две такие константы А и В, что после т наблюдений дальней-
шие действия определяются правилами:
1) если \п^В, то прекратить испытания и принять Но-,
2) если Хт^А, то прекратить испытания и принять Hf,
3) если В<\т<А, то продолжить испытания.
* г (rejected) означает отклоняемый, бракуемый, a (accepted) — принимаемый. —
Примеч. пер.
93
13.2.1. ПРИБЛИЖЕННЫЕ ЗНАЧЕНИЯ ДЛЯ ГРАНИЦ ОСТАНОВКИ
Предположим, что гипотеза Но отклоняется именно при т-м на-
блюдении, т. е. что
В<\<А, i= —1,
и
Хте>Л.
Последнее неравенство эквивалентно
Uffx^A-
Обозначим через Rm множество всех выборок (хь Х2,...,хт), для кото-
рых Тогда, в предположении существования плотности веро-
ятностей,
= И „ №1, Х2..Хт; 90)dxldx1...dxm.=
= И f fi/fx,.; e0)dxxdx2...dxm^
т i '~т
СИ н- bi П.Ж’ e,)dx.dx2...dxm.=
= ^ЛХ„>Л|#1)= 1(1-0),
откуда
А ^(1-0)/а.
Аналогично
В >0/(1—а).
(Для дискретных распределений кратный интеграл нужно заменить на
суммирование по всем выборкам, которые приводят к отклонению ги-
потезы Но).
Для вывода этих соотношений нужно предположить, что последо-
вательная процедура в отдельных случаях заканчивается*. Доказатель-
ство того, что ПКОВ заканчивается с вероятностью 1, можно найти
в работе [Wald (1947) с. 157—158, русский перевод: с. 202—203].
Таким образом, мы получили оценки сверху для А и снизу для В,
выраженные через заданные значения а и (3. На практике ПКОВ с
фиксированными а и (3 определяется правилами:
1) если Хт^/3/(1—а), то закончить выбор и принять Но (отклонить
Н,);
2) если XW>(1—/3)/а, то закончить выбор и принять Н\ (отклонить
Но);
3) если 0/(1—а)<Хт<(1—0)/а, то продолжить выбор.
Такая замена постоянных А и В приведет к новым значениям оши-
бок I и II рода. Обозначим их а'и /3' соответственно. Повторяя пре-
дыдущие рассуждения для А = (1—(3)/а и 2?=0/(1—а), получим
Д=(1—0)/аС(1—0')/а'
* Т. е. множество Rm непусто. — Примеч. пер.
94
и
В=(3/(1—а)^(37(1—а).
Отсюда
а^а(1—/3')/(1—/3)^а/(1—/3)
и аналогично
/3^/3(1-а')/(1—а)^(3/(1—а).
Поскольку а и /3 обычно малы, то отличиями а' и (3' от а и (3, вы-
званными изменением границ, можно пренебречь. Поэтому
Можно показать, что
(а' + 3')С(а+3),
причем по крайней мере одно из неравенства а3%3 выполнено.
13.2.2. ПРИМЕРЫ
Пример 13.2.1. Биномиальный ПКОВ. Пусть наблюдения xXi х2,...
извлечены из точечного распределения Бернулли [см. II, раздел 5.2.1]
с неизвестным значением параметра в и
/(1;0) = 0, ДО;0)=1-0.
Будем называть событие х-1 успехом, а х=0 — неудачей. Предпо-
ложим, что необходимо проверить гипотезу НО:0 = 0О против Нх'.в-6х
(0i>0o) с заданными вероятностями а и 3 ошибок I и II рода соответ-
ственно.
После m наблюдений отношение правдоподобия равно:
х =
m ^\-eor-r>
где г- Ё х, — число успехов в тп испытаниях. Для упрощения перей-
дем к логарифмам:
logX,„=rlog[01(l—(9o)/<9o(l—^i)]-b/wlog[(l—00/(1—6»о)].
Определим процедуру ПКОВ:
1) если logXOT^log[3/(l— а)], принять
2) если logXw^log[(l—3)/а], принять Нх\
3) если log[3/(l—а)] <logXOT<log[(l—3)/а], то продолжить ис-
пытания.
Каждый раз, когда получено новое наблюдение, вычисляется новое
значение logXw. В случае успеха значение logXOT возрастает на величину
log(0,/0o) (которая больше нуля, так как вх >0О), а при неудаче изменя-
ется на величину log[(l—0/(1—0О)] (которая меньше нуля, так как
0]>0О). Отметим еще, что при а,3<0,5 границы log[3/(l—а)]<0 и
log[(l-3)/a]>0.
95
Рис. 13.2.1. ПКОВ для параметра в распределения Бернулли с ^0=4“, 0i=^-,
а = 0=0,05
Вместо использования logXOT как основы критерия можно восполь-
зоваться величиной г=Ехт — числом успехов в т испытаниях — и
изобразить соответствующие области графически. Для иллюстрации
положим Но:0=^- и и пусть а-0=0,05. Тогда
logXOT = rlog3 + mlog(2/3),
log[0/(l— «)]=—-logl9,
log[(l—0)/a] = Iogl9.
В этом случае процедура продолжается, если
—Iogl9/log3 + zn[log(3/2)/log3] < rm - Е х, <
< Iogl9/log3 + m [log(3/2)/log3] ‘
и прекращается с принятием одной из гипотез, когда это условие не
выполнено. Если нарисовать число успехов г в т испытаниях как
функцию от числа испытаний для т- 0,1,2,..., то границы остановки
будут представлять собой параллельные прямые вида r=a+bm с на-
клоном Z?=log(3/2)/log3 и свободными членами ±а, где a=logl9/log3.
Заметим, что в данном случае свободные члены в обоих уравнениях
равны по абсолютной величине, поскольку равны значения а и 0. Это
дает возможность графически изобразить последовательную выбороч-
ную схему еще до проведения испытаний [рис. 13.2.1]. Начиная из на-
чала координат (щ=0, г=0), каждую последовательную выборку
можно изобразить на этом графике выборочной траекторией. Как
только выборочная траектория достигает или пересекает одну из гра-
ниц, дальнейшие испытания прекращаются и принимается соответ-
96
ствующее решение. Например, последовательность испытаний 1,0, 1,
1, 0 изображается выборочной траекторией (0, 0), (1, 1), (2, 1), (3, 2),
(4, 3), (5, 3), как это показано на рис. 13.2.1. Последовательную выбо-
рочную схему в этом случае можно представить и в табличной форме
[табл. 13.2.1], где указано минимальное и максимальное число успехов
в т испытаниях, при котором гипотеза Но отвергается или прини-
мается.
По существу, в последовательной схеме следует сначала взять
фиксированное число наблюдений (в данном случае 5), а затем исполь-
зовать точки остановки, указанные в таблице. Поскольку число успе-
хов всегда целое, выборочная траектория в большинстве случаев в мо-
мент прекращения испытаний выходит за границы остановки.
Например, точные пределы для остановки при zn = 16 равны: г-3,7758
и г=9,1682.
Таблица 13.2.1. Точки остановки для ПКОВ при проверке гипотезы Яо:0=^~
против , а=/3=0,05 для объемов выборок т = 5(1)20
Число наблюдений т Принять Но, если число успехов 7^ г Отклонить Яо, если число успехов 7>г
5 5
6 — 6
7 0 6
8 0 6
9 0 7
10 1 7
11 1 8
12 2 8
13 2 8
14 2 9
15 3 9
16 3 10
17 4 10
18 4 10
19 4 11
20 5 11
В отличие от ранее рассмотренных схем выборочного контроля здесь
не существует максимального объема выборки. Границы остановки,
порождаемые ПКОВ, являются открытыми. Кажется, что существует
возможность того, что для некоторых выборочных траекторий реше-
ние прекратить наблюдения никогда не будет принято. Однако, как
уже упоминалось, в книге [Wald (1947), с. 157—158, русский перевод:
с. 202—203] приведено доказательство того, что последовательная
процедура с вероятностью 1 обрывается. Можно ожидать, что число
наблюдений до момента остановки при в около 3/8 будет больше, чем
при 0<-%- ИЛИ 0>2".
97
Другой способ графического представления ПКОВ состоит в изо-
бражении выборочной траектории в координатах log = XOT и т, причем
logX,„ возрастает на log(0i/0o) = log2 при каждом успехе и уменьшается
на log[(l—0i)/(l—0o)] = log2/3 при каждой неудаче. В этом представле-
нии границы остановки изображаются двумя прямыми, параллельны-
ми оси т, для которых logXOT = ±logl9.
Пример 13.2.2. Нормальный (гауссовский) ПКОВ. Пусть случайная
выборка хх, x2i... извлекается последовательно из нормальной гене-
ральной совокупности с неизвестным средним 0 и дисперсией 1. Пред-
положим, что мы хотим проверить гипотезу Н0:9-90 против Нх\в-вх
и пусть 0] >0О. После т наблюдений
logXw = (0,-00) Д Xi + ™ (0о—0^)
[см. пример 6.2.4] и продолжение наблюдений в ПКОВ производится,
если
log [£/( 1 -а)] < logXOT < log [(1 -3)/а].
В противном случае наблюдения прекращаются и принимается реше-
ние принять или отклонить гипотезу Но. После очередного наблюде-
ния xzlogXm возрастает на (0,—0о)х, + у(0о—0^)- Описание процедуры
можно упростить следующим образом: продолжить наблюдения, если
log[/3/(l— а)]/(01—0О) + т(0, + 0о)/2< £ Xi<
<log[(l-/W/(0i-0o) + M0i+0о)/2,
и прекратить наблюдения и принять соответствующую гипотезу в
противном случае. т
Если изобразить текущее значение суммы Ё х. в зависимости от
числа наблюдений т, то границы остановки, соответствующие ПКОВ,
окажутся парой параллельных прямых с наклоном (0]+0о)/2 и посто-
янными log[/3/(l—а)]/(01—0О) и log[(l—/3)/«]/(0,—0О). Например, при
0о = О, 01=1 и « = /3=0,05 наклон границ равен 1/2, а константы равны
±logl9. На рис. 13.2.2 изображены эти границы остановки и выбороч-
ная траектория, соответствующая выборке из 8 наблюдений из стан-
дартного нормального распределения. Эта трактория приводит к
принятию гипотезы Но.
Поскольку сумма наблюдений является непрерывной случайной ве-
личиной, выборочная траектория всегда пересекает границы останов-
ки. Вероятность того, что сумма наблюдений окажется точно на
границе, равна нулю.
13.3. ОПЕРАТИВНАЯ ХАРАКТЕРИСТИКА ПКОВ
Пусть задана последовательная случайная выборка хь х2,... значе-
ний случайной величины X с п.р.в. f(x;ff) и значение параметра 0 неиз-
вестно. Предположим, что надо проверить гипотезы Нх'.В=Вх
98
Рис. 13.2.2. ПКОВ для проверки гипотезы относительно среднего 0 нормально-
го распределения при 0о=О, 0t = l и а = /3=О,О5
на заданных уровнях а и /3. Как уже указывалось, это просто означа-
ет, что фиксированы значения OX Р(в\ а именно Р(0О)=1—а и
Вывод приближенного выражения ОХ для ПКОВ приведен в книге
[Wald (1947) с. 48—50, русский перевод: с. 75—79]. Он основан на сле-
дующих соображениях. Положим А(0О) = 1, A(0J =—1. Тогда для (абсо-
лютно) непрерывной случайной величины X математическое ожидание
функции
равно _
E{WXfit)/f(X;6„y\^\= j (13.3.1)
(Для дискретных случайных величин следует заменить интеграл сум-
мированием по всем возможным значениям х).
Из равенства (13.3.1) вытекает, что функция
• L/P60o)J
является функцией плотности вероятностей. При А(0)>О процедуру
ПКОВ для проверки гипотезы Н, что f(x;0) является истинной плот-
ностью распределения X, против гипотезы что истинной плотнос-
тью является /*<л;'0), можно описать следующим образом:
1) продолжить наблюдения, если после т наблюдений
2) прекратить наблюдения и принять Н, если
Хт^Вв
3) прекратить наблюдение и принять Н*, если
Если выбрать границы так, чтобы Ae=Ah<® и BQ-Bh{^, то выборка
99
Xi, x2,...,xm, которая приводит к принятию Н, будет приводить и к
принятию Но, поскольку
W/M)= [/Wi)/Wo)lA(<,).
ПКОВ, описываемый так, как показано выше, совпадает с исходным
ПКОВ, в котором все альтернативы «заключены» в степень Л(0). Для
модифицированного таким образом критерия вероятность ошибки I
рода равна вероятности отклонить Н, когда она верна, т. е. единице
минус вероятность принять, что истинная плотность распределения х
есть f(x;0), когда это действительно так, или (1—Р(0)\ поскольку Р(0)
равна вероятности принятия Ho:0=do[f(x;9) — истинная плотность. (За-
метим, что вертикальная черта перед условием «/(х;0) есть истинная
плотность» не означает условной вероятности, а имеет смысл союза
«когда» [см. раздел 1.4.2 п. 6]).
После простых алгебраических преобразований можно получить
ОХ исходного критерия:
/Х0)=(АЛ(&)— i)/(A^—Bhw).
Используя в этом выражении приближенные значения для границ А и
В, приведенные в разделе 13.2.1, получим приближенное выражение
для Р(0):
' а ' Ч—ст
Доказательство в случае Л(0) < 0 проводится точно так же. Для провер-
ки заметим, что поскольку Л(0О) = 1 и A(0i) =—1, то Р(0О)=1—а и
P(0i) = 3- Находя значения Л(0) для определенных значений 0, можно
получить график зависимости Р(0) от параметра 0.
13.4. ОЖИДАЕМЫЙ ОБЪЕМ ВЫБОРКИ ДЛЯ ПКОВ
Отношение правдоподобия \т является произведением сомножите-
лей вида /(x^^/f^x^o), значит, log\OT есть сумма членов вида
{^/(x^xy/ffx^Qoyi-Zj. Поэтому ПКОВ можно выразить в терминах
E zz, а именно продолжить выбор после т-го наблюдения, если
logB< Е Z/<logi4, и прекратить в противном случае.
Можно показать, что верно следующее тождество Вальда [см. на-
пример, Wetherill (1975), с. 19—21]: если случайная величина N обозна-
чает число наблюдений, необходимое для принятия или отклонения
гипотез, то
Е( Е 7 |0)=£^|0)£(2|0),
/=1 *
где £(7V|0) — ожидаемый объем выборки [см. раздел 1.4.2 п. 6] и
Z=log[/rX;01)//rX;0o)].
Вероятность того, что критерий приведет к принятию гипотезы
100
п
Но, равная Р( Е Z. ^logB), равна Р(9\ а вероятность отклонить Но,
п / = 1
равная Р( Е Z^logA), равна 1—Р(0\ Если пренебречь тем, что выбо-
'=1 п
рочная траектория (или Е Z.) пересекает границы остановки, то
/=1 1
п
Е( Е Z,|0)=/WogB+ [l-P(0)]logH
и
E(N\ 0) = ^)logB+[l-P(g)]log^
Для случая, когда £/Z|0) = O, Вальд предложил аппроксимацию
EfN|0) = m(logg>2+(l-PWl(loM>2
В этой формуле, как и раньше, можно заменить границы А и В их
приближенными значениями.
13.5. ПРИМЕРЫ
Пример 13.5.1. ОХ и ожидаемый объем выборки для биномиаль-
ного ПКОВ. ОХ для биномиального ПКОВ принимает значения
Р(0) = 1, Р(1)=0 (при 0o<0i), Р(0о) = (1—а), Р(01) = 0. Для вычисления
значения ОХ в других точках следует воспользоваться процедурой из
раздела 13.3. Нужно найти функцию Л=Л(0), удовлетворяющую
условию
*] = «(в./ад*+(1 - <ад 1 -е,)/(1 -0О)]‘=1.
Решая это уравнение относительно 0, получим
Изменяя значения А, можно получать соответствующие пары значе-
ний (0,Р(0)\ Для вычисления ожидаемого объема выборки при всех
значениях 0 можно сначала найти Р(0) из предыдущих формул, затем
E(Z\6) по формуле
£(Z|0) = 01og(01/0o) + (l-0)log[(l-01)/(l-0o)]
и, наконец, E(N\9).
График ОХ для 00=^, 0i=i“> « = /3=0,05 приведен на рис. 13.5.1, а
E(N\0) — в табл. 13.5.1.
Пример 13.5.2. ОХ и ожидаемый объем выборки для нормального
ПКОВ. Легко показать, что для нормального ПКОВ, рассмотренного
в примере 13.2.2, функция Л(0), необходимая для вычисления ОХ,
равна:
Отсюда можно вычислить Р(0) для всего диапазона 0.
101
Чтобы определить E(N\d), нужно сначала найти E(Z\0). Можно по-
казать, что
E(z\ey=4-[2(9,-e0)+(й-el)].
Интересно сравнить ожидаемый объем выборки для последовательно-
го критерия и для эквивалентной схемы с фиксированным объемом
выборки. Под эквивалентной понимается такая схема с фиксирован-
ным объемом выборки, в которой заданы оба значения а и /3, а значе-
ния объема выборки и отношения правдоподобия или выборочной
статистики определяются так, чтобы принять соответствующее окон-
чательное решение с заданными характеристиками точности а и 0.
Рассмотрим численный пример, соответствующий примеру 13.2.2,
с 0о=О и 0j=l. Как известно, для любых а и /3 наилучший в смысле
Неймана—Пирсона критерий, основанный на выборке фиксированно-
го объема [см. раздел 5.12], имеет вид
отклонить Но, если х >к,
где х — среднее выборки, а А: — постоянная, зависящая от заданных
а и /3. Чтобы найти кип для критерия, основанного на выборке фик-
сированного объема, нужно решить уравнения:
вероятность ошибки I рода=а=/уХ >£|0=О) = 1—Ф(\[пк),
вероятность ошибки II pona=j8=PfX <к\0=1) = Ф(у/п(к—1)),
где Ф(-) — функция распределения стандартного нормального распре-
деления.
В табл. 13.5.2 приведены соответствующие ожидаемые объемы вы-
борок для последовательного критерия (в предположении, что 0 есть
истинное значение в) и объемы выборок для критерия, основанного на
выборке фиксированного объема, при различных значениях а и 0. Из
этой же таблицы легко получить для сравнения результат, когда
истинным значением 6 является 1. Заметим, что E(Z\d=0)~—и
£/7|0=1) = у. Во всех случаях наблюдается существенное уменьшение
числа наблюдений. Вальд [см. Wald (1947) с. 57; русский перевод: с.85]
показал, что в данной ситуации ПКОВ приводит к экономии пример-
но 47% наблюдений по сравнению с критерием, основанным на вы-
борке фиксированного объема для любых значений в0 и 0Ь Для
выборок фиксированного объема число наблюдений округлено до
целого.
Таблица 13.5.2. Сравнение ожидаемого объема выборки E(N\6)
и фиксированного объема выборки (фл».в.) для проверки гипотезы
Но:в=О против Н}:в-1 в предположении, что истинным
значением 6 является О
а в 0,01 0,05 0,1
Е(Ы\в) ф.о.в. E(N\6) ф.о.в. E(N]6) ф.о.в.
0,01 9,01 22 8,36 16 7,64 13
0,05 5,83 16 5,3 11 4,75 9
0,1 4,45 13 4,06 9 3,52 7
13.6. ПКОВ ДЛЯ СЛОЖНЫХ ГИПОТЕЗ
До сих пор обе гипотезы считались простыми. Теперь мы займем-
ся построением последовательных критериев, когда одна или обе ги-
потезы являются сложными.
Рассмотрим сначала случай, когда НО:6=9О и Нх:0>во, а вероят-
ность ошибки I рода равна а. Решение, позволяющее построить
ПКОВ, состоит в том, чтобы заменить сложную гипотезу простой,
указав единственное значение параметра 6, такое, что 0! >0О.
Из леммы Неймана—Пирсона следует, что такая замена приводит
к наилучшему критерию для выборки фиксированного объема для
проверки гипотезы Но:0=в0 против когда для нормального
распределения с известной дисперсией математическое ожидание в не-
известно [см. раздел 5.12.2].
Мы можем пойти тем же путем для последовательного критерия,
если ОХ ПКОВ для фиксированных значений а и 0 удовлетворяет ус-
ловиям Р(0)>1—а при в<0о и Р(0)</3 при в >0Ь причем P(6i)=@.
Однако такой путь оставляет открытым вопрос о выборе 0Ь Экспери-
ментатор, выбирая определенное значение 0Ь по существу, объявляет,
что ему безразлично, какое решение (принять или отклонить гипотезу
Но) будет принято при значениях 0, заключенных между 0О и 0Р В
103
то же время для 0^6о и для он надеется, что будет принято ре-
шение принять гипотезу Но или отклонить Но соответственно. Приня-
тие гипотезы 0=0! в результате приводит к принятию 0>0О.
Предположим теперь, что проверяется гипотеза Но:0<& против
Эту ситуацию тоже можно свести к проверке двух простых
гипотез, введя такие два значения 0О и 0>, что экспериментатору без-
различно, какое решение будет принято при 0О<0<01. Однако для зна-
чений 0<0О он хотел бы принять гипотезу Но, а для 0>0х —
отклонить Но. Фиксируя значения 0О, 0Ь а и /3, экспериментатор задает
значения ОХ в двух точках: Р(0О)=1—a, = Принятие гипотезы
0=0О приводит к принятию 0<0.
Пусть 0 обозначает неизвестную долю неисправных изделий, полу-
чающихся в результате некоторого производственного процесса. Пар-
тия, содержащая большое число изделий, будет принята, если 0<0',
и забракована, если 0>0.
Решение относительно каждой партии можно вынести на основе
проверки всех изделий. При этом в каждом случае будет принято вер-
ное решение.
Более эффективный способ состоит в организации последователь-
ной проверки каждой партии и принятии в результате одного из двух
решений. Для производителя может оказаться удобным найти два
значения доли, 0О и 0Ь такие, что в диапазоне 0О<0<01 его устроит
любое решение, но чтобы при этих фиксированных значениях вероят-
ность ошибки I рода, равная вероятности отклонить партию при
0=0О, была бы равна а, а вероятность ошибки II рода, равная вероят-
ности принять партию при 0=0Ь была бы равна /3.
Значение а есть мера желания производителя уменьшить количе-
ство ошибочно забракованных партий, а /3 — мера желания произво-
дителя не отправлять заказчику партии, которые следовало бы
забраковать.
К несчастью, именно значения 0 в зоне безразличия приводят к на-
ибольшим значениям ожидаемого объема выборки в ПКОВ при про-
верке гипотезы НО:9=9О против Hi:0 = 0>.
Очень трудно построить ПКОВ для случая, когда гипотеза Но про-
веряется против альтернативы 0#0О. В этой ситуации зону безразли-
чия можно было бы задать числом 8, так что при 0< |0—0О(^5
экспериментатору безразлично, какое решение будет принято. Если
|0—0О|>6, то гипотеза Но должна быть отклонена.
Предположим, что вероятность ошибки I рода зафиксирована на
уровне а и пусть вероятность ошибки II рода равна (3(9) для 0 в диапа-
зоне |0—0о| >6. В этом случае требуется, чтобы /3(0) ^/3 для заданного
значения (3.
В гл. 4 книги Вальда [см. Wald (1947)] предлагается подход к по-
строению ПКОВ, основанный на так называемых «весовых функци-
ях». Пусть 7г(0) — весовая функция, по определению обладающая
свойствами
j 7г(0)б/0=1, 7г(0)^О для всех 0€Т,
т
104
где через Т обозначена область (0>0о + 6) U (0<0о—д). Для заданной
весовой функции положим
J 7г(0)0(0)б/0= 3-
т
Левая часть предыдущего равенства есть взвешенное среднее всех воз-
можных значений вероятности ошибки II рода. При этом условие
3(0) ^3 больше не должно выполняться при всех значениях 0.
Рассмотрим теперь только взвешенные критерии, которые удов-
летворяют последнему ограничению на /3(0). Предыдущее уравнение
для m наблюдений принимает вид
над.. • f Лх. ;0Ж;0). • .f(xm;e)dXldx2.. .dxm]d0=3.
Г Rm
Через Rm обозначено множество значений (хь х2,...,хот), приводящих к
отклонению Но. Меняя порядок интегрирования, получим
m
{ГШ ПЛУ(,-в)1г(вХ/0]Л,А2...Лт = 0.
m
Член в квадратных скобках представляет собой просто взвешенное
среднее (с той же весовой функцией, что и раньше) всех значений
плотности вероятностей в точках выборки для всех значений 0. По-
скольку это — взвешенное среднее функций плотности вероятностей,
оно также является функцией плотности вероятностей. В измененных
условиях НО:0=0О, так что при выполнении Но истинной функцией
плотности вероятностей служит f(xit х2.....хт;0о). Гипотеза Hi состоит
в том, что истинной плотностью является f 7г(0)/(<Г1....xm-j))d0. Обе
Т
гипотезы оказываются простыми, потому что в каждой из них функ-
ция плотности вероятностей полностью определена. Поэтому ПКОВ
базируется на отношении
= f(xlt х2.Хт)
т f(xx, х2,...,хт\е0)
где
f(Xi ,х2...хт)=, х2,... ,хт ;6)d0
И т .
f(xXt х2...хт\0) = П/^,-0).
Границы остановки выражаются через а и 3» как обычно.
Весовая функция тг(0), например, может иметь смысл априорного
распределения вероятностей значений 0 [см. гл. 15]. Построение после-
довательного критерия без такой модификации читатель может найти
в работах [Wald (1947), гл. 4] и [Wetherill (1975), гл. 4].
Очевидно, что такой подход может быть использован как для
сложных гипотез, которые мы рассматривали раньше, так и для ситу-
ации, в которой есть несколько неизвестных параметров и требуется
проверить часть из них при мешающих параметрах*.
* О различении сложных гипотез в последовательной схеме Вальда см. дополнитель-
ную литературу в конце главы- — Примеч. пер.
105
13.7. КРИТЕРИИ ОТНОСИТЕЛЬНО ДВУХ
БИНОМИАЛЬНЫХ РАСПРЕДЕЛЕНИЙ
Предположим, что нужно сравнить два биномиальных распределе-
ния вероятностей. Обозначим через рх и р2 вероятности успеха, а (1—
pi), (1—Рг) — вероятности неудачи в испытаниях из популяции 1 и 2
соответственно. Требуется проверить гипотезу Н0:рх >р2 против аль-
тернативы Нх‘.рх<р2. Предполагается, что все наблюдения из обеих
популяций независимы. Основные трудности при построении последо-
вательного критерия в этой ситуации связаны, во-первых, с тем, что
гипотезы содержат два неизвестных параметра и не указано ни опре-
деленное значение, ни область значений для рх и р2, во-вторых, с тем,
что наблюдения берутся из двух источников, так что при каждом ис-
пытании надо решать, из какой популяции выбирать следующее на-
блюдение. Для преодоления второго затруднения предположим, что
наблюдения берутся парами, по одному из каждой популяции. Резуль-
татом каждого испытания может быть одна из пар (1, 0), (0, 1), (1, 1),
(0, 0), в которых первый член обозначает результат испытания в попу-
ляции 1, а второй — в популяции 2. Эти четыре результата имеют ве-
роятности pi(l—р2), (1—Pi)Pz, Р1Р2, (1—Pi)(l—Рг) соответственно.
Только два из этих результатов дают информацию о разности между
рх и р2, а именно (1,0) и (0, 1), и поэтому представляется разумным
строить критерий только на основании этих исходов: (1,0) поддержи-
вает гипотезу Но, а (0, 1) — гипотезу Нх.
Если рассматривать только пары (1,0) и (0, 1), то условная веро-
ятность получения исхода (0, 1) равна:
Q - __ (1—Р.)Р2
Р1(1—р2) + (1—Рх)Р1 '
Условная вероятность исхода (1,0) поэтому равна (1—в).
Серии испытаний, в которых наблюдаются только исходы (1, 0)
или (0, 1), образуют новое множество испытаний. В нем успехом счи-
тается результат (0, 1), встречающийся с вероятностью д, а неудачей
— результат (1, 0) с вероятностью (1—в). Поэтому если среди т полу-
ченных результатов встретилось тх пар (0, 1), то правдоподобие рав-
но вт>(1—в)т—т'. Если Р\=Рг, то 6= 1; при рх>р2 исход (1, 0) более
правдоподобен, чем (0, 1) и 0< 1; при рх<Рг получаем 6> 1. Теперь
X X
мы можем изложить два метода решения этой задачи: по Вальду [см.
раздел 13.7.1] и по Армитейджу [см. раздел 13.7.2].
13.7.1. МЕТОД ВАЛЬДА
Гипотезы Но и Нх можно заменить гипотезами Hd 6 1 против
/Т1:0>1, причем принятие или отклонение гипотезы Но приводит к
X
принятию или отклонению /То-
106
Применяя идеи из предыдущего раздела, можно еще больше упро-
стить ситуацию, введя два значения параметра 0о<-1<01 так, что
для д в промежутке 0О<0<01 любое решение одинаково приемлемо
для экспериментатора. Зафиксировав а,/3,0о и 0Ь можно применить ра-
нее рассмотренный биномиальный ПКОВ для проверки гипотезы
/7О:0=0О против /4:0=01 и воспользоваться им для проверки HQ'Pi^p2
против Hx'.pi<p2 [Wald (1947)].
13.7.2. МЕТОД АРМИТЕЙДЖА
Армитейдж рассмотрел модификацию критерия Вальда в примене-
нии к планированию последовательных медицинских испытаний. Ве-
роятности pi и р2 в этом случае можно интерпретировать как долю
успехов при использовании двух методов воздействия 1 и 2.
Проблема в этом случае сводится к проверке трех гипотез (для
простоты гипотезы Нх и Н_х выбраны симметричными):
Яо:0=±,
НХ:6=6Х> 1 (воздействие 2 предпочтительнее, чем воздействие 1),
Н_х:0=1—01 (воздействие 1 предпочтительнее, чем воздействие 2).
Соответствующий критерий является двусторонним, а альтерна-
тивные гипотезы симметричны относительно Но. Значение вероятнос-
ти ошибки I рода поэтому равно вероятности принять Я>, или Н_х
при 0=1, т. е. сумме вероятности принять Нх при 0=1 и вероят-
ности принять Н-i при 0= ±.
А»
Для удобства обозначим суммарную вероятность ошибки I рода через
2а, а вероятность принять Н\ при 0=1 и равную ей вероятность при-
нять Н_х при 0= 1 — через а. Вероятность ошибки II рода обозна-
чим через (1—/3). В этой ситуации возможны два критерия, которые
следует применить: Но против Hi и Но против Н_х.
Критерий Армитейджа основан на статистике dm, которая равна
разности между числом исходов (0, 1) и (1, 0) в т испытаниях. Пусть
тх обозначает наблюдаемое число пар (0, 1), а т2 — число наблюдае-
мых пар (1, 0). Тогда т=тх+т2 и dm=mx—т2, так, что dm = 2mx—т.
Отношение правдоподобия для проверки Но против Нх равно:
После простых преобразований получаем, что log=XOT равен
1 dmlog[0,/(1 - 9,) ]- mlog[ 194(1-9,) 4].
X X
Этот критерий проверки HQ против Нх при фиксированных а и /3 и
обычных границах log[/3/(l—а)] и log[(l—/3)/а] представляет собой
ПКОВ. Получающиеся границы остановки в координатах dm и т
107
Рис. 13.7.1. Открытая последовательная схема для проверки гипотезы
Яо:0=1 против Я1:(9=О,75, Я_,:0=О,25 и 2а = 0,01, /3=0,05, N=80
представляют собой две параллельные прямые dm=ax+bm и dm=a2 +
+ bm, где
= 21og[(l—3)/«] = 21og[/?/(l-q)]
1 loglMl-fl.)] ’ logPi/(l-0,)]
и
£=21og[|0r7(l- <?1ГТ]
loglMl-M
Точно так же, используя симметрию между Н\ и H_lt получим, что
границами остановки при проверке Но против Н_х служат прямые
dm = —al—bm, dm = —a2—bm.
На рис. 13.7.1 приведены границы для 01=5,85, а=0,005, /3=0,05. Об-
ласть пересечения границ (обозначенная пунктирной линией) трудна
для интерпретации и поэтому она включается в область продолжения
испытаний. Это приводит к критерию проверки гипотез с открытыми
границами.
. Чтобы избежать слишком длительного продолжения испытаний до
принятия окончательного решения и тем самым исследования слишком
большого числа пациентов, Армитейдж предложил завершать процеду-
108
Рис. 13.7.2. Закрытая последовательная схема для проверки гипотезы Н0:в=±.
Против Ht:6=0,15, Н_Х$=Ы5 и 2а=0,01, 3=0,05, N=80
ру по достижении заранее заданного числа исходов (0, 1) или (1, 0).
При этом следует изменить внутренние границы в описанном откры-
том критерии и выбрать максимальный объем выборки п так, чтобы
новый критерий имел заданные уровни ошибок а и /3. При этом неко-
торые точки, бывшие точками остановки в открытом критерии, те-
перь станут точками продолжения испытаний. П. Армитейдж
предложил практический метод определения числа п [см. Armitage
(1973)].
На рис. 13.7.2 изображен критерий с замкнутыми границами, полу-
чающийся при 01=0,75, а=0,005, /3=0,05 и соответствующий значению
л = 80.
Ограничение по л, изображаемое прямой линией, параллельной оси
dm, можно заменить двумя отрезками, обозначенными на рисунке
буквами Mi и М2. Это позволит прекратить испытания раньше в слу-
чае, когда в результате принимается гипотеза Но. Если достигается ка-
кая-нибудь точка на этих отрезках, то ни одна из внешних границ уже
не может быть достигнута, даже если оставшиеся испытания приво-
дят к результату (0, 1) или все — к результату (1, 0).
13.7.3. ОБСУЖДЕНИЕ
Для любого ПКОВ можно задать максимальное число наблюдений
как внешнее условие эксперимента. При этом строятся обычные парал-
лельные границы остановки, но испытания прекращаются, как только
произведено л наблюдений.
109
Окончательное решение после п наблюдений при условии, что ни
одна из границ остановки не была достигнута раньше, можно задать
правилами:
принять Но, если logBw< Ё z,X0,
отклонить Но, если 0< Е z,<log4,
где
z-log^.)//^)].
К сожалению, такое ограничение изменяет значения ошибок I и II
рода и они перестают быть равными исходными значениями а и /3.
Эффект ограничения, очевидно, уменьшается с ростом п.
Обобщая предыдущий критерий, можно рассматривать проверку
гипотезы Но:0=0о против Н{:6^60 как проверку Н0:д-д0 против пары
альтернативных гипотез Н1:6>60 и H_i:0<0o. Детальное обсуждение
последовательных критериев для проверки этих трех гипотез содер-
жится в работе [Wetherill (1975), гл. 3].
13.8. ДРУГИЕ ПОСЛЕДОВАТЕЛЬНЫЕ ПРОЦЕДУРЫ
13.8.1. ПОСЛЕДОВАТЕЛЬНЫЕ ПЛАНЫ В ЗАДАЧЕ С ДВУМЯ
БИНОМИАЛЬНЫМИ РАСПРЕДЕЛЕНИЯМИ
В последнем разделе требовалось, чтобы наблюдения производи-
лись парами. Однако существует несколько довольно простых после-
довательных планов с соответствующими правилами остановки,
которые можно использовать вместо ПКОВ. Например, наблюдения
можно проводить по одному, а популяцию, из которой должно быть
извлечено следующее, определять по правилу выбора, известному как
игра на победителя. По этому правилу следующее испытание произво-
дится в той же популяции, что и предыдущее, если оно было успеш-
ным, и, наоборот, следующее испытание производится в другой
популяции, если последнее испытание закончилось неудачей. Это при-
водит к выборке вроде следующей:
популяция 1:110 1110 1 ...,
популяция 2: 0 110
где, как обычно, 1 обозначает успех, а 0 — неудачу.
Выбор популяции для первого испытания производится случайно.
Возможное правило остановки может состоять в прекращении испы-
таний, как только разница в числе испытаний, проведенных в различ-
ных популяциях, превзойдет заранее заданный порог.
Стоит заметить, что использование такого правила минимизирует
число испытаний в популяции с меньшей вероятностью успеха.
13.8.2. БАЙЕСОВСКИЕ МЕТОДЫ
При байесовском подходе [см. гл. 5] можно по-другому подойти к
решению рассмотренных задач последовательного анализа сложных
гипотез. Предположим, что проверка гипотез сведена к задаче при-
110
нятия решений [см. гл. 19]. Возьмем случай, когда наблюдения
Xi, х2>... извлечены из ф.п.р.в. f(x;0) и рассматриваются гипотезы
Но-.0^& и Н1:0>6'.
Обозначим решение принять Но через di, а решение принять Hi — че-
рез Можно задать последовательность функций потерь, которые
определяют (в денежном выражении) ущерб экспериментатора (или
лица, принимающего решение) от принятия неверного решения. Обо-
значим через потери от принятия окончательного решения
при разных значениях 0. Тогда возможна, например, следующая струк-
тура потерь:
L(di’,0) = O при 0^0',
L(di\6) = ki при 0>0',
L(d2t9)=k2 при 0^0',
L(d2;0)=O при 0>0',
где ki и кг — некоторые постоянные.
Если на множестве значений неизвестного параметра 0 задано
априорное распределение, то после извлечения последовательной вы-
борки можно вычислить апостериорное распределение 0 по теореме
Байеса. После этого можно определить апостериорные ожидаемые
потери от принятия каждого из окончательных решений. Если стои-
мость каждого наблюдения равна с, то на каждом шаге ожидаемое
уменьшение потерь в результате проведения еще одного наблюдения
стоимостью с сравнивается с ценой с.
Применение байесовского подхода в подобной ситуации описано в
книге [Wetherill (1975), гл. 7].
13.9. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Armitage Р. (1975). Restricted Sequential Procedures, Biometrika, 44, 9-26.
Armitage P. (1975). Sequential Medical Trials, 2nd Ed., Oxford Blackwell.
Wetherill G. B. (1975). Sequential Methods in Statistics, 2nd Ed., London, Chapman and
Hall.
Wald A. (1947). Sequential Analysis. New York: J. Wiley.
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Вальд А. Последовательный анализ. М.: Физматгиз, 1960. — 328 с.
Ширяев А. Н. Статистический последовательный анализ: Оптимальные правила
остановки.—М.: Наука, 1976. — 272 с.
Глава 14
МЕТОДЫ, СВОБОДНЫЕ ОТ РАСПРЕДЕЛЕНИЯ
14.1. ВВЕДЕНИЕ
Общим при рассмотрении многих статистических методов в настоя-
щем Справочнике является предположение, что распределение наблю-
дений, о которых идет речь, принадлежит некоторому параметричес-
кому семейству распределений, например соответствующие случайные
величины имеют нормальное, или гамма-, или пуассоновское, или дру-
гое распределение. Таким образом, мы предполагаем, что известна
форма или семейство распределений, хотя мы можем не знать в точ-
ности члена этого семейства, например, мы можем предполагать нор-
мальную N(;i, ст) модель, но с неизвестными параметрами ц и ст.
Методы оценивания и проверки гипотез позволяют нам делать выво-
ды о неизвестных параметрах, при этом ценность любых наших за-
ключений до некоторой степени должна зависеть от адекватности
исходного предположения о параметрическом семействе. Например,
стандартные критерии, такие, как /-критерий [см. раздел 5.8.2], строго
говоря, пригодны только в том случае, когда предположение о нор-
мальности верно, хотя, к счастью, многие из них довольно устойчивы
к отклонениям от нормальности.
Очевидно, что было бы полезно уметь строить статистические мо-
дели и критерии, которые менее ограничительны в том смысле, что
они не зависят от определенного параметрического семейства распре-
делений. Такие модели, известные как непараметрические или свобод-
ные от распределения, являются предметом обсуждения в этой главе.
Единственным предположением, которое мы делаем при большинстве
представленных здесь процедур, — это непрерывность распределения
случайных величин.
Сначала непараметрические методы развивались так, что для ре-
шения каждой новой задачи отыскивалось специальное правило. Толь-
ко относительно недавно был разработан единый взгляд на предмет
и исследованы оптимальные свойства процедур. Есть много хороших
книг по непараметрическим и свободным от распределения методам,
например [Siegel (1956); Walsh (1962); Noether (1967); Hollander and Wolfe
(1973); Lehmann (1975)]. Для многих из критериев, приведенных здесь,
имеются подробные таблицы распределения их статистик. В большин-
стве примеров мы отсылаем читателя к двум источникам: [Siegel
(1956); Owen (1962)—G]*.
* См. также список дополнительной литературы, приведенный в конце этой гла-
вы.—Примеч. пер.
112
14.2. КРИТЕРИИ, ОСНОВАННЫЕ НА ЭМПИРИЧЕСКОЙ
ФУНКЦИИ РАСПРЕДЕЛЕНИЯ
Как введение в раздел, посвященный свободным от распределения
критериям, рассмотрим базовую для проблемы в целом задачу: можно
ли считать, что данная случайная выборка наблюдений хь х2,...,хп взя-
та из полностью определенного непрерывного распределения? Эта за-
дача адекватности модели уже встречалась в гл. 7, где был предложен
критерий согласия х2- Рассмотрение этого критерия служит введением
к разделам, посвященным методам, свободным от распределения.
Основными понятиями этого раздела являются: 1) порядковые ста-
тистики выборки и 2) эмпирическая функция распределения.
Определение 14.2.7. Вариационный ряд. Расположив значения вы-
борки Х\...хп в порядке возрастания их величины, обозначим самое
меньшее через х , второе по величине — через х(2)>... и самое боль-
шое — через х(п). Множество
где
Х(1)<'Х(2)<' <Х(п)>
называют вариационным рядом, или множеством порядковых статистик
выборки. Если бы соответствующие случайные величины были дискрет-
ны, то мы должны были бы принять во внимание возможность совпа-
дения наблюдений, что несколько усложнило бы теорию порядковых
статистик. Для непрерывных случайных величин возможность совпаде-
ния наблюдений можно игнорировать при условии, что наблюдения ре-
гистрируются с достаточной точностью [см. II, раздел 15.1.].
Некоторые функции от порядковых статистик известны: это про-
центили (включая нижнюю квартиль, медиану и верхнюю квартиль) и
размах. Они определяются следующим образом.
Размах. Размах — это просто х(п-~х()).
Медиана. Если число наблюдений нечетно, скажем и = 2ди + 1, то
медиана — это х(т+1}, т. е. срединное наблюдение, когда наблюдения
расположены в порядке возрастания их величины. Если число наблю-
дений четно, скажем п=2т, то обычно в качестве медианы берут
"2" (\m)+X(m+l)'
Квартили, процентили. Нижняя квартиль, медиана и верхняя
квартиль вводятся для того, чтобы обеспечить разбиение порядковых
статистик на 4 подмножества равного размера. Строго говоря, это
возможно в том случае, когда объем выборки имеет вид и=4£+3; тог-
да нижняя квартиль — это х(А.+1), медиана — x(2k+2V верхняя квартиль
-^рАг+З)'
Децили (доли, кратные десятой) и процентили (процентные точки)
определяются аналогично.
Определение 14.2.2. Эмпирическая функция распределения. Эмпи-
рическая функция распределения, или функция эмпирического распре-
деления Fn(x), определяется следующим образом:
Fn(x)=.
О, х<ха),
k/п, х(к<х<х(к+{}
!, х>х(п}.
к=\, 2,
,л—1,
11.3
Рис. 14.2.1. Эмпирическая функция распре-
деления F6(x) для примера 14.2.1
Другими словами, Fn(x) —
ступенчатая функция со
скачками \/п в каждом из
значений х(1), х(2).х(п).
Пример 14.2.1. Эмпи-
рическая функция распреде-
ления. Предположим, что
случайная выборка объема
л=6 из непрерывного рас-
пределения состоит из на-
блюдений
2,1, —0,6, 0,2, 3,0 —1,0 1,3.
Вариационный ряд в этом
случае — упорядоченное (по
возрастанию) множество
—1,0, —0,6, 0,2, 1,3, 2,1, 3,0.
Эмпирическая функция рас-
пределения начинается с 0
и возрастает скачками по 1/6 в точках —1,0, —0,6, 0,2, 1,3, 2,1, 3,0,
как показано на рис. 14.2.1.
Если мы получим другую случайную выборку объема 6 из того же
непрерывного распределения, значения наблюдений будут отличаться,
и, следовательно, эмпирическая функция распределения F6(x) будет дру-
гой. Именно природу этого отличия F6(x) от теоретической функции
распределения Fix') случайной величины X мы исследуем с позиций про-
верки согласия (адекватности модели).
14.2.1. КРИТЕРИЙ КОЛМОГОРОВА*. ОДНА ВЫБОРКА
Предположим, что мы хотим проверить простую гипотезу, что
определенная непрерывная функция Fo(*) является функцией распределе-
ния, из которого получена случайная выборка х2,---,хл. Таким обра-
зом, мы хотим проверить гипотезу
Н{: F(x)=F0(x) для всех х
против альтернативы
Н2: F(x)^F0(x) для некоторых х.
В одновыборочном критерии Колмогорова используется статистика
Пл(х) = sup <j<jFrtU)—F0U)|,
* В Справочнике этот и последующий статистические критерии названы критериями
Колмогорова—Смирнова. Критериями Колмогорова—Смирнова в настоящее время на-
зывают критерии, статистики которых основаны на сопоставлении выборочных (эмпи-
рических) и теоретических функций распределения либо их оценок. При этом расстояние
между этими объектами измеряется через верхнюю (нижнюю) грань их разностей (иног-
да с переменным весом). В этой главе описываются некоторые из оригинальных резуль-
татов А. Н. Колмогорова и Н. В. Смирнова. При переводе упомянутым далее
критериям присвоены имена их открывателей.—Примеч. ред.
114
Рис. 14.2.2. Эмпирическая функция распределения F6(x) для примера 14.2.1 и
определенная F0(x)
т. е. самое большое отличие эмпирической функции распределения от
определенной функции распределения. На рис. 14.2.2 показано, напри-
мер, значение D6(x) для данных из примера 14.2.1, если F0(x) такая,
как изображено.
Статистикой критерия является значение случайной величины
/?Л(Х), которая зависит от Хи Х2,...,Хп, через Fn(z). Она дает меру
того, как далека Fn(z) от F0(z)- Ясно, что большие значения £>л(х) за-
ставят нас усомниться в так как тогда Fn{z) существенно отлича-
ется от F0(z) хотя бы для некоторых значений z. Поэтому в качестве
критической области возьмем [см. раздел 5.12.2] множество
А2= {наблюдения: Z)/I(x)>ca],
где са — константа, выбранная таким образом, что Р(Л2|//1) = а. Вы-
числение са на первый взгляд представляется безнадежной задачей
для столь общего непараметрического подхода. На самом же деле с
помощью простых теоретико-вероятностных рассуждений, включаю-
щих преобразование интеграла вероятностей [см. II, теорема 10.7.2.],
можно получить замечательный результат, состоящий в том, что при
выполнении нулевой гипотезы Н\ Dn(x) имеет распределение, которое
зависит только от объема п выборки и не зависит от вида распределе-
ния F0(x). Другими словами, у нас есть метод, свободный от распреде-
ления, так как, чтобы определить А2, нужно только указать са для
определенного уровня значимости а, положив РС42|//1) = а; для задан-
ных а и п мы получим одно и то же значение са, каково бы ни было
распределение F0(x) — равномерное, нормальное, гамма- или любое
другое.
115
Критические значения са для точного распределения £>Л(Х) при
выполнении гипотезы Hi были вычислены для различных значе-
ний п [см., например, Siegel (1956), с. 251 или Owen (1962), табл. 15.1,
с. 423—425—G]*.
Аппроксимация критических значений, которая хороша для
п>35**, приводит к следующим результатам:
а=0,20 0,10 0,05 0,01
1,07 1,22 1,36 1,63
“ Vn Vz? Ул Ул
Пример 14.2.2. Критерий Колмогорова. Предположим, мы хотим
проверить гипотезу, что шесть наблюдений в примере 14.2.1 образуют
случайную выборку из распределения N(l, 1). Другими словами, F\№
— функция распределения нормальной N(l, 1) случайной величины,
как это изображено на рис. 14.2.2. Мы можем тогда определить D6(x)
графически либо аналитически следующим образом. Сначала отме-
тим, что значение Z)6(x) должно появиться в точке z, соответствую-
щей одной из наблюдаемых величин. Затем пары величин di и d2,
показанных на рис. 14.2.3, вычисляются для каждого такого значения.
Они приведены в табл. 14.2.1. В третьем столбце содержатся значения
F0(z)=P(X^z) = $(z~ 1), где Ф(-) — функция стандартного нормально-
го распределения [см. приложение 3].
Таблица 14.2.1. Вычисление £>6(х) в примере 14.2.2
Z ^(z) Т>(*) d. 4,
— 1,0 0,1667 0,0228 0,1439 0,0228
—0,6 0,3333 0,0548 0,2785 0,1119
0,2 0,5000 0,2119 0,2881 0,1214
1,3 0,6667 0,6179 0,0488 0,1179
2,1 0,8333 0,8643 0,0310 0,1976
3,0 1,0000 0,9772 0,0228 0,1439
* В таблицах Оуэна [Owen (1962)—G] и Л. Н. Болыпева, Н. В. Смирнова [см. спи-
сок дополнительной литературы] приводятся критические значения для l^n^lOO. В
табл. 19А И. Ликеша и Й. Ляги содержатся критические значения с + для распределе-
ния статистики одностороннего критерия Т>л+ = sup(Fn(z)—F0(z)) в пределах л= 1(1)100(5)
200(10) 300(20)500(100)1000. При этом выполняется соотношение са(л)»с^(л).—При-
меч. пер. ?
** При больших п значения са(п) можно вычислить по приближенной формуле
са(л) = п-,/2[— 1/21п(а/2)]'/2.
Эта аппроксимация для указанных выше значений а и используется в тексте. Зависи-
мость распределения Dn от п устраняет преобразование Стефенса 1Тл=Дл(7л+0,12 +
+0,11/7л). Критические точки совпадают с приведенными в тексте до второго знака.
Об этом преобразовании и другие вопросы, связанные с применением критерия Колмо-
горова, см. в книге Ю. Н. Тюрина.—Примеч. пер.
116
Из таблиц, упоминав-
шихся выше, мы найдем,
что для критерия с 5°7о-
ным уровнем значимости
и п = 6 критическая область
имеет вид
Аг - {наблюдения:
Z?6(x)>0,52).
Из табл. 14.2.1 получаем
Z)6(x) = 0,2881. Наше мно-
жество наблюдений не по-
падает в эту критическую
область. Поскольку уро-
вень значимости больше,
чем 5%, можно считать,
Рис. 14.2.3. Разности dx и
что данные не противоре-
чат гипотезе о том, что они подчиняются распределению N(l, 1).
Следует заметить, что подобные задачи можно было бы решать с
помощью критерия согласия х2 [см. раздел 7.4]. Потенциальное пре-
имущество критерия Колмогорова в том, что он не группирует дан-
ные (с обязательной потерей информации), а дает возможность
рассматривать индивидуальные наблюдаемые значения. Его также
можно успешно применять для малых выборок. Считается, что его
мощность, вообще говоря, выше, чем у критерия х2.
Вопрос о том, можно ли обобщить критерии на случай сложной
нулевой гипотезы, которая не полностью определена (например, пред-
положим, что в примере 14.2.2 Н\ относится к распределению N(0, 1)
с неизвестным 0), остается открытым*.
14.2.2. КРИТЕРИЙ СМИРНОВА. ДВЕ ВЫБОРКИ
Критерий Смирнова для двух выборок также использует понятие
эмпирической функции распределения. Но в этом случае нас интересу-
ет, являются ли две независимые выборки наблюдений выборками из
одного и того же распределения. Точнее говоря, имеется случайная
выборка Хь л-2,...,хл из совокупности с непрерывной функцией распре-
деления F(x) и независимая случайная выборка _уь Л,---из совокуп-
ности с непрерывной функцией распределения G{y). 2 Мы хотим
проверить гипотезу
//1:Ffz) = G(z) для всех z
против
H2-F(z)^G(z) для некоторых z.
* Это не совсем так. Для многих семейств параметрических распределений (напри-
мер, нормального, показательного и др.) составлены таблицы процентных точек для
модифицированных статистик Колмогорова—Смирнова, в которых в качестве теорети-
ческой функции F(x, (^-распределения используется F(x, ёп), где в0 — истинное (неиз-
вестное) значение (многомерного) параметра, а бп — его оценка по той же выборке, по
которой построена F„(x). О распределении этих статистик при больших п см.:
Тюрин Ю. Н. О предельном распределении статистик Колмогорова—Смирнова для
сложной гипотезы.—М.: Изв. АН СССР. Сер. математическая.—1984.—№ 6.—С. 1314—
1343.—Примеч. ред.
Заметим, что мы не уточняем, какова на самом деле общая форма
F(z) и G(z) в
По двум выборкам можно определить две эмпирические функции
распределения Гп~(х) и Gn(y}. В двувыборочном критерии Смирнова
используется статистика
&пи л2(х> У)=
которая является наибольшим отклонением между двумя эмпириче-
скими функциями распределения. Случайная величина Dn Лг(Х, Y) за-
висит от X', Х2,...,ХПх, через Fn{z) и от Уь У2.УПг через 6„2(z).
Если выполняется Н2, то можно ожидать, что эмпирические функции
распределения будут «далеки». Так что в качестве критической обла-
сти размера а мы можем взять
А2= (наблюдения: Dni Пг(х, у)>са],
где снова са — константа, выбранная так, что Р(Л2|//1)=а. Точное
выборочное распределение Dn п^, Y) при выполнении Нх известно.
Его таблицы содержатся в [Siegel, (1956) — табл. L, с. 278], для
Я1=л2 = л^40 — в [Owen (1962), табл. 15.4, с. 434—436—G], а для
«1, и2^10 — в [Massey (1952)]*.
Снова распределение не зависит от общей формы F и G в Нх. Для
больших «1 и п2 (больше 40)** для определения са можно использо-
вать следующие аппроксимации:
а=0,20 0,10 0,05 0,01
са 1,22V1,36V-^- l,63V-^i-
Пример 14.2.3. Двувыборочный критерий Смирнова. Предположим,
что мы получили две независимые выборки из двух совокупностей:
Выборка 1: 2,1 —0,6 0,2 3,0 —1,0 1,3
Выборка 2: 1,0 2,6 —0,5 0,6 1,8
На Ьис. 14.2.4 показаны обе эмпирические функции распределения
F6(z) и G5(z). Можно видеть, что
Рб>5(х, У)-О,33.
* В табл. 19Б И. Ликеша, Й. Ляги приведены критические значения для
1^Л!<л2^40, а в табл. 19В — для ЗСЛ!=л2С100. —Примеч. пер.
" Подробное описание применения критерия Смирнова см. в книге М. Холлендера
и Д. Вулфа, §10.1. Там же (табл. А.24, с. 428) даны, вероятности предельного распреде-
ления (гшп(иь л2)-»-=~) статистики J'3 = \nxn2/(nx +л2)]1/2Дл > . Это предельное распре-
деление аналитически задается как P(J3<y)-*-K(y)= . "S’ (—1)уехр(—2/'2у2), у>0.
у=—
Распределение К(у) называется распределением Колмогорова и является предельным и
для 'TnDn при-*—— одновыборочная статистика Колмогорова из раздела 14.2.1).
Значения К(у) для у=0,20(0,01)2,49 приводятся и в табл. 6.1. Л. Н. Большева, Н. В. Смир-
нова. Там же подробно обсуждаются вопросы аппроксимации (см. с. 83—87). —
Примеч. пер.
118
Рис. 14.2.4. Эмпирические функции распределения F6(z)[-1 и Gi(z)[-—] для
примера 14.2.3
Найдем из таблиц [Massey (1952)], что для критерия при 5%-ном
уровне значимости ni=6, п2 = 5 критическая область имеет вид
Л2= (наблюдения: D6 5(x, у) >0,67).
Наблюдаемое значение Z>65(x, у) не попадает в критическую об-
ласть. Поэтому наш уровень значимости превышает 5% и данные
можно считать согласующимися с гипотезой /7,, что две совокупности
имеют одно и то же распределение.
14.3. КРИТЕРИИ, ОСНОВАННЫЕ НА ПОРЯДКОВЫХ
СТАТИСТИКАХ
Критерии из раздела 14.2 основаны на представлении наблюдений
в виде эмпирической функции распределения [см. определение 14.2.2].
Другой большой класс свободных от распределения критериев осно-
ван на порядковых статистиках [см. определение 14.2.1].
Вариационный ряд выборки выстраивает (численные) значения на-
блюдений в порядке возрастания величины. Статистики критериев за-
тем строятся как различные функции от этих порядковых статистик.
Например, некоторые включают сравнения членов вариационного ря-
да с медианой [см. раздел 14.2] распределения, в других требуется свя-
занное с вариационным рядом понятие рангов: самое маленькое
наблюдение получает ранг 1, следующее по величине — ранг 2 и т. д.
При определении рангов иногда сталкиваются с проблемой совпа-
дения наблюдений (связок). Поскольку мы предполагаем, что распре-
деление, о котором идет речь, непрерывно, теоретически связок быть
не должно, т. е. никакие два наблюдения не должны совпадать. Тем
не менее, например, из-за практических ограничений в процессе изме-
119
рения иногда оказывается, что некоторые наблюдения совпадают.
Когда мы рассматриваем ранги в вариационном ряду, общая
практика* состоит в том, чтобы давать каждому из связанных наблю-
дений среднее значение рангов, которые бы они получили, если бы
слегка отличались. Например, если у нас выборка
-3, -1, 0, 2, 2, -1, 2, 1, 3,
то вариационный ряд и ранги имеют вид
—3 —1 —1 0 1 2 2 2 3
ранги: 1 2,5 2,5 4 5 7 7 7 9.
В следующих четырех разделах мы продемонстрируем ранговые и
другие непараметрические критерии и приведем примеры процедур,
которые пригодны для одной выборки [см. раздел 14.4], для выборки
сопоставленных пар [см. раздел 14.5], двух выборок [см. раздел 14.6]
и нескольких выборок [см. раздел 14.7].
14.4. ОДНОВЫБОРОЧНЫЕ КРИТЕРИИ
В этом разделе обсуждается случайная выборка, состоящая из на-
блюдаемых значений Х2,...,хл случайной величины X с неизвестной
функцией распределения F(x). В соответствующей параметрической си-
туации проверки гипотез мы рассматривали, например, /-критерий
[см. раздел 5.8.2], с помощью которого проверяются гипотезы о мате-
матическом ожидании. В непараметрическом контексте математиче-
ское ожидание во многом теряет свое значение** и внимание следует
обратить на понятие медианы т генеральной совокупности, т. е. на
такое значение т случайной величины X, для которого F(m) = 1/2.
14.4.1. КРИТЕРИЙ ЗНАКОВ
На основе случайной выборки х2,...,хл мы хотим проверить ну-
левую гипотезу Hi, что медиана т равна определенному значению т0.
Построим критерий для проверки
Н{: т = т0
против
Н2: т*т0.
* Средние ранги — только один из способов действий при наличии связок. Другой
способ состоит в назначении случайного порядка совпадающим наблюдениям; это так
называемый метод рандомизованных рангов. Наконец, можно строить условные непа-
раметрические процедуры при данной структуре связок. Излагаемые в главе методы
применимы, возможно, с модификациями и для дискретных распределений. Все эти во-
просы полно излагаются в работе У. Коновера (см. список дополнительной литературы
в конце главы). — Примеч. пер.
** Математическое ожидание, как и другие моменты распределения F(x), может про-
сто не существовать, например, при распределении Коши. Роль центра выроятностей
здесь играет именно медиана. — Примеч. пер.
120
В критерии знаков в качестве статистики используется число на-
блюдений R, бблыних т0. Если какое-нибудь наблюдение равно mQ,
принято игнорировать его и уменьшать п на 1. Каково бы ни было
распределение X (при условии, что оно непрерывно), мы знаем, что
каждое наблюдение с вероятностью 1/2 больше медианы т независи-
мо от всех остальных наблюдений. Отсюда если Hi выполняется и
т = т0, то R имеет биномиальное распределение с
= (г-0, 1, 2..п). (14.4.1)
Очевидно, что сравнительно малые или большие значения R заставят
нас усомниться в том, что Hi верна, поэтому мы построим критиче-
скую область вида
А2= [0, 1,...,са, п—са, п—са + 1,...,л],
где значение са — размер критерия [ср. с разделом 5.2.1, е)]. Оно
определяется из условия Р(Л2|//1)^а. Вычислить са можно либо пря-
мым подсчетом с использованием таблиц биномиального распределе-
ния, либо с помощью нормальной аппроксимации биномиального
распределения [см. II, раздел 11.4.7]. При выполнении Hi статистика
R приближенно нормальна с параметрами (уи, и аппроксима-
ция достаточно хороша для п >10*.
Описанный выше критерий является двусторонним [см. раздел
5.2.1]. Мы можем построить аналогичные односторонние критерии,
когда Н2 утверждает, что т>т0(или т<т0). В этих случаях А2 будет
иметь вид {п—са, п—са+1,...,п} (или [0, 1,...,са)).
Пример 14.4.1. Критерий знаков. Случайная выборка из непрерыв-
ного распределения содержит 10 наблюдений:
6,4, 5,9, 4,9, 4,8 6,0, 4,7, 7,0, 5,5, 7,1, 5,6.
Предположим, что гипотеза Hi утверждает, что т = т0 = 5,0, а альтер-
натива Н2 утверждает, что ди >5,0. Критическая область А2 имеет вид
Л2={10—с, 10—с+1,...,10),
и нам нужно выбрать самое большое с, такое, что Р(Л|//1)^0,05 (для
критерия с 5%-ным уровнем значимости) [см. раздел 5.2.1, е)]. Из
(14.4.1) следует:
P(^ = 1O|/7,) + P(/? = 9|/Z1) = (^)1o+1O(4-)1o=O,O11,
P(R=10\Hi)+P(R = 9\Hi)+P(R = S\Hi) =
= (т)10+ Ю(4-)1О+45(у)1О=О,О55.
* В реальных задачах использование нормальной аппроксимации для биномиального
распределения может быть оправдано лишь для п порядка нескольких десятков. При
л <50 необходима «поправка на непрерывность», согласно которой
//?—О,5л+О,5 \ _ ч
Точные критические значения для л = 5(1)2ОО содержатся в книге И. Ликеша, Й. Ляги
(см. табл. 18, с. 256—259), а критические значения для л=4(1)100(10)200(20)500(50)1000
табулированы в [Owen (1962), с. 362—365.—6].—Примеч. пер.
121
Поэтому для критерия с уровнем значимости ^5% мы берем с=1 и
получаем А2 = {9, 10). Мы наблюдаем значение R = l, которое не попа-
дает в критическую область. Поэтому на 5%-ном уровне значимости
у нас нет оснований отвергнуть нулевую гипотезу о том, что т = 5,0.
Альтернативный подход состоит в вычислении достигаемого уров-
ня значимости [см. раздел 5.2.1, п. е)]; т. е. вероятности получить при
нулевой гипотезе результат не меньше наблюдаемого. Здесь мы на-
блюдаем R = l, поэтому достигаемый уровень значимости для этого
одностороннего критерия равен:
P(R > 71//()=P(R = 71//()+P(R = 8 |Н() + P(R=9]^)+P(R = 10|Н,) =
= 120(4-)10+45(4)10+ 1О(4-)1О+(т)1О=О,172.
Это большая вероятность [см. табл. 5.2.1], и данные надо расцени-
вать как согласующиеся с нулевой гипотезой.
14.4.2. КРИТЕРИЙ ЗНАКОВЫХ РАНГОВ УИЛКОКСОНА
Очевидно, что критерий знаков не использует значительную часть
информации, содержащуюся в выборке. Лучший непараметрический
критерий должен учитывать не только информацию о том, положи-
тельны или отрицательны разности xt—т0, но и относительные раз-
меры этих разностей. Снова рассмотрим двусторонний критерий для
проверки
Нс.
против
^2*
Положим по определению
Zi=Xj—m0
а затем упорядочим абсолютные значения |zj, т. е. ранжируем |zi|,
|Za|.|гл|. Как и в критерии знаков, мы игнорируем те наблюдения,
которые дают z;=0.
Пример 14.4.2. Знаковые ранги Уилкоксона. Значения z;- в примере
14.4.1 с zno = 5,O равны
1,4, 0,9, -0,1, -0,2, 1,0, -0,3, 2,0, 0,5, 2,1, 0,6.
Мы приписываем им ранги, не учитывая знаков:
—0,1 —0,2 —0,3 0,5 0,6 0,9 1,0 1,4 2,0 2,1
ранги: 1 2 3456789 10
В критерии знаковых рангов Уилкоксона эти ранги используются в
одной из двух статистик:
К+ = сумма рангов положительных разностей z,
или
V_=сумма рангов отрицательных разностей Z/.
Если выполняется гипотеза Hi, мы будем ожидать, что V+ и V_
примерно равны, тогда как при Н2 — что одна из этих двух сумм до-
минирует. В нашем примере
V+ =4+5 + 6 + 7 + 8 + 9+10=49
и
К_ = 1+2+3 = 6.
т = т0
тАт0.
о* = 1, 2,...,л),
122
Предположим, что мы выбрали меньшую величину V_ в качестве
статистики критерия. Сравнительно малые или большие значения V_
заставят нас отклонить Н\, поэтому наблюдения, которые дают такие
значения, войдут в критическую область. Чтобы определить критиче-
скую область или, взамен этого, достигаемый уровень значимости,
нам нужно знать распределение V_ при справедливости гипотезы Н\.
При выполнении Нх каждое наблюдение с вероятностью 1/2 больше
или меньше медианы /и0; поэтому каждое из значений (и соответствен-
но каждый из рангов) имеет вероятность 1/2 быть + или —. Каждая
из 2п различных возможных расстановок знаков для значений z имеет
поэтому одну и ту же вероятность 1/2" при Н{. Чтобы получить на-
блюдения, попадающие в критическую область, нужно перечислить
все возможные случаи, которые приводят к крайним значениям И__.
Вместо этого мы можем вычислить достигаемый уровень значимости.
Так, в нашем примере
P(V <6|Н1)= Число способов И^6
Числитель вычислим следующим образом:
Значение Множество рангов
0 Пустое множество
1 И)
2 (2}
3 (31, (1,2}
4 (4}, (1, 3}
5 (5}, (1,4}, (2,3}
6 (6), (1,5}, (2,4}, (1,2,3}
Таким образом, есть 14 способов получить И_<6, поэтому
Р(К_^6|Н1) = ^=0,0137.
Для двустороннего критерия достигаемый уровень значимости имеет
вид
Р(И_^6 или И_^55—6=49|Н,).
Здесь наибольшее значение К_ равно 1+2+... + 10=55. Поскольку при
выполнении Н, распределение V_ симметрично, достигаемый уровень
значимости равен 2-0,0137=0,027. Следовательно, на 5%-ном уровне
значимости мы отвергнем нулевую гипотезу, что медиана равна 5,0 в
пользу гипотезы Нг. Из значения статистики V_ следует, что медиа-
на больше 5,0. Вообще говоря, эта процедура несколько утомительна.
К счастью, доступны таблицы, которые содержат критические значе-
ния V_ (или К+) в критической области [см., например, Siegel (1956),
табл. G, с. 254] или функцию распределения V_ (или К+) [см., напри-
мер, Owen (1962), табл. 11, 1, с. 325—330—G]*.
* В книге И. Ликеша, Й. Ляги (с. 302—306) приводятся таблицы критических значе-
ний для и=4(1)100. Распределение статистики И+ для л = 3(1)15 см. в книге М. Холлен-
дера и Д. Вулфа, табл. А. 4. — Примеч. пер.
123
Для больших значений л(>20) мы можем использовать нормаль-
ную аппроксимацию* для К__, а именно при выполнении Нх V_ при-
ближенно нормальна с математическим ожиданием л(л + 1)/4 и
дисперсией л(л+1)(2л+1)/24. (14.4.2)
При Hi статистики И+ и V_ распределены одинаково.
Если есть совпадающие наблюдения, мы припишем им средние
ранги. Влияние этой процедуры на распределение V_ (или И+) прене-
брежимо мало, если только доля связок не слишком велика. Коррек-
ция к аппроксимации в (14.4.2) состоит в уменьшении дисперсии на
J=1 J J
где Т — число связок и у-я связка состоит из Л наблюдений
(/=1,2...Г). 1
14.5. СОПОСТАВЛЕННЫЕ ПАРЫ
Из-за большой вариабельности экспериментальных единиц часто
выгодно при сравнении двух способов или методов обработки подби-
рать экспериментальные единицы, похожие во всех отношениях, со-
ставлять из них пары и применять один из двух способов обработки к
каждой из единиц [ср. с разделом 9.3]. Такое сравнение более адекватно
в том смысле, что любое различие в результатах (на это можно наде-
яться) будет следствием различия в способах обработки, а не следстви-
ем различия экспериментальных единиц [см. пример 5.8.1]. Другая
реализация этой идеи состоит в том, что при выявлении эффекта каж-
дый индивидуум дает одно измерение до, а другое после обработки.
В каждом случае мы получаем пары взаимосвязанных измерений
(Xi, ji), (х2, л).(хп> Уп) в качестве наблюдений, и нам нужно рас-
сматривать выборки из сопоставленных пар. Для таких данных обыч-
но переходят к рассмотрению разностей
di=x~yj (/=1, 2.......................л).
В гауссовском параметрическом случае Z-критерий для сопоставленных
пар [см. пример 5.8.1] обеспечивает способ проверки равенства мате-
матических ожиданий или равенства нулю математического ожидания
случайной величины D=X—Y. При непараметрическом подходе мы
можем использовать критерий знаков и критерий знаковых рангов
Уилкоксона из раздела 14.4 применительно к случайной выборке раз-
ностей di, d2.dn. В этих критериях надо учеть, что медиана то=0
при гипотезе Н,.
* Более точная аппроксимация Р. Имана (см. список дополнительной литературы,
работа 1974 г.) состоит в замене стандартизованной статистики
V* = [ V— п (п +1 )/4] [п(л +1 )(2n +1 )/24]"1 /2
статистикой ... <-----=—
и вычислении для нее процентных точек
/а(«)=[У«-1)+га]/2,
где ta(n—1) и za — верхние а%-ные точки распределения Стьюдента и N (0, 1) соответ-
ственно. Двусторонний критерий размера а отвергает Нх при или J^Ja(n),
ai + a2 = a.—Примеч. пер. 2 1
124
14.6. ДВУВЫБОРОЧНЫЕ КРИТЕРИИ
Предположим, что х,, x2t...,xni — случайная выборка из совокуп-
ности с непрерывной функцией распределения F(x) и yif у2,...уп — не"
зависимая случайная выборка из совокупности с непрерывной
функцией распределения G(y).
Объединенный вариационный ряд этих двух выборок — просто со-
вокупность всех наблюдений, расставленных в порядке возрастания их
величины, без учета принадлежности к выборке.
Пример 14.6.1. Объединенный вариационный ряд двух выборок.
Предположим, мы наблюдаем случайную выборку объема 7 из сово-
купности I: 3 71 ] 2 6 2 4 ! од 3 9
и вторую независимую случайную выборку объема 5 из совокупное-
™ П: 4,6, 4,0, 5,3, 4,4, 3,0.
Результат можно представить с помощью диаграммы, как на рис.
14.6.1. Объединенный вариационный ряд и ранги наблюдений показа-
ны ниже:
—1,1 0,8
ранги: 1 2
х
—।----г-
-2 -1
Выборка 1
2,3 2,6 3,0 3,7 3,9 4,0 4,1 4,4 4,6 5,3
3 4 5 6 7 8 9 10 И 12
X XX х XX
~1 ।---1----1----1----1----г
0 1 2 3 4 5 6
х ххх х
Выборка 2
Рис. 14.6.1. Наблюдения в примере 14.6.1
Три критерия, которые мы опишем в этом разделе, позволяют ре-
шить вопрос о том, имеют ли две совокупности одно и то же распре-
деление с центром в одной и той же точке. Следовательно, они
являются критериями проверки гипотезы
Н\: F(z) = G(z) для всех z
против
Н2: F(z)^G(z) хотя бы для некоторых z.
Эти критерии особенно мощные против альтернатив сдвига. В нор-
мальном параметрическом случае их аналогом является двувыбороч-
ный ^-критерий [см. раздел 5.8.4].
14.6.1. ДВУВЫБОРОЧНЫЙ МЕДИАННЫЙ КРИТЕРИЙ
Первый критерий основан на медиане объединенной совокупности
и может рассматриваться как обобщение критерия знаков [см. раздел
14.4.1] на случай двух независимых выборок. Пусть тх обозначает
число элементов выборки из совокупности I, которые превосходят ме-
диану объединенной выборки.
125
Пример 14.6.2. Двувыборочный медианный критерий. Медиана
объединенной совокупности из примера 14.6.1. равна: -у(3,7 + 3,9) = 3,8.
Мы можем разбить наблюдения на следующие категории:
Превосходят медиану Меньше медианы Всего
Выборка из I 2 5 7
Выборка из II 4 1 5
Всего 6 6 12
В более общем случае, когда пх + п2 четно, мы получим классифика-
цию вида
Превосходят медиану Меньше медианы Всего
Выборка из I /п, П,— т. «I
Выборка из II /п2 п2—тг «2
Всего т(Л1+и2) yOh + и2) я, + л2
В случаях, когда л,+л2 нечетно, одно из наблюдений будет совпа-
дать с выборочной медианой. Принято игнорировать то наблюдение,
которое попадает точно на медиану, и уменьшать либо п2 на 1. За-
тем можно составить такую же таблицу, как выше. Далее мы продол-
жаем изложение так, как если бы это уже было сделано.
Если две совокупности имеют одну и ту же медиану, мы можем
ожидать, что наблюдения из каждой совокупности равномерно рассея-
ны в объединенном вариационном ряде. В медианном критерии в каче-
стве статистики используется случайная величина М,, которая
является числом наблюдений в выборке из совокупности I, превосхо-
дящих медиану объединенной выборки. При выполнении Hi величина
Mi должна иметь распределение с центром в точке -ywi- В результате
простых комбинаторных рассуждений получим
Р(М =тд= (g~M , a=Uni+n2),
т. е. Му имеет гипергеометрическое распределение [см. II, раздел 5.3]
при выполнении Hi. Значения М{, далекие от ^ni, заставят нас от-
вергнуть Hi в пользу Н2. Поэтому в качестве критической области мы
возьмем .
Л2= [mr.lmi—
где & выбрано так, чтобы размер критерия не превышал а.
126
Другой способ состоит в вычислении достигаемого уровня значи-
мости, т. е. вероятности получить результат такой же, как мы получи-
ли, или еще более далекий от центра, а именно
или Mi<ni—mi), если тх> ,
или
P(Mi<mi или Mi>ni—mi), если т{< .
Это пример точного критерия Фишера для табл. 2x2 [см. раздел
5.4.2].
Если объемы выборок велики, можно применять метод х2 (см. раз-
дел 7.2.1] для проверки гипотезы Hi. Этот приближенный критерий
используется при л,+л2^20, если при этом ожидаемое число наблю-
дений в каждой клетке не слишком мало, например не менее 5 [ср. с
критерием Кокрена из раздела 7.5.1].
Пример 14.6.3 (продолжение примера 14.6.2). Вычислим достигае-
мый уровень значимости для выборки, приведенной в примере 14.6.1.
Множество значений, столь же или более далеких от центра, чем на-
блюдаемое, в табличной форме имеет вид:
5 2
1 4
6 1
О 5
Достигаемый уровень значимости равен
Ф (ft + Ф Ф 4- Ф Ф + Ф (О5) =
Ф Ф Ф Ф
=0,0076+0,1136 + 0,1136+0,0076=0,242.
Это высокая вероятность. Данные следует считать согласующимися с
гипотезой Hi, согласно которой распределения двух совокупностей
одинаковы. Кроме того, мы можем видеть из приведенных выше ве-
роятностей, что критическая область для критерия на 5%-ном уровне
значимости равна:
А2= [mi’.mi = 1 или 6].
Поскольку тх =2, наше наблюдение не попадает в критическую об-
ласть на уровне 5%, и мы делаем то же заключение, что и выше.
14.6.2. КРИТЕРИЙ УИЛКОКСОНА—МАННА—УИТНИ
Ясно, что при медианном тесте теряется значительная часть ин-
формации, содержащейся в данных. Мы можем более эффективно ис-
пользовать информацию, содержащуюся в объединенной выборке,
если будем рассматривать ранги наблюдений. Следующая непара-
метрическая процедура предложена Уилкоксоном, Манном и Уитни
[см. Wilcoxon (1945); Mann and Whitney (1947)]. Опишем ее в терминах
данных примера 14.6.3.
127
Объединенный вариационный ряд и ранги, как мы уже видели,
имеют вид
—1,1 0,8 2,3 2,6 3,0 3,7 3,9 4,0 4,1 4,4 4,6 5,3
ранги: 1 2 3 4 5 6 7 8 9 10 11 12
Полужирным шрифтом указаны ранги наблюдений из совокупности II
(меньшая выборка). Статистика, используемая в критерии Уилкоксо-
на—Манна—Уитни, — это сумма рангов одной из выборок. Мы мо-
жем взять
/?! = 1+2+3 + 4+6+7 + 9=32
или
Я2=5+8+10+11 +12 = 46.
В более общем случае, если и, г2..— ранги х,, х2.....и s2,...,sn2
— ранги У1, у2,...уП2 в объединенной совокупности, то можно предпо-
честь любую из двух статистик:
R\ — г\+ г2 +... + гп^
или
/?2=51+52 + ...+5П2.
Заметим, что если мы знаем Rlt то мы знаем также и R2, поскольку
Ri +R2 = 1 + 2+... + («i + л2)= y(^i + ^г)(Л1 + п2 +1).
Эти две статистики эквивалентны, поэтому проще воспользоваться
статистикой из меньшей выборки.
Если верна гипотеза , что F и G являются одной и той же функ-
цией распределения, то мы не должны ожидать преобладания наблю-
дений из одной выборки на одном из концов объединенного вариа-
ционного ряда: их значения должны быть рассеяны по всему объеди-
ненному вариационному ряду. Для альтернативной гипотезы Н2 обще-
го вида сравнительно большие или сравнительно малые значения
тестовой статистики (скажем, /?2) должны заставить нас усомниться в
выполнении гипотезы Н{. Поэтому в качестве критической области
возьмем множество
А2= {наблюдения: /?2^cj или R2^c2], (14.6.1)
где Ci и с2 — константы, выбранные таким образом, чтобы размер А2
не превышал а. Альтернативно можно оценить уровень значимости
как вероятность наблюдать такое же или еще более крайнее значение
статистики, чем то, что мы получили.
Пример 14.6.4. Уровень значимости критерия Уилкоксона—
Манна—Уитни. При выполнении Н\ статистика R2 имеет симметрич-
ное распределение с математическим ожиданием y«2(«i+л2 +1) = 32,5
(см. ниже). Поэтому уровень значимости есть
Р(Я2^46 или Я2^19|Н,).
Если Н{ выполняется, то п2 = 5 рангов у-в являются случайной вы-
боркой (без возвращения) объема л2 = 5 из набора целых чисел
1, 2..Л1+л2 = 12. Поскольку при выполнении Н\ все возможные по-
следовательности рангов в объединенной совокупности равновероят-
ны, уровень значимости равен
Число способов получить Я2>46 или ^19 (14 6 2)
ф
128
Вычисление этой вероятности можно провести, просто выписав все
комбинации, для которых /?2^46:
12+ 11 +10+9 + 8 = 50
12+11 + 10+9 + 7 = 49
12 + 11 + 10+9 + 6 = 48
12+11 + 10+8 + 7 = 48
12+11 + 10+9 + 5 = 47
12+11 + 10+8 + 6 = 47
12+11+9+8 + 7 = 47
12+11 + 10+9+4 = 46
12+11 + 10+8 + 5=46
12+11 + 10 + 7 + 6 = 46
12+11+9 + 8 + 6 = 46
12+10 + 9 + 8 + 7 = 46
Таким образом, число комбинаций, для которых R2 ^46, равно 12. Так
как R2 имеет симметричное распределение при выполнении Hi, число
комбинаций, для которых R2^. 19, тоже равно 12, поэтому уровень
значимости (14.6.2) равен:
*2* =0,030.
е52)
Это достаточно низкая вероятность. Она довольно сильно свидетель-
ствует против гипотезы, что две совокупности имеют одну и ту же
функцию распределения. Вспомним, что, применяя критерий знаков и
отбрасывая слишком много информации, содержащейся в данных, мы
не смогли получить свидетельства против выполнения Н{.
Приведенной выше трудоемкой процедуры можно избежать, вос-
пользовавшись существующими таблицами для критических значений
Ci и с2 в (14.6.1) [см., например, Owen (1962), табл. 11.5].
В некоторых таблицах используется другая тестовая статистика £/,
определяемая как
{/= Л1Л2 + +1)]—Я1
или
и=П{П2 + [~2-n2(n2 + 1)]—R2.
Здесь U измеряет число случаев, когда наблюдение из большей выборки
находится левее наблюдения из меньшей выборки в объединенном вари-
ационном ряду; таблицы для U см., например, в [Siegel (1956), табл.
J, К, с. 271—277] или в [Owen (1962), табл. 11.2—11.4, с. 331—353]*.
Для больших выборок мы можем использовать нормальную ап-
проксимацию для R\, R2 (или U), и эти аппроксимации работают хо-
* В таблицах Оуэна приводятся критические значения для 1Oi^«2^20. Распределе-
ние /?! (либо /?2) содержится в табл. А.5 в книге М. Холлендера, Д. Вулфа (с. 283—293).
Критические значения для U приведены в табл. 18 книги П. Мюллера, П. Ноймана, Р.
Шторма (с. 231—234). Более полные таблицы можно найти в книге Л. Н. Большева,
Н. В. Смирнова (табл. 6.8. для 1 ^и2^25), а для 1 <Л| Сл2<40 см. табл. 20 И. Пике-
та, Й. Ляги (с. 284—301). Самые полные таблицы для 3^л(^л2^50 содержатся в ра-
боте Ф. Уилкоксона, С. Кати, Р. Уилкокса (см. список дополнительной литературы в
конце главы). — Примеч. пер.
129
рошо даже для таких небольших значений пи п2, как 7*. При
выполнении нулевой гипотезы мы ожидаем, что средний ранг наблю-
дения из совокупности I примерно равен среднему рангу наблюдения
из совокупности II. Поскольку общая сумма рангов равна у(Л1+Лг)х
х(л, + п2 +1), средний ранг равен -у(Л1 +п2 +1). Поэтому
£(/?,)= +п2 + 1) и E(R2)=^n2(ni+n2 + V).
Можно показать, что
var(7?i) = var(7?2) = Wi«2(«i + п2 +1)/12. (14.6.3)
В нашем примере объемы выборок несколько маловаты для того,
чтобы ожидать очень аккуратной аппроксимации, но в качестве иллю-
страции допустим, что R2 имеет приблизительно нормальное распре-
деление N(32,5,^37,9167) при выполнении Нх. Отсюда приближенно
ЛЯ2>46|Я,) = 1-Ф(^£^) = 1-Ф(2,192)=0,0142.
Уровень значимости, следовательно, равен 2-0,0142=0,028, что срав-
нимо с точным значением 0,030, вычисленным ранее.
Вполне возможно, что среди наблюдений могут оказаться равные.
Мы припишем им средние ранги. Если связки встречаются лишь в од-
ной из выборок, это не повлияет на или R2. Если в связки входят
наблюдения из различных выборок, то эффект, вообще говоря, будет
невелик, но при использовании нормальной аппроксимации следует
умножить дисперсию (14.6.3) на корректирующий множитель
(Л1+n2)((n,+n2)2—1}
где Т — число связок и j-я связка состоит из /. наблюдений (/ =
= 1, 2,...,7).
Односторонние критерии могут быть получены для тех ситуаций,
когда альтернатива Н2 означает, что F и G отличаются сдвигом в
определенном направлении.
14.6.3. КРИТЕРИЙ СЕРИЙ
В другом двувыборочном свободном от распределения критерии
равенства двух распределений используется понятие серий в объеди-
ненном вариационном ряду. В этом критерии также используются
данные из объединенного вариационного ряда, но иным образом.
* Но не слишком хорошо, даже для п2, которые больше 20. Здесь предлагается
использовать нормальную аппроксимацию /?* = (/?—£(/?))/Vvar (Я). Гораздо лучше поль-
зоваться аппроксимацией Р. Ймана (см. список дополнительной литературы, работа
(1976 г.) J= -^—[1 + (~п +”‘)'/21- Нулевая гипотеза отвергается при —Ja (N—2)
или 2), a, + a2 = ot, nx+n2=N, процентные точки 7a(i')=0a(i')+Za)/2, где ta(y),
za — процентные точки распределения Стьюдента с v степенями свободы и N (0, 1). —
Примеч. пер.
130
Пример 14.6.5. Данные из примера 14.6.1, исследуемые для выяв-
ления серий. В объединенной порядковой статистике вместо записи
рангов мы просто укажем выборку, из которой взято каждое наблю-
дение:
—1,1 0,8 2,3 2,6 3,0 3,7 3,9 4,0 4,1 4,4 4,6 5,3
выборка: Д I I I, .1 I. П, J. II II II,
В качестве тестовой статистики здесь взято число W серий, состоя-
щих из наблюдений одной и той же совокупности, в объединенном ва-
риационном ряду. В примере W=6.
Если выполняется гипотеза Ни что два распределения равны, то
наблюдения из I и II совокупностей должны быть хорошо перемеша-
ны и общее число серий должно быть велико. С другой стороны, если
два распределения различны, например, если они далеко разнесены
или если одно из них обладает большим разбросом, а второе относи-
тельно компактно, то W, по всей видимости, будет мало.
Точное распределение W при выполнении может быть получено
с помощью комбинаторного анализа (см. например, [Siegel (1956),
с. 138] и критическая область имеет вид
А2 = {наблюдения: w са}.
Существуют таблицы критических значений сп [см. Siegel (1956),
табл. Л с. 252—253] или [Owen (1962), табл. 12.4, 12.5, с. 373—382]*.
Пример 14.6.6 (продолжение примера 14.6.5). Значимость выбор-
ки. Из таблицы критических точек на уровне значимости 5% для
«1=7, «2 = 5 получаем
А2= (наблюдения: w^3}.
Поскольку в нашем примере w=6, значение W лежит вне критической
области, поэтому нет оснований отклонить Нх (на 5 %-ном уровне
значимости).
Снова пригодна нормальная аппроксимация**, при которой учиты-
вается тот факт, что при выполнении Д IV приближенно нормальна с
Е( И7) = 1 + 2п 1 л2/(«1 + л2)
и „
2Л|И2(2л1и2—Hj—и2)
varW= (П|+„г№,^,-1)
* В табл. 26А И. Ликеша и Й. Ляги (с. 319—334) приводятся критические значения
для 2^Л!<л2^30, а в табл. 26Б (с. 335—336) — значения для 4^ = /<2^ 100. Послед-
няя таблица имеется и в книге [Owen (1962)], а таблица для неравных объемов выборок
там доведена до значений и = 20. Точные значения вероятностей P(lV-w\nl, п2) равны
пр» »=2*и .=2*+i,
откуда и вычисляются критические значения са, см. книгу Л. Н. Большева, Н. В. Смир-
нова (с. 91—93). — Примеч. пер.
** Нормальная аппроксимация лучше «работает» в виде P(W^w)=>$( w+0,5—ДГГ))
V var(H')1''2 7
и применима для значений п{ и л2 одного порядка. В том случае, когда одна из выборок
существенно меньше другой, предпочтительнее биномиальная аппроксимация:
P(W ^w) ~ I \_х(\—w+2, w—1)=1—I/w—1, N—w+2),
где — функция бета-распределения с параметрами а, Ь и х=1—2л1л2/(и1+и2) х
х(л,+л2— 1), N=(ni + п2— l)(2ntn2—пх—n2)/{nt(nl—1)+л2(л2—1)]. Подробное описание см.
в книге Л. Н. Большева, Н. В. Смирнова (с. 9i—93). — Примеч. пер.
131
Для точности этой аппроксимации требуется, чтобы каждое из значе-
ний Л] и л2 было хотя бы не менее 20.
Проблема связок для критерия серий может представлять труднос-
ти, если имеются совпадения наблюдений из разных выборок. Заинте-
ресованного читателя отсылаем к книге [Siegel (1956), с. 143].
Интересно заметить, что три критерия, рассмотренные в разделах
14.6.1, 14.6.2 и 14.6.3, не обязательно приводят к одним и тем же вы-
водам. Используя объединенный вариационный ряд различными спо-
собами, мы можем получить различные выводы. Вообще считается,
что критерий Уилкоксона—Манна—Уитни наиболее чувствительный
или наиболее мощный [см. раздел 5.3.1], по крайней мере при альтер-
нативной гипотезе о сдвиге (о параметре положения).
14.7. НЕСКОЛЬКО ВЫБОРОК
Разовьем теперь те же идеи для сравнения нескольких выборок. С
помощью этих критериев изучают ситуации, аналогичные моделям
однофакторного дисперсионного анализа в гауссовском параметриче-
ском случае [см. раздел 5.8.7].
Имеется к совокупностей. ^Из совокупности с номером i извлечено
П; наблюдений (1=1, 2,...,к, Е П; = п). Мы хотим проверить гипотезу
/=1
все совокупности имеют одно и то же распределение
против
Н2: это не так.
Как в случаях медианного теста [см. раздел 14.6.1] и критерия
Уилкоксона—Манна—Уитни [см. раздел 14.6.2], их обобщения, кото-
рые мы рассмотрим сейчас, относятся скорее к ситуациям, в которых
альтернатива означает изменение медиан (или положения), а не фор-
мы распределений.
14.7.1. МЕДИАННЫЙ КРИТЕРИЙ
Двувыборочный медианный критерий из раздела 14.6.1 можно пря-
мо обобщить на случай к выборок. Снова строится объединенный ва-
риационный ряд и определяется медиана выборки. Затем в каждой
выборке мы подсчитываем число наблюдений, которые больше или
меньше этой выборочной медианы. Снова условимся игнорировать
наблюдения, равные выборочной медиане (уменьшив соответственно
объемы выборок).
Пример 14.7.1. Трехвыборочный медианный критерий. Предполо-
жим, у нас есть к-3 совокупности и случайные выборки из них:
Из 1: 21, 50, 6, 69, 42, 34, 26, 57, 14, 31
Из II: 10, 49, 22, 40, 24, 54, 12, 29, 25, 17, 32, 61
Из Ill: 3, 15, 9, 18, 1, 33, 11, 5, 16, 30, 41
132
Здесь И1 = 10, и2 = 12, и3 = 11. Можно построить объединенный вариаци-
онный ряд и найти, что выборочная медиана, здесь семнадцатое зна-
чение, равна 25. Классификация наблюдений приводится ниже.
Заметьте, что мы игнорируем наблюдение 25 в выборке II и уменьша-
ем пг на 1.
Больше медианы Меньше медианы Всего
Выборка I Выборка II Выборка III 7 6 3 3 5 8 10 11 и
Всего 16 16 32
Если выполняется Ни то можно ожидать, что около половины
каждой выборки из каждой совокупности будет меньше общей выбо-
рочной медианы и около половины будет больше. При условии, что
объем каждой выборки больше 10, мы можем использовать критерий
согласия х2> как описано в разделе 7.5.2, для таблицы сопряженности
к *2. Для статистики критерия
(число наблюдений)2
— по всем ожидаемое число П
клеткам наблюдений
известно, что X2 имеет распределение х2(к—1), если выполняется ги-
потеза Hi, и что большие значения X2 означают отклонения от Hi.
Пример 14.7.2. х2-аппроксимация к процедуре из примера 14.7.1.
В нашем примере ожидаемые значения при выполнении Нх сле-
дующие:
Больше медианы Меньше медианы
Выборка I 5 5
Выборка II 5,5 5,5
Выборка III 5,5 5,5
Отсюда
V2- 72 , З2 , 62 , 52 , З2 , 62 , 52 , З2 , 82 Qz-
х- 1 + Т + TT + TF+ sT + 5?+ W +ХУ + ТГ“32~3’96'
Поскольку для к=3 критическая область размера 0,05 имеет вид
А 2 = {наблюдения: X2 > х* 95 (2) = 5,99},
где х^>95(2) означает 95%-ную точку распределения х2 с 2 степенями
свободы, мы видим, что на 5%-ном уровне значимости нет оснований
отклонить нулевую гипотезу Нх о равенстве распределений.
133
14.7.2. КРИТЕРИЙ КРАСКЕЛА—УОЛЛИСА
Снова мы можем полнее учесть информацию, содержащуюся в
объединенном вариационном ряду. Как и для критерия Уилкоксона—
Манна—Уитни из раздела 14.6.2 для двух выборок, мы используем
ранги наблюдений в объединенной совокупности.
Для каждой из к выборок вычислим суммы рангов:
Rj = сумма рангов элементов i-й выборки (/=1, 2,...,к).
Пример 14.7.3. Обработка данных из примера 14.7.1 с помощью
критерия Краскела—Уоллиса. Объединенный вариационный ряд вмес-
те с рангами для данных примера имеет вид
1 3 5 6 9 10 1 1 12 14 15 16
ранги: 1 2 3 4 5 6 7 8 9 10 11
17 18 21 2: 1 24 25 26 27 30 31 32
ранги: 12 13 14 if 16 17 18 19 20 21 22
33 34 40 4 1 42 49 50 54 57 61 69
ранги: 23 24 25 2( 11 28 29 30 31 32 33
Здесь мы показали ранги для совокупности I, например, как 4_ , ранги
для совокупности II - как 6 (полужирный шрифт) i 1 ранги для сово-
купности III - как 1 (светлый шрифт). Тогда
=4+9+... + 33 = 210,
Я2 = 6+8 + ... + 32=230,
Я3 = 1 + 2+... + 26=121.
Для каждого наблюдения в конкретной выборке мы можем указать
средний ранг Я/иД/^1, 2,...,к). Если выполняется гипотеза и рас-
пределения одинаковы, то можно ожидать, что все средние ранги при-
мерно равны, а именно, что они примерно равны общему среднему
рангу: , _
R = 1 + 2±... + л = ^_(л+1).
В качестве статистики критерия мы_ используем меру, которая чув-
ствительна к отклонениям R[/nt от R . Поэтому статистика критерия
Краскела—Уоллиса равна:
Р к 1
дУ= Е Ri я(я + 1)2* *.
/=1 l\ л / /=1 л( 4
Ясно, что большие значения К должны быть значимы, поэтому кри-
тическая область имеет вид
А2= {наблюдения: К>константы}.
12
* Обычно табулируется и используется статистика V= К. — Примеч. пер.
134
Для выборок небольшого объема существуют таблицы точных крити-
ческих значений /Г[см. Siegel (1956), табл. О, с. 282—283; Owen (1962),
табл. 14.2, с. 420—422]. В них предусмотрены случаи, когда к=3 и
5(i- 1, 2, 3)*. Если почти все и,>5, то удобна аппроксимация, ко-
торая основана на том, что К имеет распределение х2(к—1) при
выполнении Н\**.
Если среди наблюдений имеются связки, мы вновь припишем соот-
ветствующим наблюдениям средние ранги в объединенной совокуп-
ности. Малое число связок оказывает малый эффект на статистику
критерия К', тем не менее, удовлетворительная коррекция при приме-
нении х2-аппроксимации состоит в замене К на К/a, где
f/A2-1)
для случая Т связок по tj наблюдений каждая (/= 1, 2,...,7).
Пример 14.7.4. хг-оппроксимация для процедуры из примера
14.7.3. Здесь пх = 10, и2 = 12, и3 = 11, поэтому мы можем применить
Х2-аппроксимацию. Для критерия размера 0,05 мы имеем критическую
область вида
А2= {наблюдения: К> Хо^С2)^560’1 )•
Для наших данных
(210)2 (230)2 (121)2
=612,3.
4
Тем самым наше наблюдение попадает в критическую область, мы
отвергаем нулевую гипотезу на 5%-ном уровне и заключаем, что рас-
пределения трех выборок различаются. Заметьте, что снова, используя
информацию, содержащуюся в объединенном вариационном ряду, бо-
лее эффективно, мы пришли к другому заключению по сравнению с
выводами, сделанными в разделе 14.7.1.
14.8. РАНДОМИЗИРОВАННЫЕ КРИТЕРИИ
В критериях, обсуждаемых в разделах 14.3—14.7, мы учитывали
информацию, содержащуюся в выборочных данных, предварительно
преобразовав ее в ранги. Поскольку при этом не были использованы
настоящие значения, мы, возможно, что-то теряли в эффективности.
* Самая обширная из имеющихся на русском языке таблиц содержится в книге
И. Ликеша, Й. Ляги (табл. 22, с. 307—311). Она содержит критические точки для £=3,
л(^6, Л1=л2 = л3 = 7, 8; £=4, nz-^4, k=5, п^З. Подробнее критерий Краскела—Уоллиса
и аналогичные критерии, основанные на квадратичных формах от линейных ранговых
статистик, а также другие проблемы непараметрического однофакторного анализа рас-
смотрены в книгах Я. Гаека, 3. Шидака и М. Холлендера, Д. Вулфа. Там же имеются
ссылки на соответствующую литературу. — Примеч. пер.
“ Более точная аппроксимация, предложенная Р. Иманом и Дж. Давенпортом (см.
список дополнительной литературы в конце главы), состоит в применении статистики
J- v(l + —ЛТ* ) и критических точек J =—[(&— '(k— 1, л—Аг) + хДАг— 1)], где
Fa(a, b)— а^о-ная точка F-распределения с (а, Ь) степенями свободы. Гипотеза Н, отвер-
гается на уровне а при — Примеч. пер.
135
Рандомизированные критерии [см. раздел 5.7] — это непараметриче-
ские правила, основанные на настоящих наблюдаемых (численных)
значениях и их случайной природе. Они полезны для малых выборок,
но могут стать очень громоздкими при увеличении объемов выборок
[см. пример 5.7.1]. Уже знакомые нам критерии знаковых рангов Уил-
коксона [см. раздел 14.4.2] и критерий Уилкоксона—Манна—Уитни
[см. раздел 14.6.2] можно рассматривать как примеры рандомизиро-
ванных критериев, основанных на рангах. Проиллюстрируем лежащие
в основе рандомизированных критериев идеи на двувыборочной ситуа-
ции. Детали применений в других случаях можно найти, например, в
книгах [Siegel (1956), с. 88, 152; Silvey (1975), с. 148—150, С]*.
Пример 14.8.1. Рандомизированный критерий для двух выборок.
Предположим, что мы хотим сравнить эффекты двух обработок I и
II на 8 экспериментальных единицах. Назначим случайным образом
«1=4 единицам обработку I, а оставшимся л2=4 единицам — обра-
ботку II: обработка I: 3, 8, 1, 5
обработка II: 10, 4, 6, 14
Проверим гипотезу Нх, что различие между обработками несу-
щественно против альтернативы Н2, что обработка II дает более вы-
сокие результаты. При справедливости гипотезы Нх мы получили бы
8 результатов, приведенных выше, как бы мы ни назначили обработ-
ки. Фактически имеется
(".-г) = ф=70
различных возможных группировок в два множества по 4 элемента.
При случайном назначении все возможные группировки равновероят-
ны, и поэтому каждая из них имеет вероятность
Если S2 — сумма откликов, полученных при обработке II, то относи-
тельно большие значения S2 заставят нас сомневаться в справедливос-
ти нулевой гипотезы. Поэтому возьмем критическую область вида
А2= {наблюдения: S2>c]
или вычислим вероятность получения столь же высокого результата
или еще более высокого, чем тот, что мы наблюдаем.
Здесь 52 = 10+4+6+14=34 и достигаемый уровень значимости
равен Число способов S2^34
70
Существует 6 способов наблюдать 52^34:
14+10 + 8 + 6 = 38,
14+10 + 8 + 5 = 37,
14 + 10+8+4=36,
14+10+8 + 3 = 35,
14 + 10 + 6+5 = 35,
14+10 + 6+4=34.
* Рандомизированные критерии для дисперсионного анализа обсуждаются также в
книге Г. Шеффе (см. список дополнительной литературы в конце главы). — Примеч. пер.
136
Поэтому достигаемый уровень значимости равен: 6/70=0,086. Эта от-
носительно высокая вероятность указывает, что данные не противоре-
чат нулевой гипотезе об отсутствии различия между обработками.
Очевидно, что для больших гц, п2 эта процедура станет более тру-
доемкой. В работе [Siegel (1956), с. 154] обсуждается приближенное ре-
шение. Альтернативно можно использовать с удовлетворительными
результатами критерий Уилкоксона—Манна—Уитни и аппроксимацию
для него*.
14.9. МЕРЫ РАНГОВОЙ КОРРЕЛЯЦИИ
В параметрических моделях мы встречали понятия ковариации и
корреляции [см. (2.1.8)], которые измеряют степень связи между пара-
ми случайных величин из двумерного распределения. Можно постро-
ить оценки этих мер по случайной выборке наблюдений, например
вспомните выборочный коэффициент корреляции (2.1.9). Можно по-
строить и аналогичные меры связи при непараметрическом подходе,
используя понятие рангов наблюдений при упорядочении. В качестве
примера построим две такие меры: коэффициент ранговой корреляции
Спирмена и коэффициент ранговой корреляции Кендэла. Заинтересо-
ванный в более детальном рассмотрении этих и других мер читатель
может обратиться к книге [Kendall (1962)].
Предположим, что у нас есть п пар наблюдений (хь уЭ,
(х2, Уг),---,(хп, Уп), которые составляют случайную выборку из некото-
рого (неизвестного) двумерного непрерывного распределения. Мы со-
ставим вариационный ряд для х1} х2,...,хп и отдельно для у1г у2,...уп.
Если две переменные сильно зависимы или имеют высокую степень
связи, мы вправе ожидать, что ранги двух элементов каждой пары
примерно одинаковы (или, возможно, взаимно обратны, если корреля-
ция отрицательна). С другой стороны, если зависимости нет, то мы
не будем ожидать такого рода тренда**.
* Коротко пояснить изложенное в примере 14.8.1 можно так. После проведения
опыта 8 его результаты оказались разделенными на 2 группы (в соответствии с назна-
ченными обработками). Сумма результатов по каждой группе дает некое представление
о действии обработок. Как всегда при проверке гипотезы об однородности, мы спраши-
ваем себя, значимо ли видимое различие между этими суммами. Различие надо считать
большим (значимым), если при случайном выделении 4 результатов из имеющихся 8
(т. е. при выделении, не связанном с назначением обработок) окажется малой вероят-
ность получить такое же, как в опыте, или большее различие. В данном случае — с ка-
кой вероятностью можно получить сумму ^34?
Надо обратить внимание на то, что при этом подходе речь идет о вероятности, по
природе своей отличающейся от рассматривавшейся ранее. В частности, численные ре-
зультаты опыта (т. е. 3, 8, 1,...,14) не обязательно считать реализациями случайных ве-
личин. Здесь случайность связана с назначением обработок. — Примеч. ред.
**Речь идет о мерах линейной или, точнее (поскольку ранги инвариантны при моно-
тонном преобразовании данных) монотонной связи. Для нормального распределения
действительно нулевая корреляция означает отсутствие зависимости случайных величин.
Для произвольного распределения это не так, и существуют критерии, например крите-
рий Хефдинга, для выявления зависимости общего вида (см., например, книгу М. Хол-
лендера, Д. Вулфа, §10.2, с. 242—250). — Примеч. пер.
137
14.9.1. КОЭФФИЦИЕНТ РАНГОВОЙ КОРРЕЛЯЦИИ СПИРМЕНА
Коэффициент ранговой корреляции Спирмена является простой мо-
дификацией коэффициента корреляции Пирсона (2.1.19), при которой
величины Xj и заменяются их рангами. Поскольку ранги являются
некоторой перестановкой чисел 1, 2,...,п для каждой переменной, мож-
но показать с помощью элементарных преобразований, что коэффици-
ент ранговой корреляции Спирмена rs сводится к
п ->
b'Hd]
Г — 1---------------------------------—-— ’
s 1 л(л2—1)
(14.9.1)
где
dj = rank (xz)—rank (yz) (/ = 1, 2,...,n).
Строго говоря, в (14.9.1) необходима коррекция, если имеются связки
в двух ранжируемых множествах, но эффект коррекции пренебрежимо
мал, если доля связок не слишком велика.
Коэффициент имеет следующее свойство: —1^г5^1. Мы получим
значения около +1, если большим значениям х-в отвечают большие
значения у-в, и значения около —1, если большие х отвечают мень-
шим у. При выполнении гипотезы Hi о независимости случайных ве-
личин выборочное распределение rs таково, что математическое
ожидание rs равно нулю. Существуют достаточно полные таблицы
точного распределения rs при выполнении Hi [см., например, Siegel
(1956), табл. Р, с. 284; Owen (1962), табл. 13.2, с. 400—406]*. Для
п ^10** критерий для проверки гипотезы Hi основан на том факте,
имеет приближенно распределение Стьюдента с п—2 степенями свобо-
ды при выполнении //Jcm. раздел 2.5.5]. Критическая область разме-
ра а для проверки Hi против альтернативной гипотезы Н2, что
переменные зависимы, имеет в этом случае вид
А2 = {наблюдения: |r5|V >/а(и—2)},
* В книге И. Ликеша, Й. Ляги (см. табл. 24, с. 312—313) приводятся критические
значения точного распределения для л=4(1)16. — Примеч. пер.
“В книге М. Холлендера, Д. Вулфа (см. табл. А.30, с. 440—441) приведены точ-
ные критические значения для л = 4(1)11 и приближенные критические значения для
л = 12(1)50(2)100, полученные с помощью аппроксимации кривой Пирсона типа II. Отно-
сительная ошибка этой, гораздо более точной аппроксимации для л >11 и а >0,05 не
превышает 3%. Можно также пользоваться следующей аппроксимацией Р. Имана и
У. Коновера. Вместо коэффициента Спирмена rs введем статистику j = rj_ [Vn—1 +
+ ]• Верхние а%-ные точки для нее следующие: Jr а(п—2)= у(га + /а(л—2)),
где za, ta(n—2) — верхние а*7о-ные точки нормального N(0, 1) распределения и распре-
деления Стьюдента с (л—2) степенями свободы. Гипотеза Н\ отклоняется при
Jr^Jr,aSn—2) или Jr ai(n—2), а, + а2 = «- —Примеч. пер.
138
где ta(n—2) — (1—-уа)‘квантиль распределения Стьюдента с (л—2)
степенями свободы. Можно вывести аналогичные критические обла-
сти для односторонних критериев, для которых Н2 означает положи-
тельную (отрицательную) связь.
Пример 14.9.1. Коэффициент ранговой корреляции Спирмена.
Предположим, что в двух тестах 7 индивидуумов набрали следующие
баллы:
индивидуум: 1 2 3 4 5 6 7
тест 1: 31 82 25 26 53 30 29
тест 2: 21 55 8 27 32 42 26
Ранги имеют вид: индивидуум: 1 2 3 4 5 6 7
тест 1: 5 7 1 2 6 4 3
тест 2: 2 7 1 4 5 6 3
разность df. 3 0 0 —2 1 —2 0
Отсюда Hd] = 18
и r5=0,68.
Из таблиц находим, что достигаемый уровень значимости
Р(|г5|^0,68) равен 2-0,055=0,11. Это высокая вероятность, и крите-
рий указывает на то, что данные не противоречат нулевой гипотезе,
т. е. гипотезе, что баллы, набранные по двум тестам, независимы.
14.9.2. КОЭФФИЦИЕНТ РАНГОВОЙ КОРРЕЛЯЦИИ КЕНДЭЛА
Коэффициент ранговой корреляции Кендэла г является другой ме-
рой корреляции, которая строится следующим образом. Предполо-
жим, что мы упорядочили индивидуумов по возрастанию значений х;
посмотрим на соответствующее упорядочение у-в.
Пример 14.9.2. Коэффициент ранговой корреляции Кендэла. Если
мы расположим индивидуумов в порядке возрастания значений х, то
получим
индивидуум: 347 6152
ранги: тест 1 1 2 3 4 5 6 7
ранги: тест 2 1 4 3 6 2 5 7
баллы: 6 1 2 —1 2 1 0
Рассмотрим соответствующее ранжирование у-в, чтобы получить
баллы, приведенные выше. Каждому индивидууму поочередно начис-
лим +1 столько раз, сколько индивидуумов правее него получили
больше баллов, чем он сам, другими словами, во скольких парах ран-
ги стоят в правильном порядке. Аналогично начислим —1 для каждо-
го ранга справа, который меньше данного. Наример, для индивидуума
4 начислим
(—1)+1+(—!) +1 +1 = 1,
139
тогда как для индивидуума 6 —
(—1) + (-П+1 = -1.
Коэффициент ранговой корреляции т Кендэла определяется как
т= сумма баллов у 2)
-ул(л—1)
Знаменатель на самом деле равен максимально возможному числу
баллов, которое будет начислено в том случае, когда имеется полное
согласие между ранжировками. Заметьте, что т должно удовлетворять
соотношению —Фактически т обладает свойствами, анало-
гичными свойствам rs. Например, при выполнении гипотезы Нх о не-
зависимости мы должны ожидать примерно равного числа значений
+ 1 и —1, поэтому мы можем ожидать, что сумма очков будет около
0. Критическая область размера а для проверки Н\ против альтерна-
тивы Н2 относительно зависимости переменных имеет вид
А2={ наблюдения: |т|>са}.
Для определения константы са существуют таблицы точного распре-
деления т при выполнении гипотезы Н\ [см., например, Siegel (1956),
табл. Q, с. 285; Owen (1962), табл. 13.1, с. 396—399]*.
Для п ^10 мы можем воспользоваться тем фактом, что при спра-
ведливости 771 т имеет приближенно нормальное распределение** со
средним 0 и дисперсией, равной
2(2л + 5)
9л(л—1) ’
При наличии связей в наших ранжировках мы должны переопределить
т в (14.9.2). В нашей системе баллов мы припишем 0 любой паре из
одинаковых рангов и определим коэффициент ранговой корреляции
следующим образом:
т__ сумма баллов
±{ л(л-1)~ Е ^-1)} 1/2{£ Sjis—l)}
где Т — число связок при ранжировании х-в, J-я связка состоит из tj
наблюдений (/=1, 2,...,7); аналогично S — число связок при ранжиро-
вании у-в, j-я связка содержит Sj наблюдений (/=1, 2,...,5).-
Пример 14.9.3 (продолжение примера 14.9.2). Здесь сумма баллов
равна 11, что дает значение 7=0,52. По таблицам найдем, что дости-
гаемый уровень значимости равен 2-0,068=0,14, так что снова на
5 %-ном уровне значимости нет оснований отвергать гипотезу Нх о не-
зависимости.
* Таблицу критических значений точного распределения статистики К, являющейся
числителем (14.9.2), для л=4(1)40 см. в книге М. Холлендера, Д. Вулфа (табл. А.21,
с. 393—402). Там же (гл. 8, с. 199—213) подробно рассматриваются коэффициент ранговой
корреляции Кендэла т и другие меры связи. Таблица критических значений К для
п=4(1)100 приводится в книге И. Ликеша, Й. Ляги (табл. 25, с. 314—318). — Примеч. пер.
“ Проблемы точности нормальной аппроксимации при наличии связок обсуждают-
ся в ряде работ, перечисленных на с. 207 книги М. Холлендера, Д. Вулфа. Погрешности
аппроксимаций при наличии связок, как правило, велики, так что лучше табулировать
точное распределение для различных вариантов связок. — Примеч. пер.
140
14.10. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Книги, посвященные статистическим выводам, часто включают
раздел о свободных от распределения (непараметрических) методах
[см., например, Silvey (1975), гл. 9—С]. Кроме того, как указывалось
в разделе 14.1, существует множество специальных работ. Лучшие из
них перечислены ниже. Работа [Neave (1978)] содержит таблицы, отно-
сящиеся к материалу этой главы. Она может служить очень полезным
пособием.
Kendall М. G. (1962). Rank Correlation Methods, Griffin, London.
Hollander M., Wolfe D. A. (1973). Nonparametric Statistical Methods. New
York: Wiley.
Lehmann E. L. (1975). Nonparametrics: Statistical Methods Based on Ranks. San
Francisko: Holden-Day.
Mann H. B., W h i t n e у D. R. (1947). On a Test of Whether One of l\vo Random
Variables is Stochastically Larger than the Other. — Ann. Math. Statist., v. 18, p. 50—60.
Massey F. J. (1952). Distribution Table for the Deviation Between Two Sample Cu-
mulatives. — Ann. Math. Statist, v. 23, p. 435—441.
Neave H. R. (1978). Statistical Tables. — London: G. Allen & Unwin.
Noether G. E. (1967). Elements of Nonparametric Statistics, New York: Wiley.
Siegel S. (1956). Nonparametric Statistics for the Behavioural Sciences. New York:
McGraw-Hill.
Walsh J. E. (1962). Handbook of Nonparametric Statistics, vol. I, V an Nostrand,
Princeton, N. J.
Walsh J. E. (1965). Handbook of Nonparametric Statistics, vol. II, V an Nostrand,
Princeton, N. J.
Walsh J. E. (1968). Handbook of Nonparametric Statistics, vol. Ill, V an Nostrand,
Princeton, N. J.
Wilcoxon F. (1945). Individual Comparisons by Ranking Methods. — Biometrics
Bulletin, vol. I, p. 80—83.
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Большее Л. Н., Смирнов Н. В. Таблицы математической статистики. —
М.: Наука, 1983. — 414 с.
Гаек Я., ШидакЗ. Теория ранговых критериев. — М.: Наука, 1971. — 376 с.
К е н д э л М. Ранговые корреляции. — М.: Статистика, 1975. — 214 с.
Колмогоров А. Н. Об эмпирическом определении закона распределе-
ния//К олмогоров А. Н. Теория вероятностей и математическая статистика. —
М.: Наука, 1986. — С. 134—141.
Л и к е ш И., Л я г а Й. Основные таблицы математической статистики. — М.:
Финансы и статистика, 1985. — 356 с.
Мюллер П., Нойман П., Шторм Р. Таблицы по математической ста-
тистике. — М.: Финансы и статистика, 1982. — 271 с.
Смирнов Н. В. Оценка расхождения между эмпирическими кривыми рас-
пределения в двух независимых выборках//С мирное Н. В. Теория вероятностей и
математическая статистика. — М.: Наука, 1970. — С. 117—127.
Тюрин Ю. Н. Непараметрические методы статистики. — М.: Знание, 1978. — 64 с.
141
Хеттманспергер Т. Статистические выводы, основанные на рангах. — М.:
Финансы и статистика, 1987. — 334 с.
Холлендер М., Вулф Д. Непараметрические методы статистики. — М.:
Финансы и статистика, 1983. — 518 с.
Ш е ф ф е Г. Дисперсионный анализ. — 2-е изд. — М.: Наука, 1980. — 512 с.
Conover W. J. Rank tests for one sample, two samples and К samples without the
assumption of a continuous distribution function. — Ann. Statist., 1973, v. 1, N 6,
p. 1105—1125.
Iman R. L., D a v e n p о r t J. M. New approximations to the exact distribution at the
Kruskal—Wallis test statistic. — Commun. Statist., 1976, A5, p. 1335—1348.
Iman R. L. Use of t-statistic as an approximation to the exact distribution of the
Wilcoxon signed rank test statistic. — Commun. Statist., 1974, v. 3, p. 795—806.
Iman R. L. An approximation to the exact distribution of the Wilcoxon—Mann—
Whitney rank sum test statistic. — Commun. Statist., 1976, A5, p. 587—598.
Wilcoxon F., К a t t i S. K., Wilcox R. A. Critical values and probability
levels for the Wilcoxon rank tests. — In: Selected tables in mathematical statistics, v. 1/2-d ed.
H. L. Harter, D. B. Owen, eds. — Providence, R. I.: Am. Math. Soc., 1973, p. 171—235.
Глава 15
БАЙЕСОВСКИЙ ПОДХОД В СТАТИСТИКЕ
15.1. ВВЕДЕНИЕ
В этой главе мы попытаемся получить ответы на следующие
вопросы.
Что такое байесовские методы и в чем их отличие от других стати-
стических методов?
Допустимо ли применение байесовских методов для всех типов ста-
тистических задач?
В чем отличие результатов, полученных с помощью байесовских
методов, от результатов, полученных другими методами?
В действительности даже на первый из этих вопросов нет вполне
однозначного ответа. Никакого руководства, в котором бы точно ука-
зывалось, какие методы должны и какие не должны рассматриваться
в качестве байесовских, не существует. Те, кто мог бы считаться ста-
тистиками «байесовского» направления, имеют разные точки зрения
по этому поводу как в методологическом, так и в практическом аспек-
тах. Тем не менее очевидно, что необходимо выделить некоторые об-
щие категории (положения). Приступим к этому исходя из
следующего утверждения: байесовскими методами являются мето-
ды, разработанные в результате систематических попыток сформу-
лировать и решить статистические проблемы на основе теоремы
Байеса.
Начнем с детального изучения теоремы Байеса как в дискретном
[см. раздел 15.2], так и в непрерывном [см. раздел 15.3] случаях.
В теореме выражено соотношение между различными вероятностя-
ми, и спецификация каждой из них служит предпосылкой к ее исполь-
зованию. При рассмотрении некоторых простых примеров выявляет-
ся, что готовность статистиков систематически пользоваться теоре-
мой Байеса зависит, по существу, от того, из какой концепции в
интерпретации понятия вероятности они исходят. Те статистики, для
кого «узаконено» рассмотрение вероятности как меры «степени дове-
рия» [см. de Finetti (1974, 1975)], которая может быть определена для
любого неопределенного реального объекта, не видят препятствий в
систематическом применении теоремы Байеса. В то же время стати-
стики, которые единственно законной считают частотную интерпре-
тацию вероятности [см. II, гл. 2], ограничивают возможность исполь-
143
Рис. 15.1.1. Основная байесовская парадигма
зования теоремы Байеса
только теми ситуациями,
когда определение вероят-
ностей может основываться
на наблюдаемых частотах.
Таким образом, ответ на
второй из поставленных на-
ми вопросов частично зави-
сит от того, можно ли в
каком-либо смысле под-
твердить заявления, что
степени доверия могут и
должны рассматриваться в
качестве вероятностей и им
могут присваиваться число-
вые значения. Эти пробле-
мы обсуждаются в гл. 19*.
Многие статистические задачи независимо от методов их решения
обладают общим свойством: до того как получен конкретный набор
данных, в качестве потенциально приемлемых для изучаемой ситуации
рассматривается несколько вероятностных моделей; после того как
получены данные, возникает выраженное в некотором виде знание об
относительной приемлемости этих моделей.
Отличие байесовской парадигмы [см. разделы 15.2—15.4] от дру-
гих статистических подходов состоит в том, что до того, как будут
получены данные, статистик рассматривает степени своего доверия к
возможным моделям и представляет их в виде вероятностей. Как
только данные получены, теорема Байеса позволяет статистику рас-
считать новое множество вероятностей, которые представляют пере-
смотренные степени доверия к возможным моделям, учитывающие
новую информацию, поступившую благодаря данным. На рис. 15.1.1
схематически суммируется процесс, лежащий в основе байесовской ме-
тодологии при заданном множестве возможных данных.
Согласно стандартной терминологии первоначальные вероятности
принято называть априорными вероятностями (так как они принима-
ются прежде, чем получены данные), а пересмотренные вероятности
— апостериорными (так как они вычисляются после получения дан-
ных). Конечно, понятия «априорный» и «апостериорный» относятся к
конкретному множеству данных; сегодняшние представления являют-
ся апостериорными по отношению к вчерашним данным, априорными
— к завтрашним.
* Иной взгляд на концепцию субъективных вероятностей и на спор по поводу ча-
стотной и субъективистской вероятностных концепций кратко сформулирован в книге:
Айвазян С. А., Енюков И.С., Мешалкин Л. Д. Прикладная статистика:
Основы моделирования и первичная обработка данных. — М.: Финансы и статистика,
1983. — С. 48—49. —Примеч. ред.
144
Чтобы ответить на третий из вопросов, поставленных в начале
главы, следует рассмотреть:
а) конкретные формы вывода, такие, как точечное или интерваль-
ное оценивание [см. раздел 3.1], и идеи более общего характера, отно-
сящиеся к понятию достаточных статистик [см. раздел 3.4];
б) необходимость технических упрощений и приближений для того,
чтобы стало возможным использовать парадигму для получения чис-
ловых результатов;
в) подробный, основанный на байесовской парадигме анализ ситуа-
ций, включающих стандартные вероятностные модели, такие, как би-
номиальное, пуассоновское и нормальное распределение [см. разделы
5.2.2, 5.4 и 11.4].
Пункт а) будет подробно разобран в разделе 15.4, пункт б) рассмат-
ривается в разделе 15.3.5. В разделе 15.5 обсуждается байесовский ана-
лиз некоторой стандартной одномерной модели, а в разделе 15.6
изложены основные идеи байесовской статистики в многопараметриче-
ских ситуациях. Соответствующая литература приведена в разделе 15.7.
15.2. ТЕОРЕМА БАЙЕСА: ДИСКРЕТНЫЙ СЛУЧАЙ
15.2.1. ЗНАНИЯ, ИЗВЛЕКАЕМЫЕ ИЗ ЕДИНСТВЕННОГО
МНОЖЕСТВА ДАННЫХ
Предположим, что статистик рассматривает конечный список
моделей
чтобы составить исчерпывающее множество возможных взаимоис-
ключающих вероятностных моделей, пригодных для описания кон-
кретной изучаемой ситуации.
Далее допустим, что до того, как были получены данные, стати-
стик присваивает этим моделям значения априорных вероятностей
[см. раздел 15.1]:
[Р(МХ), Р(М2),...,Р(Мк)],
где 0^P(Mj)^\, и
P(Mi) + P(M2)+-... + Р(Мк) = \.
Каждая вероятностная модель определяет распределение вероятно-
стей множества возможных данных, которые можно было бы полу-
чить. В частности, если обозначить данные, полученные в
действительности, как D, то вероятности данных, определяемых каж-
дой из альтернативных моделей, будут задаваться с помощью услов-
ных вероятностей [см. II, раздел 3.9.1]
{P(D | М.), P(D | Л/2),..., P(D | Мк)\.
145
Эти величины часто называют правдоподобиями Mi при заданных D
[см. разделы 3.5.4 и 4.13.1], когда их рассматривают в терминах
[М{, М2,...,Мк] при заданных D.
Рассматривая исчерпывающее множество взаимоисключающих ве-
роятностных моделей и полученные данные D, статистик специфици-
рует множество априорных вероятностей совместно с множеством
правдоподобий. Это позволяет ему пересмотреть свои априорные ве-
роятности в свете информации, содержащейся в данных. В математи-
ческом выражении это означает, что он пересчитывает вероятности
[Р(М, | D), Р(М2 | £>),..., Р{Мк | D)}
для альтернативных моделей, условно зависящие теперь от данных
наблюдений D. Математическим результатом, с помощью которого
выражаются эти апостериорные вероятности [см. раздел 15.1] в тер-
минах априорных вероятностей и правдоподобий, является теорема
Байеса [см. II, раздел 16.4], которую можно сформулировать в следу-
ющем виде для рассматриваемой ситуации.
Теорема 15.2.1, Теорема Байеса (дискретный вид). Если
[Mlf М2,...,Мк] — исчерпывающее множество взаимоисключающих
вероятностных моделей и априорные вероятности [Р(Мд, Р(М2),...,
Р(Мк)] и правдоподобия [P(D | М{), P(D | M2),...,P(D | Мк)] определе-
ны так, что P(D) > 0, то апостериорные вероятности задаются как
/=1>2...
где
P(D)=P(D | MdP(Md+P(D | М2)Р(М2)+... + Р(£> | Mk)P(Mk).
Доказательство. По определению условной вероятности [см. II,
раздел 3.9.2]
Р(М, | Г>)Р(Р)=Р(М,. U D)=P(D | М,)Р(М,),
откуда непосредственно следует искомый результат.
Выражение для P(D) определяется просто формулой полной веро-
ятности [см. II, раздел 16.2].
Пример 15.2.1. В некотором «царстве животных» генотипам ВВ и
ВЬ соответствуют животные с черной окраской, генотипам bb — с ко-
ричневой, а при всех спариваниях неизменно получают помет из семи
детенышей. Черное животное, о котором известно, что оно получи-
лось в результате спаривания ВЬ*ВЬ, само спаривается с коричневым
животным, и оказывается, что все семь детенышей — черные.
146
Каковы вероятности того, что черный родитель имеет генотип ВВ
или ВЬ соответственно?
Если обозначить М\ модель, в которой предполагается тип ВВ, а
М2 — модель, по которой предполагается тип ВЬ, и если допустить,
что D обозначает наблюденные данные (семь черных детенышей), то
требуется определить Р(М\ | D) и Р(М2 | D). Так как в этом случае
[Mlt М2] — исчерпывающее множество взаимоисключающих моделей,
можно применить теорему Байеса при условии, что мы можем специ-
фицировать [Р(М^, Р(М2)] и [P(D | A/,), P(D | M2)].
Начнем с рассмотрения именно этих последних величин.
Когда задана модель спаривания М{, а именно ВВ*ЬЬ, все потом-
ство обязательно будет относиться к типу ВЬ (от каждого из родите-
лей получено по одному гену), и поэтому P(D | A/,) = l. Если задано
спаривание М2, т. е. ВЬ * ЬЬ, то законы Менделя устанавливают, что у
каждого отпрыска имеется независимо от остальных вероятность у
унаследовать тип ВЬ. Отсюда следует, что P(D | М2) = (-^-)7 = . Те-
2 128
перь рассмотрим априорные вероятности Р(М}) и Р(М2). Согласно за-
конам Менделя спаривание ВЬ х ВЬ родителей черного животного при-
водит к появлению потомства типов ВВ, ВЬ и ЬЬ с вероятностями
у, у и у соответственно. Величины Р(М\) и Р(Л/2) обозначают веро-
ятности типов ВВ и ВЬ, когда задано, что получается один из них (на-
помним, что мы рассматриваем черного родителя). Отсюда следует,
1 2
что Р(Л/])= у, Р(Л/2) = у, так как
1 1
Р(М,)= , Р(М2)= .
2 +4 2 +4
Применяя теорему Байеса, получаем
P(D\Mt)P(M,) 1'3" 64
Р(МХ D) = ------------------------ = —;----:—т— - — .
P{D | + P(D | M2)P(M2) 1T+4f’3 65
Так как P(M2 | D)=\—P(Ml | D), то
Р(М21 D) = -1_ . .
Конечно, этот последний результат можно было бы получить, непо-
средственно применяя теорему.
Пример 15.2.2. Давайте рассмотрим такую же задачу, как и в при-
мере 15.2.1, за исключением того, что теперь известно, что черный ро-
дитель появился в результате спаривания типов ВВ*ВЬ.
147
Используя те же обозначения, мы по-прежнему имеем P(D | =
Р(Р | М2) = —при рассмотрении только конечного черно-коричне-
128
вого спаривания.
Однако величины P(Mi) и Р(М2) теперь меняются. Согласно зако-
нам Менделя при спаривании ВВ*ВЬ, которое приводит к появлению
черного родителя, тип ВВ будет появляться с вероятностью у, а тип
ВЬ — также с вероятностью у. Таким образом, получим, что
Р(М,) = Р(М2)=у,
™ Р(Р I М})Р(М,) 14" 128
Р (Л*/ ] D) — — ] j j — ,
P(D | + P(D | M2)P(M2) 1 2 + T28- -T 129
а Р(Мг | G) = 1-P(M, I D) =
Оба эти примера хорошо иллюстрируют особенности ситуации,
когда априорные вероятности, основанные на частотах, имеются в
распоряжении (законы Менделя получили исчерпывающее эксперимен-
тальное подтверждение). Они также показывают, как изменение апри-
орных вероятностей модифицирует апостериорные вероятности, даже
если данные (и, следовательно, правдоподобия) остаются теми же.
Пример 15.2.3. Давайте на этот раз предположим, что нам неиз-
вестно, какое из спариваний — ВЬ*ВЬ или ВВ *ВЬ — привело к появ-
лению черного родителя (хотя мы знаем, что именно одно из них).
Можем ли мы теперь присвоить значения Р(Л/,) и Р(Мг)1 Если
обозначить через Gt спаривание ВЬ*ВЬ, а через G2 — спаривание
ВВ*ВЬ, то может показаться, что нужно воспользоваться теоремой
полной вероятности [см. II, раздел 16.2], чтобы записать
P(M,) = P(Mt | G])P(Gi)+P(Mi | G2)P(G2),
P(M2) = P(M2 | G,)P(G1)+P(M2 j G2)P(G2).
Из примера 15.2.1 имеем
P(M, |G,)=p P(M2|G,)=|,
а из примера 15.2.2 —
р(м, |g2)=1, нм, | G2)=|.
Поэтому проблема сводится к присваиванию значений P(GJ и P(G2),
и именно в этом месте начинаются противоречия.
48
В разделе 15.1 говорилось о различиях в мнениях относительно
правильного использования понятия вероятности: в частности, было
обращено внимание на частотную интерпретацию и интерпретацию,
основанную на степени доверия. В контексте данного примера стати-
стики, приверженные к той или другой из этих интерпретаций, могли
бы привести следующие доводы.
Частотная интерпретация. Без каких-либо знаний относительно
механизма, в соответствии с которым происходит неизвестное спари-
вание Gi или G2, невозможно осуществить основанное на частотных
представлениях присваивание вероятностей P(G]) и P(G2). Из-за этого
невозможно провести основанное на знании частот присваивание зна-
чений P(Mi) и Р(М2). Таким образом, теорема Байеса оказывается не-
применимой, когда дело касается подобной проблемы статистичес-
кого вывода.
Интерпретация, основанная на степени доверия. Все вероятности
являются в своей основе представлениями степени доверия. Поэтому
P(G,) и P(G2) можно присвоить значения, чтобы отразить суждения
об относительной возможности обоих типов спаривания. Например,
если нет никакой информации, за исключением того, что произошло
либо Gi, либо G2, то спецификация
P(G,)=y. P(G2) = y
могла бы представлять интерес для статистика в качестве представле-
ния «неведения» и привела бы к
5
12 ’
2
Р(М2) =
L.X. _L._L
3 2 + 2 2
7
12 '
Подставляя эти величины в теорему Байеса, получим:
640
Р(М. । D) = । -------= - fr , _
P(D | Л/,)Р(М,) + P(D | M2)P(M2) 1 • ft + iT8 ’if 647
при этом
P(M2|D)=1-P(M, |z>)=-2
149
При сравнении этого примера с двумя предыдущими видно, на-
сколько ограниченной становится возможность применения теоремы
Байеса, когда законными считаются только вероятности, основанные
на частотной интерпретации. Это служит подтверждением утвержде-
ния из раздела 15.1, что для систематического применения теоремы
Байеса в качестве инструмента статистического анализа необходима
готовность выразить все виды априорных суждений в виде вероятно-
стей независимо от того, существует ли частотная интерпретация этих
вероятностей.
Еще один важный вывод, вытекающий из сравнения примеров
15.2.1 и 15.2.2 с примером 15.2.3, состоит в следующем. В первых
двух примерах априорные вероятности Р(Л/,) и Р(Л/2) могут сравни-
ваться как «объективные», поскольку между учеными существует со-
гласие относительно приемлемости установленных значений. В
примере же 15.2.3 мы неизбежно оказываемся вовлеченными в
«субъективное» оценивание P(G]) и P(G2); как правило, в нашем рас-
поряжении нет данных, и эти оценки неизбежно становятся предметом
индивидуального суждения. Для иллюстрации были использованы
значения P(Gi)=P(G2) = у. Очевидно, что такой выбор обладает не-
которой привлекательностью и означает «установку на неведение» от-
носительно предпочтений G, и G2; однако если у кого-либо возникает
индивидуальное «предчувствие» в пользу, например, Gb то этим вели-
чинам можно было бы предпочесть другие.
В общем, суть дела в том, что если допускается использование ве-
роятности в качестве представления индивидуальных предположений
(суждений), то после этого нельзя говорить о «корректном выборе»
априорных вероятностей. Сделанный выбор зависит от индивида и от
информации, которой он располагает к этому времени. В тех случаях,
когда индивиды располагают большим количеством общей информа-
ции, их представления о значениях «априорных» вероятностей часто
совпадают или близки, и тогда возможна «объективная» согласован-
ность. Если строго определенной информации мало, то субъективное
оценивание может различаться, и тогда становится невозможным
«объективное» единодушие.
15.2.2. ЗНАНИЯ, ИЗВЛЕКАЕМЫЕ ИЗ НЕСКОЛЬКИХ
МНОЖЕСТВ ДАННЫХ
Предположим, что, как и в разделе 15.2.1, имеется исчерпывающее
множество взаимоисключающих моделей [Мх, а также за-
данные вероятности [Р(МХ), Р(М^,...,Р(М0}. Однако данные на этот
раз получены в два этапа, что выражается в наличии двух множеств
данных Dx и D2.
150
Если их просто скомби-
нировать и образовать од-
но множество, обозначае-
мое как D-D{ (J D2i то,
задавая вид правдоподобий
[P(D\Ml), P(D\M2),...,
P(D | M0], можно продол-
жить рассмотрение таким
же образом, как в предыду-
щем разделе, чтобы полу-
чить апостериорные вероят-
ности [Р(М{ | D), Р(М2 | D),
..., Р{Мк | £))]. Однако во
многих практических ситу-
ациях данные поступают
последовательно, так что
D\ появляется раньше, чем
D2, и мы хотим сначала
проанализировать наши
вероятности в свете Dit
а позднее пересмотреть их в
бражен на рис. 15.2.1.
Рис. 15.2.1. Поэтапное изучение с использо-
ванием теоремы Байеса
свете D2. Схематически этот процесс изо-
С точки зрения здравого смысла у нас есть надежда прийти к оди-
наковым конечным апостериорным вероятностям P(Mt | Dx U Z>2),
z = 1,2,...Л, независимо от того, поступили ли данные D=DX (J D2 все
одновременно и теорема Байеса применялась один раз или два, как на
рис. 15.2.1.
Действительно, легко проверить математически, что этот резуль-
тат, основанный на здравом смысле, вполне правильный.
Предположим, что у нас имеются наблюдения D{, и первый этап,
изображенный на рис. 15.2.1, завершен. Тогда, вспомнив, что все
«входы» изображенного на рисунке второго этапа условны по Du по-
лучим необходимые для применения теоремы Байеса на втором этапе
величины:
[PM \D^...,P(Mk\D^
вероятности моделей, апри-
орные по отношению к D2,
и
[P(D2 | Mi P| Di),...,P(D2 I Mk P Z>i)}, правдоподобия, используе-
мые на втором этапе.
151
Пользуясь теоремой Байеса, получим:
P{Mi | Dx U А) =
Р(Рг\М^Рх)Р(МДР})
РФ11Dx)
(/=1,2,
Л),
где
Р(Р2 | DX)-P(D2 I М, П D^P(MX | £>,) + ...
+ P(Z>2 I Mk П Dx)P(Mk I D,}.
Однако в результате применения теоремы Байеса на первом этапе
имеем:
Р(М, | £>,) =
P(D, I MJPjMD
P{DX)
(/=1,2,...Л).
Подставляя это выражение в выражение для P(MZ | Dx Z>2),
получим:
Р(М,- | Dt J D2) =
Р(Р2 I и П PX)P(PX I
P(D2 I PX)P(PX)
(/=1,2,
Л),
P(DX Ц P2 I М,)Р(М)
P(DX U P2)
(Z= 1,2,...,£).
Но к такому же результату приводит и однократное применение тео-
ремы Байеса для объединенного множества данных D-Dx |J D2. Сле-
довательно, искомый результат получен.
Отметим еще два момента:
а) как схему, изображенную на рис. 15.2.1, так и проведенные мате-
матические рассуждения можно обобщить на любое число этапов
(порций данных);
б) часто встречаются ситуации, когда множества данных Dx и D2,
условно зависящие от каждого из Mit содержат независимую инфор-
мацию, такую, что P(D2 | Л/,- р| Z>I) = P(Z>2 | Л/,-). Это упрощает вы-
числения.
Пример 15.2.4. При предварительном медицинском обследовании
пациента обнаружено, что он находится в одном из взаимоисключаю-
щих медицинских состояний М]у М2 и М3, каждое из которых первона-
чально оценивается как равновероятное. При дальнейшем
обследовании выявилось наличие симптома X (данные Dx) и симптома
Y (данные £>2), о которых известно, что они существуют независимо
друг от друга, если задано какое-либо конкретное медицинское состоя-
ние. Имеются многочисленные прошлые записи, позволяющие врачам
рассчитать P(Dj | Л/,) для j= 1,2 и /=1,2,3. Ниже суммируются полу-
ченные результаты:
152
M} м2 м3
Di 0,5 0,7 0,8
D2 0,5 0,25 0,9
Используя эти значения, можно рассмотреть вероятности состояний
Mi, М2, Mi, взяв сначала Dx, а затем на втором этапе включив D2.
С помощью теоремы Байеса на первом этапе получим:
Р(М, | 7)0=---—------ (/=1,2,3),
где
Р(7),)=Р(7)1 | Mi)P(Mi) + P(Di | M2)P(M2) + P(Di I Л73)Р(Л73) =
_ _5_ _L 2_ J_ I 1-1
~ io' з + io ’ з + io ’ з ~ з ’
Отсюда
5_.-L
P(Mi |7),) = =0,25,
2__L
Ж I />,)= = J =0,35,
J-.J. .
)=-!»’ =±=0,40.
На втором этапе, учитывая независимость 7), и Т)2 при заданных Мь
запишем теорему Байеса в виде
wulnllm Р(Р; I I о,> ....
Р(М(|Р,иад =-------7^-^------ 0 = 1,2,3),
где
P(D2 | Т),)=Р(Т)2 | Mi)P(Mi | Di) +
+ Р(Т)2 | М2)Р(М2 | Т)1) + Р(Т)2 | М3)Р(М1 | 7)0 =
= io _5_ А.2_
“ 20 20 + 20 20 + 20 20 ~ 400‘
153
Рис. 15.2.2. Последовательный пересмотр P(Mj | данные)
В результате получим:
Р(М21 О, U D2)=(:i.Z)/(^) = 2L=0,153,
\ 2 1 i и 2/ \ 20 20' 4007 229
Р(М3 | U Z>2)=( •^)/@ = 4S’=0’629-
v л 2/ V 20 207 4007 229
Пересчет этих вероятностей по мере увеличения количества информа-
ции продемонстрирован на рис. 15.2.2.
15.2.3. ТЕОРЕМА БАЙЕСА, ВЫРАЖЕННАЯ
В ТЕРМИНАХ «ШАНСОВ» (odds)
В обозначениях раздела 15.1 простую версию теоремы можно
представить в виде
. | W I W(M,)
P(Mi | D)=
или кратко
P(MZ I D) « P(£) I
154
так как P(D) не включает явно агрумент Mj. Другими словами,
апостериорная
вероятность
пропорциональна J правдоподобие х
априорная
вероятность
Это выражение дает некоторую возможность понять, как форми-
руется влияние ингредиентов на апостериорную вероятность. Однако
существует альтернативная форма записи теоремы, которая, очевид-
но, в большей степени способствует пониманию этого.
Если рассматривать только две альтернативные модели, например
Mi и М2, то по теореме Байеса
P(Mt | D) _ P(D | Mi) P(Mi)
P(M2 I 5) “ P(D I M2)' P(M2) ‘
Теперь, назвав для любого события А отношение Р(Л)/(1—Р(Л))
шансами А, написанное выше выражение можно представить так:
/ апостериорныеХ / отношение X / априорные X
( шансы у ~ ( правдоподобия J х ( шансы 1
При таком способе записи видно, каким образом отношение правдо-
подобия играет основную роль в преобразовании относительного
априорного доверия к двум моделям в относительное апостериорное
доверие.
В некоторых отношениях логарифм шансов оказывается более
удобным инструментом для измерения относительных показателей
доверия. Применительно к предыдущей записи получим выражение
/апостериорныеХ / отношение X
log ( ) = log I + log
\ шансы / управдоподобия/
априорные
шансы
При пользовании масштабом логарифмических шансов отношение
правдоподобия ведет себя как аддитивное преобразование априорных
характеристик доверия в апостериорные.
155
15.2.4. ОБОБЩЕНИЕ НА СЛУЧАЙ БЕСКОНЕЧНОГО СПИСКА
ВОЗМОЖНЫХ МОДЕЛЕЙ
В разделе 15.2.1 предполагалось, что набор возможных вероят-
ностных моделей, подлежащих изучению, можно записать в виде ко-
нечного списка [Mi, М2,...,Мк].
В действительности все результаты, полученные при конечном
списке, можно легко перенести на случай бесконечного списка возмож-
ных моделей [Мь М2,...]. Если заданы априорные вероятности P(Mj),
/=1,2,..., такие, что EP(MZ)=1 при правдоподобиях P(D\Ml),
/= 1,2,..., то для заданного множества данных D теорема Байеса при-
нимает вид
ЛЧ | Р)=
P{D I
Р(Р)
/=1,2,...,
где
P(P)=^P(D | М-)Р(МХ
j= i J J
Доказательство осндвано непосредственно на тех же аргументах, ко-
торые использовались при конечном списке.
Пример 15.2.5. Чтобы увидеть, каким образом может возникнуть
бесконечный список возможных моделей, рассмотрим следующую си-
туацию. Предположим, известно, что число X телефонных звонков,
раздающихся в минуту на коммутаторе, является случайной перемен-
ной пуассоновского типа [см. И, раздел 5.4], среднее значение, 0, кото-
рой есть неизвестное целое положительное число. Тогда, если данные
D состоят из наблюдения Х=х, то получится бесконечный список воз-
можных моделей [МХ,М2,...], генерирующих правдоподобия
P(D | А/,), /=1,2,..., пуассоновского типа, где Mi соответствует моде-
ли 0=i, i=l,2,... .
15.3. ТЕОРЕМА БАЙЕСА: НЕПРЕРЫВНЫЙ СЛУЧАЙ
15.3.1. ВИД ТЕОРЕМЫ БАЙЕСА В НЕПРЕРЫВНОМ СЛУЧАЕ
В предыдущем разделе мы обсуждали приемлемый вид теоремы
Байеса, когда множество рассматриваемых возможных моделей мож-
но представить в форме конечного или бесконечного списка. Однако
во многих случаях существует континуум таких моделей, и поэтому
дискретное представление их в форме списка невозможно. Примеры
такой ситуации:
156
а) случайная переменная X имеет биномиальное распределение [см.
II, раздел 5.2.2], соответствующее п испытаниям с неизвестными шан-
сами на успех в при каждом испытании; если единственное ограниче-
ние на параметр в состоит в том, что 0^0^ 1, то множество
возможных моделей отождествляется с множеством [0;О^0^1] всех
возможных значений параметра;
б) если рассматривать X, определенную в примере 15.2.5, но при
этом предположить только, что параметр 0 положительный, то мно-
жество всех возможных моделей снова будет соответствовать множе-
ству всех возможных значений параметра; в этом случае множество
имеет вид действительной прямой с положительными значениями
[0;0€R+1;
в) по определению случайная переменная X имеет нормальное рас-
пределение с неизвестным средним /г и неизвестной дисперсией а2; если
не существует ограничений на значения этих параметров, то множе-
ство возможных моделей соответствует множеству [д.а2; /z€R; c/eR ].
Каждый из этих примеров является частным случаем следующей
общей ситуации: случайная переменная X имеет распределение вероят-
ностей, определенное в терминах неизвестного параметра 0, который
принадлежит к определенному множеству возможных значений пара-
метра 0.
Распределение X может оказаться дискретным или непрерывным,
а X или 0 либо обе величины одновременно могут характеризоваться
вектором значений; в любом случае будем использовать форму записи
р(х | 0) для обозначения правдоподобия [см. разделы 3.5.4, 6.2.1] от-
дельного значения параметра 0, если задано, что наблюдается Х=х\
когда р(х | 0) рассматривается как функция х при заданном 0, то оно
может восприниматься как функция «вероятностных масс», т. е. как
полигон вероятностей или как плотность распределения вероятностей
в зависимости от того, является X дискретной или непрерывной пере-
менной.
Априорные вероятности для множества возможных моделей соот-
ветствуют в общем случае распределению вероятностей на множестве
0 возможных значений параметра; так как 0 будет интервалом на
действительной прямой, или областью на плоскости, или в некотором
пространстве большего числа измерений, размерность которого зави-
сит от размерности параметра, то априорные характеристики доверия
(суждения) придется определить в виде априорной плотности веро-
ятности
/?(0), 0€0, такой, что (р(0) d0 = \.
ё
Получив в распоряжение данные Х-х, мы хотим пересмотреть
априорное распределение и получить апостериорную плотность веро-
ятностей р(0 | х), 0€0. Результат, с помощью которого устанавливает-
ся связь между р(0 I х), р(х | 0) и р(в) выглядит следующим образом.
157
Теорема 15.3.1. Теорема Байеса (непрерывный случай). Если О —
множество возможных значений параметра с р(0), 0€О — априорной
плотностью вероятностей на множестве О и если р(х I 0) обознача-
ет правдоподобие 0 при заданных наблюдениях Х-х, то апостериор-
ная плотность вероятностей р(0 | х) задается выражением
р(в I «е,
' р(х)
где
р(х)- \ р(х | 0)p(0)d0.
о
Доказательство. В соответствии с определением условной плот-
ности вероятностей
v 1 * 7 р(х) Р(Х)
где р(х, 0) — совместная плотность [см. II, раздел 13.1.1]. Вид р(х)
вытекает из определения маргинальной (частотной) плотности [см. II,
раздел 13.2.1].
р(х) — \р(х, 0)d0- \р(х | 0)p(0)d0.
ё ё
Содержание теоремы Байеса в непрерывном виде легче всего запоми-
нается с помощью такого представления:
апостериорная \ / априорная
) пропорциональна (правдоподобие) х I
плотность / \ плотность
Символически это выражается следующим образом:
р(0 | х)оср(х | 0)р(0),
где, как и раньше, обозначения р(-), р(- | •) используются, чтобы пред-
ставить маргинальную или совместную плотность. При этом необхо-
димо понимать, что, например, р(0 | х) и р(х | 0) являются совершенно
различными плотностями.
Символ пропорциональности указывает, что в правой части выра-
жения пропущен сомножитель, не включающий 0. «Форма» р(0 | х)
определяется произведением р(х | 0)р(0), а отсутствующий сомно-
житель
[PW]”1 = [ \р(х | 0)p(0)d0]~l
е
служит для нормирования р(0 | х) таким образом, чтобы
I р(0 | x)d0 = 1.
е
158
Рис. 15.3.1. Возможные варианты формы кривых для р(0)
Для определения вида р(0) требуется некоторое обсуждение. Пре-
жде всего необходимо снова выделить утверждение, сделанное в раз-
деле 15.2.1. В данной задаче не существует такого понятия, как
«корректный выбор» р(0). Действительный выбор р(0) зависит от ин-
дивидуального представления в свете информации и опыта, имеющих-
ся в распоряжении статистика в данный момент времени.
Пример 15.3.1. На рис. 15.3.1 изображены возможные виды р(0)
для биномиального распределения с неизвестным параметром 0,
O^0s$l.
В случае а) представлено суждение, что все значения 0, 0 0 1,
рассматриваются как равно возможные в том смысле, что подинтер-
валам одинаковой длины присвоены одни и те же вероятности незави-
симо от того, где они расположены в пределах интервала от 0 до 1.
з
В случае б) представлено суждение, что [0 = —} является наиболее
вероятным значением, а вероятность события [0<— ] примерно в
з
пять раз больше, чем вероятность события [0>—], и т. д. (Напом-
ним, что априорная вероятность того, что 0 лежит в любом отдель-
ном интервале, определяется площадью под кривой плотности р(0) в
пределах этого интервала.)
; В случае в) представлено суждение, что значения 0, близкие к 0 и
1, гораздо более вероятны, чем значения в центре интервала.
15.3.2. ФОРМИРОВАНИЕ АПРИОРНЫХ ПЛОТНОСТЕЙ
Выше было установлено, что определение априорной плотности за-
висит от индивидуального опыта суждений. Это приводит к постанов-
ке весьма реалистичной проблемы: как превратить такие опыт и суж-
159
Рис. 15.3.2. Плотность р(0) как функция, сглаживающая данные о предыстории
дения в конкретный вид функции плотности вероятностей р(6). Эта
проблема подверглась исчерпывающему изучению как статистиками,
так и психологами, опубликовано множество теоретических и экспери-
ментальных работ, в которых сообщалось о результатах таких иссле-
дований. В статье Хэмптона, Мура и Томаса [см. Hampton, Moore and
Thomas (1973)] в удобной форме описаны эти результаты и содержит-
ся большой список литературы.
Среди многих возможных подходов следующие два подхода имеют
наибольшее значение.
7. Сглаживание данных о предыстории. Предположим, что произ-
водитель не уверен относительно доли в дефектных единиц при новом
производственном процессе. Однако он располагает гистограммой
[см. раздел 3.2.2], показывающей относительные частоты, с которы-
ми доля дефектных единиц попадала в различные интервалы, когда
внедрялось несколько очень похожих производственных процессов.
Подобная гистограмма изображена на рис. 15.3.2 вместе со сглажива-
ющей кривой, нормированной так, чтобы полностью содержать об-
ласть 1. Эта кривая могла бы служить вполне разумным
отображением априорного представления производителя о виде плот-
ности вероятности р(0).
Методика очень проста: мы стремимся получить сглаженную плот-
ность, которая отражает вид наблюдавшегося раньше распределения
частот. Однако даже в этом случае нельзя избавиться от субъектив-
ной, зависящей от характера суждений природы определения ее вида,
так как мы должны оценить соответствие и однородность данных о
предыстории по отношению к текущей проблеме.
160
2. Подбор кривой на основании суждений. При отсутствии доста-
точного объема подходящих данных о предыстории, которые позво-
ляют использовать подход (1), мы вынуждены пытаться выявить
наши представления с помощью процесса опрашивания самих себя.
Рассмотрим пример с производителем, внедряющим совершенно
новый тип производственного процесса. У него нет ощущения, что
прошлые данные, касающиеся долей дефектных единиц при процессах
других типов, непосредственно подходят к новому процессу.
Чтобы непосредственно выявить его представления относительно
в, доли дефектных единиц при новом процессе, можно использовать
процедуру следующего типа:
а) производителя просят задать верхний и нижний пределы, между
которыми, по его мнению, находится значение 0. На практике можно
было бы попросить его задать такие значения, для которых, как он
считает, существует только один шанс из ста, что может быть пре-
взойден хотя бы один из этих пределов. Определенные таким образом
значения позволят затем задать приближенно 1470-ную и 99%-ную
квантили его распределения [см. раздел 5.2.2 (обратные таблицы)];
б) после этого надо попросить производителя задать значение ме-
дианы (или 50%-ную квантиль) [см. раздел 14.2] его распределения.
Другими словами, надо спросить, чему равно значение в, которое у не-
го вызывает одинаковое ощущение риска, что доли дефектных изде-
лий окажутся либо больше, либо меньше этого числа;
в) получив значение медианы, которая делит его распределение по-
полам, производителя просят затем разделить распределение на чет-
верти, задавая таким образом 25%-ную и 75%-ную квантили.
Например, чтобы проделать это для 75%-ной квантили, попросим
производителя сконцентрировать внимание на тех значениях в, кото-
рые лежат между медианой и верхней границей, а затем выбрать та-
кое значение из этого диапазона, чтобы по его оценке вероятности в,
лежащих выше или ниже этого значения, оказались приблизительно
равными.
В конце опроса у нас будет пять точек, принадлежащих функции
распределения (ф.р.) в зависимости от 6, а именно 1%-, 5%-, 25%-,
50%-, 75%- и 95%-ные квантили. Чтобы получить разумную аппрок-
симацию субъективной функции распределения производителя, по ним
можно построить сглаженную кривую.
На рис. 15.3.3 показана такая функция, соответствующая следую-
щим (гипотетическим) выявленным точкам:
а) 0,05, 0,6; б) 0,2; в) 0,125, 0,3.
Соответствующая гистограмма для подынтервалов 0,05—0,1,
0,1—0,15 и т. д. показана на рис. 15.3.4 вместе со сглаженной аппрок-
симацией функции плотности распределения вероятности (п.р.в.).
161
Рис. 15.3.3. Гипотетическая субъективная ф.р.
р(0)
Рис. 15.3.4. Гистограмма и сглаженная п.р.в., соответствующая ф.р., изображен-
ной на рис. 15.3.3.
Мы рассмотрели процедуру формирования априорного распределе-
ния для одного параметра. Если априорное определение распределе-
ний отдельных параметров может проводиться независимо, то
определение совместного распределения для двух и более параметров
проводится непосредственно (так как в этом случае процедура сво-
162
дится к последовательности формирований одномерных распределе-
ний). Но если между параметрами существуют сложные зависимости,
то могут возникать значительные трудности. В разделе 15.6 рассмот-
рен один из аспектов этой проблемы.
15.3.3. ТЕОРЕМА БАЙЕСА ДЛЯ ЕДИНСТВЕННОГО
НЕИЗВЕСТНОГО ПАРАМЕТРА
Пример 15.3.2. Предположим, что два инженера А и В интересу-
ются значениями измеренной в соответствующих единицах разрушаю-
щей силы 9 материала, который ранее не подвергался систематичес-
ким лабораторным проверкам. Инженер А проводил в широком
масштабе исследования аналогичных материалов. Когда применялась
описанная в предыдущем разделе процедура подбора кривой на основе
суждений, она дала следующие результаты:
а) 450, 550, б) 500, в) 485, 515.
Примерные схемы ф.р. и соответствующей п.р.в., предполагаемые на
основании субъективно оцененных значений квантилей, позволяют об-
наружить, что с высокой степенью приближенности априорное рас-
пределение инженера А для 9 можно представить с помощью
нормального распределения со средним, равным 500, и стандартным
отклонением, равным 20. Будем далее обозначать его символически
как pA(9)=N (500, 20).
Инженер В не настолько хорошо знаком с материалами такого ти-
па, и когда его опрашивают в соответствии с процедурой выбора кри-
вой на основании суждений, отвечает следующим образом:
а) 215, 585; б) 400; в) 345, 455.
Легко видеть, что эти значения приводят к априорному распределе-
нию, которое хорошо аппроксимируется нормальным распределением
со средним, равным 400, и стандартным отклонением, равным 80. Бу-
дем его символически обозначать как pfl(0) = N (400, 80).
Предположим теперь, что обоим инженерам стал известен резуль-
тат эксперимента, в котором наблюдалось значение силы разрушения
х=450, и что оба считают это реализацией случайной переменной X,
нормально распределенной со средним 9 и стандартным отклонением,
равным 40. Поэтому инженеры принимают в качестве входного вида
правдоподобия в теореме Байеса выражение
163
Инженер А будет использовать ее вместе с априорной функцией плот-
ности анализируемого параметра
1 г 1 /0—500\21
а инженер В с
1 г 1 /0—400\21
рв(&)- V^8o ехр1 2 ( 80 ) 1’
Если определить в качестве стандартизованного правдоподобия от-
ношение
р(х | 0) _ р(х | 0)
Р(х) \р(х \d)p(O)dd ’
0
то на основании результатов из раздела 15.3.1 становится видно, что
теорема Байеса имеет вид
/ апостериорная\ /стандартизованное \ / априорная \
1 1 = 1 1 х 1 1
\ плотность / \ правдоподобие / \ плотность /
На рис. 15.3.5 — 15.3.7 показан приближенный вид функций апри-
орных плотностей, стандартизованного правдоподобия и апостериор-
ных плотностей для А и В. В случае А априорная плотность имеет
более сконцентрированный вид, чем стандартизованное правдоподо-
бие, и поэтому, когда эти функции перемножаются для получения апо-
стериорной плотности, априорная плотность доминирует, а
результирующая апостериорная плотность выглядит аналогично апри-
орной плотности. Все это отражает тот факт, что единственное до-
вольно неточное наблюдение не может оказывать большого
воздействия на априорные представления, имеющие довольно основа-
тельные подтверждения.
Однако в случае В более сконцентрированный вид имеет стандар-
тизованное правдоподобие, а не априорная плотность. Это приводит
к тому, что апостериорная плотность по виду гораздо больше похожа
на стандартизованное правдоподобие, чем на априорную плотность, и
отражает тот факт, что если априорные представления довольно раз-
мыты, то даже несколько неточное наблюдение будет вызывать ради-
кальный пересмотр априорных представлений.
164
Рис. 15.3.5. Априорные плотности для А и В
Рис. 15.3.6. Стандартизованное правдоподобие
Рис. 15.3.7. Апостериорные плотности для А и В
В действительности можно показать [см. раздел 15.5.3], что
pA(Q | x)=N (490, 17,9), a pB(Q | x) = N (440, 35,7). Сравнивая их вид с
соответствующими априорными плотностями, видим, что инженер А
мало узнал нового в результате эксперимента (в том смысле, что его
апостериорное представление не очень отличается от априорного пред-
ставления), в то время как инженер В обучился довольно многому (его
апостериорное представление в значительной степени отличается от
165
Рис. 15.3.8. Априорные плотности и стандартизованное правдоподобие при
100 наблюдениях
Рис. 15.3.9. Апостериорные плотности для А и В, полученные на основании 100
наблюдений
его априорного суждения). Все это иллюстрирует фундаментальный
принцип байесовского подхода: данные не создают представлений;
они скорее видоизменяют существующие представления.
С другой стороны, из рис. 15.3.8 и 15.3.9 видно, что в результате
появления данных наблюдений происходит сближение видов обоих
распределений, отражающих представления инженеров. Это движение
в направлении согласования мнений становится еще более заметным,
когда увеличивается количество данных. Предположим, что всего про-
ведено 100 независимых экспериментов, и в результате получилось,
166
что среднее значение наблюдаемой разрушающей силы х=470. Оно
может рассматриваться как реализация нормально распределенной
случайной переменной со средним 9 и стандартным отклонением
40/^100=4. Поэтому правдоподобие, получаемое в результате прове-
дения 100 экспериментов, имеет вид
₽(^)=^ехр[-1(^)2],
(приближенный) стандартизованный вариант которого показан на рис.
15.3.8 вместе с видом априорных плотностей рА(в) и рв{9). На рис.
15.3.9 изображены результирующие апостериорные плотности, при-
чем можно показать [см. раздел 15.5.3], что
рА{9 | x)=N(471,2; 3,9),
PBQ | x)=N(469,8; 3,995),
что практически не различается.
Рис. 15.3.5 — 15.3.9 хорошо иллюстрируют, каким образом вид
апостериорной плотности зависит от того, насколько пологий или пи-
кообразный (заостренный) вид имеет априорная плотность по сравне-
нию с теми же характеристиками кривой правдоподобия. Когда
имеется совсем немного данных, может оказаться, что априорная
плотность будет такой же заостренной, как и правдоподобие, и вид
апостериорной плотности будет отражать компромисс между априор-
ными предположениями и информацией, которую привносят данные.
Однако если в распоряжении имеется большой объем данных, то по
сравнению с очень узким пиком, характерным для кривой правдоподо-
бия, типичная априорная плотность будет казаться очень пологой. Так
как апостериорная плотность задается произведением стандартизован-
ного правдоподобия и априорной плотности, умножение на послед-
нюю скорее напоминает умножение на постоянную функцию (по
отношению к переменной 0), и форма, и расположение апостериорной
плотности будут почти полностью предопределяться видом правдо-
подобия.
15.3.4. ТЕОРЕМА БАЙЕСА ДЛЯ ДВУХ НЕИЗВЕСТНЫХ ПАРАМЕТРОВ
Пример 15.3.3. П. Рейли [см. Reilly (1976)] рассматривает данные,
приведенные в табл. 15.3.1, которые были получены с помощью ими-
тационной модели
logOy)=log(a + 0xz) + i=0,1,2,... ,5,
где е, — независимые, нормально распределенные с нулевыми средни-
ми и одинаковыми дисперсиями, равными (0,1398)2. Фактически значе-
ниями параметров, использованными при имитации, были а = 5, 3 = 2,
167
но Рейли анализирует данные при допущении, что а и 3 — неизвест-
ные параметры, значения которых должны быть выведены с по-
мощью теоремы Байеса. Если вектор наблюдений (у0, yif...t у5)
обозначить как у и опустить конкретную ссылку на заданные значения
х, то в этом примере можно записать теорему Байеса, игнорируя нор-
мализующую постоянную, в виде
р(а,/3 | у)«р(у | а,3)р(а,3),
где
Р(У I а,/3) п ^2i(0 1398) ехр[ 2(0,1398)2 а + рх,
«ехр[-25,58E[10g(^-)j2],
и р(а, 3) — совместная априорная плотность в соответствующей об-
ласти изменения значений.
Таблица 15.3.1
X 0 1 2 3 4 5
У 4,11 6,32 8,21 10,43 14,29 16,78
На рис. 15.3.10 представлены уровни постоянства совместной апо-
стериорной плотности р(а, (3 | у), соответствующие определению
р(а, 3) как равномерной функции плотности в диапазоне 2^ а ^7,
1С3^4. Изображенные уровни (изокванты) содержат (начиная с
внешнего контура) 99,9%-, 98,6%-, 74,6%- и 49,5%-ные области для
совместной апостериорной вероятности.
На рис. 15.3.11 изображены функции маргинальной апостериорной
плотности для ск и 3, определенные в виде
4 7
Р(« | У)= J Р(«,3 I УМЗ, р(3 | У)= J Р(а,3 | V)da.
1 2
В действительности в этом примере и при вычислении изоквант со-
вместной плотности, и при интегрировании совместной плотности для
получения маргинальных плотностей требуется тщательная численная
обработка, выполняемая с помощью компьютера. В статье Рейли опи-
168
2,0 2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 5,5
<х
Рис. 15.3.10. Изокванты Р(а,0|у)
Рис. 15.3.11. Маргинальные (частные) апостериорные плотности для а и /3
сывается в общих чертах вид грубой численной процедуры для осу-
ществления таких вычислений. В работе [Naylor and Smith (1982)] опи-
саны и проиллюстрированы более эффективные численные методы
интегрирования.
В разделе 15.4 обсуждаются возможные подходы, которые можно
было бы применить для суммирования информации, содержащейся в
апостериорных плотностях. Однако легко понять основной смысл со-
169
Рис. 15.3.12. Маргинальная апостериорная плот-
ность для у
держания рис. 15.3.11.
Начав с априорных пред-
ставлений, согласно ко-
торым все значения (а,0)
в диапазоне 2^»^ 7,
1 С 3 С 4 считаются в
равной мере возможны-
ми, после того как полу-
чено шесть наблюдений,
записанных в табл.
15.3.1, мы становимся
вполне уверенными, что
2,5 С 6, причем на-
иболее вероятное значе-
ние находится около
а=4, и что 1,5^3 С 3,5,
где наиболее вероятным
значением является
(8=2,4. Области неопре-
деленности несколько
сократились, но если
. число наблюдений мало,
то представления не станут еще достаточно сконцентрированными.
Когда спецификация модели включает два или больше параметров,
для практических целей часто представляет интерес изучение свойств
только одной из функций этих параметров. Например, в случае, кото-
рый рассматривался выше, нас мог интересовать параметр у=а/0.
Маргинальная апостериорная плотность р(у | у) находится из совмест-
ной апостериорной плотности р(а,0 | у) или с помощью обычных ме-
тодов преобразования переменных [см. II, раздел 10.71, если
преобразование можно выразить аналитически, или непосредственно
численными методами, которые предлагаются и разъясняются в ста-
тьях Рейли или Нейлора и Смита. На рис. 15.3.12 показан приближен-
ный вид, определенный из р(а,0 | у) численными методами.
15.3.5. ПРИБЛИЖЕННЫЙ АНАЛИЗ ПРИ БОЛЬШОЙ АПРИОРНОЙ
НЕОПРЕДЕЛЕННОСТИ
В разделе 15.3.3 мы видели, что ситуации с большой степенью
априорной неопределенности (по сравнению с объемом информации,
содержащейся в данных) в математическом смысле соответствуют
функции априорной плотности с относительно пологой формой в об-
ласти, где (стандартизованное) правдоподобие, соответствующее дан-
ным х, имеет остроконечную форму. Это может быть при экспери-
менте небольшого масштаба из-за большой разбросанности априор-
170
Рис. 15.3.13. Априорная плотность, по сравнению с которой правдоподобие
играет доминирующую роль
ных суждений или при очень крупном эксперименте с умеренно точны-
ми априорными представлениями. Подобная ситуация представлена
на рис. 15.3.13 для случая одного параметра 0.
Напомним, что теорема Байеса в краткой форме может быть пред-
ставлена как
апостериорная плотность = стандартизованное правдоподобие х априорная плотность.
Таким образом, если априорная плотность будет приближенно посто-
янной как функция 0 в диапазоне, где правдоподобие имеет сконцент-
рированный характер, то при относительно высокой степени
априорной неопределенности теорема Байеса приводит к приближен-
ному результату
р(9 | х) = р^х । ** р(х | 0),
!р(х I 9)d0
е
так как и в числителе, и в знаменателе появляется р(&) — приближенно
постоянная величина, которую можно сократить.
Можно видеть, что когда априорные суждения относительно сла-
бые, неопределенные, апостериорные суждения диктуются расположе-
нием и формой кривой правдоподобия. В частности, значением 0*
параметра 0, которое считается «наиболее вероятным», когда извест-
ны данные х, оказывается значение, максимизирующее правдоподобие
р(х | 0), а именно оценка максимального правдоподобия [см. гл. 6], ча-
сто используемая статистиками, придерживающимися небайесовского
подхода. 171
На основании полученных приближенных аргументов можно ска-
зать, что при высокой степени априорной неопределенности функция,
изображающая апостериорные суждения, будет иметь пик в области
оценки максимального правдоподобия в* параметра в. Действительно,
если мы сделаем несколько больше приближенных допущений, то уз-
наем не только расположение, но и форму функции правдоподобия, а
следовательно, и приближенной апостериорной плотности.
Чтобы лучше увидеть это, давайте вспомним, что на основании
приведенных выше доводов имеем приближенно
р(в | х)« exp[L(0)},
где
L(ff)=\og[p(x | 0)}.
Теперь предположим, что L(&) можно хорошо аппроксимировать пу-
тем разложения в ряд Тейлора [см. IV, раздел 3.6] в окрестности 0* с
точностью до квадратического члена разложения. Другими словами,
предполагается, что логарифмическую функцию правдоподобия мож-
но хорошо аппроксимировать с помощью квадратической функции
вблизи значения оценки максимального правдоподобия в*. Приняв
предположение о виде аппроксимации, получим
L(0)«L(0*)+(0—0*)£'(0*) + у(0—0*)2L"(0*),
где L"(9*) обозначают первую и вторую производные 1(0) по
0, вычисленные в точке 0 = 0*. Если далее предположить, что р(х\ в)
имеет единственный максимум в точке 0*, то 1(0) будет достигать
максимума в той же точке, так как при переходе к логарифму функции
положение поворотной точки не изменяется. Отсюда, в частности,
следует, что 1/(0*) = 0 (производная в точке максимума равняется
нулю).
Отметив, что 1(0*), рассматриваемая как функция 0, будет посто-
янной, получаем аппроксимацию
L (0)=const—у (0—0 *)2 / (—L "(6 *)).
Основания для того, чтобы переписать квадратический член в та-
ком виде, становятся ясными, если заметить, что
р(0 I х)« ехр (— -Ц- (0—0*)2},
Ч
где а2 = (—1"(0*))—1 [ср. с разделом 6.2.5.]
172
Когда р(в | х) имеет такой вид и при условии, что сделанные ранее
предположения вполне разумны, апостериорные представления о в хо-
рошо приближаются с помощью нормальной функции плотности со
средним в* и дисперсией а*. Поэтому расположение кривой, отобра-
жающей апостериорные представления, определяется значением О*
(оценкой максимального правдоподобия), а разброс апостериорных
представлений о параметре 0 обратно пропорционален второй произ-
водной логарифмической функции правдоподобия (в точке 0*), взятой
со знаком минус. Последняя величина действительно вполне может
служить интуитивной мерой размаха: вторая производная показыва-
ет, насколько быстро изменяется градиент логарифмической функции
правдоподобия (от положительных значений к отрицательным, из-за
чего и появляется знак минус в выражении для разброса). Если гради-
ент изменяется быстро, то это указывает, что функция правдоподобия
имеет резко выраженный заостренный максимум и, следовательно, ее
разброс будет малым.
Пример 15.3.4. Предположим, что данные х представляют собой
число успешных результатов при п независимых испытаниях, в каж-
дом из которых шанс на успех равняется 0, так что х является реали-
зацией биномиальной случайной переменной
р{х | 0)= ( ;)0Х(1-0)Л~Х; х=0,1,...,л; 0^0^ 1.
Если п довольно велико, а р(0) — относительно пологая функция, то
можно ожидать, что обсуждавшаяся перед этим аппроксимация ока-
жется разумной, и поэтому ею можно воспользоваться для вычисле-
ния 0* и Z/'(0*).
Отметив, что
L(0)=log[p(x | 0)] = const + xlog{0] +(п—x)log[l—0],
легко получить
и решение уравнения
Z/(0*)=O
приводит к оценке максимального правдоподобия
0* = -.
п
173
Дифференцируя Ц0) второй раз, получаем
Г'(0\=__—___ --
в2 (1—0)2
и, следовательно,
На основании выведенного выше общего результата можно сде-
лать заключение, что апостериорные представления относительно 6
должны хорошо приближаться с помощью
р(« | х)=к[
1 1 п п^п п' J
Если вспомнить, что при нормальном распределении вероятность по-
падания в интервал, границы которого определяются как «среднее =ь 2
стандартных отклонений», равняется 95%, то становится очевидным,
что при такой аппроксимации статистик «байесовского толка» придет
к заключению, что параметр в будет лежать в интервале
А± г [А(,_А)]'/2
п vn п v п
с апостериорной вероятностью 0,95 (т. е. с соотношением апостериор-
ных шансов 19:1) [см. пример 4.7.1].
Представляет интерес сравнение этого утверждения с выводом по-
добного рода, который можно было бы сделать, не прибегая к теоре-
ме Байеса. «Естественной» оценкой в является Х/п, среднее которой
равняется в, а дисперсия — (1/и)[0(1—0)]. Если п большое, то значение
оценки X/п будет приближаться к в и распределение Х/п будет при-
близительно нормальным [см. пример 4.7.1]. Таким образом, возника-
ет возможность рассматривать
в качестве величины, определяющей приближенный 95%-ный довери-
тельный интервал для в. Пользуясь значениями Х=х, статистик «не-
байесовского толка» мог бы в этой ситуации прийти в конце концов
к числовому результату, аналогичному тому, который получил стати-
стик «байесовского толка» (несмотря на то, что логика анализа совер-
шенно различная; см. также раздел 15.4).
174
Пример 15.3.5. Предположим, что х — полное число событий, на-
блюдавшихся при п независимых процессах, в каждом из которых со-
бытия подчиняются распределению Пуассона с параметром 6.
Поэтому х может рассматриваться как реализация случайной перемен-
ной X, имеющей распределение Пуассона с параметром пв, следова-
тельно,
р(х | 0) = (пбуе~п9/х1, 9 > 0.
Если последовательно осуществить этапы преобразований, необходи-
мые для приближения в этом случае (большое п, относительно поло-
гая р(0)), то получим
L(0) = log[p(* I 0)} = constant+ xlog[0]—п0,
и тогда
L'(9)=±-n.
и
Решение уравнения
Z/(0*)=O
приводит к оценке максимального правдоподобия
0*=х/и.
Повторное дифференцирование дает
Л"(0)=—х/02,
следовательно,
/.-(О’)--
В этом случае апостериорные представления о 0 разумно будет при-
близить с помощью выражения
подразумевая, что приближенные апостериорные шансы появления
значений 0, лежащих в интервале
А±2[±(А)]1/г,
п L п v п 7 л
оцениваются как 19 к 1.
В такой ситуации рассуждения небайесовского типа приводят к та-
кой же аппроксимации, если заметить, что оценка Х/п при больших
п распределена приближенно нормально со средним 0 и дисперсией
9/п [см. пример 4.7.2].
175
Рис. 15.3.14. Изокванты совместной апостериорной плотности для (а,
В разделе 15.4.2 будут более подробно рассмотрены интервалы,
полученные на основе апостериорных плотностей, и проведено их сис-
тематическое сравнение с небайесовскими доверительными интер-
валами.
При умеренных значениях п часто можно улучшить качество при-
ближения, занимаясь скорее функцией 9, чем самим параметром 0. Бо-
лее подробное изложение этих проблем можно найти в работе [Lindley
(1965), раздел 7.2]. Перенесение доводов, приводившихся выше, на си-
туацию, когда имеется более одного параметра, приводит к нормаль-
ному распределению большей размерности (многомерному). В
качестве иллюстрации рассмотрим два параметра а и /3 и связанные
с ними правдоподобие р(х | а,/3) и логарифмическое правдоподобие
L(a,/3) = log[p(x | а,/3). Если р(а, приближенно постоянная, то апо-
стериорная плотность задается как
р(а,(3 | х)« ехр[£а,0)}.
176
Если L(a,/3) разложить в двумерный ряд Тейлора с точностью до ква-
дратичных членов [см. IV, раздел 5.8] в окрестности оценок совмест-
ного максимального правдоподобия а*, (3*, то получим
L(a,/3)«L(a*,/3*) + (a-a*)La(a*,/3*) + (/3-/?*)^(a*,/3*) +
+ -i-(a-a')2/."(a',0')+(a-a')(0-0')L"|S(a',0') +
+ у(/3-0*)2£^(а',0'),
где La, L'q обозначают частные производные L по а, (3 соответствен-
но, a L", L'^, L"$ обозначают частные производные второго поряд-
ка. Так как ,^*)=L'l3(a*,/3*) = 0, можно записать
Р(а>0 | х)~ ехр[—у[а—а*,0—0']'Ё’ [а—а',0—0']],
где
- -£"(а',0*) -£"ц(а',0') Т”1
-Л"3(а',0') 0')
Таким образом, приближенная форма р(а,(3 | х) принимает вид дву-
мерного нормального распределения со средним (а*,/3*), оценками
максимального правдоподобия и матрицей ковариаций Е.
Данный метод приближения очевидным образом переносится на
случай, когда более двух параметров.
15.4. БАЙЕСОВСКИЕ ПОДХОДЫ К ТИПИЧНЫМ
СТАТИСТИЧЕСКИМ ЗАДАЧАМ
15.4.1. ТОЧЕЧНОЕ ОЦЕНИВАНИЕ
Одной из задач, которые обычно ставятся в статистике, является
задача получения оценки [см. раздел 3.1] неизвестного параметра на
основании наблюдаемых данных.
Как следует из раздела 15.3, если задана модель, включающая не-
известный параметр 9, и заданы данные х, то статистик, прибегаю-
щий к байесовским методам, может рассчитать апостериорную
плотность р(9 | х), соответствующую любой конкретной спецификации
априорной плотности для параметра 9. Иначе говоря, если заданы х
и определены правдоподобие и априорная плотность, то описание ви-
да р(9 | х) аналитически (т. е. с помощью математической функции)
или графически позволяет создать «законченную картину» тех пред-
177
ставлений, которые теперь имеются относительно неизвестного пара-
метра в. Если нас попросят дать единственную (точечную) оценку в,
то для статистика «байесовского толка» задача принимает вид: «Чему
равняется единственное число, в котором наилучшим образом сумми-
руются представления, отображенные с помощью р(в | х)?».
Конечно, выражение «наилучший итог» в такой постановке пока не
определено: нужно сначала выяснить, по отношению к какому крите-
рию он наилучший. Но как только мы начинаем задавать подобные
вопросы, сразу же приходим к идее: для того чтобы судить о степени
чувствительности метода к выбору оценки, необходимо что-нибудь
знать об исследуемой проблеме, возникающей на практике, и о дей-
ствительных последствиях расхождений, которые могут возникнуть
между «оценкой» и «действительными значениями». Если рассматри-
вать статистическое оценивание в таком свете, то это особый вид «ре-
шения», потенциальные последствия принятия которого необходимо
выразить количественно прежде, чем принять «оптимальное решение»
(или, в данном случае, получить «наилучшую оценку»).
Теоретический подход к оцениванию как к процессу принятия реше-
ния подробно изложен в разделе 19.2.1. Здесь же рассматриваются
только три из возможных результирующих характеристик апостери-
орной плотности, которые могли бы представлять интерес согласно
интуитивным предположениям (эти вопросы будут далее обсуждаться
в разделе 19.2.1).
а) Мода. Мода 9* апостериорной плотности определяется как
р(6* | x) = supp(0 | х)
0€0
[см. II, 10.1.3], и обычно функция плотности имеет единственную мо-
ду. Оценка 0* есть наиболее вероятное значение 0 и, как указывалось
в разделе 15.3.5, равняется (приближенно) оценке максимального прав-
доподобия в тех случаях, когда задано, что априорная плотность (при-
ближенно) постоянная. _
б) Медиана. Медиана 0 апостериорной плотности определяется как
j р(0 | х)dd = j р(9 | x)d9
и обычно единственна. Это такая точка, относительно которой пред-
полагается, что с равной вероятностью истинное значение может ле-
жать как выше, так и ниже этого значения.
в) Среднее. Среднее 0 апостериорной плотности определяется как
9 = 0р(0 | x)d9
и обладает свойством единственности.
178
р (0 |х)
а b
Рис. 15.4.1. Иллюстрация понятия правдоподобного интервала
В разделе 15.5 приводятся примеры точечных оценок, в иллюстра-
тивных целях в основном используется апостериорное среднее. Однако
еще раз необходимо подчеркнуть, что можно найти разумные доводы
в пользу любого из этих видов оценок, а также в пользу любого дру-
гого вида [см. раздел 19.2.1]. Поэтому в каждой конкретной задаче
действительный выбор должен зависеть от соответствующих сообра-
жений, основанных на теории принятия решений.
15.4.2. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
Ясно, что при любом выборе вида точечной оценки выводы, кото-
рые можно сделать на ее основе относительно апостериорной плот-
ности р(9 | х), будут «бедными». Промежуточным вариантом между
сложным законченным описанием функции плотности и предельно
упрощенной точечной оценкой может служить идея правдоподобного
интервала (credible interval)*.
Задавая функцию апостериорной плотности р(9 | х), мы получаем
возможность выделить два значения 9:а и b (а < Ь), такие, что апосте-
риорная вероятность попадания в интервал значений а и b принимает
некоторое определенное значение (например, 90, 95, 99% или любое
другое, приемлемое в исследуемой проблеме). Более точно об этом
можно сказать так: при заданной р(9 | х) интервал {а, Ь) называется
апостериорным правдоподобным интервалом для 9 уровня (100(1—
—а)%, если
ь
\р{9 | Х)б70 = 1—а(0^а^1)
а
[ср. с определением 4.1.1]. Когда для а используются значения 0,1,
0,05 или 0,01, имеются в виду правдоподобные интервалы для 9 уров-
ня 90, 95 или 99%. На рис. 15.4.1 иллюстрируется эта идея в общем
виде.
* Обращаем внимание читателя на различие понятий доверительного (confidence) и
правдоподобного (credible) интервалов. — Примеч. ред.
179
Рис. 15.4.2. Два различных правдоподобных интервала (at, b}) и (а2, Ь2) уровня
100(1— а) %
Легко увидеть, что правдоподобный интервал формально напоми-
нает вероятностный интервал, задаваемый определением 4.1.1, когда
вероятностный интервал определяется по апостериорному распределе-
нию р(0 | %).
В общем случае можно найти много пар значений {а, Ь), которые
обусловливают правдоподобный интервал уровня 100(1—а)% для за-
данного значения а. Все это легко увидеть на рис. 15.4.1, представляя
мысленно, что точка b смещается вправо от изображенного положе-
ния. Тогда заштрихованная область будет накрывать значение пара-
метра 0 с вероятностью, большей чем (1—а). Эта область может
быть уменьшена (при сохранении уровня доверия 1—а) путем соответ-
ствующего смещения интервала вправо. Независимо от того, какой
конкретный интервал выбран, правдоподобный интервал будет интер-
претироваться в терминах апостериорных представлений относитель-
но 0 при заданных х как уверенность на 100(1—а)% в том, что 0
лежит в интервале {а, Ь).
Если затем рассмотреть обстоятельство, что при любом частном ва-
рианте выбора а можно задать много различных правдоподобных ин-
тервалов, то станет очевидным, что пока предложенное понятие
правдоподобного интервала не вполне удовлетворительно. Например,
оба интервала (аь Ьх) и (а2, Ь2) на рис. 15.4.2 являются апостериорными
правдоподобными интервалами для 0 уровня 100(1—а) %, но с точки
зрения информации, содержащейся в них относительно 0, очевидна пред-
почтительность (аь bi), так как в этом случае при заданном а можно сде-
лать более определенный вывод. Это наблюдение дает основание для
уточненного понятия правдоподобного интервала. Считают, что интервал
180
(a, b) есть интервал наивысшей апостериорной плотности (вероят-
ности) уровня 100(1—а)%, если: 1) (а, Ь) — правдоподобный интервал
уровня 100(1—а)%; 2) для всех 6'€(а,Ь) и (a,b), p(Q' | х)>р(0" | х).
Дополнительное условие 2 требует, чтобы не существовало значе-
ния 0, заключенного в интервале {а, Ь), ордината которого (т. е. значе-
ние апостериорной плотности) р(0 | х) оказалась бы ниже ординаты в
каком-либо значении 0, не включенном в интервал (а,Ь). Ясно, что это
определение позволяет получить самый короткий из возможных прав-
доподобных интервалов при заданном а и, следовательно, наиболее
информативную интервальную оценку для выводов относительно
р(в | х). В разделе 15.5 приводятся соответствующие примеры.
Важно осознавать различия между подходом, основанным на прав-
доподобных интервалах, и чрезвычайно сходным подходом к интер-
вальному оцениванию, основанным на понятии доверительного
интервала [см. разделы 4.1.3, 4.2]. При первом р(0 | х) используется
непосредственно для вычисления вероятности того, что 0 лежит в пре-
делах конкретного интервала. При втором рассматриваются интерва-
лы со случайными граничными точками а(Х) и Ь(Х), обладающими
следующим свойством, выраженным в терминах распределения
/(х | 0): вероятность того, что интервал (а,Ь) содержит 0, равняется
1—а для заданного подходящим образом а. Конкретный интервал
[д(х),Ь(х)], который получается, когда наблюдается Х=х, и называет-
ся доверительным интервалом уровня 100(1—а)°7о.
15.4.3. ПРОВЕРКА ЗНАЧИМОСТИ
Во многих ситуациях, которые моделируются с помощью семей-
ства функций плотности р(х | 0) с неизвестным параметром 0, важно
проверить совместимость наблюденных данных с предположением о
том, что неизвестный параметр на самом деле принимает некоторое
конкретное значение 0О. Если в качестве интересующей нас основной
гипотезы (обычно называемой нулевой) [см. раздел 5.2.1] рассматри-
вается Н0:в = в0, то проблема сводится к поиску процедуры отверже-
ния или неотвержения такой гипотезы [см. §5.12], или, как говорят,
проверяется факт статистически значимого отличия значения парамет-
ра 0 от заданной величины 0О.
Процедура проверки значимости разрабатывалась в рамках небайе-
совского подхода и подробно представлена в гл. 5. В случае параметри-
ческих моделей /(х | 0) один из способов, который позволяет взглянуть
на такие небайесовские критерии значимости, состоит в том, чтобы от-
метить, что отвергается Н0:в=в0 с уровнем значимости 100 а %, если
разумный доверительный интервал уровня 100(1—а) % не содержит 0О.
Рассуждая аналогично, получим возможный вид байесовского кри-
терия значимости путем отвержения Н0:в=в0 с уровнем 100а%, если
0о лежит вне интервала наивысшей апостериорной плотности уровня
100(1— а)%.
181
Джефрис [см. Jeffreys (1967)] разработал другой вариант байесов-
ского подхода к проверке значимости; краткое введение в основные
идеи этого подхода даны Линдли [см. Lindley (1972)]. Здесь мы не ста-
нем вдаваться в подробности, однако в разделе 19.2.2 будет рассмот-
рен этот подход к проблеме сравнивания вероятности двух частных
конкурирующих гипотетических значений.
15.4.4. ПРОГНОЗИРОВАНИЕ
Если рассматривать «предсказание» будущего наблюдения или на-
блюдений, например х, на основании предыдущих данных наблюде-
ний у, то окажется, что статистик байесовского толка будет
стремиться вывести распределение представлений относительно х при
заданных значениях у. С вероятностной точки зрения это приводит к
рассмотрению тг(х | у), так называемой прогнозной плотности, опи-
сывающей изменения при заданных у.
В типичных ситуациях у нас нет модели, в которой непосредствен-
но задается вид такой плотности. Имеется скорее вероятностная мо-
дель для х, выраженная в терминах g(x | 0), зависящей от неизвестного
параметра 0, который в свою очередь появляется из модели, описыва-
ющей у. Если р(0 | у) есть апостериорная плотность вероятности 0 при
заданных ранее полученных данных у и если х и у независимые при
заданном 0, то можно получить прогнозную плотность вероятности х
из выражения
тг(х | у)= J g(x | 0)р(0 \ у) dO.
е
Если нужно найти прогноз в виде единственного числа, то доста-
точно просто выбрать точечную оценку, получаемую на основании
свойств плотности тг(х | у), пользуясь идеями, изложенными в разделе
15.4.1. Если требуется найти прогнозный интервал, то можно воспо-
льзоваться идеей правдоподобного интервала или «интервала наивыс-
шей прогнозной плотности», являющегося очевидной модификацией
идей из раздела 15.4.2 применительно к тг(х | 0).
Исчерпывающий обзор теории и приложений прогнозной плотнос-
ти представлен в работе [Aitchison and Dunsmore (1975)]. В разделе
15.5. приводятся некоторые частные примеры.
15.4.5. ПРИВЕДЕНИЕ ДАННЫХ: ДОСТАТОЧНЫЕ СТАТИСТИКИ
В одной из первых глав рассматривалась проблема приведения
(т. е. лаконичного концентрированного выражения) множества наблю-
дений к виду небольшого числа результирующих статистик без потери
содержащейся в нем информации. Это приводит к понятию доста-
точных статистик [см. раздел 3.4].
182
Чтобы пересмотреть эту проблему с точки зрения байесовского
подхода, можно рассуждать следующим образом. Когда заданы прав-
доподобие, определенное с помощью f(x | 0), и априорная плотность
р(0), то в соответствии с байесовским подходом их нужно соединить,
пользуясь теоремой Байеса, чтобы определить р(0 | х), апостериорную
плотность, после того как заданы все значения данных х. Предполо-
жим теперь, что t(x) есть некоторая результирующая функция данных
х; например, можно взять x=(xi,...,xn) и t(x)=n~ ^х,- или
/(x) = min{xi,...,xj и т. д. Так как р(0 | х) дает «полное» представление
о текущих суждениях относительно 0 при заданных х, о результирую-
щей функции /(х) можно сказать только, что она не приводит к потере
какой-либо содержащейся в данных информации, если р(0 | t(x)) равня-
ется р(0 | х). Более того, когда достигнуто согласие относительно
fix | 0), придется потребовать, чтобы
Р(0 | Г(х))=р(0 | х)
для всех р(0), если статистики, придерживающиеся различных опреде-
лений р(0), готовы согласиться, что /(х) представляет основу для до-
статочной результирующей функции приемлемого вида. Если это
условие выполняется, то можно сказать, что /(х) есть байесовская до-
статочная статистика.
Может показаться, что это определение достаточной статистики
отличается от небайесовского определения, которое давалось в разде-
ле 3.4.1. Однако в действительности можно показать, что оба опреде-
ления эквивалентны. В работе [Raiffa and Schlaifer (1961)] подробно
демонстрируется это обстоятельство. Таким образом, при условии,
что относительно вида вероятностной модели /(х | 0) достигнуто согла-
сие, статистики, использующие как байесовский, так и небайесовский
подходы, будут при проведении анализа основываться на одних и тех
же результирующих функциях от данных (достаточных статистиках).
15.4.6. ПРИНЦИП ПРАВДОПОДОБИЯ
Предположим, что исследование состоит из последовательности
экспериментов, для каждого из которых имеет шанс, равный 0, закон-
читься успешно, и 1 — 0 — закончиться неудачно. Далее предполо-
жим, стало известно, что проведено всего п экспериментов и из них
у экспериментов закончились успешно.
Если данные обозначены как х=(п,у), то остается выяснить, доста-
точна ли эта информация, чтобы сформулировать вероятностную мо-
дель, соотносящую х с 0. Ответ на этот вопрос, конечно, будет
отрицательный, так как ничего не было сказано о способе проведения
183
эксперимента (или получения выборки). Например, если бы значение
п было фиксировано заранее и просто наблюдалось бы у, то мы име-
ли бы дело со стандартным биномиальным распределением вероятно-
стей вида
Лу | 9,л) = 0)^(1-9)"-Л >-=0.1.п.
С другой стороны, если предварительно фиксировалось значение у, а
затем наблюдалось, каким будет п (т. е. эксперимент продолжался,
пока не было получено у успешных исходов, и тогда замечалось,
сколько раз, п, пришлось его повторять), то этот случай будет описы-
ваться отрицательным биномиальным распределением вида
п=у, y+i,y+2...
Существует, естественно, много других правил формирования выбор-
ки, которые могли бы использоваться. Например, «эксперимент про-
должается, пока не наступит время второго завтрака, а затем
прекращается» (не фиксируется ни п, ни у). Но обстоятельство, к кото-
рому хотелось бы привлечь внимание, вполне можно проиллюстриро-
вать, пользуясь только биномиальным и отрицательным биномиаль-
ным распределением.
Основной вопрос состоит в следующем: можно ли сделать стан-
дартные выводы относительно 0, когда заданы только данные наблю-
дений, но ничего не сказано о порядке получения выборки? Например,
можно ли найти точечные или интервальные оценки? При байесов-
ском подходе можно получить выводы, не зная, какое из распределе-
ний, биномиальное или отрицательное биномиальное, является
подходящим, в то время как многие процедуры небайесовского типа
не позволяют этого сделать.
Чтобы это показать, примем предположение, что на априорные
представления относительно 0 не влияет вид процедуры получения вы-
борки и можно определить вид р(0) независимо от вида правдо-
подобия.
При допущении о биномиальном распределении [см. пример
3.4.6, а)] по теореме Байеса имеем
р(0 | х)=р(6 | n,y)<*f(y | 0,и)р(0)°с ( пу )0У(1—0)п~Ур(0)ос
ос 0У(1— еу~Ур(р),
так как (” ) не содержит 0, и, таким образом,
Р(0 I х)
&04i-f))n-yP(e)de '
184
При допущении отрицательного биномиального распределения [см.
пример 3.4.6, б)] с помощью теоремы Байеса получим
р(0 | х)=р(0 | п,у)«Ап | 0,j)p(0)«
ос 07(1— eyi-yptf).
Так как (”_}) не содержит 0, то
р(0 | х) =
бУ(1—е)п~ур(0)
Таким образом, апостериорная плотность р(0 | х) в обоих случаях
имеет одинаковый вид.
Однако если рассмотреть небайесовские процедуры, такие, как полу-
чение несмещенной оценки с минимальной дисперсией (НОМД) [см.
раздел 3.5.2], доверительных интервалов [см. гл. 4] или критериев зна-
чимости [см. гл. 5], то точный вид этих оценок будет различным в со-
ответствии со сделанным предположением о виде распределения
(биномиальное или отрицательное биномиальное). Например, если
предполагается биномиальное распределение, оценка Y/n будет НОМД,
в то время как при допущении об отрицательном биномиальном рас-
пределении НОМД будет иметь вид (У—1)/(и—1) [см. пример 3.4.8].
Пример с использованием биномиального и отрицательного бино-
миального распределений является частным случаем следующей ситу-
ации. Имеются две различные вероятностные модели /i(x | 0) и
/2(х | ^), удовлетворяющие условиям
/1(х | 0) = Ci(x)^(x, 0), /2(х | 0)=c2(x)g(x, 0),
причем области изменения возможных значений х у них различны. Ча-
сти выражения для плотности, зависящие от 0, одинаковы в обоих
случаях. Теорема Байеса, записанная в виде пропорции, позволяет уви-
деть, что при заданных х и р{$) р(9 | х) будет иметь одинаковый вид
в обоих случаях, так как для ее выражения не требуется cz(x), i= 1,2,
в явном виде.
Другая интерпретация этой ситуации возникнет, если отметить,
что в g(x, 0) принимаются во внимание только те значения х, которые
наблюдались в действительности, в то время как выражение для сД-),
/=1,2, отражает всю область возможных изменений х, которые могли
бы быть получены.
Согласно принципу правдоподобия [см. Сох and Hinkley (1974) —С]
предполагается, что выводы относительно 0 должны основываться
только на g(x,0) без учета с;(х), / = 1,2. Можно сказать, что байесов-
ские процедуры (а также некоторые другие, такие, как метод макси-
мального правдоподобия) подчиняются принципу правдоподобия; в
процедурах, аналогичных методу НОМД, принцип правдоподобия на-
рушается. Аргументы в пользу этого принципа и против него обсуж-
даются в работе [Barnett(1982) — С].
185
15.5. БАЙЕСОВСКИЙ ВЫВОД ДЛЯ НЕКОТОРЫХ
ОДНОМЕРНЫХ ВЕРОЯТНОСТНЫХ МОДЕЛЕЙ
15.5.1. ВЫВОДЫ В СЛУЧАЕ БИНОМИАЛЬНОГО РАСПРЕДЕЛЕНИЯ
И БЛИЗКИХ К НЕМУ РАСПРЕДЕЛЕНИЙ
Если у обозначает число успешных результатов при п независимых
испытаниях, в каждом из которых существует 0 шансов на успех, то
в случае, когда п заранее фиксируется, получим вероятностную модель
с биномиальным распределением
/О' I = >=0,1...п.
Предположим, что априорные представления относительно в зада-
ны в виде плотности р(в). Тогда апостериорная плотность [см. раздел
15.3.1] задается с помощью
Как отмечалось при общем обсуждении теоремы Байеса в непре-
рывном случае, вид р(6 | у, п) можно легко получить численными мето-
дами для любого варианта р(0). Однако это станет слишком
трудоемким процессом, если мы захотим исследовать, как изменяется
р(6 | у,п) при различных вариантах выбора р(0), так как придется про-
водить отдельные вычисления для каждой спецификации. Более того,
простое построение кривой численными методами не может привести
к аналитическому пониманию того, каким образом «взаимодейству-
ют» данные и априорные представления при формировании вида апо-
стериорных представлений. В силу этих причин интересно изучить
конкретное математическое выражение р(0) (одновременно удерживая
в памяти практические подходы к оцениванию действительного вида
р(0), которые обсуждались в разделе 15.3.2). Чтобы получить матема-
тические выражения, обеспечивающие понимание этого взаимодейст-
вия как на теоретическом, так и на практическом уровне, желательно
обнаружить семейство функций плотностей вероятностей, которое
можно использовать при изменении небольшого числа параметров
для генерации априорных суждений с различной формой функции
плотности, чтобы адекватно отразить многие виды суждений.
При биномиальном распределении нам потребуется семейство
функций, определенных на интервале 0^0 1 и заданных в виде функ-
ций с небольшим числом параметров, которые можно изменять, чтобы
186
получить несколько видов функций с гибкими свойствами. Таким се-
мейством функций является семейство бета-функций [см. II, раздел
11.6], определенных при а>0, Ь>0 с помощью
р(»)= WTO (° <9 *>•
где Г(-) — гамма-функция [см. IV, раздел 10.2], обладающая свой-
ством r(z)=zT(z—1), z>0. Так как р(0) есть плотность, то \p(0)dO = l,
поэтому
j ‘о^-1 (1 — e)b~lde=г(о)Г(б)
Г(а + Ь) ‘
Изменяя а и Ь, можно
генерировать семейство
функций, вид которых ме-
няется в очень широком
диапазоне. На рис. 15.5.1
показаны примеры некото-
рых из них. При работе за
дисплеем компьютера в
интерактивном режиме
оказалось возможным
опрашивать индивида,
чтобы обнаружить, можно
ли его представления отно-
сительно 0 (а если да, то
для каких а, Ь) адекватно
отобразить с помощью
плотности, имеющей вид
бета-функции.
При конкретном выбо-
ре значений а, b теорема
Байеса, записанная в виде
пропорции, дает
Рис. 15.5.1. Примеры плотностей бета-
распределения: 1) о=1, Ь=2; 2) о=2, Ь = 2\
3) а=3, Ь = 3; 4) а=5, Ь=3
р(0 | У,п}~ЛУ | 0,и)р(0)<* е)"-Ух 0*-1(1-0)Ь-1
Оценивая интеграл, получим
,л I ч ^+y-\[-0)b + n-y-J
р(0 у, п)= —-----;----------;-- =
1 е)ь+п-у~Че
— Г(а+Ь+п) па+у—щ_________g\b+n_y—i
Г(а+у)Г(Ь + п—у) 1 7
187
Теперь мы располагаем интересным результатом. Апостериорная
плотность также имеет форму бета-функции, но вместо априорных па-
раметров а, b она включает параметры а+у, b+n—у. Схематически
это можно записать так:
априорное параметра апостериорному
бета (а, Z?)-pac- для биномиального приводит к бета (а+у,
пределение (п, _у)-распреде- b + п—у)-распреде-
ления лению
Из этого результата следует очень простое правило усовершенство-
вания представлений в случае вероятностной модели с биномиальным
распределением, когда априорные представления отражены в виде
плотности, имеющей вид бета-функции. Проведенный выше анализ
оказывается тогда достаточным в качестве единственного решения
при любом выборе а, b и для любых данных п, у. Например, можно
непосредственно задать расположение правдоподобных интервалов,
обратившись к таблицам значений бета-распределений. Если же ве-
личина
Ь + п—у\/ в
а+у / \ 1—в
имеет f2(a+y),2(b+n—^-распределение [см. раздел 2.5.6, б)], то можно
пользоваться таблицами F-распределения. Когда F, F обозначают
верхнюю и нижнюю процентные точки уровня 100(о;/2)% для F-pac-
пределения [см. раздел 2.5.6, а)], апостериорный правдоподобный ин-
тервал уровня 100(1—а)% для 0 задается с помощью
(а+y)F / (b + п—у) (a+y)F/(b + n—y)
l + (a+y)F/(b + n—у) ’ 1 + (a+y)F /(b + n—у)
Поскольку нижние процентные точки F-распределения не табулиру-
ются, удобно воспользоваться тем, что нижняя точка уровня 100/?%
Fu ^распределения равняется величине, обратной значению верхней
точки уровня 100/?% Fv „-распределения [см. раздел 2.5.6, а)]. Если
обозначить последнее как F*, то при и=2(а+у), v=2(b + n—y) правдо-
подобный интервал для 0 можно переписать в виде
’________1__________________1________’
. l + (b + n—y)F*/(a+y) ’ l + (b+n—y)/(a+y)F J
188
Пример 15.5.1. Если а—1, b=l, п=15, j=4, то величина (12/5)*
х[(0/(1—0)] подчиняется апостериорному распределению вида F10 24.
Например, при а=0,05 получим F =2,64, F* = 3,37, и, таким образом,
апостериорный 95%-ный правдоподобный интервал для 0 будет иметь
вид
' 1
. 1 + (12)(3,37)/5
1
1+(12)/(5)(2,64)
= (0,11, 0,52).
(Отметим, что этот интервал не является интервалом наивысшей апо-
стериорной плотности, так как в стандартных таблицах не приводятся
верхние и нижние значения, рассчитанные на таком базисе, за исключе-
нием случаев симметричной функции плотности. В таблицах для стати-
стиков байесовского направления [см. Isaacs, Christ, Norvick and Jackson
(1974) — G] содержатся результаты для получения интервалов наивыс-
шей апостериорной плотности. Однако чаще всего результаты оказыва-
ются очень похожими.)
Некоторое представление о способе, которым при получении апосте-
риорных выводов комбинируются априорная информация и информа-
ция, содержащаяся в данных, можно получить при изучении вида
точечной оценки 0, найденной в виде среднего апостериорного распре-
деления. Апостериорное среднее задается с помощью
0=\l0p(0\yn)d0 =
- Г^О+Ь+п) (10<а+>'+1)—if]—0\Ь+п—у— \dQ —
V(a+y)V(b + n-y) J0 7
— Г(д+д + и) Г(д+у+1)Г(6 + п—у) _
Г(а+у)Г(&+и—у) Г(а+b+п +1)
а+у
а+Ь+п
где используются результаты, установленные выше для интеграла та-
кого типа и для гамма-функции.
При более внимательном изучении 0 становится видно, что его вы-
ражение можно переписать в виде
а+Ь+п
где w=n/(a+b+n). При этом выявляется, что среднее апостериорного
распределения будет взвешенным средним двух величин: а/(а+Ь) и
у/ п. Первая из них фактически оказывается средним априорного рас-
пределения (что можно показать с помощью непосредственных расче-
тов или вывести дедуктивно исходя из вида апостериорного среднего
189
при п=0, J=O); вторая — «естественная» оценка в, основанная только
на данных (являющаяся также оценкой максимального правдоподобия
и НОМД).
Таким образом, в апостериорной оценке соединяется то, что нам
сообщают данные (у/п), с «наилучшими предположениями», сущест-
вовавшими у нас до того, как мы увидели данные (а/(а+Ь)). По мере
того как увеличивается объем данных, т. е. п становится все больше,
вес w, связанный с оценкой, основанной на данных, у/п, становится
больше:
а + Ь + п \. + (а+Ь)/п
И наоборот, если данные отсутствуют, т. е. и=0, то приходится по-
льзоваться априорной оценкой а/(а+Ь) (так как w=0). Поэтому адап-
тация формы апостериорной оценки происходит способом, который
интуитивно ясен, если принимать в расчет объем имеющихся данных,
видоизменяющих априорные представления.
В дополнение к результирующей характеристике апостериорной
плотности, полученной с помощью точечной оценки, можно проана-
лизировать, что происходит с «разбросом» апостериорного распреде-
ления, когда п увеличивается. Если мы собираемся оценивать размах
с помощью дисперсии апостериорного распределения, то нам потребу-
ется выражение дисперсии бета-распределения с параметрами (а+
+у, b + n—у). Применяя стандартные методы для нахождения диспер-
сии [см. раздел 10.4.1], легко показать, что она будет равняться
[ (а+у) (b -I- п—у) ] / [(а + b+п )2 (а+b+п +1) ].
Когда и — дисперсия, выраженная таким образом, явно стре-
мится к 0. Поэтому независимо от выбора конкретного априорного
вида а и b по мере того, как увеличивается объем данных, кривая
представлений становится все более сконцентрированной вокруг апо-
стериорного среднего. Последнее в свою очередь больше напоминает
у/п (как было видно ранее), и поэтому неважно, какой вариант кон-
кретного вида априорного бета-распределения был принят. В любом
случае мы будем во все большей степени приходить к убеждению, что
значение истинного шанса на успех 0 лежит «очень близко» к наблю-
даемой частоте успешных исходов у/п.
Если у и п—у становятся очень большими по сравнению саиб,
то апостериорная плотность приобретает вид (приближенно) бета-
распределения с параметрами (у, п—у). Таким образом, воздействие
большого объема данных выразится в том, что разнообразие различ-
ных априорных представлений (отображенных с помощью многих ва-
риантов выбора а и Ь) сведется к апостериорному единодушию во
мнениях. Это обстоятельство играет ключевую роль в ответе на обви-
нения в отсутствии «объективности» в байесовских методах вследствие
190
вторжения «субъективности» априорных представлений. Для последо-
вателей байесовского подхода кажется естественным рассматривать
субъективные представления в качестве первичных, а «объективное со-
гласие» — как особую ситуацию, возникающую, когда объем доступ-
ных данных достаточно велик, чтобы возобладать над априорными
представлениями всех заинтересованных и стать доминирующим, при-
водя к преобразованию их в апостериорные представления единого
вида.
Когда количество данных недостаточно велико, чтобы обеспечить
такой тип согласования мнений, статистик байесовского направления
считает вполне правильным, что априорные представления оказывают
влияние на апостериорные выводы. Если условия для достижения со-
гласия не удовлетворяются, то стремление создать видимость сущест-
вования «объективного» ответа не может считаться похвальным. Все,
что может сделать статистик в таких случаях, — это отразить разноо-
бразие различных видов априорных представлений. Тогда читатель
(научного доклада) или клиент (консультант по вопросам статистики)
сможет оценить собственное отношение к данным, выяснив, какой
именно из результатов анализа соотношения между конкретными
априорными и апостериорными представлениями лучше всего соот-
ветствует его собственному априорному представлению. Такое отобра-
жение результатов анализа можно существенно облегчить, применяя
математические (но не чисто численные) методы с использованием
гибкого, хорошо интерпретируемого семейства априорных распределе-
ний. Если удается обнаружить семейство, которое: а) достаточно бо-
гато, чтобы с его помощью можно было бы представить
большинство форм кривых, соответствующих априорным представле-
ниям, встречающимся на практике, и б) прекрасно согласуется с видом
правдоподобия, так что легко можно идентифицировать математиче-
ский вид описания апостериорной плотности, то процесс вывода ока-
зывается полностью завершенным после того, как будет отмечено,
каким образом преобразуются параметры априорной плотности в па-
раметры апостериорной плотности. В случае плотности в виде бета-
распределения видно, что априорные параметры (а, Ь) преобразуются
в апостериорные параметры (а+у, Ь + п—у), при этом роль данных в
подобном преобразовании отражается посредством достаточных ста-
тистик пну.
Теперь предположим, что, получив в результате наблюдений у ус-
пешных исходов при п испытаниях, мы захотели предсказать число ус-
пешных исходов, которые будут получены при последующих tn
независимых испытаниях. Если X обозначает число будущих успеш-
ных исходов, то статистик, пользующийся байесовским подходом, за-
хочет рассчитать
7г(х | т,у,п)=Р(Х=х | т,у, и)(х=0,1,...,м).
191
Проведя простой расчет, эти вероятности можно задать в виде
тг(х | т,у,п)= Jo/(* | m,0)p(0 | y,n)d0,
что дает нам пример прогнозного распределения [см. раздел 15.4.4].
Предполагая, что в рассматриваемом случае 0 имеет априорное бе-
та-распределение (а,Ь), получим при х=0,1,...,/и
тг(х | т,у,п)=(т )
Г(а+Ь + п)
Г(а+у)Г(Ь + п—у)
х
X ,fo0x(l— 0)^-х0а+У-Ц\— 0)b+ п—у—\dQ =
V(a + b+ri)
Г(а+у)Г(6 + л—у)
x J‘^+y+x-l(i— 0)b+n-y + m-x-ld0 =
Г(о+6+и) Г(а+у+х)Г(Ь+п—у+т—х)
Г(а+у)Г(Ь+п—у) Г(а+Ь+п + т)
Пример 15.5.2. Если а=Ь=\, благодаря чему можно исходить из
того, что р(0) — однородная функция плотности на интервале (0,1), и
если т=х=\, мы можем рассматривать вероятность того, что един-
ственное последующее испытание закончится успешным исходом, то,
воспользовавшись фактом, что Г(г+l)=zF(z), тг(х | т,у,п) можно
упростить, чтобы получить
РГ(Х= \ \ т=\,у,п)=--------------г(у + 2)Г(и >>+1) = у+£
Л 1 Z ’ Г(у+1)Г(л—7+1) Г(л + 3) л + 2
Обсуждавшиеся в этой главе результаты получены на основе бино-
миальной вероятностной модели. Однако, как отмечалось в разделе
15.4.6, такие модели, как отрицательная биномиальная, приводят к
аналогичному виду р(0 | у,п) при любом выборе р(0).
15.5.2. ВЫВОДЫ ДЛЯ РАСПРЕДЕЛЕНИЯ ПУАССОНА
Если x=(xi, х2,...,хп) — случайная выборка из распределения Пуас-
сона с параметром 0 [см. II, раздел 5.4], то получим вероятностную
модель
(xz>0, /=1,2,...,л)
где пх =(xi+x2 +... +хп).
192
Рис. 15.5.2. Примеры плотностей гамма-распределений: а=1, 6=1; а=3, 6=1;
а=4, 6 = 8
Чтобы провести байесовский анализ, нужно задать вид априорной
плотности вероятностей р(0) для 0, параметра, появляющегося в рас-
пределении Пуассона. В этом случае 0 может быть любым действи-
тельным положительным числом, поэтому
р(0 | х) = —, 0 0 <
f Лх | 0)p(ff)de
Как было показано в предыдущем разделе, ситуация стала бы го-
раздо более удобной, если бы удалось найти семейство функций плот-
ности вероятности, чтобы можно было генерировать широкий
диапазон видов кривых, соответствующих априорным представлени-
ям, изменяя параметры функций семейства, и подгонять их способом,
поддающимся интерпретации, к виду, согласующемуся с функцией
правдоподобия, определяемой моделью Пуассона.
В качестве такого семейства можно взять плотности гамма-
распределения [см. II, раздел 11.3], имеющие вид
193
при любом выборе а > О, b > 0. Варьируя значения а и Ь, можно гене-
рировать разнообразные виды кривых, отдельные примеры которых
показаны на рис. 15.5.2. Так как р(0) характеризует плотность, полу-
чим p(6)df) = 1, следовательно,
J о «==»
0о-1е-*М=Г(д)/М.
J о
Пользуясь этим результатом, легко показать, что среднее значение
гамма-распределения равняется а/b, а дисперсия равняется а/Ьг. Вы-
бирая соответствующие значения параметров а, Ь, можно подобрать
такой вид кривой, который будет отражать размещение и разброс
действительных априорных представлений в широком диапазоне.
Для конкретно выбранных а и b теорема Байеса, записанная в фор-
ме пропорции, дает
р(о | | е)р(е)^еп^е~пвеа-1е-Мосеа+п^-1е-(<ь+пУв.
Следовательно, получим
аа+пх ——(Ь + п)9
Р(в I Х)= —2-------------- =
р + пх — le-(b + n)6dg
(Ь + п)а+пх ва + пх~1 е~ №+
Г(а + лх)
— выражение для интеграла, выведенное из его формы, о которой го-
ворилось раньше.
Сравнивая вид р(6) и />(.А | х), отметим, что последнее также являет-
ся плотностью гамма-распределения и что таким образом продемон-
стрирован общий результат, который схематически можно выразить в
виде
априорное параметра апостериорному
гамма (а, Ь)- для распределения приводит к гамма-распре-
распределение Пуассона [лх] делению
(а+лх, Ь+л)
Этот результат позволяет сформулировать простое правило для уточ-
нения вида представлений в случае’вероятностной модели пуассонов-
ского типа и априорных представлений, выраженных с помощью
плотности гамма-распределения. Параметры последней легко преоб-
разовать, пользуясь достаточными статистиками лих.
Выражения для апостериорных правдоподобных интервалов легко
вывести, пользуясь таблицами распределения хи-квадрат, если заме-
тить, что величина 2(Ь+п)0 имеет распределение хи-квадрат с 2(а+
+ лх) степенями свободы. Этот факт легко продемонстрировать с по-
мощью стандартных методов преобразований [ср. с разделом
2.5.4, а)].
194
Апостериорное среднее, являющееся одним из возможных вариан-
тов точечной оценки для 0, задается с помощью
0 = ( 0р(0 I X)d0= ( 0(a + »x + l)-le-(b + n)ede =
Jo ' Г(а+лх) Jo
_ (b + n)a+nx . Г(а+лх + 1) _ а + пх
Г(а+пх) (b+n)a+nx+ 1 Ь + п ’
где используется тот факт, что Г(г+l)=zF(z).
Отметив, что можно записать
а + пх _ Ь(а/Ь) + п(х)
Ь+п Ь+п ’
снова видим, что апостериорное среднее есть взвешенное среднее
априорной оценки 0(а/Ь) и оценки (х), полученной на основе данных.
Когда п становится большим, коэффициент взвешивания становится
больше и приближается к 1. Более того, апостериорная дисперсия
(а+пх )/(Ь + п)2 стремится к нулю, и, таким образом, происходит все
большая концентрация представлений в окрестности х независимо от
того, каким был точный первоначальный выбор а и Ь, при условии,
что последние будут малыми по сравнению с пх и п. В этом случае
различные, широкие в пределах возможного множества априорных
представлений будут стягиваться к апостериорному согласию в мнени-
ях, которое хорошо выражается с помощью гамма-распределения с
параметрами пх и п. Среднее и дисперсия этого апостериорного рас-
пределения задаются в виде х и х/п, и если взять в качестве прибли-
женного значения 95%-ного правдоподобного интервала величину,
равную среднему ±2 стандартных отклонения, то можно верифициро-
вать результат, полученный в примере 15.3.5 из раздела 15.3.5 на
основе другого подхода.
Если потребовалось прогнозное распределение для наблюдения, ко-
торое будет получено при первом из последующих испытаний,
+ то нужно рассчитать
тг(у | х)= ( f(y | 0)р(0 | x)d0 =
* о
= + ПХ ( Qa+nT+y— \e-(b + n+VfidQ_
у!Г(а+/гХ) J о
= (Ь+п)°^ У(а + пх+у)
у1Г(а+пх) (Ь + п+1)а+пх +у'
195
Пример 15.5.3. Предположим, что у-0, и, следовательно, нам
нужно узнать вероятность того, что следующее наблюдаемое значение
будет нулевым. Тогда
РЛ(У=0 | х)= ( )а+лГ.
Интуитивно кажется, что это выражение разумно. При прочих равных
условиях малые значения пх (т. е. малое полное число наблюдений
для предыдущих п случаев) будут приводить к значениям, близким к
1 (особенно если п велико). С другой стороны, если пх велико, то ве-
личина в скобках (которая меньше 1) будет возводиться в степень с
большим значением и получится малое значение вероятности.
15.5.3. ВЫВОДЫ В СЛУЧАЕ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
а) Неизвестное среднее, известная дисперсия. Если x=(xi, хг,...,хп) —
случайная выборка из нормального распределения с неизвестным
средним д и известной дисперсией о2, то из (2.5.1) получим вероят-
ностную модель
f(x\ /<У) = П[(~)1/2ехр(—^(х,—д)2)] =
=< )”/2ехр(-2Ь >2+«(^-м)2]).
Для проведения байесовского анализа необходимо задать вид р(д) и
рассчитать
f(x | n,a2)p(ii)dn
Хотя при любом выборе р(/х) апостериорную плотность можно рас-
считать численными методами, представляет определенный интерес,
так же как и в разделах 15.5.1 и 15.5.2, исследование вида р(у | х,а2),
когда задается конкретное математическое выражение р(д). В этом
случае выбранная в виде
р(д) = (тк)1/2ехр(~ i (д-«)2)
Z%P ZP
функция отражает вид распределения параметра д, концентрирующего-
ся около значения а и спадающего симметрично в обе стороны от него
так же, как изменялась бы кривая нормального распределения. Пара-
196
метр дисперсии 0 отражает степень определенности наших убеждений.
Если 0 мало, то кривая будет крутой с острым пиком; если 0 велико,
то кривая будет пологой и простираться далеко в сторону (т. е. пред-
ставления носят неопределенный, размытый характер).
Чтобы вывести выражение для апостериорной плотности, заме-
тим, что
р(д | д;<?)ос/(х | /А.СТ2)^)»
ехр(— Д(х — д)2х ехр(— (д—а)2).
Отметив, что
4(д~ х)2 + а)2= (4 + у)д2—2(4х + у )д + ...,
I/ fJ v fJ V fj
где остальные (опущенные) члены не содержат д, увидим, выписав
полностью члены этого выражения, что
( । 2\ ( 1 Г (п/о2)Х + (а//3)12'>
Из полученного выражения ясно, что апостериорное распределение /а
будет нормальным со средним
и дисперсией
Полученные выше результаты кратко можно суммировать так:
априорное параметра сдвига апостериорному
нормальное (а,/3) для нормального [лх,а2] приводит к нормальному (а*,/?*)
распределение распределения распределению
Мы видим, что снова а* имеет вид взвешенного среднего от х
(основанная на данных наблюдений оценка д) и а (априорное среднее
для д). Если а2/п мала по сравнению с 0, то больший вес придается
х и 0*~*а2/п. В последнем случае, соответствующем относительно
неопределенным априорным представлениям, можно сказать, что апо-
стериорное распределение д будет приближенно нормальным со сред-
ним х и дисперсией ст2/п. Иначе говоря, в терминах апостериорных
представлений относительно д при заданном х величина
X)
а
197
имеет стандартное нормальное распределение [см. II, раздел 11.4.1].
Правдоподобные интервалы для д можно получить с помощью прос-
тых вычислений, воспользовавшись таблицами нормального распреде-
ления [см. приложение 4], чтобы найти верхнюю и нижнюю
процентные точки.
Важно не смешивать приведенные выше результаты с утверждени-
ем, что при заданном д статистика
g)
а
имеет стандартное нормальное распределение. Распределение вероят-
ностей, на основании которых делаются оба утверждения (т. е. рас-
пределение X при заданных значениях д и распределение д при
заданных значениях х), относятся к различным типам; одно из них
определяется с помощью вероятностной модели /(х | д,ст2), а другое —
с помощью распределения р(д |х, ст2), описывающего вид представле-
ний, полученных на основании теоремы Байеса. С другой стороны,
численные выражения правдоподобных и доверительных интервалов
(при заданном уровне 100(1—а)%) будут одинаковыми для любых за-
данных значений X =х.
Таким образом, когда априорные представления относительно рас-
плывчаты, числовые выражения, получаемые статистиками, исполь-
зующими байесовский подход, не будут отличаться от результатов,
полученных статистиками, пользующимися небайесовскими методами,
несмотря на то, что применяемые методы выведены совершенно раз-
личным образом. Однако заметим, что если априорные представления
будут не очень расплывчаты по сравнению с информацией, содержа-
щейся в данных наблюдений (т. е. если ст2/и нельзя считать малой по
сравнению с /3), то не будет существовать единственного результата
байесовского анализа и, следовательно, не будет совпадения с резуль-
татами, полученными небайесовскими методами.
б) Неизвестное среднее, неизвестная дисперсия. В более распро-
страненной ситуации, когда не известны ни д, ни ст2, приходится зада-
вать вид априорной совместной функции плотности р(д,ст2) для двух
неизвестных параметров, чтобы вывести вид функции апостериорной
совместной плотности
р(д,СТ2 | х)ос/(х | д,СТ2)р(д,СТ2).
Чтобы рассмотреть множество возможных ситуаций, возникающих
при определении вида р(д,ст2), потребовалось бы провести обсуждение
самого общего характера. Например, должны ли быть, априорные
представления относительно д и ст2 независимыми для того, чтобы
можно было р(д,ст2) записать в виде р(д)р(ст2) — произведения оценен-
ных раздельно значений маргинальных плотностей для д и ст2? Очевид-
но, что конкретный выбор будет зависеть от соображений подобного
рода, которые невозможно отразить в однопараметрическом случае.
198
Мы не будем приводить здесь перечень возможных вариантов ана-
лиза соотношений между априорными и апостериорными представле-
ниями, а только кратко рассмотрим частный случай независимых и
расплывчатых априорных представлений относительно ц и а2. Причи-
ны такого выбора станут ясны позднее.
При проведении анализа этого особого случая поступим следую-
щим образом. Сначала припомним, что в предыдущем разделе (д не-
известно, а а2 известно) «расплывчатые» априорные выражения для
представлений относительно д получены путем рассмотрения априор-
ной нормальной плотности, дисперсия /3 которой считалась большой.
Это приводило к тому, что функция р(ц) имела очень плоскую форму,
такую, что можно было принять р(д) приближенно постоянной. Ана-
логично в разделе 15.5.2 было показано, что расплывчатая априорная
спецификация параметра, имеющего положительные значения, могла
получиться при рассмотрении гамма-плотности с параметрами (а,Ь)
при малых значениях этих параметров. Перенося последнюю идею на
случай а2 и присоединяя ее к упомянутому выше предположению о
приближении р(ц) в виде «постоянной», находим, что результирующая
«расплывчатая априорная аппроксимация» р(д,а2)« а-2. Конечно, она
не является представлением плотности вероятностей в верном смысле
и не может всерьез рассматриваться как подлинное выражение апри-
орных представлений. Скорее ее можно интерпретировать следующим
образом. Если бы мы собирались оценить и найти выражения для
подлинных представлений, когда они оказываются «очень расплывча-
тыми» в том смысле, что апостериорная плотность будет сильно за-
висеть от того, «что говорят данные» (т. е. правдоподобие будет
иметь более узкую заостренную форму, чем априорная плотность), то
результирующие апостериорные представления, полученные из оце-
ненных соответствующим образом априорных представлений, совсем
немного отличались бы-от тех, которые получены при аппроксимации
такого вида. Поэтому при выборе р(д,ст2)ос а~2 легко прийти к удоб-
ному приближенному «урезанному» выражению для иллюстрации ха-
рактера выводов, возникающих в этом случае.
Пользуясь теоремой Байеса, получаем
р(ц,а2 | х)«Дх | д.^рСд.а2)»
ос (а2)-Кя/2) + 1)ехр [—2-р [.£ (х,—х )2 + п(х — д)2] ].
Чтобы найти маргинальные апостериорные плотности для д и а2,
нужно проинтегрировать это выражение совместной плотности снача-
ла по а2, а затем по д. Подробности этой процедуры просты, но сами
199
по себе они не представляют особого интереса, поэтому мы просто
приводим результаты интегрирования. Когда речь идет о /а, они сво-
дятся к тому, что величина
Уй(0—х)
VE(x;—х)2/л—1
имеет /-распределение Стьюдента с п—1 степенями свободы [см. раз-
дел 2.5.5]. Что касается параметра ст2, то величина
£(х—х~)2
а2
имеет распределение х2 с п—1 степенями свободы [см. раздел
2.5.4, а)].
Интервальные оценки для /аист2 можно легко получить из стан-
дартных таблиц t- и х2-распределений.
Необходимо подчеркнуть, что распределения рассмотренных выше
величин основаны на p(jt,a21 х), приближенном апостериорном распре-
делении представлений относительно /аист2 при заданных значениях
данных х.
Эти результаты могут напомнить похожие, но отличающиеся в
концептуальном смысле результаты, основанные на частотной интер-
претации, которые приводились в разделе_2.5. Те результаты выводят-
ся исходя из частотных распределений X и E(XZ—X)2 при заданных
/а и ст2. Однако снова (как и в предыдущих разделах) можно увидеть,
что, когда байесовский анализ проводится на основе расплывчатых
априорных представлений, выводы, о которых здесь говорилось, бу-
дут иметь численное выражение, тождественное выводам, к которым
приводят небайесовские методы.
15.6. БАЙЕСОВСКИЕ МЕТОДЫ ДЛЯ МОДЕЛЕЙ,
СОДЕРЖАЩИХ МНОГО ПАРАМЕТРОВ
15.6.1. НЕПРИЕМЛЕМОСТЬ «СОВЕРШЕННО РАСПЛЫВЧАТЫХ»
АПРИОРНЫХ СПЕЦИФИКАЦИЙ
Одно из заключений общего характера, которое можно сделать на
основании рассмотренных примеров, состоит в следующем. Хотя кон-
цептуально байесовский подход сильно отличается от стандартных
статистических методов, на практике результаты, полученные с его
помощью, зачастую незначительно отличаются от тех, что дает при-
менение стандартных процедур. В частности, как было показано,
именно так обстоит дело в случае большинства стандартных вероят-
ностных моделей, содержащих один или два неизвестных параметра,
когда первоначальные представления не очень строго определены по
сравнению с объемом информации, заключенной в данных.
200
Конечно, нельзя утверждать, что даже в случае моделей, содержа-
щих только один или два параметра, байесовские «ответы» будут
всегда совпадать с небайесовскими. Этого не произойдет, когда в рас-
поряжении имеется мало данных, а априорная информация играет су-
щественную роль.
Однако если модель содержит много параметров, то даже выбор-
ка, кажущаяся большой, в действительности может содержать реаль-
но не слишком много «ошеломляющих» данных относительно
неизвестных аспектов модели, так как информация в ней «разбросана»
по многим параметрам. С другой стороны, если модель содержит
много параметров, типичной оказывается ситуация, когда имеется су-
щественная для анализа информация относительно зависимостей меж-
ду параметрами. В конце концов, параметры «отражают» обычно
нечто «реальное», и вполне вероятно, что индивидуальные «реаль-
ные» характеристики сильно взаимосвязаны или их нельзя все вместе
рассматривать в одной модели.
В таких ситуациях присваивание независимых, расплывчатых апри-
орных представлений каждому параметру обычно не может считаться
правильной формой выражения априорной информации. Тем не менее
сохраняется соответствие между типичными небайесовскими процеду-
рами и байесовскими процедурами, выведенными на основании даже
такой априорной спецификации. Отсюда следует, что в многопарамет-
рических случаях должны существовать возможности для обнаруже-
ния байесовских форм выводов, в значительной мере отличающихся
от стандартных форм.
15.6.2. ПРОСТЫЕ ПРИМЕРЫ
Предположим, данные состоят из к групп наблюдений по п наблю-
дений в каждой группе и можно принять допущение, что все наблюде-
ния независимые и нормально распределенные с одинаковой
дисперсией (известной или неизвестной, что не имеет значения) и неиз-
вестными математическими ожиданиями в каждой из групп
0Ь 02,...,0*. Каким образом следует оценивать параметры, когда зада-
ны такие предположения?
Стандартные процедуры (например, метод наименьших квадратов
[см. раздел 3.5.2] или метод максимального правдоподобия [см. раз-
дел 3.5.4]) привели бы к использованию выборочных средних х\, х2,
..., хк, где х;=(ху+Х12 + ...+xjn)/n, в качестве оценок 0Ь 02,...,0*. О™
могли бы считаться решениями и с байесовской точки зрения, если бы
совместная априорная спецификация для (0Ь 02,...,0р имела бы сле-
дующий вид:
а) р(0ь 02,...Л) = ПЛ)>
так что представления о любом из отдельных параметров 0, не зави-
сят от представления о других 0у-; это означает, что все 0у рассматри-
ваются как несвязанные параметры;
201
б) любая p(Ot) соответствует расплывчатой априорной специ-
фикации.
Возникает вопрос о реалистичности такой формы априорной спе-
цификации. Анализ конкретных примеров, общую структуру которых
можно представить в виде к групп по п наблюдений в каждой, гово-
рит о том, что она нереалистична.
Предположим, что наблюдения касаются урожайности определен-
ной сельскохозяйственной культуры, при этом группы соответствуют
слегка различающимся условиям произрастания. Далее предположим,
что имеется двадцать групп (к=20) по два растения в каждой (л = 2).
В этом случае интуитивно кажется, что гораздо большая чувствитель-
ность достигается при оценивании 0, с помощью оценки вида wXj +
+ (1—w)x, где 0<w<l их — среднее по совокупности всех групп
(Хп +х{2 +...+хкп)/кп. Эта оценка является взвешенным средним ин-
формации, содержащейся только в ьй группе (х;) и получаемой из
всего множества данных информации (х). Она отражает ощущение,
что п~2 мало по сравнению с £л=40. Следовательно, может оказать-
ся, что пользоваться информацией, основанной только на двух наблю-
дениях, неэффективно, если в действительности предполагается, что
последствия, связанные с различными условиями произрастания, дол-
жны быть только слегка различными. Вес w должен отражать соотно-
шение величин Аг и л, а также служить некоторой мерой того, насколь-
ко похожими нам кажутся эти группы.
В качестве еще одного примера рассмотрим ситуацию, когда, как
выявилось, наблюдения внутри каждой группы повторяются, являясь
наблюдаемыми откликами на стимул с заданным уровнем, причем
уровень стимула фиксирован для каждой группы, но возрастает по ме-
ре того, как мы продвигаемся от первой группы к к-й. (например, меж-
ду уровнями задаются соотношения sx<s2< Структура
«стимул-отклик» может относиться к связям между удобрениями и
урожайностью культур, между дозами лекарств и темпами выздоров-
ления пациентов, между сенсорными воздействиями и физиологиче-
скими реакциями и т. д. [ср. с разделом 6.6].
В большинстве подобных ситуаций область изменения уровней
стимулов охватывает такой диапазон, о котором известно, что в его
пределах наблюдаются тенденции усиления, выравнивания и, наконец,
ослабления отклика в результате усиления стимула. Если снова взять
л=2, к=20, то многие будут интуитивно испытывать неудовлетворе-
ние из-за того, что приходится использовать х, для оценки истинного
отклика 0/, соответствующего стимулу s,-. Некоторые могут предпо-
честь, например, подбор кривой квадратического типа при помощи
графика xj вместо sit чтобы затем использовать подобранное значе-
ние, соответствующее sit в качестве оценки. Другие могут отдать
предпочтение среднему этого подобранного значения й среднего для
группы xj, при этом в общем случае относительные значения весов
будут зависеть от Аг и л.
202
Выбор этих конкретных примеров в действительности не относит-
ся к существу проблемы. Обстоятельство, которое хотелось бы отме-
тить, заключается в том, что основополагающие характеристики
реальной ситуации могут преподнести информацию, совершенно от-
личную от той, которая подразумевалась в понятиях «независимые,
расплывчатые априорные» представления. Вывод из байесовского ана-
лиза состоит в том, что знания взаимосвязей, существующих между
параметрами в соответствии с их смысловым значением, следует ин-
корпорировать в модель с помощью априорного распределения. В ма-
тематическом виде это означает использование иерархической модели
типа
Г Р{Х | 0ц 02,...Л)’
< Р(01, 02,...,0)t | Ф),
< Р(Ф),
в которой на первом этапе устанавливаются соотношения между пара-
метрами и наблюдениями, на втором выявляется природа взаимосвя-
зей, существующих между параметрами, и на третьем включается в
рассмотрение числовая информация (если таковая имеется), касающая-
ся общего вида взаимосвязей, заданных на втором этапе.
В качестве примера можно смоделировать ситуацию типа «сти-
мул—отклик», рассматривая [см. раздел 1.4.2, п.1)]
Xy-Ntf^2) /=1,...,Л» 7=1,...,п,
0/~У(фо + Ф15/ + ф2^, 72) /=!,...Л
р(Фо,Ф\,Фг)- const.
В этом случае на втором этапе будет представлена информация о том,
что истинные значения отклика лежат на квадратической кривой, в то
время как на третьем будет указано на неопределенность точного чис-
лового выражения этой кривой.
Можно показать, что апостериорное среднее для 0, в такой модели
принимает вид
ых( + (1—w)(<fo + + <fes}),
где w=nT2/(nr2 + a2) и фо + Ф^+Фг^ обозначают квадратическую кри-
вую, подобранную методом наименьших квадратов с помощью значе-
ний Xj.
203
Введение в основные понятия байесовских иерархических моделей
можно найти в статьях [Lindley and Smith (1972)] и (Smith (1973)]. В
работе (Harrison and Stevens (1976)] содержится хорошее введение в
приложение этих идей к моделям временных рядов.
15.7. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Приведенный ниже краткий список литературы включает книги,
которые могут помочь при дальнейшем изучении байесовских методов
и методологии.
AitchisonJ. and Dunsmore I.R. (1975). Statistical Prediction Analysis. Cam-
bridge University Press.
Box G.E.P. and T i a о G.C. (1973). Bayesian Inference in Statistical Analysis. Addison-
Wesley.
Hampton J.M., Moore P.G., T h о m a s H. (1973). Subjective Probability and Its
Measurement, Journal of the Royal Statistical Society, v. 136., s. A, p. 21.
de F i n e 11 i B. (1974, 1975). Theory of Probability, v. I, II, Wiley.
Harrison P.J., Stevens C.E (1976). Bayesian Forecasting, Journal of the Royal
Statistical Society (B), v. 38, p. 205.
Jeffreys H. (1967). Theory of Probability, Third edition, Clarendon Press, Oxford.
Lindley D.V. (1965). Introduction to Probability and Statistics from a Bayesian View-
point, Part 2, Inference. Cambridge University Press.
Lindley D.V. (1972). Bayesian Statistics: A Review, S.I.A.M., Philadelphia.
Lindley D.V, Smith A.F.M. (1972). Bayes Estimates for the Linear Model, Journal
of the Royal Statistical Society (B), v. 34, p. 1.
Naylor J.C., Smith A.F.M. (1982). Application of a Method for the Efficient
Computation of Posterior Distributions, Applied Statistics, v. 31.
Raiffa H., Schlaifer R. (1961). Applied Statistical Decision Theory. Harvard
Business School, Boston.
Reilly P.M. (1976). The Numerical Computation of Posterior Distributions in Bayesian
Statistical Inference, Applied Statistics, v. 25, p. 201.
Smith A.F.M. (1973). Bayes Estimates in One-way and Tvo-way Models, Biometrica,
v. 60, p. 319.
Глава 16
МНОГОМЕРНЫЙ АНАЛИЗ: КЛАССИЧЕСКИЕ
МЕТОДЫ
16.1. ВВЕДЕНИЕ
Статистика имеет дело с совокупностями (популяциями) объектов
и выборками из этих совокупностей. Когда каждый объект в выборке
имеет одну количественную или качественную характеристику, интере-
сующую статистика, совокупность и выборка являются одномерными.
Объектами могли бы быть, например, взрослые люди, а переменной
— их рост (количественная переменная) или цвет волос (качественная
переменная). Когда для каждого объекта в выборке определены значе-
ния двух и более переменных, мы имеем дело с многомерной совокуп-
ностью: двумерной, если число переменных у объекта два,
трехмерной, если три и т. д. Для совокупности взрослых людей таки-
ми переменными могли бы быть: Х{ — рост, Х2 — вес, Х3— возраст
и Х4 — кровяное давление. Тогда мы бы имели дело с четырехмерной
совокупностью и векторной случайной переменной X с четырьмя ком-
X
Из математических соображений удобно представлять объект в ви-
де вектора-столбца. Но это неудобно с полиграфической точки зрения.
Поэтому обычно записывают вектор в транспонированной форме [см.
I, раздел 6.5], указывая на это с помощью штриха:
Вообще для /7-мерной совокупности мы нуждаемся в случайных векто-
рах X с р компонентами Xi- X=(Xb X2,...,a^,)z; случайную величину
az, соответствующую z-му измерению объекта из совокупности, бу-
дем называть z-й компонентой векторной случайной переменной. Век-
торное наблюдение над j-м объектом из выборки будет присваивать
некоторое скалярное численное значение для каждой из скалярных слу-
чайных величин Xi, X2t Х3, Х4. Обозначим эти значения через
xif xij* X3j> х4р где втоРой индекс (j) служит для идентификации /-го
объекта из выборки. Векторное наблюдение над этим объектом опре-
деляется теперь как вектор
Ху = (х;у, X2J, X3J, X4j) .
205
Так, примером двумерного наблюдения служит
х.= ( хи\ = /65,2\
Здесь Х} измеряет рост в дюймах, а Х2 — вес в фунтах случайно вы-
бранного взрослого человека из совокупности людей; для /’-го челове
ка рост оказался 65,2 дюйма, а вес 110,5 фунта. Выборка объема к из
р-мерной совокупности содержит к векторных наблюдений — по од-
ному на каждый объект в выборке:
Хь Х2,...,Хк,
каждое — порядка (pxl) с
ху=(х/у, x2j,..., xpj)\ j=l,2,...,k.
Эти к выборочных векторов ху являются к реализациями векторной
случайной величины, р-мернре распределение которой служит предме-
том исследования.
Часто удобно агрегировать векторные наблюдения в форме выбо-
рочной матрицы S [см. I, раздел 6.2]:
S = (Xj :Х2:...:Х^)
(16.1.1)
порядка (рхк). Для двумерной выборки объема к=4 из двумерного
распределения роста (X/) и веса (Х2) людей эта матрица могла бы
иметь следующий вид:
/ %11 ' *12
S= / I
\ *21 1 хп
х f 1
1-й индивид 2-й индивид
в выборке в выборке
*в 1 *14 \ 1 \ <= рост
*23 1 1 1 *24 J <= вес
♦ 7
3-й индивид 4-й индивид
в выборке в выборке
(16.1.2)
Вообще (ij)-A элемент в j-\,2,...,k) есть xip который
представляет собой наблюдение z-й компоненты X, у j-го члена
выборки.
Введем для дальнейшего вектор-столбец 1 с компонентами
(1,1,...,1) и заметим, что
1) S1 есть вектор-столбец (pxl)
Sl=(Ex/y, Ех2у,...,Ех/у);
2) 1S есть вектор-строка (IxA:)
1/S=(Exj7, Ех(2,...,Ех(Д;
3) SSZ = Ехух) есть симметричная матрица (р*р), (ij)-ft элемент ко-
торой есть ^xiryJr.
В нашей выборке объема к среднее значение веса (переменной Х2
есть
к
Х2 = Е Ху:/к.
J=1 V
206
Аналогично определим среднее /-й компоненты вообще:
х( = Е хи/к, i=l,2,...р, (16.1.3)
j=i j
т. е. кхг — сумма элементов r-й строки выборочной матрицы S
(16.1.1).
Для матрицы выборки (16.1.2) это дало бы
Х1 = (Х11+Х12+Х1з+Х14)/4
и
Хг— (*21 + *22 +*23 +*24)/4
для среднего значения роста Xi и среднего значения веса х2. Используя
правило сложения векторов [см. II, раздел 6.2], можно сделать эквива-
лентную запись:
= l(xi+x2 + x3+x4)=x.
Вообще средний вектор выборки
- /*\
V V
компонентами которого будут выборочные средние 1-й, 2-й и т. д. ха-
рактеристик. Он может быть альтернативно определен как
х = 1(х1+х2 + ... + хк)= ЕхД (16.1.4)
л /=1
Эквивалентно
x = 1S1,
АС
где 1 = (1, l,...,l)z [см. I, раздел 6.2], так как S1 — вектор, компоненты
которого есть сумма элементов строк выборочной матрицы S.
Для каждой из р характеристик (рост, вес и т. д.) определим выбо-
рочную сумму квадратов:
к
к
,г 1, 2,...,р,
(16.1.5)
^2
и выборочные суммы произведений:
ars= хЛ
, г,s=l,2,..., p(r*s),
(16.1.6)
5
где по определению (Отметим условность употребления тер-
мина «сумма квадратов». В действительности это означает «сумму ква-
дратов отклонений от соответствующего выборочного среднего». То
же относится и к произведениям.) Для матрицы данных (16.1.2) имеем
207
au=(xn—X!)2+(xi2—Xi)2 + (Xi3—х,)2 + (х14—Xi)2
как выборочную сумму квадратов для роста и а22 для веса. Выбороч-
ная сумма произведений:
01!—х i)(x2l—x2) + (xi2— Xi)(X22—х2) + (xl3— xj(x23— x2) +
+ <X14—XjfXu—X^.
Суммы квадратов и произведений могут быть агрегированы в форме
матрицы А, имеющей ars как элемент. Это — матрица выбо-
рочных сумм квадратов и произведений:
А= ( : :*PY (16.1.7)
\flpi ••• арР /
Она является симметричной матрицей порядка (рхр/
Из введенных определений следует, что матрица А может быть
выражена в виде [см. (16.1.6)]
A=SS— Агхх (16.1.8)
или, более подробно,
А=.?,(х,-х)(х,-х)= (1б19)
= Е х,х;—£Хх
Выборочные дисперсии определяются как величины
агг/^—1), г=1,2,...,р,
а выборочные ковариации — как
ars/(k— i), r,s=l,2,...,p (r*s)
[см. раздел 2.1.2, п. б)]. Делитель к—1 выбирается так, чтобы обеспе-
чить несмещенность оценок [см. раздел 3.3.2] соответствующих вели-
чин для совокупности. Выборочная ковариационная матрица
(выборочная дисперсионно-ковариационная матрица, выборочная дис-
персионная матрица) есть симметричная матрица С порядка (р*р),
определяемая как л
C = k/(k— 1)
= (SS-^x)/^_-l) (16190
= Е (х —х )(х —х у/(k— 1) J
Диагональные (г,г)-е элементы С представляют собой выборочные
дисперсии, a (r,s)-e элементы — выборочные ковариации.
Определим теперь математическое ожидание векторной пере-
менной
х=<х1, х2,...,хру
как вектор
Е(Х)= [Е(Х3),Е(Х2),...,Е(Хр)}' (16.1.10)
208
и математическое ожидание матрицы случайных величин
/ ZH, z12zM\
2=(гг,,г!!....z;„ )=[Z„] (16.1.11)
\z ,, z ,,.... z /
x ml’ m2' ’ mn'
как
E(Z)=[E(Zrs)], (6.1.12)
t. e. в матрице Z [см. (16.1.11)] каждый случайный элемент замещает-
ся его математическим ожиданием E(Zrs).
Из несмещенности выборочных дисперсий и ковариаций как оценок
соответствующих параметров совокупности следует, что
E(X) = /z ]
(16.1.13)
E(C)=V J
где ft — вектор математических ожиданий, а V — дисперсионная мат-
рица совокупностей.
Введем следующие определения.
Определение 16.1.1. Дисперсионной матрицей (называемой также
матрицей ковариаций и вариационно-ковариационной матрицей) век-
торной случайной величины X=fAr1, Х2,... ,Х^ называется матрица V
размера рхр, где
vf,.=varfM
V,y = CON(XitXj), J ’
Матрица корреляций получается из этой матрицы замещением vtj на
zj = l, 2,...,р.
Определение 16.1.2. Кросс-ковариационная матрица двух случай-
ных векторных переменных 'К=(ХЪ Х2,...,Х^' и ¥=(У], Y2,...,Y^' есть
прямоугольная (р х {//матрица С = <<?-), где
с—со^ХДЦ, i=l,2,...,p, j=l,2,...,q.
Кросс-корреляционная матрица получается из С заменой ctJ на
Ci/Jv^j, i=l,2,...,p, j=l,2,...,q, где v(7=var^ и и^=уаг(Т/
Введем терминологию, которая будет использоваться в даль-
нейшем.
Определение 16.1.3. Положительно и неотрицательно определен-
ные матрицы. Квадратная действительная матрица V называется по-
ложительно определенной, если
a Va > О
для любого вектора а с действительными компонентами и такого, что
не все его компоненты — нули. Матрица V называется неотрица-
тельно определенной, если
a Va>0
при тех же условиях.
209
В частности, если V — дисперсионная матрица случайного вектора
Х = (Х1, Х2,...,Хр), компоненты которого линейно независимы в том
смысле, что все нетривиальные линейные комбинации вида LajXj яв-
ляются невырожденными случайными величинами (т. е. не будут кон-
стантами и будут иметь положительную дисперсию), то [см. I, раздел
19.6.14]
aVa=var(Etz/A^ > О,
где а = (аь а2,...,др). Так что V — положительно определенная матри-
ца. (Предупредим читателя, что положительные матрицы, т. е. мат-
рицы, у которых все элементы положительны, не обязательно
положительно определены. Аналогичное замечание верно и относи-
тельно неотрицательно определенных матриц.)
Результаты, представленные равенствами (16.1.13), указывают на
некоторые трудности, связанные с обозначениями. Их мы попытаемся
избежать, приняв некоторые соглашения.
Замечание. До настоящего момента мы делали различие между
случайной переменной X и ее реализацией х; в этом разделе, следова-
тельно, нужно различать случайную переменную Xj и ее реализацию
Xjj. В то же время необходимо различать матрицу G и ее элементы
gtJ. Соглашение теории вероятностей «прописная буква — строчная
буква» и такое же соглашение в теории матриц вступают в противоре-
чие. Мы могли бы, скажем, греческими буквами обозначать вектор-
ные или матричные случайные переменные, а латинскими — векторы
и матрицы. Но в этом случае выигрыш от однозначности обозначе-
ний был бы перевешен их сложностью. Поэтому мы принимаем сле-
дующее соглашение.
Соглашение об обозначениях. Будут применяться стандартные
обозначения линейной алгебры: х — вектор-столбец; xz — транспо-
нированный ему вектор-строка; А — матрица и т. д. В предыдущей
главе, там, где это было удобно, мы отбрасывали ранее принятое со-
глашение, согласно которому мы обращались к индуцированной слу-
чайной величине X [см. определение 2.2.1], чтобы описать выборочное
распределение некоторой выборочной статистики х, используя Е(Х)
для обозначения выборочного математического ожидания х [см. опре-
деление 2.3.1] и т. д. Здесь будет использоваться Е(х) для обозначения
(там, где контекст позволяет избежать двусмысленности) выборочно-
го математического ожидания х. Это же относится к дисперсиям, ко-
вариациям, векторным (х) и матричным (G) случайным величинам.
16.2. ВЫБОРКИ ИЗ МНОГОМЕРНЫХ НОРМАЛЬНЫХ
(MVN) РАСПРЕДЕЛЕНИЙ
Оценки некоторых параметров совокупности в многомерном слу-
чае можно получить по выборочным данным таким же образом, как
и в одномерном, что было показано в разделе 16.1. Однако не все ме-
тоды многомерного анализа представляют собой простые аналоги
210
методов, применяемых в одномерном случае. Большинство методов,
рассматриваемых в данной главе, не имеет эквивалента в одномерном
анализе.
16.2.1. ОЦЕНКИ МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ
Для заданной выборки (хн х2,...,хк) объема к из многомерного
нормального распределения (MVN) [см. II, раздел 13.4] со средним
вектором ц и матрицей ковариаций V (для обозначения этого распре-
деления возьмем аббревиатуру MVN (/x,V)) функция правдоподобия
как функция параметров д и V имеет вид
1(цУ)= ^ljypt72exP т у?] *^х/ м)» (16.2.1)
так как векторные наблюдения х( независимы. (Заметим, что компо-
ненты векторной случайной переменной не будут взаимонезависимы-
ми, если V не является единичной матрицей I.) Лог-правдоподобие
есть
log/(/xV) = -1kpXoglK-lArlog|V|-1 E (х,—M)V'(x —д).
Последний член, который зависит только от ц, может быть записан
в форме
-± £ (x(-x)V*'(xr-x)-U(x-/l)V-1^-/l), (16.2.2)
z z = l z
откуда видно, что лог-правдоподобие максимизируется при значении
/x-х; следовательно, х — оценка максимального правдоподобия для
м-
Проблема оценивания матрицы V не гак проста. Поскольку матри-
ца V — симметрична [см. I, раздел 6.7], имеется не р2, а р(р +1)/2 эле-
ментов, которые нужно оценить, среди них р дисперсий и р(р—1)/2
ковариаций.
Уравнения правдоподобия удобнее переписать, взяв матрицу
W=V— вместо V. Тогда определитель |V| заменяется на 1/|W|. Оце-
нивая элементы в W и используя многомерный аналог свойства инва-
риантности оценок максимального правдоподобия [см. раздел 6.2.6],
можно показать, что оценкой максимального правдоподобия для V
будет
\1=к/к, (16.2.3)
где матрица А определена выражением (16.1.9). Эту оценку можно
сделать несмещенной в результате умножения на к/(к—1). Детали до-
казательства приведены в работах [Andersen (1958), с. 47—48] и
[Morrison (1976), с. 99—100]. Рассмотренные результаты аналогичны
результатам, полученным для оценок максимального правдоподобия в
случае одномерного нормального распределения [см. пример 6.4.1].
Пример 16.2.1. Оценка дисперсионной матрицы двумерного нор-
мального распределения. Рассмотрим случайную выборку (х1( х2,...,хк)
211
из двумерного нормального распределения с вектором средних
М = (Д1,Д2)/
и матрицей ковариаций
,, / Vll Vl2\ / 0) Q0,0?
~( 2
\ v12 V22 j \ Qa\a2 а2
Обратная матрица для V будет
V-1 =W= ( и'" w,2\
И-12 W22J
Членом л^г-правдоподсбия, соответствующим последнему члену в
(16.2.2), будет
- у 2 [Wi i(x1(—gi)2 + 2w12(x, — gi)(x2 — g2) + w22fx2z—g2)2].
X I — 1
Дифференцируем его сначала no gi, а затем по g2. Получаем, что мак-
симум функции лог-правдоподобия достигается, когда
WuLfXy—Hi) + wi2£(x2 — g2)=0
и
w12E(x/,.--ai1) + w22£(x2i— g2)=0,
т. e. когда
WnMi + W12g2 = W11Xi+W12X2
и
W12/-I1 "b W22/-l2 = W12^1 "b W22X2.
Следовательно, оценка максимального правдоподобия (ОМП) для
есть
/Ч ~xi,
а для ц2
g2 =х2,
так что
g=X.
Члены лог-правдоподобия, включающие W(=V-1), можно предста-
вить в виде
l*log|W|-l* Е (х,—X)'W(xf—х)=
— I .^[Wi/Xi—xtf+lwnfX' —Xi)^—x2) + w22(x2—x2)2].
Л» I - 1
Дифференцируя это выражение no w,i, w12 и Wi3, получим следующие
уравнения правдоподобия ОМП для wrs:
^w22
W,1W22—w,22
-Efx,,—Xj)2=0,
212
—2kwu
Wuw12—w122
-E(xlz—Xi)(x2i—x2)=0,
i
kwi}
w^w22—w22
—Efx2/—x2)2 =0.
Из свойства инвариантности ОМП вытекает, что ОМП для коэффици-
ента корреляции
е=v12/Vvnv22
есть
Q = Vj2/VviiVi2,
и знак q совпадает со знаком v12.
Поскольку
7 = = 1 / W22 -^12\
WnW22—W,22 -W12 И-н)>
из записанных выше уравнений следует, что
vn = lEfXj — х\)2/к= —К—Сц,
К I К~~1
Vi2=|E('x1/-x1)('x2/-x2)= -Jl_c12
v22= 1lYx2—x2)2= -^c12,
где Си и c22 — выборочные дисперсии, a c12 — выборочная ковариация
[см. (16.1.9)].
16.2.2. НЕКОТОРЫЕ ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯ
В настоящем разделе мы рассмотрим случайный вектор X, кото-
рый имеет распределение MVN с вектором средних значений д и дис-
персионной матрицей V [см. II, раздел 13.4]. Пусть Хц Х2,...,Х^ —
статистические копии X, т. е. это независимо распределенные случай-
ные векторы, каждый из которых имеет такое же распределение, как
и X. Они могут рассматриваться как случайные векторы, индуциро-
ванные векторами наблюдений хн х2.....хк.
Очевидно, что выборочным распределением [см. раздел 2.2] выбо-
рочного вектора средних X = Ех7 к будет MVN (/х, У/к).
Обратимся теперь к выборочному распределению матрицы выбо-
рочных сумм квадратов произведений, а именно матрицы (16.1.9):
к
А= Е (х-Х)(х,—Х)\
Векторы х,—X, i=l,2,...,k, не являются независимыми друг от друга,
213
поскольку содержат общий член X. Когда речь идет о выборочном
распределении матрицы А, конечно, имеется в виду совместное рас-
пределение р(р+1)/2 алгебраически различающихся статистик
агг(г= 1,2,...,р), ars(r,s=l,2,...,p) (r<s). *
Обобщение одномерной задачи нахождения распределения Ё(хг—х-)2,
следовательно, не является тривиальным. В одномерном случае, с не-
зависимыми наблюдениями из N(g,a), после некоторого ортогонально-
го преобразования можно записать
к , *-i „
L(x—х)2= Ezr2,
где zr — реализации независимых нормально распределенных величин
с нулевым математическим ожиданием и дисперсией а2; отсюда следу-
ет, что выборочное распределение Ё(хг—х)2/#2 будет распределением
хи-квадрат с (к—1) степенями свободы [см. 2.5.4, п. а)]. В настоящем
случае обобщение этой техники дает
А—1
А= Е z,z<,
j=\ J J
vrq. zy — взаимонезависимые случайные векторы, каждый из которых
имеет одно и то же распределение MVN(0,V). Отсюда выборочным
распределением для А будет распределение Уишарта с параметром V
и п-к—1 степенями свободы с функцией плотности
ЛА(Чл>=________IAI'—l)/2exp_4.raceAV-' , (16,2,4)
2<л/’)/27Гр<р— D/4|V|"/2.n Г[|<л+1—
А — положительно определена.
Если р=1,
А = Е(х—х)2
и V= 1, то это выборка из нормального распределения с ожиданием д
и дисперсией 1. Плотность (16.2.4) переходит в плотность распределе-
ния хи-квадрат, что подтверждает хорошо известный в одномерном
случае результат. Когда К=а2, плотность для
AV-1 = EfY—Т)2/*2
имеет распределение хи-квадрат с (к—1) степенями свободы. Анало-
гично соответствующим результатам в одномерном случае для выбо-
рок из нормального распределения X и А являются также независимо
распределенными и совместна достаточными статистиками для д и V
[см. пример 3.4.8].
Результаты, приведенные в этом разделе, можно распространить на
случай нескольких независимых выборок из распределений MVN с век-
торами математических ожиданий/^ и и одинаковой ковариационной
матрицей V. Тогда разность Х2 имеет распределение MVN с векто-
ром математических ожиданий /*!—д2 и ковариационной матрицей V(l/
к}+Л/к2). Далее, пусть А^Аг,...^ — независимые случайные мат-
214
рицы, подчиненные распределению Уишарта с параметром V и числа-
ми степеней свободы nif п2...пк. Тогда Ё А- имеет распределение
/=1
т
Уишарта с Е л. степенями свободы. Когда р=1 и V=l, это свойство
/ж 1
воспроизводит свойство независимых величин с распределением хи-
квадрат.
16.2.3. ПРОВЕРКА ГИПОТЕЗ И ДОВЕРИТЕЛЬНЫЕ ОБЛАСТИ
ДЛЯ ВЕКТОРА МАТЕМАТИЧЕСКИХ ОЖИДАНИЙ
Методы, применяемые при построении доверительных интервалов
или проверке гипотез (например, Но:ц = цо) для математического ожи-
дания ц в случае одномерного нормального распределения с известной
дисперсией <г [см. примеры 4.2.1 и 4.5.2], основаны на использовании
процентных точек стандартной нормальной случайной величины z,
где
Когда значение а неизвестно, соответствующие процедуры могут
быть построены с помощью распределения Стьюдента с (к—1) степе-
нями свободы для статистики
/= Jk(x
где s2 — обычная несмещенная оценка для а2. Можно воспользоваться
и квадратами величин z и t, что приводит к величине, имеющей рас-
пределение хи-квадрат с 1 степенью свободы, в случае z, и к величине,
имеющей F-распределение с 1 и (к—1) степенями свободы, в случае t.
Трудности, возникающие при одномерном подходе в процессе по-
лучения соответствующих статистик в многомерном случае, очевид-
ны. Они связаны с тем, что эта процедура основана не на
использовании известного выборочного распределения статистики
V£(X—д),
которым будет MVN(0,V), а на использовании квадратичной формы,
обобщающей квадраты статистик z и t.
Выборочное распределение квадратичной формы
(скалярной величины) есть распределение хи-квадрат с р степенями
свободы. При проверке гипотезы //о*д=Мо> когда V известна (это ана-
лог одномерного случая с нормальным распределением и известной
дисперсией), критическая область для уровня значимости а [см. раз-
дел 5.12] есть множество векторов х, для которых выполняется соот-
ношение
к(х— цо)'У~ (Х—цо)^с(р,а), (16.2.5)
где с(р,а)= х2р)(1—а) есть (1—а) х 100%-ная точка распределения хи-
квадрат с р степенями свободы.
Доверительную область для ц в /7-мерном пространстве можно по-
лучить, обращая в неравенство
215
к(Х—цУ\/~1(Х—/У)^с(р,а). (16.2.6)
Эта область представляет собой эллипсоид с центром в X.
Для двумерной выборки в примере 16.2.1 неравенство (16.2.6) при-
мет вид
tfXi—Д1)2 + 2w12(Xi— Д1)(х2—/*2) + w22(x2—д2)2] С с(р,а).
Это эллипс в двумерном пространстве координат д2 с центром в
(х}, х2).
Когда матрица V неизвестна, обобщение одномерной статистики
квадрата t, имеющей распределение Стьюдента, приводит к статисти-
ке Т Хоттелинга:
Г2 = Ar(X—д/С-’ОС—д), (16.2.7)
где С — выборочная матрица ковариаций (16.1.9). При проверке гипо-
тезы Hq'.ii-hq критическая область для уровня значимости а есть мно-
жество векторов х, для которых выполняется неравенство
£(Х—доУО'Сх—Ho)>d(p,a), (16.2.8)
где
И F(pk_p)(\—а) есть 100(1—а)%-ная точка F-распределения с р и (к— 1)
степенями свободы [см. раздел 2.5.6].
Доверительная область для g в р-мерном пространстве может
быть получена с помощью процентных точек F-распределения. Мы
снова получаем эллипсоид.
16.2.4. ЗАДАЧИ ДЛЯ ДВУХ ВЫБОРОК
Предположим, что X. — выборочные средние векторы, сь с2—
выборочные ковариационные матрицы для выборок объема к\ и к2 из
р-мерных распределений MVN(gbV) и MVN(g2,V). Тогда если матрица
V известна, то критическая область для проверки гипотезы Н0:ц1 = д2
с доверительны.м уровнем а есть
/ yX-Ty-V^fX.-Ty >с(р,а\
где величина с(р,а) уже была определена в связи с (16.2.5).
Если матрица V неизвестна, то несмещенные оценки Ci и С2 могут
быть объединенными, что дает
С = [(А:1-1)С1+^2— 1)С2]/^,+Аг2—2), (16.2.9)
и критическая область для проверки гипотезы HQ:ni = д2 для уровня
значимости а конструируется с помощью статистики
Т2 =
Критическая область есть множество векторов, для которых выпо-
лняется
ЭТА
т2>( ki+k2~2 \р (1—оЛ
+ к2-р-1 )ГР.к^к2-Р-Л1 <*)'
16.2.5. ВЫВОДЫ ДЛЯ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ
Рассмотрим случайную выборку объема к из двумерного нормаль-
ного распределения с вектором средних (/*i,/*2)' и матрицей кова-
риаций
у 6<T1<T2 <J2
Как было показано в примере 16.2.1, оценкой максимального правдо-
подобия Q=r для коэффициента корреляции q будет
к _____ _
г- ^ХЦ-Хг)(х2-Х2) (16.2.10)
х/ ~ £
Ч Е(х1-х1)^(х2-х2у]
i = l i=l
Можно показать [см. Anderson (1959), с. 62—64], что когда е = 0, ста-
тистика г имеет следующую выборочную плотность:
Пт(*—1)] (1-г2ук~4)/2 , — 1 г 1,
Г[^-2)]х^
или, что эквивалентно, выборочным распределением величины
(к—2)1/2—г-— (16.2.11)
<(1—г2)
будет распределение Стьюдента с (к—2) степенями свободы.
Наиболее важным приложением этого результата является провер-
ка гипотезы Hq:q-0 против Hi'.q^O. Гипотеза Но отвергается на уров-
не значимости а, если
где Г. ,.(1—есть (1—!,а) 100%-ная точка 1-распределения Стью-
(л *-) 2 2
дента с (к—2) степенями свободы.
Предположим, что регрессия Е(Хг\Х1 -х/) переменной Х2 на Xt [см.
пример 4.5.3] задается как
Тогда
31 = Qffi/az-
Из этого следует, что, когда выполнено условие ^оъХ), предпо-
ложения
6 = 0 и (31 =0
равнозначны. И проверка значимости (31 то же самое, что проверка
217
значимости q. Обычная процедура [см. пример 5.5.2] проверки нуле-
вой гипотезы
Но:01=О
«отвергает» ее на уровне а, если
|*1|/s.d.№,)3='i_2(l-|a), (16.2.12)
где bi — оценка наименьших квадратов для /3t [см. раздел 6.5.3, п. 1],
a s.d/di) означает оценку выборочной стандартной девиации (остаточ-
ной суммы квадратов). После некоторых преобразований можно пока-
зать, что левая часть неравенства (16.2.12) переходит в левую часть
неравенства (16.2.11), что, конечно, и должно быть, так как последняя
имеет распределение Стьюдента. Проверка, равна ли корреляция q ну-
лю, эквивалентна проверке, зависимы ли Xt и Х2. Для умеренных и
больших объемов выборки к может быть использовано преобразова-
ние для г, известное как ^-преобразование Фишера [см. раздел 2.7.3,
п. б)]:
Величина z асимптотически нормально распределена со средним
и дисперсией \/ (к—1). (Здесь log взят по основанию е.)
Гипотеза H0:q=q0 может быть, следовательно, проверена с по-
мощью таблиц стандартного нормального распределения. Например,
рассмотрим выборку объема к из трехмерного нормального распреде-
ления. Частный коэффициент корреляции между Хх и Х2 при заданном
значении Х3=х3 есть
612—612623
612,3“ , , ----- ’
V(i—е?з)(1—еЬ)
(16.2.13)
где Qjj — корреляция между Х, и Xj. (Это, по определению, коэффи-
циент корреляции условного распределения (Хх,Х2) при заданном зна-
чении Х3-х3.)
Если верна гипотеза е 12,3-О, оценка максимального правдоподо-
бия 2, з,полученная из (16.2.13) замещением на соответствующие
оценки максимального правдоподобия, величина
/к—Зг12, з /VT—Г12,з (16.2.14)
имеет распределение Стьюдента с (к—3) степенями свободы. Отсюда
следует тест для е^.з- Проверки гипотез индивидуальных коэффици-
ентов частной корреляции в р-мерном нормальном распределении,
когда фиксированы значения q переменных, основаны на статистике
вида (16.2.14), имеющей распределение Стьюдента с (к—q—2) степе-
нями свободы.
218
16.2.6. НЕЦЕНТРАЛЬНЫЕ РАСПРЕДЕЛЕНИЯ
В разделах 16.2.3 и 16.2.4 обсуждались проверки гипотез для векто-
ров средних и были определены распределения тестовых статистик в
случае истинности нулевой гипотезы. Однако распределения этих ста-
тистик для альтернатив определены не были.
Предположим, например, что и матрица V известны. Те-
стовая статистика _
—go) V (X—до)
имеет центральное хгг>2-распределение, если д=д0. Если необходима
функция мощности этого критерия или вероятность ошибки II рода
при д#д0> то тестовая статистика уже не будет подчиняться этому
распределению, а будет иметь нецентральное хГр2-распределение [см.
раздел 2.8.1] с параметром нецентралъности
(16.2.15)
Заметим, что если u=g0, т0 эта величина равна нулю.
В случае, когда V неизвестна, статистика критерия имеет /^^-рас-
пределение с параметром нецентральности (16.2.15) и с неизвестной
матрицей V. Таблицы нецентральных распределений для нецентраль-
ного х2 содержатся в [Hartor and Owen (1970), Т. 1—G], для всех не-
центральных распределений — в [Owen (1962); Resnikoff and Lieberman
(1957)—G], а для нецентрального F — в [Graybill (1976)—С].
16.3. ГЛАВНЫЕ КОМПОНЕНТЫ
16.3.1. ВВЕДЕНИЕ
В этом разделе для упрощения изложения мы будем предполагать,
что р-компонентная случайная переменная X имеет вектор средних 0
и положительно определенную [см. определение 16.1.1] дисперсионно-
ковариационную матрицу V [см. (16.1.13)]. Другими словами, мы пе-
реходим к векторной случайной величине Х = Х*—/а где Х‘ — исходная
случайная величина с вектором средних д. Заметим, что пока нет не-
обходимости делать каких-либо предположений относительно формы
распределения.
Главные компоненты представляют собой ортогональные линей-
ные преобразования (т. е. некоррелированные случайные переменные)
[см. раздел 2.5.3, п. е)] векторной случайной величины X, такие, что
первая из них имеет наибольшую дисперсию, дисперсия убывает с
ростом номера переменной, так что p-я имеет минимальную диспер-
сию. При некоторых предположениях относительно шкал можно пока-
зать, что дисперсии главных компонент являются собственными
числами матрицы V, а коэффициенты при компонентах X в линейных
преобразованиях являются компонентами соответствующих собствен-
ных векторов.
Анализ главных компонент направлен на сокращение числа пере-
менных для анализа с использованием небольшого числа первых глав-
ных компонент и исключением линейных комбинаций (главных
компонент) с минимальной дисперсией.
219
16.3.2. ГЛАВНЫЕ КОМПОНЕНТЫ СОВОКУПНОСТИ
Пусть У1 — первая главная компонента случайного вектора X:
р
Г,= Ес.Д-ОХ.
Ясно, что
E(YX)=O
и
уаг(У1)=Е(У?)= £ 1с^(Х^ = С'Ус..
Вектор коэффициентов ct выбран таким образом, чтобы дисперсия Y}
имела максимальное значение при условии, что
£<,>0(0, = !. (16.3.1)
Таким образом мы приходим к проблеме максимизации при наличии
ограничений, которая может быть решена с применением множителей
Лагранжа [см. IV, раздел 5.15]. Тогда задача сводится к нахождению
вектора сь максимизирующего
Ci'VCj—XiCCf'Ci—1),
где Xi — множитель Лагранжа. Взяв производную по С] и приравняв
ее к 0, получаем уравнение
(V— XJ)C,=O, (16.3.2)
где I — единичная матрица. Поскольку нас интересуют только реше-
ния, когда С]#0, должно удовлетворяться условие на определитель
[см. I, раздел 5.9], а именно
|V—XJ|=O.
Следовательно, X] — собственное число матрицы V, a Ci — соответ-
ствующий собственный вектор.
Выражение (16.3.2) может быть переписано в виде
Vc, = X,C,. (16.3.3)
Умножая слева на сь получаем
Ci'Vc^XjC/C^X, из (16.3.1). (16.3.4)
Но левая часть равенства (16.3.4) есть уаг(У]), а поскольку решалась
задача максимизации varfy^, следовательно, Xi есть максимальное
собственное число матрицы V.
Чтобы найти вторую главную компоненту
У2 = С2%
потребуем выполнения двух условий — условия нормировки:
С2С2 = 1 (16.3.5)
и условия ортогональности:
CiC2=0. (16.3.6)
Вектор с2 определяется теперь так, чтобы уаг(У2) была максималь-
220
на при выполнении двух указанных условий. Эта задача требует ис-
пользования двух множителей Лагранжа Х2 и /?. Мы должны максими-
зировать выражение
с2 Vc2—Х2(с2с2— 1)—/3(с /с2—0). (16.3.7)
Взяв производную от (16.3.7) и приравняв ее к 0, находим в соответст-
вии с условием ортогональности (16.3.6), что /3-0. А в силу условия
нормировки (16.3.5) получаем, что Х2 есть второе по величине соб-
ственное число матрицы V, X2=varfK2), а с2 — соответствующий соб-
ственный вектор.
Процесс повторяется до тех пор, пока все собственные числа и
собственные векторы не окажутся дисперсиями и коэффициентами ли-
нейных комбинаций главных компонент. Чтобы доказать этот резуль-
тат для к-й главной компоненты, мы должны максимизировать
var(Yk) с учетом к условий, включающих условие нормировки
и (к—1) условий ортогональности: С^=0, г=1,2,...,к—1.
К сожалению, свойства главных компонент зависят от шкал изме-
рений исходных переменных, т. е. они не являются масштабно-
инвариантными. Например, переход при измерении некоторого разме-
ра от футов к дюймам и при измерении времени от часов к секундам
приведет, вообще говоря, к другим собственным числам и векторам.
По этой причине, возможно, наиболее оптимальной будет работа со
стандартизованными переменными
XAi-z,,
которые имеют нулевые средние значения и единичные дисперсии. В
этом случае ковариационная матрица для Z будет корреляционной
матрицей для X, скажем R, после такого преобразования. Главные
компоненты могут быть получены как собственные векторы матрицы
R, а их дисперсии — как соответствующие им ее собственные числа.
Ранее мы не делали никаких предположений относительно ранга
[см. I, раздел 5.6] матрицы V. Если матрица V не является матрицей
полного ранга, то несколько наименьших ее собственных чисел будут
нулевыми и вектор X может быть преобразован в меньшее, чем р,
число главных компонент. Требуется только, чтобы V была неотрица-
тельно-определенной матрицей [см. определение 16.1.3].
Поскольку
Е X.* — trace V,
сумма собственных чисел может рассматриваться как полная диспер-
сия совокупности, а о первых т главных компонентах с т наибольши-
ми дисперсиями можно сказать, что они учитывают долю полной
дисперсии, определяющуюся как
т р
Е X/ Е X,..
/=1 ' /=1 1
Если эта доля достаточно велика, то компоненты с дисперсиями
221
Хот+,,...,Хр могут не учитываться и совокупность будет адекватно
представлена с помощью т первых главных компонент.
Если используется корреляционная матрица R, то (предполагается,
что V полного ранга)
р
На практике должен быть сделан выбор, получать ли главные компо-
ненты на основе ковариационной матрицы или на основе корреляци-
онной. Доля дисперсии, объясненная первыми главными компонента-
ми, в обоих случаях будет различной. С помощью ковариационной
матрицы можно получить компоненты с большими дисперсиями про-
сто в силу выбора шкалы измерений одного их х-ов.
16.3.3. ВЫБОРОЧНЫЕ ГЛАВНЫЕ КОМПОНЕНТЫ
В предыдущем разделе обсуждалась проблема получения главных
компонент для совокупности, когда параметры совокупности извест-
ны. На практике же параметры совокупности оцениваются по выбор-
ке, например, объема к.
Матрица данных может быть центрирована, и выборочные глав-
ные компоненты оценены на основе выборочной ковариационной мат-
рицы или выборочной корреляционной матрицы с помощью тех же
методов, что описаны в предыдущем разделе. Необходимо иметь в
виду, что имеется различие в вычисляемых значениях главных компо-
нент для ^-мерных наблюдений при использовании этих двух матриц.
Когда применяется ковариационная матрица, эти значения представ-
ляют собой просто линейные функции исходных переменных (предва-
рительно центрированных). Для корреляционной матрицы — это
линейные комбинации нормированных переменных.
16.3.4. ЧИСЛЕННЫЙ ПРИМЕР
Оценивались главные компоненты девяти характеристик, измерен-
ных для шести клонов тополей. Дж. Джефферс [см. Jeffers (1965)] в
этой задаче с помощью главных компонент попытался определить ли-
нейные комбинации девяти переменных, представляющих собой изме-
рения на листьях шести клонов тополей. Эти комбинации должны
были наилучшим образом разделять эти шесть клонов. Эти девять пе-
ременных следующие:
Xi — длина черешка;
х2 — длина листа;
х3 — наибольшая ширина листа;
х4 — ширина листа на середине длины;
х5 — ширина листа на одной трети длины;
х6 — ширина листа на двух третях длины;
х7 — расстояние от основания листа до точки прикрепления
черешка;
222
х8 — угол между первой главной прожилкой и средним ребром;
х9 — угол между первой второстепенной прожилкой и средним
ребром.
Для каждого из шести клонов было сделано пять наблюдений
<£=30). Выборочная матрица корреляций для девяти наблюдений при-
ведена в табл. 16.3.1. Собственные числа и соответствующие им со-
бственные векторы представлены в табл. 16.3.2.
Таблица 16.3.1. Корреляции между девятью переменными
[см. Jeffers (1965)]
1,000
—0,409 1,000
0,731 0,156 1,000
0,624 —0,121 0,781 1,000
0,699 0,190 0,982 0,820 1,000
0,674 0,012 0,907 0,940 0,935 1,000
0,767 —0,570 0,567 0,583 0,515 0,597 1,000
0,364 —0,569 0,268 0,427 0,239 0,401 0,743 1,000
0,564 —0,428 0,535 0,652 0,496 0,635 0,822 0,833 1,000
Из табл. 16.3.2 видно, что большая часть дисперсии объясняется с
помощью первых двух главных компонент.
Чтобы попытаться дать содержательную интерпретацию главных
компонент, полезно разделить коэффициенты каждого собственного
вектора на его наибольший по абсолютной величине коэффициент и
обосновать интерпретацию на тех коэффициентах, абсолютная величи-
на которых после такого деления больше или равна 0,7 [см. Jeffers
(1967)].
Например, в табл. 16.3.2 компоненты 1 и 2 вместе дают некоторую
суммаризацию размерам листа, а компонента 5, напротив, связана с
углами (х8,х9). Знаки коэффициентов не играют существенной роли,
так как они все могут быть изменены на обратные, что не влияет на
результат анализа. Они могут служить только для индикации проти-
воположных тенденций на компоненте. В нашем примере стандартизо-
ванные значения наблюдений, соответствующие двум первым
главным компонентам, могут быть графически отображены и исполь-
зованы потом для дискриминации клонов.
16.3.5. НЕКОТОРЫЕ ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯ
В случае, когда X подчиняется многомерному нормальному распре-
делению с вектором средних 0 и ковариационной матрицей V, главные
компоненты совокупности будут распределены нормально, так как
они являются линейными функциями случайных величин Хр
[см. II, раздел 13.4.7]. Не имеет значения, какая из матриц использо-
валась — ковариаций или корреляций.
Распределение собственных чисел и векторов для выборочных глав-
223
ных компонент при применении ковариационной матрицы известно
только в общих чертах. Точные распределения для малых выборок
имеют весьма сложную форму. Ситуация существенно усложняется,
если некоторые собственные числа V совпадают. При больших выбор-
ках из многомерного нормального распределения известны асимпто-
тические результаты, которые могут оказаться полезными при
проверке гипотез относительно собственных чисел и собственных век-
торов для V. В работе [Morrison (1976), с. 292 — 299] читатель найдет
более детальное обсуждение этих вопросов.
Таблица 16.3.2. Собственные векторы и соответствующие им
собственные значения для матрицы корреляций из табл. 16.3.1
Компоненты
Перемен- ная 1 2 3 4 5 6 7 8 9
xt 0,349 —0,029 0,644 —0,174 —0,036 0,382 0,524 0,081 0,071
*2 —0,121 0,600 —0,393 —0,423 —0,151 —0,098 0,504 0,028 0,066
*3 0,362 0,321 0,066 —0,271 0,145 0,089 —0,458 —0,407 0,532
X, 0,370 0,149 —0,134 0,679 —0,146 —0,158 0,325 —0,459 0,016
х5 0,357 0,356 0,034 —0,103 0,236 0,061 —0,210 —0,030 —0,793
х6 0,384 0,235 —0,112 0,287 0,103 —0,085 —0,097 0,780 0,256
Ху 0,356 —0,286 0,130 —0,340 —0,155 —0,795 0,047 0,007 —0,038
X* 0,268 —0,428 —0,486 —0,155 0,615 0,155 0,276 0,063 0,052
х9 0,349 —0,257 —0,378 —0,155 —0,682 0,383 —0,156 0,050 —0,089
Собственное число X, 5,648 2,051 0,663 ^0,338 0,128 0,097 0,042 0,023 0,009
Процент дисперсии 62,8 22,8 7,4 V 7
Накоплен- ный про- цент дис- персии 62,8 85,6 93,0 100
16.4. ФАКТОРНЫЙ АНАЛИЗ
16.4.1 . ВВЕДЕНИЕ
Факторный анализ связан с анализом главных компонент в том от-
ношении, что в обоих случаях рассматриваются зависимости между р
скалярными случайными переменными, образующими вектор X, на
основе анализа матрицы ковариаций или корреляций этих переменных.
Однако вместо применения к вектору X линейного преобразования, в
факторном анализе предполагается, что векторная случайная величина
может быть представлена в виде некоторой линейной модели, включа-
ющей случайные переменные, известные как факторы, число которых
существенно меньше, чем р. Эта модель включает также и член, свя-
224
занный с ошибкой. Следовательно, корреляции между переменными
%1, Х2,...,Хр могут быть вычислены как корреляции между линейны-
ми комбинациями факторов, число которых много меньше, чем р.
Поскольку факторы наблюдаемы, анализ направлен на разложение
ковариационной или корреляционной матрицы в предположении ли-
нейной модели.
16.4.2 . ФАКТОРНАЯ МОДЕЛЬ
Предположим, что р-мерная случайная величина X имеет среднее О
и ковариационную матрицу V полного ранга р. В противном случае X
получается вычитанием среднего вектора g из исходной случайной пе-
ременной X .
Предположим, что каждая переменная X, может быть выражена
как линейная комбинация к ненаблюдаемых факторов с
б6.---Л)'=*. к<р, так 4Tof
Х, = ДХ/j+e,, 1=1,2...р, (16.4.1)
где параметры линейной модели Х^- известны как факторные нагруз-
ки, a et — случайная ошибка, ассоциированная только с %,-.
Для дальнейшего предположим, что fj — некоррелированные слу-
чайные переменные со средним 0 и дисперсией 1, е( — некоррелиро-
ванные случайные величины с нулевыми средними и неизвестными
дисперсиями величины fj и е,- некоррелированы.
При таких предположениях дисперсия X, из (16.4.1) может быть
представлена в виде
var(X,.)=4=
где ЕХ?- известна под названием общности, которая представляет
часть дисперсии Xit обусловленную «факторами», а — часть дис-
персии Xt, обусловленная ошибкой.
Ковариация между Xr, Xs задается выражением
coN(Xr,XJ=E(Xr,XJ= h\rJXSJ, r*s.
Аналогично получаем
coN(Xi,fj)=cov( i + eitf) = \j.
Представим факторную модель в матричной форме:
X=Af+e,
где Л есть (£>хЛ7-матрица нагрузок. Тогда будем иметь разложение
ковариационной матрицы
V=AA+¥,
где ¥ — диагональная матрица порядка р, содержащая дисперсии
ошибок.
225
16.4.3 . НЕКОТОРЫЕ СВОЙСТВА
В отличие от анализа главных компонент, факторный анализ (или
разложение матрицы V) нечувствителен к изменению шкал перемен-
ных. Это легко увидеть, умножая каждую переменную Xi на констан-
ту с,- и переписывая затем факторную модель и соответствующую ей
декомпозицию матрицы V. В частности, предположим, что c-s^..)-1.
Тогда условия на средние значения, дисперсии и ковариации факторов
и ошибок не изменятся, хотя факторная модель теперь включает фак-
торные нагрузки вида Х,у/ай=Х^. и дисперсии ошибок /о2,— ^*2. При
таком преобразовании ковариационная матрица X становится матри-
цей корреляций R. Из этого следует, что
к
(16.4.1 а)
и к
.ЕХ^*=соггГВД).
Уравнение (16.4.1а) дает соотношение между дисперсией преобразо-
ванной ошибки и факторными нагрузками. Число к должно быть вы-
брано так, чтобы обеспечить неотрицательность величин
Хотя факторный анализ инвариантен к преобразованиям шкал,
факторное решение не является единственным. Если В — ортогональ-
ная матрица размера (к* к), то общая факторная модель
X=Af+e с e=fa, ег,...,епУ
может быть переписана в виде
X=A(BB)f+e
(так как ВВ=1), что можно рассматривать как модель с факторными
нагрузками ЛВ и факторами B'f. Предположения о случайных пере-
менных, сделанные для исходной матрицы, не нарушаются при таком
преобразовании. Разложение матрицы будет, как и прежде, иметь вид
V= ABBA + ¥= АЛ' + ¥.
Это означает, что имеется бесконечное число факторных нагрузок,
удовлетворяющих исходным предположениям модели. Эта трудность
может быть преодолена [см. Lawley and Maxwell (1971), с. 7—11] вве-
дением ограничений на Л, таких, как диагональность матрицы
(16.4.2)
(Это, конечно, предполагает, что ¥ единственна.)
В факторном анализе делается попытка декомпозиции ковариаци-
онной матрицы V, содержащей ±р(р+1) параметров, в две матрицы:
матрицу (АЛ), содержащую рк параметров, и матрицу (¥), содержа-
щую р параметров. Ограничение такое, как, например (16.4.2), нак-
ладывает ~к(к—1) связей между параметрами Л и ¥. Экономное
£
представление внутренних связей между компонентами X будет, сле-
226
довательно, получено, если разность t между числом параметров в V
и числом эффективных параметров модели совместно с числом огра-
ничений будет положительной, что дает
*= | {(р—к)2—(р + к)] > 0.
Для модели, основанной на корреляционной матрице, значение t
будет тем же, несмотря на соотношение (16.4.1а), поскольку число па-
раметров в R будет ^p(p+Y)—р.
Если /=0, решение для Л и I может быть получено. Однако это
приведет только к новому представлению зависимостей между компо-
нентами X, которое содержит такое же количество параметров, как и
исходное. К сожалению, в случае экономного представления точное
решение отсутствует.
16.4.4 . ОЦЕНИВАНИЕ
На практике ковариационная матрица совокупности неизвестна, и
факторные нагрузки и дисперсии должны быть получены на основе
выборочной ковариационной матрицы С, оцененной по выборке объ-
ема п. Прежде чем приступать к оценке параметров факторной моде-
ли, необходимо фиксировать число факторов к. Это число выбирается
таким образом, чтобы количество эффективных параметров модели
было самое большее тем же, что и в исходной ковариационной матри-
це При этом обычно предполагается, что X,f и е имеют много-
мерные нормальные распределения. Это дает возможность построить
тест для проверки гипотезы согласия относительно числа параметров
к.
В факторном анализе существует два общих подхода к оценива-
нию. Один основан на методе максимального правдоподобия [см. гл.
6] при явных предположениях о многомерной нормальности [см. II,
раздел 13.4]. Второй «эксплуатирует» факторизацию матрицы ковари-
аций в манере анализа главных компонент. При втором подходе пред-
положения о нормальности используются только для получения
критерия гипотезы согласия.
Метод максимального правдоподобия в факторном анализе на-
правлен на получение оценок Л и I (подчиненной условию диагональ-
ности), максимизирующих функцию правдоподобия, в которой вектор
средних исходных наблюдений заменен его оценкой х.
Из результатов раздела 16.2.1 следует, что логарифмы правдопо-
добия g=x есть
log/(V) = — у nplog2-7r— у zilog | V |— у tranceAV-1.
At li L
В предположениях факторной модели матрица V замещается на ЛД' +
+ ¥ и функция log/fA,^) максимизируется для получения оценок Л,1^.
Это не простая проблема, и она не может быть решена аналитически.
Более подробное описание содержится в работе [Lawley and Maxwell
(1971)]. 227
Другой метод известен как анализ главных факторов. Он основан
на идее анализа главных компонент. Анализ главных компонент мож-
но рассматривать как ортогональное преобразование для X вида
У=ГХ,
где i-я строка ортогональной матрицы Г есть транспонированный
собственный вектор с,-, соответствующий /-му по величине собствен-
ному числу а,. Ковариационная матрица Уу для Y будет диагональ-
ной с диагональными элементами а,-, где
Уу = ГУГ
и
v=rv7r. (16.4.3)
В [Press (1972), с. 318—319] предложено решение, основанное на
(16.4.3), при котором предполагается, что ошибки являются малыми
или —0. В этом случае факторная модель принимает вид
V^AA,
давая
A = F'(Vy)1/2,
где V,/2 — диагональная матрица с диагональными элементами, рав-
ными квадратным корням диагональных элементов Уу.
Более экономное представление для V может быть получено, если
выбрать Л таким образом, чтобы остались только к наибольших соб-
ственных чисел, и отбросить (р—к) наименьших вместе с соответ-
ствующими собственными векторами. В результате получится матри-
ца факторных нагрузок размера (р*.к).
Если предположение ¥ = 0 неприемлемо, то аналогичный подход
может быть основан на применении редуцированной матрицы
V—* = АЛ'
или, что более удобно,
R—¥* = Л*Л* (16.4.4)
в терминах собственных чисел и векторов. Заметим, что в обоих слу-
чаях матрица АЛ' диагональна.
На практике используются выборочные матрицы ковариаций С
или корреляций R. Когда ^*^0, необходимо угадать диагональные
элементы матрицы R—¥*, которые являются оценками общности.
Детальное обсуждение этих проблем содержится в работе [Mardia,
Kent and Bibby (1979), с. 261—263].
Декомпозиция симметричных матриц в анализе главных факторов
представляет собой просто применение хорошо известных результатов
матричной алгебры [см. I, гл. 6, 7]. Условие некоррелированности
факторов можно ослабить. Если предположить, что ковариационная
матрица для f есть положительно определенная матрица Ф размера
(к* к), то разложение ковариационной матрицы примет вид
У=АФЛ +¥.
228
16.4.5 . ОБСУЖДЕНИЕ
В интерпретации факторных нагрузок имеются очевидные труднос-
ти. Можно попытаться дать описание некоторого фактора, рассмат-
ривая только наибольшие нагрузки этого фактора и соответствующие
им случайные переменные. Для облегчения такой интерпретации мож-
но сделать ортогональное преобразование факторов, что не меняет
факторное разложение ковариационной матрицы. Эта процедура из-
вестна как вращение факторов. Факторы при этом стараются преобра-
зовать таким образом, чтобы как можно больше нагрузок было
близко к нулю, что упрощает интерпретацию. Подробное описание
одного из подобных методов, известного как варимакс, можно найти
в работе [Kaiser (1958)].
16.5. КАНОНИЧЕСКАЯ КОРРЕЛЯЦИЯ
16.5.1. ВВЕДЕНИЕ
Рассмотрим две векторные случайные переменные
Х=<АГ1, Х2,...,ХХ и Y=fyt, У2,...,У у, обе с математическим ожидани-
ем, равным 0. (Это не является ограничением, поскольку мы интересу-
емся только корреляциями между переменными.) Пусть
ковариационные матрицы [см. определение 16.1.2] для X и Y будут со-
ответственно
Vn=E(XX), V22=E(YY),
а матрица кросс-ковариаций между X и Y
V12=F(XY).
Предположим, что VH, V22 являются положительно определенны-
ми [см. определение 16.1.3] и V]2 — матрица полного ранга (q). Кано-
ническая корреляция используется для упрощения описания
зависимости между X и Y, задаваемой матрицей V12, при рассмотре-
нии корреляции между линейными комбинациями двух наборов пере-
менных.
Этот метод продуцирует некоррелированные пары скалярных (од-
номерных) случайных переменных, таких, что оба члена некоторой па-
ры коррелированы друг с другом. Пара с наибольшей парной
корреляцией (по абсолютному значению) называется первой парой, и
далее пары упорядочиваются вплоть до q-й. пары, которая имеет на-
именьшую (ненулевую) корреляцию. Таким образом может быть по-
лучено более экономное описание зависимости между X и Y, чем
определяемое матрицей Vi2.
Соответствующие линейные комбинации известны как канониче-
ские переменные. По аналогии с анализом главных компонент не-
сколько первых канонических переменных с наибольшими
каноническими корреляциями может быть использовано для прибли-
229
женного описания зависимости между X и Y.
16.5.2. КАНОНИЧЕСКИЕ КОРРЕЛЯЦИИ СОВОКУПНОСТИ
Рассмотрим линейную комбинацию компонент X и комбинацию
компонент Y, задаваемые как
СаХ
и
IF-bY.
Тогда U и W имеют нулевое математическое ожидание, дисперсии и
ковариации
varfC9 = a'Vna,
varfW7 = bV22b,
cov^H9=aVi2b.
Коэффициент корреляции между U и W, следовательно, есть
= (aV*b)
6 [(а'У„а)(Ь'У22Ь)]1/2
Это приводит к задаче максимизации (минимизации) безразмерной ве-
личины q [см. II, раздел 9.8.2]. Так как значение q инвариантно к вы-
бору шкал для измерения U и W, без ограничения общности можно
считать, что а и Ь выбраны так, чтобы дисперсии U и W были
единичны.
Задача теперь сводится к нахождению стационарного значения
e = aV12b
при ограничениях на а и Ь:
var(U)=a'V\ia = l,
var(H/) = b/V22b = 1.
С помощью множителей Лагранжа а и /3 мы должны найти безуслов-
ное стационарное значение для
С= a V12b—а(а V, ,а—1)—/3(Ь V22b—1).
Это ведет к решению уравнений
*r=V12b-2aV„a=0, (16.5.1)
Оа
<£=V,'2a-2(3V22b=0. (16.5.2)
dD
Умножая с обеих сторон (16.5.1) на а', а (16.5.2) на Ь', после преоб-
разования получаем
гааУца^аУ^Ь
и
2/?bV 22b = bV i2a.
230
Ограничивая на а и Ь:
a/Vi1a = l и b/V22b=l,
где b V12b = bVi2b ' = q влекут равенство 2а = 2/3 = X. Эта величина есть
стационарное значение д.
Из (16.5.1) с учетом несингулярности 5/ц имеем
a^lVT/V^b. (16.5.3)
Подставляя это выражение для а в (16.5.2), получим
(V12VH'V22-VV22)b=0.
Итак,
(V27‘V'12V171V12-V|)b = 0. (16.5.4)
Ненулевое решение для (16.5.4) существует, если и только если матри-
ца слева сингулярна [см. I, раздел 5.9], т. е. если
|V27‘v;2 Vo1 V12—ХЧI =0 (16.5.5)
или, что эквивалентно, если X2 — собственное число матрицы
v27 v;2v,, v12. Наибольшее из ее собственных чисел есть максималь-
ное значение р2, а b — ассоциированный с этим числом собственный
вектор. Соответствующий вектор а получается из (16.5.3).
Альтернативный метод решения этой проблемы состоит в подста-
новке выражения для b и решении получающегося для определения
вектора а аналога уравнения (16.5.4).
(V1?1V12V271V1^X2l)a=0.
В работе [Anderson (1958), с. 292—295] показано, что нет ничего уди-
вительного в том, что второй метод дает решение, идентичное перво-
му. Заметим, что в обоих случаях получаемые матрицы имеют ранг
q (равный рангу для V)2) и, следовательно, имеют q ненулевых соб-
ственных значений.
Канонические переменные, полученные выше, называются первыми
каноническими переменными Uit W\. Их коэффициент корреляции
Q = corr(Ui,W\) равен Xi (по абсолютному значению). Соответствующи-
ми коэффициентами являются at и Ьь
Вторая пара канонических переменных
U2 = а2Х,
И7 = Ь2У
выбирается из условия максимума абсолютного значения их коэффи-
циента корреляции а 2 V]2&2 с учетом условия единичности дисперсий
и условия ортогональности
cov<{/. ,{/2)=covf Wx ,W2) = cov<H7 ,[/2)=0,
t. e.
Э] V) i82 = bjV 22b2 = b 1'5/1282=0.
Векторы a2,b2, соответствующие стационарному значению q, получа-
ют при нахождении стационарного значения для
231
С—32У 12^2—«(ЯгУ 1182— 1)—3(b2V 2гЬ2—1) +
4- ^8^1182 4- <5bfV22b2 4- сЬ^УпЯг,
где а, 0, 7, 6, е — множители Лагранжа. С учетом условий ортого-
нальности после взятия производных от С по а2 и Ь2 можно показать,
что 7=6= 6=0. А учет ограничения на дисперсию влечет 2а=2/?=Х2-
Второе наибольшее значение р2 есть второе по величине собственное
число матрицы У^У/Уп V12, а b2 есть ассоциированный собственный
вектор. Вектор а2 может быть тогда получен из уравнения, аналогич-
ного (16.5.3).
Такая процедура может быть продолжена, чтобы найти остальные
(q—2) канонических переменных и ассоциированных с ними квадратов
корреляций [см. Anderson (1958), с. 291]. Собственные числа должны
быть строго различны, чтобы получилось q пар канонических пере-
менных.
Зависимость между X и У будет в результате суммаризована с по-
мощью корреляций между q парами канонических величин вместо pq
ковариаций в V12 (и, строго говоря, ковариаций в VB и V22).
Как и в предыдущем разделе, процедуру можно проводить с по-
мощью корреляционных матриц Rn и R22 [см. определение 16.1.1] и
кросс-корреляционной матрицы R12 [см. определение 16.1.2]. Это при-
ведет к тем же каноническим корреляциям, что и раньше, но коэффи-
циенты канонических переменных будут отличаться.
16.5.3. ВЫБОРОЧНЫЕ КАНОНИЧЕСКИЕ КОРРЕЛЯЦИИ
На практике ковариационные матрицы совокупности неизвестны и
должны быть оценены по выборке из п случайных наблюдений над
(X,Y).
По аналогии с анализом главных компонент необходимо использо-
вать только канонические переменные с большими значениями корре-
ляций, представляя зависимости между X и У с помощью меньшего,
чем q, числа переменных. Кроме того, если матрица Cj2 не полного
ранга, то имеется меньше, чем q, ненулевых собственных чисел или
корреляций.
Чтобы получить формальный тест для проверки гипотезы относи-
тельно равенства нулю некоторых канонических корреляций совокуп-
ности, предположим, что случайные переменные (X,Y) имеют
многомерное нормальное распределение (MVN) размерности (p+q).
Проверка гипотезы Vi2=0, что означает независимость X и Y, может
быть основана на статистике
- (л-Up+<7+3) Jlog П (1-XJ),
At 1 — 1
где — упорядоченные по величине векторы Сй’СиС^’Си. Эта
статистика асимптотически имеет х^-распределение.
Тест можно модифицировать для проверки частной гипотезы, что
последние t канонических корреляций равны нулю (t<q), используя
статистику
232
. ?
— In—lfa+tf+3)}log . П (1—X2),
Z i = q—t+l 1
которая асимптотически распределена как х}р—q+t)t [см. раздел 2.5.4,
п. а)].
16.5.4. ЧИСЛЕННЫЙ ПРИМЕР
В этом примере канонические переменные связаны с оценкой роста
яблонь разных сортов. В работе [Pearce and Holland (I960)] рост яб-
лонь изучался с момента зрелости. Были рассмотрены следующие че-
тыре характеристики за четыре года:
%]=log (вес части зрелого дерева над грунтом);
Х2=log (базальный обхват ствола зрелого дерева);
Ki=log (общий прирост побегов за первые четыре года);
y2 = log (базальный обхват ствола на четвертом году).
Получены следующие корреляционные матрицы:
/ 1
R” “ \0,951
1
0,898
/0,596
R’2 \0,694
0,951
1
0,898
1
0,517^
0,619,
что дает
- , - - . - /0,4939
”22 R|2 R7, R|2 = (о,0340
0,4403'
0,0414
Эта матрица имеет ранг, близкий к единице, так как близкий к едини-
це ранг имеет матрица Ri2. Второе собственное число, следовательно,
близко к нулю, его можно отбросить. Первое собственное значение
Х? = 0,5249 (величина второго примерно 0,02) соответствует канониче-
ской корреляции qi-0,125, которая больше, чем корреляции в R12.
Канонические коэффициенты Ьх и Ь2 могут быть получены из
(16.5.4):
—0,0310^1 + 0,4403Z>2 = 0,
0,0340^!—0,483562 = 0.
Полагая Ьх = 1, получаем 62 = 0,0704. Из (16.5.3) находим, подставляя
Ьх и Ь2,
ах = —0,994
и
а2 = 1,966.
Вычисленные значения получены при условии Ьх=1. Однако их нужно
модифицировать так, чтобы дисперсия канонических переменных была
233
единичной. (Это нужно сделать только для Ьх и Ь2, так как из (16.5.3)
следует, что тогда ах и а2 обеспечат необходимую величину дис-
персии.)
Модифицированные значения коэффициентов будут следующими:
ах =—0,877, </2 = 1,734, bx =0,882, b2 = 0,0621. Первыми каноническими
переменными, таким образом, являются
Ux = —0,887^ + 1,734X2,
Wx = 0,882 У]+0,0621 У2,
где X, У — стандартизованные переменные. Переменная Ux есть кон-
траст между Хх (log (вес зрелого дерева)) и Х2 (log (базальный обхват
ствола)) с коэффициентом при Х2, который вдвое больше, чем при Хх.
Wx почти совпадает с Yx (log (общий прирост побегов за первые четы-
ре года)). Как отмечено в работе [Pearce and Holland (I960)], содержа-
тельная интерпретация этих переменных должна быть оставлена
биологам.
16.6. ДИСКРИМИНАНТНЫЙ АНАЛИЗ
16.6.1. ВВЕДЕНИЕ
Цель дискриминантного анализа — получение правил для класси-
фикации многомерных наблюдений в одну из нескольких категорий
или совокупностей. В медицине, например, это может помочь при
диагностике или прогнозе заболеваний. В этом случае наблюдаются
пациенты, и каждому из них приписывают несколько характеристик,
определяющих его состояние. В работе [Titterington et al. (1981)] приве-
дены примеры приложения дискриминантного анализа для прогноза
пациентов с травмами головы. Существует и много других приложе-
ний дискриминантного анализа, описанных в литературе [см., напри-
мер, Press (1972), библиография].
При дискриминантном анализе предполагается, что число совокуп-
ностей, или категорий, известно заранее. Задачей же кластер-анализ а
является идентификация кластеров, ’ или категорий, из данных.
16.6.2. ДИСКРИМИНАЦИЯ В ДВЕ ИЗВЕСТНЫЕ СОВОКУПНОСТИ
Рассмотрим задачу классификации одного многомерного наблюде-
ния х = (х 1, х2,...,хрУ в одну из двух совокупностей, для которых из-
вестны р-мерные плотности /i(x), f2(x) (т. е. известны как форма
плотности, так и ее параметры). Предположим, что р{\) и р(2) = 1—
—р(1) — априорные вероятности появления наблюдения х из совокуп-
ностей 1 и 2. Тогда по теореме Байеса апостериорная вероятность то-
го, что наблюдение х принадлежит совокупности 1, есть [см. гл. 15]
234
J3(l|x) =
Pdlftfx)
p(ll/,(x)+p(2V2(x) ’
а апостериорная вероятность для x принадлежать совокупности 2 есть
/?(2|х) =
Р(2)Л(х)
р(11/,(х)+р(21/-2(х)
= 1-р(1|х).
Классификация наблюдения может быть теперь осуществлена с по-
мощью отношения, основанного на апостериорной вероятности для
наблюдения принадлежать совокупности 1:
/э(1|х)/[1—/Xl|xB=Jp(lV'i(x)//>(2V2(x). (16.6.1)
При такой процедуре можно было бы отнести объект к совокупности
1, если это отношение больше 1, т. е. /э(1 |х)> 1/2, и к совокупности 2,
если отношение меньше 1. В работе [Anderson (1958), с. 130—131] по-
казано, что подобная процедура минимизирует вероятность ошибоч-
ной классификации.
Если ввести функцию штрафа (потерь) [см. гл. 19] и обозначить че-
рез С(2| 1) и С(112) цены ошибочной классификации наблюдения из со-
вокупности 1 в совокупность 2 и наоборот, то можно показать [см.
Anderson (1958), с. 130—131], что математическое ожидание значения
апостериорной функции потерь, обусловленное ошибочной классифи-
кацией, минимизируется, если использовать следующую модификацию
правила (16.6.1): относить наблюдение к совокупности 1, если
C(2|l)p(D/-,(x)
Cd^p^x)^1’
и к совокупности 2 — в противном случае.
Для обеих ситуаций правило можно записать в форме отношения
правдоподобия /1(х)//2(х): если /1(х)//2(х)^А:, то наблюдение следует
отнести к классу 1, в противном случае — к классу 2. Константа к за-
висит от априорных вероятностей и цены ошибочной классификации.
Когда априорные средние потери удовлетворяют равенству
С(2|1)р(1) = С(1|2)р(2), константа к=\.
16.6.3. ДИСКРИМИНАЦИЯ В ДВЕ МНОГОМЕРНЫЕ СОВОКУПНОСТИ
Предположим, что наблюдение принадлежит одной из двух /?-мер-
ных MVN-распределейных совокупностей с известными векторами
средних Д1 и д2 и известной одинаковой матрицей ковариаций V. Тогда
отношение правдоподобия будет иметь вид
"OS=ехр[х/7~1(д1—д2)—у (Д1—д2)У-1(д1 + д2)]. (16.6.2)
Это приводит к следующему правилу классификации: пусть
w = xV 1(д1—д2)—y(#i—A2>V ’(д1+д2); (16.6.3)
если и^с, то наблюдение следует отнести к классу 1, в противном
случае — к классу 2. Здесь c=\ogek.
235
Итак, это правило зависит от скалярной случайной величины £/,
которая является линейной функцией от X. Распределение U обладает
некоторыми интересными свойствами.
Если X принадлежит совокупности, подчиняющейся распределению
MVN(/i,,V), то U=UX имеет нормальное распределение с математиче-
ским ожиданием 1/26 и дисперсией 6. В то же время, если X принадле-
жит второй совокупности, подчиняющейся распределению MVN(/»2,V),
U=U2 имеет нормальное распределение с математическим ожиданием
—у 6 и дисперсией 6, где
6=(Mi —Дг).
Величина 6 известна как расстояние Махаланобиса между двумя
совокупностями. Теперь можно получить выражение для вероятности
ошибочной классификации наблюдения. Предположим, что наблюде-
ние принадлежит совокупности 1, но было отнесено к совокупности 2.
Вероятность такого события равна
Р(и,<с)=Фс-=&,
Vo
где через Ф обозначена стандартная функция нормального распре-
деления.
Качество правила классификации можно оценить, вычисляя ожида-
емую потерю от ошибочной классификации:
С(21 1)P(UX < c)p(V)+С( 1 \1)P(U2>с)р{2).
Предположим теперь, что параметры многомерных нормальных рас-
пределений неизвестны, но имеются выборки объема п± и п2 для двух
/j-мерных нормальных распределений. Векторы Xi и х2 могут быть
использованы как оценки цх и ц2, а общая матрица ковариации V оце-
нивается с помощью объединенной выборочной ковариационной
матрицы
С=[(Л1—l)Ci + (п2—1)С2]/(п\ + п2—2),
где С] и С2 — обычные несмещенные оценки V по каждой из выборок
в отдельности.
Дискриминантную функцию можно теперь получить подстановкой
в (16.6.3) оценок параметров. Тогда пусть
и’=х'С-'(Х|—х2)—1(Х|—х2)С-'(Х| +х2), (16.6.4)
если то новое наблюдение х следует отнести к совокупности 1,
в противном случае — к совокупности 2.
Первый член в (16.6.4) известен как линейная дискриминантная
функция Фишера. К сожалению, распределение величины w является
очень сложным, так что вычислить вероятность ошибочной классифи-
кации для этого правила трудно. Точное распределение w коротко об-
суждается в [Anderson (1958), с. 138—139]. Асимптотически, когда пх
и л—”, вероятности ошибочной классификации могут быть получе-
236
ны, если использовать приближение для б в виде
(Xi—ХзУС-^—х2).
Другой подход к получению оценок вероятностей ошибочной клас-
сификации может быть основан на применении оцененного правила
классификации к выборкам, для которых известна принадлежность
объектов к совокупностям, иногда называемым в медицинских прило-
жениях обучающими выборками*. Тогда оценкой вероятности оши-
бочной классификации в совокупность 2 будет отношение числа
наблюдений из совокупности 1, но классифицированных в совокуп-
ность 2, к общему числу наблюдений из совокупности 1. Однако, как
показано в [Morrison (1972)], этот подход может привести к оценкам
с сильным смещением.
В этом разделе применялся байесовский подход, поскольку иссле-
дователь приписывал вероятности р(1) и р(2) принадлежности наблю-
дений к классам, оцениваемые им на основе априорного знания о
совокупностях. В работе [Anderson (1958), с. 133—136] также обсужда-
ется минимаксное решение, когда константа с выбирается при отсутст-
вии априорных вероятностей так, чтобы выполнялось условие
0(1 |2)ф(=^) = С(2|
Во многих приложениях дискриминантных функций используется зна-
чение с=0. Если ковариационные матрицы совокупностей не предпо-
лагаются одинаковыми, то дискриминантные функции становятся
квадратичными по X.
16.6.4. ДИСКРИМИНАЦИЯ В НЕСКОЛЬКО СОВОКУПНОСТЕЙ
Существует несколько методов классификации наблюдений в одну
из совокупностей, когда их больше, чем две. Правила дискриминации
(16.6.3) или (16.6.4) могут применяться для всех пар совокупностей, и
с помощью значений случайных переменных U и W индивидуальные
наблюдения будут тогда классифицированы в одну из них [см., напри-
мер, Morrison (1972), с. 239—245].
Предположим, что имеется дп(>2) совокупностей и что Wy — зна-
чение дискриминантной функции для классификации между совокупно-
стями i и j. Тогда, если для всех пар совокупностей предполагается
с=0, правило классификации может быть таким: классифицировать в
совокупность /, если для всех j^i.
Для классификации может быть использована также некоторая мо-
дификация функции расстояния. Определим
5z=(x-x/)C-1(x—xz)
и будем относить х к совокупности, которой соответствует мини-
* Речь, по-видимому, идет о выборках, по которым оценивались параметры совокуп-
ностей. — Примеч. пер.
237
мальное значение <5;, /=1,2.т. В [Morrison (1972), с. 241] показано,
что это правило эквивалентно правилу, основанному на
Рао [см. Rao (1973)] предложил правило, основанное на полной
средней потере от ошибочной классификации в некоторую, например
/-ю, совокупность:
т
7 = 1
где P(i\J) — вероятность ошибочной классификации наблюдения из со-
вокупности j в совокупность i, а потери C(i\j) определены раньше
(C(i\i)=O). Выбирается совокупность, для которой значение потери ми-
нимально. Предполагается, что распределения совокупностей извест-
ны. Эйтчинсон и Дансмор [см. Aitchinson and Dunsmore (1975), гл. 11]
рассматривают байесовский подход, когда параметры неизвестны, но
известна форма функций плотности. Неизвестным параметрам припи-
сываются некоторые априорные распределения, и по заданным для
каждой совокупности выборкам вычисляются апостериорные распре-
деления.
Новое наблюдение х классифицируется с помощью вычисления
предиктивной вероятности [см. гл. 15]:
X*|x,Data) ос p(x|/,Data)p(7|Data),
и выбирается совокупность с наибольшим значением такой вероятнос-
ти. Значение p(x|f,Data) есть маргинальное предиктивное распределе-
ние для х в предположении, что х принадлежит совокупности i, а
p(z|Data) — вероятность появления наблюдения из совокупности i.
Для иллюстрации этого подхода рассмотрим случайную одномер-
ную величину X с плотностью f(x; 0), где единственному параметру 6
приписывается априорное распределение тг(0). Тогда для заданной слу-
чайной выборки х = (х,, х2..хп)', рассматриваемой как Data, апосте-
риорное распределение 6 будет следующим:
7r(0|Data)«./(x;0)7r(0).
Предиктивная вероятность нового наблюдения есть
р(£| Data) Ч/(х;0)тг(01 Data)rf0.
В разделе 16.3.5 обсуждалось применение метода главных компо-
нент к данным о лесе. Было показано, что большая часть дисперсии
объясняется с помощью двух первых главных компонент. Графическое
отображение значений главных компонент в этом случае позволяет
выделить кластеры, рассматриваемые как разные совокупности. Для
каждого нового наблюдения можно вычислить значения двух первых
главных компонент, и с их помощью наблюдение может быть класси-
фицировано в один из существующих кластеров.
Чтобы избежать пересечения кластеров, иногда вычисляют средние
значения главных компонент для кластеров и новое наблюдение клас-
сифицируют по близости к этим средним. Другой метод, основанный
на сокращении размерности данных с помощью канонических корре-
ляций, представлен в работе [Maxwell (1977), гл. 9].
238
16.7. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Aitchison J. and Dunsmore I. R. (1975). Statistical Prediction Analysis, Cam-
bridge University Press.
Anderson T. W. (1958). An Introduction to Multivariate Statistical Analysis, Wiley.
Bishop Y. M. M., Fienberg S. E. and Holland P. W. (1975). Discrete Mul-
tivariate Analysis, M.I.T. Press.
Giri N. C. (1977). Multivariate Statistical Inference, Academic Press.
Goldstein M. and Dillon W. R. (1978). Discrete Discriminant Analysis, Wiley.
Jeffers J. N. R. (1965). Principal components Analysis in Thxonomic Research, Fore-
stry Commission Statistics Section Paper no. 83.
J e f f e r s J. N. R. (1967). T\vo Case Studies in the Application of Principal Components,
Appl. Statist. 16, 225—236.
Kaiser H. F. (1958). The Varimax Criterion for Analytic Rotation in Factor Analysis,
Psychometrica 23, 187—200.
Kendall M. G. (1957). A Course in Multivariate Analysis, Griffin.
L a w 1 e у D. N. and Maxwell A. E. (1971). Factor Analysis as a Statistical Method
(2nd ed.), Butterworths.
Lochenbruch P. A. (1975). Discriminant Analysis, Hafner.
M a r d i а К. V., К e n t J. T. and В i b b у J. M. (1979). Multivatiate Analysis, Aca-
demic Press.
Maxwell A. E. (1977). Multivariate Analysis in Behavioural Research, Chapman &
Hall.
Morrison D. F. (1976). Multivariate Statistical Methods (2nd ed.), McGraw-Hill.
Pearce S.C. and Holland D. A. (1960). Some Applications of Multivariate
Methods in Botany, Appl. Statist. 9, 1—7.
Press S. J. (1972). Applied Multivariate Analysis, Holt, Rinehart & Winston.
R а о C. R. (1973). Linear Statistical Inference and its Applications, Wiley.
Titterington D. M., Murray G. D, Murray L. S., Spiegelhalter
D. J., Skene A. M., H a b b e m a J. D. F. and G e p к e G .J. (1981). Comparison of
Discrimination Techniques Applied to a Complex Data Set of Head Injured Patients (with dis-
cussion), Journ. Roy. Statist. Soc., Series A 144 (to appear).
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Рао С. P. Линейные статистические методы и их применения. — М.: Наука, 1968.
— 548 с.
Айвазян С. А., Б у х ш т а б е р В. М., Е н ю к о в И. С., М е ш а л к и н Л. Д.
Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и
статистика, 1989. — 607 с.
Айвазян С. А., Бежаева 3. И., Староверов О. В. Классификация
многомерных наблюдений. — М.: Статистика, 1974. — 239 с.
Глава 17
МНОГОМЕРНЫЙ АНАЛИЗ: ОРДИНАЦИЯ,
МНОГОМЕРНОЕ ШКАЛИРОВАНИЕ И СМЕЖНЫЕ
ВОПРОСЫ
17.1. ВВЕДЕНИЕ
В многомерном анализе под ординацией понимают метод, пред-
ставляющий элементы многомерных выборок точками в геометриче-
ском пространстве, обычно евклидовом*. При этом исследователь
надеется, что беспорядочный массив чисел будет заменен на некото-
рый (менее беспорядочный) разброс точек, выявляющий интересую-
щую его структуру в виде кластеров, коллинеарностей, трендов или
обнаруживающий другие характерные свойства выборки. Поскольку
визуально трудно распознать структуру в многомерном пространстве,
основное внимание уделяется методам, предназначенным для получе-
ния интерпретируемого отображения рассеяния данных в простран-
стве двух или трех измерений. На диаграмме такого рода близкие
точки обычно соответствуют похожим отображаемым ими объектам,
а далекие — очень непохожим. Таким образом, расстояние — основ-
ное понятие, подлежащее интерпретации в большинстве ординаций,
но существуют другие виды представлений, и они будут рассмотрены
в разделе 17.13.
Термин «ординация» пришел из экологии, где различные экологи-
ческие сообщества растений пытались представить точками на пря-
мой. Это — одномерная ординация, или упорядочение. Вскоре
обнаружилось, что одномерного представления часто недостаточно для
адекватного отображения, поэтому сочли допустимым использование
двух или большего количества измерений. При этом термин «ордина-
ция» (т. е. упорядочение), конечно, потерял свой истинный смысл. По-
добная же ситуация связана с термином «многомерное шкалирование».
* Более распространенным (и, с нашей точки зрения, более правильным) является
определение многомерного шкалирования (по терминологии данного издания — орди-
нации) как математического инструментария, предназначенного для обработки данных
о попарных сходствах, связях или отношениях между анализируемыми объектами с
целью представления этих объектов в виде точек некоторого координатного простран-
ства. — Примеч. ред.
240
Долгое время усилия психологов были сосредоточены на представле-
нии интенсивности косвенно наблюдаемых стимулов точками на шка-
ле, аналогичной шкале обычных физических измерений. Это снова
привело к одномерной конфигурации, а для адекватного представле-
ния оказалось необходимым использовать дополнительные измерения,
что привело к понятию многомерное шкалирование, которое в настоя-
щее время широко применяется статистиками и специалистами по ана-
лизу данных. Таким образом, «ординация» и «многомерное шкалиро-
вание» — синонимы, заимствованные из разных научных областей, и
для них нет нейтрального статистического термина*.
Простейший вид ординации — двумерная диаграмма рассеяния, на
которой сопоставляются две переменные (например, высота и вес),
каждая точка представляет одно наблюдение из выборки. Цель по-
строения таких диаграмм, как и более сложных ординаций, — обнару-
жить определенные свойства данных. Они также могут быть исполь-
зованы для обнаружения выделяющихся точек, что может рассматри-
ваться как отклонения от закономерности. Диаграммам рассеяния
присущ, в определенной мере, основной недостаток многих методов
ординации — зависимость от масштаба. Измерение высоты в дюймах
и веса в фунтах приведет к одной диаграмме, а измерение высоты в
сантиметрах и веса в килограммах — к другой. Этот дефект становит-
ся более серьезным для обобщенных ординаций, опирающихся на ли-
нейные комбинации значений переменных.
В случае, когда наблюдения хь х2..хп выборки объема п измере-
ны в неспецифических единицах, наиболее общими формами стандар-
тизации являются следующие:
a) 7z = log х/5
б) Zi=Xj/St
где s — стандартное отклонение. Заметим, что расстояние у, — yj меж-
ду z-м и J-м наблюдениями инвариантно при мультипликативном пре-
образовании шкалы (например, дюймы в сантиметры), но не инвари-
антно при аддитивном преобразовании (например, фарингейты в граду-
сы) или относительно комбинации аддитивного и мультипликативного
преобразований. Расстояние z, — Zj инвариантно относительно обоих
типов преобразований шкалы — аддитивной и мультипликативной.
Эти соображения облегчают выбор типа стандартизации, но большая
степень произвольности все же остается. Если все переменные много-
мерной выборки измерены на одной и той шкале, необходимость стан-
дартизации менее очевидна, но вполне вероятно, что дисперсия для
одних переменных значительно больше, чем для других, и целесообраз-
но сгладить такое различие с помощью б).
* Наряду с этими терминами во французской научной школе анализа данных использу-
ется термин анализ близостей (L’analyse des proximites). — Примеч. ped.
241
Идея введения стандартной ошибки для нормировки возникает
обычно у каждого, кто вынужден интерпретировать результаты орди-
нации. Все s2, оценивающие дисперсию а2 совокупности, обычно легко
интерпретируемы, но использование оценки s2 по гетерогенной выбор-
ке, извлеченной из некоторой неизвестной смеси генеральных совокуп-
ностей, уже менее оправдано. Во многих ординациях значения xz пере-
менной не могут рассматриваться как элемент случайной выборки или
даже как реализация случайной переменной. Реалистичнее рассматри-
вать их как полный перечень всех значений переменной в конечной со-
вокупности, не связанный с какими-либо вероятностными соображе-
ниями. Например, в таксономии обычно интересуются ординацией ко-
нечного числа биологических видов, описанных набором характеристик.
Отдельные представители видов могут также подлежать рассмотре-
нию, по крайней мере по некоторым характеристикам. Это будет да-
вать внутривидовой разброс. Могут представлять интерес ординации
выборочных представителей отдельно для каждой из групп. Однако ча-
ще сосредоточивают внимание на межвидовых различиях, для чего вы-
числяют средние или другие типичные показатели для переменных
каждой группы. Иногда могут быть обнаружены качественные характе-
ристики, не меняющиеся внутри группы, что идеально соответствует
описанию различий между группами в терминах ординации.
Все изложенное выше привлекает внимание читателя к проблемам,
связанным с ординацией групп. И внутригрупповая, и межгрупповая
ординация являются важными, и определенный интерес представляет
их комбинация [см. Gower and Digby (1980)]. Межгрупповую ординацию
часто маскируют под внутригрупповую, возможно, потому, что внут-
ригрупповой разброс либо неизвестен, либо не принимается во внима-
ние как малозначащий.
17.2. АНАЛИЗ ГЛАВНЫХ КОМПОНЕНТ
Пусть пХр — матрица данных, содержащая значения п наблюдений
р-мерного признака. Версия метода главных компонент для ситуации,
когда п наблюдений могут рассматриваться как случайная выборка
мультинормального (многомерного нормального) распределения [см.
II, раздел 13.4], изложена в разделе 16.3. Этот подход обычно можно
найти в учебниках. В настоящей главе рассматривается другой подход,
который сам по себе представляет интерес и, кроме того, служит вве-
дением в более общие проблемы ординации. При данном подходе, ко-
торый связывают со статьей К. Пирсона [см. Pearson (1901)], удобно
считать, что п наблюдений представляют различные группы, а связан-
ные с ними р переменных задают типичные или средние значения коли-
чественных переменных для каждой группы.
242
Геометрически можно считать, что значения i-ro наблюдения
(х/i, xi2,...,xip) представляют точку в р-мерном пространстве, натяну-
том на ортогональные координатные оси. Поскольку мы рассматри-
ваем межгрупповой разброс, не имеет смысла ожидать
эллипсоидального рассеяния точек в многомерном пространстве, как
при мультинормальном распределении. Для обсуждаемого подхода
допустим любой тип рассеяния, о типе распределения не требуется ни-
каких предположений. Простая диаграмма рассеяния, скажем, для г-й
и s-й переменных, представляет ортогональную проекцию выборки на
плоскость, заданную r-й и s-й осями. Правомерен вопрос: не может ли
какая-либо другая плоскость дать в некотором смысле более репрезен-
тативную проекцию? В методе главных компонент наилучшая аппрок-
симирующая плоскость определяется из условия минимизации суммы
квадратов расстояний от анализируемых наблюдений до их проекций
на эту плоскость. Вместо плоскости можно рассматривать проекции
на любое /r-мерное линейное подпространство полного р-мерного про-
странства.
Пусть /r-мерное подпространство образовано любыми к линейно-
независимыми векторами — столбцами матрицы „Н^. Тогда стан-
дартный результат линейной алгебры состоит в том, что координаты
точек „Хр, спроецированных на это подпространство, задаются пре-
образованием ХНСНД-О НТ (Здесь и далее в главе „Н*. — обозначе-
ние для матрицы Нел строками и к столбцами, Н' — обозначение
для транспонированной матрицы.) Не теряя общности, можно нало-
жить требование ортогональности линейно-независимых векторов
[см. I, раздел 10.2]. Тогда координаты проекций будут определяться
как ХННГ, где Н7Н = 1. Остатки [см. раздел 8.2.4] задаются координа-
тами, ортогональными к подпространству, и могут быть вычислены
как Х(1—НН7). Отсюда остаточная сумма квадратов равна
ТгасеХ(1—ННГ)ХГ.
Это выражение должно быть минимизировано по Н. Минимизация
может быть заменена на максимизацию
Тгасе(ХННгХг),
что можно переписать в виде Trace(HrSH), где S=XrX — матрица
сумм квадратов и произведений. Записав S в спектральной форме
S = UAUr [см. I, раздел 7.10], где U *— ортогональная матрица, а А —
diag(Xb Х2,...,Хр), получаем р
Trace(HrSH) = ,Е \ + g}2 +... + gfk),
где gy — элементы ортонормированной матрицы G^U^H. Обо-
значим
fi~Si\ + + ••• ^Sik >
тогда
0^/;<1, (17.2.1)
поскольку сумма квадратов элементов в строке ортонормированной
матрицы G не превосходит единицы; единичное значение достигается,
когда к-p и G становится ортогональной.
р
= (17.2.2)
243
поскольку это выражение соответствует сумме квадратов всех элемен-
тов матрицы G, каждый из к столбцов которой сам имеет единичную
сумму квадратов элементов. Таким образом, необходимо максимизи-
ровать I ы
при ограничениях (17.2.1) и (17.2.2). Это задача линейного программи-
рования [см. I, гл. 11], максимум должен достигаться, когда
(/ьЛ»••.,/,) “ вершина допустимой области, заданной уравнениями
(17.2.1) и (17.2.2). Все вершины обходятся, когда к значений/- равны
единице, а остальные р—к — нулю. Упорядочим собственные значе-
ния [см. I, гл. 7] Xi^X2>...>Xp. Ясно, что максимум равен Е X/ и
достигается при /1=/2 = ...=Д = 1 и /=0 для i>k. Если то
максимум достигается и при других условиях. До сих пор мы не ис-
пользовали дополнительные ограничения, состоящие в том, что
столбцы матрицы G ортогональны. Однако решение, полученное при
отсутствии этого ограничения, дает матрицу G, которая в действи-
тельности ортонормирована и поэтому должна максимизировать след
по всем ортонормированным матрицам. Таким образом, мы показа-
ли, что в точке максимума ортонормированная матрица G превраща-
ется в матрицу, строки и столбцы которой имеют единичную длину.
В свою очередь это означает, что матрица G может быть разбита в
виде .
где Gfr — ортогональная матрица порядка к. Итак, H=UG — матри-
ца с ортогональными столбцами, которые являются линейными ком-
бинациями к первых собственных векторов матрицы S.
Из изложенного следует, что наилучшая аппроксимация в виде к-
мерного линейного подпространства, содержащего начало координат,
совпадает с пространством, образованным к (ортогональными) еди-
ничными векторами, соответствующими к наибольшим собственным
значениям матрицы S. Остаточная сумма квадратов, подлежащая ми-
нимизации, равна к р
'li’ace(S)
это — сумма р—к наименьших собственных значений матрицы S.
Если опустить требование, чтобы /r-мерное подпространство со-
держало начало координат, то можно добиться меньшей остаточной
суммы квадратов. Хорошо известно, и это легко доказывается, что
суммы квадратов отклонений от центра тяжести (т. е. среднего) мень-
ше, чем суммы квадратов отклонений от любой другой точки. Отсю-
да следует, что наилучшее аппроксимирующее Zr-мерное подпростран-
ство должно содержать среднее. Это означает, что X следует заме-
нить на матрицу отклонений от среднего (I—N)X, где все элементы
матрицы N равны 1/п. Тогда матрица S заменяется на Хг(1—N)X —
скорректированную матрицу сумм квадратов и произведений для п на-
блюдений на р случайных переменных. В дальнейшем будем предпо-
лагать, что столбцы матрицы X содержат отклонения от своих
средних, так что суммы элементов по столбцам равны нулю и матри-
цу N можно отбросить.
244
Основной результат анализа главных компонент, изложенный вы-
ше, отличается от того, как это обычно описывается в учебниках. Как
правило, используя дифференцирование с множителями Лагранжа, по-
казывают, что при £=1 матрица Н (которая в данном случае является
вектором) определяется собственным вектором матрицы S, соответ-
ствующим наибольшему собственному значению Хр Аналогично если
г направлений определяются г первыми собственными векторами мат-
рицы S, то направление, ортогональное этому подпространству и ми-
нимизирующее остаточную сумму квадратов, определяется (г+1)-м
собственным вектором матрицы S. Эта процедура приводит к услов-
ным оптимумам на уже определенных размерностях [см. раздел 16.3].
Описанный подход показывает, что эти условные оптимумы являются
глобальными.
Для ординации необходимы координаты ХНН7 спроецированных
точек. Такая форма не пригодна для графического представления, и даже
при к=1 одномерное множество координат выражается в р-мерном ви-
де. Удобнее выбрать в подпространстве к ортогональных осей; наиболее
простой способ — взять в качестве координат ХН. Любой другой набор
ортогональных осей в подпространстве также допустим, но ХН облада-
ет преимуществом: ее первые с столбцов задают координаты, соответ-
ствующие наилучшему приближению в пространстве с измерений.
В терминологии компонентного анализа собственные векторы, за-
даваемые столбцами матрицы Н, являются главными компонентами
или главными осями, а координаты ХН — значениями по главным
компонентам. Коэффициенты матрицы Н называются нагрузками
/-го наблюдения на j-ю случайную переменную. Положив к~р, мы по-
лучим все главные оси, и Н превращается в ортогональную матрицу,
содержащую все собственные векторы матрицы S. Поскольку евкли-
довы расстояния инвариантны относительно ортогональных преобра-
зований, главные оси задают переход от первоначальных координат-
ных осей к новым осям, обладающим обсуждаемыми выше опти-
мальными свойствами. При таких преобразованиях взаимное располо-
жение точек не меняется. Можно также в качестве преобразования
рассматривать такое, в котором исходные переменные становятся
главными и их значения — значениями по главным компонентам.
Нередко новые переменные отождествляются со скрытыми свойст-
вами изучаемой выборки; такая процедура соответствует описанию
объектов через обнаруженные свойства. В некоторых случаях такая
идентификация весьма убедительна, но к описанию объектов через об-
наруженные свойства, как и к идентификации факторов в факторном
анализе [см. раздел 16.4], следует подходить с осторожностью. Как и
в факторном анализе, Ar-мерное пространство определяется с по-
мощью компонентного анализа, и любое множество линейно-не-
зависимых направлений в этом пространстве может быть выбрано в
качестве координатных осей. Причина, по которой математически
определенные главные оси должны иметь интерпретаций лучше, чем
любые другие координатные оси в том же пространстве, не очевидна.
245
Поэтому для получения интерпретируемых осей в компонентном ана-
лизе имеется целый арсенал вспомогательных средств ортогонального
и косоугольного вращения факторов. Нельзя забывать и о таящихся
в них опасностях. К счастью, процедура описания объектов через об-
наруженные свойства менее важна, когда компонентный анализ при-
меняется для ординации, и более важна, когда анализируются
выборки из единственного многомерного распределения. При ордина-
ции акцент делается на графическом изображении множества точек,
представляющих выборки.
Переход от р-мерного пространства к хорошей аппроксимации в
пространстве размерности к{к<р) — ключевой момент всех ордина-
к р
ций. Простая мера качества отображения — Е X,-/Е X,-, обычно она
задается в процентах и представляет собой отношение суммы квадра-
тов расстояний всех спроецированных точек до начала координат
(обычно центра тяжести) к общей сумме квадратов расстояний до
проецирования. Это то же самое, что отношение суммы квадратов
всех попарных расстояний между спроецированным, чками к той
же сумме для исходных точек. Высокое значение этого коэффициента
при малом к означает хорошее соответствие в пространстве несколь-
ких осей. Итак, при компонентном анализе неявно выражена надежда,
что р-мерное облако точек представляет собой (хотя бы приближенно)
/r-мерный линейный образ, где к< <р. Если множество точек имеет
простую структуру, но лежит на нелинейном образе, то маловероятно,
что компонентный анализ окажется успешным. Например, множество
точек, лежащих на сфере, не допускает простого отображения в про-
странстве менее трех осей, если только не допустить для полярных
областей отображение, подобное представлению глобуса на карте в
виде двух полушарий.
Чаще всего нагрузки первой компоненты все положительны и нере-
дко имеют близкие значения. В таком случае первая компонента часто
идентифицируется как объемная. В биологических задачах, где измере-
ния производятся на развивающихся организмах, такая ситуация тра-
диционна, поскольку разные части организма развиваются с
одинаковой скоростью {аллометрический рост). В такой ситуации
корреляции между всеми парами признаков будут положительны и
матрица S будет содержать неотрицательные элементы. Теорема Фро-
бениуса—Перрона [см. I, теорема 7.11.1] утверждает, что максималь-
ное собственное значение матрицы S соответствует собственному
вектору неотрицательных нагрузок. Таким образом, присутствие объ-
емной компоненты связано с феноменом, наблюдаемым на практике.
Если объемная компонента не представляет первостепенного интереса,
обычно изображают проекции на координатные оси начиная со вто-
рой, поскольку, вообще говоря, считается, что представление должно
подчеркивать различия в форме. При более формальном подходе XI
рассматривают как объемную переменную. Исключение объемной
246
компоненты при проецировании приводит к «переменным формы»
Х(1—11г/р) и модифицированной матрице сумм квадратов и попар-
ных произведений 8формь1 = (1—Р)ХЛ(1—N)X(I—Р), где Р = 11г/р. Матри-
ца имеет нулевое собственное значение, соответствующее вектору 1.
Ее ненулевые собственные значения используются для анализа пере-
менных формы методом главных компонент.
Замечания, приведенные в разделе 17.1, относительно чувствитель-
ности некоторых видов многомерного анализа к изменениям шкалы
относятся в полной мере и к методу главных компонент. В случае,
когда шкалы для измерения переменных не совпадают, обычно пер-
вое, что необходимо сделать, это стандартизовать X так, чтобы обра-
тить S в матрицу корреляций. В исследованиях объемных переменных
(или переменных формы) наиболее общим является логарифмическое
преобразование матрицы X. Поскольку под «формой» часто подразу-
мевают отношение двух переменных, на это отношение не влияет ал-
лометрический рост. Исключение объемной компоненты, о котором
говорилось выше, приводит к переменным формы (logX)x
х(I—11г/р), что дает i-ю объемную переменную log {x/(Xi, х2,...,хр)1/р]
с требуемым видом отношения. Заметим, что две выборки, в одной
из которых все значения переменных кратны значениям другой, после
преобразования имеют одну и ту же форму.
17.3. МУЛЬТИПЛИКАТИВНЫЕ МОДЕЛИ И ТЕОРЕМА
ЭКАРТА—ЮНГА
Линейные модели являются основными для многих стандартных
типов статистического анализа. Они изучаются уже около 200 лет
[см. гл. 8, 10, 11, 12]. Теория мультипликативных моделей гораздо ме-
нее освоена и сравнительно мало известна, хотя эти исследования на-
чаты более 50 лет назад. Их место в данной главе оправдывается тем,
что анализ простой мультипликативной модели методом наименьших
квадратов естественно приводит к теореме Экарта—Юнга, а она явля-
ется фундаментальной для некоторых методов, обсуждаемых далее.
Рассмотрим таблицу тхп наблюдений у у и предположим, что мы
хотим подогнать под данные мультипликативную модель
_yzy fj,y otj + + y^yj ~i"tjj (j 1, 2,...,/и, j 1, 2,...,л),
где e,j — независимые и одинаково распределенные (н.о.р.) ошибки.
Как и линейная модель, эта модель переопределена, и можно оценить
только разности между значениями параметров. Однозначные оценки
можно получить, только если зафиксировать начало координат для
каждого множества оценок. Как обычно, мы полагаем начало коорди-
нат в центре тяжести конфигурации, т. е. Еа=Е/?; = Е7; = Е7,/:=0.
i 1 j j I j j
Эти ограничения не являются существенными, но они имеют преиму-
щество единообразного представления всех параметров, что приводит
247
нас к алгебраически упорядоченной схеме. Оценки, полученные мето-
дом наименьших квадратов, следующие:
Z?' = Г 7,
z^iv,
где • (точка) означает среднее по соответствующему индексу, Z —
матрица остатков с элементами Zij=yij—yi—y.j+y.. и
т ч л
Оценки линейных параметров д, az, Зу настолько же точные, как и
для линейной модели. Два уравнения для оценок мультипликативных
параметров могут быть записаны в виде
(Z^)-y-=rr7, ]
(ZZr)7=ГГ'-у, J
где 7 и у7 — собственные векторы матриц ZrZ и ZZr, отмасштаби-
рованные таким образом, что собственное значение Х=ГГ'. Остаточ-
ная сумма квадратов равна
Ъ(Уц—У. .)2—У. .)2—n'Lty.j—у. .)2—ГГ.
Для ее минимизации за X берется наибольшее собственное значение
матрицы ZrZ. Тогда собственные векторы матриц ZrZ и ZZr могут
быть выражены одновременно как сингулярные векторы матрицы Z в
виде Z=UEVr, где U — ортогональная матрица размерности /их/и, V
— ортогональная матрица размерности и хи, а Ё — матрица размер-
ности /ихи, содержащая ненулевые (и положительные) элементы ozy
только для i=j. Обозначим эти «диагональные» значения через а,
(/=1, 2,...,/), где Z=min(/n, и), и предположим, что они упорядочены:
ai>a2>...>az>0. а, — невырожденные значения матрицы Z. Тогда
ZrZ=VErEVr
и
ZZr=UEErUr,
V и U — собственные векторы, соответствующие собственным значе-
ниям оь ci,...,oj, и следовательно, у — первый столбец матрицы U, а
у' — первый столбец матрицы V. Так же, как аддитивные параметры
определены с точностью до аддитивной константы, мультипликатив-
ные же параметры определены с точностью до мультипликативной
константы. Поэтому у и у' могут быть заменены на qy и Для
любой ненулевой мультипликативной константы.
Если r=rank(Z)<Z, то мы имеем ровно г ненулевых сингулярных
значений. Если мы хотим оценить дополнительную пару мультипли-
кативных членов 6z6y, то § и & определяются второй парой сингуляр-
248
ных векторов матрицы Z, соответствующих сингулярному значению
а2. Поскольку матрицы U и V ортогональны, 6 ортогонален у, а
ортогонален у/. Третья и последующие пары мультипликативных
членов могут быть оценены по третьей и последующим парам сингу-
лярных векторов. Этот результат эквивалентен утверждению, что Zs,
наилучшая в смысле наименьших квадратов матрица ранга s, соответ-
ствующая Z, может быть получена как Zs = UEsVr, где Es — та же Е,
но с а, = 0 для i>s. Результат справедлив для любой прямоугольной
матрицы Z. Впервые он был доказан Экартом и Юнгом [см. Eckart
and Young (1936)]. Теорема Экарта—Юнга является фундаментальным
результатом, который лежит в основе многих наших последующих
рассмотрений.
Дальнейшее развитие мультипликативной модели здесь мы обсуж-
дать не будем, дадим лишь некоторые краткие комментарии.
В предыдущем изложении предполагалось, что любой из аддитив-
ных параметров g, a,, (3j может быть опущен, но для оставшихся со-
храняются оценки наименьших квадратов, и эти оценки могут
использоваться для определения матрицы остатков Z. Тогда теорема
Экарта—Юнга утверждает, что мультипликативные константы оцени-
ваются из разложения матрицы Z нового вида по сингулярным значе-
ниям. Однако теперь суммы по строкам и столбцам матрицы Z
одновременно не обращаются в нуль, и, следовательно, соотношения
E7z=0 и Ету=О не могут выполняться одновременно. Все эти вари-
анты простой мультипликативной модели порождают разложения с
ортогональными членами. Их анализ может быть сведен к дисперси-
онному анализу. Такой дисперсионный анализ отличается от анализа
для соответствующей линейной модели в основном количеством сте-
пеней свободы, сязанных с мультипликативным(и) членом(ами) и те-
стами на значимость.
Использование трех или более индексов расширяет модель в двух
направлениях. Либо допускаются дополнительные произведения пар
параметров, либо допускаются произведения более двух параметров.
Расширенные модели первого типа естественны, но модели второго
типа порождают много затруднений, связанных, в частности, с вопро-
сом единственности и с проблемами оценивания. Более подробное из-
ложение содержится в [Gower (1977)]. В разделе 17.12 обсуждается
одна простая модель с тремя входами.
17.4. ДВОЙСТВЕННЫЕ ГРАФИКИ (биплоты)
Основная идея двойственных графиков (биплотов) состоит в том,
чтобы представить элементы, для которых задана матрица данных,
точками, как и в компонентном анализе, а переменные — векторами
в том же самом пространстве. Приставка «би» используется не в
обычном смысле двумерного представления, для которого ограниче-
ния скорее практического характера, а не теоретического, а для обо-
значения двойственности.
249
Пусть имеется матрица данных X, содержащая отклонения от
средних. Пусть п наблюдений в ординации представлены проекциями
на плоскость двух первых главных осей. Интересно выяснить, как эти
отображенные точки соотносятся с исходными случайными перемен-
ными. Один способ анализа — спроецировать каждую из р первона-
чальных осей, соотносящихся с одной из случайных переменных, на ту
же плоскость, что и выборки. Каждая ось будет представлена векто-
ром, проходящим через начало координат. Самый простой способ —
представить проекцию точки на каждую ось и вычислить ее расстоя-
ние до начала координат. Для этого требуются значения на компоне-
нтах для псевдонаблюдений, определенных единичной матрицей 1р
порядка р. Это не что иное, как строки матрицы нагрузок Н, два пер-
вых столбца которой задают соответствующие координаты случай-
ных переменных в двумерном пространстве. Соединив каждую из этих
точек с началом координат, получим один тип двойственного графика.
Точки, лежащие вблизи вектора и далеко от начала координат, долж-
ны иметь большие значения (положительные или отрицательные) по
соответствующей случайной переменной.
Метод проще понять, если проанализировать разложение матрицы
X по сингулярным значениям, которое в данном разделе будем запи-
сывать в виде LEHr. Отсюда следует, что дисперсионно-ковариацион-
ная матрица [см. определение 16.1.1] S = XXsHE2Hr и столбцы
матрицы Н идентифицируются как компонентные нагрузки, введенные
в разделе 17.2. Следовательно, наблюдениям соответствуют строки
матрицы XH = LE, а псевдонаблюдениям, представляющим случайные
переменные, соответствуют строки матрицы 1Н = Н. Строки матриц
LE и Н задают двойственные графики, и произведение двух матриц
воспроизводит матрицу данных X, по крайней мере в том случае, ког-
да представлена полная размерность пространства. Если представлено
только г измерений, то, как следует из теоремы Экарта—Юнга, такое
представление является наилучшей, в смысле наименьших квадратов,
аппроксимацией ранга г для матрицы X. Следовательно, если Pi пред-
ставляет z-е наблюдение, Qj — j-ю переменную, О — начало коорди-
нат, то AiOP^AtOQj) х cos(PpQj) является аппроксимацией для х^.
Вместо графического изображения единичных псевдонаблюдений
может представлять интерес проецирование точек на первоначальные
оси, которые, скажем, находятся на расстоянии одного среднеквадра-
тичного отклонения от начала координат. При хорошей аппроксима-
ции длины результирующих векторов дают полезную информацию об
относительной вариабильности исходных случайных переменных. Ес-
ли сначала нормализовать матрицу X так, чтобы все случайные пере-
менные имели единичное среднеквадратичное отклонение, то все
спроецированные векторы должны быть одинаковой длины. Однако
это возможно лишь при немногих аппроксимациях. Используя другой
тип биплота, можно добиться лучшей аппроксимации дисперсий и ко-
вариаций. При этом столбцы матрицы L задают координаты выбо-
рок, НЕ являются векторами случайных переменных, так что скаляр-
250
ное произведение двух множеств воспроизводит матрицу X. Длины
векторов определяются как НЕ2НГ, т. е. матрицей S. Следовательно,
длины равны среднеквадратичным отклонениям, а скалярные произве-
дения пар векторов определяют ковариации. Косинус угла между дву-
мя векторами соответствует корреляции между двумя случайными
переменными; полностью коррелированные переменные порождают
совпадающие векторы, а слабо коррелированные переменные порож-
дают почти ортогональные векторы. Двумерное приближение, конеч-
но, является аппроксимацией Экарта—Юнга для матрицы S. Доля
суммы квадратов, вычисленная для размерности к, равна
к Р к , р
Е о\/ Е а] = Е X?/ Е XI,
где Xz — z-е собственное значение матрицы S. Такой тип двойственно-
го графика лучше передает распределение случайных переменных по
сравнению с прежним. Однако здесь искажаются расстояния между
элементами. В предыдущем варианте расстояния аппроксимировали
евклидовы расстояния между строками матрицы X, вычисленные по
теореме Пифагора. В данном варианте расстояния вычисляются из ус-
ловия LLr=XS~1Xr. Это один из типов расстояния Махаланобиса
[см., например, Rao (1965) — С], однако следует помнить, что S = XXr
и не является независимо вычисленной матрицей дисперсий внутри со-
вокупности. Идемпотентность LLr=X(XrX)~1X7' означает, что если
вводится расстояние Махаланобиса, то точки обладают следующим
свойством: их сумма квадратов постоянна во всех направлениях, и
любая /r-мерная проекция имеет сумму квадратов, равную к. Доля вы-
численной суммы квадратов равна к/p, для двумерного графика она
равна 2/р. Существует мнение, что на биплоте первого типа точки
адекватно передают наблюдения, но векторы плохо передают случай-
ные переменные в отличие от графика второго типа. Наилучший вари-
ант — представить графически LE для наблюдений и НЕ для
случайных переменных, но при этом теряется связь скалярных произ-
ведений с матрицей X.
Другой тип биплота соответствует ситуации, когда X рассматрива-
ется как таблица с двумя входами размерности mxn [см. раздел 7.5.2],
а не как матрица данных. Тогда нет смысла работать с отклонениями
от средних по столбцам. Поскольку строки и столбцы имеют одина-
ковый статус, умножение на сингулярные значения в качестве весовых
коэффициентов должно быть сбалансированным, и поэтому лучше
отобразить 1_Е1/2 и НЕ12. Процедура построения биплота та же, что
и прежде, но в данном случае нельзя интерпретировать два множества
точек в терминах случайных переменных/наблюдений.
Особый интерес представляет случай, когда матрица X имеет ранг
2, и, следовательно, ее разложение по сингулярным значениям содер-
жит только два члена:
X=a1U)v1 + а21М2.
251
Такой вид соответствует простой аддитивной модели
X=/4117'+alr+ 10т,
в которой всегда можно ввести новую параметризацию, приводящую
к £«, = £/^ = 0. Выразив X в виде
Х=(р1 + а)17'+1(^1 + Д)7',
где p+q-p., легко обнаружить, что матрица X имеет необходимый
вид ранга 2. Записав N = ll77« и М = 11г/т, приходим к
(I—N)X(I—М) = аДЬ vf + ffaUiVT,
_ п
где Ui — вектор с элементами wu-—— отклонениями от сред-
него значения ut и т. д. для других векторов. Геометрическая интер-
претация такого преобразования состоит в том, что начало координат
для точек-строк находится в точке, соответствующей их среднему;
аналогично и для точек-столбцов. Итак, две конфигурации остаются
неизменными, за исключением того, что одно множество сдвинуто от-
носительно другого и введено новое общее начало координат. Старые
и новые оси параллельны, поэтому преобразование не изменяет углов
и не нарушает коллинеарности. Поскольку матрица X имеет специаль-
ную аддитивную форму, ее левая часть заполнена нулями, так что с
учетом вида ее разложения по сингулярным значениям имеем для эле-
мента (О') а.П-.-Г.
1 н V ___j
Поэтому линия, соединяющая точку о2гй2^ со средними зна-
чениями U] и и2, ортогональна линии, соединяющей точку
о22 Г2у) со средними значениями Vi и v2. Это справедливо для всех i и
j, и, следовательно, точки, соответствующие строкам матрицы X, ле-
жат на одной прямой так же, как и точки, соответствующие столб-
цам. Эти две прямые ортогональны. Результат не зависит от того,
распределены ли сингулярные значения одинаково по строкам и
столбцам. Любое разбиение удовлетворительно.
Более общее представление ранга 2 таблицы с двумя входами:
Х= /х11т + <xlr+ lflr+ ХссфЛ
Такая модель предложена Дж. Тьюки [см. TUkey (1949)] для анализа
неаддитивности. Легко увидеть, что структура имеет ранг 2, если за-
писать X в виде Х=(д-Х-,)117'+(Х-1/214-Х1/2а)х(Х-1/21 + Х1/^)г.
Как и в случае линейной модели,
(l-N)X(l-M) = Ха0г,
что, вообще говоря, не равно нулю, поэтому в данном случае двойст-
венные графики не сводятся к парам ортогональных осей. Факт, что
они вообще сводятся к линиям, следует только из того, что вид X ран-
га 2 обозначает, что векторы ut и и2 лежат на плоскости, содержащей
векторы 1 и а. Таким образом, существуют числа pit qlt р2 и q2 такие,
что ,, , ,
и2=р21+<72а.
252
Исключив а, получаем <72Ui—Q\^i = (P\Qi—Piddl- Это означает колли-
неарность двойственного графика для точек, соответствующих стро-
кам. Подобным же образом можно продемонстрировать свойство
коллинеарности для точек, соответствующих столбцам.
Общая модель ранга 2 для таблицы с двумя входами не приводит
к коллинеарности, хотя подмножества точек могут быть расположены
на одной прямой. Это означает, что, хотя для представления всей таб-
лицы необходима общая модель, отдельные ее подтаблицы могут
быть аппроксимированы более простыми моделями.
Промежуточной между простой аддитивной и самой общей мо-
делью ранга 2 является постолбцовая регрессионная модель Мандела
[см. Mandel (1961)]
Х = д11г+а1г+1^+Хатг
и соответствующая построчная регрессионная модель. Поскольку
Х=1(д1 + и)г+а(1 + ХУ)г,
существуют числа рх, qif р2, q2, такие, что
Ui=pil + 4ia,
U2==P2l + <?2a,
откуда, как и в предыдущем случае, следует, что точки, представляю-
щие строки, лежат на одной прямой. Однако V! и v2 лежат на плоскос-
ти /Л+Д и 1 + Ху и не образуют линейный график. Из выражений для
Ui и и2 следует, что расстояние между парами точек Р, и Pj, соответ-
ствующих /-й и J-й строкам, пропорционально at—Таким образом,
легко визуально оценить значения параметров. Этот результат также
справедлив для более простой линейной модели, задаваемой Х=0.
Выше было показано, как вид модели порождает различные виды
двойственных графиков. Справедливо также обратное: различные ви-
ды графиков могут порождаться только рассмотренными моделями.
Двойственные графики могут служить для проверки адекватности ли-
нейной модели, модели Тьюки или постолбцовой/построчной регрес-
сии; в частности, они показывают, адекватна ли простая линейная
модель для описания таблицы с двумя входами (более подробное из-
ложение этих проблем см. в работе [Bradu and Gabriel (1978)], где бла-
годаря энтузиазму К. Р. Габриеля содержатся многочисленные ссылки
на литературу по двойственным графикам).
17.5. АНАЛИЗ СООТВЕТСТВИЙ
Метод анализа соответствий, как и двойственный график, — версия
общей мультипликативной модели, обсуждаемой в разделе 17.3. Как
специальная модель для анализа таблиц сопряженности с двумя входа-
ми она нашла применение и при обработке других типов данных. Ме-
тод (во французском варианте: analyse factorielle des correspondences)
широко используется группой французских статистиков под руковод-
ством профессора Ж. Бензекри (J. Р. Benzecri). Совсем недавно С. Ни-
шисато [см. Nishisato (1980)] ввел термин дуальное шкалирование для
целой области анализа данных; кроме того, он сделал замечательный
253
исторический обзор, отражающий развитие интереса к этому направле-
нию. Стартовая точка — таблица X с двумя входами, которая рассмат-
ривается как таблица чисел. Пусть суммарные значения по строкам и
столбцам матрицы X «упакованы» в диагонали матриц R=diag(Xl) и
C = diag(lrX). При применении метода анализа соответствий опериру-
ют с матрицей Y, которая является специальной стандартизованной
формой матрицы X, вычисленной по формуле
Y=R-1/2XC-12.
(В этом выражении R~l/2 — диагональная матрица с 7-м диагональ-
ным элементом ry12, г- — /-й диагональный элемент матрицы R.)
Имеем YC1/21 = R-1/2X1 = R-1/2R1 = R1/21. Аналогично lrR,/2Y=lrC1/2.
Следовательно, Rl/21 и С1/21 — пара сингулярных векторов (если они
нормализованы должным образом), соответствующих единичному
сингулярному значению. Тогда разложение матрицы Y по сингуляр-
ным значениям может быть записано в виде
Y=R1/2ll7'Cl/2/x_. + E^u.vf,
1=2 1 1 1
где х,, — нормализующий множитель, который определяется из ус-
ловия, что сумма квадратов элементов обеих матриц R1/21 и С1/21
равна сумме элементов матрицы X. Когда X — неотрицательная мат-
рица, единичное сингулярное значение является максимальным. Это
следует из того, что сингулярные значения матрицы Y являются ква-
дратными корнями из собственных значений матрицы YrY, которая
сама неотрицательна. Как было показано, единичное сингулярное зна-
чение соответствует положительному вектору, из теоремы Фробениу-
са—Перрона [см. I, теорема 7.11.1] следует, что оно должно быть
максимальным. Если матрица X не является положительной, то сум-
мы по строкам и столбцам могут не быть положительными и не обя-
зательно существуют действительные матрицы Rl/2 и С1/2. Даже если
суммы по строкам и столбцам положительны, YrY не обязательно
положительна, и, следовательно, максимальное сингулярное значение
матрицы Y не обязательно единичное. Преобразовав определенное
выше разложение матрицы Y по сингулярным значениям, получим
R-1/2XC~1/2—R1/2llrC1/2/x = Е ff/U.-vf. Отсюда видно, что правая
i=2
часть равенства есть разложение матрицы в левой части по сингуляр-
ным значениям. Ее элементы:__________
xii ^х-)
7- =-- ---------------—
lJ 'fix^Xj)
Последнее выражение представляет собой квадратный корень из эле-
мента критерия Пирсона х2 Для проверки независимости классифика-
ций строк и столбцов таблицы сопряженностей X [см. раздел 7.5.1].
Отсюда следует, что Е aj задает декомпозицию статистики х2 с со-
i=2 ‘
ответствующими модельными членами ff/U/V,-. Проще рассматривать
этот метод как способ подгонки простых мультипликативных моделей
(включая двойственные графики) к производной матрице Z, что в
большой мере зависит от того, является ли преобразование X в Z
адекватным и интерпретируемым.
254
Переход к матрице Z полезен в экологических исследованиях. Здесь
строки матрицы X соответствуют разным участкам, а столбцы —
разным видам растений. Тогда задает количество видов j, произ-
растающих на участке /. Часто интерес представляют численности для
участков и в меньшей мере численности для видов. При этом участки
могут быть упорядочены (и, следовательно, построена ординация) в
соответствии с предположениями об экологических тенденциях. По-
скольку одни участки богаче по видам растений, чем другие, и одни
виды произрастают в гораздо большем количестве, чем другие, необ-
ходима специальная корректировка. Запишем неизвестные численнос-
ти, относящиеся к участкам (строки матрицы), в вектор р, а
неизвестные численности, относящиеся к видам (столбцы), — в вектор
q. Тогда средняя численность для /-го участка, рассчитанная по чис-
т
ленности для видов, равна Е х^/х,-.. Она должна быть пропорцио-
нальна численности pi для /-го участка. В матричном виде это запи-
сывается как
R-1Xq = op.
Аналогично из численностей по участкам вычисляются численности по
видам:
ргХС> = aqr.
Из этих соотношений следует, что R1/2p и C1/2q — сингулярные век-
торы матрицы Y, соответствующие сингулярному значению а. Макси-
мальное значение <г=1, определенное выше, соответствует векторам
ri/2P=ri/21 и C1/2q=C1/2l,
которые содержат одинаковые численности р = 1 и q = l и поэтому не
представляют интереса.
Численности, вычисленные по второй паре сингулярных векторов
матрицы Y, находятся из уравнений
R1/2p=u2 и C1/2q=v2.
Отсюда p = R~1/2u2 и q = C~1/2v2. Могут быть использованы последую-
щие пары сингулярных векторов; они будут определять второй набор
численностей, третий и т. д. Вторая и третья пары отмасштабирован-
ных сингулярных векторов могут быть представлены одновременно в
виде, напоминающем двойственный график, а иногда интересно пред-
ставить визуально сами численности. Таким образом, как и в «биплот-
ной» технике, здесь мы имеем «свободное от распределения»
сингулярное значение а, по и, и vz при любом способе действий, одна-
ко метод анализа соответствий обеспечивает, кроме того, возмож-
ность выбора графического представления R-’^u,- и C-1/2Vy. Обычно
используется комбинация двух видов шкалирования, состоящая в на-
глядном представлении R_ 1/2UE и C~,/2VE. Расстояния (или их квад-
раты) между парами точек, соответствующих строкам, вычисляются
КаК R~1/2UE2U rR-‘/2 = R-1/2ZZrR~1/2 = R-1XC~1XrR-1.
255
(Мы опустили члены, не влияющие на расстояние.) Квадрат расстоя-
ния между /-й и j-й строками (в пространстве полной размерности)
определяется выражением
\г/ rjJ \ri rjJ
которое называется расстоянием х1- Если /-я и j-я строки пропорцио-
нальны, соответствующие им точки совпадают. Аналогичное выраже-
ние определяет расстояния между точками-столбцами. При таком
подходе процедура представления данных в пространстве более низ-
кой размерности не является приближением в смысле наименьших
квадратов.
Совершенно ясно, что существует множество сингулярных значе-
ний и множество способов шкалирования строк и столбцов. В практи-
ческих ситуациях зачастую трудно сделать выбор между ними.
17.6. МЕТРИЧЕСКОЕ ШКАЛИРОВАНИЕ: АНАЛИЗ ГЛАВНЫХ
КООРДИНАТ И КЛАССИЧЕСКОЕ ШКАЛИРОВАНИЕ
Стартовая точка для всех методов многомерного шкалирования —
симметричная матрица М порядка п. Ее элементы ту задают некото-
рые меры связей (например, близости, различия, расстояния) между
объектами i и j. Связи могут быть наблюдаемы непосредственно, а мо-
гут быть вычислены из других более фундаментальных данных, таких,
как матрицы данных, обсуждаемые в разделе 17.1. Необходимо про-
анализировать матрицу М и построить ординацию в виде множества
из п точек в ^-мерном пространстве таким образом, чтобы расстояния
между ьй и У-й точками аппроксимировали ту или по крайней мере не-
которую функцию от ту. При метрическом шкалировании, которое
обсуждается в настоящем и последующих разделах, критерии для оцен-
ки качества отображения — просто функции /(ту, ту), где ту — ап-
проксимирующие значения. При неметрическом подходе, рассматривае-
мом в разделе 17.8, используются более общие критерии качества ото-
бражения.
Анализ главных координат и классическое шкалирование — сино-
нимы, они употребляются для обозначения метода метрического шка-
лирования, основанного на идее главных компонент [см. раздел 17.2].
Предполагается, что существуют п точек P/i=l, 2,...,п) в простран-
стве не более чем п—1 измерений, расстояния Д(Р/, PJ) между ними в
точности равны ту. Еще раз кратко обсудим смысл этих предполо-
жений и каким образом они могут быть ослаблены. Анализ главных
компонент можно применять для получения аппроксимирующей кон-
фигурации точек Р{ в пространстве к измерений. При этом осущест-
вляется проецирование в ^-мерное подпространство, минимизирующее
сумму квадратов отклонений расстояний в подпространстве от рассто-
яний в полном пространстве.
256
Предположение, что величины — расстояния, влечет за собой
следующее:
a) mz/=0, /=1, 2,...,л;
б) существует действительное множество точек Pz.
В действительности и а), и б) могут нарушаться. В случае, если
можно попытаться аппроксимировать расстояниями основную
часть таблицы, игнорируя диагональные элементы, и/или подобрать
преобразование, корректирующее данные. Обычное преобразование —
—ту, оно хорошо подходит для мер сходств с т/7=1. Удобное
свойство метода главных координат состоит в том, что с его по-
мощью можно определить ситуацию, когда реальной конфигурации не
существует, и оценить, насколько серьезна эта проблема.
Основной алгебраический результат, лежащий в основе анализа
главных координат, следующий: если М — симметричная матрица, до-
пускающая разложение YYr, то строки Y могут быть взяты в качестве
координат. Квадрат расстояния между точками с координатами, задан-
ными /-й и j-й строками матрицы Y, равен ти + т^—2т^. Для матри-
цы с нулевыми диагональными элементами квадраты расстояний
просто равны —Ътц- Таким образом, чтобы определить координаты,
воспроизводящие расстояния dy, достаточно положить = —^dy.
Для матрицы мер сходства с единичными диагональными элементами
матрица Y дает квадраты расстояний 2(1—тф. При этом большие ме-
ры сходства (ту близко к единице) отображаются в малые расстояния,
а малые меры сходства (тц близко к нулю) — в большие. После
определения координат Y ^-мерная аппроксимация может быть завер-
шена с помощью компонентного анализа. Но прежде необходимо пре-
одолеть основную сложность. Чтобы оценить ее, рассмотрим
спектральное разложение М = ХЛХГ. Тогда Y может быть выражена в
виде Y=XA1/2. След матрицы расстояний равен нулю, и, следователь-
но, по крайней мере одно собственное значение отрицательно, что при-
водит к мнимой части в Л1/2 и мнимому множеству координат. Это
означает, что координаты Y, определенные описанным выше способом,
не могут быть действительными, если М — матрица расстояний. То же
относится и к любой другой декомпозиции матрицы М.
Оказывается, действительное множество координат, когда оно су-
ществует, может быть найдено в результате преобразования элементов
матрицы М в М* способом, описанным ниже. Это преобразование до-
лжно обеспечить, чтобы М* имела нулевое собственное значение (стро-
го говоря, на одно больше, чем матрица М, если точки лежат на
гиперсфере, и на два больше при любой другой конфигурации). Рас-
смотрим преобразование g,—gj, где gz(/=l, 2,...,л) — произ-
вольные слагаемые. Тогда
/л.” + /и;; — 2т * = ти+ти—2тц,
и это означает, что любое разложение матрицы М* порождает конфи-
гурацию с теми же расстояниями, что и расстояния в матрице М. Мат-
рица М* — наиболее общий вид матрицы, обладающей таким свойст-
257
вом, ‘поскольку если преобразование М—G сохраняет расстояния, то
Sn+gjj—2gjj=0. Отсюда G=glr+lgr, где 1 — единичный вектор, a g
содержит элементы gi = ^ga- Для выбора значений gj можно исполь-
зовать любой способ, обеспечивающий нулевое собственное значение
для матрицы М*. Например, можно обратить к-ю строку матрицы
М* в нули, взяв ,
gj = ™kj ~ -Тткк,
тогда элементы матрицы есть = —mik—rnjk + mkk.
Любое разложение M*=YYr обращает к-ю строку Y в нули, поэ-
тому к-я выборка попадает как раз в начало координат. Альтернатив-
ный вариант: можно подобрать g так, чтобы сумма элементов
каждой строки (или столбца) обращалась в нуль. Для этого требуется
Тогда т^ = ту—т^—т^ + гП'. определяют матрицу М*. Точка в ин-
дексе означает, что среднее берется по соответствующему индексу. MJ
часто называют дважды центрированной формой матрицы М.
После преобразования получаем
Мо*1=О.
Отсюда 1 — собственный вектор, соответствующий нулевому корню.
Для любого разложения Mo =YYr имеем (lrY)(Yrl)=0. (lrY)/n=yr —
вектор-строка центроида конфигурации; как было показано, Еу/=0,
отсюда следует, что все _у, = 0. Сумма координат Y по столбцам равна
нулю, геометрически это означает, что начало координат находится в
центре тяжести конфигурации. Если Y=XA1/2 и ХЛХГ является спект-
ральным разложением матрицы MJ, то YrY=A диагональна. Поэто-
му координатные оси являются главными осями конфигурации точек.
Отсюда следует, что собственные значения Хь Хг^.-.Х^р расположен-
ные в порядке убывания, дают суммы квадратов, вычисленные для по-
следовательных осей, и могут, как и в компонентном анализе, исполь-
зоваться для определения размерности, достаточной для хорошего
отображения. Заметим, что преобразование гарантирует Хл = 0. Это ме-
тод главных координат, который для любой симметричной матрицы М
порядка п дает набор координат п точек, такой, что Д2(РР°у)=
=ти+т^—2ту, начало координат находится в центре тяжести конфи-
гурации, и главные оси совпадают с координатными осями. В случае,
когда расстояния евклидовы, найденные таким образом координаты —
действительные. Для существования действительного решения необхо-
димо и достаточно, чтобы матрица М* была положительно полуопре-
делена для некоторого вектора д. Достаточность очевидна,
необходимость доказать сложнее [см. Blumenthal (1970)]. М* может
быть вычислена из матрицы М для любым способом выбранного век-
тора д, лишь бы он давал дополнительное нулевое собственное значе-
ние. Оба способа, обсуждаемые выше, в матричном обозначении
записываются так:
M£=(l-Et)M(l-E/)
И
Мо = (1—N)M(I—N),
258
где ЕА. = еА.1г, N = llr//! и ек — вектор, к-я компонента которого рав-
на единице, а все остальные — нули.
Общее требование, предъявляемое к выбору д, порождающему ну-
левое собственное значение в матрице М*:
(1гМЧ)(дгМ- ’д) = (1—1гМ~‘д)2.
Можно показать, что векторы д, приводящие к М£ и Мо, удовлетво-
ряют этому соотношению. Условия, обеспечивающие евклидово пред-
ставление расстояний (ти + т^—2т^/2, удобнее задать в виде
симметричной матрицы
F=(l—lsr)M(l—slr), ’
где s — любой вектор с единичной суммой элементов, не являющийся
нулевым вектором матрицы М. Такой выбор s эквивалентен определе-
нию g как g=Ms—^(srIVIs)l. Говер [см. Gower (1982)] показал, что
конфигурация является евклидовой тогда и только тогда, когда F по-
ложительно полуопределена. Разложение F=YYr дает конфигурацию
Y с центром, удовлетворяющим соотношению srY=0. Введенные
мультипликативные формы показывают, что s = l/nl для Мо и s = e^
для М^. Квадрат расстояния каждой точки от выбранного начала ко-
ординат задается как diag F. Эта диагональная матрица может быть
записана в виде вектора-столбца (diagM)l—2Ms + (srMs)l, где первый
элемент отсутствует, если М является матрицей расстояний. Эти ре-
зультаты могут быть использованы для получения S с хорошими гео-
метрическими свойствами. Например, если начало координат должно
быть в центре гиперсферы, описанной вокруг конфигурции, то налага-
ется условие
(diagM)l—2Ms + (srMs)l = /?2l,
где R — радиус. Это уравнение может быть решено непосредственно,
но процедура достаточно громоздка. Если М — матрица расстояний
с diagM=0, то
Ms = Al
для некоторого к. Для невырожденной матрицы М
s-ЛМ-Ч,
и поскольку srl = l, то Аг=(17'М-11)~1 определяет S и задает R2-
= —Такое s определяет М* = М—(11Г/1ГМ-Ч).
Эти результаты представляют скорее геометрический, чем стати-
стический интерес. Все определенные таким образом наборы коорди-
нат задают идентичные геометрические конфигурации с точностью до
начала координат и направления осей, что зависит от выбора разло-
жения YYr. Главные координаты, определяемые спектральным разло-
жением матрицы Мо, являются, особенно важными, поскольку, как и
главные компоненты, обладают свойствами наименьших квадратов.
259
F может не оказаться положительно полуопределенной. Тогда от-
вергается предположение, что существует реальная евклидова конфи-
гурация в пространстве размерности п—1 с заданными расстояниями;
это вызывает сомнение в обоснованности геометрических аргументов,
базирующихся на проекциях. Отрицательность малых собственных
значений не представляет серьезной проблемы. В исследованиях эф-
фектов добавления возмущений в матрицу евклидовых расстояний
Р. Сибсон [см. Sibson (1979)] показал, что может быть порождено не-
сколько малых отрицательных собственных значений. Он предложил
удобное правило для определения размерности: сумма оставшихся по-
ложительных собственных значений должна быть приблизительно
равна сумме всех собственных значений. Можно считать, что малые
отрицательные собственные значения уничтожают несущественно ма-
лые положительные собственные значения.
Наличие большого по абсолютной величине отрицательного соб-
ственного значения отвергает идею об евклидовом пространстве.
Оправданность использования классической процедуры шкалирования
может быть проверена по теореме Экарта—Юнга [см. раздел 17.3].
Мы имеем Мо=ХЛХг, и теорема Экарта—Юнга для симметричных
матриц утверждает, что наилучшее приближение ранга г матрицы М*
можно получить, положив равными нулю все меньшие по модулю
п—г собственные значения. Если при этом остаются отрицательные
собственные значения, то евклидово представление нереализуемо. Да-
же если г наибольших по модулю собственных значений положитель-
ны и евклидово представление допустимо, оптимизируемый при этом
критерий наименьших квадратов не идентичен первоначальному кри-
терию. Эти два критерия совпадают, только когда все собственные
значения неотрицательны. Хотя аппроксимации, включающие отрица-
тельные собственные значения, не могут интерпретироваться в терми-
нах расстояний, они дают полезные упрощающие преобразования
данных. Из всех метрических методов шкалирования только классиче-
ское шкалирование/метод главных координат позволяет распознать
хорошую неевклидову аппроксимацию, если она существует. Другие
методы, обсуждаемые в разделе 17.7, аппроксимируют только евкли-
довы конфигурации и не могут быть модифицированы так, чтобы ре-
ализовывать достаточно гибкие неевклидовы модели. Трудность в
том, что в r-мерной аппроксимации каждая из г осей может быть
мнимой, и их 2Г возможных представлений только одно евклидово. В
анализе главных координат отрицательные собственные значения ука-
зывают, сколько нужно включить мнимых осей. В других методах
приходится независимо просчитывать 2Г возможных решений, что не-
практично, особенно если это должно быть сделано для каждого зна-
чения г потенциальных размерностей.
Для полноты изложения следует упомянуть и о проблеме аддитив-
ной константы, которая является одной из составных частей классиче-
ского шкалирования. Рассмотрим случай, когда diag(M)=0, а вне-
диагональные элементы матрицы М — предполагаемые расстояния.
260
Встает вопрос, можно ли подобрать константу к, чтобы ту + к стали
действительными евклидовыми расстояниями и, следовательно, при-
водили к действительной ординации, даже когда исходные ту к ней
не приводят. До недавнего времени не было известно точного реше-
ния этой проблемы, хотя У. Торгерсон [см. Torgerson (1958)] разрабо-
тал численный итеративный алгоритм. Прежде чем описывать новое
решение проблемы аддитивной константы, приведем решение, предло-
женное Дж. Линго [см. Lingoes (1971)] для более простой задачи. Не-
обходимо подобрать наименьшую константу к, чтобы ту + к были
квадратами действительных евклидовых расстояний. Поскольку для
воспроизведения расстояний ту необходима матрица с элементами
—Tmij’ в дальнейшем в данном разделе будем предполагать, что
матрица М задана именно в таком виде. Тогда матрица с эквивалент-
ными скорректированными квадратами расстояний будет следующей:
L=M—4-jt(nN—I).
Для классического шкалирования получаем дважды центрирован-
ную матрицу
M0* = (l—N)M(l-N)=XAXr.
Для матрицы L двойное центрирование:
Lo* = Мо* + -U(l-N) = Х(А + 4-Аг1)Х т—^к(11Т/п).
Было показано, что и~1/21 — собственный вектор матрицы Мо, соот-
ветствующий нулевому собственному значению. Отсюда следует, что
1 — собственный вектор матрицы Lo, соответствующий нулевому соб-
ственному значению, и что другие собственные векторы также оста-
ются неизменными, а собственные значения преобразуются в Х; + у£.
Чтобы обеспечить существование действительной конфигурации, до-
статочно выбрать к, такое, чтобы все \ + -^к были неотрицательны.
Если наименьшее собственное значение Хо отрицательно, достаточно
выбрать к^—2Х0. Если &=2Х0, то следует учесть также второе соб-
ственное значение, и тогда расстояния (ту—2Х0)1/2 порождают дей-
ствительную конфигурацию в пространстве размерности не более
п—2. Если п—1 собственных значений матрицы Мо совпадают, то все
собственные значения матрицы Lo равны нулю, что приводит к вы-
рожденному решению. Такая ситуация исключается, если потребовать,
чтобы Хо было отрицательным.
Вернемся к проблеме аддитивной константы. Ф. Кайез [см. Cailliez
(1983)] показал, что к является наибольшим собственным значением
матрицы /
/ U 2Мо \ >
^-l 2Р; J
где Ро*=(1-N)P(I—N) и ру = ту. При таком к расстояния ту + к по-
рождают действительную конфигурацию в пространстве размерности
не более п—2.
261
17.7. МЕТРИЧЕСКОЕ ШКАЛИРОВАНИЕ: ДРУГИЕ МЕТОДЫ
Настоящий раздел является продолжением предыдущего: в нем
рассматриваются критерии для построения ординации по выборочной
матрице, элементы которой считаются расстояниями. Заменим сим-
метричную матрицу М общего вида на симметричную матрицу D с
элементами —-^dfj и нулями на диагонали. Данные — положитель-
ные элементы djj, и хотя, вообще говоря, их можно рассматривать
как расстояния, нет никакой уверенности в том, что они представляют
собой евклидовы (или другие) расстояния между точками в реальной
конфигурации.
В этой области известно очень немного аналитических результа-
тов, но существуют алгоритмические процедуры. Разница между ана-
литическим и алгоритмическим решениями достаточно иллюзорна,
поскольку алгебраический подход к классическому метрическому шка-
лированию, основанный на собственных значениях, сам опирается на
численные алгоритмы. Численные алгоритмы, реализующие обсужда-
емые далее критерии, не имеют хорошо разработанной алгебраиче-
ской теории, поэтому они менее открыты для анализа. В этом
отношении методы, рассматриваемые в данном разделе, гораздо ме-
нее обоснованы, чем те, которые обсуждались в разделе 17.6.
В дальнейшем мы сосредоточим внимание на поиске множества ко-
ординат X в пространстве размерности к, которые порождают евкли-
довы расстояния Будем предполагать, что элементы —матри-
цы Д аппроксимируют данные D. Один из возможных подходов — по-
добрать X, минимизирующую С} = ^(djj—Это — шкалирование по
методу наименьших квадратов, а сам критерий иногда называют
стрессом (STRESS) [см. в разделе 17.8 соответствующее определение
для неметрического шкалирования]. Если наблюдения t/zy независимы и
одинаково нормально распределены, то за критерий принимается мак-
симум правдоподобия. Дифференцирование этого критерия по элемен-
там матрицы X приводит к нормальным уравнениям относительно
элементов матрицы X:
FX = 0,
где F — симметричная матрица с нулевыми суммами элементе > по
строкам и столбцам; = для Z#/. Элементы матрицы F —
функции от Д, а следовательно, и от X, поэтому нормальные уравнения
нелинейны. Прежде чем прокомментировать методы их численного ре-
шения, приведем несколько простых результатов. Сначала отметим,
что если X является решением, то Х(Н + 1т), где Н — ортогональная
матрица, ат — произвольный вектор, тоже является решением. Тако-
вы условия (вращение и параллельный перенос), обеспечивающие со-
хранность расстояний между строками матрицы X, а следовательно, и
инвариантность F. Хотя при решении нормальных уравнений на X не
налагаются ограничения, можно предположить, что X задает конфигу-
рацию в удобном виде в смысле положения центра и ориентации. На-
262
пример, из условия нулевой суммы элементов X по столбцам следует,
что ХХг=До — центрированная матрица расстояний, соответствую-
щая А [см. Мо в разделе 17.6]. Умножив нормальное уравнение на Хг,
получим
F4o*=O.
Это запись нормальных уравнений через наблюдаемые и аппроксими-
рующие расстояния: т уравнений для пк координат. Уравнения могут
интерпретироваться как идентичность наблюдаемых и аппроксимиру-
ющих расстояний, но они не представляют интереса. Важный резуль-
тат следует из условия Trace(FA*)=0:
Trace(FA*)-Trace [F(l—N)A(I—N)} =TYace((l—N)F(I—N)A] =Trace(FA).
Итак, или —д^)дц=О. Отсюда при минимальном значе-
нии критерия имеем
Е(^—
что может использоваться как основа для дисперсионного анализа.
При этом общая сумма квадратов (наблюдаемых расстояний) равна
сумме квадратов аппроксимирующих расстояний плюс сумма квадра-
тов остаточных расстояний. Поскольку остаточная сумма квадратов
должна быть неотрицательной, среднее из всех аппроксимирующих
расстояний никогда не превышает (и почти всегда меньше) среднего
из всех наблюдаемых расстояний. Для большего сходства допускается
помещение начала координат в одну из точек выборки, что дает
fa;=o.
Для решения уравнения FX=0 относительно X предлагается два ме-
тода. В первом используется одна из процедур многоцелевой оптимиза-
ции, разработанных специалистами по численному анализу [см.,
например, Murray (1972)]. Второй подход более эвристический, он опи-
рается на работу Л. ГУттмана [см. Guttman (1968)]. Имеем F=F* +
+ (ц|—11т), где F* — симметричная матрица с нулевой суммой по
строкам (и столбцам), У* =6^/6^, Если X задана в центрированном
виде, то можно записать нормальное уравнение:
^F*X=X.
Оно может служить основой для итеративной последовательности
±Г*Х=Х
П Г1Л1 Л1+1>
где X] — начальное приближение, которое может быть задано спосо-
бом, описанным в разделе 17.6. Заметим, что если X,- центрирована, то
Х/+] тоже центрирована. Показано, что эта последовательность никог-
да не увеличивает значение критерия Сив нормальной ситуации схо-
дится к решению. Скорость сходимости может быть мала, но ее
можно увеличить путем выбора константы а в последовательности
X,41 = 4-F;X,.+a(X,—lF^1X/_1).
263
Выбор а = 8—1 с малым положительным значением 8 квадратично
увеличивает скорость сходимости и сокращает количество необходи-
мых итераций. Процедура в целом очень близка к методу вычисления
собственных векторов с помощью мультипликативного итеративного
процесса, описанного выше. Для улучшения сходимости можно ис-
пользовать вариант метода улучшения сходимости Эйткена (Aitken).
Он заключается в аппроксимации трех векторов, полученных на трех
последовательных итерациях, параболой. Основное различие состоит
в том, что матрица F* сама меняется на каждой итерации. Из нор-
мальных уравнений видно, что столбцы матрицы X являются со-
бственными векторами матрицы (1/«)F*, соответствующими
единичным собственным значениям.
' Другой возможный итеративный способ нахождения решения —
изменить дистанционный вид нормальных уравнений так, чтобы по-
лучить .
Такая процедура обладает важными свойствами. Например, если (До)/
центрирована по строкам и столбцам, то (Ао)/+1 тоже центрирована и
в случае точного соответствия (Ао)/+1 =(До),. Кроме того, если матри-
ца (Ао){- имеет ранг к, то все последующие центрированные матрицы
в последовательности имеют тот же ранг. Допустимо работать пол-
ностью в терминах расстояний. Тогда можно избежать затруднений,
связанных с произвольным вращением и переносом конфигурации X.
Заметим, однако, что нет гарантии, что (А*), останется симметрич-
ной, но если процесс сходится к решению, то (А*); должна сходиться
к симметричной матрице. Однако о свойствах сходимости метода ни-
чего не известно.
Другой критерий, применяемый в метрическом шкалировании, —
найти конфигурацию X, минимизирующую С2 = ЕЦу—6?)2. Такой под-
ход называют квадратичным шкалированием по методу наименьших
квадратов, а критерий иногда называют стрессом (STRESS). Нор-
мальные уравнения
GX = 0
напоминают нормальные уравнения для шкалирования по методу на-
именьших квадратов. G — симметричная матрица с нулевой суммой
элементов по строкам (и столбцам), gzy = ^,y—5?-. Как и ранее,
GAo=O и GA£=0.
В данном случае
Trace(G Ао) = ЕЦ?—6 ?)6 =0.
Мы приходим к дисперсионному анализу квадратов расстояний:
Хотя нормальные уравнения в виде GAo=O содержат только квадра-
тичную форму от метод прямого их решения неизвестен, а итера-
тивный способ поиска аппроксимирующей последовательности не
распространяется на F. Поэтому для нахождения численных решений
следует применять общие методы оптимизации.
264
Критерии Cj и С2 обычно задаются в форме с весовыми коэф-
фициентами:
G = Lwy(dy—djj)2
и
C2 = Ew,y(^-6?)2.
Веса могут быть заданы или вычислены как функции от расстояний.
Хотя иногда желательно веса выразить через неизвестные аппрокси-
мирующие расстояния бу, привычнее и, конечно, удобнее использо-
вать наблюдаемые расстояния. Обычно полагают Wy = dy, приписы-
вая тем самым больший вес малым расстояниям и, следовательно,
точности локального отображения, или Wy = dy, что направлено на
точность передачи больших расстояний. Отображение, минимизирую-
щее Ci с Wy-dy, называют нелинейным мэппингом (mapping). Нор-
мальные уравнения для Cj и С2 легко модифицировать с учетом
весовых коэффициентов, и итеративная последовательность для мини-
мизации Ci может быть тоже модифицирована.
Существует и другая формулировка критериев. Допустим, вы-
числен для некоторой конфигурации (и не обязательно соответствует
минимуму). В этом случае можно промасштабировать координаты и
получить новые расстояния Хбу в ^-мерном пространстве. Тогда
C^ZWytdy-Xdy)2,
его можно минимизировать, выбрав
Х= TiWydyby/TiWyby,
что приводит к
C,(X)=Ewvdl(l-e?),
где
= (Lwydy6y)2/(Lwydy)(Lwy6y).
Теперь q имеет вид коэффициента корреляции, 0^ р2^ 1, и, следо-
вательно, Ci можно уменьшить для X # 1. В точке минимума С\ даль-
нейшее уменьшение невозможно, следовательно, К=1. Это то же
условие, которое вытекает из Тгасе(ГДо)=О, но в форме с весовыми
коэффициентами. При таком подходе видно, что минимизация Ci эк-
вивалентна максимизации g2, последний достигает максимального
значения g2(max) = 'Lwyby/'Lwydy.
Аналогичные рассуждения приводят к выражению для
C2(X) = Ew/y^(l-g22),
где
поэтому С2 минимизируется при максимизации g2, последнее
достигает максимального значения g2(max) = Zwyby/'Lwydy при
Х= ^Wydyby/’Lwyby = 1.
Предлагается другой тип метрического шкалирования, называемый
параметрическим мэппингом. Здесь критерий минимизации
С3 = (Е^/5^)/(Е1/5^)2.
Взвешенная нецентрированная корреляция между dy и 8у может
быть определена как
ei=(Ew,y^5,y)V(EW,y^)(EW,y5--4).
Положив 'Wa = dl'h получаем
откуда следует, что при минимизации С3 максимизируется q23. Рассуж-
дения, подобные проведенным выше для шкалирования по методу на-
именьших квадратов с множителем X, приводят к выводу, что
максимизация q3 эквивалентна минимизации критерия взвешенных на-
именьших квадратов для обратных квадратов расстояний, т. е.
^y(dy-8^
с Wy=dy. В точке минимума
Y.Wy(dy 8 у )2= 12wydy Ew/y5/y ,
и это сопоставимо с другими соотношениями рассматриваемого дис-
персионного анализа. Ясно, что параметрический мэппинг идентичен
шкалированию по методу наименьших квадратов на квадратах рассто-
яний с весом ™^ц8ц -dy при условии, что dy и 8у сравнимы по
величине. В данном методе малые веса приписываются большим рас-
стояниям, а большие веса — малым. Это соответствует исходной идее
метода, основанного на индексе непрерывности, где важна точность
передачи малых расстояний.
В разделе 17.6 было показано, что классическое шкалирование мат-
рицы М дает максимальное количество г действительных осей, где
г— количество положительных собственных значений матрицы Мо - В
данном разделе матрица М заменена на матрицу D. Какая же размер-
ность достаточна для аппроксимации D в смысле метрического шкали-
рования? Точного ответа на этот вопрос нет, но существует мнение,
что не более г, а может быть, и меньше. Иначе говоря, если попы-
таться аппроксимировать ее в пространстве размерности более г, то
значение критерия не будет уменьшено и rank (Х)^г. Приведем не-
сколько аргументов в поддержку этого предположения. Во-первых,
при г=п—1 все методы дают точное приближение в пространстве раз-
мерности п—1. Во-вторых, для г<п—1 элементарно можно доказать,
что решение может быть найдено в пространстве размерности не бо-
лее п—2. Эта граница может быть достигнута только при г-п—2, но
она не всегда достигается. Полученные совсем недавно и еще не опуб-
ликованные результаты могли бы служить формальным доказатель-
ством справедливости данного утверждения.
17.8. НЕМЕТРИЧЕСКОЕ МНОГОМЕРНОЕ ШКАЛИРОВАНИЕ
Другая проблема — аппроксимация данных, подобных расстояни-
ям и заданных в виде элементов dy матрицы, расстояниями 8 у (обыч-
но евклидовыми) между п точками в пространстве размерности к.
(днюха мы будем аппроксимировать не сами dy, а некоторую функ-
266
цию Мф от наблюдаемых расстояний. Если функция /(•) известна за-
ранее, то нужно к преобразованным данным применить методы, опи-
санные в разделах 17.6 и 17.7- Обычно Д') неизвестна и должна быть
определена; однако может быть задан ее общий вид. Например, можно
потребовать, чтобы /(•) была полиномиальной или гладкой монотон-
ной функцией, выражаемой в терминах В-сплайнов [см. II, раздел 6.5];
можно также решать задачу для общей монотонной функции. Послед-
нее и есть классическая задача неметрического шкалирования. Целесоо-
бразность поиска монотонного преобразования от dy в общем виде
оправдана тем, что даже в случае слабой уверенности в абсолютных
значениях наблюдаемых данных, как это бывает во многих прикладных
задачах, они могут быть проранжированы достаточно надежно. Так
что большую уверенность вселяют порядковые, а не абсолютные или
кардинальные значения данных. По этой причине заслуживают иссле-
дования методы ординации, опирающиеся только на порядковую ин-
формацию. Такие методы могут быть сконструированы. Они приводят
к хорошо определенной устойчивой конфигурации точек.
Должны быть решены две основные проблемы:
а) как определить критерий качества отображения, инвариантный
относительно монотонного преобразования данных <7,у?
б) как, выбрав подходящий критерий, найти конфигурацию X,
оптимизирующую его?
Эти проблемы не имеют однозначного решения. Далее мы приве-
дем основные подходы, применяемые в настоящее время.
Для любой ординации X может быть изображена диаграмма рассе-
яния djj относительно 5,у. Отображение будет точным, если dy моно-
тонно возрастают с ростом 5,у. Тогда ломаная линия, соединяющая
пары последовательных значений <5Z/, идет только вправо и вверх. Мо-
нотонная функция, представленная на графике, может быть взята в ка-
честве /(•). Она должна удовлетворять соотношению /(rf,y) = 6/y. Нельзя
ожидать точного соответствия, но всегда можно аппроксимировать
монотонную (или изотопную) регрессию от <5;у относительно поряд-
ковых значений d^. Для этой цели существуют прямые алгоритмы
[см. Barlow et al. (1978)]. Значения /(d,y) зависят только от порядка dy
и могут сопоставляться с аппроксимирующими величинами 6,у. За ме-
ру качества отображения естественно принять критерий Е(5,у—/(6гу))2,
подобный используемому при шкалировании по методу наименьших
квадратов. На практике обычно этот критерий нормализуют, чтобы
облегчить сравнение двух или более неметрических решений. Суще-
ствует два способа нормализации, приводящие к критериям:
5? = Е(6,у-Л^))2/Е6?-,
Sl= Е(6,у—/(^у))2/Е(6,у— 6J2,
где 6.. — среднее по всем 6,у. Критерий Si называют стресс-формулой
1, a S2 — стресс-формулой 2. В случае ранговых данных возникает
проблема, как обращаться со связанными рангами. В настоящем кон-
тексте рассматриваются две возможности. Либо совпадающим значе-
ниям djj должны соответствовать совпадающие значения 6,у, либо это
не обязательно. Последнее допущение приводит к более удовлетвори-
тельным результатам.
267
Стрессом можно оперировать достаточно гибко. Если какие-либо
dy неизвестны, то при суммировании соответствующие члены просто
могут быть опущены. Тогда можно использовать экспериментальную
схему, в которой наблюдения dy опускаются в систематической мане-
ре, что сокращает работу экспериментатора по сбору исходных дан-
ных. Исследования, проведенные в последнее время, показали, что
даже если пропущено около трети данных, то оставшихся достаточно
для получения удовлетворительной ординации. Другая возможность
— разбить стресс на отдельные компоненты, каждая компонента мо-
жет использовать свою монотонную регрессию; при этом даже допу-
стимы разные типы регрессий. Наиболее общий подход — разбиение
по строкам (или столбцам). Иногда такой подход называют локаль-
ным порядковым шкалированием. Здесь стресс вычисляется отдельно
для каждой строки (или столбца) данных и минимизируется сумма от-
дельных значений S2. Такой подход целесообразен, например, когда
данные собираются в виде ранжировок по строкам (или столбцам),
как в многомерной развертке [см. раздел 17.9]. В предыдущих разде-
лах мы налагали ограничение dy=dji, сейчас оно не требуется, но ап-
проксимирующие значения всегда симметричны, т. е. 8ij = dji. Обычно
симметризуют данные по формуле Заметим, что, если да-
же этого не сделано, при неметрическом шкалировании не анализиру-
ют асимметричные свойства данных. Для этой цели требуются специ-
альные методы. Они обсуждаются в разделе 17.13.
Существуют также критерии, отличные от стресса.
Большинство критериев метрического шкалирования может быть
распространено на неметрический случай при замене dy на f(dy), где
ftdy) инвариантна относительно монотонного преобразования значе-
нии dy. Формулировка критерия в терминах корреляций между Ьу и
f(dy) приводит к выражению критерия
Д2 = (Е5/Цу))2/Е^.Е(/Цу))2,
что очень похоже на корреляционные критерии метрического шкали-
рования,, обсуждаемые в разделе 17.7. По-видимому, если Jldy) опре-
деляется по аппроксимирующим значениям монотонной регрессии, как
было предложено выше, то максимизация ц эквивалентна минимиза-
ции стресса, за исключением незначительных эффектов от нормирую-
щих делителей, вводимых при определении стресса. Непосредственное
сравнение критериев затруднено, поскольку обычно тот, кто предпочи-
тает критерий g, предпочитает также другой вид функции /(•), участ-
вующей в определении стресса. Функцию Д-) называют ранговым
образом. Это очень простое преобразование: если dy в данных пропу-
щено, то полагают f(dy) = 8y, если dy в данных имеет ранг г, то f(dij)
полагают равным тому значению Ъу, которое находится на r-м месте;
при этом делается условленная корректировка на связанные ранги. Та-
кое преобразование обеспечивает следующее: если поддерживается мо-
нотонное соотношение между dy и 8у (допустимое для связанных
рангов в одной или обеих последовательностях), то f(dy) = 8y и д=1.
Если монотонное соотношение нарушается, то ^<1.
268
Рамсей [см. Ramsay (1977)] использует процедуру, основанную на
оценке максимума правдоподобия. Поскольку предполагается, что на-
блюдения dy содержат только порядковую информацию, удобнее вве-
сти предположения о распределении преобразованных значений f(dy),
а именно предположить, что они распределены нормально или лог-
нормально. Такие предположения могут показаться нереалистичными,
но если все же можно принять их, то последовательность подходов,
основанных на правдоподобии, позволит оценить доверительные об-
ласти для каждого аппроксимирующего множества координат.
Независимо от того, используется ли стресс с монотонным преоб-
разованием или корреляция с ранговыми образами, вычислительные
проблемы очень сходны, и в обоих случаях могут применяться стан-
дартные оптимизационные процедуры [см., например, Murray (1972)]
для оптимизации выбранного критерия. Необходимо оценить пк эле-
ментов матрицы X, поэтому вычислительная проблема является здесь
одной из главных, и специалистами были приложены большие усилия
для разработки удобных и надежных алгоритмов, включающих вспо-
могательные средства для работы с данными. Результат получился в
определенном смысле даже более значительным, чем для большин-
ства других методов. Методология реализована в виде нескольких ши-
роко распространенных вычислительных программ. Это большой
регулярный проект. Первая программа была написана в 1962 г., к на-
стоящему времени с учетом предыдущего опыта создано второе поко-
ление программ. Следует перечислить такие важные программы, как
KYST* (Краскал, Юнг, Шепард, Торгерсон), ALSCAL** (де Лью, Тей-
кен, Юнг), MULTISCALE*** (Рамсей), MINISSA**** (Гутман, Линго,
Роскам). Краткое и простое введение в неметрическое шкалирование,
включающее детальное описание перечисленных программ, содержит-
ся в [Kruskal and Wish (1978)].
Работа с программами требует определенного опыта. Они могут,
что часто и бывает, сходиться к локальным оптимумам, а не к истин-
ному оптимуму выбранного критерия; они могут вообще не сходиться.
Пользователь должен распознать такие ситуации и предпринять кор-
ректирующие действия. Он должен уметь оценить достаточную раз-
мерность пространства. Проблема интерпретируемости ординации
связана с вопросом об удовлетворительном значении критерия. Одним
из важных выходов такого анализа является доступность значений
f(dy). Они могут быть представлены графически вместе с dy, что поз-
волит отразить вид найденного преобразования. Для монотонной ре-
грессии функция может быть разрывной. Это проливает свет на
свойства данных dy, в другом случае функция может быть достаточно
* Kruskal, Young, Shepard, Torgerson. — Примеч. ped.
** Alternative Least Square Scaling. — Примеч. ped.
*** MULTI dimensional SCAling Likelyhood Estimations. — Примеч. ped.
**** Michigan Israeli Netherland Integrated Smallest Space Analysis. —Примеч. ped.
269
гладкой; тогда возможна ее аппроксимация в функциональной мате-
матической форме. В начале данного раздела мы упоминали полино-
миальные регрессии или гладкие монотонные функции в виде
5-сплайнов. В вычислительных программах обычно заложены сред-
ства для реализации такого выбора. Они должны рассматриваться как
связующие звенья между основными подходами метрического шкали-
рования и общими подходами неметрического шкалирования.
Раздел 17.7 заканчивается замечаниями относительно максималь-
ной размерности, при которой могут работать метрические методы
шкалирования. Было показано, что существуют константы c'i и с2, та-
кие, что простые монотонные преобразования + и (б/^+Сг)12
всегда приводят к точным евклидовым решениям в пространстве раз-
мерности п—2. Можно ли добиться лучших результатов с помощью
монотонного преобразования общего вида?
17.9. МНОГОМЕРНАЯ РАЗВЕРТКА
Многомерная развертка впервые была предложена психологами.
Однако ее приложения в настоящее время широко распространены и
в других областях. Пусть мы имеем таблицу с двумя входами. Ее
строки соответствую! различным людям, а столбцы — деятельности
или опыту этих людей. Для иллюстрации предположим, что столбцы
соответствуют газетам, которые они читают. Для заполнения табли-
цы с двумя входами каждого человека просят проранжировать газеты
по предпочтительности. Результатом многомерной развертки является
совместная ординация, включающая как людей, так и газеты. Газеты
с высоким рангом для данного человека представляются точкой, кото-
рая находится вблизи точки, представляющей этого человека. По по-
становке этот метод похож на биплоты [см. раздел 17.4] и на анализ
соответствий [см. раздел 17.5], но в отличие от них многомерная раз-
вертка позволяет определить расстояния между двумя множествами
точек, которые потом получают непосредственную интерпретацигд. В
своем первоначальном виде совместная ординация была одномерной.
Можно вообразить линию, сложенную (подвешенную) в точке, соот-
ветствующей индивиду, который интересует исследователя. Все точки,
представляющие газеты, должны быть по одну сторону от точки под-
веса и в порядке, соответствующем предпочтениям индивида. По
крайней мере так было бы, если бы была возможна точная ордина-
ция. Точки, представляющие индивидов, называют идеальными точ-
ками. Одномерная совместная ординация очень редко точно отражает
предпочтения всех индивидов. Ординации в пространстве более высо-
кой размерности дают более точное представление.
Один из путей реализации многомерной развертки — применение
стандартных методов неметрического шкалирования. В разделе 17.8
мы обращали внимание на то, что алгоритмы неметрического шкали-
рования могут работать с пропущенными данными. Таблица пред-
270
почтений А размерности т х т может рассматриваться как угол
(л + т7х(л + /и) симметричной матрицы, в которой отсутствуют две
оставшиеся части — симметричные матрицы порядков пхп и тхт.
Отсутствующие матрицы должны были бы отражать неизвестные
связи между индивидами и неизвестные связи между газетами. При
обработке матрицы порядка п + т неметрическое многомерное шкали-
рование позволяет получить ординацию точек, п из которых представ-
ляют строки матрицы А, а т — столбцы. В случае ранговых данных
о предпочтениях мы не имеем прямой информации об упорядочении
индивидов по отношению к каждой газете и поэтому находимся в си-
туации, когда следует вычислять стресс отдельно по строкам, как это
было предложено в разделе 17.8. Чтобы избежать вырожденного ре-
шения с нулевым значением стресса (формула 1) в ситуации, когда все
газеты представляются единственной точкой, следует использовать
стресс-формулу 2. Поскольку данные слабо структурированы, необхо-
димо позаботиться о том, чтобы предотвратить вырожденное реше-
ние, и обратить особое внимание на возможность попадания в недо-
пустимые локальные оптимумы.
Хотя развертка зародилась для данных о предпочтениях, к настоя-
щему времени она обобщена и на количественные данные. В этом слу-
чае элементы строк и столбцов матрицы А измерены в одной системе
и нет необходимости в разбиении критерия по строкам; здесь немет-
рическое многомерное шкалирование «работает» лучше. При коли-
чественных данных подобного типа целесообразно испробовать воз-
можности метрического подхода. Исследуем случай, когда А — часть
матрицы расстояний между точками в пространстве размерности к.
Будем оперировать квадратами расстояний. Матрица D той же раз-
мерности, что и А, но ее элементы могут быть функциями от элемен-
тов матрицы А. Тогда проблема развертки состоит в нахождении
координат Х(их&) и У(тхк), порождающих матрицу D. На данный
момент допустим, что возможно точное отображение. Тогда по теоре-
ме Пифагора
D=EU + UF—2XYr,
где E=diag(XXr), F=diag(YYr), Щих/и) — единичная матрица. Пусть
N = llr/?7 и М = 11г/щ. Тогда
(|-N)(-4-D)(l-M)=XYr.
Совместное преобразование матриц X и Y не влияет на решение, поэ-
тому мы можем предположить, что центр тяжести X находится в на-
чале координат, т. е. NX=0. Предположим, что разложение левой
части по сингулярным значениям записывается в виде GHZ, где Н по-
глощает к ненулевых сингулярных векторов. Тогда GrG = l, X = GT и
(I—N)Y=H(Tr)~', где Т — произвольная невырожденная матрица по-
рядка к. Тогда нетрудно вычислить X и Y с точностью до произволь-
ного преобразования относительно их центров тяжести, пренебрегая
сдвигом одной относительно другой. Умножим первое уравнение сле-
ва на I—N, а справа на 1 и подставим X вместо GT. Получим
(I—N) D1 + G(2TYrl) = т{\—N)diag(GTTrG .
271
Пусть TTr=S — симметричная положительно определенная матрица,
d = Dl/zn — средние матрицы D по строкам, Yrl/zn = y — смещение
центра тяжести Y относительно центра тяжести X. Тогда последнее
уравнение переписывается в виде
(I—N)d+2GTy=(l-N)Cs,
где (GSG^^Cs, s — вектор длины у£(£+1)» содержащий различа-
ющиеся элементы матрицы S(sn, $21, $22, s32, $зз, С —
матрица размерности (пх^к(к+1)), содержащая функции от элемен-
тов матрицы Т, вычисленные для i-й строки матрицы С, i-й строки
(gj) матрицы G и симметричной матрицы gzgzr=Az. Элементы ниж-
него треугольника матрицы 2 Az—diag(Az) в построчном порядке и
есть искомые величины.
Поскольку Grl = 0 и GrG = l, можно упростить уравнение относи-
тельно у:
Y=yT-'Gr(Cs—d),
что после обратной постановки дает
BCs=Bd,
где В = 1—N—GGr — идемпотентная матрица. Уравнение может
быть решено относительно S, оно содержит п линейных соотношений
для определения ^к{к+\) элементов S. Поскольку GrB=0 и 1гВ=0,
не более п—к—1 уравнений независимы. Для нахождения решения не-
обходимо п—к—1^ т- е- п'^\к(к+3). Если это неравенство
не выполняется и т > п, то решение может быть получено транспони-
рованием матрицы D. Если неравенство нарушается и для т, и для п,
то может все же существовать единственное решение, но его нельзя
найти с помощью данного подхода. Когда система уравнений перео-
пределена, решение по методу наименьших квадратов есть
s=(CrBC)-*CrBd,
оно является точным, если, как и предполагалось, существует един-
ственное решение. Оценив вектор S, можно пересчитать матрицу S, и
тогда Т может быть взято в качестве решения для любого разложения
S=TTr. Каждое разложение соответствует определенной совместной
ориентации конфигураций X и Y. Разложение по собственным векто-
рам S=LALr дает T=LA12 и
у= yA-1/2LrGr(Cs—d),
где S определяется из предыдущего уравнения. Наконец, вычисляются
координаты
X=GLA12, Y=HLA-1/2 + lyr.
Описанный выше метод применим для точных данных, и в прин-
ципе ожидается, что он будет эффективен, даже когда точного реше-
ния не существует. Однако здесь появляются затруднения. Во-первых,
D и Dr порождают разные результаты, которые не могут быть не-
272
посредственно соотнесены друг с другом. Во-вторых, матрица S,
определенная описанным выше способом, может не быть положи-
тельно полуопределенной, и к ее наибольших собственных значений
могут не быть положительными. В-третьих, разложение GHr может
не иметь ранга к, и хотя для подтверждения существования аппрокси-
мации ранга к в смысле наименьших квадратов можно привлечь тео-
рему Экарта—Юнга, применение метода наименьших квадратов для
определения S приводит к решению, которое весьма сомнительно и,
конечно, не является решением первоначальной проблемы в смысле
наименьших квадратов. Эти и другие затруднения превращают опи-
санный метод в процедуру, которая в лучшем случае может дать на-
чальное приближение для итеративного процесса.
Одна из таких итеративных схем следует из анализа нормальных
уравнений для шкалирования квадратов расстояний по методу наи-
меньших квадратов [см. раздел 17.7] применительно к развертке. Вве-
дем остаточную матрицу
R = D—EU—UF+2XY7
Тогда в качестве критерия минимизации используют trace (RRr), что
приводит к нормальным уравнениям:
RY=diag(RUr)X,
RrX = diag(RrU)Y.
Прямое решение этих уравнений невозможно, но они могут слу-
жить основой для итеративного процесса, который мы сейчас обсу-
дим. Сначала приведем несколько результатов.
R инвариантна относительно вращений и переносов конфигураций
X и Y. Легко увидеть, что решение нормальных уравнений недоопреде-
лено в этом отношении. В случае точного приближения R=0 обе ча-
сти уравнений также обращаются в нуль. Умножив оба уравнения
слева на 1Г (соответствующей длины), получим
lrRY=lrRrX,
что связывает аппроксимирующие величины и суммы остаточной мат-
рицы по столбцам и строкам. Остаточная сумма квадратов равна
5=Trace(RRr)=Trace(DRr—EURr—UFRr+2XYrR7).
После подстановки результатов решения нормальных уравнений по-
ЛУ“аеМ 5=Trace(RRr)=Trace(DRr),
откуда
Trace(DDr) =Trace(RRr) +Trace(D—R)(D—R)r.
Мы видим, что результат дисперсионного анализа, приведенный в
разделе 17.7 для шкалирования квадратов расстояний полной матри-
цы D по методу наименьших квадратов, справедлив и для прямоу-
гольной матрицы D, используемой в развертке. Заметим, что в
развертке аппроксимирующая сумма квадратов Trace(D— R)(D— R)r в
дальнейшем может быть разбита на компоненты, соответствующие
строкам и столбцам, в обычном для таблиц с двумя входами виде.
273
Нормальные уравнения порождают естественный альтернативный
алгоритм наименьших квадратов для итеративного решения задачи
развертки. Если У известно, то первое уравнение дает оценку для X
при шкалировании квадратов расстояний по методу наименьших ква-
дратов. Эта оценка уменьшает (или по крайней мере не увеличивает)
остаточную сумму квадратов. Аналогично если известна X, то из вто-
рого нормального уравнения можйо получить оценку для Y. Процеду-
ра повторяется до сходимости к удовлетворительному решению. К
сожалению, даже когда Y(X) известна, не всегда просто решается пер-
вое (второе) уравнение относительно Х(У).
Для упрощения первого нормального уравнения допустим, что
центр конфигурации Y находится в начале координат, а оси совпадают
с главными осями, так что — диагональная матрица соб-
ственных значений матрицы YYr. Тогда уравнение переписывается в
виде
(D—UF)Y+2XA = diag[(D—-EU—UF)Ur]X = diag(DUr-mE—(lrFl)l)X.
Если бы Е была известна, то уравнения были бы линейны относи-
тельно элементов матрицы X и были бы легко разрешимы. В действи-
тельности Wjj
Хй'~ тР1)-2Х:—тЕи ’
* 2 7
где W=(D-UF)Y и £•.= Ех.2.-. Заметим, что ни одно из уравнений
7=1 J
относительно к элементов /-й строки матрицы X не включает элемен-
тов других строк. М. Гринакр [см. Greenacre (1978)] предлагает для ре-
шения этих уравнений ввести новую переменную ф:
ф1=mDi, — (1 rFl)—mEih
тогда w
XU= 4>r-2Xj ’
Подстановка x/z- в формулу для 0Z дает
к W--
Ф;=с—т Е ______2___,
1 ‘ >=1 (^—2X^)2
где c^mDj.—lrFl. Это выражение — полином от ф, степени 2£+1.
Следовательно, он имеет хотя бы один действительный корень. Про-
блема в том, как найти наилучшее решение этого полинома. В задачах
такого типа обычно наименьший корень ф0 должен соответствовать
минимальной остаточной сумме квадратов [см., например, косоуголь-
ный прокрустов анализ в разделе 17.10]. М. Гринакр отмечает, что он
не встречал примеров, когда ф0 не было бы оптимальным корнем, но
нет доказательств того, что он всегда оптимален. Поэтому необходи-
мо исследовать все действительные решения полинома, хотя, конечно,
допустимо редуцирование этого процесса. Например,
0о^2Хь 2Xi^0i, Фг ^2Хг; 2X2 ^0з, 04 ^2Хз и т. д.,
и тогда нет действительного корня, превосходящего по величине с,.
Эти простые правила, ограничивающие действительные корни поли-
нома, допускают применение аппроксимационных методов, таких, как
метод Ньютона для решения полиномиальных уравнений или метод
деления пополам. Более тонкие правила приводят к более экономным
процедурам.
274
Для каждого возможного ф;- необходимо вычислить остаточную
сумму квадратов. Мы имеем
S=Trace(RrR)=Tr(DrR—UrER—FUrR + 2YXrR),
но из первого нормального уравнения Trace(XXrP)=Trace(UrER), откуда
S=Trace(DrR + UrER—FUrR) =
=Trace(D7+U7E—FU7)(D—EU—UF-bXYr).
Выделим члены, содержащие X:
S’=Trace(2WrX—UrE2U) + члены, не содержащие Х,=
п
-2 'LwaX;;- -т Е EjjA члены, не содержащие X.
I, j ‘
Подставив значение х^ в точке минимума, получим
W- / W-- \j
S=2 Е ф;_12х'.—т у + члены, не содержащие Х,=
w-2- П
= 2 Е.ф " + + члены, не содержащие X.
Составляющая, соответствующая z-й строке матрицы D и включаю-
щая ф.-, равна . ,
1 * W А
Это дает простой способ оценки ф, с целью получения минимального
значения S,.
С помощью таких методов для каждой строки матрицы D можно
найти оптимальное значение ф;, а следовательно, и определить мат-
рицу X. Центрируя эту новую матрицу X и поворачивая координатные
оси до положения главных осей конфигурации X, представляем X в ви-
де, подобном описанному выше при получении новой оценки для Y, и
так далее до тех пор, пока не будет достигнута удовлетворительная
сходимость. Определенный прогресс в этом направлении уже достиг-
нут, но еще нельзя считать, что существует полностью приемлемый
метрический алгоритм для решения задачи многомерной развертки.
Необходимы дальнейшие усилия.
Проблема развертки для симметричной матрицы не получила
должного внимания. Например, если D — матрица расстояний с нуле-
выми диагональными элементами, то ее развертка задается обычной
ординацией, при которой точки, представляющие строки и столбцы,
попарно совпадают. Однако если мы согласны не принимать во вни-
мание диагональные значения, то можно использовать неметрические
алгоритмы шкалирования. Обсудим некоторые интересные результа-
ты. Например, рассмотрим регулярный симплекс с п вершинами и
ребром d. Для него все элементы матрицы D равны, за исключением
нулевых диагональных элементов. Если мы не принимаем во внимание
диагональ, то развертка матрицы D будет просто множеством совпада-
ющих точек, представляющих столбцы (скажем, точка R), и множе-
ством совпадающих точек, представляющих строки (скажем, точка Q;
275
расстояние между R и С равно d. Такое представление в точности од-
номерно. Оно вступает в резкое противоречие с л—1-мерной конфигу-
рацией, необходимой для представления регулярного симплекса в
обычных ординациях. Симметричная развертка предлагает способ по-
нижения размерности за счет отказа от представления каждой точки
дважды; один раз в качестве точки-строки, а другой — в качестве точ-
ки-столбца.
Полезно рассмотреть способы представления симметричной мат-
рицы, предлагаемые в развертке. В введенных ранее обозначениях
D= D , т. е.
’ EU + UF—2XYr=UE+FU—2YX7.
Записав 2G = E—F и переставив члены, получим
GU—UG = XYr—YX7
Записав g = diag(G)lr, получим
gl7—lgr=XYr—YXr.
Кососимметричная матрица в правой части имеет ранг 2. Мы не про-
водили детальный анализ того, что же порождает такое условие,
однако представляют интерес некоторые специальные решения. Одно
очевидное решение получаем при Y=X, тогда д = 0. Существует ли
решение Y=XH для ортогональной матрицы Н? Из этого условия сле-
дует, что д = 0 и Х(НГ— Н)ХГ=О, поэтому если X имеет ранг, равный
количеству столбцов, то Н = НГ. Симметричными ортогональными
матрицами являются диагональные матрицы с элементами ± 1, кото-
рые соответствуют различным отражениям относительно координат-
ных осей (или относительно начала координат). Тогда преобразование
Хаусхолдера дает Н = 1—2uur, где к — единичный вектор. Такое ре-
шение представляет отражение относительно гиперплоскости с нор-
малью к [см. III, раздел 4.10]. Существуют более сложные решения.
Например, если Y=XS, где S — симметричная матрица, то правая
часть уравнения обращается в нуль, а левая дает gj = k, т. е. констан-
ту. Тогда diagX(l—S2)X7"=A;I, и конфигурация X лежит на конусе об-
щего вида, задаваемого квадратичной формой хг(1—S2)x = k.
Конфигурация Y лежит на конусе, задаваемой квадратичной формой
yr(S-2—l)y = k. Эти два конуса опираются на одни и те же главные
оси. Когда D симметрична, кажется, что расстояния между точками-
строками и расстояния между точками-столбцами должны совпадать.
Однако последний пример показывает, что это вовсе не обязательно.
Как и в случае общей ординации, двумерное решение задачи раз-
вертки представляет особый интерес. Кроме двумерных решений су-
ществуют другие очевидные варианты. Например, точки-строки могут
располагаться на окружности, а точки-столбцы — на концентрической
окружности; соответствующие точки должны лежать на общем радиу-
се. Специальный случай такого представления — два множества точек
на двух параллельных прямых, или мы можем рассматривать три
равноудаленные параллельные прямые: центральная, скажем, содер-
жит точки-строки и точки-столбцы, спроецированные с двух сторон.
Хотя эти решения являются регулярными в определенном геометриче-
ском смысле, принцип расположения двух множеств точек относитель-
но друг друга не совсем ясен.
276
Интерпретация двумерной симметричной развертки пока не до
конца осмыслена, но некоторые эмпирические правила можно сформу-
лировать:
а) если развертка дает пары совпадающих точек, то вероятно, что
исходные расстояния соответствуют конфигурации, близкой к дву-
мерной;
б) если результатом является отраженная развертка, то вероятно,
что исходные расстояния соответствуют конфигурации высокой раз-
мерности;
в) если обнаружены отражения относительно пар осей, то скорее
всего это означает, что выборочные расстояния соответствуют конфи-
гурациям в двух отдельных подпространствах.
Возможности этих методов еще мало освоены, и, по-видимому, они
эффективнее, когда размерность выборки либо очень мала, либо очень
высока. При средней размерности удобно удвоить размерность матри-
цы D, повторив каждый ее элемент, не обращая внимание на диаго-
нальные значения. Тогда каждая выборка представляется двумя
строками и двумя столбцами. Развертка такой матрицьглает четыре
точки для каждой выборки. Процесс может быть продолжен с целью
получения компромиссного решения относительно размерности, необ-
ходимой для хорошего представления, и количества точек в ординации.
17.10. ОРТОГОНАЛЬНЫЙ ПРОКРУСТОВ АНАЛИЗ
В предыдущих разделах рассматривалась проблема поиска расстоя-
ний бу, аппроксимирующих наблюдения dy путем оптимизации крите-
рия качества отображения, подобного используемому при шкалирова-
нии по методу наименьших квадратов. При таком критерии предпола-
гается сравнение аппроксимирующего множества координат X и мно-
жества координат Y (если таковое существует), порождающих наблю-
даемые расстояния. Проблема сравнения двух матриц X и Y, где стро-
ки соответствуют одним и тем же выборкам или совокупностям, до-
статочно общая. Например, X и Y могут быть результатами двух
разных ординаций для одних и тех же данных или же результатами
применения одного метода ординации к двум множествам данных, от-
носящимся к одним и тем же п объектам. Как произвести такое срав-
нение? Обозначим через 6;. и &у расстояния, порожденные координа-
тами X и Y. Ясно, что/1(5, 8) = Е(5/у—8^)2 и/2(5, 8) = Е(5-—8?-)2 — под-
ходящие критерии для сравнения двух множеств. Они инвариантны
относительно переносов и ортогональных преобразований конфигура-
ций X и Y, что, очевидно, является необходимым условием для любого
разумного критерия. Почти отсутствуют данные о том, какие значе-
ния / и /2 означают хорошее и какие плохое приближение, хотя могут
представлять интерес относительные величины / 2(d, 5), / 2(</ 2)
и / 2(5, 8). Имеет смысл нарисовать график, отложив по одной оси
ду, а по другой — &у. Линейное соотношение означает хорошую со-
гласованность двух конфигураций. По криволинейному соотношению
можно выделить участки, где расстояния в одной из конфигураций
увеличены или, наоборот, уменьшены по сравнению с другой.
277
Другой вариант — соотнести координаты, задаваемые матрицами
X и Y, с их главными осями. Такая возможность должна быть преду-
смотрена во всех вычислительных программах, реализующих ордина-
ции, поскольку это облегчает сравнение r-мерной и (г-И)-мерной
ординаций. Без повррота к главным осям /-я ось r-мерного представ-
ления не может быть соотнесена с z-й осью 5-мерного представления,
и тогда трудно оценить эффект добавления или исклюДения одной
оси. Например, если исключенная ось вносила существенный вклад в
качество отображения, то этот эффект мог быть за счет одной или
двух точек, что легко обнаружить на главных компонентах.
В крайнем случае X и Y могут быть двумя представлениями одной
и той же конфигурации и может казаться, что они никак не соотносят-
ся друг с другом. Тогда естествен вопрос: можно ли подобрать такие
оси и такое начало координат для конфигурации X, чтобы она совпа-
дала или была похожа на Y? Для этого необходимы ортогональная
матрица Н (соответствующая поворотам осей и отражению) и вектор-
строка m (соответствующая переносу начала координат), такие, что
ХН + 1ГП аппроксимирует Y. Критерий для измерения степени соответ-
ствия должен быть инвариантен относительно совместных поворотов
и переносов двух конфигураций. В этом смысле удобно использовать
комбинацию расстояний из конфигураций Y и ХН + lm. Критерий в ви-
де суммы квадратов соответствует нашим целям и приводит к алге-
браическим вычислениям. Итак, мы хотим отыскать Нит,
минимизирующие
/3(6, 8) =Trace(Y—ХН—lm)r(Y—НХ- 1т).
Без потери общности можно предположить, что центры тяжести
конфигураций X и Y совпадают с началом координат. Тогда
/3 =Trace(Y—XH)r(Y—ХН) + nLm],
и возможно разделение эффектов переноса и вращения. При переносе
/з минимизируется при условии т^О для всех осей, т. е. перенос осу-
ществляется таким образом, чтобы обеспечить совпадение центров
тяжести для конфигураций X и Y, в данном случае в начале координат.
Минимизация /3 по Н эквивалентна максимизации Trace(YrXH). Запи-
сав разложение по сингулярным значениям YrX = UFVr, получим
Trace(YrXH) =Trace(UTVrH) =Trace(FVrHU).
VrHU = Q — ортогональная матрица. Следовательно,
Trace(YrXH) = E7ztf/7,
где ненулевые сингулярные значения положительны и —1 Qu 1.
Верхняя граница Е77 достигается при Яц=Л для всех /, когда Q = l —
ортогональная матрица, соответствующая H = VUr, которая задает
необходимое преобразование. Остаточная сумма квадратов
/3(<5, 8) =Trace(XrX) +Trace(YrY)—2ТгасеГ.
278
Ранее ничего не говорилось о размерности (количестве столбцов)
матриц X и Y, но неявно предполагалось, что U и V ортогональны и
коммутативны. Это соответствует предположению, что YrX — квад-
ратная, а следовательно, X и Y содержат одинаковое количество
столбцов. Если в действительности это не так, то к меньшей матрице
можно добавить нулевые столбцы, чтобы вращение Н производилось
в пространстве более высокой размерности. В этом случае некоторые
сингулярные значения у, обратятся в нуль, и соответствующие значе-
ния <7/z- потеряют смысл. Найденное решение оптимально, но не един-
ственно. Другие оптимальные решения соответствуют произвольным
поворотам в пространстве, ортогональном меньшему пространству. В
разделе 17.11 обсуждается проблема подгонки X и Y для случая, когда
Y меньшей размерности, чем X.
Задачу минимизации /3(-) называют ортогональной прокрустовой
задачей. Герой греческой мифологии Прокруст, владелец гостиницы,
подгонял рост постояльцев под свою постель, вытягивая или обрубая
им конечности. Здесь мы подгоняем X к Y. Преимущество подхода в
том, что полученная после поворота и переноса конфигурации ХН мо-
жет быть изображена вместе с Y. Если конфигурации совпадают, то
два множества точек должны совпадать, и обратно: позиции пар по-
хожих точек относительно друг друга указывают на согласованность
или на расхождения между двумя ординациями или двумя решениями
многомерного шкалирования.
Следует иметь в виду, что одна из двух конфигураций X или Y мо-
жет быть по размеру больше, чем другая. Наиболее простой способ
для преодоления этого затруднения — нормализовать X и Y так, что-
бы Trace(XrX)=Trace(YrY). Или можно подобрать масштабный мно-
житель, минимизируя
Trace(Y— eXH)r(Y-eXH).
Н оценивается так же, как и в предыдущем случае, и простое диффе-
ренцирование приводит к оценке р для величины @:
q = Trace(XHYr) = Тгасе(Г) .
Тгасе(ХгХ) Тгасе(ХЛХ)
Суммы квадратов связаны соотношением
Trace(YrY) = e2Trace(XrX) +Trace(Y-pXH)7'(Y-pXH),
откуда видно, что скорректированная сумма квадратов для координат
Y равна скорректированной сумме квадратов для аппроксимирующих
значений рХН плюс остаточная сумма квадратов. Это может быть по-
ложено в основу ортогонального разложения в дисперсионном анализе.
Поскольку /з(-) инвариантна относительно совместных вращений X
и Y, то повернув X с использованием матрицы Н так, чтобы она ап-
проксимировала Y, можно применить обратное преобразование Нг к
обеим конфигурациям. Тогда X восстанавливается в первоначальное со-
стояние, a Y преобразуется в YHr. Если Н приводит матрицу X в
оптимальное соответствие с матрицей Y, то Нг приводит матрицу Y в
оптимальное соответствие с матрицей X, и в обоих случаях /3(-) прини-
мает одно и то же значение, скажем, т^у. Тогда mXY симметричны:
"?.¥У=/з(<5, 8)=/з(8, =
279
Очевидно, что тхх=0 (идеальное приближение) и, легко показать,
что mXY удовлетворяет метрическому неравенству, т. е. для любых
трех конфигураций X, Y и Z mXY^mxz + mYZ. Хотя mXY удовлетворя-
ет метрической аксиоматике, можно показать, что в общем случае эта
метрика не является евклидовой, за исключением специальных набо-
ров данных.
Если введен параметр q, то перестает быть справедливым равен-
ство mXY=mYX, и тогда mXY не удовлетворяет метрической аксиома-
тике. Такая асимметрия очень неудобна, и один из путей ее преодоле-
ния рассматривается в разделе 17.12 как специальный случай общего
прокрустова анализа.
Обычная цель прокрустова анализа — изучить соотношения между
двумя конфигурациями. Иногда большее внимание уделяется значе-
нию критерия /3(6, 8). Один из таких случаев описан в разделе 17.12.
Э. Дейвис [см. Davies (1978)] предложил асимптотическое среднее и
дисперсию этого критерия для случая, когда <5zy и 8,у — множества
расстояний Махаланобиса, основанных на п порождающих мульти-
нормальных распределениях. Р. Сибсон [см. Sibson (1979)] исследовал
робастность классических методов шкалирования; он налагал возму-
щения на квадраты расстояний dy, вычисленных между точками в
r-мерной конфигурации Y, и, используя классические методы шкалиро-
вания для обработки новых значений dy+&fy, получал конфигурацию
X в r-мерном пространстве. Эти две конфигурации можно сравнивать
с помощью прокрустова анализа, который дает:
1 (e'FeJ2
ли2 = 4-82Е __к + члены, содержащие 83, и высших порядков,
у Hj-*k
где еу — у-й собственный вектор, а ру — у-е собственное значение мат-
рицы Mq, введенной в разделе 17.6. Суммирование производится по
всем различающимся парам у, к^г. Если отсутствует член, линейный
по 8, то это означает, что классическое шкалирование — достаточно
робастный метод.
17.11. ОБЩЕЕ СРАВНЕНИЕ МЕТОДОВ ШКАЛИРОВАНИЯ
Эта тема была начата в разделе 17.10, мы обсудили ортогональ-
ный прокрустов анализ. Критерий /3 записывался в виде ||Y—ХН1|, где
Н — ортогональная матрица, a ||Z|| — обозначение для Trace(Z'Z). В
данном разделе обсуждаются другие критерии того же общего вида,
однако Н заменена на матрицу, содержащую различного рода ограни-
чения. Если мы откажемся от ортогональных матриц, то свойства
расстояний после преобразования не сохранятся, и тогда интерес бу-
дут представлять сами координатные матрицы. Чтобы подчеркнуть
это, возьмем обозначение /(X, Y). Z может интерпретироваться как
матрица остатков. Если допустим сдвиг конфигурации X, то X и Y
должны быть преобразованы так, чтобы их центры тяжести совпада-
ли. Удобнее, чтобы это было начало координат, как в ортогональном
прокрустовом анализе.
280
Первый такой критерий был исследован Дж. Хели и Р. Кателлом
[см. Hurley and Cattel (1962)]. Они требовали, чтобы С минимизировала
/з(У, Х)= IIY-ХСЦ.
Именно эти авторы ввели термин прокрустов анализ. Решение оты-
скивается в виде C = (XrX)-1XrY: результат в действительности очень
близок к результату классической множественной регрессии.
Интерес к критериям такого типа возник в факторном анализе, и
имеется обширная литература, освещающая возможности преобразо-
вания факторных нагрузок (которые могут быть записаны как множе-
ство координат) в более простую структуру. Р. Кателл и Д. Кхана
[см. Cattel and Khanna (1977)] недавно опубликовали обзор, а Тен Берж
[см. ten Berge (1977)] представил всесторонний отчет, где произвел
таксономию таких процедур, классифицируя их в 36 типов (к счастью,
маловероятно, что многие из них могут иметь приложения).
Критерий /4(-) не налагает ограничений на С, за исключением, ко-
нечно, того, что ее размерность должна соответствовать размерно-
стям Y(flxr) и X(zixs), т. е. С должна быть размерности (sxr).
М. Браун [см. Browne (1967)] обсуждает задачу косоугольного про-
крустова анализа, которая состоит в отыскании С, минимизирующей
/5(Y, Х)= ||Y-ХСЦ,
Рис. 17.11.1. Точка Р имеет ко-
ординаты (х,, х2, х3) по ортого-
нальным осям (i„ i2, i3) и
координаты (и,, и2) по косоу-
гольным осям с направляю-
щими косинусами с, и с2 (от-
носительно ортогональных
осей). Величины Uj и и2 изме-
ряются как расстояния точ-
ки Р от косоугольных осей.
Два множества координат
связаны соотношением и=хС,
где (в данном случае) С —
матрица размерности 3x2, ее
столбцы — направляющие
косинусы Cj и с2 и, следова-
тельно, diag (CrC) = l
где на С наложено ограничение: она должна удовлетворять соотноше-
нию (CrC) = l. Это ограничение означает, что ьй столбец матрицы С
может рассматриваться как направляющие косинусы z-й из г осей по
отношению к 5 ортогональным осям. Строки X задают координаты п
точек относительно ортогональных осей, а ХС — проекции этих точек
на г осей, которые в общем случае будут под углом одна к другой.
281
Критерий /5(-) подразумевает, что направления косоугольных осей
должны быть выбраны таким образом, чтобы проекции были как
можно ближе в смысле наименьших квадратов к значениям, заданным
в целевой матрице У. Геометрическая иллюстрация приведена на рис.
17.11.1, где показано, как точка в пространстве размерности s=2 про-
ецируется на косоугольные оси в пространстве размерности г=3. Поз-
же станет ясно, что критерий /5(-) не является суммой квадратов
расстояний между положениями точек в заданной и преобразованной
конфигурациях в косоугольном пространстве. Критерий У8(*)» который
мы рассмотрим далее, предназначен именно для такой ситуации.
Заметим сначала, что мы можем минимизировать /5(-) относитель-
но с,, z-го столбца матрицы С, независимо от других столбцов. Это
означает, что мы подгоняем У,-, z-й столбец матрицы У, к Хс, при ус-
ловии cfc/=l; при этом другие столбцы матрицы С могут во внима-
ние не приниматься. Введем обозначение у для У, и с для С/. Тогда
мы должны минимизировать ||у—Хс||, что то же самое, что максими-
зировать 2угХс—сгХгХс при условии сгс=1. Дифференцирование по
с и использование множителя Лагранжа Х(сгс—1) приводят к соот-
ношению
(ХГХ—Х1)с=Хту,
так, что условие сгс=1, приводит к полиному относительно X:
угХ(ХгХ—Х1)-2Хгу= 1.
Для упрощения полинома выразим ХГХ через разложение по собст-
венным векторам ХгХ = ОгдО (Q — ортогональная, ад — диагональ-
ная). При подстановке в предыдущее уравнение получаем
yrXQr(g—XI)-2QXry=l.
Обозначим известный вектор QXry через Z, тогда полином преобра-
зуется в
„2
Е _______ =1
<=1 ц—хр '•
Это полином степени 2г, а следовательно, он имеет 2г корня. Для лю-
бого корня X, остаточная сумма квадратов равна
Г „1
е;=УТУ+Х;— Е _____Ь___
7 7 '=1 (Я/—Ху)
Следовательно, если е,- и ек — остаточные суммы квадратов, соответ-
ствующие двум корням, то
7 к 7 Z=1 (д.-хрц-xpj
Обозначив z/Oif—Xj) = u/ и Хк) = vb получим Eu? = Ev? = l, а из
неравенства Коши
Е-------.у. 1
zi
282
Таким образом, из Ху<Х^ следует ej<ek. Это означает, что для мини-
мума /5(-) необходим наименьший корень полинома. М. Браун (см.
Browne (1967)] показал, что наименьший корень Хо удовлетворяет усло-
вию Хо < Д1, где Д1 — наименьшее собственное значение матрицы ХГХ,
и для решения полиномиального уравнения рекомендовал итератив-
ный метод Ньютона—Рафсона. Э. Крамер [см. Cramer (1974)] предла-
гает альтернативный подход и обсуждает проблему неединственности
минимального корня. Тен Берж и Невелс [см. ten Berge and Nevels
(1977)] разработали процедуру получения решения в такой ситуации.
Если возможно оценить нижнюю границу для Хо, то можно приме-
нить метод деления пополам для его определения. Этот метод вполне
удовлетворителен, если использовать следующую нижнюю границу.
Пусть z=max(z,) и Х = /4,— z/r. Тогда
r z2 Z~
V ___Л___ 1 _ V 1_______
i~\ (nj-^ + z/ry
zi
rz-
Следовательно, X0>/*i—z/r дает необходимую нижнюю границу.
Специальный случай косоугольной прокрустовой задачи, рассмот-
ренный Брауном, состоит в минимизации /6(У, Х)= ||У—ХС|| с ортонор-
мированной матрицей С. Тогда СС = | и оси, которые ранее
допускались косоугольными, теперь должны быть ортогональными.
Если конфигурации У и X r-мерны, а С — ортогональная матрица, то
мы приходим к ортогональной прокрустовой задаче, которая обсужда-
лась и решалась в разделе 17.10. Проблема остается нерешенной толь-
ко для случая, когда матрица У имеет размерность (пхг), а матрица
X — размерность (их$). Тогда С имеет размерность ($хг) и предпола-
гается s>r. Даже при s>r ортонормированную оценку критерия /6(-)
лучше заменить поворотом У в пространстве X более высокой размер-
ности, что совсем тривиально сделать, добавив $—г нулевых столбцов
в матрицу У и использовав методы из раздела 17.10. Б. Грин и Дж.
Говер [см. Green and Gower (1981)] обсуждают ситуацию, когда необ-
хрдим именно критерий /6(-). Геометрически критерий /6(-) означает,
что сначала X проецируется ортогонально в пространство меньшей
размерности г, а затем эта проекция поворачивается так, чтобы лучше
соответствовать матрице У. Альтернативный подход — сначала по-
вернуть матрицу У в пространстве более высокой размерности, а за-
тем осуществить проецирование в пространстве более низкой
размерности. При г=1 задача идентична косоугольной прокрустовой
задаче, поэтому не удивительно, что она сводится к решению похоже-
го уравнения
Х7ХС-СЛХ7У.
где Л — симметричная матрица множителей Лагранжа размерности
(гхг). Ранее Л рассматривалась как скаляр, а уравнение СЛ = ЛС допу-
скало для С явное решение через X и, следовательно, определенно при-
водило к практическому решению. В данной ситуации это стало
невозможно. Однако уравнение все же остается линейным относитель-
но элементов матрицы Сив принципе может иметь решение. Условие
ортонормированности СС = 1 приводит к уг(г+1) полиномиальным
уравнениям относительно -уг(г+1) элементов матрицы Л.
283
Решение системы полиномиальных уравнений — сложная вычисли-
тельная проблема. Она осложняется еще и тем, что не известно, какое
множество корней соответствует минимальной сумме квадратов кри-
терия /6(-). Так что такой подход не применим на практике. Б. Грин
и Дж. Говер [см. Green and Gower (1981)] предложили итеративный
алгоритм, который должен хорошо работать на практике, хотя авто-
рам не удалось показать, что он должен сходиться к глобальному ми-
нимуму. Алгоритм состоит в следующем:
1) добавить s—г нулевых или произвольных столбцов к матрице Y;
2) использовать ортогональную прокрустову процедуру для по-
строения X, соответствующей новой Y;
3) заменить последние s—г столбцов матрицы Y на соответствую-
щие столбцы повернутой матрицы X и повторить шаг 2.
В результате такого процесса /6(-) уменьшается на каждом шаге и
решение должно сходиться к оптимуму. Последние 5—г столбцов мат-
риц Y и X согласованы и ничего не вносят в /6(-), поэтому необходимы
только первые г столбцов полной ортогональной матрицы, которые и
дают оценку для ортонормированной матрицы.
Интересная связь между ортогональной и косоугольной прокрусто-
вой задачами следует из записи разложения по собственным векторам
в виде Л = ОДСГ. Тогда основное уравнение может быть записано
так:
XrX(CQ)—(CQ)A = XrYQ.
Отсюда следует, что если бы Q была известна, то /-й столбец орто-
нормированной матрицы CQ и /-й диагональный элемент матрицы
Д, давали бы косоугольное прокрустово решение X, соответствующее
Yqz. Таким образом, существует матрица ортогонального вращения
Q, поворачивающая Y в пространстве меньшей размерности (что не
вносит реальных изменений в задачу) до положения, в котором реше-
нием косоугольной прокрустовой задачи является ортонормированная
матрица, способная также минимизировать критерий /6(-). Попытки
разработать итеративный алгоритм поиска матрицы Q, минимизиру-
ющей ffk), не увенчались успехом.
На рис. 17.11.1 показано, как координаты точки относительно ко-
соугольных осей могут быть выражены через кратчайшие расстояния
этой точки до осей. Это один из способов работы с косоугольными
осями, но он не является обычным. Обычный способ представлен на
рис. 17.11.2: координатные значения вычисляются не ортогональным,
а параллельным проецированием точки на косоугольные оси. Если ко-
соугольные оси ортогональны, то оба подхода эквивалентны обычной
декартовой системе координат. При проекционном подходе координа-
ты относительно косоугольных осей и связаны с координатами отно-
сительно ортогональных осей соотношением
и=хС,
а при параллельном подходе — соотношением
x=vCr.
284
Рис. 17.11.2. Точка Р имеет ко-
ординаты {xlt х2) по ортого-
нальным осям (h, 12) и коорди-
наты (v„ v2) по косоугольным
осям с направляющими коси-
нусами ct и с2. Два множества
координат связаны соотноше-
нием x=vCr
Следовательно, соотношение
связывает два типа косоугольных представлений. Расстояние dy меж-
ду двумя точками с координатами х,, ху- вычисляется по формуле
d}j=(\— Xj)T,
следовательно,
£?? = (v/-vy)CrC(v/-vy)r=(u/—uy)(CrC)-4u—uy)T.
Предполагается, что СГС — невырожденная. При этом, в частности,
подразумевается, что как и ранее для косоугольного прокрустова
анализа. Симметричная матрица СТС задает косинусы углов между
всеми парами косоугольных осей, и, следовательно, ее диагональные
элементы равны единице.
Из изложенного ясно, что для минимизации сумм квадратов оста-
точных расстояний между целевой матрицей У, строки которой соот-
ветствуют косоугольным осям «проекционной» системы координат, и
матрицей X, приведенной к этой координатной системе, необходимо
минимизировать критерий
/7(У, X)=Trace(Y—XC)(CrC)-1(Y—ХС)Г.
Такой вариант брауновской задачи; кажется, еще не изучался. Если
С ортонормирована, то критерий */7(-) сводится к/6(-). Если С — ква-
дратная и невырожденная, то критерий сводится к |УС-1—Х| и зада-
ча очень напоминает ту, которую обсуждает Дж. Грювиус [см.
Gruvaeus (1979)], за исключением того, что он накладывает ограниче-
ние diag (ССГ)=1 вместо diag(CrC) = l. Соответствующая задача для
«параллельной» координатной системы сводится к минимизации
Л(У, Х)=Тгасе(У—ХСГ~1)СГС(У—ХС7'”1)7’.
Такую проблему обсуждают М. Браун и У. Кристоф [см. Browne and
Kristof (1969)]. Критерии подобного типа обычно рассматриваются в
контексте факторного вращения, и они имеют очень слабое отношение
к сравнению методов многомерного шкалирования. Для минимизации
критерия /8(*) и, вероятно, критерия /7(-) нужны итеративные процедуры.
285
Матрицы весов (СгС)-‘ и (СГС) могут быть заменены на другие
типы весовых коэффициентов, которые часто соотносятся с моделя-
ми, постулирующими неодинаковые остаточные дисперсии. Р. Лисиц,
II. Шонеман и Дж. Линго [см. Lissitz, Schonemann and Lingoes (1967)]
рассматривают взвешенный ортогональный прокрустов критерий
Tr(Y—XH)D2(Y—ХН)7 и Tr(Y—• XH)rD2(Y— ХН), который должен мини-
мизироваться при условии ортогональности матрицы Н для заданной
матрицы D. Заметим, что в произведении множители не являются
коммутативными, как это было при отсутствии весовых коэффициен-
тов. Вторая задача тривиальна, поскольку D известна, и, следователь-
но, Y и X могут быть заменены на DY и DX, поэтому мы можем
использовать предыдущую процедуру. Первая задача более сложная и
приводит к уравнениям, очень похожим на те, которые выведены
Б. Грином и Дж. Говером [см. Green and Gower (1981)]. Р. Лисиц и его
соавторы отмечают, что трудности исчезают, если заменить требова-
ние ортогональности Н требованием ортогональности HD. Но это ед-
ва ли решает первоначальную проблему.
Проблема, которая предположительно может встретиться в кон-
тексте многомерного шкалирования, связана с тем, что Y и X могут
относиться к одним и тем же (или похожим) объектам, но представ-
ленным в разных порядках. Следует попытаться найти матрицу пере-
становок Р, которая переставляет сроки матрицы X так, чтобы их
порядок соответствовал порядку строк в матрице Y. Тогда следует
минимизировать Л(У> Х)Чу_рХ|.
Матрица перестановок — специальная ортогональная матрица с нуле-
выми и единичными элементами. В каждой строке и каждом столбце
стоит одна и только одна единица. Максимизация критерия /9(-) экви-
валентна максимизации Trace(PXYr), которая является линейной
функцией от элементов матрицы Р. Матрица перестановок представля-
ет собой специальный случай дважды стохастической матрицы, содер-
жащей неотрицательные элементы с единичными суммами по строкам
и столбцам. Тогда можно рассматривать следующую задачу: макси-
мизировать Trace(PXYr) при ограниченных
•I
Таким образом, нужно максимизировать линейную функцию с линей-
ными ограничениями, а это задача линейного программирования.
Максимум достигается в вершине допустимой области, задаваемой
ограничениями. Эти вершины должны соответствовать матрицам пе-
рестановок и давать требуемое решение.
На практике, кроме матрицы перестановок, вводят еще и ортого-
нальное вращение. Тогда можно минимизировать
/10(Y, X) = ||Y—РХН ||,
286
/12(Y, Х)= IIY—TyXS||,
что эквивалентно максимизации Тгасе(РХНуг). Способ решения такой
задачи неизвестен. Возможно, здесь окажется применимой итератив-
ная процедура, сначала при фиксированном Р определяется Н, как в
разделе 17.10, затем при фиксированном Н определяется Р с помощью
линейного программирования и процесс повторяется до сходимости.
Каждый шаг итерации уменьшает значение критерия /ю(-), так что
сходимость обеспечена, но не обязательно к глобальному оптимуму.
Двусторонние прокрустовы задачи также обсуждаются в литерату-
ре. Их связь с многомерным шкалированием очень туманна. Основ-
ные результаты представляют интерес, поскольку они связаны с
проблемой перестановок, которая была нами затронута. Наиболее
простая задача такого типа — минимизировать
/И(У,Х)= ||Y-TyXT||,
где Y и X симметричны, а Т ортогональна. П. Шонеман [см. Schone-
mann (1968)] показал, что если Y имеет разложение по собственным
векторам в виде UrAyU, а X в виде VrAxV, то оценка для Т имеет
вид VrU. Тогда Y=UrAyU приближается IHA^U. Оси двух конфигу-
раций совмещаются, но разбросы по осям не изменяются. Введение
масштабного множителя q могло бы привести к изменению масштаба
по осям для матрицы X, тогда она была бы сопоставима с матрицей
Y. Общая двухсторонняя прокрустова задача, которую рассматривает
П. Шонеман [см. Schonemann (1968)], более сложна. Необходимо ми-
нимизировать
где Y и X квадратные, а Т и S ортогональные. Разложения по сингу-
лярным значениям 1
Y=PTyQr и X=UT*Vy
приводят к аппроксимации матрицы Y с помощью метода наимень-
ших квадратов матрицей PTxQr, т. е. с S=VQr и T=UPr. Осложне-
ние состоит в том, что элементы матриц Гу и Гх допускают любые
перестановки и произвольный знак. При параллельных изменениях в
ортогональных матрицах эти разложения инвариантны. Существует
множество возможных ортогональных матриц Т и S, минимизирую-
щих /12(9» но все они дают одно и то же приближение для Y.
Связь между проблемой перестановок и двухсторонней прокрусто-
вой задачей становится понятной после анализа выражений для /ю(-)
и /1г(-)- Единственная разница в том, что Т — ортогональная матрица
общего вида, а Р — матрица перестановок, т. е. специальный случай
ортогональной матрицы. Это приводит к приближенной неитератив-
ной процедуре минимизации /10(-):
а) найти Т по методу Шонемана [см. Schonemann];
б) взять в качестве Р ближайшую к Гг матрицу перестановок.
Шаг б) эквивалентен минимизации ||ТГ—Р1|, ее можно осущест-
вить, положив Y=Tr и Х=1 в /9(«) и используя решение, полученное с
помощью линейного программирования.
Что касается критериев J^(Y, X), рассматриваемых в данном разделе,
то при р=4, 5, 8, 11 и 12 они имеют аналитические решения, в осталь-
ных же случаях приходится полагаться на итеративные алгоритмы.
287
17.12. ШКАЛИРОВАНИЕ МАТРИЦ С ТРЕМЯ ВХОДАМИ
Пусть данные представлены в виде т матриц расстояний Db
D2,...,DW, каждая порядка п. Обозначим через dyk расстояние между
z-м и у-м объектами в к-й матрице. Мы ввели в рассмотрение третий
индекс. Методы многомерного шкалирования для таких данных назы-
вают трехиндексным шкалированием или шкалированием матриц с
тремя входами. Предполагается, что строки и столбцы всех матриц
соотносятся с одними и теми же объектами, и цель обсуждаемых в
данном разделе методов состоит в том, чтобы оценить, в какой мере
разные матрицы согласуются друг с другом. Обычно индекс к соотно-
сится с индивидами или разными методами анализа.
Как и в предыдущих разделах, мы располагаем двумя возможно-
стями: использовать матрицы или координаты Х^, порождаемые
ординацией матриц D^.. В дальнейшем мы рассмотрим оба подхода.
Из контекста будет ясно, какой из них доминирует.
Очевидный подход состоит в применении одного из методов, рас-
смотренных в разделе 17.11 для сравнения -^т(т—1) пар матриц,
формирующих матрицу М порядка т. Ее элементы являются остаточ-
ными суммами квадратов выбранного критерия /(X;, Ху). При мини-
мизации большинства критериев М не будет симметричной, но будет
содержать нулевые элементы на диагонали. Если воспользоваться ор-
тогональной прокрустовой статистикой, то М будет симметричной и,
как уже говорилось, ее элементы будут удовлетворять метрическим
аксиомам. Сформировав матрицу М, можно анализировать ее метода-
ми, описанными в предыдущих разделах, и построить ординацию, в
которой близкие точки соответствуют парам матриц, содержащих
близкие по значению элементы.
Такой подход иногда используется, но более популярны методы,
которые дают своего рода среднюю конфигурацию и позволяют оце-
нить, насколько матрица D*. (или Х^) отличается от средней.
Один путь состоит в обобщении ортогонального прокрустова под-
хода и поиске множества ортогональных вращений, приводящих Х1НЬ
Х^.^Н^ к некоторому оптимальному согласию. Обозначим к-е
точки в т конфигурациях, полученных после вращения, через (Р1Л.,
P2£,...,P,„£), а центры тяжести этих точек — через Gk. Тогда опти-
мальным будет отображение, минимизирующее суммы квадратов рас-
стояний т точек z-го множества от их центра тяжести по всем п
значениям индекса к. Геометрическая интерпретация для трех мно-
жеств из четырех точек приведена на рис. 17.12.1. Обозначим через Y
множество координат для п центров тяжести, тогда
1 т
Y=~ Е Х*Н*.
Критерий обеспечивает выбор Н/} таких, что
/(Хь Х2,...,ХШ) = E||Y—Х*Н*Й
минимальна. Это эквивалентно минимизации
Е|Х*Н*-Х,Н;|,
288
Рис. 17.12.1. Обобщенный прокрустов анализ. Три множества из четырех точек
с координатами Рй, Ра, Рй(/=1, 2, 3, 4) имеют общий центр тяжести О. Gk —
центр тяжести конфигурации точек Р1к, Р2к и Р3к. Оптимальное соответствие
(на рис. не указано) определяется направлениями, минимизирующими сумму
4 3
квадратов остатков E^P^Gp (отмечены на диаграмме)
просуммированного по всем парам к, I. Если бы Y была известна, то
достаточно просто повернуть каждую до положения, в котором
она оптимально соответствует Y, в точности, как это сделано в разде-
ле 17.10. Но сама Y зависит от неизвестной Н^., поэтому мы вынуж-
дены прибегнуть к итеративной процедуре, начав с исходной
центроидной конфигурации Y, а затем повернуть каждую Х^, чтобы
она соответствовала Y, подобрав для этого ортогональные матрицы
Нд., которые в свою очередь порождают новый центр тяжести. Де-
тальное описание этого процесса содержится в [см. Gower (1975)].
Автор называет такого рода анализ обобщенным прокрустовым ана-
лизом и приводит пример. Параллельный перенос каждого множества
легко осуществляется помещением центра тяжести каждой конфигура-
ции Х^., а следовательно, и Y в начало координат. Для каждого мно-
жества может быть также введен масштабирующий множитель
Тогда мы должны минимизировать E||Y— gpQHjJ, где Y=(l//n)
Eg^X^H^. Можно исключить тривиальное решение gt=0, наложив
ограничение Sg^lXJI = E||XJ|, которое сохранит неизменным общий
размер конфигураций после шкалирования. Оценивание матрицы
производится так же, как и прежде, за исключением того, что Х^ всю-
ду заменяется на е^Х^. Масштабирующий множитель вычисляется по
формуле
qI =И-(еЛН^)Е II *к II /т IIXJII Ук II,
289
которая может быть использована для пересчета итеративных оценок.
В своем альтернативном подходе Тен Берж [см. ten Berge (1977)] пока-
зал, что на каждом шаге итерации вектор q всех масштабирующих
множителей может быть записан в качестве собственного вектора не-
которой матрицы. Теоретически его метод дает существенное улучше-
ние решения на итерациях за счет увеличения объема вычислений.
При обсуждении обобщенного прокрустова анализа утверждалось,
что может быть повернута вся конфигурация целиком (т. е. У, Х^Н^,
£=1, 2,...,ди) и расстояния между точками в ней останутся неизмен-
ными. Единственное подходящее представление получается при соот-
несении Y с ее главными осями и соответствующими уточнениями
всех Хд. после вращения.
Проведем сравнение двух конфигураций (положим т=2). Посколь-
ку X] и Х2 должны соответствовать своей совмещенной центроидной
конфигурации, не допустимо асимметричное соотношение /И122#т2ь
введенное в разделе 17.10 для ортогонального прокрустова анализа с
масштабирующим множителем. Дж. Говер [см. Gower (1975)] показал,
что если X] и Х2 предварительно стандартизируются и имеют одина-
ковую (скажем, единичную) сумму квадратов, а затем a)Xi и Х2 приво-
дятся к общему центру тяжести, б) X! шкалируется так, чтобы соот-
ветствовать Х2, в) Х2 шкалируется так, чтобы соответствовать Хь то
в конце концов мы получаем одно и то же значение ml2- В результате
такой стандартизации gi = g2 = l. Все это выливается в настоятельную
рекомендацию предварительно стандартизовать данные, что особенно
существенно, когда Xi и Х2 измерены на несоизмеримых шкалах и
масштабирующий множитель q не имеет никакого смысла.
Обобщенные прокрустовы идеи могут быть в принципе сформули-
рованы в терминах других критериев из раздела 17.10. Можно, сохра-
нив ортогональные вращения Щ и центроидную конфигурацию У,
вместо того, чтобы работать в терминах квадратов расстояний между
соответствующими точками, использовать любой критерий подобия
или же следующую процедуру. Среднее значение dyk по всем т кон-
фигурациям равно dyk. Обозначим через by расстояния в
конфигурации У. Тогда можно минимизировать fp(by, Dy), где Р —
индекс выбранного критерия. Алгоритм должен обеспечить итератив-
ный подбор Н^, чтобы получить центроидную конфигурацию У, при-
водящую к минимуму fp{-). Подводные камни такого подхода еще не
исследованы. Обобщенная прокрустова процедура реализована в про-
грамме PINDIS [см., например, Borg (1977)]. Кроме того, программа
содержит другие процедуры и включает возможности построения мо-
делей индивидуального шкалирования такого типа, который обсуж-
дался выше.
290
Наиболее широко распространенный класс моделей шкалирования
матриц с тремя входами описан в [Carroll and Chang (1970)]. Она на-
зывается шкалированием индивидуальных различий или INDSCAL* —
по названию соответствующей вычислительной программы. В этой
модели аппроксимируемые величины записываются в виде
йда=(Х~X;)W(t(X/-X,)’',
где xf- — i-я строка матрицы X размерности nxr, a — диагональ-
ная матрица положительных весов. Матрица X берется как средняя
конфигурация для всех т матриц D^, и ее значения могут быть пред-
ставлены в обычном для ординации виде. X часто называют средней
групповой конфигурацией. Величины wik (т. е. z-й диагональный эле-
мент матрицы W^) интерпретируются как веса к-ro индивида для z-й
координатной оси конфигурации X. Координаты (wlktw^t...twrk) мо-
гут быть изображены для каждого из к=1, 2....т индивидов. Для
распространенного случая, когда г=2, точки, лежащие на линии, со-
ставляющей 45° с осями координат, представляют индивидов, припи-
сывающих одинаковые веса обеим осям средней групповой
конфигурации. Точки, лежащие по одну или другую сторону от этой
линии, указывают на предпочтение одной из двух осей.
Реализация моделей индивидуального шкалирования порождает та-
кое же количество критериев, как и в обычном многомерном шкали-
ровании. Здесь разрабатываются оба подхода: метрический и
неметрический. Оригинальный метод Дж. Керрола и Дж. Чанг [см.
Carroll and Chang (1970)] основан на идее классического метрического
шкалирования о разложении дважды центрированной матрицы Мо
[см. раздел 17.6] в виде скалярного произведения ХХТ. Таким же об-
разом для дважды центрированной формы от D£=XWXr. Теперь
мы предполагаем, что элементами являются —-^dyk или же они
могут быть приведены к такому виду. Керрол и Чанг [см. Carroll and
Chang (1971)] методом наименьших квадратов отыскивают решение,
соответствующее минимуму
т
EjIDj-wxwq.
Такой критерий носит название STRAIN. Заметим, что подобное при-
менение центрированной матрицы D£ не допускает возможности про-
пущенных данных. Проблема, по существу, та же, что была
рассмотрена Р. Харшманом [см. Harshman (1972)] в модели
PARAFAC**. Керрол и Чанг решают более общую задачу мйними-
зации г
5=1
* INdividual Differences SCALing. — Примеч. ped.
** PARAmetrik FACtors. — Примеч. ped.
291
по параметрам ais, bjs, cks. Это может рассматриваться как обобще-
ние на трехмерный случай задачи наилучшей аппроксимации заданной
матрицы матрицей ранга г, решенной теоремой Экарта—Юнга. Кер-
рол и Чанг разработали алгоритмическую процедуру CANDECOMP*
для обычного итеративного режима. Вводятся начальные оценки для
bjs и cks, значения отыскиваются по обычной формуле для мно-
жественной регрессии. Затем ais, cks фиксируются и отыскиваются
оценки для bjs. На следующем шаге фиксируют ais, bjS и получают
оценки для cks. Вся процедура повторяется столько раз, сколько это
необходимо. На каждом шаге остаточная сумма квадратов уменьша-
ется. Процедура CANDECOMP может применяться для минимизации
критерия индивидуального шкалирования, если положить
ais=xist bjs~xjs и cks~wks‘
Это накладывает очевидные ограничения на общую модель, но не по-
рождает дополнительных трудностей. Не гарантируется, что глобаль-
ный оптимум достижим, хотя есть основания полагать, что обычно
он достигается. Важное свойство индивидуального шкалирования в
таком виде состоит в том, что средняя групповая конфигурация един-
ственна. При повороте ее осей расстояния остаются неизменными, но
весовые коэффициенты теряют свой смысл. Свойство единственности
обычно подчеркивается в качестве преимущества метода.
Система ALSCAL** [см. Tkkane, Young, de Leeuw (1977)] реализует
модель индивидуального шкалирования с использованием другого
критерия качества соответствия, а следовательно, и вычислительного
алгоритма, отличного от того, который применяется в INDSCAL.
Минимизируемый критерий (SSTRESS)
из семейства критериев для шкалирования квадратов расстояний по ме-
тоду наименьших квадратов [см. раздел 17.7]. Алгоритм ALSCAL счи-
тается очень эффективным в ситуациях, более общих, чем INDSCAL.
Он допускает, например, пропущенные данные, повторную информа-
цию от одного и того же индивида(ов), более широкое разнообразие
данных и реализует неметрическую версию.
Другая подобная, но более простая модель использована в
SMACOF-I [см. Heiser and de Leeuw (1979)]. Минимизируется
E ™ijl№ijk ^ij)2>
где dy — расстояния в средней конфигурации, ы^к — заданные веса,
подобные описанным в разделе 17.7; их не следует путать с весами
wks, которые используются в INDSCAL и ALSCAL и подлежат оцени-
ванию. Обычное разбиение суммы квадратов приводит к
$kwijkftijk ^kwijkWijk tf)2+ ? wij(d ij ^jj)2»
* CANonic DECOMPosition. — Примеч. ped.
** Alternative Least Square SCALing. — Примеч. ped.
292
где
— i т
W:: = -Д- Е Wi;lr
IJ т к=\ lJK
т
_ Y.wijkdijk
и 6ZZ;= *=1-r j •
mWjj
Левая часть принимает минимальное значение при такой X, которая
порождает ду, минимизирующие ЕЯу((Гу—ду)2. Это в точности зада-
ча шкалирования по методу наименьших квадратов, обсуждаемая в
разделе 17.7, и здесь применима разработанная методология. Модель
дает среднюю групповую конфигурацию X, однако информация о при-
роде индивидуальных различий ограничена компонентами суммы ква-
дратов ^4jtkwijk^ijk—dij)2' Заметим, что при таких вычислениях не
вводится предположение о симметрии dyk-djik, поэтому последняя
сумма квадратов может быть разложена на компоненты, один из ко-
торых измеряет степень симметрии, а другой — степень отклонения
от нее.
Керрол и Чанг [см. Carroll and Chang (1972)] обобщили свою мо-
дель шкалирования индивидуальных различий на любые положитель-
но определенные матрицы W^. Тогда каждому индивиду соответст-
вует собственное метрическое пространство. Метод носит название
идиосинкразического шкалирования, а реализующая его программа
называется IDIOSCAL*. Здесь также оценивается средняя групповая
матрица X, но индивидуальные различия выражены симметричными
матрицами W. Нет простого графического представления индивиду-
альных весов, но в наиболее распространенном двумерном случае не-
сложно сравнить т матриц W^. При г>2 мы сталкиваемся с
сложными проблемами, для решения которых следовало бы произве-
сти индивидуальное шкалирование матриц W^!
Трехфакторные расширения мультипликативных моделей с двумя
входами, кратко упомянутые в разделе 17.3, открывают еще один
путь анализа трехиндексных данных. Акцент делается на модели для
наблюденных данных Xk(k-l,
В настоящем разделе сделан лишь краткий обзор быстро расширя-
ющейся сети методов. Очень трудно сравнить предлагаемые модели,
которые различаются критериями (метрический и неметрический) для
подгонки этих моделей и вычислительными программами. Речь шла
о роли данных, записанных в виде т матриц Х^ или матриц дис-
танционного типа. Мы видели, что даже на квадратную матрицу D*.
не налагаются ограничения симметричности, по крайней мере для ме-
тода SMACOF-I. Не удается выяснить четкую природу данных в слу-
чае, когда программа использует прямоугольные куски симметричной
матрицы расстояний, как это делается при многомерной развертке
[см. раздел 17.9].
* IDIOsyncratic SCALing. — Примеч. ред.
293
17.13. АНАЛИЗ АСИММЕТРИИ
Многие из рассмотренных методов могут применяться для анализа
прямоугольных матриц. В разделе 17.3 обсуждаются мультипликатив-
ные модели, в разделе 17.5 — анализ соответствий, в разделе 17.9 —
дистанционные модели многомерной развертки. Теперь мы коснемся
проблем квадратных асимметричных таблиц. Здесь применимы мето-
ды анализа общих прямоугольных матриц, но для квадратных таблиц
специальной структуры, где строки и столбцы классифицируются по-
добным образом, нужны новые модели. В таком случае строки и
столбцы обычно соотносятся по сути с одними и теми же вещами, но
отражают разные аспекты. Например, строки могут соответствовать
местам иммиграции, а столбцы — тем же местам, но рассматривае-
мым как центры эмиграции. Мы можем интерпретировать строки как
социальные классы отцов, а столбцы — как социальные классы сыно-
вей. Для таких данных часто характерны как симметричные аспекты,
так и отклонения от симметрии. Методы, о которых до сих пор шла
речь, не позволяют различать эти два аспекта, и поэтому в анализе
данных подобного типа они не столь эффективны. В настоящем раз-
деле мы рассмотрим модели, включающие симметричную и асиммет-
ричную компоненты. Обозначим через D квадратную матрицу данных
размерности пхп.
В модели Бекера, Юнга и Тейкена [см. Baker, Young, Takane (1977)]
элемент матрицы D записывается в виде
, к
dy = ^r(x^r
Координаты, записанные в строках матрицы X размерности пхк,
порождают обычное евклидово представление. Величины wjr, называ-
емые весами, определяют асимметрию, поскольку веса для расстояний
dy и djk различаются. На двумерном графике (Аг=2) веса и wi2
представляются в i-й точке направленными линиями соответствующей
длины, ориентированными соответственно на восток/запад и север/
юг. Эта модель принадлежит тому же семейству, что и модель шкали-
рования индивидуальных различий из раздела 17.12.
Рассмотренная модель — модель дистанционного типа. Р. Харш-
ман [см. Harshman (1972)] предложил асимметричную модель, осно-
ванную на векторных произведениях
D=XRXr,
где матрица R размерности sxs асимметричная, хотя матрица D сим-
метрична. Конечно, ситуация сильно упрощается для малых s, но это
не является необходимым. Если матрицы X и R дают хорошее при-
ближение, то эквивалентные решения существуют для произвольной
ортогональной матрицы Н, при этом X заменяется на ХН, a R — на
HrRH. Это открывает возможности применения методов факторного
вращения для получения более простых и более интерпретируемых ре-
шений. Матрица X или результат ее вращения могут быть графически
294
представлены множеством из п точек. Такое представление передает
симметричные аспекты матрицы D. Поскольку в качестве данных вы-
ступают векторные произведения между элементами, интерпретация
производится не в терминах расстояний, а в терминах углов между ра-
диусами-векторами. Вариант модели Харшмана, где в качестве R вы-
ступает матрица с очень специальной структурой, изучался Чино. При
к=2 R заменяется на al + /3S2, где S2 — кососимметричная матрица
размерности 2x2 с Si2 = 1. Обозначим два столбца матрицы X через
Xi и х2. Тогда очевидно, что Х82Хг=Х]хГ—x2xf, т. е. имеет вид, экви-
валентный первому члену в выражении, полученном по методу на-
именьших квадратов. S — кососимметричная матрица с Sy = (—1 )»’+>-1
для j>i При к=3 любая кососимметричная матрица третьего по-
рядка имеет ранг 2. В действительности 33-^(аЬт—Ьа^), где ат=
=(1, —2, 1) и Ьг=(1, О, —1). Разбиение матрицы X на три столбца
(Xi, х2, х3) и вычисление XS3Xr приводят к очень специальной модели
(Х2х[—Х3х[) +(х3х[—XiXf) 4- (XiXf— х2х[),
которая анализируется как кососимметричная составляющая. В другой
ситуации эти же векторы (хь х2, х3) анализируются как симметричная
компонента. Аналогичные замечания относятся и к моделям более вы-
сокого порядка к. Модель такого типа описана в работе [Escoufier and
Grorud (1980)].
В большинстве случаев удобнее иметь дело отдельно с симметрич-
ной и асимметричной компонентами. Это ведет к разбиению
D = M + N,
где М — симметричная, a N кососимметричная. Нетрудно заметить, что
откуда следует, что общая сумма квадратов разбивается на независи-
мые компоненты: симметричную и кососимметричную. Тогда появля-
ется возможность раздельного анализа матриц М и N методом
наименьших квадратов. Матрица М поддается анализу любым из ме-
тодов, рассмотренных в предыдущих разделах, включая неметриче-
ские. Обычно нас интересуют аппроксимации матрицы N низкого
ранга. Это как раз ситуация, в которой применяется теорема Экар-
та—Юнга. Здесь необходимо разложение матрицы N по сингулярным
значениям. Для кососимметричных матриц оно имеет специальный
ВВД N = UEJUr,
где U ортогональна, a E=diag(ab сть а2, ст2,...), откуда видно, что син-
гулярные значения образуют пары, и
Если п нечетное, то последний элемент Е равен нулю, а последний
элемент J — единице.
295
Разложение по сингулярным значениям может быть записано в ви-
де суммы [Л/2]
N= Eia.(U2(_1uJ-u2,u';_1),
где [п/2] — наибольшее целое, не превышающее п/2, а и2/—27-й стол-
бец матрицы U. Совпадение пар сингулярных значений означает, что
аппроксимация нечетного ранга не единственна, допустимы только ре-
шения четного ранга. Сконцентрируем внимание на первом члене раз-
ложения N, и чтобы освободиться от индексов, через и обозначим Ui,
а через V — и2.
Тогда
N = CTi(uvr—vur),
что соответствует определенной выше кососимметричной компоненте
Чино для к=2. Существует много способов параметризации этого
члена путем замены и и v на любые два вектора а и b (не обязательно
ортогональные) в той же плоскости. Все параметризации такого рода
эквивалентны в том смысле, что они дают одну и ту же сумму ква-
дратов 2af. Иногда удобна параметризация, для которой 1га=0 и
вектор b ортогонален вектору а.
Значения (uf, vf) /=1, 2,...,л могут быть приняты в качестве коор-
динат п точек и графически представлены в пространстве двух измере-
ний. Аппроксимация Пу = ах(и^—vtUj) показывает, что площадь
треугольника, содержащего в качестве7 вершин начало координат, i-ю
и j-ю точки, приблизительно пропорциональна Пу. Кососимметрич-
ность получается за счет знака площади, который зависит от того,
следуют ли вершины треугольника по часовой стрелке или против нее.
Разные параметризации соответствуют разным парам осей, разным
поворотам и разным относительным шкалам. Все это отражается на
площади, в крайнем случае в виде постоянного множителя.
Представление в терминах площадей существенно отличается от
обычной дистанционной интерпретации ординации. Например, две
точки, лежащие на одной прямой с началом координат, дают нулевую
площадь, даже если они сильно разнесены. В смысле расстояний точ-
ки, равноудаленные от заданной точки Р, образуют окружность с
центром в Р. В смысле площадей точки, образующие с ОР треуголь-
ники постоянной площади, лежат на линии, параллельной ОР. Пло-
щадь треугольника, построенного на векторах Р;, Ру и Рк,
пропорциональна ny + rijk + nki. Эти особенности нужно иметь в виду
при интерпретации диаграмм в терминах площадей.
Диаграммы в терминах площадей могут также использоваться как
средство диагностики в том же качестве, что и диагностические
двойственные графики [см. раздел 17.4]. Рассмотрим наиболее прос-
тую модель асимметрии
nij = ai~ar
Можно предположить Еа;=0, поскольку значения заданы с точнос-
тью до аддитивной константы. В матричной форме это записывается
как
N=alr—1аг,
где 1га=0.
296
Если одна из координат постоянна, то график линеен. Линейный
график соответствует простой кососимметричной форме at—at. Этот
простой вид асимметрии является важным, и имеет смысл отобразить
значения а, на какой-либо ординации симметричной части М, при
этом удобно соединить контуром близкие значения.
Мы обращаем внимание на раздельный анализ симметричной и ко-
сосимметричной компонент матрицы D. Мы вовсе не отрицаем целесо-
образность попыток воссоединения этих двух частей и установления со-
отношений между параметрами в обеих частях. Это серьезная пробле-
ма, и она требует больших усилий. В настоящее время наблюдаются
успехи в изучении эксплицитных моделей для матрицы D. Аналитичес-
кими средствами получены некоторые соотношения и их геометриче-
ская интерпретация. Для более детального ознакомления следует обра-
титься к работам [Gower (1977b)] и [Constantine and Gower (1981)].
17.14. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Baker R. Е, Y о u n g Е W. and Т a k a n е Y. (1977). An Asymmetric Euclidean
Model (available from E W. Young), Psychometric Laboratory, Dave Hall 013a, University of
North Carolina, Chapel Hill, NC 27514.
ten В e r g e J. M. F. and Nevels K. (1977). A General Solution to Mosier’s Oblique
Procrustes Problem, Psychometrika 42, 593—600.
Barlow R. E., Bartholomew D. J., Bremmemr J. M. and Brunk H.D.
(1972). Statistical Inference Under Order Restrictions: the Theory and Application of Isotonic
Regression, J. Wiley. Chichester, New York, Brisbane.
Borg I. (1977). Some Basic Concepts of Facet Theory. In J. C. Lingoes (Ed.) Geometric
Representations of Relational Data, Ann Arbor, Mathesis Press.
Blumenthal L. M. (1970). Theory and Applications of Distance Geometry, 2nd
edition, Chelsea, New York.
В r a d и D. and Gabriel K. R. (1978). The Biplot as a Diagnostic Tool for Models
of Two-way Tables, Tfechnometrics 20, 47—68.
Browne M. W. (1967). On Oblique Procrustes Rotation, Psychometrika 32, 125—132.
Browne M. W. and К r i s t о f W. (1969). On the Oblique Rotation of a Factor matrix
to a Specified Pattern, Psychometrika 34, 237—248.
C a i 11 i e z E (1983). The Analytical Solution to the Additive Constant Problem,
Psychometrika 48, 305—308.
С a г г о 11 J. D. and Chang J. J. (1970). Analysis of Individual Differences in
Multidimensional Scaling via an n-way Generalization of’Eckart-Young’Decomposition,
Psychometrika 35, 283—319.
С a г г о 11 R. В. and Chang J. J. (1972). IDIOSCAL (Individual Differences in
Orientation Scaling), Paper presented at the Spring meeting of the Psychometric Society,
Princeton, New Jersey, April 1972.
C a 11 e 1 1 R. B. and Khanna D. K. (1977). Principles and Procedures for Unique
Rotation in Factor Analysis, Chapter 9 of Statistical Methods for Digital Computers (Vol. Ill
of Mathematical Methods for Digital Computers) Ed., Einstein, A. Ralston and H. S. Wilf.
New York, Wiley-Interscience.
Cramer E. M. (1974). On Browne’s Solution for Oblique Procrustes Rotation,
Psychometrika 39, 139—163.
Constantine A. G. and Gower J. C. (1978). Graphical Representation of Asym-
metric Matrices, Journal of the Royal Statistical Society, C., Applied Statistics 27, 297—304.
297
Constantine A. G. and Gower J. C. (1981). Models for the Analysis of Inter-
regional Migration, Environment and Planning A, 14, 477—497.
Davies A. W. (1978). On the Asymptotic Distribution of Gower’s m2 Goodness-of-fit
Criterion in a Particular Case, Ann. Inst. Statist. Math. 30, 71—79.
Digby P. G. N. and Gower J. C. (1981). Ordination Between- and Within-groups
Applied to Soil Classification, Down to Earth Statistics: Solutions Looking for Geological
Problems, Syracuse University Geology Contributions (ed. D. F. Merriam), 63—75.
Eckart C. and Young G. (1936). The Approximation of One Matrix by Another
of Lower flank, Psychometrika 1, 211—218.
Escoufier Y. and G г о r u d A. (1980). Analyse Factorielle des Matrice Carrees non
Symmetriques. In: Data Analysis and Informatics, 17—19 October 1979 (Eds. E. Diday,
L. Lebart, J. P. Pages, R. Tommassone, North-Holland, Amsterdam), pp. 2633—2276.
Gower J. C. (1975). Generalised Procrustes Analysis, Psychometrika 40, 33—51.
Gower J. C. (1977). The Analysis of the Three-way Grids. In: Dimensions of Intra-
Personal Space, Vol. 2: The Measurement of Intra-Personal Space by Grid Technique
(Ed. P. Slater), J. Wiley & Son, 163—173.
Gower J. C. (1977b). The Analysis of Asymmetry and Orthogonality. In Recent
Developments in Statistics (Eds. F. Brodeau, G. Romier, B. van Cutsem), North-Holland,
Amsterdam, pp. 109—123.
Gower J. C. (1982). Euclidean Distance Geometry, Mathematical Scientist 7, 1—14.
Guttman L. A. (1986). A. General Non-metric "technique for Finding the Smaller
Coordinate Space for a Configuration of Points, Psychometrika 33, 469—506.
Green B. F. and Gower J. C. (1981). A Problem with Congruence (Available on
request).
Greenarce M. J. (1978). Some Objective Methods of Graphical Display of a Data
Matrix. Translation of doctoral thesis (Universite de Paris, VI). Published as special report by
University of South Africa, Pretoria.
Cruvaeus G. T. A General Approach to Procrustes Pattern Rotation, Psychometrika
35, 493—505.
Harshman R. A. (1972). PARAFAC2: Mathematical and Technical Notes. In Working
Papers in Phonetics 22, University of California at Los Angeles.
Heiser W. and de L e e u w J. (1979). How to Use SMACOF-I, A Program for Metric
Multidimensional Scaling, Department of Datatheory, Faculty of Social Sciences, University of
Leiden, Wassenaarseweg 80, Leiden, the Netherland, 1—63.
Hurley J. R. and C a 11 e 11 R. B. (1962). The Procrustes Program: Producing Direct
Rotation to Test Hypothesized Factor Structure, Behavioural Science 7, 258—262.
Lingoes J. C. (1971). Some Boundary Conditions for a Monotone Analysis of
Symmetric Matrice, Psychometrika 36, 195—203.
L i s s i t z R. W, Schonemann P. H. and Lingoes J. C. (1976). A Solution
to the Weighted Procrustes Problem in which the Trans formation is in Agreement with the
Loss Function, Psychometrika 41, 547—550.
Mandel J. (1961). Non-additivity in Two-way Analysis of Variance, J. Amer. Statist.
Assn 56, 878—888.
M u г г a у W. (ed.) (1972). Numerical Methods for Unconstrained Optimisation, Academic
Press, London and New York.
NishisatoS. (1980). Analysis of Categorical Data: Dual Scaling and its Applications,
University of Toronto Press, Toronto, Buffalo, London.
Pearson K. (1901). On Lines and Planes of Closest Fit to a System of Points, Phil.
Mag. ser. 62, 559—572.
Ramsay J. O. (1977). Maximum Likelihood Estimation in Multidimensional Scaling,
Psychometrika 42, 241—266.
298
S i b s о n R. (1978). Studies in the Robustness of Multidimensional Scaling: Procrustes
Statistics, J. Roy. Statist. Soc. 40, 234—238.
S i b s о n R. (1979). Studies in the Robustness of Multidimensional Scaling: Perturbational
Analysis of Classical Scaling, J. Roy, Statist. Soc. В 41 217—229.
Schonemann P.H. (1968). On TWo-sided Orthogonal Procrustes Problems, Psy-
chometrika 33, 19—33.
TakaneY., Young F. and de L e e u w J. (1976). Non-metric Individual Differences
Multidimensional Scaling: an Alternating Least Squares Method with Optimal Scaling
Features, Psychometrika 42, 7—67.
Torgerson W. S. (1958). Theory and Methods of Scaling, New York, Wiley.
T u к e у J. W. (1949). One Degree of Freedom for Non-additivity, Biometrics 5,
234—242.
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д.
Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и ста-
тистика, 1989. — 607 с.
Дэйвисон М. Многомерное шкалирование: Методы наглядного представления
данных. — М.: Финансы и статистика, 1988. — 254 с.
Терехина А. Ю. Анализ данных методами многомерного шкалирования.—М.:
Наука, 1986.—168 с.
Глава 18
ВРЕМЕННЫЕ РЯДЫ
18.1 ВВЕДЕНИЕ
Временной ряд — это совокупность измерений некоторой перемен-
ной (будем обозначать ее X), производимых по мере возрастания вре-
мени. Теоретически измерения могут регистрироваться непрерывно,
но обычно они осуществляются через равные промежутки времени и
нумеруются аналогично элементам выборки (объема п):
х = (Xi, х2, .... хп)'.
Для временных рядов главный интерес представляет описание или
моделирование их структуры. Подобное описание, осуществляемое без
использования какой-либо другой наблюдаемой переменной, относят
к анализу одномерных рядов. Мы посвящаем таким методам основ-
ную часть этой главы. Цель исследования, как правило, шире модели-
рования, хотя некоторую информацию исследователь может получить
и непосредственно из модели (например, амплитуду циклической ком-
поненты). Обычно модель применяется для экстраполяции или прог-
нозирования временного ряда. Качество прогноза может служить по-
лезным критерием при выборе среди нескольких моделей. Для других
применений, таких, как корректировка сезонных эффектов, выделение
сигнала и сглаживание, обычно необходимо построение хороших мо-
делей ряда. Наконец, модели могут использоваться для статистиче-
ского моделирования [см. II, раздел 5.6] длинных рядов наблюдений,
при исследовании больших систем, для которых временной ряд рас-
сматривается как входная информация. В этой главе мы ограничива-
емся приложениями к прогнозированию.
При исследовании временных рядов необходим статистический под-
ход. Действительно, ошибки измерения присутствуют всегда; кроме то-
го, случайные флуктуации, видимо, свойственны наблюдаемой системе,
относится ли она к окружающей среде, экономике, технике или биоло-
гии. При анализе одномерных рядов почти неизбежно применение эм-
пирических методов. Полная математическая модель наблюдаемой
системы, вероятно, не имеет большого значения, если измеряется толь-
ко одна переменная. В этой главе приводятся относительно простые
эмпирические модели, достаточно гибкие для подгонки данных и хоро-
шо зарекомендовавшие себя за годы успешного применения.
300
Рис. 18.1.1. Примеры временных рядов: а) ряд авиаперевозок; б) ряд поголовья
свиней; в) продолжительность дня; г) случайный ряд; д) случайное блуждание
301
Мы неявно предполагаем, что временной ряд имеет какую-то
структуру, т. е. наблюдения не являются набором совершенно незави-
симых числовых значений. Структуру ряда в некоторых случаях мож-
но определить на глаз. Это относится, например, к таким компонен-
там ряда, как тренд и циклы. Однако «на глаз» можно прийти к вы-
воду о наличии структуры и там, где в действительности имеет место
лишь чистая случайность. Мы предполагаем, что структуру ряда мож-
но описать моделью, содержащей небольшое число параметров по
сравнению с количеством наблюдений, — это практически важно при
использовании модели для прогнозирования. Временной ряд является,
таким образом, совокупностью наблюдений случайного процесса [см.
II, гл. 18]:-
{X_j, Хо, Xj, Х2, ...}.
Обычно такой процесс, так же как и выборочные данные, называют
временным рядом. Начиная с этого места, мы будем для удобства
символом xt обозначать как наблюдения, так и случайный процесс,
полагаясь для уточнения смысла на контекст.
На рис. 18.1.1 показаны графики пяти временных рядов, выбранных
для иллюстрации различных свойств. Логарифм числа авиапассажиров
(называемый далее рядом авиаперевозок) представляет собой ежемесяч-
ный ряд, содержащий ярко выраженные тренд и внутригодовые изме-
нения. Численность поголовья свиней в стране (в дальнейшем — ряд
поголовья свиней, предиктор для величины прироста стада) измеряется
ежеквартально. В этом ряду чередуются подъемы и спады, интервал
между соседними пиками составляет два-три года, что служит приме-
ром нерегулярного цикла. Измерения скорости вращения Земли (в даль-
нейшем — ряд продолжительности дня) образуют ряд из ежегодных
данных, в котором обнаруживается слабый возрастающий тренд с
большими долгопериодическими колебаниями вокруг тренда. Случай-
ный ряд — это случайная выборка из нормального распределения [см.
II, раздел 11.4], скорректированная с учетом среднего значения. Слу-
чайное блуждание [см. II, раздел 18.3] — это ряд, являющийся накоп-
ленной суммой значений случайного ряда; на его примере видно, как
подобный ряд создает впечатление циклического поведения.
18.2. КЛАССИЧЕСКИЕ РЕГРЕССИОННЫЕ МОДЕЛИ
ДЛЯ ВРЕМЕННЫХ РЯДОВ
18.2.1. МОДЕЛЬ СЕЗОННЫХ ЭФФЕКТОВ
Естественно предположить, что ярко выраженные тренд и сезон-
ность можно моделировать при помощи компонент, являющихся де-
терминированными функциями времени. Например, ряд авиаперевозок
можно представить как
xt=a + bt + ofjA/j t +...+ t + (18.2.1)
302
Рис. 18.2.1. Анализ ряда авиаперевозок: а) подгонка модели тренда и месяч-
ных эффектов (18.2.1) к ряду авиаперевозок; б) остаточные ошибки после под-
гонки модели (18.2.1); в) сезонные разности ряда авиаперевозок; г) первые
разности для сезонных разностей ряда авиаперевозок; д) ошибка прогноза на
один шаг вперед сезонной модели скользящего экспоненциального взвешива-
ния для ряда авиаперевозок; е) ошибка прогноза на один шаг вперед в модели
Бокса—Дженкинса для ряда авиаперевозок; ж) выборочная автокорреляцион-
ная функция для второй разности ряда г)
303
где (а + Ы) — линейный тренд, а М, р AfI2 t — индикаторные
переменные, по одной на каждый месяц года. Так, М, t = 0 для всех
t, кроме января каждого года, для которого М, t = 1 и т. д. Тогда
величина «1 характеризует отклонение январских значений от тренда,
получаются 12 различных месячных эффектов. Последний член et вы-
ражает ошибку, которая, как мы ожидаем, должна быть малой в
сравнении с главным трендом и сезонными эффектами; Чтобы пара-
метризация модели была однозначной, необходимо, конечно, какое-
либо ограничение, например равенство нулю суммы сезонных эффек-
тов. Оценивая параметры модели как коэффициенты стандартного ли-
нейного уравнения регрессии по методу наименьших квадратов [см.
разделы 6.5 и 8.2], мы получаем хорошую подгонку ряда [см. рис.
18.2.1, а)]. Однако в анализе временных рядов осуществляется, в част-
ности, тщательное исследование остатков (ошибок модели) [см. раз-
дел 8.2.4]. Действительно, эксперименты, в которых осуществляются
наблюдения, не являются независимыми, и последовательные ошибки
должны рассматриваться как, быть может, статистически связанные.
Для приведенного примера остатки показаны на том же рисунке в ви-
де кривой б). Они, очевидно, неслучайны, имеют длинные участки по-
стоянства знака, постепенные и внезапные изменения уровня и слу-
чайные выбросы. Модель, допускающая изменения формы тренда и
сезонности, по-видимому, может оказаться лучше. Подогнанная мо-
дель на самом деле дает, как показывает рис. 18.4.1, хорошую экстра-
поляцию на один год вперед. Но наши знания о структуре ошибок не
позволяют привести какие-либо точные доверительные утверждения о
•прогнозе.
18.2.2. МОДЕЛЬ ЦИКЛИЧЕСКИХ КОМПОНЕНТ
Сезонные изменения в ряде авиаперевозок имеют сложную форму
вследствие влияния зимних, весенних и летних отпусков. Для некото-
рых сезонных рядов с достаточно гладкими сезонными изменениями
можно добиться хорошей подгонки модели, обходясь меньшим чис-
лом параметров, а именно используя в качестве регрессионных компо-
нент синусоидальные волны [см. IV, раздел 2.12] с соответствующим
периодом, что будет рассмотрено в разделе 18.3.2. Для других ситуа-
ций период или длина волны цикла могут быть точно неизвестны. На
рис. 18.2.2, а) изображен ряд измерений звездной величины звезды Т
Большой Медведицы, полученных усреднением наблюдений за после-
довательные десятидневные интервалы. Здесь очевидно наличие ярко
выраженного цикла, который можно учесть с помощью регрессионной
модели вида
xt = ц + Rcosfat + ф) + et, (18.2.2)
где д — среднее, w — угловая частота (в радианах в единицу времени),
R — амплитуда (неслучайная величина) и ф — фаза волны. Член
304
13
11 -
a)
9
7 -
2 -
в) ‘
о
Рис. 18.2.2. Анализ звездной величины переменной звезды: а) измерения звезд-
ной величины переменной звезды Т Большой Медведицы; б) остаточные ошиб-
ки после подгонки к измерениям одной циклической компоненты; в)
остаточные ошибки после подгонки дополнительной гармонической компоне-
нты и уточнения частоты; г) выборочная автокорреляция остатков (в); д) выбо-
рочная частная автокорреляция остатков (в)
305
et снова обозначает ошибку. Как видно из расположения неизвестных
параметров ц, ш, R и ф, модель линейна по д и R, но не по аз и ф.
Однако можно написать
xt = ц + Лсово)/ + BsinwZ + et, (18.2.3)
где А = l?cos0 и В = —/?sin0; в такой форме модель линейна по па-
раметрам д, А и В, которые можно оценить с помощью обычной ре-
грессии, если предварительно с достаточной степенью точности
определить w. На рис. 18.2.2, а) видны пять циклов за 130 единиц вре-
мени, и в качестве начального приближения для периода мы использу-
ем число 26, а для угловой частоты — величину 2тг/26 = ш0. Таким
образом, мы вводим два вектора-регрессора, или две переменные, со-
держащие значения
cosw0Z, sino)0/, t = 1, .... 131, (18.2.4)
и, оценивая параметры регрессии по методу наименьших квадратов
[см. раздел 8.2], получаем оценки (± их стандартные ошибки [см.
определение 3.1.1]):
А = 0,247 ± 0,078, В = —2,277 ± 0,078.
Отсюда к = 2,290 и ф = 83,8°, или 1,46 радиана.
Снова исследуем остатки, показанные на рис. 18.2.2, б). Модель
учитывает 86,8% дисперсии данных, так что дисперсия остатков зна-
чительна. Остатки далеки от случайности, и для этого возможны два
объяснения. Во-первых, ошибка в определении частоты w0 могла быть
достаточно большой, чтобы привести к плохому согласованию с дан-
ными. Во-вторых, может быть более важна несимметричность формы
наблюдаемой волны, подсказывающая нам, что гармоника основной
волны, т. е. волна удвоенной частоты, способна улучшить подгонку.
Мы исследуем эти возможности по очереди.
Значение частоты w0 = 2я726 можно очень просто уточнить с по-
мощью регрессионных методов. Представим истинную частоту w как
ш0 + 3, где 6 предполагается малым. С помощью элементарных вы-
числений [см. IV, раздел 3.6] приближенно находим:
Rcos(a>t + ф) ~ Rcos(u0t + Ф) — [/?/sin(o)0^ + Ф)]3 =
=Лсо8ш0^ + Bsinwo/ + 5[/(—/Isinwof + Bcosw00]«
Расширим регрессионное уравнение (18.2.3), введя новый вектор
/(—/4sinw0Z + BcoswoO, t = 1» •••, 131, (18.2.5)
с компонентами, вычисляемыми по уже оцененным значениям А и В.
Оценивание параметра 6 дает значение £ = 0,00337 ± 0,00084 и малое,
306
но значимое улучшение качества подгонки. Уточненная оценка часто-
ты равна <3 = «о + £ = 2тг/26 + 0,00337 = 0,02450, что соответствует
периоду 25,64 временных единиц (256,4 дня).
Гармоника основной волны и первая гармоника (с удвоенной ос-
новной частотой) оцениваются при введении новых регрессионных
векторов
cos2co0Z, sin2a)0^, t = 1, ..., 131, (18.2.6)
J
с удвоенной основной частотой в дополнение к уже имеющимся в
(18.2.4). На практике это было сделано с заменой частоты w0 на уточ-
ненную частоту ш. Улучшение подгонки снова оказалось малым, но
значимым, оценка амплитуды первой гармоники равнялась 0,34, дис-
персия остатков составила 10% дисперсии исходных данных. Частота
была снова уточнена, но это не привело к значимым изменениям.
Остатки, показанные на рис. 18.2.2, в), заметно уменьшились, но их
все еще нельзя считать хотя бы похожими на случайный ряд. Они бу-
дут проанализированы в разделе 18.11.
В этом практическом примере присутствие детерминированных си-
нусоидальных компонент не вызывает сомнений. Дальнейшие приме-
ры показывают, что детерминированные функции следует вводить с
осторожностью, и если хорошей подгонки можно достичь лишь с
использованием большого числа членов, то к интерпретации результа-
тов надо относиться критически.
18.3. ПЕРИОДОГРАММА ВРЕМЕННОГО РЯДА
18.3.1. ГАРМОНИЧЕСКИЕ КОМПОНЕНТЫ ПЕРИОДИЧЕСКОГО
ВРЕМЕННОГО РЯДА
Периодический временной ряд — это ряд, который в точности по-
вторяет свои значения по прошествии целого периода р, т. е. х(+р =
= xt для всех t. В разделе 18.3.2 мы покажем, что такой ряд может
быть представлен как сумма среднего уровня и линейной комбинации
(р — 1) синусоидальных волн — гармонических компонент. Эти во-
лны имеют основной период р и гармоники с периодами р/2, р/Ъ, ...,
соответствующие 1, 2, 3, ... целым волнам в течение периода р. Так,
при р = 12, что может понадобиться при анализе ежемесячных дан-
ных, кроме среднего уровня или постоянной составляющей, с каждым
из периодов 12, 6, 4, 3 и 12/5 можно связать синусоидальную и коси-
нусоидальную компоненты. Наконец, для периода 2 синусоидальную
компоненту можно опустить, так как она тождественно равна 0;
sinir/ = 0 для целых t. Таким образом, остается косинусоидальная
307
компонента с периодом 2, доводящая общее число компонент до 12,
и, как мы видим, cos(irO = (—1)г, поэтому в этой компоненте просто
чередуются значения +1 и —1. Объединим первые 12 значений, отве-
чающие значениям t = 1, 2, ..., 12 каждой из этих компонент, в векто-
ры-столбцы Со, ..., с6, Si, ..., s5, задаваемые формулами
cJt = cos(2ir/7/12), sJt = sin(27ry7/12).
Мы можем представить эти векторы в виде матрицы (напомним, что
cosir/6 = V3/2, sin-jr/6 = 1/2) следующим образом:
Со С1 С2 с3 с4 с5 С6 Si s2 s3 s4 s5
1 1 VJ 1 0 1 —1 1 VJ 1 VJ . 1
2 2 2 2 2 2 2 2
2 1 1 1 —1 1 1 1 V3 VJ 0 VJ _VJ
2 2 2 2 2 2 2 2
3 1 0 —1 0 1 0 —1 1 0 —1 0 1
4 1 1 1 1 1 1 1 V3 VJ 0 VJ _yj
2 2 2 2 2 2 2 2
5 1 1 0 1 _1 1 vj 1 VJ 1
2 2 2 2 2 2 2 2
* 6 1 —1 1 —1 1 — 1 1 0 0 0 0 0
7 1 /3 1 0 1 VJ __1 1 vj —1 VJ 1
2 2 ~ 2 2 2 2 2 2
8 1 1 1 1 1 1 1 /3 vj 0 VJ VJ
2 2 2 2 2 2 2 2
9 1 0 —1 0 1 0 —1 —1 0 1 0 —1
10 1 1 1 —1 _ 1 1 1 /3 vj 0 VJ VJ
2 2 2 2 2 2 2 2
И 1 1 0 1 _\з. —1 1 _V3_ —1 VJ 1
2 2 2 2 2 2 2 2
12 1 1 1 1 1 1 1 0 0 0 0 0
Графики соответствующих волн изображены на рис. 18.3.1. Столб-
цы Cjl j = 2, ..., 6, можно просто получить из столбца Ci, взяв каж-
дое у-е по времени значение Ci и возвращаясь к его началу, если это
необходимо. Становится ясно, почему нам не понадобились никакие
длины волн, меньшие двух временных промежутков (или частоты,
большие тг); действительно, если мы возьмем в столбце Ci каждое
308
WWb
в)
а) косинусоидальные волны
б) синусоидальные волны
Рис. 18.3.1. Синусоидальные волны:
изображают гармоники основного периода
12, наблюдаемые с единичным временным
интервалом;
в) искаженное представление высоты прилива (сплошная линия), измеряемой
ежедневно в 6 часов вечера, в виде долгопериодической волны (штриховая
линия), которую можно условно провести через выбранные точки
309
седьмое по времени значение, мы снова получим с5. Аналогично s7 со-
впадает с —s5. В терминах абсолютной частоты /, определяемой как
число волн за интервал между наблюдениями (величина, обратная пе-
риоду, или угловая частота, деленная на 2тг), синусоидальная волна с
частотой f при рассмотрении лишь целых значений t неотличима от
волн с частотой 1 — f, 1 + f, 2 — f, 2 + f, ..., т. e.
cos(2tt[£ ±/]0 = cos2ir/r, sin(2ir[£ ± f\t) = ± sin27r//.
Поэтому принято считать, что частота f находится в пределах
О f 0,5, так как любой большей частоте отвечает волна, совпада-
ющая в моменты наблюдений с аналогичной волной, отвечающей
некоторой частоте из указанного интервала. Наибольшая частота
f = 0,5 отвечает периоду, равному двум временным интервалам, и на-
зывается частотой Найквиста. Такое соглашение может привести к не-
правильным выводам, но оно будет давать правильный ответ, если
временной интервал между наблюдениями достаточно мал — не более
половины периода самой короткопериодической из предполагаемых
волн. Рис. 18.3.1, в) показывает значения, которые были бы зафикси-
рованы, если бы уровень прилива измерялся ежедневно в 6 часов утра
и 6 часов вечера. Вышеупомянутое соглашение привело бы к ошибоч-
ному предположению о том, что f = 1/28 (один прилив за 14 дней),
тогда как в действительности f = 1 — 1/28 (27 приливов за 14 дней).
Измерения высоты каждые 6 часов приведут к правильной частоте
приливов.
18.3.2. ГАРМОНИЧЕСКИЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Рассмотрим гармонические векторы, определенные для некоторого
периода р формулами
Су = { cos2irj7/p }*=1, i = 0, ..., р/2,
Sj = (вт21гЛ/р);ж1> 1=1.......р/2 — 1, (1831)
если р четно. Для нечетного р максимальное значение для j следует в
обоих случаях взять равным (р —1)/2; осциллирующий вектор будет
отсутствовать.
Можно показать, что эти векторы образуют ортогональную систе-
му [см. I, раздел 10.2], и сумма квадратов элементов каждого вектора
равна р/2, за исключением с0 и (только для четных р) Ср/1, для ко-
торых эта величина равна р. Таким образом, любой вектор из р эле-
ментов, скажем, х = (хь х2, •••> хр), можно однозначно представить
как линейную комбинацию гармонических векторов, т. е.
xt = n+t [Aisin2irjt/p+Bicos2irjt/p] + v(— l)z, /=1,...,р, (18.3.2)
j=i J J
310
где q = [(р — 1)/2] — целая часть числа (р — 1)/2, и если р нечетно,
то последний член необходимо опустить.
Заметим теперь, что если правую часть (18.3.2) рассмотреть при
t > р, то все гармонические компоненты при t = р + 1, ..., 2р или же
t = 2р + 1, ..., Зр и т. д. примут те же значения, что и при
t = 1, ...,р. Таким образом, правая часть (18.3.2) по построению пе-
риодична с периодом р. Если xt, ..., хр — первые р значений перио-
дического временного ряда с периодом р, то представление (18.3.2)
будет справедливо для всех t.
Этот результат применяется для моделирования временных рядов
с жестко фиксированным периодическим поведением с целым перио-
дом р. Так, при рассмотрении ежемесячного временного ряда длины
п, взяв р = 12 и продолжив во времени гармонические регрессионные
векторы Со, .... с6, Si, .... s5 до полной длины ряда л, мы получаем
заманчивую альтернативу индикаторным переменным t, рассмот-
ренным в разделе 18.2.1. Если используется вся совокупность гармо-
нических компонент, то модели равносильны. Преимущество
рассмотренной здесь модели в том, что, возможно, будет достаточно
меньшего числа компонент; для гладких рядов вклады высокочастот-
ных компонент будут пренебрежимо малы. Свойство ортогональнос-
ти компонент сохраняется, если п кратно р, но для применений это
условие не существенно.
18.3.3. ПЕРИОДОГРАММА
Методы гармонической регрессии можно плодотворно использо-
вать в более общей ситуации, когда временной ряд достаточно боль-
шой длины п предположительно содержит одну или несколько
синусоидальных компонент с неизвестными частотами (в противопо-
ложность известному и достаточно малому периоду р). Подставляя
длину п вместо периода р в формулу (18.3.2), мы получаем набор
частот* о)у = 2тг/7л, j m = [(л — 1)/2]. Временной ряд можно, та-
ким образом, представить в следующем виде (беря v = 0, если п
четно):
m t
x, = n+L [A.sinw,7+B.cosa).7] + р(— 1), t=1,...,л. (18.3.3)
Свойства ортогональности [см. IV, раздел 20.4] непосредственно
п
позволяют выразить коэффициенты по формулам д = х = (1/л)Ехр
V = (1/л)£(—1)'х, и__________________________________________1
Aj = (2/w)Exrsino)77, Bj = (2/n)Extcos(Pjl; j = 1, ..., m. (18.3.4)
* Эти частоты называются далее гармоническими частотами. — Примеч. пер.
311
Амплитуда Rj компоненты с частотой дается формулой
л; = а] + в;,
а разложение суммы квадратов (несколько вольно называемое диспер-
сионным анализом [см. раздел 8.3]) — формулой
£ (xt — х)2 = (n/2)S R2. + nv2. (18.3.5)
Представление (18.3.3) нельзя взять в качестве модели ряда, так
как в нем предполагается периодичность с периодом п. Вернее будет
рассматривать его как некоторое преобразование данных, надеясь, что
исследование амплитуд Rj откроет неочевидные до сих пор свойства,
которые удастся проинтерпретировать в терминах частот периодичес-
ких компонент. Для того чтобы такую интерпретацию можно было
делать осмысленно, исследуем свойства величин R2, i = 1, ..., т, для
различных моделей, представляющих временной ряд xt. Сначала да-
дим определение, мотивированное предыдущим обсуждением.
Определение 18.3.1. Периодограмма ряда xit ...,хп в интервале
О ш <7г определяется формулой
/,;(ш) = (2/п) [ (Еx;sinwO2 + (Еx;cosw02) =
= (2/п) | (Еxtexp(iuf) | 2.
Для гармонической частоты величина /и(шу) равна (n/2)Rj —
составляющей в разложении дисперсии (18.3.5), связанной с этой ча-
стотой. Данное определение просто распространяет этот конечный на-
бор значений на весь непрерывный интервал частот. Альтернативное
выражение, включающее комплексную экспоненту [см. IV, (9.5.8)],
удобно для некоторых алгебраических преобразований.
18.3.4. ВЛИЯНИЕ ИСКЛЮЧЕНИЯ СРЕДНЕГО ЗНАЧЕНИЯ
НА ПЕРИОДОГРАММУ
Значение периодограммы в начале координат равно 1п(0) = 2пх2.
Так как среднее значение х обычно вносит до некоторой степени про-
извольный базисный уровень для наблюдений, на практике (как и в
дисперсионном анализе) среднее значение исключают, т. е. заменяют в
определении 18.3.1 xt на (xt— х). После такого преобразования
1п(0) = 0. Из свойств ортогональности следует, что прибавление (или
вычитание) любой константы к данным не влияет на значения перио-
дограммы для гармонических частот Однако промежуточные час-
тоты при этом затрагиваются. Отказ от исключения среднего значе-
ния из данных приводит к увеличению функции 1п(ы) на интервале
0 < w < Ш] на величину того же порядка, что и /„(О), т. е. порядка
312
пх2. Внутри последующих интервалов соу- < со < соу+1,у = 1, 2,
величина 7л(ш) возрастает колоколообразно на величину порядка
пх2/(тг2}2), и можно показать, что для любой фиксированной часто-
ты ш, отделенной от начала координат, эффект имеет (в худшем слу-
чае) порядок х/у/п. Общая картина эффекта показана на рис.
18.3.2, а), на котором изображена периодограмма константы xt = 1,
t = 1, ..., 64.
Рис. 18.3.2. Периодограммы простейших рядов с выделенными гармонически-
ми частотами: а) периодограмма ряда xt = 1, t = 1,..., 64; 6) периодограмма ря-
да xt = Rcos>{<j>'t + ф), t = 1,..., 64 с и>' = 2т/16, ф = т/'З, R = 2; в)
периодограмма ряда xt = 7?cos(w7 + ф), t = 1,..., 64 с w' = 2тг(4, 5)/16, ф = т/3,
R = 2
18.3.5. ПЕРИОДОГРАММЫ ДЛЯ ПРОСТЫХ МОДЕЛЕЙ
В этом разделе периодограммы будут вычисляться для значитель-
но более мелкого разбиения частот, нежели гармонические частоты,
которые тем не менее будут отмечены на графиках.
Модель 1. xt = 7? cos (со 7 + ф), t = 1, ..., п.
Периодограмма этого ряда 7\;(со) показана на рис. 18.3.2, б) для
R = 2, п = 64, а/ = 2тг/16 и ф = тг/З. Так как ш' — гармоническая
частота, рассматриваемый ряд — пример представления (18.3.3) с
единственной гармонической компонентой, отвечающей j = 4. Следо-
вательно, = 0 для всех у, за исключением /л(со4) = (n/2)R2 =128.
Однако на промежуточных частотах обращают на себя внимание ко-
локолообразные поднятия, подобные рис. 18.3.2, а).
313
Модель 2. По сравнению с моделью 1 значение частоты о/ здесь
заменено на величину 2тг(4, 5)/64. Периодограмма, показанная на рис.
18.3.2, в), похожа на периодограмму б) того же рисунка, но максимум
на ней достигается не в точности в точке w', и его значение не равно
в точности 128. Так происходит потому, что ы не является гармони-
ческой частотой. В этом случае векторы
(sinwV} ”, (coswZ} f
не являются в точности ортогональными, и суммы квадратов их ком-
понент не равны в точности (л/2). Тем не менее пик на периодограм-
ме дает правильное представление о частоте и квадрате амплитуды,
или мощности. Если рассматриваются только гармонические частоты,
то вклад в формирование пика в основном разделяется пополам меж-
ду частотами ш4 и ш5. Подобную периодограмму естественно можно
интерпретировать как свидетельство того, что ряд содержит одну си-
нусоидальную компоненту с частотой, лежащей между ш4 и ш5, но
равным образом ряд может представлять собой смесь компонент, от-
вечающих гармоническим частотам. Вообще группу синусоидальных
компонент с частотами, лежащими в полосе шириной порядка 2тг/и,
трудно разделить с помощью периодограммы.
Модель 3. Ряд хь ...,хп является случайной выборкой из нор-
мального распределения со средним д и дисперсией а2. Разложение
дисперсии (18.3.5) можно рассматривать как разбиение на независи-
мые компоненты, так что величина (n/2)Rj/а2 имеет распределение
хи-квадрат с двумя степенями свободы [см. раздел 2.5.4, п. а)]; в мо-
дели отсутствуют какие-либо истинные эффекты. Другими словами,
величины In<Uj) для j = 1, ..., т образуют случайную выборку из
экспоненциального распределения [см. II, раздел 11.2] со средним 2а2.
Этот вывод проиллюстрирован для п = 64 и о2 = 1 на рис. 18.3.3, а),
где приведена периодограмма ряда, изображенного на рис. '18.1.1, г).
Можно ожидать, что в случайной выборке объема 31 окажутся какие-
то выделяющиеся значения, которые опрометчивый исследователь
может истолковать как значимые синусоидальные компоненты, кото-
рых в действительности не существует. Эта опасность возрастает при
построении периодограммы для промежуточных частот. Наибольший
(и совершенно бессмысленный) пик на рис. 18.3.3, а) при рассмотре-
нии только гармонических частот полностью исчезает.
Модель 4. Рассматривается ряд ylf ..., уп, где У1 = хг — х и
yt = yt_r + (х, — х), t = 2, ..., n. (18.3.6)
Таким образом, yt есть накопленная сумма значений ряда xt из приве-
денной выше модели 3 после исключения из него среднего значе-
314
10
5
а)
0
я
Рис. 18.3.3. Периодограммы чисто случайного ряда а) и случайного блуждания
б) с выделенными гармоническими частотами
ния. Такой ряд образует случайное блуждание [см. II, раздел 18.3] с
ограничением — условием возвращения в нуль, так как уп = 0. Мы
могли бы прийти к тому же результату, не исключая из ряда xt сред-
него значения, а вместо этого исключив из ряда yt тренд — прямую
линию, выходящую из нуля и проходящую через последнюю точку
графика обычного случайного блуждания. Так как исключение тренда
в той или иной форме часто рекомендуют осуществлять до построе-
ния периодограммы, эта операция не является необычной и в действи-
тельности позволяет нам продемонстрировать тесную связь между
периодограммами рядов yt и xt для гармонических частот. Если ряд
315
(xt— x), t = 1, и, искусственным образом периодически продол-
жить, то из равенства уп = 0 следует, что ряд yt, определяемый фор-
мулой (18.3.6) при t > п, также будет периодичен, так что
У( — Уt^.i = xt — х для всех t.
Если RjCOs((jjjt + фу) — компонента в гармоническом разложении yt,
то в ряду yt — yt—l она преобразуется следующим образом:
jR-cosO,/ + ф) — JR cos(w:(r — 1) + ф.) =
J J J J J J
= 21? sin (о? /2) cos (со .7 + ф . — со ./2 + тг/2).
J J J J J
Как мы видим, частота не изменилась; умножив амплитуду на за-
висящий от частоты (но не от данных) множитель 2sin(coy/2), мы по-
лучим соответствующую гармоническую компоненту ряда (х{ — х).
Следовательно,
У) = x)/4sin2(w/2), j = 1, ..., т,
и в силу результатов, полученных для модели 3, периодограмма ряда
у образует последовательность независимых экспоненциально распре-
деленных величин со средними значениями 2a2/4sin2(wy/2). Для ма-
лых значений j эти величины могут оказаться довольно большими.
На рис. 18.3.3, б) показана периодограмма ряда, приведенного на рис.
18.1.1, д). Не зная чисто случайной природы ряда, можно заподо-
зрить, что большой пик в низких частотах соответствует детермини-
рованной синусоидальной компоненте.
18.3.6. ИНТЕРПРЕТАЦИЯ ПЕРИОДОГРАММЫ
Очевидно, что при интерпретации периодограммы данных, пред-
ставляющих собой суммы рядов, могут возникать трудности, подоб-
ные описанным выше. Соответствующие частотные компоненты
могут усиливать или взаимно уничтожать друг друга, но при усредне-
нии их периодограммы суммируются (так же, как и дисперсии). Детер-
минированную синусоидальную компоненту можно распознать по
острию на периодограмме в соответствующих частотах с высотой,
пропорциональной п, и шириной порядка 1/и. Это острие должно, та-
ким образом, подниматься над средним уровнем периодограммы, воз-
никающим за счет случайных эффектов и не имеющим тенденции
меняться с ростом п. Однако случайные модели могут также давать
высокие пики, и их интерпретация будет неясна до тех пор, пока не
станут доступны последующие данные или не будут использованы
другие критерии, касающиеся природы ряда. В качестве примера
316
на рис. 18.3.4 показана часть периодограммы ряда продолжительнос-
ти дня, изображенного на рис. 18.1.1, в), после удаления тренда. За-
манчиво объяснить некоторые из пиков как циклы астрономи-
ческого происхождения, но мы далее покажем, что эти свойства столь
же хорошо можно объяснить простой стохастической моделью. Сход-
ство с рис. 18.3.3, б) совершенно очевидно.
Рис. 18.3.4. Часть периодограммы ряда продолжительности дня (150 точек) с
выделенными гармоническими частотами и соответствующими периодами
18.4. РАЗНОСТНЫЕ ОПЕРАТОРЫ
При рассмотрении временных рядов естественно представлять де-
терминированные функции времени простыми рекуррентными уравне-
ниями [см. I, раздел 14.3], показывающими, как связаны между собой
последовательные значения. Например, тренд
xt = а + bt
можно представить двумя простыми способами:
Xt = xt_} + b,
Х{ — Х(—] + (Xf—j Xt—2) ~ 2х^—I Xt—2 у
317
первый из них сохраняет одну постоянную, второй исключает обе. Ис-
пользуя оператор взятия обратной разности, определяемый формулой
V xt = xt — xt_j,
v Ч = V (V xt) = (xt — X'-J — (xt_j — xt_2),
мы можем более удобно записать приведенные выше соотношения как
V xt = b, V 2х( = 0.
Если во временном ряде yt обнаруживается трендовая компонента,
может оказаться проще и естественнее анализировать ряд 'Ч уt после-
довательных приращений или даже ряд V 2уг Более того, если ряд yt
содержит в качестве компоненты случайное блуждание подобное
изображенному на рис. 18.1.1, д), структура такого ряда также упро-
стится, так как по определению V w, есть случайный ряд, аналогич-
ный ряду на рис. 18.1.1, г).
Чисто периодический ряд, могущий составлять компоненту сезон-
ного временного ряда с периодом сезонности s, удовлетворяет соот-
ношению
X, = xt_s.
Вводя оператор взятия сезонной обратной разности, определяемый
как
V5X/ — Xt Xt_s,
мы получим для сезонной компоненты соотношение Vsxt = 0. Таким
образом, для сезонного ряда у( может оказаться проще анализиро-
вать ряд V syt, в котором исключена любая детерминированная се-
зонная компонента. Для ряда авиаперевозок сезонные разности приве-
дены на рис. 18.2.1, в). Интересно сравнить их с рядом остатков на
рис. 18.2.1, б), построенным по модели (18.2.1). Оба этих ряда получе-
ны в результате применения операций, уничтожающих сезонность. На
рис. 18.2.1, б) ко всему ряду было подогнано и затем исключено
вместе с трендом фиксированное сезонное колебание (одинаковое для
всех лет). На рис. 18.2.1, в) для каждого года исключаются различные
сезонные колебания, а именно значения предыдущего года. Поскольку
сезонные колебания столь заметны и устойчивы, результаты очень по-
хожи, хотя на рис. 18.2.1, в) еще присутствует положительный сред-
ний уровень (средний прирост за год), возникающий из-за тренда.
Однако стоит заметить, что, не считая среднего уровня, ряд на рис.
18.2.1, в) является сезонной разностью ряда рис. 18.2.1, б). Эффект
удаления любого сезонного колебания теряется после взятия сезонной
разности.
Если ряд содержит и тренд, и сезонную составляющую, их можно
исключить, применяя последовательно операторы V и V5 (в любом
порядке), т. е.
318
= O'," y,-s) - <y,-i ~ yt-s-i)-
Результат такого преобразования для ряда авиаперевозок показан
на рис. 18.2.1, г), получившийся ряд является попросту первой разнос-
тью ряда, изображенного на рис. 18.2.1, в). Этот ряд с близким к ну-
лю средним значением имеет вид совершенно случайного ряда.
Аргумент за использование этих операторов для преобразования
рядов с целью упрощения их структуры необходимо дополнить кон-
структивной интерпретацией. Ряд, состоящий только лишь из детер-
минированного тренда и сезонной компоненты, после применения
этих операторов полностью вырождается, так как V Vsxt = 0. Одна-
ко переписав это уравнение как
Xt ~ Xt—S + (Xt—S Xt—S—])’ (18.4.1)
мы видим, каким образом ряд можно неограниченно продолжать,
имея в начале по крайней мере s + 1 последовательных значений. Это
правило можно применить, например, к построению прогноза (ежеме-
сячного) ряда авиаперевозок на основе данных за последний год. Пра-
вило предписывает взять последнее доступное приращение за год от
декабря 1958 г. до декабря 1959 г. и прибавить его к январским, фев-
ральским и т. д. данным за 1959 г., получая прогноз на январь, фев-
раль и т. д. 1960 г. Результаты показаны на рис. 18.4.1. Сравнение
результатов с экстраполяцией по подогнанной модели (18.2.1) показы-
вает, что они оказываются лучше для первых четырех месяцев. Эти
две процедуры являются в определенном смысле крайними, так как
модель (18.2.1) приписывает равные веса всем доступным данным, а
правило (18.4.1) приписывает ненулевые веса только самым послед-
ним данным (за последние 13 месяцев). Мы увидим в разделе 18.7.6,
что между этими двумя крайностями возможен компромисс.
18.5. СТАЦИОНАРНЫЕ ВРЕМЕННЫЕ РЯДЫ
Содержание предыдущего раздела подводит нас к проблеме опре-
деления оптимальных весов для наблюдений при построении прогно-
за. Такие веса должны зависеть от статистической корреляции между
значениями, относящимися к настоящему, и будущими значениями ря-
да. Наша дальнейшая цель состоит в исследовании корреляционной
структуры наблюдаемого ряда после необходимого исключения детер-
минированного тренда, циклов и сезонности с помощью регрессион-
ных или же разностных методов.
319
Рис. 18.4.1. Прогноз ряда авиаперевозок: • реальные значения ряда; О прог-
ноз с помощью экстраполяции модели суммы тренда и месячных эффектов
(18.2.1); ▼ прогноз по экстраполяционному правилу (18.4.1), связанному с раз-
ностным оператором v V 12; х прогноз, построенный по сезонной модели экс-
поненциального скользящего суммирования (18.7.42); + прогноз по модели
Бикса—Дженкинса (18.7.43)
18.5.1. АВТОКОРРЕЛЯЦИОННАЯ ФУНКЦИЯ (АКФ)
Общим для всего раздела является предположение о том, что вре-
менной ряд стационарен, т. е. порождающий его механизм не меняет-
ся во времени, а соответствующий процесс достиг статистического
равновесия. На практике наиболее интересными статистиками явля-
ются моменты первого и второго порядков [см. раздел 2.1.2], так что
мы накладываем на временной ряд xt следующие условия:
1) математическое ожидание и дисперсия ряда [см. II, гл. 8 и 9]
постоянны во времени:
E(xt) = цх, var(xz) = ох при всех t; (18.5.1)
2) ковариация между любыми двумя членами ряда [см. II, раздел
9.6.1] зависит только от расстояния во времени между этими наблю-
дениями, или от разности между их номерами:
cov(xp xt+k) = ух(к) для всех t. (18.5.2).
По определению ух(0) = агх. Автокорреляционная функция (АКФ)
определяется формулой
320
е,(*) = т,(*)/«’. к > о, е,(О) = 1, (18.5.3)
[см. II, раздел 22.2]. Полезно рассматривать АКФ как бесконечную в
обе стороны последовательность, полагая qx(—к) - Qx(k).
Для выборочных данных ..., хп обычно используют выбороч-
ное среднее и выборочную дисперсию
х=(1/л)Ех/, 52 = (1 /n)£(xt — х)2 (18.5.4)
и выборочные автоковариацию и автокорреляцию, определяемые фор-
мулами п_к
Сх(к) = (1/и)Е (xt — x)(xt+k — х);
(18.5.5)
rx(k) = Cx(k)/sx; к = 1, ..., л—1,
где полагают rx(0) = 1 [см. раздел 2.1.2, п. б), в]. Их следует рас-
сматривать как выборочные описательные статистики. В них усредне-
ние осуществляется по времени, а не по независимым реализациям
процесса. Тем самым гх(1) не обязательно окажется наилучшей оцен-
кой для cx(l), если предположить, что ряд xt описывается некоторой
параметрической моделью. Однако при должном понимании их недо-
статков эти выборочные статистики оказываются наиболее полезны-
ми. Чтобы установить их свойства, необходимо сделать дополнитель-
ные предположения о распределении xt. Приводимые ниже результа-
ты выполняются для гауссовских рядов — это означает, что все част-
ные и совместные распределения [см. II, раздел 13.1] членов
временного ряда должны быть нормальными. Будет предполагаться
также, что сумма Е | Qx(k) | конечна. Это предположение не может
оказаться слишком жестким, так как для подавляющего большинства
практических задач Qx(k) оказывается пренебрежимо малым для зна-
чений к, превышающих некоторую (возможно, большую) величину.
Если, однако, из ряда не удалось исключить какую-либо детерминиро-
ванную компоненту, например, синусоидальную волну, то выбороч-
ные автокорреляции гх(к) отразят это обстоятельство — они не
будут затухать при больших лагах.
Следующие приближенные равенства справедливы при фиксиро-
ванных к и достаточно больших п с ошибкой порядка 1/п:
Е(х) = var(x) = (Уп)агх{ 1 + 2ТеД/)}, (18.5.6)
Е(^) « a*, var(^) « (1/л)2ах[ 1 + 2Е ех(/)2}, (18.5.7)
E(rx(k)) « Qx(k), var(rx(£)) «
(18.5.8)
« (1/w) {1 + 2Тех(/)2} + (1/л?) + k)Qx(j — к)}.
321
Выборочные величины являются, таким образом, состоятельными
оценками [см. раздел 3.3.1, п. в)], хотя для малых п величина гх(к)
имеет заметное смещение [см. определение 3.3.2]. Польза этих фор-
мул ограничена в таких задачах, как построение доверительного ин-
тервала для Qx(k) [см. раздел 4.2] или выделение значимых
корреляций [см. раздел 5.1], так как они содержат те же самые вели-
чины, для которых строится оценка. Для этих целей необходим более
осторожный подход типа «бутстреп». Начальной точкой является ги-
потеза о равенстве $х(к) = 0 для всех к > 0, и в этом случае стан-
дартная ошибка S. E.(rx(£)) » 1/Vn. Значения, не попадающие в
интервал ±2/Тл, следует рассмотреть отдельно. Возьмем в качестве
примера показанную на рис. 18.5.1, б) выборочную АКФ ряда первых
разностей продолжительности дня, изображенного на рис. 18.5.1, а).
Применение операции взятия разности связано с высказанным выше
предположением, что этот ряд содержит компоненту типа случайного
блуждания. Использовались первые 140 точек ряда, остальные точки
мы оставили про запас для сравнения с прогнозом, который мы соби-
раемся построить.
В первую очередь мы замечаем, что | rx(k) | > 2/Vw(=0,17) для
к = 1, 2, 3, 12, 13, 14, 27, ..., 33. Сам факт, что в этом списке так
много значений, означает, что мы занизили величину стандартной
ошибки (определение стандартной ошибки см. в разделе 2.1.2, п. в)).
Соблюдая осторожность, пересмотрим нашу гипотезу, предположив,
что только ех(1) и ех(2) отличны от нуля, что соответствует двум
первым выделяющимся значениям гх(1) - 0,76 и гх(2) - 0,52.
Теперь воспользуемся формулой (18.5.8), полагая Qx(k) = 0 для
к > 2 и беря в качестве оценки для ех(1) и @х(2) величины гх(1) и
гх(2). Мы получим
2S. E.[rx(£)] « 0,17 V { 1 + 2(0,762 + 0,522)] = 0,28 для к > 2.
Заметим, что вообще при проверке гипотез вида qx(J) = 0 для
j > К второе слагаемое в формуле (18.5.8) для var(гх(к)) пропадает
при к > К. Используя новые доверительные границы, мы видим
смутное свидетельство, возможно, значимого отклонения от нуля ве-
личин, отвечающих лагам 29 и 30, для которых автокорреляция имеет
порядок 0,29; однако при рассмотрении свыше 40 коэффициентов два
выделяющихся значения могут появиться и за счет случайных причин.
Поэтому мы сохраняем скептицизм по поводу значимости этих корре-
ляций. Таким образом, наше предположение о том, что лишь ех(1) и
бх(2) отличны от нуля, не противоречит имеющимся данным. Мы
увидим далее, что это предположение является слишком жестким и
должно быть ослаблено. Тем не менее у нас есть полезное начальное
322
приближение для подгонки параметрических моделей, которое можно
подвергнуть более тщательной проверке, как это будет сделано в раз-
деле 18.7.3. В заключение выскажемся по поводу соблазна придать со-
держательный смысл хорошо заметным на глаз циклам в выборочной
АКФ. Чтобы понять возникающий здесь эффект, рассмотрим следую-
щую формулу (не зависящую от л):
correlation {гх(к), гх(к + /)} «
(18.5.9)
« Qx(j)Qx(j + 0} /.^бхО)2},
которая справедлива при к > К в предположении, что Qx(j) = 0 для
j > К (в нашем случае К = 2). Итак, последовательность гх(к) при
к > 2 сама оказывается стационарным временным рядом, но по срав-
нению с исходным рядом его автокорреляция сильнее и отлична от
нуля вплоть до расстояния между коэффициентами, равного i = 4.
Значения гх(к) независимы, лишь если они разделены пятью интерва-
лами или более. Их автокорреляция гладко ведет себя для промежу-
точных лагов. Это и приводит к появлению волнообразных колеба-
ний, или циклов.
18.5.2. СВЯЗЬ МЕЖДУ ПЕРИОДОГРАММОЙ И АКФ
Периодограмма временного ряда связана с выборочной АКФ очень
простым образом — это другая точка зрения на ту же самую инфор-
мацию. Считая, что среднее значение уже исключено из ряда, мы по-
лучаем для периодограммы следующее представление в виде триго-
нометрического ряда с коэффициентами, зависящими от выборочной
АКФ:
1/2/л(и) = s*{ 1 + 2Ё* гх(к)соьшк}, 0 и тг. (18.5.10)
Этот результат выводится из первого равенства в определении
18.3.1; так, например,
п п п
(Exzsinu/)2 = (Ex,sinu/)(Ex sinus),
1 t= 1 5=1
и, раскрывая скобки и группируя члены в двойной сумме, получаем
п п
1/21п(ш) = (1/л)Е Еx(xs(sinи/sinus + cosuZ cosus) =
= (1/л)Е Ex.x.cos(u[Z— s]).
1=15=1 ‘ Л
Объединим теперь члены с xtxs, для которых |z— s| = к для
к = 0. ..., п — 1; мы получим выражение
323
(1/и) {Ex*) + 2J£ {(l/и)lxtxt+k ) cos co/с,
из которого непосредственно следует (18.5.10).
В свою очередь АКФ можно просто восстановить по периодо-
грамме:
s>,(t)=(l/«) (1/27„(0) +"E7„(a>,)cosfco>, + 1/2Z„(t) J. (18.5.11)
где = ttv/п, у = 1, ...» л — 1 — гармонические и полугармониче-
ские частоты. Обратную формулу можно вывести из (18.3.4); она дает
косвенный, но эффективный способ вычисления АКФ через периодо-
грамму для длинных рядов данных. Для этой цели используются ал-
горитмы быстрого преобразования Фурье.
18.5.3. СПЕКТР И ВЫБОРОЧНЫЙ СПЕКТР
Представление (18.5.10) периодограммы через выборочную АКФ
непосредственно основано на следующем определении, использующем
теоретическую АКФ.
Определение 18.5.1. Спектр. Спектром временного ряда с АКФ
Qx(k) называется функция
/х(со) = (1/тг)агх{ 1 + 2Е gx(fc)cosw£ ], 0 < w т.
Определение 18.5.2. Выборочный спектр. Выборочным спектром
наблюдений хн ..., хп называется функция
£(а>) = (1/тг)5* {1 + 2*Е r/£)cosco£} =(1/27г)/л(со), 0 со тг.
Множите^ (1/2тг), составляющий единственное отличие выбороч-
ного спектра от периодограммы, обеспечивает равенство
J/,(«)<7« = а2. (18.5.12)
о
Это соотношение показывает, как можно распределить полную дис-
персию ах в интервале [0, т]с плотностью /х(со), аналогично разложе-
нию дисперсии (18.3.5), из которой в случае четного п следует
равенство т п
Е 7л(соу) = Е(х,-х)2 - (18.5.13)
распределение выборочной дисперсии по гармоническим компонентам.
В различных ситуациях спектр приходится нормировать с помощью
различных множителей, например, если используется абсолютная
частота f = со/2тг, пробегающая интервал [0, 0,5], то множитель
(1/тг) нужно заменить на 2. Неравенство /х(со) > 0 будет кратко объ-
яснено в следующем разделе.
324
Эквивалентность спектра и АКФ доказывается формулой обраще-
ния, аналогичной (18.5.11). Поскольку спектр является бесконечным
тригонометрическим рядом, можно воспользоваться свойствами орто-
гональности для тригонометрических функций в интегральной форме
[см. II, раздел 20.4] для вычисления коэффициентов ряда:
г
<^qx(*) = J/x(w)coswArdw, к = 0, 1, 2, .... (18.5.14)
о
Определение спектра мотивированно главным образом соотно-
шением
ДЫ прил^.„, (18.5.15)
которое само по себе не удивительно и непосредственно следует из то-
го, что E[rx(k)]^ Qx(k).
Более значительным и удивительным фактом является то, что хотя
для каждого фиксированного к rx(k)—~ Qx(k) при и-*. «« в смысле
сходимости по вероятности и каждый член суммы в определении
18.5.2 сходится к соответствующему члену в определении 18.5.1, тем
не менее /*(со) не сходится к Д(ш) ни в каком смысле. Фактически вы-
борочный спектр имеет некоторое фиксированное распределение, зави-
сящее от теоретического спектра.
Теорема 18.5.1 (Распределение выборочного спектра). Для боль-
ших п величины являются независимыми экспоненциально рас-
пределенными случайными величинами со средним где —
гармонические частоты.
Мы не будем доказывать эту теорему, но отметим, что ее справед-
ливость уже доказана нами для частного случая, когда Qx(k) = 0 при
к > 0, т. е. Xi, .... хп образуют случайную выборку и спектр
Д(ш) = агх/к постоянен. Это было сделано при исследовании свойств
периодограммы для модели 3 в разделе 18.3.5. Простейшими условия-
ми для справедливости теоремы являются условия из раздела 18.5.1,
но, как будет показано в разделе 18.6.4, их можно значительно
ослабить.
То обстоятельство, что выборочный спектр не является состоя-
тельной оценкой [см. раздел 3.3.1, п. в)], имеет большое практическое
значение, но не следует непосредственно из определения 18.5.2. Причи-
на этого явления состоит в том, что с ростом п в сумме, стоящей в
этом определении, появляются новые слагаемые; для построения сос-
тоятельных оценок спектра необходимо, чтобы количество членов в
этой сумме было в определенном смысле ограничено. Подобные мето-
ды описаны в разделе 18.10.2; однако при визуальном исследовании
выборочного спектра или периодограммы нетрудно увидеть форму
лежащего в их основе спектра.
325
18.5.4. СВОЙСТВА СПЕКТРА И АКФ
Из соотношения (18.5.15) непосредственно следует неравенство
/х(со) 0» так как выборочный спектр или периодограмма по опреде-
лению неотрицательны. В остальном спектр может быть любой до-
статочно гладкой непрерывной функцией. Непрерывность спектра —
следствие нашего условия Е | Qx(k) | < «=». В свою очередь это ус-
ловие выполняется, если функция /x(w) достаточно гладкая. Таким
образом, спектр является естественным способом описания структуры
стационарного временного ряда. Широкие пики в спектре соответству-
ют нерегулярным циклам, а узкие пики — более регулярным циклам,
которые на малых выборках будет трудно отличить от детерминиро-
ванных циклов. В самом деле, подобные детерминированные компоне-
нты, если их заранее не исключили из ряда, должны рассматри-
ваться как дискретная часть спектра по аналогии с дискретными веро-
ятностными распределениями и в противоположность непрерывной
спектральной плотности /х(со). Ряд с дискретной и непрерывной ком-
понентами имеет смешанный спектр, примером может служить рас-
смотренный в разделе 18.2.2 ряд звездной величины переменной
звезды, который будет ниже рассматриваться в разделе 18.11.
В противоположность спектру АКФ удовлетворяет обычным огра-
ничениям на корреляции. Эти ограничения можно резюмировать, рас-
сматривая корреляционную матрицу Rn [см. определение 16.1.1] для
п последовательных членов ряда, скажем,
1 6х(1) 6х(2)
ех(1) 1 ех(1)
ех(л—!)
... Qx(n — 1)
... ₽х(« - 2)
• 6х(1) (18.5.16)
2х(1) 1 •
Условие положительной определенности [см. определение 16.1.3]
этой довольно просто устроенной матрицы при любом п является не-
обходимым и достаточным для того, чтобы набор значений Qx(k)
был АКФ некоторого стационарного временного ряда, и это условие
в точности эквивалентно условию положительности спектра. Возьмем
в качестве примера АКФ, удовлетворяющую условию Qx{k) = 0 при
к > 1. В этом случае диапазон возможных значений для qx(1) — это
интервал [—0,5, 0,5]. Это следует, например, из формулы для спектра
/х(со) = ах{1 + 2qx(1)coscj }, который дает отрицательные значения
326
на одном из концов интервала [0, тг], если неравенство | 2gx(l) | 1
не выполняется. Если Qx(k) = 0 для к > 2, то qx(1) не может превос-
ходить 1/V2, и это значение достижимо лишь при qx(2) = 4“ . Значе-
ния гх(1) и гх(2), полученные для первой разности ряда
продолжительности дня и равные соответственно 0,76 и 0,52, заметно
выходят за допустимые пределы, даже с учетом случайных флуктуа-
ций, и свидетельствуют о необходимости ослабить предположение
Qx(k) = 0 при к > 2.
18.5.5. ЧАСТНАЯ АВТОКОРРЕЛЯЦИОННАЯ ФУНКЦИЯ (ЧАКФ)
Несколько другой способ полезного представления информации,
содержащейся в АКФ, появляется в связи с задачей построения про-
гноза. Зная АКФ qx(k) стационарного временного ряда, мы распола-
гаем всей необходимой информацией для построения линейного
МНК-предиктора (на один шаг вперед) по конечному числу предыду-
щих значений, скажем, для х( по xt_l} ..., xt_k. Если временной ряд
является гауссовским, такой предиктор можно интерпретировать как
уоловное математическое ожидание [см. II, раздел 8.9] значения х(
при известных xt_}, ..., х(_к, которое в этом случае совпадает с ли-
нейной регрессией на эти переменные. Обращение к линейному МНК-
предиктору позволяет нам отказаться от предположения относитель-
но гауссовского закона, и мы получаем тот же ответ, что и в гауссов-
ской ситуации. Коэффициенты предиктора определяются по
корреляциям между переменными, т. е. по величинам qx(1), ..., Qx(k).
Выпишем прогноз, или регрессионное уравнение
xt = 4>k,\xt-\ + 4>k,ixt-i + ••• + <h,kxt-k + ek, „(18.5.17)
где линейная комбинация xt_}, ..., xt_k — предиктор, a ek t — ошиб-
ка прогноза. Первый индекс к у коэффициента фк у, j = 1, и у
ошибки ек t подчеркивает то обстоятельство, что при включении в
уравнение новых членов, например вычисленные ранее коэф-
фициенты должны измениться. Мы не включаем в предиктор констан-
ту, предполагая, что цх = 0; в противном случае xt нужно просто
заменить на х1 — цх. Обозначим дисперсию ошибки прогноза
var(e^ ,) через ак, и отношение ох/ок — через vk.
Формально для нахождения коэффициентов необходимо решить
систему к линейных уравнений, определяющих минимум суммы ква-
дратов, однако автокорреляционная структура ряда позволяет указать
быстрый рекурсивный способ нахождения решения. Этот факт, бес-
спорно, имеет большое практическое значение, в частности, в таких
областях, как геофизика, где для построения хороших оценок АКФ ис-
пользуется большой объем данных. Порядок предиктора к при этом
может достигать нескольких сотен.
327
Приведем рекурсивную процедуру вычисления коэффициентов.
Вначале полагаем v0 = 1. На первом шаге имеем
Ф,,, = е/1), v, = г„|1-ф5,] (18.5.18)
и далее для к > 1
<W*+i = — Фк, i6xW —•••— Фк, kQx(V ) / vk> (18.5.19)
Фк+lJ = Фк, j Фк+[, к+\Ф к, к + 1—J’ J ~ •”» ’ (18.5.20)
V*+I = М 1 - Ф*+,,t+11 (18.5.21)
Поясним вывод этих уравнений из стандартной теории метода на-
именьших квадратов [см. гл. 8], которая излагалась в более общей си-
туации.
Пусть вычислена МНК-регрессия [см. раздел 6.5.1] зависимой пе-
ременной на множество переменных xit ..., хк с ошибкой ек. Если в
уравнение вводится новая переменная х^+1, некоррелированная с
Xi, ..., хк, то вычисленные ранее коэффициенты не меняются, а коэф-
фициент аА.+ 1 при хЛ+] может быть представлен в виде
"k+i = cov(j, x(t+1)/var(xA.+1) = cov(e*, x^+1)/var(x^+1) =
= р {var(eA.)/var(xA.+ 1),/2}, (18.5.22)
где
q = correlation (ek, xk+l). (18.5.23)
В свою очередь дисперсия ошибки преобразуется следующим образом:
var(£?£+1) = var(^) - ak+l var(x^+1) = var(^)(l — q2). (18.5.24)
Если же новая переменная х^+1 не является некоррелированной с
Xt, ...,хк, ее можно заменить на переменную хк+1, полученную ор-
тогонализацией, т. е. коррекцией хк+1 путем вычитания из нее ее ли-
нейного предиктора, использующего уже существующие переменные
Xi, ..., хк. Коэффициент корреляции q в (18.5.23) в этом случае назы-
вают частной корреляцией между х^+1 и у, и в гауссовском случае он
является просто условной корреляцией при известных хп ...,хк.
Применим эти результаты к временному ряду, основываясь на
уравнении (18.5.17). Вводя новую переменную x,_(jt+1), мы не можем
считать ее некоррелированной с х,_7, ...,х(_к, так что необходимо
построить скорректированную переменную xj_(jt+1). Но для нее
имеем
Х7_(А.+ 1) = X,_((t+1) фк> iXt_k фк' 2хt—к+1 ••• Фк, kXt—l ’ (18.5.25)
328
т. е. для построения обратного предиктора для коррекции xt_(kJrV)
можно использовать те же самые коэффициенты и те же самые пере-
менные, что и для х/+1, но взятые в обратном порядке.
На этом последнем шаге как раз и используют для вычислитель-
ных нужд специальную структуру стационарного временного ряда.
Это следует непосредственно из того факта, что корреляция между пе-
ременными зависит от величины временного лага между переменны-
ми. Более того, так как является ошибкой (обратного)
прогноза,
var(x'_(it+1)) = var(e^) = a2xvk. (18.5.26)
Новый коэффициент при xt_(k+V) вычисляется теперь с помощью
(18.5.22) по формуле
^+1,^+1 = cov(*r> ^_(jt+1))/var(rr_(Jfc+1)). (18.5.27)
Из уравнений (18.5.25) и (18.5.26) вместе с (18.5.27) непосредственно
следует первое уравнение цикла (18.5.19). Добавление нового члена
Фк+1 k+\x't—(л+1) к предыдущему предиктору вносит поправки в суще-
ствующие коэффициенты, как и во втором уравнении цикла (18.5.20).
Наконец, с учетом (18.5.26) и (18.5.23) замечаем, что новый коэффици-
ент Фк+\>к+1 совпадает с корреляцией q (между ek>t и x't_{k+{}). От-
сюда в силу (18.5.24) получаем последнее уравнение цикла (18.5.21).
Частной автокорреляцией между xt и xt__(k+V) при известных xt_x,
..., xt__k называют коэффициент фк+х *+1, который выражает величи-
ну дополнительной информации, полученной при включении x,_(jt+1) в
линейный предиктор для х(. Частной автокорреляционной функцией
(ЧАКФ) называют последовательность этих коэффициентов. Они
удовлетворяют единственному ограничению: | фкк | < 1, в осталь-
ном они могут принимать любые значения, и если задана такая после-
довательность значений, по ней можно построить соответствующую
АКФ, обратив рекурсивную процедуру. Однако практически неизмен-
ное условие существования положительного нижнего предела для дис-
персии ошибки прогноза u2xvx влечет за собой сходимость ряда 12ф2к к,
в частности фк к -»• 0.
18.5.6. ВЫБОРОЧНАЯ ЧАКФ
Если вместо величин Qx(k) используются выборочные характери-
стики гх(к), возникает выборочная ЧАКФ Фк>к. Знание ее свойств
требуется при решении вопроса, является ли порядок предиктора к пъ-
статочно большим для адекватного описания структуры временного
ряда с возможной целью использовать коэффициенты фкj для прог-
нозирования будущих значений ряда.
329
В предположении нулевой гипотезы, что истинные значения фк к
удовлетворяют соотношению
фк>к = 0 для к > К, (18.5.28)
для их оценок, построенных по выборке ..., хп, имеем
Е^к,к> * °’ ™Г(фк к) « 1/л,
Е(а*) = (1 — к/п)о2к для к > К. (18.5.29)
Один из возможных подходов — установить пределы ± 2/Vn вокруг
нуля на графике фк, к и найти такое значение К, после которого гра-
фик фактически укладывается в эти пределы. Поскольку приближен-
ные равенства в (18.5.29) справедливы при к < < п, выбранное
значение К должно быть относительно мало, для того чтобы непос-
редственное применение для прогноза было достаточно эффективно.
Другой подход состоит в построении графика несмещенной оценки
ок, вычисляемой по формуле (1—к/п)~1ок. Далее находят такое
значение К, после которого график стабилизируется, показывая, что
возрастание порядка не улучшает подгонку. В последнее время испо-
льзуется критерий КОП, конечной ошибки прогноза, (1 + к/п)(1 —
— к/п)~1ак. Множитель (1 +к/п) учитывает увеличение ошибки прог-
ноза из-за использования оценок коэффициентов фк j при построении
предиктора. Тем самым налагается штраф на возрастание порядка К.
Выбирается тот порядок К, для которого величина КОП минимальна.
Разумнее использовать эти процедуры для зондирования данных на
предмет выявления возможной структуры, нежели для окончательных
выводов о порядке предиктора. В качестве примера на рис. 18.5.1, в),
г), д) и е) показаны графики величин Фк>к, ок, (1 —к/п)~хогк и
(1 + к/п)(\ —к/п)~хок для первой разности ряда продолжитель-
ности дня. Выбранный порядок К по последнему критерию при этом
равен 7. Соответствующие коэффициенты предиктора показаны на
рис. 18.5.1, ж). Хорошо видно, что вскоре после стабилизации после-
довательность несмещенных оценок начинает монотонно расти, по-
правочный множитель становится очень большим для больших к.
Прогноз последних 10 точек ряда продолжительности дня, построен-
ный с помощью предиктора, приведен на рис. 18.5.2. Для вычисления
прогноза более чем на один шаг вперед каждый следующий прогноз
рассматривался как фактическое значение, и процедура построения
прогноза на один шаг вперед повторялась. Прогноз для исходного ря-
да строился сложением соответствующих прогнозов для разности.
Резкое падение точности прогноза с ростом времени типично для по-
добных рядов, по своей природе сходных со случайным блужданием.
Для сравнения на том же рисунке показаны фактические значения и
прогноз, полученный с помощью более строгой процедуры построе-
ния модели, описанной в разделе 18.11.
330
40
Рис. 18.5.1. Анализ ряда продолжительности дня с помощью выборочных авто-
корреляций: а) первые разности ряда продолжительности дня; б) выборочные
автокорреляции ряда (а); в) выборочные частные автокорреляции ряда (а);
г) оценка дисперсии ошибки прогноза ак для линейного предиктора порядка к\
д) несмещенная оценка (1 —- к/п}~хдгк, е) оценка конечной ошибки прогноза
(КОП) (1 + к/п)(1 — к/п)~1ик-, ж) коэффициенты фкр У = 1.7 линейного
предиктора порядка К = 7
331
400
300 -
200
Рис. 18.5.2. Прогноз ряда продолжительности дня: • фактические значения;
х прогноз, построенный с помощью линейного МНК-предиктора порядка 7
для ряда V xt ; + прогноз, построенный с помощью тренда + АРСС(2, 2) — мо-
дели (18.11.2); верхние и нижние 90%-ные доверительные границы для
прогноза +
18.6. ОБЩАЯ ЛИНЕЙНАЯ МОДЕЛЬ
18.6.1. ОПРЕДЕЛЕНИЕ И СВОЙСТВА
Простейшим стационарным временным рядом является последова-
тельность [at] независимых одинаково распределенных случайных
величин. Создание нового временного ряда как линейной комбинации
текущего и прошлых значений ряда at приводит к автокорреляции. В
основе общей линейной модели (ОЛМ) лежит предположение о том,
что данный временной ряд [xt) возник аналогичным образом, т. е.
что
xt - фоа( + ф}а(_г + ^о,_2 + ...= Е (18.6.1)
Ряд at непосредственно не наблюдаем. Его часто называют «белым
шумом», поскольку шум, который часто слышен в динамиках (в от-
сутствие какого-либо передаваемого сигнала), описывается электри-
ческим сигналом с аналогичными свойствами. При разложении его на
частотные составляющие последние равно представлены в спектре,
332
подобно тому, как при разложении белого света возникает приближен-
но равномерный спектр. Как мы увидим, автокоррелированный ряд
xt уже не имеет равномерного спектра, так что его иногда называют
«цветным шумом», а оператор (18.6.1), с помощью которого он полу-
чен, — «фильтром». Хотя шум часто рассматривают как нежелатель-
ное дополнение к данным из-за ошибок наблюдений, модели шума,
такие, как ОЛМ, играют все возрастающую роль при моделировании
различных явлений.
Модель ОЛМ очень полезна при теоретическом исследовании
свойств распределений выборочных автокорреляций и спектра. Част-
ным случаем ОЛМ являются имеющие большое практическое значе-
ние модели с конечным числом параметров, рассматриваемые в
последующих разделах. Их корреляционные свойства будут вскоре
установлены. Предполагая, что дисперсия var(я,) = оа конечна,
имеем
var(x,) = (18.6.2)
поэтому для того, чтобы модель имела смысл, ряд Е ф* должен схо-
диться. Обычно используют даже более сильное условие сходимости
ряда Е | 1 . Тогда
7(Zr) = cov(x>, xt+k) = cov(E^a,_,., E^tzf+*_,.) =
(18.6.3)
= (E iMwtK»
так как слагаемое в ряду для xt коррелирует лишь со слагае-
мым ^jat+k_j с j = i + к в ряду для xt+k .
Из (18.6.1) непосредственно вытекают также следующие простые
свойства: cov(ap xt_k) = 0, cov(tzf, xf) = фоаа, cov(x,, at_k) = фкоа
при к 1.
18.6.2. ЛИНЕЙНЫЕ ОПЕРАТОРЫ НАД ВРЕМЕННЫМИ РЯДАМИ
ОЛМ — пример применения линейного оператора (или линейного
фильтра) к одному ряду для создания другого ряда. Подобные опера-
ции обычны в анализе временных рядов. Рассмотрим уравнение
v, = Еа,«, ,, (18.6.4)
где мы требуем лишь, чтобы временной ряд [wj удовлетворял усло-
вию Е( | ut | ) <К для всех t и коэффициенты а,- удовлетворяли усло-
вию Е | а, | М. Тогда величины {vt} корректно определены и
Е( | v J ) < КМ. Интервал суммирования может быть от —•=*> до
хотя в большинстве случаев более естественно рассматривать
333
интервал от 0 до . При исследовании таких операторов полезно ис-
пользовать в обозначениях оператор обратного сдвига В, при дейст-
вии которого на временной ряд {и,} возникает ряд {ut_t}. А именно
полагают
Ви, = wr_j, &и( = ut_j. (18.6.5)
Тогда операцию (18.6.4) можно записать в виде
v, = = a(B)ut, (18.6.6)
где оператор
а(В) = La.Bf (18.6.7)
j J
с формальной точки зрения является степенным рядом по В [см. IV,
раздел 1.10]. Это обозначение удобно с алгебраической точки зрения,
поскольку если в свою очередь
w, =J^jBivt = 0(B)vt, (18.6.8)
то
wt = 0(B)a(B)ur (18.6.9)
Под этой записью мы подразумеваем, что wt можно выразить через
и(, а именно
wt = L8jBiut = 6(B)ut, (18.6.10)
где
6(B) = 0(B)a(B). (18.6.11)
Таким образом, последовательному применению линейных опера-
торов соответствует их формальное произведение.
Одно из характеристических свойств линейных операторов состоит
в том, что такие операторы оставляют синусоидальные ряды неиз-
менными с точностью до изменения амплитуды и фазы. Действитель-
но, полагая без потери общности
ut =-cosw/l, (18.6.12)
мы после применения оператора (18.6.4) получаем
V, = {coswZcosw/ + sinwZsinw/J =
J (18.6.13)
== C(w)cosw/ + S(w)sinwZ = /?(w)cos {+ ф(а>)},
где
C(w) = EaycoswJ, S(o)) = EotySina>j — (18.6.14)
действительная и мнимая части [см. IV, раздел 9.5.8] выражения
334
'Laje^j = a(e'w), (18.6.15)
полученного формальной подстановкой е‘ш вместо В в соответствую-
щий оператор (18.6.7).
Значительный интерес представляет коэффициент усиления 7?(ш),
определяемый формулой
RW = С(о>)2 + S(w)2 = | а(е'“) |2 (18.6.16)
и рассматриваемый как функция частоты в интервале 0 ш тг.
Многое в классическом анализе временных рядов в таких приложени-
ях, как сезонная корректировка и сглаживание, связано с построением
фильтров с определенными свойствами, например выделяющих либо
исключающих из ряда определенные частотные компоненты. Более
того, соотношение (18.6.6) обратимо, если только 7?(ш) # 0 при всех
ы, т. е. при этом условии можно записать:
ut = v{B')vt, Е | Vi | < (18.6.17)
где v(B)a(B) al.
18.6.3 . ЛИНЕЙНЫЕ ОПЕРАТОРЫ И СПЕКТР
Влияние линейных операторов на корреляционную структуру ряда
довольно просто. Предположив, что ряд {«,} в (18.6.4) стационарен с
cov(i/f, u,+Jt) = уи{к), мы непосредственно получаем
cov(v,, v(+k) = yv(k) = ррх^у^к — i + j), (18.6.18)
что можно более удобно записать в виде, аналогичном (18.6.6):
yv(k) = а(В)а(В-1)уи(к), (18.6.19)
где В теперь действует на индекс к. Вычисляя произведение
a(B)a(B~l) = А(В) = pAtBl, (18.6.20)
где
Л / = Л_, = Eaza/+/, (18.6.21)
мы получаем симметричный линейный фильтр, связывающий ковари-
ационные функции:
1v(k) = pAtyu{k - /) = А(В)уи(к). (18.6.22)
Например, если
v, = 1/3 [w, + ut_x + ut_2\ — (18.6.23)
односторонний трехточечный фильтр с равными весами, так что
335
«о = «1 = oil = 1/3,
то
Ло = «о + -i- q/ = 3/9,
Ai = aoai + oti ct2 = 2/9,
A2 = aQa2 = 1/9
и
7v(k) = У9уи(к + 2) + 2/97м(Аг + 1) + 3/97и(Аг) +
(18.6.24)
+ 2/97и(Аг - 1) + 1/97м(Аг - 2) -
фильтр, захватывающий пять значений.
Влияние линейного оператора на спектр можно выразить простой
формулой:
7» = R(^fu(a). (18.6.25)
Это интуитивно означает, что применение линейного оператора
приводит к умножению дисперсии каждой частотной компоненты ря-
да на квадрат коэффициента усиления, отвечающего данной частоте.
Для доказательства (18.6.25) введем производящую функцию для кова-
риации
Г„(В) = Т7„(*)В* (18.6.26)
(формально сходную с производящей функцией вероятностного рас-
пределения, см. II, раздел 12.1). В ее терминах (18.6.22) эквивалентно
соотношению
ГДВ) = Л(В)Г„(В) = а(В)о(В_’)Г „(В). (18.6.27)
Подставим далее В = е‘и и используем тот факт, что
Гм(е'ш) = Е уи(к)е‘шк =
(18.6.28)
= 7м(0) + 2*£ yu(k)cosku> = 2т/м(«)
и
а(е/ш)а(е-'“) = | а(е'“) | 2 = Я(а>)2. (18.6.29)
Опуская множитель 2-зг, мы получаем отсюда (18.6.25). Полезно также
следующее соотношение:
R(a)2 = Л(е'«) =Тл/е/а/ = Ло + 2Е Л/COs/w, (18.6.30)
иначе говоря, /?(ш)2 — тригонометрический ряд. Например, для филь-
тра (18.6.23) квадрат коэффициента усиления равен
336
R(<jo)2 = 1/9 {3 + 4cosw + 2cos2co}.
В частном случае ОЛМ, переписывая (18.6.1) как
xt = (18.6.31)
мы видим, что формула для ковариации (18.6.3) — частный случай
(18.6.22). Поскольку/а(ш) = сг^/тг, спектр {хД пропорционален коэф-
фициенту усиления R^(&)2 для оператора 0(B), и из (18.6.25) имеем
fxM = (18.6.32)
18.6.4 . ЛИНЕЙНЫЕ ОПЕРАТОРЫ НА КОНЕЧНЫХ ВЫБОРКАХ
Для конечной выборки иь и2, ..., ип, вообще говоря, невозможно
вычислить значения v2, .... vn по формуле (18.6.4). Например, для
фильтра (18.6.23) можно точно вычислить лишь v3, ..., vn. Прибли-
жения для значений v2 можно вычислить, либо предположив, что
неизвестные значения и_1, и0 (которые необходимы для вычислений)
равны нулю, либо тем или иным способом экстраполировав эти
значения.
Вообще величина подобных нестационарных ошибок, или краевых
эффектов, будет зависеть от того, как быстро убывают весовые коэф-
фициенты фильтра. Для выборок щ, и2, ..., ип и vb v2, ..., vn из ря-
дов, связанных при всех t соотношением (18.6.4), их выборочные
автоковариации связаны между собой аналогично (18.6.22), т. е.
Cv(k) = ЕД/СДАг - /), (18.6.33)
а их выборочные спектры — аналогично (18.6.25), т. е.
4*(W) = /?(ш)2/и*(«). (18.6.34)
Приближения, возникающие из-за краевых эффектов, имеют порядок
1/л, если только фильтр конечен или убывает достаточно быстро (на-
пример, геометрически).
Применяя последний результат к ОЛМ, получаем
Д*(Ш) =
или Z
/*(")/Л(") =Л*(")/Л("). если только/х(ш) # 0. (18.6.35)
Таким образом, ОЛМ позволяет непосредственно связать свойства
выборочного спектра ряда {xt} с аналогичными свойствами для
{дД. Установленные в разделе 18.3.5 свойства периодограммы оз-
начают, что для гармонических частот = Zirj/n правая часть
337
Рис. 18.6.1 Сходство картины колебаний выборочного спектра по отношению
к теоретическому для исходного и профильтрованного рядов: а) выборочный
спектр случайного ряда at, t = 1,64 и его теоретический спектр/в(ш) = 1/тг;
б) выборочный спектр случайного ряда xt, t = 1,..., 64, полученного из ряда at
с помощью фильтра (18.6.36), и его теоретический спектр
(18.6.35), а следовательно, и левая часть образуют случайную выборку
из экспоненциального распределения. Отсюда, в частности, следует
утверждение теоремы 18.5.1. Более того, распределение ряда {а;] не
обязано быть нормальным. Так как ряд {at} состоит из независимых
значений, можно воспользоваться центральной предельной теоремой
[см. II, раздел 17.3] и ослабить это условие.
Для примера на рис. 18.6.1,а) показан выборочный спектр для ряда
а( вместе с его теоретическим спектром /а(ш) = 1/тг. На рис.
18.6.1,6) показан выборочный спектр ряда xt, построенного по
формуле
xt = 1/3 {а, + at_j + а(_2] (18.6.36)
вместе с теоретическим спектром
/х(ш) = (1 /9тг) {3 + 4cosw + 2cos2w}.
Обе выборки имеют длину п = 64. Обращает на себя внимание почти
идентичная картина колебаний выборочного спектра относительно те-
оретического. Заметим также, что /х(ш) = 0 при ш = 2я73, т. е. коэф-
фициент усиления фильтра (18.6.36) на этой частоте равен нулю.
338
18.6.5 . ОГРАНИЧЕНИЯ НА ОЛМ
ОЛМ содержит односторонний оператор, действующий на настоя-
щее и прошлое значения ряда аг Вместе с дополнительным условием
на оператор ф(В) из (18.6.31) это ограничение позволяет дать полез-
ную интерпретацию для ряда {at}. Дополнительное условие — это
условие обратимости:
0(B) 0 при | В | С 1, (18.6.37)
где вместо В допускается подстановка как действительных, так и ком-
плексных чисел. Из этого условия следует, что обратный оператор су-
ществует и также является односторонним, так что а, — линейная
комбинация настоящего и прошлых значений xt:
at = iroxf + iriXr_j + тг2Х(_2 + ...
или
at = тг(В)х,,
где 'тг(В) = {0(B)}-1 и Е | тг, | < —=». В рамках ОЛМ удобно счи-
тать, что 0о = тго = 1» так как о2 допускает масштабный множитель,
так что
xt = { viXt_t + iC2Xt__2 +...} + at. (18.6.38)
Это соотношение выглядит, как регрессионное уравнение, в котором
ошибка at оказывается некоррелированной с регрессионными пере-
менными xt_j,x(_2, ..., поскольку, как было установлено в разделе
18.6.1, cov(az, xt_k)=0 при к > 0. Следовательно, {тГ]Х,_7 + 7r2x,_2 +
+ ...} является линейным МНК-предиктором для xt по всем прош-
лым значениям, a at — соответствующая ошибка прогноза на один
шаг вперед, или обновляющий процесс. В качестве примера рассмот-
рим весьма частный случай ОЛМ,
xt = at — да!_1 = (1 — 6В)а(.
Единственный нуль полинома (1 — в В) есть В = 1/В, и он лежит
вне круга | В | 1, если только | 0 | 1. В этом случае нужный
нам обратный оператор равен
(1 — 0В)-1 = 1 + 0В + 02В2 + ...,
откуда
xt = — [0х,_7 + 02х,_2 + ...} + at. (18.6.39)
В случае | 0 | > 1 также возможно построить обратный оператор
(1 — 0В)-1 = — 0-1В~1(1 — 0-1В“1)-1 = —0“^-’ — 0-2В“2 —...,
339
т. е.
at = -0 lxt+i -0 2xt+1- ...»
но это соотношение нельзя интерпретировать в терминах прогноза.
Естественно спросить, всегда ли стационарному временному ряду
отвечает обратимая ОЛМ. Упрощая, с точки зрения практики, на этот
вопрос следует ответить положительно, если только из ряда исключе-
ны все детерминированные синусоидальные компоненты и если усло-
вие независимости для ряда {tzj ослабить, заменив его на условие
отсутствия корреляций: Qa(k) = 0 при £ > 1. Тем самым уравнения
ОЛМ (18.6.1) и (18.6.38) являются естественной стартовой точкой для
разработки моделей с конечным числом параметров. Обновляющий
ряд {а(} для произвольного стационарного временного ряда теорети-
чески можно построить, как предел ошибок прогноза {ек t} в
(18.5.17), при неограниченном возрастании порядка предиктора к. Ко-
эффициенты можно далее вычислить как cov(xp at_j)/a2, откуда и
получается представление (18.6.1).
18.6.6 . ПРОГНОЗИРОВАНИЕ С ПОМОЩЬЮ ОЛМ
Форма ОЛМ удобна для представления способов построения про-
гноза на несколько шагов вперед. Для набора наблюдений xt, t С и,
и обратимой ОЛМ (18.6.1) мы можем также (теоретически) вычислить
значение а, для t С п с помощью (18.6.38). Любое будущее значение
хп+к, к > 0, можно представить в виде
%п+к ~ &п+к + ^^п+к—1 *"••• + ^к—1^п + 1
(18.6.40)
+ tkan +
где мы разделили правую часть на две строки: строку из компонент,
включающих будущие (неизвестные) значения at для t > п, и строку,
включающую лишь начальные и прошлые значения at для t С п-
Чтобы построить МНК-прогноз *„(£) для хл+А., мы должны лишь
заметить, что будущие значения- an+v ..., ап+к некоррелированы с
наблюдениями хп, xn_j.......и, следовательно, их МНК-прогноз тож-
дественно равен 0. Таким образом, в качестве прогноза для х„+к оста-
ется вторая строка (18.6.40):
*»(*) = Мл + +•••» (18.6.41)
а ошибка прогноза — эта первая строка (18.6.40):
ап(к) = хп+к — кп(к) =
(18.6.42)
— &п+к *" ^^^п+к—1 + --- + Фк—1^п + \ ’
340
Тем самым в принципе нам известно и значение прогноза, и дисперсия
его ошибки
var(0„(*)) = (1 + ^+...+ (18.6.43)
с помощью которой при предположении о гауссовском законе можно
построить доверительный интервал для хп+к. Практические следствия
этих фактов будут очевидны в следующих разделах при рассмотрении
параметрических моделей.
18.7. МОДЕЛЬ СКОЛЬЗЯЩЕГО СРЕДНЕГО (СС)
18.7.1. ОПРЕДЕЛЕНИЯ
Простой класс моделей временных рядов с конечным числом пара-
метров получается, если предположить, что ОЛМ (18.6.1) содержит
лишь конечное число членов, т. е. что, например, = 0 при к > q.
Переобозначим оставшиеся коэффициенты, чтобы подчеркнуть сде-
ланное предположение. Получающаяся модель называется моделью
скользящего среднего порядка q или моделью СС(</):
xt = at — Bxat_j — ... — 6qat_q =
(18.7.1)
= (1 — 6ХВ — ... — 6qB«)at = 6(B)at.
Напомним, что по предположению at — последовательность неза-
висимых одинаково распределенных величин [см. раздел 1.4.2, п. 1] с
E(at) - 0, var(a,) = а2. Замена xt на xt — /л позволяет учесть в моде-
ли ненулевое среднее значение р. для xt.
Условие обратимости (18.6.37) записывается теперь как 6(B) О
при | В | <1. Если разложить на множители многочлен 6(B):
6(B) = (1 - 5,В)(1 - s2B) ... (1 - sqB),
то условие обратимости можно переписать в виде | st | < 1,
i = 1, .... q. Такое разложение может быть полезно и при построении
обратного оператора с помощью элементарных дробей [см. I, раздел
14.10]. Например, если q = 2 и 6(B) = (1 — гВ)(\ — sB), то
6(B)-1 = (г — 5)~1 {г(1 — гВ)~1 — 5(1 — 5В)-1 ] =
= (г — 5)-1 (Т гк+1Вк -Тsk+lBk ],
' о о
откуда в представлении (18.6.38) ък = —(г — 5)~Цг**1 — 5*+1). Здесь
мы для удобства предположили, что г, s — действительны и различ-
ны. Если они действительны и равны, то irk = —(к + 1)гк, а если
341
они комплексные, то тгк = —rksin {(к + 1)Х)/sinX, где г и X опреде-
ляются из соотношений гг = — ф2, 2rcosX =
18.7.2. ХАРАКТЕРИСТИЧЕСКИЕ СВОЙСТВА МОДЕЛИ СС(<?)
Формулу для АКФ процесса xt нетрудно вывести из следующих
соотношений, являющихся в силу (18.7.1) частным случаем (18.6.3):
_ Я—к 1
к + Е Wi+k^a при к С q,
= (18.7.2)
^0 при к > q,
<т2 = (1 + 02 +...+ 02)а2.
Конечная протяженность АКФ является характеристическим свой-
ством модели. А именно стационарный временной ряд, для которого
ух(к) = 0 при к > <7, всегда можно описать обратимой моделью
СС(<у), если только спектр ряда строго положителен. Кроме того, ес-
ли xt не является гауссовским, то величины at не обязаны быть неза-
висимыми, хотя они останутся некоррелированными .
Для q = 1 ех(1) = —01/(1 + 02) и qx(k) = 0 при к > 1. Легко ви-
деть, что, когда 0х пробегает допустимый интервал от —1 до 1, вели-
чина ех(1), монотонно убывая, изменяется в пределах от 1/2 до
—1/2. Как было показано в разделе 18.5.3, при ограничении
Qx(k) = 0 при к > 1 и условии строгой положительности спектра
этот интервал — полное множество значений для @x(l).
Таким образом, для того чтобы узнать, может ли модель СС(<?) с
достаточно малым q описывать наблюдаемый временной ряд, проще
всего исследовать его выборочную АКФ, обрезав ее надлежащим об-
разом. Например, в разделе 18.5.1 было высказано предположение о
том, что модель СС(2) пригодна для описания ряда продолжительнос-
ти дня. Однако в разделе 18.5.3 мы установили, что, полагая
Qx(k) = 0 при к > 2 и беря в качестве @х(1) и qx(2) соответствующие
выборочные значения ех(1) = 0,76 и qx(2) = 0,52, мы получаем недо-
пустимый набор значений, поскольку соответствующий спектр будет
отрицателен в некоторых точках, в частности при ш = 2тг/3. Равным
образом не существует набора параметров модели СС(2), дающих в
точности такой набор значений для АКФ. Даже если мы перейдем к
модели СС(3) и положим @х(3) = гх(3) = 0,21 и Qx(k) = 0 при к > 3,
мы все равно получим недопустимый набор значений. Однако, рас-
смотрев соответствующий спектр в этом случае, мы видим лишь не-
большие отрицательные значения в области малых частот. Более
того, можно проверить, что, взяв в модели СС(3) 0х = 02 = 03 = —1,
342
х( = at + at_j + at_2 + at_ (18.7.3)
мы по формуле (18.7.2) получим значения АКФ, равные
ех(1) = 0,75, 6х(2) = 0,5, бх(3) = 0,25,
и они хорошо укладываются в доверительные границы, полученные
по выборочным значениям
гх(1) = 0,76, гх(2) = 0,52, гх(3) = 0,21,
которые мы пытаемся получить. Единственное опасение вызывает то,
что модель (18.7.3) не является строго обратимой без малой коррек-
ции ее параметров, например при предположении в, - —0,999, так
как соответствующий спектр обращается в нуль в точках тг/2 и тг, бу-
дучи положительным в остальных точках. Этот факт наводит на
мысль, что корреляции во многом обусловлены применением к дан-
ным равномерного сглаживающего фильтра, ср. (18.7.3) и (18.6.23).
Это обсуждение свидетельствует также о необходимости более надеж-
ных и эффективных методов оценки параметров модели скользящего
среднего, чем процедура нахождения параметров путем подгонки вы-
борочных корреляций.
18.7.3. ЭФФЕКТИВНЫЕ ОЦЕНКИ ДЛЯ МОДЕЛИ CC(q)
Продемонстрировать общий метод можно, рассматривая простей-
ший случай модели СС(1). Отталкиваясь от наблюдений х2, ...» хп,
воспользуемся методом максимума правдоподобия (ММП) [см. гл. 6].
Для эТого нам необходимо вычислить для модели функцию плотности
распределения вероятности (п. р. в.) [см. II, раздел 10.1.1]. Это легче
всего сделать, перейдя от последовательности xt к последовательнос-
ти а(, которую мы вновь считаем последовательностью независимых
случайных величин, имеющих одинаковое нормальное распределение
со средним 0 и дисперсией о2 [см. раздел 1.4.2, п. 2]. Поскольку наш
набор данных конечен, необходимо ввести в рассмотрение величину а0
с тем, чтобы можно было восстановить величины а}, а2, ..., ап, пере-
писав уравнение модели
xt = at — eat_j (18.7.4)
в виде
at = xt + 0at__lt t = 1, ..., n, (18.7.5)
где для удобства мы пишем в вместо 01.
Рекурсивное уравнение (18.7.5) можно в точности записать как
ах = Xi + 0до,
343
Д2 = Х2 + вХ} + 02<7О,
at = xt + 6xt_j + ...+ B^Xi + O‘a0,
(18.7.6)
an = xn + Oxn_t +...+ 0Л~;Х1 + 0„ao,
где мы просто произвели последовательную подстановку, например,
а2 = х2 + 0Д1 = х2 + 0(Xi + 0ао) = х2 + 0Х[ + 02ао.
Уравнения (18.7.6) показывают, что величины а0, ...,хп связа-
ны с а0, ..., ап линейным преобразованием с единичным якобиа-
ном [см. IV, (5.12.2)], хотя это преобразование существенно
нелинейно по 0. Отсюда п. р. в. записывается в виде
f(aQ, а}, ..., ап) = f(aQ, ..., х„) =
= (2тга2)-<л+1)/2ехр[-(1/2а2)Да2} . (18.7.7)
Ее можно вычислить, непосредственно воспользовавшись (18.7.5), для
любого набора данных х2, ..., хп и любого значения 0, задавшись
дополнительно некоторым значением а0. Метод ММП заключается в
нахождении такого значения 0, при котором (18.7.7) достигает макси-
мума, или, что эквивалентно, достигает минимума сумма квадратов
5(0|ао)=Да2. (18.7.8)
В нашем простом случае минимум можно найти, построив график
функции S в интервале —1 < 0 < 1. В общем случае модели CC(q)
можно воспользоваться стандартными процедурами оптимизации [см.
III, гл. 11], очень хорошо работающими в этой ситуации.
Необходимо рассмотреть теперь проблему определения величины
а0. Проще всего положить а0 = 0 — среднему значению, если бы у
нас не было вообще никаких выборочных данных. Обозначая через
a t аппроксимацию для а,, полученную заменой а0 на а0 = 0, мы ви-
дим из (18.7.6), что
at — a t = в‘а0, (18.7.9)
и эта величина стремится к нулю с ростом t. Для значений 0, не слиш-
ком близких к единице, и достаточно больших п возникающая при та-
ком подходе ошибка будет мала по сравнению с любым истинным
значением а0. Полученное таким путем решение мы будем называть
решением условной проблемы наименьших квадратов или условным
МНК-решением, так как оно сводится к минимизации
344
S(6 I a0 = 0) = ia2t. (18.7.10)
При втором подходе величину а0 в сумме квадратов (18.7.8) рас-
сматривают как мешающий параметр и включают вместе с в в число
подлежащих минимизации свободных параметров. Это оказывается
очень удобным и без труда обобщается на модели CC(q) ценой удвое-
ния числа параметров. Именно этот метод использовался при пост-
роении оценок в последующих примерах. Однако так как величина а0
входит в выражение для at линейно, можно частично облегчить опти-
мизационную процедуру, точно вычислив и подставив вместо а0 значе-
ние а0, минимизирующее функцию S при данном в. Для этого целевая
функция преобразуется следующим образом:
S(0) = S(6 | aQ) = minS(0 | a0). (18.7.11)
a0
С учетом сказанного относительно модели СС(1) уточним зависи-
мость от а0, написав на основе (18.7.6) и (18.7.9)
at - a t + 0'яо,
так как ах, ..., ап зависят только от х,, ..., хп. Тогда
Ё< = £«;+ 2(Е«'в,)в„ + (Е«2')в2. (18.7.12)
Далее, любую неотрицательную квадратичную функцию
QU) = Az2 + 2Bz + С (18.7.13)
можно представить в виде
A(z — z)2 + Q(z), (18.7.14)
где z = —В/ А — то значение z, при котором Q(z) достигает миниму-
ма. Минимум по а о в (18.7.12) достигается в точке
а0 = — (18.7.15)
где в соответствии с (18.7.13) и выражением для В имеем
к = £ 0^ = (1 — 02"+2)/(1 _ 02). (18.7.16)
Следуя (18.7.14), мы преобразуем (18.7.12) к виду
ia2 = К(а„ - аоу + 1а2, (18.7.17)
или, что то же самое,
S(0 | во) = К(а„ - а„у + S(0). (18.7.18)
345
Требуемые дополнительные расчеты, помимо вычисления а ь
а п, необходимых для нахождения условного минимума суммы ква-
дратов, — это вычисление К и а0 по формулам (18.7.15) и (18.7.16), а
затем вычисление di, ..., dn в соответствии с равенством
at = х( + 0d(_}, t = 1, ..., п,
если в качестве начального значения взято я0- Окончательно
5(0) = Ея2. (18.7.19)
Получаемое при этом подходе значение, минимизирующее функ-
цию 5(0), мы будем называть точной МНК-оценкой для 0. Неболь-
шой дополнительный анализ приводит к точным ММП-оценкам.
Воспользуемся тождеством (18.7.17) и разложим на множители
п. р. в. (18.7.7):
/(а0,-Vi, = (Х72тг<т2)1/2ехр {— (К/2а2)(ас — д0)2} X
х /С-1/2(2тга2)-”/2ехр{— (1/2а2)£ а2}. (18.7.20)
“О'
В правой части величина а0 содержится лишь в первой строке, а мно-
житель К1/2 введен сюда для того, чтобы интеграл по а0 в первой
строке был равен единице. Поэтому вторая строка, содержащая в ка-
честве компенсации множитель К—1/2, оказывается частной функцией
плотности распределения вероятности наблюдений:
/(х„ Х2...х„) = K-'z2(2iraj)-»^exp(-S(#)/2O’). (18.7.21)
В сущности первая строка (18.7.20) представляет собой условное рас-
пределение неизвестного значения а0 при известных наблюдениях и яв-
ляется нормальной п. р. в. со средним а0 и дисперсией К~~}а2.
Возвращаясь к (18.7.21), можно найти логарифм функции правдо-
подобия [см. раздел 6.2.1] и максимизировать его по аа, получая в
результате монотонную функцию от
А'1/л5(0), (18.7.22)
минимум которой и определяет точную ММП-оценку. Заметим, что
функция К зависит лишь от 0 и не зависит от наблюдений, и с ростом
п величина К1/п стремится к единице. Поэтому этот множитель су-
ществен лишь для малых объемов выборок и в этом случае не пред-
ставляет труда для вычислений, а при умеренно больших п без него
часто можно обойтись, соглашаясь с незначительным смещением
оценки, но сильно сокращая объем вычислений, особенно в случае об-
щей модели CC(q). Этим обстоятельством объясняется использование
точных МНК-оценок.
346
Асимптотически при п -*• <=><=• описанные оценки становятся неотли-
чимы, и можно показать, что их свойства аналогичны свойствам оце-
нок наибольшего правдоподобия для независимых одинаково распре-
деленных наблюдений. Так, эти оценки — асимптотически несмещен-
ные и асимптотически нормальные, их ковариационную матрицу мож-
но оценить с помощью вычисленного в точке оптимума обратного
гессиана от взятого с обратным знаком логарифма функции правдопо-
добия [см. раздел 6.2.5, п. в)]. Эту информацию обычно получают как
дополнительную при применении оптимизационных процедур. Кроме
того, можно перенести сюда из стандартной линейной регрессии те-
сты, основанные на сумме квадратов S(0), если их использовать осто-
рожно. Тот факт, что остатки at можно рассматривать как ошибки
прогноза на один шаг вперед, полученные при использовании подог-
нанной модели для последовательного прогноза выборочных данных,
убеждает нас в том, что 5(0) — осмысленная характеристика качества
модели. Эта величина используется в оценке
а2а= (п — d)~lS(9),
где d — число степеней свободы, связанное с оцениваемыми парамет-
рами, например, d = 1 для модели СС(1) и на единицу больше, если
оценивалось также среднее значение д.
Для примера приведем две модели, подогнанные к первой разнос-
ти ряда продолжительности дня. Модель СС(2) выражается в виде:
xt = 3,1 + at + 0,91 at_} + 0,79az_2,
(±3,6) (±0,05) (±0,05)
где для параметров приведены их стандартные ошибки [см. определе-
ние 3.1.1]. Сумма квадратов остатков СКО = 33870 и а2 = 249,0.
Модель СС(3) имеет следующий вид:
xt = 3,2 + at + 0,99az_; + 0,93az_2 + 0,18<z,_5,
(±4,1) (±0,09) (±0,09) (±0,09)
где CKO = 32813 и о2 = 243,1.
Отношение величины, на которую уменьшилась СКО, к дисперсии
аа равно 1057/243 = 4,34, и его не следует считать значимым, так как
4,34 лишь незначительно превосходит верхнюю 5%-ную точку для
распределения хи-квадрат с одной степенью свободы. Аналогично но-
вый параметр 03 равен лишь удвоенной величине своей стандартной
ошибки, и мы можем сделать вывод, что модель СС(3) в лучшем слу-
чае является некоторым усовершенствованием модели СС(2). Заметим
также, что модель дает значение Oq/ox = 0,34, так что при прогнозе
на один шаг вперед обеспечивается 66%-ное снижение дисперсии, но
для прогноза более чем на 3 шага вперед модель СС(3) вообще не
347
приводит к уменьшению ошибки прогноза. Более того, оценка средне-
го значения ряда вообще не значима, что создает сомнения по поводу
утверждения, что исходный ряд продолжительности дня содержит
растущий тренд.
18.7.4. ПРОГНОЗИРОВАНИЕ С ПОМОЩЬЮ МОДЕЛЕЙ СС
Поскольку модель СС(д) — конечная форма ОЛМ (18.6.1), прогноз
хп(к) значения хп+к по известным х,, Г < л, можно просто выразить
через значения at для t п, преобразовав соответствующим образом
формулу (18.6.41): " —0кап—. •“ Qqan+k_q при к « $ Q,
$п(к) = ‘ (18.7.23)
0 при к > »
Так, например, если q = 1, то
х„(1) = —0ia„, хп(к) = 0 при к > 1. (18.7.24)
Из обращенной формы модели (18.6.38), в данном случае имеющей
вид (18.6.39), в свою очередь следует соотношение
*я(1) = -(6хп + 02х„_7 + Vxn_2 + ...), (18.7.25)
которое в точной форме выражает зависимость прогноза от предыду-
щих наблюдений.
На практике наблюдения имеют конечную протяженность, напри-
мер Х\, х„, но, предположив, что параметры модели были оцене-
ны, мы в процессе оценивания получили бы участвующие в (18.7.19)
остатки 6t, что и дало бы нам значения, которые нужно подставить
вместо at в (18.7.23). Если п велико и 0 не слишком близко к единице,
т. е. 0я мало, использование значений at может оказаться приемлемым.
Альтернативная возможность борьбы с конечной протяженностью
данных — это четкий и эффективный метод, известный как обратное
прогнозирование, который мы продемонстрируем снова на примере
модели СС(1). Для удобства мы будем обозначать просто через xt
прогноз за пределами интервала 1 С t С п, и через at — соответ-
ствующие остатки или ошибки прогноза. Мы знаем, что
xt = 0 при t > п + 1, at = 0 при t > п, (18.7.26)
Мы уже пользовались в разделе 18.5.4 тем, что структура времен-
ного ряда, рассматриваемого в обратном направлении.— с уменьше-
нием времени, в точности совпадает со структурой в прямом
направлении, т. е. мы можем по аналогии написать
348
xt = b( — ebt+i, (18.7.27)
где bt — ошибка при прогнозировании xt по будущим значениям xt+l,
xt+2, .... По аналогии с (18.7.26) мы имеем
х, = О при t < 0, bt = 0 при t < 1, (18.7.28)
а поскольку at — линейная комбинация х(, xt_}, ..., то в соответст-
вии с обращенной формой модели далее имеем
at = 0 при t < 0, bt = 0 при t > п + 1,
так что за пределами интервала 0, ..., п + 1 все величины равны ну-
лю, если известны лишь xh...,xn. Далее рассуждаем следующим
образом.
Если Хо было бы известно, мы могли бы восстановить а0........ап с
помощью соотношения
at = xt + 0а(_п t = 0, ..., п, (18.7.29)
поскольку мы знаем, что а_г = 0. Тогда мы можем положить (ис-
пользуя равенство а„+1 =0)
*л+1 = (18.7.30)
Аналогично если бы хл+1 было известно, то мы могли бы восста-
новить Ьп+1, bt по формуле
bt = x( + 0bt+I, t = n+l1, (18.7.31)
поскольку нам известно, что Ьп+2 = 0. Но тогда мы можем поло-
жить (учитывая равенство = 0)
х0 = — 0bi. (18.7.32)
Эта процедура не является порочным кругом. Начиная с некоторо-
го приближения для х0, скажем х0 = 0, мы можем циклически испо-
льзовать последние четыре уравнения, получая итеративный процесс,
быстро сходящийся к истинным значениям х0 и хл+1; величина ошиб-
ки на каждой итерации умножается на величину 02п+2. Поэтому эта
процедура широко применяется не только при прогнозировании, но и
для вычисления а0 или, более точно, а0 в рамках процедуры построе-
ния оценок в разделе 18.7.3. Все это легко переносится на случай боль-
ших значений q, и при этом не требуется решения больших систем
уравнений. Для модели СС(1) легко вывести точную форму конечного
предиктора. Заменяя в (18.7.25) xt на 0 при t < 0 и J?„(l) на хл+1,
имеем
хл+1 = —0хп — в2хп—1 —•••— OnXi — 0"+1хо. (18.7.33)
349
Аналогичное соотношение верно и в обращенном времени:
х0 = — 9х{ — 92хг —...— 9пхп — 9п+1хп+1. (18.7.34)
Подставив выражение для х0 из (18.7.34) в (18.7.33), получаем
хл+1 = — Ц0 — 02"+1)хл + ...+ (0я — ^Л+2)лг1}/(1 — 02я+2).
Отметим, что коэффициент при Xi выражает ЧАКФ для модели
СС(1):
Фп>п = -0Я(1 -02)/(1 -02Л + 2).
Подобное приближенно геометрическое убывание, наблюдаемое в
выборочной ЧАКФ, служит свидетельством пригодности модели
СС(1).
18.7.5. ЭВСС ПРЕДИКТОР
Весьма популярная и удобная процедура построения прогноза со-
стоит в усреднении всех прошлых значений, но с геометрически или
экспоненциально убывающими весами с тем, чтобы наибольшие веса
имели самые последние значения. Так, для наблюдений wt, t С п,
прогноз следующего значения имеет вид
w л+1 = (1 - 0)(в>„ + 0w„_7 + 02w„_2 +...), (18.7.35)
где множитель (1 — 0) гарантирует, что это действительно усредне-
ние, т. е. что сумма весов равна единице. Такой прогноз называют экс-
поненциально взвешенным скользящим средним (ЭВСС), сокращение
СС имеет здесь другой смысл, нежели в моделях CC(q), — это беско-
нечное скользящее среднее, примененное к прошлым значениям ряда.
На практике ЭВСС вычисляется с помощью простой процедуры
пересчета:
»„+1 = (1 — 9) wn + 9w„ = wn — 9(w„ — wn). (18.7.36)
Таким образом, при поступлении нового наблюдения wn вычисляется
прогноз w„+1 следующего значения. Параметр 0 можно выбрать та-
ким, чтобы минимизировать ошибку прогноза на множестве исходных
данных.
Если предположить, что ошибки прогноза at = wt — w t являются
независимыми и одинаково распределенными, что соответствует
оптимальной ситуации, когда невозможно построить лучшую схему
прогноза, то из (18.7.36)
Wn+1 = + an+i = Wn~ еап + *„+i • (18.7.37)
350
Подставив t вместо п + 1 и положив w(— wt_} = xt, получаем
V w( = х( = at — (18.7.38)
Следовательно, ЭВСС-предиктор применим в случае, когда первая
разность ряда описывается моделью СС(1). Этой идее соответствует
простая по структуре схема возникновения данных. В типичной ситуа-
ции величина w(, которая, например, может выражать цену текущей
недели на некоторый продукт, имеет базисный уровень, медленно сме-
щающийся вверх или вниз непредсказуемым образом, т. е. может
быть представлен как случайное блуждание
и( = ut_t + at, (18.7.39)
где at — независимые и одинаково распределенные величины. Реаль-
ная цена — это результат случайных флуктуаций, накладываемых на
этот базисный уровень, например, возникающих из-за погодных
условий:
wt = ut + 0t, (18.7.40)
где /3, — также независимые и одинаково распределенные величины,
не зависящие от аг Тогда
xt = - w,_7 = at + ,
так что
var(x,) = а2а + 2^,
COV(X,, Х/+1) = — (70,
cov(xr, xt+k) = 0 при к > 1.
Стало быть, xt — стационарный ряд, и
еД1) = —1/(2 + г), Qx{k) = 0 при Аг >1, (18.7.41)
где г равно отношению дисперсий Следовательно, xt можно
описать моделью СС(1), в которой параметр в зависит от г.
Про такой ряд wt говорят, что он описывается моделью ИСС
(или моделью интегрированного скользящего среднего), так как он
представляет собой накапливающуюся сумму значений xt:
w( = W0 + Xi + x2 +...+ xt.
Модель можно легко обобщить, считая, что xt имеет ненулевое
среднее д, так что E(wt) = E(w0) + t . Тем самым в модели допуска-
ется линейный тренд.
351
18.7.6. СЕЗОННАЯ МОДЕЛЬ БОКСА—ДЖЕНКИНСА
ДЛЯ РЯДА АВИАПЕРЕВОЗОК
Мы уже отмечали, что взятие разности в форме
= V vsxt
может упростить временной ряд при исключении из него явно выра-
женных временного тренда и сезонных изменений. Привлекательное
обобщение ЭВСС-предиктора на сезонные временные ряды автомати-
чески приводит к моделям, включающим такие операторы взятия раз-
ности. Для ряда авиаперевозок построим прогноз январских значений
ряда с помощью ЭВСС-предиктора лишь по предшествующим январ-
ским значениям; аналогично поступим для февраля, марта и всех дру-
гих месяцев. Можно надеяться, что для всех месяцев можно будет
взять один и тот же сглаживающий параметр 9 и трендовую постоян-
ную g. Результат подгонки такой модели показан на рис. 18.2.1, д),
где изображены ошибки прогноза на один шаг вперед. Они похожи на
ошибки, возникающие при подгонке классической модели и показан-
ные на рис. 18.2.1, б). Они также тесно связаны с сезонной разностью
ряда V 12х,, изображенной на рис. 18.2.1, в), так как
V 12х, = ft + at — (18.7.42)
что является сезонной версией модели ИСС (18.7.38); значения пара-
метров равны g = 0,123, 9 = 0,546.
Построенный по этой модели прогноз наблюдений за последний
год показан на рис. 18.4.1, он в целом лучше, чем прогноз по класси-
ческой модели. На самом деле можно показать, что в пределе, когда
9 — 1, модель (18.7.42) становится эквивалентной классической моде-
ли (18.2.1), так что можно ожидать, что введение свободного пара-
метра 9 может улучшить подгонку.
На самом деле тренд ряда медленно меняется, так что ошибка at
на рис. 18.2.1, д) помимо более или менее случайной составляющей
содержит еще медленные изменения уровня. Далее, при рассматривае-
мом сезонном предикторе не используются самые последние 11 значе-
ний ряда, так что естественно попытаться улучшить прогноз, пред-
сказывая эти изменения уровня на основании последних ошибок про-
гноза, скажем, с помощью обычного ЭВСС-предиктора с параметром
д, применяемым к месячному интервалу. Полученный прогноз уровня
используется затем для коррекции сезонного прогноза, давая оконча-
тельный прогноз. Ошибки at в такой схеме показаны на рис. 18.2.1, е)
и оказываются заметно меньше, нежели любые другие.
352
Модель, возникающую в результате этого двухшагового процесса,
можно получить следующим образом. Ряд ошибок at после примене-
ния сезонной процедуры ЭВСС связан с рядом xt формулой
V 12^, = g + ott — &ott_x2 = g + (1 — 9B12)a(,
а ряд ошибок at, возникающих после применения последней процеду-
ры ЭВСС, связан с at формулой
V at = at — Gat—i = О — 0B)at.
Соединяя эти соотношения вместе, получаем
wt = V V ]2Х/ = (1 — 0В)(1 — ея12)дг, (18.7.43)
где мы снова предполагаем, что at — последовательность независи-
мых одинаково распределенных величин. Это — знаменитая модель
авиаперевозок, предложенная Боксом и Дженкинсом [см. Box and
Jenkins (1976)], включающая двойной разностный оператор VV]2,
введенный нами в разделе 18.4. Оба значения 0 и 9 были подобраны
так, чтобы обеспечить наилучшую подгонку с помощью точных
МНК-оценок, согласно которым 0 = 0,34, 6 = 0,63. Отметим, что ве-
са, приписываемые предыдущим наблюдениям сезонной ЭВСС-
составляющей модели, практически вырождаются за пределами пяти-
летнего промежутка времени, тогда как аналогичные веса, связанные
с несезонной частью, вырождаются за пределами двух-трехмесячного
промежутка. Это — свидетельство того, что сезонные изменения весь-
ма устойчивы, хотя колебания уровня и тренда также необходимо
учесть.
Указание на применимость этой модели для описания ряда можно
обнаружить при исследовании выборочной АКФ разностного ряда,
которая соответствует сезонной модели СС. Для такой модели АКФ
обладает следующими свойствами:
еЛП = —^/(1 + 02), еД12) = —9/(1 + 92),
еДН) = еД13) = ви,(1)еД12)
и Qw(k) = 0 в остальных случаях.
На практике, как следует из рис. 18.2.1, ж), величины /*^(1) и
/„,(12) дают наиболее ясное свидетельство в пользу именно такого по-
ведения выборочной АКФ.
Прогнозирующая функция для модели авиаперевозок также имеет
простую структуру. Поскольку ряд wt описывается моделью СС(13) в
соответствии с (18.7.43), то wn(k) = 0 при к > 13, откуда
V V 12хл(Аг) = 0 при к > 13,
353
где операторы действуют по к. В силу (18.4.1) это означает, что
£п(к) содержит регулярный сезонный цикл и линейный тренд, опре-
деляемые начальным множеством значений для к = 1, ..., 13. Кон-
кретное поведение будет наиболее сильно зависеть от недавних
наблюдений и с ростом п пересчитывается по мере поступления новых
данных.
18.8. АВТОРЕГРЕССИОННЫЕ МОДЕЛИ
18.8.1. ОПРЕДЕЛЕНИЯ
Другой класс простых моделей с конечным числом параметров по-
лучается в предположении, что обращенная форма ОЛМ (18.6.38) со-
держит конечное число членов, т. е. наилучший прогноз ряда исполь-
зует конечное число прошлых значений. Итак, пусть тгк = 0 при
к > р. Снова переобозначаем оставшиеся коэффициенты. Получаемая
модель называется авторегрессионной моделью порядка р или мо-
делью АР(р):
xt = Ф1Х,_7 + ф2Х'_2 + ...+ ФрХ(_р + at, (18.8.1)
или
(1 _ фхв - ф2В2 -...- фрВР)х( = Ф(В)Х{ = at, (18.8.2)
где at — снова последовательность независимых одинаково распреде-
ленных величин с Е(«,) = 0, var(a,) = о2, a xt можно заменить на
xt — ц, допуская возможность наличия у xt ненулевого среднего д.
Так как в рамках ОЛМ (18.6.31) функция Ф(В) — обратная к ф(В),
она должна удовлетворять условию ф (В) # 0 при | В | <• 1, т. е. ес-
ли разложить ее на множители
ф(В) = (1 -г,В)(1 -г2В)...(1 —грВ), (18.8.3)
то | г, | <1 для всех / = 1, ...,р.
Если рассматривать (18.8.2) как соотношение, задающее случайный
процесс, начинающийся в некоторый отдаленный момент времени, то
последнее условие эквивалентно предположению, что процесс xt со
временем достигнет статистического равновесия, или стационарности.
Поэтому это условие называют условием стационарности.
Авторегрессионные модели, в частности, пригодны (и первона-
чально были созданы) для описания случайных систем, обладающих,
по аналогии с механикой, инерцией и подверженных действию сил,
возвращающих систему в состояние равновесия. В частности, модели
второго порядка с р = 2 оказались очень хорошими при описании по-
ведения приблизительно циклической природы, прообразом которого
может служить маятник, на который воздействуют малые случайные
импульсы. Колебательное движение будет очевидно, но амплитуда и
фаза будут все время меняться.
354
18.8.2. ПРИМЕРЫ ПЕРВОГО И ВТОРОГО ПОРЯДКОВ
Рассмотрим модель АР(1), для удобства употребляя обозначение ф
вместо фс.
xt = Фх^] + а(, | ф | <1. (18.8.4)
Переписывая это соотношение в виде
(1 — фВ)Х' = at,
получаем
xt = (1 — фВ)—1а( = (1 + фВ + ф2В2 =
= at + </>az_y + Фга^2 + •••> (18.8.5)
и мы видим, что зависимость xt от прошлых значений at_k убывает
геометрически. Можно вывести корреляционные свойства модели из
(18.8.5), но более прямой путь состоит в использовании модели
(18.8.4), если вспомнить свойства ОЛМ из раздела 18.6.1, такие, как
cov(af, xt_j) = О,
var(x,) = 02var(xz_7) + а2а
и в предположении стационарности (1 Ф2)ах = а*, или
ах = "«А1 - <Я- (18.8.6)
Отсюда, умножая обе части (18.8.4) на х(__к с к > 0 и беря мате-
матическое ожидание, получаем
Тх(*) = фух(к— 1), (18.8.7)
что приводит к соотношению
Тх(£) = ф*7х(0), Сх(*) = Фк- (18.8.8)
Автокорреляционное поведение с таким простым геометрическим
убыванием до некоторой степени популярно в экономическом модели-
ровании, где модель АР(1) часто рассматривается для описания струк-
туры ошибок в линейной регрессии, связывающей экономические
показатели.
Свойства модели АР (2)
xt = ФхХ^ + ф2х,_2 + at (18.8.9)
на качественном уровне зависят от корней полинома
ф(В) = (1 — ф'В — ф2В2) = (1 — г В) (1 — sB).
В форме (18.6.1) для ОЛМ такая модель АР(2) в случае действи-
тельных г и s имеет коэффициенты
355
фк = —(г — s)~l(rk+1 — sk+i),
вычисляемые в точности так же, как были подсчитаны коэффициенты
irk в модели СС(2) в разделе 18.7.1. Можно показать, что АКФ ряда
xt ведет себя сходным образом:
Qx(k) = A rk+i + Bsk+1,
где
А = ($2 — 1)/ { (5 — г)(1 + rs)}, В = (г2 — 1)/ {(S — г) (1 + rs)) .
В случае, когда Ф(В) имеет комплексные корни, смесь двух геометри-
чески убывающих последовательностей заменяется затухающей сину-
соидой. Полагая
Ф1 = 2rcosX, —02 = г2, (18.8.10)
мы можем в терминах г и X записать АКФ как
Qx(k) = A rk cos (кХ — р),
где
tgi, = {(1 — г2)/(1 + г2)) ctgX, А = 1/cosp.
Эта синусоидальная волна, наиболее заметная, когда г близко к едини-
це, отражает общий феномен приблизительной цикличности ряда xt.
Что-то подобное наблюдается в ряду поголовья свиней, изображен-
ном на рис. 18.1.1. Соответствующее поведение спектра в этой ситуа-
ции — это пик в спектре на частоте ш', близкой к X (это верно снова
в предположении, что г достаточно близко к единице). В действи-
тельности
cosw' = {(1 + r2)/2r)cosX = —0i(l — 0z)/402. (18.8.11)
Когда множитель г -• 1 и ога -* 0, модель (18.8.9) фактически ста-
новится неотличимой от чистой синусоидальной волны
xt = Rcos(Xt + rj),
которую можно описать рекурсивным уравнением второго порядка:
xt = (2cosX)x,_7 — xt_2.
Поэтому на практике для конечного набора данных иногда трудно от-
личить чистую синусоидальную волну от авторегрессионной модели,
в частности, если она образует единственную составляющую ряда,
быть может, включающего также ощутимые ошибки наблюдений.
356
18.8.3. ХАРАКТЕРИСТИЧЕСКИЕ СВОЙСТВА МОДЕЛИ АР(р)
В этом общем случае автокорреляционная функция является
смесью затухающих экспонент и синусоидальных волн, отвечающих
действительным и комплексным корням полинома ф(В). Эти свой-
ства можно вывести из соотношения (18.8.1), умножив его на xt_k
с к > О, беря математическое ожидание и деля на а2х. Так как
= О, в результате имеем
вх(к) = ф1бх(к — 1) +...+ фр6х(к-р), к > 0. (18.8.12)
Для значений к = 1...р эти уравнения называются уравнениями
Юла—Уолкера, которые играют важную роль в теории модели АР(р).
Они линейны как по параметрам ф}, ..., фр, так и по ех(1), .... Qx(p),
и их можно использовать для определения одного из наборов значе-
ний по другому. Например, если р = 2, уравнения
Gx0) = Ф1+ 0гех(1), ех(2) = 0iCx(l) + 02
можно разрешить следующим образом:
6Х(1) = 01/(1 —0г), ех(2) = 02 + 0^/(1 —0г)-
Полезна также формула для отношения дисперсий
= 1 - ф, е,(1) фрвх(р), (18.8.13)
которую выводят аналогично (18.8.12), но с к = 0, используя вытека-
ющее из (18.6.1) соотношение E(atxt) = о2.
Для к > р уравнение (18.8.12) дает способ вычисления последова-
тельных значений АКФ, а общая теория дифференциальных уравнений
[см. I, раздел 14.13] приводит к сформулированному утверждению о
затухающих экспонентах и синусоидальных волнах.
Главное характеризационное свойство модели АР(р) — это вытека-
ющая практически из определения конечность ее ЧАКФ:
фкк = 0 при к > р, (18.8.14)
так как модель (18.8.1) выведена из (18.6.38) в предположении, что ко-
эффициенты при xt_k равны нулю для к > р.
Итак, если момент затухания выборочной ЧАКФ, описанный в
разделе 18.5.6, невелик, скажем не более 3 или 4, то это сильный до-
вод в пользу применимости модели АР соответствующего порядка. В
самом деле, описанная в разделе 18.5.5 рекурсивная процедура для вы-
числения коэффициентов конечного предиктора, остановленная при
к = р, сводится к решению уравнений Юла—Уолкера для параметров
0ь •••, Фр ( = 01.1, •••, 0ДР) и для отношения дисперсий о2/о2( = vp)
по данным ех(1), ..., qx(p). Используя вместо них выборочные зна-
357
чения гх(1)....rx{p)t мы получаем довольно хорошие оценки
Ф1, фр, например, в случае р = 1 имеем фх = гх(1).
Можно доказать, что для любого набора значений автокорреляций
ех(1), ..., qx(p) решение уравнений Юла—Уолкера дает допустимое
множество значений авторегрессионных параметров фх, ..., фр, в том
смысле, что автоматически будет выполнено условие стационарности,
если только матрица Rn в (18.5.16) положительно определена для
п = р + 1. Это условие без труда проверяется, если воспользоваться
упоминавшейся рекурсивной процедурой для проверки неравенств
| фк к | <1 для к = 1, ...,р. Этот результат противоположен отме-
ченной в разделе 17.7.2 ситуации для модели СС(д), когда набору
ех(1), ..., Qx(p) может не соответствовать ни один набор параметров
скользящего среднего. Это, конечно, не означает, что всегда нужно
предпочитать модели АР Go), как в последующих примерах, однако
придает им определенную привлекательность. Так как последователь-
ность гх(к) всегда положительно определена, полученные из нее оцен-
ки параметров АР всегда допустимы.
18.8.4. ЭФФЕКТИВНЫЕ ОЦЕНКИ ДЛЯ МОДЕЛИ АР(р)
Мы рассмотрим только случай модели АР(1), на примере которого
хорошо видна и общая ситуация. Чтобы воспользоваться методом
максимума правдоподобия, вычислим функцию плотности распределе-
ния вероятности наблюдений хь ..., хп как
Ж, х2, ..., х„) =
= f(xi)f(x2 | х^Ж | х2).../(хл | хл_7). (18.8.15)
Такое разложение возможно, так как процесс АР(1) образует цепь
Маркова с единичным интервалом зависимости [см. II, раздел 19.2].
Далее, снова предположим, что условное распределение xt при из-
вестном xt_] нормально. В соответствии с моделью (18.8.4) это рас-
пределение имеет среднее фхг_7 и дисперсию о2а, так что
Ж, х2, ..., хп) = /(х,) х
X 5(2raj)-'-2«p(-(l/2^)(x, -0х,_;)2), (18.8.16)
ИЛИ
Ж, х2, ..., Хл) = /(Х1)(27Г^)-<л-1>/2 X
2 п
х ехр{-(У2а2а)Х (xt - фх^?}. (18.8.17)
358
Если мы будем рассматривать величину х, как известную и тем
самым потеряем одну степень свободы, функция правдоподобия как
функция от ф будет эквивалентна сумме квадратов
$(ф I х,) = E(x,-0x,_z)2 = Ео2. (18.8.18)
Минимум этого выражения по ф равен просто
Ф = (Е x,x,+1)/(e'xJ). (18.8.19)
Эта величина очень близка к выборочной автокорреляции гх(1),
для которой без учета поправки на смещение верхний предел сумми-
рования во второй сумме равен п. Одна, возможно, существенная
разница заключается в том, что в отличие от г (1) (18.8.19) может
приводить в крайних ситуациях к значениям ф > 1. Это можно
обойти, учитывая информацию о %i. Для этого воспользуемся тем,
что частное распределение Х] имеет среднее 0 и дисперсию ах =
= а2а/(1 -ф2), т. е. ,
/(X)) = (1 - ф2)-1/2(27г^)-1/2 х
х ехр {—(1/2йд)(1 — Ф2)х]}. (18.8.20)
Учитывая это соотношение в (18.8.17) и максимизируя по а2, прихо-
дим к функции
(1 _ <Д2)-1/я5(ф), (18.8.21)
где
Х(ф) = ((1 - ф^х] + Ё (х, - фх,_,)2). (18.8.22)
Множитель (1 — ф2)~1/л обеспечивает существование минимума в
допустимом интервале —1 < ф < 1, хотя теперь для нахождения ми-
нимума требуются итерационные процедуры. Для таких процедур
оценка гх(1) может послужить хорошим начальным приближением.
Хотя в (18.8.22) X] играет особую родь, легко проверить, что выраже-
ние для 5(ф) останется неизменным, если переупорядочить данные в
обратном порядке; фактически
5(ф) = х\ + х2 + (1 + ф2)^ х2— 2фЕх,х,+1. (18.8.23)
Эту симметрию можно использовать в различных замкнутых по фор-
ме выражениях при вычислении функции правдоподобия для общих
моделей АР(р).
Другое замечание касается обычно требуемого оценивания средне-
го значения ряда g, для чего в сумме £(</>) величины х, заменяют на
х, — g. При заданном значении ф оценка g, получающаяся при мини-
мизации (18.8.23), равна
359
fi = {хх+хп + (1 —ф)£Х'}/[2 + (п—2)(1— ф)). (18.8.24)
Если ф близко к 1, эта величина может на малых выборках замет-
но отличаться от х. Поэтому рекомендуется использовать для /г
ММП-оценку, а не простую корректировку данных с помощью выбо-
рочного среднего.
Наконец, без множителя (1 — ф2)~1/п в (18.8.21) часто можно
обойтись по той же причине, по которой обходятся без множителя
Кх,п в (18.7.2). То, что при этом получается, называют точными
МНК-оценками, а не ММП-оценками.
В качестве примера к первой разности ряда продолжительности
дня была подогнана модель АР(3) с тем, чтобы провести ее сравнение
с моделью СС(3), построенной в разделе 18.7.3. Обозначая через
разности xt — ц, можно записать результат в виде
wt = 0,85 wt_j + 0,12wt_2 — 0,32w(_3 + at
(±0,08) (±0,12) (±0,08)
c g = 2,7 ± 4,0, OCK = 38043 и a2 = 281,8.
Хотя подгонка не так хороша, как в модели СС(3), ее можно рас-
сматривать как хорошее приближение.
Другой пример модели АР(1) будет приведен в разделе 18.11 для
описания структуры ошибок, показанных на рис. 18.2.2, в), которые
получены после подгонки синусоидальных компонент к данным о све-
тимости переменной звезды. Модель АР(2) дает хорошую подгонку
ряда поголовья свиней, если только принять во внимание кварталь-
ную сезонную составляющую, как будет показано в разделе 18.11.
18.8.5. ПРОГНОЗ С ПОМОЩЬЮ МОДЕЛИ АР(р)
Авторегрессионные модели удобны, в частности, при построении
прогноза. Ясно, что конечная протяженность данных xt, ..., хп влечет
очень слабое ограничение р < п. Далее, в соответствии с принципом
замены нулем будущих значений at, описанным для ОЛМ в разделе
18.6.5, получаем
•^и(1) = Ф1*л + ••• + Фрхп+^_р,
х„(2) = Ф1Х„(1) + ф2хп + ... + ФрХп+2_р
и т. д. Уже построенные прогнозные значения используются в авто-
регрессионном уравнении с увеличением глубины прогноза для по-
строения следующего прогнозного значения. Так, для модели АР(1)
xn(k) = фкхп.
360
Для модели АР (2) с комплексными корнями прогнозирующая
функция хп(к), к = 1, 2, .... является затухающей синусоидальной
волной, проведенной через два последних наблюдения — представьте
себе маятник, медленно качающийся до полной остановки при от-
сутствии внешних импульсов. На рис. 18.5.2 показан пример примене-
ния такой процедуры, описанной в разделе 18.5.5 для конечного
предиктора порядка 7.
Вычисление доверительных границ для ошибок прогноза с по-
мощью (18.6.43) требует нахождения коэффициентов фк путем обра-
щения и разложения в сумму
1Ф(В) }-1 = ф(В) = 1 + фгВ + ф2В2 + ...,
примеры можно найти в разделе 18.8.2.
18.9. СМЕШАННЫЕ МОДЕЛИ АВТОРЕГРЕССИИ
И СКОЛЬЗЯЩЕГО СРЕДНЕГО (АРСС)
18.9.1. ОПРЕДЕЛЕНИЕ И СВОЙСТВА МОДЕЛИ
В определенном смысле моделями CC(q) и АР(р) можно с любой
степенью точности приблизить любой стационарный ряд, для которо-
го применима ОЛМ, надо только выбрать q или р достаточно боль-
шими. Цель должна состоять в построении моделей, дающих хоро-
шую аппроксимацию с помощью небольшого числа параметров. До-
стижению этого очень помогает рассмотрение смешанных моделей ав-
торегрессии и скользящего среднего или моделей АРСС(р, q):
xt = Ф1Х,_7 + ФгХ(_2 + ... + Фрх(_р +
+ at — — 02at_2 — ... — 6qat_q (18.9.1)
или, в другой форме,
Ф(В)Х' = 6(B)at,
(18.9.2)
где Ф(В) и 6(B) — операторы, определенные ранее для моделей АР(р)
и CC(q) и удовлетворяющие соответственно условиям стационарности
и обратимости, a at — такие же, как и раньше. Такая модель может
оказаться применимой, например, когда временной ряд является сум-
мой двух или более независимых составляющих, каждая из которых
описывается либо моделью АР, либо моделью СС, но которые непо-
средственно не наблюдаются. В простейшем случае если ut описыва-
ется моделью АР(1), a vt — моделью СС(1), то их сумма xt = ut + vt
описывается моделью АРСС(1, 2).
361
Рис. 18.9.1. Качественное поведение автокор-
реляций (АКФ) и частных автокорреляций
(ЧАКФ) для модели АРСС(1, 1) xt = +
+ at — eat_j
Модели АРСС следует
рассматривать тогда, ког-
да при исследовании вы-
борочных статистик не
обнаруживаются характе-
ристические свойства мо-
делей CC(q) и АР(р), т. е.
конечная протяженность
АКФ или ЧАКФ. Возмож-
но, что слово «конечная»
здесь нужно понимать как
«меньше пяти». Геометри-
ческое или синусоидальное
убывание в выборочной
АКФ все еще можно рас-
сматривать как признак
присутствия в модели ав-
торегрессионных членов
соответствующего поряд-
ка р, и теоретически ана-
логичным образом можно
использовать ЧАКФ для
того, чтобы выбрать зна-
чение для q, хотя на практике ЧАКФ спадает заметно быстрее. Теоре-
тические АКФ и ЧАКФ для модели АРСС(1, 1)
xt = Фх(_] + at — Oat_j
показаны на рис. 18.9.1. Заметим, что ф^ j = и эта величина
имеет тот же знак, что и (ф — 0). Для запаздываний, больших едини-
цы, картина убывания АКФ зависит от знака ф, а для ЧАКФ — от
знака 0.
При оценивании и прогнозировании соединяются идфи, описанные
ранее для моделей АР(р) и СС(<?). Существенно новых эффектов не
происходит.
18.9.2. ПРИМЕР
К первой разности ряда продолжительности дня была подогнана
модель АРСС(1, 2). Эту модель следует рассматривать как другое
обобщение модели СС(2), альтернативное модели СС(3). Авторегрес-
сионная часть была предложена также ввиду приблизительно геомет-
рического убывания значений АКФ для лагов к = 2, 3, 4, показанных
на рис. 18.5.1, б), хотя выборочные флуктуации в этом интервале отно-
сительно велики. Для модели с двумя членами скользящего среднего
362
такая картина убывания должна была бы начаться с лага 2. Подог-
нанная модель имеет вид
wr = 0,33 wf_j + at + 0,70a,_j 4- 0,72a,_2,
(±0,10) (±0,08) (±0,07)
где снова wt = xt — p и д = 3,3 ± 4,7, OCK = 3221 и a2 = 238,7; она
является наилучшей из уже построенных. Естественно задать вопрос:
нельзя ли еще улучшить модель путем увеличения порядка? Конечно,
имея достаточные вычислительные возможности, разумно проверить
модель таким путем. Делать это надо осторожно, так как если и р,
и q одновременно и необоснованно увеличить, то при решении опти-
мизационной задачи может появиться плохая обусловленность, отра-
жающая возникшее в модели вырождение. Рекомендуется также ана-
лиз остатков и их выборочной АКФ для исследования их структуры.
Это будет сделано для слегка модифицированной модели в разделе
18.11.
Можно сопоставить приведенную выше модель АРСС(1, 2) с мо-
делью СС(3), вычислив значения первых трех коэффициентов:
= 1,03, ^2 = 1,06, ^з = 0,35, что близко к ——02, —Оз- Обра-
тим внимание также на сходство коэффициентов конечного предикто-
ра с первыми семью коэффициентами irk для модели АРСС(1, 2):
1,03, 0,00, —0,74, 0,52, 0,17, —0,49, 0,22. Такие сопоставления полез-
ны для установления сходства между внешне непохожими моделями.
18.10. ОЦЕНИВАНИЕ СПЕКТРА
18.10.1. ТРУДНОСТИ
Выборочный спектр /х(ш) наблюдаемого стационарного временно-
го ряда Xi, ..., хп, введенный в разделе 18.5.3, дает [(и — 1)/2] неза-
висимых оценок теоретического спектра /х(ш), по одной для каждой
частоты = 2-wj/n, j = I, ...,[(п — 1)/2]. Каждая из них имеет
ровно две степени свободы, и поэтому независимо от величины п они
не являются состоятельными оценками /х(ш), т. е.
/х*(ш)У*/х(ш) при 77 —*•«=» •
Любые способы построения состоятельных оценок должны по су-
ществу искать представление спектра с помощью меньшего числа па-
раметров, а именно значительно меньшего, чем (п/2).
363
18.10.2. ПРЯМЫЕ МЕТОДЫ ОЦЕНКИ
Один из распространенных методов основан на том, что если име-
ется много независимых реализаций ряда, то можно усреднить их вы-
борочные спектры и получить состоятельную оценку. Для одной
реализации х,, ...,хп в соответствии с этим методом необходимо
разбить ее на К подрядов длины т, скажем Кт = п. Выборочные
спектры процессов к = 1, ..., т, затем усредняют. В предполо-
жении, что автокорреляция ряда xt достаточно быстро убывает, так
чтобы можно было считать подряды независимыми, итоговая оценка
на частоте vk = 2irk/m, 0 < vk < тг, обозначается fx(vk), и эти ве-
личины независимы со средним fx(vk) и дисперсией К~если
только т достаточно велико — на самом деле здесь имеется смещение
порядка \/т. При фиксированном п приходится искать баланс между
выбором большого т и малого К, что дает больше значений частот
и тем самым меньшее смещение, но приводит к росту дисперсии или
же к обратной ситуации при малом т и большом К. Эта процедура
была применена к первым 140 точкам первой разности ряда продол-
жительности дня, использовались 10 подсерий длины 14, результаты
показаны на рис. 18.10.1, а). Главный недостаток — провал до нуля
в точке и> = 0, вызванный отдельной корректировкой среднего значе-
ния в каждом подряду. Этого можно было избежать, сделав коррек-
цию среднего значения лишь по всему ряду целиком.
Второй метод, в настоящее время очень популярный, состоит в
следующем. Отправляясь от выборочного спектра построенно-
го по ..., хп, строят оценки для более глубокого разбиения частот
vk = 2-кк/т путем усреднения значений, ближайших к каждой из
этих точек, например,
= K~^_Lfx{vk + 2тг//л), (18.10.1)
где К = 2L + \ = п/т. Статистические свойства этих оценок такие
же, как и у f x{vk). Ясно, что /г(ш) должно лишь слегка меняться в
каждом частотном интервале усреднения, иначе появится заметное
смещение, в частности в пиках или по всему спектру. Взвешивание с
весами, спадающими на краях, но по чуть более широкому частотно-
му диапазону, вообще говоря, кажется более привлекательным. На
практике выборочный спектр fx(w) вычисляется для разбиения час-
тот, значительно более тонкого, чем 2тг/«, и усреднение (18.10.1) мо-
дифицируется так, чтобы учесть все эти значения, превращаясь факти-
чески в интегральное усреднение в частотном интервале длины 2-к/т
с центром в vk. Результат для разности ряда продолжительности дня
снова с т = 14 показан на рис. 18.10.1, б). Вычисления снова были
364
1000
к истинному зна-
чению
Рис. 18.10.1. Сглаженные оценки спектра для первой разности ряда продолжи-
тельности дня: а) усреднение выборочных спектров десяти подрядов длины
14; б) выборочный спектр полного ряда, усредненного по частотному интерва-
лу с изображенным равномерным весом; в) аналогично б), но с изображенны-
ми на рисунке трапецеидальными весами; г) оценка с помощью временного
окна Парзена с точкой усечения М = 26; д) оценка на основе коэффициентов
линейного предиктора порядка 7; е) оценка на основе модели АРСС(1,2)
вал между неза-
висимыми оцен-
ками
365
проведены для более тонкого разбиения частот v, хотя следует прини-
мать во внимание, что оценки на промежуточных частотах сильно
коррелированы с оценками в окрестностях частот vk. На рис. 18.10.1,
в) показаны более гладкие результаты, полученные с применением
убывающих по краям весов.
Классический метод вычисления оценок спектральной плотности
тесно связан с предыдущими двумя и направлен на упрощение вычис-
лений. Для описания метода заметим, во-первых, что математическое
ожидание оценок, построенных по первому методу через выборочные
спектры подрядов, можно более точно вычислить, с точностью до
смещения на малых выборках, в виде
£(7Х00) = ^(1 + 2Е (1 - k/m)Qx{k)cQsvk\.
Тем самым слагаемые более высоких порядков «обрезаются» с по-
мощью множителя (1 — к/т) и исключаются при к т. Близкий ре-
зультат справедлив для усреднения или сглаживающей процедуры
(18.10.1) во втором методе. Таким образом, более общий класс спект-
ральных оценок можно получить, используя совокупность весов wk,
называемых временным окном, по формуле
2 м
/х(ш) = (1/тг)5х{ 1 + 2L wkQx(k)cQswk},
0 w ir. (18.10.2)
Для непосредственных вычислений по этой формуле удобно ис-
пользовать веса, равные нулю после точки обрезания М. Такую опен-
ку можно представить и как свертку выборочного спектра с весовой
функцией, называемой частотным окном и равной
м
Ж(о>) = 1 + 2Б Mucosa,*, (18.10.3)
так что
/х(о> ) = J W(u}f*x(u' + a>)Ja>. (18.10.4)
Эта форма удобна для исследования статистических свойств оценки. В
практических рассмотрениях стремятся для любого фиксированного М
к получению концентрированного унимодального положительного
окна W(w). Предлагались различные профили окна, для которых вре-
менное окно имеет вид
wk = w(k/M), к = 0, 1, ..., М,
где функция w(a) определена в интервале 0 а 1. Меняя М, мож-
но управлять уровнем сглаживания. При этом число значений часто-
ты, для которых оценки спектра приблизительно независимы, будет
пропорционально М, а дисперсия каждой оценки — пропорциональна
М/п. Например, для окна Парзена, задаваемого формулой
366
r 1 — 6a2 + 6a3, 0 a 1/2,
w(a) =
12(1 - a)3,
1/2 < a 1,
справедливо соотношение
var(7x(w)J = 0,54(Л//л)/х(и)2.
Выбирая для этого окна М = 26, получаем спектральную оценку для
первой разности ряда продолжительности дня с дисперсией, очень
близкой к дисперсии в предыдущих методах. Эта оценка показана на
рис. 18.10.1, г), и она очень близка к кривой на рис. 18.10.1, в).
18.10.3. КОСВЕННЫЕ МЕТОДЫ ОЦЕНИВАНИЯ
Эти методы основаны на подгонке к данным параметрической мо-
дели. Наиболее популярный подход состоит в построении по выбо-
рочной АКФ коэффициентов конечного предиктора фкj с помощью
рекурсивной процедуры из раздела 18.5.4. Порядок К можно опреде-
лить по критерию КОП из раздела 18.5.5 или же выбрать заранее. Ре-
зультат рассматривается как модель АР(Х) с остаточной дисперсией
ад = о*/(1 —К/п) и авторегрессионным оператором
ф(В) = 1-фкjB —... — Фк>кВК.
Соответствующий спектр вычисляется на основании равенства
ф(В) = ф(В)~1, так что использование (18.6.32) и (18.6.16) приводит к
оценке
Лк(«) = I I 2- (18.10.5)
Ее можно вычислить, используя тригонометрические формулы
(18.6.14) и (18.6.16) или же представив знаменатель как ряд из косину-
сов порядка К, на основе (18.6.21) и (18.6.30). Если К выбрано заранее
и таково, что К и п/К велики, то
£(Ar(“)I =/». var(7AR(«)) = (2^/л)/»2.
На самом деле эта оценка асимптотически близка к оценке, получае-
мой методом сглаживания с прямоугольным временным окном
Wk = 1, к = 1, ..., К. Это окно редко используют на практике, так
как соответствующее частотное окно не является строго положитель-
ным и в оценке спектра могут появиться отрицательные значения.
Однако авторегрессионная оценка спектра (18.10.5) всегда положи-
тельна. На рис. 18.10.1, д) показан результат применения этого мето-
да к первой разности ряда продолжительности дня на основе
предиктора порядка К = 7, дисперсия которого близка к дисперсиям
оценок на рис. 18.10.1, а), б), в).
367
Если к данным с помощью эффективной процедуры была подогна-
на модель АРСС, соответствующий спектр также можно вычислить.
Если главной целью является оценка спектра, это весьма продолжи-
тельная процедура для того, чтобы ее можно было рекомендовать в
общей ситуации. С другой стороны, спектр может помочь «почувство-
вать» модель. Спектр модели АРСС (18.9.2) можно вычислить с по-
мощью формулы ^(В) = 6(В){ф(В)}~1 как
ДМ = (<7>т) I 0(е-“) I V I ф(е'“) Iг. (18.10.6)
Числитель | 0(е'ш) | 2 и знаменатель | ф(е'ш) | 2 можно снова вы-
числить с помощью (18.6.14) и (18.6.16). Интересна гибкость (18.10.6)
в приближении всего разнообразия форм, которые может иметь
спектр. Если 0(B) имеет корень вблизи точки границы единичного кру-
га В = е'ш, т. е. корень, по модулю близкий к единице, то спектр в
этой точке будет иметь значение, близкое к нулю. Аналогично если
ф(В) имеет корень, по модулю близкий к единице, то спектр будет
иметь в этой точке пик. Присутствие как числителя, так и знаменате-
ля позволяет, в частности, создать в спектре острые ямы и пики и да-
ет моделям АРСС большие возможности для аппроксимации разных
форм спектров. Это было бы гораздо труднее, если бы использова-
лись лишь модели АР и СС.
Числитель и знаменатель также можно представить с помощью
(18.6.21) и (18.6.30) как синусоидальные ряды и полиномы по с = cosw
степеней р и q соответственно. Тем самым (18.10.6) является рацио-
нальной функцией от cosw; такие функции известны своей гибкостью
в задачах аппроксимации. На рис. 18.10.1, е) показан спектр модели
АРСС(1, 2), подогнанной к первой разности ряда продолжительности
дня. Его статистические свойства можно (не без труда) вывести из
свойств оценок параметров моделей АРСС.
18.10.4. ПРИМЕНЕНИЕ СПЕКТРАЛЬНОГО АНАЛИЗА
Польза этой техники заключается в выявлении с помощью пиков
спектральной плотности (разнообразной формы) скрытой цикличнос-
ти данных, замаскированной ошибками наблюдений или другими
сильно выраженными эффектами. Напомним, что присутствие в пери-
одограмме случайных пиков может вводить в заблуждение, но техника
сглаживания и знание статистических свойств предохраняют от такого
риска. Использование спектрального анализа возможно, в частности,
для больших объемов данных, возникающих во многих инженерных
задачах или же задачах, связанных с окружающей средой. Сглаженные
оценки спектра полезны также для определения порядков р и q при
подгонке к данным моделей АРСС.
368
18.11. РЕГРЕССИОННЫЕ МОДЕЛИ ВРЕМЕННЫХ РЯДОВ
Проблемы выяснения реальной связи между двумя временными
рядами весьма многообразны. Вполне возможно предположить, что
каждый ряд зависит от одного или нескольких прошлых значений дру-
гого. Если эти ряды составляют часть большой системы взаимозави-
симых рядов и остальные ряды не наблюдаются, то может оказаться
невозможным установить причинную связь. В этом разделе мы огра-
ничимся рассмотрением одного временного ряда с объясняющей пе-
Рис. 18.11.1: а) логарифм периодограммы ряда светимости переменной звезды
с выделенными главным циклом и первой гармоникой; б) периодограмма ряда
поголовья свиней с ясно видной сезонной компонентой на частоте я72
369
ременной, характеризующей детерминированные компоненты модели,
такие, как циклы, тренд или сезонность. Модели будут иметь форму
xt = с + mvt + et, (18.11.1)
где с и т — константы, vt — объясняющая переменная, a et подчиня-
ется модели АРСС. Мы видели на примерах, что иногда главной со-
ставляющей является детерминированная часть, а иногда случайная
часть (АРСС), но всегда важно построить для обеих составляющих
правильные модели.
В качестве первого примера рассмотрим ряд светимости перемен-
ной звезды [см. рис. 18.2.2, а)]. Периодограмма этих данных показана
в логарифмической шкале на рис. 18.11.1, а). Кроме пиков на частотах
0,245 и 0,491, отвечающих главному циклу в данных и его первой гар-
монике, видно также общее возрастание уровня при сдвиге к низким
частотам. Рассмотрим остатки на рис. 18.2.2, в), полученные после
подгонки циклической компоненты ряда. Их АКФ и ЧАКФ показаны
на рис. 18.2.2, г), д). Они типичны для моделей АР(1). Выделенную
в разделе 18.2.2 циклическую компоненту можно теперь заново подог-
нать с одновременной подгонкой модели АР(1) к случайной компонен-
те. Остаточная дисперсия при этом уменьшается, так что модель
объясняет 97,5% полной дисперсии. Оценки параметров при этом не-
сколько меняются, и хотя эти изменения оказываются не значимыми,
их стандартные ошибки при этом возрастают. В частности, стандарт-
ная ошибка оценки частоты цикла почти удваивается. Это могло бы
иметь значение, если бы спустя некоторое время были проведены но-
вые измерения для проверки, не изменилась ли частота. Оцененные
коэффициенты при косинусоидальной и синусоидальной частях основ-
ного цикла равны
А = 0,82 ± 0,21, В = —2,22 ± 0,16,
а для первой гармоники
Аг = 0,31 ± 0,08, Вх = —0,19 ± 0,09.
Оценка частоты равна w = 0,2452 ± 0,0012, что соответствует перио-
ду 256,26. Параметр авторегрессии равен ф = 0,86 ± 0,05.
При анализе новых остатков не обнаружилось никаких признаков
остаточной автокорреляции, на основании чего можно считать по-
строенную модель адекватной. Это пример ряда со смешанным спект-
ром [ср. с разделом 18.5.4].
Второй пример — ряд продолжительности дня. Модель АРСС(1, 2),
подогнанную к первой разности ряда, можно переписать в терминах
исходного ряда xt как
370
(I -ФВ)[(1 -вих,-дН] =
= (1 — (1 + ф)В + фВ2){х, — nt] = (1 —е.В — 02B2)at,
где сделана подстановка V = 1 — В, а среднее ц первой разности ря-
да включено как тренд в исходном ряду. Цель такого преобразова-
ния — последующая модификация разностного оператора путем под-
гонки к исходному ряду модели АРСС(2, 2) с трендом, а именно
— c + + (18.11.2)
где et описывается моделью АРСС(2, 2).
При подгонке этой модели остаточная дисперсия слегка уменьша-
ется до 233,1 по сравнению с 238,7 для модели АРСС(2, 1). При этом
одна степень свободы была потеряна и соответствующее значение ста-
тистики хи-квадрат равно 4,22, что значимо на уровне 5%. Оценки па-
раметров равны
с = —173 ± 137, п =. 2,80 ± 1,48, фх = 1,31 ± 0,13,
02 = —0,35 ± 0,13, £ = —0,68 ± 0,09, ё2 - 0,72 ± 0,07. .
Разлагая на множители, получаем
0(B) = (1 — 1,31В + 0,35В2) = (1 — О,38В)(1 — 0,93В)
и видим, что оператор V = (1 — В) предыдущей модели, характери-
зующий случайное блуждание, теперь заменен на чисто авторегресси-
онный множитель (1 — 0,93 В). Остатки в этой последней модели
выглядят случайными, хотя и содержат небольшое количество выде-
ляющихся значений и их автокорреляционная функция не обнаружива-
ет какой-либо остаточной структуры. Прогнозы для последних 100
точек ряда (не использовавшихся при подгонке модели) вместе с дове-
рительными границами для ошибок прогноза показаны на рис. 18.5.2,
они заметно ближе к фактическим данным.
В качестве третьего примера рассмотрим ряд поголовья свиней.
Периодограмма этого ряда, показанная на рис. 18.11.1, б), содержит
широкий пик в спектре в области низких частот, который мог бы со-
ответствовать модели АР(2), и острый пик в точке ш = тг/2, который
может соответствовать сезонной компоненте с периодом 4. Вполне
естественно ожидать наличие такой компоненты в квартальном ряду,
нЬ она оказалась замаскированной размашистыми колебаниями ряда,
показанными на рис. 18.1.1, б). АКФ и ЧАКФ ряда, показанные на
рис. 18.11.2, свидетельствуют об авторегрессионном поведении, но не
о чистой авторегрессии, поскольку ЧАКФ простирается до лага 7,
быть может, вследствие сезонности.
371
Рис. 10.11.2. Выборочная АКФ (а) и ЧАКФ (б) для ряда поголовья свиней
Поэтому к ряду была подогнана модель
xt = «121/ + OL2Q2 t + a3Q3 t + a4Q4i t + e,, (18.11.3)
в которой Qj t — индикаторные переменные, принимающие значения
1 для j-x кварталов и 0 в остальных случаях. Для описания случайной
составляющей была взята модель АРСС(2, 1); член скользящего сред-
него включен в модель для сравнения с предшествующим вариантом,
в котором не было квартальной компоненты, но член скользящего
среднего значим. Необходимость включения квартальной компоненты
дмказывастся резким снижением остаточной дисперсии от 68,1 в ста-
рой модели до 39,3 в модели (18.11.3). Оценки параметров модели
АРСС следующие:
Ф1 = 1,55 ± 0,16, ф2 = —0,74 ± 0,14, $1 = 0,28 ± 0,22,
и параметр скользящего среднего 0lt очевидно, не нужен. В соответст-
вии с (18.8.11) параметрам авторегрессии отвечает пик в спектре на
частоте, соответствующей периоду в 14,8 квартала.
Ряд остатков и его автокорреляционная функция не обнаруживают
какой-либо остаточной структуры. Тем не менее к ряду была подогна-
на и другая модель, учитывающая сезонные эффекты аналогично мо-
дели (18.7.43) для ряда авиаперевозок, основанной на ЭВСС-предик-
торе. Эта модель допускает изменяющуюся, а не постоянную сезон-
ную компоненту; сихраняя модель АРСС(2, 1) для несезонной части,
получаем модель
(1 -ф.в-ф2В2)[ V<xt-n} =
= (1 — OB) (1 — еВ4)е,. (18.11.4)
Остаточная дисперсия уменьшилась до 36,9. При этом из-за новых
параметров 0 и д (описывающего среднегодовой прирост или убыль)
были потеряны две степени свободы. Соответствующее значение ста-
372
тистики хи-квадрат, основанной на изменении суммы квадратов
остатков, равно 5,6 и не является значимым. Оценки параметров
равны:
ф! = 1,62 ± 0,09, ф2 = —0,86 ± 0,09, д = —1,4 ± 0,8,
§ = —0,41 ± 0,17, 0 = 0,68 ± 0,10.
Хотя нет четких указаний в пользу к одели (18.11.4), ее испош ювание
может оказаться предпочтительнее ввиду ее гибкости и присг коблен-
ности к изменениям формы сезонной волны.
18.12. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Применения методов анализа временных рядов весьма многообраз-
ны, что приводит к появлению многих книг, написанных специалиста-
ми в разных предметных областях; часто в этих книгах используется
различная терминология. Широкое распространение получили две ра-
боты: [Jenkins and Watts (1968)] и [Box and Jenkins (1976)]. Первая из
них содержит полное изложение спектральных методов, включающее
приложения к многомерным рядам, а вторая полностью освещает ме-
тодологию построения моделей АРСС, а также их обобщения — мо-
дели, описывающие значимость ряда от одного или нескольких
рядов-факторов.
В более поздней книге [Bloomfield (1976)] рассматриваются методы
преобразования рядов. Работа [Granger and Newbold (1977)] великолеп-
на в свой области. Книга [Robinson (1980)] посвящена главным обра-
зом задачам выделения полезного сигнала с применениями к геофи-
зике. Наиболее полное в настоящее время изложение предмета содер-
жится в [Priestley (1981)].
Для практического применения методов анализа временных рядов
почти неизбежно необходимы хорошие программы для ЭВМ. Суще-
ствуют разные источники таких программ. Вычисления, приведенные
в примерах этой главы, выполнены с помощью библиотеки и пакета
программ GENSTAT, разработанного в Numerical Algorithms Group,
Banbury Road, Oxford, U. K.
Ниже приведен список упомянутых книг.
Bloomfield Р. (1976). Fourier Analysis of Time Series, Wiley.
Box G.E.P. and Jenkins G. M. (1976). Time Series Analysis, Forecasting and
Control. Second edition, Holden-Day, San Francisco.
Granger C. W. J. and Newbold P. (1977). Forecasting Economic Time Series,
Academic Press.
373
Jenkins G. M. and Watts D. G. (1968). Spectral Analysis and Its Applications.
Holden-Day, San Francisco.
Priestley M. B. (1981). Spectral Analysis and Time Series. Academic Press.
Robinson E. A. (1980). Physical Application of Stationary Time Series. Griffin.
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз и управление. —
М.: Мир, 1970. — Вып. 1, 2.
Дженкинс Г., Вате Д. Спектральный анализ и его применения. — М.: Мир,
1972. — Вып. 1, 2.
Глава 19
ТЕОРИЯ ПРИНЯТИЯ РЕШЕНИЙ
19.1. ОСНОВНЫЕ ИДЕИ
19.1.1. МАТЕМАТИЧЕСКИЙ ФОРМАЛИЗМ
Основные элементы задачи принятия решения допускают следую-
щую формализацию:
задается множеством [см. I, раздел 1.1], называемое простран-
ством действий, которое состоит из всех действий , доступных
лицу, принимающему решение (ЛПР);
задается множество О, называемое пространством параметров,
состоящее из всех возможных «состояний природы», 0€0, из которых
реализуется одно и только одно (это истинное состояние природы не-
известно ЛПР в момент, когда нужно принять решение);
задается функция L, называемая функцией потерь, с областью
определения 0х л (множество всех пар (0,а), 0€0, а€М[см. I, раздел
1.2.6]) и областью значений R (вещественная прямая) [см. I, определе-
ние 1.4.1]; пара (в,а) называется последствием (от принятия решения
а, если истинное состояние природы есть 0);
наблюдается случайная величина X, возможные реализации кото-
рой х^Х образуют выборочное пространство X [см. II, раздел 3.1] и
распределение которой задается плотностью распределения вероятно-’
стей [см. II, раздел 10.1.1], принадлежащей заданному семейству
(/(ЭД; 0€0);
определяется множество D, называемое пространством решений и
состоящее из всех отображений d множества X в Л [см. I, определе-
ние 1.4.1].
Описанный формализм можно интерпретировать следующим обра-
зом. В момент выбора действия ЛПР не знает истинное состояние при-
роды и поэтому ему неизвестны истинные последствия его действия
(если ЛПР изберет действие а£Л, то истинное последствие (0,о) неиз-
вестно, поскольку 0€0 неизвестно). Однако ЛПР знает ущерб при каж-
дом возможном последствии (в,а), определяемом его выбором
действия а$Я и состоянием природы 0€0 (конечно, «ущерб» может
быть и «выигрышем»; в этом случае численное значение, приписанное
функции Ц0,а), должно быть отрицательным либо мы можем рабо-
тать не с функцией потерь, а с функцией выигрыша или полезности).
Чтобы уменьшить неопределенность относительно О, ЛПР получает
информацию в виде наблюдений случайной величины X, распределение
375
которой зависит от параметра в. Зная, что Х-х, и зная вид п.р.в.
f(x\0), Л ПР может извлечь информацию относительно состояния 9, ко-
торая поможет ему в выборе общей стратегии, определяющей выбор
для каждого Х-х. Формально ДПР выбирает действие а£Л на
основе имеющегося наблюдения . Выбор общей стратегии, опре-
деляющей для каждого Х=х действие , эквивалентен выбору ре-
шающей функции d$D. Функция d определяет действие,
предпринимаемое ДПР при всех возможных Х-х.
Таким образом, теорию принятия решений можно считать наукой
о том, как выбирать решающую функцию d из пространства решений
D. Эта теория включает два аспекта: первый, философский, состоит
в выборе критерия для сравнения элементов множества £>; второй,
технический, состоит в том, как найти элемент d, оптимальный в
смысле выбранного критерия.
Иногда задачу принятия решения рассматривают как игру против
Природы. Это естественно, поскольку Природа выбирает элемент 0€0
и затем ДПР, не зная этого состояния 0, выбирает действие а^А . В
результате этих двух выборов ДПР терпит ущерб Ц6,а) (измеренный
в соответствующих единицах, не обязательно денежных). Возмож-
ность наблюдать случайную величину X с п.р.в. f(x\0) дает ДПР неко-
торую ограниченную информацию относительно выбора Природы.
Выбор решающей функции d можно рассматривать как стратегию, из-
бираемую ДПР для этой игры.
Хотя впоследствии мы рассмотрим это более подробно [см. раздел
19.2], следует уже сейчас отметить, что два основных раздела теории
статистических выводов — оценивание и проверка гипотез — являют-
ся частными случаями сформулированной общей задачи принятия
решений.
При оценивании положим Я = О (обычно это — вещественная пря-
мая или подмножество прямой), поскольку в данном случае действие
состоит в выборе значения параметра (т. е. оценки). Вид функции по-
терь зависит от практических особенностей моделируемой задачи, но
наиболее типичными являются Ц0,а)= |0—а\ или Ц0,а) = {9—а)1. Реша-
ющая функция обычно называется процедурой оценивания, а
ее значение d(x) является оценкой параметра 0 по заданным данным
Х=х [ср. с определением 3.1.1].
При проверке гипотез [см. раздел 5.12] пространство параметров 0
представляется в виде объединения двух непересекающихся множеств
0О и 0]:0 = 0О (J 0]. Множество?? в этом случае содержит всего два
элемента Л = определенные таким образом, что действие а0
состоит в отклонении гипотезы 0€0i, а действие а} — в отклонении
гипотезы 0€0О- Функция потерь зависит от природы множеств 0О и
е>.
При проверке простой нулевой гипотезы против простой альтерна-
тивной гипотезы [см. раздел 5.2.1, п. в), г)] пространство параметров
также состоит из двух точек 0= {0o,0i ], и можно, например, положить
^(0o,^o)=^(0i^i) = O (поскольку в этом случае предпринимается пра-
вильное действие); выбор двух других значений £(0О,Я1) и £(0],ао) дол-
жен отражать относительную важность ошибок I и II рода.
376
Материал в этой главе расположен следующим образом. В остав-
шейся части раздела 19.1 мы обсудим альтернативные критерии для
оценивания решающих правил, а затем сформулируем ряд основных
результатов, показывающих, какие критерии приводят к хорошим ре-
шениям. В разделе 19.2 некоторые из этих идей будут проиллюстри-
рованы на статистических задачах принятия решений (оценивания и
проверки гипотез).
Ясно, что функция потерь (или, что то же самое, функция полез-
ности или отрицательных потерь) играет фундаментальную роль в
построении теории принятия решений. В разделе 19.3, работая в тер-
минах функции полезности, мы рассмотрим, каким образом выбор
этой функции связан с ожидаемым риском.
В разделе 19.4 дано краткое введение в важный класс задач, в кото-
рых решения принимаются последовательно по времени, одно за дру-
гим, так что более позднее решение зависит от последствий
предыдущих. Мы определим дерево решений и проиллюстрируем его
применение. Наконец, в разделе 19.5 вновь кратко вернемся к вопросу,
как обосновать критерии для принятия решений, отправляясь от не-
большого числа очевидных постулатов или аксиом. Рекомендации по
выбору литературы для дальнейшего изучения приведены в разделе
19.6.
19.1.2. МИНИМАКСНЫЕ И БАЙЕСОВСКИЕ РЕШАЮЩИЕ ПРАВИЛА
Можно подумать, что выбор оптимальной решающей функции до-
лжен быть очевиден, поскольку мы просто хотим выбрать такое deD,
чтобы ущерб был минимальным вне зависимости от того, каким ока-
жется состояние природы.
Однако короткое размышление приводит к выводу, что такой вы-
бор невозможен никогда, если только мы не знаем истинного состоя-
ния природы, а в этом случае мы по-настоящему и не можем
говорить о проблеме принятия решений. Для иллюстрации предполо-
жим, что мы встретились с задачей оценки неизвестного вещественно-
го параметра 0 [см. раздел 3.1] с функцией потерь Ц0,а) вида (0—а)2.
Допустим, что мы наблюдаем значение Х=х и что a=d(x) есть
оценка параметров 0, задаваемая решающей функцией d.
Если истинное значение параметра равно 0, то ущерб составит
(0—d(x))2. Если на самом деле 0 = 0О, то для минимизации потерь сле-
дует взять d(x) = 0o’, в то же время, если 0 = 0it то следовало бы при-
нять d(x) = 0\. Но нам неизвестно значение 01 Поэтому мы не можем
выбрать d(x) так, чтобы минимизировать потери, — здесь просто нет
правильно поставленной математической задачи.
Один из возможных путей оценки качества решающей функции d в
показателях, которые можно вычислить, состоит в том, чтобы опре-
делить, насколько хороша выбранная стратегия «в среднем». Для это-
го полезно следующее определение.
377
Функцией риска от принятия решения d при состоянии природы О
называется функция R с областью определения QxD и областью зна-
чений R, определяемая равенствами
R(0,d) = $L(0,d(x))f(x\9)dx (для непрерывных случайных величин X)
[см. IV, определение 4.1.3] и
R(0,d) = Е L(0,d(x))f(x\6) (для дискретных случайных величин X)
xtZ
[см. IV, (1.7.1)].
Риск R(0,d) имеет смысл меры ожидаемых потерь от использова-
ния решающей функции d, если природа находится в состоянии в (ма-
тематическое ожидание вычисляется по отношению к распределению,
задаваемому функцией f(x\0). Таким образом, обозначая оператор ма-
тематического ожидания через Ехе [см. II, раздел 10.4.1], можно за-
писать риск в другой форме:
ЕШ=Ех^[Ц0^(Х))].
Чтобы избежать скучного переписывания формул, вызванного не-
обходимостью различать случаи дискретного и непрерывного распре-
деления, мы будем либо использовать эту общую запись оператора
математического ожидания, либо чаще просто ограничиваться инте-
гральной формой, соответствующей непрерывным распределениям.
Оператор математического ожидания ЕХ\в может быть применен к
любой функции h(X,0), у которой существует математическое ожида-
ние относительно распределения случайной величины X, так что
h(X,0)} = pifx W(x\e)dx.
Мы будем также использовать оператор дисперсии, задаваемый ра-
венством
кх|е{ад0))=Ех|в{ад0)}2-[Ех|в{ад0)}]2.
Для одномерного параметра 6 графики риска R(0,d) как функции от
О дают возможность сравнить относительное качество решающих пра-
вил, оцениваемое при помощи этих функций риска.
Пример 19.1.1. Рассмотрим рис. 19.1.1. На нем изображены три
функции риска для задачи оценивания параметра 0 по случайной вы-
борке Х=(Хх,...,Хп) из нормального распределения N(0,1) с достаточ-
но большим п. Функция потерь равна: £(0,а)=(0—а)1, а решающие
функции —
d,(X,...Х„)= ух, + ...+Х„)=Х,
d2(Xt ,...,Хп)=median {Xj,... ,Хп ],
ад.............
Функция di задает среднее выборки, d2 — выборочную медиану, а про
d3 можно сказать, что она «игнорирует данные и всегда оценивает 0
нулем». Для вычисления функций риска заметим, что
378
Рис. 19.1.1. Функции риска, соответствующие решениям dlt d2, d3 из примера
19.1.1
W,d,)=£^/X-«)2 = i
(так как величина X в данном случае имеет распределение N(0,l/Vn)
и что
Я(0,^)=E^(O-0)2 =E^(02) = 02.
Результат для медианы вытекает из известного результата, который
мы приведем без обоснования: при больших п медиана medfXi,...,^^
имеет асимптотически нормальное распределение М(0,7('тг/2л/ Сравне-
ние графиков на рис. 19.1.1 показывает, что при наших предположени-
ях (нормальное распределение, квадратичная функция потерь) никогда
не нужно использовать медиану для оценивания 0, поскольку график
функции риска для среднего при всех значениях 0 расположен ниже
графика для медианы. Однако среднее не всегда лучше, чем «слепая»
оценка d3, поскольку для достаточно близких к нулю значений 0 «сле-
пая» оценка приводит к меньшему риску. Сами по себе функции риска
показывают только, что оценку d2 никогда не нужно использовать
(при всех 0 по меньшей мере одна из решающих функций dx и d3 ока-
зывается лучше), и не дают основания для выбора между dx и d3.
Чтобы глубже понять трудности, возникающие при выборе реша-
ющих функций, рассмотрим пример.
Пример 19.1.2. Пусть X=(Xx,...,XJ — случайная выборка из нор-
мальной генеральной совокупности с параметрами (0V0), где 0>О, т.е.
из нормального распределения, среднее и дисперсия которого равны 0.
Попробуем оценить 0, используя функцию потерь £(0,д>=(0—а)2.
Рассмотрим с иллюстративными целями две решающие функции:
И
379
< п __
<MX)~±i Е (Xt-Xf.
Стандартное вычисление математического ожидания дает
R(0,dj=Ех[6(0-Х )2 = Vx^(X) = 0/п
[см. II, раздел 9.2.4], где Ух^ обозначает определенный ранее опера-
тор дисперсии, и
K(6,d2) = Exie I f)-d2(X) 12 = (d2 (X) I,
поскольку Exi6fd2(X)} =0. Поэтому [см. (2.5.22)]
Отсюда следует, что R(0,dесли и 2?(0,di)>/?(0,d2),
если 0<(n—V)/2n. В точке (n— 1)/2л функции R(0,dx) и R(0,d2) равны.
Примерные графики функций риска для п=2 изображены на рис. 19.1.2.
Рис. 19.1.2. Функция риска для решений
di и d2
И снова мы стоим перед
выбором. Если известно,
что 0<-^-, то ясно, что луч-
ше использовать d2, чем di.
Если мы знаем, что 0>-\~,
то наоборот. Однако мы не
знаем значение 0 и поэтому
для обоснованного выбора
вынуждены искать дополни-
тельные критерии.
Вообще говоря, конкрет-
ная задача принятия реше-
ний приводит к огромному
числу возможных решающих
функций (множество D очень
велико), и поэтому нельзя,
как в предыдущих примерах,
свести дело к графическому сравнению небольшого числа решающих
функций. Вместо этого нужно искать общий подход, позволяющий
выбрать «оптимальное» правило во всем классе D.
В этом разделе мы рассмотрим только два таких подхода — так
называемые минимаксный и байесовский. Для обоснования дальней-
ших определений рассмотрим сначала рис. 19.1.3, на котором изобра-
жены графики двух (гипотетических) функций риска, соответствующих
решающим правилам d\ и d2 для некоторой (не важно какой) задачи
принятия решений с одномерным параметрическим пространством 0.
Для большинства значений 0 решающая функция d2 приводит к
меньшему риску, чем dif но для некоторых 0 значение риска при d2
380
| R (<7, dl
Рис. 19.1.3. Два гипотетических решающих правила
намного больше, чем при dt. Что же делать в такой ситуации?
Возможны следующие два подхода:
а) Оградить себя от наихудшего! Разумно проявить осторожность
и выбрать d}, поскольку это предохранит от наихудшего возможного
исхода; такое решение минимизирует максимум потенциального
риска.
б) Принимая во внимание дополнительную информацию, можно
сформировать определенное мнение о том, каких значений 0 следует
скорее всего ожидать. Если вы убеждены, что значения в окажутся в
области, где решающая функция d2 очень плоха, следует выбрать di.
И наоборот, если вы считаете маловероятным, что 0 попадает в эту
область, разумно выбрать d2. Во всяком случае при анализе следует
учитывать ваше субъективное суждение относительно возможных зна-
чений параметра 0.
Эти два альтернативных интуитивных подхода легко формали-
зовать.
В случае а) мы выбираем такое решающее правило d*, чтобы
sup R(0,d*)= inf sup RlPtd)
060 (fcD 060
[см. I, раздел 2.6.3]. Другими словами, мы выбираем решающую
функцию, для которой максимальное значение риска равно наимень-
шему возможному максимуму риска (по всему пространству решений
D). Именно поэтому d* называется минимаксной решающей
функцией.
В случае б) предположим, что суждение относительно параметра 0
может быть выражено в виде плотности распределения вероятностей
381
р(0) на параметрическом
пространстве 9 (дальнейшее
обсуждение этого вопроса
содержится в гл. 15, посвя-
щенной байесовскому подхо-
ду, и в разделе 19.5.2 этой
главы). Например, эти суж-
дения могут соответство-
вать графикам pi и р2 на
рис. 19.1.4, на котором ось 0
изображена в том же масш-
табе, что и на рис. 19.1.3.
Интуитивно ясно, что ес-
ли ваше суждение соответ-
Рис. 19.1.4. Возможная форма предполага- ствует распределению Pi, то
емого распределения параметра 6 все основания считать реше-
ние d2 опасным и предпо-
честь сЦ. И наоборот, тот, кто верит в распределение р2, может пред-
почесть решающую функцию d2. Мы формализуем этот подход следу-
ющим образом.
Функция риска R(0,d) выражает ожидаемые потери от использова-
ния решающей функции d при условии, что 0 — истинное состояние
природы. Рассматривая ее как функцию 0 при фиксированном d, мож-
но вычислить ожидаемое значение риска по отношению к предполага-
емому распределению р(0). Определим байесовский риск r(d),
соответствующий решающей функции d, равенством
r(d)= f R(0,d)p(0)d0 (если 0 — непрерывный параметр)
е
ИЛИ
r(d)= Е R(0,d)p(0) (если 0 — дискретный параметр).
Естественно выбрать решающую функцию, которая минимизирует
средний ожидаемый ущерб -{r(d)-E^^L(0,d(X)^. Назовем d* байе-
совской решающей функцией, если-
r(d*)= inf r(d).
cteD
Заметим, что в каждой задаче принятия решения функция <7* не един-
ственна, поскольку она, в частности, зависит от выбора распределе-
ния р(0). Поэтому лучше говорить, что d* является байесовской
решающей функцией по отношению к р(0). В задачах оценивания d(X)
называется байесовской процедурой оценивания, а значение d(x) —
байесовской оценкой, соответствующей Х=х.
Для иллюстрации минимаксного и байесовского подходов рассмот-
рим пример.
Пример 19.1.3. Для задачи, рассмотренной в примере 19.1.1,
sup/?(0,6/i)=l/n,
е
382
sup-R(0,6Z2) = l,57/n,
e
sup7?(0,<73) = —.
e
так что di оказывается минимаксным решающим правилом (из dif d2
и d3).
Предположим теперь, мы уверены в том, что 0 заключено в интер-
вале между —и + а внутри этого интервала нет никаких осно-
ваний считать одну точку предпочтительнее другой. Эти предположе-
ния соответствуют равномерному распределению на интервале (—
1^), так что в нем р(0) = 5 и
1/10
r(d,)= J (|)-5<Я=|,
• —1/10
1/10
r№)= I & -5<№ = ,
-1/10
r/cZ3)= 02-5б70 = 1/300.
—1/10
При л>300 байесовской решающей функцией будет d}; при л = 300
функции di и d3 имеют одинаковый байесовский риск, а при л <300
предпочтительнее d3 (по отношению к этому частному выбору р(0)).
Однако если наше априорное мнение будет другим, например, со-
ответствующим равномерному распределению на интервале (—1, 1),
то значения байесовского риска изменятся:
rfd,)= r/d2)= цр , г№)= !?,
так что d3 окажется наименее предпочтительным решением с байесов-
ской точки зрения.
Итак, мы определили два возможных подхода к выбору решаю-
щих правил: минимаксный и байесовский — и показали, что они
обычно приводят к различным ответам (хотя при некоторых априор-
ных распределениях оба подхода могут привести к одинаковому ре-
зультату). Обсудим теперь более «нейтральное» условие, которое
позволяет разделить решающие функции на «овец» и «коз».
19.1.3. ДОПУСТИМЫЕ РЕШАЮЩИЕ ФУНКЦИИ
Общая картина, с которой мы встречались, иллюстрируется на рис.
19.1.5. Ясно, что решения dx и d2 (судя по изображению на рисунке) не
стоит больше рассматривать. Оба решения d3 и d4 равномерно по 0
имеют меньшие риски, чем d3 и d2, и окончательный выбор нужно де-
лать только между ними. На обиходном языке решения d} и d2 оказа-
лись неподходящими, а решения d3 и d4 заслуживают рассмотрения.
383
Рис. 19.1.5. Общая картина соотношения функций риска для нескольких реша-
ющих правил d
Эту идею можно выразить и более формально.
Если для заданной решающей функции dtD существует другая
решающая функция d'^D, такая, что
R(fi,d')^R(fi,d) для всех 0€б
и
R(G ,d) < R(0 ,d) для некоторого значения 0€О,
то говорят, что решение d доминируется решением d" или что реше-
ние d" доминирует решение d.
Решающая функция, доминируемая некоторой другой решающей
функцией, называется недопустимой, а в противном случае — допу-
стимой.
На рис. 19.1.5 решающие функции d\ и d2 доминируются функция-
ми d3 и <74, и поэтому являются недопустимыми. В классе
D= {бЛ, di, d3, d4} d3 и cZ4 являются допустимыми, поскольку ни одна
из них не доминирует другую. Если взять большее множество D, но
так, чтобы d2, d3, d4} было его подмножеством, то решающие
функции d3 и dA сами могут оказаться доминируемыми какими-нибудь
другими функциями и поэтому быть недопустимыми. Допустимость
всегда является относительным понятием, связанным с выбором кон-
кретного множества D.
Со многих точек зрения изучение теории принятия решений естест-
венно начинать с концепции допустимости. Можно достичь гораздо
большей ясности, исключив недопустимые решения и сосредоточив
384
выбор только на допустимых решающих функциях. Поэтому многие
фундаментальные работы по теории принятия решений были посвя-
щены выяснению природы множества допустимых решающих функ-
ций. В разделе 19.1.5 мы приведем краткий обзор общих результатов
такого рода.
Но прежде интересно рассмотреть важный частный случай, когда
0={0!,...0Л} представляет собой конечномерное пространство пара-
метров (а более точно, когда к =2). Это позволит нам получить гео-
метрическое представление и интерпретацию понятий, которые мы
будем обсуждать в дальнейшем.
19.1.4. ГЕОМЕТРИЧЕСКАЯ ИНТЕРПРЕТАЦИЯ
Прежде чем перейти к геометрической интерпретации, нужно вве-
сти еще одну идею. Зададимся вопросом: «Может ли выбор решения
основываться на бросании монеты?». Поскольку мы имеем в виду ра-
зумный процесс принятия решения, интуиция подсказывает: «нет».
Но рассмотрим следующую таблицу, определяющую функцию потерь
для задачи, в которой 0= {0Ь 02], Л = (яь а2, а3].
Таблица потерь
°2 а.
&2 4 1 1 4 3 3
Следует ли иногда предпринимать действие а3? На первый взгляд а3
нельзя исключить из рассмотрения, поскольку в состоянии 01 действие
а3 лучше, чем а}, а в состоянии 02 лучше, чем а2.
Однако предположим, что мы рассматриваем рандомизированное
действие, определяемое бросанием монеты: если выпадет герб, изби-
раем аь а если решка — а2. Тогда для такого рандомизированного
действия ожидаемые потери при состоянии природы равны:
у L(0,cii)+ yZ(01,a2) = у‘4+ у ’1= Т»
а в состоянии 02
yL(02,<Ij) + у^(02>О2)= у *1 + у '4= у.
Поскольку у <3, то в обоих состояниях рандомизированное действие
предпочтительнее, чем а3.
Этот пример показывает, что рандомизация может быть разум-
ным рецептом. На самом деле удобнее рандомизировать решающие
385
Д RUb, ’>)
Точка риска для S
правила dtD, а не действия
Мы будем обозна-
чать через = ad\ + (1—
—a)-d2 (O^a^l) рандоми-
зированное правило, при
котором с вероятностью а
принимается решение d\, а
с вероятностью (1—а) —
решение d2.
Точка риска для
рандомизации 5 [ и 6
Риск такого решающе-
го правила, естественно,
определяется равенством
Точка риска для 6,
/?(0,6а) = оЯ(0Д) +
+ (1-а)ЖМ2).
R (01,6)
Рис. 19.1.6. Общая форма выпуклого множества
И вообще, если « = («!,...,
aw) и «1 +а2 + ... + аот = 1,
а£>0, то определим реша-
ющее правило 3a = o£i<7i +
7... + amdm, рандомизиро-
ванное по элементам d\,...,dm из множества решений D. (Мы можем
даже, интерпретируя а как «метку» распределения вероятностей, гово-
рить в некотором смысле о рандомизации по «непрерывным» обла-
стям в множестве D.) При рандомизации по т элементам положим по
определению
R(0,8a) = а,Я(0 Д) +... + <*mR(0,dmY
Допустив возможность рассмотрения любых рандомизаций эле-
ментов множества D, обозначим множество всех рандомизированных
решений через D*. Ясно, что DQD*. Элементы множества D* будем
обозначать через 6.
Геометрическая интерпретация в случае 0 = {,... ,0к} существенно
упрощается, если использовать понятие множества риска, У :
У = где yj = R(0j,b'}, у=1,...Л, для некоторого б€£>*}.
Здесь R* есть множество всех упорядоченных наборов (У1,...^), со-
стоящих из к вещественных чисел; так, например, R3 = RxRxR [см. I,
раздел 1.2.6]. Приведенное определение означает, что подмножество
7 в R состоит из точек, j-я координата которых равна значению в
точке 0J функции риска R(0y,6) для некоторого (рандомизированного)
решающего правила 6.
Важно заметить, что J — выпуклое множество. Это значит, что от-
резок, соединяющий любые две точки множества У , никогда не выхо-
дит за его «пределы». Для случая к=2 это показано на рис. 19.1.6.
Легко понять, как можно доказать выпуклость <7 . Все точки на отрезке,
соединяющем значения риска для двух решающих правил, скажем и
<52, соответствуют значениям риска некоторой рандомизации 6, и 62. На-
пример, 6=a6i+(l—а)82. Если 8i = a,d{ + - + ot^d^ и 62 = a'{d'{ +... +
386
Рис. 19.1.7. Геометрическая интерпретация минимаксного подхода
где а/+... + = 1 и af + ... + а" —1» то 8—aa{d{ + oiot2d2 + ... + oiotmdm +
+ а1//(1—a)d{' + oi2 (1—oijdi' +...+а"(1—ot)d". Причем окх\ + а«2+— 4-аа/п'4-
4- af(l —а) + (1—а) + — + (1— а) = а(а{ 4- ai 4-... 4- а^) 4- (1—a)(af 4- а£ + —
+ а„") = а4-(1—а) = 1-
По определению <7 все такие точки принадлежат J и, стало быть, J
выпукло.
Сейчас мы, используя этот факт, приведем геометрическую интерпре-
тацию минимаксного и байесовского подходов.
Минимаксный подход. При заданном 8ZD* величина |ugR(0,6) в слу-
чае 0= есть просто тдх ур где у=(У1,-..у^ — точка риска, со-
ответствующая решающему правилу 8. При минимаксном подходе реша-
ющие правила сравниваются по величине тдхуу, так что при таком под-
ходе все решающие правила с одинаковым значением тдху, одинаково
хороши. В двумерном случае множество точек (У1У2), У которых
шах (у, у2} равен заданной величине, образует «выступ» или «угол». По-
скольку при минимаксном подходе ищется наименьшее значение max к,
J J
то минимаксным решающим правилом является такая точка (или точ-
ки), где угол в 90° соприкасается с нижней (т. е. юго-западной) границей
множества риска <7 . Эта ситуация показана на рис. 19.1.7, а) и 19.1.7,
б), причем во втором случае видно, почему минимаксное решающее пра-
вило может быть не единственным (единственность зависит от формы
множества 7 , которая в свою очередь определяется задачей принятия
решений).
387
R (02,6) = y2
Рис. 19.1.8. Геометрическая интерпретация байесовского подхода
Приведенная интерпретация непосредственно переносится и на к-
мерный случай — просто нужно воспользоваться соответствующим
обобщением понятия угла в 90°.
Байесовский подход. В случае 0= {01,...,0Л} априорное распределе-
ние задается некоторым набором р=(р\,...р^, в котором ру>0,
/=1,...,к, и рх +р2 + ... +Рк = \- Байесовский риск, соответствующий
(рандомизированному) решающему правилу 6, равен:
к к
zPjR(ep= ъРр>,.
Предыдущее равенство при фиксированном г(<5) задает гиперплоскость
в ^-мерном пространстве. В простейшем случае, когда к=2, все точки
(У\у2), дающие одно и то же значение байесовского риска, лежат на
прямой Ухрх +УгР2 = constant. Так как 0^Рх,р21 и рх +р2 = 1, то все та-
кие прямые идут с северо-запада на юго-восток. Но при байесовском
подходе ищется минимум рхУ\ Урууъ поэтому байесовским решающим
правилом оказывается точка, в которой прямая вида рхУ\ +
+р-2У1 = constant касается нижней границы множества <7 . Это показа-
но на рис. 19.1.8, а) и рис. 19.1.8, б), причем во втором случае видно,
почему и байесовское решающее правило может быть не един-
ственным.
Та же интерпретация непосредственно переносится и на ^-мерное
пространство, если только заменить прямую на касательную гипер-
плоскость.
Пример 19.1.4. Предположим, что в задаче принятия решений с
0= {0ь02}, D- {dx,d2,d3,dt,d5} функция риска /?(0ра^ задается следую-
щей таблицей:
d\ (?2 dy d4 d}
0! 0 4 2 1 5 02 4 5 0 1 4
388
R Mi, 8)
Рис. 19.1.9. Множество 7, соответствующее таблице функции риска /?(0,5)
Множество 7 и пять точек риска, соответствующие элементам из D,
показаны на рис. 19.1.9. Ясно, что множество <7 состоит из тех и
только тех точек, которые можно получить рандомизацией исходных
пяти точек риска.
Допустимые решающие правила соответствуют таким точкам в
J, для которых в этом множестве нет точек к юго-западу от них
(включая направления строго на юг и на запад; это значит, что для
таких точек нельзя найти решающее правило 6 в D*, в точке риска ко-
торого одна координата была бы меньше, а другая — не больше, чем
у исходной). В данном случае множество допустимых правил соответ-
ствует точкам, лежащим между d\ и d4, а также между <74 и d5. Иначе
говоря, множество допустимых точек состоит из всех рандомизаций
правил di,dA и d^d^.
Минимаксным решающим правилом оказывается d^, поскольку 90°-
ный угол (с наименьшей постоянной) касается нижней границы мно-
жества 7 в (единственной) точке с?4.
Байесовское решающее правило зависит от выбора (р\,рд- Пред-
ставив себе, что вертикальная прямая (Pi = l) постепенно поворачива-
ется (против часовой стрелки) до совпадения с горизонтальной (pi=0),
и, рассматривая точки, в которых прямая касается нижней границы,
легко составить следующую таблицу:
389
Pi Байесовское решающее правило
> 2 3 = 2 3 от у ДО J _ £ 2 dx (единственное) любая рандомизация dx и </4 d4 (единственное) любая рандомизация </4 и (единственное)
Хотя при некоторых рх и рг можно использовать рандомизированные
решающие правила, в этом нет необходимости, потому что при
Р1 = У можно с тем же эффектом выбрать d\ или d4, а при р=у —
dt или d3.
19.1.5. НЕКОТОРЫЕ ОСНОВНЫЕ ТЕОРЕМЫ
Приводимые далее результаты показывают, на каком пути пыта-
ются искать общие связи между понятиями допустимого, байесовско-
го и минимаксного решающих правил, и каковы эти связи.
Прежде чем сформулировать первую теорему, заметим, что может
существовать два различных решающих правила и
для которых Л(0,61)=Л(0,62) при всех 0€0. Так бывает, например, ког-
да для непрерывной случайной величины X правила 6, и 62 различают-
ся лишь в конечном числе точек. Поскольку функции риска Л(0,6/),
1 = 1,2, выражаются интегралами, их значения совпадут. В этом случае
мы будем говорить, что правила 61 и <52 равны с точностью до эквива-
лентности (т. е. их нельзя различить по значениям /?(0Д), < = 1,2). Это
понятие использует следующая теорема.
Теорема 19.1.1 Пусть Q,A,L произвольны, X — выборочное про-
странство непрерывной случайной величины X и р(0) — заданное
априорное распределение. Если байесовская решающая функция 6*
единственна с точностью до эквивалентности, то она допустима.
Доказательство. (Мы считаем, что р(0) есть плотность; случай
дискретного множества 0 рассматривается точно так же.) Предполо-
жим, что функция 6* недопустима. Тогда существует такое правило
8=D*, что
/?(0,6)^/?(0,6*) для всех 0€0
и
/?(0о,6)</?(0о,5*) для некоторого 0О€0,
поэтому
r(6)= f R(0,6)p(0)d0^ f Я(0,6*)р(0)<70 = г(6*).
е е
Но неравенство () не может быть строгим, потому что это противо-
речило бы предположению, что 6* — байесовское решающее правило.
Оно не может быть и равенством, ибо это противоречило бы тому,
что байесовское правило 6* единственно с точностью до эквивалент-
390
R (02, S) =y2
Рис. 19.1.10. Пример, показывающий недопустимые байесовские правила
ности. Таким образом, мы пришли к противоречию, и 6* должно
быть допустимым.
Теорема 19.1.2. Если 0= и — байесовская решаю-
щая функция по отношению к распределению (P\,...,PiJ, где р£>0,
i=l,...,k, то функция 6* допустима.
(Интерпретация. Если множество 0 конечно, а байесовское реше-
ние соответствует невырожденному априорному распределению (нет
р£=0), то оно допустимо.)
Доказательство. Предположим, что байесовское решение недопу-
стимо и покажем, что это предположение приводит к противоречию,
и, стало быть, неверно. Если недопустимо, то существует такое
d€D*, что л
для всех j=l,...,к
для некоторого i
/?(0/КД(0/*)
и
(*)
(Это и значит, что решение 6* доминируется решением 6.) Но
г(6)= Е Д(0/)р.< Е/?(0/*)Р; = г(5*).
j=\ j j j=i j >
Строгое неравенство вытекает из условий (*) и из того, что Pj>d при
всех j=\,...,k. Но для байесовского решения 6* должно быть
r(5*) = infr(6), так что мы пришли к противоречию.
6
Чтобы понять, что может измениться, если условие (р7>0 для
всех у) нарушено, рассмотрим множество риска , изображенное на
рис. 19.1.10. Если /21 = 1 (так что /?2=0), то все точки левой границы
множества У соответствуют байесовским решениям. Но только вер-
шина юго-западного угла прямоугольника соответствует допустимому
решению.
R (02.5) = ?2
Pj У i+ P2 У 2 ~ constant
Рис. 19.1.11. Набросок доказательства, что допустимое правило — байесовское
Теорема 19.1.3. Если множество 0= (0ь...,0*} конечно, а 6* — до-
пустимое решение, то существует такое распределение p=(p\t>..tp^,
р^О для всех i, Р\+Рг + ...+рк = 1, что решение 6* является байесов-
ским по отношению к р.
(Интерпретация. Для задач с конечным множеством состояний 0
класс допустимых решений является подмножеством класса байесов-
ских решений.)
Набросок доказательства (к=2). Обозначим через х точку риска,
соответствующую допустимому решению 6*, а через Qx — множество
всех точек плоскости, расположенных к юго-западу (включая направле-
ния строго на юг и на запад) от точки х. И наконец, через Qx обозна-
чим множество Qx, из которого удалена точка х.
Так как 6* — допустимое решение, то в множестве <7 нет точек, от-
личных от х и расположенных к юго-западу от х. Поэтому множества
7 и Q•' не пересекаются [см. I, раздел 1.2.1]; кроме того, оба они вы-
пуклы [см. раздел 19.1.4].
Знаменитая теорема (теорема о разделяющей гиперплоскости) ут-
верждает, что (когда к=2) существует прямая руу{ +Ргуг=constant вроде
изображенной на рис. 19.1.11. Для этой прямой Pi,p2^0, и без потери
общности можно считать (поделив при необходимости на сумму Р\ +
+Рг), что Р1+рг=1. Но эта прямая является касательной к множеству
У в точке х и, стало быть, 6* есть байесовское решение по отношению
к (РьРг).
Эти три теоремы показывают существо связей между допустимыми
и байесовскими решениями. Следующие две теоремы характеризуют
аналогичные связи между допустимыми и минимаксными решениями.
Более детальное рассмотрение можно найти в книге [Ferguson (1967)].
392
Теорема 19.1.4. Если в некоторой задаче принятия решения мини-
максное решение 6* единственно, то оно допустимо.
Доказательство. Предположим обратное. Тогда найдется решение
8$D*, для которого
R(9,8)^R(9,8*) для всех 0€0,
R(e,8)<R(ft,8*) для некоторого 0€0.
Но отсюда следует, что
sug/?(0,6) sugR(0,6*).
Строгое неравенство противоречит тому, что 6* — минимаксное ре-
шение, а равенство — тому, что минимаксное решение 6* единственно.
Следовательно, наше исходное допущение о недопустимости 6*
ошибочно.
Теорема 19.1.5. Если решение 8* допустимо и функция риска
R(0,8*) постоянна при всех 0€0, то решение 8 является минимакс-
ным. [Эта теорема описывает стратегию поиска минимаксных реше-
ний: сначала найти допустимое правило, а потом проверить, что для
него функция риска постоянна.]
Доказательство. Предположим противное. Тогда существует такое
решение 8*$D*, что
sugR(0,6) < sugR(0,6*).
Но если R(9,8*)=constant, то
R(0,8)<R(0,8*) при всех 0€0,
что противоречит допустимости решения 6*.
Основная классификационная теорема теории принятия решений
утверждает, что, вообще говоря, чтобы быть допустимым, решение
должно быть байесовским. (Конечно, при выполнении некоторых ус-
ловий регулярности.) Это служит основанием для построения более
простого метода поиска байесовских решающих правил, чем прямой
поиск ^inf EqE^L^^X))}. Следующая теорема раскрывает сущест-
во этого простого метода.
Теорема 19.1.6. (нестрогая формулировка}. Байесовская решающая
функция 8* по отношению к априорному распределению р{В) задается
равенством 8*(х) = а*, в котором действие а* ищется из условия ми-
нимизации интеграла
\L(B,a)p{B\x)de,
где
p(0|x)=/(x|0)p(0)/V’(x|0)p(0)d0.
[Интерпретация. Для любого Х=х выбирается действие а*, которое
минимизирует апостериорные ожидаемые потери E^x[L(B,a).}
Доказательство (нестрогое).
r{8} = \QR{e,8}p(B)de=
= | [\L(e,8(x))f(x\e)dx}P(e)de.
393
Предположим, что мы можем поменять порядок интегрирования (это
и есть то место, где следует проявить наибольшую аккуратность при
строгом доказательстве). Тогда
Г(«)=И iL(e,&(x))p(e\x)d9}f(x)dx, (.)
X 0
поскольку по определению условной плотности распределения вероят-
ностей
f(x\6)р(в) =p(0\x)f(x).
Нахождение правила 6*, минимизирующего выражение (*), эквива-
лентно минимизации внутреннего интеграла в последнем равенстве
при каждом Х=х. Это и доказывает теорему.
Таким образом, поиск байесовских решающих функций может
быть проведен в два этапа. На первом, используя теорему Байеса [см.
гл. 15], находится р(9\х), а на втором минимизируются апостериорные
ожидаемые потери.
19.2. СТАТИСТИКА И ТЕОРИЯ ПРИНЯТИЯ РЕШЕНИЙ
19.2.1. ОЦЕНИВАНИЕ
Как мы указывали в разделе 19.1.1, задачу оценивания неизвестно-
го параметра можно рассматривать как частный случай общей задачи
статистического решения, когда 0 = Я (т. е. требуемое действие состо-
ит в выборе элемента параметрического пространства). Более того,
если ограничиться байесовскими решающими функциями, то теорема
19.1.6 из предыдущего раздела показывает, что для каждого Х=х та-
кая функция 6 задается выбором действия а=8(х), минимизирующего
апостериорный ожидаемый риск
j це.дмме^е.
е
Следующие теоремы описывают общие формы байесовских оценок
при различных стандартных функциях потерь L(f),a).
Теорема 19.2.1. Если используется так называемая квадратичная
функция потерь Ь(в,а)=(в—а)2, то байесовская оценка задается сред-
ним значением апостериорного распределения.
Доказательство. Мы хотим выбрать а-Ь(х) так, чтобы минимизи-
ровать
f (9-a)2p(e\x)de.
е
Дифференцируя по а и приравнивая производную нулю, получим
j 0p(0\x)d0
а= да» = j
0
поскольку [ p(9\x)d0 = 1.
e
Теорема 19.2.2. При использовании так называемой абсолютной
функции потерь L{0,a)~ |0—а\ байесовская оценка задается медианой
апостериорного распределения.
394
Доказательство. (Для случая 0 = R). Нам нужно выбрать а так,
чтобы минимизировать апостериорные ожидаемые потери
j |0—-а\р(в\х)дв= J (а—в)р(в\х)дв+ j (в—a)p(0\x)d0.
—«> —<-• а
Продифференцируем по а, учитывая, что
j g(x)dx= —g(a), Jg(x)dx=g(a).
Приравняв производную нулю, получим
I p(9\x)d6= J p(0\x)d9= 2
— ’* а
(так как сумма этих интегралов равна 1). По определению [см. II, раз-
дел 10.3.3] это означает, что а — медиана апостериорного распре-
деления.
Теорема 19.2.3. Если Ь(в,а)=1 при От^а и L(0,a)=O (так называе-
мые «потери ноль-один»), то байесовское решение совпадает с мо-
дой апостериорного распределения.
Доказательство (только для дискретного пространства 6). Мы ис-
пользуем функцию потерь вида
т(п л|_(1 при а*е,
LVW~ (0 при <7=0
и хотим минимизировать риск
Е Ь(в,а)р(в\х).
Если положть а=0*, то апостериорные ожидаемые потери окажутся
равными:
Очевидно, что последнее выражение принимает наименьшее значение,
когда а=0* выбрано так, чтобы максимизировать р(в\х). Но такое
значение в и называется модой (т. е. наиболее вероятным значением)
апостериорного распределения.
Несколько частных примеров байесовских оценок с использованием
квадратичной функции потерь были приведены в гл. 15.
Вообще говоря, изучение минимаксных оценок не так просто; для
операции типа sup и inf нет очевидных аналогов процедур интегриро-
вания (суммирования) и дифференцирования, которыми мы пользова-
лись при поиске байесовских решений. Тем не менее теорема 19.1.5
часто оказывается полезной основой для отыскания минимаксных
решений.
Пример 19.2.1. Предположим, что Х=х — наблюдаемое число ус-
пехов в п независимых испытаниях, в каждом из которых вероятность
успеха равна 0. Найдем минимаксную оценку вероятности при квадра-
тичной функции потерь.
Заметим прежде всего, что по теореме 19.1.5 стоит сначала найти
допустимую процедуру оценивания с постоянным риском. Напомним
395
еще, что по теореме 19.1.1 единственная байесовская решающая функ-
ция всегда допустима. Поэтому мы попытаемся найти вид байесов-
ской оценки в случае, когда она единственная, а затем посмотреть,
при каких условиях эта оценка приводит к постоянному риску. Если
нам это удастся, мы найдем минимаксную процедуру оценивания.
Чтобы справиться с первой задачей, вспомним, что если априорное
распределение параметра в имеет вид бета-распределения с параметра-
ми а и 0, так что
р(0)ос0“-‘(1— еу-1,
то и апостериорное распределение в имеет тот же вид, но вместо а
нужно взять а+х, а вместо 0 — 0 + п—х. А так как среднее значение
распределения Beta(a+x, 0 + п—х) равно (а+х)/(а + 0+п) и это — един-
ственная байесовская оценка при квадратичной функции потерь, то
единственной байесовской решающей функцией, соответствующей
априорным параметрам а, 0, будет (а+х)/(а+0+п) = 8(х).
Выпишем теперь функцию риска R(0,8) и выясним, при каком вы-
боре а и 0 она оказывается постоянной (по 0). По определению
RM = Ех[ Д(а + Х)/(а + 0+п)-0] 2 =
= (а+0+п)~2Ех[в[(Х— п0) + а(1— 0)—/30]2 =
= (а+ 0+ п)~2{Ех^Х-п0)2 + [а(1 - 0)-00?};
поскольку Е(Х) = п0, член ЕХ\е(Х— и0)[а(1—0)—/30] пропадает. Далее,
так как E(X—n0)=VX=n0(l—0), то после простых преобразований
получим
R(0,8) = (а+ 0+ п)~2 {02((а + 0)2—п) + 0[п—2а(а + /3)] + а2}.
При а=0= Уп риск R(0,8) оказывается не зависящим от 0, так как
коэффициенты при 02 и 0 равны нулю. Поэтому минимаксной оценкой
вероятности 0 будет
Х+>/п/2
п + >/п *
19.2.2. ПРОВЕРКА ПРОСТОЙ ГИПОТЕЗЫ ПРОТИВ
ПРОСТОЙ АЛЬТЕРНАТИВЫ
В разделе 19.1.1 кратко описан способ, как свести процедуру про-
верки статистических гипотез к специальному классу задач принятия
решения. Теперь мы детально проиллюстрируем его в случае проверки
простой нулевой гипотезы против простой альтернативной. Если
Яо-*0=0о — нулевая гипотеза, а Нь0= 01 — альтернативная [см. раздел
5.12.2], то параметрическое пространство 0 будет содержать ровно
два элемента [0o,0i}. Как уже говорилось, в задаче проверки гипотез
пространство действий тоже состоит из двух элементов Я = {ай,аi} :а0
обозначает действие «отклонить Н\», а ах — «отклонить Но».
396
Предположим еще, что функция потерь задается таблицей
00 0!
53 СЗ о ° ° Г
и что мы наблюдаем случайную величину X с плотностью распределе-
ния вероятностей f(x\6).
Найдем сначала вид байесовского решения при заданных априор-
ных вероятностях р(0о)=яо> Р(^1)=^ь To + Ti = l.
Вспоминая, что по теореме 19.1.6 байесовское решение при задан-
ном Х=х может быть определено как действие, минимизирующее
ожидаемые априорные потери, поступим следующим образом. Вычис-
лим апостериорные ожидаемые потери, если в качестве решения взять
д(х)=а0:
Oxp(0o\x)+L0l xp(0llx)=Lol7r1f(xl0l)/[7rQf(x\0o)+TTif(x\0l)]
и если взять 8(x)=at:
Lloxp(6olx)-kOxp(6ilx)=LiO7rQf(x\0o)/[TrQf(xl0o)-l-TrJf(x^i)]‘
Здесь мы использовали теорему Байеса, чтобы исключить р(0о|*) и
Отсюда следует, что нужно выбрать решение 8fc)=ai, если
blO^o/frl^o) <^о17Гк/Гх|01),
или в другом виде, если
f(x\ 0о) < ^iqTTi
/6*|01) 6/0|1Г0
Последнее неравенство означает: отклонить гипотезу Но, если отно-
шение значения функции правдоподобия при в0 к значению при
меньше некоторого порога. Это есть не что иное, как привычная фор-
мулировка леммы Неймана—Пирсона [см. раздел 5.12.2]. Отметим
еще, что здесь пороговое значение в правой части неравенства опреде-
ляется в терминах отношения потерь [L0l/Li0] и априорных шансов ги-
потез Но и Нг.
Чтобы еще лучше понять ситуацию (и метод нахождения мини-
максного критерия), рассмотрим случай LOi=^io = l и будем работать
в геометрических терминах.
19.2.3. ЛЕММА НЕЙМАНА-ПИРСОНА
Пусть L0i=£10 = l, а 6 определяется разбиением выборочного про-
странства X = {X о, X1}, так что
397
pi 5(x) = aj при X€2*,.
Вычислим риск R(0,8)'
R(00,8) — jL(00,d(x))f(x\Oo)dx=
У/Ъ. = \f(x\0o)dx=Pr(X €Х ,|0О).
Я(0О|3) равен вероятности
\////\ отклонить гипотезу /70, ког-
хУ/Я//\ да она истинна (=«)•
Y//Точно так же
Х//А = tf(x\&dx=Pr(X $Х о|0|).
0‘--------„ Я(0,,6) равен вероятности
' отклонить гипотезу Нх, ког-
Рис. 19.2.1. Типичное множество риска для да она истинна (=/?).
проверки гипотезы //0 против нх Напомним [см. раздел
5.12.2], что а называется
ошибкой I рода, а /3 — ошибкой II рода.
Чтобы нарисовать множество риска У [см. раздел 19.1.4], заме-
тим прежде всего, что точки риска (0, 1) и (1, 0) соответствуют двум
критериям, из которых один всегда принимает, а другой всегда откло-
няет гипотезу Но (независимо от значения х). Поэтому эти точки всег-
да входят в J . Заметим еще, что множество J симметрично
относительно прямой, проходящей через точки (0, 1) и (1, 0), посколь-
ку у каждого критерия, соответствующего разбиению выборочного
пространства X = {х 0,х х], есть «симметричный образ», соответ-
ствующий разбиению X = {х ьЯГо)» т. е. перестановке а0 и ах. Нако-
нец, множество 7 должно быть выпукло. Учитывая все это, получим,
что геометрическое представление множества 7, типичное для задач
проверки гипотез, имеет вид, изображенный на рис. 19.2.1.
Как мы видели в разделе 19.1.4, точки риска, соответствующие
байесовским критериям, являются точками касания прямых, идущих с
северо-запада на юго-восток с наклоном — tto^i- Для такого множе-
ства риска минимаксный критерий соответствует точке, в которой
биссектриса первого координатного угла пересекает нижнюю (юго-за-
падную) границу множества <7 . В частности, при минимаксном крите-
рии величины ошибок I и II рода равны (а = @). Допустимые критерии
характеризуются тем, что соответствующие им точки риска лежат на
нижней (юго-западной) границе множества 7 . Стоит заметить, что
эта граница состоит из точек, минимизирующих ошибку II рода 0 при
заданной величине ошибки I рода а. Но именно эти точки выделяются
при подходе Неймана—Пирсона к построению критериев [см. раздел
5.12]. Другими словами, в них достигается максимум мощности (1—/3)
при фиксированном размере критерия (а). Более того, лемму Нейма-
на—Пирсона можно теперь сформулировать как теорему из теории
принятия решений.
398
Лемма Неймана—Пирсона. При использовании функции потерь
ноль-один в задаче проверки простой гипотезы Н0:6=90 против прос-
той альтернативы Нх:д=в\ допустимые критерии определяются ус-
ловием
Ь(х) = ах, если f(x\d^/f(x\d^<k для некоторого fc€R].
19.3. ОТНОШЕНИЕ К РИСКУ И ТЕОРИИ ПОЛЕЗНОСТИ
19.3.1. НЕЖЕЛАНИЕ РИСКОВАТЬ
В этом разделе мы рассмотрим основные идеи, позволяющие ма-
тематически исследовать задачу «учета риска». Под этим названием
мы понимаем задачу выбора между решениями, оставить ли все по-
прежнему или решиться на действия с неопределенным исходом, в ре-
зультате которых можно выиграть, а можно и проиграть. Примеров
такой ситуации очень много: предложение страховки со стороны стра-
ховой компании (взносы могут привести к «выигрышу», но обязатель-
ства выплат в случае «бедствия» в итоге могут привести к «ущербу»),
сельское хозяйство (активы можно запасать или потратить на зерно,
урожай которого может принести «доход», а может и «потери», если
случится засуха) или различные азартные игры (после уплаты входно-
го взноса или «ставки» можно «выиграть» или «проиграть» в зависи-
мости от того, произойдет или нет некоторое согласованное событие:
например, определенная лошадь выиграет заезд, выпадет определен-
ная карта из колоды, определенный номер в рулетке и т. д.). Для про-
стоты в этом разделе мы будем рассуждать об эффекте в денежном
выражении, но важно понимать, что те же соображения (может быть,
с небольшими изменениями) применимы во всех ситуациях, когда мы
имеем дело с риском.
На рис. 19.3.1 схематически изображена простая задача принятия
решений, проясняющая существо всех задач учета риска. Одно дейст-
вие сохраняет существующее положение и не приводит к неопределен-
ности; все остальные порождают ситуации, в которых события могут
развиваться так, а могут и иначе, приводя к улучшению ситуации при
благоприятном исходе или к ухудшению при неблагоприятном.
Используя ранее введенные обозначения [см. раздел 19.1.1],
получим:
.Я - (не играть, играть}= (ai,a2],
0= (без изменений, выигрыш, потери] = {01,02,0з}
с возможными последствиями:
(0i,ai) = текущий капитал не изменился,
(02,0г) = текущий капитал увеличился на денежный выигрыш,
(0з,^г)= текущий капитал уменьшился на поставленную сумму.
399
Действия
Возможные исходы
Последствия
Рис. 19.3.1. Простая задача «учета риска» в принятии решений
В этом разделе мы будем придерживаться байесовского подхода к
принятию решений. При этом подходе для примера, изображенного
на рис. 19.3.1, нужно задать следующие величины: во-первых, вероят-
ности состояний (01,02,0з) при заданном действии ах или а2, а во-вто-
рых, приписать определенные значения всем последствиям.
В разделе 19.1.1 мы рассуждали в терминах функции потерь:
£:0х Л R, так что значение, сопоставляемое каждому следствию,
ЦОра}, имело смысл «ущерба», происходящего при выборе действия
ар если состоянием природы окажется 0? В этом разделе мы, наобо-
рот, будем использовать функцию полезности R. Ее значение
интерпретируется как положительный результат или выи-
грыш, получающийся при сочетании действия и состояния 0(. Если
угодно, можно считать выигрыш отрицательным ущербом или наобо-
рот. Выбор той или иной терминологии объясняется только приняты-
ми соглашениями. В статистических задачах типа оценивания мы
почти всегда говорим о плохих ответах и поэтому оказывается естест-
венным говорить об ущербе; в задачах капиталовложений, например,
мы надеемся, что принятые решения в итоге приведут к выигрышу и
поэтому более естественно говорить в терминах полезности. В первом
случае байесовское решение минимизирует ожидаемый ущерб, в по-
следнем максимизирует ожидаемый выигрыш.
Рассмотрим конкретный пример ситуации, изображенной на рис.
19.3.1. Предположим, что ваше текущее состояние в денежном выра-
400
Рис. 19.3.2. Иллюстрация к условию неравенства
жении составляет £С, денежная ставка равна £5, а чистый выигрыш
— £Р. Положим еще, что при действии aip(0t) = l, а при действии
а2р(0з)=Р(0з)=^-
Выигрыш каждого последствия (в денежном выражении) при этом
равен:
(0bC!)=G (М = С+Р, (e3,a2) = C-S.
Тем самым выигрыш определен при любых значениях С, Р и S при по-
мощи функции полезности U:X-+R, где X обозначает множество со-
стояний (активов), которые могут возникнуть при такой игре. Отсюда
ожидаемый выигрыш двух действий будет следующим:
Действие
а\
аг
Ожидаемый выигрыш
U(C)
x-U(C+P)+'-U(C-S)
Если мы стремимся к максимизации ожидаемого выигрыша, то опти-
мальными будут решения:
Играть (а2)-
Любое, если U(C) [ 2 U(C+ Р)+U(C—S).
Не играть (at).
Соответствующая ситуация изображена на рис. 19.3.2,а) и 19.3.2.6),
где мы предполагали, что S>0, P>S.
Рассмотрим теперь частный случай P=S, т. е. в денежной терми-
нологии «честную игру»:
401
в)
Рис. 19.3.3. Формы функций полезности, для
которых при Р=С оптимальными решениями
являются: а) никогда не играть; б) всегда иг-
рать; в) всегда безразлично, играть или нет
Анализируя рис. 19.3.2 и
условия выбора решений,
мы можем выяснить, при
каких обстоятельствах ли-
цо, принимающее реше-
ние, может решить,
следует ли ему или нет
вступить в игру (т. е. вы-
брать действие ах или д2).
Ясно, что следует вы-
брать аг, если
U(C+S)— U(C)> U(C)—
-U(C-S),
и ait если
U(C+S)— U(C) < U(C)—
—U(C—S).
В случае равенства оба ре-
шения равноценны.
Предположим теперь,
что во всей изучаемой об-
ласти изменения х задан-
ная лицом, принимающим
решение, функция полез-
ности такова, что опти-
мальное решение не
зависит от С и S, т. е. что
при любом выборе С и S
оптимальным решением
всегда окажется ах или
всегда д2, или всегда оба
решения будут равноцен-
ны. Легко видеть, что при
этом функция полезности
(если только она непре-
рывна) должна иметь вид,
изображенный на рис.
19.3.3, а), б), в).
Ситуация, показанная
на рис. 19.3.3, а), соответствует убывающей частной полезности денег:
добавки одной и той же суммы (скажем, S) дают все меньший допо-
лнительный выигрыш при добавлении к возрастающему капиталу (на-
пример, переход от C—S к С дает больший дополнительный выигрыш,
чем переход от С к S+C). При такой функции полезности Л ПР всегда
предпочтет наверняка иметь капитал С, чем бросать монетку при вы-
402
боре между С—5 и C+S. Поэтому лицо, принимающее решение исхо-
дя из такой функции полезности, называется сверхосторожным (или
не рискующим). Для него статус-кво всегда предпочтительнее, чем не-
определенная ситуация, математическое ожидание исходов которой
равно исходному состоянию (честная игра).
Чтобы игра с исходом С—S и C+S была предпочтительнее, чем га-
рантированный капитал С, сверхосторожному ЛПР нужна большая
вероятность исхода C+S. Если обозначить ее через тг, то ЛПР предпо-
чтет играть, если
U(C) < тг U(C+ S) + (1 —г) U(C—S).
Другими словами,
тг >U(C)—U(C—S)> j
1—тг U(C+S)~ U(C) '
Последнее неравенство означает, что сверхосторожному игроку нуж-
но, чтобы отношение шансов его выигрыша превосходило отношение
приростов функции полезности.
Рис. 19.3.3, б) соответствует возрастающей частной полезности:
дополнительные приращения фиксированного размера (например, 5)
приводят ко все большему и большему выигрышу по мере роста капи-
тала (например, переход от С к C+S дает больший выигрыш, чем пе-
реход от С—S к С). Такая форма функции полезности заставляет ЛПР
вступить в честную игру (с ожидаемым денежным результатом С)
вместо того, чтобы остаться с гарантированным капиталом С. Такого
игрока естественно называть авантюрным (или рискующим).
Легко видеть, что авантюрный игрок иногда будет вступать в игру
с исходными C+S и С—5, даже когда шансы на выигрыш C+S, рав-
ные тг/(1—тг), будут неблагоприятными. Поскольку такой игрок будет
играть, если
U(C) < tvU(C+ S)+(1—ir)U(C— S),
то требуется только, чтобы
тг U(C)—U(C—S)
1-ir 1/fC+SbW’
а из рис. 19.3.3, б) видно, что правая часть строго меньше 1; отсюда
следует, что существуют значения тг<у, при которых авантюрный
игрок предпочтет играть вместо того, чтобы сохранить статус-кво.
Ситуация, изображенная на рис. 19.3.3 в), приводит к равноценнос-
ти вступления в игру и сохранения статус-кво. Заметим, что если S
очень мало в сравнении с С, то локально (в окрестности С) обе кри-
вые на рис. 19.3.3, а) и 19.3.3, б) выглядят примерно так же, как на
рис. 19.3.3 в) (поскольку в достаточно малой области непрерывная
функция хорошо аппроксимируется прямой линией). В частности, это
объясняет, почему осторожные люди предпочитают не вступать в де-
нежные игры, если ставки (и выигрыши) достаточно малы.
403
Рис. 19.3.4. Определение тгс
19.3.2. ОДНОМЕРНЫЕ
ФУНКЦИИ ПОЛЕЗНОСТИ
Дальнейшее изучение
рассматриваемых проб-
лем может привести к бо-
лее точному математиче-
скому пониманию и пред-
ставлению типов функций
полезности, ранее введен-
ных (с иллюстративными
целями мы сосредоточим
внимание на убывающей
частной полезности де-
нег).
Если предположить,
что функция полезности
непрерывна, то для «чест-
ного» денежного пари с
исходами C+S и С—S получим
U(C) >^U(C+S)+± U(C—S),
и поэтому существует такая величина тгс, что 0<irc<S и
и(с— 7г j = 1 и<с+ s) + 4- U(C—S).
Эта ситуация показана на рис. 19.3.4.
Величину тгс можно представлять себе как «отступные», или вы-
куп, который игрок еще хотел бы заплатить, чтобы избежать обязан-
ности менять существующее состояние С на участие в (честной, но
неопределенной) игре с исходами C+S и С—S.
Эти доводы, очевидно, обобщаются в случае убывающей частной
полезности на любую игру, включающую возможность перехода от С
к С+Х, где X — случайная величина с нулевым средним (в рассмот-
ренном простом случае X с вероятностью 1/2 принимает значения
±5). Выкуп тгс определяется из уравнения
U(C-*c)=E(U(C+ )),
где математическое ожидание Е(-) вычисляется по распределению ве-
роятностей величины X.
Чтобы лучше понять смысл выкупа тгс, который сам по себе мо-
жет служить мерой нежелания рисковать, предположим, что диспер-
сия Х(назовем ее а2) достаточно мала, так что переходы происходят
в небольшой окрестности исходного состояния С(а стало быть, и тгс
также мал). Если теперь разложить обе части предыдущего уравнения
в ряд Тейлора [см. IV, раздел 3.6], то получим
U(C-tQ~U(C)-vcU(C)
и 1
E[U(C+X)} = U(C)+XU(C)+ ^X^U'fC)} =
= U(C) + ^U'(C)o2.
404
В первом выражении мы отбросили все члены, начиная с 7гс2, а во
втором — с EfX3). Если наши предположения разумны, то, приравни-
вая эти два выражения, получим
Отсюда видно, что величина — играет фундаментальную
роль в определении меры (локального) неприятия риска. Чем она
больше, тем больший выкуп готов заплатить игрок (что указывает на
высокую степень нежелания рисковать).
Полученное представление тгс поможет нам выбрать вид функции
полезности (7. Например, предположим, что мы знаем (или предпола-
гаем), что для заданного распределения исходов X степень нежелания
рисковать игрока не зависит от С, так что и тгс не должно зависеть
от С. Тогда должно быть
—U"(C)/U(C)=k,
где к — некоторая постоянная.
Это дифференциальное уравнение легко решить, и если определить
высшую и низшую точки на шкале полезности как U( >=1 и 17(0)=О,
то получим решение
U(x) = \—erkx (0<х<«~).
Это сильное заключение. В нем утверждается, что если игрок (в рас-
сматриваемой области изменения значений х) руководствуется убыва-
ющей частной полезностью денег и постоянным уровнем нежелания
рисковать, то ему соответствует однозначно определенное математи-
ческое представление функции полезности, требующее задание только
одного параметра. При увеличении этого параметра меняется и вид
функции полезности, и она становится все более крутой вначале, как
это показано на рис. 19.3.5.
В действительности большинству игроков свойственно убывание
неприятия риска; другими словами, тгс убывает с ростом С. Это при-
водит к тем большему желанию рисковать, чем большим активом он
располагает.
Полученное представление тгс можно использовать для изучения
нежелания рисковать при различных формах функции полезности. На-
пример, можно рассмотреть случай (7(x> = log(x> (по крайней мере в не-
котором диапазоне значений исходного капитала). Непосредственное
дифференцирование показывает, что в этом случае
—U'(C)/l/(C)=\/C
и, следовательно, эта функция соответствует уменьшающемуся неже-
ланию рисковать.
В этом разделе мы дали только краткое введение в то, как можно
математически изучить и описывать полезность. Намного более об-
ширное изложение можно найти в книге: Н. R a i f f a, R. L.
Keeney. Decision-Making with Conflicting Objectives.
405
19.3.3. ОЦЕНИВАНИЕ
ФУНКЦИЙ ПОЛЕЗНОСТИ
Ясно, что полезность
денег (как и многого дру-
гого) для разных людей
различна, и необходимо
иметь эффективный спо-
соб для изучения вида ин-
дивидуальной функции
полезности.
Один из таких спосо-
бов состоит в следующем.
Предположим, что актив
индивидуума составляет
£С и мы хотим изучить
функцию полезности денег
в диапазоне от С до С+
Рис. 19.3.5. Формы функций полезности: +1000. Будем задавать
k3>k2>ki ему такую последователь-
ность вопросов.
Сначала попросим его представить себе, что у него есть лотерей-
ный билет, на который он с равными шансами может выиграть £1000
или £0. А потом спросим его, за какую минимальную сумму (только
честно, не для игры, без жульничества!) он согласился бы продать
этот лотерейный билет. Обозначим эту сумму £S2.
Затем мы попросим его представить себе, что он участвует в лоте-
рее с одинаковыми шансами на выигрыш £S2 и £0. За какую мини-
мальную сумму от согласился бы продать такой билет?
Предположим, что он ответил, что за £Sb
Наконец, мы попросим его повторить это упражнение снова, но на
этот раз с равновероятными выигрышами £S2 и £1000. Пусть мини-
мальная плата за билет в этом случае равна £ S3.
Что же мы выяснили в результате такого «допроса»? Чтобы гово-
рить о полезности в конкретной шкале, договоримся считать, напри-
мер, что U(C)=0 и U(C+1000)= 100. Будем считать также, что
опрашиваемый, по крайней мере приближенно, принимает байесовское
решение по отношению к соответствующей функции полезности U(-).
Тогда ответ на первый вопрос показывает, что
U(C+ S2) = | U(C +1000) + | U(C) =
= 1-100+ 1-0 = 50.
Иными словами, сумма S2 такова, что полезность величины C+S2 по
согласованной шкале равна 50.
Точно так же другие ответы показывают, что
Рис. 19.3.6. Построение графика функции полезности
U(C+ SO = | U(C+ S2) + I u(c) = T • 50 + 1 -0=25
и
UfC+S3) = ±-U(C+S2) + ±U(C+1000)= 4--5O+ 1-100 = 75.
X X XX
Эти соотношения можно изобразить графически так, как показано на
рис. 19.3.6. В данном случае (гипотетические) ответы соответствуют
уменьшающейся маргинальной полезности, которая показана пунктир-
ной линией.
Такими средствами мы можем найти эмпирическую форму для
функции полезности. Если сделать дополнительные предположения
вроде постоянного уровня нежелания рисковать [см. раздел 19.3.2], то
можно попытаться аппроксимировать эти эмпирические данные соот-
ветствующей математической зависимостью. Конечно, процедура не
ограничивается указанными тремя частными вопросами. В действи-
тельности стоит задать еще дополнительные вопросы, чтобы прове-
рить корректность предыдущих ответов. Например, можно было бы
попросить рассмотреть случай лотереи с равновероятными выигры-
шами £Si и £S3 и проверить, совпадает ли ответ с £S2 (как это должно
быть, если ответы основывались на некоторой функции полезности).
Мы рассмотрели только один из возможных способов оценивания
функций полезности. Дальнейшее обсуждение читатель сможет найти в
статье: J. Hull, Р. G. М о о г е, Н. Thomas. Utility and its Measu-
rement. J. R. Statist. Soc., A., 1973, p. 226—247.
407
19.3.4. ФУНКЦИИ ПОЛЕЗНОСТИ ВЫСШИХ РАЗМЕРНОСТЕЙ
В предыдущих разделах мы обсуждали примеры, в которых окон-
чательный результат можно было оценить единственной величиной
(мы считали ее деньгами). Однако, вообще говоря, оцениваемые ситу-
ации чаще включают несколько различных факторов. Например, в
промышленности последствия естественно оценивать частично в де-
нежном выражении, а частично — по влиянию на окружающую среду;
в здравоохранении оценка последствий должна учитывать боль, не-
трудоспособность и риск смерти. Поэтому мы можем считать, что
каждому последствию ставится в соответствие вектор, оценивающий
эффекты различных факторов, так что
(6,a) = (xlt х2,...,хт).
В этом случае методы, подобные описанным в предыдущем разделе,
позволяют нам оценить отдельные одномерные функции полезности
Ul,...,Um для различных факторов. Таким образом, задача определе-
ния полной полезности последствия (6,а) сводится к нахождению вида
функциональной зависимости для комбинирования С/^хО,...,^^).
Для этого существуют различные возможности: например, можно
считать, что
U(6,a)=Wi UM + w2U2(x2) +... + wmUm(xJ,
где вес w, отражает важность, приписываемую z-му фактору. С дру-
гой стороны, могут быть нетривиальные изменения в полезности, вы-
текающие из практических последствий сочетания, например, уровня
х,- фактора i с уровнем ху фактора j, и эти «обмены» могут приводить
к нелинейным комбинациям отдельных полезностей.
Все это приводит к трудной и тонкой области теории полезности,
и мы не будем в нее углубляться дальше. Интересующемуся читателю
мы снова рекомендуем книгу Райфы и Кини, упомянутую в разделе
19.3.2.
19.4. ПОСЛЕДОВАТЕЛЬНЫЕ ПРОЦЕДУРЫ ПРИНЯТИЯ
РЕШЕНИЙ
19.4.1. ОСНОВНЫЕ ИДЕИ
Теория последовательного принятия решений развивается очень ин-
тенсивно, и мы в этом разделе ограничимся только описанием суще-
ства основных задач, а в деталях рассмотрим только «деревья
решений».
Для определенности рассмотрим такую задачу. Предпринимается
начальное действие ^“’и после этого мир оказывается в (неопределен-
ном) состоянии 0°’; затем предпринимается дальнейшее действие о12’,
408
Рис. 19.4.1. Схема «двухэтапной» последовательной задачи принятия решений
приводящее к неопределенному состоянию 0(2), и в итоге получаем
последствие (0(1), 0(2), , о12’). Каким образом исследователь должен
подходить к задаче выбора начального действия?
Описанная ситуация изображена на рис. 19.4.1, где квадратами обо-
значены точки принятия решений (в которых исследователь выбирает
действие), а кружками — точки неопределенности (в которых выясняет-
ся неконтролируемое состояние природы). Предположим, что конечно-
му последствию приписана определенная полезность t7(0(1), О®, а('\ cP).
Мы изобразили лишь конечный «веер» возможных действий, выхо-
дящий из каждой точки принятия решений. Конечный веер возмож-
ных исходов, исходящий из точки неопределенности, вообще говоря,
может быть непрерывным диапазоном как решений, так и исходов.
Поэтому на рис. 19.4.1 нужно смотреть лишь как на чисто условную
схему ситуации.
Существо проблемы последовательного принятия решений состоит в
том, что мы не можем разумно решить, что делать на начальной ста-
дии, пока не продумаем все возможные последствия (0°’, 0*2), а*1’, а*2)).
Поэтому мы начинаем с правого конца дерева и спрашиваем, что бы
мы хотели сделать во второй точке принятия решений, если первона-
чально было выбрано действие о10, а исход оказался 0°’. Такой под-
ход приводит к дереву, изображенному на рис. 19.4.2. При данном
выборе о12’ распределение вероятностей для неизвестного второго ис-
хода 0*2) имеет вид /?<&<2>|а<1>,0<1>,а<2>). Используя для удобства интеграль-
ную форму (соответствующую непрерывному диапазону изменения
0(2)), можно записать условие, определяющее оптимальное действие и
ожидаемую полезность, в виде
(7*(0(1),йг(1)) = maxj/>(0(2’|cr,’,0(1),tz(2))(7(0(1),0(2),6r(1),<7*2))^0(2).
Д(2)
Таким образом, для данных 0°> и О» определена максимальная полез-
ность. Ситуацию, с которой исследователь встретился на первом эта-
пе, можно теперь изобразить так, как это показано на рис. 19.4.3.
Отсюда видно, что полное решение задачи определяется из условия
maxfp(0(I)|o(I))t7*(0(1),a(1))d0(1).
а<|)
409
Рис. 19.4.2. Модификация рис. 19.4.1 для случая, когда известно, что исходом
на начальном этапе является 0(1)
а,2>)
U* (0
(1)
а<1>)
Рис. 19.4.3. Решение на первом этапе (в предположении оптимальности реше-
ния на втором)
Очевидно, что для «-шаговой задачи структура решения остается та-
кой же. Начиная с правой стороны дерева и проходя последовательно
через вершины неопределенности и решения, мы будем повторять
процедуры взятия математического ожидания и максимизации. При
использовании этой процедуры возникают сложности. Во-первых, за-
метим, что в ней неявно используются все возможные «предыстории»
процесса (т. е. все комбинации действий, которые можно было пред-
принять, и исходов, которые могли быть). Во-вторых, распределение
вероятностей исходов на данной стадии должно быть условным по
отношению к предшествующей истории процесса. При этом вычисле-
ния могут стать очень сложными, если только структура задачи не
позволяет упростить возникающие рекуррентные формулы.
Рассмотрение многих частных случаев и соответствующего мате-
матического аппарата можно найти, например, в книге [DeGroot
(1970)], к которой мы и отсылаем интересующегося читателя.
Однако в случае конечных множеств действий и исходов задачи мо-
гут быть описаны и решены при помощи стандартного простого под-
хода с использованием дерева решений. Эти методы описываются в
следующем разделе.
19.4.2. ДЕРЕВЬЯ РЕШЕНИЙ
Проиллюстрируем применение деревьев решений на одной частной
задаче.
410
Рост
.x's./Xv Спрос
Вкладывать s'
s' Падение
Л К Не вкладывать
N. Рост у'
Спрос
Падение
Рост s'
s\ Спрос
Вкладывать s' ^х.
\ s' Падение
Рост s'
Спрос
Падение ~
—’ Падение \
Не вкладывать п
—___ Рост .х
-( jx Спрос
Падение ^х.
Рис. 19.4.4. Дерево решений для задачи о капиталовложениях
Предположим, что некая компания рассматривает вопрос о не-
больших капиталовложениях, которые могут оказаться выгодными,
если спрос на определенный вид производимой продукции возрастет,
и напрасными, если он упадет. Компания может либо сразу принять
решение, вкладывать ли капитал, либо заказать исследование рынка,
411
чтобы лучше оценить относительное правдоподобие подъема или па-
дения спроса. Пусть отчет об исследовании рынка просто содержит
прогноз — спрос возрастет или спрос упадет, а конечный исход (со-
стояние природы) можно описать, сказав, что спрос действительно
возрос или действительно упал.
Структура соответствующего дерева решений изображена на рис.
19.4.4.
В ранее принятых обозначениях [см. раздел 19.1]
Л = {а^а^сь,} = {обследовать рынок, вкладывать капитал,
не вкладывать капитал],
0= {01,02] = {спрос возрос, спрос упал],
X- {хьх2] = {прогноз «подъема», прогноз «падения»}.
Теперь следует ввести вероятности для всех неопределенных исхо-
дов. Предположим, что справедливы следующие утверждения.
Известно, что прогнозы, выдаваемые компанией, исследующей ры-
нок, оправдываются на 8О«¥о в случае подъема спроса и на 70% в слу-
чае падения. Это значит, что в наших обозначениях
p<Xi|0i)=O,8 р<х2|01) = О,2,
p<Xi|02)=O,3, р<х2|02)=О,7.
Предположим, что первоначально (т. е. без дополнительной ин-
формации об исследовании рынка) компания считает, что шансы на
подъем спроса равны 60%, так что
p(0i)=O,6, р(02)=О,4.
На самом деле компании нужна прямая оценка вероятностей нео-
пределенного исхода, которую можно получить простым вычислени-
ем, если она закажет исследование рынка:
рМ =Р(хх |0i)p(0i) +p(Xi |02)р(02) =
=0,8-0,6+0,3-0,4=0,6,
р<х2) = 1—p(Xi)=0,4.
Чтобы пересмотреть вероятности 01 и 02 на основании заданной ин-
формации об исследовании рынка, воспользуемся теоремой Байеса
[см. раздел 15.2]:
P(0i I*) =pfa 10i)p(0i)/Xx!) = (0,8-0,6)/0,6=0,8,
p(02|xi) = 1 —p(0i |xi)=0,2
и
p(0i |х2) =p(x2\0i)p(0l)/p(x2) = (0,2-0,6)70,4=0,3,
Р(021 х2) = 1 —p(0i |х2)=0,7.
Для дальнейшего нужно знать полезность различных исходов. Пред-
положим, что в рассматриваемом диапазоне компания считает функ-
цию полезности денег примерно линейной. Предположим также, что
412
Рис. 19.4.5. Задача о капиталовложениях с
вероятностями и доходами
1000-С
992—С
Рис. 19.4.6. Первый шаг — вычисление
1012—с
1000-С
Рис. 19.4.7. Второй шаг — максими-
зация выигрыша — для ветви at
ожидаемого выигрыша — для ветви at
413
если спрос возрастает, то в результате капиталовложений чистый вы-
игрыш компании составит 1020 (в тысячах фунтах стерлингов), а если
спрос упадет — то 980; если же отказаться от капиталовложений, то
ожидаемый чистый выигрыш компании составит 1000. Стоимость об-
следования рынка равна С (тысяч фунтов стерлингов).
На рис. 19.4.5 показано то же дерево решений, что и на рис. 19.4.4,
по со всей дополнительной числовой информацией.
Вспомним теперь, как, начиная с правого края дерева, мы вычисля-
ли ожидаемые эффекты полезности. Результаты этих вычислений для
ветви решения ах показаны на рис. 19.4.6, где, например,
992—С= (1020— С)-0,3 + (980—С/0,7
и
1012—С=(1020—Q-0,8 + (980—Q-0,2.
Применяя принцип максимизации ожидаемого выигрыша, мы видим,
что при прогнозе хх оптимальным действием является а2, а при про-
гнозе х2 оптимальным будет действие д3. Это приводит к рис. 19.4.7.
Снова вычисляя ожидаемый выигрыш, получим, что для а2 он равен:
(1012—0-0,6+ (1000—0’0,4 =1007,2—С.
Ожидаемые выигрыши для а2 и а3 составляют:
(д2) 1020-0,6+980-0,4=1004,
(д3) 1000-0,6 + 1000-0,4=1000.
Чтобы выбрать начальное решение, следует сравнить ожидаемые вы-
игрыши так, как показано на рис. 19.4.8.
Теперь ясно, что никогда не следует выбирать действие а3 и что ах
предпочтительнее, чем а2, только если плата за исследование рынка не
превышает 3,2.
Конечно, мы рассмотрели только очень частный пример, но все де-
ревья решений формируются и анализируются тем же способом:
1) записать логическую структуру дерева в хронологическом по-
рядке, описывая узлы решений и неопределенности, вместе со
всеми разветвлениями в каждом узле;
2) определить вероятность для всех дуг неопределенностей, поза-
ботившись о соответствующих условиях для каждой дуги;
3) приписать значения выигрыша финальным дугам;
4) двигаясь по дереву справа налево, вычислить математическое
ожидание в узлах неопределенностей, максимизировать выигрыш
в узлах решений и таким образом определить наилучшие дей-
ствия и их ожидаемые выигрыши.
414
Рис. 19.4.8. Ожидаемые
выигрыши при разных ис-
ходных действиях
19.5. АКСИОМАТИЧЕСКИЕ ПОДХОДЫ
19.5.1. АКСИОМЫ СОГЛАСОВАННОСТИ В ПРИНЯТИИ РЕШЕНИЙ
В разделе 19.1 мы заметили, что у задачи выбора «наилучшего»
действия нет нейтрального, чисто математического решения. Затем
мы рассмотрели два различных подхода для выбора оптимального ре-
шения: байесовский и минимаксный. Однако все это очень произволь-
но. Почему следует рассматривать именно эти два подхода? И откуда
мы знаем, что поступаем разумно, принимая наши исходные матема-
тические конструкции? Откуда мы знаем, что разумно принять су-
ществование функций полезности (или потерь)?
Другой подход ко всему кругу задач состоит в том, чтобы начать
с гораздо более примитивных понятий (не предполагая еще существо-
вания функции полезности и не ограничивая себя в выборе подхода
для отбора решений) и вывести из них вид требуемой структуры и
подход к выбору оптимального решения.
Для этого составим список аксиом (или «очевидных» постулатов),
а затем попытаемся вывести из них необходимые следствия. В этом
разделе мы не будем стремиться излагать все детально и строго, но
постараемся дать почувствовать «аромат» аксиоматического подхода
и соответствующих доводов. В частности, мы обсудим формальную
аксиоматическую систему, которая закладывает основы «рациональ-
ного предпочтения» между последствиями. В следующем разделе ме-
нее формально обсудим, каким образом можно проанализировать
понятие «разумной степени уверенности».
Пусть в — множество всех последствий, которые могут возник-
нуть в задаче принятия решений. В обозначениях раздела 19.1
6 - 0 хЛ . Обозначим через Р множество всех распределений вероят-
ностей, определенных на в , так что Р обозначает множество всех
возможных неопределенностей при рассмотрении последствий. Пред-
положим теперь, что у ЛПР есть определенные предпочтения между
элементами множества^, и будем писать Pi<P2, чтобы показать,
что Р2 строго предпочтительнее, чем Рь Р\^Р2, чтобы показать, что
Р2 нестрого предпочтительнее, чем Рь и Pi~P2, чтобы показать, что
ни Рь ни Р2 не предпочтительнее другого.
Предполагается, что предпочтения подчиняются двум аксиомам:
А1. Если Pi, Р2 — элементы пространства , то либо Р\<Р2, либо
415
P2<Pi, либо P\~P2.
A2. Если Pi, P2, P3 — такие элементы P, что P\^P2 и P2^P3, то
Р^Рз-
Другими словами, мы предполагаем, что любые две неопределен-
ные ситуации при рассмотрении последствий сравнимы и что предпо-
чтения транзитивны.
Сделаем теперь еще одно допущение.
АЗ. Если Р], Р2 и Р3 — элементы пространства Р и а — любое
число, 0<а<1, то Р\<Р2 тогда и только тогда, когда
аР\ + (1 —а)Рз < аР2 + (1 —а)Рз •
Эта аксиома формализует интуитивную идею, что если две ситуа-
ции неопределенности относительно последствий имеют общую ком-
поненту, то сравнение этих ситуаций не должно зависеть от их общей
компоненты.
Предположим, далее, что:
А4. Если Pi, Р2, Рз — такие элементы пространства Р , что
Pi<P2<P3, то существуют такие числа а и 3 (0<а<1, О<0< 1), что
Р2<аР3 + (1-а)Р1 и Р2>0Р3 + (1—0)Pi.
Эта аксиома формализует идею, что среди последствий нет ни «бе-
сконечного выигрыша», ни «бесконечного проигрыша». Например,
условия
Pi<P2<P3 и Р2<аР3 + (1—a)Pi
показывают, что хотя Р2>РЬ существует такое число (1—а) (может
быть, совсем маленькое), что смесь аР3 + (1—a)Pi все еще предпочти-
тельнее, чем Р2. Если бы Pi был «бесконечным проигрышем», то это
было бы не так. Аналогичные замечания относятся и ко второму не-
равенству.
Эти аксиомы и их обсуждение должны были показать, как можно
подойти к формализации интуитивных представлений о «рациональ-
ном» или «согласованном» предпочтении. Сейчас мы попробуем выве-
сти из этих предположений форму, которую должны иметь разумные
процедуры принятия решений.
Оказывается, что ответ состоит в том, что для разумного приня-
тия решения необходимо:
й) предположить существование функции полезности;
б) действовать так, чтобы максимизировать ожидаемую по-
лезность.
При этом «разумность» означает согласие с ранее приведенными акси-
омами для предпочтений.
Короче говоря, аксиоматические системы такого рода (а существу-
ет много различных вариантов полного списка выбираемых аксиом)
показывают, что байесовский подход к принятию решений необходим,
если только мы собираемся действовать в согласии с принятой аксио-
матикой.
Детальное рассмотрение системы аксиом, близкой к описанной,
можно найти в [DeGroot (1970), гл. 7].
416
19.5.2. СТЕПЕНЬ УВЕРЕННОСТИ КАК ВЕРОЯТНОСТЬ
В гл. 15 и в многих разделах этой главы при разработке байесов-
ских выводов и процедур принятия решений мы предполагали, что
«степень уверенности» можно выразить числами или плотностью,
подчиняющимися правилам исчисления вероятностей. Некоторым из
читателей это может показаться совершенно естественным и не требу-
ющим дальнейших обоснований, другим же необходимы по крайней
мере общие доводы в поддержку такого предположения.
Вот один из таких доводов. Предположим, что некто (например,
вы) встретился с неопределенной ситуацией, включающей событие Е,
исход которого (Е или не Е) неизвестен. Во всех практически важных
для вас ситуациях у вас есть некоторое ощущение — назовем его сте-
пенью уверенности — относительно «правдоподобия» исходов Е и
~Е. Именно это ощущение мы прежде всего и хотели бы перевести
в количественную форму, а затем показать, что соответствующие ве-
личины должны (при выполнении некоторых дополнительных усло-
вий) подчиняться правилам исчисления вероятностей.
Приведем операционную схему перевода степени уверенности в
числовую форму. Рассмотрим игру, в которой вы получаете сумму £$,
если происходит событие Е, и нуль, если происходит ~Е. Получение
какой суммы (обозначим ее £С) было бы для вас равноценно одно-
кратному участию в такой игре?
Ясно, что если С очень мало по сравнению с S, то вы предпочтете
сыграть; если же С велико по сравнению с S, то выгоднее наверняка
получить сумму С, а не ввязываться в игру.
Предположим, что вы продумаете свою реакцию на получение раз-
личных сумм, начиная с малых С, по мере их увеличения, или с боль-
ших сумм по мере их уменьшения. Тогда найдется промежуточное
значение С, получение которого равноценно участию в игре. Обозна-
чим его через £С*. (Конечно, на практике существует целый «нечет-
кий» интервал таких сумм, а не одно точно определенное значение. Но
мы несколько «идеализируем» все виды измерения, например, во мно-
гом основываемся на предположении, что все тела имеют точную
«длину» или «температуру», хотя на практике они могут быть изме-
рены только с точностью до некоторого «нечеткого» интервала.)
По определению будем считать вашей (выявленной) степенью уве-
ренности в исходе Е такое число р, что
C*=pS.
Заметим прежде всего, что это согласуется с нашими интуитивными
представлениями: низкой степени уверенности соответствуют малые
значения р, а высокой — большие значения р.
Чтобы убедиться в честности ваших ответов при определении ней-
трального значения С*, добавим еще следующую проверку. Предпо-
ложим, что когда вы называете значение С*, вам еще неизвестно,
417
Рис. 19.5.1. «Честное» С* приводит к равно-
ценности ситуаций а и б
пригласят ли вас сыграть
(в соответствии с выбран-
ным значением вы не от-
казались бы заплатить
сумму С* за участие в
игре с выигрышем £S, ес-
ли событие Е произойдет,
и £0, если произойдет
— Е) или выполнять роль
букмекера (проводящего
эту игру со ставкой С*).
Это значит, что вы долж-
ны выбрать такое С*, которое было бы нейтральным в обоих ситуа-
циях, показанных на рис. 19.5.1.
Указав таким образом способ получения неискаженной количест-
венной оценки степени уверенности в осуществлении события Е, про-
следим теперь, как могут быть связаны между собой степени
уверенности в осуществлении различных событий.
Рассмотрим такую ситуацию. Задан полный набор попарно несо-
вместимых событий Ei, E2,...,EN. Описанным способом вы определи-
ли степени уверенности p2,...,pN для каждого из них. После того
как вы зафиксировали pit p2,...,pN, ваш оппонент совершенно свобод-
но назначает цены Sif S2,...,SN в предположении, что вы согласитесь
уплатить PiSi, p2S2i...tPffSN за участие в игре, в которой вы получаете
выигрыш С,, если происходит событие ЕР Как должны быть согласо-
ваны числа Ру, чтобы избежать ситуации, в которой противник смо-
жет выбрать значения St- так, чтобы наверняка выиграть? Будем
называть нерациональным любой способ задания pit при котором вы
можете неизбежно проиграть. Таким образом, наш вопрос можно
сформулировать и так: каким правилам должны подчиняться рацио-
нальные степени уверенности?
Во-первых, заметим, что для всех должно быть O^Py^l.
Действительно, по определению степени уверенности любой выбор р,
вне этого интервала позволяет противнику выбрать свою роль (игрока
или букмекера) так, что он наверняка выиграет. А именно выбор
Ру>1 означает, что вы готовы заплатить сумму, большую, чем Sif за
участие в игре с максимальным выигрышем А выбор р, <0 означа-
ет, что вы хотите заплатить противнику за участие в игре, в которой
он получит (от вас!) 0 или Sf. Во-вторых, заметим, что ваши «выи-
грыши» Gy (которые, конечно, могут быть и отрицательными) удов-
летворяют системе линейных уравнений
G( = Sy—(piSi + ...+PyV5'N),
если происходит событие Eif (Суммарный вступительный
взнос равен 'EPjSj, а выигрыш составляет Sy, если событие Et про-
исходит.)
418
Запишем систему полностью:
и переформулируем задачу. Противнику заданы числа pjf и он стре-
мится выбрать Sj так, чтобы получить значения Gh которые он хо-
чет. В частности, он хотел бы сделать все G( отрицательными
(напомним, что G, — это ваши выигрыши). Сможет ли он при задан-
ных Gj и Pi решить систему уравнений и найти необходимые значения
S,? При рациональном выборе множества значений Pj он не сможет
решить соответствующую систему уравнений. Напомним известный
факт из линейной алгебры: решение приведенной системы можно вы-
писать явно, если матрицу (определяемую величинами р) можно об-
ратить. Напомним еще, что обращение невозможно, если
определитель матрицы равен нулю.
Простое вычисление показывает, что определитель равен 1—(pi +
+p2 + ...+pN), так что рациональный набор степеней уверенности для
полного множества попарно несовместимых событий должен удовлет-
ворять условию
Pi +p2 + ...+pN=l.
Таким образом, мы показали, что рациональные степени уверенности
должны обладать основными свойствами вероятностей:
их значения заключены между 0 и 1;
они удовлетворяют аксиоме сложения вероятностей.
Чтобы завершить краткое оправдание обоснованности рассмотре-
ния степени уверенности как вероятности, нам нужно разобрать поня-
тие «условной» степени уверенности, т. е. проследить, как степень
уверенности меняется при получении новой информации.
Рассмотрим два способа Е и Е', и пусть
кх=р(ё\ё\
к2=р(Ё и Ё'),
тг3=р(Ё') >
обозначают степени
уверенности в осу-
ществлении
Ё при условии Ё'-,
обоих событий Ё и Ё'\
события Ё'.
Сыграем теперь в игру, аналогичную предыдущей, исходы которой
определяются в терминах событий Ей Е', с условием, что если со-
бытие Е" не происходит, то пари, заключенные на осуществление Е'
при условии осуществления Е", расторгаются (т. е. входные ставки
возвращаются). Как должны быть связаны я2 и я3, чтобы не дать
противнику возможность выбрать такие ставки, при которых вы заве-
домо проиграете?
Рассмотрим три исхода: 1) осуществление Е при условии, что Е'
произошло; 2) осуществление Е' и Е"; 3) осуществление /Г с соответ-
ствующими «выкупами» Si, S2 и S3. Подсчитаем ваши выигрыши во
всех трех случаях.
419
Фактический исход
Выигрыш
Ё YL Ё , Gj =(1 — TrJS, +(1—TT2)S2 + (1— 7T3)S3,
~Ё и Ё', " G2 =—TTjSj—TT2S2 + (1—tt3)S3,
~Ё'. J G3 = —TT2S2—7T3S3.
Перепишем эти равенства в виде
1—TTi
—TTt
о
G,
g2
G3
1—ТГ2
—ТГ2
—т2
1—7Г3
1—7Г3
—ТГз
S2
S3
Те же аргументы, что и раньше, показывают, что для обеспечения ра-
циональности решения следует выбрать я, так, чтобы определитель
матрицы был равен нулю.
В данном случае определитель равен тг2—т^тгз, так что степени уве-
ренности должны удовлетворять условию
Тем самым показано, что рациональные условные степени увереннос-
ти подчиняются обычному определению условной вероятности.
Можно было бы возразить, что если суммы S, велики, то сама
процедура определения степеней уверенности неприменима из-за фено-
мена «нежелания рисковать», обсуждаемого в разделе 19.3.1. Это вер-
но, и поэтому предыдущие рассуждения допустимы либо при «малых»
значениях Sif при которых полезность можно считать (приближенно)
линейной, либо при значениях S,-, определяемых заранее заданной
шкалой полезности (построенной, например, при помощи метода,
описанного в разделе 19.3.3).
19.6. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
В следующих двух книгах содержится без сложного математическо-
го аппарата глубокое изложение основных идей теории принятия
решений:
Lindley D. V. (1971). Making Decisions, Wiley.
R a i f f a H. (1968). Decision Analysis: Introductory Lectures on Choices under
Uncertainty, Addison-Wesley.
Более развитый математический формализм можно найти в моно-
графиях:
DeGroot М. Н. (1970). Optimal Statistical Decisions, McGraw-Hill.
Ferguson T. S. (1967). Mathematical Statistics. A Decision-Theoretic Approach,
Academic Press.
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
Де Гроот М. Оптимальные статистические решения. — М.: Мир, 1974.
Л ь ю и с Р. Д., Р а й ф а Г. Игры и решения. — М.: ИЛ, 1961.
Райфа Г., Шлейфер Р. Прикладная теория статистических решений. —
М.: Статистика, 1977.
420
Глава 20
КАЛМАНОВСКАЯ ФИЛЬТРАЦИЯ
20.1. ИСТОРИЧЕСКАЯ СПРАВКА
Калмановская фильтрация, впервые предложенная в статьях Р.
Калмана и Р. Бьюси [см. Kalman (1960); Kalman and Вису (1961)], —
это метод предсказания поведения сигнала s(t) по имеющимся наблю-
дениям ХО, содержащим ошибку v(t) таким образом, что Х0=Х0+
+ v(Z). Термин фильтрация указывает на стремление удалить шум v(t)
из наблюдений, так чтобы получить наилучшую оценку истинного
сигнала s(t). Указанная процедура предусматривается в моделях специ-
ального вида, когда поведение s(t) подчиняется дифференциальному
или разностному уравнению, которое в свою очередь подвержено вли-
янию случайных возмущений.
Хотя методы фильтрации были развиты задолго до появления
фильтра Калмана, а именно в работах А. Н. Колмогорова (1941 г.) и
Н. Винера [см. Wiener (1949)], с точки зрения вычислений они были
гораздо менее удобными, чем рекуррентный подход, используемый в
фильтре Калмана. Более того, для последнего переход к векторным и
нестационарным процессам новых проблем, по существу, не создает.
В настоящее время по калмановской фильтрации имеется обширная
литература. Ряд книг и статей содержит доступное рассмотрение
предмета. В монографиях [Kwakernaak and Sivan (1972)] и [Gelb (1974)]
предлагается хорошее введение в теорию на относительно элементар-
ном математическом уровне. Более строгое математическое изложение
дается в книге [Jazwinski (1970)]. Хорошая статья с подробной библио-
графией и историческим обзором — [Kailath (1974)]. Интересное изло-
жение теории с углубленной проработкой отдельных вопросов
содержится в [Willens (1978)]. В [Harrison and Stevens (1976)] представ-
лена калмановская фильтрация с байесовской точки зрения ?Бо л ее де-
тальную информацию, касающуюся библиографии, можно найти в
разделе 20.9.
Приложения фильтра Калмана разнообразны и многочисленны; воз-
можно, что самым знаменитым было его применение в исторической
миссии Аполлона-XI, когда он использовался в системе слежения за
космическим кораблем и лунным модулем. Помимо аэрокосмической
техники и навигации (см., например, [Schmidt (1966); Вису and Joseph
421
(1968)]), об использовании калмановской фильтрации сообщалось в
управлении производственными процессами [см. Mehra and Wells
(1971); Bohlin (1976)], в теории связи [см. Snyder (1969)], в экономике
и социально-экономических исследованиях [см. Stevens (1974); Athans
(1974); Mehra (1978)], в прогнозировании циклонов [см. Takeuchi
(1976)], гидрологии и анализе водных ресурсов [см. Chiu (1978); Wood
and Szollosi-Nagy (1980); O’Connell (1980); IAHS (1980)]. Именно на по-
следнюю из перечисленных областей приложений мы будем ориенти-
роваться в настоящем изложении калмановской фильтрации. При
этом будет приниматься во внимание, что потенциальные пользовате-
ли, возможно, имеют весьма скромную подготовку в теории вероят-
ностей, статистике и матричной алгебре.
По-видимому, читателю будет полезно получить качественное опи-
сание, каким образом фильтр Калмана может быть использован в
гидрологии. Чтобы обеспечить базу для системы принятия решений
по краткосрочному прогнозу и управлению водными потоками, все ча-
ще применяются схемы непрерывного мониторинга, осуществляющие
передачу в центральный компьютер результатов измерений количе-
ства осадков и расхода воды (т. е. объема, протекающего через сече-
ние реки в единицу времени) в различных точках речного бассейна.
Как правило, данные о количестве осадков затем поступают в модель,
связывающую количество осадков с расходом воды, которая может
быть использована для прогноза речного потока. Однако общепризна-
но, что измерения как уровня осадков, так и водного расхода (в осо-
бенности первая группа измерений) производятся с ошибками, в силу
чего требуется метод удаления шума. Кроме того, специфика задачи
такова, что в каждый момент времени становятся известными все но-
вые данные о расходе и осадках, которые желательно учесть в модель-
ном прогнозе рекуррентным образом. Фильтр Калмана удовлетворяет
обоим указанным требованиям и к тому же дает возможность оценить
величину неопределенности прогноза будущего расхода. Поскольку
фильтр Калмана представляет собой рекуррентный алгоритм, он осо-
бенно удобен для применения в реальном масштабе времени.
В разделе 20.2 вводятся модели в фазовом пространстве*, обеспе-
чивающие необходимый формализм для применения фильтра Калма-
на. Их формулировка иллюстрируется простым примером дискретной
линейной задачи. Раздел 20.3 содержит теорию дискретных линейных
уравнений фильтра Калмана; приводимый вариант вывода уравнений
дает возможность понять суть функционирования фильтра. Качество
функционирования фильтра изучается в разделе 20.4, где описываются
некоторые статистические тесты, а также обсуждается проблема рас-
ходимости фильтра. Раздел 20.5 посвящен применению фильтра Кал-
мана к непрерывному времени и нелинейным системам; последний
случай приводит к обобщенному фильтру Калмана. Во многих при-
* В данном разделе будут эквивалентно употребляться термины пространство со-
стояний и фазовое пространство. — Примеч. ред.
422
кладных задачах структура и параметры модели в фазовом простран-
стве неизвестны, поэтому в разделе 20.6 описаны некоторые процеду-
ры для идентификации модели и оценки параметров. Два варианта
применения фильтра Калмана, один в линейном, а другой в нелиней-
ном случае, приводятся в разделе 20.7. Оба касаются задачи прогнози-
рования величины водного стока по количеству осадков в режиме
реального времени. Заключительные замечания даны в разделе 20.8.
Литература приведена в разделе 20.9.
Некоторые замечания по поводу обозначений. В настоящей главе
читатель увидит, что обозначения векторов и матриц не имеют отли-
чий от обозначений скалярных величин. Однако из контекста всегда
будет ясно, что обозначает тот или иной символ. Транспонированный
к вектору х будет обозначаться хТ; аналогично Ат есть матрица, по-
лученная транспонированием матрицы А.
Дисперсия или ковариационная матрица векторной случайной вели-
чины х, для которой в литературе употребляются различные симво-
лы, будет обозначаться var(x).
20.2. МОДЕЛИ В ФАЗОВОМ ПРОСТРАНСТВЕ
20.2.1. УРАВНЕНИЯ СИСТЕМЫ И ИЗМЕРЕНИЯ
Для применения фильтра Калмана требуется, чтобы поведение изу-
чаемой системы описывалось величиной, называемой состоянием сис-
темы, и которая может быть определена в терминах
дифференциального или разностного уравнения первого порядка (в за-
висимости от того, непрерывно или дискретно время t), известного
под названием уравнения системы. Рассмотрим линейную модель с
дискретным временем, что облегчит вывод уравнений фильтра Кал-
мана, а также будет соответствовать наиболее важному случаю, когда
фильтр реализуется на вычислительной машине. Тогда уравнение сис-
темы будет иметь вид
xt+\~Ftxt + we (20.2.1)
где х( — (пх1)-вектор фазовых переменных состояния (в связи с чем
и возникает термин «фазовое пространство состояний»), Ft — (nxri)-
матрица перехода, a wt — (их1)-вектор шума системы (или ошибки
модели), который можно интерпретировать как процесс, «ведущий»
xt. С уравнением системы связано уравнение измерения
yt=Hfxt + vtt (20.2.2)
где yt — (лих 1)-вектор измерений, Ht — (mхи)-матрица измерений,
описывающая при отсутствии шума линейные комбинации фазовых
переменных, vt — (лих 1)-вектор ошибок измерений. Для завершения
описания спецификации модели предположим, что средние значения
423
шумов wt и vt равны нулю, а ковариационные матрицы — Q и R:
E[wt]=Q; Q^variWt^ElWtWt1],
(20.2.3)
E[vt]=Q\ R=\w(vt)=E{vtyT].
Предположим также, что процессы, описывающие шумы, не являют-
ся сериально или кросс-зависимыми; в частности,
=0, £’[vzV£r] =0, t#k (20.2.4)
и
=0 для всех t, к.
Наконец, обычно предполагают, что шумы и vt имеют гауссов-
ское (нормальное) распределение; однако это условие не обязательно
при рассмотрении фильтра Калмана, хотя в гауссовском случае линей-
ная оценка, используемая при применении фильтра Калмана, является
оптимальной (в смысле среднеквадратичной ошибки) среди всех воз-
можных оценок. В негауссовском случае нелийейные оценки в принци-
пе обеспечивают лучшее качество, но, как правило, их гораздо труднее
реализовать; фильтр Калмана дает линейную несмещенную оценку с
минимальной дисперсией [см. раздел 3.3.2].
Для данной дискретной линейной динамической системы в фазо-
вом пространстве (уравнения (20.2.1) и (20.2.2)) задача состоит в том,
чтобы оценить состояние (фазовую переменную) xt из зашумленных
наблюдений у1г Уг,---У;- При этом можно сформулировать три раз-
личные задачи:
а) фильтрации: измерения yu...yt используются для того, чтобы
сформировать оценку xt состояния в момент t;
б) сглаживания (интерполяции): измерения y\,...yt используются,
чтобы построить оценку xt состояния xs в некоторый предшествую-
щий момент, т. е. когда 1 s < t;
в) прогноза (экстраполяции): измерения y\,...yt используются для
построения оценки xt состояния xs в будущий момент времени, т. е.
при s> t.
Во многих практических ситуациях принятие решения производит-
ся с учетом самой последней доступной информации о поведении сис-
темы, поэтому в первую очередь представляют интерес задачи
фильтрации и прогноза; эти задачи решаются при помощи фильтра
Калмана рекуррентным образом, что делает его особенно удобным
при принятии решений в реальном времени.
424
20.2.2. ПРОСТОЙ ПРИМЕР
Чтобы проиллюстрировать формализм моделей в фазовом про-
странстве, предположим, что процесс Q (например, расход воды в ре-
ке в данной точке) описывается авторегрессионной схемой
Qt = aQt—i + bQt—2 + cQt—з + —i’ (20.2.5)
где шум обусловлен несовершенством представления Qt через
Qt—\> Qt~2 и Qt—з» а константы а, Ь, с считаются известными [см.
Weiss (1980)].
Хотя для нас существенный интерес представляет лишь величина
Qt, она не годится в качестве фазовой переменной, поскольку Q явля-
ется функцией не только но также Qt_2 и Qt—з- Однако если
рассматривать в момент t вектор
то он будет содержать всю требуемую информацию о процессе Qt и
(20.2.6)
Уравнение системы можно записать так:
(20.2.7)
т. е. в виде
(20.2.8)
где
а
t— 1_
1
0
b с
0 0
1 0
425
Хотя уравнение (20.2.8) выглядит проще, чем (20.2.5), эта простота
кажущаяся, поскольку (20.2.8) является векторным уравнением с век-
торными переменными xt> xt_\, и матричным коэффициентом
^-1-
Уравнение измерения, отвечающее уравнению системы (20.2.7),
формулируется следующим образом. В момент времени t производит-
ся измерение величины Qt (т. е. измеряется только первая компонента
вектора xt). Это измерение yt содержит ошибку и, следовательно,
yt = Qt + Vt> (20.2.9)
где vt — погрешность измерения. В терминах фазовой переменной
это можно записать в виде
Л = (1 0 0)
(20.2.10)
или, в векторных обозначениях,
yt=Htxt + vt, (20.2.11)
где
Я, = (1 0 0).
В дальнейшем будем предполагать, что среднее значение vt равно ну-
лю. Если среднее значение vt — известная величина Г, то измерение
yt может быть переопределено путем вычитания из него У.
Уравнение системы можно применять для прогноза. Так, в предпо-
ложении, что xt_} известно, вычисляется значение
aQt— 1 + bQt—2 + cQt—з»
отличающееся от Qt только на величину шума Поскольку
не зависит от xt_x (иными словами, xt_x не содержит никакой инфор-
мации о W/_i), wz_i прогнозируется своим средним значением, рав-
ным нулю.
Прогноз Qt есть
Qt=aQt_ 1 +bQt_ 2 + cQt_ 3, (20.2.12)
и, следовательно, для прогноза х( имеем
- а b с
0,-1 = 1 0 0 Qt—2 , (20.2.13)
Qt—2 0 1 0 Qt—з
426
что в векторных обозначениях записывается в виде
(20.2.14)
Ошибка прогноза (20.2.14) есть вектор
=
w,_i
0
о
(20.2.15)
совпадающий с шумом системы в момент t.
20.3. ВЫВОД ФИЛЬТРА КАЛМАНА ДЛЯ ДИСКРЕТНОЙ
линейной динамической системы
20.3.1 . ПРЕДПОЛОЖЕНИЯ
В разделе 20.2.1 утверждалось, что если шумы системы и измере-
ний являются гауссовскими, то фильтр Калмана дает наилучшую ли-
нейную несмещенную оценку состояния xt\ более того, эта оценка
наилучшая и в классе всех возможных оценок. При таких предположе-
ниях вывод уравнений для фильтра естественно получать при помощи
рассмотрения соответствующих распределений. Вывод уравнений, ко-
торый приводится здесь и дает более глубокое понимание функциони-
рования фильтра, свободен от предположений относительно
распределений. Фильтр Калмана должен обеспечивать наилучшую ли-
нейную несмещенную оценку состояния xt. При этом результат тот
же, что и при применении метода, опирающегося на гауссовское рас-
пределение шумов.
20.3.2 . КОЭФФИЦИЕНТ УСИЛЕНИЯ КАЛМАНА
В примере, приведенном в разделе 20.2.2, прогноз xt был сделан в
предположении точного знания значения xt_t. Однако в силу наличия
шума в измерениях истинное значение никогда не будет извест-
ным, а известны только измерения произведенные до мо-
мента t—1, при помощи которых можно оценить х(_{. Прогнозное
значение xt будет основываться на этой оценке величины xt_{. Пусть
xt । — такая оценка, где индекс 11 t—1 означает, что она делается
для момента t с использованием информации, доступной к моменту
t—1. Предположим на время, что такая оценка построена. Пусть стал
известным результат нового измерения yt: он сам по себе представля-
ет собой оценку xt, но, конечно, содержит шум. Чтобы получить
427
наилучшую линейную несмещенную оценку xt, формируется взвешен-
ная линейная комбинация двух имеющихся оценок:
<2о.зл)
где Lt и Kt — зависящие от времени весовые матрицы, которые вы-
бираются так, чтобы оценка в каждый момент времени была несме-
щенной и имела минимальную дисперсию [ср. с разделом 3.2.2].
Сначала воспользуемся условием несмещенности. Если определить
ошибки оценок состояния равенствами
х 111= 11 xt>
(20.3.2)
x 111— i ~ xt 11—i xt
и осуществить подстановку выражений для и yt в (20.3.2),
то получим соотношение
х 111~ Т\х^Л-LfX (20.3.3)
где /—единичная матрица. По определению E[vt] =0, и если Е[х ,_J=0,
то подправленная оценка будет несмещенной, т. е. при
выполнении равенства [Lt+KtHt—/]=0- Таким образом, несмещен-
ность оценки xt обеспечивается, если
Lt=I—KtHt. (20.3.4)
Использование последнего соотношения в (20.3.1) приводит к пред-
ставлению
А | | z—i
(20.3.5)
После перегруппировки членов получаем
| | z—i + K&t 11—J* (20.3.6)
Соответствующая ошибка оценивания представляется в виде
х , 11 = [I—KtHt}x ф-! + Ktvt. (20.3.7)
Уравнение (20.3.6) связывает подправленную оценку xt 11 и предва-
рительную оценку jc, । r_j. Оно может быть записано как
11= Л | z—i
428
где взвешивающая матрица Kt и есть коэффициент усиления Калмана,
а величина
vt ~yt 11—i (20.3.8)
называется обновляющим процессом, поскольку она представляет но-
вую информацию, содержащуюся в измерении yt, которая в принципе
может быть использована при оценивании xt. Очевидно, в функциони-
ровании фильтра коэффициент усиления Калмана играет решающую
роль, поэтому желательно выбрать Kt оптимальным, чтобы получен-
ная оценка состояния xt обладала минимальной дисперсией.
20.3.3 . ОПТИМАЛЬНЫЙ ВЫБОР ФИЛЬТРА КАЛМАНА
Чтобы описать неопределенность в оценках состояния^ понадобят-
ся ковариационные матрицы случайных векторов х 111 и х 11, зада-
ваемые равенствами
| t=E[x 11 tx Tt\ J»
(20.3.9)
?t 11—i =E{x 11 t—ix 7| t—11 •
Подставляя xt ।1 из (20.3.7) в (20.3.9), получаем, что
Pt । , = [/-ед]Р, । (20.3.10)
где R — ковариационная матрица yt, определенная в (20.2.3). Члены
Е[х 11 f_i vJJ и равны нулю из-за некоррелированности vt и
V/—1 и, следовательно, они не влияют на оценку Диагональные
элементы матрицы Pt 11 есть дисперсии компонент оценки х, । век-
тора состояния. Именно их мы и будем минимизировать. Например,
дисперсия r-й компоненты есть элемент с индексом (г, г) матрицы
(/— КН) A (J—HTK7)+KRK7=
^A-KHA—AHTKT+K(HAHT-l-R)KT,
где на время мы опустили временндй индекс и заменили Pt । на А.
Указанный элемент равен:
Jr=Arr—2JXrs(HA)sr+EEKrs(HAHT+R)SjKrj, (20.3.11)
где индексы указывают номера элементов матриц. Чтобы найти ми-
нимизирующее значение К, будем решать уравнения
dJr/dKuv=0 (20.3.12)
429
при всех и, v и г. Соответствующие скалярные уравнения могут быть
записаны в матричной форме:
-АН1 + К^НАН7 4- R) = О,
откуда
K=AHT(HAHT+R)~l.
Таким образом, возвращаясь к нашим обычным обозначениям, мы
получаем, что оптимальное значение Kt задается формулой
Kt=Pt (t_xH7[HtPt ,t_,H7+/?]-’. (20.3.13)
Подстановка Kt в (20.3.10) дает следующее представление для ковари-
ационной матрицы оценок состояния, отвечающей оптимальному зна-
чению Kt, определяемому равенством (20.3.13):
Л | /=Л | ,-1-Л | /-.НДЯЛI ,-Н+R]-'H,P,!=
(20.3.14)
= [7-^]^!^.
Это уравнение обеспечивает удобную рекуррентную формулу, позво-
ляющую осуществлять пересчет ковариационной матрицы состояния
для учета измерений, произведенных в момент времени t.
20.3.4 . ПРОГНОЗ СОСТОЯНИЯ
До сих пор наше внимание было сосредоточено на том, как исходя
из полученного наблюдения yt найти отфильтрованную оценку состо-
яния и ковариационную матрицу ее ошибки. В соответствии с (20.2.1)
прогноз в момент t состояния системы в момент /+1 может быть
представлен в виде
*z+i1 11’ (20.3.15)
Вычитая отсюда уравнение системы (20.2.1), получаем, что ошибка
прогноза х f+1|f удовлетворяет соотношению
* t+i\t=Ft* t\t + wt> (20.3.16)
из которого, аналогично формуле (20.3.10), выводим следующее выра-
жение для ковариационной матрицы ошибки прогноза:
Л+1|'=/7Л|ЛГ+е> (20.3.17)
где Q — ковариационная матрица
Отметим снова, что Pt+l 11 легко рекуррентно пересчитывается ис-
ходя из Pt 1t.
430
20.3.5 . ИНТЕРПРЕТАЦИЯ УРАВНЕНИЙ ФИЛЬТРАЦИИ
Выражение (20.3.13), дающее оптимальное значение Kt, может
быть упрощено, если переписать его в виде
или
+*,я=о.
Следовательно,
Отсюда с помощью (20.3.14) получаем
Таким образом, приходим к упрощенному выражению для К(:
Kt=Pt\tH^R~\ (20.3.18)
Анализ этого соотношения позволяет глубже понять одну особен-
ность функционирования фильтра [см. Gelb (1974)]. Предположим,
что Ht — единичная матрица; в этом случае обе матрицы, Pt ।1 и R,
имеют размер (п х л). Если матрица R~l диагональная (отсутствуют
перекрестные корреляции между шумами), то Kt получается умноже-
нием каждого столбца Pt 11 на величину, обратную соответствующей
дисперсии шума измерения и, следовательно, она пропорциональна не-
определенности в оценке состояния и обратно пропорциональна шуму
измерения. Если шум измерения велик, а ошибки оценки состояния
малы, то обновление vt в (20.3.8) определяется в основном шумом из-
мерения, а элементы Kt будут относительно малы. Следовательно, в
соотношении (20.3.6) изменения оценки состояния будут незначитель-
ными. С другой стороны, малый шум измерения и большая неопреде-
ленность в оценках состояния означают, что vt содержит
значительную информацию об ошибках в оценках состояния, а значит,
элементы Kt будут относительно большими.
Неопределенность в проекции состояния, полученного с помощью
уравнения (20.3.17), как легко видеть, зависит от корреляционной мат-
рицы шума системы. Мощность шума системы отражает, насколько
хорошо модель представляет динамику системы: если Q велико (что
соответствует плохому модельному приближению), то неопределен-
ность в xf+1|f также будет значительна. Если Q, R, Ft, Ht являются
известными постоянными матрицами, заданы начальные оценки х0 10
и соответствующая им матрица ковариации ошибок Р0|0, то уравне-
ния фильтра можно последовательно решать в каждый момент време-
ни. Сначала матрицы Pt । Pt । г—1 и Kt будут меняться с течением
времени, однако для стационарной системы они будут сходиться к
равновесным значениям, не зависящим от будущих наблюдений. Эти
стационарные значения для каждой схемы фиксированы.
431
20.3.6. РЕЗЮМЕ
Для реализации рекуррентной процедуры фильтрации необходимо
знать начальную оценку состояния, обозначаемую х0|0 = х0, а также
ковариационную матрицу ошибки оценивания Ро । 0; они могут быть
получены на основании какой-либо априорной информации.
Таблица 20.3.1. Алгоритм дискретного линейного фильтра Калмана
Уравнение системы: Уравнение измерения: x,+ i=Flxl+Dlul + w, y, = H,x, + v,
Начальные условия и другие предположения: ~ -^0’ FlXoX 0 i = F0' var{w’J=Q, =0; varSvJ=7?, £[wtp + T) = 0 для т =0, ± 1, ±2,...
При наблюдении: Ошибка обновления:
Коэффициент усиления Калмана:
Уточненное состояние:
Ковариация ошибки состояния:
При прогнозе:
Прогноз состояния:
Ковариация ошибки прогноза
состояния: +Q
Рекуррентный цикл функционирования фильтра может быть кратко
описан следующим образом. По данному наблюдению в момент t вы-
числяется вектор обновления vt (20.3.8), коэффициент усиления Кал-
мана Kt (20.3.13), отфильтрованный или уточненный вектор
состояния xt 11 (20.3.6) и ковариационная матрица ошибок уточненно-
го состояния Р,| t (20.3.14). Прогноз состояния х/+1 р задается уравне-
нием (20.3.15), а ковариационная матрица ошибок прогноза Р/+1 р —
уравнением (20.3.17).
432
Табл. 20.3.1 дает резюме относительно алгоритма фильтра Калма-
на для дискретного линейного случая с одной небольшой модификаци-
ей: в систему уравнений введен вектор ut экзогенных входных
воздействий с весовой матрицей Dt. Он может представлять собой из-
вестный детерминированный входной сигнал или управляющую пере-
менную для управления фазовой траекторией; в уравнениях для
фильтра ut появляется только при прогнозе состояния.
20.4. ТЕСТЫ ПРОВЕРКИ КАЧЕСТВА ФИЛЬТРА
20.4.1. СВОЙСТВА ОБНОВЛЕНИЯ
Обновляющая последовательность (риопределенная урав-
нением (20.3.9), может быть использована для тестирования качества
фильтра. По определению
vt -yt—-Htxt—Ht(xt । t_x —xt) = (20.4.1)
= v—Ht(xt । t__—xt). (20.4.2)
Отсюда ясно, что обновление зависит от ошибки прогноза состояния,
основанного на последовательности наблюдений [уь у2,---, yt_J, и от
наблюдения в момент /. Обновляющая последовательность имеет
среднее и дисперсию, выражаемые формулами
£U]=0, (20.4.3)
var[r,]=»гг]=Л+Н,Р, (20.4.4)
Если шум системы и шум измерений гауссовские, то vt — также гаус-
совский процесс. В [Jazwinski (1970)] показано, что в случае оптималь-
ного фильтра vt некоррелировано с vs при s < / и ys при s t. Из
оптимальности функционирования фильтра следует, что параметры
Ро, Ft, Dt, Ht О и R специфицированы корректно. Три соотношения:
Е[ртг;}=0 и E[i>rjJ’}=0 для 5^/ называются свойствами
обновления и составляют основу для проверки качества функциониро-
вания фильтра.
Статистические тесты, опирающиеся на Q- и S-тесты, описанные
под названием диагностической проверки в книге [Box and Jenkins
(1976)], могут применяться для того, чтобы установить, выполняются
ли свойства обновления. Предположим, что элементы [jJ и [pj явля-
ются скалярными величинами и представляют собой соответственно
выходной сигнал и значения обновлений, вычисленные в моменты
времени 0,1,...,/. Пусть F — среднее выборки у и Sy — среднее
выборки и дисперсия [yt}.
433
Введем следующие ковариационные функции:
/=0,1...L, QOA.5)
[—1 S-/ + 1
!=0’1’2.....L- (20-4-6)
С их помощью определим статистики:
М= V/rQ, (20.4.7)
Q=/E(r2/r02), (20.4.8)
S=ti(cj/4r*s}). (20.4.9)
Если свойства обновления выполняются, то М имеет распреде-
ление Стьюдента с t—1 степенями свободы [см. раздел 2.5.5], a Q и
S-распределение х2 [см. раздел 2.5.4, п. а)] с т степенями свободы.
Здесь m-L—р, р — число параметров во всей модели. Число членов
L в приведенных соотношениях выбирается превосходящим память
модели. Представляется разумным выбрать L таким образом, чтобы
матрица г (произведение L последовательных переходных матриц)
имела все элементы очень малые.
Хотя указанные тесты полезны, они не гарантируют адекватности
модели. Некоторые очевидные дефекты с их помощью обнаружить не
удается, поэтому рекомендуется производить и визуальный анализ об-
новлений.
20.4.2. РАСХОДИМОСТЬ ФИЛЬТРА
Алгоритм фильтрации, приведенный в табл. 20.3.1, весьма прост и
пригоден в любом случае, когда параметры модели специфицированы.
Эффект расходимости фильтра может возникнуть в ситуации, ког-
да параметры (Ft, Dt, Ht, Ро, R и Q) известны неточно; это может
произойти из-за упрощения модели динамики системы или недоста-
точной точности оценивания параметров. В результате этого обстоя-
тельства фильтр оценивает состояния неправильно, «уклоняясь» от
истинных значений. Указанная проблема становится особенно острой,
когда член, соответствующий шуму, в уравнениях системы мал, тогда
малы ковариации ошибок и коэффициент усиления Калмана, а после-
дующие наблюдения незначительно влияют на оценивание.
При практических применениях расходимость проявляет себя через
обновление. В результате фильтр больше не является оптимальным,
матрица Pt ।1 не есть мера дисперсии ошибок оценивания, а ошибка
х 111 становится растущей с ростом t.
434
Один из способов борьбы с расходимостью фильтра состоит в мо-
дифицировании уравнения фильтра таким образом, чтобы последние
измерения имели большее влияние на оценки фильтрации, а воздейст-
вие предыдущих измерений постоянно уменьшалось. Этого можно до-
стичь применением весов
1, е-1/т«г-2/т,..., (20.4.10)
к наблюдениям yt, yt_y yt_2vt где параметр т характеризует «па-
мять» фильтра. Табл. 20.4.1 дает описание такого фильтра с экспонен-
циально взвешенной памятью. Если параметры уравнений системы и
измерений известны точно, то фильтр из табл. 20.4.1 работает хуже,
чем фильтр из табл. 20.3.1, поскольку ошибка оценивания Pt 11 будет
больше, чем в фильтре Калмана. Однако его использование может
предотвратить эффект расходимости, если в значениях параметров
имеются погрешности.
Таблица 20.4.1. Алгоритм Калмана со взвешенной памятью
для линейной дискретной системы
При наблюдении:
При прогнозе (в момент t):
^^\rF^,\,+D,uP
Л+1|,=/?А|Л + G
20.5. КАЛМАНОВСКАЯ ФИЛЬТРАЦИЯ ДЛЯ НЕПРЕРЫВНОГО
ВРЕМЕНИ И НЕЛИНЕЙНЫХ СИСТЕМ
20.5.1. СИСТЕМЫ С НЕПРЕРЫВНЫМ ВРЕМЕНЕМ
До настоящего момента мы рассматривали только дискретные
системы. Хотя некоторые системы эволюционируют дискретно (на-
пример, цены на фондовой бирже), многие системы изменяются не-
прерывно (например, водный расход в реке) и естественным образом
должны описываться случайным процессом х(/), где t — вещественное
неотрицательное число. Процесс х(/), который содержит всю интере-
сующую нас информацию о непрерывно эволюционирующей сис-
435
теме, называется состоянием системы, если его можно представить в
виде уравнения
х (/)=/(*(/), О+#(К0,0, (20.5.1)
где х (/) — производная x(t) по времени t. Здесь $(/) — (непрерывный)
процесс шума. Из соотношения (20.5.1) эволюция х(-) во все моменты,
следующие за t, полностью описывается значением x(f) и шумом, ко-
торый предполагается непредсказуемым по траекториям х(-). В неко-
торых случаях x(t) сопровождается непрерывными (зашумленными)
измерениями y(t) (например, сигнал в приемнике и т. п.), хотя в боль-
шинстве ситуаций доступны только измерения в дискретные моменты
времени: yt, /=1,2,3,....
В непрерывном времени система является линейной и гауссовской,
если уравнение, описывающее ее поведение, имеет следующий вид:
dx(t)=f^t)x(f)ut+g{t)dB(f), />0, (20.5.2)
где B{t} — винеровский (гауссовский) процесс [см. II, пример 22.1.1],
a dB(t) означает инфинитезимальные приращения (dB(t) есть так назы-
ваемый непрерывный гауссовский белый шум). С этой линейной сис-
темой связан процесс измерений y(t) в дискретные моменты времени
yt и с гауссовским шумом измерений:
yt=Htx(t) + vt. (20.5.3)
При заданных измерениях yi,...yt можно оценить x(t) (задача филь-
трации) или x(sj, s<t (задача сглаживания), или x(sj, s>t (задача про-
гноза). Однако если нужны только оценки х(*) в дискретные моменты
времени 0,1,...,/, то указанная задача может быть заменена на стан-
дартную линейную дискретную задачу калмановской фильтрации.
Чтобы сделать это, уравнение (20.5.2) заменяется на разностное
уравнение
х(/)=Ft_1x(t—1) + wt, (20.5.4)
где ,
= F(t— 1, /) = ехр [— J f(z) dz],
t— i
wt= \F(T,t)g(T)db(r),
причем последовательность [wj является гауссовской.
Далее можно применить стандартный линейный фильтр Калмана
и получить обычные оценки состояния вместе с ковариационными
матрицами ошибок. Более подробно эти проблемы описаны в работах
[Jazwinski (1970)] и [Gelb (1974)].
436
20.5.2. НЕЛИНЕЙНЫЕ СИСТЕМЫ:
ОБОБЩЕННЫЙ ФИЛЬТР КАЛМАНА
Во многих практических ситуациях изучаемые системы не являют-
ся линейными. Обычно состояния таких систем эволюционируют в не-
прерывном времени в соответствии с дифференциальным уравнением
первого порядка вида
dx(t)=J{x(t))dt+g(t)d^t), (20.5.5)
причем механизм измерений также может быть нелинейным и описы-
ваться формулой
y(f)=h(x(t)) + v(f). (20.5.6)
Задача фильтрации, заключающаяся в оценивании x(t) по непрерыв-
ным измерениям y(t) или дискретным наблюдениям yt, допускает ана-
литическое решение с явными формулами для оптимального фильтра.
Однако вычисления, которые необходимо проделать, чтобы получить
численные результаты для такого фильтра, оказываются чрезвычайно
трудоемкими. Поэтому для указанных нелинейных задач возникает
необходимость в их приближенном решении. Мы опишем здесь одну
из возможных аппроксимаций — обобщенный фильтр Калмана, кото-
рый оценивает x(t) по данным yx,...yt при помощи применения филь-
тра Калмана к разложению Тейлора первого порядка для уравнений
(20.5.5) и (20.5.6) [см. Jazwinski (1970), раздел 8.3].
Указанное разложение берется в окрестности решения x(t) детер-
минированной компоненты уравнения (20.5.5), т. е. функции, удовлет-
воряющей уравнению
dx(t)=f(x(t))dt. (20.5.7)
Линеаризованные выражения для (20.5.5) и (20.5.6) имеют вид
dx(t) =f(x(t)) dt +fVc{t)) (x(t)-x(t))dt+g(t) d£(t), (20.5.8)
y(t)=h(x (/)) + h'(x (t))(x(t)—x (/))+v(/). (20.5.9)
Здесь f'(x(ff) и h'(x(t)) — матрицы частных производных функций f и
А, вычисленные в точке x(t). Подставляя (20.5.7) и (20.5.8), получим
rf(X0-x(0)VTO)(x(0-x(0)rf/+g(0rf«0. (20.5.10)
Введем новые переменные:
Z(0=(X0—Л(х(0)»
х*(0=(*(0—x(t))>
437
в терминах которых пара уравнений (20.5.10) и (20.5.9) может быть
переписана в виде
Получившаяся линейная непрерывная модель в пространстве состояний
в точности того же типа, что и модель, заданная уравнениями (20.5.2)
и (20.5.3). Отметим, что все функции от x(f) могут быть вычислены с
любой желаемой степенью точности при помощи, например, метода
численного интегрирования Рунге—Кутта [см. И, раздел 8.2.2].
При применении обобщенного фильтра Калмана требуется некото-
рая осторожность, поскольку о качестве его функционирования мало
что можно сказать. Так как ряд Тейлора оборван на первом члене, ап-
проксимация нелинейной системы будет лучше, если члены (xt—xt 11)
и (xt—xt । r—1) малы. Следовательно, если отношение сигнал—шум ве-
лико, можно предполагать, что при указанном подходе трудностей не
возникает. В процессе работы фильтра матрицы pt 11 и pt 1t_x могут
служить показателями того, являются ли достаточно малыми величи-
ны (xt—xt 11)2 и (xt—xt । ,_j)2.
В отличие от линейных систем матрицы pt 11 и pt\t_v связаны с
уравнениями фильтрации через xt\t и Хф_Р В общем случае послед-
ние величины не могут быть вычислены с учетом доступной информа-
ции. Они не стремятся к стандартным значениям, как в случае
линейных систем с постоянными параметрами. Как и для линейного
фильтра Калмана, качество функционирования обобщенного фильтра
Калмана можно проверять с использованием обновлений, причем чем
ближе последние к белому шуму, тем ближе фильтр к оптимальному.
Устойчивость обобщенного фильтра Калмана обсуждается в работе
[Ljung (1979)].
Можно построить фильтры для случая, когда в разложениях Тей-
лора берутся два члена. Такие фильтры называют обобщенными
фильтрами Калмана второго порядка. Применение фильтров указан-
ного типа описано в [Moore and Weiss (1980 b)].
Общих критериев, дающих представление о том, какой алгоритм
работает лучше при данной конкретной задаче, не существует. Каждая
ситуация должна изучаться отдельно. Читатель, впрочем, должен
иметь в виду, что эффект расходимости и плохое функционирование в
нелинейных системах возникает достаточно часто, поэтому построение
фильтров требует значительных усилий.
438
20.6 ИДЕНТИФИКАЦИЯ МОДЕЛИ И ОЦЕНИВАНИЕ
ПАРАМЕТРОВ
20.6.1. ВВОДНЫЕ ЗАМЕЧАНИЯ
В предыдущих разделах описывалось применение фильтра Калма-
на к линейным и нелинейным системам. При этом предполагались из-
вестными как структурная форма модели в фазовом пространстве, так
и ее параметры. Однако в большинстве практических задач возникает
одна из следующих ситуаций: а) структура модели известна, но неиз-
вестны параметры; б) и структура модели, и параметры неизвестны.
Для иллюстрации можно привести пример из раздела 20.1, где описы-
вались различные модели, в частности, модель прогноза в реальном
времени водного расхода в реке по данным об осадках. В бассейне ре-
ки движение воды по земной поверхности, в почве, в водоносных го-
ризонтах, в руслах ручьев подчиняется определенным физическим
законам, основанным на сохранении массы и количества движения.
Для описания указанных процессов можно выписать замкнутую систе-
му нелинейных дифференциальных уравнений в частных производных.
Поскольку ее аналитическое решение найти не удается, эта система
приближенно может быть решена с помощью конечноразностных
схем [см. Beven and O’Connell (1982)]. Сложность вычислений при
этом настолько велика, что хотя подобные модели и могут быть за-
писаны в виде моделей в фазовом пространстве, высокая размерность
вектора состояний и имеющиеся вычислительные средства делают
этот подход совершенно непригодным на практике. Процессы, в ре-
зультате которых осадки превращаются в водный расход, можно ус-
реднять по пространственным переменным. Для усредненных
процессов удается построить модели квазифизического типа, основан-
ные на нелинейных уравнениях в частных производных и с определен-
ной степенью адекватности описывающие превращение осадков в
расход. Подобного рода модели обычно выводятся из уравнения не-
разрывности и эмпирического уравнения, связывающего расход с ко-
личеством воды, накопленной в бассейне реки, вид которого
устанавливается исходя из наблюдаемого поведения расхода. Эти мо-
дели могут быть сформулированы как модели в фазовом простран-
стве [см. (20.5.7) и (20.5.8)]. При этом структура модели оказывается
заданной априори, однако ее параметры неизвестны и их необходимо
оценить по имеющимся данным. Для этой цели применяются разно-
образные методы, о чем пойдет речь в разделе 20.6.3, п. б). Пример
исследования, иллюстрирующий указанный подход, описан в разделе
20.7.2.
Если о структуре модели, связывающей осадки с водным расхо-
дом, заранее ничего не предполагается, то можно применять процеду-
ры идентификации модели, основанные на изучении структуры
выборочной ковариации выхода системы (т. е. водного расхода). С по-
439
мощью этих процедур можно подобрать размерность матриц Ft, Ht,
Q и R в представлении модели в фазовом пространстве:
x(+l=Ftxt + wt, (20.6.1)
yt=Htxt + vt, (20.6.2)
а также их структуру. Если указанный подход применяется при уста-
новлении связи между осадками и водным расходом в реке, то линей-
ная модель в фазовом пространстве может иметь, например,
следующий вид:
xt+\
(20.6.3)
(20.6.4)
Л = xt + vt.
В приведенной выше формулировке и осадки, и расход воды представ-
лены системой линейных разностных уравнений. Следовательно,
фильтр Калмана может применяться для удаления ошибок измерений
в обеих переменных, а предсказание водного расхода будет основано
на фильтрационной оценке количества осадков. Ограниченность тако-
го рода моделей заключается в том, что они представляют нелиней-
ный отклик водного расхода в зависимости от осадков линейной
функцией. Однако указанная форма модели в фазовом пространстве
может быть сохранена, если считать отклик кусочно-линейным, и
этот прием позволяет использовать процедуры идентификации и оце-
нивания параметров, разработанные для линейного случая.
440
Пример применения указанного подхода приводится в разделе
20.7.1; методы идентификации структуры модели и ее параметров
описываются в разделах 20.6.2 и 20.6.3.
Теоретически при идентификации структуры модели в фазовом
пространстве и оценивании ее параметров должны выполняться неко-
торые условия. Например, теоремы, касающиеся поведения фильтра
Калмана, основаны на предположении, что истинная модель наблюда-
ема и устойчива. Именно от этих условий зависит, что можно выи-
грать от фильтрации данных. Как нетрудно понять, указанные
условия в значительной степени определяются структурой истинной
модели системы. Понятие наблюдаемости системы связано с тем,
можно ли восстановить состояния из наблюдений. Условие наблюдае-
мости выполняется, если матрица
н]\. .
имеет ранг п, где п — размерность вектора состояния. Управляемость
связана с условиями, при которых можно управлять состоянием де-
терминированной линейной динамической системы, т. е. когда пере-
менная управления включена в уравнение системы. Состоянием можно
управлять, если матрица
[Dt \FtDt\. . .;
имеет ранг п.
Понятие устойчивости относится к поведению оценок состояния,
когда влияние измерений подавлено. Предположим, что поведение
системы описывается дифференциальным уравнением первого порядка
(20.5.2). Тогда система называется асимптотически устойчивой, если
х(/)~*0 при Z—для любого начального условия ДО). Это весьма не-
формальное определение устойчивости. Теоретические условия, гаран-
тирующие устойчивость, гораздо более ограничительны и во многих
практических приложениях они не выполняются, хотя фильтры Кал-
мана, построенные обычным образом, работают удовлетворительно.
Этот факт связан с тем обстоятельством, что решение системы диф-
ференциальных уравнений часто приближается к нулю на конечном
интервале, где и производится исследование, хотя асимптотической
устойчивости в строгом смысле определения может и не быть. Э.
Джелб [см. Gelb (1974)] предположил, что ключевыми причинами, вы-
зывающими неустойчивость, являются ошибки моделированной схем-
ной реализации. В его работе по этому поводу приводится подробная
дискуссия.
Для некоторых систем представляет интерес вопрос: в достаточной
ли степени входной сигнал возмущает систему, чтобы идентификация
модели и оценивание параметров оказались возможными? В гидроло-
гическом моделировании система может быть возмущена только спо-
441
радически в те моменты, когда происходит выпадение осадков, поэто-
му некоторые компоненты модели (или параметры) иногда оценить
нельзя. Особенно это относится к имитационным моделям с большим
числом параметров. В алгоритмах оценивания, как правило, предпола-
гается непрерывное и существенное возмущение системы, в против-
ном случае в оценках параметров может быть большой разброс.
20.6.2. ИДЕНТИФИКАЦИЯ МОДЕЛИ
По заданной стационарной выборочной ковариационной функции
временного ряда можно построить модель в фазовом пространстве,
выходной процесс которой будет иметь приблизительно те же стати-
стические характеристики, хотя первоначально точный вид ее неизве-
стен. В этом отношении модели в фазовом пространстве подобны
авторегрессионным моделям со скользящим суммированием (ARMA)
[см. раздел 18.9]:
yt + + • • • + = 00 + 01 vr-i + • • •+ 0Л-</’ (20.6.5)
где vt одинаково распределены, независимы и в точности соответ-
ствуют обновляющему члену в фильтре Калмана, а Фь...,Фр и
0о, ...,09 являются матрицами параметров размерности (zwxzw). На
самом деле между двумя указанными представлениями имеется тесная
связь. В терминах предикторов фильтр Калмана может быть записан
в виде
yt=HXt\t_x+vt, (20.6.6.)
11,=«, |11 ,"Т(«Л+11 ,^+Л)-1 v, (20.6.7)
с ковариационной матрицей ошибок
л+1|,=-рЛ|,-1^+с,с,ог+е,
где Gt=FKt и Ct=E[vt vf]. Здесь и далее предполагается, что система
имеет постоянные коэффициенты, поэтому индекс t у матриц Н и F
опускается. При таких условиях матрица Р(+1достигает своего ста-
ционарного состояния Р, так что коэффициент усиления постоянен и
может быть обозначен буквой К. Тогда так называемая обновляющая
форма модели может быть записана в виде
х,+ 1 =Fxt+Kvt, (20.6.8)
yt=HXt + vt, (20.6.9)
где х,+ 1 интерпретируется как одношаговый прогноз х,+1|Г Эквива-
лентность ARMA-представления и представления в фазовом простран-
стве можно продемонстрировать теперь следующим образом. Исполь-
442
зуя оператор прямого сдвига z, определенный равенством z(xt)=xt+i,
запишем модель ARMA (20.6.5) в виде
Л= (20.6.10)
где
A(z~l) = (I+^iZ~l + ... + &pz~p),
B(z~1) = (O0 + OiZ~1 + ... + 6gz~«).
Подставляя (20.6.8) в (20.6.9), получим для представления в фазовом
пространстве следующую формулу:
yt=H(I—Fzr-1)-1Gzr1vt + vt. (20.6.11)
Указанные представления эквивалентны в том смысле, что для любой
пары [А, В] можно найти тройку [Н, F, G], которая дает ту же кова-
риационную структуру, и наоборот. Отметим, что условие стационар-
ности требует, чтобы корни многочлена А лежали вне единичного
круга, или, что эквивалентно, чтобы собственные значения матрицы F
были по модулю меньше единицы (это равносильно устойчивости мо-
дели, обсуждавшейся в разделе 20.6.1).
Модель ARMA может быть обращена:
v,= [B(z~^)}~^ A(z~^}y t.
Нетрудно проверить, что обращение модели в фазовом пространстве,
записанной равенством
[I+H(z.—F)—iG)vt, (20.6.12)
имеет вид
v,= [Z—H[z~ (F- GH)]~ 'G]yt. (20.6.13)
Это обращение возможно только в случае, когда матрица (F—GH)
имеет собственные значения по модулю меньше единицы [см I, гл. 7],
или, что эквивалентно, когда многочлен В имеет корни вне единично-
го круга (условие обратимости для модели ARMA).
Установим теперь связь между моделью ARMA и моделью в фазо-
вом пространстве для одномерных рядов. Для представления
У, + Ф1Л-1 + • • • + ФрУ(-р=vt + 01 Vr-1 + • • • + eqvt-q (20-6-14)
443
эквивалентная модель в фазовом пространстве имеет вид
(20.6.15)
j, = [l 0 ... ОЦ + v,, (20.6.16)
где л = тах[р, g] и ф(=0, если i>p. Числа g, являются элементами
импульсного отклика, связывающего v с у. Отметим, что матрицы F
и Н разреженные. Указанная модель имеет канонический вид. Это
означает, что у нее специфическая, эффективно параметризированная
структура. Существуют и другие канонические формы, например, при-
веденный выше пример может быть записан в виде
Л=[1 0 ... 0]^+ур (20.6.17)
^+1= —01 1 • 0 0 ... 1 ... 0 0 х,+ 01 (20.6.18)
• • •
-фл 0 ... 0 1 0п
С определенной точки зрения последняя форма предпочтительней, по-
скольку в ней фигурируют в точности те же параметры, что и в
ARMA-представлении. Канонические формы можно получать, выби-
рая подходящую матрицу М и переписывая модель следующим
образом:
Mxt+ j =MFM~'Mxt+MGvt,
(20.6.19)
Очевидно, что матрица М может быть найдена исходя из связи между
[01,...,0Л] и [gi,...,gn], однако состояния для этих двух форм имеют
различную интерпретацию.
444
Выбор моделей ARMA подходящей размерности — своего рода ис-
кусство. Но как только подходящая структура идентифицирована,
можно записать эквивалентное представление в фазовом пространстве
и использовать для получения прогноза фильтр Калмана.
После того как обновляющая форма модели в фазовом простран-
стве найдена, может оказаться желательным возврат к исходной мо-
дели, содержащей шум системы и шум наблюдений. Это означает,
что по данным матрицам (С, G) требуется найти (Q, R], пользуясь со-
отношениями
C=R + HPHT, (20.6.20)
G=FPFP(HPHT+R)~\ (20.6.21)
P=FPFT— GCGT + Q (20.6.22)
и имея в виду, что все матрицы [7* Q, R] должны быть положительно
полуопределенными. В общем случае указанные уравнения дают бе-
сконечно много решений для Q, хотя в отдельных ситуациях нельзя
найти {Р, Q, R], которые удовлетворяли бы требуемым ограничениям.
Первой неприятности можно избежать, вводя ограничения на шум
системы. Достаточно предположить, что
xt+1 =Fxt + Twt (20.6.23)
и
yt=Hxt + vt, (20.6.24)
где Г — матрица, имеющая столько столбцов, сколько строк имеет
уг Эта модель может рассматриваться как модель ARMA (уравнение
системы) с шумом наблюдений vt. Исходный шум системы w( с кова-
риационной матрицей Q заменяется на шум Г w'(, имеющий ковариа-
ционную матрицу Г0ТТ. В общем случае эта матрица имеет
меньше независимых элементов, чем Q, и при наличии ограничений на
некоторые элементы Г уравнение (20.6.22) имеет конечное число реше-
ний для Г и Q', когда Q заменено на Г0Тт. При этом только одно
из этих решений дает обратимую модель ARMA в уравнении (20.6.23).
В отличие от методов, предложенных Боксом и Дженкинсом [см.
Box and Jenkins (1976)], а также другими авторами для идентификации
структуры моделей ARMA, Акайке [см. Akaike (1974)] разработал ме-
тод, который позволяет идентифицировать непосредственно структу-
ру мод ел и. в фазовом пространстве в канонической форме. Этот метод
предполагает применение канонического корреляционного анализа
[см. например, Cooper and Wood (1982 а)]. По-видимому, он особенно
эффективен для многомерных временных рядов, где канонические
формы, смысл которых для многомерной модели ARMA неясен, воз-
никают естественным образом. Здесь приведены ключевые моменты
процедуры. Более детально эти проблемы изложены в работах
[Akaike (1974)] и [Cooper and Wood (1982 а)].
445
Подлежащая идентификации модельная структура задается уравне-
ниями (20.6.8) и (20.6.9). Указанная процедура используется, чтобы
найти подходящую размерность матрицы F (и, следовательно, Н и G).
Она дает некоторые предварительные оценки параметров этих мат-
риц. Идентифицируемая модель имеет каноническую форму: для к-
мерного вектора наблюдений yt имеются к строк матрицы [Н7:!*7]7,
которые содержат свободные параметры, остальные же строки состо-
ят из нулей и единиц. Матрица G заполнена и состоит из элементов
импульсного отклика модели.
Первый шаг идентификации состоит в нахождении начальной оцен-
ки импульсного отклика, т. е. скаляров или матриц А1г А2, А3,..., та-
ких, что
= +A2vt_2 + .... (20.6.25)
Способ их нахождения следует Боксу и Дженкинсу. Авторегрессионная
модель высокого порядка
У(+В1У(-1 + • •. +Bkyt_k = et (20.6.26)
подгоняется к ряду yt с использованием уравнений Юла—Уолкера.
Предполагая, что et = vt, подставляя значение у{, выраженное в терми-
нах [ури приравнивая коэффициенты при [УрУ^,...], видим,
что [Ai,A2,A3,...] находятся как решение системы уравнений
—Л1=В1,
—А2—BiAi + В2,
(20.6.27)
—Л3 —+ В2А1 -I- В3>
Элементы G выбираются исходя из матрицы
[ЛТ:Л?:ЛГ...]Л
При этом используются только те строки матрицы, которые зависят
от следующей стадии процедуры идентификации, когда находятся
структуры матриц Н и Е Это делается при помощи канонического
корреляционного анализа [см. Anderson (1958)] векторов прошлых на-
блюдений Yp=[yt_},yt_2,...] и YF=[yt,yt+i,yt+2,...] [см. раздел 16.5].
В одномерном примере выборочные ковариационные матрицы
SpP,SPF,SFF вычисляются для конечного числа, скажем, к прошлых
наблюдений и для Y вида [[jJ, [_ур_у,+1],...]. Далее решается уравне-
ние для детерминанта
I $рр3рр$рр—^$FF I —0
(20.6.28)
446
относительно X; если некоторое его решение Хо не слишком отличается
от нуля, то это означает, что имеется ассоциированная с Хо линейная
комбинация будущих значений, не зависящая от прошлого. Она нахо-
дится из уравнения
{SppS^SpF—\oSpp)L~O, (20.6.29)
где вектор £=(Л, 4,-••>/;) таков, что
АЛ+/| t-i+^t+j-i | t-i + —( t-i =0> (20.6.30)
а (/—1)-я строка матрицы F есть {—/2//ь...,—Z/А], причем предикто-
ры у идентифицируются как состояния. Предыдущие строки матрицы
F с номерами i- l,...j—2 имеют единицы в (/—1)-м столбце и нули на
всех остальных позициях в соответствии с уравнением
Л+У I i— 1 =$t+j I i—2 + ^i+lVt—l‘ (20.6.31)
В одномерном случае Н= [1 0 ... 0]; при этом очевидно, что элементы
G есть Многомерная задача приводит к переходным
матрицам с более чем одной строкой параметров, и интерпретация та-
ких моделей сложнее. В работах [Akaike (1974)] и [Cooper and Wood
(1982 а)] содержатся детали, относящиеся к многомерному случаю.
20.6.3. ОЦЕНИВАНИЕ ПАРАМЕТРОВ
а) Линейное оценивание. После того как подходящая модель в фа-
зовом пространстве выбрана, возникает задача, как оценивать ее пара-
метры. Обычно это можно сделать, минимизируя некоторую
функцию от данных и параметров, чтобы получить прогноз, близкий
к наблюдаемым значениям. Чаще всего эта функция есть взятый со
знаком минус логарифм функции правдоподобия данных, что приво-
дит к оценкам параметров по методу максимума правдоподобия [см.
гл. 6]. Функция правдоподобия для некоторого множества данных
есть их совместная плотность вероятности, вычисленная в точке, отве-
чающей этим данным, и рассматриваемая как функция параметров.
Эта плотность может быть факторизована следующим образом:
Р(УрЛ-1>—I У-1)Р(Л-1 I У-2)...р(У1), (20.6.32)
где Каждая функция р(у, | У-Ь (для модели в фа-
зовом пространстве с гауссовскими шумами системы и измерений)
есть функция плотности, определяемая фильтром Калмана. Целесоо-
бразно заметить, что в соответствии с теоремой Байеса [см. гл. 15]
р(У, I y_1)«P(yz I ^)р(х, | у-1), (20.6.33)
где p(Xj | У-1) — нормальная плотность N(x, । ^,р^ । у), зависящая только
447
от у—1 и от параметров. Чтобы найти функцию правдоподобия, вы-
числим произведение индивидуальных плотностей yif задаваемых
фильтром Калмана. Это можно сделать численно. Функция правдопо-
добия вычисляется для последовательности множеств значений пара-
метров, и ее значение запоминается. При применении тех или иных
алгоритмов численной оптимизации выбираются новые множества
значений параметров, уменьшающие значение функции правдоподобия
и сходящиеся к точке минимума. Альтернативный подход заключается
в том, что градиент логарифма функции правдоподобия может быть
получен в аналитическом виде, а для получения улучшенных оценок
параметров можно использовать алгоритм Гаусса—Ньютона. Этот
алгоритм дает последовательные оценки в соответствии с формулой
^- ^-1 1 ’ (20.6.34)
где L — полная функция правдоподобия:
L=p(yl)Up(yi\yi-'). (20.6.35)
В общем случае указанный алгоритм сходится к нулю функции
dlogL/dO, который, если матрица вторых производных положительно
определена, является локальным максимумом функции правдо-
подобия.
Аналитическое вычисление производных — утомительное занятие,
если только модель не записана в форме обновления.
В одномерном случае, когда
=Fxt + Gvt = Fxt + G(yt—Hxt । r-1) (20.6.36)
и
yt=Hxt + vt, (20.6.37)
логарифм функции правдоподобия для одного наблюдения имеет вид
/,.= -ylog2™2—|-v?/a2. (20.6.38)
Дифференцирование по любому параметру 0у, отличному от о2, при-
водит к соотношению
dl. dv.
---£_ = у-------------L ,
de. 102эе.
где
dv тт dx dH Л
v,. =~Hsi—5»:x‘
J J J
(20.6.39)
(20.6.40)
448
и
Эх 3F л „ Эх dG
Х(_} + F —!=! +------V
де де де де
J J J J
(20.6.41)
Последнее равенство дает рекуррентную формулу для производной со-
стояния.
Если нельзя сделать предположения о виде распределения, для ми-
нимизации можно брать функцию, отличную от функции правдоподо-
бия, но сам принцип оценивания остается прежним. Однако желатель-
но, чтобы эта функция обладала минимумом в области изменения па-
раметров, а такую функцию иногда нелегко подобрать. К тому же
выяснение свойств полученных оценок также может оказаться труд-
ной задачей.
Метод, описанный выше, предназначен для использования «off-
line», т. е. когда значения параметров фиксированы в течение каждого
просмотра данных. В принципе возможно и рекурсивное оценивание
параметров, если после каждого вновь поступившего наблюдения про-
изводится небольшая перестройка оценок параметров. Существует
множество разновидностей рекурсивных алгоритмов, причем сходи-
мость некоторых строго не доказана. Они попадают в разряд общих
алгоритмов стохастической аппроксимации [см., например, Невельсон,
Хасьминский (1972)]. Их общий вид таков:
et+l^et+A-V(yM, (20.6.42)
где функция f(yt,0) представляет уклонение yt от предсказанного зна-
чения, А — весовая матрица, такая, что А~1 стремится к нулю. При
надлежащем выборе Л алгоритм сходится к значению 0, для которого
среднее значение f(yt,0^ равно нулю. Для эвристического объяснения
самым подходящим является вариант, сходный с алгоритмом Гаус-
са—Ньютона, о котором речь уже шла. Ниже дана его модификация
для случая, когда 7, — гауссовские плотности:
0/+i -0/+.£ J
d log/.')
«/log Л
~di
’«/log/,
~de~ ’
(20.6.43)
Отметим, что в матрицу А входит сумма произведений логарифмиче-
ских производных по всем /, тогда как f(yt,0^ содержит только по-
следнее значение d\oglt/d0.
Предлагаются также и многие другие эвристические методы. Если
для модели в фазовом пространстве известны дисперсии Q и R, то
функцию f(yt,0^ можно заменить функцией dv2/dO (имеющей мини-
449
мум по F), где vt — обновление (yt—.рф—^.В этом случае
0,+ j = 0,+ В(у —yt । ,_,), (20.6.44)
где матрица В появляется в виде «коэффициента усиления». Этот ал-
горитм может быть записан так:
х/+1 -Fxt + Gvt, (20.6.45)
0,+1 = #,+Bvp (20.6.46)
yt=Hxt + vt. (20.6.47)
Указанная схема совместного оценивания состояния и параметров мо-
жет быть реализована при помощи обобщенного фильтра Калмана
[см. раздел 20.6.3, п. б)]. Матрица В находится с помощью ковариаци-
онных соотношений. Описанный метод нельзя применять для оцени-
вания Q и R, поскольку для этого требуются квадратичные члены по
у(. В работах [Mehra (1969)], [Sage and Husa (1969)], [Martin and
Stubberud (1976)], [Brewer (1976)], [Todini (1978)] и других предложены
схемы для оценивания Q и R, подобные методам стохастической ап-
проксимации. И. Тодини использует алгоритмы вида
Ь, = И,_1 +Bslv,v[-(^l_I +ЯР(| ,_,№)] (20.6.48)
6, = £,-i +B<!(KvrfXT+Pl | ,-Р, ।(20.6.49)
где Вд и Bq принимаются равными 1/1. Как подтверждают числен-
ные эксперименты с применением метода Монте-Карло, эта схема до-
статочно удовлетворительна. Здесь мы изложили только основной
принцип. Детальное описание содержится в работах [Todini (1978)] и
[Todini and O’Connell (1980)]. Для оставшихся параметров можно при-
бегнуть к алгоритму вида
0t+1=0t+Bff(yt-yt |,_,), (20.6.50)
где Вв снова определяется с помощью фильтра Калмана, применяемо-
го для оценки параметров. Более привлекательный алгоритм для оце-
нивания всех параметров, основанный на производных функции
правдоподобия, предложен в работе [Ljung (1979)], где приводится и
доказательство его сходимости.
б) Нелинейное оценивание. До сих пор мы обсуждали методы оце-
нивания параметров с упором на простейшую модель, а именно на ли-
нейную дискретную модель в фазовом пространстве. Для нелинейных
моделей новые принципиальные идеи не нужны. Поскольку же мы
450
имеем дело с аппроксимацией истинной модели, это обстоятельство
надо принимать во внимание при оптимизации оценок параметров. В
общем случае при заданных дискретных наблюдениях может быть
приемлемой следующая целевая функция:
£о= [-у Iog2% I VI -±.[У1-Е(у,Ц (20.6.51)
где V — ковариационная матрица j-ов. Если y-t распределены по нор-
мальному закону, то процедура оптимизации 20 дает оценки максиму-
ма правдоподобия. Однако и в других случаях £0 оказывается
полезной целевой функцией. Общий рекуррентный алгоритм, задавае-
мый формулой (20.6.42), может применяться и для нелинейных моде-
лей, несмотря на то, что могут потребоваться численные оценки для
производных d\oglj/dd. В [Cooper (1982)] приведены примеры приме-
нения этого очень общего алгоритма для некоторых нелинейных
задач.
Другой возможный подход к оцениванию параметров как для ли-
нейных, так и для нелинейных моделей основан на обобщенном филь-
тре Калмана. Если определить расширенный вектор состояния как
x; = [xf:0f]r, (20.6.52)
где 0t — вектор параметров, то уравнения системы и измерения (ли-
нейные и нелинейные) можно переформулировать в терминах расши-
ренного вектора состояния х*. При этом даже если исходное
уравнение системы было линейным [ср. с уравнением (20.2.1)], то
уравнение состояния для расширенного вектора состояния будет нели-
нейным из-за членов, содержащих произведения элементов х на эле-
менты 0. Для решения возникшей нелинейной задачи оценивания
можно применить обобщенный фильтр Калмана по схеме, описанной
в разделе 20.5.2.
20.7 . ПРИМЕНЕНИЯ
20.7.1. ПРИМЕНЕНИЕ ДИСКРЕТНОГО ЛИНЕЙНОГО
ФИЛЬТРА КАЛМАНА
а) Введение. В дальнейшем изложении предполагается, что струк-
тура и параметры модели априори неизвестны, поэтому применяются
методы идентификации и оценивания дискретных линейных моделей в
фазовом пространстве, описанные в разделах 20.6.2 и 20.6.3. Наша
цель состоит в построении модели, пригодной для прогноза водного
расхода в реке в зависимости от осадков в реальном времени. Как от-
мечалось в разделе 20.6.1, величина водного расхода нелинейно зави-
сит от уровня осадков, главным образом вследствие того, что речной
бассейн по разному реагирует на осадки в зависимости от состояния
451
«увлажненности». Тем не менее оказывается, что кусочно-линейный
подход во многих случаях позволяет получить удовлетворительные
результаты. Он может быть применен путем разложения исходной по-
следовательности осадков на две или более входные последователь-
ности, каждая из которых характеризует «отклик» бассейна при
различных состояниях увлажненности [см. Todini and Wallis (1977),
(1978)]. Таким образом, хотя отклик на величину осадков в результи-
рующей модели будет нелинейным, проблема оценивания остается ли-
нейной.
В приведенном примере были доступны ежедневные данные об
осадках и водном расходе за период с 1 октября 1962 г. по 31 марта
1970 г. для Хиллсборо-Ривер около Зефирвилла, штат Флорида. Зара-
нее были идентифицированы три входные последовательности осад-
ков, каждая из которых, как было указано, отвечала различным
условиям в бассейне реки.
Рассматриваемая модель имеет вид
yt=Hxt + vt, (20.7.1)
xt+l=FXt+Dut + Gvt, (20.7.2)
где yt — выход модели, а матрица и, — три раздельные входные по-
следовательности осадков. Требуется идентифицировать размерность
и структуру матриц Н, F и оценить свободные параметры Н, F, D и
G. Эта задача должна быть разбита на две части, поскольку модель,
связывающая yt и ut и имеющая данный вид, непосредственно иден-
тифицирована быть не может, если только ut не является белым шу-
мом. Сначала модель в фазовом пространстве для процесса
выпадения осадков записывается в обновляющей форме:
jct+l=FXt + Gat, (20.7.3)
ut-Hxt + at, (20.7.4)
где at — белый шум. Затем последовательность at используется для
получения прогноза расхода при помощи модели в фазовом про-
странстве
7,=H^ + v„ (20.7.5)
x't+i =F'X't +Dat + G'vt, (20.7.6)
б) Идентификация и оценивание параметров. Модель в фазовом
пространстве для осадков. Первый шаг состоит в «отбеливании»
входного процесса. Это может быть сделано путем подгонки авторе-
грессионной модели высокого порядка
ut+BYut_x +B2ut_2 +...+Вkut_k = et. (20.7.7)
452
Вычисление ковариаций для {и?, и?_к} дает уравнения Юла—
Уолкера
Ск-\... Со
(20.7.8)
которые могут быть решены относительно [Вх,...,Вк}, когда каждое
Cz заменено его выборочной оценкой. Найденные В используются для
получения первой оценки матриц импульсного отклика [Aif...,Ak] в
представлении
ut = et + А! +... + Aket_k,
(20.7.9)
опирающемся на соотношения (20.6.27).
Структура подходящей модели в фазовом пространстве для трех по-
следовательностей осадков находится при помощи канонического кор-
реляционного анализа с последовательностью
...,и®*}, взятой в качестве вектора прошлых наблюдений; при этом
требуется, чтобы к было достаточно большим. В данном случае к вы-
биралось равным двенадцати. Следуя процедуре, предложенной в
[Cooper and Wood (1982 а)], находим, что
” 0,325 0,003 —0,221 0 0 0 0
0 0 0 1 0 0 0
0 0 0 0 1 0 0
F= 0 0 0 0 0 1 0
0 0 0 0 0 0 1
0,154 0,382—0,612 -0,772 -0,041 0,582 0,907
-0,236- -0,857 0,801 1,645 0,701 0,055 1,007
Н= [7:0],
453
G =
0,182 —0,103 —0,023
0,014 0,268 —0,024
0,004 0,228 0,231
0,013 0,129 —0,017
0,010 0,359 0,187
0,006 0,043 —0,015
0,004 0,228 0,129
Строки G являются строками [1 2 3 5 6 8 9] матрицы [AltA2tA3]r. 1
Заметим, что в матрице F имеется 17 свободных параметров, тогда 1
как в общей авторегрессионной модели третьего порядка для трех пе- 1
ременных их 27. Приведенные здесь значения являются весьма грубы- 1
ми оценками параметров; они могут быть использованы в качестве J
первоначального приближения в итеративной процедуре Гаусса— 1
Ньютона при условии, что модель устойчива, т. е. собственные значе-
ния матрицы F по модулю меньше единицы. В данном случае это не |
так, и предварительные оценки должны быть возмущены, чтобы по-
лучить полезные начальные приближения. К настоящему времени нет I
рекомендаций, каким образом это надо делать. Указанная модель, по- 1
лученная с помощью процедуры идентификации и содержащая 17 па- я
раметров, может быть подвергнута дальнейшей редукции, если I
положить равными нулю некоторые из параметров F и G, которые |
представляются достаточно малыми. Оценивание по методу Гаусса— <<
Ньютона дает следующие значения: ’
~ 0,384 0 -0,246 0 0 0 0
0 0 0 1 0 0 0
0 0 0 0 1 0 0
F = 0 0 0 0 0 1 0
0 0 0 0 0 0 1
—0,007 0,127 -0,557—0,023 0,610—0,194—0,022
0,005 —0,015 1,294—0,007 0,160—0,890—0,778
454
0,1687 —0,093 0
0 0,254 0
0 0,311 0,186
6 = 0 0,124 0
0 0,288 0,171
0 0 0
0 0,229 0,153
Значения элементов G похожи на те, что получены в процессе проце-
дуры идентификации, тогда как значения элементов F существенно от-
личаются. При данных оцененных значениях F и 6, зная структуру Н,
мы можем преобразовать измерения осадков к процессу белого шума,
используя соотношения
xt=Fxt_x +Gat_lt. (20.7.10)
at = u— Hxt. (20.7.11)
Модель в фазовом пространстве, связывающая расход воды в реке
с осадками. Идентифицируем модель, связывающую речной поток и
осадки. Она имеет структуру, описываемую уравнениями (20.7.5) и
(20.7.6). Сначала подгоним модель импульсного отклика высокого
порядка
^=24'1^ +...+Л/12^_11 + (20.7.12)
с использованием значений а, полученных из соотношения (20.7.11).
При этом каждое из А\ является вектором размерности (1 х 3). Под-
гонка осуществляется путем решения ковариационных уравнений для
(afНачальные оценки для векторов А\—А\ приведены
в табл. 20.7.1; они необходимы для нахождения параметров матрицы
в уравнении (20.7.6).
Таблица 20.7.1. Параметры импульсного отклика
для входных последовательностей
Импульсный отклик
41 0,000 0,003 0,009
4г 0,029 0,049 0,076
4j 0,030 0,072 0,092
Л4 0,021 0,080 0,096
455
Модель импульсного отклика для
17, — CQet +... + Cj j е,_ j j
(20.7.13)
требуется, чтобы оценить матрицу G' в уравнении (20.7.6). При дан-
ных А и процесс rjt может быть получен из (20.7.12), поскольку
значения последовательностей yt и at известны. Модель подгоняется
точно так же, как и модель для и,: при помощи авторегрессионной
модели высокого порядка с последующим ее обращением. Применяя
этот метод, получаем следующие начальные значения для [С0,...,Сц]:
[1,00 1,06 0,77 0,62 0,52 0,42 0,30 0,24 0,23 0,22 0,20 0,22]. Указан-
ные числа являются приближенными значениями соответствующих
элементов G'. Заключительная стадия процедуры идентификации со-
стоит в проведении канонического корреляционного анализа с исполь-
зованием в качестве вектора прошлых наблюдений
fv /7(1) л(2) о(3) v fl(1) а{1} а{3) 1
(7/—1’ «г-1 > «г-1 > «,-1 »• • 12’ «Г-12 ’ “г-12 ’ «t—121 •
В нашем примере вектор будущих наблюдений состоял последователь-
но из [у,], {уРу/+1], {УрЛ+рЛ+J и вектор будущих на-
блюдений расширяется до тех пор, пока результаты каноническогс
корреляционного анализа не указывают на хорошее качество подгон
ки. Подробное описание этих проблем содержится в [Cooper and Wooc
(1982 а)].
Идентифицированная модель, связывающая расход воды и осадки
задается матрицами
0 1 0 0
F = 0 0 1 0
0 0 0 1
0,004 0,048 —0,720 1,636
0,000 0,003 0,009
0,029 0,049 0,076
0,030 0,072 0,092
0,022 0,080 0,076
456
1,06
0,77
0,62
0,52
Я=[1 0 0 0].
Оценивание параметров с исключением тех из них, которые близки к
нулю, проведенное с помощью указанных матриц, взятых в качестве
начального приближения, дает окончательный вид модели:
0 1 0 0
0 0 10
0 0 0 1
0 0,067 —0,646 1,536
0,0 0,0 0,0
0,027 0,045 0,065
0,029 0,070 0,085 ’
0,021 0,071 0,071
1,093
0,770
0,615
0,482
Модели для осадков [см. (20.7.3) и (20.7.4)] и для расхода воды при
заданных осадках [см. (20.7.5) и (20.7.6)] могут быть объединены в
одну общую модель в фазовом пространстве для осадков и расхода.
Легко проверить, что они имеют вид
457
(х 1000)
Рис. 20.7.1. а). Ежедневные осадки для Хиллсборо-Ривер вблизи Зефирвилла
(штат Флорида) за период с 21 июля по 29 сентября 1964 г. [Cooper and Wood
(1982 b)J
Рис. 20.7.1. б). Наблюдаемые (—) и прогнозные (на один день вперед) значения
для Хиллсборо-Ривер за период с 21 июля по 29 сентября 1964 г. [Cooper and
Wbod (1982 b)]
458
s
s
=f
tt
m
га
x
<u
X
=f
-0,5
6,25
12,5
18,75
О
X
О
Лаг К
Рис. 20.7.2. Автокорреляционная функция ошибок одношагового прогноза за
период с 1 октября 1962 г. по 31 марта 1970 г. для Хиллсборо-Ривер [Cooper and
Wood (1982b)]
н
н
Структура объединенной модели такова, что будущие значения осад-
ков не зависят от прошлых значений расхода воды, однако фильтр
Калмана оперирует как со значениями осадков, так и со значениями
расхода,
в) Результаты. Описанная выше модель применялась к данным по
Хиллсборо-Ривер [см. раздел 20.7.1, п. а)], а ее качество оценивалось
путем сравнения наблюдаемого поведения обновления с ожиданием
при оптимальных условиях. Рис. 20.7.1, а) показывает количество вы-
павших за день осадков за период с 21 июля по 29 сентября 1964 г.,
а рис. 20.7.1, б) — наблюдаемые и прогнозируемые (на один шаг впе-
ред) значения водного расхода реки за тот же период. Выборочные ав-
токорреляции обновления за полный период с 1 октября 1962 г. по 31
марта 1970 г. приведены на рис. 20.7.2 вместе с границами для их уд-
военных стандартных отклонений. Из вида автокорреляций для об-
новлений ясно, что модель является адекватной. Этого следовало
ожидать, поскольку модель сконструирована с учетом моментов вто-
рого порядка на исследуемом периоде. Однако более детальное иссле1
дование обновлений (например, изучение рис. 20.7.1, б)) показывает,
459
что модель может давать не очень хорошее описание в периоды силь-
ных дождей, которые как раз и представляют наибольший интерес. А
именно имеет место занижение прогноза на восходящей ветви, т. е.
когда интенсивность потока растет, и занижение прогноза, когда пик
интенсивности потока пройден. Эти особенности не выявляются при
исследовании автокорреляции. Они возникают в силу типа выбранной
модели, которая в принципе не в состоянии отражать некоторые из
характеристик связи между расходом воды и осадками; кроме того,
спорны и предположения относительно характеристик шума. Этот ас-
пект обсуждается в разделе 20.7.2.
20.7.2. ПРИЛОЖЕНИЯ ОБОБЩЕННОГО ФИЛЬТРА КАЛМАНА
а) Гидрологическая модель. Второй из рассматриваемых примеров
исследования также относится к прогнозу в реальном времени расхода
воды в реке в зависимости от осадков в районе Хирнант (площадь
33,9 км2) реки Ди в Северном Уэлсе, Великобритания [см. Moore and
Weiss (1980 b)]. Здесь, в отличие от примера из раздела 20.7.1, прог-
нозирующая модель формируется как нелинейное дифференциальное
уравнение первого порядка. Таким образом, модельная структура по-
лучила предварительное описание на гидрологическом уровне, и зада-
ча состоит в использовании обобщенного фильтра Калмана для
оценивания состояния и прогноза.
Дифференциальное уравнение модели записывается в виде
dj = a(cp’-g)gb, (20.7.14)
где g — поток, ар* — входной процесс осадков, задаваемый
формулой
р;=^р{Ч_т, (20.7.15)
где т — чистый временной лаг, а
Лагирование и сглаживание входного процесса осадков представля-
ют собой традиционные методы в гидрологическом моделировании.
Значения параметров скользящего суммирования определяются от-
дельно от оценки параметров а, b и с в дифференциальном уравнении.
Параметр с является коэффициентом, который отвечает за «потери»
при превращении осадков в расход, возникающие, например, за счет
влажности почвы в районе водосбора. Параметры а и Ъ управляют,
главным образом, характером динамического отклика расхода на вто-
рой процесс осадков. Подробности, касающиеся формулировки моде-
ли, содержатся в работах [Moore and Weiss (1980 a, b)].
460
• НАБЛЮДЕНИЯ
О ПРОГНОЗ
Рис. 20.7.3. Изменение функции прогноза в момент наблюдения для нелиней-
ной гидрологической модели
б) Формулировка в фазовом пространстве. Необходимо отдавать
себе отчет о том, что описанная выше модель не может быть идеаль-
ным представлением реальной ситуации, она является лишь некото-
рым приближением к ней.
Пусть t обозначает непрерывный временной параметр, а к — ин-
декс дискретного времени, обозначающий значение tky которое совпа-
дает с к-м. точкой дискретного. времени. Пусть расход в момент tk
известен и равен qk. Пусть hk = hk(t) — функция, удовлетворяющая
равенству
^*=в(Ф,-**М> tk^t^tk+x (20.7.16)
с hk(tj)—qk. Истинное, но пока неизвестное значение величины расхо-
да в момент ^+1, а именно qk+x, будет отклоняться от экстраполиро-
ванного значения hk(tk+^ на величину у*+1 [см. рис. 20.7.3], так что
Qk+i ~hk(tk+l) + vk+l. (20.7.17)
Предполагается (для равноотносящихся tk), что Vfc+1 независимы,
одинаково распределенные случайные величины с нулевым средним и
дисперсией R. Следовательно, Vfc+1 представляет собой член, отража-
ющий отклонение модельной динамики от идеальной и наличие шума
в модели. Когда параметры известны, эта модель может служить для
прогноза потока в момент tk+l по формуле
(20.7.18)
461
Возникающая здесь практическая задача состоит в оценивании пара-
метров. После ее решения прогноз будущих значений расхода получа-
ют путем решения дифференциального уравнения для hk(tk+i).
Состояние системы в произвольный момент времени tk описыва-
ется тремя параметрами а, b и с, которые мы будем обозначать век-
тором состояния
хк = {а,Ь,с)т. (20.7.19)
Предположим априори, что в начальный момент времени t0 этот век-
тор состояния нормально распределен со средним значением х0 и дис-
персией Ро. Предполагается также, что параметры не меняются в
зависимости от времени, поэтому уравнение системы записывается в
виде
xk+i=xk. (20.7.20)
Чтобы иметь согласие с предыдущими обозначениями, обозначим че-
рез ук измеренную величину потока в момент tk, так что
Ук=Як- (20.7.21)
Соотношение (20.7.17) дает уравнение измерения
Zt+i =hk({k + \) + vk+v (20.7.22)
Для того чтобы подчеркнуть зависимость hk от значения параметров
х и начального условия hk(tk)=yk = qk, заменим hk на h(t,x,yk). В ре-
зультате уравнение наблюдений примет вид
Ук+1=^+1,*к+1’Ук) + *к+1’ (20.7.23)
где предполагается, что х0 не зависит от последовательности [vj.
Уравнения (20.7.20) и (20.7.23) являются формулировкой модели в фа-
зовом пространстве. Этот подход к определению вектора состояния в
терминах параметров, требующих оценивания, и величины, которую
необходимо прогнозировать, описан в работах [Mayne (1964)], [Graupe
(1972)] и [Szollosi-Nagy (1975)], но только для линейных моделей.
Отметим, что в данной формулировке предполагается, что величи-
на водного расхода измеряется без ошибки. Это предположение явля-
ется фундаментальным при рассмотрении приведенных выше
уравнений состояния. Одно из физических оправданий указанного
предположения состоит в том, что наблюдения потока, будучи про-
странственно интегрированными измерениями водного объема, су-
щественно менее зависят от шума, чем измерения величины осадков,
произведенные в различных точках. Ошибки в измерениях осадков до-
бавляются к ошибкам, вызванным неадекватностью модели, и компен-
сируются членом стохастических возмущений vk. Предыдущий опыт с
получением фильтрационных оценок водного расхода совместно с
462
оценкой параметров посредством обобщенного вектора состояния [см.
раздел 20.6.3, п. б)] свидетельствует об отсутствии выигрыша при та-
ком способе фильтрации и укрепляет уверенность в том, что лучше
всего сразу считать измерения потока свободными от ошибок.
в) Оценивание параметров. Параметры, определяющие распреде-
ленные во времени входные воздействия wy(/ = l,2,...,s) и чистый вре-
менной лаг 7, получаются с помощью процедуры «отбеливания»,
подобной той, что описана в работе [Box and Jenkins (1976)]. Главную
проблему составляет оценивание параметров а, b и с, которая решает-
ся путем применения обобщенного фильтра Калмана к данной выше
формулировке модели в фазовом пространстве.
В настоящем контексте, когда нелинейность имеется только в урав-
нении измерения, обобщенный фильтр Калмана выводится из обычно-
го алгоритма фильтра Калмана для линейных систем путем
линеаризации уравнения измерения около текущей оценки х так, как
было описано в разделе 20.5.2. Для этого случая матрица измерений
Нк (здесь вектор-строка размерности три), отвечающая линеаризован-
ному уравнению, состоит из частных производных первого порядка
функции h по трем параметрам. Ее z-й элемент определяется ра-
венством
(ЯД = . (20.7.24)
Процедура, применяемая для вычисления производных dh/dxit описа-
на в [Moore and Weiss (1980, а, b)]. Во избежание расходимости филь-
тра используется фильтр, экспоненциально взвешенный по времени
[см. раздел 20.4.2]. Результирующий алгоритм приведен в табл.
(20.7.2). Отметим, что введение фильтра с затухающей памятью поз-
воляет ослабить предположение о стационарности, сделанное в урав-
нении системы (20.7.20). Такой подход, по-прежнему предупреждая
расходимость фильтра, дает возможность ввести в модель нестацио-
нарность, обусловленную, например, сезонностью или увлажнением
бассейна. Изучение изменения параметров во времени может привести
к дальнейшей модификации ее структуры, которая позволит описать
причины изменений и предсказать события в будущем.
Таблица 20.7.2. Алгоритм обобщенного фильтра Калмана
для нелинейной гидрологической модели
Уравнение системы: Уравнение измерения: Хк+1 Хк Ук=Шк,хк,ук_) + Ук
Прогноз состояния: Матрица ковариации ошибок: Коэффициент усиления Калмана: При наблюдении: Хк\к~Хк\ A--I ^^к^к У к |
463
Продолжение
При прогнозе:
Прогноз состояния: Хк+\ |* = Хк\к
Прогноз выходного процесса: У к+\\к~Ь(1к+ОХк+1 \к'У^
Матрица ковариации ошибок: р =р 1 к +1 Д 1 к ,к
г) Результаты. В описанной выше задаче оценивания состояния и
прогноза использовались данные, представляющие собой измерения
количества осадков и величины водного расхода, производимые каж-
дые полчаса за период с 1 ноября по 30 декабря 1972 г. Графики дан-
ных представлены на рис. 20.7.4, а) и б). Входной процесс осадков Р*
в (20.7.15) определялся как p*=pt_v т. е. считалось, что адекватным
являлся простой лаг на 1/2 часа.
Начальные значения для параметров, образующих вектор состоя-
ния х, были выбраны совершенно произвольными: я=0,2, Ь = 0,5,
с=0,66. Степень доверия, связанная с этими начальными оценками,
выражалась ковариационной матрицей ошибки состояния, Ро । 0, кото-
рая была диагональной с диагональными элементами, равными 0,05.
Дисперсия шума измерения R была фиксирована на уровне 0,01. Заме-
тим, что относительные значения Р и R влияют на поведение фильтра
[см. (20.3.18)] в большей степени, чем их абсолютные значения, вызы-
вающие меньший практический интерес. Временная константа экспо-
ненциально взвешенного по времени фильтра была выбрана таким
образом, что ценность наблюдений для фильтра падала вдвое через
три дня.
Автокорреляционная функция для ошибок одношагового (получа-
сового) прогноза (или обновлений) изображена на рис. 20.7.5. Обнов-
ления должны быть некоррелированы, если фильтр оптимален;
однако рис. 20.7.5 показывает, что имеются небольшие, но существен-
ные корреляции на коротких лагах, и это находит свое отражение в
статистически значимой величине статистики Q [см. (20.4.8)], равной
288 (х205 =40,11 для 27 степеней свободы). Статистика S [см. (20 4.9)]
также указывает на некоторую остаточную кросс-корреляцию между
обновлениями и входным процессом осадков; значение S равно 191.
Эти результаты говорят об субоптимальности фильтра, которая, воз-
можно, имеет место в силу использования линейной аппроксимации
для нелинейной системы и (или) того, что шум в истинной системе не
удовлетворяет предположениям рассматриваемой модели в фазовом
пространстве. Графики прогнозов на один час (т. е. на 2 шага вперед)
и ошибок прогнозов на трехдневный период иллюстрируют существо
464
a
Рис. 20.7.4 а). Получасовые обобщенные данные об осадках в районе Хирнант
реки Ди, Северный Уэлс, Великобритания, за период с 1 ноября по 30 декабря
1972 г.
Рис. 20.7.4 б). Получасовые данные о величине потока (м3/с) для района Хир-
нант реки Ди за период с 1 ноября по 30 декабря 1972 г.
465
1,00
0,80
0,60
0,40
0,20
0,00
-0,20
о
54 а: : $ Ь л
-
Лаг
-0,40
-0,60 -
-0,80 -
-1,00>-
Рис. 20.7.5. Автокорреляционная функция на одношаговый прогноз в период с
1 ноября по 30 декабря 1972 г. для района Хирнант реки Ди, Северный Уэлс,
Великобритания
Время (час)
Рис. 20.7.6. Часовые прогнозы для района Хирнант реки Ди в период с 1 ноя-
бря по 30 декабря 1972 г.
466
Рис. 20.7.7. Ошибки часового прогноза для района Хирнант реки Ди в период
с 1 ноября по 30 декабря 1972 г.
проблемы [см. рис. 20.7.6 и 20.7.7]: на восходящей волне интенсивнос-
ти дождей прогнозы величины потока завышаются, а на пике и в на-
чале нисходящей волны занижаются. Изучение рис. 20.7.1, б)
показывает, что та же проблема возникает и в случае линейного филь-
тра Калмана, даже если автокорреляционная функция [см. рис. 20.7.2]
указывает на то, что обновления образуют белый шум. Перечислен-
ные особенности результатов можно отнести к тому факту, что шум,
входящий в гидрологические модели, не является белым: он имеет
тенденцию концентрироваться «кусками» вблизи моментов выпадания
осадков и быть более похожим на дробовой шум [см., например, Раг-
zen (1962)], чем на белый. Тем не менее с функциональной точки зре-
ния обобщенный фильтр Калмана — по-прежнему удовлетворитель-
ный инструмент для сглаживания и прогнозирования, поэтому
субоптимальность не является сдерживающим фактором для его прак-
тических применений. Таким образом, статистические тесты не до-
лжны рассматриваться как пробный камень для вынесения суждений
о модели и качестве фильтра, к тому же они могут не учитывать и не-
которых недостатков. Пользователь должен исходить из того, явля-
ются ли полученные с помощью модели результаты приемлемыми
для дальнейшего применения.
20.8 . ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
В настоящей главе мы рассматривали фильтр Калмана, опираясь в
первую очередь на концепции и идеи, а не на строгие математические
доказательства. Это позволит читателю и будущему пользователю
глубже понять этот элегантный алгоритм. Мы достаточно детально
описали фильтр в наиболее простом случае дискретной линейной дина-
мической системы с известными параметрами и надеемся, что читатель
получил полное представление об основах этого метода. Материал, ка-
сающийся непрерывного времени, нелинейных систем, идентификации
модели и оценивания параметров изложен конспективно, и при желании
можно обратиться к соответствующей литературе.
467
Если изучаемая система может быть описана линейным векторным
дифференциальным или разностным уравнением первого порядка и ее
параметры, включая дисперсии шума системы и шума измерения, из-
вестны, то алгоритм фильтрации применяется непосредственно.
Фильтр является оптимальным при условии, что структура модели и
параметры заданы точно. В случае нелинейных систем можно испо-
льзовать обобщенный фильтр Калмана. При этом необходимо пони-
мать, что алгоритм применяется к аппроксимации истинной системы
и, следовательно, его оптимальность гарантировать нельзя. Для ситу-
ации, когда априори ничего не известно о структуре модели и ее пара-
метрах, описан метод выбора возможной модели. Эта модель
является линейной дискретной моделью в фазовом пространстве в об-
новляющей форме, причем ее теоретические первый и второй момен-
ты близки к соответствующим выборочным статистикам. Структура
указанной модели такова, что предсказание поведения процесса может
быть легко получено с помощью фильтра Калмана. Когда аппрокси-
мация достаточно хороша и первые два момента адекватно описыва-
ют статистические особенности интересующего нас процесса,
подобная процедура может оказаться весьма полезной. Но если су-
щественные особенности данных не находят своего отражения в выбо-
рочных ковариациях, что характерно для гидрологии, такие модели
могут давать плохое описание. Это может быть обнаружено визуаль-
ным анализом ошибок прогноза, указывающим на то, что исходные
предположения о свойствах шума системы и шума измерений не вы-
полняются. Однако такая ситуация не является редкой при моделиро-
вании и прогнозировании реальных систем, и пользователь должен
решить, адекватна ли степень аппроксимации, обеспечиваемая его мо-
делью, целями исследования.
20.9 . ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
Anderson Т. W. (1958). An Introduction to Multivariate Statistical Analysis, John
Wiley, New York.
A k a i k e H. (1974). Markovian Representation of Stochastic Processes and its Appli-
cation to the Analysis of Autoregressive Moving Average Processes, Ann. Inst. Stat. Math. 26,
363—387.
A t h a n s M. (1974). The Importance of Kalman Filtering Methods for Economic
System, Annals Econ. Social Measurement 3, 49—64.
В e v e n K. J. and O’C о n n e 11 P. E. (1982). On the Role of Physically-based
Distributed Modelling in Hydrology, Institute of Hydrology Report No. 81, Wallingford.
В о h I i n T. (1976). Four Cases of Identification of Changing Systems for Discrete Time
Series. In: System Indentification, Advances and Case Studies. (Eds. R. K. Mehra and K. G.
Lainiotis), Academic Press, New York.
Box G. E. P. and Jenkins G. M. (1976). Time Series Analysis Forecasting and
Control, Holden-Day, San Francisco.
468
Bucy R. S. and J о s e p h P. D. (1968). Filtering for Stochastic Processes with Appli-
cation to Guidance, Interscience, New York.
Chiu C. L. (ed) (1978). Applications of Kalman Filter to Hydrology, Hydraulics and
Water Resources, Proc. AGU Chapman Conference, Pittsburgh, University of Pittsburgh.
Cooper D. M. (1982). Adaptive Parameter Estimation for Non-linear Hydrological
Models with General Loss Functions, J. Hydrol. 58, 29—45.
С о о p e r D. M. and W о о d E. F. (1982a). Indentification of Multivariate Time Series
and Multivariate Input-Output Models, Water Resources Research 18 (4), 937—946.
Cooper D. M. and Wood E. F. (1982b). Parameter Estimation of Multiple Input-
Output Time Series Models: Application to Rainfall-Runoff Processes, Water Resources Research
18 (5), 1352—1364.
Gelb (1974). Applied Optimal Estimation, MIT Press, Cambridge, Massachusetts.
G г a и p e D. (1972). Indentification of Systems, Van Nostrand-Reinhold, New York.
Harrison P. J. and Stevens C. F. (1976). Bayesian Forecasting (with discussion),
JRSS В 38 (3), 205—247.
JazwinskiA. H. (1970). Stochastic Processes and Filtering Theory, Academic Press,
New York.
К a i 1 a t h T. (1974). A View of Three Decades of Linear Filtering Theory, IEEE IT—20.
146—180.
К a 1 m a n R. E. (1960). A New Approach to Linear Filtering and Prediction Problems,
Trans. ASME, J. Basic Eng. 82, 35—45.
Kalman R. E. and Bucy R. S. (1961). A New Results in Linear Filtering and
Prediction Theory, Trans. ASME, J. Basic Eng. 83, 95—107.
Колмогорова. H. Интерполирование и экстраполирование стационарных слу-
чайных последовательностей //Известия АН СССР.—Серия математическая, 1941.—Т. 5.
Kwakernaak Н. and Sivan R. (1972). Linear Optimal Control Systems, Wiley,
New York.
L j u n g L. (1979). Asymptotic Behaviour of the Extended Kalman Filter as a Parameter
Estimator for Linear Systems, IEEE AC—24 (1), 36—50.
M a у n e D. Q. (1965). Optimal Non-stationary Estimation of the Parameters of a Linear
System with Gaussian Inputs, Jour. Electronic Control 14, 101—112.
M e h r a R. K. (1973). Identification and Control in Econometric Systems, Similarities
and Differences, Second Workshop on Economic and Control Systems, Chicago, June (also
Annals of Economic and Social Measurement, January 1974).
M e h r a R. K. and W e 11 s С. H. (1971). Dynamic Modelling and Estimation of Carbon
in a Basic Oxygen Furnace, Third International IFAC+IFIP Conference, Helsinki, 2—5 June.
M о о r e R. J. and W e i s s G. (1980a). Real-time Parameter Estimation of a Non-Linear
Catchment Model Using Extended Kalman Filters. In: Wood, E. F. and Szollosi—Nagy, A.
(eds.), op. cit.
НевельсонМ. Б., Хасьминский (1972). Стохастическая аппроксимация и
рекуррентное оценивание. — М.: Наука.
О’С о и n е 11 Р. Е. (ed.) (1980). Real-time Hydrological Forecasting and Control,
Institute of Hydrology, Wallingford, England.
P a s z e n E. (1962). Stochastic Processes, Holden-Day, San Francisco.
Schmidt S. F. (1966). Application of State-space Methods to Navigation Problems,
Advan. Control Systems 3, 293—340.
S n у d e r D. L. (1969). The State Variable Approach to Continuous Estimation with Ap-
plications to Analog Communication Theory, MIT Press, Cambridge, Massachusetts.
Stevens C. F. (1974). On the Variability of Demand for Families of Items, Oper. Res.
Quart. 25,156—178.
S z о 11 о s i-N a g у A. (1975). An Adaptive Identification and Prediction Algorithm for
the Real-time Forecasting of Hydrologic Time Series, Research Memorandum RM—75—22,
IIASA, Laxenburg.
469
Takeuchi К. (1976a). Applications of the Kalman Filter to Cyclone Forecasting 1.
Methodology, 2. Typhoon Forecasting, Research Memorandum RM—76—9, International
Institute for Applied Systems Analysis, Laxenburg.
Takeuchi K. (1977b). Application of the Kalman Filter to Cyclone Forecasting 3.
Hurricane Forecasting,4. Addition Typhoon Forecasting, Research Memorandum RN—76—62,
International Institute for Applied Systems Analysis, Laxenburg.
Todini E. (1978). Mutually Interactive State-parameter (MISP) Estimation. In: Chiu
C. L. (ed.), op. cit.
Todini E., O’C о n n e 11 P. E. and J о n e s D. A. (1980). Basic Methodology: Kal-
man Filter Estimation Problems. In: O’Connell P. E. (ed.), op. cit.
T о d i n i E. and W a 11 i s J. R. (1977). Using CLS for Daily or Longer Period Rainfall-
Runoff Modeling. In: Mathematical Models in Surface Water Hydrology (eds. T. A. Ciriani,
U. Maione and J. R. Wallis), London, J. Wiley and Sons, 149—168.
T о d i n i E. and W a 11 i s J. R. (1978). A Real-time Rainfall-Runoff Model for an On-
line Flood Warning System. In: Chiu C. L. (ed.), op. cit.
W e i s s G. (1980). Basic Methodology: the Kalman Filter. In: O’Connell P. E. (ed.), op.
cit.
Wiener N. (1949). The Extrapolation, Interpolation and Smoothing Stationary Time
Series, Wiley, New York.
Willems J. C. (1978). Recursive Filtering, Statistica Neerlandica 32 (1), 1—39.
Wood E. F. and S z о 11 о s i-N a g у A. (1980). Real-time Forecasting/Control of
Water Resource Systems, IIASA Proceedings, Vol. 8, Pergamon, Oxford.
Литература
А. Библиография
Anderson D. W., Das Gupta S., S t у a n G. D. H. (1972). A Bibliography of
Multivariate Statistical Analysis, Oliver & Boyd.
Lancaster H. O. (1968). Bibliography of Statistical Bibliographies, Oliver & Boyd.
Savage I. R. (1962). A Bibliography of Nonparametric Statistics, Harvard University
Press. ’
Subrahmaniam K., Subrahmaniam K. (1973). Multivariate Analysis:
Selected and Abstracted Bibliography, 1957—1972, Dekker.
В u с к I a n d W. R., F о x R. A. (1963). Bibliography of Basic Texts and Monographs on
Statistical Methods 1945—1960, Second edition, Oliver & Boyd.
В. Словари, энциклопедии, справочники
В u r i n g t о n R. S., May D. C. (1970). Handbook of Probability and Statistics with
Tables, Second edition, McGraw-Hill.
Burrington G. A. (1972). How to Find Out About Statistics, Pergamon Press.
Freund J., Williams F. (1966). Dictionary of Statistical Terms, McGraw-Hill.
Kendall M. G., В u c k 1 a n d W. R. (1971). A Dictionary of Statistical Terms, Third
edition, Oliver & Boyd.
К e n d a 11 M. G., В u c k 1 a n d W. R. (1960). A Dictionary of Statistical Ibrms, Sup-
plement. (A combined glossary in English, French, German, Italian and Spanish), Oliver &
Boyd.
К о t z S. (1964). Russian-English Dictionary of Statistical Terms and Expressions, and
Russian Reader in Statistics, University of N. Carolina Press.
К о t z S., Johnson N. L. (editors) (1982). Encyclopedia of Statistical Sciences, 8
volumes, Wiley.
Kruskal W. H., Tanner J. M. (editors) (1968). International Encyclopedia of
Statistics, 2 volumes, The Free Press (New York) and Collier Macmillan (London).
W a 1 s h J. E. (1962, 1965). Handbook of Nonparametric Statistics, 2 vols., Van Nostrand.
С. Общие работы
Barnett V. (1982). Comparative Statistical Inference, Second edition, Wiley.
В r e i m a n L. (1973). Statistics With a View Toward Application, Houghton-Mifflin.
С о x D. R., H i n k 1 e у D. V. (1974). Theoretical Statistics, Chapman & Hall.
Cramer H. (1946). Mathematical Methods of Statistics, Princeton Univer-
sity Press.
D a v i e s D. L. (editor) (1975). Statistical Methods in Research and Production, Oliver &
Boyd.
de F i n e t t i B. (1974, 1975) Theory of Probability, Vol. I, II, Wiley.
Fisher R. A. (1970). Statistical Methods for Research Workers, Fourteenth edition,
Macmillan. jti
F i s h e r R. A. (1959). Statistical Methods and Scientific Inferences, Second edition, Oliver
& Boyd.
G г a у b i 1 1 F. A. (1976). Theory and Application of the Linear Model, Duxbury Press,
Massachusetts.
H a 1 d A. (1957). Statistical Theory with Engineering Applications, Wiley.
Hogg R. V., Craig A. T. (1965). Introduction to Mathematical Statistics, Collier-
Macmillan.
Kalbfleisch J. G. (1979). Probability and Statistical Inference, I and II (2 vols.),
Springer.
Kendall M. G., S t u a r t A. (1969, 1973, 1976). The Advanced Theory of Statistics.
Third edition, three vols. Vol. 1 (1969). Distribution Theory; Vol. 2 (1973). Inference and
Relationship; Vol. 3 (1976). Design and Analysis, and Time Series, Griffin.
К r u m b e i n W. C., G г a у b i 1 1 F. A. (1965). An Introduction to Statistical Models in
Geology, McGraw-Hill.
L i n d 1 e у D. V. (1965). Introduction to Probability and Statistics from a Bayesian View-
point (2 vols.). Cambridge University Press.
M о о d A. M., G г a у b i 1 1 F. А., В о e s D. C. (1974). Introduction to the Theory of
Statistics, Third edition, McGraw-Hill.
О 1 к i n I., G 1 e s e r L. J., D e r m a n C. (1980). Probability Models and Applications,
Macmillan.
R а о C. R. (1965). Linear Statistical Inference and Its Applications, Wiley.
S i 1 v e у S. D. (1975). Statistical Inferences, Chapman & Hall.
W e t h e r i 1 1 G. B. (1981). Intermediate. Statistical Methods, Chapman & Hall.
W i 1 к s S. S. (1961). Mathematical Statistics, Wiley.
Zacks S. (1971). The Theory of Statistical Inference, Wiley.
D. Исторические и библиографические материалы
В о х, J о a n F. (1978). R. A. Fisher; the Life of a Scientist, Wiley.
F i s h'-e-r R. A. (1950). Contributions to Mathematical Statistics, Wiley.
Pearson E. S. (editor) (1978). The History of Statistics in the Seventeenth and
Eighteenth Centuries Lectures by Karl Pearson 1921—1933, Griffin.
P e a r s о n E. S., К e n d a 1 1 M. G. (editors) (1970). Studies in the History of Statistics
and Probability, Griffin.
Westergaard H. (1932). Contributions to the History of Statistics, P. S. King,
London.
E. Руководство по статистическим таблицам
Greenwood A., Hartley H. О. (1962). Guide to Tables in Mathematical Statistics,
Princeton University Press.
F. Таблицы случайных чисел
Barnett V. D. (1964). Random Negative Exponential Deviates: Tracts for Computers,
No. XXVII, Cambridge University Press.
Clark C.E., H о bz B. (1960). Experimentally Distributed Random Numbers, Johns
Hopkins Press.
F i e 1 1 e r E. C., L e w i s T., P e a r s о n E. S. (1957). Correlated Random Normal Devi-
ates: Tracts for Computers, No. XXVI, Cambridge University Press.
N e w m a n T. G., Odell P. C. (1971). The Generation of Random Variates, Griffin.
The RAND Corporation (1953). A Million Random Digits with 100,000 Normal Deviates,
The Free Press, New York and Collier-Macmillan, London.
472
W о 1 d Н. (1954). Random Normal Deviates: Tracts for Computers, No. XXV. Cambridge
University Press.
G. Таблицы статистических функций
Abramowitz M., S t e g u n I. R. (editors) (1970). Handbook of Mathematical
Functions with Formulas, Graphs and Mathematical Thbles. (§ 26. Probability Functions),
National Bureau of Standards, Washington, D. C.
В e у e r W. H. (editor) (1966). Handbook of Tables for Probability and Statistics, Chemi-
cal Rubber Co., Cleveland.
В u r i n g t о n R. S., May D. C. (1970). Handbook of Probability and Statistics with
Tables, Second edition, McGraw-Hill.
Fisher R. A., Yates F. (1974). Statistical Thbles for Biological Agricultural and
Medical Research, Sixth edition, Longman.
General Electric Company (1962). Tables of Individual and Cumulative Terms of the
Poisson Distribution, Van Nostrand.
H a 1 d A. Statistical Tables and Formulas, Wiley.
H a r t e г H. С., О w e n D. B. (editors) (1970, 1974, 1975). Selected Tables in Mathemati-
cal Statistics, 3 Vbls. Vol. 1 (second printing with revisions) (1970); Vol. 2 (1974); Vol. 3 (1975).
Harvard Computer Laboratory, Staff of (1953). Tables of the Cumulative Binomial
Probability Distribution, Harvard University Press.
I s a a c s G. L., C h r i s t D. E., N о r v i c k M. R., J a c k s о n P. H. (1974). Tables for
Bayesian Statisticians, University of Iowa.
L i e b e r m a n n G. J., О w e n D. B. (1961). Tables of the Hypergeometric Distribution,
Stanford University Press.
Lindley D. V., Miller J. С. P. (1966). Cambridge Elementary Statistical Tables,
Cambridge University Press.
Murdoch J., Barnes J. A. (1968). Statistical Tables for Science, Engineering and
Management, Macmillan.
N e a v e H. R. (1978). Statistical Tables, George Allen & Unwin.
О w e n D. B. (1962). Handbook of Statistical Tables, Pergamon Press, and Addison-Wesley.
P e a r s о n E. S., H a r t 1 e у H. O. (editors) (1966). Biometrika Tables for Statisticians,
Vol. 1, Third edition, Cambridge University Press.
Resnikoff G. J., Liebermann G. J. (1957). Tables of the Non-Central t-Dist-
ribution, Stanford University Press.
Romig H. G. (1947). 50—100 Binomial Tables, Wiley.
Thompson Catherine M. (1941). Tables of the Percentage Points of the Incomplete
Beta Function. Biometrika, 37, 168.
Williamson E., Bretherton M. H. (1963). Tables of the Negative Binomial
Probability Distribution, Wiley.
H. Специальные темы
Arkin H. (1963). Handbook of Sampling for Auditing and Accounting, 2 vols.,
McGraw-Hill.
ArthanariT. S., Dodge Y. (1981). Mathematical Programming in Statistics, Wiley.
Barnett V. (1974). Elements of Sampling Theory, English University Press.
Barnett V., Lewis T. (1978). Outliers in Statistical Data, Wiley.
Cochran W. G. (1963). Sampling Techniques, Second edition, Wiley.
D e n n i n g W. E. (1950). Some Theory of Sampling, Wiley.
G u m b e 1 E. J. (1958). Statistics of Extremes, Columbia University Press.
H a 1 d A. (1981). Statistical Theory of Sampling Inspection by Attributes, Academic Press.
473
H a n s e n M. H., H u г w i t z W. A., M a d о w W. G. (1953). Sample Survey Methods
and Theory, 2 vols., Wiley.
M a r d i а К. V. (1972). Statistics of Directional Data, Academic Press.
Savage L. J. (1954). The Foundations of Statistics, Wiley.
Stuart A. (1976). Basic Ideas of Scientific Sampling, Second edition, Griffin.
Tryon R. С., В a i 1 e у D. E. (1970). Cluster Analyses, McGraw-Hill.
W e t h e r i 1 1 G. B. (1969). Sampling Inspection and Quality Control, Methuen.
Y a t e s E (1968). Sampling Methods for Censuses and Surveys, Third edition, Griffin.
Handbook of Applicable Mathematics, John Wiley & Sons.
Vol. I. Algebra (1980).
Vol. II. Probability (1980).
Vol. III. Numerical Methods (1981).
Vol. IV. Analysis (1982).
Vol. V. Geometry and Combinatorics (1985).
Vol. VI. Statistics. Part A (1984), Part В (1984).
Приложения
СТАТИСТИЧЕСКИЕ ТАБЛИЦЫ
ПРИЛОЖЕНИЕ 1
Накопленные (справа) биномиальные вероятности. В таблице при-
ведены значения
П /Их
P\R(n, 0)^г] = Е (")0Д1—0)«-* г=о,1,...,л,
5= Г 5
где R(n, в) обозначает случайную величину Bin (л, в), т. е. распреде-
ленную по биномиальному закону с параметрами п, в. Поэтому
P{R(n, 6)^ г] есть вероятность г или более успехов в п независимых
испытаниях, причем вероятность успеха в отдельном испытании равна
0. Таблицы дают значения Р для 0 = 0,01(0,01)0,10(0,05)0,50. Для зна-
чений 0, превосходящих 0,50, можно использовать соотношение
P[R(n, еу^г] = Р[Р(п, \—6)^п—г} =
= \—P[R(n, 1—0)>«—г+1], г=1,2,...,л.
Например,
Р[Д(20, 0,7)^12} = 1 — Р[Д(20, 0,3) ^9} = 1—0,1133=0,8867.
Таблицы позволяют найти и такие величины:
P[R(n, 6)^r\^\—P[R(n, 0)^г+1], r=0 n—1
P(R(ji, 6)~r]-P[R(n, 6)^r]—P[R(n, 0)>r+l], л=0,1,1.
475
и
Накопленные биномиальные вероятности
(воспроизведено с разрешения Macmillan Publishers Ltd. из [Murdoch and Barnes (1968) — G]). в — вероятность успе-
ха в отдельном испытании; п — число испытаний. В таблице приведены вероятности получить г или более успехов
в п независимых испытаниях, т. е.
Е (”)^(1—
г -
Если в таблице для какой-либо пары г и в значение вероятности отсутствует, это значит, что оно меньше 0,00005. Ана-
логично (за исключением случая, когда г=0, где табличные значения точные) число 1,0000 представляет вероятности,
превосходящие 0,99995
0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
л = 2 т = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1 0000 1,0000
1 0,0199 0,0396 0,0591 0,0784 0,0975 0,1164 0,1351 0,1536 0,1719
2 0,0001 0,0004 0,0009 0,0016 0,0025 0,0036 0,0049 0,0064 0,0081
л = 5 г = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1 0000
1 0,0490 0,0961 0,1413 0,1846 0,2262 0,2661 0,3043 0,3409 0,3760
2 0,0010 0,0038 0,0085 0,0148 0,0226 0,0319 0,0425 0,0544 0,0674
3 0,0001 0,0003 0,0006 0,0012 0,0020 0,0031 0,0045 0,0063
4 0,0001 0,0001 0,0002 0,0003
л = 10 г = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,0956 0,1829 0,2626 0,3352 0,4013 0,4614 0,5160 0,5656 0,6106
2 0,0043 0,0162 0,0345 0,0582 0,0861 0,1176 0,1517 0,1879 0,2254
3 0,0001 0,0009 0,0028 0,0062 0,0115 0,0188 0,0283 0,0401 0,0540
4 0,0001 0,0004 0,0010 0,0020 0,0036 0,0058 0,0088
5 0,0001 0,0002 0,0003 0,0006 0,0010
6 0,0001
п = 20 г = 0
1
2
3
4
5
6
7
8
п = 50 г —О
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
0,1821 0,3324 0,4562 0,5580 0,6415 0,7099 0,7658 0,8113 0,8484
0,0169 0,0010 0,0599 0,1198 0,1897 0,2642 0,3395 0,4131 0,4831 0,5484
0,0071 0,0210 0,0439 0,0755 0,1150 0,1610 0,2121 0,2666
0,0006 0,0027 0,0003 0,0074 0,0010 0,0001 0,0159 0,0026 0,0003 0,0290 0,0056 0,0009 0,0001 0,0471 0,0107 0,0019 0,0003 0,0706 0,0183 0,0038 0,0006 0,0001 0,0993 0,0290 0,0068 0,0013 0,0002
1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
0,3950 0,6358 0,7819 0,8701 0,9231 0,9547 0,9734 0,9845 0,9910
0,0894 0,2642 0,4447 0,5995 0,7206 0,8100 0,8735 0,9173 0,9468
0,0138 0,0784 0,1892 0,3233 0,4595 0,5838 0,6892 0,7740 0,8395
0,0016 0,0178 0,0628 0,1391 0,2396 0,3527 0,4673 0,5747 0,6697
0,0001 0,0032 0,0168 0,0490 0,1036 0,1794 0,2710 0,3710 0,4723
0,0005 0,0037 0,0144 0,0378 0,0776 0,1350 0,2081 0,2928
0,0001 0,0007 0,0001 0,0036 0,0008 0,0001 0,0118 0,0032 0,0008 0,0002 0,0289 0,0094 0,0027 0,0007 0,0002 0,0583 0,0220 0,0073 0,0022 0,0006 0,0001 0,1019 0,0438 0,0167 0,0056 0,0017 0,0005 0,0001 0,1596 0,0768 0,0328 0,0125 0,0043 0,0013 0,0004 0,0001
£866'О l$66'0 om'o 9$$6'0 6268'0 8HZ/0 988$'0 £2$£'O 0££l'0 V
8666'0 1666'0 V966'0 6£86'0 $*96*0 £806'0 6£6£*0 l$6S'O l£2£'O £
0000'1 6666'0 $666'0 6£66*0 *266*0 £$£6'0 80£6'0 ms'o £809'0 2
0000'I 0000‘ I oooo'i 8666'0 2666'0 8966*0 $886'0 2196'0 fr8£8'0 I
0000'1 0000'I oooo'i oooo'i OOOO'I oooo'i 0000'1 0000'1 0000'1 0 = -< 02 = “
0100'0 £000'0 1000'0 01
£010'0 $too'o L100'0 sooo'o 1000'0 6
£fr$O'O tz.zo'o £210*0 8frO()'O 9100*0 tooo'o 1000'0 8
6l£l'0 ozoi'o 8t$0'0 0920'0 9010'0 S£00'0 6000'0 1000'0 £
O£££'O 9192'0 2991*0 6fr60'0 ££*0*0 £610'0 woo'o tioo’o 1000‘0 9
0£Z9 0 9$6t'O 699£'O $8F2'O £0$ I '0 I8£0'0 82£0'0 6600'0 9100 0 $
18Z8'O 0£Г£*0 LL 19'0 298fr'O fr0S£'0 IVZZ'O 60ZI 'o ooso'o 8210'0
£$fr6'0 fr006*0 £2£8'O F8££'O 2£I9*0 mt'o zzze'o 86£l'0 20£0'0 £
£686’0 £9£6*0 9£$б'о ОМб'О £0S8'0 09$£'0 ZfrZ9'0 £$$t'O 6£92'0 2
0666'll $£6б'О 0fr66'0 $986'0 8l£6*0 ££t6'0 9268'0 l£08'0 £l$9'0 I
0000 1 0000' I oooo'i OOOO'I OOOO'I OOOO'I oooo'i OOOO'I 0000'1 0 = ' 01 = “
tito'o ssio'o zoio'o £$00'0 *200'0 0100'0 £ООО '0 1000'0 $
$£81'0 EI£l'O ()£80'0 orso'o 80£00 9SI0'0 £900'0 2200'0 $000'0
ooo$’o 690t'0 fr£ 1 £'o c$£2'0 I £91*0 $£01'0 6£S0'0 9920'0 9800'0 £
$218'0 8£fr£'O 0£99'0 9I£$’O 8I£*'O 2£9£'O £292'0 8t9I'0 $1800 2
8896*0 £6F6'0 2226'0 0F880 6l£8'0 £29£ 0 £Z£9'0 £9S$'O $60t'0 I
0000'1 0000'1 0000' 1 OOOO'I oooo'i oooo'i OOOO'I 0000'1 oooo'i 0 = ' $ = “
00$ 2*0 $202'0 0091'0 $221*0 0060'0 SZ90'0 OOfrO'O $220'0 ooio'o 2
00$£*0 $£69*0 00F9 '0 $££$*0 oois’o $££t‘O 009£*0 $££2’0 0061'0 I
0000'1 oooo'i OOOO'I 0000' I oooo'i oooo'i oooo'i 0000'1 oooo'i 0=>
os' ‘o $r'o Ofr'O S£*0 O£'o sz'o 02'0 Sl'O oi'o 0
5 0,0432 0,1702 0,3704 0,5852 0,7625 0,8818 0,9490 0,9811 0,9941
6 0,0113 0,0673 0,1958 0,3828 0,5836 0,7546 0,8744 0,9447 0,9793
7 0,0024 0,0219 0,0867 0,2142 0,3920 0,5834 0,7500 0,8701 0,9423
8 0,0004 0,0059 0,0321 0,1018 0,2277 0,3990 0,5841 0,7480 0,8684
9 0,0001 0,0013 0,0100 0,0409 0,1133 ,02376 0,4044 0,5857 0,7483
10 0,0002 0,0026 0,0139 0,0480 0,1218 0,2447 0,4086 0,5881
11 0,0006 0,0039 0,0171 0,0532 0,1275 0,2493 0,4119
12 0,0001 0,0009 0,0051 0,0196 0,0565 0,1308 0,2517
13 0,0002 0,0013 0,0060 0,0210 0,0580 0,1316
14 0,0003 0,0015 0,0065 0,0214 0,0577
15 0,0003 0,0016 0,0064 0,0207
16 0,0003 0,0015 0,0059
17 0,0003 0,0013
18 0,0002
л =50 r = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 . 1,0000 1,0000 1,0000
1 0,9948 0,9997 1,0000 1,0000 1,0000 1,0000 1 0000 1,0000 1,0000
2 0,9662 0,9971 0,9998 1,0000 1,0000 1,0000 1,0000 1,0000 1 0000
3 0,8883 0,9858 0,9987 0,9999 1,0000 1,0000 1,0000 1,0000 1,0000
4 0,7497 0,9540 0,9943 0,9995 1,0000 1,0000 1,0000 1,0000 1,0000
5 0,5688 0,8879 0,9815 0,9979 0,9998 1,0000 1,0000 1,0000 1,0000
6 0,3839 0,7806 0,9520 0,9930 0,9993 0,9999 1,0000 1,0000 1,0000
7 0,2298 0,6387 0,8966 0,9806 0,9975 0,9998 1,0000 1,0000 1,0000
8 0,1221 0,4812 0,8096 0,9547 0,9927 0,9992 0,9999 1,0000 1,0000
9 0,0579 0,3319 0,6927 0,9084 0,9817 0,9975 0,9998 1,0000 1,0000
10 0,0245 0,2089 0,5563 0,8363 0,9598 0,9933 0,9992 0,9999 1,0000
И 0,0094 0,1199 0,4164 0,7378 0,9211 0,9840 0,9978 0,9998 1,0000
12 0,0032 0,0628 0,2893 0,6184 0,8610 0,9658 0,9943 0,9994 1,0000
13 0,0010 0,0301 0,1861 0,4890 0,7771 0,9339 0,9867 0,9982 0,9998
14 0,0003 0,0132 0,1106 0,3630 0,6721 0,8837 0,9720 0,9955 0,9995
е 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
15 0,0001 0,0053 0,0607 0,2519 0,5532 0,8122 0,9460 0,9896 0,9987
16 0,0019 0,0308 0,1631 0,4308 0,7199 0,9045 0,9780 0,9967
17 0,0007 0,0144 0,0983 0,3161 0,6111 0,8439 0,9573 0,9923
18 0,0002 0,0063 0,0551 0,2178 0,4940 0,7631 0,9235 0,9836
19 0,0001 0,0025 0,0287 0,1406 0,3784 0,6644 0,8727 0,9675
20 0,0009 0,0139 0,0848 0,2736 0,5535 0,8026 0,9405
21 0,0003 0,0063 0,0478 0,1861 0,4390 0,7138 0,8987
22 0,0001 0,0026 0,0251 0,1187 0,3299 0,6100 0,8389
23 0,0010 0,0123 0,0710 0,2340 0,4981 0,7601
24 0,0004 0,0056 0,0396 0,1562 0,3866 0,6641
25 0,0001 0,0024 0,0207 0,0978 0,2840 0,5561
26 0,0009 0,0100 0,0573 0,1966 0,4439
27 0,0003 0,0045 0,0314 0,1279 0,3359
28 0,0001 0,0019 0,0160 0,0780 0,2399
29 0,0007 0,0076 0,0444 0,1611
30 0,0003 0,0034 0,0235 0,1013
31 0,0001 0,0014 0,0116 0,0595
32 0,0005 0,0053 0,0325
33 0,0002 0,0022 0,0164
34 0.0001 0,0009 0,0077
35 0,0003 0,0033
36 0,0001 0,0013
37 0,0005
38 0,0002
ПРИЛОЖЕНИЕ 2
Накопленные пуассоновские вероятности. В таблице приведены
значения
P[S(X)^r] = E e-xXVs!,
s = r
где S(X) обозначает случайную величину Poisson(X), т. е. распределен-
ную по Пуассону с параметром X. Поэтому P[S(X)^r] означает веро-
ятность появления г или более событий. Таблицы позволяют также
найти
P[S(X)^rj = l—P[S(X)^r+l], r=0,l,...
и
P{S(X) = r]=P[S(X)>r}—P[S(X)>r+l}, r=0,1,...
Накопленные пуассоновские вероятности
(воспроизведено с разрешения Macmillan Publishers Ltd. из [Murdoch and Barnes (1968) — G]). В таблице приведены
вероятности появления г или более случайных событий в интервале времени, для которого в среднем число таких со-
бытий равно X, т. е.
Если в таблице для какой-либо пары г и X значение вероятности отсутствует, это значит, что оно меньше 0,00005. Ана-
логично (за исключением случая, когда г=0, где табличные значения точные) число 1,0000 представляет вероятности,
превосходящие 0,99995
Л 0,2 0,3 0,4 °,5 0,6 0,7 °,8 0,9 1,0
г = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1 0000
1 0,0952 0,1813 0,2592 0,3297 0,3935 0,4512 0,5034 0,5507 0,5934 0 6321
2 0,0047 0,0175 0,0369 0,0616 0,0902 0,1219 0,1558 0 1912 0,2275 0 2642
3 0,0002 0,0011 0,0036 0,0079 0,0144 0,0231 0,0341 0*0474 0,0629 0*0803
4 0,0001 0,0003 0,0008 0,0018 0,0034 0,0058 0*0091 0,0135 0,0190
5 0,0001 0,0002 0,0004 0,0008 0,0014 0,0023 0 0037
6 0,0001 0,0002 0,0003 0,0006
7 0,0001
Л 1J 1,2 1,3 1,4 1,5 I,6 1,7 I,8 1,9 2,0
г = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,6671 0,6988 0,7275 0,7534 0,7769 0,7981 0,8173 0,8347 0,8504 0,8647
2 0,3010 0,3374 0,3732 0,4082 0,4422 0,4751 0,5068 0,5372 0,5663 0,5940
3 0,0996 0,1205 0,1429 0,1665 0,1912 0,2166 0,2428 0,2694 0,2963 0,3233
4 0,0257 0,0338 0,0431 0,0537 0,0656 0,0788 0,0932 0,1087 0,1253 0,1429
5 0,0054 0,0077 0,0107 0,0143 0,0186 0,0237 0,0296 0,0364 0,0441 0,0527
6 0,0010 0,0015 0,0022 0,0032 0,0045 0,0060 0,0080 0,0104 0,0132 0,0166
7 0,0001 0 0003 0,0004 0,0006 0,0009 0,0013 0,0019 0,0026 0,0034 0,0045
8 0,0001 0,0001 0,0002 0,0003 0,0004 0,0006 0,0008 0,0011
9 0,0001 0,0001 0,0002 0,0002
A 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3,0
7 = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,8775 0,8892 0,8997 0,9093 0,9179 0,9257 0,9328 0,9392 0,9450 0,9502
2 0,6204 0,6454 0,6691 0,6916 0,7127 0,7326 0,7513 0,7689 0,7854 0,8009
3 0,3504 0,3773 0,4040 0,4303 0,4562 0,4816 0,5064 0,5305 0,5540 0,5768
4 0,1614 0,1806 0,2007 0,2213 0,2424 0,2640 0,2859 0,3081 0,3304 0,3528
5 0,0621 0,0725 0,0838 0,0959 0,1088 0,1226 0,1371 0,1523 0,1682 0,1847
6 0,0204 0,0249 0,0300 0,0357 0,0420 0,0490 0,0567 0,0651 0,0742 0,0839
7 0,0059 0,0075 0,0094 0,0116 0,0142 0,0172 0,0206 0,0244 0,0287 0,0335
8 0,0015 0,0020 0,0026 0,0033 0,0042 0,0053 0,0066 0,0081 0,0099 0,0119
9 0,0003 0,0005 0,0006 0,0009 0,0011 0,0015 0,0019 0,0024 0,0031 0,0038
10 0,0001 0,0001 0,0001 0,0002 0,0003 0,0004 0,0005 0,0007 0,0009 0,0011
11 0,0001 0,0001 0,0001 0,0002 0,0002 0,0003
12 0,0001 0,0001
A 3? 3,2 3,3 3,4 3,5 3,6 3,7 3,8 3,9 4,0
r = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,9550 0,9592 0,9631 0,9666 0,9698 0,9727 0,9753 0,9776 0,9798 0,9817
2 0,8153 0,8288 0,8414 0,8532 0,8641 0,8743 0,8838 0,8926 0,9008 0,9084
3 0,5988 0,6201 0,6406 0,6603 0,6792 0,6973 0,7146 0,7311 0,7469 0,7619
4 0,3752 0,3975 0,4197 0,4416 0,4634 0,4848 0,5058 0,5265 0,5468 0,5665
5 0,2018 0,2194 0,2374 0,2558 0,2746 0,2936 0,3128 0,3322 0,3516 0,3712
6 0,0943 0,1054 0,1171 0,1295 0,1424 0,1559 0,1699 0,1844 0,1994 0,2149
7 0,0388 0,0446 0,0510 0,0579 0,0653 0,0733 0,0818 0,0909 0,1005 0,1107
8 0,0142 0,0168 0,0198 0,0231 0,0267 0,0308 0,0352 0,0401 0,0454 0,0511
9 0,0047 0,0057 0,0069 0,0083 0,0099 0,0117 0,0137 0,0160 0,0185 0,0214
10 0,0014 0,0018 0,0022 0,0027 0,0033 0,0040 0,0048 0,0058 0,0069 0,0081
11 0,0004 0,0005 0,0006 0,0008 0,0010 0,0013 0,0016 0,0019 0,0023 0,0028
12 0,0001 0,0001 0,0002 0,0002 0,0003 0,0004 0,0005 0,0006 0,0007 0,0009
13 0,0001 0,0001 0,0001 0,0001 0,0002 0,0002 0,0003
14 0,0001 0,0001
A 4,1 4,2 4,3 4,4 4,5
r = 0 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,9834 0,9850 0,9864 0,9877 0,9889
2 0,9155 0,9220 0,9281 0,9337 0,9389
3 0,7762 0,7898 0,8026 0,8149 0,8264
4 0 5858 0,6046 0,6228 0,6408 0,6577
5 0 3907 0,4102 0,4296 04488 0,4679
6 0,2307 0,2469 0,2633 0,2801 0,2971
7 0.1214 0,1325 0,1442 0,1564 0,1689
8 0 0573 0,0639 0,0710 0,0786 0,0866
9 0,0245 0,0279 0,0317 0,0358 0,0403
10 0 0095 0,0111 0,0129 0,0149 0,0171
11 0,0034 0,0041 0.0048 0,0057 0,0067
12 0,0011 0,0014 0,0017 0,0020 0,0024
13 0,0003 0,0004 0,0005 0,0007 0,0008
14 0,0001 0,0001 0,0002 0,0002 0,0003
15 0,0001 0,0001
16
4,6 4,7 4,8 4,9 5,0
1,0000 1,0000 1,0000 1,0000 1,0000
0,9899 0,9909 0,9918 0,9926 0,9933
0,9437 0,9482 0,9523 0,9561 0,9596
0,8374 0,8477 0,8575 0,8667 0,8753
0,6743 0,6903 0,7058 0,7207 0,7350
0,4868 0,5054 0,5237 0,5418 0,5595
0,3142 0,3316 0,3490 0,3665 0,3840
0,1820 0,1954 0,2092 0,2233 0,2378
0,0951 0,1040 0,1133 0,1231 0,1334
0,0451 0,0503 0,0558 0,0618 0,0681
0,0195 0,0222 0,0251 0,0283 0,0318
0,0078 0,0090 0,0104 0,0120 0,0137
0,0029 0,0034 0,0040 0,0047 0,0055
0,0010 0,0012 0,0014 0,0017 0,0020
0,0003 0,0004 0,0005 0,0006 0,0007
0,0001 0,0001 0,0001 0,0002 0,0002
0,0001 0,0001
A 5,2 5,4 5,6 5,8 6,0 6,2 6,4 6,6 6,8 7,0
r = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,9945 0,9955 0,9963 0,9970 0,9975 0,9980 0,9983 0,9986 0,9989 0,9991
2 0,9658 0,9711 0,9756 0,9794 0,9826 0,9854 0,9877 0,9897 0,9913 0,9927
3 0,8912 0,9052 0,9176 0,9285 0,9380 0,9464 0,9537 0,9600 0,9656 0,9704
4 0,7619 0,7867 0,8094 0,8300 0,8488 0,8658 0,8811 0,8948 0,9072 0,9182
5 0,5939 0,6267 0,6579 0,6873 0,7149 0,7408 0,7649 0,7873 0,8080 0,8270
6 0,4191 0,4539 0,4881 0,5217 0,5543 0,5859 0,6163 0,6453 0,6730 0,6993
7 0,2676 0,2983 0,3297 0,3616 0,3937 0,4258 0,4577 0,4892 0,5201 0,5503
8 0,1551 0,1783 0,2030 0,2290 0,2560 0,2840 0,3127 0,3419 0,3715 0,4013
9 0,0819 0,0974 0,1143 0,1328 0,1528 0,1741 0,1967 0,2204 0,2452 0,2709
10 0,0397 0,0488 0,0591 0,0708 0,0839 0,0984 0,1142 0,1314 0,1498 0,1695
11 0,0177 0,0225 0,0282 0,0349 0,0426 0,0514 0,0614 0,0726 0,0849 0,0985
12 0,0073 0,0096 0,0125 0,0160 0,0201 0,0250 0,0307 0,0373 0,0448 0,0534
13 0,0028 0,0038 0,0051 0,0068 0,0088 0,0113 0,0143 0,0179 0,6221 0,0270
14 0,0010 0,0014 0,0020 0,0027 0,0036 0,0048 0,0063 0,0080 0,0102 0,0128
15 0,0003 0,0005 0,0007 0,0010 0,0014 0,0019 0,0026 0,0034 0,0044 0,0057
16 0,0001 0,0002 0,0002 0,0004 0,0005 0,0007 0,0010 0,0014 0,0018 0,0024
17 0,0001 0,0001 0,0001 0,0002 0,0003 0,0004 0,0005 0,0007 0,0010
18 0,0001 0,0001 0,0001 0,0002 0,0003 0,0004
19 0,0001 0,0001 0,0001
A 7,2 7,4 7,6 7,8 8,0 8,2 8,4 8,6 8,8 9,0
= 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,9993 0,9939 0,9994 0,9995 0,9996 0,9997 0,9997 0,9998 0,9998 0,9998 0,9999
2 0,9949 0,9957 0,9964 0,9970 0,9975 0,9882 0,9979 0,9982 0,9985 0,9988
3 0,9745 0,9281 0,9781 0,9812 0,9839 0,9862 0,9900 0,9914 0,9927 0,9938
4 0,9368 0,9446 0,9515 0,9576 0,9630 0,9677 0,9719 0,9756 0,9788
5 0,8445 0,8605 0,8751 0,8883 0,9004 0,9113 0,9211 0,9299 0,9379 0,9450
6 0,7241 0,7474 0,7693 0,7897 0,8088 0,8264 0,8427 0,8578 0,8716 0,8843
7 0,5796 0,6080 0,6354 0,6616 0,6866 0,7104 0,5746 0,7330 0,7543 0,7744 0,7932
8 0,4311 0,4607 0,4900 0,5188 0,5470 0.6013 0,6272 0,6522 0,6761
9 0,2973 0,3243 0,3518 0,3796 0,4075 0,4353 O'4631 O'4906 0,5177 0,5443
10 0,1904 0,2123 0,2351 0,2589 0,2834 0,3085 0,3341 0,3600 0,3863 0,4126
11 0 1133 0,1293 0,1465 0,1648 0,1841 0,2045 0,2257 0,2478 0,2706 0,2940
12 0,0629 0,0735 0,0852 0,0980 0,1119 0,1269 0,1429 0,1600 0,1780 0,1970
13 0,0327 0,0391 0,0464 0,0546 0,0638 0,0739 0,0850 0,0971 0,1102 0,1242
14 0,0159 0,0195 0,0238 0,0286 0,0342 0,0405 0,0476 0,0555 0,0642 0,0739
15 0,0073 0,0092 0,0114 0,0052 0,0141 0,0173 0,0209 0,0251 0,0299 0,0353 0,0415
16 0,0031 0,0041 0,0066 0,0029 0,0082 0,0102 0,0125 0,0152 0,0184 0,0220
17 0,0013 0,0017 0,0022 0,0037 0,0047 0,0059 0,0074 0,0091 0,0111
18 0,0005 0,0007 0,0009 0,0012 0,0016 0,0021 0,0027 0,0034 0,0043 0,0053
19 0,0002 0,0003 0,0004 0,0005 0,0006 0,0009 0,0011 0,0015 0,0019 0,0024
20 21 22 23 0,0001 0,0001 0,0001 0,0002 0,0001 0,0003 0,0001 0,0003 0,0001 00005 0,0002 0,0001 0,0006 0,0002 0,0001 0,0008 0,0003 0,0001 0,0011 0,0004 0,0002 0,0001
A 9 2 9,4 9,6 9,8 10,0 11,0 12,0 13,0 14,0 15,0
г = 0 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
1 0,9999 0,9999 0,9999 0,9999 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
2 0,9990 0,9991 0,9993 0,9994 0,9995 0,9998 0,9999 1,0000 1,0000 1,0000
3 0,9947 0,9955 0,9962 0,9967 0,9972 0,9988 0,9995 0,9998 0,9999 1,0000
4 0,9816 0,9840 0,9862 0,9880 0,9897 0,9951 0,9977 0,9990 0,9995 0,9998
5 0,9514 0,9571 0,9622 0,9667 0,9707 0,9849 0,9924 0,9963 0,9982 0,9991
6 0.8959 0,9065 0,9162 0,9250 0,9329 0,9625 0,9797 0,9893 0,9945 0,9972
7 0,8108 0,8273 0,8426 0,8567 0,8699 0,9214 0,9542 0,9741 0,9858 0,9924
8 0,6990 0,7208 0,7416 0,7612 0,7798 0,8568 0,9105 0,9460 0,9684 0,9820
9 0,5704 0,5958 0,6204 0,6442 0,6672 0,7680 0,8450 0,9002 0,9379 0,9626
10 0,4389 0,4651 0,4911 0,5168 0,5421 0,6595 0,7576 0,8342 0,8906 0,9301
11 0,3180 0,3424 0,3671 0,3920 0,4170 0,5401 0,6528 0,7483 0,8243 0,8815
12 0,2168 0,2374 0,2588 0,2807 0,3032 0,4207 0,5384 0,6468 0,7400 0,8152
13 0.1393 0,1552 0,1721 0,1899 0,2084 0,3113 0,4240 0,5369 0,6415 0,7324
14 0,0844 0,0958 0,1081 0,1214 0/1355 0,2187 0,3185 0,4270 0,5356 0,6368
15 0,0483 0,0559 0,0643 0,0735 0,0835 0,1460 0,2280 0,3249 0,4296 0,5343
16 0,0262 0,0309 0,0362 0,0421 0,0487 0,0926 0,1556 0,2364 0,3306 0,4319
17 0,0135 0,0162 0,0194 0,0230 0,0270 0,0559 0,1013 0,1645 0,2441 0,3359
18 0,0066 0,0081 0,0098 0,0119 0,0143 0,0322 0,0630 0,1095 0,1728 0,2511
19 0,0031 0,0038 0,0048 0,0059 0,0072 0,0177 0,0374 0,0698 0,1174 0,1805
20 0,0014 0,0017 0,0022 0,0028 0,0035 0,0093 0,0213 0,0427 0,0765 0,1248
21 0,0006 0,0008 0,0010 0,0012 0,0016 0,0047 0,0116 0,0250 0,0479 0,0830
22 0,0002 0,0003 0,0004 0,0005 0,0007 0,0023 0,0061 0,0141 0,0288 0,0531
23 0,0001 0,0001 0,0002 0,0002 0,0003 0,0010 0,0030 0,0076 0,0167 0,0327
24 0,0001 0,0001 0,0001 0,0005 0,0015 0,0040 0,0093 0,0195
25 0,0002 0,0007 0,0020 0,0050 0,0112
26 0,0001 0,0003 0,0010 0,0026 0,0062
27 0,0001 0,0005 0,0013 0,0033
28 0,0001 0,0002 0,0006 0,0017
29 0,0001 0,0003 0,0009
30 0,0001 0,0004
31 0,0001 0,0002
32 0,0001
ПРИЛОЖЕНИЕ 3
Накопленные стандартные нормальные вероятности. В таблице
приведены значения
7’ I —
P(U^u)=\ —-— е dy=l—Ф(м),
и У2тг
где Ф(и) — ф. р. стандартной нормальной переменной U. Например,
1—Ф(2,32)=0,010170.
Перед выделенными жирным шрифтом значениями надо поставить
столько же нулей (после запятой), сколько перед числами идущей ни-
же строки. Например,
1—Ф(2,36)=0,0091375.
Таблица дает значения 1—Ф(и) для и^0. Для отрицательных и следу-
ет использовать соотношение
Ф(и) = 1—Ф(—и).
Например,
Ф (—2,36) = 1 —Ф (2,36)=0,0091375.
Если X распределено по нормальному закону со средним д и стан-
дартным отклонением а (т. е. дисперсией а2), то
Р(Х^х)=Ф(^)_
Р(Х>х)= 1-ф( *=* ).
488
Нормальный интеграл вероятности 1—Ф(х)
(воспроизведено с разрешения Longman Group Ltd. из [Fisher and Yates (1974) —G])
X 0 1 2 3 4 5 6 7 8 9
0,0 0,0 50000 . 49601 49202 48803 48405 48006 47608 47210 46812 46414
o,i 46017 45620 45224 44828 44433 44038 43644 43251 42858 42465
0,2 42074 41683 41294 40905 40517 40129 39743 39358 38974 38591
0,3 38209 37828 37448 37070 36693 36317 35942 35569 35197 34827
0,4 34458 34090 33724 33360 32997 32636 32276 31918 31561 31207
0,5 30854 30503 30153 29806 29460 29116 28774 28434 28096 27760
0,6 27425 27093 26763 26435 26109 25785 25463 25143 24825 24510
0,7 24196 23885 23576 23270 22965 22663 22363 22065 21770 21476
0,8 21186 20897 20611 20327 20045 19766 19489 19215 18943 18673
0,9 18406 18141 17879 17619 17361 17106 16853 16602 16354 16109
1,° 15866 15625 15386 15151 14917 14686 14457 14231 14007 13786
1,1 13567 13350 13136 12924 12714 12507 12302 12100 11900 11702
1,2 11507 11314 11123 10935 10749 10565 10383 10204 10027 98525
1,3 0,0 96800 95098 93418 91759 90123 88508 86915 85343 83793 82264
1,4 80757 79270 77804 76359 74934 7352$ 72145 70781 69437 68112
1,5 66807 65522 64255 63008 61780 60571 59380 58208 57053 55917
1,6 54799 53699 52616 51551 50503 49471 48457 47460 46479 45514
1,7 44565 43633 42716 41815 40930 40059 39204 38364 37538 36727
1,8 35930 35148 34380 33625 32884 32157 31443 30742 30054 29379
1,9 28717 28067 27429 26803 26190 25588 24998 24419 23852 23295
2,0 22750 22216 21692 21178 20675 20182 19699 19226 18763 18309
2,1 17864 17429 17003 16586 16177 15778 15386 15003 14629 14262
2,2 13903 13553 13209 12874 12545 12224 11911 11604 11304 non
2,3 10724 10444 10170 99031 96419 93867 91375 88940 86563 84242
2,4 0,02 81975 79763 77603 75494 73436 71428 69469 67557 65691 63872
X 0 1 2 3 4 5 6 7 8 9
2,5 62097 60366 58677 57031 55426 53861 52336 50849 49400 47988
2,6 46612 45271 43965 42692 41453 40246 39070 37926 36811 35726
2,7 34670 33642 32641 31667 30720 29798 28901 28028 27179 26354
2,8 25551 24771 24012 23274 22557 21860 21182 20524 19884 19262
2,9 18658 18071 17502 16948 16411 15889 15382 14890 14412 13949
з.о 13499 13062 12639 12228 11829 11442 11067 10703 10350 10008
3,1 0,03 96760 93544 90426 87403 84474 81635 78885 76219 73638 71136
3,2 68714 66367 64095 61895 59765 57703 55706 53774 51904 50094
з,з 48342 46648 45009 43423 41889 40406 38971 37584 36243 34946
3,4 33693 32481 31311 30179 29086 28029 27009 26023 25071 24151
3,5 23263 22405 21577 20778 20006 19262 18543 17849 17180 16534
3,6 15911 15310 14730 14171 13632 13112 12611 12128 11662 11213
3,7 10780 10363 99611 95740 92010 88417 84957 81624 78414 75324
3,8 0,04 72348 69483 66726 64072 61517 59059 56694 54418 52228 50122
3,9 48096 46148 44274 42473 40741 39076 37475 35936 34458 33037
4,0 31671 30359 29099 27888 26726 25609 24536 23507 22518 21569
4,1 20658 19783 18944 18138 17365 16624 15912 15230 14575 13948
4,2 13346 12769 12215 11685 11176 10689 10221 97736 93447 89337
4,3 0,0s 85399 81627 78015 74555 71241 68069 65031 62123 59340 56675
4,4 54125 51685 49350 47117 44979 42935 40980 39110 37322 35612
4,5 33977 32414 30920 29492 28127 26823 25577 24386 23249 22162
4,6 21125 20133 19187 18283 17420 16597 15810 15060 14344 13660
4,7 13008 12386 11792 11226 10686 10171 96796 92113 87648 83391
4,8 0,06 79333 75465 71779 68267 64920 61731 58693 55799 53043 50418
4,9 47918 45538 43272 41115 39061 37107 35247 33476 31792 30190
ПРИЛОЖЕНИЕ 4
Процентные точки стандартного нормального распределения. В
таблице приведены значения 100а%-ных точек иа стандартного нор-
мального распределения, т. е. значения иа, для которых
P(U^ua) = a.
В обозначениях приложения 3
1—Ф(иа) = а,
или
иа = Ф~](1—а).
Центральный интервал вероятности 1—а (справа и слева от которого
остаются вероятности а/2) имеет вид (—и_^,
2 2
491
Процентные точки нормального распределения
(воспроизведено с разрешения Macmillan Publishers Ltd. из [Murdoch and Barnes (1968) — G])
a ua a “a a И„ a «. a «. a "a
0,50 0,0000 0,050 1,6449 0,030 1,8808 0,020 2,0537 0,010 2,3263 0,050 1,6449
0,45 0,1257 0,048 1,6646 0,029 1,8957 0,019 2,0749 0,009 2,3656 0,010 2,3263
0,40 0,2533 0,046 1,6849 0,028 1,9110 0,018 2,0969 0,008 2,4089 0,001 3,0902
0,35 0,3853 0,044 1,7060 0,027 1,9268 0,017 2,1201 0,007 2,4573 0,0001 3,7190
0,30 0,5244 0,042 1,7279 0,026 1,9431 0,016 2,1444 0,006 2,5121 0,00001 4,2649
0,25 0,6745 0,040 1,7507 0,025 1,9600 0,015 2,1701 0,005 2,5758 0,025 1,9600
0,20 0,8416 0,038 1,7744 0,024 1,9774 0,014 2,1973 0,004 2,6521 0,005 2,5758
0,15 1,0364 0,036 1,7991 0,023 1,9954 0,013 2,2262 0,003 2,7478 0,0005 3,2905
0,10 1,2816 0,034 1,8250 0,022 2,0141 0,012 2,2571 0,002 2,8782 0,00005 3,8906
0,05 1,6449 0,032 1,8522 0,021 2,0335 0,011 2,2904 0,001 3,0902 0,000005 4,4172
ПРИЛОЖЕНИЕ 5
Накопленные вероятности распределения Стьюдента ^-распреде-
ления). В таблице приведены значения
где случайная величина T(v) имеет распределение Стьюдента с v сте-
пенями свободы.
Вероятность превысить t равна 1—pt{v).
Таблицы дают значения pt{v) для р=1(1) 24, 30, 40, 60, 120,
Для этих значений v приведены значения pt(v) для неотрицательных
t. Для отрицательных используйте соотношение
рМ-
493
Интеграл вероятности pt(v) для /-распределения
(воспроизведено с разрешения Biometrika Trustees из Biometrika Tables for Statisticians. Vol. 1, 3rd edition, 1966)-
^4 p t x 1 2 3 4 5 6 7 8 9 10
0,0 0 50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000
0,1 0,53173 0,53527 0,53667 0,53742 0,53788 0,53820 0,53843 0,53860 0,53873 0,53884
0,2 0,56283 0,57002 0,57286 0,57438 0,57532 0,57596 0,57642 0,57676 0,57704 0,57726
0,3 0,59277 0,60376 0,60812 0,61044 0,61188 0,61285 0,61356 0,61409 0,61450 0,61484
0,4 0,62112 0,63608 0,64203 0,64520 0,64716 0,64850 0,64946 0,650’*) 0,65076 0,65122
0,5 0,64758 0,66667 0,67428 0,67834 0,68085 0,68256 0,68380 0,68473 0,68546 0,68605
0,6 0,67202 0,69529 0,70460 0,70958 0,71267 0,71477 0,71629 0,71745 0,71835 0,71907
0,7 0,69440 0,72181 0,73284 0,73875 0,74243 0,74493 0,74674 0,74811 0,74919 0,75006
0,8 0,71478 0,74618 0,75890 0,76574 0,76999 0,77289 0,77500 0,77659 0,77784 0,77885
0,9 0,73326 0,76845 0,78277 0,79050 0,79531 0,79860 0,80099 0,80280 0,80422 0,80536
1,0 0,75000 0,78868 0,80450 0,81305 0,81839 0,82204 0,82469 0,82670 0,82828 0,82955
1,1 0,76515 0,80698 0,82416 0,83346 0,83927 0,84325 0,84614 0,84834 0,85006 0,85145
1,2 0,77886 0,82349 0,84187 0,85182 0,85805 0,86232 0,86541 0,86777 0,86961 0,87110
1,3 0,79129 0,83838 0,85777 0,86827 0,87485 0,87935 0,88262 0,88510 0,88705 0,88862
1,4 0,80257 0,85177 0,87200 0,88295 0,88980 0,89448 0,89788 0,90046 0,90249 0,90412
1,5 0,81283 0,86380 0,88471 0,89600 0,90305 0,90786 0,91135 0,914(8) 0,91608 0,91775
1,6 0,82219 0,87464 0,89605 0,90758 0,91475 0,91964 0 92318 0,92587 0,92797 0,92966
1,7 0,83075 0,88439 0,90615 0,91782 0,92506 0,92998 0,93354 0,93622 0,93833 0,94002
1,8 0,83859 0,89317 0,91516 0,92688 0,93412 0,93902 0,94256 0,94522 0,94731 0.94897
1,9 0,84579 0,90109 0,92318 0,93488 0,94207 0,94691 0,95040 0,953^2 0,95506 0,95669
2,0 0,85242 0,90825 0,93034 0,94194 0,94903 0,95379 0,95719 0,95974 0,96172 0,96331
2Д 0,85854 0,91473 0,93672 0,94817 0,95512 0,95976 0,96306 0,96553 0,96744 0,96896
2,2 0,86420 0,92060 0,94241 0,95367 0,96045 0,96495 0,96813 0,97050 0,97233 0,97378
2,3 0,86945 0,92593 0,94751 0,95853 0,96511 0,96945 0,97250 0,97476 0,97650 0,97787
2,4 0,87433 0,93077 0,95206 0,96282 0,96919 0,97335 0,97627 0,97841 0,98005 0,98134
2,5 0,87888 0,93519 0,95615 0,96662 0,97275 0,97674 0,97950 0,98153 0,98307 0,98428
2,6 0,88313 0,93923 0,95981 0,96998 0,97587 0,97967 0,98229 0,98419 0,98563 0,98675
2,7 0,88709 0,94292 0,96311 0,97295 0,97861 0,98221 0,98468 0,98646 0,98780 0,98884
2,8 0,89081 0,94630 0,96607 0,97559 0,98100 0,98442 0,98674 0,98840 0,98964 0,99060
2,9 0,89430 0,94941 0,96875 0,97794 0,98310 0,98633 0,98851 0,99005 0,99120 0,99208
3,0 0,89758 0,95227. 0,97116 0,98003 0,98495 0,98800 0,99003 0,99146 0,99252 0,99333
3,1 0,90067 0,95490 0,97335 0,98189 0,98657 0,98944 0,99134 0,99267 0,99364 0,99437
3,2 0,90359 0,95733 0,97533 0,98355 0,98800 0,99070 0,99247 0,99369 0,99459 0,99525
з,з 0,90634 0,95958 0,97713 0,98503 0,98926 0,99180 0,99344 0,99457 0,99539 0,99599
3,4 0,90895 0,96166 0,97877 0,98636 0,99037 0,99275 0,99428 0,99532 0,99606 0,99661
3,5 0,91141 0,96358 0,98026 0,98755 0,99136 0,99359 0,99500 0,99596 0,99664 0,99714
3,6 0,91376 0,96538 0,98162 0,98862 0,99223 0,99432 0,99563 0,99651 0,99713 0,99758
3,7 0,91598 0,96705 0,98286 0,98958 0,99300 0,99496 0,99617 0,99698 0,99754 0,99795
3,8 0,91809 0,96860 0,98400 0,99045 0,99369 0,99552 0,99664 0,99738 0,99789 0,99826
3,9 0,92010 0,97005 0,98504 0,99123 0,99430 0,99601 0,99705 0,99773 0,99819 0,99852
4,0 0,92202 0,97141 0,98600 0,99193 0,99484 0,99644 0,99741 0,99803 0,99845 0,99874
4,2 0,92560 0,97386 0,98768 0,99315 0,99575 0,99716 0,99798 0,99850 0,99885 0,99909
4,4 0,92887 0,97602 0,98912 0,99415 0,99649 0,99772 0,99842 0,99886 0,99914 0,99933
4,6 0,93186 0,97792 0,99034 0,99498 0,99708 0,99815 0,99876 0,99912 0,99936 0,99951
4,8 0,93462 0,97962 0,99140 0,99568 0,99756 0,99850 0,99902 0,99932 0,99951 0,99964
5,0 0,93717 0,98113 0,99230 0,99625 0,99795 0,99877 0,99922 0,99947 0,99963 0.99973
5,2 0,93952 0,98248 0,99309 0,99674 0,99827 0,99899 0,99937 0,99959 0,99972 0,99980
5,4 0,94171 0,98369 0,99378 0,99715 0,99853 0,99917 0,99950 0,99968 0,99978 0,9.9985
5,6 0,94375 0,98478 0,99437 0,99750 0,99875 0,99931 0,99959 0,99975 0,99983 0,99989
5,8 0,94565 0,98577 0,99490 0,99780 0,99893 0,99942 0,99967 0,99980 0,99987 0,99991
6,0 0,94743 0,98666 0,99536 0,99806 0,99908 0,99952 0,99973 0,999-4 0,99990 0,99993
6,2 0,94910 0,98748 0,99577 0,99828 0,99920 0,99959 0,99978 0,99987 0,99992 0,99995
6,4 0,95066 0,98822 0,99614 0,99847 0,99931 0,99966 0,99982 0,99У90 0,99994 0,99996
6,6 0,95214 0,98890 0,99646 0,99863 0,99940 0,99971 0,99985 0,99992 0,99995 0,99997
6,8 0,95352 0,98953 0,99675 0,99878 0,99948 0,99975 0,99987 0,99993 0,99996 0,99998
7,0 0,95483 0,99010 0,99701 0,99890 0,99954 0,99979 0,99990 0,99994 0,99997 0,99998
7,2 0,95607 0,99063 0,99724 0,99901 0,99960 0,99982 0,99991 0,99995 0,99997 0,99999
7,4 0,95724 0,99111 0,99745 0,99911 0,99964 0,99984 0,99993 0,99996 0,99998 0,99999
7,6 0,95836 0,99156 0,99764 0,99920 0,99969 0,99986 0,99994 0,99997 0,99998 0,99999
7,8 0,95941 0,99198 0,99781 0,99927 0,99972 0,99988 0,99995 0,99997 0,99999 0,99999
8,0 0,96042 0,99237 0,99796 0,99934 0,99975 0,99990 0,99996 0,99998 0,99999 0,99999
Интеграл вероятности для /-распределения (продолжение)
11 12 13 14 15 16 17 18 19 20
0,0 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000
0,1 0,53893 0,53900 0,53907 0,53912 0,53917 0,53921 0,53924 0,53928 0,53930 0,53933
0,2 0,57744 0*57759 0,57771 0,57782 0,57792 0,57800 0,57807 0,57814 0,57820 0,57825
0,3 0,61511 0,61534 0,61554 0,61571 0,61585 0,61598 0,61609 0,61619 0,61628 0,61636
0,4 0,65159 0,65191 0,65217 0,65240 0,65260 0,65278 0,65293 0,65307 0,65319 0,65330
0,5 0,68654 0,68694 0,68728 0,68758 0,68783 0,68806 0,68826 0,68843 0,68859 0,68873
0,6 0,71967 0,72017 0,72059 0,72095 0,72127 0,72155 0,72179 0,72201 0,72220 0,72238
0,7 0,75077 0,75136 0,75187 0,75230 0,75268 0,75301 0,75330 0,75356 0,75380 0,75400
0,8 0,77968 0,78037 0,78096 0,78146 0,78190 78229 6,78263 0,78293 0,78320 0,78344
0,9 0,80630 0,80709 0,80776 0,80833 0,80883 0,80927 0,80965 0,81000 0,81031 0,81058
1,0 0,83060 0,83148 0,83222 0,83286 0,83341 0,83390 0,83433 0,83472 0,83506 0,83537
1,1 0,85259 0,85355 0,85436 0,85506 0,85566 0,85620 0,85667 0,85709 0,85746 0,85780
1,2 0,87233 0,87335 0,87422 0,87497 0,87562 0,87620 0,87670 0,87715 0,87756 0,87792
1,3 0,88991 0,89099 0,89191 0,89270 0,89339 0,89399 0,89452 0,89500 0,89542 0,89581
1,4 0,90546 0,90658 0,90754 0,90836 0,90907 0,90970 0,91025 0,91074 0,91118 0,91158
1,5 0,91912 0,92027 0,92125 0,92209 0,92282 0,92346 0,92402 0,92452 0,92498 0,92538
1,6 0,93105 0,93221 0,93320 0,93404 0,93478 0,93542 0,93599 0,93650 0,93695 0,93736
1,7 0,94140 0,94256 0,94354 0,94439 0,94512 0,94576 0,94632 0,94683 0,94728 0,94768
I,8 0,95034 0,95148 0,95245 0,95328 0,95400 0,95463 0,95518 0,95568 0,95612 0,95652
1,9 0,95802 0,95914 0,96008 0,96089 0,96158 0,96220 0,96273 0,96321 0,96364 0,96403
2,0 0,96460 0,96567 0,96658 0,96736 0,96803 0,96861 0,96913 0,96959 0,97000 0,97037
2,1 0,97020 0,97123 0,97209 0,97283 0,97347 0,97403 0,97452 0,97495 0,97534 0,97569
2,2 0,97496 0,97593 0,97675 0,97745 0,97805 0,97858 0,97904 0,97945 0,97981 0,98014
2/3 0,97898 0,97990 0,98067 0,98132 0,98189 0,98238 0,98281 0,98319 0,98352 0,98383
2,4 0,98238 0,98324 0,98396 0,98457 0,98509 0,98554 0,98594 0,98629 0,98660 0,98688
2 5 0,98525 0,98604 0,98671 0,98727 0,98775 0,98816 0,98853 0,98885 0,98913 0,98938
2,6 0,98765 0,98839 0,98900 0,98951 0,98995 0,99033 0,99066 0,99095 0,99121 0,99144
2,7 0,98967 0,99035 0,99090 0,99137 0,99177 0,99211 0,99241 0,99267 0,99290 0,99311
2,8 0,99136 0,99198 0,99249 0,99291 0,99327 0,99358 0,99385 0,99408 0,99429 0,99447
2,9 0,99278 0,99334 0,99380 0,99418 0,99450 0,99478 0,99502 0,99523 0,99541 0,99557
3,0 0,99396 0,99447 0,99488 0,99522 0,99551 0,99576 0,99597 0,99616 0,99632 0,99646
3,1 0,99495 0,99541 0,99578 0,99608 0,99634 0,99656 0,99675 0,99691 0,99705 0,99718
3.2 0,99577 0,99618 0,99652 0,99679 0,99702 0,99721 0,99738 0,99752 0,99764 0,99775
з,з 0,99646 0,99683 0,99713 0,99737 0,99757 0,99774 0,99789 0,99801 0,99812 0,99821
3,4 0,99703 0,99737 0,99763 0,99784 0,99802 0,99817 0 99830 / 0,99840 0,99850 0,99858
3.5 0,99751 0,99781 0,99804 0,99823 0,99839 0,99852 0,99863 0,99872 0,99880 0,99887
3,6 0,99791 0,99818 0,99838 0,99855 0,99869 0,99880 0,99890 0,99898 0,99905 0,99911
3,7 0,99825 0,99848 0,99867 0,99881 0,99893 0,99903 0,99911 0,99918 0,99924 0,99929
3,8 0,99853 0,99874 0,99890 0,99902 0,99913 0,99921 0,99928 0,99934 0,99939 0,99944
3,9 0,99876 0,99895 0 99909 0,99920 0,99929 0,99936 0,99942 0,99948 0,99952 0,99956
4,0 0,99896 0,99912 0,99924 0,99934 0,99942 0,99948 0,99954 0,99958 0,99962 0,99965
4,2 0,99926 0,99938 0,99948 0,99955 0,99961 0 99966 0,99970 0,99973 0,99976 0,99978
4,4 0,99947 0,99957 0,99964 0,99970 0,99974 О'999 78 0,99980 0,99983 0,99985 0,99986
4,6 0,99962 0,99969 0 99975 0,99979 0,99983 0,99985 0,99987 0,99989 0,99990 0,99991
4,8 0,99972 0,99978 О'99983 0, 99986 0,99988 0,99990 0,99992 0,99993 0,99994 0,99995
5,0 0,99980 0,99985 0,99988 0,99990 0,99992 0,99993 0,99995 0,99995 0,99996 0,99997
•\2 0,99985 0,99989 0,99992 0,99993 0,99995 0,99996 0,99996 0,99997 0,99997 0,99998
5,4 0,99989 0,99992 0,99994 0,99995 0,99996 0,99997 0,99998 0,99998 0,99998 0,99999
5,6 0,99992 0,99994 0,99996 0,99997 0,99997 0,99998 0,99998 0,99999 0,99999 0,99999
5,8 6,0 6,2 6,4 6,6 6,8 7,0 0,99994 0,99995 0,99997 0,99997 0,99998 0,99998 0,99999 0,99996 0,99997 0,99998 0,99998 0,99999 0,99999 0,99999 0,99997 0,99998 0,99998 0,99999 0,99999 0,99999 0,99998 0,99998 0,99999 0,99999 0,99999 0,99998 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999 0,99999
498
Интеграл вероятности для /-распределения (продолжение)
20 21 22 23 24 30 40 60 120 00
0,00 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000 0,50000
0,05 0,51969 0,51970 0,51971 0,51972 0,51973 0,51977 0,51981 0,51986 0,51990 0,51994
0,10 0,53933 0,53935 0,53938 0,53939 0,53941 0,53950 0,53958 0,53966 0,53974 0,53983
0,15 0,55887 0, 55890 0,55893 0,55896 0,55899 0,55912 0,55924 0,55937 0,55949 0,55962
0,20 0,57825 0,57830 0,57834 0,57838 0,57842 0,57858 0,57875 0,57892 0,57909 0,57926
0,25 0,59743 0,59749 0.59755 0,59760 0,59764 0,59785 0,59807 0,59828 0,59849 0,59871
0 30 0,61636 0,61644 0,61650 0,61656 0,61662 0,61688 0,61713 0,61739 0,61765 0,61791
0,35 0,63500 0,63509 0,63517 0,63524 0,63530 0,63561 0,63591 0,63622 0,63652 0,63683
0,40 0,65330 0,65340 0,65349 0,65358 0,65365 0,65400 0,65436 0,65471 0,65507 0,65542
0,45 0,67122 0,67134 0,67144 0,67154 0,67163 0,67203 0,67243 0,67283 0,67324 0,67364
0.50 0,68873 0,68886 0,68898 0,68909 0,68919 0,68964 0,69009 0,69055 0,69100 0,69146
0, 55 0,70579 0,70594 0,70607 0,70619 0,70630 0,70680 0,70731 0,70782 0,70833 0,70884
0,60 0,72238 0,72254 0,72268 0,72281 0,72294 0,72349 0,72405 0,72462 0,72518 0,72575
0,65 0,73846 0,73863 0,73879 0,73893 0,73907 0,73968 0,74030 0,74091 0,74153 0,74215
0, 70 0,75400 0,75419 0,75437 0,75453 0,75467 0,75534 0,75601 0,75668 0,75736 0,75804
0,75 0,76901 0,76921 0,76940 0,76957 0,76973 0,77045 0,77118 0,77191 0,77264 0,77337
0,80 0,78344 0,78367 0,78387 0,78405 0,78422 0,78500 0,78578 0,78657 0,78735 0,78814
0,85 0,79731 0,79754 0,79776 0,79796 0,79814 0,79897 0,79981 0,80065 0,80149 0,80234
0,90 0,81058 0,81084 0,81107 0,81128 0,81147 0,81236 0,81325 0,81414 0,81504 0,81594
0,95 0,82327 0,82354 0,82378 0,82401 0,82421 0,82515 0,82609 0,82704 0,82799 0,82894
!,(»<) 0,83537 0,83565 0,83591 0,83614 0,83636 0,83735 0,83834 0,83934 0,84034 0,84134
1,05 0,84688 0,84717 0,84744 0,84769 0,84791 0,84895 0,84999 0,85104 0,85209 0,85314
1,10 0,85780 0,85811 0,85839 0,85864 0,85888 0,85996 0,86105 0,86214 0,86323 0,86433
1,15 0,86814 0,86846 0,86875 0,86902 0,86926 0,87039 0,87151 0,87265 0,87378 0,87493
1,20 0,87792 0,87825 0,87855 0,87882 0,87907 0,88023 0,88140 0,88257 0,88375 0,88493
1,25 0,88714 0,88747 0,88778 0,88807 0,88832 0,88952 0,89072 0,89192 0,89313 0,89435
1,3(1 0,89581 0,89616 0,89647 0,89676 0,89703 0,89825 0,89948 0,90071 0,90195 0,90320
1,35 0,90395 0,90431 0,90463 0,90492 0,90519 0,90644 0,90770 0,90896 0,91022 0,91149
1,40 0,91158 0,91194 0,91227 0,91257 0,91285 0,91-411 0,91539 0,91667 0,91795 0,91924
1,45 0,91872 0,91908 0,91942 0,91972 0,92000 0,92128 0,92257 0,92387 0,92517 0,92647
1,50 0,92538 0,92575 0,92608 0,92639 0,92667 0,92797 0,92927 0,93057 0,93188 0,93319
1,55 0,93159 0,93196 0,93230 0,93260 0,93289 0,93419 0,93549 0,93680 0,93811 0,93943
1,60 0,93736 0,93773 0,93807 0,93838 0,93866 0,93996 0,94127 0,94257 0,94389 0,94520
1,65 0,94272 0,94309 0,94342 0,94373 0,94401 0,94531 0,94661 0,94792 0,94922 0,95053
1,70 0,94768 0,94805 0,94839 0,94869 0,94897 0,95026 0,95155 0,95284 0,95414 0,95543
1,75 0,95228 0,95264 0,95297 0,95327 0,95355 0,95483 0,95611 0,95738 0,95866 0,95994
1,80 0,95652 0,95688 0,95720 0,95750 0,95778 0,95904 0,96030 0,96156 0,96281 0,96407
1,85 0,96043 0,96078 0,96110 0,96140 0,96167 0,96291 0,96414 0,96538 0,96661 0,96784
1,90 0,96403 0,96437 0,96469 0,96498 0,96524 0,96646 0,96767 0,96888 0,97008 0,97128
1,95 0,96733 0,96767 0,96798 0,96827 0,96852 0,96971 0,97089 0,97207 0,97325 0,97441
2,0 0,97037 0,97070 0,97100 0,97128 0,97153 0,97269 0,97384 0,97498 0,97612 0,97725
2,1 0.97569 0,97601 0,97629 0,97655 0,97679 0,97788 0,97896 0,98003 0,98109 0,98214
2,2 0,98014 0,98043 0,98070 0,98094 0,98116 0,98218 0,98318 0,98416 0,98514 0,98610
2,3 0,98383 0,98410 0,98435 0,98457 0,98478 0,98571 0,98663 0,98753 0,98841 0,98928
2,4 0,98688 0,98712 0,98735 0,98756 0,98774 0,98860 0,98943 0,99024 0,99103 0,99180
2,5 0,98938 0,98961 0,98982 0,99000 0,99017 0,99094 0,99169 0,99241 0,99312 0,99379
2,6 0,99144 0,99164 0,99183 0,99200 0,99215 0,99284 0,99350 0,99414 0,99475 0,99534
2,7 0,99311 0,99329 0,99346 0,99361 0,99375 0,99436 0,99494 0,99550 0,99603 0,99653
2,8 0,99447 0,99463 0,99478 0,99492 0,99504 0,99557 0,99608 0,99657 0,99702 0,99744
2,9 0,99557 0,99572 0,99585 0,99596 0,99607 0,99654 0,99698 0,99740 0,99778 0,99813
3,0 0,99646 0,99659 0,99670 0,99681 0,99690 0,99730 0,99768 0,99804 0,99836 0,99865
3,1 0,99718 0,99729 0,99739 0,99748 0,99756 0,99791 0,99823 0,99853 0,99879 0,99903
3,2 0,99775 0,99785 0,99793 0,99801 0,99808 0,99838 0,99865 0,99890 0,99912 0,99931
3,3 0,99821 0,99829 0,99837 0,99844 0,99849 0,99875 0,99898 0,99918 0,99936 0,99952
м 0,99858 0,99865 0,99871 0,99877 0,99882 0,99904 0,99923 0,99940 0,99954 0,99966
Г \. 20 21 22 23 24 30 40 60 120 ОС
3,5 0,99887 0,99893 0,99899 0,99904 0,99908 0,99926 0,99942 0,99956 0,99967 0,99977
3,6 0,99911 0 99916 0,99920 0,99925 0,99928 0,99943 0,99957 0,99968 0,99977 0,99984
3,7 0,99929 0,99933 0,99937 0,99941 0,99944 0,99957 0,99967 0,99976 0,99984 0,99989
3,8 0,99944 0,99948 0,99951 0,99954 0,99956 0,99967 0,99976 0,99983 0,99989 0,99993
3,9 0,99956 0,99959 0,99961 0,99964 0,99966 0,99975 0,99982 0,99988 0,99992 0,99995
4,0 0,99965 0,99967 0,99970 0,99972 0,99974 0,99981 0,99987 0,99991 0,99995 0,99997
5,0 0,99997 0,99997 0,99998 0,99998 0,99998 0,99999 0,99999
Ведение процентные точки для t
1 - р,( И р = 1 . 2 3 4 5 6 7 8 9 10
10'3 318,3 22,33 10,21 7,17 5,89 5,21 4,79 4,50 4,30 4,14
10 4 3183 70,7 22,20 13,03 9,68 8,02 7,06 6,44 6,01 5,69
10~5 31831 224 47,91 23,33 15,54 12,03 10,11 8,90 8,10 7,53
5Х106 63652 316 60,40 27,82 17,89 13,55 11,22 9,79 8,83 8,15
ПРИЛОЖЕНИЕ 6
Процентные точки распределения х2. В таблице приведены значе-
ния 100а*7о-ных точек х2(«» v) распределения х2 с v степенями свобо-
ды; значение х2(«» у) таково, что
Р[Х2^х2(<х, v)] = ot,
где случайная величина Xv распределена по закону хи-квадрат с v сте-
пенями свободы.
п.р.в. х2 с V степенями свободы
501
Процентные точки распределения х2
(воспроизведено с разрешения Longman Group Ltd. из [Fisher and Yates (1974) — G])
V 0,99 0,98 0,95 0,90 0,80 0,70 0,50 0,30 0,20 0,10 0,05 0,02 0,01 0,001
1 0,0’157 0,0’628 0,00393 0,0158 0,0642 0,148 0,455 1,074 1,642 2,706 3,841 5,412 6,635 10,827
2 0,0201 0,404 0,103 0,211 0,446 0,713 1,386 2,408 3,219 4,605 5,991 7,824 9,210 13^815
3 0,115 0,185 0,352 0,584 1,005 1,424 2,366 3,665 4,642 6,251 7,815 9,837 11,345 16,266
4 0,297 0,429 0,711 1,064 1,649 2,195 3,357 4,878 5,989 7,779 9,488 11,688 13,277 18,467
5 0,544 0,752 1,145 1,610 2,343 3,000 4,351 6,064 7,289 9,236 11,070 13,388 15,086 20,515
6 0,872 1,134 1,635 2,204 3,070 3,828 5,348 7,231 8,558 10,645 12,592 15,033 16,812 22,457
7 1,239 1,564 2,167 2,833 3,822 4,671 6,346 8,383 9,803 12,017 14,067 16,622 18,475 24,322
8 1,646 2,032 2,733 3,490 4,594 5,527 7,344 9,524 11,030 13,362 15,507 18,168 20,090 26,125
9 2,088 2,532 3,325 4,168 5,380 6,393 8,343 10,656 12,242 14,684 16,919 19,679 21,666 27,877
10 2,558 3,059 3,940 4,865 6,179 7,267 9,342 1 1,781 13,442 15,987 18,307 21,161 23,209 29,588
11 3,053 3,609 4,575 5,578 6,989 8,148 10,341 12,899 14,631 17,275 19,675 22,618 24,725 31,264
12 3,571 4,178 5,226 6,304 7,807 9,034 11,340 14,01 1 15,812 18,549 21,026 24,054 26,217 32,909
13 4,107 4,765 5,892 7,042 8,634 9,926 12,340 15,119 16,985 19,812 22,362 25,472 27,688 34,528
14 4,660 5,368 6,571 7,790 9,467 10,821 13,339 16,222 18,151 21,064 23,685 26,873 29,141 36,123
15 5,229 5,985 7,261 8,547 10,307 И 721 14,339 17,322 19,311 22,307 24,996 28,259 30,578 37,697
16 5,812 6,614 7,962 9,312 11,152 12,624 15,338 18,418 20,465 23,542 26,296 29,633 32,000 39,252
17 6,408 7,255 8,672 10,085 12,002 13,531 16,338 19,511 21,615 24,769 27,587 30,995 33,409 40,790
18 7,015 7,906 9,390 10,865 12,857 14,440 17,338 20,601 22,760 25,989 28,869 32,346 34,805 42,312
19 7,633 8,567 10,117 11,651 13,716 15,352 18,338 21,689 23,900 27,204 30,144 33,687 36,191 43/820
20 8,260 9,237 10,851 12,443 14,578 16,266 19,337 22,775 25,038 28,412 31,410 35,020 37,566 45,315
21 8,897 9,915 11,591 13,240 15,445 17,182 20,337 23,858 26,171 29,615 32,671 36,343 38,932 46,797
22 9,542 10,600 12,338 14,041 16,314 18,101 21,337 24,939 27,301 30,813 33,924 37,659 40,289 48,268
23 10,196 11,293 13,091 14,848 17,187 19,021 22,337 26,018 28,429 32,007 35,172 38,968 41,638 49,728
24 10,856 11,992 13,848 15,659 18,062 19,943 23,337 27,096 29,553 33,196 36,415 40,270 42,980 51,179
25 11,524 12,697 14,611 16,473 18,940 20,867 24,337 28,172 30,675 34,382 37,652 41,566 44,314 52,620
Для нечетных значений v между 30 и 70 можно усреднить табличные значения для v—1 и г+1. Для больших значе-
ний v можно использовать преобразование V 2y2 — V 2v—1 к стандартной нормальной величине
26 12,198 13,409 15,379 17,292 19,820 21,792 25,336 29,246 31,795 35,563 38,885 42,856 45,642 54,052
27 12,879 14,125 16,151 18,114 20,703 22,719 26,336 30,319 32,912 36,741 40,113 44,140 46,963 55,476
28 13,565 14,847 16,928 18,939 21,588 23,647 27,336 31,391 34,027 37,916 41,337 45,419 48,278 56,893
29 14,256 15,574 17,708 19,768 22,475 24,577 28,336 32,461 35,139 39,087 42,557 46,693 49,588 58,302
30 14,953 16,306 18,493 20,599 23,364 25,508 29,336 33,530 36,250 40,256 43,773 47,962 50,892 59,703
32 16,362 17,783 20,072 22,271 25,148 27,373 31,336 35,665 38,466 42,585 46,194 50,487 53,486 62,487
34 17,789 19,275 21,664 23,952 26,938 29,242 33,336 37,795 40,676 44,903 48,602 52,995 56,061 65,247
36 19,233 20,783 23,269 25,643 28,735 31,115 35,336 39,922 42,879 47,212 50,999 55,489 58,619 67,985
38 20,691 22,304 24,884 27,343 30,537 32,992 37,335 42,045 45,076 49,513 53,384 57,969 61,162 70,703
40 22,164 23,838 26,509 29,051 32,345 34,872 39,335 44,165 47,269 51,805 55, 759 60,436 63,691 73,402
42 23,650 25,383 28,144 30,765 34,157 36,755 41,335 46,282 49,456 54,090 58,124 62,892 66,206 76,084
44 25,148 26,939 29,787 32,487 35,974 38,641 43,335 48,396 51,639 56,369 60,481 65,337 68,710 78,750
46 26,657 28,504 31,439 34,215 37,795 40,529 45,335 50,507 53,818 58,641 62,830 67,771 71,201 81,400
48 28,177 30,080 33,098 35,949 39,621 42,420 47,335 52,616 55,993 60,907 65,171 70,197 73,683 84,037
50 29,707 31,664 34,764 37,689 41,449 44,313 49,335 54,723 58,164 63,167 67,505 72,613 76,154 86,661
52 31,246 33,256 36,437 39,433 43,281 46,209 51,335 56,827 60,332 65,422 69,832 75,021 78,616 89,272
54 32,793 34,856 38,116 41,183 45,117 48,106 53,335 58,930 62,496 67,673 72,153 77,422 81,069 91,872
56 34,350 36,464 39,801 42,937 46,955 50,005 55,335 61,031 64,658 69,919 74,468 79,815 83,513 94,461
58 35,913 38,078 41,492 44,696 48,797 51,906 57,335 63,129 66,816 72,160 76,778 82,201 85,950 97,039
60 37,485 39,699 43,188 46,459 50,641 53,809 59,335 65,227 68,972 74,397 79,082 84,580 88,379 99,607
62 39,063 41,327 44,889 48,226 52,487 55,714 61,335 67,322 71,125 76,630 81,381 86,953 90,802 102,166
64 40,649 42,960 46,595 49,996 54,336 57,620 63,335 69,416 73,276 78,860 83,675 89,320 93,217 104,716
66 42,240 44,599 48,305 51,770 56,188 59,527 65,335 71,508 75,424 81,085 85,965 91,681 95,626 107,258
68 43,838 46,244 50,020 53,548 58,042 61,436 67,335 73,600 77,571 83,308 88,250 94,037 98,028 109,791
70 45,442 47,893 51,739 55,329 59,898 63,346 69,334 75,689 79,715 85,527 90,531 96,388 100,425 112,317
ПРИЛОЖЕНИЕ 7
Процентные точки F-распределения. В таблицах приведены
1ООа°7о-ные точки ха(т, п) распределения Fmn для а=0,05, 0,01 и
0,001, т. е. верхние 5°7о-, 1%- и 0,1%-ные точки этого распределения.
В таблицах приведены значения ха(т, п), превосходящие 1. Для
меньших 1 значений используйте соотношение
ха(т, n) = l/Xj_a(n, т).
504
/^-распределение: верхние 5%-ные точки
(воспроизведено с разрешения Biometrika Trustees из Biometrika Tables for Statisticians. Vol. 1, 3rd edition, 1966)
\T1 "2 X 1 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120 X
1 161 4 199,5 215 224,6 230,2 234,0 236,8 I 238,9 : 240,5 241,9 243,9 245,9 248,0 249,1 250,1 251,1 252,2 253,3 254,3
2 18,51 19,00 19,16 19,25 19,30 19,33 19,35 19,37 19,38 19,40 19,41 19,43 19,45 19,45 19,46 19,47 19,48 19,49 19,50
3 10,13 9,55 9,28 9,12 9,01 8,94 8,89 8,85 8,81 8,79 8,74 8,70 8,66 8,64 8,62 8,59 8,57 8,55 8,53
4 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5,91 5,86 5,80 5,77 5,75 5,72 5,69 5,66 5,63
5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,77 4,74 4,68 4,62 4,56 4,53 4,50 4,46 4,43 4,40 4,36
6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 4,00 3,94 3,87 3,84 3,81 3,77 3,74 3,70 3,67
7 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,64 3,57 3,51 3,44 3,41 3,38 3,34 3,30 3,27 3,23
8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 3,28 3,22 3,15 3,12 3,08 3,04 3,01 2,97 2,93
9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 3,07 3,01 2,94 2,90 2,86 2,83 2,79 2/75 2,71
10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,98 2,91 2,85 2,77 2,74 2,70 2,66 2,62 2,58 2,54 2,40
11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2 85 2,79 2,72 2,65 2,61 2,57 2,53 2,49 2,45
12 4,75 3,89 3,49 3,26 3,00 2,91 2,85 2,80 2,75 2,69 2,62 2,54 2,51 2,47 2,43 2,38 2,34 2,30
13 4,67 3,81 3,41 3,18 3,03 2,92 2,83 2,77 2,71 2,67 2,60 2,53 2,46 2,42 2/38 2,34 2,30 2,25 2,21
14 4,60 3,74 3,34 3,11 2,96 2,85 2,76 2,70 2,65 2,60 2,53 2,46 2,39 2,35 2,31 2,27 2,22 2,18 2,13
15 4,54 3,68 3,29 3,06 2,90 2,79 2,71 2,64 2,59 2,54 2,48 2,40 2,33 2,29 2,25 2,20 2,16 2,11 2,07
16 4,49 3,63 3,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 2,42 2,35 2,28 2,24 2,19 2,15 2,11 2,06 2,01
17 4,45 3,59 3,20 2,96 2,81 2,70 2,61 2,55 2,49 2,45 2,38 2,31 2,23 2,19 2,15 2,10 2,06 2,01 1,96
18 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 2,34 2,27 2,19 2,15 2,11 2,06 2,02 1,97 1,92
19 4,38 3,52 3,13 2,90 2,74 2,63 2,54 2,48 2,42 2,38 2,31 2,23 2,16 2,H 2,07 2,03 1,98 1,93 1,88
20 4,35 3,49 3,10 2,87 2,71 2,60 2,51 2,45 2,39 2,37 2,35 2,28 2,20 2,12 2,08 2,04 1,99 1,95 1,90 1,84
21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,32 2,25 2,18 2,10 2,05 2,01 1,96 1,92 1,87 1,81
22 4,30 3,44 3,05 2,82 2,66 2,55 2,46 2,40 2,34 2,30 2,23 2,15 2,07 2,03 1,98 1,94 1,89 1,84 1,78
23 4,28 3,42 3,03 2,80 2,64 2,53 244 2,37 2,32 2,27 2,20 2,13 2,05 2,01 1,96 1,91 1,86 1,81 1,76
24 4,26 3,40 3,01 2,78 2,62 2,51 2,42 2,36 2,30 2,25 2,18 2,11 2,03 1,98 1,94 1,89 1,84 1,79 1,73
25 4,24 3,39 2,99 2,76 2,60 2,49 2,40 2,34 2,28 2,24 2,16 2,09 2,01 1,96 1,92 1,87 1,82 1,77 1,71
26 4,23 3,37 2,98 2,74 2,59 2,47 2,39 2,32 2,27 2,22 2,15 2,07 1,99 1,95 1,90 1,85 1,80 1,75 1,69
27 4,21 3,35 2,96 2,73 2,57 2,46 2,37 2,31 2,25 2,20 2,13 2,06 1,97 1,93 1,88 1,84 1,79 1,73 1,67
28 4,20 3,34 2,95 2,71 2,56 2,45 2,36 2,29 2,24 2,19 2,12 2,04 1,96 1,91 1,87 1,82 1,77 1,71 1,65
29 4,18 3,33 2,93 2,70 2,55 2,43 2,35 2,28 2,22 2,18 2,10 2,03 1,94 1,90 1,85 1,81 1,75 1,70 1,64
30 4,17 3,32 2,92 2,69 2,53 2,42 2,33 2,27 2,21 2,16 2,09 2,01 1,93 1,89 1,84 1,79 1,74 1,68 1/62
40 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,08 2,00 1,92 1,84 1,79 1,74 1,69 1,64 1,58 1,51
60 4,00 3,15 2,76 2,53 2,37 2,25 2,17 2,10 2,04 1,99 1,92 1,84 1,75 1,70 1,65 1,59 1,53 1,47 1,39
120 3,92 3,07 2,68 2,45 2,29 2,17 2,09 2,02 1,96 1,91 1,83 1,75 1,66 1,61 1,55 1,50 1,43 1,35 1,25
00 3,84 3,00 2,60 2,37 2,21 2,10 2,01 1,94 1,88 1,83 1,75 1,67 1,57 1,52 1,46 1,39 1,32 1,22 1,00
LZ1
О
O\
/-’-распределение: верхние 1%-ные точки
»» \ 1 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120 00
1 4052 4999,5 5403 5625 5764 5859 5928 5981 6022 6056 6106 6157 , 6209 6235 6261 । 6287 6313 6339 6366
2 98,50 99,00 99,17 99,25 99,30 99,33 99,36 99,37 99,39 99,40 99,42 99,43 99,45 99,46 99,47 99,47 99,48 99,49 99,50
3 34,12 30,82 29,46 28,71 28,24 27,91 27,67 27,49 27,35 27,23 27,05 26,87 26,69 26,60 26,50 26,41 26,32 26,22 26,13
4 21,20 18,00 16,69 15,98 15,52 15,21 14,98 14,80 14,66 14,55 14,37 14,20 14/12 13,93 13,84 13,75 13,65 13^56 1346
5 16,26 13,27 12,06 11,39 10,97 10,67 10,46 10,29 10,16 10,05 9,89 9,72 9,55 9,47 9,38 9,29 9,20 9,11 9 02
6 13,75 10,92 9,78 9,15 8,75 8,47 8,26 8,10 7,98 7,87 7,72 7,56 7,40 7,31 7,23 7,14 7,06 6,97 6,88
7 12,25 9,55 8,45 7,85 7,46 7,19 6,99 6,84 6,72 6,62 6,47 6,31 6,16 6,07 5,99 5,91 5,82 5,74 5,65
8 11,26 8,65 7,59 7,01 6,63 6,37 6,18 6,03 5,91 5,81 5,67 5,52 5,36 5,28 5,20 5,12 5,03 4,95 4,86
9 10,56 8,02 6,99 6,42 6,06 5,80 5,61 5,47 5,35 5,26 5,И 4,96 4,81 4,73 4,65 4,57 448 4,40 4,31
10 10,04 7,56 6,55 5,99 5,64 5,39 5,20 5,06 4,94 4,85 4,7] 4,56 4,4] 4,33 4,25 4,17 4,08 4,00 3 91
11 9,65 7,21 6,22 5,67 5,32 5,07 4,89 4,74 4,63 4,54 4,40 4,25 4,10 4,02 3,94 3,86 3,78 3,69 3^60
12 9,33 6,93 5,95 5,41 5,06 4,82 4,64 4,50 4,39 4,30 4,16 4,01 3,86 3,78 3,70 3,62 3,54 345 3,36
13 9,07 6,70 5,74 5,21 4,86 4,62 4,44 4,30 4,19 4,10 3,96 3,82 3,66 3,59 3,51 3,43 3,34 3,25 3,17
14 8,86 6,51 5,56 5,04 4,69 4,46 4,28 4,14 4,03 3,94 3,80 3,66 3,51 3,43 3,35 3,27 3,18 3,09 3,00
1S 8,68 6,36 5,42 4,89 4,56 4,32 4,14 4,00 3.89 3,80 3,67 3,52 3,37 3,29 3,21 3,13 3,05 2,96 2 87
16 8,53 6,23 5 29 4,77 4,44 4,20 4,03 3,89 3,78 3,69 3,55 3,41 3,26 3,18 3,10 3,02 2,93 2^84 2,75
17 8,40 6,11 5,18 4,67 4,34 4,10 3,93 3,79 3,68 3,59 3,46 3,31 3,16 3,08 3,00 2,92 2,83 2’75 2,65
18 8,29 6,01 5,09 4,58 4,25 4,01 3,84 3,71 3,60 3,51 3,37 3,23 3,08 3,00 2,92 2,84 2,75 2,66 2,57
19 8,18 5,93 5,01 4,50 4,17 3,94 3,77 3,63 3,52 3,43 3,30 3,15 3,00 2,92 2,84 2,76 2,67 2,58 2,49
20 8,10 5,85 4,94 4,43 4,10 3,87 3,70 3,56 3,46 3,37 3,23 3,09 2,94 2,86 2,78 2,69 2,61 2,52 2,42
21 8,02 5,78 4,87 4,37 4,04 3,81 3,64 3,51 3,40 3,31 3,17 3,03 2,88 2,80 2,72 2,64 2,55 2,46 2Д6
22 7,95 5,72 4,82 4,31 3,99 3,76 3,59 3,45 3,35 3,26 3,12 2,98 2,83 2,75 2,67 2,58 2,50 2,40 2,31
23 7,88 5,66 4,76 4,26 3,94 3,71 3,54 341 3,30 3,21 3,07 2,93 2,78 2,70 2,62 2,54 2,45 2,35 2,26
24 7,82 5,61 4,72 4,22 3,90 3,67 3,50 3,36 3,26 3,17 3,03 2,89 2/74 2,66 2,58 2,49 2,40 2,31 2,21
25 7,77 5,57 4,68 4,18 3,85 3,63 3,46 3,32 3,22 3,13 2,99 2,85 2,70 2,62 2,54 2,45 2,36 2,27 2,17
26 7,72 5,53 4,64 4,14 3,82 3,59 3,42 3,29 3,18 3,09 2,96 2,81 Ifib 2,58 2,50 2,42 2,33 2,23 2,13
27 7,68 5,49 4,60 4,11 3,78 3,56 3,39 3,26 3,15 3,06 2,93 2,78 г/Л 2,55 2,47 2,38 2,29 2,20 2,10
28 7,64 5,45 4,57 4,07 3,75 3,53 3,36 3,23 3,12 3,03 2,90 2,75 2,60 2,52 2,44 2,35 2,26 2,17 2,06
29 7,60 5,42 4,54 4,04 3,73 3,50 3,33 3,20 3,09 3,00 2,87 2,73 2,57 2,49 2,41 2,33 2,23 2,14 2,03
30 7,56 5,39 4,51 4,02 3,70 3,47 3,30 3,17 3,07 2,98 2,84 2,70 2,55 2,47 2,39 2,30 2,21 2,Н 2,0!
40 7,31 5,18 4,31 3,83 3,51 3,29 V2 2,99 2,89 2,80 2,66 2,52 2,37 2,29 2,20 2,Н 2,02 1,92 1,80
60 7,08 4.98 4,13 3,65 3,34 3,12 2,95 2,82 2,72 2,63 2,50 2,35 2,20 2,12 2,03 1,94 1,84 1,73 1,60
120 6,85 4,79 3,95 3,48 3,17 2,96 2,79 2,66 2,56 2,47 2,34 2,19 2/13 1,95 1,86 1,76 1,66 1,53 1,38
00 6,оЗ 4,61 3,78 3,32 3,02 2,80 2,64 2,51 2,41 2,32 2,18 2,04 1,88 1,79 1,70 1,59 1,47 1/32 1,00
F-распределение: верхние 0,1%-ные точки
'к Р) I 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120 ОС
*2 \
1 4053* 5000* 5404* 5625* 5764* 5859* 5929* 5981* 6023* 6056* < 5107* 6158* 6209* 1 5235* < 5261* 1 52 87* । 6313* 6340* 6366*
2 998,5 999,0 999,2 999,2 999,3 999,3 999,4 999,4 999,4 999,4 999,4 999,4 999,4 999,5 999,5 999,5 999,5 999,5 999,5
3 167,0 148, 141,1 137,1 134,6 132,8 131,6 130,6 129,9 129,2 128,3 127,4 126,4 125,9 125,4 125 0 124,5 124,0 123,5
4 74,14 61,25 56,18 53,44 51,71 50,53 49,66 49,00 48,47 48,05 47,41 46,76 46,10 45,77 45,43 45,09 44,75 44,40 44,05
5 47,18 37,12 33,20 31,09 29,75 28,84 28,16 27,64 27,24 26,92 26,42 25,91 25,39 25,14 24,87 24,60 24,33 24,06 23,79
6 35,51 27,00 23,70 21,92 20,81 20,03 19,46 19,03 18,69 18,41 17,99 17,56 17,12 16,89 16,67 16,44 16 21 15,99 15,75
7 29,25 21,69 18,77 17,19 16,21 15,52 15,02 14,63 14,33 14,08 13,71 13,32 12,93 12,73 12,53 12,33 12,12 11,91 11,70
8 25,42 18,49 15,83 14,39 13,49 12,86 12,40 12,04 11,77 11,54 11,19 10,84 10,48 10,30 10,11 9,92 9,73 9,53 9,33
9 22,86 16,39 13,90 12,56 11,71 11,13 10,70 10,37 10,11 9 89 9,57 9,24 8,90 8,72 8,55 8,37 8,19 8,00 7,81
10 21,04 14,91 12,55 11,28 10,48 9,92 9,52 9,20 8,96 8,75 8,45 8,13 7,80 7,64 7,47 7,30 7,12 6,94 6,76
11 19,69 13,81 11,56 10,35 9,58 9,05 8,66 8,35 8,12 7,92 7,63 7,32 7,01 6,85 6,68 6,52 6,35 6,17 6,00
12 18,64 12,97 10,80 9,63 8,89 8,38 8,00 7,71 7,48 7,29 7,00 6,71 6,40 6 25 6,09 5,93 5,76 5,59 5,42
13 17,81 12,31 10,21 9,07 8,35 7,86 7,49 7,21 6,98 6 80 6,52 6,23 5,93 5,78 5,63 5,47 5,30 5,14 4,97
14 17,14 11,78 9,73 8,62 7,92 7,43 7,08 6,80 6,58 6,40 6,13 5,85 5,56 5,41 5,25 5,10 4,94 4,77 4,60
15 16,59 11,34 9,34 8,25 7,57 7,09 6,74 6,47 6,26 6,08 5,81 5,54 5,25 5,1° 4,95 4,80 4 64 4,47 4,31
16 16,12 10,97 9,00 7,94 7,27 6,81 6,46 6,19 5,98 5,81 5,55 5,27 4,99 4,85 4,70 4,54 4,39 4,23 4,06
17 15,72 10,66 8,73 7,68 7,02 6,56 6,22 5,96 5,75 5,58 5,32 5,05 4,78 4,63 4,48 4,33 4,18 4 02 3,85
18 15,38 10,39 8,49 7,46 6,81 6,35 6,02 5,76 5,56 5,39 5,13 4,87 4,59 4,45 4,30 4,15 4,00 3,84 3,67
19 15,08 10,16 8,28 7,26 6,62 6,18 5,85 5,59 5,39 5,22 4,97 4,70 4,43 4,29 4,14 3,99 3,84 3,68 3,51
20 14,82 9,95 8,10 7,10 6,46 6.02 5,69 5,44 5,24 5,08 4,82 4,56 4,29 4,15 4,00 3,86 3,70 3,54 3,38
21 14,59 9,77 7,94 6,95 6,32 5,88 5,56 5,31 5,И 4,95 4,70 4,44 4,17 4,03 3,88 3,74 3,58 3,42 3,26
22 14,38 9,61 7,80 6,81 6,19 5,76 5,44 5,19 4,99 4,83 4,58 4.33 4,06 3,92 3,78 3,63 3,48 3,32 3,15
23 14,19 9,47 7,67 6,69 6,08 5,65 5,33 5,09 4,89 4,73 4,48 4,23 3,96 3,82 3,68 3,53 3,38 3,22 3,05
24 14,03 9,34 7,55 6,59 5,98 5,55 5,23 4,99 4,80 4,64 4,39 4,14 3,87 3,74 3,59 3,45 3,29 3,14 2,97
25 13,88 9,22 7,45 6,49 5,88 5,46 5,15 4,91 4,71 4,56 4,31 4,06 3,79 3,66 3,52 3,37 3,22 3,06 2,89
26 13,74 9,12 7,36 6,41 5,80 5,38 5,07 4,83 4,64 4,48 4,24 3,99 3,72 3,59 3,44 3,30 3,15 2,99 2,82
27 13,61 9,02 7,27 6,33 5,73 5,31 5,00 4,76 4,57 4,41 4,17 3,92 3,66 3,52 3,38 3,23 3,08 2,92 2,75
28 13,50 8,93 7,19 6,25 5,66 5,24 4,93 4,69 4,50 4,35 4,11 3,86 3,60 3,46 3,32 3,18 3,02 2,86 2,69
29 13,39 8,85 7,12 6,19 5 59 5,18 4,87 4,64 4,45 4,29 4,05 3,80 3,54 3,41 3,27 3,12 2,97 2,81 2,64
30 13,29 8,77 7,05 6,12 5,53 5,12 4,82 4,58 4,39 4,24 4,00 3,75 3,49 3,36 3,22 3,07 2,92 2,76 2,59
40 12,61 8,25 6,60 5,7° 5,13 4,73 4,44 4 21 4,02 3,87 3,64 3,40 3,15 3,01 2,87 2,73 2,57 2,41 2,23
60 11,97 7,76 6,17 5,31 4,76 4,37 409 3,87 3,69 3,54 3,31 3,08 2,83 2,69 2,55 2,41 2,25 2,08 1,89
120 11,38 7,32 5,79 4,95 4,42 4,04 3,77 3,55 3,38 3,24 3,02 2,78 2,53 2,40 2,26 2,11 1,95 1,76 1,54
00 10,83 6,91 5,42 4,62 4,10 3,74 3,47 3,27 3,10 2,96 2,74 2,51 2,27 2,13 1,99 1,84 1,66 1,45 1,00
Эти значения надо умножить на 100
ПРИЛОЖЕНИЕ 8
Случайные числа. Таблица содержит 5000 (фактически 2500. —
Примеч. пер.) «случайных цифр», т. е. независимых реализаций слу-
чайной переменной N, принимающей значения 0,1,...,9 с равными ве-
роятностями, т. е.
P(N=n)=0,l для л=0,1,...,9.
Таблицу можно читать в любом направлении, начиная с любого ме-
ста. Случайное число с d знаками после запятой можно получить, по-
мещая десятичную запятую перед любыми d последующими
цифрами. Например, начиная с девятой цифры седьмой строки и по-
ложив d=5, получим случайное число 0,31572. Его можно рассматри-
вать как реализацию (с округлением) случайной переменной Z,
распределенной равномерно на (0, 1). П.р.в. Z в точке z равна:
Е1, если OCzC 1»
0 в противном случае.
508
Случайные числа
(воспроизведено с разрешения Longman Group Ltd. из [Fisher and T&tes (1974) — G])
03 47 43 73 86 36 96 47 36 61 46 98 63 71 62 33 26 16 80 45 60 11 14 10 95
97 74 24 67 62 42 81 14 57 20 42 53 32 37 32 27 07 36 07 51 24 51 79 89 73
16 76 62 27 66 56 50 26 71 07 32 90 79 78 53 13 55 38 58 59 88 97 54 14 10
12 56 85 99 26 96 96 68 27 31 05 03 72 93 15 57 12 10 14 21 88 26 49 81 76
55 59 56 35 64 38 54 82 46 22 31 62 43 09 90 06 18 44 32 53 23 83 01 30 30
16 22 77 94 39 49 54 43 54 82 17 37 93 23 78 87 35 20 96 43 84 26 34 91 64
84 42 17 53 31 57 24 55 06 88 77 04 74 47 67 21 76 33 50 25 83 92 12 06 76
63 01 63 78 59 16 95 55 67 19 98 10 50 71 75 12 86 73 58 07 44 39 52 38 79
33 21 12 34 29 78 64 56 07 82 52 42 07 44 38 15 51 00 13 42 99 66 02 79 54
57 60 86 32 44 09 47 27 96 54 49 17 46 09 62 90 52 84 77 27 08 02 73 43 28
18 18 07 92 46 44 17 16 58 09 79 83 86 19 62 06 76 50 03 10 55 23 64 05 05
26 62 38 97 75 84 16 07 44 99 83 11 46 32 24 20 14 85 88 45 10 93 72 88 71
23 42 40 64 74 82 97 77 77 81 07 45 32 14 08 32 98 94 07 72 93 85 79 10 75
32 36 28 19 95 50 92 26 11 97 00 56 76 31 38 80 22 02 53 53 86 60 42 04 53
37 85 94 35 12 83 39 50 08 30 42 34 07 96 88 54 42 06 87 98 35 85 29 48 39
70 29 17 12 13 40 33 20 38 26 13 89 51 03 74 17 76 37 13 04 07 74 21 19 30
56 62 18 37 35 96 83 50 87 75 97 12 25 93 47 70 33 24 03 54 97 77 46 44 80
99 49 57 22 77 88 42 95 45 72 16 64 36 16 00 04 43 18 66 79 94 77 24 21 90
16 08 15 04 72 33 27 14 34 09 45 59 34 68 49 12 72 07 34 45 99 27 72 95 14
31 16 93 32 43 50 27 89 87 19 20 15 37 00 49 52 85 66 60 44 38 68 88 11 80
68 34 30 13 70 55 74 30 77 40 44 22 78 84 26 04 33 46 09 52 68 07 97 06 57
74 57 25 65 76 59 29 97 68 60 71 91 38 67 54 13 58 18 24 76 15 54 55 95 52
27 42 37 86 53 48 55 90 65 72 96 57 69 36 10 96 46 92 42 45 97 60 49 04 91
00 39 68 29 61 66 37 32 20 30 77 84 57 03 29 10 45 65 04 26 И 04 96 67 24
29 94 98 94 24 68 49 69 10 82 53 75 91 93 30 34 25 20 57 27 40 48 73 51 92
Случайные числа (продолжение)
16 90 82 66 59 83 62 64 И 12 67 19 00 71 74 60 47 21 29 68 02 02 37 03 31
11 27 94 75 06 06 09 19 74 66 02 94 37 34 02 76 70 90 30 86 38 45 94 30 38
35 24 10 16 20 33 32 51 26 38 79 78 45 04 91 16 92 53 56 16 02 75 50 95 98
38 23 16 86 38 42 38 97 01 50 87 75 66 81 41 40 01 74 91 62 48 51 84 08 32
31 96 25 91 47 96 44 33 49 13 34 86 82 53 91 00 52 43 48 85 27 55 26 89 62
66 67 40 67 14 64 05 71 95 86 11 05 65 09 68 76 83 20 37 90 57 16 00 И 66
14 90 84 45 11 75 73 88 05 90 52 27 41 14 86 22 98 12 22 08 07 52 74 95 80
68 05 51 18 00 33 96 02 75 19 07 60 62 93 55 59 33 82 43 90 49 37 38 44 59
20 46 78 73 90 97 51 40 14 02 04 02 33 31 08 39 54 16 49 36 47 95 93 13 30
64 19 58 97 79 J5 06 15 93 20 01 90 10 75 06 40 78 78 89 62 02 67 74 17 33
05 26 93 70 60 22 35 85 15 13 92 03 51 59 77 59 56 78 06 83 52 91 05 70 74
07 97 10 88 23 09 98 42 99 64 61 71 62 99 15 06 51 29 16 93 58 05 77 09 51
68 71 86 85 85 54 87 66 47 54 73 32 08 11 12 44 95 92 63 16 29 56 24 29 48
26 99 61 65 53 58 37 78 80 70 42 10 50 67 42 32 17 55 85 74 94 44 67 16 94
14 65 52 68 75 87 59 36 22 41 26 78 63 06 55 13 08 27 01 50 15 29 39 39 43
17 53 77 58 71 71 41 61 50 72 12 41 94 96 26 44 95 27 36 99 02 96 74 30 83
90 26 59 21 19 23 52 23 33 12 96 93 02 18 39 07 02 18 36 07 25 99 32 70 23
41 23 52 55 99 31 04 49 69 96 10 47 48 45 88 13 41 43 89 20 97 17 14 49 17
60 20 50 81 69 31 99 73 68 68 35 81 33 03 76 24 30 12 48 60 18 99 10 72 34
91 25 38 05 90 94 58 28 41 36 45 37 59 03 09 90 35 57 29 12 82 62 54 65 60
34 50 57 74 37 98 80 33 00 91 09 77 93 19 82 74 94 80 04 04 45 07 31 66 49
85 22 04 39 43 73 81 53 94 79 33 62 46 86 28 08 31 54 46 31 53 94 13 38 47
09 79 13 77 48 73 82 97 22 21 05 03 27 24 83 72 89 44 05 60 35 80 39 94 88
88 75 80 18 14 95 75 42 49 39 32 82 22 49 02 48 07 70 37 16 04 61 67 87
90 96 23 70 00 39 00 03 06 90 55 85 78 38 36 94 37 30 69 32 90 89 00 76 33
509
ПРИЛОЖЕНИЕ 9
Стандартные нормальные числа. Таблица содержит 500 независи-
мых реализаций, округленных до трех знаков после запятой! стан-
дартной нормальной переменной U, для которой п.р.в. в точке и
равна:
Ф(м) =
—< и < .
Реализацию и стандартной нормальной величины V можно превра-
тить в реализацию х случайной величины N(pt, ст) по формуле
X=/l+CTU.
Стандартные нормальные числа
(воспроизведено с разрешения Macmillan Publishers Ltd. из [Murdoch and Barnes (1968) — GJ)
0 1 2 3 4 5 6 7 8 9
00 -0,179 -0,399 -0,235 -0,098 -0,465 + 1,563 -1,085 +0,860 +0,388 +0,710
01 +0,421 +1,454 +0,904 +0,437 -2,120 + 1,085 -0,277 -2,170 +0,018 -0,722
02 +0,210 -0,556 +0,465 -1,812 -2,748 -0,345 -0,251 +0,622 -1,015 +0,762
03 -1,598 +0,919 -0,266 -0,999 +0,308 -0,592 +0,817 -0,454 + 1,598 +0,240
04 +1,717 +1,514 -0,012 -0,852 +0,118 +0,399 -0,123 +0,432 -0,470 +0,776
05 -0,308 +0,867 -0,372 +0,697 -1,787 +0,568 -0,002 -0,133 +0,545 -0,824
06 -0,421 +0,516 -0,038 +1,200 +0,063 -0,377 -1,007 -0,334 + 1,299 +0,038
07 -0,776 +0,874 -1,265 -0,580 +0,377 -0,697 -2,226 -1,299 -0,796 -0,628
08 +0,640 -0,522 +0,023 -0,393 -1,142 -2,457 -1,580 +1,160 +0,008 +0,487
09 -0,319 +0,889 +1,180 -0,404 + 1,322 +0,410 + 1,468 +0,235 -0,810 -1,131
10 +0,610 -0,383 +1,812 +0,729 +0,204 -0,225 +0,169 -0,729 -0,432 +0,634
11 -0,174 -0,154 +0,098 +0,393 -3,090 + 1,762 + 1,530 +0,C28 +0,950 -0,935
12 +2,576 -0,684 -1,200 +0,002 +0,261 -0,415 +0,598 -0,769 -0,169 -1,498
13 -1,103 +1,398 -0,653 +1,739 +0,476 +0,510 +0,782 -0,634 +0,562 -0,053
14 + 1,635 +0,448 -1,530 -0,043 +2,290 -0,063 -1,695 +0,199 + 1,211 -1,360
15 -0,068 -0,860 -0,194 -1,616 +0,334 +0,189 +0,927 -1,454 +0,958 +0,404
16 -1,960 + 1,076 -0,671 -0,103 +1,041 +2,226 + 1,838 -0,510 -1,322 +2,366
17 +0,443 -0,912 +0,251 -0,574 +1,131 -0,204 -0,324 -0,487 -1,287 +0,522
18 +1,360 +0,533 +1,094 +0,671 +0,852 -2,576 -0,539 -0,568 +0,225 -0,545
19 +0,810 +0,319 -1,514 +0,556 +1,112 -0,210 +0,292 +0,749 +0,882 +0,033
20 +0,616 + 1,347 -1,866 -0,755 +0,329 +0,148 -0,058 -0,199 +0,048 + 1,546
21 -0,598 -2,366 -0,831 +0,454 -0,118 -1,762 +0,493 +1,103 +0,361 +0,113
22 +0,426 +1,580 -1,112 +0,550 -1,254 -0,033 +0,143 -1,141 +0,366 - 0,073
23 +0,831 -0,516 -1,717 -0,340 +1,655 +0,194 -0,388 -0,942 -1,243 -0,292
24 -0,640 -0,128 +1,276 -1,838 -0,410 +0,646 +2,075 -0,159 + 1,695 +0,527
Стандартные нормальные числа (продолжение)
0 1 2 3 4 5 6 7 8 9
25 -0,927 +0,838 -1,546 +0,246 -0,742 -0,143 +2,457 +0,043 -1,058 -0,867
26 + 1,232 +2,170 +0,088 -0,803 +0,574 +0,058 +0,282 +0,356 +0,350 -1,927
27 +0,935 +0,665 +2,034 -1,995 +0,703 -0,083 -1,468 +0,078 -0,966 -0,303
28 -1,739 -0,622 -1,563 +0,313 +0,220 -0,586 +0,272 +0,789 -1,335 + 1,440
29 +0,990 -1,483 +0,154 -1,372 -1,896 + 1,385 -1,041 +0,974 +0,482 -1,211
30 -0,189 -0,240 +0,133 -2,290 -0,616 -0,437 +0,459 -0,499 +0,845 +0,383
31 + 1,866 -1,398 +0,068 +0,053 -2,034 + 1,426 + 1,254 + 1,067 +0,592 +0,174
32 -0,018 +0,628 +0,230 +0,659 -0,298 + 1,927 -0,282 +0,769 -0,690 + 1,675
33 -0,646 -0,350 +0,324 -1,675 + 1,190 -1,076 + 1,287 -1,426 +0,345 -0,215
34 -1,150 -0,220 -0,533 +0,912 ' -0,710 -0,904 -0,817 -1,160 -0,919 -0,659
35 +0,103 -0,361 + 1,024 -0,6-0,482 -0,562 +0,277 -1,440 -0,366 -0,256
37 -0,093 -1,190 +0,580 -1,276 +0,653 -0,048 +0,742 -1,170 + 1,960 + 2 120
38 -0,261 -0,194 +0,303 +0,340 + 1,498 -1,232 -0,078 -0,443 + 1,141 4 1,787
39 -0,230 -0,550 +0,266 -1,655 +0,999 -1,067 + 1,058 +0,796 +0,415 + 1,995
40 -0,148 +0,504 -0,028 +0,083 +0,824 -1,024 + 1,412 -0,164 + 1,150 -0,272
41 + 1,122 +0,896 -0,789 +0,215 -0,426 -1,049 -0,974 +0,586 + 1,311 -0,736
42 +0,499 -1,032 +0,159 +0,123 +2,748 -0,749 -0,665 -1,221 -1,180 + 1,049
43 +0,678 -0,782 +0,470 +0,256 +0,298 -0,990 +0,287 +0,942 +0,128 + 1,372
44 -1,347 +3,090 -0,896 +0,138 -0,838 +0,690 + 1,007 +0,184 +0,164 +0,179
45 -1,094 -0,610 -0,287 +0,755 -0,459 -1,635 -0,108 -0,246 + 1,032 -0,527
46 -0,088 -0,889 +0,803 -1,311 -0,703 + 1,170 -0,113 +0,108 -0,874 +0,372
47 +0,093 -0,476 + 1,265 -0,448 + 1,015 -0,313 -0,958 +0,716 + 1,483 +0 722
48 -0,950 -0,008 +0,012 +0,073 -0,762 -0,493 + 1,896 +0,982 + 1,616 + 1'221
49 -0,329 -0,138 -0,504 -0,678 + 1,335 -2,075 -1,385 -0,023 -0,356 -0,982
ПРИЛОЖЕНИЕ 10
Доверительные границы для параметра биномиального распреде-
ления. Номограммы указывают доверительные границы для парамет-
ра в распределения Bin (я, в) при данном значении отношения г/п.
(Воспроизведено с разрешения Biometrika Trustees.)
r/n
r/n
Числа вдоль кривых указывают объем выборки п. Для данного значения r/п грани-
цы доверительного интервала (0 х, О") с помощью соответствующей верхней и нижней
кривой надо считать с оси ординат. Коэффициент доверия >0,99.
513
r/n
1,00 0,96 0,92 0,88 0,84 0,80 0,76 0,72 0,68 0,64 0,60 0,56 0,52
0,90 ртглти—i—i—i—i—i—i—i—i—i—i—i—j—i—i—i—f—i—i—i—i—i—r-h 0,10
0,02 0,06 0,10 0,14 0,18 0,22 0,26 0,30 0,34 0,38 0,42 0,46 0,50
r/n
Числа вдоль кривых указывают объем выборки п. Для данного значения г/п грани-
цы доверительного интервала (в', в") с помощью соответствующей верхней и нижней
кривой надо считать с оси ординат. Коэффициент доверия >0,95.
514
ПРИЛОЖЕНИЕ 11
Доверительные границы для параметра X распределения Пуассона при данном значении с пуассоновских событий. Таблиц;
дает верхние и нижние доверительные границы для X с коэффициентом доверия 1—2а.
Доверительные границы для параметра распределения Пуассона
(воспроизведено с разрешения Biometrika Trustees из Biometrika Tables for Statisticians. Vol. 1, 3rd edition, 1966)
1—2a 0,998 0,99 0,98 0,95 0,90 1—2а
a 0,001 0,005 0,01 0,025 0,05 а
c Нижние Верхние Нижниэ Верхние Нижние Верхние Нижние Верхи >э Нижние Верхние с
0 0,00000 6,91 0,00000 5,30 0,0000 4,61 0,0000 3,69 0,0000 3,00 0
1 0,00100 9,23 0,00501 7,43 0,0101 6,64 0,0253 5,57 0,0513 4,74 1
2 0,0454 11,23 0,103 9,27 0,149 8,41 0,242 7,22 0,355 6,30 2
3 0,191 13,06 0,338 10,98 0,436 10,05 0,619 8,77 0,818 7,75 3
4 0,429 14,79 0,672 12,59 0,823 11,60 1,09 10,24 1,37 9 15 4
5 0,739 16,45 1,08 14,15 1,28 13,11 1,62 11 67 1,97 10,51 5
6 1,11 18,06 1,54 15,66 1,79 14,57 2,20 13,06 2,61 11,84 6
7 1,52 19,63 2,04 17,13 2,33 16,00 2,81 14,42 3,29 13,15 7
8 1,97 21,16 2,57 18,58 2,91 17,40 3,45 15,76 3,98 14,43 8
9 2,45 22,66 3,13 20,00 3,51 18,78 4,12 17,08 4,70 15,71 9
10 2,96 24,13 3,72 21,40 4,13 20,14 4,80 18,39 5,43 16,96 10
11 3,49 25,59 4,32 22,78 4,77 21,49 5,49 19,68 6,17 18,21 11
12 4,04 27,03 4,94 24,14 5,43 22,82 6,20 20,96 6,92 19,44 12
13 4,61 28,45 5,58 25,50 6,10 24,14 6,92 22,23 7,69 20,67 13
14 5,20 29,85 6,23 26,84 6,78 25,45 7,65 23,49 8,46 21,89 14
15 5,79 31,24 6,89 28,16 7,48 26,74 8,40 24,74 9,25 23,10 15
16 6,41 32,62 7,57 29,48 8,18 28,03 9,15 25,98 10,04 24,30 16
17 7,03 33,99 8,25 30,79 8,89 29,31 9,90 27,22 10,83 25,50 17
18 7,66 35,35 8,94 32,09 9,62 30,58 10,67 28,45 11,63 26,69 18
Ui L/l 19 8,31 36,70 9,64 33,38 10,35 31,85 11,44 29,67 12,44 27,88 19
20 21 8,96 9,62 38 04 39,38 10 35 11'07 34 67 35^95 11 08 11,82 33 10 34’36 12,22 13,00 30,89 32,10 13,25 14;07 29,06 30,24 20 21
10,29 40,70 11,79 37,22 12,57 35,60 13,79 33,31 14,89 31,42
23 10,96 42,02 12,52 38,48 13,33 36,84 14,58 34,51 15,72 32,59 23
24 11,65 43,33 13,25 39,74 14,09 38,08 15,38 35,71 16,55 33,75 24
25 12,34 44,64 14,(И) 41,(И) 14,85 39,31 16,18 36,90 17,38 34,92 25
26 13,03 45,94 14,74 42,25 15,62 40,53 16,98 38,10 18,22 36,08 26
27 13,73 47,23 15,49 43,50 16,40 41,76 17,79 39,28 19,06 37,23 27
28 14,44 48,52 16,24 44,74 17,17 42,98 18,61 40,47 19,90 38,39 28
29 15,15 49,80 17,00 45,98 17,96 44,19 19,42 41,65 20,75 39,54 29
30 15,87 51,08 17,77 47,21 18,74 45,40 20,24 42,83 21,59 40,69 30
35 19,52 57,42 21,64 53,32 22,72 51,41 24,38 48,68 25,87 46,40 35
40 23,26 63,66 25,59 59,36 26,77 57,35 28,58 54,47 30,20 52,07 40
45 27,08 69,83 29,60 65,34 30,88 63,23 32,82 60,21 34,56 57,69 45
50 30,96 75,94 33,66 71,27 35,03 69,07 37,11 65,92 38,96 63,29 50
предметный указатель
Автоковариация (autocovariance) Т. 2, 318
Автокорреляционная функция (autocorrelation func-
tion) Т. 2, 317—324, 453, 459, 460
Автокорреляция (autocorrelation) Т. 2, 803
Авторегрессионная модель (autoregression model) Т. 2,
354—361
— авторегрессии и скользящего среднего смешанные
модели (autoregression moving average (ARMA) models)
T. 2, 361—373, 442—445
— определение и свойства (definition and properties)
T. 2, 361—362
— пример (example) T. 2, 362
— пример первого и второго порядка (first and second
order example) T. 2, 355—356
— прогноз (с ее помощью) (forecasting using auto-
regression model) T. 2, 360
— состоятельное оценивание (efficient estimation for)
T. 2, 358—360
— спектр (spectrum for) T. 2, 368
— сравнение с моделью скользящего среднего (com-
parison with moving average model) T. 2, 362
— характеристические свойства (characteristics propet-
ries) T. 2, 357
Аддитивная модель (additivity model)T. 1, 486
Адекватность моделей (validity of the model) T. 1,
355-358
Аллометрический рост (allometric growth) T. 2, 243
Альтернативные гипотезы (alternative hypothesis) T. 1,
214, 222, 233, 234, 263—265, 277
Анализ «внутри» н «между» (within and between
analysis) T. 1, 475
Анализ главных координат (principal coordinates
analysis) T. 2, 256
Анализ главных факторов (principal factor analysis)
T. 2, 228
Анализ остатков (residual analysis) T. 1, 507—509
Анализ соответствий (correspondence analysis) T, 2,
253-256
Апостериорная вероятность (posterior probability)
T. 1, 142, T. 2, 144, 146
Апостериорная плотность (posterior density) T. 2,
164—167, 176, 181, 182, 185, 186, 188, 196, 197
Байеса теорема (Bayes’ Theorem) T. 1, 88, T. 2, 143,
394, 412, 447
Байесовская достаточная статистика (Bayes sufficient
statistic) T. 2, 183
Байесовская оценка (Bayes estimate) T. 2, 394—396
Байесовские решающие правила (Bayes decision rules)
T. 2, 377—394, 397
Байесовский риск (Bayes risk) T. 2, 382, 383
Байесовская парадигма (paradigm) T. 2, 144
Байесовская статистика (statistics) T. 2, 143—204
Байесовские методы (methods) T. 2, 110, 111, 143
Байесовский вывод (inference) T. 1, 12, 88
— для одномерных вероятностных моделей (for
univariate probability models) T. 2, 186—200
Байесовский доверительный (апостериорный) интер-
вал (posterior credible interval) T. 2, 179, 188, 194
Байесовский интервал (interval) T. 1, 209
Байесовский критерий значимости (significance test)
T. 2, 181 — 182
Бернулли испытания (Bernoulli trials) T. 1, 80, 305,
307, 308
Бернулли распределения (Bernoulli distribution) T. 1,
25, 122, 174, 212, 304
Бета-распределение (Beta distribution) T. 1, 59
Бета-фуикция (Beta function) T. 1, 178
Биномиальная вероятностная модель (binomial
probability model) T. 2, 192
Биномиально-логистическая модель (binomial-logistic
model) T. 2, 10, 14, 18, 21, 26
Биномиальное распределение как член экспоненциаль-
ного семейства распределений (binomial, as member of
expornential family)
— приближение (binomial approximation) T. 1, 237
— распределение (binomial distribution) T. 1, 25, 71—
73, 80, 84, 109, 125, 146, 170, 216, 218, 305—306, 359,
369, T. 2, 121, 159
— таблица (table) T. 1, 174—176
Биномиальные выборки (binomial samples) T. 1,
378—379
Блокирование (blocking) T. 1, 450
Блокирование эффект (block effect) T. 2, 37, 44
Бокса—Дженкинса сезонная модель (Boks—Jenkins
seasonal model) T. 2, 352—354
Броуновское движение (Brownian motion) T. 2, 436
Вальда метод (Wald’s method) T. 2, 106
Вариации коэффициент (variation) T. 1, 68, 70, 71
Вектор выборочных средних (sample mean vector) T. 2,
207
Вектор данных (data vector) T. 1, 282, 304, 358
Вектор единичный (unit vector) T. 2, 10
Вектор собственный (eigenvector) T. 2, 220, 221, 223,
228, 231, 244, 258—261, 280
Векторная запись (vector notation) T. 2, 210
Векторная случайная величина или случайный вектор
(vector random variable) Т. 2, 205 , 206, 209, 213 , 229
Векторное уравнение (vector equation) Т. 2, 426
Векторы (vectors) Т. 2, 7, 8, 57
Вероятностная бумага (probability graph paper) Т. 1,
99, 270—271, 507
Вероятностное упорядочение (probability ordering)
Т. 1, 216-217
Вероятностные модели (probability models) Т. 1, 212,
247, 278, 335—337, 358, Т, 2, 6, 52
Вероятность условная (conditional probability) Т. 1, 26,
Т. 2, 50, 106, 146, 420
Взаимно независимые стандартные нормальные пе-
ременные (mutually independent standard Normals) T. 1,
48
517
Взаимодействие первого порядка (двух факторов)
(first order interaction) Т. 1, 491
Взаимодействия второго порядка (second-order intera-
ction) Т. 1, 491
Взвешенное среднее (weighted average) Т. 2, 189
Взвешивание (weighting procedure) Т. 1, 73
Вращение факторов (factor rotation) Т. 2, 229, 285
Временные ряды (time series) Т. 1, 22, Т. 2, 300—374
Вторые монеты (second moments) Т. 2, 69—70
Выборочная автоковариация (sample autocovariance)
Т. 2, 337
Выборочная асимметрия (sampling skewness) Т. 1, 41,
42
Выборочная дисперсия (sample variance) Т. 1, 34, 41,
53, Т. 2, 208, 213
Выборочная, или эмпирическая, функция распределе-
ния (empirical c.d.f.) Т. 1, 99, 131, 193—194
Выборочная ковариационная матрица (sample
covariance matrix) Т. 2, 208 , 222
Выборочная ковариация (sample covariance) Т. 1, 34—
35, 41, Т. 2, 208
Выборочная приемка, или выборочный контроль (sam-
pling inspection) Т. 1, 29, 275, Т. 2, 89, 91—93
Выборочная сумма квадратов, или сумма квадратов
выборки (sample sum of squares) T. 1, 51, T. 2, 207
Выборочная сумма произведений (sample sum of
products) T. 2, 207
Выборочная траектория (sample path) Т. 2, 96
Выборочное (математическое) ожидание (sampling ex-
pectation) Т. 1, 39
Выборочное пространство (sample space) Т. 2, 375
Выборочное распределение (эмпирическое распреде-
ление) (sample distributions) Т. 1, 12—15, 29—83
Выборочное среднее (sample mean) Т. 1, 13, 38, 46
Выборочное стандартное отклонение (sample standard
deviation) Т. 1, 34, 42, 53, 54, 69
Выборочные главные компоненты (sample principal
components) Т. 2, 222
Выборочные канонические корреляции (sample canoni-
cal correllations) Т. 2, 232—233
Выборочные модели (sampling models) Т. 2, 46
Выборочные частные автокорреляционные функции
(sample partial autocorrelation function) T. 2, 329
Выборочный коэффициент корреляции (sample corre-
lation coefficient) Т. 1, 60—62, 74—75
Выборочный спектр (sample spectrum)
— определение (definition) Т. 2, 324
— распределение (distribution) Т. 2, 325
Высокая концентрация (maximal concentration) Т. 1,87
Гамма-распределение (gamma distribution) Т. 1, 122—
123, 127, 151, 165, 299, 315
Гамма-распределение двухпараметрические (2-рага-
meter gamma distribution) Т. 1, 117—118
Гармонические компоненты (harmonic components)
Т. 2, 307
Гармонические частоты (harmonic frecuency) Т. 2, 313
Гармонический регрессионный анализ (harmonic
regression analysis) Т. 2, 310—311
Гаусса—Маркова теорема (Gauss—Markov theorem)
Т. 1, 134, 391—393, Т. 2, 70—71
Гаусса—Ньютона алгоритм (Gauss-Newton algorithm)
Т. 2, 448—451
Гауссово распределение (gaussian distribution) Т. 2, 424
518
Гауссовский временной ряд (gaussian time-series) Т. 2,
321, 326
Геометрическое распределение (geometric distribution)
Т. 1, 101, 307
Гипергеометрическое распределение (hypergeometric
distribution) Т. 1, 30, 84, 237, 244, 245, 309, Т. 2, 126
Гистограмма (histogram) Т. 1, 89, 92—98
Главные компоненты (principal components) Т. 2,
219—224, 245
Главные компоненты генеральной совокупности (po-
pulation principal components) Т. 2, 220—222
Графические методы (grafical methods) Т. 1, 89—99
Греко-латинский квадрат (graeco-latin square) Т. 1,
466—467
Группированная таблица частот (grouped frequency
table) Т. 1, 283, 350
Группировка данных (grouped data) Т. 1, 93—94,
350—351, 366
Групповая ортогональность (group orthogonality) Т. 1,
434—436
Данные Уэлдона об игральных костях (Weldon's dice
data) Т. 1, 358, 362
Данные гомоскедастические (homoscedastic data) Т. 1,
324
Данные дискретные (discrete data) Т. 1, 89, 92—95,
348—351
Данные неоднородные (гетероскедастические) (het-
eroscedastic data) Т. 1, 324
Данные непрерывные (continuous data) Т. 1, 95—98,
366, 368
Данные о близнецах (twinning data) Т. 1, 376—377
Данные о количестве осадков (rainfall data) Т. 1, 400,
419, 428
Данные об игральных костях (dice data) Т. 1, 358, 362
Данные, значимые на уровне Р (data significant at level
P) T. 1, 221
Данных однородность (homogeneity) T. 1, 371, 378,
448
Дарвина эксперимент (Darwin’s experiment) T. 1,
450—451
Дважды стохастические матрицы (double-stochastic
matrices) T. 2, 286
Двойственные графики, (biplot) T. 2, 249—253
Двувыборочные задачи (two-sample problems) T. 2,
216—217
Двувыборочные критерии (two-sample tests) T. 2,
125—132
Двувыборочный медианный критерий (two-sample
median test) T. 2, 125—127
Двумерная регрессия (bivariate regression) T. 2, 30
Двумерное распределение (bivariate distribution) T. 1,
38, 183—185
Двумерные выборки (bivariate samples) T. 1, 34—35
Двумерные решения (в задаче развертывания) (two-
dimensional solution) Т. 2, 276
Двупараметрические гамма-распределенне (two-pa-
rameter gamma distribution) Т. 1, 117—118
Двусторонний критерий (two-sided test, two-tailed test)
T. 1, 212—220, 233—235
Двусторонняя (двухфакторная) перекрестная класси-
фикация (two-side cross-classification) Т. 1, 483—490, 498
Двухфакторная иерархическая классификация (two-
way hierarchial classification) Т. 1, 479—482
Двухфакторная модель (two-factor model) Т. 2, 36—39
Двухфакторная модель (two-way model) Т. 2, 35—38
Девиация, или отклонение (deviance) Т. 2, 22—24, 60
Дерево решений (trees) Т. 2, 377, 408—414
Децили (deciles) Т. 2, 113
Диагональная матрица (diagonal matrix) Т. 2, 228,
259, 431
Диаграмма рассеяния, разброса (scatter diagram) Т. 2,
241
Дискретное распределение (discrete distribution) Т. 1,
211
Дискриминантная функция (discriminant function) Т. 2,
236
Дискриминантный анализ (discriminant analysis) Т. 2,
234—238
Дискриминация в две известные совокупности
(discrimination in two known population) T. 2, 234—235
Дискриминация в две многомерные совокупности
(discrimination in two multivariate population) T. 2,
235—237
Дискриминация в несколько совокупностей (discri-
mination in several population) T. 2, 237—238
Дисперсии оператор (variance operator) T. 2, 380
Дисперсионная матрица двумерного нормального
распределения (dispersion matrix of bivariate normal)
T. 2, 211
Дисперсионная матрица, или матрица ковариаций
(dispersion matrix, variance matrix) T. 2, 209
Дисперсионное отношение (variance ratio) T. 1, 263,
270
Дисперсионный анализ (analysis of variance) T. 1, 20,
264—270, 356, 406—445, T. 2, 4, 15, 71—78, 308—313
Дисперсия (variance) T. 1, 104, 326, 357, 402, 503, T. 2,
173
Дисперсия биплотов (variance biplots) T. 2, 250
Дисперсия ошибки (error variance) T. 2, 226, 328
Дифференциальный эффект (differential effect) T. 1,
453
Доверительная область (confidence region) T. 1, 181—
183, 302, 303, 407—409
Доверительная полоса (confidence band) T. 1, 168,
329, 333, 345
Доверительный интервал (confidence interval) T. 1,
143, 147—197, 299, 300, 302, 312, 328, 329, 348, 407—
409, 474, T. 2, 174, 175
Доверительный эллипсоид (confidence ellipsoid) T. 1,
408—409
Допустимость (admissibility) T. 2, 376, 382—386
Достаточная статистика (sufficient statistic) T. 1, 165,
212, 222, T. 2, 182—183, 194
Естественный параметр (natural parameter) T. 2, 15
Значение, или число собственное (eigenvalue) Т. 2,
220—222 , 228 , 231—233 , 244, 257— 261, 266, 274, 280
Значения одинаково правдоподобные (equiplausible
values) Т. 1, 203
Значения по главным компонентам (component scores)
Т. 2, 245
Идеальная точка (ideal point) Т. 2, 270
Идентификация модели (model identification) Т. 2, 442
Избегание риска, уклонение от риска (risk aversion)
Т. 2, 399—403, 405, 420
Имитация (simulation) Т. 1, 38—39
— доверительные интервалы (simulation confidence
intervals) Т. 1, 502
Интервал вероятности (probability interval) Т. 1,
143-147, 150, 151, 155, 174, 176, 209
— для J-образных распределений (for J-shaped distribu-
tion) Т. 1, 145
— для дискретных случайных величин (for discrete
random variables) T. 1, 145—147
— для непрерывных случайных величин (for
continuous random variables) T. 1, 143
— для стандартного нормального распределения (for
standard Normal distribution) T. 1, 144
— определение (definition) Т. 1, 143
Искусственные выборки (artificial samples) Т. 1,
38—39
Исследование формы методом главных компонент
(principal components analysis of shape) T. 2, 247
Каноническая корреляция (canonical correlation) T. 2,
229-234
— генеральной совокупности (population canonical
correlation) T. 2, 230—232
Канонические переменные (variates) T. 2, 229, 231,
234, 238
Квадратичная форма (quadratic form) T. 1, 49—56
Квадратичная функция нормальных величин (quad-
ratic functions of normal variables) T. 1, 49
Квадратного корня преобразование (square root trans-
formation) T. 1, 71—72
Квадратичные асимметричные таблицы (square
asymmetric tables) T. 2, 294
Квази-центральный доверительный интервал (quasi-
central confidence interval) T. 1, 177
Квантили (quantiles) T. 2, 113
Квантильный отклик (quantil response) T. 1, 334—335
Квартили (quartiles) T. 2, 113
Классификация более высокого порядка (higher order
classification) T. 1, 490—494
Классификация перекрестная (cross-classification) T. 1,
483
Классификация no одному признаку (с одним входом)
(one-way classifications) Т. 1, 389, 393, 417, 439
— с сопровождающей переменной (one-way classifi-
cations with concomitant variable) T. 1, 389
Ковариации матрица (variance-covariance matrix) T. 2,
209, 222, 423, 429—431
Ковариационная матрица, или дисперсионная матри-
ца (covariance matrix) Т. 2, 209, 212, 222, 223, 226, 227,
228, 229, 235
Ковариационный анализ (analysis of covariance) Т. 1,
494—498, Т. 2, 41
Ковариации (covariance) Т. 1, 33, 326, 345
Кокрен У. (Cochran W. G.) Т. 1, 365
Кокрена условие (Cochran’s criteria) Т. 1, 375
Контраст (contrast) Т. 1, 503
Концентрация (concentration) Т. 1, 103
Корреляционная матрица (correlation matrix) Т. 2,
209, 222, 226, 233, 326
Кососимметрическая компонента Чино (Chino skew-
symmetric component) Т. 2, 296
Кососимметрическая составляющая (skew-symmetric
components) Т. 2, 295—297
Коэффициент асимметрии (skewness coefficient) Т. 1,
271, 366
Коэффициент доверия, или уровень доверия
(confidence coefficient) Т. 1, 148, 162, 178, 179, 409, 502
Коэффициент корреляции (correlation coefficient) Т. 1,
33, 35, 74, 77, 223, 225, 345, Т. 2, 213, 217—218
519
Коэффициент множественной корреляции (multiple
correlation coefficient) Т. 2, 57
Коэффициент при независимой переменной (predictor
coefficient) Т. 2, 330
Краевые эффекты (end-effects) Т. 2, 337
Крамера—Рао граница (Cramer—Rao bound) Т. 1,
108—118
Крамера—Рао неравенство (Cramer—Rao inequality)
Т. 1, 108
— для независимых векторных наблюдений (for
independent vector observation) T. 1, 114
— обобщение (generalization of Cramer—Rao inequal-
ity) T. 1, 115
Крейга теорема (Craig’s theorem) T. 1, 64
Критерии (admissible tests) T. 2, 391
Критерии значимости (significance tests) T. 1, 211, 328,
T. 2, 125
— байесовский подход (Bayesian approach) T. 2,
181 — 182
Критерий STRAIN (strain criterion) T. 2, 291
Критерий STRESS (stress criteria) T. 2, 262, 264, 268
Критерий Бартлетта (Bartlett’s test) T. 1, 272—274
Критерий знаков (sign test) T. 2, 120—122
Критерий нелинейности (non-linearity test) T. 2, 30
Критерий равномерно наиболее мощный (uniformly
most powerful test) T. 1, 278
Критерий согласия (goodness-of-fit test) T. 1, 356, 361,
364, T. 2, 133, 246
Критерий условный (conditional test) T. 1, 236, 247
Критическая область (critical region) T. 1, 215, 222,
278
Кросс-ковариации матрица, кросс-ковариационная
матрица (cross-covariance matrix) T. 2, 209, 229
Кросс-корреляции матрица, кросс-корреляционная
матрица (cross-correlation matrix) Т. 2, 209
Логарифмическая функция связи (log-link function)
Т. 2, 40, 49
Логарифмически нормальное распределение (log-Nor-
mal distribution) Т. 1, 315
Логарифмическое преобразование (log-transform) Т. 1,
73—74
Логистическая функция (logistic functions) Т. 2, И
Логлинейная модель (log-linear models) Т. 2, 49
Маргинальная апостериорная плотность (marginal
posterior density) Т. 2, 168—170, 199
Маргинальное распределение (marginal distribution)
Т. 1, 82
Маркова цепь (Marcov chain) Т. 1, 286, Т. 2, 358
Масштаба параметр (scale parameter) Т. 1, 25, Т. 2, 15,
20, 27
Математическое ожидание векторной величины (ex-
pectation of vector variable) T. 1, 208—209
Матрица переходных вероятностей (transition
probability matrix) Т. 1, 288
Матричное представление линейной модели (matrix
formulation for linear model) T. 1, 383—390
Махаланобиса расстояние (Mahalanobis distance) T. 2,
236
Медиана (median) T. 2, 113, 120, 123, 126
Медианный критерий (median test)
— двувыборочный (two-samples) T. 2, 125—127
— для нескольких выборок (К samples), Т. 2, 132, 133
— трехвыборочный (three-samples), Т. 2, 132—133
Мера точности статистического оценивания (accuracy
of the estimate) T. 1, 88
Меры ранговой корреляции (rank correlation measu-
res), Т. 2, 137—140
Метод главных компонент (principal components
analysis) Т. 2, 242—247
Метод максимального правдоподобия (method of ma-
ximum likelihood) T. 1, 20, 136—139, 282—313, T. 2,
343, 358
— в факторном анализе (in factor analysis) Т. 2, 227
— теоретическое обоснование Т. 1, 295—303
Метод моментов (method of moments) Т. 1, 134—136,
317—321
Метод наименьших квадратов (method of least squa-
res) T. 1, 20, 132—143, 139, 381
— неортогональный случай Т. 2, 76—79
— с весами (weighted least squares) Т. 1, 403, Т. 2,
80—82
Метрическое шкалирование (metrik scaling) Т. 2,
256—266
Мешающий параметр (nuisance parametr) Т. 2, 12, 15,
345
Минимаксная оценка (minimax estimate) Т. 2, 395
Минимаксная решающая функция (minimax decision
function) Т. 2, 381
Минимаксные решающие правила (minimax decision
rules) Т. 2, 377—394
Минимаксный критерий (minimax test) Т. 2, 398
Минимальная дисперсия (minimal varianc) Т. 1,
391—392
Минимальность среднего квадрата ошибки (minimal
mean square errors) T. 1, 104
Многомерная развертка (multidimensional unfolding)
Т. 2, 270—277
Многомерная совокупность (multivariate population)
Т. 2, 205
Многомерное нормальное распределение, или закон
(multivariate Normal) Т. 1, 25, 47, 48, Т. 2, 210—219,
223
Многомерное шкалирование (multidimensional scaling)
Т. 2, 240, 256, 286, 288
Многомерный анализ (multivariate ahalysis ) Т. 1, 21,
Т. 2, 240
— классические методы (classical methods) Т. 2,
205—238
Множественная линейная регрессия (multiple linear
regression) Т. 1, 386, 399
Множественные критерии (multiple tests) Т. 1,
498—500
Множественные сравнения (multiple comparisons) Т. 1,
500—506
Мода апостериорной плотности (mode of posterior de-
nsity) T. 2, 178
Модели в фазовом пространстве (state-space models)
Т. 2, 423—427, 439—442, 445, 452, 455
Модель второго порядка, квадратичная модель (qua-
dratic model), Т. 1, 425, 427, 428, 429,
Модель скользящего среднего (moving average model)
Т. 2, 341, 354
Модель, учитывающая сезонные влияния, влияния
сезонов (seasonal effects model) Т. 2, 302—307
Момент смешанный (product-moment) Т. 1, 35
Момент уравнения (moment equation) Т. 1, 135
Моменты (moments) Т. 1, 32—39, Т. 2, 69—70
520
Моменты (генеральной совокупности) (population
moments) Т. 1, 32—33
Моменты первые (first moments) Т. 2, 69—70
Моменты смешанные (mixed moments) Т. 1, 33
Монте-Карло метод (Monte-Carlo simulation) Т. 2, 450
Муавра—Лапласа теорема (de Moivre—Laplace theo-
rem) T. 1, 67
Мультипликативные модели (multiplicative models)
Т. 2, 247—249
Мультипликативные оценки параметров (multiplicat-
ive parameter estimates) Т. 2, 248
Найквиста частота (Nyquist frequency) Т. 2, 310
Насыщенная модель (saturated model) Т. 2, 22
Неймана—Пирсона критерий для выборки фиксиро-
ванного объема (Neyman—Pearson fixed-sample-size
test) T. 2, 90
Неймана—Пирсона лемма (Neyman—Pearson lemma)
Т. 1, 279, Т. 2, 397—399
Неймана—Пирсона теория (Neyman—Pearson theory)
Т. 1, 229, 232 , 276—279
Нелинейное оценивание (non-linear estimation) Т. 2,
50—51
Неметрическое многомерное шкалирование (non-
metric multidimensional scaling) Т. 2, 266—270
Неотрицательно определенная матрица (non-negative
definite matrix) Т. 2, 209
Непараметрические модели (non-parametric models)
Т. 2, 112
Несколько выборок, сравнение (comparison of several
samples) T. 2, 132
Несмещенная оценка (unbiased estimate) Т. 1, 115
Несмещенность (unbiasedness) Т. 1, 40, 390, Т. 2, 428
Норма (norm) Т. 2, 9
Нормализации условия (normalizing condition) Т. 2,
220,267
Нормализующие преобразования (normalizing trans-
formations) Т. 1, 73—77
Нормализующие преобразования х2 (normalizing tran-
sform of х2) Т. 1, 75
Нормальная вероятностная бумага (normal probability
graph paper) T. 1, 130—132
Нормальная, нли гауссовская, плотность (normal de-
nsity) Т. 2, 173
Нормальное приближение (аппроксимация) (normal
approximation) Т. 2, 124, 129, 175
Нормальное распределение (normal distribution) Т. 1,
25, 45, 98, 122, 135, 208, 232, 254—270, 287, 291—292,
313—315, 337, 355, 367, 451, Т. 2, 68, 69 , 98, 101-103,
163, 196, 314, 424
Нормальности критерии (normality tests) Т. 1,
270—272
Нормальные случайные величины (normal variables)
— квадратичные функции от (quadratic functions of)
Т. 1, 49—56
— линейные преобразования Т. 1, 45—46
— линейные функции от (linear function of) Т. 1,
46—49
Нормальные выражения (в методе наименьших ква-
дратов) (normal equations) Т. 1, 384, 396, 428, Т. 2, 60,
85 , 262, 263 , 264, 273, 274, 275
Нулевая гипотеза (null hypothesis) Т. 1, 213, 215, 220,
221, 222, 223, 224, 228, 234, 237, 238, 240, 241, 245—
247 , 248, 250, 252, 253 , 254, 257, 260, 262—264, 266,
268, 277, 371, 372, 377, 380, 449, Т. 2, 330
— простая (simple) Т. 1, 213
— сложная (composite) Т. i, 213
Нулевое распределение (null distribution) Т. 1, 213,
214, 228
Ньютона—Рафсона метод (Newton—Raphson method)
Т. 1, 317
Обновляющий процесс (innovation) Т. 2, 425
Обозначения (notations) Т. 1, 24—27
Обратное прогнозирование (back-forecasting) Т. 2, 348
Общая линейная модель (ОЛМ) (general linear model
(GLM)) T. 2, 11 — 13, 332—341
Общие линейные гипотезы (general linear hypothesis)
Т. 1, 436—444, 475—479
Общность (communality) Т. 2, 225
Объясняющая переменная (explanatory variable) Т. 2,
11, 31, 39, 60, 67—68, 70—79
Ограничительные условия (side conditions) Т. 1, 470,
475, 485, 490
Одновыборочный критерий (one-sample test) Т. 1,
120—124
Одномерная вероятность (univariate probability) Т. 1,
80
Одномерная случайная величина (univariate random
variable) Т. 2, 238
Одномерная совокупность, или выборка, или популя-
ция (univariate population) Т. 2, 205
Одномерное нормальное распределение (univariate
Normal distribution) Т. 2, 214
Одномерное распределение (univariate distribution)
Т. 1, 236, 239
Однородности критерий (homogenity test) Т. 2, 44
Односторонний критерий (one-sided test) Т. 1, 222,
231, 232
Ожидаемые частоты (expected frequencies) Т. 2, 91
Ожидаемый объем выборки (expected sample size)
Т. 2, 91
— для ПКОВ Т. 2, 100
Оперативная рабочая характеристика (operating
characteristic) Т. 1, 276, Т. 2, 91
— биномиальной SPRT (size of binomial SPRT) T. 2,
101
— для SPRT (for SPRT) T. 2, 98—100
Оператор обратного сдвига (backward shift operator)
T. 2, 334
Оператор обратной разности (backward difference
operator) T. 2, 318
Опорная случайная величина (pivot) T. 1, 150—151,
165
— определение Т. 1, 150
Ортогональная матрица (orthogonal matrix) Т. 2, 278
Ортогональная проекция (orthogonal projection) Т. 2,
58—59
Ортогональная прокрустова задача (orthogonal Pro-
crustes problem) Т. 2, 279
Ортогональное разложение (orthogonal resolution)
Т. 1, 51, 63
Ортогональное преобразование (orthogonal transfor-
mation) Т. 2, 228, 245
Ортогональности условие (orthogonality condition)
Т. 2, 55, 60, 63, 73—76, 221
Ортогональные полиномы (orthogonal polynomials)
Т. 1, 396—402
Ортогональный план (orthogonal design) Т. 1, 396,
413—422, Т. 2, 63
521
Ортогональный прокрустов анализ (orthogonal Pro-
crustes analysis) Т. 2, 277—280
Ортонормированием матрица (orthonormal matrix)
Т. 2, 243
Остатки (residuals) Т. 1, 393—396, 408
Остаточная сумма квадратов (сумма квадратов
остатков) (residual sum-of-squares) Т. 1, 405, 407, 412,
Т. 2, 244, 274, 282
Относительная эффективность (relative efficiency) Т. 1,
107
Относительное правдоподобие (relative likelihood)
Т. 1, 293
Отношение к риску, склонность к риску (risk attitudes)
Т. 2, 399
Отрицательная биномиальная случайная величина
(negative Binomial) Т. 1, 100, 124, 308, Т. 2, 184—185
Отрицательное биномиальное распределение (negative
Binomial distribution) Т. 1, 100, 124, 308, Т. 2, 184—185
Оценивание параметров (parameter estimation) Т. 2,
447—451, 457, 462
Оценивание спектра (spectrum estimation) Т. 2,
363—368
Оценка квадратичная несмещенная с минимальной
дисперсией (minimum-variance quatratic unbiased esti-
mate) T. 1, 106, T. 2, 185, 190
Оценка линейная несмещенная с минимальной дис-
персией (minimum-variance linear unbiased estimate)
T. 1, 106, 391, 470—474
Оценка несмещенная с минимальной дисперсией
(minimum-variance unbiased estimate) Т. 1, 105, 106,
125—128, 132—134
Оценки масимального правдоподобия (maximum-
likelihood estimates, MLE) Т. 1, 140, 173, 183, 291—354,
359, 366, Т. 2, 59—60, 86, 171 — 173, 175, 177, 211 —
213, 346
Оценок надежность (reliability of estimates) Т. 1,
343—346
Ошибка I рода (type I error) Т. 2, 90, 93, 94, 103, 104,
107, 110, 398
Ошибка II рода (type II error) Т. 2, 90, 93 , 94, 104,
105, ПО, 398
Ошибка прогноза (prediction error) Т. 2, 329, 330, 340,
430
Ошибки наблюдения (observational errors) Т. 1, 133
Параметр сдвига (shift parameter) Т. 1, 313
Параметр формы (shape parameter) Т. 1, 25
Параметрическое отображение (parametric mapping)
Т. 2, 265—266
Параметры (parameters) Т. 1, 12—15
Параметры избыточные (redundent parameters) Т. 1,
469, 472, 480, 491
Парзена окно (Parzen window) Т. 2, 366
Пары (pairs) Т. 2, 249
Перестановочная матрица (permutation matrix) Т. 2,
286, 287
Периодограмма (periodogram) Т. 2, 311—317
— и автокорреляционная функция (and autocorrelation
function) Т. 2, 323
— определение (definition) Т. 2, 312
Пирсон, Карл (Pearson, Karl) Т. 1, 358, 361, 362, Т. 2,
254
Пирсона коэффициент корреляции (Pearson’s corre-
lation coefficient) Т. 2, 138
Пирсона статистика (Pearson’s statistic) Т. 1, 358—365
Пифагора теорема (Pythagora’s theorem) Т. 2, 59, 251,
271
Плотность гамма-распределения с. в. (gamma density)
Т. 1, 165, 169, Т. 2, 193
Плотность распределения условная (conditional
р. d. f.) Т. 1, 308
Поверхность отклика (response surface) Т. 1, 454
Повторное проведение эксперимента (в неизменных
условиях) (replication) Т. 1, 448, 450
Покоординатное умножение двух векторов (pointwise
multiplication) Т. 2, 10
Полиномиальная модель (multinomial model) Т. 2, 40
Полиномиальное или мультиномиальное распределе-
ние как условное (multinomial as a conditional of joint
distribution of independent Poisson variables) T. 1, 80—
83, T. 2 47, 48
— свойства (multinomial properties of) T. 1, 82
Полной вероятности формула (theorem of total pro-
bability) T. 2, 146, 148
Положительно определенная матрица (positive-definite
matrix) T. 2, 209
Поправка на непрерывность (continuity correction)
T. 1, 372—376
Порядковые статистики (order statistics) T. 1, 178, 191,
192, 194, 405, T. 2, 113, 119—120
Последовательная выборочная схема (sequential
sampling) T. 2, 89
— простая (Вальд) (simple (Wald)) T. 2, 92
— с ограниченным объемом выборки (with bounded
sample size) T. 2, 92—93
Последовательная проверка гипотез (sequential testing
procedures) T. 2, 90
Последовательное планирование эксперимента
(sequential design) T. 2, 90
— для двух биномиальных распределений (for two
binomials problem) T. 2, 110
Последовательные процедуры принятия решений
(sequential decisions) T. 2, 408—414
— «двухэтапная» задача (two-stage) Т. 2, 409
— основные идеи (basic ideas) Т. 2, 408
Последовательный анализ (sequential analysis) Т. 2,
89— 111
— двух биномиальных распределений (involving two
binomials) Т. 2, 106—111
Последовательный критерий отношения вероятно-
стей (ПКОВ) (sequential probability ratio test (SPRT))
T. 2, 93—98
— биномиальный (binomial) T. 2, 95—98, 101
— для двух биномиальных распределений (involving
two binomials) T. 2, 106—110
— для сложных гипотез (for composite hypotheses)
T. 2, 103, 105
— нормальный (гауссовский) (normal) T. 2, 101—103
— ограничение, усечение (truncation) T. 2, 110
— ожидаемый объем выборки (expected sample) T. 2,
100—103
— функция оперативной характеристики (operating
characteristic function) T. 2, 98—101
Правдоподобное значение (plausible values) T. 1, 203
Правдоподобный интеграл (credible interval) T. 2,
179—181, 188
Правило выборки следующего элемента (sampling
rule) T. 2, 90
Преобразование в Стьюдентову величину (Student-
distributed transform) Т. 1, 77
522
Преобразование интеграла вероятностей (probability
integral transformation) Т. 1, 75, 77, Т. 2, 115
Преобразование, стабилизирующее дисперсию (var-
iance-stabilizing transformation) Т. 1, 71—73
Преобразования, выпрямляющие зависимость (curve-
straightening transformation) Т. 1, 76
Приближение, аппроксимация (approximation) Т. 1, 68
Принятие решений (decision making) Т. 2, 375, 377—
382, 386, 397, 408—414, 422
Принятия решения задача (decision making problems)
Т. 2, 339, 375, 377, 380, 382, 388
Присвоение имен новым переменным (в методе глав-
ных компонент), которое основывается иа свойствах
объектов (reification process) Т. 1, 89
Пробиты (probits) Т. 1, 77, 337
Проверка гипотез (hypothesis testing) Т. 1, 406—444,
475—479, 499—500, Т. 2, 376, 396—399
Проверка качества фильтра (test of filter performance)
T. 2, 433—435
Прогноз, предсказывание (prediction) Т. 2, 182,
424—427
— с использованием общей линейной модели (using
GLM) Т. 2, 340
Прогнозирование (forecasting)
— с использованием модели авторегрессии (АР)
(using autoregression model) Т. 2, 360—361
Прогнозная плотность (predictive density) Т. 2, 182
Прогнозное распределение (predictive distribution) Т. 2,
192, 238
Производящая функция ковариации (covariance gener-
ating function) Т. 2, 336
Простая линейная регрессия (simple linear regression)
Т. 1, 157—158, 261—262, 395—396, 398
Пространство действий (доступная область фактор-
ного пространства) (action space) Т. 2, 367
Пространство параметров (parameter space) Т. 2, 375
Пространство решений (decision space) Т. 2, 375
Процентиль (percentile) Т. 1, 177, Т. 2, ИЗ
Процентные точки (percentage points) Т. 1, 27, 59
Пуассона распределение (Poisson distribution) Т. 1, 25,
52, 71—72, 173, 200, 204, 233, 306, 364, 379, Т. 2, 47,
175, 192—196
Пуассоновская выборка (Poisson sample) Т. 1, 379
Пуассоновская переменная; случайная величина, рас-
пределенная по Пуассону (Poisson variable) Т. 1, 38,
82, 238, Т. 2, 48
Равенство биномиальных частот (equality of binomial
proportions) T. 1, 236
Равенство нескольких средних (equality of several mea-
ns) T. 1, 264
Равенство параметров распределений Пуассона
(equality of Ar-Poisson parameters) T. 1, 238
Равенство к дисперсий (equality of к variances) Т. 1,
272—274
Равенство двух дисперсий (equality of two variances)
T. 1, 262—264
Равномерное распределение (uniform distribution) Т. 1,
25, 312
Разбавление (delution) Т. 1, 310
Разложение суммы квадратов (sum-of-squares par-
tition) Т. 2, 60, 62—66, 70, 72, 74, 79, 80
Размах (range) Т. 1, 65, Т. 2, 113
Размерность (dimension) Т. 1, 100
Разностные операторы (differencing operation) Т. 2,
317—319
Ранговый подход, понятие о рангах (rank concept)
Т. 2, 119—120, 122
Рандомизации критерии (randomization tests) Т. 1,
253—254, 279, Т. 2, 135—137
— двувыборочные (two sample) Т. 2, 136
Рандомизационный анализ (randomization analysis)
Т. 1, 258
Рандомизация (randomization) Т. 1, 448, 450
Рандомизированное действие (randomized action) Т. 2,
385
Рао-Блеквелла теорема (Rao-Blackwell theorem) Т. 1,
120, 125-128
Расположение, классификация, ордииация (ordination)
Т. 1, 240—242
Распределение вероятностей (probability distribution)
Т. 1, 14, 15, 17,21, 31, 36, 80—81, 84, 85, 281, Т. 2,
198, 409
Распределение дисперсионного отношения, или F-pac-
пределение (variance-ratio distribution) Т. 1, 58—60,
162, 263, 264, 414—415. 490, Т. 2, 188
Распределение непрерывное (continuous distribution)
Т. 1, 223—226, 366—370, Т. 2, 113
Распределение условное (conditional distribution) Т. 1,
158
Расстояний матрица (distance matrix) Т. 2, 275
Регрессии линия (regression line) Т. 1, 329
Регрессии параметры (regression parameters) Т. 1, 249
Регрессии уравнение (regression equation) Т. 2, 339
Регрессионная модель постолбцовая (columns reg-
ression model) Т. 2, 253
Регрессионная модель построчная (rows regression
model) Т. 2, 253
Регрессионные модели (regression models) Т. 2,
369—373
— их структура (structure of) Т. 2, 302
— стационарные (stationary) Т. 2, 319—332
Регрессионные модели (уравнение регрессии) (regres-
sion models) Т. 1, 323, Т. 2, 302—307
— проходящие через начало координат (passing thro-
ugh origin) Т. 2, 24—25
Регрессионный анализ (regression analysis) Т. 2, 16
Регрессионный коэффициент (regression coefficient)
Т. 1, 261—262, 323
Регрессия (regression) Т. 1, 321—324, 385, 409
Регрессор, независимая переменная (regression variable)
Т. 1, 386
Регулярности условия (regularity conditions) Т. 1, 113
Рекуррентные уравнения (recurance equations) Т. 2, 317
Сбалансированные неполные блоки (balanced
incomplete blocks) Т. 1, 454
Свободные от распределения методы (distribution-free
methods) Т. 1, 17
Свободные от распределения модели (distribution-free
models) Т. 2, 112—140
Сезонная разность, разница (seasonal difference) Т. 2,
318
Сезонные изменения (seasonal patterns) Т. 2, 352
Серии критерий (runs test) Т. 2, 130—132
Симметричная оценка (symmetric estimate) Т. 1, 107
Симметричные компоненты (symmetric components)
Т. 2, 295—297
523
Сингулярные (вырожденные) модели (singular models)
Т. 1,468—498
Случайные величины, случайные переменные (random
variables) Т. 1, 31, 32, 36, 37, 87, 180, 283, 322
— индуцированная, порожденная (induced) Т. 1, 26
— функция (function of) Т. 1, 70
Случайные числа (random numbers) Т. 1, 39
Смешивание (confounding) Т. 1, 461—463
Смешение (bias) Т. 1, 34
Согласие (goodness-of-fit) Т. 1, 84, Т. 2, 113
Согласованность выборки с гипотезой Н (compatibility)
Т. 1, 214
Соглашения (предпосылки) (conventions) Т. 1, 24—27
Сокращения (abbreviations) Т. 1, 24—27
Сопоставленная пара (matched pair) Т. 2, 256—257,
Т. 2, 124
Сопутствующая переменная (concomitant variable)
Т. 1, 389
Состоятельная оценка (consistent estimate) Т. 1, 101
Состоятельная (consistency) Т. 1, 101—103
Спектральный анализ (spectral analysis) Т 2, 368
Спирмена коэффициент ранговой корреляции (Spear-
man’s rank correlation coefficient) T. 2, 138—139
Сравнение двух средних (comparison of two means)
T. 1, 265—267
Стабилизация дисперсии (variance stabilization) Т. 1,
72—73.
Стандартизация (standardization) Т. 1, 45—46
Стандартизованное правдоподобие (standardized likeli-
hood) Т. 2, 164—167
Стандартная нормальная случайная величина (пере-
менная) (standard normal variable) Т. 1, 45
Стандартная ошибка (standard error) Т. 1, 40, 86, 87,
143, 155, 332, Т. 2, 242, 322
— определение (definition) Т. 1, 30, 86
Стандартное отклонение (standard deviation) Т. 1, 26,
30, НО, 394, Т. 2, 163
Стандартное распределение (standard distribution)
Т. 1, 25
Стандартные критерии (standard tests) Т. 1, 254—270
Стандартный нормальный интеграл (standard normal
integral) Т. 1, 45
Статистика (statistic) Т. 1, 12, 17, 36, 85
— выборочное распределение (sampling distribution)
Т. 1, 37—39
— выборочные моменты (sampling moments) Т. 1,
39—43
— использование термина (use of term) Т. 1, 29
— определение (definition) Т. 1, 12, 31
Статистика критерия, критериальная статистика
(статистика, с помощью которой формулируется ста-
тистический критерий. — Примеч. ped.) (test statistic)
Т. 1, 226—227
Статистика согласия (goodness-of-fit statistic) Т. 1,
360—362
Статистические выводы или вывод (statistical infe-
rence) Т. 1, 10, 29, 85
Статистические копии (statistical copies) Т. 1, 26, 36,
43, 44
Статистические критерии (statistical tests) Т. 1, 19,
211—280
Статистические обозначения (statistical conventions)
Т. 1, 24—27
Степени свободы (degrees of freedom) Т. 1, 34, 57, 58
Степень недоверия (strength of evidence) Т. 1, 220
524
Степень уверенности или доверия (degree of belief)
Т. 2, 143, 144, 417—420
Столбцовая диаграмма (bar chart) Т. 1, 93
Стохастическая модель (stochastic model) Т. 2, 317
Стохастические системы (stochastic systems) Т. 2, 354
Стохастический процесс (stochastic process) Т. 2, 354
Стохастической аппроксимации алгоритм (stochastic
approximation algorithm) Т. 2, 449
Стресс-формула 1 (stress formula 1) Т. 2, 267
Стресс-формула 2 (stress formula 2) Т. 2, 267
Стьюдента величина (student’s Г) Т. 1, 56, 156, 158,
160, 333, 474, Т. 2, 215, 216
Стьюдента критерий (Student’s Mest) Т. 1, 248, 255—
258, 260—262
Стьюдента нецентральное распределение (non-central
Student distribution) Т. 1, 79—80
Стьюдента распределение (Student’s distribution) Т. 1,
56—58, 156—157, 158, 159, 161, 163, 223, 224, 232,
233 , 261, 262, 266, 328, 329, 407, Т. 2, 57, 138, 200,
217, 218, 434
Стьюдентизированный размах (studentized range) Т. 1,
65
Стьюдеитова переменная, случайная величина, рас-
пределенная по Стьюденту (Student’s variate) Т. 1, 56,
156, 158, 160, 333, 474, Т. 2, 215, 216
Стьюдеитово отношение, стьюдеитова дробь
(Student’s ratio) Т. 1, 56, 66, 250, 255, 262
Тейлора разложение (Thylor expansion) Т. 1, 352, Т. 2,
437, 438
Тейлора ряд (Thylor series) Т. 2, 85, 86, 177, 438
Теорема о преобразовании с помощью интеграла ве-
роятностей (probability integral transform theorem)
T. 1, 165
Теория полезности (utility theory) Т. 2, 408
Теория принятия решения (decision making theory)
Т. 2, 375—420
Толерантные интервалы (tolerance intervals) Т. 1,
197—198
Толерантные пределы (tolerance limits) Т. 1, 197—198
Точечная оценка (point estimation) Т. 1, 19, 88, 282,
Т. 2, 177
Трехфакториая классификация (three-way cross-clas-
sification) Т, 1, 490
Триномиальное распределение (trinomial distribution)
Т. 1, 81, 114—115
Тьюки модель (TUkey model) Т. 2, 252, 253
Уилкоксона критерий знаковых рангов (Wilcoxon-
signed ranks test) Т. 2, 122—124
Уилкоксона—Манна—Уитни критерий (Wilcoxon—
Mann—Whitney test) T. 2, 127—130
Управляемая переменная (treatment variable) Т. 1, 323
Уравнение измерения (measurement equation) Т. 2, 423,
462
Уравнения системы (system equation) Т. 2, 423
Уровень значимости случайной переменной (signifi-
cance level random variable) T. 1, 228
Уровень значимости статистики (significance level
statistic) Т. 1, 228, 234
Усечение (truncation) Т. 1, 124—125 , 349
Условное нулевое распределение (null conditional dist-
ribution) Т. 1, 247
Фактор (factor) Т. 2, 32—46
Факторная модель для кросс-классифицироваиных
данных (factorial model) Т. 2, 39—42
Факторные нагрузки (factor loadings) Т. 2, 229, 285
— интерпретация Т. 2, 229
Факторный анализ (factor analysis) Т. 2, 224—229
Феллера теорема (Fieller’s theorem) Т. 1, 158—162, 347
Фидуциальиая вероятность (fiducial probability) Т. 1,
142
Фидуциальиый подход (fiducial inference) Т. 1, 88
Фильтра расходимость (divergence) Т. 2, 434—435
Фильтрации уравнения (filter equations) Т. 2, 431
Фильтрация (filtering) Т. 2, 420, 424
Фильтры (filters) Т. 2, 333
Фишер Р. A. (Fisher R. А.) Т. 1, 88, 447—450
Фишера F-отношение (ratio F) Т. 1, 250
Фишера Z-преобразование (Fisher’s Z) Т. 1, 61, Т. 2, 218
Фишера линейная дискриминантная функция (Fisher's
linear discriminant function) T. 2, 236
Фишера точный критерий (Fisher’s exact tests) Т. 1,
224, Т. 2, 127
Фишера—Беренса критерий (Fisher—Behrens test)
Т. 1, 258—259
Фишера—Беренса статистики (Fisher—Behrens sta-
tistics) Т. 1, 258
Фишера—Кокрена теорема (Fisher—Cochran theorem)
Т. 1, 62
Фрактиль (fractile) Т. 1, 177
Функции полезности график (utility curve assessment)
Т. 2, 407
Функции, допускающие оценку (estimable functions)
Т. 1, 470—474
Функция мощности (power function) Т. 1, 229, 278
Функция накопленных относительных частот (relative
cumulative frequency function) T. 1, 99
Функция плотности (density function) Т. 2, 11—16
Функция полезности (utility function) Т. 2, 377, 400
— высокой размерности (higher-dimensional) Т. 2, 408
— одномерная (one-dimensional) Т. 2, 404—405
Функция потерь (loss function) Т. 2, 375, 377, 385, 394,
397
Функция принятия, или оперативная характеристика
(acceptance function or operating characteristic) T. 1, 276
Функция распределения вероятностей (probability
distribution function) T. 1, 77, 98—99
Функция распределения кумулятивная (накопленная,
интегральная), или просто функция распределения
(cumulative distribution function, c.d.f.) T. 1, 15
Функция распределения непрерывная (continuous
distribution function) Т, 2, 117—118
Функция решающая (decision function) Т. 2, 376, 377,
379, 381, 382, 383
— допустимая (admissible) Т. 2, 383—384
— недопустимая (inadmissible) Т. 2, 384
Функция риска (risk function) Т. 2, 378, 379, 380, 382
Функция чувствительности (sensitivity function) Т. 1,
228-232
— двустороннего критерия (two-tailed test) Т. 1,
233—235
— одностороннего критерия (one-tailed test) Т. 1,
232—233
Хал моша теорема (Halmos theorem) Т. 1, 107
Хи-квадрат нецентральное распределение (non-central
chi-squared distribution) Т. 1, 78, Т. 2, 219
Хи-к<адрат переменная (chi-square variable) Т. 1, 58
— аддитивности свойство (additive property of) Т. 1, 50
Хи-квадрат распределение (chi-square distribution)
Т. 1, 49—51, 103, 153, 154, 158, 166, 170, 226, 250, 252,
274, 275, 358, 361, 362, Т. 2, 72, 79, 194, 200, 214, 314
Хи-квадрат расстояние, метрика (chi-square distance)
Т. 2, 256
Хи-квадрат таблицы распределения (chi-square tables)
Т. 1, 52
Хи-квадрат, нормализующие преобразования (пере-
водящие распределение хи-квадрат в нормальное)
(normalizing transforms chi-square to normal) T. 1, 75
Хотеллинга статистика T1 (Hotellings P-statistics)
T. 2, 216
Целевая функция (objective function) T. 2, 345
Цензурирование (censoring) T. 1, 351
Центральная предельная теорема (central limit theo-
rem) T. 1, 46, 67 , 84, 186, 297 , 451
Центральные выборочные моменты (центральные
моменты выборки) (central sample moments) Т. 1,
33, 41
Центральные моменты (central moments) Т. 1, 32,
35, 41
Циклических компонент модель (cyclical component
model) Т. 2, 304—307
Частичное смешивание, смешение (partial
confounding) Т. 1, 463
Частная автокорреляционная функция (partial auto-
correlation function) Т. 2, 327—329
Частота (frequency) Т. 1, 89—99, Т. 2, 304, 306, 310,
312, 314
Частота накопленная относительная (relative cumula-
tive frequency) Т. 1, 89
Частотная интерпретация (вероятности) (frequentist
interpretation) Т. 2, 143, 149
Частотная таблица (frequency table) Т. 1, 89, 90, 96,
130, 269, 290, 348—350, 370—378
Частотное окно (frequency window) Т. 2, 366
Чувствительность (sensitivity) Т. 1, 448
Шеппарда поправка (оценка выборочной дисперсии
по группированным данным с использованием по-
правки Шеппарда) (Sheppard’s adjustment correction)
Т. 1, 353, 367
Шеффе S-метод множественных сравнений (Scheffe’s
S-method) Т. 1, 503—505
ЭВСС-предиктор (EWMA-predictor) Т. 2, 350—351
Экспоненциальное распределение (exponential dist-
ribution) Т. 1, 298, Т. 2, 15, 84
Экспоненциальное семейство (exponential family) Т. 1,
123—125, Т. 2, 15—18, 86
Экспоненциальное семейство Т. 1, 121—125, Т. 2,
15—16
Экстремальность (extremity) Т. 1, 113
Эффективная оценка (efficient estimate) Т. 1, 111
Эффективность (efficiency) Т. 1, 108—118
Юла—Уолкера уравнения (Yule—Walker equations) Т. 2,
357, 358, 446
525
ОГЛАВЛЕНИЕ
Глава 11. Линейные модели I (перевод И. С. Енюкова) .... 5
Глава 12. Линейные модели II (перевод Е. 3. Демиденко) .. 55
Г лава 13. Последовательный анализ (перевод И. Д. Новико-
ва) ...-............................................. 89
Глава 14. Методы, свободные от распределения (перевод
Е. В. Кулинской).................................... 112
Глава 15. Байесовский подход в статистике (перевод
И. Г. Грицевич)......................................... 143
Г л а в а 16. Многомерный анализ: классические методы (пере-
вод И. С. Енюкова)...................................... 205
Глава 17. Многомерный анализ: ординация, многомерное
шкалирование и смежные вопросы (перевод
А. Ю. Терехиной)........................................ 240
Глава 18. Временные ряды (перевод С. Е. Кузнецова)...... 300
Глава 19. Теория принятия решений (перевод И. Д. Новико-
ва) ................................................ 375
Глава 20. Калмановская фильтрация (перевод Ю. М. Каба-
нова) .............................................. 421
Литература ............................................. 471
Приложения. Статистические таблицы (перевод Ю. Н Тюрина) 475
Предметный указатель ................................... 517
С74 Справочник по прикладной статистике. В 2-х т. Т. 2: Пер. с
англ. / Под ред. Э. Ллойда, У. Ледермана, С. А. Айвазяна,
Ю. Н. Ъорина. — М.: Финансы и статистика, 1990. — 526 с.: ил.
ISBN 5-279-00246-1.
В Справочнике освещены основные математико-статистические методы. В томе 2 рас-
сматриваются линейные методы регрессионного анализа, последовательные и свободные от
распределения методы, байесовский подход, многомерный статистический анализ, анализ
временных рядов, фильтры Калмана.
Для широкой аудитории специалистов, разрабатывающих и использующих статистиче-
ские методы.
0702000000 — 024
— 1111"о5г
010(01)-90
ББК 16.2.9
Научное издание
СПРАВОЧНИК ПО ПРИКЛАДНОЙ СТАТИСТИКЕ
Под редакцией Э. Ллойда, У. Ледермана
Том 2.
Книга одобрена на заседании секции редсовета издательства 25.03.87
Зав. редакцией К. В. Коробов
Редактор Е. В. Крестьянинова
Мл. редакторы Т Т Гришкова, Н. Е. Мендрова
Ху дож. редактор Ю. И. Артюхов
Техн, редакторы Л. И. Сараева, Е. В. Воробьева, И. В. Завгородняя
Корректоры Г. В. Хлопцева, Т М. Колпакова, М. А. Синяговская, Т. Г. Кочеткова
Переплет художника А. В. Овчарова
ИБ № 2249
Сдано в набор 23.05.89. Подписано в печать 19.12.89.
Формат 60х 88V16. Бум. Тип. №1, Гарнитура «Литературная».
Печать офсетная. Усл. п. л. 32,34. Усл. кр.-отт. 32,34. Уч.-изд. л. 33,74.
Тираж 20000 экз. Заказ 1124. Цена 2 р. 70 к.
Издательство «Финансы и статистика», 101000, Москва,
ул. Чернышевского, 7
Набрано на ФКМП ГВЦ Госкомстата СССР
Отпечатано в типографии им. Котлякова издательства «Финансы и статистика»
Государственного комитета СССР по печати
195273, Ленинград, ул. Руставели, 13.