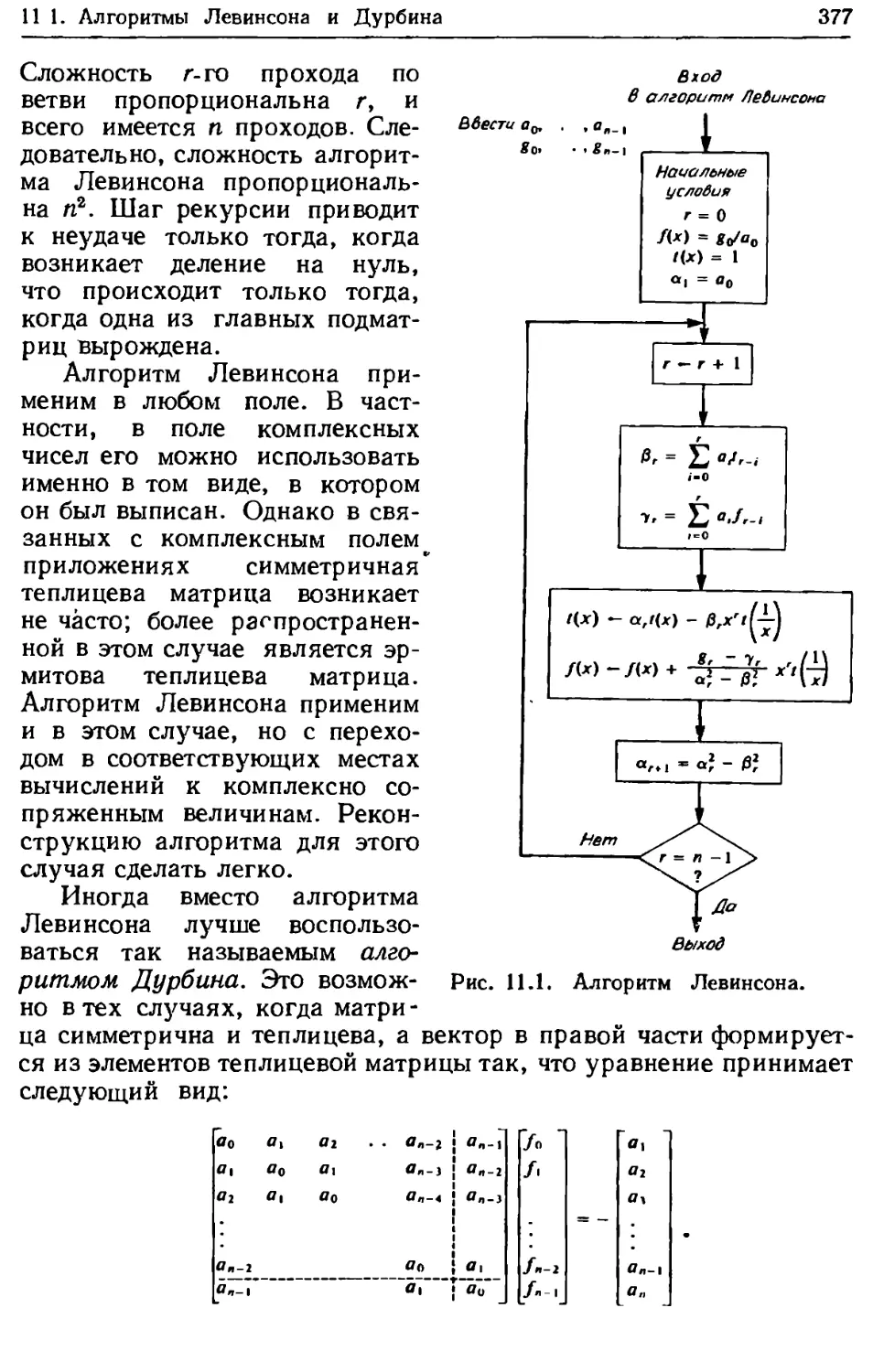
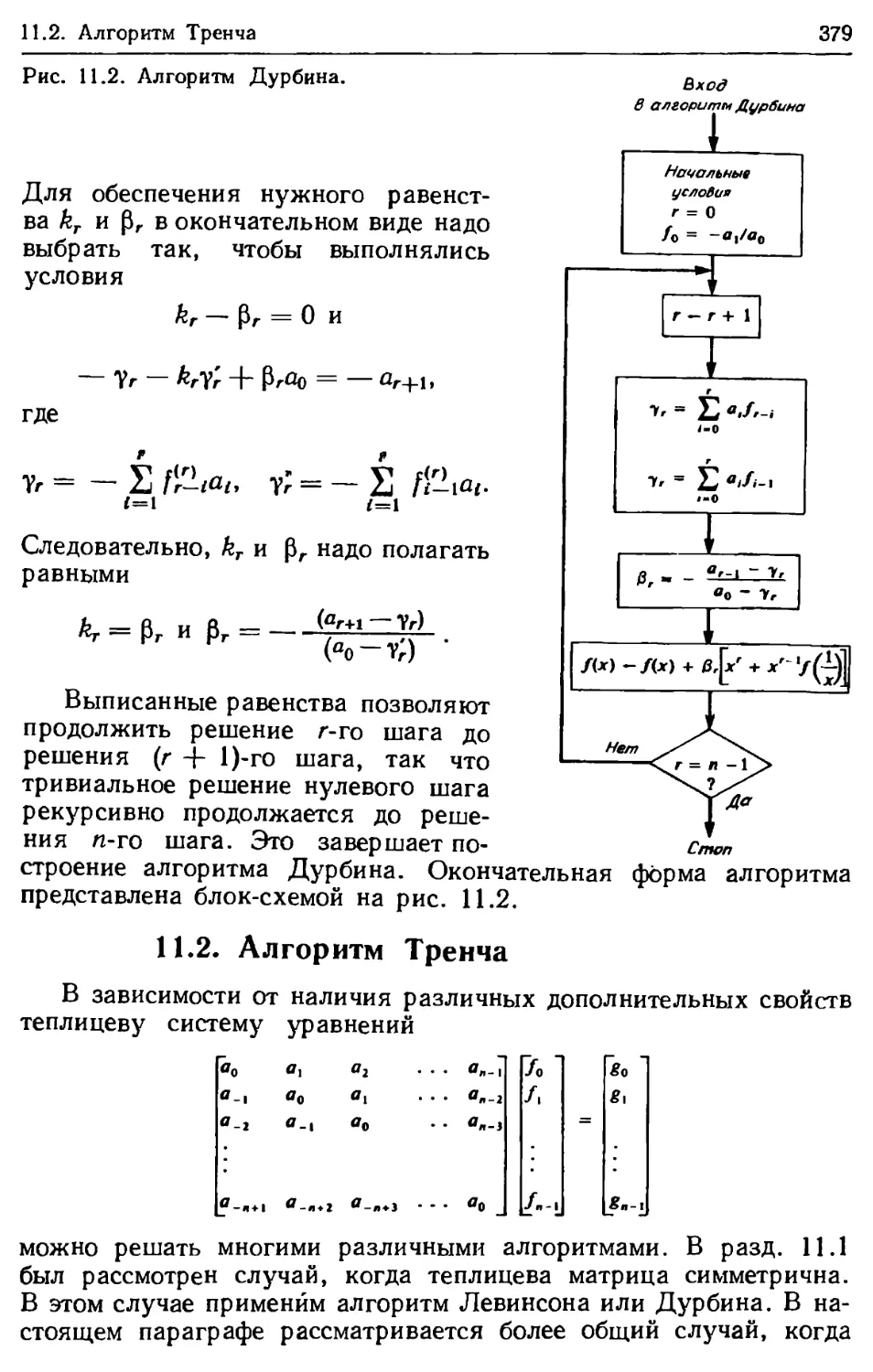
/















































































































































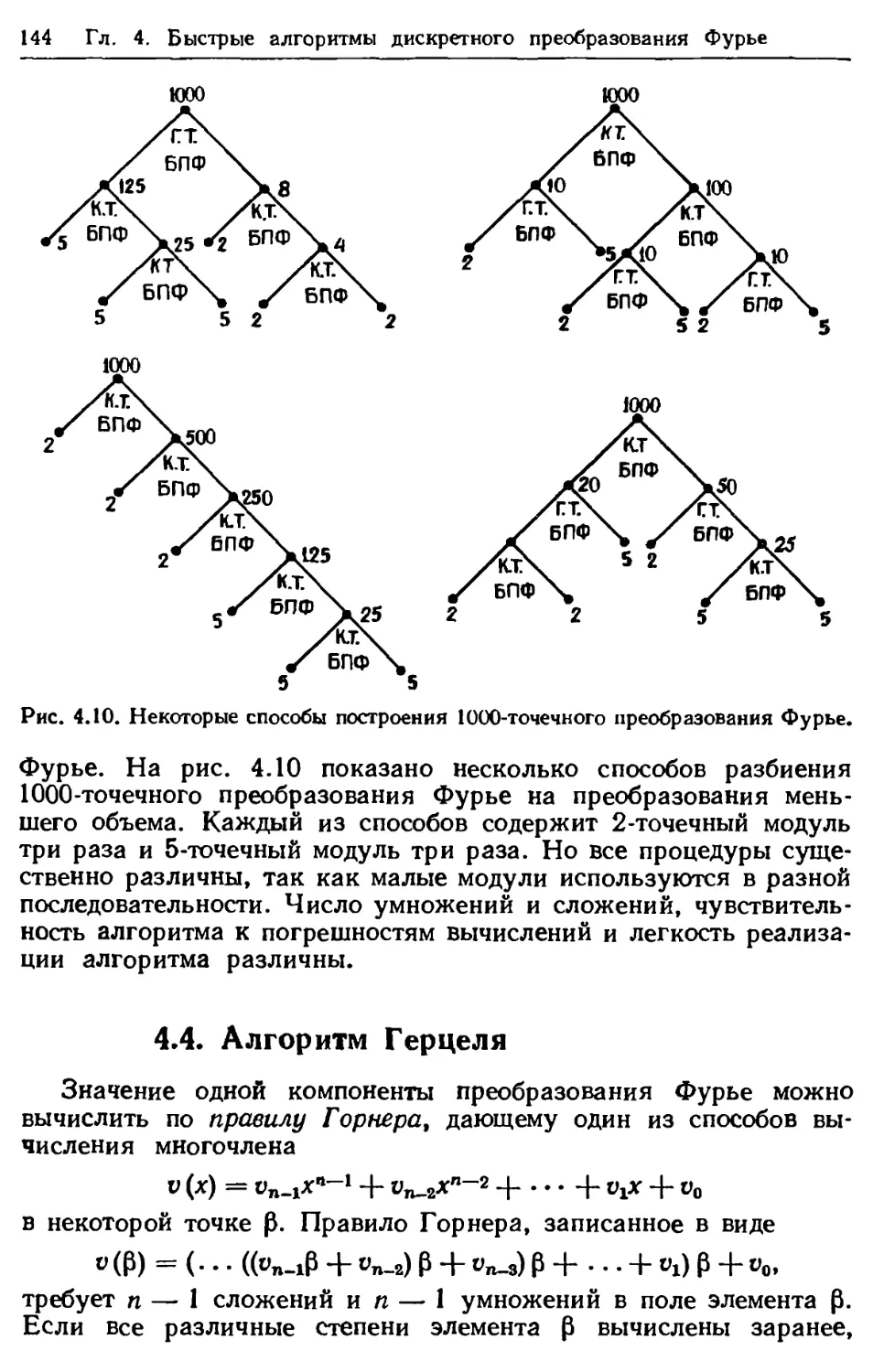





































































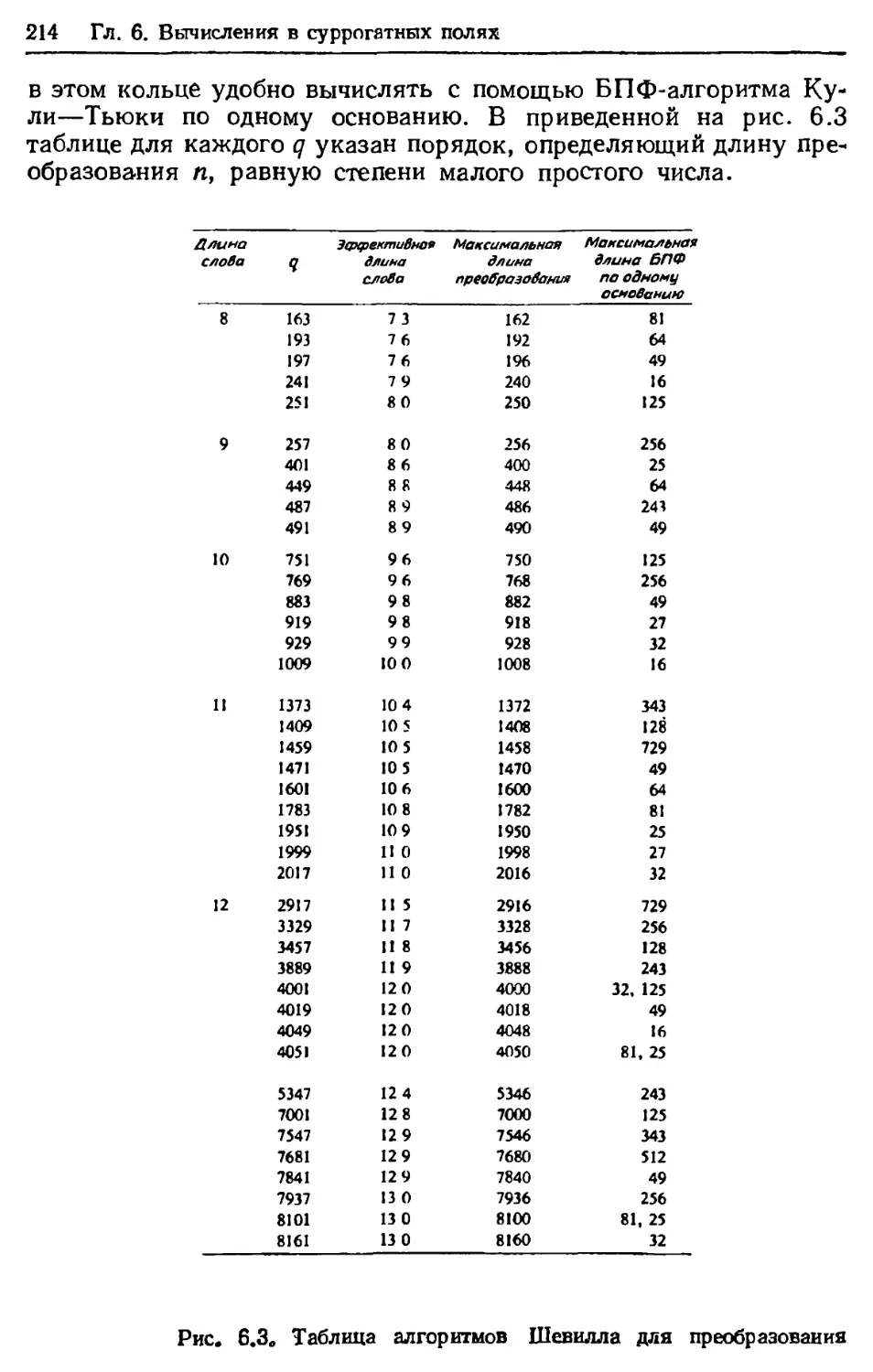










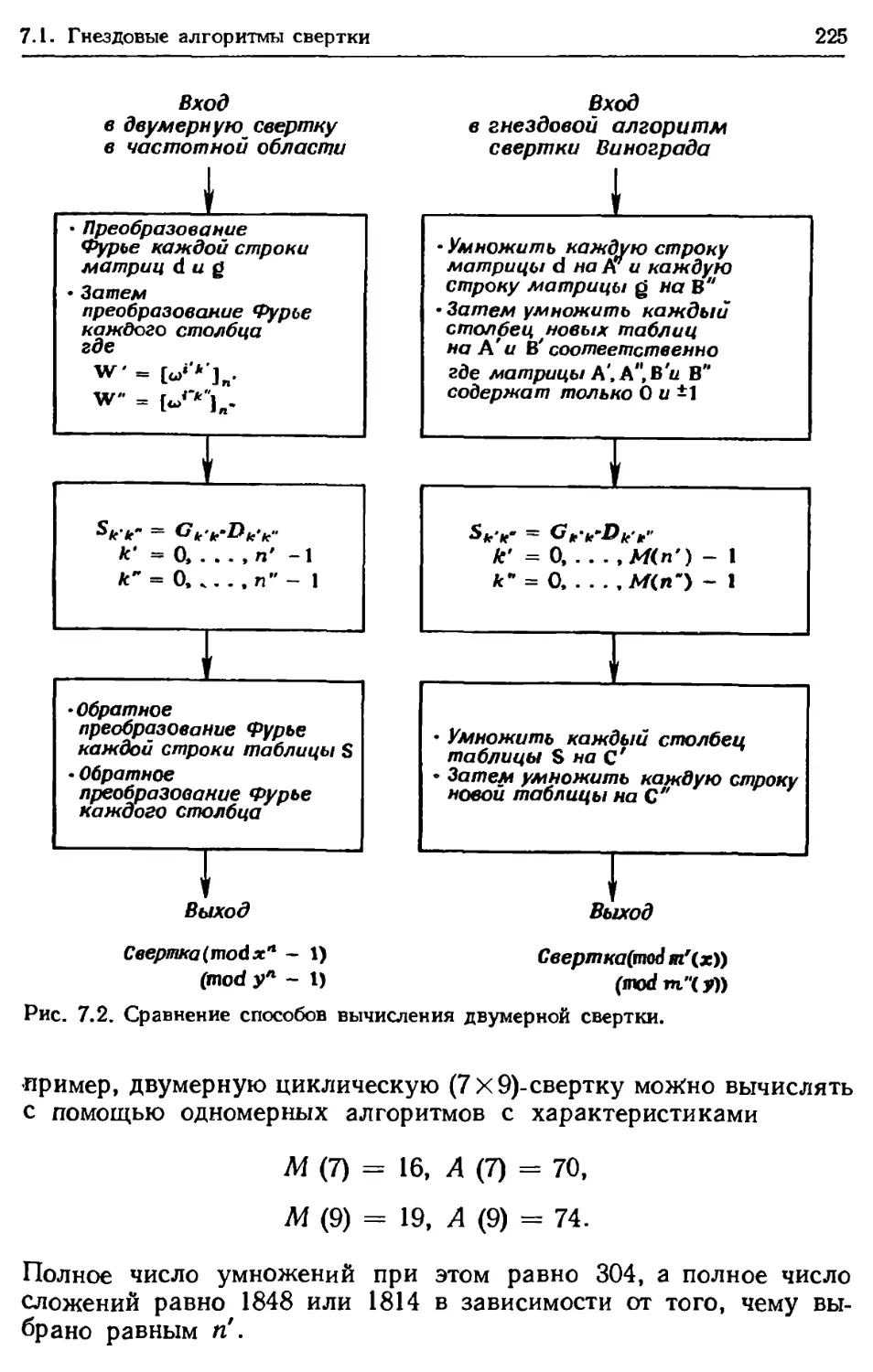





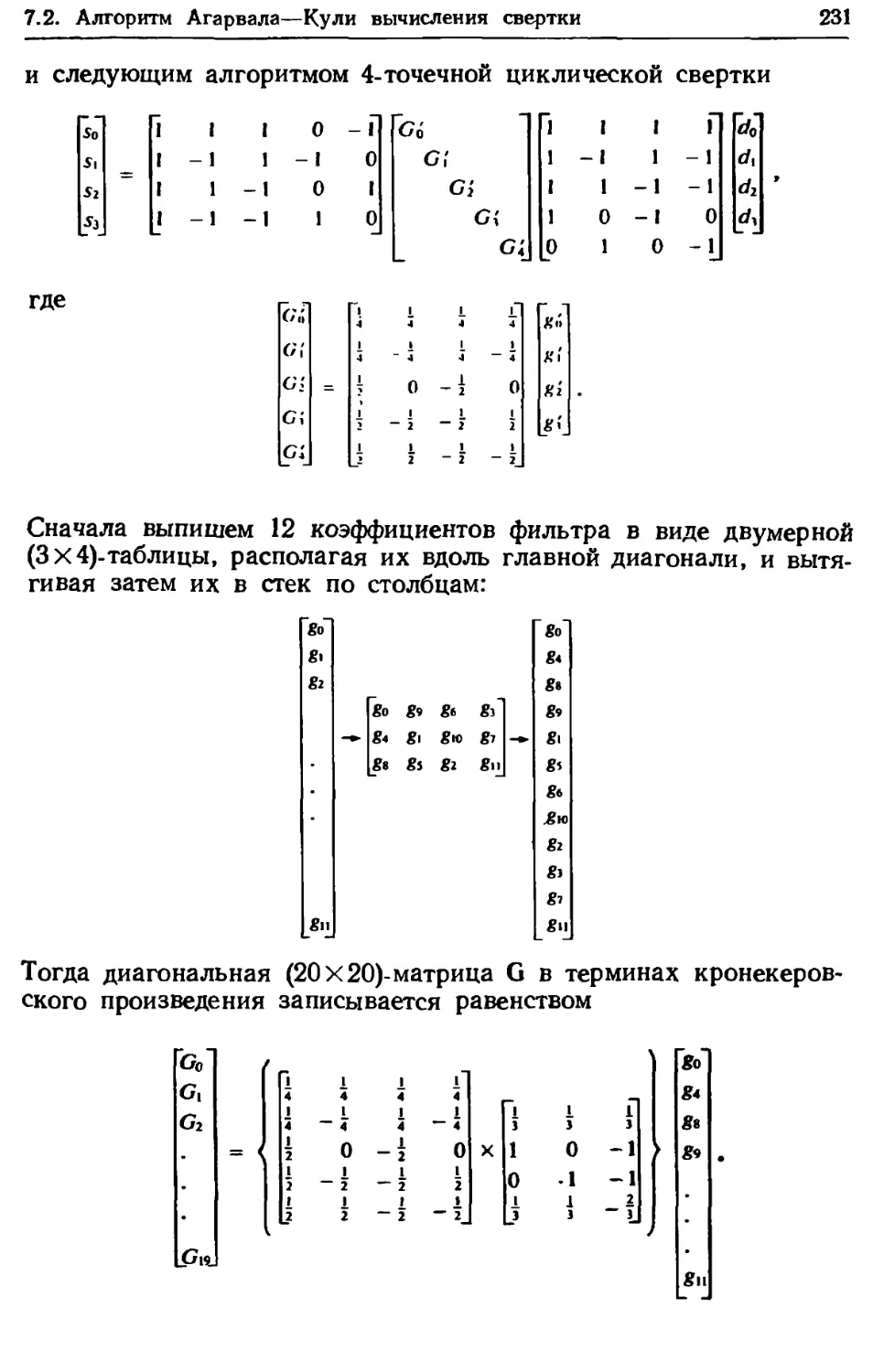














































































































































































































Author: Блейхут Р.
Tags: математическая кибернетика кибернетика математика цифровая обработка сигналов вычислительная математика переводная литература издательство мир
ISBN: 5-09-001009-2
Year: 1989




Text
БЫСТРЫ Е АЛГОРИТМБ1
ЦИФРОВОИ ОБРАБОТКИ СИГНАЛОВ
Fast Algorithms
for Digital Signal Processing
Richard Е. Blahut
Addison-Wesley Publishing Company
Reading, Nassachussetts Nen1o Park, СаИопца
Wokingham, Berkshire Amsterdam Don Mills, Ontario Sydney
Р Блейхут
БЫСТРЫЕ
АЛГОРИТМЫ
ЦИФРОВОЙ
ОБРАБОТКИ
СИГНАЛОВ
Перевод с английского
К. И. Грушко
Москва «Мир» 1989
ББК 32.811
Б68
УДК 519.725
Блейхут P.
Быстрые алгоритмы цифровой обработки сигналов: Пер.
с англ. М.: Мир, 1989. 448 с., ил.
ISBN 5-09-001009-2
Б68
1402030000 †1
041 (01)-89
ББК 32.811
Редсищия литературы ло математическим наукам
1$ВК 5-09-001009-2 (русск,)
ISBbi 0-201-10155-6 (англ.)
Copyright © 1985 by АсЫ1зоп-Rеs1ey Pub-
lishing Сопiрапу, Inc.
© перевод иа русский язык, «Мир», 1989
Книга американского специалиста, посвя щенная актуальным при-
кладным задачам построения быстрых алгоритмов цифровой обработки
сигналов (автор известен по его «Теории и практике кодов, контролирую-
щих ошибки» (М.: Мир, 1986)). Для ускорения типичных для таких задач
вычислений используется организация даниых в виде коиечиых алгебраи-
ческих структур (групп, колец, полей), что позволяет применить структур-
ные теоремы алгебры и теории чисел. В двух из двенадцати глав книги
содержится краткое, ио строгое и систематическое изложеиие соответ-
ствующих разделов математики, как правило, недостаточно известных
инженерам-прикладникам.
Для математиков-прикладииков, программистов, инженеров ‒ раз-
работчиков систем обработки дискретных сигналов, студентов и аспиран-
тов университетов.
ПРЕДИСЛОВИЕ K РУССКОМУ ИЗДАНИЮ
Предлагаемая читателю книга известного американского спе-
циалиста в области теории информации и ее приложений P. Блей-
хута посвящена построению быстрых алгоритмов цифровой об-
работки сигналов вычислительных алгоритмов, повсеместно
возникающих в таких приложениях, как все виды связи, радио-
локация, радиоастрономия, цифровая голография, медицинская
электроника и т. п. Отсутствие подобной книги остро ощущалось
многими специалистами в перечисленных областях конструк-
торами информационных систем различного назначения. В част-
ности, P. Блейхут указывает, что он почувствовал ее необходимость
во время работы над своей предыдущей книгой «Теория и практика
кодов, контролирующих ошибки», в которую ему пришлось вклю-
чить несколько специальных глав с описанием алгоритмов бы-
строго вычисления преобразования Фурье, которые, конечно,
никак не зависят от данного конкретного приложения. (Книга
была переведена в !985 г. на русский язык и быстро разошлась.}
Хотя в настоящую книгу вошли и алгоритмы решения тепли-
цевых систем уравнений (возникающих в таких приложениях,
как линейное предсказание, построение авторегрессионных фильт-
ров, теория кодирования и др.), и алгоритмы быстрого поиска по
древовидному графу (возникающие, например, при декодировании
сверточных кодов), сердцевиной книги являются быстрые ал-
горитмы преобразования Фурье и вычисления цифровой свертки
(линейной и циклической).
В основе таких быстрых алгоритмов лежит специальная орга-
низация массивов данных в виде конечных алгебраических струк-
тур (групп, колец, полей), что создает предпосылки для приме-
нения структурных теорем алгебры и теории чисел. Это позволяет
строить практически приемлемые алгоритмы, обеспечивающие
работу цифровых процессоров в реальном масштабе времени.
К настоящему времени накопился широкий ассортимент различ-
ных по своей архитектуре и теоретическим предпосылкам алго-
рйтмов, но пока инженеры-разработчики и программисты не зна-
комы с их теоретическим обоснованием, вопрос о широком ис-
пользовании этих алгоритмов остается открытым.
Я,анная книга весьма удачно ликвидирует образовавшийся
разрыв. С одной стороны, в ней в двух из 12 глав дается краткое,
но строгое и систематическое изложение необходимых разделов
алгебры и элементарной теории чисел, как правило, недостаточно
известных инженерам-прикладникам. С другой стороны, в ос-
Тальных 10 главах дается систематическое и исчерпывающее опи-
сание накопленных к настоящему времени быстрых алгоритмов
преобразования Фурье, вычисления цифровых сверток и решения
6 Предисловие к русскому изданию
систем теплицевых уравнений не только для привычных в ин-
женерной практике полей комплексных и вещественных чисел,
но и для гюлей Галуа.
Енига несомненно будет полезна широкому кругу читателей
математикам-прикладникам, программистам, инженерам-раз-
работчикам систем обработки данных, а также может быть ре-
комендована для включения в программу преподавания матема-
тики будущим инженерам-конструкторам систем обработки ди-
скретной информации.
В. Н. Сифоров
ОТ АВТОРА
Подобно тому как дети перерастают своих родителей, книги
могут выйти за рамки возможностей их авторов. Предлагаемый
церевод книги «Быстрые алгоритмы цифровой обработки сигна-
лов» является второй моей книгой, вышедшей из умелых рук
HHHbI Грушко, которой я очень благодарен, как и за перевод
первой моей книги «Теория и практика кодов, контролирующих
ошибки». Мне известно, что не существует «быстрых алгоритмов»
переводов, и поэтому я очень ценю тщательную работу над пере-
водом и исправление опечаток, допущенных в английском из-
дании.
Я полагаю, что русские читатели найдут здесь много интерес-
ного. Предмет книги, алгебраический по существу, тем не менее
ближе к цифровой обработке сигналов, чем к математике. Я на-
деюсь, что меня простят за почти полное незнание работ совет-
ских авторов в данной области.
Р. Э. Блейхут
ПРЕДИСЛОВИЕ
В настоящее время цифровая обработка сигналов переживает
взрыв. Ее используют повсюду, включая радиолокацию, сейсмо-
графию, связь, радиоастрономию н медицинскую электронику.
Активно разрабатываются и находят рыночный спрос цифровые
процессоры специализированные цифровые компьютеры для
обработки сигналов. Такое широкое использование порождает
еще более широкий спрос на цифровые процессоры, применяемые
в некоторых случаях в массовых масштабах.
Одним из путей удовлетворения этих потребностей является
выбор разумно построенных алгоритмов. Вместо того чтобы повы-
шать быстродействие процессора от одного миллиона умножений
в секунду до пяти миллионов умножений в секунду, можно для
некоторых задач попытаться так организовать вычисления, чтобы
быстродействия в один миллион умножений в секунду оказалось
достаточно. К настоящему моменту имеется хорошо разработанная
теория, позволяющая подойти к решению задач с этих позиций.
Она хорошо известна теоретикам, специалистам в данной области,
но на практике инженеры-конструкторы часто пренебрегают ей,
поскольку она пока недоступна в виде цельного учебного курса.
Инженер-конструктор должен хорошо знать предмет, чтобы выб-
рать алгоритм, нужный в данном конкретном приложении, среди
смущающего разнообразия известных быстрых алгоритмов свертки
или быстрого преобразования Фурье.
Данная книга является результатом курса, прочитанного
автором в Корнеллском университете и корпорации ИБМ под
названием «Быстрые алгоритмы цифровой обработки сигналовв.
Курс был построен с расчетом на стажирующихся инженеров-
электриков и аспирантов первого года обучения; его целью было
воспитание инженеров, которые свободно владеют предметом.
Эта же цель является первой в данной книге.
Второй целью является формирование широкого взгляда на
состояние работ в области быстрых алгоритмов цифровой обра-
ботки сигналов, который сможет стимулировать новые работы
в будущем. Если собрать воедино все нити, то многое становится
более очевидным. Например, перенесение БПФ-алгоритмов
Кули Тычки, Гуда Томаса и Винограда в произвольное поле
облегчило понимание взаимосвязи между многими последующими
идеями.
Я думаю, что важно различать быстрый алгоритм, функцию,
которую он вычисляет, и приложение, в котором он используется.
Это разные элементы, и, когда их смешивают, они могут терять
свою ясность. Таким образом, я настаиваю на том, чтобы отли-
чать дискретное преобразование Фурье от быстрого преобразования
Яредисловив
Фурье. Первое из них является преобразованием, а второе
алгоритмом для вычисления первого. Подобно этому, алгоритм,
Витерби не является методом вычисления последовательности
максимального правдоподобия; он представляет собой алгоритм
вычисления кратчайшего пути на решетке пути, который в не-
которых приложениях будет путем максимального правдоподо-
бия, но не обязан быть им. Но и тогда, когда кратчайший путь
действительно является путем максимального правдоподобия,
не следует смешивать определение максимального правдоподобия
с алгоритмом вычисления его пути. В соответствии с этим подхо-
дом в данной книге мало обсуждаются возможные приложения;
после постановки задачи все внимание уделяется построению
хорошего алгоритма ее решения. Обсуждение возможных при-
ложений цифровой обработки сигналов следует искать в других
источниках.
Идея написания этой книги возникла во время работы над
более ранней книгой «Теория и практика кодов, контролирующих
ошибки». Во многих главах этой книги приходилось рассматри-
вать быстрые алгоритмы вычислений в конечных полях, хотя по
существу алгоритмы не зависели от выбранного поля. Я почувст-
вовал, что стоило бы поместить эти алгоритмы в отдельную книгу,
описать их независимо от использования и дополнить многими
другими важными в цифровой обработке сигналов алгоритмами.
Изложение затрагивает многие области теории вычислений и тео-
рии алгоритмов. Однако в первую очередь нас интересуют инже-
нерные задачи нахождения лучших алгоритмов цифровой обра-
ботки сигналов; асимптотический анализ играет второстепенную
роль.
В настоящей книге используются разделы математики, которые
могут быть незнакомы типичному читателю с инженерным обра-
зованием. Поэтому в книгу включен весь необходимый математи-
ческий аппарат и строго доказываются все теоремы. Мне представ-
ляется, что если этому предмету предстоит стать самостоятельной
и зрелой дисциплиной, то вся необходимая математика должна
быть частью этой книги; ссылки на другие источники не могут
быть адекватной заменой. Инженер не может уверенно овладеть
предметом, если ему часто предлагается принять утверждение
на веру или обратиться к своей математической библиотеке.
Необходимая для построения быстрых алгоритмов математика
содержится в гл. 2 и 5. Эти главы можно сначала прочитать
бегло, но к ним следует возвращаться по мере необходимости.
Одним из недостатков, которые некоторые читатели заметят
в книге, является недостаточность рекомендаций по практиче-
скому использованию алгоритмов. Такие темы, как длина машин-
ного слова, погрешность округления и время работы алгоритма
А на компьютере В, вообще не рассматриваются. Это сознательное
10 Предисловив
решение вызвано тем, что я не столь мудр, чтобы делать широкие
обобщения по этим вопросам. В немногих встречавшихся мне
исследованиях на эти темы всегда рассматривались узко сформу-
лированные задачи, и я не доверяю любому общему выводу, сде-
ланному на основе имеющихся данных. Мне кажется, что конструк-
тору следует решать эти вопросы в контексте конкретной задачи
и непосредственно изучать литературу, чтобы узнать, как посту-
пают в аналогичных случаях другие конструкторы.
Среди рассматриваемых в настоящей книге алгоритмов многие
уже широко используются в практической деятельности. Другие
станут важны в будущих приложениях, когда цифровая обработка
сигналов будет более разнообразной и широко применяемой.
Некоторая часть, возможно, никогда не станет полезной. Я стре-
мился дать широкий обзор; какие из методов окажутся практи-
чески важными, предстоит решить инженер ам-конструкторам
в следующие несколько десятилетий.
Сердцевиной книги являются описываемые в гл. 3 и 7 алго-
ритмы циклической свертки и описываемые в гл. 4 и 8 алгоритмы
быстрого преобразования Фурье. В гл. 7 и 8 описываются много-
мерные аналоги алгоритмов гл. 3 и 4 соответственно, и при же-
лании их можно читать сразу после этих глав. Изучение одномер-
ных алгоритмов свертки и преобразования Фурье завершается
лишь в контексте многомерных задач. Главы 2 и 5 представляют
собой математические введения; некоторые читатели, возможно,
предпочтут пользоваться ими как приложением, обращаясь к ним
лишь по мере надобности. Главы б и 9 следует читать отдельно,
следом за гл. 3 и 4. Главы 10, 11 и 12 в основном независимы;
каждую из них вполне можно читать независимо от остального
материала книги.
БЛАГОДАРНОСТИ
Тем, что я написал данную книгу, я больше всего обязан
Шмуэлю Винограду. Без его существенного вклада в рассматривае-
мую область она была бы бесформенной и намного более короткой.
9н щедро уделял мне время, проясняя многие моменты и просмат-
ривая первоначальные наброски. Статьи Винограда, а также книга
Нуссбаумера являются источниками большей части материала,
обсуждаемого в этой книге.
Книга не достигла бы своего нынешнего уровня без неодно-
кратных рецензирований и критики. Я особенно признателен
профессору Б. В. Диксону за несколько чрезвычайно подробных
рецензий, которые сильно улучшили ее качество. Я также при-
знателен профессору Тоби Бергеру, профессору К. С. Баррасу,
профессору Дж. Гибсону, профессору Дж. Г. Проакису, про-
фессору Т. Б. Парксу, доктору Б. Райсу, профессору И. Суги-
яме, доктору В. Вандеркулку и профессору Дж. Вергезе за по-
лезную критику. Книга не была бы написана без поддержки ком-
пании «Интернейшнал Бизнес Машинз». Я глубоко благодарен
ИБМ за эту поддержку, а также Корнеллскому университету
за предоставленную возможность апробации первого варианта
рукописи с помощью курса лекций. Самую важную поддержку
мне оказала моя жена Барбара, без помощи которой эта книга
никогда не была бы написана.
Глава 1
ВВЕДЕНИЕ
Вычислительные алгоритмы встречаются повсеместно, и эф-
фективные варианты таких алгоритмов весьма высоко ценятся
теми, кто ими пользуется. Мы рассматриваем в основном только
некоторые типы вычислений, а именно те, которые связаны с циф-
ровой обработкой сигналов и включают такие задачи, как цифро-
вая фильтрация, дискретное преобразование фурье, корреляция
и спектральный анализ. Наша основная цель состоит в описании
современных методов цифровой реализации этих вычислений,
причем нас интересует не построение весовых множителей в от-
водах цифрового фильтра, а организация способа их вычисления
при реализации фильтра. Нас также не интересует, зачем кому-то
нужно, скажем, дискретное преобразование фурье; нас заботит
только то, как можно вычислить это преобразование эффективно.
Удивительно, что для решения столь узко специального вопроса
разработана столь глубоко развитая теория.
1.1. Введение а быстрые алгоритмы
Любой алгоритм, подобно большинству инженерных устройств,
можно описывать либо через соотношение между входом и вы-
ходом, либо детально объясняя его внутреннюю структуру. При-
меняя к некоторой новой задаче методы цифровой обработки сигна-
лов, мы сталкиваемся с заданием алгоритмов через соотношение
вход-выход. При заданном сигнале или записанных некоторым
образом данных основное внимание сосредоточивается на том,
что надо с этими данными сделать, т. е. каков должен быть выход
алгоритма, если на его вход подаются те или иные данные. При-
мерами такого выхода служат профильтрованная версия входа
или его преобразование фурье. Такая связь входа с выходом в ал-
горитме математически может быть записана без детального вы-
писывания всех шагов, необходимых для выполнения вычислений.
С этой, опирающейся на вход-выход точки зрения, сама задача
построения хороших алгоритмов обработки информации может
быть трудной и тонкой, но в данной книге она не рассматрива-
ется. Мы предполагаем что уже задан алгоритм типа вход-выход,
1.1. Введение в быстрые алгоритмы
описанный в терминах фильтров, преобразований фурье, интер-
поляций, прореживаний, корреляций, модуляций, гистограмм,
матричных операций и им подобных. Все такие алгоритмы могут
бьггь записаны 'математической формулой, и, следовательно, вы-
числены в прямом соответствии с этой записью. Такую реализа-
цию алгоритма вычислений будем называть прямой.
Кто-то может быть вполне удовлетворен прямой реализацией
алгоритма; в течение многих лет большинство пользователей счи-
тали такие реализации удовлетворительными, и даже сейчас
некотороые из них так считают. Но с тех пор, как люди начали
решать подобные задачи, другие люди начали искать более эф-
фективные. пути их решения. Именно эту историю мы хотим рас-
сказать историю быстрых алгоритмов. Под быстрыми алгорит-
мами мы понимаем детальное описание вычислительной процедуры,
которая не является очевидным способом вычисления выхода
по данному входу. Как правило, быстрый алгоритм жертвует кон-
цептуальной ясностью вычислений в пользу их эффективности.
Допустим, что требуется вычислить число А, равное
А = ас+ad+Ьс+bd.
В том виде, как оно записано, это вычисление содержит четыре
умножения и три сложения. Если число А надо вычислять много
раз для различных множеств данных, то мы быстро заметим, что
А = (а + ь) (с + и)
представляет собой эквивалентную форму, требующую лишь
одного умножения и двух сложений, так что она предпочтительнее
исходной. Этот простенький пример весьма тривиален, но он на
самом деле иллюстрирует большинство тем, о которых нам пред-
стоит рассуждать. Все, что мы делаем, можно представлять себе
как хитроумную расстановку скобок в вычислениях. Но для боль-
ших задач быстрые алгоритмы не удается найти простым про-
смотром вычислений; их построение потребует весьма развитой
теории.
Нетривиальным, хотя все еще простым примером служит бы-
стрый алгоритм вычисления произведения комплексных чисел.
Произведение комплексных чисел
(e +- if) = (а + ib) ° (с ~- id)
можно записать через умножения и сложения вещественных чисел:
e = ac bd, f = ad + bc.
Эти формулы содержат четыре вещественных умножения и два
вещественных сложения. Если умножение более трудоемкая опе-
14 Гл. l. Введение
рация, чем сложение, to более «эффективный» алгоритм дается
равенствами
е= (а b)d +а(с d),
f = (а Ь) d + Ь (с + d).
В такой форме алгоритм содержит три вещественных умножения
и пять вещественных сложений. Если в серии умножений комп-
лексных чисел величины с и d суть константы, то члены с + d
и с dтакже являются константами, ,и их можно вычислить
заранее, независимо от процесса умножения. Тогда для вычисле-
ния одного произведения комплексных чисел нам понадобится
три вещественных умножения и три вещественных сложения.
Мы обменяли одно умножение на одно сложение. Это может
быть целесообразно, только если в конструкции процессора уда-
стся воспользоваться этим преимуществом. Некоторые процес-
соры сконструированы в расчете на использование четырех ве-
щественных умножений для вычисления произведения комплекс-
ных чисел; в этом случае преимущества улучшенного алгоритма
теряются.
Предваряя дальнейшие рассмотрения, задержимся на этом при-
мере подольше. Рассмотренное выше умножение комплексных
чисел можно представить в виде
е с d а
d c Ь
где вектор [a, b ]~ представляет комплексное число а + jb,
с d
матрица представляет комплексное число с + jd и век-
с
тор (е, f1~ представляет комплексное число е + f. Такое матрич-
но-векторное произведение является одной из форм записи про-
изведения комплексных чисел.
Другой алгорим дается матричным равенством
с ‒ d 0 0
0 c+d 0
0 0 d
е 1 0 1
Ь
которое можно рассматривать как необычную форму разложения
матрицы.
(с d) 0 О
0 (c+d) 0
0 0 d
1 0 1
с ‒ d
В сокращенной записи алгоритм дается равенством
е а
=BDA ь
l.!. Введение в быстрые алгоригмы
15
где А матрица размера Зх2, которую мы назовем матрицей
предсложений; D диагональная матрица размера 3 х 3, которая
включает в себя все общие умножения алгоритма, и В матрица
размера 2 х 3, которую мы назовем матрицей постсложений.
Мы увидим, что многие из лучших процедур вычисления сверт-
ки и дискретного преобразования Фурье могут быть приведены
к такому же матричному виду, в котором центральная матрица
является диагональной, а стоящие по ее бокам матрицы. содержат
в качестве своих элементов только 0 и ~1. Структура таких бы-
стрых алгоритмов сводится к серии сложений, за которой следует
серия умножений, за которой следует другая серия сложений.
В качестве последнего примера этого вводного раздела рас-
смотрим быстрый алгоритм умножения матрицы. Пусть С = АВ,
где А и В матрицы размеров (lxn) и (nxm) соответственно.
Стандартное правило вычисления матрицы С дается правилами
П
с» ‒‒ ~, а,~Ь„~, 1 = 1,...,1, j = 1,..., т,
k=1
и содержит в соответствии с этой записью nlm умноженчй и (и
1) lm сложений. Мы построим алгоритм, который почти в два
раза уменьшает число умножений, но увеличивает число сложений,
так что общее число операций слегка возрастет.
Воспользуемся применительно к элементам матриц А и В
тождеством
а,b, +~b, = (а1+b,)(а, +b,) а,а, Ь,b,.
Предположим, что п четно (в противном случае можно, не меняя
произведения С, дополнить матрицу А нулевыми строками, а
матрицу В нулевыми столбцами). Применяя выписанное тож-
дество к парам строк матрицы А и к парам столбцов матрицы В,
запишем
n/2
с» = ~, '(а~, э 1+ b,~. ~) (а~,,ц + Ьм, 1 ~)
1=1
n/2 и/2
Е Qt 2Й 103, Ж Е Ь2Й-1, Ф2Й, J~г
k=1 ' ' k=l
J= l, т.
Такая форма вычислений экономит умножения, поскольку
второй член зависит только от ~ и его не надо перевычислять для
каждого j, а третий член зависит только от j и его не надо пере-
вычислять для каждого ~. Полное число умножений, необходи-
мых для такого вычисления матрицы С, равно (1/2) nlm +--
+ (1/2) п (l +- т), а полное число сложений равно (3/2) nlm +
~-1т +-- (n/2 1) (l + т). Яля матриц большого размера это
16 Гл. 1. Введение
Сложений
иа точку
Умножений
на точку
Алгоритм
Прямое вычисление
дискретного преобразования
1000х !000
БПФ-алгоритм Кули ‒ Тычки
1024х 1024
Гибридный БПФ-алгоритм
Кули ‒ Т.ыоки/Винограда
!000х 1000
БПФ-алгоритм Винограда
1008х 1008
БПФ-алгоритм Нуссбаумера ‒ Квендалла
!008х 1008
8000
4000
Фурье
40
72.8
40
91.6
6.2
4Л
79
Рис. 1.1. Сравнение характеристик некоторых двумерных алгоритмов преобра-
зования Фурье.
составляет примерно половину числа умножений, необходимых
в прямом алгоритме.
Последний пример является хорошим поводом для предосте-
режения относительно точности вычислений. Несмотря на то
что число умножений уменьшается, описанный алгоритм более
чувствителен к погрешностям округления, если не позаботиться
об этом специально. Однако можно получить почти такую же точ-
ность, как и в прямом алгоритме, если на промежуточных шагах
вычислений ввести соответствующие масштабные множители.
Вопрос о точности вычислений практически всегда в~ает при оцен-
ке быстрого алгоритма, хотя мы обычно будем им пренебрегать.
Иногда при уменьшении числа операций уменьшается и погреш-
ность вычислений, поскольку уменьшается число источников
этих помех. В других алгоритмах, хотя число источников помех
вычисления уменьшается, ответ может быть столь чувствительным
к одному или нескольким из них, что общая погрешность вычисле-
ний увеличивается.
Большая часть книги посвящена рассмотрению всего несколь-
ких задач: задачам вычисления линейной свертки, циклической
свертки, многомерных линейной и циклической сверток, дискрет-
ного преобразования Фурье, многомерного дискретного преобра-
зования Фурье, решению теплицевых систем уравнений и нахожде-
нию пути на решетке. Некоторые из рассматриваемых методов
заслуживают более широкого применения; особенно хороши алго-
ритмы многомерного преобразования Фурье, если взять на себя
труд разобраться в наиболее эффективных из них. Яля примера
на рис. 1.1 приведено сравнение некоторых алгоритмов вычисле-
ния двумерного преобразования Фурье. При приближении к концу
списка повышение эффективности алгоритмов замедляется. Умень-
шение числа умножений на одну точку вычислительной сетки на
~.2. Использование быстрых алгоритмов
17
выходе от шести до четырех может показаться не очень сущест-
венным после того, как уже получено уменьшение оТ сорока до
шести. Но это недальновидная точка зрения. Это дальнейшее улу-
чшение может вполне окупить затраты времени на разработку
алгоритма при построении больших систем.
Рис. 1.1 содержит другой важный урок. Вход таблицы, обозна-
ченный как гибридный БПФ-алгоритм Кули Тычки/Винограда,
соответствует алгоритму вычисления двумерного (1000 X 1000)-
точечного преобразования Фурье, в котором на каждую точку
сетки на выходе требуется 40 вещественных умножений. Этот
пример может помочь развеять злополучный миф о том, что дис-
кретное преобразование Фурье применимо только тогда, когда
длина блока равна степени двух. На самом деле возможность циф-
ровой обработки сигналов не ограничивается только такими дли-
нами блоков; для многих значений длин блоков имеются хорошие
алгоритмы.
1.2. Использование быстрых алгоритмов
Сверхбольшие интегральные схемы, называемые чипами, те-
перь стали доступными Чип может содержать порядка 100 000
логических элементов, и поэтому неудивительно, что теорию
алгоритмов часто рассматривают как способ эффективной органи-
зации этих элементов. Иногда выбор алгоритма позволяет су-
щественно улучшить характеристики чипа. Конечно, их можно
также улучшить, увеличив размер чипа или повысив его быстро-
действие; эти возможности более широко известны.
Предположим, что некто придумал алгоритм вычисления пре-
образования Фурье, содержащий только пятую часть от числа опе-
раций, входящих в другой алгоритм вычисления преобразования
Фурье. Тогда, используя этот алгоритм, можно реализовать та-
кое же улучшение характеристик чипа, которое получается при
увеличении в пять раз его размера или его быстродействия.
Яля реализации улучшения конструктор чипа должен, однако,
перенести архитектуру алгоритма в архитектуру чипа. Непроду-
манная конструкция может свести на нет это преимущество, уве-
личивая, например, сложность индексации или поток вход-вы-
ход. Разработка оптимальных конструкций в эпоху больших
интегральных схем невозможна без понимания быстрых алгорит-
мов, описываемых в данной книге.
С первого взгляда может показаться, что эти два направления
быстродействующие интегральные схемы и быстрые алгоритмы
конкурируют между собой. Если можно построить достаточно
большие и достаточно быстродействующие чипы, то вроде бы нет
ничего страшного в том, что используются неэффективные алго-
ритмы. В некоторых случаях такая точка зрения не вызывает сом-
18 Гл. 1. Введение
нений, но заведомо имеются случаи, в которых можно высказать
диаметрально противоположную точку зрения. Большие цифровые
процессоры часто сами создают потребность в разработке быстрых
алгоритмов, так как размерность решаемых на них задач растет.
Будет ли процессорное время алгоритма, предназначенного для
решения некоторой задачи, пропорционально n' или и', несущест-
венно при и, равном 3 или 4, но при и, равном OOOO, это стано-
вится критичным.
Рассматриваемые нами быстрые алгоритмы связаны с циф-
ровой обработкой сигналов, и их приложения столь же широки,
сколь и приложения самой цифровой обработки сигналов. Теперь,
когда стало практичным разрабатывать изощренный алгоритм
цифровой обработки сигналов, который может быть реализован
конструктивно посредством одного чипа, хотелось бы иметь воз-
можность выбрать такой алгоритм, который оптимизирует ха-
рактеристики этого чипа. Но для больших чипов это невозможно
сделать без достаточно развитой теории. В своем полном объеме
такая теория существенно выходит за рамки включенного в дан-
ную книгу материала. Чтобы учесть все аспекты сложности, надо
рассматривать и такие продвинутые разделы теории логических
схем и архитектуры компьютеров, как параллельное или конвей-
ерное исполнение.
Для оценки алгоритма обычно используют число необходимых
умножений и сложений. Эти вычислительные характеристики
почти исчерпывают сложность устройства на уровне алгоритма. На
более низком уровне оно оценивается площадью чипа или числом
логических элементов на нем и временем, необходимым для про-
ведения вычислений. Часто в качестве критерия качества схемы
используется произведение времени на площадь. Яы не будем
пытаться оценивать характеристики на этом уровне, так как это
выходит за рамки задач конструктора алгоритмов.
Актуальность рассматриваемых в данной книге вопросов нельзя
оценить без понимания масштабов будущих приложений цифровой
обработки сигналов. В настоящее время мы не можем угадать
даже размеры таких систем, но достаточно просто можно предви-
деть приложения, в которых объем необходимых вычислений будет
на несколько порядков больше, чем тот объем, обработку которого
может обеспечить современная технология.
Системы звуковой локации в последнее десятилетие стали
почти полностью цифровыми. Хотя полоса частот, в которой они
работают, равна всего нескольким килогерцам, эти системы вы-
полняют десятки миллионов или сотни миллионов умножений
в секунду и еще больше сложений. Такие системы уже сейчас
нуждаются в мощном цифровом оборудовании, и стали обыч-
ными проекты, требующие еще более мощной цифровой тех-
ники.
! .2 Исгользование быстрых алгоритмов
Радиолокационные системы тоже становятся цифровыми, нс
многие важные функции по-прежнему реализуются традиционной
микроволновой или аналоговой схемотехникой. Для того чтобь~
увидеть колоссальные потенциальные возможности использования
цифровой обработки сигналов в радиолокации, достаточно п-.ìå
тить, что радиолокационные системы в принципе очень гк:.' жи
на системы звуковой локации, отличаясь от них тем, что испо.и.зу
емая полоса частот в IOOO или более раз больше.
Цифровая обработка сейсмической информации является глав
ным методом разведки земных недр, в частности одним из важней-
ших методов поиска залежей нефти. Обработкой больших пакетов
лент данных занято все процессорное время многих компьютеров,
но многие вычисления остаются невыполненными.
Компьютерная томография представляет собой широко исполь-
зуемый ныне способ объемного синтеза изображений внутренних
органов человека с помощью множественных проекций, получае
мых при просвечивании рентгеновскими лучами. Разрабатыва-
ются алгоритмы, позволяющие существенно снизить дозы облу-
чения, но требования к цифровой обработке намного превосходят
все практически приемлемые в настоящее время. Изучаются и
другне способы получения изображений для медицинской диаг-
ностики, в том числе с помощью ультразвука, ядерного магнит-
ного резонанса или радиоактивных изотопов.
Неразрушающий контроль качества подукции, например от-
ливок, возможен с помощью воссоздаваемых на компьютере изоб-
ражений внутренних областей изделия по результатам эхолока-
ЦИИ.
В принципе обработка сигналов может быть использована для
улучшения качества плохих фотографий, смазанных движением
камеры или расфокусировкой. Однако такая цифровая обработка
требует большого объема вычислений.
Обработка на цифровом процессоре спутниковых фотографий
позволяет совместить несколько изобр ажений или выделить осо-
бенности, или скомбинировать полученную.на различных длинах
волн информацию, или создать синтетический стереоскопический
образ. Например, в метеорологических исследованиях можно соз-
дать подвижное трехмерное изображение облачного покрова,
движущегося над поверхностью земли, используя для этого после-
довательность спутниковых фотографий. снятых с нескольких то-
чек.
Можно указать и другие приложения быстрых алгоритмов для
цифровой обработки сигналов, но уже приведенных достаточно
для того, чтобы доказать, что потребность в них существует и
продолжает расти.
Каждое из описанных приложений связано с большим коли-
чеством вычислений, структура которых, однако. чрезвычай но
20 Гл. 1. Введение
прозрачна и сильно упорядочена. Кроме того, если цля решения
некоторой задачи уже создан жесткий модуль или подпрограмма, то
они и будут постоянно использоваться для этой задачи. Имеет
смысл затратить усилия на разработку добротной схемы, так как
хорошие операционные характеристики намного важнее стои-
мости разработки.
1.3. Системы счисления для проведения
вычислений
Во всей книге, говоря о сложности алгоритма, мы имеем в виду
число умножений и сложений, поскольку эти операции выбраны
в качестве единиц измерения сложности. Кто-то может захотеть
пойти дальше и, чтобы подсчитать число необходимых битовых
операций, поинтересоваться тем, как построено устрой-
ство умножения. Структура умножителя и сумматора суще-
ственно зависит от вида представления данных. Хотя вопро-
сы, связанные с системами счисления, выходят за рамки
данного курса, несколько слов во введении об этом сказать сле-
дует.
Возьмем крайний случай, полагая, что основная часть вы-
числений состоит из умножений. Тогда сложность можно понизить,
записывая данные в логарифмическом виде. Сложение при этом
станет более трудоемким, но если сложений не слишком много,
то общий результат улучшится. Тем не менее, как правило, мы
будем полагать, что входные данные записываются в одном gз
естественных видов как вещественные, как комплексные или
как целые числа.
В практической реализации процессоров для цифровой обра-
ботки сигналов имеются еще более тонкие вопросы; используются
формы записи числа как с плавающей, так и с фиксированной точ-
кой. Для большинства задач цифровой обработки вполне доста-
точной оказывается арифметика с фиксированной точкой и в этих
случаях ее и надо выбрать из соображений экономичности. Этого
положения не следует придерживаться слишком строго. Всегда
есть соблазн избавиться от многих трудностей проектирования,
перейдя к арифметике с плавающей точкой. Однако если чип или
алгоритм предназначены для одного-единственного применения
например цифровой фильтр для цифровой радиосхемы массового
выпуска, то не стоимость разработки этого чипа играет основ-
ную роль; решающую роль играют эксплуатационные характери-
стики изделия и стоимость его тиражирования. Деньги, затрачен-
ные на облегчение работы конструктора, нельзя потратить на
улучшение характер истик.
1.3. Системы счисления для проведения вычислений
21
Неотрицательное целое число J, меньшее, чем д, в т-сим-
вольной позиционной арифметике с фиксированной точкой по
основанию д записывается в виде
i =1О+11Ч+1аЧ'+ -+1 -И ' o <1и <Я.
Число 1 представляется т-последовательностью коэффициентов
(lo jx " ' 11) '). 1'lмеется несколько способов учета знака
числа с фиксированной точкой; эти способы записи отрицательных
чисел называются соответственно прямым кодом, дополнительным
кодом и обратным кодом. При любом основании q правила такого
представления одни и те же. В двоичном случае, д = 2, дополни-
тельный и обратный коды иногда называются соответственно
2-дополнительным и 1-дополнительным.
Наиболее прост для понимания прямой код. Для записи знака
числа в нем выделяется специальная позиция, которая называется
знаковой и в которую записывается О, если число положительно,
и 1, если число отрицательно. В процессе выполнения операций
сложения и умножения знаковая позиция обрабатывается от-
дельно от значимых позиций. Часто предпочтение отдается допол-
нительному или обратному кодам, поскольку они проще реали-
зуются в жестком исполнении; сумматор просто складывает два
числа, не делая различия между знаковой и значащими позициями.
Как прямой, так и обратный коды приводят к двум разным запи-
сям нуля положительной и отрицательной, которые следует
полагать равными. В дополнительном коде нуль записывается
однозначно.
В обратном коде изменение знака числа получается заменой
каждой цифры 1, включая и знаковую цифру, на q 1 j.
Например, взятое с обратным знаком десятичное число +62 (ко-
торое записывается как 062) равно в обратном коде 937, а взятое
с обратным знаком двоичное число +011 (которое записывается
как 0011) равно в обратном коде 1100. Обратный код обладает
тем свойством, что для умножения любого числа на минус один
достаточно каждую цифру заменить ее дополнением до q l.
В дополнительном коде изменение знака каждого числа полу-
чается прибавлением единицы к записи этого числа в обратном
коде. По определению минус нуль равен нулю. При таком согла-
шении взятое с обратным знаком десятичное число +62, которое
записывалось как 062, равно в дополнительном коде 938, а взятое
с обратным знаком двоичное число -+011, которое записывалось
как 0011, равно в дополнительном коде 1101.
1) 5 стандартной позиционной записи наиболее значимая цифра распола-
гается не справа а слева, так что число записывается в внде Ц„, » )~»,
у» 1,). ‒ cpu~. Р .
22 Гл. 1. Введение
1.4. Цифровая обработка сигналов
Наиболее важной задачей цифровой обработки сигналов явля-
ется задача фильтрации длинной последовательности чисел, а наи-
более важным устройством цифровой фильтр. Как правило,
длина последовательности данных заранее неизвестна и является
столь большой, что ее можно полагать при обработке бесконечной.
Числа, составляющие последовательность, являются обычно либо
вещественными, либо комплексными, но нам предстоит работать
и с другими видами чисел. Цифровой фильтр представляет собой
устройство, формирующее новую числовую последовательность,
называемую выходной последовательностью, по заданной после-
довательности, которая теперь называется входной последователь-
ностью. Широко используемые фильтры можно строить из эле-
метов, схемы которых приведены на рис. 1.2 и которые называются
разрядами регистра сдвига, сумматорами, умножителями на
скаляр и умножителями. Разряд регистра сдвига содержит одно
число, которое поступает на его выход. В дискретные моменты
времени, именуемые тактами, разряд регистра сдвига замещает
содержащееся в нем число числом, поступающим на его вход,
отбрасывая предыдущее содержимое. Как показано на рис. 1.3,
регистр сдвига представляет собой несколько соединенных в
цепь разрядов регистра сдвига. Регистр сдвига называется также
линией задержки.
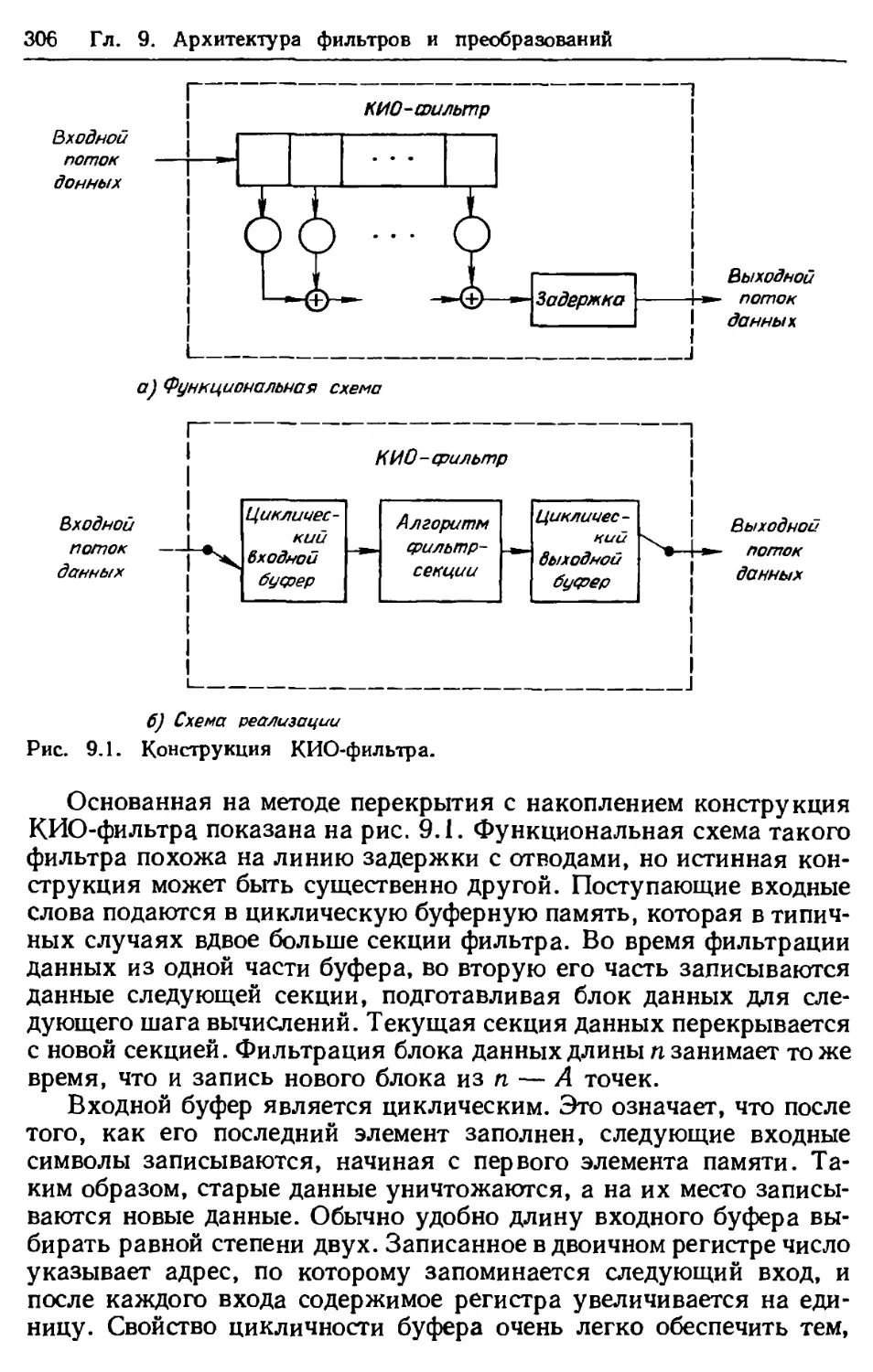
Мы будем рассматривать два наиболее важных типа регистров
сдвига, известных под названием фильтра с конечным импульс-
ным откликом (КИО-фильтр) и авторегрессионного фильтра.
КИО-фильтр, как показано на рис. 1.4, представляет собой просто
линию задержки с отводами, в которых выход каждого разряда
умножается на фиксированную константу, а результаты склады-
ваются вместе. Как показано на рис. 1.5, авторегрессионный
фильтр также является линией задержки с отводами, но с обрат-
ной связью, соединяющей выход со входом. Выходная последо-
вательность КИО-фильтра равна линейной свертке входной пс
следовательности и последовательности, описываемой весовыми
множителями в отводах фильтра.
Линейная свертка является едва ли не самой общей вычисли-
тельной задачей цифровой обработки сигналов, и большую долю
времени мы потратим на исследование вопроса ее эффективной
реализации. Еще больше времени мы уделим методам эффектив-
ного вычисления циклической свертки. Это может показаться
странным, так как в приложениях циклическая свертка возникает
естественным образом не столь уж часто. Наше внимание к цикли-
ческой свертке обусловлено тем, что для ее вычисления имеется
много хороших алгоритмов. Это позволяет разработать быстрые
методы вычисления очень длинных линейных сверток, связывая
вместе много циклических сверток.
f.4. Цифровая обработка сигналов
23
Paapad регистра сдВига
а+ Р
Умиритель
на eoecrnaemg
Сумматор
Умном инва
Рис. 1.2., Элементы схем.
Рис. 1.3. Регистр сдвига.
° .- ° ~Z À.~О
° ° е +2 ° +I ° ~0
Рис. 1.4. КИО-фильтр.
L
р;= ‒ Qh,ó.;+ а
Рис. 1.5. Авторегрессивный фильтр.
Для заданных двух последовательностей последователь-
ности данных
d= fd;, i=0, ..., N ‒ 1}
и последовательности фильтра
g = {g;, i = 0, ..., ~. ‒ 1},
s= (s;, i=0,..., L+N 2},
элементы которой определяются р авенствами
N ‒ 1
s;= g g<„d„, i=O,..., L+N, 2,
@=О
где N длина блока данных и L длина фильтра, линейной
сверткой называется новая последовательность
24 Гл. 1. Введение
а длина выходного блока равна L -+- N 1; последовательность s
называется выходной или сигнальной. В записи свертки подразу-
мевается, что g;- > ‒‒ 0 при 1 ‒ k < О. Так как все компоненты
последовательности g умножаются на все компоненты последова-
тельности d, то прямой метод вычисления свертки содержит И'
умножений.
Имеется очень разработанная теория построения КИОфильт-
ров, связанная с выбором длины Ь и весовых множителей {g;».
Эгот аспект теории конструкций фильтров мы не рассматриваем;
предметом наших исследований являются быстрые алгор итмы
вычисления выходной последовательности s по заданным после-
довательностям фильтра g и входа d.
Со сверткой тесно связана еще одна величина, которая назы-
вается корреляцией и определяется равенствами
N ‒ 1
~i = Z gi+hdhe
!=о
i=0, ..., L+N 2,
где g;-,> ‒ ‒ 0 при i + k )~ ~'. Корреляцию можно вычислять как
свертку, если просто прочитать одну из определяющих ее последо-
вательностей в обратном порядке. Все способы вычисления ли-
нейной свертки легко преобразуются в способы вычисления
корреляции.
Свертку можно записать также через многочлены. Пусть
N ‒ 1 L ‒ 1
d (х) = g d;x' и g (х) = f g;xi.
к=о к=о
Другой формой свертки, тесно связанной с линейной сверткой,
является циклическая свертка. Для заданных двух последова-
тельностей {d;, ~ = О, ..., п 1} и {g;, i = О, ..., п ‒ 1» с
одной и той же длиной блока п циклическая свертка {з~, 1 = О, ...,
п 1» с длиной блока п определяется равенствами
ЕiИ-1
Тогда з(х) = g(x) d(x), где s(x) = g s;x'. Эти равенства легко
к=о
проверяются простым вычислением коэффициентов произведения
g(x) d (х). Можно, конечно, записать также равенство s (х) =
=d(x)g(x), из которого становится очевидной симметричная роль
последовательностей g u d в определении свертки. Таким образом,
линейная свертка может быть записана в эквивалентном виде как
L ‒ 1
si = Z gkdt-й.
@=о
25
1.4. Цифровая обработка сигналов
где двойные скобки означают, что вычисления над индексами про-
изводятся в арифметике по модулю п (см. равд. 2.6). Иными сло-
вами, ((п Й)) = п Й (mod п) и 0 < ((п Й)) ( п. Заметим,
что в циклической свертке при каждом ~ каждое d> умножается
на значимую величину g((z >)). Это существенное отличие от
линейной свертки, в которой d> часто умножается на член д, >,
индекс которого выходит за диапазон определения последова-
тельности g, так что соответствующая компонента g > равна
нулю.
Циклическую свертку можно связать с линейной следующим
образом. По определению циклической свертки
Разделим эту сумму на две, выделяя в первую сумму члены, ин-
дексы которых удовлетворяют условию i Й >~ 0 (или Й.( i), а
во вторую члены, индексы которых удовлетворяют условию
Й(0 (или k)i):
2 n ‒ 1
sr = g gr rrdrr+ g gn+r~dü
~=О Ь=g~1
Полагая теперь в первой сумме g;> ‒ ‒ О при k > 1, а во второй
g„+, > ‒ ‒ О при k < t, можно изменить границы суммирования
и получить связь циклической и линейной сверток в виде
n ‒ 1 n ‒ f
si = Е яг ‒ мЦ+ Z gn+r adrr з~+ sll+r ~ =О,..., п
k~ @=О
n ‒ 1
n ‒ 1
d (x) = g с~,х', g (x) = g д;х'
к=о к=о
Скажем, что члены последовательности s, индексы которых больше
и 1, «вкладываются» обратно в члены, индексы которых мень-
ше и.
Если второй член выписанной выше суммы равен нулю, то
линейную свертку можно вычислять как циклическую. Это воз-
можно, если произведения д'„; >d> равны нулю для всех t u k.
Чтобы обеспечить эти условия, можно так выбрать длину и цик-
лической свертки, чтобы она была больше, чем N + L 1 (по-
полняя нулями g u d до длины блока и). Тогда для вычисления
линейной свертки можно пользоваться алгоритмом вычисления
циклической свертки и получать при этом правильный ответ.
Циклическую свертку можно также выразить в виде произве-
дения многочленов. Пусть
26 Гл. 1 Введение
då- Iâ
° 1 ~ь ~ю-1е - ° э daå da
ххк с„'
c~ ° c0 хх% t
Выбрать среднце г то ~ек
д wovecmde компонент
циклической с8ертки
Рис. 1.6. Использование КИО-фильтра для формнрования циклической свертки.
и s (х) = g (х) d (х). Циклическая свертка вычисляется по много-
члену s (х) «обратным вложением» членов высшего порядка. Это
можно представить в виде записи
s'(х) = s (х) (mod х" 1),
где равенство по модулю х" ‒ 1 означает, что s' (х) равен остатку
от деления многочлена s (х) на многочлен х" 1. Таким образом,
s'(õ) = g (х) d (х) (mod х" 1)
Для приведения многочлена g (x) d (х) по модулю х" 1 доста-
точно заменить х" на 1, или, что эквивалентно, член х"+~ с поло-
жительным» на член х'. Это соответствует формированию величин
я~ =я~+я„+~, i =0, °, п 1,
и, следовательно, позволяет вычислить коэффициенты цикличе-
ской свертки.
Так как
s' (х) = d (х) g (х) = g (х) d (х) (mod х" ‒ 1),
то ясно, что векторы d u g играют в определении свертки сим-
метричную роль, так что циклическая свертка задается двумя
эквивалентными равенствами
л3
si = Е gags ‒ »y>d» =
П ‒ g
= g d<<g»>>g», 1=0,.', п 1.
1=0
На рис. 1.6 приведена схема КИО-фильтра, вычисляющего
циклическую свертку, для чего последовательность d повторя-,
ется дважды. На выходе КИО-фильтра формируется последова-
тельность из Зп 1 компонент, среди которых содержатся и
последовательных компонент, равных компонентам циклической
свертки.
1.4. Цифровая обработка сигналов
27
Более важным для приложений является использование цик-
лической свертки для вычисления длинной линейной свертки.
В быстрых алгоритмах вычисления длинной линейной свертки
входная последовательность разбивается на короткие секции, со-
держащие иногда несколько сотен отсчетов. Для формирования
потока данных на выходе секции обрабатываются поочередно
зачастую методом циклической свертки. Такие способы назы-
ваются методами с перекрыпшем; в этом названии отражается
тот факт, что неперекрывающиеся секции в потоке входных дан-
ных приводят к перекрывающимся секциям в потоке выходных
данных, а перекрывающиеся секции в потоке входных данных
приводят к неперекрывающимся секциям в потоке выходных
данных.
Работа показанного на рис. 1.5 авторегрессионного фильтра
также может быть описана в терминах полиномиальной арифме-
тики. Но если КИО-фильтр вычисляет произведение многочленов,
то авторегрессионный фильтр выполняет деление многочленов.
А именно, при фильтрации конечной последовательности в авто-
регрессионном фильтре (с нулевым начальным состоянием) на
выходе фильтра формируется последовательность коэффициентов
многочлена-частного, получаемого пр и делении многочлена,
коэффициенты которого равны компонентам входной последо-
вательности, на многочлен, коэффициенты которого задаются
весовыми множителями в отводах фильтра; к моменту завершения
ввода входной последовательности содержимое фильтра равно
коэффициентам многочлена-остатка от такого деления. Напомним,
что авторегрессионный фильтр описывается равенством
L
Ру = Е hipi-z + ~Ъ
к=о
где а; есть j-A символ на входе, à h; весовой множитель в
1-м отводе фильтра. Определим многочлены
а (х) = ~, 'а,х' и и (х) = g й;х'
1=О
и запишем равенство
а (х) = Q (х) h (х) + г (х),
где Q (х) н r (х) обозначают соответственно частное и остаток
в алгоритме деления многочленов. Тогда отсчет р; на выходе
фильтра равен в точности j-My коэффициенту многочлена-част-
ного, а коэффициенты многочлена-остатка r (х) будут записаны
в самых левых разрядах регистра сдвига авторегрессионного
фильтра после того, как на его вход будут поданы все п коэффи-
циентов а> делимого.
28 Гл. 1. Введение
Другим очень важным в цифровой обработке сигналов видом
вычисления является дискретное преобразование Фурье (с этих
пор называемое в дальнейшем просто преобразованием Фурье).
Пусть ч = (о;, i = 0, ..., п 1} обозначает вектор с веществен-
ными или комплексными компонентами. Преобразованием Фурье
вектора v называется вектор V длины и с комплексными компо-
нентами, задаваемыми, равенствами
1
Vz = g и'~v;, k =0,..., п 1,
Е=0
где со ‒ g-/2ï/ë и / у~ 1 )
Иногда это определение записывается в матричном виде
V =Ò÷.
Если раскрыть эту запись,
то она принимает вид
1 ... 1
00
~0
V~
V2
1 1
02 ~1~Ю- 1
(1)4 (~2 (n ‒ g)
1 а
1 о)2
~n ‒ 1 ~2 (n ‒ 1)
ll-1
«V»
Если вектор V равен преобразованию Фурье вектора ч, то
вектор v можно вычислить по вектору V с помощью обратного
преобразования Фурье, задаваемого равенством
n ‒ 1
0
1
О~ ‒ Ей~
и
Доказательство этого факта дается следующими выкладками.
n ‒ g n ‒ 1 и ‒ Ь.
~|~~ со ‒ еа~/ g го ‒ жа g со!/гп
Й-0 k~ 1=0
и†~ и†~
4ã (l ‒ Е)
Е=О ' .=0
Если l = 1, то сумма по Й, очевидно, равна и, а если l не равно ~,
то сумма приводится к виду
Пй
(о> ‒ ( I ‒ к1)а
‒ (l ‒ Е)
1) Во всей книге буква j используется и для обозначения к' ‒ 1 и в каче-
стве индекса. Это не прнводит, однако, ни к какой путанице.
29
!.5. История быстрых алгоритмов обработки сигналов
Так как ж-" = 1, то справа стоит нуль. Следовательно,
n ‒ l
n ‒ О
Z и ‒ '~Vs = Z о~ (пбц) = пи,,
A=O l=O
тогда и только тогда, когда их преобразования Фурье удовлетво-
ряют равенствам
E> ‒ ‒ FqGq, k =0,..., и 1.
Это утверждение вытекает из того, что
n ‒ 1 n ‒ 1
1
е, =$ f(( ((» ‒ "(О„] =
/=О А=О
n ‒ 1 n ‒ 1 n ‒ 1
1
а) ‒ fkQ а)(к ‒ I) kf
!
8AG Р
и и
А=О l~ А=О
Поскольку е есть обратное преобразование Фурье от Е, то Mbl
заключаем, что Е~ = G>F~.
Можно также определить двумерные преобразования Фурье,
которые полезны при обработке двумерных таблиц данных, и
многомерные преобразования Фурье, которые используются при
обработке многомерных массивов данных. Двумерное пр еобразо-
вание Фурье определяется равенствами
в ‒ 1 n" ‒ 1 й' = О, ..., и' 1,
k-= g g(0 P og g»,
Г=О Ю.=о ' ~ =~4- ° °, ~
где у ~/ 2Я/фф и р ~/2 Я/Я»
1.5. История быстрых алгоритмов
обработки сигналов
Историю быстрых алгоритмов обработки сигналов принято
отсчитывать с момента, когда в 1965 г. Кули и Тычки опублико-
вали свой быстрый алгоритм вычисления преобразования Фурье
(БПФ-алгоритм}, хотя на самом деле эта история началась намного
где 6;< ‒ ‒ 1 при 1 = 1 и о;< ‒‒ О в противном случае.
Между циклической сверткой и преобразованием Фурье име-
ется очень важная связь, которая известна как теорема о свертке
и формулируется следующим образом. Вектор е равен цикличе-
ской свертке векторов f и g,
n ‒ 1
Z f((c — t))gt\ й О\ ( и ~(
/=О
.Ю Гл. 1, Введение
раньше. Указанная публикация [51 появилась как раз в нужный
момент и послужила катализатором применения метода цифровой
обработки сигналов в новом контексте Вскоре после опублико-
вания этой работы Стогхем [61 заметил, что БИФ-алгоритмы могут
служить удобным способом вычисления сверток. Технология циф-
ровой обработки может непосредственно использовать БИФ, так
что имеется множество приложений, и поэтому работа Кули и
Тычки стала ширко известной. Лишь несколько лет спустя было
осознанно, что другой БИФ-алгоритм, сильно отличающийся оТ
алгоритма Кули Тычки, был р азработан раньше Гудом 17 ]
(1960) и Томасом [81 (1963). В свое время публикация БПФ-ал-
горитма Гуда Томаса прошла почти незамеченной. Позже Ви-
ноград [9, 101 (1976, 1978) опубликовал свой более эффективный,
хотя и более сложный, БПФ-алгоритм, который к тому же позво-
лил значительно глубже понять, что в действительности озна-
чает процесс вычисления дискретного преобразования Фурье.
Неблагоприятным следствием популярности БПФ-алгоритма
Кули ‒ Тычки явилось широкое распространение мнения о том,
что дискретное преобразование Фурье практично применять
лишь при длине блока, равной степени двух. Это привело к тому,
что БИФ-алготитмы стали диктовать парамегры применяемых
устройств вместо того, чтобы приложения диктовали выбор под-
ходящего алгоритма Б ПФ. На самом же деле хорошие Б ПФ-
алгоритмы существуют практически для произвольной длины
олока.
Различные вариации БИФ-алгоритма Кули Тычки появи-
лись во многих обличьях. По существу та же самая идея исполь-
зуется для построения многолучевой плоско-фазированной радио-
локационной антенны и известна под иазванием матрицы Батлера
[11] (1961).
Для малых длин блоков быстрые алгоритмы сверток были
впервые построены Агарвалом и Кули [12] (1977) с использова-
иием остроумных догадок, но не на основе общего метода. Общий
метод построения быстрых алгоритмов свертки описал Виноград
[101 (1978), доказав при этом важные теоремы несуществования
лучших алгоритмов свертки для полей комплексных и веществен-
ных чисел. Агарвал и Кули [12[ также указали основанный на
китайской теореме об остатках метод разбиения задачи вычисле-
ния длинных сверток на задачи вычисления коротких сверток
Их метод в сочетании с методом Винограда, применяемый для
вычисления коротких сверток, дает хорошие результаты.
Самая ранняя идея того, что мы предпочитаем называть быст-
рыми алгоритмами, появилась намного раньше, чем БПФ-алго-
ритмы, Алгоритм Левинсона [131 был опубликован в 1947 г.
как эффективный метод решения некоторых теплицевых систем
~равнений. Несмотря на чрезвычайную важность этого алгоритма
Задачи
s обработке сейсмических данных, литература, посвященная ал-
горитму Левинсона, многие годы не пересекалась с литературой
по БПФ-алгоритмам. Как правило, в этих ранних исследованиях
не делалось попыток явно разграничить алгоритм Левинсона как
вычислительную процедуру и задачи фильтрации, н решению
которых алгоритм применялся. Подобно этому, не всегда прово-
дилось различие между БПФ как вычислительным средством и
дискретным преобразованием Фурье, для вычисления которог(о
используются БПФ-алгоритмы; аналогично зачастую не разли-
чались алгоритм Витерби как вычислительная процедура и задача
поиска пути, к решению которой применяется алгоритм Витерби.
Задачи
1.1. Построить алгоритм 2-точечной вещественной циклической свертки
(з~х+ з()) = (g>x+ g()) (d~x+ Q) (mod х~ ‒ 1),
содержащий два умножения и четыре сложения. Относящиеся к go и g1 вычисле-
ния не учитывать, полагая их константами, для которых все вычисления выпол-
няются заранее ра3 и навсегда.
1.2. Опираясь на задачу 1.1, построить алгоритм 2-точечной комплексной
свертки, содержащий только шесть вещественных умножений.
1.3. Построить алгоритм 3-точечного преобразования фурье
k=O, 2, 2,
в котором имеется только два вещественных умножения.
1.4. Доказать, что не существует алгоритма умножения двух комплексных
чисел, содержащего только два вещественных умножения.
1.6.а. Допустим, что имеется устройство вычисления линейной свертки двух
50-точечных последовательностей. Описать, как это устройство может быть
использовано для вычисления циклической свертки двух 50-точечных после-
довательностей.
б. Допустим, что имеется устройство для вычисления циклической свертки
двух 50-точечных последовательностей. Описать, как это устройство может
быть использовано для вычисления линейной свертки двух 50-точечных
последовательностей.
1.6.) Доказать, что корреляцию можно вычислять как свертку, записывая одну
из последовательностей в обратном порядке и, возможно, пополняя одну
из последовательностей отрезком нулей.
Ю Доказать, что любой алгоритм вычисления х~~, в котором используются
только сложения, вычитания и умножения, должен содержать по меньшей
мере семь умножений, но если допустить возможность деления, m суще-
ствует алгоритм, содержащий всего шесть умножений и делений.
1-8- Один из алгоритмов вычисления произведения комплексных чисел дается
равенствами
е= ас ‒ bd,
f = (а+ b) (с+ 4 ‒ ас ‒ bd.
32 Гл. 1. Введение
Записать этот алгоритм в матричном виде, подобно тому, как это сделано
в тексте главы. Каковы недостатки или преимущества этого алгоритма по
сравнению с приведенным выше
1.9. Доказать «свойство сдвиг.а» для преобразований Фурье: если (о;) ~ (Vp}
являются парой преобразования Фурье, то парамн преобразовання фурье
также являются
«и и,} ««> < „+»>} и «и<<~>>>} ««и~У„}.
1.10. Доказать, что «циклическая корреляция» двух вещественных последова-
тельностей g u d удовлетворяет соотношению
1 ‒ л
а,д- у g«,+„,н,,
Й=О
где б и D соответственно преобразования Фурье последовательностей g u d.
Замечания
Хорошее изложение начала истории быстрых алгоритмов преобразования
Фурье содержится в статье Кули, Левиса и Велча [1) (1967). Основы теории
цифровой обработки снгналов можно найти во многих книгах; укажем две из
них: Олпенгейм н Шафер [2) (1975) и Рэбинер и Голд [3] (1975).
Алгоритмы умножения комплексных чисел, содержащие три вещественных
умножения, в общем стали известны с конца 1950-х, но поначалу им не придавали
должного значения. Описанный нами алгоритм умножения матриц принадлежит
Винограду [4] (1968).
Глава 2
ВВЕДЕНИЕ В АБСТРА3(ТНУЮ АЛГЕБРУ
Хорошие алгоритмы основаны на красивых алгебраических
тождествах. Для построения таких алгоритмов необходимо зна-
комство с мощными структурами теории чисел и современной ал-
гебры. Такие структуры, как множество целых чисел, кольца
многочленов и поля Галуа, играют важную роль в построении
алгоритмов обработки дискретных сигналов. В настоящей главе
излагаются алгебраические сведения, которые необходимы для
дальнейшего, но, как правило, неизвестны студентам, специали-
зирующимся в области обработки дискретных сигналов. Сначала
изучаются математические структуры групп, колец и полей. Мы
увидим, что дискретное преобразование Фурье может быть опре-
делено в произвольном поле, хотя наиболее известно его опреде-
ление в поле комплексных чисел. Затем будут рассмотрены из-
вестные понятия матричной алгебры и векторных пространств.
Мы покажем, что их можно корректно определить для любого
поля. Наконец, мы изучим кольцо целых чисел и кольца много-
членов, уделяя особое внимание алгоритму Евклида и китайской
теореме об остатках.
2.1. Группы
Понятие группы является математической абстракцией опре-
деленной алгебраической структуры, часто встречающейся во
многих конкретных видах. Введение абстрактного понятия обус-
ловлено тем, что легче одновременно исследовать все математиче-
ские системы с общей структурой, чем изучать каждую из них
по отдельности.
Определение 2.1.1. Группой G называется множество эле-
ментов с определенной на нем операций (обозначаемой *), кото-
рая удовлетворяет следующим четырем свойствам.'
(1) (Замкнутость ) Для каждой пары элементов а и Ь из
moro множества элемент с = а~ b принадлежит этому множеству.
(2) (Ассоциативность.) Для всех элементов а, Ь и с из этого
множества
а ~ (Ь:| с) = (а ~ Ь) ь с.
34 Гл. 2. Введение в абстрактную алгебру
Рис. 2.1. Пример конечной группы.
(3) (Существование единицы.) В этом множестве существует
элемент е, называемый единичным элементом, такой что
а*е = е*а= а
для любого элемента а рассматриваемого множества.
(4) (Обратимость.) Яля любого а из данного множества су-
ществует (называемый обратным к а) некоторый элемент Ь из
этого множества, такой что
а Ь= Ь*а=е.
Если 6 содержит конечное число элементов, то она называется
конечной группой. Число элементов в конечной группе 6 называ-
ется ее порядком. На рис. 2.1 приведен пример конечной группы.
По существу здесь представлена одна и та же группа, но в разных
обозначениях. В случае когда две группы описываются одной
и той же структурой, хотя и в разных обозначениях, они назы-
ваются изоморфными ').
Некоторые группы обладают тем дополнительным свойством,
что для любых а и Ь из такой группы
а~ Ь = Ь~а.
Это свойство называется коммутативностью. Группы, обладающие
этим дополнительным свойством, называются коммутативными
группами, или абелевыми группами. Мы всегда будем иметь дело
с абелевыми гр уппами.
В случае абелевых групп знак групповой операции обознача-
ется плюсом и называется сложением (даже тогда, когда операция
не является обычным арифметическим сложением). В этом случае
единичный элемент е называется «нулем» и обозначается О, а
обратный к а элемент записывается в виде а, так что
а+( а) = ( а) +а= О.
Иногда символ групповой операции обозначатеся точкой и
называется умножением (даже тогда, когда оно не является обыч-
1) Вообще любые две алгебраические системы с одной и TQH же структурой,
но представленные в разных обозначениях наываются иэоморфяыми.
2.1. Группы
35
ным умножением). В этом случае единичный элемент называется
единицей и обозначается 1, а обратный к а элемент записывается
в виде а ', так что
а-а'= а'а= 1.
Теорема 2.1.2. Единичный элемент в каждой группе единст-
вен. Для каждого элемента группы обратный элемент также
единстеен, и (а ') ' = а.
Яоказательспио. Предположим, что е и e' являются единич-
ными элементами. Тогда е = e+e' = е'. Яалее предположим, что
Ь и Ь' являются элементами, обратными к а; тогда
Ь = b* (а~Ь') = (b*a) ~Ь' = Ь'.
Наконец, а ' ~ а = а~ а ' = е, так что а является обратным
к а '. Но в силу единственности обратного элемента (а ') ' = а. д
Многие общеизвестные группы содержат бесконечное число
элементов. Примерами являются. множество целых чисел с опе-
рацией сложения; множество положительных рациональных чи-
сел с операцией умножения '); множество вещественных (2х2)-
матриц с операций сложения. Многие другие группы содержат
только конечное число элементов. Конечные группы могут быть
устроены весьма хитро.
Если групповая операция применяется два или более раз
к одному и тому же элементу, то можно использовать степенное
обозначение. Таким образом, а' = а~а и
а" = а~а~ ... ~а,
где справа стоят Й копий элемента а.
Циклической называется группа, в которой каждый элемент
может быть записан в виде степени некоторого фиксированного
элемента, называемого образующей группы.. Каждая конечная
циклическая группа имеет вид
G = ~ае, а', а2,..., а~ ‒ '),
г
где д порядок G, а образующая, а а~ ‒ единичный элемент,
а обратный к а' элемент равен а~ ‒ '. Чтобы можно было на самом
деле задать группу таким способом, необходимо, чтобы выполня-
лось равенство а~ = ао. Это вытекает из того, что в противном слу-
чае, если а~ = а' при г =ф= О, то а~ ‒ ' = а' ‒ ' и в противоречие
с определением мы получаем меньше, чем д, элементов.
~) Этот пример дает удобный повод, чтобы сделать предостережение по
поводу терминологии. В случае произвольной абелевой группы групповая опе-
рация обычно называется сложением, но не обязательно является обычным
сложением. 3 данном примере она является обычным умножением.
36 Гл. 2. Введение в абстрактную алгебру
Важнейшей циклической группой с д элементами является
группа, обозначаемая >/(g), или иногда ~д, и задаваемая мно-
жеством
z/(g) = }0, 1, 2,..., g 1}
со сложением по модулю д в качестве групповой операции. На-
пример,
Z/(6) =- }О, 1, 2,..., 5}
и 3+4=1.
Группа Z/(g) может быть выбрана в качестве стандартного
прототипа циклической группы с д элементами. На самом деле
имеется только одна группа с и элементами; все остальные явля-
ются ее изоморфными копиями, различающимися обозначениями,
но не структурой. Любую другую циклическую группу 6 с д
элементами можно отобразить в Z/(g) с заменой групповой опера-
ции в 6 сложением по модулю д. Любые свойства структуры в G
справедливы в Z/(g), и наоборот.
По заданным двум группам G' и G" можно построить новую
группу 6, которая называется произведением групп 6' и G" и обо-
значается 6 = 6' X 6". Элементами 6 служат пары элементов (а',
а"), первый из которых принадлежит 6, а второй 6". Группо-
вая операция в произведении групп G определяется равенством
(а', а") + (Ь', Ь") = (а' + Ь', а" + Ь").
В этой формуле звездочка используется три раза в трех разных
смыслах. В левой части равенства она обозначает групповую
операцию в G, а в правой части операции в группах G и G"
соответственно.
Например, ~, Х ~, задается множеством
z, х Z, = }(0. О), (О, 1), (О, 2), (1, О), (1, 1), (1, 2)}.
Типичным элементом таблицы сложений в ~, х ~, является
(1, 2) + (О, 2) = (1, 1).
Отметим, что группа ~, X ~, сама является циклической с об-
разующим элементом (1, 1). Следовательно, Z, X ~, изоморфна
группе ~,. Причина этого роется в том, что числа 2 и 3 не имеют
общих целочисленных делителей.
Пусть G группа и Н подмножество в G. Тогда Н называется
подгруппой группы G, если Н само является группой относительно
ограничения групповой операции на Н. В качестве пр имер а,
в множеств целых чисел (положительных,. отрицательных и нуля)
с операцией сложения множество четных чисел, так же как и
множество чисел, кратных 3, образует подгруппу.
Один из способов построения подгруппы Н конечной группы 6
состоит в том, чтобы, выбрав некоторый элемент Й из 6, форми-
ровать элементы множества Н в виде последовательных степеней
2.1. Группы
37
h„
Д2 ~Я
g3
6,=1
g2 ~1 g2
gs *ha = gs
Й2 ~2
ДЗ ~2
Ятп h1 Ят g~ h2
Первый элемент в каждой строке называется лидером смеж-
ного класса. Каждая строка таблицы называется левым смежным
этого элемента: h, h2, h', h', .... Так как группа G конечна, то
элемент последовательности обязательно начнет повторяться.
Первым должен повториться сам элемент h, а непосредственно
предшествующий ему элемент является единичным элементом
группы, так как рассматриваемая конструкция дает циклическую
группу. Множество Н называется циклической подгруппой,
порожденной элементом h. Число и элементов в подгруппе Н
удовлетворяет равенству h< = 1 и называется порядком элемента
h. Множество элементов h, h', h', ..., h< = 1 называется циклом
в группе G.
Для того чтобы доказать, что непустое подмножество Н яв-
ляется подгруппой в G, достаточно только проверить, что вместе
с элементами а и Ь из Н множеству Н принадлежит элемент
а~Ь, и что обратный к произвольному элементу а из Н также
принадлежит Н. Остальные требуемые групповые свойства на-
следуются из группы G. Если группа конечна, то, как мы увидим
позже при рассмотрении циклических подгрупп, даже свойство
обратимости выполняется автоматически.
Для заданных конечной группы 6 и подгр уппы Н имеется
важная конструкция, иллюстрирующая определенную, взаимо-
связь между G и Н и известная под названием разложения группы
6 ка смежные классы по подгруппе Н. Обозначим через h>, h„
Й~, ... элементы из Н, причем через h, обозначим единичный эле-
мент. Построим следующую таблицу: первая строка состоит из
элементов подгруппы Н, причем первым слева выписан единичный
элемент и каждый элемент из Н выписан в строке один и только
один раз. Выберем произвольный элемент группы G, не содержа-
щийся в первой строке. Назовем его g, и используем в качестве
пер вого элемента второй строки. Остальные элементы второй строки
теперь получаются умножением слева элементов подгруппы на
этот первый элемент. Аналогично, строя стретью, четвертую и
пятую строки, каждый раз выбираем не использованный на пре-
дыдущих шагах элемент группы G в качестве элементов первого
столбца. Конец наступает, когда после некоторого шага оказы-
вается, что все элементы группы записаны в некотором месте
таблицы. Процесс оканчивается в силу конечности G. Таблица
имеет следующий вид.
38 Гл. 2. Введение в абстрактную алгебру
классом, а в случае абелевой группы просто смежным классом.
Если при построении разложения группы на смежные классы
использовать вместо левого правое умножение на элементы группы
Н, то строки называются правыми смежными классами. В силу
указанных правил построения разложение группы на смежные
классы всегда является-прямоугольной таблицей, все строки кото-
рой полностью заполнены. Я,окажем теперь, что в этой таблице
каждый элемент группы встречается точно один раз.
Теорема 2.1.3. В разложении группы на смежные классы каж-
дый элемент группы встречается один и только один раз.
Яоказательство. Каждый элемент появится по крайней мере
один раз, так как в противном случае процесс не остановится.
Покажем теперь, что каждый элемент ие может появиться дважды
в одной и той же строке, а затем докажем, что один и тот же эле-
мент не может появиться в двух разных строках таблицы.
Предположим, что два элемента в одной и той же строке, ска-
жем g;+h; и g<+hq, равны. Тогда умножение') каждого из них
на gs дает равенство h] = h~. Это противоречит тому, что каждый
элемент подгруппы выписан в первой строке только один раз.
Предположим, что два элемента из различных строк, скажем
gg+hj и gp+h(, равны, и что k < f' Умножение справа íà h]
приводит к равенству gI ‒ ‒ g> *h~ *hj. Тогда g~ порождает
k-й смежный класс, так как элемент h]+h]' принадлежит под-
группе. Это противоречит выбранному выше правилу выбора ли-
деров смежных классов. Q
Следствие 2.1.4. Если Н подгруппа группы 6, mo число
элементов в Н делит число элементов в G. Таким образом,
(Порядок Н) (Число смежных классов 6 по Н) = (Порядок G).
Яоказательство. Следует непосредственно из прямоугольности
таблицы разложения на смежные классы. П]
Теорема 2.1.5. Порядок конечной группы делится на порядок
любого из ее элементов. Таким образом, а~ = 1 для любого элемента
а группы G с д элементами.
Яоказательство. Группа содержит циклическую подгруппу,
порожденную любым из ее элементов, и, таким образом, доказа-
тельство теоремы вытекает из следствия 2.1.4. ~
2.2. 1(ольца
Следующей необходимой нам алгебраической структурой яв-
ляется кольцо. Кольцо представляет собой абстрактное множество,
которое является абелевой группой и наделено дополнительной
операцией.
1) Слева. ‒ Прим. перев.
2.2. Кольца
39
Определение 2.2.1. Кольцом R называется множество с двумя
определенными на нем операциями. первая называется сложением
(обозначается плюсом); вторая называется умножением (обозна-
чается записью сомножителей рядом), причем выполняются сле-
дующие аксиомы:
l. Относительно сложения (+) R является абелевой группой.
2. (Замкнутость.) Произведение аЬ принадлежит R для любых а
иЬизЯ.
3. (Закон ассоциативности.)
а (Ьс) = (аЬ) с.
4. (Закон дистрибутивности.)
а(Ь+с) = аЬ +ас,
(Ь +с)а= Ьа+-са.
Сложение в кольце всегда коммутативно, а умножение не
обязательно должно быть коммутативным. Коммутативное коль-
цо ‒ это кольцо с коммутативным умножением. аЬ = Ьа для всех
а и b из R. Дистрибутивный закон в определении кольца связы-
вает операции сложения и умножения.
Важнейшими примерами колец являются кольцо ~ целых
чисел и кольцо ~/(д) целых чисел по модулю q. Мы уже видели, что
они являются группами по сложению. Так как на этих множест-
вах имеется также умножение с необходимыми свойствами, то
они являются кольцами.
Несколько хорошо известных читателю по знакомым кольцам
свойств могут быть выведены из аксиом следующим образом.
Теорема 2.2.2. Для произвольных элементов а и b из кольца Я
выполняются равенства
(i) аО=Оа=О.
(й) а( Ь) =( а)Ь= ‒ аЬ.
Ь) = аЬ + а ( Ь). Следовательно,
а ( Ь) = ‒ (аЬ).
Аналогично доказывается вторая половина п. (й). С3
Относительно операции сложения кольцо содержит единицу,
называемую «нулевь>. Относительно операции умножения кольцо
не обязательно имеет единицу, но если единица есть, то она един-
ственна. Кольцо, обладающее единицей относительно умножения,
называется кольцом с единицей. Эта единица называется «единицей»
Доказательство.
(() аО = а (О + О) = аО + аО. Прибавляя к обеим частям
равенства аО, получим О = a0. Аналогично доказывается вто-
рая половина п. (i).
(й) О = аО = а (Ь
40 Гл. 2. Введение в абстрактиую алгебру
и обозначается символом 1. Тогда для всех а из Я имеет местр
1а‒ = а1 = а.
Относительно операции сложения каждый элемент кольца
имеет обратный. Относительно операции умножения обратные
к~цанному элементу не обязательно существуют, но в кольце с еди-
ницей обратные могут существовать. Это означает, что для за-
данного элемента а может существовать элемент Ь, такой что
аЬ = 1. Если это так, то Ь называется правым обратнь~м к а.
Аналогично, если существует элемент с, такой, что са = 1, то с
называется левым обратным к а.
Теорема 2.2.3. В кольце с единицей:
(i) Единица единственна.
(ii) Если элемент а имеет и левый обратный Ь, и правый
обратный с, то b = с. В этом случае элемент а называется обра-
тимым, причем обратный элемент единствен (и обозначается
через а ').
(iii) (а ') ' = а.
Доказательство. Аргументация аналогична использованной
в доказательстве теоремы 2.1.2. []
Если кольцо содержит единицу, то можно произвольное число
раз сложить ее саму с собой или вычесть из себя самой, получив,
таким образом, бесконечную в о6е стороны последовательность
(1+1+1), (1+1), 1, О, 1,
1+1, 1 +1 -+1, ....
Эти элементы называются целыми кольца и иногда обозначаются
просто как О, ~1, ~2, ~3, ~4, .... Кольцо может содержать
как конечное, так и бесконечное множество целых. Число целых
в кольце с единицей называется ero характеристикой. Если ха-
рактеристика кольца равна конечному целому числу д, то це-
лые этого кольца могут быть записаны в виде множества
( 1, 1 +- 1, 1 +- 1 +- 1, . ),
или в более простом, используемом для обычных целых чисел,
обозначении
(1, 2, З, ..., q 1, O).
Это подмножество является подгр уппой аддитивной гр уппы
кольца; на самом деле это циклическая подгруппа, порождаемая
элементом 1 ° Следовательно, если характеристика кольца ко-
нечное целое число, то сложение в кольце является сложением
по модулю д. Если характеристика бесконечна, то целые кольца
складываются как целые числа. Следовательно, каждое кольцо
2.2. Кольца
с единицей содержит подмножество, которое ведет себя относи-
тельно сложения либо как ~, либо как ~/(о). В действитель-
ности оно ведет себя так же и относительно умножения, так как
если а и р конечные суммы единицы кольца, то
а.р=р+р+... +P,
где справа стоит а копий элемента р. Так как сложение целых
в R ведет себя подобно сложению в > или в >/(о), то так же ведет
себя и умножение в R.
В пределах кольца R каждый элемент и может быть возведен
в целочисленную степень,' и просто означает произведение m ко-
пий элемента а. Если кольцо содержит единицу и число целых
кольца является простым, то иногда для упрощения степенных
сумм оказывается полезной следующая теорема.
Теорема 2.2.4. Пусть р просгпае, и пусть R кольцо с р
целыми. Тогди для любого положительного целого числи m и любых
элементов а и р из R
(а ~ р)~ = а~
и, по непосРедственному обоби~ению,
(~а,) = ~(а~ )
для любого множества элементов а~ из R.
Яоказательство. Согласно биномиальному разложению,
P p
(u ~ P)> = g с~с (~P)>
1-О
Р
где . интерпретируется в R как сумма такого числа копий еди-
l
ницы кольца. Напомним, что в кольце с р целыми арифметика
целых совпадает с арифметикой по модулю р. Следовательно,
можно записать
а~ (~b)'
Р
где двойные скобки вокруг . обозначают вычисление tip Mp-
L
дулю р. Теперь заметим, что
pl p (s ‒ i) l
c l (р ‒ c) l i l (p ‒ i) l
представляет собой целое число и Р простое. Следовательно, 3на-
Р
менатель делит (р 1)! в области целых чисел, и . кратно р.
Ф
42 Гл. 2. Введенне в абстрактную алгебру
р
Таким образом, . = О (mod р) для всех 1 = 1, 2, ..., р 1.
4
Итак, (а + р)р = ар + (~0)~. Наконец, либо р = 2 и
так что (~P)' = ~P', либо р нечетно и (~P)> = ~P>. Таким
образом,
(а~ р)р=ар~рР
и для т = 1 теорема доказана.
Возведем теперь последнее равенство в р-ю степень,
((а ~ р)р)р = (а~ ~- 0~)~,
и опять воспользуемся утверждением теоремы при т = 1:
(а ~ р)р =а~ ~- V.
Иовторяя это m
1 раз, получаем
(а ~ ~)~ =ар
что завершает доказательство теоремы. Q
Если в кольце с единицей элемент имеет обратный, то он назы-
вается обратимым '). Множество всех обратимых элементов кольца
замкнуто относительно умножения, так как, если а и b обратимы,
то с = ab имеет обратный элемент, равный с ' = b 'а '.
Теорема 2.2.5.
(i) Относительно умножения в кольце множество обратимых
элементов кольца образует группу.
(ii) Если с = ао и с обратимыйэлемент кольца, то а имеет
правый обратный, а b левый обратный.
(ш) Если с = ао и а не имеет правого обратного или b не имеет
левого обратного, mo с не является ооратимым элементом.
Яоказательство. Упражнение.
Многие примеры колец известны. Например:
1. Множество всех вещественных чисел относительно обычных
сложения и умножения образует коммутативное кольцо с едини-
цей. Каждый ненулевой элемент кольца является обратимым.
2. Множество Z всех целых чисел (положительные, отрица-
тельные и нуль) относительно обычных сложения и умножения
образует коммутативное кольцо с единицей. Единственными обра-
тимыми элементами кольца служат ~1.
3. Множество всех (nx n)-матриц с вещественными элементами
1) Используемые для единицы и обратимых элементов кольца английские
термины «ипру» и «нпИ» переводятся на русский язык одним словом «единица»,
так что часто в литературе обратимые элементы называются единицами кольца;
мы предпочитаем зафиксировать термнн «единица» в определенном выше смысле.‒
Прим. перев.
43
2.3. Поля
относительно матричного сложения и матричного умножения об-
разует некоммутативное кольцо с единицей. Единицей служит
единичная (nXn)-матрица. Обратимыми элементами кольца яв-
ляются все невырожденные матрицы.
4. Множество всех (nXn)-матриц, элементами которых явля-
ются целые числа, относительно матричного сложения и матрич-
ного умножения образует некоммутативное кольцо с единицей.
5. Множество всех многочленов от х с вещественными коэффи-
циентами относительно сложения и умножения многочленов обра-
зует коммутативное кольцо с единицей. Единицей кольца является
многочлен нулевой степени р (x) = 1.
2.3. Поля
4 (i) = «а+ib«
Грубо говоря, абелевой группой является множество, в кото-
ром можно «складывать» и «вычитать», а кольцо множество,
в котором можно «складывать», «вычитать» и «умножать». Более
сильной математической структурой, называемой полем, является
множество, в котором можно «складывать», «вычитать», «умно-
жать» и «делить».
Определение 2.3.1. Полем называется множество с двумя опе-
рациями сложением и умножением, которые удовлетворяют
следующим аксиомам:
1. Множество образует абелеву группу по сложению.
2. Иоле замкнуто относительно умножения и множество не-
нулевых элементов образует абелеву группу по умножению.
3. Дистрибутивный закон
(а + Ь} с = ас+ bc
выполняется для любых а, b и с из поля.
Единичный элемент относительно сложения принято называть
нулем и обозначать через О, аддитивный обратный к элементу а
обозначать а, единичный элемент относительно умножения на-
зывать единицей и обозначать 1, мультипликативный обратный
к элементу и обозначать а '. Под вычитанием (а b) понимается
а ~- ( b); под делением (а/b) понимается b 'а.
Следующие примеры полей широко известны:
1. p: множество вещественных чисел.
2. Q: множество комплексных чисел.
3. Q: множество рациональных чисел.
Все эти поля содержат бесконечное число элементов. Имеется
много других не столь широко известных полей с бесконечным
числом элементов. Одно из таких полей описывается очень просто
и известно как поле ()(/) комплексных рациональных чисел. Оно
дается определением
44 Гл. 2. Введенне в абстрактную алгебру
где а и b рациональные числа, а сложение и умножение опре-
деляются так же, как для комплексных чисел. При таком опреде-
лении множество Q (j) удовлетворяет определению 2.3.1 и, сле-
довательно, является полем.
Имеются также поля с конечным числом элементов, и MbI 6y-
дем ими также пользоваться. Поле с д элементами, если оно су-
ществует, называется конечным полем или полек Галуа и обозна-
чается GF (д).
Что представляет собой наименьшее поле? Оно обязано со-
держать нулевой элемент и единичный элемент. На самом деле
этого уже достаточно для задания поля, если сложение и умно.
жение определить таблицами
Это поле известно как GF (2). Никаких других полей с двумя эле-
ментами не существует (за исключением, конечно, изоморфных
копий поля GF (2)).
В;онечные поля можно описывать с помощью таблиц сложения
и умножения. Вычитание и деление однозначно определяются таб-
лицами сложения и умножения. Позже изучим конечные поля
детально. Сейчас мы приведем еще три примера.
Поле GF (3) = {О, !, 2) с операциями
Поле GF (4) = )0, 1, 2, 3) с операциями
Заметьте, что в GF (4) умножение не есть умножение по мо-
дулю 4, а сложение не есть сложение по модулю 4.
Поле GF (5) = «О, 1, 2, 3, 4) с операциями
45
2.3. Поля
существует, если в поле F имеется элемент а порядка n' и эле-
мент р, порядка и". Если таких элементов в поле нет, то указанное
преобразование не существует.
Например, в поле GF (5) порядок элемента 2 равен 4. Следо-
вательно, в поле GF (5) существует 4-точечное преобразование
фурье
э
Г» ‒ ‒ g 2'»о„
б=0
и двумерное (4X4)-преобразование Фурье
Д 3
g 2'""2'"""vr
А = О, 1, 2, 3,
б'=0 б"=0
Компоненты векторов v u V принадлежат полю GF (5), и вся
арифметика является арифметикой поля GF (5). Если
Это примеры очень малых полей. Мы найдем применения и для
значительно больших полей, таких как GF (2" + !).
Для произвольного поля, как бесконечного, так и конечного,
применимы почти все известные алгоритмы вычислений. Это проис-
ходит потому, что большинство процедур, используемых в полях
вещественных и комплексных чисел, зависит только от даваемой
определением 2.3.1 формальной структуры поля и не зависит
от частных характеристик конкретного поля. В произвольном
поле F имеется даже преобразование Фурье:
n ‒ 1
V» — — f и»v;, lг=О,..., и 1,
б=0
где а корень степени и из единицы в поле F, à v и Ъ' векторы
длины и над полем F. Преобразование Фурье длины и в поле F
существует тогда и только тогда, когда поле содержит корень
степени и из единицы. Если преобразование Фурье существует,
то оно ведет себя ожидаемым образом. В частности, должно су-
ществовать и обратное преобразование Фурье, и должна выпол-
няться теорема о свертке, так как если просмотреть доказатель-
ства этих свойств, то можно увидеть, что о поле F не делается
никаких предположений, за исключением того, что оно является
даваемой определением 2.3.1 формальной структурой.
Аналогично, двумерное преобразование Фурье в поле F
‒ 1 n" ‒ 1 А'=О,..., и' ‒ 1
g ° p i giipii
ф ° ° ° ф ф
V».»-= Е Е < Р ог r
46 Гл. 2. Введенне в астрактную алгебру
то одномерное преобразование Фурье вектора v равно
4
3
2
1
1 1 1 1
! 2 4 3
1 4 1 4
1 3 4 2
vo
и,
v,
~з
Определение 2.3.2. Иусть F поле. Подмножество в F на-
зывается подполам, если оно является полем относительно насле-
дуемых операций сложения и умножения; исходное поле F в этом
случае называется расширением подполя.
Иоле рациональных чисел является подполем поля веществен-
ных чисел, которое в свою очередь является подполем поля ком-
плексных чисел. Поле комплексных рациональных чисел не яв-
ляется подполем поля вещественных чисел, но является подполем
поля комплексных чисел. Легко видеть, что конечное поле GF (2}
является подполем поля GF (4}, так как элементы 0 и 1 склады-
ваются и умножаются в поле GF (4} так же, как в поле GF (2).
Однако GF (2} не является подполем ни поля GF (3}, ни поля
GF (5).
Чтобы доказать, что некоторое подмножество поля является
подполем, необходимо доказать только то, что оно содержит не-
нулевой элемент и замкнуто относительно сложения и умножения °
Все остальные необходимые свойства наследуются из поля
Обращение по сложению или умножение на элемент Р входят
в порождаемую элементом р циклическую группу соответственно
относительно операций сложения или умножения.
Каждое поле содержит в качестве подмножества множество
свои х целых
(1 }1< 1), (1»1), l, 0, 1, 1+-1,
1+1+1, ."}.
Целые поля обычно записываются просто как О, ~1, ~2, ~3, ...
Иоле может содержать только конечное число целых, и в этом
случае такое число называется характеристикой поля. (Оно
всегда простое.) Все элементы полей GF (3) и GF (5) являются
целыми, так что характеристики полей равны соответственно 3 и 5.
Так как в поле GF (4) целыми являются только 0 и 1, то характе-
ристика этого поля равна 2. Характеристика и поля веществен-
ных чисел, и поля комплексных чисел равна оо. Каждое поле
характеристики оо содержит поле рациональных чисел (или его
изоморфную копию).
Если поле имеет конечную характеристику р, То целые этого
поля образуют циклическую группу по сложению; следовательно,
сложение целых поля представляет собой сложение по модулю р,
где р число целых поля. Сумму и копий единицы поля будем
2.4. Векторные пространства
47
записывать в виде ((п)), где двойные скобки обозначают вычисле-
ние по модулю р.
Конечное поле задает группу двумя путями. все элементы поля
образуют группу относительно сложения и все ненулевые эле-
менты поля образуют группу относительно умножения. На самом
деле по умножению ненулевые элементы поля образуют цикличе-
скую группу. Я,оказать это утверждение трудно, и мы отложим
доказательство до гл. 5, но пользоваться цикличностью этой
структуры будем раньше. Так как по умножению множество
ненулевых элементов группы образует циклическую группу, то
оно порождается одним элементом.
Определение 2.3.2. Иримитивным элементом поля Галуа
GF (д) называется элемент порядка (д 1) относительно умно-
жения. Он порождает мультипликативную группу поля.
Например, в поле GF (5) степени элемента 3 равны: 3' = 3,
32 = 4, 3З = 2, 34 = 1. Следовательно, 3 примитивный эле-
мент поля GF (5).
2.4. Векторные пространства
Для заданного поля F п-последовательность (и„о„..., U„,)
элементов поля называется вектором длины и над полем F. Мно-
жество всех таких векторов длины и вместе с двумя заданными
на нем операциями сложением векторов и умножением ни ска-
ляр называется векторным иростринством над полем F. При
рассмотрении векторных пространств элементы поля F, над Ко-
торыми строются векторы, называются скалярами. Умножение
на скаляр это операция, связывающая вектор v с элементом
поля с по правилу
с (p'oi p'li ° ° ° ° оп-1) = (цэ pp'li ° ° снап 1).
Векторное сложение является операцией сложения двух векторов,
v = v' + v", выполняемого по следующему правилу:
t 1 / IT If Ф
(ppэ <i~ ° ° ° е pn ‒ i)+ (ооэ Uiý ° э пл-!) =
= (Up + Up Ui + Ui ° ° ° ол ‒ ! + ол ‒ 1).
Векторное пространство и-последовательностей представляет
собой один пример векторных пространств. Векторное простран-
ство над полем F можно определить абстрактно как множество
V элементов (именуемых векторами) с двумя заданными на нем
операциями. Первая операция определена на парах элементов
из V, называется сложением векторов и обозначается плюсом.
Вторая операция определена на элементе из V и элементе из F,
дает в результате элемент из V и называется умножением яа ска-
ляр; для обозначения такой операции эти элементы записываются
48 Гл. 2. Введение в абстрактную алгебру
рядом.,0,ля того чтобы V было векторным пространством, эти
операции должны удовлетворять следующим аксиомам.
1. V представляет собой абелеву группу относительно опера-
ции сложения векторов,
2. (Дистрибутивный закон.) Для любых векторов ч„ч, и лю-
бого скаляра с
c(v,+v,} =cv,+cv,.
3. (Дистрибутивный закон.) Для любого вектора v и любых
скаляров с, и с выполняется 1.v = v u
(с, + с,) ч = c v+ c v.
4. (Ассоциативный закон.) Яля любого вектора ч и любых
скаляров с, и с,
(с,с,) v = с, (с,ч).
Нулевой элемент из V называется началом координап и обозна-
чается через О. Отметим, что мы использовали символ + двумя
различными способами. для векторного сложения и для сложе-
ния в поле. Отметим также, что мы использовали символ О для
обозначения нулевого элемента поля и символ О для обозначения
начала координат векторного пространства. Это неопределенность
практически не приводит к недоразумениям.
Подмножество векторного пространства называется векторным
подпространством, если оно само является векторным простран-
ством относительно исходных операций сложения векторов и
умножения вектора на скаляр. Относительно сложения векторов
векторное пространство является группой, а векторное продпро-
странство подгруппой. Для того чтобы проверить, является ли
непустое подмножество векторного пространства подпростран-
ством, необходимо проверить только замкнутость подмножества
относительно сложения векторов и умножения векторов на ска-
ляр. Замкнутость относительно умножения на скаляр гаранти-
рует принадлежность подмножеству нулевого вектора. Все осталь-
ные требуемые свойства наследуются из исходного пространства.
Векторное пространство и-последовательностей над F обозна-
чается через F". В этом пространстве сложение векторов и умно-
жение вектора на скаляр определены покомпонентно. В F" имеется
еще одна операция, называемая покомпонентным произведением
двух векторов. Если и = (а„а„..., а„,) и ч = (Ь„Ь1, ...,
b„,}, то покомпонентное произведение определяется равенством
ич = (а,Ь„а,b>, ..., а„,Ь„,). Оно представляет собой вектор,
компоненты которого получаются в результате перемножения
компонент векторов а и ч.
Скалярным произведением двух п-последовательностей из F„
называется скаляр, определяемый равенством
и.v = (а„..., и„— ) (Ь„..., bn 1) =а,Ь,+... +а„,Ь„,.
2.4. Ве~торнме пространства
49
Немедленно проверяется, что и.v = v.и, (си).v = с (и.v) н что
также w. (и + ч) = (w. и) + (и ч). Если скалярное произведение
двух векторов равно нулю, то векторы называются ортогональ-
ными. Над некоторыми полями возможна ортогональность нену-
левых векторов самим себе, но это невозможно над полем веще-
ственных чисел. Вектор, ортогональный к каждому вектору из
данного множества, называется ортогональным к этому множеству.
Теорема 2.4.1. Пусть V векторное простринство и-после-
Яножестао векторов, ортогональных к Я7, само образует под-
пространство.
Яоказительство. Пусть U обозначает множество всех векторов,
ортогональных к ~. U не пусто, так как О принадлежит U.
Пусть w произвольный вектор из Я7, а ц, и ц, некоторые
векторы из U. Тогда ф.u~ = w u2 ‒ ‒ О и
и ид + w ll~ = О = w (и~+ и~)~
так что и, + и, также вектор нз U. Далее, и (си,) = с (w и1) = О,
так что СО1 также вектор из U. Следовательно, U является под-
пространством.
Множество всех векторов, ортогональных к подпространству W',
называется ортогональным дополнением поди ространства W u
обозначается через ~~~. В векторном пространстве ~" всех п-по-
следовательностей над полем вещественных чисел пересечение
подпространств _#_ и 5'> содержит только нулевой вектор; но
в векторном пространстве над GF (q) подпространство Г~ может
иметь нетривиальное пересечение с W или может даже лежать
в W, содержать W и совпадать с ЯГ. Например, подпространство
нз двух векторов (00) н (11) пространства 6Е' (2) является своим
ортогональным дополнением.
В векторном пространстве V сумма вида
и = а,ч, + а,ч, + ... + a„v„,
где а; скаляры, называется линейной комбинацией векторов v„
~~, ..., ч~. Говорят, что множество векторов порождает линейное
пространство, если каждый вектор этого пространства представим
в виде некой линейной комбинации векторов из этого множества.
Тогда говорят также, что такое линейное пространство натянуто
на это множество векторов. Линейное пространство, которое на-
тянуто на конечное множество векторов, называется конечномер-
ным векторным простронством. Число векторов в наименьшем
множестве, порождающем некое пространство, называется раз-
мерносщью этого пространства. Пространство и-последовательно-
стей над, Р дает пример конечномерного векторного пространства
размерности и.
50 Гл. 2. Введение в абстрактную алгебру
Множество векторов [v„v„..., v>} называется линейно за-
висилым, если существует множество скаляров [а„..., aÄ}, не
все из которых равны, таких что
aA + а,ч, + ... + адчд ‒‒ О.
Множество векторов, не являющееся линейно зависимым, назы-
вается линейно независимым. Ни один вектор из линейно незави-
симого множества не может быть представлен как линейная ком-
бинация остальных. Заметим, что нулевой вектор О не может
принадлежать линейно независимому множеству; каждое мно-
жество, содержащее О, является линейно зависимым. Множество
из Й линейно независимых векторов, порождающих линейное
пространство, называется базисом этого пространства.
2.5. Матричная алгебра
~дд ~12 ° ~1т
~21 ~22 ° ° ° ~2ш
= [а~;].
А=
~4~1 ~у~2 ° ° ° <~m
Если и = m, то матрица А называется квадратной. Две
(nxm)-матрицы А и В над полем F можно складывать по правилу
п11 + b>z п1~ + (~1.. a»+ b»
° ° °
а,„,+b„, а„,+b„, ... а„+ b„
А+В=
Всякую (nxm)-матрицу А можно умножить на элемент р поля
по правилу
рой Pais Ьв
° ° °
Pa„, Pa„, ... Pa„
Всякую (Ixn)-матрицу А можно умножить íà (nxm)-матрицу В,
получив в результате (Ixm)-матрицу С по правилу
i=1, '., 1,
с„= ~', а,„b„~,
1=1 ) 1э ° ° ° э
Методы матричной алгебры обычно изучаются только для полей
вещественных и комплексных чисел,.хотя большинство операций
справедливо в произвольном поле (а иногда даже в произвольном
кольце).
Определение 2.5.1. (ax т)-матриией A над полем F назы-
вается прямоугольная таблица, состоящая из и строк и m столб-
цов и содержащая nm элементов из поля F:
2.5. Матричная алгебра
51
Множество элементов а;, для которых номер строки совпадает
с номером столбца, называется главной диагональю. (пхп)-ма-
трица, все элементы главной диагонали которой равны единице,
а остальные элементы равны нулю, называется единичной матри-
цей размера и и обозначается через 1. Матрица, все элементы
побочной диагонали (элементы, для индексов которых j = n +
+ 1 i) которой равны единице, а остальные элементы равны
нулю, называется обменной мшприцей и обозначается через J.
Отметим, что У = 1. Примерами единичной и обменной матриц
являются следующим (3X 3)-матрицы:
1= О 2 О, Я=
dqt (А) = g Я;, ~ аи,ар~ ...а„~,
где i„~2, ..., ~„перестановка на множестве целых чисел
(1, 2, ..., и}(; gg f равно +1, если перестановка содержит
четное число транспозиций, и 1 в противном случае, а сумми-
Относительно введенного определения произведения и суммы
матриц, как легко проверить, множество квадратных (nXn)-ма-
триц образует кольцо. Это кольцо некоммутативно, но обладает
единицей, а именно единичной (nXn)-матрицей.
Транспонированной к (nxm)-матрице А называется (mxn)-ма-
трица А, такая что ац ‒ ‒ а~~. Таким образом, строками ма-
т т»
трицы Ат служат столбцы матрицы А, а столбцами матрицы Ат
служат строки матрицы A. Легко проверить, что если С = AB,
то Ст = ~тАт
Обратной к квадратной матрице А, если таковая существует,
называется квадратная матрица А ', такая что А 'А = АА ' =
= 1. Как нетрудно проверить, множество всех обратимых ква-
дратных (пхп)-матриц относительно операции умножения обра-
зует группу. Следовательно, если матрица имеет обратную, то
обратная единственна, так как в силу теоремы 2.1.2 это свойство
выполняется в каждой гр уппе. Матрица, имеющая обр атную,
называется невырозсденной; в противном случае матрица назы-
вается вырожденной. Пусть С = АВ. Как следует из п. (ш) тео-
ремы 2.2.5, если хотя бы у одной из матриц А или В нет обрат-
ной, To H у матрицы С нет обратной. Если матрицы А и В обра-
тимы, то С'=В А', так как (В'А')С=1=С(В'A').
Определение 2.5.2. Пусть поле F задано.,Яля каждого и опре-
делитель квадратной (nX и)-матрицы А равен величине det (А),
являющейся функцией из множества всех (nX и)-матриц над F
в поле F. Функция det (А) задается формулой
52 Гл. 2. Введение в абстрактную алгебру
рование ведется по всем перестановкам. Транспозицией назы-
вается перестановка двух членов.
Если матрица А' получается из матрицы А перестановкой двух
строк, то каждую перестановку строк матрицы А', получаемую
в результате четного (нечетного) числа транспозиций, можно рас-
сматривать как соответствующую перестановку строк матрицы A.
Отсюда следует, что при перестановке любых двух строк матрицы
знак определителя меняется на противоположный. Аналогичные
рассуждения показывают, что если две строки матрицы равны,
то определитель равен нулю.
Следующая теорема, приводимая без доказательства, содержит
вытекающие непосредственно из определения 2.5.2 свойства опре-
делителя.
Теорема 2.5.3. (i) Если все элементы некоторой строки ква-
дратной матрицы равны нулю, mo определитель arnou матрицы
равен нулю.
(11) Определитель матрицы равен определителю транспониро-
ванной матрицы.
(iii) Если две строки квадратной матрицы поменять местами,
mo определитель поменяет знак.
(iv) Если две строки равны, то определитель равен нулю.
(v) Если все элементы одной строки матрицы умножить на
элемент поля с, mo определитель новой матрицы будет равен
определителю исходной матрицы, умноженному на с.
(vi) Если матрицы А и В отличаются только ~-й строкой,
mo сумма их определителей равна определителю матрицы С,
i-я строка которой равна сумме ~-х строк матриц А и 3, а осталь-
ные строки равны соответствующим строкам матрицы А или B.
(vii) Если к элементам некоторой строки матрицы k раз при-
бавить соответствующие элементы некоторой другой ее строки,
mo определитель матрицы не изменится.
(viii) Определитель матрицы отличен от нуля тогда и только
тогда, когда ее строки (столбцы) линейно независимы.
f Если в квадратной матрице удалить строку и столбец, содер-
жащие элемент а~~, то определитель оставшейся квадратной таб-
лицы размера и 1 называется минором элемента а~~ и обозна-
чается через М,~. Алгебраическое дополнение, обозначаемое здесь
через С,.;, определяется равенством
C,, = ( ‒ «~+Щц.
Из способа задания определителя матрицы следует, что ал-
гебраическое дополнение элемента а~> является коэффициентом
при а,~ в разложении определителя:
Л
4е1(А) = g а,~С~~.
А-1
53
2.5. Матричная алгебра
Это известная формула Лапласа для разложения определителей.
Формула разложения Лапласа лежит в основе рекуррентного спо-
соба вычисления определителей. Она дает выражение определи-
теля (п X п)-матрицы через определители ((и 1) х (п 1))-матриц.
Л
Если а;„заменить на а;~, то получится сумма f а~~С,„,
а=1
равная определителю новой матрицы, полученной из старой за-
меной элементов i-й строки элементами j-й строки,' этот определи-
тель равен нулю, если j + ~. Таким образом,
~Ф),
i =ф'= j.
Поэтому если det (А) + О, то матрица А имеет обратную, равную
Если det (А) = О, то обратной матрицы не существует.
Матрицу можно разбить на блоки по правилу:
Дд }А
А=
1
Агд } Ага
где А„, А„, А„и А„меньшие матрицы, размеры которых
очевидным образом дополняют друг друга до размеров исходной
матрицы А. A именно, число строк матрицы А» (или A») плюс
число строк матрицы А» (или A») равно числу строк матрицы А;
аналогичное утверждение выполняется для числа столбцов. Ма-
трицы можно перемножать поблочно. А именно, если
1 !
Ац} Ац в, s»
А =
Э
В = ‒ +-
Apt ~ Aqi В21 . Ва
и С=АЗ, то
1
At®tt + A~q+t ~ А11Ви + АгВи
А21Ви + АдВР1 ~ АпВа + А 2Вгг
п~и условии, что все размеры блоков выбраны корректно в том
смысле, что все матричные произведения и суммы определены.
Такое разложение может быть выведено как простое следствие
аксиом ассоциативности и дистрибутивности основного поля.
Определение 2.5.4. Пусть А = [ад3 и В = [b~<3 матрицы
соответственно размеров Ix К и Jx L. Тогда кронекеровским про-
54 Гл. 2. Введение в астрактную алгебру
изведением матриц А и В, обозначаемым Ах В, называется ма-
трица, содержащая IJ строк и E(L столбцов, у которой на пере-
сечении строки с номером (1 () J + j и столбца с номером
(k <) L + 1 стоит элемент
с~~, qt ‒‒ а;~Ь~,.
Кронекеровское произведение представляет собой (1 x Ê)-таб-
лицу, состоящую из (J x L)-блоков, (i, k)-й из которых равен а,.„В.
Непосредственно из определения вытекает, i To кронекеровское
произведение матриц некоммутативно, но ассоциативно:
А х B + B х А, (А х B) х С = А (B х С).
Элементы матрицы АХ В те же, что и у матрицы В ХА, но упоря-
дочены по-другому. Очевидно также, что кронекеровское произ-
ведение дистрибутивно относительно обычного сложения матриц.
Наиболее известным примером кронекеровского произведения
является внешнее произведение двух векторов. Предположим,
<То А и В обе представляют собой векторы-столбцы, скажем,
а = (а„..., а )г и b = (b„..., b~)> соответственно. Тогда К. =
= L = 1, и аХ bг является (1X 1)-матрицей, на пересечении
i-й строки и j-го столбца которой стоит элемент а,Ь;. Оно обозна-
чается просто через ab~, так как в этом случае кронекеровское
произведение совпадает с обычным произведением матриц.
Следующая полезная теорема утверждает, что кронекеровское
произведение произведений матриц равно матричному произве-
дению кронекеровских произведений соответствующих матриц.
Теорема 2.5.5. Если все матричные произведения определены,
mo кронекеровское произведение удовлетворяет равенству
(А х B) (С х D) = (АС) х (В0).
Доказательство. Пусть матрицы А, В, С и D имеют соответ-
ственно размеры 1ХК, JxL, КХМ и LXN. Так как матрица
Ах В содержит KL столбцов, а матрица С x D содержит I(L строк,
то матричное произведение (Ax B) (Cx D) определено. Оно со-
держьт 1Ю строк, которые мы занумеруем парами (i, /), и M Ж столб-
цов, которые мы занумеруем парами (т, n). Элемент, стоящий
на пересечении строки (1, /) и столбца (т, n), равен f a~~b;,cq d~„.
и
Так как матрица АС содержит I строк и М столбцов, а матрица BD
содержит 1 строк и L столбцов, то матрица (AC)X(BD) также
является (11 X l(L)-матрицей. Стоящий на пересечении строки (1, j)
и столбца (и, n) элемент этой матрицы равен
f апд,~ Z bgldln = Z ап,б~,с„„Д„,
k l а.с
что и завершает доказательство. Р
2.5. Матричная алгебра
(пХп)-матрица, в которой а~~ = а~.i, если 1 f = в' j',
называется теплицевой (п Х n)-матрицей. Теплицева матрица
имеет вид
а 1 а2 ~4-1
ао а1
а1 ао
а
а ‒ 2
а (n ц
вдоль любой ее диагонали стоит один и тот же элемент.
Элементарными операциями над строками матрицы назы-
ваются следующие действия:
1) перестановка двух произвольных строк;
2) умножение произвольной строки на ненулевой элемент поля;
3) замена произвольной строки на сумму ее самой и некото-
рого кратного любой другой строки.
Каждая элементарная операция над строками (п X т)-ма-
трицы А может быть выполнена путем левого умножения А на
соответствующим образом подобранную так называемую элемен-
тарную (nXn)-матрицу Е. Элементарные матрицы определяются
как следующие модификации единичной матрицы:
иЛи
Каждая элементарная операция над строками обратима, и
обратная операция имеет такой же вид.
Элементарные операции над строками используются для при-
ведения матрицы к стандартному виду, называемому канониче-
ским ступенчатым видом и определяемому следующим образом:
1) ведущий ненулевой элемент каждой ненулевой строки ра-
вен единице;
2) все остальные элементы каждого столбца, содержащего
такой ведущий элемент, равны нулю;
3) ведущий элемент любой строки находится правее любого
ведущего элемента любой расположенной выше строки. Нулевые
строки расположены ниже всех ненулевых строк.
56 Гд. 2. Введение в астрактную алгебру
Примером матрицы, приведенной к каноническому ступенча-
тому виду, является
110130
001100
000001
000000
Заметим, что нулевая строка расположена снизу и что если уда-
лить последнюю строку, то все столбцы единичной (3x 3)-матрицы
появятся среди столбцов матрицы, но в разбросанном виде. В об-
щем случае если имеется Й ненулевых строк и по меньшей мере
такое же количество столбцов, то матрица в каноническом сту-
пенчатом виде будет содержать все столбцы единичной (kxk)-ма-
трицы, но в разбросанном виде.
Строки (num)-матрицы А над полем F являются подмноже-
ством векторов пространства F~, т. е. векторами с т компонен-
тами. Пространством строк матрицы А называется множество
всех линейных комбинаций строк матрицы А. Пространство строк
образует подпространство в F . Размерность пространства строк
называется рангом матрицы по строкам. Аналогично, столбцы
матрицы А можно рассматривать как множество векторов в про-
странстве F" векторов с и компонентами. Пространстао столбцов
матрицы А определяется как множество всех линейных комбина-
ций столбцов матрицы А, и размерность этого пространства на-
зывается рангом матрицы по столбцам. Множество векторов v,
таки х что Av~ = О, называется нулевым пространством ма-
трицы А. Нулевое пространство, очевидно, является векторным
поппространством пространства F . В частности, нулевое про-
странство матрицы А является ортогональным дополнением про-
странства строк матрицы А, так как нулевое пространство может
быть описано как множество всех векторов, ортогональных
ко всем векторам пространства строк матрицы.
Теорема 2.5.6. Если две матрицы А и А' переводятся друг
в друга некоторой последовательностью элементарных операций
над строками, то они имеют одно и то же пространство
строк.
Яоказшлельство. Каждая строка матрицы A' является линей-
ной комбинацией строк матрицы А; следовательно, любая линей-
ная комбинация строк матрицы А' также является линейной
комбинацией строк матрицы А, и тем самым пространство строк
матрицы А содержит пространство строк матрицы А'. Но А может
быть получена из А' с помощью обратных операций, и, следова-
тельно, пространство строк матрицы А' содержит пространство
строк матрицы А. Следовательно, пространства строк матриц А
и А' равны. р
2.6. Матричная алгебра
Теорема 2.5.7. Если матрицы А и А' связаны последователь-
ностью элеменгпарных операций над строками, то любое мно-
жество линейно независимых столбцов матрицы А является также
линейно независимым в А'.
Яоказательство. Теорема очевидна для первой и второй эле.
ментарных операций, так что достаточно провести доказательство
для единственной третьей операции. Итак, пусть А' получается
из А прибавлением строки а, умноженной на элемент поля
к строке р. Если в А' имеется некоторая линейная зависимость
столбцов, то она приводит к нулевой линейной комбинации соот-
ветствующих элементов строки а, которая поэтому никак не ска-
зывается на строке р. Следовательно, это множество столбцов
в А также линейно зависимо. Q
Теорема 2.5.8. Если Й строк (Axn)-матрицы А линейно не-
зависимы, то эта матрица содержит А линейно независимых
столбцов.
Яоказательство. Приведем матрицу А к каноническому сту-
пенчатому виду А'. Так как строки линейно независимы, то ни
одна строка не будет нулевой. Следовательно, для каждой строки
иайдется столбец, который в пересечении с этой строкой содержит
единицу, а во всех остальных позициях ‒ нуль. Это множество
из А столбцов матрицы А' линейно независимо, и, следовательно,
по теореме 2.5.7 в матрице А это же множество столбцов также
лииейно независимо. Р
Теорема 2.5.9. Ранг матрицы по строкам равен ее рангу по
столбцам и оба равны размерам любой наибольшей квадратной
подматрицы, определитель которой отличен от нуля. (Эта вели-
чина называется просто ранеом матрицы.)
Докааательство. Необходимо только доказать, что ранг ма-
трицы А по строкам равен размеру наибольшей квадратной под-
матрицы с отличным от нуля определителем. То же самое дока-
зательство, примененное к транспонированной матрнце, тогда
дает этот же результат для ранга матрицы по столбцам, и, таким
образом, служит доказательством равенства ранга по строкам
рангу по столбцам.
Подматрицей матрицы А называется матрица, получающаяся
из А удалением произвольного числа строк и столбцов. Пусть М
яевырожденная квадратная подматрица матрицы А наибольшего
размера. Так как М невырожденна, то, согласно п. (viii) тео-
ремы 2.5.3, ее строки линейно независимы, и, следовательно,
эти же строки матриць~ А должны быть линейно независимы.
Таким образом, ранг матрицы А по строкам по меньшей мере
столь же велик, сколь размер подматрицы М.
58 Гл. 2. Введение в абстрактную алгебру
С другой стороны, выберем произвольное множество из k ли-
нейно независимых строк. Согласно теореме 2.5.7, образованная
этими строками матрица содержит k линейно независимых столб-
цов. Выбирая эти k столбцов на рассматриваемых k строках,
получаем подматрицу с ненулевым определителем. Следовательно,
размер наибольшей квадратной невырожденной подматрицы по
меньшей мере столь же велик, сколь ранг матрицы А по строкам.
Это завершает доказательство.
2.6. Кольцо целых чисел
Целые числа (положительные, отрицательные и нуль) образуют
обманчиво простое математическое множество. Ничего, кажется,
не может быть более регулярного и равномерного, чем целые
числа, но присмотревшись пристальнее, можно увидеть сложные
внутренние связи и модели этого множества. Разумный конструк-
тор использует эти свойства множества целых чисел при построе-
нии эффективных алгоритмов цифровой обработки сигналов.
Относительно обычных операций сложения и умножения целые
числа образуют кольцо, которое принято обозначать ~. В кольце
целых чисел вычитание возможно всегда, а деление не всегда.
Ограниченность деления является одной из причин, делающих
кольцо целых чисел столь интересной и богатой структурой.
Говорят, что целое число sдели,тся на целое число r, или
что r делит s, или что r является делителем s, если s = ra для
некоторого целого числа а. Этот факт записывается символом
r (s, который читается «r делит s». Если r и делит s, и делится
на s, то r = ~в. Действительно, r = sa u s = гЬ для некоторых
целых чисел а и b. Следовательно, r = rab u ab должно равняться 1.
Так как а и b оба целые, то они равны 1 или 1.
Положительное целое число р ~ 1, которое делится только
на ~р или +-!, называется простым. Наименьшими простыми
числами являются 2, 3, 5. 7, 11, 13, ...; число 1 не является про-
стым. Не являющееся простым положительное целое число назы-
вается составным. Наибольший общий делитель двух целых чи-
сел r u s обозначается HOgl [r, s] и определяется как наибольшее
положительное число, которое делит" оба из них. Наименьшее
обиднее кратное двух положительных чисел r u s обозначается
НОК (r, s J и определяется как наименьшее положительное число,
которое делится на оба из них. Два числа называются взаимно
простыми, если их наибольший общий делитель равен 1.
В кольце целых чисел всегда, возможно сокр ащение; если
са = cb и с отлично от нуля, то а = Ь. В кольце целых чисел
имеется также слабая форма деления, известная под названием
деления с остатком или алгоритма деления.
2.6. Кольцо целых чисел
59
Теорема 2.6.! (Алгоритм деления). Для каждого целого числа с
и положительного целого числа d найдется единственная пара
целых чисел Q (частное) и s (остаток), таких что с = dQ + s,
где 0~<s <d.
Частное иногда обозначается
=~:]
Обычно нас будет больше интересовать остаток, чем частное.
Если s и с при делении íà d имеют один и тот же остаток, то это
записывается в виде
s = с (mod d).
Выражение этою вида называется сравнением и читается так:
s сравнимо с с по модулю d. В сравнении ни s, ни с не должны быть
обязательно меньше d. Мы больше интересуемся остатком. Оста-
ток записывается в виде равенства
s= R~ [с),
которое читается так: s равно остатку от деления с Hà d, или s равно
вычету с по модулю d. Мы будем также пользоваться скобками
((с)) для обозначения этих же величин; в этом случае d ясно из кон-
текста. Еще одним обозначением является
s= с (modd),
в котором вместо знака сравнения стоит знак равенства. Теперь
это не сравнение, а остаток от деления с на d.
Вычисление остатка от сложного выражения облегчается сле-
дующей теоремой, которая утверждает, что можно менять после-
довательность выполнения операции вычисления остатка со сло-
жением и умножением.
Теорема 2.6.2. Для фиксированного модуля d
(1) Ra [а + Ь] = Ra [Яг [а] + Ra [Ь]],
(11) Ra [а. Ь] = Ra [Ra [а] Ra [Ь]].
Доказательство предоставляется читателю в качестве упраж-
нения.
Наибольший общий делитель двух заданных положительных
чисел s u t может быть вычислен с помощью итеративного приме-
нения алгоритма деления. Эта процедура известна как алгоритм
Евклида. Предположим, что 3 < s; алгоритм Евклида сводится
к последовательности шагов
s = Q<'×+ tt»
Q(2)t(1) + ~(2)
60 Гл. 2. Введение в абстрактную алгебру
t(() Я(ЗЦ(2) + ~(З)
~(л ‒ 2) Q(n)t(n ‒ () ] t(n)
~(л ‒ )) Q(n+l)t(n)
где остановка процесса наступает при получении нулевого остатка.
Последний ненулевой остаток, t("), равен наибольшему общему
делителю. Этот факт будет доказан в следующей теореме. Матрич-
ные обозначения позволяют кратко записать шаги алгоритма
Евклида в виде
s(ã ‒ 1)
~(г ‒ 1)
s(') 0 1
~(~) [ Q(~)
Теорема 2.6.3 (Алгоритм Евклида).
жительных чисел s и t, где s ~ t, пусть
ние рекуррентных уравнений
«)
Для двух заданных поло-
я;(О) ~ и ~(0) / Pp~
$
( ‒ 1)
g(r ‒ 1) ъ
s« ‒ ))
t«1) 1
s() О 1
/(~) ! Q(~)
при r = 1, ..., п дается величиной
s(") = НОД fs, tl,
где п равно наименьшему целому числу, для которого t("' = О.
Яоказательство. Так как t('+') < t(') и все остатки неотрица-
тельны, то в конце концов наступит п, для которого t(") = О,
так что завершение работы алгоритма произойдет обязательно.
Легко проверить, что
0
‒ 1
Q (r)
1 0
1
Q(r)
Поэтому
я " Q(() ! s(n)
П
г,= 1 О О
так что s( ) должно делить оба числа s u t и, следовательно, делит
НОД [s, t]. Далее,
о =~, 1 ц)') I c
так что любой делитель чисел s u t делит s("). Следовательно,
НОД [я, t] делит я(") и делится на я("). Таким образом,
s("» = НОД [я, t].
Это завершает доказательство. []
2.6. Кольцо целых чисел
6]
Из этой теоремы вытекает несколько важных следствий. Пусть
1 0 1 О 1
А< =П А(' ‒ ').
Я(О 1 Q(~)
Тогда получаем следствие, являющееся важным и интуитивно
непредсказуемым результатом теории чисел, утверждающим, что
наибольший общий делитель двух целых чисел равен их линейной
комбинации.
Следствие 2.6.4. Для любых целых чисел s и t найдутся такие
целые числа а и Ь, что
НОД [s, tl = as + bt.
Докаэательство. Достаточно доказать следствие для положи-
тельных s u t. Так как
(;(л)
А(л)
s ((~) = НОД [s, tI
то утверждение выполняется при а = А11 и Ь = А12. []
(л) (а)
Из доказательства этого следствия видно, как целые числа а и Ь
вычисляются в виде элементов матрицы A. Остальные два эле-
мента матрицы также имеют свою интерпретацию, для описания
которой нам понадобится обратная к матрице А('). Напомним, что
О 1
А(') = П
Q(<)
Отсюда видно, что определитель матрицы A<'> равен ( 1)'. Обрат-
ная к А(') матрица равна
д( ) д() ‒ 1 д(г) д(г)
11 12 22 12
А~'~ А(' А"' А"
21 22 21 11
Следствие 2.6.5. Получаемые в процессе алгоритма Евклида
матричные элементы А~< и А2~ удовлетворяют равенствам
(л) (л)
s = ( ‒ 1)" А@> НОД [s, t],
( 1)" А<",> НОД [s, t].
Яокаэательство. Используя выписанное выше выражения для
д5ратной матрицы и обращая первое равенство из доказательства
следствия 2.6.4, получаем
(n)
цв A 2ß
-А 21
(л)
,д(и) (и
-А и
А',",) О
Утверждение вытекает отсюда непосредственно. П
б2 Гл. 2. Введенне в абстрактную алгебру
Используя алгоритм деления, можно вычислить наибольший
общий делитель двух целых чисел. Например, НОД [814, 187]
находится следующим образом:
8 l4
187
3 ‒ l3 8~
l7 74 l87
Из этих вычислений с азу следует, что НОД [814, 187] равен 11
и что НОД [814, 187 = 3'Х 814 13 Х 187.
2.7. Кольца многочленов
Для каждого поля F имеется кольцо F [х), называемое коль-
цом многочленов Hà F. Во многих отношениях кольцо многочле-
нов аналогично кольцу целых чисел. Чтобы сделать эту анало-
гию очевидной, в изложении данного раздела мы следуем разд. 2.6,
Многочленом над полем F называется математическое выра-
жение
f (х) = f„x" + f„,õ" '+... j f,õ+ f, = ~'~ f;x',
где символ х называется неопределенной переменной, а коэффи-
циенты f„..., /„ принадлежат полю. Нулевым многочленом назы-
вается многочлен f (х) = О. Степень многочлена обозначается
deg f (х) и определяется как индекс старшего ненулевого коэффи-
циента. По определению степень нулевого многочлена полагается
равной отрицательной бесконечности ( оо). Приведенным много-
членам называется многочлен, старший коэффициент ~„которого
равен 1. Два многочлена равны, если равны все их коэффи-
циенты /~.
В кольце всех многочленов над заданным полем сложение H
умножение определяются как обычные сложение и умножение
многочленов. Такое кольцо многочленов определено для каждого
поля F и обозначается символом F [х[. B исследованиях по этому
кольцу элементы поля F иногда называются скалярами.
Суммой двух многочленов из F [х) называется другой много-
член из F [х], определяемый равенством
f (х) + g (х) = Z (f i + g;) х',
где, конечно, члены с индексом, болыиим наибольшей из степеней
многочленов f (х) и g (х), равны нулю. Степень суммы не превос-
ходит наибольшей из этих двух степеней. Произведением двух
2.7. Кольца многочленов
63
многочленов из F [х) называется многочлен из F [х), определяе-
мый равенством
С
) )х) у (х) ‒ Z Z /ia ~)) х'.
С j~
Степень произведения равна сумме степеней множителей. Если
f (х) + О и g (х) ‒,е= О, то f (х) g (х) + О, так как deg p (х) равно
отрицательной бесконечности тогда и только тогда, когда р (х) = О.
В кольце многочленов вычитание возможно всегда, а деление
не всегда. Будем писать r (х) ~s (х) и говорить, что многочлен
s (х) делится на многочлен r (х), или что многочлен r (х) делит
s (х, нли что r (х) является делителем многочлена s (х), если су-
ществует многочлен а (х), такой что r (х) а (х) = s (х). Ненулевой
многочлен р (х), делящийся только íà р (х) или на произвольный
элемент а поля, называется неприводимьсм многочленом. Приве-
денный неприводимый многочлен называется простым много-
членом.
Чтобы выяснить, является ли многочлен простым, надо знать
поле, над которым он рассматривается. Многочлен х4 ‒ 2 яв-
ляется простым над полем рациональных чисел, но не над полем
вещественных чисел, над которым он распадается в произведение
двух простых многочленов: р (х) = (х' у 2) (х'+ к'2). Над
полем комплексных чисел каждый из последних многочленов
не является простым.
Если r (х) и делит s (х), и делится íà s (х), то r (х) = ns (х),
где а элемент поля F. Это доказывается следующим образом.
должны существовать многочлены а (х) и Ь (х), такие что г (х) =
= s (х) а (х) и s(х) = r (х) Ь (х). Следовательно, r (х) = r (х) X
х Ь (х) а (х). Но степень стоящего справа многочлена равна сумме
степеней многочленов r (х), а (х) и Ь (х). Так как эта сумма должна
равняться степени многочлена, стоящего слева, то многочлены
а (х) и Ь (х) должны иметь степени, равные нулю, т. е. являться
скаля рами.
Наибольший общий делитель двух многочленов r (х) и s(x)
обозначается HOg [r (х), s (x)] и определяется как приведенный
многочлен наибольшей степени, делящий одновременно оба из них.
Если наибольший общий делитель двух многочленов равен 1,
то они называются взаимно простыми.
Наименьшее общее кратное двух многочленов r (х) и s (х)
обозначается НОК [r (х), s (х) ] и определяется как приведенный
многочлен наименьшей степени, делящийся на оба из них. Мы
увидим, что наибольший общий делитель и наименьшее общее
кратное многочленов r (х) и s (х) определены однозначно.
В поле вещественных чисел операция дифференцирования вво-
дится через операцию предельного перехода. Это определение
возможно не всегда, так как в некоторых полях отсутствует по-
64 Гл. 2. Введение в абстрактную алгебру
нятие произвольно малого числа. В таких полях удобно просто
ввести операцию над многочленами, результат которой ведет себя
так, как вела бы производная. Такой многочлен называется
формальной производной от многочлена.
Определение 2.7.1. Пусть г (х) = rÄx" + г„,х" ‒ ' + +
+ r>x + ro есть многочлен над полем F. Формальной производной
от r (х) называется многочлен вида
r' (я) = (пг„) х" ‒ '+ ((п 1) r„,) х" ‒ '+... + r,,
где новые коэффициенты вычисляются в поле F как суммы 1 ко-
пий элемента I ~'.
(ir~) = r; + r; +... + r~.
Легко проверить, что сохраняются многие полезные свойства
производных, а именно, что
(r (х) s (х) }' = r' (х) s (х) + r (х) s' (х),
и что если а' (х) делит r (х), то а (х) делит r (х).
В кольце многочленов над полем возможно сокращение; если
с (х) а (х) = с (х) о (х) и с (х) отличен от нуля, то а (х) = Ь (х).
Кроме того, в кольце многочленов имеется слабая форма деления,
известная под названием деления с остатком или алгоритма
деления.
Теорема 2.7.2 (Алгоритм деления для многочленов). Для
каждого многочлена с (х) и ненулевого многочлена d (х) существует
единственная пара многочленов Q (х) (частное) и s (х) (остаток),
таких что
с (х) = Q (х) d (х) + s (х)
и deg s {х) ( deg d (х).
Доказательство. Частное и остаток находятся по элементар-
ному правилу деления многочленов. Они единственны, так как
если
с (х) = Q, (х) d (х) + s, (х) = Q, (х) d (х) + ss (х),
то
Н (х) (Q. (х) Я, (х) ] = в, (х) в, (х).
В правой части равенства стоит ненулевой многочлен, степень
которого меньше deg d (х), а в левой ‒ ненулевой многочлен,
степень которого не меньше deg d (х). Следовательно, оба много-
члена равны нулю, и представление единственно.
Практически вычисление частного и остатка выполняется
с помощью простого правила деления «уголком». Частное иногда
обозначается
2.7. Кольца многочленов
Обычно мы будем больше интересоваться остатком, чем частным.
Остаток часто записывается в виде
s (х) = Ял<» [с (х)],
ИЛИ
s (х) = с (х) (mod d (х)).
Можно записать также сравнение
s (х): ‒ с (х) (mod d (х)),
которое обозначает, что многочлены s (х) и с (х) имеют один и
тот же остаток при делении на d (х). Чтобы найти Лл<» [c (х)!,
казалось бы, надо выполнить деление. Однако имеется несколько
приемов, позволяющих сократить и упростить необходимую для
этого работу. Прежде всего заметим, что
Ял<» [с (х)] = Rd<» [с (х) + а (х) d(х)!.
Не изменяя остатка, к с (х) можно прибавить любое кратное много-
члена d (х). Следовательно, не изменяя остатка, можно исключить
старший коэффициент многочлена с (х), прибавляя соответству-
ющее кратное многочлена d (х). Используя этот метод при при-
ведении многочлена с (х) по модулю приведенного многочлена
и ‒ 1
d(x) = х" + f d,õ',
1=0
для упрощения можно член х" заменить многочленом f<", <<d;x'
всюду, где это удобно. Такой прием упрощает вычисление остатка
путем деления многочленов «уголком».
Другой способ упрощения задачи вычисления остатка от деле-
ния дается следующей теоремой.
Теорема 2.7.3. Если многочлгн d (х) кратен многочлгну g (х),
Rs <» [а (х)] = Rs <» [R«» [а (х)Ц
для любого а (х).
Доказательство. Пусть d (х) = g (х) h (х) для некоторого h (х).
Раскрывая правую часть, получаем
а (х) = Q, (х) d (х)+ Лл<» [а (х)] =
= Q< (х) Й (х) д' (х) + Яг (х) а (х) + Rs<» [R«» [а (х)Ц,
где степень остатка меньше degg (х). Раскрывая левую часть,
имеем
а (х) = Q (х) g (х) + Яг< » [а (х) ],
и, согласно алгоритму деления, такая запись однозначна при
степени остатка, меньшей deg g (х). Теорема вытекает из отожде-
ствления подобных членов в обоих выражениях. П
В качестве примера использования теоремы 2.7.З разделим
66 Гл. 2. Введение в абстрактную алгебру
х' + х + 1 на х' + х» + х' + х + 1. Яеление «уголком» было бы
утомительно, но если вспомнить, что (х 1) (х' + х~ + х +
+ х + 1) = х' 1, то можно сначала разделить на х' 1,
а затем на х4 + хз + х2 + х + 1. Тогда
Я,' ~ [х'+ х+ 1! = х2+ х+ 1,
и теперь деление на х4: + хз + х2 + х + 1 тривиально, так что
Я;+„..+„+,.+< [х'+х+ 1] = х'+х+ 1.
Другое удобное правило дается следующей теоремой.
Теорема 2.7.4.
(i) R«<» [а (х} + b (х)] = Rd <» [а (х}] + R«<» [b (х)].
(й) R«» [а (х). Ь (хЦ = Р«<» [Ra <» [а (х}] Л«<» [b (х)]}.
Доказательство. Применяя алгоритм деления к обеим частям
первого равенства, запишем
а (х )+ Ь (х) = Q (х) d (х) + Rd <» [а (х) + Ь (х) ]
И
а (х) + Ь (х) = Q' (х) d (х) + Я«<Ä) [а (хЦ +
+ Q" (х) d(х)+ Рл <» [b (хЦ.
Часть (i) вытекает ив однозначности алгоритма деления. Часть (ii)
доказывается аналогичным образом. ~]
Подобно тому как часто бывает полезным представление целых
чисел в виде произведения простых сомножителей, часто бывает
полезным представление многочленов в виде произведения непри-
водимых многочленов. Чтобы сделать разложение целых чисел
на простые множители однозначным, приходится ограничить рас-
смотрение только положительными простыми числами. Анало-
гично, для однозначности разложения многочленов приходится
условиться, что используемые в качестве простых делителей
многочлены являются приведенными многочленами.
Теорема 2.7.5 (теорема об однозначном разложении). Много-
член над некоторым далем однозначно разлагается в произведение
элемента паля и npocmbn над данным полем мнагачленов, npuw>
степень каждого из них равна по меньшей мере 1.
Доказательство. Ясно, что входящим в произведение элемен-
том поля является коэффициент р„, где п степень равлагаемого
многочлена р (х). Эгиы элементом можно пренебречь и доказь<-
вать теорему для приведенных многочленов.
Предположим, что теорема не верна и пусть р (х) приве-
денный многочлен наименьшей степени, для которого она не верна.
2,7. Кольца многочленов
67
Гогда имеются два разложения,
р (х) = а, (х) а (х) ... а~ (х) = b, (х) Ь, (х) ... b> (х),
где а~ (х) н b; (х) ‒ простые многочлены.
Все многочлены аь (х) должны отличаться от всех многочле-
нов b; (х), так как в противном случае можно было бы сократить
общие члены и получить многочлен меньшей степени, который
можно разложить двумя разными способами.
Без потери общности предположим, что степень многочлена
b~ (х) не больше степени многочлена а, (х). Тогда
а, (х) = Ь, (х) Q (х) + а (х),
где deg s (х) ( deg b, (х) ~( deg а, (х). Далее,
s (х) <> (х)... а>, (х) = b, (х) [b, (х)... b; (х) Q (х) а, (х)... а>, (х)].
Разложим многочлен а (х) и стоящий в квадратных скобках много-
член на простые множители, разделив, если надо, на соответ-
ствующий элемент прля так, чтобы все множители были приве-
денными. Поскольку Ь, (х) не содержится в левой части, мы полу-
чили два различных разложения приведенного многочлена, сте-
пень которого меньше степени многочлена р (х). Это противоречие
доказывает теорему. П
В силу теоремы об однозначном разложении теперь ясно, что
НОД [а (х), t (х)] н НОК [s (х), t (х)! являются единственными
для любых двух многочленов s (х) и t (х}, так как наибольший
общий делитель равен произведению всех общих для s (х) и t (х)
простых делителей, причем каждый делитель входят в наимень-
шей нв степеней, в которой он входит в s (х) н в t (х), а наименьшее
общее кратное равно произведению всех простых делителей, вхо-
дящих либо в s (х), либо в t (х), причем каждый делитель входит
в наибольшей степени, в которых он входит в а (х) или в t (х).
Из алгоритма деления для многочленов вытекает важное след-
ствие, известное под названием алгоритма Евклида для много-
членов. Для заданных двух многочленов s (х) и t (х) их наиболь-
ший общий делитель может быть вычислен с помощью итератив-
ного применения алгоритма деления. Без потери общности можно
полагать, что deg s (х) )~ deg t (х); алгоритм состоит ив последо-
вательности шагов
s(x) = Q<'> (х) t (x)+t<'> (х),
t (х) = Q<~> (х) t<'> (х) -«/<г> (х),
t< > (х) = Q<s> (х) ~<'> (х) -«- t<» (х),
° °
i<и ‒ 2> (х) = q<tE> (х} t<n ‒ i> (х) + t<n> (x)
t< ‒ » (х) q<~+ (х) ~<> („),
68 Гл. 2. Введение в абстрактную алгебру
где остановка процесса наступает при получении нулевого остатка.
Последний ненулевой остаток t<") (х) равен наибольшему общему
делителю. Доказательство этого факта дается следующей теоремой.
Теорема 2.7.6 (Алгорнтм Евклида для многочленов). Для двух
заданных многочленов s (х) и t (х) с deg s (х) )~ deg t (х) пусть
s<0) (х) = s (х) и t<0) (х) = t (х). Решение рекуррентных уравнений
х =
~(l ‒ 1 )
(х) =,<,,> ("}
s<'> (х) 0 1 в«' ‒ > (x)
t<'> (х) 1 Q<') (х) t<' ‒ ') (х)
лри r = 1, ..., n Baemcs величиной
s<") (х) = u НОД [s (х), t (х)!,
где и ‒ наименьшее положительное число, для которого 1<") (х) =
= 0 и сс + 0 принадлежит солю.
Доказательство. Так как deg t<'+') (х) ( deg t<') (х), то для
некоторого и обязательно наступит событие t<") (х) = О, так что
алгоритм будет завершен. Легко проверить, что
0 1 ‒ ' Q<') (х) 1
1 ‒ Q<'> (х) 1 0
Следовательно,
к (х) " ()") (х) ( ) к(") (х)
П
t (x) << 1 0 0
так что многочлен s<") (х) должен делить оба многочлена s (х)
и t (х} н, следовательно, НОД [s (х), t (х)!. Далее,
s<"> (х) ' 0 1 s (x)
0 <=„1 Q<') (х) t (х)
так что любой делитель обоих многочленов s (х} и t (х) должен
делить н многочлен s<"> (х). Таким образом, НОД [s (х), t (х) !
делит s«) (х} и делится íà s" (х), н, следовательно,
s<") (х) = а НОД [s (х), t (х) ),
элемент поля. Это завершает доказательство
где а ненулевой
теоремы. Q
Снова, как и в
важных следствия.
случае с кольцом целых чисел, получаем два
Определим матрицу, многочленов
1 О
Q<') (х) 1
1
А<i ‒ <) („)
А<') (х) = +
l=r
69
2.7. КОЛЬЦа МНОГОЧЛЕНОВ
где А«»» (х) есть единичная матрица. Тогда мы имеем следующий
результат.
Следствне 2.7.7. Для любых двух многочленов s (х) и t (х) над
полем F существуют два других многочлена а (х) и b (х) над тем же
полем, такие что
НОД [s (х), t (х) ! = а (х) s (х) + Ь (х) t (х).
Доказательство. Так как
я<л» (х) s (х)
= А~"» (х)
и s<"» (х) = а НОД [s (х), t (х) ], то утверждение следствия вы-
полняется при а (х} = <x 'А<«» (х) и Ь (х) = а 'АI~~ (х). [~
Многочлены а (х) и Ь (х) получаются из элементов матрицы
A<"» (х) делением на а '. Два других элемента матрицы А (х)
также имеют прямую интерпретацию, для описания ксггорой нам
надо вычислить обратную к матрице А<'» (х). Напомним, что
О
'А<'» (х) = Г]
1
1
Q<'» (х)
Отсюда видно, что определитель матрицы A<'» (х) равен ( 1),
а обратная матрица дается равенством
t А<«» (x) А1г' (х)
Агя' (х)
1
Аф (х)
А<»' (х}
s (x) = ( 1)" А,",» (х) а НОД [s (x), t (x)],
t (х) = ( 1)" А<",» (х) а НОД[з (х), t (х)].
Доказательство. Обратим первое равенство в доказательстве
следствия 2.7.7, используя выведенную формулу для [А<'» (х)]-':
g х ‒ А<"~ х
А<,"» (х) э<"» (х)
А<",» (х) О
()тсюда утверждение следствия очевидно.
(:ледствие 2.7.8. Вычисляемме в процессе алгоритма Евклида
элементы А'<» (х) и А'z~ (х) удовлетворяют равенствам
70 Гл. 2. Введение в абстрактную алгебру
В качестве примера использования алгоритма Евклида для
многочленов вычислим НОД [s (х), t (х)1 прн s (х) = х' 1 и
t (х) = x' + 2х'+ 2х+ 1. Имеем
3 s(x)
‒ х+ 2 t(x)
1 !
2Х 4
4 2 4
ЗХ + 3Х+
4(Х + 1)
1 2 3
2Х 4Z + ‒ 1
3 ‒ Зх + 3х 3х + 3 х + ~Z + ~x +
Таким образом, НОД [х'
Кроме того,
1,х'+2х'+2х+ 1! =х+ 1.
х+ 1 = ( ‒ х ‒ ‒ ) s (х} + ( х' ‒ x + ‒ ) t (х},
как обещано следствием 2.7.7.
Можно вычислить значение многочлена р (х} над полем F
в любом элементе р этого поля. Для этого надо вместо неопреде-
ленной переменной х подставить соответствующий элемент р н
найти элемент р (р} этого поля. Можно также вычислить значение
многочлена в элементе из любого большего поля, содержащего
поле F. Для этого надо вместо неопределенной переменной х
подставить значение элемента из расширения поля. Если F—
поле вещественных чисел, то вычисление многочлена в расшире-
нии поля является знакомой операцией. Многочлены с веществен-
ными коэффициентами часто приходится вычислять в поле ком-
плексных чисел.
Элемент р поля называется корнем многочлена р (х}, если
р (P} = О. 1~орнн многочлена не обязательно лежат в его соб-
ственном поле. Многочлен р (х) = х'+ 1 не имеет корней в поле
вещественных чисел.
Доказательство. Согласно алгоритму. деления,
р (х) = (х P) Q (х) + s (х),
где степень многочлена s (х) меньше единицы, так что s (х) яв-
ляется элементом поля, s,. Следовательно,
О= р(Р) =(Р Р) @(Р)+ „
Теорема 2.7.9. Элемент р поля является корнем ненулевого
многочлена р (х) тогда и только тогда, когда (х P) является
делителем многочлена р (х}. Более того, если степень,многочлена
равна n, mo многочлен имеет в поле не более и корней.
2.8. Китайские теоремы об остатках
так что s (х) = s, = О. Наоборот, если (х ‒ р} делит р (х), то
р (х) = (х ‒ P) Q (х)
и р (P) = (P P) Q (P) = О, так что р является корнем много-
члена р (х).
Теперь разложим многочлен в произведение скаляра и про-
стых многочленов. Степень многочлена р (х} равна сумме степеней
простых делителей, и один такой простой делитель имеется для
каждого корня. Следовательно, число корней не может превос-
ходить и. [3
Теорема 2.7.10 (Интерполяция Лагранжа}. Пусть
множество из и + 1 различных точек, и пусть р (P„) за-
даны для всех k = О, 1, ..., и. Тогда найдется в точности один
многочлен р (х} степени и или меньше, принимающий значения
р (Ps) для всех Й = О, ..., и. Этот многочлен дается равенством
(х ‒ pz)
n ( ) = g п 04) '",
П (~~ ‒ ~~)
с=о
)wc
Доказательство. Непосредственной подстановкой Рь вместо х
можно убедиться, что многочлен р (х) принимает в этих точках
указанные значения; Однозначность представления следует из
того, что если р' (х) и р" (х) два таких многочлена, то много-
член P (х) = р' (х) р" (х} имеет степень, не превосходящую и,
но и + 1 корней ~„при k = О, ..., п. Следовательно, P (х}
является нулевым многочленом. р
2.8. 3(итайские теоремы об остатках
Любое неотрицательное целое число, не превосходящее произ-
ведения модулей, можно однозначно восстановить, если известны
его вычеты по этим модулям. Этот результат был известен еще
в древнем Китае и носит название китайской теоремы об остатках.
Формулировка китайской теоремы об остатках приведена на
рис. 2.2. Мы будем доказывать ее в два этапа. Сначала будет
доказана единственность решения, а затем (построением процедуры
отыскания решения) его существование.
Прежде чем строить формальную теорйю, приведем простой
пример. Выберем в качестве модулей то = 3, m> = 4 и т, = 5
и положим M = т,т,т~ = 60. Для заданного числа с, лежащего
в интервале 0 ~ с < 60, обозначим c; = R. [c]. Китайская
теорема утверждает, что между шестьюдесятью такими числами с
и шестьюдесятью векторами (с„с1, с,} соответствующих вычетов
72 Гл. 2. Введение в абстрактную алгебру
Прямые уравнения
с~= Я [с3
m~~
где т~ взаимно просты
О, . ° °, Й
Обраяные уравнения
k
с= g с;Ф~М; (mod М)
8=0
k
где М = П m~ М; = М~~71~
Ю=~}
и N~ являются решениями уравнений
N-М;+ а;т~ = 1
Рис. 2 2. Китайская теорема об остатках.
существует взаимно однозначное соответствие. Предположим, что
с, = 2, с, = 1 и с, = 2. Тогда эти условия приводят к следующим
возможностям:
с 6 «2, 5, 8, 11, 14, 17, 20, 23, 26, 29, ...),
с C (1, 5, 9, 13, 17, 21, 25, 29, 33, ... },
с 6 (2, 7, 12, 17, 22, 27, 32, 37, ...}.
Теорема 2.8.1. Для заданного множества целых положитель-
ных попарно взаимно простых чисел т„т„..., m> и множества
нео~прицательных целых чисел с~, с~, ..., сд при с; < т; система
c,=с (modm), i=0, ..., k,
k
имеет не более одного решения в интервале 0 ( с ( П т~.
i=l
Доказательство. Предположим, что с и с' являются двумя
лежащими в рассматриваемом интервале решениями. Тогда
с = Q;m;+ c; и с' = Q~mg+cg
и, следовательно, с с' кратно m; для каждого i, а так как m;
k
попарно взаимно просты, то с с> кратно Д т~. Но число c ‒ с
к=а
Единственным решением служит с = 17. Позже будет дан про-
стой алгоритм вычисления числа с по его вычетам.
В рассмотренном примере число однозначно было восстанов-
лено по его вычетам. В следующей теореме доказывается, что это
имеет место в общем случае.
2.8. Китайские теоремы об остатках
73
k k
лежит между g т, 1 и Пт,. Единственным положитель-
i=0 i=0
ным числом, удовлетворяющим этим условиям, является с с' =
= О. Следовательно, с = с'. Д
КОД [s, t l = es + bt.
Для заданного множества попарно взаимно простых положитель-
ных чисел т„т>, ..., m>, используемых в качестве модулей,
k
положим M = Дт; и М; = М/т;. Тогда НОД [М,, m;1 = 1,
S 0
и, следовательно, существуют такие целые N; и и;, что
NM;+nm;=1, i=0,..., k.
Теперь можно доказать следующую теорему.
k
Теорема 2.8.2. Пусть M = P m; ‒ произведение попарно вза-
~=0
имно простых положительных чисел, пусть М; = М/т, и пусть
для каждого ~ Ni удовлетворяют равенствам У;М; + п~т~ = 1.
Тогда единственным решением системы сравнений
c; = с (mod m;), i = О, ..., Й,
является
k
с = f c;N;M; (mod M).
8=0
Яоказательство. Поскольку мы уже знаем, что решение рас-
сматриваемой системы сравнений единственно, надо только до-
казать, что выписанное выше с действительно является решением.
Но для такого с
k
с = f с,N,M, = c;N;M; (mad т;),
ибо т; делит М, при r =,ф ~. Наконец, так как У;М; + n;m; = 1,
то N;M, = 1 (mod т;) и с = с, (mod т;), что и завершает дока-
зательство. ~]
Чтобы проиллюстрировать теорему 2.8.2, продолжим преды-
дущий пример. Заметим, что М = 60, Мо = 20, М1 = 16 и
М, = 12. Далее, как можно вычислить по алгоритму Евклида
или просто проверить, 1 = ( 1) M, + 7mo, 1 = ( 1) M~ + 4т1,
Имеется простой путь построения решения системы сравнений
из теоремы 2.8.1, основанный на следствии из алгоритма Евклида.
Согласно этому следствию, в кольце целых чисел для каждого s u t
найдутся такие а и Ь, что
74 Гл. 2. Введение в абстрактную алгебру
Прямьи уравнения
с~ ~(x)= R < ° > [c(x)], с О, ..., й.
m (х)
где т~ > (х) взаимно прость~
Обрсииные уравнения
k
с(х) = f c~ ~ (х) N~ ~ (х) МП~ (х) (mod М (х))
1=0
k
где М (х) = 11 т~~~ (х), М~~~ (х) = М (х)/т~~~ (х)
1=0
и N~ ~ (x) являются решениями уравнений
Ф~~~ (x) М~'> (х)+ п~~~ (х) т~~~ (x) = 1
Рис. 2.3. Китайская теорема об остатках для многочленов.
1 = ( 2) М, + Бт,. Следовательно, Ш,М, = 20, N,Ì~ = 15,
У~И~ = ‒ 24 и
с = ‒ 20с, 15с, 24с, (mod 60).
В частности, при со = 2, с, = 1 и с, = 2 имеем с = ‒ 103
(mod 60) = 17, что мы видели и раньше.
Китайская те~зрема об остатках является основой представле-
ния целых чисел, в котором просто выполняется операция умно-
жения. Допустим, что надо выполнить умножение с = ab. Пусть
a; = R«[al, b; = R~~ [Ь] и c~ = R«[с] для каждого 8 =
= О, ..., k. Тогда c; = a;b; (mod т,), и это умножение вычислить
легче, так как а; и b; являются малыми целыми числами. Анало-
гично, при сложении с = а + Ь имеем c; = а; + b; (mod т;) для
всех ~ = О, ..., k. В обоих случаях для получения окончатель-
ного ответа с должно быть восстановлено по вычетам в соответ-
ствии с китайской теоремой об остатках.
Переход к системе вычетов позволяет разбить большие целые
числа на маленькие кусочки, которые легко складывать, вычи-
тать и умножать. Если вычисления состоят только из этих опе-
раций, то такое представление является альтернативной арифме-
тической системой. Если вычисления достаточно просты, то пере-
ход от естественной записи целых чисел к записи через систему
остатков и обратное восстановление ответа в целочисленном виде
могут свести на нет все возможные преимущества при вычисле-
ния х. Если, однако, объем вычислений достаточно велик, то
такой переход может оказаться выгодным. Это происходит по-
тому, что при вычислениях все промежуточные результаты можно
сохранять в виде системы остатков, выполняя обратный переход
к целочисленному виду только при окончательном ответе.
75
2.8. Китайские теоремы об остатках
В кольце многочленов над некоторым полем также имеется
китайская теорема об остатках, формулировка которой приве-
дена на рис. 2.3 и которая доказывается по той же схеме, что
и для целых чисел.
Теорема 2.8.3. Для заданного множества попарно взаимно про-
стых многочленов т«» (х), т<'> (х), ..., т<~> (х) и множества много-
членов с<в> (х), с<'> (х), ..., с~~~ (х), таких что deg с<~> (х) (
( deg т<'> (х) система уравнений
с<'> (х) = с (х) (той т<'> (х)), i = О,..., Й,
имеет не более одного решения с (х), удовлетворяющего условию
k
deg с (х) ( ~'.~ deg т<'> (х).
й=0
Доказательство. По существу доказательство совпадает с до-
казательством теоремы 2.8. 1. Предположим, что имеются два
решения, а именно
с (х) = Q«> (х) т<'> (х) + с<'> (х)
с' (х) = Q' «> (х) т<'> (x) + с<'> (х),
так что разность с (х) с' (х) кратна многочлену т<'> (х) для
каждого с. Тогда многочлен с (х) с' (х) кратен и многочлену
Дт«> (х), причем
1=0
deg [с (х) с' (х)] ( deg П т<'> (х)
1=0
Следовательно, с (х) с' (х) = О, и доказательство закончено. р
Система сравнений может быть решена так же, как и в случае
кольца целых чисел. В кольце многочленов над некоторым нолем
для любых заданных s (х} и t (х) существуют многочлены а (х)
и Ь (х), удовлетворяющие условию
НОД [s (х), 3 (х) l) = а (х) s (х) + Ь (х) t (х).
k
Пусть М (х) = P т<'> (х) и М<'> (х) = М (х)/т, (х); тогда
r=0
НО~ [М<~> (х), т<'> (х) 1 = I. Пусть N«> (х) и и«> (х) удовлетво-
ряют равенству
И«> (х) М «> (х) + и«> (х) т«> (х) = 1.
Теорема 2.8.4. Пусть М (х} = Дт<'> (х) произведение no-
r=0
парно взаимно простых многочленов; пусть М<'> (х) = М (х}/т«> (х}
и для всех i многочлены й/<'> (х) удовлетворяют условиям
Гл. 2. Введение в абстрактную алгебру
76
Задачи
а. Показать, что существует только одна группа с тремя элементами. По-
строить ее и показать, что она абелева.
б. Показать, что существу~от только две группы с четырьмя элементами.
Построить их и показать, что они обе абелевы. Показать, что одна из двух
групп с четырьмя элементами не содержит элементов порядка четыре.
Эта группа называется четверной группой Клейна.
Пусть групповая операция на группах из задачи 2.1 называется сложе-
нием.
а. Определить умножение на трехэлементной группе так, чтобы она стала
кольцом. Является ли такое определение единственным?
б. Для каждой из четырехэлементных групп определить умножение так,
чтобы превратить их в кольца. Является ли каждое определение един-
ственнымм?
Какое из трех построенных в задаче 2 2 колец является полем? Можно ли
задать другое умножение так, чтобы получить поле?
Доказать, что в циклической группе с д элементами выполняются равенства
ае = ао и (d) > = аа
а. Показать, что 22 Х Zz изоморфно Z<.
б. Показать, что Z2 Х Zq не изоморфно Zq.
Привести пример кольца без единицы.
Отталкиваясь от пары (о;} ~ (Vg} преобразования Фурье, доказать сле-
дующие стандартнь1е свойства дискретного преобразования Фурье:
в. Линейность: (ао + Ьо>) « (аде+ Ьу~}.
б. Свойство сдвига: «о<<>>>> «-~ >и >~я).
в. Модуляционное свойство: 1и ог) (V„>>+»>j.
1г1
Показать, что преобразование Фурье вектора даниых og = о ~, где r‒
целое число, содержит единственную ненулевую спектральную компоненту.
Какова эта компонента, если r = О? Показать, что see спектральные ком-
поненты вектора, имеющего только одну ненулевую компоненту, не равны
нулю-
Доказать, что если А ‒ теплицева матрица, а Я ‒ обменная матрица
той же размерности, то A~ = JAJ.
а. Найти НОД [1573,308], используя алгоритм Евклида.
2.1.
2.2.
2.3.
2.4.
2.6.
2.6.
2-7.
2.8.
2.9.
2.10.
Ж<'> (х) М<'> (х) + и<'> (>с) т«> (х) = 1. Система сравнений
с«>(х) = с(х) (той т«>(х)), i = О, ..., Й,
имеет единственное решение, даваемое многочленом
с (х) = ~", c«> (х) N«> (х) М«> (х) (mod М (х)).
8=0
Доказательство. Нам нужно только доказать, что многочлен
с (х) удовлетворяет каждому сравнению данной системы. Но
с (х) = с<'> (х) К<'> (x) N«> (х) (mod m«> (x)),
так как т<'> (х) является делителем многочлена М<'> (х), если
r + i. Наконец, так как N«> (х) М«> (х) + и>'> (х) т<'> (х) = 1,
то Ж<'> (х) М«> (х) = 1 (той т<'> (х)) и с (х) = с<'> (х) (mod m<'> (х)),
что и завершает доказательство теоремы. []
3адачи
77
б. Найти целые числа А и В, удовлетворяющие равенству
НОД [1573,308] = A 1573 + В 308.
2.11. Рассмотрим множество S = (О, 1, 2, 3), на котором заданы операции
тогда и только тогда, когда преобразуемая последовательность данных
является вещественной.
Пусть G ‒ произвольная группа (не обязательно конечная). Условимся
называть групповую операцию умножением и единичный элемент едини-
цей. Пусть g ‒ произвольный элемент группы и v ‒ наименьшее положи-
тельное число, если оно существует, такое что g = 1, где под g понимается
v-кратное произведение g a g * ... e g. Dîêàçàòü, что подмножество
° ° °
g, g~, ..., g»~, g»} образует в G подгруппу. Доказать, что эта подгруппа
является абелевой даже тогда, когда G неабелева группа.
Доказать, что множество вещественных чисел вида }а+ Ь ~2}, где а
и Ь ‒ рациональные числа, образует поле относительно обычных операций
сложения и умножения.
Кольцо кватернионов состоит из всех выражений внда
2.13.
2.14.
2. 15.
а = ао + а~~ + ~j + аф,
где ао, а„а2 и аэ ‒ вещественные числа, à 1, ( и Й ‒ неопределенные
переменные. Сложение и умножение определяются иравилами
а+ Ь = (ао+ bp) + (а, + ЬД с+ (а~+ 6g) ) + (аз+ Ьз) А,
аЬ = (аоЬо ‒ а1Ь1 ‒ Qgbg ‒ азЬЙ +
+ (а,Ьо + аоЬ1 ‒ а~Ь2 + а2ЬЗ) i +
+ (,чдЬо+ адЬ~+ аоЬ~ ‒ адЬд) у+
+ (алло ‒ а2Ь~+ а~Ь2+ ао"з) >.
Доказать, что кольцо кватериионов действительно образует кольцо, ио
не поле. Какое из свойств поля в этом кольце не выполняется7
Доказать теорему 2.2 5.
Поле из трех элементов GF (3) задано арифметическими таблицами
2.16.
2.17.
Является ли это множество полемик
2.12. Доказать„что комплекснозначное дискретное преобразование Фурье
удовлетворяет условию симметрии
Гл. 2 Введение в абстрактную алгебру
Вычислить определитель следующей матрицы и показать, что раиг ее равен
трем:
1 2
1 2
О 1
2.18. (ДПФ переставленной последовательности). Рассмотрим дискретное пре-
образование Фурье
л ‒ 1
и,= fm"î,, k=o, ..., n ‒ I,
8=0
и предположим, что а взаимно просто с и. Пусть перестановка компонент
вектора v задается равенством о~ = о(( ~)>. Доказать, что
является перестановкой компонент вектора V, задаваемой равенством
V~ = V((~~)) для некоторого целого Ь, взаимно простого с и.
Год содержит самое большое 366 дией. Предположим, что все месяцы за
исключением последнего содержат по 31 дню.
а. Можно ли однозначно определить порядковый иомер дия в году по задаи-
ным его иомерам в месяце и иеделе?
6. Предположим далее, что месяц содержит 31 день, а неделя ‒ 12 дией.
Можно ли теперь одиозначно определить порядковый номер дня в году
по заданным его номерам в месяце и неделе?
в. Используя 31-дневный месяц и 12-дневную неделю, выписать формулу
для вычислеиия порядкового номера дия в году через его номера в месяце
и неделе.
г. Сделать несколько числовых примеров.
Сколько векторов содержится в векторном простраистве GF" (2)?
Правильно ли утверждение о том, что если х, у и г линейно независимы
над GF (q), то также линейно иезависимы векторы х+ у, y+ г и г+ х?
Доказать, что если S и Т ‒ два двумерных различных подпространства
трехмерного пространства, то их пересечение образует одномериое под-
пространство.
Пусть S ‒ произвольное конечное множество. Пусть G ‒ множество
всех подмножеств множества S. Для двух множеств А и В через А ~ В
обозначим миожество всех элементов, которые прииадлежат хотя бы одному
из множеств А или В; через А Р В ‒ множество scex элементов, которые
принадлежат одновременно и А, и В; через А ‒ В ‒ множество элемен-
тов, принадлежащих А, но не принадлежащих В.
а. Показать, что множество G с операцией объединения U множеств в ка-
честве групповой операции е не является группой.
6. Операция симметрической разности миожеств ~ определяется равен-
ством
2.19.
2.20.
2.21.
2.22.
2.23.
А д В = (А ‒ В) 0 (В ‒ А)
Показать, что множество G с симметрической разностью в качестве груп-
повой операции образует группу Является ли она абелевой?
в. Показать, что множество G с операциями < и Д образует кольцо. Яв-
ляется ли это кольцо коммутативным? Содержит ли это кольцо единицу?
Замечания
79
Заыечания
1) Не требующее предварительной подготовки хорошее изложение начал
линейной алгебры и теории матриц можно найти также в книге. 'Головина Л. И.
Линейная алгебра и некоторые ее приложения. ‒ 4-е изд. ‒ N. Наука, 1985.
Более углубленное изложение содержится в следующих книгах. Курош А. Г.
Курс высшей алгебры. ‒ 11-е изд. ‒ М.: Наука, 1975; Мальцев А. И. Основы
линейной алгебры. ‒ 4-е изд. ‒ М.: Наука, 1975. ‒ Прим. перев.
В этой главе рассматривался обычный материал современной алгебры.
Можно указать много учебников, в которых этот материал излагается более
детально. В качестве легко усваиваемого вводного курса, по уровню достаточного
для данной книги, мц рекомендуем книгу Биркгофа и Маклейна [1] (1941).
Монография Ваи дер Вардена [2] (1949, 1953) представляет собой курс более
высокого уровня, адресованный в основном математикам и углубленно изла-
гающий многие вопросы. Материал по линейной алгебре и теории матриц мощно
найти также и в учебниках, специально посвященных этим разделам алгебры.
Особенно подходящей представляется книга Тралля и Торнгейма [3] (1957),
так как в отличие от миогих других книг в ней не предполагается, что рассма-
триваемое поле является подем веществеиных или комплексных чисел ~). В книге
Полларда (7] в явном виде изложено понятие преобразования Фурье в произ-
вольном поле.
Поля Галуа назваиы в честь Эвариста Галуа (18!1 ‒ 1832). Абелевы группы
названы в честь Нильса Хенрика Абеля (1802 ‒ 1829).
Глава 8
Б ЫСТР Ы Е АЛГОРИТМЫ
КОРОТКИХ СВЕРТОК
Наилучший известный способ эффективного вычисления свер-
ток состоит в использовании теоремы о свертке и быстрого алго-
ритма преобразования Фурье. Этот способ обычно бывает доста-
точно удобен и часто работает с удовлетворительной скоростью,
хотя существуют и лучшие методы. Однако в тех приложениях,
в которых стоит заботиться о дальнейшем снижении вычисли-
тельных затрат, целесообразен переход к другим методам. В слу-
чае когда длина свертки мала, лучшими с точки зрения числа
умножений и сложений являются алгоритмы Винограда вычисле-
ния свертки. Описание алгоритмов Винограда занимает основ-
ную часть данной главы. В следующих главах будет показано,
как можно, соединяя вместе эти малые алгоритмы, строить алго-
ритмы для длинных сверток. При таком подходе алгоритмы для
длинных сверток окажутся хорошими, только если хороши алго-
ритмы для коротких. Поэтому поиску алгоритмов коротких
сверток уделяется большое внимание.
влетали алгоритмов свертки могут зависеть от конкретного
поля, над которым вычисляется свертка, но общая идея постро-
ения таких алгоритмов от поля не зависит. Хотя, конечно, наи
более важные приложения имеют поля вещественных и комплекс-
ных чисел, мы описываем методы построения алгоритмов свертки
применительно к любому представляющему интерес йолю.
3.1. Циклические свертки и линейные свертки
В компактном виде линейная свертка записывается как произ-
ведение многочленов
s (х) = g (х) d (х).
Коэффициенты s, этого многочлена даются равенствами
N ‒ 1
s, = g g, „а. = О, ..., Ь +- Л ‒ 1,
@=О
где degg(х) = L 1 и degd(х) = N
3.1. Циклические и линейные свертки
81
s (х) = g (х) d (х) (mod х" 1),
где deg g (х) = deg d (х) = n 1, коэффициенты даются равен-
ствами
и†!
sf g g((f~))cd i = O, ..., n ‒ 1,
a=o
и двойные скобки обозначают вычисления по модулю л, если
вычислять ее прямо по выписанным формулам, содержит п~ умно-
жений и n (n 1) сложений. Циклическую свертку можно также
вычислять как линейную свертку с последующим приведением
по модулю х" 1 (). Следовательно, эффективные способы вы-
числения линейной свертки приводят также к эффективным мето-
дам вычисления циклической свертки. Наоборот, эффективные
методы вычисления циклической свертки можно легко превратить
в эффективные методы вычисления линейной свертки.
Популярным способом вычисления циклической свертки яв-
ляется использование теоремы о свертке и дискретного преобра-
зования Фурье. Согласно теореме о свертке в частотной области,
S> G<D>, k=0, ..., n ‒ 1,
так что свертку можно вычислять,1 выполняя последовательно
преобразование Фурье, поточечное умножение и обратное пре-
образование Фурье. Эта процедура иллюстрируется рис. 3.1.
Средний блок содержит п комплексных умножений, что мало
по сравнению с л~. Если л имеет много делителей, то описываемое
в следующей главе быстрое преобразование Фурье может привести
к существенному уменьшению числа вычислений в первом и
третьем блоках, сведя их к величинам, также малым по сравне
нию с л'.
Приведенная на рис. 3.1 продЪдура вычисления циклической
свертки относится к комплексному случаю. Поэтому естественно
ожидать, что в случае вещественных последовательностей этот
алгоритм сильнее, чем требуется, и его эффективность может быть
повышена. Некоторая модификация позволяет почти тем же самым
алгоритмом вычислять одновременно две вещественные свертки.
1) При N = L лииейную (L )( N)-свертку часто называют N-точечной
линейной сверткой, а циклическую свертку по модулю х" ‒ 1 часто называю~
и-точечной циклической сверткой. ‒ Прим. перев.
Прямые способы вычисления произведения многочленов со-
держат число умножений и сложений, примерно равное произ-
ведению степеней многочленов, LN; возможны, однако, другие
способы вычисления такого произведения, содержащие меньшее
число вычислений.
Циклическая свертка,
82 Гл. 3. Быстрые алгоритмы коротких сверток
Вход
Вычислить
n ‒ I
>a= g о~"4
~=о
A=0, ...,n ‒ 1
n ‒ 1
ta= g~
C=O
1=0, ...,n ‒ 1
Вычислить
Sg брР~ 1=0, ..., л ‒ 1
Вычислить
n ‒ I
8g = ‒ (0 Sg
-И
й
i=0, ...,n ‒ 1
1
Выход
Рис. 3.1. Вычисление циклической свертки с помощью преобразования Фурье.
Вещественное преобразование Фурье обладает свойством симме-
трии (см. задачу 2.12)
V~=@„' ~, А=О, ..., и ‒ 1.
Предположим, что d' и d" ‒ ~- вещественные векторы длины и
и пусть компоненты комплексного вектора d длины п задаются
правилом
d~ = d; + jd~, i = О, ..., n ‒ 1.
Тогда его дискретное преобразование Фурье удовлетворяет равен-
ствам
Р =И+у~ь
в
л~ л~ л'
еа ъ~з ° ° ° з И 1.
~п ‒ Й ‒ ~a )~a,
Следовательно,
>i = р Фж+ >:~],
k=0, ..., и ‒ 1.
~Й ‒ [+k ~~П ‒ й] з
2)
Эти формулы позволяют вычислить преобразование Фурье двух
вещественных последовательностей, выполняя одно дискретное
преобразование Фурье и некоторые дополнительные сложения-
3.1.. Циклические и линейные свертки
83
Яыкод
Рис. 3.2. Вычисление двух вещественных циклических сверток с помощью пре-
образования фурье.
Описанную идею можно применять и в обратном порядке,
начиная с двух комплексных преобразований двух вещественных
последовательностей. Для заданных комплексных преобразова
ний D' и 0" пусть
D> = D>+ j'D>, k = 0, ..., и ‒ 1,
где в общем случае и Р~ и Р~ являются комплексными числами.
Ч'огда обратное преобразование Фурье приводит к равенствам
d< d; + /d~', ~ = О, ..., n ‒ 1,
из которых обе вещественные последовательности вычисляются
немедленно.
84 Гл. 3 Быстрые алгоритмы коротких сверток
Используя описанную идею, процедуру на рис. 3.1 можно
заменить более эффективной процедурой одновременного вычисле
ния двух вещественных сверток, представленной на рис. 3.2.
3.2. Алгоритм Кука Таама
Алгоритм Кука Тоома является алгоритмом вычисления
линейной свертки, который был разработан как метод умножения
двух многочленов. Запишем линейную свертку в виде произведе-
ния двух многочленов
s (х) = g (х) d (х),
где deg d (х) = N 1 и degg (х) = L 1. Степень многочлена
s (х} равна N + L 2, так что этот многочлен однозначно опре
деляется своими значениями s N + L 1 различных точках.
Пусть (3„(3„..., Izaak множество из L+ Ш 1 различных
вещественных чисел. Если нам известны s(P„) для k = О, ...,
N + L 1, то s (х) можно вычислить по интерполяционной фор-
муле Лагранжа. Согласно теореме 2.7.10, многочлен
‒ П (х ‒ Ц)
s (х) = s (P,)
П (pt ‒ ~,)
1=0 f ôü~
является единственным многочленом степени и 1, принима-
ющим значения s (t3„) при х = I3„~~~ s~~x k = О, ..., п 1.
Идея алгор итма Кука Тоома состоит в том, чтобы сначала
вычислить величины s (P„) для k = О, ..., п 1, а затем восполь-
зоваться интерполяцией Лагранжа.
Алгоритм Кука Тоома приведен на рис. 3.3. Умножения
даются равенствами
s (Ц) = g (~3~) d(P„), k = О, ..., L + К ‒ 2.
Всего имеется L + N 1 таких равенств, так что здесь мы имеем
L + N 1 умножений, и, если разумно выбирать точки I3<, то
полное число умножений будет исчерпываться этими умноже-
ниями. Имеются еще и другие умножения, а именно те, которые
входят в вычисление величин Й (~3„) и g (0~) и те, которые уча-
ствуют в интерполяционной формуле Лагранжа. Но эти умноже-
ния представляют собой умножения на малые константы, и мы
не будем их учитывать при подсчете полного чйсла умножений '},
хотя полностью их игнорировать нельзя.
1) На самом деле не учитывать можно только умножения на О и ~1; ко,
как правило, за счет некоторых предварительных проделанных раз и навсегда
вычислений удается свести рассматриваемые константы к трем указанным.‒
Прим. мрев.
3.2. Алгоритм Кука ‒ Тоома
85
Вход
Вь~ход
Рис. 3.3. Структура алгоритма Кука ‒ Тоома.
i) Первым, еще до Тоома (1963) и Кука (1966), способ выполнения (2X2)-
свертки с тремя умиожениями и четырьм. сложеииями описал А. Карацуба
[ДАН, 145 (1962), 293, 294]; его алгоритм состоит в следующем.' зо = додо, зй =
(
Простейшим примером является линейная (2Х2)-свертка:
d(x) = Идх+ И~, g(x) =g,õ+g, и я(х) = d(x)g(x). К та-
кому вычислению сводится прохождение двух отсчетов данных
через КИО-фильтр с двумя отводами. Очевидный алгоритм вы-
полнения такого вычисления содержит четыре умножения и одно
сложение, но мы построим алгоритм с тремя умножениями, тремя
сложениями. Может показаться, что эта задача слишком мала
для каких-либо практических применений. Но на самом деле
хороший алгоритм решения этой задачи является хорошим бло-
ком, из которого можно строить тщательно проработанные алго-
р итмы. Таким образом, рассматриваемый пример представляет
собой нечто большее, чем простую иллюстрацию алгоритма
Кука Тоома; он важен практически ').
B качестве первой попытки опишем алгоритм с тремя умно-
жениями и пятью сложениями, а затем ег) улучшим. Так как
86 Гл. 3. Быстрые алгоритмы коротких сверток
степень многочлена s (х} равна двум, то надо выбрать три точки.
Выберем их равными [3« = О, [3h = 1 и [3« = 1. Тогда
d ([3«) = do,
~1 (}3h) = «о + 4
d ([3«) = «о Chý,
а ([3о) = a'î
g (}3h) = gо + и
g([2) ЙО Й1
s ([3«} = g (13«} d (l3«}
s ([3h) = g ([3h) d ([3h)
° ([32) g ([3») ~ ([32)г
так что требуются три умножения.
Если КИО-фильтр задается фиксированным многочленом g (х},
то константы g ([3„) не надо каждый раз вычислять заново; их
можно вычислить заранее один раз и запомнить. Коэффициенты
многочлена g (х) в запоминании не нуждаются.
Наконец, согласно интерполяционной формуле Лагранжа
s (x) = s ([3«} L«(х) + s ([3h} L, (х) + s ([3«} L, (х),
где интерполяционные многочлены равны
L„(x) = х'+ 1, L, (х) = (1/2) (х'+ х}, L, (х} = (1/2} (х' х).
Это завершает описание алгоритма Кука Тоома для вычисле-
ния s (х). Но вычисления можно организовать в более компактной
форме. Деления на 2 можно «похоронить» так, чтобы они не были
видны. Для этого просто заменим константы g (P„) новыми, по-
глощающими этот делитель. Пусть
GP = gP Gh = (1/2) (go + gh) G« = (I/2) (gо Д'1).
Так как в большинстве случаев многочлен g (х) фиксирован. то
эти константы можно вычислить заранее, и ничто не мешает нам
определить их таким образом. Гогда
L,> (x) = х' + 1, L, (õ) = х' + х, L« (x) = х' х.
Построенный алгоритм показан на рис. 3.4, а и в компактной
форме может быть записан в матрично-векторных обозначениях
в виде
s = С j[Bg].[Ad]},
где точкой обозначено покомпонентное умножение векторов Bg
и Ad. Матричная запись дает удобную форму обозрения алго-
ритма, но вычисления, конечно, проводятся не посредством
умножения матриц. Умножение на матрицы А и С выполняется
как серия сложений. Возможная последовательность вычислений
показана на рис. 3.4, Ь.
87
3.2. Алгоритм Кука ‒ Тоома
1 0 0 Go 1 0
0 1 ‒ 1 G,
‒ 1 G !
где
Рис. 3.4. Алгоритм Кука ‒ Тоома вычисления линейной свертки 2-точечных век-
торов.
Алгоритм Кука Тоома можно рассматривать как фактори-
зацию матрицы. В рассматриваемом примере свертка может быть
записана в виде
Яю Йо
или, кратко, s = Td. На рис. 3.4с,алгоритм Кука Тоома
,п,пя этой свертки переписан с использованием диагональной ма-
трицы, также обозначенной 6 и содержащей элементы вектора Q.
Алгоритм теперь имеет форму
s = CGAd,
что позволяет интерпретировать его как факторизацию матрицы
Т = CGA, где А матрица предсложений, С есть матрица
постсложений, а б диагональная матрица, ответственная за
see умножения. Число умножений равно размерности матрицы G.
Такое представление алгоритма очень полезно для обозрения его
структуры.
Ь) Dî
D)
D,
S)
S.
~о
S)
~э
do
do + di
do
GOD0
G)D,
0~0
So
S ‒ S„
5о + Si + Sz
88 Гл. 3. Быстрые алгоритмы коротких сверток
В общем случае линейная свертка может быть выражена
в виде
s= Td,
где d входной вектор длины N, s выходной вектор длины
N + L 1 и Т представляет собой ((N + L 1) х N)-матрицу,
элементами которой являются компоненты вектора g. Алгоритм
Кука Тоома в такой форме представляет собой алгоритм фак-
торизации матриць~
g (Ро) = иод
ch, Ы (Рд) = go gh
~(Ро) = g(Po) < (Ро) ‒ Д~АРоо
~(Р) =g(Ри) 1(Р1) ‒ вАРд
где t (х) = g (х) d (х) ддд1дх'. Согласно интерполяционной фор-
муле Лагранжа,
s (х) ghdh»' = 1(Рд) Lh (х) + t(po) Lo (х),
где L, (х) = х + 1 и Lh ,(х) = х.
Объединение всех этих фрагментов дает искомый алгоритм ')д
s(») ghdh»' + ( (d, 4) (ио й) + иА + ид4) х+ Мо.
Алгоритм содержит три сложения и три умножения. Его матрич-
ная форма выписана на рис. 3.5, который полезно сравнить
с рис. 3.4.
1) Это приведенный на стр. 85 алгоритм А. Карацубы (1962), в котором не
учтено в числе сложений вычисление go ‒ дд. ‒ Прии. перев.
Т =CGA,
где G диагональная матрица, а матрицы А и С содержат
только малые целые числа.
Алгоритм Кука Таама можно модифицировать к другому
варианту, содержащему то же число умножений, но меньшее
число сложений. Заметим, что sz», = уьдд1дод. Для вычисле-
ния этого коэффициента необходимо одно умножение. Степень
модифицированного многочлена
s (») ‒ ат„+дт,» + = к (») d (») ‒ а,.+~,о» +
равна L + N 3, так что использующее идеи алгоритма Кука
Тоома вычисление этого многочлена требует L + N 2 умножь
ний. Общее число умножений опять равно L + N1, ,но сложе
ний теперь будет меньше.
Рассмотрим поведение этой модификации алгоритма Кука
Тоома при вычислении линейной (2x2)-свертки. Выберем Po = О
и Ph = 1. Тогда
дд (Ро) = do~
1(Рд) = d
3.2. Алгоритм Кука ‒ TooMa
(ao ‒ а)
1 ‒ 1
~о
dg
Рис. 3.5. Улучшенный алгоритм Кука ‒ Тоома вычислеиия лииейной (py,2)
свертки.
Выход
Рис. 3.6. другое описание алгоритма Кука ‒ TooM>.
Алгоритм Кука Тоома эффективен по числу умножении;
но если объем задачи растет, то число необходимых сложений
также начинает быстро расти. Это происходит потому, что хоро
ший выбор чисел Pq в виде О, 1 и 1 уже сделан, и с ростом задачи
m,~ должны использовать также «+2, +3 и другие малые целые
числа. При этом матрицы А и С будут содержать эти числа. Ко
нечно, умножения на них можно заменить соответствующим
числом сложений, но это резонно делать только в случае, когда
выбираемые числа малы. Поэтому алгоритм Кука Гоома ста
новится слишком громоздок при вычислении сверток, болыдих
чем Зх4 или 4х4. Для больших задач надо пользоваться описы-
ваемыми в следующем разделе алгоритмами Винограда вычисле
ния сверток или итерировать малые алгоритмь| Кука ‒ Тоома,
используя изучаемые в гл. 7 гнездовые методы.
Имеется еще один подход к пониманию алгоритма Кука
Тоома, и эта альтернатива перекидывает мостик к следующему
Вход
90 Гл. 3. Быстрые алгоритмы коротких сверток
разделу. Вместо того чтобы выбирать множество различных чисел
(Po, [3„..., PL+Nz}, выберем множество многочленов (х Ро,
х P„..., х P~~,}. Тогда можно, как на рис. 3.6, записать
g(6~) = Яаь[у(хЦ, d9~) = Я„а„[с1(х)].
Это просто несколько более сложный способ сказать то же, что
говорилось и раньше. Преимущество, реализуемое в следующем
разделе, состоит в замене многочленов первой степени многочле-
нами более высоких степеней, что увеличивает конструктивные
возможности. С этой более изощренной точки зрения интерполя-
ционную формулу Лагранжа можно рассматривать как некото.
рую форму обращения китайской теоремы об остатках для того
частного случая, когда в качестве многочленов-модулей выбраны
только многочлены первой степени. В более общем случае интер-
поляционную формулу Лагранжа приходится отвергнуть, отдавая
преимущество китайской теореме об остатках.
3.3. Алгоритмы Винограда
вычисления коротких сверток
Предположим, что требуется вычислить
s (х) = g (х) d (х) (mod и (х)),
где и (х) фиксированный многочлен степени и над полем F,
а g(x) и d (х} многочлены над этим же полем, причем их степени
меньше п. Задача вычисления линейной свертки s (х) = g (х) d (х)
может быть вложена в эту задачу, если в качестве и выбрать целое
число, большее степени многочлена s (х}, а в качестве и (х}
произвольный многочлен этой степени и. Тогда задача
s (х) = g (х) d (х) (mod и (х))
становится тривиальной переформулировкой задачи вычисления
линейной свертки, так как приведение по модулю и (х} не меняет
s (х). коль скоро степень и (х) больше степени s (х). Это позволяет
включить задачу о линейной свертке в общую задачу, рассматри-
ваемую в данном разделе. Выбирая и (х} равным х" ‒ 1, мы
включаем сюда также задачу вычисления циклической свертки,
s (х) = g (х) d (х) (то4 х" 1).
Мы хотим заменить задачу вычисления
s (x) = g (x) d (х) (mod и (х))
некоторым множеством задач с меньшим числом вычислений.
Чтобы разбить задачу на подзадачи, разложим многочлен и (х)
3.3. Алгоритмы Винограда вычисления коротких сверток
91
на взаимно простые над некоторым подполем поля F многочлены:
и (х) = и«» (х) т<'> (x) ... и<" †'> (х).
Обычно если F поле вещественных или комплексных чисел, то
в качестве подполя разложения выбирается поле рациональных
чисел, и мы будем ссылаться на такой выбор, хотя теория до-
пускает и другие подполя. (Если свертка вычисляется в конечном
поле GF (р~), то в качестве подполя разложения обычно выби-
рается простое подполе GF (р)). Процедура ставит своей целью
минимизацию числа умножений в поле F, не пытаясь минимизи-
ровать число умножений в подполе. В большинстве практических
случаев этими умножениями в подполе оказываются умножения
на малые целые числа, обычно на 1, О или 1, которые триви-
альны. Начиная с данного момента, мы не будем учитывать умно-
жения на рациональные числа в полном числе умножений, хотя
практически всегда надо проверять, являются ли эти рациональ-
ные числа на самом деле малыми целыми числами.
Быстрые алгоритмы свертки основаны на вычетах
я<>'>(х) = R <q» „[s(x)], А = О, ..., К ‒ 1.
Согласно китайской теореме для многочленов, многочлен s (х)
можно вычислить по системе остатков в соответствии с формулой
s(x) = a«»(x)s«»(x)+ .. +а<" ‒ '> (x) s<" ‒ '> (х) (то4и(х)),
где а<о> (х), ..., а<к ‒ '> (х) соответствующие многочлены с раци-
ональными коэффициентами. Разобьем это вычисление на три
шага. Сначала вычисляются остатки ««'> (х) = R «,> <Ä [d (х) ]
и g<~> (х) = Я «,><„[g (х)] для всех lг = О, ..., K 1. Эти
вычисления не содержат умножений. Затем вычисляются вели-
чины
з«'> (х) = g (х) d (х) (то4 и<" > (х)) =
R «>l [ R <>,> ~ [g (X)]' R «» р [d (x)] ]
= Я «,> <„, [g«'> (х) <><~> (х)].
Наконец, вычисляется многочлен
s(x) = а<о>(х) s<о> (x) + ° .. + а<к ‒ '> (х) s« ‒ '> (х) (то4и (х)).
Так как коэффициенты всех многочленов а<~>(х) являются раци-
ональными числами, то последний шаг также не содержит умно-
жений.
Структура алгоритма Винограда для вычисления свертки
показана на рис. 3.7. Умножения возникают только на втором
шаге при вычислении коротких сверток, задаваемых произведе-
ниями многочленов, g<~> (х) d«'> (х); так как число коэффициентов
у многочленов g<~> (х) и d<~> (х) равно степени MHoro
92 Гл. 3. Быстрые алгоритмы коротких сверток
Вход
Выход
Рис. 3.7. Структура алгоритма Винограда для коротких сверток.
члена т<~> (х), то полное число умножений, необходимых
для стандартного способа вычисления этих произведений,
К ‒ 1
равно ~ [deg т<~> (х) ]2. Это дает существенное уменьшение
@=О
числа необходимых умножений. Позже мы увидим, что исполь-
зование той же самой идеи разбиения на еще более мелкие под-
задачи позволяет добиться улучшения и при вычислении этих
составляющих коротких сверток.
На рис. 3.8 дается поучительное сравнение алгоритма Вино-
града вычисления свертки и алгоритма, основанного на дискрет-
ном преобразовании фурье. Для того чтобы сделать это сравнение
более наглядным, алгоритм Винограда выписан в приведенных
выше матричных обозначениях. После группировки членов и
перехода к матричным обозначениям этот алгоритм записывается
в виде равенства
s = С ([Bg].[Ad]},
где точка обозначает покомпонентное произведение векторов Bg
и Ad. Из этого сравнения видно, что алгоритм Винограда яв-
ляется обобщением метода вычисления сверток с помощью пре-
образования Фурье.
В качестве примера рассмотрим вычисление свертки Зточеч-
ного вектора с 2-точечным вектором. Пусть
g (x) = gent + gs
d(х) = й,х'+ d,õ+'d,.
93
3.3. Алгоритмы Винограда вычисления коротких сверток
Вход
Вход
Свертка
Ю частютной абласти
сдертюа
Винограда
Вьян
с~ертка (mod й' ‒ Ц
ВИМОд
свертка (mod Ж('©))
Рис. 3.8. Сравнение двух способов вычисления сверток.
Прямое вычисление содержит шесть умножений и два сложения.
Мы сначала построим алгоритм, содержащий пять умножений
и восемь сложений. Это не очень хороший алгоритм, но его по-
строение является поучительным. Позже будет приведен алго-
ритм, который лучше и содержит четыре умножения и семь сло-
жений.
Степень линейной свертки s (х) = g (х) d (х) равна трем. Вь>-
берем
m(х) = х (х ‒ 1}(х'+ 1) = m<»> (х) m<'> (х} m>'> (х).
Мяоищтели взаимно просты', возможно и другое разложение
многочлена m (х), но для иллюстрации метода мы остановимся
94 Гл. 3. Быстрые алгоритмы коротких сверток
на выбранном разложении. Вычеты равны
g<О>(А) = go, d(o> (z) = d,
g<'> (х) = д1 + go d< > (х) = ds + d~+ do
g<'>(x) = g,х + g„ d<'>(x) = d,õ + (d, ‒ d,).
Следовательно,
s<o> (x) = g,((О,
""(x) =«~+g)«+d +d.)
s<'> (х) = «,х + g(>) (d,õ + (do ‒ d,)) (mod х'+ 1).
При вычислении s<o> (х) требуется одно умножение, при вычисле-
нии s<'> (х) требуется одно умножение и, как мы увидим, при
вычислении s<'> (х) требуются три умножения.
Вычисление s<2> (х) сводится к вычислению двух величин
(2) (2)д(2) (2)д(2)
О = 00 0 ‒ К1
~(2) (2)й(2) 1 (2) д(2)
81 =КО 1 ~01 ~
(которые случайно имеют структуру произведения комплексных
чисел). Алгоритм этой части вычислений дается равенством
( (o> (2>)
(2)
Д'о
L', l
(и> ‒ g )
и содержит три умножения.
Последний шаг состоит в вычислении s (х) по формуле
s(x)=a<o>(x)s(o>(x)+а<'>(x)s<'>(x)+a<2>(x)s< (х) (mod õ4 ‒ х~+х2 х).
где а<о> (х), а('> (х) и а<2> (х) вычисляются по китайской теореме
об остатках следующим образом. Воспользуемся соотношением
и(('> (х) m<~>(х) + N<~>(х) М<('> (х) = 1
и построим следующую таблицу.'
V' (x)
и (х)
и' '(х) М"'(х)
х ‒ х +х †!
2
х + х
2
Х ‒ Х
x ‒ к + !
2
‒ 2(х + к+ 2)
2
1
‒ 2(х ‒ 2)
‒ !
l
2
1
2(~
О х
! х ‒ !
2 х +!
Тогда а<~> (х) = N<s>(x) М<~> (х). Следовательно,
s (х) = (ха ‒ х' + х ‒ 1) s<o> (х) + ‒ (хз + х) s<'> (х) +
+ ‒ (хз ‒ 2х2+ х) s<o> (х) (m(>d х4 ‒ хз+ х' ‒ х).
2
3.3. Алгоритмы Вииограда вычислеиия коротких сверток
95
Последнее равенство может быть перезаписано в виде матричного
равенства
so
Si
Sg
‒ ! !
! ‒ !
Sg
Ч'еперь для построения искомого алгоритма надо собрать
вместе его отдельные части. Всего имеются пять умножений,
которые мы выпишем в выбранной единообразной форме
S~ G~Dg„k = 0, ..., 4.
Определим новые обозначения, соответствующие этой форме.
Используя проделанные вычисления, для вектора D получаем
определение
1 0 0 0
1 0 ‒ 1
Вектор б определяется аналогично, но в его определение мы
включим знаменатели, которые должны появиться в матрице
постсложений. Поэтому в данном ниже определении вектора б
появляется самая левая матрица, содержащая извлеченные из
~0
D,
Р
рз
D~
! 0 0 0
‒ 1 1 1
l 0 ‒ 2 0
0 1 0 0
0 0 111 lill
0 0 ,'0 llii
1 0 0 0
0 1 0 0
0 0 1 1
0 0 1 0
0 0 0 1
! {})
7 и
Х ~Р)
о
1 (~)
2 !
96 Гл. 3. Быстрые алгоритмы коротких сверток
матрицы постсложений множители 1/2. Таким образом,
'J
1
2
l
2
I
2
l
2
Так как вычисление вектора G является предваряющим алго-
ритм вычислением, то эту матрицу можно в дальнейшем просто
отбросить.
Наконец, матрица постсложений имеет вид
о о о
‒ ! I 1 !
о -г о
†! ! 1 ‒ 1
о
о о
о ! о
о о
Sî
S,
S,
~1 Э
~4
!
‒ t
1
‒ 1
о о
г
о ‒ 2
о
о о
! ‒ !
о г
‒ 1 ‒ 1
Описанный алгоритм в матричной форме приведен на рис. 3.9.
Порядок выполнения сложений в такой форме алгоритма не ука-
зан. Читатель может сам поэкспериментировать с выбором по-
рядка сложений, минимизируя их число; никакой специальной
теории выполнения такой минимизации не разработано. Легко
выполнить все предсложения с помощью четырех вещественных
сложений. Постсложения можно реализовать с помощью следу-
ющих восьми вещественных сложений:
so = So.
Ъ ‒ ~1+ ~1+ Sp
С1 S4 ~2т 01 ~1 + A Ъ~
с!! ~8 + S4 sg cg SP + ~1
3то завершает рассматриваемый пример построения алгоритма
Винограда для свертки, но построенный алгоритм можно улуч-
шить. Более общая форма алгоритма Винограда соответствует
G0
С,
С2
Ñ4
А
2 2
0
l
2 2
l l
2 2
1 0 0 0
0 1 0 0
0 0 ~ 1 и
3.3. Алгоритмы Винограда вычисления коротких сверток
97
! 0 0
1 1 !
1 ! ‒ !
! 0 ‒ !
0 ! 0
! 0 0 0 0
†! ! 2 ! ‒ 1
! 0 ‒ 2 0 2
‒ 1 ! 0 ‒ ! ‒ 1
<о
О,
G2
~'э
G4
~о
S(
S2
$э
1 0
!
2 2
0
I
2
l
2 2
l l
2 2
<о
G,
G2
G3
~~~4
Рис. 3.9. Пример алгоритма Винограда вычисления свертки.
выбору многочлена и (z) меньшей степени. Это приводит к не
правильному вычислению свертки, но ошибка легко подправляется
с помощью нескольких дополнительных вычислений.
Согласно алгоритму деления для многочленов можно записать
s (х) = Q (х) т (х) + R <,1 [я (х) ].
Мы уже рассмотрели случай deg т (х) ) deg s (х), E котором
частное Q (х) тождественно равно нулю. Если deg и (х} .< deg s (x),
то алгоритм Винограда позволяет вычислить я (х) по модулю
многочлена и (х}. Член Q (х) т (х) представляет собой погреш-
ность, которую можно вычислить дополнительно и прибавить
к результату. Простейшим является случай, когда deg т (х) =
= deg s (х). Тогда многочлен Q (х) является константой, так как
его степень должна быть равной нулю. Если т (х) приведенный
многочлен степени п, то, очевидно, Q (х) = s„, где я„коэффи-
циент при х„в многочлене s (х). Следовательно,
s (x) = я„т (х) + R <> [я (x) ],
и я„легко вычисляется как произведение старших коэффициентов
многочленов g (х} и d (х).
Эту модификацию можно формально включить в основной
алгоритм Винограда для вычисления свертки путем замены
многочлена т (х} формальным выражением и (х) (х ‒ оо). Утвер-
ждение
s (х) = s (х) (mod и (х) (х оо))
представляет собой просто удобное сокр ащение для данного
выше точного утверждения.
Вернемся к предыдущему примеру и применим описанную
модификацию алгоритма к вычислению свертки
s (х) = (д,х + ~,) (д,х' + d,õ + d,).
качестве модуля выберем теперь многочлен х (х 1) (х+
+ 1) (х oo). Алгоритм будет содержать четыре умножения;
98 Гл. 3. Быстрые алгоритмы коротких сверток
множителю (х оо) соответствует произведение дф,, а остальные
три умножения это произведения вычетов по модулям х, х 1
и х + 1. Сразу видно, что
1 d
1 d
1
Коэффициенты многочлена s (х) вычисляются в соответствии
с китайской теоремой об остатках.'
s (x) = а)о> (х) S, + а<) > (х) S) + a<s> (x) S, + х (х ‒ 1) (х + 1} S~ =
=( '+1)S,+ ( х'+ х) Я,+( х' ‒ ‒ х) 5,+
+ (х' ‒ х) S,.
Следовательно,
1 0 0 0
0 1 ‒ ! ‒ 1
So
S)
‒ о
Sg
0 0 0 1
Окончательная формулировка алгоритма приведена на
рис. 3.1Q. Алгоритм содержит четыре умножения и семь сложений
при условии, что диагональная матрица вычисляется Заранее.
ю, = 1 ‒ 1 1 (go ‒ g)) 1 ‒ 1 д
Рис. 3.10. другой пример алгоритма Винограда вычисления свертки.
ЗА. Построение алгоритмов
коротких линейных сверток
Рассмотренный в предыдущем разделе метод Винограда по-
строения коротких сверток приводит к хорошим алгоритмам.
Однако следует подчеркнуть, что эта конструкция не исчерпы-
вает всех возможных путей построения хороших алгоритмов.
So
S)
S
S,
с
�[Фа
1 ‒ 1
О 1
о
1
1 ‒ 1
о о
3.4. Построение алгоритмов коротких линейных сверток
99
Иногда хорошие алгоритмы удается получить с помощью удачной
факторизации. Рассмотрим следующие тождества:
аоА = ао~1о
амит+ grado = (go+ а1) (d + А) ао4 аА
gpg + Adg + godo = (go + ао) (dp + do) godo +
+ а1~11 godown
g~4 + god~ = (g~ + go) (d~ + do) g~d4 godo
аы4 = а4.
Эти тождества позволяют вычислить коэффициенты свертки s (х) =
= (g, + g,õ + а,х') (d, + d,õ + d,õ"-) c помощью шести умноже-
ний и десяти сложений. Этот алгоритм, однако, не может быть
построен с помощью китайской теоремы об остатках. Матричная
форма записи алгоритма дается равенством
о о о
‒ 1 ‒ 1 О 1
‒ 1 1 ‒ 1 О
О -1 -1 О
О О 1 О
о о
о о
о
о
о о
о о
О 1 О
о о
1 О
о
о
гд,
81
t2
48o + gi)
(8О + 82)
(81 + g2)
S2
2
Этот алгоритм следует сравнить с «наивным» алгоритмом, содер-
жащим девять умножений и четыре сложения, и с «оптимальным»
алгоритмом, который вскоре будет построен и содержит пять
умножений и 20 сложений. Нельзя сказать, какой из этих алго-
ритмов лучше. Это зависит от области применения. Позже мы
будем строить большие алгоритмы из малых так, что и число
умножений, и число сложений большого алгоритма будут в основ
ном зависеть от числа умножений в малом алгоритме. В этой
ситуации число сложений малого алгоритма не играет суще-
ственной роли.
На рис. 3.11 затабулированы характеристики некоторых
алгоритмов линейных сверток; на рис. 3.12 приведены некоторые
из них.
Оптимальный алгоритм линейной (3 X 3)-свертки выписан в виде
примера на рис. 3.12. Оптимальный по числу умножений алго-
ритм содержит пять умножений. Он подсказан описанным
в разд. 3.8 алгоритмом Кука Тоома, который также содержит
пять умножений. По существу он совпадает с алгоритмом Кука‒
Тоома и получается выбором многочлена
т (х) = х (х 1) (х + 1) (х 2) (х ‒ оо).
Так как все множители являются многочленами первой степени,
то всего имеется пять умножений. (Если заменить один из множи-
100 Гл. 3. Быстрые алгоритмы коротких сверток
s (х) = д (х) d (х)
Деаа(х) = L ‒ 1
degd(х) = 1V ‒ 1
Веществеиные свертки
Число вещественных
умножеиий
Число вещественных
сложений
Длина и
L
Комплексные свертки
Число комплексных
сложений
Число комплексиых
умножеиий
3
15
Рис. 3.11. Характеристики некоторых алгоритмов вычислеиия коротких линей-
иых сверток.
Линейная свертка 2~3
3 умножения. 3 сложения
8о + 8~
Линейная сеертю 33~3
Ь умо3неннй, 20 сложений
0 ‒ 1
1
ago
I
2(80 + gl + g2)
l
o(go gl + Я2)
j(ge + egg + 4gg)
Ю
[!]
2 0 0
‒ 2 -2
-2 ! 3
I -I
0 0 0
~о
S)
S2
~3
S4
Рис. 3.12. Некоторые алгоритмы зычислеиия линфйных сверток.
Оредсложения
А + 4~2
lg m Д ‒ g)
Ро 4~о
~о+ <>
Рг ~4+<3
Р3 =I>+I>+I>4-D>
Р =д
Постсложения
~о = 8о + 8о
Т, = S, + S,
Т2 = sz + 82
Т3 84+ 84
Т4 Т3 80 83
Т =З,+S
=Т,‒ Т +Т
s2 so+ Т2+ Т3 54
‒ ‒ Т4 ‒ Т3
~4 = 84
3
7
20
10
4
41
15
3.4. Построение алгоритмов коротких линейных сверток
телей многочленом второй степени, то получим шесть умножений,
но меньшее число сложений.) Выходной многочлен дается равен-
ством
з (х) = Жх (х ) ) (х(-) ) (х ‒ р) [д (х) (( (х)] + Яффах (х ‒ 1) (х + 1) (х ‒ 2).
Остатки определяются матричными уравнениями
1 0 0
1. 1 1
1 ‒ ! 1
1 2 4
0 0 1
о,
G,
G2
G3
о,
1 ‒ 1 1
~0
D,
D~
~3
D~
2 ~0
2 0 0 0 0
‒ 1 2 ‒ 2 ‒ 1 2
‒ 2 1 3 0
$0
!
I
б S2
I
6S3
$1
$2
1 ‒ 1 ‒ 1
1 ‒ 2
$3
S,
0 0 0 0 1
Постоянные множители можно похоронить в константах диаго-
нальной матрицы, переопределяя величины S> и Gq. Яля выпол-
нения свертки требуется пять умножений. Матрица предсложений
может быть реализована семью сложениями, а матрица пост-
сложений 13 сложениями.
Окончательная форма алгоритма показана на рис. 3.12. Хотя
алгоритм построен для поля вещественных чисел, он пригоден
и в поле комплексных чисел: пять умножений становятся пятью
комплексными умножениями, а 20 сложений становятся 20-ю
комплексными сложениями.
где с целью сохранения стройности и упорядоченности принятых
обозначений G4 и D4 формально определяются как вычеты по
модулю многочлена (х оо). Таким образом, S), = G„D), для
Й = О, ..., 4. Наконец, используя китайскую теорему об остатках,
для многочлена s (х) получаем выражение
.9 Я
1
з(х) = Я, (х' ‒ 2х' ‒ х+ 2) ‒ ‒ S, (х' ‒ х' ‒ 2х) +
2 2
+ ‒ Я, ( х'+ Зх' ‒ 2х) + ‒ Яз (хз ‒ х) + S' (х4 ‒ 2х'+ х'+ 2х).
Запись последнего шага в матричном виде дается равенством
102 Гл. 3. Быстрые алгоритмы коротких сверток
0 0
1 1
‒ 1 1
/ ‒ !
-/ -1
0 0
! 1
‒ 1 1
/ ‒ 1
‒ / ‒ 1
Do
в,
Вг
~з
О,
Китайская теорема об остатках (или интерполяционная фор-
мула Лагранжа) дает
s (x) = $, ( х'+ 1) + ‒ S, (х4 + х'+ х'+ х) +
+ S, (x4 ‒ х'+ х' ‒ х) + Ss (x'+ ух' ‒ х' ‒ ух) +
+ ‒ я (х4 ‒ jx' ‒ -+ jx).
4
В матричной форме это равенство записывается в виде
4 Я
I 0 0 0 0
So
0
4) 1 1 ‒ 1 ‒ 1
$)
Sg
0 1 ‒ 1 / ‒ /
‒ 1 1 1 1 1
4
Множители 1/4 можно спрятать в диагональной матрице.
Алгоритм содержит пять комплексных умножений, эквивалент
шести комплексных сложений в матрице предсложений и экви-
валент девяти комплексных сложений в матрице постсложений.
Процедуру Винограда можно использовать для построения
сверток и большей длины, чем те, что приведены на рис. 3.12;
однако построенные таким образом большие алгоритмы, как пра-
вило, громоздки и содержат слишком много сложений. Вместо
этого можно строить большие алгоритмы из малых. Есть не-
сколько способов построения алгоритмов данных сверток из
Можно также специально строить алгоритм над полем ком-
плексных чисел. Он также будет содержать пять комплексных
умножений, но число комплексных сложений уменьшится. Вы-
берем многочлен
з (х) = х (х 1) (х + 1) (х ‒ 1) (х + j).
Вычисление остатков дается равенствами
3.5. Вычисление произведения многочленов по модулю
103
алгоритмов коротких сверток. Некоторые из них, а именно гнездо-
вой метод и метод Агарвала Кули, будут рассмотрены в гл. 7.
Такие алгоритмы содержат несколько больше умножений, чем
требуется для алгоритма Винограда, но число сложений у них
существеннр меньше.
3.5. Вычисление произведения многочленов
по модулю некоторого многочлена
Мы уже видели, как можно разбивать задачу вычисления
циклической свертки или задачу вычисления линейной свертки
на несколько подзадач меньшего размера. Меньшие задачи опять
имеют вид
s (х) = g (х) d (х) (mod т (х)),
s (х) = g (х) d (х) (mod х' + 1),
где deg m (х) = п и степени обоих многочленов g (х) и d (х)
меньше и, т. е. форму произведения многочленов в кольце много
членов по модулю т (х). Для того чтобы построить хороший
алгоритм исходной линейной свертки, необходимо построить
хорошие алгоритмы для каждого из меньших произведений
многочленов. Достаточно рассмотреть только случай неприводи-
мого многочлена m (х}, так как в противном случае разложение
можно продолжить дальше.
Как будет доказано в разд. 3.8, для неприводимого многочлена
т (х) степени п число умножений, необходимых для вычисления
s (х}, равно 2п 1. Обычно в алгоритме с наименьшим возможным
числом умножений требуется большое число сложений. В прак-
тически приемлемых алгоритмах должен достигаться разумный
баланс между числом умножений и числом сложений. В данном
разделе рассматриваются практические аспекты построения таких
алгоритмов.
Наиболее прямой метод состоит в вычислении линейной свертки
g (х} d (х) (на что требуется по меньшей мере 2л 1 умножений}
и дальнейшем приведении результата по модулю т (х} (что вообще
не требует умножений}. Это на первый взгляд может показаться
парадоксальным, так как мы предлагали вычислять линейную
свертку путем разбиения на подзадачи, соответствующие непри-
водимым многочленам, а теперь сводим задачу обратно к линей-
ным сверткам. Однако этим маневрированием «вперед- назад»
мы существенно снижаем степень линейной свертки, что и улуч
шает ситуацию.
Мы уже рассматривали произведение многочленов
!04 Гл. 3. Быстрые алгоритмы коротких сверток
которое формально совпадает с комплексным умножением. Сейчас
пришло время построить этот алгоритм. Одновременно мы будем
рассматривать произведения многочленов
s (х) = g (х) d(х) (mod х')
s (х) = g (х) d (х) (mod х' + x -+- 1).
Во всех этих примерах g (х) = д,х + -gp u d (х} = ~1,»
Мы будем модифицировать описанную в равд. 3.2 линей-
ную (2x2)-свертку. Алгоритм этой линейной свертки в поли-
номиальной форме записывается в виде равенства
s(x) = g(x) d (x) = ИА1»' + [g~d~ + gpdp (gi gp) (dg dp)]„+
+ @о~о
и содержит три умножения.
Наша задача состоит в вычислении этого произведения по
трем модулям: х' + 1, х' и х' + х -+- 1. Соответствующие три
произведения получаются простой заменой x'- на ‒ 1, О и х 1
соответственно. А именно,
s (х) = g (х) d (х) (mod х~ + 1) =
ЫФ1 gpdp (g~ go) (~4 dp) ] x + gpdо
‒ gals
s(x) = g(x) d(x) (modx') =
[ggd1 gpdp (gl gp) (d1 dp) [ «+ gpdp
s (х) = g (х) d (х) (mod х' + х + -1) =
= [Мо (g~ ио) (~4 dp) ) х + ао4 ‒ а<4.
В матричной форме эти три алгоритма соответственно имеют вид
о
! ‒ ! g
8О 81
о
о
! !
105
Второй иэ этих алгоритмов не очень хорош. Следуя по формаль-
ному пути, мы построили алгоритм,. характеристики которого
хуже следующего эвристического алгоритма, содержащего только
одно сложение:
о о
О 1 ! go Р
А !
Характеристики некоторых алгоритмов вычисления произ-
ведения многочленов по модулю неприводимого многочлена затабу-
лированы на рис. 3.13. В некоторых случаях указаны характе-
ристики двух алгоритмов решения одной и той же задачи. На-
пример, для модуля х' + 1 указан алгоритм, содержащий 9 умно-
жений и 15 сложений, и алгоритм, содержащий 7 умножений
Число
умножений
Число
сложений
Простой многочлен р (х)
х~+ х+ 1
ха+ 1
х4+ хэ+ хэ+ х+ 1
P+ х~+ 1
х~+ х~+ х4+ х~+ ~~+ х+ 1
xxs+ xe+ 1
Рис. ЗЛЗ. Характеристики некоторых алгоритмов вычисления произведения
многочленов по модулю простых многочленов.
и 41 сложение. При выборе того или иного алгоритма надо оцени-
вать ситуацию и понимать, как данный алгоритм вкладывается
в алгоритм большей задачи. Часто случается, что несущественные
преимущества в числе умножений в малом алгоритме приводят
к большим преимуществам, когда этот алгоритм используется
'в виде блока в большом алгоритме, в то время как большие потери
в числе сложений малого алгоритма приводят лишь к незначи-
тельным потерям в числе сложений большого алгоритма. 'Гак,
например, для модуля х4 + 1 алгоритм с семью умножениями
может на самом деле дать больше, чем это может показаться.
Можно построить также и библиотеку хороших алгоритмов
для вычисления коротких циклических сверток. Эти алгоритмы
можно строить как по методу Винограда построения коротких
3.6. Построение алгоритмов коротких циклических сверток
3
9
7
9
7
15
15
75
3.6. Построение алгоритмов
коротких циклических сверток
3
15
41
16
46
39
53
267
106 Гл. 3. Быстрые алгоритмы коротких сверток
сверток, так и другими способами. Для построения алгоритма
по методу Винограда надо быть уверенным в том, что каждое из
рассматриваемых малых произведений многочленов может быть
вычислено хорошим алгоритмом. Яля этих подзадач мы будем
пользоваться уже построенными в предыдущем разделе алго-
ритмами.
В настоящем разделе в качестве примеров будут построены
несколько хороших алгоритмов. Некоторые алгоритмы вычисле-
ния коротких циклических сверток приведены в приложении A.
Излагаемый в гл. 7 метод, известный под названием алгоритма
Ага рвала Кули, позволяет строить алгор итмы вычисления
сверток больших длин, комбинируя известные алгоритмы для
коротких циклических сверток.
Рассмотрим задачу вычисления циклической свертки
s (x) = g (x) d (х) (mod - 1),
где оба многочлена g (х) и d (х) имеют степень, равную п l.
Один из способов решения состоит в том, чтобы найти сначала
линейную свертку, а затем выполнить приведение по модулю
х" 1. Чтобы реализовать такой' способ, надо модуль т (х)
для вычисления линейной свертки выбрать так, чтобы его степень
была по меньшей мере равна 2п ‒ 1, так как она должна быль
больше суммы степеней g (х) и d (х).
Альтернативный способ состоит в использовании китайской
теоремы об остатках, на последнем шаге которой для восстановле-
ния многочлена s (х) в качестве модуля т (х) используется не-
посредственно х" 1, а в качестве взаимно простых модулей
используются делители и' (х), m«> (х), ..., m<< ‒ '> (х) многочлена
и (х). Так как сумма степеней этих простых делителей должна
быть равна и, что меньше чем 2п 1, то можно ожидать упро-
щения вычислений. С другой стороны, делители уже нельзя
выбирать так, как нам удобно. Первый метод допускает выбор
произвольных делителей, но сумма их степеней должна быть
равной 2п ‒ 1, а не и.
В качестве простейшего примера рассмотрим вычисление
4-точечной циклической свертки:
s (х) = g (х) d (х) (mod ха 1).
Я;елителями многочлена х4 1 служат циклотомические много-
члены,
х' ‒ 1 = (х ‒ 1) (x + 1) (х'+ 1) = т<о> (х) т<'> (х) т<'> (х).
8 этой задаче у нас нет реального выбора: циклотомические много-
члены представляют собой такие модули, которые необходимо
3.6. Построение алгоритмов коротких циклических сверток
107
использовать в алгоритме Винограда. Коэффициенты вычетов
даются равенствами
‒ ) !
Мы уже построили несколько алгоритмов вычисления умножения
по модулю х' -+- 1. Одним из них является правило
0 4~о
0 0
0
Следовательно, внутренние переменные даются определениями
1 О ‒ 1 О
1 ‒ 1 1 ‒ 1
1 О О О
Далее, S„= G~Dz для Й = 0, ..., 4. Китайская теорема о6
Остатках дает
s (х) = (х'+ хз + х+ 1) s<s> (х) ‒ ‒ (хз ‒ х2+ х ‒ 1) s<'> (х)‒
‒ ‒ (х2 ‒ 1) в<2> (х) (mod х~ ‒ 1).
б'0
б,
G,
б',
G,
1 О
1
О,‒ 1
О ',1
! !
‒ ! !
0 ‒ ! 0
! 0 ‒ )
108 Гл. 3. Быстрые алгоритмы коротких сверток
Таким образом,
! S'О)
4 0
! ~!!
! ~<n
э~о
г4"
1 1 1 0
1 ‒ 1 0 1
1 1 ‒ 1 0
1 ‒ 1 0 ‒ 1
SI
Sg
!
4 S0
-S
I
1 1 0
‒ 1 1 1
1 ‒ 1 0
‒ 1 ‒ 1
!
†2,S,
‒ S
!
2 З
I
2 ~4
Окончательный вид алгоритма показан на рис. 3.14. B упоря-
дочивании элементов матриц, конечно, имеется некоторый произ-
вол. В матрице предсложений допустима произвольная переста-
новка строк, а в матрице постсложений перестановка столбцов;
это не влияет на результаты вычислений.
На рис. 3 15 приведены характеристики некоторых наилучших
известных алгоритмов вычисления коротких сверток. Эти алго-
ритмы, часть из которых приведена в приложении А, построены
по описанному методу. В некоторых случаях для уменьшения
~исла сложений использовались дополнительные методы, анало-
гичные тем, которые будут описаны ниже в оставшейся части
раздела.
Рис. 3.15 следовало бы дополнить характеристиками коротких
сверток для поля комплексных чисел. Каждый алгоритм вы-
числения свертки в вещественном поле подходит в качестве алго-
р итма для комплексного поля. Но иногда многочлен х" 1
над полем комплексных чисел разлагается на большее число
простых делителей, чем над полем вещественных чисел. Эго в ком-
плексном случае дает конструктору алгоритма дополнительные
ВОЗМОЖ КОСТИ-
Алгоритм Винограда можно рассматривать как метод разло-
жения некоторых матриц. Пусть s, g u d векторы длины и,
компонентами которых являются соответственно коэффициенты
многочлеиов s (х), g (х) и d (х). Циклическая свертка s (х) =
3.6. Построение алгоритмов коротких циклических сверток
<о
с,
С2
~3
~~4
‒ 1
0
!
0
! 1 0
‒ 1 ! 1
! ‒ 1 0
†! †! †!
1 !
I ‒ 1
‒ 1 ‒ 1
‒ 1 0
0 ‒ 1
1 I
1
! 1
1 0
0 !
do
dI
~з
d~
SO
SI
Sg
~э
гдв
l
4
Рис. 3.!4. Алгоритм 4-точечной циклической свертки.
s (х) = g (х) d (х) (то4 х" ‒ 1)
degg(х) = n ‒ 1
degas (х) = n ‒ 1
Вещественные свертки
Число вещественных
умн ожеиий
Число вещественных
сложений
Длина п
Рис. 3.15. Характеристики некоторых алгоритмов вычисления циклической
свертки.
= g (х) d (х) (mod х" I) может быть записана в виде матричного
произведения
gss- I
gII
S0
gI ga
SI
Я -I
g. -г
Я -i
д» I
go
2
3
4
5
5
7
8
8
9
16
16
2
4
5
8
10
16
12
14
19
33
35
4
11
15
62
31
70
72
46
74
181
155
110 Гл. 3. Быстрые алгоритмы коротких сверток
ИЛИ
s= Td.
Алгоритм Винограда, записываемый равенством
в = С [(BQ)-(АЙ)],
может быть записан также в виде
s =CGAd,
где А представляет собой матрицу размера М (и) х и, С является
диагональной матрицей размера М (и) х М (и), а С является
матрицей размера и X M (и). Таким образом, алгоритм Винограда
можно рассматривать как алгоритм разложения матрицы
Т =CGA,
где Gдиагональная матрица, ,а С и А ‒ матрицы, элементами
которых являются малые целые числа.
Так как в большинстве приложений многочлену g (х) соответ-
ствует фиксированный КИО-фильтр, или по крайней мере КИО-
фильтр, коэффициенты которого меняются не слишком часто,
то вычисление G = Bg приходится выполнять не слишком часто
и при подсчете общей вычислительной нагрузки им можно пре-
небречь. Следовательно, сложность матрицы В особой роли не
играет.
Роли матриц АиВ симметричны, ,так как их можно поменять
местами путем простого переименования векторов d u g. Алгоритм
Винограда вычисления свертки допускает построение матриц А
и В, отличающихся только перестановкой строк, и, следова-
тельно, имеющих одну и ту;же сложность; но в общем случае
более целесообразно одну из матриц строить более сложной и
именно ей приписывать роль матрицы А. Удивительно то, что
в алгоритме циклической свертки можно менять ролями даже
матрицы С и А. Способ сделать это описывается следующей
теоремой.
Теорема 3.6.1 (теорема об обмене матриц). Если теплицева
матрица S допускает факторизацию вида
$ =CDE,
mo она может бьопь также эаиисана в виде
(E) рт (С)т
где матрица Е отличается от матрицы Е обращенным порядком
столбцов, а матрица С отличается от матрицы С обращенным
лорядком строк.
3.7. Свертки в общих полях и кольцах
Доказательство. Пусть Я представляет собой обменную ма-
трицу того же размера, что и матрица S. Тогда
Ьт JS3 ()С) 0 (Е.)) CDE
Операция транспонирования завершает доказательство. Q
Применим эту теорему к умножению многочленов по модулю
многочлена х" ‒ (, где Р некоторая константа. Пусть надо
вычислить
, s (х) = g (х) d (х) (mod х" g),
где g (х) и d (х) многочлены степени не более п ‒ 1. Если g = 1,
то мы имеем задачу о циклической свертке. Случай ~ = 1
(а в поле комплексных чисел и случаи g = ~j) также очень важен.
Запишем это произведение многочленов в малерично-векторном
виде
gd„ ,
А)
do
d)
dg
gn
S)
d)
g2
или
s= Tg,
теплицева матрица. Алгоритм
s = С [(Bd) (Ag))
где Т
3.7. Свертки в общих полях и кольцах
Любой алгоритм свертки, такой как алгоритм Кука Тоома
или алгоритм Винограда, представляет собой некоторое тожде-
ство, опирающееся на свойства операций в данном поле, в ча-
стности на свойства ассоциативности, дистрибутивности и комму-
можно перезаписать в виде
s = CBAg,
где О диагональная матрица, диагональные элементы которой
равны компонентам вектора Bd. Согласно теореме 3.6.1,
s = (А) г D (С) г g.
Применительно к задаче вычисления циклической свертки тео-
рема 3.6.1 означает, что наиболее сложную из трех матриц А,
B и С можно выбрать множителем при векторе g и «включить»
ее в матрицу G.
112 Гл. 3. Быстрые алгоритмы коротких сверток
тативности. Алгоритм, построенный в одном поле, может быть
использован в любом расширении этого поля. Он, однако, может
оказаться не столь хорошим, как алгоритм, разработанный спе-
циально для данного поля.
В частности, алгоритм свертки двух вещественных последова-
тельностей можно без изменений использовать для свертки после-
довательностей комплексных чисел. Если обозначить через М
и А соответственно числа вещественных умножений и сложений,
необходимых для вычисления вещественной свертки, и если для
вычисления комплексной свертки использовать тот же алгоритм
с обычными комплексными умножениями и обычными комплекс-
ными сложениями, то в общей сложности получится 4М веще-
ственных умножений и 2А + 2М вещественных сложений. Если
вместо этого воспользоваться построенным B разд. 1.1 комплекс-
ным умножением и рассматривать одну часть свертки как отводы
фиксированного фильтра, то потребуется только ЗМ веществен-
ных умножений и 2А +ЗМ вещественных сложений.
Если длина комплексной циклической свертки равна некото-
рой степени двойки, то можно построить даже еще лучший алго-
ритм. Для пояснения того, как это делается, рассмотрим свертку
по модулю x" -+- 1.
В кольце многочленов по модулю многочлена х" + 1, ~ )~ 1,
имеется элемент, квадратный корень из которого равен минус
единице. Действительно,
1 =х~' (mod х" + 1)
так что в рассматриваемом кольце ~1 = x'~ . Воспользуемся
этим элементом, чтобы выписать комплексную свертку через две
вещественные свертки.
Для вычисления комплексной свертки
s (х) = g (х) d (х) (mod x"~ +- 1),
где
g(x) = gR(x)+]gs(x) и d(x) = d„(x)+jd,(х),
можно вычислить по модулю х' + 1 четыре вещественных свертки
С
g„(x) d„(x), g, (х) d„(x), дл(х) dz (х) и g, (х) dz (х) и записать
s„(x) = g„(x) d„(x) ‒ g, (х) d( (х),
~(х) = gR(x) dz(x)+ gi(x) dR(x).
Лучшая процедура, содержащая вдвое меньше умножений, сво-
дится к введению многочленов
а(х) = (g„(x) ‒ х" 'gi(x)) (d„(x) ‒ xÐ' 'di (х)) (mod х~'+ 1)
b(x) = (ул(х)+ х' ~~,(х)) (d„(x) + х' 'dz (х)) (mod х" + 1),
113
3.8. Сложиость алгоритмов свертки
вычисление которых сводится к вычислению двух вещественных
сверток. Выходной многочлен s (х) = g (х) d (х) (mod х' + 1)
дается при этом равенствами
sR(x) = а(х)+ Ь(х),
з/(х) =х' '(а(х) ‒ Ь(х)) (то4 х' + 1).
Мы хотим воспользоваться этой процедурой для вычислени я
комплексной циклической свертки
s (х) = g (х) d (х) (mod х" ‒ 1),
где и равно степени двойки. Запишем
х~ ‒ f = (z ‒ 1)(z+ f)(хи+ f)(х4+ Ц .. (хп/2+ 1).
Тогда задача сводится к коротким циклическим сверткам вид
s</1(х) = g</>(x)d</~ (x) (mod x2 + 1).
Комплексные свертки по модулям s 1 и х + 1 являются ска-
лярами, и их произведение вычисляется как произведение ком-
плексных чисел. Их вклад в общую сложность очень мал. Если
остальные комплексные свертки вычислять через две веществен-
ные свертки, то рассматриваемый способ вычисления комплексной
свертки потребует примерно вдвое больше вычислений, чем веще-
ственная свертка той же длины.
Этот метод конкурирует с методом разложения многочлена
х" 1 B поле комплексных чисел:
xä 1 = (x 1) (x+ 1) (x j) (x +j) (xà/4 ‒ j) (xë/4 + j)
Каждая из индивидуальных подзадач теперь меньше, но арифме-
тика является комплексной.
3.8. Сложность алгоритмов свертки
Пусть задан алгоритм решения некоторой задачи; следует ли
этим удовлетвориться или следует попытаться найти лучший
алгоритм? На этот вопрос трудно ответить по нескольким при-
чинам. Во-первых, трудно выбрать критерий, согласно которому
можно утверждать, что алгоритм является наилучшим. Яалее,
если даже такой критерий выбран, то трудно утверждать, что
характеристики оптимального алгоритма соответствуют выбран-
ному критерию.
Во многих задачах критерием оптимальности служит мини-
мизация числа умножений. Этот кр итерий достаточно прост,
так что удается доказать некохорые теоремы, описывающие харак-
теристики оптимального алгоритма. Конечно, после отыскания
оптимального алгоритма может оказаться, что он нам не подойдет,
114 Гл. 3. Быстрые алгоритмы коротких сверток
скажем, по числу сложений, но все-таки хочется знать, что пред-
ставляет собой такой алгоритм.
В данном разделе мы будем исследовать характеристики опти-
мального (в смысле минимального числа умножений) алгоритма
свертки. Для этого надо уточнить понятие умножения, и мы
сделаем это так, чтобы можно было ответить на интересующие
нас вопросы. А именно, мы хотим определить умножение таким
специальным образом, чтобы под произведением d-g понималось
произведение произвольных вещественных чисел, но туда бы не
входило произведение 2g, так как его можно интерпретировать
как g + g. Такое различие легко принять, но как быть с произве-
дением 3g или (5/7) g? Мы выберем определение, которое приводит
к полезным результатам. Вычисление d.g будем считать умноже-
нием только тогда, когда оба сомножителя -принимают произволь-
ные вещественные значения, и не будем считать умножением,
если произвольные вещественные значения допустимы только
для одного из них, а другой должен быть рациональным. Мы уви-
дим, что это определение, хотя интуитивно и кажется несколько
ущербным, приводит к осмысленным результатам. Выбранный
нами критерий может также вызвать подозрение злотому, что
возникающие в приложениях числа всегда записываются словом
конечной длины, так что все вбзникающие в приложениях числа
являются рациональными. Тем не менее если в принципе пере-
менные принимают вещественные значения, то указанное вы-
числение будет называться произведением.
В указанном смысле алгоритмы Винограда вычисления корот-
ких циклических сверток являются оптимальными. Ни один
алгоритм вычисления и-точечной циклической свертки не содер-
жит умножений меньше, чем алгоритм Винограда. Яоказатель-
ство этого факта составляет одну из сложных задач данного
раздела. Мы докажем следующие результаты:
1. Никакой алгоритм вычислени я линейной свертки двух
последовательностей длин L u N не может содержать меньшее
число умножений, чем L + N 1.
2. Если число простых делителей многочлена х" 1 равно t,
то никакой алгоритм вычисления и-точечной циклической свертки
не может содержать меньшее число умножений, чем 2п
3. Если число простых делителей многочлена р (х) равно t,
то никакой алгоритм вычисления произведения многочленов
g (х) d (х) по модулю р (х) не может содержать меньшее число
умножений, чем 2п
Вторая задача, конечно, является частным случаем третьей,
но она столь важна, что ее следует выделить отдельно.
Рассматриваемые идеи не зависят or поля. Пусть F некото-
рое поле, которое мы назовем полем вычислений, а Е его под-
поле, называемое полем констант или основным полем. Элементы
115
3.8. Сложность алгоритмов свертки
из Е называются скалярами. Пусть d = (d~ ..., д„,) и g =
= (g" g.,) произвольные векторы фиксированных длин а
и r с компонентами из поля F. Компоненты векторов d u g будем
называть неопределенными переменными или просто перемен-
ными. Эти и + г переменных величин независимы. их не связы-
вают никакие соотношения. Алгоритмом называется правило
вычисления последовательности элементов /„ ..., fg из F, таких
что каждый элемент f~ последовательности равен одной из Следу-
ющих величин: (1) или компоненте вектора d, или компоненте
вектора g, или сумме, разности или произведению двух таких
компонент; (2) сумме, разности или произведению компонент
вектора d или вектора g на элемент f; последовательности с номе-
ром /, меньшим номера i; (3) сумме, разности или произведению
двух элементов fi и f„ïîñëåäîsàòåëúíîñòè, номера j и ~г кото-
рых меньше номера i; (4} элементу поля Е.
Скажем, что алгоритм вычисляет выходной вектор s, если
компоненты вектора s содержатся в последовательности f„ f,
Необходимо подчеркнуть, что являющиеся компонентами век-
тора s переменные величины связаны некоторыми функциональ-
ными соотношениями с переменными, являющимися компонен-
тами векторов d u g. Алгоритм, вычисляющий вектор s, пред-
ставляет собой фиксированную процедуру правильного вычисле-
ния s для любых возможных значений входящих в d u g пере-
менных.
Заметим, что данное определение алгоритма не включает в себя
ни ветвления, ни деления. В алгоритмах, которыми мы зани-
маемся, эти операции не являются необходимыми, к тому же ни
деление, ни ветвление не могут уменьшить числа умножений.
Яанное определение алгоритма можно проиллюстрировать
примером комплексного умножения. Сначала запишем его в виде
d а
d c
Ч'огда равенства
fr=ca, fa=db. fa= fi
f4 da 4 СЬ Й f4 +fá
aKvr описание алгоритма в виде последовательности правил вы-
числения.
Вычисление произведения комплексных чисел можно также
записать в виде
( ‒ 0~ о î i 0
о (+<)
о о у
116 Гл. 3. Быстрые алгоритмы коротких сверток
Тогда равенства
f1 = a К fm = c А 4 = c + ~( ° f4 = f2а~
1Б = f3~> f6 = 4Ъ> f1 = f4 +f6 ° f8 = fi> + f6
дают описание последнего алгоритма в виде последовательности
правил вычисления.
Рассмотрим набор всех таких множеств правил вычисления
комплексного умножения. Оптимальным из этого набора алго-
ритмов является тот из них, который содержит наименьшее число
умножений.
Теперь можно формализовать определение задачи вычислений.
Будем рассматривать только задачи вида
s= Hd,
где d входной вектор данных длины k, à s выходной вектор
длины и. Элементы матрицы Н представляют собой линейные
комбинации г неопределенных переменных ~„..., ~,.1. В типичных
случаях r меньше числа элементов матрицы Н и каждая перемен-
ная может присутствовать в матрице Н более одного раза. Такая
структура включает в себя все рассмотренные задачи вычисления
свертки.
Под элементами матрицы Н будем понимать не элементы поля,
а линейные комбинации неопределенных переменных вида
r ‒ 1
» юу Е ~хюл> А>
А=О
где сс;~„являются скалярами. Яве такие линейные формы можно
складывать, любую линейную форму можно умножать на скаляр.
Множество таких линейных форм над полем Е образует векторное
пространство, которое мы обозначим Е [д„..., д,, ]. Таким
образом, Н является матрицей над множеством линейных форм.
Для матрицы Н не выполняются многие известные свойства
матриц, поскольку она является матрицей не над полем (и даже
не над кольцом), а над множеством E [g„..., g,,). В частности,
ранг по столбцам не обязательно равен рангу по строкам. Как
мы увидим, ранг по строкам и ранг по столбцам каждый дают
нижнюю границу для числа умножений в задаче s = Hd. Воз-
можность менять ролями векторы g u d дает два пути применения
этих двух границ.
Ранг по строкам определяется следующим образом (анало-
гично определяется ранг по столбцам). Каждая строка матрицы Н
представляет собой вектор длины Й с компонентами из множества ')
1) Это множество образует векторное пространство, но мы предпочитаем
называть его множеством, так как не рискуем говорить «вектор векторою.
117
3.8. Сложность алгоритмов свертки
Е tgp, -, g, 11. Линейная комбинация строк матрицы Н также
является вектором длины k с компонентами из того же множества
п
вида ~~ ~~И,, где элементы Pq принадлежат полю E для всех
1=1
~ = 1, ..., и. Рангом по строкам матрицы И называется мощность
наибольшего множества линейно независимых строк, т. е. такого
наибольшего множества строк, что никакая ненулевая их линей-
ная комбинация не равна нулю.
Например, над полем рациональных (вещественных) чисел
ранг по столбцам матрицы
4go яо
Н = 2g> ‒ g,
2© ‒ 2яо go
равен двум, так как
4gn
2g,
2gi - 2g
но никакая линейная комбинация двух столбцов не равна тожде-
ственно нулю.
Теорема 3.8.I (теорема о ранге по строкам). Для проимоль-
ного алгоритма вычисления s = Hd число умножений по меньшей
мере равно рангу по строкам матрицы К.
До~азцтельство. Без потери общности можно предположить,
что линейно независимыми являются первые р строк матрицы К,
и в дальнейшем рассматривать тол~ко эти строки. Обозначим
через М матрицу, образованную этийи строками, и рассмотрим
только частичное вычисление
= М4.
Идея доказательства сводится к построению подходящей ма-
трицы А над полем Е, для которой выполняются известные свой-
ства матриц.
Предположим, что в алгоритме, задаваемом последователь-
ностью f„..., f~, имеется 1 шагов умножения, задаваемых соот-
ветственно 1 членами последовательности е1, ..., е~. Тогда первые р
компонент вектора s должны быть линейными комбинациями
f l8 Гл. 3. Быстрые алгоритмы коротких сверток
этих членов-произведений, линейных членов и элементов основ-
ного поля. Таким образом,
(:.1
‒ AI
Доказательство. Доказательство проведем индукцией. Если
ранг по столбцам равен единице, то любой алгоритм должен
содержать по меньшей мере одно умножение. Пусть при ранге
по столбцам, равном 1 1, теорема верна. То есть если ранг по
столбцам матрицы Н равен 1 1, то любой алгоритм вычисления
в = Hd содержит по меньшей мере 1 1 умножение. Igar ин-
дукции состоит в доказательстве соответствующего утверждения
для случая, когда ранг по столбцам равен 1.
Предположим, что задан алгоритм вычисления
s= Hd,
где элементы матрицы А принадлежат основному полю Е, а ком-
поненты вектора Ь являются линейными комбинациями неопре-
деленных переменных и элементов основного поля.
Предположим теперь, что р больше, чем 1. Тогда матрица А
содержит строк больше, чем столбцов, и, следовательно, строки
матрицы А линейно зависимы, т. е. существует такой вектор с
над полем Е, что стА = От. Следовательно,
c~ (Md) = сг (Ае + Ь),
и так как с~А = О, то это приводится к виду
(стМ) 4 = стЬ
В этом равенстве правая часть не содержит произведений неопре-
деленных переменных, так как с содержит только элементы
поля Е, а в Ь не входят произведения неопределенных перемен-
ных; следовательно, и левая часть не содержит произведений
неопределенных переменных. Так как компонентами вектора d
являются неопределенные переменные, то отсюда следует, что
с~М не содержит неопределенных переменных. Но стМ является
вектором, компоненты которого равны линейным комбинациям
неопределенных переменных. Следовательно, он равен нулю и
строки матрицы М линейно зависимы. Полученное противоречие
означает, что 1 больше, чем р, и число умножений по меньшей мере
равно рангу по строкам матрицы H. P
Теорема 3.8.2 (теорема о ранге по столбцам). Для произволь-
ного алгоритма вычисления s = Hd число умножений по меньшей
мере равно рангу по столбцам матрицы Н.
119
3.8. Сложиость алгоритмов свертки
причем ранг по столбцам матрицы Н равен 1. Без потери общности
можно предположить, что последний столбец матрицы Н содержит
по крайней мере один ненулевой элемент (в противном случае
его можно удалить из Н}. Следовательно, переменная d, содер-
жится в некотором члене-произведении, скажем, последнем таком
члене.
Это означает, что для некоторого множества скал яров и<
сумма ~~ u<d; является множителем в некотором умножении,
причем а~ ® О. Так как на скаляры не наложено никаких огра-
ничений, то можно полагать сх~ равным 1, так что член д~ +
! ‒ 1
+ ~ а;а; является множителем в некотором члене-произведении.
r=o
Чтобы завершить доказательство, нам надо при любом данном
алгоритме решения исходной задачи построить, хотя и искус-
ственную, новую задачу
s' = Н'd'
s' = Н'd',
где d' представляет собой вектор длины ( 1, формируемый
из вектора d удалением последней компоненты, а матрица Н'
получается из матрицы Н заменой у-го столбца h; на столбец
Й( а(й,. Таким образом,
d)
Н'
= Н
4-)
ранга 1 1, которую можно решить данным алгоритмом, удаляя
из него одно умножение. Тогда, согласно предположению индук-
ции, любой алгоритм решения новой задачи содержит по меньшей
мере 1 1 умножение, и, следовательно, исходная задача данным
алгоритмом решается по меньшей мере с l умножениями.
Чтобы это сделать, заменим в исходной задаче переменную d<
1 ‒ 1
на f u;d~. Тогда последний член-произведение, содержащий
~~}
! ‒ 1
множителем сумму d< + f u;d<, будет представлять собой
f О
умножение на нуль и, следовательно, может быть удален из алго-
ритма. Алгоритм теперь решает некоторую новую задачу,
а именно,
120 Гл. 3. Быстрые алгоритмы коротких сверток
и данный алгоритм вычисляет Н'ci', что и завершает доказатель-
ство. Q
Теорема 3.8.3. Каждьсй алгоритм вычисления линейной
свертки
s (х) = g (х) d (х),
где degg (х) = L 1 и deg d (х) = N ‒ 1, содержит по мень-
шей мере L+ N 1 умножений.
)7оказательство. Рассматриваемое вычисление можно в матрич-
ном виде записать равенством
s= Hd,
где
gp О ' О О
g, g. - - - o o
Н=
Юс ‒ г
о
является ((L + N 1) X N)-матрицей. Как элементы множества
E t00 й> " ф. >), строки матрицы Н, очевидно, линейно неза-
висимы, следовательно, применение теоремы 3.8.1 показывает,
что число умножений равно по меньшей мере L + N 1. С)
Теорема 3.8.4. Пусть р (х) является простым многочленом cme-
пени п. Каждый алгоритм вычисления произведения многочленов
s (х) = g (х) d (х) (mod р (х))
содержит по меньшей мере 2п 1 умножений.
Доказательство. Предположим, что алгоритм содержит
умножений. Тогда на выходе алгоритма получим линейную ком-
бинацию этих t членов-произведений
s =AS,
где А является (и X t)-матрицей над полем Е, à S вектор
длины t, компонентами которого являются эти члены-произ-
ведения.
Ясно, что многочлены g (х) и d (х) всегда можно выбрать так,
чтобы сделать некоторую одну компоненту многочлена s (х) не-
нулевой, а остальные нулевыми. Следовательно, п строк ма-
трицы А должны быть линейно независимыми, так что А должна
содержать и и линейно независимых столбцов. Без потери общ-
ности можно полагать, что первые и столбцов матрицы А яв-
ляются линейно независимыми, так что матрица А может быть
разбита на блоки вида
> = [А',' А")$
121
3.8. Сложность алгоритмов ыертки
где А' обратимая (и х п)-матрица. Умножим на обратную
к А' матрицу С:
Cs = )l> PQ
= СН4 °
Так как многочлен р (х) неприводим, то можно показать, что
все элементы любой строки матр и цы Н ли нейно независимы,
равно как и все элементы любой линейной комбинации строк
матрицы Н. Эго утверждеиие является стандартным результатом
теории матриц и будет доказано отдельно в виде теоремы 3.8.6
в конце настоящего раздела. Следовательно, все элементы первой
строки матрицы CH линейно независимы, так что согласно тео-
реме 3.8.2 для вычисления первой компоненты вектора CHd
требуется по меньшей мере и умножений.
С другой стороны, первая строка вычисления
Cs = [l,' P)S,
1=1
содержит самое большое 1+ (t n) умножений, так как ма-
трица Р содержит E и столбцов, а вектор $ длины t содержит
все члены-произведения. Следовательно, 1+ (t n) ) п, так что
t)~ 2n 1, что и доказывает теорему. []
В качестве приложения этой теоремы рассмотрим комплексное
умножение как задачу умножения по модулю многочлена х' + 1.
Согласно теореме 3.8.4, для выполнения одного комплексного
умножения необходимо по меньшей мере три вещественных умно-
жения.
Хотя мы и не будем этого делать, теорему 3.8.4 можно доказать
и для умножения многочленов по модулю многочлена p' (х),
где р (х) ‒ простой многочлен. Вместо этого мы рассмотрим слу-
чай, когда р (х) распадается в произведение k простых много-
членов. В этом случае китайская теорема об остатках позволяет
разбить задачу на k подзадач, каждая длины п~, где f и; = п.
t
Дополнительных умножений при этом не возникает. Следова-
тельно, используя для каждой из подзадач теорему 3.8.4, с по-
мощью китайской теоремы об остатках для полной задачи вы-
числения произведения многочленов по составному модулю полу-
чаем по меньшей мере
122 Гл. 3. Быстрые алгоритмы коротких сверток
умножений. Следующая теорема утверждает, что ни один алго-
ритм решения этой задачи не может быть лучше такого исполь-
зования китайской теоремы об остатках.
Теорема 3.8.5. Пусть многочлен р (х) степени и распадается
8 произведение k различных простых множителей. Каждый алго-
ритм вычисления произведения многочленов
s (х) = g (х) d (х) (mod р (х))
содержит по меньшей мере 2n k умножений.
Яоказательстео. Так как китайская теорема об остатках
задает не требующее умножений обратимое преобразование, то
достаточно рассмотреть вычисление s = Hd, в котором матрица
Н блочно-диагональная, т. е.
д)
clg
S)
S2
1
!
)
1
1
1
б
д»
5»
и соответствующая китайской теореме об остатках i-я подзадача
задается вычислением s; = H;d,.
Теперь повторим доказательство теоремы 3.8.4. Иредиоложим,
что алгоритм содержит t умножений. Тогда
s=AS,
Сь = [I' ,P]5
s = [A' , 'А")S
где С обозначает матрицу, обратную к матрице А'. Следова-
тельно, для вычисления первой компоненты вектора Се требуется
самое большое 1+ (t и) умножений. Но, кроме того, выпол-
няется равенство
н,
Нг
. где S вектор длины t, содержащий все члены-произведения,
и А представляет собой (и X t)-матрицу над полем Е. Так как
А содержит и линейно независимых строк, то она содержит и и
линейно независимых столбцов, в качестве которых можно вы-
брать первые и столбцов. Тогда
3.8. Сложность алгоритмов свертки
123
Рассмотрим теперь некоторую линейную комбинацию строк ма-
трицы Н. Любая линейная комбинация строк каждой из матриц
Н~ содержит лишь линейно независимые столбцы. Следовательно,
любая линейио независимая комбинация строк матрицы Н со-
держит по меньшей мере п (Й 1) линейно независимых
столбцов. Следовательно, по теореме 3.8.2 вычисление первой
компоненты вектора CHd требует по меньшей мере п (Й 1)
умножений. Эти верхняя и нижняя границы числа умножениф,
необходимых для вычисления первой компоненты вектора Cs,
приводят к неравенству
1+ (t n) )~ п ‒ (Й 1),
так что t )~ 2п k, что,фоказывает теорему. []
Теперь мы должны завершить незаконченное доказательство
теоремы 3.8.4.
Доказательство.
Шаг 1. Обозначим через С„сопровождающую матрицу много-
члгна р (х), определяемую следующей (п X n)-матрипей:
о -р,
о -p,
о
о о
l О
О 1
с =
Р
О О
Тогда с-й столбец матрицы Н равен C~g, и через свои вектор-
столбцы матрица Н записывается в виде
н=[д сд с',д ... с,"-'a).
Пусть w произвольная ненулевая вектор-строка, à wН
соответствующая линейная комбинация строк матрицы Н. Надо
показать, что никакая линейная комбинация столбцов wH не
равна нулю. Предположим, что
n ‒ 1 п ‒ 1
о= zo,(c',þ) = т,щс,']я.
8=0 ~=0
Теорема 3.8.6. Пусть s = Hd представляет собой матричную
запись произведения многочленов
s (х) = g (х) d (х) (mod р (х)),
гдг р (х) нвприводимый многочлгн, и матрица Н составлгна
из коэффициентов многочлгна g (х). Тогда всг элементы любой
строки матрицы Н, так же как и все элементы любой линейной
комбинации строк матрицы Н, линейно независимы.
124 Гл. 3. Быстрые алгоритмы коротких сверток
Так как это равенство должно выполняться для любого g, то
w a(CÄ) = 0,
где
а(С~) = f а~С
представляет собой матрицу размера и х и, вычисленную по
матрице Ср. Поскольку строка w отлична от нулевой, то матрица
а (С„) должна быть вырожденной, так как в противном случае
w а(С„) не может равняться нулю. Следовательно, нам надо
показать, что единственным многочленом степени не более и 1,
таким что подстановка в него матрицы С„приводит к вырожден-
ной матрице, является нулевой многочлен.
Шаг 2. Легко проверить, что любой простой многочлен р (х)
обращается в нуль при подстановке в него его сопровождающей
матрицы. Таким образом, р (С„) = О, где О обозначает нулевую
(и х и)-матрицу. Пусть а (х) обозначает многочлен степени ие
более и I, такой что матрица а (С„) вырожденна, и пусть v
обозначает ненулевой вектор из нулевого пространства матрицы
а (С„). Тогда, так как р (х) является неприводнмым многочлеиом
степени и, то существуют многочлены А (х) и P (х), такие что
А (х) а (х) + Р (х) р (х) = 1.
Следовательно,
[A(C„) a(C„)+ P(C„) p(C„)]v = Iv.
Но р (CÄ) = О, так что мы имеем А (С„) а (С„) v = v, что про-
тиворечит выбору v: а (С„) v = О. Следовательно, за исключе-
нием нулевого многочлена, не существует многочлена а (х) степени
и 1 или меньше, такого что матрица а (С„) является вырожден-
ной. Это заверша~ доказательство теоремы. Q
Задачи
3.1. а. Комплексное умножение (е+ j f) = (а+ /Ь) (c+ jd) можно вычислить
с тремя вещественными умножениями и пятью вещественнымн сложениями
по алгоритму
е = (а ‒ Ь) d+ а (с ‒ d),
f = (а ‒ Ь) d+ Ь(c+ d).
Положил с и d константами и записать алгоритм умножения в матричной
форме
е а
f
=»A ь
где A и В представляют собой матрицы предсложений и постсложений,
а 0 ‒ диагональную матрицу.
Эадачи
‒ а. ‒ г, 1 -3 d
Предположим, что многочлены d (х) и g (х) имеют комплексные коэффи-
циенты. Сколько потребуется вещественных сложений и вещественных
умножений для выполнения этого алгоритма, если комплексная арнфме-
тика реализуется обычным классическнм cIloco6OMP
в. Представить теперь входные и выходные данные в виде векторов длины
четыре и выписать объединенный алгоритм с шестью вещественными умно-
жениями. Сколько вещественных сложений содержнт этсл алгоритм7
При заданиом устройстве для вычисления линейной свертки двух после-
довательностей длины и описать, как оно может быль использовано для
n ‒ 1
вычисления вэвиыной корреляционной функции f g~+pf; этих после-
д=0
3.2.
довательностей.
Построить алгоритм фильтрации 4-точечной последовательности входных
данных в КИО-фильтре с тремя отводами, используя для этого алгоритм
Кука ‒ Тоома для свертки.
а. Начиная с алгоричма вычисления 2-точечной линейной свертки
З.З.
3.4.
s(x) = ад~l+ [g~d~+ йФо ‒ (й ‒ go) (4 ‒ do)] x+ В4.
построить алгоритм вычисления
s (х) = g (х) d (х) (mod х~ ‒ х+ 1).
б. Пов'горить задачу, начиная с алгоритма
s (x) = аФ.х'+ f(g, + ао) (4+ d ) ‒ аА ‒ ВМ x+ В4.
Какой из алгоритмов заслуживает предпочтениями
Допустим, что у нас имеется устройство (жесткий модуль или подпро-
грамма) для вычислеиия 315-точечной циклнческой свертки, и что требуется
пропустить 1000-точечиый вектор данных через КИО-фильтр с 100 отво-
дами. Описать, как надо разбить даииые и организовать устройство
свертки, чтобы получить требуемый ответ.
Построить алгоритм 4-точечной циклической свертки комплексных после-
довательностей, содержащий четыре комплексных умножения. Сравнить
построениый алгоритм с алгоритмом 4-точечиой циклической свертки
вещественных последовательностей, используемым для свертки комплекс-
ных последовательностей.
Одним из способов определения поля комплексных чисел является рас-
ширеиие поля вещественных чисел с помощью неприводимого многочлена
р (x) = х~+ 1. Комплексное умножение при этом определяется равенством
3.6.
З.B.
3.7.
е+ fx= (а+ Ьх) (с+ dx) (mod х'+ 1).
Используя это определеиие, преобразуйте алгоритм линейной свертки
в алгоритм умножения комплексных чисел.
а. Сколько умножений содержит алгоритм Винограда вычислеиия 16-то-
чечной циклической свертки, если в качестве модулей используются только
рааложеиия
у~6 ‒ 1. = (х ‒ 1) (х+ 1) (х~+ 1) (х4+ 1) (х~+ 1)?
3.8.
б. 2-точечная циклическая свертка з (х) = g (x) d (х) (mod х~ ‒ 1) может
быть вычислена по алгоритму
Гл. 3. Быстрые алгоритмы коротких сверток
126
б . Предположим, что допускается разложение многочлена над полем ком-
плексных рациоиальных чисел, т. е. чисел вида а+ jb, где а и Ь ‒ раци-
ональные числа. Сколько теперь потребуется комплексных умножений,
если B качестве модулей допускаются многочлены, имеющие числа 1, +j
в качестве коэффицнентовР (Замечание: теперь комплексные числа счи-
таются внутренними переменными и умножение на у не считается умно-
жением.)
в. Имеет ли алгоритм (б) преимущества перед алгоритмом (а)Р (Укаэаяие:
рассмотреть, является ли циклическая свертка вещественной или ком-
плексной.)
3.9. Выписать всю последовательиость равенств вычисления линейной (4 X
X 3)-свертки по алгоритму Винограда, основанному иа миогочлене
т (х) = х~ (х+ 1) (х ‒ 1) (х~+ 1).
3.10. Для представлеиия в ЭВМ чисел с двойной точностью можно использовать
запись числа в виде многочлена d~x+ d(). Для такой записи чисел с двой-
ной точностью выписать алгоричм умножения без округления, содержащий
и умножения и четыре сложения чисел с одинарной точностью.
3.11. спользуя алгоритм
1 0 0
0 ! 0
0 0 !
! ! 0
! 0 1
0 !
Ю 0 0
0 0
О ! О
О 1
0 0 0
0 0
‒ 1 0
1 ‒ !
‒ 1 ‒ 1
0 1
I
‒ 1
‒ 1
0
0
-о
S(
52
~э
S4
и принцип трансформации~), построить пя1ь иовых алгоритмов. чем онн
интересными
3.12. Доказать, что для любого n .> 1 в поле вещественных чисел лучший алго-
ритм вычисления
а (х) = g (х) Ш (х) (mod х" + ()
содержит больше умножений, чем лучший алгоритм вычисления
s (х) = g (х) d (х) (mod х" ‒ I).
3.13. Найти такие целые числа и и n', что n ( n', но и-точечная циклическая
свертка требует большего числа умножений, чем и'-точечная цикличес-
кая свертка.
3.14. Используя знание быстрых алгоритмов свертки, построить алгоритм 3-то-
2
чечного преобразования Фурье, Vk= f и~"vg, k = О, 1, 2, содержащий
С=Ж
только два нетривиальных вещественных умножения.
3.16. Построить алгорнтмы для следующих вычислений:
а. s (х) = g (х) d (х) (mod хз+ х+ 1).
б. s (х) = g (х) d (х) (mod хз).
в- s (х) = g (х) d (х) (mod х~+ g~+ 1).
3.16. а. Сколько вещественных умножений требует описанный в разд. 3.7
метод вычисления циклической комплексной свертки по модулю х~ ‒ 17
б. Сколько комплексных умножений требуется по теореме Винограда
о сложности для вычисления в поле комплексных чисел циклической
свертки по модулю многочлена хв ‒ 17
в. Объяснить все кажущиеся несоответствия.
См. теорему 9.2.1. ‒ Прим. перев.
Замечания
3.17. а. Предполагая, что все переменные являк~гся незавнсимыми веществен-
нымн величинами, доказать, что для вычнслення двух комплексных произ-
ведений
е
+if = (а+ib) (с+ 14,
е'+ if' = (а'+ уЬ') (с'+ усГ),
требуется выполнить шесть вещественных умножений.
б. Сколько потребуется умноженнй для одновременного вычнсления следу-
ющих двух комплексных призведений:
е + )f = (а+ ib) (с+ 4.
е'+if' = (а ‒ ib) (с+ ф)~
В данном случае переменные повторяются.
в. Сколько потребуется умножений для одновременного вычнсления сле-
дующих двух комплексных произведений:
е + >f (а+ уЬ) (с+ Щ
е'+ yf' = (а ‒ уЬ) (с ‒ ф)Р
3.18. а. Доказать, что вычисление
so go gy
ga Оо 4
где все переменные являются комплексными, требует шести вещественных
умножений.
б. Доказать, что вычисление
~о+ Iso 8о igi. ~о+ Фо
~1+ А' igi ~о 1+ (4
где все переменные являются вещественными, также требует шести веще-
ственных умноженнй. Таким образом, равенство нулю величин go и g,',
как и в задаче а, не уменьшает числа необходимых умножений.
в. Доказать, что вычисленне
so Оо gé do
81 ‒ а1 ао 4
где все переменные являются комплексными, требует шести вещественных
умножений.
г. Доказать, что вычнсленне
"so+iso й'о Ж "о+ do
si + jsi ‒ 136 go d; + jdi
где все переменные вещественны, требует четырех вещественных умно-
жений. В этом случае равенство нулю переменных g" и g' уменьшает.необ-
ходимое число умножений.
3.!9. Построить алгоритм 4-точечной циклической свертки над полем комплекс-
ных чисел. Сравнить этот алгоритм с алгоритмом, основанным на БПФ
и теореме о свертке.
Заиечания
Без какой-либо общей теории первые быстрые алгоритмы сверток коротких
длин были опнсаны Агарвалом и Кулн [1] (1977) в связи с развитымн ими много-
мерными гнездовыми методами. Описанный намн обший метод был предложен
Внноградом [2] (1978). Примеры нспользования этого метода приведены в моно-
графни [4) 1980 г. Внноград также доказал [3) (1977) теоремы о сложности
рассмотренных алгоритмов свертки для полей комплексных и вещественных
чисел.
Глава 4
БЫСТРЫЕ АЛГОРИТМЫ
ДИСКРЕТНОГО ПРЕОБРАЗОВАНИЯ
ФУРЬЕ
Построение набора методов вычисления дискретного преобра-
зования Фурье является одной из основных наших целей. Мы по-
строим много таких методов, каждый из которых обладает раз-
личными преимуществами перед другими и каждый из которых
наиболее пригоден при соответствующих обстоятельствах. Основ-
ных стратегий имеется две. Одна из них состоит в сведении дис-
кретного преобразования Фурье к свертке, которая затем вы-
числяется описанными в предыдущей главе методами. Другая
стратегия состоит в переходе от одномерного преобразования
Фурье к двумерному, которое вычисляется проще. Хорошие алго-
ритмы вычисления дискретного преобразования Фурье для мини-
мизации сложности вычислений используют обе эти стратегии.
Многие из изучаемых нами алгоритмов не зависят от частных
особенностей поля, над которым определено дискретное преобразо-
вание Фурье. Поэтому мы часто будем опускать указание на
конкретное поле и в этом случае алгоритм справедлив для любого
поля. В других случаях, хотя общая идея алгоритма и не зависит
от поля, над которым рассматривается дискретное преобразование
Фурье, но некоторые детали алгоритма определяются спецификой
поля. В этих случаях алгоритм должен строиться для конкретного
интересующего нас поля.
4.1. Алгоритм Кули Тычки
быстрого преобразования Фурье
Преобразование Фурье вектора v,
t3 ‒ 1
1/ ~ <,)ио.
к=о
в том виде, как оно записано, требует порядка и' умножений и
и" сложений. Если число и является составным, то имеется не-
сколько способов перейти от этого преобразования Фурье к дву-
мерному преобразованию или к чему-либо ему аналогичному.
Это позволяет перевести вычисления в более эффективную форму,
4 1. Алгоритм Кули ‒ Тычки быстрого преобразования Фурье
129
~ПФ-алгоритм Кули ‒ Тыоки (1965)
и = n'n"
i = с™+ и'i'
с'=0, ...,и' ‒ 1;
i"=О, ..., и ‒ 1.
=O,...,л' ‒ 1;
=О, ...,и ‒ 1;
л ‒ I
Число умножений
ти (n'+ и )+ и
но за это приходится платить усложнением структуры. Алгоритмы
подобного сорта известны под общим названием быстрого преоб-
разования Фурье (БПФ}. На рис. 4.1 приведена структура БПФ-
алгоритма Кули Тычки, изучаемого в данном разделе. Рис. 4.1
интересно сравнить с рис. 4.8 из разд. 4.3, на котором приведена
структура БПФ-алгоритма Гуда Томаса.
Для построения БПФ-алгоритма Кули Тьюки предположим,
что n = и'и". В выражении для преобразования Фурье сделаем
следующую замену записи каждого индекса:
с= ~'+и'С,
1™ =
О, ...„n" ‒ 1,
k' = О, ..., и'
k = и"й, '-+- k™,
k"=0,...,n
Тогда
Раскроем скобки в показателе степени и положим а"' = у и
и" = P. Так как порядок элемента и равен и'и", то член
®n'~'~"~' = 1 можно опустить. Определим теперь двумерные пере-
менные, которые тоже обозначим через v и V, задавая их равен-
ствами
Qge ga ‒ Це+~э~н
..., и" ‒ 1,
..., и' ‒ 1,
..., и" ‒ 1.
Рис. 4.1. БПФ-алгоритм Кули ‒ Тычки.
~'=О,
i™ =О,
k' = О,
k =О,
130 Гл. 4. Быстрые алгори1мы дискретного преобразования Фурье
Индексы
fS тсигек
р]а дэиоде
Индексь!
fS move~
на &оде
0
gggg > '
отображение I3
!4
0 ! 2 3 4
З б 7 В 9
IO l l !2 l3 !4
быиисление
отображение
33
!4
Индексы
21поцки
на Юходв
Индексы
7f точки
на Юыкоде
0
!
0 I 2 3 4 5 б 0 3 б 9 И IS IS
7 8 9 IO ! I !2 l3 + ! 4 7 IO !3 16 l9
4 IS !б l7 !8 !9 20 т 2 5 8 II l4 l7 20 г
оаюбрамеиие Вычисление отображение 19
I9
20
Рис. 4.Я. Яримеры переиндексации по методу Кули ‒ Тыоки.
При этом векторы входных и выходных данных преобразунугся
в двумерные массивы. Заметим, что компоненты преобразова-
ния ~ упорядочены в таблице не так, как компоненты сигнала ч.
Это упорядочивание известно под названием адресного тасования.
В терминах двумерных переменных формула преобразуется к виду
л' ‒ ! n" ‒ !
<a - = E V"' '" E v'"'ú,-, ]
С'0 С=О
Хотя для понимания эта формула более трудна, чем исходная,
но число входящих в нее умножений и сложений существенно
меньше. А именно, она содержит не более п (n' + и" t 1) ком-
плексных умножений и п (n' + и" 2) комплексных сложений
вместо nР комплексных умножений и и' комплексных сложений
исходной формулы.
Визуально БПФ-алгоритм Кули Тычки выглядит как ото-
бражение двумерной таблицы в двумерную таблицу, как показано
на рис. 4.2 для примеров с n = 15 и и = 21. Вычисления состоят
из п™-точечного дискретного преобразования Фурье каждого
столбца, поэлементного умножения всех элементов таблицы соот-
ветственно на ас"~" и и'-точечного дискретного преобразования
Фурье каждой строки.
Чтобы для комплексного входного вектора v подсчитать пол-
ное число комплексных умножений и комплексных сложений,
предположим, что внутреннее и внешнее преобразования Фурье
вычисляются обычным способом, содержащим соответственно
(п")~ и (п')~ комплексных умножений и и" (и" 1) и и' (и' 1)
131
4.1. Алгоритм Кули ‒ Тычки быстрого преобразования Фурье
7Уложк
З-аюмеч
~реобразод
Марье
Х-mocrevHee 5-точвчнов
ареобразодаиие яреобразоВаицв
9ypse ~дрьв
Рис. 4.3. Структура 75-точечного БПФ-алгоритма Кули ‒ Тычки,
комплексных сложений. Каждое из этих преобразований Фурье
используется n' и и™ раз соответственно. Помимо этого имеется
n'n" комплексных умножений на множители «регулировки» m~'~".
Таким образом, полное число умножений, М, (n), н полное число
сложений, А, (n), в данном случае равны
М,(n) = и'(и")'+ и" (й')'+и'и = и(и'+ и + 1),
A, (n) = и'и (и" ‒ 1) + и и' (n' ‒ 1) = и (и' + и" ‒ 2),
что и утверждалось ранее. Среди умножений имеются и тривиаль-
ные умножения на 1. Это происходит всякий раз, когда в множи-
теле регулировки целые числа i' или й" в показателе обращаются
в нуль. При желании алгоритм можно перестроить так, чтобы
выкинуть эти умножения; тогда число комплексных умножений
станет равным
1) (и"
= (и
М, (и} = и (и' + и") + (и' 1) =
1} (и' + и") + (и + 1).
Внешнее и внутреннее преобразования Фурье в свою очередь
могут быть вычислены с помощью быстрых алгоритмов, не обя-
зательно с помощью БПФ-алгоритма Кули Тычки. Тогда для
числа комплексных сложений и для числа комплексных умноже-
ний, йходящих в БПФ-алгоритм Кули Тычки, получаем соот-
ношения
М,(n) = и'М,(и")+ и"М,(и')+ и,
А, (n) = n'A, (и") + и "А, (и'),
где новые члены, стоящие в правых частях равенств, обозначают
числа комплексных умножений и комплексных сложений, входя-
щих соответственно в n'-точечный и n"-точечный быстрые алго-
ритмы преобразования Фурье. Конечно, если n' или и" опять яв-
ляется составным числом, то меньшее преобразование о,пять
132 Гл. 4. Быстрые алгоричмы дискретного преобразования Фурье
Яыкоо Выл оо
5-точечного лреобразо8ания 5-точечного преобразодания
Рис. 4.4. Разбиение БПФ-алгоритма Кули ‒ Тычки иа подпрограммы.
Вход б/7~:
75' жажа
дюкоо ОПФ:
75'пючж
Вход
5-точечного лреобразо8ания
В~ою бп@:
гХ оч~~
Вь~код бйФ
25 о~очек
8ход
5-точечного иреобразодания
4.2. алгоритм Кули ‒ Тычки по малому основанию
можно вычислять с помощью БПФ-алгоритма Кули Тычки.
На этом пути преобразование длины и = +n, может быть пред-
!
ставлено в такой форме, в которой требуется выполнения n fn,
1
комплексных умножений. Ка рис. 4 3 показан один из многих
способов разбиения 75-точечного преобразования Фурье. Каждый
из узлов этого рисунка можно представлять себе как обращение
к подпрограмме. Если вычисления реализуются с помощью такого
разбиения на подпрограммы, то один из способов организации
программного вычисления показан на рис. 4.4. На самом нижнем
уровне вычислений находятся 3-точечное и 5-точечное преобразо-
вания Фурье, выполняемые буквально. Позже мы построим малый
БПФ-алгоритм Винограда, который можно использовать на этом
уровне в качестве подпрограммы. Малые БПФ-алгоритмы Вино-
града представляют собой сильно оптимизированные процедуры
вычисления преобразования Фурье для длин, являющихся про-
стым числом или степенью простого числа.
4.2. Алгоритм 3(ули Тьюки
по малому основанию
л/2 ‒ !
Va= Е
f=p
л/2 ‒ !
<a~~gg = )~
г=о
л/2 ‒ !
~~21йо + <вй f <в2ио
г=о
л/2 ‒ !
,2И ~, а „2И,,
8=0
й = О, ..., а/2 ‒ 1,
1) Термин «по основанию два» относится к факту записи индексов по осио-
ванию два. Компоненты данных могут быть представлены в любой системе счис-
ления, в частности по основанию два.
Во многих приложениях, в которых используется алгоритм
Кули Тычки, длина преобразования равна степени двух или
четырех. для построения БПФ-алгоритма длина 2~ преобразо-
вания представляется в виде 2.2 ‒ ' или 2 ‒ '2. В этом случае
говорят о БПФ-алгоритме Кули Тычки по основанию два ').
Аналогично, длина 4'" преобразования разлагается в виде 4-4 ‒ '
или 4m ‒ ' 4, и тогда говорят о БПФ-алгоритме Кули Тычки
по основанию четыре. Если в 2'"-точечном алгоритме Кули Тычки
.по основанию два полагается и' = 2 и и" = 2 ‒ ', то он назы-
вается БПФ-алгоритмом Кули Тычки по основаниюдва с проре-
живанием по времени. Используя тот факт, что P = и"<2 = 1,
в этом случае уравнения, задающие БПФ, можно записать в следу-
ющем простом виде:
134 Гл. 4. Быстрые алгоричмы дискретного преобразования Фурье
л/2 ‒ 1
V2a = Z (ог+ vt-+п/2) +
Г=О
л/2 ‒ 1
V2k'+! ‒ Z (о6' ог'+л/2) ш ш
8'=О
й' = О, ..., и/2 ‒ 1,
Прореживание по частоте разбивает компоненты входного век-
тора на два подмножества, содержащие соответственно первые
и/2 компонент и вторые и/2 компонент. Компоненты выходного
вектора разбиваются на подмножество компонент с четными ин-
дексами и подмножество компонент с нечетными индексами.
Алгоритм с прореживанием по времени и алгоритм с прорежи-
ванием по частоте отличаются структурой и последовательностью
вычислений, хотя имеют одно и то же число операций Характе-
ристики алгоритмов совпадают, но пользователь может предпо-
честь один из них из соображений реализации. Мы подробно рас-
смотрим только характеристики алгоритма с прореживанием
по времени.
Алгоритм с прореживанием по времени сводит и-точечное пре-
образование Фурье к двум (и/2)-точечным преобразованиям Фурье
с некоторыми дополнительными сложениями и умножениями.
Часть из умножений представляют собой умножения на единицу
иФи + j. Они тривиальны и не требуют действительного вычисле-
ния. Чтобы обойтись без тривиальных умножений в алгоритме,
их следует обрабатывать отдельно. Иногда конструктор предпо-
читает включить в процедуру вычисления все умножения, даже
тривиальные.
Алгоритм с прореживанием по времени работает рекурсивно,
разбивая на каждом шаге и-точечное преобразование на два
(и/2)-точечных преобразования, которые, в свою очередь, раз-
биваются точно таким же образом. Из уравнений ясно видно, что
число М, (и) комплексных умножений и-точечного БПФ удовле-
творяет рекуррентному уравнению
M, (n) = 2М, (n/2) + и/2,
Прореживание по времени разбивает множество компонент вход-
ного вектора на два подмножества: множество компонент с чет-
ными индексами и множество компонент с нечетными индексами.
Множество компонент выходного вектора разбивается при этом
на множество первых и/2 компонент и множество вторых и/2
компонент.
2 -точечный БПФ-алгоритм Кули Тычки по основанию
два, в котором и' = 2 ‒ ' и n" = 2, называется БПФ-алгоритмом
Кули Тычки по основанию два с прорежцванием по частоте.
Уравнения БПФ в згом случае преобразуются к виду
4.2. Алгоритм Кули ‒ Тычки по малому основаиию
а число А, (и} комплексных сложений удовлетворяет рекуррент-
ному уравнению
А, (и) = 2А, (и/2) + и,
где и равно степени двойки. Решения этих уравнений даются
равенствами
М, (п) = (и/2) log п, А, (u) = п log u.
Комплексные умножения можно реализовать алгоритмом с че-
тырьмя вещественными умножениями и двумя вещественными
сложениями. В этом случае характеристики БПФ по основанию
два даются равенствами
Мя (и} = 2n log, и, Ая (и) = 3n log, п.
Альтернативный алгоритм выполнения комплексного умножения
содержит три вещественных умножения и три вещественных
сложения. В этом случае характеристики имеют вид
MÄ (n) = (3/2) и log, и, А„(п) = (7/2) и log, и.
Теперь предположим, что ма хотим построить алгоритм,
в котором выброшены все тривиальные умножения. Тогда полу-
ченные нами характеристики сложности алгоритма улучшатся.
Тщательный анализ алгоритма показывает, что все умножения
на самом внутреннем шаге алгоритма тривиальны и имеют вид
умножений на ( 1}» для А = О, 1; все умножения на следующем
шаге тривиальны и имеют вид умножений на j~ для k = О, 1, 2, 3;
на последующих шагах число тривиальных умножений равно
n/4, и/8, .... Следовательно. число комплексных умножений
равно
М, (n) = (и/2) ( 3 + log, n) + 2.
Используя для реализации комплексного умножения алгоритм
с четырьмя вещественными умножениями и двумя вещественными
сложениями, для БПФ-алгоритма по основанию два получаем
MR (и) = 2n ( 3 + log~ и} + 8,
Ая (и} = 3n ( 1 + log» и) + 4.
Используя для комплексного умножения алгоритм с тремя веще-
ственными умножениями и тремя вещественными сложениями,
получаем характеристики
MÄ(n) = (3/2) п( 3+ log,и}+6,
Ая (и) = (1/2) и ( 9 + 71og, и) + 6.
Еще немного можно улучшить алгоритм, если воспользоваться
свойством симметрии тригонометрических функций. Заметим, что
щп/а (1 ‒ j)/~/2
136 Гл. 4. Быстрые алгоритмы дискретного преобраэоваиия Фурье
Умножение на эту комплексную константу требует всего двух
вещественных умножений и двух вещественных сложений. Таких
умножений на шагах 3, 4, ... алгоритм содержит соответственно
и/4, и/8, .... Их можно реализовать с помощью специальной
процедуры умножения. При этом в зависимости от выбранной
реализации комплексного умножения характеристики алгоритма
будут даваться равенствами
M„(n) = n ( 7 + 2 1оц, и} + 12,
A„(n) = Зп ( 1 + log, n) + 4
или
л/2 ‒ 1
А ]~ ги,.
г=о
1=0, ..., и/2 ‒ 1.
Так как
n/2 ‒ 1
А~,1 ‒ А„= g и~'"а; (m2~ ‒ 1) =
с=о
л/2 ‒ 1 л/2 ‒ 1
и'ци~а~2~з1ц(2яЕ/n) = g (>c ‒ й-1-д) >'> "~
с=о С=1
M
Ä (n) = (1/2) п ( 10 + 3 log, и} + 8.
А„(п} = (1/2) n ( 10 + 7 log, n) + 8.
Как мы видим, число вариантов алгоритма Кули Тычки
весьма велико, но мы еще не перечислили все возможности;
имеются и другие возможности улучшения алгоритма. На рис. 4.5
приведены характеристики некоторых БПФ-алгоритмов Кули
Тычки. В таблицу помимо обычной формы алгоритма Кули
Тычки включен БПФ-алгоритм Рейдера Бреннера. Эгот БПФ-
алгоритм является модификацией алгоритма Кули Тычки, осно-
ванной на том, что с помощьк> переупорядочивания уравнений
БПФ некоторые умножения на комплексные константы можно
заменить умножением на вещественные константы.
Алгоритм Рейдера Бреннера можно строить, исходя из урав-
нений для алгоритма с прореживанием по времени, но мы пред-
почитаем отталкиваться от уравнений для алгоритма с прорежи-
ванием по частоте:
л/2 ‒ 1
~2й = f (Vl + оГ+и/2) K y
Й=О, ..., и/2 ‒ 1,
V2kyl = g (Dt Vl+n/2) > ш
tw
Определим рабочий вектор д, равенствами
О, i =0,
(о~ ‒ vq~~q)/[2/з1п (2nl/n)), 1 = 1, ..., и/2 ‒ 1,
и положим
к
Л фф
хх
о> х
ИЮ~
О Ш
И'вg
О
t а
арх
д,йi g
©ха
4j х
gg
3gp
Цод
р, М
О
м,'
к
~Д Вф
g L
охх
0~
о х~~
3
Ой~
х
R6.Q
р ~о
Ям
Ю.
хИ
ФЩ
3p®
О~,й
+ОK
L' х
Agх
од Я
Яйся
х~а
~ C Pg
Cgp
ООХ
~М Ц
фабр
~хи
N д
О
~'. 3
6g
p~X
gpO
олаф
i~i g
К
3 ф
охх
Вэх
vs~
ФЬф
Q
g Q
о
о
g
М
Ц р
00 g
~ф,р
ХД:
рC
0
е
аида Щ Я~1 чф~
К
л ~~»
° Ц
охх
3~ 4t O
Р'~~ х
й
С~ Q ~1 ~ а ф
LO Q ) ~-> -- ~ @Ь Ql
CO W M C) ° Ю
еч Щ 0Q QQ
ЯЖ3-ЖЯРЖЗ
LQ +3 ~) е~м щ 00
сф ~ cQ Ю
Щ
СМ ~ Ce О 00
Щ cO lA
Ф ~0 я СЧ я я CO Я Я
Б д~ @~ в@
чФ' С> <О ~Э
В ао О СЕ а e e О Е
Э' СЧ О~ Ю Ch О~ ~ аО йэ 4.,
ео ~ ~ o сч .э 3 со
сп о ж в
° Э О)
о0 Ю СЧ Я ~0 ЧР СЧ 'Ф ф ®
СМ ~Э
Я
Ю
к 8
ю х
д к
( р
И
О
р РЪ
б д
В:(
9 Я
Зm
й~
g x
р
д ~~
~ Н
йн
Щ
М
~ a
3t
.f,
[ и
р М
3 д,
о
О
03 х
~к~
(." к
ее ф Оа
х и
хх~
а х 3
Ю g V
Е
х о хк
р, fJ
138 Гл. 4. Быстрые алгорипкы дискретного преобразования Фурье
f=О
j (и +„‒ а )/[2sin (2и!/и)1 ю = 1, ..., n/2 ‒ 1
л/2-1
а~иМ~ k = О, ..., и/2 ‒ i
l=O
п/2-1
~ ( + а,+ /2) < ' й = О, .... и/2 ‒ <
Г=О
= A>+< ‒ Аж+("о vÄ/z) k= О, ..., и/2 ‒ i
~и+-1
Рис. 4.6. БПФ-алгоритм Рейдера ‒ Бреннера.
то величины V,z+ä и А„связаны равенствами
~и+) = ~ayi ‒ Аа+ (Vo ‒ ~и/2}.
Таким образом, умножение на комплексные константы о~ уда-
лось заменить на умножения на мнимые константы [2j sin (2Ы/и) 1 ',
что уменьшает вычислительную сложность. Необходимо, однако,
проследить, чтобы не произошло переполнение по длине слова
потому, что когда и ввееллииккоо, а ~ мало, новые константы становятся
весьма большими.
Вкратце форма алгоритма показана на рис. 4.6. Каждое из
двух (и/2)-точечных дискретных преобразований Фурье можно
в свою очередь разбить точно таким же образом. На каждом
шаге алгоритма требуется (n/2) 2 умножений комплексных
чисел на мнимые, для чего в итоге используется и 4 веществен-
ных умножений. (Мы предпочли избежать умножения на 1/2
при ~, равном и/4.) На каждом шаге алгоритма всего имеется 2п
комплексных или 4п вещественных сложений. Характеристики
алгоритма Рейдера Бреннера описываются рекуррентными урав-
нениями
М„(п) = и ‒ 4+ 2М„(п/2), AÄ(n) = 4n+2AÄ(n/2)
при начальных условиях М„(4} = О, А„(4} = 16. Здесь Йе
учтены имеющиеся на двух самых внутренних шагах умножения
на (~1) и (~i)
Вместе с другими формами БПФ-алгоритма Кули Тычки на
рис. 4.5 приведены характеристики БПФ-алгоритма Рейдера
Бреннера. Отметим, что полностью оптимизированные Б ПФ-
алгоритмы по основанию 2 для малых длин содержат меньше
сложений. Это позволяет предложить гибридный алгоритм: раз-
бивать преобразование Фурье по алгоритму Рейдера Бреннера
до тех пор, пока не достигнем длины 16, а затем переходить на
полностью оптимизированный алгоритм. Использование на самом
внутреннем этапе рассматриваемого в разд. 4.6 16-точечного
БПФ-алгоритма Винограда позволяет еще больше улучшить
4.2. Алгоритм Кули ‒ Тычки по малому основаиию
139
результаты. Характеристики гибридного алгоритма описываются
теми же рекуррентными уравнениями, но с начальными условиями
М„(16) = 20, А„(16) = 148.
Очень популярны также БПФ-алгоритмы Кули Тычки по
основанию 4. Они могут быть использованы в случаях, когда
длина преобразования и ррааввнна а ссттееппеенни и 44, и получаются ее разло-
жением в виде 4-4 ‒ ' или 4 ‒ ' 4. Мы рассмотрим БПФ-алгоритм
Кули Тычки по основанию 4 с прореживанием по времени.
Уравнения этой формы БПФ можно получить простой подста-
новкой и' = 4 и и = и/4 в приведенные на рис. 4.1 общие урав-
нения БПФ-алгоритма Кули Тычки. При k = О, ..., и/4
соответственно имеем
а/4- )
и и»
i=O
1 1 1 1
п/4- )
4')")/4+)
1 ‒./ ‒ 1,у
i-=0
n/4- !
1 -1 1 ‒ 1
/0
v»„„„
и/4- )
1 / ‒ 1 ‒ р
)0
»4
i~O
I'»
1 0 1 0
1 0 1 0
40 Ю У 41+ !
0 1 0 ‒./
1 0 ‒ 1 0
и/4- )
и %ч 4М
4и ~ Ы "4)+2
1 0 ‒ 1 0
~»+n/2
0 1 0 1
л/4- )
3» ~ 4й
~~~ру ~)»'4)+ 3
0 1 0 ./
0 1 0 ‒ 1
~»+ 3ë/4
Яля каждого из и/4 рассматриваемых значений индекса » такое
матричное уравнение определяет четыре компоненты преобразо-
вания. Этот метод позволяет и-точечное преобразование Фурье
заменить четырьмя (и/4)-точечными преобразования Фурье и не-
которыми дополнительными вычислениями. Из выписанного урав-
нения следует, что для каждого й имеется только три различных
комплексных умножения и 12 комплексных сложений. Самый
внутренний шаг 4-точечное преобразование Фурье вообще
не содержит умножений.
Число сложений можно еще уменьшить. Яля этого перепишем
последние уравнения для k = О, ..., и/4 ‒ 1 в виде
140 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
для числа комплексных умножений и сложений соответственно.
Если для вычисления комплексных умножений используется
алгоритм с тремя вещественными умножениями и тремя веще-
ственными сложениями. то характеристики описываются равен-
ствами
MÄ (n) = (9/8) n (log, и 2), AÄ (n) = (28/8} n log, и (9/4} и.
Можно получить и лучшие результаты, если вложить в про-
грамму способность выловить все умножения на (~1} и íà (~i)
или на нечетные степени элемента (1/1/2) (1 j), поскольку они
не требуют трех вещественных умножений, и убрать их из алго-
ритма. Тогда характеристики будут даваться равенствами
9 43 16
Мн (п) = nlog,п ‒ ‒ п+ ‒,
12
25 43 16
Аа (n) = и log, n ‒ n +‒
Характеристики БПФ-алгоритма Кули Тычки подытожены на
рис. 4.7.
Основной алгоритм
комплексного БПФ
по основаиию 4
Полиостью оптимизированное ~
комплексное БПФ
по основаиию 4
Число Число Число Число
Длииа
вещественных вещественных вещественных вещественных
lL
умножений сложений умножений сложений
4
16
64
256
1024
4096
0
36
288
1 728
9 216
46 080
0
20
208
1 392
7 856
40 642
16
164
1 128
5 824
29 696
144 384
16
148
976
5 488
28 336
138 928
® Комплексное умножение с использованием 3 вещественных Умножений и 3 веществен-
ных сложений.
Тривиальные умножения иа ~1 или ~/ ие учитываются.
Рис. 4.7. Характеристики некоторых БПФ-алгоритмов но основанию 4.
Разложив исходную (4х4)-матрицу в произведение двух, мы полу-
чили 8 сложений вместо 12. Это дает окончательную форму БПФ
алгоритма Кули Тычки по основанию 4. Характеристики алго-
ритма описываются равенствами
М, (и} = (3/4} п (1од, и 1) = (3/8) и (log, n 2),
А, (и} = 2n log~ и = и log, и
4.3. Алгоритм Гуда ‒ Томаса быстрого преобразовання Фурье
4.3. Алгоритм Гуда Томаса
быстрого преобразования Фурье
Алгоритм Гуда Томаса с использованием простых делителей
представляет собой БПФ-алгоритм второго типа. Концептуально
он несколько сложнее алгоритма Кули Тычки, но в вычисли-
тельном отношении несколько проще. Показанный на рис. 4.8
алгоритм Гуда Томаса представляет собой другой способ отобра-
жения линейной последовательности. из и = и'и" целых чисел
в (n' X и"}-таблицу, преобразующего одномерное преобразова-
ние Фурье в двумерное преобразование Фурье. Лежащая в основе
отображения идея сильно отличается от идеи алгоритма Кули
Тычки. Теперь числа и' и и" должны быть взаимно простыми,
а основой отображения линейной последовательности в таблицу
служит китайская теорема об остатках. Обращаясь к рис. 4.9,
мы видим, как переупорядочены входн~де данные. В двумерную
таблицу они выписываются, начиная с верхнего левого угла,
вдоль «расширенной диагонали». Поскольку число строк таб-
лицы взаимно просто с числом ее столбцов, расширенная диаго-
наль последовательно проходит через все элементы таблицы.
После выполнения над этой таблицей двумерного преобразования
Фурье компоненты преобразования оказываются записанными
в двумерной таблице по иному правилу, чем были записаны ком-
поненты преобразуемого вектора. Способ упорядочивания вход-
ной и выходной таблиц будет описан ниже.
БПФ-алгоритм Гуда ‒ Томаса (1960 ‒ 1963)
и = n'è", где л' и и" взаимно просты
Перестановка входных
i' = t' (mod n')
индексов:
l = с'N'n + c A' n' (mod n),
где
N'n'+ N"n" = 1.
г" = ю (mod n")
Перестановка выходных индексов:
А' = N"It, (mod и')
A = и A.'+ n'k" (mod п),
А = N'À (mod n")
и' ‒ 1
n~ ‒ 1
Число умножений ~ n (n'+ n")
Рис. 4.8. БПФ-алгоритм Гуда ‒ Томаса.
142 Гл. 4. Быстрые алгоритмы днскретного преобразования Фурье
~ис~ексы
~~ ~иочек
иа Bxpde
~иденсо~
l5 ~почек
на ды~оДе
0
~ ЩЩф
l4
ИНдеяцу
21mcweu
иа Выходе
Йидегсы
2f точки
на &оое
0
!
2
0 I5 9 3 18 12 6 0 3 6 9 12 15 18
7 ! 16 !0 4 19 13 7 10 13 16 19 ! 4
14 8 2 17 11 5 20 !4 17 20 2 1 8 I!
pmobparreeup 8bsqucneeu8 отобраиениг I 9
Рис. 4.9. Примеры переиндексации по методу Гуда ‒ ToMaca.
Построение БПФ-алгоритма Гуда Томаса основано на китай-
ской теореме об остатках для целых чисел. Входные индексы
задаются вычетами по правилу
i' = i (mod и'), i" = г (mod n").
Это правило представляет собой отображение индекса ~ на расши
реннув диагональ двумерной таблицы, элементы которой зану-
мерованы парами индексов (i', ~"}. Согласно китайской теореме
об остатках, существуют такие целые числа N' и N", что выпол-
няется равенство
с = ГN"'n" + ю"N'и' (mod и),
где
N'и' + N"è" = 1.
Выходные индексы определяются несколько иначе. Пусть
k' = N"k (mod и'), k" = N'k (mod n").
Эти равенства можно переписать в эквивалентном виде
Й' = ((N' mod и') k mod и'), lг" = ((N' mod и"} k mod n"}.
Выходные индексы А вычисляются по правилу
lг = и"/г' -1- и'lг" (mod и).
Для проверки этого равенства выпишем;
k = и" (N"Й -ф- Q,n') + и' (N'k + Q,n") (mod а'и") =
= k (и"N" 1- и'N') (mod и) = k.
4.3. Алгоритм Гуда ‒ Томаса быстрого преобразования Фурье
143
В этих новых индексных обозначениях формула
V» Е (~ "о<
С=О
преобразуется к аиду
‒ 1 n' ‒ 1
У,„,~, „~' f (о(<»<" -(-<-и 1<к»'+и»">о~, „,
С-=0 С =О
Выполним умножения в показателе степени. Поскольку поря-
док элемента со равен n'n", то члены с этим показателем пропа-
дают. Тогда выписанное выше преобразование индексов для эле-
ментов входной и выходной таблиц дает
‒ 1n" 1
(<», »„~~~ ~ <><Ч"(К')г <'»'<> N'(ë') ° <"»"V<,
С'=0 C" — 0
‒ 1 n" ‒ 1
p<'»'~<"»"(<,
С'=0 l" — 0
где P = и»<"«'>' и у = и»<'("'>'. Элементы р и у являются про-
стыми корнями из единицы степеней n' и n", задающими и'-точеч-
ное преобразование Фурье и n"-точечное преобразование Фурье
соответственно. Чтобы увидеть это, достаточно заметить, что
p = (<ок)»<- ". Так как и"" = е ‒ »«~ и N"n" = ] по модулю и',
то P = е-»«"'. Аналогичное утверждение справедливо и для
элемента у.
Уравнение теперь записано в форме двумерного (и' 'х n")-
точечного преобразования Фурье. Число умножений и число
сложений равно примерно и (и' + n"). Преобразование Фурье
по строкам и по столбцам, если соответствующая размерность
задается составным числом, можно в свою очередь упростить,
применяя алгоритм БПФ. Таким образом, если длина и преоб-
разования разлагается в произведение простых множителей д,,
то описанная форма БПФ-алгоритма требует примерно и g n,
!
умножений и столько же сложений.
Яля вычисления преобразования Фурье можно пользоваться
как БПФ-алгоритмом Кули Тычки, так и БПФ-алгоритмом
Гуда Томаса. Можно даже строить алгоритмы, содержащие
БПФ-алгоритм Кули Тычки и БИФ-алгоритм Гуда Томаса
одновременно. Например, используя Б ПФ-алгоритм Гуда То-
маса, можно 63-точечное преобразование Фурье разбить на 7-то-
чечное и 9-точечное; используя далее БПФ-алгоритм Кули
Тычки, 9-точечное преобразование можно разбить на два 3-точеч-
ных преобразования. Вычисления при этом преобразуются
форму, аналогичную трехмерному (3 х 3 х 7)-преобразованию
144 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
52
Рис. 4.10. Некоторые способм построения 1000-точечного преобразования Фурье.
Фурье. На рис. 4.10 показано несколько способов разбиения
1000-точечного преобразования Фурье на преобразования мень-
шего объема. Каждый из способов содержит 2-точечный модуль
три раза и 5-точечный модуль три раза. Но все процедуры суще-
ственно различны, так как малые модули используются в разной
последовательности. Число умножений и сложений, чувствитель-
ность алгоритма к погрешностям вычислений и легкость реализа-
ции алгоритма различны.
4.4. Алгоритм Герцеля
Значение одной компоненты преобразования Фурье можно
вычислить по правилу Горнера, дающему один из способов вы-
числения многочлена
Q(X) = O~~Õ" + УддХ" + ° ° . + ОдХ+ Оо
в некоторой точке р. Правило Горнера, записанное в виде
(1) =(". (( 1+ .)1+о-.)1+".+ )1+о"
требует и 1 сложений и и 1 умножений в поле элемента р.
Если все различные степени элемента р вычислены заранее,
4.4. Алгоритм Герцеля
145
то правило Горнера не дает никаких преимуществ по сравнению
с прямым вычислением. Преимущество правила Горнера состоит
в том, что оно не требует предварительного вычисления и запоми-
нания этих степеней.
Если P = и~, то правило Горнера вычисляет Й-ю компоненту
преобразования Фурье посредством n ‒ 1 комплексных умноже-
ний и и 1 комплексных сложений. Более эффективным для
этого вычисления является алгоритм Герцеля.
Алгоритм Герцеля нредставляет собой процедуру вычисления
дискретного преобразования Фурье. Он позволяет уменьшить
число необходимых умножений, но на очень малый множитель.
Он не принадлежит к алгоритмам БПФ, так как его сложность
по-прежнему пропорциональна и'. Алгоритм Герцеля полезен
в тех случаях, когда требуется вычислить малое число компонент
преобразования Фурье, как правило, не более чем Jog u
из и компонент. Так как БПФ-алгоритмы вычисляют все ком-
поненты преобразования, то в этих случаях приходится выбрасы-
вать ненужные компоненты.
Для вычисления одной компоненты преобразования Фурье
n — I
~„= g ии'о, рассмотрим многочлен р (х) = (х и~) (х и-~).
1=0
Он представляет собой многочлен наименьшей степени с веще-
ственными коэффициентами, для которого элемент и-а является
корнем. Это минимальный многочлен элемента ь" над полем
вещественных чисел, и он равен
р (х) = х' ‒ 2 cos ( ‒" Й) х+ 1.
Пусть
v(x) = f v;x~
и запишем
v (х) = р (х) Q (х) + r (х}.
Многочлен-частное Q (х) и многочлен-остаток г (х) могут быть
найдены с помощью алгоритма деления многочленов. Тогда вели-
чина Vz может быть вычислена по остатку согласно равенству
т"у, = о(в~) = I (m"),
так как по построению величина р (и~) равна нулю. Ббльшая часть
работы приходится на деление многочленов. Если коэффициенты
многочлена v (х} являются комплексными, то для его деления на
многочлен р (х) требуется 2 (и 2) вещественных умножений;
если же коэффициенты многочлена о (х) являются вещественными,
то требуется и 2 вещественных умножений. Аналогично, не-
обходимое число сложений в комплексном случае равно 4 (и 2),
а в вещественном 2 (и 2).
146 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
Замечания: Входные данные вещественные или комплексные.
2л,
° А= 2cos k.
П
° r (х) остается в регистре сдвига после завершения деления
- Для каждого Vg, своя цепь деления.
- ~a = + ra+ ~o-
k
Рис. 4. )1. Блок-схема алгоритма Герцеля.
Так как степень многочлена r (х) равна единице, то для вы-
числения r (и~} требуется только одно комплексное умножение и
одно комплексное сложение. Таким образом, при комплексном
входе для вычисления одной выходной компоненты алгоритму
Герцеля требуется 2п 1 вещественных умножений и 4п 1
вещественных сложений.
Блок-схема алгоритма Герцеля показана на рис. 4.11. Эта
схема имеет форму авторегрессионного фильтра. Это является
следствием того, что схема деления многочленов имеет форму
авторегрессионного фильтра. После ввода многочлена v (х} цепь
на рис. 4.1 I будет содержать остаток r (х) от деления 'многочлена
v (х) на многочлен р (х). Частное Q (х) интереса не представляет
и поэтому отбрасывается.
4.5. Вычисление преобразования Фурье с помощью свертки
147
4.5. Вычисление преобразования Фурье
С ПОМОЩЬЮ СВер;Ш И
Одним из эффективных способов вычисления дискретного пре-
образования Фурье
где р равно квадратному корню из и. В этом варианте преобра-
зования Фурье производятся следующие вычисления:
П ‒ )
и ‒ 1
Чирп-алгоритм содержит и поточечных умножений v; на
циклическую свертку с P' в КИОфильтре с и отводами и следую-
щие за этим и поточечных умножений íà P-~*. Поэтому полное
число операций по-прежнему имеет порядок п~~, так что чирп-
алгоритм асимптотически не эффективнее прямого вычисления
йреобразования Фурье. Однако в некоторых приложения х он
допускает более простую аппаратурную реализацию. Кроме того,
является сведение к вычислению свертки. Это может показаться
странным, так как мы уже знаем, что хорошим методом вычисле-
ния свертки является использование БПФ и теоремы о свертке.
И на самом деле, возможно поэтому, многие годы рассматриваемые
в данном разделе методы привлекали мало внимания. сейчас,
однако, стало понятно, что иногда выгодно вычислять преобразо-
вание Фурье сведением к вычислению свертки, а иногда, наобо-
рот, выгоднее вычислять свертку через преобразование Фурье.
Что еще удивительнее, иногда выгодно вычислять свертку через
преобразование Фурье, реализуя при этом преобразование Фурье
через алгоритм вычисления свертки, хотя и на длинс, отличной
от исходной.
Два различных способа перехода от преобразования Фурье
к свертке дают чирп-алгоритм Блюстейна и алгоритм Рейдера для
простых чисел (см. рис. 4.12). Алгоритм Блюстейна переводит
и-точечное преобразование Фурье в и-точечную свертку и 2п
дополнительных умножений. Алгоритм Рейдера переводит и-
точечное преобразование Фурье в (и 1)-точечную свертку, но
только для простых чисел и.
Алгоритм Блюстейна менее полезен, но проще в описании,
так что мы начнем с него. Он описывается равенством
Чирп-алгоритм Блюсп~ейна
СО
Vupn
Чорни
Ллгоритм Рейдера с~ли простой длины
Длина и преобразодония яблдется простым числом
Исподьзодать 3C ‒ лримитидный элемент пору ОЕ(а)
(!, 2, 3,..., д ‒ Ц = (к, у, у,..., ~г
и-3
t-o
mod n)
~0 ‒ ~i
ck
~~к= up+
k=O,...,n ‒ 1
a=0
вЧа+~М>
Рр+ И Ug
с-т
° Vj,
Рис. 4.12. Сведение преобразования Фурье к свертке.
148 Гл. 4. Быстрые алгоритмы дискретного преобразования фурье
f49
4.5. Вычисление преобразования Фурье с помощью свертки
прямое вычисление свертки можно заменить рассмотренными
в гл. 3 алгоритмами быстрой свертки.
Алгоритм Блюстейна содержит 2п умножений и свертку
длины и. Более предпочтителен следующий алгоритм алго-
ритм Рейдера, так как он не содержит 2п дополнительных
умножений. Алгоритм Рейдера содержит только некоторые опе-
рации по переиндексации входных данных и циклическую сверт-
ку, длина которой теперь уже равна п 1.
Алгоритм Рейдера можно использовать для вычисления пре-
образования Фурье в любом поле F, если только длина преобразо-
вания и является простым числом. Так как п простое число,
то можно воспользоваться структурой поля GF (n) для переин-
дексации компонент входного вектора. Поле GF (и) не следует
путать с полем F, в котором вычисляется преобразование Фурье.
Выберем примитивный элемент и простого поля GF (и). Тогда
каждое не превосходящее п целое число можно однозначно запи-
сать в виде степени элемента я. Преобразование Фурье
А=О, ...,и ‒ 1,
Пусть r (i) обозначает единственное для каждого i от 1 до и 1
целое число, такое что в поле GF(n) выполняется равенство
st«~> = <. Функция r (i) является отображением множества
«1, 2, ..., и 1} на множество «1, 2, ..., и 1}; она задает пе-
рестановку на множестве «1, 2, ..., n 1}. Тогда Г„можно за-
писать в следующем виде:
Так как r (i) задает перестановку, то можно положить 1 = r (k)
н / = и 1 r (i) и выбрать j в качестве индекса суммирова-
ния; это дает
можно переписать, заменив индексы 1 и k соответствующими
степенями элемента я. Индексы г и k принимают и нулевые значе-
ния; эти компоненты входного и выходного векторов удобнее
рассматривать отдельно. Тогда
150 Гл. 4. Быстрые алгоритмы дискретного преооразомния Фурье
ИЛИ
n ‒ 2
V~ = ~+ g и"' тот,
/=0
где V~ ‒ ‒ V > и о~ ‒ ‒ 0„„) у соответственно переставленные
компоненты последовательностей входных и выходных данных.
Теперь мы получили уравнение для вычисления циклической
свертки последовательностей }о~} и }и"I}. Таким образом, пере-
ставляя индексы входных и выходных данных, мы записали пре-
образование Фурье в виде свертки. Однако для того вида, в кото-
ром эти формулы выписаны, необходимое число операций для
вычисления свертки опять имеет порядок и'. В следующем раз-
деле мы скомбинируем алгоритм Рейдера для простой длины
с алгоритмом Винограда для свертки и получим малый ОПФ-
алгоритм Винограда.
Построим, используя алгоритм Рейдера, двоичное пятиточеч-
ное преобразование Фурье, для которого
4
Vg = ~ и'~v;, k = 0, ..., 4,
~=ц
где ь = е-»"~5. Сначала перепишем преобразование в виде
4
Vo= Z~r
j~
4 4
Vq=>o+ Еи'"ц=1/о+ К(и'" 1)о~, А=1, ..., 4,
1=1 j~)
и будем заниматься только членами f (и'" 1) о;. Элемент 2
1=1
в поле GF (5) является примитивным, и, следовательно, в этом
поле выполняются р авенства
2' = 1, 2' = 2, 2' = 4, 2' = 3,
2' = 1, 2 ' = 3, 2 ' = 4, 2-з 2
Таким образом,
3
f (и2 т 1) о'.
/=()
В этой сумме легко узнается 4-точечная циклическая свертка.
Выделим постоянные члены и определим фильтр Рейдера, задавая
его многочленом g (х) над полем комплексных чисел, где
g (x) = (и' 1) ха+. (и' 1) х'+ (и' 1) х+ (и 1)
(с коэффициентами g~ = и~' 1). Вход и выход фильтра описы-
ваются многочленами, коэффициенты которых равны перестав-
4.5. Вычислейие преобразования Фурье с помощью свертки
151
ленным компонентам векторов ч и V. Итоговая форма 5-точечного
алгоритма Рейдера задается уравнениями:
d (x) oâx + u4x' + oçx + u„
s (х) ‒ (Vs — V<>) х' + (V4 V ) х~ + (V V<>) х + (V, Vo}
s (х} = g (х} d (х} (mod х4 1}.
Многочлен g (х) фиксирован. Многочлен Н (х) образуется
перестановкой коэффициентов многочлена о (х}. Многочлен V (х)
получается обратной перестановкой коэффициентов многочлена
s (х}. Схематически этот алгоритм представлен на рис. 4.13.
Поучительно переписать алгоритм Рейдера в матричной фор-
мулировке. Для 5-точечного преобразования Фурье такая фор-
мулировка имеет вид
Ui
Ug
04
Отсюда получаем Vî = оо + о1 + oà + oç + р4 и
2 ‒ 1
,„2 1,„3 1
в4 ‒ 1 са ‒ 1
I
1 1 4
UI
И2
1 ИЗ ‒ 1 ю2 ‒ 1
U4
Правило перестановки алгоритма Рейдера приводит это равенство
к эквивалентному равенству
2
1 са4 ‒ 1
1 &3 ‒ 1
1 си1 1
V, — У~~
~ 2 О
Я 1 4
1 cuI ‒ 1
1 ы2 ‒ 1 au'‒
4 1 2
UI
U3
Од
4
U4
v4 ‒ VÎ
V3 VQ
U2
в котором легко распознать матричную форму записи цикличе-
ской свертки
UI
U4
U2
V0
V)
2
~ гЗ
~4
V„- ~
V2 ‒ Vo
V4 ‒ Vo
~3 Vo
1 1
~д gy ((Д Cd
) ~~) ~) Cd Cd
~~) g04 Cd'
1 си
gO g3 g2 gI
gI 80 83 ~2
g2 gi g0 g3
g3 g2 gi gO
152 Гл. 4. Быстрые алгоритмы дискретного преобразоваиия Фурье
Вкод
(~0~ >)e 921 РЯэ >g)
Выход
(У~, Vq V~ V~, V~~)
Рис. 4.13. Алгоритм РеКдера вычисления 5-точечного преобразоваиия Фурье.
153
4.5. Вычисление преобразования Фурье с помощью свертки
~ „,ип,
1=4)
А О -, p 1,
воспользуемся структурой кольца z/(p ) для того, чтобы пере-
упорядочить компоненты векторов. Эта структура описывается
теоремой 5.1.8. Если д равно степени простого нечеткого числа,
то Z/(p ) содержит циклическую подгруппу порядка р-' (р 1}.
Из (р'" х р'"}-матрицы W = [и'~[ просто выбросим все вызы-
вающие трудности строки и столбцы так, чтобы к оставшейся
матрице размерности р-' (p 1) была применима идея Рейдера.
Выброшенные строки и столбць~ будем обрабатывать отдельно.
Как мы увидим в следующем разделе, обработку даже этих вы-
зывающих трудности столбцов и строк можно организовать как
вычисление еще меньших циклических сверток.
Таким образом, вычисление р'"-точечного преобразования
Фурье, хотя и слишком нерегулярного для того, чтобы быть вы-
числяемым как единое целое, можно реализовать в виде всего
нескольких разумных фрагментов.
Случай, когда длина преобразования равна степени двойки,
является несколько более сложным и требует еще одного уровня
вычислений.
Это объясняется тем, что множество индексов, взаимно про-
стых с 2~ множество нечетных индексов ‒ ке образует цикли-
ческой группы по умножению. Как доказывается в теореме 5.1.8,
это множество образует группу, изоморфную группе Zq Х ~„„z.
Ядея организации процедуры вычислекий состоит в следующем.
Из (2'" X 2'"}-матрицы W = [и'~1 выбрасываются все строки и
столбцы с четными икдексами, так что остается матрица размер-
ности 2 -1. Все оставшиеся индексы являются нечетными и по
умножению образуют группу, изоморфную группе Zz X Z~ z.
Этот изоморфизм используется для того, чтобы определить такую
go = (o 1, g~ = (o ‒ 1, g~ = (o ‒ 1, g~ = o)
1.
Идея алгоритма Рейдера перекосится на случай, когда длина и
преобразования равка степени нечетного простого числа. В этом
случае, подобно тому, как нулевые компоненты временного и ча-
стотного векторов обрабатывались отдельно, еще некоторое коли-
чество компонент временного и частотного векторов должны обра-
батываться отдельно. Это объясняется тем, что в кольце Z/(pm)
не существует элемента порядка р~ 1. Теорема 5.1.8 (которая
будет доказана в гл. 5} гарантирует, однако, что для простого
нечетного р в этрм кольце имеется элемент порядка pm-' (р 1),
и мы этим воспользуемся.
При вычислении
154 Гл. 4. Быстрые алгоритмы дискретиого преобразюваиия Фурье
перестановку строк и столбцов матрицы, когорая переводит ее
в матрицу вида
где W, и W, представляют собой (2 -г><2 -')-матрицы, каждая
из которых задает структуру циклической свертки.
Точнее, пусть д = 3 и о = 2'" 1. Тогда по модулю
им™ ~2 ~ ~ . На самом деле группа нечетных целых чисел отно-
сительно умножения по модулю 2 порождается элементами л
и 0: каждый элемент группы может быть однозначно представлен
в виде о'л'", где 1' = 0, 1 и l" = 0, ..., 2 -2. Следовательно,
О ! 'л ! "Ог' ЛГ"
и подходящей перестановкой строк и столб-
цов матрица W приводится к виду
где l" и r" соответственно индексы строк и столбцов в каждой из
подматриц. Каждая из четырех подматриц задает циклическую
свертку длины 2 ‒ ~.
После выполнения перестановки рассматриваемое вычисление
приводится к виду матричной 2-точечной циклической свертки
один из способов вычисления которой дается формулой
р (~ 1 + ~' 2)
']
(:Н'
Этим задача сводится к вычислению двух комплексных цикличе-
ских сверток длины 2 ‒ 2; мы увидим, что вычисления можно
организовать несколько лучше.
В качестве примера рассмотрим две 4-точечные циклические
свертки, образующие сердцевину 16-точечного преобразования
Фурье. Пусть
IS
V„=pm'"а;, А=О, ..., 15,
f-О
4.5. Вычислеиие преобразования Фурье с помощью свертки
155
где а" = 1. Рассмотрим матрицу, образуемую в результате вы-
брасывания всех четных индексов в рассматриваемом диапазоне
значений ~ и й. Получим
1 3 S 7 9 I I )3 IS
3 9 IS S 11 1 7 13
S IS 9 3 )3 7 1 II
S 3 1 IS 13 II 9
9 II 13 IS I 3 5 7
I 1 1 7 13 3 9 IS S
US
И9
И 7 ! !)
5 15 9 3
IS 13 l) 9 7 S 3 )
И)5
Чтобы кайти нужную перестановку, выпишем индексы в виде
чисел 15'-3'" для 1 = О, 1 и "= О, 1, 2, 3. Степени тройки по
модулю 16 имекгг вид
3О = 1,
31 = 3,
3' = 9, 3' = 11
3О = »1 13-1 ‒ 11 3-~ = 9 3-з 3
и соответственно
15 3' = 15, 15 3' = 13, 15.3' = 7, 15.3' = 5,
153'= 15, 153'= 5, 153'=7, 153э= 13.
Выполним перестановку входных икдексов, записывая их в по-
рядке )5-'.3-'" (mod )6), и перестановку выходных индексов,
записывая их в порядке )6'.3'" (mod 16). Тогда
1
7 51
I
!з 7 '
1
)5 )31
1
1
1
IS1
И
yI
~9
~3
)з
И)
15
!!3
9 1
1
з
I
1
1
!
1
5 1
40 Cd
1
)З 7
1
1
15 13,'
1
1
5 )51
Л
3 9
з
1) )
9 < II
~')5
и,'
~7
I
+I3
И!5
!) 13
Чтобы показать четыре образовавшиеся при этом циклические
свертки, матрица разбита на блоки. Если преобразование Фурье
вычисляется в поле комплексных чисел, то блоки связакы соот-
yI
1
~з
и,'
~7
и,'
и,',
~!3
<)S
Г
1
3
1
Il I
14л)
1
! 9 Il
)И
1
3 9
)Ю
1
1
)5 И
!
5 15
1
1
„5
1
!з
1
9 I)1
1
1
1
3 9 1
1
1
) 3
1
1
)! I 1
1
л
Г
)5
I
I
5
1
1
7
)И
1
)з
)И
l
r
1
1 фД
1
1 ))
1
9
I
1
1
)„З
1-
156 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
ношением комплексной сопряженности. Чтобы наглядно выявить
эту связь, перепишем матричное уравнение в виде
U1
„3
г
I
‒ l
1
-!!
I
I
1
‒ 9
1
1 -3
1М
Отметим, что четыре верхние строки комплексно сопр яжены
с четырьмя нижними строками; выполнять надо только вычисле-
йия, связанные с первыми четырьмя строками. Следовательно,
дальнейшие вычисления можно организовать в виде пары цикли-
ческих сверток
Vox + Vgx + V11x+ V! ‒‒
= (и"х'+ и'х'+ и'х+ и)(о„х'+ о,х'+ u,õ+ u,) +
+ (и "х'+ й'х'+ и 'х + и ') (о,х'+ u,õ'+ о„х + о„)
(mod х' ‒ 1).
Для комплексного поля можно использовать и альтернативный
способ, основанный на выписанной выше 2-точечной циклической
свертке блоков:
VI 1 1 2(WI+ Wz)
где при 6 = 2п/!6
соз Зд cos 98
соз д cos 36
соз 116 cos д
cos 96 cos 118
I
2(% + Wy)
И
j sin 6,/яп Зд
/з~п118 /яп 8
/яп 9д /яп 116
~sin 36 jяп96
/яп 96 /яп I18
,/яп Зд /sin 96
/sin 6 /яп 36
jÿï 116 ./яп д
I
g(WI ‒ Wg) =
и,'
К!
й
V3
1
1
!!
I
I 9
1
3
I ~~!
V ‒ 3
‒ !
‒ Il
-9
cos д
cos 116
cos 96
cos 36
-9
-3
‒ !
,‒ II
II
1
1
9
3
1
1
! 1
I
‒ I II
!
(
1
‒ 9 !
1
1
‒ 3 1
I
1
‒ 11
1
r
-1
1 Ю
1
1 - II
1Ю
1
-9
-3
1
r
1~, е
~ °
I
1
!!
1
1
9
)
1
„3
1-
-9
,„-3
-I
‒ ll
соз 11
cos 96
cos 36
cos 6
‒ 11
1
1
1
-9 !
1
1
‒ 11
1
1
‒ 11
I
I
1
11
1
I
1
9
1
1
„3
1
1
1
l
157
4 ° 6. Алгоритм Винограда для быстрого преобразования Фурье
Заметим, что теперь мы получили две циклические свертки,
одка из которых ~исто вещественная, а другая чисто мнимая.
Я,ля случая вещественного входного вектора необходимо вычис-
лить только две вещественные свертки,
s (х) = ]соя 36х' + cos 96х' + cos 116х + cos 8] d (х)
(mod ха
s' (х) = Ь!и 30х' + э1п 96х' + э1п 116х + а!и 8] d' (х)
(mod х4 1).
Используя китайскую теорему об остатках для разложекия
х' ‒ 1 = (х' 1) (х' + 1), видим, что некоторые вычисления
излишки, так как
cos 30х' + cos 98mÐ + cos 116х + cos 8 = 0 (mod х'
в!п 36~Р + э!и 96х'+ sin 110х + sin 0 = 0 (mod х' ‒ 1).
Следовательно, умножения, связанные с модулем х' 1, не
нужны. Вычеты по модулю х'+ 1 требуют трех умножений каж-
дый. Следовательно, для вычисления двух циклических сверток
необходимо в общем только шесть умножекий. Исходное 16-то-
чечкое преобразование требует, таким образом, всего 10 нетри-
виальных умножений.
4.6. Алгоритм Винограда для быстрого
преобразования Фурье малой длины
Этот БПФ-алгоритм Винограда предназначен для эффектив-
ного вычисления дискретного преобразовакия Фурье малой
длины. В основу алгоритма заложены две идеи. рассмотренный
в предыдущем разделе алгоритм Рейдера для простых длин и
рассмотренный в разд. 3.4 алгоритм Винограда для свертки. Рас-
смотрению подлежат три случая: (1) длина равна простому числу;
(2) длина равна степени простого нечетного числа и (3) длина равна
степени двойки. Наиболее популярными длинами являются 2, 3,
4, 5, 7, 8, 9 и 16. Характеристики БПФ-алгоритма Винограда
для этих длин приведены на рис. 4.14. (Сами алгоритмы выписаны
в приложении В.) Число умножений на этом рисунке упоми-
нается дважды: один раз приведеко число умкожений без учета
тривиальных умножений, а другой раз полкое число умкоже-
ний, включающее умножения на (~1) и (Я). Если БПФ-алго-
ритм малой длины используется в качестве блока для гкездового
алгоритма, который будет изложен в гл. 8, m умножекия ка
(=Е1) и (+f) в малом алгоритме приводят к нетривиальным умно-
158 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
Число нетривиаль-
ных вещественных
сложений
Число вещестаенных
умиоженнй ~
Длина
2
6
8
17
36
26
44
84
94
74
157
186
0
2
0
5
8
2
10
20
20
10
35
38
2
3
4
5
7
8
9
11
13
!6
17
19
2
3
4
6
9
8
11
21
21
18
36
39
Включая умножения на ~I или ~j.
Рис. 4.14. Характеристики БПФ-алгоритмов Винограда малой длины.
4
V» = f co'"о;, k = 0, ..., 4,
к=м
жениям (и сложениям) в большем алгоритме. Поэтому мы выпи-
сываем как полное число умножений, так и число умножений без
учета тривиальных.
В характеристики алгоритмов, приведенные ка рис. 4. I 4,
включены также некоторые тривиальные сложения. Сюда отно-
сятся чисто вещественные и чисто мнимые сложения, которые
согласно принятым определениям не являются сложениями.
Но при подсчетах сложности мы не будем различать тривиальные
и нетривиальные сложения. Если заменить вещественный вектор
комплексным, то все сложения становятся нетривиальными ком-
плексными сложениями.
Ялина преобразования равна простому числу. Первый шаг
состоит в замене преобразования Фурье сверткой. Если и мало,
то воспользуемся алгоритмом Рейдера для замены преобразования
Фурье сверткой, которую вычислим затем, используя алгоритм
Винограда для сверток малой длины. Длина и выбирается не
слишком большой, так как необходимые уравнения выписываются
вручную. Переход от преобразования Фурье к свертке с помощью
алгоритма Рейдера осуществляется только перестановкой ин-
дексов; этот шаг не содержит ни умножений, ни сложений. Струк-
тура алгоритма свертки такова, что сначала выполняется некото-
рое множество сложений, затем некоторое множество умножений,
а затем опять некоторое множество сложений.
Рассмотрим 5-точечный двоичный БПФ-алгоритм Винограда,
вычисляющий
4.6. Алгоритм Вииограда для быстрого преобразования Фурье
159
где в = е-<'~~. Скачала воспользуемся описанным в разд. 4.5
алгоритмом Рейдера, переводящим рассматриваемое преобразо-
вание Фурье в циклическую свертку
s (х) = g (х) d (х) (mod х' 1),
где многочлен Рейдера
g (x) = (и' 1) х' + (и' 1) х'+ (и' 1) х + (и 1)
имеет фиксированные коэффициенты. Вход и выход фильтра опи-
сываются соответственно многочленами
d (х) = u,õ' + о,х' + о,х + u,,
s(x) = (V, V,) х'+ (V, V,) х'+ (V, V,) х+ (V,— Vo).
Коэффициенты многочлена d (х) получаются перестановкой коэф-
фициентов входного многочлена о (х); коэффициенты многочлена
V (х) на выходе алгоритма (с точностью до слагаемого V,) полу-
чаются обратной перестановкой коэффициентов многочлена s (х)
на выходе фильтра.
5-точечный БПФ-алгоритм Винограда получается, если про-
изведение g (х) d (х) вычислять с помощью алгоритма Винограда
для малой свертки. Воспользуемся приведенным на рис. 3.14
и содержащим пять умножений алгоритмом 4-точечной цикличе-
ской свертки. Его можно приспособить для вычисления преобразо-
вания Фурье, введя в матрицу свертки операции перестановок
путем соответствующей перестановки ее строк и столбцов. Так
как коэффициенты многочлена g(x) фиксированы, то вычисление
произведекия вектора g на его матрицу также можно выполнить
заранее. Если в алгоритме 4-точечной свертки произвести все эти
изменения и внести в него члены оо и Vo, то и получится 5-точеч-
ный БПФ-алгоритм Винограда, стандартная матричная форма
которого показана на рис. 4.15. Эта стандартная форма окажется
очень полезной при построении в гл. 8 гкездовых методов. Заме-
тим, что в алгоритме на рис. 4.15 матрицы предсложений и пост-
сложений не являются квадратными. 5-точечный входной вектор
дополняется до 6-точечного вектора, к компонентам которого
применяется умкожекие. Верхние две строки связующей матрииы
не содержат умножений, так как связывают о, и V<>. Другие пять
строк соответствуют алгоритму вычисления 4-точечной цикличе-
ской свертки. Одна из кокстакт умкожекия оказалась равной
единице, так что ка самом деле алгоритм содержит'только пять
нетривиальных умножений и одно тривиальное.
На рис. 4.15 видка также и другая важная деталь алгоритма.
Хотя нет никаких причин ожидать этого, все диагональные эле-
менты оказались чисто вещественными или чисто мнимыми ').
1) При желании множитель t можно переиести из диагональной матрицы
в матрицу постсложений. Тогда элементы диагональной матрицы окажутся
чисто веществениыми.
160 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
i'= 0, .4
-j 2rlS
и=Г
v = wv
= CBAv
! 0 0 0 0 0
! ! 1 1 0 ‒ !
! ! ‒ ! ! 1 0
! 1 †! †! ‒ 1 0
! ! 1 ‒ 1 0 !
1 1 1 1 1
0 1 1 1 1
0 1 ‒ 1 ‒ 1 1
0 1 ‒ 1 ! ‒ 1
0 ! 0 0 ‒ 1
0 0 ‒ 1 1 0
В0
в,
Вг
вз
в
в
г~в В,=1
2! (соя д + cos 26) ‒ 1
!
i (cos д ‒ cos 26)
j sin 6
j ( ‒ sin д + sin 26)
./ (sin 6 + sin 28)
! ! ! 1
! ‒ 1 ! ‒ 1
2 0 ‒ 2 0
2 2 2 ‒ 2
2 2 -2 ‒ 2
I
4
и д = 2т/5
Рис. 4.15. 5-точечный БПФ-алгоритм Винограда.
gP ‒ ' ‒ 1 = (х<~ ‒ <)I> ‒ 1) (х<~<)I>+ 1).
Делители многочлена х<' ‒ ' 1 делят один из множителей, стоя-
щих справа в этом равенстве. Следовательно, когда алгоритм Ви-
нограда для вычисления свертки разбивается на подзадачи, соот-
ветствующие делителям мкогочлека хр»! 1, то ситуация опи-
сывается следующей теоремой.
Теорема 4.6.1. Пусть g (х) многочлен Рейдера, тогда для
каждого нечетного р когффициенты многочлена g (х) (mod x<p <>~г
1) являются вещественными, а ковффициенты многочлена
g (x) (mod х«' ‒ <>~2+ 1) являются мнимыми.
Это существенно потому, что означает, что в случае вещественного
входного вектора каждому умножению отвечает одно веществен-
ное умножение, а в случае комплексного входного вектора каж-
дому умножению отвечают два вещественных умножения. Это яв-
ление оказывается довольно общим.
Если р нечетко, то можно записать
l61
4.6. Алгоритм Винограда для быстрого преобразования Фурье
Яоказательство. Так как элемент я примитивен, то лР ‒ ' = 1
и я(р ‒ '>~2 = ‒ 1. Так как
р ‒ 2
g(x) = f-(и" ‒ 1) х4,
то коэффициенты многочлена g (х) (mod х<~ ‒ '>~2 ~ 1) даются ра-
венствами
(о~п~ 1) ~ ( л~+ (y ‒ >>/> 1)
Утверждение теоремы вытекает теперь из того, ~0 ~(pg)]2
1.
Мы показали, как строится БПФ-алгоритм Винограда малой
длины для случая, когда длина преобразования и является про-
стым числом. БПФ-алгоритм Винограда малой длины может быть
построен и в случае, когда длина и преобразования равна степени
простого числа. Эта конструкция также основана на аналогичной
алгоритму Рейгера идее перехода от преобразования Фурье
длины р, р простое, к свертке. Однако множество целых чисел
по модулю р не образует поля, так что в этом случае отсутствует
элемент л порядка р 1.
Случаи р = 2 и нечетного простого р решаются двумя различ-
ными методами. Сначала рассмотрим случай нечетного простого р.
Длина преобразования равна степени простого нечетного
числа. Конструкция несколько усложняется. Сначала для выде-
ления циклической группы порядка р' ‒ ' (p 1} из множества
(1, 2, ..., р' ‒ 1) всех индексов удаляются целые числа, крат-
ные р. Эта циклическая группа приводит к свертке длины
р '(р 1), которая образует ядро алгоритма вычисления пре-
образования Фурье. Как и прежде, она вычисляется быстрым алго-
ритмом свертки. Компоненты свертки нужно переставить по
правилу, обратному перестановке входных компонент свертки,
и подправить членами, учитывающими выброшенные р' ‒ ' строк
и столбцов. Как мы увидим, эти поправочные члены можно вы-
числить алгоритмами еще меньших сверток, так как они пред-
ставимы в виде алгоритмов преобразования Фурье малой длины.
Например, при N = 9 = 3' удаление номеров О, 3 и 6 из мно-
жества всех индексов приводит к подмножеству {1, 2, 4, 5, 7, 8),
образующему относительно умножения по модулю 9 циклическую
группу, изоморфную аддитивной группе z< целых чисел {О, 1,
2, 3, 4, 5} относительно сложения по модулю 6. Мультипликатив-
ная группа порождается степенями 2 по модулю 9, так как эти
степени равны соответственно (1, 2, 4, 8, 7, 5}. Таким образом,
9-точечное преобразование Фурье содержит шесть строк, которые
можно изолировать, переставить и вычислить в виде свертки.
Нетрудно предвидеть, что остальные строки и столбцы (c индек-
сами, равными О, 3 и 6} имеют структуру, близкую к 3-точечному
162 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
преобразованию Фурье, так что некоторые из поправочных членов
могут быть выражены в виде свертки малой длины.
Построение 9-точечного БПФ-алгоритма Винограда пр оводится
следующим образом. Выпишем матричное уравнение
1
2 3 4
! 1 ! !
5 6 7 8
Cd Cd Cd ' Cd
6 ! 3 6
Сд' Cd Cd
Uo
2 4 6 8
3 6 ! 3
4 В 3 7
U2
U4
5 „„6 2
1 дб сд' 1 Cd'
„3 8 „4
З ! 6 З
В 6 4 2
иб
7 3
В 7
И' Ю' И' И
U8
Посмотрев на эту матрицу, можно убедиться, что строки и столбцы
с номерами О, 3 и 6 являются для нас новыми, так как содержат
повторяющиеся элементы. Переставим строки и столбцы матрицы
так, чтобы эти строки и столбцы оказались в новой матрице пер-
выми, остальные строки расположились в порядке степеней
двойки по модулю 9, т. е. в порядке 1. 2, 4, 8, 7, 5, а столбцы
в порядке степеней 2 ' по модулю 9, т. е. в порядке 1, 5, 7, 8, 4, 2.
Тогда вычисление преобразуется к виду
1 1
! ! ! ! 1
з'о
V3
г
1
1
I
I 6
I Cd
б
~д I
I
3
Cd
5
б
~0 I
1
3
Cd
в
Cd
Иб
С0
1
2
Cd
У7
4
Cd
в
Cd
7
Cd
U8
И4
И2
Пунктирные разбиения, сделанные в матрице, показывают сформи-
ровавшиеся циклические свертки. одну 6-точечную циклическую
свертку и шесть 2-точечных циклических сверток. Те 2-точечные
свертки, которые расположены во второй и третьей строках ма-
трицы, содержат повтор яющиеся вычисления, что позволяет
переписать входящие в эти две строки вычисления в виде
~2
V4
ve
v„
V~
v„
v„
V2
V3
4
v„
6
V7
ve
! ',ы~
I Cd
6
! ',Cd
1~,)
3
!
6
6( (
Ы' '(0
1
1 !
31 1 2
Cd ( ( Cd
I
бч
6(
1
3( В
Cd -! ( Cd
3 l 11 5
C0 ( Cd
3
I
Cd
2
Cd
4
Cd
в
С0
07
f
Cd
1
Cd
М2
4
Cd
Э б((
(~д ~д !
1 1
1 6 31
( Сд Сд 1
4 2
(д (0 1
1
8 4(
Cd Я 1
I
7 В!
~д ~0 !
1
71
Cd 10 1
) з!
~д ~д 1
1
2 111
Cd Сд 11
4.6. Алгоритм Вииограда для быстрого преобразования Фурье
Таким обрайом, подходящим способом выполненные перестановки
и разбиения входных данных и матрицы преобразования позво-
лили представить рассматриваемое преобразование Фурье в виде
одной 6-точечной циклической свертки и двух 2-точечных цикли-
ческих сверток. Можно было бы ожидать, что так организованное
вычисление потребует 12 комплексных умножений. Однако, как
показывает следующая теорема, происходят две вещи:
1. Все умножения являются чисто вещественными или чисто
мнимыми, так что 12 комплексных умножений превращаются
в 12 вещественных умножений.
2. Число необходимых умножений уменьшается до 10, так
как два коэффициента оказываются равными нулю.
На самом деле мы выпишем алгоритм с 11 умножениями. Одно
умножение на единицу необходимо добавить для того, чтобы строку
с номером нуль записать в алгоритме в таком же виде, как и
остальные строки.
1) являются
1) равны
Доказательство. Яоказательство первых двух утверждений
теоремы аналогично доказательству теоремы 4.6.1 Так как поря-
док числа л равен b, а Ь четно, то л~ = 1 и яь~~ = ‒ 1. Тогда
коэффициенты многочлена g (х) (mod хь~2 ~ 1) равны g„= и"
~ аР + ~. Так как ль~г = ‒ 1, то отсюда сразу вытекают пер-
„И-+-Ь(г>
вые два утверждения теоремы.
Яля доказательства утверждения (й!) рассмотрим многочлен
Ь ‒ 1
g'(õ) = g (x) (mod хьн' ‒ 1) = g и"~х~ (mod хь~р ‒ 1).
Коэффициент ао равен сумме тех коэффициентов многочлена g (х),
индекс k которых кратен числу Ь/р. Таких членов имеется р
штук и
р ‒ 1
go= Z~ °
к=о
Теорема 4.6.2. Пусть т > 1 целое, а р простое нечетное
число. Пусть Ь = (р 1) р '. Пусть g (х) ‒ обобщенный мно-
Ь ‒ 1
гочлен Рейдера, g (х) = g и""х", где и корень иэ единицы cme-
й=О
пени р и я целое число порядка Ь относительно умножения
по модулю р. Тогда:
(i) Коэффициенты многочлена g (х) (то4 хь~'
вещественными числами,
(й) Коэффициенты многочлена g (х) (mod хь~' + 1) являются
мнимыми числами.
(И) Коэффициенты многочлена g (х) (то4 хь~р
нулю.
164 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
В общем случае коэффициент g,' дается равенством
р ‒ 1
С ЛГ+СЬIР
't
8=0
г = О, ..., (Ь/р) ‒ 1.
Требуется доказать, что g' равен нулю для всех таких f. Пере-
пишем выражение для g„в виде
р ‒ 1
~~ ~[ з~]я~в~~
р ‒ 1
з
где в' является корнем степени р из единицы. Следовательно,
gp = О, и доказательство теоремы закончено. П
Таким образом, мы умеем строить БПФ-алгоритм Винограда
малых длин, равных степени нечетного простого числа. Матрица
преобразования Фурье размера р X p разбивается на
(p р ‒ ')-точечную циклическую свертку и р ' + 1 (р 1)-
точечных циклических сверток. Согласно теореме 4.6.2, все э1и
свертки вычисляются с помощью алгоритма Винограда для цикли-
ческих сверток, содержащего только чисто вещественные и чисто
мнимые умножения.
Ялина преобразования равна ствпени двойки. Преобразование
Фурье, длина которого равна степени двойки, приходится рас-
сматривать отдельно, так как целые числа, не превосходящие 2,
взаимно простые с 2, не образуют относительно операции умноже-
ния по модулю 2 циклической группы (за исключением случаев
т = 1 и т = 2). Эго множество чисел образует группу, изоморф-
ную группе z> Х z~ z. По этой причине конструкция БПФ-
алгоритма Винограда длины 2 содержит на один шаг больше.
Прежде всего, отберем 2 ‒ ' строк и столбцов матрицы с нечет-
ными индексами, подобно тому как это было сделано в разд. 4.5.
Это подмножество элементов матрицы будет переупорядочено
теперь не в одну, а в четыре циклические свертки.
Строки и столбцы с четными индексами можно представить
в виде преобразования Фурье длины 2 ' несколькими способами.
Эта часть вычислений представляет собой 2 ‒ '-точечное преобра-
зование Фурье.
Так как аР' опять является корнем степени р из единицы,
то утверждение достаточно доказать только для r, равного нулю,
p ‒ 1
„ю
т. е. для дв = g и, где n = пв~р представляет собой элемент
c=o
порядка р. Последнее равенство можно переписать в виде
4.6. Алгоритм Винограда для быстрого преобразования Фурье
Разбиение в некотором смысле аналогично одному шагу алго-
ритма Кули Тычки по основанию 2. Предположим, что мы уже
умеем строить 2 ‒ '-точечное быстрое преобразование Фурье.
л ‒ 1
Для заданного V~ = ~,' и'го;, k = О, ..., п ‒ 1, компоненты
с=О
с четными значениями индекса й можно записать в виде
л/2 ‒ 1
2СУИ Р
V2k ° = g (0~ +ор+„д) ь), k = О, ..., n/2 ‒ 1.
с-=о
Это 2 ‒ '-точечное преобразование Фурье может быть вычислено
уже известным алгоритмом. Компоненты с нечетными значениями
индекса Й можно записать в виде
л/г-1 л/2 ‒ 1
2С' (2k'+1) (гс -+-ц (» -+-ц
~гг'-+~ = Е огг+ . + a огс+1ь>
с =0 с =о
Так как в' является корнем из единицы степени 2 г, то неболь-
шие вычисления позволяют первую сумму переписать в виде
преобразования Фурье длины 2 ‒ г. Таким образом,
л/4 ‒ 1
гс' гс.. ъ 4i'k'
Ггй'+I = Z (+ U2i' + огГ+л/4/ + +
c"=0
л/г ‒ I
+ ,'), 'ог,+~и~" +'1~ +'~, Й =О, ..., а/2 ‒ 1,
с =о
где первая сумма подлежит вычислению только для первых и/4 зна-
чений индекса Й', Й = О, ..., и/4 1, так как потом эти значения
суммы повторяются. Если входная последовательность данных
является вещественной, то эта часть вычислений состоит из
(п/2) 6 вещественных умножений и (п/4)-точечного преобразо-
вания фурье, а если входная последовательность данных является
комплексной, то к (п/4)-точечному преобразованию Фурье добав-
ляется (3/4) п 8 вещественных умножений.
Вторая сумма в уравнениях для V» +1 может быть вычислена
рассмотренным в предыдущем разделе обобщенным алгоритмом
Рейдера. Он сводится к вычислению двух циклических сверток
длины 2 ‒ г. Следующая теорема показывает, что если эти цикли-
ческие свертки вычисляются на основании китайской теоремы
об остатках, то часть умножений является умножением на нуль
и может быть выброшена.
Теорема 4.6.3. Пусть т ) 2 есть целое число и g (», у)
обобщенный двумерный многочлен Рейдера вида
Л' ‒ 1 1 с cI
g(». у)= Z )~и ' ху,
с=о с =о
где в является корнем степени 2" иэ единицы. 7огда
166 Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
1 ! 1 1
4 б Р
! СО' l Cu4'
1 б и4,„2 и
Vo
V3
V4
~б
t Cd (Up ‒ иб)
+
Ю (и3 ‒ иб)
V)
~3
V5
~7
U1
05
07
Вторую часть сначала выпишем в следующем виде.
I 3 7
4И Cd Ю
Cal Cd Cd
Э I 5
Cd Cd Cd
7 5
5 7 3
Cd 40 Cd
5
7
С0
3
Cd
1
07
05
(i) Коэффициенты многочлена g (х, у) (mod у 1) являются
вещественными числами.
(й) Коэффициенты многочлена g (х, у) (mod у + 1) являются
мнимыми числами.
(ш) Коэффициенты многочлена g (х, у) (mod х"'~~ 1) равны
нулю.
Яоказательсжво аналогично доказательству теоремы 4.6.2. П
Согласно первой части теоремы циклическая свертка по мо-
дулю х"~4 1 представляет собой две вещественные циклические
свертки (точнее, одну чисто мнимую и одну чисто вещественную).
Вторая часть теоремы утверждает, что вычисление циклической
свертки сводится только к вычислениям, связанным с модулем
х"~8 + 1, так как остальные вычеты обращаются в нуль. В силу
неприводимости многочлена х"~~ + 1 на эти вычисления требуется
2 (п/8) вещественных умножений.
Теперь мы получили разбиение преобразования Фурье на
следующие фрагменты: (1) 2 '-точечное преобразование Фурье;
(2) 2 '-точечное преобразование Фурье, которому предшествует
2 ‒ ' 1 комплексных умножений; (3) два произведения многочле-
нов по модулю неприводимого многочлена х"~8 + 1.
8-точечное преобразование Фурье разбивается на две части,
4-точечное преобразование Фурье
Задачи
167
Теперь преобразуем эти равенства несколько иначе, чем в общем
случае, а именно, воспользуемся условием в4 = ‒ 1 и перепишем
уравнения в виде
И1
ИЗ
т
Cd
!
С0
I
4а1
7
Cd
Тогда
Циклическую свертку можно вычислить по правилу
‒ 1 О /яп6
Описанный 8-точечный БПФ-алгоритм Винограда содержит
всего два нетривиальных умножения; кроме того, имеется шесть
тривиальных умножений.
Если длина преобразования равна большой степени двух,
то выписывать все необходимые для вычисления по БПФ-алго-
ритму Винограда уравнения становится скучно. Лучше предста-
вить этот алгоритм в рекуррентном виде. Мы отложим такое пред-
ставление до гл. 10. В равд. 10.4 будет описан эффективный БПФ-
алгоритм по основанию два, построенный на идее Винограда,
выписанной в рекуррентной форме.
Задачи
4.й. Пусть задано устройство вычисления и-точечного комплексного преобра-
зования Фурье; описать, как это устройство можно использовать для
одновременного вычислення двух веществениых и-точечных преобразова-
ний фурье.
4 2. Пусть задано устройство вычисления и-точечного преобразования Фурье;
описать, как это устройство можно использовать для вычисления и-точеч-
ного обратного преобразования фурье.
4 З. Приведите блок-схему устройства вычисления 5-точечного преобразования
Фурье, осиованного на чирп-алгоритме Блюстейна.
4 4. а.,Яоказать, что 2 является примитивным элементом поля GF (1)).
б. Используя алгоритм Рейдера, записать 11-точечное преобразов ание
ю
Фурье иад нолем комплексных чисел Уа = f и~~в~ в виде свертки
с=о
Гл. 4. Быстрые алгоритмы дискретного преобразования Фурье
!68
4.5.
4.6.
4.7.
4.8.
4.9.
4. 10.
4.11.
5 2
2 2
5 2
Испольэовать всюду, где можно, алгоритм Гуда ‒ Томаса; в других слу-
чаях нспользовать алгоритм Кули ‒ Тычки. Найти число умножений,
включая тривиальные (на 31, ~f).
б. Найти число умножений без учета тривиальных умножений на ~1, ~(.
в. Теперь предположим, что имеется подпрограмма вычисления 2-точеч-
иого преобразования Фурье без иетривиальиых умножений и подпрограмма
5-точечного преобразования Фурье с пятью (нетривиальиыми) умноже-
ииями. Повторить и. б) задачи.
4. 12.
Иэ того, что возникающие в алгоритме Рейдера свертки вычисляются
оптимальными алгоритмами, еще не вытекает оптимальность БПФ-алго-
ритма Винограда. Это следует и из того, что коэффициеиты фильтра Рей-
дера не произвольные числа, а степени элемента в, которые, вообще говоря,
могут оказаться зависимыми, и эта эависимосчь может быть использована
для уменьшення числа умножений. А именно, мы видели, что комплексные
умножения сводятся к вещественным и иногда коэффициенты оказываются
равиыми нулю. Доказать, что 5-точечный БПФ-алгоритм Винограда опти-
мален по критерию числа умиожений.
16-точечный БПФ-алгоритм Винограда содержит 18 умножений, 8 из кото-
рых тривиальны, и 74 сложения.
4.13.
s(x) = g (x) d (х), выписывая многочлены d (х), s(x) и g (х) через компо-
иенты векторов v u V и элемент а.
Показать, что использование для вычисления линейиой свертки двух
последовательностей длины n/2 алгоритма Кука ‒ Тоома с и точками
р; = (e "} приводит к тому же самому алгоритму, что и исиольаоваиие
преобразоваиия Фурье и теоремы о свертке.
Указап две различные причины того, что сочетание алгоритма Рейдера
для простых чисел с алгоритмом Винограда вычисления свертки приводит
к лучшему БПФ-алгоритму, чем сочетание алгоритма Блюстейна с алго-
ритмом Винограда вычисления свертки. Можете ли Вы указа1ь третью
причину?
Найти простые целые числа и и л', такие что n(n', íî и-точечный
БПФ-алгоритм Винограда содержит больше умножеиий, чем n'-точечиый
БПФ-алгоритм Винограда.
Сколько умножений содержит 25-точечный БПФ-алгоритм Винограда,
если все составляющие свертки оптимальны? Как это соотносится с про-
цедурой, осиованной на алгоритме Кули ‒ Тычки, сочетающем два 5-то-
чечных БПФ-алгоритма Винограда?
Показать, что связывая вход с выходом, любой БПФ-алгоритм можно
использовать для вычисления обратного преобразования Фурье.
В алгоритме Гуда ‒ Томаса вход и выход переиндексируются по-разному.
Показать, -ne можно поменять местами схемы индексации входа и выхода
без принципиальных изменений алгоритма.
,Паны вычисляемые непосредственно 2-точечное и 5-точечное преобра-
зования Фурье (с 4 и 25 умножеииями соответственно).
а. Найти число умножений, необходимых для вычисления 100-точечного
преобразоваиия Фурье по каждой из,нижеследующих схем:
Замечания
169
а. Постронть 256-точечный БПФ-алгоритм, используя для построения
16-точечный БПФ-алгоритм Винограда и алгоричм Кули ‒ Тычки.
б. Сколько умножений потребуется, если входные данные вещественны?
в. Сколько умножений потребуется, если входные данные комплексны?
Замечания
В цифровой обработке сигналов алгоритмы быстрого преобразования Фурье
начали широко использоваться в результате рабслы Кули и Тычки [1] (1965)
и близкой к ней работы Синглтона [2] (1969). Однако другие алгоричмы БПФ,
осцованиые на китайской теореме об остатках, появились в более ранних работах
Гуда [3] (1960) и Томаса [4] (1963). Различия в этих работах были описаны
рудом [5] (1971). Эффективная организацня алгоритма Кули ‒ Тьюкн была
предложена Рейдером и Бреннером [6 ] (1976) и модифицирована Преусом [7 ]
(1982). Рейдер [8] (1968) и Блюстейн [9] (1970) описали метод сведения преобра-
зоваиия Фурье к свертке. Целью работы Рейдера было вычисление дискретного
преобразования Фурье, длина которого равна большому простому числу; но,
по иронии судьбы, этот метод оказался наиболее важным для длин, равных малым
простым числам. Обобщение алгоритма Рейдера на случай длин, равных степени
простого числа, было сделано Виноградом [11] (1978).
БПФ-алгоритм Винограда был анонсирован в работе [10] в 1976 г. и с по-
дробностями опубликован в 1978 r. Наше изложение не отражает всей значи-
мости оригинальной работы; развитие ее результатов включено в другие темы.
Яы затабулировали те БПФ-модули для малых длин, которые представляются
нам наиболее полезными. БПФ-модули для больших длин были построены Джон-
соном и Баррасом [12] (1981). Другие методы вычисления преобразования Фурье
изучались Герцелем [13] (1968) и Сервейтом [14] (1978).
Глава 5
ТЕОРИЯ ЧИСЕЛ
И АЛГЕБРАИЧЕСКАЯ ТЕОРИЯ ПОЛЕЙ
В предыдущей главе при построении БПФ-алгоритмов мы уже
пользовались некоторыми результатами теории чисел, которые,
однако, доказаны не были. В настоящей главе, представляющей
собой математическую интерлюдию, доказываются все использо-
ванные ранее результаты, а также результаты, которые понадо-
бятся в дальнейшем.
Мы также вернемся к рассмотрению полей, поскольку нам
понадобится более глубокое развитие идеи расширения полей.
Алгебраическая структура поля будет играть важную роль в сле-
дующей главе при построении теоретико-числовых преобразова-
ний, а также в гл. 7 и 8 при построении многомерных алгоритмов
свертки и преобразования Фурье.
5.1. Элементарная теория чисел
В кольце целых чисел 2q по модулю q некоторые элементы
взаимно просты с О, а некоторые делят д. Нам важно знать, сколько
именно элементов относится к каждому типу.
Определение 5.1.1 (Эйлер). Функция Эйлера, обозначаемая
q (q), для q ) 1 определяется как число ненулевых элементов
в уч, взаимно простых с q; q (q) = 1 для q = 1.
Если д = р простое, то все ненулевые элементы кольца 2q
взаимно просты с q, так что ~р (р) = р ‒ 1. Если q равно степени
простого числа, q = р™, то не взаимно простыми с q являются
только те элементы, которые кратны р. Следовательно, д (р ) =
= р ‒ ' (p 1). Все остальные значения функции Эйлера можно
получить, используя следующую теорему.
Теорема 5.1.2. Если HOli (q', q") = 1, mo ~р (ч'q") = q (q') Ч (q ).
доказаогельство. Занумеруем элементы кольца Z~ g индек-
сом ~ для ~ = p, ..., qq 1, а затем выпишем их в видедвумерной
таблицы, нумеруя каждый элемент кольца 2 ~ парой индексов
по правилу
i' = i (mod q'), i" = i (mod q"),
171
5.1. Элементарная теория чисел
так что t' и t' являются соответственно элементами колец
и zit-. Так как КОД (q', q") = 1, то отображение индекса i в пару
индексов (~', i") является взаимно однозначным, и для некоторых
Q' и Q" выполняются равенства
i = q'Q' + i', i = q"Q" + i".
Предположим, что ~' не имеет общих делителей с q', а ~" не имеет
общих делителей с q". Тогда ~ не имеет общих делителей ни с q',
ни с q", и, следовательно, общих делителей с q'q". Следовательно,
ч И4') > ч (ч') ч (ч")-
Обратно, если t не имеет общих делителей с q'q", то t не имеет
общих делителей ни с q', ни с q". Следовательно, ~' не имеет общих
делителей с q', а ~" не имеет общих делителей с q". Таким образом,
рр (qq } ~( ср (q') ср (q ), и теорема доказана. ~3
Следствие 5.1.3. Если разложение числа q на простые множи-
С С С
'щели дается равенством q = р1'р~' ... р;, mo
С,‒ 1 С~ ‒ 1 Сг
Ч (q) = Р1 Рв . ° . Рг (вое ‒ 1) (p2 ‒ 1) (p ‒ 1). С3
Часто оказывается полезным другое важное свойство функции
Эйлера. Предположим, что d делит q и обозначим через f (q) не-
которую функцию от q. Под символом ff (d) будем понимать
<Ie
сумму значений f (d) для всех d, делящих q. Очевидно, что
так как (q/d) делит q всякий раз, когда d делит q. Более удивитель-
ной является следующая теорема.
Теорема 5.1.4. Функция Эйлера удовлетворяет равенству
Яоказательство. Для каждого d, делящего q, рассмотрим
в Кд множество {i ( НОД (i, q) = d). Каждый элемент кольца
Zq принадлежит точно одному такому множеству. Следовательно,
суммируя числа элементов во всех этих множествах, мы должны
получить q.
Теперь рассмотрим эквивалентное определение этого же мно-
жеетве, ~'(НОд (, Е ) = I). Э о мможеет о ооаер
172 Гл. 5. Теория чисел и алгебраическая теория полей
точно ~р (q/d) элементов. Суммируя по всем подмножествам, по-
лучаем
( Ч
diq
откуда вытекает утверждение теоремы. Q
Элементы кольца z' относительно сложения образуют группу.
Относительно умножения ненулевые элементы кольца z также
могут образовывать группу, хотя и не обязательно. Однако в zq
всегда можно указать подмножество, образующее относительно
умножения в кольце группу, и, следовательно, являющееся под-
группой группы ненулевых элементов кольца Z в том случае,
когда ненулевые элементы также образуют подгруппу относи-
тельно умножения.
Пусть а произвольный элемент кольца zq. Порождаемая
элементом а циклическая группа равна множеству 1а, а', а', ...
..., а ‒ ', 1 }. Порядком элемента а называется число элементов в ци-
клической подгруппе, порождаемой элементом а. Пусть Gq обо-
значает множество положительных целых чисел, меньших q
и взаимно простых с д. Относительно умножения по модулю q
множество G образует группу с ~р (q) элементами. Следующая
теорема дает информацию о порядке элементов из группы Gq.
Теорема 5.1.5 (теорема Эйлера). Если КОД (а, q) = 1, то
а~<в> = 1 (mod q), так что порядок элемента а делит у (а).
Доказательство. Утверждение вытекает из теоремы 2.1.5,
так как группа Gq содержит ~р (q) элементов. ~)
Следствие 5.1.6 (теорема Ферма). Если р простое, то для
каждого а выполняется равенство а~ ' = 1 (mod р), или, экви-
валентно, ар = а (mod р).
Доказательство является тривиальным следствием теоремы
Эйлера, так как iр (р) = р 1 для любого простого р. Q
Теорема Ферма является также простым следствием следующей
теоремы.
Теорема 5.1.7. Если р просто, то относительно умножения
по модулю р ненулевые элементы кольца zf(p) образуют цикличе-
скую группу, порождаемую примитивным элементом л.
Доказательство сразу вытекает из теоремы 5.6.2, которую мы
оставляем на конец главы. Q
Согласно теореме Эйлера, если а и д взаимно просты, то по-
рядок элемента а делит ~р (q) но не обязательно равен ~р (q) Сле-
дующая теорема дает более подробную информацию об этом для
5.1. Элементарная теория чисел
173
случая д, равного степени простого числа. Это весьма сложная
теорема теории чисел, и ее доказательство занимает всю остав-
шуюся часть настоящего раздела. Оно опирается на еще не дока-
занную теорему 5.1.7, что, однако, не создает порочного круга,
так как в доказательстве теоремы 5.1.7 не используется тео-
рема 5.1.8.
Прежде чем переходить к этой теореме, приведем два примера.
Пусть q = 9; тогда G~ = (1, 2, 4, 5, 7, 8}. Легко проверить, что
порядок элемента 2 равен б, так что его можно использовать в ка-
честве образующей циклической группы G,,..
Пусть q = 16. Тогда G, 11, 3, 5, 7, 9, 11, 13, 15}. Пере-
бирая все элементы, можно убедиться, что наибольший порядок
всех элементов равен 4. (Таким элементом порядка 4 является
элемент 3.) Следовательно, группа б„не является циклической.
Так как в следующей теореме д равно степени простого числа
р,д=р'", то ~р(р )=р р ‒ '=р ‒ '(р 1).
Теорема 5.1.8. Пусть число р простое; тогда.'
(i) Если р нечетно, то группа Gpm является ииклической и
изоморфной группе Z m 1 <,>.
(ii) Если р = 2 и р™ )~ 8, то группа G не является цикли-
ческой и изоморфна группе Zq X Z p.
(ш) Если р = 4, mo группа G изоморфна группе z,.
%
Доказательство. Утверждение п. (ш) теоремы тривиально,
так как существует только одна группа с двумя элементами. Дока-
зательство остальных утверждений теоремы разбивается на пять
шагов. Шаг 1 и шаг 2 содержат доказательство и. (i). Ha шаге 1
доказывается, что для нечетного р найдется элемент порядка р ‒ ',
на шаге 2 доказывается, что для нечетного р найдется элемент
порядка р 1. Так как pm ‒ ' и (p 1) взаимно просты, то произ-
ведение этих двух элементов является элементом порядка
р ' (р 1), что и доказывает п. (i) теоремы.
Доказательство и. (ii) теоремы дается шагами 3 и 4. На шаге 3
доказывается, что если р = 2, то порядок каждого элемента
делит 2"' ‒ ~. Ha шаге 4 доказывается, что найдется элемент по-
рядка 2 ‒ ~.
Начнем с доказательства на шаге О одного полезного соот-
ношения.
Шаг О. Для всех целых чисел а и Ь и произвольной степени р
простого числа р выполняется сравнение
(а+ Ьр)Р = а~ (modp ).
Доказательство этого шага проведем индукцией по т. Для т = 1
угверждение проверяется непосредственной проверкой.
174 Гл. 5. Теория чисел и алгебраическая теория полей
Предположим, что для некоторого m справедливо
(а+ Ьр): ‒ а (modр ).
Тогда для некоторого целого k
(а+ ьр)~
= а~ +/гр
Возведем это выражение в р-ю степень:
а bp = а~ kp
P
(a+ Ьр)Р = аР + pkp à'P "Р ' + $ (~) k р' а~р
(=г
Второй член справа, так же как и все члены суммы, делится на
р'"+', следовательно,
(а+ Ьр)Р = аР (mod р +'),
так что утверждение справедливо при переходе от m к m + 1,
что и завершает индукцию.
Шаг 1. Положим в утверждении шага О числа а и Ь равными 1.
Тогда
Непосредственно проверяется справедливость утверждения для
m = 2. Предположим, что оно выполняется для некоторого m.
Тогда для некоторого k выполняется равенство
(1+p) =1+p '+kp".
Следовательно,
p ‒ 1
(1+ )'" =1+ р(р -'+kp")+~~ (',.) (р--'+kp )'+
(=2
+(p '+kp )'.
Р Р P
Если Р нечетно, то каждое из чисел,, ..., де-
2 ' 3 '"' р 1
лится на р. Каждый член в сумме делится по меньшей мере на
р2( ‒ 1}+1, и, следовательно, делится на р+' при m))~ 2. По-
(1+ р)~: ‒ 1 (modp ),
так что порядок элемента (1+ р) делит р ‒ '. Покажемтеперь,
что при нечетном р порядок этого элемента в точности равен р ‒ ',
для чего докажем, что этот порядок не делит числа р ‒ 2. А именно,
для завершения доказательства шага! докажем, что если m + 1, то
(1+р)Р: ‒ 1+p ' (modр ).
175
5.1. Элементарная теория чисел
следний член в правой части равенства делится на р~' ", и,
следовательно, при р )~ 3 и и ) 2 делится на р~+'. (Заметим,
что доказательство не проходит при р = 2.} Следовательно, по-
рядок элемента (1 + р} (mod р} не делит р ‒ ~. Это завершает до-
казательство того, что порядок элемента (1 + р) равен p ‒ '.
lllaa 2. Так как группа 6 содержит р ‒ ' (р 1) элементов,
то порядок каждого ее элемента делит р ‒ ' (р 1). Чтобы найти
элемент группы порядка (р 1) (mod р}, выберем и равным
примитивному элементу кольца z/(р). Тогда порядок и равен
(p 1) (mod р). Покажем, что a = п~ ' представляет собой
искомый элемент порядка (р 1} (mod р}. Так как пР
= 1, то порядок элемента и должен делить р 1; поэтому надо
только показать, что порядок элемента а не меньше, чем р 1.
Так как п примитивен в кольце z/(р), то р ‒ 1 степеней и'
для с = О, ..., р 2, могут быть записаны в виде целых чисел
n' = а; + Ь;р, где а; пробегает все различные ненулевые целые
чиыа, не превосходящие р 1. Следовательно, используя шаг О,
имеем
(л')~ = (а~+ Ь(p)Р = af (той р ),
клк
~Ь~ (modp ),
то отсюда следует, что порядок элемента и больше, чем р 2.
т ‒ 1
Но ар = а для любого элемента кольца Z/(р), так что аР
= а (mod р). Счедовательно, если
а~ = Ь (modр ),
то, конечно,
аР = bP (mod p),
и, таким образом,
а = Ь (modр),
что противоречит предположению о том, что а и Ь различные не
превосходящие р 1 целые числа. Следовательно, порядок эле-
мента а равен р 1 и п. (i) теоремы доказан.
Шаг 8. Порядок каждого элемента группы 6~ делит 2 ‒ ~.
Чтобы доказать это, сначала докажем, что для любых целых а
и Ь выполняется сравнение
(а+ 4Ь)' а (mod 2 ).
а =ар (то~1р ),
где а~ пробегает все различные ненулевые целые числа, не превос-
ходящие р 1. Следовательно, если мы докажем, что для любых
двух целых чисел а и Ь, не превосходящих р 1, выполняется
соотношение
176 Гл. 5. Теория чисел и алгебраическая теория полей
Поскольку элементами группы 6~ являются только нечетные
числа, то, полагая а = -~» 1 и варьируя Ь, сразу получаем из этого
сравнения нужное утверждение.
Сравнение доказывается индукцией. Для т = 2 оно прове-
ряется непосредственно. Предположим, что оно справедливо для
некоторого положительного целого m. Тогда для некоторого
целого Й
(а+ 4Ь) = а~ +k2
и, следовательно,
Ъ
(a+4b)~ =(а +k2 ) =а +ka 2 + +k2
Таким образом,
(а+ 4Ь) = а (mod2 +').
Шаг 4. Нам осталось найти элемент порядка 2 -~ при m >~ 3.
~ ‒ з
Покажем, что 3 фи 1 (mod 2), так что 3 должно быть эле-
ментом порядка 2 ‒ ~. При m = 3 это утверждение проверяется
непосредственно. Доказательство утверждения при m )~ 4 со-
состоит в доказательстве сравнения
(1+2) =‒ 1+2 ' (mod2 ).
Это сравнение просто проверяется для т = 4. Предположим, что
оно справедливо для некоторого m ~ 4. Тогда для некоторого А
(1+2) = 1+2 '+k2 .
Следовательно,
(1-+2)~ ' =(1+-2--' -)-а-)' =
=1+2 +2" "+12 +'+k2 +k2
и, таким образом, так как т больше трех,
(1+ 2)2‒ : 1+ 2 (mod 2 + ).
Следовательно, при всех m + 3 выполняется сравнение
(1+2) = 1+2 ' (mod 2 ).
Таким образом, порядок 3 (mod 2) не делит 2 ‒ з, н, следова-
тельно, он равен 2 ‒ ~, что и завершает доказательство.~
5.2.,Конечные поля, основанные
на кольце целых чисел
Имеется очень важная конструкция, позволяющая по задан-
ному кольцу построить новое кольцо, называемое его фактор-
кольцом. В случае произвольного кольца построение его фактор-
5.2. Конечиые поля, основанные на кольце целых чисел
177
кольца опирается на смежные классы. В случае кольца целых
чисел факторкольцо строится просто: оно представляет собой
кольцо целых чисел по модулю д, с которым мы уже встречались
ранее, и обозначается через Z/(q) (или, более кратко, уч}; в этом
случае его называют кольцом вычетов.
Пусть д положительное целое число. Кольцом вычетов
z/(q) называется множество «О, 1, ..., q 1} с операциями
сложения и умножения, определяемыми равенствами а + b =
= Rq [а+ Ь], а Ь = Rq [аЬ].
Элементы, обозначенные через [О, 1, ..., q 1{, принадлежат
как Z, так и Z/(q). Элементы кольца Z/(q) названы так же, как
и первые д элементов кольца Z. Яело вкуса, подразумевать ли
под ними те же самые математические объекты или некоторые
другие объекты с теми же именами.
Два элемента а и Ь кольца Z, отображаемые в один и тот же
элемент кольца Z/(q), называются сравнимыми по модулю q,
и а = Ь+ тд для некоторого целого т.
Теорема 5.2.1. Кольцо вычетов Z/(q) является кольцом.
Доказательство. Непосредственная проверка выполнения
свойств кольца. Q
Теорема 5.2.2. Ненулевой элемент s rconsqa Z/(q) обратим
относительно умножения тогда и только тогда, когда s и у взаимно
просты.
Доказательство. Пусть s ‒ такой ненулевой элемент кольца,
что s и д взаимно просты. Тогда согласно следствию 2.6.4 най-
дутся целые числа а и Ь, такие, что 1 = aq+ bs. По модулю д
соответственно имеем
1 = R~ [1] = R~ [aq+ bs] = R, {R, [aq]+ R~ [bs]} =
= Rä[bs] = Яц(Яд[Ь] Яд[в]} = Яч {R~[b].s].
Следовательно, относительно умножения по модулю д мультипли-
кативный обратный к s равен Rq[b].
Пусть теперь s такой элемент кольца, что s и д не взаимно
просты. Сначала рассмотрим случай, когда s делит д: д = s-r.
Пусть у элемента s есть обратный s '. Тогда
r = Pq [r] = Rq fs '-я г] = Pq [s '-д] = О.
Но r + О (mod q), так что получаем противоречие. Таким образом,
если s является делителем д, то он не имеет обратного.
Теперь рассмотрим случай, когда s и д не взаимно просты,
но s не делит q. Пусть d = HOg [s, q]. Тогда s = ds' для неко-
торого s, взаимно простого с д, и делителя d числа д. Если эле-
мент sобратим, ,то и элемент dтакже обратим. :d ' = s 'я', что
178 Гл. 5. Теория чисел и алгебраическая теория полей
противоречит только что доказанному утверждению. Следова-
тельно, s не может быть обратимым, и теорема доказана.П
Поскольку обращение в кольце Z/(q) возможно не всегда,
то в общем случае ненулевые элементы кольца Z/(q) группы по
умножению не образуют. Однако в z/(q) можно найти подмно-
жества, образующие подгруппы. Выберем в кольце Z/(q) ненуле.
вой элемент р и сформируем подмножество (P, P', ..., P' = 1},
остановив процесс, как только получим единичный элемент.
Мы уже видели, что единичный элемент всегда достижим и что
конструкция приводит к циклической группе. Она является под
группой кольца Z/(q), и целое число r называется порядком эле
мента р в ~/(q).
Мы уже видели в примерах равд. 2.3, что арифметика полей
GF (2) и GF (3) может быть задана как сложение и умножение по
модулю 2 и 3 соответственно, но арифметика поля GF (4) так
описана уже быть не может. В символической записи GF (2) =
= Z/(2), GF (3) = Z/(3), GF (4) ~ь Z/(4). Общий результат опи-
сывается следующей теоремой.
1
Теорема 5.2.3. Кольцо вычетов Z/(q) является полем тогда
и только тогда, когда д равно простому числу.
Доказательство. Предположим, что д просто. Тогда каждый
элемент кольца у/(q) взаимно прост с д и, следовательно (по
теореме 5.2.2), обратим относительно умножения.
Предположим теперь, что д составное число. Тогда д = r.s
и согласно теореме 5.2.2, r u s не могут иметь обратных элемен-
тов. Ц
Если кольцо вычетов Z/(q) является полем, то чтобы подчерк-
нуть этот факт, оно обозначается через GF (q). Конечные поля,
построенные как кольца вычетов целых чисел, не исчерпывают
всего множества полей, но конечные поля с простым числом эле-
ментов всегда могут быть построены как кольца вычетов.
Если поле GF (о) не содержит квадратного корня из 1, то
его можно расширить до GF (р') точно таким же способом, как
поле вещественных чисел расширяется до поля комплексных чи-
сел. Например, в поле GF (7) выполняется равенство 6 = 1,
но, как легко проверить, поле не содержит элемента, квадрат
которого равен 6. Следовательно, поле GF (49) можно задать
множеством элементов вида
GF(49) = (a+jb:а, Ь6GF (7)},
определив на нем операции сложения и умножения так же, как
для комплексных чисел:
(a + jb) + (с + jd) = (a + с) + j (Ь + d),
(а + jb) (с+ jd) = (ac bd) + j (ab + cd),
5.2. Конечные поля, основанные на кольце целых чисел
179
где во всех скобках справа операции обозначают сложение и ум-
ножение в поле GF (7). При таком определении множество GF (49)
является полем. Целыми поля GF (49) являются элементы поля
GF (7), так что характеристика поля GF (49) равна 7.
Теорема 5.2.4. Каждое поле содержит однозначно определяе-
мое наименьшее подполе, которое либо изоморфно полю рациональ
ных чисел, либо содержит конечное число элементов. Следовательно,
характеристика каждого поля Галуа либо бесконечна, либо равна
простому числу.
Доказательство. Каждое поле содержит 0 и 1. Для построения
подполя рассмотрим подмножество 6 = 10, 1, 1 + 1, 1 + 1 +
+ 1, ...}, обозначая его элементы соответственно «О, 1, 2, 3, ...}.
Это подмножество содержит либо бесконечное множество эле-
ментов, либо конечное множество, скажем р. Мы покажем, что
если это число конечно, то оно просто и 6 = GF (р). Так как 6
является циклической группой, то сложением в нем служит сло-
жение по модулю р. В силу наличия в поле дистрибутивного за-
кона умножение в 6 также является умножением по модулю р,
так как
а . P = (1 + 1 + ... + 1) P = P + P + ... + P
В поле Галуа GF (q) всегда можно найти простое подполе
GF (р). В частности, если то q, с которого мы начинаем, само яв-
ляется простым числом, то это простое подполе можно интерпре-
тировать как поле вычетов целых чисел по модулю д. Следова-
тельно, на самом деле имеется только одно поле с заданным числом
элементов, которое, конечно, допускает много различных пред-
ставленийй.
где сумма содержит а копий элемента р и сложение выполняется
как сложение по модулю р. Следовательно, умножение также яв
ляется умножением по модулю р. Относительно умножения каж-
дый ненулевой элемент р имеет обратный, так как последователь
ность р, 2р, Зр, ... образует в 6 циклическую подгруппу.
Поскольку а.P + 0 для любых ненулевых а и р из исходного
поля, то ар + 0 по модулю р для всех целых поля, и, следова
тельно, р должно быть простым. Таким образом, подмножество 6
образует в точности простое поле, описываемое теоремой 5.2.3.
Альтернативным является случай, когда множество 6 беско-
нечно. В этом случае оно изоморфно кольцу целых чисел. Наимень
шее содержащее 6 подполе F изоморфно наименьшему полю,
содержащему кольцо целых чисел, каковым является поле рацио-
нальных чисел. Q
180 Гл. 5. Теория чисел и алгебраическая теория полей
5.3. Иоля, основанные
на кольцах многочленов
Поля можно строить, отталкиваясь от колец многочленов, та-
ким же образом, как были построены конечные поля из кольца
целых чисел. Такая конструкция приводит как к конечным, так
и к бесконечным полям в зависимости от того, было ли исходное
кольцо многочленов определено над конечным или бесконечным
полем. Эти расширения оказались полезными в нескольких
,направлениях дискретной обработки сигналов. Они были ис-
пользованы для построения теоретико-числовых преобразований,
рассматриваемых в гл. б, и для построения алгоритмов много-
мерной свертки, рассматриваемых в гл. 7.
Пусть имеется кольцо многочленов F fx J над полем F. Так же
как для кольца Z б~~ы~л~и H п~оOс~тTр~о~енH~ы ~ кKоoл~ь~ц~а ~ вB~ы~ч~еeтTоOвB, можно по-
строить и для кольца F hl его факторкольцо. Выбирая из F [х]
произвольный многочлен р (х), можно определить такое кольцо,
используя р (х) в качестве модуля для задания арифметики этого
кольца. Мы ограничим рассмотрение только приведенными много-
членами, так как это ограничение снимает ненужную неопреде-
ленность построения.
Определение 5.3.1. Для произвольного приведенного много-
члена р (х) ненулевой степени над полем F кольцом многочленов
по модулю р (х} называется множество всех многочленов над F,
степень которых не превосходит степени многочлена р (х}, с опе-
рациями сложения и умножения многочленов по модулю р (х).
Это кольцо принято обозначать через F [х]/(р (х)).
Произвольный многочлен r (х) из F [х] можно отобразить
в F [х]/(р (х)), отображая r (х) в Я~<„> [г (х) ]. Два сравнимых
по модулю р (х) элемента а (х) и Ь (х) из F (х} отображаются в один
и тот же многочлен из F [х]/(р (х}}.
Теорема 5.3.2. Кольцо многочленов по модулю р (х) является
кольцом.
,[[оказательство. Доказательство проводится прямой провер-
кой выполнения свойств кольца.
В качестве примера рассмотрим кольцо многочленов над GF (2},
выбирая модуль равным р (х} = xÐ + 1. Тогда кольцо многочленов
по модулю р (х} равно GF (2) [x]/(õ' + 1}. Оно состоит из эле-
ментов 10, 1, х, х + 1, х', х~ + 1, х' + х, х' + х + 1, j и умно-
жение в этом кольце выполняется, например, следующим образом.
(х'+ 1) . (х') = R»ç+, [(х'+ 1) х'] = R»â+i [х(х' + 1) + х'+ х] =
= х~4-х,
где использована редукция по правилу х4 = х (х~ + 1} + х.
5.3. Поля, основанные на кольцах многочленов
181
В качестве другого примера рассмотрим кольцо многочленов
над полем рациональных чисел»,>, выбирая р (х = х'+ 1. Тогда
кольцо многочленов по модулю р (х} есть Q х]/(х'+ 1) Оно
содержит многочлены вида а + хЬ, где а и b рациональные
числа. Умножение выполняется по правилу
(а + хЬ) (с + xd) = (ас bd) + х (ad + Ьс).
Умножение имеет ту же структуру, что и комплексное умножение;
на самом деле рассматриваемое кольцо является полем. Это вы-
текает из следующей общей теоремы.
Теорема 5.3.3. Кольцо многочленов по модулю приведенного
многочлена р (х) является полем тогда и только тогда, когда много-
@лен р (х} r>poem '}.
~) Напомним что простой многочлен является одновременно приведенным
и неприводимым. Для построения поля достаточно только неприводимости р (z),
ио мы условились рассматривать только приведенные многочлены, так что даль-
нейшие результаты носят менее общий характер.
Доказательство. Пусть многочлен р (х} прост. Чтобы доказать,
что рассматриваемое кольцо образует поле, достаточно показать,
что каждый ненулевой элемент имеет мультипликативный обрат-
ный. Пусть s (х} некоторый ненулевой элемент кольца. Тогда
deg s (х) ( deg р (х). Так как многочлен р (х} прост, то НОД
fs (х}, р (х}] = 1. Согласно следствию 2.7.7,
1 = а (х) р (х) + Ь (х) s (х)
для некоторых многочленов а (х) и Ь (х). Следовательно,
1 = Rp <„> [1] = Rp <„> [а (х) р (х) + Ь (х) s (х)]
= Rp <„.> [b (x)]- Rp <,,> [s (x)] = R <„> [Ь (x)] s (x).
Таким образом, в кольце многочленов по модулю многочлена
р (х) многочлен R <„> [Ь (х)] является мультипликативным об.
ратным к s (х).
Теперь предположим, что многочлен р (х не прост. Тогда
р (х} = r (х} s (х} для некоторых r (х) и s (х}. Если кольцо явля-
ется полем, то многочлен r (х) имеет обратный г' (х}, и поэтому
s (x) = Rp (~> [s (x)] = Я>~ ~~> [г ' (х).r (X) 's (X)]
= R <„> [г '(х).р(х)] = О.
Но s (х) + О, и мы получаем противоречие. Следовательно, такое
кольцо не может быть полем. []
Теорема описывает один из способов построения поля комплекс
ных чисел С как расширения поля вещественных чисел р. Так
как многочлен х' + 1 является простым над полем вещественных
182 Гл. 5. Теория чисел и алгебраическая теория полей
чисел, то р можно расширить до множества 1а + Ьх}, где а и Ь
вещественны, задавая сложение и умножение по модулю х'+ 1.
Тогда
(а + Ьх) (с + dx) = (ас bd) + (ad + Ьс) х,
(а + Ьх) + (с + dx) = (а + с) + (Ь + d) х.
Эти формулы будут более привычны, если вместо х поставить 1:
(а + !Ь) + (с + jd} = (а + с) + i (Ь + d},
(а+ jb) (с+ jd) = (ac bd) + 1(ad + Ьс).
Эта же самая конструкция может быть использована для расшире
ния любого поля, над которым многочлен х' + 1 простой. Таким
полем является, например, GF (7}, и его можно расширить до
поля GF (49) точно так же, как поле вещественных чисел до поля
комплексных чисел, что и было формально проделано перед до-
казательством последней теоремы.
С другой стороны, многочлен х' + 1 не является простым мно
гочленом над полем GF (5} и не может быть использован для его
расширения. Чтобы построить расширение GF (25) поля GF (5),
надо воспользоваться многочленом х' + х + 1, который является
простым над GF (5). При этом модуле правило умножения прио-
бретает вид
(а+ хЬ) (с+ xd) = (ас bd) + x (ad+ Ьс bd).
Умножение в этом поле отлично от умножения в комплексном
поле. Умножение'всегда будет задаваться этим правилом, если
поле GF(p'} получается как расширение поля GF (p) с помощью
многочлена х' + х + 1, и такое расширение всегда возможно,
если х' + х + 1 является простым над GF (p). В частности, этот
многочлен можно использовать при расширении GF (2) до GF (4).
5.4. Минимальные многочлены и сопряжения
Элемент некоторого поля может быть корнем многочлена, ко-
эффициенты которого принадлежат некоторому меньшему полю.
Если элемент является корнем хотя бы одного такого многочлена,
то с ним оказывается связанным один специальный многочлен,
представляющий особый интерес.
Определение 5.4.1. Пусть F некоторое поле, а элемент
принадлежит некоторому расширению поля F. Минимальным
мноаочленом f (х) элемента р над полем F называется ненулевой
приведенный многочлен наименьшей степени, такой что коэффи-
циенты его принадлежат основному полю F, а элемент р является
корнем.
5.4. Минимальные многочлены и сопряжения
183
Минимальный многочлен над полем F существует не для вся-
кого элемента расширения элементы вещественного поля, не
имеющие минимальных многочленов с рациональными коэффи-
циентами, называются траясцендентными числами но если
для данного элемента минимальный многочлен существует, то
он единственен. Действительно, если f«> (х) и f<'> (х) оба являются
минимальными многочленами элемента р, то они оба приведенные,
имеют одну и ту же степень и р является их корнем. Тогда мно-
гочлен f (х) = f<'> (х) f<'> (х) имеет меньшую степень и р яв-
ляется его корнем. Следовательно, f (х) = 0 и /«> (х) равен
f<'> (х).
Теорема 5.4.2. Каждый минимамный многочлен является
единственным и простым. Если f (х) минимальный многочлен
влемента р, а g (х) некоторый многочлен, для которого р яв-
ляется корнем, то f (х) делит g (х).
Доказательство. Единственность минимального многочлена
мы уже доказали. По определению многочлен f (х) является при-
веденным. Предположим, что f (х) разлагается в произведение двух
многочленов, f (х) = а (х) Ь (х). Тогда f (P) = а y) Ь y) = О, так
что хотя бы один из многочленов а (х) и Ь (х) имеет степень, мень-
шую чем степень f (х), и элемент р служит его корнем. Следова-
тельно, минимальный многочлен является простым.
Для доказательства второй части теоремы запишем
g (х) = f (х) h (х) + s (х).
Степень многочлена s (х) меньше степени f (х), так что s (х) не
может иметь элемент р своим корнем. Но
0 = g (р) = f (р) и (р) + в (р) = в (р)
так что многочлен s (х) равен нулю, и теорема доказана. ~)
Каждый элемент р поля F имеет над F минимальный много-
член первой степени, равный f (х) = х ‒ P. Если элемент
не принадлежит полю F, то степень его минимального многочлена
равна двум или больше. Следовательно, минимальный многочлен
может иметь и другие корни. Но тогда минимальный многочлен
элемента р является минимальным многочленом и для других,
отличных от р, элементов.
Определение 5.4.3. Два элемента некоторого расширения поля
F, имеющие общий минимальный многочлен над F, называются
сопряженными (относительно F).
В общем случае один элемент может иметь более одного сопря-
женного элемента, на самом деле столько, какова степень его ми-
нимального многочлена. Подчеркнем, что отношение сопряжен-
184 Гл. 5. Теория чисел и алгебраическая теория полей
ности двух элементов зависит от основного поля. Два элемента
комплексного поля могут быть сопряженными относительно поля
рациональных чисел, но не быть сопряженными относительно
поля вещественных чисел. Например, минимальный многочлен над
(;) комплексного числа j~2 равен х' 2, а над R равен х' + у~2.
!
Множество сопряженных с / ф 2 элементов, содержащее этот
элемент, относительно поля Q равно (1~2, ~2, j ф% j~2I
а относительно поля р равно (д/ 2, /1~ 2).
5.5. 3(руговые многочлены
Над произвольным полем F можно выписать разложение мно-
гочлена х" 1 в произведение его простых делителей:
х" 1 = р,(х) р,(х) ...рк(х).
Если F поле рациональных чисел, то простые делители нахо-
дятся сравнительно легко. Они представляют собой многочлены,
которые дак~гся следующим определением.
Определение 5.5.1. Над произвольным полем F для каждого и
круговой многочлен определяется равенством
Q„(x) = П (х ‒ и'„),
нодо. щ=з
где и„равно корню ') степени и иэ единицы в некотором расши-
рении поля F.
Главным образом нас будут интересовать круговые многочлены
над полем рациональных чисел Q В этом случае и„= е-~~"~"
принадлежит полю комплексных чисел, а для п(105 коэффи-
циентами круговых многочленов являются 1, О или +1.
В достаточно большом расширении поля F для поля рацио-
нальных чисел таковым является комплексное поле многочлен
х" 1 может быть разложен в виде
л ‒ 1
х ‒ 1= П (х и„'),
8=Ф
где а„корень степени и из единицы. Следовательно, каждый
круговой многочлен можно выразить в виде произведения неко-
торых из этих линейных множителей. Определение кругового
многочлена специально построено так, чтобы все его коэффици-
енты были рациональными.
1) Имеется в виду, конечно, первообразный корень степени и из единицы.‒
Прим перев.
5.5. Круговые многочлены
185
При малых и круговые многочлены можно легко вычислить,
разлагая многочлен х" 1. Очевидно, что Q> (х) = х 1. Лля
выяснения общей ситуации найдем несколько начальных много-
членов. Пусть n = 2. Тогда
х' 1=(х 1)(х+1) =Q,(x)Q,(х).
Пусть и = 3. Тогда
х' 1 = (х
Пусть и = 4. Тогда
х' 1 = (х
1) (х' + х + 1) = Q, (х) Q, (х).
1) (х + 1} (х' + 1) = Q, (х) Q, (х) Q, (х).
Отметим, что на каждом шаге появляется только один новый
множитель. Пусть n = 5. Тогда
х' 1 = (х 1) (х' + xÐ + х' + х + 1) = Q, (х) Q, (х).
Пусть n = 6. Тогда
х' 1 =(х 1)(х+ 1)(х'+х+ 1)(х' х+ 1) =
= Qi (х) Q. (х) Q. (х) q, (х).
Пусть n = 7. Тогда
х' 1 = (х 1) (х' + х' + х' + x' + õ' + х + 1) =
=Q, (х) Q, (х).
Пусть и = 8. Тогда
хг 1 = (х 1) (х + 1) (х'+ 1) (х4+ 1) =
(Х) Qà (Х) (~4 (Х) Qg (Х)
Пусть n = 9. Тогда
х' 1 = (х 1) (х' + х + 1) (х' + xÐ + 1) =
= q, (х) Q, (х) q, (х).
Общий случай описывается следующей теоремой.
Теорема 5.5.2. Для каждого и
дед qÄ (x) = q> (и),
где q> (n) функция Эйлера.
Теорема 5.5.3. Яля каждого п
х" ‒ 1 = П Q„(x).
A)n
Доказапмластво. q> (и) определяется как число целых чисел,
меньших и и взаимно простых с и, и это в точности совпадает
с числом линейных множителей, входящих в определение Q- (х}. П
186 Гл. 5. Теория чисел и алгебраическая теория полей
Доказательство. Непосредственные вычисления дают:
х" ‒ 1 = Г1(х ‒ и.'} = П П (x ‒ и„') =
2=1 цл Код (с, л)=л/й
= 11 Я„(х).
Цл
Теорема 5.5.4. Над произеольным полем коэффициенты кру
гового многочлена всегда являются целыми этого поля.
Доказательство. Воспользуемся индукцией по п. Коэффици-
енты многочлена Q, (х) = х 1 являются целыми. Согласно
теореме 5.5.3,
Деление приведенного многочлена с целыми коэффициентами на
приведенный многочлен с целыми коэффициентами дает в виде
частного приведенный многочлен с целыми коэффициентами.
Следовательно, утверждение теоремы верно для любого и, если
оно верно для всех меньших положительных целых и. Р
Теорема 5.5.5. Над полем рациональных чисел все круговые
многочлены являются простыми и, следовательно, минимальными
многочленами для соответствующих корней из единицы.
Доказательство. Приведенность круговых многочленов оче
видна. Яоказать надо только неприводимость круговых многочле-
нов над полем рациональных чисел. Пусть f (х) обозначает мини-
мальный многочлен элемента co„над полем рациональных чисел.
Пусть hпроизвольное целое число, ,взаимно простое с и, и
пусть g (х) минимальный многочлен элемента и„над полем
рациональных чисел. Предположим, что g (х) = f (х) для каж-
дого такого h. Тогда многочлен f (х) должен быть кратным много-
члену Q„(x), и так как Q„(x) приведен и имеет рациональные
коэффициенты, f (х) = Q„(x). Тогда наша задача сводится к до-
казательству того, что для каждого взаимно простого с и числа h
минимальный многочлен g (х) элемента и„равен многочлену f (х).
Й7аг 1. Л;окажем сначала это утверждение для случая, когда h
равно простому числу р, не являющемуся делителем и. Пусть
g (x) минимальный многочлен элемента и и предположим, что
он не равен многочлену f (х). Тогда
х" 1= f(х)g(х) t(х),
для некоторого многочлена t (х), коэффициенты которого целые
числа, так как оба многочлена f (х) и g (х) являются делителями
5.6. Примитивные элементы
187
многочлена х" 1 и имеют целые коэффициенты. Так как эле-
мент и„является корнем многочлена д (х~), то многочлен g (х«')
кратен многочлену f (х):
g (хр) = f (х) k (х)
для некоторого многочлена k (х) с целыми коэффициентами. 3а-
меним теперь оба равенства вычетами по модулю р.
х" 1 = f (x) g (x) t (x) (mod р),
g (х«') = f (х) /г (х) (mod р).
Согласно теореме 2.2.4, второе равенство записывается в виде
(g (х))р = f (х) Й (х) (m««d р).
Рассмотрим разложение этого уравнения над полем GF (р). Каж-
дый простой делитель р (х) многочлена f (х) должен быть простым
делителем многочлена (g (x))>, и, следовательно, многочлена g (х).
Следовательно, (х" 1) должен делиться на (р (х))'. Но тогда
формальная производная nx ' от многочлена (х" 1) делится
над GF (р) на р (х). По предположению р не делит и, à х не может
быть делителем f (x)(mod р), так как f (х) делит х" 1. Полу-
ченное противоречие показывает, что g (х) не может быть не рав-
«ь«м f (х).
Шаг 2. Теперь докажем утверждение для произвольного h,
взаимно простого с и. Запишем разложение h на простые множи-
тели:
h Р1Р2 ' p$ ,°
Каждый из'этих множителей взаимно прост с и, так как h взаимно
просто с и. Согласно утверждению шага 1, если в„корень
многочлена f (х), то и~' также является корнем этого многочлена.
Теперь опять воспользуемся шагом 1: если в„' корень много-
члена f (x), то и и~'~' является корнем этого многочлена. Исполь-
зуя индукцию, получаем, что и и является корнем f (х).~
h
5.6. Примитивные элементы
Согласно данному в разд. 2.3 определению, примитивным эле-
ментом поля Галуа называется такой элемент а, что каждый не-
нулевой элемент поля можно однозначно записать в виде степени
этого элемента. Например, в поле GF (7) выполняются равенства
3'=3,3 =2,3 =6,34 =4,3'=5,3'= 1,такчтоЗявляется
примитивным элементом поля GF (7). Примитивные элементы
полезны при построении полей, так как, коль скоро один из них
найден, то, перемножая степени этого примитивного элемента,
можно построить таблицу умножения в этом аоле. В полях Галуа
188 Гл. 5 Теория чисел и алгебраическая теория полей
примитивные элементы играют роль основания логарифмов.
В данном разделе будет доказано, что каждое конечное поле со-
держит примитивный элемент.
Конечное поле образует абелеву группу двояким способом.
Множество всех элементов поля образует абелеву группу по сло-
жению, и множество всех элементов поля, исключая нуль, обра-
зует абелеву группу по умножению. Мы будем работать с группой
по умножению. Согласно теореме 2.1.5, порядок этой группы де-
лится на порядок каждого ее элемента.
Теорема 5.6.1. Пусть P„P„..., Pq, ненулевые элементы
поля GF (q); тогда:
Доказательство. Множество ненулевых элементов поля GF (q)
образует конечную группу по умножению. Пусть р какой-
либо элемент из GF (q), и пусть h мультипликативный порядок
этого элемента. Тогда, согласно теореме 2.1.5, h делит д ‒ 1.
Следовательно,
~q ‒ t (PR)(q ‒ I)/R 1(q ‒ ()/h 1
так что р является корнем многочлена х~ ‒ '
Теорема 5.6.2. Группа ненулевых элементов поля GF (q) no
умножению является циклической.
Доказательство. Если число q 1 простое, то теорема триви-
альна, ибо порядок всех элементов, за исключением нуля и еди-
ницы, равен д 1, так что каждый такой элемент примитивен.
Доказывать теорему надо только для составного числа Ч 1.
Рассмотрим разложение числа д 1 на и ростые множители.
Так как GF (q) поле, то среди его q 1 ненулевых элементов
должен найтись хотя бы один, не являющийся корнем многочлена
(Р ‒ 1)/Р-
'/Р ‒ 1, поскольку этот многочлен может иметь не более
(q 1)/р; корней. Следовательно, для каждого ! можно найти
(e †>)/u~ (а ‒ () /р,'
такойэлемента, поля GF (q), чтоа( '~1. Пустьb( = а(
S
и пусть b = П b;. Покажем, что порядок b равен q ‒ 1, и,
ю=i
следовательно, группа является циклической.
Шаг 1. Порядок элемента b( равен р('. Докаэа/пельство.
189
Задачи
V~
Р~ Vf
Очевидно, что Ь~' ‒ ‒ 1, так что порядок Ь~ делит pc . Он ра-
рVC ‒ '
Ля l
вен числу вида р~ . Если п~ меньше ч~, то Ь~
v< ‒ 1
(q — >)/Ð~
bi ‒ ‒ <c =ф» 1, и, следовательно, порядок элемента bt
Vg
равен pi .
Шаг 2. Порядок элемента Ь равен q 1. Доказательство.
Предположим, что Ь" = 1. Покажем сначала, что из этого вы-
V)
текает равенство и = 0 (mod p> ) для всех ! = 1, ..., s. Для
каждого i можно записать
= 1. Но
(л П p~l)
S М~
Pg
Заменив b на Ц b> и используя равенство b>' = 1, находим
К=1
Таким образом,
и П p>> = 0 (mod р> >).
)~t
Поскольку р; представляют собой различные простые числа, то
и = 0 (mod p>') для каждого !. Следовательно, и =0 (mod q 1}.
Теорема доказана. ~]
До>шза>иельство. Так как ненулевые элементы поля GF (q)
образуют циклическую группу, то среди них имеется элемент
порядка д 1. Этот элемент является примитивным.
Задачи
а. Приводим ли иад полем рациональных чисел многочлен р (х) = х4+
+ 2хз+ х~ ‒ 2? Если приводим, то разложить его.
б. Приводим ли иад полем вещественных чисел миогочлеи р (х) = х4+
+ 2хз+ х~ ‒ 27 Если приводим, то разложить его.
s, Приводим ли миогочлеи р (х) = ха+ 2х~+ z~ ‒ 2 над полем комплекс-
ных чисел? Если приводим, то разложить его.
Над полем рациональных чисел пусть
рд(z) = х8+ 1, р (z) = ха+ х8+ х+ 1.
Теорема 5.6.3. В каждом поле Галуа имеется примшпивный
элемент.
Гл. 5. Теория чисел и алгебраическая теория полей
6.3.
6.4.
6.5.
6.В.
6.7.
6.8.
6.9.
6.10.
6.11.
6.12.
5.13.
5.14.
6.16.
а. Найти НОД 'fp> (х), р~ (х)].
б. Найти НОК [рд (х), р~ (х)].
в. Найти миогочлены А (х) и В (х), удовлетворяющие равенству
НОД [рд (х), рз (х)] = А (х) рд (х)+ В (х) р2 (х).
Пусть тд (х) = хз+ х+ 1, тз (х) = х~+ 1, m (х) = х~ ‒ 1.
Пусть даны сд (х) = с (х) (mod тд (х)),
с, (х) = с (х) (mod т, (х)),
с~ (х) = с (х) (mod т~ (х)),
где степень многочлеиа с (х) не превосходит 5. Найти все многочлены, необ-
ходимые для вычисления многочлена с (х) по этим вычетам.
Сколько круговых многочлеиов делят хд~ ‒ 1? Найти их.
59
Пусть р (х) = f х~. Ислользуя соотиошеиие
С=О
H~ ‒ I = (х ‒ ]) р (х),
найти R < > 1хд~+ х~~+ ха~].
Доказать, что для формальной производной многочлеиа выполняется
равенство
fr (х) s (х) ]' = r' (х) s (х) + r (х) s" (х),
и что если а~ (х) делит r (х), то а (х) делит r' (х).
Доказать, что в кольце 7/(15) целых чисел по модулю 15 многочлеи р (х) =
= х2 ‒ 1 имеет более двух корней: Этот же миогочлен над полем имеет
только два корня. В каком месте в случае кольца ие проходит доказатель-
ство теоремы?
Яногочлеи р (х) = ха+ хз+ ха+ х+ 1 неприводим над полем 6Р (2)
Следовательно, кольцо миогочленов по модулю р (х) является полем GF (16).
а. Доказать, что в этой конструкции элемент поля, соответствующий
миогочлену х, не является примитивным.
6. Показать, что многочлеиу х+ 1 соответствует примитивный миого-
члеи
в. Найти минимальный миогочлен элемента х+ 1.
Над полем GF (16):
а. Сколько имеется различных приведенных многочлеиов второй степени
вида х'+ ах+ Ь, Ь =фО?
6. Сколько имеется различных многочленов вида (х ‒ P) (х ‒ у), р, у =ф=
=ф= О?
в. Доказывает ли это существование неприводимых многочленов второй
степени? Сколько простых многочлеиов второй степеии имеется над по-
лем GF (16)?
а. Построить расширение поля вещественных чисел R, используя простой
миогочлеи х4+ 1. Объясиить, почему это расширение является полем ком-
плексных чисел С, которое можно построить также, используя простой
многочлеи х~+ 1.
б. Построить расширеиие поля рациональных чисел Q, используя простой
миогочлен ха+ !. Объяснидь, почему это расширение отличается от рас-
ширения поля рациоиальиых чисел с помощью простого миогочлеиа ха+ 1-
Построить поле GF (7), задавая его таблицами сложения и умножения.
Вычислить 32~ (mod 7).
Доказать, что кольцо вычетов Z< является кольцом.
Найти элементы порядка р~ 1 (p ‒ 1) в каждом из следующих полей:
GF (9), GF (25), GF (27), QF (49).
Доказать, что многочлеи хе+ х + ! иеприводим иод полем рациональных
чисел.
Замечания
191
Замечая яя
Материал данной главы обычен для математической литературы. Хорошее
изложение теории чисел можно найти у Оре [1] (1948) и Харди и Райта [2]
(1960). Свойства полей Галуа описываются во многих книгах по абстрактной
алгебре, например, в книгах Биркгофа и Маклейна [3] (1941), а также Ван дер
Вардена [4] (1949). В большинстве материала, однако, это стандартное изложение
является формальным, уделяет основное внимание абстрактным свойствам и
содержит мало примеров и прнложений. Большее внимание вычислительным
аспектам полей Галуа уделил Берлекэмп [5] (1968). Более детальное изложение
колец многочленов и крутовых многочленов можно найти в книге Маклеллана
и Рейдера [6] (1979).
Глава б
ВЬ!ЧИСЛЕНИЯ В СУРРОГАТНЫХ ПОЛЯХ
Часто задачу вычисления в заданном поле можно вложить
s другое поле, произвести там необходимые вычисления, а затем
ответ вернуть в заданное поле. Целесообразность такого перехода
может мотивироваться различными причинами. Может оказаться,
что в новом поле необходимые вычисления выполнить легче, и это
уменьшает объем работ или упрощает реализацию вычислений.
Иногда электронные компоненты для вычислений в некотором поле
доступнее, чем для заданного поля, и тогда, если требуемые вы-
числения допускают подходящую переформулировку, резоннее
перейти в это поле. Возможны ситуации, когда желательно раз-
работать стандартный вычислительный модуль обработки боль-
ших массивов данных и использовать его при решении разнооб-
разнь~х задач для обработки дискретных сигналов. Подгонка одного
типа вычислений к другому может осуществляться тогда с целью
стандартизации.
Другой важной причиной использования суррогатных полей
является улучшение точности вычислений. Вычисления в полях
Галуа не содержат погрешностей округления и поэтому всегда
точны. Если задачу вычисления в поле вещественных или комп-
лексных чисел удастся погрузить в поле Галуа, то это может при-
вести к увеличению точности результата. В большинстве задач
обработки дискретных сигналов можно ограничиться вычисле-
ниями с фиксированной запятой; обычно оказывается достаточной
16-битовая арифметика с фиксированной запятой. Если поле
Галуа достаточно велико, чтобы содержать 16-битовые целые
числа, то в его пределах можно правильно осуществлять многие
целочисленные операции, если только результаты не выходят
за пределы )6-битовых целых чисел.
6.1. Свертка s суррогатных полях
Свертка в поле вещественных чисел часто может быть заме-
нена сверткой в подходящем поле Галуа. В реальных задачах
вещественные числа записываются в виде конечного числа де-
сятичных или двоичных знаков; в цифровой обработке сигналов
6.1 Свертка в суррогатньш полях
193
обычно используется запись с фиксированной запятой. Двоич-
ное представление с конечным числом знаков может ограничива-
'.ться 12 или 16 битами. При вычислениях можно предполагать,
что двоичная точка находится справа все числа являются
целыми- Сдвиг двоичной точки во входных данных с целью вклю-
чения остальных случаев является очень простым делом-
Итак, линейную свертку
s (х) = g (х) d (х)
8 поле вещественных чисел мы заменяем сверткой в кольце целых
чисел. Для этого нужно только входные данные интерпретировать
как целые числа. Внешний вид уравнения, описывающего свертку,
не меняется, но операции приобретают смысл стандартной цело-
численной арифметики. Затем уравнение в кольце целых чисел
можно погрузить в подходящее поле Галуа, скажем, простое поле
Галуа, GF (р), если простое число р достаточно велико. Если все
входящие в свертку целые числа положительны, то задающее про-
стое поле GF (р) простое число р должно быть столь большим,
чтобы выходные коэффициенты свертки не превосходили р ‒ 1.
Ч'огда выполняется сравнение
s (х) = g (х) d(х) (mod p),
и условие вычислений по модулю р излишне. Если s< могут при-
нимать и отрицательные значения, то задающее простое поле GF (р)
пробое число р надо выбирать так, чтобы s< попадали в диапазон
(р 1)/2 ( s~ < (р 1)/2. Тогда отрицательные целые числа
могут быть представлены положительными целыми числами в ин-
тервале от (p+ 1)/2 до р l.
Свертка в поле Галуа может быть вычислена любым из при-
годных в данном поле методов. Некоторые прямые методы рас-
сматриваются в следующем разделе. Можно также воспользо-
ваться преобразованием Фурье в данном поле и теоремой о свертке.
На рис. 6.1 приводится сравнение такого вычисления в поле Га-
луа и в поле комплексных чисел. Мы видим, что на обеих сторо-
нах рисунка выписаны одинаковые уравнения, хотя, конечно,
заложенные в них арифметики различны.
Так как циклическая свертка в поле Галуа приводит к тому
же самому ответу, что и циклическая свертка в кольце целых
чисел, то использование преобразования Фурье данного поля
Галуа также приводит к правильному ответу. Так как арифмети-
кой поля GF (р) является арифметика по модулю р, то перепол-
нения по модулю р в промежуточных вычислениях роли не играют,
но могут оказаться существенными в выходных вычислениях;
если р выбрано достаточно большим, то переполнения в выходных
данных невозможны.
194 Гл. 6. Вычисления в суррогатным полящ
вычисление целочисленной с>ерт«
у(м) = s(a)d(~)
Лроцедрра Г
Вложение цель~к чисел
8 бЕ(р),
арисрметика поля б~(Р).
Процедура /
8ложение целык чисел В ~;
арифметика поля 4:
Я(Х)
4)'(Х)
Рис. 6.4. Сравнение двух процедур свертки.
В качестве примера рассмотрим вычисление 5-точечной цикли-
ческой свертки,
s (х) = g (х) d (к) (mod х' 1).
Выберем простое р равным 31 и будем работать в поле GF (31).
Это поле подходит к рассматриваемой задаче постольку, поскольку
нам известно, что коэффициенты свертки s (х) не превосходят 30.
Для реально возникающих задач поле GF (31) слишком мало и
мы его выбрали только для примера.
Так как 5 делит р 1 = 30, то в данном поле существует
преобразование Фурье длины 5. Ядром преобразования можно
6.1. Свертка в суррогатных полях
195
выбрать элемент 2, так как его порядок равен 5. Пусть
d,=2, d,— 6, +=4, Н,=4, d,=О,
Ко Э, дд ‒ ‒ О, gq = 2, Кз = 1ю Д'д = 2.
5-точечное преобразование вектора d задается равенствами
4
Da ‒ Z2'"dt> é=О, ..., 4;
~=0
для вектора g имека место аналогичные соотношения. В матрич-
ной записи соответственно имеем
~')о
D,
D,
D,
~4
6
4
1
о
Таким образом, компоненты векторов- преобразований даются
равенствами
Ро=16, Рд=О, Р2 ‒‒ 5, Рз=29, Р4=22,
6о=8, 6, =20, 6, =22, 6з=О, 64=27-
Перемножая Р; и Q;, для S; получаем:
~о = 4, Яд = О, 8~ = 17, ~з = О, Я4 = 5-
Так как 5.25 = 1 в поле GF (31), то 5 ' = 25. Следовательно,
обратное преобразование Фурье задается равенством
"o
! ! ! !
!6 Я 4 2
Я 2 !6 4
4 !6 2 Ь
2 4 Я !6
S0
"()
24
2Ь
l8
$)
2с
$p
$3
$4
определяющим окончательный результат. Непосредственное вы-
числение этой свертки в кольце целых чисел дает тот же результат.
Если мы выберем большие входные компоненты, то некоторые ком-
поненты свертки окажутся больше 30. В этом случае вычисление
свертки в GF (31) приведет к переполнению выходных компонент
и даст неправильный результат. Тогда нужно использовать
большее поле; в практических приложениях полезны поля,
содержащие по меньшей мере 2" элементов.
Если длина слова слишком велика для поля желаемой мощно-
em, то можно воспользоваться китайской теоремой об остатках
и работать с вычетами целых чисел, разбивая таким образом длин-
ные слова на короткие подслова. Это использование китайской тео-
196 Гл. 6. Вычисления в суррогатных полях
ремы об остатках отличается от ее предыдущего использования
при построении переупорядочивания линейного потока данных
в таблицу. Теперь она используется только для разбиения самих
чисел, не затрагивая индексацию данных: данные следуют в своем
естественном порядке. Новые свертки, конечно, можно вычислять,
используя опять китайскую теорему об остатках, но на сей раз,
в отличие or предыдущего, она будет использоваться для вновь
сформированных многочленов и их индексов.
Пусть я~ обозначает вычет >< (mod т~} для r взаимно простых
(ц
целых чисел т„т„..., т,. Тогда
<и ‒ ' сп <к> i=0, ... ° ~+Л' ‒ 1 °
~~, g;2Pq~ (mod т~),
А=43 э ° ° ° э ~э
где gf~'~ = gf (mod т~) и d~'~ = dg (mod т~). По китайской теореме
об остатках величины s;- восстанавливаются по вычетам s;-
(О
Следовательно, вычисление свертки, содержащей большие це-
лые числа, мы свели к вычислению r сверток, содержащих малые
целые числа. Для вычисления этих составляющих сверток можно
пользоваться уже описанными способами или быстрыми алгорит-
мами вычисления сверток в кольце целых чисел.
6.2. Числовые преобразования Ферма
Простейший вид алгоритмы вычисления преобразования Фурье
имеют в полях Галуа вида GF (2~ + 1), которые действи-
тельно являются полями, если р = 2 + 1 простое число.
Известно, что число 2 + 1 не является простым, если m не равно
степени двух. Однако обратное утверждение неверно, так как
число 2" + 1 является составным. Но при т = 2, 4, 8 и 16
число 2 + 1 является простым, равным соответственно 5, 1(,
257 и 65 537. Это множество целых чисел известно под назва-
нием простых чисел Ферма. Если q простое число Ферма, то
в поле GF (q) число q 1 и любой его делитель равны некоторой
степени двойки. Преобразование Фурье
n ‒ !
Гх=~и'v;, k=O,..., и ‒ 1,
1=0
определено, если и делит 2 и существует элемент св порядка n '>.
Таким образом, в поле GF (2" + 1) определены преобразования
Фурье длин 2' 2'~, 2'4, ..., 2~~, 2. Используя алгоритм Кули‒
Тычки, преобразование Фурье в поле GF (2 + 1) можно пред-
') Такое преобразование Фурье называют часто числовым иреобразованаем
Ферма. ‒ Прим. леев.
6.2. Ч исловые преобразования Ферма
197
ставить в виде последовательности преобразований по основанию
два, для реализации которой требуется всего лишь примерно
(п/2) log, п умножений и (п/2) log, п сложений.
Преобразования длины 32 и меньше в поле GF'(2" + 1) дела-
ются на самом деле намного проще. Это обусловлено тем, что по-
рядок элемента 2 в этом поле равен 32. Чтобы увидеть это, доста-
точно заметить, что 2" + 1 = О в поле GF (2" + 1). Следовательно,
21' = 1 и 2" = 1. Преобразование Фурье записывается в виде
31
V» = ,"~', 2" о„k = О, ..., 31,
4=0
и умножение в данной арифметической системе сводится просто
к циклическому сдвигу, так как представляет собой умножение на
степени двойки. Такое преобразование вычисляется чрезвычайно
просто, но длина 32 слишком мала для многих приложений.
В общем случае простого числа Ферма 2'" + 1 порядок эле-
мента 2 в поле GF (2 + 1) равен 2т, так что 2 может быть ис-
пользовано в качестве ядра преобразования длины 2т. Для по-
строения преобразования Фурье длины 4т можно воспользоваться
ядром»'2. В этих полях, как легко проверить возведением в квад-
рат и использованием соотношения 2 = ‒ 1, выполняется ра-
венство 1~2 = 2 ~'(2 ~2 1). Поэтому каждая степень элемента
V 2 имеет вид 2' + 2».
Например, преобразование Фурье длины 61 в поле GF (2" + 1)
записывается в виде
V» ‒ ‒ ~(2' ‒ 2) vg, k =О, ..., 63.
Если для этого вычисления воспользоваться БПФ-алгоритмом
Кули Тычки по основанию два, то все умножения на константы
будут умножениями на числа вида 2 -+ 2 и, следовательно,
могут быть реализованы как пара циклических сдвигов и вычита-
ние. В общем случае поля GF (2 + 1) преобразование Фурье
длины большей чем 2 всегда содержит нетривиальные умноже-
ния. Число этих умножений можно уменьшить сведением БПФ-
алгоритма Кули Тычки в форму многомерного преобразования,
в каждом из измерений которого используется не более чем 2т-
точечное преобразование..
Например, рассмотрим 1024-точечное преобразование в поле
Я (2~» + 1). '
югз
V» ‒‒ ,~~ <~ v;, k=О, ..., 1023,
1=0
где св элемент порядка 1024, который можно полагать равным
я~, где л, примитивный элемент поля. Элемент 3 в поле
И8 Гл. 6. Вычисления в суррогатных полях
1024
52-точечный
БПФ-алгоритм Нули- 7ьюни
„de3 умножений "
~2-точечный
ЕРФ-алгоритм Кули- Тыщи~
„оез умножений "
~ис. 6.2. Структура 1024-точечного БПФ-алгоритма в доле Я-" (2~~+ ))
GF (2" + 1)' является примитивным, но, возможно, такой выбор
не является лучшим. Мы хотим ~~ выбрать так, чтобы выполнялось
равенство оР' = 2; следовательно, я надо выбрать так, чтобы
л2О'~ = 2. БПФ-алгоритм Кули Тычки приводит преобразование
к виду
aI 3I
V
%3 sAr' f А" %1 ГА"
„- +и= Ь2 и Ь2 и,+„-
Е'=~~ ~)I1~
Для каждого значения i' внутренняя сумма является 32-точечным
преобразованием Фурье, и для каждого k" внешняя сумма явля-
ется 32-точечным преобразованием Фурье. Каждое 32-точечное
преобразование фурье в свою очередь может быть разбито по
БПФ-алгоритму Кули Тычки по основанию два и вычислено
с помощью только циклических сдвигов и сложений. Умножения
на св'а представляют 'собой нетривиальные умножеНия, но та-
ких умножений имеется всего 1024, и все они являются целочис-
ленными. На самом деле при ~' или k", равном нулю, эти умноже-
ния тривиальны, и остается только 931 нетривиальных умноже-
ний. Структура этого БПФ-алгоритма показана на рис. 6.2. Б
общем случае преобразование Фурье в поле GF (2" + 1) может
быть вычислено с помощью примерно п (f'log,2 ï~ 1) умноже-
ний в поле GF (2" + 1), (1/2) п log, п сложений в этом поле и
(1/2) и 10Я, ю циклических сдвиГОВ.
Арифметикой поля GF (2" + 1) являются обычные целочис-
ленные сложение и умножение с последующим приведением ре-
зультата по модулю 2" + 1. Но так как 2" = ‒ 1, то 2'~+' =
2', так что биты порядка больше чем 16 переводятся в млад-
шие р азряды и вычитаются.
6.3. Числовые преобразования Мерсенна
Полями Галуа, в которых умножение выглядит наиболее
естественным образом, являются поля вида GF (2 1), которые
являются на самом деле полем только для простых т, так как
6.3. Числовые преобразования Мерсенна
если m число составное, то 2 ~ 1 делится на 2' 1. Про-
стые числа вида 2 1 называются простыми числами Мерсенна.
Наименьшие значения т, для которых число 2 1 является
простым, равны 3, 5, 7, 13, 17, 19 и 31; соответствующие им
простые числа Мерсенна равны 7, 31, 127, 8191, 131 071, 524 287
и 2 147483647.
Арифметика поля GF (2 1) очень хорошо согласуется с
представлением целых чисел в виде т-битовых чисел, так как
в этом поле 2 = 1. Следовательно, арифметикой поля является
обычная целочисленная арифметика, в которой биты переполнения
переносятся слагаемыми в соответствующие низшие разряды.
Это и есть арифметика 1-дополнений ').
Поле GF (2~ 1) существует для всех простых чисел 2 l.
В поле Галуа GF (q) преобразование Фурье существует для всех
длин п,‒ êîòîðûå делят число q 1. Следовательно, в простом
поле GF (2~ 1) преобразование Фурье существует для всех
длин и, которые делят число 2 2. Эти преобразования иногда
,называют числовыми преобразованиями Мерсенна.
Так как число (2 1) 1 не равно степени двух, то число-
вые преобразования Мерсенна нельзя вычислять с помощью
БПФ-алгоритма Кули Тычки IIo основанию два. Этим они су-
щественно отличаются от числовых преобразований Ферма, для
которых БПФ-алгоритм Кули Тычки оказался вполне подходя-
щим. Яля вычисления числового преобразования Мерсенна мо-
жно воспользоваться любым БПФ-алгоритмом по смешанному
основанию.
Например, поле GF (2" ‒ 1) можно рассматривать как поле,
элементы которого заданы в виде 13-битовых представлений це-
лых чисел. Свертка двух векторов, компоненты которых заданы
12-битовыми числами, может быть вычислена в этом поле, если
только не происходит переполнения выходных коэффициентов
свертки. Таким образом, линейная свертка s (х) = g (х) d (х),
где коэффициентами многочленов g (х) и d (х) служат 12-битовые
положительные целые числа (что эквивалентно 13-битовому пред-
ставлению целых чисел в обратном коде), может быть выражена
в виде
s (х) = g (х) d (х) (mod 2~з 1),
если известно, что коэффициенты многочлена s (х) меньше чем
2'з 1.
Для длин п, которые делят число 2" ‒ 2, в поле GF (2~З 1)
существует преобразование Фурье. В данном случае выбор воз-
<) Напомним, что речь идет о двоичном представлении целых чисел в обрат-
aîM коде, в котором взятое с обратным знаком число записывается в виде допол-
нения ero двоичной записи. Например, при m =- 3 и р = 7 число 2 записывается
в виде 010, а число ‒ 2 = 5 в виде 101. ‒ Прим. ëåðåâ.
200 Гл. 6. Вычисления в суррогатных полям
можной длины и преобразования дается разложением 213 2 =
= 2-5-7-9-13. В качестве ядра преобразования Фурье можно
выбрать элемент 2, так' как 2'3 1 = О (mod 2" 1), и, сле-
довательно, порядок 2 равен 26. Таким образом, преобразование
Фурье записывается в виде
25
V> = ~~~~( 2) v~, Й=О, ..., 25.
с=о
В этом преобразовании Фурье все умножения исчерпываются
умножениями на степени двух, и, следовательно, вычисление мо-
жно реализовать одними циклическими сдвигами, без умножений.
С другой стороны, делители числа 26 не очень пригодны в качестве
длин БПФ-алгоритмов; на этой конкретной длине трудно приду-
мать что-то лучшее, чем вычислять преобразование Фурье как
оно записано посредством 25' циклических сдвигов и 26.25 сло-
жений.
Для построения преобразований на других длинах приходится
допустить наличие умножений. Алгоритм на большой длине,
скажем 70, строится из алгоритмов малых длин, в данном случае
2, 5 и 7, подобно тому, как рассматриваемый в гл. 8 БПФ-ал-
горитм Винограда большой длины для поля комплексных чисел
строится из БПФ-алгоритмов Винограда малых длин. Эти алго-
ритмы полностью аналогичны, за исключением того, что по-раз-
ному определяются константы умножения, связанные с различ-
ным определением ядра со.
В качестве примера построим 5-точечный БПФ-алгоритм
Винограда в поле GF (2'3 1). Непосредственной проверкой мо-
жно установить, что 3 является примитивным элементом поля
GF (2" 1); следовательно, порядок элемента 3'7 9'" (что равно
4 794) равен 5. Далее, порядок элемента 1904 также равен 5,
так как 1904 = (4794)'. Тогда 5-точечное преобразование Фурье
в поле GF (2" 1) имеет вид:
4
Уь ‒ ‒ g (1904) о;, lг =О, ..., 4.
С ‒ 0
Сначала воспользуемся алгоритмом Рейдера для замены этого
вычисления сверткой. Так как алгор итм Рейдера оперирует
только с индексами компонент- данных, то эта конструкция пол-
ностью повторяет конструкцию для поля комплексных чисел.
Этим задача сводится к вычислению циклической свертки s (х) =
= g (х) d (х) (mod х' 1), в которой многочлен Рейдера равен
g (x) = (аР 1) ~Р+ (и' 1) х'+ (и' 1) х+ (и 1) =
и = 3001xÐ 1511х' + 4793х + 1903
d (х) = п,х' + v,õ' + пах + vi,
6.3. Числовые преооразования Мерсенна
Vo) х'+
а (<) ()~в ~о) х + (Vo
+ (Vo Vo) ~ + (Vi ‒ Vo).
Теперь воспользуемся быстрым алгоритмом вычисления 4-то-
чечной циклической свертки. Так как разложение многочлена
х4 1 в поле GF (2" 1) дается равенством х4 1 = (х
1) (х + 1) (х' + 1), То этот алгоритм циклической свертки
имеет тот же самый вид, что и для полей комплексных и вещест-
венных чисел. Это позволяет воспользоваться выписанным на
рис. 4.13 алгоритмом, интерпретируя арифметические операции
как операции в поле GF (2" 1). Итак,
4
4793
~о
G,
G,
1 I 1 I
6!42
2245
8!!
26оз
тл
! ‒ 1 I ‒ I
1 ‒ 2 ‒ 2 2
2 ‒ 2 ‒ 2
О ‒ 2 О
и 5-точечный БПФ-алгоритм Винограда в поле QF (2'~ ‒ 1)
записывается в виде
о о о о о
О-1
‒ ‒ о
О-1
о
! 1 1 1
1 1 1 I
1 †1 †! 1
О О-1
О-1 ! О
]-1 1-1
1
6142
2245
811
260з
17т
ир
G
V)
v,
))2
))э °
э
v„
В качестве второго примера рассмотрим поле GF (2" ‒ 1},
элементы которого записаны как 17-битовые представления це-
лых чисел в обратном коде. Линейная свертка последовательно-
стей 16-битовых целых чисел может быть вычислена как свертка
в поле GF (2" 1}: здесь не происходит переполнения выходных
компонент свертки. Для вычисления свертки можно воспользо-
ваться БПФ-алгоритмами в поле GF (2" 1} и теоремой о свертке.
Длины преобразования Фурье в поле GF (2' 1) исчерпы-
ваются делителями числа 2" 2, которые полностью определя-
ются разложением 2" 2 = 2.3.5-17.257. Можно выбрать,
например, и = 510, и строить 510-точечное БПФ-преобразование
из 2-точечного, З-точечного, 5-точечного и 17-точечного БПФ-
алгоритмов. Модули для 2-точечного, 3-точечного и 5-точечного
преобразований очень просты и даются малыми БПФ-алгорит-
мами Винограда. Хотя эти малые алгоритмы рассматриваются над
полем GF (2" 1}, записываются они точно так же, как и в слу-
чае поля комплексных чисел.
17-точечное преобразование тоже представляет собой простой
модуль, но строится он другим способом. А именно, элемент 2
202 Гл. 6. Вычислеиня в суррогатных полях
поля GF (2" 1) имеет порядок 17, так как 2" = 1. Следова-
тельно, 17-точечное преобразование в этом поле задается равен-
ствами
k=0 ..., 16,
и может быть вычислено с помощьюоднихциклических сдвигов
и сложений. Умножения не нужны.
Если необходимо вычислить свертку, длина которой больше
510, то надо использовать также множитель 257. 257-точечное
преобразование Фурье с помощью алгоритма Рейдера сводится
к 256-точечной циклической свертке, которая затем вычисляется
с помощью БПФ-алгоритма Кули Тычки по основанию два и
алгоритма свертки.
6.4. Алгоритмы свертки
В КОНОЧНЫХ ПОЛЯХ
В полях Галуа вместо того, чтобы пользоваться преобразова-
нием Фурье и теоремой о свертке, можно строить прямые методы
вычисления свертки. Для построения алгоритмов свертки приме-
нимы все описанные в гл. 3 методы. Другой путь построения пря-
мых алгоритмов свертки состоит в модификации уже построенных
алгоритмов свертки для поля вещественных чисел.
Для преобразования алгоритма свертки, построенного для
поля вещественных чисел, в алгоритм свертки в поле Галуа
~~ (Ч) характеристики р начнем с алгоритма свертки, записанного
в виде
s = С [(Ag) ° (Bd)],
где А, В и С . матрицы с рациональными элементами. Умно-
жим обе части равенства на наименьшее целое число L, такое,
чтобы ликвидировать все знаменатели во всех компонентах;
жгда равенство перепишется в виде
Ls = С [(A g) ° (В d)],
где L целое число и А', В', С" целочисленные матрицы.
Это равенство можно рассматривать как алгоритм вычисления
целочисленной свертки; следовательно, его можно рассматривать
и как уравнение по модулю p:
Ls = С' [(А'g) ° (В'd)] (mod р).
Если L + О (mod р), то, разделив обе части равенства Hà L no
модулю р, получаем алгоритм свертки в GF (р), и, более того,
алгоритм в любом расширении поля 6Р (р).
6.4. Алгоритмы свертки в конечных поляз
Если L сравнимо с нулем по модулю р, то алгоритм свертки
для поля вещественных чисел не переносится в поле Галуа, и
надо строить такой алгоритм прямо в самом поле Галуа. Эта
задача возникает даже тогда, когда L не равно нулю по модулю р,
так как может оказаться, что алгоритм свертки, построенный спе.-
циально для данного поля Галуа, лучше алгоритма, перенесенного
из другого поля. Для построения такого алгоритма можно поль-
зоваться разработанными в гл. 3 методами, конечно, при этом
требуется, чтобы разложение
m (х) = m<О1 (х) ... m<~> (x)
было разложением в том поле, в котором вычисляется
свертка.
В большей части данной главы мы будем интересоваться по-
лями, характеристика р которых велика. Так как для таких по-
лей L будет намного меньше р, то все алгоритмы свертки для поля
рациональных чисел могут быть перенесены в GF (р) и будут
выглядеть точно так же. В оставшейся части этого раздела мы
займемся противоположным случаем случаем полей малой
характеристики, или, еще конкретнее, случаем полей характери-
стики два. Поля Галуа характеристики два играют важную роль
в нескольких приложениях.
Начнем с построения алгоритма 3-точечной циклической сверт-
ки для полей характеристики два. В поле бесконечной характери-
стики этот алгоритм записывается уравнением
! о ‒ 1
‒ I ‒ 1 2
о
з(4+ gs + 8р1
I I I
о-!
о
! l ‒ 2
(Ro ‒ Rz)
<а, ‒ ю,)
з (~о + 8ю 28г1
Ни один из знаменателей не кратен двум. Следовательно, алгоритм
может быть перенесен в поля характеристики 2. Арифметикой
целых чисел в полях характеристики два является арифметика
по модулю два, так что все целые числа равны нулю или единице.
Соответственно новый алгоритм записывается в виде
1 1 1
1 0 1
0 1 !
1 1 0
1 1 0 1
1 1 1 0
1 0 ! 1
~8о + gi + 82)
~~о + 8i~
(gg + Ыг)
~~о + ~»
So
6)
~2
S(
204 Гл. 6. Вычисления в суррогатных полях
С другой стороны, алгоритм 2-точечной свертки содержит эле-
(gp + а )
менты с четным знаменателем и, следовательно, не может быть
перенесен в поля характеристики два, так как знаменатели
обратятся в нуль. Лучший алгоритм 2-точечной циклической сверт-
ки в полях характеристики два задается равенством
n+Ri
и содержит три умножения. Причина необходимости трех умно-
жений кроется в том, что над полем GF (2) многочлен х' 1 не
разлагается B произведение двух взаимно простых множителей,
так как в полях характеристики два 1 = 1, и, следовательно,
х' + 1 = (x + 1)'; следовательно, в конструкцию алгоритма
в качестве модуля входит многочлен х' + 1 степени два.
Такая ситуация, когда число умножений в конечном поле
больше числа умножений в рациональном поле,.встречается для
циклических сверток многих длин. Зто происходит потому,
что несколько простых делителей многочлена х" 1 оказываются
равными. С другой стороны, некоторые циклические свертки в по-
лях конечной характеристики требуют меньше умножений, чем
свертки тех же длин в рациональном поле. Это происходит потому,
что круговые многочлены в конечных полях могут распадаться
в произведение простых множителей. Например, над полем ра-
циональных чисел разложение на неприводимые множители мно-
гочлена х' ‒ 1 имеет вид
х' 1 = (х 1) (х' + х' + х' + x' + х' + х + 1),
а над полем характеристики два это разложение можно продол-
жить:
х' 1 = (х
1) (х' + х + 1) (х' + х'+ 1).
Следовательно, согласно выписанной в разд. 3.8 общей границе,
оптимальный (относительно числа умножений) алгоритм 7-то-
чечной циклической свертки над полем рациональных чисел дол-
жен содержать 12 умножений, а оптимальный алгоритм 7-точеч-
ной циклической свертки над полем характеристики два долже~
содержать 11 умножений. Яля первого случая извесген хороший
с практической точки зрения алгоритм, содержащий 16 умноже-
ний, а для второго хороший алгоритм с 13 умножениями.
6.4. Алгоритмы свертки в конечных полях
Последний алгоритм строится методами главы 3 и задается равен-
ством
So
Еп
S2
g2
g e
R4
Sg
Rs
S6
86
Такого сорта улучшения можно найти и в полях большей ха-
рактеристики. Например, в поле GF (11) разложение на простые
множители того же многочлена х' 1 имеет вид
х' 1 = (х ‒ !) (х~ + 5х' + 4х 1) (х~ ‒ 4х' 5х ‒ 1).
Следовательно, в полях характеристики одиннадцать алгоритм
вычисления 7-точечной циклической свертки содержит 11 умно-
жений. Таким алгоритмом является
! 4-1 0-4 1-5 3 0 2 !
! ‒ 1 2 4 2 4-1 4-5 ‒ ! ‒ 5
I-5 4 ‒ 5 0 ‒ I 4 2 4 ‒ 2 ‒ 1
1 ! 3 0 ‒ 5 ‒ 5 ! ‒ I 0 S 4
I 0 1 ! 4 1 0 I I 4 1
I 0 I ‒ 1 2 0 0 I ‒ ! 2 0
I 1 1 ! 1 0 I ! I 1 0
$2
В алгоритм входит только 11 умножений общего вида, но
умножений на малые фиксированные константы (~2, ~3, ~4,
~5) он содержит достаточно много. Каждое из таких умножений
можно заменить несколькими сложениями, но тогда мы получим
большое число сложений. Возможности улучшения этого алго-
pHTlvIB и являются открытой задачей. Ее решение зависит оТ
~oHMQcTH сложений и умножений. В достаточно больших расши-
рениях поля GF (11 ) умножения обходятся существенно дороже
сложений, так что такой алгоритм может оказаться вполне при-
годным. В простом поле GF (11), по-видимому, замена умножений
сложениями не дает преимуществ.
l 1 1 ! l 1 l
О1ОО
ОО111О
О1ОО
О 1ОО
О О111 О
О111О1О
О! ! 1ОО
О1О111О
О О 1 О
ОО1О
О О1О 11
ОО1О
l 1 l 1 l l l
О111ОО
О!1!О О
ОО1О
ОО1О
О!О!1!О
ОО1О
О!1 ! О1О
О1О О
О1ОО
О О111О
ОООО
ОО ! 11 О
l ! I I ! I I
I 0 0 1 †5 †! 4
1 I I 3 4 2 ‒ I
I- I 1 О-S 4 0
I 2 4-$ 0 2-4
0 1 ‒ S ‒ I 4 I
0 0 I 4-1-5
1 1 I-I 2 4 3
I ‒ 1 ! 0 4 ‒ 5 0
l 2 4 S †2 †! 2
0 1 4 †1 в !
1 1 1 1 1 1 1
О1 ! 1ОО
О1О111О
ОО1О
О О1О
ОО1О
о о ! о
О111О1О
О О111О
ОО111О
О1О О
О1О О1
О1ОО
-3-3-3 ‒ 3-3-3-3
5 0 3 ! 5 ‒ 4 !
-4 ‒ 4 4 3-2 2 !
3 ‒ 3 2 5-3 †3 в
0 0 I ‒ 5 ‒ I 4 I
0-5 2 ‒ I 3 2-!
-5 0-3 5 5-2 0
-4-4 †! 5 0 2 2
-3 3 ‒ 2 4 ‒ 2-1 !
0 0-1-4 I 5 †!
0 5 †1 †! ‒ 4 0
ди
d,
d2
d3
~4
d
d„
206 Гл. 6. Вь~числения в суррогатных полях
6.5. Комплексная свертка
в суррогатных полях
В последних двух разделах мы видели, как свертку в ве-
щественном поле можно вложить в поле Галуа, где ее удобнее
вычислять. Теперь мы займемся этой же задачей для свертки
комплексных чисел. В зависимости от наличия в поле GF (р)
элемента ~/ 1 здесь имеются два различных случая, которые
приводят к совершенно разным действиям. Мы рассмотрим только
два класса простых чисел: простые числа Мерсенна и простые
числа Ферма. В случае простых чисел Мерсенна поле GF (р) не
содержит элемента ~ 1; в случае простых чисел Ферма элемент
1 принадлежит полю GF (р). Мы будем рассматривать лишь
эти два класса простых чисел, но к любому другому простому
числу можно применить один из этих методов.
Мы начнем с простых чисел Мерсенна, р = 2 1, где т
нечетное простое число. Это поле не содержит элемента ~~ 1.
Расширим поле GF (2 1) до поля GF ((2 1)') подобно
тому, как поле вещественных чисел R расширяется до поля комп-
лексных чисел С. Тогда преобразование Фурье в поле GF ((2
1)' ) можно использовать для вычисления свертки в поле
комплексных чисел.
В поле вещественных чисел многочлен х' + 1 не имеет корней.
Обозначим через j некоторый новый элемент и присоединим его
к полю вещественных чисел, образуя множество C = 1а + bj},
где а и b вещественные числа, а сложение и умножение за-
даются правилами
{а+ bi)'+ {с+ di) = {а+ с) + (b + d) /,
{а + bj) (с + di) = (ас bd) + (ad + bc)' j.
Легко проверить, что это множество образует поле.
Аналогично, в поле Галуа GF (2 ‒ 1) многочлен x'+ 1 не
имеет корней. Расширим это поле, присоединив к нему некоторый
обозначаемый через / элемент и сформировав множество GF ((2~
1)') = 1а ~- bj}, где а и Ь произвольные элементы поля
GF (2 1). Сложение и умножение опять зададим правилами
(а + Ь/) + (с + dj) = (а + с) + (0 + d) /,
{а + by) (с + dj)' = (ас bd) + (ad + bc) /,
где операции спр ава являкггся операциями в исходном поле
GF (2~ 1). Легко проверить, что такое определение задает поле,
содержащее (2 1)' элементов.
Подытожим сказанное в виде двух теорем.
207
6.5. Комплексная свертка в суррогатным ooJlHxi
Теорема 6.5.1. Если 2 1 простое число Мерсенна, то
ноле GF (2 1) не содержит среди своик элементов квадратного
корня из 1~ следовательно, многочлен xÐ+ 1 не имеет в этом
лоле корней.
Доказательство отложим до конца раздела.
Теорема 6.5.2. Относительно определенных выше оперсщий сло-
жения и умножения множество GF ((2'" 1)') образует лоле.
Яоказательство. Утверждение вытекает непосредственно из
того, что многочлен х' + 1 прост. []
Теперь рассмотрим преобразование Фурье в поле GF ((2
1)'). Длина преобразования равна (2 1)' 1 или делит
это число. Так как имеет место разложение (2 ‒ 1)' 1 =
= 2 +' (2 ‒ ' 1), то возможной длиной преобразования Фурье
в поле GF ((2 1)') является 2+', и тогда это преобразование
можно вычислять с помощью БГ1Ф-алгоритма Кули Тычки по
основанию два. Другие возможные длины преобразования Фурье
задаются делителями числа 2 ' 1.
Выберем, например, т = 17. Тогда (2" 1)' 1 = 2" Х
X 3 5 17 257. В качестве длины преобразования можно взять
любую степень двойки вплоть до 2", а большие длины получа-
ются присоединением остальных делителей.
Пусть и делит 2" и пусть
k=0,..., п ‒ 1,
где и ‒ элемент поля GF ((2'~ 1)')' порядка и. (В табл. 6.1
приведены найденные на ЭВМ соответствующие элементы в.)
Так как п равно некоторой степени двух, то для вычисления преоб-
разования Фурье можно воспользоваться ОПФ-алгоритмом Кули
Тычки по основанию два.
Возможности выбора длины преобразования Фурье в поле
GF ((2" 1)') существенно шире, чем в поле GF (2" 1); в част-
ности, это относится к длинам, равным степени двойки. Поэтому
для вычисления циклической свертки в GF (2" 1) можно перейти
в поле GF ((2" 1)'), рассматривая исходную свертку как свертку
целых чисел поля GF ((2" 1)').
В случае, когда р является простым числом Ферма, у ‒ 1 явля-
ется элементом простого поля, и построение расширения 6Р (р')
с операцией умножения, аналогичной умножению в поле комплекс-
ных чисел, невозможно. Действительно, для р = 2 + 1, где т
равно степени двух, возведением в квадрат легко убедиться, что
208 Гл. 6. Вычисления в суррогатньи полял
Fv
+
4
о
~Ч
Фч
о
+ cv
4+
Я
гЧ '4
I
О
+
;Ч
Ю
О
~Ч
+
~Ч
+
еч
+
1
FЧ
+ +
+ +
Ф
~Ч
л
М ~Ч
° ею' мщу
\
+
<Ч
C
ЕЧ
ЕЧ
+
Р
юл, р4
~Ч
+ +
~Ч
+
~Ч
+
~Ч
+
4
4
СЧ +
+м
лЧ +
л
Ь ~
~Ч
+ +
1
~Ч
4
+ о
л ~С~
СЧ
+
~Ч
~Ч с
+ +
ГЧ
ЕЧ +
~Ч
+
h
+
+
ОЧ
1
л
к
+
л t4
й
+ о
Й
1 +
гв. ~Ч
СЧ 1
1 О
о ФЧ
~Ч
+ +
лЧ
I
лч
1
4
ЕЧ
1
л
ФЧ
1
ю 8 3
О г~л
~Ч
1
1
Ф
еЧ
Ъю'
Fv
~в~
4
+
л
Й
1
о
+
fv
ЕЧ
л
+
+
л
~Ч
~Ч
+
е
ЕЧ
+
л
ФЧ
+
~Ч
1
4
+
O
ЕЧ
1
~Ч
1
О
~Ч
+
О
СЧ
+
лЧ
+
~Ч
+
+
ОЧ
+
О
ГЧ
+
л
~Ч
+
л
~Ч
1
О
Fv
1
л
~Ч
+
л
+
+
с-
Ч 'Ч
+
~Ч
hl
+ ~
а
CV
' я
(Ч
~Ч
л
л
~Ч
hl
+ a
лЧ
РЧ
+ g
еч
('Ч
+
я
('Ч
ЕЧ
й фЧ
1
О
Fv ~
1
O
л
hi
+
а l4
F4
1 r
л
л
а ~Ч
СЧ
+ g
и
~Ч
1 +
+ е
4
1 °
° lV
CV
+ i
о СЧ
СЧ
1 е
л
о ЕЧ
~Ч
+ л
° Fv
л ъг
hl
+ +
~ь ~Ч
hl
+ °
ЕЧ
~Ч
+ °
л
о
~Ч
1
~Ч
~б
+я
° e ~Ч
84
6.5. Комплексная свертка в суррогатных полям
~/ 1 = 2"'~4 (2"'~~ 1)'. Для вычисления свертки я (х)
= g (х) d (х), где
д (х) = д„(х)+ igr (x) и d(x) = d„(x) + /dr (x),
приходится вычислять четыре свертки g~ (х) d~ (х), g„(x) dr (х),
gr (х) d~ (х) и д (x) dr (х) и пользоваться равенствами
яв (х) = g„(x) d„(x) ‒ gr (х) dr (х),
sr (х) = g„(x) dr (х) + gr (х) da (х)
Лучшая процедура, содержащая вдвое меньше умножений, осно-
вана на определении в кольце GF (р) [x]/(х" 1) многочленов
а(х) = ‒ (д„(х) ‒ 2 ~~д (х))(dÄ(x) ‒ 2 ~ d,(х)),
~ (х} = ‒ (д„(х) + 2 ~ д~ (х)) (Н„(х) + 2 "dr (х)),
для вычисления которых надо сделать только две свертки. Все
вычисления проводятся в кольце бр (р) [х]/(х" 1), и свертка
я (х) Вычисляется по правилу
я„~ = (а (х) + Ь (х)),
я~ (х)' = 2"'~з (а (х) Ь (х)).
Для завершения раздела нам осталось провести доказательство
mopier 6.5.1. Оно достаточно длинно и опирается на понятие
квадратичного вычета. Те элементы простого поля GF (р}, для
которых в этом поле существуют. квадратные корни, называются
квадратичными вычетами (поскольку по модулю р они равны квад.
ратам своих квадратных корней). Если р нечетко, то ровно поло»
вина элементов поля GF (р) имеют квадратные корни. Чтобы это
показать, заметим сначала, что каждая четная степень примитив-
ного элемента и имеет квадратный корень. Сдругой стороны, каж-
дый элемент, равный квадратному корню, может быть записан
в виде а' для некоторого г, так что его квадрат равен а<<~'», где
двойные скобки в показателе степени использованы для обозна-
чения того, что вычисления проводятся по модулю р 1, так
как мультипликативная группа поля является циклической по-
рядка р 1. Но число р 1 четко, и, следовательно, ((21)) также
четно. Таким образом, только четные степени элемента и могую
иметь квадратный корень.
Теорема 6.6.3. Яля нечетных р в поле GF (р) элемент r яв-
ляется квадратичным вычетом тогда и только тогда, когда
у (Р ‒ >)/2=
Доказательство. Предположим, что r<> ‒ '>r~ 1. То.-дэ g г~
не может существовать в данном поле, так как в противном с.чучае
210 Гл. 6. Вьччнсления в суррогатных полям
должно бы было выполняться равенство (!/г)~ ~ = 1, которое
не выполняется.
Предположим, что r« ')/2= 1, и пусть а примитивный эле-
мент поля GF (р). Очевидно, что все четные степени элемента и
являются квадратичными вычетами, а все нечетные степени эле-
мента а квадратичными вычетами не являются. Надо только по-
казать, что r равно четной степени элемента и. Допустим против-
ное: r = а2'+', тогда, так как порядок элемента а равен р 1,
имеем
(р ‒ 1)/2 / 22+1~(р ‒ 1)/2 Ю (р ‒ I) (р ‒ I)/2 (р ‒ 1)/2 ~ 1
r =~а у =а а
Таким образом, из равенства r(p ‒ ')/2= 1 вытекает, что г равно
четной степени элемента а и, следовательно, является квадратич-
ным вычетом. Q
Теперь у нас уже все готово для доказательства теоремы 6.5.1.
Теорема 6.6.!. Элемент 1 поля GF (2 1), аде 2 1
простое число Мерсенна, не имеет в этом поле кваоратного дворня.
Следовательно, щцогочлен х'+ 1 не имеет в этом поле корней.
Яоказательство. Предположим, что 1 имеет квадратный ко-
рЕНь, раВнЫй r. ТОгда r' = 1 И, СОгЛаСНО тЕОрЕмЕ 6.5.3, r(p ‒ ')/2=
(2~~! ‒ 2)/2 2m ‒ 1
=1. Таккакр=2 1, то r ~ =1 или r r ‒ '=1.
2~~! ‒ 1
Но r' = ‒ 1 и т 1 четно. Следовательно, r = 1 и г-' = 1.
Но тогда r не равно 1. Полученное противоречие показывает,
что в данном поле не существует квадратного корня из 1.
П
6.6. Преобразования в числовом кольце
Если поле F содержит элемент порядка и, то в этом поле сущест-
вует преобразование Фурье длины п. Если преобразование Фурье
существует, то оно обЛадает всеми элементарными свойствами
такого преобразования.
Часто возможно также определить преобразование в кольце,
но при этом ситуация не является столь простой. В настоящем
разделе рассматриваются преобразования в кольце Z/(q) целых
чисел по модулю д. Если д простое число, то Z/(q) является
полем, и, как мы уже видели, в нем существует преобразование
Фурье со всеми его основными свойствами. Поэтому надо рассмо-
треть только случай составного числа д. Как мы увидим, даже для
составных д можно дать осмысленное определение преобразования
Фурье. Однако структура этих преобразований представляет со-
бой точную копию преобразований Фурье для простых делителей
числа д, так что переход к составному д прибавляет мало возмож-
ностей.
6.6. Преобразования в числовом кольце
211
Мы хотим определить в целочисленном кольце преобразование
Й=О,..., и ‒ 1,
вектора v над кольцом z/(q) так, чтобы существовало обратное
преобразование
f=O,..., и ‒ 1,
и была справедлива теорема о свертке. Для того, чтобы такое опре-
деление преобразования фурье было возможным, необходимо
выполнение двух условий: (1) должен существовать элемент и
порядка и; (2) элемент п в кольце Z/(q) должен быть обратимым.
Нужна, конечно, еще и обратимость элемента ь, но из условия
со" = 1 автоматически следует, что со ' = GP '.
Итак, надо определить те значения и, для которых существует
элемент со порядка и. Начнем с простейшего случая g, равного сте-
пени простого нечетного числа р, q = р'". Кольцо Z/(ð'") не об-
разует поля, так как его умножением является умножение по
модулю р. Согласно теореме 5.1.8, в этом кольце имеются эле-
менты порядка (р 1) р ', и согласно теореме 5.1.5 (теореме
Эйлера), порядок каждого взаимно простого р элемента делит
(р 1) р †'. Согласно этому условию, для каждого делителя п
числа (р 1) р ' можно выбрать элемент и порядка п. Однако
теорема 5.2.2 утверждает, что число и обратимо тогда и только
тогда, когда и и р взаимно просты. Следовательно, и не может
делиться на р. 'Гаким образом, в качестве со можно выбрать только
элементы, порядок которых и делиг р 1. Следующая теорема
показывает, что для каждого такого и существует соответствующее
преобразование фурье. Однако длины такого преобразования
в Z/(р'") в точности совпадают с теми длинами, которые допустимы
для преобразования Фурье в поле GF (р). Изменения касаются
только разрядности используемых чисел, которая увеличивается
примерно с log> p до m log2 р. Но обычно разрядность является
достаточно большой и для преобразований в поле GF (р), что еще
больше уменьшает преимущества перехода к у /(р-)
Ситуация для произвольного д аналогична и описывается
следующей тоеремой.
Теорема 6.6.1. Обратиаое преобразование Фурье длины и над
кольцом Z/(q) существует тогда и только тогда, когда п делит
р 1 для всех простых делителей р числа д.
Яокаэательство. Сначала мы приведем доказательство для
случая, когда д равно етепени простого числа. Затем используем
212 Гл, 6. Вычисления в суррогатных полях
китайскую теорему об остатках, чтобы связать этот случай со
случаем произвольного числа д.
Проще всего доказывается обратная часть теоремы. Длина и
преобразования обратима, только если и и д взаимно просты,
так как
nn'= 1+Qq,
t3 ‒ 1 t3 ‒ 1
Q) ~~, = Q) Q) ()~~
1=0 г=о
ф .и ll]
I
Если 1' = 1, то сумма по lг равна п. Для 1 ~ 1' имеем
n ‒ 1
‒ (t' t) n
-(C'-C) ~
(<~ ) = > „-<к-к>
a=o
Так как оба индекса 1 и 1' меньше п н 1' i + О (то4 n), то вы-
ражение справа равно нулю. Таким образом,
‒ и 1
й
Va = ‒ us (Аг) = ut,
и
Г=О
a=o
что и требовалось доказать.
ш m /и
ТЕпЕрь ПрЕдПОЛОжИм, ЧтО д = p1 p> ... p, . ВОСпОЛьэуЕмСя
китайской теоремой об остатках и алгоритмом' Гуда Томаса для
и, следовательно, любой делитель чисел и и д должен быть и де-
лителем единицы, так что он должен равняться единице. Далее,
теорема 5.1.5 утверждает, что если порядок и элемента со вза-
имно прост с q, то он делит q (q) = (р 1) р ‒ '. Следовательно,
преобразование Фурье в кольце ~/(р) существует только на
длинах и, которые делят р 1.
Теперь докажем прямое утверждение теоремы. Полагать р
равным 2 смысла нет, так как тогда и равно I и утверждение три-
виально. Следовательно, р нечетное простое число и согласно
теореме 5.1.8 существует элемент и порядка (р 1) р ‒ '. Для
bpm ‒ 1
любого делителя b числа р 1 положим а = л; тогда по-
рядок элемента и равен (р 1)/Ь. Таким образом, для любого
делителя Ь числа р 1 имеется элемент о этого порядка, и
остается доказать существование обратного преобразования
Фурье. Для этого запишем
6.7. Числовые преобразования Шевилла
213
отображения кольца z/(g) в прямое произведение z/(ð, ') х
>< z/(~ã ) >< ... z z/(р, '). Условия существования преобразо-
вания Фурье в кольце Z/(g) связаны с условиями существования
преобразований Фурье в каждом из z/(o < '), так что условие де-
лимости р; 1 Hà и должно выполняться для всех г. Q
По-видимому, описываемое теоремой 6.6. 1 преобразование
Фурье в целочисленном кольце z/(g) при составном g может иметь
весьма ограниченные приложения. Тем не менее они могут в не-
которых специальных случаях оказаться весьма подходящими.
Рассмотрим, например, разложение
2" + 1 = (257) (4278255361) = р,р,.
В кольце z/(2" + 1) существует преобразование Фурье длины
256, так как 256 делит и р, 1 и р, 1. Это преобразование
при разрядности чисел в 41 бит обеспечивает точность вычисле-
ний в 40 бит. Кольцо допускает БПФ-алгоритм Кули Тычки
по основанию два. Арифметика переполнения легко учитывается
равенством 24О = ‒ 1. Элемент 2 нельзя в этом случае использо-
вать в качестве ядра преобразования, так как порядок 2 равен 80,
а порядок ядра должен быть равен 256. Следовательно, умножения
не могут быть реализованы в виде циклических сдвигов, а явля-
ются умножением 40-битовых чисел общего вида. Таким образом,
такая конструкция приводит к процедуре 256-точечной цикличе-
ской свертки, содержащей примерно 256 + 2561og~ 256 умноже-
ний общего типа для 40-разрядных двоичных чисел с точностью
в 40 битовых разрядах. По сравнению с комплексным БПФ-ал-
горитмом для 40-разрядных двоичных чисел эта процедура явля-
ется и более точной и содержит меньшее число умножений.
6.7. Числовые преобразования Шевилла
k=0,..., и ‒ 1,
Числа Шевилла (как правило, простые, но не всегда) в нестро-
гом определении задаются как числа д, для которых в кольце
z/(g) существует преобразование Фурье по одному основанию
для больших длин преобразования. Числа Шевилла связаны только
с хорошими преобразованиями Фурье и не имеют специального
теоретико-числового значения. Таблица этих чисел, построен-
H»õ с помощью 3ВМ, приведена на рис. 6.3.
Если элемент и кольца Z/(g) имеет порядок, равный степени
малого простого числа, то преобразование Фурье
214 Гл. 6. Вычисления в суррогатных полях
в этом кольце удобно вычислять с помощью БПФ-алгоритма Ку-
ли Тычки по одному основанию. В приведенной на рис. 6.3
таблице для каждого q' указан порядок, определяющий длину пре-
образования и, равную степени малого простого числа.
Максимальное
ай~о бПФ
по одному
оснооанию
У~иректийюе
дпла
спада
Дпииа
спо8а о
Nna симажнае
dnueo
преоЮрозодЬал~
10
750
768
882
918
928
100В
1372
1408
1458
1470
1600
1782
1950
1998
2016
12
2916
3328
3456
зввв
4000
4018
4048
4050
5346
7000
7546
7680
7840
7936
8100
8160
pic. 6.3. Таблица алгоритмов Шавилла. даи
преобрааоваииа
163
193
197
24I
251
257
401
449
487
491
751
769
ввз
919
929
1009
1373
!409
!459
1471
!60!
1783
1951
1999
2017
2917
3329
3457
3889
4001
4019
4049
4051
5347
7001
7547
7681
7841
7937
8101
8161
73
76
76
79
80
80
86
88
89
89
96
96
98
98
99
100
10 4
10 5
10 5
10 5
10 6
I0 8
109
11 0
110
l l 5
l l 7
11 8
119
120
!го
12 0
120
124
12 8
129
129
12 9
!30
1Зо
1З0
162
192
196
240
250
256
400
448
486
490
81
64
49
16
125
256
25
64
24~
49
125
256
49
27
зг
16
343
128
729
49
64
8I
25
27
32
729
256
128
243
32, 125
49
16
81, 25
243
125
З4З
512
49
256
81, 25
зг
~.7. Числовые преобразования Шевилла
Длина
слоба
Здирвктиднаю
длина
слаба
Моксцмалаиая Моксцмалвнаю
дюна длина 0/7Ф
иреобрамВЫною по оймону
оснобанию
14
15
16
8263
13751
14407
15361
16001
16073
16193
1630!
16363
16369
17497
18433
25601
28751
28813
30871
32077
32251
32257
32401
32537
32563
32609
32689
39367
40961
52489
61441
62501
63001
64153
64513
65089
65101
65171
65269
65281
65449
65521
Фурье по одному основанию.
13.0
13.7
13.8
13.9
14.0
14.0
14.0
14.0
14.0
14.0
14.1
14.2
14.6
14.8
14.8
14.9
15.0
15.0
15.0
15.0
15.0
15.0
15.0
15.0
15.3
15.3
15.7
15.9
15.9
! 5.9
16.0
16.0
16.0
16.0
16.0
16.0
16.0
16.0
16.0
8262
13750
14406
15360
1 6000
16072
16192
16300
16362
16368
17496
18432
25600
28750
28812
30870
32076
32250
32256
32400
32536
32562
32608
48
39366
40960
52488
61440
62500
250
64152
645!2
65088
65100
65170
65268
96
65448
65520
243
625
2401
1024
128, 125
49
64
25
81
16
2187
2048
1024
625
2401
343
729
125
512
25
49
243
32
16
19683
8)92
6561
4096
15625
125
729
1024
64
25
343
49
32'
81
16
216 Гл. 6. Вычисления в суррогатиых полях
Для вычислений в кольце Z/(q) необходимо знать вычеты по
модулю д, которые в общем случае вычисляются не столь просто,
как в случае простых чисел Ферма или Мерсенна. Это является
одним из основных недостатков числовых преобразований Ше-
вилла; возможным выходом является предварительное вычисление
и табулирование вычетов по модулю простых чисел.
6.8. Алгоритм Препараты Сервейта
Так же как вычисления в поле комплексных чисел вкладыва-
ются в поля Галуа, вычисления в полях Галуа можно вложить
в поле комплексных чисел. Для вычисления свертки в GF (q)
можно воспользоваться комплекснозначным БПф-алгоритмом.
Предположим, что в поле GF (q), где q равно степени простою
числа р, требуется вычислить произведение з (х) = g (х) d (х).
Представим элементы поля 6Р (q) в виде многочленов; тогда
произведение элементов поля в GF (q) можно интерпретировать
как свертку многочленов по модулю неприводимого многочле-
на р (х). Вычисление всех вычетов по модулю этого неприводи-
мого многочлена можно отложить до тех пор, пока не будут
вычислены все свертки. Исходная свертка при этом превращается
в двумерную свертку.
Запишем элементы g; и d~ поля GF (q)' над простым полем
GF (p) в виде многочленов
т=~ m ‒ f
~ч 1
Я,= ~~~~Я„2 и Й,= ~Ипата
1=0 l~
si ЕВАь=
й=а
л ‒ t m ‒ f ng ‒ g
~'.~ gudg~у pz + (шой p)(mod p (х))у
~о с-а ю'=а
где р характеристика поля, а р (х) простой многочлен сте-
пени т. Определим двумерную целочисленную свертку равенством
л=I tn ‒ g
sjp = Е Е gkk.d(t~>п~ »
&=Я k' Ö
E=O,..., и ‒ 1,
k' =О, ..., 2т ‒ 1.
где о = р, а g~~ и d;~ обозначают неотрицательные целые числа,
не превосходящие р 1. Тогда линейная свертка векторов g
и d равна
217
Задачи
Задачи
6-1. а. Построить логические схемы, реализующие операции умножения и сло-
жения s поле Мерсенна GF (7). Позволяет ли представление О в двух видах
получить какое-то преимущество?
Каждый элемент такой двумерной таблицы представляет собой
число между 0 и р 1. Тогда
2m ‒ 1
sg = Д'., з«z' (modр) (modp(x)).
g г~)
Вычисления вычетов делаются на последнем этапе вычислений,
причем сначала вычисляются вычеты целых чисел по модулю р,
2m ‒ !
а затем вычеты многочленов sq (z) = f s«z' по модулю много-
l'=0
члена р (х). Сложностью вычисления вычетов можно пренебречь
по сравнению со сложностью вычисления двумерной свертки.
Двумерную свертку можно вычислять в любом подходящем сурро-
гатном поле, например в поле вещественных или поле комплекс-
ных чисел.
Вместо поля комплексных чисел можно использовать как сур-
рогатное поле любое подходящее конечное поле, даже с харак-
теристикой, отличной от характеристики исходного поля. На-
пример, для свертки последовательностей над GF (2), длина п
которых меньше, чем половина простого числа Ферма 2 + 1
(при rn = 2, 4, 8, 16 соответственно 2 + 1 = 5, 17, 257,
65537), можно использовать поле GF (2 + 1). Для этого доста-
точно проинтерпретировать последовательность над GF (2) как
последовательность целых чисел, которые принимают только зна-
чения, равные 0 и 1. Длина линейной свертки таких целочисленных
последовательностей, хотя и больше и, но не превосходит 2, и,
следовательно, эту линейную свертку можно вычислять как цик-
лическую свертку в поле GF (2 + 1) с последующим приведе-
нием целых чисел по модулю 2.
Для вычисления циклической свертки в поле GF (2 + 1)
можно воспользоваться любым допустимым быстрым алгорит-
мом. Так как в поле GF (2 + 1) существует преобразование
Фурье длины и, равной любому делителю числа 2, то одной из
возможных схем вычислений является использование преобразо-
вания Фурье и теоремы о свертке. Преобразование фурье при
этом можно вычислять по БПФ-алгоритму Кули Тычки, содер-
жащему (п/2) log, п умножений и столько же сложений в поле
GF (2 + 1). Далее, так как элементы поля CrF (2~ + 1) допу-
скают запись в виде (т + 1)-разрядных двоичных чисел, то слож-
ность такого алгоритма свертки сравнима со сложностью в поле
комплексных чисел.
218
Гл. 6. Вычисления в суррогатных полям
6.2.
6.3.
6.4.
6.6.
6.6.
6.7.
6.8.
6.9.
6.10.
6.11.
б. Построи'пь логические схемы, реализующие операции умножения и сло-
жения в поле ферма GF (5). Позволяет ли представление чисел О, 1 и 2
получить какие-то преимущества?
l г~
а. Проверить, что если ядро преобразования Фурье в поле GF(2 + 1}
равно 2, то все необходимые умножения на самом деле являкггся умноже-
ниями на степени двойки и могут бысть заменены циклическими сдвигами.
б. Элемент в = 8 в поле GF (193) имеет порядок, равный 32, и, следова-
тельно, может быть выбран в качестве ядра 32-точечного преобразования
Фурье в этом поле. Можно ли как-то осмысленно утверждать, что все умно-
жения такого преобразования являются умножениями на степени двойки
и могут быть заменены циклическими сдвигами?
Порядок элемента 2 в кольце У/(15) равен четырем. Выписать (4Х4)-ма-
трицы 4-точечного преобразования фурье и ему обратного преобразования.
Показать, что эти матрицы не ведут себя стандартным для матриц преобра-
зования фурье образом. Какие свойства оказываются неверными? Почему?
а. Чему равен порядок элемента 2 в простом поле Ферма GF (17)?
б. Описать 8-точечный БПФ-алгоритм Кули ‒ Тычки по основанию два
для поля GF (17). Сколько умножений содержит этот алгоритм?
в. Описать 4-точечный БПФ-azrropam Кули ‒ Тычки по основанию два,
ядром которого является элемент 4.
г. В поле бг (17) имеет место равенство 17 2 = 1l. Является ли 11 при-
митивным элементом поля? Описать 16-точечиый БПФ-алгоритм Кули‒
Тычки для поля GF (17) с минимальным числом умножений.
Пусть О= (28+ 1) (2'+ 1). Чему равен порядок элемента 2 в кольце
z/(д)?
Число 31 является простым числом Мерсенна.
а~ Чему равен порядок элемента 2 в поле GF (31)?
б. Выписать 5-точечный БПФ-алгоритм Винограда в поле GF (31).
в. В поле GF (31) элемент ‒ 1 не имеет квадратного корня. Чему равен
порядок элемента 1+ у в расширении GF (312) поля?
г. Чему равна наибольшая допустимая длина преобразования Фурье
в поле GF (31~)?
д. Описать структуру 8-точечного БПФ в поле GF (312).
Показать, что порядок элемента 1+ у в поле комплексных чисел Мер-
сенна GF ((21~ ‒ 1)~) равен 136. Это означает, что в данном поле существует
преобразование Фурье длины 136. Описать структуру быстрого алгоритма
вычисления этого преобразования.
Построить 5-точечный БПф-алгоритм Винограда для поля GF (41). (Ука-
зание: чему равен порядок элемента 2 в поле GF (41)?)
В поле GF ((2~> ‒ 1)в) существует 17-точечное преобразование Фурье.
а. Описать алгоритм вычисления этого преобразования с помощью 16-то-
чечного преобразования Фурье в поле комплексных чисел. Выписать блок-
схему такого вычисления.
б. Сколько потребуется веществеиных умножений и сложеиий, если 16-то-
чечное преобразование Фурье в поле комплексньл чисел вычислять с по-
мощью малого БПФ-алгоритма Винограда?
в. Каковы должны быть разрядность и процедура округления для того,
чтобы комплексные вычислеиия приводили к правильному ответу в поле
GF ((21~ ‒ 1)2')?
В поле комплексных чисел имеется 17-точечное преобразование Фурье.
а. Описать, как это преобразоваиие может быть вычислено с помощью
двух 16-точечных преобразований в поле комплексных чисел Мерсенна.
б. Сколько умножений и сложений в суррогатном поле потребуется при
таком вычислении?
а. Показать, что многочлен хе2 ‒ 1 имеет в поле GF (2'+ 1) 32 различ-
иыл корня.
219
Замечаиия
б. Сколько умножений обшего типа содержит 32-точечный алгоритм Вино-
града вычисления циклической свертки в расширении QF ((2га + 1) )
поля GF (2~6+ 1)?
в. Сколько умножений общего типа требуется для вычисления 32-точечной
циклической свертки в QF ((21а + !)з) при использовании БПФ и теоремы
о свертке?
г. Объяснить взаимосвязь между и. (б) и (в) задачи.
6.12. Выпишите детально 16-точечный БПФ-алгоритм В инограда для поля
GF (17) и его расширений. Сколько требуется нетривиальных умножений?
Замечания
Преобразования Фурье рассматривались в произвольных полях, но тот
факт, что вещественную свертку можио вычислять, переходя в поле целых чисел
по модулю простых чисел Мерсенна или простых чисел Ферма, впервые отметил
Рейдер [1] (1972). Это погружение было разработано им в связи с приложением
к цифровой обработке сигналов, как существенно упрощающее необходимые
вычисления. Агарвал и Баррас [2] (!973) также описали применение числовых
преобразований Ферма и разработали их структуру [3, 4] (1974, 1975). Ше-
вилла [11] (1978) рассмотрел возможности использования других простых полей.
Некоторые вопросы реализации этих числовых преобразований были рассмотрены
Макклелланом [5] (1976) и Лейбовицем [6] (1976). Предложение использовать
комплексные расширения полей Галуа для вычисления комплексных сверток
сделали Рид и Труонг [7] (1975) и Нуссбаумер [8] (1976). Приведенная нами
табл. 6.1 основана на работе Рида и Труонга.
Алгоритмы свертки в полях Галуа малой характеристики могую отличаться
от алгоритмов свертки в поле вещественных чисел Алгоритмы свертки в полях
малой характеристики рассмотрел Райс [9] (1980), и мы воспользовались не-
которыми ero примерами. Идея использования суррогатных полей принадлежит
Препарате и Сервейту [10] (1977), которые вложили вычисление свертки в полях
Галуа в поле комплексных чисел.
Использование китайской теоремы об остатках для представления данных
(в противоположность использованию для переупорядочивания индексов) хорошо
известно; можно сослаться на учебник Сабо и Танаки [12] (1967) или более не-
давнюю работу Дженкинса и Леона [13] (1977).
Глава 7
БЫСТРЫЕ АЛГОРИТМЫ
И МНОГОМЕРНЫЕ СВЕРТКИ
Подобно тому, как определяется одномерная свертка, можно
определить многомерную свертку. Для многомерных таблиц дан-
ных можно дать полезные во многих отношениях определения
линейной и циклической сверток для любого представляющего
интерес поля вычислений. Многомерные таблицы данных и много-
мерные свертки создаются чскусственным образом как часть
алгоритмов обработки одномерных векторов данных. Многомер-
ные таблицы данных возникают также естественным образом
во многих задачах цифровой обработки сигналов, в частности,
в задачах обработки изображений, например фотографий, полу-
ченных со спутников, и медицинских изображений, в том числе
рентгенограмм, в задачах сейсмографии и электронной микро-
скопии.
Глава начинается с гнездового метода построения быстрых
алгоритмов вычисления многомерных сверток из быстрых алго-
ритмов для одномерных сверток. Затем рассматривается способ
построения быстрых алгоритмов вычисления одномерной свертки
путем временного отображения в многомерную свертку, про-
цедура, известная под названием алгоритм Агарвала Кули вы-
числения свертки. Алгоритм Агарвала Кули для одномерной
циклической свертки представляет собой мощное дополнение
к развитым в гл. 3 методам, которые становятся чрезмерно гро-
моздкими для длинных сверток. Он позволяет строить алгоритмы
для длинных сверток из коротких сверток. Наконец, последняя
половина главы содержит методы, развитые специально для вы-
числения двумерных сверток.
7.1. Гнездовые алгоритмы свертки
Двумерная свертка представляет собой операцию, задаваемую
на паре двумерных таблиц. Ее можно представлять себе как опе-
рацию фильтрации, в которой одна двумерная таблица представ-
ляет собой двумерный фильтр, через который пропускается вто-
рая двумерная таблица и на выходе которого формируется выход-
ной двумерный сигнал. Такого сорта операции возникают в зада-
чах обработки изображений.
22l
7.l. Гнездовые алгорнтмы сверткн
Заданную (N' x N")-таблицу
й=(И~,-, i'=О,..., N' ‒ 1; i"=О, ..., N" ‒ 1)
назовем таблицей данных, а (L' xL")-таблицу
g=(gg.p, 1'=О, ..., L' ‒ 1; i"=О, ..., L" ‒ 1)
1) x(L" +
назовем таблицей фильтра, и вычислим ((L' + N'
+ N" 1))-таблицу сигнала
i' =О, ..., L'+N' ‒ 2,
'"=О,..., L +N" ‒ 2
задавая правила вычисления ее элементов равенствами
‒ ‒ 1'=О, ..., L'+N' ‒ 2,
Й', 1 = Z g gr ‒ Й'. e ‒ й'Ай'. Й" е П к а ютюсь 1ъ
hi" ‒ 1
А (У) = Z А'. ю-У".
Е"=о
или как многочлен от двух переменных
е'=о е"=о
Аналогичные обозначения можно ввести для g и s:
1'" ‒ 1 L+h ‒ 2
f // %~ irr
gg (ó) = Х gg'ë"ó ° sg.(y) = Ь s( l-y
е"=о
е"=о
L' ‒ 1 L" ‒ 1
Еи it
g (x, у) = ~, g g; ;-у .х ,
i. о е"=о
L'+N' ‒ 2 L"+N" ‒ 2
Е- Е'
з(х, у) = g g з~.<-у х .
i' о е"=о
1) Так определенная двумерная свертка в дальнейшем часто называется
(N'>< N")-сверткой; ее не следует путать с определенной в гл. 3 линейной (L X N)-
сверткой. ‒ Прим. перев.
Это определение можно непосредственно перенести и на свертки
большей размерности. Однако мь1 ограничим рассмотрение в ос
новном двумерными ') свертками, так как все идеи легко обоб-
щаются на случай произвольной размерности.
Двумсрная свертка может быть выписана в терминах много-
членов; полиномиальные обозначения можно вводить как по лю-
бому из измерений, так и по обоим измерениям одновременно.
Таким образом, таблицу д можно записать или как вектор много-
членов,
222 Гл. 7. Быстрые алгоритмы и многомерные свертки
Двумерная <;рертка в этих обозначениях может быть записана
или как одномерная свертка многочленов,
з~с (у) = Z a~ д (у) da~ (у)
д'=О
или как произведение многочленов or двух переменных,
з (х, у) = у (х, у) d (х, у).
Двумерная циклическая свертка также может быть выписана
в терминах мноючленов, а именно,
з(х, у) = g (>, у) d (х, у) (mod х" 1) (mod у"" 1},
где и' не обязательно равно и". Для двумерной циклической
свертки выполняется теорема о свертке. Если 3Э и б обозначают
двумерные преобразования Фурье таблиц d u g соответственно
и Sk д- ‒ ‒ бд д-Dk, k-, то $ является двумерным преобразо-
ванием Фурье таблицы s. Следовательно, для вычисления дку-
мерной циклической свертки можно пользоваться двуь ерным
БПФ-алгоритмом. Можно, конечно, пользоваться и прямыми мь
тодами вычисления двумерных сверток.
Имеется много способов прямого вычисления двумерной ли-
нейной или циклической свертки. Простейший путь состоит в том,
чтобы попытаться вычислить ее как последовательность одномер-
ных сверток сначала по строкам, а затем по столбцам. Заметим,
однако, что в формуле
~ч" ‒ у л- ‒ i
gvв = Х Хй» ~«йа]
k' 0 k" 0
выделенная в квадратные скобки линейная свертка по k" должна
быть вычислена для всех i' и k'.
Понять двумерную свертку легче, если выписать ее в виде
свертки многочленов,
Pf Ó
sg (у) = f д „.(y)dä (у) 1' =О, ..., L'+N' ‒ 2.
k 0
Из этой формулы ясно видна реализация двумерной свертки
как L'jV' произведений многочленов, каждое из которых, в свою
очередь, является сверткой, требующей ЫЧ" умножений. Всего,
таким образом, получаем L'L"N'N' умножений, что, конечно,
недопустимо для больших задач, так что нужны быстрые алго-
ритмы.
Хотя рассмотренные в гл. 3 алгоритмы свертки строились над
полями, они на самом деле выполнимы и в некоторых кольцах,
в частности, в кольце многочленов. Следовательно, свертка много-
7.1. Гнездовые алгоритмы свертки
членов может быть вычислена любым из этих быстрых алгоритмов.
Сложение в этих алгоритмах становится сложением многочленов,
а умножение умножением многочленов. Эти последние умно-
жения, в свою очередь, являются свертками и могут быть вы-
числены с помощью быстрых алгоритмов свертки. Таким образом,
мы получаем способ вычисления двумерной свертки, состоящий
во включении одного быстрого алгоритма одномерной свертки
в другой быстрый алгоритм одномерной свертки.
Все сказанное здесь относительно линейной свертки, конечно,
относится и к циклической свертке и к вычислению произведения
многочленов по модулю многочлена т (х).
Например, для вычисления двумерной циклической (4X4)
свертки воспользуемся алгоритмом 4-точечной циклической сверт-
ки в виде, представленном на рис. 3.14: s = С [(Bg) (Ad) l. Эгот
алгоритм содержит пять умножений и 15 сложений. Следова-
тельно, применение его для циклической свертки многочленов
потребует пяти умножений многочленов и 15 сложений много-
членов. Каждое умножение многочленов само является сверткой,
и, следовательно, для его вычисления по этому алгоритму потре-
буется пять вещественных умножений и 15 вещественных сложь
ний. Таким образом, для вычисления двумерной циклической
(4X4)-свертки потребуется в данном алгоритме 25 вещественных
умножений и 135 вещественных сложений. Эта процедура пред-
ставлена на рис. 7.1 для вычисления циклической (и' х и")-свертки.
Как показано на рисунке, подпрограмма должна знать индекс k"
и иметь доступ к заранее вычисленной таблице бд ~".
Используя последовательные операции над двумерными таб-
лицами, этот составной алгоритм можно представить в виде еди-
ного алгоритма. Сначала умножим строку таблицы d на ма-
трицу A", а каждую строку таблицы g на матрицу В". Затем умно-
жим каждый столбец первой новой таблицы на А' и каждый стол-
бец второй новой таблицы на В'. Это даст нам две таблицы раз-
мера M (п') XM (n'). Перемножим покомпонентно эти таблицы.
Полученную таким образом (М (и') х М (n"))-таблицу преобразуем
к нужной выходной таблице s размера и'хп", умножив сначала
каждый ее столбец на С', а затем каждую строку полученной
таблицы на С .
Яа рис. 7.2 для сравнения выписаны эта процедура и про-
цедура, основанная на двумерном преобразовании Фурье и теореме
о свертке. Ясно, что рассматриваемая процедура является обобщь
нием процедуры, основанной на двумерном преобразовании
Фурье. Теперь «преобразование» состоит только из сложений, но
размер промежуточной таблицы равен не и' 'к и", à M (п') х
XM (n ).
Гнездовой алгоритм является более общим и в другом отно-
шении.. 0H позволяет вычислять двумерное произведение много-
224 Гл. 7. Быстрые алгоритмы и многомерные свертки
Ввод вектора d
коэффициентов
многочлена
d(~) = >~(~)
Ввод вектора
многочленов
4<»
Вьюход
Рис. 7.1 ° Алгоритм двумерной циклической свертки.
членов по модулю любых многочленов т' (х) и т" (у), а метод,
основанный на преобразовании Фурье, позволяет вычислять про-
изведение только по модулю х"' 1 и у"" 1.
Характеристики гнездового алгоритма задаются числом M (и' Х
X и") необходимых умножений и числом А (n'хп") необходимых
сложений. Легко видеть, что полное число умножений равно
M (и' xn") = M (п') M (n").
Аналогично, из рис. 7.1 легко увидеть, что
А (n' xn") = и'А (и") + М (n") А (n').
Полное число умножений не зависит от того, какой из делите-
лей назван и', а какой и . Но число сложений зависит от такого
выбора, и поэтому необходимо просматривать оба варианта. На-
7.l. Гнездовые алгоритмы свертки
Вьыод
Выход
eepmaa(mod х ‒ 1) Свертка(тод т~~Я
(mod y" ‒ 1) (33gd т."( y))
Рис. 7.2. Сравнение способов вычисления двумерной свертки.
нример, двумерную циклическую (7 х 9)-свертку можно вычислять
с помощью одномерных алгоритмов с характеристиками
М (7) = 16, А (7) = 70,
M (9) = 19, А (9) = 74.
Полное число умножений при этом равно 304, а полное число
сложений равно 1848 или 1814 в зависимости от того, чему вы-
~рано равным и'.
Вход
в двумерную свертку
в частовной области
Вход
в гнездовой алгорцшм
свертки Винограда
226 Гл. 7. Быстрые алгоритмы и многомерные свертки
7.2. Алгоритм Агарвала 1(ули
вычисления свертки
Алгоритм Агарвала Кули представляет собой метод преоб-
разования и'и"-точечной одномерной циклической свертки в дву-
мерную циклическую (и' Х и")-свертку прн условии, что числа
и' и и" взаимно просты. Его можно использовать для того, чтобы
скомбинировать алгоритм Винограда вычисления и'-точечной цик-
лической свертки, содержащий M (n') умножений, с алгоритмом
Винограда вычисления и"-точечной циклической свертки, содер-
жащим М (n') умножений, и построить алгоритм вычисления
п'и"-точечной циклической свертки, содержащий N (п') N (n")
умножений.
В основе алгоритма Агарвала Кули преобразования одно-
мерной циклической свертки в многомерную циклическую свертку
лежит китайская теорема об остатках для целых чисел. Этим алго-
ритм отличается от алгоритма Винограда, в котором исполь-
зуется китайская теорема об остатках для многочленов. Он не
обеспечивает столь сильного уменьшения числа умножений, как
алгоритм Винограда вычисления свертки, но, с другой стороны,
он не имеет и тенденции к чрезмерному росту с ростом и числа
сложений, как в алгоритме Винограда. Кроме того, он лучше
структурирован. Если и велико, то алгоритм Агарвала Кули
более управляем, так как может быгь разбит на подпрограммы.
Для построения хороших алгоритмов свертки надо использовать
алгоритм Агарвала Кули разбиения длинной свертки на корот-
кие циклические свертки, для вычисления которых использовать
затем эффективные алгоритмы Винограда вычисления коротких
циклических сверток.
Алгоритм Агарвала Кули строится на'трех идеях. Сначала
одномерная циклическая свертка с помощью китайской теоремы
об остатках (К. Т. 0.) для целых чисел преобразуется в много-
мерную циклическую свертку; затем вдоль каждой координаты
используется алгоритм Винограда вычисления короткой свертки;
и, наконец, для сборки вместе полученных преобразований ис-
пользуется теорема о кронекеровском произведении для матриц.
Пусть заданы d; и g~ для ~ = О, ..., и 1, и нам надо по-
строить компоненты циклической свертки
1=0,..., и ‒ 1,
где двойные скобки в индексах обозначают вычисление по мо-
дулю и.
Мы хотим преобразовать одномерную свертку в двумерную.
Для этого воспользуемся китайской теоремой об остатках, позво-
7.2. Алгоритм Агарвала ‒ Кули вычислення свертки
Явумерная
вникли геская О
свертка
l(T. о
Рис. 7.3. Иллюстрацня алгоритма Агарвала ‒ Кули.
ляющей отобразить одномерный вектор входных данных в дву-
мерную таблицу и выходную двумерную таблицу п одномерный
вектор. Заменим индексы i и Й парами индексов (i', )") и (Й', й")
по правилу
i' = i (mod и'), i" = i (п)оД и'~,
Й' = k (mod n'), Й' = Й (mod n").
Занимаясь китайской теоремой об остатках, мы уже видели, что
старые индексы восстанавливаются по новым согласно формулам
!
i = N"и"i' + N'и')" (mod и), )' = О, ..., n' ‒ 1,
i"=О, ..., n" 1,
Й = И"и"И + N'n'Ê (mod n), Й' = О, ..., n' 1,
k"=О,...,n 1,
где целые числа N' и N" определяются равенством
N'n' + N"n" = 1.
Это то же самое соответствие между компонентами вектора и ком-
понентами двумерной таблицы, которое было использовано в алго-
ритме Гуда Томаса. Описанное отображение иллюстрируется
рис. 7.3.
Свертку
n ‒ 1
можно записать в виде
n' ‒ 1 n" ‒ 1
аи"и~)'+лГ'и'й" = f ~.~ gN"è" (l' ‒ )а')+N'è' <й ‒ и)г1И"и"3а'+N'è'~
фУ О ЯювО
228 Гл. 7. Быстрые алгоритмы и многомерные свертки
Число
Число Число вещесвенных
вещественных вещественных умножении
умножений сложений на точку
М(п) A(и) М(л)/л
Число
вещественщог
сложений
на точку
Д(п)/л
Длино
л
Рис. 7.4. Характеристики алгоритма Агарвала ‒ Кули вычисления свертки.
Двойное суммирование по Й' и Й" эквивалентно одинарному сум-
мированию по k, так как затрагивает одни и те же члены. Опреде-
лим двумерные переменные, которые назовем также d, g и з,
задавая их равенствами
d
у/
kФ ',kþ dNÂýnèkВ'+N эnУ'kè к ‒ 0, ...
, и' ‒ 1,
k" =0,
k' =0,
k" =0,
k' =0,
, и" ‒ 1,
gk â kþi ‒ ЯД!юnþkã+ N ~ n~ k â
°, и' ‒ 1,
, и" ‒ 1,
. ° ., и' ‒ 1,
Sk k" = SAi"~k.+N пт,
k" =0, ..., и" ‒ 1.
В новых переменных свертка записывается в виде
n ‒ 1 n" ‒ 1
Й . к- = Е Е Кцк ‒ a'>>. цк- a"»À I-,
k' 0 k" 0
где первые и вторые индексы вычисляются соответственно по мо-
дулю и' и и". Теперь это двумерная циклическая свертка. Тем
не менее, мы пока не получили никакого уменьшения сложности
вычислений. Для каждой пары индексов (i', ~") каждое число
dk- д- на что-то умножается, так что пока полное число умно-
жений равно (п'n")~.
Для того, чтобы сделать алгоритм эффективным, надо восполь-
зоваться развитыми в предыдущем разделе методами быстрого
18
20
24
30
36
48
60
72
84
120
180
210
240
360
420
504
840
1008
1260
2520
38
50
80
95
132
200
266
320
560
950
1280
1056
2280
3200
3648
7680
10032
12160
29184
184
230
272
418
505
900
1! 20
1450
2100
Ю96
5470
7958
10176
14748
20420
26304
52788
71265
95744
241680
2 I I
2 50
2 33
2 67
2 64
275
3 33
3 69
3 81
4 67
5 28
6 10
4 40
633
7 62
7 24
9 14
9 95
965
11.58
!О 22
I l 50
!! ~З
I3 93
14 03
!8 75
IS 67
20 14
25 00
25 80
30 39
37 90
42 40
40 97
48 62
52 19
62 84
70 70
75 99
95 90
7.2. Алгоритм Агарвала ‒ Кули вычнсления свертки
вычисления двумерной свертки. Алгоритм Агарвала Кули вы-
числения свертки состоит в переходе от одномерных векторов
к двумерным таблицам, в применении быстрых алгоритмов дву-
мерной свертки и в обратном переходе от двумерной таблицы
к одномерному выходному вектору.
Характеристики и-точечного алгоритма Агарвала Кули поды-
тожены в таблице на рис. 7.4. Полное число сложений и умноже-
ний определяется гнездовым методом построения алгоритмов дву-
мерной циклической свертки из эффективных одномерных алго-
ритмов составляющих длин и' и и" по формулам
А (п) = и'А (п') + М (п") А (п'),
M (п) = М (п') М (п').
Из этих формул видно, что число умножений в малых алго
ритмах играет существенно более важную роль, чем число сло-
жений. Например, предположим, что алгоритм 504-точечной цик-
лической свертки строится из 7-, 9- и 8-точечных циклических
сверток с
М (7) = 16, А (7) =- 70,
М (9) = !9, А (9) = 74,
М (8) = 14, А (8) = 46 или М (8) = 12, А (8) = 72.
Может показаться, что алгоритм 8-точечной циклической свертки
с 14 умножениями лучше, так как он содержит всего на два умно-
жения больше, но зато на 26 сложений меньше. Однако включе-
ние его в алгоритм 504-точечной свертки приводит к удивитель-
ным результатам:
М (504) = 4256,
М (504) = 3648,
А (504) = 28 240
А (504) = 26 304.
или
Таким образом, использование в 504-точечном алгоритме 8-точеч
ного алгоритма с 12 умножениями приводит к уменьшению и
числа умножений, и числа сложений.
Выполнять вычисления надо следующим образом. Сначала
каждый столбец двумерной таблицы умножается на матрицу А".
Затем начинается вычисление произведений многочленов. Эгот
процесс начинается умножением каждой строки двумерной таб-
лицы на матрицу А'. Затем каждая строка покомпонентно умно-
жается на вектор констант, так что и вся двумерная таблица
умножается покомпонентно на таблицу констант. Умножение
многочленов завершается умножением каждого столбца на ма-
трицу С', а затем каждой строки на матрицу С".
230 Гл. 7. Быстрые алгоритмы и многомерные свертки
Эта последовательность вычислений может быть представлена
в более компактном виде, если собрать воедино два алгоритма
циклических сверток. Запишем входную двумер ную таблицу
в виде стека по столбцам, представив ее одномерным входным
массивом. Аналогично запишем и выходную двумерную таблицу,
вытянув ее в выходной одномерный массив. Тогда алгоритм
примет вид
s = ((С х С') (G' x С") (A' х А")) d.
Аналогично, можно выходную двумерную таблицу записывать
в виде одномерного массива, считывая ее по строкам. Тогда алго-
ритм запишется даже в более симметричной форме
s = ((С' х С") (б' х С") (А' х А")) Й,
где компоненты вектора s выписаны в другом порядке, хотя и
остаются неизменными. В любом из случаев, вводя очевидные
обозначения для матриц, можно записать
s = CGAd.
Есть еще одна последняя деталь, о которой надо позаботиться.
компоненты векторов s u d выписаны не в своем естественном
порядке. Сначала они выписывались в двумерную матрицу вдоль
главной диагонали, а затем в виде стека столбцов (или строк).
Для того, чтобьг вернуть компоненты на их естественное место,
надо переставить столбцы матрицы А и строки матрицы С.
В качестве примера построим алгоритм 12-точечной циклично
ской свертки. Воспользуемся следующим 3-точечным алгоритмом
циклической свертки:
Gll 0
! О ‒ 1
‒ ‒ г
о
где
1
Э Э
о
1 ‒ 1
g0
gi
l
Э 3
7.2. Алгоритм Агарвала ‒ Кули вычисления свертки
и следующим алгоритмом 4-точечной циклической свертки
1 t t 0 ‒ l
t ‒ 1 1 ‒ t 0
t 1 ‒ 1 0 t
G2
G(
S2
1 0 ‒ t 0
0 1 0 ‒ 1
1 ‒ 1 ‒ 1 1 0
где
I
4
О
l
К2
1 l
2 2
Gj
I 1
2 2
I
2
G4
Сначала выпишем !2 коэффициентов фильтра в виде двумерной
(3X4)-таблицы, располагая их вдоль главной диагонали, и вытя-
гивая затем их в стек по столбцам:
go
go
g4
gl
g2
gs
g9
gl
go g9 ga 82
g4 g l g lO g2 «1О
gS 85 82 g»
g3
gll
glI
Тогда диагональная (20x20) матрица С в терминах кронекеров-
ского произведения записывается равенством
g0
g4
О -1
g9 °
О
Gl
gII
G0
Gl
~2
! ! !
4 4 4
! ! I
4 4
о ‒ о
l
I ! l
2 2 2
! ! 1
2 2 2
1 l l 1
1 ‒ l 1 ‒ 1
I 1 ‒ 1 ‒ 1
g$
Яе
Яю
g2
~о
dl
d2
д!
232 Гл. 7. Быстрые алгоритмы и многомерные сверткн
Ту же самую конструкцию надо применить к !2 компонентам
входного вектора данных; выпишем кронекеровскую матрицу
А' х А" полностью:
о.
D,
0)
Рд
1 I 1
о
о
I ‒ 2 !
1 1
о
1 I
) -г
I !
‒ 1 1
1 1
о
I -I
1 -2
о
-2 1
1 1 I — I †)
О -1 -1 0
О ! ‒ ) 0 ‒ 1
‒ 1 1 1 !
1 О
о
1 -2
‒ ! ‒ 1 ‒ )
о
о
1 I ‒ 2 ‒ 1 ‒ )
‒ 1 -1 2
1 -1 -1 -1 -1 -1 ‒ 1
о
о
‒ ‒ о
‒ о
‒ 2 ‒ 1 ‒ ! 2 ‒ 1 -) 2
О ‒ 1 ‒ 1 ‒ 1
О ‒ I О 1
О О ‒ 1 I
Π†) -I 2
О О О
О О О
о о о
о о о
— I -1 †)
‒ I О 1
О ‒ 1 I
‒ 1 ‒ I 2
О 0
О О
О О
О. О
%
о,
Р)
D)
D)
I I
1 О ‒ I
о
dg
dg
~]~1
О
‒ 1 0 1
‒ 2 1 1
1 ‒ 1 )
‒ 1 †) О
‒ 1 О )
1 1 ‒ 2
I ‒ I 1
I О -1
о
1 ‒ I
d)
dg
-2 ‒ )
‒ I ‒ 1
I ‒ 1
— I ‒ 1 0 ‒ 1
†) О ‒ 1 †!
‒ 2 — I ‒ 1 ‒ 2
I ‒ 1
I О
2 ‒ !
о
1 О
1 О
2 0
О
О ‒ 1
0 О
0 ‒ )
0 -I О
О ‒ I О
О О О
О -1 О
1 О ‒ )
‒ 1 О 0
‒ 1 О
‒ 2 Π†!
-2
О
О
0
О
Это полностью определяет вычисление 0 = Ad. Аналогичные
рассуждения приводят к построению матрицы С, и, в итоге,
к стандартной матричной форме s = CGAd алгоритма вычисле-
ния !2 точечной циклической свертки. В такой форме алгоритма
все операции перестановки компонент скрыты в матрицах пред-
сложений и постсложений.
1 I 1 I 1
О -1 ) О
О 1-1 О
1 I -2 I
о о
О -1 О О
О 1 -1 О О
1 1 -2 О О
о о о
о о о
о о о о
о о о
Наконец, перестановка столбцов дает
1 1
1 О
0 I
1 !
1 -I
I О
о
1 ‒ 1
1 I
1 О
О 1
1 I
1 О
О
О О
1 О
О I
о о
О 1
О !
1 1
1 О -I
О 1
1 1
‒ I I
о
О 1
‒ I 1
I -I
I О )
О
‒ 1 2
О ‒ 1 0
О О 0
О
О ‒ 1 О
I О
I О
0 О
1 О 2
do
d,
dg
dy
d)
d$
~~л
4а
d)
d)
И)
4i
233
7.3. Алгоритмы разложения
7.3. Алгоритмы разложения
Мы уже видели, как гнездовой метод позволяет преобразовать
алгоритм одномерной свертки в многомерные алгоритмы. Для
вычисления
s (х, у} = g (х, у) d (х, у) (mod х"' 1) (mod у"" 1)
мы объединяли алгоритмы для вычислений
s (х} = g (x) d (х) (то4 х"' 1} и s (у) = g(y) d(у} (mod у"" 1}.
В более общей формулировке, для построения алгоритма вычис
ления
р (х) = р ' (х) р< '(x),
где многочлены р«'> (х} и р«> (х) взаимно просты. Вычисление
произведения многочленов
s (х, у} = g (х, у} d (х, у} (mod р (х}} (mod q (у})
можно разбить на вычисления произведений
s<0'(x, у} =g<0'(x, y)d'0'(õ, у} (то4р<о'(x)) (mod q(y))
s~'~(x, у} = g< '(x, y)d'" (х, у) (то4р"~(х}) (mod q(y)).
Китайская теорема об остатках позволяет восстановить произв~
дение из этих фрагментов. Если q (у) = q<о> (у} q<ц (у}, то можно
произвести факторизацию и по переменной у. Обе эти возмож-
ности позволяют разбить задачу на следующие фрагменты:
s<0'0'(õ, у) = g<0'0'(x, у) d~'~'(x, у) (то4р'о'(x)) (modq~'(y)),
s~''(x, у) = g~''(x, y)d<0'"(õ, у} (mod р'о'(x)) (modq<''(y)),
s (х, у) = g (х, у} d (х, у) (mod р (х)} (то4 q (у)),
где р (х} и q (у) представляют собой многочлены степеней n' и n"
соответственно, мы комбинировали алгоритмы для решения двух
простых одномерных задач
s (х} = g (х} d (х} (mod р (х)} и s (у} = g (у) d (у} (то4 q (у}).
Если каждый из подалгоритмов содержит соответственно М (n')
и М (n"} умножений, то полученный таким методом алгоритм
решения двумерной задачи содержит М (п') М (и") умножений.
Используемый вдоль каждого из направлений индивидуальный
одномерный алгоритм был построен на основании китайской
теоремы об остатках. Это открывает еще одно направление воз
можных исследований. Можно попытаться использовать китай-
скую теорему об остатках для разбиения двумерной задачи на
подзадачи вычисления двумерных сверток меньших размеров.
Предположим, что
234 Гл. 7. Быстрые алгоритмы и миогомериые свертки
s~' '(x, у) = g'"' ''(x, у) d~"' '(x, у) (mod р' «(х)) (mod q' '(y)),
s~'" (х, у} = g~ '«(х, у) d~ "(x, у) (mod р"'(х}) (modq~'~(у}),
где
g" ~«(х, у) = g (x, у} (то4 р'" (х)) (mod q'1«(у)),
и остальные многочлены определяются аналогично. Выходной
многочлен s (х, у} можно восстановить по этим фрагментам,
дважды применяя китайскую теорему об остатках для много-
членов.
Пусть Мо и М~ обозначают число умножений, необходимых
для вычисления произведения многочленов по модулю р«о«(х)
и р ' (х} соответственно, à М««и М«число умножений, необ
ходимых для вычисления произведения многочленов по модулю
д<«««(у} и q<'«(у} соответственно. Тогда прямой метод вычисления
произведения
з (х, у} = g (х, у) d(x, у} (то4 р (х)) (то4 q (у))
требует М = (Мо + ~i) (Мо + М«) умножений, а описанное ис
пользование китайской теоремы об остатках на двумерных фраг-
ментах М = МоМо+ МоМ«+ М«МО + М«М«умножений, так
что число умножений не уменьшается.
Хотя описанный метод и не приводит к улучшениям по числу
необходимых умножений, он полезен в том отношении, что рас-
ширяет возможности разбиения задачи на подзадачи и уменьшает
число сложений.
Имеется много способов разбиения задачи вычисления дву-
мерной свертки с помощью китайской теоремы об остатках. На
рис. 7.5 приведены примеры характеристик, которые могут быть
получены путем модификации алгоритма Агарвала Кули с по-
мощью описанных разбиений. Данные на рис. 7.5 следует сравнить
с приведенными на рис. 7.4 характеристиками.
В качестве примера опишем построение. алгоритма 20-точечной
циклической свертки. Сначала преобразуем свертку в двумерную
(4 X5)-свертку
s (х, у) = g (х, у} d (х, у} (mod х4 1} (mod у' 1}.
Разложим теперь этот алгоритм на двумерные фрагменты в виде
s~ «(х, у} =g' «(х, y)d~ «(х, у} (то4х ‒ 1) (mody ‒ 1},
s' '(х, у} =g~ '(х, y)d"'(õ, у} (то4х ‒ 1) (то4у + у +
+у'+у+1).
Дальнейп«его разложения на двумерные фрагменты делать не бу-
дем, а применим к вычислению s<о«(х, у} гнездовой алгоритм
вычисления произведения многочленов по модулю х' 1, исполь-
235
7.3. Алгоритмы разложения
Число число
Число еещестеенных еещестеенных
еещестеенных умножений сложений
сложений на точку на точку
A(n) M(n)ln А (n)/n
Число
еещестеенмык
умножений
M(n)
Длина
и
Рнс. 7.5. Характеристики усиленного алгоритма Агарвала ‒ Кули вычисления
свертки.
зуя для свертки многочленов произведения по модулю у 1,
а для вычисления s<ц (х, у} гнездовой алгоритм, основанный
на свертке многочленов по модулю х4 1, вложив в него умно
жение многочленов по модулю у4 + уэ + у' + у + 1. Наконец,
произведение s (х, у) вычислим по правилу
s (х, у) = а~ ' (у) s' ' (х, у) + а"' (у} s~ ' (х, у} (то4 у ‒ 1),
где а~о> (у} и а<'> (у} вычисляются в соответствии с китайской
теоремой об остатках для многочленов. Они равны тем же много-
членам, которые должны использоваться для зо (у} и s (у} в одно-
мерной задаче вычислени я произведения многочленов по мо-
дулю y' 1.
Как мы видим, вычисление разбито на те же подзадачи, что
рассматривались и ранее, но сочетаются они несколько иначе.
Теперь мы пользуемся китайской теоремой об остатках после
выполнения гнездового алгоритма, перед которым была прове-
påHà одна редукция многочленов. Чтобы подсчитать число необ-
ходимых сложений, остановимся подробнее на числе сложений,
необходимом для выполнения 5-точечной циклической свертки.
Оно равно.
1: О сложений,
умножение многочленов по модулю у
умножение многочленов по модулю
y4+y~+ уя+ у+
китайская теорема об остатках:
16 сложений,
15 сложений.
18
20
24
30
36
48
60
72
84
120
180
210
240
360
420
504
840
1008
1 260
2520
38
50
56
80
95
132
200
266
320
560
950
1280
1056
2280
3200
3648
7680
10032
12160
29184
184
2I5
244
392
461
840
964
1186
1784
2468
4382
6458
9696
11840
15256
21844
39884
56360
72268
190148
2. 11
2.50
233
2.67
2 64
2 75
3 33
3 69
3 81
4 67
5 28
6. 10
4 40
6 33
7 62
7 24
9 14
9 95
9 65
II 58
10 22
10 75
10 и
13 07
12 81
17.50
16 07
16.47
21 24
20 57
24. 34
30 75
40.40
32 89
36 32
43.34
47 48
55 91
57 36
75 46
236 Гл. 7. Быстрые алгоритмы и многомерные свертки
Вычисления по модулю х4 1 содержат 15 сложений. Таким
образом, перебирая все три составляющие, для полного числа
сложений в рассматриваемом двумерном алгоритме получаем
А (20) = (4.0 + 1 15) + (4 15 + 5 16) + (15 4) = 215,
что меньше, чем 230 сложений, необходимых в чистом алгоритме
Агар вала Кули.
Заметим, что метод разложения и гнездовой алгоритм не
вызывают заметного усложнения организации вычислений. Все
изменения сводятся к повторным переходам от вычислений, свя-
занных со сложениями по строкам, к вычислениям, связанным
со сложениями по столбцам, и обратно. Это можно считать про-
стым изменением последовательности обращений к вызываемым
подпрограммам.
Чтобы на основании китайской теоремы об остатках добиться
дальнейшего уменьшения числа умножений, надо ввести еще одну
идею: надо подняться в такое расширение поля, в котором задача
начнет распадаться. Можно допустить разложение многочлена
q (у} HR взаимно простые множители, коэффициенты которых
зависят от неопределенной переменной х. (Говоря формально,
можно рассмотреть разложение многочлена q (у) в расширении
поля, получаемом присоединением формальной переменной х.} Это
приведет к тому, что многочлен q (у} может распасться на множи-
тели, степени которых меньше возникавших ранее в одцомерных
задачах степеней. Следовательно, могут быть построены алго-
ритмы с лучшими характеристиками. При этом символ х появится
в свертке по у, так что сама по себе свертка по у становится более
сложной. Но при переходе в алгоритм свертки по х возникающий
при разложении q (у) символ х может алге<5раически взаимодей-
ствовать с символом х в свертке по х, что упрощает двумерный
алгоритм.
Поясним идею на конкретном примере. Пусть надо вычислить
двумерную циклическую свертку
s (х, у} = g (х, у} d (х, у} (то4 х4 ‒ 1} (mod у4 1}.
Разобьем задачу на две подзадачи.
s<о> (х, у) = @<0' (х, у) d<0> (х, у} (то4 у' 1} (то4 х'
s~'~(õ, у} =g~'~ (х, y)d~'~(õ, у} (то4у' ‒ 1) (modx + 1).
Решение первой подзадачи уже рассматривалось; алгоритм вы-
числени я этой свертки содержит десять умножений, если его
строить на основании 4-точечного и 2-точечного алгоритмов цик-
лических сверток, содержащих 5 и 2 умножения соответственно.
Если для решения второй подзадачи воспользоваться лучшими
известными алгоритмами вычисления произведений по модулю
7.4. Итеративные алгоритмы
237
у4 1 и по модулю х' + 1 соответственно, требующими 15 умно-
жений, то получим в результате алгоритм, содержащий 25 умно-
жений, тот же результат, который получится, если использо-
вать по обоим измерениям алгоритм 4-точечной циклической
свертки.
Вместо этого рассмотрим разложение
у4 1 = (у 1} (у+ 1} (у х} (у+х} (то4х'+ 1}.
Такая запись осмысленна, поскольку по модулю х' + 1 выпол-
няется равенство х' = 1. Теперь можно построить алгоритм
вычисления по модулю у' 1 с четырьмя умножениями. Каждое
из умножений представляет собой умножение многочленов от х
первой степени по модулю х'+ 1. Но умножения многочленов
первой степени в любом случае входят в алгоритм. Используя
разложение у' + 1 = (у х} (у + х), мы как бы частично умень
шаем зависимость по у, перенося ее в зависимость по х и пере-
кладывая часть работы в вычисления по х, которые приходится
выполнять в любом случае.
Этот путь позволяет вычислить s<'> (х, у} за 12 умножений,
так что исходный алгоритм циклической (4x 4) свертки будет
содержать 22 умножения.
Идею можно продолжить дальше, вводя еще больше формаль
ных переменных в качестве корней многочлена у" + 1. В пределе
этот метод приведет к вычислению преобразования Фурье в поле
разложения этого многочлена, записанном в полиномиальном
представлении. Мы сейчас оставим эту тему, но встретимся с ней
в измененном виде позже в разд. 7 5 при рассмотрении полино
миальных представлений полей расширения.
7.4. Итеративные алгоритмы
Итеративные методы построения алгоритмов свертки бази-
руются на том, что малые алгоритмы свертки, независимо от того,
в каком именно поле F они были построены, на самом деле пред-
ставляют собой некоторые тождества, справедливые в любом со-
держащем поле F кольце. Окончательнь1й алгоритм не предпола-
гает коммутативности умножения и не содержит делений, за
исключением деления на некоторые малые константы. В качестве
операций над входными переменными допускаются только сло-
жения, вычитания и умножения.
Сначала рассмотрим линейную одномерную 4-точечную свертку
s (х) = g (х} d (х}, где степень многочленов g (х) и d (х) равна
трем. Расставим скобки по правилу.
д(х) = (a.х+ д,) х'+ (у,х+ д„),
d (х) = (d~ + 64} х' + (d1õ + d,)
233 Гл. 7. Быстрые алгоритмы н многомерные свертки
Определим следующие многочлены от двух переменных:
g (у, z) = (gsg + д,} z + (д1у + д,),
d(у, z) = (d,ó+ d,}z+ (d,ó+ d,},
s (у, z) = g (у, z) d (у, z) °
Тогда искомая свертка получается из многочлена з (у, z) по пра-
вилу
s (х) = s (x, х').
В сокращенной форме эти вычисления могут быть записаны ра
вен ством
s,(ó} Р + э,(у} z+ э,(у} = (g,(у) z+ д,(у)) (d,(ó} z+ do(y)),
в котором все коэффициенты представляют собой многочлены от у
первой степени.
Алгоритм 2 точечной линейной свертки записывается в виде
5р 0 0 0 >е
51 = ‒ 1 1 ‒ 1 go+Ь Д~ б
s 0 0 1 о
Эти тождества справедливы даже тогда, когда входные перемен-
ные являются элементами кольца многочленов. Соответственно
г ну) 1 0
s>(y) = ‒ 1 1
$2(y) о о
a(y) о
ИУ) +8 (1) 1 1
В() 0
А(у
Здесь имеются три умножения многочленов и три сложения много-
членов, исключая сложения, относящиеся к коэффициентам мно-
гочлена g (х). Каждое произведение многочленов само является
2-точечной линейной сверткой и, следовательно, требует три
умножения и три сложения. Таким образом, полное число умно-
жений в итеративном алгоритме 4-точечной линейной свертки
равно 9, тогда как оптимальный алгоритм содержит только семь
умножений. Преимущество итеративного алгоритма состоит
в уменьшении числа сложений: исключая сложения, касающиеся
коэффициентов многочлена g (х), он содержит всего 15 сложений.
Полученный алгоритм 4-точечной свертки можно итерировать
опять и построить алгоритм 16-точечной свертки, содержащий
81 умножение и 195 сложений (5.06 умножений и 12.19 сложений
на одну компоненту на выходе}. Этот алгоритм можно в свою оче-
редь итерировать опять для построения 256-точечной свертки
алгоритма с 6561 умножениями и 18 915 сложениями (25.63 умно-
жений и 73.89 сложений на одну компоненту на выходе}.
7.4. Итеративные алгоритмы
239
В общем случае для вычисления s (х} = g (х) d (х) можно ис
пользовать итерацию, если число коэффициентов многочлена у (х)
и число коэффициентов многочлена d (х} имеют общий делитель.
Пусть deg d (х) = МЖ 1 и deg g (х) = hfL 1. Преобразуем
многочлен d (х) в многочлен от двух переменных d (у. z), полагая
jv ‒ 1 М ‒ 1
d(y, г) = ~~~, g d~g+~y zi,
(=0 4=0
где старый индекс 1 связан с парой (k, 1) новых индексов равен-
ством (=М1+й, 1=0, ..., N 1, k=0, ..., М ‒ 1. Ана-
логично, миогочлен g (х) также преобразуем в многочлен от двух
переменных g (у, z), полагая
L ]:М-I
g(t z)= Е f ямцьу 7,
1=0 4=0
где i=Ml+k, l ‒ О, ..., L ‒ 1 и 4=0, ...,M ‒ 1. Вы-
числим произведение s (у, z) = g (у, z) d (у. z). Тогда s (х) можно
вычислить согласно равенству
s (х) = s (х, х"),
для чего требуются только сложения. Этот двумерный алгоритм
свертки основан на алгоритме линейной свертки последователь-
ностей длины L u N и алгоритме М-точечной линейной свертки.
Число необходимых умножений равно произведению чисел необ-
ходимых умножений в двух составляющих малых алгоритмах
линейных сверток.
Один из двух составляющих алгоритмов может быть построен
с помощью итерации. В общем случае этот процесс можно исполь-
зовать любое число раз. Более того, даже если числа коэффициен-
тов многочленов g (х) и d (х} не имеют общего делителя, то это
легко подправить, введя в один из них члены с пулевыми коэф-
фициентами, и воспользоваться итерацией
Итерацию можно использовать и для вычисления произве-
дения
s (х) = g (х) d (х) ( пюЙ m (х)).
Простейший способ состоит в вычислении линейной свертки с по-
следующим приведением по модулю многочлена т (х). Но обычно
удается добиться лучшего, если усложнить процедуру.
Мы рассмотрим только случай, когда и (х) равно х" + 1,
причем и представляет собой некоторую степень двойки. Это
важный случай, так как
х2" ‒ 1 = (х" ‒ 1) (х" + 1),
так что произведение многочленов по модулю к" + 1 возникает
и тогда, когда надо вычислить 2л-точечную циклическую свертку,
опираясь на китайскую теорему об остатках.
240 Гл. 7. Быстрые алгоритмы и мкогомерные свертки
Для вычисления
s (х) = g (х) d (х) (mod х" + 1)
л ‒ 1
заменим многочлен d (х) = g d;x' от одной переменной много-
в=О
членом от двух переменных, полагая и = n'ë'.
а"-1 ю' ‒ 1
Л(у, ~) = Z Z d~+„ i"ó' г'".
а"=0 t'=Î
Исходнмй многочлен получается из этого многочлена подстанов-
кой у = х и z = х"'. Аналогично определим g (у, z) и положим
s (у, z) = g (у, z) d (у, z) (пюЙ z"" + 1).
Искомый многочлен s (х) получается из этого многочлена по пра-
вилу
s (х) =- s (х, х"') (то4 х" + 1),
не требующему никаких умножений. Следовательно, наша задача
свелась к вычислению многочлена я (у, z).
Рассмотрим линейную свертку s (у) = g (у) d (у), в которой
коэффициенты многочленов s (у}, g (y) и d (у) в свою очередь пред
ставлякгг собой многочлены от z и умножение этих многочленов
от z понимается как умножение по модулю z"" + 1.
Возможно, эту процедуру легче понять, если выбрать и = 2
и заменить z на 1. Тогда проделанный шаг обозначает замену про-
изведения вещественных многочленов по модулю х" + 1 произве-
дением комплексных многочленов по модулю х"'~ + 1. Преиму-
щество, даваемое таким шагом, состоит в возможности примене-
ния алгоритма Кука ‒ TooMa с корнями в точках + j. В общем
случае можно г понимать как корень степени и иэ ‒ 1.
Воспользуемся алгоритмом Кука ‒ Тоома, допуская в качестве
«корней» степени формальной переменной z. (Формальное утвер-
ждение состоит в том, что мы выбираем корни в расширении поля,
получаемом присоединением z.} Тогда при приведении по модулю
у ‒ z' коэффициенты многочленов g (у) и d (у) становятся много
членами от z. Так как они уже являются многочленами от z, то
проделанный шаг не приводит к какому бы то ни было усложнь
нию, если позаботиться о том, чтобы степень этих многочленов
от z не начинала превышать свою первоначальную границу. Эго
приводит к некоторому неравенству, связывающему делители n'
и а числа и.
Алгоритм Кука Ч оома можно использовать для вычисления
линейной свертки, если корни выбранного многочлена располо-
жены в точках ~z' при 1 меньших и". Степень многочлена
t3" ‒ 1
m(y) = у(у ‒ оо) П (у ‒ z~) (у+ z)
l=0
241
7.4. Итеративные алгоритмы
М (n) = (2n' 1) М (n"),
А (n) = (2n' 1) А (и") + А, (n) + А, (n),
где А1 (n) обозначает число предсложений, связанных с приведе.
кием d (y) по модулю множителей многочлена т (у), а А, (и) обо-
значает число сложений, необходимых для восстановления много-
члена s (у) по его вычетам. Истинные значения величин А1(n)
и А, (n) зависят от выбора 2n' 1 множителей разложения мно-
гочлена m (у).
Например, вычисление произведения многочленов по модулю
х4+ 1 можно свести к вычислению трех произведений многочле-
нов по модулю х2 + 1, каждое из которых требует трех умноже-
ний; это дает алгоритм, содержащий девять умножений. Анало-
гично, вычисление произведения по модулю х" + 1 можно свести
к вычислению семи произведений многочленов по модулю х4 + 1,
что приведет к алгоритму с полным числом умножений, рав-
ным 63 или 49 в зависимости от выбора алгоритма вычисления
произведения многочленов по модулю х4 + 1. Характеристики
описанного итеративного алгоритма в зависимости от выбора
составляющих подалгоритмов приведены на рис. 7.7. Варианты
определяются способом разложения длины и на множители
и n"; д" можно разложить далее. Все они выписаны в последнем
столбце таблицы.
равна 2п" + 2, так что его можно использовать для вычисления
свертки s (у) степени не более 2n" + 1. Если степень многочлена
s (у) меньше, то часть множителей можно из т (у) отбросить.
Мы будем пользоваться многочленом т (у), удовлетворяющим
условию deg т (у) = deg s (y) + 1 = 2n' 1.
Так как все входящие в m (у) множители являются многочле
нами первой степени, то для вычисления каждого из коэффи-
циентов многочлена s (у) требуется только одно умножение, кото-
рое, конечно, представляет собой умножение многочленов оТ 2
по модулю z + 1.
Итеративный алгоритм применим, если 2п' 1 + 2п" + 1.
Если это условие выполнено, то вычисление произведения много-
членов по модулю х" + 1 разбивается на вычисления 2п' 1
произведений многочленов по модулю х"" + 1. В свою очередь,
это произведение повторением описанной процедуры может быть
разбито на еще более мелкие подзадачи так, как это показано
на рис. 7.6. (На диаграмме выпущены детали, связанные с кри-
терием выбора разложения n'ï" = n и с общими правилами
предсложенМй и постсложений.) Число необходимых в алгоритме
умножений и сложений описывается рекуррентными равенствами
242 Гл. 7. Быстрые алгоритмы и миогомерные свертки
Вход
е процедуру во4 х" + 1
Выкод из лроцедуры mod x" + 1
Рис. 7.6. Принципиальная схема итеративного алгоритма.
Несколько видоизмененная версия алгоритма получается, если
выбрать
и' ‒ !
т (х) = П (х ‒ z ) (х + а') =
П (x ‒ z'') (mode + 1).
'Геперь степень основного модуля т (х) равна 2n", хотя доста-
точной является степень 2п" 1. Следовательно, такой выбор
многочлена т (х) приводит к одному дополнительному (по сравне-
243
7.5. Полииомиальное представление расширений полей
Число
умножений
Модули
Число
сложений
Итеративная
(и'х ц") с~~ща
х~+ 1
х'+ 1
3
l5
41
57
77
205
2Х 2
хв+ 1
х'б+ 1
хз2+ 1
+1
х'~ + 1
х'~в + 1
z»2+ 1
х)о24 + 1
хо4~+ 1
x~+ 1
Рис. 7.7. Характеристики некоторых алгоритмов вычислеиия произведения много-
членов по модулю х" + !.
нию с необходимым их числом) вычислению произведения много-
членов. Однако такая форма алгоритма позволяет при больших и'
получить преимущества в числе предсложений и посгсложений,
.если воспользоваться БПФ-алгоритмом Кули Тычки по осно-
ванию 2. Здесь мы уже продвинулись в исследованиях столь глу-
боко, что подошли к новому методу, известному под названием
полиномиального преобразования. Этому методу посвящена остав
шаяся часть данной главы. Мы прервем нить изложения, которой
следовали до сих пор, так как полиномиальное преобразование
должно быть введено более фундаментальным образом.
7.5. Полиномиальное
представление расширений полей
Наиболее часто применяемое дискретное преобразование Фурье
длины и отображает вектор с вещественными компонентами
в вектор с комплексными компонентами. В практических задачах
обработки дискретных сигналов векторы с произвольными веще
ственными значениями компонент никогда не нужны; всегда ока-
зывается достаточным ограничить рассмотрение рацнональными
числами, или, даже еще проще, целыми. В данном разделе область
определения преобразования Фурье ограничена множеством ра-
циональных чисел. Это ограничение не снижает практической
ценносги алгоритмов, но при этом оно приводит к совершенно
другому взгляду на характер вычислений.
Преобразование Фурье длины и отображает вектор длины и
с рациональными компонентами в вектор длины и, компоненты
3
9
7
27
21
63
49
189
147
405
'315
945
1953
5859
11907
25515
51435
599
739
1599
1899
4563
10531
26921
58889
143041
304769
2к (2x 2)
2Х 4
4х (2x 2)
4Х 4
4Х (2х (2x 2))
4х (2x 4)
8х (2х (2x 2))
8Х (2х 4)
8 х (4 X (2 х 2))
16х (4x (2x 2))
16 х (4 х (2 х (2 х 2)))
32 Х (4 X (2 X (2 Х 2)))
32х (8x (2х (2х 2)))
64х (Sx (2x (2х 2)))
244 Гл. 7. Быстрые алгоритмы и многомерные свертки
которого принадлежат некоторому подмножеству комплексных
чисел, на самом деле счетному подмножеству. Обычно в исследо-
ваниях преобразования Фурье в качестве значений компонент
выходного вектора допускаются произвольные комплексные числа,
которые в практических вычислениях ограничиваются конечным
множеством путем фиксации разрядности допустимых чисел. Эго
можно сделать до некоторой степени произвольно; условность
представления проявляется в выборе необходимой длины слова
с учетом допустимой погрешности округления. Даже тогда, когда
областью определения преобразования Фурье является множество
целых чисел, для точного вычисления преобразования необхо-
димо, чтобы разрядность двоичного представления числа была
бесконечной.
В настоящем разделе рассматривается другой подход к зада-
нию областей определения и значения преобразования Фурье.
Он состоит в полиномиальном описании расширений полей ра-
циональных или комплексных чисел.
Пусть v представляет собой вектор длины и с рациональными
компонентами и аусгь а = е ‒ >'"~". Тогда задаваемый преобразо-
ванием Фурье вектор
и ‒ 1
и'~v;, А=О,..., п 1,
c=o
имеет комплексные компоненты. Тем не менее произвольное ком-
плексное число не может быть результатом преобразования. Все
возможные в результате вычисления преобразования Фурье ком-
поненты принадлежат подпалю Q (и), или, в более простых обо-
значениях, подполю 1,,, которое представляет собой наименьшее
содержащее а подполе поля комплексных чисел. Это подполе
содержит поле рациональных чисел, поскольку любое подполе
поля комплексных чисел содержит все рациональные числа.
Пусть над полем рациональных чисел разложение многочлена
х" 1 на простые множители дается равенством
х" 1 = р, (х} р, (х}... р, (х).
Простые делители являются круговыми многочленами, и для ма-
лых п их коэффициенты равны 1, О, 1. Так как элемент и яв
ляется корнем многочлена х" 1, то он должен бьггь корнем
одного из круговых многочленов, скажем, корнем многочлена
р (х) степени т со старшим коэффициентом, равным единице:
р (х) = х + р,х ‒ '+... + р,х+ р,.
Так как р (и) = О, то
Р~-~~ ° ° ° Р~~ Ро.
Следовательно, а может быть выражен в виде линейной комби-
нации меньших степеней элемента и. Для меньших степеней
7.5. Полииомиальиое представление расширений полей
245
элемента а такое представление невозможно, так как в против-
ном случае (0 был бы корнем многочлена сгепени меньше, чем
степень многочлена р (х).
Поле Q может быть задано как множество всех многочленов
от и с рациональными коэффициентами степеней, не превосходя-
щих и 1. Операцией сложения в таком представлении поля
является сложение многочленов, а операцией умножения умно-
жение многочленов по модулю многочлена р (и). Многочлены
задаются списком своих т коэффициентов. Такой способ задания
элементов поля Q" требует т слов памяти вместо двух, необхо-
димых для запоминания комплексного числа.
Чтобы подчеркнуть, что сами числа задаются многочленами,
а не их комплексными значениями в точке а, будем в записи
чисел пользоваться символом х вместо а. Тогда числа поля равны
а = а,х~ ‒ '+ а,х ‒ '+... + а,х+ а,
и даются списком коэффициентов а;. Конечно, если мы пожелаем
узнать «исгинное» комплексное значение числа а, то надо вмесго х
в многочленное выражение для а подставить а и произвести соот-
ветствующие этому многочлену вычисления. Однако наша цель
состоит в разработке алгоритмов, внутренние переменные которых
имеют полиномиальное представление, и в некогорых отношениях
такая форма действительно приводит к более простым алгоритмам.
Например, если и равно степени двух, то
(х" 1) = (х""+ 1) (х"~~+ 1)... (х+ 1) (х 1).
Круговой многочлен х"~2 + 1 приводит к расширению поля Q,
все элементы которого предсгавляют собой многочлены с рацио-
нальными коэффициентами степени меньше, чем п/2. Сложением
в поле является сложение многочленов, а умножением умно-
жение многочленов по модулю х"~~ + 1.
Например, поле Q' состоит из всех мноючленов с рациональ-
ными коэффициентами степени не более семи с арифметикой,
выполняемой по модулю многочлена х'+ 1. Пример умножения
г
в поле дается равенством х' ‒ ‒ х' + х2 1 = P х'
2 4
1 3, 1, 1 3 1
4 4
х4+ ‒ х ‒ ‒ = х ‒ ‒ х4+ ‒ х ‒ х ‒ ‒.
2 4 4
Полиномиальное представление расширения полей относится
не только к полю рациональных чисел. Его можно использовать
и для расширений поля комплексных чисел. Например, поле
комплексных рациональных чисел это множество комплексных
чисел вида о = a+ jb, где а и Ь рациональные числа. Это
подмножество является подполем поля комплексных чисел, кото-
рое иногда обозначается через Q (j). Во многих приложениях
цифровой обработки сигналов компоненты обрабатываемых век-
246 Гл. 7. Быстрые алгоритмы и миогомериые свертки
торов являются комплексными. Так как разрядность записи ком-
плексных чисел практически всегда ограничена, то по существу
всегда рассматриваются векторы с комплексными рациональными
компонентами (или, даже более частный случай, с комплексными
целыми компонентами).
Поле комплексных рациональных чисел можно расширить,
присоединив корень а степени и из единицы. Это дает наименьшее
расширение Q (и), в котором имеется преобразование Фурье
длины и. Если Q (и) содержит / (т. е. содержит корень много-
члена х' + 1), то такое расширение 'Q (и) содержит все комплекс
ные рациональные числа. Это именно то расширение, которое
нам нужно. Если круговой многочлен равен х'+ 1 для некого-
рого четного числа r, то это всегда так. В противном случае эле-
мент ) надо присоединять.
Пусть и не равно степени двойки, а обозначает корень сте-
пени п из единицы, а р (х) обозначает круговой многочлен сте-
пени т, корнем которого и является. Тогда расширение Q (j, и),
нли, в более простых обозначениях, Q (j), представляет собой
множество многочленов с коэффициентами из поля Q (j), степени
которых не превосходят и 1. Сложение в поле совпадает со сло-
жением многочленов, а умножение с умножением многочленов
по модулю р (х). Коэффициенты этих многочленов складываются
и вычитаются как комплексные числа.
Для такого задания одного элемента поля Q (j, и) требуется
2и рациональных чисел. С точностью до этого различия и более
общих правил сложения и умножения коэффициентов многочле-
нов, все, что будет сказано в следующих разделах главы относи-
тельно обработки последовательностей рациональных чисел, спра-
ведливо и для последовательностей комплексных рациональных
чисел. Таким образом, к полю комплексных рациональных чисел
можно больше не возвращаться.
7.6. Свертка в полиномиальных расширениях
полеЙ
Если v вектор с рациональными компонентами, то компо-
ненты
А = О,..., и 1,
его преобразования Фурье принадлежат полю Q (и);.в более
общем случае, если компоненты v принадлежат Q (и), то компо-
ненты его преобразования Фурье также принадлежат Q (и).
Пусть степень кругового многочлена, корнем которого яв-
ляется и, равна т. Тогда каждый элемент в Q (и) записывается
7.6. Свертка в полииомиальных расширениях полей
247
в виде многочлена над (;) степени, меньшей m. В полиномиальной
записи преобразование Фурье имеет вид
и ‒ 1
V< = f х'~v; (тод р(х)), Й = О,..., и 1.
Г=О
Эта формула вычисляется проще, так как умножение Hà х сво-
дится к операциям над индексами, а приведение по модулю р (х)
содержит не более и сложений. Можно воспользоваться любым
БПФ-алгоритмом, например БПФ-алгоритмом Кули Тычки, но
все умножения представляют собой умножения на х, и, следова-
тельно, требуют для своего выполнения не более и вещественных
сложений и не содержат вещественных умножений. Аналогично,
каждое сложение является сложением многочленов и выполняется
с и вещественными сложениями.
Применительно ко входу с рациональными компонентами пре-
образование Фурье можно рассматривать как отображение век-
торов из многочленов первой сгепени в векторы из многочленов
степени и 1. В более общем случае, преобразование Фурье
в такой трактовке отображает векторы, компонентами которых
служат многочлены сгепени и 1, в векторы из многочленов
степени и 1.
Справедливосгь теоремы о свертке не зависит от того, KBK
именно представлены числа в данной арифметической системе.
()на применима в равной степени как к векторам, компоненты
которых записаны в полиномиальной форме, так и к векторам,
компоненты которых записаны в обычном виде. Следовательно,
для вычисления циклической свертки последовательностей с ра-
Л ‒ !
циональными компонентами, я, = g д<<,~> дд, можно взять пре-
п-о
образование Фурье векторов g и д в поле Q„вычислить в частот
ной области покомпонентное произведение S< ‒ ‒ C>D< и взять
обратное преобразование Фурье. В поли номи альной записи
поля Q оба преобразования Фурье при этом не содержат умно-
жений. Покомпонентное спектральное произведение, однако, те-
перь является произведением многочленов по модулю р (х), и,
следовательно, требует большого числа вещественных умножений.
Сложность вычислений переместилась с одного этапа на другой.
Усложнение вычисления спектрального произведения сводит на
нет выигрыш, полученный в преобразованиях Фурье. Позже мы
увидим, что при вычислении двумерной циклической свертки
все же можно получить выигрыш от полиномиального предсгав-
ления.
Например, пусть и = 64; круговой многочлен равен р (х) =
= х" + 1. Элементы поля Q (от) представляют собой многочлены
степени 31 и задаются списком из 32 рациональных чисел. Каждое
248 Гл. 7. Быстрые алгоритмы и многомерные свертки
произведение S> ‒ ‒ G>D> является произведением многочленов
по модулю )Р2 + 1. Этот многочлен неприводи,м, так что для каж-
дого такого произведения необходимо по меньшей мере 2 ° 32 1 ве-
щественное умножение. На самом деле число умножений суще-
ственно больше 63; практически используемый 32 точечный алго-
ритм, приведенный на рис. 7.7, содержит 147 умножений.
Таким образом, каждая из 64 компонент преобразования Фурье
требует 147 вещественных умножений. Это существенно больше,
чем число вещественных умножений, необходимых при исполь-
зовании общепринятого для этого случая БПФ-алгоритма.
На самом деле вели чи ны Яд не являются произвольными,
а должны удовлетворять некоторым ограничениям, связанным
с тем, что обратное преобразование Фурье должно иметь рацио-
нальные компоненты. 64 компоненты ь; обратного преобразова-
ния Фурье представляют собой 64 многочлена, каждый из кото-
рых задается 32 рациональными числами. На самом деле, 31 из
этих чисел равны нулю, так как каждый из многочленов является
многочленом нулевой степени. Это позволяет выписать ограниче
ния, которым должны удовлетворять величины S>, и окажется,
что 64 из 147 этих величин нет надобности вычислять. Детальное
выписывание этой процедуры, однако, приводит к алгоритму,
очень похожему на алгоритм, основанный на китайской теореме
об остатках, который проще выписать непосредственно. Поэтому
мы не будет продолжать рассмотрение этой процедуры.
В полиномиальном расширении поля, Q~, можно определить
более короткие преобразовани я Фурье. Предположим, что
число и является составным: и = и'и". Тогда и'-точечное преобра-
зование Фурье определяется равенством
‒ 1
V» ‒ ‒ g (х"")'» v;, k =О,..., n' 1,
8=0
где арифметика задается как полиномиальная арифметика по-
ля Q. Ядро преобразования теперь вместо х равно х"". При та-
ком определении преобразования Фурье, так же как и ранее,
существует и обратное к нему преобразование и справедли ва
теорема о свертке.
7.7. Полиномиальиое преобразование
Н уссбау'мера
Преобразования, построенные как преобразования Фурье в по-
линомиальных расширениях полей, заслуживают самостоятель-
ного исследования. Мы определили их для поля рациональных
чисел, так что коэффициенты всех многочленов рациональны.
Так как построенное преобразование обратимо, то оно задает
249
7.7. Полиномиальное преобразование Нуссбаумера
некоторое множесгво тождесгв для многочленов с рациональными
коэффициентами. Тождества остаются справедливыми, даже если
в качестве коэффициентов многочленов допустить вещественные
(или комплексные} числа.
В данном разделе мы вновь обращаемся к изучению полино-
миального преобразования, но на сей раз мы будем его рассматри-
вать не как преобразование Фурье, а как самостоятельное преоб-
разование.
B кольце многочленов по модулю р (х) полиномиальное преоб-
разование определяется равенством
V» (х) = g и (х)'» v; (х), Й = О,..., и
C=O
где и (х) представляет собой элемент порядка и и умножение,
конечно, является кольцевым умножением многочленов по мо-
дулю р (х). Наше рассмотрение будет ограничено случаем, когда
и (х) = х и многочлен р (х) делит х" 1. Как представляется,
никакие другие случаи не имеют какого-либо реального практи-
ческого интереса.
Определение 7.7.1. Пусть р (х) некоторый многочлен сте
пени т и пусть многочлены v; (х}, 1 = О, ..., и 1, над полем F
имеют степени не более m 1 и представляют собой компоненты
полиномиального вектора. Полиномиальным преобразованием этого
вектора называется вектор с компонентами
и ‒ 1
V» (х) = g х'»v~ (х) (то4 р(х)), Й =О,..., и
с=о
Полиномиальное преобразование легко вычислить, так как оно
не содержит умножений элементов кольца общего вида. Умножь
ния на х'» тривиальны, и, если многочлен р (х) выбран так, что
все его коэффициенты равны О, 1 или 1, то приведение по мо-
дулю р (х) также выполняется одними сложениями.
Ценность полиномиального преобразования обуславливается
двумя теоремами: теоремой о сущесгвовании обратного преобра-
зования и теоремой о свертке. Оба эти утверждения, конечно,
~разу вытекают из возможности интерпретации лолиномиального
преобразования как преобразования Фурье, подобно тому, как
~0 делалось в предыдущем разделе. Тем не менее поучительно
дать более прямое доказательство.
Пусть и обозначает наименьшее целое число, для которого
P (х} делит х" 1. В доказательстве следующей теоремы исполь-
зуется тот факт, что если многочлен а (х) делит х" 1, то
250 Гл. 7. Быстрые алгоритмы и миогомерные свертки
для произвольного многочлена f (х) выполняется равенство
Яд <д) (f (х)] = Ro <х) [Л л (f (х)]]
Начнем с простейшею случая, когда число п просто.
и†I
v; (x) = $ x<" ‒ ')'~V), (x) (mod (p(x)), ! =О,..., и 1.
Доказательство. Исключая тривиальный случай, можно пола-
гать, что степень многочлена р (х) равна по меньшей мере двум.
Вычислим правую часть второго равенства:
n ‒ 1 n ‒ 1 n ‒ 1
1 1
х(" '>~У (х)= xt" '>' gх'"юц)х)] (~о)р(х))=
А=о А=о !=О
л ‒ 1 л ‒ 1
и, (х) ~, ын "'-') "] (тоа р (х)).
С=О ~=О
I
Вычислим внутреннюю сумму. Если ! равно 1, то так как р (х)
делит х" 1, имеем:
n ‒ 1 n ‒ 1 n ‒ 1
1 1 1
л
х(1+пс ‒ c) k = хли (mod х" !) =
й й
= 1 (mod р (х)).
При (, не равном l, воспользуемся тождеством, справедливым
в кольце:
(1 х~) К х" = 1 х'".
Так как г = l+ fit g не кратно п, то
1 х' =,)~ 0 (mod х" 1),
I х'" = 0 (mod х" 1).
в то время, как
Теорема 7.7.2. Предположим, что многочлен р (х) над полем F
степени т делит многочлен х" 1, причем число п является
простым. Тогда полиномиальный вектор v (х) длины и, компонен-
тали которого являются многочлены степени т . 1, и его поли-
номиальное преобразование Ч (х) связаны соотношениями
л ‒ 1
V), (x) = f х'~v, (х) (то4р (х)), 1=0,... и 1,
8=О
7.7. Полиномиальное преобразование Нуссбаумера
Так как р (х) делит х" 1, то отсюда вытекает, что
o ‒ f
f х'« = О (mod р(х)).
k=0
Итак, мы доказали, что
!, если 1=1 (mod р(х)),
X(l+nC ‒ С) k
О, если 1~1 (mod р (х)).
Следовательно,
1
х<" '> '«V» (õ) =о, (х) (mod р (х)),
что и завершает доказательство. Q
Так как х" = !, то обратное полиномиальное преобразование
сюжет быть записано в более простом виде
n ‒ 1
v; (х) = ~ л — '«V„(x) (mod р(х)),
хотя формально х-'«не является многочленом. Точно так же,
как умножение на х выполняется с помощью переиндексации
коэффициентов и приведения х по модулю р (х), умножение
на х ' также можно выполнить с помощью переиндексации коэф-
фициентов и приведения по модулю р (х), причем для исключе-
ния х ' надо воспользоваться тем, что р х + р 1х ‒ '+ -+
+ р (х) + р, = О, так что
х '=po' [р,~х '+p~ ix '+ ... +рД-
Следовательно, обратное полиномиальное преобразование вычис-
ляется столь же просто, сколь и прямое полиномиальное преоб
разование.
Теорема 7.7.3 (теорема о свертке). Если в кольце мноеочленов
по модулю р (х) вектор многочленов с компонентами s; (х), j =
= О, ..., и !, связи с векгпорами многочленов, имеющими ком-
йоненты g, (х) и d; (х), 1 = О, ..., и ‒ !, соотношением цик-
лической свергпки многочленов
и†I
s, (х) = Z g; t(x)dr(x) (mod р(х)),
то полиномиальный спектр Я» (х) связи со спектрами G» (x)
D» (х) покомпонентным произведением многочленов
Я»(х) = Q» (x) D»(x) (mod р(х)), k =0,..., и 1.
252 Гл. 7. Быстрые алгоритмы и многомерные свертки
Яока~ательство. Используя обратное полиномиальное преоб-
разование, имеем
и ‒ 1 и ‒ 1
и ‒ 1
я, (*) = g t,- (х) Н, (х) = „ $ g х"~'""-''t''-" % (х) Н, (х) =
1
!=О k~
и ‒ I
и ‒ 1
х<" ‒ '> '«G» (x) ~~~~ ~х'»г!~ (х),
>=0
где х"" следует положить равным единице, потому что, как и
ранее, все вычисления производятся по модулю х" !. Следо-
вательно,
и ‒ 1
s~ (х) = х<" ‒ ц '»6» (х) D» (х),
1
л
и G» (х) D» (х) должны бьггь равным $» (g).
7.8. Быстрая свертка многочленов
Полиномиальное представление расширения поля оказывается
полезным при вычислении многомерных сверток. Так как прН
этом мЫ исходно имеем дело с произведениями многочленов, то
переход от произведений спектров к произведениям многочленов
не требует дополнительных вычислений, поскольку их можно
включить в ту часть работы, которая все равно должна быть вы-
полнена в любом случае.
Достаточно рассмотреть двумерную циклическую свертку.
Запишем эту свертку в виде одномерной циклической свертки
многочленов:
n~ ‒ 1
sg (у) = f g((g. ».)) (у) d» (у) (mod у" !).
k' Î
Так как многочлен у"' ! распадается в произведение круговых
многочленов, то эту задачу можно разбить на множество подзадач
вида
s~ (у) = f д<<~ » и (у) d» (у) (mod р (у)),
>'=О
где р (у) представляет собой один из круговых многочленов, ска-
жем, степени т', делящих у"' !. Алгоритм решения каждой
из этих подзадач может быть погружен в алгоритм решения
исходной задачи.
253
7.8. Быстрая свертка миогочленов
Рассмотрим элементы gl (у) и dl (у) для всех ! = 0, ...,
n' ! как элементы поля Q (и). Тогда для спектров соответ-
ственно имеем для всех k' = О, ..., и' !:
n' ‒ !
6». (у) = Z у'»'gi (у) (той р(у)),
Е'=0
n' ‒ !
Р». (у) = f у'Щ. (у) (mod р(у))
Г'=0
S» (у) =G» (у) Р» (у) (mod р(у)), k' =0,..., n'
Используя обратное преобразование Фурье, получаем
л' ‒ !
л" — ! ( "(г+. !) ( í"" !)
л "+!)" ( и "+!)( п'(г ‒ ц
Вообще говоря, последний член можно разлагать и дальше, но
мы здесь остановимся. Обозначим члены разложения В правой
sq (у),=, ~ у-'»'S» (у) (mod р (у)).
k'=0
Преобразования Фурье не содержат вещественных умножений.
Все умножения в описанной процедуре сосредоточены в спек-
тральных произведениях G». (у) Р» (у). Всего имеется и' таких
произведений многочленов по модулю р (у), каждое из которых
содержит по меньшей мере 2m' ! умножений. Таким образом,
в общей сложности для вычисления двумерной свертки, содержа-
щей n'т' чисел, требуется n' (2т' !) умножений. На самом
деле число умножений, необходимых для вычисления произведе-
ния многочленов по модулю р (у), существенно больше, чем
2т' !, но все же достаточно мало для того, чтобы приводить
к эффективным алгоритмам. Некоторые подходящие для этой цели
алгоритмы приведены на рис. 7.7.
Рассмотрим теперь двумерную циклическую свертку, записан-
ную в виде произведения.многочленов:
s (х, у) = g (х, у) d(х, у) (mod х"' !) (mod у"" !).
Используя китайскую теорему об остатках, разобьем эту задачу
на подзадачи. Детально остановимся только на частном случае,
когда n' и и равны степеням двойки (и могут совпадать). Метод
вычисления является рекуррентным, основанным на использова-
нии двумерных циклических сверток меньшего размера. Таким
образом, с помощью рекурсии двумерная циклическая свертка
по основанию 2 сводится к некоторому числу меньших подзадач.
Пусть и' = 2 ' и и = 2 " при т )~ т'. Тогда имеет место
разложение
254 Гл. 7. Быстрые алгоричмы и многомерные свертки
части соответственно через f, (у), ..., f, (у) и для r = О, ...,
l определим
d<'> (х, у) = d (x, у) (mod f„(y)),
g<'> (х, у) = g (х, у) (mod f, (ó))
s<'> (х, у) = s (х, у) (mod f, (у)).
Тогда
s<'> (х, у) =g'(õ, у) d'(õ, у) (mod х"' !) (mod f„(y)),
и, согласно китайской теореме об остатках для многочленов,
Я ‒ !
s (х, у) = ~,' а<'> (у) s<'> (х, у) (то~! х"" !),
7'=0
где а<'> (у) при г = О, ..., P ! определяются этой же теоремой.
Вычисления на этом последнем шаге не содержат вещественных
умножений.
Основная часть вычислений падает на вычисление остатков
s<'> (х, у). Зти вычисления разбиваются на два типа, а именно,
s<'> (х, у) = g<'> (х, у) У'> (х, у) (mod х"' !) (mod (у"'+!))
s<'> (х, у) = g<'> (х, у) d<'> (õ, у) (mod х" ‒ !) (mod y"'< !).
Второй тип вычислений, с точностью до замены х и у друг на друга,
представляет собой копию решаемой задачи меньшего размера.
Опираясь на приведенную на рис. 7.8 рекуррентную формулу,
можно полагать, что эта меньшая задача решена; поскольку ре-
шена задача большего размера.
Опуская индекс r, первый тип вычислений запишем в виде
задачи
s (х, у) = g (х, у} d (х, у) (mod х"' !) (mod y '+!),
где т' )~ n'/2. Эту задачу можно рассматривать как задачу вы-
числения одномерной свертки в поле Я ', а именно,
з(х) = g (x) d(х) (mod х"' !),
где все коэффициенты выписанных многочленов представляют
собой элементы поля ! Р' и, следовательно, записываются в виде
многочленов от у степени, меньшей т'. Так как и' ~( 2т', то для
вычисления свертки можно воспользоваться имеющимся преобра-
зованием Фурье длины и'. Преобразование Фурье выполняется
с помощью одних сложений и не содержит умножений.
В частотной области свертка преобразуется к произведениям
Яде = Qg еДу е °
7.8. Быстрая свертка многочлеиов
Вход
е <глзорииим циклической сеервки и п'
n' =2,n X,rn" >т'
ия
Выход
Ðèñ. 7.8. Алгоритм многомерной циклической свертки.
1~ля их вычисления нужно n' умножений в Q, каждое из которых
представляет собой произведение многочленов по модулю у ' + 1
и поэтому требует 2т' 1 вещественных умножений. Следова-
тельно, для вычисления
s(х, у) = g (х, у) d(х, у) (mod х" ‒ 1) (mod у '+ 1)
256 Гл. 7. Быстрые алгоритмы и многомерные свертки
испо ислО
Число Число вецес твен- вещвствен-
вещестеенных вещественных нык умножв- ных сложе-
умножений сложений ний на точку кий на точку
Размер
таблице!
13
22
55
52
121
130
193
220
484
634
772
1402
2893
3658
17770
78250
70
122
369
424
1163
750
1382
1876
5436
4774
6576
12954
21266
24854
142902
720502
7.78
7.62
l4.76
11.78
23.73
И.72
17.06
! 8.76
27.73
18.65
20 30
22.49
29.17
24.27
34.89
43.98
! 44
l 37
2.20
! 44
2.47
2.03
2.38
2.20
2.47
2.48
2'.38
2.43
3.97
3 57
4.34
4.78
Зх 3
4)c' 4
5Х 5
бх6
7Х7
ВхВ
9х9
1ОХ 10
14 х 14
!6~16
!8 Х18
24 х 24
27 X 27
32 X 32
64 X 64
128 X 128
Рис. 7.9. Характеристики некоторых BJII.OpHTMOB вычисления двумерной цикли-
ческой свертки.
необходимо всего n' (2т' 1) вещественных умножений, а для
вычисления исходной двумерной циклической свертки требуется
сделать несколько таких вычислений.
Например, для вычисления двумерной циклической (64X64)-
свертки требуется 64. (63) вещественных умножений и вычисления
двумерной циклической (64X32)-свертки. В свою очередь, для
вычисления двумерной циклической (64X32)-свертки требуется
в идеале 32 (63) + 32 (31) вещественных умножений и вычисле-
ния одной двумерной циклической (16X32)-свертки. В свою оче-
редь, вычисление двумерной циклической (32X16) свертки тре-
бует 16.(31) + 16 (16) умножений и свертки еще меньшего раз-
мера. Продолжая этот процесс до тех пор, пока не дойдем до
тривиальной свертки, получаем около 800 умножений. Это су-
щественно меньще, чем число умножений, необходимое при ис-
пользовании двумерного алгоритма Кули Тычки и теоремы
о свертке, равное 73 728.
Практические алгоритмы вычисления произведений многочле-
нов, как видно из затабулированных на рис. 7.7 данных, содержат
большее число умножений, чем равный n' (2т' 1) теоретиче-
ский минимум. В частности, рассмотренный алгоритм вычисления
двумерной циклической (64 X 64)-свертки содержит на самом деле
l7 770 вещественных умножений. Характеристики некоторых дру-
гих практических алгоритмов вычисления двумерной циклической
свертки, построенных по описанному методу, приведены на
рис. 7.9.
257
Задачи
Задачи
а. Вычислить характеристики алгоритма 7560-точечной циклической
свертки, построениого на основе алгоритма Агарвала ‒ Кули.
б. Вычислить характеристики гнездового алгоритма двумерной (504 X
X 504)-свертки.
Алгоритм вычисления 12-точечной циклической свертки можно построить
прямо по методу Винограда или по алгоритму Агарвала ‒ Кули, сочетая
алгоритм 1точечной циклической свертки с алгоритмом 4-точечной цикли-
ческой свертки. Сравнить числа умножений, необходимых в каждом из
этих методов.
а. Описать метод построения алгоритма вычисления 6-точечной цикли-
ческой свертки s(x) = д (х) d (х) (mod хв ‒ 1). Сколько необходимо умно-
жеиий?
б. Воспользуйтесь алгоритмом Агарвала ‒ Кули построения 6-точечной
циклической свертки из алгоритма 2-точечной циклической свертки и алго-
итма 3-точечной циклической свертки. Сколько необходимо умножений?
пользовавшись алгоритмом Агарвала ‒ Кули, привести матрицы алго-
ритма 15-точечной циклнческой свертки к стандартному виду
s = CGAd.
7. 1.
7.2.
7.3.
7.4.
Пусть длина циклической свертки равна п = n>p~>n~, где все делители
взаимно просты. Различные алгоритмы вычисления циклической свертки
такой длины получаются различиыми способами сочетания алгоритмов
циклическнх сверток длин п~, п2, п8 и п4 Две возможные схемы построения
алгоритмов даются следующими правилами расстановки скобок: и =
= ((nz~) (n>ng) и n=(n~ (а, (ne(п4)))). Доказать, что если в каждом паро-
сочетании используемые алгоритмы оптимальны, то обе схемы содержат
одинаковое число умножений и сложений.
Алгоритм вычисления комплексной свертки по модулю х" ‒ 1 описан
в разд. 3.7.
а. Построить этот алгоритм как алгоритм двумерного произведения много-
членов по модулям х + 1 и у~ + 1.
б. Для этой же задачи можно построить два алгоритма, отталкиваясь
соответственно от
7.5.
7.6.
7.7.
s(x, у) = g(x, у) d (х, у) (mod х~'+ 1) (mod у + 1)
или от
s(x,ó) =g(x,y)d(x,у) (mody + 1} (modx + 1).
Какой из алгоритмов лучше?
Кольцо кватерниоиов было определено в задаче 2.15.
а. Записать двумерную циклическую (2X2)-свертку
s (х, у) = g (х, у) d (х, у) (mod хй ‒ 1) (mod у~ ‒ 1)
в виде произведения (4X4)-матрицы на вектор, содержащий 4 компоненты.
Дать алгоритм, содержащий четыре умножения.
б. Записать полиномиальное произведение
s,(х, у) = g(x, у) d(x, у) (mod x~+ 1) (mod y~ ‒ 1)
в виде произведения (4Х 4)-матрицы на вектор, содержащий 4 компоненты.
Дать алгоритм, содержащий шесть умножений.
B- Записать полиномиальное произведение
я(х, у) = g(x, у) d(х, у) (mod х~+ 1) (mod у~+ 1)
в виде произведения (4Х4)-матрицы на вектор, содержащий 4 компонеиты.
,Пать алгоритм, содержащий шесть умножений.
258 Гл. 7. Быстрые алгорнтмы и миогомериые свертки
г. Записать произведение кватерниоиов s = gd в виде произведения
(4Х 4)-матрицы на вектор, содержащий 4 компоненты. Дать алгоритм,
содержащий девять умножений.
7.8. Определить число умножений и число сложений в алгоритме Агарвала‒
Кули для вычисления 45-точечной циклической свертки. Какое улучшение
дает переход к алгоритму разложения?
7.9. а- Найти характеристики гнездового алгоритма вычислеиия циклической
(15X15)-свертки, сочетающего алгоритм цнклической (ЗХЗ)-свертки с ал-
горитмом циклической (5X5)-свертки. Сравнить эти характеристики с ха-
рактеристиками гнездового алгоритма, сочетающего алгоритм 15-точечной
одномериой циклической свертки с ним самим.
б. Повторить вычисления для двумерной циклической (21Х21)-свертки.
7.10. Для вычисления циклической (пХп)-свертки комплексных векторов можно
попросту воспользоваться алгоритмом вычисления циклической (nX n)-
свертки вещественных векторов, заменив все вещественные умноження
и сложения иа комплексиые умножения и сложения. На сколько можно
улучшить алгоритм вычислеиия циклической (5X 5)-свертки комплексных
векторов? Насколько лучше циклическая (4Х 4)-свертка комплексных
векторов?
Замечания
На простейшем уровне конструкций двумериое преобразование Фурье
состоит из двух независимых преобразований Фурье, применяемых отдельно
вдоль каждой из осей; аналогичное утверждение отиосится к двумерной свертке.
Следовательно, быстрые алгоритмы вычисления одномерной свертки в равной
мере применимы и для вычисления двумерной свертки. Являющиеся по существу
двумерными алгоркгмы возникли позже. Пионером в этой области явился Нусс-
баумер [1] (1977), введя свои полиномиальные преобразования. Они были сна-
чала определены эвристически по аналогии с преобразованиями Фурье, по-
скольку эти преобразования и представляли интерес Только позже стало по-
нятно, что полиномиальные преобразования представляют нечто большее, чем
просто аналогию преобразоваииям Фурье. Их интерпретация в виде преобразс»
вания Фурье в полиномиальном представлении расширений полей была дана
Блейхутом [2] (1983). Аналогичные идеи были высказаны Бетом, Фуми и Мах-
вельдом [3] (1982). Другое полиномиальное преобразование, с более ясной
структурой, но с большей сложностью вычислений, введено Арамбеполой и Рай-
иером [4] (1979).
Использование иидексации типа Гуда ‒ Томаса для вычисления одномериых
сверток принадлежит Araps»y и Кули [5] (1977). Они преобразовали одно-
мерную светку в многомерную и для вычисления последней применили гнездовой
алгоритм, сочетающий одномерные алгоритмы, ‒ процедура, описанная иами
в терминах кроиекеровского произведения. Их гиездовой метод совпадает с пред-
ложенным Виноградом [8] (1978) для вычислении многомерных преобразований
Фурье.
Идея использования для уменьшения числа сложений при вычислении много-
мерной свертки китайской теоремы об остатках для многочленов принадлежит
Нуссбаумеру [6] (1978). Использовать в качестве модулей многочлены с козф-
фициеитами в полиномиальных расширеииях полей было предложено Питасом
и Стринзисом [7] (1982). Многие из приведениых в главе таблиц основаиы на
работе Нуссбаумера.
Глава 8
БЫСТРЫЕ АЛГОРИТМЫ
МНОГОМЕРНЫХ ПРЕОБРАЗОВАНИЙ
В предыдущих главах были рассмотрены способы разбиения
задачи вычисления преобразования Фурье иа подзадачи и спо-
собы преобразования алгоритмов свертки в алгоритмы вычислв
ния преобразования Фурье. Задачу вычисления многомерного
преобразования Фурье также можно разбить иа подзадачи и
использовать алгоритмы вычисления многомерных сверток для
вычисления многомерных преобразований Фурье. В данном слу-
чае эти возможности даже богаче, чем в одномерном случае. Мь~
рассмотрим многие из иих.
Алгоритмы многомерных преобразований Фурье рассматри-
ваются на простейшем примере двумерных преобразований Фурье.
Методы и формулы, полученные для двумерного преобразования
Фурье, переносятся на произвольный многомерный случай непо-
средственно.
Многомерные преобразования Фурье возникают естественно
в тех задачах цифровой обработки сигналов, которые по существу
многомерны. Но оии возникают и искусственным путем как спо-
соб вычисления одномерного преобразования Фурье. В данной
главе изучаются зги методы и тем самым даются практические
способы построения алгоритмов одномерного преобразования
Фурье больших длин из рассмотренных в гл. 4 малых алгоритмов
' преобразования Фурье.
8.1. Алгоритмы Кули Тычки
по малому основанию
Для вычисления двумерного преобразования Фурье монино
использовать БПФ-алгоритм Кули Тычки, применяя его сна-
чала к каждой строке, а потом к каждому столбцу. Это обосновы-
вается простой расстановкой скобок в уравнениях, определяющих
двумерное преобразование Фурье. Обозначим через v двумерную
таблицу с элементами о;;-, ю' = О, ..., и' 1, c" = О, ...,
и" 1, из поля F. Двумерное преобразование Фурье таблицы v
260 Гл. 8. Быстрые алгоритмы многомерных преобразований
определяется как двумерная таблица V
вычисляемыми по формулам
n' ‒ 1 n" ‒ 1
<a a» = f ~,' и'~'p'"~ ор
Ci~ C» Î
с элементами из поля F,
А' = О, ..., и' 1,
k"=0,..., и" I,
где а ‒ первообразный корень степени и' из единицы в поле F,
а р, первообразный корень. степени и" из единицы в поле F;
при и' = и" обычно полагают в = p,. ясно, что
n" ‒ 1
C»ô»
Р, QCю У»
C"=М)
л' ‒ 1
1'й'
~1) ~C Р С»
C'=О
л» ‒ 1
р К" й"
~» 0
Отсюда видно, что двумерное преобразование Фурье можно вы-
числять, либо вычисляя сначала одномерные преобразования по
столбцам и вслед за этим одномерные преобразования по строка~л,
либо сначала по строкам, а вслед за этим по столбцам. Любые
из БПФ-алгоритмов пригодны и для строк и для столбцов, и даже
не нужно, чтобы они совпадали. В нашем распоряжении имеется
много хороших БПФ-алгоритмов, и любой из них можно выбрать,
чтобы уменьшить число необходимых умножений и число необхс~
димых сложений.
При больших объемах таблиц помимо числа сложений и умно-
жений возникает задача управления данными. (1024x 1024)-таб-
лица над полем вещественных чисел содержит более одного мил-
лиона чисел, и вдвое больше над полем комплексных чисел. Прсь
цессор может запоминать большую часть таблицы в глобальной
памяти, выбирая только часть данных в локальную память. Обмен
данными между глобальной и локальной памятью является не
менее важным моментом, чем число умножений и число сложений.
Мы рассмотрим простейшую модель механизма обмена дан-
ными, в которой данные в глобальную память записываются по
строкам и считываются в локальную память по строкам. Тогда
процесс вычисления двумерного преобразования Фурье сводится
к одномерному преобразованию Фурье каждой строки, транспо-
нированию таблицы и повторному применению одномерного пре-
образования Фурье к каждой новой строке. Если окончательный
результат должен быть записан в глобальной памяти в виде истин-
ных строк преобразования, то нужно еще раз выполнить транспо-
нирование. Быстрые алгоритмы транспонирования будут рас-
смотрены в гл. 10.
Для того, чтобы избежать операции транспонирования, по-
смотрим более внимательно на используемые в алгоритме Кули‒
Тычки правила разбиения и применим их к построению много-
26]
8Л.Алгоритмы Кули ‒ Тычки по малому основанию
Ло основанию два
Одномерная
двумерная
йо основанию четыре
Яеумерная
Одномерная
Рис. 8.1. Некоторые схемы прореживания.
мерных алгоритмов БПФ. В многомерных алгоритмах будем де-
лать разбиения не по строкам и столбцам, а прямо разбивая дву-
мерную таблицу. Различие этих способов разбиения показано
на рис. 8.!. В частности, двумерное разбиение по основанию 2 раз
бивает (пx п}-таблицу на четыре ((п/2) х (п/2))-таблицы, а двумер-
ное разбиение по основанию 4 разбивает (пxn)-таблицу на шест
надцать ((п/4) X(n/4)}-таблиц. Последнее разбиение, в частности,
привлекательно не только тем, что преобразует данные к малым
объемам, но также и тем, что позволяет уменьшить число необ-
ходимых умножений и сложений.
Рассмотрим задачу вычисления двумерного (п Х п}-точечного
преобразования Фурье
VA l= Е Е 0> K~Uüj,
1=0 j~
262 Гл. 8. Быстрые алгоритмы многомерных преобразований
где и = и'и". Отметим, что мы специально убрали штрихованные
обозначения индексов, чтобы воспользоваться разбиением Кули
Тычки. Теперь и' и и" размеры прямоугольной таблицы.
Напомним приведенную на рис. 4.1 формулу разбиения Кули
Тычки:
‒ 1 П" ‒ 1
]~, 'Pl' ° <~в A" f yf"~"о.,
i'=0 8"=0
Применим эту формулу к двумерному преобразованию дважды
один раз к строчным индексам, а другой раз к столбцовым индек-
сам. Тогда, меняя порядок суммирования, можно записать
П ‒ 1
П~ ‒ 1
с'k' ) '! '
) '=0
i '=0
Теперь мы получили запись преобразования в виде двумерного
(и" Xn") точечного преобразования для каждых i' и j', за которым
следует покомпонентное умножение, а за ним (n'Xn')-точечное
двумерное преобразование Фурье для каждых k" и l".
,Иля построения двумерного алгоритма БПФ с разбиением по
времени по основанию 2 выберем и' = 2 и и" = и/2. Тогда ypas.
нения в матричном виде для k = О, ..., и/2 1 и i = О, ...,
и/2 1 даются равенством
n/2 ‒ 1
n/2 ‒ 1
)=0
л/2 ‒ 1
)=0
П/2 ‒ 1
)=0
n/2 ‒ 1
)=0
2ik 2)С
23з 2~
1 1
i=o
n/2 ‒ 1
8=0
n/2 ‒ 1
i=o
2И 2) l
2ю+1, 2)
k+n/2, 1
l †1 â€
2ik 2Д
~28, 2)+1
~k, 1+Л/2
l 1 ‒ 1 ‒ 1
n/2 ‒ 1
2СД г)У
2i+1, 2)+1
,~й 1
i=o
k+n/2, l+n/2
1 ‒ 1 ‒ l
Этот БПФ-алгоритм разбивает таблицу входных данных на четыре
таблицы в соответствии с четностью или нечетностью обоих ин-
дексов. Выходная таблица также разбивается на че'гыре таблицы,
хотя и по другому правилу, определяемому принадлежностью
строк и столбцов к первой или второй половине. Вычисления
теперь свелись к четырем двумерным ((n/2) X (и/2))-точечным преоб-
разованиям Фурье и (3/4) и умножениям на степени элемента и.
Мы здесь не учитываем (1/4) и' тривиальных умножений, которые
8 1. Алгоритмы Кули ‒ Тычки по малому основанию
263
ИЛИ
формируются в один блок и легко из алгоритма выбрасываются.
Оставшаяся часть тривиальных умножений мала и входит в пол-
ное число (3/4} n' умножений. Пусть и равно степени двойки
и М (nxn) обозначает число умножений в поле F, необходимых
для вычисления двумерного (и X n)-точечного преобразования Фурье
описанным алгоритмом. Тогда мы получаем следующую рекурсию:
М(и х и)=4М( х )+
Решение этого рекуррентного уравнения дается равенством
М(и X и) = и2(log,и С),
3 2
где константа С определяется числом умножений в самом внутрен-
нем шаге. В частности, можно отталкиваться от (2x2)-преобра
зования Фурье, не содержащего умножений, так что М (2x2) = О,
или от (4 X 4)- преобразования Фурье, также не содержащего
умножений, так что М (4х4) = О. Тогда
М (и х и} = и'(log, и 1}
М (n.х и) = nÐ (log, и 2).
Возможно и дальнейшее уменьшение числа умножений, но струк-
тура алгоритма при жом усложняется.
Полученные формулы интересно сравнить с числом
М (nxn) = nÐ log, и
умножений в поле F, необходимым в двумерном алгоритме, осно-
ванном на использовании БПФ-алгоритма Кули Тычки по осно-
ванию 2 по столбцам и по строкам.
Некоторое уменьшение числа необходимых умножений яв-
ляется приятным свойством рассмотренного двумерного алгоритма.
Но намного более важной является используемая в нем форма
записи входных данных, так как она уменьшает необходимое
число обменов данными между глобальной и локальной памятью
процессора. Входная таблица считывается в локальную память
по две строки одновременно. Объем локальной памяти должен
быть достаточен для запоминания двух строк. Вдоль каждой
пары строк вычисляются все двумерные (2x2)-преобразования.
Этот процесс для данной таблицы повторяется log и раз. В каж-
дой итерации процесс спаривания двух строк управляется алго-
ритмом адресного тасования Кули Тычки; формирование (2 X 2)-
таблиц в пределах двух спаренных строк также управляется алго-
ритмом адресного тасования Кули Тычки. Так как входная
таблица содержит и строк, и так как она трансформируется
всего 1од, и раз, то в общей сложности мы получаем и log, и пе-
реносов строк из глобальной памяти в локальную и такое же
число обратных переносов.
264 Гл. 8. Быстрые алгоритмы многомерных преобразований
Чтобы построить двумерный БПФ-алгоритм по основанию 4
положим и' = 4 и и" = и/4. Это разобьет исходную двумерную
таблицу на 16 подтаблиц. Вычисления можно записать в виде
следующего матричного уравнения.
и/4- 1 п(4 ‒ 1
и ююиъ2
о ~-о
и/4 1 и/4-1
4/% 4((
0> 1~( иЪ „2 °
Vg(+ и/4 I
iaO
) О
n/4- 1 и/4-1
4й 4Я
и2(+2 Ц
Vk -nI
i ~O j~O
и/4-1 4- 1
43k 4jl
cd cd и2.3 2
1/»+ э/4(
!по
ja0
и/4- 1 п/4- )
<~4~»0э4/(и
h.2j+ I
Vk (+ «/4
( О
п/4-1 и/4-1
Сд 1а) иЪ-+ ~ 2~+ !
»+(
1 1 1 1
1 1 1
Vk + n/4, I + n/4
jeO
п/4 1 п/4-1
Cd Cd'Уи Ъ+ 2,2j+ !
‒ i ‒ 1 i
1 ‒ i l
Vk+n„„,
гео jeO
п/4 - 1 и/4- 1
4ik 4ф
41 а иъ+ 3,2 !
3»+(
1 ‒ 1 1 ‒ 1
1 ‒ 1 !
и»+ + /4
IeO
jaO
n/4-1 п/4- I
4Ф 4Я
я -1 -я
1 j ‒ l
V».("/2
!по
n/4- 1 n/4- I
4ik 4jI
с! ы иъ„~ 2
„*+ 2(
~» + и/4.(+ и/2
(aO j aO
и/4-1 и/4- I
4!k 4jI
д ы I(2 +2.2j+2
2k+2(
~»+ п/~I+ и/2
jaO
и/4- 1 и/4- !
4Й 4Я
и ъ'+ 3.2/+2
3k+ 2I
Cd
~» + Зп/4,(+ и/2
IaaO jaaO
и/4-1 п/4-1
4(й 4j(
"2tPj+ 3
3(
Vk(-3 /4
и/4-1 и/4-1
4Й 4Я
иЪ'+ 1.2/+ 3
»+3(
Cd
Vk+ n/4,(+ Зй/4
i О j 0
и/4-1 и/4- I
4ik 4JI
"2~+ 2'+
2»+»
Vk+ (+3n/4
/-О
и/4- I п/4- 1
4ik 4jl
Ы !1 иъ.+ 3.2;+
3»+ 3(
Vk+ Зп/4.(+ Зп/4
j~O
юо
8.2. Гие~довые алгоритмы преобразоваиия
Здесь (16 X 16}-матрица, на которую выполняется умножение,
представлена в виде кронекеровского произведения двух (4x4)-
матриц с элементами ~1 и ~/. 15/16 из стоящих в правой части
равенства членов умножаются на степени элемента а. Небольшая
часть из них представляет собой тривиальные умножения, но,
чтобы структура оставалась простой и удобной для расчетов, мы
их выбрасывать не будем. Тогда число умножений описывается
рекуррентным соотношением
М (п х п) = 16М ( x ‒ ) + ‒ n',
решением которого является
М(п у п) = n'(logn С},
16
где константа С имеет такой же смысл, как и для алгоритма по ос-
нованию 2. Если выбрать внутреннюю свертку так, что М (4 х 4} =0,
то
M (п x n) = и'(log п 2),
и мы видим, что в добавление к хорошей структурированности
алгоритм по основанию 4 эффективен в смысле числа необходимых
умножений.
Для того, чтобы воспользоваться двумерным разбиением по
основанию 4, локальная память должна быть столь большой, чтобы
можно было одновременно записать четыре строки матрицы вход-
ных данных. В общей сложности таблица входных данных будет
переноситься 1од и раз, так что всего потребуется ‒ и log u
1
2
переносов строк из глобальной памяти в локальную и наоборот.
8.2. Гнездовые алгоритмы преобразования
Теперь мы рассмотрим другой метод, известный под названием
гнездового, в котором многомерные БПФ-алгоритмы строятся
сочетанием одномерных БПФ-алгоритмов, как в БПФ-алгоритме
Винограда. Напомним, что следствием возможности изменения
порядка суммирования
л' ‒ ! л" ‒ !
‒ 1 й
т f/ÔД//
й.'=,~i +'" ~ P ~ю,ю-
К =0 l" Î
n" ‒ ! n' ‒ !
Z Р'" Е и'"'v~ °,-
Ю"=0 Ю'=0
является то, что двумерное преобразование Фурье можно вычис-
лять как последовательность одномерных преобразований Фурье
266 Гл. 8. Быстрые алгоритмы многомерных преобраэований
сначала по строкам, а затем по столбцам, или сначала по столбцам,
а затем по строкам. Для вычисления одномерных преобразований
Фурье можно пользоваться любой удобной комбинацией алгорит-
мов вычисления, применяя их к строкам и столбцам, входящим
в двумерное преобразование. Мы будем работать с малыми БПФ-
алгоритмами Винограда, отыскивая эффективные способы их со-
четания.
Пусть M (п') и А (п') обозначают соответственно числа умно-
жений и сложений некоторого имеющегося в нашем распоряжении
одномерного алгоритма и'-точечного преобразования Фурье. Для
выполнения и" таких одномерных преобразований нужно и" М (п'}
умножений и n"ß (п') сложений. Аналогично, чтобы выполнить и'
преобразований длины и", необходимо и'М (и"} умножений и
и'А (и") сложений. Таким образом, используя последовательно
одномерные преобразования, получаем, что вычислительная слож-
ность двумерного преобразования Фурье равна
М (и' Х и''} = и"М (п') + и'М (n"),
А (и' х и''} = и"А (п') + и'А (и").
Какое из измерений таблицы выбрано первым, не играет роли.
Поскольку в такой процедуре обработка осуществляется последо-
вательно, то сложность будет той же самой.
К лучшей процедуре вычислений приводит сочетание алгорит-
мов по гнездовому методу Винограда. Так как для двумерного
преобразования фурье несущественно, что именно, строки или
столбцы, обрабатываются в первую очередь, то, возможно, суще-
ствует и путь их,совместного вычисления. Именно это и делает
гнездовой метод Винограда. Он так связывает вычисления по
строкам и по столбцам, что полное число необходимых умножений
уменьшается. Таким образом, мы будем пользоваться одномерными
алгоритмами преобразования Фурье, но сочетая их более эф-
фективным образом. Для описания метода воспользуемся кроне-
керовским произведением матриц.
Пусть W' и W" обозначают соответственно матрицы преобра-
зования Фурье длин и' и n", так что V' = W'v', V" = W 'v"
И
n' ‒ 1 л" ‒ I
~'= Е Р'"Й, }'"-= Е у'"о".
к=о к=о
Двумерное (и' х и"}-преобразование Фурье двумерного сигнала
vc'. c" получается применением матрицы W к каждому столбцу
(столбец содержит и' компонент} и последующим применением
матрицы W" к каждой строке. Эго двумерное вычисление можно
преобразовать в одномерное так, как показано на рис. 8.2.
Выпишем двумерные таблицы v u V в виде одномерных таблиц,
считывая их в стеки по столбцам, и сохраним за ними те же обоз-
° ~0 -)
И. ‒ )
)~г» -)
lf io
иг)
)~ -).) )~л -),г
~л' ‒ ),0
)~л' ‒ I.o
Lf OI
~»' ‒ ),л ‒ )
Рис. 8.2. Отображение двумерной таблицы в одномерную.
начения, так что входной и выходной одномерные векторы содер-
жат и'и" компонент и имеют вид
vo
V =
чг
V„- )
чл-
где vc" и ~c" обозначают соответственно столбцы исходных дву-
мерных таблиц:
0 и
Ч;- =
~л'-).ю"
n ‒ I.y
Если под v и Ч понимать так построенные одномерные и'и"-то-
чечные векторы, то двумерное преобразование Фурье записывается
8.2. Гнездовые алгоритмы преобразования
Чо
v)
Чг
268 Гл. 8. Быстрые алгоритмы многомерных преобразований
в виде кронекеровского произведения. Сначала запишем вычисле-
ния в виде
W'0 О...
ОW' 0
0 0 Ю'
ющ1 wo)1 юа1
~~о1 ~)11 ~и1
ю 201 ю2! I юю1
ч,
v,
Чг
vo
v,
чг
0 0 0 W
v„„-,
где W' определенная выше (и' X и'}-матрица, О нулевая
(и' X и')-матрица и I единичная (и' х и')-матрица. В этом
произведении матриц легко узнать кронекеровское произведение
матриц, так что в сокращенной записи имеем
V = Wv,
где W = W" X W' представляет собой (и'и" X и'и")-матрицу.
В БПФ-алгоритмах Винограда длин и' и и" соответственно ма-
трицы W' и W" разлагаются в виде W' = С'В'А' и W" = С"В"А",
где А', А", С' и С" представляют собой матрицы, состоящие только
из нулей и единиц, а матрицы В' и В" являются диагональными.
Все умножения в алгоритмах Винограда исчерпываются умноже-
ниями на матрицы В' и В" соответственно. Пусть W = W" X W';
применяя дважды теорему 2.5.5., получаем
W = (С"В"А") х (С'В'А') = (С" х С') (В" х В') (А" х А') =
= СВА,
где кронекеровское произведение С = С" X С' и А = А" X А'
приводит опять к матрицам, состоящим только из нулей и единиц,
а кронекеровское произведение В = В" X В' представляет собой
диагональную матрицу. Таким образом, мы построили алгоритм
двумерного и'и"-точечного преобразования Фурье в той же форме,
что и БПФ-алгоритм Винограда. Это и дает способ построения дву-
мерных БПФ-алгоритмов из одномерных алгоритмов.
Хороший способ организации вычисления двумерного преобра-
зования Фурье диктуется формулой
V =- (С" х С') (В" х В') (А" х А') v,
и иллюстрируется рис. 8.3. Здесь предполагается, что данные
записаны в виде двумерной таблицы. Для умножения на (А" X
X А') сначала каждый столбец входной двумерной таблицы умно-
жается на матрицу А', а затем каждая строка полученной матрицы
умножается на А". Первая из этих операций не содержит умно-
жений и преобразует входную (и'хи }-таблицу в таблицу раз-
8.2. Гнездовые алгоритмы преобразования
Умножение
стол бцое
на А'
Умножение
М(п")
П
Сигнал во М(п )
временной области
млонент-
умножение
Умножение
строк
на С'
M(n' )
Сигнал в
частотной
области
Рис. 8.3. Гнездовой метод вычисления двумерного преобразования Фурье.
Формула для полного числа сложений выводится несколько слож-
нее, так как зависит от распределения числа сложений в состав-
ляющих алгоритмах между предсложениями и постсложениями.
Чтобы упростить эту формулу и ее вывод (и даже уменьшить число
необходимых сложений}, предположим, что можно менять порядок
мера (М (п'} х и"}}; вторая операция также содержит только сложе-
ния и преобразует данные в таблицу размера (М (п'} Х М(п" }}. Далее
происходит умножение каждого столбца на матрицу В' и затем
умножение каждой строки на матрицу В". Эта процедура содер-
жит 2М (п') М (и"} умножений. Другой способ реализации этого
шага вычислений состоит в предварительном вычислении и за-
поминании (М (п') X М (и"))-матрицы В = В" Х В'. Тогда на
этом шаге потребуется только М (п') М (и") умножений, но память
для констант вычисления растет. Наконец, вычисленная на вто-
ром шаге (М (п') Х М (п"))-матрица преобразуется в (и' Х и }-
матрицу умножением сначала каждого столбца на С', а затем каж-
дой строки на С". Последний шаг содержит только сложения.
Полное число умножений в алгоритме равно
М (и' Х и) = М (п') М (и").
270 Гл. 8. Быстрые алгоритмы многомерных преобраэований
применения матриц С' и С". (Изменение порядка суммирования оп-
равдано общим тождеством ~С~ а ~С~-r, Vr ~- = ~С~-ф- Х
Сг g// С"
Х ECr r,.Vr r" ) Тогда
С'
А (и' X n") = и'А (и") + М (и") А (и').
Теперь мы уже имеем два способа вычисления двумерного пре-
образования Фурье. Первый из них содержит
М (и' Х и) = и"М (и') + и'М (и")
умножений, но строится на основе любого одномерного БПФ-
алгоритма, а второй содержит
М (и' Х и"} = М (и') М (и")
умножений, но в конструкции используются только БПФ-алго-
ритмы Винограда вдоль каждого из измерений
Например, реализация (1008Х 1008)-преобразования Фурье
для комплексного входа в первоы случае требует 4Х1008х1782
вещественных умножений (см. равд. 8.3}, а во втором случае 2Х
X 1782 вещественных умножений. (В случае вещественного входа
во втором случае требуется вдвое меньше вещественных умноже-
ний, а в первом случае только 3/4 от указанного числа, так как
после применения БПФ-алгоритма по строкам данные становятся
комплексными.)
Второй способ, очевидно, лучше, но для его реализации тре-
буется создание временного массива памяти для запоминания ком-
плексных данных объема 2Х 1782Х 1782 (который в начале может
содержать 2х 1008х 1008 входных данных); для первого способа
необходима только временная одномерная память для запомина-
ния 3564 слов.
8.3. Алгоритмы Винограда
быстрого вычисления преобразования
Фурье большой длины
Гнездовые методы построения двумерных БПФ-алгоритмов
можно использовать, наоборот, для построения алгоритмов вы-
числения одномерного преобразования Фурье. В настоящем раз-
деле мы возвращаемся к задаче вычисления одномерного преобра-
зования Фурье и строим БПФ-алгоритм Винограда для больших
длин преобразования (большой БПФ-алгоритм Винограда).
Большой БПФ-алгоритм Винограда представляет собой метод
эффективного вычисления дискретного преобразования Фурье,
если длина и преобразования распадается в произведение взаимно
8.Q. Алгоритм Винограда
271
272 Гл. 8. Быстрые алгоритм ы многомерных преобразований
простых делителей, для которых
существуют малые БПФ-алгорит-
мы Винограда. В основу алгори-
тма заложены четыре самостоя-
тельные идеи'. алгоритм Рейдера
для простого числа, описанный
в разд. 3.4, малый алгоритм свер-
тки Винограда, схема Гуда
Томаса индексации для простых
делителей и гнездовой метод
В н Большой БПФ-алго-
~ержндексация на вкоде
0
9
б
3
4
!
l0
7
8
5
2
II
0
1
2
3
4
5
б
7
8
9
I0
ll
mod 3
mod 4
Стек
столбцов
и ограда
ритм Винограда, как видно из
рис. 8.4, лучше БПФ-алгоритма
Кули Тычки по числу умноже-
ний, но имеет более сложную
9 структуру. Платой за уменьшение
4 8 Столбцы 4 числа операций я вляется отсут-
иЗ стека 7
,о '2 ‒,о ствие малых повторяющихся цик-
лов; повторяющиеся циклы имеют
11
большую длину.
В общем случае БПФ-алгоритм
Винограда применим для вычи-
сления преобразования, длина и
Рис. 8.5. Переиндексация в 12-го- которого р авна произведению
чечном алгоритме Винограда.
малых простых чисел или произ-
ведению степеней малых простых
чисел.,Мы рассмотрим только случай двух делителей: и = и'и".
Используя алгоритм Гуда ‒ Томаса для простых делителей, пре-
образуем и-точечное преобразование Фурье в двумерное (и' X
X и"}-точечное преобразование Фурье. Для вычисления этого
двумерного преобразования можно воспользоваться малым и'-
точечным БПФ-алгоритмом Винограда и малым и"-точечным
БПФ-алгоритмом Винограда, применяя их вдоль соответствующих
длине измерений. Вместо этого мы воспользуемся описанным
в предыдущем разделе гнездовым методом Винограда, позволяю-
щим так сочетать эти два алгоритма, что число умножений
падает.
Рассматриваемая нами процедура иллюстрируется приведен-
ным на рис. 85 примером 12точечного БПФ-алгоритма. На
рисунке показано преобразование входного 12-компонентного
вектора данных в двумерную таблицу по алгоритму Гуда Томаса,
сводящее задачу к вычислению двумерного преобразования Фурье.
3а этим следует преобразование полученной двумерной таблицы
в новый одномерный массив, формируемый как стек столбцов.
(Bce эти манипуляции можно проделывать с индексами; совсем не
обязательно физически переупорядочивать данные.)
О
t
2
3
4
5
б
7
8
9
10
11
к т.о
8.3. Алгоритм Винограда
273
Формирование 12-точечной матрицы преобразования Фурье
в виде кронекеровского произведения матриц-составляющих 3-
точечного и 4-точечного преобразований Фурье показано на рис. 8.6.
Пусть n = и'и" и W' и W обозначают соответственно матрицы
и'-точечного и и"-точечного преобразований Фурье, так что Ч'
= %'v' и V" = W"v". Двумерное (и' X п")-преобразование Фурье
двумерного сигнала v;;- получается применением W' к каждому
столбцу сигнала, а затем применением W" к каждой строке. Если
двумерный (и' X п") сигнал v~;- был получен описанным пере-
упорядочиванием компонент из одномерного, то надо выполнить
обратную перестановку, считывая двумерный результат по столб-
цам.
Если под ч и V понимать соответственно входной и выходной
векторы, компоненты которых переставлены описанным образом,
то в терминах кронекеровского произведения преобразование запи-
сывается равенством V = (W X W') v. Но W' = С'В'A' и
W" =- С"В"A", где элементами матриц A', A", С' и С" являются
только нули и единицы, а матрицы В' и B" являются диагональ-
ными. Так же, как в предыдущем разделе, получаем
W = ‒ (C" В"А") х (С'В'А') = (С" х С') (В" х В') (А" х А') = СВА,
где кронекеровские произведения С = С" Х С' и А = А" Х A'
представляют собой матрицы, состоящие только из нулей и еди-
ниц, а кронекеровское произведение В = В" Х В' является диа-
гональной матрицей. Следовательно, мы построили алгоритм
п'и"-точечного преобразования Фурье в форме БПФ-алгоритма
Винограда: V = CBAv.
При построении алгоритма мы предполагали, что компоненты
векторов ч и Ч переупорядочень необходимым образом. Но коль
скоро алгоритм в данной форме уже построен, то выполняя три-
виальную перестановку столбцов матрицы А, можно работать с
естественным пбрядком компонент вектора v, а переставляя строки
матрицы С, с естественным порядком компонент вектора V.
Обозначим через М (п') и M (и") размеры матриц В' и B"
соответственно. Эти числа равны числу умножений соответственно
в и'-точечном БПФ-алгоритме и в n,"-точечном БПФ-алгоритме
с учетом тривиальных умножений на единицу. Тогда число умно-
жений, необходимых для выполнения и'и"-точечного БПФ-алго-
ритма Винограда, включая и умножения на единицу, равно
М (п) = М (п') М (и"). Это происходит потому, что матрица
Х В' снова является диагональной, а размер ее равен
М (п') М (и").
На рис. 8.7 приведен перечень малых БПФ-алгоритмов Вино-
града, из которых можно строить большие БПФ-алгоритмы Вино-
града, а на рис. 8.8 выписаны характеристики больших БПФ-
алгоритмов Винограда. На рис. 8.9 дается пример 1008-точечного
274 Гл. 8. Бь!стрые алгоритмы многомерных преобразований
U0
UI
иг
Иа
иэ
иб
и7
Us
ир
»о
UIt
о !
И
9
б
И
з 1
Cd
о ! о
И 1 И
9 ! 0
Cd ! Cd
б t 0
Cd ! Cd
э ! о
И ! И
V
о о о
Cd Cd Cd
О Э б
Cal Cd Cd
О б О
Cd И И
О 9 Ь
Cd Cd Cd
О 0
Cd Cd
о з
Cd Cd
О б
О 9
Cal И
о
Cal
6
о
б
о
3
Cd
б
9
Cd
о о
CJ Cd
9
И Cd
О 6
Cd И
б Э
Vo
V3
и
~9
U0
иб
о о о о
Cal Cd Cd Cd
О 3 Ь 9
Cal Cd Cal И
О б О б
Cd Cal И Cd
О 9 б 3
Cd И Cd Cd
4 4
Cd И
7 (О
И И
ю
И Cd
ю
Cd И
1
~!0 '
1
Cal
4-
в в
Cd Cd
в и
Cd Cd
8 2
в s
Cd Cd
в в
2 5
Cd Cd
в г
2 It
Cd Cd
V4
и
~'!о
V„
и4
и!
о о
Cal И
о э
Cd И
О б
Cd Cd
О 9
Cal Cal
в в
Cal И
1) 2
г в
Cal Cal
5 2
Cd И
о о
Cd Cal
б 9
Cal Cd
о ь
Cd Cd
б 3
Cal Cd
В ! 4
Cd И
Cd ' Cd
4
2 4
Cd ' Cd
И ! И
tt 4
4
7
ю
Cd
I
И
4 4
Cal Cd
!о
Cd И
4 Io
Cd Cd
!о
И Cd
V8
~'и
V2
~з
ив
иэ
иг
и!!
!"о
в'3
~б
~9
Uo
ир
иб
И И И Х
~4
В'7
~!о
к,
иа
и!
Uto
и7
!'в
Vt«
~2
~э
US
иг
ии
Рис. 8.6. Сведение 12-точечного преобразования фурье к кронекеровскому про-
изведению.
в'о
V„
V2
в'3
и
V„
~б
V7
!'в
и
~!о
Vtt
о
Cd
о
о
о
о
Cd
о
о
о
Cd
о
Cal
о
Cd
о
И
о
о о
И Cd
I 2
И И
2 4
Cd И
з ь
Cal Cd
4 В
э !о
6 О
И И
7 2
в
И Cd
9 б
Cd И
ю в
Cd Cd
t0
Cd И
о
3
б
И
9
о
И
з
И
б
9
Cd
о
И
з
И
6
9
о о о
Cd И Cal
4 5 б
И Cal И
в ю о
Cd Cd И
О 3 б
Cd И Cal
4 8 0
Cd Cd Cd
8 1 б
Cd И И
о б О
Cd ° Cd И
!! б
И Cd Cal
8 4 О
Cd И Cd
О 9 б
И Cal Cd
4 2 0
Cd И Cd
8 7 б
Cd И Cal
Г 4
1 И
! 4
И
4
I
И
Ф
I И
в
! Cd
1 в
И
в
I
о о
7 В
Cd Cd
2 4
Cd Cd
9 0
Cd И
а в
Cd Cd
tt 4
И Cal
б 0
Cd Cd
в
И И
8 а
з о
Cd И
в в
Cal Cd
4
Cd Cd
о
9
Cd
6
И
э
о
р
б
з
Cd
о
Cd
9
б
Cd
э
Cd
о о
Cd И
!о н
И И
в и
И Cal
6 9
Cd Cd
4 В
cd cd
2
Cd И
О б
И И
ю
Cd Cd
8 а
Cd Cd
б з
Cd Cal
4 2
И Cd
2 t
Cd И
8.4. Алгоритм Вииограда
275
Вход ео
ерем енной
области
и точек
Выход в
частотноц"
области
чек
Сложность
Сложения
Число
нетри-
виальных Число
умножений сложении
на точку"" на ~почку
Длина л
15 18 17 81 1.13 5.4
21 27 26 I SO 1.24 7.14
30 36 34 192 1.13 6.40
35 54 53 333 1.51 9.51
48 54 46 318 0.96 6.62
63 99 98 704 1.56 11.17
~~0 94 86 676 1.07 8.45
120 144 138 1038 1.15 8.65
168 216 210 1746 1.25 10.39
240 324 316 2508 1.32 10.45
420 648 644 5676 !.S3 13.51
504 792 786 7270 1.56 14.42
840 1296 1290 12402 !.54 14.76
1008 1782 1774 17334 1 76 17.20
2520 4752 4746 49814 1.88 19.77
8.8. Х арактеристики больших БПФ-алгоритмов Винограда.
Малый БЛФ- алгоритм Винограда
Меню
Рис. 8.7. Набор малых преобразований Винограда.
Число
вещественных Число
умножений вещест-
етривиаль- @~ííûõ
Полное ных сложений*
При комплексном входе удвоить
Умножения
О (2)
2 (3)
О (4)
5 (б)
8 (9)
2 (8)
10 (11)
20 (21)
Щ (21)
10 (18)
2
6
8
17
36
26
44
84
94
74
276 Гл. 8. Быстрые алгоритмы многомерных преобразований
Временные Малый БПФ-
вы~орки алгоритм
Винограда
Малый БПФ-
алгоритм
Винограда
Малый ЬПФ- Частотные
алгофитф~ оы(юрки
Оиног ааа
©Оу© ©ЮЮ ©ОЮ
I �9 точек
Гнездовой метод
Винограда
16 точек
7 точек
С С С
С С С
Рис. 8.9. Структура большого ИЮ8-точечного БПф-алгоритма Винограда.
Временнив Малый Б~~Ф-
выбо
Малый БЛФ-
Малый БПФ- Часлютные
ки
7mpvек
9 точек
16 точек
I нездовой метод
Винограда
С С У ~ С С С У С
63 точки
Рис. 8.10. Структура другого )008~гочечного преобразования.
преобразования. Этот ОПФ-алгоритм содержит 3564 вещественных
умножений, которое получено как произведение чисел необходи-
мых умножений в 7-, 8- и 16-точечных БПФ-алгоритмах Вино-
града, удвоенное для комплексного входа.
Более регулярный БПФ-алгоритм с разбиением данных на
меньшие блоки приведен на рис. 8.10. В этом алгоритме сочета-
ются только 7-точечное и 9-точечное преобразования. 1008-точеч-
.ное преобразование вычисляется затем как двумерное (63X16)-
преобразование Фурье. Каждая составляющая вычисляется БПФ-
алгоритмом Винограда. Полное число вещественных умноже-
ний равно 4396 = 2 (16М (63) + 63М (16)).
8.4. Алгоритм Джонсона ‒ Барраса
277
8.4. Алгоритм Джонсона Барраса
быстрого преобразования Фурье
Мы рассмотрели два способа сочетания малых БПФ-алгорит-
мов Винограда, а именно, гнездовую схему Гуда Томаса для вза-
имно простых делителей и гнездовой метод Винограда. ОПФ-ал-
горитмы Джонсона Барраса представляют собой целое семей-
ство гнездовых алгоритмов, включающее в себя методы Гуда
Томаса и Винограда в качестве двух экстремальных случаев.
Идея БПФ-алгоритма Джонсона Барраса состоит в модерниза-
ции использования кронекеровского произведения для переупоря-
дочивания последовательности вычислений. Это позволяет умень-
шить число необходимых умножений, сохраняя малым число не-
обходимых сложений. Кроме того, архитектура алгоритма позво-
ляет улучшить структурирование и управление потоком данных.
Мы рассмотрим только случай, когда длина и преобразования
распадается в произведение двух взаимно простых множителей и'
и n . Можно, конечно, применить тот же метод и к большему числу
делителей, но тогда число конструктивных возможностей стано-
вится необозримым. Например, если и разлагается в произведение
четырех множителей, то из одних и тех же малых ОПФ-алгорит-
мов Винограда можно построить больше чем 10" различных
БПФ-алгоритмов Джонсона Барраса. Чтобы все их проанализи-
ровать, необходима специальная процедура поиска типа динами-
ческого программирования.
Предположим, что и-точечный входной вектор преобразуется
в двумерную (и' X и")-таблицу V с помощью отображения на рас-
ширенную диагональ. Согласно алгоритму Гуда Томаса для вы-
числения одномерного преобразования Фурье исходного вектора
данных можно сначала вычислить и'-точечное преобразование
Фурье каждого столбца таблицы, а затем и"-точечное преобразова-
ние Фурье каждои строки. Это можно записать в виде Ч = W W'v.
Такая запись не является общепринятой, так как ч представляет
собой двумерную таблицу. Под W'v понимается умножение каж-
дого столбца таблицы ч по одному разу на матрицу W', а под W"÷
понимается умножение каждой строки таблицы ч по одному
разу на матрицу W". Для большей строгости надо было бы ввести
дополнительные обозначения для отделения матриц, действующих
на столбцы, от матриц, действующих на строки; но мы предпочи-
таем для указания этой информации пользоваться штрихом и
двумя штрихами.
Так как безразлично, вычисляются ли первыми преобразова-
ния по строкам или преобразования по столбцам, то можно также
записать V = W'W"v. Это объясняется тем, что операции по
строкам коммутируют с операциями по столбцам, так как такая
запись означает просто изменение порядка суммирования. Пред-
278 Гл. 8. Быстрые алгоритмы многомерных преобразований
положим теперь, что имеются малые ОПФ-алгоритмы Винограда
с W' = С'В'A' и W" = С В"А". Тогда
V = (C"Â"А") (С'В'А') v = (C'В'А') (С В"A") v.
Две матрицы с одним и тем же количеством штрихов не коммути-
руют. Однако, как мы видели при исследовании гнездового метода
Винограда, матрицы с различным количеством штрихов коммути-
руют. Для формального доказательства можно обратиться к тео-
реме о кронекеровском произведении матриц. На самом деле, это
опять не более чем изменение порядка суммирования. Таким об-
разом, можно записать равенство
V = С'С" B'B""A'А"ч,
которое представляет собой большой БПф-алгоритм Винограда.
Его можно записать также в виде
V = C'В'С"8"А'А v.
Для построения БПФ-алгоритма Джонсона Барраса необхо-
дима еще одна хитрость. Прежде чем менять порядок следования
матриц суммирования, разложим их в виде произведений:
W' = (С'Н') В' (Е'F'), W" = (б"Н") В (Е"F"),
где С' = б'Н' и так далее. Тогда мы получаем произведение
V = б'Н'В'Е'F'á'Н "В "Е F"v>
которое можно переупорядочить следующим образом:
V = (O'á" Н" Н') (В'В") (E'Е"F'F") v.
В этой форме записи обе диагональные матрицы В' и В" собраны
вместе и даже заключены в скобки, чтобы подчеркнуть этот факт.
Эти идеи хорошо иллюстрируются 35-точечным преобразова-
нием Фурье. На рис. 8.11 выписаны 5-точечный и 7-точечный
БПФ-алгоритмы Винограда, каждый из которых состоит из пяти
этапов вычислений. Имеется множество способов сочетания их
в 35-точечный алгоритм ОПФ, наиболее интересные три из кото-
рых указаны на рисунке. Два из них соответствуют гнездовому
методу Гуда Томаса и гнездовому методу Винограда. Гнездовой
метод Гуда Томаса приводит к меньшему числу сложений, а
гнездовой метод Винограда к меньшему числу умножений. На-
добности выбирать между этими альтернативами, однако, не воз-
никает, так как имеется гнездовой алгоритм Джонсона Барраса,
который содержит столько же умножений, сколько алгоритм
Винограда, и число сложений, близкое к числу сложений в ал-
горитме Гуда Томаса, и, следовательно, ему надо отдать предпо-
чтение.
Я,4. Алгоритм Джонсона ‒ Барраса
279
-о--о
1
о
I
1 1
о
1
о о
оооо оo
ч е ср
И И й
о
1
оооо
ф
ф
ф
Cl
Ci
оооо-
ооо-о
ооо-
1
оо -оо
о-ооо
-оооо
о о
1
° ю
1
о-о
о
1
оо--о
1
° рф Ю °
1
- о
1
о-оо-
1
оо-
1
о-о -о-
о‒
1
о--
о
оооо-
ооо-о
-о оо
о ‒ оооо
-ооооо
ооооооо
оооо
ооооо-о
о о о
оо-о
о-ооооо
-оооооо
ооо оо
ооооо-о
с îîî о-
оооо-оо
ооо ооо
оо-оооо
оо -ооо
о оооо о
-оооооо
о о
!
о о
о о
Ф
о о
Ю
о о:у
М
Яф
ф
~6
Ф
Ф
1
СЭ
о
И
280 Гл. 8. Быстрые алгоритмы многомерных преобразований
Использование БПФ~алгоритма Джонсона Барраса не при-
водит к каким-либо осложнениям. Все новое, что он привносит,
сводится к разбиению сложений на отдельные пакеты, которые
можно реализовать в виде отдельных подпрограмм и затем обра-
щаться к ним, вызывая их в нужной последовательности. В про-
цессе вычислений мы постоянно переходим от сложений по строкам
к сложениям по столбцам и обратно.
8.5. Алгоритмы разложения
Малый БПФ-алгоритм Винограда сводит задачу вычисления
одномерного преобразования Фурье к задаче вычисления одномер-
ной циклической свертки, используя для этого алгоритм Рей-
дера. Теперь мы воспользуемся этой же процедурой для много-
мерных преобразований. В общем случае вычисление преобразова-
ния разлагается в вычисление нескольких циклических сверток.
Число точек преобразования по каждой из осей многомерного
преобразования должно быть равно простому числу или степени
простого числа, хотя и не обязательно одной и той же для раз-
личных измерений. Сначала, используя вдоль каждой из осей ал-
горитм Рейдера или его обобщение, сведем многомерное преобразо-
вание Фурье к многомерной свертке. Теперь применим алгоритм
быстрого. вычисления многомерной свертки. Для того случая,
когда число точек преобразования вдоль всех осей одно и то же,
в разд. 8.7 будет описан алгоритм с лучшими характеристиками,
которому и следует отдать предпочтение. Поэтому алгоритмы
разложения представля ют интерес в первую очередь для тех
случаев, когда соответствующие различным осям числа точек пре-
образования различны.
Идея сводится к простому обобщению процедуры для одномер-
ного случая. Начнем с двумерного (n' X и "}-преобразования Фурье
для взаимно простых n' и n", возможно, различных:
Й'=О,..., n' 1,
$ t P t )tl Ptl
Vy и= Е Q c0''р''о г
Для того чтобы воспользоваться алгоритмом Рейдера, надо ис-
ключить нуль из показателя степени. Для этого по аналогии с
алгоритмом Рейдера разобъем уравнения на четыре группы.
n' ‒ ! n" ‒ 1
Го.о = Z
Г=О
8.5. Алгоритмы разложения
281
n' ‒ 1
1) f u~.;-, k'=I,..., и' I,
'/'ь . о ‒ Vo.о = Z (<~'
i»=0
n' ‒ 1 n" ‒ 1
'/ь .ь" ‒ Vq о ‒ Vo a" + Vo.o = Z Е (ш' "
l» ‒ О
Й"=1,..., и
Сделав такое разбиение и применив перестановку, даваемую алго-
ритмом Рейдера, мы сводим задачу к вычислению (п' I)-точеч-
ной свертки, (и" I)-точечной свертки и (n' I) Х (n" I)-
точечной двумерной свертки. Для вычисления обеих одномерных
сверток можно воспользоваться построенными в гл. 3 алгоритмами
Винограда. Согласно теоремам 4.6.1 и 4.6.2, все умножения в этих
алгоритмах являются умножениями только на вещественные или
только на мнимые константы, и, следовательно, требуют в случае
вещественного входа только по одному вещественному умножению.
Для вычисления двумерной свертки можно воспользоваться
любым хорошим методом. Одним из них является описанное в гл. 7
полиномиальное преобразование. Алгоритм двумерной ((и' I) x
Х (n I))-точечной свертки можно также строить гнездовым ме-
тодом, используя подходящие двумерные циклические свертки
меньших объемов или даже малые алгоритмы одномерных цикли-
ческих сверток. Например, задачу вычисления двумерной (4 х
х 12)-свертки можно преобразовать, используя по второй оси
алгоритм Агарвала ‒ Кули, в задачу вычисления трехмерной цик-
лической (4x 4 X 3)-свертки. Для решения последней задачи можно
воспользоваться гнездовым методом сочетания алгоритма вычисле-
ния двумерной циклической (4X4)-свертки с алгоритмом 3-точеч-
ной циклической свертки.
Если для вычисления двумерного преобразования фурье ис-
пользуется алгоритм двумерной циклической свертки, то во всех
умножениях один из множителей всегда оказывается либо чисто
вещественным числом, либо чисто мнимым числом. Частный слу-
чай этого утверждения дается следующей теоремой, представляю-
щей собой аналог теоремы 4.6.1.
Теорема 8.5.1. Пусть р нечетное простое число и g (х, у)
многочлен Рейдера от двух переменных степени р 1 по каждой
из них. Пусть Q (х) и Q' (х) круговые многочлены, делящие х/
1. Тогда по модулю Q (х) и по модулю Q' (у) коэффициенты мно-
гочлена g (х, у) представляют собой либо чисто вещественные
числа, либо чисто мнимые числа.
Доказательство аналогично доказательству теоремы 4.6.1. ~
Можно доказать более общую теорему для случая, когда числа
точек преобразования по обеим осям равны (не обязательно одина-
ковым) простым числам или степеням простых чисел.
282 Гл. 8. Быстрые алгоритмы многомерных преобразований
Число вещественных
умножений
Нетривиальных Сложений
умножений иа иа точку
точку на выходе на выходе
Число
вещественных
сложений
Размер
массива
пХл
общее нетривиальных
32
68
108
86
113
5х 5 33
7х7 69
9х 9 109
7х 9 87
5х l3 114
230
650
908
712
917
9.20
13.26
11.21
I1.30
14. IO
1. 28
I.39
1.33
1.36
1. 74
Для комплексных входных psHHblx все цифры удваиваются
Рис. 8.I2. Характеристики некоторых алгоритмов разложения Нуссбаумера‒
Квенделла.
Характеристики некоторых по-
строенных таким способом двумерных
алгоритмов выписаны на рис. 8.12.
Если сравнить эти характеристики с
приведенными на рис. 8.18 характерч-
стиками, то можно увидеть, что для
(р X р)-точечных БПФ-алгоритмов дан-
ный способ проигрывает приведенному
на рис. 8.18.
В качестве примера рассмотрим
в мерное (7 X 7)-точечное преобразова-
7 ~У
ние Фурье. Как показано на рис. 8.13,
Рис. 8.13. Разбиение
(7X 7)-преобразования фурье. Оно РаспадаетсЯ в вычисление ДВУХ
6-точечных циклических сверток и одной
двумерной (6X6)-точечной циклической свертки. Для вычисления
каждой 6-точечной циклической свертки необходимо восемь ве-
щественных умножений. Алгоритм вычисления двумерной (6 X 6)-
свертки можно строить гнездовым методом, сочетая алгоритм
циклической (2 X 2)-свертки с алгоритмом циклической (3X 3)-
свертки, данным на рис. 7.9. Для такого вычисления необходимо
52 умножения, так что в общей сложности полу 1аем 68 умножений.
Еще одно, тривиальное, умножение (на 1) нужно для того, чтобы
представить в том же виде вычисление компоненты V0,0, это суще-
ственно при использовании данного (7 X 7)-БПФ-алгоритма в ка-
честве составляющей в гнездовом методе построения больших
БПФ-алгоритмов.
Подсчет числа сложений несколько более громоздок, и резуль-
тат зависит от того, насколько удачно организованы уравнения.
Сначала рассмотрим уравнения в том виде, как они были выписаны
выше. Тогда вычисления состоят из некоторых предсложений,
предшествующих обращению к двум 6-точечным циклическим сверт-
кам и одной (6X6)-точечной двумерной циклической свертке, и
8.5. Алгоритмы разложения
следующих за этим постсложений. Некоторые предсложения и
постсложения входят также и в алгоритмы сверток. Полное число
сложений тогда вычисляется так:
Предсложения
Две 6-точечные циклические свертки
Циклическая (6 X 6)-свертка
Постсложения
84
68
424
84
660
78
36
34
424
78
650
Это, конечно, небольшое улучшение.
В качестве второго примера рассмотрим двумерное (5X13)-
преобразование Фурье. Как показано на рис. 8.14, разобъем его
на 4-точечную циклическую свертку, f2-точечную циклическую
свертку и двумерную циклическую (4Х12)-свертку.,Яля вычисле-
ния двумерной циклической (4 X 12)-свертки преобразуем ее в трех-
мерную циклическую (4Х4ХЗ}-свертку и воспользуемся гнездо-
вым алгоритмом, сочетающим алгоритм циклической (4 Х 4}.
свертки с алгоритмом 3-точечной циклической свертки этот алго-
ритм содержит 88 вещественных умножений и 608 вещественных
сложений. Присоединяя 4-точечную циклическую свертку и 12-
точечную циклическую свертку (20 вещественных умножений и 100
вещественных сложений} и учитывая одно связанное с компонен-
Однако мы знаем, что если собрать вместе все предсложения,
включая и те, которые входят в алгоритмы сверток, то возможно
уменьшение числа сложений. Аналогичйого уменьшения числа сло-
жений можно добиться, собирая вместе все постсложения. Мы не
можем сделать это в достаточно общем виде, поскольку нет ника-
кой общей теории минимизации числа сложений и, что еще важнее,
поскольку это не позволяет построить алгоритм, хорошо распада-
ющийся на мелкие подпрограммы так, как рассматриваемый ал-
горитм. Тем не менее кое-что можно сделать. 6-точечные цикличе-
ские свертки можно скомбинировать с некоторыми предсложе-
ниями и постсложениими так, чтобы сформировать 7-точечные
преобразования Фурье. Это не меняет числа необходимых умно-
жений. Вычисления в так организованном алгоритме будут со-
стоять из некоторых предсложений, одного 7-точечного преобразо-
вания Фурье, одной 6-точечной циклической свертки, одной дву-
мерной (6Х6)-свертки и некоторых постсложений. Полное число
сложений уменьшается следующим образом:
Предсложения
7-точечное БПФ
6-точечная циклическая свертка
Циклическая (6 X 6)-свертка
Постслож ения
284 Гл. 8. Быстрые алгоритмы многомерных преобразований
4- лючечная
ццкличесиая
сеервиа
12
Рис. 8.!4. Разбиение (5X]3)-преобразования Фурье.
ную циклическую (6 X 6)-сверт-
ку и две двумерные цикличес-
кие (2X 6)-свертки. Таким об-
разом, как показано на
рис. 8.15, двумерный (7 х 9)-
БПФ-алгоритм строится из
двумерной циклической (6x6)-
свертки, двух двумерных цик-
лических (6 X 2)-сверток, 9-то-
чечного БПФ-алгоритма и 6-то-
чечной циклической свертки.
В общей сложности такой
алгоритм требует 52 + 2 х
Х16 + 10 + 8 = 102 умноже-
бх2
(дважды)
Рис. 8.! 5. Разбиение (7Х9)-преобра-
зования Фурье.
той V, тривиальное умножение, получаем (5X 13)-БПФ-алгоритм,
содержащий 114 вещественных умножений и 939 вещественных
сложений.
(5x 13)-БПФ-алгоритм с несколько лучшими характеристиками
получается, если подпрограмму 13-точечного БПФ с 20 нетри-
виальными вещественными умножениями и 94 вещественными
сложениями использовать вместо 12-точечной циклической свертки;
тогда число вещественных умножений равно 114, а число необхо-
димых вещественных сложений равно 917.
Описанный метод пригоден и в том случае, когда числа точек
по осям равны степеням простых чисел. Разбиения множеств ин-
дексов на подмножества даются теперь более сложными правилами.
Например, рассмотрим задачу вычисления двумерного (7x 9)-
преобразования Фурье. Так как число Р не является простым, то
для построения алгоритма нужен более общий, чем рассмотренный
выше, метод. Напомним, что обобщая в гл. 4 алгоритм Рейдера
на случай вычисления 9-точечной свертки, мы выбросили все
не взаимно простые с 9 индексы и свели задачу к вычислению
6-точечной циклической свертки и двух 2-точечных циклических
сверток. Поступая так же и
теперь, мы получаем двумер-
8.5. Алгоритмы разложения
2 Ъ
+~+1 к ‒ I к+1 x ‒ x+ )
1
S +У+~
у ‒ I
у+ 1
‒ У+~
2
Рис. 8.16. Разбиение двумерной (6X6)-свертки.
ний, ноэто число можно уменьшить, если более тщательно струк-
турировать алгоритм. Мы не учли того факта, что 6-точечная сверт-
ка, получающаяся при преобразовании 9-точечного преобразова-
ния Фурье по алгоритму Рейдера, приводит к нескольким умноже-
ниям на нуль. Эти умножения, описываемые .теоремой 4.6.2,
можно не учитывать.
(6X6)-свертка возникает из двумерного аналога обобщенного
алгоритма Рейдера. Для двумерного (7 X 9)-преобразования Фурье
многочлен Рейдера от двух переменных равен
б 5
g(x, у} = f (и'~ ‒ 1) x> g (pÐ ‒ 1) у"
/=0 k=0
где о первообразный корень степени шесть из единицы, a p,
первообразный корень степени девять из единицы.
Для построения алгоритма циклической (6X6)-свертки запи-
шем
1 = (х' + х + 1) (х 1) (õ + 1) (х' х + 1),
у' 1 = (S + u+ 1) (e ‒ 1) (e + 1) Ь e + 1).
и вычислим вычеты многочлена g (х, у} по модулям, равным этим
делителям. Как показано на рис. 8.16, эти вычисления можно раз-
бить на 16 фрагментов. Согласно теореме 4.6.2, фрагменты, свя-
занные с модулями (у 1) и (у+ 1), приводят K равным нулю
вычетам, и, следовательно, могут быть выброшены. В квадратах
на рис. 8.16 указаны числа умножений, необходимых при вычис-
лении кащдого фрагмента, причем в скобках приведено число ум-
ножений, необходимое в случае, когда вычет не равен нулю. От-
сюда видно, что для вычисления циклической (6X6)-свертки тре-
буется только 36 умножений, так что полное число умножений
в алгоритме (7X9)-точечного БПФ равно 86.
286 Гл. 8. Быстрые алгоритмы многомерных преобразований
8.6. Улучшенный алгоритм Винограда
быстрого преобразования Фурье
Коль скоро задача вычисления одномерного преобразования
Фурье с помощью алгоритма Гуда ‒ Томаса сведена к задаче вы-
числения многомерного преобразования Фурье, то дальше можно
ее решать сведением к многомерной свертке. Такой путь вычисле-
ния одномерного преобразования Фурье очень похож на большой
БПФ-алгоритм Винограда, но с одним отличием. Напомним, что
большой БПФ-алгоритм Винограда комбинирует два или больше
малых БПФ-алгоритмов, но не меняет их структуру. Однако
каждый из малых алгоритмов строится на основании быстрого
алгоритма свертки, так что можно ожидать, что в большой задаче
содержитея многомерная свертка. Большой БПФ-алгоритм Вино-
града не пытается извлечь из многомерной свертки никакой пользы
и он в конечном счете вычисляет ее, сочетая гнездовым способом
два одномерных алгоритма. Если многомерная свертка достаточно
велика, то характеристики можно улучшить, применяя для вы-
числения этой свертки более сильные алгоритмы. Характеристики
n'n"-точечного улучшенного БПФ-алгоритма Винограда лучше,
чем характеристики большого и'и"-точечного БПФ-алгоритма Ви-
кограда, если rp (п') и q (и") имеют обший делитель, равный по
меньшей мере четырем. Характеристики для некоторых таких
алгоритмов приведены на рис. 8.17.
В основе улучшенного алгоритма лежит сочетание трех идей:
сведение одномерного преобразования Фурье к многомерному
с помощью алгоритма Гуда Томаса, многомерный аналог алго-
ритма Рейдера и использование полиномиального преобразова-
ния для вычисления многомерной свертки Рейдера. Первая из
этих идей относится только к индексации данных. Сочетание вто-
рой идеи с третьей уже рассматривалось в предыдущем разделе
при построении алгоритмов разложения. Яля построения улуч-
шенного алгоритма надо модифицировать один из двумерных ал-
горитмов, используя перестановку столбцов матрицы предсложе-
ний и перестановку строк матрицы постсложений.
Рассмотрим сначала 15-точечное преобразование Фурье. Его
можно трансформировать в двумерное (3 X 5)-точечное преобразова-
ние Фурье. Используя далее алгоритм Рейдера вдоль каждой оси,
выделим двумерную циклическую (2X4)-свертку, записываемую
в виде
s (х, у) = g (х, у} d (х, у) (mod х4 1) (mod у' 1}.
Эта свертка так коротка, что наилучшим способом ее вычисления
является гнездовое сочетание одномерных алгоритмов свертки.
Яля п = 15 улучшенный БПФ-алгоритм не лучше большого БПФ-
287
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла
Число вещественных
умножений
Нетривиальных Сложений
умножений на на точку
точку на выходе иа выходе
Число
вещественных
сложений
Длина
л
общее нетривиальных
18
27
54
86
114
159
15
21~
35~
63
65
91
103
184
411
712
917
1560
17
26
53
85
113
158
1 ° 13
1. 24
l.51
1.37
1.74
1. 75
6. 87
8. 76
11. 74
11.30
14.10
17. 14
Для комплексных входных данных все цифры удваиваются. Для длин. помеченных звез-
дочкой. число умножений совпадает с таковым для большого БПФ-алгоритма Винограда.
Рис. 8.17. Характеристики улучшенного быстрого алгоритма преобразования
Фурье.
алгоритма Винограда, а на самом деле даже хуже, так как содер-
жит больше сложений.
Теперь рассмотрим 63-точечное преобразование Фурье. Боль-
шой БПФ-алгоритм Винограда содержит в этом случае 98 нетри-
виальных вещественных умножений и 704 вещественных сложений.
Рассмотрим улучшенный Б ПФ-алгоритм, начинающийся сведением
63-точечного преобразования Фурье к двумерному (7 х 9}-преобра-
зованию Фурье, для вычисления которого используется показан-
ная на рис. 8.15 структура. Такой алгоритм содержит 85 нетри-
виальных вещественных умножений и 712 вещественных сло-
жений.
8.7. Перестановочный алгоритм
Нуссбаумера 3(венделла
В предыдущей главе, записав многомерную свертку в виде сверт-
ки многочленов, мы смогли воспользоваться полиномиальным пред-
ставлением расширений полей для построения алгоритмов много-
мерных сверток. Теперь мы воспользуемся полиномиальным пред-
ставлением расширений полей для того, чтобы построить алго-
ритмы вычисления многомерных преобразований Фурье. Одним
из применений многомерных преобразований Фурье является,
конечно, вычисление многомерных сверток, так что фактически мы
построим другой способ вычисления многомерных сверток.
Еще раз нам удается построить хорошие алгоритмы для од-
ного класса задач, сведя этот класс к другому классу задач, для
которого решение уже имеется. Такой подход может показаться
чрезвычайно искусственным, так как сначала мы ввели полино-
миальное преобразование как одну из форм записи преобразова-
ния Фурье, а затем отказались or этой точки зрения. Теперь мы
288 Гл. 8. Быстрые алгоритмы многомерных преобразованнй
опять переворачиваем всю постановку задачи и используем поли-
номиальное преобразование для вычисления преобразования
Фурье, хотя и не того самого, которое первоначально привело
нас к определению полиномиального преобразования.
Перестановочный алгоритм Нуссбаумера Квенделла пред-
ставляет собой алгоритм многомерного быстрого преобразования
Фурье. Он строится сведением многомерного преобразования к вы-
числению некоторого количества одномерных преобразований
фурье, что и отличает его от рассмотренных в разд. 8.5 алгоритмов
разложения, в которых многомерное преобразование Фурье сво-
дится к вычислению нескольких многомерных сверток. БПФ-ал-
горитм Нуссбаумера Квенделла имеет лучшие характеристики,
но применим только тогда, когда многомерное преобразование име-
ет одинаковую длину по всем измерениям или когда все длины
имеют общий множитель, так что можно применить китайскую
теорему об остатках. В настоящем разделе рассматривается БПФ-
алгоритм Нуссбаумера Квенделла; характеристики этого алго-
ритма для двумерного случая приведены на рис. 8.18, а для трех-
мерного случая на рис. 8.19.
Алгоритм Нуссбаумера Квенделла является алгоритмом
вычисления многомерного преобразования Фурье в случае, когда
число точек во всех измерениях равно одному и тому же числу и,
которое либо просто, либо равно степени простого числа. Кон-
струкции различны для трех случаев: и простое число; и равно
степени нечетного простого числа; и равно степени двойки, и =
= 2 . Гнездовой метод позволяет из этих алгоритмов строить
большие многомерные преобразования точно таким же образом,
как это делается в случае одномерного преобразования Фурье.
Например, для построения (63x63)-преобразования Фурье сна-
чала оно отображается в четырехмерное ((7x9) X (7x9))-преоб-
разование, которое затем рассматривается как ((7x7) х (9x9))-
преобразование, для вычисления которого используется гнездовой
метод сочетания (7x 7)-алгоритма с (9x 9)-алгоритмом. Это приво-
дит к 49-кратному применению двумерного (9x9)-преобразова-
ния фурье к 49 подтаблицам данных, за которым следует 81-крат-
ное применение двумерного (7x7)-преобразования Фурье к 81
подтаблицам данных. Все алгоритмы могут быть приведены в стан-
дартную форму в виде матрицы предсложений при условии, что
каждая из (7x7)-подтаблиц сформирована как 49-компонентный
вектор и каждая из (9x9)-подтаблиц сформирована как 81-компо-
нентный вектор. (Все описанные манипуляции с входной (63x 63)-
таблицей относятся только к индексам. Они не содержат арифме-
тических вычислений и не требуют никакой физической переста-
новки данных.) Далее, так же как н для одномерного случая, можно
использовать теорему о кронекеровском произведении матриц для
приведения вычислений к стандартному виду, выделяя все пред-
289
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла
Ч исло вещественных
умножений
Нетривиальных Сложений
умножений иа иа точку
точку иа выходе иа выходе
Число
вещественных
сложений
Раэмер
массива
общее нетривиальных
Для комплексных входных данных все цифры удваиваются
Рис. 8 18. Характеристики БПФ-алгоритмов Нуссбаумера ‒ Квенделла.
Число вещественных
умножений
Равмер
массива
tt X tt X <
Число
вещественных
сложений
Нетривиальных Сложений
умножений иа иа точку
точку на выходе иа выходе
нетри-
общее виалъиых
Для комплексного входа все цифры удваиваются
Рис. 8.19. Характеристики трехмерных БПФ-алгоритмов Нуссбаумера ‒ Квен-
делла.
сложения перед всеми умножениями и все умножения перед всеми
постсложениями. Такой гнездовой метод построения алгоритма
вычисления (n'и" X и'и")-преобразования Фурье содержит
N (n n X и'и") = N (n' X n ) N (n X и")
умножений. Число тривиальных умножений описывается равен-
ством такого же типа; число сложений в алгоритме равно
А (n и" X и'и") = (и')'А (и" X и ) + М (и" X и") А (и' X и').
Вывод этих формул полностью совпадает с рассуждениями, про-
ведеными в случае одномерного преобразования Фурье. Характе-
ристики гнездовых БПФ-алгоритмов Нуссбаумера Квенделла
приведены на рис. 8.20.
2Х2 4
ЗХЗ 9
4Х4 16
5Х5 31
7Х7 65
8Х8 64
9Х 9 l05
16Х 16 304
2Х 2Х2 8
ЗХЗХЗ 27
4Х4Х4 64
5Х 5Х 5 156
7Х 7Х 7 457
8х 8х 8 512
9х 9х 9 963
16Х 16Х 16 4992
0
8
0
30
64
24
104
216
0
26
0
155
456
224
962
3808
8
36
64
221
635
408
785
2264
24
162
384
1 686
6 767
4 832
10 383
52 960
0
0.89
0
I.20
l.31
0.375
1. 28
0.84
0.00
0.96
0.00
1.24
1.33
0.44
1.32
0.93
2
4
4
8. 84
12.96
637
9,69
8 85
3.0
6.0
6.0
13.5
19. 7
9.4
14.2
I2.9
290 Гл. 8. Быстрые алгоритмы многомерных преобразований
Число вещественных
умиожеиий
Число
вещественн-
ыхх сло-
жений
Нетривиальных Сложений
умножений иа иа точку
точку на выходе иа выходе
Размер
массива
нетри-
виальных
общее
Для комплексных данных все цифры удваиваются
Рис, 8.20. Характеристики некоторых гнездовых БПФ-алгоритмов.
Изучаемые в настоящем разделе алгоритмы строятся сведением
двумерного (р х р}-преобразования Фурье к вычислению (р + 1}
одномерных р-точечных преобразований Фурье для случая, когда
число р простое. Яля иллюстрации структуры, с которой мы будем
работать, рассмотрим пример двумерного (ЗхЗ}-преобразования
Фурье. Если записать входную и выходную (3x3)-таблицы по
столбцам в виде векторов с 9 компонентами, то рассматриваемое
[3 x3)-преобразование запишется в виде
VÎ.0
V>,0
и2.0
U0!
и11 ч
и02
и~2
где разделение на подматрицы сделано для того, чтобы выявить
структуру кронекеровского произведения. Кратко это равенство
записывается в виде Ч = Wv, где v и Ч обозначают выписанные
выше входной и выходной векторы соответственно, а элементы ма-
трицы W равны степеням элемента о. Нашей целью является по-
12 12
l5 l5
21 21
30 30
35 35
48 48
63 63
80 80
120 120
I68 168
240 240
420 420
504 504
840 840
1008 1008
2520 2520
144
279
585
I 116
2 015
2 736
6 825
9 424
17 856
37 440
84 816
290 160
436 800
I 160 640
2 074 800
13 540 800
V2,0
~'о >
V,,
~2Ю
V02
"12
v„„
128
278
584
I 112
2 014
2 648
6 824
9 336
17 816
37 400
84 728
290 144
436 760
1 160 600
2 074 712
13 540 760
I 152
2 889
7 499
13 356
30 240
29 592
102 460
123 784
276 696
658 584
I 344 456
5 765 760
8 176 792
24 738 840
40 133 656
298 481 560
0.89
I.24
1.32
I.24
I.64
I. I5
I.72
I.46
I.24
I.32
I.47
' l.65
I.72
I.64
2.04
2. 13
8.00
I2.84
I6.96
I4.84
24.90
I2.84
25.81
I9.34
I9.21
23.33
23.34
32.69
32. 19
35.06
39.50
47.00
291
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла
строение разложения % = СВА, где А и С представляют собой
соответственно матрицы предсложений и постсложений, а матрица
В задает набор одномерных преобразований Фурье. В данном при-
мере матрица В имеет вид
где незаполненным блокам соответствуют нулевые (Зх 3)-матрицы.
Разложение % = СВА замечательно похоже на запись малого
БПФ-алгоритма Винограда. Сейчас, однако, мы находимся на
совершенно ином уровне: стоящая в центре разложения блочно-
диагональная матрица представляет собой пакет одномерных пре-
образований Фурье, а не пакет умножений. Коль скоро такое раз-
ложение уже получено, двумерное (3~3)-преобразование Фурье
вычисляется последовательным выполнением предсложений, за-
даваемых матрицей А, четырехкратным обращением к 3-точечному
одномерному БПФ и выполнением постсложений, задаваемых
матрицей С. Как мы увидим позже, для некоторых одномерных пре-
образований Фурье надо вычислять не все члены; эта обсуждае-
мая дальше процедура названа выколотыми БПФ-алгоритмами
и позволяет еще немного уменьшить вычислительную нагрузку.
Одномерное преобразование Фурье можно трактовать как про-
цесс вычисления значений многочлена v (х) в точках и":
~д ‒ ‒ v(e~), Й= О, ...,n 1,
где
n ‒ 1
v(x) = g цх'.
4 =4)
:Хта же трактовка применима и к двумерному преобразованию
фурье, причем более плодотворным оказалось использование та-
кого описания только вдоль одного из измерений двумерного пре-
образования. Запишем (п X и)-таблицу в.виде вектора длины п,
~компонентами которого являются многочлены
и ‒ 1
v( (х)= g v~ ~-х', Е"=О,..., п ‒ 1.
с '=о
292 Гл. 8. Быстрые алгоритмы многомерных преобразований
Определим одномерное преобразование Фурье вектора многочле-
нов равенствами
л ‒ 1
Vq- (х) = g ь)'"~"v<- (х), k" = 0,..., п ‒ 1.
l" — 0
\
Тогда двумерное преобразование Фурье запишется в виде
k' О, ..., и ‒ 1,
Va ..- = R,, [V~. (x)) = Vk- (~'),
ф ° ° ° ф у
В этом определении оси двумерного преобразования Фурье не-
равноправны и играют разную роль.
Теперь у нас уже все готово для того, чтобы, используя
некоторую разумную технику перестановок, начать переход от
преобразования Фурье к полиномиальному преобразованию.
Пусты обозначает некоторое положительное целое число, взаимно
простое с п. Пусть Й" = ((Йг}}„для некоторого Й из множества
«О, ..., п 1}. Это задает неявный способ перебора всех зна-
чений индекса k", так как в силу взаимной простоты r и и, когда k
пробегает все значения от 0 до и ‒ 1, число k также пробегает все
значения от 0 до и ‒ 1. Тогда, так как порядок элемента ь равен и,
ь~" = ®~', и два предыдущие равенства можно для любого r, вза-
имно простого с и, переписать в виде
tl ‒ 1
)'«д,)) (х) = g ь)'"~'о)- (х),
ю"=о
k' = О, ..., n ‒ 1,
1~~ . «ь» = 1~. ~' Жи.» (х})
э ° ° ° ч
Если k' само взаимно просто с и, то можно положить r равным k'
и тогда второе равенство принимает вид
k О, ..., и ‒ 1.
НОД(Й', n) =
Каждая компонента выходной таблицы, первый индекс которой
взаимно прост с и, может быть записана таким образом.
Завершив на этом вводную часть, переходим к построению
полиномиального преобразования. Следующая теорема представ-
ляет собой скачок прямо к окончательному результату. Читая эту
теорему, необходимо иметь в виду, что все те k которые относятся
к одному и тому же круговому многочлену, требуют одних и тех же
вычислений, что один и тот же индекс k' используется и в качестве
выходного индекса, и для формирования перестановки, и что де-
ление на k' определено, так как k' и и взаимно просты.
Теорема 8.7.1. Пусть Й' фиксированное целое число, взаимно
простое с п. Пусть Q (х) обозначает круговой многочлен, корнем
293
8.7. Перестановочный алгорнтм Нуссбаумера ‒ Квенделла
которого является элемент ь~'. Тогда вычисление компонент
д- для k" = О, ..., и ‒ 1 может быть реализовано в виде
следующих трех шагов: (1) вычислить полиномиальное преобраэо-
вание
и ‒ 1
Vk (x) = g о~-(х) x'"k (mod Q (x)), Й =0, ..., п ‒ 1;
(2) вычислить и преобраэований фурье
Й': НОД (Й', п) = 1,
й=О,..., n ‒ 1;
л ‒ 2
Vk . k = $ ь)'ь'Vi . ь
С'«1
(3) сделать перестановку
Й'. НОД (Й', п) = 1,
Vp . ~- = Vp . ((g,-gp )),
к = О, ...e n ‒ 1.
Яокаэательство. Рассмотрим равенства
л ‒ 1
V<<kk )) (х) = g cD~ kk'о~- (х),
C"=0
Vk . ((kk )) = Я, „k [V((kk )) (x)l
I
Так как х ь)~' делит круговой многочлен Q (х}, то второе из
авенств не нарушится, если первое вычислять по модулю Q (х}.
о позволяет переписать равенства следующим образом:
Л ‒ g
V((kk )) (х) = g о)- (х} ь)~'"" (mod Q (х)),
С"=0
n ‒ 2
Vk . ((kk )) = R „ь [V((kk )) (x)l = z k) "k'Vi ((kk )).
С '=0
С"=0
л ‒ 2
4 . ((kk'í = R, Äk Г«ы )) (x)] = p"'Vi . «и )).
С'=0
Теперь для завершения доказательства теоремы остается уточ-
нить обозначения и переписать равенства в окончательном виде. ~
Зту теорему надо применить к трем различным случаям, соот-
ветствующим равенству числа точек по каждой размерности дву-
мерного преобразования простому числу, степени нечетного про-
Ио теперь, согласно второму равенству, элемент ь~' сравним с х.
Поэтому замена а~' на х в первом равенстве не приведет к измене-
нию окончательного результата. Это позволяет еще раз переписать
исходные равенства в виде
л ‒ 3
Г«ц, » (х) = Z о)" (х) х'"" (mod Q (х)),
294 Гл. 8. Быстрые алгоритмы многомерных преобразований
Иреобраэования
Фурье
Дополнительуц~е
сложения
Дли
Полиномиальные
преобразования
ина и
Простое р-точечное прербразо- р + 1 преобразова- р~ + р2 ‒ 5p + 4
число р вание по модулю ний» длины р
(х ‒ i)/(» ‒ Ц
Степень
простого
числа р2
p + 1 преобразова-
ний' длины р
Pm+ Ц Р ‒ -"
(3/'2) 2'" преобразо-
ваний»* длины 2~
Степен ь 2~-точечное преобразо-
двойки 2ò вание по модУлю
» '+!
2~-точечное преобра-
зование по модулю
х2 +1
Одно двумерное
преобразование раз-
мера 2~1 ~Х2~ 1
И8 которых р выколотыi
Из которых все выколоты.
Рис. 8.2l. Подпрограммы, используемые в БПФ-алгоритмах Нуссбаумер� ‒-
аКвенделл.
стого числа и .степени двух. Рассмотрим последовательно все три
случая; результаты анализа подытожены на рис. 8.21.
Число r точек в каждом измерении просто. Ири простом числе
точек теоремой можно воспользоваться для того, чтобы свести вы-
числение двумерного (р X р)-преобразования Фурье к р + 1 раз-
личным одномерным преобразованиям Фурье. В более общем слу-
чае метод позволяет свести N-мерное, р-точечное по каждому из-
мерению преобразование Фурье к (р~ 1)/(р 1) различным
одномерным р-точечным преобразованиям Фурье. Это можно срав-
нить с прямым методом вычисления N-мерного р-точечного по каж-
дому измерению преобразования Фурье, содержащим Npw ' раз-
личных одномерных р-точечных преобразований Фурье.
Для простых р имеет место разложение
хр ‒ 1 = (х ‒ 1) (хр ‒ '+ хр ‒ '+... + х+ 1).
р~-точечное преобразо-
вание по модулю
(хР ‒ 1)/(хР ‒ 1)
р-точечное преобразо-
вание по модулю
(х ‒ i)/(» ‒ S)
р-точечное преобразо-
вание по модулю
(хР ‒ i )/(х ‒ 1)
р2+ р преобразо- 2р~+ р~ ‒ 5p +
ваний»» длины p~ + р~+ 6
295
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла
ВхОд
ВьюОд
Рис. 8.22. Перестановочный алгоритм Нуссбаумера ‒ Квенделла.
Каждое ненулевое й" является корнем второго кругового много-
члена. Согласно теореме 8.7.1, для вычисления компонент V~ д
при Й' = О, ..., р 1 и Й" = 1, ..., р надо вычислить одно поли-
номиальное преобразование и р одномерных преобразований
Фурье длины р. Чтобы завершить вычисление, надо найти еще ком-
296 Гл. 8. Быстрые алгоритмы многомерных преобразований
Выколотое вреобразование Фурье
т-! ~
свС оС, й ~~= 0 (moC} P),
С=1
л 1 т
Нормальное БПФ Винограда
Выколотое БПФ Винограда
Число умножений
Длина Число умножений~
Число Число
сложений обш нетРи сложений~
ви'альных
нетри-
виальных
2
3
4
6
9
8
11
18
0
2
0
5
8
2
10
10
2
6
8
17
36
26
44
74
2
3
4
5
7
8
9
16
4
2
15
34
10
28
32
2
2
5
8
4
8
10
~ Для комплексных входных данных все цнфры удванваются
Рис. 8.23. Характеристики некоторых выколотых БПФ-алгоритмов.
поненты V>-, >- с й", равным нулю. Но они получаются сразу как
результат еще одного преобразования Фурье:
р ‒ 1 р ‒ 1
V, ~ ‒‒ ~; и'~' g v;.~-, k'=0, ..., p ‒ 1.
С"=О
Таким образом, всего получаем р+ 1 одномерных преобразо-
ваний Фурье длины р. На рис. 8.22 приведена блок-схема алгоритма
для простого р. На последнем шаге осуществляется обратная
перестановка компонент, для чего используется обращение k'
по модулю р.
Есть еще одно упрощение. У большинства преобразований
Фурье некоторые коэффициенты отсутствуют, так что соответ-
ствующие преобразования можно упростить с помощью выкалыва-
ния выбрасывая те входные компоненты, которые заведомо рав-
ны нулю, и те выходные компоненты, вычислять которые нет на-
добности. Как видно из блок-схемы на рис. 8.22, в основном шаге
алгоритма, связанном с вычислением р-точечных преобразований
Фурье векторов длины р 1, коэффициент старшего порядка
всегда равен нулю и нужны только р 1 выходных компонент,
а младший коэффициент можно отбросить. Такие выколотые
БПФ-алгоритмы и их вычислительные характеристики представ-
лены на рис. 8.23.
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла
В качестве примера БПФ-алгоритма Нуссбаумера Квенделла
построим пример (Зк3)-БПФ-алгоритма. Первый фрагмент вы-
писывается проще всего:
V01 = 1 Q) Q) U01 + U11 + U21
Теперь заметим, что круговой многочлен равен Q (х) = х' + х +
+ 1 = (х' 1)/(х 1) и
Up (») = va,î» + оьох + vo.o
и (х) = va.a»a + va,>» + v,o,,„„
Од (Х) = по,о» + Ul.a» + Оо,о °
Вычисление полиномиального преобразования по модулю х' +
+ х + 1 приводит к многочленам первой степени. Хотя приведе-
ние по модулю Q (х) можно и отложить, мы сразу заменим исход-
ные многочлены их вычетами по модулю Q (х):
Vo (») = (Ua,о Va,î)» + (Vo,î Va,о)в
va (») = (п1,1 пи,1)» + (Up,д Ua,a).
о (Х) (01,2 оо,a) Х + (Uo,о Va.a) .
Полиномиальное преобразование равно
0(X
I 1 1'0(Ъ
е g(L
.2
l 2(L
.2
(mod Q(v)).
1(Х)
2(>
Это равенство можно переписать в виде
~0,0
~l.0
~0,1
<00 1~2 0
UI 0 2~20
>О1 U2 i
U11 ‒ u2 >
U02 и22
U1.2 U2,2
Следующий шаг состоит в 'вычислении результатов выколотых
ОПФ-алгоритмов. Вместо полного преобр азова ни я Фур ье вида
VOp ~ ~ ~ ~Ok
1
<а 2 Са О
298 Гл. 8. Быстрые алгоритмы многомерных преобразований
нужны только выколотые преобразования Фурье
при й = О, 1, 2. Соединяя их вместе, получаем
У"
У;„
уи
I..I
у
У;,
у~э
уою
у~а
уо >
У~,
Уо2
г
Теперь надо выполнить обратную перестановку компонент:
0 0
0 0
0 0
0 !
! 0
0 0
~>,о
У2о
У»
у2]
У,"~
У~"д
1 0 0 0
0 ! 0 0
0 0 ! 0
0 0 0 0
0 О 0 0
0 0 0 l
~i,î
уело
у.
уг.
У.2
У*
Наконен, собирая вместе все фрагменты, получаем окончатель-
ную форму алгоритма, показанную на рис. 8.24.
Число точек по осям раано степени простого нечетного числа.
Для описания техники построения алгоритма достаточно рассмо-
треть случай, когда число точек по каждой оси двумерного преобра-
зования равно квадрату нечетного простого числа. По существу
техника остается той же, что и в первом случае, несколько услож-
няясь за счет того, что сначала надо отобрать индексы, идентифи-
цирующие подлежащие отдельной обработке компоненты. В этом
отношении очень полезной оказывается многочленная символика-
Например, так как единственными делителями p' являются 1,
р и p', то, согласно теореме 5.5.3, многочлен x>' 1 разлагается
по правилу
хр' ‒ 1 = (х ‒ 1) (x> ‒ ' + x> ‒ з +... + х+ 1) (x> <> '>'+
-+-х "-">+."+x +1)=@ (х)Д (х) О.(х)
на круговые многочлены. Индексы й разбиваются на три подмно-
жества, соответствующие трем множествам сопряженных элемен-
тов, на которые корни из единицы, в~, разделяются круговыми
многочленами. Воспользуемся теоремой 8.7.1 для обработки ком-
понент, индексы которых входят в множество сопряженных эле-
8-7. Перестаиовочный алгоритм Нуссбаумера ‒ Квенделла
299
О О О
1 1
О О О
О
1 1
О О О
1
О
1
О О
1
»ОО
О О О
О
1
О О О О
О О
1
1 1 1
я' = О, ..., р' ‒ 1,
O O O -. О ‒ O
1=0,..., р ‒ 1.
О О О О O
р ‒ !
1
о( ° г= Е vl.r+Ip
С=О
i'=0,..., р' ‒ 1,
Оэ ° ° ° ф р 1э
o o o — гч еч еч
2ь ~ ь 2~ ~ «ь
О
3Ф
С4
ментов, соответствующее многочле-
ну Qp. (х). Это потребует выполне-
ния одного полиномиального пре-
образования p' членов по мо-
дулю Qps (х} и р' выколотых р'-то-
чечных преобр азований Фурье.
Для завершения этого фра-
гмента вычислений надо найти
компоненты ~д- д- с индекса-
ми Й", кратными р. Эти компо-
ненты задаются равенствами
ре ~ рв [
СюДю Я~ 9 Р~С
VP'gp= Е co Z >
С '=0 С-=0
Внутреннюю сумму можно транс-
формировать в р-точечное преоб-
разование Фурье. Обозначим че-
рез у = оР корень степени р из
единицы, пусть
и пусть V> с ‒‒ ~д,ср. Тогда
рв ‒ ! р ‒ 1
У»,, ~>',дат ~ у~о,',,
С => =0
Теперь поменяем порядок сумми-
рования и Опять примеHHM тео-
рему 8.7.1. Для этого нам потре-
буется еще одно полиномиальное
преобразование р членов по мо-
дулю Qp. (х) и еще р выколо-
тых р'-точечных преобразований
фурье. Остающееся при этом
О О О О О О О О
О O O О О О О О
О О О О О О О
О О О О О О О О
О О О О О О О О О
О О О О О О О O
О O О О О О » «О O
О О О О О О О О
О О О О О О О
5
Ф~
М
t
О
О
X
й
И
о
Фю
ФЯ
~8~
Е
N
фф
X
Щ
300 Гл. 8. Быстрые алгоритмы многомерных преобразований
двумерное (р х р)-преобразование Фурье может быть вычислено
как и ранее.
В общей сложности алгоритм содержит р' + р одномерных
р'-точечных преобразований Фурье и р + 1 одномерных р-точеч-
ных преобразований Фурье. 3а исключением одного р-точечного
преобразования все преобразования Фурье являются выколотыми.
Число точек по осям равно апепени двух. Хотя конструкция для
случая, когда число точек по осям двумерного преобразования рав-
на степени двух, по существу совпадает с описанной выше, она
все-таки отличается настолько, что заслуживает отдельного рас-
смотрения. Так как все нечетные меньшие чем 2 целые числа
взаимно просты с 2, ~о к компонентам с этими индексами опять
применима теорема 8.7.1. Компоненты ~д, ~- для нечетных A,'
и й" = О, ..., п 1 вычисляются применением и;точечного поли-
номиального преобразования по модулю (х"~з + 1) и п одномерных
п-точечных преобразований Фурье при n = 2 . В данном случае
полиномиальное преобразование может быть организовано в виде
БПФ-алгоритма Кули Тычки по основанию 2. Тогда число сло-
жений будет пропорционально и log, п. Все преобразования
Фурье будут выколотыми с равными нулю входными компонен-
тами с четными индексами.
Мы описали вычисление одной половины компонент ~д д-,
для которой Й' нечетно и Й" = О, ..., п 1. Теперь поменяем ро-
лями Й' и Й" и вычислим оставшиеся невычисленными компоненты
1га., д- с нечетными k" и четными k'. Для этого нам понадобится еще
одно полиномиальное преобразование и еще п(2 одномерных пре-
образований Фурье.
Наконец, остается вычислить компоненты ~д д-, оба индекса
которых четны. Но они образуют (2 ‒ ' x2 ')-точечное преобра-
зование Фурье, вычисление которого можно организовать по той
же схеме, что и вычисление (2 x2 )-точечного преобразования
Фурье.
Задачи
8. 1. Выписать таблицу для числа сложений и умножений алгоритма вычисления
двумерного преобразования Фурье, использующего различные одномерные
алгоритмы преобразования Фурье по строкам и по столбцам.
8.2. Для рассмотренных в разд. 8.1 БПФ-алгорнтмов Кули ‒ Тычки по осно-
ванию 2 и 4 определить число необходимых сложений.
8.3. Пусть A (и) и М (и) обозначают число сложений и число умножений в БПФ-
алгоритме Винограда длины Ь.
а. Доказать, что а гнездозом методе сочетания н'-точечного алгоонтма
с и"-точечным алгоритмом для минимизацни числа сложений числа д и и
должны выбираться так, чтобы выполнялось условие
[М (и') ‒ и')/А (и') О [М (и") ‒ и" ЦА (и").
6. Провести аналогичный анализ отдельно для числа предсложеиий и чис-
ла постсложений.
30!
Задачи
а. По заданным малым 2-точечному и 5-точечному БПФ-алгоритмам Вино-
града
8.4.
0 I
! 0 0 0 0 0
1 1 ‒ 1 0
! ! - I I 0 I
I I ‒ I ‒ I 0 ‒ 1
I l I 0
1 1 ! ! I
О 1 I ! 1
0 I ‒ I ‒ I I
О l ‒ I I †!
0 0 ‒ I I 0
0 1 0 0 ‒ 1
!
‒ I 25
559
J.951
g 1538
‒ / 363
и<>
V(
Vg
V1
~4
построить большой !0-точечный БПФ-алгорнтм Винограда
б. Сколько вещественных умножений содержит этот алгоритм?
в. Сколько вещественных умноженнй будет содержать алгоритм, в KOToðoì
2-точечный и 5-точечный алгорнтмы сочетаются по методу Гуда ‒ Томаса?
г. Предположим, что этот 10-точечный БПФ-алгоритм используется по
методу Кул и ‒ Тьюкн для построення 1000-точечного БПФ-алгорнтма.
Сколько вещественных умножений будет содержать такой алгоритм? Как
он соотносится с 1024-точечным БПФ-алгоритмом Кули ‒ Тьюкн по осно-
ванию 2?
д. Предположнм, что вместо выписанного ранее 2-точечного алгорнтма
используется следующий алгоритм:
Ii
Что получится, проигрыш нли выигрыш?
Для вычнслення преобразованнй Фурье длин 72, 315 н 5040 можно восполь-
. зоваться большим БПФ-алгоритмом Винограда. Найти число необходимых
сложений и чнсло необходимых умноженнй в таких алгорнтмах.
Построить алгоритм вычнсления двумерного (256Х256)-точечного преобра-
зования Фурье, сочетая БПФ-алгоритм Кули ‒ Тычки с перестановочным
алгоритмом Нуссбаумера ‒ Квенделла. Сколько умножений и сложений
содержит алгоритм?
Описать построение !040-точечного БПФ-алгоритма, основанного иа трех-
мерйой цнклнческой свертке. Сколько умножений необходимо?
Имеется много способов построения двумерного (63Х 63)-БПФ-алгоритма.
Найти чнсло умножений, необходимых н каждой из следующих процедур.
а. Гнездовой метод сочетання 63-точечного одномерного БПФ-алгорнтма
с самим собой. (Какие здесь име1отся возможности выбора?)
б. Гнездовой метод сочетання двумерного (7Х7)-БПФ-алгоритма с дву-
мерным (9Х 9)-БПФ-алгоритмом.
в. Алгоритм разложения Нуссбаумера ‒ Квенделла, снодящий задачу
к четырехмерному (7Х 7Х9Х9)-БПФ-алгоритму.
Для каких значений и перестановочный алгоритм Нуссбаумера ‒ Квен-
делла вычисления двумерного преобразования Фурье ие прнносит преиму-
ществ по сравнению с гнездовым методом сочетания одномерных алго-
ритмов? Изменится ли вывод в случае трехмерных преобразований (если
число точек простое)?
8.6.
8.6.
8.7.
8.8.
8.9.
302 Гл. 8. Быстрые алгоритмы многомерных преобразований
8.10. Описать структуру алгоритма разложения для вычисления двумерного
(5X5)-преобразования Фурье, содержащую 230 сложений, и структуру,
содержащую 236 сложений.
8.11. а. Доказать, что многочлен Рейдера от двух переменных g (х, у) равен
произведению многочлена от х на многочлен от у.
б. Сформулировать н доказать для двумер ных преобразований Фурье
аналог теоремы 4.6.2.
8.12. Построить (5Х5)-БПФ-алгоритм Нуссбаумера ‒ Квенделла.
8.13. Отталкиваясь от 4-точечного БПФ-алгоритма и двумерного (ЗХЗ)-БПФ-
алгоритма, описанного в данной главе, построить двумерный (12Х 3)-БПФ-
алгоритм.
Замечания
Простейший нз алгоритмов вычисления двумерного преобразования Фурье
сводится к последовательному выполнению одномерных преобразований по обеим
осям двумерной таблицы. Поэтому все быстрые алгоритмы вычисления одномер-
ных преобразований в готовом виде были перенесены íà двумернь;й случай.
Существенно двумерные алгоритмы возннклн позже. Двумерное разбиение типа
Кули ‒ Тычки было предложено Райвордом [1] (1977) и обобщено в работе
Гарриса, Макклеллана, Чэна и Шусслера [2] (1977). Мерсере и Спик [3] (198!)
описали изящную унификацию различных двумерных БПФ-алгоритмов Кули‒
Тычки.
С целью создании более эффективной упаконки алгоритмов Виноград [4]
(1976) предложил гнездовой метод соединения своих малых одномерных алго-
ритмов. Двумерные алгоритмы его интересовали как некоторое искусственное
средство построения алгоритмов одномерных преобразований Фурье, но эта же
техника применима н к возникающим естественным путем двумерным преобра-
зованиям Фурье. Дальнейшее развитие гнездовой метод Винограда получил
в работах Колбы и Паркса [5] (1977) и Сильвермена [6] (1977). Методы по-
строения последовательности БПФ-алгоритмов, промежуточных по отношению
к БПФ-алгоритмам Гуда ‒ Томаса и БПФ-алгоритму Винограда, были рассмо-
трены Джонсоном и Баррасом [7] (1983). Использовать полиномиальное преобра-
зование Нуссбаумера для вычисления преобразований Фурье предложили Нусс-
баумер и Квенделл [8] (1~79). Другую структуру алгоритма вычнсдения дву-
мерного преобразования, основанную на связанных с циклическими структурами
расширений полей Галуа перестановках, описали Ауслендер, Фейг и Виноград
[10] (1983). Характернстики этого алгоритма близки к характеристикам БПФ-ал-
горитма Нуссбаумера ‒ Квенделла.
Глава 9
АРХИТЕКТУРА ФИЛЬТРОВ
И ПРЕОБРАЗОВАНИЙ
Сейчас, когда у нас уже есть такой большой набор алгоритмов
цифровой обработки сигналов, пришло время обсудить их реализа-
цию. Основной целью данной главы является рассмотрение вопро-
сов реализации построенных алгоритмов на цифровых фильтрах.
Будут рассмотрены также некоторые другие задачи, такие как
интерполяция, прореживание и дискретное преобразование Фурье.
Используя гнездовые и каскадные методы, мы построим из малых
фрагментов большие структуры для обработки дискретных сиг-
налов.
Наиболее важным устройством в обработке дискретных сигна-
лов является КИП-фильтр. На фильтр поступает входной поток
отсчетов цифровых данных, и на выходе фильтра формируется вы-
ходной поток отсчетов данных. Длины этих потоков данных
очень велики; возможно, каждую секунду через фильтр проходят
миллионы отсчетов. Быстрые алгоритмы фильтрации всегда раз-
бивают поток входящих данных на пакеты, содержащие, возможно,
сотни отсчетов. Единовременно обрабатывается только один пакет;
результат обработки помещается в выходной буфер, данные из
которого считываются с необходимой скоростью.
9.1. В ычисление свертки секционированием
В гл. 3 было построено много алгоритмов вычисления цикличе-
ской свертки. Их можно использовать как непосредственно, так
и в качестве модулей для построения хороших алгоритмов преобра-
зования Фурье подобно тому, как это сделано в гл. 4. БПФ-алго-
ритмы, в свою очередь, могут быть использованы для построения
эффективных алгоритмов вычисления свертки, особенно когда
длина велика. В основе такого вычисления лежит теорема о сверт-
ке, согласно которой циклической свертке во временной области
n ‒ 1
й = ~'.~ яцж ‒ ж>>А ю=О,..., и ‒ 1,
А=О
в частотной области соответствует произведение
S> ‒‒ G>D~, А=О,..., и ‒ 1.
304 Гл. 9. Архнтектура фильтров н преоораэованнй
Следовательно, одним из возможных путей вычисления цикли-
ческой свертки являегся вычисление преобразования Фурье, по-
компонентного произведения и обратного преобразования Фурье.
Обычно для такого вычисления длину преобразования Фурье
выбирают равной длине свертки; цо иногда этот способ оказы-
вается полезным даже при нарушении столь разумного условия.
Для БПФ-алгоритма может оказаться более подходящей другая
длина преобразования.
Выберем удобную для построения преобразования Фурье
длину и', такую, чтобы выполнялось условие и' >~ 2и, и удлиним
векторы g, d u s так, чтобы компоненты с индексами i = О, ...,
и 1 принимали предписываемые им циклической сверткой дли-
ны и значения, несмотря на то, что вычисления производятся на
удобной для преобразования Фурье длине и'. Например, определим
i 0, ..., и ‒ 1,
i = О, ..., и' ‒ 1,
~=0,..., и ‒ 1,
gpss
О,
i=n,..., и' ‒ и ‒ 1,
gr =
i=n' ‒ и,..., и' ‒ 1,
gt+O ‒ l3 ' э
л ‒ 1
где теперь двойные скобки обозначают вычисление по модулю и'.
Тогда sg ‒‒ sg для ~ = О, ..., и 1. Остальные значения sg
не представляют интереса и могут быть отброшены.
Имеется много методов сведения вычисления длинных линей-
ных сверток к последовательности вычислений коротких цикличе-
ских сверток. Повсеместно возникает необходимость фильтрации
столь длинных последовательностей, что при прохождении через
КИО-фильтр с конечным числом отводов их можно считать беско-
нечными. Такая фильтрация должна вычисляться по частям по
ходу дела. Накопить все входные данные перед началом вычисле-
ний выходной последовательности невозможно, так как это при-
водит к задержкам и к тому же требует большой буферной па-
мяти, и хорошие алгоритмы вычислений не используют всех
входных данных сразу. Входные данные разделяются на сегменты,
и, как только один сегмент становится полностью доступным,
начинается его обработка.
Мы сначала опишем метод, известный под названием метода
иерекрыяия с накоплением. Предположим, что у нас имеется уст-
ройство вычисления циклической свертки длины и, и что нам нужно
умножить многочлен g (х), степень А которого меньше п, на мно-
9.1. Вычисление свертки секционнрованием
гочлен d (х), степень В которого больше и. Обычно В очень ве-
лико и можно полагать его равным бесконечности. По миогочлену
d (х) построим множество многочленов (И<о> (х), d«> (х), ...} сте-
пеней и < или меньше, полагая их коэффициенты равными
дгО) д i=0,..., и ‒ 1,
(1)
А = 4+(ю ‒ А), ю=О,..., и ‒ 1,
А = А+2 (л ‒ А)ю 1=0,..., и ‒ 1,
° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° °
Ъ
Многочленов должно быть достаточно для исчерпания всех коэф-
фициентов многочлена d (х). Заметим, что так построенные много-
члены перекрывают друг друга. Для каждого l определим
з«> (х) = g (x) d«> (х) (mod х" ‒ <).
Тогда, так как s (х) = g (х) d (х), то за исключением первых
А коэффициентов, коэффициенты многочлена s (х) находятся среди
коэффициентов многочленов з<'> (х). А именно,
i=A,..., n ‒ 1,
i=A,..., и ‒ 1,
(о>
Ф E э
Й+(~ ‒ А) =Sc э
(1)
(2)
Й+2 (n ‒ А) = Sg э
i=A,..., и ‒ 1
и так далее. Таким образом мы получаем на выходе фильтра бес-
конечную последовательность данных. Первые А младших коэф-
фициентов многочлена s (х) теряются. Во многих приложениях
линейной свертки такая потеря в начале фильтрации является
несущественной. Если же на выходе нужны все коэффициенты, то
надо просто заменить многочлен d (х) на многочлен х" d (х). При
этом будут вычислены все коэффициенты свертки, на индексы их
будут сдвинуты на величину А.
Каждая из рассмотренных циклических сверток за исключе-
нием последней вычисляет и А коэффициентов искомой линей-
ной свертки и А бесполезных коэффициентов, которые просто
отбрасываются. Поскольку степень последнего входного сегмента
d<'> (х) может быть меньше и <, то последняя свертка может
содержать больше, чем и А, значимых коэффициентов.
На самом деле в методе перекрытия с накоплением нет необхо-
димости вычислять полную циклическую свертку, так как нужны
не все ее коэффициенты, а только и А из них. Следовательно,
подавляя ненужные коэффициенты, можно построить алгоритм,
который несколько проще полного алгоритма вычисления цикли-
ческой свертки. Алгоритмы описанного типа, независимо от того,
проводится ли прямое вычисление или используется алгоритм
вычисления циклической свертки, называются алгоритмами сек-
ционной филыпрации. Они будут изучаться в следующем разделе.
306 Гл. 9. Архитектура фильтров и преобразований
КИО-шильтр
Входной
попгок
донных
Выходной
поток
данных
а) Функциональная схема
КИО- (рильтр
Входной
Выходнос7
покупок
даиных
поток
данных
б) Схема реалилщии
Рис. 9.1. Конструкция КИО-фильтра.
Основанная на методе перекрытия с накоплением конструкция
КИО-фильтра показана на рис. 9. I. Функциональная схема такого
фильтра похожа на линию задержки с отводами, но истинная кон-
струкция может быть существенно другой. Поступающие входные
слова подаются в циклическую буферную память, которая в типич-
ных случаях вдвое больше секции фильтра. Во время фильтрации
данных из одной части буфера, во вторую его часть записываются
данные следующей секции, подготавливая блок данных для сле-
дующего шага вычислений. Текущая секция данных перекрывается
с новой секцией. Фильтрация блока данных длины и занимает то же
время, что и запись нового блока из и А точек.
Входной буфер является циклическим. Это означает, что после
того, как его последний элемент заполнен, следующие входные
символы записываются, начиная с первого элемента памяти. Та-
ким образом, старые данные уничтожаются, а на их место записы-
ваются новые данные. Обычно удобно длину входного буфера вы-
бирать равной степени двух. Записанное в двоичном регистре число
указывает адрес, по которому запоминается следующий вход, и
после каждого входа содержимое регистра увеличивается на еди-
ницу. Свойство цикличности буфера очень легко обеспечить тем,
9.1. Вычисление свертки секционированнем
E 0,...,n ‒ А ‒ 1,
i=0,..., и ‒ А ‒ 1.
dg = dg+(n nА),
г2)
= 4+2 (~ ‒ А)э
~э)
Отметим, что так построенные многочлены не перекрываются.
Тогда многочлен d (х) может быть записан в виде
ОО
d (x) = g d<'> (х) х<' ‒ ц <" ‒ ">
l=l
что предусмотреть возможность переполнения адресного ре-
гистра после достижения состояния, в котором во всех его раз-
рядах записаны единицы.
Секционный фильтр отыскивает в памяти блок данных, адреса
которых равны ((Ь)), ..., ((Ь + и 1)), где b начальный адрес
и двойные скобки обозначают вычисление по модулю, равному
длине буфера памяти. После обработки секции данных Ь заменяется
на ((b + А)) и начинается фильтрация следующей секции.
Блок, формируемый на выходе секции фильтра, помещается
в выходной буфер с помощью такой же техники, которая исполь-
зуется и во входном буфере. Поскольку для заполнения и очистки
буферной памяти и для выполнения вычислений требуется время,
то метод перекрытия с накоплением всегда приводит к некоторым
задержкам. В приведенной на рис. 9.1 функциональной схеме эта
задержка указана для того, чтобы сделать эквивалентными оба
приведенных представления.
В методе перекрытия с накоплением используются перекры-
вающиеся блоки данных и часть каждого выходного блока отбра-
сывается. В основе метода лежит алгоритм вычисления цикличе-
ской свертки той же самой длины, что и блоки входных данных.
Другой метод, известный под названием метода перекрьтия
с суммированием, не использует перекрытия входных блоков дан-
ных, но основан на алгоритме вычисления линейной свертки, длина
которой существенно больше длины входных блоков. В нем ис-
пользуются все компоненты выходных блоков и некоторое допол-
нительное множество вычислений, связывающих вместе отдельные
выходные блоки. Оба эти метода иллюстрируются рис. 9.2.
Снова предположим, что у нас есть устройство вычисления ли-
нейной свертки, выходная длина которой равна и. Пусть нам надо
умножить многочлен g (х), степень A которого меньше и, на много-
член d (х), степень В которого больше и. Величина В опять столь
велика, что можно полагать ее равной бесконечностц. По много-
члену d (х) построим последовательность многочленов степени не
более и А 1, определяя их равенствами
4" = А, i 0,...,и ‒ А ‒ 1,
308 Гл. 9. Архитектура фильтр<щ и преобррзований
СдублироВать
Выходнои поток данных
&ицию
Суом ить
Выкодмой поток данных
а) Перекрытие с наноплениеи
Входной потак данных
и оходных
omce arnot
ф Перекрьипие с суммироВанием
Входной поток гЪнных
(n Ф)
Входнык
оюсжтоВ
Рис. 9.2. Свертка по секциям.
и Входных
omce em'
и Вылодньи
отсиелоо
9.1. Вычисление свертки секционироваинем
Оо
s (х) = g (х) d (х) = f g (х) d<'> (х) х<' †'1<" ‒ А>.
1=!
Для каждого 1 положим
я<'> (х) = g (х) Н'> (х).
Тогда коэффициенты многочлена s (х) даются равенствами
(1)
Й Ч э
i Î,...,и ‒ А ‒ 1,
(2) ! (1)
St+ (л ‒ я) = Sl ! SC+ (л ‒ А)~
(3) ! (2)
St+> (л ‒ А) = St [ SC+ (e ‒ А)~
i=0,..., и ‒ А ‒ 1,
i=0,..., n ‒ А ‒ 1,
и так далее. Этим исчерпываются все вычисления метода пере-
крытия с суммированием.
Метод перекрытия с суммированием основывается на алгоритме
вычисления линейной свертки. Однако, поскольку deg g (х) = А
и deg d«> (х) = п А ), то при желании можно воспользовать-
ся и циклической сверткой. Циклическая свертка длины и на самом
деле будет линейной сверткой; все выходные точки циклической
свертки будут давать правильные значения коэффициентов линей-
ной свертки.
Отметим, что и метод перекрытия с накоплением, и метод пере-
крытия с суммированием, для каждой вычисляемой и-точечной
свертки используют и А выходных отсчетов. Метод перекрытия
с накоплением обладает тем небольшим преимуществом, что после
вычисления сверток не содержит сложений, и потому предпочти-
тельнее. С другой стороны, метод перекрытия с суммированием
основан на вычислении линейной свертки, вход которой содержит
только п А ненулевых коэффициентов. Это позволяет построить
алгоритм линейной свертки с меньшим числом сложений.
Например, в разд. 3.4 были рассмотрены алгоритмы итератив-
ного построения линейных сверток большой длины из линейных
сверток малой длины. В частности, для построения 256-точечной
линейной свертки была использована итерация 2-точечной линей-
ной свертки. Эта же задача может быть решена методом перекры-
тия с суммированием. Параметры алгоритма: и = 511 выходных
точек; А = 255, что соответствует фильтру с 256 отводами; п
А = 256 входных точек. Каждая составляющая свертка дает
пакет из 256 выходных точек, для вычисления. которых в данной
конструкции требуется 6561 умножений и 19171 сложений, считая
дополнительные сложения алгоритма перекрытия с суммирова-
нием. Таким образом, реализация вычислений на КИО-фильтре
с 256 отводами требует 25,6 умножений на одну точку на
выходе.
310 Гл. 9. Архитектура фильтров и преобразований
9.2. Алгоритмы для коротких секций фильтра
д
° ° <з d, d,
~4 ~3 ~2
d,,
d,
~ге 1
S,
8о
81
Si
Settr 2
Хг
Это уравнение описывает вычисление и компонент на выходе
КИО-фильтра с r отводами. Такое вычисление будем называть
(г, n)-фильтр-секцией, или, при r = n,n-фильтр-секцией. Зга задача
представляет собой задачу вычисления усеченной свертки. Как
будет доказано ниже, (r, п)-фильтр-секция требует r + n 1
умножений, и поэтому алгоритм с r + и 1 умножениями на-
зывается оптимальным. Этот термин, однако, может ввести в за-
блуждение, поскольку алгоритмы подобного сорта могут содер-
жать слишком много сложений, если r и и не малы. Мы будем поль-
зоваться оптимальными алгоритмами только при малых значениях
гип.
Алгоритм секционной фильтрации можно получить из алго-
ритма вычисления линейной свертки. Основой преобразования ал-
горитма для одной из этих задач в алгоритм для другой задачи
является следующий общий принцип.
Теорема 9.2.1 (Трансформационный принцип). Пусть задан
алгоритм
s= Td=CGAd,
где матрица 6 является диагональной, а матрицы А и C содержат
только малые константы. Тогда
е = <~G<~f
является алгоритмом вычисления е = Т Е Если исходный алгоритм
вьяисления вектора s оптимален, mo второй алгоритм дает отпи-
мальный алгоритм вькисления вектора е.
Цифровые КИО-фильтры можно строить, используя описанные
в предыдущем разделе методы перекрытия. Для применения этих
методов нужны хорошие алгоритмы для отдельных секций филь-
тра. Сейчас мы дадим хорошие алгоритмы для коротких секций
фильтра, а в разд. 9.3 опишем способы их сочетания для построе-
ния длинных секций фильтра.
Метод перекрытия с накоплением можно записать в матричном
виде. Опуская отбрасываемые выходные компоненты, получаем
следующее матричное уравнение:
9.2. Алгоритмы для коротких секций фильтра
Доказательство. Алгоритм представляет собой факторизаци~о
матрицы в виде
Т = СбА.
Так как матрица б является диагональной, то Т~ = А~ССт и,
следовательно,
~т~ А т~СТ~
Вторая часть утверждения следует отсюда очевидным образом,
так как если существует алгоритм с наименьшим числом умноже-
ний для вычисления вектора е, то его трансформация дает алго-
ритм с тем же числом умножений для вычисления вектора s. Q
Воспользуемся трансформационным принципом для построения
алгоритмов коротких фильтр-секций. Начнем с алгоритма линей-
ной свертки
8i Я
~о + Й~
Согласно теореме 9.2.1 теперь можно записать
о у,
0 go gl f
Л
О 1 1 g, + g,
g~
Лля построения алгоритма 2-фильтр-секции заменим теперь
(е„еД на (я„з,) и (/„/„ fg) на (д„И„<p) '
312 Гл. 9. Архитектра фильтров и преобразований
Ч исло вых одных
Число умиожениЯ Число сложениЯ
Число отводов
2
3
2
3
4
3
4
3
4
8
8
15
20
Рис. 9.3. Характеристики некоторых алгоритмов коротких фильтр-секций.
При желании этот алгоритм после переупорядочивания можно пе-
реписать в виде
А dï
Яля 2-фильтр-секции этот алгоритм оптимален; он содержит три
умножения и четыре сложения, не считая суммирования g, + g>,
связывающего отводы фильтра.
Так же можно построить и другие алгоритмы коротких секций
фильтра. Характеристики некоторых из таких алгоритмов приве-
дены на рис. 9.3.
9.3. Итерироваиие секций фильтра
Итерируя алгоритмы для коротких секций фильтров, можно
получать алгоритмы для секций фильтра большей длины, на вы-
ходе которых формируются длинные блоки отсчетов. Характери-
стики таких итерированных секций фильтра затабулированы на
рис. 9.4. Используя описанный в разд. 9.l метод перекрытия с на-
коплением, можно строить каскады произвольного числа этих
секций фильтра, на выходе которых будет формироваться беско-
нечный поток данных.
В рассмотренных нами малых алгоритмах свертки не исполь-
зовалось свойство коммутативности умножения чисел поля. Лю-
бой алгоритм линейной свертки,
N ‒ 1
~i = Е к1-кА~
k~O
9.3. Итерирование секций филь'гра
313
Число
умножений
на точку
иа выходе
Число
сложений
на точку
на выходе
Число входиых
точек ма
секцию
Число
сложений
Число
отводов
Число
умножений
15
120
260
735
844
4080
5
25
81
125
243
625
3
9
16
27
32
81
1.33
2. 78
5.06
4.63
7.59
7. 72
5
13.33
16.25
27.22
26.37
53. 70
3
9
16
27
32
81
Рис. 9.4. Характеристики некоторых реальных алгоритмов КИО-фильтров.
в котором не используется ни деление, ни свойство коммутатив-
ности умножения, в такой же мере применим к элементам кольца,
как к элементам поля. Пусть, например, надо вычислить свертку
матриц
где теперь D; представляет собой ~-ю матрицу в списке из N ма
триц, а б; представляет собой ~-ю матрицу в списке из L матриц.
Построенные нами ранее алгоритмы свертки применимы в данном
случае так же, как и ранее. Сложение превращается в сложение
матриц, а умножение становится умножением матриц.
Построим итерацию 2-фильтр-секций для формирования сек-
ций фильтра большей длины. Малый алгоритм возьмем в виде
И
Алгоритм содержит 1,5 умножений на каждый отсчет на выходе
фильтра. Его можно использовать повторно для вычисления двух
отсчетов на выходе одновременно, и такое вычисление всегда будет
содержать 1,5 умножений и 2 сложения на один отсчет на выходе.
2-фильтр-секция, однако, не имеет существенного значения для
практических приложений, а используется для итеративного по-
строения алгоритмов больших фильтров с 2 отводами, на выходе
которых вычисляются одновременно 2 отсчетов дискретного
сигнала.
для иллюстрации идеи рассмотрим построение алгоритма вы-
числения четырех точек на выходе секции фильтра с четырьмя
314 Гл. 9. Архитектура фильтров и преобразований
отводами (4-фильтр-секции). В матричном виде это вычисление за-
писывается равенством
d3 d3 d) dP
d4 d3 d3 d
d3 da d) А
~4 А А d)
8z
g3
Разбивая это вычисление на блоки размерности два на два, полу-
чаем
1 ) О О
где
$) =, S)-=
Теперь эта задача имеет точно такой же вид, как и предыдущая
задача. Скалярные величины заменились матрйцами, но алгоритм
является системой тождеств и остается справедливым и в данном
случае. Имеем
‒ О,-О> 0 0
0 0 В
0 0 (О) ‒ О
Как и ранее, сумма б, + б, должна быть вычислена заранее
и не влияет на оценку числа необходимых в алгоритме операций.
Алгоритм содержит четыре матричных сложения и три матрич-
ных умножения. Остановимся сначала на сложениях матриц. Ява
из них имеют вид
А
В2 ‒ 0) =
Оь
dg ‒ dg
А ‒ д3
А ‒ ~о
О3 ‒ О)
d)
д3
~3
о, ‒ о, =
d4
9.3. Итерирование секций фильтра
315
Здесь имеется пять различных сложений. (Позже мы увидим, как
одного из них можно избежать, так что останется только четыре
сложения.) Ещ@ здесь имеется два сложения 2-точечных векторов,
выполняемых после завершения умножения; для их выполнения
требуется четыре вещественных сложения.
Каждое из матричных умножений имеет тот же вид, что
и 2 фильтр-секция, и, следовательно, может быть вычислено
с помощью трех умножений и четырех сложений. Таким образом,
алгоритм 4-фильтр-секции всего содержит девять умножений и
21 сложение.
Если алгоритм 4-фильтр-секции используется повторно для
одновременного вычисления четырех отсчетов на выходе каждый
раз, то одно из сложений пропадает, так как g d, в одном
пакете равно д, ~, в следующем пакете.
процесс итерации носит вполне общий характер. Если и.
четно, то матрица алгоритма и. фильтр-секции разбивается на
четыре ((и/2) X (и/2))-блока. Используя теперь алгоритм 2
фильтр-секции, построим алгоритм и-фильтр-секции в виде трех-
кратного обращения к алгоритму (и/2)-фильтр-секции. При этом
число дополнительных сложений, необходимых для вычисления
матрицы О, О„равно и 1, а число дополнительных сложе-
ний, необходимых для вычисления матрицы D, О„равно и/2.
Это происходит потому, что все рассматриваемые матрицы яв-
ляются теплицевыми ((и/2) х (и/2))-матрицами. Яля вычисления
матрицы О, D, надо выполнить вычитания только в первой
строке и левом столбце. Некоторые из полученных при этом вели-
чин повторяются в матрице О, О,, так что для вычисления по-
следней требуется только и/2 вычитаний. Если алгоритм исполь-
зуется в режиме повторения, то некоторые из ранее вычисленных
величин повторяются, так что для вычисления каждой из матриц
О, D, и D, О, в каждом новом пакете требуется только
и/2 сложений. Еще и дополнительных сложений требуется в вы-
ходном векторе. Подводя итог, получаем, что если алгоритм
(и/2)-фильтр-секции содержит М умножений, и А сложений, то
построенный описанным образом алгоритм и-фильтр-секции будет
содержать 3М умножений и 2и + ЗА сложений.
Если и = 2, то эта процедура может быть проитерирована;
алгоритм 2'" фильтр-секции строится из алгоритмов 2 ‒ ' фильтр-
секции, которые, в свою очередь, строятся из алгоритмов 2 ‒ 2-
фильтр-секции и т. д. Число умножений в таком алгоритме равно
3 = n'5~5, а число сложений описывается рекурсией А (и) =
= 2и + 3A (и/2) при А (1) = О.
Если и не равно степени двух, то в качестве блоков построения
можно использовать секции фильтров других длин. Альтерна-
тивной возможностью является дополнение числа отводов фильтра
до степени двух с помощью нулевых отводов.
316 Гл. 9. Архитектура фильтров и преобразований
Числа Что
умножеиий сложений
Алгоритм g f
250
240
Ялгоритм ф 2
Яюгорити ф 8
188
Рпгоритм ф 4
20б
108
Алгоритм g S
2бО
81
Рис. 9.5. Некоторые алгоритмы 16-точечных КИО-фильтров.
Если и достаточно велико, то рассматриваемый алгоритм
с n'-5~' умножениями становится хуже алгоритма, основанного на
БПФ и содержащего О (и log и) умножений. Значение п, для кото-
рого это происходит, можно сдвинуть, если итеративный алгоритм
по основанию два заменить итеративным алгоритмом по основанию
четыре, содержащим в своей начальной форме семь умножений.
Тогда число умножений растет как 7m~2 = и'404
Для дальнейшей иллюстрации богатства конструктивных воз-
можностей рассмотрим несколько алгоритмов вычисления 16 от-
счетов фильтра с 16 отводами. Структура алгоритмов показана
на рис. 9.5.
Алгоритм 1. Выходы фильтра вычисляются стандартным спо-
собом. Алгоритм содержит 16x16 = 256 умножений и 16х15 =
= 240 сложений.
9.4. Симметрические и кососимметрические фильтры
317
Алгоритм 2. Алгоритм 2-фильтр-секции, в котором для вы-
числения выходов трех секций с 8 отводами используется любой
подходящий алгоритм и 4Х8 дополнительных сложений. Если
выходы трех фильтров с 8 отводами вычисляются стандартным
способом, то каждый из них требует 8x8 = 64 умножений и
8x 7 = 56 сложений'. В общей сложности получаем алгоритм
с 3x64 = 192 умножениями и 32 + 3x56 = 200 сложени-
ЯМИ.
Алгоритм 8. Алгоритм 2-фильтр-секции используется для
сведения к трем 8.фильтр-секциям, каждая из которых реализуется
в виде 4 X 4 = 16 сложений и трехкратного использования 4
фильтр-секций. Если каждая 4-фильтр-секция реализуется стан-
дартным алгоритмом фильтрации, содержащим 16 умножений и
12 сложений, то такой алгоритм 16.фильтр-секции в общей слож-
ности содержит 32 + 3x 16 + 9x 12 = 188 сложений и 9х 16 =
= 144 умножения.
Алгоритм 4 получается из алгоритма 3 модификацией алго.
ритмов для 4-фильтр-секций, в которой они заменены 4x2 = 8
дополнительными сложениями и трехкратным использованием
алгоритма 2-фильтр-секции. Таким образом, этот алгоритм 16-
фильтр-секции содержит 32 + Зх16 + 9x8 = 162 сложения и
27 кратное вычисление 2-фильтр-секции. Стандартный алгоритм
2 фильтр-секции содержит два умножения и четыре сложения,
так что в общей сложности получаем 152 + 27х2 = 206 сложе-
ний и 27X4 = 108 умножений.
Алгоритм б получается итеративным использованием 2-
фильтр-секции на всех этапах; такой алгоритм содержит 260 сло
жений и 81 умножение.
Нельзя сказать, какой из этих. алгоритмов предпочтительнее
других. Только детальный анализ алгоритма в контексте его при-
менения может сказать, что, например, алгоритм с 206 сложе-
ниями и 108 умножениями предпочтительнее, чем алгоритм
с 260 сложениями и 81 умножениями. Все что мы можем сделать,
это предложить конструктору различные альтернативы.
9А. Симметрические
и кососимметрические фильтры
Развитые в предыдущем разделе методы можно усилить, если
коэффициенты задающего фильтр многочлена g (х) обладают до-
полнительным специальным свойством, а именно, для построения.
хороших алгоритмов коротких секций фильтра можно воспользо-
ваться симметрией коэффициентов многочлена фильтра. В мето-
дах, основанных на преобразовании Фурье, подобные тонкости
использовать не удается.
3)8 Гл. 9. Архитектура фильтров и преобразований
Мы построим алгоритм для малых симметрических и косо-
симметрических фильтров. Комбинируя эти короткие секции,
можно строить более длинные фильтры. Для увеличения размеров
фильтра, к сожалению, нельзя использовать итерацию, так как
фильтр перестает быть симметрическим. Возможен, однако, дру-
гой метод. Как мы Увидим, вычет симметрического многочлена
по модулю симметрического многочлена столь тесно связан с сим-
метрией многочленов, что китайская теорема об остатках позво-
ляет использовать эти свойства симметрии для построения алго-
ритмов для длинных симметрических фильтров из алгоритмов для
коротких симметрических фильтров.
Фильтр с L отводами, описываемый многочленом g (x, назы-
вается симметрическим фильтром, если многочлен g (х равен
своему взаимному многочлену, т. е. если g (х) = хс ‒ 'g (х-') или,
эквивалентно, если g; = g~>;. Фильтр с L отводами, описывае-
мый многочленом g (х}, называется кососим'иетрическим фильтром,
если многочлен g (х) равен своему взаимному многочлену со зна-
ком минус, т. е. если g (х} = х~ ‒ 'g (х-'), или, эквивалентно,
если g;- = ‒ д~ 1,. Мы начнем рассмотрение симметр ических
фильтров. Для симметрического фильтра с L отводами имеется
очевидный алгоритм, содержащий для вычисления каждого вы-
ходного отсчета L 1) сложений и только L/2 умножений, если L
четно, и (L + 1 /2 умножений, если L нечетно. В этом очевидном
алгоритме перед умножением на общий множитель g;- склады-
ваются точки с индексами ~ и L i 1.
Алгоритм Винограда для свертки в случае симметрического
фильтра строится точно так же, как и ранее. Построим алгоритм
для вычисления выхода симметрического фильтра с тремя отво-
дами, на вход которого подается 4-точечный вектор. Пусть
g (x) = gpx + glx + gp
d (х) = dpx + dpx + d~x + dp
s (х) = g (х) d (х) (mod (х' х) (х оо)).
Поскольку deg s(x) = 5, то приведение по такому модулю никак
не сказывается на s(х}. Простыми делителями модуля являются
четыре многочлена первой степени, каждый из которых в алго-
ритме приводит к одному умножению. Имеется также простой
делитель х' + 1, который, как можно было бы ожидать, приводит
к трем умножениям. Но, как мы увидим, в силу симметрии он
вносит в алгоритм только два умножения. Пусть
sP (х) = g<P> (х) И<ь> (х) (mod х' + 1),
где
d<p> (х) = (d, d,) х + (d, d,)
g<~> (х) = g,х + (gp ‒ g,) = g,õ.
9.4. Симметрические и кососимметрические фильтры
319
Таким образом, для вычисления я<о> (х} нужно только два умноже-
'ния. Остальная часть алгоритма остается без изменений и в окон-
чательном виде алгоритм записывается равенством
~о
Gi
G,
~э
1 О О О
1 1 ? 1
1 ‒ 1 1 ‒ 1
1 О ‒ 1 О
о ‒ 1 о
о о о
S2
~4
S~
где
Go
о
1 l
2 4
1
О
Э
I 11
2
о
G,
Этот алгоритм содержит шесть умножений и 14 сложений
Его можно использовать в методе перекрытия с суммированием
для реализации симметричной З-фильтр-секции, содержащей
1.5 умножений и 4.5 сложений на каждую точку на выходе.
даваемый теоремой 9.2.1 принцип трансформаций позволяет
преобразовать этот алгоритм в алгоритм симметричной (4, 3)-
фильтр-секции, содержащий 1.5 умножений и 4 сложения на
каждую точку на выходе. Этот алгоритм дается равенством
[
d4 d3 ,d2
1 I I 0
1 0 0
0 1 1
0 ‒ I 1
0 1 0
0 0 ‒ 1
‒ 1 0
I ‒ I 0 ‒ 1
) I ‒ I 0
1 ‒ 1 0 1
~3
d2
d)
d
4
G5
1 0
1
2 4
где
l 1
2 4
0
!
2
0
2
1 0
о о о о о
о 1 ‒ 1 1 о ‒ 1
О 1 1 О ‒ 1 О
о 1 -1 -1 о о
‒ 1 1 1 О 1 О
О О О О О 1
~0
G,
G2
G,
G0
G)
\
G,
~3
G,
G,
0 ‒ 1 ‒ 1
I I 1
‒ I 1 1
‒ ! 0 0
0 1 1
0 0 0
320 Гл. 9. Архитектура фильтров и преобразований
Причина того, что в данном случае алгоритм для симметриче-
ского фильтра оказывается лучше, чем для несимметрического
фильтра, кроется в том, что один коэффициент симметрического
многочлена равен нулю. Эго простейший пример общего фено-
мена приведения симметрического многочлена по модулю сим-
метрического многочлена. Пусть
Й' (х) = Йох + Ыгх + Йгх + gl> + go.
и рассмотрим вычеты
g<<<'> (х) = Й (х)
g<'2"> (х) = g (х)
и<" (х) = и (х)
g<4> (х) = g (х)
(mod х' -1- 1},
(mod х' -1- х + 1),
(mod х' х ~- 1),
(mod х' ~- 1).
Легко проверить, что эти вычеты равны
g <'"> (х) = 2g g„
g<"' (Х} (ао + Йг иг) ~ (ио + и иг)
= (х + 1) (go + gl go).
Й'» (х) ( До+Й1ФЙ2)х ( Йо+Д1 < Йг)
= (») ( go + gl + g.),
g ~ (х) =Йдх ф gox +ддх = х(glx +gox+go) °
то мы можем запрятать этот дополнительный множитель, «спря-
тавг его в переопределенном остатке d<'> (х). Пусть
d«> (х) = d (х) (mod х' -1- 1),
d<2> (х) = (х -+- 1) d (х) (mod х' + х + 1),
d<» (х) = (х 1) d (х) (mod х' х + 1),
<1<4> (х) = x d (х) (mod х' ~- 1).
Тогда вычеты g«> (х} переопределятся по правилам
g<«'> (х) = 2a, g'
g< ' (Х) = gO + gl go.
В каждом случае число независимых коэффициентов на два
меньше, чем в соответствующем модуле т<'>(х). В силу симмет-
рии один из независимых коэффициентов пропадает. Вообще
говоря, вычет представляется в виде произведения симметричес-
кого многочлена степени deg и<'1 (х} 2 на дополнительный
многочлен, не содержащий неопределенных коэффициентов. Так
как нас интересуют только вычисления вида
s«> (х) = g<'> (х) d<'> (х) (mod т<'> (х)),
9.4. Симметрические и кососимметрические фильтры
321
d' (х) = go + gl + gs
g® (х) = g,õ' -+- g,õ ~- g,.
Для вычисления каждого из остатков в<'> (х), и<'> (х) и з<'> (х)
потребуется два умножения, а остаток в<~> (х) надо вычислять как
линейную свертку с последующим приведением по модулю х4 + 1.
Эта линейная свертка представляет собой прохождение 4-точеч-
ного вектора через симметрический фильтр с тремя отводами.
Алгоритм такой фильтрации с шестью умножениями мы уже
построили.
Используя построенные фрагменты, можно формировать ал-
горитмы линейной свертки для симметрического фильтра с пятью
отводами. Предположим, что требуется построить алгоритм вы-
числения последовательности на выходе такого фильтра, если на
его вход подается 6-точечная последовательность. Тогда выберем
т (х) = х (х 1) (х + 1) (х оо) (х" + 1) (х' х + 1) X
X (х' + х + 1).
каждый из первых четырех многочленов приводит в алгоритме
к одному умножению, а каждый из остальных трех к двум
умножениям. Окончательный алгоритм будет содержать десять
умножений (1.67 умножений на один отсчет на выходе).
Предположим, что требуется пропустить через этот же фильтр
14-точечную последовательность. Тогда к использовавшемуся
ранее многочлену т (х) добавим еще один множитель, ха + 1.
Это добавит в алгоритм еще шесть умножений. Окончательный
алгоритм будет содержать 16 умножений (1.14 умножений на
один отсчет на выходе).
В общем случае необходимы симметрические фильтры с числом
отводов, большим пяти. Следующая теорема говорит о том, как
надо выбирать модули для того, чтобы строить алгоритмы для
больших симметрических фильтров из малых симметрических
фильтров.
Теорема 9.4.1. Пусть четное число t ие меньше четного и
и пусть r (х) обозначает остаток от деления симметрического
многочлена g (х) степени t на симметрический многочлен т (х)
степени и над основным полем G. Тогда r (х) можно записать
в виде
r (х) = f (х) r' (х) (mod т (х)),
где r' (х) представляет собой симметрический многочлен степени
и 2 и f (х) некоторый многочлен над основным полем Q (не
зависящий, следовательно, от коэффициентов многочлена g (х)).
Доказательство. Без потери общности можно полагать, что
многочлен т (х) приведен. Так как т (х) является симметрическим
322 Гл. 9. Архитектура фильтров и преобразований
многочленом степени п, то т (х) = х"т (х '). Если п = <, то
положим т' (х) = т (х); в противном случае, пусть
т' (х) = т (х) + х'-"т (х).
Этот многочлен является симметрическим степени t, так как
х' [m(x ‒ ')+х ‒ '+"т (х ‒ ')] = х' ‒ "т (х) + т (х).
Определим многочлен g (х) равенством
xg' (х) = g (х) g,ò' (х).
Многочлен xg' (х) при делении на т (х) дает тот же остаток, что
и многочлен g (х), но многочлен g' (х) является симметрическим
и ero степень равна четному числу, которое по меньшей мере на
два меньше степени многочлена g (х). Если степень многочлена
g' (х) не меньше п, то этот процесс можно повторить до тех пор,
пока не получим многочлен r' (х) степени п ‒ 2. Тогда остаток
от деления многочлена x<' ‒ "+"~'г' (х) на т (х) равен остатку от
деления g (х) на т (х). Для завершения доказательства положим
f (х) = R <„., [х<' ‒ "+г)~'].
Теперь мы перейдем к алгоритмам для кососимметрических
фильтров. С этой задачей мы справимся значительно скорее,
указав, как алгоритмы для симметрических фильтров можно
превратить в алгоритмы для кососимметрических фильтров.
Теорема 9.4.2. Пусть кососимметрический фильтр содержит
L отводов; тогда, если L четно, то эта задача фильтрации может
быть решена по алгоритму для симметрического фильтра с L 1
отводами, а если L нечетно, mo эта задача может быть родена
по алгоритму для симметрического фильтра с L 2 отводами.
Яоказательство. Предположим, что многочлен g (х) описы-
вает кососимметрический фильтр с четным числом L отводов.
Тогда g (1) = О, так как g, = ‒ g~, < для < = О, ..., (L/2) 1.
Следовательно, (х 1) делит многочлен g (х). Определим фильтр
g' (х) = g (х)/(х 1).
Ясно, что' многочлен g' (х) задает симметрический фильтр с L 1
отводами. Симметричность фильтра вытекает из того, что,равенство
g (х) = хс ‒ 'g (х-') влечет за собой равенство
<х ‒ 1) ))' <х) = х~' ( ‒ „‒ l) )) ( ),
или равенство
g (х) = х'-'а'(х-<).
Таким образом, фильтр, описываемый многочленом а (х),
эквивалентен фильтру с многочленом g' (х), за которым следует
9.4. Симметрические и кососимметрические фильтры
323
(или которому предшествует) фильтр с двумя отводами, описывае-
мый многочленом (х 1).
Теперь предположим, что многочлен g (х) задает кососимме-
трический фильтр с нечетным числом L отводов. Тогда 1 и 1
являются корнями многочлена g (х), так как центральный коэф-
фициент равен нулю и
д(~1) = ~,' gi+ gL, i + ~; gi+gL, i) = О.
l чет. 1 нечет
Следовательно, можно определить симметричный фильтр с L 2
отводами, задавая его многочленом
g' (х) = g (x)/(х~ 1).
Таким образом, фильтр, описываемый многочленом g (х), экви-
валентен фильтру, задаваемому многочленом g' (х), которому
предшествует (или за которым следует) фильтр с многочленом.
х -~- 1.
Фильтры, задаваемые многочленами х 1 или х~ 1, при-
водят к некоторым дополнительным сложениям на входе или вы-
ходе. Следовательно, изменяя соответствующим образом матрицу
предсложений или матрицу постсложений, мы преобразуем алго-
ритм для симметрического фильтра в алгоритм для кососимме-
трического Фильтра. Как всегда, еслл этот алгоритм используется
в методе перекрытия с суммированием, то его следует брать
в форме алгоритма для линейной свертки. Напротив, если в кон-
струкции используется метод перекрытия с накоплением, то
следует воспользоваться даваемым теоремой 9.2.1 принципом
трансформаций для преобразования алгоритма в алгоритм сек-
ционной фильтрации.
К;ак оказалось, тот же метод, который позволяет свести за-
дачу для кососимметрических фильтров к задаче для симметри-
ческих фильтров, позволяет при нечетном числе L отводов свести
задачу для симметрического фильтра с L + 1 отводами к задаче
для симметрического фильтра с L отводами.
Теорема 9.4.3. Если Lнечетно, ,mo алгоритм для симметри-
ческого фильтра с L+1 отводами получается из алгоритма для
симметрического фильтра с L отводами без дополнительных
умножений.
Доказательство. Пусть (L + 1)-точечный фильтр задается
симметрическим многочленом g (х) нечетной степени L. Тогда
g ( 1) = О, так что (х -1- 1) делит многочлен g (х). Следовательно,
g (х) = (х + 1) g' (х), где g' (х) симметрический многочлен сте-
пени Е 1. Таким образом, фильтр, задаваемый многочленом
g (х), может быть реализован в виде каскада фильтров, задавае-
мых многочленами х + 1 и g' (х), без дополнительных умно-
жений. Q
324 Гл. 9. Архитектура фильтров и преобразований
9.5. Фильтры прореживания и итерполяции
о о
g2 go 0
84 82 80
г4
о о
О О
о
g3 g)
о
О 0
О О О О
о о
81 82 gi Юо
О 84, gi g2
о о'о
dï
d,
d2
d,
~4
S2
g2
4
84
Алгоритм записан в виде вычисления 3-точечной линейной свертки,
2-точечной линейной свертки и трех дополнительных сложений,
сочетающих результаты этих сверток. Таким образом, рассмо-
тренный алгоритм прореживающей фильтрации содержит восемь
умножений и 26 сложений иа каждые пять точек на выходе. Если
этот алгоритм использовать в методе перекрытия с суммирова-
нием, то для сочетания секций, каждая из которых содержит пять
входных точек, потребуется еще четыре дополнительных сложе-
ния. Такой алгоритм будет содержать восемь умножений и 30 сло-
Фильтром прореживания называется КИО-фильтр, который
вычисляет только каждый r-й выходной отсчет; часто r равно 2
или 3. Все прочие выходные отсчеты нежелательны и по-
давляются, даже если они вычисляются. Можно надеяться на
существование более простых алгоритмов, не вычисляющих не-
нужные выходные точки. Фиаьтр интерполяции действует про-
тивоположным образом: отсчеты на выходе такого фильтра фор-
мируются с большей скоростью, чем на входе. Прореживающий
и интерполирующий фильтры иногда называются фильтром
с подавлением и фильтром с восстановлением соответственно.
Конструкции прор ежи вающего и интерполирующего КИО-
фильтров аналогичны общим конструкциям КИО-фильтров. Од-
нако, их специфические особенности можно использовать для
построения более эффективных алгоритмов. В первом случае
более эффективные алгоритмы можно строить из-за выбрасывае-
мых выходных точек, а во втором из-за выбрасываемых вход-
ных точек.
Для фильтров прореживания алгоритмы линейной свертки и
алгоритмы секционной фильтрации не связаны между собой
описываемым теоремой 9.2.1 трансформационным принципом.
Трансформационный принцип преобразует алгоритм свертки для
прореживающего фильтра в алгоритм секционной фильтрации
для интерполирующего фильтра.
Рассмотрим алгоритм линейной свертки для прореживающего
в отношении 2: 1 фильтра с пятью отводами, на вход которого
подается 5-точечный вектор. Необходимый выходной вектор
дается вычислением
9.5. Фильтры прореживания и интерполяции
325
жений на каждые пять выходных точек (1,6 умножений и 6 сло-
жений на одну точку на выходе).
Теперь рассмотрим такую же задачу для секции прореживаю-
щего фильтра с пятью отводами и тремя выходными отсчетами.
Алгоритм для такой секции можно записать равенством
d d
+ А
~2
4 d2 4!
Ь ~4 ~2
К АЬ ~4
d4 ~з d2 d!
d„d9 ,d4 dз,
Н 7 Ь 5
gO
gi
g2
Юз
84
В этом алгоритме с помощью трех дополнительных сложений
сочетаются алгоритмы 3-фильтр-секции и (3, 2)-фильтр-секции,
так что в общей сложности этот алгоритм прореживающей филь-
трации содержит девять умножений и 26 сложений.
Посмотрим, какие алгоритмы получаются из построенных
алгоритмов при их трансформации. Мы увидим, что в обоих слу-
чаях это приведет к алгоритмам интерполирующих фильтров.
Трансформация выписанного выше алгоритма линейной свертки
дается равенством
gO g2 34
о g, g, о о
О go ~, gi 0
о о g, g, о
О 0 go g2 g4
"e,
е,
Заменим теперь (е„е„е„е„е4) на(s„s„s„s„s,) и (fo, /„ f, /„Ц
на (Н„д„do do, do) Тогда
d8 О d6 О d4
О с~ О d, О
d~ Î d, О d2
0 d4 О d, 0
d, О d2 О
Хв
gO
gi
82
84
Мы получили уравнения для интерполирующего фильтра, по-
скольку нулю теперь равны входные точки. Таким образом,
применение трансформационного принципа к прореживающей
в отношении 2: 1 5-фильтр-секции привело к интерполирующей
в отношении 2: 1 5-фильтр-секции. Алгоритм содержит восемь
умножений.
g, g, g4 О О
О 8' g, О О
о g, g, ~, о
О О gi ~, 0
0 0 gP g2 g4
fO
Л
Л .
Л
f.
326 Гл. 9. Архитектура фильтров н преобразований
Таким же образом, алгоритм прореживающей 5-фильтр-сек-
ции, записываемый равенством
с g. g, g, g, g. о о о о
$4 ‒ 0 0 gî g1 g2 g2 g4 О О
0 О О О g0 g~ g2 ~З g4
S0
S1
$2
4
$2
$в
Этот алгоритм является алгоритмом линейной свертки, входные
элементы в которой через один равны нулю, алгоритм интер-
полирующей фильтрации, содержащий девять умножений.
Следующим рассмотрим (на примере) алгоритм симметричной
прореживающей фильтрации. Построим алгоритм симметрического
прореживающего в отношении 2: 1 15-фильтра. Как и в предыду-
щем примере, разобъем задачу на симметрическую линейную
8-точечную свертку и симметрическую линейную 7-точечную
свертку. Согласно теореме 9.4.3 первая из них может быть вы-
числена с помощью алгоритма фильтрации 8-точечного входа
в фильтре с 7 отводами.
Яля вычисления обеих линейных симметрических сверток
воспользуемся разработанным в предыдущем параграфе методом.
Степень многочлена
со) (х~ + 1) (х'+
+ х ф- 1) (хз ‒ х + 1) (х4 + 1)
т (х) = х (х 1) (х + 1) (х
равна 14 и, следовательно, им можно воспользоваться для по-
строения алгоритма линейной фильтрации 8-точечного входа
в фильтре с 7 отводами. В равд. 9.4 было определено число умно-
жений, связанных с использованием в качестве модуля каждого
из указанных симметрических многочленов. Это приводит к об-
может быть трансформирован к алгоритму
g, о о
g2 g0 О
g, g, о
g4 g2 80
о
g4 g2
о о
о о
~в
~2
~а
d
d,
d,
d
d,
do
9.6. Автокорреляция и взаимная корреляция
327
щему числу умножений в алгоритме, равному 16. Аналогично,
выбрасывая один линейный множитель, получаем алгоритм филь-
трации 7-точечного входа в фильтре с 7 отводами, содержащий
15 умножений. Следовательно, для решения рассматриваемой
задачи можно построить алгоритм, содержащий 31 умножение.
9.6. Автокорреляция
и взаимная корреляция
Выражение вида
N ‒ 1
r(= g g~+d„, i=0,..., L+N ‒ 2,
й=о
называемое корреляцией, если g совпадает с d, H взаимной кор-
реляцией, если g и dразличны, ,очень тесно связано со сверткои.
Ero можно сделать похожим на свертку, если просто прочитать
одну из последовательностей в обратном порядке. В принципе,
любой из рассмотренных нами методов вычисления линейной
свертки годится для вычисления корреляции. Тем не менее,
имеется одно практически существенное различие. Длина КИО-
фильтра обычно намного меньше, чем длина фильтруемой после-
довательности данных, а входящий в корреляцию «фильтр» g (x)
на самом деле представляет собой другую последовательность
данных, длина которой примерно равна длине последовательности,
обозначаемой многочленом d (х); часто длина записи обеих после-
довательностей неопределена и весьма велика возможно, не-
сколько сотен отсчетов. Хорошие алгоритмы разбивают g u d
на секции.
Яы начнем рассмотрение с вычисления автокорреляции
N ‒ 1
1
г~ ‒ ‒ й~й~,„~ =О, ..., и/2 ‒ 1,
k~
возможно, опуская в сумме деление на At. В интересующих нас
задачах длина N блока данных значительно больше длины n/2
блока выходных данных, так что использование для вычислений
преобразования Фурье длины Ж было бы слишком расточитель-
ным. Разобьем сумму на части по и слагаемых в каждой из частей,
и будем решать, задачу, используя преобразование Фурье длины и.
Запишем
L 1
(О
Tg = ~ Tg ,
1=9
где
n/2 ‒ 1
ю
g А+ l n/ Й+1и/2+~э
й=О
1=0, ..., и/2 ‒ 1,
1=0, ..., L ‒ 1,
328 Гл. 9. Архитектура фильтров и преобрязовяний
и L (n/2) = N. Таким образом, задача свелась к вычислению
вектора г(') для 1 = О, ..., L 1, который мы будем находить
используя БПФ и подходящую циклическую свертку.
Определим два вида блоков длины и один состоящий пол-
ностью из данных, и второй, состоящий наполовину из нулей.
Позже будет показано, как избегать блоков первого вида. Пусть
( g) df+lO]2 i 0 n/2 1
dg
О, i=n/2, ..., и ‒ 1,
(О
gl А+1л/2в
1=0, ..., n ‒ 1.
Тогда
и-1
~'~' ‒ ‒ ~ д~р~+~, ~ =О, ..., n/2 ‒ 1.
(О
А=О
Пусть О(') и б(') обозначают векторы, полученные преобразова-
нием Фурье из векторов d(') и g('). Тогда согласно задаче 1.10,
Sy ‒ ‒ Dk "Gk равно преобразованию Фурье циклической кор-
реляции
и ‒ 3
(1) ~р
sg' = ~~ dkg((c~))t i=0, ..., n ‒ 1,
й=О
и половина из этих компонент дает искомые нами величины
'с =+sg i =О, ..., и/2 ‒ 1.
Таким образом, сначала мы вычисляем вектор
L 1
S»,=f Я»G»",», k=0, ..., и ‒ 1,
~=0
а затем вычисляем его обратное преобразование Фурье s и пола-
гаем r> ‒‒ (1/N) s» для» = О, ..., n/2 1.
Для завершения описания алгоритма покажем, как исключить
некоторые вычисления. Вместо использования БПФ для вычисле-
ния G<'» воспользуемся формулой
G~~» = L)»~~'» + ( ‒ 1)"Е)~~~~ ~».
Эта формула является прямым следствием свойства задержки для
преобразования Фурье, 'умножение в частотной области на в~~
соответствует временному сдвигу на Ь позиций. Если Ь = n/2,
то это соответствует умножению D»,'~ на ( 1)~. Во временнбй
9.6. Автокорреляция и взаимная корреляция
329
области происходит сдвиг ненулевых позиций вектора d<<+'>
в нулевые позиции вектора d<'>; во временной области сумма
равна g<'>, и, следовательно, в частотной области сумма равна 6<'>.
Таким образом, это вычисление можно записать в виде
Ф
д ~ рп) [р(1) + ( 1))~ р()+))]
1=0
do 4, ~г
d, d, d,
d, d, d4
Sè
к)
S2
d„„,
d„d„
S„)
где r намного больше и.
Мы опишем структуру алгоритма для частного случая и = 120
и r = 10 000. Основываясь на некотором опыте, примем произволь-
ное решение разбить последовательность из 120 выходных точек
на четыре пакета по 30 выходных точек в каждом, и организуем
вычисления, опираясь на 60-точечный БПФ-алгоритм Вино-
града.
Алгоритм завершается вычислением обратного преобразования
Фурье.
Блок-схема вычислений в окончательном виде показана на
рис. 9.6. Отметим, что каждый цикл содержит только один БПФ-
алгоритм, хотя в начальной точке и в последней точке алгоритма
добавляется еще по одному БПФ. Таким образом, хотя вычисление
одной циклической свертки содержит три преобразования Фурье,
мы построили алгоритм, который в среднем на цикл содержит
только одно БПФ.
Все Lциклов на рисунке показаны одинаковыми, ,хотя в по-
следнем из них вычисляется преобразование Фурье для нулевого
вектора, добавленного в конец последовательности данных; это
преооравование Фурье можно исключить, модифицировав по-
следний цикл вычислений.
Аналогичный метод применйм и к задаче вычисления взаимной
корреляции. Обе последовательности данных разобьем на от-
резки, комбинируя которые в частотной области, мы уменьшаем
число необходимых обратных преобразований Фурье.
Теперь на одном очень подробном примере покажем, как
можно использовать другие методы в рассматриваемом способе
r ‒ 1
вычисления корреляций. Запишем корреляцию s; = g d„„g„
k=O
в матричном виде,
330 Гл. 9. Архитектура фильтров и преобразований
Crn'îï
Рис. 9.6. Вычисление автокорреляций.
9.6. Автокорреляция и взаимная корреляция
В таком блочном виде матричное уравнение принимает форму
/
I
d2„dul l- - - d%vv d~» ... г(„„,
Ro
° (! ~црщ
~нл ° ° ° ~~ мю~ч
Ак Ач
elÄÄ d~
° ° °
d
d
эн
d d
d~v ° --
d
6O o ° °
Ав
А~ч
ф ° ° °
d
~в ° . °
где к g (х) и к d (х) добавлены 20 нулевых компонент так, чтобы
новое значение r = 10 020 делилось на 30. Каждый из малых бло-
ков, например, первый
. Л1
мо'н~о вычислить, используя 60-точечный БПФ-алгоритм Вино-
града и взяв в качестве ответа первые 30 выходных точек.
Теперь рассмотрим блочную структуру
G,
G3ээ
В, О4
~~333 +3)6 ~~337 ~~ЭМ
о
1 ~~2
2 ~3
~~о
~2
В2 ОЭ
~~3 О4
- ° ~))
~~3 )34
~~4 ' D)3
~) ° -.
~~4 ~~3
~~6
В6 О,
~~в
+i)2 ~~333
В)33 О)34
0 )34 +3)5
~Ь
~т ~в
Ds 09
~~у ~ ~О
~~)34 ~~Ш
+333
+336 D)3>
G 332
~ 333
G AD)4
332 Гл. 9. Архитектура фильтров и преобразовакий
Входной
цинммвоний
4~жор
бу~рер
четирт
hPeObPaSOdahacl
Ъамвчанив матрицу лмтомвпмаи7 ноано ояинуте hrahpabo носов суннм
Рис. 9 7. Коррелятор.
где опять дописаны нулевые блоки так, чтобы получалось число
блоков, кратное четырем. Теперь надо построить алгоритм вы-
числения вида
~)О D> 02 ~)3
~~)) ~~)4
~~) 2 ~~) 3 ~~)4 ~~5
D3 D4 +5 Ь
Это вычисление идентифицируется как 4-фильтр-секция. То, что
элементами, над которыми выполняются вычисления, являются
матрицы, роли не играет; можно воспользоваться построенным
в разд. 9.2 алгоритмом, содержащим девять умножений и 21 сло-
жение. Каждое из умножений является на самом деле 30-фильтр-
секцией, которую мы уже решили вычислять через 60-точечный
БПФ-алгоритм Винограда. Это вычисление должно быть повто-
рено 84 раза, после чего для вычисления нужного ответа надо
просуммировать все полученные ответы.
Окончательная форма этого алгоритма вычисления корреля-
ции показана на рис. 9.7. Символами D~ и G~ на рисунке обозна-
333
9.7. Устройства для вычисления БПФ
чены преобразования Фурье блоков отрезков данных dj и g>.
'Ге преобразования, которые используются более одного раза,
сохраняются, а не перевычисляются. Большинство сложений
выполняются в частотной области, хотя мы описывали их во вре-
менной области. Это позволяет уменьшить число необходимых
обратных преобразований Фурье. Можно еще несколько умень-
шить число требуемых сложений, если умножение на матрицу
постсложений в каждом из алгоритмов секций отложить до того
момента, пока не будут просуммированы выходы всех фильтр-
секций. Тогда эти сложения будут выполняться только один раз.
Теперь обсудим сложность такой реализации рассматриваемого
вычисления, имея в виду число умножений. В общей сложности
алгоритм содержит 676 обращений к 60-точечному БПФ-алгоритму
Винограда, что приводит к 48 672 умножениям. Алгоритм содер-
жит также 84-кратное использование алгоритма для 4-фильтр-
секции, каждое из которых содержит девять векторных умноже-
ний, представляющих собой покомпонентное 'произведение 60-
точечных комплексных векторов, для вычисления каждого из
которых, в свою очередь, необходимо три вещественных умноже-
ния. Это приводит к 146 080 умножениям. Таким образом, полное
число умножений в рассматриваемом алгоритме вычисления
120 точек корреляции последовательностей из 10 000 отсчетов
равно 194 752. Для задач, в которых требуется вычисление высоко-
скоростной корреляции, типа задач обработки радиолокацион-
ных сигналов, приведенный на рис. 9.7 алгоритм можно реа-
лизовать в виде дискретно-логического устройства.
9.7. Устройства для вычисления БПФ
Хороший БПФ-алгоритм можно использовать успешно только-
тогда, когда удается реализовать заложенные в нем возможности.
Конструируя аппаратурный модуль или подпрограмму, необ-
ходимо тщательно анализировать структуру алгоритма.
БПФ-алгоритмы Кули Тычки по основанию два и четыре
обладают регулярной структурой и допускают относительно пря-
мую реализацию. Алгоритм задается несколькими инструкциями.
Поэтому, если в программной реализации длина памяти, в кото-
рой записываются инструкции, является более важным параме-
тром, чем время выполнения программы, то БПФ-алгоритму
Кули Тычки следует отдать предпочтение перед другими, более
быстрыми алгоритмами.
Те же соображения применимы и к аппаратурной реализации.
Регулярность архитектуры устройства для вычисления преоб-
разовани я может оказаться важнее общего числа компонент.
Тогда опять следует отдать предпочтение БПФ-алгоритму Кули
334 Гл. 9. Архитектура фильтров и преобразований
Тычки в силу его регулярности. Регулярность БПФ-алгоритма
Кули Тычки очевидным образом вытекает из его блок-схемы,
показанной на рис. 9.8 для случая прореживания по времени.
На всех шагах итерации используется простое 2-точечное пре-
образование Фурье. Основной вычислительный модуль состоит
из 2-точечного дискретного преобразования Фурье и фазовраща-
теля. Показанная на рис. 9.9 диаграмма этого модуля определила
его название: он называется 2-точечной бабочкой. Алгоритм Кули
Тычки по основанию два с прорежинанием по частоте, показанный
на рис. 9.10, также строится на основе подобной бабочки, диа-
грамма которой приведена на рис. 9.11 °
Если 2-точечная бабочка задана, в виде ли программной реа-
лизации, в виде ли аппаратурного модуля, то БПФ-алгоритм Ку-
ли Тычки по основанию два с прореживанием по времени сво-
дится просто к определенной последовательности прохождения
входных данных через 2-точечную бабочку. При каждом таком
прохождении вычисляется соответствующее преобразование Фурье,
но индексы данных переставляются. На рис. 9.8 указана пере-
становка на входных данных, которая предопределяет вычисление
выходных данных в естественном порядке. При желании можно
входные данные подавать в естественном порядке, но тогда пе-
ресечения линий на диаграмме примут более сложный вид.
При написании программы БПФ-алгоритма Кули Тычки
удобнее выбрать форму, в которой вычисляемые выходные данные
записываются в памяти в переставленном виде. Depend использова-
нием этих данных надо выполнить обратную перестановку. Другой
возможностью является написание программы алгоритма в таком
виде, когда на каждом шаге итерации вычисленные данные воз-
вращаются в память в таком порядке, что адресация данных на
следующем шаге итерации совпадает с адресацией на прошлом
шаге. Имеется много способов таких перестановок; их детали-
зация является существенной частью структуры программы или
аппаратурного модуля. Конструктор должен решить, какая часть
данных будет переиндексирована при запоминании, какая часть
данных будет переиндексирована при вызове, и какая часть рабо-
чей памяти может быть использована сверх того объема, который
отведен для запоминания входного массива данных.
Большой БПФ-алгоритм Винограда не является столь регу-
лярным, так что его реализация не может иметь такого аккурат-
ного вида. Однако, если приступая к программной или аппара-
турной реализация, тщательно проанализировать структуру ал-
горитма, то ее можно сделать достаточно упорядоченной. Проил-
люстрируем некоторые возможности на примере построения 63-
точечного БПФ-алгоритма Винограда из 7-точечного и 9-точечного
БПФ-алгоритмов Винограда. Предположим, что в малых БПФ-
алгоритмах Винограда матрицы профакторизованы в виде %т =
9.7. Устройства для вычисления БПФ
V()
ио
)
v„
и4
v„
и5
v„
и7
РНс. 9.8. Б11Ф-алгоритм Кули ‒ Тычки по основанию два с прореживанием по
времени.
Рис. 9.9. Двуточечная бабочка.
Ро
v„
uq
, и3
V,
v„
Ug
Рис. 9.11. Двуточечная бабочка.
Рис. 9.10. БПФ-алгоритм Кули ‒ Тычки по основанию два с прореживанием
по частоте.
336 Гл. 9. Архитектура фильтров и преобразований
= С,В,А, и %9 ‒‒ C,Â,À~, где В~ и В, представляют собой диаго-
нальные матрицы соответственно размерностей 9 и 11. Тогда
большой БПФ-алгоритм Винограда записывается в виде
%1(ю = (Cт х Câ) (В т X 89) (Ат x A,) = (Cт х C9) В ю (Ат х Aý) °
Каждый из крайних множителей мы будем использовать в виде
кронекеровского произведения, не производя 'вычисления новой
матрицы, равной этому кронекеровскому произведению. Член
В, х В~ заменим, однако, на диагональную матрицу В„.
Реализация рассматриваемого БПФ-алгоритма начинается с пе-
резапнсн данных в виде двумерной (7x9)-таблицы. Первое умно-
жение каждого из 7 столбцов таблицы на матрицу А, удлиняет
столбцы до 11. Следующее за этим умножение каждой из 11 строк
на матрицу А, приводит к их удлинению до 9. Теперь данные
записаны в виде двумерной (9X 11)-таблицы. Умножнм поэлементно
эту матрицу на 99 констант матрицы В„, которые заранее должны
быть записаны в постоянном запоминающем устройстве. (Более
точно, В„представляет собой диагональную матрицу размер-
ности 99, но для простоты ее здесь лучше рассматривать как
(9 х 11)-таблицу, элементами которой служат упорядоченные соот-
ветствующнм образом элементы диагонали матрицы Вээ.)
Полученную таблицу данных уменьшим теперь в объеме,
умножая сначала каждый из 9 столбцов на С„а затем каждую
из 9 строк на матрицу С,. Это приведет к вычислению всех 63 ком-
понент преобразования Фурье входного вектора, записанных
в виде (7х9)-таблицы. Остается только переупорядочнть компо-
ненты, одновременно записывая их в виде одномерного массива.
На рис. 9.12 иллюстрируется структура использования малых
преобразований Фурье в 15-точечном БПФ-алгоритме Винограда.
Из рисунка ясно, как простые логические цепи многократно ис-
пользуются для реализации указанных функций. Аналогичную
структуру можно использовать и для других длин преобразова-
ний. В тех приложениях, в которых необходимо вычислять п-то-
чечное преобразование Фурье непрерывного потока данных,
можно воспользоваться конвейерной схемой. Показанная на
рнс. 9.13 конвейерная архитектура относится к высокоэффек-
тивному К08-точечному оПФ-алгоритму. Такая структура может
быть предложена для гипотетической радиолокационной задачи,
в которой необходимо вычислять 1008-точечное преобразование
Фурье бесконечной последовательности данных. Этот способ
позволяет достигать скоростей вычисления порядка миллионов
отсчетов в секунду. Входные данные распределяются по банкам
16-точечных модулей БПФ, пройдя через которые они поступают
в банк 63-точечных модулей БПФ. Во время обработки данных
в 63-точечных модулях в 16-точечных модулях начинается об-
работка следующего пакета данных. Этим достигается одновре-
9.7. Устройства для вычисления БПФ
337
338 Гл. 9. Архитектура фильтров и преобразований
Рис. 9.13. Архитектура 1008-точечного ВПФ.
Данные
до дргмеиной
odnmmu
Шина
с~анньи
Ыана
данных
Шина
даннык
Данные
д частотной
области
339
9.8. Преобразование фурье ограниченного диапазона
менность вычисления обоих БПФ. B такую конвейерную архи-
тектуру можно добавить параллельно работающие преобразова-
тели, реализующие необходимые перестановки компонент дан-
ных. Тогда конвейер будет содержать четыре каскада два для
вычислений и два для перестановок компонент.
Может оказаться удобным, например, выбрать для первого
банка девять 16-точечных модулей, а для второго восемнадцать
63-точечных модулей. Тогда каждый 16-точечный модуль должен
в пределах одного пакета выполнять 7 вычислений. Выбор соот-
ветствующих семи векторов с шины данных регулируется про-
стыми методами управления памятью и циклическими выборками
из памяти. Аналогично, передача данных с выхода 16-точечных
модулей на центральную шину данных управляется некоторым
фиксированным протоколом. Определенный протокол управляет
также обработкой данных в 63-точечных модулях.
9.8. Преобрааование Фурье
ограниченного лиаиазона
Предположим, что при п временных компонентах преобразо-
вания Фурье интерес представляют меньше чем и частотных ком-
понент. Скажем, имеется приложение, в котором обработке под-
лежат 10 000 временнйх компонент. Это позволяет вычислить
10 000 компонент спектра, из которых нужны не Все, а, возможно,
только 100. Воспользовавшись 10 000-точечным БПФ, можно
вычислить все спектральные компоненты, а затем ненужные
отбросить. Но лучше воспользоваться прореживающей фильтра-
цией и преобразованием Фурье ограниченного диапазона.
Преобразование Фурье ограниченного диапазона относится
скорее всего к другой области цифровой обработки сигналов;
оно ие представляет собой быстрого алгоритма в том смысле,
который вкладывается в это понятие в данной книге. Мы только
хотим упомянуть его как некоторый другой метод, характер
которого сильно отличается от изучаемых нами алгоритмов.
В своем большинстве наши алгоритмы носят характер математи-
ческих тождеств. Вопросы точности относятся к реализации алго-
ритмов, но не к их построению. Если ответ неточен, то это не вина
алгоритма, как такового, а скорее связано с невозможностью
записи чисел бесконечной длины при выполнении сложения и
умножения.
В преобразовании Фурье ограниченного диапазона появляется
новый феномен. Оно представляет собой не математическое тожде-
ство, а всего лишь приближенное вычисление, хотя и дает сколь
угодно точное приближение. Общий вид преобразования Фурье
ограниченного диапазона представлен на рис. 9.14.
340 Гл. 9. Архитектура фильтров и преобразований
Яьиодной
спектр
Входной
поток даннь
Рис. 9.14. Вычисление преобразования Фурье ограниченного диапазона.
Задачи
9.1. Доказать, что если и равно степени двух, то п-фильтр-секция, построенная
итерацией 2-фильтр-секции, содержит М (n) = nÏ~'3 умножений и число
сложений, описываемое рекурсией
А (и) = 2n+ ЗА (и/2)
с начальным условием А (1) = О.
9.2. Отталкиваясь от описанного в гл. 3 алгоритма двумерной 3-точечной линей-
ной свертки, построить методом итерации двумерную 9-точечную линейную
свертку.
9.3. Для линейной свертки можно предложить метод перекрытия, который
по своему духу будет чем-то средним между методом перекрытия с накопле-
Центральной теоремой в исследованиях прореживающих филь-
тров является теорема отсчетов. Скорость отсчетов временного
дискретного сигнала не может быть меньше скорости Найквиста.
Если скорость отсчетов сделать меньше, чем удвоенная максималь-
ная частота ненулевой компоненты, то эти компоненты начинают
«накладываться» на компоненты с меньшими частотами, создавая
фальшивый «образ».
При вычислении преобразования Фурье ограниченного диапа-
зона данные сначала пропускаютСя через низкочастотный проре-
живающий фильтр, который подавляет ненужные спектральные
компоненты и сохраняет те спектральные компоненты, которые
представляют интерес. Практически используемые низкочастот-
ные фильтры, построенные методами дискретной техники, не
являются совершенными низкочастотными фильтрами. Они не-
много изменяют нужные спектральные компоненты и не полностью
подавляют нежелательные спектральные компоненты, так что
преобразование фурье ограниченного диапазона не является
точным.
После выполнения прореживающей фильтрации для вычисле-
ния нужных спектральных компонент можно воспользоваться
БПФ-алгоритмом малой длины. Если полоса нужных спектраль-
ных компонент начинается не с нуля, то надо просто ввести пока-
занный на рис. 9.14 модулирующий множитель о". Это обеспе-
чивает такой частотный сдвиг представляющих интерес частотных
компонент, что они начинаются с нуля.
Замечания
нием и методом перекрытия с суммированием. Выписать уравнения для
этого гибридного метода. Каковы его преимущества и каковы недостатки?
9.4. Доказать, что алгоритм, вычисляющий три последовательных отсчета на
выходе симметрического фильтра с четырьмя отводами, должен содержать
по меньшей мере пять умножений.
9А. Допустим, что имеется устройство (в виде жесткого модуля или подпро-
граммы) для вычисления 315-точечной цикличеатй свертки, и что необхо-
димо пропустить вектор, содержащий 1000 сасчетов данных, через КИО-
фильтр с 100 огводами. Описать, как нужно разбить данные и организовать
вход и выход устройства свертки для того, чтобы произвести необходимые
вычисления.
9.6. а. Построить содержащий семь умножений алгоритм 4-точечной симметрич-
ной фильтрации вектора с четырьмя компонентами.
б. Построить содержащий шесть умножений алгоритм 4-точечной косо-
симметрической фильтрации вектора с четырьмя компонентами.
9.7. Если последовательность данных d является комплексной, то автокорреля-
цию обычно определяют равенствами
l=0, ..., Ж+Е ‒ 2.
Показать, как надо изменить блок-схему на рис. 9.6 для того, чтобы она
стала пригодной для обработки комплексных данных.
9.8. Для вычисления сверток можно использовать метод перекрытия с накопле-
нием и короткие БПФ-алгорипиы, добавляя к ним некоторые поправочные
члены. Используя 48-точечный БПФ-алгоритм Винограда, применить этот
метод для вычисления 25 точек на выходе КИО-фильтра с 25 отводами.
Сколько сложений и умножений потребуется в таком алгоритме?
9.9. Выписать алгоритм 3-фильтр-секции для поля комплексных чисел. Сколько
вещественных сложений и умножений содержит алгоритм?
Замечания
Методы перекрытия для вычисления данных линейных сверток разбиением
их на отрезки представляются естественными и использовались, по-видимому,
независимо во многих работах. Стокхэм первым (1966) отметил, что сочетание
БПФ-алгорипиа Кули ‒ Тычки с теоремой о свертке дает хороший способ вы-
числейия циклических сверток. Агарвал и Баррас (1974) показали, как можно
одномерную свертку преобразовать в многомерную свертку, используя схему
переиндексации, которую мь~ назвали гнездовым или итеративным методом.
Эта конструкция представляет собой одну из форм секционирования по методу
перекрытия с накоплением, в котором секции упорядочены в внде матрицы.
Та же самая идея, но основанная на методе перекрытия с суммированием, была
предложена Дюбуа и Венецианопулосом (1978) для вычисления больших цикли-
ческих сверток. Конструкции хороших алгоритмов коротких секций фильтров,
включая симметрические и кососимметрические фильтры, были описаны Вино-
градом (1979, 1980). Конструкции для интерполирукацих секций фильтров яв-
ляются непосредственным приложением методов Винограда к этим частным
задачам. Трансформационный принцип описан Хопкрофтом и Мюзинским (1973).
Метод секционирования для вычисления автокорреляции принадлежит Рейдеру
(1970) ° Имеется очень много публикаций, посвященных вопросам организации
памяти для построения БПФ-алгоритмов. Одной из недавних работ является
работа Барраса и Эшенбечера (1979).
Использование прореживания для вычисления преобразования Фурье было
предложено Лю и Минцером [1978]. Они пошли дальше нашего краткого обзора
342 Гл. 9. Архитектура фильтров и преобразований
и рассмотрели многокаскадные конструкции прореживающих фильтров. Обзор
работ по интерполяции и прореживанию можно найти s статье Крошьера и Ре-
бинера (1981).
За исключением числа умножений и числа сложений, мы не проводили
сравнений характеристик различных БПФ-алгоритмов, так как, даже если
отбросить аппаратурную реализацию и рассматривать только программную
реализацию алгоритма, эти характеристики зависят от точности выбранного
варианта алгоритма, уровня языка программирования, архнтектуры процессора
и искусства программиста. Некоторые исследования характеристик были npb-
ведены Колбой и Парксом (1977), Силверменом (1977), Моррисом (1978), Навабом
и Макклелланом (1979), Паттерсоном и Макклелланом (1978) и Пандой, Полом
и Чаттерджи (1983). Было бы опрометчиво заявить, что из всех этих разнообраз-
ных работ можно сделать единое Заключение.
Глава 10
БЫСТРЫЕ АЛГОРИТМЫ,
ОСНОВАННЫЕ НА СТРАТЕГИИ
ДУБЛИРОВАНИЯ
Некоторые хорошие алгоритмы удается строить на основе
стратегии, которая дублирует алгоритм решения половины задачи.
Выберем объем задачи и в качестве параметра и разобьем, если
можно, задачу на две подзадачи объема и/2 той же самой струк-
туры, что и исходная задача. Если решения этих подзадач можно
скомбинировать в решение исходной задачи, то получается алго-
ритм решения данной задачи, который часто оказывается эффек-
тивным. БПФ-алгоритм Кули Тычки по основанию два можно
понимать как алгоритм, полученный разбиением задачи на две
половины и дублированием, так как и-точечный алгоритм строится
нз двух (и/2)-точечных БПФ-алгоритмов. Алгоритм итерирования
фильтр-секций также имеет эту структуру, так как и-фильтр-
секция строится из двух (и/2)-фильтр-секций. В настоящей главе
строятся другие быстрые алгоритмы основанные на делении за-
дачи пополам и дублировании. Они иллюстрируют способ по-
строения алгоритмов,' пригодных для многих видов задач.
!О.!. Стратегия деления пополам
и дублирования
Рассмотрим задачу нахождения многочлена р (х) степени и,
заданного своими корнями ро, P„..., р„1. Мы должны найти ко-
эффициенты многочлена р (х) вида
р (х) = (х ~,) (х ‒ р,) ... (х Р„,).
Наиболее естественным путем решения этой задачи является по-
следовательное умножение на одночлены, начиная с какого-
нибудь конца, скажем правого, согласно процедуре
р<'>(х) =(х ‒ р,) р<' ‒ '>(х), i = 1, ..., и ‒ 1,
при начальной точке р'о> (х) = (х P0). На i-м шаге итерации
такая процедура требует i умножений и ~ сложений, что в общей
сложности приводит к (1/2) и (и 1) умножениям и такому же
числу сложений.
344 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублировання
Деление задачи пополам и дублирование позволяет построить
более эффективный алгоритм. Предположим, что п равно степени
двух, а именно п = 2 . (Процедуру легко модифицировать для
других значений п, пополняя данные фиктивными входами.)
Положим теперь
n/2 ‒ 1 n/2 ‒ 1
p' (z) = H (х ‒ Il<), р" (х) = П (х ‒ ~„~2+~)
Ю=О МО
р (х) = р" (х) р' (х).
Последнее равенство в том виде, в котором оно записано, требует
(п/2)' умножений. Если р' (х) и р" (х) вычисляются непосред-
ственным образом, то каждое из этих вычислений требует
(1/2) (п/2) ((п/2) 1) умножений. Полное число умножений равно
2 ‒ ‒ ‒ 1 = и и ‒ 1,
что не лучше, чем при прямом методе вычислений.
Для извлечения из стратегии дублирования какой-то выгоды
надо применить лучшие способы сочетания двух частей вычисле-
ния р (х) = р' (х) р' (х). Но эта задача представляет собой линей-
ную свертку, которую мы столь интенсивно изучали и которую
можно вычислить не более чем с An log и операциями, где A
некоторая малая константа. Следовательно, полное число умно-
жений в таком алгоритме не превосходит величины
М(п) = An log,n+ ‒" ( ‒ ‒ 1),
которая при больших и уже лучше выписанной ранее. Это число
можно уменьшать еще дальше, применяя к вычислению каждого
из многочленов р' (х) и р" (х) ту же самую идею. Каждая из этих
задач может быть разбита на две и вычислена по алгоритму, со-
четающему содержащие А (п/2) log, (п/2) операций решения двух
половин, что дает в итоге меньше чем An log, (и/2) операций.
Продолжая таким образом, мы уменьшим число умножений до
m
М (и) = А $ п log2 (n/2i) = А (log2n ‒ logan).
8=1
При не очень малых и эта величина меньше, чем (1/2) и (и ‒ 1),
так что стратегия разбиения задачи пополам и дублирования
позволила построить улучшенный алгоритм.
На рис. 10.1 приведена схема организации вычисления про-
изведения многочленов с помощью рассмотренной процедуры
дублирования. Эта схема является хорошим примером так назы-
ваемых рекурсивных процедур. Рекурсивная процедура представ-
10.1. Стратегия деления пополам и дублирования
Но мало
Вход
Выход
Выкпд
Рис. 10.1. Процедура ПолиКоэф.
Замечанид: r ‒ глобальная переменна я.
г+л ‒ 1
Процедура Полн Козф вычисляет Ц (х ‒ P ) и увеличивает значение r.
l=r
346 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
6мпд
Выход
Рис. 10.2. Процедура БПФ.
10.2. Структуры данных
ляет собой искусный программный модуль, который не содержит
точного описания каждого уровня вычислений, а описывает только
один уровень, содержащий копию той же самой процедуры.
Процедура обращается с вызовом к самой себе. Это предполагает
запись текущих данных в виде стека, который буд~ описан в
следующем разделе. При каждом вызове процедуры происходит
проталкивание вниз существующего стека данных с целью осво-
бождения чистого рабочего пространства.
Подобная стратегия дублирования может использоваться для
решения многих задач. Если задача некоторого вычисления зави-
сит от некоторого целого числа и, то при и = 2 можно попы-
таться получить ответ из ответов для двух подзадач с и = 2
Рекурсивная форма БПФ-,алгоритма Кули Тычки с дублирова-
нием выписана на рис. 10.2. Полезно проследить, насколько от-
личаются последовательности операций на рис. 9.8 и 10.2. Ре-
курсивный алгоритм приводит к расточительному использованию
текущей памяти, так как создает временный стек для запомина-
ния результатов вычисления преобразований Фурье разных объ-
емов. С другой стороны, рекурсивную форму алгоритма удобно
использовать в единой программе, позволяющей вычислять про-
извольное преобразование Фурье по основанию два. Рекурсивная
форма может быть также удобна для организации БПФ-алгорит-
мов по смешанному основанию, так KBK легко разветвляется
в другие подпрограммы.
Стратегию дублирования обычно удается распространить на
задачи, в которых параметр и не равен степени двух. Один из
способов состоит в добавлении достаточного для превращения
числа п в ближайшую степень двух числа фальшивых итераций,
хотя иногда, как, например, в случае преобразования Фурье,
этот способ не проходит. Можно также разбивать задачу на под-
задачи другого объема, равного, скажем, трети или пятой части
объема исходной задачи, но, если задача допускает, разбиение
на половинки, как правило, дает лучший результат.
10.2. Структуры данных
Входящий в некоторое вычисление набор данных перед нача-
лом обработки должен быть соответствующим образом упорядо-
чен. Данные промежуточных вычислений также подлежат опреде-
ленному запоминанию; в рассмотренных в предыдущем параграфе
алгоритмах дублирования для этого использовался обратный стек.
Двумя основными методами организации данных являются списки
и деревья. Списком длины L называется упорядоченное множество
из L позиций; каждая позиция сама может представлять собой
сложный набор данных, даже, в частности, тоже содержать
списки.
348 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
Запись
~аннь!х
Корень
Рис. 10.3. Дерево.
Рис. 10.4. Двойной связанный список.
Список, все элементы которого являются числами, часто назы-
вается вектором. Если все элементы списка принадлежат некото-
рому конечному алфавитя,, список иногда называется иепочкой.
Цепочка не обязательно ймеет фиксированную длину, но длина
вектора обычно фиксирована. Различие между вектором и це-
почкой лежит скорее в применении, чем в существе дела.
Списком переменной длины называется список, длина которого
не фиксирована, а со временем растет или уменьшается. Список
переменной длины может расти или укорачиваться путем добавле-
ния новой позиции в любую точку списка или удалением позиции
из любой точки списка, но во многих случаях позиции добав-
ляются или удаляются только на двух концах списка. Список,
добавление или удаление позиций в котором происходит только
на одном конце, скажем, а вершине ‒ называется стеком,
или обратным списком, или последним-пришел-первым-ушел-бу-
фером. Список, в котором добавление позиций происходит на
одном конце, а удаление на другом, называется очередью, или
первым-пришел-первым-ушел-буфером.
Деревом называется такая структура данных, в которой за
каждой позицией могут следовать одна или более позиций, назы-
ваемых потомками; пример графического изображения такой
структуры приведен на рис. 10.3. Каждому узлу соответствует
позиция данных, и каждая позиция имеет в качестве своих потом-
ков другие позиции, с которыми она связана. Возможна ситуация,
в которой несколько узлов дерева соответствуют одной и той же
позиции данных. В противоположность дереву каждая позиция
списка может иметь только одного потомка.
Позиция данных в списке или в дереве может быть достаточно
сложной, включая, возможно, текст на естественном языке; но
10.3. Быстрые алгоритмы сортировки
349
с точки зрения исследования структуры списков каждая позиция
рассматривается как некая единица. В памяти вычислительного
устройства списки и деревья запоминаются с помощью некоторых
имен, присваиваемых позициям; хорошими именами являются
адреса ячеек памяти, в которых начинаются данные позиций.
Список {или дерево) запоминается в виде последовательности
имен позиций, входящих в список. Список не обязательно запо-
минать в непосредственной близости к позициям данных.
Другим, иногда более удобным методом, является метод не-
прямой адресации, называемый связанным списком; он показан
на рис. ! 0.4. Позиции данных появляются в произвольном порядке,
и каждый вход начинается с адреса следующей позиции данных
списка. На рис. !0.4 показан двойной связанный список. В двойном
связанном списке данные записаны двумя способами скажем,
в алфавитном и хронологическом порядке но не обязательно
запоминаются дважды. Если список часто пересматривается, то
удобнее пользоваться связанным списком, так как это позволяет
не двигать данные.
Организация стека даже из сложных позиций данных реали-
зуется простым присваиванием адреса первой позиции данных и
привязыванием к каждой позиции данных адреса следующей по
списку позиции данных. Для записи новой позиции данных в вер-
шину стека надо просто привязать адрес предыдущей вершины
к новой вершине и изменить адрес первой позиции данных на
адрес новой позиции. Для извлечения позиции данных из вершины
стека надо обратить процедуру.
10.3. Быстрые алгоритмы сортировки
Задача сортировки формулируется следующим образом. За-
дана произвольная последовательность из и элементов, выбранных
из множества, на котором имеется некоторый естественный поря-
док; Необходимо переупорядочить заданную последовательность
в том же естественном порядке. Алгоритм сортировки может
относиться непосредственно к позициям данных и перезаписи их
в памяти, а может и не затрагивать позиции данных, а оперировать
только с некоторыми привязанными к ним параметрами. Данные
сортируются переупор ядочиванием списка непрямых адресов.
Сортировка переупорядочиванием адресов полезна в тех случаях,
когда объем данных в каждой позиции сам по себе очень велик.
Предположим, что с каждой позицией данных связан некото-
рый целочисленный параметр, и необходимо упорядочить позиции
данных так, чтобы целочисленный параметр менялся от своего
наибольшего значения к наименьшему. Любая задача сортировки
может быть сформулирована в таком виде.
350 Гл. 10. Быстрые алгоритмы, Основанные на стратегии дублирования
Наивная процедура сортировки состоит в просмотре одной
позиции за другой и выборе той, которой соответствует наиболь-
шее значение параметра'. Затем так же просматриваются остав-
шиеся позиции и находится та из них, которой соответствует
наибольшее значение параметра. Это продолжается до тех пор,
пока не будут рассортированы все позиции. В повседневной жизни,
когда и мало, это вполне удовлетворительная процедура. Однако,
среднее число шагов в ней пропорционально ~п.,Яля сортировки
больших списков можно действовать намного лучше.
Хорошие алгоритмы сортировки основываются на делении
списка пополам и дублировании. Одним из них является алго-
ритм сортировки слиянием; его сложность пропорциональна ве-
личине п 1og~ и. Разобьем список из и позиций данных на две
половины и упорядочим каждую из них. Из этих упорядоченных
списков половин организуем общий упорядоченный список, сли-
вая их вместе по следующему правилу. Сравним верхние элементы
в обоих списках. Выберем из них тот, который соответствует
большему значению параметра, и разместим ero в качестве сле-
дующей позиции объединенного списка, выбросив из той поло-
вины, где он находился раньше. Так как каждая позиция попадает
в объединенный список после операции сравнения, то в общей
сложности придется сделать и сравнений. Следовательно, слож-
ность С (и) алгоритма сортировки слиянием описывается ре-
курсией
С(n) <2С ( ‒ ) +n.
Эта рекурсия дает оценку сложности для алгоритма сортировки
слиянием:
С (и) .< п log, п.
Так как имеется только одно значение аргумента, при котором
здесь выполняется равенство, то при слиянии некоторые сравнения
не нужны, так что алгоритм можно немного улучшить. Тем не
менее, мы полагаем, что эта оценка является достаточно точной.
Име~отся другие способы разбиения задачи сортировки. В ал-
горитме «быстрой сортировки» случайно выбирается один из па-
раметров данных в качестве основы для разбиения списка. Харак-
теристики такого алгоритма являются случайными величинами,
достатбчно хорошими в среднем, но очень медленными в наихуд-
ших случаях.
Так как в алгоритме «быстрой сортировки» параметр разбиения
списка выбирается непосредственно из данных, то этот параметр
должен быть случаен. В противном случае можно было бы по-
строить тестовый список, для которого «быстрый алгоритм»
оказался бы очень плохим. Например, если в качестве параметра
разбиения списка всегда выбирать первый вход данных, то «бы-
10.3. Быстрые алгоритмы сортировки
Л ‒ 1
C(n) = ‒ An+ ‒ ~~~ C (i) + ‒ ~~~ C (n ‒ 1 ‒ i),
г=о
к=о
где А некоторая константа. Для и ) 2 это приводит к следую-
шей рекурсивной формуле для сложности С (n) алгоритма «быстрой
сортировки»:
С (и) = А и + ‒ $ С (i)
<=o
при начальных условиях С (О) = С (1) = О. (Иногда предпочи-
тают полагать С (О) и С (1) некоторыми малыми константами,
но это мало что меняет и никак не влияет на асимптотику слож-
ности.) Покажем, что при и ) 2 величина С (и) меньше, чем
2Ап log п. È0êàçàòåëüñòs0 проведем индукцией: предположим,
что для всех 1 < и величина С (i) меньше, чем 2Ai 1п,1. Это
справедливо для и = 2. Тогда
Л ‒ ]
С (и) < An + ‒ ~~ ~1 1п,1.
4А
г=г
Так как функция i 1n,1 выпукла, то правую часть можно огра-
ничить величиной вида
С (и) < An+ ‒ x1п,хdx.
4А
2
Следовательно,
п~
= 2Ап 1п,п.
C(n) < Аи+ ‒ [
стрый алгоритм» будет сортировать список чрезвычайно
ме енно.
«]стрый алгоритм» работает следующим образом. Выберем
случ йно из данных некоторый элемент с параметром а. Все дан-
ные, за исключением а, разделим на два подмножества: те данные,
параметр которых меньше а, и те данные, параметр которых не
меньше а. Упорядочим каждое из этих подмножеств и соединим
их в один список, расположив позицию а между ними. Каждое
из двух подмножеств упорядочивается по такому же правилу.
,И,ва списка, на которые разбивается исходный список, содер-
жат по и 1 i u i элементов, где г ‒ случайная величина,
равновероятно распределенная на множестве 10, ..., n 1).
Сложность формирования этих множеств пропорциональна и.
Средняя сложность сортировки исходного списка из и точек pasHa
352 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
Средняя характеристика алгоритма «быстрой сортировки» асимп-
тотически лучше средней характеристики алгоритма сортировки
слиянием, но в наихудшем случае характеристика становится
намного хуже.
10.4. Рекурсивное быстрое
преобразование Фурье
по основанию два
Комплексное преобразование Фурье по основанию два опре-
деляется формулой
и ‒ 1
Vk=g и'kv;, /г=О, ..., n ‒ 1,
c=o
где и = 2, m целое число и v вектор с комплексными компо-
нентами. В гл. 4 мы интересовались построением алгоритмов,
представляющих собой малый пакет уравнений, непосредственное
применение которых позволяет вычислить преобразование Фурье
радиуса два. Этот способ очень подходит для длин и, равных 8
или 16, но может оказаться неподходящим при больших и. В на-
стоящем параграфе мы выпишем алгоритм по основанию два
в рекурсивной форме. Входные данные в комплексном виде мы
выбираем потому, что при п = 32 и более эта форма алгоритма
применительно к комплексным данным эффективнее, чем двойное
использование БПФ-алгоритма для вещественного входа.
Так же, как и в гл. 4, воспользуемся методом Винограда для
разбиения вычисления преобразования Фурье на отдельное вы-
числение компонент с четными индексами и компонент с не~ет-
ными индексами. Для обработки компонент с четными индексами
заменим А на 2k и запишем
л/2 ‒ 1
Vgk = Е (og+6(+n)г1о)гп Й = О, ..., и/2 ‒ 1.
g~
Мы получили и/2-точечное преобразование Фурье нового вектора,
компоненты которого равны о~ + оц /2, так что для их вычисле-
ния требуется ))/2 комплексных сложений. Для обработки компо-
нент с нечетными индексами заменим й íà 2k + 1 и запишем
л/2 ‒ 1 и/2 ‒ l
у ~ () .~2( (2k+)) ~ g () ~(2(+l) (2k+))
с=о с~
=О, ..., и/2 ‒ 1.
Эти две суммы будут рассматриваться отдельно. Яля их сочета-
ния потребуется еще и/2 комплексных сложений.
10.4. Рекурсивное БПФ по основанию два
В первой сумме выписанного уравнения необходимо вычис-
лить только первые компоненты для Й = О, ..., и/4 1, так как
в дальнейшем они повторяются. Эти компоненты представляют
собой (п/4)-точечное преобразование Фурье вектора с компонен-
тами v,; а ', для вычисления последнего вектора требуется
(3/4) п 8 вещественных умножений (так как это вычисление
содержит п/4 4 комплексных умножений, каждое из которых
может быть выполнено с тремя вещественными умножениями,
и два комплексных умножения, для вычисления каждого из
которых нужно только два вещественных умножения) и столько же
сложений.
Основная часть рассуждений связана с вычислением промежу-
точного результата,
n/2 ‒ l
4к+1 = Е g~;+~~<"+'><"+'>, й = О, ..., „/2 ‒ 1.
8=0
Так как порядок элемента а равен и, то вычисления в показателе
степени должны проводиться по модулю и, где и = 2 . Все эти
вычисления представляют собой умножения нечетных чисел по
модулю 2 . Согласно теореме 5 1.8, относительно операции умно-
жения по модулю 2 множество нечетных чисел образует группу,
изоморфную группе Zg X Zy. и, следовательно, имеет две обра-
зующие. В качестве таких образующих можно выбрать 3 и 1;
тогда множество показателей степени образует мультипликатив-
ную группу {3' ( 1)': 1 = О, ..., 2 ~ 1; 1' = О, 1), групповой
операцией в которой является умножение по модулю 2 . На вход-
ных и выходных индексах это задает соответственно подстановки
2i+1 = 3'( 1)' и 21+ 1 =3 ‒ '( 1) ‒ ".
При таком представлении индексов предыдущее уравнение при-
водится к виду
2т ‒ г
г'=О 1
с. =-о с===о
Г ‒ э ф
где элементы t,,, и о~ ~ двумерных таблиц равны тем компонен-
»«~~+~ и о„+„индексы которых определяются выписанными
выше подстановками. Рассматриваемое уравнение преобразуется
при этом в двумерную циклическую свертку:
i(x, у) = g(x, y) u(x, y)(modx' ' ‒ 1)(тобу' ‒ 1),
где g (x, у) равен обобщенному многочлену Рейдера,
2гп ‒ 2 1
g(x, y) = Е Е m"' — '"xÓ',
г=о с=о
354 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублнрования
а о (х, у) и t (х, у) представляют собой многочлены от двух пере
менных, задаваемые входными и выходными данными соответ-
ственно равенствами
г ‒ г ~
о(х, у) = ~, ~, о/ /-х'у',
1'=0 1=0
гг ‒ г
t(x, у) = ~, ~'., t/ / х'у' .
1'=0 1=0
Чтобы задать многочлен о (х, у) по компонентам о„.„, нужно вы-
полнить только перестановки. Аналогично, для вычисления ком-
понент 1,/,„по многочлену t (х, у) нужны только перестановки.
Структуру легче увидеть,'если переписать многочлены в виде
о (х, у) = о, (х) + уо, (х), t (х, у) = t, (х) + у1, (х)
2m ‒ 2 1
gm ‒ г
g(», у) = Z из'х'+ Z и "/('ó =д(х)+уд'(х).
1=0 l~
гm ‒ г 1
где g (x) = g и' х'.
1=0
Тогда
t, (х) g (х) g* (х) о, (х)
t, (х) g* (х) g (х) о, (х)
Если входные данные вещественны, то ti (х) = tp (х) и вычислять
надо только
t, (х} = g (х) оо (х} + g* (х) о, (х) (mod х"/' 1).
На следующем шаге воспользуемся разложением
<n/4 1 (хл/8 1) (хл/8+ 1)
и китайской теоремой об остатках. Пусть
д(') (х) = g (х) (mod х"" 1)
g(') (х) = g (х) (mod х"/~ + 1)
и остальные необходимые многочлены определены аналогичным
образом. Так как согласно теореме 4.6.3 д(о) (х) = 0, то вычислять
надо только члены, содержащие g(') (х):
с ф'(х) g"'(õ) g'"я'(х ф'(х)
1',"(х) д"'~( ) g"'(х) ~'(х)
Яалее воспользуемся алгоритмом 2-точечной циклической свертки
-'fg' '(õ) ‒ g' '~(õ)j ) ‒ ) и~"(х)
1',"(х)
355
8ь|ход
Число вещественных
умножений
Число вещественных
умножений
Длнна
Число ве-
щественных
сложений
Число ве-
ществен ных
сложений
нетрн-
полное
внальных
нетри-
виальных
полное
0
0
2
10
36
102
258
608
1370
2994
2
4
8
16
32
64
128
256
512
1024
2
4
8
18
50
124
294
666
1464
3146
2
8
26
74
0
0
4
20
68
188
468
1092
2444
5316
4
16
52
148
4
8
16
36
96
232
540
1208
2632
5620
!0.4. Рекурсивное БПФ по основанию два
Рис. 10.5. Рекурсивная форма БПФ-алгоритма
Винограда по основанию два.
Многочлен [д<» (х) + д<'>' (х)] содер-
1
2
жит только вещественные коэффи-
циенты, а многочлен tg" > (<)
1
g<' > ' (х)) содержит только чисто
мнимые коэффициенты. Следовательно,
задача свелась к вычислению четы-
рех произведений по модулю х"~8+ 1
многочленов с вещественными коэф-
фициентами. Теоретически, каждая
нз этих задач требует и/4 1 веще-
ственных умножений; практически из-
вестные алгоритмы требуют несколько
большего числа умножений.
На рис. 10.5 приведена блок-схема
описанного рекурсивного вычисления;
на рис. 10.6 затабулированы по-
лучаемые при этом хар актер истики.
Рис. 10.6. Характеристики некоторых БПФ-ал-
горитмов Винограда по основанию два.
Вещественные входные данные
Вкод д 2 -точечное БПФ
Комплексные входные данные
356 Гл. !О. Быстрые алгорнтмы, осиованные на стратегии дублирования
10.5. Быстрая транспозиция
Во время обработки больших двумерных таблиц, подобных
оцифрованным изображениям, процессор может воспринять только
малую часть этой таблицы. Например, для запоминания (1024x
X 1024)-таблицы требуется более, чем миллион ячеек памяти и
более, чем два миллиона, если таблица комплексная. В большин-
стве случаев таблица запоминается во внешней памяти системы
и считывается по частям в оперативную память процессора. Как
правило, (n х п)-таблица запоминается по столбцам (или по
строкам) во внешней памяти, и в каждый момент времени между
оперативной памятью и внешней памятью происходит обмен одним
столбцом. Обмен двух элементов из двух различных столбцов
столь же трудоемок, сколь обмен двух целых столбцов. Таким
образом, для формирования одной строки матрицы приходится
считывать п столбцов, а для формирования всех строк приходится
считывать и' столбцов, так что прямое транспонирование матрицы
приводит к считыванию и столбцов.
В тех приложени я х, в которых оперативная память мала. для
перестановки строк и столбцов во внешней памяти можно пользо-
ваться алгоритмом быстрой транспозиции. Мы рассмотрим случай,
когда оперативная память допускает запоминание двух столбцов
из квадратной таблицы. Это наиболее интересный и позволяющий
продемонстрировать все основные идеи случай. Для транспони-
рования (n х п)-таблицы во внешней памяти алгоритм делает
и log, и считываний столбцов в оперативную память. Если в опе-
ративную память нельзя записать двух столбцов, то алгоритм
приходится дублировать, что снижает его эффективность; если
оперативная память допускает запись более двух столбцов, то
алгоритм можно улучшить на некоторую константу.
Транспонирование матрицы, записанной в оперативной памяти
прямого доступа, является тривиальной задачей, так как реали-
зуется простым изменением адресов при вызове данных. Мы будем
полагать, что транспонирование малых матриц сводится к считы-
ванию таблицы в оперативную память и последующему считыва-
нию ее во внешнюю память. Пусть (2 х2 )-матрица А разбита
на блоки размерности 2 ‒ ' в виде
A„ A„
А=
А„ А„
Предположим, что у нас имеется способ вычисления матрицы
~0.5. Умножение матриц
357
Тогда для вычисления матрицы
достаточно переставить матрицы А» и Aä. Эго можно сделать,
т т
считывая и одновременно переставляя один столбец из А» с одним
Т
столбцом из А 1. Яля полной перестановки матриц потребуется
переставить п)2 пар столбцов (или п столбцов).
Т
Теперь применим эту идею рекурсивно к вычислению А»,
Т Т Т Т
A2~, А~~ и А~~, разбивая каждую из них на подблоки. Так как А»
и А» расположены в одних и тех же столбцах таблицы, то входя-
Т
щие в них транспозиции выполняются перестановкой одних и
тех же столбцов. Таким образом, каждый уровень рекурсии за-
трагивает и столбцов, а всего уровней имеется log и. Следова-
тельно, в противоположность прямому методу транспонирования
матрицы, содержащему и' перестановок столбцов, построенный
быстрый алгоритм транспозиции содержит и log2 и перестановок
столбцов.
10.6. Умножение матриц
Произведение матриц размерности два
С11 С12 a» a» b» b»
С21 С22 а2~ а22 Ь2 Ь22
можно вычислить по правилам
С11 = а11Ь11 + а12Ь21
c12 = a11b» + a»b22
<21 = а21Ь11 + a22Ь..
СЯ2 = а21Ь12 + а22Ь22
из которых следует, что так организованное вычисление содержит
восемь умножений и четыре сложения. Алгоритм Штрассена
позволяет так организовать вычисление, что оно будет содержать
семь умножений.
В алгоритме Штрассена сначала выполняются следующие
вычисления:
mõ = (a„a„) (b i + Ьгг).
т, = (а„+ а„) (Ь„+ Ь„),
т, = (а„а~,) (Ь„+ b„),
m4 = (~gi + ~is) "
358 Гл. 1О. Быстрые алгоритмы, основанные на стратегии дублирован ия
т, = а„ (Ь„ Ь„),
me ‒ а22 (Ь21 Ьы),
т, = (а„+ а„) Ь„.
Затем элементы произведения матриц вычисляются по формулам
Сдд ‒ Шд + m2 m4 + mg,
Сд2 m4 + m6s
С,д= т„+т„
С22 ~~!2 ~!8 + m5 m7 °
В матричном виде алгоритм Штрассена записывается равенством
ь„
Ь2!
~~~г
0 0 1 1
1 0 0 !
1 1 0 0
0 0 0
0 1 0-1
‒ ! 0 ! 0
1 0 0 0
G,
1 0 ‒ 1 0
0 0 0 1 1 0
0 0 0 0 0 1
0 1 ‒ ! 0 1 0‒
с,
~3
G4
G,
~6
G,
в котором элементы стоящей в центре диагональной матрицы
вычисляются по правилу
G)
С2
~3
с,
G5
~Ь
~з
0 1 0 ‒ !
0 0 1
1 0 ‒ 1 0
! 1 0 0
1 0 0 0
0 0 0 !
0 0 ! 1
Алгоритм Штрассена содержит семь умножений и 18 сложений.
Если одна из двух перемножаемых матриц является постоянной и
используется много раз, то некоторые сложения можно вычислить
заранее вне процесса умножения и тогда число сложений стано-
вится равным 13.
По сравнению со стандартным алгоритмом умножения матриц
алгоритм Штрассена даже в лучшем случае меняет одно умноже-
ние на девять сложений. Практически этот алгоритм умножения
матриц размерности два не дает преимуществ.
Теперь рассмотрим задачу умножения двух матриц размер-
ности и. Прямой метод такого вычисления требует и' умножений
и (n 1) и сложений. Предположим, что п равно степени двух:
и = 2 для некоторого целого т; в противном случае дополним
матрицу справа таким количеством нулевых столбцов и снизу
~аким количеством нулевых строк, чтобы и стало равным степени
двух.
10.6. Умножение матриц
359
Произведение матриц С = АВ можно разбить на блоки
с
С„Сц А„Аlg BII В,2
где каждый блок представляет собой матрицу размерности 2 ‒ '.
Вычисление блоков слева прямым умножением блоков справа
содержит восемь умножений матриц размерности и/2 и четыре
сложения матриц размерности и/2. Если все эти вычисления про-
водить стандартными способами, то полное число умножений
будет равно
М(дд) =8( ) =дд',
A(n) =8( 1) ( ) +4 ( ) =(n ‒ 1)n'.
Мы получили те же самые величины, что и раньше, так что стра-
тегия дублирования не приводит к увеличению эффективности,
если не воспользоваться некоторыми другими возможностями.
Такие возможности дает алгоритм Штрассена.
Алгоритм Штрассена можно применить на уровне блоковых
матриц, так как он не зависит от свойства коммутативности умно-
жения. Итак, применим сначала алгоритм Штрассена в следую-
щем виде:
Мд ‒ ‒ (А„‒ A„) (B„+ В„),
M, = (A„+ A„) (Вдд+- В„),
Мз =- (Адд ‒ А,д) (В,д + Вд,),
М, = (А„+ А„) В„,
М, = Адд (Вдя ‒ В22)
М, = А„(В„‒ В„),
М, =(А„+ А„) В„.
Блоки матрицы' С вычисляются по правилам
сдд ‒ мд+ мд ‒ м4+ м
Сдд = М4 + Мьэ
С„=М +M„
Caa ™a Ms+ Me Мд.
Если матрица А является матрицей констант, то вместо имев-
шихся ранее восьми умножений и четырех сложений матриц раз-
мерности и/2, мы получаем семь умножений и тринадцать сложений
матриц размерности и/2. Если каждое из этих вычислений прово-
дить стандартным способом, то для полного числа умножений по-
лучаем
М(п) =7( ) = n',
36О Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
что меньше пз. Для полного числа сложений имеем
А (и) = 7 ( ‒ ‒ !) ( ) +!3 ( ‒ ) = ( п+ ‒ ) n',
что прн п ) 20 также меньше, чем (n 1) и'.
Еще большее улучшение дает рекурсивное использование ал-
горитма Штрассена, основанное на разбиении блоков на более мел-
кие подблоки и использовании тех же самых уравнений. В этом
случае число умножений равно
Число сложений вычисляется сложнее. Оно удовлетворяет ре-
курсии
А(п)=7А( )+13(" )
Число сложений больше числа умножений, но также растет как
и' 8'. При достаточно больших и это число меньше числа сложений,
необходимых в прямом методе вычисления. При и = 1024 число
необходимых в алгоритме сложений примерно равно числу сложе-
ний прямого метода вычислений, но число умножений равно при-
мерно одной четверти от числа умножений прямого метода вычис-
ления произведения матриц размерности 1024.
10.7. Рекурсивный алгоритм Евклида
Стратегия дублирования позволяет ускорить алгоритм Евклида
и построить алгоритм, сложность которого имеет порядок и log' и.
Основные вычисления в алгоритме Евклида описываются уравне-
ниями
ф )(x) О ! > "(> А )(z) s(x)
где
н алгоритм останавливается, когда многочлен t<'+'> (х) обра-
щается в нуль.
ясно, что вычисление матрицы А<'> (х) имеет ту же самую струк-
туру, что и показанное на рис. 10.1 вычисление произведенця мно-
l0.7. Рекурсивный алгоритм Евклида
361
гочленов, которое оказалось столь пригодным для стратегии дуб-
лирования. Поэтому можно ожидать, что стратегия деления задачи
пополам и дублирования позволит улучшить характеристики ал-
горитма Евклида. Нам надо набор итераций разделить на две
группы. Если это деление удастся осуществить так, что каждая из
групп будет похожа (или может быть сделана похожей} на исход-
ную задачу, то мы получим рекурсивную структуру.
Имеется, однако, несколько деталей, о которых следует поза-
ботиться. Первая трудность состоит в том, что мы не знаем заранее
число итераций, так что невозможно сказать, когда половина
итераций завершена. Эту трудность можно исключить, прерывая
вычисления в точке, в которой выполнена примерно половина
итераций.
Другая трудность состоит в том, что Q«> (х} зависит от
А<' '> (х). и, в свою очередь, А<'> (х) зависит от Q<'> (х}. Следова
тельно, заранее не известны все участвующие в вычислении
А'> (х) его делители. Г1ри разбиении на группы необходимо по-
заботиться о том, чтобы ни один делитель не использовался рань-
ше, чем он станет известным. Теорема 10.7.1 утверждает, что если
разбиение алгоритма происходит в правильной точке, то структура
обеих групп аналогична структуре исходной задачи.
Пусть матрица А<'+'> (х} факторизуется в виде
А<' (х) = A« "+' > (х) A«' (х},
где
"+' 0
A<' "+'> (z) = П
l=r
1
Q<'> (х)
0
А<">(х) = П
1=г'
1
Q<'> (х)
для некоторого фиксированного r'. Первая группа уравнений со-
стоит из r итераций, совпадающих с первыми r итерациями ис-
ходной задачи. Вторая группа содержит уравнения для r = г' +
+1, ...,P:
Эта группа вычислений, очевидно, имеет ту же форму, что и исход-
ная задача.
Первая группа также имеет эту же структуру, но если для ее
вычисления использовать тот же путь решения, то стратегия деле-
ния задачи не даст ожидаемого улучшения. Чтобы уменьшить слож-
ность, надо упростить вычисление первой группы. Такое упрощение
362 Гл. 10. быстрые алгоритмы, основанные на стратегии дублирования
является источником значительной экономии числа вычислений
и основывается на следующей теореме, описывающей условия,
при которых возможно усечение делимого и делителя, не изме-
няющее частотного и остатка.
Теорема 10.7.1. Пусть два заданных многочлена f (х) и g (х},
степени которых связаны соотношением deg g (х} ( deg f (х}, за-
писаны в виде f (х) = f' (х} х~ + f" (х и g (х) = g'(х) х~ + д"(х),
где степени многочленов f" (х} и g" (х меньше некоторого числа Й,
удовлетворяющего неравенству Й < 2 deg g (х) deg f (х}. Пусть
алгоритм деления приводит соотаетственно к равенствам f (х) =
= Q (х) g (х) + r (х) и f' (х) = Q' (х) g' (х) + r' (х). Тогда
(i) Q (х) = Q' (х),
(ii) r (х} = r' (х} х + r" (х}, где степень многочлена r" (х}
меньше, чем Й+ deg f (х} degg (х).
Доказательство. Утверждение теоремы является легко доказы-
ваемым следствием однозначности алгоритма деления. Начнем
с равенства
f' (х) = Q' (х) g' (х) + r' (х).
Тогда
f' (х) х~ + f' (х) = Q' (х) g' (х) хь + r' (х) Q + / (z)
f (х) = Q' (х) g (х) + r' (х) х" + f" (х) Q' (х) g" (х).
В силу однозначности алгоритма деления мы сможем заключить,
что
Q (х) = Q' (х) и г (х) = г' (х) хь + f" (х) Q' (х) д" (х),
если покажем, что
deg [r' (х) хь + f' (х) Q' (х) а" (х) ] ( deg g (х).
Но, используя условия теоремы, это легко проверить для каждого
из трех многочленов, стоящих в левой части неравенства:
(i) deg [r' (х) х" ] ( deg g' (х) + Й = deg g (х),
(ii) deg f" (х) ~< Й 1 ( deg g (х),
(Ш) deg [Q' (х) g" (х) ] ( deg f' (х) deg g' (х) + Й =
= (deg f (х) Й) (deg g (х) Й) + Й.< deg g (х).
Второе утверждение теоремы получится, если заметить, что из
неравенств (й) и (Ш) следует, что степень многочлена f' (х}
Q' (х) g" (х) меньше, чем Й + deg f (х) deg g (х). ~
Следствие 10.7.2. Пусть целое число k удовлетворяет нера-
венству
Й .< 2 deg g (х} deg f (х).
10 7 Рекурсивный алгоритч Евклида
Тогда частное Q (х) при делении многочлена f (х) на многочлен g (х)
не зависит от й младших коэффициентов многочленов f (х) и g (х)
и Й младших коэффициентов многочленов f (х) и g (х) оказь<вают
влияние только на те коэффициенты остатка r (х}, индексы ко-
торых меньше, чем Й+ deg f (х) deg g(x). Q
Согласно теореме 10.7.1, и многочлен-частное Q (х} и сегмент
многочлена-остатка r (х) могут быть получены при усечении мно-
гочленов f (х) и g (х) до более коротких многочленов. Мы сейчас
покажем, что отбрасывание сегмента многочлена остатка r (х) не
затрагивает некоторые последующие итерации алгоритма Евкли-
да. На самом деле, если выбрать k разумно, то примерно половина
итераций может быть вычислена без знания отброшенного сег-
мента остатка r (х).
Теорема 10.7.3. Пусть f (х} = f' (х) хь + f" (х) и g (х} =
= g' (х) х~ + ~ (х), где deg f" (х) ( Й и deg g" (х} ( k. Пусть
deg f (х) = и, deg g (х) ( deg f (х), и пусть A'<'> (х) и«А<'> (х)
обозначают матрицы из алгоритма Евклида, вычисленные coomaem-
если deg g'<'> (х) ) (и Й)/2, то для каждого r выполняется ра-
венство А<'> (х) = А'<'> (х). (Иными словами, частные оста-
точных последовательностей, порождаемых в процессе выполнения
алгоритма Евклида, для нештрихованных и штрихованных пере-
менных совпадают по меньшей мере до тех nop, nopca не будет до-
стигнут остаток g'<'> (х}, степень которого меньше, чем поло-
вина степени f' (х).)
Яоказательство. Доказательство сводится к применению след-
ствия 10.7.2 на каждом шаге итерации алгоритма Евклида для не-
штрихованных и штрихованных переменных при начальных усло-
виях Р<» (х) = f (х), g<'> (х) = д (х) и f <o> (х} = f' (х), g <'> (х) =
= д' (х).
Шаг 1. Следствие 10.7.2 можно применять на каждом шаге при
условии, что выполняется неравенство Й ( 2 deg g'> (х)
deg f<'> (х). Но нам дано, что
deg g' <'> (х} )
Мы покажем, что это условие эквивалентно нужному условию,
связывая степени штрихованных многочленов со степенями не-
IIITpHxoBBHHblx многочленов. 3ти связи следуют из равенств
/ "' '(х
‒ Ял.) g "(x
364 Гл. 10. Быстрые алгоритмы, основанные на стратегни дублирования
deg f'<'> (х) = deg f<'> (х) Й,
<'> (») = dе~ g<'> (x} k
Следовательно, пдскольку многочлен-частное является одним
и тем же многочленом в штрихованном и нештрихованном слу-
чаях, имеют место равенства
deg f'<'>(х) = deg f<'>(х) Й,
deg g'<'> (х) = deg g<'>(х) k.
Таким образом, нам дано, что
~('> ~~ ‒ ~
deg g<'> (х) ‒ Й ) )
так как и = deg f<0> (х) ) deg /'> (х). Это неравенство сразу сво-
дится к условию
Й .( 2 deg g<'> (х} ‒ deg /'> (х),
так что следствие 10.7.2 можно применять на каждом шаге итера-
ции, если только на предыдущем шаге итерации мновочлен Q (х}
вычислен правильно.
Шаг 2. Согласно следствию 10.7.2, каждый многочлен-частное
вычисляется правильно, если только предыдущий многочлен-част-
ное был вычислен правильно и последний полученный многочлен-
остаток содержит достаточное число правильных коэффициентов.
Чтобы проверить последнее условие, опять воспользуемся след-
ствием 10.7.2, заменив число k числом
k«> = Й+ deg f<' ‒ '> (х) ‒ degg« ‒ » (x)
и полагая 9~) = k. Согласно следствию 10.7.2 к началу r-го шага
итерации многочлен-остаток будет правильно вычислен за исклю-
чением, возможно, младших И'> членов, что согласно тому же
следствию не влияет на вычисление многочлена-частного при ус-
ловии, чго Й<'> -( 2 deg g<'> (х) deg f'> (х). Тот факт, что это
неравенство выполняется, проверяется следующим образом:
Й<'> ‒ 2 deg g<'> (х) + deg f<'> (х) = Й + deg /<' ‒ '> (х) ‒ deg g<' ‒ '> (х)‒
‒ 2 deg g<'> (х) + deg /<'> (х) = k + deg f <' ‒ '> (х) ‒ 2 deg g«> (х) (
(@+и ‒ 2( + )=0,
где использованы неравенства deg f<' '> (х} ( и и
deg g<'> (х) = ‒ deg g'<'> (х) + Й.(
Таким образом,
k<'>.(2 deg g<'> (х) ‒ deg f«> (х)
l0.7. Рекурсивный алгоритм Евклида
,&каЮ
Ю ироцвддру ЕВк4лг
Рнс. 10.7. Процедура ЕвкАлг.
и, следовательно, на r-м шаге итерации многочлен-частное не за-
висит от неизвестных коэффициентов. Это завершает доказатель-
ство теоремы. Р
Условие «deg g'<'> (х} ) (n Й}/2» теоремы для нештрихо-
ванных переменных можно переписать в виде «deg g<'> (х} )~ (n +
+ Й}/2». Эквивалентность этих условий используется в формули-
ровке рекурсивной процедуры.
Разбиение алгоритма Евклида пополам показано на диаграмме
на рис. 10.7. В основной точке ветвления алгоритма выносится ре-
366 Гл. 10. Быстрые алгорнтмы, основанные на стратегнн дублирования
Влад
8аавд
Рис. 10.8. Процедура Половина ЕвкАлг.
шение о немедленном разбиении задачи или о выполнении стан-
дартной итерации алгоритма Евклида, поскольку процедура ра~
биения и дублирования неприменима. Последнее решение прини-
мается только в том случае, когда степень многочлена g (х} меньше
половины степени многочлена f (х). В этом случае стандартная
итерация алгоритма Евклида на половину снижает размерность
задачи, и мы ничего не теряем, поскольку процедура дублирования
неприменима.
l 0.8. Вычисление тригонометрическнх функций
Форма полученной при разбиении второй половины задачи сов-
падает с формой исходной задачи, так что для ее вычисления можно
опять вызвать процедуру ЕвкАлг. Первая половина задачи имеет
аналогичную, но не идентичную форму, так как вычисления сле-
дует закончить, если степени многочленов слишком малы. Поло-
вину задачи можно также разбить пополам, так что мы приходим
к формулировке вычислений в рекурсивном виде. Такая рекур-
сивная процедура показана на рис. 10.8. Обоснование этой про-
цедуры можно провести методом индукции. Нам надо показать, что
вычисляются те же самые итерации алгоритма Евклида, которые
описываются теоремой 10.7.3. Это всегда выполняется при п рав-
ном 1 и 2, так как в этом случае мы движемся по левой ветви на
рис. 10.8. При движении по правой ветви в результате первого
обращения к процедуре «Половина ЕвкАлг» согласно предположе-
нию индукции степень deg f (х) уменьшается до (n + Й)/2, что со-
ставляет примерно 3/4 исходной степени многочлена f (х). Второе
обращение к процедуре «Половина ЕвкАлг» завершает описывае
мые теоремой 10.7.3 итерации.
10 8. Вычисление тригонометрических функций
Для вычисления триюнометрических функций обычно исполь-
зуется некоторое разложение в степенной ряд. Такие методы сильно
отличаются от рассматриваемых нами методов. Имеется, однако,
ряд приложений с привкусом стратегии дублирования, для кото-
рых более подходящими являк~гся описываемые нами методы.
Первый из рассматриваемых нами методов дается алгоритмом
одновременного вычисления значений функций sin 8 и cos 8 при
заданном угле О. Процесс вычисления основывается на тригоно-
метрических тождествах для удвоения угла
sin 26 = 2 sin 6 cos 6,
cos26 = 1 2sin'6,
или
sin 20 = 2 sin 0 2 sin 0 vers О,
vers 20 = 2 sin.' О,
где vers 0 = 1 cos О.
Для вычисления начальных значений данный угол 8 делится
на некоторую степень двух и используются приближенные фор-
е е е
мулы для малых углов: sin = и vers = О.
gm =,,уи
~~) т
Точность алгоритма управляется выбором числа т. Величина
угла 0 выражается в радианах и расположена в пределах ~л.
Алгоритм автоматически помещает результат в правильный квад-
368 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
рант, так что не требуется никакого специального определения
квадранта. Окончательным результатом работы алгоритма яв-
ляется вычисление sin 6 и 1 cos 6.
Для того, чтобы числовые величины не становились слишком
малыми, введем новые переменные
2 2~
X„= „(sin 8)„, Y„= „(чега 8) „.
При этом рекуррентные уравнения принимают вид
Хп = Хи 1 ‒ 2"+' Х 1Ув 1,
Х =2"+ Х2
где т обозначает полное число шагов рекурсии, и начальные ус-
ловия равны X> ‒ ‒ 6, Y< ‒ ‒ О. На первой итераций точность
алгоритма определяется погрешностью начального приближения
и равна (Х,), = (1/6) (8/2'")'. Эта погрешность приводит к
финальным погрешностям, ограниченным сверху величиной
(1/6) дз2-s:
(а1п 8), .( л'2 ‒ "", (cos 8), -( л«2 ‒ "".
1 1
Следовательно, если при умножении обеспечено достаточное число
точных битов, каждый шаг итерации увеличивает точность в двух
битах.
Второй тригонометрический алгоритм представляет собой метод
поворота. Его можно использовать для вычисления декартовых
координат точки, повернутой на угол 6,
Х созЕ s16 х
y' = sin6 cos6 y '
или для вычисления полярных координат точки, заданной декар-
товыми координатами,
8 = аг~t[!, г = у х'-';- д'.
g
Алгоритм состоит из некоторых вычислений и проверки логиче-
ских условий В основе алгоритма лежит тот факт, что тригоно-
метрические тождества
1д6 1
sin6 = ~ и cos6 =
1 1~-Ж«Е. ~'1+tg*e
позволяют легко вычислить поворот вектора на конкретный угол
8 = arctg (2-«). В этом случае
2 ‒ 1
sin [аг~[[[ 2~[ = соя [аг~t[, 2 ‒ "I—
! ~ (2 †«)г 1~-[2 l
10.8. Вычисление три1 онометрическнх функций
369
Ноиеринтерации Масштаб Прирмцение g»<
k 2 ‒ Ф д;= Сап i2
Рнс. 10.9. Алюритм поворота коордннат.
так что поворот вектора (х, у} на угол 8« = arctg 2-«задается
равенствами
х' = [х+2 «у],
[/1+ (2 ‒ «)г
у' = [у ‒ 2-«х].
1
3/ i + (2-«}г
Для поворота на отрицательный угол arctg 2-» используются те
же уравнения, но с заменой знака у 2-~. Это не влияет на величину
стоящего перед скобкой множителя. Длина вектора умножается
на фиксированную константу.
Произвольный угол 0 может быть представлен в виде
CO
8 = ~90'+ f (~ arctg2 ‒ «)
k=0
или
8 = g ~90'+ ~.", g~arctg2 ‒ « = g g~8«,
k~ k= ‒ 1
где Й = 1, О, 1, ..., P«равно 1 или 1, а 8«затабулированы
на рис. 10.9. Поворот на угол 0 просто сводится к поворотам на каж-
дый из углов 8«с направлением, определяемым F«.
Независимо от знака каждого индивидуального поворота после
т итераций усиление равно
+ 1~1+2 г«.
й=!
В окончательном виде алгоритм показан на рис. 10.10. Правило
поворота вектора на первом шаге на угол +90 несколько отли-
чается от правила остальных поворотов. В дальнейшем решение
‒ 1
0
1
2
3
4
5
6
7
8
9
I0
0
1
I/2
1/4
I/8
1/16
1/32
1/64
1/128
I/256
!/5I2
I/1024
90О
45
26.565051
I4.036243
7.125016
3.576334
1 7899!1'
0.895174
0 4476I4'
0.2238 I I
0.1 I 1906
0.055953
370 Гл. 10. Быстрые алгоритмы, основанные на стратегии дублирования
Ягод
агсФц
Вмод
IIoeopom
Выход
Рис. 10.10.
о повороте на угол 0~ или О„принимается в зависимости от зна-
ков координат х и у. Это определяет дальнейшее сложение или
вычитание с умножением на скаляр. Так как скалярный множи-
тель равен 2-", то умножение сводится к двоичному сдвигу, так
что алгоритм почти не содержит умножений. Даваемое алгоритмом
представление величины усиления известно. Оно может быть ни-
велировано умножением на обратную величину после выполнения
всех шагов алгоритма. В больших задачах еще лучше упрятать
его в константы, встречающиеся в других местах.
Для вычисления aretg (х/у} вектор (х, у} на каждой ите-
рации вращается в том направлении, которое уменьшает текущее
значение координаты ц, а формирование угла 8 проводится сумми-
рованием величин 6> с учетом их знаков.
371
Замечания
Задачи
Найти алгоритм дублирования для умножения вектор-столбца на тепли-
цеву матрицу.
Провести сортировку списка {3, 1,5. 2,7, 3, 9, 8, 2, 6, 1, 4, 9, 2, 5, 1),
используя алгоритм слияния.
а. Привести блок-схему БПФ-алгоритма Кули ‒ Тычки по основанию
два с прореживанием по частоте в виде алгоритма дублирования.
б. Привести блок-схему алгоритма дублирования в рекурсивной форме
для вычисления фильтр-секции, длина которой равна степени двух.
в. Привести блок-схему алгоритма дублирования в рекурсивной форме
для вычисления произведения многочленов от двух переменных.
Пусть и равно степени двух и пусть а и Ь ‒ два произвольных целых числа,
запись которых содержит и позиций. Найти эффективный алгоритм умно-
жения чисел а и Ь, используя дублирование.
Разработать алгоритм транспортирования матрицы на процессоре, который
может одновременно запоминать четыре столбца из таблицы Построить
блок-схему алгоритма. Сколько необходимо обменов столбцами?
Сколько умножений потребуется для вычисления следующего преобразо-
вания координат?
10.1.
10.2.
10.3.
10.4.
10.5.
10.6.
Х
cos0 sin 0 х
у' sin 0 со$0 у
приведенный на рис. 10.10 алгоритм, вычислить arctg (2).
точность алгоритма, сравнивая вычисленное значение с истин-
10.7. Используя
Установить
ным.
10.8. Используя
алгоритм Штрассена, вычислить произведение матриц
1 5 4 8
7 3 6 2
Замечания
Стратегия деления задачи пополам и дублирования является одной из основ-
ных и появилась во многих работах. Данная короткая глава только затрагивает
этот раздел общей теории алгоритмов. Более широкое введение можно найти
в работах Кнута (1968) и Ахо, Хопкрофта и Ульмана (1974). Общеизвестные
примеры алгоритмов дублирования и сортировки, такие как рассмотренный
алгоритм слиянием, или как алгоритмы пирамидальной сортировки и быстрой
сортировки, были введены Уильямсоном (1964) и Хоаром (1962) соответственно.
Известны и многие другие алгоритмы сортировки Описание БПФ-алгоритма
Кули ‒ Тычки с точки зрения стратегии дублирования предложил Стейглиц
(1974). Фидуччиа (1972) применил к построению БПФ-алгоритма Кули ‒ Тычки
полиномиальные идеи алгоритма Герцеля, позволившие использовать стратегию
делеиия задачи пополам и дублирования. Стратегию дублирования для задачи
транспонирования матрицы использовал Эклунд (1972). Первая усиленная с по-
мощью стратегии дублирования форма алгоритма Евклида появилась в книге
Ахо, Хопкрофта и Ульмана в связи с вычислением наибольшего общего знаме-
нателя.
Алгоритм поворота вектора используется уже многие годы под названием
«согйс algprithrn» и обычно приписывается Волверу (1959); детальная его про-
работка выполнена Волтером (1971). Алгоритм дублирования для вычисления
синусов и косинусов взят из работы Блейхута и Волдекера (1970).
Глава 11
БЫСТРЫЕ МЕТОДЫ РЕШЕНИЯ
ТЕПЛИЦЕВЫХ СИСТЕМ
Стандартный метод решения системы и линейных уравнений с и
неизвестными состоит в записи этой системы в матричном виде,
Af = g, и отыскании решения либо с помощью обращения матрицы,
f = А 'g, либо с помощью метода Гаусса. Сложность стандартных
методов обращения матрицы пропорциональна и'. Иногда матрица
имеет такой частный вид, что им можно воспользоваться для по-
строения более быстрого алгоритма.
Система линейных уравнений называется теплицевой, если ее
матрица А теплицева. Задача решения теплицевой системы урав-
нений возникает во многих приложениях, включающих спектраль-
ное оценивание, линейное предсказание, построение авторегрес-
сионных фильтров и теорию кодов, контролирующих ошибки.
Так как теплицевы системы уравнений имекгг очень частный вид,
то для их решения существуют методы, которые намного лучше
общих методов решения систем линейных уравнений. Э1и методы,
составляющие предмет исследования в данной главе, справедливы
ДЛЯ ПРОИЗВОЛЬНОГО ПОЛЯ.
Рассматриваемые в настоящей главе алгоритмы несколько от-
личаются от тех алгоритмов, которые мы построили для вычисления
свертки или преобразования Фурье. Свертка и преобразование по
существу сводятся к матричному умножению, а в данной главе
рассматривается задача решения системы линейных уравнений.
Поэтому неудивительно, что мы не сможем прямо воспользоваться
построенными ранее алгоритмами, хотя такой метод, как дубли-
рование, окажется полезным.
11.1. Алгорихмы Левинсона
и Дурбина
Задачи обращения свертки или спектрального оценивания со-
дер жат задачу решения теплицевой системы уравнений, зада-
ваемой матричным равенсгвом
Af =g,
11.1. Алгоритмы Левинсона и Дурбина
373
где А представляет собой теплицеву (n x n)-матрицу
Рг ° ° ° Рл ‒ i
Р! -.- а г
а!
а !
а-г
Ро
а!
Р n+I
fo
fi
,а,!
1
1
1
1 а»
I
1a» ъ
1
1
1
1
1
', а!
ао а! аг ... а„г
ао Р! .. Рл ъ
go
gi
аг а! ао
Рл-4
f--2
л-2 an ‒ 2
° ° ° ao
gn -2
g»- i
‒ --«-4»
л ‒ ! an-2 а1, Ро
I
Разделение матрицы и векторов на блоки здесь сделано для того,
чтобы подчеркнуть лежащую в основе алгоритма повторяемость
структуры. На каждом шаге (итерации!к матрице А добавляется
«половина границы», состоящая из новой строки снизу и нового
столбца справа. Используя обменную матрицу J, уравнение Af =
= g можно переписать в виде МАЯЛ = Jg, и JAJ = А, так как
матрица А является симметричной и теплицевой. Следовательно,
имеет место также равенство
fn- 1
)и-2
ф-i
gn -2
a2 - ° - ° an !
Ð I ° ° ° Рл 2
РО ° .. ал Ъ
Ро
Р2
f1
fo
gi
go
а„ ! а. г
Ро
Эга форма уравнения также будет использоваться при построении
алгоритма Левинсона. Алгоритм оперирует с (r х r)-подматрицами
матрицы А вида
ао а, аг... ° а,
РО Р! ... Рг
О2 Р! Ро ... Р~ ъ
А
И
Вычислительная задача состоит в вычислении вектора f по за
данным вектору g и теплицевой матрице А. ()дним из возможных
методов решения, конечно, является обращение матрицы А, од-
нако, практически и может быть больше 100 или даже 1000, так
что важно отыскать более эффективные методы решения задачи.
Алгоритм Левинсона является эффективным алгоритмом, при-
менимым в том частном случае, когда матрица А является одно-
временно теплицевой и симметричной. В этом случае система урав
нений записывается в виде
374 Гл. 11. Быстрые методы решения теплицевых систем
которые получаются из матрицы А отбрасыванием последних и r
столбцов и такого же числа нижних строк.
Алгоритм Левинсона является итеративным; эти итерации
индексируются буквой r. Ha r м шаге алгоритм Левинсона вычис-
ляет решение r-го усечения задачи.'
ун
ул
ао а
а) ао
а~ .. а,)
а ... а, ~
go
g)
° °
аг ‒ ) Ра- 2
Ре-3 . - ° РО
gr-
где верхний индекс r указывает на то, что вектор f<'> является ре-
шением r-ro усечения задачи. ясно, что если даже f<'> и является
решением усеченной задачи, он не равен усечению решения
исходной задачи. Алгор итм Леви нсона рекурси вно модер низи-
рует f(<) таким образом, что f(n) равно решению исходной
задачи.
Помимо вектора f<~~ в итерациях алгоритма Левинсона участ-
вует несколько рабочих переменных, задаваемых следующим обра-
зом. Скалярные рабочие переменные обозначаются через сс„
и у,; рабочий вектор длины r обозначается через t<'>. Все эти ра-
бочие переменные выбираются на каждом r м шаге так, чтобы вы-
пол нялось следующее дополнительное матричное р а ве нство:
и
(93
а1 ал ... a< )
ао а1 ... а, ~
а~ ао - .. а,-з
а, 1
° - ° ао
»
1
a„
»
,а,)
»
»
I
1
»
»
» О,
е
go
О~ ... ar
О) ° . а, ~
О»
g»
О»
Оо
gr- )
О-г
Оо
а,
а» ) ао
а,,
где в стоящем в правой части равенства векторе все за исключением
одной компоненты равны нулю. Введение рабочего вектора t('>
и дополнительного уравнения является разумной идеей, позво-
ляющей продолжать итеративный процесс. Мы хотим итерации
организовать так, чтобы все уравнения имели одну и ту же форму.
Следующая итерация начинается с уравнения
11.1. Алгоритмы Левинсона и Дурбина
375
которое определяет 1)„и с уравнения
1
, а,
1
I
а,
1
1
1
1
1
1
1
0»
Ф
(И
»»
(1~)
1
0) ... а, 1
01 ° ° ° Qg >
Ои
О»
01
Оц
»л
(, 1
о
Р.
0»»
0» а
1 а»1
и
а,
а 1 а,
а.~ a,,,
01
01 ао
Q0 О, Qi
Оо 01
0» а
а, а, ,
- ° ° ао
g)
go
f»t)
ао
а, ... а,, а,
О» ° . ° 0«i О, »
а,
()г)
t‒ - »
а,
ао
(И
1
(Ю
О
а
О.-г
0»
а, а,
а, ао
О
Из этих уравнений можно сформировать следующую итера-
цию. Пусть для подлежащих дальнейшему выбору констант k u k
выполняется
Ъ
((г4 ))
0
(trt))
)
((г)
0
((г)
)
= k)
(И
r-)
О
(fr+ ))
r-)
((г+ ) )
l
которое определяет р„и в правой части которого стоит вектор,
все внутренние компоненты которого равны нулю. Если 1), = g,
и р„= О, то f<'+'> и t<'+'> равны соответственно f<'> и t<'>, но
с добавленными нулевыми компонентами, увеличивающими их
длину. В этом случае итерация завершается. В противном слу-
чае векторы f<'> и t<'> должны быть модифицированы.
Как всегда в рекурсивном алгоритме, выберем начальные зна-
чения всех переменных так, чтобы при r = О выполнялись все
уравнения, и предположим, что эти уравнения выполняются к
концу (r 1)-го шага итераций. Нам надо только показать, как
надо модифицировать рабочие, переменные, чтобы эти уравнения
выполнялись и к концу r-го шага. Но мы можем также записать
уравнения
376 Гл. 11. Быстрые методы решения теплицевых систем
Тогда
(г+ 1)
(о
(rt I)
Ф)
дг
0
ао а,
а) ао
° Рг
а,
а,t)
а,)
= kI
+ kg
(г+ 1)
(г-1
(гt 1)
г
0
O.
а)
а, )а, ~
Р, Р 1
ао
а,
откуда следует, что Й, и k, должны выбираться так, чтобы выпол-
нялись равенства
О = Й«р„+ k~u„H u„+» = k,à„+ k~PÄ.
В силу произвольности выбора k, положим k, = u„. (Различ-
ные возможности выбора kg приводят, однако, к различной точ-
ности.) Тогда k, = P, и а,+« = а~ P,'. .Наконец, положим
(г+ ()
1
1)
f
(г+ ))
I
~ (r)
о
/(г)
)
((г+ ) )
r
((r+ ) )
r ‒ 1
+ I,
f
(г+! )
r 1
f
(r+ ))
r
((г4 1)
l
((r+ I )
о
f,")
О
где константа k, также подлежит вычислению; тогда
и(» а» а,
и) ao .. а, 1
Irt II
f
(»
f
)rt 1)
I
gu
go
gI
gI
+ k3
rt II
f'
г- I
f
(rt 1)
г
а
иг- I
gr-)
и,
gr
+at)
где для обеспечения правого равенства k должно быть выбрано
так, чтобы 1), + k,à,+, ‒ ‒ g,. Это завершает итерацию.
Алгоритм Левинсона подытожен на рис. 11.1. На нем векторы
t~"'» и f" представлены соответственно многочленами t (х) =
= t,'»õ'+- t,' õ' ' + -... +- t,'"õ+- t," и f (x) = f,'х'+-
+ fi'««х + ... + fi'~õ+ Д «, в которых опущен индекс г. Вы-
числения не нуждаются в фактическом вычислении матрицы A('»;
во время итераций достаточно вычислять многочлены f (х) и t (х).
377
Bxod
Ю алгоритм Педесона
8дести
вектор в правой части формирует-
ицы так, что уравнение принимает
1
i а„~
1
1
,'а-г
ал-3
1
1
1
1
1
1
i iul
fo
fi
а, а~ . ° а„ 2
ао а> ап ‒ 3
а~ ао аи-4
а1
ао
а>
f.--x
./л ‒ ]
ао
аю-2
aÄÄ= i
r
аь ~ ао
1
а„
11 1. Алгоритмы Левинсона и Дурбина
Сложность r- го прохода по
ветви пропорциональна r, и
всего имеется и проходов. Сле-
довательно, сложность алгорит-
ма Левинсона пропорциональ-
на и'. Шаг рекурсии приводит
к неудаче только тогда, когда
возникает деление на нуль,
что происходит только тогда,
когда одна из главных подмат-
риц вырождена.
Алгоритм Левинсона при-
меним в любоы поле. В част-
ности, в поле комплексных
чисел его можно использовать
именно в том виде, в котором
он был выписан. Однако в свя-
занных с комплексным полем
приложениях симметричная
теплицева матрица возникает
не часто; более распространен-
ной в этом случае является эр-
митова теплицева матрица.
Алгоритм Левинсона применим
и в этом случае, но с перехо-
дом в соответствующих местах
вычислений к комплексно со-
пряженным величинаы. Рекон-
струкцию алгоритма для этого
случая сделать легко.
Иногда вместо алгоритма
Левинсона лучше воспользо-
ваться так называемым алго-
ритмом Дурбина. Это возмож-
но в тех случаях, когда матри-
ца симметрична и теплицева, а
ся из элементов теплицевой матр
следующий вид:
Рис. 11.1. Алгоритм Левинсона.
378 Гл. 11. Быстрые методы решения теплицевыл систем
а,
а а~ ... а, )
ао а, ~
ао
а2
а,
° ° ° ао
аГ-я
Следующая итерация начинается с уравнения
1
а, 1,
1
Q,-q,
I
I
1
1
1
I
I
jr1
у{Г)
а1
а,
а1 а)
ао а1
ао
а,,
а1
а)
1
ао 1 а1
Ч
у)
0
а,
а, 1
а1 , 'ао
I
а, а, )
определяющего переменную у,. Целью итерации является такая
модификация вектора f<'>, при которой величина у, становится
равной a„>. Пусть Р'+'> задается равенством
fft+ 1)
f
(Г+ 1)
1
jr)
ff r)
Хг 2
+k,
Р
0
f r'- 1 '
f
(r+ 1)
Г
y(r)
О
Если нам удастся выбрать k, и р, так, чтобы регенерировать же-
лаемый вид уравнений, то мы построим хороший алгоритм. Но
при некоторых у, и у,' имеет место равенство
1
а 1 а
1
1 °
9
1
1
ао 1 а)
\
r+ l)
/
о
а)
аГ
аГ
ао
а)
‒ k,
уф+ Ц
art))
аГ
а)
а,
а,
аГ-1
7Г
а),' ао
7
а„,
ао
аГ
Матрицу и оба вектора можно опять разбить на блоки, чтобы
выявить лежащую в основе алгоритма повторяющуюся блочную
структуру. Специальные свойства стоящего справа вектор-столбца,
формируемого из элементов теплицевой матрицы, позволяют вдвое
уменьшить необходимые в алгоритме Левинсона вычисления, так
как в итерации включается только один многочлен. В рассматри-
ваеыом виде теплицевы матрицы часто встречаются в задачах спек-
трального анализа, и в этих случаях полезен алгоритм Дурбина.
r-й шаг алгоритма Дурбина начинается с решения следующей
усеченной задачи:
379
11.2. Ллгоритм Тренча
Рис. 11.2. Ллгоритм Дурбина.
Bxod
8 апаодити Дурбино
Для обеспечени я нужного р авенст-
ва k, и р, в окончательном виде надо
выбр ать так, чтобы выполнялись
условия
k,— P,=Î и
у, ‒ /г,у,'+ P,àö = а,+,,
где
c(r)
э
(r ~а~, у,=
c=i
Е ‒ 1~~ °
8=1
Следовательно, k, и р, надо полагать
равными
(<g+g ‒ 7г)
(аО 7,)
Й,=р, и P,=
Выписанные равенства позволяют
продолжить решение I'-го шага до
решения (r + 1)-го шага, так что
тривиальное решение нулевого шага
рекурсивно продолжается до реше-
ния и-го шага. Это завер шает по- Слюп
строение алгоритма Дурбина. Окончательная форма алгоритма
представлена блок-схемой на рис. 11.2.
11.2. Алгоритм Тренча
fo
f,
8о
8>
а„,
а. 2
ал-3
ио
а,
а,
а,
а,
а -2
ао
ио
а,
ао
и-в+3
а л+!
+-и+2
можно решать многими различными алгоритмами. В разд. 11.1
был рассмотрен случай, когда теплицева матрица сиыметрична.
В этом случае применйм алгоритм Левинсона или Дурбина. В на-
стоящем параграфе рассматривается более общий случай, когда
В зависимости от наличия различных дополнительных свойств
теплицеву систему уравнений
380 Гл. 11. Быстрые методы решения теплицевых систем
теплицева матрица не является симметричной. В этом более общем
случае алгоритмом решения является алгоритм Тренча. В своей
наиболее полной форме алгоритм Тренча вычисляет обратную ма-
трицу А ' и вектор f. Мы остановимся только на вычислении ма-
трицы А 1.
В общем случае не всякая теплицева матрица симметрична, но
всякая теплицева матрица персимметрична. Матрица называется
персимметричной, если стоящие симметрично относительно по-
бочной диагонали ее элементы равны. Если (и х и)-матрица А
персимметрична, то а~,- ‒ ‒ а„+1,. „+~ ~. Другими словами, матри-
ца А персимметрична тогда и только тогда, когда ЯАЯ = А, где
обменная матрица той же размерности, что и А. Матрица,
обратная к теплицевой, в общем случае теплицевой не является,
но остается персимметричной.
Теорема 11.2.1. Обратная к персимметричной матриие А
является персимметричной.
Доказательство. Пусть J обозначает обменную матрицу той
же самой размерности, что и матрица А. Напомним, что Р = I.
так что J ' = J. Ho JAJ =- А. Следовательно, ЯА 'Я =- А '
и матрица А ' является персимметричной. ~]
Другое свойство, которое сохраняется при обращении тепли-
цевой матрицы, состоит в том, что она полностью определяется
своей границей. Более точно, она полностью определяется зада-
нием своих первой строки и первого столбца или своих последней
строки и последнего столбца. В продолжение этого раздела дается
доказательство этого свойства и затем выписывается рекурсивная
процедура вычисления матрицы по ее нижней полугранице, со-
стоящей из последней строки и последнего столбца. Для вычисле-
ния матрицы А ' в алгоритме Тренча используется полуграница
матрицы А ' °
Определим вектор-столбцы а, и а» длины r 1 каждый ра-
венствами
1Т
а, =,'а,, а2, Q), а, 1'
1Т
Ф-1 а -2 а-3 а-(T-1))
Пусть а, и а» обозначают два вектора, компонентами которых
являются компоненты векторов а, и а соответственно, выписан-
ные в обратном порядке. Иныыи словами, а, = Ja, и а» '= Яа,
где J равно обменной матрице размерности (r 1) X (r 1).
Матрицу А<'~ можно следующим образом разбить на блоки.'
А" =
381
11 2 Алгоритм Тренча
Аналогично можно разбить на блоки обратную матрицу B(') =
= (А<'>) '.
ae(Г) l g(г)
1
g(<)T 1 b(r)
1 О
Нашей целью является описание блоков этого последнего разбие-
ния.
Теорема 11.2.2. Блоки обратной матрицы В<'~ удовлетво-
ряют равенству
Яоказательство. Так как А< ~В<'~ =- 1, то имеет место равен-
ство
a34i') +а,ьi')т Ф
Следовательно,
А(к !)щ(к) + a,f {'к)т
Ф
ф~-))я(~) + a ~(~) o
атМ" + аДЬ"~ = 0
Э
аТь" ,+ аф~~'
Матрицу М<'~ можно исключить, выразив ее через обратную к
А<' " матрицу В<' ‒ 1~. Умножая первое уравнение на В<' ‒ 1~ слева,
получаем
М~т~ = В~т '> ‒ В~т '1a+Ü<ò1ò
Теперь утверждение теоремы следует непосредственно из второго
из выписанных уравнений. Q
До сих пор мы мало что предполагали о матрице В<'>, требо-
валось только существование матрицы В<' ‒ 1~. Теперь для по-
строения рекурсивной процедуры вычисления матрицы В~'1 по
ее полугранице воспользуемся свойством персимметричности.
Теорема 11.2.3. Пусть В обозначает матрицу, обратную
к теплицевой матрице. Тогда В полностью определяется своей
верхней полуграницей по восходящей рекурсии
~~+1. ~+1 = Ь+ а Ib~b ‒ ‒ b+b ‒ 1
ьо j=1, ...„n ‒ 1,
382 Гл. 11, Быстрые методы решення теплицевых систем
а своей нажнейс полугранацей по нисходящей рекурсии
°, 2,
i=a,
Ь,, у, = Ь,!+ ь fb~b ‒ Ь,Ь'],
Оо
..., 2,
j=и,
Доказательство. В теореме 11.2.2 мы уже доказали, что
в" =
1
в« " + ‒ „ь'9" , 'ь7
з.«)
е~О
+
b{r)T ' о«'
О
Так как матрица В(') является персимметричной, то можно также
записать равенство
ь~' ~ ь'"
ь" 'в'-" + .‒ ь"ь''
аЯг~
1
оо
Используя эти два разбиения матрицы В(', выразим ее элементы
bq~ двумя способами. Первый из них дает
(г)
Ь() = Ь(- ) a ' ~~()~() т~
с) = с) ~- (,) i + ,цу,
ь,
) 1~ ° ° ° y и 1е
Второй дает
ьой 1=1, ..., n ‒ 1.
Исключая элементы b;I 1', приходим к равенствам
~(~) цУ) 1 lа (~)~(~) т Г(~) ~(~) т1
которые теперь содержат только помеченные индексом r величины.
Эти равенства задают восходящую рекурсию. Аналогично строится
нисходящая рекурсия, и это заканчивает доказательство. O
доказательство содержит еще один информативный фрагмент,
который будет ниже использован. Выражая стоящий в первой стро-
ке и первом столбце элемент из первого равенства, получаем урав-
нение
ь," = ь",;"+ ‒ '(ь+" ь'")„.
boo
(г)
где первая а последняя строка латрсщы равны соответственно
(b„b ) г и (b, Ь,) ~, а первый и последний столбцы матрицы равны
соответственно (b„, Ь,) и (Ь„b,).
11.2. Алгоритм Тренча
Так как b+b . = b~b и согласно второму равенству b>'1
-т т (г ‒ 1)
= b(' ", то оно может быть переписано в виде
~Ь"Ь" т~
т (,) <+ ‒ дь
ь,
связывающем величины Ьо ) и Ьц
Теперь нам нужно построить алгоритм, вычисляющий полу-
границу матрицы В(") по полугранице матрицы А(") Но у нас
уже выписаны уравнения, связывающие границу матрицы В(')
с границей матрицы А'), так что для построения этого алгоритма
нам остается только исключить матрицы А<' ‒ ') и М. Такое исклю-
чение можно выполнить, вводя обратно полуграницу предыду-
щего шага итераций.
Теорема 11.2.4. Полуграница матрицы В(') удовлетворяет
следующим рекуррентным уравнениям:
g('I
Ь' "
о
Ь' "
° °,) ~о
о
Оо'
Доказательство. Третье уравнение уже было выведено как
следствие из теоремы 11.2.3. Из соображений симметрии ясно, что
если выполняется первое равенство, то выполняется и второе. Его
можно получить тем же самым способом. Следовательно, надо
доказать только первое равенство. Начнем со второго в множестве
полученных в доказательстве теоремы 11.2.2 четырех равенств:
А'-" Ь",‒ (;) Ь" = О.
Так как матрица А(' ‒" является персимметричной, то это равен-
ство можно также переписать в виде
А(' 1) тЬ(б) т! (б)Ь(б) =0
+ -Г а+ О
откуда
b(r) b(r)B(r ‒ 1) т (r)
"-+ = 0 а~.
Теперь воспользуемся снова уже применявшимся ранее разбие-
нием матрицы В(' ‒ '):
Ь'," = -t4'
Ь"-'"
где a+(' записан в виде вектора а+ ~ с одной дополнительной
компонентой. Это уравнение уже определяет искомую рекурсию,
384 Гл. 11. Быстрые методы решения теплкцевых систем
Вход 8 а~~гориом
7ренча
Стоп
Рис. 11.3. Алгоритм Тренча.
равенством Ь+ ~ 1=
но MbI уточним его,
= ‒ о а+
b(< ‒ 1) иь (г ‒ 2) Т (г ‒ 1)
воспользовавшись
Тогда
что можно переписать в виде, входящем в формулировку теоремы. []
Теперь у нас уже есть все необходимое для формулировки ал-
горитма Тренча. Все, что осталось сделать, сводится к такому пере-
определению обозначений, при котором все величины, индекси-
11 ° 3. Алгоритм Берлекэмпа ‒ Месси
385
руемые символом г, стоят в левых частях рекуррентных уравнений,
а величины, индексируемые символом I ‒ 1, стоят в правой части.
Алгоритм Тренча подытожен на рис. 11.3. Блок-схема основана
на теореме 11.2.4, но величины b, b» и bo в итерациях заменены
нормализованными величинами с, с и Х в соответствии с равен-
ствами
Ь'" Х' =
(r) (r)
b0 bo
(r) 1 (r)
с~ = b~Ä
, ь(г)
Соответственно рекурсия
описывается уравнениями
{i-))Т {г-l)
а, +и,
Л~ "
(r- Ц
т
с" =
Ф
-9- l)T (r-!)
с а -)- а,,
с{Г)
л'-')
Л" = Л' "(1 ‒ с"'с'"~)
+- 1)
На рис. 11.3 использована эта форма уравнений.
11 3. Алгоритм Берлекэмпа Месси
Алгоритм с)ерлекэмпа Месси представляет собой алгоритм
решения в произвольном поле F теплицевой системы уравнений
вида ')
Л
fz
‒ а
и
0п- 3
0 tl 7
Ол ‒ 1
0 -1
0 ъ
0„)
0л+)
0n)
0л
0-
02л-4
и,„,
Матрица системы не является симметрической, что требуется для
применимости алгоритма Левинсона. С другой стороны, стоящий
в правой части системы вектор не является произвольным, а со-
ставлен из компонент матрицы системы.
Лучшим подходом к алгоритму Берлекэмпа Месси является
интерпретация выписанного матричного уравнения как описания
авторегрессионного фильтра. Предположим, что вектор f изве-
стен. Тогда первая строка рассматриваемого матричного уравнения
определяет а„через а,), а,, ..., а„, вторая строка определяет а„,
через а,, ..., а„, и т. д. Этот последовательный процесс описывается
уравнением
ff;a~;, j=n, ..., 2п ‒ 1.
c=i
а;=
д) В настоящем разделе более удобйо нумеровать компоненты вектора f
числами от! до и и обозначать элементы матРицы А величинами af), ад, ..., а «д.
386 Гл. 11. Быстрые методы решения теплицевых систем
аз ~з а~ ио
Подставить начальные значения а 1 а 2' ..., ao в выражение
л
a = ‒ ~ f~ /=и .. 2n ‒ 1
) ~ ) 1е ° °
l ‒ 1
Рис. 11.4. Авторегрессионный фильтр.
При фиксированном f это уравнение является уравнением авторе-
грессиониого фильтра, который может быть реализован в виде
линейного регистра сдвига с обратной связью, в отводах которого
стоят умножители на компоненты вектора f.
С этой точки зрения задача решения данной теплицевой системы
уравнений становится задачей построения показанного на рис. 11.4
авторегрессиониого фильтра, на выходе которого формируется за-
данная последовательность символов. Если теплицева матрица
обратима, то существует точно один авторегрессиониый фильтр,
удовлетворяющий данной системе уравнений. Если матрица необ-
ратима, то таких решений может существовать много или не суще-
ствовать ни одного. Однако, алгоритм Берлекэмпа Месси всегда
в качестве решения дает кратчайший авторегрессионный фильтр,
удовлетворяющий данным уравнениям. Отводы этого фильтра
описываются вектором f, содержащим не более и ненулевых ком-
понент, если исходная теплицева система имеет по меньшей мере
одно решение, и большее, чем и, число ненулевых компонент f;,
i > и, если исходная теплицева система не имеет решений.
Любая процедура построения авторегрессионного фильтра
является также методом решения рассматриваемого матричного
уравнения с заданным вектором f. Мы сейчас опишем такую про-
цедуру построения регистров сдвига. В процедуре не предпола-
гается наличие каких бы то ни было специальных свойств последо-
вательности ао, а,, ..., а,„,. Произвольный линейный регистр
сдвига с обратной связью можно задать многочленом f (х) обрат-
ных связей,
f (x) = f„x" y f „,х" ‒ ' + ° + f,õ + 1,
и длиной L регистра сдвига. Длина регистра сдвига может быть
больше степени многочлена f (х), так как самые правые ячейки
регистра могут не включаться в обратную связь.
Для построения регистра сдвига надо определить две величины:
длину L регистра и многочлен f (х) обратных связей степени
deg f (х) < L. Обозначим эту пару через (L, f (х)). Надо найти
l 1.3. Алгоритм Берлекэмпа ‒ Месси
регистр сдвига с обратной связью, который при соответствующих
начальных условиях порождает заданную последовательность
а„..., а~„, и является при этом кратчайшим-
Рассматриваемая процедура построения является рекурсив-
ной. Для каждого г, начиная с г = 1, мы будем строить регистр
сдвига, порождающий последовательность ао, ..., а,. Регистр сдви-
га минимальной длины, порождающий последовательность a~, ...,
а„обозначим через (L„ f«> (х)). Этот регистр не обязательно дол-
жен определяться однозначно, возможно существование несколь-
ких таких регистров с одной и той же длиной. К началу r-го шага
имеется список регистров сдвига
(L,, f<»(x)}, (L,, f<~>(x)), ..., (L,,, f<' ‒ '>(х)).
Алгоритм Берлекэмпа Месси вычисляет новый кратчайший ре-
гистр (L„, Р«> (х}}, генерирующий последовательность а„..., а,.
Для этого используется самый последний из вычисленных регист-
ров, в котором по мере надобности модифицируются длина и весо-
вые множители в отводах.
На r-м шаге вычисляется следующий элемент на выходе
(r 1}-го регистра сдвига:
Г ‒ 1
L
а,= f 1>
1=1
Так как L, может быть больше степени многочлена f« ‒ '> (х}, то
некоторые члены суммы могут быть равными нулю. Эту сумму
следовало бы записать с пределами суммирования от 1 до
deg f« ‒ '> (х). Мы, однако, выбрали менее громоздкое обозначение.
Пусть Л, обозначает разность между требуемым элементом на
выходе а, и истинным элементом, полученным на выходе самого
последнего регистра сдвига:
Л,=а,‒ а,=а,+ f f>' а,
/=1
Эквивалентно,
L
l'-g
Л,=~ f< >а, >.
]=а
Если Л, = О, то полагаем (1.„, f«> (х}} = (1., „/< ‒ '> (х)) и за-
вершаем этим r-ю итерацию. В противном случае изменим весовые
множители в цепи обратной связи регистра сдвига по правилу:
f<'>(x) = f« '>(х) + Ах'f<~ '> (х},
где А ‒ элемент поля, 1 целое число и P~ ‒ '> (х) один из
многочленов обратной связи, встречавшийся ранее в списке ре-
гистров сдвига.
388 Гл. 11. Быстрые методы решени я теплицевых систем
Используя этот новый многочлен, определим
i
L Lr i
д, = ~ фа, > = ~ ~~~' '>а, <+ А ~, ~) "а, >,.
/=О j=O 1=0
Теперь все готово для определения величин т, I и А. Выбе-
рем т меньше r и такое, что Ь:ф= О; выберем также l = r т
и А = Ь 'Ь,. Тогда
Ь, = Ь,‒ ‒ '6=0,
так что новый регистр сдвига будет генерировать последователь-
ность а„..., а,,, а,. У нас остался произвол в выборе т, для
которого Ь + О. Выбрав в качестве т номер ближайшей итера-
ции, для которой выполнялось условие L > L~ получим в
каждой итерации регистр сдвига минимальной длины, однако та-
кое усовершенствование требует дополнительных рассуждений
и будет описано позже.
Практическая интерпретация того, что было изложено до на-
стоящего момента, представлена иа рис. 11.5. Ява регистра сдвига,
отвечающие итерациям с номерами т и r, показаны на фрагменте(!)
рисунка. В качестве т-й итерации выбирается та, при которой ре-
гистр сдвига (L~ f<~ ‒ '> (х)} не способен генерировать компо-
ненту а, и минимальная длина регистра сдвига, генерирующего
требуемую компоненту при m-й итерации, больше L ~ Будем
также считать, что регистр сдвига (L, „ f<' ‒ '> (х)) не способен ге-
нерировать компоненту а„так как в противном случае мы не дол-
жны ничего с ним делать.
На фрагменте (ii) рис. 11.5 регистр сдвига (L~~, f<~ '> (х}}
превращен во вспомогательный регистр путем увеличения его дли-
ны, позиционирования и такого изменения его выхода, которое
позволяет скомпенсировать неспособность регистра (L, „ f<' ‒ '> (х))
генерировать компоненту а,. Отметим, что вспомогательный ре-
гистр имеет дополнительный отвод с весовым множителем еди-
ница, соответствующим коэффициенту Д ". На протяжении пер-
вых r 1 итераций в остальных отводах цепи обратной связи
формируется отрицательное значение соответствующей этому до-
полнительному отводу величины, и поэтому на выходе вспомога-
тельног>> регистра формируется последовательность нулей. При
r-й итерации эти величины взаимно не уничтожаются, и выход
вспомогательного регистра оказывается ненулевым. Коэффициент
А выбирается таким образом, чтобы его добавление к r-му выход-
ному сигналу обратной связи главного регистра сдвига приво-
дило бы к получению нужной компоненты а„.
На фрагменте (>>>) рис. 11.5 показано, как два регистра сдвига,
изображенные на фрагменте (ii), сливаются в один регистр, что
в силу принципа суперпозиции не меняет общего поведения схемы.
11.3. Алгоритм Берклекэмпа ‒ Месси
Рис. 11.5. Конструкция Берлекэмпа ‒ Месси.
Это дает регистр (L„ f<'> (х)). Иногда L, = L, иногда 1.,)
> L, 1. В последнем случае при проведении дальнейших итера-
ций т заменяется Hà r.
Точное описание процедуры дается теоремой 11.3.2, которая
утверждает, что эта процедура приводит к наименьшему регистру
390 Гл. 11. Быстрые методы решения теплицевых систем
сдвига с требуемым свойством. Прежде, чем доказывать эту тео-
рему, получим границу для длины регистра сдвига.
Теорема 11.3.1. Пусть (L, „ f<' ‒ '> (х}} регистр сдвига с ли-
следовательность а,, ..., а,, а (L„P'> (х}) регистр сдвига с ли-
нейной обратной связью минимальной длины, генерирующий по-
следовательность а„..., а,~, а„и f«> (х} ~ f« ‒ '> (х}. Тогда
L,Qrmax [L,,, r
Доказательство. Неравенство, которое требуется доказать,
разбивается на два неравенства
Lr )r Lr 1 H Lr >r r ‒ Lr 1-
Первое неравенство очевидно, поскольку если регистр сдвига
с линейной обратной связью генерирует некоторую последователь-
ность, то он генерирует и любую меньшую последовательность,
являющуюся началом исходной. Если L, ~ ) r, то второе неравен-
ство также становится очевидным. Поэтому предположим, что
L, 1 с. r и второе неравенство не выполняется, и попытаемся
прийти к противоречию. Из предположения следует, что L
~< r 1 L,, Для сокращения записи введем временные обо-
значения: с (х) = f« ‒ '> (х), Ь (х) = j«> (х}, L = L, и L' = L,.
В новых обозначениях исходные предположения принимают вид:
L < r u r )~ L ф- L' + 1. Крометого, из условий теоремы следует,
что
L
а,,‒й ‒ ~ с;а,;,
Е=1
L
с;а;;,
f=1
j=L+1, ..., r ‒ 1,
,'~, 'Ь~а; ~, i = 1.'+ 1, ..., е.
k=1
Теперь установим противоречие. С одной стороны,
Lr L' L
а, = f b~a~~ = ~', Ьд f с;а, ~;,
в=1 ~=1 С=1
L / °
а,+ ‒ fс;а„q= fс;f Ь~а„; ~,
К=1 С=1 ~М
где справедливость разложения а, „следует из того, что r й
пробегает целые значения от r 1 до r L', содержащиеся среди
чисел L + 1, ..., r 1, в силу предположения r )r L +'L' f- 1.
С другой стороны,
11.3. Алгоритм Берлекэмпа ‒ Месси
391
где справедливость разложения а,; следует из того, что r
пробегает содержащиеся среди чисел L' + 1, ..., r 1 целые
значения от r 1 до r L, а это, в свою очередь, следует из
предположения r ) L + L' + 1. Изменение порядка суммирова-
ния в правой части последнего равенства приводит к выражению
для а„полученному в правой части предыдущего равенства. Та-
ким образом, получаем доказывающее теорему противоречие а, «у"-
~ а,.
Если удастся построить регистр сдвига с длиной, удовлетворя-
ющей соотношению из теоремы 11.3.1 с заменой знака нестрогого
неравенства знаком равенства, то тем самым будет построен ре-
гистр сдвига минимальной длины. Доказательство теоремы 11.3.2
предъявляет конструкцию такого регистра сдвига.
Теорема Il.3.2. Предположим, что (L„P'>(х}), ~ = 1, ..., г,
является последовательностью регистров сдвига минимальной
длины с линейной обратной связью, таких, что (L;, f<'> (х}} еенери-
руегп последовательность а„..., а;. Если f<'> (х) ~ f<' ‒ '> (х), то
L„= шах [L, „r ‒ L,,)
и любой регистр сдвига, генерирующий а„..., а, и имеющий длину,
совпадающую с величиной правой части последнего равенства, яв-
ляется регистром сдвига минимальной длины.
Доказательство. Согласно теореме И.З.! L, не может быть
меньше величины в правой части последнего равенства. Если
удастся построить какой-либо регистр сдвига, который генерирует
требуемую последовательность и длина которого совпадает с ука-
занной величиной, то он будет регистром сдвига минимальной дли-
ны. Доказательство будет проводиться по индукции. Мы построим
удовлетворяющий теореме регистр сдвига в предположении, что
такие регистры последовательно построены для всех k ( r 1.
Для каждого k, k = 1, ..., r 1, обозначим через (Lz, P~> (х))
регистр сдвига минимальной длины, генерирующий а1, ..., а~.
Примем за предположение индукции, что
L~ = шах[1.~„k ‒ 1.д,), k = 1, ..., r ‒ 1,
каждый раз, когда f<~> (x) чь f<~ ‒ '> (х}. Это, очевидно, верно для
-k = О, если а1 отличен от нуля, поскольку Lo = О и L1 = 1.
В более общем случае, если а; ‒ первый ненулевой элемент в за-
данной последовательности, то L]y ‒ ‒ О и L; = i. Тогда предпо-
ложение индукции относится к индексу k =
Значение k в последней итерации, приведшей к изменению
длины, будем обозначать через т. Последнее означает, что при за-
вершении (г 1)-й итерации т является целым числом, таким,
что
Lr-1 Lm W ~~1 °
392 Гл. 11. Быстрые методы решения теплицевых систем
Теперь имеет место следующее равенство:
L L
r-1 г ‒ 1 О j т
а<+ g fi' '~а< < = ~', f<' "а< < =
C=l с=О
Если Л, = О, то регистр (L, „ f< ‒ ') (х)) также генерирует пер-
вые r символов, и, таким образом,
L, = L,, и f<') (õ) = f<' ‒ ') (х).
Если Л, ~'= О, то необходимо построить новый регистр сдвига.
Напомним, что изменение длины регистра сдвига произошло при
й = т. Следовательно,
ИЪ-1 О, ..., т ‒ 1,
i+ Z f< ~- А„~О, /=т,
) = ~~1.
и по предложению индукции
L„,=L =max[L „m ‒ L»t=т ‒ L
Из теоремы 11.3.1 при условии, что (L„ f<') (х)} генерирует
а„..., а„, следует, что L, = max [L,»,, r Е,,). Осталось
только доказать, что регистр сдвига (L„<') (х)) генерирует тре-
буемую последовательность. Я,окажем это непосредственным вы-
числением разности между а> и сигналом на выходе обратной связи
регистра сдвига:
Lrr
Г-1
~1 (г) ~1 (r ‒ 1)
ау ‒ ~ с а) ‒ с ‒ ‒ ау ~ с ai ‒ с‒
С=1 С=1
(m ‒ 1)
и< ‒ i+т + Z < < с<< ‒ r+m ‒ <
)=1
О j=L„,L+1,...,r 1,
Л,‒ Л,Л 'Л =О, j=r.
Итак, регистр (L„ f<') (х)) генерирует а„..., а,. В частности,
(1.„, /<") (х)) генерирует а,, ..., а„и теорема доказана. О
Теорема 11.3.3 (Алгоритм Берлекэмпа Месси}. Пусть за-
даны а„..., а„из некоторого поля, и пусть при начальных усло-
виях f<0) (х) = 1, t«)) (x) = 1 и Lo = 0 выполняются следующие
поскольку L > L ~. Теперь выберем новый многочлен
~<г) ( } р<г ‒ 1) ( } Л Л ‒ 1 т ‒ тр<т ‒ 1) (
и положим L, = deg f«) (х). В этом случае поскольку
deg f<' ‒ ') (х) ~( L,, и deg [х' ‒ ~f<~ ‒ ') (х)] ( г т + 1.», то
L, (<пах[1.,1, r ‒ т+1. 1(тах[1.,», г ‒ L,,).
11.3. Алгоритм Берлекэмпа ‒ Месси
393
рекуррентные равнапва, использ-
уемыее для вычисления f<"> (х):
ва
л ‒ 1
Л,=gf>' "а,>,
)=0
L, =6,(r ‒ L, i)+(1 ‒ 6,) L„
f«> (х)
1(Г> (х)
1 ‒ Л,х /« ‒ '> (х)
Л,'6, (1 ‒ 6,)х t« ‒ '> (x)
r= j,..., 2n, где о, =1, если
одновременно Л, ~ О и 2L,, (
(r ‒ 1, и О, = О в противном
случае. Тогда f<2'> (х) является мно-
гочленом наименьшей степени,
коэффициенты которого удовле-
творяют равенствам Д"> = 1 и
а,+g f~'а, =О,
г ) г I э
r=L~+1, ..., 2ã.
Доказательслмо. Следует из
теоремы 11.3.2. ~]
В этой теореме Л, может об-
ращаться в нудь, но только в том
случае, когда о, = О. Положим
тогда по определению Л,'О, = О.
Сггю~
Блок-схема алгоритма Бер- р . 11.6. Алгоритм Берлекэм-
лекэмпа Месси приведена на па ‒ Месси.
рис. 11.6. На r-м шаге указанный
алгоритм содержит число умноже-
ний, равное примерно удвоенной степени многочлена f«> (х).
Степень многочлена f«> (х) равна примерно г/2, и всего имеется
2п итераций, так что всего алгоритм содержит примерно
2л
2п' = ~",г умножений и примерно такое же число сложений. Ко-
/=4)
роче можно сказать, что порядок числа умножений в алгоритме
Берлекэмпа Месси равен п~, или, формально, О (п ).
394 Гл. 11. Быстрые методы решеиия теплицевых систем.
11.4. Рекурсивный алгоритм Берлекэмпа Месси
Все рассмотренные нами до сих пор методы решения теплице-
вых систем уравнений содержат число умножений, пропорциональ-
ное n'. В настоящем параграфе мы воспользуемся стратегией дуб-
лирования для того, чтобы снизить вычислительную сложность
алгоритма Берлекэмпа Месси при больших и.
Число используемых на r-м шаге итераций умножений примерно
равно удвоенной степени многочлена /<'> (х). На первых шагах
итераций эта степень мала, и итерации выполнякггся легко, но
с ростом r растет и сложность вычислений. И ускоренном алго-
ритме за счет одновременного выполнения нескольких итераций
используется преимущество, которое дается простотой вычислений
на первых шагах. После выполнения каждой такой группы итера-
ций исходная задача модифицируется так, чтобы учесть это полу-
ченное решение. Затем сызнова начинается выполнение новой груп-
пы итераций алгоритма Берлекэмпа Месси, но уже для модифи-
цированной задачи и модифицированного начального значения
многочлена f (х).
Рассматриваемое ниже построение начинается с более компакт-
ной организации алгоритма Берлекэмпа Месси. Заменим много-
члены f<'> (х) и t<'> (х) полиномиальной матрицей размера 2x2:
F~!)(х) F 2(x
Я (x) F Я(х
%"'(х) =
Коэффициенты многочлена ф' (х) будем обозначать через Ец",>.
Матрица Г<'> (х) определяется так, чтобы многочлены /'> (x)
и К<'> (х) можно было вычислить, используя уравнения
"(х
'й'(х) + ~'з'г(х
= F '(x)
1 F~'(x) + РЯ(х) 1
Напомним, что сначала выполняемые в алгоритме Берлекэмпа
Месси вычисления записываются в виде двух уравнений:
м)(х)
j~0
11.4. Рекурсивный алгоритм Верлекэмпа ‒ Месси
395
Следовательно,
~~) „ l -LL X 1 -box
h, 'b, (3 ‒ b,)õ Ь b, (1 ‒ ~Дх
Алгоритм модифицирует как матрицу Г(') (х), так и много-
члены f(') (х) и t(') (х). Прямой метод перевычисления F(') (х)
требует примерно в два раза больше умножений, поскольку
матрица содержит не два элемента, а четыре. Хотя в такой форме
вычисления и допускают использование метода дублирования, HO
мы получаем большее, чем хотим, число умножений. Надо соответ-
ствующим образом реорганизовать вычисления.
Рекурсивная форма алгоритма Берлекэмпа Месси строится
вокруг следующих уравнений, эквивалентных выписанным ра-
нее:
и ‒ 1
и ‒ 1
Л, = ~ Fj( /)а,/+ g F((g /)'à,;,
у‒ = O у=о
1 ‒ Ь,х
Г(') (х) =, Г(' ') (х).
Предполагая и четным, разобьем алгоритм пополам и положим
Г(") (х) = F'(") (х) F" ("/') (х),
где
~1/2+~ 1 ~ х
F'(") (х) = П
Л,'6, (1 ‒ 6,) х
1 ‒ Ь,х
F.«/»(x) = П
р=а 2 /-)i Ь (1 ‒ бг) х
Мы будем вычислять каждую из половин отдельно, а затем их пе-
ремножать. Сложность при этом получается меньше, чем в исход-
ном способе решения. Необходимо также реорганизовать уравне-
ние, определяющее Ь,. Будем величину Ь, вычислять как r-й
коэффициент первой компоненты двумерного вектора многочленов
Л(х) F(() "(х) F((; "(х) а(х)
Л'(х) Г(; ‒ ') (x) F('; ‒ ''(x) а(х)
Таким образом, для r, больших чем /(/2,
г
Л (х) а(х)
= F' '(Г ‒ 1) (х) F" (п/2) (х) = F' (' ‒ ') (х) а("/') (х),
Л' (х) а (х)
где
а (х)
а("/2) (х) = F" (n/2) (х)
а (х)
396 Гл. 11. Быстрые методы решения теплицевых систем
B8od
Рис. 11.7. Разложение
Берл екэмпа ‒ Месси.
алгоритма Рис. 11.8. Рекурсивный алгоритм Бер-
лекэмпа ‒ Месси.
Это завершает описание разбиения алгоритма Берлекэмпа ‒ Месси.
Основная форма алгоритма теперь записывается в виде
n ‒ 1 и†I
(r ‒ 1) ~~ 1 (r ‒ 1)
Л,=~ ~F»;а<,;+~ ~F, а2, >,
j~ /=0
1 ‒ Ь,х
F<'> (х) =, F<' ‒ ц (х),
где вместо F<'> (х) подставляется F'<'> (х) или F"<'> (х), а вектор
(а, (х), а, (х)) в первой половине вычислений равен (а (х), а (х)),
а во второй половине вычислений модифицируется в вектор
a"~2 (х). После того, как вычислены обе половины задачи, ма-
трица F<"> (х) получается перемножением своих двух половин.
Разбиение алгоритма Берлекэмпа Месси показано на рис. ) 1.7.
Заметим, что каждая из половин алгоритма сама является алгорит-
мом Берлекэмпа ‒ Месси. Следовательно, если п/2 четно, то каждая
из половин может быть разбита в свою очередь', если и равно сте-
пени двух, то такое разбиение можно продолжить до тех пор, пока
не будут получены фрагменты, состоящие только из одной итера-
l 1.5. Методы, основаниые на алгоритме Евкл~ща
397
11.5. Методы, основанные
на алгоритме Евклида
В некоторых методах решения теплицевых систем уравнений
используется алгоритм Евклида. Наиболее подходящей для этого
является описанная в разд. 10.7 рекурсивная .форма алгоритма
Евклида.
Начнем со следующей теплицевой системы уравнений
ап ‒ (
аи-я
ап-I
° - ° ао
‒ a„.
‒ а.(
ал-3
а г
а.
an
а(
ар
an+ (
ап
1
-а~,(
а~„2 а2. з a~ <
- - е ал-(
Это та же самая теплицева система уравнений, которую в ~ 11.3
мы решали с помощью алгоритма Берлекэмпа Месси.
,Пусть
2п ‒ 1
а(х) = g а,х', f(x) = 1+ 1„ f;x',
к=о К=1
и рассмотрим произведение этих многочленов g (х) = f (х) а (х).
Из выписанного матричного уравнения видно, что
g;-=0, i =n,...,2n 1,
но при значениях индекса (, больших чем 2п 1, коэффициенты
g; могут быть и ненулевыми. Рассмотрим задачу вычисления таких
f (х) и а (х), которые удовлетворяют условиям de f (х) < и,
degg (х) ( п 1 и
g (х) = f (х) а (х) (mod х'").
Одним из путей решения этой задачи, конечно, является решение
исходного матричного уравнения относительно вектора f и даль-
нейшего вычисления многочлена g (х}. Другой метод основан на
использовании алгоритма Евклида для многочленов.
Для того, чтобы увидеть, как можно решать это уравнение
относительно f (х) и g (х), вернемся к доказательству алгоритма
ции. В этих фрагментах выполняются уже все вычисления, но они
достаточно тривиальны.
На рис. 11.8 алгоритма приведена рекурсивная форма Берле-
кэмпа Месси. Вся вычислительная работа сводится к вычислению
полиномиальных произведений, сочетающих половинные резуль-
таты. Эти вычисления представляют собой свертки многочленов
и могут быть выполнены с помощью любого алгоритма линейной
свертки.
398 Гл. 11. Быстрые методы решения теплицевых систем
Евклида. Из этого доказательства легко увидеть, что
s«i (х) А'i'(х) Аф (х) s(x)
i<ii (X) А<;< (X) А<;i (X) t (X)
так что
t" (х) = A~<) (х) t(х) (mods(x)),
что при t (х) = а (х) и s (х) = х2" является одной из форм решае-
мого нами уравнения. Выписанное уравнение справедливо при
всех r. Чтобы решить задачу, надо найти такое r, при котором
deg А~;< (х) ~( п и deg t«i (х) ~( п 1. Если такое r существует,
то многочлены А22~ (х) и t«~ (х) должны равняться искомым мно-
гочленам f (х) и g (х}. Выберем значение r, при котором удовлетво-
ряются неравенства
degt<' ‒ '> (х)) п и degt<' (х).<п ‒ 1.
Так как deg t«i) (х} = 2n и с ростом r степень мчогочленов t<'i (х)
строго убывает, то это определяет r однозначно. При таком опре-
делении r требование deg t«i (x) ~( n 1 удовлетворено. С ро-
стом r степень многочлена Аф (х} растет, и надо только показать,
что deg А2<2' (х} ~( п.,<(ля того, чтобы это доказать, воспользуемся
матрицей, обратной к матрице А<'> (х). Сначала напомним, что
О 1
А<'>(х) = П
Отсюда ясно, что deg A22~ (х) > deg А", (х). Напомним также,
что deg з<'> (х) > deg t<'i (х). Из этих неравенств и матричного
уравнения
s (х) А 2<2' (х)
1 г
t (x) А,", (х)
Аф (х) з<'> (х)
A<<'< (х) t<'> (х}
следует, что deg s (х) = deg А@ (х) + deg s" (х), и так как
s«i (х) = t<' ‒ 'i (х), то это преобразуется к соотношению
deg А2~~ (х) = degs(x) ‒ degt<" "(x) (2n ‒ п = п,
где неравенство вытекает из определения параметра r.
Яы получили почти полное доказательство следующей теоремы.
Теорема ll.5.I. При заданных s«i (х) = х'" и И~ (х) = а (х)
пусть
1 О
A« ii (x) =
О 1
399
l l.5. Методы, основанные на алгоритме Евклида
Вход
Рис. 11.g. Решение теплицевой системы с помощью алгоритма Евклида.
Продолжая рекурсию до тех пор, пока deg Ь'> (х) ( и
следующую систему рекуррентных уравнений:
О 1
А<'> (х) =
1 Q<'> (х)
А<' ‒ '> (х),
О 1 s<' ‒ '> (х)
1 Q<'> (х) t<' ‒ '> (х)
1, решим
е(г) (x)
1<'> (х)
и положим g (х) = Л 't" (х) и f (х) = Л 'А", (х), где Л =
= А2~2~ (О). При условии, что Л отлично от нуля, эти многочлены
удовлетворяют уравнению
g (х) = f (х) а (х) (mod х'").
причем deg f (х) ~( n, deg g (x) ~( и 1 и f, = 1.
Доказательство. Деление на Л обеспечивает равенство f, = 1.
Справедливость остальных утверждений была установлена ра-
нее. Р
400 Гл. 11. Быстрые методы решения теплицевых систем
Таким образом, мы получили другой способ решения той же
самой теплицевой системы уравнений (в случае, когда эта система
обратима), которую мы уже решали раньше, используя алгоритм
Берлекэмпа Месси', блок-схема этого метода показана на
рис. 11.9. Если теплицева система не обратима, То описанное при-
менение алгоритма Евклида также приводит к многочлену А(;> (х)
наименьшей степени, который удовлетворяет определяющему его
равенству, но в этом случае (ъ = О и поэтому многочлен f (х) не
определен. Если Л = О, то описанный алгоритм приводит к реше-
нию системы
и„,
h,
h,
h„
Задачи
11.1. Используя алгоритм Левинсона, решить в поле GF (7) уравнение
4
2
3
Реконструировать алгоритм Левинсона для случая, когда основное поле
является комплексным, а матрнца А эрмитовой.
Предположим, что входящая в алгоритм Берлекэмпа последовательность а
является периодической, период N которой намного больше, чем 2п.
а. Показать, как можно полностью вычислить последовательность по
ее первым 2п компонентам.
б. Предположим, что вместо вектора а задано его преобразование Фурье,
вектор A. Показать, как надо модифицировать алгоритм Берлекэмпа‒
Месси для того, чтобы использовать непосредственно вектор А, не вычисляя
обратного преобразоваиия Фурье.
Используя алгоритм Берлекэмпа ‒ Месси для входной последователь-
HocTH (a(), ад, ..., а,) = (О, С, О, О, О, О, О, 1), найти решеиие f, длииа кото-
рого больше 4. Эта задача является примером того, как алгоритм Бер-
лекэмпа ‒ Месси приводит к авторегрессионному фильтру даже в тех
случаях, когда теплицева матрица вырождеиа.
Используя алгоритм Евклида, решить уравнение
11.2.
11.3.
11.4.
t 3 2 1 f~
3
332 У, =- г
2 3 3 Уз 1
11.6. Доказать, что все шаги рекурсии алгоритма Левинсона можно провести
в том и только в том случае, когда все -вложенные главиые подматрицы
невырождеиы.
! 1. 7. Сформулировать условия невырожденности алгоритма Дурбина.
Замечания
401
Замечания
Первый быстрый алгоритм решення теплнцевых систем уравнений был раз-
работан Левинсоном (1947). Он был сразу >ке отнесен скорее к области прило>ке-
ний к задачам вииеровской фильтрации, чем к задачам построения быстрых алго-
ритмов как таковых. Другие быстрые алгоритмы решения некоторых теплицевых
систем уравнений были построены Дурбиным (1960), Тренчем (1964) и Берле-
кэмпом (1968). Упрощение алгоритма Тренча предложил Зонар (1974). Месси
(1969) упростил алгорнтм Берлекэмпа, интерпретнруя его как метод построения
регистра сдвига с линейной обратной связью Велч и Шольц (1979) описали
этот >ке алгоритм с точки зрения алгоритма построения непрерывной дроби.
Рекурсивную форму алгоритма Берлекэмпа ‒ Мессн описал Блейхут (1983).
Использование алгоритма Евклида для решения теплицевых систем уравнений
предложено Сугиямой, Касахарой, Хирасавой и Намекавой (1975). Ускорение
алгоритма Евклида с помощью дублирования в его приложении к решению
теплицевых систем уравнений разработали Брент, Густавсон и Юн (1980).
Неудивительно, что быстрые алгоритмы решения теплицевых систем урав-
нений связаиы со многими другими задачами. Если выписать шаги алгоритма
Левинсона s обратном порядке, то он преобразуется в алгоритм, нзвестный как
критерий Шура ‒ Коена для тестирования стабильности авторегрессионного
фильтра, задаваемого многочленом а (х). Эту связь отметили Вийера и Кайлат
(1977).
Объем книги немедленно бы удвоился, если бы мы стали рассматривать
такие обобщения и специализации теплицевых матриц, как блочио-теплицевы
матрицы или почти теплицевы матрицы. К таким работам относятся статьи Внг-
гинса н Робннсона (1965), Дикинсона (1979), gl,èêííñîíà, Морфа и Кайлата (1974),
Фридлендера, Мо~, Кайлата и Льюнга (1979), Морфа, Дикиисона, Кайлата
н Вайеры (1977), Мондена и Аримото (1980).
Глава 12
БЫСТРЫЕ АЛГОРИТМЫ ПОИСКА
ПО РЕШЕТКЕ И ПО ДЕРЕВУ
Машина с конечным числом состояний, производящая в каждый
момент времени один или более элементов некоторого поля F,
генерирует последовательность элементов этого поля. Множество
всех возможных таких последовательностей на выходе машины
с конечным числом состояний описываются графом определенного
вида, который называется решеткой или, в случае очень большого
числа состояний, деревом. Имеется много приложений, в которых
по результатам наблюдений в шуме одной из таких последователь-
ностей тр ебуется оценить либо саму эту последовательность,
либо историю машины с конечным числом состояний. Это задача
поиска по решетке или по дереву такого пути, который лучше всего
отвечает данной последовательности. Такое направление в обра-
ботке дискретных сигналов сильно отличается от других направле-
ний, и алгоритмы, рассматриваемые в настоящей главе, сильно
отличаются от уже изученных нами алгоритмов.
Алгоритмы поиска по решетке и по дереву находят приложения
в таких областях, как декодирование сверточных кодов, демодуля-
ция сигналов при наличии межсимвольной интерференции, демо-
дуляция сигнала по частичному отклику или фазово-разностно-
модулированных сигналов, распознавание речи и текстовых сим-
волов.
12.1. Поиск по решетке и по дереву
Решетки и деревья, по которым реализуется поиск, возникают
как описания машин с конечным числом состояний. Машина с ко-
нечным числом состояний задается множеством состояний, в ко-
торых она может находиться, множеством переходов между этими
состояниями и выходными символами, соответствующими каждому
такому переходу. Простейший способ построения машинь1 с ко-
нечным числом состояний с помеченными переходами состоит в ис-
пользовании регистра сдвига так, как показано на примере на
рис. 12.1. Состояния машины в этом примере описываются двумя
содержащимися в ячейках регистра сдвига битами; всего имеется
четыре так определяемых состояния. В каждый момент времени на
вход поступают два бита, так что из каждого состояния возможны
12.1. Поиск по решетке и по дереву
403
2-бит
ВХ
3-битов ыа
выход
Рис. 12.1 Пример машины с конечным
числом состояний.
+ обозначает сложение по модулю 2 (ис-
ключающее ИЛИ)
Рис. 12.2. Другой примср машины
с конечным числом состояний.
+ обозначает сложенне по модулю 2 (ис-
ключающее ИЛ И)
четыре перехода. В данном частном примере из каждого состояния
возможен прямой переход в любое другое состояние. Изображен-
ная на рис. 12.1 схема имеет три выходных бита; каждый переход
порождает трехбитовую последовательность.
На рис. 12.2 показан другой пример, в котором уже нельзя из
произвольного состояния перейти в любое другое состояние. Для
достижения некоторых состояний требуется совершить два пере-
хода. Схема на рис. 12.2 имеет двухбитовый выход.
Диаграмма переходов для машины с конечным числом состоя-
ний показана на рис. 12.3. Переходы помечены векторами длины
два. В каждый момент времени машина делает переход между со-
стояниями вдоль пути и метит путь переходов. Приведенная на
рис. 12.3 диаграмма соответствует схеме на рис. 12.2.
Как правило, вид графа, который называется рпиггакой, можно
использовать для описания выходных последовательностей произ-
вольной машины с конечным числом состояний. Типичная решетка,
из каждой вершины которой выходят два ребра, показана на рис.
12.4. Вершины любого столбца решетки обозначают состояния,
в которых может находиться машина. К,аждый последовательный
столбец соответствует последовательным моментам времени и со-
держит одно и то же множество состояний. Ребра, связывающие
вершины двух столбцов, представляют собой все возможные пе-
реходы в течение данного временного интервала, именуемого кад-
ром. В общем случае решетка представляет собой полубесконеч-
ный вправо прямоугольный граф, число вершин в каждом столбце
которого конечно, Расположение ребер, связывающих вершины
данного столбца с вершинами следующего справа столбца, одно
и то же для каждого столбца. Яиаграмма начинается B верхней
левой вершине; так как движение осуществляется только вправо,
то недостижимые левые узлы на диаграмме не указываются.
Длиной кодового ограничения решетки называется число битов,
необходимых для определения состояния на решетке. Длина ко-
дового ограничения решетки, показанной на рис. 12.4, равна двум.
404 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
/
()). ) ))
(02 И
/
()~~, и5)
I
3, ))3)
I
()), ).) )
Рис. 12.3. Диаграмма
(~ „) состоянии.
Рис. 12.4. Простая решетка.
/
(us- ив)
Каждый кадр машины с конечным числом состояний приводит
к изменению состояния. На решетке это изменение показано реб-
ром, входящим в следующую вершину. Каждое ребро на рис. 12.5
помечено. В общем случае ребро маркируется некоторым фикси-
рованным числом и, элементов основного поля F. При переходе
от кадра к кадру множество меток на ребре может быть как фик-
cHpoBBHHbIM, так и переменным. Машина с конечным числом со-
стояний может двигаться по решетке слева направо по многим
путям решетки. Идя по каждому из этих путей, она вычисляет
некоторую последовательность элементов поля F, которая и яв-
ляется ее выходной последовательностью.
Пусть с = {c;, ) = О, ...{ обозначает последовательность сим-
волов источника над полем F, генерируемых машиной с конечным
числом состояний, и пусть v = {v;, 1 =- О, ...{ обозначает после-
довательность символов данных над F. Во многих приложениях
v; = с; + е~, где е; составляющая ошибки. О такой ситуации
говорят, что последовательность на выходе источника наблюдается
в аддитивном шуме.
Задача поиска по решетке состоит в вычислении такого пути на
решетке, для которого последовательность с согласуется с задан-
ной последовательностью ч данных наилучшим образом. Для из-
мерения меры согласованности необходимо ввести функцию рас-
стояния.
Рассгпояние на множестве S определяется как вещественная
функция d (а, р) на паре элементов из 5, удовлетворяющая условиям
1. d (а, {3} ) О и d (а, а} = О,
2. d(а, ,{3} = d ({}, а).
Если эта функция удовлетворяет также условию
12.1. Поиск по решетке и по дереву
405
(о „м1) (и,, и ~ )
!О
О!
("е us)
Рис. 12.5. Маркированная решетка
3. < (n, р) < d (n, ')) + d (у, I)) для всех у из 5,
то она называется метрикой. Евклидоео расстояние, определяе)!
на п-мерном векторном пространстве формулой
и ‒ 1
Н(ч, т) = Z (о, ‒ и;)',
C=-О
является метрикой. Каждый состоящий из l кадров путь Hà ре»
шетке определяет вектор длины ln() над полем F. Если ыз каждой
вершины решетки выходит д путей, то на длине путей в l кадров
мы получаем о таких векторов длины ln,. Задача поиска по решетке
состоит в выделении того из этих векторов, который ближе всего
в данном расстоянии подходит к данному вектору v длины 1ц,
Наиболее простой для понимания метод поиска по решетке ~о
стоит в вычислении всех расстояний данного вектора ч от д' ~о
следовательностей, производимых данной решеткой, и нахожу
нии в полученном списке наименьшего расстояния. Это мои~но
проделать, мысленно накладывая заданную последовательность z
на каждый из возможных путей на решетке. Сложность этой про
цедуры растет экспоненциально по l, так что при больши~ <
она практически неприемлема. Обычно l столь велико, что ~го
можно полагать бесконечным. Практически алгоритм не мо~ет
рассматривать вою входную последовательность целиком пр и
больших l. Он начинает с самого начала и, двигаясь вдоль
следовательности, принимает окончательные решения. Эффектна
ный поиск по решетке можно осуществлять'по алгоритму ~и
терби, который будет описан в следующем разделе.
В некоторых случаях число состояний машины с конечным ч~с
лом состояний велико. ТоГда число узлов в каждом кадре решетки
также велико, иногда настолько, что его можно полагать неогра»
ниченным. В этом случае исходная часть решетки тоже рас~ет
неограниченно, и в графе мы пренебрегаем тем, что на самом д~ле
при возврате машины с конечным числом состояний в некоторое
состояние в конечном итоге пути рекомбинируют. Ведь в каж-
дый момент времени приходится рассматривать лишь ма «цые
фрагменты решетки. Хорошим изображением того, что происходит,
406 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
Рис. 12 6. Дерево с двумя ребрами в каждом узле.
является представленное на рис. 12.6 дерево. Число узлов дерева
растет неограниченно.
Так же как на решетке, l кадров маркированного дерева опре-
деляют q векторов. Задача поиска по дереву состоит в нахождении
того из этих векторов, который ближе всего к заданному вектору v
данных. Мы можем мысленно наложить данную последователь-
ность на каждый из возможных путей дерева длиной в 1 кадров
и определить наилучшее совпадение. Опять сложность этой про-
цедуры растет экспоненциально по l, так что практически она не-
приемлема. Эффективные процедуры поиска по дереву даются
последовательными алгоритмами, рассматриваемыми в следую-
щих параграфах.
12.2. Алгоритм Витерби
При нци п оптимальности динамического программирования ут-
верждает, что если в некотором смысле оптимальный путь от точки
А к точке С проходит через точку В, то отрезок пути из точки В
в точку С совпадает с оптимальным путем из точки В в точку С.
Этот принцип применим к задаче отыскания лучшего пути по ре-
шетке, Основанная на этом принципе итеративная процедура по-
строения переменного множества претендентов на лучший путь по
решетке известна под названием алгоритма Витерби.
Алгоритм Витерби для решетки с О ребрами в каждой вершине
и длиной кодового ограничения v оперирует д~ претендентами,
так что его сложность пропорциональна д'. Практически алго-
ритм пригоден только при малых v. Если длина кодового ограниче-
ния равна 10 и из каждой вершины решетки выходят два ребра, то
алгоритм Витерби оперирует 1024 претендентами. Практически
это допустимо. Но при длине кодового ограничения 20 число пре-
тендентов уже больше миллиона, так что алгоритм практически
неприемлем.
Двигаясь вдоль решетки, алгоритм Витерби итеративно обра-
батывает кадр за кадром. Находясь на некотором кадре в момент l,
!2.2. Алгоритм Витерби
407
алгоритм не знает, какая из вершин является ближайшей, и даже
не пытается вычислить эту вершину. Вместо этого алгоритм опре-
деляет лучший из путей от начальной вершины до каждой из вер-
шин I-го кадра. Он вычисляет расстояния между данной последова-
тельностью и всеми претендентами для каждой вершины l-го кадра.
Для каждого из путей-претенденгов это расстояние называется его
расходимосгиью. Если все пути-претенденты проходят в первом
кадре через одну и ту же вершину, алгоритм находит первый кадр
ближайшего пути, но не принимает при этом никакого решения
относительно I-ro кадра.
Я,алее алгоритм вычисляет пути-претенденты в каждую новую
вершину (l + 1)-го кадра. Но чтобы попасть в любую новую вер-
шину (l + 1)-го кадра, путь должен пройти через одну из старых
вершин 1-го кадра. Таким образом, пути-претенденты в новые вер-
шины можно получить продолжением старых претендентов, кото-
рые допускают такое продолжение. Ближайший путь вычисляется
прибавлением приращений расходимости каждого пути к расхо-
димости лучшего пути в старую вершину. В каждую новую вер-
шину ведут д~ путей, и путь к новой вершине с минимальным при-
ращением является ближайшим. Этот процесс повторяется для
каждой из новых вершин. В конце вычислений, связанных с новым
кадром, алгоритм вычисляет ближайший путь в каждую из вершин
этого кадра I + 1. Если опять все эти пути проходят через одну
и ту же вершину второго кадра, то алгоритм Витерби успешно вы-
числяет второй кадр.
Этот процесс повтор яется во всех успешных кадр ах. Если
в некоторый момент возникает несколько ближайших путей
в данную вершину, то алгоритм должен разрешить этот конфликт,
используя некоторое правило. Альтернатива состоит в сохра-
нении всех решений, так что, например, находятся два пути в дан-
ную вершину. Для лучшего понимания этого момента следует
обратиться к рассматриваемому ниже примеру.
Яля реализации алгоритма Витерби надо выбрать окно ши-
рины b, которое, как правило, в несколько раз превышает ши-
рину кодового ограничения v и диктуется возможностями исполь-
зуемого компьютера. В момент и алгоритм просматривает все
выжившие пути. Если в первом кадре они совпадают, то этот
кадр выбирается в качестве первого кадра правильного пути,
его можно передать пользователю.
Я;алее алгоритм отбрасывает первое ребро и переходит к вы-
числению следующей итерации, беря для этого новый кадр. Если
опять все выжившие пути проходят через одну и ту же вершину
'наиболее старого кадра, то этот кадр принимается. Это'г процесс
повтор яется бесконечно, вычисля я кадр за кадром.
Если b выбрано достаточно большим, то в данном кадре почти
всегда можно принять однозначное решение. Редко, но встре-
408 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
чаются ситуации, когда при-
нять однозначное решение
и отбросить кадр не удается
Ф Э Э Ф °
либо потому, что имеется
Э Э Э Ф Э Э
несколько ближайших пу-
Э Э Э Э Э Э
тей, либо потому, что ши-
рина окна Ь слишком мала
кно
для принятия решения.
Тогда используется некото-
Рис. l2.7. Прикципиальиый вид алго- Р ОЕ пР авИЛО Р аЗРЕшЕН и Я
ритма Витерби. этой неопределенности. Та-
кое событие случается пре-
небрежимо редко.
Вместе с ростом числа кадров растет расходимость каждого
пути. Чтобы избежать переполнения памяти, приходится время
от времени редуцировать расходимость. Простое правило такой
редукции ° äàåòñÿ вычитанием наименьшей расходимости из всех
расходимостей. Это не влияет на выбор минимальной расходи-
мости.
Полезно представлять себе декодер Витерби как окно, через
которое можно наблюдать часть решетки. 3то и,ллюстрируется
рис. 12.7. На рисунке можно видеть только часть решетки конеч-
ной длины, на которой отмечены выжившие пути и их расходи-
мости. С течением времени решетка скользит влево. При появле-
нии справа новых вершин некоторые пути продолжаются в них,
а другие исчезают; самый старый столбец выходит из-под наблю-
дения налево. Со временем левый столбец вершин исчезает, и
лишь для одной из его вершин будет существовать проходящий
через нее путь.
На рис. 12.8 приведен пример. Яля простоты и метки на ре-
шетке, и последовательность данных в примере выбраны двоич-
ными. Евклидово расстояние заменяется просто числом пози-
ций, в котором различаются две последовательности. Выберем
ширину окна Ь равной 15. Предположим, что заданная последо-
вательность равна
ч = 101000001000000000000000 ...,
и требуется найти путь на решетке, ближайший к заданной после-
довательности.
диаграмма состояний декодера показана на рис. 12.8. На
третьей итерации алгоритм находит ближайший путь к каждой
вершине третьего кадра. Затем, продолжая пути, ведущие к вер-
шинам (г 1)-го кадра, и сохраняя ближайший путь к каждой
вершине г-го кадра, алгоритм íà r-й итерации находит ближай-
шие пути в вершины r-го кадра. Иногда может возникнуть неопре-
409
12.2. Алгоричм Витерои
Итерация 9
ю ю
~ - ~о~аккююооооахкюо
ю ю
Итерация 3
и~щищия 4
Ил~ерация Я
Рис. 12.8. Пример алгоритма В итерби.
деленность. В данном примере имеются две неопределенности
в пятой итерации.
Алгоритм может разрешить неопределенность случайным обра-
зом или сохранить оба пути, относительно которых существует
неопределенность. В данном примере неопределенность сохр а-
няется до тех пор, пока не находится лучший путь или сомнитель-
ный участок не выводится за пределы буфера. Если имеется только
один путь, проходящий через вершину наиболее старого кадра,
то принимается однозначное решение.
410 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
В этом примере ближайшей к данной последовательности
будет либо нулевая последовательность, либо последовательность
с началом 1110001011000....
Истинная реализация р ассматриваемого алгор итма может
сильно отличаться от приведенного на рис. 12.8 символического
описания. Например, выживающие пути на решетке можно за-
давать в виде таблицы 15-битовых чисел. При каждой итерации
некоторые из этих 15-битовых чисел сдвигаются влево, выталки-
вая наиболее левый бит и добавляя справа новый бит. Другие
из 15-битовых чисел этого списка не видоизменяются, а выбрасы-
ваются из списка.
12.3. Стек-алгоритм
Для больших решеток алгоритм Витерби быстро становится
непрактичным; при длине кодового ограничения 10 алгоритм
требует запоминания 1024 путей-претендентов. Я,ля того чтобы
ослабить влияние больших длин кодового ограничения, была
разр аботана стр атегия, игнор ир ующая маловер оятные пути по
решетке, как только они становятся маловероятными. Стратегия
поиска на решетке только наиболее вероятных путей известна
под общим названием последовательный алгоритмов. Как пра-
вило, в последовательных алгоритмах не принимается оконча-
тельных решений о непрерывном отбрасывании путей. Время от
времени последовательный алгоритм принимает решение вер-
нуться обратно и продолжить оставленный ранее путь. Последо-
вательные алгоритмы в равной мере пригодны и для поиска по
дереву, и для поиска по решетке.
Представим себе решетку с большой длиной кодового ограни-
чения, скажем, равного 40.,Ц,ля принятия первого решения в та-
кой решетке надо обработать несколько сотен кадров. Каждый
кадр содержит и вовсе огромное число вершин, а именно 24',
или, примерно, 10'2 вершин. Последовательный алгоритм должен
найти наиболее близкий к заданной последовательности путь
на этой решетке; он должен сделать это, по крайней мере, с очень
высокой вероятностью, хотя время от времени ему - дозволено
отказаться от декодирования. Этот отказ связан не с недостаточ-
ностью данных, а с неполнотой алгоритма. В алгоритме Витерби
мы не встречались с ошибками подобного сорта.
Последовательный алгоритм просматривает только первый
кадр, принимает решение и переходит в вершину решетки первого
уровня. Затем он повторяет эту процедуру. На каждом уровне,
находясь только в одной вершине, он просматривает следующий
кадр, выбирая ребро, ближайшее к принятому кадру, и перехо-
дит в вершину следующего уровня, прокладывая таким образом
12 3. Стек-алгоритм
411
путь на дереве. Если задаииая последовательность точно совпа-
дает с иекоторым путем на дереве, то эта процедура работает хо-
рошо. Однако при иаличии иесовпадений последовательный алго-
ритм выбирает ииогда иеправильиый путь. Если алгоритм про-
должает следовать по ложному пути, он внезапио обнаружит,
что в каждом кадре расходимость слишком велика и, по-видимому,
он на иеправильном пути. Последовательный алгоритм вериется
назад иа иесколько кадров и иачнет исследовать альтернативные
пути до тех пор, пока не найдется правдоподобный путь. Затем
он будет двигаться вдоль этого альтериативиого пути. Ниже
будут кратко описаны правила, которыми ои руководствуется
при этом поиске.
Характеристики алгоритма зависят от ширины Ь окиа. Если
алгоритм нашел путь, проходящий через b кадров дерева, он
прииимает окончательиое решение относительно самого старого
кадра, выводит этот кадр и вдвигает в окно новый кадр.
Число вычислений, иеобходимое последовательному алго-
ритму для продвижеиия по дереву на одиу вершину вглубь,
является случайиой величииой. Эта величина служит основной
характеристикой последовательного алгор итма. Он а представ-
ляет собой основной параметр, определяющий сложность алго-
ритма, необходимую для обеспечения задаиного уровня его ха-
рактеристик. Если помехи малы, то алгоритм может двигаться
по правильиому пути, используя для продвижеиия вглубь по
дереву на одну вершину только по одиому вычислеиию s каждом
кадре. Но если имеются сбивающие помехи, то алгоритм может
пойти по неправильному пути, что приводит к задержке и боль-
шому числу вычислеиий, предшествующих выходу иа правиль-
ный путь. Перемеиность числа вычислений влечет за собой необ-
ходимость большого объема памяти для входиых даииых. Любой
буфер конечного объема, независимо от его величины, при исполь-
зовании в последовательном алгоритме имеет иенулевую вероят-
ность переполнения. Такое поведен ие алгор итма следует р ас-
сматривать как одну ив его характеристик. Переполнение буфер-
ной памяти является существенным фактором любого алгоритма,
который осуществляет по меиьшей мере одно вычисление в каж-
дой посещаемой вершине и который последовательно просматри-
вает ребра так, что записаиные на более глубоких ребрах дерева
данные не используются. Второе условие оказывается крити-
ческим и приводит к особому поведению алгоритма.
Используемые последовательные алгор итмы р азбиваются на
два класса: стек-алгоритм, рассматриваемый в иастоящем разделе,
и алгоритм Фаио, который будет рассмотрен в следующем разделе.
Структура их совершенио различиа. Используемые в этих двух
подходах метрики являются предметом непрерывиых обсужде-
ний. Необходимое число вычислений в стек-алгор итме меиьше,
412 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
Рис. 12.9. Упрощенный
рнтм.
чем в алгоритме Фаио. Стек-
алгоритм запоминает уже вы-
численный набор путей. Это
коитрастирует с поведеиием
алгор итма Фаио, который,
найдя свой путь в иекоторую
вершину, может вернуться на
какое-то р асстояние обр атио
только для того, чтобы повто-
рить во всех деталях путь в ту
же вер шину. Стек-алгор итм
предпочитает запомииать про-
деланиую работу, а не повто-
рять ее. С другой стороны, для
стек-алгоритма требуется суще-
ственно больший объем памяти
и большая вычислительная
р абота на каждой итера-
ции.
Стек-алгоритм легок для
понимания; его упрощеииая
блок-схема приведена на
р ис. 12.9. Алгор итм орган и-
зуется вокруг стека уже вы-
числеиных на предыдущих
итерациях путей различной
длины. Каждый вход в стек
представляет собой путь, опи-
сываемый тремя величинами:
длиной пути, последователь-
иостью перемеиной длииы, со-
держащей определившие дан-
ный путь переходы между со-
Сюоп
1
ыдапь фершимь/Й лущй gee~a стояииями; и расходимостью
даниого пути. В начальный
стек-~о момеит стек содержит только
тривиальный путь нулевой
длины.
Расходимость пути определяется как расстояние между сегмен-
том пути и начальиым сегментом данных той же самой длииы.
Используемые в последовательных алгоритмах расстояния изме-
ряются миогими разиыми способами. Во многих важных задачах
последовательность 'данных представляет собой последователь-
иость записаиных на ребрах символов, искажеииых аддитивным
шумом. В этом случае мера расстояния известна как метрика
Фано, которая сейчас будет определена.
12.3. Стек-алгоритм
413
Расходимость пути определяется как логарифмическая функ-
ция правдоподобия этого пути и вычисляется следующим обра-
зом. Первые N + 1 кадров заданного слова можио записать
в виде
(N) / 1 и© 1 пе 1 по~
i09 ° ° ) OP f u)f ° 9 01 ) ° ° 9) ON) e° . ° f ON /J
Первые т + 1 кадров символов вдоль произвольиого пути можно
записать в виде
(m) / 1 1 по 1 п~~)
=iсО, --., СО, C), --., C1, ..., Cm, ..., Cm).
I
Мы хотим отыскать отрезок пути иа дереве, который максими-
вирует Рг (с() ~ v()')). Последовательный алгоритм выбирает на-
чальный отрезок пути по дереву, не заглядывая в глубь дерева.
По правилу Б айеса,
Pr (v()ч))
Член Pr (ч()() ) c(m)) можно разбить на два множителя
m no N no
Pr(v(~)(c™) = П П Pr(v(~с~~) П П Pr(u()
С=~) ]=1 Ю=ы+1 /=1
Первый член равен произведению условных вероятностей для
m + 1 кадров истинного пути; второй множитель равен произ-
ведению безусловных вероятностей по тем кадрам, где путь не
определен. Эго р азложеиие я вляется следствием определения
последовательного алгоритма. Алгоритм более общего вида не
обязательно допускает такое разбиение.
Теперь будем максимизировать вдоль путей величину
П П рг(()(~ (()
Z=O )=1
П П P(U',)
С=О ]=1
Pr (v()ч) ) с(~)) Рг (с(~))
Pr (v(~))
Pr (с('")).
Так как все пути предполагаются равновероятными, то члеи
Рг (c(m)) является константой. Его можно отбросить, и это не
влияет иа выбор максимума. Используемая в рассматриваемом
последовательном алгоритме метрика, именуемая метрикой Фано,
задается логарифмической функцией
рг ()()v) ) с(m)) рг (с(m))
Р. (с("')) = logv P, („(m))
414 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
Здесь ~-я скобка представляет собой вклад метрики Фано на
~-м кадре
p(u~ ~ с~)
Fi gq
Яля каждого рассматриваемого пути в ~-м кадре требуется вы-
числять только этот член. Метрика р,(c<~>) получается прибавле-
нием нового приращениА к метрике Фаио пути, который записан
на предыдущей итерации в вершине стека.
12.4. Алгоритм Фаио
В алгоритме Фаио требуется зиать средиюю расходимость
на кадр правильной последовательности d или хотя бы верхнюю
границу для д. Это предполагает наличие некоторой меры ста-
тистической регуляриости расходимости, так что средияя расхо-
димость может быть использована как типичиая. Пока алго-
ритм Фано следует по правильному пути, можио ожидать, что
в пределах первых 1 кадров расходимость равиа примерио dI.
Алгоритм допускает несколько большую величииу расходимости,
но если она намного больше, то алгоритм сделает вывод, что он
на неправильном пути. Выберем (быть может, моделированием)
некоторый параметр д', больший, чем d, и определим перекошен-
ное расстояние формулой ')
t(l) =д'l dЩ,
где d (1) равно расходимости текущего пути-претендента на де-
реве. Для правильного пути d (l) приблизительно равно dl,
а t (t) положительно и возрастает. Алгоритм следует по пути на
дереве до тех пор, пока t (1) возрастает. Если вдруг t (t) станет
уменьшаться, алгоритм заключает, что в некоторой вершине он
выбрал ошибочиое ребро и возвращается по дереву обратно, про-
веряя другие пути. Он может найти лучший путь и следовать
по нему или может возвратиться к той же самой вершине, но уже
более уверенно продолжать путь через нее. Для того чтобы ре-
шить, когда t (1) начинает уменьшаться. в алгоритме Фано исполь-
зуется переменный порог'Т, который всегда кратен приращению
~ порога. Пока алгоритм движется вперед, порог, оставаясь не
большим 1 (I) и кратным приращению Л, принимает максимально
возможное при этих ограничениях значение. Благодаря тому,
что Т квантуется с шагом Ь, допускается небольшое убывание
t (t) без пересечения порога.
~) В этом выражеиии знак выбран так, чтобы правильной работе алгоритма
соответствовало положительное значекие расстояния.
12.4. Алгоритм фано
415
В алгоритме Фано требуется, чтобы д ребер, выходящих из
каждой вершины, были перенумерованы согласно некоторому
пр авилу упор ядочивания. Это пр авило ставит в соответствие
каждому ребру индекс j, j = О, ..., д 1. Нет необходимости
запоминать эти индексы в каждом ребре; достаточно зна'гь пра-
вило, по которому при возвращении алгоритма в вершину по
ребру с известным индексом j он может переупорядочить ребра,
найти ребро ) и затем найти ребро с индексом ) + 1. Наиболее
общим правилом является правило минимального расстояния.
Ребра упорядочиваются в соответствии с их расстояниями до
соответствующего кадр а заданного слова, а неопределенность
разрешается по любому удобному подпр авилу. Однако алго-
ритм будет правильно работать при любом фиксированном по-
рядке ребер.
Фиксированное правило упорядочивания может привести к бо-
лее длительному поиску назад-вперед, но освобождает от необхо-
димости вычисления и перевычислеиия при достижении каждой
вершины. Какое правило упорядочивания более просто в реали-
зации, зависит от деталей конструкции. Яля простоты понимания
структуры алгоритма правило упорядочивания лучше оставить
несколько н~ определенным; предположим только, что в каждой
вершине ребро, ближайшее к ребру данных, занумеровано пер-
вым. Алгоритм будет отыскивать ребра из каждой вершины в со-
ответствии с этим пр авилом.
Основанная на регистрах сдвига реализация алгоритма Фаио
показана на рис. 12.10. Основой реализации является копия ма-
шииы с конечным числом состояний, которая иа рисунке представ-
леиа регистрами сдвига, к ним добавлено несколько вспомогатель-
ных запоминающих регистров. Алгоритм пытается подать сим-
волы в копию машины с конечным числом состояний таким обра-
зом, чтобы на ее выходе сформировалась последовательность,
достаточно близкая к заданной последовательности. На каждой
итерации алгоритм имеет доступ к самому последнему кадру,
введенному в копию машины с конечным числом состояний. Ои
может изменить символ в этом кадре, вернуться к более раннему
кадру или ввести новый кадр. Что именно делать, алгоритм ре-
шает на основе сравнения величины перекошенного расстояния
t (t) и текущего значения порога Т.
В упрощенной форме алгоритм Фано показан на рис. 12.11.
Практические детали, связанные с конечностью размеров буфера,
временно игнорируются.
Если последовательность данных близка к генерируемой после-
довательности~ то алгоритм будет циркулировать по правой петле
на рис. 12.11, и при каждом цикле все регистры на рис. 12.10 сдви-
гаются на один кадр вправо. Qo тех пор пока t (l) остается выше
порога, алгоритм продолжает сдвигаться вправо и повышать
416 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
Иопия молочника
Номанда на eoapocma~«
данноао кадра
Batxo8
(к попазо-
в апрелю)
Первая
проба
6 кадром
Рис. 12.10. Реализация алгоритма Фано на регистрах сдвига.
порог так, чтобы тот оставался близким к t ((). Если t (() спускается
ниже порога, то алгоритм Фано проверяет альтернативные ребра
этого кадра, пытаясь найти то ребро, которое делает t (l) выше
порога. Если ему не удается сделать этого, то он возвращеется
назад. Как мы увидим в дальнейшем, если алгоритм начал возвра-
щаться обратно, то логика заставит двигаться его назад до тех
пор, пока ие будет найден альтернативный путь, который нахо-
дится над текущим значением порога, или вершина, в которой
был устаиовлен текущий порог. Затем алгоритм сиова движется
вперед с уже поииженным значением порога; но теперь, как мы
убедимся позднее, порог не повышается до тех пор, пока алго-
ритм йе придет в новую, раиее не рассматривавшуюся вершину.
Каждый раз, когда алгоритм, двигаясь вперед, посещает ранее
исследовавшуюся вершину, он имеет меньший порог. Алгоритм
никогда не посетит одну и ту же вершину дважды с одинаковым
значением порога. Следовательно, он может посещать любую вер-
шииу только конечное число раз. Это поведение гарантирует нас
от зацикливания алгоритма; он должен продолжать движеиие
вперед по последовательиости данных.
12.4. Алгоритм Фаио
417
HavaNoNoIc
ус«авил
С 3--Оз
(в ‒ О
т- о
М-
о
Индикатор предыдущего деиженил
l,åñëè вперед,
M = О. если назад,
‒ ( в осталвнви случми
бы я ли сдвиг iipelLagyag;u
итераг(ии сдвигом назад з
да- лроееритв,
был ли последний
«a(((( еьиие порога
((ат-проееритв,
М ‒ 1 преевипает ли «'др паров
г
Да - лроееритв,
нояойякн пи
данный узел в неис-
следованной vayu
дерееа‒
тогда деижение
праоилвное
Hem- е этом кадре
был установлен
те«ущий порое-
понизитв пороз и
аT
,,а
г
Нет-
опробреот в
ноеыц путв
лжотв
ние„
новви nymeu
г,а r
1
Если возможно
pm e,ecru iraq~),mo
yeenuvums последний кадр
Лрисеоитв
((озможно,«ет
'tig (т+ Ь
9
Т ‒ Т ‒ а
i-J+ !
( ‒ (
м - о.
В пропювном сяучое деиганпвсю
назад Лрисвоитв
(-( ‒ !
М- ‒ !
азонсео
еычислитв j
gfa-
ппеыситв
порог до мок
симо«в«аз~
кратной
ееяичины.
менииеи Cг
Т ‒ n -~
Сдеинутвс«
06йн кодр
(-(+ l
Af !.
Нпчотв новый
кадр с первого
значения (i > 0)
Рис. 12.11. Аинотироваииая блок-схема алгоритма Фаио.
Замечани я Кадры и ндекснрова иы указателем кадров l.
Итерации не индексированы.
Ответвления от текущего узла
нндексирова иы с помощью f
Теперь необходимо доказать два сделанных ранее утвержде-
ния: 1) если алгоритм Фана не может найти альтернативный
путь, то он движется назад к вершине, в которой было установлено
текущее значение порога, H понижает его; 2) алгоритм не будет
повышать порог до тех пор, пока не достигнет ранее не исследовав-
шегося узла. Что касается первого утверждения, очевидно, что
если алгоритм Фано не может найти ребро, от которого он должен
двигаться вперед, то он в конце концов должен вернуться B ука-
занную вершину. Но если в предшествующем некоторой вершине
кадре перекошенное расстояние t (( 1) меньше текущего зна-
чения порога Т, то порог был увеличен в l-м кадре. В блок-схему
на рис. 12.11 включен этот тест для нахождения вершины, в ко-
торой был установлен текущий порог; теперь в этой вершине по-
рог уменьшается.
413 Гл. 12. Быстрые алгоритмы поиска по решетке и по дереву
Яля доказательства второго утверждения заметим, что после
того, как порог понижен на Л, алгоритм Фано ищет ребра в том
же порядке, что и до этого, до тех пор, пока не найдет место,
в котором перекошенное расстояние, ранее бывшее меньше по-
рога, становится больше него. Яо этого места порог Т измениться
не может. Это происходит из-за того, что после понижения по-
рога на Ь перекошенное расстояние в тех вершинах, где оно
превышало первоначальный порог, никогда не будет меньше
Т + Л. Когда алгоритм продвигается в новую часть дерева,
он в конце концов достигает состояния, в котором 3 (1 1) (
( Т + Л и t (l) )~ Т. В этой точке порог повышается. Зто и
является тестом для определения того, что алгоритм посетил
новую вершину H нет необходимости помнить точно все посещен-
ные ранее вершины. Этот тест включен в схему на рис. 12.11.
Алгоритм Фано зависит от двух параметров р' и Ь, которые
можно выбрать моделированием на ЭВМ. Практически необхо-
димо время от времени уменьшать t (1) и Т так, чтобы эти числа
не становились слишком большими. Вычитание из обеих величин
некоторого числа, кратного Ь, не влияет на последующие вы-
числения..
В практической реализации существенен также выбор ши-
рины окна Ь. На рис. 12.12 приведена более полная блок-схема
алгоритма Фано, отображающая важную роль параметр à b.
Каждый раз, когда самый старый кадр достигает конца буфера,
что отмечается указателем кадра, он выходит из окна, а указа-
тель кадра изменяется так, чтобы всегда указывать на самый
старый имеющийся кадр. Иногда алгор итм может попытаться
вернуться назад так далеко, что отыскиваемый им кадр оказы-
вается уже выведенным. Такое явление называется переполне-
нием буфера и случается, когда указатель кадров принимает
отрицательные значения. Переполнение буфера является су-
щественным ограничением алгоритма Фано. Во многих приложе-
ниях вероятность переполнения буфера так медленно убывает
с ростом размера буфера, что вне зависимости от того, насколько
большим выбран буфер, эта проблема полностью не снимается.
Существует два способа управления переполнением буфера.
Наиболее надежным является периодическая подача на вход
машины с конечным числом состояний известной последователь-
ности переходов, длина которой равна длине кодового ограни-
чения. Если буфер переполнится, то алгоритм декларирует отказ
и ждет начала следующей известной ему последовательности,
при котором он снова начинает работу. Все данные, поступившие
между моментом переполнения буфера и следующим включением,
тер яются.
В случае, когда длина кодового ограничения не слишком ве-
лика, альтернативный путь состоит в движении указателя кад-
Задачи
419
Рис. 12.12. Алгоритм Фаио.
ров вперед. Если алгоритму удастся найти правильную вершину,
то он сможет перенастроиться. Это возможно, если заданная по-
следовательность содержит достаточно длиннь~й сегмент, в ко-
тором генерируемая последовательность с ней в точности совпа-
дает.
Задачи
]2.3. Дать простую формулу метрики Фаио для случая, когда разность между
данной и полученной последовательностями задается гауссовским шумом
с независимыми и одинаково распределенными отсчетами.
420 Гл. 12. Быстрые алгори'псы поиска по решетке и по дереву
12.2. Повторить приведенный иа рис. 12.7 пример для входной последователь-
ности v = 1000100000100000....
13.3. Алгоритм Витерби может быть запрограммирован в виде, в котором рас-
ходимости путей иа i-й итерации запоминаются в том >ке массиве, что и рас-
ходимости путей иа (i ‒ 1)-й итерации. Выписать последовательность
адресов и вычислений, позволяющих сделать такую программу.
2.4. 2 выживающих в алгоритме Витерби (при q = 2) путей можно записать
в виде 2 Ь-битовых двоичных слов. В типичных случаях Ь = 40 бит. По-
строить (используя такие средства, как указатели и битовые срезы) схему
управления памятью для алгоритма Витерби, которая исключает необхо-
димость считывания на каждой итерации 2~6-битовых слов.
Замечания
Алгоритмы поиска по решетке появились сначала в связи с кодами, контро-
лирующимии ошибки, для которых задачу декодирования сверточиых кодов можно
интерпретировать как задачу поиска по решетке (илн по дереву). Большинстг~
публикаций по данному вопросу выполнено на языке кодов, контролирующих
ошибки. Однако, в настоящее время к этим алгоритмам проявляется более широ-
кий интерес, и в данкой главе сделана попытка их изложения вне зависимости
от какого бы то ни было приложения.
Хотя ретроспективно наиболее подходящим в качестве качала изложения
данного круга вопросов представляется алгоритм Витерби, на самом деле пер-
BbIMH были разработаны последовательные алгоритмы. Последовательные алго-
ритмы были введены Возеикрафтом (1957) и подробно описаны Возенкрафтом
и Рейффеном (1961). Дальнейшее развитие они получили у Фаио (1963), Зигаиги-
рова (1966) и Джелинека (1969). Разработки Джелинека (1968) и Фории (1974),
а также работы Шевилла и Костелло (1978) и Хаккоуиа и Фергюсона (1975)
также продвинули исследование данного вопроса. Наше изложение алгорйтма
Фаио тесно связано с данным Галлагером (1968) изложением этого алгоритма.
Первоначально Витерби (1967) опубликовал свой алгоритм скорее в учебных
целях, чем в качестве серьезного алгоритма. Программные реализации алго-
ритма Витерби с эффективным использованием памяти описаны Рейдером (1981) °
Нижние границы для распределения числа операций получили Джекобсон
и Берлекэмп (1967), а верхние ‒ Севедж (1966).
Приложение А
НАБОР АЛГОРИТМОВ ЦИКЛИЧЕСКИХ
СВЕРТОК
В данном приложении приводится набор алгоритмов цикли-
ческих сверток над полем вещественных чисел для длин и =
= 2, 3, 4, 5, 7, 8 и 9. Алгоритмы имеют вид равенств
s = CGAd.
Матрица 6 является диагональной и ее диагональные элементы
выписываются в виде компонент вектора б = Bg. Матрицы А
и С выписываются полностью. Кроме того, используя обозначения
D=Ad, S=GD, s=Ñ~,
мы пр иводим последовательности сложений, которыми можно
заменить умножения на матрицы А и С.
2-точечная цикл~ческая свертка; 2 вещественных умножения,
4 вещественных сложения
А = [
]
Do=do+ dl
D l dP dl
so=So+5
sl = So ‒ Sl
3-точечная циклическая свертка; 4 вещественных умножения,
] ] вещественных сложений
! о
С = 1 — I †! 2
о
о
о ‒ 3
[
Sl ‒ 53
52 53
5о + ~о
5о‒
5о с- Tl
To =
Tl =
~о =
Sl
S2
lo do+ dl
Do = ~o + d2
Р~ = do ‒ d2
D2=di ‒ А
~3 = dl + ~2
422 Приложение A. Набор алгоритмов циклических сверток
4-точечная вещественная свертка; 5 вещественных умноже-
ний, 15 вещественных сложений
о
о
‒ о
‒ ‒ о
1 ! ‒ 1 -1
! 1 1
— I 1 ‒ 1
О -2 О
2 2 ‒ 2
2 ‒ 2 ‒ 2
I
I
2
‒ 2
2
<o = do + d3
l) =di+d3
В)) = <o + I l
в,=ю,‒ I,
вэ =~о ‒ А
В4 dl Иэ
в =в+в.
5-точечная циклическая свертка; 10 вещественных умножений
31 вещественных сложений
1 О ! О О О ‒ ! О ‒ 1
! ‒ ! ‒ 2 ‒ ! ‒ 1 ‒ 2 О О О
OOOO I I О
О О О ! О 1 ! О
О ! 1 О О О О ‒ 1 ‒ I
А=
go
gl
1
5
О О О-1
О ! О О-1
1 1 О О ‒ 2.
О О ! О ‒ !
о о о
О О 1 1 ‒ 2
О-1 О О
О ! О ‒ ! О
‒ ‒ о
1 ! 1 1 1
~о
G)
G2
~~э
~4
Gc
Ge
G>
~е
Gq
To =
T
т2 ‒‒
T3 =
~)) =
S)
S3 =
S3 =
5 О ‒ 5 5 ‒ 5
О 5 ‒ 5 5 ‒ 5
2 ‒ 2 3 ‒ 2 3
5 5 ‒ 5 5 О
5 5 ‒ 5 О 5
3 -2 3 ‒ 2 ‒ 2
О О ‒ 5 5 О
О 5 ‒ 5 О О
1 — I 4 ‒ 1 ‒ 1
1 ! 1 1 1
S)+ Sl
5 -Sl
S2 54
S3 + S)
Ty + ~2
Т) + Тэ
Ti> ‒ Т~
Tl ‒ ~3
Приложение A. Набор алгоритмов циклических сверток
423
Во = do ‒ d4
Di = di ‒ d4
То= So+S2
Т~ =S)+Sg
Т4 ‒ ‒ .'~5 + S5
Тъ = 34 + S5
Т4 56 + 5н
в =в,
вЗ d2
В4 = d5
D5 = Di
+ D,
‒ d4
~4
+ В4
Т5 =
Sn
S)
Sg
Sy
~4
Ь+~Н
Т<, ‒ Т4+
‒ Т ‒ Т
Т+ Т5+
Т, + T4 +
Ti ‒ T5 +
в,=в ‒ в
В = В, ‒ В4
5»
‒ Т~ ‒ Т5 + S»
5»
S»
S»
Ds = В
D9= do
‒ В5
+ ~! + ~2 + ~3 + ~4
7-точечная циклическая свертка; 16 вещественных умножений~
70 вещественных сложений
А =
о
о о
‒ 4 ‒ ! !
‒ 2 О
‒ о
4
2 о
О О О О О О ] ! !
†! †! ‒ 3 ! ‒ 7 †! О О 0
О О ! ! 4 ] О ‒ ! ‒ !
О О ! ‒ ! 2 О о ‒ ! !
О ] ! ! ! О ‒ ] ‒ ! ‒ !
! О О О О О О !
О О О О О О О ! ‒ !
! ! ! !
†! ‒ 3 †] -7
О р О О
О р О О
О р О О
О ! ! 4
О ! ‒ ! 2
о
! 1
1 ‒ 1
1 2
о о
о о
о о
о о
о о
о о
о
‒ 1 ‒ 1
‒ 1 1
‒ 1 ‒ 2
о о
1 I
о о
о
о
4 о
о
о
о
о
о
о о
о
‒ 1 1
‒ 1 1
‒ 4 1
‒ о
1 1
о о
о о -з
о о
О О ‒ 7
о о
о о
-з
‒ I 1 ‒ 1
2 4 ‒ 7
о
о о о
о
‒ 1 1 О
о
О 1 О
1 1
]
‒ !!
go
g)
g2
!О
!О
‒ 2
‒ !
‒ 2
g4
3
‒ !]
‒ !
‒ !
!О
g5
Яб
‒ !
2
‒ !
!2
‒ 2
!
-2
1
-9
‒ !
!
-2
!
‒ !
2
!
2Ge
14G)
бО2
б~) э
G4
G5
!4G6
6С,
6Gå
G9
2Ge
14G»
бО)2
б~)э
~)4
7G»
2
‒ 4
О
О
!
‒ !
!О
‒ 2
‒ !
3
0
-2
0
0
!
!
-2
3
3
0
‒ !
‒ 2
3
3
0
‒ !
‒ 2
S
3
0
‒ !
!
3 ‒ 2
‒ !! 3
‒ 3
! О
‒ 2 †!
2 !
‒ 4 ‒ ll
О ‒ !
0 !
] ‒ 2
2 О
‒ 2 ‒ 2
О О
0 0
0 О
] !
2
‒ 2
3
3
О
‒ !
О
‒ 2
О
О
0
!
(о = А
() — d2
(2 ~4
~6
~6
~б
~о + ~э)о
$) + S))
S2 + S)2
S3+ S))
4+ Э)4
S5 ‒ S Io
S6 S l l
то =
Т) =
Ti =
Тэ =
т=
Ts
Тб ‒‒
Ty =
~)э = ~а
D)4 ~9
D l5 = D) I
S)
S4
(3 = А - ~б
l4 = lO + ()
(5 = ‒ (Р+ ()
(б (2 + (э
~4+А
~о ~0 ~б
~~1 = ~~4 + (4
D2 = DO + (5
~3 D) + (4 + (4 + (5
D4= ()
aS = 03 ‒ dá
~6 В + (6
D5 + (7
~8 = D6+ (б + (6+ (1
~9 (3
D)o D5 Do
~~'~ ) 1 ~б D I
~)2=%- D2
‒ ~э
‒ D4
+ 2ф2 + d) + do)
т,
Т9
TIo
Т»
т)2
T13
Т)4
Т„
TI6
Т)а
Tl8
т,
т
Т2)
Т22
+ ~б
~)2
S8 ~)э
S9 ‒ S)4
TI + T3
Т)о + Т2
То + T)l
Tlo + T3
Т)3 ‒ Т2
(Т)э + T3 +
Т)2 T)3
Тб + Тв
т)э + Tv
Т5 + Т)в
T»+ Тв
т ‒ т
(Т20+ Тв +
TI9 Тэо
Т)2 + ЯI5
Т)б + Т2э +
Т22 + S)5
Т2) + S)5
Т9 + S»
Т)5 + S„
T„+ S»
Тэ + Т4) + Т2
(Т)э + T3 + Тэ + Т4)
Т,+Т9)+ 7;
‒ (т2о + т, + т, + Т9)
Приложение А.
Наоор алгоритмов щикличес~сих сверток
8-точечная циклическая свертка; 14 вещественных умножений,
46 вещественных сложений
о о
О 1 О
o o
О О О
о
О ! О
1 1 1
‒ 1 !
О l О
о
1 -1 1
О О 1
‒ о
1 ‒ 1
О О
О О
‒ о
о
‒ о
о
о о
О О
о
‒ о
‒ 1 1
О О
‒ ]
О 1 ‒ 1 О 1
о о о
О О-1
О 1 О
о о
о о о
о о
О-1 О
‒ 1 О О
о
I
О 1 О
‒ о
1 ‒ 1
‒ 1 -1
О ‒ 1 ! О
о
-1 1 ‒ 1
О ‒ 1 О ‒ 1
‒ о
-1 -!
‒ ]
‒ 1 ‒ 1
‒ 1 1
‒ 1
-1 -1 1
go
gi
gz
gs
g4
gs
ge
2~о
2GI
2G
2~~ э
4G4
40э
SG6
SG~
2ов
2~9
2G lo
2G(r
2Сц
2Gi3
‒ 1
1
1
‒ 1
]
1
1
1
1
!
!
‒ !
!
О -1 О
о о
О О О
о о
О ! О
о
1 О О
‒ о о
о
О ‒ 1 О
‒ ‒ 1 1
‒ о о
о
‒ 1 1
‒ О ‒ 1
О 1 О
О О 1
О-1 О
О ‒ 1
О 1 О
о о
О ‒ 1 О
1 1
1 1
1 1»‒
1 1
! ‒ 1
! 1
‒ 1 1
0 О
! О
О О
0
О ]
О ‒ !
1 1 1
о
1 1 1
‒ о
1 1 ‒ 1
о
1 1 ‒ 1
! ‒ 1 О
1 1 1
1 1 -1
1 ‒ 1 ‒ 1
1 ‒ 1 -1
1 ‒ ] 1
1 1 1
1 1
1 ! ‒ 1
! ‒ 1 О
Π†] †]
О ‒ 1 О
О ‒ ! О
О 1 О
О ] О
‒ 1 ‒ 1
1
] ‒ !
О !
0 О
О О
‒ ! О
‒ 1 О
‒ 1 0
426 Приложеиие А. Набор
алгоритмов циклических сверток
~0 + ~4
= d) + d3
=*А+ de
‒ ~Э +
fo
I)
Юг
вэ
fP t ~2
l4
+ ~Э
- d4
= do
Оо
‒ дэ
d6
d)
О
d2
= ~э
Ог
Оэ
О
= fo ‒ ~г
Оэ
= ~в ‒ ~э
De
~б + f5
D7
D8
О9
DIo
D«
D)2
О)3
~4 f5
= D) + D3
= Do + Ог
= О ‒ Ds
)
= D2 ‒ Оэ
= D0 ‒ D)
= О. + D7
$6 =
I
S7
9-точечная циклическая свертка; 19 вещественных умноже-
ний, 74 вещественных сложений
1 1 1 1
о
о о о
1 ‒ 1 ‒ 1 ‒ 1
о
о о о
1 ‒ 1 1 ‒ 1
О 1 О О
О ‒ 1 О О
о о о о
о о о
о о
о о о
о
О ‒ 1 О
‒ ‒ о
‒ о
‒ о
‒ 2 1 1 -2
1 1 1
‒ ‒ 1 ‒ 1
‒ 1 ‒ 1 ‒ 1
о о о
‒ 1 1 ‒ 1
‒ 1 1 ‒ 1
о о о
о о
о о о
о о
о о
о о о
о о
о
о
‒ о
о
о
‒ 2
1 1
о о
1 1
1 1
о о
1 ‒ 1
1 ‒ 1
о о
о
о
о о
о о
о о
о
1 ‒ 1
о
о
о
] 1
Т0 =
т
Тг =
тэ =
Тб
Тэ =
Ть
Т7 =
Т6 =
Т9
Т)0 =
Т)) =
Т)2 =
твэ =
Т)4
т =
Т)ь =
т, =
S0
S)
~2
S3 =
S4
Хэ =
s8+ ЗИ
s9 S lO
73 + 7)В
S)) ‒ S2
S) + S)2
S0 ‒ SI2
~)Э ‒ -')Э
~)вэ + S4
~7 + ~6
S6 ‒ S7
т ‒ т
Т6 + ТВ
Т, + Тэ
Т7 + Т9
T0 + Тб
‒ Ть + Т6
T) + Т.
‒ Т7 + Т9
Т)0 + Т))
Т)2 + Т)3
TI4 + Т)3
т,. + Т»
‒ Т)0 + Т))
‒ Т) + Т)3
‒ Т)4 + Т)3
‒ Т)6 + T)7
427
циклических сверток
0
1 0 ‒ !
‒ 1 ‒ ! 2
0 ! ‒ !
! 0 ‒ 1
‒ 1 ‒ ! 2
0 1 ‒ 1
! 0 ‒ !
†! ‒ 1 2
0 1 ‒ 1
1 0 !
0 1 ‒ 1
0 ‒ 1 1
О
0
0
0 0
0 ‒ 1
0 0
0 0
‒ 1 0
0 0
0 0
1 1
0 0
1 0 1
0 1 ‒ ]
0 1 ‒ ]
0 1 ‒ ]
‒ 1 ‒ 1 0
‒ 1 ‒ 1 0
‒ 1 ‒ 1 0
‒ 1 1
0 0
0 0
0 ‒ !
0 0
0 0
1 0
0 0
0 0
0 ! 1
1 ‒ ] 0
‒ ! 0 ‒ 1
1 †‒ 1
1 ‒ 1 0
‒ 1 0 ‒ 1
‒ 1 0
1 0
‒ 1
0
0 0 '1
0 ‒ ! 0 ‒ 1
0 0 1
‒ 1 0
0 1
1 0 !
1 0 !
0 ‒ 1
! !
) !
О
2 !
! !
-2
2 ‒ !
2 ‒ !
‒ 2
]
0
!
1
-2
1
‒ !
2
4
! !
go
gt
gz
фэ
ф6
gs
g6
Я9
gs
! 0
‒ 2 ‒ !
‒ ! ‒ 1
! -2
‒ 2 !
†! †]
†! †!
‒ 2 ‒ !
1 !
-2
!
‒ !
‒ 2 ]
‒ ! 2
‒ 2
‒ 4
1 !
2 ‒ 1
‒ ! 2
! 4
2 2
0 ‒ !
0 ‒ !
0 0
0 ‒ 1
1 ‒ 1
1 ‒ 2
! ‒ 2
†! ‒ 4
0 1
2
‒ 1
0 ‒ 1
0 ‒ 1
1 ‒ 1
! ‒ 2
Приложение
А. Набор алгоритмов
9Ср
бО1
бСэ
бСэ
бО4
бОэ
бС6
ЗС7
ЗСв
ЗС9
ЗС)о
ЗС,
ЗС~э
ЗСц
ЗС~6
ЗС~5
ЗС~6
3G~~
ЗС~в
2
2
!
‒ ]
0
‒ !
‒ 1
1
0
1
‒ 1 †!
†! -4
-2 -2
‒ ! 2
0 0
0 !
0 !
0 ‒ !
/
1 ‒ !
1 -2
428 Приложение
A. Набор алгоритмов циклических сверток
Т.
to
Т1
Тг
1
Т3
t2
Т4
Т
Т,
Ту
te
Т,
Т„
Т„
D)
Т!г
t)0 + t4
Рг
Т13
t9+ 6
Рг ‒ D)
1)0 ~4
Р3
Т)4
D4
Т
Ds
Т,.
t9 ‒ tg
Рэ Р4
l3
Рб
Т17
Ру
Т)в =
Р8
Т,
~0 ‒ ~3
~0
Р9
Р)о
ts
~2 ~5
Р)г
S2
D)3
D!4
Dis
Ss
Р!б
~б ~8
Sá
Р)у
Sy
Di8
~0 ~б
А ‒ А
А ‒ ~в
~3 ~б
d4 ‒ d7
А ‒ ~в
~0 + ~3 + ~б
д1 + d4 + d7
d2 + А + ~В
i0+ tг
73+ 4
76 + 17 + 18
t2
Р1) + ~0 ~4
Dg + ts ‒ t1
D!4 + Р~)3
~У ~8
D)6 + D)7
S) + S2
S4 + Ss
'))4 + S)s
T0 + Т1
5) + 53
S4 + Sá
~~)3 + S)s
Тз + S7
Т4 + Тц
') )0 ‒ Тб
S8 + Тг + Ту
T8 + S)i + Т9
Т4 ‒ Т; + Тг
Ту + Тв + Sy + Тб
Тз + 312 + Т9 + Тг
Т0 ‒ T). + Тб
"~16 ~ )В
~)у ‒ S)8
SO + Т16
SQ Т)6 ‒ Т)у
So + Т)у
Т13 ‒ Т10 + Ти
Т)4 Т11 + TI9
Т)5 Т)г + Тщ
‒ Тз + Т)в
Т)4 + Т)9
- T)s + Тг
Т„+ Т)в
Т1~ + Т!9
Т!2 + Тго
Приложение Б
НАБОР МАЛЫХ БПФ-АЛГОРИТМОВ
ВИНОГРАДА
Ниже приводятся малые БПФ-алгоритмы Винограда для
длин и = 2, 3, 4, 5, 7, 8,9 и 16. Алгоритмы записываются в виде
матричного равенства
V = CBAv.
Матрица В является диагональной и выписываются только ее
диагональные элементы. Матрицы А и С выписываются полностью-
Кроме того, в обозначениях
a=Av, Ь= Ва, Ч =Cb
выписываются последовательности сложений, которыми можно
заменить умножения на матрицы А и В. Тривиальные сложения
(сложения чисто вещественных или чисто мнимых чисел) отме-
чены звездочкой, но включены в полное число сложений. Они
перестают быть тривиальными, если входные данные являются
комплексными. Во всех алгоритмах мнимая единица j из диаго-
пальной матрицы передвинута в матрицу постсложений С.
2-точечное преобразование Фурье; О (2) вещественных. умно-
жений, 2 вещественных сложения
с [ia
А =
Vo= ~о
VÄ = P))
В.=1
В,=!
~о= uo+»
Ю) ‒‒ uo ‒ u)
3-точечное преобразование Фурье; 2 (3) вещественных умно-
жения, 6 вещественных сложений
О О
1 ‒ /
1
1 !
1 !
! ‒ !
А =
Vo Oo
7~ ‒ ‒ Ьо + Ь)
V) = То ‒ jb2 '
V2= T~+ /Ьг
в- газ
а u)+ )2
0) = U) Ug
~o ub +
Во=1
B) = cos8 ‒ !
B2= зшд
430 Приложение Б. Набор малых БПФ-алгоритмов Винограда
4-точечное преобразование Фурье; О (4) вещественных умно-
жений, 8 вещественных сложений
1 1 1
! ‒ 1 1
1 О ‒ 1
О 1 О,
1 О О О
О О ! ‒./
О 1 О О
О О 1 /
В.=1
В,=1
В2= 1
~3
vo — = ьо
v, = ь ‒ ~ь
V2- bl
~3 Ь2+Ф3
5-точечное преобразование Фурье; 5 (6) вещественных умно-
жений, 17 вещественных сложений
1 ! 1 1 1
О 1 1 ! !
О 1 ‒ 1 ‒ 1
О 1 ‒ 1 1
О О ‒ 1 1 О
О 1 О P ‒ 1
1 О О О О О
1 ! ‒./ / О
‒ о -/
! ! ‒ ! / О
‒ о
А =
0 = 2~г/5
+ ь1
‒ b4
+ b$
+ b2
‒ Ь2
-~т,
‒ jт2
+jT„
+ .}Тг
4') Тривиальные сложения
422 =
423 =
~0
I)
ap =
a> ‒‒
to= Й+ И
t l ~22 + ~3
а4 ‒ и3 v2
а5 ° ~3
а~ = tp+ t>
аг = ~о ‒ ti
а3 а» + а5
ао = ц + а~
uo ‒ И
И~ и3
up+ ~И
u~+ и3
<p + t>
Io ‒ 4
В0
в,=
В2 =
~3
B4 =
В~ ‒‒
1
icos 0 + cos 20) ‒ )
2(cos 0 ‒ cos 20)
яп 0
яп 0+ sin 20
яп 20 ‒ яп 0
Vo= Ьо
т. = ь,
т,=ь,
Т2 b3
Т3 = Тд
Т» = Tp
Vl= Т3
v,=т4
V3 Т3
‒ Т4
Приложение 5. Набор малых БПФ-алгоритмов Винограда
431
7-точечное преобразование Фурье; 8 (9) вещественных умно-
жений, 36 вещественных сложений
! 1 1
о
О ! О
о о
о
о
О ! О
о о
о
1 1
1 1
о
‒ 1 ‒ 1
‒ о
1 ‒ 1
‒ 1 ‒ 1
1
о
!
‒ !
I
о
о
о о
о о о
‒ о
о
о
о
о
о
о о
о
‒ 1 ‒ 1
1
1 ‒ 1
‒ ! /
о
о о
1 !
1 ‒ 1
о
о
! ‒ 1
1 1
д=
В0
в,=
B2 =
Вэ
B4 =
в =
B6 =
В7 =
вв =
27г/7
1
3 (сов д + cos 28 + cos 38)‒
э (2 cos д ‒ cos 28 ‒ cos 38)
э (cos д ‒ 2 cos 28 + cos 38)
3 (cos д + cos 28 ‒ 2 cos 38)
э'(ял д + sin 28 ‒ sin 38)
3(2ял д ‒ sin 28 + ял Зд)
э (яп д ‒ 2 sin 28 ‒ ял 38)
3 (ял д + sin 28 + 2 ял 38)
77 J 7Ip
т, ‒ 17„
76 + 1? ~~
Тв ‒ jTII
79 + )Ти
77 + )Тю
~ Тривиальные сложения
tp = Ui + U6
ti = Ui ‒ иб
17 = иЭ + иЭ
13 = и2 ‒ иэ
14 = иб + иэ
13 = Рб Рэ
16 12 + tp
a4 = tz ‒ tp
аг = 1о ‒ 14
аэ = 14 ‒ 13
17 = 15 + 13
а7 15 13
аб ‒ ‒ 1~ ‒ 13
ав = 1э ‒ ti
ai = 16 + 14
аз=17+ ti
ао ио+
т. =
т=
1 Тэ=
73
74
Тъ
76
Т7 =
76 =
Т, =
т,. =
т„=
Т~~ =
Vp =
V, =
V2 =
V3 =
V4 =
v,=
V6
Ь+Ь,
Ь +Ьэ
Ь. ‒ Ьэ
-Ь ‒ Ьб
Ьб + Ь7
ь ‒ ь
-b8 ‒ b6
7о+ Т
То + 72
7о + 73
Т4+ Ьэ
Тэ + Ьэ
Тб+ Ьэ
Ьо
432 Приложение Б. Набор малых БПФ-алгоритмов Винограда
8-точечное преобразование Фурье; 2 (8) вещественных умно-
жений, 26 вещественных сложений
1 1 1 1 1
1 ‒ 1 1 ‒ 1 1
1 0 ‒ 1 0 1
1 0 0 0 ‒ 1
0 1 0 ‒ 1 0
0 1 0 ‒ 1 0
0 0 1 0 0
0 1 0 1 0
1 1
1 ‒ 1
‒ 1 0
0 0
0 1
0 ‒ 1
‒ 1 0
0 ‒ 1
0 0 0 0 0
о
о о-~ о о
о
о о о о о
о
о о ~ о о
о
0
о о
о о
о о
о
о о
о о
о о
д = 27т/8
)0~ и0+ иб
ВО=1
В,=1
В2 )
Вэ-1
Вб ‒ ‒ СОа д
В5
Вб
В7 = ЮП6
б25 =
и0 ‒ иб
‒ уь ®
+ jb5
+ ьб
Ь4
+ Ьэ
‒ Ь7
t) ~ и) 4 иэ
)2 ~ U) ‒ U5
Уэ= и2+ иб
и2 иб
f~ иэ + и7
f5 иэ
‒ JT2
+ JT2
‒ /Тч
+ )Тэ
f0+ ~э
)О ‒ ~Э
)22
f)+fg
)) )4
~5
б2б ю
и7
б20 m
O)
)2 ‒ 4
)2 + )5
fá + ° 7
)б f7
~ Тривиальные сложения.
о
о
1
о
о
о
1
о
0
0
‒ 1
1
0
‒ 1
V0~ Ьо
v.- ь)
V2 Ь2
4= Ь2
Т.= Ьэ
Т) =Ьэ
Т2 Ьб
Тэ Ьб
V) T0
V5- Т0
~7 Т)
V2 Т)
Приложение Б. Набор малых БПФ-алгоритмов Винограда
9-точечное преобразование Фурье; 10 (11) вещественных умно-
жений, 44 вещественных сложения
1
0
1
‒ 1
1
1 1 1
1 0 0 1
0 1 1 0
0 0 0 0
0 ‒ 1 ‒ 1 0
0 1 1 0
0 2 0 0
0 1 ‒ 1 0
0 0 0 0
0 ‒ 1 1 0
0 ‒ 1 1 0
0
0
0
о о
о
J
о о
о
о
‒ о
о
о
о
о
о
J J
‒ о
о о
о
о
J J
./
о о
о
‒ J ‒ J
о
о
J
l
о
о
То
= -ь,
2Ы9
1
3
г
1
г
> (2 cos д ‒ соз 26 ‒ соа 46)
э (сов д + cos 26 ‒ 2 cos 46)
э (cos д ‒ 2 cos 26 + cos 46)
яп 36
в1п 36
‒ ип6
‒ sin 46
‒ sin 26
fo и1 4
ti ‒‒
ai
Фг =
иг 4
иэ 4
и4 4
az=fo4
f3 =
fe =
и1‒
ивЂ
fe= иэ‒
~6=4+
ai = fo‒
Tio ~ Ьч‒
т„ь‒
Тэг= b>+
Vo= Ьо
Vi= T7+
~г = То
ag =
ae =
~9 ~4 ~7
ио + ai + ~г
‒ ay ay
ae + ae
~о =
а3
~ю =
Рэ
Т6 +
То 4
т‒
Te‒
Те 4
Тт‒
V,
Vd
Ve
~) Тривиальные сложеиия.
1 !
0 0
0 1
0 1
0 0
0 0
0 0
0 0
0 ‒ 1
0 0
0 1
ио д
и7 Во
иь В~
иэ Вг
fi 41г Вз
и, В~
иг Вэ
ио ~е
иэ Вг
fi+ av Be
~1 В9
~г Вю
fy
о о
1 1
о
о о
1 ‒ 1
1 ‒ 1
о о
о
1 1
о о
о
‒ 1
о о
о
о
о о
‒ 1
о
1
0
1
1
1
0
1
0
1
1
0
тэ
тг
Тэ
Те
Т5
То
Тэ
То
То
1
0
1
1
0
1
0
0
1
0
‒ 1
= Ьэ‒
= -Ьо
= Ьо‒
= bo+
Т4‒
Tq 4
Т5
a Ti+
То
‒ Ь~
be
‒ Ьо
Ью
b,+b
ь~
ь
то
т,
Т1 + Тэ
Тг
Т3
т,+т,
j Tio
~т„
JJbe
/TI2
JTiz
JJbe
j Tii
JTio
Винограда
БПФ-алгоритмов
434 П
Б.
Набор
малых
! 1-
О-1
О-1
о
о
о-!
о
О-1
О-1
О О
О-1
О ‒ 1
о о
О-1
о о
О-1
О ‒ 1
о-
О-1
о
о
о-
о о
о-!
О О
О-1
1 О‒
о
О-1
о-
О‒
о
о-
о
о
о
о
О ‒ 1
О-1
о о
о
О-1
о о
О-1
О 1
О-1
О-1
о
О-1
О ‒ 1 О
О ‒ 1
О О
О ‒ 1
О‒
О-1
О О-1 О
О-! О-1
О-1
о-
о-
о-
о
о о
О ‒ 1
О-1
о о
О‒
о о
о
о о
1-1
о
./
о
./
о
./
о
о-/
О О
0-/
о о
О ‒ 1
J
О
о
О ‒ 1
О
./
О
J
О
J
О
О О
О ‒ /
/ О
О
./
О
О О
Π†/
О О
/ О
О О
О ‒ /
О О О О
О-!†!
О ‒ 1 О О
о
оооо
‒ ‒ о
О О
1 ‒ 1
О
J
О О
О ‒ /
0 ‒ 1
о-/
О О
1 О
о-/
О ./
О О
0-1-1
О О О
О
О
J ‒ i
О О
О /
о-/-/
О ‒ 1
О ‒ 1
О ~ О-/ О О О О
О О ‒ / О ‒./ ‒./ ‒./ 0
О О
1 ‒ 1
16-точечная циклическая свертка;
жений, 74 вещественных сложений
о
о
о
О
О
о
О
О
1
о
О
О
О
О
О
О
10 (18) вещественных умно-
Кабор малых БПФ-алгоритмов Винограда
Приложенне Б.
В = 2гг/16
to =
ИО + ив
Во
В) ‒‒
Вг =
Вз =
В4
Вз =
Вв =
Вг =
Be =
ВР =
1
1
1
1
1
со 2В
сов 2В
cos ЗВ
сов В + соз ЗВ
‒ сов В + cos ЗВ
И4 1 и 12
t2 =
из + и))з
uz ‒ »o
t4 =
ив + И!4
и6 и)4
° 6
и) + ир
и) ‒ ир
Из + ull
te =
из ‒ ип
tIO =
us+ и»
B)o= 1
в
B)2= 1
t)) =
из ‒ и)э
1)2
и) + uls
и) ‒ ин
‒ sin 2В
‒ sin 2В
‒ яп ЗВ
-sine+ s)n3e
‒ sin В ‒ sin ЗВ
В)з =
a„=
В)э =
В)6 =
В)з =
tO + t)
t2 + t4
t)s =
)!б
~ 14 + ~ )Э
te + )10
tn =
‒ t>n
te + )!2
te ‒ t)2
t2) =
)Р + t)9
t2 + t)s
а)6 =
Ь ‒ Г)э
ав =
З)) + ~9
а)з
t1) )9
а9
t)6 + )2!
! )б зг)
а)
t) ° ‒ t)S
O2 =
4Е ‒ )!
т, ‒ ~Тэ
Тю ‒ ./Т)в
ь ‒ ~ь
Тц + /Т)9
~ю
v»,
V12
~)З
ио ‒ ив
tre ‒ )20
~э ‒ ts
аг ue + u9
аю = t)9 ‒ t)9
ап = t4 ‒ l2
а)2 = и)г ‒ ив
а)э = t)e + t20
а)4 = )З + )Э
а)э а16 + а17
1~)4
V)s
Тв ‒ ./Тг
Te J T16
) Трнвиальные сложения.
Т,
Т!
Тг
Тз
Т4
Тз
Т6
Тз
Тв
Тр
Т!О
T))
T)2
Т)э
Т)4
Т)э
Т)6
Т»
Т)В
Tl9
v„
v„
~2
е'з
V,
Vs
V6
Vg
<в
~9
bs + b,
b,‒ — Ь,
+ Ь!э
b» ‒ Ь!1
b4 + b6
b4 ‒ b6
b, ‒ b,
b9 ‒ Ьз
T4 + Тв
Т4 ‒ Тв
Ts + Тз
Тз ‒ Тз
b12 + ~14
ь ‒ ь
b)s f b)6
Ь)s b)l
Т)2 + Т„
Т12 Т)4
Т» + Т„
Т» ‒ Т)э
b.
Тв + /Т)б
ТО + JT2
Т„- jTe
Ьг +./Ью
Т)0 + /Т)в
Т,+/Т,
Т, ‒ ~Т„
b,
ТР + /Т)1
ЛИТЕРАТУРА
Монографии
[1] Nussbaumer, Н. J., Fast Fourier Transform and Convolution Algorithms,
2nd ed., Springer-Verlag, BeFlin, 1982. [Имеется перевод: Нуссбаумер Г.
Быстрое преобразованне фурье и алгоритмы вычисления свертки. ‒ М.:
Радио и связь, 1985.]
[2] Kronsjo L. I., Algorithms: Their Complexity and Efficiency, John Wiley,
New York, 1979.
[3] Aho, А. V., J. E. Hopcroft, and J. D. Ullman, The Design and Analysis of
Computer Algorithms, Addison-Wesley, Reading, Mass., 1974. [Имеетсй
перевод: Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычис-
лительных алгоритмов. ‒ М.: Мяр, 1979. ]
[4] Elliott, D. F., and R. Rao, Fast Transforms: Algorithms, Analyses, and
Applications, Academic Press, New York, 1983.
Сборники статей
McC1ellan, J. Н., and С. М. Rader, Number Theory in Digital Signal Pro-
cessing, Prentice-Ha11, Englewood Cliffs, N. J., 1979. [Именя перевод:
Макклеллан Дж. Х., Редер Ч. М. Применение теорни чисел в цифровой
обработке снгналов. ‒ М.: Радио и связь 1983.]
Глава 3
[1] Cooley, J. W., P. А. W. Lewis, and P. D. Welch, Historical Notes on the
Fourier Transform, IEEE Trans. Audio Electroacoust. AU ‒ 15 (1967): 76‒
79.
[2] Oppenheim, А. V. and R. W. Shafer, Digital Signal Processing, Prentice-
Hall, Englewood Cliffs, N. J °, 1975.
[3] Rabiner, L. R., and В. Gold, Theory and Application of Digital Signal Pro-
cessing, Prentice-Hall, Englewood Cliffs, 1975. [Имеется перевод; Pà-
бинер Л. P., Гоулд Б. Теория и применение цифровой обработки сигна-
лов. ‒ М. Мир., 1978.]
[4] Winograd S., А New Algorithm for Inner Product, IEEE Trans. Comp. С-17
(1968): 693 ‒ 694.
[5] Cooley, J. W., and J. W. Tukey, An Algorithm for the Machine Computation
of Complex Fourier Series, МаЖ Comp. 19 (1965): 297 ‒ 301.
[6] $tockham, Т. G., High Speed Convolution and Correlation, Spring Joint
Comput. Conf., AFIPS Conf. Proc. 28 (1966): 229 ‒ 233.
[7] Good, I ° J., The Interaction Algorithm and Practical Fourier Analysis,
J. Яоуа1 Statist. Soc., Ser. В 20 (1958); 361 ‒ 375; addendum, 22 (1960):
372 ‒ 375.
[8] Thomas, L. H., Using à Computer to Solve Problems in Physics, 1п Appli-
cations of Digital Computers, Ginn an/ Co., Boston, Mass., 1963.
[9] Winograd, $., On Computing the Discrete Fourier Transform, Proc. Nat
Acad. Sci. USA, 73 (1976): 1005 ‒ 1006.
[10] Winograd, $., On Co~puting the Discrete Fourier Transform, Math. Comp.,
32 (1978): 175 ‒ 199. [Имеется перевод: см. сб. статей [1], с. 117 русск.
изд.]
[1! ] ВиИег, J., and R. Lowe, Beam forming Matrix Simplifies Design of Electro-
п1са11у $canned Antennas, Electronic Design 9 (1961): 170 ‒ 173.
[12] Agarwal, R. С., and J. W. Cooley, New Algorithms for Digital Convolution,
IEEE Trans. Acoust., Speech, Signal Proc. ASSP-25 (1977): 392 ‒ 410.
[Имеется перевод: см. сб. статей [1], с. 91 русск. изд.]
Литература
[13] Levinson, N., The Wiener КМ$ Error Criteria in Filter Design апд Ргей-
ction, Л. Math. Phys. 25 (1947): 261 ‒ 278.
Глава 2
[1] ВИйоН, G., and S. MacLane, А Survey of Modern Algebra, Macmillan, New
York, 1941; rev. ed., 1953.
[2] Van der Waerden, В. L., Modern Algebra, 2 vols. trans. by F. Blum and
T. J. Вепас, Frederic Ungar Publishing Co., New York, 1949, 1953. [Имеется
перевод нем. изд. 1967 г.: Ван дер Варден Б. Л. Алгебра. ‒ М.: Наука,
1976; 2-е изд. 1979.]
[3] Thrall, R. М. and L. Tornheim, Vector Spaces and Matrices, John Wiley,
New York, 1957.
[4] Fraleigh, J. В., А First Course in Abstract Algebra, 2nd. ed. Addison-Wes-
ley, Reading, Mass. 1976.
[5] Strang, G., Linear Algebra and Its Applications, 2nd ed., Academic Press,
New York, 1980. [Имеется перевод изд. 1976 г.: Стренг Г. Линейная алгебра
и ее применения. ‒ M. Мир, 1980.]
[6] Baumslag, В. and В. СЬапйег, Theory and Problems of Group Theory,
Schaum's Outline Series, McGraw-Hill, New York, 1968.
[7] Pollard, J. М., The Fast Fourier Transform in à Finite Field, Math. Comp. 25
(1971): 365 ‒ 374. [Имеется перевод: см. сб. статей [1], с. 147 русск. изд.]
Глава 3
[1] Agarwal, R. С., and J. W. Cooley, New Algorithms for Digital Convolution,
IEEE Trans. Ас иМ., Speech, Signal Proc. ASSP ‒ 25 (1977): 392 ‒ 410.
[Имеется перевод: см. сб. статей [1], с. 91 русск. изд. ]
[2] Winograd . °, On Computing the Discrete Fourier Transform, Math. Comp. 32
(1978): 175 ‒ 199. [Имеется перевод: см. сб. статей [1), с. 117 русск. изд.]
[3] Winograd, S., Some Bilinear Forms Whose Multiplicative Complexity De-
pends on the Feild of Constants, Math. Syst. Theor. 10 (1977): 169 ‒ 80.
[Имеется перевод: сМ. сб статей [1), с. 225 русск. изд.)
[4) Winograd S., Arithmentic Complexity of Computations, CBMS-NSF Regional
Conf. Series Appl. Math., Siam Publications 33, 1980.
Глава 4
[1) Cooley, J. W. and J. W. Tukey, An Algorithm for the Machine Computa-
tion of Complex Fourier Series, Math. Comp. 19 (1965): 297 ‒ 301.
[2) Singleton, Р. С., An Algorithm for Computing the Mixel Radix Fast Fourier
Transform, IEEE Trans. Audio Electroacoust. AU-17 (1969): 93 ‒ 103.
[3) Good, I. J., The Interaction Algorithm and Practical Fourier Analysis, J. Royal
Statist. Soc., Ser. В 20 (1958): 36 ‒ 375; addendum, 22 (1960): 372 ‒ 375.
[4) Thomas, L. Н., Using à Computer to Solve Problems in Physics, Applica-
tions of Digital Computers, Ginn and Со., Boston, Mass. 1963.
[5) Good, I. J., The Relationship between Two Fast Fourier Transform, IEEE
Trans. Comp. С-20 (1971): 310 ‒ 317. [Имеется перевод: см. сб. статей
[1), с. 136 русск. изд.)
[6) Rader, C. М., and N. М. Brenner, А New Principle for Fast Fourier Trans-
format ion, I EEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 24 (1976):
264 ‒ 265.
[7] Preuss, R. D., Very Fast Computation of the Райх-2 Discrete Fourier Trans-
form, IEEE Trans. Aucoust., Speech, Signal Proc. ASSP-30 (1982): 595 ‒ 607.
[8) Rader, С. М., Discrete Fourier Transforms When the Number of Data Samples
Is Prime, Proc. IEEE 56 (1968): 1107 ‒ !108. [Имеется перевод: см. сб. ста-
тей [1), с. 89 русск. Озд.)
[9) Bluestein, L. I., А. Linear Filtering Approach to the Computation of the
Discrete Fourier Transform, IEEE Trans. Audio Electroacoust. AU-18 (!970):
451 ‒ 455.
438 Литература
[1О) Winograd, S., On Computing the Discrete Fourier Transform, Math. Comp.
32 (1978): 175 ‒ 199.
[11) Winograd S., On Computing The Discrete Fourier Transform, Math Comp.
32 (1978): 175 ‒ 199. [Имеется перевод: см. сб. статей [1), с. 117 русск.
изд. )
[12) Johnson, Н. W., and C. S. Burrus, Large DFT Modules: 11, 13, 17, 19 and
25, Tech. Rep. 8105, Dep. Elec. Eng., Rice University, Houston, Texas,
1981.
[13) Goertzel, G., An Algorithm for the Evaldation of Finite Trigonometric
Series, Amer. Math. Monthly 65 (1968): 34 ‒ 35.
[14) Sarwate, D. V., Semi-Fast Fourier Transforms Over GF (2~), IEEE Trans.
Comp. С-27 (1978): 283 ‒ 284.
Глава 5
[1) Ore, О., Number Theory and its History, McGraw-Hill, New York, 1948.
[2) Hardy, G. Н., and Е. М. Wright, The Theory of Numbers, Oxford University
Press, Oxford, Engl and, 1960.
[3) Birkhoff, G., and S. MacLane, А Survey of Modern Algebra, Macmillan,
New York, 1941; rev. ed., 1953.
[4) Van der Waerdefl, В. L., Modern Algebra, 2 vols. transl. by F. Blum and
Т. J. Benac, Frederic Ungar Publishing Co., New York, 1949, 1953. [Имеется
перевод: см. гл. II [2). )
[5) Berlecamp, Е. R., Algebraic Coding Theory, McGraw-Hill, New York,
1968. [Имеется перевод: Верлекэмп Э. Алгебраическая теория кодирова-
ния. ‒ М.: Мир, 1971.)
[6) McClellan, J. Н., and С. М. Rader, Number Theory in Digital Signal Pro-
cessing, Prentice-Hall, Englewood Cliffs, N. J., 1979. [Имеется перевод:
см. сб. статей [1).)
Глава 6
[1) Rader, С. М., Discrete Convolution via Mersenne Transforms, IEEE Trans.
Comp. С ‒ 21 (1972): 1269 ‒ 1273.
[2) Agarwal, R. С., and С. S. Burrus, Fast Digital Convolution Using Fermat
Transforms, Soutwest IEEE Conf. Rec. Houston (1973); 538 ‒ 543.
[3) Agarwal, R. С., and С. S. Вигтцз, Fast Convolution Using Fermat Number
Transforms with Applications to Digital Filtering, IEEE Trans. Acoust.,
Speech, Signal Proc. ASSP 22 (1974): 87 ‒ 97. [Имеется перевод: см. сб.
статей [1), с. 156 русск. иэд.)
[4) Agarwal, К. С., and С. S. Burrus, Number Theoretic Transforms to Imple-
ment Fast Digital Convolution, Proc. IEEE 63 (1975): 550 ‒ 560.
[5) МсС1е11ап, J. Н., Hardware Realization of à Fermat Number Transform,
IEEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 24 (1976): 216 ‒ 225.
[6) Leibowitz, L. М., А. Simplified Binary Arithmetic for the Fermat Number
Transform, IEEE Trans. A@oust., Speech, Signal Proc. ASSSP ‒ 24 (1976):
356 ‒ 359. [Имеется перевод: см. сб. статей [1), с. 202 русск. изд.)
[7) Reed, I. S., and Т. К. Truong, The Use of Finite Fields to Compute Con-
volutions, IEEE Trans. Inf. Theor. IT ‒ 21 (1975): 208 ‒ 213. 1Имеется пере-
вод: см. сб. статей [1), с. 207 рус. изд.1.
[8) Nussbaumer, Н. J., Digital Filtering Using Complex Mersenne Transforms,
IBM Journal Кез. Devel. 20 (1976): 498 ‒ 504. [Имеется перевод: см. сб.
статей [1), с. 216 русск. нзд.)
[9) Rice, В., Winograd Convolution Algorithms over Finite Fields, Congressus
Numberatium 29 (1980): 827 ‒ 857.
[10) Preparata, F. P. and D. W. Sarwate, Computational Complexity of Fourier
Transforms over Finite Fields, Math. Comp. 31 .(1977): 740 ‒ 751.
439
Литература
[11) Chevillat, P. R., Transform-Domain Р11tering with Number ТЬеогейс
Transforms, and Limited Word Length, IEEE Trans. Acoust., Speech,
Signal Proc. ASSP ‒ 26 (1978): 284 ‒ 290
[12) Szabo, N. S., and R. I. Tanaka, Residue Arithmetic and Its Application
to Computer Technology, McGraw-Hill, New York, 1967.
[13) Jenkins, W. К. and В. J. Leon, The Use of Residue Number Systems in the
Design of Finite Impulse Response Digital Filters, IEEE Trans. Circuits
Syst. CAS — 24 (1977): 191 ‒ 201.
Глава 7
[1) Nussbaumer, Н. J., Digital Filtering Using Polynomial Transforms, Electron.
Lett. 13 (1977): 386 ‒ 387.
[2) Blahut, R. Е., Fast Convolution of Rational Sequences, Abstr. 1983 IEEE
Internat. Sympos. Inf. Theor., St. Jovite, Quebec, Canada, 1983.
[3) Beth, Т., W. Fumy, and R. Muhlfeld, On Algebraic Discrete Fourier Trans-
forms, Abstr. 1982 IEEE Internat. Sympos. Inf. Theor., Les Агсз, France,
1982.
[4) Arambepola, В., апд P. J. W. Rayner, Efficient Transforms for Multidimen-
sional Convolutions, Electron. Lett. 15 (1979): 189 ‒ 190.
[5) Agarwal, К. С., and J. W. Cooley, New Algorithms for Идйа1 Convolution,
IEEE Trans. ASSP ‒ 25 (1977): 392 ‒ 410. [Имеется перевод: см. сб. статей
[1), с. 91 русск. иэд.)
[6) Nussbaumer, Н. J., New Algorithms for Convolution and DFY Based on Po-
lynomial Transforms, Proc. 1978 IEEE Internat. Conf. Acoust., Speech,
Signal Proc. (1978): 638 ‒ 641.
[7) Pitas, 1., and М. G. Strintzis, On the Multiplicative Complexity of Two-
Dimensional Fast Convolution Methods, Abstr. 1982 IEEE Internat. Sympos.
Inf. Theor., I es Arcs, France, 1982.
[8) Winograd, S., On Computing the Discrete Fourier Transform, Math. Comp. 32
(1978): 175 ‒ 199. [Имеется перевод: см. сб. статей [1), с. 117 русск. иэд.)
[1) Rivard, G. Е., Direct Fast Fourier Transform of Bivariate Functions, IEEE
Trans. Acoust., Speech, Signal Proc. ASSP ‒ 25 (1977): 250 ‒ 252.
[2) Harris, D. В., J. Н. ЯсС1е11ап, D. S. К. Chan, and Н. W. ЯсЬиезз1ег, Vector
Radix Fast Fourier Transform, Rec. 1977 IEEE- Internat. Conf. Acoust.,
Speech, Signal Proc. (1977): 548 ‒ 551.
[3) Mersereau, R., and Т. С. Speake, А Unified Treatment of Cooley ‒ Tukey
Algorithms for the Evaluation of the Multidimensional DFT, IEEE Trans.
Acoust., Speech, Signal Proc. ASSP ‒ 29 (1981): 1011 ‒ 1018.
[4) Winograd, S., On Computing the Discrete Fourier Transform, Proc. Nat.
Асад. Sci. USA 73 (1976): 1005 ‒ 1006.
[5) Ко1Ьа, D. P., and Т. W. Parks, А Prime Factor FFT Algorithm Using High
Speed Convolution, IEEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 25
(1977): 281 ‒ 294. [Имеется перевод: см. сб. статей [1], с. 72 русск. изд. )
[6) Silverman, Н. F., An Introduction to Programming the Winograd Fourier
Transform Algorithm (WFTA), IEEE Trans. Acoust., Speech, Signal Proc.
ASSP ‒ 25 (1977): 152 ‒ 165.
[7) Johnson, Н. W., апд С. S. Виггцз, The Design of Optimal DFT Algorithms
Using Dynamic Programming, IEEE Trans. Acoust., Speech, Signal Proc.
ASSP ‒ 31 (1983): 378 ‒ 387.
[SJ Nussbaumer, Н. J., and P. Quandalle, Fast Computation of Discrete Fourier
Transforms Using Polynomial Transforms, IEEE Trans. Acoust., Speech,
Signal Proc. ASSP ‒ 27 (1979): 169 ‒ 181.
440
Литература
[9) Nussbaumer, Н. J., and P. Quandalle, New Polynomial Transform Algorithms
for Fast DFT Computations, Proc. IEEE 1979 Internat. Acoust., Speech,
Signal Proc. Conf. (1979): 510 ‒ 513.
[10) Auslander, L., Е. Feig, and S. Winograd, New Algorithms for the Multidi-
mensional Discrete Fourier Transform, IEEE Trans. Acoust., Speech,
Signal Proc. ASSP ‒ 31 (1983): 388 ‒ 403.
Глава Э
[1) Stockham, Т. G., High Speed Convolution and Correlation, 1966 Spring
Joint Comput. Conf., AFIPS Proc. 28 (1966): 229 ‒ 233.
[2) Agarwal, К. С., and С. S. Burrus, Fast One-Dimensional Digital Convolu-
tion by Multidimensional Techniques, IEEE Trans. Acoust., Speech, Signal
Proc. ASSP ‒ 22 (1974): 1 ‒ 10. [Имеется перевод: см. сб. статей [1), с. 172
русск. изд.)
[3) DuBois, Е. and А. N. Venetsanopoulos, Convolution Using à Conjugate Sym-
metry Property for the Generalized Discrete. Fourier Transform, IEEE Trans.
Acoust., Speech, Signal Proc. ASSP ‒ 26 (1978): 165 ‒ 170.
[4) Winograd, S., On the Complexity of Symmetric Filters, Proc. Internat.
Sympos. Circuits Syst. Tokyo (1979): 262 ‒ 265.
[5) Winograd S., Arithmetic Complexity of Computations, CBMS ‒ NSF Re-
gional Conf. Ser. Appl. Math. Siam Publications 33, 1980.
[6) Норсгой, J. Е., and J. Musinski, Duality Applied to the Complexity of
Matrix Multiplication and Other Bilinear Forms, SIAM J. Comput. 2 (1973):
15 ‒ 173.
[7) Rader, С. М., An Improved Algorithm for High Speed Autocorrelation with
Applications to Spectral Estimation, IEEE Trans. Audio Electroacoust.,
AU ‒ 18 (1970): 439 ‒ 441.
[8) Burrus, С. S., and P. W. Eschenbacher, An In-Place Prime Factor FFT Algo-
rithm, IEEE Trans. Acoust., speech, Signal Proc. ASSP ‒ 29 (1979):806 ‒ 817.
[9) ~.ш, В., and F. Mintzer, Calculation of Narrow-Band Spectra by Direct
Decimation, IEEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 26 (1978):
529 ‒ 534.
[10) Crochiere, К. Е., and L. R. Rabiner, Interpolation and Decimation of Digi-
tal Signals ‒ А Tutoria1 Review, Proc. 1ЕЕЕ 69 (1981): 330 ‒ 331.
[11) Ко1Ьа, D. P:, and Т. W. Parks, А Prime Factor FFT Algorithm Using
High Speed Convolution. IEEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 25
(1977): 281 ‒ 294. [Имеется перевод: см. сб. статей [1), с. 72 русск. иэд.]
[12) Silverman, H. F., An Introduction to Programming the Winograd Fourier
Transform Algorithm (ЮРТА), 1ЕЕЕ Trans. Acoust., Speech, Signal Proc.
ASSP ‒ 25 (1977): 152 ‒ 165.
[») Morris, P. L., А Comparative Study of Tune Efficient FFT and WFTA Pro-
grams for General Purpose Computers, IEEE Trans. Acoust., Speech, Signal
Proc. ASSP ‒ 26 (1978): 141 ‒ 150.
[14) Nawab, Н., and J. H. McClellan, Bounds on the h!inimum Number of
Data Transfers in ЮРТА and Programs, IEEE Trans. Acoust. Speech, Sig-
nal Proc. ASSP ‒ 27 (1979): 393 ‒ 398.
[15) Patterson, Р. W., and J. Н. McClellan, Fixed-Point Error Analysis of
Winograd Fourier Transform Algorithms, IEEE Trans. Acoust., Speech,
Signal Proc. ASSP ‒ 26 (1978): 447 ‒ 455.
[16) Panda, G., R. N. Pal, аль. B. Chatterjee, Error Analysis of Good ‒ Winograd
Algorithm Assuming Correlated Truncation Errors, IEEE Trans. Acoust.,
Speech, Signal Proc. ASSP ‒ 31 (1983): 508 ‒ 512.
Глава f0
Knuth. D. Е., The Art of Computer Programming, ~/о1. l; Fundamental
Algorithms, Addison-Wesley, Reading, Mass., 19б8. [Имеется перевод.
Киут Д. Искусство программироваиия, том 1.‒ М.: Мир, 1976.]
Литература
441
[2) Aho, А. V., J. Е. Horcroft, and J. D. Ullman, The Design and Analysis
of Computer Algorithms, Addison-Wesley, /eading, Mass., 1974. [Имеется
перевод: см. Монографии [3) .)
[3) Williams, J. М. J., Algorithm 232; Heapsort, Comm ACM 7 (1964): 347‒
348.
[4) Hoare, С. А. Я., Quicksort, Comp. J. 5, 1962.
[5) Steiglitz, К., An Introduction to Discrete Systems, John Wiley, New York,
1974.
[6) Fiduccia, С. М., Polynomial Evaluation via the Division Algorithm ‒ The
Fast Fourier Tranform revisited, Proc. 4th Annual АСМ Symp. Theory
Comput. (1972): 88 ‒ 93.
[7) Eklundh, J. О., А Fast Computer Method for Matrix Transposing, IEEE
Тгайз. Comp. С ‒ 21 (1972): 801 ‒ 803.
[8] Winograd, $., Signal Processing and Complexity of Computation, Proc. Int.
Conf. Acoust., Speech, Singnal Proc. (1980): 94 ‒ 101.
[9) Voider, J. Е., IgE Trans. Electr. Comp. ЕС ‒ 8 (1959): 330 ‒ 334.
[1О) Walther, J. S., Proc. 1971 Spring Joint Comp. Conf. (1971): 379 ‒ 385.
[11) Blahut, Я. Е., and D. Е. Waldecker, Half-Angle Sine-Cosine Generator,
IBM Tech. Disclosure Bull. 13, по. 1 (1970): 222 ‒ 223.
Глава 11
[1) Levinson, N., The Wiener ЯМ$ Error Criterion in Filter Design and Pre-
diction, J. Math. Phys. 25 (1947): 261 ‒ 278.
[2) Durbin, J., The Fitting of Time ‒ Series Models, Pev. Internat. Statist. Inst.
23 (1960): 233 †2.
[3) Trench, W. F., An Algorithm for the Inversion of Finite Toeplitz Matrices,
J. SIAM 12, по. 3 (1964): 512 ‒ 522.
[4) Berlecamp, Е. Я., Algebraic Coding Theory, McGraw-НШ, New York,
1968. [Имеется перевод: см. гл. V [5). ]
[5] Zohar, $., The Solution of à Toeplitz Set of Linear Equations, J. Assoc.
Comput. МаЖ 21 (1974): 272 ‒ 276.
[6) Massey, J. L., Shoft ‒ register Synthesis and ВСН Decoding, IEEE Trans.
Inf, ТЬеог. IT ‒ 15 (1969): 122 ‒ 127.
[7) Welch, L. Я., and Я. А. Scholtz, Continue Fractions and Berlecamp's Algo-
rithm, IEEE Trans. Inf. Theor. IT ‒ 25 (1979): 19 ‒ 27.
[8) Blahut, Я. Е., Theory and Practice of Error Control Codes, Addison-Wes-
ley, /eading, Mass., 1983. [Имеется перевод. 'Блейхут P. Теория и прак-
тика кодов, контролирующих ошибки. ‒ М.: Мир, 1986.)
[9) Sugiyama, Y., М. КазаЬага, S. Hirasawa, and Т. Namekawa, А Method
for Solving Кеу Equation for Decoding Goppa Codes, Inf. Control 27 (1975):
87 ‒ 99.
[10] Brent, Я. P., F. G. Gustavson, and D. Y. Y. Yun, Fast Solution of Toeplitz
Systems of Equations and Computation of Раде Approximants, J. Algo-
rithms 1 (1980): 25 ‒ 295.
[11) Vieira, А. and Т. Kailath, On Another Approach to the Schur ‒ Cohn Cri-
terion, IEEE Trans. Circuits Syst. CAS ‒ 24, йо. 4 (1977): 218 ‒ 220.
[12) Wiggins, Р. А., and E. А. robinson, Pecursive Solution to the Multichannel
Filtering Problem, J. Geophys. Кез. 70 (1965): 1885 ‒ 1891.
[13) Dickinson, В. W., Efficient Solution of Linear Equations with Banded
Toeplitz Matrices, IEEE Trans. Acoust., Speech, Signal Proc. ASSP ‒ 27
(1979): 421 ‒ 423.
[14] Dickinson, В. W., М. Morf, and Т. 3(ailath, А Minimal realization Algo-
rithm for Matrix Sequences, IEEE Trans. Automatic Control АС ‒ 19 (1974):
31 ‒ 38.
[15) Friedlander„B., М. Morf, Т. 3(ailath, and L. Ljung, New Inversion For-
mulas for Matrices Classified in Terms of Their Distance from Toeplitz Matri-
ces, Linear Algebra and Its application 27 (1979): 3t ‒ 60.
Литература
[16) Morf, М., В. W. Dickinson, Т. Kailath, and А. С. G. Vieira, Efficient
Solution of Covariance Equations for Linear Prediction, IEEE Trans. Acoust.,
Speech, Signal Proc. ASSP ‒ 25 (1977): 429 ‒ 433.
[17] Monden, Y., and $. Arimoto, Generalized Rouche's Theorem and Its Appii-
cation to Multivariate Autoregressions, IEEE Trans. Acoust., Speech, Sig-
nal Proc. ASSP ‒ 28 (1980): 733 ‒ 738.
Глава 12
[1) Viterbi, А. J., Error Bounds for Convolutional Codes and an Asymptoti-
cally Optimum Decoding Algorithm, IEEE Trans. Inf. Theor. IT ‒ 13 (1967):
260 ‒ 269.
[2) Wozencrafi, J. М., Sequential Decoding for Reliable Communication, 1957
Nat. IRE Conv. Кес. 5, part 2 (1957): 11 ‒ 25.
[3] Wozencraft, J. М., and В. Reiffen, Sequential Decoding, MIT Press, Camb-
ridge, Mass., 1961.
[4] Fano, R. М., А. Heuristic Discussion of Probabilistic Decoding, IEEE Trans.
Ы. Theor. IT ‒ 9 (1963): 64 ‒ 74.
[5) Зигангиров К. Ш. Некоторые процедуры последовательного декодирова-
ния. ‒ Проблемы передачн информации, 1966, вып. 2, с. 13 ‒ 25.
[6) Jelinek, F. А. Fast Sequential Decoding Algorithm Using à Stack, IBM
J. Res. Devel. 13 (1969): 675 ‒ 685.
[7] Jelinek, F., Probabilistic Information Theory, McGraw-Hill, New York,
1968.
[8) Forney, G. D., Convolutional Codes Ш: Sequential Decoding, Inform. Contr.
25 (1974): 267 ‒ 297.
[9J Chevillat, P. R., and D. J. Costello, Jr., An Analysis of Sequential Deco-
ding for Specific Time-Invariant Convo1utional Codes, IEEE Trans. Inf
Theor. IT ‒ 24 (1978): 443 ‒ 4Я.
[10) Haccoun, D., and. М. J. Ferguson, Generalized Stack Algoritms for Decoding
Convolutional Codes, IEEE Trans. Inf. Theor. IT ‒ 21 (1975): 638 ‒ 651.
[11) Gallager, R. G., Information Theory and Reliable Communications, John
Wiley, New York, 1968. [Имеется перевод: Галлагер Р. Теория инфор-
мацин и надежная связь. ‒ М.: Сов. радио, 1974.)
[12) Pader, C. М., Memory Management in à Viterbi Decoder, IEEE Trans. Com-
rnunicat. СОМ ‒ 29 (1981): 1399 ‒ 1401.
[13) Jacobs, I. М., and Е. R. Berlecamp, А Lower Bound to the Distribu-
tion of Con utations for Sequential Decoding, IEEE Trans. Inf. Theor.
IT ‒ 13 (196: 167 ‒ 174.
[14] Savage, J. Е., Sequental Decoding ‒ The Computation Problem, Bell Syst.
Tech. J. 45 (1966): 149 ‒ 175.
[15] Jelinek, F., An Upper Bound on Moments of Sequential Decoding Effort,
IEEE Trans. Inf. Theor. 1Т ‒ 15 (1969). 140 ‒ 149.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
абелева группа 34
автокорреляция 327
адресное тасование 130
алгебра матричная 50
алгебраическое дополнение 52
алгоритм 115
‒ БПФ Винограда l57
‒ ‒ ‒ для больших длин преобразо-
вания 270
‒ ‒ ‒ улучшенный 286
‒ ‒ выколотый 294
‒ ‒ гнездовой 265
‒ ‒ Гуда ‒ Томаса 141
‒ ‒ Кули ‒ Тычки 128
‒ ‒ ‒ по осиованию два 133
четыре 139
‒ ‒ перестановочный Нуссбаумера‒
Квенделла 287
‒ ‒ Рейдера ‒ Бреннера 136
‒ быстрой сортировки 350
‒ ‒ транспозиции 356
‒ Вятербя 406
‒ Герцеля 144
‒ деления 59, 64
‒ Дурбина 377
‒ Евклида 60, 68
‒ ‒ рекурсивный 360
‒ поиска по решетке 402
‒ решения теплицевой системы Берле-
кэмпа ‒ Месси 385
, рекурсивиый 394
‒ ‒ ‒ ‒ Дурбина 377
‒ ‒ ‒ ‒ Левинсона 373
‒ ‒ ‒ ‒ Тренча 380
‒ ‒ ‒ ‒, основанный на рекурсив-
ном алгоритме Евклида 397
‒ свертки Лгарвала ‒ Кули 226
‒ ‒ Винограда 90
‒ ‒ гнездовой 220
‒ ‒ итеративный 237
‒ ‒ Карацубы 85
‒ ‒ Кука ‒ Тома 84
‒, метод разложения 233
‒ ‒ Препараты~;ервейта 216
‒ секциониой фильтрации 306, 310
‒, сложность 113
‒ сортировки 349
‒ ‒ слиянием 350
‒ Тренча 380
‒ Фано 414
‒ Штрассена умножения матриц 357
ассоциативность 33, 39, 48
бабочка 352
базис 50
буфер 418
быстрая сортировка 350
‒ транспозиция 356
быстрое преобразование Фурье (БПФ)
129
вектор 47
векторное пространство 49
векторы ортогональные 49
взаимная корреляция 327
взаимно-простые многоучены 63
‒ ‒ числа 58
внешнее произведение (векторов) 54
вычет 177, 180
‒ квадратичный 209
группа 33
‒ абелева 34
‒ коммутативная 34
‒ конечная 34
‒, образующая 35
‒, порядок 35
‒, произведеиие 36
‒, разложеиие на смежные классы 37
‒ циклическая 35
деление с остатком 39
делимость 39
дерево 348
диаграмма переходов 403
дискретное преобразование Фурье
(ДПФ) 28
дистрибутивность 39, 48
длина кодового ограничения 403
единица группы 35
‒ кольца 39
единичная матрица 51
единичный элемент 34
замкнутость 33, 39
изоморфизм 34
интерполяция Лагранжа 71, 84
итеративный алгоритм 237
итерация 237
кольцо 39
‒ вычетов 177
‒ коммутативное 39
444 Предметный указатель
‒ многочленов 62
‒ ‒ no модулю р (х) 180
‒ с единицей 39
‒ целых чисел 58
коммутативность 34
корень многочлена 70
корреляция 24
‒ взаимная 327
‒ циклическая 32
кронекеровское произведение (ма-
триц) 53
левый смежный класс 38
лидер смежного класса 38
линейная зависимость векторов 50
‒ комбинация векторов 49
‒ свертка 23
линия задержки 22
матрица 50
‒ вырожденная 51
‒ главная диагональ 51
‒ единичная 51
‒, канонический ступенчатый вид 56
‒ квадратная 50
‒ невырожденная 51
‒ обменная 51
‒ персимметричная 380
‒, побочная диагональ 5l
‒ сопровождающая 115
‒ теплицева 54, 373
‒ транспонированная 51
‒ элементарная 55
машина с конечным числом состояний
402
метод перекрытия с накоплением 304
‒ ‒ ‒ суммированием 307
метрика 405
‒ Фано 412
минор 52
многочлен 62
‒ круговой 184
‒ минимальный 182
‒ неприводимый 63
‒ нулевой 62
‒ приведенный 62
‒ простой 63
‒, формальная производная 64
наибольший общий делитель (НОД) 58,
63
наименьшее общее кратное (НОК) 58,
63
начало координат 48
иулевое пространство матрицы 56
нуль группы 36
‒ поля 43
обратимость 34
обратимый элемент 40, 42
обратный элемент 34
‒ ‒, левый 40
‒ ‒, правый 40
определитель (матрицы) 51
ортогональное дополиение 49
ортогональный вектор 49
очередь 348
перекрытия метод 27
веременная 115
‒ неопределенная 115
подгруппа 36
подполе 46
‒ констант 114
воле 43,
‒ вычисления 114
‒ Галуа 44
‒ конечное 44
‒, характеристика 46
порядок группы 34
‒ элемента 37, 172
потомок 348
правило Горнера 144
правый смежный класс 38
преобразование полиномиальное 243,
249
‒ Нуссбаумера 248
преобразование Фурье см. дискретное
преобразование Фурье (ДПФ)
‒ ‒ рекурсивное по основанию 2 352
‒ ‒ свойства 76
‒ числовое Иерсенна 198
‒ ‒ Ферма 196
прймитивный элемент поля 47
произведение внешнее 54
‒ групп 36
‒ кронекеровское 53
‒ на скаляр 47
‒ подкомпонентное 48
‒ скалярное 48
пространство векторное 47
‒ столбцов матрицы 56
‒ строк матрицы 56
размерность векторного простран-
ства 49
ранг матрицы 57
‒ ‒ по столбцам 56
‒ ‒ по строкам 56
расстояние 405
‒ евклидово 405
‒, расходимость 407
расширение поля 46
регистр сдвига 22
рекурсивная процедура 344
Предметный указатель
445
решетка 403
‒, диаграмма состояний 404
‒, длина кодового ограничеиия 403
‒ маркироваиная 405
свертка двумерная 220 †2
‒ линейная 22, 80
‒ по секциям 308
‒ циклическая 24, 81
свойства преобразования Фурье 76
скаляр 47, 62, 115
смежный класс 37
‒ ‒ левый 38
‒ ‒ правый 38
список 347
‒ двойной связанный 349
‒ обратный 348
‒ связанный 349
сравнение по модулю 59, 65
стек 348
‒ алгоритм 410
степень многочлена 62
стратегия дублирования 341
сумматор 22
существование единицы 34
такт 22
теорема о свертке 29
теплицева матрица 54, 379
‒ система уравнений 372
транспозиция 52
транспонированная матрица 51
трансформационный принцип 310
факторкольцо 176
фильтр 22
‒ авторегрессионный 22, 27
‒ интерполяционный 324
‒ кососимметрический 319
‒ прореживаиия 324
‒ с восстановлением 324
‒ симметрический 319
‒ с конечным импульсным откликом
(КИО) 22
‒ с подавлением 324
фильтрация секциониая 305
функция Эйлера 170
характеристика кольца 40
‒ поля 46
целый элемент кольца 40
цепочка 348
цикл 37
циклическая группа 35
чип 17
числа взаимно-простые 58
‒ Шевилла 213
число простое 58
‒ ‒ Мерсенна 195
‒ ‒ Ферма 195
‒ трансцендентное 183
числовое преобразование Мерсенна 198
‒ ‒ Ферма 196
‒ ‒ Шевилла 213
элемент единичный 34
‒ образующий 34
‒ обратимый 40
‒ обратный 34
‒ примитивный поля 47, 187,
‒ сопряженный 183
‒ целый кольца 40
элементарные операции над строками
матрицы 55
ОГЛАВЛЕНИЕ
Предисловие к русскому изданию.................. 5
О
т автора
° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° O ° ° °
7
Предисловие 8
Глава 1. Введеиие 12
1 ° 1. Введение в быстрые алгоритмы................. 12
1.2. Использование быстрых алгоритмов... °........... 17
1.3. Системы счисления для проведения вычислений......... 20
1 ° 4. Цифровая обработка сигналов . ° .. °... °......... 22
1.5. История быстрых алгоритмов обработки сигналов........ 29
3 адачи ° 31
3 амечания
° ° ° ° ° ° ° ° ° ° ° ° ° ° а ° а ° ° ° ° ° ° ° °
32
Глава 2. Введеиие в абстрактную алгебру.............. 33
2.. у
° 1. Гууппы
° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° е ° ° ° ° е ° е е е
33
2.. Ь,
.2. агольца 38
2 .3. Поля
° ° ° ° ° ° ° ° ° ° ° ° ° ° ° 1 ° ° ° ° ° ° ° ° ° ° ° а °
43
2.4. Векторные пространства .....,.............. 47
2.5. Матричная алгебра....................... 50
2.6. Кольцо целых чисел...................... 58
2.7. Кольца многочленов ...................... 62
2.8. Китайские теоремы об остатками................. 71
3 адачи . Р6
3 амечаиия 99
Глава 3. Быстрые алгоритмы коротких свертов............ 80
3.1. Циклические и линейные свертки... ° . °.......... 80
3.2. Алгоритм Кука ‒ Тоома ....... ° . ° °......... 84
3.3. Алгоритмы Винограда вычисления коротких сверток....... 90
3.4. Г~остроение алгоритмов коротких линейных сверток ......... 98
3.5. Вычисление произведения многочленов по модулю некоторого много-
ч лена
е ° ° ° ° ° е ° ° е ° ° ° ° ° ° е ° ° е ° е ° ° ° ° ° ° °
103
3.6. Построение алгоритмов коротких циклических сверток . . . . . . 105
3.7. Свертки в общих полях и кольцал....;.......... 111
3.8. Сложность алгоритмов свертки................. 113
3 адачи . 124
В амечания 127
Глава 4. Быстрые алгоритмы дискретного преобразования Фурье... 128
4.1. Алгоритм Кули ‒ Тычки быстрого преобразования Фурье.... 128
4.2. Алгоритм Кули ‒ Тычки по основанию два........... 133
4.3. Алгоритм Гуда ‒ Томаса быстрого преобразования Фурье..... 141
4.4. Алгоритм Герцеля ° ° .. ° °....... ° . °....... 144
4.5. Вычисление преобразования Фурье с помощью свертки...... «47
4.6. Алгоритм Винограда для быстрого преобразования Фурье малой
Д
лины ° ° ° ° ° ° ° ° ° s ° ° е ° ° ° ° ° ° ° е ° ° ° ° ° ° ° ° 157
3 адачи . 167
3 амечания 169
Оглавление 447
Глава 5. Теория чисел и алгебраическая теория полей.......... 170
5.1. Эл емеитарная теория чисел .................. 170
5.2. Конечные поля, основанные на кольце целых чисел...... ° ° 176
5.3. Поля, основанные на кольцах многочленов ° ° °......... 180
5.4. Минимальные многочлены и сопряжения ............ 182
5.5. Круговые многочлены...... ° .. ° . ° ° . °...... 184
5.6. Примитивные элементы .... °... °....... ° .. ° 187
3 189
Замечания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
Глава 6. Вычисления в суррогатных полях.............. 192
6.1. Свертка в суррогатных полях ° °............... ° 192
6.2. Числовые преобразования Ферма................ 196
6.3. Числовые преобразования Мерсенна............... 198
6.4. Алгоритмы свертки в конечных полях.............. 202
6.5. Комплексная свертка в суррогатных полях........ ° . ° . 206
6.6. Преобразования в числовом кольце... ° . ° ° ° .. ° .. ° . 208
6.7. Числовые преобразования Шевилла............... 213
6.8. Алгоритм Препараты ‒ Сервейта................. 216
3 адачи .
° ° ° 6 ° ° ° ° ° ° ° ° ° ° ° ° °
217
Замечания............................. 219
Глава 7. Быстрые алгоритмы и многомериые свертки.......... 220
7.1. Гнездовые алгоритмы свертки ................. 220
7.2. Алгоритм Агарвала ‒ Кули вычисления свертки ° . ° ° . ° . ° . ° 226
7.3. Алгоритмы разложения.................. ° . 233
7.4. Итеративные алгоритмы..................... 237
7.5. Г~олиномиальное представлеиие расширений полей........ 243
7.6. Свертка в полииомиальных расширениях полей .. °.... ° . ° 246
7.7. Полиномиальиое преобразование Нуссбаумера ......... 248
7.8. Быстрая свертка многочлеиов................. 252
3 адачо . 257
3 амечания 258
Глава 8. Быстрые алгоритмы миогомерных преобразований..... 259
8.1. Алгоритмы Кули ‒ Тычки по малому оановаиию......... 259
8.2. Гнездовые алгоритмы преобразования.............. 265
8.3. Алгоритм Вииограда быстрого вычисления преобразования Фурье
большой длины ......... ° .. ° . °....... ° . 270
8.4. Алгоритм Джонсона ‒ Барраса быстрого преобразования Фурье 277
8.5. Алгоритмы разложения ........... ° .. ° ° . ° . ° 280
8.6. Улучшенный алгоритм Винограда быстрого преобразования Фурье 286
8.7. Перестановочный алгоритм Нуссбаумера ‒ Квенделла....... 287
3 адачи . 300
Замечания 302
Глава 9. Архитектура фильтров и преобразоваиий . . . . . . . . . . . 303
9.1. Вычисление свертки секционироваиием . . . . . . . . . . . . . . 303
Ц.2. Алгоритмы для коротких секций фильтра............. 310
9.3. Итерироваиие секций филътра................. 312
9.4. Симметрические и кососимметрические фильтры.......... 317
9.5. Фильтры прореживания и интерполяции............ 324
448 Оглавление
9.6. Автокорреляция и взаимная корреляция . ° . ° . . . . . ° ° ° 327
9.7. Устройства для вычисления БПф............... 333
9.8. Преобразование Фурье ограничениого диапазона......... 339
3 адачи .
° ° ° ° ° ° ° ° ° ° ° ° °
340
3 амечания............................. 341
Глава 10. Быстрые алгоритмы, основанные на стратегии дублирования 343
10.1. Стратегия деления пополам и дублирования.......... 343
10.2. Структуры даиных..................... 347
10.3. Быстрые алгоритмы сортировки................ 349
10.4. Рекурсивное быстрое преобразование Фурье по осиовавию два .. 352
10.5. Быстрая транспозиция .................., . 356
10.6. Умножение матриц .................... 357
10.7. Рекурсивный алгоритм Евклида................ 360
10.8. Вычисление тригонометрических функций ........... 367
Задачи... ° . °................... 371
Замечания ° . °........ ° °...... °.... ° °... 371
Глава 11. Быстрые методы решения теплицевых систем....... 372
11.1. Алгоритмы Яевинсоиа и Дурбина............... 372
11.2. Алгоритм Треича....................... 379
11.3. Алгоритм Берлекэмпа ‒ Месси................. 385
11.4. Рекурсивный алгоритм Берлекэмпа ‒ Месси ........... 394
11.5. Методы, основанные на алгоритме Евклида........... 397
3 адачи........ ° ............ °....... 400
3 амечания
° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° °
401
Глава 12. Быстрые алгоритмы поиска по решетке и по дереву...... 402
12.1. Поиск по решетке и по дереву................. 402
12.2. Алюритм Виттерби..................... 406
12.3. Стек-алюритм ........................ 410
12.4. Алгоритм Фано.................... ° . ° . 414
3 ада ч и ° ° ° ° ° ° . ° ° .. ° ° ° ° ° ° ° ° ° . ° ° ° .. ° ° ° 419
Замечания...................... °,... °, 420
Приложение А. Яабор алгоритмов циклических сверток......... 421
Приложение Б. Набор малых БПФ-алгоритмов Винограда....... 429
Л итература . 436
Научное нэдаиие
Ричард Э. Блейхут
БЫСТРЫЕ АЛГОРИТМЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Зав. редакцией чл.-корр. АН СССР В. И Арнольд. Зам. эав. редакцией А. С. Попов.
Научный ред. С. В. Чудов. Младший научи. ред. Н С. Полякова.
Художник А. Рейице. Художественный ред. В И. Шаповалов.
Технический ред. М. М. Кренделева.
ИБ № 6681
Сдано s набор 17,.05.88. Подписано к печати 27.12.88. Формат 60)<90'/~~.
Бумага офсетная № 2 Печать офсетная. Гарнитура латинская.
Объем бум. л. 14,00. Усл. печ. л. 28,00. Усл. кр=отт. 28,00. Уч.-нэд. л. 27,05.
Иэд. № 1/5877. Тираж 15000 экэ. Зак. 524. Цена 2 р. 80 к.
ИЗДАТЕЛЬСТВО «МИР» В/О «Совэкспорткнига» Государственного комитета СССР
по делам иэдательств, полиграфии и книжной торговли,
129820, ГСП, Москва, И-110, 1-й Рижский пер., 2
Ленинградская типография № 6 ордена Трудового Красного Знамени Ленинградского
объединення «Техинческая кинга» им Евгении Соколовой Союэполиграфпрома прн fo-
сударственном комитете СССР по делам иэдательств, полиграфии и книжной торговли.
193144. г. Ленинград, ул. Моисеенко, 10.