



























































































































































































































































































































































Author: Сулицкий В.Н.
Tags: экономические науки основные понятия стоимость капитал фонды рынок: суть и структура экономика менеджмент системы управления статистический анализ
ISBN: 5-7749-0234-X
Year: 2002




В.Н. Сулицкий
МЕТОДЫ
СТАТИСТИЧЕСКОГО
АНАЛИЗА
в УПРАВЛЕНИИ
УДК 330.101.541(075.8)
ББК 65.012.2я73
С89
Об авторе:
Сулицкий Владимир Николаевич - окончил механико-
математический факультет МГУ, доктор экономических наук,
кандидат технических наук, профессор, зав. кафедрой высшей
математики и статистики факультета ‘'Информационные технологии
в бизнесе” Академии народного хозяйства
при Правительстве Российской Федерации
Сулицкий В.Н.
С89 Методы статистического анализа в управлении: Учеб,
пособие. — М.: Дело, 2002. — 520 с.
ISBN 5-7749-0234-Х
Учебное пособие содержит системное изложение методов приклад-
ного статистического анализа в применении к количественному обо-
снованию решений В доступной форме, не требующей значительной
математической подготовки, ихтагаются основы математико-статис-
тических расчетов в менеджменте, экономике и бизнесе. Приведены
многочисленные примеры таких расчетов для практических ситуаций,
взятых из рахтичных областей управленческой деятельности.
Учебное пособие предназначено для студентов экономических спе-
циальностей, преподавателей, менеджеров, предпринимателей и слу-
шателей, занимающихся в сети переподготовки управленческих кад-
ров.
УДК 330.101.541(075.8)
ББК 65.012.2я73
ISBN 5-7749-0234-Х
© Издательство “Дело”, 2002
ОГЛАВЛЕНИЕ
Предисловие........................................... 10
Глава 1. ПРЕДСТАВЛЕНИЕ ДАННЫХ В СТАТИСТИЧЕСКОМ
АНАЛИЗЕ.................................................11
1.1. Основные направления статистического анализа.......11
1.2. Количественные измерения статистических данных.......13
1.3. Уровни измерения данных............................14
1.4. Сбор данных........................................15
1.5. Формирование и виды выборки....................... 17
Основные положения главы /................................20
Глава 2. ГРУППИРОВКА И ГРАФИЧЕСКОЕ
ПРЕДСТАВЛЕНИЕ ДАННЫХ ..................................23
2.1. Ряд распределения................................. 23
2.2. Графическое представление ряда распределения.......32
2.3. Диаграммы как способ графического |Цедставления
статистических данных...................................39
Основные положения главы 2..............................42
Глава 3. ИЗМЕРЕНИЕ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ................44
3.1. Вычисление центральных значений .для несгрунпированных
.данных.................................................45
3.1.1. Средняя арифметическая......................45
3.1.2. Медиана................................... 48
3.1.3. Мода........................................50
3.2. Оценка характеристик центральной тенденции для сгруппи-
рованных .данных........................................52
3.2.1. Средняя арифметическая для ряда распределения.52
3.2.2. Медиана для сгруппированных данных..........53
3.2.3. Оценка моды для сгруппированных данных......55
3.2.4. Сравнение типов средних при анализе центральной
тенденции..........................................56
Основные положения главы 3..............................59
3
Глава 4. ИЗМЕРЕНИЕ ВАРИАЦИИ..............................61
4.1. Основные характеристики вариации.................. 62
4.1.1. Размах колебаний.............................62
4.1.2. Среднее линейное отклонение..................63
4.1.3. Дисперсия и среднее квадратическое (стандартное)
отклонение..........................................65
4.1.4. Интерпретация стандартного отклонения на основе
неравенства Чебышева................................71
4.1.5. Коэффициент вариации.........................71
4.2. Измерение вариации на основе порядковых характеристик .... 73
4.2.1. Размах квартилей и квартильное отклонение....74
4.2.2. Размах процентилей...........................77
4.3. Характеристики формы кривой распределения...........78
Основные положения главы 4...............................80
Глава 5. ЭЛЕМЕНТЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ....................83
5.1. Основные понятия теории вероятностей ................83
5.1.1. Общее понятие вероятности....................83
5.1.2. Объективный и субъективный подходы к определе-
нию вероятности. Закон больших чисел................84
5.2. Основные правила действий над вероятностями ........87
5.2.1. Типы событий. Алгебра событий................87
5.2.2. Правила сложения вероятностей................90
5.2.3. Условная вероятность. Правила умножения вероят-
ностей ............................................ 93
5.2.4. Таблица сопряженности и дерево возможных
исходов.............................................96
5.2.5. Формула полной вероятности. Теорема Байеса...99
5.3. Основные формулы комбинаторного анализа............. 102
5.3.1. Перестановки................................102
5.3.2. Принцип умножения......................... 103
5.3.3. Сочетания...................................104
Основные положения главы 5............................... 105
Глава 6. ДИСКРЕТНЫЕ РАСПРЕДЕЛЕНИЯ
ВЕРОЯТНОСТЕЙ........................................... 109
6.1. Случайные величины ................................. 109
6.2. Ряд распределения дискретной случайной величины..... 110
6.3. Характеристики дискретной случайной величины ....... 112
6.3.1. Математическое ожидание...................... 112
6.3.2. Дисперсия и стандартное отклонение...........114
6.3.3. Графическое представление распределения дискрет-
ной случайной величины..............................117
6.4. Биномиальный закон распределения ................. 117
6.4.1. Биномиальные вероятности..................... 118
4
6.4.2. Математическое ожидание и дисперсия биномиаль-
ной случайной величины............................. 123
6.5. Гипергеометрическое распределение....................... 125
6.5.1. Распределение гипергсометрических вероятностей.... 125
6.5.2. Математическое ожидание и дисперсия гипергео-
метрического распределения..........................127
6.5.3. Использование биномиального закона для замены
гипергеометрического распределения..................127
6.6. Распределение Пуассона................................ 128
6.6.1. Распределение вероятностей пуассоновской
случайной величины................................. 128
6.6.2. Математическое ожидание и дисперсия пуас-
соновской случайной величины...................... 129
6.6.3. Замена биномиального распределения распределе-
нием Пуассона..................................... 131
6.7. Функции и комбинации случайных величин.................. 132
6.7.1. Математическое ожидание и дисперсия функций
случайной величины..................................132
6.7.2. Сумма и произведение независимых случайных
величин.............................................135
Основные положения главы 6................................... 138
Глава 7. РАСПРЕДЕЛЕНИЯ НЕПРЕРЫВНЫХ СЛУЧАЙНЫХ
ВЕЛИЧИН ..................................................... 141
7.1. Непрерывные случайные величины. Функция и плотность
распределения. Числовые характеристики............... 141
7.2. Равномерное распределение .............................. 145
7.3. Нормальный закон распределения..................... 149
7.3.1. Кривая нормального распределения и ее свойства... 149
7.3.2. Площади под кривой нормального распределения... 153
7.3.3. Вероятность попадания на заданный промежуток.
Стандартное нормальное распределение................156
7.3.4. Нормальное распределение как замена биномиаль-
ного распределения................................. 163
7.4. Экспоненциальное распределение.......................... 166
Основные положения главы 7................................... 169
Глава 8. ОЦЕНКА ПАРАМЕТРОВ................................... 172
8.1. Точечные оценки..................................... 172
8.1.1. Критерии качества точечных оценок................ 173
8.2. Распределение выборочных средних. Центральная предель-
ная теорема 174
8.3. Интервальные оценки генеральной средней................. 182
8.3.1. Общие принципы построения доверительных
интервалов........................................ 183
5
8.3.1.1. Вычисление доверительных интервалов при из-
вестном генеральном стандартном отклонении ... 186
8.3.1.2. Вычисление доверительных пределов при неиз-
вестном генеральном стандартном отклонении
Использование 1-распределения Стьюдента.... 189
8.3.1.3. Общие правила определения доверительных
интервалов...................................... 196
8.3.1.4. Объем выборки и точность интервальной
оценки средней.................................................. 197
8.3.2. Доверительные интервалы для разности средних двух
генеральных совокупностей (случай двух больших
независимых выборок)................................... 199
8.3.3. Доверительные интервалы для разности средних
(случай двух малых независимых выборок).................200
8.3.4. Объем выборки и допустимая ошибка оценки раз-
ности генеральных средних...............................204
8.4. Оценка долей.....................................!......205
8.4.1. Распределение выборочных долей (пропорций).......205
8.4.2. Доверительные интервалы для доли................207
8.4.3. Объем выборки и допустимая ошибка оценки доли ... 208
8.4.4. Доверительные интервалы для разностей долей......210
8.4.5. Объем выборок и допустимая ошибка разности
долей...................................................212
Основные положения главы 8...................................213
Глава 9. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
СРЕДНИХ......................................................217
9.1. Общая постановка задачи проверки гипотез.
Нулевая гипотеза и статистические критерии..............217
9.1.1. Критическая область. Уровень значимости.........219
9.1.2. Ошибки первого и второго вида...................222
9.1.3. Двусторонние и односторонние проверки гипотез
относительно средней....................................224
9.2. Проверка гипотез относительно средней: случай одной
генеральной совокупности,.....................................226
9.2.1. Значение генерального стандартного отклонения
известно................................................226
9.2.2. Значение генерального стандартного отклонения
неизвестно: большая выборка.............................227
9.2.3. Значение генерального стандартного отклонения
неизвестно: малая выборка...............................229
9.3. Проверка гипотез относительно разности средних двух
генеральных совокупностей.....................................231
9.3.1. Случай больших выборок..........................231
9.3.2. Случай малых выборок............................235
9.3.3. Сравнение средних двух нормальных совокупностей
на основе пар наблюдений................................239
Основные положения главы 9...................................241
6
Глава 10. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО ДОЛЕЙ ... 245
10.1. Проверка гипотез относительно доли одной генеральной
совокупности..................................................245
10.1.1. Двусторонняя проверка...........................245
10.1.2. Односторонние проверки..........................247
10.1.3. Поправка на конечность генеральной
совокупности............................................249
10.2. Проверка гипотез относительно разности долей двух
генеральных совокупностей ....................................251
10.2.1. Двусторонняя проверка...........................251
10.2.2. Односторонние проверки..........................254
Основные положения главы 10........................................................... 257
Глава 11. ДИСПЕРСИОННЫЙ АНАЛИЗ...............................258
11.1. Общая схема однофакторного анализа.....................258
11.2. Межгрупповая и внутригрупповая дисперсии...............261
11.3. Сравнение межгрупповой и внутригрупповой дисперсий
на основе ^-распределения.....................................264
11.4. Проверка гипотез относительно дисперсий двух генераль-
ных совокупностей ............................................ 268
Основные положения главы 11................................,...........‘J.............. 271
Глава 12. РАСПРЕДЕЛЕНИЕ х2 И ЕГО ПРИМЕНЕНИЕ
В ВЫБОРОЧНОМ МЕТОДЕ..........................................274
12.1. Распределение х2 и оценка генеральной дисперсии........274
12.2. Проверка гипотез относительно дисперсии и стандартного
отклонения....................................................279
12.3. х2-распределение как критерий согласия.................281
12.4. Проверка гипотез относительно формы распределения .....286
12.5. Таблица сопряженности .................................292
Основные положения главы 12..................................297
Глава 13. КОРРЕЛЯЦИЯ И ПРОСТАЯ ЛИНЕЙНАЯ
РЕГРЕССИЯ.................................................. 299
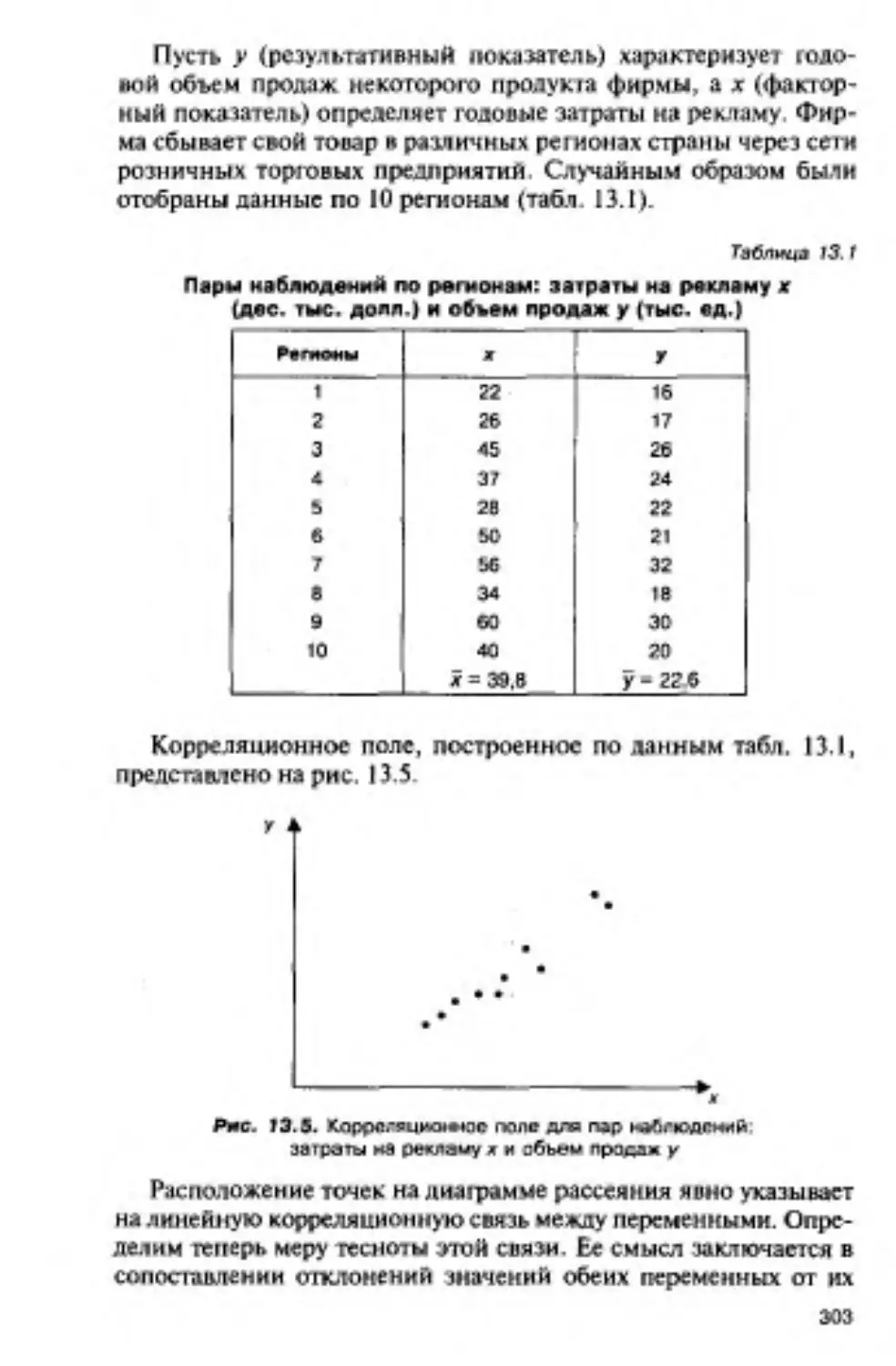
13.1. Линейная корреляция....................................299
13.1.1. Корреляционная связь и корреляционное поле.....299
13.1.2. Коэффициент корреляции.........................302
13.1.3. Существенность выборочного коэффициента кор-
реляции ................................................307
13.1.4. Ранговый коэффициент корреляции................309
13.2. Простой линейный регрессионный анализ .................314
13.2.1. Уравнение простой регрессии. Метод наименьших
квадратов...............................................314
13.2.2. Стандартная ошибка регрессии...........;........317
7
13.2.3. Доверительные интервалы уравнения
регрессии.......................................319
13.2.4. Коэффициент детерминации...................325
13.2.5. Проверка существенности коэффициента
регрессии.......................................327
13.2.6. Возможные ошибки при практическом использо-
вании корреляционно-регрессионного анализа.......329
Основные положения главы 13.............................331
Глава 14. МНОЖЕСТВЕННАЯ РЕГРЕССИЯ.......................334
14.1. Уравнение множественной линейной регрессии........334
14.2. Оценка качества множественной регрессии: стандартная
ошибка и коэффициент множественной детерминации......338
14.3. Проверка статистической значимости множественной
регрессии............................................342
14.4. Подбор переменных в модель множественной регрессии .347
14.5. Проверка допущений относительно статистических свойств
ошибок регрессии. Критерий Дарбина—Уотсона...........351
14.6. Множественная линейная регрессия как модель прогнози-
рования .............................................357
14.7. Нелинейная регрессия..............................359
Основные положения главы 14.............................366
Глава 15. АНАЛИЗ ВРЕМЕННЫХ РЯДОВ ..................369
15.1. Компоненты временного ряда........................369
15.2. Анализ тренда...............................L... 372
15.3. Измерение циклической компоненты..................376
15.4. Определение сезонной составляющей............... 378
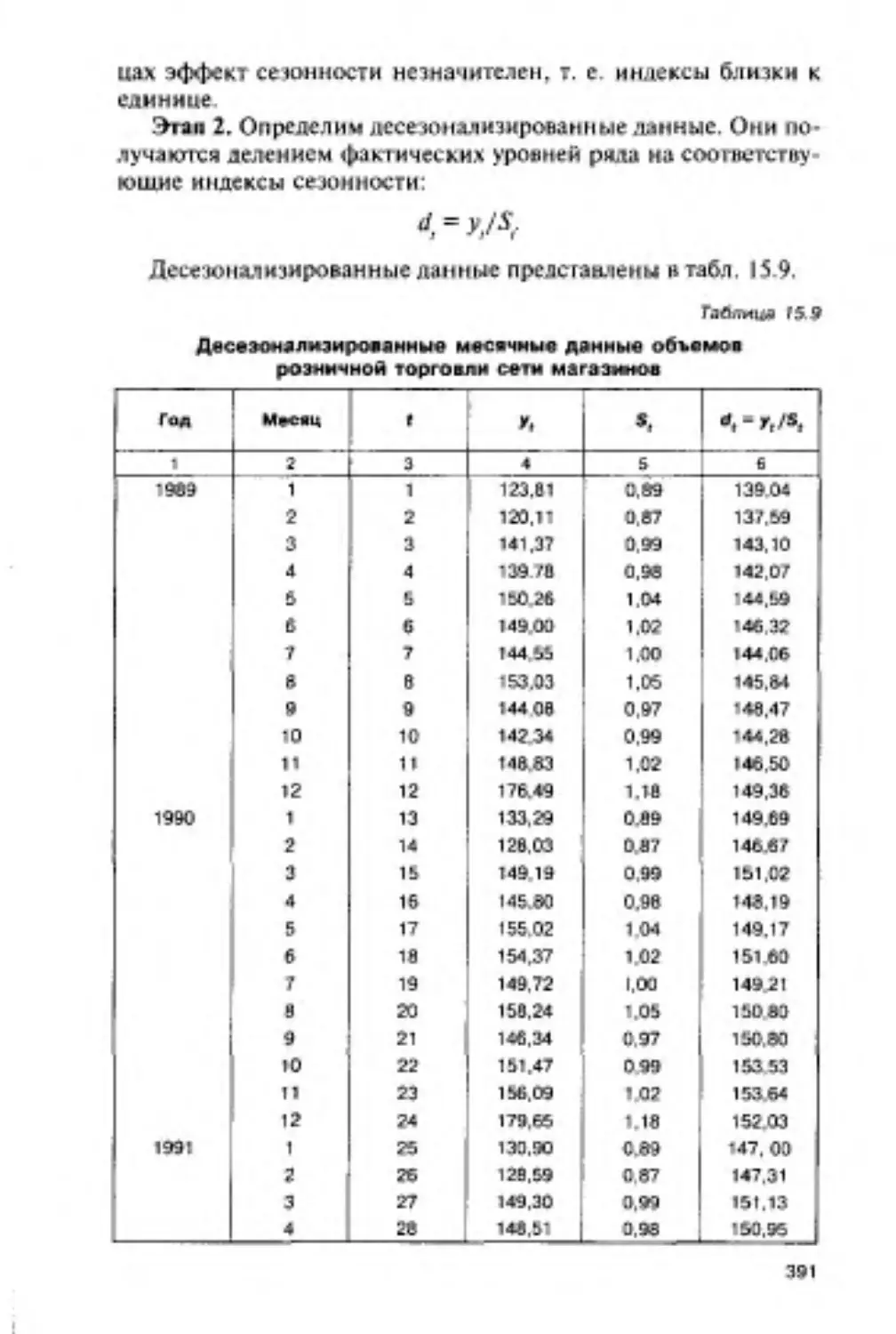
15.5. Дессзонализацня данных и сезонное прогнозирование.384
15.6. Процедура общей декомпозиции временного ряда......386
Основные положения главы 15.............................398
Глава 16. СТАТИСТИЧЕСКИЕ МЕТОДЫ И МОДЕЛИ
В ПРОГНОЗИРОВАНИИ..................................... 401
16.1. Простейшие модели.................................402
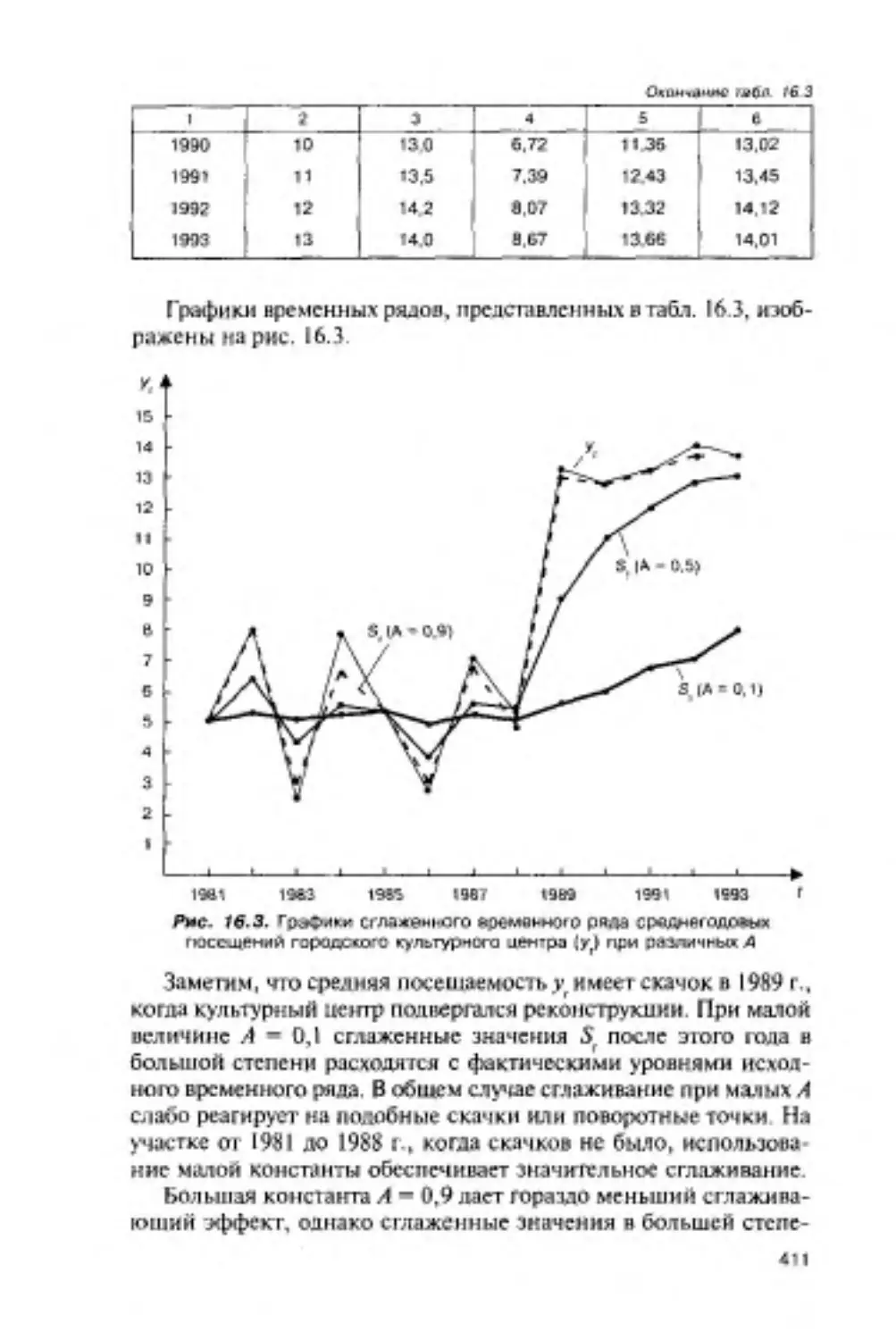
16.2. Методы экспоненциального сглаживания..............407
16.2.1. Простое экспоненциальное сглаживание.......407
16.2.2. Экспоненциальное сглаживание с учетом
тренда..........................................415
16.2.3. Экспоненциальное сглаживание с учетом
одновременно тренда и сезонности......................421
16.2.4. Измерение ошибок и сравнение методов прогно-
зирования .......................................428
8
16.2.5. Сравнительная оценка методов экспоненциального
сглаживания и сглаживающих констант..............431
16.3. Авторегрессионные модели прогнозирования........435
16.3.1. Коэффициент автокорреляции и определение
лагированных переменных модели...................438
16.3.2. Выявление и устранение нестационарности вре-
менных рядов..............................441
16.4. Искусственные переменные в линейной регрессионной
модели................................................443
16.5. Проблема устранения автокорреляции ошибок.......448
Основные положения главы 16...........................451
Глава 17. СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБОСНОВАНИЯ
УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ В УСЛОВИЯХ
НЕОПРЕДЕЛЕННОСТИ......................................455
17.1. Описание проблемной ситуации....................456
17.2. Критерии выбора оптимального варианта действии
при неизвестных вероятностях состояний природы........462
17.2.1. Максиминный критерий Валвда..............462
17.2.2. Минимаксный критерий Севиджа........... 463
17.2.3. Максимаксный критерий....................464
17.2.4. Комбинированный критерий пессимизма—опти-
мизма Гурвица..............................465
17.3. Выбор решений при известных вероятностях состояний
природы ..............................................466
17.3.1. Критерий максимального ожидаемого выигрыша .... 466
17.3.2. Критерий минимальных условных потерь.....469
17.3.3. Анализ чувствительности..................470
17.3.4. Измерение риска..........................471
17.4. Исследование проблемы с помощью дерева решений .474
17.4.1. Общие принципы построения дерева решений..474
17.4.2. Использование теоремы Байеса для уточнения
вероятностей состояний природы.............476
Основные положения главы 17...........................484
Приложения ......................................... 489
Литература............................................518
Моей дочери Ксении посвящаю
ПРЕДИСЛОВИЕ
Учебное пособие написано на основе курсов, прочитанных
автором на различных факультетах и в рамках программ в Акаде-
мии народного хозяйства при Правительстве РФ. Пособие может
быть полезным для студентов экономических специальностей и
слушателей системы переподготовки профессиональных управ-
ленческих кадров. Автор стремился дать последовательное изло-
жение вероятностных и статистических методов, делая основной
акцент на их практическом использовании в менеджменте и биз-
несе. Каждое формальное понятие теории вероятности и матема-
тической статистики поясняется на практических примерах из
различных областей управленческой деятельности. В конце посо-
бия представлен список некоторых отечественных и зарубежных
работ, посвященных прикладным вопросам математико-статис-
тического анализа. Приведенные иностранные источники послу-
жили основой для разработки большинства примеров по исполь-
зованию статистических методов в практических ситуациях.
Решение задач статистического анализа связано со значи-
тельными объемами вычислений. Проведение реальных много-
вариантных статистических расчетов без использования ком-
пьютера практически невозможно. Это прежде всего относится
к задачам корреляционно-регрессионного анализа и статисти-
ческого прогнозирования. В ряде примеров, относящихся к дан-
ным темам (главы 13—16), промежуточные расчеты были сде-
ланы с помощью статистических пакетов прикладных программ.
В настоящее время разработано достаточное количество уни-
версальных и специализированных программных средств для
статистического анализа данных. С наиболее популярными из
них можно ознакомиться, например, в книге: Тюрин Ю.И.,
Макаров А.А. Статистический анализ данных на компьютере/
Под. ред. В.Э. Фигурнова. — М.: ИНФРА-М, 1998.
Ю
Г J ПРЕДСТАВЛЕНИЕ ДАННЫХ
В СТАТИСТИЧЕСКОМ
АНАЛИЗЕ
1.1. ОСНОВНЫЕ НАПРАВЛЕНИЯ
СТАТИСТИЧЕСКОГО АНАЛИЗА
В статистическом анализе можно выделить два основных на-
правления. Одно из них представляет собой статистическое опи-
сание (описательная статистика) какого-либо явления на ос-
нове только тех данных, которые были собраны. Например, к
методам статистического описания относится представление
данных в виде различных типов таблиц и графиков, которые
служат как бы фотографиями исследуемого явления в различ-
ных ракурсах. г>ги методы также включают получение обобщен-
ных показателей, характеризующих свойства и структуру ис-
следуемых данных. Описательная статистика упорядочивает и
систематизирует имеющуюся информацию, облегчает понима-
ние изучаемого явления. Наиболее ярким примером статисти-
ческого описания служат результаты переписи населения, пред-
ставленные в виде соответствующих таблиц, графиков и
показателей распределения населения по демографическим и
социальным признакам.
Другое направление статистического анализа (аналитичес-
кая статистика) — обработка собранных данных с целью про-
ведения анализа и получения статистических выводов отно-
сительно исследуемого массового явления. При этом данное
явление, как правило, характеризуется значительно боль-
шим количеством данных, чем участвует в обработке. Реша-
ющую роль здесь играют математико-статистические методы.
Они позволяют анализировать и интерпретировать массивы
полученных данных независимо от их качественного содер-
жания. Например, это могут быть значения показателей, от-
ражающих различные массовые явления в экономике и биз-
несе. Массовым явлениям соответствуют статистические co-
ll
вокупности, в рамках которых они проявляются. Статисти-
ческая совокупность — это масса отдельных качественно од-
нородных единиц или элементов. Элементами статистичес-
кой совокупности могут быть отдельные индивиды или их
группы, а также какие-либо объекты: предприятия отрасли,
единицы продукции, акции, транспортные средства, стра-
ны и т. д. Если совокупность состоит из всех элементов, кото-
рые соответствуют данному явлению, то в этом случае ис-
пользуется термин “генеральная совокупность”. В то же вре-
мя термин “выборка”, или “выборочная совокупность”,
используется для обозначения части (подмножества) гене-
ральной совокупности. Состав генеральной совокупности пол-
ностью определяется соответствующим явлением. Пусть цель
статистического исследования — выявление мнения избира-
телей, живущих в крупном регионе страны, относительно
избрания определенного кандидата на пост губернатора дан-
ного региона. В этом случае генеральная совокупность вклю-
чает в себя всех жителей региона, имеющих право голоса.
Численность такой совокупности для крупного региона мо-
жет составлять более миллиона человек. Очевидно, оператив-
но организовать опрос всех потенциальных избирателей, т. е.
провести обследование всех единиц совокупности, практи-
чески невозможно, так как это требует значительных затрат
людских, материальных и финансовых ресурсов. Поэтому в
подобных случаях для изучения свойств генеральной сово-
купности обследуют некоторую ее часть — выборку, извле-
ченную случайным образом. Например, в рассматриваемой
ситуации для проведения опроса имеет смысл случайным об-
разом отобрать приемлемое число респондентов (проблема
численности выборки будет рассмотрена в гл. 8) — взрослых
жителей региона. Случайный отбор предполагает, что до его
осуществления все взрослые жители (единицы генеральной
совокупности) имели равные возможности для включения в
число респондентов (выборку). С помощью случайного отбо-
ра формируется случайная выборка, которая лежит в основе
выборочного метода. С этим методом в статистическом ана-
лизе ассоциируется целое направление — получение статис-
тического заключения. Оно связано с использованием мето-
дов математической статистики для обоснования наиболее
правдоподобных выводов о характерных признаках генераль-
ной совокупности только с помощью данных случайной вы-
борки.
12
1.2. КОЛИЧЕСТВЕННЫЕ ИЗМЕРЕНИЯ
СТАТИСТИЧЕСКИХ ДАННЫХ
Пусть в качестве статистической совокупности рассматри-
вается множество семей, живущих в некотором округе. На-
пример, это делается с целью проведения маркетинговых ис-
следований некой торговой фирмой, которая собирается
организовать на территории округа сеть магазинов. Очевидно,
для определения покупательной способности местного насе-
ления одним из важнейших показателей будет годовой доход
каждой семьи. Можно сказать, что каждой единице совокуп-
ности (семье) соответствует значение некоторого варьирую-
щего признака (сумма годового семейного дохода). Вариация
(изменение) признака отражает тот факт, что он принимает
различные значения у различных единиц совокупности. Се-
мейный доход является не единственным варьирующим при-
знаком, характеризующим элементы совокупности. Так, при-
знаками семьи могут служить количество детей дошкольного
или школьного возраста, общая площадь квартиры или дома,
наличие автомобиля, удовлетворенность работой коммуналь-
ных служб и т. п. В общем случае для каждой статистической
совокупности может существовать множество варьирующих
признаков, имеющих количественное или качественное зна-
чение. Кроме того, при изучении совокупности часто рассмат-
риваются количественные обобщенные характеристики, на-
пример: общая численность совокупности; процент единиц
совокупности, обладающих данным свойством; средние по-
казатели по ряду признаков. Численные данные, являющиеся
измерителями всей совокупности этих характеристик и вари-
ации признаков, представляют собой ту исходную информа-
цию, которой оперирует статистический анализ. Некоторые
методы обработки данных рассчитаны на определенный вид
данных. В этой связи перед изложением этих методов имеет
смысл рассмотреть главные характерные признаки числовых
данных. Анализируемые данные можно разделить на две ос-
новные категории: дискретные и непрерывные.
Дискретные данные выражаются в виде целых положитель-
ных чисел. Например, это могут быть результаты опроса груп-
пы лиц по поводу согласия с каким-либо фактом, где степень
согласия кодируется по следующей системе: 1 — полностью
согласен, 2 — согласен, 3 — нейтрален, 4 — не согласен, 5 —
полностью не согласен. В основном дискретные данные возни-
кают в тех случаях, когда есть необходимость подсчета каких-
13
либо единиц, например при определении числа детей в семье;
числа автомобилей, проезжающих в течение 5 минут через же-
лезнодорожный переезд; числа младенцев, родившихся в тече-
ние дня в городе, и т. п.
В отличие от дискретных непрерывные данные могут непре-
рывно заполнять некоторый промежуток. Например, пусть в
качестве данных рассматривается вес посылок, прибывающих
в некоторое почтовое отделение. Теоретически вес каждой по-
сылки может быть выражен в килограммах с любой точностью
(это зависит от точности весов), т. е. представлен в виде деся-
тичного числа с бесконечным числом знаков после запятой.
Непрерывные данные могут принимать любые значения в за-
данных пределах. В рассматриваемом случае каждая посылка
может иметь любой вес в пределах нормативов, установленных
для приема посылок в почтовых отделениях. Непрерывные дан-
ные также могут быть получены при измерении роста, веса и
возраста индивида; диаметра подшипника; срока годности при-
бора; времени обслуживания клиента и т. д.
Важно отметить, что дискретные данные могут выражать
значения не только дискретных переменных, но и некоторых
непрерывных. Так, когда говорят о возрасте человека, то, как
правило, имеют в виду целое число прожитых лет.
1.3. УРОВНИ ИЗМЕРЕНИЯ ДАННЫХ
Численные данные не только делятся на дискретные и не-
прерывные, но и классифицируюся по уровням измерения,
которые определяют тип шкалы измерений. Выделяют четыре
типа шкал: шкала наименований, порядковая шкала, шкалы
интервалов и отношений.
Шкала наименований используется для описания качествен-
ных данных, характеризующих принадлежность элементов со-
вокупности к каким-либо классам. Всем объектам одного класса
присваивается одно и то же число, а объектам разных классов —
разные числа. Например, при распределении людей по полу:
мужчина - 1, а женщина = 2; при классификации человеческих
глаз по цвету: голубой = 1, зеленый = 2, коричневый = 3; при
учете фирм — производителей автомобилей: "Форд" = 1, “Дже-
нерал моторе" = 2, "Крайслер" = 3. Смысл шкалы наименова-
ний — присваивание каждому классу определеного кода. Эта про-
цедура необходима для организации и хранения поиска
информации в компьютерных системах. Однако проводить ка-
кие-либо вычисления на основе данных такого типа не имеет
«4
смысла. Так, утверждение о том, что средний цвет глаз равен
2,73, абсурдно.
Порядковая шкала используется для упорядочения (ранжи-
рования) объектов (например, распределение мест среди участ-
ников какого-либо состязания или конкурса). Числа в шкале
определяют порядок следования объектов, однако не дают воз-
можности установить, на сколько или во сколько раз один
объект предпочтительней другого. Если участник конкурса А
занял первое место, участник В — третье, участник С — пятое
и участник D — седьмое, то это не означает, что D по отноше-
нию к С стоит гак же близко, как В по отношению к Л. В шкале
порядка отсутствуют понятия масштаба и начала отсчета.
Для определения меры различия между значениями при-
знака, присущего разным элементам совокупности, использу-
ется шкала интервалов. Классическим примером интервальной
шкалы является измерение температуры в градусах по Фарен-
гейту или Цельсию. Ясно, что разница между 15 и 10‘С та же,
что и между 17 и 12’С. В общем случае шкала интервалов может
иметь произвольные точки отсчета и масштаб.
Шкала отношений является частным случаем шкалы интер-
валов. В отличие от шкалы интервалов она имеет фиксирован-
ную точку отсчета. В этой шкале можно измерять, во сколько
раз значение признака, характеризующего одну единицу сово-
купности, превосходит значение признака для другой едини-
цы. Это невозможно сделать, пользуясь шкалой интервалов.
Например, нельзя утверждать, что температура 20*С в два раза
выше темсратуры 10’С, так как температура О’С не означает
отсутствия температуры вообще. В шкале отношений измеря-
ются, например, площадь, длина, вес, денежные потоки. Ну-
левая точка отсчета в шкале отношений означает полное от-
сутствие измеряемого признака.
Использование типа шкалы при измерении признака зави-
сит от самой природы этого признака. Если он носит качествен-
ный характер, то измерения производятся в шкалах наименова-
ний и порядка (качественные данные), если количественный,
го применяются шкалы интервалов и отношений (количествен-
ные данные).
1.4. СБОР ДАННЫХ
Методы статистического заключения оперируют выбороч-
ными данными. Справедливость получаемых выводов относи-
тельно свойств генеральной совокупности зависит от каче-
15
ства исходных данных, подвергаемых обработке, т. е. их точ-
ности и способности в достаточной мере отражать свойства
анализируемой статистической совокупности. Очевидно, это
качество зависит от источников и способов сбора данных, а
также правильности составления выборки. Анализируемые дан-
ные можно разделить на две категории — первичные и вто-
ричные.
Первичные данные собираются непосредственно в резуль-
тате проведения специально ориентированных опросов, ин-
тервью, наблюдений и экпериментальных исследований. Тра-
диционным методом сбора первичных данных является
составление вопросника, предназначенного для изучения фак-
торов и условий, влияющих на исследуемую проблему. Этбт
вопросник целенаправленно распространяется среди выбороч-
ной группы лиц, представляющих, по мнению исследователя,
всю совокупность людей, которые заинтересованы в данной
проблеме. Полученные ответы кодируются и вводятся в память
компьютера для последующей обработки. Результаты расчетов
являются основой для получения заключения относительно ис-
следуемой проблемы.
Вторичные данные собираются из различных информаци-
онных источников: периодических печатных изданий финан-
сового, экономического и социологического характера, пуб-
ликуемых годовых финансовых и бухгалтерских отчетов фирм
и банков, котировок акций, биржевых сводок, показателей
различных внутренних и внешних рынков и т. п. Как видно,
вторичные данные всегда предварительно собираются, запи-
сываются и публично представляются в определенной форме.
Приобрести вторичные данные, как правило, дешевле, чем
организовать сбор первичных данных. Однако в большинстве
случаев содержание, точность и новизна вторичных данных не
могут быть в полной мере адекватны объектам конкретного
статистического исследования. Это связано с тем, что в основе
их сбора и публикации были заложены другие, более общие
цели и задачи. Поэтому в статистическом анализе стараются по
возможности использовать первичные данные, которые, на-
пример, регулярно могут собираться специальными агентства-
ми (сеть таких агентств стабильно функционирует в развитых
странах).
Важно понимать тот факт, что эффективность решений в
бизнесе, принимаемых на основе выборочного метода, в пол-
ной мере зависит от качества исходной информации. На практи-
16
ке получение детальных и адекватных первичных данных не
всегда бывает технически возможным или требует значитель-
ных затрат. Поэтому при выборе типов данных для статистичес-
кого анализа следует соотносить надежность и соответствие
изучаемой проблеме первичных данных с доступностью и удоб-
ством в получении вторичных данных.
1.5. ФОРМИРОВАНИЕ И ВИДЫ ВЫБОРКИ
Основная цель формирования выборки — эффективное ис-
пользование ее состава данных в качестве входной информации
для статистического анализа в целях получения наиболее прав-
доподобных статистических выводов о свойствах генеральной со-
вокупности. Поэтому важнейшим требованием, которое должно
выполняться при организации выборки, является репрезента-
тивность. Репрезентативность, или представительность, означа-
ет, что выборка должна в максимальной степени (как в “капле
воды") отражать свойства и структуру генеральной совокупнос-
ти. Она достигается с помощью объективного отбора, т. е. прави-
ла равных возможностей попадания в выборку элементов гене-
ральной совокупности. Тип выборки определяется способом
отбора данных. Различают простой случайный отбор, отбор по
заранее определенному принципу и их комбинацию. Если из ге-
неральной совокупности численностью Nединиц отбирается слу-
чайным образом п единиц, то такой отбор называется простым
случайным отбором, или собственно случайным. Например, про-
стой случайный отбор реализуется при розыгрышах различных
лотерей. В результате простого случайного отбора формируется
простая случайная выборка, или собственно случайная выборка
(часто используют термин “случайная выборка”). Схема просто-
го случайного отбора предполагает регистрацию элементов со-
вокупности, например в виде списков, реестров, картотек, кви-
танций и т. п. Если регистрация в том или ином виде проведена,
то для формирования простой случайной выборки можно ис-
пользовать таблицу случайных чисел, которая может быть взята
в готовом виде или сгенерирована с помощью компьютерной
программы.
Пример. Рассмотрим ситуацию, когда аудитору требуется полу-
чить случайную выборку из 50 записей финансовой отчетности
фирмы, состоящей из 1000 записей, пронумерованных пос-
17
ледовательно от 1 до 1000. В данном случае он может воспользо-
ваться таблицей случайных чисел, представленной в Приложе-
нии 1.
Зафиксируем произвольную позицию в таблице, например
ряд 5, колонка 3 (24127). Далее составим список из 50 случай-
ных чисел, произвольным образом двигаясь по таблице. В каж-
дом выбранном пятизначном числе для отделения дробной
части поставим запятую между третьим и четвертым знаками
и затем округлим полученное дробное число до ближайшего
целого. Например, первое выбранное число 24127 запишем в
виде 241,127 и затем округлим его до 241. Отобранные таким
образом трехзначные числа будут порядковыми номерами за-
писей финансовой отчетности, образующих случайную вы-
борку.
Кроме собственно случайного отбора существуют и другие
методы организации выборки. Например, к ним относятся си-
стематический, экспертный, районированный и многоступен-
чатый отборы.
Систематический отбор предполагает формирование вы-
борки согласно некоторому плану. Он может использоваться,
когда получение простой случайной выборки затруднительно
или связано с большими издержками. Например, пусть гене-
ральная совокупность состоит из 2000 накладных, которые
хранятся в специальных выдвижных ящиках. Пусть требуется
осуществить случайный отбор 100 накладных для бухгалтерс-
кой проверки. Теоретически следует пронумеровать все наклад-
ные числами от 0 до 1999 и, используя таблицу случайных
чисел, отобрать среди них случайным образом 100 номеров.
Очевидно, эта процедура займет достаточно много времени.
Гораздо проще было бы, выдвигая ящики и механически про-
сматривая подряд все накладные, отбирать из них каждую
двадцатую. Систематический отбор может привести к тем же
результатам, что и случайный, если элементы генеральной
совокупности хорошо перемешаны. Однако если элементы рас-
положены в определенном порядке, то фактор случайности
уже не будет решающим.
При экспертном отборе в выборку включаются те едини-
цы, свойства которых в наибольшей степени соответствуют
целям исследования. Исследователь считает, что он включа-
ет в выборку именно такие элементы, что полученные на ее
18
основе выборочные характеристики будут наилучшими оцен-
ками соответствующих характеристик генеральной совокуп-
ности. Очевидно, экспертный отбор будет эффективен в слу-
чае небольших выборок и из небольших генеральных сово-
купностей. Используя экспертный отбор, исследователь
должен хорошо знать свойства отдельных элементов гене-
ральной совокупности. Экспертный отбор чаще всего приме-
няется в торговле.
Районированный отбор является разновидностью случайного.
При этом исследователь делит генеральную совокупность на
несколько “районов” и элементы, составляющие выборку, от-
бираются случайным образом не из всей генеральной совокуп-
ности как целого, а из каждого “района” отдельно. При опре-
деленных предпосылках районированный отбор может дать более
высокую точность результатов, чем простой случайный отбор.
Точность будет зависеть от того, как было проведено “райони-
рование”. Общая оценка анализируемого параметра генераль-
ной совокупности находится (с помощью специальных спосо-
бов) как объединение выборочных оценок по каждому “району”.
Часто для статистического анализа представляет интерес оценка
параметров не только для всей совокупности, но и для отдель-
ных “районов”. Районированный отбор используется при со-
циологических опросах, когда районирование может произво-
диться по территориальному, социальному и демографическому
признакам.
При многоступенчатом отборе реализуется процедура несколь-
ких последовательных случайных отборов, причем извлечение
единиц в выборку происходит на последней стадии озбора. На-
пример, необходимо обследовать областные города. Такой отбор
может быть проведен в три ступени: единицы отбора первой
ступени — края, единицы отбора второй ступени — области,
единицы отбора третьей ступени (составляющие выборку) —
Областные города. Данный метод не увеличивает точность оцен-
ки по сравнению с простым случайным отбором, но его приме-
нение может существенно сократить затраты на проведение об-
следования.
С уществует еще несколько методов отбора выборки, кото-
рые по сути являются комбинацией описанных выше спосо-
бов В дальнейшем в статистических заключениях будем счи-
шть, что выборка получена на основе простого случайного
отбора.
19
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 1
Статистический анализ направлен на изучение количествен-
ного аспекта массовых явлений. В нем можно выделить два ос-
новных направления: описательная и аналитическая статисти-
ка. Описательная статистика представляет собой статистическое
описание какого-либо явления на основе только тех данных,
которые были собраны. К методам статистического описания
относится представление данных в виде таблиц, графиков и
обобщающих показателей.
В основе аналитической статистики лежит статистическое
заключение или выборочный метод. Это направление связано с
использованием методов математической статистики. Осново-
полагающими понятиями здесь являются генеральная совокуп-
ность и выборочная совокупность (выборка). Генеральная сово-
купность включает в себя все единицы, которые соответствуют
данному явлению. Термин “выборка” используется для обозна-
чения части генеральной совокупности. Методология этого на-
правления заключается в том, что с помощью математико-ста-
тистических методов на основе данных выборки делаются
выводы о признаках и свойствах генеральной совокупности. При
этом выборка должна удовлетворять требованию случайности,
т. е. отбор элементов в нее должен производиться случайным
образом.
Единицы генеральной совокупности могут характеризоваться
некоторым варьирующим признаком, который изменяется от
одной единицы совокупности к другой. Признаки могут иметь
количественное и качественное содержание. Количественные
измерения значений признака, а также различных обобщен-
ных показателей совокупности представляют собой исходные
данные для статистического анализа. Анализируемые данные
можно разделить на две основные категории — дискретные и
непрерывные. Дискретные данные выражаются в виде целых
положительных чисел. Они используются для кодирования и
подсчета каких-либо единиц. Непрерывные данные непрерыв-
но заполняют некоторый промежуток. Они получаются при
измерении непрерывных переменных (например, времени, га-
баритов изделий и т. д.).
Численные данные классифицируются по уровням изме-
рения, которые определяют тип шкалы измерений. Выделяют
шкалу наименований, порядковую шкалу, шкалы интервалов
и отношений. Шкала наименований используется для описа-
20
ния качественных данных, характеризующих принадлежность
элементов совокупности к каким-либо классам или категори-
ям; порядковая шкала — для упорядочения (ранжирования)
объектов; шкалы интервалов и отношений — для определе-
ния меры различия между значениями признака. С помощью
последних можно измерять, на сколько (шкала интервалов)
и во сколько раз (шкала отношений) значение признака, ха-
рактеризующего одну единицу совокупности, превосходит зна-
чение признака для другой единицы. Использование типа шка-
лы зависит от содержания измеряемого признака. Если он носит
качественный характер, то прибегают к шкалам наименова-
ний и порядка (качественные данные), если количественный —
к шкалам интервалов и отношений (количественные данные).
По источникам получения данные можно классифицировать
как первичные и вторичные. Первичные данные собираются
непосредственно в результате проведения специально ори-
ентированных опросов, интервью, наблюдений и экспери-
ментальных исследований. Вторичные данные собираются из
различных информационных источников: периодических пе-
чатных изданий финансового, экономического и социоло-
гического характера. Вторичные данные всегда предварительно
собираются, записываются и публично представляются в оп-
ределенной форме. Первичные данные, как правило, более
адекватны анализируемой проблеме, однако их получение
менее удобно и требует больших затрат по сравнению со вто-
ричными.
Для выборочного метода важнейшим условием является реп-
резентативность (представительность) выборки. Она означает,
что выборка должна в максимальной степени отражать свой-
ства и структуру генеральной совокупности. Репрезентативность
достигается с помощью объективного отбора, т. е. принципа
равных возможностей попадания в выборку единиц генераль-
ной совокупности. Тип выборки определяется способом отбора
данных. Если из генеральной совокупности элементы, состав-
ляющие выборку, отбираются случайным образом, то такой
отбор называется случайным, или собственно случайным. В ре-
зультате формируется простая случайная выборка, или собствен-
но случайная выборка.
Кроме простого случайного отбора существуют другие спо-
собы организации выборки, например: систематический, экс-
пертный, районированный и многоступенчатый отборы. Сис-
тематический по своей сути является механическим отбором,
21
который производится по какому-либо плану. Например, если
каждому элементу генеральной совокупности приписать поряд-
ковый номер, то в выборку может попасть каждый пятый эле-
мент. Экспертный отбор заключается в выборке по субъектив-
ному мнению исследователя. Он решает, какие элементы
должны составлять выборку, чтобы полученные выборочные
характеристики дали наилучшую оценку соответствующей ха-
рактеристики генеральной совокупности. При районированном
отборе случайная выборка извлекается не из всей генеральной
совокупности как целого, а из двух или нескольких “районов”,
на которые исследователь делит всю генеральную совокупность.
Метод многоступенчатого отбора включает ряд стадий или сту-
пеней, при этом извлечение единиц совокупности в выборку
происходит на последней стадии.
TAAZA
ГРУППИРОВКА
И ГРАФИЧЕСКОЕ
ПРЕДСТАВЛЕНИЕ ДАННЫХ
2.1. РЯД РАСПРЕДЕЛЕНИЯ
В предыдущей главе были рассмотрены основные понятия,
связанные с представлением и сбором статистических данных.
Собранные данные являются исходной информацией для про-
ведения статистических исследований. Как правило, эта инфор-
мация представляет собой хаотический набор данных. Очевид-
но, начальным этапом се обработки должна быть систематизация
беспорядочной массы чисел с целью придания ей удобной фор-
мы и структуры для проведения первичного анализа, смысл
которого заключается в оценке данных в связи с исследуемой
проблемой и облегчении сравнения с другими данными того же
рода. Например, пусть имеются две совокупности данных, одна
из которых отражает доходы всех семей страны А, а другая —
страны В. Численность каждой совокупности может составлять
несколько миллионов числовых значений. Требуется сделать об-
щие заключения о структуре распределения семейных доходов
каждой страны и провести сравнительный анализ семейных до-
ходов этих стран. Ясно, что без определенной обработки и обоб-
щения всей этой огромной массы чисел никакой анализ невоз-
можен. Необходимо сжать исходную информацию, т. е. представить
ее в виде существенно меньшего по численности набора дан-
ных, которые было бы легко и удобно интерпретировать.
Основным способом обобщения и сжатия статистической
информации является группировка данных или построение ряда
распределения. Ряд распределения (вариационный ряд) пред-
ставляет собой упорядоченное распределение единиц совокуп-
ности на группы по какому-либо варьирующему признаку, име-
ющему количественное выражение. Каждой группе соответствует
определенная частота, т. е. количество единиц совокупности, для
которых значения признака принадлежат этой группе.
23
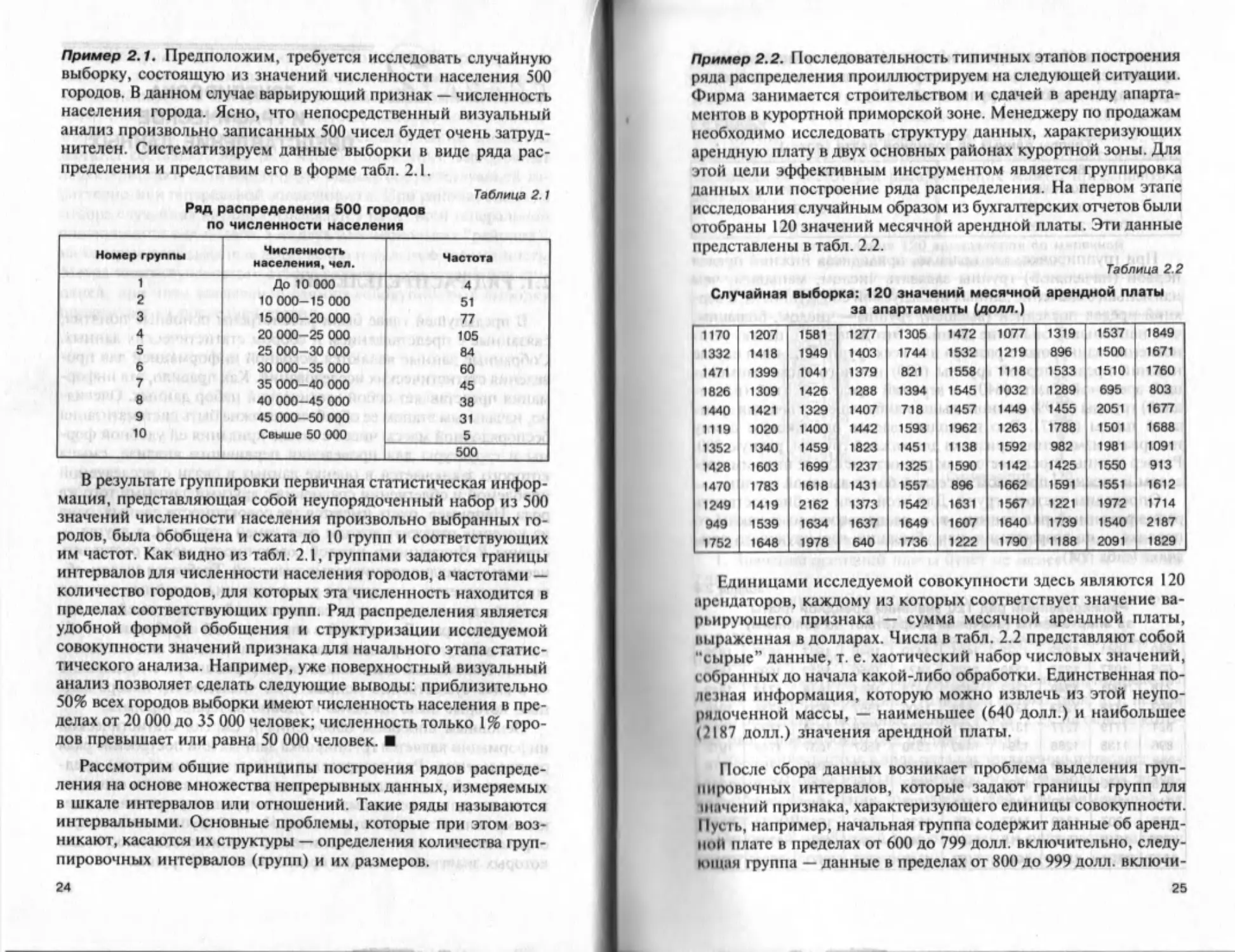
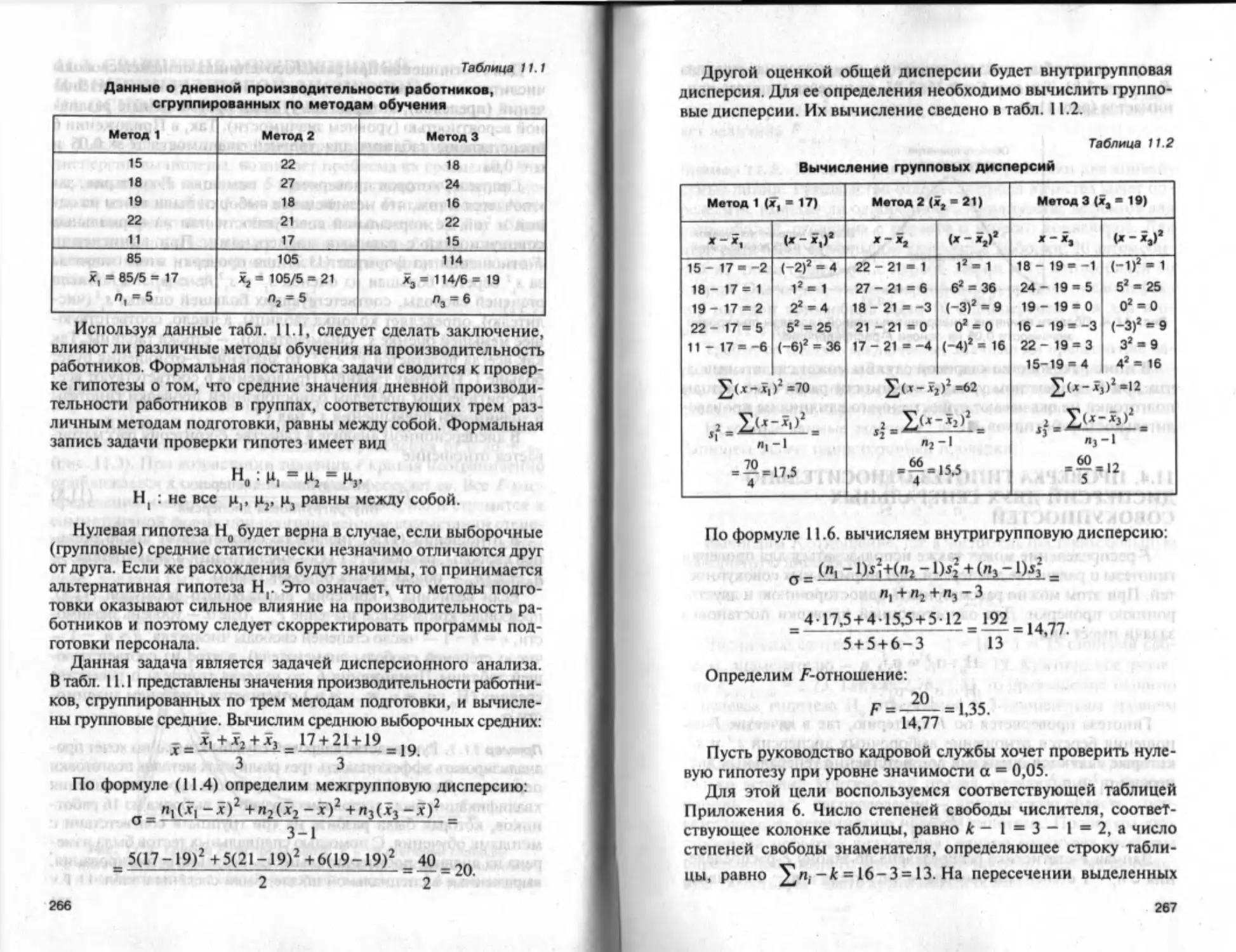
Пример 2.1. Предположим, требуется исследовать случайную
выборку, состоящую из значений численности населения 500
городов. В данном случае варьирующий признак — численность
населения города. Ясно, что непосредственный визуальный
анализ произвольно записанных 500 чисел будет очень затруд-
нителен. Систематизируем данные выборки в виде ряда рас-
пределения и представим его в форме табл. 2.1.
Таблица 2.1
Ряд распределения 500 городов
по численности населения
Номер группы Численность населения, чел. Частота
1 До 10 000 4
2 10 000-15 000 51
3 15 000-20 000 77
4 20 000-25 000 105
5 25 000 30 000 84
6 30 000-35 000 60
7 35 000-40 000 45
8 40 000-45 000 38
9 45 000-50 000 31
10 Свыше 50 000 5
500
В результате группировки первичная статистическая инфор-
мация, представляющая собой неупорядоченный набор из 500
значений численности населения произвольно выбранных го-
родов, была обобщена и сжата до 10 групп и соответствующих
им частот. Как видно из табл. 2.1, группами задаются границы
интервалов для численности населения городов, а частотами —
количество городов, для которых эта численность находится в
пределах соответствующих групп. Ряд распределения является
удобной формой обобщения и структуризации исследуемой
совокупности значений признака для начального этапа статис-
тического анализа. Например, уже поверхностный визуальный
анализ позволяет сделать следующие выводы: приблизительно
50% всех городов выборки имеют численность населения в пре-
делах от 20 000 до 35 000 человек; численность только 1% горо-
дов превышает или равна 50 000 человек.
Рассмотрим общие принципы построения рядов распреде-
ления на основе множества непрерывных данных, измеряемых
в шкале интервалов или отношений. Такие ряды называются
интервальными. Основные проблемы, которые при этом воз-
никают, касаются их структуры — определения количества груп-
пировочных интервалов (групп) и их размеров.
24
Пример 2.2. Последовательность типичных этапов построения
ряда распределения проиллюстрируем на следующей ситуации.
Фирма занимается строительством и сдачей в аренду апарта-
ментов в курортной приморской зоне. Менеджеру по продажам
необходимо исследовать структуру данных, характеризующих
арендную плату в двух основных районах курортной зоны. Для
этой цели эффективным инструментом является группировка
данных или построение ряда распределения. На первом этапе
исследования случайным образом из бухгалтерских отчетов были
отобраны 120 значений месячной арендной платы. Эти данные
представлены в табл. 2.2.
Таблица 2.2
Случайная выборка: 120 значений месячной арендной платы
за апартаменты (долл.)
1170 1207 1581 1277 1305 1472 1077 1319 1537 1849
1332 1418 1949 1403 1744 1532 1219 896 1500 1671
1471 1399 1041 1379 821 1558 1118 1533 1510 1760
1826 1309 1426 1288 1394 1545 1032 1289 695 803
1440 1421 1329 1407 718 1457 1449 1455 2051 1677
1119 1020 1400 1442 1593 1962 1263 1788 1501 1688
1352 1340 1459 1823 1451 1138 1592 982 1981 1091
1428 1603 1699 1237 1325 1590 1142 1425 1550 913
1470 1783 1618 1431 1557 896 1662 1591 1551 1612
1249 1419 2162 1373 1542 1631 1567 1221 1972 1714
949 1539 1634 1637 1649 1607 1640 1739 1540 2187
1752 1648 1978 640 1736 1222 1790 1188 2091 1829
Единицами исследуемой совокупности здесь являются I20
арендаторов, каждому из которых соответствует значение ва-
рьирующего признака — сумма месячной арендной платы,
выраженная в долларах. Числа в табл. 2.2 представляют собой
"сырые" данные, т. е. хаотический набор числовых значений,
собранных до начала какой-либо обработки. Единственная по-
лезная информация, которую можно извлечь из этой неупо-
рядоченной массы, — наименьшее (640 долл.) и наибольшее
(2I87 долл.) значения арендной платы.
После сбора данных возникает проблема выделения груп-
пировочных интервалов, которые задают границы групп для
(ничений признака, характеризующего единицы совокупности.
Пусть, например, начальная группа содержит данные об аренд-
ной плате в пределах от 600 до 799 долл, включительно, следу-
ющая группа — данные в пределах от 800 до 999 долл, включи-
25
тельно и т. д. Каждая группа имеет нижний и верхний пределы,
причем верхний предел каждой группы отличается от нижнего
предела последующей группы (табл. 2.3).
Таблица 2.3
Группы данных об арендной плате (долл.)
600-799 1400-1599
800-999 1600-1799
1000-1199 1800-1999
1200-1399 2000-2199
При группировке, как правило, приходится нижний предел
первой (начальной) группы задавать числом, меньшим, чем
наименьшее значение данных исследуемой совокупности, а вер-
хний предел последней (высшей) группы— числом, большим,
чем наибольшее значение данных. Это делается с целью уста-
новления одинакового размера для всех групп. В данном случае
нижний предел первой группы (600) немного ниже наимень-
шей арендной платы (640), а верхний предел десятой (после-
дней) группы (2199) немного выше наибольшего значения арен-
дной платы (2187). Это позволяет задать одинаковую длину
интервала изменения признака для каждой группы, равную 200.
Размер группы определяется как разность между ее нижним пре-
делом и нижним пределом соседней более высокой группы.
Определим частоты групп. Для этой цели удобно составить
ранжированный ряд данных, т. е. расположить их в каком-то
порядке — по возрастанию или убыванию варьирующего при-
знака (табл. 2.4).
Таблица 2.4
Ранжированный ряд 120 значений арендной платы
за апартаменты (значения возрастают по колонкам)
640 1041 1222 1332 1421 1470 1545 1607 1677 1826
695 1077 1237 1340 1425 1471 1550 1612 1699 1829
718 1091 1249 1352 1426 1472 1551 1618 1714 1849
803 1118 1263 1373 1428 1500 1557 1631 1736 1949
821 1119 1277 1379 1431 1501 1558 1634 1739 1962
896 1138 1288 1394 1440 1510 1567 1637 1744 1972
896 1142 1289 1399 1442 1532 1581 1640 1752 1978
913 1170 1305 1400 1449 1533 1590 1648 1760 1981
949 1188 1309 1403 1451 1537 1591 1649 1783 2051
982 1207 1319 1407 1455 1539 1592 1662 1788 2091
1020 1219 1325 1418 1457 1540 1593 1668 1790 2162
1032 1221 1329 1419 1459 1542 1603 1671 1823 2187
26
Просматривая данные табл. 2.4 последовательно по колон-
кам, легко подсчитать количество чисел (т. е. число арендато-
ров), попавших в границы каждой группы. Так, например, в
интервал от 600 до 799 попадают числа 640, 695, 718 (частота
1-й группы — 3); в интервал от 800 до 999 — числа 803, 821,
896, 896, 913, 949, 982 (частота 2-й группы — 7) и т. д. После
определения частот ряд распределения можно представить в
виде табл. 2.5.
Таблица 2.5
Ряд распределения 120 арендаторов по месячной
арендной плате за апартаменты
Месячная арендная плата, долл. Частота
600-799 3
800-999 7
1000-1199 11
1200-1399 22
1400-1599 40
1600-1799 24
1800-1999 9
2000-2109 4
Сумма частот — 120
На основе ряда распределения, представленного в табл. 2.5,
менеджер по продажам может сделать следующие заключения.
1. Значение арендной платы будет не менее 600 и не более
2200 долл.
2. Подавляющее большинство арендаторов платят за апарта-
менты в пределах от 1000 до 1800 долл, в месяц.
3. Наибольшее число арендаторов принадлежат группе с гра-
ницами 1400—1599 долл.
Следует отметить, что при группировке данных происходит
потеря части информации. Пользуясь только табл. 2.5, нельзя
точно определить исходные данные (табл. 2.2), на основе кото-
рых был сформирован ряд распределения.
Обобщение данных в виде ряда распределения позволяет сде-
лать выводы относительно наименьших и наибольших значе-
ний признака, а также зон наибольшей или наименьшей их
концентрации.
Основной проблемой при построении ряда распределения
является проблема построения группировочных интервалов.
27
В частности, возникает вопрос определения границ между груп-
пами. Для ряда распределения (табл. 2.5) границы каждой груп-
пы задавались его нижним и верхним пределами: 600—799, SOO-
999 и т. д. Значения арендной платы были округлены до
ближайших целых чисел. Например, величина 799,5 округля-
лась до 800 и попадала во вторую группу, а все значения свыше
799, но меньше, чем 799,5, округлялись до 799 и относились к
первой группе. Таким образом, группа 600—799 фактически со-
стоит из всех значений от 599,5 (включительно) до 799,5 (не
включая 799,5). Аналогично следующая группа 800—999 содер-
жит на самом деле значения от 799,5 (включительно) до 999,5
(не включая 999,5). В отличие от пределов, которые иногда на-
зывают номинальными границами, фактические границы груп-
пы являются ее точными границами. Точная нижняя граница
группы располагается посередине между ее нижним пределом
и верхним пределом предыдущей группы, а точная верхняя —
между ее верхним пределом и нижним пределом последующи
группы.
Для сравнения пределов групп и их точных границ рассмот-
рим ряд распределения, представленный в табл. 2.6.
Таблица 2.6
Пределы и точные границы групп ряда распределения
(табл. 2.5)
Пределы групп Точные границы групп Частота
600 799 599.5—799,5 (не включая) 3
800 999 799,5-999,5 (не включая) 7
1000—1199 999,5—1199,5 (не включая) 11
1200-1399 1199,5—1399,5 (не включая) 22
1400-1599 1399,5—1599,5 (не включая) 40
1600-1799 1599,5—1799,5 (не включая) 24
1800-1999 1799,5—1999,5 (не включая) 9
2000-2199 1999,5—2199,5 (не включая) 4
Следует отметить, что размер группы можно определить,
вычитая ее нижний предел из нижнего предела последующей
группы, а также вычитая ее соответствующую точную ниж-
нюю границу из соответствующей точной нижней границы
последующей группы.
Выбор размеров групп или их числа является наиболее труд-
ной проблемой построения ряда распределения. Решая этот воп-
рос, следует руководствоваться принципом: необходимо выби-
28
рать такое число групп, чтобы распределение данных внутри
каждой группы было как можно ближе к равномерному. В этом
случае среднюю точку группы можно рассматривать как ти-
пичную величину признака, представляющую весь интервал
изменения признака в границах данной группы. Средняя точка
вычисляется как полусумма нижнего и верхнего пределов груп-
пы или ее точных нижней и верхней границ. Среднюю точку
часто называют меткой группы, и ею пользуются в вычислени-
ях и построениях графиков, где она представляет все данные,
принадлежащие этой группе.
Очень важно, особенно при графической иллюстрации груп-
пировки, чтобы все группы имели одинаковый размер. Однако
при этом могут получиться “пустые группы” или группы, ко-
торым соответствуют “провалы” в распределении частот. Тогда
возникает небходимость построения ряда распределения с раз-
ными по размеру группами. Особенно это касается больших по
размеру неоднородных совокупностей. В этом случае построен-
ный ряд содержит такое большое количество однородных ipynn,
что это смазывает общую структуру данных и сильно затрудня-
ет дальнейший статистический анализ.
Пример 2.3. В табл. 2.7 представлен ряд распределения количе-
ства налоговых поступлений в зависимости от величины скор-
ректированного (для уплаты налогов) валового дохода инди-
видов в некоторой условной стране.
Таблица 2.7
Распределение количества налоговых поступлений
в зависимости от величины скорректированного
валового дохода (долл.)
Группы скорректированных валовых доходов Число налоговых поступлений, тыс. ед.
До 2 000 135
2 000-2 999 3 399
3 000-4 999 8 179
5 000- 9 999 19 740
10 000-14 999 15 539
15 000-24 999 14 944
25 000 49 999 4 451
50 000-99 999 699
100 000-499 999 162
500 000 999 999 3
1 000 000 и свыше 1
29
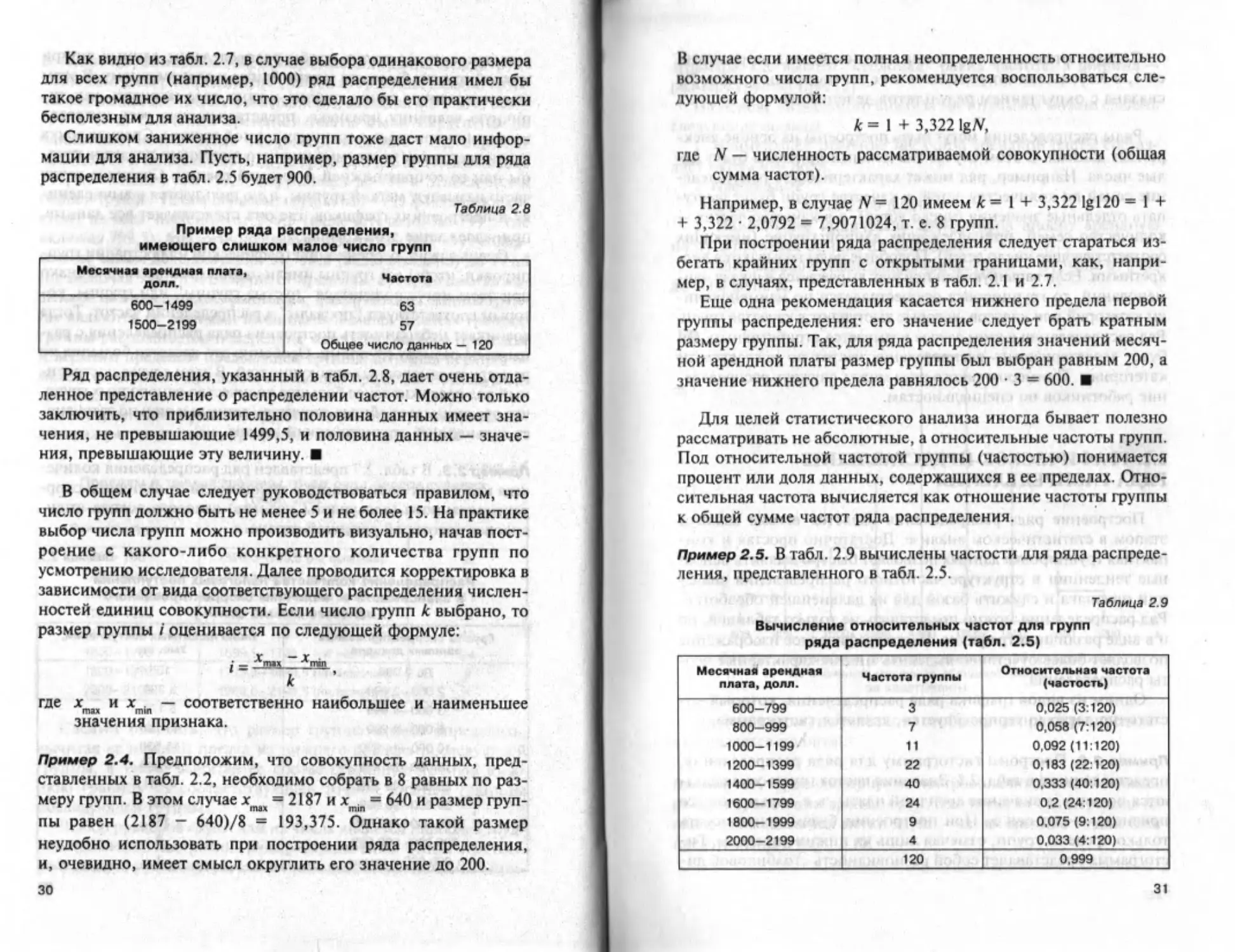
Как видно из табл. 2.7, в случае выбора одинакового размера
для всех групп (например, 1000) ряд распределения имел бы
такое громадное их число, что это сделало бы его практически
бесполезным для анализа.
Слишком заниженное число групп тоже даст мало инфор-
мации для анализа. Пусть, например, размер группы для ряда
распределения в табл. 2.5 будет 900.
Таблица 2.8
Пример ряда распределения,
имеющего слишком малое число групп
Месячная арендная плата, долл. Частота
600—1499 1500-2199 63 57 Общее число данных — 120
Ряд распределения, указанный в табл. 2.8, дает очень отда-
ленное представление о распределении частот. Можно только
заключить, что приблизительно половина данных имеет зна-
чения, не превышающие 1499,5, и половина данных — значе-
ния, превышающие эту величину.
В общем случае следует руководствоваться правилом, что
число групп должно быть не менее 5 и не более 15. На практике
выбор числа групп можно производить визуально, начав пост-
роение с какого-либо конкретного количества групп по
усмотрению исследователя. Далее проводится корректировка в
зависимости от вида соответствующего распределения числен-
ностей единиц совокупности. Если число групп к выбрано, то
размер группы / оценивается по следующей формуле:
i - inm.
к
где х их.— соответственно наибольшее и наименьшее
max min
значения признака.
Пример 2.4. Предположим, что совокупность данных, пред-
ставленных в табл. 2.2, необходимо собрать в 8 равных по раз-
меру групп. В этом случае хмх = 2187 и xmin = 640 и размер груп-
пы равен (2187 — 640)/8 = 193,375. Однако такой размер
неудобно использовать при построении ряда распределения,
и, очевидно, имеет смысл округлить его значение до 200.
зо
В случае если имеется полная неопределенность относительно
возможного числа групп, рекомендуется воспользоваться сле-
дующей формулой:
к = 1 + 3,322 lg/V,
где N — численность рассматриваемой совокупности (общая
сумма частот).
Например, в случае ^ = 120 имеем к = I + 3,322 Igl20 = 1 +
+ 3,322 • 2,0792 = 7,9071024, т. е. 8 групп.
При построении ряда распределения следует стараться из-
бегать крайних групп с открытыми границами, как, напри-
мер, в случаях, представленных в табл. 2.1 и 2.7.
Еще одна рекомендация касается нижнего предела первой
группы распределения: его значение следует брать кратным
размеру группы. Так, для ряда распределения значений месяч-
ной арендной платы размер группы был выбран равным 200, а
значение нижнего предела равнялось 200 • 3 = 600.
Для целей статистического анализа иногда бывает полезно
рассматривать не абсолютные, а относительные частоты групп.
Под относительной частотой группы (частостью) понимается
процент или доля данных, содержащихся в ее пределах. Отно-
сительная частота вычисляется как отношение частоты группы
к общей сумме частот ряда распределения.
Пример 2.5. В табл. 2.9 вычислены частости для ряда распреде-
ления, представленного в табл. 2.5.
Таблица 2.9
Вычисление относительных частот для групп
ряда распределения (табл. 2.5)
Месячная арендная плата, долл. Частота группы Относительная частота (частость)
600-799 3 0,025 (3:120)
800-999 7 0,058 (7:120)
1000-1199 11 0,092 (11:120)
1200-1399 22 0,183 (22:120)
1400-1599 40 0,333 (40:120)
1600-1799 24 0,2 (24:120)
1800-1999 9 0,075 (9:120)
2000-2199 4 0,033 (4:120)
120 0,999
31
Следует отметить, что сумма частостей должна равнять-
ся 1, а небольшая погрешность в ее вычислении в табл. 2.9
связана с округлением результатов делений.
Ряды распределения могут быть построены на основе диск-
ретных данных. В этом случае значениями признака будут це-
лые числа. Например, ряд может характеризовать распределе-
ние семей по количеству детей: в качестве групп будут высту-
пать отдельные значения (число детей), а в качестве частот —
количество семей, принадлежащих данной группе (имеющих
соответствующее число детей). Подобные ряды называются дис-
кретными. Если варьирующий признак выражается в шкале наи-
менований, то группировка осуществляется по наименовани-
ям категорий или классов, которые выступают в качестве групп.
Ряд распределения в этом случае называется атрибутивным. Он
будет характеризовать распределение частот по исследуемым
категориям. Примером такого ряда может служить распределе-
ние работников по специальностям.
2.2. ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ
РЯДА РАСПРЕДЕЛЕНИЯ
Построение ряда распределения является весьма важным
этапом в статистическом анализе. Достаточно простая и ком-
пактная группировка данных позволяет быстро выявить основ-
ные тенденции в структуре частотного распределения значе-
ний признака и служить базой для их дальнейшей обработки.
Ряд распределения можно представить не только таблицей, но
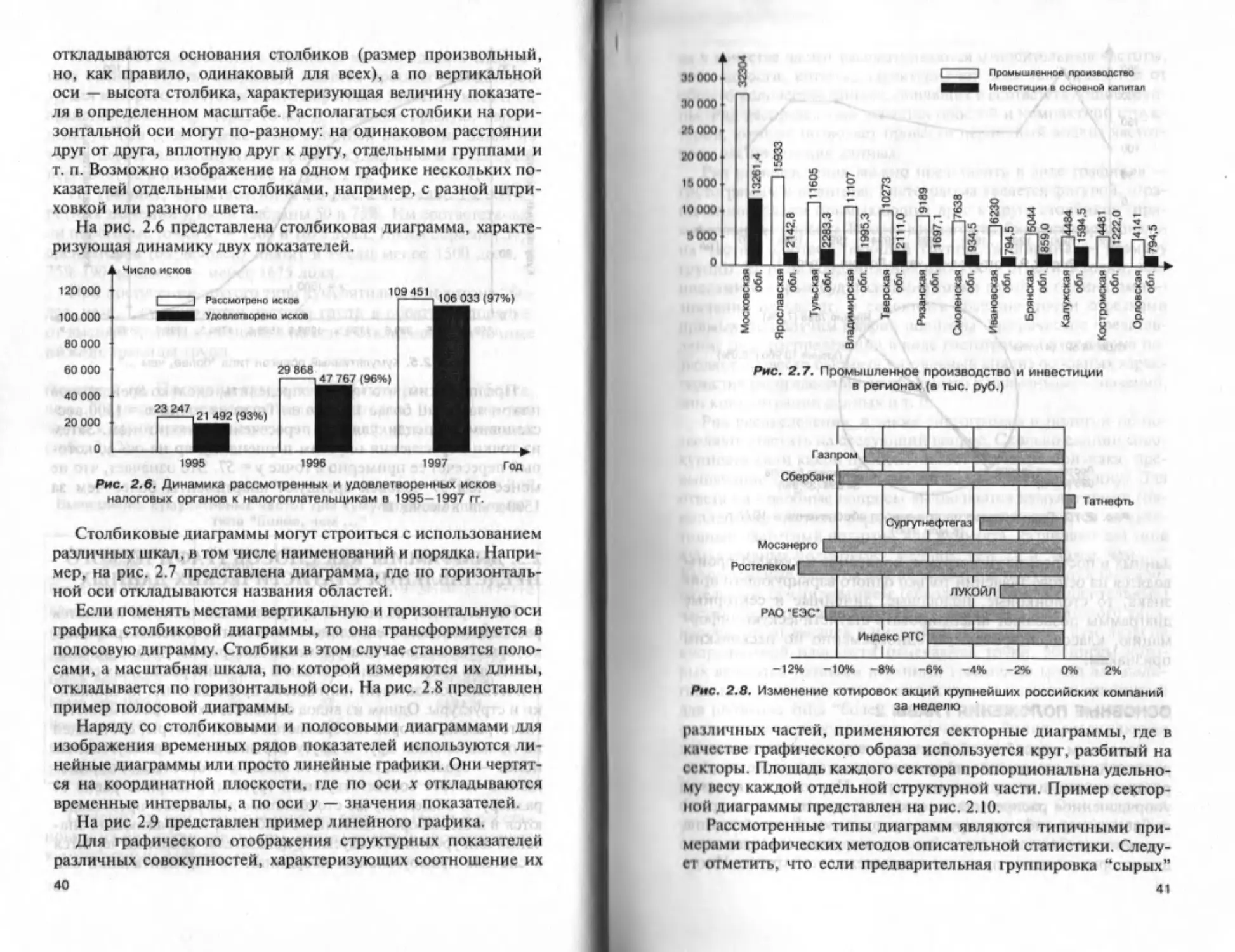
и в виде различных (рафиков. Часто графическое изображение
позволяет более отчетливо выделить многие характерные чер-
ты распределения.
Одним из видов графика ряда распределения, который до-
статочно легко интерпретируется, является гистограмма.
Пример 2.6. Построим гистограмму дтя ряда распределения,
представленного в табл. 2.5. Значения частот групп откладыва-
ются по оси у, а значение арендной платы, т. е. варьирующего
признака, — по оси х. При построении будем использовать
только пределы групп, отмечая лишь их нижние пределы. Ги-
стограмма представляет собой разновидность столбиковой ди-
32
аграммы. где высота “столбика” равна частоте, а ширина —
размеру группы (рис. 2).
На основе визуального анализа гистограммы можно сделать
следующие выводы.
I. Наименьшее значение месячной арендной платы состав-
ляет около 600 долл.
2. Наибольшее
значение — около 2200 долл.
3. Наибольшее количество арендаторов вносит арендную
плату в пределах от 1200 до 1800 долл.
4. Наибольшая концентрация арендаторов — в группе от 1400
до 1600 долл.
Рис 2.1. Гистограмма ряда распределения 120 арендаторов
по значению месячной арендной платы
за апартаменты
Другим видом графического отображения ряда распределе-
ния является полигон.
Пример 2.7. Проиллюстрируем построение полигона на приме-
ре о распределении арендаторов. В отличие от гистограммы на
оси х откладываются метки групп, т. е. их средние точки. Они
представлены в табл. 2.10.
зз
Таблица 2.10
Группы, их средние точки и частоты
(данные для построения полигона)
Пределы группы Средняя точка Частота
600-799 699.5 3
800-999 899,5 7
1000-1199 1099,5 11
1200-1399 1299,5 22
1400-1599 1499,5 40
1600-1799 1699.5 24
1800-1999 1899,5 9
2000-2199 2099,5 4
График полигона (рис. 2.2) строится следующим образом.
На оси х откладываются средние точки групп. Из каждой точки
восстанавливается к оси х перпендикуляр, длина которого рав-
на частоте группы. Затем верхние концы соседних перпендику-
ляров соединяются отрезками прямых. Для того чтобы график
полигона был замкнут, вводятся дополнительные фиктивные
группы: самая нижняя группа размером 200 (400—599) со сред-
ней точкой 499,5 и самая верхняя группа того же размера 200
(2200—2399) со средней точкой 2299,5.
Рис. 2.2. Г рафик полигона для распределения
120 арендаторов апартаментов
34
Графическое представление ряда распределения в виде гис-
тограммы или полигона позволяет получить быстрый визуальный
анализ основных характеристик распределения данных: наиболь-
шее и наименьшее значения, точки концентрации и т. д.
Следует отметить, что гистограмма имеет определенные пре-
имущества по сравнению с полигоном в смысле большей на-
глядности изображения групп. На гистограмме каждая группа
четко обозначена соответствующим столбиком: высота столби-
ка дает представление о частоте группы, ширина столбика и его
расположение на оси х — о размере и границах группы. Однако
использование графика полигона будет более предпочтительным
при сравнительном анализе двух и более рядов распределений.
Пример 2.8. Обратимся опять к ситуации с арендаторами. Слу- •
чайная выборка из 120 арендаторов была составлена из лиц,
снимающих апартаменты в двух различных районах курортной
зоны (обозначим их район 1 и район 2). Пусть менеджера по
продажам интересует сравнительный анализ условий сдачи в
аренду апартаментов в этих районах. Предположим, что слу-
чайная выборка была разделена на две совокупности, в одну из
которых вошли лица, арендующие апартаменты в районе 1, а в
другую — в районе 2. Для каждой группы арендаторов постро-
им отдельный ряд распределения и соответствующий ему гра-
фик полигона. Оба графика поместим на одной координатной
плоскости (рис. 2.3).
Рис. 2.3. Графики полигонов для рядов распределений
двух районов курортной зоны
35
Из рис. 2.3 видно, что величина месячной арендной платы в
районе 2 в целом выше, чем в районе I.
В примере 2.8 исследуемые ряды распределений имеют оди-
наковые размеры групп и приблизительно равные общие суммы
частот. Выполнение этих условий дает возможность визуально
сравнивать формы графиков полигонов. В случае когда общие
суммы частот (т. е. численности совокупностей, на основе кото-
рых были построены ряды распределений) значительно отлича-
ются друг от друга, следует величины абсолютных частот заме-
нить на их относительные значения (относительные частоты).
Ряд распределения, а также гистограмма и полигон не дают
возможности ответить на вопросы, подобные следующим. Сколь-
ко единиц совокупности имеет значение признака, превыша-
ющее заданное число? Какой процент составляют единицы
совокупности, значения признака которых меньше определен-
ной величины?
Для ответа на подобные вопросы вычисляются кумулятив-
ные (накопленные) частоты ряда распределения и строится
график кумулятивного частотного полигона, который иногда
называют кумулятой. Кумулятивный частотный полигон, или
просто кумулятивный полигон, используется для оценки чис-
ла наблюденных значений, которые превышают или остаются
меньше некоторой величины. В этой связи различают два типа
кумулятивных полигонов: “меньше, чем ...” и “более, чем ...”.
Пример 2.9. Построим кумулятивный полигон типа “меньше,
чем ...” для ряда распределения арендаторов (табл. 2.6). Три че-
ловека платят за апартаменты в пределах от 600 до 799 долл.,
т. е. попадают в 1-ю группу. Учитывая точные границы 1-й груп-
пы, можно утверждать, что величина арендной платы для каж-
дого из них находится в интервале от 595,5 до 799,5 долл, (не
включая 799,5). Кроме того, очевидно, что нет ни одного арен-
датора, платившего менее 599,5 долл, в месяц. Поэтому можно
выделить следующие группы, имеющие только точные верх-
ние границы: 0 арендаторов попали в группу “меньше, чем
595,5 долл.”; 3 арендатора попали в группу “меньше, чем 795,5
долл.”. Прибавим к 3 арендаторам 1-й группы 7 арендаторов
2-й группы (800—999). Очевидно, эти 10 арендаторов попадают
в новую группу “меньше, чем 999,5 долл.”. Кумулятивная час-
тота этой группы будет равна 10. Аналогично вычисляются ку-
мулятивные частоты остальных групп: последовательно сумми-
руются частоты групп исходного ряда распределения (табл. 2.11).
36
Таблица 2.11
Вычисление кумулятивных частот для кумулятивного полигона
типа “меньше, чем ...”
Месячная арендная плата, долл. Частоты групп Кумулятивные частоты Вычисления
Меньше, чем 599.5 0 0
Меньше, чем 799,5 3 3
Меньше, чем 999,5 7 10 3+7
Меньше, чем 1199,5 11 21 3+7+11
Меньше, чем 1399,5 22 43 3+7+11+22
Меньше, чем 1599,5 40 83 И т. п.
Меньше, чем 1799,5 24 107
Меньше, чем 1999,5 9 116
Меньше, чем 2199,5 4 120
Для построения полигона типа “меньше, чем ...” на коор-
динатной плоскости отметим точки, имеющие в качестве абс-
цисс точные верхние границы групп, а в качестве ординат —
соответствующие им кумулятивные частоты. Отрезки прямых,
соединяющие каждые две соседние точки, образуют график
полигона (рис. 2.4). Для удобства проведения анализа на <рафи-
ке поместим две оси ординат: слева — ось кумулятивных час-
тот, справа — ось кумулятивных частостей, выраженных в про-
центах.
Рис. 2.4. Кумулятивный полигон типа ‘меньше, чем ..."
37
На основе построенного полигона можно сделать следую-
щие оценки. Пусть, например, задается процент арендаторов
у0, для которого требуется найти пороговое значение месячной
арендной платы х0. Через точку у0 проведем прямую, парал-
лельную оси х, до пересечения с линией полигона. Затем из
точки пересечения опустим перпендикуляр на ось х, который
пересечет се в искомой точке х0 (рис. 2.4).
На графике, представленном на рис 2.4, в качестве конк-
ретных значений у(|были выбраны 50 и 75%. Им соответствова-
ли пороговые точки х0— 1500 и 1675 долл. Таким образом, 50%
арендаторов (60 человек) платят в месяц менее 1500 долл, и
75% (90 человек) — менее 1675 долл.
При построении другого типа кумулятивного полигона “бо-
лее, чем...” суммируются частоты групп в обратном порядке:
от высшей группы к низшей, а на оси х откладываются точные
нижние границы групп.
Пример 2. Ю. Построим кумулятивный полигон типа “более,
чем...” для ряда распределения арендаторов. Вычислим для
этого кумулятивные частоты от высшей группы к низшей
(табл. 2.12).
Таблица 2.12
Вычисление кумулятивных частот для кумулятивного полигона
типа “более, чем ..."
Арендная плата, долл. Частоты групп Кумулятивные частоты Вычисления
Более чем 599.5 3 120 4+9+24+40+22+11+7+3
Более чем 799.5 7 117 4+9+24+40+22+11+7
Более, чем 999,5 11 110 4+9+24+40*22+11
Более, чем 1199,5 22 99 4+9+24+40+22
Более, чем 1399,5 40 77 4+9+24+40
Более, чем 1599,5 24 37 4+9+24
Более, чем 1799,5 9 13 4+9
Более, чем 1999,5 4 4 4
Более, чем 2199,5 0 0 0
Отметим на оси х точные нижние границы групп и восста-
новим из них перпендикуляры, длины которых соответствуют
кумулятивным частотам (рис. 2.5).
38
Рис. 2.5. Кумулятивный полигон типа 'более, чем ...*
Предположим, что нужно определить, сколько арендаторов
платят за месяц более 1500 долл. Тогда из точки х = 1500 вос-
становим перпендикуляр до пересечения с полигоном. Затем
из точки пересечения опустим перпендикуляр на ось у, кото-
рый пересечет ее примерно в точке у = 57. Это означает, что не
менее чем 57 человек арендуют апартаменты более чем за
1500 долл, в месяц.
2.3. ДИАГРАММЫ КАК СПОСОБ ГРАФИЧЕСКОГО
ПРЕДСТАВЛЕНИЯ СТАТИСТИЧЕСКИХ ДАННЫХ
Гистограмма, полигон и кумулятивный полигон являются
разновидностями специального типа статистических графиков,
которые называются диаграммами. Диаграммы удобно исполь-
зовать для сравнительного анализа значений различных стати-
стических показателей, наглядного представления их динами-
ки и структуры. Одним из видов столбиковых диаграмм является
гистограмма, которая изображается в виде фигуры, состоящей
из примыкающих друг к другу вертикальных прямоугольных
полос — столбиков, где высота каждого столбика пропорцио-
нальна частоте соответствующей группы, а ширина равна ее
размеру. В общем случае столбиковые диаграммы представля-
ются в виде набора отдельных столбиков, изображающих зна-
чения или уровни исследуемого показателя. Столбики чертятся
в системе прямоугольных координат: по горизонтальной оси
39
откладываются основания столбиков (размер произвольный,
но, как правило, одинаковый для всех), а по вертикальной
оси — высота столбика, характеризующая величину показате-
ля в определенном масштабе. Располагаться столбики на гори-
зонтальной оси могут по-разному: на одинаковом расстоянии
друг от друга, вплотную друг к другу, отдельными 1руппами и
т. п. Возможно изображение на одном графике нескольких по-
казателей отдельными столбиками, например, с разной штри-
ховкой или разного цвета.
На рис. 2.6 представлена столбиковая диаграмма, характе-
ризующая динамику двух показателей.
Рис. 2.6. Динамика рассмотренных и удовлетворенных исков
налоговых органов к налогоплательщикам в 1995—1997 гг.
Столбиковые диаграммы могут строиться с использованием
различных шкал, в том числе наименований и порядка. Напри-
мер, на рис. 2.7 представлена диаграмма, где по горизонталь-
ной оси откладываются названия областей.
Если поменять местами вертикальную и горизонтальную оси
графика столбиковой диаграммы, то она трансформируется в
полосовую диграмму. Столбики в этом случае становятся поло-
сами, а масштабная шкала, по которой измеряются их длины,
откладывается по горизонтальной оси. На рис. 2.8 представлен
пример полосовой диаграммы.
Наряду со столбиковыми и полосовыми диа<раммами для
изображения временных рядов показателей используются ли-
нейные диаграммы или просто линейные графики. Они чертят-
ся на координатной плоскости, где по оси х откладываются
временные интервалы, а по оси у — значения показателей.
На рис 2.9 представлен пример линейного графика.
Для графического отображения структурных показателей
различных совокупностей, характеризующих соотношение их
40
Рис. 2.7. Промышленное производство и инвестиции
в регионах (в тыс. руб.)
Рис. 2.8. Изменение котировок акций крупнейших российских компаний
за неделю
различных частей, применяются секторные диаграммы, где в
качестве графического образа используется круг, разбитый на
секторы. Площадь каждого сектора пропорциональна удельно-
му весу каждой отдельной структурной части. Пример сектор-
ной диаграммы представлен на рис. 2.10.
Рассмотренные типы диаграмм являются типичными при-
мерами графических методов описательной статистики. Следу-
ет отметить, что если предварительная группировка “сырых”
41
Рис. 2.10. Производство программного обеспечения в 1977 г.
(в млн экю)
данных и построение гистограмм, полигонов и кумулят произ-
водятся на основе значений только одного варьирующего при-
знака, то столбиковые, полосовые, линейные и секторные
диаграммы позволяют анализировать статистическую инфор-
мацию, классифицированную одновременно по нескольким
признакам.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 2
Основным способом обобщения и сжатия несистематизи-
рованной статистической информации является построение ряда
распределения, или вариационного ряда. Под этим понимается
упорядоченное распределение единиц совокупности на груп-
пы по какому-либо варьирующему признаку. Каждой группе
соответствует частота, т. е. количество единиц совокупности,
для которых значения признака принадлежат этой группе. Иног-
да
да в качестве частот рассматриваются относительные частоты,
или частости, которые характеризуют доли или проценты от
общего количества данных, попавших в соответствующие груп-
пы. Ряд распределения является простой и компактной струк-
турой, которая позволяет провести первичный анализ частот-
ного распределения данных.
Ряд распределения можно представить в виде графиков —
гистограммы и полигона. Гистограмма является фигурой, огра-
ниченной рядом примыкающих друг к другу столбиков (пря-
моугольных полосок). Высота каждого столбика пропорциональ-
на частоте соответствующей группы, а ширина — размеру
группы. Если на координатной плоскости отметить точки, абс-
циссами которых будут средние точки групп, а ординатами —
значения их частот, и соединить соседние точки отрезками
прямых, то получим график полигона. Графическое представ-
ление ряда распределения в виде гистограммы и полигона по-
зволяет провести быстрый визуальный анализ основных харак-
теристик распределения: наибольшего и наименьшего значений,
зон концентрации данных и т. п.
Ряд распределения, а также гистограмма и полигон не по-
зволяют ответить на следующий вопрос. Сколько единиц сово-
купности (или какой процент) имеет значения признака, пре-
вышающие (или не превышающие) заданную величину? Для
ответа на подобные вопросы вычисляются кумулятивные (на-
копленные) частоты ряда распределения и строится кумуля-
тивный частотный полигон, или кумулята. Рахтичают два типа
кумулятивных полигонов: “меньше, чем ...” и “более, чем ...”.
Кумулятивные частоты для первого типа получаются последо-
вательным суммированием (абсолютных или относительных)
частот групп от низшей группы к высшей, а для второго типа,
наооборот, от высшей к низшей. Для построения кумуляты на
координатной плоскости отмечаются точки, абсциссы кото-
рых являются точными верхними границами групп для поли-
гона типа “меньше, чем...” или точными нижними границами
для полигона типа “более, чем...”, а ординаты — значениями
соответствующих кумулятивных частот. Линия, соединяющая
эти точки, является кумулятивным полигоном.
В описательной статистике кроме гистограмм, полигонов и
кумулят используются другие разновидности диаграмм: стол-
биковые, полосовые, линейные и секторные. Они являются
удобным инструментом для анализа динамики показателей и
соотношения структурных частей исследуемых объектов.
ИЗМЕРЕНИЕ
ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
В первых двух главах рассматривались типы статистических
данных, способы их измерения и обобщения. Систематизация
массы “сырых” данных в виде ряда распределения, его графи-
ческое представление в форме гистограммы, полигона и куму-
ляты, а также построение линейных, столбиковых, полосовых
и секторных диаграмм — все эти средства являются удобным
инструментарием для первичного визуального анализа свойств
совокупности.
Для того чтобы перейти к рассмотрению методов статисти-
ческого заключения, прежде всего следует изучить основные
количественные характеристики статистических совокупнос-
тей. Дело в том, что важнейшим направлением аналитичес-
кой статистики является оценка ключевых числовых характе-
ристик, отражающих свойства генеральной совокупности. Эти
характеристики, вычисленные на основе выборочных данных,
будут оценочными для соответствующих характеристик гене-
ральной совокупности, т. е. приближенно отражать свойства
генеральной совокупности. Каждая выборка представляет со-
бой некоторую часть большей по размеру генеральной сово-
купности. При статистическом анализе это обстоятельство все-
гда следует иметь в виду, даже если о генеральной совокупности
совсем не упоминается. Условимся в дальнейшем все те конк-
ретные характеристики, которые были вычислены на основе
данных генеральной совокупности, называть параметрами, а
вычисленные на основе выборочных данных — статистиками.
В этой главе будут рассмотрены количественные характерис-
тики, измеряющие центральную тенденцию распределения
данных. Центральная тенденция характеризует свойство дан-
ных скапливаться вокруг какого-то центрального значения.
Пусть центральная тенденция ярко выражена, т. е. данные в
подавляющем большинстве концентрируются около некото-
44
рого центрального значения, или центра. Тогда значение цен-
тра можно рассматривать как наиболее типичное для всей со-
вокупности. Это означает, что центр обладает способностью
представлять всю совокупность, и его можно использовать в
качестве сравнительной характеристики при сопоставлении
двух или более совокупностей, состоящих из качественно од-
нородных данных. Основными характеристиками, измеряю-
щими положение центра, в статистическом анализе являются
средняя арифметическая, медиана и мода.
3.1. ВЫЧИСЛЕНИЕ ЦЕНТРАЛЬНЫХ ЗНАЧЕНИЙ
ДЛЯ НЕСГРУППИРОВАННЫХ ДАННЫХ
3.1.1. Средняя арифметическая
Чаше всего для измерения центральной тенденции исполь-
зуется средняя арифметическая, которую, как правило, назы-
вают просто средней. Для “сырых”, т. е. несгруппированных,
данных средняя арифметическая получается суммированием всех
значений совокупности и делением этой суммы на общее чис-
ло данных.
Пусть выборочная совокупность состоит из л наблюдений:
Хр х2,..., хя. Тогда формула для вычисления средней арифмети-
ческой будет иметь вид
где х обозначает выборочную среднюю арифметическую (чи-
тается “х с чертой”);
л — численность, или объем, выборки;
х — любое из л значений совокупности;
S — знак суммирования (в статистической литературе ин-
Я
деке суммирования часто опускается, т. е. £х = х,).
i=i
Величина х является статистикой, так как она вычислена на
основе выборочных данных. Соответствующим параметром для
нее будет средняя генеральной совокупности ц, которая вы-
числяется по аналогичной формуле:
где N — численность, или объем, генеральной совокупности.
45
Генеральная средняя обозначается греческой буквой р. В даль-
нейшем будем придерживаться следующего принципа в обо-
значениях: все статистики (количественные выборочные харак-
теристики) будем обозначать латинскими буквами, а параметры
(количественные характеристики генеральной совокупности) —
греческими.
Пример 3.1. Автоматическая производственная линия напол-
няет пузырьки одеколоном. Случайным образом были отобра-
ны пять наполненных пузырьков, в которых чистый вес одеко-
лона составил 85,4, 85,3, 84,9, 85,4 и 85 г. Найти средний вес
одеколона в пузырьке для данной выборки из пяти наблюде-
ний.
По формуле (3.1) находим
_ 85,4 + 85,3 + 84,9 + 85.4 + 85 426 ое _
'*---------------------------.85,2 г.
Следовательно, средний арифметический вес для выборки
из пяти пузырьков составляет 85,2 г.
Средняя арифметическая обладает следующими свойствами.
I. Средняя арифметическая может быть вычислена в шкалах
интервалов и отношений (например, в таких шкалах измеря-
ются доходы, возраст, вес, габариты и т. п.).
2. При вычислении средней арифметической необходимо
использовать все данные рассматриваемой совокупности.
3. Множество данных может иметь единственное значение
средней арифметической (далее в главе будет показано, что
другой тип средней может иметь два или более значений для
одной и той же совокупности).
4. Средняя арифметическая является очень удобной характе-
ристикой для сравнения двух или более совокупностей, одина-
ковых по качественному составу значений признака (напри-
мер, при сравнении прозводительности труда работников
первой смены с производительностью труда работников вто-
рой смены на одном предприятии).
5. Средняя арифметическая есть единственная мера цент-
ральной тенденции, для которой сумма отклонений каждого
значения от нее всегда равна нулю. Математически это свой-
ство можно записать следующим образом:
£(х-х) = 0.
46
Пример 3.2. Средняя арифметическая чисел 3, 8 и 4 равна 5.
Вычислим сумму отклонений этих чисел от 5:
£(х-х) = (3-5) + (8-5) + (4-5) = -2 + 3-1=0.
При использовании средней арифметической в статистичес-
ком анализе всегда следует иметь в виду свойство 2. Если одно
или два крайних значения совокупности сильно отличаются от
всех остальных данных (крайнее правое значительно больше и
(или) крайнее левое значительно меньше всех остальных), то
средняя арифметическая не будет типичной величиной, пред-
ставляющей все множество данных.
Пример 3.3. Пусть годовые доходы пяти предпринимателей со-
ставляют 62 900, 61 600, 62 500, 60 800 и 1 200 000 долл. Сред-
ний арифметический годовой доход будет 289 560 долл. Оче-
видно, он не отражает доходы всей группы предпринимателей,
гак как все предприниматели, кроме одного, имеют доход в
интервале от 60 000 до 63 000 долл.
Особой формой средней арифметической является взвешен-
ная средняя арифметическая. Она вычисляется в случае, когда
изучаемая статистическая совокупность велика и ее можно раз-
бить на группы, имеющие постоянное значение признака.
Пусть вся совокупность разбита на л групп, имеющих зна-
чения признака хг,..., хяс численностями w(, (значе-
ния весов). Взвешенная средняя арифметическая вычисляется
по формуле
Н-.Х. + МЧХ» +... + W.X.
xw = —L-1--—--------—. (3.3)
W1 + w2+... + wB
Пример 3.4. Почасовая оплата продавцов на фирме дифферен-
цирована и составляет 6,5; 7,5 и 8,5 долл. Известно, что 14 про-
давцов имеют ставку 6,5 долл.; 10 — 7,5 и 2 — 8,5 долл. В каче-
стве средней арифметической почасовой ставки в данном случае
выступает взвешенная средняя арифметическая:
6,514 + 7,510 + 8,5-2 _ _.
х =--------------------» 7,04.
* 14 + 10 + 2
Таким образом, средняя почасовая ставка составляет при-
близительно 7,04 долл.
47
3.1.2. Медиана
При описании основных свойств средней арифметической
отмечалось, что выбор ее в качестве центра не имеет смысла,
если есть одна или две величины, одна из которых значительно
больше, а другая значительно меньше, чем все остальные дан-
ные. В этом случае в качестве более точной меры центральной
тенденции выбирается другой, структурный тип средних, ко-
торые определяются не как результат арифметических действий
над значениями признака. К такому типу относится медиана.
Для иллюстрации необходимости такого выбора рассмот-
рим следующую ситуацию.
Пример 3.5. Предположим, что некто хочет купить квартиру в
определенном районе. Из рекламы он получил информацию о
том, что в наличии имеется несколько апартаментов и их сред-
няя цена составляет 110 000 долл. Однако бюджет данного лица
позволяет купить квартиру по цене в пределах от 60 000 до 75 000
долл. На первый взгляд может показаться, что предлагаемые ва-
рианты ему не по карману. В действительности же на продажу
было предложено пять квартир по следующим ценам: 60 000,
65 000, 70 000, 80 000 и 275 000 долл. Очевидно, что средняя
арифметическая цена 110 000 долл, не является представитель-
ной для данного набора цен. Как раз более типичная цена нахо-
дится в пределах личного бюджета заинтересованного лица.
В подобных случаях следует в качестве центра рассматривать
другой тип центральной величины, которая называется медиа-
ной. Медиана характеризует величину, обладающую свойством:
слева от медианы находится ровно половина всех данных, ко-
торые меньше ее, и справа — половина всех данных, которые
ее больше. Для определения медианы следует из всего множе-
ства данных составить ранжированный ряд, т. е. упорядочить
данные либо последовательно по возрастанию: от наименьше-
го значения к наибольшему, либо, наоборот, последовательно
по убыванию: от наибольшего к наименьшему. Если последо-
вательно пронумеровать все члены упорядоченного (ранжиро-
ванного) ряда, то в качестве медианы берется средний по но-
меру член этого ряда.
В примере 3.5 упорядочим цены на квартиры по возраста-
нию и убыванию:
60 000, 65 000, 70 000, 80 000, 275 000;
275 000, 80 000, 70 000, 65 000, 60 000.
48
Как видно, медианной ценой в данном случае будет 70 000
долл., так как эта величина стоит в середине ранжированного
ряда. Заметим, что слева и справа от нее находится одинаковое
количество данных. Поэтому на величину медианы не оказыва-
ют влияние значения крайних членов ранжированного ряда,
т. е. наименьшее и наибольшее значения всей совокупности дан-
ных. Так, например, если бы самая дорогая квартира стоила
90 000 или даже 1 000 000 долл., то медианная цена не измени-
лась бы. Аналогично, если бы цена самой дешевой квартиры
была 20 000 или 50 000 долл., то медианная цена оставалась бы
по-прежнему равной 70 000 долл.
Отметим, что медианная цена располагается на третьем мес-
те ранжированного ряда. В рассмотренном случае число данных
было нечетным (равно 5). Ввиду этого номер среднего члена ран-
жированного ряда вычисляется как (п +1)/2 : (5 +1)/2 = 3.
В случае четного числа данных медиана находится как полусум-
ма двух средних членов ранжированного ряда, которые распо-
лагаются на местах с номерами п/2 и п/2 +1.
Пример 3.6. За восемь дней представлены следующие данные,
отражающие количество пациентов, которые были на приеме
у врачей одной поликлиники: 52, 86, 49, 43, 35, 11, 31, 30.
Требуется определить медиану.
Составим ранжированный ряд по возрастанию: 11, 30, 31,
35, 43, 49, 52, 86.
Медианой является полусумма чисел, находящихся на
4 (8/2)-м и 5 (8/2 + 1)-м местах ранжированного ряда:
(35 + 43)/2 = 39.
Заметим, что сама медиана (число 39) нс входит в совокуп-
ность данных, для которой она была вычислена.
В общем случае если число данных четно, то медиана не
обязательно будет входить в их состав.
Можно выделить следующие основные свойства медианы.
1. Если имеется одно или два крайних значения, которые
сильно отличаются от всех остальных, то это не влияет на ве-
личину медианы.
2. Так же как и для средней арифметической, значение ме-
дианы является единственным для данной совокупности зна-
чений признака.
3. Медиана может быть определена, даже если представлены
не все данные. Необходимо, чтобы были известны их общее
49
число, расположение и точные данные только о тех значени-
ях, которые располагаются вблизи медианной величины.
4. Медиана может быть определена для данных, измеряемых
как в шкалах отношений и интервалов, так и в порядковой
шкале.
Пусть, например, респонденты дают оценку некоторому
явлению по следуюшей шкале, включающей пять градаций:
отлично, хорошо, удовлетворительно, плохо, очень плохо. До-
пустим, что респондентов было пять человек. Один из них дал
оценку “отлично”, один — “хорошо”, один — “удовлетвори-
тельно”, один — “плохо” и один — “очень плохо”. Медианная
оценка в данном случае будет “удовлетворительно”, так как
половина ответов характеризует явление ниже, чем “удовлет-
ворительно”, а половина — выше.
5. При большом количестве данных процедура нахождения
медианы является более трудоемкой, чем вычисление средней
арифметической, так как требует предварительной ранжиров-
ки всего множества значений признака.
3.1.3. Мода
Под модой понимается наиболее часто встречающаяся ве-
личина в рассматриваемом множестве значений признака. Как
и медиана, она принадлежит к структурному типу средних.
Мода не всегда яазяется мерой центральной тенденции, так
как по определению необязательно должна находиться в центре
данного множества значений. Мода часто используется, напри-
мер, в швейной и обувной отраслях, где рассматриваются такие
понятия, как наиболее распространенные размеры различных
типов одежды и обуви. В данном случае представляет интерес не
средний размер, а тот, который носит наибольшее число людей.
Мода может быть полезной в случае данных, представлен-
ных в шкале наименований. Например, автомобильную фирму
может интересовать, какая марка автомобиля имеет наиболь-
шее количество рекламаций.
Пример 3.7. Рассмотрим множество данных: 4, 8, 7, 6, 9, 8,
19, 5, 8.
Мода будет равна 8, так как 8 встречается наибольшее чис-
ло раз, равное 3.
Множество данных может иметь несколько мод в случае,
если несколько значений повторяется одинаковое (самое боль-
50
шое) количество раз. Если множество имеет две моды, то оно
называется бимодальным, если мод больше двух, то — поли-
модальным.
Пример 3.8. Пусть выборка состоит из возрастов 13 служащих
небольшого предприятия (в голах): 22, 27, 30, 30, 30, 30, 34,
58, 60, 60, 60, 60, 65. Данное множество имеет две моды: 30 и
60 лет. Часто наличием двух мод характеризуется неоднород-
ность исследуемой совокупности. Очевидно, в данном случае
генеральная совокупность работников может быть составлена
из двух качественно различных групп: группы молодых работ-
ников, которые были недавно наняты, и группы работающих
на предприятии уже долгое время.
Предположим, что рассматривается выборка достаточно
большого объема, для которой построены ряд распределения и
полигон с большим числом групп. Сгладим ломаную линию
графика полигона с помощью плавной кривой. Если сглажен-
ный график будет иметь два отдельных пика, но разной высо-
ты (рис. 3.1), то такое распределение будет называться бимо-
дальным.
Аналогично если число локальных пиков графика рас-
пределения, имеющих необязательно одинаковую высоту,
больше двух, то такое распределение называется полимо-
дальным.
Множество данных может вообще не иметь моды, если все
значения признака повторяются одинаковое количество раз.
51
Отметим основные характерные свойства молы.
1. Наличие одного или двух крайних значений признака,
сильно отличающихся от всех остальных значений, не влияет
на величину моды.
2. Мода совпадает с точкой наибольшей плотности данных.
3. В отличие от средней арифметической и медианы мода
может иметь несколько значений.
4. Мода может существовать для совокупностей значений
признака, которые измеряются в шкалах наименований, по-
рядка, интервалов и отношений.
3.2. ОЦЕНКА ХАРАКТЕРИСТИК ЦЕНТРАЛЬНОЙ
ТЕНДЕНЦИИ ДЛЯ СГРУППИРОВАННЫХ ДАННЫХ
3.2.1. Средняя арифметическая
для ряда распределения
При оценке средней арифметической для данных, сгруппи-
рованных в виде ряда распределения, все величины одного груп-
пировочного интервала представляются его средней точкой.
Средняя арифметическая оценивается по формуле
(3.4)
п
где х — средняя арифметическая;
хс — средняя точка группы;
f — частота группы;
л = Е/— общая сумма частот (общее число данных).
Пример 3.9. Вычислим среднюю арифметическую для ряда рас-
пределения, представленного в табл. 2.10.
Средняя точка первой группы (699,5) представляет одно-
временно три значения месячной арендной платы, входящие в
эту группу. Можно сказать, что эти значения аппроксимируют
(т. е. приближают) в целом величину 3 • 699,5 = 2098,5, которая
является частью суммарной арендной платы для всех 120 аренда-
торов, попавших в выборку. Аналогично средняя точка 899,5
представляет все семь значений арендной платы для второй
группы, а величина 7 • 899,5 = 6296,5 аппроксимирует часть
общей суммы арендной платы. Этот процесс можно продол-
жить для всех оставшихся групп (табл. 3.1).
52
Таблица 3.1
Пример вычисления средней арифметической
для сгруппированных данных
Месячная арендная плата (группы), долл. Частота t Средняя тонка хв
600-799 3 699,5 2098,5
800-999 7 899.5 6296,5
1000-1199 11 1099,5 12094,5
1200-1399 22 1299,5 28589
1400-1599 40 1499.5 59980
1600-1799 24 1699,5 40788
1800-1999 9 1899,5 17095,5
2000-2199 4 2099,5 8398
Общая сумма 120 = л 175340
Средняя арифметическая равна 175340/120 = 1461,17.
При вычислении средней арифметической для сгруппиро-
ванных данных происходит потеря информации. Она связана с
тем, что отдельные данные, на основе которых строился ряд
распределения, были неизвестны и заменены на значения сред-
них точек соответствующих групп. Например, вычисленное зна-
чение средней арифметической в предыдущем примере отлича-
ется от ее точного значения 1457,93, полученного на основе
“сырых” данных (см. табл. 2.2).
Таким образом, средняя арифметическая, вычисленная на
основе сгруппированных данных, является оценкой точного
значения средней арифметической для несгруппированных
(“сырых”) данных. Среднюю арифметическую затруднительно
вычислить для ряда распределения, имеющего хотя бы одну
крайнюю группу с открытой границей.
Пример 3.10. Пусть ряд распределения индивидов по величине
годового дохода имеет группу “100 000 долл, и более”, причем
в эту группу попали 10 человек. Очевидно, этой информации
недостаточно, чтобы определить, близки ли их доходы, на-
пример, к 100 000, 500 000 или 1 600 000 долл.
3.2.2. Медиана для сгруппированных данных
При вычислении медианы для ряда распределения, как и в
случае средней арифметической, можно получить только ее
оценочное значение. Для этой цели нужно определить группу,
53
в которой находится медианное значение, и внутри медианно-
го интервала провести интерполяцию для оценки положения
медианы. При этом предполагается, что данные внутри меди-
анного интервала располагаются равномерно.
Формула для вычисления медианы будет иметь вил
л г-
—-cF
Ма - / ц. 2__; п.
где L — точная нижняя граница медианной группы;
л — сумма частот всех классов (общее число данных);
f— частота медианной группы;
cF — кумулятивная (накопленная) частота группы, не-
посредственно предшествующей медианной;
i — размер медианного интервала.
Для использования формулы (3.5) необходимо выявить груп-
пу, в которой содержится медиана. Это можно сделать на осно-
ве значений кумулятивных частот групп.
Пример 3.11. Найдем медиану для ряда распределения, пред-
ставленного в табл. 2.11, где вычислены также кумулятивные
частоты. По определению слева и справа от медианы должно
находиться по 50% всех данных, т. е. по 60 значений арендной
платы. Очевидно, медианным интервалом будет тот, кумуля-
тивная частота которого впервые будет равна или превзойдет
половину всех значений л/2 (в данном случае величину, рав-
ную 60). Из табл. 2.11 видно, что медиану содержит интервал
1400—1599, так как его кумулятивная частота равна 83, в то
время как кумулятивная частота предыдущей группы (1200—
1399) равна 43, т. е. меньше 60. Отсюда следует, что точная
нижняя граница (£) медианного интервала — 1399,5, а точная
верхняя — 1599,5.
Проведем интерполяцию внутри группы 1399,5—1599,5 в
предположении, что все значения месячной арендной пла-
ты, которые ей принадлежат, равномерно располагаются
между ее точными границами. Если рассматриваемые 120
арендаторов упорядочить по возрастанию месячной аренд-
ной платы, то между 43-м и 60-м по порядку членами ран-
жированного ряда будет содержаться 17 значений. Медиан-
ная группа содержит 40 значений, поэтому медиана должна
54
располагаться в точке, равной 17/40 расстояния между 1399,5
и 1599,5. Это расстояние равно размеру группы, т. е. 200. От-
сюда получаем, что 17/40 200 = 85 следует прибавить к
нижней точной границе 1399,5. Оценочное значение для ме-
дианы равно 1484,5. Этот результат можно также получить,
используя формулу (3.5) (L = 1399,5, п = 120, cF = 43,
/= 40, г = 200):
—44 17
Me = 1399,5 + - • 200 = 1399,5 + — • 200 =
40 40
= 1399,5 + 85 = 1484,5 долл.
Вычисленная величина 1484,5 представляет собой некоторую
оценку точного значения медианы — 1464,5, которое определя-
ется на основе ранжированных первичных данных табл. 2.4. По-
грешность возникает в связи с предположением о равномерно-
сти распределения данных в медианной группе, которое в общем
случае редко выполняется.
Медиану можно определить по формуле (3.5) и для ряда
распределения с относительными или процентными частота-
ми групп. Абсолютные величины частот (/) и кумулятивных
частот (cF) заменяются при этом на их соответствующие отно-
сительные значения (частости). Сумма процентных частот рав-
на 100, поэтому по 50% данных должно находиться слева и
справа от значения медианы.
Медиана может быть вычислена для ряда распределения,
имеющего крайнюю группу с открытой границей, при усло-
вии, что она не принадлежит к этой группе.
3.2.3. Оценка моды для сгруппированных данных
По определению модой является такое значение, которое
встречается наиболее часто в рассматриваемой совокупности
значений признака. Для сруппированных данных оценкой моды
может являться средняя точка группировочного интервала, име-
ющего максимальную частоту.
Пример 3.12. Выборка, составленная из данных о ежедневных
продажах изделий фирмы, была сгруппирована в виде ряда
распределения, представленного в табл. 3.2.
55
Таблица 3.2
Ряд распределения ежедневных продаж фирмы
Ежедневные продажи (ед.) Частоты
80-90 5
90-99 9
100-109 20
110-119 8
120-129 6
130-139 2
Для определения моды распределения выделим группу с
наибольшей частотой (100—109) и найдем ее середину: 104,5.
Таким образом, если бы в наличии были первичные данные,
то, вероятно, наиболее типичный объем продаж приблизи-
тельно составлял 104—105 изделий вдень.
Так же как и медиана, мода может быть определена для
рядов распределений с крайними группами, имеющими от-
крытые границы.
3.2.4. Сравнение типов средних при анализе
центральной тенденции
Одной из проблем статистического анализа является опре-
деление такого типа средней (т. е. средней арифметической, ме-
дианы или моды), который в наибольшей степени характери-
зовал бы положение центра.
Для решения этой проблемы рассмотрим полигон исследу-
емого ряда распределения, построенный на основе выбороч-
ных данных. Их значения могут быть неточными, так как связа-
ны со случайными ошибками наблюдения, которые искажают
основную закономерность распределения генеральной совокуп-
ности. Пусть число данных (объем выборки) возрастает и одно-
временно уменьшаются размеры группировочных интервалов.
В результате зигзаги полигона начнут сглаживаться, и в преде-
ле ломаная линия графика полигона будет представлять собой
плавную кривую. Эта кривая называется кривой распределения
и теоретически отражает распределение генеральной совокуп-
ности при условии полного устранения случайных ошибок
выборочных наблюдений. На практике для получения кривой
распределения полигон, построенный на основе эмпиричес-
ких данных, сглаживается визуально (например, сглаженный
56
полигон представлен на рис. 3.1). По форме кривой распределе-
ния можно делать выводы относительно характеристик цент-
ральной тенденции. Если кривая имеет симметричную форму
(рис. 3.2), то в этом случае мода, медиана и средняя арифмети-
ческая совпадают. Проблема выбора средней, представляющей
центральную тенденцию, решается сама собой.
Рис. 3.2. Кривая симметричного распределения
Если распределение асимметрично, то различают положи-
тельную и отрицательную асимметрию. В случае положитель-
ной (правосторонней) асимметрии график кривой распреде-
ления имеет “хвост”, вытянутый вправо (рис. 3.3).
Рис.3.3. Кривая распределения с положительной (правосторонней)
асимметрией
Наибольшее значение из всех трех характеристик принима-
ет средняя арифметическая. Это связано с тем, что на нее в
значительной степени влияет несколько больших величин, т. е.
значения, максимально удаленные вправо. Следующей по ве-
57
личине после средней арифметической обычно идет медиана,
и наименьшее значение принимает мода. В случае если положи-
тельная асимметрия ярко выражена, средняя арифметическая
не может служить в качестве наилучшей средней для характе-
ристики центральной тенденции. Более представительными здесь
будут медиана и мода.
При отрицательной (левосторонней) асимметрии наблюда-
ется обратная картина (рис. 3.4).
Рис. 3.4. Кривая распределения с отрицательной (левосторонней)
асимметрией
В этом случае “хвост” кривой распределения вытянут влево
и средняя арифметическая принимает наименьшее значение,
так как на нее влияет несколько небольших значений, макси-
мально удаленных влево. Мода будет иметь наибольшее значе-
ние среди всех трех характеристик. Как видно, если распреде-
ление имеет достаточно сильную отрицательную асимметрию,
то аналогично случаю положительной асимметрии средняя
арифметическая не является представительной средней вели-
чиной.
Когда распределение имеет достаточно сильно выраженную
асимметрию (положительную или отрицательную), медиана
часто является лучшей мерой центральной тенденции, так как
обычно расположена между средней арифметической и модой.
На медиану почти не влияет, как на моду, частота отдельного
значения, и она не зависит, как средняя арифметическая, от
отдельных крайних величин распределения.
Пусть имеется достаточно большое количество данных для
того, чтобы построить гладкую кривую распределения (сгла-
женный полигон). В этом случае расстояние между медианой и
средней арифметической составляет примерно одну треть рас-
стояния между средней арифметической и модой.
58
Если значения двух из трех типов средних известны, то ве-
личина неизвестной средней может оцениваться с помошью
следующих формул: Mo = х - 3(i - Me), (3.6) _ ЗМе-Мо х , ') 2 .. 2х + Мо Me = , (3.8)
Выбор типа средней в статистическом анализе часто зави-
сит от предметной области исследования. Например, для при-
нятия решений в социальной сфере важным показателем явля-
ется среднее арифметическое количества детей в семье. В то же
время конструктора автомобиля может больше интересовать
модальное количество детей (число детей, которое имеет наи-
большее количество семей), когда он приступает к разработке
новой модели.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 3
Выборочный метод предполагает обоснование статистичес-
ких заключений о свойствах генеральной совокупности по дан-
ным выборки. Количественные характеристики, приближенно
отражающие эти свойства и вычисленные на основе выбороч-
ных данных, называются статистиками. Те же характеристики,
полученные на основе данных генеральной совокупности, на-
зываются параметрами.
В главе рассматриваются различные типы средних величин,
отражающие центральную тенденцию, т. е. свойство быть цент-
ром, около которого в наибольшей степени концентрируются
все данные совокупности. Наиболее часто встречающейся сред-
ней в статистическом анализе является средняя арифметичес-
кая, или просто средняя. Она определяется как сумма всех зна-
чений, деленная на общее катичество данных. Для несгруппи-
рованных данных средняя арифметическая вычисляется по
формулам (3.1) и (3.2).
Особым случаем средней арифметической является взвешен-
ная средняя арифметическая (3.3). Она вычисляется, когда мно-
жество данных велико и его можно разбить на группы одина-
ковых значений. Для сгруппированных данных оценочное
значение средней арифметической находится по формуле (3.4).
59
В некоторых случаях в качестве центра имеет смысл рас-
сматривать не среднюю арифметическую, а медиану. Под ме-
дианой понимается величина, слева и справа от которой нахо-
дится по половине всех данных. В отличие от средней
арифметической она не зависит от крайних значений, сильно
отличающихся от всех остальных. Для данных, представленных
в виде ряда распределения, оценка медианы находится из со-
отношения (3.5).
Иногда наиболее подходящей характеристикой для выраже-
ния точки наибольшей плотности данных является мода. Она
представляет собой наиболее часто встречающуюся величину в
данной совокупности. Возможны случаи, когда может быть не-
сколько мод. Если совокупность имеет две моды, то она назы-
вается бимодальной, если более двух, то — полимодальной.
Медиана и мода суть структурные средние, они не являются
результатами арифметических действий над значениями при-
знака, входящими в исследуемую совокупность.
Для сгруппированных данных в качестве оценки моды рас-
сматривается средняя точка группировочного интервала, име-
ющего наибольшую частоту.
В статистическом анализе может возникнуть проблема — ка-
кой из перечисленных средних следует отдать предпочтение при
выборе центральной величины. Для этой цели рассматривается
форма графика сглаженного полигона, называемого кривой
распределения. В случае симметричной кривой средняя ариф-
метическая, медиана и мода совпадают. Если кривая распреде-
ления достаточно сильно вытянута вправо (положительная, или
правосторонняя, асимметрия) или влево (отрицательная, или
левосторонняя, асимметрия), то средняя арифметическая не
является типичным представителем всей совокупности данных.
Более представительными здесь будут структурные средние —
медиана или мода. Кроме того, выбор средней зависит от каче-
ственного содержания исследуемого явления.
Средняя арифметическая, медиана и мода связаны соотно-
шением: расстояние между медианой и средней арифметичес-
кой составляет примерно одну треть расстояния между сред-
ней арифметической и модой. Если значения двух из трех типов
средних известны, то величина неизвестной средней оценива-
ются с помощью формул (3.6)—(3.8).
ИЗМЕРЕНИЕ ВАРИАЦИИ
В предыдущей главе были рассмотрены различные типы сред-
них. Каждая из них определялась как наиболее типичная вели-
чина для всего множества данных, т. с. представляющая при-
близительно центр этого множества.
Предположим, что средняя (например, средняя арифмети-
ческая) уже вычислена. Далее возникает вопрос, насколько
надежно она представляет в целом исследуемую совокупность.
Другими словами, необходимо оценить в количественной форме
степень представительности полученной средней. Очевидно, чем
плотнее и ближе концентрируются данные вокруг средней ариф-
метической, тем она более надежна или представительна. На-
оборот, если данные сильно отклоняются от средней, то ее
надежность низкая.
В статистическом анализе для характеристики разброса дан-
ных относительно центра распределения часто используется
термин “вариация”.
Пример 4.1. На рис. 4.1 представлен график кривой распределе-
ния возрастов служащих некой фирмы.
Рис. 4.1. Кривая распределения возрастов служащих фирмы
61
Как видно, возраст служащих изменяется в диапазоне от 18
до 75 лет. Такой значительный разброс говорит о том, что сред-
няя (40 лет) не является представительной для всего распреде-
ления возрастов.
Необходимость измерения вариации может возникнуть при
сравнительном анализе двух или более распределений.
Пример 4.2. Пусть двое рабочих производят на станке одинаковые
детали. В течение 9 дней выпуск деталей первым рабочим имел
следующее распределение: 49, 48, 50, 49, 50, 51, 50, 51, 52.
Для второго рабочего распределение выпуска деталей по дням
имело вид: 40, 47, 50, 47, 53, 50, 60, 53, 50.
Средний дневной выпуск деталей для обоих рабочих одина-
ков и составляет 50 штук. Однако степень разброса ежедневных
выпусков деталей для второго рабочего значительно выше, чем
для первого: выпуск деталей в течение дня у первого рабочего
колеблется в пределах от 48 до 52, в то время как у второго —
от 40 до 60. Ясно, что средний ежедневный выпуск в количе-
стве 50 деталей является гораздо более типичным для первого
рабочего.
В общем случае при сравнении нескольких распределений
вычисления средних в качестве сравнительных характеристик,
как правило, недостаточно. Очевидно, наряду со средней в ста-
тистическом анализе следует рассматривать количественные
показатели, характеризующие вариацию данных.
4.1. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ВАРИАЦИИ
4.1.1. Размах колебаний
Простейшей, грубой характеристикой является размах ко-
лебаний (R):
где х — максимальное значение во множестве данных;
х — минимальное значение во множестве данных,
min
Пример 4.3. Дадим количественное обоснование выводам, по-
лученным в примере 4.2, используя при этом понятие размаха
колебаний. Для первого рабочего R = 52 — 48 = 4, для второ-
го — R = 60 — 40 = 20. Как видно, размах колебаний для перво-
62
го рабочего в пять раз меньше, чем для второго. Это говорит о
том, что производимые ежедневно первым рабочим количе-
ства деталей более плотно концентрируются около значения
средней арифметической (50 штук) по сравнению с количе-
ствами деталей, производимыми ежедневно вторым рабочим.
Иначе говоря, средняя, равная 50, будет более представитель-
ной для первого рабочего.
Если данные представлены уже в сгруппированном виде, т. е.
в виде ряда распределения, то величина размаха колебаний оце-
нивается как разность между верхним пределом высшей (после-
дней) группы и нижним пределом низшей (первой) группы
(иногда вычисляют разность между точной верхней границей
высшей группы и точной нижней границей низшей группы).
Пример 4.4. Пусть 40 значений почасовых ставок (долл.) сгруп-
пировано в виде ряда распределения:
Почасовые ставки Частота
6-9 10
10-13 21
14-17 9
Размах колебаний составляет
R = 17 - 6 = 11 долл, или R - 17,5 - 5,5 = 12 долл.
4.1.2. Среднее линейное отклонение
Размах колебаний зависит только от двух значений — наи-
большего и наименьшего. На его величину совершенно не вли-
яют остальные значения. Поэтому размах колебаний является
очень грубой оценочной характеристикой вариации.
Этот серьезный недостататок учитывается при вычислении
среднего линейного отклонения. Среднее линейное отклоне-
ние (d) определяется как средняя арифметическая из абсолют-
ных значений отклонений от средней арифметической. Для
выборочных данных среднее линейное отклонение вычисляет-
ся по формуле
м.2)
п
где х — данные (значения признака элементов выборки);
х — выборочная средняя арифметическая;
п — объем выборки.
63
В формуле (4.2) фигурируют абсолютные величины откло-
нений всех данных от средней, т. е. среднее линейное отклоне-
ние учитывает все значения рассматриваемого множества дан-
ных. Отрицательные значения игнорируются, гак как берутся
их абсолютные значения. В этой связи среднее линейное откло-
нение часто называют средним абсолютным отклонением.
Если бы в формуле (4.2) обозначения модуля отсутствова-
ли, то вычислялась бы алгебраическая сумма положительных и
отрицательных отклонений от средней. Значение этой суммы
всегда равно нулю, так как положительные и отрицательные
отклонения всегда взаимно погашаются (это следует из свойств
средней арифметической, представленных в разделе 3.1.1). Оче-
видно, такая характеристика не имела бы смысла в статисти-
ческом анализе.
Пример 4.5. Рассматривается выборка из пяти упаковок това-
ра, имеющих следующий вес (кг): 103, 97, 101, 106, 103. Опре-
делим среднее линейное отклонение по формуле (4.2). Для это-
го сначала вычислим среднюю арифметическую:
х = (103+97+101 +106+1ОЗ)/5 = 102 кг.
Для вычисления среднего линейного отклонения необходи-
мо произвести следующие действия (табл. 4.1):
а) из каждого значения веса вычесть среднюю арифмети-
ческую и взять абсолютную величину разности;
б) просуммировать все абсолютные отклонения от средней;
в) сумму абсолютных отклонений разделить на общее число
данных.
Таблица 4.1
Вычисление среднего линейного отклонения
Вес к, кг х - X Ijt-kI
103 +1 1
97 -5 5
101 -1 1
106 4 4
103 1 1
12
= 2,4 кг.
d =
64
Полученный результат можно легко интепретировать: вес
упаковок отклоняется от среднего арифметического веса в сред-
нем на 2,4 кг.
Среднее линейное отклонение обладает одним важным свой-
ством. Пусть среднее линейное отклонение рассматривается
относительно не средней арифметической, а медианы, т. е. вы-
числяется по формуле
- Ух - Мс|
d = —-------L (4.3)
п
В этом случае значение среднего линейного отклонения бу-
дет наименьшим, т. е. меньше, чем от средней арифметической
и любой другой величины. Это означает, что среднее линейное
отклонение обладает свойством минимальности относительно
медианы.
4.1.3. Дисперсия и среднее квадратическое
(стандартное) отклонение
Определение дисперсии и среднего квадратического откло-
нения также основано на вычислении отклонений от средней
арифметической. Однако вместо абсолютных значений в вы-
числительных формулах фигурируют квадраты величин откло-
нений.
Дисперсия определяется как средняя арифметическая квад-
ратов отклонений от средней арифметической. Формула для
дисперсии, вычисляемой на основе данных генеральной сово-
купности, имеет следующий вид:
о ------------• (4.4)
где о2 — генеральная дисперсия;
х — значение признака;
ц — генеральная средняя;
N — объем генеральной совокупности.
Пример 4.6. Пусть распределение возрастов пяти больных, на-
ходящихся в изоляторе больницы, следующее: 38, 26, 13, 41 и
42 года. Требуется определить дисперсию, рассматривая приве-
денные данные как генеральную совокупность.
Все действия и результаты вычислений сведем в табл. 4.2.
65
Таблица 4.2
Вычисление генеральной дисперсии
Возраст х, лет х-р (х-в)1
38 + 10 100
26 -2 4
13 -15 225
41 + 13 169
22 -6 36
— — —
140 0 534
Н= = 140/5 = 28 лет
N
i У(х-Ц)2
СТ- = = 534/5 = 106,8.
N
Из соотношения (4.4) можно вывести более удобную для
вычислений формулу:
В данной формуле не требуется вычислять разности, харак-
теризующие отклонения от средней, что упрощает расчеты.
Используем формулу (4.5) для вычисления дисперсии в
примере 4.6:
2 382 + 262 +132 + 412 + 222 /38 + 26+13 + 41 + 22
О =----------------------------------------------
5 5
= 4454/5 - (140/5)2 = 106,8.
Как видно, результаты вычислений по формулам (4.4) и
(4.5) совпадают.
Дисперсию, так же как размах колебаний и среднее абсо-
лютное отклонение, можно использовать для сравнения двух
или более совокупностей по степени вариаиии.
Пример 4.7. По расчетам примера 4.6 дисперсия распределения
возрастов больных составляет 106,8. Предположим, что диспер-
сия распределения возрастов пациентов, лежащих в онкологи-
ческом отделении, равна 342,9. Так как 106,8 < 342,9, то, оче-
видно, степень вариации возрастов для пациентов изолятора
меньше, чем для больных раком. Это означает, что возрасты
66
пациентов изолятора концентрируются ближе к средней ариф-
метической по сравнению с возрастами больных раком. Поэто-
му средний возраст 28 лет является более представительной
величиной для больных изолятора, чем неизвестное значение
среднего возраста больных онкологического отделения.
Значения размаха колебаний и среднего абсолютного откло-
нения легко интерпретируются. Размах колебаний — это раз-
ность между наибольшим и наименьшим значениями, а среднее
абсолютное отклонение — средняя арифметическая абсолютных
отклонений данных от средней. Однако неясно, как интерпре-
тировать дисперсию для одной совокупности. Так, в примере 4.6
единицей измерения дисперсии, равной 106,8 для возрастов па-
циентов, будет не “год”, а “год в квадрате”. Для того чтобы мера
вариации данных, характеризуемая дисперсией, выражалась в
тех же единицах, что и исходные данные, имеет смысл из зна-
чения дисперсии извлечь квадратный корень. Например, корень
квадратный из 106,8 приблизительно равен 10,3 года.
Корень квадратный из дисперсии называется средним квад-
ратическим отклонением, или стандартным отклонением. Со-
ответственно записываются формулы для его вычисления:
а =
или
Формулы (4.4)—(4.7) предназначены для вычисления пара-
метров, т. е. характеристик генеральной совокупности. В них
фигурируют значения: N — объем генеральной совокупности
иц — средняя генеральная.
Рассмотрим аналогичные формулы для вычисления соот-
ветствующих статистик, т. е. подобных характеристик, опреде-
ляемых на основе выборочных данных. Очевидно, для этого не-
обходимо заменить величину объема генеральной совокупности
/V на объем выборки п, а значение генеральной средней ц — на
значение выборочной средней х. Однако такая механическая
замена не будет правомерной. В математической статистике до-
казывается, что отклонения от выборочной средней в боль-
шинстве случаев меньше соответствующих отклонений от ге-
неральной средней. Поэтому оценки дисперсии и стандартного
отклонения (т. е. значения статистик) в среднем будут зани-
67
женными, т. е. смещенными. Для получения более точных (не-
смещенных) оценок знаменатель формулы (4.4) заменяют не
на л, а на л - 1. Отсюда следует, что формула для вычисления
выборочной дисперсии будет иметь вид
2 У(Х-Х)2
* = U, (4.8)
п-1
где л2 — обозначение выборочной дисперсии;
х — выборочные данные;
х— выборочная средняя;
п — объем выборки.
Аналогом формулы (4.5) для выборки является
у 2
s =--------°—. (4.9)
л -1
Пример 4.8. Рассматриваются почасовые ставки для выборки
из пяти работников-совместителей некоторого предприятия: 2,
10, 6, 8, 9 долл. Требуется определить дисперсию.
Вычислим значение средней:
х = (2 + 10 +6 + +8 + 9)/5 = 35/5 = 7 долл.
Все последующие вычисления сведем в табл. 4.3.
Таблица 4.3
Вычисление выборочной дисперсии
По формуле (4.8) По формуле (4.9)
Почасовые ставки х, долл. к - X ж»
2 -5 25 4
10 3 9 100
6 -1 1 36
8 1 1 64
9 2 4 81
— — — —
И о II 5 м 1 3 С GJ С । । 01 II " hi о ** II 0 40 285 s2=— а_. л-1 ^285-35*75 |0
68
Выборочное стандартное отклонение определяется как ко-
рень квадратный из выборочной дисперсии:
|У(х-х)2
s = \ " (4.10)
V л -1
или
Пример 4.9. Определим стандартное отклонение для примера 4.8:
з =-710 = 3,16 долл.
Вычисленное стандартное отклонение измеряется в долла-
рах (т. е. в тех же единицах, что и исходные данные), так как
было получено извлечением квадратного корня из величины,
измеряемой “долларами в квадрате”.
Так же как и дисперсия, стандартное отклонение использу-
ется при сравнении степени разброса данных около средней в
двух или более совокупностях. Чем меньше его значение, тем
ближе располагаются данные к средней или тем более предста-
вительна эта средняя.
В случае сгруппированных данных стандартное отклонение
может быть оценено на основе формул (4.10) и (4.11). Для этой
цели следует все значения х, принадлежащие одной группе,
заменить на среднюю точку хг величину Ех2 — на Ъ/х* и ве-
личину Ех — на Е/х (f — частота группы, L/= л). Тогда фор-
мула для оценки стандартного отклонения примет вид
где х вычисляется по формуле (3.4).
Пример 4.10. Множество станков предприятия было сгруппи-
ровано по времени износа в виде следующего ряда распределе-
ния:
69
Время износа, лет Количество станков
2—4 2
5-7 5
8-10 10
11-13 4
14-16 2
Используя формулу (4.12), оценим стандартное отклонение
и дисперсию. Результаты вычислений сведем в табл. 4.4.
Таблица 4.4
Износ, лет f ч **
2-4 2 3 6 18
5—7 5 6 30 180
8-10 10 9 90 810
11-13 4 12 48 576
14-16 2 15 30 450
23 45 204 2034
2034,__________________
s _ _ 23__ - , 2034-1809,3913 =
1 23-1 ~~Ч 22
= .10,209486 = 3,195 года.
Дисперсия оценивается как квадрат стандартного отклоне-
ния:
s2 = 10,209.
Дисперсия и стандартное отклонение обладают свойством
минимальности относительно средней арифметической. Это
означает, что сумма квадратов отклонений данных от средней
арифметической будет всегда меньше, чем от произвольного
значения. Иначе говоря, подставляя в формулы (4.4) и (4.6)
вместо величины ц (или в формулы (4.8) и (4.10) вместо зна-
чения х) любое другое значение, в результате получим вели-
чину, большую, чем вычисленную для ц (или для х ).
Средняя арифметическая — наиболее часто используемая
статистика (параметр) в статистическом анализе. Ввиду этого,
а также свойства минимальности дисперсия и стандартное от-
клонение являются наиболее важными характеристиками ва-
риации.
70
4.1.4. Интерпретация стандартного отклонения
на основе неравенства Чебышева
Используя величину стандартного отклонения, можно про-
вести более глубокий анализ разброса данных. Для этой цели
служит неравенство Чебышева, доказанное в теории вероятно-
стей. В терминах статистической совокупности оно имеет сле-
дующую трактовку.
Для любой совокупности доля значений, попадающих в
интервал х ±As (или ц + кв для генеральной совокупности),
будет равна, по крайней мере, 1 — 1Д2, где к — любое число,
большее 1.
Пример 4.11. Средний недельный доход группы менеджеров
составляет х = 500 долл., стандартное отклонение j = 40 долл.
Пользуясь неравенством Чебышева, найти нижнюю границу
для процента работников, имеющих доход в пределах от 400 до
600 долл.
Интервал от 400 до 600 можно представить как интервал от
(500 - 100) до (500 + 100), или 500 ±100.
Как видно, к = 100/40 = 2,5, и в силу неравенства Чебышева
минимально возможный процент равен
= = —= 0,84.
5 А2 25 25
2 )
Отсюда следует, что не менее 84% всех менеджеров имеют
недельный доход в заданных границах.
Ценность неравенства Чебышева заключается в том, что оно
будет верно для любого частотного распределения данных. Так,
исходя из этого неравенства, можно утверждать, что на интер-
вале с границами х ±2$ содержится, по крайней мере, 3/4 (75%)
всех данных, а на интервале с границами х ±3з — 8/9 (89,9%)
всех значений.
Неравенство Чебышева верно для любой совокупности не-
зависимо от формы кривой распределения.
4.1.5. Коэффициент вариации
Пусть для выборочной совокупности, которая представляет
собой группу служащих одной организации, рассматриваются
значения двух качественно различных признаков: годовой до-
71
ход и невыход на работу в течение года. Первый признак изме-
ряется в долларах, второй — в днях. Предположим, что стан-
дартное отклонение для первого признака равно 1200 долл., а
для второго — 4,5 дня. Возникает проблема непосредственного
сравнения этих двух совокупностей по степени вариации. Было
бы бессмысленно в качестве сравнительных характеристик рас-
сматривать стандартные отклонения, так как они выражены в
разных единицах (заключение о том, что 1200 долл, больше,
чем 4,5 дня, является абсурдным). В этой связи для сравнения
двух или более совокупностей используется специальная ха-
рактеристика, которая не зависит от единиц измерения при-
знака. Она называется коэффициентом вариации и является
относительной безразмерной величиной, выражаемой в долях
или процентах. Коэффициент вариации (к) вычисляется как
отношение среднего квадратического отклонения к средней
арифметической:
к= — или к = -100%. (4.13)
X X
Коэффициент вариации полезно использовать при сравни-
тельном анализе нескольких совокупностей в двух случаях:
1) данные измеряются в качественно различных единицах;
2) данные совокупностей измеряются в одинаковых едини-
цах, но значения средних арифметических существенно отли-
чаются друг от друга.
Пример 4.12. Группа менеджеров фирмы окончила курсы повы-
шения квалификации. По окончании курсов было проведено те-
стирование, результаты которого оценивались по специальной
балльной шкале. После обобщения результатов было установле-
но, что средний результат составляет 200 баллов при стандарт-
ном отклонении 40 баллов. Дополнительные исследования по-
казали, что средний стаж работы на фирме для данной группы
менеджеров — 20 лет при стандартном отклонении 2 года.
Требуется сравнить вариации двух совокупностей значений
признаков: результаты тестирования и значения стажа работы.
Вычислим по формуле (4.13) коэффициент вариации для
множества балльных оценок:
40
t = —100% = 20%.
200
Таким образом, стандартное отклонение составляет 20% от
средней арифметической. Аналогично определим коэффици-
ент вариации для значений стажа работы:
72
* = — •100% = 10%.
20
Стандартное отклонение составляет 10% от средней ариф-
метической.
Можно сделать вывод, что совокупность оценок тестирова-
ния имеет ббльшую вариацию по сравнению с совокупностью
данных о стаже работы.
Ту же самую процедуру можно использовать для случая оди-
наковых единиц измерений, но значительно отличающихся
величин средних.
Пример 4.13. Средний годовой доход высших менеджеров од-
ной крупной фирмы составляет х = 500 000 долл, при стан-
дартном отклонении з = 50 000 долл. Средний годовой доход
неквалифицированных служащих этой фирмы — 12 000 долл,
при s = 1200 долл. Для сравнительного анализа вариаций было
бы сомнительно использовать величину стандартного откло-
нения (т. е., исходя из того, что 50 000 > 1200, утверждать,
что вариация для высших менеджеров выше, чем для неква-
лифицированных служащих).
Для высших менеджеров имеем
* = 50000 ,100% = 10%
500000
Для неквалифицированных служащих
ПОО
к = —~ 100% = 10%.
12 000
Отсюда следует, что множества имеют одинаковую вариа-
цию.
4.2. ИЗМЕРЕНИЕ ВАРИАЦИИ НА ОСНОВЕ
ПОРЯДКОВЫХ ХАРАКТЕРИСТИК
К порядковым характеристикам относятся значения, зани-
мающие определенное место в ранжированном ряду. Из ранее
рассмотренных характеристик таковыми являются наибольшее
и наименьшее значения, а также медиана. К другим порядко-
вым характеристикам относятся квартили и процентили.
Рассмотрим их использование для анализа разброса дан-
ных.
73
4.2.1. Размах квартилей и квартильное отклонение
Под квартилями понимаются значения, которые делят весь
ранжированный в порядке возрастания ряд на четыре равные
по численности группы. Так, ниже первого квартиля ((?) ле-
жит 25% всех данных. Между первым (О,) и вторым (QJ квар-
тилями также располагается 25% всех данных. Отсюда получа-
ем, что ниже и выше второго квартиля лежит по 50% общей
численности, т. е. он совпадает с медианой: Q2 = Me.
Между вторым и третьим квартилями, а также выше третье-
го расположено 25% всех значений.
В качестве меры разброса рассматривается расстояние меж-
ду третьим и первым квартилями, которое называется разма-
хом квартилей. Размах квартилей вычисляется по формуле
По определению между Q2 и должно лежать 50% всех дан-
ных рассматриваемой совокупности. Очевидно, чем меньше
расстояние между и (размах квартилей), тем ближе к
средней располагаются данные.
Если данные сгруппированы в виде ряда распределения, то
для оценки второго квартиля, т. е. медианы, можно использо-
вать формулу (3.5). Для расчетов первого и третьего квартилей
выводятся аналогичные формулы:
--cF
Ql=L+^——i,
(4.14)
где L — точная нижняя граница группы, содержащей первый
квартиль;
п — сумма частот всех групп (общее число данных);
f — частота группы, содержащей первый квартиль;
cF — кумулятивная частота группы, непосредственно пред-
шествующей группе, содержащей первый квартиль;
i — размер группировочного интервала, в котором содер-
жится первый квартиль;
Зп _
----cF
Q3 = L+-±y-----i, (4.15)
где L — точная нижняя граница группы, в которой содержит-
ся третий квартиль;
п — сумма частот всех групп (объем совокупности);
74
f — частота группы, содержащей третий квартиль;
cF— кумулятивная частота группы, непосредственно пред-
шествующей группе, в которой содержится третий квар-
тиль;
/ — размер группировочного интервала, содержащего тре-
тий квартиль.
Так же как и в случае медианы (второго квартиля), для оп-
ределения точной нижней границы L в формулах (4.14) и (4.15)
необходимо использовать кумулятивные частоты.
Пример 4.14. Вычислим размах квартилей для ряда распределе-
ния, представленного в табл. 2.11.
По определению первого квартиля Q, слева от него должно
находиться 25% всех данных, т. е. 30 значений (л = 120). Очевид-
но, группой, содержащей Q, будет такая группа, кумулятив-
ная частота которой равна или превосходит 30. Из табл. 2.11
видно, что первый квартиль содержит группа 1200—1399 долл.,
так как ее кумулятивная частота равна 43, а кумулятивная ча-
стота предыдущей группы — 21. Для искомой группы точная
нижняя граница L = 1199,5 долл., частота / = 22 и размер
/ = 200 долл. По формуле (4.14) найдем оценку для первого
квартиля:
125-2!
С, =1199.5 + ^-----200= 1281,32 долл.
Для группы, содержащей третий квартиль Q)t кумулятивная
частота должна быть равна или впервые превзойти 75% всех дан-
ных (л = 120), т. е. 90. Такой группе будет соответствовать интер-
вал 1600—1799 долл., имеющий кумулятивную частоту 107 (для
предшествующей группы cF = 83). Отсюда L = 1599,5 долл.,
f = 24, / = 200 долл. Проведем расчет по формуле (4.15):
5^5-83
= 1599,5 + —4------200 = 1657,51 долл.
3 24
Найдем оценку для размаха квартилей:
Q = G, - С, = 1657,83 - 1281,32 = 367,51 долл.
Иногда наряду с размахом квартилей рассматривают полу-
размах, или квартильное отклонение, равное половине рас-
стояния между третьим и первым квартилями:
?=(CJ-(21)/2. (4.16)
75
В примере 4.14 квартильное отклонение равно q = 376,51/2 =
= 188,26 долл.
Значения первого и третьего квартилей могут быть прибли-
женно определены на основе графика кумулятивного полигона.
Пример 4.15. Выборка, состоящая из торговых работников
фирмы, сгруппированных по годовым доходам, была пред-
ставлена в виде кумулятивного полигона типа “меньше, чем
...” (рис. 4.2).
Рис. 4.2. Оценка первого и третьего квартилей
с помощью кумулятивного полигона
На рис. 4.2 по левой вертикальной оси откладывается чис-
ленность торговых работников, а по правой — проценты от их
общего числа, равного 800. По горизонтальной оси графика
отмечаются годовые доходы. По определению первым кварти-
лем будет такая точка на горизонтальной оси, ниже которой
расположено 25% всех значений годовых доходов. Она находит-
ся следующим образом: на вертикальной оси процентов отме-
чается точка 25 (она соответствует '/ от 800, т. е. 200 на верти-
кальной оси численностей), далее из этой точки проводится
горизонталь до пересечения с (рафиком кумулятивного поли-
гона и затем вертикаль до пересечения с горизонтальной осью
годовых доходов. Точка пересечения вертикали с осью доходов
есть первый квартиль. На графике видно, что он равен пример-
но 30 000.
Аналогично находится третий квартиль. На оси процентов
отмечается точка 75, из нее проводится горизонталь до пересе-
чения с графиком кумулятивного полигона, далее из точки их
пересечения опускается перпендикуляр на горизонтальную ось
(ось доходов), который пересекает ее приблизительно в точке
40 000.
76
4.2.2. Размах процентилей
Так же как три квартиля делят все распределение на 4 рав-
ные по численности группы, процентили делят его на 100 рав-
ных по количеству данных частей. Формулы для процентилей
записываются аналогично формулам для квартилей:
^-cF
= L + 100-
(4.17)
где Рк — обозначение Л-го процентиля (к = 1,2, ..., 99);
L — точная нижняя граница группы, содержащей к-й про-
центиль;
к — порядковый номер процентиля;
cF— кумулятивная частота группы, предшествующей груп-
пе, содержащей Jt-й процентиль;
f — частота группы, в которой содержится к-й процен-
тиль;
i — размер группового интервала, содержащего к-й про-
центиль.
В качестве размаха процентилей на практике часто рассмат-
ривается расстояние между 10-м и 90-м процентилями:
(4.18)
90 W
Исходя из обшей формулы процентилей (4.17), формулы
для 10-го и 90-го процентилей будут иметь вид
I^-cF
PI0 = L + -^---i,
(4.19)
^-cF
P9O=L + -lfi2--------
i.
(4.20)
Очевидно, между 10-м и 90-м процентилями содержится
80% всех значений распределения.
Пример 4.16. Рассмотрим ряд распределения, представленный
в табл. 2.11. Вычислим для него размах процентилей, измеряе-
мый расстоянием между 90-м и 10-м процентилями.
По формуле (4.18) рассчитаем 10-й процентиль. Для этой
цели необходимо определить группу, в которой он содержится.
77
Кумулятивная частота этой группы должна быть равна или впер-
вые превзойти 10% всех данных (л = 120), т. е. 12. Из табл. 2.11
видно, что такой группой является интервал 1000—1199 долл,
(кумулятивная частота ее равна 21, в то время как кумулятив-
ная частота предыдущей группы равна 10). Подставляя данные
в формулу (4.19), получим
1^-ю
Р10 = 999,5 + —----200 = 1035,9 долл.
Группа, содержащая 90-й процентиль, должна иметь куму-
лятивную частоту, которая равняется или превышает 90% всех
данных, т. е. 108. Этой группой будет интервал 1800—1999 долл.
Вычислим 90-й процентиль по формуле (4.20):
90^20-107
Р90 = 1795,5 + --К&--200 = 1821,7 долл.
По формуле (4.18) вычислим размах процентилей:
Р = 1821,7 - 1035,9 = 785,8 долл.
Интерпретируя результаты, можно сказать, что 80% всех
арендаторов платят за апартаменты приблизительно от 1035,9
до 1821,7 долл.
4.3. ХАРАКТЕРИСТИКИ ФОРМЫ
КРИВОЙ РАСПРЕДЕЛЕНИЯ
Наряду с количественными характеристиками центральной
тенденции и разброса данных можно ввести измерители степе-
ни асимметрии распределений.
В разделе 3.2.4 рассматривались симметрия и различные типы
асимметрии кривых распределений. Если распределение симмет-
рично, то, очевидно, асимметрия равна нулю. В этом случае сред-
няя арифметическая, медиана и мода совпадают: х = Me = Мо.
Если во множестве данных одно или несколько значений
существенно превышают все остальные значения, то имеет
место положительная асимметрия. В этом случае средняя ариф-
метическая будет больше медианы и моды. Наоборот, если одно
или несколько значений существенно меньше всех остальных,
то возникает отрицательная асимметрия. В этом случае средняя
арифметическая остается меньше медианы и моды.
78
Для измерения степени асимметрии вводится коэффициент
асимметрии
$ (4.21)
s
где х — средняя арифметическая;
Me — медиана;
з — стандартное отклонение.
Коэффициент асимметрии колеблется в пределах от -3
до +3.
Если St > 0, то асимметрия положительна; если Sk < 0, то
асимметрия отрицательна; если = 0, то распределение будет
симметричным.
Пример 4.17. Данные о времени пребывания пациентов в кар-
диологическом отделении больницы были сгруппированы в виде
ряда распределения. Среднее арифметическое время лечения
составляло 28 дней, а медианное время — 23 дня. Вычисленное
стандартное отклонение равнялось 4,2 дня. Необходимо опре-
делить, является ли данное распределение симметричным или
имеющим положительную (отрицательную) асимметрию. Для
ответа на поставленные вопросы вычислим коэффициент асим-
метрии:
_ _3(х-Ме) 3 (28-25) _ , .
□ 1 —--------—----------—
* S 4.2
Величина коэффициента асимметрии +2,14 свидетельствует
о значительной положительной асимметрии. По-видимому, не-
сколько пациентов оставались на лечении значительно доль-
ше, чем все остальные. Это повлияло на то, что значение сред-
ней арифметической превысило медиану и моду.
Для симметричных распределений вводится понятие курто-
зиса. Под куртозисом понимается крутость кривой распределе-
ния, которая определяется сопоставлением с кривой нормаль-
ного распределения (оно достаточно подробно рассматривается
в гл. 7). Если вершина распределения находится выше вершины
нормального распределения, то оно называется высоковершин-
ным, или островершинным. Если же она находится ниже, рас-
пределение называется низковершинным, или плосковершин-
ным. На рис. 4.3 показаны кривые нормального, островершинного
и плосковершинного распределений.
79
В качестве меры крутости рассматриваются специальные
показатели, которые характеризуют отклонение вершины фак-
тического распределения от вершины нормального распреде-
ления. Формулы для вычисления этих показателей достаточно
сложны и в данной работе не рассматриваются.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 4
В главе рассматривались вопросы количественного измере-
ния вариации, или разброса данных. Одной из характеристик
вариации является размах колебаний, который вычисляется как
разность между наибольшим и наименьшим значениями (фор-
мула (4.1)). Размах колебаний — грубая характеристика, зави-
сящая только от двух значений всего множества данных. Более
точным показателем, зависящим от всех значений, является
среднее линейное отклонение. Оно вычисляется как средняя
арифметическая абсолютных величин отклонений от средней
(формула (4.2)). Если в качестве средней выбирается медиана,
то среднее линейное отклонение будет наименьшим. Среднее
линейное отклонение часто называют средним абсолютным от-
клонением. Другой тип характеристики разброса относительно
средней арифметической представляет собой дисперсия. Ее
определение основано на вычислении среднего значения для
квадратов отклонений. Дтя генеральной совокупности диспер-
сия вычисляется по формуле (4.4), а для выборки — по форму-
ле (4.8). В формуле для выборочной дисперсии в знаменателе
стоит число, равное общему числу данных, уменьшенному на
единицу (в отличие от формулы для генеральной дисперсии
80
(4.4), где знаменатель равен объему генеральной совокупнос-
ти). Это делается с целью корректировки оценки выборочной
дисперсии, которая получается заниженной в связи с заме-
ной генеральной средней на выборочную среднюю. Диспер-
сия не очень удобная характеристика при сравнительном ана-
лизе, так как выражается в единицах измерения, которые
имеют неясный смысл: квадрат единицы измерения первич-
ных данных. Более удобно пользоваться стандартным откло-
нением, которое вычисляется как корень квадратный из дис-
персии (формулы (4.6) и (4.10)). Стандартное отклонение
измеряется в тех же единицах, что и значения исходной сово-
купности.
Для более глубокого анализа разброса данных около сред-
ней можно использовать неравенство Чебышева, которое име-
ет следующую трактовку: для любой совокупности доля значе-
ний. попадающих в интервал л ±ks (или ц ±к<з) для генеральной
совокупности), будет равна по крайней мере 1 - l/к2, где к —
любое число, большее 1.
При сравнительном анализе двух или более совокупностей
по степени вариации данных возникает проблема, связанная с
единицами измерения признаков элементов различных сово-
купностей или с ситуацией, когда средние совокупностей зна-
чительно отличаются друг от друга. Для решения этой пробле-
мы вводится относительная характеристика — коэффициент
вариации. Он равен отношению стандартного отклонения к
средней арифметической.
Степень вариации измеряется также с помощью порядко-
вых характеристик, т. е. значений, занимающих определенные
места в ранжированном ряду. К ним относятся квартили и про-
центили. Квартили делят ранжированный по возрастанию ряд
на четыре равные по численности группы, а процентили — на
КМ) равных частей. В качестве характеристик разброса часто рас-
сматривают размах квартилей и размах процентилей. Под раз-
махом квартилей понимается расстояние между третьим и пер-
вым квартилями. На этом отрезке концентрируется 50% всех
данных совокупности. Для ряда распределения оценка первого
и третьего квартилей осуществляется по формулам (4.14) и (4.15).
Половина размаха квартилей называется квартильным откло-
нением. Под размахом процентилей часто понимают длину
интервала между 90-м и 10-м квартилями. На нем располагает-
ся 80% общего числа данных. Для ряда распределения оценка
всех процентилей производится по формуле (4.17).
81
Для характеристики формы кривой распределения исполь-
зуется коэффициент асимметрии, который вычисляется по
формуле (4.21). Он изменяется в границах от -3 до +3 и равен
нулю для симметричного распределения. Знак коэффициента
асимметрии отражает направление асимметрии (положитель-
ная или отрицательная).
Куртозис характеризует крутость распределения, которая
определяется сопоставлением кривой фактического распределе-
ния с кривой нормального распределения. Если вершина рас-
пределения находится выше вершины нормального распределе-
ния, то оно называется высоковершинным, или островершинным.
Если же она находится ниже, то распределение называется низ-
ковершинным, или плосковершинным.
ЭЛЕМЕНТЫ ТЕОРИИ
ВЕРОЯТНОСТЕЙ
Главная задача аналитической статистики состоит в том,
чтобы сделать максимально правдоподобные выводы о свой-
ствах и характеристиках генеральной совокупности на основе
доступной части данных из этой совокупности. При этом все-
гда существует риск, что эти выводы будут неправильными
ввиду неполноты имеющейся информации. Отсюда возникает
проблема количественных оценок степени этого риска. Наибо-
лее адекватным научным подходом в данном случае является
использование понятий и методов теории вероятностей. Тео-
рию вероятностей можно назвать “наукой о неопределеннос-
ти” или “математикой случайного”.
5.1. ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ
ВЕРОЯТНОСТЕЙ
5.1.1. Общее понятие вероятности
В быту и профессиональной деятельности человек постоянно
сталкивается с такими понятиями, как вероятность или шансы
чего-то, что еще не произошло, но может произойти. Напри-
мер, прогноз погоды, возможность выигрыша любимой коман-
ды, шансы продвижения нового товара, оценка будущего ва-
лютного курса и т. д. В практической жизни слова “вероятность”
и “шансы” имеют одинаковый смысл. Они выражают степень
уверенности в том, что некоторое событие должно произойти.
Понятие события является основополагающим в теории ве-
роятностей. Всякое событие появляется в результате некоторо-
го опыта или испытания. Для проведения опыта необязательно
наличие каких-либо лабораторных условий, как, например, для
исследования химической реакции. Под опытом (или испыта-
нием) в теории вероятностей понимаются всякие действия,
83
связанные с наблюдениями и измерениями. Событие рассмат-
ривается как один или несколько возможных исходов данного
испытания. Обычно события обозначают прописными буква-
ми: А, В, С и т. п.
Рассмотрим описания нескольких опытов и соответствую-
щих событий.
I. Опыт: бросание двух игральных костей; событие А — вы-
падение на костях суммы очков, равной 7; В — выпадение сум-
мы очков, большей 8; С — выпадение двух четверок.
2. Опыт: сдача студентом предстоящего экзамена; событие
А — сдал, В — не сдал.
3. Опыт: поворот ключа в замке зажигания автомобиля, со-
шедшего с конвейера; событие А — двигатель запустился, В —
двигатель не запустился.
4. Опыт: наблюдение за числом автомобилей, прибывающих
на стоянку; событие А — ни одного автомобиля, В — 1 автомо-
биль, С — 2 автомобиля и т. д.
Под определением вероятности всегда понимается вычис-
ление вероятности какого-либо события. Например, пусть бро-
саются две игральные кости (опыт). Тогда вероятность того,
что сумма выпавших очков на костях будет равна 7 (событие
А), есть вероятность, что произойдет событие А (или просто
вероятность события А). Эта вероятность обозначается Р(А).
Вероятности событий выражаются числом, заключенным
между 0 и 1. Если вероятность события равна 1, то это собы-
тие обязательно произойдет. Такое событие называется досто-
верным. Чем ближе вероятность события к единице, тем оно
достовернее. Так, событие, что любой человек рано или по-
здно умрет, является достоверным, т. е. имеет вероятность,
равную 1.
Событие, которое не может произойти ни при каких обсто-
ятельствах, называется невозможным. Его вероятность равна 0.
Например, выпадение 8 очков при бросании игральной кости
является невозможным событием. Чем ближе вероятность со-
бытия к нулю, тем это событие менее вероятно.
5.1.2. Объективный и субъективный подходы
к определению вероятности. Закон больших чисел
Объективный подход имеет две основные схемы вычисле-
ния вероятности: классическое определение вероятности и ста-
тистическая вероятность.
84
Классическое определение вероятности основано на поня-
тии случаев. Под случаями понимаются все возможные исходы
опыта, которые равновозможны (равновероятны) и являются
взаимоисключающимися (т. е. никакие два из них не могут по-
явиться вместе в данном опыте). Если появление определенно-
го случая влечет за собой появление некоторого события А, то
этот случай называется благоприятствующим этому событию.
Классическое определение вероятности основано на схеме слу-
чаев. Вероятность события А вычисляется как отношение числа
случаев, благоприятствующих событию А, к общему числу слу-
чаев:
Число случаев, благоприятствующих событию А
Р\А)в л— • (5.1)
Общее число случаев
Пример 5.1. Рассмотрим опыт — бросание игральной кости. Дан-
ный опыт имеет ровно шесть единственно возможных, равно-
вероятных и взаимоисключающихся исходов (случаев): выпа-
дение вверх грани с соответствующим количеством очков от 1
до 6. Ясно, что вероятность каждого случая равна '/t, так как
выпадение определенного числа очков есть единственный бла-
гоприятствующий этому событию случай. Следует отметить, что
сумма вероятностей всех случаев будет всегда равна 1. Возьмем
более сложное событие, заключающееся в выпадении четного
числа очков. Тогда данному событию будуг благоприятствовать
уже три случая: выпадение 2, 4 и 6 очков. Исходя из классичес-
кого определения вероятности (5.1) вероятность выпадения чет-
ного числа очков будет равна 3/6 = 1/2 = 0,5.
Классическое определение вероятности применимо только
тогда, когда реализуется схема случаев. Однако во многих ситу-
ациях, связанных с производством, экономикой и бизнесом,
возможные исходы опыта могут быть не обязательно равнове-
роятными и взаимоисключающимися.
Пример 5.2. Пусть некоторая деталь выгачивается на станке (про-
ведение испытания). В качестве возможных исходов будем рас-
сматривать два единственно возможных и взаимоисключающих-
ся события — выпуск детали в допуске и выпуск бракованной
детали. Если станок хорошо налажен, то, очевидно, вероят-
ность производства годной детали будет превышать вероятность
выпуска бракованной детали. Следовательно, в данной ситуа-
ции использование схемы случаев становится невозможным.
85
Другим объективным подходом к вычислению вероятности
является статистическая вероятность. Пусть в прошлом было
произведено достаточно большое количество опытов, где в
результате каждого из них наблюдалось появление или непояв-
ление события А. Если отношение частоты, т. е. количества по-
явления события А, к общему числу опытов приближается к
некоторой величине, то эта величина принимается за вероят-
ность события А. Обозначим число проведенных опытов через
п, а частоту появления события А — через т. Тогда формула
статистической вероятности будет иметь вид
Р(А) — т/п. (5.2)
Формула (5.2) выражает относительную частоту события А,
которая является оценочным значением вероятности. Чем боль-
шее количество опытов произведено, тем точнее оценка. Ста-
тистическая вероятность является одним из проявлений закона
больших чисел в теории вероятностей. В широком смысле под
законом больших чисел понимается свойство устойчивости
массовых явлений, которое проявляется при большом числе
опытов. При этом конкретные особенности каждого отдельно-
го случайного явления почти не сказываются на среднем ре-
зультате массы таких явлений. В теории верятностей закон боль-
ших чисел объединяет ряд теорем, в каждой из которых
доказывается, что при определенных условиях средние харак-
теристики большого числа опытов приближаются к некоторым
определенным константам. В частности, доказывается, что при
большом числе опытов относительная частота события при-
ближается к вероятности этого события.
Пример 5.3. Статистическая отчетность в здравоохранении по-
казала, что за последние годы на каждые 883 смерти приходит-
ся 24 смерти вследствие автомобильных аварий, 182 — вслед-
ствие заболевания раком, 333 — заболеваний сердца. Используя
статистическую вероятность, определить вероятность того, что
причиной смерти любого умершего, выбранного случайным
образом, является:
автомобильная авария (событие А}),
онкологические заболевания (событие AJ,
заболевания сердца (событие Л3).
Оценим вероятности данных событий по формуле (5.2):
РЦ) = 24/883 = 0,027, /\AJ = 182/883 = 0,206,
АЛ3) = 333/883 = 0,377.
86
Вычисленные величины являются относительными часто-
тами событий. Их надо рассматривать как оценочные значения
вероятностей. Под испытанием в данном случае понимается слу-
чайный выбор какого-либо умершего и установление причины
его смерти.
Для использования объективного подхода к определению
вероятности необходимо наличие либо схемы случаев, либо
информации о появлении события в прошлом. Если эти усло-
вия не выполняются, то объективный подход становится не-
возможным. В этом случае единственный путь определения ве-
роятности — субъективная оценка. Субъективная вероятность
основывается на индивидуальном или коллективном мнении
людей, которые выступают в роли экспертов. Они высказыва-
ют свои оценки вероятности события на основе какой-либо
информации, а также своего опыта и интуиции. Субъективная
вероятность отражает степень уверенности отдельного челове-
ка или группы лиц в том, что данное событие произойдет.
В качестве примеров, отражающих необходимость получения
субъективной вероятности, можно рассмотреть следующие за-
дачи:
оценить вероятность того, что данная команда выиграет пер-
венство страны по футболу;
оценить вероятность того, что объем продаж нового про-
дукта в течение года составит более 1000 штук.
5.2. ОСНОВНЫЕ ПРАВИЛА ДЕЙСТВИЙ
НАД ВЕРОЯТНОСТЯМИ
5.2.1. Типы событий. Алгебра событий
Всякое событие, которое рассматривается в теории вероят-
ностей, является случайным, т. е. оно может произойти или не
произойти.
События Ан В называются совместимыми, если в условиях
опыта появление одного события не исключает появления дру-
гого. Если возможно появление только одного из событий, т. е.
они не могут появиться вместе в одном опыте, то эти события
называются несовместимыми.
Пример 5.4. Рассматривается множество деталей двух сортов. Слу-
чайным образом вынимается одна деталь. Появление детали оп-
87
ределенного сорта является случайным событием. Пусть событие
А заключается в появлении детали первого сорта, а событие В —
в появлении детали второго сорта. Ясно, что эти события несов-
местимы. Если испытание заключается в случайном выборе двух
деталей, то события А и Сбудут совместимыми.
Определение двух совместимых или несовместимых собы-
тий можно распространить и на группу, состоящую из несколь-
ких событий. В этом случае для любых двух событий этой груп-
пы должно соответственно выполняться условие совместимости
или несовместимости.
Суммой, или объединением, п событий Л(, Л2, .... назы-
вается случайное событие, состоящее в том, что в результате
опыта произойдет хотя бы одно из этих событий. Сумма собы-
тий обозначается следующим образом:
А. + А, + ... + А .
I 2 к
Пример 5.5. Событие D. состоящее в выпадении нечетного числа
очков при бросании игральной кости, является суммой собы-
тий А. В, С:
D = А + В + С,
где А — выпадение 1 очка,
В — выпадение 3 очков,
С — выпадение 5 очков
Несовместимые события Лр Av ..., Ая образуют полную груп-
пу, если одно из зтих событий должно обязательно осуществить-
ся. Ясно, что сумма вероятностей полной группы событий рав-
на единице:
АЛ,) + АЛ2) + ... + АЛ,) = ь
Если полная группа событий состоит из двух событий, то
эти события называются противоположными. Событие, проти-
воположное событию А, обозначается А. Для противоположных
событий верно соотношение
АЛ) + АЛ) = 1. (5.3)
Пример 5.6. Пусть событие Л состоит в выпадении четного числа
очков при бросании игральной кости. Тогда противоположное
событие Л заключается в выпадении нечетного числа очков.
88
Произведением, или пересечением, событий А , Аг ..., Ап
называется случайное событие (обозначается A Ar..Aj, кото-
рое состоит в том, что в результате испытания произойдут все
эти события.
Пример 5.7. Пусть испытание заключается в том, что по мише-
ни производятся три выстрела. Событие Af характеризуется по-
паданием в мишень только при первом выстреле, событие Л2 —
только при втором выстреле, событие Л, — только при третьем
выстреле.
Произведением событий Лр Л, и Л3 будет событие С= AtA2A},
которое означает, что при трех выстрелах будет ровно три по-
падания.
Наглядную геометрическую интерпретацию действий над
двумя случайными событиями Л и Я дает диаграмма Венна. Для
построения диаграммы Венна представим все возможные исхо-
ды испытания в виде совокупности точек некоторого квадрата.
Событие Л (или В) заключается в том, что выбранная про-
извольным образом точка квадрата лежит внутри соответству-
ющего круга. Противоположное событие Л (или В) заключает-
ся в том, что выбранная произвольным образом точка лежит
вне соответствующего круга. Заштрихуем соответствующие со-
бытия и получим геометрическую интерпретацию производи-
мых действий над событиями (рис. 5.1).
Рис. 5.1. Диаграмма Венна:
а — событие А. б — событие В; а — событие А; г — событие В; д — сумма совмести-
мых событий Див; е - произведение совместимых событий Див; ж - несовмести-
мые события Див
89
Два случайных события называются зависимыми друг от
друга, если вероятность появления одного из них изменяется в
зависимости от появления или непоявления другого.
Пример 5.8. В ящике находится 25 деталей. Среди них — 23
годные и 2 бракованные. Пусть испытание состоит в том, что
одна деталь случайным образом выбирается из ящика и не
возвращается обратно. Событие А заключается в том, что при
первом отборе вынимается годная деталь, а событие В — при
втором отборе вынимается дефектная деталь. Тогда вероятность
события В будет зависеть от того, произошло событие А или
нет. В самом деле, если при первом испытании была вынута
годная деталь, то вероятность, что при втором испытании
будет извлечена бракованная деталь, равна 2/24 = 1/12, а
если при первом испытании была извлечена бракованная,
то — 1/24.
Два события называются независимыми, если вероятность
появления одного из них не зависит от появления или непояв-
ления другого.
Пример 5.9. Подбрасываются две монеты. Под событием А, по-
нимается выпадение цифры для первой монеты, под событием
А} — выпадение герба для второй монеты. Ясно, что вероят-
ность появления события Я,(Я2) никак не влияет на появление
события Я2(Л,).
5.2.2. Правила сложения вероятностей
Если события А и В несовместимы, то вероятность суммы
этих событий (т. е. вероятность того, что произойдет или собы-
тие А, или событие В) равна сумме вероятностей наступления
каждого события:
Р[А + В) = ЛЯ) + Р[В). (5.4)
Аналогично это правило распространяется на сумму п не-
совместимых событий:
ЛЯ, + Я2 + ... + Ая) = ЛЯ,) + ЛЯ2) +...+ ЛЯ,). (5.5)
Из этого правила следует, что сумма вероятностей един-
ственно возможных и несовместимых событий равна 1.
90
Пример 5.10. Автомат заполняет пластиковые пакеты смесью
овощей. Большинство наполненных пакетов имеет стандартный
вес. Однако ввиду небольших отклонений в размерах кусочков
овощей часть пакетов имеет перевес, а часть — недовес. Резуль-
таты проверки большого числа наполненных пакетов (4000)
были сведены в табл. 5.1.
Таблица 5.1
Результаты проверки весов автоматически
наполненных пакетов
Тип пакета Событие Число пакетов Вероятость события
Недовес А 100 0.025(100:4000)
Стандартный вес В 3600 0,9 (3600 4000)
Перевес С 300 0,075 (300:4000)
Требуется определить, чему равна вероятность того, что
наугад вынутый пакет окажется нестандартного веса (будет иметь
или недовес, или перевес). В табл. 5.1 событие “недовес” обо-
значено буквой А, а событие “перевес” — буквой С. Требуется
найти вероятность суммы событий А и С.
По формуле (5.5) имеем
Р(А + О = ЛЛ) + ЛО = 0,025 + 0,075 - 0,1.
Заметим, что события А, В, С являются несовместимыми.
Иначе говоря, любой случайным образом выбранный пакет
будет иметь либо стандартный вес, либо недовес, либо перевес.
Отсюда получаем
Р{А + В + С) = Р(А) + Р(В) + ЛО = 1
Случайные события не всегда бывают несовместимыми.
В случае двух совместимых событий правило сложения вероят-
ностей принимает вид (теорема сложения вероятностей)
Р(А + В) = Р(А) + Р(В) - Р[АВ). (5.6)
Теорема сложения вероятностей, выраженная формулой (5.6),
является общим правилом сложения вероятностей как для со-
вместимых, так и для несовместимых событий. В случае несовме-
стимых событий их произведение будет невозможным событи-
ем, т. е. вероятность произведения этих событий будет равна нулю:
Р[АВ) = 0. В этом случае формула (5.6) примет вид (5.5).
91
Пример 5.11. Из 200 студентов 120 факультативно изучают ан-
глийский язык и 100 немецкий. Какова вероятность того, что
произвольным образом выбранный студент изучает или анг-
лийский, или немецкий? Какова вероятность, что он не изу-
чает ни английский, ни немецкий?
Вероятность, что студент изучает английский (событие А),
равна /\А) = 120/200 = 0,6. Вероятность, что студент изучает
немецкий (событие В), равна Р{В) = 100/200 = 0,5. Нас инте-
ресует вероятность суммы событий. Если использовать формулу
(5.4) для несовместимых событий, то вероятность суммы со-
бытий Р(А + В) = Р(А) + f\B) = 1,1. Это невозможно, так как
вероятность любого события не может превышать 1. Единствен-
ное объяснение данного факта состоит в том, что некоторые
студенты изучают оба языка и были просчитаны дважды. Пусть
таких студентов оказалось 60. Тогда вероятность того, что сту-
дент изучает оба языка одновременно, равна 60/200 = 0,3. Для
определения вероятности суммы событий воспользуемся фор-
мулой (5.6):
Р(А + В) = ЛЛ) + Р(В) - 1\АВ) = 120/200 +
+ 100/200 - 60/200 = 160/200 = 0,8.
Событие, что студент не изучает ни английский, ни немец-
кий, будет противоположным событию А + В. Обозначим его
А + В Ввиду (5.3) сумма вероятностей противоположных со-
бытий равна I:
Р(А + В) + Р(АТ~В) = 1.
Отсюда вероятность события, что случайным образом выб-
ранный студент факультативно не изучает ни одного языка,
равна Pt А + В) = 0,2. Группа таких студентов составляет 40
человек.
Описанную ситуацию можно наглядно проиллюстрировать
с помощью диаграммы Венна (рис. 5.2).
Р(АВ) - 0.3
Рис. 5.2. Диаграмма Вонна для ситуации со студентами, изучающими
английский (событие А), немецкий (событие S) и оба языка одновременно
(событие АВ)
92
5.2.3. Условная вероятность.
Правила умножения вероятностей
В примере 5.8 был рассмотрен случай зависимых событий,
связанных со случайным выбором бракованной или годной
детали. Было показано, что вероятность выбора годной или бра-
кованной детали при втором отборе зависит от того, какая де-
таль (годная или бракованная) была выбрана в первый раз. Ве-
роятность события вычисленная при условии осуществления
другого события Аг называется условной вероятностью. Она
обозначается PiAt/A2). В примере 5.8 были вычислены две ус-
ловные вероятности:
вероятность выбора дефектной детали при втором отборе
(событие В) при условии, что в первый раз была выбрана год-
ная деталь (событие А), т. е. Pi В/А) = 1/12;
вероятность выбора при втором отборе бракованной детали
при условии, что в первый раз была выбрана также бракован-
ная деталь, т. е. Pi В/А) = 1/24.
Если события Ли В независимые, то условная вероятность
одного из них при условии, что другое произошло, будет рав-
на безусловной вероятности первого из событий:
Р[А/ В) = Р(А), (5.7)
PiB/A) = PiB). (5.8)
Соотношения (5.7) и (5.8) следуют из определения незави-
симых событий.
Пусть события А и Я являются независимыми. Тогда вероят-
ность, что оба эти события произойдут в результате одного
испытания (т. е. произведения АВ), равна произведению веро-
ятностей этих событий:
Pi АВ) = PiA)PiB). (5.9)
Формула (5.9) характеризует частный случай правила ум-
ножения вероятностей.
Пример 5.12. Из стандартной колоды игральных карт (52 кар-
ты) случайным образом последовательно с возвратом выбира-
ются две карты. Какова вероятность, что одна карта будет ко-
ролем, а другая — пиковой масти?
93
Пусть выбор короля является событием Л, а выбор карты
пиковой масти — событием В. Ввиду того что выбор каждой
карты осуществляется с возвратом, то события А и В будут не-
зависимыми. Искомая вероятность равна вероятности произве-
дения событий А и В, т. е. в данном случае верна формула (5.9).
Найдем вероятность Р(А). Событию А (выбор короля) благо-
приятствуют 4 случая. Отсюда Р(А) = 4/52 = 1/13. Событию В
(выбор карты пиковой масти) благоприятствует 13 случаев:
ЛЛ) = 13/52 = 1/4.
По формуле (5.9) имеем
ЛЛ5) = Р(А)/\В) = 1/13 • 1/4 = 1/52.
Следует отметить, что выполнение одного из соотношений
(5.7), (5.8), (5.9) является необходимым и достаточным усло-
вием независимости событий А и В.
Пример 5.13. Рассмотрим следующие события:
Л — компания Procter and Gamble выпустит новое моющее
средство, которое в будущем году займет по крайней мере 5%
рынка;
В — компания General Motors введет новую линию произ-
водства компактных автомобилей.
Очевидно, что от того, свершится или не свершится собы-
тие В, никаким образом не зависит появление или непоявле-
ние события Л, т. е. 1\А/В) = Р(А). Отсюда следует, что события
Л и В независимые.
Заменим теперь событие Л на новое событие: компания Toyota
предполагает сокращение в следующем году объема продаж ма-
лолитражных автомобилей. В данном случае было бы неправильно
полагать, что Р(А/В) = Р(А). Здравый смысл подсказывает, что
условная вероятность f\A/B) будет больше, чем безусловная
вероятность Р(А).
Заметим, что вопрос о конкретных значениях величин F\A/B)
и Р[А) не обсуждается. Было только установлено, что эти вероят-
ности не равны: f\A/B) * ЖЛ), что является доказательством
зависимости данных событий.
Рассмотрим теперь общее правило умножения вероятнос-
тей, которое учитывает случай зависимых событий А и В. Это
правило, или теорема об умножении вероятностей, выражает-
ся в виде следующей формулы:
94
Р(АВ) = f\A)P(B/A) = P(B)P(A/B).
(5.10)
Иначе говоря, вероятность того, что события А и В могут
совместно произойти в результате испытания, равна произве-
дению безусловной вероятности события Л (Я) и условной ве-
роятности события В (А).
Пример S. 14. В коробке находится 10 шаров: 3 белых и 7 черных.
Из коробки вынимают наугад один за другим два шара, при-
чем первый вынимается без возврата. Какова вероятность того,
что оба шара окажутся белыми?
Пусть событие А состоит в выборе первого белого шара, а
событие В — в выборе второго белого шара. Очевидно, необхо-
димо определить вероятность совпадения этих двух событий,
т. е. вероятность их произведения Р{АВ). Для того чтобы исполь-
зовать формулу (5.10), следует найти безусловную вероятность
Р(А) и условную Р(В/А).
При выборе первого шара появлению белого шара благо-
приятствуют 3 случая, следовательно, Р(А) = 3/10. Если собы-
тие А произошло, то при втором выборе появлению белого
шара соответствуют 2 случая из 9. Отсюда Р[В/А) = 2/9.
По формуле (5.10) найдем вероятность Р(АВ);
3 2
Р(АВ) = Р(А)Р(В/А) = — • -«0.07.
Статистический смысл этой вероятности состоит в том, что
если данный опыт повторить 100 раз, то в семи исходах следует
ожидать появления одного за другим двух белых шаров.
Теорему умножения вероятностей можно распространить и
на случай трех событий:
Р(АВС) = Р(А)Р(В/А)Р(С/АВ). (5.11)
Пример 5.15. Пусть соблюдаются условия примера 5.14 и выни-
маются последовательно три шара, причем первые два без воз-
врата. Используя формулу (5.11), определить, какова вероят-
ность, что все три шара окажутся белыми.
Величины /\А) и 1\В/А) уже были вычислены в примере
5.14. Определим вероятность события, что при третьем выборе
появится белый шар при условии, что в результате двух преды-
95
луших были также вынуты белые шары, т. е. найдем величину
Р[С/АВ). Данному событию благоприятствует один случай из
восьми, следовательно, Р(С/АВ) = 1/8.
По формуле (5.11) вычислим вероятность появления трех
белых шаров:
3 2 1 1
КАВС) = F\A)P{B/A)P(C/AB) = = — «0,00833.
1U V о 1ZU
Заметим, что в примере 5.15 вычисление условной вероят-
ности зависело от принципа организации отбора. В данном слу-
чае отбор производился по схеме невозврашенного шара, т. е.
те элементы, из которых формировалась выборка, уже не воз-
вращались в генеральную совокупность. Такая выборка, эле-
менты которой отбираются из генеральной совокупности с
соблюдением принципа случайности и не возвращаются в ге-
неральную совокупность, называется выборкой без возвраще-
ния, или бесповторной . Если выборка формируется по схеме с
возвращением отобранных элементов в генеральную совокуп-
ность, то она называется выборкой с возвращением или по-
вторной.
5.2.4. Таблица сопряженности и дерево
возможных исходов
Общее правило умножения вероятностей применяется при
анализе так называемой таблицы сопряженности, которую удоб-
но использовать для статистических заключений. Для иллюст-
рации этого понятия рассмотрим следующую ситуацию.
В некой компании был проведен социологический опрос.
Цель опроса — выяснить, желают ли служащие остаться на
фирме или намерены перейти на другую работу. В анонимной
анкете необходимо было указать стаж работы на фирме и в
форме “да/нет” ответить на вопрос: “Перейдете ли вы в дру-
гую компанию, если вам будет предложена работа на таких
же (или чуть лучше) условиях, которые вы имеете на нашей
фирме?”
Результаты анализа ответов 200 работников были сведены в
таблицу, которая называется таблицей сопряженности (табл. 5.2).
В ней отражается перекрестная классификация работников по
двум признакам: стаж работы на фирме и намерения остаться
или переменить место работы.
96
Таблица 5.2
Таблица сопряженности признаков: стаж работы
и намерения относительно перемены места работы
Намерения Стаж работы, годы
До 1 1-5 5-10 Более 10 Итого
Собираются остаться Собираются перейти 10 25 30 15 5 10 75 30 120 80
200
Данные таблицы сопряженности позволяют вычислять ве-
роятности потенциальных предпочтений: продолжать работать
на фирме или нет в сочетании со стажем. Например, вычислим
вероятность того, что случайным образом выбранный работ-
ник остается на фирме (событие Я) и одновременно имеет стаж
более 10 лет (событие В). Из табл. 5.2 видно, что общее число
работников, собирающихся остаться, равно 120. Поэтому
Р(А) = 120/200 = 3/5. Далее необходимо вычислить условную
вероятность Р(В/А), т. е. вероятность того, что служащий со ста-
жем более 10 лет останется на фирме, несмотря на предложе-
ние новой работы на таких же (или немного лучше) условиях.
По данным табл. 5.2 из 120 потенциально остающихся работ-
ников 75 имеют стаж более 10 лет, следовательно, Р{В/А) =
= 75/120 = 15/24.
По формуле (5.10) вычисляем искомую вероятность:
3 5
Р(АВ) = Р{А)Р[В/А) = - - = 0,375.
D о
Наряду с таблицей сопряженности полезным инструмен-
том для вычисления условных вероятностей и вероятностей
произведений событий является дерево возможных исходов.
Подобное дерево, построенное на основе таблицы сопря-
женности 5.2, представлено на рис. 5.3. Выделим свойства и
принципы построения, которые присущи любому другому де-
реву возможных исходов.
1. Начальная точка в левой части диаграммы обозначает
“ствол” дерева.
2. Из ствола выходят две “ветви”, которые формируют пер-
вый уровень дерева и соответствуют двум возможным исходам:
верхняя ветвь — “собираются остаться”, нижняя ветвь — “со-
бираются перейти”. Безусловные вероятности этих событий
указаны на соответствующих ветвях.
97
1-5
6-10
5
120
75
120
Стаж
10 работы
120
30
120
<1
120 ’0
200 120 " 0,05
120 30
200 120 S
120 5
200 120 ’ 0,025
120 75 „
200 120 0,375
>10
80 15
200 80 = 0,075
80 25 „ ,
200 80 “ 0,125
80 30 „
200 80 "0,15
80 ’0 „ „
200 80 0,05
1.00
Рис. 5.3. Дерево возможных исходов для таблицы сопряженности 5.2
3. Второй уровень дерева образуют восемь ветвей: из нижней
и верхней ветвей первого уровня “растут” по четыре ветви,
характеризующие возможные исходы, связанные со стажем
работы на фирме (менее 1 года, 1—5 лет, 6—10 лет, свыше 10
лет). Соответствующие условные вероятности записаны у каж-
дой ветви. Для данной проблемы дерево возможных исходов
имеет два уровня.
4. Любой путь из исходной точки в концевую точку послед-
него уровня (в данном случае второго) будет характеризовать-
ся произведением событий на соответствующих ветвях, обра-
зующих этот путь. Вероятность каждого такого произведения
вычисляется как произведение вероятностей, соответствующих
ветвям рассматриваемого пути. Эти вероятности указаны на
диаграмме справа около концевых точек дерева. Например, ве-
роятность события, что наугад выбранный работник не со-
98
бирается уходить с работы и имеет стаж менее одного года,
нычисляется как произведение:
120 10
200 120
= 0,05.
Ввиду того что концевые точки дерева характеризуют все
возможные исходы, которые получаются в результате испыта-
ния, сумма их вероятностей, очевидно, равняется единице.
5.2.5. Формула полной вероятности. Теорема Байеса
Полная вероятность события А вычисляется на основании
его условных вероятностей. Пусть событие А может произойти
тогда и только тогда, когда имеет место одно из нескольких
несовместимых событий Ае А.,..., Ап (называемых гипотезами).
Тогда полная вероятность события А равна сумме слагаемых,
где каждое из них есть произведение вероятности гипотезы на
вероятность события А при условии осуществления этой гипо-
тезы, и сумма берется по всем гипотезам:
Р(А) - PlAJPtA/AJ + Р(А2)Р(А/А2) + ... + ЛЛл)АЛ/Ля). (5.12)
Пример 5.16. Пусть имеются 3 одинаковых ящика. В каждом
ящике содержится по 10 деталей, причем из них в 1-м ящи-
ке — 2 бракованные детали, во 2-м — 3, в 3-м — 4. Опреде-
лим вероятность того, что при выборе наудачу одной детали
из произвольно взятого ящика деталь окажется годной (со-
бытие Л).
Гипотезой в данном случае является отбор детали из соот-
ветствующего ящика: At — выбор детали из ящика I, А2 — вы-
бор детали из ящика 2, А3 — выбор детали из ящика 3. Ввиду
того что выбор ящика случайный, имеем = ЛЛ2) =
• ДЛЭ) = 1/3.
Условные вероятности отбора годной летали по гипотезам
таковы: PtA/AJ = 8/10, Р(А/А2) = 7/10, PIA/AJ = 6/10.
Полная вероятность события А вычисляется по формуле
(5.12):
Р(А) = PtAJPtA/AJ + Р(А2)Р(А/А2) + Р(А2)Р(А/А}) =
= 1.А + 1.2 + 1.А=21=о,7.И
3 10 3 10 3 10 30
99
Р(А/А) =------- Р^А'У
Р(\)Р(А/А,)+Р(А2)Р(А/А2) +
Формула полной вероятности является основой для теоре-
мы Байеса, или теоремы о вероятности гипотез. Эта теорема
позволяет оценить величину вероятности какого-либо предпо-
ложения после того, как получен определенный результат ис-
пытания. По теореме Байеса вероятность гипотезы А после ис-
пытания равна произведению вероятности этой гипотезы до
испытания на вероятность события по этой гипотезе, деленно-
му на полную вероятность события А (сумму таких произведе-
ний по всем гипотезам Л , Ар ..., AJ:
---------------, (5.13)
... + /’(Ав)Р(А/Д1)
где Р(А./А) — вероятность гипотезы Л после испытания, или
апостериорная вероятность;
Р(А ) — вероятность гипотезы AI (i — 1,...,л) до испыта-
ния, или априорная вероятность;
Р(А/А) (I = 1,2,...,л) — вероятность события А в предпо-
ложении, что гипотеза Л. осуществилась.
На основе теоремы Байеса можно корректировать априор-
ные вероятности гипотез (т. е. принятые до испытания) по ре-
зультатам уже произведенного испытания (т. е. получить значе-
ния апостериорных вероятностей).
Пример 5.17. Фирма производит компоненты для электропри-
боров в три рабочие смены. Известно, что 50% всех компонен-
тов производится в течение 1-й смены, 20% — в течение 2-й
смены, 30% — в течение 3-й смены. Дополнительный анализ
качества производимых компонентов показал: 6% компонентов,
сделанных за 1 -ю смену, являются дефектными; 8% компонентов,
выпускаемых в течение 2-й смены, дефектны; доля дефектных
компонентов за 3-ю смену составила 15% (ночная смена).
1. Требуется определить, какова вероятность, что наугад ото-
бранный компонент из обшей партии, произведенной за три
смены, окажется дефектным?
2. Предположим, что в результате проверки отобранного слу-
чайным образом компонента было установлено, что он дефект-
ный. Какова в этом случае вероятность того, что этот компонент
был произведен: а) в 1-ю смену; б) во 2-ю смену; в) в 3-ю
смену?
Будем рассматривать случайный отбор дефектного компо-
нента как событие А. Систему гипотез составляют следующие
события:
100
A. — компонент произведен в 1-ю смену, А2 — компонент
произведен во 2-ю смену, Л3 — компонент произведен в 3-ю
смену. Из процентного распределения выпуска компонентов по
рабочим сменам следует: Р(А^ = 0,5; НА2) = 0,2; Р(А2) = 0,3.
Эти вероятности являются априорными.
Условные вероятности отбора дефектного компонента по
гипотезам находятся на основе результатов анализа качества
выпускаемых компонентов по сменам:
KA/AJ = 0,06; Р(А/А2) = 0,08; Р(А/А}) = 0,15.
Величина 1\А/А) означает вероятность, что компонент, вы-
пускаемый в смену i (i = 1, 2, 3), будет дефектным. По формуле
полной вероятности (5.12) найдем вероятность события А:
НА) = KAJHA/AJ + НА2)НА/А2) + НА2)НА/А2) =
= 0,5 • 0,06 + 0,2 • 0,08 + 0,3 • 0,15 = 0,091.
Таким образом, 9,1% всех выпускаемых за три смены дета-
лей будут дефектными. Предположим, что в результате испы-
тания событие А произошло (в результате проверки случайным
образом отобранного компонента было установлено, что он
дефектный).
Скорректируем априорные вероятности с учетом получен-
ной информации о результатах испытания (стало известно, что
собыгис А произошло). Для этой цели используем формулу Бай-
еса (5.13):
Р(А/Л)=-----------------------------------------
Р(А)Я(Л/А)+Р(Лг)Р(Л/Л.)+Р(Л!>Р(Л/Л,)
где (=1,2,3.
Подставляя в формулу (5.14) соответствующие вычислен-
ные значения вероятностей, получим апостериорные вероят-
ности:
0,5 0.06
‘wT' °'33;
0,2 0,08
=-0091 = °’18;
0,3 0.15
°’495
101
Величина РЩА) означает вероятность того, что если слу-
чайным образом отобранная деталь оказалась дефектной, то
она сделана в /-ю смену (/ = 1, 2, 3).
5.3. ОСНОВНЫЕ ФОРМУЛЫ
КОМБИНАТОРНОГО АНАЛИЗА
При классическом подходе определения вероятности требу-
ется найти общее количество случаев (равновероятных и взаи-
моисключающихся исходов испытания), а также число случа-
ев, благоприятствующих данному событию. Часто вычисление
искомого количества случаев удобно проводить по формулам
комбинаторного анализа. Рассмотрим основные из них.
5.3.1. Перестановки
Пусть требуется найти количество способов расположения
совокупности объектов на одной линии. Например, сколькими
способами могут 10 человек встать в очередь друг за другом?
Сколько существует различных автомобильных номеров,
имеющих структуру: буква — 3 цифры — 2 буквы?
В данном случае рассматривается линейное размещение
объектов, которые располагаются подобно отдельным точкам
на прямой. Перестановкой некоторого количества объектов
называется любое линейное размещение этих объектов в опре-
деленном порядке.
Пусть число объектов равно п. Тогда число способов их рас-
положения на одной линии равно
л! = п (л - I) (л - 2)...3 -2 1.
Символ л! читается как “л факториал” и обозначает произ-
ведение всех натуральных чисел от 1 до л. По определению счи-
тается 0! = 1.
Каждое линейное расположение л объектов является пере-
становкой из л объектов. Если в перестановке участвуют все л
объектов, то она называется перестановкой из л элементов по
л. Общее число возможных перестановок из л элементов по л
вычисляется по формуле
Ля=Л/=л!, (5.15)
где А и А ” — обозначения числа перестановок из л элементов
по л. "
102
Пример 5.18. Сколькими способами можно расставить на пол-
ке в ряд 5 книг?
По формуле (5.15) имеем Л5 = Л55 = 5 • 4 • 3 • 2 • 1 = 120.
Следовательно, существует 120 различных комбинаций рас-
становки в ряд на книжной полке пяти книг.
Рассмотрим теперь случай, когда перестановка образуется
не из всего множества элементов, а только из его части.
Предположим, что из п элементов отбирается к элементов
(к<п), из которых образуют перестановку. Такая перестановка
называется перестановкой из п элементов по к. Общее число
различных перестановок из п элементов по к обозначается Апк и
вычисляется по формуле
А* = п\/(п - к)\ = п(п - I )...(л - к + 1). (5.16)
Пример 5.19. Студенту необходимо сдать 4 экзамена в течение
7 дней. Сколькими способами можно составить расписание эк-
заменов, если учитывать, что в один день он может сдавать
только один экзамен?
Каждый отдельный вариант расписания представляет собой
перестановку из 7 элементов (дней) по 4. По формуле (5.16)
вычислим общее число вариантов:
Л/ = 7!/3! = (7 6 • 5 4 • 3 • 2 • 1)/(3 • 2 • I) =
= 7 6 • 5 • 4 • 1 = 840.
5.3.2. Принцип умножения
Пусть требуется выполнить одно за другим к действий. Пер-
вое действие можно выполнить л( способами; после того как
первое действие выполнено, второе действие может быть вы-
полнено л2 способами; после того как выполнено второе дей-
ствие, третье действие можно выполнить л, способами, и так
далее до Л-го действия, которое можно выполнить пк способа-
ми. Принцип умножения заключается в том, что при этих усло-
виях все к действий могут быть выполнены вместе п} п2... пк
способами.
Пример 5.20. При продаже новых автомобилей предлагаются раз-
личные варианты цвета кузова без крыши, отдельно крыши и
обивки салона: в первом случае имеется 8 цветов (л(), во вто-
ром — 10 цветов (л2) и в третьем — 4 цвета (л5). Определить
103
количество возможных комбинаций цветов для одного автомо-
биля.
Исходя из принципа умножения общее число сочетаний цве-
тов для одного автомобиля составит: л, п2 л, = 8 • 10 4 = 320.
5.3.3. Сочетания
Сочетанием называется набор элементов, рассматриваемых
без учета порядка их следования. Пусть рассматривается мно-
жество из п элементов. Сочетанием из п элементов по к (к<п)
называется его произвольное неупорядоченное подмножество,
содержащее к элементов. Общее число таких подмножеств (со-
четаний) определяется по формуле
<517>
к\(п-ку.
где С* — обозначение числа сочетаний из п элементов по к.
20 19...2-1
Пример 5.21. Из партии, включающей 20 деталей, случайным
образом для проверки выбираются 3 детали. Партия содержит 6
дефектных деталей. Какова вероятность, что в число отобран-
ных деталей войдут: 1) только дефектные детали (событие Л);
2) только годные детали (событие В); 3) одна дефектная и две
годные детали (событие С).
Для данной ситуации подходит классическое определение
вероятности. В качестве системы случаев рассматриваются раз-
личные подмножества, состоящие из трех деталей, отобран-
ных из партии. Иначе говоря, случаем является сочетание из 20
элементов (деталей) по 3. Тогда общее число случаев вычисля-
ется по формуле (5.17):
С1 - 20' 20 19...21 _ 20-19-18 _
20 ЗМ7! 3-2-1-17-16-15...21 3-2-1
= 20-19-3 = 1140.
Определим число случаев, благоприятствующих событию А.
Очевидно, оно равняется числу подмножеств из трех деталей,
каждое из которых состоит только из дефектных деталей. Ввиду
того что партия содержит 6 бракованных деталей, все подмно-
жества должны включать какие-либо три детали из их числа.
Количество таких подмножеств, очевидно, соответствует чис-
лу сочетаний из 6 элементов по 3, т. е. величине
С?= —= 20.
6 3!-3!
104
Таким образом, количество случаев, благоприятствующих
событию А, равно 20, а общее количество случаев — 1140. От-
сюда Р[А) = 20/1140 = 0,017. Аналогично находится вероят-
ность события В. Количество годных деталей — 14. Поэтому число
благоприятствующих случаев равно
С,4 = —- = 364.
14 3!11!
Следовательно, Р(В) = 364/1140 = 0,319. Для вычисления
количества исходов, благоприятствующих событию С, следует
воспользоваться принципом умножения. Формирование выбор-
ки из трех деталей в данном случае можно рассматривать как
результат двух действий. Первое действие заключается в отборе
из партии одной бракованной детали, второе — двух годных
деталей. Ясно, что количество способов, с помощью которых
можно реализовать первое действие, — C<J, а количество спо-
собов для второго действия — С\. Согласно принципу умноже-
ния, общее число благоприятствующих случаев равно
' С^С|24=—^^- = 546.
6 14 11-51-2М2!
Отсюда получаем, что вероятность события С вычисляется
следующим образом:
Р(О = 546/1140 = 0,479.
Следует отметить, что формирование подмножества из трех
деталей, извлеченных из партии в 20 деталей, можно рассмат-
ривать как случайную бесповторную выборку. В этом случае
объем выборки равен 3, объем генеральной совокупности — 20.
Поэтому вероятность любой бесповторной выборки есть 1/С^.
Очевидно, в общем случае вероятность бесповторной вы-
борки объема л, т. е. полученной по принципу невозвращения
отобранного элемента обратно в генеральную совокупность
численностью N(n<N), равна 1/С£ .
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 5
Понятие вероятности определяет меру возможности появ-
ления некоторого события в результате опыта (испытания). Под
опытом понимаются некоторые действия, связанные с наблю-
дениями и измерениями. Событие рассматривается как один
105
или несколько возможных исходов данного опыта. Вероятность
может принимать наибольшее значение, равное I. Это означа-
ет, что событие обязательно произойдет, т. е. является досто-
верным. Наименьшее значение вероятности равно 0, что соот-
ветствует невозможному событию, которое никогда не прои-
зойдет.
Можно выделить три подхода к определению вероятности.
Одним из объективных подходов является классическое опре-
деление вероятности. Оно применяется только в тех случаях,
когда реализуется схема случаев. Под случаями понимаются
единственно возможные, равновероятные и несовместимые ис-
ходы испытания. Вероятность события определяется как отно-
шение числа случаев, благоприятствующих данному событию,
к общему числу случаев.
Другой объективный подход — определение статистической
вероятности. Он используется, когда не может быть реализова-
на схема случаев. Пусть в прошлом было проведено достаточно
большое количество опытов, в результате которых наблюда-
лось появление или непоявление некоторого события. Если от-
ношение частоты появления данного события к общему числу
опытов приближается к некоторой величине, то эта величина
принимается за вероятность события.
Третьим подходом к определению вероятности является
субъективное оценивание вероятности, т. е. субъективная веро-
ятность. Он используется, когда схема случаев не выполняется
и недостаточно информации о прошлых испытаниях.
Суммой, или объединением, событий называется событие,
состоящее в том, что в результате опыта произойдет хотя бы
одно из этих событий. Два события называются совместимыми,
если в условиях опыта появление одного события не исключа-
ет появления другого. Если в результате опыта возможно появ-
ление только одного из событий, то эти события называются
несовместимыми. Если речь идет о совместимости или несов-
местимости трех или более событий, то условие совместимос-
ти или несовместимости выполняется для любых двух из них.
Несовместимые события образуют полную группу, если одно
из этих событий обязательно должно осуществиться.
Сумма вероятностей событий, входящих в полную группу,
равна 1. Если полная группа состоит из двух событий, то эти
события называются противоположными. Произведением, или
пересечением, нескольких событий называется событие, кото-
рое состоит в том, что в результате испытания произойдут все
эти события. Для несовместимых событий вероятность суммы
106
этих событий равна сумме вероятностей наступления каждого
события (формула (5.4)). В обшсм случае двух совместимых или
несовместимых событий правило (теорема) сложения вероят-
ностей формулируется следующим образом: вероятность сум-
мы двух событий равна сумме вероятностей каждого события
минус вероятность произведения этих событий (формула (5.6)).
Два события называются независимыми, если вероятность по-
явления одного из них не зависит от появления или непоявле-
ния другого. Вероятность произведения двух независимых со-
бытий равна произведению вероятностей этих событий. Два
события называются зависимыми, если вероятность появления
одного из них изменяется в зависимости от появления или не-
появления другого. Пусть рассматриваются два зависимых со-
бытия. Вероятность одного из зависимых событий, вычислен-
ная при условии осуществления другого, называется условной
вероятностью этого события. Общее правило (теорема) умно-
жения вероятностей гласит: вероятность произведения двух со-
бытий равна произведению безусловной вероятности одного
из них на условную вероятность другого (формула (5.10)). В слу-
чае независимых событий условная вероятность события равна
его безусловной вероятности. Если рассматриваются три собы-
тия, то правило нахождения вероятности их произведения за-
дается формулой (5.11).
На условную вероятность влияет способ организации слу-
чайной выборки. Если отбор элементов производится без их
возвращения в генеральную совокупность, то она называется
выборкой без возвращения, или бесповторной выборкой. Если
отбор прозводится с возвратом, то формируется выборка с воз-
вращением, или повторная выборка. Теорему умножения веро-
ятностей удобно использовать при анализе ситуаций, которые
можно описывать с помощью таблицы сопряженности или де-
рева возможных исходов.
Пусть событие может произойти тогда и только тогда, когда
имеет место одно из нескольких несовместимых событий (на-
)ываемых гипотезами). В этом случае полная вероятность этого
события равна сумме слагаемых, где каждое слагаемое есть
произведение отдельной гипотезы на вероятность данного со-
бытия при условии осуществления этой гипотезы (формула
(5.12)). На основе полной вероятности формулируется теорема
Байеса (формула (5.13)): вероятность каждой гипотезы после
испытания равна произведению вероятности этой гипотезы до
испытания на условную вероятность события по этой гипоте-
1С, деленному на полную вероятность события. С помощью те-
107
оремы Байеса производится корректировка априорных вероят-
ностей гипотез (т. е. оцененных до проведения испытания). После
того как испытание было проведено и результат стал известен,
делается новая, более правдоподобная оценка вероятностей ги-
потез, которые называются апостериорными.
Для вычисления необходимого количества случаев при клас-
сическом определении вероятности часто используются поня-
тия и формулы комбинаторного анализа. Перестановкой п о^гъек-
тов (элементов) называется любое линейное размещение этих
объектов (элементов). Число перестановок из п элементов оп-
ределяется по формуле (5.15). Перестановкой из п элементов
по к (к<п) называется перестановка из какого-либо Л-элемент-
ного подмножества этих элементов. Число перестановок из п
элементов по к определяется по формуле (5.16).
Пусть требуется выполнить одно за другим к действий. Пер-
вое действие можно выполнить п} способами; после того как
первое действие выполнено, второе действие может быть вы-
полнено л2 способами; после того как выполнено второе дей-
ствие, третье действие можно выполнить л способами, и так
далее до к-ro действия, которое можно выполнить пк способа-
ми. Принцип умножения заключается в том, что при этих усло-
виях все к действий могут быть выполнены вместе п} п2... пк
способами.
Сочетанием назывется множество из п элементов, рассмат-
риваемых без учета порядка их следования. Сочетанием из п
элементов по к (к<п) называется произвольное неупорядочен-
ное ^-элементное подмножество этого множества. Число соче-
таний из п элементов по к вычисляется по формуле (5.17).
ДИСКРЕТНЫЕ
РАСПРЕДЕЛЕНИЯ
ВЕРОЯТНОСТЕЙ
6.1. СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
В предыдущей главе рассматривалось понятие случайного
события, которое является исходом некоторого испытания. Если
исходы могут быть количественно измерены (например, общее
число очков, выпавших на двух игральных костях), то пред-
ставление этих исходов и их вероятностей удобно анализиро-
вать, используя понятие случайной величины.
Случайная величина — это функция, которая ставит в соот-
ветствие каждому исходу испытания определенное численное
значение. Ввиду того, что исход испытания является случай-
ным событием, заранее неизвестно, какое именно значение
примет случайная величина.
Если все значения случайной величины могут быть заранее
перечислены, то такая величина называется дискретной.
Пример 6.1. Пусть на станке вытачиваются детали. Число бра-
кованных деталей, которые будут произведены на следующей
неделе, является случайной величиной, гак как точно неизве-
стно, какое значение она примет. Однако можно перечислить
все ее возможные значения: 0, 1,2,п, где п — общее число
деталей, которое будет произведено на станке. Следовательно,
рассматриваемая случайная величина является дискретной.
Другим типом случайной величины является непрерывная
случайная величина. Для нее в отличие от дискретной величи-
ны нельзя заранее перечислить все возможные значения, кото-
рые она может принять. Значения непрерывной случайной ве-
личины непрерывно заполняют некоторый промежуток.
Пример 6.2. Рассмотрим две случайные величины: X — прогноз
числа дождливых дней в определенном месяце в данном реги-
109
оне, Y— прогноз уровня дождевых осадков за этот период. Ясно,
что X — дискретная случайная величина, a Y — непрерывная
(теоретически она может принять любое неотрицательное зна-
чение).
Данная глава посвяшена описанию дискретных случайных
величин. Свойства и характеристики непрерывных величин бу-
дут рассмотрены в гл. 7.
6.2. РЯД РАСПРЕДЕЛЕНИЯ ДИСКРЕТНОЙ
СЛУЧАЙНОЙ ВЕЛИЧИНЫ
Обозначим через Xдискретную случайную величину, кото-
рая может принимать одно из п единственно возможных значе-
ний хр хг,..., хп. Ввиду того что X — случайная величина, любое
значение х. (/= 1, 2,..., п) возможно, но не достоверно. Сможет
принимать каждое из этих значений с некоторой вероятнос-
тью:
Р(Х = х,) = />|( Р(Х = х,) = рг..., /\Х = хя) = х„.
В результате испытания случайная величина X обязательно
примет одно из значений х (/ = 1,2. п). Следовательно, п
событий, каждое из которых заключается в том, что Xприни-
мает конкретное значение, равное х (X = х, i = 1, 2,..., п),
образуют полную группу событий.
Отсюда .
п п
£p(x=xi)=2}ft=i. (6.1)
<=i i=i
Из соотношения (6.1) можно заключить, что суммарная
вероятность случайной величины равна 1 и она как бы распре-
делена между всеми отдельными ее значениями. Случайная ве-
личина X считается заданной с вероятностной точки зрения,
если точно известно это распределение вероятностей. Будем
полагать, что задан закон распределения дискретной случай-
ной величины, если точно известны все ее значения, которые
получаются в результате испытания, а также вероятности, с
которыми она принимает соответствующие значения. Закон
распределения дискретной случайной величины, который еще
называется рядом распределения, можно представить в виде
табл. 6.1.
110
Таблица 6.1
Закон (ряд) распределения дискретной случайной величины
Значения X ... X
Вероятности Р(Х = х,) Pi Pi ... рп
Пример 6.3. Пусть опыт заключается в трехкратном подбрасы-
вании монеты. Рассмотрим случайную величину X, значения
которой определяются количеством выпадений герба.
Требуется записать ряд распределения этой случайной ве-
личины. Очевидно, Xможет принимать четыре единственно воз-
можных значения: 0, 1,2, 3. Определим распределение вероят-
ностей, т. е. Р{Х = 0), Р(Х = 1), 1\Х = 2), 1\Х = 3). Для этого
используем схему случаев. При однократном подбрасывании
монеты возмджны два равновероятных исхода — герб и цифра
При трехкратном подбрасывании общее число случаев нахо-
дится по принципу умножения (раздел 5.3.2), т. е. 2 • 2 • 2 = 8.
Если представить каждый случай как последовательность
выпадений гербов и цифр, то все случаи можно записать в сле-
дующем виде:
Ц Ц Ц, Г Г Ц, Ц Г Ц, Г Ц Ц, Г Г Ц, Г Ц Г, Ц Г Г, Г Г Г.
Тогда:
событию X = 0 благоприятствует 1 случай (ЦЦЦ);
событию X — 1 - 3 случая (ЦЦГ, ЦГЦ, ГЦЦ);
событию X = 2-3 случая (ГГЦ, ГЦГ, ЦГГ);
событию Х= 3 — 1 случай (ГГГ).
Запишем распределение вероятностей:
Р(Х = 0) = 1/8, Р(Х = 1) = 3/8, Р[Х = 2) = 3/8,
Р(Х = 3) = 1/8.
Ряд распределения случайной величины Xбудет иметь вид
Значения X (X = х,) 0 1 2 3
Вероятности Р(Х = х() 1/8 3/8 3/8 1/8
Заметим, что в примере 6.3 использовалась схема случаев,
т. е. классическое определение вероятности. Предположим, что
число опытов (трехкратные бросания монеты) будет достаточ-
но большим и при этом наблюдаются относительные частоты
соответствующих событий (отношения числа опытов, в резуль-
П1
тате которых герб выпадал определенное количество раз, к
общему числу опытов). При стремлении числа опытов к беско-
нечности значения относительных частот по закону больших
чисел будут стремиться к соответствующим вероятностям, по-
лученным по схеме случаев.
Чем больше опытов наблюдается, тем относительные час-
тоты будут более точными оценками вероятностей.
Можно сказать, что в терминах статистического подхода к
определению вероятности распределение вероятностей диск-
ретной случайной величины получается в результате подсчета
относительных частот отдельных событий при бесконечном
числе опытов. Под отдельным событием в данном случае пони-
мается тот факт, что в результате опыта случайная величина
принимает одно из возможных своих значений.
6.3. ХАРАКТЕРИСТИКИ ДИСКРЕТНОЙ
СЛУЧАЙНОЙ ВЕЛИЧИНЫ
6.3.1. Математическое ожидание
В гл. 3 было рассмотрено понятие средней арифметической
для выборочной и генеральной совокупностей. Введем анало-
гичное понятие средней для дискретной случайной величины.
Рассуждения будем проводить для случайной величины, пред-
ставленной в примере 6.3. Пусть монета подбрасывается три
раза подряд и фиксируется, сколько раз выпал герб, т. е. значе-
ние величины X. Затем этот опыт повторяется и опять записы-
вается число выпадения герба. Предположим, что опыт был
повторен 10 раз и результаты подсчетов выпадения герба в каж-
дом опыте были следующие:
2, 1, 1, 0, 2, 3, 2, I, 1, 3.
Найдем среднюю арифметическую (статистику), рассмат-
ривая результаты наблюдений как выборочные данные:
- 2+1+1+0+2+3+2+1+1+3 , z _
х ------------------------= 1,6 герба.
10
Можно сказать, что в результате проведения опытов герб в
среднем выпадал 1,6 раза.
Значение 1,6 можно было бы получить как среднюю взве-
шенную величину, если использовать в качестве весов относи-
тельные частоты значений:
112
X -
01 + 14 + 2 3 + 32
10 ’
1 . , 4 л 3 2
-----F 1-----к 2-----+ 3‘------
10 10 10 10
Как видно, относительная частота представляет собой долю
общего числа опытов, в которых случайная величина прини-
мает соответствующее возможное значение.
Пусть число опытов бесконечно возрастает. Рассмотрим,
какова в этом случае будет средняя. Будем полагать, что все
опыты следуют непрерывно один за другим и длятся одинако-
вое время.
Случайная величина дописывается следующим образом:
X = 0 с вероятностью 1/8,
X = 1 с вероятностью 3/8,
X = 2 с вероятностью 3/8,
Х= З'с вероятностью 1/8.
Предположим, что процесс проведения опытов бесконечен
(длится бесконечное время) и за ним непрерывно осуществля-
ются наблюдения (отмечаются количества выпадения герба).
Тогда распределение вероятностей можно интерпретировать как
долю общего времени наблюдений, когда случайная величина
X принимает соответствующие значения: 1/8 всего времени на-
блюдается Х= 0; 3/8 всего времени — Х= 1; 3/8 всего време-
ни — X = 2; 1/8 всего времени — X - 3.
Если рассматривать вероятности как значения относитель-
ных частот при бесконечном числе опытов, то среднюю слу-
чайной величины X можно вычислить так:
13 3 1
0 - + 1- + 2- + 3- = 1,5 герба.
8 8 8 8
Заметим, что 1,5 не является возможным значением случай-
ной величины X, оно только характеризует то значение, кото-
рое X может принимать в среднем при очень большом числе
опытов.
В общем случае пусть задан закон распределения дискрет-
ной случайной величины X, т. е. она принимает значения х,
х хя с вероятностями Р(Х = х,) = Ах,) = р}, Р(Х = х2) =
Ах2) = р2... Р(Х = х) = F\xJ = ря. Тогда среднее значение
случайной величины X вычисляется по формуле
Е(Х) = Ц = £х,Р(Х =xi)='^xipi =^x</’(*i)=2}x/’(x). (6.2)
i=l i=l i=l
Обозначение ц вводится по аналогии со средним значением
генеральной совокупности. В теории вероятностей среднее зна-
нз
чение случайной величины чаще называют ее математическим
ожиданием, используя при этом запись ц = Е(Х). Математичес-
кое ожидание является аналогом центра распределения гене-
ральной совокупности, т. е. характеризует наиболее типичное
значение для всего распределения, около которого концент-
рируется основная масса возможных значений случайной ве-
личины X.
6.3.2. Дисперсия и стандартное отклонение
Для того чтобы определить, насколько тесно располагаются
значения случайной величины около ее математического ожи-
дания, существуют специальные характеристики — дисперсия
и стандартное отклонение, которое еще называют средним квад-
ратическим отклонением. Они определяются по аналогии с
соответствующими характеристиками для статистических со-
вокупностей. Вычислим по формуле (4.8) выборочную диспер-
сию для совокупности из десяти значений, представляющих
результаты подсчета выпадения герба при 10 трехкратных под-
брасываниях монеты (раздел 6.3.1):
2 У(х--?)2 (2-1.6)2+(1-1.6)2+... + (3-1,6)2
л-1 10-1
= (O-1.6)2-1 + (1-1,6)2-4 + (2-1,6)2 3-ь(3-1,6)2-2 = Q
10-1
Чтобы определить дисперсию, в числителе находится сумма
произведений квадратов отклонений данных от средней на со-
ответствующие частоты значений.
Вычислим стандартное отклонение s =^'0,944 = 0,97. Пусть
число опытов будет достаточно большим. В этом случае для вы-
числения дисперсии и стандартного отклонения можно исполь-
зовать формулу (4.4), где знаменатель равен общему числу опы-
тов N. При бесконечном числе опытов (У-и») относительные
частоты будут стремиться к вероятностям, а выборочная сред-
няя — к математическому ожиданию. Отсюда очевидны форму-
лы для дисперсии и стандартного отклонения случайной вели-
чины X:
о2 = ^(х<-ц)2Р(х|) = £(х-ц)2Р(х), (6.3)
1-1
о = ^£(х-ц)2Р(х). (6.4)
114
Выражение (6.3) можно интерпретировать как математичес-
кое ожидание квадрата отклонения случайной величины от ее
математического ожидания:
д2 = Е(Х-ц)2.
Формулу (6.3) можно записать в более удобном для прове-
дения вычислений виде:
Л
о2 = Sх'2 ) - и2 = Е( X 2) - Е( X )2. (6.5)
<1
Пример 6.4. Фирма продает новые автомобили. Известно, что
наиболее интенсивная продажа бывает по субботам. На основа-
нии данных о проданных автомобилях за ряд прошедших суб-
бот менеджер оценил возможные субботние продажи и рас-
пределение вероятностей.
Пусть случайная величина Xозначает количество автомоби-
лей, продаваемых по субботам. Закон распределения X, кото-
рый установил менеджер, имеет вид
Значения X“к 0 1 2 3 4
Вероятности Р(х) 0,1 0.2 0.3 0,3 0.1
Как видно, 10% составляют субботы, в течение которых не
было продано ни одного автомобиля; 20% — субботы, за кото-
рые объем продаж составил 1 автомобиль в день; 30% — 2 ав-
томобиля в день, 30% — 3 автомобиля в день, 10% — 4 автомо-
биля в день.
Определим, какое количество автомобилей в среднем ожи-
дает продавать менеджер в будущем по субботам. Другими сло-
вами, необходимо, используя формулу (6.2), вычислить мате-
матическое ожидание случайной величины X:
ц = Е(Х) =£хР(х)= 0 0,1 + 1 • 0,2 + 2 • 0,3 +
+ 3 • 0,33 + 4-0,1 » 2,1.
Величину 2,1 можно интерпретировать следующим образом:
в течение большого числа суббот в среднем будут продавать по
2,1 автомобиля.
Следует особо подчеркнуть, что 2,1 не является точным зна-
чением продаж, которые ожидают совершать в течение каждой
отдельной субботы Это только средняя дневная величина, ко-
торая ожидается в течение большого количества суббот.
115
Вычислим дисперсию случайной величины X. Для этого удобно
промежуточные вычисления по формуле (6.3) свести в табл. 6.2.
Таблица 6.2
Расчет дисперсии
Продажи х Вероятность Р(х) х-р (х -1»)1 (х - p)»F(x)
0 0.1 0-2,1 4,41 0.441
1 0.2 1-2.1 1.21 0,242
2 0.3 2-2,1 0,01 0,03
3 0,3 3-2.1 0,81 0,243
4 0.1 4-2.1 3,61 0,361 о2 = 1,29
Стандартное отклонение определим по формуле (6.4):
ст = \'ст* =л/1,29= 1,14 автомобиля. Вычислим также диспер-
сию по упрошенной формуле (6.5):
о2 = £х2Р(х)-р2 = О2 • 0,1 + I2 • 0,2 + 22 • 0,3 +
+ З2 0,3 + 42 • 0,1 - 2,12 = 1,29.
Дисперсия является характеристикой вариации или разбро-
са данных около математического ожидания. Ее можно исполь-
зовать для сравнительного анализа нескольких случайных ве-
личин, принимающих качественно схожие значения.
Пример 6.5. Продолжим ситуацию примера 6.4. Менеджер той
же автомобильной фирмы, но в другом регионе установил на
основе собранных данных, что средние субботние продажи
составляют также 2,1 автомобиля, но дисперсия о2 = 1,91.
Очевидно, в первом случае (о2 = 1,29) значения продаж
более тесно располагаются около величины 2,1, представляю-
щей математическое ожидание субботних продаж.
Если рассматривать математическое ожидание как прогноз-
ную величину, то, очевидно, дисперсия будет отражать меру
риска или надежность прогноза: чем меньше дисперсия, тем
надежнее прогноз. Когда дисперсия нулевая, случайная вели-
чина перестает быть случайной, так как с вероятностью 1 она
будет принимать в каждом опыте одно и то же значение. Так,
можно сделать вывод, что прогноз продаж, сделанный менедже-
116
ром в примере 6.4, более надежен, чем прогноз, полученный
менеджером в примере 6.5 (1,29 < 1,91).
6.3.3. Графическое представление распределения
дискретной случайной величины
Распределение может быть представлено в виде линейного
графика, где по оси х откладываются возможные значения слу-
чайной величины X, а по оси у — величины вероятностей Лх)
Пример 6.6. Пусть испытание заключается в двукратном под-
брасывании монеты. При одном подбрасывании может выпасть
либо герб, либо цифра. Под случайной величиной Xбудем по-
нимать число выпаданий цифры при двух подбрасываниях. По-
строим график распределения случайной величины X.
Возможные исходы испытания: Г Г, Ц Г, Г Ц, Ц Ц. Возмож-
ные значения случайной величины X: 0, 1, 2. Распределение ве-
роятностей: ДХ- 0) = 1/4, Р(Х = 1) = 2/4, 2) = 1/4. На
рис. 6.1 представлен график распределения X.
Рис. 6.1. Графическое представление распределения дискретной
случайной величины X: выпадание цифры при двукратном
подбрасывании монеты
6.4. БИНОМИАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
Дискретная случайная величина Xбудет иметь биномиаль-
ный закон распределения, если выполняются следующие ус-
ловия.
I. Имеет место эксперимент, который заключается в после-
довательном повторении п опытов.
2. В результате каждого опыта могут произойти два един-
ственно возможных и взаимно исключающихся исхода — два
117
противоположных события: появление или непоявление неко-
торого события А. Эти события можно рассматривать как “ус-
пех” (появление А) или “неудача” (непоявление А).
3. Все п проводимых опытов являются независимыми.
4. Величина вероятности “успеха” в каждом из п опытов ос-
тается постоянной (обозначается р).
5. Случайная величина X характеризует число “успехов”,
которые имеют место при п испытаниях.
Пример 6.7. Социологический опрос, проведенный в одном го-
роде, показал, что 30% всего взрослого населения читают го-
родскую вечернюю газету. Случайным образом выбираются че-
тыре взрослых городских жителя. Покажем, что если под
случайной величиной X понимать число читающих вечернюю
газету среди этих четырех человек, то X подчиняется биноми-
альному закону распределения.
Определим, удовлетворяет ли рассматриваемая ситуация ус-
ловиям биномиального распределения, т. е. проверим выполне-
ние каждого из вышеуказанных условий.
I. В данном случае число опытов п = 4, где каждый опыт
состоит в случайном выборе одного взрослого жителя.
2. В результате каждого опыта имеют место два единственно
возможных и взаимно исключающихся исхода — человек чита-
ет газету (“успех”) и человек не читает газету (“неудача”).
3. Опыты являются независимыми, так как выбор людей осу-
ществляется случайным образом.
4. Вероятность “успеха” при проведении каждого из четырех
опытов постоянна: р = 0,3.
5. Случайная величина Д'принимает значения, равные числу
“успехов” в результате проведения п опытов (л = 4).
Как видно, все условия для биномиального распределения
выполнены, т. е. можно утверждать, что случайная величина X
распределена по биномиальному закону.
6.4.1. Биномиальные вероятности
Пусть рассматривается схема опытов, удовлетворяющая ус-
ловиям биномиального распределения. Чтобы вычислить рас-
пределение вероятностей, необходимо подсчитать общее чис-
ло событий, каждое из которых является исходом п испытаний
и заключается в том, что “успех” наблюдался определенное
число раз. Например, пусть монета подбрасывается четыре раза
118
подряд (л = 4). Сколькими способами могут выпасть два герба?
Иначе говоря, требуется подсчитать число событий, где каж-
дое событие характеризуется выпаданием двух гербов при че-
тырех подбрасываниях монеты (в двух оставшихся подбрасыва-
ниях естественно выпадает цифра). Очевидно, таких событий
будет шесть: ГГЦЦ, ГЦГЦ, ГЦЦГ, ЦГГЦ, ЦГЦГ, ЦЦГГ.
Рассмотрим теперь следующую задачу. Сколькими способа-
ми из группы, включающей четырех человек, можно выбрать
двух человек, если порядок людей в выборке неважен? Обо-
значим людей в группе /, /,, /3, /4. Тогда задача выбора по два
человека будет иметь шесть вариантов решений. Сравним их с
вариантами выпадания двух гербов при четырех подбрасыва-
ниях монеты.
Выпадание двух гербов при
четырех подбрасываниях монеты
ГГЦЦ
ГЦГЦ
ГЦЦГ
ЦГГЦ
ЦГЦГ
ЦЦГГ
Выбор двух человек из группы,
состоящей из четырех человек
Как видно, существует взаимно однозначное соответствие
между вариантами: порядковые номера двух подбрасываний
монеты, в которых выпал герб, в общей последовательности
четырех подбрасываний соответствуют номерам двух выбран-
ных индивидов. Очевидно, в обоих случаях мы составляем под-
множество из двух элементов, выбираемых из множества, со-
стоящего из четырех элементов. Количество таких подмножеств
равно числу сочетаний из 4 элементов по 2 (формула 5.17):
’ (4-2)!-2!
Данный вывод можно распространить на общий случай. Пусть
осуществляется п подбрасываний монеты (проведение п опы-
тов). Требуется подсчитать количество вариантов, в каждом из
которых герб выпадал ровно к раз (“успех” появлялся ровно к
раз). Очевидно, эту задачу можно свести к подсчету числа вы-
борок, состоящих из к человек, взятых из группы в составе п
человек: к порядковых номеров подбрасываний монеты, в ко-
торых выпал герб, соответствуют номерам к отобранных инди-
видов (порядок индивидов в выборке неважен). Очевидно, ис-
комое число вариантов будет с*
п
119
Сформулируем этот вывод для любой схемы, удовлетворя-
ющей условиям биномиального распределения. Пусть прово-
дится п независимых опытов, в каждом из которых может по-
явиться (успех) или не появиться (неудача) некоторое событие
А. Тогда количество вариантов, в которых событие А (успех)
появляется ровно к раз (к < л), равняется числу сочетаний из л
элементов по к, т. е. С*.
Предположим, что вероятность “успеха” в каждом опыте
равна р. Тогда вероятность “неудачи”, очевидно, равняется
q = 1 ~ р. Рассмотрим один из вариантов, когда в л опытах
“успех” появляется ровно к раз. Его можно рассматривать как
сложное событие, которое является произведением л незави-
симых простых событий: к “успехов” и (л - к) “неудач”. Тогда
вероятность этого произведения равна р*(1 - />)*"* = рк<?'к.
В общем случае число рахтичных произведений, где каждое
произведение соответствует варианту появления ровно к “ус-
пехов” в л опытах, будет С*. Отсюда получаем, что вероят-
ность события, что при л испытаниях “успех” наступит ровно
к раз (к < л) (обозначим ее Р{к, л)), является вероятностью
суммы событий, где каждое слагаемое есть один из вариантов
произведения к “успехов” и (л - к) “неудач”:
Р(*,л) = С*р*(1-рГ* =С*АЯ*. (6.6)
Например, вероятность события, что при четырех подбра-
сываниях монеты герб выпадет ровно 2 раза, вычисляется сле-
дующим образом:
Р(2,4) = С42
=6.±Л.
16 8
Выражение (6.6) задает распределение вероятностей для
биномиальной случайной величины X
л = 0 с вероятностью Спр q = q ,
Х = 1 с вероятностью C'nplqn~',
X = 2 с вероятностью C2p2qn2,
(6.7)
X = л с вероятностью C^pnqn " = рп.
120
Распределение (6.7) определяет дискретную случайную ве-
личину X, распределенную по биномиальному закону, где л —
число испытаний, р — вероятность появления события А (“ус-
пеха") в результате каждого опыта, q = I - р — вероятность
ненаступления события А (“неудачи”), к — число появлений
события А (“успехов”) (к < п). Для биномиальной X как для
любой дискретной случайной величины сумма вероятностей
равна 1: „
We*=1
i=0
।
Пример 6.8. В примере 6.7 случайная величина X, распределен-
ная по биномиальному закону, характеризовала число читаю-
щих вечернюю городскую газету среди случайным образом ото-
бранных четырех жителей. Определим ряд распределения
величины X. В данном случае число опытов л = 4 (случайный
отбор четырех человек). Событие А (“успех”) заключается в том,
что отобранный случайным образом человек читает вечернюю
газету. Вероятность АЛ) ~ Р = 03, так как по результатам со-
циологического опроса 30% всего взрослого населения города
читают вечернюю газету. Вероятность противоположного собы-
тия А (человек не читает вечернюю газету) равна АЛ) = q =
- I - 0,3 = 0,7.
Определим вероятности, что среди случайным образом ото-
бранных четырех человек читают вечернюю газету: I) 0 чело-
век; 2) 1 человек; 3) 2 человека; 4) 3 человека; 5) 4 человека.
Эти вероятности вычисляются по формуле (6.6):
АО,4) = Сд 0,3° 0,74 =0,74 =0.2401;
А 1,4) = С\ 0,3' 0,7’ =0,4116;
А2,4) = Сд • 0,32 0,72 = 0,2646;
АЗ,4) = Сд 0,3’- 0,71 =0,0756;
А4,4) = С4 0,34 0,7° =0,3* =0,0081.
Запишем ряд распределения для случайной величины X:
Х-ж 0 1 2 3 4
Ах) 0,2401 0,4116 0,2646 0,0756 0.0061
Заметим, что ^Р(х,4) = 1.
121
Значения вероятностей имеют вполне определенную стати-
стическую интерпретацию. Например, Л2,4) = 0,2646 означа-
ет, что если много раз случайным образом набирать группы из
четырех жителей, то 26,5% всех отобранных групп будут вклю-
чать ровно два человека, которые читают вечернюю газету.
Пусть нас интересует событие, что случайная величина X не
превзойдет некоторого значения к. Так, для ситуации примера
6.8 определим вероятность, что среди выбранных случайным
образом четырех человек не более двух читают вечернюю газе-
ту. Вероятность данного события PtX'i 2). Она является суммой
вероятностей событий, что случайная величина X примет одно
из значений 0, 1,2:
Р(Х<. 2) = Р[Х = 0) + Р[Х = I) + Р[Х = 2) =
* АО,4) + Л1,4) + Л2.4) = 0,2401 + 0,4116 + 0,2646 =
= 0,9163.
В общем случае вероятность события, что случайная вели-
чина X, распределенная по биномиальному закону, примет
значения, не превышающие к (к < л), вычисляется следующим
образом:
Р(Х<к) = Р(0,п) + Л1Л) + ... + /\к,п) =
-<7"+CiW-’+...+C*pV-*. (6.8)
Выражение (6.8) является накопленной вероятностью, ко-
торая получается суммированием величин 1\х) для соответ-
ствующих значений х. Она характеризует вероятность того, что
при п опытах событие А наступит не более к раз.
Соответственно вероятность события, что случайная величи-
на Xпримет значение, превышающее к (т. е. вероятность, что в п
опытах событие А появится более чем к раз), определяется так:
Р(Х> к) = 1 - 1\Х< к). (6.9)
В примере 6.8 вычислим по формуле (6.9) вероятность со-
бытия, что среди выбранных четырех человек более двух чита-
ют вечернюю газету:
Р(Х>2) = 1 - /\Х<2) = 1 - 0,9163 = 0,0837.
Заметим, что вероятности Р(к,п), вычисляемые по формуле
(6.6), можно получить как члены разложения бинома:
122
/ . _ В . z-,I l _B“1 i i ''1 j Л
(p + <?) =p +Cnpq +.- + Cn p q + q
Для удобства вычислений в Приложении 2 приведены таб-
лицы биномиальных вероятностей для п = 1, 2,..., 20, 25 и
р = 0,05; 0,1; 0,2; 0,9; 0,95. Каждая таблица соответствует
определенному значению п. В строках таблицы задаются вели-
чины к (к<п), в столбцах — значения вероятности р. На их пере-
сечении находим биномиальную вероятность С*рп(\- р)п * .
»
6.4.2. Математическое ожидание и дисперсия
биномиальной случайной величины
Математическое ожидание дискретной случайной величи-
ны находится по формуле (6.2). В случае биномиального рас-
пределения необходимо вычислить выражение
ц = £ XiP(x,) = о • С°пр V +1 • С'„p'q-1 +... + п • с; Pnq°.
м
Так, в примере 6.8 математическое ожидание числа читаю-
щих вечернюю газету среди отобранных случайным образом
четырех жителей города определяется следующим образом:
ц = 0 0,2401 + 1 • 0,4116 + 2 • 0,2646 +
+ 3 • 0,0756 + 4 • 0,081 = 1,2.
Можно доказать, что для математического ожидания бино-
миальной величины верна следующая формула:
ц = пр. (6.10)
Для ситуации примера 6.8 математическое ожидание можно
было бы вычислить гораздо проще по формуле (6.10):
ц = 4 - 0,3 = 1,2 чел.
В общем случае дисперсия дискретной случайной величины
X определяется по формулам (6.3) и (6.5).
Для биномиального распределения можно доказать:
о2 = (0 - лр)2С„ р0^'1 + (1 - np)2c\plqn-} +... +
+ (n-np)2C"pnq0 = np(l-p) = npq. (6 1 D
123
Стандартное отклонение соответственно определяется так:
а = -]пр( 1 - р j = -jnpq. (6.12)
Для ситуации в примере 6.8 вычислим дисперсию и стан-
дартное отклонение по формулам (6.11) и (6.12):
о2 = 4 • 0,3 0,7 = 0,84,
о = ai'0,84 = 0,92 чел.
Пример 6.9. Анализ большого количества деклараций о доходах
показал, что одна из десяти деклараций заполнена с ошибка-
ми. Пусть случайная величина Xпредставляет собой число дек-
лараций с ошибками среди 20 выбранных случайным образом
деклараций.
Требуется определить:
1) какова вероятность события, что по крайней мере три
декларации будут содержать ошибки?
2) какова вероятность события, что не более чем в одной
декларации содержатся ошибки?
3) математическое ожидание, дисперсию и стандартное от-
клонение случайной величины X.
Случайная величина X имеет параметры: п = 20, р = 0,1.
Событие А заключается в наличии ошибок при заполнении
декларации (“успех”). Вероятность, что по крайней мере три
декларации содержат ошибки, будет вычисляться с использо-
ванием формул (6.8) и (6.9):
ЛЛ>3) = 1 - Р(Х<3) = 1 - Р(Х$2) =
= 1 - [ Л0,20) + Я 1,20) + Р(2,2О)1.
Вероятности Л0.20), Л 1,20) и Л2.20) определим по таб-
лице Приложения 2 (л = 20; р = 0,1; к = 0,1,2);
Р[Х^З) = 1 - (0,122 + 0,27 + 0,285) = 0,323.
Вероятность события, что среди 20 случайно отобранных
деклараций будет не более одной, содержащей ошибки, опре-
деляется по формуле (6.10):
Р (Х<, 1) = Л0.20) + Л1.20) = 0,122 + 0,27 - 0,392.
Математическое ожидание равно:
ц - пр = 20 • 0,1 = 2 декларации.
124
Это означает, что для большого количества случайных вы-
борок объемом в 20 деклараций средняя величина дефектных
деклараций в одной выборке равняется 2.
Дисперсия вычисляется по формуле (6.11):
ст2 = пр( I - р) = 20 • 0,1 • 0,9 = 1,8.
Соответственно стандартное отклонение рассчитывается по
формуле (6.12):
а = yjnp(l - р)- \ 1,8 = 1,34 декларации.
6.5. ГИПЕРГЕОМЕТРИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ
6.5.1. Распределение гипергеометрических вероятностей
Другим типом распределения дискретной случайной вели-
чины, который часто соответствует ситуациям, связанным с
организацией выборок, является гипергеометрический закон
распределения. Он имеет большое сходство с биномиальным
распределением: опыт повторяется п раз, причем каждый опыт
имеет только два исхода — появление или непоявление собы-
тия А (успех или неудача).
Для использования гипергеометрического распределения
должны выполняться следующие условия.
1. Численность генеральной совокупности равна N. В ней име-
ется к элементов “успехов” и (2V- £) элементов “неудач”.
2. Выборка состоит из п элементов и является бесповторной.
3. Случайная величина X, распределенная по гипергеомет-
рическому закону, характеризует количество “успехов” в п
опытах (т. е. в случайной выборке, состоящей из п элементов).
Основное отличие от биномиального закона состоит в том,
что опыты не являются независимыми. Поэтому вероятность
“успеха” в каждом опыте зависит от результатов предыдущих
опытов. Такая ситуация возникает, когда случайная выборка
отбирается из конечной генеральной совокупности по схеме
без возвращения^
Сходство с ситуацией, которая описывается биномиальным
распределением, заключается в подсчете числа “успехов”. Од-
нако если выполняются условия гипергеометрического распре-
деления, то генеральная совокупность обязательно конечна
(имеет объем N) и известно число “успехов” (к) и “неудач”
(N - к), которые составляют генеральную совокупность.
125
Пусть /\х) обозначает вероятность события X = х, т. е. веро-
ятность, что в п опытах (выборке из п элементов) “успех” по-
явится ровно п раз. Распределение вероятностей для гипергсо-
мегрического закона выражается в виде соотношения
Р(х)а....С Jf*. (6.13)
здесь N — объем генеральной совокупности (общее число “ус-
пехов и “неудач”);
п — объем случайной выборки (число опытов);
к — количество “успехов”;
N - к — количество “неудач”;
х = а, а + 1, а + 2.Ь, где а — максимальное значение из
чисел Онп + к— N(a = max (0,л + к — Л)), b — минималь-
ное значение из чисел к и п (b = min (к,л)), Дх) = 0 для
всех остальных значений х.
Пример 6.10. Партия из 50 чипов (N) для компьютеров содер-
жит 5 дефектных (к) и 45 годных чипов (N — к). Из партии
случайным образом отбирается 10 чипов (л) для проверки. Ка-
кова вероятность, что в выборке будет ровно 1 дефектный чип?
Пусть событие А (“успех”) характеризует дефектный чип, а
противоположное событие А (“неудача”) — годный чип. При
отборе первого чипа вероятность, что он будет дефектным,
можно записать следующим образом:
Р(А в 1-м опыте) = 5/50 = 0,1.
Условные вероятности события А во втором опыте следую-
щие:
ДЛ/ А в 1-м опыте) = 4/49 = 0,082;
ДЛ/ Л в 1-м опыте) = 5/49 = 0,102.
Как видно, вероятность появления “успеха” (дефектность
чипа) во втором опыте зависит от результататов первого опыта
(отбора первого чипа). Следовательно, рассматриваемая ситуа-
ция удовлетворяет условиям гипергеометрического распреде-
ления.
По формуле (6.13) найдем вероятность Д1):
Д1) =
Cj-C?5 = 5-45110140!
С'® 9136150!
= 0,431.
Иначе говоря, 43% всех выборок по 10 чипов, взятых из
каждой партии, состоящей из 50 чипов, будут иметь ровно один
дефектный чип.
126
6.5.2. Математическое ожидание и дисперсия
гипергеометрического распределения
Можно доказать, что математическое ожидание гипергео-
метрической случайной величины X вычисляется по формуле
М = (6.14)
/V
где /V — объем генеральной совокупности;
п — объем выборки;
к — число “успехов” в генеральной совокупности.
Соответственно выражение для дисперсии имеет вид
аг _ *.¥,.* (6.15)
№(W-1) I N Л Л/Лл,-17
где обозначения те же, что и в формуле (6.14).
Для ситуации примера 6.10 вычислим математическое ожи-
дание, дисперсию и стандартное отклонение. Имеем N = 50,
к = 5, п = 10.
По формуле (6.14) получим
ц = 10 5/50 = 1 чип.
По формуле (6.15) вычислим дисперсию:
2 5-45 10-40
о =-----=-----= 0,735.
502 49
Отсюда получаем а = \'0,735 = 0,857 чипа.
Таким образом, теоретически наблюдая непрерывный бес-
конечный процесс составления случайных выборок по 10 чи-
пов в каждой, отбираемых из партии в 50 чипов, мы обнару-
жим в среднем по одному дефектному чипу в каждой выборке
(ц = 1). При этом стандартное отклонение как мера вариации
равна о = 0,857 (дисперсия о2 = 0,735).
6.5.3. Использование биномиального закона
для замены гипергеометрического распределения
Пусть выполняется условие, что объем выборки п не превы-
шает 5% от объема генеральной совокупности N (n/N < 0,05).
В этом случае биномиальное распределение с достаточной точ-
ностью заменяет гипергеометрическое.
127
Вычислим отношение:
Число “успехов” в генеральной совокупности п
? Объем генеральной совокупности W
Тогда величина X, характеризующая число “успехов" в вы-
борке, будет приблизительно распределена по биномиальному
закону с параметрами: п — число опытов и р — вероятность
“успеха” в каждом опыте.
Пример 6.11. Пусть в ситуации примера 6.10 рассматривается
партия из 500 чипов (N), из которой отбирается случайным обра-
зом 10 чипов (и). В этом случае выполняется условие n/N < 0,05,
так как 10/500 = 0,02. Известно, что число дефектных чипов (“ус-
пехов”) к в партии составляет 50. Отсюда р — 50/500 = 0,1. Слу-
чайную величину X, которая принимает значения, равные числу
дефектных чипов в выборке, можно считать распределенной по
биномиальному закону с параметрами п = 10 и р = 0,1. Опреде-
лим вероятность, что выборка содержит ровно I дефектный чип.
Она будет равна биномиальной вероятности Л 1,10) = 0,387 (При-
ложение 2).
6.6. РАСПРЕДЕЛЕНИЕ ПУАССОНА
6.6.1. Распределение вероятностей пуассоновской
случайной величины
Данное распределение часто используется при исследовании
ситуаций, когда требуется оценить число появлений некоторого
события за определенный промежуток времени или на задан-
ной пространственной области. Например, такие ситуации воз-
никают при регистрации дорожно-транспортных происшествий
на определенном участке дороги; оценке числа абонентов теле-
фонной сети, получивших при вызове сигнал “занято”; опреде-
лении числа повреждений в изоляции кабеля; определении чис-
ла слабых звеньев в различного рола цепях и т. п.
В дальнейшем ограничимся рассмотрением пуассоновской
случайной величины, характеризующей появление опреде-
ленного числа “успехов” в течение заданного промежутка
времени.
Распределение Пуассона имеет вид
Р(Х =х) = Р(х) = £^—, (6.16)
х!
128
где X — пуассоновская случайная величина;
х = 0, 1, 2,...;
е — константа (число е — основание натурального лога-
рифма, приблизительно равное 2,71828);
ц — математическое ожидание (среднее значение) числа
появлений'“успеха” за рассматриваемый промежуток вре-
мени (определяется исходя из условий конкретной ситуа-
ции).
Распределение Пуассона имеет заметное сходство с бино-
миальным распределением. В обоих случаях рассматриваются
опыты, каждый из которых может иметь только два исхода —
появление или непоявление некоторого события А (“успех” или
“неудача”). Опыты независимы друг от друга, и вероятность р
успешного исхода остается постоянной в каждом опыте. В При-
ложении 3 приведена таблица, где представлены значения пу-
ассоновских вероятностей Р(х) для х — 1, 2.. 24 (строки
таблицы) и ц = 0,005; 0,01; 0,02;..; 0,09; 0,1; 0,2;...; 9,9; 10 (столб-
цы таблицы), стоящие на пересечении соответствующих строк
и столбцов.
В отличие от биномиального распределения для пуассоновс-
кой случайной величины Xчисло опытов п не является фикси-
рованным числом и она может принимать бесконечное множе-
ство целых неотрицательных значений: х = 1,2, 3,... (каждый
опыт может длиться очень малый промежуток времени). Теоре-
тически предполагается, что п стремится к бесконечности
(объем выборки бесконечен), а вероятностьр стремится к нулю,
но при этом величина пр = ц должна оставаться постоянной.
Для пуассоновской величины характерно, что число “успехов”
в одном большом интервале не зависит от их числа в непе-
ресекающемся с ним другом интервале.
6.6.2. Математическое ожидание и дисперсия
пуассоновской случайной величины
Математическое ожидание равно ц, что следует из опреде-
ления распределения Пуассона, заданного соотношением (6.16).
Это утверждение можно было бы доказать, используя общую
формулу (6.2) для математического ожидания дискретной слу-
чайной величины:
И» £хр(х) = 0е’и +1цеи+2-£-^~ + 3—... = ц.
129
Дисперсия для распределения Пуассона равна математичес-
кому ожиданию, т. е. о2 = ц. Это также можно доказать, исполь-
зуя формулу (6.3):
о2 = £(х -Ц)2 р(х) = ц2 • е~ц + (1 - Ц)2цг + (2 - ц)2 = Н-
Особо отметим, что для пуассоновской случайной величи-
ны имеет место следующее свойство. Пусть случайная величина
рассматривается на определенном промежутке времени. Если
этот промежуток увеличится (уменьшится) в некоторое число
раз, то точно в такое же число число раз увеличится (умень-
шится) математическое ожидание случайной величины. Пока-
жем это на следующем примере.
Пример 6.12. На станции автосервиса в течение получаса оформ-
ляют заказы на мелкий ремонт автомобилей в среднем у четы-
рех клиентов. Требуется определить:
I) какова вероятность, что ровно 4 клиента сделают заказы
в течение получаса?
2) какова вероятность, что более чем 1 клиент сделает заказ
в течение получаса?
3) какова вероятность, что ровно 6 клиентов сделают зака-
зы в течение часа?
В данном случае ситуация моделируется с помощью пуассо-
новского процесса, где ц = 4. Вычисления будем проводить,
используя таблицу Приложения 3.
43 4е*4
1. ЛТ = 4) = Л4) 0,1954.
4!
Следовательно, непрерывно наблюдая за оформлением за-
казов в течение многих получасовых периодов, можно убедить-
ся, что 19,5% всего времени наблюдения заказы будут оформ-
лять ровно 4 клиента.
2. Р(Х > 1) = Р(Х й 2) = 1 - Р(Х = 1) - f\X = 0) =
, 4°е~* 4'е4
= 1-------------- = 1 - 0,183 - 0,0733 = 0,9084.
3. Ввиду того что интерват наблюдения увеличился в 2 раза
(с получаса до одного часа), ц = 2 • 4 = 8. Тогда
о<>«
/ХХ = 6) =—— = 0,1221.
о!
130
6.6.3. Замена биномиального распределения
распределением Пуассона
В ситуациях, когда выполняются условия биномиального рас-
пределения, вычисления вероятностей при большом числе опы-
тов достаточно трудоемкие. Однако они значительно упроща-
ются, если биномиальную случайную величину X заменить на
пуассоновскую с тем же математическим ожиданием. При боль-
шом числе опытов и малой вероятности р такая замена дает
достаточно точный результат. На практике наиболее благопри-
ятны условия, когда п > 20, р < 0,05 и пр < 7.
На рис. 6.2 представлены графики распределений вероятно-
стей для биномиальной величины с параметрами п = 20,
р = 0,1 (т. е. ц = пр = 2) и для пуассоновской с ц = 2.
Рис. 6.2. Графики распределения Пуассона (ц 2) и биномиального
распределения (п = 20, р = 0,1)
Можно сказать, что распределение Пуассона — это бино-
миальное распределение при большом числе опытов и малой
вероятности р.
Пример 6.13. Пусть рассматривается ситуация примера 6.10,
только объем партии значительно увеличился и составляет 2500
чипов (Л0- Из партии случайным образом отбирается 100 чипов
(л) для тестирования. Вся партия принимается в производство,
если среди отобранных 100 чипов окажется не более одного
дефектного. Если предположить, что 5% всех чипов в партии
являются дефектными, то определить, какова вероятность, что
партия будет принята.
131
Рассмотрим отношение n/N= 100/2500 = 0,04 < 0,05. Следо-
вательно, в данной ситуации можно использовать биномиаль-
ное распределение вместо гипергеометрического.
Биномиальное распределение имеет параметры п - 100,
р = 0,05.
Для определения вероятности приемки партии необходимо
вычислить:
Лприемки) = /1(0,100) + Л1,100) =
= С’оо • 0,05° • 0,95100 + С]ж • 0,05* • 0,95" = 0,037.
Очевидно, вычисления достаточно трудоемки. Расчеты можно
значительно упростить, если использовать распределение Пу-
ассона с математическим ожиданием ц = пр = 100 0,05 = 5.
Условия для замены являются благоприятными: п > 20,
р = 0,05, пр = 5 < 7. Используя Приложение 3, получим
Лприемки) = ДО) + Л1) = 0,0067 + 0,0337 = 0,0404.
Как видно, результат замены (0,0404) достаточно близок к
0,037 — значению биномиальной случайной величины.
6.7. ФУНКЦИИ И КОМБИНАЦИИ
СЛУЧАЙНЫХ ВЕЛИЧИН
6.7.1. Математическое ожидание и дисперсия
функций случайной величины
Пусть X — случайная величина, численное значение кото-
рой зависит от испытания. Если каждое значение Xразделить
на 5, то в зависимости от исхода испытания мы получим чис-
ла, которые характеризуют случайную величину Х/5. Аналогич-
но, возведя значение X в квадрат, получим случайную величи-
ну X1; линейное преобразование X даст случайную величину
аХ+ b и т. д. В общем случае некоторое преобразование значе-
ний Xявляется функцией Дх). Пусть случайная величина Xимеет
ряд распределения:
Х-х, xi *2 Жп
ЖХ = хД Р. Pi Рп
где 5jPi=1-
i=i
132
Очевидно, математическое ожидание случайной величины
ДЛ) можно вычислить по формуле
I
л
E(/(X)] = Sa/U). (6.18)
<-i
Заметим, что формула (6.18) была получена не на основе
какой-либо информации о законе распределения зависимой от
Л'случайной величины ДА), а непосредственно из ряда распре-
деления случайной величины X.
пример 6.14. Пусть случайная величина X имеет ряд распреде-
ления
X -1 2 4 8
р. 0.1 0,4 0,3 0,2
Определим Е(Х2 — 1).
По формуле (6.18) имеем
Е(Х2- 1) = ((-I)2- 1)0,1 + (22- 1) 0,4 + (42 - 1) 0,3 +
+ (82— 1) 0,2 = 0 0,1 + 3 0,4 + 150,3 + 63 0,2 = 16,3.
Рассмотрим линейную функцию Y = аХ + Ь, где X — слу-
чайная величина с рядом распределения (6.17). Найдем мате-
матическое ожидание Е(У) по формуле (6.18):
П ЯП
Е(Г ) = + Ь)р, = + ^Ьр, =
1=1 1-1 г-1
п л
= a^xtPl+b^p,=aE(X) + b. (6.19)
i=i «=1
Из (6.19) следует, что если Ь = 0, то
Е(ах) = аЕ(х). (6.20)
Соотношение (6.20) означает, что константу можно выно-
сить за знак математического ожидания.
Если а = 0, то из (6.12) получим Е(Ь) = Ь, т. е. математичес-
кое ожидание константы равно этой константе.
Данный результат имеет следующую вероятностную интер-
претацию. Константа не является случайной величиной, одна-
ко условно ее можно рассматривать как случайную величину,
133
которая принимает одно возможное значение b с вероятнос-
тью 1. Отсюда
Е(Л) = 61 = Ь.
Пусть случайная величина имеет дисперсию o2(J). Вычис-
лим дисперсию о2(К) линейной функции Y= аХ + Ь, исполь-
зуя (6.19):
ст2( Y) = £|(ах,, + Ь) - Е(аХ + 6)[2 Pi = £[ах,+ b - «Е( X) - Ь]2р, =
1-1 i=l
« „ (6.21)
= £ [ах, - аЕ( X )J2 Pi =а2 £ Ц - Е( X )]2 р, = а2 а2 (X).
««I i«l
Если b = 0, то (6.21) можно переписать:
сг(аХ) = rfoXX). (6.22)
Соотношение (6.22) означает, что константу можно вынес-
ти за знак дисперсии, возведя ее в квадрат. Как следствие ра-
венства (6.22) имеем
<j(aX) = lala(A'),
т. е. константу можно выносить за знак стандартного отклоне-
ния в виде ее абсолютной величины.
Определим дисперсию константы Ь. По определению дис-
персии
о2(6) = Е[(6 - Е(6))2] = Е[(6 - 6)21 = Е(0) = 0.
Следовательно, дисперсия константы равна нулю.
Пример 6.15. Автомат фасует чай в пакетики. Средний вес па-
кетика — 2 г со стандартным отклонением 0,05 г. Пакетики в
свою очередь пакуются в пачки по 25 штук. Определить сред-
ний вес чая в пачке и соответствующее стандартное отклоне-
ние.
Пусть X — случайная величина, характеризующая вес паке-
тика с чаем. Тогда случайная величина 25Хбудет характеризо-
вать вес пачки. Отсюда если Е(%) = 2 г, то Е(25Х) = 25Е(ЛГ) =
=25-2 = 50 г. По условию о{Х) = 0,05 г. Следовательно, а(25Л)=
= |25| о(Х) = 25 0,05 = 1,25 г.
134
Пусть/(А*) и g(X) — любые функции случайной величины
X. Можно показать, что математическое ожидание суммы фун-
кций равно сумме математических ожиданий каждой функции:
Е(Я%) + g(X)) = E(/t¥)) + Е(£(Х)).
6.7.2. Сумма и произведение независимых
случайных величин
Случайные величины Хи У называются независимыми, если
закон распределения каждой из них не зависит от того, какое
значение приняла другая. Формально можно записать, что если
х — любое возможное значение случайной величины X, а у —
величины Y, то Хи У будут независимыми, если выполняется
условие
f\X = х и У=у) = ДХ = х)ЛУ = у).
Покажем, что для любых двух случайных величин (как неза-
висимых, так и зависимых) выполняется равенство
Е(ЛГ + У) = Е(Х) + Е(У),
т. е. математическое ожидание суммы двух случайных величин
равно сумме их математических ожиданий.
Пусть случайные величины X и У имеют следующие ряды
распределений:
X ... *л У У| Уг ... уп
р, Pl р2 ... Рл Ч. Pl ... РЛ
Рассмотрим случайную величину Z = X + У и запишем ее
ряд распределения:
Z х^Уу х,+Уг ... *1^5», ... *2+Кл ... VKn
р РЫ РЪ ... р^т ... РгРп, ...
Математическое ожидание E(Z) вычисляется как сумма про-
изведений (х + yt\Pfif Запишем (х, + y^pfl. = хр^ + у^р,.
При составлении суммы, определяющей математическое
ожидание E(Z), сгруппируем слагаемые следующим обра-
зом:
135
<7,(Р,х, +рЛ + р3х3+... +рЛ)
+ ^Л + ед + ед+-+/’Л>
+
?.О’Л + РЛ + /’А+ • +^х.)
+ Р&М + ед + «Л + - + VJ (6.23)
р2( V, + ед + ?»У3 + ... +<7Х>-
+
+ ед + ед + -+vJ w Е<* )(<?. + ч2 + «з + - +<?„) +
+ Е( У) (р, + р2 +л + ... + ря) = Е(Х) + Е( Г).
Соотношение (6.23) обобщается на произвольное число сла-
гаемых:
=ЕЕ<Х<)-
i*i
То есть математическое ожидание суммы нескольких слу-
чайных величин равно сумме их математических ожиданий.
Если Хм Y — независимые случайные величины, то анало-
гично можно показать, что
Е(ХУ) = Е(Х)Е(У). (6.24)
Для независимых Xи Убудет верно соотношение
а\Х+ У) = о2(Х) + о2(У). (6.25)
Докажем (6.25). Ввиду (6.5) можно записать
oV+ У) • Е|(Х + Г)2] - (Е(Х + Г)]2 = Е(Г + 2АТ+ Г2) -
- [Е(Х) + Е(Г)]2 = Е(Х2) + 2Е(ЛТ) + £(№)- Е(ЛГ2) -
- 2Е(ЛГ)Е(Г) - Е(Г2) = Е(Л2) - E(J)2 + 2(E(XY) -
- Е(Х)Е(У)) + Е(Г2) - Е(У)2 = а\Х) + 0 + о2(У).
136
Таким образом, если X и У — зависимые случайные величи-
ны, то равенство Е(% + У) = Е(Х) + Е(У) останется верным.
Однако соотношения (6.24) и (6.25) будут верными только
при условии независимости случайных величин X и У.
Ввиду равенств (6.22) и (6.25) можно записать:
а2(Х — У) = а2(Х + (~1)У) = а2(Х) + сН((—1)У) =
= <ЛХ) + (-1)2 <Т2(У) = <?(%) + а2(Г).
То есть для независимых случайных величин дисперсия раз-
ности равна сумме дисперсий. Обобщая полученные соотноше-
ния для суммы и разности двух независимых случайных вели-
чин, можно сделать следующие выводы относительно алгебраи-
ческой суммы нескольких случайных величин:
математическое ожидание алгебраической суммы случайных
величин (необязательно зависимых) равно соответствующей
алгебраической сумме их математических ожиданий;
дисперсия алгебраической суммы нескольких независимых
случайных величин равна сумме их дисперсий.
Пример 6.16. Некоторый товар укладывается в одинаковые ящи-
ки. Средний вес товара составляет 10,5 кг со стандартным от-
клонением 0,8 кг. Средний вес ящика — 3,5 кг со стандартным
отклонением 0,1 кг. Требуется определить средний вес напол-
ненного ящика, соответствующие стандартное отклонение и
дисперсию.
Путь X — случайная величина, характеризующая вес това-
ра, уложенного в ящик, а У — случайная величина, соответ-
ствующая весу отдельного ящика. Ясно, что Хи У — независи-
мые случайные величины. Средний вес наполненного ящика
равен
E(J+ У) = E(J) + Е(У) = 10,5 + 3,5 = 14 кг.
Найдем дисперсию:
а\Х + У) = а2(Х) + о2(У) = 0,82 + 0,12 = 0,65 кг2.
Определим стандартное отклонение:
о(Х + У) = <65" = 0,806 кг.
Пример 6.17. Пусть X— случайная величина, характеризующая
число очков, которое выпадает при бросании игральной кос-
ти; У — случайная величина, значением которой является коли-
137
чество выпадений гербов при подбрасывании четырех монет.
Требуется определить: математическое ожидание, дисперсию и
стандартное отклонение случайной величины Z = 2Х - Y + 4.
Величина X имеет ряд распределений
X 1 2 3 4 5 6
р 1/6 1/6 1/6 1/6 1/6 1/6
Вычислим Е(А'):
Е(Х) = 1/61 + 1/6 2 + 1/6-3 + 1/6 4 + 1/6 5 + 1/6 6 = 3,5.
Определим ст2^):
<ЛХ) = Е(Х}) - Е(ЙГ)2 = 1/61» + 1/6 2» + 1/6 3» + 1/6 42 +
+ 1/6-5» + 1/6-62 - (3,5)» =
= 91_12£ = 35=2_Н
6 4 12 12’
Случайная величина У распределена по биномиальному за-
кону с параметрами л = 4, р = 1/2. Следовательно,
Е(У) = пр = 4 1/2 - 2,
о2(У) = лр(1 - р) = 41/21/2 = 1.
Определим E(Z):
E(Z) = E(2J - Г + 4) = Е(2Х) - Е(У) + Е(4) =
“ 2Е(ЛГ) - Е(Г) + 4 = 2-3,5 -2 + 4 = 9.
Вычислим o2(Z) и o(Z):
o2(Z) = о2 (2 А" - Y +4) = <j2(2X) + crV) + а2(4) =
11 2
= 4а2(Х) + о2(У) + 0 = 4-2^ + 1 = 12^12,67.
o(Z) = 3,56.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 6
При описании случайных событий удобно использовать по-
нятие случайной величины, под которой понимается функ-
ция, ставящая в соответствие каждому исходу испытания чис-
138
ленное значение. Исход испытания является случайным собы-
тием, поэтому заранее неизвестно, какое значение примет слу-
чайная величина. Если все значения случайной величины мо-
гут быть перечислены, то она называется дискретной. Если
значения случайной величины непрерывно заполняют некото-
рый промежуток и все эти значения невозможно перечислить,
то она называется непрерывной. Дискретная случайная вели-
чина с вероятностной точки зрения считается заданной, если
известен ее закон (ряд) распределения. Ряд распределения пред-
ставляет собой таблицу возможных значений случайной вели-
чины с соответствующими вероятностями. Одной из характе-
ристик случайной величины является математическое ожидание
(среднее значение). Оно вычисляется по формуле (6.2) и опре-
деляет положение центра распределения, около которого кон-
центрируется основная масса значений. Их разброс около ма-
тематического ожидания измеряется с помощью дисперсии
(формула 6.3). Дисперсия вычисляется как математическое ожи-
дание квадрата отклонения значений случайной величины от
ее математического ожидания. Для выражения разброса в еди-
ницах измерения исходной случайной величины используется
стандартное отклонение (среднее квадратическое отклонение),
которое вычисляется как корень квадратный из дисперсии. Чем
меньше величина дисперсии или стандартного отклонения, тем
более плотно значения случайной величины располагаются
около математического ожидания.
Дискретная случайная величина, распределенная по бино-
миальному закону, характеризует количество появлений неко-
торого события А в п независимых опытах. При этом предпола-
гается, что каждый опыт имеет только два исхода — появление
(“успех”) или непоявление (“неудача”) события А. “Успех” в
каждом опыте появляется с постоянной вероятностью р. Рас-
пределение вероятностей для биномиального распределения
выражается членами разложения бинома.
Пусть опыты зависимы, известны численность генеральной
совокупности (N) и число “успехов” (к), содержащихся в ней.
В этом случае для оценки вероятности появления ровно х успе-
хов в выборке из п элементов используется гипергеометричес-
кое распределение (формула (6.13)).
Если производится много независимых опытов, каждый из
них имеет два противоположных исхода (“успех” и “неудача”)
и вероятность “успеха” в каждом опыте мала, то вероятность
появления определенного числа “успехов” следует рассчиты-
вать на основе распределения Пуассона (формула (6.16)). Это
139
распределение часто используется при исследовании ситуаций,
когда требуется оценить число появления некоторого события
за определенный промежуток времени. На практике в случае
возникновения трудностей при вычислениях возможна замена
одного распределения другим. Так, если для гипергеометри-
ческого распределения выполняется отношение n/N < 0,05, то
оно достаточно точно приближается биномиальным. Замена
биномиального распределения пуассоновским дает хорошие
результаты при условиях, что л > 20, р < 0,05 и пр < 7.
Пусть рассматривается функция от случайной величины.
Математическое ожидание этой функции можно вычислить,
зная только закон распределения исходной случайной величи-
ны (формула (6.18)). Если случайная величина умножается на
константу, то эту константу можно выносить за знак матема-
тического ожидания, а если возвести в квадрат, то за знак дис-
персии. Математическое ожидание алгебраической суммы слу-
чайных величин равно соответствующей алгебраической сумме
их математических ожиданий. Случайные величины называют-
ся независимыми, если закон распределения каждой из них не
зависит от того, какое значение приняла другая. Дисперсия ал-
гебраической суммы нескольких независимых случайных вели-
чин равна сумме дисперсий. Математическое ожидание произ-
ведения независимых случайных величин равно произведению
их математических ожиданий.
РАСПРЕДЕЛЕНИЯ
НЕПРЕРЫВНЫХ
СЛУЧАЙНЫХ ВЕЛИЧИН
7.1. НЕПРЕРЫВНЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ.
ФУНКЦИЯ И ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ.
ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ
В гл. 6 было дано общее определение случайной величины.
Отмечалось, что случайные величины могут носить дискрет-
ный и непрерывный характер. Были рассмотрены основные за-
коны распределения дискретных случайных величин, которые
часто используются в прикладном статистическом анализе.
Данная глава будет посвящена описанию непрерывных слу-
чайных величин и их законов распределения.
Дискретная случайная величина является прерывной, т. е.
все ее возможные значения отделены друг от друга конечными
интервалами и могут быть заранее перечислены. Возможные же
значения непрерывной случайной величины непрерывно за-
полняют некоторый промежуток и не могут быть заранее пере-
числены.
Примерами непрерывных случайных величин могут служить
сроки службы различных товаров: электрических лампочек,
батареек, автомобильных покрышек, электроприборов и т. п.
Так, срок службы каждого из перечисленных товаров может
измеряться промежутком времени от нуля до некоторой ко-
нечной верхней границы. В общем случае непрерывные случай-
ные величины могут характеризовать результаты измерений:
длительности процесса, веса, длины, площади, высоты, на-
пряжения в электросети и т. д.
Теоретически (предполагается, что возможна любая точность
измерений) результат измерения может быть выражен любым
действительным числом, взятым из некоторого промежутка.
Дискретная случайная величина в вероятностном смысле
будет полностью определена, если задан ее ряд распределения.
141
Для непрерывной случайной величины записать таблицу ряда
распределения невозможно, так как она должна включать все
ее возможные значения (непрерывная случайная величина имеет
бесконечное множество значений, которые невозможно пере-
числить). Поэтому для характеристики распределения вероят-
ностей непрерывной случайной величины удобно воспользо-
ваться не вероятностью события X- х, а вероятностью события
Х<х, где х — некоторая текущая переменная. Очевидно, веро-
ятность того, что Х<х, зависит от текущей переменной х и явля-
ется некоторой функцией от х. Эта функция называется функ-
цией распределения случайной величины х и обозначается Дх):
F(x)~P(X<x). (7.1)
Функция распределения F(x) называется также интеграль-
ной функцией распределения или интегральным законом рас-
пределения.
Функция распределения может существовать как для непре-
рывных, так и для дискретных случайных величин. С вероятно-
стной точки зрения функция распределения полностью харак-
теризует случайную величину, т. е. является одной из форм закона
распределения.
Рассмотрим основные свойства функции распределения (7.1).
1. Так как значение вероятности неотрицательно и не может
быть больше единицы, то 0 < Дх) < 1.
2. Функция распределения есть неубывающая функция, т. е.
при х2 >Xj имеем Дх2) 2 FlxJ.
3. Предельное значение функции распределения при х -» —<»
равно нулю, а при х -> +°° равно единице.
В случае дискретной случайной величины X, заданной ря-
дом распределения, Fix') для каждого х есть сумма вероятнос-
тей значений X, которые лежат до точки х: Дх) = Р(Х<х) =
= ^Р(Х = х,), где неравенство х<х под знаком суммы пока-
то ,
зывает, что суммирование распространяется на все те значе-
ния х, которые меньше х. Отсюда следует, что вероятность Дх)
увеличивается скачками всякий раз, когда х проходит через
одно из возможных значений х( величины X (между двумя со-
седними значениями х( и х функция Дх) постоянна). Таким
образом, график функции Дх) является ступенчатой кривой
(рис. 7.1).
142
Рис. 7.1. Г рафик функции распределения F(x)
для дискретной случайной величины
Для непрерывной случайной величины функция распреде-
ления представляет собой функцию, непрерывную и диффе-
ренцируемую во всех точках. Ее график является плавной кри-
вой, имеющей касательную в любой точке (рис. 7.2).
Рис. 7.2. График функции распределения непрерывной
случайной величины
На практике часто возникают ситуации, когда требуется
определить вероятность того, что случайная величина прини-
мает значения, находящиеся в некотором промежутке, напри-
мер от а до р. Другими словами, требуется определить вероят-
ность события а<*<0. Было отмечено, что F(x) имеет
производную в любой точке х. По определению производной
F(x + Ax)-F(x) ,
hm =-------т---------г- (л).
Дх
143
Введем обозначение
Лх) = Г(х).
Функция Дх) характеризует плотность, с которой распре-
деляются значения вероятности случайной величины в данной
точке. Она называется плотностью распределения непрерыв-
ной случайной величины X. Ее также называют дифференци-
альной функцией распределения. Очевидно, вероятность собы-
тия, что случайная величина X примет значение, лежащее в
границах от а до 0, равна
₽
Ла<х<0) = / /(х) dx = Л 0) - Да). (7.2)
а
График кривой, изображающей плотность распределения,
называется кривой распределения. Приближением кривой рас-
пределения является сглаженный полигон, рассматриваемый
ранее как кривая частотного распределения данных.
Рассмотрим кривую распределения заданной случайной ве-
личины х и отметим участок, ограниченный абсциссами а и 0.
Тогда ввиду (7.2) площадь, ограниченная частью кривой, опи-
рающейся на отрезок [а, 0], и прямыми х = а и х = 0, будет
характеризовать вероятность попадания случайной величины X
на промежуток (а, 0) (рис. 7.3).
л*) 4
Рис. 7.3. Графическая интерпретация вероятности попадания значения
непрерывной случайной величины на промежуток от а до fl
Плотность распределения является одной из форм закона
распределения. Однако она не является универсальной и суще-
ствует только для непрерывных случайных величин.
Отметим основные свойства плотности распределения.
144
I. Плотность распределения есть неотрицательная функция,
т. е. Дх) > 0. Отсюда график кривой распределения не может
лежать ниже оси абсцисс.
2. Интеграл в бесконечных пределах от плотности распреде-
ления равен единице:
н»
J/(x)dx=l. (7.3)
-♦о
Геометрически это означает, что площадь, ограниченная
кривой распределения и осью абсцисс, равна единице.
Количественные характеристики непрерывной случайной
величины выражаются в виде интегралов. Так, математическое
ожидание (среднее значение) вычисляются как интеграл:
♦«>
ц = Е(х)= |х/(х)<й. (7.4)
—OQ
Аналогично дисперсия определяется как математическое
ожидание квадрата отклонения значения случайной величины
х от ее математического ожидания:
ст2 = |(x-g)2/(x)dx. (7.5)
—оо
Отсюда получаем, что стандартное отклонение есть
J+<~
J(x - n)2/(x)dx . (7.6)
Для непрерывных случайных величин верны все свойства,
указанные в разделе 6.7 для математических ожиданий и дис-
персий функций и комбинаций дискретных случайных величин.
7.2. РАВНОМЕРНОЕ РАСПРЕДЕЛЕНИЕ
Иногда в практических ситуациях встречаются непрерыв-
ные случайные величины, распределение которых удовлетво-
ряет условию: значения случайной величины внутри опреде-
ленных границ равновероятны. Иначе говоря, плотность
распределения является постоянной величиной. Такие случай-
ные величины называются равномерно распределенными или
распределенными по закону равномерной плотности.
145
Пусть дана случайная величина X, равномерно распреде-
ленная на промежутке от а до р. Запишем для нее выражение
плотности распределения Лх). Плотность постоянна и равна с
на промежутке (а, Р) и нулю вне этого промежутка (т. с. обра-
зует прямоуголиник):
Лх) =
с при а < х < р,
О прих<а или х^р.
Ввиду (7.4) площадь, ограниченная кривой распределения,
равна единице:
с(а - Р) = I или с = -о
а-р
Тогда плотность распределения имеет вид (рис. 7.4)
1
- при а<х<р,
р а (7.7)
О прих^а или х>р.
Ф) м
Лх) =
X
Рис. 7.4. Кривая плотности равномерного распределения
Формула (7.8) является математическим выражением зако-
на равномерной плотности на промежутке (а, Р).
Вероятность попадания значения случайной величины на
промежуток, находящийся внутри отрезка (а, Р), вычисляется
по формуле
P(a<x<h)=f-^- = ^. (7.8)
JP-a p-а
а
Графически выражение (7.8) представляет собой площадь
прямоугольника, заштрихованного на рис. 7.5.
146
Пх) л
По формулам (7.4)—(7.6) найдем математическое ожида-
ние, дисперсию и стандартное отклонение:
• <79>
<710)
ст= |(Р~а); (7.11)
V 12 Т/з
Пример 7.1. На фармацевтической фирме установлена автомати-
ческая линия, наполняющая пузырьки некоторыми лекарствами.
Случайным образом отбирается 150 наполненных лекарством пу-
зырьков и измеряется объем лекарства в каждом пузырьке. Оказа-
лось, что он колеблется в пределах от 19 до 21 мл. Для определе-
ния вида распределения построим гистограмму, где по оси ординат
отложим относительные частоты (оценки вероятности), а по оси
абсцисс — значения объема лекарства в пузырьке (рис. 7.6).
Очевидно, форма гистограммы свидетельствует, что распре-
деление объемов лекарств, содержащихся в пузырьках, близко
к равномерному. Согласно (7.7), плотность этого распределе-
ния имеет вид (график плотности распределения представлен
на рис. 7.7)
Лх)
1
21-19
при 19 < х< 21,
0 при х < 19 или х > 21.
147
Относительная
частота
для выборки из 150 пузырьков
Рис. 7.7. Кривая плотности распределения объемов лекарства
в пузырьках
Вычислим средний объем лекарства в пузырьках, наполня-
емых на автоматической линии, по формуле (7.9):
19 + 21 „
Ц =----— = 20 мл.
2
Дисперсия и стандартное отклонение вычисляются соответ-
ственно по формулам (7.10) и (7.11):
ст2 ,(21-19/ _ 1
12 3’
1
СТ =
148
Пусть требуется определить вероятность, что случайно вы-
бранный пузырек будет содержать объем лекарства, заключен-
ный между 19,5 и 20,5 мл. Используем для этого формулу (7.8):
20,5-19,5
/К19,5 <х< 20,5) = =0,5.
Следовательно, объем лекарства в 50% всех пузырьков, на-
полняемых на автоматической линии, находится в пределах от
19,5 до 20,5 мл.
7.3. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
В практических ситуациях равномерно распределенные не-
прерывные случайные величины встречаются достаточно ред-
ко. Как правило, массовые явления в различных сферах дея-
тельности подчиняются нормальному закону распределения.
Этот закон играет исключительно важную роль в статистичес-
ком анализе. Главная его особенность состоит в том, что он
является предельным законом, к которому приближаются дру-
гие законы распределения при определенных условиях, часто
встречающихся на практике.
В математической статистике доказывается, что сумма боль-
шого числа независимых (или слабо зависимых) случайных
величин распределяется почти нормально. При этом слагаемые
случайные величины могут подчиняться каким угодно законам
распределения. Чем больше число слагаемых случайных вели-
чин, тем ближе к нормальному будет распределение их суммы.
Большинство массовых явлений формируется как наложе-
ние многих отдельных причин (факторов). Каждая из них но-
сит, как правило, случайный характер, т. е. является случайной
величиной, подчиненной какому-либо закону. При сложении
большого числа причин особенности их распределений ниве-
лируются и сумма оказывается подчиненной нормальному за-
кону.
На практике, например, нормальному закону подчинены по-
грешности различного рода измерений, отклонения от установ-
ленного стандарта при производстве какой-либо детали и т. д.
7.3.1. Кривая нормального распределения и ее свойства
Нормальный закон распределения характеризуется плотно-
стью распределения, имеющей вил
149
Д*) =
___1 , 2в1
О\'2л
(7.12)
Как видно из формулы (7.12), для построения кривой нор-
мального распределения необходимо знать два параметра ц и о.
Кривая распределения по нормальному закону имеет сим-
метричную колоколообразную форму (рис. 7.8).
Рис. 7.8. Кривая нормального распределения
Максимальная ордината кривой нормального распределе-
ния, равная —1= , соответствует точке х = ц. По мере удаления
<ь/ 2п
от точки ц значение плотности распределения падает и асимп-
тотически приближается к оси абсцисс.
Можно доказать, что для случайной величины X, распреде-
ленной по нормальному закону (7.12), значение ц есть матема-
тическое ожидание (центр распределения), а о — стандартное
отклонение (мера разброса данных около центра).
Пусть все возможные значения случайной величины рас-
сматриваются как генеральная совокупность. Если Д'распреде-
лена нормально, то распределение случайной выборки из этой
совокупности будет близко к нормальному. Поэтому на прак-
тике при проверке нормальности распределения строят гис-
тограмму на основе полученных данных, которые рассматри-
ваются как случайная выборка из всех возможных значений
некоторой случайной величины X. Далее сравнивают форму сгла-
женного графика гистограммы, приближенно отражающего вид
кривой распределения случайной величины X, с кривой нор-
мального распределения.
Пример 7.2. Фирма производит электрические лампочки. Объек-
том исследования является срок их службы (время непрерыв-
но
ного горения), который можно рассматривать как случайную
величину X. Случайным образом выбирают 200 лампочек и про-
водят специальное тестирование для определения их сроков
службы. На основе данных тестирования была построена гис-
тограмма (по оси ординат откладывались относительные час-
тоты, а по оси абсцисс — сроки службы) и сглаживающая ее
кривая (рис. 7.9).
Рис. 7.9. Гистограмма распределения 200 лампочек по сроку их службы
Сглаживающая прямая характеризует кривую распределения
сроков службы всех лампочек, выпускаемых фирмой. Как вид-
но, ее форма очень близка к кривой нормального распределе-
ния с центром 400 ч.
В общем случае существует не одно распределение, а беско-
нечное семейство нормальных распределений, так как вид кри-
вой нормального распределения полностью определяется зна-
чениями параметров ц и о. Каждой паре значений ц и а
соответствует отдельное нормальное распределение.
На рис. 7.10 представлены кривые распределений работни-
ков трех фирм по стажу работы. Все кривые имеют одинаковые
средние значения ц = 20 лет, но разные стандартные отклоне-
ния.
Как видно из рис. 7.10, чем больше значение стандартного
отклонения о, тем более пологая и растянутая вдоль оси абс-
цисс кривая распределения. Наоборот, при уменьшении о кри-
вая распределения сжимается вдоль оси абсцисс и вытягивает-
ся вверх вдоль оси ординат.
151
Рис. 7.10, Кривые нормальных распределений,
имеющих одинаковые математические ожидания, но разные
стандартные отклонения
На рис. 7.I I представлены кривые двух нормальных распре-
делений с разными средними, но с одинаковыми стандарт-
ными отклонениями. Одна из кривых характеризует распределе-
ние по росту студенток некоторого университета (ц( = 1,65 м),
а другая — студентов (ц2 = 1,76 м).
Рис. 7.11. Кривые нормальных распределений, имеющих одинаковые
стандартные отклонения, но разные средние значения
Таким образом, если изменять математическое ожидание р
нормального распределения, не изменяя при этом стандарт-
ное отклонение о, то кривая распределения будет перемещать-
ся вдоль оси абсцисс, не меняя своей формы. Следовательно,
математическое ожидание ц определяет положение кривой нор-
мального распределения на оси абсцисс, а стандартное откло-
нение о — ее форму. Все возможные значения нормального
распределения случайной величины X представляют собой ге-
неральную совокупность. На практике, как правило, возможно
получение лишь выборочных значений X. Поэтому значения
152
параметров ц и о заменяют на значения соответствующих ста-
тистик х и 5. Так, в примере 7.2 средний срок службы 150
электрических лампочек равен х ” 400 ч. Предположим, что
было вычислено стандартное отклонение s = 50 ч. Ясно, что
для генеральной совокупности (всего множества выпущенных
лампочек) значения параметров ц и о будут отличаться от со-
ответствующих вычисленных статистик. Однако можно пред-
положить, что х достаточно близко к ц, a s — к о. Тогда теоре-
тическая кривая нормального распределения будет приближать-
ся к кривой
. <rs>
/(х) = - Ue ь’
зу12п
5OV2n
(л-400)1
250’
7.3.2. Площади под кривой нормального распределения
Исходя из свойства (7.3) площадь между всей кривой нор-
мального распределения с любыми параметрами ц и о и осью
абсцисс равна 1: .
2о’ dr = l.
Это соответствует вероятности достоверного события, что
нормально распределенная величина ^обязательно примет одно
из своих возможных значений.
Будем откладывать на оси абсцисс интервалы с центром ц и
границами (ц - о, ц + о), (ц — 2о, ц + 2о) и (ц + Зо, ц — Зо).
Площади, находящиеся под кривой распределения любого нор-
мального закона, обладают следующими свойствами (рис. 7.12).
1. Площадь под кривой, распределенная на интервале от
ц - о до р 4- о (или ц ±о), составляет 68,27% всей площади,
ограниченной всей кривой. Это означает, что на этом участке
сосредоточено 68,27% всех значений распределения.
2. Площадь под кривой распределения на участке от ц - 2о
до ц + 2о составляет 95,45% площади под всей кривой. Это
означает, что на этом участке располагается около 95,45% всех
значений распределения.
3. Площадь под кривой распределения на интервале от
ц — Зо до ц + Зо (ц ±3о) составляет 99,73% площади под
всей кривой, т. е. практически вся кривая располагается над
участком ц ±3о, следовательно, практически все значения
распределения сосредоточены в границах трех о по обе сто-
роны от ц.
153
Рис. 7.12. Доли площадей под кривой нормального распределения
над участками м ±в, м т2о, ц ±3а
Перечисленные выше свойства площадей под кривой нор-
мального распределения используются при выяснении, явля-
ется ли изученное распределение нормальным. Для различных
статистических заключений наиболее часто берутся следующие
пределы:
ц ±1,64 ст — ограничивает площадь, равную 90% площади
под кривой;
ц ±1,96 ст - 95%;
р ±2,5 о - 99%.
Кривая нормального распределения является симметричной.
Это означает, что площадь под кривой на участке от ц до +«>
(или от -о» до ц) составляет половину (50%) площади под
всей кривой. Аналогично площадь над участком от ц до ц + ст
(или от ц - о до ст) приблизительно равна 0,34 (34%) площади
под всей кривой; площадь над участком от р до ц + 2ст (или от
И - 2о до ц) — 0,475 (47,5%); площадь над участком от ц до
ц + Зо (или от ц - За до ц) — 0,5 (50%).
Следует еще раз отметить, что перечисленные выше про-
порции площадей будут верны для всех нормальных законов
распределения независимо от значений параметров ц и о. Они
могут использоваться при проверке соответствия исследуемого
распределения нормальному закону.
Пример 7.3. Специальное тестирование большого количества
батареек показало, что их средний срок службы —19 ч. Распре-
деление сроков службы батареек предполагается нормальным.
Значение стандартного отклонения равно 1,2 ч.
Можно утверждать: 1) примерно 68,27% всех батареек име-
ют срок службы в границах от 17,8 до 20,2 ч (19±11,18);
154
2) средний срок службы примерно 95,45% всех батареек зак-
лючен в пределах от 16,6 до 21,4 ч (19±21,8);
3) около 99,73% всех батареек имеют срок службы в преде-
лах от 15,4 до 22,5 ч ( 19±3-1,2).
Любой интервал с центром в точке ц можно рассматривать
как промежуток вида ц±го, где г>0 — любое положительное
действительное число (необязательно целое). В этом случае рас-
стояние между математическим ожиданием ц и любой точкой на
оси абсцисс определяется в единицах стандартного отклонения.
Рассмотрим две различные кривые нормального распреде-
ления. Одна из них характеризуется параметрами ц, и в(, а дру-
гая — ц, и о2. Пусть г— положительное число. Для первой кри-
вой построим интервал а для второй — ц2±го2. Тогда
площади между соответствующими кривыми и отрезками бу-
дут составлять одинаковые доли общих площадей кривых. Вви-
ду симметрии одинаковые доли площадей будут соответство-
вать также интервалам pf+ rat и ц2+ го2 (или — и
Таким образом, для всего семейства нормальных кривых
будет верно следующее свойство площадей, ограниченных этими
кривыми: если для каждой кривой измерять расстояние между
математическим ожиданием ц и какой-либо точкой на оси абс-
цисс в единицах стандартных отклонений о, то все площади,
заключенные между кривыми и интервалами ц±га (г>0 — оди-
наковое для всех кривых число, характеризующее длину ин-
тервала в масштабе стандартного отклонения о), будут состав-
лять одинаковые доли площадей соответствующих кривых.
Рис. 7.13. Площади, ограниченные нормальными кривыми
и отрезками ц + 1,5с
155
Пример 7.4. На рис.7.13 представлены три кривые нормально-
го распределения с разными параметрами ц и о: распределение
1 (р( 100, = 45), распределение 2 (ц, = 60, о, = 30), рас-
пределение 3 (цз = 50, оз = 20). Для каждой кривой справа от р
на оси абсцисс отметим отрезок ц+1,5а. Все заштрихованные
площади, ограниченные кривыми и отмеченными отрезками,
будут составлять одинаковые доли площадей кривых.
7.3.3. Вероятность попадания на заданный промежуток.
Стандартное нормальное распределение
Используя соотношение (7.2), можно определить вероятность
попадания значения случайной величины X, распределенной
по нормальному закону с параметрами ц и о, на произволь-
ный участок (а, 0):
Р (in)'
Р(а<. х<0) = —I— fe 2о’ dx. (7.13)
Стл/2л *
а
Геометрически вероятность (7.13) соответствует площади,
заключенной между кривой распределения и промежутком (а,
0). Она равна некоторой доле площади, ограниченной всей
кривой (т. е. некоторой доле 1).
Пример 7.5. Пусть случайная величина X, взятая из примера 7.2,
имеет параметры ц = 400, о = 50. Тогда для определения вероят-
ности события, что взятая наугад лампочка будет иметь срок
службы в пределах от 300 до 360 ч, следует вычислить интеграл:
360 (х-400)1
f е 250 dx. (7.14)
300
что соответствует заштрихованной площади на рис. 7.14.
Л300<х<360) = —I
300 360 400
Рис. 7.14. Геометрическое выражение вероятности Р(300<х<360)
Вычисление с необходимой точностью интегралов типа (7.13)
в каждом конкретном случае (например, (7.14)) является трудо-
емкой процедурой. Поэтому на практике при вычислении вероят-
156
ности Я(а<х<Р) поступают следующим способом: рассматрива-
ют соответствующую площадь под кривой нормального распре-
деления. Затем эту площадь представляют как алгебраическую сум-
му площадей определенного вида, значения которых рассчитывают
заранее. Данный способ основан на свойствах площадей, ограни-
ченных кривой нормального распределения и отрезком между
средним значением ц и какой-либо точкой на оси абсцисс, при-
чем длина этого отрезка должна выражаться в единицах стандар-
тного отклонения ст. Как было отмечено в п. 7.3.2, доли площадей
под кривыми нормального распределения, ограниченных отрез-
ками ц ± га, где ц и а принимают любые значения, а г>0 имеет
постоянное значение для всех кривых, будут равны между собой.
Поэтому имеет смысл составить таблицу площадей данного вида
для одного специального нормального распределения и сопос-
тавлять с ним кривую любого другого нормального распределе-
ния. Для этой цели любой нормальный закон с параметрами цист
можно стандартизировать, используя преобразование
Z=—(7.15)
о
где х — значение случайной величины X, распределенной по
нормальному закону с параметрами ц и о;
ц — математическое ожидание X,
а — стандартное отклонение данного распределения;
Z — число стандартных отклонений, содержащихся на от-
резке между ц и х.
Преобразование (7.15) называется стандартизацией нормаль-
ного закона распределения. Оно позволяет перейти от конкрет-
ных единиц размерности случайной величины X (например,
единиц измерения денежных потоков, габаритов физических
тел, времени, экономических показателей и т. д.) к безразмер-
ному масштабу. Величина 7для любого нормального распреде-
ления характеризует отклонение от математического ожидания
ц в единицах стандартного отклонения а.
Математически выражение (7.15) можно рассматривать как
преобразование переменной х в переменную Z. При этом лю-
бой нормальный закон с параметрами ц и а приводится к виду
1 ~
Ж--4-е 2. (7.16)
У2Л
Функция (7.16) представляет собой плотность нормального
распределения с параметрами ц = 0 и ст = 1. Она характеризует
стандартный нормальный закон распределения.
157
Для стандартного нормального распределения в Приложе-
нии 4 представлена специальная таблица. В ней указаны доли
площади, ограниченной кривой стандартного нормального
распределения и заключенной между ц = 0 и различными зна-
чениями Z>0 (т. е. соответствующие положительным отклоне-
ниям от средней). Ввиду симметричности кривой нормального
распределения площади под кривой, расположенной по одну
сторону от средней, эквивалентны соответствующим площа-
дям по другую сторону. Это позволяет использовать таблицу
Приложения 4 для нахождения площадей, соответствующих от-
рицательным отклонениям от средней. По этой таблице можно
определить вероятность попадания значений стандартной нор-
мальной величины в промежуток (0; Z).
Пример 7.6. Пусть требуется определить вероятность, что стан-
дартная нормально распределенная случайная величина при-
мет значение в интервале между —1,5 и 1,62, т. е. вычислить
/X~1,5<Z<1,62). Это означает, что необходимо вычислить пло-
щадь под кривой распределения, ограниченную интервалом
(-1,5; 1,62). Эта площадь заштрихована на рис. 7.15.
-1.5 0 1,62
Рис. 7.15. Заштрихованная площадь соответствует вероятности
P(-1,5<Z<1.S2)
Искомую площадь можно представить в виде двух частей
(различная штриховка на рис. 7.15). Одна площадь ограничена
интервалом (-1,5; 0), а другая — интервалом (0; 1,62). Соответ-
ственно вероятность f\-\,5<Z<\,62) является суммой вероят-
ностей Р(— 1,5<Z<0) и /XO<Z<1,62). Вероятность P(0<Z<l,62)
определяется по таблице Приложения 4. Для этого в колонке Z
находится строка, соответствующая значению 1,62. Затем на
пересечении этой строки с колонкой 0,02 находится значение
искомой площади 0,4474. Как видно из таблицы, значение Z
должно указываться с точностью не более двух знаков после
запятой (колонка Z задает точность до первого знака после
запятой, остальные колонки уточняют значение Z до второго
знака).
Дтя того чтобы найти площадь, соответствующую интервалу
(—1,5; 0), т. е. отрицательному отклонению от средней ц = 0, сле-
дует учесть свойство симметричности кривой нормального рас-
158
пределения. Очевидно, искомая площадь будет соответствовать
площади, ограниченной интервалом (0; 1,5), в правой половине
кривой. Она находится по таблице для Z = 1,5 и равна 0,4332.
Искомая вероятность вычисляется как сумма: 0,4474 + 0,4332 =
= 0,8806.
Таким образом, вероятность события, что случайная вели-
чина, распределенная по стандартному нормальному закону,
примет значение в границах от -1,5 до 1,62, равна 0,8806.
Пример 7.7. Для стандартного нормального распределения зре-
буется вычислить вероятности: a) AZ>1,82); б) /\Z<-0,78);
в) Л 1,73<Z< 1,96).
а) Вероятности P(Z>1,82) соответствует площадь, ограни-
ченная бесконечным интервалом (1,82; +~). Из рис. 7.16 видно,
что величину этой плошали можно получить, если вычесть из
половины площади, всей кривой (т. е. из 0,5) значение площа-
ди, ограниченной интервалом (0; 1,82). Площадь между 0 и 1,82
вычисляется по таблице Приложения 4. Она соответствует значе-
нию Z— 1,82 и равна 0,4656. Отсюда AZ>1,82) = 0,5 - 0,4656 =
= 0,0344.
б) Ввиду симметрии кривой распределения вместо площа-
ди, ограниченной интервалом (-«>; -0,78) (рис. 7.16), можно
рассматривать площадь под интервалом (0,78; +<»). Тогда по ана-
логии со случаем а имеем p(Z<—0,78) = 0,5 — P(0<Z<0,78)=
= 0,5 - 0,2823 = 0,2177.
в) Искомая площадь ограничена интервалом 1,73<Z<1,96.
По таблице можно вычислить площади под интервалами
(0; 1,73) и (0; 1,96). Из рис. 7.16 видно, что искомая площадь
представляется как разность этих площадей, что соответствует
разности вероятностей:
P(0,73<Z<l,96) = 7XO<Z<1,96) - fl(0<Z<l,73) =
= 0,475 - 0,4582 = 0,0168.
а
Рис. 7.16. Заштрихованные площади соответствуют вероятностям:
a) ₽(Z>1,82); б) Я(2<0.78). в) Pf1,73<Z<1.96)
159
Используя преобразование (7.15) и данные таблицы пло-
щадей под кривой стандартного нормального распределения
(Приложение 4), можно по аналогии с примерами 7.5 и 7.6
вычислять необходимые вероятности для произвольного нор-
мального распределения.
Пример 7.8. Вернемся к примеру 7.5 и вычислим вероятность
(7.14). Для этой цели границы интервала (300; 360) в распреде-
лении с параметрами ц = 400 и о = 50 переведем с помощью
преобразования (7.15) в соответствующие границы для стан-
дартного нормального распределения:
_ _ 300 - 400 _
Zi —--------— ”2,
1 50
„ _ 360 - 400 ___
4S-) —------ — ~U,O.
2 50
Отсюда получаем, что площадь ограниченная интервалом
(300; 360) для исследуемого распределения, будет эквивалент-
на площади, ограниченной интервалом (—2; -0,8) для стан-
дартного нормального распределения. В свою очередь эта пло-
щадь будет равна площади, ограниченной отрезком между 0,8
и 2 для правой половины кривой стандартного нормального
распределения (рис. 7.17).
Рис. 7.17. Геометрическое представление эквивалентных площадей:
а) Р(300<2<360); б) P[-2<Z<-0,6). •) P(0.8<Z<2)
Вероятность P(0,8<Z<2) вычисляется как разность площа-
дей:
Л0,8<7<2) = Л0<7<2) - fl(0<Z<0,8) =
= 0,4772 - 0,288 = 0,1892.
Вычисленную вероятность можно интерпретировать следу-
ющим образом: 18,9% всех лампочек имеют срок службы, за-
ключенный в пределах от 300 до 360 ч.
160
Пример 7.9. Средний месячный доход большой группы менед-
жеров составляет ц = 1000 долл, со стандартным отклонением
о = 100 долл. Какова доля менеджеров, имеющих доход в пре-
делах от 840 до 1200 долл.?
Для решения задачи необходимо вычислить вероятность
Я(840<Л’<1200), где X — случайная величина, распределенная
по нормальному закону с параметрами ц = 1000 и о = 100.
Найдем границы интервала для стандартного нормального рас-
пределения, который соответствует интервалу (840; 1200). Най-
дем точку Z, в которую перейдет точка х в 840 в результате
преобразования (7.15):
, 840-1000 -160
1 100 100
Аналогично определим точку Zr соответствующую х = 1200:
1200-1000
Z.’X “ — L.
2 100
Площади, соответствующие обоим распределениям, за-
штрихованы на рис. 7.18.
1000 1200
Рис. 7.18. Геометрическая интерпретация эквивалентных площадей:
а) P(840<Z< 1200). б) Р(-1.6<2<2)
Из рис. 7.186 видно, что искомую площадь можно рассмат-
ривать как сумму двух площадей (вероятностей): P[-\,6<Z<2)
= = A-1.6<Z<0) + P(0<Z<2).
Из симметрии кривой распределения относительно ц = О
следует
a-i.6<z<o) = ao<z<i,6).
Вероятности P(O<Z<1,6) и A(0<Z<2) находятся по таблице
Приложения 4: P(0<Z< 1,6) = 0,4452 (соответствует значению
Z = 1,6), P(0<Z<2) = 0,4772 (соответствует значению Z = 2).
Суммируя две площади, получим P(-1,6<Z<2) =
= P(840<Z<1200) = = 0,4452 + 0,4772 = 0,9224.
Итак, вероятность случайным образом выбрать менеджера,
имеющего месячный доход от 840 до 1200 долл., равна 0,9224.
Это означает, что 92,24% всех менеджеров имеют доходы в ука-
занных пределах.
звз
В примерах 7.7—7.9 рассматривались ситуации, которые сво-
дились к нахождению доли площади (вероятности), соответству-
ющей событию, что случайная величина X примет значение,
большее (или меньшее), чем некоторая заданная величина х.
В содержательном смысле это означает, что требовалось най-
ти, какой процент всех наблюдаемых значений превышает (или
меньше) определенную величину х.
Рассмотрим теперь в некотором смысле обратную задачу.
Пусть требуется определить такое значение х, правее (или ле-
вее) которого располагается заданный процент всех значений.
В терминах вероятности проблему можно сформулировать так:
найти такое значение х, что нормально распределенная слу-
чайная величина X примет значение Х>х (или Х<х) с заданной
вероятностью р\
f\X>x) = р (Р(Х<х) = />).
Геометрически это означает, что на оси абсцисс требуется
найти такую точку х, которая отделяла бы заданную долю пло-
щади под кривой распределения.
Пример 7.10. Фирма производит автомобильные шины нового
типа. Специальное тестирование показало, что средний пробег
шины до ее износа равен 47 900 км при стандартном отклоне-
нии 2050 км. Руководству фирмы необходимо оценить величи-
ну гарантийного пробега при условии, что при этом пробеге
будет заменено не более 5% всех используемых шин. Геометри-
ческая иллюстрация данной проблемы представлена на рис. 7.19.
Точках характеризует искомый гарантийный пробег. Она отсе-
кает заштрихованный “хвост” распределения, площадь кото-
рого составляет 5% всей площади кривой.
х = ? 47 900
Рис. 7.19. Геометрическая интерпретация решения:
х — искомый гарантийный пробег шины (км)
Если площадь заштрихованного “хвоста" равна 0,05, то пло-
щадь, ограниченная интервалом (х; 47 900), очевидно, будет
0,5 - 0,05 = 0,45. Следовательно, задача сводится к нахожде-
нию такого отрицательного отклонения от ц, которое ограни-
162
чивало бы площадь, равную 0,45. Запишем преобразование
(7.15) для искомой величины х:
х-47900
2050
(7.17)
В равенстве (7.17) две неизвестные величины — Z и х. По
условию доля площади, ограниченной интервалом (Z; 0), рав-
на 0,45. В таблице Приложения 4 найдем значение, ближайшее
к 0,45. Как видно из таблицы, существуют два ближайших зна-
чения, равноотстоящих от 0,45: 0,4505 и 0,4495. Им соответ-
ствуют значения Z: 1,65 и 1,64. Возьмем среднее значение меж-
ду ними: 1,645. Так как Zнаходится в левой половине кривой,
то на самом деле Z= —1,645. Подставляя Z = -1,645 в (7.17),
получим уравнение относительно х
-1,645 =
х-47900
2050
Отсюда
-1,645 • 2050 = х - 47900,
х = 44 528 км.
Полученный результат имеет следующую содержательную ин-
терпретацию. Пусть фирма утверждает, что гарантийный пробег
шин нового типа равен 44 528 км. В этом случае можно ожидать,
что только 5% всех шин, находящихся в эксплуатации, будет
заменено еще до окончания гарангийного пробега.
7.3.4. Нормальное распределение как замена
биномиального распределения
Нормальное распределение иногда можно использовать в ка-
честве биномиального. Основная проблема, которая при этом
возникает, заключается в том, что дискретное биномиальное
распределение должно заменяться непрерывным нормальным
законом распределения. Эта проблема легко решается с помо-
щью корректирующей величины, которая называется поправ-
кой на непрерывность. Смысл этой поправки поясним на сле-
дующем примере.
Пусть монета подбрасывается 10 раз (число опытов п = 10).
Требуется вычислить вероятность того, что герб в этом случае
выпадет 5, 6, 7 или 8 раз. Вероятность “успеха” (выпадение
герба) в каждом опыте р = 0,5, а вероятность “неудачи” (выпа-
дение цифры) q = 1 - р = 0,5. Отсюда получаем, что рас-
163
сматриваемая случайная величина будет иметь параметры
ц = пр = 10 0,5 =5, о = Jnpq = -./100,5 • 0,5 = Л/2Л = 1,58.
Рассмотрим случайную величину, распределенную по нор-
мальному закону, но имеющую те же параметры: ц. = 5, ст = 1,58.
Построим графики обеих случайных величин и совместим их на
одной координатной плоскости (рис. 7.20). График биномиаль-
ной случайной величины строится как гистограмма, в которой
столбики симметричны относительно целых значений 0, 1,2,
.... 10. Ширина каждого столбика равна I, а высота — соответ-
ствующей биномиальной вероятности. Гистограмма сглаживает-
ся кривой нормального распределения
Рис. 7.20. Графики биномиального и нормального распределений
с параметрами ц = 5, о = 1.58
Построенная гистограмма обладает следующими свойства-
ми: площадь каждого столбика равна соответствующей бино-
миальной вероятности, а ее общая площадь — I.
Например, вероятность события, что из I0 бросаний монеты
герб выпадет ровно 5 раз, равна площади столбика, имеющего в
качестве основания интервал от 5 -0,5 до 5 +0,5 (заштрихован-
ная полоска на рис. 7.20). Величина 0,5 характеризует поправку
на непрерывность. Она прибавляется к 5 и вычитается из 5. Ис-
пользуя таблицу вероятностей для биномиального распределе-
ния (Приложение 2), вычислим вероятность суммы событий:
Лх = 5) + Р(х = 6)+Лх = 7) + Лх = 8) =
= 0,2461 + 0,2051 + 0,1172 + 0,0439 = 0,6123.
Вычисленная вероятность равна сумме площадей соответ-
ствующих столбцов гистограммы биномиального распределе-
ния. Как видно из рис. 7.20, она приблизительно соответствует
164
плошали под кривой нормального распределения, ограничен-
ной интервалом (4,5; 8,5). Найдем значение этой площади, ис-
пользуя преобразование (7.15). Вычислим:
Z, = ^—- = -0,32;
1,58
=8^ = 2,21.
2 1,58
Z
Ввиду симметрии площадь, ограниченная интервалом
(-0,32; 0), равна площади, ограниченной интервалом (0; 0,32).
По таблице Приложения 4 площади для Z= 0,32 и Z = 2,21
будут равны соответственно 0,1255 и 0,4864. Суммируя, полу-
чаем 0,1255 + 0,4864 = 0,6119.
Сравнивая значения 0,6123 и 0,6119, видим, что ошибка
аппроксимации меньше, чем 0,1%.
В общем случае наиболее благоприятные условия замены
биномиального распределения нормальным имеют место тог-
да, когда число опытов п сравнительно велико, а генеральная
доля р не слишком велика и не слишком мала. Для практичес-
ких расчетов достаточно, чтобы выполнялись условия: лр>5 и
л(1 - р)>5. В этом случае сглаживающая кривая графика бино-
миального распределения будет близка к нормальной кривой.
Пусть X — биномиальная случайная величина, которая ха-
рактеризуется числом опытов п и вероятностью “успеха” р. Тогда
правила использования поправки на непрерывность можно за-
писать в следующем виде:
1) Р(Х <b)= Р (Z<('b +0,5)-~^);
ст
2) Р(Х >a) = P(Z>^0,5^); (7.18)
п
3) Р(а<Х <b)-P(^^^^<Z<---°'5)-M).
ст ст
где ц = пр\
о = %/пр(1-р);
Z — случайная величина, распределенная по нормально-
му закону.
Пример 7.11. Администрация сети ресторанов национальной
кухни провела социологический опрос посетителей. В результа-
те было выяснено, что обычно 70% новых посетителей повто-
165
ряют свой визит. Пусть в течение некоторой недели было отме-
чено, что 80 человек посетили рестораны в первый раз. Какова
вероятность, что по крайней мере 60 из них посетят ресторан
еще раз?
Для вычисления искомой вероятности требуется вычислить
и сложить биномиальные вероятности:
С^ОЛ.З2" + С“О,761О,3*’ +... + С,® О,78оО,3°.
Очевидно, в данном случае имеет смысл заменить биноми-
альное распределение нормальным, поскольку выполняются
все условия:
пр = 80 0,7 = 56>5; л(1 - р) = 80 0,3 = 24>5.
Найдем параметры аппроксимирующего нормального рас-
пределения:
ц = пр = 800,7 = 56;
о = - р) = -у'80 • 6,7-03 = <16,8 = 4.1.
Для замены биномиального распределения нормальным вос-
пользуемся правилом 2 из списка правил (7.18). Вычислим:
„ (я-0,5)-ц (60-0,5)-56 _ 59,5-56 ЛО<
о 4,1 4.1
По таблице Приложения 4 найдем долю ллощаци под кри-
вой стандартного нормального распределения, ограниченную
отрезком между 0 и 0,85. Она равна 0,3023. Вычтем эту величи-
ну из 0,5: 0,5 - 0,3023 = 0,1977.
Следовательно, вероятность того, что 60 или более человек
из 80 новых посетителей посетят еще раз ресторан националь-
ной кухни, равна 0,1977.
7.4. ЭКСПОНЕНЦИАЛЬНОЕ РАСПРЕДЕЛЕНИЕ
Экспоненциальное показательное распределение использу-
ется в различных приложениях статистического анализа, на-
пример при оценке времени между заказами на телефонной
линии, между прибытиями транспорта и т. п., а также при ана-
лизе сроков службы компонент, составляющих некоторый аг-
регат. В разделе 6.6 рассматривалось распределение Пуассона,
которое часто используется для характеристики числа поступ-
166
лений каких-либо заказов или прибытий (числа появления “ус-
пехов”) каких-либо объектов в течение определенного перио-
да времени. Если случайная величина ^представляет собой число
появлений “успеха” в течение периода Т и распределена по
закону Пуассона, то случайная величина X, характеризующая
промежутки времени между двумя последовательными “успе-
хами”, будет иметь экспоненциальное распределение. Экспо-
ненциальная случайная величина имеет много приложений при
моделировании ситуаций, описывающих процесс ожидания
людей или объектов, стоящих в очереди на различного рода
обслуживание. Случайная величина, распределенная по экспо-
ненциальному закону, имеет кривую графика экспоненциаль-
ной функции
/(х) = Ае-Ах, (7.19)
где А — константа.
Вид кривой распределения типа (7.19) представлен на рис.
7.21. Можно доказать, что общая площадь, ограниченная этой
кривой, равна 1: +<ю
A je-x,dr = l.
о
Рис. 7.21. Кривая экспоненциального распределения
При увеличении текущей переменной х вероятность собы-
тия, что значение экспоненциальной случайной величины бу-
дет не меньше х, убывает по экспоненциальному закону. Пусть
х = х0, тогда можно показать, что
Р(х>х0) = А = (7.20)
167
Геометрической интерпретацией вероятности (7.20) явля-
ется площадь, ограниченная кривой распределения и интерва-
лом х 2 х0 (рис. 7.22).
*□ а
Рис. 7.22. Геометрическая интерпретация вероятности Р(ж i
Параметр А имеет следующую содержательную интерпрета-
цию. Пусть рассматривается пуассоновская случайная величина
с параметром А, т. е. А соответствует среднему числу появлений
“успехов” за единицу времени. Рассмотрим соответствующую
экспоненциальную случайную величину, характеризующую зна-
чения промежутков времени между последовательными “успе-
хами”. Тогда величина 1/А будет представлять собой среднее время
между появлениями двух последовательных “успехов".
В общем случае можно показать, что значение 1/А является
математическим ожиданием экспоненциальной случайной ве-
личины, которая равна также ее стандартному отклонению:
ц = A Jxe’^dx»-, (7.21)
о
В практических ситуациях, где используется экспоненциаль-
ное распределение, значение параметра А либо известно, либо
каким-то образом определяется.
Пример 7.12. Владелец крупного косметического салона счита-
ет, что наибольшую прибыль он получает в случае обслужива-
ния клиентов, посещающих салон произвольным образом, а
не делающих заказ на обслуживание заранее. Из прошлого опыта
известно, что среднее число клиентов, которые обслуживались
в течение часа, составляет А = 4.
168
Требуется определить:
I) если в салон вошел клиент, то какова вероятность, что
следующий клиент придет в течение 30 мин?
2) если ^обозначает время между появлениями двух клиен-
тов, которые придут один за другим, то каково будет матема-
тическое ожидание и стандартное отклонение случайной вели-
чины А?
Для решения задачи 1 следует промежуток времени 30 мин
исчислять как 0,5 ч, так как размерность А — 4 ед. за час. Тогда
искомая вероятность есть Р(х<0,5). Исходя из (7.20), получим
Р(х > 0,5) = е’4Д5=е~2 = 0,135.
Очевидно,
Р(х < 0,5) = 1 - Р(х г 0,5) = 1 -0,135 = 0,865.
Следовательно, вероятность, что в течение 30 мин после
прихода первого клиента салон посетит второй клиент, равна
0,865. Иначе говоря, 86,5% всего времени работы салона про-
межутки между приходами клиентов не превышают 30 мин. Ре-
шение задачи 2 получим на основе соотношений (7.21):
11
И = о = — = - ч (т. е. 15 мин).
А 4
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 7
Рассматриваются характеристики, свойства и основные за-
коны распределений непрерывных случайных величин. Возмож-
ные значения непрерывной случайной величины непрерывно
заполняют некоторый промежуток и не могут быть перечисле-
ны заранее как в случае дискретных случайных величин. Поэто-
му для характеристики распределения вероятностей непрерыв-
ной случайной величины пользуются не вероятностью события
X = х, а вероятностью события Х<х, где х — некоторая теку-
щая переменная. Вероятность, что Х<х, зависит от текущей
переменной х и является некоторой функцией от х. Эта функ-
ция называется функцией распределения непрерывной случай-
ной величины X. Ее также называют интегральной функцией
распределения или интегральным законом распределения. Функ-
ция распределения является универсальной характеристикой
как для непрерывных, гак и для дискретных случайных вели-
169
чин. С вероятностной точки зрения функция распределения пол-
ностью характеризует случайную величину, т. е. является одной
из форм закона распределения. График функции распределе-
ния непрерывной случайной величины есть плавная кривая,
имеющая касательную в любой точке. Ее значения лежат в ин-
тервале от 0 до 1.
В практических задачах иногда встречаются непрерывные
случайные величины, распределенные по закону равномерной
плотности. Такие величины еще называются равномерно рас-
пределенными. Для равномерно распределенной случайной ве-
личины имеются определенные границы, внутри которых все
значения равновероятны, т. е. плотность распределения являет-
ся постоянной величиной на всем промежутке изменения слу-
чайной величины.
Исключительно важную роль играет в статистическом ана-
лизе нормальный закон распределения. Сумма достаточно боль-
шого числа независимых (или слабо зависимых) случайных
величин распределена почти по нормальному закону, причем
слагаемые случайные величины могут подчиняться каким угодно
законам распределения. Это свойство широко реализуется на
практике, так как большинство массовых явлений формирует-
ся как наложение многих отдельных факторов (причин).
Нормальный закон распределения характеризуется плотно-
стью вероятности, имеющей вид (7.12). Существует бесконеч-
ное семейство нормальных распределений, каждое из которых
задается двумя параметрами — математическим ожиданием ц и
стандартным отклонением а. Кривая нормального распределе-
ния имеет симметричную относительно ц колоколообразную
форму. Значением ц определяется положение кривой распреде-
ления, а величиной о — форма этой кривой. Чем больше р, тем
больше кривая распределения смещена вправо по оси абсцисс.
С увеличением о кривая растягивается вдоль оси абсцисс, а
при уменьшении — сжимается и вытягивается вверх вдоль оси
ординат.
Независимо от значений параметров ц и о для всех нор-
мальных кривых сохраняются единые пропорции для площа-
дей, ограниченных этими кривыми и определенными интерва-
лами на оси абсцисс. Так, вся площадь между любой нормаль-
ной кривой и осью абсцисс будет равна I, а площади, ограни-
ченные промежутками ц±го(г>0), будут одинаковыми для всех
кривых при фиксированном г. Эти свойства площадей можно
использовать для вычисления вероятностей попадания значе-
ния случайной величины X, распределенной по нормальному
170
закону, на заданный промежуток (а, р). Для этой цели любой
нормальный закон можно стандартизировать с помощью пре-
образования (7.15). При этом переменная х переходит в пере-
менную Z, а исходное нормальное распределение с любыми
параметрами ц и о преобразуется в стандартное нормальное
распределение с параметрами ц = 0, о = 1. Используя симмет-
рию кривой нормального распределения и свойства площадей
под нормальными кривыми, можно с помощью преобразова-
ния (7.15) необходимую площадь под любой нормальной кри-
вой перевести в соответствующую площадь под кривой стан-
дартного нормального закона распределения. Для него рассчи-
тана таблица специальных площадей, ограниченных кривой
стандартного распределения и интервалом между ц и Z, где
Z>0.
Учитывая симметрию кривой стандартного нормального
распределения и рассматривая любую площадь как алгебраи-
ческую сумму площадей, ограниченных интервалом (0; Z), по
таблице Приложения 4 можно найти искомую площадь.
При определенных условиях нормальное распределение ис-
пользуется в качестве биномиального распределения в случае,
если расчет биномиальных вероятностей затруднен. Основная
проблема, которая здесь возникает, заключается в том, что
дискретное биномиальное распределение заменяется непрерыв-
ным нормальным законом распределения. Поэтому при замене
вводится специальная корректировочная величина, которая
называется “поправкой на непрерывность”. Правила использо-
вания этой поправки задаются соотношениями (7.18).
В различных прикладных задачах, связанных с ситуациями,
когда люди или объекты образуют очередь на какое-либо об-
служивание, а также когда требуется оценить время между при-
бытиями транспорта или сроки службы компонентов, состав-
ляющих некоторый агрегат, используется экспоненциальное
распределение. Случайная величина, распределенная по экс-
поненциальному закону, имеет кривую плотности, которая
является графиком экспоненциальной функции. Вид этой функ-
ции задается уравнением (7.19).
ОЦЕНКА ПАРАМЕТРОВ
8.1. ТОЧЕЧНЫЕ ОЦЕНКИ
Проблема оценки является особенно актуальной в приклад-
ном статистическом анализе, связанном с принятием реше-
ний в бизнесе, экономике и других сферах общественной дея-
тельности. Например, производители не знают точно, сколько
новых товаров они продадут в будущем году; администрация
учебного заведения точно не знает, сколько студентов посту-
пят на первый курс в новом учебном году, и т. д.
Существуют два типа оценок — точечные и интервальные.
Рассмотрим вначале точечный тип оценок. Под точечной оцен-
кой понимается отдельное число (называемое точкой), кото-
рое используется в качестве оценки параметра генеральной
совокупности. Например, выборочная средняя х, вычисленная
по формуле (3.1), есть точечная оценка средней генеральной
совокупности ц, а выборочная дисперсия з2 и стандартное от-
клонение з, вычисленные соответственно по формулам (4.8) и
(4.10), являются точечными оценками параметров а2 и а.
Пример 8.1. Для определения емкости автомобильных аккуму-
ляторов нового типа было проведено специальное исследова-
ние. Оно заключалось в запуске двигателя до тех пор, пока те-
стируемый аккумулятор не садился. Такое исследование было
проведено для выборки, состоящей из 40 случайным образом
выбранных аккумуляторов. Результатами были следующие ко-
личества запусков:
26 27 26 20 21 42 30 22 22 21 26 9 21 22 28 26
19 16 20 32 18 23 32 26 21 41 19 31 21 22 16 23
30 21 37 28 39 30 21 23
Данные 40 аккумуляторов были выбраны из очень большой
партии, которую теоретически можно рассматривать как бес-
конечную генеральную совокупность.
172
Точечная оценка для средней арифметической такова:
х= (26 + 27 + 26 + ... + 23)/40 = 1000/40 = 25 запусков.
Точечные оценки для дисперсии и стандартного отклоне-
ния:
? = [(26 - 25)2 + (27 - 25)2 +...+ (23 - 25)21/39 =
= 2031/39 = 52,077,
5 = 752.077 = 7,216.
8.1.1. Критерии качества точечных оценок
Различные статистики могут служить оценками истинных па-
раметров генеральной совокупности. Чтобы оценить их качество,
в статистическом анализе рассматриваются четыре критерия.
1. Несмещенность. Пусть из данной генеральной совокупнос-
ти извлекается большое количество выборок. На основе значе-
ний каждой из них рассчитывается точечное значение оценки
параметра генеральной совокупности (т. е. статистики). При этом
статистика называется несмещенной, если все выборочные
значения располагаются симметрично относительно истинно-
го значения оцениваемого параметра. В этом случае математи-
ческое ожидание распределения статистики будет равно ис-
тинному значению параметра. Далее будет показано, что такая
картина наблюдается для распределения выборочных средних,
которое является нормальным (т. е. симметричным), а матема-
тическое ожидание распределения выборочных средних равно
математическому ожиданию генеральной совокупности (т. е. ге-
неральной средней).
2. Эффективность. Будем рассматривать дисперсию как сред-
ний квадрат отклонения или ошибки выборочной средней. Тог-
да стандартное отклонение можно рассматривать как ее стан-
дартную ошибку. Вместо выборочной средней в формулу
дисперсии или стандартного отклонения подставим любую дру-
гую статистику (например, медиану). Стандартное отклонение,
вычисленное относительно этой статистики, будем называть стан-
дартной ошибкой статистики. Критерий эффективности харак-
теризует минимальность стандартной ошибки статистики, ис-
пользуемой в качестве точечной оценки параметра генеральной
совокупности. Иначе говоря, стандартная ошибка эффективной
оценочной статистики должна быть меньше стандартной ошиб-
ки любой другой статистики, выбираемой в качестве точечной
173
оценки. Например, в разделе 4.13 отмечалось, что дисперсия и
стандартное отклонение обладают свойствами минимальности
относительно средней арифметической. Поэтому выборочная
средняя будет эффективной оценкой генеральной средней.
3. Состоятельность. Говорят, что оценка истинного значения
параметра является состоятельной, если по мере увеличения
объема выборки ее значение приближается к истинному значе-
нию параметра. Например, состоятельной оценкой является вы-
борочная средняя.
4. Достаточность. Оценка является достаточной, если при ее
вычислении используется вся содержащаяся в выборке инфор-
мация. Иначе говоря, для вычисления любой другой оценки
нельзя будет извлечь из выборки дополнительную информа-
цию об истинном значении оцениваемого параметра.
Выборочная средняя является наилучшей оценкой генераль-
ной средней. Она удовлетворяет всем четырем критериям.
Критерии качества оценок могут служить не только для вы-
бора, но и для улучшения оценок. Пример тому формула (4.8)
для вычисления выборочной дисперсии, в которой для кор-
ректировки смещенности выборочных дисперсий (заниженно-
сти) в знаменателе величина п заменяется нал - 1.
Следует отметить, что лучшими оценками для параметров
генеральной совокупности соответствующие статистики быва-
ют не всегда. Рассмотрим, например, генеральную совокуп-
ность, имеющую симметричное распределение. В этом случае
средняя арифметическая и медиана совпадают. Возьмем в каче-
стве оценок медианы выборочную медиану и выборочную сред-
нюю. Обе эти оценки будут несмещенными и состоятельными
оценками медианы. Однако ввиду свойства минимальности стан-
дартной ошибки средней арифметической выборочная сред-
няя будет более эффективной оценкой медианы.
8.2. РАСПРЕДЕЛЕНИЕ ВЫБОРОЧНЫХ СРЕДНИХ.
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
Реализация выборочного метода, т. е. получения статисти-
ческого заключения относительно характеристик и свойств всей
генеральной совокупности на основе выборочных значений,
обязательно предполагает простой случайный отбор. Предпо-
ложим, что условие формирования простой случайной выбор-
ки будет всегда выполняться. Нас в этом случае интересует связь
между некоторой выборочной характеристикой (статистикой)
и определенным параметром всей совокупности. Маловероят-
174
но, что значение статистики точно совпадает со значением па-
раметра. Разность между этими величинами будем называть
ошибкой выборки.
Пример 8.2. Генеральная совокупность состоит из 5 работников.
Эффективность их работы была оценена с помощью некоторо-
го теста. Результаты теста были представлены в специальной
балльной шкале: 97, 103, 96, 99, 105. Вычислим средний балл
для всей совокупности (генеральную среднюю):
И = (97 + 103 + 96 + 99 + 1О5)/5 = 500/5 = 100.
Рассмотрим две выборки, состоящие из двух значений каж-
дая: 97, 105 и 103, 96. Вычислим для каждой из-них значение
среднего балла (статистики): xf = (97 + 105)/2 = 101,х2 = (103 +
+ 96)/2 = 99,5. В первом случае ошибка выборки будет х - р -
= 101 — 100 = 1, а во втором — xj — д = 99,5 - 100 = -0,5.
Каждая из разностей (1 и -0,5) является ошибкой, или погреш-
ностью, которая будет допущена, если в качестве оценочного
значения генеральной средней взять соответствующую выбороч-
ную среднюю (т. е. точечную оценку генеральной средней).
Возникает проблема, как на основе выборки дать макси-
мально точную оценку генеральной средней. Для этой цели
рассмотрим выборочное распределение этой статистики или
распределение выборочных средних. Зафиксируем объем вы-
борки и возьмем из исследуемой генеральной совокупности
все возможные выборки данного объема. Затем для каждой из
этих выборок вычислим среднюю и составим распределение
частот, т. е. дисретный ряд распределения. Далее полученное
распределение будем анализировать как распределение выбо-
рочных средних. '
Пример 8.3. Семь работников фирмы (генеральная совокуп-
ность) имеют следующие почасовые ставки:
№ работников Почасовые ставки (долл.)
1 7
2 9
3 8
4 8
5 7
6 8
7 9
175
Требуется определить генеральную среднюю, построить рас-
пределения выборочных средних и генеральной совокупности.
Провести сравнительный анализ этих распределений.
Вычислим среднюю почасовую ставку для генеральной со-
вокупности:
ц = (7+ 9 + 8 + 8 + 74-8 + 9)/7 = 8 долл.
Чтобы построить распределение выборочных средних, рас-
смотрим все возможные выборки, состоящие из четырех чело-
век, из семи данных работников. Очевидно, количество таких
выборок определяется числом сочетаний из 7 элементов по 4:
С* - 7!/(4!-3!) = 35. Все они вместе с выборочными средними
представлены'втабл. 8.1.
Таблица 8.1
Выборки объема л = 4 из совокупности объема N = 7
и выборочные средние
№ работников в выборке Почасовые ставки, долл. Выборочные средние, долл.
1 2 3
1234 7. 9, В. 8 32/4 = 8
1235 7. 9. 8. 7 31/4 7,75
1236 7, 9, 8. 8 32/4 = 8
1237 7, 9, 8, 9 33/4 8,25
1245 7. 9. 8, 7 31/4 = 7,75
1246 7, 9. 8, 8 32/4 = 8
1247 7, 9, 8, 9 33/4 = 8,25
1256 7. 9, 7, 8 31/4 = 7,75
1257 7, 9, 7, 9 32/4 8
1267 7. 9, 8. 9 33/4 = 8,25
134 5 7. 8, 8, 7 30/4 = 7.5
1346 7, 8. 8. 8 31/4 = 7,75
1347 7, 8, 8. 9 32/4 = 8
1356 7, 8. 7, 8 30/4 = 7,5
13 57 7, 8, 7, 9 31/4 = 7,75
1367 7. 8. 8, 9 32/4 8
14 56 7, 8, 7, 8 30/4 = 7,5
1 457 7. 8, 7, 9 31/4 = 7,75
1467 7. 8, 8. 9 32/4 = 8
1567 7. 7, 8. 9 31/4 = 7,75
2345 9, 8. 8. 7 32/4 - 8
2347 9, 8. 8. 8 33/4 = 8.25
176
Окончание табл в 1
1 2 3
2356 9. 8. 8, 9 34/4 = 8,5
2357 9. 8. 7, 8 32/4 = 8
2367 9, 8. 8, 9 34/4 = 8.5
2436 9. 8. 8. 8 33/4 = 8,25
24 56 9, 8. 8, 9 34/4 8.5
24 57 9, 8, 7, 8 32/4 = 8
2467 9, 8. 7, 9 33/4 = 8.25
2567 9, 7. 8, 9 33 /4 = 8.25
34 56 8, 8. 7, 8 31/4 = 7.75
3457 8, 8, 7, 9 32/4 = 8
3467 8. 8. 8. 9 33/4 = 8,25
3567 8. 7, 8, 9 32/4 8
4 567 8, 7, 8, 9 32/4 = 8
Вычислим среднюю распределения выборочных средних,
приведенного в табл. 8.1, как сумму всех выборочных средних,
деленную на общее число выборок:
ц. = (8 + 7,75 + ... + 8)/35 = 280/35 = 8 долл.,
где обозначает среднюю распределения выборочных сред-
них.
Подсчитаем частоты и частости (вероятности) возможных
отдельных значений выборочных средних и результаты пред-
ставим в виде дискретного ряда распределения — распределе-
ния выборочных средних (табл. 8.2).
Таблица 8.2
Распределение выборочных средних
(объем выборок л = 4; объем генеральной совокупности N = 7)
Выборочные средние, долл. Частота Вероятность
7.5 3 3/35 = 0.0857
7.75 8 8/35 = 0.2286
8 13 13/35 0,3714
8.25 8 8/35 = 0,2286
8,5 3 3/35 = 0.0857
35 35/35 = 1
Из табл. 8.2 видно, что распределение выборочных средних
отражает, по существу, закон распределения некоторой диск-
ретной случайной величины.
177
Запишем теперь частотное распределение первичных дан-
ных о почасовых ставках, т. е. распределение генеральной сово-
купности (табл. 8.3).
Таблица 8.3
Распределение генеральной совокупности
Почасовые ставки Частота Вероятность
7 2 2/7 = 0,2857
8 3 3/7 = 0,4286
9 2 2/7 = 0,2857
7 7/7 = 1
Графики распределений, приведенных в табл. 8.2 и 8.3, ука-
заны на рис. 8.1.
Рис. 8.1. Распределение а) генеральной совокупности (объем N = 7);
б) выборочных средних (объем выборок п - 4)
Проведя сравнительный анализ распределений, можно сде-
лать следующие выводы.
1. Средняя генеральной совокупности равна средней выбо-
рочных средних, т. е. р = щ = 8. Это утверждение будет всегда
справедливо в случае, если рассматриваются все возможные
выборки заданного объема, отобранные из данной генераль-
ной совокупности.
178
2. Из рис. 8.1 видно, что разброс данных в распределении
выборочных средних меньше, чем в распределении генераль-
ной совокупности. Так, выборочная средняя варьирует в пре-
делах от 7,5 до 8,5, значения генеральной совокупности — в
пределах от 7 до 9.
3. Графики распределений генеральной совокупности и вы-
борочных средних имеют сходство с нормальным распределе-
нием (если начертить огибающие кривые).
Рассмотрим теперь ситуацию, когда распределение генераль-
ной совокупности значительно отличается от нормального.
Пример 8.4. Пусть стаж работы пяти администраторов фирмы
имеет равномерное распределение:
Администраторы Стаж работы, годы Частота Вероятность
1 20 1 1/5
2 22 1 1/5
3 26 1 1/5
4 24 1 1/5
5 28 1 1/5
Вычислим средний стаж работы: ц = (20 + 22 + 26 + 24 +
+ 28)/5 = 24 года.
Построим распределение выборочных средних при объеме
выборок п = 2. Число таких выборок из 5 администраторов бу-
дет Cj = 5!/(2!-3!) « 10. Состав выборок и выборочные средние
представлены в табл. 8.4.
Таблица 8.4
Выборочные средние для всех выборок (л = 2),
извлеченных из генеральной совокупности (N = 5)
Выборки, состоящие из двух администраторов Стаж работы Выборочные средние
1 2 20. 22 21
1 3 20. 26 23
1 4 20. 24 22
1 5 20. 28 24
23 22. 26 24
24 22, 24 23
25 22. 28 25
34 26. 24 25
3 5 26. 28 27
4 5 24. 28 26
179
Вычислим среднюю выборочных средних:
Mi =(21 + 23 + ... + 26)/10 = 24.
Представим данные табл. 8.4 в виде распределения (табл. 8.5).
Таблица 8.5
Распределение выборочных средних
для совокупности выборок (л - 2)
Выборочные средние Частота Вероятность
21 1 0,1
22 1 0,1
23 2 0.2
24 2 0.2
25 2 0.2
26 1 0.1
27 1 0.1
10 1
Графики распределения генеральной совокупности и выбо-
рочных средних указаны на рис. 8.2.
• б
-Illi 1.1.11111
20 22 24 26 28 21 22 23 24 25 26 27
Рис. 8.2. Распределение а) выборочной совокупности (N = 5),
б) выборочных средних (л = 2)
Как видно из графиков распределений (рис. 8.2), разброс
данных для генеральной совокупности выше, чем для выбо-
рочных средних. В первом случае значения колеблются в грани-
цах от 20 до 28 лет, а во втором — от 21 до 27 лет. Если прове-
сти сглаживающую кривую для графика б, то она будет иметь
сходство с кривой нормального распределения.
В примерах 8.2 и 8.3 размеры генеральной совокупности и вы-
борок были взяты небольшими в целях упрощения вычислений.
Тем не менее отчетливо проявились следующие закономерности.
1. Если генеральная совокупность распределена нормально,
то распределение выборочных средних также будет иметь нор-
мальный закон распределения. В этом можно убедиться, если
нарисовать сглаживающие кривые для почасовых ставок работ-
ников, представленных в примере 8.2 (рис. 8.3).
180
Выборочные средние
почасовых ставок
Ямс. 8.3. Сглаженные распределения генеральной совокупности
(Л/ = 7) и выборочных средних (л = 4)
2. В случае если распределение генеральной совокупности не
является нормальным, распределение выборочных средних все
равно оказывается близким к нормальному. Это видно из гра-
фиков распределений примера 8.4 (рис. 8.2),
Отмеченные закономерности не случайны, так как в дан-
ном случае выполняются условия центральной предельной те-
оремы, если рассматривать повторную выборку объема п как
совокупность п независимых случайных величин, имеющих одно
и то же распределение. Тогда центральная предельная теорема
имеет следующую трактовку.
Для генеральной совокупности со средней ц и дисперсией
ст5 распределение выборочных средних для всех возможных вы-
борок с возвращением объема л, составленных из этой гене-
ральной совокупности, будет нормальным со средней м и
О2 _
дисперсией —. При этом предполагается, что объем выборки
л
л достаточно большой.
Центральная предельная теорема играет исключительную
роль в статистическом анализе, поэтому имеет смысл более
подробно пояснить ее основные положения.
I. Если объем выборки л достаточно велик, то распределе-
ние выборочных средних будет почти нормальным. Данное ут-
верждение будет справедливым независимо от вила распреде-
ления генеральной совокупности, откуда извлекаются выборки.
Например, теорема будет верна, когда генеральная совокуп-
ность имеет нормальное, асимметричное или равномерное рас-
пределение.
2. Из приведенных примеров следует, что средняя генераль-
ной совокупности ц и средняя выборочных средних равны
между собой. Если генеральная совокупность имеет достаточно
181
большой размер и из нее извлечено достаточно большое коли-
чество выборок, то величина средней выборочных средних бу-
дет близка к генеральной средней.
3. Дисперсия распределения выборочных средних определя-
ется по формуле
2 О'
- П
где о2 — генеральная дисперсия;
п — объем выборки.
Величина стандартного отклонения
of=% (8.1)
•уп
называется стандартной ошибкой средней.
Возникает вопрос, какое значение п считать достаточно боль-
шим. В примере 8.2 объем выборок был небольшой (и = 4), тем
не менее распределение выборочных средних оказалось близко
к нормальному. Это произошло ввиду того, что генеральная
совокупность, откуда извлекались выборки, имела распреде-
ление, близкое к нормальному. Чем сильнее распределение ге-
неральной совокупности отличается от нормального, тем боль-
шее влияние оказывает увеличение объема выборки на точность
результата. При статистических заключениях считается, что
использование центральной предельной теоремы дает прием-
лемые результаты, если объем выборки нс меньше 30.
8.3. ИНТЕРВАЛЬНЫЕ ОПЕНКИ
ГЕНЕРАЛЬНОЙ СРЕДНЕЙ
Из распределения выборочных средних табл. 8.2 видно, что
только 37,14% всех значений статистик совпадает с истинным
значением параметра — генеральной средней. В общем случае,
когда рассматривается одна небольшая случайная выборка из боль-
шой по объему генеральной совокупности, полное совпадение
точечной опенки с истинным значением параметра будет мало-
вероятным. На практике большую ценность в статистическом ана-
лизе представляют интервальные оценки, когда определяется
интервал, внутри которого с известной вероятностью находится
истинное значение параметра. Такой интервал называется дове-
рительным интервалом, его границы — доверительными преде-
лами, а связанная с ним вероятность — доверительной вероягно-
стью, измеряющей степень доверия к этому интервалу.
182
8.3.1. Общие принципы построения
доверительных интервалов
Нахождение доверительных пределов для оценки средней
арифметической генеральной совокупности основывается на
центральной предельной теореме и свойствах площадей под
кривой нормального распределения (раздел 7.3.2). Согласно цен-
тральной предельной теореме, при определенных условиях рас-
пределение выборочных средних будет близко к нормальному.
Средняя выборочного распределения совпадает с генеральной
средней ц, откуда извлекаются выборки, а стандартная ошиб-
ка средней определяется по формуле (8.1).
Возьмем значение генеральной средней ц, а затем приба-
вим к нему и отнимем от него величину 1,96вг . Тогда, как
отмечалось в разделе 7.3.2, 95% всей площади под кривой рас-
пределения выборочных средних будет ограничено интервалом
(ц - 1,96в;; ц + 1.96 ). Это означает, что 95% всех значений
выборочных средних лежит в пределах от ц — 1,96д;
до ц + 1,96 ст-. Они являются доверительными пределами, ко-
торые соответствуют доверительной вероятности, равной 95%.
Рассмотрим геометрическую интерпретацию данного факта.
Возьмем несколько выборок, извлеченных из генеральной со-
вокупности, и рассчитаем для них средние значения х. Для каж-
дой выборочной средней построим 95-процентный доверитель-
ный интервал (рис. 8.4).
Рис. 8.4. Построение доверительных интервалов
183
Из рис. 8.4 видно, что интервалы, соответствующие выбор-
кам 1, 2, 3 и 5, содержат значение средней генеральной сово-
купности р, а в интервал для выборки 4 значение ц не попало.
В общем случае верно следующее утверждение. Если взять мно-
го выборок и для каждой из них подобным образом построить
доверительные пределы, то в среднем 95% всех интервалов бу-
дет содержать истинное значение генеральной средней. Напри-
мер, если рассмотреть 1000 выборок, то следует ожидать, что
примерно для 950 из них доверительные интервалы включат
истинное значение параметра.
В практических ситуациях, как правило, возможно получе-
ние данных, соответствующих только одной выборке опреде-
ленного размера. При этом статистические заключения отно-
сительно доверительного интервала для ц делаются на основе
единственной точечной оценки х (выборочной средней) и
а
величины стандартной ошибки средней
В общем виде доверительный интервал, соответствующий
доверительной вероятности 95%, имеет вид
jt ± 1,96
ст
(8.2)
Доверительный интервал (8.2) можно определить в терми-
нах доверительной вероятности:
Я л-1,96 <р<х + 1,96 П-
I -Jn
= 0,95.
Аналогично ставя в соответствие доверительной вероятнос-
ти площадь под кривой нормального распределения, ограни-
ченную интервалом (ц-пз--, ц+ га,) (г > 0), можно постро-
ить интервалы с заданной доверительной вероятностью.
В связи со свойствами площадей, ограниченных кривыми
нормального распределения и интервалами ц ± гст. в качестве
значения г можно рассматривать значение Z для стандартного
нормального распределения. Тогда доли площади будут равны
между собой и, в частности, равны доле площади, заключен-
ной между кривой стандартного нормального распределения
(ц = 0, о = I) и интервалом (-г, г).
Пусть Z
ХВОСТОВОЙ ’
— такое значение Z, справа от которого площадь
части кривой равна а/г. При определении довери-
тельных интервалов величину а называют уровнем доверия или
184
значимости. Доверительная вероятность определяется как
1 — а (или (1 - а) 100%).
Геометрическая интерпретация уровня значимости и дове-
рительной вероятности представлена на рис. 8.5.
Рис. в. 5. Площади под кривой нормального распределения,
соответствующие уровню доверия (значимости) а и доверительной
вероятности (1 - а): а) произвольное нормальное распределение;
б) стандартное нормальное распределение (ц = 0, в = 1)
Значения Z;J для любого а находятся из таблицы Приложе-
ния 4.
Для нахождения доверительных пределов с уровнем значи-
мости а (или доверительной вероятностью I - а) следует ум-
м °
ножить величину Z;, на стандартную ошибку средней -у- и
затем полученный результат вычесть и прибавить к значению
точечной оценки средней (т. е. выборочной средней):
i±Zal2-~. (8.3)
В соответствии с формулой доверительного интервала (8.3)
нижний и верхний доверительные пределы будут ограничивать
интервал
Смысл доверительной вероятности можно представить в виде
соотношения
p(x-Za/2-^<»<i + Za/2 (8.4)
\ л/Л 'Jn )
Кроме доверительных интервалов с вероятностью 0,95 (95%)
в практических задачах часто используются интервальные оцен-
ки с вероятностями 0,9 (90%) и 0,99 (99%).
185
В случае если а = 90%, доверительные пределы определяют-
ся соотношением
х±1,64
(8.5)
При доверительной вероятности 99% оценочный интервал
будет иметь вид
х±2,58 (8.6)
у/п
В терминах доверительной вероятности доверительные ин-
тервалы (8.5) и (8.6) будут соответственно иметь следующую
интерпретацию:
р! л-1,64 -?=<ц<л + 1,64 °
I -ул
п
Р[ х - 2,58 < Ц < X + 2,58-Я=
. -Ул -Ул
= 0,9(90%);
= 0,99(99%).
Очевидно, чем больше доверительная вероятность (степень
уверенности в том, что истинное значение генеральной сред-
ней принадлежит соответствующему доверительному интерва-
лу), тем шире доверительный интервал. Это в свою очередь оз-
начает уменьшение точности оценивания.
В практических приложениях при построении доверитель-
ных интервалов выделяют два случая:
значение стандартного отклонения генеральной совокупно-
сти о известно;
значение о неизвестно.
8.3.1.!. Вычисление доверительных интервалов
при известном генеральном стандартном отклонении
На практике иногда возникают ситуации, когда значение
генеральной средней приходится оценивать много раз подряд.
При этом значение стандартного отклонения генеральной со-
вокупности о может быть вычислено заранее и есть основание
предполагать, что оно не изменяется. Тогда при оценке ц имеет
смысл использовать это известное значение, чтобы не оцени-
вать его заново по каждой новой выборке.
Пусть генеральная совокупность распределена нормально со
средней ц и стандартным отклонением о. Тогда стандартная
186
ошибка средней равна = ~г~ (п ~ объем выборки). По цснт-
-\Г/1
ральной предельной теореме распределение выборочных сред-
них будет нормальным со средней ц и стандартным отклонени-
CI
ем - ~г~ •
•Jn
Необходимым условием выполнения указанных свойств яв-
ляется также неограниченность размера генеральной совокуп-
ности, откуда извлекаются выборки. На практике часто огра-
ниченная, но большая по объему совокупность теоретически
рассматривается как бесконечная. При этом предполагается, что
эта гипотетическая совокупность формируется под постоянным
влиянием тех же факторов, что определяли состав, свойства и
структуру действующей ограниченной совокупности.
Общая формула для построения доверительных пределов в
случае бесконечной генеральной совокупности и известного
значения а имеет вил (8.3), а се частные случаи для довери-
тельных вероятностей 90, 95 и 99% — соответственно вил (8.5),
(8.2) и (8.6). Объем выборки п при этом не оказывает суще-
ственного влияния на адекватность результатов опенки, полу-
ченных на основе данных формул.
Пример 8.5. Компания производит определенный тип электри-
ческих приборов. Ранее были проведены исследования сроков
службы приборов, которые показали, что стандартное откло-
нение ст для большой партии приборов составляет 50 ч. Из про-
изведенной партии была извлечена выборка объемом п = 10
приборов, для которых сроки службы имели следующие значе-
ния, выраженные в часах:
308, 419, 432, 362, 302, 440, 430, 375, 383.
На основе выборочных данных определим доверительные
интервалы для среднего срока службы прибора при вероятнос-
тях 90. 95 и 99%.
Вычислим выборочную среднюю:
х = (308 + 419 + ... + 383)/1О = 384 ч.
Доверительные пределы с вероятностью 90% вычисляются
по формуле (8.5):
384 ± 1,64
50
/10
= 384 ±16 = 368-ь 400.
187
Отсюда с вероятностью 90% можно утверждать, что истин-
ное значение среднего срока службы прибора содержится в
интервале от 368 до 400 ч.
По формуле (8.3) вычисляется интервал с доверительной
вероятностью 95%:
384 ±1,96
50
716
= 384 131 = 353 + 415.
Следовательно, с вероятностью 95% можно быть уверен-
ным, что средний срок службы для всей партии приборов на-
ходится в пределах от 353 до 415 ч.
Определим доверительный интервал, соответствующий ве-
роятности 99% (формула (8.6)):
38412,58 В =384141 = 343 + 425.
^10
Ввиду бесконечности генеральной совокупности можно счи-
тать, что случайные выборки извлекаются из нее по принципу
“с возвращением" (повторная выборка). Однако на практике ча-
сто требуется проводить статистические заключения для огра-
ниченной генеральной совокупности, имеющей заданный обьем
N. В этом случае имеет место отбор элементов в выборку по прин-
ципу “без возвращения элементов в генеральную совокупность”
(бесповторная выборка). Это в свою очередь влияет на величину
стандартной ошибки средней. Она уменьшается и принимает вид
о । N — п
@ г Г Л J ''
* .'п У N-1
(8.7)
V Л N-n
Корректирующий множитель J——- называется поправ-
V N -1
кой на конечность генеральной совокупности. Его включение в
формулу для вычисления стандартной ошибки средней являет-
ся обязательным. Однако если объем выборки п мал по сравне-
нию с размером генеральной совокупности N, значение кор-
ректирующего множителя будет близко к единице и он не
повлияет на стандартную ошибку средней. При расчетах во всех
случаях, когда и<0,05Х корректирующий множитель полага-
ется равным единице. Он учитывается, когда n>0,05/V, т. е. объем
выборки составляет более 5% от объема генеральной совокуп-
ности.
188
Общая формула для доверительных пределов при условии
л>0,057¥будет иметь вид
<«»
-Jn i N -1
Пример 8.6. Рассмотрим ситуацию примера 8.5. Предположим,
что партия произведенных приборов имеет размер W = 100,
тогда объем выборки п — 10 будет превышать 5% объема гене-
ральной совокупности: n/W = 0,1 >0,05. Поэтому при определе-
нии доверительных пределов следует учитывать поправку на
конечность генеральной совокупности. Вычислим стандартную
ошибку средней по формуле (8.7):
о [N-n= 50 1100-10 _ 50 190 = 50
7Й V/V-l ~7ioY 100-1 "710^99 3,16*
= ,0,909 = 50 0.95 = 15.82 • 0,95 = 15.03ч.
3,16 3,16
Используя формулу (8.8), найдем доверительные пределы
(измеряемые в часах), соответствующие доверительным веро-
ятностям 90, 95 и 99%:
364 ± 1,64 15,03 = 384 ± 25 = 359 + 409,
364 ± 1,96 • 15,03 = 384 ± 29 = 355 + 413,
364 ± 2,58 15,03 = 384 ± 39 = 345 + 423.
8.3.1.2. Вычисление доверительных пределов при неизвестном
генеральном стандартном отклонении. Использование
t-распределения Стьюдента
Пусть исследуется генеральная совокупность, распределен-
ная по нормальному закону, и известно значение стандартно-
го отклонения а. В этом случае независимо от объема выборок п
распределение выборочных средних х будет нормальным со
о о In —п
стандартной ошибкой (или = ~Г Л'1Я ко’
нечной генеральной совокупности) и средней, равной гене-
ральной средней ц. Тогда, как было показано в 7.3.3, величина
Л g будет иметь стандартное нормальное распределение.
Заметим, что нормальность Z получается ввиду того, что из
189
нормально распределенной величины выборочной средней х
вычитается постоянная и полученная разность делится на по-
стоянную.
Полагая Z = Zy, где а — заданная доверительная вероят-
ность. по формулам (8.3) и (8.8) можно построить соответ-
ствующий доверительный интервал для оценки значения р.
Предположим теперь, что значение о неизвестно. В этом слу-
чае оно заменяется соответствующей статистикой, т. е. выбо-
рочным стандартным отклонением х, и тогда стандартная ошиб-
ка средней вычисляется по формулам
(для бесконечной генеральной совокупности),
- s Z2*
5з ~ Tn \ n-i
(для конечной генеральной совокупности).
Полагая, что объем выборки постоянный, рассмотрим те-
X —ц
перь величину = —" . Очевидно, знаменатель этого выра-
жения уже не будет постоянным, так как значение si не
является одинаковым для всех различных выборок заданного
объема. Поэтому величину Z в этом случае нельзя считать
нормально распределенной. Она подчиняется другому зако-
ну распределения, который получил название /-распределе-
ния Стьюдента.
Обозначение Z, используемое для стандартной нормальной
величины, заменяется буквой /, которая обозначает отноше-
ние
Величина (8.9) распределена по закону /-распределения. В
действительности существует целое семейство /-распределений.
Каждое отдельное распределение этого семейства соответству-
ет фиксированному объему выборки л. Степень отклонения
/-распределения от нормального связана с объемом выборки
л, для которой вычисляется величина стандартного отклоне-
ния х Чем меньше объем выборки, тем больше отклонение от
нормальности.
При малых выборках (л<30) использование распределения
Z для интервальных оценок средней возможно только при из-
вестном о.
190
Кривая /-распределения (рис. 8.6) имеет симметричную плос-
ковершинную форму (см. раздел 4.3). Чем меньше объем вы-
борки п, тем более пологой будет кривая /-распределение.
С ростом объема выборки кривая /-распределения сжимается
по оси абсцисс и вытягивается вдоль оси ординат. При л > 30
она почти полностью совпадает с кривой стандартною нор-
мального распределения.
Рис. 8.6. Сравнение кривых стандартного нормального распределения
и /-распределения
Как видно из рис. 8.6, в “хвостовых" частях /-распределения
заключены большие плошали по сравнению с соответствую-
щими “хвостами" распределения Z Поэтому при фиксирован-
ной доверительной вероятности интервал, построенный на
основе /-распределения, будет шире соответствующего интер-
вала, вычисленного на основе распределения Z. Отсюда при
неизвестном о и л<30 использование распределения Z ведет к
существенным погрешностям. Наоборот, с увеличением объе-
ма п /-распределение будет приближаться к стандартному нор-
мальному закону.
В практических приложениях считают, что в случае большой
выборки, т. е. когда п > 30, /-распределение почти совпадает со
стандартным нормальным распределением. Поэтому если вы-
борка большая и о неизвестно, то для построения доверитель-
ных интервалов можно пользоваться распределением Z, а в
качестве стандартной ошибки средней рассматривать статис-
s
тику Хх —~ . Тогда для бесконечной генеральной совокупнос-
ти формула вычисления доверительных пределов с доверитель-
ной вероятностью 1 — а имеет вид
* S f v vi
x±Za/2 г или \ x-Za/2~f=-,x+Za,2 > . (8.10)
УЛ I л/Л Ул I
191
В случае конечной генеральной совокупности объема Л/при
условии n/N>0,05 следует учитывать поправку на конечность
генеральной совокупности:
, _ s । N -п
X±ZanTn^- ,8">
I
Пример 8.7. На фирме работают несколько тысяч служащих.
Предполагается, что показатели их недельных заработков рас-
пределены нормально. Составлена случайная выборка из 49 слу-
жащих. Средний недельный заработок служащих в выборке ра-
вен 110 долл, со стандартным отклонением 10,5 долл. Требуется
найти 95-процентные доверительные пределы для среднего не-
дельного заработка всех служащих фирмы.
В данном случае генеральную совокупность составляют все
служащие фирмы. Ее объем можно считать бесконечным. Обьсм
выборки п = 49 превышает 30, следовательно, можно исполь-
зовать формулу (8.10) для вычисления искомых пределов. Ис-
ходными данными задачи будут х = 110 долл., s - 10,5 долл.,
I — а = 0,95, Z,,= 1,96. Получим
110± 1,96 10,5 = 11011,96—= 11011,96-1,5 =
.49 7
= 11012,94 = 107,06+112.94.
Таким образом, с уверенностью на 95% можно утверждать,
что средний недельный заработок служащего фирмы заключа-
ется в пределах от 107 до 113 долл.
Пример 8.8. Пусть рассматривается та же ситуация, что и в
предыдущем примере, только общее число служащих фирмы
составляет W= 645 человек. В этом случае n/N - 49/645 = 0,07>0,05.
Поэтому для вычисления 95-процентных доверительных пре-
делов следует учитывать поправку на конечность генеральной
совокупности, т. е. воспользоваться формулой (8.11):
110± 1,96 10,5 /145 49 = 11011,961,5— =
V49 V 145-1 12
= 11012,94 0,82 = 11012,41 = 107,6+112,4.
С вероятностью 95% можно утверждать, что средний недель-
ный заработок служащего фирмы находится в пределах от 108
до 112 долл.
192
В статистике с каждым отдельным /-распределением связы-
вают определенное понятие — число степеней свободы, кото-
рое в свою очередь тесно связано с объемом выборки. Число
степеней свободы определяется при нахождении различных ста-
тистик, например средней, дисперсии и т. д. Под числом степе-
ней свободы понимается количество данных, которые входят в
формулу для вычисления статистики и которые могут свободно
изменяться, сохраняя при этом заданную величину статистики.
Например, число степеней свободы для средней арифмети-
ческой будет df = п - 1 (где df — обозначение числа степеней
свободы). Действительно, пусть выборка состоит из четырех
значений х(, х2, х3, х4, а средняя х = 5. Это означает, что верно
соотношение -1 *- -2 £ = 5. Очевидно, можно задавать лю-
бые три значения х, четвертое значение при этом всегда будет
единственным, так как вычисляется из данного равенства в
качестве неизвестного. Поэтому в данном случае df = 4 - 1 = 3.
При вычислении площадей, заключенных под кривыми
/-распределения, используется специальная таблица, подобная
таблице для распределения Z. Она представлена в Приложении 5.
Если в Приложении 4 указаны доли общей площади под кри-
вой, заключенные между ц = 0 и Z>0, то в аналогичной табли-
це для /-распределения представлены доли площади между />0
и +оо. По сравнению с таблицей для распределения Zтаблица
для /-распределения сильно сжата. Имеется в виду, что каждую
строку таблицы Приложения 5 можно развернуть в целую таб-
лицу, эквивалентную таблице для распределения Z Сжатие
каждой таблицы в одну строку достигается путем указания зна-
чений /лишь для некоторых долей плошали кривой. Значения
долей соответствуют столбцам таблицы Приложения 5, а ее
строки — числу степеней свободы. Как видно, при увеличении
числа степеней свободы характеристики /-распределения при-
ближаются к характеристикам стандартного нормального рас-
пределения Z. В последней строке для df = +«> эти характерис-
тики полностью совпадают.
Например, в этой строке доле площади, равной 0,01, соот-
ветствует значение / = 2,326. По таблице Приложения 4, учи-
тывая округление, найдем, что доля площади, заключенной
между ц = 0 и Z = 2,33, равна 0,4901, т. е. 0,5 — 0,01 = 0,49.
Пусть — такое значение />0, которое отсекает долю
площади под “хвостовой” частью кривой /-распределения, со-
ответствующего числу степеней свободы df = п — 1, которая
193
равна а/2. По таблице площадей под кривыми /-распределения
(Приложение 5) значение г и_| находится на пересечении
строки, соответствующей df = п — I, и столбца, соответствую-
щего а/2.
Тогда доверительные пределы при доверительной вероят-
ности I — а и объеме выборки п находятся по формуле
(8.12)
УЛ
Доверительные пределы ограничивают интервал
(- * 5 5
х ^а/2л-1 /" • ±^а/2л-1 •
\ УЛ УЛ /
Еще раз отметим, что формулой (8.12) следует пользовать-
ся, если значение а неизвестно и л<30. В этой связи /-распреде-
ление получило название распределения малых выборок.
Пример 8.9. Предполагается, что значения уровня напряжения
на выходе трансформатора подчиняются нормальному закону.
Было произведено 18 измерений выходного напряжения:
10,85; 11,4; 10,81; 10,81; 10,23; 9,49; 9,89; 10,11; 10,57; 11,21;
10,1; 11,22; 10,31; 11,24; 9,51; 10,52; 9,92; 8,33.
Требуется найти 95-процентные доверительные пределы для
среднего уровня выходного напряжения трансформатора.
Точечная оценка для р:
- 10,85+ 11,4+ ... + 8,33
х =--------------------= 10,331.
18
Точечная оценка для о:
I (10,85 -10,331)2 + (11.4 -10,331)2 +... + (8,83 -10.331)2 _
s =,-----------------------------------------------= о,/о/.
V 17
Заданная доверительная вероятность I — а = 0,95. Отсюда
а = 0,05, т. е. а/2 = 0,025. Число степеней свободы df = л - 1 =
= 18 - 1 = 17. По таблице Приложения 5 найдем значение
/оои.17 ~ 2.Н» которое находится на пересечении строки
df - 17 и столбца 0,025.
По формуле (8.12) определим доверительные пределы с
вероятностью 95%:
10,331 ±2,11 9^ = 10,331 ±0,381 = 9,95 +10,71.
-./18
194
Следовательно, на 95% можно быть уверенным, что сред-
ний уровень напряжения на выходе трансформатора заключен
в пределах от 9,95 до 10,71 В-
Пусть выборка объема л<30 извлекается из конечной гене-
ральной совокупности размера N. Если п a 0.05/V, то в формулу
In -п
(8.10) следует ввести корректирующий множитель — п0‘
правку на конечность генеральной совокупности:
s W-п
•»±'а/2и.-1
(8.13)
Пример в. 10. Дирекция электростанции хочет оценить средний
недельный расход угля в течение года. Для этой цели было ото-
брано Ю недельных показателей расхода угля из I50 показателей,
накопленных за 3 года. Средний показатель по выборке оказался
равным х - 11 400 т со стандартным отклонением s = 700 т.
Пользуясь 95-процентными доверительными пределами, дать
оценку среднего недельного расхода угля на электростанции.
Объем выборки п удовлетворяет условию л>0,05/У, так как
Ю>0,05-150 = 7,5. Следовательно, для вычисления доверитель-
ных пределов можно воспользоваться формулой (8.I3).
Вычислим оценочное значение для стандартной ошибки
средней:
з Г/У-л_7ОО П50-10_ 700 |Т40
/nNN-i 710 V 150-1 3,1627144
= 221,38 0,97 = 214,59.
По таблице Приложения 5 определим значение t „ , при
л= 10иа = 0,05:гооИ;, = 2,262.
По формуле (8.13) найдем пределы:
11400 +2,262 • 214,59 = 11400 ±485,4 = 10914,6-11885,4.
Таким образом, с вероятностью 95% можно быть уверен-
ным, что средний недельный расход топлива — от 10 914,6 до
И 885,4 т.
195
8.3.1.3. Общие правила определения доверительных
интервалов
В итоге сформулируем несколько правил вычисления дове-
рительных интервалов для генеральной средней ц.
1. Рассматривается случайная выборка объемом п, полученная
из генеральной совокупности, распределенной по нормальному
закону. Известно значение стандартного отклонения генеральной
совокупности о. Пусть генеральная совокупность либо бесконеч-
на, либо конечна и имеет объем N, но при этом выполняется
условие л<0,05У Тогда доверительный интервал с уровнем дове-
рия а (т. е. до не ригельной вероятностью 1 — а) имеет вид
.г ± Za/2 • -т—.
Ул
2. Рассматривается случайная выборка объема п, полученная
по принципу “без возвращения” в генеральную совокупность.
Пусть генеральная совокупность нормальна, конечна (объем
Л) и л>0,05У Известно значение а. Тогда доверительный ин-
тервал с уровнем доверия а имеет вид
СТ I N -п
/л N .N^\'
3. Рассматривается случайная выборка, объем которой л>30.
Она получена из нормальной генеральной совокупности. Пусть
генеральная совокупность либо бесконечна, либо имеет объем
N при условии л<0,05У Значение о неизвестно. Вычислим вы-
борочное значение стандартного отклонения s. Тогда довери-
тельный интервал с уровнем доверия а имеет вид
x±Z •
ЛХГ-а/2
4. Пусть из конечной нормальной совокупности объема N
извлекается бесповторная выборка размера л>30. При этом
лй 0,05Л'и значение а неизвестно. Вычислено выборочное стан-
дартное отклонение з. Тогда доверительней интервал с уров-
нем доверия а имеет вид
a±Z„,2
з - л
5. Пусть объем случайной выборки л< 30. Генеральная сово-
купность, откуда получена выборка, распределена по нор-
196
мальному закону. Она бесконечна или конечна с объемом N.
При этом выполняется условие п <0,05N. Значение о неизвест-
но и вычислено выборочное значение з. Тогда доверительный
интервал с уровнем доверия а имеет вид
л1П
6. Пусть случайная выборка, полученная по принципу “без
возвращения”, имеет объем п< 30. Генеральная совокупность
нормальна и имеет конечный объем N, а также выполняется
условие п> 0,05М Значение ст неизвестно, и вычислено выбо-
рочное значение х. Тогда доверительный интервал с уровнем
доверия а имеет вид
з \N -п
Х±Гп . ----
л V N-1
7. В случае если распределение генеральной совокупности
достаточно близко к нормальному, для вычисления довери-
тельных пределов можно использовать первые шесть правил.
Если распределение генеральной совокупности сильно отли-
чается от нормального (например, сильно асимметрично или
равномерно), то первые четыре правила также могут быть при-
емлемыми на практике. В этом случае использование правил 5
и 6 для малых выборок (п< 30) не имеет смысла.
8.3.1.4. Объем выборки и точность интервальной
оценки средней
Точность оценки средней, т. е. ширина доверительного ин-
тервала, зависит от объема выборки. Очевидно, с увеличением
_ з
объема п значение стандартной ошибки средней 5;=-т—
уменьшается. Это в свою очередь приводит к сужению дове-
5
рительного интервала ,x±Zal2-j— или к повышению точности
* у1П
оценки средней при заданной доверительной вероятности. Отсю-
да следует, что при достаточно большом п доверительный ин-
тервал будет настолько узким, что его можно рассматривать в
качестве точной генеральной средней ц. Однако на практике
получение выборки большого объема сопряжено со значитель-
ными затратами на исследования. Поэтому имеет смысл оп-
197
ределить такой объем выборки л, которого было бы достаточ-
но для обеспечения допустимой ошибки.
Пусть Е = Za/2 — допустимая ошибка. Выразим отсюда
-Jn
значение п:
Z2 s2
(814)
С
Таким образом, если известно значение выборочного стан-
дартного отклонения s (например, в результате предваритель-
ных или пробных исследований), то, задаваясь доверитель-
ной вероятностью 1 — а и допустимой ошибкой Е, с помощью
выражения (8.14) можно вычислить необходимый объем вы-
борки.
Следует отметить, что иногда может быть известно значе-
ние генерального стандартного отклонения о. В этом случае
при вычислении п в выражение (8.14) вместо ? следует под-
ставить о2.
Пример В.11. Торговая фирма хочет открыть супермаркет на
территории некоторого округа. Для проведения маркетинговых
исследований руководству фирмы необходимо иметь инфор-
мацию о головых доходах семей, живущих в данном округе. Пред-
варительные обследования показали, что доходы варьируются
в пределах от 9000 до 29 000 долл. Однако для более надежных
прогнозов необходима точность в размере 200 долл, с довери-
тельной вероятностью 95%. Требуется определить, сколько се-
мей нужно обследовать, чтобы получить заданную точность
оценки. Для определения стандартного отклонения з было про-
ведено пробное обследование 50 семей. В результате была полу-
чена оценка стандартного отклонения s = 3000 долл.
По формуле (8.14) найдем необходимый объем выборки:
п =
1,962-30002
2ОО2
= 864,36.
Очевидно, выборка из 865 семей может обеспечить задан-
ную ошибку.
Следует отметить, что точность оценки необходимого объе-
ма п будет зависеть от достоверности информации о величине
стандартного отклонения г.
198
8.3.2. Доверительные интервалы для разности средних
двух генеральных совокупностей (случай двух больших
независимых выборок)
Рассмотрим две различные генеральные совокупности (тео-
ретически бесконечные): совокупность 1 и совокупность 2. Пусть
совокупность 1 имеет параметры ц] и о^, а совокупность 2 — ц2
и о22. Булем из каждой генеральной совокупности извлекать не-
зависимые случайные выборки постоянных объемов. При этом
процедура формирования выборок строится следующим обра-
зом: вначале извлекается случайная выборка постоянного объема
nf из совокупности I, затем независимо от нее из совокупнос-
ти 2 извлекается случайная выборка постоянного объема л, и
т. д. Если выборки большие, т. е. л, > 30 и л2£ 30, то, очевидно,
по центральной предельной теореме независимо от законов рас-
пределения генеральных совокупностей 1 и 2 соответствующие
распределения выборочных средних будут нормальными с па-
ст, ст,
раметрами ц , -j-L и ц2, .
У я| у п2
Пусть первое из выборочных распределений характеризу-
ет случайную величину Хр а второе — Х2. Рассмотрим раз-
ность случайных величин X — Хг Очевидно, она является
2 2
нормальной с параметрами - ц2 и °L + (см. раздел 6.7.2).
«1 «2
Это означает, что распределение разностей выборочных сред-
них двух генеральных совокупностей нормальное и имеет
„2 _,2
2 СТ. &•>
параметры = ц, - ц2 и о,- =-»- + -1.
Пусть имеется информация только о двух случайных неза-
висимых выборках, полученных из рассматриваемых генераль-
ных совокупностей 1 и 2. Так, выборка из совокупности 1 имеет
объем Лр среднее значение х( и дисперсию з(2, а выборка из
совокупности 2 — объем я , среднее значение х и дисперсию
2 4 2
V-
Построим доверительный интервал для разности генераль-
ных средних ц1 - ц2. Очевидно, точечной оценкой для нее бу-
дет разность выборочных средних x(-x2, а оценкой стандарт-
I? 7
ной ошибки разности — Х.,, ял~ + ~-
V"l П2
199
Отсюда получаем, что доверительный интервал для разно-
сти средних двух генеральных совокупностей имеет вид
(xt-x2)±Za/2 - + ^- (8.15)
V ”| П2
или
| 9* I Т*" <S*
(X! - х2) - Zal2 > ' + < р, -ц2 < (Л, - х2) + Zal2 р- + - . (8.16)
1J Л] /Ij J Л| л>
Пример В. 12. Фирма имеет филиалы в двух разных городах. Ру-
ководству фирмы необходимо выяснить, как отличаются друг
от друга средние почасовые ставки малоквалифицированных
рабочих в этих филиалах. В первом филиале была сделана слу-
чайная выборка из 200 рабочих. Для нее были вычислены сле-
дующие значения статистик: х, = 8,93 долл., 5, = 0,4 долл.
Во втором филиале случайная выборка имела объем
Wj= 175, статистики: х2 = 9,1 долл., = 0,6 долл.
Определим 95-процентный доверительный интервал для
разности средних. По формуле (8.15) имеем
(8,93-9,1) ± 1,96д!^ + —2
I 200 175
= -0,17 ±1,96 0,053 =
= -0,17 ±0,104 = -0,274 + -0,066.
Как видно, с вероятностью 95% можно утверждать, что сред-
няя ставка во 2-м филиале превышает среднюю ставку в 1-м
филиале на 0,07—0,27 долл.
8.3.3. Доверительные интервалы для разности средних
(случай двух малых независимых выборок)
Если при интервальной оценке разности двух генеральных
средних используются малые выборки (л^ЗО, л2<30), то рас-
пределение разностей выборочных средних может значительно
отличаться от нормального. Например, это будет в том случае,
когда распределения исходных генеральных совокупностей силь-
но отличаются от нормального. Как известно, при малых вы-
борках большую точность при оценке средних лает /-распреде-
ление. Формула для вычисления доверительных интервалов в
этом случае будет иметь вид
200
(xt
(8.17)
где /— значение /, соответствующее уровню значимости
а й числу степеней свободы, которое вычисляется по фор-
муле
И| -1 л2 -1
Результаты вычислений по формуле (8.18) следует округ-
лять до целой части, так как число степеней свободы характе-
ризуется целым положительным числом.
Пример В. 19. Руководство компании по перевозке грузов хочет
определить, какой тип покрышек для грузовых автомобилей
более надежен в эксплуатации. В результате проведенного ана-
лиза рынка покрышек были отобраны два типа: тип 1 и тип 2.
Для того чтобы осуществить выбор между ними, было решено
провести проверку покрышек на специальном оборудовании.
Покрышки разных типов ставились на задние колеса грузовика.
Грузовик заезжал задними колесами на свободно вращающие-
ся специальные металлические валики. После включения пере-
дачи колеса катились по валикам, что приводило к быстрому
износу покрышек. При этом засекалось точное время, за кото-
рое каждая покрышка приходила в негодность. Обстоятельства,
связанные со сроками и ресурсами, позволили проверить только
по 15 покрышек каждого типа. В результате испытаний были
получены две независимые выборки, каждая из которых вклю-
чала 15 временных значений.
После обобщения данных каждой выборки были вычисле-
ны средние значения и стандартные отклонения (в часах):
х, = 3,33, з, = 0,68; х2= 3,98, з2 = 0,38.
Требуется определить 90-процентный интервал для разно-
сти ц. - р2, где ц, характеризует среднее время до полного
износа для всех покрышек типа I, а ц2 — для всех покрышек
типа 2.
201
Для того чтобы использовать формулу (8.17), вначале необ-
ходимо определить число степеней свободы или вычислить
выражение (8.18):
0,682 О!38* f
^__L15 15 .
Г 2 Т2 Г 2 П2
О,682 О,382
15 15
14 + 14
0.04042
= 21,9.
0,0000679 + 0,00000662
Округляя, получим <#= 21. Используя таблицу г-распреде-
ления (Приложение 5), найдем /00, 2| = 1,721 (а = 1).
По формуле (8.17) вычислим доверительный интервал:
О^2.О.382 =Ч)1б5±о,35 = -1 + Ч),3.
(3,33- 3,98) ± 1,721..
V 15 15
Таким образом, среднее время до полного износа покры-
шек типа 2 превышает среднее время до полного износа по-
крышек типа 1 в пределах от 0,3 ч (т. е. 18 мин) до 1 ч с вероят-
ностью 90%. Выбор очевиден — покрышки типа 2 имеют
больший срок эксплуатации.
На практике в некоторых случаях следует учитывать условие
равенства дисперсий исходных генеральных совокупностей,
т. е. о « о » о. Например, такая ситуация может возникнуть
при исследовании производственных процессов с долговремен-
ным циклом производства. Тогда, основываясь на прошлых на-
блюдениях, с достаточной степенью достоверности можно ут-
верждать, что дисперсия генеральной совокупности 1 равна
дисперсии генеральной совокупности 2.
Если известно, что обе генеральные совокупности имеют
одинаковые дисперсии, то возникает проблема оценки общей
дисперсии на основе выборочных дисперсий 1/и $22. В качестве
аппроксимирующего значения можно рассматривать среднюю
взвешенную величину значений 5(2и s22’
52 = + (п2~Од2 (8.19)
«I + п2 -1
Заметим, что комбинированная из выборочных дисперсий
величина ? будет ближе к дисперсии той выборки, которая имеет
больший объем. Если объемы выборок равны (л, = л, = л), то
комбинированная выборочная дисперсия равна средней ариф-
202
метической значений S(2 и s2. Стандартная ошибка разности сред
них примет вил
f_ + £_=j ± + -L. (8.20)
"1 "2 V "I п2
Число степеней свободы, соответствующее статистике t, в
данном случае равно df = л) + я - 2. С учетом выражения (8.20)
формула для доверительных интервалов имеет вид
(8.21)
(-4 “ *2) ^а/2;п,+л,-2
где ? вычисляется по формуле (8.19).
Следует отметить, что в случае равенства дисперсий вычис-
ление числа степеней свободы для статистики t значительно
облегается. На практике, если не оговаривается условие нера-
венства дисперсий (о,2 * о22), можно полагать, что они равны.
При этом пофешность будет несущественной.
Пример 8.14. Пусть рассматривается ситуация, представленная
в примере 8.13, причем предполагается, что дисперсии гене-
ральных совокупностей сроков износа для покрышек типа I и
типа 2 равны. Определить 90-процентный доверительный ин-
тервал для ц, - щ.
По формуле (8.21) вычислим комбинированную выбороч-
ную дисперсию:
2 (15-1)0,682+(15-1)0,3«1 8,495
15 + 15-2 28
Определим стандартную ошибку разности средних:
j = Дзоз = 0,55 ч.
По таблице Приложения 5 найдем значение 1, соответству-
ющее числу степеней свободы df=n} + я2 — 2 = 28, при уровне
значимости а = 0,01: = 1,701.
Используя формулу (8.21), найдем доверительный интер-
вал:
1 1 2
(3,33 - 3,98) ± 1,701 0,55 J - + — = -0,65 ± 1.701 0,2 =
V15 15
= -0,65 ± 0,34 = -0,99 + -0.31.
203
Как видно, вычисленный доверительный интервал незна-
чительно отличается от интервала, полученного в примере 8.15.
Следует отметить, что он немного уже, т. е. использование сред-
ней взвешенной дисперсии дает более точную интервальную
оценку разности генеральных средних.
8.3.4. Объем выборки и допустимая ошибка оценки
разности генеральных средних
В выражении (8.15) величина Za/2л L+i прибавляется к
V И| П2
точечной оценке разности генеральных средних и вычитается
из нее. Обозначим Е = 2ay2.i-L+ - . Тогда Е характеризует
V Л1 Л2
ошибку интервальной оценки или ширину доверительного
интервала. Очевидно, чем меньше Е, тем уже доверительный
интервал и меньше погрешность оценки. Зададимся допусти-
мым значением ошибки Е и предположим, что обе выборки
имеют одинаковый о^ъем: л( = п2~ п. Определим в этом случае,
какое значение объема л обеспечивает заданную ошибку Е.
Имеем
E = Za/2M + ^
V л л
(8.22)
Из (8.22) выразим л:
п = (8.23)
Е2
Отметим, что общий объем двух выборок равен л( + л2 = 2л.
Пример В. 15. Две научно-исследовательские лаборатории не-
зависимо друг от друга занимаются разработкой и производ-
ством таблеток для больных артритом. Таблетки предназначены
для снятия боли в период приступов болезни.
Были проведены испытания действия обоих типов таблеток.
Действие первых типов таблеток было опробовано на 50 боль-
ных. Оказалось, что он снимает боль в среднем в течение 8,5 ч
(х,) со стандартным отклонением 1,8 ч (S]). Для таблеток, про-
изведенных второй лабораторией и действие которых было оп-
робовано на 40 больных, результаты такие: х2 = 7,9 ч, х2 = 2,1 ч.
204
Определим ошибку разности двух средних для 95-процент-
ного доверительного интервала:
г = 1.96, /+ — = 1,96/0,0648 + 0,1102 = 1,96 0,418 = 0,82.
*’* У 50 50 4
Определим доверительный интервал:
(8,5 - 7,9) ±0,82 = 0,6 ±0,82 = -0,22+1,42.
Как видно, полученная точность недостаточна для досто-
верного сравнительного анализа эффективности обоих типов
таблеток.
Пусть требуется, чтобы допустимая ошибка не превышала
0,5 ч. По формуле (8.23) вычислим, каков должен быть в этом
случае объем каждой выборки:
1,962(1,82 + 2.I2) 3,842(3,24 + 4,452) 3,842-7,692 110,
О,52 0,25 0,25
Таким образом, для получения нужной точности следует
опробовать действие таблеток каждого типа на 118 больных. Об-
щая выборка составит 236 больных.
8,4, ОЦЕНКА ДОЛЕЙ
8.4.1. Распределение выборочных долей (пропорций)
Под долей (или пропорцией) понимается относительная или
процентная характеристика, определяющая часть элементов
совокупности, обладающих некоторым признаком (свойством).
В статистическом анализе часто требуется оценить доли появ-
ления “успехов” в генеральной совокупности. Например, ста-
тистические обследования проводятся правительством с целью
определения уровня безработицы в стране, который выража-
ется как процент безработных по отношению к активному на-
селению.
Чтобы определить точечную оценку доли, следует подсчи-
тать число “успехов” в совокупности (т. е. выявить число эле-
ментов, обладающих данным признаком), а затем вычислить
отношение этого числа к общему количеству элементов в сово-
купности. При этом должно выполняться условие дихотомнос-
ти генеральной совокупности. Это означает, что ее можно раз-
205
бить на две части: те элементы, которые обладают данным при-
знаком, и все остальные элементы, которые им не обладают
(например, все активное население делится на безработных и
имеющих работу на данный момент времени). Можно пока-
зать, что выборочная доля является наилучшей оценкой гене-
ральной доли, т. е. удовлетворяет критериям несмешенности,
эффективности, состоятельности и достаточности.
Рассмотрим следующую ситуацию. Для выявления обществен-
ного мнения относительно усиления мер по охране окружаю-
щей среды правительство крупного региона организовало со-
циологической опрос. Были опрошены 2000 человек, из которых
1600 высказались за принятие более жестких мер. Точечная оцен-
ка доли населения региона, которая выступает за принятие более
жестких мер, такова: р = 1600/2000 = 0,8. Иначе говоря, при-
близительно 80% всего населения региона выступают за ужес-
точение мер по охране окружающей среды.
Как было показано в разделе 6.4, распределение вероятнос-
тей числа “успехов” характеризуется биномиальным законом
распределения. Математическое ожидание и стандартное откло-
нение биномиальной случайной величины определяются соот-
ветственно по формулам ц = пр, а2 = npq, где п — число испы-
таний, р — вероятность появления “успеха”, q = 1 — р —
вероятность “неудачи”.
Величина ц = пр отражает среднее ожидаемое число “успе-
хов ”. Для того чтобы получить соответствующую долю, эту ве-
личину следует разделить на п: пр/п = р.
Величина р, таким образом, определяет ожидаемую долю
или, что то же самое, среднюю распределения выборочных
долей: = р.
Аналогично для вычисления стандартного отклонения рас-
пределения выборочных долей величину о = yjnpq следует раз-
делить на п:
_ Jnpg _ Ipq _ Ip(l-p)
* п У п N п
Величина о? называется стандартной ошибкой доли.
В отличие от средней арифметической, расчет которой про-
изводится в непрерывном масштабе, при вычислении доли
получаются дискретные данные, связанные с подсчетом коли-
чества “успехов”. Распределение этих данных подчиняется би-
номиальному закону, т. е. является дискретной случайной ве-
личиной. Поэтому теоретически при оценке долей следует
206
пользоваться биномиальным распределением. Однако на прак-
тике использование биномиального распределения сопряжено
со значительными трудностями как теоретического, так и вы-
числительного характера. В разделе 7.3.4 отмечалось, что при
определенных условиях (лр>5 и л(1 - р)>5) биномиальное рас-
пределение достаточно точно приближается к нормальному. Это
позволяет применять центральную предельную теорему, рас-
сматривая при больших выборках распределение выборочных
долей как нормальное со средней Цр = р и стандартным откло-
_ jp(l-p)
нением ------------
V л
Величина генеральной доли р является оцениваемой вели-
чиной. Поэтому на практике в выражение для стандартной
ошибки доли вместо р подставляется ее точечная оценка р:
5р ~
Р(1 ~ Р)
л
(8.24)
Величина является оценочным значением стандартной
ошибки доли.
8.4.2. Доверительные интервалы для доли
Доверительные интервалы для доли генеральной совокуп-
ности можно найти по формуле, аналогичной формуле (8.3)
для генеральной средней:
P±Zal2s-p. (8.25)
где р — выборочная доля (точечная оценка генеральной доли);
з. — оценочное значение стандартной ошибки доли;
п — объем выборки;
а — уровень доверия (значимости);
Z „ — значение стандартного нормального распределения,
ограничивающее правую “хвостовую” часть кривой рас-
пределения с долей площади а/2.
Учитывая (8.24), формулу (8.25) можно записать следую-
щим образом:
Р ^а/2
рО-р)
П
(8.26)
207
Пример в. 16. Аудиторская проверка финансовой деятельности
фирмы за год показала, что среди 250 случайно выбранных
платежных поручений 12 содержат ошибки, допущенные при
оформлении счетов. Определить доверительные пределы с до-
верительной вероятностью 90% для доли неправильно оформ-
ленных в течение года платежных поручений (общий объем
оформленных за год платежных поручений составил несколько
тысяч).
Вычислим точечную оценку доли:
р = —-=0,048.
г 250
Доверительная вероятность 1 - а = 0,9(90%), тогда Z^., ” 1,64.
По формуле (8.26) вычислим соответствующий доверитель-
ный интервал:
i 0 048 0 95’
0,048 ± 1,64. ’ — = 0,048 ± 1,64 • 0.013 = 0,048 ± 0,022.
V 250
Отсюда получаем доверительные пределы:
0,0264-0,07.
Можно утверждать, что с вероятностью 90% доля непра-
вильно оформленных платежных поручений содержится в гра-
ницах от 0,026 до 0,07 (или в пределах от 2,6 до 7%).
Формула (8.26) будет верна, если объем генеральной сово-
купности очень большой (теоретически может считаться беско-
нечным). В общем случае, если объем генеральной совокупности
конечен и равен N, а объем выборки п составляет более 5%
объема# (n/N > 0,05), то в формулу для доверительного интер-
\N -п
вала (8.26) следует ввести коэффициент J» характеризу-
ющий поправку на конечность генеральной совокупности.
8.4.3. Объем выборки и допустимая ошибка
оценки доли
Аналогично тому, как был определен объем выборки, обес-
печивающий допустимую погрешность при оценке средней,
можно определить объем выборки для допустимой ошибки
доли.
208
Ошибка доли имеет вид
Е = 7 Ip^-p)
Е Ла/2 -у
V И
Отсюда
ns7i/2P^-P\ (8.27)
Е2
Таким образом, если известна какая-нибудь точечная оцен-
ка доли р, то при заданной ошибке Е можно вычислить необ-
ходимый объем выборки.
Если рассматривать величину р как переменную, то выра-
жение (8.27) будет достигать максимума при р = 1/2. Тогда верх-
ней границей для п будет
Z2
л=а';. (8.28)
4Е2
С помощью формулы (8.28) можно найти такой объем вы-
борки, который заведомо обеспечивает ошибку, не превыша-
ющую допустимое значение Е:
p±ZaJ&^J^ (8.29)
\ л V /V — 1
Пример 8.17. Автоматический станок производит детали. Из
500 деталей, произведенных станком, случайным образом было
отобрано 80 деталей. Из них 4 оказались нестандартными. Опре-
делить 95-процентный доверительный интервал для вероятно-
сти изготовления станком нестандартной детали.
По условию задачи объем генеральной совокупности N —
500, объем выборки л = 80. В качестве точечной оценки вероят-
ности можно рассматривать относительную частоту появления
нестандартной детали в выборке р 4/80 = 0,05.
Так как n/N = 80/500 = 0,16>0,05, то следует учитывать по-
правку на конечность генеральной совокупности. Вычислим
доверительный интервал по формуле (8.29):
0,05±1,96
V 80 V 500-1
= 0,05 ± 1,96 • 0,024 • 0,917 = 0,05 ± 0,43 = 0,007 + 0,093.
Отсюда с вероятностью 95% можно утверждать, что вероят-
ность события, что автомат произведет нестандартную деталь,
209
заключена в пределах от 0,007 до 0,093 (или процент нестан-
дартных деталей, произведенных станком, находится в преде-
лах от 0,07 до 9,3%).
Пример 8.18. Администрация крупного региона хочет оценить
мнение избирателей относительно переизбрания действующе-
го губернатора на новый срок. Предварительный опрос несколь-
ких сотен избирателей показал, что примерно 40% из них под-
держивают действующего губернатора. Сколько избирателей
необходимо опросить, чтобы ошибка прогноза составляла 2%
с вероятностью 95%?
Так как имеется некоторая оценка доли р = 0,4, то можно
использовать формулу (8.27):
1.962 0,4 0,6
О,О22
= 2304,96 = 2305 чел.
Вычисленное значение п может быть завышено или заниже-
но в зависимости от точности оценки р . В случае если бы не
было логически приемлемой информации о значении доли р,
то можно было положить р = 1/2 и, используя формулу (8.28),
получить верхнюю границу для п:
п = —'= 2401 чел.
4 0,022
8.4.4. Доверительные интервалы для разностей долей
Пусть требуется вычислить доверительный интервал для раз-
ности долей, взятых из двух разных генеральных совокупнос-
тей.
Для обеих генеральных совокупностей рассмотрим распре-
деления выборочных долей. Если значение генеральной доли
совокупности 1 равно р, а для совокупности 2 — р, то при
выполнении условий п Pt>5 и я((1 - р)>5, '^Р-^ и л2(1 - р2)>5
оба распределения выборочных долей будут близки к нормаль-
ному. Каждое распределение приблизительно соответствует
нормальной случайной величине с параметрами = р(.
Pi(l ~ Pi)
".
°э,=
и = Р2. <*-Рг
, Р2(1~Рг)
п2
Очевидно, если выборки из различных совокупностей неза-
висимы, то распределение разности выборочных средних мож-
п =
210
но рассматривать как разность этих случайных величин. Она так-
же будет распределена приблизительно нормально с параметра-
мн = р, - oU - < + 05, = М + .
П| л2
Величина в = .£l1 + £iC!—£11 является стандарт-
” V ”1 Л2
ной ошибкой разности средних.
На практике почти всегда имеется информация только о
двух независимых выборках, взятых из разных совокупностей,
т. е. известны выборочные доли р, и р2. Поэтому средняя и
дисперсия распределения разности выборочных долей оцени-
ваются соответствующими статистиками
Л| л2
Оценочной величиной стандартной ошибки будет
. ₽;(!.--&>. (8.30)
' П Л! Л2
Исходя из нормальности распределения можно записать
формулу для доверительных интервалов:
(8.3D
1 "1 "г
Пример В. 19. Две конкурирующие фирмы выпускают двигате-
ли для грузовых автомобилей. Каждая фирма осуществляет так-
же ремонт своих двигателей. Выпускаемые двигатели имеют га-
рантийный срок эксплуатации. Доля двигателей, которые
ремонтируются по гарантии в общей совокупности ремонти-
руемых за определенный период двигателей, характеризует сте-
пень надежности двигателей каждой фирмы. Требуется опреде-
лить 90-процентный доверительный интервал для разности этих
долей, соответствующих различным фирмам.
Рассмотрим две независимые случайные выборки, каж-
дая из которых содержит 100 отремонтированных двигате-
лей, выпущенных одной из фирм за определенный период.
Оказалось, что для фирмы 1 из 100 двигателей 28 были в
гарантийном ремонте, а для фирмы 2 этот показатель со-
ставлял 32 из 100.
211
Вычислим значения точечных оценок долей:
р, = 28/100 = 0,28, р2 = 32/100 = 0,32.
Определим оценку стандартной ошибки по формуле (8.30):
0,28 0.72 0,36~6ф8
s- - =, —-----— + —----’— = 0,059.
* V 100 100
Для доверительной вероятности 1 — а = 0,9 значение
^=,’64‘
По формуле (8.31) вычислим:
(0,28 - 0,32) ±1,64 0,059 = -0,04 ±0,097 = -0,137+0,057.
По данному доверительному интервалу нельзя установить,
какая из двух фирм выпускает более надежные двигатели. С ве-
роятностью 90% можно только утверждать, что для фирмы 1
доля двигателей, сломавшихся в период гарантийного срока,
может быть на 13,7% ниже и на 5,7% выше соответствующей
доли двигателей фирмы 2.
8.4.5. Объем выборок и допустимая ошибка
разности долей
Согласно формуле (8.30) ошибка разности двух долей будет
иметь вид
E=z ЕЕЕЩЗЕЫ. (8.32)
V "I "2
Полагая в (8.32) п = л = и, можно записать:
п = Zg/afciO-PO+PzCl-Pz)] (8.33)
Е2
Пример 8.20. Торговая фирма проводит маркетинговые иссле-
дования рынка пищевых продуктов. В частности, руководство
фирмы интересует отношение покупателей к двум сортам чая.
Для выяснения данного факта были произведены две случай-
ные выборки численностью 100 покупателей каждая. Покупа-
телям, попавшим в 1-ю выборку, задавали вопрос, нравится
ли им сорт 1, а покупателям из 2-й выборки — сорт 2. В 1-й вы-
борке положительно ответили на вопрос 69 человек, во 2-й —
54 человека. Определить, каков должен быть объем каждой вы-
212
борки, чтобы точность оценки разности долей покупателей,
одобряющих разные сорта чая, была ±5% с вероятностью 95%.
Вычислим: р} = 69/100 = 0,69, />, = 54/100 = 0,54.
По формуле (8.33) найдем:
_ 1,962 (0,69 0,31 + 0,54 0,46) _ 3,842(0,214 + 0,248) =
П ~ О.О52 0,0025
= = 7Ючел.
0,0025
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 8
Под точечной оценкой понимается отдельное число (назы-
ваемое точкой), которое используется как оценка параметра
генеральной совокупности. Различные статистики могут слу-
жить оценками истинных параметров генеральной совокупно-
сти. Для оценки их качества в статистическом анализе рассмат-
риваются четыре критерия: несмещенность, эффективность,
состоятельность и достаточность. Статистика является несме-
щенной, если при вычислении большого количества точечных
выборочных оценок их значения располагаются примерно сим-
метрично относительно истинного значения оцениваемого па-
раметра. При этом математическое ожидание распределения
статистик будет равно значению оцениваемого параметра. Кри-
терий эффективности характеризует минимальность стандарт-
ной ошибки статистики, используемой для оценки. Это озна-
чает, что стандартная ошибка должна быть меньше стандартной
ошибки всех других возможных оценок. Оценка является состо-
ятельной, если при увеличении объема выборки значения ста-
тистик стремятся к истинному значению оцениваемого пара-
метра. Оценка является достаточной, если при ее вычислении
используется вся содержащаяся в выборке информация.
Значение отдельной статистики очень редко совпадает с
истинным значением оцениваемого параметра. Разность между
этими величинами называется ошибкой выборки. Пусть в каче-
стве искомого параметра рассматривается средняя арифмети-
ческая генеральной совокупности. Выборочная средняя будет
наилучшей оценкой генеральной средней, так как удовлетво-
ряет всем четырем критериям качества оценок. Возникает про-
блема, как на основе случайной выборки дать максимально
точную оценку генеральной средней. Зафиксируем объем вы-
борки и возьмем из генеральной совокупности все возможные
213
выборки данного объема. Затем для каждой из них вычислим
среднюю и составим распределение выборочных средних. По
центральной предельной теореме можно утверждать: для гене-
ральной совокупности со средней ц и дисперсией о1 распреде-
ление выборочных средних для всех возможных выборок боль-
шого объема (п > 30),составленных из ее элементов, будет
нормальным со средней ц и дисперсией и2/п.
На основе центральной предельной теоремы возможно по-
строение интервальных оценок параметров генеральной со-
вокупности, в частности доверительных интервалов для гене-
ральной средней. Под доверительным интервалом понимается
интервал, внутри которого с известной вероятностью нахо-
дится истинное значение параметра. Границы этого интервала
называются доверительными пределами, а связанная с ними
вероятность — доверительной вероятностью, которая изме-
ряет степень доверия к этому интервалу. Имея в виду свойства
площадей под кривой нормального распределения и утверж-
дения центральной предельной теоремы, можно вывести фор-
мулы для доверительных интервалов. При нахождении дове-
рительных пределов задаются уровнем значимости или доверия
а. Доверительная вероятность тогда вычисляется как 1 - а (или
(I - а)-100%). В случае больших выборок п> 30 или при усло-
вии заданного значения генеральной дисперсии о2 рассмат-
ривается стандартное нормальное распределение Z. Для него
определяется величина Za/2 >0, справа от которой доля пло-
щади под “хвостовой” частью кривой равна а/2. Для нахожде-
ния доверительных пределов с доверительной вероятностью
1 — а на основе одной случайной выборки объема п величину
Z^ следует умножить на стандартное отклонение (называе-
мое стандартной ошибкой средней) и затем полученный ре-
зультат вычесть и прибавить к значению выборочной средней
х (формула(8.3)).
Если объем выборки п > 30, а значение о неизвестно, то ве-
личина стандартной ошибки в формуле (8.3) заменяется на
величину $ — выборочное стандартное отклонение (формула
(8.10)).
Для малых выборок (л<30) при определении доверительных
интервалов использование стандартного нормального распре-
деления приводит к значительным погрешностям. В этом слу-
чае используется /-распределение Стьюдента, которое дает боль-
шую точность оценки. При этом рассматривается величина
/и;, * (, которая соответствует /-распределению при числе сте-
214
пеней свободы df = п - I и справа от которой доля плошади
под “хвостовой” частью кривой равна а/2. Под числом степе-
ней свободы понимается количество данных выборки, кото-
рые могут свободно изменяться, сохраняя при этом заданную
величину статистики.
При вычислении доверительных пределов с заданным уров-
нем значимости а на основе выборки объема я<30 величина Z
в формуле (8.10) заменяется на величину г , ((формула (8.12)).
В случае когда объем генеральной совокупности N конечен и
объем выборки составляет более 5% от объема генеральной
совокупности («>0,05АО, при вычислении доверительных пре-
делов следует учитывать поправку на конечность генеральной
совокупности J------. Во всех формулах для доверительных
J N -1
интервалов она умножается на стандартную ошибку средней.
В практических исследованиях часто возникает необходимость
определить такой объем выборки, который обеспечивал бы
заданную ошибку оценки. Под ошибкой оценки понимается
ширина доверительного интервала. При заданной ошибке и
доверительной вероятности объем выборки определяется по
формуле (8.14).
Доверительные интервалы для разности двух средних, взя-
тых из разных генеральных совокупностей, определяются по
формуле (8.15). В этом случае точечной оценкой является раз-
ность двух выборочных средних, где каждая выборка берется
из соответствующей генеральной совокупности (выборки пред-
полагаются большими и независимыми). Стандартная ошибка
разности средних равна корню квадратному из суммы квадра-
тов стандартных ошибок каждой средней.
В случае двух малых выборок («,<30, «2<30) используется
формула (8.17), где стандартная ошибка умножается на вели-
чину t (число степеней свободы «увычисляется по формуле
(8.18)>.
На практике при оценке разности двух средних иногда сле-
дует учитывать условие равенства дисперсий генеральных со-
вокупностей. В этом случае в качестве оценки обшей дисперсии
рассматривается средняя взвешенная величина значений вы-
борочных дисперсий, которая вычисляется по формуле (8.19).
В формуле для доверительных интервалов (8.21) она умножает-
ся на величину / соответствующую числу степеней свобо-
ды df = л, + л — 2. Объем каждой выборки, обеспечивающий
215
заданную ошибку для оценки разности двух средних, рассчи-
тывается по формуле (8.23).
Под долей, или пропорцией, понимается относительная ха-
рактеристика, определяющая часть элементов совокупности,
обладающих некоторым признаком или свойством. Определе-
ние точечной оценки доли — это подсчет числа “успехов” в
совокупности (т. е. выявление числа элементов, обладающих
данным признаком) и вычисление отношения этого числа к
общему количеству элементов в совокупности. При этом долж-
но выполняться условие дихотомности генеральной совокуп-
ности, т. е. ее можно разбить на две части: элементы, которые
обладают данным признаком, и все остальные элементы, ко-
торые им не обладают.
В общем случае при определении доверительных интервалов
долей следует использовать биномиальное распределение. Од-
нако при определенных условиях (пр>5 и л(1 - />)>5) биноми-
альное распределение достаточно точно аппроксимируется нор-
мальным. Аналогично распределению выборочных средних для
определения доверительных интервалов долей рассматривает-
ся распределение выборочных долей. Это распределение будет
близко к нормальному со средней р, равной генеральной доле,
и стандартным отклонением, вычисляемым по формуле (8.24).
На практике доверительные интервалы для доли определяются
на основе одной выборки и значение генеральной доли р заме-
няется на выборочное р. В случае бесконечной генеральной со-
вокупности доверительный интервал для доли вычисляется по
формуле (8.26). Если генеральная совокупность конечна, а объем
выборки составляет более 5% от объема генеральной совокуп-
ности, то необходимо учитывать поправку на конечность гене-
ральной совокупности (формула (8.29)). При определении ми-
нимального объема выборки, обеспечивающего заданную
ошибку оценки, можно воспользоваться формулами (8.27) и
(8.28).
При интервальной оценке разности долей, взятых из двух
различных генеральных совокупностей, рассматривается раз-
ность двух распределений выборочных долей. Точечной оцен-
кой в этом случае является разность выборочных долей, а стан-
дартной ошибкой — корень квадратный из суммы дисперсий
этих распределений (формула (8.30)). Для определения объема
каждой выборки, обеспечивающего заданную ошибку интер-
вального оценивания, можно использовать формулу (8.33).
ПРОВЕРКА ГИПОТЕЗ
ОТНОСИТЕЛЬНО СРЕДНИХ
9.1. ОБЩАЯ ПОСТАНОВКА ЗАДАЧИ ПРОВЕРКИ
ГИПОТЕЗ. НУЛЕВАЯ ГИПОТЕЗА
И СТАТИСТИЧЕСКИЕ КРИТЕРИИ
Оценка генеральной совокупности осуществлялась на осно-
ве заранее собранных выборочных данных. В качестве точечных
оценок рассматривались соответствующие выборочные статис-
тики (выборочная средняя или доля). Проверка гипотез пред-
полагает обратную последовательность действий. Еше до полу-
чения выборочных данных выдвигается предположение
(гипотеза) о точном значении некоторого параметра генераль-
ной совокупности. Затем собираются выборочные данные, об-
разующие случайную выборку. На их основе вычисляется оце-
ночная статистика и проверяется, насколько правдоподобна
выдвигаемая гипотеза (т. е. правильность предположения о том,
что принятое значение параметра является истинным). Гипоте-
зу о нулевой разности между предполагаемым и истинным зна-
чениями параметра генеральной совокупности называют нуле-
вой гипотезой.
Расхождение между выборочной статистикой и истинным
значением параметра связано с фактором случайности выбор-
ки. Интуитивно ясно, что чем меньше по абсолютной величи-
не разность между ними, тем более правдоподобна нулевая
гипотеза и, наоборот, если статистика и параметр сильно от-
личаются друг от друга, то степень правдоподобия уменьшает-
ся. Часто на практике расхождение между вычисленной стати-
стикой и гипотетическим значением параметра бывает очень
большим. В такой ситуации невозможно объективно подтвер-
дить или опровергнуть нулевую гипотезу, руководствуясь толь-
ко здравым смыслом и интуицией. Возникает необходимость в
разработке формальной процедуры, обеспечивающей количе-
217
ственное обоснование принимаемого решения. Данные рассуж-
дения поясним на следующем примере.
Пример 9.1. Крупная торговая фирма имеет несколько филиа-
лов в различных городах страны. На фирме работают более ты-
сячи продавцов. Для проверки эффективности их работы была
создана специальная система тестов. Руководство фирмы пред-
полагает, что 90% продавцов работают эффективно. Возникает
проблема, как проверить эту гипотезу, если сплошная провер-
ка продавцов невозможна в силу ограниченности средств.
Для решения задачи используем выборочный метод. Для этого
случайным образом отберем приемлемое для статистических
заключений количество продавцов и проведем среди них тес-
тирование, затем по результатам выборочной проверки сдела-
ем заключение о правильности предположения, что ровно 90%
всего состава продавцов работают эффективно.
Пусть результаты тестирования показали, что 95% продав-
цов успешно прошли испытание. Очевидно, в этом случае ну-
левая гипотеза будет достаточно правдоподобной. Предполо-
жим, что проверку прошли только 46% продавцов. Тогда здравый
смысл подсказывает, что есть достаточные основания для не-
принятия нулевой гипотезы.
Как видно, в обоих случаях нет четкого формального пра-
вила или критерия для подтверждения или неприятия нулевой
гипотезы. Заключения делались только на основе здравого смыс-
ла и интуиции. Пусть, например, значение выборочной про-
центной доли — 88%, тогда принятие решения о правильности
нулевой гипотезы на уровне здравого смысла будет очень за-
труднительным.
Формальная процедура проверки гипотез заключается в ус-
тановлении критических пределов для оценки значимых от-
клонений вычисленной статистики от гипотетического значе-
ния параметра генеральной совокупности.
Если выборочное значение статистики попадает внутрь про-
межутка, ограниченного критическими пределами, то откло-
нение считается статистически незначимым и нулевая гипоте-
за принимается. Если же разность столь велика, что статистика
выходит за критические пределы, то отклонение считается ста-
тистически значимым и нулевая гипотеза отвергается. При этом
решение принимается с некоторой вероятностью, так как раз-
ность между выборочной статистикой и гипотетическим зна-
чением параметра является случайной величиной. Эта величи-
218
на называется статистическим критерием (или просто крите-
рием). Таким образом, критерий является разностью между
распределением выборочных статистик и константой — гипо-
тетическим значением параметра генеральной совокупности.
Отсюда следует, что как случайная величина он будет распре-
делен по тому же закону, что и выборочная статистика.
В общем случае возможна проверка гипотез относительно
произвольного параметра в условиях любого статистического
критерия. В этой главе нас будет интересовать проверка гипотез
относительно генеральной средней. Как было показано в гл. 8,
соответствующие выборочные распределения выборочных сред-
них могут быть двух типов: нормальное распределение и г-рас-
пределение Стьюдента. Выбор критерия зависит от объема вы-
борки, а также от того, известно или нет значение генерального
стандартного отклонения о.
9.1.1. Критическая область. Уровень значимости
Пусть выдвигается нулевая гипотеза относительно парамет-
ра генеральной совокупности. Рассмотрим соответствующее рас-
пределение выборочных статистик. Рассуждения теперь будем
проводить для проверки гипотез относительно средней, пола-
гая, что объем выборки достаточно большой (л > 30).
В этом случае согласно центральной предельной теореме
распределение выборочных средних является нормальным. Если
нулевая гипотеза верна, то значения статистик располагаются
симметрично относительно гипотетической средней. Пусть ге-
неральная совокупность, откуда извлекались выборки объема
л, имеет параметры ц и о2. Тогда распределение выборочных
средних характеризуется средней Ц, = ц и стандартным от-
клонением (стандартной ошибкой) =
sill
Построим критические пределы для проверки нулевой ги-
потезы, используя понятие доверительных пределов для оцен-
ки средней. Так, можно утверждать, что внутри промежутка
+ ) сосредоточено (I — а)% всех выбороч-
ных средних. Доля плошали под кривой распределения, огра-
ниченная этим промежутком, также будет равна (I — а).
Если вычисленная статистика находится в доверительных
пределах, то можно записать:
H-2o/2aj<i<p + Za/2or. (9.1)
219
Используя понятие доверительной вероятности, соотноше-
ние (9.1) можно интерпретировать так:
P(M-Ze72ai<x<H+Ze/2ai) = l-a. (9.2)
Очевидно, вероятность того, что значения рассматриваемых
статистик выйдут за доверительные пределы, будет равна уров-
ню значимости а:
Р(х<ц~2а/2о5 или х>ц + Za/2oa) = а. (9.3)
Рассмотрим теперь формальную постановку задачи провер-
ки гипотез относительно генеральной средней.
Пусть до сбора выборочных данных была выдвинута нулевая
гипотеза относительно средней. Нулевая гипотеза обозначается
символом Н(), и ее формальная запись имеет вид
Н0:ц=ц0. (9.4)
Запись (9.4) читается так: нулевая гипотеза заключается в
предположении, что значение средней генеральной совокуп-
ности равно цц. В результате сравнения с выборочным значени-
ем средней нулевая гипотеза может быть отвергнута. В этом слу-
чае принимается альтернативная гипотеза, которая обозначается
Н(. Ее запись имеет вид
(9.5)
Выражение (9.5) читается так: альтернативная гипотеза зак-
лючается в том, что генеральная средняя не равна ц0.
После того как сформулированы нулевая и альтернативная
гипотезы, необходимо задать правило, по которому принима-
ется решение о принятии или непринятии нулевой гипотезы.
Это правило следует из соотношений (9.2) и (9.3). Если а дос-
таточно мало, то получение большого отклонения выборочной
статистики от истинного значения параметра будет маловеро-
ятным событием. Пусть, например, a = 5% (или a = 0,05). Тогда
такая большая разность будет наблюдаться в среднем в 5 из 100
случайных выборок. Поэтому проверка гипотез всегда привя-
зывается к определенному уровню значимости, т. е. формули-
ровка задачи обязательно предполагает задание уровня значи-
мости, при котором проверяется нулевая гипотеза. Если
выполняется условие (9.2), то говорят, что нулевая гипотеза
принимается или не отвергается с уровнем значимости а. Вы-
ражение “не отвергается” будет более точным, так как прини-
220
мать гипотезу можно в случае, если известно точное значение
параметра. Если выполняется условие (9.3), то говорят, что
нулевая гипотеза не принимается или отвергается с уровнем
значимости а.
Таким образом, доверительные пределы играют роль кри-
тических пределов. Между ними находится область принятия
нулевой гипотезы, а вне них — критическая область, или об-
ласть непринятия гипотезы (рис. 9.1).
Рис. 9.1. Области принятия или непринятия нулевой гипотезы
относительно средней при уровне значимости а
Полагая ц = ц0, преобразуем соотношение (9.1) к виду
-Za/i<^<Za/2. (9.6)
Соотношение (9.6) можно переписать:
^<Za/2. (9.7)
Соотношение (9.7) задает критические пределы и область
принятия гипотезы для стандартного распределения Z, где
Z = -—— характеризует отклонение выборочной средней от
гипотетической средней в единицах стандартной ошибки сред-
ней.
Критическая область задается условием
^^а/2. (9.8)
221
На практике проверка гипотезы производится при следую-
щих уровнях значимости:
« 0.01 0,05 0.1
ZV2 2.58 1.96 1,64
Пример 9.2. Автоматический станок производит болты. Извест-
но, что дойна болтов распределена по нормальному закону с
дисперсией 0,16 мм2. Станок должен быть налажен на выпуск
болтов со средней дойной 20 мм. Из большой партии болтов,
произведенных за смену на станке, была извлечена выборка из
25 болтов. Средняя длина выбранных болтов оказалась равной
20 мм. Требуется проверить при 5-процентном уровне значимо-
сти нулевую гипотезу о том, что станок производит болты со
средней дойной 20 мм, т. е. не требует переналадки.
Запишем формальную постановку задачи проверки гипотез:
Ио: = 20 мм,
Н: цо * 20 мм.
Параметры задачи имеют следующие значения: п = 25,
х =20,1 мм, а2 = 0,16 мм2 (ст = 0,4 мм), а = 0,05, Z(l(|,5 = 1,96.
Вычислим критерий Z:
Z = = 20,*~2° = 1,25.
о 0,4
т
Ввиду того что |Z| = 1,25 < 1,96, статистика попадает в об-
ласть принятия нулевой гипотезы. Следовательно, нулевая ги-
потеза Нп не отвергается с уровнем значимости 5%.
9.1.2. Ошибки первого и второго вида
При проверке гипотезы необходимо прийти к решению:
принимается гипотеза Hfl или отвергается (т. с. принимается
альтернативная гипотеза Нр. При этом возможны ошибки двух
видов:
непринятие правильной гипотезы (т. е. непринятие нуле-
вой гипотезы, в то время как она верна) — ошибка первого
вида;
принятие неправильной гипотезы (принятие нулевой гипо-
тезы, в то время как она неверна) — ошибка второго вида.
222
Всегда в принятии нулевой гипотезы есть риск совершить
ошибку второго вида, а в ее отклонении — ошибку первого
вида. Как было отмечено, установление критических пределов
всегда предполагает задание уровня значимости а. Очевидно, а
есть вероятность попадания выборочной статистики в зону не-
принятия нулевой гипотезы при условии правильности этой
гипотезы. Иначе говоря, проверка значимости непосредствен-
но отражает степень риска появления ошибки первого вида, т.
е. характеризует вероятность совершения этой ошибки в при-
нятии решений.
Ошибка второго вида зависит от того, насколько правдопо-
добна альтернативная гипотеза. Пусть, например, нулевая ги-
потеза (Н(): ц = ц0) неверна, а истинное значение средней
ц = ц Тогда ошибка второго вида будет характеризоваться по-
паданием значения выборочной средней в заштрихованную
область на рис. 9.2.
Рис. 9.2. Геометрический смысл ошибки второго вида: заштрихованная
площадь равна вероятности ошибки второго вида (Р)
Из рис. 9.2 видно, что чем больше площадь области принятия
нулевой гипотезы (т. е. чем шире промежуток (Цо~^а/2ао'
ц0 + Za/2o0)), тем больше площадь пересечения под кривыми
двух распределений, характеризующая ошибку второго вида.
С другой стороны, с увеличением области принятия нулевой
гипотезы уменьшается суммарная площадь под “хвостовыми”
частями соответствующей кривой распределения. Как раз эта пло-
щадь и характеризует ошибку первого вида. Таким образом, если
уменьшается вероятность ошибки первого вида (т. е. уровень зна-
чимости а), то одновременно увеличивается вероятность ошиб-
ки второго вида р, связанной с принятием нулевой гипотезы,
которая в действительности неверна.
В данной работе вычисление ошибки второго вида не рас-
сматривается.
223
9.1.3. Двусторонние и односторонние проверки гипотез
относительно средней
Пусть альтернативная гипотеза задается выражением (9.5).
Это означает, что альтернативой нулевой гипотезе может быть
либо выполнение неравенства ц < ц0, либо неравенства
ц > ц0.Тогда существуют два симметричных критических преде-
ла и, как видно из рис. 9.1, две соответствующие области не-
принятия гипотезы под “хвостовыми” частями кривой распре-
деления. Подобные проверки называются двусторонними.
Возможны также односторонние проверки гипотез. В этом
случае рассматривается альтернативная гипотеза (Н() о том,
что истинное значение параметра не просто отличается, а боль-
ше (или меньше) гипотетического значения. Так, возможны
две постановки задачи односторонней проверки гипотез:
Но;М = Мо,
Н,:ц>мв. (9.9)
Но; Н = Н0.
Н,:ц<м0. (9.10)
Выражение (9.9) ((9.10)) характеризует предположение: вы-
борочная средняя значимо больше (меньше) гипотетичес-
кого значения средней.
В отличие от двусторонней проверки односторонней соот-
ветствует только один критический предел. Так, в случае (9.9),
когда проверяется значимость превышения выборочной сред-
ней гипотетического значения, критический предел будет за-
даваться неравенством
х>В0 + гаЛ, (9.11)
или
(9.12)
Vn
где Za характеризует такое значение Z для стандартного
нормального распределения, которое отделяет правую
“хвостовую” часть кривой с долей площади, равной а%
(рис. 9.3).
224
Рис 9.3. Односторонняя проверка гипотезы Н,: ц>ц0:
а) произвольное нормальное распределение.
б) стандартное нормальное распределение
Если производится проверка предположения о том, что
выборочная средняя значимо меньше гипотетической средней,
то критическая область задается неравенством
isn.-z.4-. ОН)
у п
или
(9.14)
где величина —Za отделяет левую “хвостовую” часть кривой
стандартного нормального распределения, площадь под ко-
торой составляет а% всей площади кривой.
Величина Z задается уровнем значимости а. На практике
при односторонних проверках чаще всего используют следую-
щие значения:
a 0.01 0,05 0,1
±z s2,33 ±1,64 si,58
Пример 9.3. Рассмотрим условия примера 9.2. Пусть теперь тре-
буется проверить гипотезу, что станок производит болты со
средней длиной, превышающей 20 мм. Задача в этом случае
записывается так:
Но: ц0 = 20 мм,
Н(: ц0 > 20 мм.
Параметры задачи те же, за исключением значения крити-
ческого предела Za, который равен Z00i= 1,64. Величина крите-
рия Z меньше критического предела:
Z- 1,25 < 1,64.
225
Следовательно, гипотеза Но принимается с 5-процентным
уровнем значимости. Это говорит о том, что предположение о
разладке станка (т. е. о том, что он производит болты со сред-
ней длиной, превышающей 20 мм) не подтвердилось.
9.2. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
СРЕДНЕЙ: СЛУЧАЙ ОДНОЙ ГЕНЕРАЛЬНОЙ
СОВОКУПНОСТИ
9.2.1. Значение генерального стандартного
отклонения известно
Пусть выборка объема п берется из бесконечной или очень
большой генеральной совокупности, распределенной по нор-
мальному закону (или близкому к нему). Стандартное отклоне-
ние генеральной совокупности известно и равно о. В этом слу-
чае независимо от объема выборки критическая область для
двусторонней проверки находится из соотношения (9.8).
Если требуется односторонняя проверка, то критические
области задаются соотношениями (9.11), (9.12) или (9.13),
(9.14).
В примерах 9.2 и 9.3 рассматривалась ситуация, когда вы-
полнялись перечисленные выше условия: распределение зна-
чений длины болтов предполагалось нормальным и было из-
вестно значение а = 0,04 мм. Следует отметить, что в данных
примерах гипотеза проверялась на основе малой выборки (л
= 25<30).
Если нормальная совокупность конечна и имеет объем N,
то следует проверить соотношение между N и объемом выбор-
ки л. В случае л > 0,05А при вычислении стандартной ошибки
средней необходимо учитывать поправку на конечность гене-
„ ст |Л/-л _ „ „
ральнои совокупности, т. е. стк =-?—л- Тогда критерий Z
•Jn \ N-I
для проверки гипотез имеет вид:
Z = — М— (915)
ст । N - п
Tn V А-1
Пример 9.4. Рассмотрим условия примеров 9.2 и 9.3. Будем пред-
полагать, что партия, откуда была извлечена выборка объема
226
25, составляет 300 болтов. Таким образом, n/N = 25/300 =
= 0,0833>0,5.
Вычислим поправочный множитель:
_ 130°-25 -092
V /V -1 V 299
Критерий Z определим по формуле (9.15):
z= 2ОЛ-_2О= 0,1 =
2d. о 92 °”074 ’
5 ’
Следовательно, при а =0,05 двусторонняя и односторонняя
проверки показывают, что нулевая гипотеза не может быть от-
вергнута.
9.2.2. Значение генерального стандартного отклонения
неизвестно: большая выборка
На практике значение стандартного отклонения генеральной
совокупности о, как правило, неизвестно. В этом случае его можно
заменить на соответствующую статистику — выборочное стан-
дартное отклонение з. При этом для адекватности результата
проверки объем выборки должен быть не менее 30. Стандартная
ошибка средней заменяется оценочным значением:
s
°iasi = -T-
•sin
Величина Z вычисляется следующим образом:
Z = ^do. (9.16)
s
-Jn
Если генеральная совокупность относительно_мала и вы-
з Гл/ -п
полняется соотношение л>0,05Л/, то «j = “p-klT,-Т- Тогда
критерий Z имеет вид ™ “
Z = —. (9.17)
5 UV-fl
7л V N-1
Пример 9.5. Фирма выпускает компоненты для электронных при-
боров со средним сроком службы 100 ч. После того как была
227
введена новая технология производства, случайным образом было
проверено 100 компонентов. Результаты теста показали, что сред-
ний срок службы равен 102,5 ч с дисперсией 99 ч2. Требуется
проверить гипотезу о том, что новая технология способствовала
увеличению среднего срока службы компонентов. В данном слу-
чае следует провести одностороннюю проверку на превышение:
Н0:ц= 100,
Н(:ц> 100.
Значение о неизвестно, поэтому вычислим значение 5. Ве-
личина выборочной дисперсии известна (? = 99). Отсюда
5 = V99 = 9,95 ч. По формуле (9.16) вычислим значение Z:
102,5-100 2,5 _
9,95 0,995
10
Критическим пределом при уровне значимости 5% является
ZOI)5= 1,64. Таким образом, 2,51 >1,64, что свидетельствует о том,
что нулевая гипотеза о равенстве средних с 5-процснтным уров-
нем значимости отвергается: принимается предположение, что
новая технология удлинила срок работы компонентов.
Пример 9.6. Фермер выращивает кур. В течение нескольких лет
средний вес кур составлял 1,85 кг. За последние месяцы на
ферме было выращено 350 кур с использованием корма нового
типа. Случайным образом фермер отобрал 35 кур и определил,
что их средний вес равен 2,03 кг со стандартным отклонением
0,8 кг. Фермеру нужно выяснить, повлияло ли использование
нового корма на увеличение среднего веса кур. Проверку сле-
дует вести при а = 0,05.
Данная ситуация предусматривает одностороннюю провер-
ку на превышение. Задача имеет следующие параметры:
N — 350, п = 35, ц0 = 1,85 кг, х = 1,93 кг,
5 = 0,8 кг, Za = 1,64.
Так как n/N = 35/350 = 0,1 >0,05, то критерий Z вычисляет-
ся с учетом поправочного множителя по формуле (9.17):
Z = 2,03-1,85 _ 0,18 _ 37
0,8 }350 -35 0.76
г/35 V 350-1
228
Имеем Z=2,5I>),64. Следовательно, нулевая гипотеза (Но:
ц = 1,85 кг) отвергается, а альтернативная об увеличении сред-
него веса кур (Н^ ц >1,85 кг) не отвергается при а = 5%.
9.2.3. Значение генерального стандартного отклонения
неизвестно: малая выборка
Как было показано в разделе 8.3.1.2, в случае малых выбо-
рок (л<30) при неизвестном о для опенки параметров следует
использовать /-распределение. Аналогично для проверки нуле-
х — ц
вой гипотезы вычисляется /-критерий / =—- , который
'!п
сравнивается по абсолютной величине с критическим значением
U.-r Критический предел определяется из таблицы площа-
дей кривой /-распределения (Приложение 5). Он находится на
пересечении строки, соответствующей числу степеней свобо-
ды df = п — 1, и столбца, соответствующего а/2, т. е. доли
отсекаемой площади в “хвостовой” части /-распределения.
Область принятия нулевой гипотезы в случае двусторонней
проверки задается соотношением
</а/2и-1-
(9-18)
Соответственно критическая область задается неравенством
*-Цо
(9.19)
S/a/2»-l’
Для односторонней проверки критическая область задается
неравенствами без модуля. Если проверяется гипотеза о значи-
мом превышении выборочной средней значения генеральной
средней, то критическая область задается неравенством
(9.20)
fn
где / _ (является критическим пределом, отделяющим под кри-
вой /-распределения (df= п — 1) правую “хвостовую” часть,
площадь под которой составляет а% площади всей кривой.
229
Аналогично для проверки значимости отклонения влево
область непринятия нулевой гипотезы характеризуется соотно-
шением
s " (9.21)
/п
где значение -tu я_ (отделяет левый “хвост” с площадью, рав-
ной а% площади под всей кривой /-распределения при
df= л - I. Для нахождения качения / _, можно исполь-
зовать таблицу Приложения 5, соответствующую двухсто-
ронним проверкам.
Если генеральная совокупность конечна, имеет объем N, а
размер выборки п > 0,057V, то стандартная ошибка средней
т
в неравенствах (9.18)—(9.21) умножается на коррек-
-ул I----
„ N-n
тирующий множитель J—------, характеризующим поправку на
V N -1
конечность генеральной совокупности.
Пример 9.7. Известно, что средний срок службы определенно-
го типа батареек для часов составляет 305 дней и подчиняется
нормальному закону. Рассматриваемый тип батареек был усо-
вершенствован с целью продления срока службы. Случайным
образом было выбрано 20 батареек нового типа, которые были
протестированы. Результаты проверки показали, что средний
срок службы новых батареек равен 3! I дням со стандартным
отклонением 12 дней. При 5-процентном уровне значимости
требуется проверить, что средний срок новых батареек превы-
шает 305 дней.
В данном случае осуществляется односторонняя проверка,
задаваемая соотношениями (9.18) и (9.19). Критический пре-
дел задается значением / = 1,729 (Приложение 5). Вычис-
лим /:
„Ц13О5.2,„6.
/20
Следовательно, нулевая гипотеза ( Н : ц = 305) отвергается
в пользу альтернативной гипотезы (Н ; ц>305). Можно утверж-
дать с 5-процентным уровнем значимости, что средний срок
службы батареек увеличился.
230
Пример 9.В. В магазин поступила партия из 300 килограммовых
пакетов сахара. Возникло подозрение, что средний вес пакетов
в партии существенно отличается от I кг. Для проверки случай-
ным образом было выбрано и взвешено 20 пакетов. Их средний
вес оказался равным 920 г со стандартным отклонением 75 г.
Требуется проверить данное предположение, используя 1-про-
центный уровень значимости.
Параметры задачи: ц0= 1000 г, х = 920 г, 5 = 75 г, п = 20,
У = 300, а = 0,01.
Проверим соотношение n/N = 20/300=0,067>0,05. Следова-
тельно, при вычислении значения г следует учитывать поправ-
ку на конечность генеральной совокупности:
t - = ?20-1000 _ -80 = _348
fN-n 75 1280 23,73 0,97
TnVN-l 710 V299
Определим критические пределы для двусторонней провер-
ки по таблице Приложения 5: ±/0 00$. „ = ±2,86.
Так как |-3,48|> 2,861, то нулевая гипотеза (Но: ц= 1000) не
может быть принята с уровнем значимости, равным 1%.
Следовательно, предположение о том, что средний вес па-
кета значимо отличается от 1кг (т. е. альтернативная гипотеза Н :
ц # 100), является правильным.
В данном случае, очевидно, имеет смысл сделать односто-
роннюю проверку, т. е. проверить альтернативную гипотезу, что
средний вес пакетов в партии меньше 1 кг (Н : ц< 100). Крити-
ческим пределом тогда будет значение -г00)Так как
-3,48<-2,539, то это предположение принимается с 1-процен-
тным уровнем значимости.
9.3. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
РАЗНОСТИ СРЕДНИХ ДВУХ ГЕНЕРАЛЬНЫХ
СОВОКУПНОСТЕЙ
»
9.3.1. Случай больших выборок
На практике достаточно часто приходится сравнивать сред-
ние двух различных генеральных совокупностей. Например, две
фирмы выпускают батарейки для бытовых приборов. Требуется
определить, какая фирма выпускает батарейки с большим сред-
ним сроком службы.
231
Пусть рассматриваются две различные генеральные совокуп-
ности с параметрами и ц2,ог Из каждой совокупности из-
влекаются большие случайные независимые выборки фикси-
рованного объема соответственно и п. Тогда соответствующие
распределения выборочных средних будут нормальными с па-
раметрами
Очевидно, разность этих распределений является случайной
величиной, распределенной по нормальному закону со сред-
ней р.! — ц2 и дисперсией, равной сумме дисперсий:
_2
X, “Xj X,
Л1 «2
Таким образом, распределение разности выборочных сред-
них будет нормальным с параметрами
10^ ст2
Н,-Ц2.ог г = +
' ’ V«i л2
При проверке гипотезы о значимости разности между вы-
борочными средними рассматривается нулевая гипотеза
(9.22)
В случае двусторонней проверки альтернативная гипотеза
имеет вид
Н(:р, *ц2.
При односторонней проверке возможны случаи:
(9.23)
Н,:ц1<ц2. (9.24)
Пусть х( — средняя выборки объема л, из первой генераль-
ной совокупности, х2— средняя выборки объема л, из второй
генеральной совокупности.
Вычислим отношение Z для проверки нулевой гипотезы
(9.22):
Z =
Л1 л2
(х, —х2)-(ц,-ц2)
(9.25)
232
Для двусторонней проверки нулевая гипотеза не отвергает-
ся с уровнем значимости а, если выполняется условие
и=
< Za/2-
(9.26)
Критическая область задается соответственно неравенством
Za,2-
(9.27)
Для односторонних проверок критические пределы для уров-
ня значимости а будут соответственно ±Za. Так, при альтерна-
тивной гипотезе (9.23) соотношения для областей принятия и
непринятия нулевой гипотезы будут иметь вид
Z = .\~Хг <Za, (9.28)
'j «1 «2
z = 2 Za. (9.29)
\ л, л2
Для альтернативной гипотезы (9.24) соответствующие об-
ласти задаются неравенствами
Z» .ЛгЛ, 2-Za, (9.30)
\ "1 п2
Z = -^-^2—^-Za. (9.31)
I О? СГ
V «1 «2
Если анализируемые генеральные совокупности распреде-
лены нормально, то соотношения (9.26)—(9.31) можно исполь-
зовать при проверки гипотез и в случае малых выборок (л^ЗО,
л2<30).
На практике значения стандартных отклонений о, и о2для
енеральных совокупностей часто бывают неизвестны. Для боль-
ших выборок возможна замена их значений на соответствую-
233
щие выборочные статистики и Тогда критерий Z в выра-
жениях (9.26)—(9.31) примет вид
• <9з2>
"1 «2
Пример 9.9. Две независимые автоматизированные линии вы-
пускают кабель. Для обеих линий средняя длина кабеля должна
быть одинаковой. Предполагается, что длина кабеля в обоих
случаях распределена нормально со стандартными отклонени-
ями оа1мио«1,5м. Возникло предположение, что линии
выпускают кабель с различной средней длиной. Требуется про-
верить данное предположение с уровнем значимости а = 0,05.
Для этой цели были рассмотрены две случайные выборки: одна
выборка состояла из 15 кусков кабеля, произведенных на пер-
вой линии, другая — из 13 кусков, выпускаемых второй лини-
ей. Для первой выборки средняя длина кабеля оказалась равной
52 м, для второй — 51м.
Обозначим среднюю длину кабеля, выпускаемого первой
линией, ц^а второй —
Тогда задачу проверки гипотезы формально можно записать
так:
Но: Н, =
Н,: Ц1 * Ц,.
Задача имеет следующие исходные данные: х,= 52 м, х2 =
51 м, 0,= I м, о(= 1,5 м, л( = 15, л2= 13, ZOO25 = 1,96.
Вычислим величину Z:
Z- ,52~51 - 1 - 1 -2СИ
l|2 1.52 70.067 + 0,173 0,49 ’
V 15 + 1Т
Отсюда |Z| = 2,04> 1,96, т. е. нулевая гипотеза не может быть
принята при уровне значимости 5%. Следовательно, предположе-
ние о том, что линии производят куски кабеля разной средней
длины, оправдалось с 5-процентным уровнем значимости.
Пример 9.10. Исследуем ситуацию, представленную в примере
8.15, как задачу проверки гипотез. Пусть две научно-исследо-
вательские лаборатории независимо друг от друга занимаются
разработкой лекарственных препаратов для больных, страдаю-
234
ших артритом. Таблетки, произведенные первой лаборатори-
ей, были опробованы на 90 больных в период сильных присту-
пов боли. В среднем прием таблетки обеспечивал снятие боли в
течение 8,5 ч со стандартным отклонением 1,8 ч. Действие таб-
леток второй лаборатории, опробованное на 80 больных, обес-
печивало снятие боли в среднем на 7,9 ч со стандартным от-
клонением 2,1 ч. Требуется при 5-лроцентном уровне значимости
проверить предположение о том, что период действия табле-
ток второй лаборатории значимо меньше, чем период действия
таблеток первой лаборатории.
Формальная запись задачи проверки гипотез будет иметь вид
Но: и, = и2,
Н,: < И|.
Параметры задачи: х(= 8,5 ч, х2- 7,9 ч, $ 1,8 ч, $2 = 2,1 ч,
л, = 90, „,-80,2^-1,64.
Вычислим Z:
7,9-8,5 _ -0,6
I1.82 2.12 70’036 + 0,055
J 90 + 80
Следовательно, —1,99<-1,64 и нулевая гипотеза не может
быть принята с уровнем значимости, равным 5%, т. е. выска-
занное предположение подтверждается с 5-процентным уров-
нем значимости.
9.3.2. Случай малых выборок
Пусть объемы выборок, которые берутся из рахтичных ге-
неральных совокупностей, меньше 30. В этом случае процедура
проверки гипотез относительно разности генеральных средних
мало чем отличается от случая больших выборок. Единственное
отличие состоит в том, что критическая область определяется
на основе /-распределения Стьюдента.
В качестве критерия оценки рассматривается отношение
•= (9-33>
i£l + £l
V «1 П2
Отношение (9.33) имеет приблизительно /-распределение
для числа степеней свободы, задаваемого формулой (8.18).
235
Пример 9.11. Рассмотрим ситуацию примера 8.13. Пусть требу-
ется проверить гипотезу, что средние сроки износа покрышек
двух типов не равны между собой:
Но: И, = Н2,
Н,: h * h-
Воспользуемся формулой (9.33):
t_ 3,3-3,98 _-0.65^ 325
^0,682 t 0,38~ 0.2
V 15 + 15
Чисто степеней свободы, найденное по формуле (8.18), равно
df = 21. Проведем проверку с IО-пропентным уровнем значи-
мости, т. е. критическая область задается неравенством
= 1,721. Так как |—3,25|> 1,721, то нулевая гипотеза не может
быть принята. Следовательно, предположение о том, что сред-
ние сроки износа двух типов покрышек не равны между собой,
подтверждается с уровнем значимости 10%.
Рассмотрим теперь одностороннюю проверку, т. е. предпо-
ложение, что покрышки типа В имеют больший срок износа,
чем типа Л:
Но: М1 = и2;
Н,: ц, < ц2.
В этом случае критический предел задается величиной
tQ 1 21 = -1,323, т. е. проверяется условие К—10)21. Ввиду того что
—3,25 < —1,323, нулевая гипотеза о равенстве сроков износа
отвергается и принимается альтернативная гипотеза о превы-
шении срока износа покрышек типа В.
Особый случай представляет ситуация, когда дисперсии ге-
неральных совокупностей равны: о(2 = о22. Такая ситуация дос-
таточно часто встречается в производственных процессах с дол-
госрочным циклом. В таких случаях обработка статистических
данных за предыдущие периоды времени подтверждает равен-
ство дисперсий.
Кроме того, подобная ситуация может возникнуть при про-
верке гипотезы о том, что выборки были получены из одина-
ковых или одной и той же генеральной совокупности. Тогда про-
верку следует производить в предположении, что о,2 = о22 = о.
На практике, если нет очевидных аргументов, указывающих
236
на то, что дисперсии не равны, можно вполне допускать их
равенство.
Пусть объем выборок не превышает 30 и выполняются усло-
вия:
I) выборки извлекаются из двух различных генеральных со-
вокупностей независимо друг от друга;
2) обе генеральные совокупности приблизительно нормаль-
ные;
3) дисперсии совокупностей равны.
Рассмотрим выборочное распределение разностей выбороч-
ных средних, принадлежащих различным совокупностям. Об-
щая дисперсия генеральной совокупности неизвестна, но она
может быть оценена, если вычислены выборочные дисперсии
j(2 h'j22. Если л( и л, — соответствующие объемы выборок, то в
качестве оценки общей генеральной дисперсии можно рассмат-
ривать взвешенную среднюю величину
s2 (»i ~ D*? + («2 ~
(л,-1) + (л2-1)
где л( — 1 и л2 - I — степени свободы соответственно для вы-
борок из первой и второй совокупностей.
Так как дисперсии равны, то выборочное распределение
разностей выборочных средних будет иметь дисперсию
+ f! = ± +
х,-х’ Л] л2 л, + л2 - 2 [ л, л2 J
Соответственно стандартное отклонение или стандартная
ошибка разности средних такова:
= ± + |±71. (,.34)
11 ч Л| + л2 - 2 Л] л2 J ул, л2
Если средние генеральных совокупностей совпадают, то
можно считать, что обе выборки берутся из одной или одина-
ковых совокупностей.
Пусть рассматривается задача проверки гипотез:
Но: Ц, = ц2,
Н,: м, * м2.
237
В качестве критерия возьмем величину
t = . (9.35)
(И,-1)*?-Ь("2-1)4Г 1 + ±1
Л| + п2 - 2 л1 л2 J
При уровне значимости а величина сравнивается со значе-
нием где df = + л2 - 2.
Если И<Га/2 я . _2, то нулевая гипотеза не может быть от-
вергнута с уровнем2 значимости а. В случае |г^г , . „ _ 2 раз-
ность средних попадает в критическую зону и нулевая гипотеза
Но отвергается при уровне значимости а. Для односторонних
проверок рассматриваются соответствующие критические пре-
делы ±1
“• "1 "2 ~ *
Пример 9.12. Проверим гипотезу примера 9.11 в предположе-
нии, что дисперсии сроков износа покрышек обоих типов рав-
ны между собой. Найдем взвешенную среднюю дисперсию и
стандартное отклонение:
2 (15-1)0.682 + (15-1)0,382 _ 8,495
15 + 15-2 28
5 = 70,303=0,55.
По формуле (9.34) найдем стандартную ошибку разности
= 0,55
£ 1
15 + 15
= 0,2.
Вычислим значение критерия оценки:
х.-х, 3,33-3,98
t = —г---=— =----------= -3.25.
I 1 1 0,2
5 — +---
V «1 п2
Критическое значение г при а = 0,1 находится для df = 28:
'0.0,2 = ‘.701.
Следовательно, |-3,25| = 3,25> 1,701 и нулевая гипотеза от-
вергается.
Аналогично осуществляется односторонняя проверка, для
которой критическое значение равно f01 м = -1,313. Отсюда
следует, что гипотеза Но отвергается, а предположение о пре-
вышении срока износа покрышек типа В над сроком покрышек
238
типа А принимается с 10-процентным уровнем значимости. Как
видно, предположение о равенстве дисперсий двух совокупно-
стей никак не повлияло на результаты проверок, которые сов-
пали с результатами примера 9.11 (где предполагалось, что
°.2*°АВ
9.3.3. Сравнение средних двух нормальных совокупностей
на основе пар наблюдений
Ранее при сравнении двух выборочных средних необходи-
мым условием было получение выборок из двух нормальных
совокупностей независимо друг от друга. Однако часто возни-
кает ситуация, когда элементы выборок рассматриваются по-
парно. Например, пара наблюдений соответствует одному и тому
же городу, моменту времени, супружеской паре или даже од-
ному и тому же лицу.
Пусть имеется п пар наблюдений:
Ц.У,). (х2,у2),..., (хя,уя).
Рассмотрим разности, соответствующие каждой паре:
= Xj - у, = х2 — у,,..., dn — хп — уя. Проблему сравнения
двух совокупностей данных сведем к анализу одной совокуп-
ности, состоящей из разностей d. Для этой цели вычислим вы-
борочное стандартное отклонение разностей
где d = ~-----выборочная средняя разностей,
л
Ввиду того что каждый элемент пары берется из нормаль-
ной генеральной совокупности, распределение выборочных
разностей будет также нормальным. Предположим, что нужно
проверить гипотезу о том, что средняя этого распределения
равна Do, тогда задачу проверки гипотез можно записать так:
Но: М, = Д>.
239
Если число рассматриваемых пар п £30, то для проверки
можно использовать стандартное нормальное распределение.
В случае л <30 в качестве критерия используется /-распределе-
ние Стъюдента. При этом проверяется отношение
которое сравнивается со значениями /-распределения при
dfx п - I и заданном уровне значимости а. Если |/.|>/и.,„ J,, то
гипотеза Но отвергается с уровнем значимости а. Односторон-
ние проверки выполняются аналогично: Н : ц <Л (/>/ )
либо Н(: ^>D0(td<-/__,).
Пример 9.13. Руководство отдела маркетинговых исследований
фирмы, торгующей пищевыми продуктами, должно принять
решение о форме упаковки для быстрого завтрака (овсяные
хлопья). Было предложено два вида упаковки: прямоугольная
коробка и цилиндрический контейнер. Пробное исследование
проводилось в 10 супермаркетах, где в каждом супермаркете на
противоположных сторонах торговой секции выставлялись на
полках упаковки соответствующей формы (на каждой стороне —
упаковки одной и той же формы). Цель исследований — понять,
существует ли разница в продажах для упаковок разных типов?
Проверку гипотез следует осуществлять при а = 0,05.
Данные о продажах в 10 супермаркетах были объединены в
пары:
Супермаркеты 1 2 3 4 5 6 7 8 9 10
Коробка (шт.) 194 152 160 172 110 137 126 176 145 118
Цилиндр (шт.) 184 161 153 184 123 155 111 156 129 105
Определим соответствующие разности пар элементов выбо-
рок и вычислим их квадраты.
Супермаркеты 1 2 3 4 5 6 7 8 9 10 сумма
d 10 -9 7 -12 -13 -18 15 20 16 13 29
d2 100 81 49 144 169 324 225 400 256 169 1917
Пусть ц — средняя разностей между продажами упаковок
различной формы. Требуется проверить нулевую гипотезу:
Нв: Ма=^о=О.
Н,:ц^0.
240
Вычислим:
/n '1917-292/10
n-1 V 9
Вычислим /-отношение (9.36):
2.9-0 Л,.а
ta — "“жи" = 0,643.
14,72/^'40
По таблице Приложения 5 найдем г = 2,262.
Так как |zj =0,643<2,262, то гипотеза Но не может быть от-
вергнута. Таким образом, нет достаточных оснований предпо-
лагать, что форма упаковки влияет на продажу.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 9
В отличие от оценки параметров проверка гипотез предпо-
лагает обратную последовательность действий. Еще до получе-
ния выборочных данных выдвигается предположение (гипоте-
за) о точном значении некоторого параметра генеральной
совокупности. Затем собираются выборочные данные, образу-
ющие случайную выборку. На ее основе вычисляется оценоч-
ная статистика и проверяется, насколько правдоподобна вы-
двигаемая гипотеза относительно того, что принятое значение
параметра является правильным. Гипотеза о нулевой разности
между предполагаемым и истинным значениями параметра ге-
неральной совокупности называется нулевой гипотезой.
При проверке нулевой гипотезы оценивается статистичес-
кая значимость разности между вычисляемым выборочным зна-
чением статистики и предполагаемым истинным значением
параметра. Расхождение возникает в связи со случайностью
выборки. Формальная процедура оценки гипотез заключается в
установлении критических пределов для оценки значения от-
клонения от истинного значения параметра. Если выборочное
значение попадает внутрь промежутка, ограниченного крити-
ческими пределами (область принятия гипотезы), то нулевая
гипотеза принимается. Если же значение статистики выходит
за критические пределы (область непринятия гипотезы), то
отклонение считается статистически значимым и нулевая ги-
241
потеза отвергается. Решение о принятии или непринятии нуле-
вой гипотезы характеризуется некоторой вероятностью, так как
разность между выборочной статистикой и гипотетическим
значением параметра является случайной величиной, которая
называется критерием. При проверке гипотез относительно сред-
ней генеральной совокупности возможны два вида критериев:
нормальное распределение и /-распределение Стьюдента. Нор-
мальное распределение имеет место, если известно значение
генерального стандартного отклонения или в случае больших
выборок (яг30). При малых выборках (л<30) и неизвестном
значении о распределение выборочных средних точнее прибли-
жается /-распределением.
Пусть нулевая гипотеза Но заключается в предположении,
что значение генеральной средней равно Ц0(Н0: ц= цп).В ре-
зультате сравнения с выборочным значением нулевая гипотеза
может быть отвергнута и принята альтернативная гипотеза
которая заключается в том, что генеральная средняя не равна
р.о( Н(: цх ц0). Для определения критических пределов в приня-
тии решений о правильности нулевой гипотезы вычисляется
отношение — Нй или (если о неизвестно).
о s
-7»
В случае больших выборок величина данного отношения
подчиняется стандартному нормальному закону распределения
и обозначается Z. Если то гипотеза Но принимается;
если lZfeZa/2, то отвергается с уровнем значимости а. В данном
случае а характеризует риск, что правильная гипотеза Но будет
отвергнута. Проверка гипотез всегда привязывается к опреде-
ленному уровню значимости.
При проверке правильности гипотезы Но возможны ошиб-
ки двух видов: непринятие правильной гипотезы (ошибка пер-
вого вида) и принятие ложной гипотезы (ошибка второго вида).
Вероятностью ошибки первого вида является уровень значи-
мости а. Ошибка второго вида Р зависит от того, насколько
правдоподобна альтернативная гипотеза Нг При уменьшении
вероятности ошибки первого вида одновременно возрастает
вероятность ошибки второго вида.
Пусть альтернативная гипотеза задается в виде Н,: ц > ц0
(или Н: ц < ц0), т. е. рассматривается гипотеза о том, что истин-
ное значение параметра не просто отличается, а больше (мень-
ше) гипотетического значения. В этом случае осуществляется од-
242
посторонняя проверка гипотез, т. е. рассматривается только один
из критических пределов ±Za. Если Z>+Za, то принимается ги-
потеза Н[: ц > ц0; если Z<-Z, то гипотеза Hj: ц< ц0.
При малых выборках и неизвестном о распределение отно-
шений Л будет приближаться /-распределением Стьюден-
л/л
та, соответствующим числу степеней свободы df= п - 1. В этом
случае критериальное отношение обозначается t. Для двусто-
ронней проверки критическая область (область непринятия Но)
задается соотношением ,» где а — уровень значимости.
Если генеральная совокупность конечна, имеет объем У и
при этом выполняется условие n>0,05W, то в знаменатель крите-
риального отношения Z (или /) вводится поправочный мно-
j N — п -
житель J——который характеризует поправку на конеч-
ность генеральной совокупности.
На практике часто приходится сравнивать средние двух раз-
личных генеральных совокупностей. Нулевая гипотеза при этом
характеризует равенство средних: Hft: = цп. В качестве альтер-
нативных гипотез можно рассматривать соответствующие од-
ностороннюю и двустороннюю проверки:
Н,: и, * U2,
Н,: ц, > Ь.
Н,: р, < ц2.
Критериальное отношение будет иметь вид (9.25), если из-
вестны дисперсии генеральных совокупностей, или (9.32), если
они неизвестны. Проверка производится по тем же правилам,
что и в случае одной генеральной совокупности. В случае малых
выборок и неравенства генеральных дисперсий число степеней
свободы /-распределения вычисляется по формуле (8.18). Если
полагать, что генеральные дисперсии равны, то в качестве об-
шей дисперсии можно рассматривать взвешенную среднюю двух
выборочных дисперсий. Вид критерия в этом случае задается
выражением (9.35).
При сравнении средних двух генеральных совокупностей
обязательным условием является независимость получения
выборок из каждой совокупности. Если это условие нарушает-
ся, то рассматриваются пары связанных наблюдений. В этом
случае сравнение двух совокупностей сводится к сравнению
243
разностей, вычисленных для каждой пары. Генеральные сово-
купности предполагаются нормальными, поэтому выборочное
распределение разностей также будет нормальным. Пусть нуле-
вая гипотеза заключается в том, что среднее значение распре-
деления разностей предполагается равным D№. Тогда задача про-
верки имеет вид
Н»: = Do,
Hrl*? Do-
Если число пар п >30, то в качестве критерия используется
распределение Z. В случае п< 30 адекватным критерием являет-
ся ^-распределение.
ПРОВЕРКА ГИПОТЕЗ
ОТНОСИТЕЛЬНО ДОЛЕЙ
10.1. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
ДОЛИ ОДНОЙ ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ
10.1.1. Двусторонняя проверка
Теорию и методы построения доверительных интервалов,
изложенные в разделе 8.4, можно использовать для определе-
ния критических пределов в задачах проверки гипотез относи-
тельно долей.
Теоретически распределение выборочных долей наиболее
адекватно характеризуется биномиальным законом распреде-
ления. Однако при больших выборках возможна замена бино-
миального распределения выборочных долей нормальным рас-
пределением с теми же параметрами. Такая замена дает вполне
приемлемые результаты, если одновременно выполняются ус-
ловия пр>5 и л(1 - р)>5, где п — объем выборки, ар — значе-
ние генеральной доли.
Пусть выдвигается нулевая гипотеза На относительно того,
что доля генеральной совокупности р принимает определенное
значение. Тогда задача двусторонней проверки имеет следую-
щую формальную запись:
Но:р = /’о-
НГР*РО.
Распределение выборочных долей для больших выборок за-
данного объема п приближается нормальным законом со сред-
ним значением, равным генеральной доле р, и стандартной
ошибкой о- = . В расчетах будем полагать, что гене-
ральная доля р равна гипотетическому значению р1}.
245
Как и в случае средней, проверка гипотез осуществляется
на основе только одной выборки. Пусть значение выборочной
доли равно р . Рассмотрим отношение Z, имеющее стандарт-
ный нормальный закон распределения:
<ю.1>
V п
Область принятия нулевой гипотезы Н() и критическая об-
ласть задаются (ври уровне значимости а) соответственно ус-
ловиями
Р~Ро
РоО-Ро)
п
Пример 10.1. Руководство телевизионной редакции утвержда-
ет, что ее специальную тематическую передачу регулярно смот-
рят, по крайней мере, 20% телезрителей. Специальная социо-
логическая служба провела опрос 2000 телезрителей. Среди
респондентов 390 человек подтвердили, что они достаточно
часто смотрят данную передачу. Следует ли доверять утвержде-
нию руководства редакции, если при проверке использовать
5-процентный уровень значимости?
Вначале проверим, выполняются ли условия использования
нормального распределения: пр = 2000 0,2 = 4ОО>5, 2000(1 —
- 0,2) = 2000 0,8 = 16ОО>5.
Запишем постановку задачи двусторонней проверки:
Но: р = 0,2,
Н,: pt 0,2.
Параметры задачи: п - 2000 (число респондентов), р0 = 0,2
(значение заявленной доли телезрителей, смотрящих переда-
чу), а = 0,05(Z0O25 = 1,96).
246
Вычислим выборочную долю: Р = - 0,195.
Определим значение отношения (10.1):
„ 0,195-0,2 -0,005
Z = —I =-------= -U,5o.
0,2 0,8 0,0099
V 2000
Таким образом, нулевая гипотеза не может быть отвергнута
при 5-процентном уровне значимости, так как |-0,56|<1,96. Ут-
верждению редакции можно доверять при 5-проиентном уров-
не значимости.
10.1.2. Односторонние проверки
Пусть альтернативная гипотеза Н( характеризует не просто
отличие гипотетического значения параметра от истинного, а
указывает направление этого отклонения:
Н,:р>р0, (10.2)
Н, :/></,,. (10.3)
Рассмотрим случай (10.2). Область принятия нулевой гипо-
тезы задается соотношением
/7? <za,
PoU-Po)
ч л
а критическая область — неравенством
Р-Р0- *Za.
РрО-Ро)
\ л
Значение а характеризует уровень значимости, а величина Z.
имеет тот же смысл, что и в соотношении (9.12) (рис. 9.3).
Аналогично записываются неравенства соответственно для
области принятия нулевой гипотезы и критической области в
случае альтернативной гипотезы (10.3):
Pq(I-Pq)
N
247
,PH s-za.
iPq(I-Pq)
V N
Пример 10.2. Геологоразведочное объединение рассматривает воп-
рос о покупке большой партии специальных компьютеров, пред-
назначенных для наблюдения за сейсмической активностью ре-
гиона. Эти компьютеры должны работать в экстремальных
условиях низких температур. Компания-производитель утверж-
дает, что не менее 80% выпушенных компьютеров может устой-
чиво работать при температуре -20’С. Объединение собирается
сделать закупку, если утверждение фирмы будут подтверждено
независимым тестированием. Для проверки случайным образом
отобрали 30 компьютеров. В результате тестирования 9 компью-
теров были забракованы. Можно ли доверять утверждениям фир-
мы при 5-процентном уровне значимости?
Прежде всего выясним, выполняются ли условия для ис-
пользования нормального распределения: пр = 30 0,8 = 24>5,
л( I - р) = 300,2 = 6>5.
Задача проверки гипотез сводится к односторонней (лево-
сторонней) проверке:
Н0:/>>0,8,
Н, : р < 0,8.
Нулевая гипотеза Н(| в данном случае формулируется как
“равно или больше", а критическая область задается левой “хво-
стовой” частью кривой стандартного нормального распределе-
ния, ограниченной критическим пределом -Zo. = —(,64 (отсе-
кающим “хвост” с долей площади, равной 0,05).
Вычислим выборочное значение доли. Известно, что из 30
тестируемых компьютеров 21 (30 — 9) успешно прошел про-
- 21 m
верку. Отсюда Р = ~~ = О, 7.
Вычислим отношение (10.1): Z = । । । = —= -1,37.
|°>80'2 °’073
f 30
Так как —1,37>—1,64, то нулевая гипотеза не может быть
отвергнута при 5-процентном уровне значимости. Следователь-
но, объединение может произвести закупку партии компьюте-
ров.
248
Пример 10.3. Руководство компании, которая производит кет-
чуп, решает вопрос о производстве новой марки продукта. Идея
производства нового продукта возникла год назад. Тогда были
проведены маркетинговые исследования, которые показали,
что 5% домохозяйств одобряют новую марку. Для выявления
отношения к новому кетчупу в настоящее время было опроше-
но 6000 домохозяйств, 635 из них заявили, что хотели бы ку-
пить новый продукт. Требуется определить при 2-процентном
уровне значимости, возрос ли интерес покупателей к новому
кетчупу.
В данном случае рассматривается правосторонняя проверка
гипотез:
Но:р = О,05;
Н, : р > 0,05
при уровне значимости а = 0,02.
Объем выборки п = 6000. При этом выполняются условия
пр = 6000 0,05 = ЗОО>5 и л(1 - р) = 6000 0,95 = 5700>5. По
таблице Приложения 4 найдем величину критического преде-
ла: ZOI)2 = 2,05 (соответствует значению 0,4798, ближайшему к
0,48, таблицы площадей, ограниченных кривой стандартного
нормального распределения). Определим выборочную долю:
Вычислим значение критерия Z по формуле (10.1):
„ 0,056 - 0,05 0,006
Z = । =-------= 2,14.
[0,05 0,95 0,0028
\ 6000
Ввиду того что 2,14>2,05, нулевая гипотеза не может быть
принята с уровнем значимости 2%, т. е. при данном уровне
значимости можно считать, что интерес покупателей к новой
марке кетчупа возрос.
10.1.3. Поправка на конечность генеральной
совокупности
Пусть генеральная совокупность конечна и имеет объем N.
При этом объем выборки л, на основе которой вычисляется
выборочная доля р , составляет не менее 5% от объема N. Как
249
и в случае распределения выборочных средних, стандартная
ошибка статистики (теперь доли) умножается на поправочный
l~N -п
множитель J——т:
V N -1
_ - 1ро(1~Р^ Р^“п
? X л Vn-г
Критерий Z принимает вид
Z = -----ILZES-——. (10.4)
iPo(l-Po) \N-n
У п NN-1
Если объем выборки л составляет менее 5% от объема гене-
ральной совокупности N, то поправку на конечность можно не
учитывать.
Пример 10.4. Компания хочет закупить партию калькуляторов
в количестве 2500 штук. По условию закупки количество де-
фектных калькуляторов не должно превышать 4%. Случайным
образом было отобрано 150 калькуляторов. После проверки 13
из них оказались дефектными. Требуется определить, выполня-
ется ли условие закупки при уровне значимости а = 0,05.
Рассмотрим правостороннюю проверку гипотез:
Но : р<. 0,04;
Н, : р > 0,04.
Проверим выполнение условий правомерности использова-
ния нормального распределения: пр = 150 0,04 = 6>5, л(р) =
= 150 0,96= 144>5. Вычислим выборочную долю:
13
р = — = 0,087.
150
Ввиду того что N/n = 150/2500 =0,06>0,05, необходимо учи-
тывать поправку на конечность генеральной совокупности. По-
этому отношение / следует вычислить по формуле (10.4):
_ 0,087 - 0,04 0,047
|0Д)4 0,96 12500-150 0,016
V 150 V 2500-1
250
Как видно (2,94> 1,96), гипотеза Нп отвергается, а альтерна-
тивная гипотеза о превышении процента дефектных калькуля-
торов критического значения (4%) принимается при 5-про-
центном уровне значимости. Следовательно, компания вправе
отказаться от закупки.
10.2. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
РАЗНОСТИ ДОЛЕЙ ДВУХ ГЕНЕРАЛЬНЫХ
СОВОКУПНОСТЕЙ
10.2.1. Двусторонняя проверка
Пусть рассматриваются две генеральные совокупности и сто-
ит вопрос о сравнении долей этих совокупностей. Будем отби-
рать из совокупности 1 все возможные выборки объема л(, а из
совокупности 2 — объема п2, причем выборки из различных
совокупностей являются независимыми. Пусть значение гене-
ральной доли для совокупности 1 - р, а для совокупности
2 Тогда если одновременно выполняются условия «^^5 и
л,(1 ~ Р1)>5, л2/’2>5 и л;(1 - р2)>5, то, как отмечалось в разделе
8.1.4, распределение разностей выборочных долей будет нор-
мальным. Стандартная ошибка разности долей будет вычисляться
как корень квадратный из суммы дисперсий двух выборочных
распределений:
п _ |ptU-Pt) . Рг^-Рг)
п, п2 •
При проверке гипотез информация о точных значениях па-
рамегров р и р2 отсутствует, поэтому стандартная ошибка раз-
ности средних ст-заменяется на оценочное значение
где фигурируют статистики р} и р2.
+ (10.5)
А у П| п2
Рассмотрим нулевую гипотезу Но, смысл которой заклю-
чается в том, что предполагается равенство долей двух сово-
купностей (Н#: />! = р2). Очевидно, в случае правильности ну-
левой гипотезы лучшей точечной оценкой должна быть
комбинированная оценка, полученная на основе выборочных
долей р} и рг
251
Пусть Х} — число единиц в выборке из совокупности 1, об-
ладающих данным свойством (число “успехов”), а X, — число
_ X 1 _ X,
“успехов” в выборке из совокупности 2. Тогда Р] = —Ч р-, = —
«1 л2
Рассмотрим комбинированную величину
р = Х1 + Х2 = л1Р|+я2Р2
И| + л2 л( + л2
(10.6)
Величина (10.6) является взвешенной средней величиной
долей pt и р2, где в качестве статистических весов выступают
объемы выборок л, и лг Подставляя вместо значений статистик
р, и р2 величину (10.6) в формулу (10.5), получим оценку для
стандартной ошибки средней:
Sp-Pi
P(l~P)+Р(1~Р) _
«1 л2
Р(1"Р)
1 + ±
Л| л2
Z-критерий для проверки нулевой гипотезы относительно
разности средних двух генеральных совокупностей будет иметь
вид
Z =
(Pi -Р2)-<Р1 -Р2)
Jp(l-p)[—+~ |
V n2 J
(Ю.7)
Если в качестве альтернативной гипотезы Н, рассматривать
предположение о неравенстве долей, то задачу двусторонней
проверки можно записать так:
Но:Л ~Рг
Н1-Р^Рг
При уровне значимости а область принятия гипотезы Но бу-
дет задаваться условием
р(1-р)[—+ —
I "I л2
< ^-а/2-
252
Соответственно критическая область задается неравенством
Пример 10.5. Два типа лекарств были опробованы на двух раз-
личных группах пациентов. Лекарство типа А принимала груп-
па пациентов, состоящая из 60 человек, из которых 20 испыта-
ли положительное воздействие. Группа из 70 человек принимала
лекарство типа В. Из этой группы 25 пациентов испытали по-
ложительный эффект. При 5-процентном уровне значимости
определить, имеется ли различие в эффективности двух типов
лекарств.
Пусть мера эффективности лекарства заключается в величи-
не пропорции пациентов, испытавших положительный эффект
от приема лекарства. Для проверки нулевой гипотезы о равен-
стве пропорций вычислим величину средней взвешенной доли
по формуле (10.6):
Условия нормальности распределений выборочных долей вы-
полняются:
Л|Р = 6ОО,35 = 21>5и г, и1- р) = 60 0,65 = 39> 5,
л2р = 70 0,35 = 29,5,
л2(1-р) = 7ОО,65 = 45,5>5.
Пусть рх — генеральная доля пациентов, испытавших поло-
жительный эффект от лекарства типа А, а рг — от лекарства
типа В. Запишем задачу проверки гипотез:
H0:Pi =Р2.
НгЛ*^-
Вычислим выборочные значения долей:
20 1
Р1 60 3
= 0,33 ;р2=^ = 0,36.
253
Определим по формуле (10.7) значение Z:
z= ..ОЗЗгОЛб =Ч)34
Jo,35O,65f— + --1
V I 60 70 J
Так как |z| = |-0,34| = 0,34 < 1,96, то нулевая гипотеза о ра-
венстве двух типов лекарств принимается при а = 0,05.
10.2.2. Односторонние проверки
Пусть альтернативная гипотеза Н при сравнении долей двух
генеральных совокупностей имеет вид Н(: >/>г или Н(: р, < рг
Тогда
Но:Л =Рг
^C-P^Pr <Ю.8)
Область принятия гипотезы Но для задачи (10.8) при уровне
значимости а задается соотношением
....<za.
.'р(1-р)| — + — I
V I Л| «2 I
а критическая область — условием
Р(1-Р)| —+ —1
V”l «2 J
Задача левосторонней проверки имеет вид
Но:Л =Рг
НхР<<рг (10.9)
Область принятия гипотезы Но и критическая область для
задачи (10.9) при уровне значимости а будут задаваться соот-
ветственно неравенствами
254
Р\-Ръ
р(1-р)| —+—
1 Л| n2
<-Za.
Пример 10.6. Компания производит жестяные консервные бан-
ки для хранения соков. Банка считается некондиционной, если
она не круглой формы или имеет вмятины. Банки произво-
дятся в две смены (дневная и вечерняя). В отделе качества про-
дукции подозревают, что доля некондиционных банок, про-
изводимых в дневную смену, меньше, чем в вечернюю. Для
проверки данного предположения случайным образом было
отобрано по 500 банок, произведенных в каждой смене. В ре-
зультате проверки оказалось, что для дневной смены 70 ба-
нок были некондиционными, а для вечерней смены — 110.
Проверить предположение отдела качества при 5-процентном
уровне значимости.
Пусть Р] — генеральная пропорция некондиционных банок,
выпушенных в дневную смену, ар, - в вечернюю смену.
Задача односторонней проверки будет иметь вид
но: Л = Р2<
Н,: р, < р2.
По условию задачи л( = 500, = 70 и п2 = 500, Х2 = 110.
Вычислим выборочные пропорции и комбинированную общую
пропорцию:
р{ = — = 0,14; р, = — = 0,22;
500 500
_ 500 0,14 + 500 0,22 180 Л,о
р =-----------------------=------= (J.1 о.
500 + 500 1000
Выборки достаточно большие и являются независимыми,
что дает право использовать Z-критерий:
Z =
0.14-0,22
= 22^08 =_329
0,0243
Отсюда -3,29<—1,96, что свидетельствует о том, что Но от-
вергается, а следовательно, предположение отдела качества
подтверждается при a = 0,05.
255
Пример 10.7. Торговая фирма собирается открыть сеть магази-
нов в двух регионах. Для организации торговли важно иметь
сведения о численности семей, живущих в этих регионах. Есть
предположение, что доля семей в регионе I, имеющих в своем
составе более четырех человек, превышает долю подобных се-
мей в регионе 2. В рамках маркетинговых исследований в реги-
оне I была составлена случайная выборка из 180 домохозяйств,
а в регионе 2 выборка содержала 155 домохозяйств. Оказалось,
что число семей, в составе которых более четырех человек, для
региона I — 89, а для региона 2 — 61. Можно ли на основе этих
данных заключить, что доля семей с численностью более че-
тырех человек в регионе 1 выше? При оценке следует исполь-
зовать уровень значимости а = 0,05.
Определим выборочные доли для регионов:
р. = -- = 0,47; р, = — = 0,39.
1 180 'п 155
Вычислим комбинированную долю:
. 89 + 61 150
р =--------=----= 0,45.
' 160 + 155 335
Проверим, выполняются ли условия использования крите-
рия Z:
Л]Р = 180 0,45 = 81 > 5 и П](1-р) = 180 0,55 = 99>5;
п2р = 155 0,45 = 69,75>5 и
л2(1-р) = 155 0.55 = 85,25>5.
Проверка гипотез будет правосторонней:
^Р^Рг
Н,: р, > р2.
Вычислим Z:
Ввиду того что 1,85> 1,64, гипотеза Но не может быть приня-
та при 5-процентном уровне значимости. Подтверждается пред-
положение о том, что доля семей, в составе которых более 4
человек, в регионе I выше.
256
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 10
Содержание нулевой гипотезы Н. в задачах проверки гипо-
тез относительно генеральной доли заключается в предполо-
жении, что доля генеральной совокупности р принимает опре-
деленное значение pQ (Но: р = р0). Если объем выборки п
достаточно большой (выполняются условия пр>5 и л(1 - р)>5),
то распределение выборочных долей будет приблизительно нор-
мальным. Поэтому для проверки нулевой гипотезы можно ис-
пользовать стандартное нормальное распределение, вычисляя
Р Рп
значение критерия Z = । "— и сравнивая его с соот-
IPo(I-Pq)
V л
ветствующими критическими значениями. Если осуществляет-
ся двусторонняя проверка при уровне значимости а, т. е. рас-
сматривается альтернативная гипотеза Н(: р * pQ, то критерий
Z сравнивается по абсолютной величине с Z . При односто-
ронних проверках (Н( : р > р0 или Н1 : р < р0) величина Z
сравнивается соответственно с +Zu (или -Za).
Если генеральная совокупность конечна и имеет объем N, то
в случае выполнения условия л/^0,05 следует учитывать по-
правку на конечность генеральной совокупности. Для этого не-
обходимо стандартную ошибку доли домножить на поправоч-
ный множительу. Если n/N<0,05, то поправку на
конечность можно не учитывать.
Пусть рассматриваются две генеральные совокупности и
необходимо провести сравнение долей этих совокупностей. Пусть
р. и р2 — соответственно доли первой и второй совокупности.
Если из совокупностей извлекаются независимые выборки до-
статочно больших объемов (пр >5 и л((| — pt)>5, пру>5 и
л (1 - р2)>5), то распределение разностей выборочных средних
будет близко к нормальному. Пусть в качестве нулевой гипоте-
зы рассматривается Н(: = р тогда при вычислении стандарт-
ной ошибки разности средних следует рассматривать взвешен-
ную среднюю выборочных средних pt и р2: р = + п2Р2
И1+л2
Критерий оценки будет иметь вид (10.7).
При односторонних проверках (Н( : или Н( : pt < р2)
критерий Z сравнивается соответственно с +Za или —Z.
J J ДИСПЕРСИОННЫЙ
АНАЛИЗ
11.1. ОБЩАЯ СХЕМА
ОДНОФАКТОРНОГО АНАЛИЗА
Одна из важнейших проблем статистического анализа, ко-
торая очень часто возникает на практике, — выявление влия-
ния различных факторов на исследуемый показатель. Для ре-
шения подобных задач используется дисперсионный анализ.
В зависимости от числа влияющих факторов дисперсион-
ный анализ может быть однофакторным и многофакторным.
Мы будем рассматривать только однофакторный дисперсион-
ный анализ. Метод дисперсионного анализа был создан для
обработки результатов агрономических опытов при исследо-
вании влияния различных типов удобрений на урожайность.
Данный подход затем стал широко использоваться в различ-
ных сферах деятельности, в том числе экономике, управле-
нии и бизнесе.
Пусть, например, несколько фирм выпускает электричес-
кие лампочки и требуется проанализировать, отличаются ли
средние сроки службы лампочек, произведенных различными
фирмами. В данной ситуации можно провести аналогию: уро-
жайность, измеряемая в центнерах на гектар, будет соответ-
ствовать сроку службы лампочек, выраженному в часах, а раз-
личные типы удобрений — торговым маркам фирм. В случае
двух фирм задача сводится к проверке гипотез относительно
разности средних двух генеральных совокупностей. Дисперси-
онный анализ используется, когда требуется одновременно
сравнить генеральные средние нескольких совокупностей (число
фирм больше двух).
Предположим, имеются три различные торговые марки элек-
трических лампочек Л, В и С, соответствующие трем различ-
ным фирмам. Пусть требуется проверить, имеются ли различия
258
в средних сроках службы лампочек этих фирм. Случайным об-
разом отберем по четыре лампочки каждой марки и протести-
руем их для выяснения срока службы. Пусть результаты испы-
тания, измеренные в часах, были сгруппированы по торговым
маркам в следующем виде:
Марка А: 30, 31, 32, 33
Марка В: 40, 41, 42, 43
Марка С: 50, 51, 52, 53
Отметим данные о сроках службы на оси времени:
АВС
--НН-----НН----НН-------►
Без всяких статистических заключений ясно, что лампочки
марки С горят дольше, чем лампочки марки В, которые в свою
очередь горят дольше, чем лампочки марки А. Очевидно, сред-
ние сроки службы лампочек различных марок отличаются друг
от друга.
Предположим теперь, что результаты тестирования были
другими:
Марка А. 30, 40, 50, 60
Марка В. 31, 31, 51, 61
Марка С: 32, 42, 52, 62
Отметим полученные данные на оси времени:
АВС АВС АВС АВС
--НН---НН---НН---НН-----►
Во втором случае, очевидно, трудно сделать вывод о значи-
мости различия между средними сроками службы лампочек
марок А, В, С. Причина заключается в том, что величина вари-
ации (разброса) значений внутри группы для каждой марки
гораздо больше, чем вариация между группами. В первом же
случае наоборот: вариации между группами значительно выше,
чем разброс внутри группы.
Данный принцип сравнения двух дисперсий, одна из кото-
рых характеризует вариацию внутри групп, а другая — между
группами, является методологической основой дисперсионно-
го анализа. При этом обязательно должны выполняться следу-
ющие условия относительно генеральных совокупностей, для
которых проводится сравнение средних:
1) распределения генеральных совокупностей нормальные
или близкие к нормальным;
259
2) все генеральные совокупности имеют одинаковую дис-
персию, которая в общем случае может быть неизвестной.
Если данные условия выполняются для ситуации с лампоч-
ками. то можно предположить, что в первом случае данные
были взяты из нормальных совокупностей, распределения ко-
торых могли иметь вид, указанный на рис. 11.1.
30 40 50
Рис. 11.1. Случай большой вариации между группами
Второй случай мог бы характеризоваться распределениями,
представленными на рис. 11.2.
30 40 50 60
Рис. 11.2. Случай большой вариации внутри групп
Как видно, в обоих случаях генеральные и средние не со-
впадают. Однако во втором случае (рис. 11.2) правильное зак-
лючение, сделанное только на основе визуального анализа
выборочных данных, будет неочевидным. Исследуемую ситуа-
цию можно рассматривать как проблему проверки гипотез. Обо-
значим средние сроки службы лампочек марок А, В, С соответ-
ственно ц , ц и Тогда нулевая гипотеза будет иметь вил
Но = Нс •
Под альтернативной гипотезой понимается условие
Hj : среди ц4, ця, цс имеется хотя бы одна, не равная двум
остальным.
Формально дисперсионный анализ можно рассматривать как
задачу проверки гипотез относительно равенства средних п
260
нормальных генеральных совокупностей, имеюших одинако-
вую дисперсию:
Но : h = Р, = - = = Ц.
Н, : не все ц , ц2,..., pvравны между собой.
Если нулевая гипотеза окажется правильной, то это будет
означать, что все совокупности идентичны, т. е. являются од-
ной и той же нормальной совокупностью со средней ц и дис-
персией ст2.
Процедура проверки нулевой гипотезы заключается в вы-
числении с помощью двух различных подходов оценочного
значения дисперсии, которая должна быть общей для всех ге-
неральных совокупностей. Первый подход основан на предпо-
ложении, что нулевая гипотеза верна, т. е. имеет место равен-
ство средних генеральных совокупностей. При втором подходе
исходят из того, что верна альтернативная гипотеза. Если рас-
хождение между оценками дисперсии значимо, то предполо-
жение о равенстве генеральных средних считается неправиль-
ным и нулевая гипотеза отвергается. Наоборот, если расхождение
будет незначимо, то нулевая гипотеза не отвергается.
11.2. МЕЖГРУППОВАЯ И ВНУТРИГРУППОВАЯ
ДИСПЕРСИИ
В дисперсионном анализе сравниваются две оценки гене-
ральной дисперсии — межгрупповая и внутригрупповая дис-
персии.
Предположим, что все значения признака элементов гене-
ральной совокупности разбиты на несколько групп. Каждую
группу можно рассматривать как отдельную выборку. Напри-
мер, общая совокупность лампочек может быть разбита на три
группы, соответствующие трем различным маркам А, В, С.
Значением признака здесь является срок службы каждой лам-
почки. Пусть в общем случае значения признака нормальной
генеральной совокупности с параметрами цист2 разбиты на к
групп. Каждую группу можно рассматривать как отдельную
выборку. Вычислим значения выборочных средних и диспер-
сий: Х|,Х2.и J|2.i2...5*.
Рассмотрим совокупность выборочных средних как некото-
рую выборку и вычислим выборочную дисперсию:
261
где
i-1
*-l
(11.1)
— средняя выборочных средних.
к
Величина (11.1). очевидно, является оценкой дисперсии
распределения выборочных средних, т. е. квадрата стандартной
ошибки средней:
Sr «о? =
(11.2)
(113)
(114)
ст У ст2
!п J п
Обозначим оценочное значение генеральной дисперсии а2.
Тогда из соотношения (11.2) получим
-2 2 £«(^-^)2
ст = ns- = -------
х к-1
Использование формулы (11.3) для оценки генеральной
дисперсии будет возможным, если группы или выборки, на
которые была разбита генеральная совокупность, имеют оди-
наковый объем л. В общем случае группы разбиения генераль-
ной совокупности могут иметь различные объемы. Пусть объем
Ай выборки будет л (/ = 1,..., к). Умножим каждый квадрат откло-
нения (х, -х)2 на соответствующий объем л( и скорректируем
оценку (11.3) с учетом различных объемов групп:
ст2 _ £”<(<<-*)2
к-1
Величина (11.4) называется межгрупповой дисперсией. Она
характеризует различия в величине изучаемого признака, ко-
торые возникают под влиянием фактора (признака), заложен-
ного в основу группировки. Так, в ситуации с лампочками в
качестве такового фактора фигурировала сортировка лампочек
по трем торговым маркам А, В и С.
Определим внутригрупповую дисперсию, которая является
второй оценкой генеральной дисперсии. Для Ай группы дис-
персия вычисляется по формуле выборочной дисперсии
s2 =
л,-1
(115)
где X, — средняя выборки /.
262
Величина л — 1 в выражении (11.5) характеризует число
степеней свободы для дисперсии г2. Общее число степеней
свободы по всем выборкам будет равно сумме
(л, - 1) + (л2- 1) + ...+ (л4 - 1) =
= (Л[ + л, + ... + nt) - к = лт - к,
где л обозначает общую сумму объемов выборок (лт= Ел.).
Внутригрупповая дисперсия вычисляется как средняя взвешен-
ная величина выборочных дисперсии, где в качестве весов высту-
пают удельные веса степеней свободы соответствующих выборок;
ст
л, -1'
Vt-1,
(116)
2
Внутригрупповая дисперсия характеризует вторую оценку
обшей генеральной дисперсии ст2. Она отражает случайные из-
менения признака, происходящие под влиянием других неуч-
тенных факторов и не зависящие от фактора, положенного в
основу группировки.
Проверка нулевой гипотезы в дисперсионном анализе про-
водится по следующему принципу. Пусть гипотеза Но верна
(Но: = ц2 = ... = цг). Это означает, что фактор группировки
не должен оказывать влияния на выделение групп, так как
все группы берутся из одной и той же генеральной совокуп-
ности (или образуют лишь одну исходную генеральную сово-
купность). Иначе говоря, можно полагать, что выделения групп
как бы не существует (межгрупповая дисперсия равна нулю),
а имеет место только внутригрупповая дисперсия, совпадаю-
щая с обшей генеральной дисперсией о2.
Предположим теперь, что верна альтернативная гипотеза
Нр т. е. существует, по крайней мере, одна совокупность, сред-
няя которой отличается от средних других совокупностей. В этом
случае фактор, заложенный в основу группировки, оказывает
значительное влияние на выделение групп. Средние значения
групп существенно отличаются друг от друга, в то время как
каждая группа характеризуется внутренней однородностью.
Очевидно, дисперсия общей совокупности, составленной из
таких групп, должна совпадать с межгрупповой дисперсией,
отражающей разнородность общей совокупности.
Дисперсионный анализ основан на следующем фундамен-
тальном правиле: если межгрупповая дисперсия статистически
значимо превышает внутригрупповую, то делается вывод, что
групповые средние значимо различны, т. е. нулевая гипотеза Но
отвергается.
263
11.3. СРАВНЕНИЕ МЕЖГРУННОВОЙ
И ВНУТРИГРУППОВОЙ ДИСПЕРСИЙ
НА ОСНОВЕ Г-РАСПРЕДЕЛЕНИЯ
После того как значения межгрупповой и внутригрупповой
дисперсий вычислены, возникает проблема их сравнения. Она
осуществляется на основе F-критерия (критерия Фишера), ко-
торый еще называют F-статистикой, или F-отиошением. F-m-
ношение представляет собой отношение оценок и v обшей
дисперсии, полученных из независимых выборок, элементы
которых взяты из одной или нескольких совокупностей с оди-
наковой дисперсией: ,
Г = Д-. (11.7)
32
F-отношение подчиняется закону F-распределсния Фишера.
Существует целое семейство F-распределений, каждое из ко-
торых характеризуется двумя параметрами: степенями свобо-
ды, соответствующими числителю и знаменателю отношения
(11.7). Кривая F-распределсния всегда расположена в положи-
тельной полуплоскости с областью определения от 0 до + оо
(рис. 11.3). При возрастании значения /кривая неограниченно
приближается к оси х, но никогда не пересекает ее. Все F-рас-
пределения имеют положительную асимметрию и стремятся к
симметричной форме при неограниченном возрастании степе-
ней свободы. F-распределение является непрерывным, поэто-
му данные совокупностей, которые анализируются на его ос-
нове, должны быть непрерывными и изменяться, по крайней
мере, в шкале интервалов.
Рис. 11.3. Кривые F-распределений: 1 — 29 степеней свободы
в числителе и 28 в знаменателе; 2—19 степеней свободы в числителе
и 6 в знаменателе; 3 — 6 степеней свободы в числителе и 6 в знаменателе
264
Для F-отношения при разных сочетаниях степеней свободы
числителя и знаменателя построены таблицы критических зна-
чений (пределов), которые могут быть превзойдены с различ-
ной вероятностью (уровнем значимости). Так, в Приложении 6
представлены таблицы для уровней значимости а = 0,05 и
а = 0,01.
Гипотеза, которая проверяется с помощью F-критерия, за-
ключается в том, что независимые выборки были взяты из од-
ной и той же нормальной совокупности или из нормальных
совокупностей с равными дисперсиями. При вычислении
F-отношения по формуле (11.7) для проверки этой гипотезы
за з(2 берется ббльшая из оценок ^2 и з22, т. е. з(2 > з22. Число
степеней свободы, соответствующих большей оценке з(2 (чис-
лителю), определяет колонка таблицы, а число, соответствую-
щее меньшей оценке з22 (знаменателю), — строка таблицы. Так
как всегда полагается з(2 > зЛ то значение F-отношения будет
больше 1. Поэтому таблицы Приложения 6 соответствуют все-
гда критическим пределам односторонней проверки гипотезы
о значимости превышения з(2 над з22.
В дисперсионном анализе в качестве F-критерия рассматри-
вается отношение
Межгрупповая дисперсия (118)
Внутригрупповая дисперсия ’
В отношении (11.8) числителю соответствует число степе-
ней свободы, равное к — 1 (к — число групп), а знаменателю —
л — к (лт — общая сумма объемов групп).
Если величина F-критерия, выраженного формулой (11.8),
превзойдет критическое значение Fand (где а — уровень значимо-
сти, л = к - 1 — число степеней свободы числителя, с/= л_ - 1 —
число степеней свободы знаменателя), взятое из соответствую-
щей таблицы Приложения 6, то нулевая гипотеза о равенстве
средних (Но : = ц. = ... = pj отвергается с уровнем значимо-
сти а.
Пример 11.1. Руководство кадровой службы компании хочет про-
анализировать эффективность трех различных методов подготовки
персонала. Для этой цели после завершения курсов повышения
квалификации была составлена случайная выборка из 16 работ-
ников, которая была разбита на три группы в соответствии с
методами обучения. С помощью специальных тестов была изме-
рена их дневная производительность. Результаты тестирования,
выраженные в специальной шкале, были сведены в табл. 11.1.
265
Таблица 11.1
Данные о дневной производительности работников,
сгруппированных по методам обучения
Метод 1 Метод 2 Метод 3
15 22 18
18 27 24
19 18 16
22 21 22
11 17 15
85 105 114
х, = 85/5 = 17 Xj 105/5 = 21 Х3 = 114/6= 19
л, = 5 л2 = 5 Л3 = 6
Используя данные табл. 11.1, следует сделать заключение,
влияют ли различные методы обучения на производительность
работников. Формальная постановка задачи сводится к провер-
ке гипотезы о том, что средние значения дневной производи-
тельности работников в группах, соответствующих трем раз-
личным методам подготовки, равны между собой. Формальная
запись задачи проверки гипотез имеет вид
Ио: И, = = ц,,
Н( : не все у , g2, ц, равны между собой.
Нулевая гипотеза Но будет верна в случае, если выборочные
(групповые) средние статистически незначимо отличаются друг
от друга. Если же расхождения будут значимы, то принимается
альтернативная гипотеза Н . Эго означает, что методы подго-
товки оказывают сильное влияние на производительность ра-
ботников и поэтому следует скорректировать программы под-
готовки персонала.
Данная задача является задачей дисперсионного анализа.
В табл. 11.1 представлены значения производительности работни-
ков, сгруппированных по трем методам подготовки, и вычисле-
ны групповые средние. Вычислим среднюю выборочных средних:
_ х. + х2 + х» 17 + 21 + 19
х = -1—а—-А =----------= 19.
3 3
По формуле (11.4) определим межгрупповую дисперсию:
а - *11*1 Г*)2 + л2(хг-х)2+л3(х3-х)2 _
3-1
= 5(17- 19)2 +5(21-19)2 +6(19-19)2 = 40 =
2 2
266
Другой оценкой общей дисперсии будет внутригрупповая
дисперсия. Для ее определения необходимо вычислить группо-
вые дисперсии. Их вычисление сведено в табл. 11.2.
Таблииа 11.2
Вычисление групповых дисперсий
Метод 1 (х, “ 17) Метод 2 (х, - 21) Метод 3 (х, - 1»)
х - ж, (* - *,)* х - xt (х - X,)2 х - ж3 (» - *>)*
15- 17- -2 (-2)г = 4 22-21-1 1»-1 18 - 19 = -1 (-D2- 1
18- 17= 1 12- 1 27 - 21 = 6 62 = 36 24 - 19 = 5 5’ = 25
19-17-2 22 = 4 18- 21 = -3 (-3)2 = 9 19 - 19 = 0 02-0
22 - 17 = 5 52 = 25 21-21-0 О2 = 0 16 - 19 = -3 (-3)2 - 9
11 - 17 = -6 (-6)2 = 36 17-21 --4 (-4)2 = 16 22 - 19 = 3 15-19 = 4 З2- 9 42 = 16
Х(х-х« )2 =70 £(х-х2)2-62 £(х-х})2=12
-V ——— = г *2 ж з,2-^ •*з>\
«1 -I "2 -1 "3 -1
70 = = 4 17J 66 Ж = 4 15,5 60 = —— = 5 12
По формуле 11.6. вычисляем внутригрупповую дисперсию:
а _ (л, - Ф,+(лг ~ + (из ~ =
л, + л2 + л3 - 3
417,5 + 415,5 + 512 192
=-------------------=----= 14,77.
5 + 5 + 6-3 13
Определим /"-отношение:
Пусть руководство кадровой службы хочет проверить нуле-
вую гипотезу при уровне значимости а = 0,05.
Для этой цели воспользуемся соответствующей таблицей
Приложения 6. Число степеней свободы числителя, соответ-
ствующее колонке таблицы, равно к — 1=3-1= 2, а число
степеней свободы знаменателя, определяющее строку табли-
цы, равно ^л,-Л = 16-3 = 13. На пересечении выделенных
267
строки и столбца найдем значение критического предела
Foai |3 = 3,81. Так как F— 1,35<3,81, то нулевая гипотеза при-
нимается (рис. 11.4).
Рис. 11.4. Области принятия и непринятия нулевой гипотезы при уровне
значимости 0,05 на основе F-раслределения
В итоге руководство кадровой службы может сделать вывод,
что при 5-процентном уровне значимости различные методы
подготовки не оказывают существенного влияния на произво-
дительность работников.
11.4. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
ДИСПЕРСИЙ ДВУХ ГЕНЕРАЛЬНЫХ
СОВОКУПНОСТЕЙ
F-распределение может также использоваться для проверки
гипотезы о равенстве дисперсий двух нормальных совокупнос-
тей. При этом можно рассматривать одностороннюю и двусто-
роннюю проверки. Для односторонней проверки постановка
задачи имеет вид
Но:о>2 = стЛ
Гипотеза проверяется по F-критерию, где в качестве Г-от-
ношения берется отношение выборочных дисперсий и $22,
которые являются оценками соответственно генеральных дис-
персий о(2 и о22:
г-4
s2
Данная F-статистика распределена по закону F-распрсдслс-
ния с — 1 степенями свободы в числителе и пг~ 1 степеня-
268
ми свободы в знаменателе, где л( — объем выборки из первой
совокупности, а л — из второй. Проверка производится при
заданном уровне значимости а, т. е. критическим пределом бу-
дет величина F
® «|-1; л2-1
Пример 11.2. На автомобильном заводе работают две конвей-
ерные линии. Руководство отдела контроля качества хочет оп-
ределить, имеется ли однородность в количестве дефектов для
автомобилей, сходящих с первого и второго конвейеров. Для
этой цели были сделаны две случайные выборки: 20 автомоби-
лей из числа сошедших с первой линии и 16 автомобилей со
второй. Оказалось, что для первой линии среднее число дефек-
тов на один автомобиль было 10 с дисперсией 9, а для вто-
рой — 11 с дисперсией 25.
Требуется сделать заключение, значимо ли превышение ва-
риации числа дефектов для второй линии при уровне значимо-
сти а = 0,05. Если превышение будет значимым, то, очевидно,
следует провести переналадку работы конвейеров.
Исходные данные задачи: $2 = 9, л) = 20, з* = 25, л2 = 16.
Запишем задачу односторонней проверки:
Но: а,2 « о22,
Hi: < > °Л
Вычислим F-отношение, где в числитель поставим большую
выборочную дисперсию:
Числителю соответствует л2 - 1 = 16 - 1 = 15 степеней сво-
боды, знаменателю — л( — 1 = 20 - 1 = 19. Критическое значе-
ние F005 |5 = 2,23. Так как 2,78>2,23, то превышение значимо
и нулевая гипотеза Но отвергается с 5-процентным уровнем
значимости.
Как видно, при односторонней проверке рассматривается
только верхний критический предел, отделяющий правосто-
ронний “хвост” распределения — критическую область, соот-
ветствующую непринятию нулевой гипотезы. Процедура дву-
сторонней проверки аналогична, однако возникает проблема
определения нижнего критического предела, отделяющего ле-
вую “хвостовую” часть критической области.
269
Пусть F(a, п, d) — значение F, соответствующее п степеням
свободы числителя, d степеням свободы знаменателя и отделя-
ющее правой “хвост” F-распределения с долей площади а. Для
него верно следующее соотношение:
1
F(a,n,d) =-----------,
F(l-a,d,n)
(11.9)
Величина - a, d, п) в формуле (11.9) характеризует ниж-
ний критический предел, ограничивающий область в левой
части распределения с долей площади I — а. Таким образом,
определение нужного нижнего критического предела для дву-
сторонней проверки сводится к нахождению табличного зна-
чения F-статистики, которая является для него обратной вели-
чиной.
Пример 11.3. Большая фармацевтическая фирма разрабатывает
два типа препарата для местной анестезии. Препарат вводится
с помощью инъекций. Для принятия решения о запуске препа-
ратов в производство необходимо сравнить вариацию средних
сроков действия препаратов. Под сроком действия подразуме-
вается время, прошедшее от момента инъекции до начала дей-
ствия анестезии. Ввиду сходства в химическом составе двух пре-
паратов ожидалось, что степень вариации будет одинаковой у
обоих препаратов.
Для проверки этой гипотезы действие препарата 1 было ис-
пытано на выборке из 31 пациента (и, = 31), а препарата 2 —
на выборке из 41 пациента (п, = 41). Выборочная дисперсия в
первом случае была = 1296, а втором — j22 = 784. Фирма
хочет проверить предположение о равенстве вариаций при 2-
процентном уровне значимости.
Формальная запись задачи имеет вид
Н,: о/ * о/.
Вычислим F-статистику:
F = 4 = 1~- = 165.
sj 784
Эта статистика соответствует F-распределению с 30 - 1 =
= 31-1) степенями свободы числителя и 40 (я} - I » 41 - I)
270
степенями свободы знаменателя. Так как проверка должна быть
двусторонней при а “ 0, 02, то нижний и верхний критические
пределы должны отделять области, имеющие доли площади,
равные 0,01. Верхний предел F00i. 0 найдем непосредственно
по таблице для а = 0,01 Приложения 6: F001 30. w = 2,2. Однако
величины нижнего предела F ?t) в этой таблице нет. Исходя
из соотношения (11.9), можно записать:
^0.99.30.40 - ~----= ЧЧ = 0’4}
^o.oi.wjo
Следовательно, значение F-статистики попадает в область
принятия гипотезы Но (рис. 11.5).
Рис. 11.5. Область принятия нулевой гипотезы
при уровне значимости а “ 0,02
Нулевая гипотеза Но принимается при 2-процентном уров-
не значимости. Следовательно, предположение о равенстве ва-
риаций сроков действия препаратов подтвердилось.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 11
Дисперсионный анализ используется для выявления влия-
ния различных факторов на результативный показатель. Если
влияющий фактор единственный, то дисперсионный анализ
называется однофакторным, если факторов несколько — мно-
гофакторным. В главе приведены основные принципы и мето-
ды однофакторного анализа. Формально дисперсионный ана-
лиз можно рассматривать как задачу проверки гипотез, где
нулевая гипотеза Но заключается в предположении о равенстве
нескольких генеральных средних.
271
Если Но верна, то это означает, что все совокупности иден-
тичны, т. е. являются одной и той же генеральной совокупно-
стью со средней ц и дисперсией о3. Процедура проверки нуле-
вой гипотезы заключается в вычислении с помощью двух
различных методов оценки общей дисперсии. Первый подход
основан на предположении, что нулевая гипотеза верна. Вто-
рой подход предполагает, что верна альтернативная гипоте-
за, которая за-ключается в том, что не все генеральные сред-
ние имеют одинаковые значения. Если расхождение между
оценками значимо, то нулевая гипотеза отвергается. В диспер-
сионном анализе одной из опенок общей дисперсии является
межгрупповая дисперсия, а другой — внутригрупповая дис-
персия. Пусть все значения признака элементов генеральной
совокупности разбиваются на несколько групп. Каждую груп-
пу можно рассматривать как отдельную выборку. Под меж-
групповой дисперсией (формула (11.4)) понимается диспер-
сия выборочных средних относительно их среднего значения,
где каждый квадрат отклонения умножается на объем соот-
ветствующей группы. Она характеризует различия в величине
изучаемого признака, которые возникают под влиянием фак-
тора, заключенного в основу группировки. Внутригрупповая
дисперсия вычисляется как средняя взвешенная величина
выборочных дисперсий, где в качестве весов выступают удель-
ные веса степеней свободы соответствующих выборок (фор-
мула (11.6)). Она отражает случайные изменения признака,
происходящие под влиянием других неучтенных факторов и
не зависящие от фактора, положенного в основу группиров-
ки. Дисперсионный анализ основан на следующем правиле:
если межгрупповая дисперсия статистически значимо превы-
шает внутригрупповую, то делается вывод, что групповые
средние значимо различны, т. е. нулевая гипотеза Но отверга-
ется. Сравнение дисперсий осуществляется с помощью F-ста-
тистики, которая представляет собой отношение межгруппо-
вой дисперсии к внутригрупповой. Распределение F-статистик
является F-распределением, которое соответствует (к — 1)
степеням свободы в числителе (к — число групп) и (лт — к)
степеням свободы в знаменателе (лт — общая сумма объемов
групп). Значение F-статистики сравнивается с соответствую-
щим критическим значением где а—• заданный
уровень значимости. Критические значения находятся изтаб-
272
лип Приложения 6. Если F-отношение превышает критичес-
кое значение, то превышение межгрупповой дисперсии счи-
тается значимым при заданном уровне значимости.
F-распределение также используется для проверки гипотезы
о равенстве дисперсий двух нормальных совокупностей. При этом
можно рассматривать одностороннюю и двустороннюю провер-
ки. При двусторонней проверке возникает проблема определе-
ния нижнего критического предела, отделяющего область, име-
ющую долю площади а/2, где а — уровень значимости. Для его
определения можно использовать соотношение (11.9).
РАСПРЕДЕЛЕНИЕ х2
И ЕГО ПРИМЕНЕНИЕ
В ВЫБОРОЧНОМ МЕТОДЕ
12.1. РАСПРЕДЕЛЕНИЕ %2
И ОЦЕНКА ГЕНЕРАЛЬНОЙ ДИСПЕРСИИ
Пусть Z, Z2,..., Zv — независимые случайные величины,
каждая из которых распределена по стандартному нормально-
му закону с параметрами ц( = О, О( = I (/ = 1. v).
Рассмотрим случайную величину, равную сумме квадратов
этих величин и имеющую особое распределение, называемое
хи-квадрат (х2):
X2=Z2 + Z2+... + Zv2. (12.1)
Распределение х2 всегда неотрицательно, зависит только
от значения V, которое называется числом степеней свободы
и полностью определяет конкретное распределение Сред-
нее значение х 2 равно V, а стандартное отклонение — 2v. На
рис. 12.1 представлены графики нескольких распределений для
различных значений v. При возрастании v распределение стре-
мится к нормальному.
Рис. 12.1. Кривые распределений х\ Для v = 2, 4 и 10
274
Для распределения х2. как и для любого непрерывного рас-
пределения, вероятность попадания значения случайной вели-
чины в определенный промежуток характеризуется соответству-
ющей площадью под кривой распределения. Форма кривой
распределения х2 зависит от числа степеней свободы. Как и для
семейства /-распределений, была рассчитана таблица площа-
дей под кривыми распределений х2. соответствующих различ-
ным степеням свободы. Эта таблица представлена в Приложе-
нии 7. Ее строки задают степени свободы, обозначаемые df, а
столбцы — определенные доли (а) для площадей под правыми
“хвостовыми” частями кривой, которые ограничиваются зна-
чением х^фис. 12.2). Эти значения находятся на пересечении
соответствующих строк и столбцов (рис. 12.2).
Рис. 12.2. Геометрическая интерпретация величины Х2[[СЛ
Пример 12.1. Используя кривую х2 для df= 12, вычислим веро-
ятность Лх2> 18,5494) и Лх2<6,3038). В таблице Приложения 7
в строке, соответствующей df 12, найдем значение 18,5494.
Оно находится в столбце х201П0, т. е. ограничивает правый “хвост”
кривой с долей площади 0,1 (рис. 12.3).
Таким образом, Лх2> 18,5494) = 0,1. Аналогично значение
6,3038 находится в строке “df = 12” и в столбце х20,. т. е. вероят-
ность, что х,|2> 6,3038, будет Лх212>6,3038) = 0,9 (рис 12.4).
Ввиду того что правее 6,3038 доля площади под кривой равна
0,9, а правее 18,54494 — 0,1, очевидно, Л6,3038$х2|2^ 18,5494)=
= 0,9-0,1 =0,8.
275
Пример 12.2. Используя данные примера I2.1, определить преде-
лы а и Ь, которые удовлетворяют условию Р(а <Х?а<Ь) - 0,95. При
этом а и bдолжны отделять “хвосты” с одинаковыми площадями.
Очевидно, площади левого “хвоста” (ограниченного пре-
делом а) и правого “хвоста” (ограниченного пределом Ь) дол-
жны быть равны (I — 0,95)/2 = 0,025. Относительно величины
а это означает, что справа от нее должна находиться область с
площадью, равной I - 0,025 = 0,975. Следовательно, а = Х20,7?|2-
По таблице Приложения 6 найдем а - х2.... = 4,40, Ь =
= Х2о.ОИ;12 = 23,3 (рис. 12.5).
Рис. 12.5. Геометрическая интерпретация Р^а <х*,2<Ь) = 0,095
Распределение х2 можно определить другим способом. Рассмот-
рим случайную выборку хр х2,.... хя, взятую из нормальной гене-
ральной совокупности с параметрами ц и о2. Тогда статистика
? = (|22)
ст ст ст
будет распределена по закону х2„-
Если ц неизвестно, то в качестве оценки рассмотрим выбо-
рочную среднюю х , которую подставим в (12.2) вместо ц:
2(х,-х)2 (х2-х)2 (*„-х)2 _
* ст2 ст2 ст2 "
- +(х2 ~*>2 + ••• + (*, ~*)2 (12.3)
276
Числитель выражения (12.3) является числителем в форму-
ле для выборочной дисперсии:
2
5 = “-------.
Л-1
Отсюда
2_(л-1)?
* „2
(12.4)
где г является несмещенной оценкой генеральной дисперсии и2.
По определению несмещенности математическое ожидание
распределения оценочных статистик должно быть равно оце-
ниваемому параметру, т. е. Е(з2) = о2. Следовательно, ввиду (12.4)
имеем
е(х2) = е
о2
= —Е(?) = л-1.
Таким образом, распределение статистики (12.4) можно
рассматривать как распределение х\.г Потеря одной степени
свободы произошла ввиду того, что в формуле для выборочной
дисперсии s2 фигурирует выборочная средняя х , которая свя-
зывает одну из переменных х, х.,..., хя (при известных значени-
ях х, х2,.., хд| и х значение хя будет единственным).
При построении доверительных интервалов для генераль-
ной дисперсии о2 следует рассмотреть распределение выбо-
рочных дисперсий J2. Для этого будем извлекать из нормаль-
ной генеральной совокупности с параметрами ц и о случайные
выборки объема л и вычислять соответствующие выборочные
дисперсии J2. Из формулы (12.4) видно, что выборочное рас-
пределение зг можно определить на основе распределения
Очевидно, оно зависит от величин л и а2 и его можно
использовать для построения доверительных интервалов при
оценке о2.
Например, рассмотрим выборку объема л = 13, что соот-
ветствует #=12. Для данных примера 12.2 было установлено,
что
Ж4.40<х2<23,3) = 0,95.
На основе соотношения (12.4) можно записать:
Р 4,40 <
12s2
_2
<23,3 =0,95.
277
или
12?
23,3
12?'
4,40
= 0,95.
Это означает, что 95-процентный доверительный интервал
12s2 12s2
имеет пределы -----;----.
23,3 4,40
По аналогии можно выразить доверительные пределы для
а2 при доверительной вероятности 1 — а и объеме выборки п:
(я-1)т2е (я-1)з2
„2 ’
Ха/2л-1 Х1-ц/2л-1
(12.5)
Соответственно доверительный интервал для стандартного
отклонения имеет вид
(я-l)s2. । (я-l)s2
Ха/2;л-1 у Х|-а/2л-1
(12.6)
Пример 12.3. Фасовочный автомат наполняет пакеТики специя-
ми. Стандартный вес наполненного пакетика должен быть 50 г.
Одним из показателей качества работы автомата является ве-
личина вариации весов пакетиков. Чтобы определить степень
вариации, была извлечена случайная выборка из 15 пакетиков
с весами (в граммах):
51,2 ; 47,5; 50,8; 51,5; 49,5; 51,1; 51,3; 50,7;
46,7 ; 49,2; 52,1; 48,3; 51,6; 49,2; 51,5.
Для этих данных х = 50,15 г и s = 1,65 г. Вычислить 90-про-
центный доверительный интервал для дисперсии о2 и стандар-
тного отклонения о. Предполагается, что веса пакетиков рас-
пределены нормально.
Требуемая доверительная вероятность I - а = 0,9, т. е. уро-
вень значимости а = 0,1. Число степеней свободы df= п - I =
= 15 - I = 14. Отсюда доверительные пределы для ст2 находятся
из выражения (12.5):
14 • 1,65^. 14-1.652 V Г 14 1.652.14-1.652"
XO.05J4 Xo,9J;l4 , k ^,7 >
278
Соответственно 90-процентный доверительный интервал
для о:
(71,61; Д8) = (1,27; 2,41),
т. е. с вероятностью 90% можно утверждать, что стандартное
отклонение о изменяется в пределах от 1,27 до 2,41 г.
12.2. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
ДИСПЕРСИИ И СТАНДАРТНОГО ОТКЛОНЕНИЯ
Во многих приложениях приходится решать вопрос, превы-
шает ли дисперсия или стандартное отклонение определенное
значение. Например, вариация параметров выпускаемой про-
дукции может служить характеристикой стабильности работы
оборудования. В подобных ситуациях проблему можно свести к
проверке гипотез. Так, возможна постановка задачи двусторон-
ней проверки:
Но: о = о2,
Н,: о2 # о/.
В качестве критерия оценки рассматривается статистика
2 (л-1)№ п
X =-----/—. При уровне значимости а критическими пре-
°о
делами будут значения % (левый предел) и X (пра-
вый предел). Нулевая гипотеза Но отвергается, если х2>^^г
или xJ<x’1HVfc,.r
Пример 12.4. Психолог изучает возможности обучения детей
до-школьного возраста. Его интересует максимальное время, в
течение которого ребенок может быть внимателен и сосредо-
точен. Исследования показали, что разброс указанных проме-
жутков времени для пятилетних детей характеризуется диспер-
сией а2 = 64. Для выборки из 20 шестилетних детей s2 — 28.
Необходимо сделать заключение при а = 0,05, отличаются ли
вариации значений промежутков внимательности для пятилет-
них и шестилетних детей.
Рассмотрим задачу двусторонней проверки:
Нв: а2 = 64,
Н,: о2 #64.
279
Вычислим статистику х2:
64
Критические пределы задаются значениями: Х2О,„19 =
= 8,90655, Х^ои и” 32,8523, которые находятся по таблице
Приложения 7. Ввиду того что 8,31 <8,90655, гипотеза Но отвер-
гается при уровне значимости 5%, т. е. подтверждается гипотеза
о различии вариаций.
Если альтернативная гипотеза характеризует одностороннее
отклонение, то возможны два типа задач:
Но: о = оД
Н(: о1 > о02 (или о2<о02).
Соответственно нулевая гипотеза Н(| отвергается, если
Х2>Х2и;я.1 (или Х,<Х21НС„1).
Пример 12.5. Предприятие точных приборов выпускает элект-
ронные весы. Весы считаются качественными, если стандарт-
ное отклонение при взвешивании 500-граммовой гирьки зна-
чимо меньше 1 мг. На новых весах взвешивание было
произведено 30 раз, причем выборочное стандартное отклоне-
ние оказалось 0,73 мг. Определить, являются ли данные весы
достаточно точными при а = 0,01.
Исходные параметры: oQ = 1, з = 0,73, п = 30. В данном
случае ставится задача односторонней проверки:
Но: а =1,
Н(: о < 1
или
Но: о2 =1,
Н,: о2 < I.
Вычислим статистку %2:
,,29^ = 1
1!
280
По таблице Приложения 7 найдем критический предел
Х2|.„ „ । = X20W|9 ~ 14,2565. Так как 15,45> 14,2565, то нулевая
гипотеза не может быть отвергнута с уровнем значимости 1%
(рис. 12.6).
Рис. 12.6. Геометрическая интерпретация области принятия нулевой
гипотезы для односторонней проверки при а = 0,01
12.3. х2-РАСГ1Р£ДЕЛЕНИЕ
КАК КРИТЕРИИ СОГЛАСИЯ
В разделе 12.2, а также в главах 9, 10 рассматривались гипо-
тезы относительно отдельных параметров генеральных совокуп-
ностей, причем данные этих совокупностей измерялись, по
крайней мере, в шкале интервалов (например, вес, доход, воз-
раст и т. д.).
Рассмотрим теперь следующую си туацию. Пусть высказыва-
ется предположение о законе распределения исследуемой ге-
неральной совокупности. На основе выборочных данных стро-
ится частотное распределение значений признака (например,
в виде ряда распределения). Возникает задача проверки нуле-
вой гипотезы о том, что расхождение между предполагаемым
(теоретическим) распределением и наблюдаемым (эмпиричес-
ким) распределением незначимо. Критерии, с помощью кото-
рых проверяется эта гипотеза, называются критериями согла-
сия. Один из таких критериев, основанный на распределении
X2, получил название критерия согласия х2 или критерия со-
гласия Пирсона. Его преимущество по сравнению с другими
критериями состоит в том, что он позволяет оперировать дан-
ными, выраженными как в шкалах интервалов и отношений,
так и в шкалах наименований и порядка. Как было показано в
гл. 1, шкала наименований характеризует такой тип измерения
данных, когда они могут классифицироваться только по ка-
ким-либо категориям. Шкала порядка позволяет судить о том,
что одна категория данных по рангу выше, чем другая.
281
Критерии проверки гипотез, связанные с данными, изме-
ряемыми в шкалах наименований и порядка, называются не-
параметрическими или свободными от распределений. Это оз-
начает, что статистические критерии, которые при этом
используются, не зависят от определенного распределения, ко-
торому могут принадлежать выборочные данные. Пригодность
же рассмотренных ранее критериев зависела от правильности
предположения о распределении генеральной совокупности,
откуда бралась выборка. Например, /-критерий, строго говоря,
можно использовать, если выполняется условие нормальности
генеральной совокупности.
В этой связи критерий согласия х2 является наиболее удоб-
ным и часто используемым непараметрическим критерием.
Применим его как критерий согласия для сравнения наблюда-
емого распределения частоте ожидаемым (теоретическим) рас-
пределением.
Пусть имеет место ситуация, когда требуется сравнить серию
наблюдаемых значений признака (полученных в результате экс-
перимента) с соответствующей серией значений, которая рас-
сматривается в качестве гипотетической. Последовательность
значений, входящих в серию, распределим по определенным
категориям. Например, детали, производимые на станке, будем
сортировать на годные и дефектные; служащих компании разо-
бьем на возрастные группы; сгруппируем данные об объемах
продаж продукции фирмы по регионам; специалистов с выс-
шим образованием распределим по специальностям. Каждая ка-
тегория будет характеризоваться частотой, т. е. числом данных, в
нее попавших в результате эксперимента. Распределение наблю-
даемых частот по категориям является результатом случайного
выбора, если эксперимент представляет собой последователь-
ное проведение независимых опытов.
Пусть эксперимент удовлетворяет следующим условиям
1. Эксперимент состоит из п независимых повторных опытов
(испытаний).
2. Каждый опыт может иметь к исходов, причем каждый ис-
ход точно попадает в одну из к категорий.
3. Вероятности осуществления исходов рг рг,..., рк в каждом
опыте остаются неизменными, и выполняется соотношение
Р, + р2+...
Очевидно, если к = 2, то схема эксперимента будет биноми-
альной: имеются два исхода — “успех” и “неудача” с соответ-
ствующими вероятностями р} = р и р, = 1 — р. Когда к>2, схема
называется полиномиальной. В условиях полиномиальной ситу-
282
ации можно определить к случайных величин О, Оу..., Ок как
к наблюдаемых значений частот:
О = наблюдаемое число значений, попавших при п опытах
в категорию 1;
О, = наблюдаемое число значений, попавших при п опытах
в категорию 2;
Ot = наблюдаемое число значений, попавших при п опытах
в категорию к.
Наблюдаемые частоты являются оценками ожидаемых час-
тот Ер Е2,..., Et, которые вычисляются следующим образом:
Е1 = л/>р Е2 = пр2.Ед = npt. (12.7)
Для полиномиальной схемы рассмотрим следующую стати-
стику, имеющую распределение %2:
(12.8)
Распределение (12.8) соответствует числу степеней свободы
df ~ к — 1, где к — число категорий.
Статистику (12.8) можно использовать в качестве критерия
проверки гипотез для решения следующей задачи.
Пусть рассматривается ситуация с полиномиальной схемой
эксперимента. Точные значения вероятностей исходов ру ру
..., pk неизвестны. Выдвигается гипотеза о том, что эти вероят-
ности имеют конкретные значения р{ = />(°, рг = рк = р*.
По результатам эксперимента требуется при определенном уров-
не значимости либо подтвердить, либо опровергнуть эту гипо-
тезу. Формальная запись задачи:
Р. = Р°> Pi = Рг..Р> = Р^
Н : по крайней мере одно из значений pt не совпадает с
гипотетическим.
На основе наблюдаемых значений частот О{, Оу..., Ot вы-
числим точные оценки вероятностей исходов (ру ру ..., рк)'.
О{ _ О2 _
— .Р2=— Pk =
п п п
(12.9)
283
Если нулевая гипотеза верна, то, очевидно, расхождения
между оценками р (i = и соответствующими гипотети-
ческими вероятностями р° (i = должны быть статисти-
чески незначимыми. Если же верна альтернативная гипотеза,
то, наоборот, следует ожидать значимых расхождений. Ввиду
(12.7) и (12.9), значимость отклонений будет эквивалентна
значимости расхождений между соответствующими наблюдае-
мыми и ожидаемыми частотами. Она определяется с помощью
Х2-критерия (12.8): если х2>Х2(1 t l. то нулевая гипотеза Но от-
вергается при уровне значимости а. Таким образом, критичес-
ким пределом здесь служит значение х t ( (а— уровень значи-
мости, к — число категорий). Если Jc = 2, то использовать
Х2-критерий нс имет смысла, так как можно осуществить обыч-
ную проверку гипотез с помощью Z-критерия. Однако когда
число категорий к больше 2, то следует рассматривать несколь-
ко Z-критериев отдельно для каждой пропорции. Поэтому ис-
пользовать критерий согласия х* гораздо удобнее, так как он
позволяет оценить отклонения всех пропорций одновременно.
Пример 12.6. Исследования, проведенные в прошлом году в
области медицинской статистики, показали, что имело место
следующее процентное распределение людей по возрасту, ре-
гулярно принимающих лекарства от расстройств желудка:
Возрастные кате- гории 18-24 25-34 35-44 45-44 55-64 55 и старше
Процент 5,7 16,4 20 15 16,2 26,7
В текущем году были проведены новые исследования. Для
случайной выборки численностью 150 человек, регулярно при-
нимающих данные лекарства, частотное распределение по
возрастным категориям имеет вид
Возрастные кате- гории 18-24 25-34 35-44 45-44 55-64 55 и старше
Процент 12 19 39 23 26 31
Используя 5-процентный уровень значимости, определить,
изменилось ли возрастное распределение людей, регулярно
принимающих лекарства.
Исходные данные задачи:
объем выборки п = 150;
число категорий к = 6;
гипотетические пропорции: р ° = 0,057; р,° = 0,164;
р,° = 0,2; р° = 0,15; = 0,162; р“ = 0,267.
284
Наблюдаемые частоты: О{ = 12, О2 = 19, О, = 39, ОА = 23,
(\ = 26, = 31.
Уровень значимости: а = 0,05.
Гипотезы, которые требуется проверить:
Н#: рх°= 0,057, />2°= 0,164, />3° = 0,2, р4° = 0,15, р5° = 0,162,
р4° = 0,267;
Н : по крайней мерс, одно из равенств гипотезы Но не вы-
полняется.
Вычислим ожидаемые частоты:
Е( = р*п = 0,057 • 150 = 8,55, Е2 = р2°п = 0,164 • 150 = 24,6,
Е, = р*п = 0,2 • 150 = 30, Е, = р4пп = 0,15 • 150 = 22,5,
Е, = 0,162- 150 = 24,3,
Е = 0,267- 150 = 40,05.
о
Вычислим статистику х2 по формуле (12.8):
2 _ у (£ -БУ _ (12-8.55)2 + (19-24.6)2 + (39-30)2 +
Z ~ Е; 8,55 24,6 30
х (23-22.5)2 х (26-24.3)2 . (31-40.05)2 _ _ м
22,5 24,3 40,05
По таблице Приложения 7 найдем критический предел
X2 ... = Х2Л„< « = 11,0705. Следовательно, х2 = 7,34<11,0705 и
нулевая гипотеза Н ( не может быть отвергнута при уровне зна-
чимости 5%. Таким образом, при уровне значимости а = 0,05
можно утверждать, что процентное распределение по возраст-
ным категориям людей, регулярно принимающих лекарства от
расстройства желудка, не изменилось.
При вычислении статистики по формуле (12.8) мы опреде-
ляем разность между двумя частотами (О — Е), относящимися
к одной категории, возводим ее в квадрат и делим на ожидае-
мую частоту Е. Если одно из значений Е очень мало (напри-
мер, меньше 5), то соответствующее отклонение может быть
достаточно большим и в значительной степени повлиять на
конечный результат вычислений статистики х2- Иначе говоря,
небольшое значение ожидаемой частоты для какой-то одной
категории может сильно поднять величину х2» что вполне мо-
жет привести к неоправданному непринятию гипотезы Hft. Чтобы
предотвратить такую возможность, следует соблюдать правило:
ожидаемая частота Е должна быть не меньше 5.
285
В ситуации, если одна или несколько ожидаемых частот ока-
жутся меньше 5, следует укрупнить соответствующие катего-
рии таким образом, чтобы ожидаемая частота каждой новой
категории была не меньше 5.
12.4. ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО
ФОРМЫ РАСПРЕДЕЛЕНИЯ
Критерий согласия х2 можно использовать для проверки на
“согласие” наблюдаемого распределения с каким-либо конкрет-
ным распределением. Например, могут возникнуть ситуации, когда
нужно определить, насколько согласуется наблюдаемое распре-
деление частот с ожидаемым распределением при условии, что
ожидаемое распределение имеет биномиальный, равномерный,
нормальный или любой другой закон распределения.
Пример 12.7. Плавкие электрические предохранители укладыва-
ются в пачки по 20 штук в каждую. Отдел контроля качества
утверждает, что в среднем только около 10% предохранителей в
пачке дефектны. Случайным образом отбирают 41 пачку предох-
ранителей. Результаты подсчета дефектных предохранителей были
систематизированы в виде следующего распределения:
Число дефектных предохранителей в лачке Число пачек с данным числом дефектных предохранителей
0 7(0,) 12(Ог)
1
2 Ю(О3)
3 7(О4)
4 1(О5)
5 2(О6)
>5 2(О7)
Если верить утверждению отдела качества, то рассматри-
ваемая выборка должна была извлечена из генеральной сово-
купности, имеющей биномиальный закон распределения с
р = 0,1. Требуется проверить это утверждение при а = 0,05.
Данная ситуация описывается полиномиальным эксперимен-
том. Проведен 41 независимый опыт, каждый из которых со-
стоял в том, что случайным образом отбиралась пачка предох-
ранителей. Исходом опыта является количество дефектных
предохранителей в пачке.
286
Ввиду того что частоты Os, О'и О, меньше 5, объединим
три последние категории в одну. Тогда в соответствии с числом
исходов можно выделить пять следующих категорий:
категория 1 — наблюдается 0 дефектных предохранителей в
пачке (О( = 7);
категория 2 — 1 дефектный предохранитель в пачке (О2 = 12);
категория 3 — 2 дефектных предохранителя (О3 = 10);
категория 4 — 3 (О4 = 7);
категория 5 — более 3 (О5 = 5).
Запишем гипотезы:
Но: данные распределены по биномиальному закону с р = 0,1;
Н : закон распределения не соответствует биномиальному
закону с р — 0,1.
Предположим, гипотеза Но верна. Рассмотрим биномиаль-
ное распределение с параметрами п = 20 и р = 0,1. В данном
случае опыт заключается в проверке каждого предохранителя в
пачке, состоящей из 20 предохранителей. Вероятность появле-
ния дефектного предохранителя (“успеха”) равна 0,1.
Пусть X — биномиальная случайная величина с данными па-
раметрами. Рассмотрим следующие биномиальные вероятности:
р0= р(Х = 0) = С?о 0,9м, Р] = р(Х — 1) = Сго • 0,1 • 0,9*’,
Рг = р(Х = 2) = С& • 0,12 • 0,9", р} = р(Х = 3) =
= С& • 0,Р • 0,9”, р4 - р(Х= 4) = С^о • 0,14 • 0,9",
Р, = । “ (Л + Р2 + Pj + р4).
Найдем значения р. по таблице Приложения 2 и выразим
гипотезы в следующем виде:
Но: />, = 0,122, р2 = 0,27, Pj = 0,285, р4 = 0,19, />5 = 0,133;
Н(: по крайней мере, одно значение р не равно соответ-
ствующей биноминальной вероятности.
Вычислим ожидаемые частоты:
Е( =41 -0,122 = 5,22; Е, = 41 0,27 = 11,07; Е, - 41 -0,285 =
= 11,68; Е4 = 4 0,19 = 7,79; Е5 = 41 -0,133 = 5,45.
Сравним наблюдаемые частоты с ожидаемыми по крите-
рию х2: , - ,
2 = (7-5,22)2 (12-11.07)2 (10-11,68)2
Х 5,22 + 11,07 + 11,68 +
( (7-7,79)2 t (5-5,45)2 =
7,79 5,45
287
По таблице Приложения 7 найдем критическое значение:
Х2ОО5 4 ~ 9,48773. Так как 1,23<9,48773, то нулевая гипотеза не
может быть отвергнута при а - 0,05.
В примере 12.7 осуществлялась проверка на согласие наблю-
даемого распределения с биномиальным распределением, при-
чем параметрр был известен. Часто возникает ситуация, когда
необходимо проверить на согласие наблюдаемое распределе-
ние с конкретным распределением, однако параметры теоре-
тического распределения не представлены.
Пример 12.8. Менеджер по продажам телефонных автоответчи-
ков предполагает, что недельные продажи подчиняются зако-
ну распределения Пуассона. Данные о продажах за 50-недель-
ный период были обобщены в следующем виде:
Число проданных единиц Число модель Число проданных единиц Число недель
0 1 5 7
1 3 6 5
2 6 7 3
3 11 8 4
4 10 >8 0
50
Рассмотрим, как можно проверить гипотезу о согласии с
распределением Пуассона при а = 0,1:
Но: недельные продажи распределены по закону Пуассона;
Н : недельные продажи не распределены по закону Пуас-
сона.
Распределение Пуассона имеет один параметр:
цЛе-и
Р(Х=л) = *Ц-,
ли
где х = 0,1,2,... характеризует число единиц, проданных за не-
делю.
Значение ц представляет собой среднее значение пуассонов-
ской случайной величины. Вычислим его оценку на основе вы-
борочных данных:
. 01 + 1-3+2-6+3 11 + 410+5-7 + 6-5 + 7-3 + 8-4
|1 --------------------—---------------------= 4.1.
50
288
Подставим |1 = 4,1 в функцию вероятностей:
где х~ 0,1,2,....
Используя таблицу Приложения 3, найдем оценки пуассо-
новских вероятностей и вычислим оценочные значения ожи-
даемых частот Е:
X Р(Х = X» Е О
0 0,0166 0,0166 50 = 0,83 1
1 0,0679 0,0679 50 = 3.39 3
2 0,1393 0,1393 50» 6.97 6
3 0,1904 0,1904 50 = 9,52 11
4 0,1951 0,1951 50 = 9,76 10
5 0,16 0.16 50 = 8 7
6 0,1093 0,1093 50 = 5.46 5
7 0,064 0,064 50 3.2 3
8 0,0328 0,0328 50 = 1,64 4
>8 0,0246 0,0246 50 = 1,23 0
1 50 50
Заметим, что величина Р(Х>8) = 1 - (0,0166 + 0,0679 +...+
+ 0,0328) = 0,0246.
Проверим, все ли значения ожидаемых частот Е больше или
равны 5. Очевидно, необходимо объединить первые три катего-
рии (0,83 + 3,39 + 6,97 = 11,19) и последние три категории
(3,2 + 1,64 + 1,23 = 6,07).
Вычислим ^’-статистику:
X Е О (О-в) (О - Е)2/Е
s2 11.9 10 -1,19 0,127
3 9,59 11 1,48 0,23
4 9,76 10 0,24 0,006
5 8 7 -1 0,125
6 5,46 5 -0,46 0,039
г7 6,07 7 0,93 0,142
50 50 0 0,669
289
В общем случае, если необходимо провести оценку неизвест-
ных параметров, число степеней свободы для критерия согла-
сия вычисляется по формуле
df = (число категорий) — 1 — (число оценочных
параметров).
В данном случае для распределения Пуассона был оценен
один параметр. Поэтому df= 6 - 1 - 1 = 4. По таблице Прило-
жения 7 найдем
Х2о.|;4 = 7,779.
Отсюда х2 ~ 0,669<7,779, и нулевая гипотеза не может быть
отвергнута при а = 0,1. То есть выборочные данные согласуются
с распределением Пуассона, имеющим параметр ц = 4,1.
Пример 12.9. В архиве метеослужбы некоторого региона хра-
нятся данные о годовых дождевых осадках за 120 лет. Выдвига-
ется гипотеза, что высота осадков имеет нормальное распреде-
ление. Для проверки данной гипотезы был составлен ряд
распределения (высота осадков измерялась в дюймах):
Высота осадков X, дюймы Число лет (частота), f Относительная частота р
25-29.99 3 3/120 = 0,025
30—34,99 14 14/120 = 0.117
35-39.99 31 3/120 = 0,258
40-44,99 31 31/120 = 0.258
45-49,99 29 29/120 = 0,242
50-54.99 8 8/120 = 0,067
55-59,99 3 3/20 = 0,025
60 -64,99 1 1/120 = 0,008
Требуется проверить гипотезы:
Но: высота годовых дождевых осадков распределена нормально,
Hf распределение высоты дождевых осадков отличается от
нормального.
Группы ряда распределения можно рассматривать как кате-
гории, а частоты (/) — как наблюдаемые частоты.
Если предположить, что нулевая гипотеза верна, то следует
вычислить ожидаемые частоты, рассматривая данное распре-
деление как нормальное. Для проведения расчетов необходимо
знать параметры ц и о предполагаемого нормального распреде-
ления. Вычислим оценки этих параметров на основе сгруппи-
290
рованных данных. Среднее значение ряда вычисляется по фор-
муле (3.3):
_ 27,5-3 + 32,5-14 + 37,5-31 + 42,5-31 + ... + 62.5-1 .....
х =-----------------------------------------= 42.06.
120
Дисперсия оценивается по формуле (4.12):
г _ (27Л - 42.O6)2 + (32,5 - 42,06)2 +... + (62,5 - 42,О6)2 _
120-1
Рассмотрим нормальный закон с параметрами ц = 42,06 и
о = \40.425 = 6,348.
Будем использовать стандартное нормальное распределение
7для вычисления вероятностей попадания случайной величи-
ны в группировочные интервалы ряда распределения.
Из соотношения (7.12) определим значение Z, соответству-
ющее границам групп ряда распределения, и по таблице При-
ложения 4 найдем вероятности:
25<Х<30 R-2.68 <2<-1,9) ’ 0,025
30<х<35 ₽(-1,9<Z<—1,13) = 0,1005
35<Х<40 Р(-1,13<Z<-0,32) = 0,2453
40<х<45 Р(-0.32<2< 0,46) - 0,3027
45<х<50 Р{0,46<2< 1,25) = 0,2172
50<х<55 P(1,25<Z<2.04) = 0,0849
55<х<60 P(2,04<Z<2.82) = 0,0183
60<Х<65 P(2.82<Z) = 0,0024
Теперь вычислим ожидаемые частоты, т. е. ожидаемые коли-
чества лет, когда высота осадков будет находиться в границах
групп ряда распределения. Если рассматривать данные за 120
лет как выборку объема п = 120 из нормальной генеральной
совокупности с параметрами ц = 42,06 и а = 6,358, то ожида-
емые частоты вычисляются следующим образом:
Группы, дюймы Ожидаемые частоты
25-30 0,025 120 = 3
30-35 0,1005 120 = 12,06
35-40 0,2453 120 = 29,44
40-45 0,3027 120 = 36,22
45-50 0,2172 120 = 26,06
50-55 0,0849 120 = 10,19
55-60 0,0183 120 = 2.2
60-65 0,0024 120 = 0,29
291
Объединим первые три группы и последние три группы в
общие категории, чтобы все ожидаемые частоты были не мень-
ше 5.
Получим следующее распределение ожидаемых (вычислен-
ных в предположении, что данные взяты из нормальной сово-
купности) и наблюдаемых (полученных на основе архивных
данных) частот:
Группы (категории) Ожидаемые Наблюдаемые частоты О
частоты Е
25-35 15.06 17
35-40 29.44 31
40-45 36.32 31
45-50 28,06 29
50-65 12.68 12
Вычислим статистику:
2 _ (17-15.06)2 + (31-29.44)2 + (31-36.32)2 +
* 15,06 29,44 36,32
(29-26.06)2 (12-12.68)2 ..в
26,06 12,68
В ситуации, когда число категорий — л, а ожидаемое рас-
пределение имеет к параметров, число степеней свободы опре-
деляется по формуле
df = п - к - 1.
В данном случае п = 5 и к = 2 (два параметра ц и о). Поэтому
5 - 2 - 1 “ 2.
Из таблицы Приложения 7 видно, что х2 = 1.48 меньше всех
значений х2. соответствующих df - 2. Следовательно, нулевая
гипотеза Но не может быть опровергнута, т. е. можно утверж-
дать, что годовая высота осадков распределена нормально с
параметрами ц = 42,06 и а = 6,358.
12.5. ТАБЛИЦЫ СОПРЯЖЕННОСТИ
В предыдущих разделах было рассмотрено использование
критерия х2 в качестве критерия согласия наблюдаемого рас-
пределения с ожидаемым распределением. При этом данные
распределяются по различным категориям. Такое распределе-
ние является одномерным, т. е. данные характеризуются только
292
одним признаком, например принадлежностью к торговой мар-
ке, возрастом, производственным стажем и т. д.
Часто возникают ситуации, когда одни и те же данные мо-
гут соответствовать двум различным признакам, например про-
фессия покупателя и его отношение к определенному типу то-
вара. Если данные классифицируются по одному признаку, то
все категории наблюдаемых частот можно расположить в од-
ной строке (или в одном столбце). В случае двумерной класси-
фикации, когда она производится одновременно по двум при-
знакам, категории частот образуют таблицу сопряженности. Ее
можно использовать для выяснения зависимости между при-
знаками. Это означает, что требуется определить, оказывает ли
влияние положение элемента в распределении по одному при-
знаку на его положение в распределении по другому признаку.
Заключение о зависимости признаков можно сделать на осно-
ве критерия х2-
Пример 12.10. Фирма выпускает электронный прибор. Одним из
компонентов прибора является специальная схема, которая про-
изводится в виде съемной платы. Анализ проверок выпускаемых
плат показал, что в основном могут иметь место три типа неис-
правностей: отсутствие какого-либо элемента схемы (тип 1), по-
вреждение основания платы(тип 2), неправильное соединение
элементов схемы (тип 3). Платы выпускаются тремя видами обо-
рудования (А, В, С). Оборудование А на 90% управляется компь-
ютером и выпускает в 2 раза больше плат за день, чем В и С,
которые управляются компьютером на 50%. Требуется опреде-
лить, имеется ли связь между типом неисправности и видами
используемого оборудования. Для этой цели было обследовано
500 дефектных плат: 250, выпущенных на оборудовании А, и по
125, выпущенных на Bn С. Распределение частот было система-
тизировано в виде таблицы сопряженности (табл. 12.1).
Таблица 12.1
Таблица сопряженности двух признаков:
тип неисправности платы и вид оборудования
Оборудование Тип неисправности
1 2 3 Итого
А 50 80 120 250
В 60 55 10 125
С 65 45 15 125
Итого 175 180 145 500
293
Требуется проверить гипотезы:
Но: типы неисправностей не зависят от вида выпускающего
оборудования,
Н,: типы неисправностей зависят от вида выпускающего
оборудования.
Каждая пара признаков в таблице образует клетку, в кото-
рой помещается число неисправных плат, обладающих данной
парой признаков. Если верна нулевая гипотеза, т. е. признаки не
связаны между собой, то платы должны быть разбросаны слу-
чайным образом по двум распределениям. Визуальный анализ
табл. 12.1 показывает, что третий тип неисправностей в боль-
шей степени присущ оборудованию А. Однако если рассматри-
вать 500 отобранных плат как случайную выборку, то эта зави-
симость может объясняться просто выборочной ошибкой.
Предположим, что зависимость между признаками отсут-
ствует. Тогда пропорции в распределении плат по типам неис-
правностей для всех видов должны быть одинаковыми. Они со-
впадают с общими пропорциями для всей выборки. Вычислим
значения этих пропорций. Как видно из табл. 12.1, для типа 1
общее число плат в выборке составляет 175. Тогда ожидаемая
пропорция вычисляется как отношение р} = 175/500. Отсюда
ожидаемая частота (ожидаемое количество дефектных плат),
соответствующая сочетанию признаков “оборудование А” и
“неисправность типа 1 ”, должна быть равна р (общее количе-
ство плат, выпущенных на оборудовании А), т. е. 175 • 250/500 =
= 87,5. Аналогично вычисляем ожидаемые частоты для сочета-
ний признаков “оборудование В" и “неисправность типа 1”,
“оборудование С" и “неисправность типа 1” (общее количе-
ство плат в выборке для В и С равно 125): 175 • 125/500 = 43,75.
Общая пропорция для неисправностей типа 2 (табл. 12.1)
является отношением общего числа плат с неисправностями
типа 2 к объему выборки: р, = 180/250. Соответствующие ожи-
даемые частоты для сочетаний признака “неисправностей типа
2” с признаками “оборудование А”, “оборудование В”, “обо-
рудование С” вычисляются следующим образом:
180 • 250/500 = 90, 180 125/250 = 45, 180 • 125/250 = 45.
Общее число плат, имеющих неисправности типа 3, равно
145 (табл. 12.1). Пропорция, соответствующая этому признаку:
р} = 145/500. Вычислим соответствующие ожидаемые частоты
для комбинаций с признаками “оборудование А”, “оборудова-
ние В” и “оборудование С”: 145 • 250/250 = 72,5; 145 • 125/500 =
= 36,25; 145 • 125/500 = 36,25.
294
Из логики вычисления ожидаемых частот следует правило
их расчета на основе таблицы сопряженности 12.1. Рассмотрим
каждую наблюдаемую частоту как некоторый элемент таблицы
сопряженности. В столбце “Итого” найдем сумму по строке, в
которой расположен рассматриваемый элемент, а в строке
“Итого” — сумму по столбцу этого элемента. Ожидаемая часто-
та получается как отношение произведения указанных сумм к
обшей сумме всех частот.
Для удобства сравнения наблюдаемых и ожидаемых частот
поместим их в одну табл. 12.2, где рядом с наблюдаемой часто-
той в скобках стоит соответствующая ожидаемая частота.
Таблица 12.2
Наблюдаемые и ожидаемые (в скобках) частоты сопряженности
признаков “вид оборудования” и “тип неисправностей"
Оборудование Тип неисправности
1 2 3 Итого
А 50 (87,5) 80 (90) 120 (72,5) 250
В 60 (47,75) 55(45) 10 (36,25) 125
С 65 (43,75) 45 (45) 15 (36,25) 125
Итого 175 180 145 500
Вычислим х2-критерий по данным табл. 12.2:
2 = (5O-87.5)2 + (80-90)* + (120-72,5)* +
Х 87,5 + 90 + 72,5
+ (60-47,75)* + (55-45)* (10 - 36,25)* +
47,75 45 36,25
(65-43,75)* (45-45)* + (15-36,25)* _
+ 43,75 + 45 36.25
= 16,071 + 1,111 + 31,121 + 6,036 + 2,222 +19,09 +
+ 10,321 + 0+12,457 = 98,35.
Для нахождения критического значения, ограничивающего
область принятия нулевой гипотезы, следует определить число
степеней свободы соответствующего распределения %2. Число сте-
пеней свободы определяется как число данных, которые входят
в формулу для вычисления статистики и могут свободно изме-
няться. В каждой строке табл. 12.1 содержатся три значения час-
тот, связанные суммой, представленной в строке “Итого”. По-
этому число свободных данных в каждой строке равно 3-1=2.
295
Аналогично, в каждом столбце содержатся три значения с изве-
стной суммой. Поэтому число свободных данных для каждого
столбца равно 3-1=2. Отсюда общее число степеней свободы
для всей таблицы определяется так: (3 - 1) (3 — 1) = 4.
Пусть уровень значимости проверки гипотез а = 0,1 .Тогда по
таблице Приложения 7 найдем критическое значение х2О]4 =
= 7,78. Так как 98,35>7,78, то нулевая гипотеза отвергается при
а = 0,1.
В итоге можно сделать вывод, что совокупности дефектных
плат, выпускаемых на оборудовании А, В, С, не являются одно-
родными относительно трех типов неисправностей. Типы не-
исправностей неравномерно распределяются среди дефектных
плат, выпускаемых на различном оборудовании. Очевидно, зна-
чительное количество неисправностей третьего типа для плат,
выпускаемых на оборудовании А, не является случайным.
Рассмотрим общий случай использования критерия х2 для
проверки однородности наблюдаемых частот, сгруппирован-
ных в таблицу сопряженности. Пусть таблица сопряженности
имеет вид
°11 °12 •••
°21 °22 ...
•
°Л2 ... ®пт Л» °nt
Хоп Хов ... ES о.
Рис. 12.7. Общий вид таблицы сопряженности:
О, — наблюдаемые частоты, i — индекс строки (/ 1.п),
/ — индекс столбца (J = 1.т)
Таблица сопряженности на рис. 12.7 имеет л строк и т столб-
цов, где располагаются наблюдаемые частоты, т. е. рассматри-
вается л значений признака 1 и т значений признака 2. В край-
нем правом столбце таблицы, который носит вспомогательный
характер, вычисляются суммы частот по строкам. В нижней
(вспомогательной) строке вычисляются суммы частот по столб-
цам.
296
Ожидаемая частота, стоящая в г-й строке и к-м столбце (Е^,
вычисляется как произведение суммы наблюдаемых частот по
r-й строке на сумму наблюдаемых частот по jt-му столбцу, от-
несенное к обшей сумме наблюдаемых частот:
т п
5Х So.
Е„ = С, . (12.10)
М J-I
На практике следует придерживаться правила* величины Е*
должны быть не меньше 5. В противном случае следует объеди-
нить некоторые категории частот таблицы сопряженности, что-
бы данное условие выполнялось.
Число степеней свободы для статистики х2 определяется по
формуле
#»(л-l) (m-1). (12.11)
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 12
Распределение х2 характеризует случайную величину, рав-
ную сумме квадратов независимых стандартных нормальных ве-
личин. Оно зависит только от количества слагаемых v, входя-
щих в эту сумму, которое называется числом степеней свободы
и которое полностью определяет конкретное распределение х,2.
Среднее значение распределения у 2 равно v, а стандартное
отклонение — 2v. Распределения х' образуют семейство рас-
пределений, где каждое отдельное распределение соответству-
ет определенному числу степеней свободы. Так же как для се-
мейства /-распределений, рассчитана таблица площадей под
кривыми распределений х2 (Приложение 7).
Распределение х2 можно использовать для построения дове-
рительных интервалов дисперсии нормальной генеральной со-
вокупности. Эго связано с тем, что распределение выборочных
дисперсий ? можно определить на основе распределения х2„Р
где п — объем выборки (выражение (12.4)). Доверительные ин-
тервалы для дисперсии и стандартного отклонения определя-
ются соответственно по формулам (12.5) и (12.6).
Распределение х2 можно использовать для проверки гипотез
о равенстве дисперсии гипотетическому значению. В качестве
критерия оценки рассматривается статистика (12.4).
297
Распределение х2 можно рассматривать в качестве критерия
согласия наблюдаемого распределения выборочных данных с
теоретическим (ожидаемым) распределением генеральной со-
вокупности, откуда была взята выборка. Пусть требуется срав-
нить серию наблюдаемых значений признака (полученных в
результате эксперимента) с соответствующей серией значений,
которая рассматривается в качестве гипотетической. Последо-
вательность значений, входящих в серию, распределим по оп-
ределенным категориям. Каждая категория будет характеризо-
ваться частотой, т. е. числом данных, попавших в нее в результате
эксперимента. Распределение наблюдаемых частот по катего-
риям является результатом случайного выбора, если экспери-
мент представляет собой последовательное проведение неза-
висимых опытов. Наблюдаемыми частотами характеризуются
оценки ожидаемых частот. Сравнение на согласие наблюдае-
мых и ожидаемых частот производится по критерию х2, где
необходимая статистика вычисляется из соотношения (12.8). Она
имеет число степеней свободы, равное к — 1, где к — число
категорий. Если ожидаемые частоты вычислять, предполагая
конкретный закон распределения, то с помощью х2-критерия
можно проверять гипотезу относительно формы распределе-
ния (например, проверка на согласие с равномерным, бино-
миальным или нормальным законом распределения).
Может возникнуть ситуация, когда одни и те же данные
должны соответствовать двум различным признакам. В случае
двумерной классификации наблюдаемые частоты образуют таб-
лицу сопряженности. Ее можно использовать для выяснения
зависимости между признаками. Это означает, что требуется
определить, оказывает ли влияние положение элемента в рас-
пределении по одному признаку на его положение в распреде-
лении по другому признаку. Если такой зависимости нет, то
значения должны быть разбросаны случайным образом по двум
распределениям. Ожидаемые частоты вычисляются по формуле
(12.7). Сравнение ожидаемых и наблюдаемых частот таблицы
сопряженности осуществляется по критерию (12.8).
-J3
КОРРЕЛЯЦИЯ И ПРОСТАЯ
ЛИНЕЙНАЯ РЕГРЕССИЯ
В предыдущих главах рассматривались методы, позволяющие
обобщать все множество значений одной случайной перемен-
ной либо в виде графика (например, гистограммы), либо в
виде сводной количественной характеристики (например, сред-
ней).
Переменная в данном случае представляет собой признак,
характеризующий элементы генеральной совокупности. Значе-
ния признака могут измеряться или наблюдаться в результате
эксперимента и далее входить в случайную выборку, представ-
ляющую генеральную совокупность.
Будем теперь рассматривать ситуацию, когда генеральная
совокупность и выборка состоят из измерений не одной, а двух
переменных и при этом требуется описать, как связаны эти
переменные.
13.1. ЛИНЕЙНАЯ КОРРЕЛЯЦИЯ
13.1.1. Корреляционная связь н корреляционное поле
Можно выделить два типа связи между парой переменных.
Первый тип — функциональная (или детерминированная)
связь — выражается в виде формульной зависимости. В этом слу-
чае одна из переменных полагается независимой, а другая —
зависимой. Зная точное значение независимой переменной и
подставляя его в связующую формулу, получим единственное
значение зависимой переменной. Рассмотрим другой тип свя-
зи, который проявляется как тенденция, т. е. в общем, при
массовых наблюдениях. Такая связь называется статистической.
Ее частным случаем является корреляционная связь. При кор-
реляционной связи изменение независимой переменной влия-
299
ет на изменение среднего значения зависимой переменной
Будем обозначать л независимую переменную (факторный по-
казатель), у — зависимую переменную (результативный пока
затель). Для корреляционной связи значению факторного по-
казателя х ставится в соответствие нс единственное значение
результативного показателя у, как при функциональной свя-
зи, а некоторое распределение значений у.
Корреляционно-регрессионный анализ заключается в уста-
новлении степени тесноты связи (корреляционный анализ) и
ее формы, т. с. аналитического выражения, связывающего пе-
ременные (регрессионный анализ).
Первым шагом в проведении исследования является по-
строение специального графика, называемою корреляционным
полем, или диаграммой рассеяния. На координатной плоско-
сти по оси абсцисс отэстадывается значение факторною пока-
зателя, а по оси ординат — соответствующее значение резуль-
тативного показателя. На плоскости отмечается точка, для
которой отложенные по осям значения являются координата-
ми Каждой паре наблюдений (х, у) будет соответствовать точ-
ка корреляционного поля Чем теснее связь между переменны-
ми, тем более плотно точки должны располагаться вокруг
некоторой линии. Эта линия будет графиком аналитической
зависимости между переменными. Если точки корреляционно-
го поля беспорядочно разбросаны на координатной плоско-
сти. го это означает отсутствие тесной взаимосвязи между пе-
ременными.
Прнхюр 13.1. Рассмотрим взаимосвязь между весом человека х
и его ростом у. Пусть имеются пары наблюдений 10 случайно
выбранных человек :
х. кг. 67.3 68.3 70,9 70 65,9 68,2 71,8 74 71,9 69.5
у, и: 1,74 1,69 1.82 1,79 1,61 1,83 1,95 1,92 1,81 1,75
Соответствующее корреляционное поле представлено на
рис 13.1.
Визуальный анализ графика на рис 13 1 показывает, что за-
висимость между переменными вполне реальна В данном слу-
чае в качестве ее аналитического выражения может выступать,
например, прямая с положительным угловым коэффициентом
В общем случае если с увеличением или уменьшением фак-
торного показателя наблюдается концентрация значений ре-
зао
Рис. 13.1. Корреляцио1*«се папе записимосзм роста от веса удивила
(полами те (иная корреляция)
зультзтинного показателя окаю прямой с положительным на
клоном. то говорят. что имеет место линейная положительная
корреляционная связь, или просто положительная корреляция.
Если факторный показатель изменяется в одном направлении,
а соответствующие значения результативного показателя рас-
полагаются достаточно тесно около прямой, имеющей отри-
цательный угловой коэффициент, то такая связь называется
линейной отрицательной корреляционной связью, или просто
отрицательной корреляцией На рис 13.2 представлен график
корреляционного поля для пар наблюдений, х — затраты на
фильтрацию вредных выбросов в атмосферу ну- концентра*
ния вредных примесей в атмосфере. Отрицательная корреляция
здесь очевидна
Рве. 13.2. Пример отрифпяльмоА коррслтцы
ж - »чр«-ы на фильтрацию «рохгъ» воВюоссе » жгиосферг.
Г псм4»-траигй >p«ahui мидетв и Атмосфере
Корреляционное поле на рис. 13.3 характеризует отсутствие
какой-либо корреляции.
301
Рте. 13.3. Пример отсутствия корреляции
Корреляция может быть не обязательно линейной (рис. 13.4).
Рте. ГЭ.4. Пример нелинейной коррелыионной сейм
В данной главе мы булем рассматривать методы анализа ли-
нейной корреляции, которые также при определенных усло-
виях можно использовать и случае нелинейной корреляции.
13.1.2. Коэффициент корреляции
Пусть расположение точек корреляционного поля наводит
нас на мысль, что имеет место линейная корреляция. Это пред-
положен ие, основанное на визуальном анализе, носит предва-
рительный характер Очевидно, необходима объективная коли-
чественная характеристика, определяющая тесноту линейной
связи между переменными. То есть требуется определить, в ка-
кой степени мы можем оценивать связь результативного пока-
зателя с факторным » виде прямой линии. Для измерения тес-
ноты линейной корреляционной связи вычисляется коэффи-
циент корреляции Его смысл и вывод вычислительной формулы
рассмотрим на следующем примере.
эог
Пусть у (результативный показатель) характеризует годо-
вой объем продаж некоторою продукт фирмы, а х (фактор-
ный показатель) определяет годовые затраты на рекламу. Фир-
ма сбывает свой товар в различных ретионах страны через сети
розничных торговых предприятий Случайным образом были
отобраны данные по 10 регионам (табл. 13.1).
Таблица 13.1
Пары наблюдений по регионам: затраты на рекламу х
(дее. тыс. долл.) и объем продаж у (тыс. ед.)
Ьпюыы М Г
1 22 16
2 26 17
3 45 26
4 37 24
5 2В 22
в ЬО 21
7 Ь6 32
в 34 IB
9 60 3D
10 40 20
Х = 39.8 у-гав
Корреляционное поле, построенное по данным табл. 13.1,
представлено на рис. 13.S.
Рис. T3.S. Корр«.-яцио*-«ит поле для пар ньПгкхпений
заняты на рекламу я и пбьем продаж у
Расположение точек на диаграмме рассеяния явно указывает
на линейную корреляционную связь между переменными. Опре-
делим теперь меру тесноты этой связи. Ее смысл заключается в
сопоставлении отклонений значений обеих переменных от их
ЗОЭ
средних (в табл. 13.1 указаны значения л =39,8 и у =22,6). Эти
отклонения приведены в табл. 13.2.
Таблица 13.2
Отклонения от средних факторного
и результативного показателей
JT - X У" У
22 - 39,8 = -17,8 16 - 22,6 = -6,6
26 - 39.8 = -13,8 17 - 22,6 = -5,6
45 - 39,8 = 5,2 26 - 22,6 = 3.4
37 - 39.8 - -2.8 24 - 22,6 - 1,4
28 - 39.8 = -11,8 22 - 22,6 = -0.6
50 - 39,8 = 10,2 21-22,6 = -1,6
56 39,8- 16.2 32 - 22,6 - 9,4
34 - 39,8 = -5.8 18 - 22,6 = -4,6
60 - 39,8 = 20,2 30 - 22,6 = 7.4
40 - 39,8 = 0.2 20 - 22,6 = -2,6
Заметим, что в табл. 13.2 преобладают пары отклонений с
одинаковым знаком. Эго говорит о том, что отклонения от сред-
ней в одном направлении значений факторного показателя вы-
зывают в большинстве случаев отклонения от средней в ту же
сторону значений результативного показателя. Таким образом,
вычисление пар отклонений от средних позволяет сопоставить
эти отклонения с учетом знака. Однако их сопоставление с уче-
том размера невозможно, так как отклонения факторного и
результативного показателей измеряются в разнокачественных
единицах. Так, для х это денежные единицы, а для у — физи-
ческие единицы, т. е. единицы товара. В общем случае независи-
мо от ситуации данного примера сравнение отклонений, как
правило, невозможно адекватно провести даже и тогда, когда
переменные измеряются в одинаковых единицах. Эго связано с
тем, что размеры отклонений зависят от величин самих при-
знаков. Например, один из показателей выражается трехзнач-
ными числами, а другой — двузначными. Поэтому при сопос-
тавлении имеет смысл абсолютные отклонения заменить на
относительные в каждой паре (х, у). Сделать это можно по ана-
логии со стандартным нормальным распределением, когда от-
клонение от средней нормировалось, т. е. делилось на величину
стандартного отклонения (см. раздел 7.3.3).
Нормировав отклонения для обеих переменных, т. е. разде-
лив их на соответствующие стандартные отклонения, мы смо-
жем попарно сравнить их друг с другом в масштабах стандарт-
304
ных отклонений. В табл. 13.3 представлены стандартные откло-
нения и нормированные отклонения затрат на рекламу и объем
продаж.
Таблица 13.3
Нормированные отклонения затрат на рекламу (х)
и объем продаж (у)
-17.8/12.2 = -1,46 -6,6/5.12 = -1,29
-13.8/12,2 = -1,13 -5,6/5,12 = -1,09
5,2/12,2 = 0,43 3.4/5.12 = 0,66
-2,8/12,2 = -0,23 1,4/5.12 = 0,27
-11,8/12,2 = -0,97 -0,6/5,12 = -0,12
10,2/12,2 = 0,84 -1,6/5,12 = -0,31
16,2/12,2= 1,33 9,4/5,12 =1,84
-5,8/12,2 = -0,47 -4,6/5,12 = -0.9
20,2/12,2= 1,66 7,4/5,12= 1,44
0,2/12,2 = 0,016 -2.6/5,12 = - 0,51
S, = 12,2 Зк=5,12
В качестве обобщающего показателя тесноты линейной свя-
зи двух переменных рассмотрим среднее произведение норми-
рованных отклонений:
«у
^(х-хХу-у)
ПЗх5у
(13.1)
где х — значение факторного показателя (независимой пере-
менной);
у — значение результативного показателя (зависимой пе-
ременной);
— выборочное стандартное отклонение факторного по-
казателя;
s? — выборочное стандартное отклонение результативного
показателя;
п — количество пар наблюдений (объем выборки).
Величина (13.1), обозначаемая г, называется выборочным
коэффициентом корреляции, который варьируется от —1 до
+ 1, так как каждое нормированное отклонение меньше еди-
ницы ввиду определения стандартного отклонения. Знак и ве-
личина коэффициента корреляции зависят от знака суммы
L(x - х )(у - у), стоящей в числителе отношения (13.1). Если
преобладают отклонения с одинаковыми знаками, то коэффи-
305
iihcht корреляции имеет знак плюс, если, наоборот. преобла-
лают отклонения с разными знаками, то коэффициент корре-
ляции будет отрицательным Чем больше абсолютная величина
каждого отклонения, тем больше абсолютная величина суммы
Х(х — i) (у — >) или абсолютная величина коэффициента
корреляции Приближение коэффициента корреляции к к I (или
I) означает увеличение степени тесноты линейной положи-
тельной (или отрицательной» корреляционной связи Если имеет
место полная линейная корреляция, т. с. переменные сказаны
линейным функциональным соотношением у “ b0 + b х, то
легко показать, что коэффициент корреляции ранен + i при
6, > 0 и -I при 4, < 0.
На диаграмме рассеяния эти случаи характеризуются распо-
ложением точек на прямой линии (рис. 13.6).
Рис. 13.6. Случаи гипчей коэреля1,ии:
1 - патнай гспигитет^тад eupjMUMuHw
- 1 го<«нэч ото««дагсгънзч *сррогкщ><«>
Котла коэффициент корреляции близок к нулю, линейная
корреляционная связь отсутствует.
Типичная диаграмма рассеяния в этом случае представлена
на рис 13 3 Следует подчеркнуть, что близость коэффициента
корреляции к нулю нс означает отсутствие какой-либо связи
вообще. Коэффициент корреляции является индикатором только
линейной связи Поэтому при небольшом по абсолютной вели-
чине значении коэффициента корреляции может существовать
какая-то достаточно тесная нелинейная связь (например, та-
кой случай представлен на рис. 13.4).
Вычислим по формуле 13,1 и Данным табл 13 3 коэффнци
ент корреляции
(-1,46) (-U9)+(-M3) (-LO9)e...+<W6 (-O,3l) _0
10
306
Как видно, между затратами на рекламу и объемом продаж
существует достаточно тесная линейная положительная корре-
ляционная связь, 1 е. с ростом затрат на рекламу объем прола*
в среднем возрастает
Формулу (13.1) можно преобразовать к более простому для
вычисления виду
<13.2)
Формула (13.2) не содержит нормированных отклонений от
средних, а оперирует только суммами, что облегчает процесс
вычислении.
13.1.3. Существенность выборочного коэффициента
корреляции
Вычисление выборочного коэффициента корреляции осу-
ществляется на основе выборочных данных, т. е. г является ста-
тистикой или оценкой некоторого параметра. Таким парамет-
ром, очевидно, будет генеральный коэффициент корреляции,
вычисляемый на основе всех значений генеральной совокуп-
ности. Формула для вычисления генерального коэффициента
корреляции (р) имеет вид
(13.3)
где и, — генеральная средняя значений факторного показате-
ля зг,
)i — генеральная средняя значений результативного пока-
зателя у;
о — генеральное стандартное отклонение значений фак-
торного показателя х;
в — генеральное стандартное отклонение значений ре-
зультативного показателя у;
N — объем генеральной совокупности
Выборочный коэффициент корреляции г, как правило, вы-
числяется по данным малых выборок {п < 30). Ввиду случайных
причин значение сможет существенно отличаться от генераль
ного коэффициента корреляции р. Например, может возник-
путь ситуация, когда линейной корреляции нет (т. е. истинное
.307
значение р - 0), а по яыборочным данным значение г суще
огненно отличается от нуля
Так, на рис 13 7 представлено корреляционное поле гене-
ральной совокупности. где разброс точек явно отражает отсут-
ствие линейной связи Однако в выборку попали точки (отме-
ченные на графике крестиками), которые расположены прак-
тически на одной прямой, имеющей положительный наклон
Поэтому следует ожидать, что выборочный коэффициент кор-
реляции будет близок к единице.
V > .
Яке. 13.7. Гсюмефмчйская мнтерлряга^в ямПорки
искажэошгй истинное з начете генерш*ы<мо мюффмияен»»
корреляции: р О, г • 1
В этой связи для выборочною коэффициента корреляции г
необходима оценка существенности, или статистической зна-
чимости. Она заключается в том, что проверяются гипотезы:
Но: р — 0 (линейная связь между хну отсутствует);
Н, р » 0 (линейная связь между х и у существует).
При п < 30 проверку нулевой гипотезы Н„ можно произво-
дить с помощью Г- критерия:
г-0
<-—•.
а,
где г — наблюдаемое (выборочное) значение коэффициента
корреляции,
р = 0 — гипотетическое значение генерального коэффи-
циента корреляции;
з — оценка стандартной ошибки коэффициента корреля-
ции, т. е стандартного отклонения распределения выбо-
рочных коэффициентов корреляции.
Величина S, вычисляется по формуле
зов
Отсюда величина /-критерия примет вид
(13 4)
г ле г выборочный коэффициент корреляции,
л — объем выборки
Статистика (13.4) имеет распределение, близкое к /-рас-
пределению, соответствующему п - 2 степеням свободы. При
заданном
величина
уровне значимости а критическим значением будет
'.а.-/-
> то коэффициент вы-
борочной корреляции / будет существенным, или значимым.
Пример 13.2. Оценим существенность коэффициента корреля-
ции, измеряющего тесноту линейной связи между х (затраты
на рекламу) и у (объем продаж), вычисленного в разделе 13.2.
Условия -задачи: г “ 0.843. л ” 10 Вычислим /-статистику по
формуле (13.4):
0,843 -0843
/ = =----= 4.44
fl-OMf 049
V 10-2
Пусть а ”0.05. Из таблицы Приложения 5 найдем критичес-
кий предел / , = 2,306. Ввиду того что 4,44>2,306. нулевая
гипотеза Н„ о равенстве генеральною коэффициента корреля-
ции нулю отвергается с уровнем значимости 5%
13.1.4. Ранговый коэффициент корреляции
Коэффициент корреляции, рассмотренный в разделе 13.1 2,
вычисляется для переменных, измеряемых в шкале интервалов
или отношений Для оценки корреляции между признаками,
которые выражаются в порядковой шкале, рассматривается
специальный ранговый коэффициент корреляции Под рангом
понимается порядковый номер значения признака в ранжиро-
ванном ряду Рассмотрим значения пар наблюдений (х, у):
зов
Составим ранжированный ряд из значений х (например,
по возрастанию) и найдем их ранги: наибольшему значению
присвоим ранг I, второму по величине - 2 и г. д. Булем обозна-
чат. ранг элемента г . Диалогично определим ранги для значе-
ний у. Заменим пары наблюдений (х, у) соответствующими
рангами (г , г ):
rl
* S ч
У г’«
Предположим, что как среди г О' = 1, 2,..., л), гак и среди
г (| • I, 2,.... л) нет одинаковых:
'' Используя формулу (13 2), запишем выражение коэффици-
ента корреляции между переменными, представленными в ран
говой (порядковой) шкале:
(13 5)
По предположению ранги для х (г ) И у (г ) являются раз,лич-
ными числами от 1 до л Поэтому можно записать:
1?’ -,2+2’ ♦-* "2
Отсюда определим подкоренные выражения в знаменателе
формулы (13.5):
_ л(л + 1К2л +1) _ лг(л + 1)г а Жл1-!)
6 4л 12
Ввиду того что ab= ' |а2 + Ь‘ -(а-6)’) .будет верно соотно-
шение г _
_ л(л + >Х2я + 1) 1 y* 12
6 '
где </ = г — г .
• »,
310
Тогда выражение в числителе формулы (13 5) имеет вил
Ev,.-E^>-=^4S'A
В результате преобразований коэффициент корреляции (13.5)
выразится формулой
л(л'-1) 1« j
и(и2-1) я<в’-1)
(13 6)
12
тле величины d обозначают разности рангов.
Формула (13 6) определяет ранговый коэффициент корре-
ляции Спирмена, обозначаемый г.
Преимущество коэффициента корреляции рангов состоит в
том, что на его основе оценивается коррелироваиность чисто
качественных признаков, не имеющих точного количествен-
ного измерения. Например, с помощью экспертов можно про-
ранжировать кандидатов на занятие определенной должности
по различным деловым и личным качествам. Коэффициент
Спирмена изменяется от -I до I. В случае полного совпадения
рангов гиг козффииие1гг г - I. что означает полную поло-
жительную корреляцию. Если имеет место полная противопо-
ложность рангов, то г = -1 и между переменными существует
полная отрицательная корреляционная связь В случае г - О
корреляционная связь отсутствует
Пример 13.3. Комитет по здравоохранению проводит иссле-
дование 11 крупнейших городов страны с целью выявления
наиболее существенных факторов, влияющих на рост легоч-
ных заболеваний у городских жителей. С помощью специаль-
ных тестов эти города были проранжированы по двум крите-
риям (г = I означает “худший", г “ 11 — "лучший"): коли-
чество легочных заболеваний на 100 тыс. жителей и уровень
загрязненности воздуха. Затем определялся ранговый коэф-
фициент корреляции Спирмена для оценки степени тесноты
связи ыежду легочными заболеваниями и загрязненностью
воздуха Промежуточные вычисления были сведены в табли-
цу (табл. 13.4).
эн
Тзбшиим 13.4 вмЧИСЛВНИЯ РАНГОВОГО коэффициента ворролвцин
и загрязненностью воздуха (X) по 11 городам |Г)
Город 4, • г - Г
Г, 5 4 1 1
Г, 4 7 -3 9
7 9 -2 4
3 1 2 4
г9 г -1 1
ге 11 10 1 1
гт 2 3 1 1
10 5 5 М
г_ 8 5 2 4
с. 6 8 -2 4
Г.1 9 11 2 4 1<Г‘- 5в
Используя данные табл. 13.4, вычислим ранговый коэффи-
циент корреляции по формуле (13.6):
г = I - 6 58/11 - <112 — I) = I - 348/1320 =
- 1 - 0,264 = 0,736
Величина коэффициента Спирмена (0,736) характеризует
высокую положительную корреляцию между появлением легоч-
ных болезней и загрязненностью воздуха в крупных городах
На практике могут возникнуть ситуации, когда среди зна-
чений признаков Xи Уесть равные между собой В этом слу-
чае несколько одинаковых значений образует связные ран-
ги. которые полагаются равными средней арифметической
их порядковых номеров в ранжированном ряду. Например,
если на 5-м и 6-м местах расположены одинаковые значения
признака, то все они будут иметь одинаковый рант , ранный
5,5((5 ♦ 6)/2 - 5,5).
Пример Г3.4. На фирме была проведена аттестация 10 менед
жеров среднего звена. С помошью специальных тестов и систе-
мы показателей эффективности работы подразделений были
получены значения рейтингов менеджеров. Кадровую службу
интересует, насколько величина рейтинга связана со стажем
работы на фирме Для вычисления коэффициента Спирмена
данные о рейтингах и стаже были переведены в ранги Все про-
312
межуточные вычисления коэффициента ранговой корреляции
прелетлклены в табл 13.5.
ГаДлица 13 5
Промежуточные вычисление для определение
коэффициента ранговой корреляции между рейтингом (X)
и стажем работы (У)
Намял ары Райгммг Стаж работы Раит Л Рыж V Ж <Р
(X) in г
1 3 10 4,5 3.5 1 1
2 5 11 5,5 9 -2.5 6.25
3 1 1 1 1 0 0
4 4 3 5 2 3 0
5 8 5 10 4.5 5,5 30.25
6 3 4 3,5 3 0.5 0.25
7 6 13 8 10 -2 4
8 2 6 2 6 4 16
9 5 9 6.5 7 0.5 0.25
10 7 10 9 8 1 1 £ й’-ва
По формуле (13.6) вычислим г:
г = I - 6 68/10 (101 - 1) - 1 - 0,412 - 0.588.
Таким обратом, существует средняя степень связи между
рейтингом менеджера и его стажем работы на фирме.
Отметим. что если число связных рангов достаточно вели-
ко. то в формулу (13.6) следует ввести корректирующий фак-
тор. Пусть г обозначает ранговую корреляцию между признака
ми X и ) В случае связных рангов коэффициент Спирмена
выражается по формуле
г =1_ (137)
(л’-н-12ЛХл’-"-12Я)’
гае л=112Е‘а)-лР;
j - номера связок по порядку для признака X.
А — число одинаковых рангов в у-й связке по X;
к номера связок по порядку для признака t;
в( — число одинаковых рангов в К-й связке no У.
333
13.2. ПРОСТОЙ
ЛИНЕЙНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
13.2.1. Уравнение простой регрессии.
Метод наименьших квадратов
После того как установлено существование и вывалена сте-
пень тесноты линейной святи, возникает проблема определе-
ния конкретного вида этой зависимости. Геометрически это оз-
начает, что нужно подобрать такую прямую, которая нанлучшим
образом сглаживала бы точки корреляционного поля На рис
13.1 и 13 2 это было сделано "на глаз" по принципу, чтобы все
точки одновременно находились хак можно ближе к прямой
Уравнение прямой, сглаживающей точки корреляционного
поля, называется уравнением простой (парной) регрессии, а
сама прямая — линией регрессии.
Если у — зависимая переменная, ах— независимая, то на-
хождение зависимости у от х будем называть определением per
рессии у на х.
Формальным аналитическим метолом определения уравне-
ния регрессии является метод наименьших киалратов. Рассмот-
рим сначала геометрическую интерпретацию этого метода.
Р>*с. 13.9. Геометрическая мг’щш »-зим*?»-ъц.мк «вадрэюв
На рис. 13.8 представлена искомая линия регрессии, на ко-
торую из каждой точки корреляционного поля опушены от-
резки, преттендикулярныс оси х Длины отрезков d},...,
характеризуют- расстояния от точек до прямой регрессии.’Пусть
критерием иаилучшей сглаживающей прямой будет миними-
зация суммы квадратов расстояний:
тптп<</|‘ ♦ di я-<(?♦..,♦</*) nrin£<tf. (13.8)
<-т
31-1
Прямая, построенная по критерию (1.18), будет линией рег-
рессии, полученной методом наименьших квадратов.
Рассмотрим аналитическую процедуру метода наименьших
квадратов,
Пусть имеется совокупность из я пар наблюдений: (х, у,).
Ц, ур,-. (*.. У)
Запишем искомое уравнение регрессии в виде
у-*„+4,х, (13.9)
где и Л] — искомые величины, а у (читается “у с крыш-
кой") характеризует оценку у при заданном х, когда Ьа и
(т| определены
Сумму квадратов расстояний (5) можно записать так:
$ = = £(у-у)’=Е(у, -ь,»,)1. (в.ю)
»т
Будем рассматривать 5 как функцию двух переменных Ьа и
найдем такие их значения, которые минимизируют сумму
квадратов расстояний Для атого продифференцируем выраже-
ние (13.10) отдельно по 4,и i и приравняем частные произ-
водные к нулю: л
т~-=-з£( У, - - Мт)=О.
«Ъ .-I
. (13.11)
дГ = -2^ х,(у,-Ат-Ь,х,)ж0.
"И м
Из (13.11) следует система так называемых нормальных урав-
нений я В
=2л- (13.12)
1-1 г-4
(|3|3>
1=1 1*1 4*1
Неизвестные значения Ьл и Ь находятся как решение систе-
мы нормальных уравнений (13.12) и (13.13):
п п
315
Величина 4, является угловым коэффициентом линии рег-
рессии Он называется коэффициентом регрессии Если неза-
висимая переменная х возрастает на единицу, то зависимая
переменная у в этом случае возрастает в среднем на b единиц
при b > 0 (или убывает в среднем на 4, единиц при bt < 0).
Величина 4П является ординатой пересечения прямой регрес-
сии с осью у, т. е характеризует значение зависимой перемен-
ной у при х “ 0. Для регрессионного анализа 4(1 не имеет осо-
бого смысла В отличие от него коэффициент регрессии 4( более
информативен и играет значительную роль в прикладном ана-
лизе.
Разделим обе части нормального уравнения (13.12) на л:
или у - 4в 4, х .
(13 16)
Соотношение (13.16) показывает, что линия регрессии (13.9)
проходит через точку (х , у). Отсюда можно записать другой
вил уравнения регрессии:
У — У -Ь,(х— х).
(13.17)
Пример 13.в. Вычислим коэффициенты уравнения регрессии
по данным табл. 13.1. Для этого проведем необходимые проме-
жуточные вычисления и сведем их в таблицу:
я Г У И
22 16 352 484
26 17 442 Б76
45 26 1170 2075
37 24 088 1369
28 22 616 704
50 21 1050 254»
56 32 1792 3136
34 18 612 1156
60 30 1 вгю 3600
40 20 800 1600
зэв 226 9522 1/330
316
По формуле (13.14) вычислим 6:
. 9522-398-226/10 ....
Л =-----------z---” U.J 34
17334)-398’/10
На основе (13.15) определим 6а:
. 226 „„.398
10 10
Уравнение регрессии имеет вил
у - 8,51 + 0,354х.
Коэффициент регрессии 0,354 означает, что возрастание на
10 000 лолл затрат на рекламу (х возрастает на 1) сопровожда
ется в среднем ростом на 354 единицы объема продаж (у возра-
стает в среднем на 0,354). Свободный член 8,51 не несет ника-
кой полезной информации. Он соответствует объему продаж
при нулевых затратах на рекламу. Однако уравнение регрессии
было построено на основе выборочных данных, где фактор-
ный показатель х изменялся в пределах от 22 000 до 60 000 долл.
Поэтому данная линейная зависимость совершенно необяза-
тельно сохраняется за границами этого промежутка
13.2.2. Стандартная ошибка регрессии
Полученное на основе метода наименьших квадратов урав-
нение регрессии можно использовать для предсказания значе-
ний у в зависимости от значений х. Ясно, что эти предсказания
не будут точны, так как уравнение регрессии задает связь меж-
ду переменными только в среднем. На рис. 13.8 данные наблю-
дений (точки корреляционного поля) разбросаны вдоль пря-
мой регрессии Расстояния </ раины абсолютным величинам
ошибок оценок фактических значений yf полученных с помо-
щью уравнения у = ba + 6,x. Обозначим ошибку е:
е, = у,-у,,г= (13.18)
Ошибки (13.18) называют также остатками Если точка на-
блюдения находится выше примой регрессии, то остаток будет
положительным, если ниже — отрицательным.
Рассмотрим пару наблюдений в исходных данных приме-
ра 13.5 :х — 44), у “ 20. На основе уравнения регрессии у = 8.51 +
+ 0.354л вычислим оценочное значение у при х " 44):
317
у = 8,51 + 0,354 40 - 22.67
Величина остатка такова:
у - у - 20 - 22,67 - -2,67.
Линия регрессии, построенная по методу наименьших квад-
ратов, обладает свойством: сумма всех остатков равна нулю
Действительно, рассмотрим уравнение регрессии, представ-
ленное в виде (13.17):
у " у + *, (х-х).
Тогда остаток е выражается следующим обратом
*, = У, - У,” (/, ~ У) - *,(х -х )•
Вычислим сумму* остатков, имея в виду свойство средней
арифметической:
X*. = У; - И ) =£(>, ~У1~Ь> Ё<*. -X) = о.
.-I ы >•<
Следовательно, остатки для прямой, построенной по мето-
ду наименьших квадратов. взаимно погашаются. Это говорит о
том, что точки наблюдений в одинаковой степени разбросаны
по обе стороны от сглаживающей прямой регрессии.
После определения уравнения регрессии возникает пробле-
ма опенки надежности этого уравнения, если его использовать
для предсказания значений у. Очевидно, чем меньше в целом
разброс точек наблюдений около прямой регрессии, тем на-
дежней будет уравнение как оценочная функция В качестве меры
разброса можно рассмотреть аналог стандартного отклонения,
только отклонения вычислять не от средней, а от оценочной
прямой. Такая характеристика называется стандартной ошиб-
кой оценки (регрессии) и вычисляется по формуле
(13 19)
где у — наблюдаемые значения независимой переменной;
у — оценочные значения, полученные из уравнения рег-
рессии и соответствующие каждому у;
л — число точек наблюдения. участвующих в вычислении
линии регрессии.
318
Заметим, что в соотношении (13.19) сумма квадратов ос-
татков делится не на и, а на и - 2. Это связано с тем, что 2
степени свободы были потеряны при оценке с помощью урав-
нения регрессии, которое задается величинами Ь„ и ht, вычис-
ленными на основе и пар наблюдений
Очевидно, чем меньше величина стандартной ошибки рег-
рессии, тем ближе располагаются точки наблюдений к прямой
ретрессии (тем лучше прямая сглаживает точки корреляцион-
ного поля).
Если 5 ,= 0, то это означает, что построенная прямая явля-
ется наилучшей сглаживающей прямой. В этом случае все точки
наблюдений располагаются на прямой, т. е. нет ни одной точ-
ки. отклоняющейся от линии регрессии
пример 13.6. Вычислить стандартную ошибку регрессии для
уравнения регрессии у ” 8,51 + 0,354х, используя исходные
данные примера 13.5. Все промежуточные вычислении сведем в
таблицу:
я F г 0-й’
22 16 16,3 -0.3 0,09
» 17 17,71 -0.71 0.504
45 26 24,44 1.56 2.434
37 24 21,61 2,39 5.712
28 22 16,42 3.58 12Л16
50 21 26.21 -5.21 77 144
56 32 2833 367 13.469
34 18 20.54 -2,54 6,452
60 30 29 75 0 25 0,063
40 20 22,67 -2.67 7,129
0 758»
Стандартная ошибка регрессии вычисляется по формуле
(13.19):
5 у'9'476 -3.078
гл У 6
13.2.3. Доверительные интервалы уравнения регрессии
Рассмотрим использование уравнения регрессии в качестве
модели прогнозирования Эта модель описывает взаимосвязь
независимой переменной х и зависимой переменной у лишь в
319
среднем, поэтому фактические значения у, как правило, не
будут совпадать с точечными оценочными (т с прогношымн)
значениями у.
Рассмотрим причины этих отклонений.
Уравнение линейной регрессии (13.9) является выборочным,
т. е. величины и t>t рассчитываются по методу наименьших
квадратов на основе выборки. Предположим, уравнение рег-
рессии определяется по данным генеральной совокупности и
имеет вид
у-0„ + Р,х (13.20)
Тогда р„ и р, можно рассматривать как параметры, а b и
Ьп — соответственно их оценочные статистики.
Генеральное уравнение (13.20) характеризует сглаживающую
прямую, полученную по методу наименьших квадратов Так же
как и выборочное уравнение, оно описывает взаимосвязь не
ременных в среднем, в общем. Среди причин, вызывающих
отклонения фактических значений от сглаживающей прямой,
можно выделить
влияние других факторов, не учтенных в модели;
ошибки измерения;
случайные возмущения.
Запишем уравнение регрессии как модель, учитывающую
подобные отклонения:
у-Я. + Р.х+е, (13.21)
где с — случайная ошибка, вызванная указанными причинами
В модели (13.21) фактическое значение у складывается из
двух компонент — детерминированной (Р( + р,х) и случайной
(е). Уравнение (13 20) характеризует некоторое среднее значе-
ние у при заданном значении х, равное оценочному значению
у. Уравнение (13.21) отражает индивидуальные значения ус
учетом возможных отклонений от средних, т. е, от линии гене-
ральной регрессии.
Для того чтобы использовать модель (13.21) для предсказа-
ния значений у, необходимо сделать следующие допущения:
— каждому значению х соответствует распределение наблю-
даемых значений у, которое является нормальным. Иначе
говоря, генеральная совокупность фактических значений
у нормально распределена вокруг линии генеральной рег-
рессии (рис. 13.9);
320
— все распределения у имеют одинаковую дисперсию вок-
руг всей прямой генеральной регрессии, т. е. дисперсия
остается постоянной при возрастании х;
— ошибка г является случайной величиной со средней, рап-
ной нулю, причем последовательные значения г незави-
симы друг от друга и имеют одинаковую дисперсию
Рис Т.З.Я. -кюмапь-пя.’ рас-средеойний у дла трех плможгых ихачммй *
вокруг гмиия генерального уравнения ре<реоони
Таким образом, при построении парной линейной регрес-
сии предполагается, что для каждого индивидуального значе-
ния у. будет верно соотношение
(13.22)
Исходя из допущений относительно случайных последова-
тельных ошибок г, можно записать:
Е<е,> - 0;
ЕХед) • E<t,)F.(ep = 0 (i * Д
Е(«,) - Е|(е, - 0) (с, - 0)1 = o’;
me i,J — 1,..., л — номера наблюдений.
Кроме того, из допущений относительно генерального
уравнения линейной регрессии получим
Е(у.) - Е(Р. + р,х, + с.) ’ р, + р,х + Е («,) - р„+ р,х - у..
Отсюда и месм
Е«у, - ЕТу )й_т - Е(>У)1 = Е(у, ~ У, >0', - У,)|* Е(се)) » o’.
Итак, если предположить линейную корреляционную связь
между переменными х и у, то дисперсия распределения у вок-
321
рут прямой генеральной регрессии совпадает с дисперсией слу-
чайных ошибок е
На практике ввиду наличия только выборочной информа-
ции построить теоретическую модель (13.21) не представляет-
ся возможным. Поэтому мы вынуждены пользоваться выбороч-
ным уравнением 03 9), в кагором значения 6, и 4, являются
статистическими оценками соотве гстауюших параметров р, и
(3„ теоретической модели
Таким образом, при определении доверительных пределов
для индивидуального значения у (т. е при определении интер-
вала, где с доверительной вероятностью будет содержаться
фактическое значение у для данною значения хф) с помо-
щью выборочного уравнения (13.9) обшая дисперсия прогноза
+ btx будет складываться из трех дисперсий: диспер-
сии. определяющей разброс точек наблюдений вокруг теоре-
тической прямой, дисперсий статистик blt и Z>,
Дисперсия разброса о’ оценивается как квадрат стандарт-
ной ошибки регрессии
221-Х.
п-2
Можно показать, что оценка дисперсии Ь* вычисляется по
формуле 2
а оиенкд дисперсии bt (см раздел 13.2.5) — по формуле
Если представить уравнение в виде у = у + Ь^х -х), то
дисперсия прогноза уЦ,) будет иметь вид (обозначение з})
Стандартное отклонение .г,называйся стандартной ошиб-
кой прогнозирования:
з х, '| + 1+ <Х?)2 (13.23)
322
Винду (13.23) и допущения о нормальности распределения
у вокруг прямой генерального уравнения регрессии можно оп-
ределить доверительный интервал для индивидуального значе-
ния у при заданном значении х.
Для больших выборок (л г 30) при доверительной вероят-
ности I — а доверительный интервал вычисляется по формуле
у +2^днлиуЦ) ±Z^ I) ♦ 1 у <5^2^.(1324)
I л-2 1J л >(д-*Г
В случае малых выборок (л < 30) стандартное нормальное
распределение Z заменяется на /-распределение при л - 2:
У ,11ИЦа-г1 <11251
’ п~г \ п хс-»-*)*
Пример /17. Рассмотрим уравнение регрессии, полученное в при-
мере 13.5, и вычислим 95-процентный доверительный интервал
для объема продаж у при затратах на рекламу xt “ 35 тыс, долл.
Вычислим точечную оценку у (-\,)
у UQ = 8,51 + 0,354 35 = 20,9 (20 900 ед.).
Величина стандартной ошибки регрессии (или стандартное от-
клонение. харакгеризуюшее разброс точек наблкиения около при
мой регрессии) была вычислена в примере 116:5 3,078.
Для определения стандартной ошибки прогнозирования
необходимо вычислить сумму квадратов отклонений хотсред-
ней х . Воспользуемся для ЭТОГО формулой L(x - х “
г, (*1
= 2jc ——**, в которую подставим соответствующие зна-
чения. вычисленные в примере 13.5:
Е(х -X )’ = 17330 » 1489,6.
Значение средней х равно
п 10
По таблице Приложения 5 найдем • 2,306.
323
В результате, используя формулу (13.25), получим
_ Г« (35-39Л)2
20.9 ±2.306 3,078 *й - 20.9 ±7.49 -
= 13,41 +28,39.
Таким образом, с вероятностью 95% можно утверждать: если
затраты на рекламу составляют 35 тыс. долл., то ожидаемый
обмм продаж будет в гранииах от 13 410 до 28 390 ед.
Как видно из формул (13.24) и (13.25). ширина довери-
тельного интервала прогноза зависит от объема выборки я. Ес-
тественно, что с ростом л точность прогноза повышается (до-
верительный интервал сужается). Очевидно, наибольшая
точность будет иметь место, когда прогнозируется значение у
при условии, что х = л . В этом случае стандартная ошибка про-
гнозирования принимает наименьшее значение:
На рис. 13.10 показан график доверительных границ прогно-
за Они представлены в виде ветвей гиперболы, расположен-
ных ныше и ниже прямой регрессии
Рис. Г3. to. Дрмритслк.>«4П границы прппяаза
Как видно на рис. 13.10. наиболее ужа я часть между МТМ
ми графика наблюдается при х =лг. Доверительные границы
расширяются по мере удаления значений хот х .
324
13.2.4. Коэффициент детерминации
Уравнение регрессии позволяет оценить, в какой степени
изменяются значения зависимой переменной в зависимости от
изменения независимой переменной Величина стандар!ной
ошибки регрессии определяет степень разброса точек наблю-
дений вокруг прямой регрессии. Коэффициент корреляции яв-
ляезся отвлеченным показателем, характеризующим тесноту
связи между переменными, если эта связь линейная
Рассмотрим теперь показатель, который измеряет интенсив-
ность связи, т. е. определяет, в какой степени изменением неза-
висимой переменной обьясняется изменчивость (вариация)
зависимой переменной. Определение интенсивности связи ос-
новано на разложении на два слагаемых суммы квадратов от-
клонений зависимой переменной от средней, сумма квадратов
характеризует общее рассеяние под воздействием всех факто-
ров, влияющих на зависимую переменную у.
Представим отклонение для индивидуального значения у. в
виде суммы:
У,~у = (У, _У) * О’,- у,). (13.26)
где у — оценочное значение, вычисленное с помощью урав-
нения регрессии у, “ 6, * 6.x,
Если возвести обе части равенства (13.26) в квадрат, то
можно показать, что сумма квадратов отклонений по всем вы-
борочным точкам представляется и виде
£( V - У)г = £(> - >)2 ♦ X < 3- Я’- (• 3-27)
Первая компонента в правой части равенства (13.27) харак-
теризует отклонения расчетных величин у от средней у. Вви-
ду того что у “ Ь. ♦ Ь'Х, эта сумма квадратов отклонений
обусловлена регрессией, т е. объясняется изменением незави-
симой переменной х Вторая компонента отражает отклонения
фактических значений у от оценочных значений, вычисленных
на основе уравнения регрессии В этом случае сумма квадратов
отклонений относительно регрессии измеряет ту часть общего
рассеяния, которая обусловлена всеми факторами, за исклю-
чением х
Если разделить обе части равенства (13 27) на п, то мы по-
лучим фундаментальное соотношение, характеризующее раз-
ложение общей дисперсии значений у
325
Из соотношения (13.28) следует, что общая дисперсия ре-
зультативного показателя у является суммой двух компонент пер-
вая характеризует ту часть обшей дисперсии, которая объясняет
ся факторным показателем х, а вторая — необъясним кую часть
обшей дисперсии. Это положение иллюстрируется на рис. 13.11.
Я*с. 13.11. Разложение обил*О огклонемия у от у
<у “ у) — пЛыг.нинсля честь |<*Г^Л«Н*Л»ИМ|»» г |,
|у и часть. и«)ОХ4пст«мя вепки фаа-ирам*'. .м левлоче-ыем м|
Ввиду уравнения (I3.I7), полученною по методу наименьших
квадратов. точный прогноз будет всегда при х “ х : у ( х) “ >•
Как видно из рис I3.l I, отклонение (у ' у) зависит от того,
насколько значение факторною показателя х отклонилось от х
Иначе говоря, оно объясняется изменением X В то же время от
клоненне (у - у) никак нс объясняется вариацией независимой
переменной х Именно величина лото отклонения имеет решаю-
щее значение для прогнозирования Если бы вариация независи-
мой переменной объяснялась только изменением х, то все откло-
нения (у _ у) были бы равны нулю и все точки наблюдений
располагались на прямой регрессии.
Рассмотрим отношение объясненной дисперсии к общей
дисперсии (обозначим его г1):
2 - £(У~ У)2 _, _ £(У~У>2
^(у-у)г Х<У-У)’
<13 29)
Величина г’ называется коэффициентом детерминации. Он
характеризует удельный вес (процент) общей дисперсии. ко-
торый объясняется уравнением ретрессии (или изменением
факторного показателя х). Чем больше этот удельный нее, тем
в большей степени вариация у объясняется изменениями пере-
менной х, и. следовательно, связь между ними является более
интенсивной.
Можно показать, что значение коэффициента детермина-
ции равно квадрату коэффициента корреляции (выбор обозна-
чения г1 связан именно с этим фактом)
В регрессионном анализе оба коэффициента играют важную
роль. Каждый из них имеет преимущество по отношению к дру-
гому
Так, знак коэффициента корреляции «-определяет направ-
ление корреляционной связи.
Значение коэффициента легерминацин изменяется от 0 до
1 и никак ие указывает на направление связи.
В то же время коэффициент детерминации измеряет интен-
сивность связи, г. е процент обшей вариации результативного
показателя у, объясняемый изменением факторного показате-
ля х.
Пример 13. в. Вычислим коэффициент детерминации для урав
нения регрессии примера 13.5, характеризующего зависимость
объема продаж (у) от затрат на рекламу (х): у - 8,51 ♦ 0,354х.
В разделе 13.2 был рассчитан коэффициент корреляции
г - 0,843. Тогда коэффициент детерминации равен г1 “
-0,843'= 0,71.
Это означает, что 71% общей вариации (дисперсии) про-
даж объясняется изменением затрат на рекламу.
Очевидно, величина I - г1 = 0,29 означает, что 29% общей
дисперсии остается необъясненной
13.2.5. Проверка существенности коэффициента
регрессии
Уравнение регрессии было получено на основе выборочных
пар наблюдений. Очевидно, выборочное уравнение у "1, + Ь х
не будет совпадать с теоретическим у - Ри + ₽,х, которое мог-
ло быть получено по данным генеральной совокупности. В уран
нении репрессии связь между переменными характеризуется ко-
эффициентом регрессии Ь По аналогии с комрфкциенгом
корреляции необходимо проверить, существует ли эта связь на
самом деле или истинный коэффициент регрессии Р равен нулю.
Иначе говоря, следует оценить существенность выборочного
згт
коэффициента регрессии А, г. е. проверить нулевую гипотезу о
том, что = 0. Если />, несуществен, то использование выбо-
рочною уравнения для дальнейшею анализа и прогнозирова-
ния не имеет- смысла
Оценка существенности сводится к проверке гипотез
Но: ₽, =0;
Н,:Р,-0.
При малых выборках (и < 30) следует использовать /-крите-
рий:
где s* — стандартная ошибка выборочного коэффициента
регрессии.
Величина а является оценочным значением стандартного
отклонения распределения выборочных коэффициентов рег-
рессии. При больших выборках распределение будет нормаль-
ным с математическим ожиданием Е(5 ) = В и дисперсией
2 а’ 2 У(у-у)г
<?ь ==—8 . (Р, = 1,11 ---- — дисперсия ошибки гене-
ральной регрессии). Оценочным значением для а; будет
величина квадрата стандартной ошибки регрессии = л1.
определяемая по формуле (13.19). Сэстовагетыю.
Отсюда /-критерий (/-статистики) вычисляется по формуле
<13 30)
При уровне значимости а критический предел задается зна-
чением Если |/| г (,ЯлГ то нулевая гипотеза Н„ отперта
стся, т е коэффициент регрессии Л. сушествен при уровне
значимости а.
Прммвр 13.9. Проверитьсушсс/иеннос/ь коэффициент? регрес-
сии для уравнения у — 8,51 + 0,354х (пример 13.5) при а “0.05.
зав
Вычислим I критерий, подставив » формулу (I3.J0) значе-
ния: ft, “ 0,354. s “ 3.078 (пример 13 6) и S(x - i)1 “ 1489,6
(пример 13.7):
0.354
I =------ -/ - 4.44
3.078/./1489,6
Критическое значение /пм,, “ 2.306
Отсюда |/| " 4.44 > 2,306. и. следовательно, коэффициент
регрессии 6, = 0,354 существен при а = 0.05.
13.2.6. Возможные ошибки при практическом
использовании корреляционно-регрессионного анализа
Корреляционно-регрессионный анализ является эффектив-
ным инструментом статистического анализа Однако следует от-
метить основные ошибки, которые возникают при его исполь-
зовании и которые могут привести к неправильным выводам.
Прогнозирование вне гравии изменения наблюдаемых данных
Эта ошибка заключается я использовании уравнения рег-
рессии в качестве прогнозной функции, когда в уравнение
подставляется значение независимой переменной, выходящее
за границы изменения выборочных значений х. При прогнози-
ровании следует всегда помнить, что уравнение регрессии яв-
ляется экстраполяционным, т. е. оно отражает зависимость,
которая действует только в диапазоне изменения данных, на
основе которых оно было получено
Причинность и статистическая зависимость
Корреляционно-регрессионный анализ позволяет выявить и
оценить статистическую связь между переменными. Однако ста-
тистическая зависимость еще не означает существование при
чинной связи между переменными. Например, если мы гово
рим, что в данном году существует коррелвиия между прибылью
предприятия й затратами на научно-исследо-ваггельские разра-
ботки (НИР), то это не означает, что прибыль в данном году
была вызвана затратами на НИР Реальными причинами при-
были могут быть, например, состояние экономики в данном
году, затраты на рекламу и другие причины Поэтому вывод о
том, ‘гго при возрастании затрат на НИР следует ожидать не-
медленного роста прибыли, будет неверным.
329
Перенесение прошлых тенденции на будущее
При использовании уравнения регрессии в прогнозирова-
нии следует иметь в виду, что исторические данные, участвую-
щие в определении уравнения, могут отражать такие условия и
факторы, которые к моменту прогнозирования уже не оказы-
вают значительного влияния на результативный показатель.
Например, пусть рассматривается регрессия объема производ-
ства на численность работников Прямая, вычисленная на ос-
нове данных за периоды, взятые несколько лет назад, может
иметь больший угол наклона (коэффициент регрессии), чем
прямая, полученная на основе наблюдений за ближайшие пе-
риоды. Причиной этого является эффект от изменения техно-
логии производства.
Величина случайной ошибки, характеризующая разброс
наблюдений вокруг прямой регрессии, также может изменять-
ся от года к году.
Интерпретация коэффициента корреляции
Коэффициент корреляции иногда пугают с коэффициен-
том детерминации, рассматривая его значение как процент ва-
риации у, который обьясняеюя уравнением регрессии Напри-
мер, если г “ 0,6. то неверно утверждать, что 60% обшей
вариации у объясняется регрессией. На самом деде этот про-
цент равен 36%, так как г1 = 0,36. Коэффициент детерминации
г1 озень часто трактуется как процент изменения переменной
у по причине изменения переменной х 'Это неверно, так как г1
измеряет, насколько хорошо одна переменная объясняет дру-
гую только в статистическом, а не в причинном смысле.
Выявление нереальных святей
Используя методы регрессионного анализа, иногда можно
выявить связи между переменными, которые противоречат здра-
вому смыслу При этом даже если одна переменная не является
причинным фактором, вызывающим изменение другой, часто
полагают, что существует какой-то общий фактор для обеих
переменных. Вполне возможно, например, обнаружить статис-
тическую связь между километражем на I литр потребляемого
бензина для восьми автомобилей и расстояниями от Земли до
восьми планет Солнечной системы. Ясно, что эта связь будет
бессм ысленной
Имея сззответствуюшую базу данных, можно строить рег-
рессии между различными парами переменных и получать нео-
жиданные связи. Поэтому регрессионный анализ должен сочс-
330
тать здравый смысл и качественное исследование переменных
Обнаруженные неожиданные связи следует перепроверять,
используя новые данные, прежде чем пытаться найти им объяс-
нения.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 13
Статистическая сеть между двумя переменными проявля-
йся как тенззенция, т. е. в общем, при массовых наблюдениях.
Ее частным случаем является корреляционная связь. При кор-
реляционной связи изменение независимой переменной влия-
ет на изменение среднего значения зависимой переменной.
Корреляционно-регрессионный анализ заключается в установ-
лении степени тесноты связи и се формы, т. с. аналитического
выражения, связывающею переменные.
Будем обозначать х независимую переменную (факторный
показатель), у — зависимую переменную (результативный по-
казатель). Пусть имеется совокупность пар наблюдений (х, у).
Представим каждую пару наблюдений как точку с координата-
ми (х. у) на координатной плоскости. Данные точки образуют
корреляционное пате, или диаграмму рассеяния Чем теснее
связь между переменными, тем более плотно точки распола-
гаются вокруг некоторой линии. Эта линия является трафиком
аналитической зависимости между переменными F-сли точки
корреляционного пазя беспорядочно разбросаны на коорди-
натной плоскости, то это означает отсутствие тесной взаимо-
связи между переменными.
Если точки корреляционного поля концентрируются вдоль
некоторой прямой, то корреляционная связь линейная Пря-
мая с положзттсльны.м наклоном характеризует положительную
корреляционную связь (положительную корреляцию), а с от-
рицательным — отрицательную корреляционную связь (отри-
цательную корреляцию). Количественной мерой тесноты ли-
нейной количественной связи между переменными является
коэффициент корреляции г, который вычисляется по формуле
(13.1) Значение гизменяется от -1 до +1. Приближение сто к
-Г I или -1 означает увеличение степени тесноты линейной связи
(соответственно положительной или отрицательной). Ехли
г" I, то имеет место полная линейная корреляция, т. е пере-
менные связаны функциональным соотношением у " А, э Ь^х.
Когда г близок к нулю, линейная корреляционная связь отсут-
ствует.
331
Коэффициент г является выборочной статистикой, или
оценкой генерального коэффициента корреляции о, вычислен
ного на основе пар наблюдений генеральной совокупности (фор-
мула (13.3)). Поэтому для выборочного коэффициента корре-
ляции необходима проверка существенности, или статистичес-
кой значимости. Она заключается в том, что проверяется нулевая
гипотеза Ht: р = 0. Проверка производится на основе г-крите-
рии (13.4) для малы* выборок
Коэффициент корреляции вычисляется для переменных,
измеряемых в шкапе интервалов или отношений Для оценки
корреляции между признаками, выраженными в порядковой
шкале, рассматривается ранговый коэффициент корреляции
Спирмена (формула (13.6)). Под рангом понимается порядко-
вый номер значения признака в ранжированном ряду Одина-
ковым значениям при знака соответствуют связные ранги, ко
торые полагаются равными средней арифметической порядко-
вых номеров значений в ранжированном ряду. Если связных
рангов много, то коэффициент ранговой корреляции вычис-
ляется по формуле (13.7).
После выявления существования и степени тесноты линей-
ной связи возникает проблема определения конкретного вида
этой зависимости. Геометрически это означает, что нужно по-
добрать такую прямую, которая нанлучшим образом опалива-
ла бы точки корреляционного поля. Аналитическим методом
определения уравнения регрессии является метол наименьших
квадратов, тле в качестве критерия наилучшей сглаживающей
прямой выступает минимизация суммы квадратов расстояний
от точек корреляционного поля до этой прямой. Коэффициен-
ты уравнения регрессии у = 6, + b х получаются как решения
системы нормальных уравнений (13.12) и (13 13) и выражают-
ся формулами (13 14) и (13 15) Коэффициент b называется
коэффициентом ретрессин. Если независимая переменная х воз
растает в среднем на единицу, то зависимая переменная у в
этом случае возрастает в среднем на А. единиц при 6, > 0 (или
убывает на 6, единиц при Л. < О).
Оценкой точности уравнения регрессии является стандарт-
ная ошибка регрессии, вычисляемая по формуле (13.19). Она
харазстсризуст разброс точек наблюдений окало прямой рег-
рессии. Уравнение регрессии можно рассматривать в качестве
модели прогнозирования. Эта модель описывает взаимосвязь
независимой переменной х и зависимой переменной у лишь в
среднем, поэтому фактические значения у. как правило, нс
будут совпадать с точечными оценочными (прогнозными) эна-
332
ченнями v Поэтому очень важно получить интервальную оцен-
ку прогноза. т е. найти доверительный интервал, где с довери-
тельной вероятностью будет содержаться фактическое значе-
ние у. При допущении о нормальности распределения у вокруг
прямой ретрессии доверительный интервал определяется по
формуле (13 24) при п > 30 и по формуле (13.25) при и < 30.
Ширина доверительного интервала прогноза зависит от объе-
ма выборки л. С ростом и точность прогноза повышается. Наи-
большая точность достигается, котла прогнозируется значение
у при .» “ х
Показателем интенсивности связи, который измеряет, в
какой степени изменением независимой переменной объясня-
ется изменчивость (вариация) зависимой переменной, являет-
ся коэффициент детерминации г*. Он вычисляется как отно-
шение части обшей дисперсии, объясненной регрессией, к общей
дисперсии к характеризует удельный вес (пропегп) обшей дис-
персии, который объясняется уравнением регрессии (или изме-
нением факторного показателя л). Значение коэффициента лс-
термншшки равно квадрату коэффициента корреляции.
Уравнение регрессии у= + Ь.х. полученное на основе
выборочных пар наблюдений, является выборочным, Оно от-
личается от теоретического уравнения у w Р, + Р.х. которое
могло быть получено по данным генеральной совокупности,
««этому необходима проверка на существенность коэффици-
ента регрессии б. т. с. проверка нулевой гипотезы Но: р, = О
При малых выборках (л < 30) лтя проверки следует использо-
вать /-критерий (13.30). Если А, не существен, то использова-
ние выборочного уравнения для прогнозирования и анализа не
имеет смысла, гак как оно не отражает реальной связи между
переменными
ГЛАВА
МНОЖЕСТВЕННАЯ
РЕГРЕССИЯ
14.1. УРАВНЕНИЕ МНОЖЕСТВЕННОЙ
ЛИНЕЙНОЙ РЕГРЕССИИ
Используя уравнение парной регрессии к качестве модели
прогнозирования, мм учитываем влияние на результативный
показатель тол ько одного факторного показателя. Однако в боль-
шинстве практических ситуаций такой подход будет слишком
упрощенным, гак как изменение зависимой переменной в зна-
чительной степени связано с влиянием нескольких факторов
Очевидно, следует обобщить уравнение парной регрессии,
включив в него до1Н1ЛНите.'1ы<ые факторные переменные. В злом
случае мы получим уравнение (модель) множественной ли-
нейной регрессии
у “ А,+ ₽Л + Ал * - * ₽Л + Е- <14 »
где xt, X,,..., xt — независимые (факторные) переменные;
е — ошибка, ассоциируемая с моделью
В уравнении (14.1) выражение ₽, + р,х, + + ... + Рд
является детерминированной компонентой, а отклонение от
нее характеризуется случайной ошибкой г В случае парной рег-
рессии графиком лстерминиронанной компоненты Рп + Р,х яв-
ляется прямая линия, а е отражает разброс точек наблюдения
около нее. Для множественной регрессии, включающей две не-
зависимые переменные, детерминированной компонентой бу-
дет плоскость у = ро + р,л, + РуХ^рис 14.1).
В общем случае, когда чисто независимых переменных Гхыыие
2, построение графика детерминированной компоненты (т. е.
гиперплоскости) невозможно.
ззз
Рис М. 1. Геомегр^чесдек ии»ерпрвта14ня модели множественном линий
мой регрессии, окг4оча»сщсН две факторные переменные х, и я.
По аналогии с парной линейной регрессией получение опе-
нок Ь*> Лр...» Ьк для 0П, 0. 0, осуществляется с помощью
метода наименьших квадратов по критерию
Zo - ь„ - - *А “ — “ */,)’ " min. (14.2)
Приравняв частные производные левой час,и равенства
(14.2) по переменным Ли, 6,,..., fct к нулю, получим систему к + 1
нормальных уравнений Решение этой системы характеризует
искомые опенки 40, Л,
В качестве примера рассмотрим определение нормальных
уравнений в случае регрессии у на три факторные переменные
a,, Xj, х,. Оценочное уравнение множественной регрессии бу-
дет иметь вил
у-Л0+*Л**А+6А
Пусть имеются данные наблюдений но переменным:
У *1 х>
У, у> У. л.а Х(„ Лп хм хв ч
335
Запишем частный случай кри1ерия метода наименьших квад-
ратов (14.2).
S(y - А, - blxl - А/, - ft,*,)1 “
= Z О', ~ Ьа ~ Мн " *А ~ “ т|П'
••1
S - S(b,. А,. A,. ft,) - j (у,- ft„ - bf,, - bfy~ ft,*,.)1.
1=1
Обозначим - Sy. У, *> - S*. У a’ -*;,
i-i i-i .-I
“ Sy*, 2^*у*и = S**, (j, к = 1, 2. 3).
i-i (->
Тогда нормальные уравнения будут иметь вид
~ "2<У‘ -"*»-^Ех1'6гЕЛ»_й1ЕЛ’,'°-
«Л»
=2(^.М |-А>ХТ' -A)5zitt
«3
=2(£у* 2 - х2 - «у £ »|.т2 - ft, £*j - *i X * г* j) = О.
пАч
" *2(y.Wf5-Ai1^Vj-6,yilx3-/»,^x2xi-6j^xJ2)«0.
d/>5
Оценки А„, ft,, 6;, А, будут решением системы
nbt + А,Х*, + A,Sx, + A^jr, = Sy,
6,S*, + ft,St,1 ♦ A;Sr, + A,S*^t, - Sy*,, (14.3)
AjSt, + A, Sr,л, + Ь£х}‘ + 6,Se,л, “ Sy*(.
A„S*,+ A.S*,*, + А^Ьсу*, + AjS»,1 •= Sy*,.
Следует отметить, что системы нормальных уравнений, по-
добные (14.3). решаются с ломошью компьютера
В предыдущей славе был проведен простой корреляциоиио-
регрессионный аналит зависимости объема продаж (у) от зат-
рат на рекламу (*) Коэффициент корреляции между * и у был
равен г = 0,843 и оказался существенным По методу наимень-
ших квадратов было определено уравнение парной линейной
336
регрессии у = 8,51 + 0,354х с коэффициентом детерминации
г' = 0.71 Проверка на существенность коэффициента регрес-
сии bt = 0,354 показала, что уравнение отражает реальную связь
между переменными
Предположим, есть основание считать, что объем продаж
зависит также еще от двух факторных переменных: х, — коли-
чество сетей предприятий розничной торговли (например, се-
тей магазинов), продающих продукт фирмы в регионе, и х, —
уровень безработицы в регионе.
Построим регрессионную модель
y = 8,+ ft|x,+ 4Л+*Л,
где у — оценка объема продаж (тыс ед );
х, — затраты на рекламу (дес тыс. долл );
х; — число сетей предприятий розничной торговли (ел );
х3 — уровень безработицы (Ж).
Значения 6. 6,, 6, являются оценками (),. ₽г
Данные по регионам были дополнены наблюдениями по
переменным х, и х,:
У V. Я9 *>
1 16 22 2 4
2 17 26 2 В
3 26 4S 3 7
4 24 37 4 0
5 22 28 4 г
6 21 50 3 10
7 32 56 Б 8
в 18 34 3 в
9 30 60 5 2
10 20 40 3
Представленные данные являются исходной информацией
для вычисления коэффициентов нормальных уравнений сис-
темы (14.3).
В результате проведенных расчетов было получено уравне-
ние множественной регрессии
у = 7,6 + 0,194х, + 2.34х, - 0, I63Xj. (14.4)
Поясним смысл коэффициентов р(,„. уравнения множе-
ственной линейной регрессии (14.1). Как и в случае парной
регрессии, они называются коэффициентами множественной
ззт
регрессии. Коэффициент регрессии П. означает, что при увели-
чении независимой переменной х на единицу можно ожидать,
что зависимая переменная у в среднем увеличится на 0, еди-
ниц. если В, > 0 (или уменьшится на (3 единиц, если р'< 0)
При этом выполняется условие, что остальные независимые
переменные остаются неизменными
В уравнении <14.4) коэффициенты b,, Ьг, />. являются выбо-
рочными оценками 0,. Р, и Р,
Так, оценкой р. является 6. = 2,34. Это означает, что при
увеличении на единицу числа сетей магазинов можно ожидать
увеличения в среднем объема продаж на 2340 единиц при ус-
ловии. что затраты на рекламу и уровень безработицы остают-
ся на прежнем уровне Смысл коэффициента bt • 0,163 за-
ключается в том, что при увеличении на I % уровня безработицы
при условии неизменности числа сетей предприятий рознич-
ной торговли и затрат на рекламу можно ожидать уменьшения
в среднем объема продаж на 163 ед.
14.2. ОЦЕНКА КАЧЕСТВА МНОЖЕСТВЕННОЙ
РЕГРЕССИИ: СТАНДАРТНАЯ ОШИБКА
И КОЭФФИЦИЕНТ МНОЖЕСТВЕННОЙ
ДЕТЕРМИНАЦИИ
Качество вычисленного по метолу наименьших квадратов
уравнения множественной регрессии зависит от того, насколь-
ко хорошо оно сглаживает данные наблюдений Метод наи-
меньших квадратов позволяет получить уравнение, миними-
зирующее сумму квадратов отклонений фактических значений
> от оценочных у, вычисленных на основе этого уравнения
Как и в случае парной регрессии, для уравнения множествен
ной регрессии определяется множественная стандартная ошиб-
ка оценки:
<и 5)
где л — число наблюдений и к — число независимых перемен-
ных
Знаменателем подкоренного выражения (14.5) харакгери
зуется число степеней свободы, которое ассоциируется с сум-
мой квадратов отклонений, к + 1 степеней свободы будут поте
ряны ввиду того, что к + 1 коэффициентов оценочного
338
уравнения регрессии у = bf + bxt + Ад, + ... + Ад уже заданы,
т. с. связывают к + 1 наблюдений
Пример 14.1. Вычислим множественную стандартную ошибку
для уравнения (14 4). используя данные предыдущего раздела.
Для этой иели необходимо вычислить оценочные значения у.
Вычислим, например, точечную оценку объема продаж для
первою региона, где я, “ 22 (затраты на рекламу 22 гыс. долл ),
з, 2 (количество сетей предприятий розничной торговли,
торгующих продуктом фирмы) и х, = 4% (уровень безработи-
цы в регионе):
у - 7.6 + 0.194 22 + 2.34 - 2 - 0.163 4 - I S.S9.
Фактическое значение объема продаж для первого региона
у = 16. Следовательно, величина остатка у — у = 16 — 15,89 =
“0,11. Аналогично вычислим оценочные значения у. остатки
и их квадраты для остальных девяти регионов:
У У ж У“У (к-й1
16 15.89 0.11 0.121
17 16.01 0.99 0.9601
26 22.19 3,81 14.5161
24 24.12 -0.12 0,0144
22 22.05 -0 05 0.0025
21 22.68 -1.68 2.6224
32 31.18 0.82 0,8724
16 19.9 -1,9 2,61
20 20,59 -0 59 0.3481
20 21,29 -1.39 1,9321
0 24.91
Вычислим множественную стандартную ошибку регрессии
по формуле (14.5):
5 J 24.91
"110-3-1
- 2.037.
Сравним полученный результат со стандартной ошибкой
парной peipeccMH S 3,078, вычисленной в разделе 13.2.2.
Следовательно, добавление еше двух факторных переменных,
объясняющих объем продаж в регионе, улучшило качество оце-
ночного уравнения
339
основе
(14.6)
(14.7)
Как и а случае парной регрессии, важнейшей характерно-
тикой качества уравнения является коэффициент множествен-
ной детерминации Л', измеряющий долю полной вариации
переменной у, объясняемую множественной регрессией.
Как отмечалось в разделе 13.2 4, общая иариация перемен -
ной у является суммой двух компонент:
Sty,- у)! - Х(у, - у)’ + Ety- у,)’,
(обшая (объяснимая (необъяснимая
вариация) вариации) вариация)
где yi — не наблюдение у,
у — среднее значение у,
у, — <-е оценочное значение у, рассчитанное на
уравнения множественной регрессии.
Тогда
или
„г £(У(-у>*-£(з>,-Мг ^(у.
' Е(у'-у)'
Величина № изменяется от 0 до I Если Л2 - I, то это означает.
что все изменения результативного показателя объясняются од-
новременными изменениями факторных (независимых) перемен-
ных При Я1 - О между результативным показателем и факторны-
ми переменными снять отсутствует Коэффициент множественной
детерминации является квадратом коэффициента корреляции межу
у и у. Можно показать, что ввиду свойства метола наименьших
квадратов для множественной регрессии величина Я‘ не умень-
шается (а может только увеличигъся) при добавлении еще одной
независимой переменной. причем увеличение /? может произойти
лаже в случае, когда добавленная независимая переменная не
свя гама с результативным показателем у.
Для учета такого автоматического роста коэффициента R2
вследствие увеличения числа независимых переменных часто
используется скорректированный коэффициент Л’, вычисля-
емый по формуле
Я2 = 1-(|-1?2) 1,-1 eft1----—(1-Я2), <|4-Ю
п-4-1 и-4-l
где * — число независимых переменных
340
При возрастании к увеличивается отношение к/(п — к — I),
что приводит к корректировке R1 в сторону уменьшения. Мож-
но показать, что добавление новой переменной к регрессии
Приведет к увеличению R2 только и случае, когда г статистика
коэффициента peipeccHH, соответствующего агой переменной
(см. раздел 14.3). по абсолютной величине будет больше 1.
Высокий коэффициент детерминации также может быть по-
лучен при статистически незначимых коэффициентах множе-
ственной регрессии Поэтому К: является только одним из кри-
териев качества регрессии
Наряду с R’ во множественном корреляционно-регресси-
онном анализе рассматривается показатель, равный корню квад-
ратному из R1:
УХот-у)1
Величина R называется когэффициетпом множественной кор-
реляции Она является обобщением коэффициента линейной
парной корреляции и отражает тесноту связи между зависимой
переменной и одновременно несколькими независимыми пе-
ременными В отличие от простого коэффициента корреляции
коэффициент множественной корреляции всегда неотрицате-
лен и изменяется от 0 до 1 Чем ближе значение Як I, тем
большее одновременное влияние оказывают независимые пе-
ременные
Пример 14.2. Вычислим значения Я!,Я’ и Я для регрессии (14 5).
Необъясненная часть обшей вариации была вычислена выше
при определении стандартной ошибки оценки:
- у)’ = 24,91.
Вычислим общую вариацию:
v _ . т ,
1(у - у)> » Zy -—-— - 162 + 172 + 262 + ... + 202 -
(16 ♦ 17 + 26 +... + 20)*
----------—--------= 262.4.
10
По формуле (14.7) вычислим Я1:
26X4-2451.237,49.^
262.4 262.4
341
Как видно, объясненная часть обшей вариации равна
Х(у - у и - 237,49.
По формуле (14 8) вычислим скоррскгированный коэффи-
циент R2.
R1 -1 - (1 - 0.905) 1°~? • О .858.
10-3-1
Определим R
Я-,/0.905 = 0,95.
Следовательно, можно утверждать, что наблюдается очень
тесная корреляционная связь между объемом продаж и фак-
торными показателями затратами на рекламу, количеством се
ей предприятий розничной торговли и уровнем безработицы.
В случае парной регрессии соответствующие коэффициенты
г = 0,843 и г’= 0,71.
Очевидно, что с введением дополнительных переменных сте-
пень тесноты связи увеличилась.
14.3. ПРОВЕРКА СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТ И
МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Пусть для генерального уравнения множественной регрес-
сии (14.1) выполняются те же допущения, что и для парной
регрессии
значения у нормально распределены вокруг плоскости мно-
жественной регрессии.
ошибки с нормально распределены со средней, равной нулю,
и одинаковой дисперсией в’ вокруг всей плоскости множе-
ственной регрессии,
ошибки t статистически независимы друг от друга.
В случае выполнения указанных допущений возможна адек-
ватная проверка статистической значимости (существенности)
уравнения множественной регрессии
Существенность каждого отдельного коэффициента множе-
ственной регрессии проверяется так же. как существенность
коэффициента парной регрессии. Если рассмотреть распреде-
ление выборочных коэффициентов Ь . то каждое из них долж-
но быть нормальным со средней, равной истинному значению
Р Дисперсия каждого параметра будет зависеть от дисперсии
ошибки регрессии а А
34?
В качестве опенки а* можно рассматривать квадрат стандарт-
ной ошибки множественной регрессии:
(14.9)
Оценкой стандартного отклонения ошибки е является стан-
дартная ошибка регрессии
(14.10)
Величины (14 9) и (14 10) наливаются соответственно ос-
таточной дисперсией и остаточным стандартным отклоне
нием.
Проверка на существенность осуществляется на основе
/-статистики
т = -\ (14.11)
ч
где й — г-й коэффициент множественной регрессии;
— стандартное отклонение (стандартная ошибка) б.
Дтя вычисления з4 удобно воспользоваться матричной ал-
геброй.
Пусть X — матрица, состоящая из л наблюдений по каждой
из к независимых переменных множественной регрессии и еди-
ничною первого столбца
*! *т •" «4
'1 *11 *|2 *14 '
1 -’ll *22 — *34
X = 1 *)| *31 ... *14 (14.12)
J *.| *.j ... *•4 t
Обозначим X' транспонированную матрицу. Вычислим про-
изведение матриц Х'Х и найдем обратную матрицу С = (ЛТД)"’.
Пусть с* —диагональный элемент матрицы С, соответству-
ющий переменной к,.
Тогда оценка дисперсии коэффициента множественной рег-
рессии б имеет выражение
С,. (14.13)
343
Отсюда получаем оценку стандартного отклонения
(14.14)
Значения (14 13) н (14 14) вычисляются с помощью компь-
ютера
Проверка существенности каждого коэффициента А явля-
ется задачей проверки гипотез:
Н„:0.-О;
Н, : е 0.
Для проверки нулевой гипотезы Нп при уровне значимости
а (-отношение (14.11) сравнивается со значением (-распреде-
ления с параметрами а/2 и df ~~ п- к —
Если
то Но отвергается и коэффициент регрессии Ь будет существен-
ным.
(Гример (4.3. Проверим существенность коэффициентов А,
и А уравнения (14 4) при а = 0,1.
Исходной информацией для расчетов является матрица
'I 22 2 4'
1 26 2 8
I 45 3 7
1 37 4 0
I 28 4 2
1 50 3 10
1 56 6 8
I 34 3 8
I 60 5 2
I 40 3 6
7
Стандартные отклонения коэффициентов были вычислены
с применением компьютера:
г = 0,0877, г - 0.9078, г - 0,2441
*i *2 Ъ
344
Вычислим лстатистики:
OlW -2.21;
0.0877
” . 2.58;
0.9078
^.-0,67
0.2441
По таблице Приложения 5 найдем ” tfK 1,943
Как видно, несущественным является коэффициент bv так как
J/J " 0.67 < 1.943. Это означает, что переменная *, (уровень
безработицы) должна быть исключена из регрессионного аиа
лиза, так как статистически очень слабо объясняет результа-
тивный показатель .»' (объем продаж).
Проводя проверку существенности каждого коэффициента
множественной регрессии, мы определяли статистическую зна-
чимое^ вклада каждой независимой переменной в объяснение
зависимой переменной.
Еще один тест, который обязательно проводится при оцен-
ке уравнения множественной регрессии, в определенном смысле
дополняет r-тесты для отдельных коэффициентов регрессии. Он
проверяет совместную способность к независимых переменных
объяснять зависимую переменную. Формально этот тесг явля-
ется проверкой нулевой гипотезы:
Н,:р,-₽>-...-р,-О. (14.15)
Если гипотеза (14 15) верна, то это означает, что все коэф-
фициенты генерального уравнения множественной регрессии
равны нулю, г е. между зависимой и независимыми переменны-
ми не существует реальной связи В этом случае регрессионное
уравнение будет статистически незначимым. Альтернативная ги-
потеза Н,о статистической значимости предполагает, что хотя
бы один из истинных параметров регрессии отличен от нуля
Нулевая гипотеза (14 15) проверяется с помощью 7-критерия:
г=
£(у-у)!Лл-*-1)’
(14.16)
тпе к — количество переменных;
п — количество наблюдений.
зав
Числитель /-отношения (14.16) представляет собой объяс-
ненную вариацию у. деленную на число степеней свободы
df- к, т. с. дисперсию, объясненную независимыми перемен-
ными.
Знаменатель /-отношения (14.16) характеризует необъяс-
ценную вариацию, деленную на число степеней свободы
df п - к - 1, т. е. необъясненную дисперсию.
Г-отношенис (14.16) может быть выражено через коэффи-
циент множественной детерминации В?:
С помощью /-статистики (14.16) проверяется, действитель-
но ли объясненная сумма квадратов отклонений превышает ту
сумму квадратов отклонений. которая может быть случайной.
Эта проверка эквивалентна проверке, осуществляемой с по-
мощью /’-статистики (14.17), определяющей, превышает ли
коэффициент /' то значение, которое может быть получено
случайно Критический предел лея /-статистики (14.16) или
(14 17) находится как значение f распределения с параметра
ми о (уровень значимости), к (число степеней свободы числи-
теля), п - к - I (число степеней свободы знаменателя).
Пример 14.4. Проверим статистическую значимость уравнения
(14 4) в целом. Следует проверить нулевую гипотезу:
Н„; Р, - = ₽, = 0.
Коэффициент детерминации Я1 - 0,905 был вычислен в
примере 14.2.
Определим /-отношение из выражения (14 17):
F= 0,905/3 0,9055/3 ^
(1-0.903X10-3-1) 0.ОТ5/6
Заладимся критерием значимости а “ 0,1 и по таблице При
ложения 6 найдем “ 3,29. Отсюда /- 19.1 > 3.29, т. е.
гипотеза Н, отвергается при а - 0.1. Следовательно, уравнение
множественной регрессии в целом статистически значимо.
Как видно из примеров 14.3 и 14 4. уравнение множественной
регрессии может быть значимо в целом, но некоторые отдельные
коэффициенты регрессии в то же время будут несущественными
зав
Может быть верно и обрашое ори существенности отдельных
коэффициентов множественной регрессии все уравнение регрес
ски будет статистически незначимым. Поэтому при построении
множественной регрессии следует учитывать обе теста,
14.4. ПОДБОР ПЕРЕМЕННЫХ В МОДЕЛЬ
МНОЖЕСТВЕННОЙ РЕГРЕССИИ
При построении модели множественной линейной регрес
сии возникает проблема выбора факторных переменных, в наи-
большей степени объясняющих результативный показатель. Для
ее решения осуществляется полный корреляционно регрееси
онный анализ зависимости между переменными На предвари-
тельном этапе следует провести качественный анализ причин-
но-следственных связей с привлечением специалистов из
предметных областей, имеющих отношение к исследуемому яв-
лению Когда крут возможных показателей выделен и собраны
необходимые данные, выясняется, насколько выделенные фак-
торные показатели коррелируют с результативным показате-
лем Для этого вычисляются коэффициенты корреляции между
зависимой переменной и каждой независимой переменной
В модель включаются только те переменные, которые имеют
высокий коэффициент корреляции. Вначале определяется пар-
ная регрессия у на переменную, имеющую наибольший коэф-
фициент корреляции. Дтя определенности обозначим сел Да-
лее исследуем оставшиеся переменные таким образом: будем
последовательно включать каждую переменную в модель со-
вместно с х, (т. е. каждый раз строить регрессию на две незави-
симые переменные) и определять значение коэффициента мно-
жественной детерминации Я‘ В модель следует включить ту
переменную, которая даст значительный прирост Я’. Обозна-
чим ее х,. Для выделения х, процедура повторяется вычисляет-
ся регрессия у на х., х, и на каждую из оставшихся переменных.
Опять выбирается х(> которая в значительной степени повы-
шает К’.
Параллельно с данной процедурой проверяется существен-
ность коэффициентов вычисляемых регрессий Если возникает
ситуация, когда при включении в модель очередной дополни-
тельной переменной какие-то из ранее включенных становят-
ся несущественными, то их исключают из модели Процесс за-
канчивается, когда остающиеся переменные незначительно
повышают Я’.
347
Пример U.S. В примере 14.3 было показано, что в регрессии
объема продаж на три переменные 04.5) переменная xs (про-
цент безработных) оказалась статистически незначимой. По-
этому в модели следует оставить только переменные х (затра-
ты на рекламу) и х, (количество сетей предприятий розничной
торговли). Модель в этом случае будет иметь вид
у = 6,74 + 0,165л, + 2,66 х,.
Можно проверить, что оба коэффициента этой множествен-
ной регрессии будут значимыми и R - 0,898
При подборе переменных в модель множественной регрес-
сии может возникнуть явление так называемой коллинеарное-
ти. Оно заключается в том, что независимые переменные, имея
высокую корреляцию с зависимой переменной, сильно корре-
лируют друг с другом В ком случае эти переменные, объясняя
однуитуже вариацию, как бы дублируют друг друга. Коллине
арность может сопровождаться высоким коэффициентом мно-
жественной детерминации R:, но одновременно низким зна-
чением т-сгатистик коэффициентов ре)рессии. Поэтому при
построении множественной регрессии желательно, чтобы не
зависимые переменные были тесно связаны с зависимой пере-
менной и слабо связаны друг с другом.
Пример (4.6. Фирма занимается продажей растительного мас-
ла. Отдел маркетинга интересует влияние различны* факторов
на объем продаж Очевидно, одним из наиболее cynteci венных
факторов является цена. Для выявления зависимости объема
продаж (у) от ueiibifx,) из отчетных данных случайным обра-
зом были отобраны сведения о недельных продажах (тыс. кг) и
иенах (долл./кг) за 10 недель:
Нгзыи Объем продаж, у Цена, х,
1 10 1,3
2 6 2
3 5 1.7
4 12 1,5
5 10 1.6
6 15 1,2
7 5 1.6
8 12 1.4
9 17 1
10 20 1.1
зла
Для определения степени тесноты линейной корреляцией
ной святи по формуле (13 2) был вычислен коэффии»ен> кор-
реляции г- -0.86. Очевидно, между у и х существует сильная
отрицательная корреляция. Можно сделать вывод, что с рос-
том цены объем продаж в среднем уменьшается.
По формулам (13.14) и (13.15) определяются коэффнцием
ты уравнения регрессии у на х(:
у = 32,14 - 14,54л,.
Коэффициент регрессии 6, = -14,54 имеет следующую ин-
терпретацию: увеличение цены растительного масла на I дай.
уменьшает в среднем недельные продажи на 14 540 кг. Если в
качестве масштаба взять I цент, то увеличение цены на 1 цент
вызывает в среднем уменьшение продаж на 145,4 кг.
По формуле (13.19) была вычислена стандартная ошибка ре-
грессии: 5 ж “ 2,72. Коэффициент детерминации г1 = (-О.86Й=
= 0,74 Это означает, что 74% общей вариации объема продаж
объясняется изменением цены.
Для проверки существенности b на основе исходных данных
вычислялась 1-статистика:
1.-------£___________-^--..-4.8.
5М1/у/£(л-г)г 2.72Л.0.824
При а » 0.05 и л - 2 • 8 по таблице Приложения 5
найдем = 2,306. Отсюда -4.8J>2.3(M. Следовательно, ко-
эффициент регрессии 6( w -14,54 существен при а « 0,05.
Специалисты отдела маркетинга предположили, что введе-
ние в регрессию дополнительного фактора — затраты на рек-
ламу - может повысить качество прогнозного уравнения Для
проверки этого предположения в таблицу исходных данных были
добавлены сведения о затратах на рекламу (х), выраженных в
сотнях долл.:
Нглс.зя 06мм яродаж, у Цсяа, х, Затраты на рекламу,
1 10 1.3 9
2 6 2 7
3 5 1.7 5
4 12 1.5 14
5 10 1.6 15
6 15 1.2 12
7 5 1.6 6
8 12 1.4 10
9 17 1.0 15
10 20 1.1 21
349
Для выявления коллинеарности следует определить корре-
ляционную матрицу, элементы которой суть коэффициенты
корреляции между парами переменных:
Очевидно, г
л, х,
г г
М| Л,
Г г
Vt
г г
Vi
элементы на главной диагона-
W VI V2
ли) ИГ = Г , Г = Г , Г —г
V **2 V Vl
В общем случае (к независимых переменных) корреляцион-
ная матрица имеет размерность (к + I) х э 1) и является сим-
метричной относительно главной диагонали, состоящей из еди-
ничных элементов
Если не записывать повторно симметричные элементы, то
после вычисления парных коэффициентов корреляции матри-
ца будет иметь вид
Продажи у 1 -0,86 0,89
Цена х J -0,65
Реклама х2 I
Как видно, между зависимой переменной (продажи) и не-
зависимыми (иена и реклама) существует тесная корреляци-
онная связь(г * -0,86, г = 0,89), в то время как между
независимыми переменными имеет место средняя отрицатель-
ная корреляция (г • -0,65). Это свидетельствует о незначи-
тельном проявлении эффекта коллинеарности. что дает осно-
вание для включения переменной хг в регрессионную модель.
Она была получена по метолу наименьших квадратов:
у - 16.41 - 8,25а, + 0,59х,.
Коэффициент регрессии 6, " -8.25 показывает, что увели-
чение цены на I цент (при условии, что затраты на рекламу
остаются неизменными) сокращает в среднем покупки расти-
тельного масла на 82,5 кг Аналогично коэффициент Ь, = 0,59
отражает тот факт, что увеличение затрат на рекламу на
100 долл (при условии постоянства цены) приводит в среднем
к росту объема продаж на 590 кг.
зю
Стандартная ошибка множественной рюресснн была вычис-
лена по формуле < 14 51: 5 “ 1.51 Сраинив ее со стандарт-
,лг 2
ной ошибкой парной регрессии ($М| = 2,72), можно сделать
вывод, что новая модель лучите сглаживает разброс наблюде-
ний. Для проверки существенности коэффициентов регрессии
были вычислены стандартные ошибки коэффициентом множе
ственной регрессии (см раздел 14.3):
г. = 2,196, л = 0,134.
•т "г
Сосптетсптенно определим значения /-статистик
т. = -8.25/2,196 - -3,76, с - 0,59/0,134 - 4.38.
•т б
Число степеней свободы для определения критического пре-
дела df- л - к- 1 = 10- 2-1 = 7. При а = 0,05 найдем в
таблице Приложения 5 величину /-критерия: /!t!1, = 2,365. От-
сюда получаем, что оба коэффициента существенны при за-
данном уровне значимости
Коэффициент множественной регрессии Я’ = 0,932 (скор-
ректированный К1 =0,912). Следовательно, процент объяснен-
ной дисперсии увеличился с 74 до 93,1 %.
Для проверки существенности уравнения множественной рег-
рессии в целом рассчитывалось /'-отношение по формуле (14.17):
Критический предел определялся при а = 0.01. В соответ-
ствующей таблице Приложения 6 найдем значение F критерия
лит комбинации степеней свободы (2; 7): rof|JI " 9,55. Так как
48,04 > 9,55. то можно сделать вывод, что полученное уравне-
ние множественной регрессии действительно объясняет зна-
чительный процент вариации объема продаж
14.5. ПРОВЕРКА ДОПУЩЕНИЙ ОТНОСИТЕЛЬНО
СТАТИСТИЧЕСКИХ СВОЙСТВ ОШИБОК
РЕГРЕССИИ. КРИТЕРИЙ ДАРБИНА-УОТСОНА
Рассмотрим допущение: ошибки нормально распределены
с нулевой средней.
Наиболее простой способ проверить его выполнение - по-
строить гистограмму распределения остатков (у у) График
351
гистограммы покажет, имеется ли с ил моя асимметрия в рас-
пределении остатков или можно полагать, что распределение
близко к симметричному с центром, равным нулю.
Другим, более точным способом является использование
критерия согласия у* .тля сравнения наблюдаемою распределе
имя с нормальным Подобная процедура была рассмотрена в
примере 12.9.
Если есть веские основания считать, что лопушеннс о нор-
мальности остатков нс выполняется, то следует изменить мо-
дель. В новую модель можно, например, вкчзочить дополни-
тельную переменную. Другой способ — преобразование
переменных — будет рассмотрен в разделе 14 7.
Рассмотрим теперь допущение о постоянстве дисперсии
ошибок Если оно выполняется, то при построении корреля-
ционного поля остатков не должна наблюдаться тенденция: с
ростом х возрастают значения остатков. Корреляционное поле в
этом случае напоминает однородное "облачко" из точек на-
блюдений (рис. 14.2, я) Явление, коша нет постоянства дис-
персии ошибок, называется гетероскедастичностыо Например,
на рис. 14.2, б отражена гетероскеластичность. когда диспср
сия ошибок возрастает с ростом независимой переменной х.
Рмс. 14.2. Вид корреляционного пог» п случае:
в) осы ген р«*.тцх?ле.’гны с нупеесА соедис*
и ,07:-утс-04и ти-иСХх*илДС»и-н«>сГи|
б, дисперсия oc'wtio* мхюостмт । ге-!ерлс«ад>сп**«иос'М
Гетероскеластичность оказывает влияние на адекватност»,
/-статистик коэффициентов регрессии, так как полученные
оценки стандартных ошибок коэффициентов в злом случае могут
быть неверны
Для устранения 1етероскеластичности можно воспользоваться
преобразованием переменных (см. раздел 14 7) или более слож-
ат
ними методами построения модели, которые в этой книге не
рассматриваются.
Рассмотрим теперь допущение относительно независимос-
ти случайных ошибок регрессии. Если это условие не выполня-
ется, го последовательные ошибки е. уже не будут полностью
случайными, так как не являются статистически независимы
ми Такое явление называется автокорреляцией, или серийной
Корреляцией ошибок. С ним обычно сталкиваются, когда дан-
ные, по которым строится регрессия, являются значениями
временных рядов Такой тип данных представлен в табл 14.1.
Гайлима J4. Г
Данные временных рядов дне построения
множественной регрессии
П«|>исды ”*7гГ* >1 ...
1 г, *. 1
2 ж|>
л У. L_
В качестве периодов времени в габл. 14 I мотут выступать
годы, кварталы, месяцы, недели, дни и т. п., выстроенные в
хронологическом порядке.
Если же значения переменных привязаны к каким-либо
объектам (например, предприятиям, торговым точкам, горо-
дам, регионам), то серийная корреляция незначительна и се
можно не принимать во внимание
В случае автокорреляции все критерии существенности для
уравнения регрессии неприменимы даже для приблизительных
расчетов. Во многих практических ситуациях наблюдается по-
ложительная серийная корреляция. Эго часто относится к пе-
ременным, имеющим положительную корреляцию со време-
нем Например, такими переменными могут быть иены и
доходы, которые растут с течением времени
Серийная корреляция проявляется в остатках et Для се об-
наружения используется критерий Дарбнна—Уотсона, который
основан на вычислении следующей статистики:
353
OU.-.oi j..----, (14.18)
S'/
где r: — остаток, соответствующий наблюдению за период г.
В числителе выражения (14.18) стоит сумма п — I квадратов
разностей последовательных остатков (с; - е,)! + (е,- е,)! + ...
+ (е~ ев. ,)’. где п — число периодов наблюдений.
Можно показать, что
шЛ(лг<^
2^е>
где г t — коэффициент корреляции между двумя соседни-
ми остатками г, и et (.
Если г - 0, го это укатывает на то, что остатки полно*
стью независимы В этом случае /W'l Когда г # приближа-
ется к +1. что характеризует положительную серийную корре-
ляцию, DW стремится к нулю. Если г , характеризует
отрицательную корреляцию, т е. приближается к 1. го DW
возрастает до 4
Таким обрахзм, если отклонения от регрессии случайные, то
значение ЛИ'. которое должно лежать в интерначе от 0 до 4, бу-
дет окаю 2 При положительной серийной корреляции Отбудет
менее 2, а при отрицательной накалиться в интервале от 2 до 4
Основная проблема автокорреляции остатков связана с по-
ложительной серийной корреляцией Дарбином и Уотсоном
были разработаны специальные таблицы, в которых приводят
ся нижние (</г> и верхние (rf,J границы значений Л1К указы
ааюшне на положительную автокорреляцию (Приложение 8).
При этом проверяются гипотезы
И. : автокорреляции не существует.
Н : существует положительная автокорреляция
В Приложении 8 представлены две таблицы: проверка гипо-
тез при уровнях значимости 0,05 и 0.01.
Величина к в таблицах характеризует число независимых
(объясняющих) переменных, ал — объем выборки (каличе-
ство периодов наблюдений).
Гипотезы проверяются последующему правилу:
принимается гипотеза Н,. если DW < </,;
принимается гипотеза Нг1. если DW> d~
354
Существует неопределенность в принятии или непринятии
гипотез, если d,< DWsd,,
Пример 14.7. Руководство компании по производству метал-
локонструкций интересует прогноз продаж на ближайшие годы
Компания осуществляет продажи в некотором регионе Анали
тики отдела маркетинга считают, что обтатм продаж зависит от
личного дохода населения региона За 21 год были собраны дан-
ные о продажах у (тыс, долл ) и располагаемом личном доходе
(после уплаты налогов) х (мли долл.) в регионе:
Г У X
1 295 273,4
2 400 291,3
3 390 306,8
4 425 317,1
5 547 336,1
6 555 349,4
7 620 362.9
Я 720 383.9
9 880 402.8
10 1050 437,0
II 1290 472,2
12 1528 510,4
13 1586 544,5
14 1960 588,1
15 2118 630,4
16 2116 685.9
17 2477 742.8
18 3199 801,3
19 3702 90.3.1
20 3316 983.6
21 2702 1076.7
На основе этих данных было получено уравнение регрессии
у - -792 + 4,25517х.
Ввиду того что значения переменных образуют временные
ряды, следует проверить наличие серийной корреляции оши-
бок. Для этого необходимо вычислить оценочные значения у,
для всех периодов и величины остатков е, = yt - у,
Например, проведем вычисления для / - 1 и / = 2
у = -792 э 4,25517 273.64 - 371.36;
е, - у, - у, - 295 - 371,36 - -76.36,
354
у, - -792 + 4,25517 291,3 - 447,53;
е, - у, - у, - 400 - 447,53 - -47.53.
Далее для определения статистики ОК' необходимо вычис-
лить квадраты остатков е’ и их разностей (е, - ек|)’.
Например:
е,2- (-76,36)’ - 5# 30,85;
(-47,53 ♦ 76,36)’ - 831,17
Все необходимые вычисления сведем в следующую таблицу:
Г у У е,
1 296 371.36 76,36 - - 5830.8$
2 4С0 447,53 -47,53 28,83 831.17 2259,10
3 390 513,91 -123,91 -76.38 5833.90 15353 69
4 425 567.32 132,32 8.41 70.73 17508.58
5 547 636.16 91,16 41,16 1604.15 8310.15
6 555 694,76 -139,76 -48.6С 2361.96 19512.86
7 «70 752,20 -132.20 Т.М 57.15 17476.84
8 720 841.56 121,56 10.64 113.21 14776.83
9 8ВС 921.96 -41.98 79.58 6332.98 1762.32
10 1050 1067,29 17,51 24.47 598 78 ЭС6.6С
11 1290 477 23 72,71 90,22 8139,65 5286 74
12 1526 1379.84 148.16 75,45 5692.70 21951.39
13 1585 1524,94 61,06 -87.10 7586,41 3728.32
14 i960 171047 249.53 188.47 35570.94 62265 22
15 2118 1890.46 227,54 21.99 483.56 5177445
«б 2115 2126.62 -10,62 -238.16 56770. t9 112.78
17 2477 7368 74 108,26 118,88 14132,45 11720.23
18 3199 26’7 67 581.33 473.07 22379572 337944.57
19 3702 3060.84 651,16 69.83 4876.23 424009.35
20 3315 3393 78 -77 38 -728 54 530770.53 5987 66
»| 2 ГО? 3789.54 1087.54 -10Ю.16 TQ2O423.23 1182743,25
1926035.14 2210641.78
Вычислим статистику Дарби иа—Уотсона (14 18):
О»'- 1926035,14/2210641,78 = 0,87
Проверку гипотез будем осуществлять при о “ 0,01 По соот-
ветствующей таблице Приложения 8 (4 = I, п = 21) опреде-
лим:
356
dt » 0,97;
<- I-16
Отсюда ВИ'- 0,87 < rft. т. e гипотеза Ho отвергается. Это
означает, что имеет место положительная автокорреляция ос-
татков. Полученное уравнение регрессии не может адекватно
отражать статистическую зависимость между переменными
В общем случае автокорреляция ошибок может указывать
на неправильное определение типа связи между переменны-
ми В частности, регрессия может быть нелинейной или в нее
нс включена важная переменная, объясняющая у. Некоторые
способы устранения серийной корреляции рассматриваются
в разделе 16.5
14.6. МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
КАК МОДЕЛЬ ПРОГНОЗИРОВАНИЯ
Уравнение множественной линейной регрессии можно ис-
пользовать в качестве модели прогнозирования.
Пример 14.8. Рассмотрим в качестве прогнозной модели урав-
нение (I4.4):
у - 7,6 + 0,194л, 4 2,34л, - 0,163л,.
Пусть требуется оценить объем продаж в ретионе при усло-
вии, что
X, (затраты на рекламу) “ 36 (дес тыс. долл.);
х, (количество сетей магазинов) “ 4;
X, (уровень безработицы) ” 8%.
Прогнозная оценка объема продаж равна
у • 7,6 ♦ 0.194 36 4 2,34 4 - 0,163 • 8 - 22,64 (тыс. ел ).
Значение у = 22 640 является точечной оценкой объема
продаж при заданных значениях независимых переменных Она
указывает, какой объем продаж в среднем следует ожидать в
регионе, если ситуация будет характеризоваться заданными зна-
чениями факторных показателей.
Следует отметить, что данный пример носит иллюстратив-
ный характер. В разделе 14 3 (пример 14 3) было установлено,
что переменная х, может быть исключена из модели, так как
не оказывает существенного влияния иа зависимую перемен
ную.
357
Для определения доверительных границ прогнозирования
необходимо вычислить стандартную ошибку прогноза Диспер-
сия модели у - 0П + Р,*, * + Р,»( включает дисперсию случай-
ной ошибки s’ и дисперсию <т-. связанную с параметрами
модели Оценка дисперсии случайной ошибки s’ задается фор
мулой (14 9). Для удобства вычисления дисперсии параметров
модели воспользуемся обозначениями матричной алгебры.
Пусть независимые регрессии принимают конкретные зна-
чения: xt = xj, xs = xuJ,„., xt = x0‘. Возьмем вектор-столбец:
Xo =
Пусть X — матрица (14.12)и С - (Х'Х)~‘. Тогда оценка дис-
персии Oj при запанном векторе X, выражается формулой
(14.19)
где — 1ранспониро8анный вектор Хо (вектор-строка).
Стандартная ошибка прогноза будет иметь и и л
s, =^*х1=,^Т7х^сх„.
(14.20)
Выразим доверительные пределы прогноза при заданном
векторе значений X, и заданной доверительной вероятности
I — а:
*»’>•• '•*> Чл.-4-1 ».71+Хй»0’ <м 2|>
гае уЦ,1, V...х^) = 6, + blx‘t + btxt’ + ... + Ад1 — точечная
оценка прогноза
Пример 14.я. Используя модель (14.4), найдем 95-процентные
доверительные пределы при х, “ 36, х{ = 4 и л,= 8.
Точечная оценка >(36, 4. 8) " 22,64 была определена в при-
мере 14.8, Величина т = 2,037 (пример 14.1). По формуле (14.19)
с помощью компьютера определим s -. где матрица X берется
из примера (14.3):
356
si
- 2,037'(I 36 4 3)-
1 1 ... 1 J 222 4 31'
2226...40 2226 2 8
2 2 ... 3 ............
4 8 ...6 1 40 3 6
' I '
36
4
I8.
Подставим вычисленные значения в выражение (14.20) и
найдем стандартную ошибку* прогноза
Sf- ДО371 + 1Л36г - 2,742.
По таблице Приложения 5 найдем t „ . , при о — 0,05.
«= 10, *=3:Т, = 2,447. •*-* '
Исходя из (14.21), вычислим доверительные пределы:
22,64 ±2.447 2,742 = 22,64 ±6,71 = 15,934-29,35.
Это означает, что с вероятностью 95% можно утверждать,
что при х, = 36, х, = 4 и х, - 8 истинное значение объема
продаж будет в указанных пределах.
Очевидно, точность интервальной оценки будет зависеть
от значения стандартной ошибки регрессии т. которая в свою
очередь уменьшается с ростом числа степеней свободы df =
= и - А -1. С увеличением числа факторных переменных к
должно увеличиваться количество наблюдений и. В практичес-
ких расчетах считается, что п должно в три-четыре раза пре-
вышать к.
14.7. НЕЛИНЕЙНАЯ РЕГРЕССИЯ
Возможны ситуации, когда связь между у и факторными
переменными может быть нелинейной. Нелинейность парной
связи устанавливается по виду корреляционного поля, когда
точки наблюдений более точно сглаживаются не прямой, а
кривой линией, В этом случае следует использовать подходы
линейного регрессионного анализа для построения криволи-
нейной регрессии. Для этой цели можно просто преобразовать
переменные н соответственно значения наблюдений по этим
переменным. Например, можно рассматривать следующие типы
парной регрессии;
3SB
У « ft,, + ft, ух ,
У ~ ь«+
у “ Ь„ + 6,1шт и т а
Для построения подобных уравнений регрессии по методу
наименьших квадратов нужно выполнить соответствующее пре-
образование каждого наблюдения независимой переменной.
Например, пусть имеются наблюдения по у и х
у х
х.
У> *т
У . *.
Требуется построить регрессию у • А, После преоб-
разования значений х имеем
У -Ух-х'
У , ’/*=*,’
У , A-V
у. х."
В формулы (13.11) и (13.12) для вычисления А, и Л„ вместо х
подставим значение хВ результате получим линейную регрес-
сию у “6,+ Ах Преобразуем обратно х" “ <х Окончатель-
но имеем у = bt + ft ,'х •
Пример 14.10. Имеются данные о продажах за шесть последо-
вательных лет:
Голы (х) Продажи (у)
I 109
2 146
3 23S
4 350
5 575
6 852
График корреляционного поля представлен на рис. 14.3.
36С
у i
S®
400
700
ООО
SOO
400'
300 *
200 _
КС *
-----------4---------------------->
I 2 3 4 S б Д
P*4C. 14.3. КоррОЛЯЦИОМИМ ПОП» ПОКвЗОТОЛЫМЯ 3MX-HMOCTI.
Расположение точек явно свидетельствует о том, что луч-
шей сглаживающей линией является некоторая кривая С рос-
том х увеличивается темп роста у. что характерно для показа-
тельной функции. Предположим, что сглаживающая кривая
имеет вид
>-4-10% (14.И)
где А и В — константы, которые должны быть найдены.
Прологарифмируем обе части равенстна (14.22):
1бУ = 1g А + Вх
(14 2?)
Уравнение (14 23) является линейным относигельно х и 1цу.
Как видно, данные (х. у) были преобразованы к виду (.г, Igy):
х_________lay
1 lg!09 = 2,04
2 Igl46 - 2,16
3 Ig235 - 2.37
4 lg35O = 2,54
5 lg575 = 2.76
6 Ig852 - 2.93
Вычислим промежуточные данные:
х Igy
I 2,CM
2 2,16
3 2,37
4 2.54
5 5,76
6 2.93
x1
I
4
9
16
25
36
x «У_
2,04
4.32
7.H
10.16
13.80
17.58
Итого:
21 14.8 91 55,01
aei
Уравнение (14.23 ) можно записать и виде
1<р « *„+ btx.
где b0 = I&4 и А, = IgB
Используя формулы (13.11) и (13.12), определим
_ 55.01-(21 )4.8)/6
О] — s- —0.1 о,
91-212/6
fcb = — -0.18- 1.84
6 6
Следовательно,
1st * 1.84 ♦ 0,18л
Выполним преобразования:
10»;= 10" (14.24)
У- 10'* IO'**’,
у= 66.07 10*"8*.
Используя уравнение (14.24). спрогнозируем объем продаж
в течение седьмого года:
у = 66,07 IO* 4’ = 1202.3.
Рассмотрим модель
у-₽о + 0,х+Р/<-е.
(14 25)
В этом случае выравнивание производится по параболе вто-
рого порядка Такая ситуация может иметь место, когда сгла-
живающая кривая, построенная визуально, является дугооб-
разной и абсолютные приросты ординаты имеют тенденцию к
росту или снижению при возрастании абсциссы.
Уравнение (14.25) является линейным относигельно неиз-
вестных коэффициентов 81Р В,. 0,. Для использования метода
наименьших квадратов необходимо выполнить преобразование
переменной при коэффициенте (1,:
362
Оттеночное уравнение у “ ft, + ft,x ♦ ft/2 находится в ре-
зультате решения системы нормальных уравнении
+ b^Lx + Л.Хг « Ху,
Л(Хх + ft,Xr + ft.Xx3 “ Хух,
ft Хс + ft,Sr1 + ft^Xx* ” Хух2
Аналогично с помощью соответствующих преобразований
переменных можно находить уравнения, отражающие рахтич
ные пилы криволинейных связей.
Если есть основание считать. что сглаживающая кривая имеет
5-образную форму (т. е лва изгиба), то использует ся уравнение
парабазы третьего порядка
у - bt ♦ ft, л + Apr2 + ftjX1.
Если с возрастанием х наблюдается резкое возрастание у, то
используется уравнение показательной функции (пример 14.10)
у “ bj>‘.
Если с возрастанием х наблюдается замедленное возраста-
ние у, то используют логарифмическую кривую
у “ ft, + Л,х + ftj 1л X-
Качество подобных кривых проверяется на основе тех же
показателей и статистических критериев, что и обычная ли-
нейная регрессия.
Пример 14.11. Фирма производит бытовые электровентилято-
ры Руководство фирмы интересует проблема рекламации по
поводу выпускаемой продукции.
С этой целью были проведены исследования зависимости
количества рекламаций от затрат на технический контроль ка-
чества готовой продукции. Были собраны данные за 15 недель:
х затраты на контроль качества в течение определенной не-
эвз
дели (тыс. лолл ) и у — количество вентиляторов. которые были
выпушены с браком и возвращены на завод в течение той же
недели.
Неделя Ко.нгчес1во ьотрашеиких ьептилятлроя (ед.) Затраты на кинтрс.ть качества
> X
1 32 5,1
2 16 13,5
3 48 2,1
15 21 11,5
Визуальный анализ графика корреляционного поля, по-
строенного с помощью компьютера, показал, что в качестве
сглаживающей линии имеет смысл выбрать параболу второю
порядка
?•»,+ 6,л + Ь/
Это уравнение можно рассматривать как лилейную регрес-
сию относительно переменных х; = х и = г1, Рассмотрим таб-
лицу данных для метола наименьших ккадратов:
г *> л,-л2
32 5.1 26,01
16 13.5 182,50
48 2.1 4.41
21 11,5 132,25
Уравнение, вычисленное с помощью компьютера, имеет нил
у- 54,805 — 4,9553л ♦ 0,15613л2. Коэффициент детерминации
R - 0,974. Существенность регрессии в целом проверяется по
Р-критерию:
F= 0.974/2_____________ 0,974/2 _2В8
(1 -0.974X15 - 2-1) 0,26/12 * '
Критический предел: F При а = 0,1 имеем FtM tl,=
“ 2,81 (Приложение 6). Следовательно, регрессия а целом ста-
тистически значима. Стандартное отклонение лля коэффици-
Э64
ентар,—з. = 9.68. Отсюда Г =-0,5119. Приа = 0,1
1 *1 9,68
критический предел ГоЯ ,я." 1гт „ " 1.782. Следовательно,
коэффициент А, = -4,9553 является существенным при 10-иро
центном уровне значимости. Стандартное отклонение " 5,45.
Тогда г 0,286 0тсюда b - 0,15613 также будет су-
5,45 1
шественным при а = 0,1
Если использовать уравнение нелинейной регрессии в каче-
стве мотели прогнозировании, то следует помнить, что оно
является экстраполяционным, т. с отражающим те закономер-
ности, которые были заложены в наблюдаемых данных. Поэто-
му, как и в случае линейной регрессии, при прогнозировании
следует значение объясняющей переменной х, для которой
проводится оценка у, брать только в границах диапазона на-
блюдаемых значений к, т. с. значений, использованных ятя вы-
числения регрессии.
Пусть, например, модель у “ + ₽,х + р^х1 6 е была постро-
ена на основе значений х. заключенных между 1 и 3 (рис. 14.4).
Рис. 14.4. Ошибка грогноаиропакия в елгучм экстрагюлаиии
Если прогнозировать значение факторного показателя у,
подставляя в модель значения х в интервале от 3 до 5, то оце-
ночные значения у будут экстраполироваться по параболе
у “ 60 + 6,х + bx1 В то же время на интервале от 3 до 5 факти-
ческие значении у могут уже не подчиняться параболическому
закону экстраполяции.
365
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 14
При парном корреляционно-регрессионном анализе учиты-
вается влияние на результативный показатель только одного
фактора. Необходимо обобщение модели парной регрессии с
помощью включения дополнительных факторных переменных,
объясняющих зависимую переменную у В этом случае мы полу-
чим уравнение (модель) множественной линейной регрессии
У “ + В,Х, + ... + рд + е.
Определение оценочного уравнения у 6( * Ji t... + bxt
осуществляется по метолу наименьших киалраюи Коэффнци
енгы 0., 0?, ., р называются коэффициентами множественной
регрессии Коэффициент регрессии Р означает, что при увели-
чении независимой переменной х на единицу можно ожидать,
что зависимая переменная у в среднем увеличится на р еди-
ниц, если В > 0 (или уменьшится на В, единиц, если р < 0).
При этом выполняется условие, что все остальные независи-
мые переменные остаются неизменными.
В качестве показателя, насколько хорошо уравнение множе-
ственной регрессии сглаживает данные наблюдений, выступа-
ет множественная стандартная ошибка оценки (14.5). Другим
показателем качества уравнения является коэффициент мно-
жественной детерминации № (см. (14.6)). Он измеряет долю пол-
ной вариации переменной у, объясняемую множественной рег-
рессией Величина R: изменяется от 0 до I. Если К‘ — I. то это
означает, что изменения результативного показателя полнос-
тью объясняются одновременными изменениями факторных
(независимых) переменных. Наряду с R' рассматривается по-
казатель, равный квадратному корню из К!, т. е. R Он называ-
ется коэффициентом множественной корреляции и является
обобщением коэффициента линейной парной корреляции г Чем
ближе значение Я к I. тем большее одновременное влияние
оказывают независимые переменные на зависимую перемен-
ную.
Для проверки статистической значимости вычисленного
уравнения множественной регрессии используются два типа
проверок. Первый тип связан с проверкой существенности каж-
дого коэффициента множественной регрессии Р,:
н. ₽, = °-
Н,: б, *0
366
Проверка нулевой гипотезы осуществляется с помощью
Ь
(-критерия I» ~ . где г — стандартная ошибка Ь
Второй тип тестирования характеризует совместную способ-
ность к независимых переменных обменять зависимую пере-
менную. В этом случае проверяется нулевая гипотеза:
н.т: ₽, = Рз = - = ₽. = 0.
Эта проверка осуществляется с помощью F-кригерия (14 16)
или (14.17).
С помощью 7-статистики проверяется, действительно ли
обьнсненная сумма квадратов отклонений превышает ту сум-
му квадратов отклонений, которая могла быть получена слу-
чайно (или. что эквивалентно, превышает ли коэффициент
Я! то значение, которое могло быть получено случайно). Кри-
тическим пределом для f-стати стики при уровне значимости
а будет величина
При построении модели множественной линейной регрес-
сии возникает проблема выбора факторных переменных, в наи-
большей степени объясняющих результативный показатель. На
предварительном этапе следует провести качественный ана-
лиз возможных переменных модели Когда крут возможных при-
знаков будет выделен и собраны необходимые данные, следу-
ет выяснить, насколько выделенные факторные показатели
коррелируют с результативным показателем. Для этого вычис-
ляются коэффициенты корреляции между независимой пере-
менной и каждой зависимой переменной В модель последова-
тельно включаются только те переменные, которые имеют
высокий коэффициент корреляции с зависимой переменной
и не сильно коррелируют между собой Параллельно с данной
процедурой проверяется существенность коэффициентов вы-
численной регрессии. Если возникает ситуация, когда при
включении в модель очередной дополни гельной переменной
какие то из ранее включенных становятся несущественными,
то их исключают из модели. Процесс заканчивается, когда
остающиеся переменные незначительно повышают Я!
При построении модели множественной линейной регрессии
необходимо, чтобы выполнялись определенные допущения от-
носительно статистических свойств случайных ошибок регрессии
ошибки нормально распределены с нулевой средней,
дисперсия ошибок остается постоянной окало всей плоско-
сти регрессии;
ЗВ7
ошибки отдельных наблюдений являются статистически не-
зависимыми,
Для проверки первого допущения можно использовать кри-
терий согласия х1. Явление, когда нет постоянства дисперсий
ошибок, называется гетероскедастичносгью. Оно проявляется
на графике корреляционного поля остатков Если ошибки кор-
релируют между собой, то такие явление называется автокор-
реляцией или серийной корреляцией Для проверки агяокорре-
ляции нс пользуется критерий Дарвина—Уотсона (14 18).
Невыполнение указанных допущений может существенно
отразизься па адекватности модели При этом следует пересмог-
реть вил связи между переменными или включить и модель
новую объясняющую переменную.
Уравнение множественной линейной регрессии можно рас-
сматривать как модель прогнозирования Точечная оценка, со-
ответствующая отдельному набору значений независимых пе-
ременных, указывает, какое при этом значение зависимой
переменной и среднем следует ожидать.
Для получения доверительного интервала прогнозирования
используется выражение (14.21)
Метод наименьших квадратов можно использовать для по-
строения нелинейной регрессии, если сделать соответствую-
щее преобразование переменных Уравнение регрессии при этом
остается линейным относительно своих коэффициентов Тил
криволинейной связи (т. е. вид преобразования переменных)
можно оценить, исходя из графика корреляционного поля и
характера поведения данных. На практике чаше всего исполь-
зуются параболы второго и третьего порядков, показательная
и логарифмическая функции. При исследовании качества по-
строенных кривых применяются методы линейного корреля-
ционно-регрессионного анализа
ГЛАЗА
АНАЛИЗ
ВРЕМЕННЫХ РЯДОВ
15.1. КОМПОНЕНТЫ ВРЕМЕННОГО РЯДА
Пол временным рядом (или динамическим рядом) понима-
ется ряд значений некоторого показателя, взятых по состоя-
нию на определенные моменты или периоды времени. Количе-
ственные значения показателя по временном ряду называются
уровнями. Уровни расположены в хронологическом порядке,
обычно через равные промежутки времени. Если они агрегиро-
ваны так, что отражаю! состояние показателя на некоторые
периоды времени, то такой ряд называется интервальным. В
качестве таких периодов могут выступать, например, годы,
кварталы, месяцы, недели Моментные временные ряды харак-
теризуют состояние показателя на короткий промежуток нре
менн, например на день, час.
Временные ряды отражают динамику социально-экономи-
ческих явлений. Если уровни временного ряда формируются
под влиянием факторов и условий, которые будут незначи-
тельно изменяться в будущем, то временной ряд можно ис-
пользовать для прогнозирования При этом его методологичес-
кой основой будет экстраполяция, т. е. перенесение в будущее
тенденции, которая сформировалась в прошлом
Действие факторов, атияюших на величины уровней вре-
менного ряда, носит различный временной характер Влияние
одних факторов проявляется постоянно в течение продолжи-
тельных промежутков времени, влияние других — периодичес-
ки. с разной длиной периода. Некоторые факторы проявляют
себя случайно и нерегулярно.
В этой связи каждый уровень временного ряда можно рас-
сматривать как результат наложения компонент, имеющих раз-
ный временной характер действия. Метод анализа временных
рядов заключается в выделении этих компонент.
369
Среди компонент временного ряда выделяют- тренд. цик-
лическую компоненту, сезонную компоненту и нерегулярную
компоненту (рмс. 15.1).
Спжьнвп имгхнпмга
*'«рвгу1-)вр*цы асмсемуита
Рис. 19.1. KjQwnoHC’iw арймомого рада
Пат трендом понимается долгосрочная составляющая, ха-
рактери туюшая общую тенденцию и вменения временного ряда
в течение длительного периода времени Под тенденцией по-
нимается возрастание или убывание уровней временного ряда
(рис. 15.1, а). Факторами, порождающими тренд, могут быть,
например, изменение состава населения, инфляция, техноло-
гические изменения, рост производства, рост цен и т. д.
Циклическая компонента характеризует повторяющиеся и
волнообразные изменения длительностью более гада. Она от-
370
ражает цикл деловой активности, периоды подъема и спада
Длина цикла, г. е время между соседними максимумами (или
соседними минимумами), може! колебаться от года до 15—20
лет. Циклическая компонента определяется тиснением остат-
ков, т. е разностей между трендом и фактическими значениями
уровней ряда вдоль линии тренда (рис 15.1, б)
Сезонная компонента также носит циклический характер
Она характеризует изменения, которые регулярно повторяют-
ся и завершаются в пределах тола (рис. 15.1, в) Например, се-
зонным фактором являются погодные условия, соответствую-
щие какому-либо времени гада, так как влияют на продажи
потребительских товаров
Нерегулярная компонента отражает быстрые изменения, как
правило, малой длительности (рис. 15.1, е). Они вызываются
непредсказуемыми и редкими событиями природными катак-
лизмами. войной, эпидемией, сменой власти и т. д.
Основная задача анализа временных рядов заключается в
определении каждой компоненты и исключении ее воздействия
на уровни временного ряда. Этот процесс называется декомпо-
зицией. или разложением временного ряда (его геометричес-
кая интерпретация представлена на рис. 15.1). Формально мо-
дель декомпозиции временного ряда можно представить в виде
уравнения
>— ТК С S I, (IS.I)
где у — уровень временного ряда, TR — тренд, С — цикличес-
кая компонента, S — сезонная компонента. / — нерегу-
лярная компонента.
Модель (15.1) называется моделью с мультипликативной
компонентой. Она строится на предположении о том, что лю-
бой уровень временного ряда является произведением воздей-
ствующих компонент.
В анализе временных рядов рассматривается также альтер-
нативный подход к агрегированию компонент — каждый уро-
вень представляется как сумма воздействующих компонент:
У-ТЯ+С+5+/. (15.2)
При допущении модели (15.2) вклад сезонной компоненты
остается постоянным с течением времени для данной части
гола.
Для мультипликативной модели (15.1) абсолютная величи-
на сезонной колеблемости возрастает по мере роста уровней
371
временного ряда. Эта модель чаше используется на практике,
ее мы и будем рассматривать
15-2. АНАЛИЗ ТРЕНДА
Тремя является долгосрочной составляющей временного ряда
При анализе тренда независимой переменной х является вре-
мя, а зависимой у — уровень временного ряда Вил тренда мож-
но выявить, если построить трафик временного ряда, откла-
дывая на оси абсцисс периоды времени, а на оси ординат —
значения уровней Визуальный анализ расположения точек гра
фика поможет сделать вывод о форме сглаживающей линии
Если тренд окажется линейным, то для вычисления парамет-
ров уравнения применяется метод наименьших квадратов При
нелинейном тренде его также можно использовать, делая со-
ответствующие преобразования переменных (см. раздел 14.7).
Пусть рассматривается линейный тренд
у “ + А/, (15.3)
где / — время (независимая переменная); у - оценка уровня
временного ряда (зависимая переменная).
Если обозначение независимой переменной / заменить на л,
то величины Ьн и b находятся по формулам (13.11) и (13.12)
как параметры линейной регрессии уровня временного ряда на
время.
Пусть тренд строится на основе последовательных головых
данных (например, /" 1990. 1991, 1992, .. ). Для удобства зако-
дируем значения: t = 1,2, 3,... . Обозначим: уг — наблюденное
значение временного ряда за период г и Г — общее число на-
блюдений во временном ряду (ап и на временного ряда). Тог-
да формулы (13.11) и (13.12) преобразуются к виду
(15.5)
где у-О; ♦ Г, ♦ ... ♦ УтУТ,
I =(1 + 2 + ...+ Г)/Г=(Г + 1)/2.
Прогнозный гол следует закодировать по той же системе.
Если / - Т — последний год в ряду наблюдений, на основе
которых было получено уравнение (15.3), то, прогнозируя в
372
году Т иа к лет вперед, следует в уравнение < 15.3) полетав»!»
значение / - Т + *:
Ут., = ♦ *,( 7" + *)
Пример тз.». Имеются данные за ряд лет о численности работ-
ников одной компании:
Гол Численность работников (тмс. ям.)
1986
1987
1988
1989
1990
1991
1992
1993
График временного ряда приведен иа рис. 15.2.
2.4
4.6
5.4
5.9
8
9.7
И.2
Рис. IS.2. Временной ред 'моленнос1сй работников аоыгмннн
и сглаживающий «инейный треод
На рис 15 2 ясно просматривается линейный тренд. Найлсы
его параметры, используя формулы (15.4) и (15.5). Для этого
закодируем значения не зависимой переменной г:
Г У,
1 1.1 -у,
2 2,4 = у
3 4.6 =У,
4 5,4 »у
5 5.9 -у.
6 8 -у.
7 9.7 -у,
8 П.2 - у,
373
Предварительно вычислим
/•1+2 + 3 + ..+ 8-36,
2р= J’ + 2f + ...+ 8! = 204,
£у = 1,1 +2,4+ ...+ 11.2 = 48,3,
Ly, - 1 1,1 + 2 2,4 + ... + 8 11,2 - 276,3,
I' = (8 + |)/2 = 4,5,
у,= 48,3/8 = 6,0375.
Подставляя результаты промежуточных вычислений п фор-
мулы (15.4) и (15.5). получим
276.3 - 36-48.3/8 58.95 , ,п1_
204-36-/8 42
Ъп - 6.0375 - 1,4036 4.5 - -0.279.
Отсюда уравнение тренда будет иметь вид
у, = -0.279 + 1,404/.
Спрогнозируем численность работников компании на 1994 г.,
полагая, что он соответствует / • Г+ I • 8 ♦ I • 9:
Л- 0,279+ 1.404 9- 12,357,
что соответствует 12 357 работникам
Аналогичную процедуру кодирования значений переменной
г можно использовать при вычислении нелинейных трендов.
Например, пусть требуется провести сглаживание временного
ряда по параболе второго порядка
у - bt + btt + bj1.
В этом случае структура данных для использования метода
наименьших квадратов будет иметь вид
у, t /’
~ • 1
у, 2 4
у, 3 9
эта
Систем* нормальных уравнений тогда записывается следу-
ющим образом:
ЬиТ+ + Ь.Ъ1 = Ъу.
Ь0Ъ + b£r + 6,Х(’ = iy,t,
b£r + 6.S? + 6,Zr‘ = EyrA
Пример is.2 Требуется проанализировать временной ряд по-
требления электроэнергии » регионе:
Голы Потребление элекгроэиергми (яю кВт)
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
95
145
174
200
224
245
26?
275
283
288
(рафик ряда представлен на рис 15 3
? W0
2 :зо
1
1934 -МБ 1386 1887 1968 1989 I99C 1991 1992 1996 1
Рис Г 5.3. Пример гир®болимес»ой зависимое™
по-рвСомм-иг. ллсктзоэмсргии п ре'номе (млн кВт|
На основе анализа данных временного ряда и его графика
можно сделать предположение о криволинейности тренда: с
течением времени потребление энергии растет при убываю-
щем приросте. Так. прирост с 1989 до 1990 г. был 18; с 1990 до
1991 г. - 12 (12< 18); с 1991 до 1992 г. - « (8< 12); с 1992 до
1993 г. — 5 (5<8> Убывающий (или возрастающий) во време-
ни прирост свидетельствует о квадратической зависимости:
у = До+ btt + bj.
375
Закодируем и преобразуем переменные
У, | ' | ''
95 I I
145 2 4
174 3 9
288 10 100
На основе преобразованных данных с помощью програм-
мных средств вычислим уравнение.
у- 58,6 ♦ 44,048г- 2.1212г'.
Сделаем ретроспективный прогноз для t = 2 (1985»:
у-58.6 + 44.048 2 - 2,1212 • 4 = 138.21.
Фактическое значение потребления электроэнергии в этот
гол было 145 млн кВт
15.3. ИЗМЕРЕНИЕ ЦИКЛИЧЕСКОЙ
КОМПОНЕНТЫ
Практически любой вре менной ряд в бизнесе содержит эле-
мент цикличности. Цикличность присуща экономике, а также
другим долговременным явлениям
Одним из способов описания циклической компоненты яв-
ляется представление ее как доли тренда. Предположим, что
рассматривается временной ряд, не содержащий сезонной со-
ставляющей Например, таким будет рил. основанный на годо-
вых наблюдениях. В этом случае можно положить, что каждый
уровень ряда у, является произведением компонент:
у, ‘ ГЛ, С,
Пусть построена модель тренда
У,- ГЛ,
Тогда оценка циклической компоненты получается ледени
ем значения уровня временного ряда на величину тренда:
у,!У, - <ГЯ С, /,2/ГЛ, - С,
зте
Если нерегулярная составляющая / оказывает незначитель-
ное влияние на уровни временного ряда (методы исключения
/ изложены в разделе 15 6), то ею можно пренебречь. Отсюда
оценкой циклической компоненты будет от шипение
С,->г/у,-
(15.6)
Если С > I, то фактическое значение уровня ряда у, будет
больше, чем оценочное значение тренда. Это означает, что ве-
личина циклической компоненты находится где-то над лини-
ей тренда. Аналогично при С < 1 значения циклической ком-
поненты будут ниже линии тренда.
Пример 15.3. В примере 15.2 на основе временного ряда чис-
ленности работников компании был вычислен линейный тренд:
у, - -0.279 + 1,404/.
гае г -> 1 соответствует 1986 г., г = 2 — 1987 г. и т. д.
Определим циклическую компоненту Для зтото вычислим
оценки у, при I = 1,2, .... 8 и определим отношения (15.6).
Результаты вычислений сведем «следующую таблицу:
t yt v,
1 l.l 1,125 0,977
2 2.4 2,529 0,949
3 4.6 3.933 1,169
4 5.4 5.337 1.012
5 5.9 6,741 0,875
6 8.0 8.145 0,982
7 9,7 9.549 1,016
8 Н.2 10,953 1,022
Как видно, для первого периода оценка циклической ком-
поненты равна 0,977. Это означает, что фактическое значение
уровня составляет 97,7% трендового значения. Аналогично для
второго периода — 94,9%, для третьего — 116,9% и т. д.
Флуктуация циклической компоненты вдоль грегиа хоро-
шо видна иа рис. 15.4. Начало цикла характеризуется Cr— 1
Пик цикла приходится на t = 3 (1988 г.), минимум слада —
на г " 5 (1990 г.) и завершение (когда опять С — I) — где-то
между t - 6 (1991 г.) и г = 7 (1992 г.).
377
Следует отметить, что на практике прогнозирование цик-
лов янлясгся достаточно сложной задачей. Предсказать период
цикла, нс п аил у я только дани ые временного ряда, практичес-
ки невозможно Выделение циклической компоненты может по-
мочь при установлении стадии, на которой находится деловая
активность.
15.4. ОПРЕДЕЛЕНИЕ СЕЗОННОЙ
СОСТАВЛЯЮЩЕЙ
Сезонная компонента проявляется, котла временной ряд со-
ставляют квартальные или месячные наблюдения. Рассмотрим
уровень ряда только как результирующую сезонности и трен-
да. т. е. представим его как произведение тренда и сезонной
компоненты:
оценка у,- TR • 5г. (15.7)
Из соотношения (15.7) взздззо. что сезонность можно рас-
сматривать как индекс, зеоторызз умззожается на ззелзгшну тренда.
Этот индекс остается постоянным каждый год для определен-
ной части гола Например, если имеет место квартальная се-
зонность. то .5, “ 5, — J>, “ .... 5, “ St — Sx “ и т д. Способом
вычисления изыексов сезонности является метол отношения к
центрированной скользящей средней. Проиллюстрируем его на
конкретном примере.
зтв
Пршлер /5.4. В табл. 15 1 приведены квартальные данные о про-
дажах фирмы за период 1990—1993 гг. (в млн долл). где в скоб-
ках указаны обозначения соответствующих уровней временно-
го ряда
Таблица 15.1
Квартальные данные об объеме продаж (млн долл.)
Год Квартал 1 Кпартал 2 Квартал 3 Кмртал 4
1990 2tXz,> •аур 47<УР «Хур
1901 «Хур заур 6ЫУ.) 76(ур
1992 мод «ХУМ1 85(У„1 ч»(у,р
1993 75|у,р w,p К»(У«> 'W,P
Булем находить индекс сезонности для калетою кваргала в
течение года, т. е. вычислим четыре значения индекса. Идея
метода отношения к центрированной скользящей средней со-
стоит в том, что вначале на основе исходного временного ряда
определяется новый временной ряд. не содержащий компо-
ненту сезонности. Уровни нового ряда рассчитываются как цен
трнрованные скользящие средние.
Для вычисления центрированных скользящих средних оп-
ределяются так называемые скользящие суммы. Для кварталы
ной сезонности первая скользящая сумма будет включать зна-
чения первых четырех квартальных уровней исходного времен
ного ряда:
<0 - У, ♦ У, + У, ♦ • 20 + 12 + 47 + 60 — 139.
Во вторую скользящую сумму входят первые четыре уровня
ряла, сдвинутого на один квартал вперед:
(2) = + У, + + Д “ 12 + 47 + 60 + 40 = 159
Третья скользящая сумма определяется аналогично при сдви-
ге уровней на два квартала вперед:
(3) “ У, +>« + 4 - 4? + 60+ 40 + 32 - 179.
Продолжая эту процедуру, получим 13 скользящих сумм (табл.
15 2), где последняя сумма вычисляется следующим образом:
(13) = -% + Ул = 75 + 70 + 101 + 123 = 369
379
Таблица 15.2
Вычисление центрированных скользящих средних
Год Квартал t ъ Цемтрмро- Otbkiumihmb цемтрм- ромниой сКсхльтаЩай средней
С кет ль да- та» сумма мини* скольэя- средмх»
1990 1 1 20 — —
2 2 12 139 - —
3 3 47 159 37,26 1.26
4 4 ВО 179 42.2 л 1.42
’992 1 5 40 197 47.00 0 85
2 6 32 213 51.25 0.62
3 7 65 229 55 25 1.18
4 В 76 247 59 50 1.28
1993 1 9 56 367 64,25 0.87
2 10 к 291 69.75 0.72
3 И 85 ЗЮ 75.13 1.13
4 12 too 330 8000 1,25
1904 1 13 76 34S 84.50 0 89
2 14 70 369 89.36 0.78
3 10 101 * —
4 16 123 —
Каждая скользящая сумма будет относиться к моменту вре-
мени, находящемуся посередине между периодами, на осно-
вании которых она была рассчитана. Если на основе каждой
скользящей суммы вычислять квартальные средние (т. е. сколь-
зящие средние, полученные делением скользящих сумм на 4),
то полученные величины будут относиться к моментам между
кварталами. Например, первая скользящая средняя (или сум
ма) соответствует моменту между !• ! и 1= 3, т. с. (’ 2,5
(конец июня—начало июля 1990 г.) Аналогично вторая сколь*
зяшая сумма относится к t = 3,5 (конец сентября -начало ок-
тября 1990 г.) и т. л.
Для того чтобы скользящая средняя относилась непосред-
ственно к периоду I (в данном случае к середине квартала г),
следует вычислить двухлетние скользящие суммы (поелмова
тсльно суммируя две соседние чегырехквартальиые скользя-
щие суммы) и разделить их на 8. Например, вычислим первую
скользящую квартальную среднюю, центрированную на сере-
дину квартала / - 3:
зао
(139 ♦ 159) / 8 - 37,52.
Аналогично для I ~ 4 имеем
(159 ♦ 179) / 8 - 42,25
ит л.
С помощью данной процедуры вычисляются 12 центриро-
ванных скользящих средних (табл. 15.2). 11онятно, что их расчет
для t = 1,2. 15 и 16 невозможен. Заметим, что первые два
значения из них соответствуют квартам 1 и 2, а последние
два — квартам 3 и 4 В общем случае, если временной ряд
содержит Г наблюдении, то для определения квартаной се-
зонности можно вычислить Т— 4 центрированных скользящих
средних.
Скользящая сумма и центрированные скользящие средние
определяются суммированием за четыре квартала (сезона) По-
этому они уже не содержат сезонной составляющей. В результа-
те усреднения снижается также влияние нерегулярной компо-
ненты Чтобы отмстить этот факт, будем нерегулярную
компоненту обозначать малой буквой г Тогда можно записать:
центрированная скользящая средняя на момент I " ... «.
Процедура получения центрированных скользящих средних
является, по существу, сглаживанием временного ряда Она по-
зволяет установить существование тренда, а также выявить его
форму (прямая или кривая линия).
Центрированные скользящие средние, представленные и
габл 15.2. характеризуют стабильно возрастающий тренд. Ввиду
того что разности между соседними средними почти одина-
ковы, тренд будет очень близок к линейному. Это можно на-
блюдать на рис. 15.5.
Для определения четырех квартальных сезонных индексов
следует разделить значение каждого уровня у на соответствую-
щую центрированную скользящую среднюю. Исходя из (15 8).
эта операция в символической форме будет имен, вид
у / центрированная скользящая средняя = ..,
- TR 5 С • 1/TR С, I, = 5 /.
К.ак видно, вычисление отношения (15.9) выявляет сезон-
ный эффект в совокупности с нерегулярной составляющей.
звг
В табл 15.2 представлены отношения (15 9) для периодов I • 3.
4. 5...14 Они определялись следующим образом:
для I “ 3 47/37,25 = 1.26 (3-й квартал 1990 г.);
ЛЛЯ t = 4 60/42.25 = 1,42 (4-й квартал 1990 г.);
Р»с. 15.5. Сглажиианис вэсмпимого ря/v» объемов продаж фирмы (ед.|
и» основе с*о>мвэмдо средних
Сведем все I4 отношений по кварталам и вычислим средние
значения по каждому кварталу (табл. 15.3). Эти средние значения
будем рассматривать в качестве соответствующих индексов.
ГаОлмца 15.3
Вычисление квартальных индексов сезонности
Квартал 1 Квартал 2 Квартал 3 Квартал 4
— - 1 26 1.42
0,85 0,62 1 18 1.28
0.87 072 1,13 1.25
0.69 0 78 •я. —
Сумам 2,61 2.12 3.57 3.95
Сры>яя 0 «70 (?. 16/3> 0.707 12,12/31 1.19013.57/3» 1,317 (3,95/31
Данная процедура позволяет значительно сократить эффект
воздействия нерегулярной компоненты и получип. практичес-
ки в чистом виде квартальные индексы сезонности.
Они имеют следующую интерпретацию. Каждый индекс пред-
ставляет собой отношение среднего значения уровня по данно-
му кварталу к общему срелнеквартальному уровню временного
ряда. Если значение индекса меньше I. то средний объем про-
зе:
лаж в данном Квартале меньше ’/4 среднегодового объема про-
даж за все периоды временного рада Если индекс больше 1, то
средний объем продаж в данном квартале превышает ‘/, средне
годового объема продаж. В случае когда индекс ровен 1, средний
объем продаж по квартану в точности равен '/4 среднегодового
объема продаж Очевидно, средняя веек квартальных индексов
есть 1. иначе сумма средних квартальных объемов продаж не
будет равна среднегодовым продажам. Следовательно. сумма всех
полученных квартальных индексов равна 4. Однако, как прави-
ло, возможны погрешности, связанные с округлениями резуль-
татов вычислении Поэтому следует проверить точность расчетов
и скорректировать полученные значения. Для этого определяет-
ся корректирующий множитель, который равен отношению4 к
сумме вычисленных индексов. На него умножается значение каж-
дого из четырех квартальных индексов. Сумма скорректирован
ных индексов должна быть равна 4.
Определим сумму квартальных индексов, вычисленных в
табл. 15.3:
0,87 + 0,707 + 1,19 + 1,317 = 4,084.
Найдем корректирующий множитель
4/4,084 - 0.9794
Скорректируем квартальные индексы:
Квартал Скорре*тм(мшаивыА нклекс сезонности
1 0,870 0,9794 - 0.852
2 0.707 0,9794 = 0,692
3 1.190 0.9794-1,166
4 1.317 0,9794-_1,290
4
Индексы сезонности часто измеряют в процентах Напри-
мер. индекс первого квартала 85,2% Это означает, что сред-
ний объем продаж по первому кварталу на 14.8% меньше '/
среднегодового объема продаж Индекс зретьего квартала, рае
ный 116,6%, означает, что средний объем продаж по третьему
кварталу на 16,6% больше ‘/4 среднегодового объема продаж
В рассмотренном примере анализировалась квартальная се-
зонная компонента. Аналогичные заключения будут верны и
для месячной сезонности, когда временной ряд содержит ме-
сячные данные При определении месячных индексовссэонио-
звз
ста (их будет 12) вычисляются 12-месячные скользящие сум-
мы и центрированные скользящие средние. Если Т длина
временного ряда, то число полученных скользящих средних
Т— 12 При корректировке вычисленных индексов следует иметь
в виду, что их сумма должна быть равна 12.
15.5. ДЕСЕЗОНАЛИЗАЦИЯ ДАННЫХ И С ЕЗОННОЕ
ПРОГНОЗИРОВАНИЕ
Десеэонализаиией данных временного ряда называется устра-
нение влияния сезонной компоненты на его уровни с целью изу-
чения тренда и долговременных циклических изменений. Лесе-
зоналкзированные данные Ц) определяются как отношение
d - у./соогветствуюшнй сезонный индекс 5 "
' ’ ' <13 Ю)
- 7/1, • S, • С, - 7/5 = TR С
Пример >5.5. Вычислим лессэошлизированные объемы продаж
для временного ряда, рассмотренного в примере 15 4. Полу
ченные результаты сведем в табл 15.4.
ГлЛ.7И14а 154
Вычисление десезомализироваммых данных
Год I У. Индекс с «эо ни ости (S,) Д*ее><мллияиро*а1н ные дакмьм* (d, у, /S3
1990 1 20 0,852 23.47
2 12 0.692 17.34
3 47 1,166 4031
4 60 1,290 46 51
1991 5 40 0,652 4695
€ 32 0.692 45 24
7 65 1,166 55 75
8 75 1.290 58.91
1992 9 56 0,852 65.73
10 50 0,692 72 25
11 85 1.166 7290
12 100 1.290 77.52
1993 13 75 0 852 88 03
14 70 0692 701.16
15 101 1.166 86.62
16 123 >200 95 35
334
Лесезомализированные данные а табл. 15 4 содержат тренд,
циклическую и нерегулярную составляющие При сравнении с
фактическими значениями уровней (у.) можно видеть. что тренд
более четко проявляется и лесезонализнрованных .тайных.
Десезонализированные значения могут служить исходной
информацией .тля оценки тренда ТК = A, + bt Для получения
параметров Ьл и Ь следует только подставить в формулы (15 4)
и (15.5) вместо фактических значений у( дессзоналтирован-
ные данные </:
Г"-(£'У'Т
й,-У,-й,7. (15.12)
Зная индексы сезонности, тренд можно использовать в про-
гнозировании Для этого нужно прогнозный период определить
в закодирован ном виде (т. е продолжить исходный временной
ряд до прогнозного периода и подсчитать его номер в общем
ряду) Далее следует подставить полученное значение периода в
уравнение тренда и определить лесе читал нитрованный прогноз,
который умножается на соответствующий прогнозному перио-
ду индекс сезонности.
Пример 13.в. Вычистим тренд на основе десезонализирован
ных данных табл. 15 4 и спрогнозируем объем продаж на 1-й и
2-й кварталы 1994 г.
Используя программное обеспечение, вычислим оценку
тренда
ТЯ - 19.372 + 5.0375г.
Уравнение тренда было построено на основе данных, “очи-
щенных" от влияния сезонности Коэффициент регрессии
А - 5.0375 свидетельствует, что продажи возрастают в среднем
приблизительно на 5 млн долл, в квартал.
С помощью уравнения тренда и индексов сезонности можно
спрогнозировать объем продаж для заданного квартала в конк-
ретном прогнозном году. Например, сделаем прогноз на пер
вый и второй кварталы 1994 г. По табл. 15.4 первому кварталу
1994 т. соответствует г - 17, а второму кварталу — г - 18 Индекс
сезонности для первого квартала — 5. “ 0,852. для второго —
•Sj • 0.692 Вычислим прогнозные оценки:
ЭВ5
уа = RT[7 st = (19,372 + 5,0375 17) • 0,852 «
= 89,5 (млн долл.),
У19 « RTllt s2 = (19,372 + 5,0375 • 18) 0,692 =
= 76,2 (млн долл.).
15.6. ПРОЦЕДУРА ОБЩЕЙ ДЕКОМПОЗИЦИИ
ВРЕМЕННОГО РЯДА
В предыдущих разделах данной главы мы рассматривали от-
дельные действия по оценке каждой компоненты временного
ряда. Эти действия можно рассматривать как этапы процедуры
общей декомпозиции временного ряда.
Этап 1. Определение методом отношения к центрированной
скользящей средней сезонного индекса 5 для каждой части
года. Для квартальных данных вычисления сводятся к нахожде-
нию четырех квартальных индексов 5 5;, 5', и 54. В случае ме-
сячных наблюдений определяется 12 индексов (5р 52, ..., S|2)
(для каждого месяца свой индекс).
Этап 2. Дсссзонализация данных. Этот этап заключается в
выравнивании эффекта сезонности, т. е. исключении сезонной
компоненты. Десезонализация осуществляется делением каж-
дого фактического уровня на соответствующий сезонный ин-
декс:
Ч = у,/^
_I5|, S, 53, 54 (квартальные данные);
где 5 .у (месячные данные).
Этап 3. Определение тренда TRt. Оценка тренда осуществля-
ется по методу наименьших квадратов на основе десезонализи-
рованных данных dt:
_ У, Г/?,-5, С, •/, =
S, ~ S
Этап 4. Определение циклической компоненты С. Эта ком-
понента определяется делением каждой десезонализированной
компоненты J на соответствующее значение тренда, получен-
ное на этапе 3:
d. „TR, C'.I z
TR, TR,
386
Дня исключения нерегулярной компоненты можно вычис-
лять, например, трехпериодные скользящие средние для вели-
чин С • /. В этом случае эффект нерегулярной компоненты зна-
чительно сокращается. Выбор именно трехпернодной скользящей
средней был произволен. Он был связан с тем, что в случае
нечетного числа слагаемых скользящей суммы скользящие сред-
ние не надо центрировать.
Все этапы декомпозиции подробно рассмотрим на следую-
щем примере.
Пример 15.7. В табл. 15.5 представлены месячные данные об
объеме розничной торговли сети магазинов за период с янва-
ря 1989 г. по декабрь 1992 г. (тыс. долл ).
Таблица 15.5
Данные об объеме розничной торговли сети магазинов
1989 1990 1991 1992
Январь 123,81 133,29 130.90 142,12
Февраль 120,11 128,03 128,59 143,15
Март 141.37 149.19 149,30 154,74
Апрель 139,78 145.80 148,51 159,07
Май 150.26 155 02 159.84 165,76
Июнь 149.00 154,37 153,91 164.63
Июль 144,55 149.72 154,64 166,01
Август 153.03 158,24 159,91 166,34
Сентябрь 144 08 146,34 146,70 160,61
Октябрь 142,34 151,47 152,11 168,73
Ноябрь 148.83 156,09 155.64 167.18
Декабрь 176,49 179,65 180.98 204,10
Используя данные табл. 15.5, проведем поэтапную декомпо-
зицию временного ряда.
Этап I. Определим индексы сезонности. Вычислим 12-ме-
сячные скользящие суммы и центрированные скользящие сред-
ние для 48 наблюдений, представленных в табл. 15.5. Все ре-
зультаты вычислений сведем в табл. 15.6.
Определим первую скользящую сумму:
у, + у, + ... +у|2 = 123,81 + 120,11 + ... + 176,49 = 1733,65.
Она будет соответствовать середине промежутка между t — 6
и t = 7, т. е. t = 6,5. Вторая скользящая сумма вычисляется так:
у2 + у, + ... +y„s 120,11 + 141,37 + ... + 133,39 = 1743,13.
387
Ее величина соответствует моменту /— 7,5.
Определим первую центрированную скользящую среднюю:
(1735,65 + 1743,13)/24 - 144,87.
Отметим, что производится деление на 24. так как именно
столько месяцев входит в качестве слагаемых в обе суммы.
Аналогично вычислим оставшиеся скользящие суммы (ко-
лонка 3 табл. 15.6) и центрированные скользящие средние (ко-
лонка 4 табл. 15.6).
Ввиду того что данные — месячные, центрированные сколь-
зящие средние не вычисляются для периодов с/“ I no г - 6 и
с I - 43 по / = 48.
Колонку 5 табл. 15.6 составляют отношения фактических дан-
ных к центрированным скользящим средним. Например, пер
яме два отношения вычисляются следующим образом:
144,55/144,87 - 0,998. 153,03/145.59 - 1.051.
Гэблииа 15 6
Скользящие средние и отношение к скользящим средним
для месячных данных о розничном торговле сети магазинов
Год Ме<-иц Г (О А Скользя- щая сумма (3) Цемтрире ••инея скользя •чая средняя (4)
к иеитрм- рояаимлй скользя щяй средне Я 1»
1 2 3 4 5 в 7
1989 1 1 123,81
2 2 120,11
3 3 141.37
4 4 139,78
5 5 150,26
8 б 149,00 •733,65
7 7 144.56 144.87 0.998
1743J3
I 8 153,00 145.59 1,051
-.751 05
9 9 144,08 1758,87 146.25 0.9В5
10 10 142.34 146 82 ММ
1 764 U9
11 11 148.83 1769 65 147,27 1.011
12 12 176.49 1775.02 147.60 1,195
1990 1 13 133,29 1780 19 148.13 0.900
2 14 128.СЗ 1785 40 148,57 0.862
3 15 149 19 1787 66 148.88 1,002
388
Овсимяннв тбл 156
1 2 3 4 8 е
4 16 145,80 1796.79 1804,05 149,35 0978
5 17 155,02 150,03 1-033
6 18 154,37 1807,21 150.47 1.026
7 1» 149.72 150.50 0 995
8 20 158,24 1804,38 150,42 1062
9 21 146.34 1805.49 150.45 0.973
10 22 151.47 1805,49 150.57 1.006
11 23 156.09 1808,20 150,88 1035
12 24 179.65 1812.56 151,07 1 1Й9
1991 1 2S 130 90 1817,48 151,25 0 865
2 26 12859 1819,15 161,63 0 849
3 27 149,30 1819,48 161,61 0 985
4 28 148.5! 1820,15 151 65 0,979
5 79 159.84 1819,70 151,66 1 ОМ
6 ЭС 153.91 1821,03 151.70 1015
7 31 154.64 1832,25 152,22 1.016
В 32 159.91 1846,81 153.54 1043
9 33 146.70 1852,25 1541.3 0 952
10 34 152.11 1862,81 154.79 0.983
11 за 155,64 1868,73 155.48 1001
12 Эб 180.98 1879,45 >56.17 1 159
1992 1 37 142,12 1890,82 157,09 0.906
2 38 143,15 1897,2$ 15/,84 0.907
3 39 154,74 1911,15 • В 1..Ч 0975
4 40 159.07 1927.78 159.96 0,904
5 41 165,76 1939,32 161.13 1,02»
« 7 1 9 10 11 12 42 43 44 45 46 47 48 164.63 166.01 166,34 160.61 168.73 167.18 204.10 1962,44 162.57 1.013
Сведем отношения в табл. 15.7, тле вычислим средние зна-
чения каждых трех отношений, соответствующих определен-
ному месяцу.
за»
Табл»*»» IS. 7
Отношения к центрированным скользящим средним
0,890 + 0,872 + ... + 1,181 = 11,993.
Отсюда корректирующий множитель для индексов сезонно-
сти равен 12/1I.993
Вычислим индексы сезонности:
5. = 0.890 • (12/11.933) = 0,89 (январь).
5, - 0,872 (12/11.933) - 0.87 (февраль».
- 1.181 (12/11.933) = 1.18 (декабрь)
Сведем скорректированные индексы в табл. 15.8
ГаОлицм 158
Индексы сезонности по месяцам
Месяц Индекс сеэоитисги Месяц Индекс
Я..цээи 0.89 кЪСГЬ 100
Феер&п*. 0.87 Ае’усл 1.05
Март 0,99 Сентябрь 0,97
Алоггь 0,98 Октябрь 0.99
Май Т.04 >02
Июнь 1.02 Детаб» 1 18
Сумма сезонных индексов (S’, + S, + ... + 5И) равна 12. Как
видно из габл. 15.8, наибольший индекс относится к декабрю:
1,18. Это означает, что пик розничной торговли приходится на
декабрь. В январе н феврале наблюдается спал розничной тор-
говли (самые низкие индексы сезонности) В оставшихся мсся-
390
пах эффект сезонности незначителен, т. е индексы близки к
единице.
Этап I. Определим десеэоналиэированные данные. Они по-
лучаются делением фактических уровней рила на соответству-
ющие индексы сезонности:
Десезоналиэмроваиные данные представлены в табл. 15-9.
Таблица 159
Деев зон а л май роев иные месячные данные объемов
розничной торговли сети магазинов
Гад Месяц t г« ». e,*T,/S,
1 2 3 4 5 fi
•989 1 1 123.81 0.89 139.04
2 2 120,11 0.87 137,89
3 3 141,3? 0.99 143,10
4 4 139 78 0.98 142,07
& 5 150.28 1.04 144,59
в б 14900 1.02 146,32
1 7 144 И 1.00 144,Св
в 8 153.03 1.05 145,84
9 9 144 06 0,97 148.47
ю 10 142.34 0,99 144,28
11 11 14883 1.02 146,50
12 12 17&49 1.18 149,38
1990 1 13 133,29 0.89 149.69
2 14 128,03 0,87 146Д7
3 15 14919 0.99 151.02
4 16 145.80 0.98 148.19
5 17 155x02 104 149.17
б 18 154,37 1,02 151 ХЮ
Т 19 149,72 1.00 14921
8 20 158,24 1.05 150 83
9 21 148.34 0.97 150,80
н> 22 151,47 099 153 53
11 23 158,09 1.02 15364
12 24 179,66 1.18 152.03
199! 1 25 130,90 С.89 147.00
2 26 128.59 087 147.31
3 27 149,30 0,99 151.13
4 гв 148.51 3,98 150.96
391
САпмлмхи* 1Л&Г H i
1 i 3 4 В 0
5 29 159.84 1.04 153.81
в 30 153 91 1.02 15U5
7 31 154.64 1.00 154.12
8 32 159.91 1.05 152.39
9 33 -.46.70 0.97 151,17
10 34 152.11 0.99 154.18
11 35 155.64 1.02 153.20
12 Зв 18098 1.18 153.16
1992 1 37 142,12 0,89 159.60
2 Зв 143,15 0,87 163.99
3 33 154,74 0.99 156.64
4 40 <59.07 0.98 161.68
5 41 165,76 1.04 159,51
6 42 1W,63 1.02 161.67
7 43 166.01 1.00 165.45
8 44 166.34 105 158.52
9 45 160,61 097 165.50
10 46 168,73 0.99 171.02
>1 47 167,18 1.02 164 ’Л>
12 48 204.10 1.18 172.72
В изменении десеюнали тированных данных вполне отчет-
ливо проявляется возрастающий тренд
Этап 3. Определим тренд методом наименьших квадратов на
основе десемжализированных данных
Для этою используем формулы (IS 11) и (15 12) В табл. 15.10
представлены промежуточные вычисления (ясно, что подоб-
Таблице 15.10
Промежуточные вычисление длв определения
тренда
t а, f-dr «»
1 139,04 13904 1
2 137,59 275,18 4
3 143,10 4?» 33 9
4 142,07 568 28 16
45 165,50 /447 50 2025
46 171.02 7866 92 2116
47 ’64.56 7734.32 2209
48 172.72 8290.56 7304
1176 7318.00 183888.34 38024
382
ные расчеты должны проводиться с помощью специального
программного обеспечения).
Подставим результаты промежуточных вычислений на
табл. 15.10 в формулы (15.11) и (15.12):
183888,34-1176-7318/48 4597,34 „
а — —т— -------я------ - « 0,449.
38024-1176Г/48 9212
ba - 7318/48 - 0.499 • 1176/48 = 152,46 - 12.23 = 140,23.
Уравнение тренда будет иметь вид
/Я - - 140.23 + 0.499/.
В среднем бет учета сезонных колебаний объем розничной
торговли возрастает на 499 лолл. в месяц.
Этап 4. Определим циклическую компоненту.
Вычислим значение тренда для всех /:
d, - 140,23 + 0.499- 1 = 140,73,
<ij - 140,23 ♦ 0,499-2 - 141,23.
</« - 140,23 + 0.499 48 - 164,19.
Разделим каждое десезонализированнос значение на соот-
ветствующую оценку тренда:
d/TRt- rf/rf, = TR С, IJTR = С,
Результирующие величины содержа! нерегулярную компо-
ненту Для ее устранения вычислим трехмесячные скользя-
щие средние для значений С, - /, Результаты всех вычислений
представлены в табл 15.11
заз
!аблица ?5 11
Вычисление цикличесжой компоненты для временного ряда
объемов розничном торговли сети магазинов
Год Мисач «г, С,
1 2 3 4 5 б
•эео 1 139.04 14073 0,9880
2 137.59 141,23 0.9743 0,99
3 143.10 141.73 1.0097 0,99
4 14207 142.23 0.9969 1.01
9 144,59 142.73 1X1131 1.01
6 148 32 143.23 10215 1.01
7 144 06 143.72 1.0023 1.01
8 14584 144,27 1.0112 1.01
9 148 47 144,72 1.0259 1.01
10 144 23 145,22 09935 1.01
11 148.50 145,72 1.0053 1.01
11 149.38 146,22 1.0218 1,02
1990 1 14989 146.72 1,0202 1.01
2 146,87 147.22 С,9962 1.01
3 151,02 147.72 1.0224 1.01
4 148,19 148,22 0.9998 1.01
5 149.17 148.71 1,0031 1.01
6 151.60 149.21 1,0160 1.01
7 149.21 149.71 0,9967 1.01
8 150,80 150.21 1.0039 1.00
9 150,80 150.71 1,0006 1.01
10 153,53 151.21 1,0153 1J01
И 153,64 151,71 1,0127 ’Л1
12 152,03 152,21 0,9988 0.99
1991 1 147.00 152.71 0,9626 0.97
2 147,31 153,21 0,9615 0,97
3 151.13 153.71 0,9632 0,97
4 150,95 154,20 0,9789 0,99
5 153,81 154,70 0.9942 0.98
в 151.18 155,20 0,9739 0,99
7 154,12 185.70 0.9698 0,98
Н 152,39 186,20 0,9756 0,98
9 151,17 185,70 0.9647 0,97
10 154,18 157,20 0,9608 0,97
153,20 157.70 0,9715 0,97
12 153,16 185,20 0,9681 0,98
394
U<CHv*rwa tai вл 15 11
1 2 3 4 Б 6
1992 1 159.60 168.70 10057 1 00
2 163.99 159,20 1.0301 1.01
3 156.64 159,69 0 9809 191
4 161.66 160,19 1 0093 0 99
5 159,51 160,69 0.9926 1.00
б 161,67 161,19 1.0030 1.01
7 1 65.45 161,69 0232 1.00
8 156,52 162,19 0,9774 1.01
9 166,50 К , IrJ 1,0173 1.01
10 171.02 163,19 1,0480 1.02
11 164.56 16369 1,0053 1,04
12 17272 164 19 1,0520 —
Для пояснения того, как определялись трсхмссячныс сколь-
зящие средние, вычислим скользящую среднюю, соответству-
ющую периоду I “ 2:
С, = (0,988 + 0,9743 + 1,0097)/! = 0,99
Анализ циклической компоненты показывает, что в роз-
ничной торговле наблюдался спад с декабря 1990 до декабря
1991 г. (С,< I),
Если ишестны три компоненты TR, С и 5. то можно выра-
зить четвертую нерегулярную компоненту / из следующего со-
отношения:
/, = у/ TR С, • 5,
Определим, например, все компоненты для периода t = 9,
который соответствует сентябрю 1989г. Изтабл 15.11 возьмем
значение тренда RTt“ 144,72. В табл 15.9 найдем сезонную ком-
поненту 5, “ 0,97 и в табл 15.11 — циклическую С." 1,01. Пе-
ремножим эти компоненты:
5, TH, С, - 0,97 144,72 1,01 - 141,782.
Выделим нерегулярную компоненту /•
Y,/S, Tf^ C,- 144,08/141,782 - 1,0162
Таким образом, фактическое значение уровня временного
ряда в период г = 9 можно представить в виде произведения
четырех компонент
у, = 144.08 = 5, ГЛ, С, /, - 0,97 144,72 1,01 1.0162
395
Если проделать данную процедуру для всех уровней, то мы
получим полную декомпозицию временного ряда (табл IS. 12)
График каждой компоненты представлен на рис. 15.6.
Л»с. »5.в. графами «смпхент временного ряда объемов
розничной юрчоегм сечи чаозиное
396
Г^б.-лмцг» 12
Компоненты временного ряда объемов розничной торговли
сети магазинов
Год Месяц Г» гя, 8, С, 1г
1 2 3 4 5 6 7
1969 1 123.81 140.73 0.89 — —
2 120.11 141.23 0.87 099 0,98
3 141.37 141.73 0.99 0.99 1,02
4 139.78 142,23 0.98 1.01 0,99
б 160,28 142,73 1.04 1.01 1.00
6 149.00 143.Z3 1.02 1.01 1.01
7 144.55 143.72 1.00 1.01 0,99
8 153,03 144.22 1.05 1.01 1,00
9 144.08 144.72 0,97 1.01 1,02
10 142,34 145.22 0,99 1.01 0,99
11 148.53 145.72 1.02 1 01 1.00
12 178,49 146 22 1.18 1.02 1.01
1990 1 133.29 146.72 0,89 1.01 1.01
2 178,03 147.22 0.87 1.01 0.98
3 149,19 147,72 0.99 1.01 1.02
4 *45.80 148,22 0.98 1.01 0.99
5 «55.02 148,71 1 04 1.01 1.00
6 154,37 149.21 1.02 1.01 1.01
7 149.72 149.71 1.00 1.01 0.99
8 «58.24 150,21 1.06 1,00 1.00
9 148.34 150,71 0,97 1.01 0.99
Ю 151,47 151.21 0,99 1.01 1 01
11 158.09 151.73 1.02 1.01 1.00
12 179,65 152.21 1 18 0,99 1.01
1991 1 130,90 152.71 0.89 0.97 0.99
2 128.59 153.21 0.87 097 0,99
3 149.30 153,71 0.99 0.97 1.01
4 148.51 154.20 0,98 0,99 099
5 159,84 154,70 1.04 0.98 1.01
6 153,91 155.20 1.02 0 99 0.99
7 154.64 152.70 1.00 0,98 1.01
8 159,91 158,20 1.05 0.96 1,00
9 148,70 156.70 0.97 0,97 0.99
10 152.11 157.20 0,99 0,97 1 01
11 155,64 157.70 1.02 0.97 1.00
12 180,98 158,20 1.18 0.98 0.99
397
Олнхмния мбл. IS >2
1 2 3 4 5 е 7
1992 1 142-12 iaa.ro 0.69 100 1.00
2 143.15 159.20 0.87 1j01 1.02
3 15474 159.69 0.99 1.01 0.97
4 15907 160.19 0.98 0 99 1.02
5 155 76 ’60.69 1.04 1.00 0.99
6 164 63 ’61 19 1.02 Ij01 1.00
7 । Ц 0' 16169 1.00 1.00 1.02
8 166 34 16219 1.05 1.01 0.97
9 160.61 •й.- м 0.97 1.01 too
10 168.73 163.19 0.99 1.02 1.02
11 167.18 153 ®9 1.02 1.04 0.97
12 204,10 164,19 1.16 — —
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 15
Пса временным рядом понимается ряд значений некоторо-
го показателя, взятых по состоянию на определенные момен
ты или периоды времени Количественные значения показате-
ля во временном ряду называются уровнями временного ряда
Уровни располагаются в хронологическом порядке, обычно
через равные промежутки времени Каждый уровень можно рас
сматривать как результат наложения компонент, имеющих раз-
ный временной характер действия. Метол диализа временных
рядов заключается в выделении этих компонент. Основными
компонентами временного ряла являются: тренд, цикличес-
кая. сезонная и нерегулярная компоненты Пол трендом пони-
мается долгосрочная составляющая, характеризующая общую
тенденцию изменения временного ряда в течение длительного
периода времени Циклическая компонента характеризует по-
вторяющиеся и волнообразные изменения длительностью бо-
лее года Сезонная компонента характеризует изменения, ко-
торые регулярно повторяются и завершаются в пределах года.
Нерегулярная компонента отражает быстрые изменения, как
правило, малой длительности. Процесс определения каждой
компоненты и исключения ее воздействия на уровни времен
ного ряла называется декомпозицией, или разложением вре-
менного ряда
Формально модель декомпозиции можно представить двумя
способами как произведение четырех компонент (модель с
зяе
мультипликативной компонентой (15.1» или как сумму этих
компонент (модель с аддитивной компонентой (15.2)). На прак-
тике чаше используется мультипликативная модель.
При анализе тренда независимой переменной является вре-
мя, а зависимой — уровень временного ряда. Для оценки трен-
да используется метод наименьших квадратов В случае линей-
ного тренда строится парная линейная регрессия уровня ряда
на время. При построении нелинейного тренда проводится пре-
образование временной переменной.
Циклическая компонента измеряется как отношение фак-
тического уровня временного ряда к оценке тренда.
Сезонная компонента проявляется, когда временной ряд
составляют квартальные или месячные наблюдения. Она из-
меряется в виде индекса сезонности, который умножается на
величину тренда Индекс сезонности остается постоянным для
определенной части года (месяц, квартал). Способом вычис-
ления индексов сезонности является метод отношения к цент
рнрованной скользящей средней. При этом на основе исход-
ного временного ряда определяется новый временной ряд. не
содержащий компонент сезонности. Его уровнями будут цент-
рированные скользящие средние. Для вычисления центриро-
ванных скользящих средних определяются скользящие суммы.
Слагаемые первой суммы представляют собой первые 4 (для
квартальной сезонности) или 12 (для месячной сезонности)
уровней временного ряда. Во вторую скользящую сумму входят
первые четыре уровня ряда, полученного сдвигом уровней на
один квартал (месяц) вперед; в третью сумму сдвигом на
два квартала (месяца) вперед и т. д Чтобы получить скользя-
щую среднюю, центрированную на середину периода, сумму
двух соседних скользящих сумм делят на Я (для квартальной
сезонности) или на 24 (для месячной сезонности). Индекс се-
зонности вычисляется как отношение фактического уровня вре-
менного ряда к соответствующей центрированной скользящей
средней. Эти отношения усредняются по каждому отдельному
кварталу (месяцу)
Если разделить фактические уровни на соответствующие
индексы сезонности, то падучим десезонализированные дан-
ные, которые содержат только тренд, циклическую и нерегу-
лярную компоненты. Десезонализированные значения уровней
служат исходной информацией для оценки тренда Зная индек-
сы сезонности и тренд, можно прогнозировать сезонные зна-
чения временного ряда
399
Общая декомпозиция кременного ряда осушесттгляется по
следующей схеме:
I) определение сезонных индексов,
2) десезомалнзация данных,
3) определение гренла,
4) определение циклической компоненты.
При атом для исключения нере|удярной компоненты иног-
да вычисляются трехпериодные скользящие средние
Если известны три компоненты временного ряда: тренд, се-
зонная и циклическая, то нерегулярная компонента измеряет-
ся как отношение фактического уровня к произведению трех
указанных компонент
OJArLA J CJ СТАТИСТИЧЕСКИЕ
МЕТОДЫ И МОДЕЛИ
В ПРОГНОЗИРОВАНИИ
В главах 11—15 рассматривались основы построения регрес-
сионных моделей и моделей анализа временных рядов Были
также кчронуты вопросы использования этих моделей в про-
гнозировании При этом отмечалось, что методологической
базой процедур прогнозирования является экстраполяция, т. е
перенесение закономерностей, которые проявились в измене-
нии данных за прошлые периоды времени, в будущее В про-
цессе прогнозирования временная последовательность значе-
нии зависимой переменной у всегда делится на две части —
прогнозные значения, которые генерируются с помощью вы-
числительных процедур, и фактические данные, которые на-
блюдаются (рис. 16.1)
Период прог»*©»
Про., л «а» ПОСМОДМ
Проходе пег*'1о»
Рис. 16.1. Временная **сследовэ«елы*остъ зчачен»*й хаеисимой
X н процессе го» мозиромния (у, - ближайшее
мэблсдеимие знамение у. У,,, — л per и оз у на идин .домаа)
Использование уравнения peipecciin в качестве модели про-
гнозирования предполагает, что изменение зависимой пере-
менной (прогнозируемого показателя) объясняется одной или
несколькими независимыми переменными. Основное преиму-
щество данного типа моделей состоит в том. что измеряется
эффекгот варьирования объясняющих переменных Кроме того,
конечный результат прогнозирования имеет ясную и нагляд-
ную интерпретацию для анализа указываются факюрные пе-
ременные, которые предположительно влияют на зависимую
4С1
переменную. Однако использование регрессионных моделей
предполагает в свою очередь прогнозирование значений объяс-
няющих переменных. Во многих случаях для факторных пере-
менных существует лакая же неопределенность, как и для за-
висимой переменной.
Прогнозирование с помощью методов анализа временных
рядов является чистой экстраполяцией, котла закономерность
изменения прогнозируемого показателя за прошлые периоды
времени в точности переносится на будущее На первый взгляд
может показаться, что методы анализа временных рядов зна-
чительно проще использовать в прогнозировании, чем регрес-
сионные модели По крайней мере, не нужно проводить иссле-
дования для определения объясняющих переменных и набирать
необходимые данные по каждой из них. Однако часто для вы-
явления сложной структуры взаимозависимых уровней времен-
ного ряда требуется построение неординарных прогнозных урав-
нений
В данной главе мы рассмотрим более подробно различные
способы и модели прогнозирования, основанные на методах
анализа временных рядов и регрессионного анализа.
16.1. ПРОСТЕЙШИЕ МОДЕЛИ
Наиболее простои ("наивный") способ прогнозирования
заключается в предположении, что текущие периоды являют-
ся нанлучшими предсказателями для будущего Простейшая
модель в этом случае имеет вид
Унт У.-
(16 1)
гае у , — прогнозное (оттеночное) значение у на период г+1,
полученное в период t;
у — фактическое (наблюденное) значение у в момент г.
Использование простейшей модели (16.1) в прогнозирова-
нии ласт хорошие результаты, если наблюдения соответствуют
коротким периодам времени (например, дни или недели) н
характер их изменения не солержит заметных скачков. В неко-
торых случаях "наивная" модель может давать более точные
результаты, чем сложные прогнозные уравнения
402
Пример 16.1. В следующей таблице представлены иены акций
некоторой компании та 12-недельиып период, которые регис-
трировались на фондовой бирже в конце каждой педели:
Неделя Цена Неделя Цена Неделя Цена
(лжи.) (долл.) (ЛОЛЛ.)
1 60 5 647, 9 637,
2 62’4 6 62 10 627,
3 6'7. 7 вз'4 II 61
4 63 8 64 ‘ 12 617,
Используя данные таблицы и модель (16.1), спрогнозируем
иену на 13-ю неделю:
А, =4, = 61'4-
Опенка точности прогнозирования характеризуется остат-
ками, которые вычисляются для каждого периода прогнозиро-
вания г:
е=У,~у,. (16.2)
Чтобы оценить точность некоторой процедуры, используе-
мой для прогнозирования на основе данных конкретного вре-
менного ряда, остатки можно вычислить ретроспективно. Оче-
видно, чем аффективней процедура прогнозирования, гем
меньше абсолютные величины остатков за все периоды вре-
менного ряда
Пример 16.2. Используя "наивную” модель, на основе данных
примера I6 I вычислим остатки (I6.2) для каждой недели. Воз-
никает проблема, как вычислить остаток е, “ у - й, соответ-
ствующий периоду г = I. В этом случае у = у0, где у0 — цена
акции на конец недели, предшествующей начальному периоду
наблюденного временного ряда Если значение уп неизвестно,
то прогнозные опенки определяются начиная со второй неде-
ли (Г 2). Вычислим остатки для г = 2, 3, 4:
е, = уг - у. “ у, - у, “ 62’4 “ 60 “ 2,25;
«> = 4 “ Уэ= У, ~У, = 61э/4 - 627, - -0,5;
е, ” у, ~ У. “У, -У, ” 63 -61’/4 = 1,25.
Проведя аналогичные вычисления для оставшихся недель,
сведем все результаты в табл. 16.1
аоз
Глвлмм* 16 t
Прогнозирование и вычисление остатков с использованием
простейшей {-наивной") модели
Неделя (0 У,(ДАЯЛ.) У« Остатм {у( - у,)
Г 61
2 627. 60 2 25
3 вт7. 627, -05
4 63 в»’/, 1,25
5 647, 63 1.5
6 62 647, -2.5
7 вз7. 6? 1.5
8 М 637, 0.5
9 637, 64 -0.7S
то 627, 637, -6.76
11 61 627, -1.5
12 617, 61 0.5
Простейшую модель можно адаптировать к структуре врс
мснного ряда. Например, сечи имеет место тенденция (тренд)
возрастания или убывания уровней во времени, го возможна
корректировка модели с учетом добавки - разности между
текущим значением уровня и предыдущим значением
л.!<1^-3)
Иногла в качестве коррекции модели на тренд имеет смысл
использовать не абсолютную разность. а темп изменения:
(16.4)
Л-1
В случае ярко выраженной сезонности в изменении уровней
простейшая прогнозная модель может быть следунтщей
Лн’Ла.г
(16.5)
где к — промежуток сезонности (например, к — 4. если имеет
место квартальная сезонность; к ж 12. если сезонность ме-
сячная).
Основной недостаток простейших моделей заключается в
том, что в ни* не учитывается влияние изменений за более
поздние периоды времени Для их учета можно комбинировать
404
различные модели, включающие тренд и сезонную компонен-
ту Например, одним из таких вариантов модели может быть
следующее уравнение:
л.. = Л.1>|+(16.6)
где у — член, учитывающий сезонность \к — промежуток
сезонности), а другое слагаемое, являющееся средним
арифметическим приращений за к прелылуших периодов, —
член, учитывающий тренд
пример Гб.З. В тайл. 16.2 представлены данные об объемах продаж
некоторого продукта в физических елниннах за 1988—1994 гг.
Тэблюа 16.2
Временной ряд объемов продаж продукта
в физических единицах за 1988—1994 гг.
Год Квартал t Продажи (ед.)
19в8 1 234 1234 500 350 2S0 *00
19вв 1234 5673 450 350 203 ЭОС
1990 1234 9 10 11 12 350 200 >53 43С
1991 1234 13 >4 13 16 550 350 250 550
1992 1 234 17 IS 19 20 550 400 350 600
1993 1234 21 22 23 24 750 500 400 650
1994 1 234 25 26 27 26 650 600 453 /00
Предположим, что мы находимся в конце четвертого квар-
тала 1993 г. и нам необходимо слелать прогноз на первый квар-
тал 1994 г., который соответствует периоду г = 25. Сделаем это
на основе простейших моделей (16.1), (16.3)—(16.6)
Используя модель (16.1), получим
Уз’^-650.
Определим ошибку прогноза на период / = 25:
“ fej * 850 - 650 - 200
Визуальный анализ временного ряда в табл 16.1 позволяет
сделать вывод о наличии возрастающего тренда Очевидно, если
использовать модель (16.1) для получения прогнозных опенок
405
на периолы 2—28. го они большей частью будут занижены Для
корректировки этой систематической ошибки используем мо-
дель (16.3). учитывающую тренд:
Узы ’ >’м * О'» ~
У» ’ У»+ % —Уп’1
is, = 650 + (650 - 400),
уа = 650 + 250,
К» = w
Ошибка прогноза уменьшилась по абсолютной величине:
«и = У„- Уз = 850 - 900 =-50.
Для иллюстрации использования модели (16 4) спрогнози-
руем на ее основе объем продаж на первый квартал 1994 г.:
Уэы-Уи"^8-.
JJ4-J
• XX <»50 lf.e,
^ = ^•^=«0-^ = 1056
Есть основания полагать, что уровни временного ряда, прел
ставленные в табл 16.2, содержат сезонную компоненту: про-
дажи в первом квартале каждого гола большей частью выше,
чем в остальных кварталах. Поэтому имеет смысл попробовать
использовать модель (16.5) с квартальной сезонностью (А - 4):
Узы " У„,.
Й5->и = 750.
Наконец, применим модель (16.6). учитывающую сезонность
и тренд одновременно:
У». = Ум т + - Уж.’ + - ♦ <Уж> " Ум -И/4-
Ум = Уд + 1<Ум " Уц> + (Уг " yrJ + (yt. - У„) + (Уп - yM)l/4.
Ув ~ 750 + 1,650 “ 400’ + <40° “ 500) + (500 - 750) +
+ (750 - 600)(/4,
уа = 750 + 12,5 = 762,5.
Следует отметить, ч то представленные простейшие ("наив-
ные'') модели далеко не исчерпывают все возможные вари
анты, которые можно получить, конструируя различные ком-
бинации подобных моде.тей Составление простейших моделей
*56
обусловливается а основном структурными характеристика-
ми временного ряла и аналитическими способностями про-
гнозиста
16.2. МЕТОДЫ ЭКСПОНЕНЦИАЛЬНОЙ)
СГЛАЖИВАНИЯ
В главе 15 рассматривался метод сглаживания временных
рядов на основе вычисления последовательности центрирован-
ных скользящих средних Скользящие средние использовались
для определения индексов сезонности Кроме того, они могут
служить в качестве уровней "нового" временного ряла, для
которых аффект сезонности полностью исключен, а влияние
нерегулярно!! (случайной) компоненты значительно меньше
Временной ряд, составленный из скользящих средних, явля-
ется более сглаженным по сравнению с исходным рядом Уже
визуальный анализ его графика позволяет выявить какой-либо
существующий тренд или циклические изменения (см., напри-
мер, рис 15 5).
Другой способ сглаживания временных рядов представляет
собой экспоненциальное сглаживание В отличие от скользя-
щих средних его вычислительная процедура включает обработ-
ку всех предыдущих наблюдений, при этом учитывасзся уста-
ревание информации по мере удаления от прогнозного периода.
Иначе говоря, чем “старше" наблюдение, тем меньше оно дол-
жно влиять на величину прогнозной оценки. Иден экспонен-
циального сглаживания состоит в том. что по мере "старения"
соответствующим наблюдениям придаются убывающие веса.
Рассмотрим содержание процедуры экспоненциального сгла-
живания, а также ее модификации, разработанные с учетом
различной структуры временного ряла — наличие тренда и се-
зонных изменений
16.2.1. Простое экспоненциальное сглаживание
Простое экспоненциальное сглаживание лает хорошие ре-
зультаты для стационарных временных рядов Ряд называется
стационарным, если его уровни не содержа! тренда, а его
среднее значение (у;) и дисперсия остаются постоянными с
течением времени I рафик стационарного ряда представлен
на рис. 16 2.
407
PtK. 16.2. графи. етатвтозарюго временгого рада
Сглаженное значение временного ряла на период г вычис-
ляется как взвешенная сумма фактического значения уровня
на этот период и сглаженного значения на предыдущий пери-
од г - I:
5,«Лу,+ (1 - 4)5,,. (16.7)
гае г - 2. 3. 4. — временные периоды;
5 — сглаженное значение на период Г;
у — фактическое значение уровня на период г,
S — сглаженное значение на период г - I;
А — сглаживающая константа (0 < А < I).
Сглаживающая константа Л характеризует фактор взвеши-
вания наблюдений. Она может быть любым числом между 0 и I
Процедура экспоненциального сглаживания начинается с
определения сглаженного значения на 1-й период, которое
полагается равным первому наблюдению:
Далее имеем
5, - Ау, + О - 4)5, - Ау3 * (1 - А)у3.
S, = *>\ + О ~ 4)5, = Ay, + (I - 4) |4>, + (I - 4)у,| -
= АУ, + Л< I - A) у3 + (I - 4):у,.
5, = Ау, + (I - 4)5, -= Ау, + (1 - 4) (Ду, ♦ 4(1 - 4)у, +
+ (I - 4)!у,) - Ау, + А(1 - 4)у, + 4(1 - 4V>, + (1 - 4ру, и т л.
В общем случае получим
5 - Ayt + А1 - Л)х„, ♦ Ж J - Л)!4: t... +
+ Л(1 -ЛГ’^ + а -ЛГ>Г (16.8)
403
Как видно на выражения 116.8), весами отдельных наблюде-
ний являются величины:
А. /1(1 - А). /1(1 - А?, ... А(1 - АУг. (I - Л/-'.
Так как (1 - .4) < J, то они убывают по экспоненциально-
му закону по мере удаления наблюдения от текущего периода г
Отсюда .данная процедура получила название экспоненциаль-
ного сглаживания
Прогнозирование с использованием экспоненциального
сглаживания подобно процедуре "наивного" прогнозирования
(16.1), когда прогнозная оценка на завтра полагаегся равной
сегодняшнему значению В данном случае в качестве прогноза
на один период вперед рассматривается сглаженная величина
на текущий период:
.... (16 9)
Исходя из (16.7) и (16 9). можно записать модель прогнози-
рования:
у,„“ '•У, * О — Лу, (16.10)
В выражении (16 10) раскроем скобки и сгруппируем члены
+ К ~4У,в Л + ^У,~ у,)- (16.11)
В выражении (16.11) величина в скобках представляет собой
остаток е = у у,. Следовательно. модель экспоненциального
сглаживания построена по следующему принципу: прогноз на
период г Т 1 равен прогнозу на предыдущий период г плюс
ошибка прогноза на период I, умноженная на сглаживающую
константу А. Определение константы А является ключевым мо-
ментом в экспоненциальном сглаживании. Если она близка к
единице, то на новый прогноз в значительной степени будет
влиять ошибка предыдущего прогноза, а если близка к нулю,
то новый прогноз будет близок к предыдущему.
Малые значения A (A S 0,1) следует использовать для сгла-
живания временных рядов, уровни которых сильно изменяют-
ся под влиянием случайных возмущений (т. с. нерегулярной
компоненты). В этом случае происходит максимальное сглажи-
вание (фильтрация) случайных отклонений
Для более стабильных временных рядов, нс подверженных
существенному влиянию случайного фактора, значение А сле-
дует увеличить При больших А каждый новый прогноз стано-
вится чувствительным к текущим изменениям прогнозируемо-
го показателя.
«от
Прммер 16.4. За периоде 1981 по 1993 г были собраны данные
о средней посещаемости (у,) основных мероприятий городс-
кою культурного центра
Годы Г у, (тыс. чяд.) 1 Гады 1 У, (ТЫС- мел.)
Н 198’ 1 5.0 ’988 8 5.0
1982 2 8.0 1989 9 14,1
1983 3 2.1 .990 10 1X0
1984 4 7.1 1991 11 13.5
1985 5 48 1992 12 14.2
•966 6 2J0 1993 13 14j0
’9в7 7 7.8
Проведем экспоненциальное сглаживание данного времен-
ного риал, используя сглаживающие константы: Л " 0.1;
А - 0.5; А = 0.9.
Пусть Л’0,1, тогда получим
S. = 0,1у, + 0.95, = 0.1 8 + 0,9 5 = 5.3,
5} = 0. 1у, + 0.95, - 0.1 2.1 + 0.9 • 5.3 - 4,98
Аналогичные вычисления проведем для А - 0.5 и А “ 0.9.
Все результаты сведем в табл. 16.3.
Голица (6 3
Результаты простого эжепоноициальното сглаживания
временного ряда сродных посещений городскими жителями
культурного центра
Год 1 Ь * ОЗ) S^’O.S) 8<М - 0.9»
1 3 3 4 5 в
1981 1 5.0 6.0 5.0 5.0
1982 2 80 5,3 6.5 7.7
1983 3 2.1 4 98 4J 2.66
1984 4 7.1 5.19 5.7 6.66
1985 5 48 5.15 5.25 4.99
1988 Б 20 4,84 3.62 2.30
1987 7 7.8 5.13 5.71 7,75
1986 8 5J0 5.12 5J36 5.23
1989 9 14.1 6 02 9.73 13.21
410
Ояимчйнмс IBtA t6 3
1 2 4 5 е
1990 10 130 6.72 1136 13.02
199» 11 13,5 7.39 12.43 13.45
1992 12 14.2 6.07 1332 14,12
1993 13 14.0 а,67 1366 14.01
Графики временных рядов, представленных в табл. 16.3. изоб-
ражены на рис. 16.3
Рис (6.3. таясмх» олаженвого ьоемпьно.0 р»ла ервлнвгалоьи»
гкзсс-цгний горадссогс культурного jwpa (уД при различных А
Заметим, что средняя посещаемость v имеет скачок в 1989 г.,
кота культурный центр подвергался реконструкции. При малой
величине А - 0,1 сглаженные значения S после этого года в
большой степени расходятся с фактическими уровнями исход-
ного временного ряда, В общем случае сглаживание при малых А
слабо реагирует на подобные скачки или поворотные точки На
участке от 1981 до 1988 г, когда скачков не было, ислользова
ние малой константы обеспечивает значительное сглаживание
Большая константа А — 0,9 лает гораздо меньший сглажива-
ющий эффект, однако сглаженные значения в большей стспе-
411
ни следуют фактическим значениям по всей длине исходного
временного ряда -Это подтверждает тот факт, что испольюватъ
большие константы следует для рядов, содержащих незначи-
тельную нерегулярную компоненту.
Константа Л " 0,5 дает промежуточный эффект между пер-
выми двумя вариантами.
При использовании результатов экспоненциального сглажи-
вания для прогнозирования следует полагать
Л “ «V
Проделаем данную процедуру при Я 0.1 и вычислим ос-
татки на каждый период. Все результаты сведем в табл 16.4.
,’дб.пица ?8.4
Прогнозны® значения посещаемости городского культурного
центра и остатки, полученные с использованием модели
экспоненциального сглаживания (4 » 0,1)
Год t П У, •, • г, - i,
1981 1 5.6 - -
198? 2 8.0 5.0 3,00
1983 3 Z1 5J -3.20
1984 4 7.1 4.98 2.12
1985 5 4.8 5.19 ’0Л9
^986 8 2.0 5.15 -3.15
1987 ? 7.8 4.М 2.96
1988 В 5.0 8,13 -0.13
1989 9 М.1 5,12 8.98
19ЭС Ю 13.0 8.02 8.98
1991 11 135 6,72 6,78
1992 12 14.2 7.39 6.81
1993 13 14.0 8.07 5,90
Г рафиком прогнозных значений у. будет график сглаженных
значений 5 (Л - 0.1), представленный на рис 16.3, но сдвину-
тый на один год вправо (сы. рис. 16.4).
Как следует из табл. 16.4, начиная с 1989 г. величины остат-
ков достаточно велики. Это связано со скачком данных, проис-
шедшим в зтом году. Ввиду неожиданного скачка исходный
временной ряд в целом уже не будет стационарным и. следо-
412
Ямс. 16.4. Г рафмк грооюзкык эгачямий сзедисгалоооР пос сила смоет*
кулыурного «Юмтрв {А * 0.1)
взгельно, плохо подходит для экспоненциального сглаживз-
ния На промежутке от 1981 до 1989 г наблюдалась относитель-
ная стационарность, и, как видно из рис. 16.4. экспоненциаль-
ное сглаживание явно указывает на отсутствие тренда
пример г6.5. Пусть рассматривается ситуация примера 16.3.
В табл. 16.2 представлен временной ряд объемов продаж но
кварталам за промежуток от 1988 до 1994 г. (периоды 1—24).
Проведем простое экспоненциальное сглаживание данного
ряда за 1988—1993 гг. Фактические .данные за 1994 г. могут быть
использованы для сравнения, чтобы оценить, какой метод
дает лучшие результаты. Расчеты будем проводить при Л = 0,1
и А “ 0,6. Положим н качестве начального сглаженного зиаче
ния 3, •)>, ’ 500 Тогда
-4 = 0,1.
5, - у, - 500,
X - 0.1у + 0.9 J - 0.1 350 + 0,9 500 - 485,
Sj= 0, !>-, + 0.9S, = 0,1 250 + 0,9 485 = 461,5 » 462 и т. д.;
413
A - 0,6.
5, - У, - 500.
5; - 0,6 350 ♦ 0.4 500 - 410.
fs - 0,6 250 + 0,4 410 - 314 н т. л
Все результаты вычислений были сведены в таблицу:
t Mt 5,14-0.11 3,(А - 0,6] г М< S,<A-<M) »УА - о.®1
1 533 500 500 13 t»0 382 45В
2 350 405 410 14 зм 378 392
3 250 462 314 ♦5 2S0 366 307
4 400 455 365 16 560 384 453
5 460 455 416 П 550 401 511
б 350 444 37В 16 400 401 444
7 200 420 270 19 350 395 368
8 300 406 268 20 600 416 515
9 350 402 325 21 /50 449 655
Ю 20С 362 250 22 5ЭО 454 662
11 100 359 IHO 23 430 449 465
12 400 363 316 24 650 469 576
Полагая у, “ 5,, получим прогнозные оценки объемов про-
даж Вычислим остатки и все результаты сведем в табл. 16.5.
Таблица 16.5
Прогнозные оценки объемов продаж, полученные методом
простого экспоненциального сглаживания (А - 0,1 и А = 0,6)
t М« уЛ*-о.п е, У,(А 0.8)
1 2 3 4 б 6
1 — - — —
2 ЗМ 530 -150 500 -150
3 250 485 -235 410 -180
4 400 462 62 314 66
5 460 455 -6 366 84
В 350 455 -105 416 -66
7 700 444 -244 375 -176
8 300 420 -120 270 30
9 350 4ОВ -58 288 Б?
414
16.5
1 2 3 4 5 6
10 200 402 202 325 ”125
II 150 362 232 250 100
12 400 359 41 190 210
13 550 363 167 316 234
14 350 382 -32 456 -106
15 250 378 -128 392 -142
16 550 366 184 307 243
17 550 364 166 453 97
16 400 4OI -1 511 -121
19 350 401 -J1 444 -96
20 600 395 205 386 212
21 750 416 334 515 236
22 600 449 51 666 156
23 400 454 54 562 -12
24 650 449 201 466 185
Ретроспективно спрогнозируем объем продаж на период
Г- 25:
Л “ 0.1: » 0,1 650 + 0.9 449 - 469,1 - 469;
А - 0,6: ум„, - 0,6 650 + 0,4 465 = 576.
Отметим, что остатки большей частью отрицательны, что
свидетельствует о наличии треша.
Простое экспоненциальное сглаживание является несложным
и удобным способом прогнозирования. Для своей реализации он
не требует хранения всех предыдущих наблюдений: для прогно-
зирования на период i + 1 необходимо знать только текущее
значение у, и сглаженную величину 5 за предыдущий периаз.
16.2.2. Экспоненциальное сглаживание с учетом тренда
Простое экспоненциальное сглаживание временных рядов,
содержащих устойчивый тренд, приводит к систематической
ошибке, связанной с отставанием сглаженных значений от
фактических уровней временного ряда. Для учета тренда в не
стационарных рядах применяется специальное лвухпарамегри
415
ческое линейное экспоненциальное сглаживание В отличие от
простого экспоненциального сглаживания с одной сглажива-
ющей константой (параметром) данная процедура сглаживает
одновременно случайные возмущения и тренд с использова-
нием звук рахтичных констант (параметров). Днухпараметри-
ческий метод сглаживания (метол Хольта) включает два урав-
нения Первое предназначено для сглаживания наблюденных
значений, а второе — для сглаживания тренда
У,-4у( + (I-Л)($, + Л | (16.12)
Ф,-Bis,-S^) + (1 В)ЬЧ. (16.13)
где t •» 2. 3, 4. ... — периоды сглаживания;
S, — сглаженная величина на период г;
Ьг — сглаженное значение тренда на период I.
А и В — сглаживающие константы (числа между 0 и I)
Уравнение (16.12) похоже на уравнение простого экспонен-
циального сглаживании, только 5 заменяезся на (5 , + Л ) с
целью учета тренда Сглаживающей константой для этоз о урав-
нения является 0 < А < I. Обычно A S 0.3.
Уравнение (16.13) добавляется в общую процедуру для
сглаживания тренда. В нем используется отдельная константа
0 < В < I. Обычно она также меньше или равна 0,3 Каждая
новая оценка тренда получается как взвешенная сумма раз-
ности между последними двумя сглаженными значениями
(текущая оценка тренда) и предыдущей сглаженной оценки
Данное уравнение позволяет значительно сократить влияние
случайных возмущений на тренд с течением времени
Оба уравнения используются в модели линейного экспо-
ненциального прогззозироваиия Прогноз на период Н 1 равен
текущей сглаженной величине плюс текущее сглаженное зна-
чение тренда:
К.з “•у, + 2. Э.... (16.14)
Данную процедуру можно использовать для прогнозирова-
ния на любое число периодов, например на т периодов:
у,^ж 5;+ 1.2, 3.. (16.15)
Процедура прогнозирования начинается с того, что сгла-
женная величина 5 полагается равной у(. Возникает проблема
определения начального значения тренда 6,. Рассмотрим два
способа оценки 6,.
азе
Слогов 1. Положим 6 • О. Такой подход хороню работает в
случае длинного исходного временного ряла Тогда сглажен-
ный тренд за небольшое число периодов прнблизится к факти-
ческому значению тренда
Слоевб 2. Можно получить более точную оценку 6,, исполь-
зуя первые пять (или более) наблюдений временного ряда. На
их основе по метолу наименьших кпалратов peiuaeica уравне-
ние у,- а + Ьг Величина b берется в качестве начального значе-
ния тренда.
Прчнор тв.6. В следующей таблице представлены суммы нало-
гов (в тыс долл ), собранных поквартально за 1989—1993 гг. в
бюджет некоторого города;
Гад KeapiM 1 Собранным* НАЛОГИ
1969 1234 1234 76 93 108 128
1900 1234 5678 196 175 141 236
1991 1234 9 W 11 12 256 190 227 299
1992 1234 13 14 15 16 403 282 288 387
1990 1234 17 16 19 20 484 384 330 497
Используй способы I и 2, вычислить начальные значения
тренда, сглаженные величины 3^ и прогнозные оценки у, на
периоды исходного временного ряда (со 2-го по 20-й), а также
прогнозные оценки на периоды 21 и 22. соответствующие пер-
вому и второму кварталам 1994 г.
В соответствии со способом 1 полагаем 6, — 0. Следуя спосо-
бу 2, на основе первых пяти уровней временного ряла было
вычислено уравнение регрессии 37,7 + 25.7г 6, - 25,7. Резуль-
таты вычислений по сбоим способам представлены в табл. 16.6.
Гэблнцл Гб б
Результаты расчетов: деухлараметрическое линейное
ажстюмемциапьное сглаживание (А - 0,1, В « 0,3)
t я Способ 1 Способ 2
«, •, У, г.-У, ». 8, • Ft У, "Г,
1 2 3 4 5 в 7 В и 10
1 76,0 76,00 0.0 •* - 7600 27 50 •
2 93.0 77.70 0,51 76.00 17.00 10(2.45 27 18 103,50 *10,50
3 108,0 81 19 1.40 78.21 29.79 17747 25.54 129.63 -21.83
4 128.0 87.13 2,27 82.59 45.41 151.41 а.76 154.01 26,01
417
O»Owvj»«hc .-»9r 6
Для пояснения вычислений к табл 16,6 рассмотрим расче-
ты, выполненные способом I. для t- 10. а также найдем про-
гнозные оценки для I = 21 и t = 22.
Для г - 10:
Л. = 190;
S„- 0,1ум + 0.9(5, + 6,) = 0,1 190 + 0.9(164,21 + 14.78) -
- 180,09;
Ь„ = 0,М5м- 5,) + 0.76, - 0,3(180,09 - 164.21) +
+ 0,7 14,78 = 15,11;
>'ю = -У, + ь, “ + М.78 “ 178.99;
W Йо-190 - 178,99 =11,01.
Для г = 21:
способ 1 дает7»,-^ + I 446,43 + I 27,03 = 473,46;
способ 2 лает = 441,38 + 1 16,76 = 458,14
410
Для t — 22:
способ I дзету.,., “ 5„ + 2 ftw “ 446,45 + 2'27,03 _ 500.49.
способ 2 лает у„ “ 441,38 + 2 16,76 = 474.9.
На рис. 16.5 представлены графики величин у. и уг Как вид
но, способ 2 получения начального значения тренда ft, дает
более точные результаты сглаживания.
। г з я s а т s s ю it <г ia I» is is <r ia 19 го
Ямс. I6.5u ripoi»«o><MC значения, 'ккгучеммье на основе гииоймаго
зестюншмиальнсго сглаживания (А - 0.1. В - 0.3)
пример 16.7. Проведем линейное экспоненциальное сглажива
ние для временного ряла объемов продаж, представленного в
табл. 16.2 (пример 16.3). Вычисления будем вести, используя
способ I для нахождения ft, при Л = 0,3 и В = 0,1. Имеем
•S, - У, - 500;
ft, -о;
5, - Лу, +(! - Л) (St + ft,) = 0,3 350 + 0,7(500 + 0) - 455;
ft, - «5, - 5,) + (1 - «ft, - 0.1(455 - 500) + 0.9 0 - -4,5;
4 " *4 г. * 0.А5-, + ft,) - 0,3 250 + 0.7 (455 - 4.5) -
= 390,04;
ft, = 0.1(5, - 5.) + 0,9ft, = 0,1 (390,4 - 455) + 0,9 (-4,5) =
- -10,5; и т. д.
Учитывая (16.14), сведем все результаты в табл. 16.7.
419
Таблица }6 7
Результаты линейного эвспоменцмалемого сглаживаиня
временного ряда объемов продаж [А 0,3. 0-0,1)
г У. ». У.
1 500 5000 0.0 — —
2 350 4560 -4.5 500.0 150,0
3 250 390.4 -10,5 4505 -200,5
4 4О0 365.9 -9.9 379.9 202
5 450 398 2 -7,7 375,3 74.7
6 350 378.3 390 5 -*0.5
7 200 318,6 -14,0 369,4 -169,4
0 300 303.2 -14.1 304 6 -4.6
9 350 307,4 -12,3 289.1 60.9
10 200 266,6 -15.2 295,1 -95.0
11 190 221,0 ’6.2 251,4 -101,4
12 403 762.0 -12.3 202.8 197,2
13 560 339.8 -3.3 249.7 300 3
14 360 340,6 -2.9 336,5 13.6
15 250 311.4 -65 337.7 •67.7
16 550 379.1 1.8 305.9 244.1
17 550 431,7 6.9 381.0 1600
16 400 427,0 5.7 438,6 38.6
19 350 407.9 3.3 432.7 -82.7
20 600 467.8 8.9 411.2 188,8
21 730 556.7 17.1 476,8 273,2
22 500 L-’-xV 14.8 675.9 -75,9
гз 400 517.6 9.8 567.9 -167.9
24 650 564.2 13,5 527,4 122.6
На основе уравнения (16.15) спрогнозируем объем продаж
на периоды / » 25 и t - 26:
V, е 1 ' ь» ” 564 2 + 1 ,3>5 * 577‘7 в 578’
у1О1 «^*2 - 6М<= 564,2 + 2 13,5 * 591,2 - 591
420
16.2.3. Экспоненциальное сглаживание с учсгом
одновременно тренда н сезонности
Метод Хольта обобщается для временных рядов, содержа-
щих наряду с трендом ярко выраженную сезонную компонен-
ту Новый метод линейного и сезонного зкспоненциалыюгосгла-
живання — метод Вишера — является трехпараметрическим,
так как включает три сглаживающие константы. Он содержит
три уравнения: к двум уравнениям, сглаживающим наблюде-
ния и тренд, добавляется уравнение для сглаживания сезонных
изменений
Уравнение для сглаживания наблюдений имеет вил
5,- '♦О'/*'..? + <1 - X) (S„ + b^),
г=£+ I, £ + 2, £+3........
Уравнение, сглаживающее сезонность:
F, = ЛуА) + (I - B)F_C
г-£+ 1,£+2,£+3........
Уравнение для тренда:
6, ’ CIS- 5 ,) ♦ (I - СУЬ^,
t-£ + 1,£*2, £ + 3, ...
(16.16)
(1617)
(16.18)
В уравнениях (16.16)—(16 18) используются следующие обо-
значения:
5 — сглаженное наблюдение на период г,
F — отлаженный сезонный фактор,
bt — сглаженная оценка тренда,
£ — число периодов в году, характеризующих сезонность
(£ “ 4 для квартальных данных, £ “ 12 для месячных на-
блюдений);
А, В, С — сглаживающие константы.
Уравнения (16.16) и (16.18) подобны соответствующим урав-
нениям линейного экспоненциального сглаживания Отличие
заключается в том, что 5 теперь обозначают десезоиализиро-
ванные сглаженные величины. Они вычисляются делением каж-
дого наблюдения уг на величину характеризующую сгла-
женную оценку сезонности на данный период сезонности
предыдущего года.
421
Процедура прогнозирования аналогична линейному экспо-
ненциальному сглаживанию В данном случае прогноз на «дан-
ный квартал (или месяц) включает эффект от сглаживания по
трем уравнениям Прогноз на т периодов вперед задается урав-
нением < г. •
у,.„ = Ц + тЬ) F„.-I- (1619>
Выражение (£ + mb) характеризует сглаженную десезона-
лизированную оценку и учитывает сглаженный тренд Оно ум-
ножается на сглаженную оценку сезонности F квартала (или
месяца) гопа, предыдущего периоду осуществления прогноза.
На начальном этапе процедуры прогнозирования возникает
проблема определения начальных значений S, и относя-
щихся к нулевому году, который предшествует первому году
временного ряда. Как н в случае линейного экспоненциального
сглаживания, возможны два способа определения начальных
значений
Способ I
I Полагаем начальные сезонные индексы равными I
2 Налагаем начальную оценку тренда Ь(1 — 0.
3 Полагаем начальное сглаженное значение для квартала 4
(месяца 12) нулевого года равным фактическому значению для
квартала 4 (месяца 12) первого года. Оно является также про
гноэом (у,) хзя каждого из четырех кварталов (каждого из 12
месяцев) первого года.
Глосы! 2
I. Используя фактические данные за первые два года, опре-
делим индексы сезонности. Эго могут быть 4 квартальных зна-
чения или 12 месячных. Положим их равными соответствую-
щим сезонным опенкам для первого гада. Отметим, что для
вычисления начальных индексов сезонности можно использо-
вать данные за период более двух лет.
2. Десезонализируем данные за первые два года (или какое-
то большее количество лет). Обозначим десезоналнзированные
данные через d:. Используя их в качестве входной информации,
решим метолом наименьших квадратов уравнение прямой
rf, = а + bt. Тогда начальная оценка тренда = Ь.
3. Начальная сглаженная величина для квартала 4 (месяца
12) нулевого года определяется так: So = |д + Ь 0] (сезонный
индекс для квартала 4 (месяца 12), полученный на шаге I)—
Л77
— a (сезонный индекс), где а — свободный член уравнения,
полученного на шаге 2 Величина также будет являться про-
гнозной оценкой (у,) для каждого из 4 кварталов (12 меся-
цев) первого года.
Пример 16.в. Анализ квартальных данных нз примера 16.5 ука-
зывает на наличие сезонности. Так, данные за первые кварталы
практически по всем годам значительно превышают среднее
квартальное значение Используя линейное и сезонное экспо-
ненциальное сглаживание, определить сглаженные величины
и прогнозные оценки у, для всех периодов, полагая А - 0,1,
в-0,3 и С-0,2.
Способом I определим начальные значения = 0, у4 и
все сезонные индексы равны I Результаты прогнозирования
сведем в табл. 16.8.
7лС.'шиэ Гб в
Результаты линейного и сезонного экспоненциального
сглаживают. Способ 1 (Л = 0,1, В - 0,3, С • 0,2)
t ft «> А У, А’#.
1.0
1.0
1.0
128 1.0 00
1309 1 76 122 ас 0.89 -1,04 ’28.00 52.00
2 93 1 Ю зн 0.93 1.6? ’28.00 -35.03
3 ’СИ 116 34 0.98 1,80 128,00 20.00
4 128 115 89 1,03 -1.53 •28,00 00
1990 5 196 125 05 1.09 0.61 101.26 94 77
в 175 131 81 1.05 1.64 117 45 57.55
7 141 134 70 1.0С 2.05 130./8 10,27
8 236 145 95 1.21 3.89 141,03 М.97
1991 9 256 15Я 34 125 5.59 183,36 92.64
10 190 165 59 1 08 5.92 177.55 17.45
11 227 177,08 108 7.04 171.33 55.6 Г
12 299 19043 1 37 8.31 772.73 76.77
199г 13 403 211,19 145 10.79 746.1’ 154.Я9
14 2Н2 225.87 1 13 11.57 239.97 42,03
15 7Й8 240.26 1 12 12,13 257.35 33.65
16 387 256,57 »37 12.97 332.12 54.88
1993 1? 484 276.05 154 14,27 389 79 94.21
1Н ЗВ4 295,23 ’ 18 15.25 328 43 55,5/
19 330 308,94 1.10 14 <м 347 21 -17.71
23 497 327.68 К42 15.70 444 89 52.Н
423
Поясним содержание процедуры сглаживания (табл 16.8).
проведя вычисления для периодов t - I и г - 10
Л - Л(У,/1) + (I “ Л) (£ ♦ б,) - 0.1 76/1 + 0.9(128 + 0) -
-7,6 + 115,2- 122,8;
Г, - Я (у/S,) + <1 - В) 1 - 0.3 76/122,8 + 0,7 - 0.89;
б, - СЦ - 5,) + (I - Об, - 0.2 (122,8 - 128) + 0.8 0 -
- -1.04,
Я “У.-128;
е, = У, ~ >) = 76 - 128 = -52;
У„ = 190;
5„ = Afy^F^) + (I - 4) (S, + б,) = 0,1 I90/F +
+ 0,9 (158,34 + 5,59) = 0,1 190/1,05 + 0,9 163,93 = 165,59;
В * <• “ " °-3 «90/165,59 + 0,7 • 1,05 - 1,08;
6„ ” Win - * (1 ~ О*, “ 0,2(165.59 - 158.34) +
+ 0,8 5,59 -5,92;
У» “IV W - (158,34 + 5,59) 1,05 - 172,55.
Уш" 190 - 172,55 = 17,45.
Начальные значения можно определить способом 2
Данные за первые два гола используем для вычисления на-
чальных значений индексов сезонности (метод определения
индексов сезонности был изложен в главе 15). В результате имеем
квартал I — 1,23;
квартал 2 — 0,98.
квартал 3 — 0,91;
квартал 4 — 0,88
Значения за первые два года десезонализируем делением на
соответствующие индексы сезонности. На основе лесезонали-
зированных данных (Л,) методом наименьших квадратов пост-
роим линию регрессии
А, - 44,03 + 23,02г.
Величина 23,02 (округленная до 23) принимается за началь-
ное значение углового коэффициента тренда (б0). После этого
определяется начальное сглаженное значение для квартала 4 в
1988 г:
<£ - 44,03 • (начальное значение индекса сезонности для
квартала 4) = 44.03 • 0,88 = 38,7 = 39.
Значение 5(, - 39 берется в качестве прогноза ( у,) для каждо-
го из кварталов 1989 г.
«24
Все результаты расчетов, когда начальные значения опре
зеляются способом 2, представлены в табл 16.9.
Гэблииа 16 9
Результаты линейного и сезонного заслоненциального
сглаживания. Способ 2 (Д - 0,1, В - 0.3, С • 0,2)
Г % F. В, Я
1909 1 76 39 61.96 1.23 С 98 0,91 0,68 1.23 24 23 39 37
2 93 85,97 1.01 23. »9 39 34
3 106 110.11 0.93 23.38 39 69
4 12В 134 69 С.9 23,87 39 89
1990 5 196 158,44 ».?3 73.65 194.55 1.45
6 175 181,19 1 23,47 184 9
7 141 199,34 о.вв 22.4 193.59 -49 59
8 236 225,76 0.94 23,21 199,81 36 19
9 256 244,86 1.18 22,39 306,58 50 56
199» 10 •93 259.57 0,92 20.85 266.48 -Тб 48
11 777 27В.65 0.Я5 20.5 242,31 -15.31
12 299 300,9 0,96 20.В5 282.5» 16,49
13 403 323,85 1.2 2U7 378,24 24.76
»992 »4 287 341,34 0.В9 20.51 316.67 -34 76
15 2&3 359,56 0,83 20.06 307,3 -19.3
»б 387 387.07 0.96 20.53 364.14 27 86
17 484 402.76 1.7 20.56 481.55 7.45
1993 18 384 424,14 0.89 20.74 376,83 7.17
19 333 439.97 0,81 19,75 371.36 -41 35
20 497 464,65 1 20,74 448.32 48.68
Графики фактических значений временного ряда (у) и про-
гнозных величин (_И представлены на рис. 166 Как вилно, более
сложный способ 2 ласт лучшие результаты сглаживания для
последних 10 кварталов.
Ди метола Винтера возможна модификация способов опре-
деления начальных прогнозных значений Так. иногда они пола-
гакпеч равными у,, т е. фактическому значению уровня времен-
ного ряда на 1-й период сезонности, а нс на последний.
Пример >6.0. Рассмотрим данные об объемах продаж примера
16.3. Определим ретроспективные прогнозные значения на все
периоды временного ряла (1—24), а также вычислим прогнозы
на периоды 25—28, используя линейное и сезонное экспонен-
циальное сглаживание при А “ 0,4, В “ 0,1, С“ 0.3.
475
Лис. f6 0. Графики фактических и прогнозных значений,
лолум»ньмк с исголмоаанисм способов • и 2 дл« ои?м«и начальных
двчны« |Д - 0,1. О - ОД С - 0.2)
В примере 16.3 было отмечено, что временной ряд. пред
ставленный в табл. 16.2, содержит квартальную сезонность. В
качестве начальных сглаженных значений за первые четыре
квартала 1988 г. будем рассматривать величину у, = 500, в каче-
стве начального тренда — 0. начальный индекс сезонности
положим равным I
Вычислим сглаженные значения на период 2
I) 5, = у, = 500,
2> F, = 1.
3) 6, - О,
4) S, = Ay/l + (I - Л) Ц , + bt,) - 0,4350/1 ♦ 0,6(500 + 0) •
= 0.4 350 + 0.6 500 - 140 + 300 = 440.
5) ьг - «5, - 52 ,) + (I - Я)^, - 0,1(440 - 500) + 0,9 0 =
- -6.
6) F} = Q/Sj + (I - 0 • I - 0,3 - 350/440 + 0,7 • 1 - 0,2386 +
+ 0.7 - 0,9386
Аналогично вычисляются сглаженные величины для осталь-
ных периодов временного ряда Все результаты вычислений све-
дены bt.i(it 16.10.
426
Т^б.-миа >6 tO
Результаты линейного и сезонного экспоненциального
сглаживания для временного ряда объемов продаж (табл. 16.2)
при А = 0,4, В = 0,1, С = 0.3
» Ъ S, Ь, Г. 7» е.
1 503 5000 0.0 1,00 500 0 0.0
2 350 4400 -6.0 0,94 500 0 -150,0
3 250 360.4 -13.4 0.91 500.0 -250,0
4 40) 368.2 -11.2 1.03 500,0 -100,3
5 450 394.2 -7,5 1.04 357.0 93.0
б 350 381.2 -8.1 0,93 362,9 -12.9
7 200 311.9 -14 2 0.83 338,8 -138.8
8 300 295.5 -14.4 1.02 305,5 5Л
9 350 303.0 -12,2 1,08 293.2 56.8
10 200 260.3 -15.3 0.88 271,2 -7U
11 150 219.5 -17.8 0.78 202,9 -529
12 400 277.5 -10,2 1.15 206.2 193.8
13 550 364.7 -0.5 1.21 287.6 262.4
14 350 377.0 0.8 0,90 321.7 28,3
15 250 354.1 -1.5 0.76 296.5 -465
16 550 403,1 3.5 1.21 404.9 145.1
17 550 426.4 5.5 1.23 490.3 59.7
18 4СО 437,5 50 0.90 387,3 12.7
19 350 450.1 6.7 0.77 337,6 12.4
20 ЬСО 471,9 8.2 1.23 564.1 46,9
21 750 531.8 13.4 1.28 591.0 159.0
22 500 5488 13.7 0,90 491.7 83
23 400 5464 12.1 0.78 430.9 -30,9
24 650 546 4 10.9 1.22 6873 -37.3
25 713J
28 611.4
27 440.1
78 7198
Покажем, как вычисляются прогнозные значения на пери-
оды, не входящие ио временной ряд, — с 25-ю по 28-й. Эти
427
периоды соответствуют 1—4 кварталам 1995 г Для этого вос-
пользуемся уравнением < 16.19):
У,,., “ <Л. + ' • МЛ.-.-. ” <546.4 ♦ 1 109> 1.2» - 713.3:
Уи.» “ <Л. * 2 МЛ.-»-. “ <546'4 + 2 10-9>' °-9 " 51
У„., = (5н + 3 МЛ.-~ = l546-4 + 3 1°.9> °.?6 “ 440-‘'.
у».. “ + 4 МЛ...-.* (546-4 + 4 ,0'9) I-22 “ 719.3.
16.2.4. Измерение ошибок и сравнение методов
прогнозирования
Эффективность метода прогнозирования определяется точ-
ностью полученных на его основе прогнозных оценок. Рассмот-
рим основные показатели погрешности прогнозирования, ис-
пользуемые на практике.
Будем рассма.ривагь значения прогнозируемой величины у
во времени как уровни временного ряда.
Пусть у, — фактическое значение уровня временного ряда
на период (момент) Г, а у, — его прогнозное (оценочное)
значение. Тогда ошибку прогноза на период / можно рассмат-
ривать как остаток:
*.“У,_ У. <• 2.......">•
где я — число периодов прогнозирования.
Общая ошибка прогнозирования образуется накоплением
ошибок за все л периодов. При оценке метода прогнозирова-
ния общая ошибка вычисляется ретроспективно в результате
сопоставления уже наблюденных данных с соответствующими
оценками, полученными на основе рассматриваемого метода
прогнозирования (эти оценки как бы имитируют процесс про
гнознрования в прошлом).
Один из способов вычисления общей ошибки основан на
суммировании абсолютных величин остатков. В качестве обоб-
щенного показателя выбирается средняя абсолютная погреш-
ность MAD [mean absolute deviation):
Показатель MAD наиболее пригоден, если ошибку прогно-
за требуется измерять в тех же единицах, в которых измеряют-
ся уровни временного ряда.
43В
Альтернативным способом определения обшей ошибки яв-
ляется вычисление средняя квадратичная ошибка MSE (mean
squared error)'
М5Е = ^(У'= . (16.21)
n n
Показатель MSE позволяет выявитз. отдельные большие от-
клонения от фактических данных, если они существуют MSE
бывает полезным при сравнительном анализе методов прогно-
зирования Например, на основе MSE можно отобрать такие
способы прогнозирования, которые стабильно лают приемле-
мые средние ошибки. При этом способы, характеризующиеся,
как правило, малыми ошибками, но допускающие иногда очень
большую погрешность, могут быть отсеяны.
Когда на величину остатков влияет размерность уровней
временного ряда, то при определении показателя обшей ошибки
удобнее использовать относительные величины Таким показа-
телем, например, может быть средняя абсолютная относитель-
ная ошибка МАРЕ (mean absolute percentage error)'
MAPE-gJ1 -У* - Ж
n n
(16.22)
Иногда требуется оценить, насколько смешенными (т. е. за-
вышенными или заниженными) являются результаты прогно-
зирования. полученные по данному методу. Для этой цели ис-
пользуется показатель средней относительной ошибки МРЕ
(mean percentage error)
МРЕ =
(16.23)
Если показатель МРЕблизок к нулю, то смешения нет. Если
он отрицательный, то имеет место завышенность прогнозных
оценок; если положительный, то оценки будут заниженными
Пример 16-10. В табл 16.11 сравниваются два метода прогнози-
рования
429
Таблица 16.11
Сравнение двух методов прогноэироаэмая по показателем
общих ошибок: среднее абсолютнее погрешность (MAD),
среднее квадратичное ошибка (MSE). средина абсолютнее
относительнее ошибка (МАРЕ) и среднее относительнее
ошибка (МРЕ)
i, •г 1*3 1*,/у,1
Метод 1
36 32 4 4 16 0,111 0,111
42 4 С, -4 4 16 0.095 -0.096
45 49 -4 4 16 0.069 0.089
4в 0,296 0,073
MAD - 12/3 - 4
M5F - 48/3 - 16
МАРЕ - 0, 295/3 - 0 096 19.84)
МРЕ - -0, 073/3 - -0.024 (-24%)
Меюо2
36 34 2 2 4 0,056 0,056
42 40 2 2 4 0.048 0.048
46 62 -7 т 49 0,166 -0.1 MS
57 0.26 0.062
МАЭ- 11/ 3 - 3.67
MSE = 57/3 = 19
МАРЕ - 0.26/3 • 0.067 (8.7%)
МРЕ - 0 052/3 - -0.017 f 1.7%|
Использование метода 1 даст небольшие остатки по абсо-
лютной величине, а метол 2 — один большой остаток. Это по-
влияло на показатели MSE и MAD. для метода 1 меньше MSE.
а для метода 2 меньше MAD. Оба метода имеют незначитель-
ное отрицательное значение МРЕ, что свидетельствует о не-
большом смешении прогнозных опенок в сторону завышения
Для метода 2 МРЕ немного ниже. Другой относительный пока-
затель МАРЕ также немного лучше для метода 2.
Ясно, что чем меньше показатели ошибки, тем более точ-
ным будет метод прогнозирования. Пусть окажется, что в ре-
зультате сравнения нескольких методов разные методы имеют
лучшие оценки по несовпадающим показателям ошибки. Тогда
430
выбор наиболее приоритетных оценочных показателей зависит
от конкретной ситуации, в условиях которой осуществляется
прогнозирование. Так. в примере 16 10 выбор следует делать
между MAD и MSE. поскольку оба метода имеют близкие по-
казатели МРЕ и МАРЕ Например, если прогнозируется уро-
вень произаодствснных запасов, имеющих высокую стоимость,
то большие отдельные отклонения будут иметь заметное влия-
ние на процесс управления запасами. Поэтому преимущество
следует отдать MSE. В случае когда цель прогнозирования —
получить оценки, близкие в общем к фактическим значениям,
лучшим показателем может быть MAD.
16.2.5. Сравнительная оценка методов экспоненциального
сглаживания и сглаживающих констант
Рассмотренные в предыдущем разделе показатели обшей
ошибки пролгозирования позволяют дать сравнительную оиен
ку различных методов прогнозирования, способствуют выбору
эффективной вычислительной процедуры, наиболее адекватной
структуре временною ряда В частности, данные покаэшели можно
использовать для выбора метода экспоненциального сглажива-
ния, а также (если метод выбран) для определения сглаживаю-
щих констант, дающих максимальный сглаживающий эффект.
Чем меньше общая ошибка, тем лучше сглаживание.
Пример 16.11. В примерах 16.6 и 16 8 использовались различ-
ные методы экспоненциального сглаживания временного ряда
квартальных данных о собранных налогах: метод линейного эк-
споненциального сглаживания (пример 16.6) и метод линей-
ного и сезонного экспоненциального сглаживания (пример 16.8).
Результаты сглаживания и протезирования по методу Хольта
представлены в табл 16 6 (Л - 0,1 и В " 0,3). а по методу Вин-
тера - в табл . 16.8 С4 = 0.1. в = 0.3 и С = 0,2).
Сравним по показателю MSE оба метола, учитывая отдель-
но результаты, полученные с использованием способов I и 2
определения начальных сглаживающих значений. Таким обра-
зом. ио существу сравниваются четыре метола, т. е, следует вы-
числить четыре значения MSF.
I Линейное экспоненциальное сглаживание (способ 1). Ос-
татки. полученные в результате вычислений, представлены в
табл. 16 6 Вычислим средний квадрат ошибки:
MSE - (17* + 29,791 + ... + 56.19’1/19 - 5670.11
431
2 Линейное экспоненциальное сглаживание (способ 2). По
значениям остатков ил табл. 16.6 определим MSE.
MSE - |(-10,5)! +(-21,63)’ + ... + 61,8’1/19 - 3426.46
3 Линей нос и селенное экспоненциальное сглаживание (спо-
соб I). Значения остатков, содержащихся в табл. 16.8, исполь-
зуем для вычисления MSE:
MSE = ((-52)’ + (-35)’ + ... + 52,11'1/20 - 4414,95.
4 , Линейное и сезонное экспоненциальное сглаживание (спо-
соб 2). Вычислим MSE по остаткам, взятым из табл. 16.9:
MSE - (37’ + 54’ * ... + 48,68’|/20 - 1828,89.
Как видно, наилучщее сглаживание дает четвертый способ
Ему соответствует определенный набор сглаживающих констант:
Л " 0.1. В - ОД н С- 0.2 Можно попробован, улучшить пока-
затель MSE, изменив значение констант Например, новый
набор констант: А = 0.1. В = 0.4 и С = 0,3 снизит MSE с
1828,89 до 1748,1.
Пример (в. 12. Проведем сравнительную оценку результатов ис-
пользования различных методов экспоненциального сглажива-
ния на конкретном примере. Рассмотрим временной ряд объе
мов продаж некоторого продукта, полученных в примерах 16 5,
16.7 и 16.9.
В табл. 16.5 представлены ошибки прогнозирования на каж-
дый период (остатки) е:, вычисленные в процессе простого
экспоненциального сглаживания при А • 0.1 и А “ 0,6 Вычис-
лим показатели MSE, МАРЕ, МРЕ, используя соответственно
формулы (16.21). (16.22) и (16 23):
4 = 0,1:
MSE = |(-150)’ + (-235)’ + .... + 201’1/23 - 25317;
МАРЕ = (J— 150/500 +1-235/350( + .... + 20I/650J/23 =
= 0,4061 (40,61%);
МРЕ “ (-150/500 + (-235/350) + ... + 201/6501/23 =
= -0,2081 (-20,81%);
А - 0,6:
MSE - ((-150)’ + (-160)’ + ... + 185!|/23 - 23216;
МАРЕ = [|-1$0/500| ♦ |— 160/350, + ... + 18S/650J/23 =
= 0,3814 (38.14%);
432
МРЕ = [-150/500 + (—235/150) + . + 185/65О|/23 -
- -0,1033 ( -10.33%).
Как видно. А = 0,6 дает лучшие результаты сглаживания ио
всем показателям обшей ошибки. Сравним прогнозные оценки
на период (- 25 с фактическим значением ув - 850. взятым из
табл. 162:
А- 0,1:850 - 469 - 381;
А = 0,6:850 - 576 = 274.
Таким образом, использование сглаживающей константы
А = 0,6 дает также более точный прогноз на 1 -й кварта;! 1994 г.
(I = 25) Отрицательное значение средней относительной ошибки
(МРЕ • -10,38%) говорит о смещенности прогнозных оце-
нок, г. е. они почти всегда превышали фактические уровни вре-
менного ряда. Это свидетельствует о наличии тренда и (или)
сезонности
Можно попытаться полобрагть такую константу А, которая
уменьшила бы ошибки сглаживания по сравнению с A w 0.6.
Например, возьмем А — 0,1 и будем каждый раз прибавлять
0,01: 0,11, 0,12; 0,13;...; 0,99. Для каждой константы вычислим
показатели ошибки и выберем среди них каилучшнй вариант.
Данная процедура очень трудоемкая и должна осуществляться
с помощью компьютера. Итак, при А " 0,34 получим
MSE = 21421; МАРЕ = 35,41%; МРЕ = -11,5%.
Таким образом, удалось уменьшить показатели MSE и МАРЕ
с незначительным ухудшением показателя МРЕ.
Проанализируем результаты экспоненциального сглаживания
с учетом тренда (А - 0,3; В - 0.1). представленные в табл. 16.7
Вычислим ошибки прогнозирования:
MSE - |(-150)! + (-2OO.5)2 + ... + 122,6'1/23 = 22380;
МАРЕ = U—150/350, * 1-200,5/250! + ... 4 122.6/650|/23 -
- 0.3348 (33.48%);
МРЕ = [—150/350 + (-200,5/250) + ... + 122,6/650[/23 =
- -0,0665 (-6,65%).
С помощью компьютерной программы можно подобрать
константы Лив. которые улучшат показатели обшей ошибки
Так, при А « 0.3 и в - 0.2 имеем
MSE - 22349; МАРЕ ’ 33.74%; МРЕ - -6.22%.
433
Сравним данные значения с показателями, полученными
при простом жспоненциальном сглаживании:
Л = 0.14: MSE = 21 421: МАРЕ - 35,41%, МРЕ--11,5%;
А - 0,3. В « 0.2: MSE - 22 349, МАРЕ « 33,74%;
МРЕ --6.22%
Как видно, показатель MSE немного увеличился, но значи-
тельно снизилась средняя относительная ошибка (МРЕ), кото-
рая характеризует завышенность результатов прогнозирования.
Однако смещенность прогнозных опенок сохраняется и вели-
чина MSE достаточно большая. Это говорит о возможном вли-
янии сезонной компоненты, которая не была учтена прн ли-
нейном экспоненциальном сглаживании.
В табл 16 10 представлены результаты линейного и сезонно-
го экспоненциального сглаживания (А = 0.4: В= 0.1; С = 0,3).
Вычислим MSE:
MSE - |(-150)! + ... + (-.37.3V1/23 - 12 431,5
Если рассматривать в качестве критерия минимизацию сред-
него квадрата ошибки, то метод Винтера является лучшим по
сравнению с двумя предыдущими моделями. Ошибка прогноза
на 1-й квартал 1994 г также заметно уменьшилась:
850 - 713,3 - 136,7
Используя специальную компьютерную программу, можно
найти набор констант А, 8 и С, позволяющий ешс уменьшить
показатель MSE.
Следует особо отметить роль компьютерных технологий при
разработке и анализе моделей экспоненциального сглажива-
ния Без использования специальных пакетов прикладных про-
грамм было бы невозможно находить оптимальные сглаживаю-
щие константы. Так, а примере 16 II требовалось найти набор
констант А, ви Сдля метода Винтера, улучшающих показатель
MSE. Если рассматривать все возможные наборы констаит, где
каждая определяется как число от 0 до 0,4 с шагом 0,05 (0,05;
0.1; 0,1$, 0,4), то потребуется сравнить друг с другом
(0.4/0.05)1 = 8’ » 512 вариантов модели Винтера по величине
показателя MSF. Вариант, дающий минимальный показатель
MSE, будет наилучщим.
434
16.3. АВТОРЕГРЕССИОННЫЕ МОДЕЛИ
ПРОГНОЗИРОВАНИЯ
Данный тип моделей может эффектно использоваться,
когда переменная у? задаваемая временным рядом, зависит от
своих значений за прошедшие периоды времени. В этом случае
строится регрессия yt на некоторую комбинацию этих Значе-
ний. Полученное уравнение регрессии используется в качестве
прогнозной модели
Формально математическая модель авторегрессии строится
как множественная линейная регрессия зависимой перемен-
ной у,, представленной исходным временным рядом, на объяс
няюшие переменные у^р у ,которые характеризуются тем
же временным рядом, но сдвинутым соответственно на 1, 2,..
периодов вперед (т. е. полученные с соответствующей задерж-
кой ням временным лат ом из исходного временного ряда). Та-
кой метол получил название авторегрессии, т. е. построение
регрессии временного ряда на самого себя.
Можно ожидать, что метол авторегрессии будет давать хо-
рошие результаты для временных рядов, которые не очень рез-
ко колеблются и не содержат значительной нерегулярной ком
поненты. Авторегрессионный метод чаще всего используют для
краткосрочных и среднесрочных прогнозов (до двух лет).
Предположим, что необходимо предсказать значение у,
используя наблюдения за два предыдущих периода / - 1 и
г' 2 Прогнозное уравнение тогда будет иметь вид
у, • f “ 3, 4, 5... . (16.24)
Значения bt, bt и b2 вычисляются методом наименьших
квадрэюв. Уравнение (16.24) содержит две объясняющие пе-
ременные у иугГ которые называются запаздывающими. или
лигированными переменными. Уравнение (16 24) является ав-
торегрессионным уравнением второго порядка, так как и нем
используются две переменные с максимальным лагом в 2 ле
риода В общем случае авторегрессионное уравнение p ro по-
рядка имеет вид
Уе • 60 + biy^l + bj^ +...+ 1, р + 2,... .
Пример 16.13. В примере 16 I рассматривалась “наивная" мо-
дель прогнозирования цен акций некоторой компании на ко-
нец недели (закрытие фондовой биржи). Построим авторегрсс-
435
сионную модель второго порядка на основе исходной инфор-
мации этого примера В тайл 16 12 представлены временные ряды
зависимой и .тэгированных переменных
Таблица '6 12
Исходные данные для определенна авторегрессионного
уравнении второго порядка
V, Уе-« »., Гг к. Ft-t
60 — 63,5 62 В4.5
62.26 м 64 63,5 62
61.76 6225 60 63.25 64 63.5
63 61.75 62 25 62,5 63,25 54
64.5 63 61.75 61 62.5 63.25
62 64.5 63 61.5 61 62.5
В табл. 16.12 зависимая переменная уг представлена исходным
временным рядом, состоящим ид 12 наблюдений Датированная
переменная характеризуется тем же исходным рядом, но сдви-
нутым на 1 период (неделю) вперед (I I наблюдений) Для пере-
менной ул; временной ряд сдвигается на 2 периода вперед
(10 наблюдений). В расчетах, выполненных методом наимень-
ших квадратов, используется 10 наблюдений по каждой пере
мениой, расположенных после горизонтальной черты а табл 16.12.
Прогнозная модель, полученная методом наименьших квадра-
тов, будет иметь вид
у,= 45,5 + 0Д78^, - 0,004^.
Данная модель характеризуется коэффициентом детермина-
ции № *= 0,0611. Отсюда следует, что только 7% общей вариации
десяти значений временного ряла объясняется датированными
переменными первого и второго порядка.
Для выявления лучшего способа прогнозирования восполь-
зуемся показателями общей ошибки Вычислим, например,
показатель MSE для авторсгресионной модели второго поряд-
ка и 'наивной" модели, С помощью компьютерной программы
была определена сумма квадратов ошибок: 10.926. Для опреде-
ления средней квадратичной ошибки разделим эту сумму на 10
(число наблюдений):
MSF. - 10,926/10= 1,09
<36
Сравним авторегрессионную модель по показателю MSE с
“наивной" моделью, для которой MSE вычисляется по остат-
кам ит табл. 16.1
MSE - [2,25’ ♦ (-0.5)2 + ... + 0Лг|/11 - 21,5/11 = 1,95.
Таким образом, авторегрессионная модель лучше подходом
лзя сглаживания данного временного ряла, однако небольшое
значение Л° говорит о том. что исследования по поиску наи-
лучшей прогнозной модели следует продолжить
пример г в. 14. Рассмотрим временной ряд доходов одной круп-
ной компании за 15 лег
Г,Owe. лоал.) <(т«тО Xf|TMC. долл.)
1 4337.9 9 В668. б
2 4961.4 10 7658.3
3 5912.6 8337.8
4 5Я69 12 6965.8
5 6249.7 13 >0 236.4
6 6829 14 11 571.6
7 7364 13 073.8
8 79039
Требуется провести сравнительный анализ восьми различ-
ных способов прогнозирования:
I) У, “Л-i (“наивная" модель),
2) У< ~ ьа + *' (линейный тренд);
3) У, “ + + (линейный и квадратичный тренд);
4) у, = А„ + btyhl (авторегрессия первого порядка);
5) простое экспоненциальное сглаживание (А “ 0,3);
6) простое экспоненциальное сглаживание (А - 0,5),
7) линейное экспоненциальное сглаживание (4 = 0,1,
Л-0.1);
8) линейное экспоненциальное сглаживание (А — 0,3;
в = 0,3).
С помощью специальных компьютерных программ опреде-
лим искомые уравнения и выберем среди них такое, которое
минимизирует средний квадрат ошибки (MSE) Используя это
уравнение в качестве прогнозной модели, дадим оценку дохо-
да компании в году 1 - 16.
Рассмотрим результаты вычислений (для уравнений регрес-
сии представлены также значения Я1):
«т
I) MSE - 746633;
2) у, - 3750.7 + 514.16л R1 = 91.2%. MSE - 474546;
3» $, - 4773.9 + 153» 6 22,57г1, R- - 93.»». MSE - 334426.
4) y, - -150.1 + I.IO332y1(. R1 = 93.4», MSE = 317569.
5) MSE = 2928791,25;
6) MSE = 1637663,63;
7) MSE = 600062,8»;
8> MSE = 703394,06.
Визуальный анализ данных временного ряда указывает на
наличие возрастающего тренда. Это отразилось на том, что ''наи-
вная'’ модель и модель простого экспоненциального сглажива-
ния дали плохие результаты. Большое значение показателя MSE
имеет место для двух вариантов констант 4 и В в методе линей-
ного экспоненциального сглаживания. Поэтому, очевидно, нет
смысла пробовать дополнительные варили гы сглаживающих
констант Минимальный показатель MSE оказался у авторег-
рессионного уравнения первого порядка (способ 4). Использу-
ем его для прогноза на период t« 16:
Л* = -U0.I + M0J32ru “15,01 + 1,10332 13 073,8 »
- 14 274 (тыс. долл.).
16.3.1. Коэффициент автокорреляции и определение
датированных переменных модели
При построении авторегрессионной модели важно опреде-
лить величины временных лагов независимых переменных,
включаемых в модель. Для этой цели можно использовать ко-
эффициект автокорреляции, который характеризует корреля-
цию между у, и некоторой лазмроваииой переменной у . По-
рядок коэффициента автокорреляции задается числом периодов
к, определяющих лаг.
Коэффициент rt автокорреляции к-ю порядка, характери
зуюший корреляцию между у, и yw. имеет выражение
г» г
* £<Уг->Ху„. -yVSCx-y)’. (16 25)
где >; — уровень временного рада на период г,
к — число периодов, образующих лаг;
Г — общее число наблюдений во временном ряду.
азв
у = j. S У, — среднее значение временного ряда
Как и коэффициент корреляции, коэффициент автокорре-
ляции любого порядка изменяется ат -I до I Он измеряет тес-
ноту взаимосвязи между переменными у, и у^4. Коэффициент
автокорреляции более удобен для авгокорреляиионного анали-
за, чем коэффициент корреляции В частности, с его помощью
можно выявить нестационарность и сезонность временного ряда.
Пример те. 15. Определить г, и г, для временного ряда:
< У,
1 5
1 12
3 20
4 15
5 13
Вычислим вначалеу = (|/Г)Ху = 1/5(5 + 12 + 20 + 15 + 13)=
- 13.
По формуле (16.25) имеем
г, “ К>, - у) (у, - у) + О1! ~ у) (у, - у) ♦ (у, - у) *
х (у, * у) + (у, _ у Ху, ~ у)1/Ку, - у)2 + (у, - у)1 +
+ (у, - у)2 + (у, - уН ♦ (у, - у)2] = (-8X-I) + (-1)7 +
+ 72 + 2 0]/[(-«)’ + (-1)’ ♦ 21 + (Н| - 15/118 - 0,13;
гг “ fO'i “ /X/, “ У> + (Уз “ уХУ4 - У) +<У, “ У> *
* (У, ~ У )|/11« - К-8) 7 + (-1) • 2 + 7 • 0J/118 = -58/118 =
- -0,49.
Коэффициент г, отражает корреляцию между у, и уг|. аг,—
между у, к у
Графическим изображением коэффициентов авторегрессии
различных порядков для данного временного ряда является
коррелограмма. Так, для примера 16.15 коррелограмма имеет
вил. представленный на рис. 16.7.
Анализируя коррелограмму, можно определить переменные,
для которых соответствующие коэффициенты авторегрессии
имеют наибольшие по абсолютной величине значения
Анализ автокорреляции позволяет также выявить сезонность
в рассматриваемом временном ряду. Например, если сезонность
439
имеет место в квартальных данных, то следует ожидать высо-
кую положительную корреляцию между у и у^ т. е. г, будет
иметь большое положительное значение. Очевидно, для месяч-
ных данных, содержащих сезонность, следует ожидать, что г,,
будет иметь большое положительное значение.
Пример те. Тб. Табл. 16.13 содержит квартальные данные о до-
ходах некоторого магазина
таблица 'в. '3
Кварталы»» доходы магазина (тыс. долл.)
Квартал 1089 1990 т. tM2 1903
1 S.B6 Ml MS 6.31 4,01
2 16 36 I5JI 14.33 15.02 16.82
3 2.12 5.72 5.» 2 83 4.75
4 3.15 2.65 6.75 4,56 8.54
Требуется обосновжгь, какие лаифованные переменные сле-
дует включить в авторегрессионную модель.
Вычислим с помощью компьютерной программы первые 14
коэффициентов автокорреляции г, “ — 0,315; г. — -0,260;
е, « - 0,286; rt 0,678; г, = -0.213; г, = -0,168; г, = -0,156;
г, - 0,512; г, - -0,235; л « -0,134, г„ = -0,104; - 0,388;
«-0.155; гм- -0.06-
Выделим большие значения га; г4 » 0.678, г* • 0,512,
r(J ® О.З&8 Замегим, что г4 > г, > что типично для чсты-
рек периодной сезонности
440
Большое значение rt указывает на возможную сезонность. а
большие значения rt и г(, подтверждают эго предположение.
Используя в качестве объясняющей переменной, решим
уравнение авторстрсссии:
у, - 1.42 + О,87у^.
Для данной модели показатель ошибки MSF. “ 4025.
С целью обоснования эффективности авторегрессионной мо-
дели для данного временного ряда следует рассмотреть другие
методы про< котирования и сравнить их ло величине MSE >
16.3.2. Выявление и устранение нестационарное™
временных рядов
Метод авторегрессии (как и простое экспоненциальное сгла-
живание) может быть эффективным, если прогнозируемый
временной ряд является стационарным Это означает, что он
не содержит тренда и имеет постоянную вариацию вокруг сред-
него значения у Один из способов определения нестационар-
ности — анализ коррелограммы. Если нет быстрого убывания
до нуля коэффициенте автокорреляции (например, сразу после
гг или г,), то рассматриваемый временной ряд является песта
ционарным
Перед построением авторегрессии нестационарный времен-
ной ряд следует специальным образом трансформировать, сде-
лав его более стационарным, и уже 1рансформироианные дан-
ные имеет смысл исследовать на сезонность
Способ преобразования нестационарного ряда заключается
в вычислении разностей
У,'^У,~У^,- (16.26)
Затем уровни исходного ряда у_ заменяются на значения у»'.
Выражения вида (16.26) для различных г называются пер-
выми разностями.
Рассмотрим ряд
2, 5, 8, II, 14.
Данный ряд содержит явный линейный тренд — каждое
последующее значение получается из предыдущего прибавле-
нием тройки. Первзае разности определяются так:
>,=5-2 = 3.
>,=8-5 = 3.
акт
>/ — 11-8 = 3,
yt' * 14 - II = 3 и т. д.
Они уже не содержат тренд, т е ряд первых разностей будет
стационарным.
Если вычисление первых разностей приведет к стационар-
ному ряду, то коррелограмма значений у ' будет быстро стре-
миться к нулю. Если процедура вычисления первых разностей
не дает нужного эффекта, следует вычислить вторые разности
У,'• У,'~ У/, - У,-* У~у
Данный процесс можно продолжать до тех пор, пока вре-
менной ряд разностей не станет стационарным Обычно это
происходит, когда вычислены разности первого или второго
порядка. Если ряд стал стационарным (тренд исключен), но
содержит сезонную компоненту, то после быстрого спада до
нуля коэффициентов автокорреляции будут наблюдаться пе-
риодические пиковые значения, соответствующие сезонному
эффекту.
Пример 1в. 17. В примере 15.4 рассматривались квартальные дан-
ные о продажах, содержащие устойчивый линейный тренд и
явный сезонный эффект — низкие продажи в первых двух квар-
талах и высокие в последних двух. Используя метод разностей,
исключим тренд.
Вычислим (с помощью компьютерной программы) коэф
фициенты автокорреляции для исходных данных:
г, - 0,541; г, - 0,105; г, - 0,28; г4 - 0.473; rf - 0.122;
г, - -0,232; г, - -0,087; г„ - 0.063. г, = -0,176, гш= -0,422,
г„ - -0,279; ru - -0,121; - -0,234, ги - -0.343.
Видна явная нестационарное™, гак как коэффициенты не
убывают до нуля После двух нити трех периодов. Ввиду сильного
влияния тренда сезонный эффект не наблюдается.
Вычислим первые разности:
У, У,' " У, ~ У,-, У,
20 — 32
12 -8
47 35
60 13 101
40 -20 123
31
22
«42
Вычислим коэффициенты автокорреляции для первых раз-
ностей:
г, - 0,01, г, = -0,821; г, = -0,034; г, = 0,698; г, = 0,001;
г, = -0,546. г, - -0,024; rt 0,431; г,- -0.005, г„ = -0,307;
Г|( = -0,019; гц = 0,148; гь = 0,01.
Теперь сезонный эффект проявляется вполне определенно:
гг г<, н гю име|огг достаточно большие отрицательные значе-
ния, а ге г, и г„ — большие положительные Остальные коэф-
фициенты близки к нулю (тренд исключен) Отрицательные
значения - результат высоких (низких) продаж в период I,
который следует за периодом низких (высоких) продаж — два
квартала ранее. Аналогично большое значение г, указывает на
явный квартальный сезонный эффект, а большие значения rt
н г это подтверждают
Для авторегрессионной модели, построенной на основе пер-
вых разностей, наилучшими объясняюшнми переменными яв-
ляются и yrt В этом случае авторегрессионная модель будет
иметь вид
у, - 6, + 6/г,'+
16.4. ИСКУССТВЕННЫЕ ПЕРЕМЕННЫЕ
В ЛИНЕЙНОЙ РЕГРЕССИОННОЙ МОДЕЛИ
Включение искусственных переменных и регрессионную
модель позволяет учитывать качественные факторы в прогно-
зировании Например, если требуется учитывать патовой при-
знак, то как искусственную переменную можно рассматривать
х e I I» «ели мужчина.
I 0, если женщина
Заметим, что присвоение значения I мужчине или женщи-
не произвольно. Прогнозируемая величина у будет та же самая,
независимо от способа кодирования
Искусственные переменные можно эффективно испольэо
нать в прогнозировании временных рядов Например, при уче-
те сезонного эффекта искусственные переменные будут харак
геризовать определенные сезоны. Так, в случае квартальной
443
сезонности один из возможных способов кодирования имеет
следующее выражение:
<?.-
I, если квартал 1;
О в остальных случаях.
I, если квартал 2;
О в остальных случаях.
(16 27)
(I, если квартал 3;
О в остальных случаях,
Заметим, что число искусственных переменных иа единицу
меньше числа кварталов При данном способе кодирования нет
необходимости вводить переменную Qe так как кварталу 4 авто-
матически будут соответствовать соотношения Qt ~ 0. Q, ” 0.
С, = 0.
Для месячной сезонности можно выбраг ь аналогичную схе-
му кодирования. Тогда число искусственных переменных рав-
няется 12 — 1 ” 11:
М,
1, если январь;
0 в остальных случаях.
Ч "
1, если февраль;
0 в остальных случаях.
(16 28)
II. если ноябрь;
0 в остальных случаях.
Для учета эффекта, вызванного декабрем, все 11 искусст-
венных переменных должны принимать нулевые значения.
Рассмотрим аддитивную модель анализа временного ряда,
учитывающую тренд, сезонность и нерегулярную компоненту:
у, - ГЛ, ♦ 4
где тренд (ГЯ() может быть выражен в пиле прямой (ТЯ, = Р.
+ р/> или кривой (Т«, - Р, + Р.г + р,г!) линии, S' —
эффект сезонности, /, нерегулярная компонента
444
Если имеет место тренд и квартальная сезонность. то воз-
можны. например, следующие модели для прогнозных оце-
нок
Xе Ьл + h,r ♦ + b<Qy (16 29)
у, - 6(1 + bt + 6/ + b,Qt ♦ Ь'0г ♦ i5C, (16 30)
В моделях (16.29) и (16.30) оценки сезонности выражаются
соответственно так:
'-= *а<?. + М?з + *.<?.
*,<?, + \Q2+ bsQt
Пример 1в.1в. Рассмотрим временной ряд квартальных про-
даж. представленный в примерах 15.4 и 16.17. В примере 15.4
предполагалось, что наиболее адекватной яатястся мультипли-
кативная модель. Предположим, что были проведены допол-
нительные исследования полученной модели и характера из-
менения временного ряда. Возникли сомнения по поводу того,
что амплитуда квартальных сезонных колебаний сильно возра-
стает вместе с трендом. Поэтому было решено попробовать для
прогнозирования аддитивную модель (16.29) с искусственны-
ми переменными, определяемыми соотношениями (16.27) Вход-
ная информация для расчета величин 6,, 6,...64 методом наи-
меньших квадратов имеет вид
У,
20
12
47
60
40
32
65
76
I
т
2
3
4
5
6
7
1!
я
I
0
0
0
1
о
о
о
А
о
1
о
о
о
I
о
о
(?,
о
о
I
о
о
о
I
о
У,
«Г
50
85
100
75
70
101
123
9
10
II
12
13
14
15
16
О,
I
0
о
о
I
о
о
о
<?, <?.
о о
1 о
0 1
о о
о о
1 о
О 1
о о
В результате компьютерных расчетов имеем уравнение
у,- 41,75 + 4,8г - 27,6Q, - 39,15^ - 10.45Q,. (16.31)
Величина коэффициента множественной детерминации
Я’ “ 0,996 свидетельствует об очень высоком уровне сглажива-
ния 16 наблюдений. Сравним модель (16.31) с мультиплика-
445
тивной моделью, которую определим как произведение тренда
на индексы сезонности:
?,= (Ь„ + 4,0 5
Используя исходные данные у,. методом наименьших квад-
ратов вычислим тренд:
ГЛ, - 19.372 + 5.0375г
Индексы сезонности за каждый квартал возьмем из приме-
ра 15.4. Тогда прогнозная модель примет вид
>,= (19,372 + 5,03751) 5,. (16 32)
где 5,-5, = 5,-.....-0,852;
5, - 5; - - ... - 0,692;
1,166;
5. = 5,-5,г- ...= 1,29
Для мультипликативной модели (16.32) и аддитивной мо-
дели (16 31) вычислим показатель MSI: (табл. 16.14 и 16.15):
Таблица 16 14
вычисление среднего квадрата ошибки (MSE)
для мультипликативной сезонности
Г У. i, у.-у«
1 20 20 80 -0.80
2 12 20.38 -8.38
3 47 40,21 8.79
4 6С 50 98 9.07
5 40 37 96 2.04
в 32 34 32 2.32
7 85 63.70 1.30
8 78 76 98 -0-98
9 56 55 13 0.87
10 50 48,26 1.74
11 85 87.20 -220
12 100 102.97 2.97
13 75 72.30 2.70
14 70 62,21 7.79
15 101 110.69 9.89
16 123 128.96 -5.96
MSF. = £(>,- у,)'/16 = 425,36/16 = 26,58;
44*
Таблица 16. >5
Вычисление MSE дм аддитивной сезонности
t Г, Г, г.-Г.
1 20 •8 95 1.06
2 12 1220 0.20
3 47 45,70 1,30
4 60 60,95 0,95
5 40 38,15 1,85
6 32 31.40 0,60
7 65 64,90 0.W
8 76 80.15 -4.15
9 56 57.35 -1,35
10 50 50,60 -0.60
11 85 84,10 090
12 1ОЭ 99 35 065
13 75 76,56 -1.56
14 70 69.80 020
15 101 103,30 -2,30
16 123 118,56 4.45
MSE - £(к, - у, >716 - 55,7/16 - 3,48.
Как видно, модель (16.31) дает значительно более точные
результаты сглаживания, что свидетельствует об аддитивной
сезонности
Из уравнения (16.31) можно сделать следующие выводы.
1 Продажи возрастают в среднем на 4.8 (млн долл.) за квар-
тал.
2 . Независимо от эффекта тренда продажи за квартал I на
27,6 (млн долл.) меньше, чем продажи за квартал 4
3 . Независимо от влияния тренда продажи за квартал 2 на
39,15 (млн лолл.) меньше, чем за квартал 4.
4 Продажи за квартал 3 на 10.45 (млн лолл ) меньше, чем за
квартал 4.
Используем аддитивную модель (16.31) ня прогнозирова-
ния объемов продаж на кварталы 1—4 1994 г.
Квартал l-й: О, “ I, ” 0, Q, ” 0;
у,, - 41,75 + 4.8 17 - 27.6 I - 39,15 0 - 10,45 0 = 95,75
(млн ДОЛЯ.).
Квартал 2-й: О, ” 0. Qj w 1. О, ” 0;
у„ = 41,75 + 4,8 18 - 27,6 0 - 39,15 I - 10,45 0 - 89
447
Квартал 3-й: 2, = О, Q, = О, Q, » I;
у„ - 41,75 + 4,8 18 19 - 27.6 О - 39.15 0 - 10,45 1 =
= 122.5.
Квартал 4-й: Qt = О, 02 “ О- Q, “ 0;
ум = 41,75 + 4,8 20 - 27,6 0 - 39.15 0 - 10,45 0 =
’ 137,75.
16.5. ПРОБЛЕМА УСТРАНЕНИЯ АВТОКОРРЕЛЯЦИИ
ОШИБОК
Проблема, которая часто возникает при использовании мо-
дели множественной линейной регрессии, полученной как рег-
рессия на временной ряд, - автокорреляция остатков е. Как
отмечалось и разделе 14.15, в этом случае все проверки гипотез
относительно параметров модели, включая '-критерий, могут
быть неадекватными Выявление автокорреляции ошибок (се-
рийной корреляции) производится по критерию Дарвина—
Уотсона (14.8).
Для устранения автокорреляции можно использовать ряд
процедур. Рассмотрим некоторые из них.
1. Замена у, первыми разностями. Новой зависимой перемен-
ной в этом случае является
Л’ “X" V
2. Замена у, на темп прироста за период t:
z, = О’," Ум/Ун) ' '«О
3. Включение и регрессионную модель датированных пере-
менных уг ), у„},- в качестве объясняющих зависимую перемен-
ную v.
4 Улучшение существующей модели с помощью включения
в нее дополнительной переменной, объясняющей yt Эффект
автокорреляции остатков может быть связан с отсутствием пе-
ременной. значимо влияющей на вариацию у,.
Пример 1в.ГЯ. Руководство некоторой фирмы, выпускающей
электронные приборы, хочет спрогнозировать продажи своей
продукции. Предполагается, что объясняющей переменной
могут быть затраты на научно-исследовательские разработки
(НИР). Для построения линейной регрессионной модели были
44В
собраны данные о продажах и затратах на НИР та 1973—1993 it.
(табл. 16.16)
Таблица >б IS
Данные о продажах фирмы (у) и затратах на НИР (х)
за 1973-1993 ст., темпы прироста у и к
Г°А Продажи у (тыс долл) Затраты на НИЯ я (тыс. долл ! Темп прироста >• предыдущий ПОР4ЮД
(у, - Г,.,1/У, к - '..У.
1973 3307 273.4 — --
1974 3566 291,3 7.5 8,5
1975 3601 306,9 1.3 5.4
197Б 3721 317,1 3,3 3,3
1977 «36 336,1 8.5 6.0
1979 4134 349,4 2.4 4.0
1979 4268 362,9 3.2 5.7
1980 4578 383,9 7.3 5.8
1981 5093 402.8 1U 6.3
1982 5716 437,0 12.2 8.5
1983 6357 472.2 п.2 8.1
1984 6789 510,4 6.5 8.1
1985 7296 644,5 7.8 6.7
1986 8178 S&8.1 12.1 8.0
’987 8844 630.4 8.1 7,2
1988 □7S1 635.9 4.6 8.8
1989 10 0Q6 742.8 8,2 8.3
1990 11 200 801.3 11,9 7.9
1991 12 500 903.1 11,6 12.7
1992 13 101 963.6 4.6 8.9
1993 13 64С 10767 .*? 95
Уравнение простой регрессии имеет вид
у - -524 + 14х
Уравнение существенно при Я, 0.99 Однако вычислен-
ное по формуле (14.8) значение критерия Дарбина—Уотсона
DH'= 0,63. По таблице хзя уровня значимости 0,1 (Приложе-
ние 8) определим нижнюю (</t) и верхнюю (dj критические
границы:
</, = 0.95.
<- 1.15
w
Вейлу того что DW = 0,63 < 0,95. имеет место положитель-
ная серийная корреляция, следомпельно, существенность ура»
нения регрессии вызывает сомнение.
Заменим переменные соответствующими гемпами прирос-
та, которые вычисляются следующим обратом;
(Уг-У,
1973 —. —
1974 13556 - 3307У3307 - * 0,075296 (7.5%) (291.3 - 273.41/273.4 • -00€S<72 (5 5%j
1975 f 3601 3556УЭ556 - 3 0.012655 (1 34) (306.9 791.31/291.3 - - 0.353553 (5.4%| rt г. Д.
Округленные значения темпов прироста (в %) представле-
ны в табл. 16.16
Методом наименьших квалраюв вычислим регрессию тем-
па прироста у на темп прироста х
* 101Ц-хм)/хг,
(16 33)
В уравнении (16.33) отсутствует свободный член, так как в
качестве переменных выступают темпы прироста. Значение кри-
терия Дарбина -Уотсона теперь будет DW- 1,27. Это означает
(1,27 > d = 1,15), что серийная корреляция ошибок была уст-
ранена
Рассмотрим процедуру прогнозирования с помощью урав-
нения 16.33. Спрогнозируем объем продаж на 1994 г.
I. Пусть прогнозная оценка личных доходов и 1994 г
*=1185
2. Вычислим темп приростах за 1993 г.;
<П«5 - I076,7)/1076,7 = 0,l0t (Ю.1ЯЬ).
3. Вычислим темп прироста у за 1993 г.:
(у1М, ~ В 640)/13 640 - 1,01 0,101 - 0,10201.
4 Определим прогнозную оценку >yw:
Jiw. “ 13 640 0.10201 «• 13 640 - 15032.
4S0
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 16
Рассматриваются различные способы и модели npoi котиро-
вания, основанные на методах л налита временных рядов и per*
рессиоинозо анализа.
Наиболее простой способ прогнозирования заключается в
предположении, что текущие периоды являются лучшими пред-
сказателями для будущего. Простейшая (“наивная*’) модель
имеет вид (16.1). Ее использование в прогнозировании дает хо-
рошие результаты. если наблюдения соответствуют коротким
периодам времени (например, дни или недели) и характер их
изменения не содержит заметных скачков Простейшие модели
можно адаптировать к структуре временного ряда Возможны
модификации “наивной” модели, учитывающие тренд и се-
зонность (например, модели (16.3)—(16 6))
Одним из способов сглаживания временных рядов является
экспоненциальное сглаживание. Вычислительная процедура
включает обработку всех предыдущих наблюдений При этом
учитывается “устаревание” информации по мере удаления от
прогнозного периода: чем “старше” наблюдение, тем меньше
оно должно влиять на величину прогнозной оценки. Идея про-
стого экспоненциального сглаживания состоит н том, что по
мере “старения" соотаетсгиукнним наблюдениям придаются веса,
убывающие по экспоненциальному закону (уравнение (16.8)).
Простое экспоненциальное сглаживание лает хорошие резуль-
таты для стационарных временных рядов, имеющих постоянное
среднее значение и дисперсию и не содержащих тренда. От ха-
рактера изменения временного ряда зависит выбор сглаживаю-
щей константы А (0 < А <1) в модели (16.7). Малые значения А
(Л < 0,1) следует использовать для сглаживания временных ря-
дов со значительной нерегулярной компонентой. В этом случае
происходит максимальная фильтрация случайных отклонений
Для более стабильных временных рядов значение А следует уве-
личить. Тогда каждый новый прогноз становится чувствитель-
ным к текущим изменениям прогнозируемого показателя.
Простое экспоненциальное сглаживание временных рядов,
содержащих устойчивый тренд, приводит к систематической
ошибке, связанной с отставанием сглаженных значений ог
фактических уровней времен немо ряда. Для учета тренда и не-
стационарных рядах используется специальное лвухпараметри-
ческос линейное экспоненциальное сглаживание (метол Холь-
та) Данный метол включает два уравнения: уравнение (16.12)
предназначено для сглаживания наблюденных значений и урав-
451
пение (16.13) — для сглаживания тренда. Каждое уравнение
содержит отдельную сглаживающую константу, значение ко-
торой заключено между 0 и 1 (параметры модели). Первый этап
процедуры прогнозирования — оценка начального значения
тренда. Предлагаются два способа. При первом способе началь-
ное значение тренда полагается равным нулю. Второй способ
(более точный) заключается в вычислении методом наимень-
ших квадратов линейного уравнения регрессии на основе пер-
вых нескольких фактических наблюдений. Коэффициент рег-
рессии берется в качестве начального значения тренда.
Для временных рядов, содержащих не только тренд, но и
значительную сезонность, эффективным является трехпарамет-
рический метод линейного и сезонного экспоненциального
сглаживания (метод Винтера). Он включает три уравнения с
отдельными сглаживающими константами и является обобще-
нием метода Хольта: кдвум уравнениям (16.16) и (16.17), сгла-
живающим прошлые наблюдения и тренд, добавляется урав-
нение для сглаживания сезонных изменений (16.18). Как и в
случае линейного экспоненциального сглаживания, возможны
два способа определения начальных значений. Способ 1 пола-
гает начальные сезонные индексы равными единице, началь-
ное значение тренда — нулю и начальное сглаженное значение
временного ряда — значению за последний (или первый) пе-
риод сезонности первого года. Более точным, но более Трудо-
емким является способ 2. На основе фактических данных за
первые несколько лет (например, 2 года) определяются ин-
дексы сезонности, которые выбираются в качестве начальных
оценок. Далее фактические наблюдения, использованные при
вычислении сезонности, десезонализируются (делятся на со-
ответствующие индексы сезонности). На их основе с помощью
метода наименьших квадратов вычисляется линейное уравне-
ние тренда. Угловой коэффициент регрессионного уравнения
берется в качестве начальной оценки тренда. Начальная сгла-
женная величина определяется как произведение соответству-
ющего индекса сезонности (за последний или первый период
сезонности) и величины, полученной при подстановке в вы-
численное ранее уравнение тренда значения t = 0.
Эффективность метода прогнозирования определяется точ-
ностью полученных на его основе прогнозов. Общая ошибка
метода прогнозирования накапливается за счет ошибок, полу-
ченных на каждый период прогнозирования. Ошибка (остаток)
за какой-либо период прогнозирования определяется как раз-
ность между фактическим наблюдением и оценочным (про-
452
гнозным) значением на этот период. При оценке метода про-
гнозирования общая ошибка вычисляется ретроспективно при
сопоставлении уже наблюденных данных с соответствующими
оценками, полученными на основе рассматриваемого метода.
Один из способов вычисления общей ошибки заключается в
суммировании абсолютных величин остатков. В качестве обоб-
щенного показателя выбирается средняя абсолютная погреш-
ность MAD (mean absolute deviation) (формула (16.20)). Показа-
тель MAD наиболее пригоден, если ошибку прогноза требуется
измерять в тех же единицах, в которых измеряются уровни вре-
менного ряда. Альтернативным способом определения общей
ошибки является вычисление средней квадратической ошибки
MSE (mean squared error) (формула (16.21)). Показатель MSE
позволяет выявить отдельные большие отклонения от факти-
ческих данных, если они существуют. Когда на величину остат-
ков влияет размерность уровней временного ряда, то при оп-
ределении показателя общей ошибки удобнее использовать
относительные величины. Таким показателем является средняя
абсолютная относительная ошибка МАРЕ (mean absolute percen-
tage error) (формула (16.22)). Иногда требуется оценить, на-
сколько смещенными (т. е. завышенными или заниженными)
являются результаты прогнозирования, полученные данным
методом. Для этого используется показатель средней относи-
тельной ошибки МРЕ (mean percentage error) (формула (16.23)).
Если он близок к нулю, то смешения нет; если отрицатель-
ный, то имеет место завышенность прогнозных оценок; если
положительный, то оценки будут занижены. Чем меньше пока-
затели общей ошибки, тем точнее метод прогнозирования.
Если переменная уе задаваемая временным рядом, зависит
от своих значений за прошедшие периоды времени, то эффек-
тивным способом прогнозирования может оказаться авторег-
рессионная модель. Она получается построением регрессии yt
на переменные у , у , .... которые характеризуются тем же
временным рядом, но сдвинутым соответственно на 1, 2,... пе-
риодов вперед (т. е. полученные с соответствующей задержкой,
или временным лагом, из исходного временного ряда). Пере-
менные у^р у,,.,... называются датированными переменными. Для
определения, с каким лагом включать переменные в модель,
можно использовать коэффициенты автокорреляции различных
порядков г Коэффициент А-го порядка характеризует корреля-
цию между yt и у^к и изменяется от —1 до 1 (формула (16.25)).
Графиком значений коэффициентов автокорреляции является
коррелограмма. По ней можно судить, какие датированные пе-
453
ременные следует включить в авторегрессию. Это будут пере-
менные, для которых соответствующие коэффициенты авторег-
рессии имеют наибольшие по абсолютной величине значения. С
помощью коррелограммы можно также выявить сезонность и
нестационарность временных рядов. Если не наблюдается быст-
рого убывания до нуля коэффициентов автокорреляции (напри-
мер, сразу после г, и г), то рассматриваемый временной ряд
будет нестационарным. Перед построением авторегрессии не-
стационарный временной ряд следует специальным образом
трансформировать, сделав его более стационарным, и уже транс-
формированные данные исследовать на сезонность. Способ пре-
образования нестационарного ряда за-ключается в вычислении
первых или вторых разностей с последующей заменой на них
уровней исходного временного ряда. Если ряд стал стационар-
ным и содержит сезонность, то после быстрого спада коэффи-
циентов автокорреляции будут наблюдаться периодические пи-
ковые значения, соответствующие сезонному эффекту.
В прогнозировании временных рядов эффективно использу-
ются регрессионные модели с искусственными переменными.
Например, при учете сезонности искусственные переменные
могут характеризовать определенные сезоны. Для введения ис-
кусственных переменных в модель они кодируются по опреде-
, ленной схеме. Так, для квартальной сезонности возможна схе-
ма (16.27), а для месячной — (16.28). Применение искусственных
переменных дает хорошие результаты в случае аддитивной се-
зонности.
Проблема, которая часто возникает при использовании мо-
дели множественной линейной регрессии, полученной как рег-
рессия на временные ряды, — автокорреляция остатков. Для
устранения этого явления можно использовать следующие про-
цедуры:
1. Замена уровней временного ряда первыми разностями.
2. Замена уровней временного ряла темпами прироста.
3. Включение в регрессионную модель лигированных пере-
менных в качестве объясняющих зависимую переменную.
4. Улучшение существующей модели с помощью включения
в нее дополнительной независимой переменной, значимо вли-
яющей на вариацию зависимой переменной.
СТАТИСТИЧЕСКИЕ
МЕТОДЫ ОБОСНОВАНИЯ
УПРАВЛЕНЧЕСКИХ
РЕШЕНИЙ В УСЛОВИЯХ
НЕОПРЕДЕЛЕННОСТИ
Управленческая деятельность в любой предметной области
(производство, торговля, финансы и т. д.) постоянно связана
с принятием решений по возникающим проблемам. Для разра-
ботки и выбора единственно правильного решения необходи-
ма полная и достоверная информация, характеризующая про-
блемную ситуацию. Иначе говоря, должна быть полная
определенность относительно всех факторов, прямо или кос-
венно влияющих на решение. Однако на практике многие фак-
торы: уровень спроса на товар, погодные условия, курс ак-
ций, цены на нефть, политическая обстановка, стихийные
бедствия и т. д. — нельзя предсказать точно. Поэтому и выбор
решения очень часто сопряжен с неопределенностью. В процес-
се принятия решений неопределенными могут быть условия
реализации решений, их последствия, а также сознательные
действия конкурентов или других субъектов, заинтересован-
ных в разрешении данной проблемы. Иногда неопределенными
могут быть цели (или критерии) выбора решения, когда эф-
фективность решения нельзя охарактеризовать одним-един-
ственным показателем.
Следует отметить, что в отсутствие полной определенности
всегда неизбежен риск принятия не самого эффективного ре-
шения. Однако в условиях сложной ситуации использование
специальных статистических методов позволяет глубже разоб-
раться в ситуации и оценить каждое возможное решение таким
образом, чтобы риск был минимальным.
Данное направление в статистическом анализе получило
название теории статистических решений (в прикладных за-
дачах часто используют термин: теория принятия решений в
условиях неопределенности). Рассмотрим элементы этой тео-
рии.
455
17.1. ОПИСАНИЕ ПРОБЛЕМНОЙ СИТУАЦИИ
Любая проблема принятия решений включает три аспекта:
1) выявление возможных вариантов действий (альтернатив-
ных решений или альтернатив);
2) описание факторов неопределенности, т. е. будущих со-
бытий, связанных с принимаемыми решениями;
3) оценка результатов (последствий) принимаемых реше-
ний.
Пусть, например, фирма рассматривает три варианта инве-
стиций — проект 1, проект 2 и проект 3. Капитал, который
фирма собирается вложить только в один из трех проектов,
составляет 100 тыс. долл. Прибыль от каждого проекта связана с
общим экономическим положением в предстоящем году. Рас-
смотрим таблицу, в которой представлены оценки прибыли от
каждого проекта в зависимости от будущего возможного со-
стояния экономики (табл. 17.1):
Таблица 17.1
Прибыль от инвестиционных проектов в зависимости
от состояния экономики (долл.)
Состояние экономики Быстрый рост Нормальный рост Медленный рост
Проект 1 10 000 6500 -4000
Проект 2 8000 6000 1000
Проект 3 6000 5000 5000
В описанной ситуации в качестве альтернативных решений
рассматриваю гея три варианта инвестирования капитала в раз-
мере 100 тыс. долл.: вложение в проект 1, вложение в проект 2
и вложение в проект 3. Выбор альтернативы осуществляется
лицом, принимающим решение (ЛИР). ЛИР — это собиратель-
ный образ. В качестве него может выступать как один человек,
так и группа людей. Например, в рассматриваемой ситуации
под ЛПР понимаются высшие менеджеры фирмы. Процесс
формирования выбора решений полностью определяется ЛПР.
Будущие события, которые могут сопутствовать принимаемым
решениям, характеризуются гремя возможными состояниями
экономики: медленный рост, нормальный рост и быстрый рост.
В теории принятия решений для возможных будущих событий
вводится термин: состояния природы. ЛПР не может контро-
лировать состояния природы, они находятся вне сферы его
влияния.
456
Последствия (результаты) каждого решения отражают не-
который выигрыш, который может быть и отрицательным, т. е.
по существу проигрышем. Величина выигрыша зависит от свер-
шения одного из возможных будущих событий (или наступле-
ния состояния природы). В рассматриваемой ситуации резуль-
таты оцениваются в денежном выражении и характеризуют
отдачу от вложения в соответствующий проект в условиях раз-
личных возможных состояний экономики. Эти оценки пред-
ставлены в табл. 17.1. Подобные таблицы в проблемах принятия
решений называются платежными матрицами. Элементы пла-
тежной матрицы могут быть получены также в результате эко-
номических расчетов.
Пример 17.1. Фирма занимается продажей небольших парус-
ных лодок в летний сезон на морском побережье. Лодки могут
закупаться у производителя только до начала лета, так как ком-
пания-производитель нс в состоянии дополнительно постав-
лять их в летний период. Основная задача торговой фирмы —
продать весь запас лодок, закупленных весной. Эго будет вы-
полнено, если запас окажется нс больше, чем летний спрос на
лодки. Если количество закупленных лодок совладает со спро-
сом, то прибыльбудег максимально возможной. ЛПР (владель-
цу фирмы) необходимо принять решение о том, какое коли-
чество лодок следует закупить перед летним сезоном. Он считает,
что спрос на лодки во многом будет зависеть от экономичес-
ких условий, в частности от ставки ссудного процента, кото-
рая будет преобладать в период продажи.
У владельца фирмы есть четыре варианта действий (альтер-
нативных решения):
Я1 — закупить 50 лодок,
Л2 — закупить 75 лодок,
Л} — закупить 100 лодок,
— закупить 150 лодок.
Состояния природы для данной проблемы характеризуются
будущими изменениями среднего ссудного процента:
•У — ссудный процент значительно возрастет (более чем на
1,5%);
.S’2 — ссудный процент останется на прежнем уровне;
5, — ссудный процент значительно снизится (более чем на
1,5%).
Для каждого состояния природы 5 (/ = 1, 2, 3) владелец
провел оценку спроса на лодки (табл. 17.2).
457
Таблица 17.2
Спрос на лодки а зависимости
от изменения ссудного процента
Состояние природы Ссудный процент Спрос
S, Возрастает 50
S2 Но изменяется 100
Снижается 150
В случае продажи одной лодки фирма получает прибыль в
размере 300 долл. Если лодка не продается в течение сезона, то
убытки составят 500 долл. Они будут связаны со стоянкой и
возвращением лодки производителю.
Исходя из предположений о спросе и состояниях природы
(табл. 17.2), оценим в финансовом аспекте возможные послед-
ствия всех вариантов действий.
Рассмотрим альтернативу Л, (закупка 50 лодок). В случае со-
стояния природы 5, спрос совпадает с предложением и все
лодки будут проданы. В результате фирма получит прибыль .
300 • 50 = 15 000 (долл.).
При других состояниях природы (5, и 55) спрос превышает
запас закупленных лодок и прибыль от продажи 50 лодок так-
же будет составлять 15 000 (долл.).
Определим последствия альтернативы Л, (закупка 75 лодок).
При состоянии природы SJ спрос на лодки будет меньше
закупленного запаса на 25 лодок (75 - 50 = 25). Поэтому при-
быль вычисляется как разность между реализацией и затратами
на возврат лодок:
300 • 50 - 500 • 25 = 2500 (долл.).
В условиях состояний природы 5, и 5, спрос на лодки йре-
высит их запас. Все лодки будут проданы, и прибыль вобоих
случаях составит
300 - 75 = 22 500 (долл).
Альтернатива (закупка 100 лодок) характеризуется следу-
ющими оценками.
В условиях 5 окажутся непроданными 50 лодок, так как спрос
составляет 50 лодок. Отсюда прибыль будет иметь отрицатель-
ное значение:
" 300 • 50 - 500 • 50 » ~IO uuu «дил*,.,.
Это означает, что фирма терпит убытки в размере 10 000
долл.
В других случаях (5, и S.) все 100 лодок будут реализованы,
так как спрос либо равен, либо превышает запас. Прибыль в
обоих случаях составляет '
300 • 100 = 30 000 (долл.).
I
Проведем оценку варианта (закупка 150 лодок).
В условиях 5 потери составляют
300 50 - 500 • 100 - -35 000 (долл.).
В случае 5, имеем прибыль:
300 • 100 - 500 • 50 = 5000 (долл.).
• г“ * •
При выполнении условий 5} прибыль будет максимальной:
300 • 150 = 45 000 (долл.). ' '»-
Сведем полученные оценки в платежную матрицу, где оцен-
ки прибыли представлены в тыс. долл. (см. табл. 17*3).
< *Г т
Таблица 17.3
Платежная матрица значения прибыли
от сочетания альтернатив
A (i = 1, 3, 4) и состояний природы SJ/= 1, 3)
Ставка среднего процента S, (возрастет) S2 (будет неизменной) (упадет)
Д, (закупка 50 ло- док) А2 (закупка 75 ло- док) Aj (закупка 100 лодок) А. (закупка 150 лодок) 15 *• -10 г» -35 15 22,5 30 5 4,. 15 ... 22,5 : 30 .- 45
В общем виде платежную матрицу можно представить следу-
ющим образом (табл. 17.4).
459
Таблица 17.4
Общий вид платежной матрицы: п — выигрыш (прибыль),
полученный от сочетания альтернативы А, (/ = 1, 2, 3,...; к)
и состояния природы S (/ = 1, 2, 3, л)
Вариант действий (альтернативы) Состояния природы
®2 ®3 ... S.
«11 «12 «13 ... «ш
а2 «21 «22 «23 ... «2п
^3 «31 «32 «33 ... «Эл
«м «*2 «« ... «*п
Иногда задачу принятия решений удобно проанализировать
не в терминах прибылей (выигрышей), а в терминах потерь от
неиспользованных благоприятных возможностей (условных
потерь).
Пример 17.2. Проанализируем задачу из предыдущего приме-
ра, используя понятие условных потерь.
Пусть фактическое состояние природы было S. (ссудный
процент возрос более чем на 1,5%), а Л ПР ранее выбрало аль-
тернативу Л] (закупило 50 лодок). Спрос на лодки в условиях
состояния природы 5. составлял 50 лодок (табл. 17.2). Следова-
тельно, благоприятные возможности были использованы пол-
ностью (т. е. получена максимально возможная прибыль, рав-
ная 15 тыс. долл.) и условные потери равны нулю. Нели выбрана
альтернатива А (закуплено 75 лодок), то прибыль составит 2500
долл. (табл. 17.3) и условные потери определяются как разность
между максимально возможной прибылью в условиях 5 и при-
былью, полученной при выборе альтернативы /1; вместо наи-
лучшей Af: 15 000 - 2500 = 12 500 долл. В общем случае услов-
ные потери L (или потери от неиспользованных благоприятных
возможностей) измеряются как разность между платежами для
альтернативы, которая имеет наибольший платеж в условиях
состояния природы S, и платежами для варианта действий А .
Очевидно, условные потери нс являются потерями в прямом
смысле. Они характеризуют дополнительную прибыль, кото-
рая могла быть получена, если был бы выбран наилучший ва-
риант действий для данного состояния природы.
460
Для состояния условные потери были вычислены в слу-
чае выбора вариантов действий Л, и Л,:
£и = 0, £2) = 12,5 (тыс. долл.).
Определим условные потери, соответствующие выбору Л3 и
Л4 (в тыс. долл.):
£}) = 15 - (-10) = 25,
£41 = 15 - (-35) = 50.
Аналогичные вычисления (в тыс. долл.) проведем для 52 и
^3'
£., = 30 - 15 = 15,
£’’ = 30 - 22,5 = 7,5,
. £~ = 30 - 30 = 0,
£42 = 30 - 5 = 25,
; £,‘ = 45 - 15 = 30,
'• £„ = 45 - 22,5 = 22,5,
£‘3 =45 - 30 = 15,
£" = 45 - 45 = 0.
43
Из величин L составим матрицу условных потерь (табл. 17.5).
Таблица 17.5
Матрица условных потерь (тыс. долл.)
Состояние природы Вариант действий
®1 А А
А 0 15 30
А2 12,5 7,5 22,5
А 25 0 15
50 25 0
£ (/ = 1, 2, 3, 4) — условные потери, соответствующие
состоянию природы 5 при выборе варианта действий Л
Заметим, что матрица условных потерь, представленная в
табл. 17.5, содержит в каждом столбце нулевой элемент, а все
остальные элементы положительны. Нули соответствуют наи-
лучшим вариантам действий.
461
17.2. КРИТЕРИИ ВЫБОРА ОПТИМАЛЬНОГО
ВАРИАНТА ДЕЙСТВИЙ ПРИ НЕИЗВЕСТНЫХ
ВЕРОЯТНОСТЯХ СОСТОЯНИЙ ПРИРОДЫ
В условиях неопределенности будущих состояний природы
Л ПР вынуждено рассматривать все значения платежной мат-
рицы, чтобы выбрать наиболее подходящий вариант действий.
Рассмотрим основные правила или критерии выбора оптималь-
ного варианта, когда вероятности состояний природы неизве-
стны. Смысл процедуры принятия решений состоит в том, что
ЛПР, стараясь учесть будущее состояние природы, выбирает
оптимальный вариант действий согласно некоторому правилу
(критерию).
17.2.1. Максиминный критерий Вальда
Данный критерий рекомендует выбирать в качестве опти-
мального варианта действий такую альтернативу, при которой
минимальный выигрыш максимален. Правило максимина га-
рантирует при любых состояниях природы выигрыш (прибыль,
доход) не меньший, чем максиминное значение. Оно находит-
ся из платежной матрицы, представленной в табл. 17.4.
В каждой ее строке выбирается минимальное значение min п
(/“ 1, 2,..., k;j = 1,2, 3, ...» и). Среди выбранных к минималь-
ных значений находится максимальное:
л (maximin) = max min п...
- Строка, в которой находится величина л (maximin), соот*
ветствуст оптимальному варианту действий.
Пример 17.3. Найдем максимальное значение платежной мат-
рицы, представленной в табл. 17,3.
Минимальные элементы в строках (min л^):
А 15
А2 2,5
А} -10
At -35
Максимальным среди минимальных будет значение
л (maximin) = max (15; 2,5; —10; —35) = 15.
462
Оно соответствует оптимальной альтернативе А, (закупка 50
лодок). Максиминный критерий ориентирует ЛПР на макси-
мальный выигрыш в худших условиях. ЛПР, которое предпо-
читает этот критерий, отличается крайним пессимизмом.
17.2.2. Минимаксный критерий Севиджа
Этот критерий, как и критерий Вальда, является критерием
крайнего пессимизма. Только пессимизм здесь характеризуется
не минимальным гарантированным выигрышем, а максималь-
ными условными потерями. ЛПР, которое руководствуется кри-
терием Севиджа, выбирает вариант действий, обеспечиваю-
щий наименьший “худший” результат. В терминах условных
потерь худшим результатом является не минимальный выиг-
рыш, а максимальная потеря выигрыша по сравнению с тем,
чего можно было бы достичь, приняв наилучший в данных
условиях вариант действий.
Рассмотрим матрицу условных потерь (табл. 17.6).
Таблица 17.6
Матрица условных потерь
Вариант действий Состояние природы
S, s2 Ss ... s„
A, ц. ^12 t.3 ... L,n
Аг ^22 <-23 ... k,
Ц| ^-32 ^33 ... Цп
И »-• A„ НИ
£ (/ = 1, 2, 3,..., к; j = 1,2, 3,..., п) — недополученный
выигрыш для варианта действий i в условиях состояния приро-
ды/.
Выберем в каждой строке матрицы условных потерь (табл.
17.6) максимальный элемент max £ (z = 1, 2, 3,..., k\j = 1,2,
3,..., п). Среди отобранных максимальных элементов найдем
минимальный:
L (minimax) = min max £,,.
z j *
463
Соответствующий L (minimax) вариант действий и будет
являться оптимальным по минимаксному критерию.
Пример 17.4. Для матрицы условных потерь, рассмотренной в
примере 17.2 (табл. 17.5) определим минимаксный вариант дей-
ствий.
В каждой строке матрицы найдем максимальный элемент:
30
Л, 22,5
А} 25
<А4 50
Среди максимумов условных потерь найдем минимальное
значение:
L (minimax) = min (30; 22,5; 25; 50) — 22,5 (тыс. долл.). ''
Величине L (minimax) соответствует оптимальная альтер-
натива А2 (закупка 75 лодок).
Минимаксный критерий является очень консервативным
подходом. Его сущность заключается в том, чтобы любыми пу-
тями избежать большого риска при принятии решений.
17.2.3 . Максимаксный критерий
ЛИР, которое придерживается этого критерия, является
крайним оптимистом, склонным к максимальному риску. По
правилу максимакса выбирается вариант действий, соответству-
ющий наибольшему выигрышу. Его значение определяется как
максимальный элемент платежной матрицы (табл. 17.4):
п (maximax) = max max тг.
Пример 17.5. Для платежной матрицы, рассмотренной в приме-
ре 17.1 (табл. 17.3), определим оптимальный вариант действий
по критерию максимакса. Максимальный элемент матрицы
л (maximax) = 45 (тыс. долл.). Он соответствует альтернативе
Ал, т. е. закупке 150 лодок. При этом Л ПР рискует понести поте-
ри в размере 35 тыс. долл, в случае повышения ссудного процен-
та (состояния природы 5().
Как правило, максимаксный вариант очень рискованный.
Его выбор может привести к значительным затратам или поте-
рям.
464
17.2.4 . Комбинированный критерий пессимизма-
оптимизма Гурвица
Это правило представляет собой компромисс между очень
консервативным критерием максимина и крайне оптимистич-
ным максимаксным критерием. В жизни ЛИР редко бывает чи-
стым пессимистом или оптимистом, занимая какую-то проме-
жуточную позицию.
При использовании критерия Гурвица рассматривается пла-
тежная матрица (табл. 17.4), в которой для каждого варианта
действий /1 выбирается лучший (максимальный элемент
max п ) и худший (минимальный элемент min лу) результаты.
Степень оптимизма задается весовым коэффициентом 0 < а <1,
соответственно уровень пессимизма — коэффициентом 1 - а.
Критерий Гурвица имеет вид
max {a (max п ) = (1 - а) (min п )}.
< J v i *
При а = 1 (чистый оптимизм) критерий Гурвица преобразу-
ется в критерий максимакса, а при а = 0 (чистый пессимизм) —
в максиминный критерий. При 0 < а < I Л ПР занимает сред-
нюю позицию между крайним оптимистом и крайним песси-
мистом. Оптимальному варианту соответствует максимальное
взвешенное значение.
Использование критерия Гурвица предполагает, что имеет-
ся достаточно информации для определения весовых коэффи-
циентов. Часто рассматривают несколько значений а, пока не
будет получена реалистичная оценка степени оптимизма Л ПР.
Пример 17.6. С помощью критерия Гурвица найдем оптималь-
ное решение при а = 0,6 для платежной матрицы, рассмотрен-
ной в примере I7.1 (табл. 17.3):
Л 15 • 0,6 + 15 • 0,4 = 15
А2 22,5 • 0,6 + 2,5 • 0.4 = 14,5
Л, 30 0.6 + (-10) • 0,4 = 14
Л 45 • 0,6 + (-35) • 0,4 = 13
По критерию Гурвица имеем
max (15; 14,5; 14; 13) = 15.
Отсюда получаем, что если ЛПР использует а - 0,6, то его
выбор по критерию Гурвица определяется вариантом А , т. е.
закупкой 50 лодок.
465
Основная проблема при использовании критерия Гурвица
заключается в определении коэффициента а. Его значение вы-
бирается из субъективных соображений. Очевидно, если ситуа-
ция связана с большим риском, то ЛИР имеет смысл “под-
страховаться" и выбрать коэффициент а ближе к нулю.
17.3. ВЫБОР РЕШЕНИЙ ПРИ ИЗВЕСТНЫХ
ВЕРОЯТНОСТЯХ СОСТОЯНИЙ ПРИРОДЫ
17.3.1. Критерий максимального ожидаемого выигрыша
Если имеются данные о вероятностях состояний природы,
то, очевидно, стратегия выбора варианта действий должна учи-
тывать эту информацию. Наиболее адекватный подход в этом
случае — вычисление математического ожидания или среднего
выигрыша для каждого альтернативного решения.
Оптимальным решением является то, которому соответ-
ствует наибольший ожидаемый выигрыш. Это означает, что в
случае многократного повторения выбора данного решения в
будущем средний выигрыш будет максимальным (при незна-
чительном изменении условий, в которых осуществляется вы-
бор).
Исходной информацией для реализации данного критерия
служит расширенная платежная матрица, включающая значе-
ния вероятностей состояний природы (табл. 17.7).
*
Таблица 17.7
Платежная матрица с вероятностями состояний природы
F(S) (/=1, 2, 3................. л)
Вариант действий Состояние природы и его вероятность
S. ₽<S,) s2 S, P(S3) ••• S„
А, *11 «12 «13 ... “to
“ *21 «22 «23 ... «2л
«31 «32 «33 :. «3л
I «*1 «W «И ... «to
466
Среднее значение выигрыша для варианта А. вычисляется
по формуле
Е[лЦ)] = Л.Л5,) + лйЛ52) + п3Л53) + ... + лйД5я). (17.1)
В качестве оптимального выбирается тот вариант, который
соответствует max Е(л(Л)).
I '
Вероятностью каждого состояния природы измеряется сте-
пень уверенности ЛПР в том, что данное состояние наступит в
будущем. Олин из способов опенки вероятностей является эм-
пирический подход, т. е. сопоставление с прошлым опытом. На-
пример, пусть исследуется фондовый рынок и в настоящее время
наблюдаются условия, сходные с теми, которые имели место в
прошлом, когда он падал 15% всего времени. В этом случае
можно предположить:
Р (паление фондового рынка) = 0,15.
Используя эмпирический подход, можно дать опенку веро-
ятности каждого состояния природы. Поскольку предполагает-
ся, что одно (и только одно) из состояний природы обязатель-
но наступит в будущем, сумма вероятностей всех состояний
будет равна единице.
Другим способом оценки вероятностей является субъектив-
ный подход. При этом ЛПР определяет вероятность как степень
собственной уверенности в наступлении каждого состояния в
будущем. Сумма субъективных вероятностей состояний приро-
ды также должна равняться единице.
Очевидно, эффективность использования вероятностей в
принятии решений зависит от того, насколько точны их оценки.
Неточность опенок может привести к выбору альтернативы,
соответствующей небольшому (или отрицательному) выигры-
шу. В результате стратегия выбора, основанная на нереалистич-
ных субъективных оценках вероятностей, будет неэффективной.
Поэтому в процессе принятия решений имеет смысл рассмат-
ривать несколько возможных значений вероятностей и анализи-
ровать, как их изменение влияет на выбор оптимального вари-
анта действий.
Пример 17.7. Предположим, что ситуация, рассматриваемая в
примерах 17.1 — 17.5, доопределяется известными значениями
вероятностей будущих изменений ссудного процента. Пусть ЛПР
полагает, что шансы возрастания процента — 30%, его неиз-
менности — 20% и снижения — 50% (табл. 17.8).
467
Таблица 17.8
Вероятности состояний природы
для ситуации с продажей лодок
Состояние природы Вероятность
S, (ссудный процент возрастет) P(S,) = 0.3
S2 (ссудный процен г не изменится) P(S2) = 0.2
S3 (ссудный процент снизится) P(S3) = 0,5
Заметим, что сумма вероятностей состояний природы рав-
на единице, так как они образуют полную группу событий (яв-
ляются взаимоисключающимися и одно из них обязательно дол-
жно произойти).
Расширим платежную матрицу (табл. 17.3), введя в нее ве-
роятности l\S) (i = 1, 2, 3), см. табл. 17.9.
Таблица 17.9
Платежная матрица с известными вероятностями
будущих изменений ставки ссудного процента
«э
P(S,) = 0.3 P(S2) = 0.2 P(S3) = 0.5
Л, 15 15 15
д2 2.5 22.5 22,5
*з -10 30 30
-35 5 45
На основе платежной матрицы, представленной в табл. 17.9,
вычислим ожидаемый выигрыш (прибыль) при выборе каждо-
го из вариантов действий по формуле (17.1), см. табл. 17.10.
Таблица 17.10
Вычисление ожидаемой прибыли для каждого варианта
закупки лодок у производителя
Варианты действий Ожидаемая прибыль
A} (закупка 50 лодок) Аг (закупка 75 лодок) А3 (закупка 100 лодок) Д4 (закупка 150 лодок) 15 • 0,3 + 15 • 0.2 + 15 • 0,5 = 15 2,5- 0.3 + 22,5 • 0.2 + 22,5 • 0.5 - 16,5 -10 • 0.3 + 30 • 0.2 + 30 • 0,5 = 18 -35 • 0,3 + 5 • 0,2 + 45 0.5 = 13
468
Как видно из табл. 17.10, по критерию максимума ожидае-
мой прибыли оптимальным будет решение соответствую-
щее решению ЛПР закупить у производителя 100 лодок. При
долгосрочной стратегии выбора ожидаемая прибыль будет
максимальной и равна 18 тыс. долл. Однако в случае однократ-
ного выбора с вероятностью 0,3 возможны потери в размере
10 тыс. долл, и с вероятностью 0,7 (AS,) + AS,) = 0,7) может
быть получена прибыль 30 тыс. долл.
17.3.2. Критерий минимальных условных потерь
По аналогии с критерием максимума ожидаемого выигры-
ша можно рассматривать правило выбора решения по показа-
телю минимума условных потерь. Ожидаемые условные потери
для каждого альтернативного решения отражают тот дополни-
тельный выигрыш, который недополучит ЛПР, если изберет
долгосрочную стратегию постоянного выбора этой альтерна-
тивы.
Пусть известны матрица условных потерь (табл. 17.6) и ве-
роятности состояний природы AS.) (/ = I, 2, 3,..., п). Тогда
ожидаемые условные потери Е[£(Л)] при выборе решения А
определяются по формуле
Е[£(Л )] = £z)AS,) + £flAS2) + ... + Д AS ). (17.2)
Оптимальный вариант соответствует min Е[£ (Л)].
Пример 17.8. В условиях примера 17.2 предположим, что изве-
стны вероятности состояний природы ASt) = 0,3, AS,) = 0,2
и AS,) = 0,5. Используя матрицу условных потерь (табл. 17.5),
выберем оптимальное решение по критерию минимальных ус-
ловных потерь.
Найдем значения ожидаемых условных потерь для каждого
решения по формуле (17.2):
Е[ £,Mt)j = 0 • 0,3 + 15 • 0,2 + 30 0,5 = 18;
Е{£(Л,)] = 12,5 • 0,3 + 7,5 • 0,2 + 22,5 • 0,5 = 16,5;
Е(£(Л')] = 25 0,3 + 0 • 0,2 + 15 • 0,5 = 15;
Е[£(Л4)] = 50 • 0,3 + 25 • 0,2 + 0 • 0,5 = 20.
Очевидно, минимальные условные потери соответствуют
альтернативе Ау
468
17.3.3. Анализ чувствительности
Как правило, возможность с полной определенностью оце-
нить вероятности состояний природы выпадает очень редко. На
практике гораздо надежнее оценивать возможные границы из-
менения их значений. При этом важно проанализировать, как
повлияет на выбор решений изменение значений вероятнос-
тей. Подобный анализ называется анализом чувствительности.
Пример 17.9. В примере 17.7 был использован критерий макси-
мального ожидаемого вышрыша. На его основе было выбрано
решение А (закупка у производителя 100 лодок), дающее мак-
симальное значение ожидаемой прибыли — 18 тыс. долл. Веро-
ятности состояний природы имели значения:
/\St) = 0,3 (ссудный процент возрастет);
f\S2) = 0,2 (ссудный процент не изменится);
Л53) = 0,5 (ссудный процент снизится).
Пусть в качестве ЛПР выступают владелец фирмы по прода-
же лодок и его помощник по финансам. У них нет полной уве-
ренности, что данные оценки вероятностей точны. Однако они
практически не сомневаются, что:
1) существует не более 50% шансов, что ссудный процент
возрастет (Л*^) £ 0,5);
2) существует не более 30% шансов, что ссудный процент
не изменится (Л5,) £0,3);
3) вероятность, что ссудный процент снизится, заключена
между 0,3 и 0,5 (0,3<Л-5’})<0,5).
В этих условиях ЛПР решило провести анализ чувствитель-
ности, вычислив ожидаемые выигрыши (прибыль) для набо-
ров вероятностей, удовлетворяющих заданным ограничениям.
Результаты расчетов представлены в табл. 17.11.
Таблица 17.11
Анализ чувствительности решений (А,, А}, Аа, Ад) к изменению
вероятностей состояний природы (P(S,), P(S}), P(S3), P(SJ)
₽<s,) P(S2) P(S3) A A3
0.4 0.2 0,4 15 14,5 14 5
0.4 0.3 0.3 15 14,5 14 1
0.4 0.1 0.5 15 14.5 14 9
0.5 0.2 0.3 15 12,5 10 -3
0.5 0.1 0,4 15 12,5 10 1
0,3 0,3 0.4 15 16,5 18 9
0,3 0,2 0.5 15 16.5 18 13
470
В табл. 17.11 приведены значения ожидаемой прибыли для
каждого варианта закупки лодок А. при соответствующих веро-
ятностях состояний динамики ссудного процента. Например, дчя
варианта при вероятностях f\St) = 0,4, Р(5) = Р{5) = 0,3
ожидаемая прибыль составляет
(-35) • 0,4 + 5 • 0,3 + 45 • 0,3 = I (тыс. долл.).
Наибольшие значения ожидаемой прибыли заключены в
рамки. Как видно, привлекательным может быть решение
(закупка 50 лодок). Если свыше 30% шансов будет за возрас-
тание ссудного процента (P(S,) > 0,3), то выбор А обеспе-
чит наибольшую ожидаемую прибыль. Кроме того, решение
Л, наиболее стабильное, так как ожидаемая прибыль будет
всегда 15 тыс. долл, независимо от состояния природы. ЛПР
имеет также шансы получить дополнительную ожидаемую
прибыль в размере 3000 долл., если рискнет и выберет реше-
ние J, (18 000—15 000). Очевидно, в случае значительной нео-
пределенности о вероятностях P(S) наилучшим вариантом
действий будет решение Ае дающее гарантированный ре-
зультат.
17.3.4. Измерение риска
Анализ чувствительности (табл. 17.11) и платежной матри-
цы (17.3) показывает, что наименее рискованным является ре-
шение А{. Выбор 4 в любом случае (известны или неизвестны
вероятности состояний природы) дает гарантированный вы-
игрыш в размере 15 000 долл. Другими словами, выбору Л! со-
ответствует нулевой риск. В то же время решение является
более рискованным по сравнению с Л , хотя может привести к
выигрышу, равному 45 000 долл. (т. е. в три раза превышающему
гарантированную прибыль при выборе Л). Рассмотрим выиг-
рыш, получаемый от выбора Л(, как дискретную случайную
величину (строка табл. 17.9, соответствующая 44):
—35 с вероятностью 0,3;
5 с вероятностью 0,2;
45 с вероятностью 0,5.
Ожидаемый выигрыш будет характеризоваться математичес-
ким ожиданием случайной величины X. Как видно., наблюдает-
ся большая вариация значений случайной величины, причем
ее максимальному значению соответствует наибольшая веро-
471
ятность. В этой связи в качестве показателя риска имеет смысл
рассматривать меру разброса значений АГ около математичес-
кого ожидания, т. е. дисперсию.
Рассмотрим общий случай. Пусть А' — случайный выигрыш,
который ассоциируется с вариантом действий А.. Тогда
х. с вероятностью />;
х, с вероятностью р2;
хп с вероя тностью />„,
где п — число состояний природы.
Тогда ожидаемый выигрыш есть математическое ожидание
величины Х-.
Е[лЦ)] = и, = 2хр.
Риск, соответствующий решению А ., характеризуется дис-
персией Х‘.
риск Л = S(x - ц.)2р = Игр - ц.2. (17.3)
Пример 17.10. Вычислим риски для всех решений A. (i - I, 2,
3, 4) примера 17.6. Распределения соответствующих случайных
величин А' представлены в табл. 17.9, а значения математичес-
ких ожиданий ц (ожидаемая прибыль) — в табл. 17.10. Исполь-
зуя эту информацию, вычислим дисперсии, соответствующие
рискам, по формуле (17.3), см. табл. I7.12.
Таблица 17.12
Вычисление риска для вариантов решений по закупке лодок
Решения Ожидаемый выигрыш 09 Риск (дисперсия)
Л, 15 15г 0,3 + 15г 0,2 + 15’ 0,5 - 15’ = 0
* д? 16.5 2,5’ 0,3 + 22,5’ 0,2 + 22,5’ 0,5 - 16,5’ = 84
А3 18 (-10)’ 0,3 + 30’ 0,2 + 302 0.5 - 18’ = 336
А. 13 (-35)’ 0,3 + 5г 0,2 + 45г 0,5 - 13’ = 1216
Заметим, что дисперсия для решения А. равна нулю, т. е.
выигрыш, который с ним ассоциируется, не будет случайной
величиной (АТ, = 15 с вероятностью, равной 1). В рассматрива-
емой ситуации решение А, является безрисковым и имеет мак-
симальный ожидаемый выигрыш в большинстве вариантов ана-
лиза чувствительности (табл. 17.11). В то же время решение А3,
472
оптимальное по критерию максимума ожидаемого выигры-
ша, имеет значительный риск (второй по величине после ЛД
Данные заключения являются аргументом в пользу выбора ре-
шения А
Сравнительный анализ риска различных вариантов решений
по показателю дисперсии невозможен, если величины ожидае-
мых выигрышей значительно отличаются друг от друга. В этом
случае дисперсии (или стандартные отклонения), характеризу-
ющие разброс около соответствующих средних выигрышей, могут
быть несоизмеримы. Поэтому следует использовать безразмер-
ную характеристику — коэффициент вариации (см. разд. 4.1.4):
отношение стандартного отклонения к среднему выигрышу.
Пусть, например, ожидаемое значение выигрыша для реше-
ния 1 — 1000 долл, при стандартном отклонении о, = 100 долл.,
а для решения 2 средний выигрыш — 500 долл, при о, = 70 долл.
Коэффициент вариации в первом случае равен 100/1000 = 0,1
(10%), а во втором — 70/500 = 0,14 (14%). Следовательно, более
рискованным является решение 2, хотя о > о2.
Пример 17.11. Торговая фирма рассматривает возможности ак-
тивизации рекламной деятельности с целью увеличения объ-
ема продаж. Руководст во фирмы должно сделать выбор между
двумя вариантами: помещением рекламы в газетах или на теле-
видении. Специалистами отдела маркетинга были получены
прогнозные оценки прибыли и ее вероятностей.
Результат на рынке
Вероятность Прибыль (долл.)
Газеты удовлетворительный 0,2 5000
хороший 0,6 6000
очень хороший 0,2 7000
Телеви- удовлетворительный 0,2 6000
дение хороший 0,6 8000
очень хороший 0,2 10 000
Вычислим ожидаемую прибыль для первого варианта:
5000 0,2 + 6000 • 0,6 + 7000 • 0,2 = 6000 (долл.).
Определим стандартное отклонение:
V(5000 - 6ООО)2 • 0,2 + (6000 - 6ООО)2 • 0,6 + (7000 - 6000)2 • 0,2 =
= 632,46 (долл.).
473
Отсюда получаем. что коэффициент вариации равен
632.46/6000 = 0,105 (10,5%).
Дтя второго варианта ожидаемая прибыль составляет
6000 • 0,2 + 8000 • 0,6 + 10 000 • 0,2 = 8000 (долл.).
Определим стандартное отклонение и коэффициент вариа-
ции для второго варианта:
Х'(6000 - 8000)2 0,2 + (8000 - 8000)2 • 0,6 + (10000 - 8ООО)2 • 0,2=
= 1264,91 (долл.);
1264,91/8000 = 0,158 (15,8%).
Как видно, второй вариант имеет большее значение стан-
дартного отклонения и коэффициента вариации, т. е. он более
рискованный по сравнению с первым. 1
17.4. ИССЛЕДОВАНИЕ ПРОБЛЕМЫ С ПОМОЩЬЮ
ДЕРЕВА РЕШЕНИЙ
17.4.1. Общие принципы построения дерева решений
Удобным способом представления множества альтернатив-
ных решений и состояний природы является дерево решений. В
случае большой комплексной проблемы значимость дерева ре-
шений для ЛПР можно сравнить с значимостью географичес-
кой карты боевых действий для полководца. Дерево решений —
это диаграмма, которая позволяет увидеть одновременно все
возможные цепочки действий и их последствия (события),
вызванные состояниями природы. С его помощью можно на-
глядно представить все предлагаемые варианты действий и
выигрыши, получаемые в результате выбора каждого решения
в условиях соответствующих состояний природы.
На диаграмме дерева решений последовательность вариан-
тов действий изображается в виде квадратов, из которых исхо-
дят альтернативы (вилки действий). Каждый вариант ведет к
кругу с выходящими из него событиями, определяемыми со-
стояниями природы (вилка событий). Диаграмма имеет древо-
видную структуру. В “корне” дерева находится начальная вилка
действий. Каждый вариант начальной вилки является главным
“стволом” ветви дерева, состоящей из соединения вилок лей-
474
ствий и событий. В процессе принятия решений все вилки дей-
ствий контролируются ЛПР. Находясь в позиции “вилка дей-
ствий”, ЛПР может осуществить выбор варианта действий в
этой точке дерева решений. “Ветки” вилки событий не подчи-
няются влиянию ЛПР, так как они характеризуют состояния
природы (5, 5,,..., 5). В данной точке дерева решений у ЛПР
нет возможности выбора. Каждая “ветка” в данном случае яв-
ляется случайным событием, которое может произойти с не-
которой вероятностью (Я(5(), P(S2),..., P(.Sh)). Значения P(S)
будут количественными оценками неопределенности послед-
ствий принимаемых решений. Кроме того, решения могут иметь
последствия, оцениваемые в денежном выражении, например
прибыль, получаемая от реализации того или иного решения.
Эти два типа оценок указываются на диаграмме дерева реше-
ний. Дерево решений строится слева направо; в крайнем левом
положении располагается начальная вилка действий. Формаль-
ный анализ осуществляется в обратном направлении; от кон-
цевых точек дерева к начальной вилке действий. При этом про-
изводится оценка каждой ветви, ведущей от начальной вилки
к концевым точкам (т. е. порожденной выбором одного из воз-
можных вариантов действий на начальной стадии принятия
решений). Процедура оценки начинается с вычисления ожида-
емых результатов (т. е. усредненных по вероятностям) для край-
них правых вилок событий и повторяется при движении по
каждой ветви к начальной вилке действий. Полученные оценки
характеризуют ожидаемые последствия каждого решения. Если
они отражают средний выигрыш (например, прибыль), то вы-
бирается ветвь (вариант в начальной вилке действий) с наи-
большим результатом.
Пример 17.12. Построим дерево решений для проблемы закуп-
ки лодок, используя исходные данные (табл. 17.9) и результа-
ты расчетов (табл. 17.10), представленные в примере 17.7.
Дерево на рис. 17.1 отражает процесс принятия решения,
который начинается с вилки действий: выбор варианта Л(г = 1,
2, 3, 4), определяющего, сколько лодок следует закупить у про-
изводителя перед летним сезоном. Каждому варианту соответ-
ствует ветвь, которая заканчивается вилкой событий, отражаю-
щей возможную динамику ссудного процента: состояния природы
5 (/ = I, 2, 3, 4). Вероятности Л-У) указаны на диаграмме в
скобках. Рядом с каждой концевой точкой дерева указаны зна-
чения прибыли (элементы платежной матрицы), соответствую-
475
Рис. 17.1. Дерево решений для проблемы закупки лодок
щие ситуации “выбор решения А. и состояния природы 5”
(табл. 17.9). В кружках вилок событий указаны ожидаемые зна-
чения прибыли в случае выбора соответствующего варианта
действий А, (табл 17.10). В квадрате начальной вилки действий
записано максимальное из этих значений (18 тыс. долл.), со-
ответствующее А3 (закупка 100 лодок). Остальные решения ис-
ключаются (вычеркиваются на диаграмме из начальной вил-
ки действий).
Метод дерева решений можно использовать при анализе
чувствительности, определяя, как меняется оптимальный вы-
бор решения при изменении вероятностей состояния природы.
При этом следует строить дерево решений для каждого иссле-
дуемого набора вероятностей. Далее проводится анализ полу-
ченных деревьев и выделяется оптимальная “ветвь” начальной
вилки действий.
17.4.2. Использование теоремы Байеса для уточнения
вероятностей состояний природы
Оптимальное решение, полученное по критерию максиму-
ма ожидаемого выигрыша, зависит от точности оценки веро-
ятностей. Часто ЛПР имеет предварительные или априорные
476
опенки вероятностей, причем на данный момент они являют-
ся единственной имеющейся, наиболее правдоподобной ин-
формацией. Однако чтобы выбрать наилучшее решение, Л ПР
может привлекать дополнительную информацию, позволяю-
щую пересмотреть или уточнить предварительные (априорные)
вероятности. Часто дополнительную информацию получают в
результате специального эксперимента, предназначенною для
этой цели. В качестве таких экспериментов могут выступать ис-
следования рынка, сбор статистических данных, испытание
эксплуатационных качеств продукции, привлечение консуль-
тационных услуг и т. д.
Полученная дополнительная информация может быть ис-
пользована Л ПР для корректировки априорных вероятностей.
Уточненные таким способом вероятности называются апосте-
риорными. Корректировка априорных вероятностей при неко-
торых условиях может осуществляться с помощью теоремы
Байеса (см. раздел 5.2.5). Комбинируя дерево решений с вычис-
лением апостериорных вероятностей по теореме Байеса, мож-
но определить ценность дополнительной информации, полу-
ченной в результате эксперимента. Ясно, что эта информация
стоит денег, поэтому оценим две альтернативы:
1) не имеет смысла затрачивать средства на получение до-
полнительной информации и следует выбор оптимального ре-
шения производить по критерию максимума ожидаемого вы-
игрыша, используя априорные вероятности;
2) следует затратить средства на дополнительную информа-
цию, так как ожидаемый выигрыш в этом случае (вычислен-
ный на основе апостериорных вероятностей) превышает сред-
ний выигрыш относительно априорных вероятностей.
Ценность дополнительной информации определяется как
разность между ожидаемым выигрышем, определенным с ее
использованием, и ожидаемым вышрышем, полученным только
на основе оценок априорных вероятностей.
Пример 17.13. Предположим, что после анализа дерева реше-
ний (пример 17.12) владелец фирмы по продаже лодок решил
получить более объективные оценки вероятностей состояний
динамики ссудного процента в предстоящий летний период.
Он может обратиться в специальный консультационный центр,
который занимается экономическим прогнозированием, и в
частности предсказанием изменения ссудного процента. Эти
предсказания основываются на всестороннем анализе причин
и факторов, влияющих на динамику данного показателя.
477
Имеются статистические данные о надежности прогнозиро-
вания ставки ссудного процента, осуществленного консульта-
ционным центром в прошлом. Введем следующие обозначения:
/( — консультант предсказывает повышение ссудного про-
цента;
/, — консультант предсказывает, что ссудный процент не
изменится;
— консультант предсказывает снижение ссудного про-
цента.
Информация о надежности прошлых прогнозов представ-
лена в табл. 17.13. В ней содержатся условные вероятности
PtJJS), характеризующие вероятности событий: если пред-
сказание /.(/ =1,2, 3), то реальное состояние ссудного про-
цента 5 (j = 1, 2, 3).
Таблица 17.13
Условные вероятности P(l./S), характеризующие надежность
предсказаний консультанта в прошлом
Предсказание Реальное состояние ссудного процента
S. Sa
'1 0.7 0.4 0.2
>3 0,2 0,5 0.2
'з 0.1 0.1 0.6
1 1 1
В табл. 17.13 на пересечении строки I и столбца 5 стоит услов-
ная вероятность PfJ/SJ. Например, /V./S,) = 0,7;
— 0,4; = 0,2 и т. д. Вероятность = 0,7 означает,
что в 70% случаев, когда в действительности ссудный процент
повышался, предсказания были такими же. Вероятность АД/
/S) = 0,2 показывает, что в 20% случаев, когда в действитель-
ности ссудный процент повышался, предсказывалась неизмен-
ность ссудного процента. Лналогично — 0,1 характери-
зует тот факт, что при повышении в действительности ссудного
процента консультант предсказывал его снижение. Очевидно,
сумма условных вероятностей равна единице:
А/,/5,) + А//5,) + А/3/5,) = 1.
Это следует из того, что при условии свершения события
(ссудный процент повысился) одно из событий /. или
478
обязательно произойдет (консультант обязательно предскажет
один из возможных вариантов изменения ссудного процента).
Аналогичные рассуждения будут верными и для условных ве-
роятностей PUJSJ и (i — 1, 2, 3);
Ptft/S2) + А//52) + Л/,/52) = 1,
А/(Л,) + A//S,) + P(i}/S2) = 1.
Данные табл. 17.13 позволяют использовать теорему Байеса
для вычисления апостериорных вероятностей состояний при-
роды 5, которые можно рассматривать в качестве гипотез. Тог-
да каждый прогноз / является событием, которое может про-
изойти в том и только в том случае, когда будет иметь место
одно из состояний природы 5.
Пусть, например, консультант предсказывает (повыше-
ние ссудного процента). До получения прогноза вероятности
состояний природы P(S) носили априорный характер (субъек-
тивные оценки ЛПР). Предсказание консультанта можно рас-
сматривать как новую информацию, поступившую в результа-
те проведения эксперимента (исследования консультантом
динамики ссудного процента). По теореме Байеса получим апо-
стериорные вероятности, скорректированные в связи с появ-
лением новой информации:
ЛУ)Л/,/5.)
НS // --------------! । ,
*' A^AZ/S,) + A52)AV52) + А^)А</53)
A^)A/,/*S2)
a^)A/,/5,) + A52)Aft/S2) + A53)A/,/^2) ’ (17’4)
A^)A/,/5,)
A5.JA/A) + AS2)A/A) + AS3)A/,/5,)
В знаменателе каждой формулы (17.4) стоит полная вероят-
ность А/,), а в числителе — соответствующая вероятность про-
изведения P(S /) (/ = 1,2, 3). Отсюда формулы Байеса примут
более простой вид:
АВД
=-А^Г’
А^Л)
W9 =-a?J-’ <17-5>
479
Вычислим апостериорные вероятности РЦ/У), подставляя
в формулы (17.4) условные вероятности из табл. 17.13 и субъек-
тивные значения Р(У):
/ХУД) = 0,3 • 0,7/(0,3 • 0,7 + 0,2 • 0,4 + 0,5 • 0,2) =
= 0,21/0,39 = 0,538;
ЛУД) = 0,2 • 0,4/0,39 = 0,08/0,39 = 0,205;
Л-УД) = °’5 • 0,2/0,39 = 0,256.
Заметим, что ввиду (17.4) и (17.5) имеем /’(/,) = 0,39.
Ожидаемую прибыль, если консультант предскажет /, пе-
ресчитаем с учетом апостериорных вероятностей. При выборе
ЛПР варианта At имеем
15 • 0,538 + 15 • 0,205 + 15 • 0,256 = 15.
Аналогично вычислим ожидаемую прибыль для оставшихся
вариантов Av А}, А4:
2,5 • 0,538 + 22,5 • 0,205 + 22,5 • 0,256 = 11,72;
(-10) • 0,538 + 30 • 0,205 + 30 0,256 = 8,45;
(-35) • 0,538 + 5 • 0,205 + 45 • 0,256 = -6,28.
Следовательно, по критерию максимума ожидаемого выиг-
рыша ЛПР должно выбрать А. (закупка 50 лодок) в случае,
если консультант предсказывает /. (повышение ссудного про-
цента в летний период).
Дерево решений, соответствующее выбору альтернативного
варианта А, в случае предсказания консультантом /, представ-
лено на рис. 17.2.
Проведем соответствующие рассуждения для других возмож-
ных прогнозов консультанта.
Пусть предсказание будет /, (ссудный процент не изменится
в течение летнего сезона). По аналогии с формулами (17.4) и
(17.5) запишем выражение для полной вероятности /V,):
РЦ) = ЛУ,) НЩ) + P(S2) P(I2/S2) + Д53) Л/Д)- (17.6)
480
Рис. 17.2. Дерево решений с учетом предсказания консультанта lt
(повышение ссудного процента)
Подставляя в формулу (17.6) значения априорных веро-
ятностей P(S) и условных вероятностей F\IJS), взятых из
табл. 17.13, вычислим Р(/2):
Л/,) = 0,3 • 0,2 + 0,2 0,5 + 0,5 • 0,2 = 0,26.
Апостериорные вероятности найдем по формулам Байеса:
Л5//2) = РЩ2)/Р(12) = РЦ) Л/2/5)/А/2), / = 1, 2, 3. (17.7)
Подставляя значения вероятностей в формулу (17.7), получим
w Л5//2) = 0,3 0,2/0,26 = 0,231;
' P(S2/I2) = 0,2 • 0,5/0,26 = 0,385; "
ЛЗД) = 0,5 • 0,2/0,26 = 0,385. ' ’ » -
2 2 О > !.т ’Л > j 1
Вычислим ожидаемую прибыль для каждого решения А в
условиях скорректированных вероятностей: - г! .
А 15 -0,231 + 15 0,385 4 15 0,385 = 15; !
А2 2,5 • 0,231 + 22,5 • 0,385 + 22,5 • 0,385 = 17,9; '
А (-10) • 0,231 + 30 0,385 + 30 0,385 = 20,79;
Аа (-35) • 0,231 + 5 • 0,385 + 45 0,385 = 11,16.
4 >104.
’ Максимальный ожидаемый выигрыш (прибыль) соответству-
ет решению Л3 (закупка 100 лодок) — 20,79 тыс. долл. ,г.
481
Предположим, что консультант предсказал Z (снижение
ссудного процента в летний сезон). Тогда полная вероятность
Л/,) вычисляется из соотношения
А<) = РЦ) A/j/5() + Л52) PU/Sp + РЦ) Д/Д). (17.8)
Подставляя соответствующие значения в формулу (17.8),
рассчитаем величину РЦ):
Л/,) = 0,3 • 0,1 + 0,2 • 0,1 + 0,5 • 0,6 = 0,35.
Формулы Байеса для апостериорных вероятностей будут
иметь вид
f\S//3) = РЩ)/Р(13) = P(S) i = 1, 2, 3. (17.9)
Подставляя необходимые данные в формулы (17.9), опреде-
лим вероятности, скорректированные в связи с прогнозом I:
PtSJIJ = 0,3 0,1/0,35 = 0,086;
AS//,) = 0,2 0,1/0,35 = 0,057; г
P[S}/I}) = 0,5 • 0,6/0,35 = 0,857.
Вычислим ожидаемую прибыль для каждого решения с уче-
том апостериорных вероятностей:
А 15 • 0,086 + 15 • 0,057 + 15 • 0,857 = 15;
А2 2,5 • 0,086 + 22,5 • 0,057 + 22,5 0,857 = 20,78;
А3 (-10) • 0,086 + 30 • 0,057 + 30 • 0,857 = 26,56;
Л4 (-35) 0,086 + 5 • 0,057 + 45 • 0,857 = 35,84.
Максимальная ожидаемая прибыль соответствует варианту
А4 (закупка 150 лодок) — 35,84 тыс. долл.
Полное дерево, характеризующее процесс выбора решения
в различных условиях (без дополнительной прогнозной инфор-
мации от консультанта и с использованием этой информации),
представлено на рис. 17.3.
Процедура принятия решений строится по следующей схе-
ме. Если владелец фирмы (ЛПР) не будет обращаться к кон-
сультанту, то наилучшим решением для него будет Л( (закупка
100 лодок). В случае если он прибегнет к услугам консультанта,
его стратегия характеризуется альтернативами:
а) если консультант предскажет /] (повышение ссудного
процента), то следует выбрать Л (закупка 50 лодок);
б) если консультант предскажет Z, (неизменность ссудного
процента), то следует выбрать А3 (закупка 100 лодок);
482
(0.3) ,5
15
(0.5)
(6.5
22,5
(0.5)
30
0.5)
22,5
-10
(0.3)
S
(0.3)
S,
(0.2)
(0.2)
(0.2)
15
2.5
(0.538) (5
8,45
(0.39)
S.(0'
(0.205)
------ 15
(0,256)
S.,0-538,255
(0.205)
------ 22,5
(0,256)
22,5
S^-IO
(0.205)
--------30
(0.256)
(0.3)
(0.2)
-« /а.
Отсутствие
дополнительной
информации
Стоимость
дополнительной
информации
Покупка
дополнительной
информации
30
-35
.5
(0,5)
45
s(0.231)15
30
-35
(0,205)
?.’256)
45
iwi
20.79
st;
11,16
20.78
35,84
26.56
35,84
30
(0,231)2^5
(0,385)^
0385)
45
(0.26) (0,086) 15
30
’-35
(0,057)
(0,857)
45
Рис. 17.3. Полное дерево решений для проблемы закупки лодок
(0.35
(0,057)
------ 15
(0.857)
15
S|(0.036)25
(0,057)
------ 22.5
(0,857)
22.5
s<°086>-10
(0,057)
------ 30
(0.857)
(0,
(0,385)
------ 15
(0,385)
15
Si'023,)2,5
(0,385)
------ 22.5
(0.385)
22 5
S|(0'23"-10
(0.385)
------- 30
0,385)
20,79
483
в) если консультант предскажет 1} (снижение ссудною про-
цента), то следует выбрать Ai (закупка 150 лодок).
При построении дерева решений были вычислены полные
вероятности /V.) и соответствующие максимальные значения
ожидаемой прибыли. Это дает возможность вычислить общую
ожидаемую прибыль, которая может быть получена при усло-
вии получения прогнозной информации от консультанта:
0,39 • 15 + 0,26 • 20,79 + 0,35 • 35,84 = 23,8 (тыс. долл.).
Если вычесть из полученной величины затраты на услуги
консультанта, то получим чистую прибыль. Предположим, что
консультанту было заплачено 2,5 тыс. долл. Тогда чистая ожида-
емая прибыль составит 23,8 — 2,5 = 21,3 (тыс. долл.).
Максимальная ожидаемая прибыль, которая может быть
получена без дополнительной прогнозной информации, равна
18 тыс. долл. Следовательно, ценность дополнительной инфор-
мации можно определить как разность: 21,3 — 18 = 3,3 (тыс.
долл).
Вычисление ценности дополнительной информации отра-
жено на графике дерева решений (рис. 17.3).
В общем случае ценность дополнительной информации, ис-
пользуемой для оценки апостериорных вероятностей состоя-
ний природы, определяется из соотношения:
Ценность дополнительной информации - Ожидаемый
выигрыш при условии получения дополнительной инфор-
мации — Максимальный ожидаемый вышрыш без получе-
ния дополнительной информации.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ГЛАВЫ 17
Любая проблема принятия решений включает три аспекта:
1) выявление возможных вариантов действий (альтернатив-
ных решений, или альтернатив);
2) описание факторов неопределенности, т. е. будущих со-
бытий, связанных с принимаемыми решениями;
3) оценка результатов (последствий) принимаемых реше-
ний.
Выбор альтернативного решения осуществляется лицом,
принимающим решение (ЛПР). ЛПР — собирательный образ,
в качестве которого может выступать как один человек, так и
484
группа людей (например, владелец фирмы, совет директоров
и т. д.). Будущие события, которые могут сопутствовать прини-
маемым решениям (например, состояния экономики), опре-
деляются термином — состояния природы. Последствия (ре-
зультаты) каждого решения отражают некоторый выигрыш,
который может быть и отрицательным, т. е. по существу проиг-
рышем. Величина выигрыша зависит от свершения одного из
возможных будущих событий (или наступления состояния при-
роды). Выигрыш может оцениваться в денежном выражении
(например, получаемая в результате реализации решения при-
быль). Информация, характеризующая величину выигрыша в
сочетании с состоянием природы, представляется в виде спе-
циальной таблицы — платежной матрицы (табл. 17.3). Иногда
задачу принятия решений удобно проанализировать не в тер-
минах выигрышей, а в терминах потерь от неиспользованных
благоприятных возможностей (условных потерь). По аналогии
с платежной матрицей значения условных потерь в сочетании
с состояниями природы сводятся в матрицу условных потерь
(табл. 17.5).
В условиях неопределенности будущих состояний природы
ЛПР вынуждено рассматривать все значения платежной мат-
рицы (или матрицы условных потерь), чтобы выбрать наибо-
лее подходящее решение. В условиях, когда неизвестны вероят-
ности состояния природы, можно выделить ряд основных
правил или критериев выбора оптимального решения.
Исходной информацией для данных правил служит платеж-
ная матрица (или матрица условных потерь). Одним из таких
правил является максиминный критерий Вальда. В каждой стро-
ке платежной матрицы (соответствующей определенному реше-
нию) выбирается минимальный выигрыш. Оптимальное по кри-
терию Вальда решение соответствует строке с максимальным из
минимальных элементов. Правило максимина гарантирует при
любых состояниях природы выигрыш не меньший, чем макси-
минное значение. Так же как и критерий Вальда, минимаксный
критерий Севиджа является критерием крайнего пессимизма.
Только пессимизм здесь характеризуется не минимальным га-
рантированным выигрышем, а максимальными условными по-
терями. В каждой строке матрицы условных потерь выбирается
максимальный элемент. Оптимальному выбору соответствует
решение (строка) с минимальным из максимальных элементов.
Сущность минимаксного критерия состоит в том, чтобы любы-
ми путями избежать большого риска при принятии решений.
Критерием с наибольшим риском является правило максимак-
485
са, по которому выбирается решение, соответствующее наиболь-
шему выигрышу (максимальному элементу платежной матри-
цы). Максимаксный вариант очень рискованный. Его выбор мо-
жет привести к значительным затратам или потерям. В качестве
компромиссного между очень консервативным критерием мак-
симина и крайне оптимистичным максимаксным критерием слу-
жит комбинированный критерий Гурвица. При его использова-
нии в платежной матрице для каждого решения (в каждой строке)
выбирается максимальный (самый оптимистичный выигрыш)
и минимальный (самый пессимистичный выигрыш) элементы.
Степень оптимизма задается весовым коэффициентом 0 < а 51,
а уровень пессимизма — коэффициентом 1 — а. Значения а и
(1 — а) используются в качестве весовых коэффициентов при
вычислении взвешенной суммы по каждой строке платежной
матрицы (максимальный элемент умножается на а, минималь-
ный — на (1 — а) и результаты суммируются). Использование
критерия Гурвица предполагает, что имеется достаточно инфор-
мации для определения весовых коэффициентов. Часто рассмат-
ривается несколько значений а, пока не будет получена реали-
стичная оценка степени оптимизма ЛПР.
Если имеются данные о вероятностях состояний природы,
то наиболее адекватным подходом к выбору решения является
критерий максимума математического ожидания или среднего
выигрыша. Смысл данною критерия заключается в том, что
вычисляются значения ожидаемого выигрыша для каждого ре-
шения и выбирается решение, соответствующее максимально-
му из этих значений. Это означает, что при многократном по-
вторении выбора данного решения в будущем средний выигрыш
будет максимальным (предполагается незначительное измене-
ние условий, в которых осуществляется выбор). Исходной ин-
формацией для реализации данного критерия будет расширен-
ная платежная матрица, включающая значения вероятностей
состояний природы (табл. 17.7). Среднее значение выигрыша
для каждого решения вычисляется по формуле (17.1). По ана-
логии с критерием максимума ожидаемого выигрыша можно
рассматривать правило выбора решения по показателю мини-
мума условных потерь. В качестве исходной информации здесь
рассматривается матрица условных потерь. Ожидаемые услов-
ные потери для каждого решения вычисляются по формуле
(17.2). Ожидаемые условные потери для каждого альтернатив-
ного решения отражают тот дополнительный выигрыш, кото-
рый недополучит ЛПР, если изберет долгосрочную стратегию
постоянного выбора этой альтернативы.
486
Как правило, возможность с полной определенностью оце-
нить вероятности состояний природы выпадает очень редко. На
практике гораздо надежнее оценивать возможные границы из-
менения их значений. При этом важно проанализировать, как
повлияет на выбор решений изменение значений вероятностей.
Подобный анализ называется анализом чувствительности. Он
позволяет выявить наиболее стабильные по отношению к изме-
нениям вероятностей варианты решений. Стабильные решения
будут наименее рискованными. В качестве меры риска можно
рассматривать дисперсию случайной величины X, моделирую-
щей данное решение: X принимает значения выигрышей при
соответствующих состояниях природы с вероятностями этих со-
стояний. Большая дисперсия характеризует больший риск. Одна-
ко сравнительный анализ риска различных вариантов решений
невозможен, если величины ожидаемых вышрышей значитель-
но отличаются друг от друга. В этом случае дисперсии решений
могут быть несоизмеримы и следует использовать безразмерную
характеристику — коэффициент вариации.
Удобным способом представления множества альтернатив-
ных решений и состояний природы является дерево решений.
Это диаграмма, позволяющая увидеть одновременно все воз-
можные цепочки действий и их последствия (события), выз-
ванные состояниями природы. С помощью дерева можно на-
глядно представить все предлагаемые варианты действий и
выигрыши, получаемые в результате каждого решения в усло-
виях соответствующих состояний природы. Дерево решений
состоит из соединения “вилок действий” и “вилок событий”.
В процессе принятия решений все вилки действий контроли-
руются ЛПР. Находясь в позиции вилки действий, ЛПР может
осуществить выбор варианта действий, входящих в вилку. Вил-
ки событий не подчиняются влиянию ЛПР, так как они харак-
теризуют состояния природы. Дерево решений строится слева
направо: в крайнем левом положении находится начальная
вилка действий. Формальный анализ осуществляется в обрат-
ном направлении: от концевых точек дерева к начальной вилке
действий. При этом производится оценка каждой “ветви”, ве-
дущей от начальной вилки к концевым точкам дерева решений.
Процедура оценки начинается с вычисления ожидаемых ре-
зультатов (т. е. усредненных по вероятностям) для крайних пра-
вых вилок событий и повторяется при движении по каждой
ветви к начальной вилке действий. Полученные оценки харак-
теризуют ожидаемые последствия каждого решения. Если они
отражают средний выигрыш (например, прибыль), то выбира-
487
ется “ветвь" (вариант в начальной вилке действий) с наиболь-
шим результатом. Метод дерева решений можно использовать
при анализе чувствительности, определяя, как меняется вы-
бор оптимального решения при изменении вероятностей со-
стояния природы. При этом следует строить дерево решений
для каждого рассматриваемого набора вероятностей. Далее про-
водится анализ полученных деревьев и выделяется оптималь-
ная “ветвь” начальной вилки действий.
Оптимальное решение, полученное по критерию максимума
ожидаемого выигрыша (или минимума ожидаемого проигры-
ша), зависит от точности оценки вероятностей состояния при-
роды. Часто ЛПР имеет предварительные (или априорные) оцен-
ки этих вероятностей, причем на данный момент они являются
единственной имеющейся, наиболее правдоподобной инфор-
мацией. Однако чтобы выбрать наилучшее решение, ЛПР может
привлекать дополнительную информацию. Новая информация
используется для пересмотра или уточнения априорных вероят-
ностей. Она может быть получена в результате исследования
рынка, сбора статистических данных, использования консуль-
тационных услуг и т. д. Уточненные таким способом вероятности
называются апостериорными. Инструментом корректировки ап-
риорных вероятностей при некоторых условиях является теоре-
ма Байеса. Комбинируя дерево решений с вычислением апосте-
риорных вероятностей, по теореме Байеса можно определить
ценность дополнительной информации, полученной в резуль-
тате эксперимента. Она вычисляется как разность между ожида-
емым выигрышем, определенным с использованием новой ин-
формации, и максимальным ожидаемым выигрышем, который
может быть получен только на основе оценок априорных веро-
ятностей.
ется “ветвь” (вариант в начальной вилке действий) с наиболь
шим результатом. Метод дерева решений можно использован,
при анализе чувствительности, определяя, как меняется вы
бор оптимального решения при изменении вероятностей со-
стояния природы. При этом следует строить дерево решений
для каждого рассматриваемого набора вероятностей. Далее про-
водится анализ полученных деревьев и выделяется оптималь-
ная “ветвь" начальной вилки действий.
Оптимальное решение, полученное по критерию максимума
ожидаемого выигрыша (или минимума ожидаемого проигры-
ша), зависит от точности опенки вероятностей состояния при-
роды. Часто ЛПР имеет предварительные (или априорные) оцен-
ки этих вероятностей, причем на данный момент они являются
единственной имеющейся, наиболее правдоподобной инфор-
мацией. Однако чтобы выбрать наилучшее решение, ЛПР может
привлекать дополнительную информацию. Новая информация
используется для пересмотра или уточнения априорных вероят-
ностей. Она может быть получена в результате исследования
рынка, сбора статистических данных, использования консуль-
тационных услуг и т. д. Уточненные таким способом вероятности
называются апостериорными. Инструментом корректировки ап-
риорных вероятностей при некоторых условиях является теоре-
ма Байеса. Комбинируя дерево решений с вычислением апосте-
риорных вероятностей, по теореме Байеса можно определить
ценность дополнительной информации, полученной в резуль-
тате эксперимента. Она вычисляется как разность между ожида-
емым выигрышем, определенным с использованием новой ин-
формации, и максимальным ожидаемым выигрышем, который
может быть получен только на основе оценок априорных веро-
ятностей.
Приложение 1
ПРИЛОЖЕНИЯ
Таблица случайных чисел
12CS1 61646 11769 75109 86996 97669 25757 32535 07122 76763
81769 74436 02630 72310 45049 18029 07469 42341 98173 79260
36737 98863 77240 76251 00654 64688 09343 7027В 67331 98729
82861 54371 76610 94934 72748 44124 05610 53750 95938 01485
21325 15732 24127 37431 09723 63529 73977 95218 96074 42138
74146 47887 62463 23045 41490 07954 22597 60012 98866 90959
90759 64410 54179 66075 61051 75385 51378 08360 95946 95547
55683 98078 02238 91540 21219 17720 87817 41705 95785 12563
79686 17969 76061 83748 55920 83612 41540 86492 06447 60568
70333 00201 86201 69716 78185 62154 77930 67663 29529 75116
14042 53536 07779 04157 41172 36473 42123 43929 50533 33437
59911 08256 06596 48416 69770 68797 56080 14223 59199 30162
62368 62623 62742 14891 39247 52242 98832 69533 91174 57979
57529 97751 54976 48957 74599 08759 78494 52766 68526 64618
15469 90574 78033 66885 13936 42117 71831 22961 94225 31616
18625 23674 53850 32827 81647 80620 00420 63555 74489 80141
74626 68394 88562 70745 23701 45630 65891 58220 35442 60414
11119 16519 27384 90199 79210 76965 99546 30323 31664 22845
41101 17336 48951 53674 17880 45260 08575 49321 36191 17095
32123 91576 84221 78902 82010 30847 62329 63898 23268 74283
26091 •ММ 69704 82267 14751 13151 93115 01437 56945 89661
67680 79790 48462 59278 44185 29616 76531 19589 83139 28454
15184 19260 14073 07026 25264 08388 27182 22557 61501 67481
58010 45039 57181 10238 36874 26546 37444 80824 63981 39942
56425 53996 66245 32623 78858 08143 60377 42925 42815 11159
82630 84066 13592 60642 17904 99716 63432 88642 37858 25431
14927 40909 23900 48761 44860 92467 31742 87142 03607 32059
23740 22506 07489 85986 74420 21744 97711 36648 35620 97949
32MD 97446 03711 63824 07953 85965 87089 11687 92414 67257
05310 24058 91946 78437 34365 82469 12430 84754 19354 72745
21839 39937 27534 88913 49055 19218 47712 67677 51869 70926
08833 42549 93981 94051 2ПМ 83725 72643 64233 97252 17133
58336 11139 47479 00931 91560 95372 97642 33856 54825 55680
62032 91144 75478 47431 52726 30289 42411 91886 51818 78292
45171 30557 53116 04118 58301 24375 65609 85810 18620 49198
91611 62656 60128 35609 63698 78356 50682 22505 01692 36291
55472 63819 86314 49174 93582 73604 76614 78849 23096 72825
18573 09729 74091 53994 10970 86557 65661 41654 26037 53296
60866 02955 90288 82136 83644 94455 06560 78029 98768 71296
45043 55608 82767 60890 74646 79485 13619 98868 40857 19415
17831 09737 79473 75945 28394 79334 70577 38048 03607 06932
40137 03981 07585 18128 11178 32601 27994 05641 22600 66064
77776 31343 14576 97706 16039 47517 43300 59080 80392 63189
69605 44104 40103 95635 05635 81673 68657 09559 23510 95875
19916 52934 26499 09821 97331 80993 61299 36979 73599 35055
02606 58552 07678 56619 65325 30705 99582 53390 46357 13244
65183 73160 87131 35530 47946 09854 18080 02321 05809 04893
10740 98914 44916 11322 89717 68189 30143 52687 19420 60061
98642 89822 71691 51573 83666 61642 46683 33761 47542 23551
60139 25601 93663 25547 02654 94829 46672 28736 84994 13071
489
Приложение 2
490 491
Биномиальные вероятности
р m
п к 0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
2 0 980 902 810 640 490 360 250 160 090 040 010 002 0+ 020 0
1 2 020 095 180 320 420 480 500 480 420 320 180 095 1
0+ 002 010 040 090 160 250 360 490 640 810 902 980 2
з 0 970 857 729 512 343 216 125 064 027 008 001 0+ 0+ 0
1 029 135 243 384 441 432 375 268 189 096 027 007 0+ 1
2 0+ 007 027 096 189 288 375 432 441 384 243 135 029 2
3 0+ 0+ 001 008 027 064 125 216 343 512 729 857 970 3
4 о 961 815 656 410 240 130 062 026 008 002 0+ 0+ 0+ 0
1 039 171 292 410 412 346 250 154 076 026 004 0+ 0+ 1
2 001 014 049 154 265 346 375 346 265 154 049 014 001 2
з 0+ 0+- 004 026 076 154 250 346 412 410 292 171 039 3
4 0+ 0+ 0+ 002 008 026 062 130 240 410 656 815 961 4
5 0 951 774 590 328 168 078 031 010 002 0+ 0+ 0+ 0+ 0
1 046 204 328 410 360 259 156 077 028 006 0+ 0+ 0+ 1
2 001 021 073 205 309 346 312 230 132 051 008 001 0+ 2
0-»- 001 008 051 132 230 312 346 309 205 073 021 001 3
0- 0+ 0 + 006 028 077 156 259 360 410 328 204 048 4
5 0+ 0+ 0+ 0+ 002 010 031 078 168 328 590 774 951 5
6 0 941 735 531 262 118 047 016 004 001 0+ 0+ 0+ 0+ 0
1 057 232 354 393 303 187 094 037 010 002 0+ 0+ 0+ 1
2 001 031 098 246 324 311 234 138 060 015 001 0+ 0+ 2
3 0+ 002 015 082 185 276 312 276 185 082 015 002 0+ 3
4 0+ 0+ 001 015 060 138 234 311 324 246 098 031 001 4
5 0+ 0+ 0+ 002 010 037 094 187 303 393 354 232 057 5
6 0+ 0+ 0+ 0+ 001 004 016 047 118 262 531 735 941 6
Приложение 2 (продолжение)
Л к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
7 0 932 698 478 210 082 028 008 002 0+ 0+ 0+ 0+ 0+ 0
1 066 257 372 367 247 131 055 017 004 0+ 0+ 0+ 0+ 1
2 002 041 124 275 318 261 164 077 025 004 0+ 01 0+ 2
3 0+ 004 023 115 227 290 273 194 097 029 003 0+ 0+ 3
4 0+ 0+ 003 029 097 194 273 290 227 115 023 004 0+ 4
5 0+ 0+ 0+ 004 025 077 164 261 318 275 124 041 002 5
6 0+ 0+ 0+ 0+ 004 017 055 131 247 367 372 257 066 6
7 0+ 0+ 0+ 0+ 0+ 002 008 028 082 210 478 698 932 7
8 0 923 663 430 168 058 017 004 001 0+ 0+ 0+ 0+ 0+ 0
1 075 279 383 336 198 090 031 008 001 0+ 0+ 0+ 0+ 1
2 003 051 149 294 296 209 109 041 010 001 0+ 0+ 0+ 2
3 0+ 005 033 147 254 279 219 124 047 009 0+ 0+ 0+ 3
4 0+ 0+ 005 046 136 232 273 232 136 046 005 0+ 0+ 4
5 0+ 0+ 0+ 009 047 124 219 279 254 147 033 005 0+ 5
6 0+ 0 + 0+ 001 010 041 109 209 296 294 149 051 003 6
7 0+ 0+ 0+ 0+ 001 008 031 090 198 336 383 279 075 7
8 0+ 0+ 0+ 0+ 0+ 001 004 017 058 168 430 663 923 8
9 0 914 630 387 134 040 010 002 0+ 0+ 0+ 0+ 0+ 0+ 0
1 083 299 387 302 156 060 018 004 0+ 0+ 0+ 0+ 0+ 1
2 003 063 172 302 267 161 070 021 004 0+ 0+ 0+ 0+ 2
3 0+ 008 045 176 267 251 164 074 021 003 0+ 0+ 0+ 3
4 0+ 001 007 066 172 251 246 167 074 017 001 0+ 0+ 4
5 0+ 0+ 001 017 074 167 246 251 172 066 007 001 0+ 5
6 0+ 0+ 0+ 003 021 074 164 251 267 176 045 008 0+ 6
7 0+ 0+ 0+ 0+ 004 021 070 161 267 302 172 063 003 7
8 0+ 0+ 0+ 0+ 0+ 004 018 060 156 302 387 299 083 8
9 0+ 0+ 0+ 0+ 0+ 0+ 002 010 040 134 387 630 914 9
8
Приложение 2 (продолжение)
п к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
10 0 904 599 349 107 028 006 001 0+ 0+ 0+ 0+ 0+ 0+ 0
1 091 315 387 268 121 040 010 002 0+ 0+ 0+ 0+ 0+ 1
2 004 075 194 302 233 121 044 011 001 0+ 0+ 0+ Q+ 2
3 0+ 010 057 201 267 215 117 042 009 001 0+ 0+ 0+ 3
4 0+ 001 011 088 200 251 205 111 037 006 0+ 0+ 0+ 4
5 0+ 0+ 001 026 103 201 246 201 103 026 001 0+ 0+ 5
6 0+ 0+ 0+ 006 037 111 205 251 200 088 011 001 0+ 6
7 0+ 0+ 0+ 001 009 042 117 215 267 201 057 010 0+ 7
8 0+ 0+ 0+ 0+ 001 011 044 121 233 302 194 075 004 8
9 0+ 0+ 0+ 0+ 0+ 002 010 040 121 268 387 315 091 9
11 0 695 569 314 086 020 004 0+ 0+ 0+ 0+ 0+ 0+ 0+ 0
1 099 329 384 236 093 027 005 001 0+ 0+ 0+ 0+ 0+ 1
2 005 087 213 295 200 089 027 005 001 0+ 0+ 0+ 0+ 2
3 0+ 014 071 221 257 177 081 023 004 0+ 0+ 0+ 0+ 3
4 0+ 001 016 111 220 236 161 070 017 002 0+ 0+ 0+ 4
5 0+ 0+ 002 039 132 221 226 147 057 010 0+ 0+ 0+ 5
6 0+ 0+ 0+ 010 057 147 226 221 132 039 002 0+ 0+ 6
7 0+ 0+ 0+ 002 017 070 161 236 220 111 016 001 0 + 7
^8 04 0+ 04 0+ 004 023 081 177 257 221 071 014 0+ 8
0+ 0+ 0+ 0+ 001 005 027 069 200 295 213 087 005 9
10 0+ 0+ 0+ 0+ 0+ 001 005 027 093 236 384 329 099 10
11 0+ 0+ 0+ 0+ 0+ 0+ 0+ 004 020 086 314 569 695 11
12 0 886 540 282 069 014 002 0+ 0+ 0+ 0+ 0+ 0+ 0+ 0
1 107 341 377 206 071 017 003 0+ 0+ 0+ 0* 0+ 0+ 1
2 006 099 230 263 168 064 016 002 0+ 0+ 0+ 0+ 0+ 2
3 0+ 017 085 236 240 142 054 012 001 0+ 0+ 0+ 0+ 3
4 0+ 002 021 133 231 213 121 042 008 001 0+ 0+ 0+ 4
Приложение 2 (продолжение)
п к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,50 0,70 0,80 0,90 0,35 0,99
5 0+ 0+ 004 053 158 227 193 101 029 003 04 04 04 5
6 0+ 04 0+ 016 079 177 226 177 079 016 04 04 0+ 6
7 0+ 0+ 0+ 003 029 101 193 227 158 053 004 0+ 04 7
8 0+ 04 0+ 001 008 042 121 213 231 133 021 002 0+ 8
9 0+ 04 0+ 04 001 012 054 142 240 236 085 017 04 9
10 0+ 04 0+ 04 04 002 016 064 168 283 230 099 006 10
11 0+ 04 0+ 04 0+ 04 003 017 071 206 377 341 107 11
12 0- 0+ 04 0+ 04 0+ 0+ 002 014 069 282 540 886 12
13 0 876 513 254 055 010 001 0+ 04 04 04 0+ • 0+ 0+ 0
1 115 351 367 179 054 011 002 04 04 04 0+ 0+ 0+ 1
2 007 111 245 266 139 045 010 001 04 04 04 04 0+ 2
3 0+ 021 100 246 218 111 035 006 001 0+ 0+ 04 04 3
4 0+ 003 028 154 234 184 087 024 003 04 0+ 0+ 04 4
5 0+ 0+ 006 069 180 221 157 066 014 001 04 0+ 0+ 5
6 0+ 04 001 023 103 197 209 131 044 006 04 0+ 0+ 6
7 0+ 0+ 04 006 044 131 209 197 103 023 001 04 0+ 7
8 0+ 0+ 04 001 014 066 157 221 180 069 006 0+ 0+ 8
9 0+ 04 04 0+ 003 024 087 184 234 154 026 003 0+ 9
10 0+ 04 04 0+ 001 006 035 111 218 246 100 021 0+ 10
11 0+ 0+ 0+ 04 04 001 010 045 139 268 245 111 007 11
12 0+ 0+ 04 0+ 0+ 04 002 011 054 179 367 351 115 12
13 0+ 04 0+ 04 0+ 0+ 04 001 010 055 254 513 876 13
14 0 869 488 229 044 007 001 0+ 04 0+ 04 0+ 0+ 04 0
1 123 359 356 154 041 007 001 0+ 04 0+ 04 0+ 0+ 1
2 008 123 257 250 113 032 006 001 04 0+ 04 0+ 0+ 2
3 0+ 026 114 250 194 065 022 003 0+ 0+ 0+ 04 04 3
4 0+ 004 035 172 229 155 061 014 001 04 04 04 04 4
S
Приложение 2(продолжение)
Л к ₽ т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
5 0+ 04 006 086 196 207 122 041 007 04 04 04 04 5
6 0+ 04 001 032 126 207 163 092 023 002 04 04 04 6
7 0+ 0* 04 009 062 157 209 157 062 009 04 04 04 7
8 0+ 04 04 002 023 092 163 207 126 032 001 04 04 8
9 0+ 04 04 04 007 041 122 207 196 086 008 04 04 9
10 0+ 04 04 04 001 014 061 155 229 172 035 004 04 10
11 0+ 04 04 0+ 04 003 022 065 194 250 114 026 04 11
12 0+ 0+ 04 04 04 001 006 032 113 250 257 123 006 12
13 0+ 0+ 04 04 04 04 001 007 041 154 356 359 123 13
14 0+ 04 04 04 04 04 04 001 007 044 229 468 869 14
15 0 660 463 206 035 005 04 04 04 0+ 04 04 04 04 0
1 130 366 343 132 031 005 04 04 04 04 04 04 04 1
2 009 135 267 231 092 022 003 04 04 04 04 04 04 2
3 0+ 031 129 250 170 063 014 002 04 04 04 04 04 3
4 0+ 005 043 168 219 127 042 007 001 04 04 04 04 4
5 0+ 001 010 103 206 166 092 024 003 0 + 04 04 04 5
6 0+ 04 002 043 147 207 153 061 012 001 04 04 04 6
7 0* 04 04 014 061 177 196 118 035 003 04 0* 04 7
0+ 04 04 003 035 118 196 177 061 014 04 04 04 8
04 04 04 001 012 061 153 207 147 043 002 04 04 9
10 04 04 04 04 003 024 092 186 206 103 010 001 04 10
11 04 04 04 04 001 007 042 127 219 188 043 005 04 11
12 04 04 04 04 04 002 014 063 170 250 129 031 04 12
13 0+ 04 04 04 04 04 003 022 092 231 267 135 009 13
14 04 04 04 04 04 04 001 005 031 132 343 366 130 14
15 04 04 04 04 04 04 0* 04 005 035 206 463 860 15
Приложение 2 (продолжение)
Л It Р /П
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
16 0 852 440 185 028 003 04 0+ 0- 04 04 04 04 04 0
1 138 371 329 113 023 003 0.+ 04 04 04 04 04 04 1
2 010 146 274 211 073 015 002 04 04 04 04 04 04 2
3 04 036 142 246 146 047 008 001 04 04 04 04 04 3
4 04 006 051 200 204 101 028 004 04 04 04 04 04 4
5 04 001 014 120 210 162 067 014 001 04 04 04 04 5
6 04 04 003 055 165 198 122 039 006 04 04 04 04 6
7 04 04 04 020 101 189 175 084 018 001 04 04 04 7
8 04 04 04 006 049 142 196 142 049 006 0+ 04 04 8
9 04 04 04 001 018 084 175 189 101 020 04 04 04 9
10 04 04 04 04 006 039 122 198 165 055 003 04 04 10
11 04 04 04 04 001 014 067 162 210 120 014 001 04 11
12 04 04 04 04 04 004 028 101 204 200 051 006 04 12
13 04 04 04 04 04 001 008 047 146 246 142 036 04 13
14 04 04 04 04 04 04 002 015 073 211 274 146 010 14
15 04 04 04 04 04 04 04 003 023 113 329 371 138 15
16 04 04 04 04 0+ 04 04 04 003 028 185 440 852 16
17 0 843 418 167 022 002 04 04 04 04 04 04 04 04 0
1 145 374 315 096 017 002 04 04 04 04 04 04 04 1
2 012 158 280 191 058 010 001 0+ 04 0+ 04 04 04 2
3 001 042 156 239 124 034 005 04 04 04 04 04 04 3
4 04 008 060 209 187 080 018 002 04 04 04 04 04 4
5 04 001 018 136 208 138 047 008 001 04 04 04 04 5
6 04 04 004 068 178 184 094 024 003 04 04 0+ 04 6
7 04 04 001 027 120 193 148 057 010 04 04 0> 04 7
8 04 04 04 008 064 161 186 107 028 002 04 04 04 8
9 04 04 04 002 028 107 186 161 064 008 04 04 04 9
Приложение 2 (продолжение)
п к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
10 0+ 0+ 0+ 04 010 057 148 193 120 027 001 04 04 10
11 0+ 0+ 0+ 04 003 024 094 184 178 068 004 04 04 11
12 0+ 0+ 0+ 04 001 008 047 138 208 136 018 001 04 12
13 0+ 0+ 0+ 04 04 002 018 080 187 209 060 008 04 13
14 0+ 0+ 0+ 04 04 04 005 034 124 239 156 042 001 14
15 0+ 0+ 04 04 04 04 001 010 058 191 280 158 012 15
16 0+ 0+ 0+ 04 04 04 04 002 017 096 315 374 145 16
17 0+ 0+ 0+ 04 04 04 04 04 002 022 167 418 843 17
18 0 834 397 150 018 002 04 04 04 04 04 04 04 04 0
1 152 376 300 081 013 001 04 04 04 04 04 04 04 1
2 013 168 284 172 046 007 001 04 04 04 04 04 04 2
3 001 047 168 230 105 025 003 04 04 04 04 04 04 3
4 0+ 009 070 215 168 061 012 001 04 04 04 04 04 4
5 0+ 001 022 151 202 115 033 004 04 04 04 04 04 5
6 0+ 0+ 005 082 187 166 071 014 001 04 04 04 04 6
7 0+ 0+ 001 035 138 189 121 037 005 04 04 04 04 7
8 0+ 0+ 04 012 081 173 167 077 015 001 04 04 04 8
^9 0+ 0+ 04 003 039 128 186 128 039 003 04 04 04 9
0+ 0+ (Н 001 015 077 167 173 081 012 04 04 04 10
11* 04 0+ 04 04 005 037 121 189 138 035 001 04 04 11
12 0+ 0+ 04 04 001 014 071 166 187 082 005 04 04 12
13 0+ 0+ 04 04 04 004 033 115 202 151 022 001 04 13
14 0+ 0+ 04 0* 04 001 012 061 168 215 070 009 04 14
15 0+ 0+ 04 04 04 04 003 025 105 230 188 047 001 15
16 0+ 0+ 0+ 04 04 04 001 007 046 172 284 168 013 16
17 0+ 04 04 04 04 04 04 001 013 081 300 376 152 17
18 0+ 0+ 04 04 04 04 04 04 002 018 150 397 834 18
Приложение 2 (продолжение)
п к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
19 0 826 377 135 014 001 04 04 04 04 04 04 04 04 0
1 159 377 285 068 009 001 04 04 04 04 04 0+ 04 1
2 014 179 285 154 036 005 04 04 04 04 0 + 04 04 2
3 001 053 180 218 087 018 002 04 04 04 04 04 04 3
4 0+ 011 080 218 149 047 007 04 04 04 04 04 0+ 4
5 04 002 027 164 192 093 022 002 04 04 04 04 04 5
6 0+ 04 007 096 192 145 052 008 04 04 04 04 04 6
7 04 04 001 044 152 180 096 024 002 04 Of- 0 + 04 7
8 04 04 04 017 098 180 144 053 008 04 04 04 04 8
9 04 04 04 005 051 146 176 098 022 001 04 04 0+ 9
10 04 04 04 001 022 098 176 146 051 005 04 04 04 10
11 04 04 04 04 008 053 144 180 098 017 04 04 04 11
12 04 04 04 04 002 024 096 180 152 044 001 04 04 12
13 04 04 04 04 04 008 052 145 192 096 007 04 04 13
14 04 04 04 0+ 04 002 022 093 192 164 027 002 04 14
15 04 04 04 0+ 04 04 007 047 149 218 080 011 04 15
16 04 04 04 04 04 04 002 018 087 218 180 053 001 16
17 04 04 04 0+ 04 04 04 005 036 154 285 179 014 17
18 04 04 04 0+ 04 04 04 001 009 068 285 377 159 18
19 04 04 04 04 04 04 04 0* 001 014 135 377 826 19
20 0 818 358 122 012 001 04 04 04 04 04 04 04 04 0
1 165 377 058 058 007 04 04 0+ 04 04 04 04 04 1
2 016 189 137 137 028 003 04 04 04 04 04 04 04 2
3 04 060 205 205 072 012 001 04 04 04 04 04 04 3
4 04 013 218 218 130 035 005 04 04 04 04 04 04 4
5 04 002 175 175 179 075 015 001 04 04 04 04 04 5
6 04 04 054 109 192 124 037 005 04 04 04 04 04 6
Приложение 2 (окончание)
Л к Р т
0,01 0,05 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 0,35 0,99
20 7 0+ 0+ 022 054 164 166 074 015 001 0+ 0+ 0+ 0+ 7
8 0+ 0+ 007 022 114 180 120 036 004 0+ 0+ 0+ 0+ 8
9 0+ 0+ 002 007 065 160 160 071 012 0+ 0+ 0+ 0+ 9
10 0+ 0+ 0+ 002 031 117 176 117 031 002 0+ 0+ 0+ 10
11 0+ 0+ 0+ 0 + 012 071 160 160 065 007 0+ 0+ 0+ 11
12 0+ 0+ 0+ 0+ 004 036 120 180 114 022 (к 0+ 0+ 12
13 0+ 0+ 0+ 0+ 001 015 074 166 164 054 002 0+ 0+ 13
14 0+ 0+ 0+ 0+ (Н 005 037 124 192 109 009 0+ 0+ 14
15 0+ 0+ 0+ о+ 0+ 001 015 075 179 175 032 002 0+ 15
16 0+ 0+ 0+ 0+ 0+ 0+ 005 035 130 218 090 013 0+ 16
17 0+ 0+ 0+ 0+ 0+ 0+ 001 012 072 205 190 060 001 17
18 0+ 0+ 0+ 0+ 0+ 0+ 0+ 003 028 137 285 189 016 18
19 0+ 0+ 0+ 0+ 0+ 0+ 0+ 0+ 007 058 270 377 165 19
20 0+ 0- 0+ 0+ 0+ 0+ 0+ 0+ 001 012 122 358 818 20
Приложение 3
Значения вероятностей распределения Пуассона ц'е* / х!
И
X 0,005 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0.09
0 0,9950 0,9900 0,9802 0,9704 0,9608 0,9512 0,9418 0,9324 0,9231 0,9139
1 0.0050 0.0099 0.0192 0,0291 0,0384 0,0476 0,0565 0.0653 0,0738 0,0823
2 0,0000 0,0000 0,0002 0,0004 0,0008 0,0012 0,0017 0,0023 0,0030 0,0037
3 0,0000 0.0000 0.0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001
X 0.1 0.2 0,3 0,4 0.5 0.6 0.7 0.8 0.9 1,0
0 0.9048 0,6187 0.7408 0,6703 0,6065 0,5468 0,4966 0,4493 0,4066 0,3679
1 0,0905 0,1637 0,2222 0,2681 0,3033 0,3293 0,3476 0,3595 0,3659 0,3679
2 0,0045 0,0164 0,0333 0,0536 0,0758 0,0988 0,1217 0,1438 0,1647 0,1839
3 0,0002 0,0011 0,0033 0,0072 0,0126 0,0198 0,0284 0,0383 0.0494 0,0613
4 0,0000 0,0001 0,0002 0,0007 0,0016 0,0030 0,0050 0,0077 0,0111 0,0153
5 0,0000 0,0000 0,0000 0,0001 0,0002 0,0004 0,0007 0,0012 0,0020 0,0031
6 0.0000 0,0000 0,0000 0.0000 0,0000 0,0000 0,0001 0,0002 0,0003 0,0005
7 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0.0000 0,0001
X 1.1 1,2 1,3 1,4 1.5 1.6 1.7 1.8 1.9 2.0
0 0,3329 0,3012 0,2725 0,2466 0,2231 0,2019 0,1827 0,1653 0,1496 0,1353
1 0,3662 0,3614 0,3543 0,3452 0,3347 0,3230 0,3106 0,2975 0.2842 0.2707
2 0,2014 0.2169 0,2303 0,2417 0,2510 0,2584 0,2640 0,2678 0,2700 0.2707
3 0,0738 0.0867 0,0998 0,1128 0,1255 0,1378 0,1496 0,1607 0.1710 0,1804
4 0,0203 0,0260 0,0324 0,0395 0,0471 0,0551 0,0636 0,0723 0,0812 0.0902
5 0,0045 0.0062 0,0084 0,0111 0,0141 0,0176 0:0216 0,0260 0,0309 0.0361
6 0,0008 0,0012 00018 0,0026 0,0035 0,0047 0,0061 0,007В 0,0098 0,0120
7 0.0001 0,0002 0,0003 0,0005 0,0008 0,0011 0,0015 0,0020 0,0027 0,0034
8 0,0000 0.0000 0,0001 0.0001 0,0001 0,0002 0,0003 0,0005 0.0006 0.0009
Приложение 3 (продолжение)
н
X 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
9 0,0000 0,0000 0.0000 0.0000 0,0000 0,0000 0,0001 0,0001 0,0001 0,0002
X 2.1 2,2 2.3 2.4 2.5 2,6 2.7 2.8 2,9 3,0
0 0,1225 0,1108 0,1003 0,0907 0,0821 0,0743 0,0672 0,0608 0,0050 0 0496
1 0,2572 0,2436 0.2306 0,2177 0,2052 0,1931 0.1815 0,1703 0,1596 0.1494
2 0,2700 0,2681 0,2652 0.2613 0,2565 0,2510 0,2450 0,2384 0,2314 0,2240
3 0,1890 0,1966 0,2033 0,2090 0,2138 0.2176 0,2205 0,2225 0,2237 0.2240
4 0,0992 0,1082 0,1169 0,1254 0,1336 0,1414 0.1468 0,1557 0,1622 0.1680
5 0,0417 0,0476 0,0538 0,0602 0,0666 0,0735 0.0804 0,0872 0,0940 0,1008
6 0,0146 0,0174 0,0206 0,0241 0,0278 0,0319 0.0362 0,0407 0,0455 0,0504
7 0.0044 0,0055 0,0066 0,0083 0,0099 0,0118 0,0139 0,0163 0.0188 0,0216
8 0,0011 0,0015 0,0019 0,0025 0,0031 0,0038 0,0047 0,0057 0,0068 0,0081
9 0,0003 0.0004 0,0005 0,0007 0.0009 0,0011 0,0014 0,0018 0,0022 0,0027
10 0,0001 0,0001 0,0001 0,0002 0,0002 0,0003 0,0004 0,0005 0,0006 0,0008
11 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001 0,0002 0,0002
12 0.0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
X 3 3,2 .3.3 3,4 3,5 3.6 3.7 3,8 3.9 4.0
0 0,0450 * 0,0406 0,0369 0,0334 0.0302 0,0273 0,0247 0,0224 0,0202 0,0183
1 0,1397 0,1304 0,1217 0,1135 0.1057 0,0964 0,0915 0,0650 0,0789 0.0733
2 0,2165 0,2087 0,2008 0,1929 0,1850 0,1771 0,1692 0,1615 0,1539 0,1465
3 0,2237 0,2226 0,2209 0,2186 0.2158 0,2125 0,2087 0,2046 0,2001 0,1954
4 0,1734 0,1781 0,1623 0,1858 0.1888 0,1912 0,1931 0,1944 0,1951 0/1954
5 0,1075 0,1140 0,1203 0.1264 0.1322 0,1377 0,1429 0,1477 0,1522 0,1563
6 0,0555 0,0606 0,0662 0,0716 0.0771 0,0826 0,0881 0,0936 0,0989 0,1042
7 0,0246 0,0278 0,0312 0,0346 0,0385 0,0425 0,0466 0,0506 0,0551 0,0595
8 0,0095 0,0111 0,0129 0,0148 0,0169 0,0191 0,0215 0,0241 0,0269 0,0298
501
Приложение 3 (продолжение)
н
X 3.1 3.2 .3.3 3,4 3,5 3.6 3.7 3.8 3.9 4.0
9 0,0033 0,0040 0,0047 0.0056 0.0066 0,0076 0,0069 0,0102 0,0116 0,0132
10 0,0010 0,0013 0,0016 0,0019 0.0023 0,0026 0,0033 0.0039 0,0045 0,0053
11 0,0003 0,0004 0,0005 0,0006 0,0007 0,0009 0,0011 0,0013 0,0016 0,0019
12 0,0001 0,0001 0,0001 0,0002 0,0002 0,0003 0,0003 0,0004 0,0005 0,0006
13 0,0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001 0,0001 0,0002 0,0002
14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
X 4,1 4.2 4.3 4.4 4.5 4.6 4.7 4,8 4.9 5.0
0 0,0166 0.0150 0,0136 0,0123 0,0111 0,0101 0,0091 0,0062 0.0074 0,0067
1 0,0679 0.0630 0,0563 0,0540 0,0500 0.0462 0,0427 0,0395 0,0365 0.00227
2 0,1393 0,1323 0,1254 0.1186 0,1125 0,1063 0,1005 0,0948 0 0894 0.0842
3 0.1904 0,1852 0,1798 0,1743 0,1667 0,1631 0,1574 0,1517 0.1460 0,1404
4 0,1951 0,1944 0,1933 0,1917 0,1898 0,1875 0,1849 0.1820 0,1789 0,1755
5 0,1600 0,1633 0,1662 0,1687 0,1708 0,1725 0,1738 0,1747 0,1753 0,1755
6 0,1093 0,1143 0,1191 0,1237 0,1281 0,1323 0.1362 0,1398 0,1432 0,1462
7 0,0640 0,0686 0,0732 0,0778 0.0824 0,0869 0,0914 0,0959 0,1002 0,1044
8 0,0326 0,0360 0,0393 0.0428 0.0463 0,0500 0,0537 0,0575 0,0614 0,0653
9 0,0150 0,0166 0,0188 0,0209 0,0232 0,0255 0,0280 0,0307 0,0334 0,0363
10 0,0061 0,0071 0,0081 0,0092 0,0104 0,0118 0,0132 0,0147 0,0164 0,0181
11 0,0023 0,0027 0,0032 0,0037 0,0043 0,0049 0,0056 0,0064 0,0073 0,0082
12 0,0008 0.0009 0,0011 0,0014 0,0016 0,0019 0,0022 0,0026 0,0030 0,0034
13 0.0002 0,0003 0,0004 0,0005 0,0006 0,0007 0,0006 0,0009 0,0011 0,0013
14 0,0001 0,0001 0,0001 0,0001 0,0002 0,0002 0,0003 0,0003 0,0004 0,0005
15 0.0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001 0,0001 0.0001 0,0002
X 5.1 5.2 5,3 5.4 5.5 5.6 5.7 5.8 5,9 •6.0
0 0,0061 0.0055 0.0050 0,0045 0,0041 0,0037 0,0033 0.0030 0,0027 0,0025
Приложение 3 (продолжении)
И
X 5.1 5,2 5.3 5.4 5,5 5.6 5.7 5.8 5.9 6.0
1 0.0311 0.0287 0,0265 0,0244 0.0225 0,0207 0,0191 0.0176 0.0162 0,0149
2 0.0793 0,0746 0,0701 0.0659 0,0618 0,0580 0,0544 0.0509 0,0477 0.0446
3 0,1348 0,1293 0,1239 0.1185 0,1133 0,1082 0,1033 0.0965 0.0938 0.0892
4 0,1719 0,1681 0,1641 0,1600 0.1558 0,1515 0,1472 0.1428 0.1383 0,1339
5 0,1753 0,1748 0,1740 0,1728 0,1714 0,1697 0,1678 0,1656 0.1632 0,1606
6 0,1490 0,1515 0,1537 0,1555 0,1571 0,1584 0,1594 0,1601 0,1605 0,1606
7 0,1086 0,1125 0,1163 0,1200 0,1234 0,1267 0,1298 0,1326 0,1353 0,1377
8 0,0692 0,0731 0,0771 0,0610 0,0649 0,0887 0.0925 0,0962 0,0998 0,1033
9 0.0392 0.0423 0,0454 0.0486 0,0519 0,0552 0,0586 0,0620 0,0654 0,0688
10 0.0200 0.0220 0,0241 0,0262 0,0265 0,0309 0,0334 0,0359 0,0366 0,0413
11 0.0093 0,0104 0,0116 0,0129 0.0143 0,0157 0,0173 0,0190 0,0207 0,0225
12 0,0039 0,0045 0,0051 0,0056 0.0065 0,0073 0,0082 0,0092 0,0102 0,0113
13 0.0015 0,0016 0,0021 0.0024 0.0028 0,0032 0,0036 0.0041 0,0046 0,0052
14 0 0006 0,0007 0,0006 0,0009 0.0011 0,0013 0,0015 0.0017 0,0019 0,0022
15 0.0002 0,0002 0,0003 0.0003 0.0004 0,0005 0.0006 0.0007 0.0006 0.0009
16 o.oqfti 0,0001 0,0001 0.0001 0,0001 0,0002 0.0002 0,0002 0,0003 0.0003
17 ооооо^- ^0,0000 0.0000 0,0000 0,0000 0,0001 0.0001 0,0001 0,0001 0.0001
X 6.1 6.2 6,3 6.4 6.5 6,6 6.7 6,8 6,9 7,0
0 0.0022 0,0020 0,0016 0,0017 0,0015 0,0014 0,0012 0,0011 0,0010 0,0009
1 0.0137 0,0126 0,0116 0,0106 0,0096 0,0090 0,0082 0,0076 0,0070 0.0064
2 0.0417 0.0390 0,0364 0,0340 0,0316 0,0296 0,0276 0,0258 0,0240 0,0223
3 0.0648 0,0806 0,0765 0,0726 0 0688 0,0652 0,0617 0,0584 0,0552 0,0521
4 0,1294 0,1269 0,1205 0,1162 0,1118 0,1076 0,1034 0,0992 0,0952 0,0912
5 0,1579 0,1549 0,1519 0.1487 0.1454 0,1420 0,1385 0,1349 0,1314 0,1277
6 0,1605 0,1601 0,1595 0.1586 0,1575 0,1562 0,1546 0,1529 0.1511 0,1490
7 0.1399 0,1418 0,1435 0,1450 0,1462 0,1472 0.1480 0.1486 0,1489 0,1490
Приложение 3 (продолжение)
И
X 6,1 6.2 6.3 6,4 6,5 6.6 6.7 6,8 6,9 7.0
8 0,1066 0,1099 0,1130 0,1160 0,1188 0,1215 0.1240’ 0.1263 0.1264 0,1304
9 0,0723 0,0757 0.0791 0,0825 0,0858 0.0691 0,0923 0.0954 0.0985 0.1014
10 0,0441 0,0469 0,0498 0.0528 0,0556 0.0566 0,0616 0,0649 0,0679 0,0710
11 0,0245 0,0265 0,0285 0.0307 0,0330 0,0353 0,0377 0,0401 0,0426 0,0452
12 0,0124 0,0137 0,0150 0,0164 0,0179 0,0194 0,0210 0,0227 0,0245 0,0264
13 0.0056 0,0065 0,0073 0,0081 0.0089 0,0096 0,0108 0,0119 0,0130 0,0142
14 0,0025 0,0029 0,0033 0,0037 0.0041 0,0046 0,0052 0,0058 0,0064 0,0071
15 0,0010 0,0012 0,0014 0,0016 0.0016 0.0020 0,0023 0,0026 0,0029 0,0033
16 0,0004 0,0005 0,0005 0,0006 0.0007 0,0008 0,0010 0,0011 0,0013 0,0014
17 0,0001 0,0002 0,0002 0,0002 0,0003 0,0003 0,0004 0,0004 0,0005 0,0006
18 0.0000 О.ООС1 0,0001 0,0001 0,0001 0,0001 0,0001 0,0002 0,0002 0,0002
19 0.0000 0.0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001
X 7.1 7.2 7,3 7.4 7.5 7.6 7.7 7.8 7.9 8.0
0 0,0008 0,0007 0,0007 0,0006 0,0006 0,0005 00005 0,0004 0,0004 0,0003
1 0.0059 0,0054 0,0049 0,0045 0,0041 0,0036 0,0035 0,0032 0,0029 0,0027
2 0,0208 0.0194 0,0180 0,0167 0,0156 0.0145 0,0134 0,0125 0,0116 0,0107
3 0,0492 0.0464 0,0438 0,0413 0,0369 0,0366 0,0345 0,0324 0,0305 0,0286
4 0,0874 0.0836 0,0799 0,0764 0,0729 0.0696 0.0663 0,0632 0,0602 0,0573
5 0,1241 0,1204 0,1167 0,1130 0,1094 0.1057 0,1021 0.0966 0,0951 0,0916
6 0,1468 0,1445 0,1420 0,1394 0,1367 0,1339 0,1311 0,1262 0,1252 0,1221
7 0,1483 0,1486 0,1481 0,1474 0,1465 0,1454 0,1442 0.1428 0,1413 0,1396
8 0,1321 0,1337 0,1351 0.1363 0,1373 0,1382 0,1368 0.1392 0,1395 0.1396
9 0,1042 0,1070 0,1096 0,1121 0,1144 0.1167 0,1167 0,1207 0,1224 0.1241
10 0,0740 0,0770 0,0800 0,0829 0,0658 0.0887 0,0914 0.0941 0,0967 0.0993
11 0,0478 0,0504 0,0531 0.0558 0,0585 0.0613 0.0640 0,0667 0.0695 0.0722
I
Приложение 3 (продолжение)
М
X 7.1 7,2 7,3 7,4 7,5 7.6 7.7 7.8 7.9 8.0
12 0,0283 0,0303 0.0323 0,0344 0,0366 0,0388 0,0411 0,0434 0,0457 0,0481
13 0,0154 0.0168 0.0181 0,0196 0.0211 0,0227 0,0243 0.0260 0,0278 0,0296
14 0,0078 0,0066 0,0095 0.0104 0,0113 0,0123 0,0134 0,0145 0,0157 0,0169
15 0.0037 0,0041 0.0046 0.0051 0,0057 0,0062 0,0069 0,0075 0,0083 0,0090
16 0,0016 0,0019 0.0021 0.0024 0.0026 0,0030 0,0033 0,0037 0,0041 0.0045
17 0,0007 0,0006 0.0009 0,0010 0,0012 0,0013 0,0015 0,0017 0,0019 0,0021
18 0,0003 0,0003 0.0004 0,0004 0.0005 0.0006 0,0006 0,0007 0,0008 0,0009
19 0,0001 0.0001 0,0001 0,0002 0,0002 0,0002 0,0003 0.0003 0,0003 0,0004
20 0.0000 0.0000 0.0001 0,0001 0.0001 0,0001 0,0001 0.0001 0,0001 0,0002
21 0.0000 0.0000 0,0000 0,0000 0.0000 0,0000 0,0000 0,0000 0,0001 0,0001
X 8.1 8.2 6.3 6.4 6.5 6,6 8,7 8.8 8.9 9.0
0 0.0003 0,0003 0,0002 0,0002 0.0002 0.0002 0,0002 0,0002 0,0001 0,0001
1 0.0025 * 0,0021 0,0019 0,0017 0,0016 0,0014 0.0013 0,0012 0,0011
2 0.0100 OOl»2 0,0066 0,0079 0,0074 0,0068 0,0063 0,0058 0,0054 0,0050
3 0.0269 0.0252 0,0237 0,0222 0,0208 0.0195 0,0183 0.0171 0.0160 0,0150
4 0,0544 0.0517 0,0491 0,0466 0,0443 0.0420 0,0398 0.0377 0,0357 0,0337
5 0.0682 0,0649 0,0816 0.0784 0,0752 0.0722 0,0692 0.0663 0,0635 0,0607
6 0,1191 0.1160 0,1126 0,1097 0,1066 0.1034 0,1003 0.0972 0.0941 0,0911
7 0,1378 0.1358 0,1338 0,1317 0,1294 0,1271 0,1247 0,1222 0,1197 0,1171
8 0,1395 0,1392 0,1386 0,1382 0,1375 0,1366 0,1356 0.1344 0.1332 0,1318
9 0,1256 0.1269 0,1280 0,1290 0,1299 0,1306 0,1311 0.1315 0,1317 0,1316
10 0,1017 0,1040 0,1063 0,1064 0,1104 0.1123 0,1140 0.1157 0,1172 0,1186
11 0,0749 0.0776 0,0802 0,0828 0,0853 0.0878 0,0902 0,0925 0,0948 0,0970
12 0,0505 0,0530 0,0555 0,0579 0,0604 0,0629 0,0654 0,0679 0,0703 0,0726
13 0,0315 0,0334 0,0354 0,0374 0,0395 0,0416 0.0438 0.0459 0 0481 00504
Приложение 3 (продолжение)
X 8.1 8.2 6.3 6.4 6.5 6,6 8.7 8.8 8,9 9.0
14 0,0162 0,0196 0,0210 0.0225 0,0240 0,0256 0.0272 0,0289 0,0306 0.0324
15 0,0098 0,0107 0,0116 0.0126 0,0136 0.0147 0,0156 0.0169 0,0182 0,0194
16 0,0050 0.0055 0,0060 0,0066 0,0072 0,0079 0,0086 0,0093 0,0101 0,0109
17 0,0024 0,0026 0,0029 0,0033 0,0036 0,0040 0,0044 0,0046 0,0053 0,0056
18 0,0011 0,0012 0,0014 0,0015 0,0017 0,0019 0,0021 0,0024 0,0026 0,0029
19 0,0005 0,0005 0.0006 0,0007 0,0006 0,0009 0,0010 0,0011 0,0012 0,0014
20 0.0002 0.0002 0.0002 0,0003 0,0003 0,0004 0,0004 0,0005 0,0005 0,0006
21 0,0001 0.0001 0.0001 0,0001 0,0001 0,0002 0,0002 0,0002 0,0002 0,0003
22 0,0000 0,0000 0.0000 0,0000 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001
X 9.1 9.2 9.3 9.4 9.5 9,6 9.7 9,8 9.9 10,0
0 0.0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0000
1 0,0010 0.0009 0,0009 0,0008 0,0007 0,0007 0,0006 0,0005 0,0005 0,0005
2 0,0046 0.0043 0,0040 0,0037 0,0034 0,0031 0,0029 0,0027 0,0025 0,0023
3 0.0140 0,0131 0,0123 0,0115 0,0107 0.0100 0,0093 0,0067 0.0081 0,0076
4 0,0319 0,0302 0,0285 0,0269 0,0254 0,0240 0,0226 0,0213 0,0201 0.0169
5 0,0581 0,0555 0,0530 0.0506 0,0483 0,0460 0,0439 0,0416 0,0396 0.0378
6 0,0681 0,0651 0,0622 0.0793 0,0764 0,0736 0,0709 0,0662 0,0656 0.0631
7 0.1145 0,1118 0,1091 0.1064 0,1037 0,1010 0,0962 0,0955 0,0928 0,0901
8 0,1302 0,1266 0,1269 0.1251 0,1232 0,1212 0,1191 0,1170 0,1148 0,1126
9 0,1317 0,1315 0,1311 0.1306 0,1300 0,1293 0,1264 0,1274 0,1263 0.1251
10 0,1198 0,1210 0,1219 0,1228 0,1235 0,1241 0,1245 0,1249 0,1250 0,1251
11 0,0991 0,1012 0.1031 0.1049 0,1067 0,1083 0,1098 0,1112 0,1125 0,1137
12 0,0752 0,0776 0.0799 0,0822 0.0844 0,0866 0,0688 0,0908 0,0928 0,0948
13 0,0526 0.0549 0,0572 0,0594 0.0617 0,0640 0,0662 0,0685 0,0707 0,0729
14 0,0342 0,0361 0,0380 0,0399 0,0419 0,0439 0,0459 0,0479 0,0500 0,0521
Приложение 3 (окончание)
ZOS H 90S
И
X 9,1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9 10,0
15 0,0208 0,0221 0,0235 0,0250 0 0265 0,0281 0.0297 0,0313 0,0330 0,0347
16 0,0118 0,0127 0,0137 0,0147 0,0157 0,0168 0.0180 0,0192 0,0204 0.0217
17 0,0063 0,0069 0.0075 0,0081 0,0088 0.0095 0.0103 0,0111 0,0119 0.0128
18 0,0032 0,0035 0.0039 0,0042 0,0046 0.0051 0,0055 0.0060 0,0065 0.0071
19 0,0015 0,0017 0,0019 0,0021 0,0023 0,0026 0.0026 0.0031 0,0034 0.0037
20 0,0097 0,0008 0,0009 0,0010 0,0011 0,0012 0,0014 0,0015 0,0017 0,0019
21 0.0003 0.0003 0,0004 0,0004 0,0005 0,0006 0,0006 0,0007 0,0008 0,0009
22 0.0001 0,0001 0,0002 0,0002 0,0002 0,0002 0,0003 0,0003 0,0004 0,0004
23 0.0000 0.0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0002 0,0002
24 0.0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0001 0,0001
Доли площади под кривой стандартного нормального распределения'
Приложение 4
I Второй десятичный знак z
0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 0,0000 0,0040 0,0080 0,0120 0.0160 0,0199 0,0239 0,0279 0.0319 0,0359
0.1 0,0398 0,0438 0,0478 0,0517 0.0557 0,0596 0,0636 0,0675 0,0714 0.0753
0.2 0,0793 0,0832 0,0871 0,0910 0.0948 0,0987 0.1026 0,1064 0.1103 0,1141
0.3 0,1179 0,1217 0,1255 0.1293 0,1331 0,1368 0.1406 0,1443 0,1480 0.1517
0,4 0,1554 0,1591 0,1628 0.1664 0,1700 0,1736 0,1772 0,1808 0,1844 0,1879
0.5 0.1915 0,1950 0,1985 0.2019 0,2054 0,2088 0,2123 0,2157 0.2190 0,2224
0.6 0,2257. 0.2291 0,2324 0,2357 0,2389 0,2422 0,2454 0,2486 0.2517 0,2549
0,7 0.2580 0.2611 0,2642 0,2673 0,2704 0,2734 0,2764 0,2794 0.2823 0,2852
0.8 0,2881 0.2910 0,2939 0.2967 0,2995 0,3023 0.3051 0,3078 0,3106 0,3133
0,9 0,3159 0,3186 0,3212 0.3238 0,3264 0,3289 0,3315 0,3340 0,3365 0,3389
1.0 0.3413 0,3438 0,3461 0,3485 0,3508 0,3531 0,3554 0,3577 0,3599 0,3621
1.1 0.3643 0,3665 0.3686 0.3708 0,3729 0.3749 0,3770 0,3790 0,3810 0,3830
1.2 0,3849 0,3869 0,3888 0,3907 0,3925 0,3944 0,3962 0,3980 0,3997 0,4015
1.3 0,4032 0,4049 0,4066 0,4082 0,4099 0.4115 0,4131 0,4147 0,4162 0,4177
1 В таблице указаны величины заштрихованной площади (между 0 и г).
геиие 4 (окончание)
1Л <0 СО О> О - N И Ч U0 <О Г~ СО О> О •- М П Ч ШО1ЛО
см’ о! см см см’ см’ см см см' см’ со со’ со со’ со’ со V м- ui
508
Приложение 5
Доли площадей под кривыми (-распределения ’
Имело степе- ней *-/г
f0.10D *0,060 *0.025 *0.010 *0,005
1 3,078 6,314 12,706 31,821 63,657
2 1,886 2,920 4,303 6.965 9,925
3 1,638 2.353 3,182 4,541 5,841
4 1,533 2,132 2,776 3,747 4,604
5 1,476 2,015 2,571 3,365 4,032
6 1,440 1,943 2.447 3,143 3,707
7 1,415 1,895 2,365 2,998 3,499
8 1.397 1,860 2,306 2,896 3,355
9 1,383 1,833 2,262 2,821 3,250
10 1,372 1,812 2,228 2,764 3,169
11 1,363 1,796 2,201 2,718 3,106
12 1,356 1,782 2,179 2,681 3,055
13 1,350 1,771 2,160 2,650 3,012
14 1,345 1,761 2,145 2.624 2,977
15 1,341 1,753 2,131 2,602 2,947
16 1,337 1,746 2,120 2,583 2,921
17 1,333 1.740 2,110 2,567 2,898
18 1,330 1,734 2,101 2,552 2,878
19 1,328 1,729 2,093 2.539 2,861
20 1,325 1,725 2,086 2,528 2,845
21 1,323 1,721 2.080 2,518 2,831
22 1,321 1,717 2,074 2,508 2,819
23 1,319 1,714 2,069 2,500 2,808
24 1,318 1,711 2,064 2,492 2,797
25 1,316 1,708 2,060 2,485 2.787
26 1.315 1,706 2,056 2,479 2.779
27 1,314 1,703 2,052 2,473 2,771
28 1,313 1,701 2,048 2,467 2,763
29 1,311 1,699 2,045 2,462 2.756
30 1,310 1,697 2,042 2,457 2.750
35 1,306 1,690 2,030 2,438 2.724
40 1,303 1,684 2,021 2,423 2,704
50 1,299 1,676 2,009 2,403 2,678
60 1,296 1,671 2,000 2,390 2.660
120 1,289 1,658 1,980 2,358 2,617
DO 1,282 1,645 1,960 2,326 2,576
1 В таблице указаны значения заштрихованной плошали (между / и +«•).
509
Приложение 6
Критические значения F-критерия (а ж 0,05)
Число степеней свободы знамена- теля Число степеней свободы числителя
1 2 3 4 5 б 7 8 9
1 161.4 199,5 215.7 224,6 230,2 234,0 236.8 238,9 240,5
2 18,51 19,00 19,16 19,25 19,30 19,33 19,35 19,37 19,38
3 10,13 9,55 9,26 9,12 9,01 8,94 8,89 8,85 8,81
4 7.71 6,94 6,59 6,39 6.26 6,16 6,09 6,04 6.00
5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4.77
6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4.10
7 5,59 4,74 4,35 4.12 3,97 3,87 3,79 3,73 3,68
8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39
9 5,12 4,26 3,86 3,63 3.46 3.37 3,29 3,23 3,18
10 4,96 4,10 3.71 3,48 3,33 3,22 3.14 3,07 3,02
11 4,84 3,98 3,59 3,36 3,20 3,09 3.01 2,95 2,90
12 4,75 3.89 3,49 3,26 3,11 3,00 2,91 2,65 2,80
13 4,67 3,81 3.41 3,18 3,03 2.92 2.83 2,77 2.71
14 4,60 3.74 3,34 3,11 2,96 2,65 2.76 2,70 2,65
15 4,54 3,68 3,29 3,06 2,90 2,79 2.71 2,64 2,59
16 4,49 3,63 3,24 3,01 2,85 2.74 2.66 2,59 2,54
17 4,45 3,59 3,20 2,96 2,81 2.70 2.61 2,55 2,49
18 4,41 3,55 3,16 2,93 2,77 2.66 2,58 2.51 2,46
19 4.38 3,52 3,13 2,90 2,74 2,63 2.54 2,48 2,42
20 4,35 3.49 3,10 2,87 2,71 2.60 2.51 2.45 2,39
21 4,32 3.47 3,07 2,84 2,68 2.57 2.49 2,42 2,37
22 4,30 3.44 3,05 2,82 2,66 2,55 2,46 2,40 2,34
23 4,28 3,42 3,03 2,80 2,64 2,53 2,44 2,37 2,32
24 4,26 3,40 3,01 2,78 2,62 2.51 2.42 2,36 2,30
25 4.24 3,39 2,99 2,76 2,60 2.49 2.40 2,34 2,28
26 4,23 3,37 2,96 2,74 2,59 2.47 2.39 2,32 2,27
27 4,21 3,35 2,96 2,73 2.57 2.46 2,37 2,31 2,25
28 4,20 3,34 2,95 2,71 2,56 2.45 2,36 2,29 2,24
29 4,18 3,33 2,93 2,70 2,55 2.43. 2.35 2,28 2.22
30 4,17 3,32 2,92 2,69 2.53, 2.42 2.33 2,27 2,21
40 4,08 3,23 2,84 2,61 2,4? 2,34 2,25 2,18 2,12
60 4,00 3,15 2,76 2,53 2/7 2.25 2.17 2,10 2,04
120 3,92 3,07 2,68 2,45 /29 2.17 2,09 2,02 1,96
м 3,84 3,00 2,60 2,37 2,21 2,10 2.01 1,94 1,88
510
Приложение 6 (продолжение) (а = 0,05|
Число Степа- не* с>обо- ДМ знаме- нателя Число степеней свободы числителя
10 12 15 20 24 30 40 60 120 •а
1 241.9 243,9 245.9 248.0 249,1 250,1 251,1 252,2 253,3 254,3
2 19,40 19,41 19,43 19,45 19,45 19,46 19,47 19.48 19,49 19,50
3 8,79 8,74 8,70 8.66 8.64 8,62 6.59 8,57 8.55 8,53
4 5,96 5,91 5,86 5.80 5.77 5,75 5.72 5,69 5,66 5,63
5 4,74 4,68 4,62 4,56 4,53 4,50 4.46 4,43 4.40 4.36
6 4,06 4,00 3,94 3,67 3.64 3,81 3.77 3.74 3.70 3,67
7 3,64 3,57 3,51 3,44 3.41 3,38 3.34 3,30 3.27 3,23
8 3,35 3,28 3,22 3,15 3,12 3,06 3,04 3,01 2,97 2,93
9 3,14 3,07 3,01 2,94 2,90 2,86 2.83 2,79 2.75 2.71
10 2.98 2,91 2.85 2,77 2.74 2,70 2,66 2,62 2,58 2.54
11 2.85 2,79 2,72 2,65 2,61 2.5/ 2.53 2,49 2,45 2.40
12 2,75 2,69 2.62 2.54 2.51 2.47 2.43 2.36 2,34 2,30
13 2.67 2,60 2.53 2,46 2,42 2,38 2,34 2.30 2,25 2,21
14 2.60 2,53 2.46 2,39 2,35 2,31 2,27 2,22 2,18 2.13
15 2.54 2,48 2.40 2,33 2,29 2,25 2,20 2.16 2,11 2,07
16 2,49 2,42 2,35 2,28 2,24 2,19 2,15 2.11 2,06 2.01
17 2.45 2,38 2.31 2,23 2,19 2.15 2,10 2,06 2,01 1,96
18 2.41 2,34 2,27 2,19 2,15 2,11 2,06 2,02 .97 1.92
19 2,38 2,31 2,23 2,16 2.11 2,07 2,03 1,98 1,93 1.88
20 2,35 2,28 2,20 2.12 2,08 2,04 1,99 1,95 1,90 1.84
21 2,32 2,25 2,18 2,10 2,05 2,01 1,96 1,92 1,87 1.81
22 2,30 2,23 2.15 2,07 2,03 1.98 1.94 1.89 1,64 1.78
23 2,27 2,20 2,13 2,05 2,01 1,96 1.91 1.86 1.81 1.76
24 2,25 2,16 2.11 2.03 1,98 1,94 1,89 1.84 1.79 1.73
25 2.24 2,16 2,09 2,01 1,96 1,92 1,87 1,82 1.77 1.71
26 2,22 2,15 2,07 1.99 1,95 1.90 1,85 1,60 1.75 1,69
27 2,20 2,13 2,06 1.97 1,93 1.68 1.84 1.79 1.73 1.67
28 2,19 2,12 2,04 1.96 1.91 1.87 1.82 1.77 1.71 1,65
29 2,18 2,10 2,03 1.94 1,90 1.65 1.81 1.75 1.70 1,64
30 2,16 2,09 2,01 1,93 1,69 1.64 1.79 1.74 1.66 1,62
40 2,08 2,00 1,92 1.84 1.79 1.74 1.69 1.64 1,58 1,51
60 1,99 1,92 1.84 1.75 1,70 1,65 1.59 1.53 1.47 1,39
120 1.91 1.83 1.75 1.66 1.61 1.55 1,50 1.43 1,35 1,25
1,83 1.75 1,67 1.57 1.52 1.46 1,39 1.32 1,22 1,00
511
Приложение 6 (продолжение) (а 0.01)
Число
степеней Число степеней свободы числителе
1 2 3 4 5 6 7 8 9
теля
1 4,052 4,999 5.403 5,625 5,764 5,859 5,928 5,982 6,022
2 98,50 99,00 99,17 99,25 99.30 99,33 99,36 99,37 99,39
3 34,12 30,82 29,46 28,71 28,24 27,91 27,67 27,49 27.35
4 21,20 18,00 16,69 15,98 15,52 15,21 14,98 14.80 14.66
5 16,26 13,27 12,06 11,39 10,97 10,67 10,46 10,29 10,16
6 13,75 10,92 9,78 9,15 8,75 8,47 8,26 8,10 7,98
7 12,25 9,55 8,45 7,85 7,46 7.19 6,99 6.84 6,72
8 11,26 8,65 7,59 7,01 6,63 6,37 6,18 6.03 5.91
9 10,56 8,02 6,99 6,42 6,06 5,80 5,61 5,47 5,35
10 10,04 7.56 6,55 5,99 5,64 5,39 5,20 5,06 4.94
11 9,65 7,21 6,22 5,67 5,32 5,07 4,89 4,74 4.63
12 9,33 6,93 5,95 5,41 5,06 4,82 4,64 4,50 4,39
13 9,07 6,70 5,74 5,21 4,86 4,62 4,44 4.30 4.19
14 8,66 6,51 5,56 5,04 4,69 4,46 4,28 4,14 4,03
15 6,68 6,36 5,42 4,69 4,56 4,32 4,14 4,00 3,89
16 6,53 6,23 5,29 4.77 4,44 4,20 4,03 3,69 3,78
17 6,40 6.11 5,16 4,67 4,34 4,10 3,93 3,79 3,68
18 8,29 6,01 5,09 4,58 4,25 4,01 3,84 3,71 3,60
19 8,18 5,93 5,01 4,50 4,17 3,94 3,77 3,63 3,52
20 6,10 5,85 4,94 4,43 4,10 3,87 3,70 3,56 3,46
21 8,02 5,78 4,67 4.37 4,04 3,61 3,64 3,51 3,40
22 7,95 5.72 4,82 4,31 3,99 3,76 3,59 3,45 3,35
23 7.86 5.66 4,76 4,26 3,94 3,71 3,54 3,41 3,30
24 7,82 5.61 4,72 4,22 3,90 3,67 3,50 3,36 3,26
25 7.77 5.57 4,66 4.18 3,65 3,63 3,46 3,32 3,22
26 7.72 5,53 4,64 4.14 3,82 3,59 3,42 3,29 3,18
27 7.68 5,49 4,60 4,11 3,78 3,56 3,39 3,26 3,15
28 7,64 5,45 4,57 4,07 3,75 3,53 3,36 3,23 3,12
29 7,60 5,42 4.54 4,04 3,73 3,50 3,33 3,20 3,09
30 7,56 5,39 4.51 4,02 3,70 3,47 3,30 3.17 3,07
40 7,31 5,16 4.31 3,63 3,51 3,29 3,12 2,99 2,69
60 7,08 4,96 4.13 3,65 з.з/ 3,12 2,95 2,82 2,72
120 6,85 4,79 3.95 3,46 3Л 2,96 2,79 2.66 2.56
во 6,63 4,61 3.78 3,32 «02 2,80 2,64 2.51 2.41
512
Приложение 6/окончание) (а = 0.01)
Число стапе- ней свобо- ды знаме- нателя Число степеней свободы числителя
10 12 15 20 24 30 40 60 120 ••
1 6,056 6,106 6,157 6.209 6,235 6.261 6,287 6.313 6.339 6,366
2 99,40 99,42 99,43 99,45 99,46 99,47 99,47 99,48 99,49 99,50
3 27,23 27,05 26,87 26,69 26.60 26,50 26.41 26,32 26,22 26,13
4 14,55 14,37 14,20 14,02 13.93 13,84 13,75 13.65 13,56 13,46
5 10,05 9,89 9,72 9,55 9.47 9.38 9,29 9,20 9.11 9,02
6 7.87 7,72 7.56 7,40 7.31 7,23 7,14 7,06 6,97 6,88
7 6,62 6,47 6,31 6,16 6,07 5,99 5,91 5,82 5.74 5,65
8 5,81 5,67 5,52 5,36 5,28 5,20 5,12 5,03 4.95 4,86
9 5,26 5.11 4.96 4.81 4,73 4.65 4.57 4,48 4.40 4,31
10 4,65 4,71 4,56 4,41 4,33 4.25 4.17 4,08 4.00 3,91
11 4,54 4,40 4.25 4,10 4,02 3,94 3,86 3,78 3.69 3,60
12 4,30 4,16 4,01 3,86 3,78 3,70 3,62 3,54 3,45 3,36
13 4,10 3,96 3,82 3.66 3,59 3,51 3.43 3,34 3,25 3.17
14 3,94 3,80 3,66 3.51 3,43 3,35 3,27 3,18 3,09 3,00
15 3,60 3,67 3,52 3,37 3,29 3,21 3,13 3,05 2.96 2,67
16 3.69 3,55 3.41 3.26 3,18 3,10 3,02 2,93 2,64 2.75
17 3,59 3,46 3,31 3,16 3,08 3.00 2,92 2,83 2.75 2,65
18 3,51 3,37 3,23 3.08 3,00 2,92 2.64 2,75 2,66 2.57
19 3,43 3,30 3,15 3,00 2,92 2,64 2,76 2,67 2,56 2.49
20 3,37 3,23 3,09 2,94 2,66 2,78 2.69 2,61 2,52 2,42
21 3,31 3.17 3,03 2,88 2,60 2,72 2,64 2,55 2,46 2,36
22 3,26 3.12 2,98 2,83 2.75 2,67 2,58 2,50 2,40 2,31
23 3,21 3,07 2,93 2,76 2,70 2,62 2,54 2.45 2,35 2,26
24 3,17 3,03 2,69 2.74 2.66 2,58 2,49 2,40 2,31 2,21
25 3,13 2,99 2,85 2,70 2.62 2.54 2,45 2.36 2,27 2.17
26 3,09 2.96 2,81 2,66 2.58 2,50 2,42 2.33 2,23 2,13
27 3,06 2,93 2,78 2,63 2,55 2.47 2,38 2,29 2,20 2,10
28 3,03 2,90 2,75 2,60 2.52 2.44 2,35 2.26 2.17 2,06
29 3,00 2,67 2,73 2,57 2.49 2.41 2,33 2.23 2.14 2,03
30 2,98 2,84 2,70 2,55 2.47 2.39 2,30 2,21 2.11 2,01
40 2,80 2,66 2.52 2,37 2.29 2,20 2.11 2,02 1,92 1,80
60 2,63 2,50 2,35 2,20 2.12 2.03 1.94 1.84 1.73 1,60
120 2.47 2,34 2,19 2,03 1.95 1.86 1.76 1.66 1,53 1,38
«* 2,32 2,18 2.04 1,88 1.79 -ЦО 1,59 1.47 1,32 1,00
513
Приложение 7
Площади под кривой распределения х’
Число стеле- ней свобо- ды Д
* 0.W5 х2о,»»о X 0.B7S * о.мо * о.еоо
1 0,0000393 0,0001571 0,0009821 0,0039321 0,0157908
2 0,0100251 0,0201007 0,0506356 0,102587 0,210720
3 0,0717212 0,114832 0,215795 0,351846 0,584375
4 0,206990 0,297110 0,484419 0,710721 1,063623
5 0,411740 0,554300 0,831211 1,145476 1,61031
6 0,675727 0,872085 1,237347 1,63539 2,20413
7 0,989265 1,239043 1,68987 2,16735 2,83311
8 1,344419 1,646482 2,17973 2,73264 3,48954
9 1,734926 2,087912 2,70039 3,32511 4,16816
10 2,15585 2,55821 3.24697 3,94030 4,86518
11 2,60321 3.05347 3,81575 4,57481 5,57779
12 3,07382 3,57056 4,40379 5,22603 6,30380
13 3,56503 4.10691 5,00874 5,89186 7,04150
14 4,07468 4.66043 5,62872 6,57063- 7,78953
15 4,60094 5,22935 6,26214 7,26094 8,54675
16 5,14224 5,81221 6,90766 7.96Т64 9,31223
17 5,69724 6,40776 7,56418 8,67176 10,0852
18 6,26481 7,01491 8,23075 9,39046 10,8649
19 6,84398 7,63273 8.90655 10.1170 11,6509
20 7,43386 8.26040 9.59Q83 10.8508 12,4426
21 8,03366 8,89720 10,28293 11,5913 13,2396
22 8,64272 9,54249 19,9823 12,3380 14,0415
23 9,26042 10,19567 /.6685 13,0905 14,8479
24 9,88623 10,8564 12,4011 13,8484 15,6587
25 10,5197 11,5240 13,1197 14,6114 16,4734
26 11,1603 12,1981 13,8439 15,3791 17,2919
27 11.8076 12,8786 14,5733 16,1513 18,1138
28 12,4613 13.5648 15,3079 16,9279 18,9392
29 13,1211 14,2565 16,0471 17,7083 19,7677
30 13,7867 14,9535 16,7908 18,4926 20,5992
40 20,7065 22.1643 24,4331 26,5093 29,0505
50 27,9907 29,7067 32,3574 34.7642 37,6886
60 35,5346 37,4848 40,4817 43,1879 46,4589
70 43,2752 45,4418 48,7576 51,7393 55,3290
80 51,1720 53,5400 57,1532 60,3915 64,2778
90 59,1963 61,7541 65,6466 69,1260 73,2912
100 67,3276 70,0648 74,2219 77,9295 82,3581
514
Приложение 7 (окончание)
Число стеле- ней саобо ДМ х\
2 * 0,100 х 0,050 2 * 0,025 ,2 * 0,010 2 * O.OOS
1 . 2,70554 3,84146 5,02389 6,63490 7,87944
2 4,60517 5,99147 7,37776 9,21034 10,5966
3 6,25139 7,81473 9,34840 11,3449 12,8381
4 7,77944 9,48773 11,1433 13,2767 14,8602
5 9,23635 11,0705 12,8325 15,0863 16.7496
6 10,6446 12,5916 14,4494 16,8119 18,5476
7 12,0170 14,0671 16,0128 18,4753 20,2777
8 13,3616 15,5073 17,5346 20,0902 21,9550
9 14,6837 16,9190 19,0228 21,6660 23,5893
10 15,9871 18,3070 20,4831 23,2093 25.1882
11 17,2750 19,6751 21.9200 24,7250 26,7569
12 18,5494 21,0261 23.3367 26,2170 28,2995
13 19,8119 22.3621 24,7356 27,6883 29,8194
14 21,0642 23,6848 26,1190 29.1413 31,3193
15 22.3072 24,9958 27,4884 30,5779 32,8013
16 23.5418 26.2962 28,8454 31.9999 34,2672
17 24,7690 27.5871 30,1910 33,4087 35,7185
18 25,9894 28,8693 31,5264 34,8053 37,1564
19 27,2036 30,1435 32,8523 36,1908 38,5822
20 28,4120 31,4104 34,1696 37,5662 39,9968
21 29,6151 32,6705 35,4789 38,9321 41,4010
22 30,8133 33,9244 36,7807 40,2894 42,7956
23 32,0069 35,1725 38,0757 41,6384 44,1813
24 33,1963 36,4151 39.3641 42,9798 45,5585
25 34,3816 37,6525 40,6465 44,3141 46.9278
26 35,5631 38,8852 41,9232 45,6417 48.2899
27 36.7412 40.1133 43.1944 46.9630 49.6449
28 37,9159 41.3372 44.4607 48,2782 50.9933
29 39,0875 42,5569 45,7222 49.5879 52,3356
30 40,2560 43,7729 46,9792 50.8922 53,6720
40 51,8050 55.7585 59,3417 63,6907 66,7659
50 63,1671 67,5048 71,4202 76,1539 79,4900
60 74,3970 79,0819 83,2976 88,3794 91,9517
70 85,5271 90,5312 95,0231 100.425 104,215
80 96,5782 101,879 106,629 112,329 116,321
90 107.565 113,145 118,136 124,116 128,229
100 118.498 124,342 129,561 135,807 140,169
515
Приложение 8
Критические границы для критерия Дарбина—Уотсона (а “ 0,05)
к- 1 к - 2 к « 3 к- 4 к- 5
Чи 4U ч, чи
15 1.08 1,36 0,95 1,54 0.92 1.75 0,69 1.97 0,56 2,21
16 1,10 1.37 0,98 1,54 0,86 1.73 0,74 1.93 0,62 2,15
17 1.13 1,38 1,02 1.54 0,90 1.71 0,78 1,90 0,67 2,10
18 1.16 1,39 1,05 1,53 0,93 1,69 0,82 1.87 0.71 2,06
19 1,18 1.40 1,08 1.53 0,97 1,68 0,86 1.85 0,75 2,02
20 1.20 1.41 1.10 1,54 1,00 1,68 0.90 1,83 0,79 1.99
21 1.22 1.42 1.13 1.54 1.03 1.67 0,93 1.81 0.83 1.96
22 1.24 1.43 1.15 1.54 1.05 1,66 0.96 1,80 0,86 1,94
23 1.26 1,44 1.17 1.54 1,08 1,66 0,99 1.79 0.90 1,92
24 1.27 1,45 1.19 1,55 1.10 1,66 1,01 1.78 0.93 1,90
25 1,29 1.45 1.21 1,55 1.12 1,66 1.04 1.77 0.95 1,89
26 1.30 1,46 1,22 1.55 1.14 1.65 1,06 1.76 0.98 1.88
27 1,32 1.47 1.24 1,56 1.16 1.65 1,08 1.76 1.01 1,86
28 1,33 1.48 1,26 1,56 1.18 1,65 1.Ю 1.75 1,03 1.85
29 1.34 1.48 1.27 1.56 1,20 1,65 1.12 1.74 1,05 1,84
30 1,35 1,49 1.26 1.57 1.21 1,65 1.14 1.74 1,07 1,83
31 1.36 1.50 1,30 1.57 1.23 1,65 1.16 1.74 1,09 1.83
32 1.37 1,50 1.31 1.57 1.24 1,65 1.18 1.73 1.11 1.82
33 1.38 1.51 1,32 1.58 1.26 1.65 1.19 1.73 1.13 1.81
34 1.39 1.51 1,33 1.58 1.27 1,65 1.21 1.73 1.15 1.81
35 1.40 1.52 1.34 1.58 1,28 1,65 1.22 1.73 1.16 1,80
36 1.41 1.52 1.35 1.59 1,29 1,65 1.24 1.73 1.18 1,80
37 1.42 1.53 1.36 1.59 1.31 1.66 1.25 1.72 1.19 1,80
38 1.43 1.54 1.37 1,59 1,32 1.66 1.26 1.72 1,21 1,79
39 1.43 1.54 1.38 1,60 1,33 1.66 1.27 1.72 1,22 1.79
40 1,44 1.54 1,39 1,60 1.34 1.66 1,29 1.72 1,23 1.79
45 1,48 1.57 1.43 1,62 1.3Г 1.67 1,34 1.72 1,29 1.76
50 1.50 1.59 1,46 1,63 1,67 1,38 1.72 1.34 1.77
55 1,53 1,60 1,49 1.64 $5 1,68 1.41 1.72 1,38 1.77
60 1.55 1.62 1.51 1,65 1.48 1,69 1.44 1.73 1.41 1.77
65 1.57 1,63 1,54 1,66 1,50 1.70 1.47 1.73 1,44 1.77
70 1.58 1,64 1.55 1.67 1.52 1.70 1,49 1.74 1,46 1.77
75 1,60 1,65 1.57 1.68 1.54 1.71 1.51 1.74 1,49 1.77
80 1.61 1,66 1.59 1.69 1,56 1.72 1,53 1.74 1.51 1.77
85 1.62 1.67 1,60 1.70 1.57 1.72 1,55 1.75 1,52 1.77
90 1,63 1.68 1.61 1.70 1.59 1.73 1.57 1.75 1.54 1.78
95 1,64 1,69 1.62 1.71 1,60 1.73 1,58 1.75 1,56 1.78
100 1.65 1,69 1,63 1,72 1,61 1.74 1,59 1.76 1.57 _LZL
516
Приложение в (олончение) (а «0.01)
п к- 1 к = 2 к-3 к-4 к= 5
Ч, «1
15 0.61 1.07 0,70 1,25 0,59 1,46 0,49 1.70 0,39 1,96
16 0,64 1.09 0.74 1.25 0,63 1,44 0,53 1.66 0,44 1,90
17 0,67 1.10 0.77 1.25 0,67 1.43 0,57 1.63 0.48 1,85
18 0,90 1.12 0,80 1,26 0,71 1,42 0,61 1,60 0,52 1,80
19 0,93 1.13 0,83 1.26 0,74 1.41 0.65 1.58 0,56 1.77
20 0,95 1.15 0,86 1.27 0,77 1.41 0.68 1.57 0,60 1.74
21 0,97 1.16 0,89 1.27 0,80 1.41 0,72 1,55 0,63 1.71
22 1,00 1.17 0,91 1,28 0,83 1,40 0,75 1,54 0,66 1,69
23 1,02 1.19 0,94 1.29 0,86 1,40 0.77 1,53 0,70 1,67
24 1,04 1,20 0,96 1,30 0.88 1.41 0,80 1,53 0.72 1,66
25 1,05 1.21 0,96 1,30 0.90 1.41 0,83 1.52 0,75 1,65
26 1.07 1,22 1,00 1.31 0,93 1.41 0,65 1.52 0,78 1,64
27 1,09 1,23 1.02 1,32 0.95 1.41 0,68 1.51 0,61 1,63
26 1.10 1.24 1,04 1,32 0,97 1.41 0,90 1.51 0,83 1,62
29 1.12 1.25 1,05 1,33 0.99 1.42 0,92 1.51 0,85 1.61
30 1.13 1,26 1.07 1.34 1,01 1.42 0.94 1.51 0,88 1,61
31 1.15 1.27 1.08 1.34 1,02 1.42 0,96 1.51 0,90 1,60
32 1.16 1.28 1.10 1.35 1,04 1.43 0,98 1.51 0,92 1,60
33 1.17 1.29 1.11 1,36 1,05 1.43 1.00 1.51 0,94 1,59
34 1.16 1.30 1.13 1,36 1.07 1.43 1.01 1.51 0,95 1,59
35 1.19 1,31 1.14 1.37 1,06 1,44 1,03 1,51 0,97 1,59
36 1.21 1,32 1,15 1.36 1.10 1,44 1.04 1.51 0,99 1,59
37 1,22 1,32 1.16 1,38 1.11 1,45 1,06 1.51 1,00 1,59
38 1,23 1,33 1.18 1.39 1.12 1,45 1.07 1,52 1.02 1,58
39 1,24 1,34 1.19 1,39 1.14 1,45 1,09 1.52 1,03 1,58
40 1.25 1,34 1,20 1,40 1 L5 1,46 1.10 1.52 1,05 1,56
45 1,29 1,38 1.24 1.42 1.20 1.48 1.16 1.53 1.11 1,58
50 1.32 1,40 1,28 1,45 1.24 1,49 1.20 1,54 1,16 1,59
55 1,36 1.43 1,32 1.47 1,28 1.51 1.25 1,55 1.21 1,59
60 1.38 1.45 1,35 1.48 1,32 1.52 1,28 1.56 1.25 1,60
65 1.41 1.47 1,38 1,50 1,35 1.53 1.31 1.57 1,28- 1,61
70 1.43 1,49 1,40 1,52 1.37 1.55 1,34 1,58 1.31 1.61
75 1.45 1.50 1.42 1,53 1,39 1,56 1.37 1,59 1.34 1,62
60 1.47 1.52 1,44 1.54 1.42 1.57 1,39 1,60 1,36 1,62
85 1.48 1,53 1,46 1,55 1,43 1.58 1.41 1,60 1,39 1,63
90 1.50 1.54 1.47 1,56 1,45 1,59 1,43 1.61 1.41 1,64
95 1.51 1,55 1,49 1.57 1.47 1,60 1.45 1,62 1.42 1,64
100 1,52 1,56 1,50 1,58 1,48 1,60 1,46 1,63 1.44 1,65
ЛИТЕРАТУРА
I. Венецкий И.Г., Венецкая В.Н. Основные математико-статистичес-
кие понятия и формулы в экономическом анализе: Справочник. М.:
Статистика, 1979.
2. Вен т цель Е.С. Исследование операций. М.: Советское радио, 1972.
3. Вентцель Е.С. Теория вероятностей. М.: Наука, 1978.
4. Дрейпер Н., Смит Г. Прикладной регрессионный анализ. М.: Ста-
тистика, 1973.
5. Дружинин Н.К. Математическая статистика в экономике. М.: Ста-
тистика, 1972.
6. Евланов Л. Г. Теория и практика принятия решений. М.: Эконо-
мика. 1984.
7. Елисеева И.И., Юзбашев ММ. Общая теория статистики. М.:
Финансы и статистика, 1996.
8. КазмерЛ. Методы статистического анализа в экономике. М.: Ста-
тистика, 1971.
9. Красс М.С., Чупрынов Б.П. Основы математики и ее приложения в
экономическом образовании. М.: Дело, 2000.
10. Лизер С. Эконометрические методы и задачи. М.: Статистика.
1971.
11. Мельник М. Основы прикладной статистики. М.: Энсргоатомиздат,
1983.
12. Общая теория статистики: Статистические методы и изучение
коммерческой деятельности: Учебник / Под ред. А.А. Спирина,
О.Э. Башиной. М.: Финансы и статистика, 1994.
13. Теория статистики: Учебник / Под ред. Р.А. Шмойловой. М.:
Финансы и статистика, 1998.
14. Четыркин Е.М. Статистические методы прогнозирования. М.:
Статистика, 1977.
15. Шикин Е.В., Чхартишвили А.Г. Математические методы и моде-
ли в управлении. М.: Дело, 2000.
16. Эддоус М., Стэнсфилд Р. Методы принятия решений. М.: ЮНИТИ,
1997.
17. Вгуагз D A. Advanced Level Statistics. London: Collins Educational,
1992.
518
> 18. Finkelstein M Statistics at Your Fingertips. Wadsworth Publishing
I Company, Belmont, California. 1985.
19. Hanke J.E., Reitsch A.G. Business Forecasting. Prentice Hall, Inc.,
I) 1995.
20. KvanliA H., Guynes C.S., Pavur R.J. Introduction to Business Statistics:
a Computer Integrated Approach. West Publishing Company, 1998.
21. Levin R.L, Rubin D.S. Statistics for Management. Prentice Hall
International, Inc., 1994.
22. Mason R D., Lind D.A. Statistical Techniques in Business and
Economics. Irwin. Inc., 1990.
23. Pappas J. L ., Hirschey M. Managerial Economics. The Dryden Press,
1987.
24. Zikmund W.G. Business Research Methods. The Dryden Press, 1988.
i
Учебное пособие
Владимир Николаевич СУЛ И ЦК ИЙ
МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА
В УПРАВЛЕНИИ
Гл. редактор Ю.В. Л у изо
Зав. редакцией Г.Г. Кобякова
Редактор НА Леонтьева
Художник НВ Пьяных
Компьютерная подготовка
оригинал-макета В.А. Жилкин
Технический редактор Л.А. Зотова
Корректоры Л.М. Филькова, ЛИ. Трифонова
Гигиеническое заключение № 77.99.2.953.П.16308.12.00 от 01.12.2000 г.
Подписано в печать 4,04.2002. Формат 60*90
Бумага офсетная. Гарнитура Таймс. Печать офсетная
Уса. печ. л. 32,5. Тираж 3000 экз.
Заказ 7* 166. Изд.№ 189.
Издательство "Дело"
117571, Москва, пр-т Вернадского, 82
Коммерческий отдел — тел.: 433-25-10. 433-25-02
E-mail: delo9ane.ru
Internet http://4mnr.delo.ane.ru
ФГУП «Московская типография № 6« Министерства Российской Федерации
по делам печати, телерадиовещания и средств массовых коммуникаций
109088, Москва, Ж-88, Южнопортовая ул.. 24