/

















































































































































































































































































































































































































































































































































































































































































































































Author: Хэзфилд Р. Кирби Л.
Tags: общие вопросы горного дела программирование искусство программирования язык программирования c
ISBN: 966=7393-82-8
Year: 2001




Text
Ричард Хэзфилд, Лоуренс Кирби
Искусство
программирования на
С
Реализация
на С самых
современных,
быстрых и
эффективных
алгоритмов!
Фундаментальные алгоритмы,
структуры данных и примеры
приложений
Подробно рассмотрены
издательство
DiaSoft
Фундаментальные
концепции
программирования
Широкий спектр
реальных
бизнес-приложений
Полное описание
последнего ANSI-
стандарта языка
Управление
прои зводител ьностью
приложений и теория
оптимизации
Стандарты
программирования
Абстрактные структуры
данных
Реализация алгоритмов
сортировки, поиска и
обработки древовидных
структур
Создание
инструментальных
средств для
разработчиков
Организация
параллельной
обработки данных
Концепции и реализация
CGI-приложений
SAMS
PUBLISHING
и книга-почтой интернет-магазин
Richard Heathfield
Lawrence Kirby
etal.
SAMS
UNLEASHED
Искусство
программирования
на С
Фундаментальные алгоритмы, структуры данных и
примеры приложений
Ричард Хэзфилд,
Лоуренс Кирби
и др.
ЭНЦИКЛОПЕДИЯ
-----
ББК 33.114
Хэзфилд Ричард, Кирби Лоуренс и др.
X 82 Искусство программирования на С. Фундаментальные алгоритмы, структуры данных и примеры
приложений. Энциклопедия программиста: Пер. с англ./Ричард Хэзфилд, Лоуренс Кирби и др. —
К.: Издательство «ДиаСофт», 2001. — 736 с.
ISBN 966-7393-82-8
Эта книга посвящена искусству программирования на одном из самых популярных и мощных языков.
Значительное внимание уделено таким актуальным вопросам, как обработка данных, работа с битами и
байтами, отладка программ, управление памятью, моделирование, рекурсия, а также темам, не часто встре-
чающимся в литературе, но играющим важную роль при разработке коммерческих приложений.
Описание самых разнообразных алгоритмов в книге гармонично сочетается с вопросами их практической
реализации. Приведено большое количество фрагментов кода и целых программ, которые непосредственно
можно применять в сложных приложениях.
Книга предназначена для опытных программистов, а также читателей, имеющих базовые знания по язы-
ку С и желающих повысить свою квалификацию до профессионального уровня.
Научное издание
Хэзфилд Ричард, Кирби Лоуренс и др.
ИСКУССТВО ПРОГРАММИРОВАНИЯ НА С.
ФУНДАМЕНТАЛЬНЫЕ АЛГОРИТМЫ, СТРУКТУРЫ ДАННЫХ И ПРИМЕРЫ ПРИЛОЖЕНИЙ.
ЭНЦИКЛОПЕДИЯ ПРОГРАММИСТА
Заведующий редакцией С. Н. Козлов
Главный редактор Ю.Н.Артеменко
Научный редактор к.т.н. С.Л.Попов
Верстка А,А. Коптюх
Главный дизайнер О.А.Шадрин
Н/К
Сдано в набор 10.03.2001. Подписано в печать 02.04.2001. Формат 84x108/16. Бумага
типографская. Гарнитура Таймс. Печать офсетная. Усл.печ.л. 55,20. Усл.кр.отт. 55,20
Тираж 3000 экз. Заказ № 265
Издательство «ДиаСофт», 04053, Киев-53, а/я 100, тел./факс (044) 212-1254.
e-mail: books@diasoft.kiev.ua, http://www.diasoft.kiev.ua.
Отпечатано с готовых диапозитивов в ордена Трудового Красного Знамени
ФГУП «Техническая книга» Министерства РФ по делам печати,
телерадиовещамия и средств массовых коммуникаций
198005, Санкт-Петербург, Измайловский пр., 29.
Authorized translation from the English language edition published by Sams
Copyright © 2000
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic
or mechanical, including photocopying, recording or by any information storage retrieval system, without permission
from the Publisher.
Russian language edition published by DiaSoft Publishing.
Copyright © 2001
Лицензия предоставлена издательством Sams Corporation.
Все права зарезервированы, включая право на полное или частичное воспроизведение в какой бы то ни
было форме.
ISBN 966-7393-82-8 (рус.) © Перевод на русский язык. Издательство «ДиаСофт», 2001
ISBN 0-672-31896-2 (англ.) © Sams Corporation, 2000
© Оформление. Издательство «ДиаСофт», 2001
Свидетельство о регистрации 24729912 от 11.03.97.
Гигиеническое заключение № 77.99.6.953.П.439.2.99 от 04.02.1999
Оглавление
Часть I. Пересмотренный язык С...........................................25
ГЛАВА 1. Энциклопедия С-программиста.....................................26
Для кого предназначена эта книга.........................................27
Какие знания вы должны иметь.............................................27
Как наиболее эффективно использовать эту книгу...........................28
Для чего нужна еще одна книга по С.......................................29
Почему используется стандарт ANSI С......................................29
Какие платформы охватывает эта книга.....................................30
Об исходном коде.........................................................30
Качество программного кода ................................................30
Как организована эта книга.................................................30
Проблемы авторских прав..................................................32
Общество С-программистов.................................................32
Резюме...................................................................34
ГЛАВА 2. Войны стандартов программирования: причины и пути
перемирия................................................................35
Стили расстановки фигурных скобок........................................36
Стиль 1TBS............................................................36
Стиль Алмена..........................................................36
Стиль Whitesmith......................................................36
Стиль GNU.............................................................36
Использование пробелов...................................................37
Отступы...............................................................37
Табуляторы и мэйнфреймовские компиляторы..............................38
Пробелы вокруг символов...............................................38
Косметические исправления кода........................................39
Структурное программирование........................................... 39
Оператор goto.........................................................39
Оператор break........................................................39
Оператор continue.....................................................40
Цикл while(l).........................................................40
Оператор return.......................................................41
Инициализация............................................................42
Множественные определения в одной строке..............................42
Инициализация в определении...........................................42
Статические и глобальные объекты.........................................43
Проблемы с повторным использованием...................................44
Имена идентификаторов....................................................45
Длина.................................................................45
Ясность...............................................................45
Зарезервированные имена...............................................46
Префиксы: трансильванская ересь........................................ 47
Именование переменных.................................................47
Именование констант...................................................48
Именование типов....................................................... 48
Искусство программирования на С
6
Именование макросов....................................................48
Именование функций.....................................................49
Написание полезных комментариев..........................................49
Стили размещения комментариев..........................................49
Когда комментарии излишни..............................................50
Описание выполняемых кодом действий.................................. 50
Комментирование сложного кода..........................................51
Комментирование закрывающих скобок.....................................51
Не "закомментируйте" код...............................................51
Общие ошибки и недоразумения.............................................52
Ересь void main ().....................................................52
Количество аргументов функции main ()..................................53
Целочисленная математика против математики плавающей точки.............53
Обработка сигналов...................................................... 54
Передача по значению...................................................54
Проблемы с включающим ИЛИ..............................................55
Оператор sizeof................А.......................................56
Ключевое слово return................................................ 56
Объявления, определения и прототипы......................................56
Объявления.............................................................56
Определения............................................................57
Прототипы..............................................................57
Важность переносимости программ..........................................57
Поразрядное дополнение до единицы и до двух............................57
Определение неопределенного поведения..................................57
Подавление буферов ввода............................................58
Функции is () и to ()...............................................58
Аннулирование строки................................................59
Размеры целых типов....................................................59
Заполнение структур.................................................. 60
Макросы..................................................................60
С против C+ +............................................................61
Резюме...................................................................61
ГЛАВА 3. Оптимизация................................................... 62
Привлекательность оптимизации............................................62
Не тратьте времени даром...............................................62
С — быстродействующий язык.............................................62
Важность измерений.....................................................63
Размышления об эффективности.............................................63
Смысл перспективы......................................................63
Иерархия памяти и ее влияние на эффективность.......................64
Виртуальная память..................................................65
О-нотация..............................................................65
Профайлинг...............................................................67
Плоский профиль..........*........................................... 68
Графические профили....................................................69
Другие методы профайлинга..............................................70
Алгоритмические стратегии оптимизации....................................71
Реализация стратегий оптимизации, или микрооптимизация.................72
Инлайнинг (встраивание).............................................72
Разворачивание цикла................................................73
Оглавление
7
Сжатие цикла.........................................................73
Обращение цикла.....................................................74
Редукция строгости выражения........................................74
Инвариантные вычисления цикла.......................................74
Группировка выражений...............................................74
Удаление хвоста рекурсии............................................75
Табличный поиск.....................................................76
Строковые операции..................................................76
Переменные..........................................................77
Использование плавающей точки.......................................77
Локальность ссылок.................................................. 77
Адресация главной строки............................................ 78
Некоторые дополнительные стратегии оптимизации.........................78
Кооперативная и параллельная оптимизация.................................79
Некоторые новые величины эффективности.................................79
Клиент-сервер и параллелизм............................................80
Неявный параллелизм....................................................80
Пользовательский интерфейс для медлительных алгоритмов.................81
Когда оптимизация не нужна...............................................82
Корень зла — в преждевременной оптимизации.............................82
Легче сделать корректную программу быстрой, чем быструю программу
корректной.............................................................83
Не выполняйте оптимизацию без учета переносимости......................83
Позвольте делать это компилятору.......................................83
Резюме...................................................................83
ГЛАВА 4. Работа с датами.................................................84
Функции даты и времени...................................................84
Основные функции даты и времени........................................ 84
Полезные формы представления даты и времени............................ 85
Простое строковое форматирование времени...............................86
Сложное форматирование времени.........................................86
Считывание даты и времени и манипулирование ими........................88
Определение времени выполнения программ................................90
Ошибка тысячелетия: проблемы, связанные с датами.........................91
Полезные мелочи..........................................................92
Високосные годы........................................................92
Стандарт ISO 8601: форматы дат и номера недель.........................92
Резюме...................................................................94
ГЛАВА 5. Игры с битами и байтами.........................................95
Представление величин в С................................................95
Представление целых величин..............................................96
Использование величин без знака в битовых операциях......................97
Битовый едвиг............................................................98
Другие битовые операторы.................................................98
Битовые массивы” (битовые карты)........................................ 100
Подсчет битов.......................................................... 102
Зеркальное отражение битов..............................................105
Битовые поля........................................................... 106
Переносимость программ................................................. 107
Резюме................................................................. 110
Искусство программирования на С
8
ГЛАВА 6. Хранение и извлечение данных....................................111
Цели и приложения....................................................... 111
Текстовые и двоичные форматы........................................ 112
Вопросы структурирования............................................. 112
Вопросы разработки форматов........................................... ИЗ
Основные методы......................................................... 114
Текстовые файлы...................................................... 114
Двоичные файлы....................................................... 119
Общие форматы........................................................... 126
Файлы, в качестве разделителей использующие символы пробела или табуляции... 126
Величины, разделенные запятыми....................................... 128
Файлы .ini........................................................... 130
Усовершенствованные методы.............................................. 130
Обновление записей................................................... 130
Индексная адресация.................................................. 132
Смежные вопросы......................................................... 133
Резюме.................................................................. 134
ГЛАВА 7. Исправление кода программ.......................................135
Обратимся к диагностике................................................. 135
Как нужно использовать предупреждения................................ 136
Метод "сверху-в низ"................................................. 138
Ваш друг Lint........................................................ 139
Поиск и исправление распространенных ошибок............................. 140
Ошибки завышения (или занижения) значения на единицу................. 142
Ошибки нарушения границы............................................. 142
Бесконечные циклы.................................................... 143
Присваивание вместо сравнения........................................ 143
Переполнение буфера.................................................. 144
Нарушение границ массива............................................. 144
Недостающие аргументы................................................ 145
Указатели............................................................ 145
Программные средства отладки,........................................... 149
Коммерческие отладчики............................................... 149
Макросы трассировки................................................. 149
Планируем успех, предвидя неудачи..................................... 156
Отладочный код....................................................... 156
Использование операторов контроля.................................... 157
Использование операторов контроля в процессе компиляции.............. 159
Процесс отладки......................................................... 159
Что должно происходить............................................... 159
Что происходит на самом деле......................................... 159
Определение места поломки............................................ 159
Типы ошибок...........................................................160
Ошибки Бора (Bohr Bugs) ............................................. 161
Ошибки Гейзенберга (Heisenbugs)...................................... 161
Ошибка Мандельброта (Mandelbugs)..................................... 162
Ошибка Шредингера (Schroedinbugs).................................... 163
Кошмар программиста................................................... 163
Резюме.................................................................. 165
Оглавление
9
ГЛАВА 8. Управление памятью..............................................166
Управление памятью...............................;;..................... 166
Общие ошибки использования памяти....................................... 166
Использование незаказанной памяти.................................... 166
Рассматриваем функцию gets() как вредную............................. 167
Ошибки при сохранении адреса......................................... 168
Отсутствие проверки возвращаемых значений............................ 168
Отсутствие запасного указателя для realloc........................... 168
Использование памяти, которая не выделена............................ 169
Восстановление памяти операционной системой...........................170
Сбои функции выделения памяти........................................... 171
Проанализируйте требования памяти.................................... 171
Используйте меньше памяти.......................................... 171
Используйте буфер фиксированной длины................................ 172
Выделяйте резерв на случай аварийной ситуации........................ 172
Использование дискового пространства................................. 173
Успешное выполнение функции calloc...................................... 173
Занимаемся контролем.................................................... 174
Заголовочный файл для осуществления контроля над памятью............. 175
Реализация библиотеки контроля памяти................................ 178
Перепроектирование функции realloc................................. 179
Возвращение к предыдущему проекту realloc............................ 179
Проектирование хеш-ключей............................................ 180
Сообщения о текущих заказах памяти................................... 181
Резюме.................................................................. 184
ГЛАВА 9. Моделирование и Контроллеры.....................................185
Общее представление о конечных автоматах................................ 185
Пример выключателя света................................................ 186
Превращение конечного автомата в код.................................... 186
Применение моделирования и контроллеров................................. 187
Важные аспекты безопасности в использовании контроллеров................ 187
Обычные ошибки программирования...................................... 187
Рассказ о Therac-25.................................................. 188
Мораль этой истории.................................................. 188
Моделирование простого компьютера....................................... 188
Память................................................................188
Регистры............................................................. 189
Построение С-кода.................................................... 190
Считывание ассемблерного кода........................................ 190
Выполнение программы................................................. 192
Пошаговое выполнение команд.......................................... 192
Проверка содержимого регистров....................................... 192
Проверка содержимого памяти.......................................... 193
Дисассемблирование содержимого памяти................................ 193
Собираем все вместе.................................................. 193
Резюме................................................................. 193
ГЛАВА 10. Рекурсия.......................................................194
Что такое рекурсия...................................................... 194
Факториалы: традиционный пример...................................... 195
Числа Фибоначчи: другой традиционный пример.......................... 196
Искусство программирования на С
10
Как использовать рекурсию............................................. 196
Пример использования: двоичный поиск................................ 197
Как не следует использовать рекурсию..................................199
О рекурсии подробнее.....................................................199
Еще один пример: Евклидов алгоритм....................................200
"Хвостовая рекурсия”................................................ 200
Непрямая рекурсия................................................... 203
Рекурсия и время существования данных.................................203
Практическое применение рекурсии.........................................206
Резюме................................................................. 207
Часть II. Организация данных.............................................208
ГЛАВА 11. Простые абстрактные структуры данных...........................209
Массивы..................................................................210
"Обычные" массивы.....................................................210
Массивы переменного размера...........................................213
Массивы указателей....................................................222
Массивы указателей на функции.........................................222
Массивы разнородных объектов..........................................225
Односвязные списки.......................................................227
Добавление элементов..................................................229
Обновление элемента списка............................................231
Отыскание данных......................................................231
Удаление элемента.....................................................232
Уничтожение списка....................................................232
Проход по списку.............................-........................232
Тестовый драйвер......................................................233
Двусвязные списки........................................................235
Создание двусвязного списка...........................................235
Вставка элемента в начало списка......................................237
Вставка элемента в конец списка.......................................237
Вставка элемента внутрь списка........................................237
Обновление и поиск данных.............................................237
Извлечение элемента из списка.........................................237
Удаление элемента списка..............................................238
Как поменять элементы местами.........................................238
Подсчет числа элементов...............................................238
Вырезание и вставка...................................................239
Уничтожение всего списка..............................................239
Проход по списку......................................................239
Тестовый драйвер......................................................239
Циклические списки.......................................................242
Заглавный узел........................................................242
Вставка первого узла..................................................243
Вставка последующих узлов.............................................243
Восстановление и обновление данных....................................244
Вращение списка.......................................................244
Удаление узлов .......................................................244
Проход по списку.........................................................245
Решение задачи Иосифа.................................................245
Стеки....................................................................247
Оглавление
11
Создание стека........................................................248
Занесение элементов...................................................249
Извлечение элементов..................................................249
Обращение к первому элементу..........................................250
Подсчет числа элементов в стеке.......................................250
Сохранение природы стека............................................ 250
Пример стека: программа проверки синтаксиса HTML......................250
Очереди..................................................................253
Создание очереди......................................................254
Добавление элементов в очередь........................................254
Удаление элементов из очереди.........................................254
Сохранение природы очереди............................................255
Прикладная библиотека работы с очередями.........................*....255
Очереди по приоритету....................................................255
Создание очереди по приоритету........................................256
Добавление элементов в очередь по приоритету..........................256
Удаление элементов из очереди по приоритету...........................257
Приложение с очередью по приоритету...................................259
Двусторонние очереди (деки)-».......................................... 260
Добавление элемента в начало дека........У............................261
Добавление элементов в конец дека.....................................261
Удаление элементов из начала дека.....................................261
Удаление элементов из конца дека......................................262
Сохранение природы дека...............................................262
Дек автомобилей..................................................... 262
Разнородные структуры и объектные деревья................................265
Резюме................................................................. 265
ГЛАВА 12. Поиск по двоичному дереву.................................. 266
Анализ алгоритмов поиска.................................................266
Двоичный поиск........................................................266
Добавление и удаление элементов из отсортированной таблицы............267
Двоичные деревья.........................................................267
Структура для узла в языке С..........................................268
Структура в языке С для дерева........................................268
Операции..............................................................268
Создание...........................................................268
Поиск..............................................................269
Вставка............................................................269
Удаление...........................................................270
Упорядоченное рекурсивное прохождение..............................272
Упорядоченное итеративное прохождение..............................273
Уничтожение дерева.................................................274
Счетчик.......................................................... 274
Анализ................................................................275
Формирование двоичного дерева случайным образом....................275
Формирование двоичного дерева не случайным образом.................275
Передовые методы............................:.........................776
Указатели на родительские узлы.....................................276
Ссылки.............................................................277
Сбалансированные двоичные деревья........................................278
Искусство программирования на С
12
AVL-дерево...................................................... 278
Дерево red-black.................................................. 284
Сравнение AVL-дерева и дерева red-black............................. 289
Резюме.......................................................... 290
ГЛАВА 13. Методы быстрой сортировки................................. 291
Классификация данных.............................................. 291
Типы алгоритмов сортировки........................................ 292
Когда выполнять сортировку.......................................... 292
Основы сортировки................................................. 292
Алгоритмы порядка О(п2)........................................... 295
Алгоритмы, которых следует избегать...................................295
Сортировка методом выбора..........................................295
Пузырьковая сортировка....................................... 295
Эффективные методы сортировки....................................... 296
Сортировка методом вставок............................................296
Сортировка методом Шелла.......................................... 300
Быстрая сортировка.......................................... 300
Сортировка методом Синглтона..........................................302
Пирамидальная сортировка..............................................303
Сортировка подсчетом................................................ 304
Восходящая поразрядная сортировка................................... 306
Нисходящая поразрядная сортировка............................... 307
Методы сортировки слиянием............................................ 310
Сортировка двоичным слиянием..........................................310
Сортировка слиянием с делением на секции.......................... 310
Сортировка слиянием по принципу "нарезания печенья"...................312
Резюме ........................................................... 330
ГЛАВА 14. Деревья.......................................................331
Структура данных типа дерево............................................331
В каких случаях применяются деревья...................................332
Использование деревьев.......................................... 332
Создание и разрушение............................................. 333 .
Выделение битов................................................. 333
Поиск............................................................... 335
Вставка..................................................... 335
Удаление........................................................ 338
Возможные модификации структуры типа дерево...........................340
Сравнение деревьев с двоичными древовидными
структурами и хеш-таблицами.............................................342
Резюме............................................................ 342
ГЛАВА 15. Разреженная матрица...........................................343
Что такое разреженная матрица......................................... 343
Это не просто массив другого типа................................. 343
Метод физического хранения.........................................344
Метод доступа........................................ 345
Скорость доступа................................................. 345
Заголовочные списки............................................... 345
Узлы матрицы.................................................... 346
Размерность................................................... 346
Оглавление
13
Почему данные могут быть разреженными....................................347
Что такое разреженные данные...........................................347
Сложность кода...................................................... 348
Экономия памяти.......................................................348
Когда используется разреженная матрица.......................... 349
Типы задач.......................................................... 349
Направленный граф..................................................349
Сгруппированные данные........................................... 350
Многосвязные узлы.............................................. 350
Целесообразные операции...............................................351
Обход графов.......................................................351
Параллельные операции над узлами................................. 351
Мономиальные матрицы...............................................351
Простые операции над матрицами.....................................351
Операции, которых следует избегать....................................351
Сложные операции над матрицами.....................................351
Обращение матрицы..................................................352
Поиск "нулевых" значений......................................... 352
Построение разреженной матрицы........................................ 352
Построение заголовочных списков.......................................353
Добавление элементов заголовочного списка.............................357
Удаление элемента заголовочного списка................................358
Построение списка узлов матрицы.......................................359
Вставка узлов матрицы.................................................361
Удаление узлов матрицы................................................369
Прохождение разреженной матрицы....................................... 370
Перемещение по строкам................................................370
Перемещение по столбцам...............................................370
Перемещение по упорядоченным парам....................................371
Резюме..................................................................371
ГЛАВА 16. Работа с графами ....................................... 372
Определение графов.................................................. 372
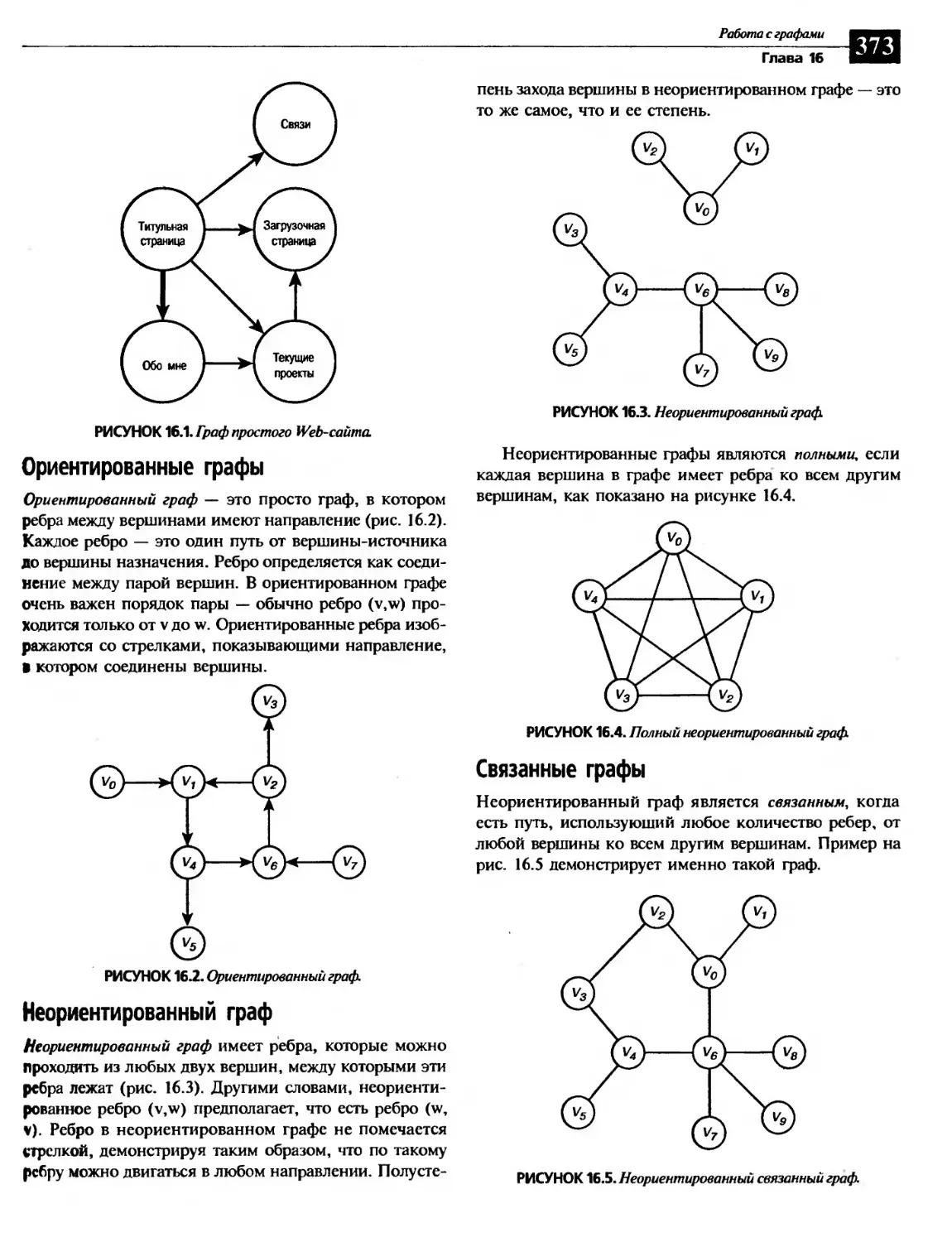
Ориентированные графы.................................................373
Неориентированный граф................................................373
Связанные графы.......................................................373
Насыщенные и разреженные графы........................................374
Циклические и ациклические графы........................................374
Представление графов....................................................374
Матрицы смежности.....................................................375
Списки смежных вершин.........................................’.......375
Топологическая сортировка.............................................377
Паросочетание.........................................................379
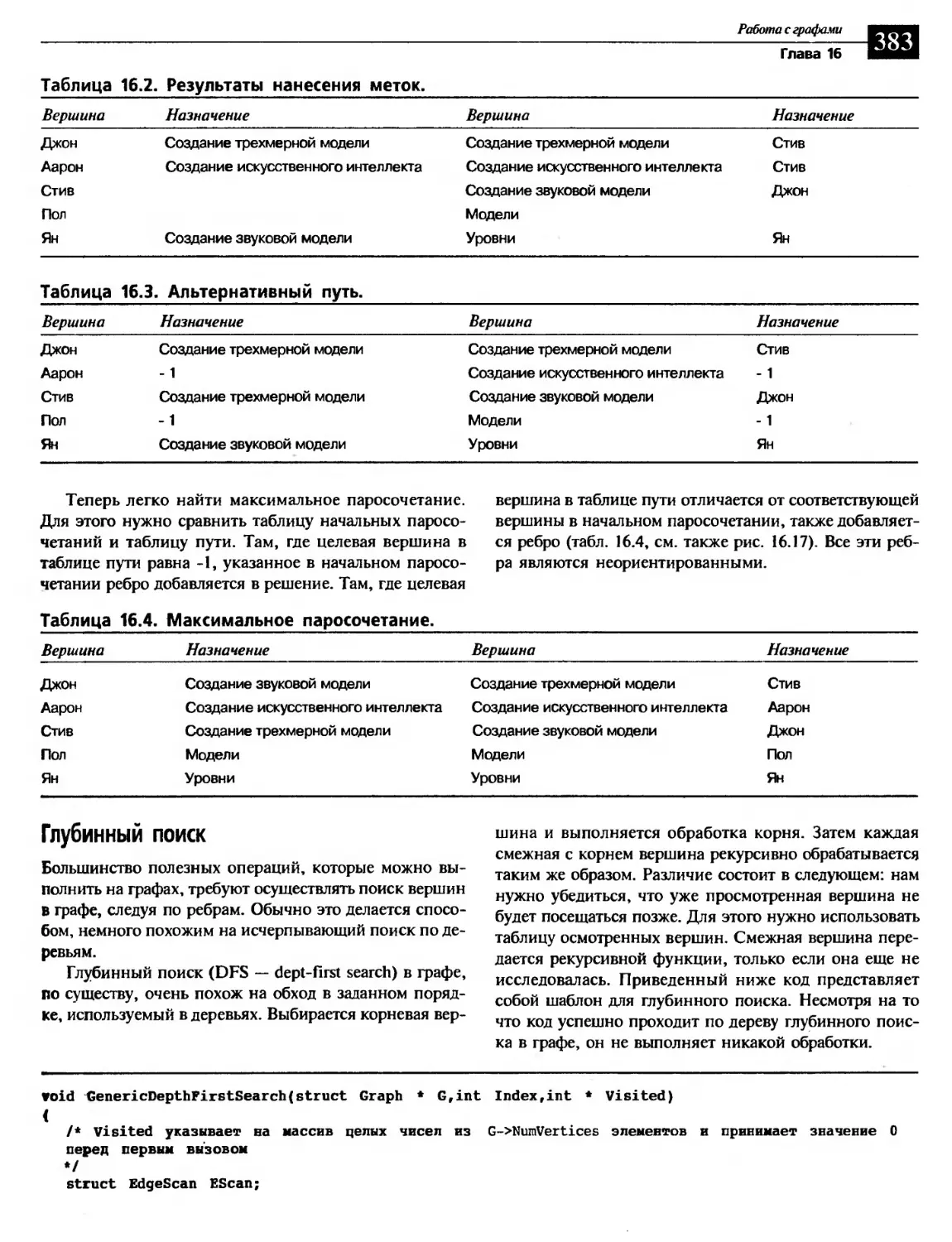
Глубинный поиск..................................................... 383
Нерекурсивный глубинный поиск....................................... 386
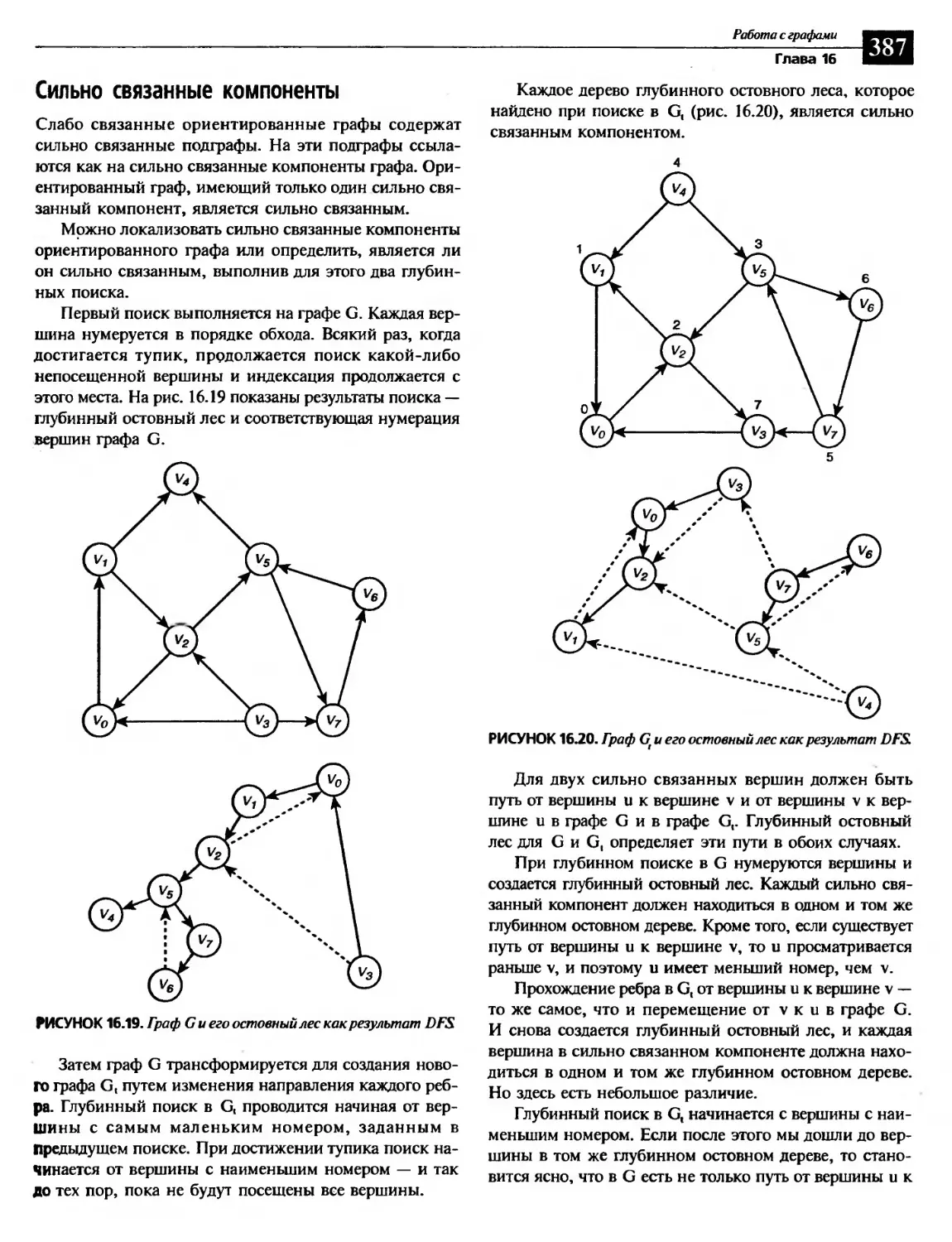
Сильно связанные компоненты...........................................387
Определение путей и контуров Эйлера...................................388
Задача коммивояжера...................................................389
Алгоритмы поиска кратчайшего пути.......................................391
Алгоритм Дийкстры: единственный источник..............................392
Алгоритм Беллмана-Форда: централизованные ребра с отрицательными
затратами.............................................................397
Искусство программирования на С
14
Алгоритм Флойда: все пары вершин......................................398
Минимальные остовные деревья............................................402
Алгоритм Крускала.....................................................402
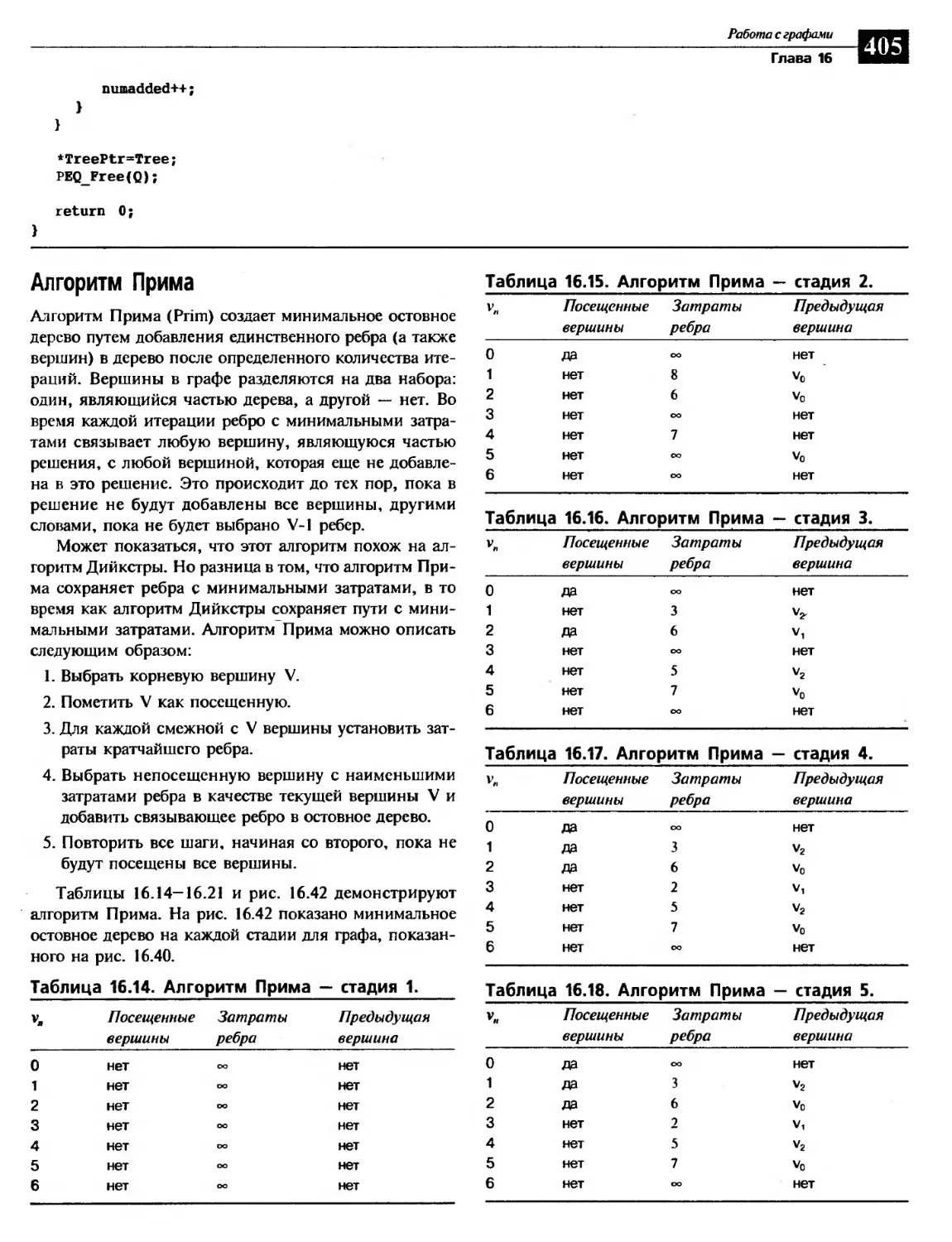
Алгоритм Прима........................................................405
Оптимизация: последнее замечание.................................... 408
Резюме........................................................ 409
Часть III. Дополнительные тематические разделы..........................410
ГЛАВА 17. Матричная арифметика........................................ 411
Что такое матрица................................................... 411
Простые операции матричной арифметики............................... 412
Реализация матричной структуры в языке С.......................... 413
Арифметика указателей и индексы массива...............................413
Что такое начальный индекс.......................................... 414
Структура MATRIX_T матричного типа....................................414
Обработка ошибок......................................................416
Другие принципы проектирования матричной библиотеки...................416
Инициализация матриц из массивов...................................... 417
Извлечение матрицы из файла........................................... 418
Запись объектов MATRIX_T в stdout или в другой файл.....................420
Полная реализация суммирования и транспонирования..................... 421
Сложные концепции матриц........................................ 422
Сложная математика матриц........................................... 422
Умножение матриц.................................................. 423
Единичная матрица............................................. 423
Определители и нормы Евклида........................................ 424
Обратная матрица.................................................... 428
Решение линейных уравнений..............................................430
Распространение ошибок при матричных вычислениях.................... 431
Исправление ошибок при решении систем линейных уравнений..............432
Дальнейшие направления работы..................................... 434
Другие подходы........................................................ 435
Резюме................................................................ 435
ГЛАВА 18. Обработка цифровых сигналов...................................436
Применение С к явлениям реального мира............................ 436
Сжатие данных...........................................................437
Типы сжатия....................................................... 437
Наиболее часто используемые алгоритмы сжатия........................ 438
Факсимильное изображение........................................ 438
Преобразование изображения в закодированный поток................... 439
Программа сжатия Т.4: encode.c.................................. 443
Функция main()................................................. 444
Функция EncodePage()...............................................445
Функция EncodeLineQ................................................445
Функция CountPixelRun()............................................445
Функция OutputCodeWordQ........................................ 448
Преобразование закодированного потока в изображение................. 451
Программа распаковки Т.4 decode.c .................................. 452
Функция main()............................................... 453
Функция DecodePageQ........................................ 453
15
Функция GetPixelRunQ...............................................456
Функция T4Compare()................................................458
Функция GetNext Bit()............................................ 458
Функция OutputPixels()........................................... 459
Генерирование символов................................................459
Выявление и исправление ошибок..........................................461
Борьба с хаосом.......................................................461
Избыточность................................................ 461
Четность.......................................................... 462
Контрольные суммы................................................... 464
Контроль, осуществляемый с помощью избыточного циклического кода... 465
Функция CRCCCITTO..................................................466
Функция main()................................................... 467
Исправление ошибок: коды Гамминга.....................................467
Технология RAID..................................................... 469
Алгоритмы управления PID............................................ 471
Программа pidloop.c............................................. 474
Структура PID__PARAMS............................................ 474
Переменные области видимости файла.................................475
Функция ComputePIDQ............................................ 475
Функция GetCurrentPV()........................................... 475
Пропорциональное управление: коэффициент Р............................478
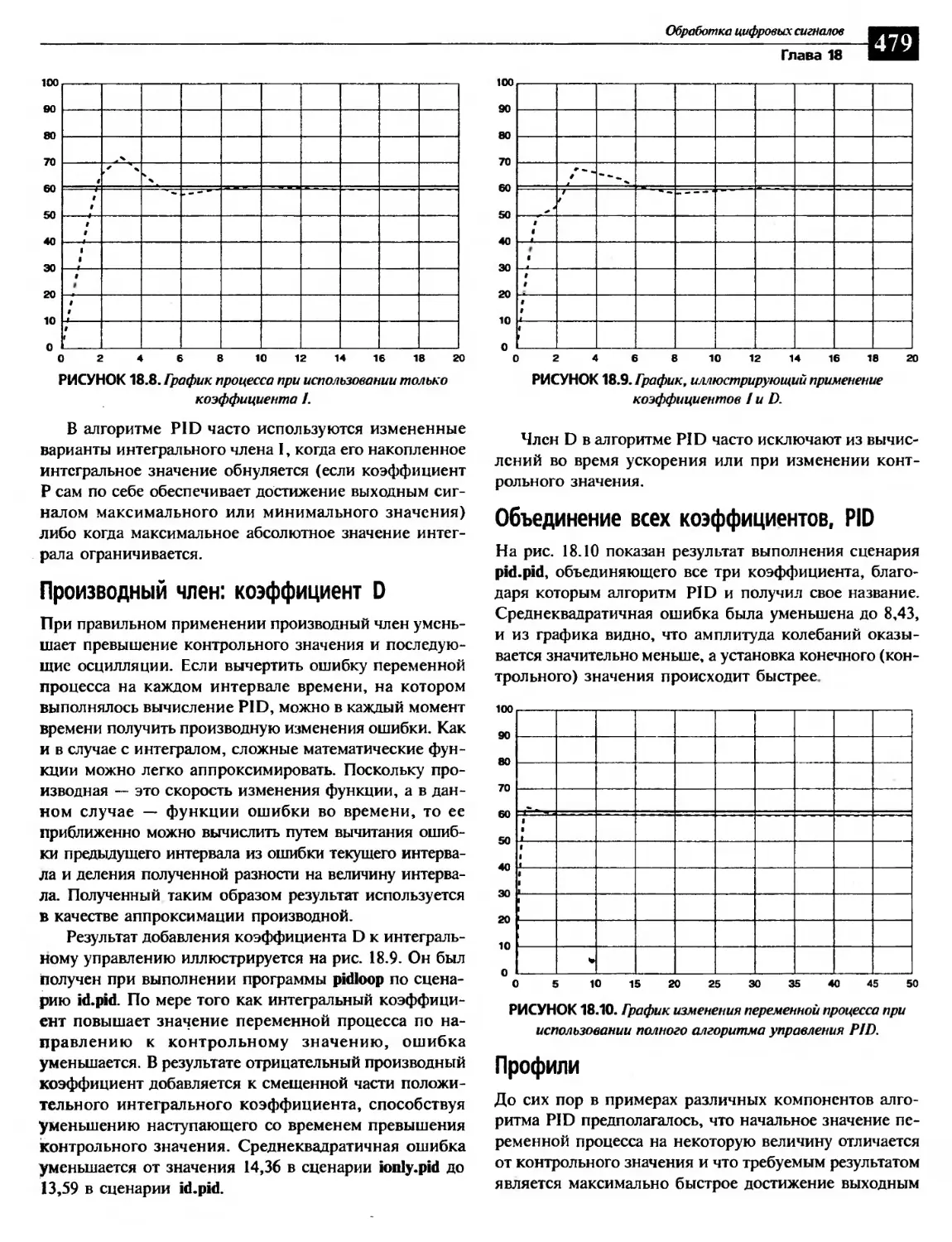
Интегральное управление: коэффициент 1................................478
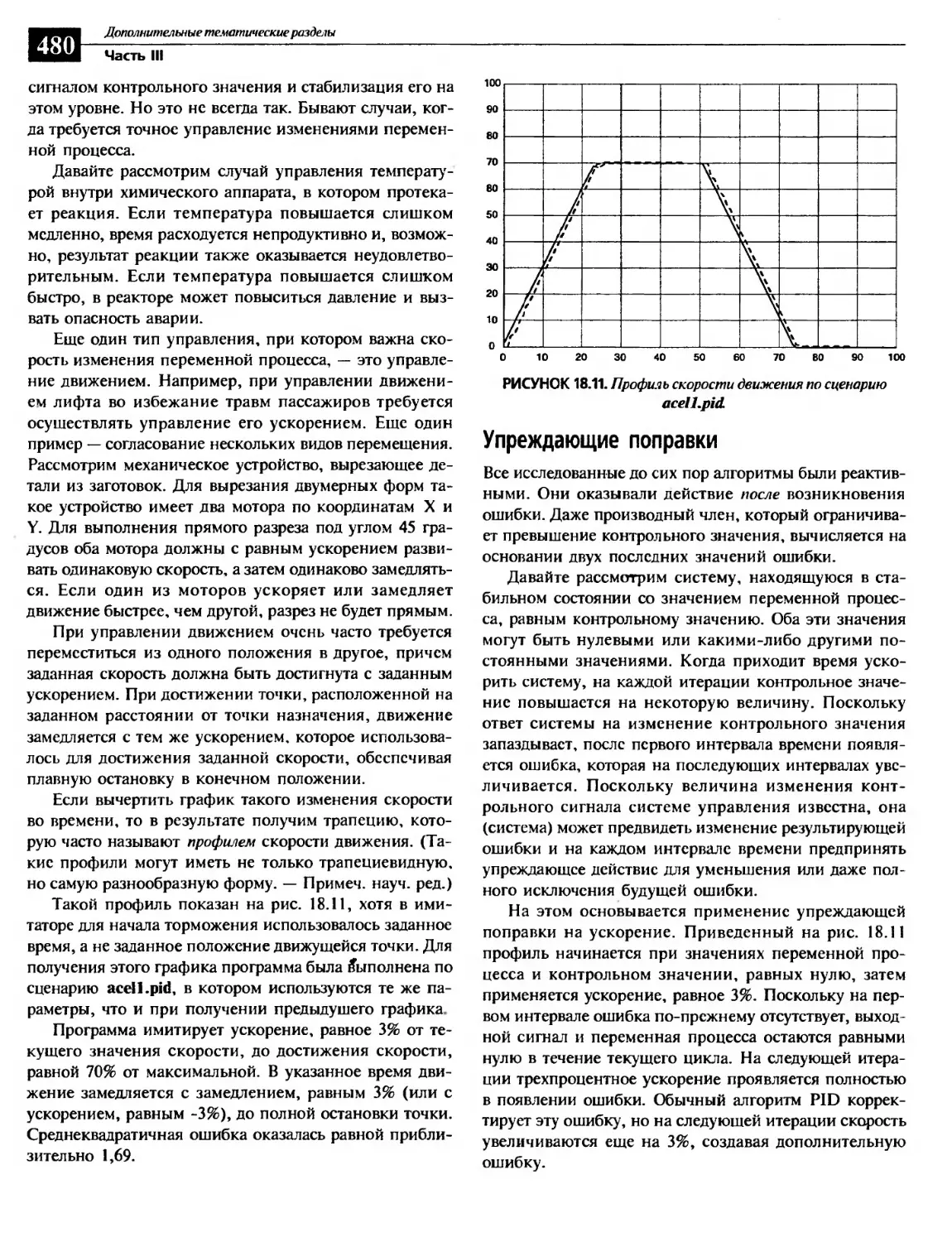
Производный член: коэффициент D.......................................479
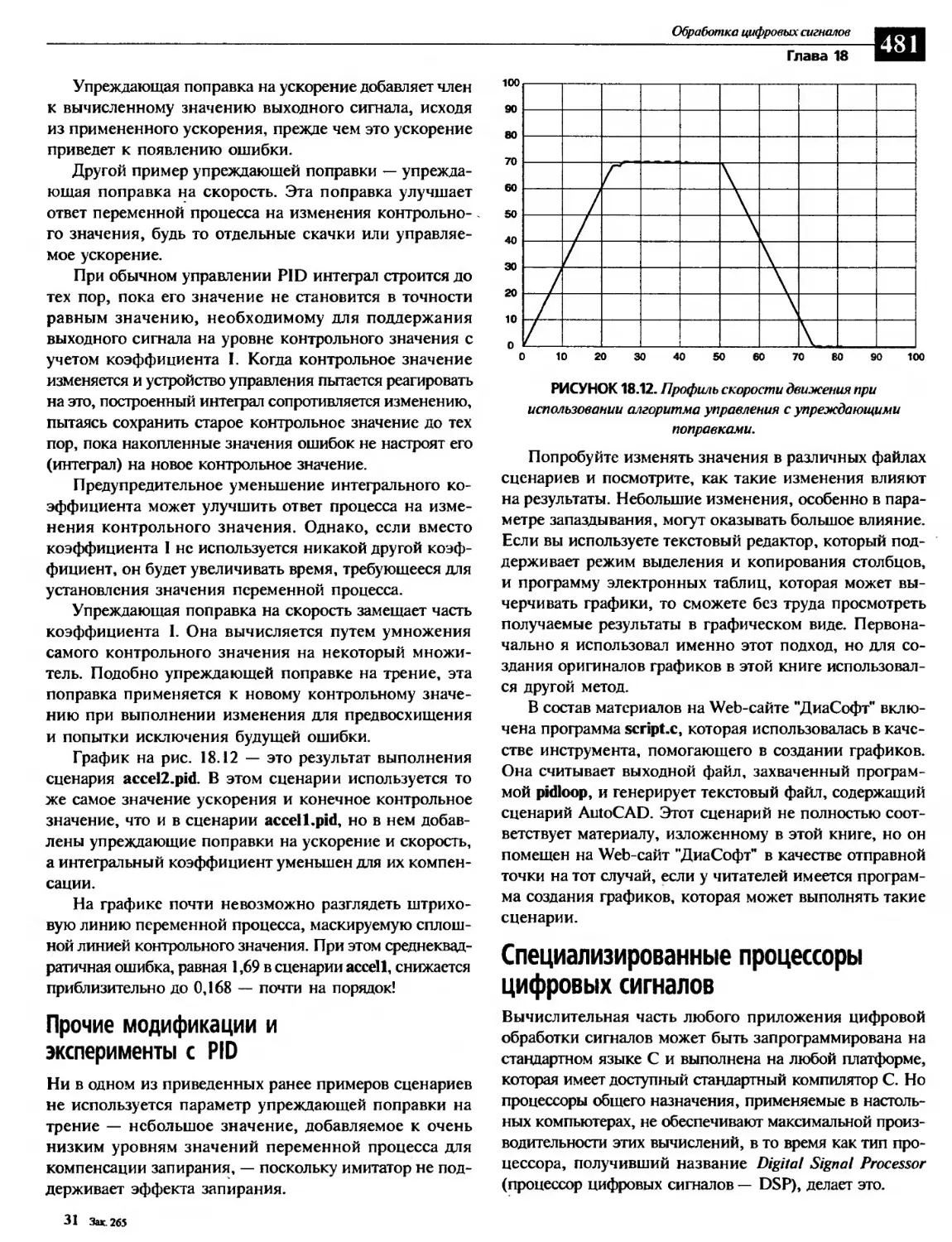
Объединение всех коэффициентов, PID............................... 479
Профили......................................................... 479
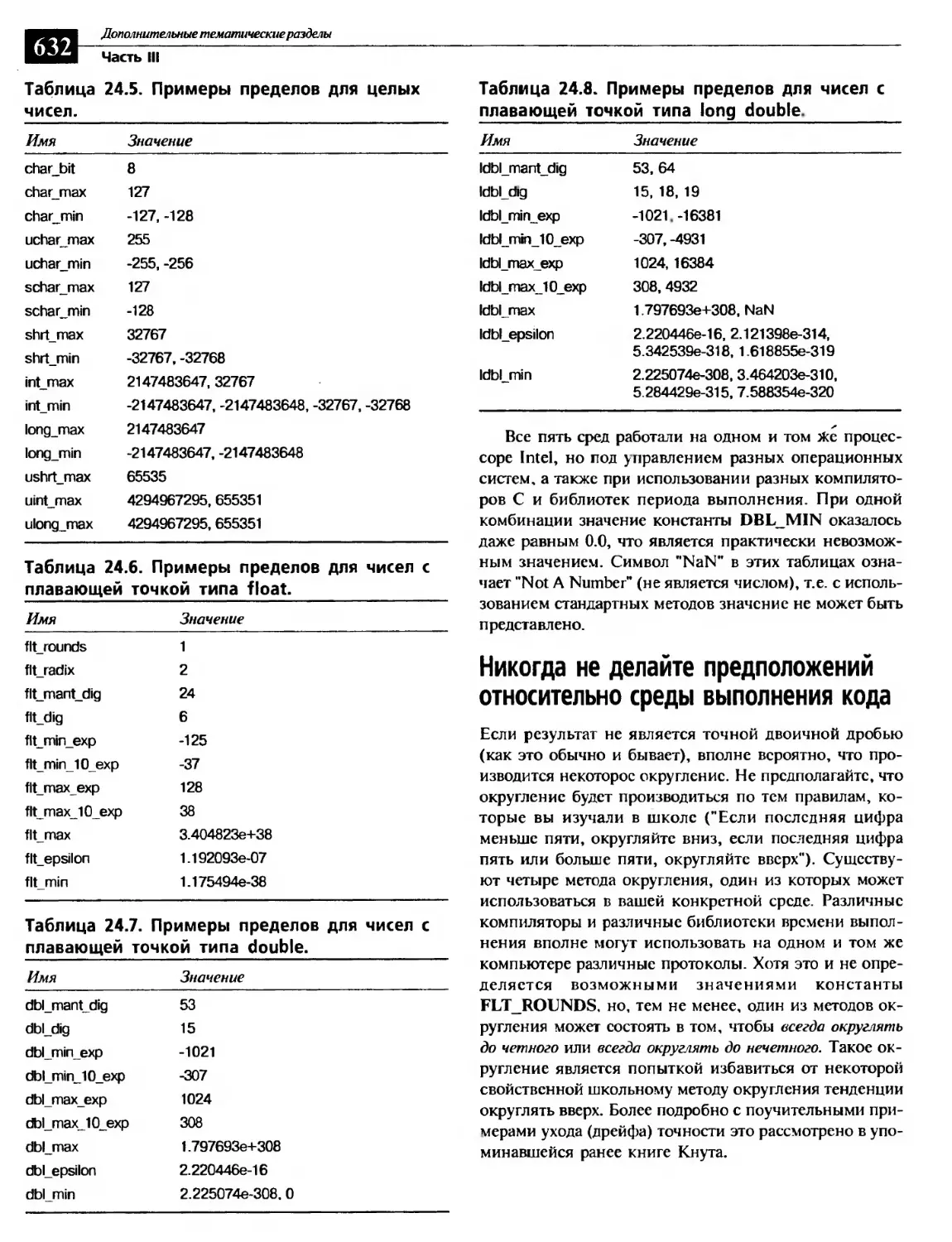
Упреждающие поправки................................................ 480
Прочие модификации и эксперименты с PID...............................481
Специализированные процессоры цифровых сигналов....................... 481
Инструкция МАС.................................................... 482
Суммирование квадратов................................................482
Индексация массивов...................................................482
Кольцевые буферы....................... ?..........................482
Арифметические операции с насыщением................................ 482
Циклы переполнения нуля............................................. 482
Множество адресных областей и шин данных..............................482
Большие внутренние области памяти............................... 482
Почему в настольном компьютере не используется DSP....................482
Расширения DSP в процессорах общего назначения........................483
Резюме..................................................................483
ГЛАВА 19. Синтаксический анализ и вычисление выражений..................485
Постановка задачи................................................. 485
Формулировка решения................................................ 486
Синтаксическая нотация................................................486
О понимании синтаксиса................................................487
Правила синтаксиса.................................................. 487
Правила старшинства и порядок вычисления..............................492
Польская нотация........................................................492
Краткая историческая справка..........................................492
Примеры обычной и обратной польской нотации...........................493
Искусство программирования на С
16
Преимущества польской нотации........................................493
Преобразование из обычной формы в форму обратной польской нотации......493
Упрощенный вариант................................................. 494
Полная версия.................................................... 521
Преобразование из формы польской нотации в оценочную функцию
Описание процесса обычным языком...........................
Пример кода для некоторого процесса......................
Синтаксический анализ ошибочного ввода.....................
Резюме...................................................................
ГЛАВА 20. Создание программных инструментальных средств..................
Характеристики хороших программных средств...............................
Интерфейс пользователя ................................................
Ошибкоустойчивость....................................................
Гибкость...............................................................
Простота...............................................................
Переносимость..........................................................
Библиотеки кодов.........................................................
Фильтры и инструменты общего применения..................................
Преобразование символов табуляции в символы пробела....................
Преобразование из EBCDIC в ASCII.......................................
Просмотр выходных данных............................................
Простой разделитель строк..............................................
Поиск и замена байтов..................................................
Шестнадцатиричные данные...............................................
Автоматическое генерирование тестовых данных.............................
Написание вспомогательных приложений для тестирования..................
Разработка тестовых данных.............................................
Написание кода генерирования тестовых данных...........................
Генераторы кода..........................................................
Квины..................................................................
Когда есть смысл генерировать код......................................
Разработка грамматики и синтаксиса входных данных......................
Простой синтаксический анализатор......................................
Образец вывода генератора кодов........................................
Управление сопровождением..............................................
Простой генератор кода.................................................
Резюме...................................................................
ГЛАВА 21. Генетические алгоритмы ........................................
Понятие генетического алгоритма..........................................
Генетическая структура...................................................
Операции мутации.........................................................
Рекомбинация.............................................................
Щдинственные родители..................................................
Скрещивание генов......................................................
Скрещивание последовательностей генов..................................
Объединение генов......................................................
Отбор....................................................................
Вскрытие “черного ящика"................................................
Оптимизация..............................................................
Параллелизм............................................................
Оглавление
Поиск эффективных генетических операторов........................565
Разделение проблемной области....................................566
Отклонение произошедших неудач................................. 566
Исправление ошибок...............................................566
Неполные решения и изменение ограничений на ресурсы..............566
Использование метафор............................................567
Пример приложения: генетический биржевой консультант...............567
Анализ проблемы..................................................567
Генетическая структура....................................... 567
Определение пригодности..........................................568
Процесс выбора...................................................568
Инициализация популяции..........................................569
Стратегия мутации................................................570
Стратегия рекомбинации...........................................570
Результаты и умозаключения.......................................572
Резюме.............................................................572
ГЛАВА 22. Межплатформенная разработка: программирование
коммуникационных средств...........................................573
Планирование переноса..............................................573
Абстрактные слои...................................................574
Сокеты.............................................................574
Сокеты, использующие TCP под управлением UNIX....................576
Сокеты, использующие TCP под управлением Windows.................581
Межплатформенное приложение........................................585
Использование препроцессора в качестве инструмента переноса......585
Написание абстрактного слоя......................................589
Резюме.............................................................603
ГЛАВА 23. Написание CGI-приложений на С ...........................604
Что такое CGI......................................................604
Основы CGI.........................................................605
Методы ввода данных в HTML.........................................605
Тег <FORM>.......................................................605
Тег <INPUT>......................................................606
Теги <SELECT> и <OPTION>.........................................607
Тег <TEXTAREA>...................................................608
Пример HTML-формы входных данных.................................608
Среда CGI..........................................................608
AUTH_TYPE........................................................609
CONTENT-LENGTH...................................................609
. CONTENT_TYPE...................................................609
GATEWAY-INTERFACE................................................609
HTTP—ACCEPT......................................................609
HTTP—CONNECTION..................................................609
HTTP_HOST.................................................... 609
HTTP—REFERER................................................... 609
HTTP-USER-AGENT..................................................609
PATH-INFO........................................................610
PATH-TRANSLATED..................................................610
QUERY-STRING.....................................................610
2 Зак . 265
Искусство ^ми.^^нияна С
REMOTE_ADDR............................................................610
REMOTE_HOST............................................................610
REMOTE_INDENT........................................................ 610
REMOTE_USER............................................................610
REQUEST-METHOD....................................................... 610
SCRIPT_NAME............................................................610
SERVER_NAME............................................................611
SERVER-PORT........................................................ 611
SERVER-PROTOCOL........................................................611
SERVER-SOFTWARE.................................................... 611
Получение данных....................................................... 611
Синтаксический разбор строки запроса................................... 612
Пример приложения: поиск прототипа функции......................... 616
Вопросы безопасности.....................................................619
Резюме................................................................. 621
ГЛАВА 24. Арифметика произвольной точности .......................... 622
Распространение ошибок при выполнении арифметических операций............623
Ошибки сложения и вычитания............................................623
Ошибка умножения..................................................... 623
Ошибка деления....................................................... 624
Выводы по размерам ошибок.......................................... 624
Переполнение, потеря значимости и деление на нуль...................... 624
Порядок выполнения операций..............................................625
Размеры целых чисел......................................................625
Точность операций над целыми числами................................. 626
Преобразования типов long и int........................................627
Размеры чисел с плавающей точкой.........................................627
Представление чисел с плавающей точкой.................................627
Максимальная точность................................................ 628
Нормализация...........................................................629
Точность операций над числами с плавающей точкой.......................629
Определение точности чисел с плавающей точкой..........................629
Никогда не делайте предположений относительно среды выполнения кода......632
Отрицательные числа не всегда представляются в виде дополнения до двух.633
Представления "от старшего к младшему" и "от младшего к старшему"......633
Примеры высокой и низкой точности...................................... 633
Различные методы представления сверхвысокой точности.....................634
Строки целых чисел................................................... 634
Пример кода для действий над строкой символов............................635
Сложение........................................................... 635
Умножение............................................................ 635
Дробные числа.......................................................... 638
Положение десятичной точки при умножении...............................638
Положение десятичной точки при делении.................................638
Общие арифметические функции...........................................639
Использование стандартных типов..........................................641
Выбор представления сверхточных чисел....................................647
Вычисление числа е с точностью до десяти тысяч знаков после точки........647
Резюме................................................................. 651
19
ГЛАВА 25. Обработка естественных языков..................................652
Синтаксис и семантика естественных языков.................... ..........652
Синтаксис естественных языков..........................................653
Семантика естественных языков.......................................... 658
Сложности ввода естественного языка......................................658
Команды обработки......................................................658
Игры...................................................................659
Машинный перевод.......................................................659
Эквивалентность...................................................... 660
Искусственный интеллект.............................................. 661
Установление авторства............................................... 661
Электронные игрушки.................................................. 662
Распознавание речи................................................. 663
Морфология........................................................... 664
Распознавание текста..........................,...................... 667
Синтаксический анализ естественно-языкового ввода......................667
Сложности вывода естественных языков................................... 668
Вывод звука.......................................................... 669
Вывод текста...........................................................669
Резюме...................................................................669
ГЛАВА 26. Шифрование.....................................................670
Оценка рисков нарушения безопасности................................. 670
Выявите угрозу....................................................... 670
Оцените ресурсы взломщика..............................................670
Определите, какова может быть цель взлома..............................671
Определитесь с оружием и тактикой взломщиков......................... 671
Узнайте своих пользователей.......................................... 671
Сосредоточьтесь на самом слабом звене..................................671
Почему не следует создавать новых алгоритмов шифрования..................672
Что плохого в новых шифрах.............................................672
Держите внешние границы на виду.................................... 672
Сложность — это не безопасность.................................... 673
Выбор алгоритма шифрования............................................. 673
Шифрование с одним ключом..............................................674
Шифрование с двумя ключами.............................................676
Одностороннее хеширование............................................ 676
Реализация шифрования....................................................678
Режимы работы.................................................... 679
Порядок байтов....................................................... 681
Обеспечение аутентичности открытого ключа............................ 684
Слишком высокая скорость шифрования.................................. 684
Слишком высокий уровень безопасности...................................685
Просто добавьте "соли”.................................................685
Постоянство памяти.....................................................686
В поисках помех.................................................... 686
Чем меньше, тем лучше..................................................687
Не оставляйте подсказок................................................687
Маскировка информации................................................ 688
Последние штрихи.......................................................688
Резюме................................................................. 689
Искусство программирования на С
20
ГЛАВА 27. Встроенные системы........................................ 690
Программирование встроенных систем на языке С.........................691
Подготовка к работе.................................................691
Запуск программы встроенной системы............................... 692
Базовые средства ввода/вывода..................................... 693
Печать сообщений и отладка программ.................................695
С-программирование встроенных систем и стандарт ANSI С................695
RTOS — операционные системы реального времени.........................696
Система RTEMS как типичный пример RTOS................................697
Резюме.............................................................. 698
ГЛАВА 28. Параллельная обработка.................................... 699
Основные концепции.................................................. 699
Компьютеры и параллельная обработка................................. 700
Приоритетная многозадачность........................................700
Кооперативная многозадачность................................... 701
Межпроцессная коммуникация........................................ 701
Потоки, многопоточность и синхронизация.............................701
Параллельная обработка в С.......................................... 702
Многозадачность в С............................................. 703
Многопоточность в С............................................... 703
Межпроцессная коммуникация в С.................................. 705
Синхронизация доступа к данным в С..................................707
Резюме................................................................709
ГЛАВА 29. Взгляд в будущее: С99.......................................710
Новое в стандарте С99............................................. 710
Новые типы.................................................... 710
Базовые типы................................................... 711
Производные типы............................................... 712
Новые свойства стандартной библиотеки............................. 712
Новые (и расширенные) ограничения...................................713
Новый синтаксис.....................................................713
Набор символов...................................................713
Синтаксис препроцессора...................................... 714
Объявления.......................................................714
Инициализация.................................................. 715
Другие новые свойства...............................................716
Потерянные возможности............................................ 716
Изменения по сравнению с С89..........................................716
Резюме................................................................717
Часть IV. Приложения..................................................719
ПРИЛОЖЕНИЕ А. Общедоступная лицензия GNU..............................720
ПРИЛОЖЕНИЕ В. Избранная библиография..................................724
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ..................................................726
Об авторах
Ричард Хэзфилд (Richard Heathfield) — владелец и раз-
работчик программного обеспечения компании Eton
Computer Systems Ltd. Когда писал коды для страховых
компаний, лечебных учреждений, банков и аэрофлота,
он всегда задавался вопросом, сможет ли он когда-либо
найти клиента, используя лишь систему C++ Builder. В
настоящее время он живет недалеко от Поттерспури в
городке Нортамптоншир. (Великобритания) вместе с
женой, тремя прекрасными детьми, сетью из пяти ком-
пьютеров и множеством С-компиляторов, с которыми
он знает, что делать. Он прекратил избегать main() не-
задолго перед тем как стать регулярным контрибьюте-
ром в группе новостей comp.iang.c; это факт, которому
он будет вечно признателен. Ричард тратит много време-
ни на поисковом Web-сайте Yahoo! Chat, занимаясь про-
блемой CDreamer, и всегда рад использовать такую воз-
можность, чтобы сказать “Привет!” всем, кто посещает на
этом сайте раздел Programming room по программирова-
нию. В настоящее время Ричард интересуется программи-
рованием на TCP/IP, автоматизированным генерирова-
нием кода на С, стандартом С99 и кофе. Когда он не
программирует, не консультирует или не пишет о про-
граммировании (или не пьет кофе), он включает свои
усилители и очень громко играет на электрогитаре. Ри-
чарда можно найти на Web-сайте по адресу http://
users.powernet.co.uk/eton.
Лоуренс Кирби (Lawrence Kirby), дипломированный
специалист Кэмбриджского университета (Англия), был
программистом на С в течение более 10 лет. Он является
соучредителем компании Netactive Systems Ltd — ком-
пании, специализирующейся на коммуникациях и на
информации финансового рынка. Ранее он в течение не-
скольких лет работал в компании British Telecom в от-
деле сетевой службы и информационных систем. Ему
нравится быть постоянным контрибьютером групп но-
востей Usenet, таких как comp.lang.c; он находит исклю-
чительно полезным как получать опыт в оказании по-
мощи другим в решении проблем языка С, так и
делиться своим собственным опытом с другими С-про-
граммистами (от новичков до членов Комитета по стан-
дартам С).
Дэн Корбит (Dann Coibit) имеет степень по числен-
ному анализу Вашингтонского университета и был ком-
пьютерным программистом начиная с 1976 г. Частич-
но список его связанных с компьютерами работ можно
найти в internet по адресу ftp://38.168.214.175/pub/
CA.P.%20Biographies/DannCorbit.htm#_Toc441048186.
Дэн программирует на С с середины 1980-х гг. и
обучался этому языку программирования в Олимпий-
ском колледже в Бремертоне (штат Вашингтон). Он
писал журнальные статьи для Dr. Dobb ’s Journal и был
соавтором научных трудов по китам Balaena
mysticetus для организации North Slope Borough, ко-
торая представила его к степени IWC. Он является
основателем и менеджером международного проекта
по шахматному анализу (Chess Analysis Project), в
котором используются компьютерные программы для
анализа позиций на шахматной доске и каталогизи-
рования результатов в базе данных. Web-сайт часто
задаваемых вопросов (FAQ) по проекту Chess Analysis
Project можно найти по адресу ftp://38.168.214.175/
pub/Chess%20Analysis%20Project%20FAQ.htm.
Как постоянного контрибьютера группы новостей
news:comp.lang.c Дэна всегда можно найти здесь и по-
лучить от него дружественный ответ в его немного экс-
центричном стиле. Длительное время интересуясь ма-
тематикой и другими науками, он занял первое место
на научной ярмарке Mid Columbia Science Fair и был
финалистом на междунарожной научной ярмарке
International Science Fair со своим проектом An Analysis
of a Solid Solution.
Чед Диксон (Chad Dixon), в течение последних семи
лет работающий сетевым инженером, имеет дело с мно-
жеством широкомасштабных технологий в области ком-
пьютерной обработки. Попутно он начал реализовать
решения для своих клиентов, обращающихся на Web-
сайт Client/Server Application development (разработка
приложений клиент/сервер), и решения по базам дан-
ных для систем сетевого мониторинга предприятий.
Работа с такими предприятиями и организациями как
NASA, Lyondell, Olin, Arco Chemical и British Petroleum
дала ему значительный опыт в разработке межплатфор-
менных сетевых приложений. Чед живет в Хьюстоне
(штат Техас) со своей любимой женой Вероникой и
Снежком — их любимым кроликом. С Чедом можно
связаться по адресу http://www.loopy.org.
Вильям Фишбурн (William Fichbume) получил уче-
ную степень бакалавра в области компьютерных наук в
1989 г. в Мэрилендском университете. В настоящее вре-
мя он старший консультант корпорации Alphatech
Corporation. Вильям обучался также в колледже Prince
George’s Community College в Мэриленде и в настоящее
время является членом ассоциации ACCU пользовате-
лей С и C++.
Вильям занимается программированием на С еще со
времени своего обучения и работал в таких разнообраз-
ных областях как спутниковая коммуникация, форми-
рование изображений и системы финансовых расчетов.
Он работал на самых разнообразных UNIX-платформах
и был одним из первых участников переноса операци-
онной системы Microsoft Widows NT на многопроцес-
сорные платформы. Вильям писал статьи для популяр-
ных компьютерных журналов по программированию
таких как Dr. Dobb’s Journal. Кроме того, он включился
Искусство программирования на С
22
в добровольную деятельность по такому проекту как
Project Gutenberg (проект Гутенберг по сохранению
книг, которые более не защищены авторским правом, и
бесплатному распространению их в электронном виде).
Вы можете встретить Вильяма в Internet по адресу
wfishbume@atcnet.com и посетить Web-страничку про-
екта Гутенберг по адресу http://www.gutenberg.net.
Скот Флурер (Scott Fluhrer) программирует на С с
1979 г. В настоящее время работает инженером по раз-
работкам компании Cisco Systems. Другие его интере-
сы включают научный вымысел (фикцию) и криптог-
рафию.
Сэм Хоббс (Sam Hobbs) занялся проблемами компь-
ютерной обработки данных еще в 1966 г., и начинал с
25-битовых последовательных компьютеров со 196 сло-
вами основной памяти барабанного типа, на которых
языком программирования был только машинный язык.
С тех пор он работал на Фортране, Бейсике, Фокале, С,
C++ и с различными сценарными языками (в основном
AWK и Perl), а также с некоторыми языками баз дан-
ных. С языком С Сэм работает начиная с 1985 г. Свой
первоначальный опыт он получил в электроэнергетичес-
кой индустрии (в основном в области коммерческой
атомной энергетики), исполняя технические, контроли-
рующие и управленческие роли. В настоящее время
работает в качестве инженерного и управленческого кон-
сультанта в индустрии атомной энергетики.
Ян Келли (Ian KeLly) является консультантом по
компьютерным системам, который впервые стал про-
граммировать профессионально в 1963 г. Он прошел
путь от оказания технической помощи в программиро-
вании главной электрогенерирующей компании Вели-
кобритании, разработки и управления написанием опе-
рационной системы (ADAM), конструирования число-
вых компиляторов — до написания материалов по
переносимости программного обеспечения для Европей-
ской Комиссии. Ян имеет специальную степень бака-
лавра по математике, и это служит оправданием тому,
что последние 35 лет он пытался сделать что-нибудь в
области математики — но безуспешно. Вместо этого он
досконально изучил (путем практического применения)
более чем двадцать компьютерных языков в самых раз-
нообразных средах. В настоящее время он консульти-
рует по вопросам о том, как могут быть улучшены и
расширены системы, в которых используются смешан-
ные языки.
Будучи убежденным, что французский язык так же
прост как и Кобол, в конце 1970-х гг. он заинтересовал-
ся проблемами машинного перевода (МТ), написал две
книги и несколько статей на эту тему и был (в течение
более 15 лет) главным специалистом группы по МТ.
Ян живет в Суррее (Англия) недалеко от пивной. Он
играет на органе в церкви с тысячелетней историей и
аранжирует музыку для женского хора, которым руко-
водит Счастриво женат уже более чем 30 лет, имеет
двоих детей, гвинейского поросенка и шиншиллу. Ян
обещает, что он вернется к пробежкам вокруг газона —
на следующей неделе.
Джек Клейн (Jack Klein) занялся программировани-
ем настольных компьютеров и, прежде всего, проекти-
рованием и программированием встроенных систем в
1980 г. Он участвовал в разработке продуктов, исполь-
зующих множество различных 8-, 16- и 32-битовых про-
цессоров, и программировал их на естественном ассем-
блерном языке, а начиная с 1983 г. — на языке програм-
мирования С.
Специализируясь на процессном контроле, контро-
ле движения и коммуникациях, Джек разрабатывал и
программировал встроенные системы для использования
в промышленном, медицинском, бытовом и офисном
оборудовании.
Джек в настоящее время является главным инжене-
ром группы ядерной медицины компании Siemens
Medical Systems, где он работает над проектными схе-
мами встроенных систем, над вопросами управления
движением и безопасности пациентов, а также разраба-
тывает программное обеспечение сборки образов для
медицинских устройств формирования изображений.
Майкл Ли (Michael Lee) занимается программиро-
ванием с 1979 г. и имеет многолетний опыт работы с
языками про1раммирования PL/1 и С. Первоначально его
деятельность была сосредоточена на разработке потреби-
тельских систем баз данных. Впоследствии его усилия
были направлены на привязку SQL-интерфейса к базе
данных, первоначально реализованной на Фортране.
Возможно, его наиболее значительным проектом
был оптимизатор запроса — небольшой фрагмент кода,
который анализирует поступающий к базе данных зап-
рос и трансформирует его в эквивалентный, но более
эффективных запрос, который улучшает использование
связей и индексов базы данных. Другие его проекты
включают исчерпывающую Web-страницу по оптими-
зации различных приемов и методов, а также программ-
ное обеспечение для генерирования списков лучшей
десятки групп новостей Usenet.
Когда Майк не программирует, он любит покатать-
ся на горном велосипеде по склонам недалеко от его
калифорнийского дома, определенно предпочитая спус-
каться по склону, а не подниматься в гору.
Бэн Пфаф (Ben Pfaff) — студент-электротехник Ми-
чиганского государственного университета, где он со-
стоит в команде фехтовальщиков MSU. После обучения
он надеется получить работу по проектированию циф-
ровых интегрированных схем. Бэн работает с компью-
терами уже 14 лет, 10 из которых — с языком програм-
мирования С. Его интересы помимо компьютеров
Искусство программирования на С
23
включают французский и японский языки, научный вы-
мысел и путешествия. В Internet вы часто можете найти его
ответы на вопросы в форуме Usenet comp.langx. Бен так-
же сопровождает систему Debian GNU/Linux
(www.drbbin.oig) и автор программ для Фонда Бесплатно-
го Программного Обеспечения (www.fsf.org)- С Бэном
можно связаться по электронной почте pbflben@msu.edu.
Питер Сибеч (Peter Seebach) является заядлым лю-
бителем языка С. Он научился читать программы на С
с принтерных распечаток и, в конечном счете, научил-
ся также писать на С. Он состоит в комитете по стан-
дартам ANSI/ISO С, поскольку, как он утверждает,
"ANSI/ISO С звучит как музыка”. Питер участвует в
группе comp.lang.c.moderated. Он обычно программи-
рует, поскольку "это — лучший способ не поддаться со-
блазну видеоигр”.
Стив Саммит (Stiv Summit) — ветеран среди про-
граммистов на С, автор и преподаватель. Вот уже 20 лет
он программирует почти исключительно на С. Он со-
провождает список наиболее часто задаваемых вопросов
в труппе новостей comp.lang.c. Его программистские ин-
тересы варьируют, но они всегда тесно связаны с тема-
ми чистоты, применимости, переносимости и подразу-
мевающейся правильностью программ на С.
Мэтью Ватсон (Mathew Watson) написал свою пер-
вую программу на машинном коде (поскольку высоко-
уровневые языки выполнялись на первом 8-битовом
процессоре очень медленно) в возрасте 10 лет, и с тех
пор был захвачен возможностями компьютеров. Он изу-
чал компьютерные науки в Лондонском университете и
работал для различных компьютерных фирм; он воочию
увидел, насколько необходимо начальное проектирова-
ние программного обеспечения для определения воз-
можных ошибок фактического выполнения программ.
Сейчас Мэтью ожидает рождения своего первенца, так
что он/она может показать ему, как запрограммировать
все, что будет эквивалентно видеомагнитофону в 21 веке —
так же, как сам Мэтью делал это для своего папы.
Стефан Уилмс (Stephan Wilms) — профессиональный
разработчик программного обеспечения с опытом в об-
ласти промышленной обработки изображений и меди-
цинских систем для кардиологических исследований и
лечения. На протяжении своей карьеры он работал с вы-
сокопараллельными встроенными системами и разраба-
тывал сложные приложения для конечных пользовате-
лей Widows.
Ян Вудс (Ian Woods) занимался профессиональным
программированием семь лет, и в настоящее время ра-
ботает над написанием встроенного программного обес-
печения реального времени для одной исследовательс-
кой компании. Он специализируется на С и различных
ассемблерных языках. Многие его проекты основывают-
ся на глубоких знаниях дискретной математики и мето-
дов обработки сигналов. Сейчас он изучает разговорный
язык, называемый Lojban — инженерный логический язык
с формальной грамматикой, которая существенно облег-
чает обработку и генерирование “живой” речи. Боль-
шинство его интересов направлены на исследования его
неординарных идей, которые охватывают многие обла-
сти в вопросах разработки программного обеспечения.
Майк Райт (Mike Wright) является главным техно-
логом Innovative Systems Architect — корпорации, кото-
рая заработала внушительную репутацию поддержкой
технических нужд тестирования и подготовки персо-
нала полигонов Министерства Обороны США. Дея-
тельность Майка направлена на проектирование и раз-
работку усовершенствованного анализа задач и наборов
инструментов визуализации для полигона Nevada
“Black” Range. Майк полностью удовлетворен трудно-
стями своей работы, постоянно проводя исследования
новых усовершенствований в инженерии программно-
го обеспечения. Вы можете встретиться с ним по адре-
су mike_wisdom@yahoo.com.
Искусство программирования на С
24
Посвящение
Моей Никки (Nicky) — самой очаровательной женщине в
мире. С любовью
— Ричард Хэзфилд
Благодарности
Я признателен многим людям. И соавторам — в первую
очередь: без них не было бы этой книги. Но особую
благодарность хочу выразить Дэну Корбиту и Бэну
Пфаффу, которые квалифицированно разобрали мои
исходные коды и уничтожили в них немало демонов, а
также Чеду Диксону, оказавшему мне большую помощь
в часы сомнений, и Яну Келли — несомненно, англий-
скому Дональду Кнуту (Donald Knuth).
Огромная признательность Кэрол Аккерман (Carol
Ackerman) из издательства Sams Publishing, которая мно-
го сделала для того, чтобы эта книга вообще появилась,
Гасу Микласу (Gus Miklos), уверенной рукой держав-
шему руль по нужному курсу, а также всем другим
сотрудникам издательства Sams, которые так тяжело ра-
ботали, чтобы довести эту книгу от идеи до ее реализации.
Множество других людей также бескорыстно отда-
ли свое время, энергию, идеи и наработки. Благодарю
Олю Энжделсмарк (Ola Angelsmark), Ника Крамера
(Nick Cramer), Марка Дэна (Mark Dean), Джонатана
Джорджа (Jonathan George), Мэта Гэсснера (Matt
Gessner), Стэфена Хэзфилда (Stephen Heathfield), Джо-
на Хиксона (John Hixson), Лейбиш Мэрмелстейн
(Leibish Mermelstein), Эдмунда Стефен-Смита (Edmund
Stefen-Smith) и Брайана Вильямса (Bryan Williams).
Наконец, большое спасибо наилучшей в мире бра-
тии хакеров, жителей тех глубоких, темных и непрохо-
димых джунглей, которые называются comp.iang.c, слу-
чайно обеспечив мне экспертную техническую помощь
своими ответами на вопросы, задаваемые другими людь-
ми, и таким образом сэкономив мои усилия, которые я
затратил бы сам, отвечая на такие вопросы.
— Ричард Хэзфилд
Пересмотренный язык С
ЧАСТЬ
В ЭТОЙ ЧАСТИ
Энциклопедия С-программиста
Войны стандартов программирования:
причины и пути перемирия
Оптимизация
Работа с датами
Игры с битами и байтами
Хранение и извлечение данных
Исправление кода программ
Управление памятью
Моделирование и контроллеры
Рекурсия
Энциклопедия С-программиста
В ЭТОЙ ГЛАВЕ
Для кого предназначена эта книга
Какие знания вы должны иметь
Как наиболее эффективно использовать книгу
Для чего нужна еще одна книга по С
Почему используется стандарт ANSI С
Какие платформы охватывает эта книга
Об исходном коде
Качество программного кода
Как организована эта книга
Проблемы авторских прав
Содержимое компакт-диска
Общество С-программистов
Ричард Хэзфилд
Добро пожаловать в страну С! Издательство Sams при-
ступило к выпуску серии компьютерных книг серии
"Энциклопедия”. На сегодняшний день имеется очень
широкий выбор таких книг-энциклопедий, предостав-
ляющих исчерпывающую информацию по тому или
иному языку либо компилятору. Что касается данной
книги, то она является результатом кропотливого тру-
да авторов по изучению и описанию особенностей при-
менения языка С.
С является простым, но чрезвычайно мощным язы-
ком; он использовался для реализации операционных
систем, видеоигр, программирования микроволновых
печей, текстовых процессоров и фактически чуть ли не
каждого современного электронного устройства, какое
только можно себе представить. Если бы язык С имел
какие-либо серьезные ограничения, он не был бы столь
популярен, а эта книга имела бы, вероятно, намного
меньший объем. По традиции эта книга называется "С.
Энциклопедия пользователя”, но я бы предпочел на-
звать ее "Энциклопедия С-программиста".
Представьте себе, что вы обратились к специалисту
с таким вопросом: "я пытаюсь выполнить некоторые
вычисления, в которых очень важна точность. Мне тре-
буется 500 значащих цифр, но я могу получить лишь 15
или около того. Как достигнуть большей точности?”
Еще недавно на этот вопрос вы получили бы такой
ответ: "Это невозможно сделать на С. На современных
системах количество значащих цифр переменных двой-
ной точности double определено константой DBL_DIG
в библиотеке <float.h> и составляет обычно 15. Вы уве-
рены, что вам требуется 500 цифр?”
Но с выходом в свет этой книги у вас появился шанс
разрешить эту задачу. Вы узнаете, как это можно сделать
на С.
В частности, вы убедитесь что осуществлять сорти-
ровку в С можно быстрее, чем с помощью программы
Quicksort. Можно более эффективно обрабатывать раз-
говорные языки, а также автоматически определять
утечку памяти, перемножать два массива и многое-мно-
гое другое.
К сожалению, не все задачи поддаются решению
при использовании чистого языка С, основанного на
стандарте ANSI С (American National Standard for
Information for С — Американский национальный ин-
формационный стандарт программирования на С. —
Прим, науч, ред.) Идея стандарта ANSI С состоит в том,
чтобы сделать язык С переносимым на любые платфор-
мы. В результате желаемые свойства, которые, как пред-
полагается, должны быть стандартными в любом язы-
ке, часто отсутствуют просто потому, что не все
платформы поддерживают эти свойства. Например, не-
возможно очистить экран из программы на С. Почему?
Да просто потому, что не все системы вообще имеют
экран! Моя собственная Linux-система большую часть
времени отключается от экрана и клавиатуры, но все же
управляет выполнением полезной работы. Как прави-
ло, программы, ориентированные на конкретные аппа-
ратные средства (такие, как лазерный принтер или во-
27
обше принтер любого типа) либо требует частной па-
радигмы операционной системы (например, концепции
структуры директории), вряд ли может быть реализо-
вано на ANSI С. В наше время следует обращаться к до-
полнительным функциям, обеспечиваемым конкретной
реализацией.
Несмотря на это ограничение, в среде языка С мож-
но выполнять множество таких операций, о которых
многие и не подозревают. Для этого придется немного
подумать и выполнить определенную работу. Мы попы-
тались, насколько смогли, сами поразмышлять и выпол-
нить черновую работу так, чтобы вы могли наслаждать-
ся ее результатами.
Для кого предназначена эта книга
Книга "С. Энциклопедия пользователя" предназначена
для тех программистов, которые уже приобрели хотя бы
самый минимальный опыт программирования на язы-
ке С, т.е. либо ежедневно используют его в своей рабо-
те, либо подробно изучают его в течение, по крайней
мере, года. Для новичков книга будет достаточно трудна,
поэтому рекомендуется сначала обратиться к одной из
многих превосходных книг по языку С, написанных для
начинающих. Если требуется рекомендация, то предлагаю
книгу К.Н.Кинга (K.N.King) С Programming: A Modern
Approach, изданную компанией W.W.Norton&Company в
1996 году, ISDN 0-393-96945-2.
Если вы хотите, чтобы ваши С-программы были как
можно более быстродействующими, читайте эту книгу.
Если вы собираетесь сделать свои С-программы бо-
лее переносимыми, читайте эту книгу.
Если вас интересует, как современные быстрые и
эффективные алгоритмы можно реализовать на С,
опять-таки, читайте эту книгу.
Если же вас не беспокоит ни один упомянутый
выше вопрос, все равно читайте эту книгу, чтобы вы-
яснить, почему эти вопросы все-таки должны вас вол-
новать.
Если вы занимаетесь программированием на C++ и
по ошибке выбрали эту книгу, а теперь обеспокоены
вопросом относительно возмещения денег за нее, не
переживайте. Все идеи и большая часть программного
кода в этой книге вполне подойдут и для C++, если
сделать несколько незначительных изменений.
Наконец, если вы, милая леди, выбрали эту книгу в
качестве подарка ко дню рождения своего внука и ин-
тересуетесь, понравится ли она ему, ответом будет бес-
спорное ДА. Немедленно берите ее и поспешите опла-
тить в кассе. И пока продавцы будут заворачивать ваш
подарок, почему бы вам не купить внуку вводную кни-
гу по С, а также С-компилятор да и сам компьютер?
Энциклопедия С-программиста
Глава 1
Какие знания вы должны иметь
При написании этой книги предполагалось, что чита-
тель имеет представление о ядре языка С. Если вам зна-
комы такие понятия, как типы, операторы, выражения,
управляющие потоки, синтаксис функций, указатели,
массивы, структуры, объединения, входной и выходной
потоки, обработка строк, область видимости и синтак-
сис базового препроцессора, то для вас не покажется
трудным восприятие материала этой книги.
Среди указанных понятий имеется одно, которое
можно отнести к разряду особо сложных, речь идет об
указателях (pointers). Учитывая это, в книге дан крат-
кий курс по элементарной теории указателей.
Указатель является переменной. Это наиболее важ-
ная идея, которую следует взять во внимание. Она явля-
ется отправной точкой для освоения всего материала.
Необходимо срезу же подчеркнуть, что это не про-
сто переменная, а специальный тип переменной, зна-
чения которой содержат адреса. Переменная-указатель
может содержать адрес другой переменной. Если у нас
нет переменной, адрес которой необходимо сохранить
в указателе прямо сейчас, можно поместить в указатель
адрес специальной ячейки NULL.
Мы назначаем указатель для адреса объекта с ис-
пользованием оператора взятия адреса, имеющего вид
амперсанда (&). Получить отмеченный таким образом
объект можно с использованием оператора косвенной
адресации, обозначаемого символом звездочки (*).
ПРИМЕЧАНИЕ
В языке С объект — это просто поименованная область
памяти, и не следует его путать с принятым в C++ оп-
ределением объекта как экземпляра класса.
Наиболее важным фактом, который связан с указа-
телями и который нужно запомнить, является то, что
они должны указывать на что-либо конкретное, преж-
де чем быть переопределенными. Таким образом, мы не
можем написать:
char *р
strcpy (р, ’’Hallo, world”) ;
Прежде всего нужно выделить пространство (па-
мять). Можно выделить памяти больше, чем требуется,
или ровно столько, сколько необходимо. Оба этих спо-
соба показаны в листинге 1.1 (этот код предназначен
исключительно для иллюстрации, ведь мы не будем в
действительности писать программы типа "hello, world”
(привет, мир) с целью заработать).
28
Пересмотренный язык С
Часть I
Листинг 1.1. Обеспечение места, на которое могут
указывать указатели.
linclude <stdio.h>
linclude <string.h>
linclude <stdlib.h>
int main(void)
{
char *p;
lifdef SCROOGE
/* Выделяется ровно столько пространства,
* сколько требуется, с учетом концевого
* признака (указателя) '\0'.
*/
р = malloc(strlen([dbl]Bello world(dblj) +
i);
lelse
/* Выделение памяти с избытком */
р = malloc(lOOO);
lendif
/* Примечание: функция malloc возвращает
* NULL, если здесь выделено недостаточно
* памяти.
*/
if(p 1= NULL)
{
strcpy(p, [dbl]Hello world(dbl));
printf([dbl]%s\n[dbl], p);
free(p);
/* Мы всегда освобождаем память, когда
* заканчиваем работать с ней.
*/
return 0;
1
Здесь использован указатель специального вида,
называемый пустым (Void pointer, или pointer to void —
указатель на пустое место. — Прим. пер.)9 который ука-
зывает на определенный тип, неизвестный компилято-
ру. Предположим, дан некоторый указатель Р на тип Т.
Можно использовать пустой указатель V для указания
на тот же объект, на который указывает Р, но никакой
серьезной работы выполнить с этим указателем невоз-
можно. Он является лишь маркером места в памяти. (И,
как можно будет убедиться, он оказывается очень по-
лезным.) Чтобы сделать что-либо полезное с памятью,
на которую мы указываем, нужно использовать указа-
тель правильного типа. Таким образом, допустима сле-
дующая запись:
т *р;
void *v;
Т *q;
р = malloc(sizeof *p);
if(p 1= NULL)
{
v = p;
/* ... */
q = v;
/* ... сделать что-либо с памятью,
используя q ... */
free(q);
)
Заметьте, что здесь полностью отсутствуют приве-
дения (типов). Приведения крайне не рекомендуется
использовать в С. Здесь в них совершенно нет необхо-
димости.
Как наиболее эффективно
использовать эту книгу
Чтобы извлечь как можно больше пользы из этой кни-
ги, настоятельно рекомендую очень внимательно про-
читать ее. Почему? Потому что на моих книжных пол-
ках лежит не менее сотни книг по компьютерной
обработке данных общим объемом, наверное, 50 тыс.
страниц. Я сомневаюсь, что фактически прочитал боль-
ше чем около 10 тыс. этих страниц. Так что я не полу-
чил максимальной пользы из своей книжной коллекции.
Пусть этого не случится с вами!
Эта книга охватывает множество методик, с которы-
ми вы раньше не встречались или которые не догадались
применить к своим конкретным нуждам программирова-
ния. Многие недооценивают силу "классических" струк-
тур и алгоритмов, полагая их несколько старомодными
и подсознательно надеясь, что современные компьюте-
ры настолько мощны, что фактически даже не возник-
нет вопроса, какой алгоритм использовать, поскольку
даже самый медлительный метод не повлияет на ско-
рость работы. Однако это не так. Да, в настоящее вре-
мя компьютеры отличаются высоким быстродействием.
Но разве не приходилось вам когда-либо сидеть перед
компьютером и нетерпеливо ждать завершения той или
иной задачи? Мне лично приходилось. Следовательно,
компьютеры являются еще недостаточно мощными,
чтобы молниеносно исправлять неадекватность наших
программ. Так что постараемся писать свои программы
разумно. И чем более скоростными становятся компь-
ютеры, тем большего мы ожидаем от них, но они ни-
когда не будут настолько быстродействующими, чтобы
превращать плохие алгоритмы в хорошие.
Так что пусть у вас будет стимул для внимательно-
го чтения этой книги. Мы попытались разбить ее на два
уровня: для заинтересованных и для ленивых читателей.
Надеемся, что вы достаточно заинтересованы в приоб-
ретении средней или даже высокой квалификации С-
программиста, чтобы тщательного изучать текст и ис-
ходные коды, стараться в полной мере понять их и
учиться применять полученные знания для решения
повседневных задач. Не исключено, конечно, что вы не
имеете времени для удовлетворения своей заинтересо-
Энциклопедия С-программиста
Глава 1
29
ванности. Начальник ждет от вас готовой программы
завтра, и ваша программа нуждается в подпрограмме
действительно быстрой сортировки, а у вас нет време-
ни, чтобы достигнуть фактического понимания напол-
нения этой подпрограммы. В такой ситуации чаще все-
го ничего не остается как только включить ее в свою
программу, а там — хоть трава не расти! Мы это пре-
красно понимаем, поэтому попытались упорядочить
текст так, чтобы читатель мог получить разумное пред-
ставление о том, о чем идет речь, без необходимости
изучать каждое отдельное слово на каждой отдельной
странице. Надеемся, что вы будете возвращаться к тексту
позже и перечитывать тот или иной материал более осоз-
нанно. Так что, если у вас действительно нет времени для
скрупулезного изучения материала, читайте только то, что
необходимо, и игнорируйте все остальное.
Можете не беспокоиться — вам не придется читать
эту книгу от корки до корки. Каждая глава является
более или менее самостоятельной, так что книга идеаль-
но подходит для чтения на ночь. Смело пропускайте
все, что вам уже хорошо знакомо, ныряйте в какой угод-
но водоем знания, к которому влечет вас воображение,
погружайтесь в него полностью, чтобы получить и
пользу, и удовольствие.
Для чего нужна еще одна книга по С
Язык С ежедневно используют десятки тысяч програм-
мистов, поскольку это быстрый, устоявшийся, достаточ-
но простой и переносимый язык. Хотя C++ все более
завоевывает рынок, пытаясь оттеснить язык С, но пос-
ледний по-прежнему не сдает своих позиций и продол-
жает занимать заслуженное место в мире программиро-
вания. Он стал языком лингва франка (lingua franca)
сообщества разработчиков и имеет высокий авторитет
среди современных программистов.
Язык С не является совершенным; его самые горя-
чие сторонники обычно первыми жалуются на прису-
щие ему дефекты. Однако он успешно выдержал испы-
тание временем.
Эта книга позволит вам стать более квалифицирован-
ным С-программистом, если вы будете следовать сове-
там и приемам экспертов, которые уже по нескольку раз
прошли сквозь огонь, воду и медные трубы. Мы пока-
жем вам, как работать. Вы получите исходный код, ко-
торый сможете встроить прямо в свои приложения.
Почему используется стандарт ANSI С
Во многих книгах по языку С делаются определенные
предположения относительно используемой вами плат-
формы. Некоторые книги охватывают конкретные ком-
пиляторы и операционные системы; очевидным приме-
ром может служить книга, посвященная программиро-
ванию Windows или языку Borland C++. (Еще хуже —
некоторые книги охватывают лишь определенные вер-
сии определенных компиляторов!) Иногда это препод-
носится более тонко, например, предполагается, что
читатель выполняет сортировку последовательности
символов стандарта ASCII. Это, в частности, нарушает
планы тех, кто вынужден (не по своей собственной
воле) иногда использовать расширенный двоично-деся-
тичный код обмена EBCDIC.
В этой книге стандарт ANSI С рассматривается по-
чти полностью, поскольку, следуя стандарту С, можно
повысить уровень переносимости программных кодов.
Эта книга не предназначена исключительно для С-про-
граммистов в Windows, в DOS или в UNIX, она пред-
назначена для всех С-программистов. Мы будем рас-
сматривать двоичные деревья, которые можно
использовать на любой платформе. Кроме того, будет
подробно описан процесс обработки естественного язы-
ка, который можно выполнять в программах LE/370, а
также в UNIX- или Windows-программах либо во всех
трех одновременно, а при необходимости и на некото-
рой совершенно отличной от них платформе. Будут
рассмотрены также методики сортиррвки, которые мож-
но использовать независимо от своего местоположения.
В любом случае, если вы имеете компилятор, эта книга
окажется полезной для вас.
Однако не всегда представляется возможным напи-
сать всю программу только на ANSI С. Всегда находят-
ся раздраженные заказчики, которые настаивают на том,
чтобы программа выполняла увертливые и сверхъесте-
ственные действия, такие как — внимание! — очистка
экрана. Стандарт ANSI С вообще не требует наличия
экрана, так что очистить экран в ANSI С довольно про-
блематично. (Фактически 100%-ной гарантии перено-
симости решения этой проблемы не существует.) Ана-
логично нет полностью переносимого способа получить
последовательность нажатия клавиш от пользователя без
отображения на экране вводимых с клавиатуры симво-
лов (как в случае, например, фиксации пароля). Так что
могут возникнуть моменты, когда будет необходимо
отойти от стандарта и использовать ориентированные на
конкретную реализацию расширения языка. Пуристы С
будут упрямиться этому, но для некоторых приложе-
ний использования расширений С не избежать. В кон-
це концов, хотя, несомненно, можно написать тексто-
вый редактор полностью на ANSI С, сомневаюсь, что
удастся его хорошо продать. Как правило, такой редак-
тор оказывается переносимым, когда это необязательно,
и непереносимым, когда это необходимо сделать. Эта
книга написана, насколько возможно, с использовани-
ем кода ANSI С. Когда нужно будет отступить от стан-
дарта, мы обязательно обратим ваше внимание на этот
факт.
Пересмотренный язык С
Часть I
30
Если наша настойчивость на максимальном исполь-
зовании ядра стандарта языка кажется вам скорее огра-
ничением, чем преимуществом, это действительно так.
Программный код, представленный в книге, вместо того
чтобы иметь возможность свободно эксплуатировать все
различные мощные опции одной частной версии одно-
го частного компилятора для одной частной операци-
онной системы, является ограниченным и подходит
только ко всем ANSI С-компиляторам на всех операци-
онных системах в мире. Наверное, мы легко можем
смириться с таким ограничением.
По закону Мэрфи (или одному из его следствий) вы
с удивлением обнаружите, что, как только напишете
некоторый непереносимый код, входящий в огромное
приложение, так уже через неделю это приложение
нужно будет переносить на некоторую совершенно чуж-
дую платформу. Такая задача чрезвычайно упрощается,
если изолировать непереносимый код для более легкой
его замены, когда придет время перемещать платформы.
Так что далее мы будем рассматривать различные спо-
собы, позволяющие сделать это, и в качестве примера
выполним программирование сокета (гнезда).
Какие платформы охватывает эта
книга
Все! В этой книге по большей части описывается про-
граммирование на языке ANSI С (строго говоря, на
ANS1/1SO С). Следовательно, она охватывает все плат-
формы, а не какую-либо одну. Здесь представлена лишь
совсем маленькая платформно-зависимая программка.
Говоря более конкретно, в книге не поднимаются воп-
росы Windows- или UNIX-программирования, хотя в
ней приведены полезные переносимые сведения и под-
ключаемые исходные коды, которые можно использо-
вать на этих (и многих других) платформах. Кроме
того, коротко описываются ядро Linux, многопоточ-
ность, многопроцессность и встроенные системы.
Об исходном коде
Почти все исходные коды в этой книге будут работать
на любом ANSI С-компиляторе для любой платформы,
обеспечивая достаточное количество ресурсов (таких,
как память), доступных во время выполнения. Несколь-
ко исключений из этого правила, в частности проблема
переносимости, рассмотрены выше.
Ранее уже было отмечено, чем отличаются заинте-
ресованные читатели от ленивых. Исходные коды раз-
работаны так, что они будут полезны и для тех, и для
других. Если вы заинтересованный читатель, то найде-
те множество увлекательных вещей, благодаря исполь-
зованию которых сможете повысить уровень своей ра-
боты. Если же у вас недостает времени или энергии
внимательно читать и прорабатывать эту книгу, просто
изучите код драйвера, посмотрите, как используются
функции, затем удалите драйвер — и вы получите биб-
лиотеку, которую сразу же можете использовать. (Факти-
чески вам даже не нужно будет удалять цк1Я1*ер, посколь-
ку он будет находиться в отдельном файле в программной
библиотеке. Но, если можете, хотя бы изучите драйвер,
чтобы узнать, как работает библиотека.)
Качество программного кода
Нет ничего необычного в книге, подобной этой, увидеть
такой демонстрационный программный код:
void cat3 (char *s, char *tf char *u)
{
strcat(s,t);
strcat(sru);
I
Это прекрасная программка, которая, несомненно,
будет работать длительное время. Хотя можно спросить:
что случится, если один или более указателей примут
значение NULL? Нетрудно проверить, что произойдет,
но автор не побеспокоился об этом, полагая, возмож-
но, что педантичный (т.е. осторожный) читатель может
самостоятельно вставить код такой проверки.
Авторы этой книги надеются, что предосторожность —
достоинство, а не грех. Нашей целью было писать ус-
тойчивый, надежный, действенный код без компро-
миссов относительно его выполнимости. Насколько мы
преуспели в этом направлении, покажет время. Если у
вас есть что сказать о качестве программного кода в этой
книге или вы обнаружите в нем ошибки, пожалуйста,
дайте нам знать.
В случае расхождения между исходным кодом в этой
книге и кодом на Web-сайте издательства "ДиаСофт",
предпочитайте код на Web-сайте. Мы попытались очень
тщательно проверить и убедиться в том, что код в этой
книге корректен, но люди есть люди, так что возможно
и появление ошибок. Код на Web-сайте издательства
"ДиаСофт", по крайней мере, был скомпилирован и
протестирован. Вы когда-нибудь пробовали достать ком-
пилятор для чтения с бумажного листа? Это непросто!
Как организована эта книга
Надеемся, что эта книга позволит вам повысить свою
квалификацию как С-программиста со среднего уровня
до профессионала. Для этого мы постараемся воору-
жить вас знаниями, которых вы прежде не имели — тех
вещей, которые отличают эксперта от профессионала.
Эта книга состоит из трех частей — "Пересмотрен-
ный язык С", "Организация данных" и "Дополнитель-
ные темы".
Энциклопедия С-программиста
Глава 1
31
В части 1 ’’Пересмотренный язык С” исследуются
некоторые аспекты программирования на С, которые
должны быть очевидными, но, как это часто бывает,
таковыми не являются. Начинается рассмотрение с не-
которых трудных проблем стиля кодирования и техни-
ческих ловушек, которые часто могут стать причиной
споров в команде разработчиков, особенно с точки зре-
ния того, что является важным и просто интересным в
конкретных стилях программирования.
Компьютеры используются для быстрого выполне-
ния наших команд, но в последние годы они, кажется,
становятся все более медлительными. Это можно час-
тично объяснить тем, что мы ожидаем от программ
слишком многого, а частично тем, что в настоящее вре-
мя пишут не слишком надежные программы. Так что
придется искать некоторые оптимизирующие методи-
ки, которые бы успешно работали для сокращения
времени выполнения программы.
Как сказал однажды Питер ван дер Линден (Peter van
der Linden), "любой, кто думает, что программирование
данных и получение сразу верного результата — простое
дело, вероятно, не слишком много сделал в этой обла-
сти". Поэтому в часть I книги включена глава, посвящен-
ная надежности обработки данных. Несколько страниц
также отводится для исследования битов и байтов. В
языке С имеется богатый набор операторов bittwidding,
позволяющих легко получать требуемые комбинации
битов. Автор этой главы — Лоренс Кирби (Lawrence
Kirby) — проведет читателя через "минное поле" воз-
можных неожиданных сюрпризов.
Остальные главы этой части книги посвящены об-
работке файлов, отладке программ, управлению памя-
тью, моделированию и рекурсии.
Часть II "Организация данных" охватывает многие
классические структуры данных. Массивы, списки, сте-
ки, обычные очереди и очереди с двусторонним досту-
пом, деревья (специальный род древовидной структу-
ры), разреженные массивы и графы. — все это описано
и реализовано в форме повторно используемой библио-
теки. Отдельная глава посвящена сортировке данных.
Содержание части III "Дополнительные темы” пол-
ностью соответствует ее названию. Здесь рассказывает-
ся о том, как выполнять арифметические действия с
матрицами (это очень полезно, если вы хотите выпол-
нить некоторую полиномиальную интерполяцию или
решить систему уравнений). Мы откроем для вас мир
обработки цифровых сигналов (быстрое преобразование
Фурье и т.п.).
Далее речь пойдет о синтаксическом анализе выра-
жений. Мне всегда хотелось создать свой собственный
(нетривиальный) компьютерный язык. Под руковод-
ством эксперта Яна Келли (Ian Kelly) я планирую сде-
лать это в рамках своего следующего проекта.
Многие программы, представленные в книге, явля-
ются короткими одноразовыми программками, которые
никто из пользователей (кроме нас с вами, конечно)
никогда даже не увидит. Эти специальные инструмен-
тальные средства очень полезны; мы нашли некоторые
способы, позволяющие сделать их еще более полезны-
ми. Затем можно сесть и помечтать о несметном богат-
стве, которое нам дал Майк Райт (Mike Wright) путем
нескольких потенциально прибыльных проникновений
на автоматическую фондовую биржу с использованием
Универсальных Алгоритмов (Generic Algorithms).
В наш век мы не можем игнорировать Internet. Вы,
несомненно, слышали о CGI (Common Gateway Interface —
Интерфейс общей шины. — Прим. науч. ред.). Надеем-
ся, сюрпризом для вас станет возможность написать
CGI-программу полностью на ANSI С. Чед Диксон
(Chad Dixon) покажет, как это сделать.
Однако иногда придется погружаться в мрачный мир
платформно-зависимого программирования. Используя
в качестве примера сетевое программирование, мы по-
кажем, как можно минимизировать проблемы при пе-
реносе программного кода.
Я — законченный фанат числа л — отношения дли-
ны окружности к ее диаметру. Где-то в темных глуби-
нах моей памяти еще со времен учебы хранится воспо-
минание о книге, в которой говорится о значении этого
числа с точностью до одного миллиона значащих цифр
после десятичной точки. Если вас когда-либо заинтере-
сует, как выполняются такого рода вычисления, прочи-
тайте главу 24, написанную Яном Келли.
Если вам приходилось использовать современный
интегрированный офисный пакет, значит, вы знакомы
с технологией типа "спроси эксперта..." или "как это
сделать", которая, кажется, "понимает" то, что пользо-
ватель набирает на клавиатуре. В главе 25 вы сможете
воочию увидеть, как с помощью электроники интерпре-
тируется человеческий язык.
Безопасность данных в современном мире является
не менее важной, чем электронная торговля и коммер-
ция. Мы опробуем несколько методик шифрования и
расшифровки данных.
Если вам невдомек, как пишутся С-программы для
стиральных машин или микроволновых печей (у кото-
рых отсутствует даже запоминающее устройство на гиб-
ком диске для загрузки программы в эти машины), по-
листайте написанную Стефаном Уилмсом (Stephan
Wilms) главу 27.
Самая грандиозная новость о С-программировании
за последние десять лет появилась в октябре 1999 года,
когда комитет ANSI/ISO окончательно ратифицировал
С99 — новый языковый стандарт. Чтобы завершить кни-
гу, Лоренс Кирби делает обзор внесенных стандартом из-
менений, многие из которых принципиально важны.
Пересмотренный язык С
Часть I
32
Это список только наиболее важных тем. Но не бес-
покойтесь, вам не нужно читать их все одновременно.
Просто уделите немного времени каждой главе. Это ведь
не соревнование, кто быстрее доберется до конца книги!
Проблемы авторских прав
Почти все исходные программные коды на сопровож-
дающем книгу компакт-диске охвачены лицензией GNU
Public License (коротко GPL). Если же вы не знакомы с
GPL, это значит, попросту говоря, что вы можете ис-
пользовать эти коды до тех пор, пока вас не попытают-
ся остановить другие люди, тоже их использующие. Для
более детального ознакомления просмотрите текст са-
мой лицензии, помещенной в приложении А.
Главная задача исходного кода, представленного в
книге, состоит в том, чтобы упростить вашу работу. Мы
не хотим ограничивать читателя в использовании про-
граммного кода. Все, о чем мы просим, — не утверж-
дайте, будто написали его сами, и не останавливайте
людей, которые тоже используют эти программы. Но не
стесняйтесь включать в свои собственные программы
наш код.
Все рисунки, диаграммы и эмблемы в книге сохра-
няют авторские права, как и сам текст книги. Если вы
хотите что-то скопировать из нее, то сначала получите
письменное разрешение издательства Sams Publishing.
Общество С-программистов
Эта книга была написана членами общества С-програм-
мистов. Если вы невольно задались вопросом: "А как
туда записаться?”, не волнуйтесь — вам совершенно
незачем записываться в это общество. Вы уже являетесь
его членом. Звание члена "Общества С-программистов"
относится ко всем С-программистам во всем мире,
включая конечно же и вас.
Лоренс Кирби и я, Ричард Хэзфилд, являемся прин-
ципиальными авторами этой книги, но мы никогда не
встречались лично. Мы лишь однажды разговаривали по
телефону, чтобы обсудить книгу, и это все. Все наши
другие контакты осуществлялись через электронную
почту и сеть Usenet. Я знаю только двоих наших соав-
торов — Мэта Уатсона и Яна Келли, с которыми я лич-
но встречался. Это едва ли удивительно, поскольку боль-
шинство авторов являются гражданами Америки, а я
никогда не был в Соединенных Штатах. Тем не менее,
мне кажется, что я знаю этих авторов уже много лет. Они
по большей части являются регулярными пользователями
группы новостей сети Usenet, которую можно найти по
адресу news:comp.Iang.c и которая представляет собой
международный форум для С-программистов. Подпис-
ка на comp.lang.c совершенно бесплатна (если не счи-
тать обычные расходы на провайдера службы Internet и оп-
лату телефонных счетов). Она позволит вам познакомиться
с обширным миром талантливых С-программистов, а
также с интеллектуальными оппонентами, но их, к сча-
стью, не много.
Указанный адрес является местом, где люди не стес-
няются в выборе выражений и не брезгуют грубоватым
обращением. Если вы обладаете мягким характером,
можете предпочесть более тихую и более вежливую
группу новостей news:comp.lang.c.moderated, где все
статьи перед публикацией проверяются модератором
(арбитром).
В случае, если ранее вы не использовали Usenet,
скажу, что эта сеть представляет собой огромную кол-
лекцию групп новостей (за последнее время я проверил
более 50 тыс. из них), каждая из которых выделена для
исследования конкретного предмета. Группа новостей
несколько напоминает электронную доску бюллетеней.
Статьи публикуются для всеобщего обозрения, и любой
человек может ответить на любую статью. Одни груп-
пы новостей придерживаются постоянной тематики,
другие — нет. Группа comp.lang.c остается верна своей
тематике на протяжении уже многих лет. В результате
она заслужила солидную репутацию как источник и
репозитарий (хранилище) экспертизы ANSI С. Группа
получает ежедневно множество статей по различным
аспектам С-программирования. Часто эти статьи пред-
ставляются в форме вопросов; на эти вопросы почти
неизменно даются исчерпывающие ответы.
Почему люди утруждают себя бесплатными ответами
на вопросы в группе новостей, подобной comp.lang.c?
Не потому ли. что им нравится демонстрировать свои
знания? Или потому, что когда-то они сами были уче-
никами. а сейчас хотят поделиться своими приобретен-
ными знаниями? Скорее всего, ими руководит следую-
щее соображение: "Однажды я лично задал вопрос
относительно языка С. Отвечая на вопросы других лю-
дей. я помогаю поддерживать деятельность междуна-
родного сообщества, так что мне это тоже необходимо".
Неважно, какие причины заставляют людей оказы-
вать помощь, главное, что такая помощь, несомненно,
существует. Если вам требуется поддержка в програм-
мировании на ANSI С, обращайтесь именно по этому
адресу. Большинство авторов этой книги, как уже было
сказано, являются постоянными контрибьютерами
(вкладчиками) группы comp.lang.c и всегда будут рады
ответить на ваши вопросы, касающиеся языка С.
Перед тем как направлять запрос в группу первый
раз, вспомните, пожалуйста, что вы имеете дело с об-
ществом (т.е. с отделением более широкого сообщества
программистов, частью которого вы уже являетесь), а
раз так, нужно следовать определенным соглашениям.
Если вы не будете соблюдать эти соглашения, вряд ли
Энциклопедия С-программиста
Глава 1
33
на свой вопрос вы получите такой ответ, какой ожида-
ете. Указанные соглашения в точности делятся на два
списка: "что нужно делать" и "чего делать нельзя". Пер-
вый список включает следующие рекомендации:
1. Тщательно вычитывайте каждое отдельное сообще-
ние, размещаемое в группе новостей, всеми мысли-
мыми способами (по крайней мере, пока не убеди-
тесь, что оно не стоит прочтения). Делайте это в
течение недели, а еще лучше — в течение двух не-
дель. Это даст вам хорошее понимание того, что
представляет собой данная группа.
2. Перед тем как задать вопрос, убедитесь, что он не
входит в список часто задаваемых вопросов FAQ
(Frequently Asked Questions — Часто задаваемые воп-
росы. — Прим. пер.). Людям надоедает снова и сно-
ва отвечать на один и тот же вопрос, поэтому об-
щие вопросы и ответы на них были собраны в одном
Web-узле, чтобы на них было проще ссылаться.
Однажды я задал вопрос в comp.iang.c о прототипе
функции, которая получается как ее аргумент-ука-
затель на функцию того же рода (т.е. функцию,
которая получается как ее аргумент-указатель на
функцию того же рода (т.е. функцию, которая по-
лучается как ее аргумент-указатель...)); короче,
идею вы поняли. Мне казалось, что я все сделал
правильно, но получил такой ответ: "Перед тем как
сделать запрос, читайте FAQ!". И я действительно
убедился, что ответ на этот вопрос был дан уже
давным-давно. Ниже указан адрес URL для списка
FAQ группы comp.iang.c, который поддерживает
Стив Саммит (Steve Summit):
http: //www. eskimo. com/-scs/C-faq/top. html
3. Если вы просите о помощи в отладке (что встреча-
ется чаще всего), постарайтесь, пожалуйста, на-
сколько это возможно, облегчить задачу людей,
помощи которых вы ищете. Для этого вручную уда-
лите из программы все, что не имеет отношения к
проблеме, и оставьте лишь минимально необходи-
мый объем программы, которая все же демонстри-
рует проблему и которую можно скомпилировать
без ошибок. Очень часто такой процесс позволяет
обнаружить источник проблемы самостоятельно и
отказаться от размещения запроса в сети. Если же
вам не повезет, вы, по крайней мере, уменьшите
нагрузку на comp.lang.c.
4. Если ваша программа не компилируется и вы не
знаете почему, убедитесь, пожалуйста, в том, что
отправляемый вами исходный код содержит все не-
обходимые определения данных (т.е. определения
структуры), чтобы можно было легче помочь вам.
Как и в предыдущем случае, отправьте минималь-
ный программный код, который демонстрирует
проблему компиляции. В свое послание включите
точный текст всех диагностических сообщений,
выдаваемых вашим компилятором (если их очень
много, выберите первые десяток-полтора), включая
предупреждения. Чтобы сделать это, выполняйте
операции копирования и вставки: люди предпочи-
тают отлаживать программный код, а не исправлять
ошибки набора текста.
5. Если полученный таким образом исходный код со
стороны выглядит правдоподобно, заключите его в
тело статьи сразу после вашего вопроса.
Итак, мы перечислили, что нужно делать. А теперь
рассмотрим, что делать не нужно. Если вы хотите сде-
лать свой опыт общения с comp.iang.c удачным, при-
держивайтесь следующих правил:
1. Когда посылаете исходный код, не надейтесь на то,
что у вашего клиента, читающего новости, есть воз-
можность открывать ваши присоединения. Для
очень многих людей открытие присоединения мо-
жет стать проблематичным. Помещайте в свое по-
слание только текст. Не используйте клиента, кото-
рый настаивает на отправлении статьи в формате
HTML, поскольку некоторые другие клиенты груп-
пы новостей отфильтровывают HTML, получая,
таким образом, совершенно пустой документ.
2. Не ждите, что люди будут выполнять работу за вас.
Завсегдатаи comp.iang.c будут счастливы вам по-
мочь, но это все же не сервисная служба выполне-
ния домашних работ. Если вы просто пошлете спе-
цификацию, разговор с вами будет очень короткий.
Они помогут вам лучше понять домашнюю работу,
но выполнять ее вместо вас не будут.
3. Избегайте многословия. Если вы просите о помо-
щи, будьте кратки. Скажите точно, что ваша про-
грамма должна выполнять и что она фактически
делает. И конечно, включите исходный код самой
этой ущербной программы, нужным образом уре-
занной по размерам с учетом требуемой ее адекват-
ности.
4. Не задавайте вопросов, связанных с платформно-
зависимыми аспектами. Согласно моему тщательно-
му исследованию (которое включало изобретение
подходящего высокого процентного отношения,
чтобы мне не нужно было беспокоиться об осуще-
ствлении статистически значимой, но утомительной
выборки), 99.0137% таких посланий остаются без^
ответов. Вместо этого автор статьи направляется для
пересылки вопроса в группу новостей, связанную с
определенной платформой или компилятором.
Имеются группы новостей для Borland С, Microsoft
3 Зак. 265
Пересмотренный язык С
Часть I
34
С и ряд других. Существуют также группы новостей
отдельно для графики, для алгоритмов, для Windiws
и для UNIX. Пожалуйста, задавайте только вопро-
сы, непосредственно связанные с языком С.
5. Не будьте нетерпеливы. Вы можете получить ответ
сразу, но может пройти два-три дня, пока кто-ни-
будь заметит ваш вопрос и даст на него ответ. Если
вы пошлете тот же вопрос снова, то, скорее всего,
получите в ответ что-то вроде ’’будьте терпеливее”,
а не разъяснение сути своего вопроса.
6. Не полагайтесь сразу же на первый ответ, который
получите. Подождите день-другой, чтобы другие
люди могли представить свои предложения. И вско-
ре вы почувствуете, кто из них говорит по делу, а
кто нет.
7. В любом случае не пытайтесь поправлять кого-
либо, пока на все 100% не будете уверены, что они
ошибаются, а вы правы. Это рассматривается как
чудовищно антиобщественное поведение. Если вы
думаете, что кто-либо сделал ошибку, но не впол-
не уверены в этом, попросите его разъяснить свою
точку зрения. Однажды я некорректно поправил
очень авторитетного специалиста Мартина Амбула
(Martin Ambuhl) по одному техническому вопросу
(не помню точно по какому), и не думаю, что он
когда-либо простит меня. Всегда убедитесь в пра-
вильности своих замечаний и лишь затем публикуй-
те поправки.
Надеюсь, что не отпугнул вас от групп новостей
навсегда! В действительности все эти наставления име-
ют лишь общий характер. Иногда очень легко забыть,
что пользователи Usenet являются фактически реальны-
ми людьми, такими же, как мы с вами. Эти наставле-
ния помогут вам помнить, что они, как и мы с вами,
ценят сообразительность, особенно когда вы просите их
о помощи ради своей пользы.
Резюме
В этой главе вы получили краткие сведения о книге,
которую позволили себе приобрести. Мы объяснили,
почему язык С не нуждается в еще одном подробном
описании и как С-программисты были несправедливо
скованы упрощенным представлением о том, что возмож-
но и что невозможно в этом языке. Смеем утверждать, что
книга является источником переносимых методик про-
граммирования даже в высоко-платформно-зависимом
мире обработки данных.
Мы остановились на дополнительных темах в этой
книге и коротко рассмотрели, что можно и чего нельзя
делать с исходным кодом на сопровождающем книгу
компакт-диске.
Заканчивается глава некоторыми советами по пере-
писке с группой новостей comp.lang.c, это действитель-
но ценный ресурс полезных советов. Если вы предпо-
читаете получить помощь из книги, просмотрите
библиографию в приложении В, содержащем список
книг, которые могут быть вам полезны.
А теперь самое время заняться серьезными вещами.
Итак, приступим!
Войны стандартов
программирования: причины и
пути перемирия
2
В ЭТОЙ ГЛАВЕ
Стили расстановки фигурных скобок
Использование пробелов
Структурное программирование
Инициализация
Статические и глобальные объекты
Имена идентификаторов
Ж Написание полезных комментариев
ж Общие ошибки и недоразумения
ж Объявления, определения и прототипы
ж Важность переносимости программ
ж Макросы
ж С против C++
Ричард Хэзфилд
Человечество ведет священные войны с древнейших
времен. Отголоски этих войн проникают во все сферы
нашей жизни, а в комфортабельном мире С-программи-
рования, похоже, они принимают особенно специфи-
ческие формы. Программисты борются за соглашения
по размещению, структуре, именованию и по всем ви-
дам связанных с этим проблем. Теперь нормальные
люди не борются за что-либо, если оно не представля-
ется им важным. Иногда они правы — это действитель-
но важно. Иногда это не так важно для дальнейшего
выживания человеческой расы, как им хотелось бы ду- ’
мать. В этой книге мы должны выбрать, какие пробле-
мы стиля являются для нас действительно важными, а
какие — нет. Поскольку в нескольких последующих
главах мы будем рассматривать множество программных
С-кодов, следует также установить заранее, какие обыч-
но используемые стандарты нам нужны, а какие будем
игнорировать и почему.
Помните, что компилятору совершенно безразлично,
какой стиль размещения кода вы приняли. Проблема
здесь состоит лишь в читабельности кода для програм-
мистов сопровождения ваших программ. А почему вы
должны заботиться о том, смогут ли программисты со-
провождения прочитать ваш код? Во-первых, это воп-
рос профессионализма. Если выполнение работы дру-
гими людьми усложняется из-за чьей-то небрежности,
это обычно расценивается как признак отсутствия про-
фессионализма. Во-вторых, отладка читабельного кода
значительно облегчается. И в-третьих, человеком, на-
значенным сопровождать ту или иную программу в те-
чение трех или, быть может, пяти лет, вполне можете
оказаться лично вы. Целью этой книги является осво-
бождение вас — С-программиста от авторитарности и
бессмысленности некоторых положений стандартов.
С другой стороны, мы также хотим предостеречь вас от
ловушек, в которые часто попадают С-программисты.
ПОВТОРНЫЙ ПРОСМОТР КОДА
Если вы думаете, что пересматривать свой собственный
код спустя многие годы вряд ли придется, могу вас уве-
рить, что это иногда случается. Я потратил более года,
выполняя тестирование системы и отладку на сложном
модуле расчета страховки. Когда моя задача была выпол-
нена, я занялся другими вещами. Четыре года спустя я
заключил контракт с совершенно другим клиентом и стол-
кнулся ’’лицом к лицу" с тем же самым модулем! В не-
урочный час этот клиент купил копию исходного кода у пре-
дыдущего моего клиента. Я был весьма доволен тем, что буду
читать свой собственный код: он был подробно прокоммен-
тирован и вполне мог претендовать на принадлежность
программисту, которым я очень восхищаюсь, но который
имел на полдесятилетия меньший опыт, чем я.
Так что давайте поближе рассмотрим эту область
стилей и стандартов программирования и попытаемся
Пересмотренный язык С
Часть I
36
выяснить, какие аспекты стиля программирования яв-
ляются важными, а какие нам просто безразличны, и
тогда, возможно, мы сможем стать посредниками в мир-
ном урегулировании упомянутых выше войн (либо, по
крайней мере, в прекращении огня). Мы начнем с темы,
близкой сердцу каждого программиста: со стилей рас-
становки фигурных скобок.
Стили расстановки фигурных скобок
Сегодня имеется четыре наиболее распространенных
стиля расстановки фигурных скобок (bracing style), ис-
пользуемых в С-сообществе. Не сомневаюсь, что вы
будете иметь свое собственное мнение о том, какой из
этих стилей правильный. Но давайте рассмотрим их по
очереди.
Стиль 1TBS
1TBS является аббревиатурой стиля One True Bracing
Style. Это единственно истинный стиль расстановки
скобок. Он получил такое прекрасное название потому,
что был использован Кернигеном (Kernighan) и Ричи
(Ritchie) в их классической книге The С Programming
Language — Язык программирования С. С-программис-
ты смотрят на Кернигена и Ричи (везде далее в этой
книге K&R) как на "полубогов*’, так что название One
True Bracing Style имеет вполне подходящий религиоз-
ный оттенок. Некоторые люди предпочитают называть
его К&В-стиль или рациональный (kernel) стиль. Сто-
ронники этого стиля обычно используют отступы в во-
семь пробелов, но это не догма.
Ниже приведен отрывок кода, иллюстрирующий
стиль 1TBS:
for (j*0; j<MAX_LEN; 3++) {
foo();
}
Большинство программистов обычно полагают, что
преимущество такого стиля состоит в экономии верти-
кального пространства. Оборотной стороной такого
преимущества является тот факт, что может оказаться
трудно найти символ {, спрятанный в конце строки.
Стиль Алмена
Эрик Алмен (Eric Allman) написал утилиты BSD в этом
стиле, и некоторые любители называют его "стиль BSD".
Отступы в стиле Алмена обычно (но не всегда) состав-
ляют четыре пробела:
for (3=0; j<MAX_LEN; j++)
{
foo();
}
Этот стиль (и последующие) занимает больше вер-
тикального пространства, чем стиль 1TBS. Аргументом
в поддержку такого стиля является тот факт, что область
видимости блочного оператора ясна и визуально ассо-
циируется с управляющим оператором.
Стиль Whitesmith
Одно время существовал С-компилятор, который назы-
вался Whitesmith С. В его документации есть пример
форматирования программного кода, подобного этому:
for (3=0; 3<MAXJLEN; 3++)
{
foo();
Этот стиль имеет преимущество в том, что скобки
более тесно ассоциируются с кодом, который они вклю-
чают и разграничивают, однако при визуальном про-
смотре текста отыскать скобки оказывается чуть более
сложно. Здесь приняты отступы в четыре пробела.
Стиль GNU
Программисты GNU фонда Free Software Foundation
используют (в частности, в коде GNU EMAKCS) гиб-
рид стилей Алмена и Whitesmith. (Между прочим, GNU
установлен для "GNU, отличных от UNIX", и аббреви-
атура EMAKCS получена из названия "Editing
MACroS". Это текстовый редактор UNIX, но называть
его текстовым редактором только UNIX все равно что
называть компьютер дополнительной машиной.) Ниже
приведен пример стиля GNU:
for (j=0; j<MAX_LEN; 3++)
{
foo();
I
Трудно сказать, дает ли такая комбинация стилей Ал-
мена и Whitesmith преимущества или имеет недостатки.
Напрашивается вопрос: "Какой способ расстановки
фигурных скобок правильный?", но, конечно, они все
корректны. Самое главное, не следует смешивать разные
стили в одной программе. Выберите для себя стиль и все
время его придерживайтесь. Он может даже не подхо-
дить вам. Если вы работаете в формальной среде разра-
ботки, то почти наверняка имеете дело с некоторым
документом стандарта кодирования, который носит
обычно авторитарный характер и дает минимальную
возможность придерживаться здравого смысла. Однако
намного легче читать код, в котором использован еди-
ный стиль, чем код, использующий несколько различ-
ных стилей одновременно. Рассмотрим следующий
ужасный код, который содержит почти предельно воз-
можную смесь разных стилей:
Войны стандартов программирования: причины и пути перемирия
Глава 2
37
for(j = О; j < MAX_bEN; j++) {
for (к = 0; к < MAXWIDTH; к++)
{
for(m = 0; m < MAX HEIGHT; m++)
{
for(n M 0; n < MAX-TIME; n++)
{
foo(j, k, m, n);
}
}
}
}
Компилятор будет вполне доволен таким кодом, но
ни вы, и никто из членов вашей команды не захотели
бы иметь с ним дело. Так что если ваши руководители
предложили некий стиль, выберите его и постарайтесь
убедить других, менее проницательных членов вашей
команды делать то же самое (если бы они были прони-
цательными, то читали бы эту книгу и вам не нужно
было бы убеждать их). Если же ваши руководители не
сослались на некий устоявшийся стиль расстановки
скобок, они должны сделать это. В действительности не
имеет значения, какой стиль они предложат. Каким бы
он ни был, используйте этот стиль для данного проек-
та и ваши товарищи-программисты (и группа сопровож-
дения!) навсегда вас полюбят.
Если вы не работаете в команде разработчиков про-
екта и, следовательно, у вас нет руководителя, это пре-
красно. Лишь выберите стиль расстановки фигурных
скобок, с которым вы чувствуете себя наиболее комфор-
тно, и последовательно его придерживайтесь.
Пока мы занимаемся темой расстановки скобок, рас-
смотрим конструкцию for, do, while, if или else с един-
ственным следующим за ней оператором:
if (condition)
foo() ;
Здесь, конечно, все правильно. А теперь посмотрим
на следующую модификацию этого кода:
if (condition)
foo();
bar () ;
Как видим, запись структурирована. Но для чего
программист сделал отступ — зависит ли вызов новой
функции от состояния (condition) в операторе if или
нет? Это трудно сказать. По этой причине в докумен-
тах по стандартам рекомендуется всегда использовать
блочный синтаксис операторов:
if (condition)
{
foo();
}
Такая методика, безусловно, помогает избегать оши-
бок. Тем не менее, многие С-программисты полагают,
что она слишком громоздка. В своем собственном коде
я лично стремлюсь использовать полный синтаксис
блочных операторов даже в случае наличия единствен-
ного оператора, поскольку это придает коду большей
ясности; во фрагментах кода в этой книге мы часто
опускаем необязательные скобки, но делаем это исклю-
чительно в интересах экономии вертикального простран-
ства.
Использование пробелов
Стили расстановки скобок — не единственное поле, на
котором происходят баталии войны стилей программи-
рования. Способы использования пробелов также ока-
зывают значительное влияние на читабельность вашего
кода. Если вы думаете, что где-то должен быть, конеч-
но, один стиль расстановки пробелов, которого придер-
живается каждый программирующий для максимизации
читабельности своего кода, я боюсь, вы ошибаетесь.
Здесь имеется столько стилей расстановки пробелов,
сколько существует С-программистов.
Отступы
Что представляют собой правильные установки табуля-
ции и отступов? Чаще всего выбирают два, три, четы-
ре, восемь пробелов или ни одного. Я надеюсь, вы со-
гласитесь, что мы можем отклонить нулевой вариант как
делающий код полностью нечитабельным, но все дру-
гие варианты являются вполне читабельными. Боль-
шинство программистов начинают с использования за-
данной по умолчанию установки табуляции, которая
часто имеет восемь колонок в ширину (но не обязатель-
но; это зависит от вашего текстового процессора). По-
степенно, особенно в случае большого числа уровней
отступов, код начинает выглядеть немного растянутым:
int foo(int arr [А] [В] [С])
{
int а, Ь, с, total = 0;
for (а « 0; а < А; а++)
{
for(b = 0; b < В; Ь++)
{
for (с “ 0; с < С; с++)
{
total += arr[a](b][c);
}
}
}
return total;
)
Поэтому многие уменьшают количество пробелов до
четырех:
38
Пересмотренный язык С
Часть I
int foo(int bar [А] [В] [С])
{
int а, Ь, с, total = 0;
for (а = 0; а < А; а++)
{
for(b ® 0; Ь < В; Ь++)
{
for (с = 0; с < С; C++)
{
total += bar[а][b][c];
}
>
>
return total;
Лично я пользовался таким способом на протяжении
многих лет. Многим позже я обнаружил, что для моих
целей наиболее удобными оказываются отступы в два
пробела. Это была установка, от которой я не отступаю
уже длительное время. Я приобрел привычку использо-
вать два пробела, когда начал регулярно публиковать
статьи в Usenet. Я использовал клавишу пробела вмес-
то табулятора не только потому, что установка табуля-
тора у моих читателей дает слишком широкий отступ,
но мне также не нравилась сама идея вставки табуля-
ции в публикации Usenet. Коль скоро такое решение
было принято, я быстро обнаружил, что уменьшение
количества символов пробела в 12 раз для трехуровне-
вого отступа позволяет мне сэкономить немало време-
ни, так что я начал использовать отступы в два пробе-
ла. К своему удивлению, я нашел, что мне нравится это
больше, чем четыре пробела, так что теперь я исполь-
зую два пробела все время.
Отступ в три пробела для многих С-программистов
представляется неестественным. Тем не менее, он ис-
пользуется на некоторых сайтах, и при этом текст выг-
лядит неплохо.
Какая же установка табуляции и отступа является
правильной! Вы опередили меня, я знаю — действитель-
но, нет одного правильного уровня. Если вашим проек-
том стандарта кодирования предусмотрена установка,
которую вы должны использовать, выберите уровень,
который, по вашему мнению, выглядит наиболее чита-
бельно, используйте его последовательно в своей про-
грамме и будьте готовы пересмотреть свое мнение че-
рез некоторое время.
Табуляторы и мэйнфреймовские
компиляторы
Некоторые мэйнфреймовские С-компиляторы не отве-
чают должным образом на вставку символов табуляции
в исходные файлы. Если вы чувствуете, что попадаете
в собственную ловушку, может оказаться необходимым
потратить время (или деньги) на программный инстру-
мент для замены табуляции пробелами. Фактически вы
можете уже иметь такой инструмент. Например, редак-
тор Microsoft Visual C++ имеет эту возможность.
Пробелы вокруг символов
Для улучшения читабельности программного кода сле-
дует творчески подходить к использованию пробелов.
Снова-таки,нет единственно правильного способа рас-
становки пробелов, но неправильных способов — мно-
жество. В приведенном ниже примере пробелы исполь-
зованы скверно:
#include <stdlib.h>
iinclude <stdio.h>
Idefine P printf
idefine I atoi
int main(int archar*v
[]){int r=5r i;if(a>l
) r=I(v[l]); if(r<=0)
r=5;if(r%2==0)++r;for
(i=0; i<r*r; P(i/r==(
3*r)/2-(i%r+l)||i/r==
r/2 - i%r||i/r==r/2+i
%r||i/r==i%r-r/2?"*":
" ")ri++, i % r==0?P(
"\n") : 0);return 0;}
(Если вы удивлены, что такое вообще может быть,
спешу сообщить, что я не выудил это из материалов
Международных соревнований по головоломному С-
кодированию. Я написал этот текст лично, так что могу
посылать его в IRC (Internet Relay Chat — Обмен дру-
жескими посланиями через Internet) всякий раз, когда
кто-то задает довольно общий для домашней работы
вопрос, к которому этот код подходит. Выяснение воп-
роса о том, какие функции выполняет эта программа,
я оставляю для вас в качестве упражнения. Сделать это
сразу практически невозможно.)
Вероятно, наиболее эффективный способ повышения
читабельности кода состоит в том, чтобы ставить пробе-
лы вокруг бинарных операторов. Рассмотрим строку
a=b+c*d/e%f;
и строку
a = b + c*d/e%f;
Какую из них, по вашему, легче читать? Именно так
делаю я.
Некоторым людям нравится также устанавливать
пробелы вокруг круглых скобок:
for ( foo = О ; foo < bar ; foo++ )
и даже вокруг прямоугольных скобок:
а [ baz ] = О ;
Лично мне кажется, что это уж чересчур усердное
использование пробелов, но это стиль, с которым вы
время от времени будете встречаться.
Войны стандартов программирования: причины и пути перемирия
Глава 2
39
Косметические исправления кода
Многие люди очень часто в процессе сопровождения
кода, который не они лично написали, поддаются ис-
кушению корректировать стили расстановки скобок и
пробелов, чтобы угодить руководителям проекта, или
даже делают это по своему вкусу. Я лично никогда это-
го не делаю (по крайней мере, не тогда, когда за мной
кто-то смотрит). Пока руководитель проекта вполне
определенно не попросил вас сделать это, не проявляйте
инициативу. Часто бывает полезно иметь возможность
сравнить две версии исходного файла: текущую и пре-
дыдущую, свободную от ошибок версию, чтобы увидеть,
чем они отличаются и. следовательно, узнать, где мо-
жет крыться ошибка. Если кто-то "поигрался" с пробе-
лами, вы обнаружите множество ложных улучшений,
которые замедляют вашу работу и оказываются причи-
ной снижения вашей производительности (не говоря
уже о явной раздражительности, которую вызывают
такие манипуляции). Если вы не ведете историю реви-
зии своего кода (хотя это и не принципиально, конеч-
но), вы должны рассмотреть вопрос о внедрении хро-
нологии изменений или системы управления версиями.
Возможно, сейчас стоит упомянуть, что имеется
утилита, называемая indent, которая может форматиро-
вать код непротиворечивым образом. Если команда со-
гласовала стиль и всегда пропускает код через утилиту
indent перед проверкой его в системе управления вер-
сиями, многие проблемы, связанные с расстановкой
пробелов, отпадут. Утилита indent включена в дистри-
бутивы Linux. Ее исходный код вы можете найти по
адресу ftp://ftp.gnu.org/gnu/indent (но проверьте снача-
ла адрес http://www.gnu.org, чтобы выяснить, имеется
ли местный аналогичный сайт, который можно было
бы использовать вместо вышеуказанного. Таким обра-
зом ускоряется загрузка нужной программы).
Структурное программирование
С тех пор как Дейкстра (Djikstra) опубликовал свой
знаменитый труд "Вредность оператора GOTO", люди
бились над методами структурного программирования
Полное описание структурного программирования вы-
ходит за рамки этой книги, но здесь имеются опреде-
ленные темы, которые регулярно неожиданно возника-
ют в документах стандартов кодирования, так что
давайте их коротко рассмотрим.
Оператор goto
Не только Дейкстра жалуется на оператор goto. На с. 65
книги K&R2 (Принятое автором сокращение для обо-
значения книг Кернигена и Ричи, см. с. 36. — Прим,
науч, ред.) мы найдем глубокие переживания Брайана
Кернигена относительно того, что "[Язык] С обеспечи-
вает бесконечно оскорбительный оператор goto". Если
вы удивлены, откуда я знаю, что это был именно он, а
не Дэннис Ричи, сообщаю: их общее соглашение состо-
яло в том, что большую половину первой части книги —
учебный раздел — пишет Керниген, а Ричи делает боль-
шую часть или даже весь раздел ссылок.)
Использование оператора goto может серьезно зат-
руднить реализацию управляющей логики вашего кода.
Исходный код, содержащий множество операторов goto,
часто графически описывается как "код-спагетти", по-
этому в документах по стандартам кодирования боль-
шинства проектов осуждается их применение.
Обычно довольно просто после некоторых размыш-
лений найти альтернативу применению оператора goto.
Этот процесс будет часто включать использование до-
полнительной переменной состояния, поэтому про-
граммисты встроенных систем (См. главу 27 "Встроен-
ные системы". — Прим. науч, ред.) используют оператор
goto чаще, чем другие, — во встроенных системах все-
гда имеет место дефицит памяти.
Основной причиной применения оператора goto
является то, что он позволяет быстрее осуществить пе-
реход из глубоко вложенного кода в случае возникно-
вения ошибки. Это оправдание представляется вполне
обоснованным, так что не следует быть догматиком и
наотрез отказываться от использования goto. Тем не
менее, по возможности самым пристальным взглядом
сначала оцените возможность других решений. Если уж
вы решили, что без goto не обойтись, имейте в виду, что
обычно проще следовать управляющей логике вниз по
коду, так что попытайтесь убедиться, что вы переходите
вперед по коду, а не назад.
Оператор break
Оператор break очень полезен при использовании внут-
ри оператора switch. Некоторым также нравится ис-
пользовать его внутри циклов для обеспечения преждев-
ременного выхода из цикла. Это не является частичным
структурированием использования оператора, поэтому
я никогда не применяю оператор break таким способом.
Я не хотел бы ошибиться, сказав, что преждевременный
выход из циклов является нежелательным. Однако я
знаю многих высококвалифицированных и вдумчивых
программистов, которые придерживаются мнения, что
код должен отражать намерения своего создателя, так
что, если вашей целью является преждевременное пре-
рывание цикла, ваш код должен ясно показывать это
намерение. Это мощный аргумент, который, случается,
не вписывается в способ, которым я предпочитаю
структурировать свои программы. Если вы все же наме-
рены использовать в цикле оператор break, потрудитесь
вставить в исходный код короткий пояснительный ком-
ментарий, особенно если код достаточно плотный.
40
Пересмотренный язык С
Часть I
Оператор continue
Подобно break, оператор continue можно использовать
для модификации логики циклов таким образом, что
пурист структурного программирования разразился бы
безудержным кашлем (хотя этот оператор еще не так
плох, как оператор ALTER в Коболе, который изменя-
ет адрес перехода по оператору goto!). В отличие от
break, оператор continue не удостоился быть связанным
с оператором switch. Хорошо ли это?
Оператор continue я использую только в пустых
циклах в качестве индикации сопровождающему про-
граммисту, что цикл является преднамеренно пустым,
наподобие этого:
while (*s++ = *t++)
{
continue;
}
Я бы хотел порекомендовать, чтобы вы ограничили
применение оператора continue только этим случаем, но
не могу этого сделать. Сторонники оператора continue
выдвигают случаи, наподобие следующего:
while (fgets (buffer, sizeof buffer, fp) !=.
NULL)
{
if (strchr ("; I buffer [0] 1= NULL)
{
/* Это строка комментария - начните с
* символа точки с запятой (;), диеза (#)
* или слэма (/), чтобы пропустить его и
* перейти на следумцу» строку
*/
continue;
}
/* Здесь помечается больной блок кода
*/
Здесь оператор continue упрощает код путем немед-
ленного отклонения бесполезного состояния и попада-
ния прямо на следующую итерацию цикла, избегая при
этом необходимости добавлять else и дополнительный
уровень отступа для большого блока, следующего за
блоком if. Так что, опять-таки, имеются совершенно
правомерные причины для принятия решения о том,
применять оператор continue или нет.
Давайте немного поразмыслим здраво. Перед тем как
использовать оператор continue, остановитесь и поду-
майте: ’’Почему я использую этот оператор: потому ли,
что это быстрее и легче, чем адаптировать более струк-
турный подход, или я искренне хочу обеспечить чита-
бельность программы?” Если имеет место последний
случай, есть все основания использовать continue.
Цикл while(1)
Это общая конструкция. Почти неизменно тело этого
цикла содержит операторы break или return или даже
вызов функции exit(). Заголовок такого цикла говорит:
’’Этот цикл выполняется вечно”, а тело цикла противо-
речит этому. Ясно, что тело цикла выполняется все вре-
мя до победного конца, но в действительности этого
быть не может. Если нашей целью является сделать
программный код легко читаемым, мы можем сделать
это путем документирования цели цикла while в его за-
головке и выбора подходящего конечного состояния.
Можно, например, написать:
int more = GetFirstItem(&foo) ;
while(more)
{
Process(&foo);
more = GetNextltem(Sfoo);
}
вместо
if(GetFirstltem(&foo))
while(l)
{
Process (lifoo);
if(!GetNextItem(&foo))
break;
I
где, хотя и делается попытка сократить объем кода,
фактически оказывается на одну строку текста больше,
чем в проверенном временем примере с использовани-
ем переменной состояния.
Иногда нам действительно необходим бесконечный
цикл, который специально предназначен для выполне-
ния в течение неопределенного времени (или, по край-
ней мере, пока кто-нибудь не отключит микроволновую
печь). С этой точки зрения, конечно, применение цик-
ла while(l) вполне обосновано. Однако имеет место слу-
чай, когда применяется цикл
for (; ;)
{
/* ... */
)
поскольку здесь почти наверняка не будет генерировать-
ся сообщение, выдаваемое некоторыми компиляторами
при использовании while (1), — что-то наподобие стро-
ки "Выражение состояния является константой”.
Я сказал ’’почти наверняка”, потому что компилятор
ANSI С может выдавать столько диагностических сооб-
щений, сколько ему нравится, включая и такое:
"Предупреждение: строка 37: ват мандарин
требует заново покрасить его в желтый цвет
и две чашки кофе”.
Войны стандартов программирования: причины и пути перемирия
Глава 2
41
или еще более взволнованное:
"Предупреждение: строка 1: вы эксплуатируете
этот компилятор уже несколько НЕДЕЛЬ,
почему бы вам не купить более совершенный?
Вы ведь знаете, что хотите этого".
в течение всего времени, пока он правильно компили-
рует правильный код и правильно диагностирует син-
таксические ошибки и нарушения ограничений.
Оператор return
Один из принципов структурного программирования
состоит в том, что программа должна иметь одну точку
входа и одну точку выхода. В языке С легко сконстру-
ировать программу с многими точками выхода. К сожа-
лению, так же просто сконструировать программу на-
подобие этой (даже не пытайтесь выяснить, что этот код
означает! Это только иллюстративный пример):
char *fоо(char *s, char *t)
{
switch(*s)
<
case 0:
return s;
case 1:
return t;
case 2:
return t - s;
case 4:
return s - t;
case 8:
return s + sizeof(long);
case 16:
return t + sizeof(double);
default:
break;
}
}
He нужно быть гением, чтобы определить, что в
общем случае не будет возвращено никакого значения.
В более крупной функции, однако, со значительно
большим числом разветвлений управляющей логики
даже гений не обнаружил бы ошибки. К счастью, боль-
шинство компиляторов предупредят вас об этом, но
здесь нет никаких нарушений ограничений или син-
таксических ошибок, поэтому Стандарт и не требует
диагностического сообщения. Если же вызывающая
функция использует значение, возвращаемое вызывае-
мой функцией, из которой фактически не был заплани-
рован возврат какого бы то ни было значения, поведе-
ние программы будет неопределенным. Кроме того,
функции со многими операторами return более сложны
для чтения, чем те, которые имеют лишь один опера-
тор return в конце программы.
Конечно, реальная жизнь непроста, и бывают вес-
кие причины для использования в некоторых функци-
ях множества операторов return. Например, программу
поиска в двоичном дереве можно написать значитель-
но более просто, если мы используем несколько возвра-
щаемых значений:
TREE *SearchTree(TREE *node, char *s)
{
int diff;
if(node == NULL)
. return NULL;
if(s == NULL)
return NULL;
diff = strcmp(s, node->data);
if (dif f == 0)
return node;
else if (diff < 0)
return SearchTrее(node->left, s);
return SearchTrее(node->right, s);
}
Здесь очень легко проследить логику управления
обработкой данных. Комментарии могут еще немного
прояснить логику, но сам код оказывается более или
менее самоопределяемым (по крайней мере, с точки
зрения управляющей логики. Если вам не посчастливит-
ся самостоятельно разобраться со смыслом вызывающей
функции в этом примере, не паникуйте — рекурсию мы
будем рассматривать далее в этой книге). Фактически
этот код значительно короче, чем эквивалентный код
только с одним оператором return.
Моя собственная библиотека обработки двоичных
деревьев фактически имеет лишь по одному оператору
return в каждой функции, возможно потому, что я —
законченный пурист. Так что есть веские аргументы для
использования обоих подходов, поэтому в каждом кон-
кретном случае придерживайтесь здравого смысла.
СУМАСШЕДШИЕ УКАЗАТЕЛИ ФУНКЦИЙ
Несколькими проектами ранее я работал на сайте, где
стандарты кодирования утверждали: "Не используйте опе-
ратор goto”. Проект предусматривал создание системы
кодировки для зарубежной компании и содержал не-
сколько переписанных со старого языка QBASIC программ
на С, но программисты не имели доступа к самим QBASIC-
программам. Актуарии (Статистики страхового общества
(actuaries). — Прим, пер.) не сидели сложа руки и пе-
ревели программы в спецификации. Актуарии сказали,
что они не хотят делать никаких предположений относи-
тельно доступных языку С возможностей, поэтому они
’’распороли” все циклы for QBASIC-программ. Таким об-
разом, вместо того чтобы сказать: "Цикл по клиентам,
вычисляющий дату их выхода на пенсию по датам их рож-
дения", они говорили примерно следующее:
1.4.9.3 Установить идентификатор клиента ClientID в 1
1.4.9.4 Вычислить дату выхода на пенсию клиента с
индексом ClientID, используя дату его рожде-
ния и системную дату
Пересмотренный язык С
42i
Часть I
1.4.9.5 Сохранить дату выхода на пенсию в поле
RetAge клиента Client с индексом ClientID
1.4.9.6 Добавить 1 к индексу ClientID
1.4.9.7 Если индекс ClientID превышает количество кли-
ентов для данной котировки, продолжить с шага
1.4.9.9
1.4.9.8 Продолжить с шага 1.4.9.4
1.4.9.9 ...
Кроме того, поскольку актуарии были экспертами в об-
ласти страховой статистики (а мы, программисты, — нет),
мы находились под прессом инструкций, предписывающих
в точности следовать спецификациям. Теперь большинство
из нас понимают, что актуарии были только помехой, так
что, естественно, мы игнорировали ограничивающие
предписания и прокрутили код так, как это делается в
соответствующем цикле (и действительно, один из них
признался мне позже, что мы сделали в точности то,
чего они и хотели). Один довольно педантичный програм-
мист (обычно таким бывает один из лучших, но не все-
гда) предложил другую идею. Он взял относительно про-
стые спецификации и решил объединить оба принципа ("В
точности следуйте спецификации" и "Не используйте
goto") в символы. Везде, где он встречал оператор goto
в спецификации, он записывал код функции обработки с
помощью цикла. Такая функция возвращала бы указатель
на следующую выполняемую функцию!
Драйвер всего этого кода выглядит достаточно жестоко.
Отладка кода и его модификация для внесения требуе-
мых изменений были учебным экспериментом. (Факти-
ческий автор кода должен был его отлаживать, поэтому
он, конечно, покинул компанию.) В конечном счете я
решил перенести сеть указателей функций и результиру-
ющий документ в диаграмму, которая вылилась в третью
самую страшную диаграмму в моей карьере.
Однажды я схематически изобразил код, и он уже не
выглядел так страшно, поскольку, по крайней мере, те-
перь мы ясно увидели, куда код должен переходить даль-
ше. Но когда мне показали оригинальную QBASIC-npo-
грамму, я начал понимать, насколько простым был этот
код и насколько ясно и легко он реализован с использо-
ванием циклов. Безумные указатели функций — очень
интересные штучки для забав, но им не место в разра-
батываемых программах (хотя у меня нет проблем с
нормальными указателями функций).
Любые обобщения неверны (включая и это), но все-
таки я намерен высказать общую точку зрения: чем более
структурированно вы будете подходить к программирова-
нию, тем меньшее количество ошибок будете получать при
работе вашей программы. Более структурированный вами
код читать очень легко. Код, который легко читать, явля-
ется более простым для понимания, а значит, будет мо-
дифицирован скорее, чем трудный код, и в результате
будет иметь значительно меньше ошибок.
Инициализация
В языке С имеются скрытые ниши. Даже такая очевид-
ная и простая вещь, как правильное выполнение ини-
циализации, может оказаться достаточно сложным де-
лом. Вопрос не только в стиле выполнения; переноси-
мая инициализация действительно не так проста, как
это кажется.
Множественные определения в одной
строке
Как вы знаете, С позволяет определять множество
объектов одного и того же типа и указатели на объекты
этого типа в одной логической строке. Вы, вероятно,
уже приготовились практически использовать такую
возможность, и я не хочу сделать ошибки, отговаривая
вас от этого. Советую, однако, принять к сведению те
преимущества, которые дает определение каждой пере-
менной в отдельной строке. Рассмотрим такой код:
int foo(char *s, char *t, size_t len)
{
float PiTo2DecimalPlaces = 3.14, q,
CircleRadius - 1.0;
/* input file output file */
FILE * fpln, fpOut;
/* ... */
>
Во-первых, если мы хотим модифицировать тип q в
тип, скажем, double, мы приходим к необходимости
поместить его новую инициализацию где-нибудь в от-
дельной строке. Так почему же не поместить ее в свою
собственную строку с самого начала?! Во-вторых, труд-
но что-либо найти среди этих соседствующих друг с
другом длинных имен. И в-третьих, ошибка в типе
IpOut (это должен быть тип FILE *, но фактически это
только FILE) случается слишком уж часто.
Инициализация в определении
Язык С позволяет вам выбирать, инициализировать ли
объект при его определении. Инициализация перемен-
ной во время определения дает вам два преимущества.
Первое заключается в том, что вам не нужно будет за-
давать переменную начального значения. А второе по-
зволяет вам быть уверенным, что функция начинает
выполнение в известном состоянии. Например, установ-
ка указателя в NULL в определении может не гаранти-
ровать отсутствие ошибок указателя в вашей функции,
но, несомненно, облегчит обнаружение и фиксацию
таких ошибок.
С другой стороны, если вы не задаете значения пе-
ременной в определении, компилятор, перед тем как
этой переменной будет присвоено значение в самом
коде, значительно лучше разместит ее для последующе-
го использования. Кроме того, некоторые компилято-
ры будут выдавать предупреждение, если вы зададите
Войны стандартов программирования: причины и пути перемирия
Глава 2
43
значение переменной, которая затем последовательно пе-
реписывается путем другого назначения, как в записи
int а = О;
for (а — О; а < 10; а++)
Опытные программисты предпочитают получать
чистую компиляцию всякий раз, когда это возможно.
Это связано с тем, что даже тривиальные предупрежде-
ния (наподобие того, какое будет сгенерировано в слу-
чае предыдущего кода), если позволить им размножать-
ся, скоро затемнят все другие, более важные сообщения,
делая их обнаружение и исправление соответствующих
ошибок более затруднительным.
Так что, повторю снова, догматиком быть неразум-
но. Возможно, лучше применять смешанную стратегию.
Конечно, хорошо сразу инициализировать указатель в
NULL; не следует недооценивать также удобство ини-
циализации массива или структуры с использованием
{0}. Большинство программистов обнуляют массив или
структуру примерно следующим образом:
struct FOO foo;
namset (&foo, sizeof foo);
К сожалению, это не гарантирует получения жела-
емого эффекта, если определение структуры FOO содер-
жит числа с плавающей точкой (типов float, double или
long double) или указатели, в которых представление
нуля не гарантирует фактического обнуления всех би-
тов. Например, в стандарте С нет ничего, что бы поме-
шало реализации представлять указатель NULL с ис-
пользованием набора битов 0x80000000 (неявно) в
предположении, что соответствующие преобразования
выполняются для кода, такого как:
char *foo = О;
Наш "нечетно мыслящий" компилятор может обна-
ружить такое назначение и инициализацию и загрузить
указатель с соответствующим битовым набором —
0x80000000 — позади сцены. К сожалению, мы не можем
прервать (перехватить) memset таким же способом; стан-
дарт ANSI С не позволяет это. Во многом такие же рас-
суждения применимы и к числам с плавающей точкой.
Большинство компиляторов не нуждаются в потвор-
стве обману такого рода, но у вас нет гарантий, что ваш
компилятор (или возможный следующий компилятор,
на котором вы будете создавать свой код) действитель-
но будет обнулять все биты в числах типа 0.0 и указа-
телях NULL. К счастью, имеется простой способ, по-
зволяющий инициализировать все элементы структуры
в соответствующие полагаемые для них величины:
struct FOO
{
double d;
int пив;
double e;
float f;
char *p;
};
struct FOO foo = {0};
При инициализации структуры struct таким спосо-
бом (применимым также к массивам) инициализация
оказывается незавершенной. Вот что говорит стандарт
о частичной инициализации:
"Инициализация должна происходить в порядке
списка инициализаторов, каждый инициализатор
для конкретного подобъекта предусматривает отме-
ну любого ранее перечисленного инициализатора
для этого же подобъекта; все подобъекты, которые
не инициализированы явно, должны быть инициа-
лизированы неявно так же, как и объекты, которые
имеют постоянный размер памяти". (Стандарт С9Х,
раздел 6.7.8, январь, 1999 г.).
Переведем это на доступный для понимания язык:
в определении
struct FOO foo = (О);
элемент foo.d принимает значение 0 в скобках (и пре-
образуется в 0.0), элемент foo.num инициализируется в
0, элемент foo.e — в 0.0, элемент foo.f — в 0.0F, а эле-
мент foo.p — в NULL — независимо от внешнего
представления чисел с плавающей точкой и указателей.
Таким образом, мы имеем полностью переносимую
методику инициализации структур и массивов.
Статические и глобальные объекты
Имеется два рода идентификаторов области видимости
файла: идентификаторы области видимости файла с
внутренней связью (статические объекты и функции) и
идентификаторы области видимости файла с внешней
связью (внешние объекты и функции). Последние обыч-
но известны как глобальные объекты (хотя упоминание
о глобальных переменных, которое я смог найти в стан-
дарте ANSI, связано только с флагами и режимами сре-
ды). Документы стандартов написания кодов программ
часто рекомендуют или даже настаивают, чтобы гло-
бальные переменные не использовались, а программи-
сты так же часто игнорируют эти рекомендации. Кто
прав?
ГРИИЕЧАНИЕ
В языке С, в котором объект представляет собой поиме-
нованную область памяти, переменные представляют
собой наиболее очевидный пример объектов. Их не сле-
дует путать с экземплярами класса в C++, которые так-
же называются объектами.
Пересмотренный язык С
Часть I
В данном случае я буду приветствовать документ
стандарта и приведу только один пример, объясняю-
щий, почему я это делаю. Прискорбно, что обычным
делом для разработчиков приложений, находящихся в
тисках установленного срока контракта, стало бросать
структурность и модульность на ветер в попытках по-
лучить программный код с первого раза В результате
часто получаются очень длинные функции.
Рассмотрим импликации особенно длинной функции,
использующей набор глобальных переменных. Код был
написан в последний день выделенного для этого време-
ни и сопровождается в последний день следующего край-
него срока. Понадобилось с помощью этого кода выпол-
нять новые расчеты. Протраммисту сопровождения нужна
новая целая переменная, поэтому он добавляет ее поверх
функции: double PresentValueOfFutureProfits = 0.0. Он
использует эту переменную в разных местах в соответ-
ствии с программой новых требований спецификации.
Если такой программист ранее не просмотрел этот код,
он обязательно потерпит неудачу, поскольку его локаль-
ное определение переменной PresentValueOfFutureProfits
было неосторожно замаскировано переменной с облас-
тью видимости файла и внешней (глобальной) связью,
видимой в том же самом исходном файле. Эта перемен-
ная случайно тоже имеет тип double. Программист не
может обнаружить этого, и кол модуля отправляется на
тестирование, которое он с блеском проходит. Насту-
пает общее тестирование, и программа проходит его с
"незапятнанной” репутацией.
К счастью, ошибка была в конечном счете выловле-
на — в группе User Acceptance Testing. (Приемочное
пользовательское тестирование. — Прим, пер.) Потребо-
валась большая часть дня, чтобы проследить фактичес-
кую причину ошибки. Когда она была найдена, ее ис-
правление оказалось тривиальным (изменение имени
локальной переменной, хотя даже затем была проведе-
на проверка с учетом истории версии функции, чтобы
гарантировать, что были изменены только корректные
ссылки на имя). Описанную историю я не выдумал —
этим программистом сопровождения был я. Не хочу
обременять вас описанием деталей моей реакции, ког-
да я обнаружил, что меня подвела глобальная перемен-
ная (явно запрещенная стандартами кодирования про-
грамм); предлагаю читателям самим прочувствовать это.
Если обстоятельства все-таки заставляют вас исполь-
зовать переменные с областью видимости файла (будь
они с внешними или с внутренними связями), рассмот-
рите возможную необходимость ограничения доступа к
ним путем написания функций доступа. Но перед тем
как вы это сделаете, нам нужно еще кое-что рассмот-
реть.
Проблемы с повторным использованием
Давайте возьмем простую стековую библиотеку. Наш
план очень прост — мы хотим помещать (проталкивать,
push) кое-какие элементы в стек и извлекать (выталки-
вать, pop) из него эти элементы. Поскольку мы имеем
две функции для доступа к стеку, нам нужно разделить
информацию между ними. Введем переменную облас-
ти видимости файла. Однако, поскольку нам не нужно
разделять информацию с другими функциями, мы по-
местим функции push() и рор() в их собственный ис-
ходный файл, который не содержит других функций,
кроме этих двух, и сделаем наш стек статическим —
static. Это хороший пример скрытия информации.
tdefine MAX_STACK 1024
int stack[MAXSTACK];
int stackptr;
int push (int i)
{
int failed = 1;
if(stackptr < MAXSTACK - 1)
{
stack[stackptr++] = i;
failed ~ 0;
}
return failed;
}
int pop(int *i)
{
int failed a 1;
if(stackptr > 0)
{
*i = stack[-stackptr];
failed = 0;
}
return failed;
Таким образом, получили одну стековую библиоте-
ку. К сожалению, пока у нас имеется несколько про-
блем, из которых сейчас интерес для нас представляет
только одна, программы могут использовать эту библио-
теку для создания и управления только одним стеком.
Имеется только один стековый указатель и только один
стек, так что каждый раз мы можем использовать толь-
ко один стек. Конечно, человеческая изобретательность
безгранична, и было бы не так трудно написать стеко-
вую библиотеку, которая будет полностью скрывать дан-
ные и все же обрабатывать множество стеков. Но сделать
это было бы труднее, в то время как существует более
простой метод, предусматривающий использование тех-
нологии передачи структуры в качестве аргумента.
Следующая проблема со статическими переменны-
ми static состоит в том, что они могут подвести вас в
многопоточных средах. Язык С не поддерживает поточ-
Войны стандартов программирования: причины и пути перемирия
Глава 2
45
ность, но его реализации часто обеспечивают такую
поддержку. В типичной потоковой среде переменные
рискуют оказаться доступными и измененными одно-
временно более чем одним потоком.
Ничего из того, о чем мы сейчас говорили, не пред-
назначено, чтобы препятствовать вам в использовании
статических переменных, но важно помнить, что со
статикой связаны и другие проблемы, отличные от про-
стых правил установления области видимости.
Имена идентификаторов
Соглашения именования часто являются источником
горячих дебатов. Я не предлагаю выделить какое-либо
конкретное соглашение, поскольку это будет еще одним
залпом в рассматриваемой нами войне стилей програм-
мирования. Следующий ниже обзор основан на моем
личном опыте, но другой опытный программист впол-
не может иметь свою отличную от моей точку зрения.
Длина
Длина имени идентификатора, конечно, оказывается
пропорциональной его описательной способности. Если
вы планируете использовать переменную интенсивно,
будет разумно дать ей осмысленное имя, что обычно
предполагает длинное имя. Если же, с другой стороны,
вам нужен лишь счетчик цикла, то в длинном имени,
вероятно, нет необходимости. Многие в качестве счетчи-
ков цикла используют i, j и к. Если они участвуют в про-
стых циклах, это хорошо. Однако, если вы заполняете
массив массива массивов (!) некоторой структуры, вы
вполне можете захотеть выбрать более удобные имена
для своих счетчиков, чтобы они напоминали вам о том,
что фактически обозначает каждый индекс массива.
Имеются ограничения на значимую длину идентифи-
каторов. Вы можете делать идентификаторы сколь угод-
но длинными, но гарантированно значимыми они бу-
дут иметь только 31 символ. Фактически и 31 символ —
это много. В именах идентификаторов с внешними свя-
зями, однако, гарантированно уникальными могут быть
только до шести первых символов. И это плохо — нет
гарантии, что редактор связей в любом случае сможет
различить внешние идентификаторы. Таким образом,
редактор вполне может рассматривать следующие опре-
деления:
int NotableValue;
int notablevalue;
int NoTableFound;
int NotAbleToExecute;
int NotABlankSpace ;
как ссылку на один и тот же идентификатор. Это серь-
езное ограничение, которое было несколько смягчено в
более поздней версии стандарта ANSI/ISO С. Однако,
пока не наступит такое время, когда компилятор С99
станет общепринятым, есть смысл просто избегать вне-
шних связей где только возможно. Заметим, что это
ограничение относится к идентификаторам вообще, а не
только к переменным. Таким образом, в именах функ-
ций, не квалифицированных ключевым словом static,
гарантированно значимыми могут быть лишь до шести
символов.
Ясность
Выбирая имя для идентификатора, помните о трех мо-
ментах. Вам самому придется набирать это имя на кла-
виатуре. Эта "темная личность" — программист сопро-
вождения — должен будет читать его. И конечно, вам
обоим нужно знать, что это имя означает. Следователь-
но, есть смысл выбирать такие имена, которые легко
читать, набирать на клавиатуре и которые однозначно
определяют свой объект.
Язык С традиционно является языком нижнего ре-
гистра, но ничто не помешает вам использовать смешан-
ный регистр. Ниже приведены несколько общеприня-
тых стилей именования идентификаторов:
all__lower_case_with_underscores_to_separate_words
lowerCaseFirstLetterThenMixedCase
AllMixedCase
UPPERCASENOSEPARATOR
UPPER_CASE_WITH_SEPARATOR
Хотя С делает различие между регистрами, исполь-
зование имен идентификаторов, отличающихся только
регистром, проблематично. Кроме того, что некоторые
редакторы связей не способны отличать регистры, име-
ется и проблема читабельности:
int foo (int Foo)
{
int foo, FoO, foO, FoO = FOO
/* ... */
1
Такое можно позволить себе в ЮССС (Input/output
control center/command — Узел/команда управления вво-
дом/выводом. — Прим. науч, ред.), но никак не в разра-
батываемом программном коде!
Йнгда нбхдмо скращть иднтфктры до аббрвтр, чсто
путм выбрсывния гленх бкв. (Как должен был догадать-
ся читатель, это не опечатки — автор демонстрирует
технику сокращения записи слов без существенной по-
тери смысла. — Прим. науч. ред.). Например, самое луч-
шее имя для переменной может оказаться довольно
длинным:
double
Presen tValueOfFutureProf itsCalculatedGros s ;
double
PresentValueOfFutureProfitsCalculatedNet;
46
Пересмотренный язык С
Часть I
Кроме того, что эти имена слишком длинны и не-
удобны для набора на клавиатуре, они еще нарушают
правило, в соответствии с которым гарантируется раз-
личение только первых 31 символа.
Аббревиатуры
double PrsntVlfFtrPrftsClcltdGrss ;
double PrsntVlfFtrPrftsClcltdNt;
конечно, представляют два различных идентификатора —
с точки зрения компилятора, но разве улучшилась их
обозримость? Я так не думаю. Такие имена переменных
выглядят просто ужасно!
Эти идентификаторы уже смотрятся лучше, пусть
даже они несколько длиннее, чем просто аббревиатуры:
double Presen tValFutureProfitsGross ;
double PresentValFutureProfitsNet;
хотя они все же слегка длинноваты, чтобы быть удоб-
ными в использовании. В таком случае есть смысл про-
сто укоротить их
double GrossPVFP;
double NetPVFP;
поскольку PVFP — вполне распознаваемая аббревиату-
ра. Как бы там ни было, используйте аббревиатуры,
распознаваемые внутри вашего приложения соответству-
ющим образом. Главным принципом должно быть то,
что различные переменные в программе должны быть
легко различимыми для читателя.
Зарезервированные имена
Что неправильно в этом заголовочном файле?
fifndef RAGBAG Н
idefine _RAGBAG_H_
extern double strength;
extern char memorandum[1024];
extern int isotope;
extern float tolerance;
#endif
Затрудняетесь сказать? Вы будете очень удивлены,
когда я скажу вам, что все идентификаторы в этом файле
заголовка, включая символьные константы, нарушают
стандарт ANSI!
Поскольку язык С имеет очень немного ключевых
слов и соответственно маленькую стандартную библио-
теку, многие программисты обычно полагают, что они
могут называть свои идентификаторы почти как угод-
но. Это совершенно не так.
Во-первых, любой идентификатор, который начина-
ется с символа подчеркивания, за которым следует либо
буква в верхнем регистре, либо другой символ подчерки-
вания, являются зарезервированными для использования
в реализации компилятора. Это обеспечивает реализа-
цию способом определения функций и переменных без
пересечения с вами и вторжения в вашу область имен. А
ведь было бы хорошо совсем оставить за реализацией фор-
мирование области имен! Безопаснее всего не начинать
имен идентификаторов с символа подчеркивания. Хотя_-
кснечносимволыподчеркиванияэтохорошаявещь.
Хорошо, что реализации обычно включают защиту
вокруг своих заголовков. Но это хорошая вещь и для
пользователей-программистов. Прискорбно, но привыч-
ка копировать соглашениеJ4AME__H_ реализатора ста-
новится широко распространенной. (Реализаторы вер-
сии компилятора разрешают использовать лидирующие
символы подчеркивания. Смысл ограничения состоит в
том, чтобы предотвратить конфликт ваших идентифи-
каторов с идентификаторами реализации.) Как бы там
ни было, используйте последующие символы подчерки-
вания, но если вы хотите, чтобы ваша программа была
переносимой, не используйте лидирующих символов
подчеркивания.
Ниже приведен хороший способ обеспечения вклю-
чения защиты:
fifndet NAME_H_
fdefine NAME_H_
/* Здесь следует содержательная часть
заголовка * /
/* ... */
fendif
А что насчет объявлений в этом заголовочном фай-
ле? Почему они недопустимы?
Все здесь связано в расширяемостью. Комитет ANSI
признает, что языки либо развиваются, либо умирают.
Недавнее обновление стандарта С, например, предста-
вило различные мощные новые методики (которые мы
рассмотрим далее в этой книге). Определенно, комитет
хотел выделить место для новых функций в стандарт-
ной библиотеке и в то же время минимизировать воз-
можность разрушения существующих программ. Чтобы
покончить с этим, они зарезервировали определенные
комбинации букв, которые частично подобны тем, ка-
кие формируют начала новых имен функций. Напри-
мер, все, что начинается с "str" (Сокращение от string —
строка. — Прим, пер.), зарезервировано, поскольку, хотя
имеется уже множество стандартных библиотечных
функций, начинающихся с "str", существует много по-
лезных процедур обработки строк, которым программи-
сты захотели бы дать имена, начинающиеся с "str". Что-
бы выйти из этого положения, комбинация букв "str"
была зарезервирована. То же самое относится и к "is" и
"to" (чтобы можно было расширять <ctype.h>), "mem"
(для функций манипуляции дополнительной памятью),
"SIG" (для новых сигналов) и несколько других пре-
фиксов. Ниже приведен сокращенный список всех иден-
тификаторов, которые вы не можете использовать.
Войны стандартов программирования: причины и пути перемирия
Глава 2
47
В целях экономии места я опустил наиболее стандарт-
ные библиотечные функции и другие идентификаторы
в глубоком убеждении, что если кто-то достаточно умен,
чтобы купить эту книгу, он будет так же умен, чтобы не
использовать эти символы. Но в список я включил неко-
торые наиболее странные и наименее известные из заре-
зервированных идентификаторов.
ПРИМЕЧАНИЕ
Чтобы еще больше сократить список, я использовал ре-
гулярный синтаксис выражений. Здесь [A-Z] означает
любой символ алфавита в верхнем регистре; [0-9] озна-
чает любую цифру; * (звездочка) означает все что угод-
но, и т.д.
Итак, без дальнейших рассуждений просто не ис-
пользуйте эти идентификаторы.
Е[0-9]*
LC[A-Z]*
Offsetof
str[a-zj*
E[A-Z]*
mem[a*-z]
raise
to[a-z]*
is[a-z]*
NDEBUG
SIG[A-ZJ*
wcs[a-z]*
А если вы все же будете это делать? Что, если у вас
есть переменная с внешней связью, называемая total?
Какой от этого может быть вред?
Строго говоря, вред состоит в том, что ваша програм-
ма не будет застрахована от сбоев в работе. Все может
выглядеть так, будто программа работает, она может
даже успешно пройти фазу тестирования, но стандарт
С не гарантирует* что программа будет работать пра-
вильно в любой своей части в любое время.
Префиксы: трансильванская ересь
Несколько лет назад Чарльз Симоний (Charles Simonyi),
который позже стал известным в Microsoft программи-
стом, изобрел основанное на префиксах соглашение
именования, которое в его честь стало называться “Вен-
герская нотация". Его идея состояла в том, чтобы дать
каждому идентификатору префикс в соответствии с
тем, что собой представляет этот идентификатор. Поз-
же Microsoft адаптировала эту идею, давая каждому
идентификатору префикс, указывающий на его тип дан-
ных. Таким образом, типы int получили бы префикс п,
long int — префикс nl, массивы типов char начинались
бы с са, а строки (массивы char, оканчивающиеся сим-
волом нуль) начинались бы с sz. Эти имена могли бы
получаться совершенно причудливыми. Например,
IpszFoo означало бы "Foo, которое является длинным (в
смысле 32-битовым или "длиннее", под архитектурой
сегментированной памяти Intel/DOS) указателем на
строку, оканчивающуюся нулем (символом нуль)".
Это соглашение дало вам преимущество идентифи-
цировать тип переменной путем простого взгляда на ее
имя без необходимости отыскивать ее определение.
К сожалению, это ведет не только к затруднительному
произношению имен, но и делает задачу изменения
типа переменной значительно более сложной. В
Windows 3.1 тип int имеет размер 16 битов. Если вы
начнете с типа int, но обнаружите (после придания это-
го int тридцати или сорока функциям в качестве фор-
мального параметра), что тип int, в конце концов, не-
достаточно велик для ваших целей, то должны будете
изменить не только тип переменной, но и ее имя — во
всех тридцати или сорока функциях!
Венгерская нотация впала в немилость у всех, за
исключением нескольких особо упорных Windows-про-
граммистов, поскольку для них это было непрактично.
(Это реплика для 30 или 40 сердитых сетевиков во всем
мире, которые уверяют меня, что венгерская нотация
по-прежнему используется и многими любима.) Нет
сомнений, что в сети имеется несколько сайтов, где она
продолжает существовать, но большинство людей отка-
зались от нее. Писать префиксы, вообще, — плохая
идея, поскольку они слишком плотно связывают пере-
менную с ее типом. По этой причине опытные програм-
мисты для функции malloc используют такую конструк-
цию (здесь Т — некоторый тип)
т *р
р = malloc (sizeof *р)
вместо
т *р
р = malloc (sizeof (Т))
В последнем случае изменение типа р приводит к
несогласованности, которую необходимо как-то зафик-
сировать, — проблема, которой просто не возникает в
первом случае.
Один из реликтов венгерской нотации, который до-
жил до наших дней, реализовался в практику предше-
ствования указателю буквы р, указателю на указатель —
букв рр и т.д., так что указатель на указатель на пере-
менную типа FOO может быть определен как
FOO **ppFoo;
Предоставляю вам возможность самим составить
свое собственное мнение о том, хорошая это идея или
плохая.
Именование переменных
Имя переменной должно отражать ее назначение. По
устоявшемуся соглашению большинство сайтов прини-
мают, что для счетчиков циклов, используемых в ма-
леньких плотных циклах, совершенно правомерно ис-
пользовать переменные i, j, k, m, n. Букву 1 лучше всего
исключить из этого списка, поскольку ее очень легко
спутать с цифрой 1, букву о по аналогичной причине
лучше всего опустить. Поскольку буква р используется
48
Пересмотренный язык С
Часть I
часто для описания указателя, ее лучше не использовать
в качестве счетчика цикла. В графических программах
нередко можно увидеть циклы, управляемые перемен-
ными х и у.
Для более постоянных переменных следует исполь-
зовать более осмысленные имена, и очень важно хоро-
шо подобрать эти имена (фактически я действительно
верю, что выбор хороших имен для идентификаторов
является одним из наиболее важных и сложных аспек-
тов программирования вообще).
Для переменных, представляющих свойства (такие,
как цвет, высота, соотношение и т.п.), лучше всего ис-
пользовать соответствующее существительное. Иногда
вам потребуется квалификатор, такой как BackColor или
ForeColor.
Переменные, представляющие булевы состояния,
должны носить имена, отражающие их текущее состо-
яние. Имеется большое искушение использовать для
этой цели слово "Is". Это можно делать, если вы ис-
пользуете локальные переменные. Таким образом,
IsInComment может быть хорошим именем переменной
в исходной программе синтаксического анализа, кото-
рая получала бы, например, значение 1, если програм-
ма в настоящий момент наткнулась на символ в ком-
ментарии, и 0 — в противном случае.
Именование констант
Большинство С-программистов предпочитают давать
символическим константам имена в верхнем регистре.
Я делаю так же. Лично мне кажется, что имена напо-
добие, скажем, DIRECTVIDEOD1SK более сложны для
чтения, чем DIRECT_V1DEO_D1SK, — когда исполь-
зуется только один регистр (верхний или нижний), раз-
деляющий символ подчеркивания помогает внести яс-
ность.
Константы, типы и макросы — все эти объекты тра-
диционно именуются В ВЕРХНЕМ РЕГИСТРЕ. Теоре-
тически это должно было бы означать, что их можно
спутать друг с другом, но практически (по крайней
мере, в моей личной практике) по контексту всегда
ясно, какое имя что означает. Поскольку я никогда не
использую директивы #define для совмещения имен
типов, я знаю, что лексема (маркер) верхнего регистра
в определении, в объявлении или в приведении либо
используемая в качестве операнда для sizeof является
псевдонимом типа. Довольно легко догадаться, что если
в верхнем регистре поименован какой-либо другой
объект, значит, это макрос или символьная константа.
Именование типов
Лучшие имена типов получаются с использованием су-
ществительных. Попытайтесь подобрать существитель-
ное, которое корректно описывает тип на нужном уров-
не общности. Например, MAN (человек) — более под-
ходящее имя типа, чем SIMON (Симон), а для боль-
шинства приложений еще лучше использовать просто
PERSON (лицо).
Иногда для упрощения объявления вам захочется
использовать typedef. В таких случаях именование все
еще важно, но уже менее важно, чем то, что имя долж-
но быть легкочитаемым существительным. Имя долж-
но меньше всего отражать смысл типа.
Давайте, например, определим указатель на массив
из 25 указателей на функцию, принимающую тип
double, и указатель на функцию, принимающую char *
и возвращающую тип int, а также возвращающую int (!).
Массив будет использоваться, скажем, для расчетов зак-
ладных.
Прежде всего давайте определим псевдоним типа
для указателя на функцию, принимающую char * и
возвращающую int:
typedef int (*I_PF_STR) (char *) ;
Здесь использованы такие элементы: 1_ — для пред-
ставления возвращаемого типа функции, на которую
указывает экземпляр типа, PF — для указателя на фун-
кцию и „STR — для представления параметра списка.
Это отголоски венгерской нотации, но ведь мы имену-
ем тип, а не переменную, а имя типа должно отражать
его природу (по этой причине целые числа именуются
int (integer), а не каким-нибудь zog).
Теперь наша проблема становится проще — мы хо-
тим указать на массив 25 указателей на функции, при-
нимающие double и I_PF STR и возвращающие int. Так
что давайте определим псевдоним типа для этого ново-
го вида указателя на функцию:
typedef int (*I_PF_DBL_I_PF_STR) (double,
I_PF_STR) ;
Теперь — массив из 25 таких же указателей:
typedef I_PF_DBL_I_PF_STR MORTGAGE_ARRAY [25] ;
А теперь определим указатель на этот массив:
MORTGAGE_ARRAY *р;
Именование макросов
Мы уже рассматривали именование символических кон-
стант; здесь я скажу лишь о "функциеподобных" мак-
росах. Если вам придется их использовать, применяй-
те, пожалуйста, для их имен верхний регистр. Имеется
опасность, свойственная использованию похожих на
функции макросов; в некоторых расширениях языка
С эта опасность может быть немного уменьшена путем
предупреждения программиста о том, что он использу-
ет фактически макрос, а не функцию. По этой же при-
чине не используйте верхний регистр для имен функ-
ций (лучше применять смешанный регистр). Регистр
Войны стандартов программирования: причины и пути перемирия
Глава 2
49
является визуальным ключом и притом высокоэффек-
тивным.
Именование функций
Правильное именование функций действительно очень
важно. Хорошие имена функций могут значительно
улучшить читабельность программы, а недостаточно тща-
тельно подобранные имена для функций могут сильно
затемнить ясную с других точек зрения программу.
Функция предназначена для выполнения ^каких-то
действий, так что кажется вполне естественным в ее имя
ввести глагол. Кроме того, функции редко существуют
в вакууме, сами по себе. Функция не просто выполня-
ет какие-то действия, но и делает это с определенной
целью. Если это так, было бы хорошо включить в на-
звание функции соответствующее существительное.
Таким образом, например, strcpy () — хорошее имя для
функции копирования строки.
Я лично предпочитаю такую форму имени функции —
Verb [Noun] () (Глагол [Существительное] (). — Прим,
пер.) — с использованием смешанного регистра (букв):
сначала идет глагол, а затем необязательное соответству-
ющее существительное (а также, возможно, прилага-
тельное). Вот несколько примеров:
Wait () ;
PollTimer ();
PrintReport ();
CalcGrossInterest () ;
Если в вашей библиотеке реализации версии языка
С использован именно такой стиль именования функ-
ций, можете применить другой стиль либо добавить к
именам своих функций уникальный префикс, не пред-
ставленный в реализации API, чтобы избежать возмож-
ных конфликтов.
Написание полезных комментариев
Прискорбно, но программисты часто слишком легко-
мысленно относятся к комментариям в текстах своих
программ. Действительно, комментарии не различают-
ся компилятором, поскольку препроцессор исключает
их. Однако комментарии могут оказаться неоценимым
подспорьем для программистов сопровождения, если
они написаны тщательно.
КОММЕНТАРИИ ПОЛЕЗНЫ, КОГДА ИХ ЧИТАЮТ!
Год или два назад я делал для банка одну превентивную
работу, связанную с проблемой 2000 года. Однажды
парень из отдела разработки программного обеспечения
спросил меня, почему я изменил некую функцию, кото-
рая вычисляла, не является ли заданный год високосным.
Эта функция до моих изменений имела такой вид:
int IsLeapYear (int Year)
{
return Year % 4 -= 0 &&
(Year ft 100 != 0 | | Year % 400 -= 0);
I
Я изменил ее следующим образом:
int IsLeapYear (int Year)
{
if (Year <= 100)
return Year % 4 == 0;
return Year % 4 == 0 &&
(Year % 100 1= 0 | | Year % 400 == 0);
I
Так почему же я изменил ее? Я бы в жизни не вспом-
нил. Я даже вызвал коллегу, который работал на том же
самом модуле; вместе мы начали просматривать код и
провозились целый час (честно!), и, когда мы были толь-
ко на шаг от решения, мне стало казаться, что я внес
совершенно бессмысленное изменение.
Затем наконец я заметил, что в самом начале кода я
написал какой-то комментарий. Из него следовало, что
функция IsLeapYear (1 вызывалась обычно с двухцифро-
вой датой, но иногда передавался элемент tm_year из
структуры struct tm. Как я знал, эта структура хранила
годы начиная с 1900. Таким образом, полная проверка
года на високос ность должна была бы в результате дать
сбой для 2000 года, если бы он хранился в элементе
tm_year структуры struct tm. Именно это и послужило
причиной изменения рассматриваемой функции. Если бы
я не вставил комментарий, когда изменял код, мне впол-
не могло показаться, что мое изменение было бессмыс-
ленным, и я мог отменить изменение, а это снова рань-
ше или позже привело бы к ошибке. Так комментарий
сэкономил мне целый день, а я получил хороший урок —
комментарии нужно не только писать, но и читать!
Когда я перечитывал эту врезку, мне припомнились
два других момента относительно функций. Первый —
что первоначальная функция была ясно написана для
ожидания четырехцифровых дат, хотя фактически она
передавала только двух- или трехцифровые даты. Вто-
рой — имя функции нарушает стандарт, поскольку вне-
шний идентификатор начинается с символов "1s” (По-
мните? Внешние идентификаторы не гарантируют
чувствительности к регистру, так как некоторые редак-
торы связей к регистру нечувствительны.)
Стили размещения комментариев
/««А**************************************
* *
* Это блочный комментарий. *
* Настоящая головная боль *
* при сопровождении. *
* *
*****************************************/
Связанная с таким стилем проблема состоит в том,
что вы не можете просто обновить комментарий без
расхода времени на выравнивание колонок звездочек (*).
4 3« 265
50
Пересмотренный язык С
Часть I
(Можно, однако, писать код, выполняя форматирова-
ние, и, во всяком случае, некоторые редакторы уже
могут делать это за вас.)
Иногда проблему сопровождения блочных коммен-
тариев можно обойти, например, так:
у***************************************
*
* Это блочный комментарий с
* удаленной с правой стороны
* колонкой звездочек.
*
***************************************/
Так намного лучше, поскольку у вас уже есть почти
все звездочки и преимущества привлекающего внимание
блока. Некоторые используют полностью минимизиро-
ванный блок:
Это блочный комментарий с
удаленными справа, слева, сверху и
снизу рядами звездочек.
*/
Нетрудно представить себе, что имеется почти
столько стилей многострочных комментариев, сколько
самих программистов:
/*
* Это мой собственный любимый метод
* написания многострочных комментариев. Здесь
* имеется хороио различимая колонка звездочек,
* но нет необходимости отступать первые три
* колонки текуцего отступа; таким образом, по
* моему мнению, это быстрый, легкий и
* эффективный метод. Вы можете изменять
* расстояние от края по своему усмотрению.
*/
/* "Крылатые” комментарии выглядят наподобие
этого - совсем неплохо..• */
int foo; /* ...дополнительный комментарий
справа от кода. */
int bar; // Это другой вид однострочного комментария
Обратите внимание, что этот последний стиль —
любимый стиль C++- и BCPL-программистов — не был
узаконен стандартом С89; он стал частью языка С лишь
в октябре 1999 года, когда был ратифицирован С9Х, а
затем — стандартом С99. Так что, если ваш компиля-
тор не поддерживает С99, вы фактически не сможете ис-
пользовать комментарии типа //.
Остерегайтесь, кроме того, использовать коммента-
рии //, когда ваш комментарий заканчивается обратным
слэшем:
foo (path) ; // работает на С: \MYAPP\
bar (path);
baz (path);
Соединяющая линия \, встречающаяся в конце ком-
ментария, удаляется, поэтому предыдущий код преоб-
разуется в следующий:
foe (path); // работает на C:\MYAPPbar (path);
baz (path) ;
Далее комментарий удаляется препроцессором, и,
таким образом, функция baz () вообще никогда не бу-
дет вызвана. Это — порочная ошибка и, по моему глу-
бокому убеждению, достаточная причина для того, что-
бы вообще не использовать комментарии типа //. Но,
конечно, вы должны составить свое собственное мнение
на этот счет.
Когда комментарии излишни
Как вы думаете, откуда взят приведенный здесь ком-
ментарий?
i++; /* добавить 1 к i */
Если вы ответили: "из маленького блока", то полу-
чаете шесть очков. Если вы ответили: "из учебника по
С", то получаете десять очков и бесплатный виноград
(пока запасы не иссякли; у меня есть только одна кисть,
и мой ребенок любит виноград).
Нет необходимости добавлять комментарий в каж-
дую строку кода. Если смысл выполняемых кодом дей-
ствий ясен программисту сопровождения, не нужно его
комментировать. Например,
int i = 0;
while (IDNumber 1= client [i].IDNumber &&
i < MAXCLIENTS)
{
i++;
)
Совершенно ясно, что происходит в этом фрагмен-
те программы, так что он, по сути, не требует коммен-
тариев.
Описание выполняемых кодом действий
Хорошие комментарии отражают то, для чего код пред-
назначен (т.е. намерения программиста), а не сам ме-
ханизм выполнения. Более того, механизм может вре-
мя от времени меняться по мере того, как
обнаруживаются усовершенствованные и новые спосо-
бы выполнения той или иной операции. Однако, если
меняется цель программы (т.е. намерения программис-
та), значит, новая программа действительно нуждается
в новом исходном коде (и в новых комментариях). Рас-
смотрим пример:
/* сохранить текущий заголовок списка */
temp = *list;
/* перенести указатель списка на следуюцую
позицию в списке */
♦list = (*list) -> next;
/* копировать даншм» из текучей позиции списка */
г»«веру (dataptx, temp -> data, sizeof *dataptx);
Войны стандартов программирования: причины и пути перемирия
Глава 2
51
Эти комментарии документируют механизм, но не
намерения программиста. Значительно лучше коммен-
тировать сразу несколько строк кода:
/* обработать этого клиента и сделать текущим
следующего клиента */
temp ® ‘list;
‘list = (‘list) -> next;
nemcpy (dataptx, tenp -> data, sizeof ‘dataptx) ;
Такой комментарий намного лучше — когда мы ре-
шим удалить список и использовать вместо него простой
массив, нам не придется переписывать комментарий.
Комментирование сложного кода
Однако иногда требуется задокументировать механизм
реализации той или иной операции. Лучше всего писать
самый простой код, но иногда невозможно совместить
простоту со скоростью кодирования. Когда вы пишете
сложный код, думайте о программисте сопровождения
и объясняйте, что и как работает.
’’Если это было трудно написать, значит будет труд-
но и прочесть”. Такой вывод ошибочен. Если даже при
написании кода возникали трудности, важно позабо-
титься, чтобы этот код читался как можно проще, по-
скольку в противном случае стоимость сопровождения
будет непомерно высока, а шансы выхода программы из
строя в процессе сопровождения существенно возрастут.
Комментирование закрывающих скобок
Когда подходит крайний срок сдачи работы, а ваши
функции слишком громоздки, бывает трудно опреде-
лить, какая закрывающая скобка } какой открывающей
скобке { соответствует. Некоторые редакторы обеспечи-
вают макросы, вызываемые нажатием клавиш, для по-
мощи в поисках соответствующих скобок (если вам
посчастливится в нужное время находиться рядом с
таким редактором). К сожалению, я не знаю ни одной
компании-поставщика, которая бы обеспечивала аппа-
ратурой для поиска соответствующих пар скобок на
нескольких листах бумаги. Следовательно, в больших
программах необходимо позаботиться о комментирова-
нии ваших закрывающих скобок:
if (IncomingMissile = TRUK)
{
/* ... 20 строк кода ... */
while (PhaseOfMoon == FULLMOON)
{
/* ... еще 40 строк кода ... */
} /* конец блока while (PhaseOfMoon
FULLMOON) */
} /* конец блока if (XncomingMissile) */
Стандарты же кодирования, которые настаивают на
том, чтобы вы делали это в конце каждого отдельного
блока операторов, становятся просто бессмысленно ав-
торитарными:
if (Р =
{
sign = NEG;
++р;
} /* конец блока if (р = ’ -') */
— делать это явно глупо.
Не "закомментируйте" код
Проблема снабжения кода символами комментариев
(закомментирование) состоит в том, что трудно заком-
ментировать его вдоль и поперек. Поскольку С не.до-
пускает наличия вложенных комментариев, использо-
вание символов комментариев для закрытия кода,
содержащего комментарии, может стать поистине испы-
танием терпения. Повторное включение кода в програм-
му также является болезненным, поскольку вам нужно
переиначить все комментарии, которые вы собрали,
когда начали весь процесс. (Если вы хотите схитрить
или используете компилятор С99, можете воспользовать-
ся комментариями типа //; в этом случае рассматрива-
емый процесс немного упрощается.)
Существует намного более простой и более удобный
способ, который намного превосходит во всех отноше-
ниях снабжение кода символами комментария: препро-
цессор. Он как-будто специально приспособлен для этой
задачи. Ведь когда вы закрываете код символами коммен-
тария, то вы фактически временно удаляете его из фазы
компиляции (либо потому, что вам не нужна его функ-
циональность после всех изменений, но вы не желаете
уничтожать его на случай обратных изменений специ-
фикации, либо поскольку вы вылавливаете ошибки).
Препроцессор сам может делать первоклассную ра-
боту по удалению кода из фазы компиляции. Ниже
приведен один пример:
finclude <stdio.h>
int main (void)
{
I if 0 /* имеются проблемы с функцией print f */
/* выборка имени из среды */
printf ("Hello %s and ", getenv ("NAME"));
lendif
printf (hello everyone else.Xn");
return 0;
Такая методика более предпочтительна, поскольку,
во-первых, она действительно очень проста для повтор-
ного разрешения кода (путем изменения #if 0 на #if 1)
и, во-вторых, вы легко можете избавить препроцессор
от лишней работы путем простого уничтожения строк
#if 0 и #endif, когда они вам уже не нужны.
52
Пересмотренный язык С
Часть!
Общие ошибки и недоразумения
Следующие несколько разделов охватывают некоторые
разнообразные обычные в С-программировании ошиб-
ки и недоразумения.
Ересь void main ()
Функция main () возвращает тип int. Если вы уже это
знаете, можете при желании сразу перейти к следующе-
му разделу.
Если вы присвоите функции main () тип возврата,
отличный от int, то в компиляторах, предшествующих
компиляторам С99, вы получите неопределенное пове-
дение своей программы. В компиляторах С99 вы полу-
чите неспецифицированное поведение, если так гово-
рит реализация версии, или неопределенное поведение —
если она этого не делает. Доверяете ли вы своей про-
грамме в этом отношении?
Многие просто не верят мне, когда я говорю им это
(точно так же, как не верил я, когда впервые узнал об
этом). Частично это связано с тем, что несколько ши-
роко известных учебников по С и, по крайней мере, по
одной авторитетной программе-компилятору использу-
ют void main () с тревожной регулярностью. Ниже при-
ведена формулировка стандарта С99 (который фактичес-
ки чуть более снисходителен, чем стандарт С89,
который вам, возможно, более знаком):
"5.1.2.2.1. Запуск программы [# 1] Функция, вызыва-
ющая запуск программы, называется main (главная).
Реализация не объявляет прототип для этой функ-
ции. Он должен быть определен путем возврата це-
лого типа int без параметров:
int main (void) { /* — */ )
либо с двумя параметрами (здесь они называются
aigc и argv, хотя можно использовать любые имена
в том порядке, как они размещены в функции, в
которой объявлены):
int main (int argc, char *argv [ ] )
{/*...*/}
либо некоторым другим определенным реализацией
способом".
Немного дальше читаем об окончании программы:
"5.1.2.2.3 Завершение программы #[1] Если возвра-
щаемый главной функцией тип является типом, со-
вместимым с int, то возврат в главную функцию эк-
вивалентен вызову функции выхода со значением,
возвращенным главной функцией в качестве ее ар-
, гумента; при достижении скобки}, которая заверша-
ет главную функцию, возвращается значение 0. Если
возвращаемый тип несовместим с типом int, состо-
яние завершения, возвращаемое в хост-среду, явля-
ется неспецифицированным".
В данном контексте "неспецифицированнЫй" озна-
чает, что стандарт не требует какого-либо специфичес-
кого поведения от компилятора, который волен возвра-
тить в хост-среду (обычно это операционная система)
любое состояние, какое ему нравится, и это применя-
ется, только если документами реализации установле-
но, что она поддерживает возвращаемые из main ()
типы, отличные от int. Если у вас пуская (void) главная
функция main () и вы пишете код для ядерного реакто-
ра или военного самолета, вы, возможно, почувствуете
легкую нерешительность, и я не виню вас. Кроме того,
определение main () для возврата типа void (пустой) не
является синтаксической ошибкой или нарушением
ограничения, так что компилятор не обязательно дол-
жен выдавать какое-либо диагностическое сообщение.
Давайте посмотрим на это несколько под иным уг-
лом. Рассмотрим четвертый аргумент функции сорти-
ровки qsort. Он специфицирован как указатель на не-
кую функцию сравнения, принимающую в качестве
аргументов две константы типа const void * и возвраща-
ющую тип int. Функция qsort вызывает эту функцию
сравнения и использует возвращенное ею значение для
установления взаимоотношений между двумя объекта-
ми в массиве, который подлежит сортировке. Так вот,
что случится, если вы напишете функцию сравнения,
подобную этой?
void Coinpints (const void *pl, const void *p2)
{
const int *nl = pl;
const int *n2 = p2;
int diff;
if(*nl > *n2)
diff = 1;
else if(*nl == *n2)
diff » 0;
else
diff = -1;
1
Слов нет, верно? У функции qsort hqt способа по-
лучить информацию, в которой она нуждается. Вы не
можете специфицировать прототип функций сравнения —
вам потребуется отбросить правила, обращения к функ-
ции qsort, если вы хотите заставить эту функцию делать
то, чего от нее ожидаете.
Хорошо, вернемся к функции main (). Здесь точно
такая же ситуация. Вы не ответственны за определение
интерфейса main (). Для этого есть вызывающая функ-
ция. Кто вызывает main ()? Это не вы (хотя фактичес-
ки вы можете, если захотите, вызвать main (), точно так
же как вы можете при желании вызвать свою функцию
сравнения из qsort). Но первичным "заказчиком" функ-
ции main О является код запуска. Как же код запуска
Войны стандартов программирования: причины и пути перемирия
Глава 2
53
определит, успешно ли завершилась программа, если вы
не сообщите ему об этом? Этот вызов "сидит" где-то
глубоко во внутренностях системы (здесь я немного
упростил его):
int returnstatus;
returnstatus = main (argc, argv);
Если вы "опустошите" функцию main (), появится
несколько интересных возможностей:
• Программа может работать в точности так, как вы
ожидаете.
• returnstatus может попасть в ловушку и вызвать ава-
рийный отказ программы (либо всего компьютера).
• Код запуска может отправить поддельный код воз-
врата операционной системе, которая затем решит
перемотать назад транзакции базы данных, посколь-
ку программа не возвратила ожидаемого значения.
• А это хуже всего — код запуска может снаружи до-
стигнуть вашего носа и начать извлекать из него де-
монов. (Демон (Demon) — процедура, запускаемая
автоматически при выполнении некоторых условий
и характеризуемая непредсказуемостью поведения. —
Прим. науч. ред.).
Функция main () возвращает тип int. Существует
только три переносимых на другие платформы значе-
ния, которые вы можете вернуть из main ():
о
EXITSUCCESS
EXIT_FAILURE
Два последние определены в <stdlib.h>, и их фак-
тические значения варьируются в зависимости от кон-
кретной системы. (Другими словами, не следует отыс-
кивать эти значения в библиотеке <stdlib.h> и
переносить их в свою программу.)
Если вы вернули 0, код запуска сообщит операци-
онной системе или другой хост-среде, что ваша про-
грамма выполнилась успешно, переведя 0 при необхо-
димости в некоторое другое значение.
Количество аргументов функции main ()
Фактически функцию можно определить путем опреде-
ления реализации. Следовательно, такое определение
main, как
int main (int argc)
ИЛИ
int main (int argc, char **argv, char **env)
не обязательно запрещено, но вы должны знать, что
компилятор обязан поддерживать любое из этих двух
определений. Они разрешены только для компиляторов,
которые документируют эти альтернативные формы и
которые конечно же не включают всех компиляторов.
Ниже приведены переносимые определения функ-
ции main ():
• int main (void)
• int main (int argc, char **argv)
• int main (int argc, char **argv [ ] )
• Любое определение, в точности эквивалентное лю-
бому из трех предыдущих
Таким образом, вы можете использовать различные
имена переменных в качестве argc и argv, а также мо-
жете использовать FOO, если определению предшеству-
ет typedef int FOO, и т.д. Но чтобы возвращаемое зна-
чение было переносимым, из main вы должны
возвращать тип int, а также задавать либо ни одного
аргумента, либо два специфицированных стандартом
аргумента. Если есть необходимость получить доступ к
среде переносимым способом, можете, конечно, ис-
пользовать функцию getenv ().
Целочисленная математика против
математики плавающей точки
"Каждый знает, что целочисленная математика быстрее,
чем математика плавающей точки, и это объясняет,
почему профессионалы выполняют вычисления в целых
числах где только возможно". Этот факт достаточно
проверен, чтобы быть истинным. В последние несколь-
ко лет, однако, математические сопроцессоры в новых
настольных компьютерах стали почти обязательными.
В результате в наше время случается, что операции с
плавающей точкой выполняются быстрее, чем их цело-
численные эквиваленты. Старое правило здравого смыс-
ла более неприменимо безусловно.
Это только один аспект более обшей точки зрения
на эффективность. Стандарт С не определяет, как быс-
тро выполняются функции языка С, ни в абсолютных
величинах, ни относительно друг друга. О любых двух
данных алгоритмах одинаковой степени сложности (бо-
лее детально алгоритмы описываются в главе 3) вы про-
сто не в состоянии сказать, какая техника программи-
рования будет более эффективной. Например, нет
гарантии, что программа
int ch;
ch = fgetc (fp);
if (ch 1= EOF)
{
будет выполняться быстрее (или медленнее), чем про-
грамма
Пересмотренный язык С
Часть I
unsigned char с;
if (freed (fcc, 1, 1, fp) > 0)
{
/* ... */
Единственный способ, позволяющий определить
это, состоит в том, чтобы запустить ее и смотреть. Даже
когда вы сделаете это, ваши результаты не будут пере-
носимыми на другой компьютер, операционную систе-
му или реализацию (или даже на другую версию одно-
го и того же компилятора). Имеет смысл инвестировать
капитал в хороший кодовый профайлер, если для ваше-
го приложения эффективность является ключевым ас-
пектом. (Если эффективность не важна для вашего при-
ложения, почему тогда вы в первую очередь озабочены
этим?) Для большинства приложений вопросы эффек-
тивности возникают только тогда, когда программа вы-
полняется подобно тому, как бежит одноногая собака.
В этих обстоятельствах вы, вероятнее всего, захотите
получить значительный выигрыш в эффективности пу-
тем пересмотра своего выбора алгоритма, а не путем
экономии в программе одного цикла здесь и одного
цикла — там.
Если ваш документ стандарта кодирования утверж-
дает, что целочисленная математика быстрее, чем ма-
тематика плавающей точки, вы должны отвечать: ’’До-
кажите это!”
Обработка сигналов
Всякий раз, когда я вижу предположительно переноси-
мую программу, которая выполняет сигнальную обра-
ботку, я становлюсь подозрительным. Большинство
программ, обрабатывающих сигналы, делают это некор-
ректно. В вашей функции обработки сигнала вам фак-
тически не разрешено (за исключением наличия опре-
деленных довольно ограниченных обстоятельств)
ссылаться на любой статический объект, если он был
объявлен как имеющий тип volatile sigatomict. (Пере-
менная atomic (атомарный), упрощенно говоря, это то,
что может ссылаться на единственную машинную опе-
рацию.) Большинство С-программистов, которых я
знаю, никогда не слышали о типе sig atomic t, и пото-
му многие из них все еще продолжают добавлять в свои
программы средства обработки сигналов.
Более того, вам запрещено вызывать любую стандар-
тную библиотечную функцию (или другую функцию,
которая может вызвать стандартную библиотечную
функцию) изнутри обработчика сигнала (исключение
делается для функций abort () и, при определенных
обстоятельствах, для функций signal ()). Это, конечно,
не останавливает людей, и они продолжают вызывать
библиотечные функции, но результат такого вызова
непереносим и должен быть пустой операцией в пере-
носимой программе.
На практике многие программы используют сигна-
лы, и не только для перехватывания прерываний при
операциях с плавающей точкой. Например, сигналы
часто используются в сетевых UNIX-приложениях. Мое
мнение таково, что такое использование основано на
реализации, разрешающей и поддерживающей его, так
что вы должны быть осторожны. (Строго говоря, вы
надеетесь на неопределенное поведение, но если ваш
поставщик задокументировал поведение и вы можете
доверять ему, у вас все должно быть в порядке, по край-
ней мере пока не будет реализована следующая версия
вашего компилятора.)
Передача по значению
Мы все знаем, что не можем делать перестановку (или
свапирование) двух типов int с помощью функции, по-
добной этой:
void swap (int a, int b)
{
int t;
t = af a = bf b = t;
)
поскольку С является языком передачи-по-значению. К
сожалению, некоторые учебники по С предполагают,
что вы вместо этого передаете по ссылке:
void swap (int *а, int *b)
{
int t;
t = *ar *a = *br *b = t;
}
Уверен, что это работает. Но это не передача по
ссылке. В языке С вообще нет такой вещи. Фактически
же происходит вот что: адреса а и b передаются, но по
значению! Более ясно это видно на примере этой про-
стой демонстрационной программы:
#include <stdio. h>
void increment(char *p)
<
++p;
}
int main(void)
{
char *s s "Hello world";
increment s);
printf("%s\n", s);
return 0;
}
Если бы С передавал указатели по ссылке, эта про-
грамма должна была бы напечатать следующее:
ello world
Но она не делает этого. Она печатает:
Hello world
Воины стандартов программирования: причины и пути перемирия
Глава 2
Это говорит о том, что модификация р функцией
increment () не оказала влияния на первоначальный ука-
затель s. Именно такого поведения мы и ожидали при
передаче по значению. По этой же причине следующий
код работать не будет (и фактически проявит неопре-
деленное поведение):
#include <stdio.h>
int openfile (char *sf FILE *fp)
{
fp = fopen(s, "г");
return fp ? 1 : 0;
}
int main(void)
{
FILE *fp;
char bufferf1024];
if(openfile("readme*, fp))
{
while(fgets(buffer, sizeof buffer, fp))
printf("%s", buffer);
fclose(fp);
printf("\n");
)
return 0;
}
Если затем вы захотите внутри функции изменить
объект, на который указывает указатель, то как вам это
сделать?
Методика будет такой же, как и в случае с перемен-
ной: вы передаете указатель на объект, который хотите
изменить. В предыдущем примере мы хотели сделать
указатель указывающим на возвращаемое значение фун-
кции fopen. Ниже представлена модифицированная
программа, которая будет работать корректно:
#include <stdio.h>
fdefine MAXBUFF 1024
int openfilefchar *s, FILE **fp)
{
*fp = fopenfs, "r");
return *fp ? 1 : 0;
}
int main(void)
{
FILE *fp;
char buffer[MAX_BUFF);
if(openfile("readme”, ifp))
{
while(fgets(buffer, sizeof buffer, fp))
printf("%s", buffer);
fclose(fp);
printf("\n");
}
return 0;
Аналогично, если вам необходимо изменить пере-
менную ppt на тип **Т (где Т является некоторым ти-
пом), вам нужно передать &ppt в свою функцию, кото-
рая была бы прототипирована, например, так:
int foo (Т *** рррТ);
(В действительности это может принять даже более
глупый вид, чем то, что написано здесь. Сначала я хо-
тел было использовать здесь пять звездочек, как в од-
ном реальном коде. К счастью, такое требуется редко.)
Проблемы с включающим ИЛИ
Некоторые компьютеры хранят числа таким образом,
что первым следует наиболее значимый байт. Говорят,
что такие компьютеры имеют порядок хранения "от
старшего к младшему" (big-endian). В других компьюте-
рах первым следует наименее значимый байт (little-
endian), поскольку такое расположение оказывается
более эффективным для их конкретной архитектуры.
Поэтому иногда бывает необходимым определять ”по-
рядок следования” ("endianness”) битов в конкретном
компьютере (По этим вопросам см. также главу 5. —
Прим, науч, ред.)
Ниже приведена обычно используемая методика для
определения порядка следования битов в компьютере:
#include <stdio.h>
union U
{
long bignum;
short littlenum[2);
);
int main (void)
{
union U u = {1L};
if(u.littlenumf0] == 1)
{
printf("Little-endian\n");
1
else
{
printf("Big-endian.\n");
return 0;
}
К сожалению, работоспособность такой методики не
гарантирована (точнее, ее работоспособность в старом
стандарте С определяется реализацией компилятора, а
в С99 она не определена). Можно лишь выяснить, что
и куда вы переносите в операции объединения union.
(Дословно — объединение, здесь — операция "включа-
ющее ИЛИ". — Прим. науч, ред.) Если вы переносите
куда-либо тип long int, то извлечь можете только тип
long int.
56
Пересмотренный язык С
Часть I
Утверждение о том, что поведение этого кода опре-
делено реализацией или не определено вообще, может
показаться слишком придирчивым, но ведь полная оп-
ределенность — вполне естественное требование для пе-
реносимости. Почему каждый программист (кроме тех,
кто занимается одноразовыми упражнениями) беспоко-
ится о том, чтобы написать процедуру для определения
во время выполнения того, имеет ли компьютер конк-
ретное представление, даже если он собирается запус-
кать ее на одной реализации одного компьютера?
Имеется исключение из этого правила объединения,
связанное с обработкой структур с общими начальны-
ми последовательностями. Это проще увидеть, чем об
этом рассказать. Следующие определения я расположил
горизонтально не только в целях экономии места, но и
чтобы выделить их общую начальную последователь-
ность:
typedef struct FOO { int i;
double j; long k; } FOO;
typedef struct BAR { int a;
double b; char c; } BAR;
typedef struct BAZ { int d;
double e; FOO f; } BAZ;
typedef union QUUX
{
FOO foo;
BAR bar;
BAZ baz;
} QUUX;
FOO first = { 3, 3.14, 42 };
QUUX q;
q.foo s= first;
printf("%d if\n*, q.bar.a, q.baz.e);
Поскольку FOO, BAR и BAZ разделяют общую на-
чальную последовательность int, double, ничто не меша-
ет проверить любой элемент этой последовательности
с использованием q.foo, q.bar или q.baz. Но если вы
сохраняете значение в элементе не в общей начальной
последовательности (например, q.fbo.first.k = 9;), то
считывание этой информации посредством q.foo, q.bar
или q.baz будет непереносимым.
Оператор sizeof
sizeof — это оператор, а не функция. Для некоторых
людей это может оказаться сюрпризом. Оператор sizeof
выдает размер объектно-типированного выражения (или
типа) во время компиляции. Это унарный оператор, так
что он принимает только один объект либо только одно
объектно-типированное выражение или тип. Таким об-
разом, этот фрагмент кода
FOO foo;
size__t sizeof foo;
вполне допустим. Если вам необходимо вместо этого
задать тип, то нужно заключать его в скобки; при этом
sizeof не становится функцией:
size_y othersize ж sizeof (FOO);
Ниже показан прием, который фактически будет
работать:
void foo(int *array)
{
printf("array is stored in tu bytes.\n",
(unsigned) sizeof array);
printf("It has %u elements.\n",
(unsigned)(sizeof array /
sizeof(int)));
1
К сожалению, sizeof array не позволит нам опреде-
лить размер массива, а только размер указателя на тип
int. Более того, предыдущий фрагмент кода будет все-
гда выдавать одно и то же число, соответствующее ко-
личеству элементов в массиве. Это значение определе-
но реализацией, компилятора, но на многих системах
этот код печатал бы 1, поскольку указатель часто полу-
чает такой же объем памяти, как и тип int.
Ключевое слово return
Ключевое слово return — это не функция, так что оно
не требует скобок. Вы можете их использовать, если
хотите, но это не обязательно.
Объявления, определения и
прототипы
С-программисты часто затрудняются сказать, в чем со-
стоит различие между объявлениями, определениями и
прототипами. Что же они действительно собой пред-
ставляют?
Объявления
Объявление (или декларация, declaration) дает компи-
лятору информацию о типе идентификатора. (Строго
говоря, объявление специфицирует реализацию и атри-
буты установки идентификаторов.) Определение — это
объявление, но объявление не обязательно должно быть
определением. Например, переменная области видимо-
сти файла с внешней связью может быть определена в
программе лишь однажды, но объявить ее вы можете
столько раз, сколько вам угодно. Таким образом, в ис-
ходном файле А мы могли бы иметь переменную
int GlobalX = О;
определенную в области видимости файла. В исходных
файлах В, С и D мы могли бы законно объявить
extern int GldbalX;
Войны стандартов программирования: причины и пути перемирия
Глава 2
Кроме того, мы вполне можем разместить это объяв-
ление прямо в А независимо от законности уже сделан-
ного определения.
Определения
Определение (definition) объекта (такого, как перемен-
ная, например) означает отведение для него памяти и
(необязательно) присвоение ему некоторого значения.
Объект внутри программы должен быть определен толь-
ко однажды.
Объект может быть определен также эксперименталь-
но (tentatively). Такое определение является определе-
нием в области видимости файла без инициализатора и
без спецификатора памяти (либо со спецификатором
static). Я был бы счастлив, если бы мог сообщить вам,
что это полезная вещь, но я не вижу абсолютно ника-
кого смысла в таком экспериментальном определении.
Определение функции означает придание функции
тела. Поэтому само определение функции включает ее
тело. Таким образом, С-программу можно рассматривать
как коллекцию определений.
Прототипы
В соответствии со стандартом, прототипом (prototype)
функции является объявление функции, которая объяв-
ляет типы своих параметров.
Прототип — это всегда объявление (и, может быть,
определение) функции. Прототипы используются ком-
пилятором для подтверждения правильности списка
аргументов в обращениях (вызовах) к прототипирован-
ным функциям. Я убежден, вы уже знаете о прототи-
пах как об объявлениях, поэтому приведу пример того,
каким образом определение функции может также быть
прототипом:
*indude <stdio. h>
linclude <string.h>
int foo(char *s)
{
return (int)strlen(s);
}
int main(void)
{
char *hi = "Hello world";
printf("The string %s is id bytes long\n",
hi, foo(hi));
return 0;
}
Здесь строка int foo (char *s) является не только
первой строкой определения функции; она является
также полным прототипом.
Важность переносимости программ
Одним из наиболее трудных для преодоления препят-
ствий является переход из “детского сада** С в реальный
мир переносимых приложений. Понятна тенденция
предполагать, что “компилятор является языком*'. Сис-
тему может хватить настоящий (кулаком) удар, когда вы
вдруг обнаружите, что функция getch () не является
частью языка С!
Поразрядное дополнение до единицы и до
двух
В языке С не подразумевается, что вы работаете на ком-
пьютере с дополнительным кодом числа (Twos
complement — поразрядное дополнение до двух в дво-
ичной системе счисления. — Прим. науч. ред.). Это
объясняет, почему стандарт ANSI требует от реализа-
торов делать параметр INT_MIN равным по крайней
мере 32767 по абсолютной величине (она может быть
и отрицательной, конечно), а не 32768. В случае обрат-
ного кода числа (Ones complement — поразрядное до-
полнение до единицы в двоичной системе. — Прим,
науч, ред.) вы не сможете хранить величину -32768 в 16
битах (хотя вы получаете дополнительную возможность
различать 0 и -0). Поскольку для хранения отрицатель-
ных чисел в компьютерах с обратным и дополнитель-
ным кодами используются различные наборы битов,
результат смещения отрицательного числа оказывается
в лучшем случае определенным реализацией компиля-
тора (как и любая операция сдвига, включающая зна-
ковый бит) и неопределенным — в худшем случае. Во-
обще, когда сдвигаются биты, безопаснее всего
придерживаться беззнаковых типов.
Определение неопределенного поведения
Посмотрим, что стандарт С говорит о неопределенном
поведении:
"3.18 [#1] Неопределенное поведение [является] по-
ведением, возникающим в результате использования
непереносимой или ошибочной программной конст-
рукции, ошибочных данных или неопределенных (по
значению) объектов, которые не охватываются требо-
. ваниями этого Международного стандарта".
Ниже приведена С-программа, не содержащая син-
таксических ошибок или нарушений каких-либо огра-
ничений. (Другими словами, компилятор ANSI С до-
пускает компиляцию этой программы без выдачи
каких-либо диагностических сообщений.)
void main ()
{
printf ("Hello world\n");
I
58
Пересмотренный язык С
Часть I
С точки зрения стандарта С эта программа может
выполнять любые функции. Наиболее вероятным ре-
зультатом будет выдача приветствия всему миру:
Hello world
на стандартное выводное устройство, но нет абсолют-
ной гарантии, что фактически будет сделано именно
это. Для этого есть две причины. Первая состоит в том,
что функция некорректно специфицирует main () как
возвращающую тип void; в языке С функция main О
должна возвращать тип int. Второй причиной является
тот факт, что функция printf была вызвана без полного
прототипа для ее введения в область видимости.
Итак, эта программа может хорошо работать на ва-
шем компьютере. Но это не означает, что она будет
работать на том компьютере, на котором вы ее скомпи-
лируете. Это не означает также, что программа будет
работать на другом компиляторе, даже если он предназ-
начен для той же самой операционной системы. Фак-
тически это даже не означает, что программа будет ра-
ботать на предыдущей или на последующей версии
вашего собственного компилятора. Завсегдатаи группы
comp.iang.c укажут вам, что ничего не остановит реа-
лизацию вытаскивать демонов из вашего носа (и дей-
ствительно, термин "носовые демоны" в этой группе но-
востей является псевдонимом неопределенного
поведения). Конечно, демонографическая ринология —
не единственно возможный результат. Если у вас хоро-
шие аппаратные средства, эта программа способна вы-
полнить любые возможные и невозможные действия.
Подавление буферов ввода
Ниже демонстрируется обычно применяемая методика
освобождения от нежелательных символов во входном
потоке:
printf ("Введите возраст:");
scant("%d"r (аде); /* Получение
возраста от пользователя */
printf ("Введите размер обуви:");
fflush (stdin);
/* Избавились от перевода строки */
scant ("%d", fishoesize); /* Получение от
пользователя размера обуви */
Почитаем, что стандарт говорит об этом фрагменте:
^include <stdio.h>
int fflush (FILE *stream);
Из раздела 7.19.5.2: "[#2] Если stream указывает на
выходной поток или на модификацию потока, в кото-
ром последняя операция не была операцией ввода, фун-
кция fflush удаляет любые непечатаемые данные, для
которых поток доставлен в хост-среду для записи в
файл; в противном случае поведение не определено".
Если вы хотите избавиться от случайных символов
между обращениями к scant, можете сделать это следу-
ющим образом:
printf ("Введите возраст:");
fflush (stdout);
scant("%d". (age); /* Получение
возраста от пользователя */
printf ("Введите размер обуви:");
fflush (stdout);
scant (" %d", Sshoesize); /* Обратите
внимание на лидируиодм пробел */
(Как вы видите, я принял возможность продемон-
стрировать, что вы можете переносимо собрать ввод на
той же строке, что и предыдущий вывод, разумно ис-
пользуя функцию fflush ().)
Фактически лучше не использовать функцию scant ()
для интерактивного получения данных. Она предназна-
чена для чтения форматированных данных из stdin, и
человечество не нашло лучшего источника форматиро-
ванных данных. Использовать scant () намного лучше,
когда stdin является, например, переназначенным из
файла с тщательно определенным форматом.
Если вы привыкли использовать scant () и теперь
предпочли бы альтернативное предложение, вниматель-
но присмотритесь к функции fgets (), которая идеаль-
но приспособлена для сбора данных от пользователя.
Функции is () и to ()
Эти функции из <ctype.h> (isupper, tolower и т.п.) при-
нимают в качестве аргумента тип int, но этот аргумент
должен быть либо EOF, либо значением, представляе-
мым как тип unsigned char. Любое другое значение вы-
зывает неопределенное поведение. Если вы хотите пол-
ностью обезопасить эти функции, предварительно
приведите их аргументы к типу unsigned char. (Это не-
посредственно будет причиной проблем, связанных с
EOF, но вы всегда можете разработать свой алгоритм
так, чтобы передача EOF в функцию просто не могла
бы иметь места.) Приведение к типу unsigned char бу-
дет гарантировать безопасность операции, а компиля-
тор позаботится о том, чтобы значению вернуть тип int.
Проблема возникает только тогда, когда ваша стро-
ка имеет символы, представленные величинами вне
диапазона от 0 до UCHARJVIAX. Например, ваша про-
грамма может выполняться в системе, такой как DOS,
где тип char обычно по умолчанию является signed
(имеет знак), и пользователь может использовать ALT
в конъюнкции с числовой вспомогательной клавиатурой
для ввода символа не из набора символов ASCII. В та-
ких ситуациях вам следует быть предусмотрительным
Приведенный ниже фрагмент кода иллюстрирует, как
можно убедиться в том, что ваш код устойчив:
Войны стандартов программирования: причины и пути перемирия
Глава 2
59
void MakeStringUpperCase(char *в)
{
while(*s)
{
*в = toupper((unsigned char)*s);
++s;
}
Аннулирование строки
Ниже показан обычный прием, используемый для об-
мена значениями двух целых чисел без участия времен-
ной промежуточной переменной:
а А= Ь А= а А= Ь;
Этот прием может выглядеть очень мило, но пользо-
ваться им корректно невозможно. А вот еще один часто
используемый способ:
void strrev(chax *s)
{
int len = strlen(s);
int ir j;
for(i = 0г j = len - 1; i < j; i++f j—)
s(i] s[j] Л= s[i] ж= s[j);
}
Если вы подумали, что этот код выглядит очень
непривлекательно, вы правы. Но дело не только в этом,
он еще и неправилен. Поскольку код модифицирует
значение объекта дважды между точками последователь-
ности, в результате можно получить неопределенное
поведение. Судите сами: сбой во включении <string.h>
для strlen, неправильный тип для len (он должен иметь
тип size_t) и нарушение области имен (strrev) кажутся
совершенно тривиальными. (Между прочим, если вы
делаете len типом size_t, то должны добавить проверку
на специальный случай, когда строка имеет длину нуль
байтов.)
Шутка ли сказать, ни одна из этих ошибок не явля-
ется синтаксической ошибкой или нарушением ограни-
чения, так что никакой диагностики не требуется!
Если вам интересно, приведу код, написанный со-
вершенно законно:
fxnclude <string.h>
void revstr(char *s)
{
size_t len = strlen(s);
size t if j;
if(len > 0)
for(i « 0г j = len - 1; i < j; i++, j—)
s[i] Л= B[j] *= s[i]f s[i] A=
s[jl;
}
Программа будет работать всегда, поскольку запятые
вводят точки последовательности в код. (Это все еще
довольно ужасно, но по крайней мере не нарушает за-
конов С. Лучшее и более ясное решение получается с
использованием временной переменной.)
"НОСОВЫЕ ДЕМОНЫ"
Мною лично засвидетельствованы два наиболее драмати-
ческих результата неопределенного поведения, и оба они
были связаны с отведением недостаточной памяти в мас-
сиве char для завершающего нулевого символа строки.
Первый случай произошел в 1989 году, и его жертвой был
мой брат Стив. Однажды он привлек мое внимание к
экрану с отображенным на нем сообщением, в котором
его совершенно неожиданно просили подтвердить, что он
желает форматировать свой жесткий диск. Он был сча-
стливчик — его спросили.
Г од или около того спустя мой коллега (его звали Кевин)
оказался не таким везучим. Первым знаком неопреде-
ленного поведения его программы было то, что его ком-
пьютер стал "зависать". Вторым знаком было то, что он
не перезагружался! После этого ему пришлось потратить
много времени, чтобы устранить неполадки, используя
диагностические гибкие диски, поставляемые производи-
телем.
Что касается лично меня, то со мной часто случались
разного рода неприятности. В некотором отношении я был
неудачником. Я с удовольствием рассказал бы вам о том,
как свергнул правительство путем разыменования указа-
теля NULL или затопил город путем передачи
(UCHAR_MAX + 1] в функцию isupper (|. Но мои соб-
ственные сбои в действительности были значительно ме-
нее драматичны. Извините, если я вас разочаровал.
Размеры целых типов
Строго говоря, длинный целый тип (long Int) имеет
длину sizeof (long int) байтов. Вы знаете, что эта длина
составляет не менее 32 битов, поскольку она должна
представлять все целые числа между -2147483647 и
+2147483647. Рассматриваемый тип может иметь раз-
мер, превышающий 32 бита. Это объясняется тем, что
на вашей конкретной реализации значение LONG_MAX
выше чем 32 бита, либо тем, что были использованы
дополнительные биты (это не обязательно, но компи-
ляторы позволяют использовать их). Чтобы определить
потребности в памяти, работайте с sizeof (long int). А
чтобы установить, как большое число может быть со-
хранено в типе long int, используйте LONG_MAX. На
текущих системах длинный целый тип long int обычно
имеет длину 32 бита.
Те же рассуждения можно применить и к коротко-
му целому типу short int, который имеет длину sizeof
(short int) байтов и по крайней мере 16 битов, посколь-
ку этот тип должен представлять все целые числа в ди-
апазоне между -32767 и +32767. Этот тип может иметь
длину более 16 битов, опять же по той причине, что для
компилятора характерны более высокие пределы реали-
зации, чем требуется (т.е. совершенно законно), либо
из-за дополнительных битов. На текущих тстемах ко-
роткий целый тип short int имеет длину 16 битов.
Пересмотренный язык С
Часть I
60
Когда мы обращается к типу int, мы можем приме-
нять те же рассуждения. Значение INT MAX должно
быть равным по крайней мере 32767 (а значение
INT MIN соответственно должно быть не более -
32767), как мы знаем int имеет длину по крайней мере
16 битов. В более старых операционных системах (и
никогда — в операционных системах, находящихся в
режиме эмуляции для поддержки программного обес-
печения от более старых систем) тип int обычно, но не
как правило, имеет длину 16 битов. Ни в одной опера-
ционной системе int не может иметь длину 32 бита.
Однако было бы не совсем правильно жестко фик-
сировать эти величины. В этом мире обязательно най-
дется по крайней мере один компьютер (типа Cray),
который использует 8 битов для типа char и 64 бита для
short, 64 бита для int и 64 бита для типа long.
Моя точка зрения состоит в том, что этот код
«include <81x110. h>
int main (void)
{
printf ("%d\n"r (int) sizeof (int));
return 0;
)
на вашем компьютере запросто может напечатать 2.
Либо он может напечатать 4 или даже 8, если вам по-
счастливилось использовать компьютер Cray (как я убе-
дился на практике, все мы счастливчики). Какое бы
значение этот код ни напечатал, он ставит перед нами
проблему, которая не исчезнет независимо от того, на
каком компьютере вы скомпилируете этот код.
Заполнение структур
Структуры предоставляют прекрасный способ совмес-
тного хранения элементов связанных данных. Вы може-
те не знать, однако, что компиляторы не требуют хра-
нить эти элементы в памяти тесно соприкасающимися
друг к другу. Для компилятора позволительно вставлять
заполняющие биты (столько, сколько ему понравится)
между элементами структуры и в конец структуры (но
не в начало). Компиляторам не только разрешается это
делать, но они фактически так и делают; это очень
удобный способ выравнивания данных в целях повыше-
ния эффективности доступа к ним.
Таким образом, для этого кода
struct FOO
{
< chat a;
char b;
char c;
char d;
char e;
' char f
};
FOO foo = {01;
char *p;
char q[] = "hello";
int i;
p = (char *)&foo;
for(p = Sfoo.a, i = 0; q[i] 1= '\0'; i++t p++)
*p = q[il;
printf("%s\n", £foo.a);
еще далекого от того, чтобы быть ужасным, стандартом
не предусмотрено абсолютно никаких гарантий, что он
напечатает "hello”.
Вы должны особенно остерегаться заполнения
структуры, когда осуществляется обмен данными меж-
ду двумя компьютерами, которые вполне могут исполь-
зовать различные стратегии выравнивания данных.
Макросы
Вы уже это знаете, но я еще раз хочу вас предостеречь:
остерегайтесь макросов и связанных с ними побочных
эффектов!
Этот простенький прелестный макрос
«define SQ (X) X * X
дает сбой при использовании кода
а = SQ (Ь + с);
поскольку этот код разворачивается в следующую за-
пись:
а=Ь + с*Ь + с;
которая является почти безусловно не тем, чего вы ожи-
дали.
Давайте исправим этот макрос:
«define SQ (X) ((X ) * (X))
Теперь мы можем заставить его сбоить другим спо-
собом:
а = SQ (++Ь);
Этот макрос не только не даст желаемого результа-
та, но этот результат также приведет к неопределенно-
му поведению. В развернутом выражении
а = ((++Ь) * (++Ь)) ;
значение объекта модифицируется несколько раз меж-
ду точками последовательности, что недопустимо.
Если вам необходимо использовать макросы, убеди-
тесь, пожалуйста, что они, по меньшей мере, поимено-
ваны в верхнем регистре, чтобы дать программисту ви-
зуальное напоминание о том, что ’’здесь сидят драконы".
Войны стандартов программирования: причины и пути перемирия
Глава 2
61
С против C++
С и C++ являются различными языками и предназна-
чены для различных людей. С — это процедурный язык,
в то время как C++ — язык объектно-ориентированный.
Те знания, которые делают вас хорошим С-программи-
стом, могут оказаться препятствием в обучении эффек-
тивному программированию на C++. Аналогично С++-
программисты иногда находят затруднительным
переход на язык С. Достигнуть мастерства в использо-
вании обоих языков можно, но это значительно труд-
нее, чем вам может показаться.
Спорить о том, какой из этих языков лучше, конеч-
но, бесполезно. Языки различны и имеют различные
достоинства и слабые места. Те, кто твердят, что C++
лучше чем С, неправы.
(Я не являюсь противником C++; я большой фанат
редактора C++ Builder, который сочетает скорость раз-
работки Windows и высокую эффективность программ-
ного кода.)
C++ отличается от С. Язык С отошел от точки, где
C++ ответвился от него, особенно с недавней (в октяб-
ре 1999 года) ратификации стандарта С99. C++ также
развивался. Ни один из этих языков не является под-
множеством другого.
Однако они имеют много общего, и это хорошо,
поскольку многие знания по С вы можете использовать
и в C++. Иногда это действительно очень выручает.
Например, когда я писал на C++, я использовал функ-
ции FILE * для доступа к файлам, поскольку работа с
потоком ввода/вывода (iostream) показалась мне слиш-
ком трудной. И так делал не только я. Некоторые мои
знакомые любители C++ признались мне, что они по-
ступают так же всякий раз, когда думают, что это сой-
дет им с рук.
Но эта книга о С, поэтому не будем слишком много
говорить о C++. Только один важный Момент: многие
С-компиляторы на рынке сегодня способны также ком-
пилировать язык C++. Это очень хорошо! К сожалению,
в мире Windows, кажется, большинство комбинирован-
ных компиляторов стали комплектоваться текстовыми
редакторами, которые по умолчанию печатают для сво-
их файлов расширение .срр, а не .с, и в результате (если
вы невнимательны) вы можете закончить компиляцию
своего С-кода так, как если бы это был код C++. По-
скольку эти два языка различны, такое положение ве-
щей неудовлетворительно. Например, следующий код
finclude <stdlib.h>
finclude <stdio.h>
finclude <&tring.h>
int main(void)
{
char *p «= malloc(1024);
if(₽)
{
strcpy(p, "Hello world.");
printf("%s\n", p);
free(p);
}
return 0;
}
является вполне законным С-кодом, но под управлени-
ем C++ вы получите диагностическое сообщение, по-
скольку конверсия void * в функции malloc вернет зна-
чение к типу char *.
Так что дам вам один мудрый совет: при использо-
вании таких комбинированных компиляторов уделите
особое внимание определенному по умолчанию расши-
рению файлов.
Резюме
Стандарты кодирования программ играют важную роль
в разработке проекта программного обеспечения. Одна-
ко они могут быть действительно эффективны, если
только вы следуете их рекомендациям. Будучи хоро-
шим и добросовестным программистом, вы, однако, не
должны следовать тем рекомендациям стандартов, ко-
торые заведомо неправильны или вводят в заблуждение.
Надеюсь, вы теперь способны критически относить-
ся к таким документам и применять их в своих собствен-
ных интересах и в интересах других людей, участвую-
щих в вашем проекте.
Мы рассмотрели также несколько проблем написа-
ния переносимого кода. Тема переносимости программ
на различные операционные системы и компьютеры
исключительно важна в книге о языке С, поскольку мы,
авторы, не имеем ни малейшего представления, на ка-
кой платформе вы будете запускать свои программы. Так
что мы будем все время возвращаться к этой теме о на-
писании кода, который будет выполняться не только на
нашей платформе, но и на вашей, независимо от того,
работаете ли вы с AmigaDOS, MVS, MacOS или с ка-
кой-либо менее известной операционной системой, та-
кой как UNIX или Windows. (Здесь нужно вспомнить,
что автор этой главы — житель Англии, где популяр-
ность систем UNIX и Windows не так широка, как в
США. — Прим. науч, ред.) Например, мы, конечно, не
предлагаем вам использовать только EBCDIC (Extended
Binary-Coded Decimal Interchange Code — Расширенный
двоично-десятичный код для обмена информацией. —
Прим. науч, ред.) Все демонстрационные коды в этой
книге поддерживают также другие С-совместимые на-
боры символов (такие, как ASCII).
Оптимизация
В ЭТОЙ ГЛАВЕ
Привлекательность оптимизации
Размышления об эффективности
Профайлинг
Алгоритмические стратегии оптимизации
Кооперативная и параллельная оптимизация
Когда оптимизация не нужна
Майкл Ли
С тех пор как появились вычислительные машины,
ведется непрестанная работа по повышению их быст-
родействия. Информационный век поднял эту деятель-
ность на новый уровень — то, что раньше выполнялось
за несколько дней или даже недель, теперь выполняет-
ся за несколько милли- и микросекунд. Часто функции,
написанные на языке программирования высокого уров-
ня, выполняются настолько быстро, что для них труд-
но определить какие-то временные рамки. Однако за
счет повторения более миллиона раз вызова той или
иной функции незначительное изменение скорости
выполнения каждой из них становится заметным. Та-
кие обширные масштабы вычислений требуют обосно-
вания необходимости и возможности оптимизации ком-
пьютерных программ. Цель настоящей главы — дать вам
такое обоснование.
В конце главы мы рассмотрим способ анализа эф-
фективности алгоритмов с использованием О-нотации,
способы измерения уровня эффективности программ с
помощью профилей, а также исследуем некоторые стра-
тегии повышения эффективности программ на основе ре-
зультатов наших измерений и проведенного анализа.
Привлекательность оптимизации
История оптимизации имеет довольно забавное начало.
На протяжении двух десятилетий цифровых вычисле-
ний компьютерное время ценилось больше, чем время
программиста. Такие учреждения, как сервисные бюро
и университеты, оплачивали эксплуатацию машины
своими пользователями часто по цене один доллар за
минуту пользовательского времени. У программистов
был стимул беречь каждую микросекунду расчетов,
причем учитывалось не только время (а следовательно,
и стоимость) выполнения программ, но и время загруз-
ки, компиляции их программ и печати результатов. Во
внимание принималось даже время суток работы на
вычислительной машине.
Теперь все это в прошлом, но некоторые проблемы
остались. Коммерческое программное обеспечение ча-
сто рано или поздно должно было столкнуться с требо-
ваниями стандартов. Трехмерные игры конкурируют на
рынке в рамках цен и качества текстуры отображения.
Далеко идущие научные проекты предусматривают изу-
чение интригующих деталей ядерных коллизий или
анализ радиоволн из удаленных галактик. По мере того
как компьютеры становились все более быстродейству-
ющими, приложения для них разрастались для более
детальной обработки большего количества данных.
Не тратьте времени даром
Оптимизация обычно подразумевает тщательное изуче-
ние своей программы. В моей собственной практике я
обнаруживал много скрытых (а иногда и не особенно
скрытых) ошибок в логике или реализации программ,
что привело меня к мысли о необходимости анализа
эффективности своего кода. Многие, конечно, стремятся
как можно скорее закончить работу, чтобы приступить
к другому проекту, однако очень важно потратить не-
много времени для обдумывания того, что вы уже на-
писали. Если вы заботитесь об эффективности своего
кода, найдите время хорошо обдумать его и написать его
как можно более аккуратно.
С - быстродействующий язык
Язык С характеризуется как высокоуровневый компо-
новочный язык. Такая репутация поддерживается лег-
костью отображения многих базовых типов и многих
базовых операций непосредственно в простые машин-
ные инструкции. Целые и с плавающей точкой числа,
а также указатели могут и должны подходить к регист-
рам отдельного компьютера. Назначение, арифметика,
63
индексация массива и переадресация прямо отобража-
ются в простые машинные инструкции на этих регист-
рах. Конечно, когда вы используете более сложные
типы, такие как списки и многомерные массивы или
библиотеку более хитроумных функций, таких как
qsort, вы более не можете ожидать, что будет поддер-
живаться однозначное отображение конструкций язы-
ка С на машинный уровень. Но вы обнаружите, что в С
переход от простых типов и операций к более сложным
типам и операциям осуществляется очень постепенно,
и всякий раз, когда это возможно, особое значение при-
дается эффективности.
Стандартная библиотека С и включенные в нее фай-
лы содержат несколько свойств для повышения произ-
водительности:
• Функции библиотеки stdio используют буферизиро-
ванный ввод и вывод. Многие функции, записыва-
ющие информацию в эти буферы, могут использо-
ваться в качестве макросов (такие, как putc и getc),
которые в отсутствие инлайнинга обычно работают
быстрее, чем вызываемые функции.
• В отдельной функции memcpy нет особой необходи-
мости, но она часто работает быстрее, чем ее более
общий аналог memmove.
• Макрос assert разработан для того, чтобы иметь ну-
левые издержки в случае, когда NDEBUG определен
инструкцией #defined.
• Существуют две версии математических операто-
ров — одинарной и двойной точности. Это дает ком-
пилятору возможность выбирать использование бо-
лее быстрой операции над числами с плавающей точ-
кой одинарной точности, когда это допустимо (хотя
и не требуется).
• Включение в программу таких высокоуровневых
функций, как bsearch и qsort, позволяет вам полу-
чить преимущество машинно-ориентированных про-
грамм реализации С без необходимости исследова-
ния переносимости пользовательских программ.
• Возможно, наиболее смелым ориентированным на
скорость выполнения свойством библиотеки С явля-
ется отсутствие навязанной парадигмы ввода/выво-
да. В других языках предполагается, что програм-
мист не должен вмешиваться в детальную работу с
битами и байтами в процессах записи и чтения.
(Язык С обеспечивает функции printf и scanf для
форматированного ввода/вывода, но не требует их
обязательного использования.)
Поскольку в С делается акцент на эффективность,
то кажется, что это действительно язык, в котором при-
меняется наиболее сложная оптимизация времени ком-
Оптимизация
Глава 3
пиляции. Только FORTRAN в свое время получал по-
добное внимание со стороны авторов компиляторов.
Конечно, поскольку вычислительные машины баз дан-
ных и выходные буферы разделены и используются
совместно, другие языки тоже выигрывают от такого
внимания, но некоторые конструкции (такие, как не-
форматированный ввод/вывод и машинно-ориентиро-
ванная оптимизация функций qsort и memcpy) просто
не могут быть доступны из других языков.
Важность измерений
В конечном счете скорость является строго количествен-
но измеримой величиной. Каждый виток автогонок,
каждый марафонский пробег и каждый заезд бобслея
находятся под беспристрастной опекой секундомера. Но
возможности секундомера очень ограничены — он из-
меряет только время вашего прихода на финишную чер-
ту. Мы, программисты, благословенны изобретением
инструментов профилирования (profiling). Мы можем
получить не только время завершения выполнения про-
граммы, но также исследовать скорость работы ее от-
дельных модулей и функций, чтобы обнаружить специ-
фические области в программе, которые могут быть
оптимизированы далее. Изменения этих областей так-
же могут быть выполнены независимо от остальных
частей программы для установления точного выигрыша
в эффективности. Профайлер (profiler), или профиль,
программы — мощный инструмент в руках программи-
ста, заинтересованного в повышении скорости выпол-
нения своих программ.
ПРИМЕЧАНИЕ
Более подробно профилирование (или профайлинг) рас-
сматривается в разделе "Профилирование" далее в этой
главе.
Размышления об эффективности
В этом разделе мы обсудим природу времени (более
подробно) и пространства.
Смысл перспективы
Если вашей целью является повышение скорости про-
граммы, вам нужно иметь представление о том, как
много времени занимает выполнение каждого операто-
ра и библиотечной функции. Вы можете подозревать,
что обращение, например, к функции qsort занимает
больше времени, чем выполнение операции сложения
двух целых величин, но какое время занимают при этом
все другие операции и функции? Если оператор или
функция требуют для выполнения разного времени при
разных обстоятельствах, от чего тогда это время зави-
сит?
Пересмотренный язык С
64
Часть I
Какая функция быстрее — malloc или free?
Какая функция выполняется дольше — fseek или
rand?
Функция exit выполняется дольше, чем system? Или
наоборот?
В табл. 3.1 приведены относительные скорости вы-
полнения отобранных операторов и библиотечных фун-
кций на несколько староватом (но до сих пор функци-
онирующем) компьютере Sun SPARCstation 2. Таблица
была построена путем выполнения операций несколь-
ко миллионов раз, вычисления потребовавшегося для
этого времени и затем его деления на число итераций.
Программа, с помощью которой составлена эта таб-
лица, помещена на Web-сайт издательства "ДиаСофт"
под названием speed.c,
В первой колонке таблицы указана операция или
функция, которая была хронометрирована. Во второй
колонке приведено время выполнения операции в мик-
росекундах. Позиции таблицы отсортированы в поряд-
ке возрастания времени выполнения: вверху расположе-
ны операции, выполняющиеся более быстро, внизу —
выполняющиеся более медленно.
Таблица 3.1. Выборочные результаты хроно-
метрирования базовых операций в языке С.
Операция Время (мкс)
int — int 0.013
deref pointer 0.025
array index 0.026
int = 0.036
bit shift 0.037
(int) float 0.038
float * float 0.049
float + float 0.049
int" int 0.050
empty func () 0.058
int + int 0.063
if — then — else 0.086
float / float 0.118
int * int 0.198
rand () 0.268
int / int 0.391
sqrt () 0.399
strcmp () 0.556
strcpy () 0.665
malloc / free 2.834
fopen 1 fclose 30.908
system () 25949.621
Базовые операции в абсолютных единицах занима-
ют исчезающе малое время, но, сравнивая их друг с
другом, мы видим, например, что деление целых чисел
требует в 7 раз больше времени, чем их сложение. Сре-
ди операций с экстремальными значениями времени
выполнения выделяется очень медлительная функция
fopen, а функция system выполняется просто неимовер-
но долго!
Иерархия памяти и ее влияние на эффективность
Первая подсистема, которой мы коснемся, — это иерар-
хия памяти. Даже функции, которые не выполняют
ввод/вывод или многозадачность, могут оказывать вли-
яние на иерархию памяти. В большинстве компьютеров
имеет место строгая иерархия скорости доступа к памя-
ти, и чем дальше мы идем по ступеням этой иерархии,
тем более увеличивается время доступа к данным:
• Регистры CPU — почти мгновенный доступ.
• Кэш L1 — очень быстрый доступ, лишь несколько
циклов синхронизации (тактов)
• Кэш L2 — тоже очень быстрый доступ, но занимает
несколько больше тактов
• RAM — удовлетворительно быстрый доступ, но для
получения чего-либо от RAM может занимать мно-
го тактов
• ROM — немного более медленный, чем к RAM, до-
ступ, в значительной мере недоступен, за исключе-
нием загрузки
• Виртуальная память — весьма медленный доступ.
Может занимать тысячи тактов.
Особое значение имеет тот факт, что, если вы хо-
тите выполнять программу быстрее и ваша программа
занимает некоторый объем памяти, вы должны из про-
граммы обеспечить доступ к памяти на таком высоком
уровне иерархии, какой только возможен. Чтобы сде-
лать это, нужно иметь представление о различных уров-
нях.
Регистры CPU — это один из самых драгоценных
ресурсов. Обычно вашей программе доступны только
три полезных регистра. Они часто используются для
счетчиков циклов или для хранения указателей, приме-
няемых для доступа к элементам массивов. Регистры
находятся фактически под управлением компилятора;
пользовательские программы, как правило, не имеют
прямого контроля над использованием регистров.
Кэши L1 и L2 похожи друг на друга (а также на кэш
L3, который, однако, используется не очень часто).
Функцией кэша является хранение копии порции дан-
ных из RAM. Как только ваша программа получает до-
ступ к данным, она запрашивает либо то, чего нет в
кэше, либо больше информации, чем кэш может содер-
65
жать. Это бывает, когда ваша программа перемалывая
числа массива что называется "захлебывается”. Не все
компьютеры имеют кэш (более старые процессоры CPU
были настолько медлительны, что скорости RAM хва-
тало с избытком). Кроме того, кэш чувствителен к шаб-
лонам, в которых вы обращаетесь к памяти.
Если вы обращаетесь к данным в шаблоне, который
повторяется через равные интервалы, подобные разме-
ру строк кэша, то при успешном доступе к памяти все
данные могут отображаться в одной и той же строке
кэша. При этом кэш недостаточно полно используется.
Вторая проблема состоит в том, что кэш не обяза-
тельно делает что-либо для повышения скорости линей-
ного доступа к памяти. Если вы просканируете 24 Мб
памяти, кэш в конечном счете все их будет читать и
пропускать через одни и те же ограничители системной
шины.
Конечно, RAM — это то, что обычно имеют в виду,
когда говорят о памяти. Интересно, что в последнее
время различные типы памяти часто получают названия
с учетом их скорости — 70ns SIMM или PC-133
SDRAM, например. Эти обозначения дают ключ к оп-
ределению скорости и частоты операций доступа соот-
ветственно.
Большинство компьютеров имеют лишь несуще-
ственный объем памяти ROM, и средняя программа не
расходует на нее много времени. ROM считается более
медлительной, чем RAM, но это обычно игнорируется,
за исключением времени загрузки операционной систе-
мы. Прием, который иногда используется на компью-
терах, часто обращающихся к ROM, состоит в копиро-
вании содержимого ROM в память RAM, доступ к
которой осуществляется быстрее. Поскольку такое ко-
пирование ROM защищено от разрушения прикладным
программным обеспечением, большинство программ не
в состоянии обнаружить различия в источнике данных.
Виртуальная память
Вы можете вызвать активность диска, даже если ваша
программа не выполняет ввод/вывод! Если программа
нуждается в большем объеме памяти, чем фактически
доступная память RAM, и ваша операционная система
поддерживает виртуальную память, то некоторые ваши
данные направляются для размещения на своп-диске
(диск обмена). Если же вам в какой-то момент действи-
тельно потребуется использовать эти данные, то они
будут вызываться чрезвычайно медленно по сравнению
с данными, хранящимися в RAM или в кэше. При ис-
пользовании такого большого объема данных (больше,
чем помещается в RAM) и быстром или беспорядочном
(произвольном) их вызове многие попытки доступа к
RAM будут заменены обращениями к диску обмена. Это
называется трешингом (thrashing). В этом состоянии
компьютер почти ничего не делает, и выполнение ва-
Оптимизация
Глава 3
шей программы может замедлиться в тысячу раз и бо-
лее.
О-нотация
О-нотация представляет собой широко используемый
метод определения скорости работы алгоритма или
функции. О-нотация для алгоритма представляет собой
формулу, которая позволяет вычислить верхний предел
ресурса, используемого алгоритмом, после вынесения за
скобки констант и времени, затраченного на все иные
операции, отличные от операций внутреннего цикла
алгоритма. Наиболее часто такая формула описывает
время, требуемое для выполнения алгоритма, но может
также использоваться для описания необходимого про-
странства памяти или некоторого другого ресурса. О-
нотация иначе может называться "сложностью" или
"большим-О" алгоритма.
В качестве упражнения ниже приведен пример про-
граммы, которая будет исчерпывающе исследовать и
точно определять, сколько времени она выполняется (в
миллисекундах), задавая число N во входной записи:
4*N + 2.1 * № + 48
Иными словами, при задании во входной записи 100
программа потребует 21448 мс для завершения. О-но-
тация упрощает это путем предварительного удаления
коэффициентов и констант, оставляя лишь
N + №
Эта запись затем еще более упрощается путем сохра-
нения только наиболее значимого с точки зрения ско-
рости вычислений элемента, в данном случаем2. Теперь
мы можем установить О-нотацию алгоритма как
о (№)
Это очень практично, поскольку другие члены (здесь
4N и 48) и постоянный коэффициент при определяю-
щем члене (здесь 2.1) становятся почти несущественны-
ми при возрастании N. Например, если N будет равно
10 000 000, то член N2 перекроет любую другую часть
формулы с точки зрения влияния на результирующее
время, затрачиваемое на выполнение алгоритма. Мы
можем применить О-нотацию для сравнения этого ал-
горитма с другими алгоритмами и установить, какой из
них лучше при больших значениях N.
Это может показаться странным, но, обладая неве-
роятным богатством методик программирования и при-
меняемой в них математики, большинство алгоритмов
имеют О-нотации, которые попадают лишь в несколько
широких категорий, и некоторые из этих категорий име-
ют широко известные названия. Мы представляем этот
список в порядке от лучших О-нотаций до самых плохих,
полагая, что алгоритм 0(1) предпочтительнее алгоритма
О(№) и что они оба выполняются адекватно.
Пересмотренный язык С
Часть I
66
0(1). Часто упоминаемый как константное время
(constant time), этот алгоритм выполняется до завер-
шения одно и то же время независимо от размера
входного набора. Это, очевидно, должно означать,
что такой алгоритм не обрабатывает весь входной
набор. Например, это может быть просто усредне-
ние первых пяти элементов и игнорирование осталь-
ных.
О (log N). Часто упоминается как логарифмический
(logarithmic) алгоритм; основание логарифма отбро-
шено (оно становится константой). Многие алгорит-
мы поиска являются O(log N)-алгоритмами. Напри-
мер, двоичный целевой поиск на сортированном
входном наборе имел бы тип O(log N).
O(N). Часто называемый линейным (linear), этот ал-
горитм занимает время, которое прямо пропорцио-
нально размеру входного набора. В основном любой
алгоритм, требующий просмотра каждого элемента
данных только один раз, будет попадать в эту кате-
горию.
O(N log N). Этот алгоритм — один из наиболее зна-
чимых, поскольку многие алгоритмы сортировки по-
падают в эту категорию, включая быструю сортиров-
ку (quick sort), "кучную” сортировку (heap sort) и
объединительную сортировку (merge sort).
O(N2). Этот алгоритм часто называется квадратич-
ным (quadratic). Некоторые алгоритмы сортировки,
такие как пузырьковая сортировка (bubble sort), яв-
ляются квадратичными. Некоторые другие, особен-
но быстрая сортировка, являются квадратичными
только для определенных патологических входных
данных, например, для входного набора, который уже
отсортирован или содержит идентичные записи.
O(NX). Здесь X — целое число, большее двух. Этот
алгоритм часто называется полиномиальным
(polynomial). Конечно, имеется существенное разли-
чие между O(N5) и O(N17), но любой алгоритм, ко-
торый медленнее чем квадратичный, становится
непригодным даже для маленьких входных наборов.
Например, алгоритм 0(N5) будет требовать порядка
10 биллионов шагов для обработки только 100 вход-
ных элементов!
O(XN). Часто называемые экспоненциальными
(exponential) или геометрическими (geometric), не
многие широко используемые алгоритмы попадают
в эту категорию. Экспоненциальный алгоритм еще
может быть полезным в случае, если основание (X
в нашей формуле) очень мало (например, 1.0001).
O(N!). Называемый факториальным (factorial), этот
алгоритм предназначен для исследования перестано-
вок и комбинаций данных и может стать совершен-
но неуклюжим в случае больших входных наборов.
Для того же набора в 100 входных элементов время
работы такого алгоритма составило бы примерно 10158
секунд.
На рис. 3.1 показаны графики изменения времени
(по вертикальной оси), соответствующего рассмотрен-
ным выше О-нотациям, в зависимости от количества
элементов входного набора, т.е. от числа N (по горизон-
тальной оси).
РИСУНОК 3.1. Графики О-нотаций обычных алгоритмов.
Таким образом, если вы выбираете алгоритм или
значительно изменяете собственный алгоритм, вы дол-
жны позиционировать его так, чтобы он имел О-нота-
цию ближе к константному времени, чем к экспонен-
циальному. И, конечно, указать, в какой конкретно он
попадает интервал, например O(sqrt(N)) и O(log log N).
Обратите внимание на поведение "лучший случай" /
"худший случай": многие алгоритмы ведут себя отлич-
но, если задано некоторое свойство набора входных
элементов. Например, если элементы поступают в оп-
ределенном порядке или выбраны из определенного
набора величин, это может заставить ваш алгоритм за-
нимать меньше или больше времени. Алгоритм, поло-
женный в основу функции сортировки, обычно занима-
ет O(N log N) времени, но оно может заметно
измениться: если входной набор уже представлен в со-
ответствующем порядке, то будет сделан единственный
проход и алгоритм закончится в линейное время. Если
алгоритм чувствителен к изменению исходных данных,
как этот, то его описание может дать для него целых три
различных О-нотации: лучший случай, самый худший
случай и средний случай. Если вам известна только одна
его О-нотация, вы, вероятно, можете предполагать про-
межуточный вариант.
Когда вы анализируете свои собственные функции
и алгоритмы, вам может потребоваться принять в рас-
чет скрытые циклы, которые неявно возникают при
вызове библиотечных функций, например, strlen или
memcpy. Чтобы уже до конца разобраться с этим, для
экстремально больших входных наборов вам потребуют-
ся данные длиной log N, просто чтобы отличить один
Оптимизация
Глава 3
67
элемент от другого. Например, если вы сортируете сту-
дентов по последнему имени для определения класса,
возможно, только первые три или четыре символа не-
обходимы для обработки их функцией st гетр. Если вы
расширяете входной набор для включения в него боль-
шего числа студентов (например, всей районной шко-
лы), вам нужно также взять в расчет первое имя и сред-
ний инициал, и функция stremp может просматривать
лишь несколько значимых символов в каждом имени,
перед тем как сделать определение.
Немного арифметики
В реальном мире ваша С-программа представляет собой
коллекцию нескольких несвязанных алгоритмов. Как вы
можете установить О-нотацию для всей программы или
для части программы, которую используют многие ал-
горитмы? Во-первых, выясните, что представляется
числом N в формуле О-нотации. Если вы обрабатывае-
те записи платежной ведомости, возможно, N — это
число сотрудников. Если вы передаете данные по сети,
возможно, N — это число пересланных битов. Проверь-
те внутренние циклы основных частей своих алгорит-
мов и установите для этих частей их индивидуальные
О-нотации в соответствии с выбранными значениями N.
Теперь скомбинируйте О-нотации различных частей
своей программы и получите полное значение О-нота-
ции программы. Имеется три способа комбинирования
О-нотаций:
• Последовательные операции. О-нотации двух алгорит-
мов складываются последовательно, одна за другой,
и их общая О-нотация оказывается больше индиви-
дуальных. Другими словами,
O(f(N)) в последовательности с O(g(N)) дает
O(max(f(N), g(N))).
Например, если f(N) больше g(N), то комбиниро-
ванная О-нотация будет f(N).
• Вложенные операции. Когда алгоритм внутри себя со-
держит обращения к другому алгоритму, результи-
рующая О-нотация находится путем перемножения
О-нотаций отдельных алгоритмов: если
O(f(N)) вызывает O(g(N)), то общая О-нотация бу-
дет равна O(f(N)*g(N)).
Например, если O(f(N)) была просто N (линейная),
a O(g(N)) была N2 (квадратичная), то результирую-
щая О-нотация двух вложенных алгоритмов будет
О(№).
• Параллельные операции. Конечно, вы уже догадались,
что язык С не поддерживает параллельных операций,
и вы правы. Но формально комбинированная О-но-
тация двух алгоритмов, которые работают парал-
лельно, равна большей из О-нотаций каждого из
алгоритмов:
O(f(N)) параллельно с O(g(N)) дает O(max(f(N),
g(N))).
Но подождите, может быть это то же самое, что и
для О-нотации последовательных алгоритмов? Да, это
так. В идеале преимущества от распараллеливания ал-
горитмов проявляются при распределении задачи меж-
ду несколькими процессорами. Для любого компьюте-
ра количество доступных процессоров фиксировано,
поэтому, отбрасывая константы О-нотаций каждого
процесса, в результате мы получим более высокий (от-
части поразительный) результат.
Хорошо, но ведь мы только программисты и отнюдь
не сильные математики. Как под всем этим подвести
черту? Мы приходим к тому, что в основе метода О-
нотации лежит идея о том, что самый внутренний цикл
наиболее критической части вашего алгоритма являет-
ся для вас наиболее проблематичным. Если вы увере-
ны, что ваш алгоритм правильный, то начните занимать-
ся именно этим внутренним циклом, если хотите
ускорить работу всего алгоритма.
В этом разделе мы рассуждали об эффективности.
В порядке принятия хорошего решения о том, как оп-
тимизировать свою программу, вам нужно хорошо, на
детальном уровне представлять себе, как долго выпол-
няются различные операции и библиотечные функции
в С и как используются различные подсистемы вашего
компьютера, а затем, на наивысшем уровне абстракции,
составить О-нотацию для своего алгоритма.
Профайлинг
Профайлинг представляет собой автоматизированный
анализ того, сколько времени тратится на выполнение
различных частей вашей программы. Хороший профиль
будет давать детальное описание количества вызовов и
количества времени CPU, занятого каждой функцией.
Это плоский профиль. А очень хороший профиль спосо-
бен на большее: он анализирует последовательности
вызовов и сообщает, какие функции вызывают другие
функции (и какие именно) чаще всего и, опять же, вре-
мя и количество этих вызовов. Такой профиль называ-
ется графическим.
Профили почти исключительно определяют время
CPU и количество вызовов, но они не в состоянии оп-
ределять время ввода/вывода, задержки сети и решать
возможные проблемы. Однако во многих случаях эти
задержки могут быть выведены из того, как часто вы-
зываемая библиотечная функция ассоциируется с про-
блемами времени в вашей задаче. Например, частые
обращения к функции tread могут говорить о том, что
ваша программа связана с вводом/выводом, а время ра-
Пересмотренный язык С
6?
Часть I
боты CPU — не проблема. Уделите особое внимание ана-
лизу этих факторов тогда, когда общее время CPU, ука-
зываемое профилем, является только долей от наблю-
даемого предельного времени, затрачиваемого вашей
программой, поскольку это указывает на то, что узкое
место программы находится в некоторой другой подси-
стеме и связано, возможно, с памятью, диском или ак-
тивностью сети".
Профайлинг требует инструментария. Прослежива-
ние и подсчет вызовов функций и затрачиваемого на их
работу времени обычно по умолчанию не предусматри-
вается, поэтому вам нужно установить соответствующие
переключатели в среде программирования для допуска
профайлинга в ваш код, а затем перетранслировать про-
грамму. Таким образом компилятор будет поставлен в
известность о том, что он должен вставить некоторый
дополнительный код в каждую функцию для подсчета
обращений и времени работы CPU, а также (в случае
построения графических профилей) для отслеживания
стека вызовов. После запуска вашей программы статис-
тика ее работы перекачивается в некоторый файл. Если
такой файл содержит сырые двоичные данные, то поз-
же вам нужно будет запустить некую другую програм-
му для анализа этих данных и представления их в чи-
табельном формате.
nPlfVtEHAHC
Небольшое дополнение: для инструментов С-профайлин-
га нет стандарта ANSI/ISO, и в настоящее время для
каждой среды программирования нужно иметь свои соб-
ственные инструменты для выполнения профиля в соб-
ственном конкретном формате этой среды. В этой гла-
ве будут использоваться примеры свойств prof и gprof из
среды программирования UNIX, но это только примеры.
Вы можете полистать документацию по вашей собствен-
ной среде программирования, чтобы определить, какие
инструменты профайлинга вам доступны. Представленные
здесь абстрактные концепции должны применяться для
всех сред, в которых выполняется профайлинг, хотя де-
тали будут, конечно, существенно различаться в зависи-
мости от конкретной среды программирования.
Плоский профиль
Это наиболее общий формат профиля, который интер-
претируется проще всего. Каждая функция хрономет-
рируется, основываясь на времени работы CPU, и наи-
более медлительные функции перечисляются в порядке
убывания затрачиваемого ими времени. Следующий
профиль был снят с программы, которая читает в фай-
ле, а затем сортирует данные с использованием метода
пузырьковой сортировки и сравнения строк с учетом
регистра:
Накопленное Накопленное Индивидуальное Количество Время Обцее Имя функции
время, % время, с время, с собственных одного время
вызовов вызова. одного
мс вызова, мс
52.9 67.71 67.71 internal_mcount
22.1 96.03 28.32 2739025 0.01 0.02 compare
13.2 112.93 16.90 208082387 0.00 0.00 toupper
2.5 116.17 3.24 5481361 0.00 0.00 strlen
li7 118.36 2.19 mcount (249)
1.5 120.25 1.89 4630519 0.00 0.00 realfree
1.2 121.79 1.54 5479717 0.00 0.00 mallocunlocked
1.1 123.25 1.46 5478052 0.00 0.00 freeunlocked
0.6 123.99 0.74 3007715 0.00 0.00 cleanfree
0.6 124.27 0.73 2739025 0.00 0.00 strcmp
0.5 125.32 0.60 5479709 0.00 0.00 mallee
0.4 125.84 0.52 10957790 0.00 0.00 muteX-Unlockstub
0.4 126.35 0.51 1 510.00 58166.22 bubblesort
0.4 126.85 0.50 3842815 0.00 0.00 t_delete
0.4 127.31 0.46 10957791 0.00 0.00 mutex_lock_stub
0.3 127.73 0.42 5478052 0.00 0.00 hree
0.1 127.87 0.14 661494 0.00 0.00 t_splay
0.1 127.98 0.11 786934 0.00 0.00 smalloc
0.1 128.07 0.09 466318 0.00 0.00 swap
0.0 128.08 0.01 1663 0.01 0.01 memccpy
А теперь подробнее рассмотрим содержащиеся в
колонках величины для этого конкретного примера:
1. В первой колонке представлено время, затраченное
на выполнение каждой функции, в процентах от
общего времени выполнения программы; сортиров-
ка порядка следования функций в списке проводи-
лась по этой колонке. Как видно, самая верхняя
функция больше других нуждается в оптимизации
и может дать существенный выигрыш по общему
времени выполнения программы.
Оптимизация
Глава 3
69
2. Накопленное время в секундах — показано суммар-
ное время, затрачиваемое всеми функциями до рас-
сматриваемой позиции. Заметим, что это общее вре-
мя на все обращения к конкретной функции, а не
время одного ее вызова.
3. Индивидуальное время показывает, сколько секунд
занимает работа каждой функции. Это также общее
время на все вызовы функции, а не время одного
вызова.
4. Четвертая колонка — это просто количество вызо-
вов каждой конкретной функции.
5. Собственное время одного вызова — это время в
миллисекундах, затрачиваемое на одно обращение
к каждой функции. Вы можете надеяться на то, что
ваш профиль будет немного более расторопным по
времени и будет измеряться не в миллисекундах,
как в нашем примере, а в микросекундах!
6. Общее время одного вызова — расширение данных
предыдущей колонки, которое включает время, зат-
рачиваемое в подпрограммах.
7. Последняя колонка содержит название каждой ис-
следуемой функции.
Теперь остановимся на нескольких важных момен-
тах. Оригинальная программа имеет только три явно
определенные функции — compare, bubblesort и main.
Но построенный профиль показывает много других,
якобы не относящихся к делу функций. Первая из них,
которую мы можем не принимать в расчет, — это фун-
кция intemal_mcount, которая фактически является ар-
тефактом (Artifact — искусственный объект. — Прим,
пер.) процесса измерений.
Некоторые другие функции являются библиотечны-
ми. Заметьте, что обращение к функциям fread или
twrite или к другой стандартной библиотечной функции
ввода/вывода сразу говорит о том, что скорость работы
вашей программы определяется в первую очередь ско-
ростью ввода/вывода, а не скоростью вычислений, и
потому должна быть оптимизирована в соответствии
именно с этим критерием.
Полученный профиль свидетельствует также о том,
что нужно было бы оптимизировать и функцию
compare. В частности, мы должны обратить внимание
на вызовы функций strlen и toupper, количество кото-
рых можно было бы сократить либо вообще отказаться
от них.
А вот о чем нам не говорит профиль, так это о том,
что фактическая проблема, связанная с этой програм-
мой, состоит в использовании функции bubblesort (по-
скольку это достаточно хилый алгоритм сортировки), а
также о том, какие вызовы strlen или toupper действи-
тельно нужны, поскольку эти функции, в принципе,
могут быть вызваны из самых разных мест в программе.
Графические профили
Графические профили не столь обычны, как плоские,
но они стали удобным средством анализа крупных про-
грамм, в которых не всегда ясно, откуда вызывается
стандартная библиотечная или ваша собственная глав-
ная целевая функция, выполняющая наиболее содержа-
тельную часть программы. В этом контексте выражение
"построение графика" не означает, что в результате про-
филирования мы получим какой-либо график или ри-
сунок. Это означает лишь, что в результате такого про-
филирования в памяти создается математический граф,
сообщающий о том, какая функция какую функцию
вызывает, и соотносит эти данные друг с другом; это
может помочь нам в решении проблем локальной опти-
мизации этих перекрестных функций.
Ниже приведен отрывок из некоего графического
профиля. (В интересах экономии места в книге некото-
рые несущественные части оригинального профиля
были опущены. Оригинальный отчет имел длину в 15
страниц.)
Вызовов/Итого Вызывавшие функции
Индекс Время в % Собственное По убываннв Вызвана+Собственное Имя Индекс
Вызвана/Итого Вызываемые функции
0.00 58.19 1/1 start [2]
[3] 46.2 0.00 58.19 1 main [3]
0.51 57.66 1/1 bubblesort [ 4 ]
0.00 0.01 1657/1657 fgets [21]
0.00 0.01 1655/1655 printf [25]
0.00 0.00 1656/5479709 malloc [7]
0.00 0.00 1656/5481361 strlen [9]
0.00 0.00 1/1 fclose [32]
0.00 0.00 1/1 calloc [36]
0.00 0.00 1/5478052 free [12]
0.00 0.00 1656/1656 strcpy [40]
0.00 0.00 1/1 f open [ 45 ]
0.00 0.00 1/1 memset [128]
Пересмотренный язык С
Часть I
70
0.51 57.66 1/1 main [3]
46.2 0.51 57.66 1 bubblesort [4]
28.32 29.25 2739025/2739025 compare [ 5 ]
0.09 0.00 466318/466318 swap [20]
28.32 29.25 2739025/2739025 bubblesort [ 4 ]
(5] 45.7 28.32 29.25 2739025 compare [ 5 ]
16.90 0.00 208082387/208082387 toupper (6 ]
0.60 5.41 5478050/5479709 malloc [7]
3.24 0.00 5478050/5481361 strlen [9]
0.42 1.69 5478050/5478052 free [12
0.73 0.00 2739025/2739025 strcmp [14]
Показанный в этой таблице профиль содержит три
раздела, в которых подытожено время выполнения и
подсчитано количество вызовов функций main,
bubblesort и compare. Каждый раздел идентифицирован
именем функции с отступом в колонке ’’Имя” (колонка
6). Внутри каждого раздела вызванные подпрограммы
перечисляются ниже строки функции, а вызывающие —
выше строки в порядке убывания затраченного на их
выполнение времени.
Смысл отдельных колонок в этом профиле следую-
щий:
1. Первая колонка представляет некоторый числовой
индекс и не несет значительной информации.
2. Время в % показывает общее количество времени,
затраченного данной функцией и всеми вызывавши-
ми ее функциями (а также функциями, которые они
вызывают повторно, и т.п.). Поскольку каждая из
них первоначально вызывалась из main, она появ-
ляется одной из первых вверху каждого раздела от-
чета, как здесь показано, но это не означает, что
именно эти функции должны быть целью оптими-
зации.
3. Собственное (время) — общее количество секунд,
затраченных на выполнение этой функции, не
включает время, затраченное вызываемыми ею под-
программами. Другими словами, хотя профиль ука-
зывает, что main затрачивает 46.2% времени в рабо-
те программы, фактически main затратила 0 секунд,
а остальное время было затрачено подпрограммами,
которые вызвала main.
4. По убыванию — общее количество секунд, затра-
ченных в функциях, вызванных данной функцией.
5. Вызвана/Итого — отношение количества вызовов
данной функции из конкретной родительской фун-
кции к количеству вызовов ею дочерних функций.
6. Имя — названия функций, как они упоминаются в
запросах. Функции, которые появляются выше за-
писанной с отступом функции, являются вызыва-
ющими, те же, которые появляются ниже ее, — это
вызываемые функции.
Графический профиль дает нам пищу для размыш-
лений о.том, какие функции следовало бы оптимизи-
ровать. В отличие от плоского профиля, на графичес-
ком профиле проявляется факт чрезмерно большого
количества обращений bubblesort к функции compare,
хотя самой функцией bubblesort расходуется совсем не
много времени.
Хотя это и не видно из предыдущего примера, но
графические профили хороши также для идентифика-
ции времени, затраченного на рекурсию. Это время
обычно указывается в колонке Вызвано+Собственное
предыдущей таблицы.
Другие методы профайлинга
Другой общий формат профиля — это профиль тесто-
вого покрытия. Обычно такой профиль объединяет ли-
стинг функции с числами, следующими за каждым опе-
ратором и показывающими, как много времени
выполнялись эти операторы, отношение этого времени
к общему времени прогона программы либо и то и дру-
гое вместе. Это очень полезно, если вы уже сосредото-
чили внимание на оптимизации какой-либо одной кон-
кретной функции.
Как же использовать профиль или график, если у вас
их пока нет? Если у вас есть удобный отладчик, вы
можете начать выполнение своей программы, а затем
время от времени прерывать ее и делать стек трассиров-
ки. Сначала напишите в стек две функции, затем дайте
программе выполняться еще некоторое время. Затем
прервите программу снова и напишите ниже новые по-
явившиеся функции или установите контрольный мар-
кер вслед за этими функциями. После пяти-десяти сте-
ковых трассировок вы должны составить ясное
представление о том, на выполнение каких функций в
вашей программе затрачивается больше всего времени,
и построить гистограмму, представляющую конт-
рольные маркеры и показывающую функции с наиболь-
шим потреблением времени.
Оптимизация
Глава 3
71
Профили обеспечивают объективное отображение
мест расположения и причин узких мест в вашей про-
грамме. Эту информацию вы можете целенаправленно
использовать для оптимизации именно этих проблем-
ных областей в вашей программе.
Алгоритмические стратегии
оптимизации
Создавая свою программу, вы, вероятно, столкнулись с
проблемой выбора используемых в программе алгорит-
мов. Теперь было бы хорошо пересмотреть выбор этих
алгоритмов с точки зрения оптимизации всей програм-
мы и рассмотреть возможность замены их другими, воз-
можно, более эффективными алгоритмами.
Часто наиболее необоснованные решения по выбо-
ру алгоритма сконцентрированы вокруг проблем сорти-
ровки. Этот предмет изучен в деталях (и даже занимает
целую главу в этой книге). К счастью, язык С обеспе-
чивает библиотечную функцию qsort — достаточно хо-
рошую для большинства ситуаций, связанных с сорти-
ровкой. Эта функция не нуждается в дальнейшей
доработке или замене се какой-либо вашей собственной
функцией сортировки (bubblesort или ей подобной),
которая бы вызывала функцию qsort. Имейте в виду, что
функция qsort не должна реализовываться как функция
quicksort (Т.е. как функция быстрой сортировки. —
Прим. науч, ред.)., хотя таковой она часто и бывает.
Конечно, иногда возникают некоторые обстоятель-
ства, при которых какой-то другой конкретный алго-
ритм сортировки, вероятно, был бы более подходящим,
чем просто вызов функции qsort. Загляните, пожалуй-
ста, в главу 13 "Методы быстрой сортировки", где вы
найдете специфическую информацию о том, какой ал-
горитм сортировки вам лучше выбрать в той или иной
ситуации.
Имеется много видов алгоритмов, отличных от ал-
горитмов только сортировки. Проведите маленькое ис-
следование в Web и посетите некоторые программно-
ориентированные Web-узлы. Посмотрите, нет ли в них
какого-либо программного кода, который вы могли бы
использовать для решения своих конкретных задач.
Многие вопросы рассматриваемой нами предметной
области хорошо представлены также в книгах и журна-
лах. Например, имеются десятки книг и журналов по
компьютерной графике, в которых задокументирован
почти каждый более или менее значимый алгоритм во
многих предметных областях. Независимо от тематичес-
кой направленности вашего проекта, использование
алгоритма, который кто-либо другой уже протестиро-
вал и оптимизировал, является хорошим началом; как
бы там ни было, есть все основания воспользоваться
преимуществами, которые предоставляют вам опыт и
помощь других людей.
Следующим шагом является практическая проверка
выбранного вами алгоритма. Далее мы обсудим пути
повышения скорости работы программы на алгоритми-
ческом уровне.
Циклы, вложенные внутрь циклов (вложенных
внутрь других циклов, и т.д.)... Каждый уровень вло-
женности цикла увеличивает значение экспоненты в О-
нотации для вашего алгоритма (а это, как мы знаем,
очень плохо). К сожалению, я не могу дать вам ника-
ких жестких и четких правил, позволяющих снизить
уровень вложенности алгоритмов вообще. Каждый ал-
горитм имеет свои собственные особенности, и иногда
действительно ничего нельзя сделать, чтобы уменьшить
уровень вложенности имеющихся в нем циклов. Но
можно, по крайней мере, устранить любые циклы, ко-
торые не связаны с работой собственно алгоритма.
Рассмотрим пример. Предположим, вам требуется
отсортировать список слов безотносительно к регистру
букв. Для начала вы вызываете функцию qsort и в ка-
честве аргумента даете ей функцию сравнения, которая
перед возвратом результата конвертирует слова к верх-
нему регистру. Каждый раз qsort вызывает вашу функ-
цию сравнения, и каждый раз происходит конвертиро-
вание. Предполагая, что ваша библиотечная функция
qsort является O(N log Ы)-алгоритмом, вы будете кон-
вертировать слова к верхнему регистру O(N log N) раз.
Лучшая альтернатива состоит в том, чтобы конвертиро-
вать слова к верхнему регистру до выполнения сорти-
ровки. Предварительное конвертирование будет выпол-
нено ровно один раз с каждым словом, т.е. будет сделано
только O(N) обращений к функции сравнения.
А вот еще один пример. Давайте представим себе,
что вы имеете два списка слов для сравнения и выясне-
ния, какие одинаковые слова имеются в обоих списках.
Простейшее, что можно сделать, — это запустить цикл
по каждому слову в первом списке и затем выполнить
сравнение этого слова с каждым словом во втором спис-
ке. Такой алгоритм содержит два вложенных друг в друга
цикла по входному набору данных, так что его О-нота-
ция будет O(N2). Мы можем внести усовершенствова-
ние путем предварительной сортировки двух списков,
которая позволит делать сравнение с единственной по-
дачи. Этот новый алгоритм имел бы О-нотацию вели-
чиной только O(N log N), подсчитанной по времени,
затрачиваемому на сортировку.
Оптимизация алгоритма на абстрактном уровне фак-
тически представляет собой довольно трудное дело.
Кроме того, ваша программа может содержать много
алгоритмов, взаимодействующих между собой сложным
образом, что делает затруднительным предположение
относительно возможности улучшений всей программы.
Но не будем этого опасаться.
Нужно сосредоточиться на реальной задаче, которую
ваша программа пытается выполнить. Можно попробо-
’ll
Пересмотренный язык С
Часть I
вать переписать ее так, чтобы задействовать в ней как
можно меньшее количество более простых и/или хоро-
шо известных алгоритмов. Важно избегать использова-
ния алгоритмов с невыгодными О-нотациями, наподо-
бие О(№), и попытаться заменить их алгоритмами с
лучшими О-нотациями, такими как O(N) или, по край-
ней мере, O(N log N).
Реализация стратегий оптимизации, или
микрооптимизация
В этом разделе мы обсудим некоторые пути, позволя-
ющие немного поправить ваш код так, чтобы ускорить
его выполнение. Оправданием этому является тот факт,
что при анализе О-нотаций алгоритмов от времени, за-
нимаемого всем алгоритмом, отбрасываются константы
и вклады более высокого порядка малости. Перенося
свои усилия по оптимизации алгоритма на этот уровень,
мы можем добиться определенных улучшений, кото-
рые, хотя и менее эффектны, чем удаление необяза-
тельных циклов, все же заслуживают внимания.
Кроме того, теперь нам удобно будет воспользовать-
ся рассмотренным выше профилем вашей программы.
Во-первых, вы используете профайлер, чтобы найти
внутренние циклы в наиболее часто вызываемых фун-
кциях; и именно здесь в первую очередь вы осуществля-
ете микрооптимизацию. Затем запустите профайлер сно-
ва и проверьте, какое сделанное вами изменение в
алгоритме фактически привело к его усовершенствова-
нию.
Одно напоминание: некоторые из этих микроопти-
мизаций являются такими задачами, которые ваш муд-
рый компилятор может выполнить автоматически, ког-
да вы установите его в режим "оптимизации". Потратьте
немного времени на изучение документации по компи-
лятору, чтобы упростить задачу переписывания своего
кода.
Инлайнинг (встраивание)
Инлайнинг (inlining) представляет собой замену обраще-
ния к функции в программе фактическим кодом этой
функции. Многие старые компиляторы способны встра-
ивать Маленькие функции автоматически, но ни один
компилятор, поддерживающий C++ или С99, не требу-
ет поддержки ключевого слова inline в своем языке.
Некоторые компиляторы — большие энтузиасты инлай-
нинга и могут выполнять даже рекурсивный инлайнинг.
Если необходимо добиться аналогичного повыше-
ния скорости на компиляторах, не способных выпол-
нять инлайнинг, очень маленькие функции можно за-
писывать как макросы. Это можно делать уже после
того, как код будет полностью отлажен. В то же время
ни один отладчик из тех, которые мне приходилось
встречать, не способен отображать расширенный мак-
росом текст или выполнять по нему отладочные опера-
ции, поскольку такой текст может получиться доволь-
но сложным.
Рассмотрим следующий пример кода до оптимиза-
ции:
int foo (а, Ь)
{
а = а - Ь;
Ь++;
а = а * Ь;
return а;
1
А ниже представлен пример эквивалентного кода,
который был преобразован путем инлайнинга макросом:
«define foo (а, Ь) (((а) - (b)) * ((b) +1))
Дополнительные круглые скобки в макросе необхо-
димы для сохранения группировки на случай, если
функция foo используется в выражении, которое имеет
более высокий приоритет, чем *, или в случае, когда а
или Ъ содержат подвыражения с более низким приори-
тетом, чем + или -.
Выражения с запятыми и конструкцию do while (0)
можно использовать для более сложных функций с не-
которыми ограничениями. Запись макроса в стиле do —
while позволяет вам создавать локальные переменные
для использования в макросе, но вы не сможете возвра-
щать значение в выражение, в котором используется этот
макрос. Напротив, выражения с запятыми вполне мож-
но использовать в макросах.
прадосгтекЕНкс
Облачение каждой используемой в программе функции
в форму макроса ведет к "раздутию" кода и может зна-
чительно увеличить объем требуемой вашей программе
памяти. Чем больше программа, тем меньше шансов
пристроить ее в кэш или в некоторую другую единицу
физической памяти, что сводит на нет возможные выго-
ды от инлайнинга.
Макрос в языке С оценивается по его аргументам вся-
кий раз, когда аргумент упоминается внутри макроса.
Если аргумент, фактически переданный в макрос, явля-
ется сложным выражением или вызывает какую-либо
функцию, то результатом вполне может быть повышение
времени занятости CPU. В результате возникновения
множества побочных эффектов вызывающая функция
неожиданно для вас почти наверняка будет наполнять
программу ошибками.
Поскольку эти макросы могут содержать сложные опе-
раторы, оптимизирующему их программисту придется
изрядно потрудиться над их конфигурированием, так что
он вполне может отказаться от этого. Кроме того, не
забывайте, что есть ограничение на количество символов,
которые может иметь макрос.
Оптимизация
Глава 3
Программы профилирования не различают макросов, так
что в дальнейшем их сложно будет оптимизировать, если
однажды вы использовали их для инлайнинга.
Разворачивание цикла
В том случае, когда время на итерирование самого цикла
становится сравнимым с временем, затрачиваемым на
выполнение инструкций внутри цикла, можно исполь-
зовать прием разворачивания цикла (loop unrolling) для
экономии времени. Для этого повторите тело цикла
несколько раз (для начала 510 раз) и вставьте минималь-
ный код, необходимый для корректировки счетчика
цикла или других состояний циклического процесса.
Многие компиляторы сами автоматически могут
выполнять такое разворачивание цикла, но, если вы
знаете, делает ли это именно ваш компилятор, попро-
буйте осуществить разворачивание самостоятельно.
Рассмотрим следующий пример с однооператорным
циклом for:
for (1 = 0; i < 100; i++)
{
code (i);
}
После оптимизации цикла путем его разворачивания
по 10 строк он примет такой вид:
for (1 = 0;
{
code(i
code(i
code(i
code(i
code(i
code(i
code(i
code(i
code(i
code(i
}
1 < 100; )
i++;
1++;
i++;
i++;
Таким образом, проверка на i < 100 и обратный пере-
ход наверх цикла выполняются только 11 раз вместо 101.
Разворачивание цикла осуществляется лучше, когда цикл
выполняется фиксированное, неизменное количество раз
и итерационная переменная модифицируется лишь в
одном месте (не там, где она инициализировалась).
Кроме того, если функция code () не использует i,
все мелкие шажки i++ можно было бы заменить на
единственный шаг i += 10. Реконструкция цикла for в
цикл do — while еще может сократить количество цик-
лов с 11 до 10. Если бы наш цикл проходил только до
i = 5 вместо i = 100, можно было бы полностью развер-
нуть цикл и вообще устранить возвраты и проверку счет-
чика цикла.
Для вычислений, которые сходятся к некоторому
результату, компиляторы будут часто отказываться раз-
ворачивать цикл на том основании, что разворачивание
будет изменять результат. Если приложение нечувстви-
тельно к излишней точности, вы можете осуществить
выполнение проверки снижения сходимости путем дуб-
лирования тела цикла. Это особенно полезно, если про-
верка на сходимость является более трудоемкой по от-
ношению к трудоемкости вычисления результата.
ГРадуПРГЖДЕНИЕ
Развернутый цикл получается больше по размерам, чем
его "свернутая" версия, и потому может не помещаться
в кэш инструкций (на компьютерах, имеющих таковые).
Это может привести к тому, что развернутая версия цикла
будет более медлительной. Кроме того, в нашем приме-
ре обращение к функции code может требовать значи-
тельно больше времени, чем модификация счетчика, так
что в данном случае любая экономия от разворачивания
цикла может оказаться незначительной по сравнению с
тем, чего бы вы достигли путем инлайнинга функции
code.
Если вам случится использовать векторизированный ком-
пилятор на суперкомпьютере, разворачивание цикла
может интерферировать с векторной оптимизацией. По-
советуйтесь с руководством по эксплуатации компилято-
ра для получения специфического совета о том, как пи-
сать циклы, чтобы получить полное преимущество от
мощи вашего конкретного компьютера.
Сжатие цикла
Идея сжатия цикла (jamming loop) состоит в том, что-
бы комбинировать смежные циклы, в которых одна и
та же переменная пробегает значения одного диапазо-
на. Оптимизацию сжатия цикла можно выполнить, если
во втором цикле отсутствует опережающее индексиро-
вание (например, array [i + 3]).
Ниже приведен пример кода с раздельными циклами:
for (1 = 0; 1 < MAX; 1++) /* инициализация
двумерного массива нулями */
for (j » 0; j < MAX; j++)
a liHil = o.o;
for (1 = 0; i < MAX; i++) /* установка единиц
по диагонали */
а [1] [1] = 1.0;
Тот же самый код после оптимизации путем сжатия
цикла:
for (1 = 0; 1 < MAX; 1++)
{
for (j = 0; j < MAX; j++)
a [i][j] = 0.0; /* инициализация
двумерного массива нулями */
a [i][i] = 1.0; /* установка единиц по
диагонали */
1
Таким образом, приращение и проверка значения i
делается ад^кк- меньшее число раз. При некоторых об-
74
Пересмотренный язык С
Часть I
стоятельствах таким образом можно улучшить локаль-
ность ссылки (определение см. ниже), что улучшает
поведение кэша. (Этот пример предоставлен Ахо (Aho)
и Ульманом (Ullman).)
Обращение цикла
Некоторые компьютеры имеют специальную инструк-
цию для уменьшения значения счетчика и сравнения его
величины с нулем. Можно использовать одну из этих
специальных инструкций и переделать ваш цикл так,
чтобы вместо прибавления к счетчику постоянного зна-
чения выполнялось вычитание и цикл останавливался
при равенстве счетчика нулю вместо равенства его не-
которому максимуму.
Предполагая, что цикл нечувствителен к направле-
нию изменения значения счетчика, можно попытаться
просто изменить его направление.
Здесь представлен типичный в языке С цикл for:
for (1 = 1; 1 <= MAX; i++)
{
1
После оптимизации цикла путем его обращения
(inversion) он будет выглядеть следующим образом:
i = МАХ + 1;
while (—i)
{
1
Если вы планируете выполнять такую оптимизацию
в комбинации с арифметикой указателей, прошу учесть,
что до сих пор ANSI С имел специальное правило, кото-
рое позволяло вам устанавливать указатель на один эле-
мент сразу после конца массива, но такого правила нет
для элемента, находящегося перед началом массива.
Редукция строгости выражения
Редукция строгости (strength reduction) выражения пред-
ставляет собой замену исходного выражения другим
выражением, которое дает то же самое значение, но
более экономно с точки зрения трудоемкости его вычис-
ления. (Многие компиляторы делают это автоматически.)
Ниже приведены классические примеры с комментария-
ми, объясняющими каждый случай оптимизации путем
редукции строгости выражений.
Это неоптимизированный код:
х = w % 8;
у - pow(x, 2.0);
z = у * 33;
for (i = 0; i < MAX; i++)
{
h « 14 * i;
printf("%d", h);
1
h « 14 * i;
printf("%d", h);
После оптимизации путем редукции строгости вы-
ражений он будет выглядеть следующим образом:
х = w & 7; /* немного экономнее, чем
вычисление остатка ст деления */
у = х ♦ х? /* умнохение экономвее, чем
возведение в степень */
z = (у « 5) + у; /* сдвиг и слохевие
экономнее, чем умнохение */
{
printf (•%<!, h);
h += 14; /* слохение экономнее, чем
умнохение */
1
Заметьте также, что индексирование массива в С в
основном осуществляется путем умножения и сложения.
Поэтому в некоторых случаях выражения умножения
можно подвергнуть оптимизации путем снижения их
строгости, особенно когда циклы осуществляются по
массиву.
Инвариантные вычисления цикла
Любая часть вычисления, которая выполняется незави-
симо от переменной цикла и не подвергается любым
другим изменениям внутри цикла, может быть полнос-
тью вынесена за этот цикл. Большинство компиляторов
довольно хорошо справляются с этим сами, но продол-
жают держать вычисления внутри цикла просто на вся-
кий случай и всегда готовы по вашей команде вынести
за цикл инвариантные вычисления. (Бывают ситуации,
когда вы точно знаете, что некоторое значение не бу-
дет изменяться в цикле, но компилятор держит его в
цикле в случае, если могут иметь место побочные эф-
фекты.) Слово "вычисление4* здесь не означает только
арифметику; это выражение применимо также к индек-
сированию массива, переопределению указателя и об-
ращению к чистой функции; все это — возможные кан-
дидаты на вынесение за цикл.
В цикле, в котором выполняются обращения к дру-
гим функциям, можно добиться некоторого повышения
скорости выполнения путем расчленения отдельных
подпрограмм, удаления тех их частей, которые являют-
ся инвариантами цикла для этого конкретного цикла в
вызывающей программе, и вызова этих частей заблагов-
ременно. Это не очень просто и ведет к значительным
улучшениям лишь тогда, когда вызываемые подпрограм-
мы неоднократно открывают и закрывают файлы, ког-
да ваши функции malloc и free при каждом вызове за-
нимают большой объем памяти или когда выполняются
еще более трудоемкие операции.
Группировка выражений
Старые С-компиляторы позволяли перегруппировывать
арифметические выражения в некоторый экстент
Оптимизация
Глава 3
(Extent — экстент, или непрерывная область (например,
в памяти с прямым доступом), резервируемая для оп-
ределенного набора данных. — Прим. науч, ред.) ANSI
предусматривает, что арифметические выражения рас-
сматриваются в той последовательности, как они сгруп-
пированы в коде, чтобы избегать любых нежелательных
сюрпризов. Это означает, что выражения
float a, b, с, d, f, g;
а = b / с * d;
f = b * g / c;
не будут рассматриваться как имеющие общее подвы-
ражение b/с. Если же вы перепишете второе выражение
так:
float а, Ь, с, d, f, g;
а « b / с * d;
f = b / с * g;
то компилятор ANSI С теперь может вычислить b/c
лишь один раз. Однако заметьте, что новый код может
вести себя не так, как исходный, в случае переполне-
ния или приводить к слегка отличным результатам, если
используются числа с плавающей точкой.
Удаление хвоста рекурсии
Когда рекурсивная функция вызывает сама себя, опти-
мизатор может при некоторых условиях заменить вы-
зов компоновкой, эквивалентной переходу по операто-
ру "goto” обратно наверх функции. Это уменьшает
затраты времени на разрастание стека, сохранение и вос-
становление регистров, а также любые другие потери,
связанные с вызовом функции. Для очень маленьких ре-
курсивных функций, которые выполняют большое ко-
личество рекурсивных вызовов, удаление хвоста рекур-
сии (tail recursion elimination, сокращенно TRE) может
вылиться в существенное повышение скорости работы
программы. При правильном применении TRE можно
рекурсивную функцию превратить в код, который бы-
стрее формирует цикл для компьютера.
Методика TRE существует уже длительное время.
Она порождена функциональными языками, такими как
LISP, который делает столько рекурсий, что TRE про-
сто необходимо. С, C++ и паскалеподобные языки по-
пали в категорию ’’императивных” языков. В высшей
степени эффективные программы, рекурсивные или
нет, могут быть написаны и откомпилированы без ис-
пользования TRE и все же выполняться не хуже (а за-
частую и лучше), чем подобные LlSP-программы. Этим
я хочу сказать, что не в каждом современном оптими-
заторе TRE представлено автоматически, хотя многие
оптимизаторы, конечно, выполняют его.
Вернемся к упоминавшимся выше условиям. Чтобы
получить преимущества от проведения оптимизирующе-
го TRE, функция должна возвращать значение рекур-
сивного вызова без каких-либо дальнейших вычислений.
Рассмотрим этот демонстрационный код:
int isemptystr (char * str)
{
if (*str '\0') return 1;
else if (1 isspace (*str)) return 0;
else return isemptystr (++str);
}
Здесь можно применить TRE для заключительного
оператора return, поскольку возвращаемое значение из
этого обращения к isemptystr будет в точности равно n+1 —
без необходимости дальнейших вычислений.
Ниже представлен пример, когда TRE не может быть
применено:
int factorial (int num)
{
if (num === 0) return 1;
else return num * factorial (num - 1);
1
Здесь TRE нельзя применить, поскольку возвраща-
емое значение не используется непосредственно. Оно
умножается на num после вызова, так что состояние это-
го обращения должно быть сохранено до следующего воз-
врата return. Даже компилятор, который поддерживает
TRE, в данном случае не может его использовать.
Следующий код переписан так, чтобы можно было
провести TRE-оптимизацию:
int factorial (int num, int factor)
{
if (num 0) return factor;
else return factorial (num - 1, factor *
num);
)
Все, что мы сделали, — это переместили умножение
на num вниз в вызывающую функцию путем передачи
num в качестве ее второго фактического параметра.
Насколько мне известно, оптимизаторы для языков,
подобных С, не выполняют такого рода перезапись
кода. Поэтому, даже если ваш компилятор реализует
TRE-оптимизацию, вы не должны полагать, что она
будет выполняться для вас автоматически. Вам нужно
самому переписать даже простейшую рекурсивную фун-
кцию перед тем, как можно будет применить TRE. Од-
нако, если после этого читабельность функции значи-
тельно снижается, такое усилие представляется крайне
сомнительным.
Существует обширное подмножество рекурсивных
алгоритмов, которые имеют простые итеративные ана-
логи. С-компиляторы весьма и весьма хорошо оптими-
зируют циклы и могут делать это без необходимости
Пересмотренный язык С
76
Часть I
выполнения достаточно жестких условий, которые вы-
ставляет TRE. Если вы с самого начала оптимизируете
исходный код, перед перезаписью кода в целях приме-
нения TRE рассмотрите использование простой итера-
ции.
Наконец, если рекурсивная функция содержит цик-
лы или большой объем кода, TRE будет лишь незначи-
тельно полезным, поскольку TRE оптимизирует толь-
ко рекурсию, а не сам алгоритм. Вызовы функции сами
по себе осуществляются очень быстро, и эффект опти-
мизации этих вызовов потеряется в массе вычислений
внутри самой функции.
Табличный поиск
Рассмотрим использование поисковых таблиц, особен-
но если приходится выполнять итеративные или рекур-
сивные вычисления, например, сходящиеся ряды или
факториалы. Вычисления, занимающие константное
время, часто могут выполняться быстрее, чем их резуль-
таты могут быть извлечены из памяти, и это не всегда
дает возможность получить выгоду от проведения таб-
личного поиска.
Ниже представлен широко используемый пример
рекурсивной функции, которая вычисляет факториал
числа:
long factorial (int i)
{
if (i == 0)
return 1;
else
return i * factorial (i - 1);
1
После оптимизации с выполнением табличного по-
иска этот код будет выглядеть так:
static long factorial table [ ] =
{1, If 2f 6, 24, 120, 720 /♦ и т.д. ♦/}
long factorial (int i)
{
return static long factorial table [i];
1
Если таблица слишком длинна для набора на клави-
атуре, вы можете написать некий инициализационный
код, вычисляющий все значения при запуске програм-
мы, или другую программу, генерирующую таблицу и
печатающую ее по printf в форму, приспособленную для
ее включения в исходный файл. Иногда таблица может
иметь большой размер и занимать слишком много мес-
та в памяти. Тогда можно в некоторых случаях постро-
ить таблицу, содержащую первые N чисел, а затем да-
вать им приращения с помощью функции для расчета
остальных элементов. До тех пор пока значительное
количество запрашиваемых значений находится в таб-
лице, вы будете иметь чистый выигрыш.
Строковые операции
Большинство библиотечных символьных и байтовых
строковых функций языка С выполняются по времени
пропорционально длине строк, переданных этим фун-
кциям в качестве параметров. Достаточно просто орга-
низовать некий цикл по их вызовам и таким образом
заставить ваш процессор долго и напряженно выполнять
множество лишней работы. Ниже перечислены некото-
рые советы, которые могут облегчить такую ситуацию:
• Избегайте вызовов функции strlen длины строки в
процессе цикла, включающего эту строку. Даже если
вы модифицируете строку, можно было бы изменять
ее длину так: перед циклом вы устанавливаете зна-
чение длины строки х = strlen(), а затем, когда внут-
ри цикла добавляете или удаляете символ, пишете
просто х++ или Х-- соответственно.
• Когда вы строите длинную строку в памяти с ис-
пользованием функции конкатенации strcat, она
будет сканировать полную текущую длину строки
при каждом обращении к этой функции. Если вы все
время следили за длиной строки (см. выше), то мо-
жете установить индекс прямо в конец строки и ис-
пользовать его при обращениях к функциям strcpy
или шешсру вместо strcat.
• При использовании функции сравнения strcmp вы
можете сэкономить немного времени путем провер-
ки первых символов сравниваемых строк, осуществ-
ляемой перед тем, как сделать вызов этой функции.
Очевидно, если первые символы различаются, нет
смысла обращаться к strcmp для сравнения осталь-
ных символов. Из-за неоднородного распределения
букв в естественных языках выигрыш от примене-
ния этой методики, конечно, не составит 26:1, но для
типичных данных в верхнем регистре будет больше,
чем примерно 15:1.
Ниже показан пример простой замены вызова фун-
кции strcmp, в котором реализована эта идея:
«define QUICKIEJ3TRCMP (а,Ь) (* (а) •= * (Ь) ? \
(int) ((unsigned char) *(а) - \
(unsigned char) *(b)) : \
strcmp ((a), (b))
• Совершенно иной подход повышения скорости опе-
раций при использовании функции strcmp состоит
в размещении всех ваших строк по порядку в един-
ственном массиве. После этого вам нужно будет
сравнивать только указатели, а не строки. Если же
смысл обращения к функции strcmp состоит в поис-
ке некоего значения из большого известного набора
данных и вам предстоит выполнить множество та-
ких поисков, значит, вам следует рассмотреть воз-
можность использования хеш-таблицы.
Оптимизация
Глава 3
77
• Проверки на незаполненность строки обычно реали-
зуются в виде strlen = 0, и даже опытные програм-
мисты для этой цели используют именно функцию
strlen. Но ведь если строки, с которыми вы работае-
те, имеют существенную длину, функция strlen бу-
дет покорно проверять каждый символ, пока не об-
наружит завершающий NULL. Заменив указанную
форму проверки на *s == ’\0’, вы проверите только
первый символ и таким образом сэкономите время
на вызове функции strlen. Так что, если ваши стро-
ки достаточно длинные, это даст существенное ус-
корение всего процесса.
• Вместо кода strcpy (s, ” ") попробуйте использовать
запись *s = "\0'. Это также позволит избежать совер-
шенно необязательного вызова функции копирования.
• Знайте, что функция strncpy дополняет короткие
строки нулями. За исключением первого нуля, ко-
торым заканчивается строка, дополнительные нули
обычно никогда не используются, так что при работе
с этой функцией некоторое время тратится впустую.
• Обычно функция шешсру работает быстрее, чем
memmove, поскольку алгоритм этой функции пред-
полагает отсутствие перекрытия ее аргументов. Если
у вас есть соблазн заменить эти функции своими соб-
ственными версиями, потрудитесь проверить, что
эти ваши версии работают, и работают быстрее.
Переменные
Избегайте обращения к глобальным или статическим
переменным изнутри уплотненных циклов. Не исполь-
зуйте квалификатор volatile, пока это действительно не
потребуется. Большинство компиляторов воспринима-
ют его как нечто противоположное register, и они пред-
намеренно не будут оптимизировать выражения, вклю-
чающие переменные volatile.
Не допускайте передачи адресов ваших переменных
в другие функции. Оптимизатор предполагает, что выз-
ванная функция способна где-либо накапливать указа-
тель на эту переменную, поэтому переменная может
быть модифицирована в результате какого-либо побоч-
ного эффекта, который не имеет совершенно никакого
отношения к назначению функции. При менее интен-
сивной оптимизации оптимизатор может даже предпо-
ложить, что обработчик сигналов может в любое время
изменять переменные. Такие случаи интерферируют
(т.е. создают взаимные помехи) с размещением пере-
менных в регистрах, что очень важно для оптимизации.
Например,
а = Ь ();
с (fid) ;
Поскольку переменная d передала свой адрес в дру-
гую функцию, компилятор более не опускает ее в ре-
гистр в процессе вызовов функции. Однако он может
опустить в регистр переменную а. Чтобы отслеживать
проблемы, подобные этим, можно использовать ключе-
вое слово register; если d будет объявлена как register,
компилятор будет предупрежден о том, что получен ее
адрес.
Использование плавающей точки
На протяжении длительного времени считалось, что
операции над числами с плавающей точкой более мед-
лительны по сравнению с операциями над целыми чис-
лами. Однако в течение последних нескольких лет опе-
рации с плавающей точкой выполняются так же быстро,
как и их целые аналоги.
Используя соответствующим образом арифметику
плавающей точки в своей программе, вы можете достиг-
нуть некоторых оптимизационных целей:
I. Часто преобразования целых чисел в числа с пла-
вающей точкой или наоборот снова и снова не-
сколько раз внутри выражения занимают больше вре-
мени CPU, чем даже выполнение всего вычисления с
плавающей точкой с самого начала. Поэтому исполь-
зуйте выражения и переменные с плавающей точкой,
не смешивая их с целыми выражениями или пере-
менными, до завершения стадий вычисления.
2. Самые современные процессоры достаточно хоро-
шо приспособлены для выполнения других задач в
то время, пока выполняются операции с плавающей
точкой. Некоторые из них могут даже выполнять
множество операций с плавающей точкой одновре-
менно. Это и есть форма ’’бесплатного" распаралле-
ливания вычислений, из которой вы, безусловно,
получите дополнительное преимущество, если при-
обретете такой процессор для своего компьютера.
Локальность ссылок
Первое, что необходимо рассмотреть при оптимизации
доступа к памяти (причем независимо от того, идет ли
речь о виртуальной памяти (virtual memory, или VM)
или о кэше), — это локальность ссылок (locality reference)
в программе. Программа хорошо отображает локаль-
ность ссылок с использованием адресов памяти, кото-
рые близки (по времени и местоположению) к другим
последним ссылкам к памяти. Главное различие между
оптимизацией для VM и оптимизацией для кэша состо-
ит в их масштабах: страницы VM могут составлять от
0,5 до 8 Кб и более и занимать десятки миллисекунд для
считывания данных с диска. Кэш-блоки обычно имеют
размер от 16 до 256 байтов и считывают данные за вре-
мя, определяемое в микросекундах. О программе, ис-
пользующей много VM-страниц или кэш-строк для заг-
рузки в быстрой последовательности, говорят, что она
будет "пробуксовывать" (thrashing). (Это слово в профес-
Пересмотренный язык С
Часть I
78
сиональной литературе означает снижение эффективно-
сти работы системы с виртуальной памятью вследствие
чрезмерного количества запросов на подкачку страниц. —
Прим. науч. ред.).
Вы можете воздействовать на локальность ссылок
путем изменения порядка, в котором осуществляете
доступ и размещаете объекты памяти, такие как масси-
вы, или путем разбиения структур данных на часто
используемые и редко используемые сегменты и разме-
стить все часто используемые наборы вместе. Не следует
полагать, что функция malloc всегда размещает рядом
вплотную друг к другу области памяти при каждом
последовательном вызове. Вы должны разместить одну
гигантскую область самостоятельно, чтобы быть в этом
уверенным. Но это может привести к другим проблемам.
Алгоритмы поиска и сортировки в широких преде-
лах различаются между собой в разнообразии доступа
к памяти. Сортировка слиянием часто рассматривается
как имеющая лучшую локальность ссылок. В отноше-
нии алгоритмов поиска можно предполагать, что пос-
ледние несколько шагов поиска, вероятно, будут осуще-
ствляться на одной и той же странице памяти, и для
выполнения этих шагов выбирать алгоритм, отличный
от первоначального и более эффективный с указанной
точки зрения.
Адресация главной строки
Когда вы обрабатываете многомерные массивы, убеди-
тесь в том, что в первую очередь приращение получает
самый крайний справа индекс. Для С-программистов это
естественно, но для программистов, пишущих на язы-
ке FORTRAN, все наоборот. Если ваш собственный код
похож на этот:
float array [20] [100];
int i, j;
for (j » 0; j < 100; j++) /* заметьте, что
j - внежний индекс */
{
for (i = 0; i < 20; i++) /* заметьте, что
i - внутренний индекс */
{
array [i] [j] = 0.0;
то для повышения скорости выполнения программы вы
можете поменять местами индексы массива. После оп-
тимизации главной строки два цикла for меняются ме-
стами, как показано ниже:
float array [20] [100];
int i, j;
for (i = 0; i < 20; i++) /* заметьте, что
i - внемвий индекс */
{
for (j = 0; j < 100; j++) /* заметьте, что
j - внутренний индекс */
array [i] [j] » 0.0;
)
Некоторые дополнительные стратегии
оптимизации
Если вы исчерпали все возможные алгоритмы и оптими-
зацию реализации и, несмотря на это, отчаялись добить-
ся хоть небольшого повышения скорости работы своей
программы, можете подумать об оптимизации вне ком-
фортабельного контекста языка программирования С.
Один подход, на который некоторые уповают, со-
стоит в записи наиболее критичных ко времени разде-
лов вашего кода на языке ассемблера. Я не являюсь бе-
зусловным сторонником такого совета, поскольку если
вы недостаточно хороший программист, чтобы написать
высококачественный код на языке ассемблера, который
бы мог конкурировать с возможностями хорошего ком-
пилятора, то' вам, скорее всего, не стоит прибегать к
языку ассемблера. Вы можете возразить, что ассемблер
не такой уж сложный язык, но в этом деле имеется на-
столько много подводных камней, что вы вскоре оце-
ните, насколько серьезную и тяжелую работу выполня-
ет ваш С-компилятор.
Если же вы все-таки решились на этот шаг, я пред-
лагаю вам оптимизировать код, насколько это возмож-
но, в С, а затем использовать компилятор для генери-
рования ассемблерного листинга своей функции,
который вы можете использовать как исходный пункт
для экспериментов. В практических целях советую
иметь минимально возможный размер кода на языке ас-
семблера, чтобы уменьшить трудности перенесения сво-
ей программы на другие платформы и процессоры в бу-
дущем.
Другой достойный рассмотрения путь повышения
скорости работы ваших программ достаточно прост и
состоит в том, чтобы обратить свой взор в направлении
поставщиков аппаратных средств. В зависимости от
источника узкого места в программе, рассмотрите апг-
рейдинг (модернизацию) вашего CPU, добавление со-
процессоров, повышение скорости Internet-связи или
инсталляцию высокоскоростного дискового массива
RAID. Еще одним, более радикальным, но и более до-
рогим решением является перенос вашего кода на супер-
компьютер.
Вы можете также обратиться за помощью к постав-
щикам программного обеспечения. Например, можете
инсталлировать компиляторы от нескольких различных
поставщиков, скомпилировать все критичные ко време-
ни функции на каждом из них и профилировать их по
отдельности, чтобы увидеть, какой компилятор генери-
Оптимизация
Глава 3
79
рует наиболее быстро выполняемый код. Типичные
различия между высококачественными компиляторами
измеряются 2-5% скорости сгенерированного кода (это
для сведения о том, почему автор тщательно выбирает
компилятор для оптимизации). Другим решением, свя-
занным с программным обеспечением, является исполь-
зование соответствующего коммерческого продукта,
такого как пакет базы данных или библиотеки числен-
ного анализа. Это позволит вам получить преимущество
от хорошо оптимизированного программного обеспече-
ния, которое иначе не попало бы в ваше распоряжение
и которое может содержать некоторые лицензионные
средства повышения скорости, которые ни мне, ни вам
никогда бы не удалось заполучить другим путем.
Но не все можно получить за деньги, и не все про-
граммы могут стать воплощением легендарной напори-
стости языка ассемблера. Какую же еще простую и до-
ступную стратегию мы можем применить? Это —
терпение. В соответствии с законом Мура, вычислитель-
ная мощь удваивается примерно каждые 18 месяцев.
Если ваш код медлителен с коэффициентом 4, просто
подождите 36 месяцев — и скорость его выполнения по-
высится до требуемой по спецификации (т.е. с коэффи-
циентом 1), а вы при этом даже пальцем не шевельне-
те. Это может показаться очень остроумным, но из
сказанного вытекает два интересных следствия.
Если принять, что вычислительная мощь возраста-
ет во времени экспоненциально, то алгоритмы с экспо-
ненциальной или лучшей О-нотацией оказываются
фактически линейными с большой константой. Все, что
требуется, — это чтобы их развитие можно было про-
верять и иногда переходить на все более усовершенство-
ванные CPU.
На более обыденном уровне вы должны рассчитывать,
как часто проводить модернизацию, чтобы не возникало
конфликтов между скоростью более новых аппаратных
средств и их стоимостью. В случае ограниченного, но
пополняющегося бюджета можно было бы приобретать
дорогой, самый престижный компьютер каждые не-
сколько лет. Но через какое-то время вы можете позво-
лить себе заменить его, поскольку прежний, который
был быстродействующим в то время, будет иметь гораз-
до меньшую скорость. Другая стратегия состоит в том,
чтобы покупать более дешевые компьютеры, которые вы
можете позволить себе заменять более часто. Оптималь-
ный выбор из этих двух стратегий — настоящее искус-
ство.
Кооперативная и параллельная
оптимизация
Было время, когда компьютеры оснащались простень-
кими операционными системами, способными выпол-
нять одновременно только одну программу. Для таких
примитивных систем программисты могли позволить
себе только повышать уровень использования ресурсов
компьютера (диска, памяти, контроллеров ввода/выво-
да). По существу, неаккуратное использование ресурсов
вредило только их собственным программам, но коль
скоро делалась какая-то полезная работа по крайней
мере одной подсистемой, то попытки сделать работу
других подсистем более эффективной не могли увен-
чаться успехом, поскольку устройства все равно долж-
ны были просто находиться в ожидании, если они за-
канчивали выполнение своих задач раньше. (Чтобы это
было похоже на правду, напомню вам, что все только
что упомянутые признаки применимы к MS-DOS.)
Многозадачные, многопользовательские и серверные
операционные системы изменили эту ситуацию. Когда
ваша программа заканчивает использование ресурсов,
может начать выполняться другая задача, которая рань-
ше находилась в ожидании. Это хорошо. Но теперь не-
эффективное использование ресурсов более не означа-
ет просто увеличение времени ожидания выполнения
вашей программы; это означает, что некоторая другая
программа фактически не даст выполняться вашей про-
грамме. Конечные пользователи могут усугубить про-
блему запуском такой же программы в то же самое вре-
мя, усиливая конкуренцию за одни и те же ресурсы.
И последняя особенность состоит в том, что под
управлением этих многозадачных операционных систем
есть возможность запускать различные задачи одновре-
менно для коммуникации их друг с другом. Если перед
продолжением работы одна задача нуждается в получе-
нии ответа от другой программы (что бывает довольно
часто), программа, сделавшая запрос, должна подождать.
Случается также, что программы не только используют
ресурсы, но сами фактически являются ресурсами.
Некоторые новые величины
эффективности
До сих пор мы использовали величину О-нотации, ко-
торая неявно характеризует время, затрачиваемое алго-
ритмом, и измеряли ее фактически в миллисекундах и
микросекундах с использованием профиля программы.
В системе (или сети) имеются некоторые другие изме-
ряемые величины, полезные для описания эффективно-
сти ресурсов:
• Производительность (Throughput) — количество дан-
ных, которое может быть передано за единицу вре-
мени. Обычно измеряется в битах за секунду (бит/с,
bps).
• Латентность (Latency) — задержка между выдачей
запроса на ресурс и началом действия по работе с
80
Пересмотренный язык С
Часть I
этим ресурсом. Обычно измеряется в милли- или
микросекундах.
• Способность пакетирования (Burstiness) — возмож-
ность быстрой последовательности запросов на ре-
сурс и пауз неактивности между ними.
• Цикл режима работы (Duty cycle) — пропорциона-
лен времени готовности ресурса к использованию.
Обычно измеряется в процентах к общему времени
запроса.
Клиент-сервер и параллелизм
Вы могли бы подумать, что если у вас есть два компь-
ютера, один из которых выполняет клиентскую про-
грамму, а второй — серверную, то, когда две програм-
мы связаны между собой, они могли бы выполняться в
некотором смысле параллельно и закончиться вдвое ско-
рее, чем в том случае, если бы они работали последо-
вательно. Ответ на этот вопрос зависит от того, какой
протокол используется для коммуникации между про-
граммами, т.е. является ли он сблокированным (blocking)
или несблокированным (non-blocking).
Многие протоколы Internet являются сблокирован-
ными. Например, если вы получаете или отправляете
электронную почту на SMTP- или POP-сервер, исполь-
зуемая вами клиентская программа должна остановить-
ся и ждать ответа от сервера, поскольку протоколы тре-
буют, чтобы ответ был получен до того, как клиент
может продолжить работу.
Имеется несколько путей для обеспечения эффекта
параллелизма в работе. К сожалению, оба этих способа
выходят за строгие рамки стандарта ANSI С.
Во-первых, проще всего использовать несблокиро-
ванный протокол. Подобный подход применяется, на-
пример, системой XII Window System. В таком прото-
коле после отправки запроса (обычно на прорисовку
экрана) в большинстве случаев клиентская программа
продолжает выполняться без выполнения проверки на
получение ответа или результата запроса. Фактически
могут быть сгенерированы несколько запросов в быст-
рой последовательности, и библиотека XII на клиент-
ской стороне может упаковать их вместе и отправить
одновременно для обеспечения максимальной эффек-
тивности. В любом случае запросы обрабатываются сер-
вером по мере их поступления, и клиент, если он вы-
полняется на другом процессоре, может продолжать
делать полезную работу, возможно, генерировать следу-
ющие запросы. Интерфейс API системы XI1 Window
System имеет еще и то преимущество, что не связанные
с ANSI С детали, которые поддерживают эту схему,
спрятаны в библиотечном коде — программист может
использовать их так, будто он пишет обычные вызовы
функций.
Другим решением может стать использование мно-
гопоточного пакета, с тем чтобы разрешить одной час-
ти вашей клиентской программы ждать ответа от сер-
вера (с использованием сблокированного протокола), но
дать другим потокам на вашем клиенте продолжать про-
изводительную работу. Этот метод используется многи-
ми Web-браузерами, позволяющими загружать множе-
ство страниц и множество изображений одновременно,
несмотря на то что лежащий в их основе протокол HTTP
является сблокированным. Этот подход имеет тот не-
достаток, что большая часть вашего кода должна быть
переписана так, чтобы следовать модели управления
потоками выполнения вашей программы, а в мультипо-
токовой программе некоторые свойства С ведут себя по-
разному или непредсказуемо.
Если быть честным, то в С нет понятия клиент-сер-
вер, нет параллелизма и нет межпроцессной коммуни-
кации. Ни одно из этих свойств не может быть постро-
ено в рамках языка или стандартной библиотеки.
Однако когда такие свойства обеспечиваются операци-
онной системой, они почти всегда доступны для вклю-
чения в заголовочный файл С и для связи с предвари-
тельно скомпилированной библиотекой. Хорошо
осведомленный С-программист знает, где проходит гра-
ница между ANSI С и OS-ориентированными библио-
теками, и при необходимости он пересекает ее несколь-
ко раз.
Неявный параллелизм
Даже в наиболее простых компьютерах вполне достаточ-
но возможностей для параллельной обработки. Каждое
устройство ввода/вывода имеет контроллер с небольшим
встроенным внутрь CPU. Это дает возможность отправ-
лять данные на модем, записывать их на диск, кроме
того, разделы RAM могут считывать информацию из
кэша, а пиксели могут записываться на экран — все это
на одном и том же компьютере и в одно и то же время:
главное CPU фактически доступно в течение всего про-
цесса для выполнения вычислений с участием целых
чисел и чисел с плавающей точкой.
Конечно, параллелизм ввода/вывода этого уровня не
может работать все время. Но вы можете написать код
так, чтобы это случалось время от времени. Рассмотрим
простую программу, которая выполняет следующее:
1. Читает большое количество записей из файла.
2. Делает некоторые изменения в них в то время, ког-
да эти записи находятся в памяти.
3. Записывает их в новый файл.
Как видим, каждая фаза процесса полностью ис-
пользует одновременно только одно устройство, а ос-
тальные ожидают. Отсутствует какое-либо перекрытие.
Теперь давайте сделаем два простых изменения.
81
Сначала рассмотрим естественные объемы (или раз-
меры), с которыми работают устройства. Для диска этот
естественный размер составляет обычно умеренное чис-
ло — 512 или 1024 байта. Подсчитаем, как много запи-
сей (из вашего файла) требуется для заполнения един-
ственного блока диска (скажем, всего блоков 8), и это
даст нам идею, насколько уменьшить единицу работы,
которая обеспечит полное использование функции чте-
ния диска. Мы пойдем немного далее и предположим,
что в операционной системе или на жестком диске име-
ется один или два уровня буферизации и что они мо-
гут фактически обработать несколько поставленных в
очередь запросов. Но нам здесь не нужно загружать ус-
тройство на все 100% цикла режима работы. Нам толь-
ко необходимо задать ему достаточно работы для того,
чтобы мы могли начать работать с какой-либо еще час-
тью программы, пока диск занят чтением. Но следует
опасаться задавать дисководу так много работы, что вся
программа будет ждать, пока он ее закончит.
Итак, мы переписываем нашу программу в следую-
щем виде:
1. Чтение небольшого числа записей из файла.
2. Выполнение некоторых изменений этих записей,
пока они находятся в памяти.
3. Запись их в новый файл.
4. Повторение описанных действий, пока не будет
обработан весь файл.
Даже на данном этапе мы уже имеем два преимуще-
ства. Многие операционные системы осуществляют
предупредительное чтение, так что, если вы читаете
файл последовательно (в противоположность беспоря-
дочному чтению), они заранее прочитывают пару бло-
ков, и, когда ваша программа начинает запрашивать
следующую порцию записей, система уже готова их
предоставить. Кроме того, имея меньшее количество
записей в памяти одновременно, мы можем все их по-
местить в кэш и избежать свопинга (перекачки) страниц
виртуальной памяти, что обычно повышает нагрузку на
жесткий диск.
Когда мы пишем записи в новый файл, то было бы
хорошо новый файл записывать на диск, отличный от
диска, с которого считывался оригинальный файл. Еще
лучше, если этот второй диск находится на другой шине
или контроллере. Теперь мы имеем следующий процесс:
1. Считываем небольшое число записей из файла на
диске.
2. Делаем некоторые изменения записей, пока они
находятся в памяти.
3. Записываем их в новый файл на другом диске.
4. Повторяем эти операции, пока не будет обработан
весь файл.
Оптимизация
Глава 3
Такая программа не будет выполняться так, как она
выполнялась бы на суперкомпьютере, но на хорошей
операционной системе она даст возможность намного
лучше распределить процессную нагрузку.
Пользовательский интерфейс для
медлительных алгоритмов
Теперь наша функция трехфазного копирования запи-
сей с диска выполняется заметно быстрее, чем прежде,
но она все еще может занимать целую минуту. Если бы
эта функция была вызвана из программы, которая име-
ет графический пользовательский* интерфейс, то наша
программа была бы безответна к вводу пользователя, и,
поскольку он бы не знал, когда она снова станет отве-
чать на запросы, у него бы появилось большое желание
каждый раз прерывать программу в самый неподходя-
щий момент.
Самое простое, что можно сделать в такой ситуации, —
это изменить курсор на песочные часы и дать таким
образом пользователю знать, что программа не "заморо-
зилась”, а вовсю работает. Следующий шаг — оценить,
как много работы требуется сделать программе и как
долго она будет ее выполнять. Можно также указать
пользователю примерное время до завершения процес-
са и номера выполняемой фазы, что пользователь мо-
жет использовать также для оценки необходимости
модернизации своих аппаратных средств.
Можно усложнить этот сервис, добавив полосы раз-
вития процесса, но не для всех алгоритмов мы можем
предусмотреть время протекания их выполнения от
начала до окончания даже на прямой линейке. Ниже
приведены некоторые руководящие наставления для
работы с таким сервисом:
• Если возможно, примите в расчет времени сначала
наиболее медлительные и непредсказуемые части
алгоритма, так чтобы с течением времени выполне-
ния можно было корректировать время окончания
процесса в сторону большей эффективности. Пользо-
вателю вряд ли будет приятно, если фактическое
время превысит указанное с самого начала.
• У вас должна быть только одна полоса развития про-
цесса для всего времени выполнения программы.
Очень печально наблюдать, как развитие одного про-
цесса проделывает весь путь только для того, чтобы
затем иной процесс снова начался на пустом месте.
Полоса развития процесса никогда не должна дви-
гаться назад. (Да, я видел, что это случается, но не со-
чтите меня безумцем, поскольку это был мой собствен-
ный код!)
Рассмотрим теперь целесообразность наличия кноп-
ки Отмена (или Стоп), предназначенной для пользова-
теля. Это дает то преимущество, что если пользователь
6 Зак. 265
82
Пересмотренный язык С
Часть I
теряет терпение, то ваша программа будет первой знать
об этом и вы сможете ответить. Например, вы можете
восстановить любую частично завершенную запись или
удалить временные файлы либо даже ответить, что опе-
рация будет завершена позже, когда пользователя нет
рядом, и что он может не беспокоиться. Без кнопки
Отмена пользователь будет прекращать выполнение ва-
шей программы насильно, а это может спутать все дан-
ные, с которыми в этот момент работала программа.
Если случайно вы последуете всем этим советам о
полосах развития процесса и кнопке Отмена, то може-
те столкнуться с неприятным фактом. На обновление
экрана, проверку на нажатие пользователем кнопки
Отмена и вызовы операционной системы из вашей про-
граммы затрачиваются время и усилия компьютера,
даже если нет необходимости выполнять все эти дей-
ствия. Эта дополнительная работа может существенно
замедлить выполнение вашей программы.
Из собственных экспериментов я обнаружил, что
хороший компромисс между частой проверкой (и тра-
той времени) и редкой проверкой (и причиной застоя)
составляет около 200 миллисекунд. Но имеется еще одна
ловушка: проверка системных часов каждый раз в тече-
ние цикла в вашем алгоритме также может требовать
определенного времени. Поэтому в листинге 3.1 пред-
ставлен псевдокод примера, демонстрирующего, кдк
писать цикл внутри вашего алгоритма, который не вы-
зовет слишком больших издержек при использовании
любых из сделанных выше GUI-дружественных пред-
ложений.
Когда оптимизация не нужна
В своих попытках сделать программу как можно более
быстрой, необходимо помнить, что оптимизация обыч-
но должна быть последней стадией процесса разработ-
ки и вообще должна быть скоординирована с другими
целями программного обеспечения.
Ниже представлены некоторые заключительные сло-
ва мудрости, которые помогут вам сберечь драгоценное
время и усилия в процессе вашей оптимизационной
деятельности.
Корень зла - в преждевременной
оптимизации
Самым плохим временем для оптимизации является
момент, когда вы начинаете писать код. Конечно, это
то время, когда вы должны сделать выбор эффективно-
го алгоритма. Но код, который вы пишете, не должен
тускнеть из-за каких-либо мыслей об экономии машин-
ных циклов. Если это будет так, то вы получите код,
трудный для сопровождения и плохо поддающийся
оптимизации, поскольку он будет очень непростым для
понимания.
Что вам нужно делать, так это писать простой код,
который реализует правильный алгоритм, настолько яс-
ный, насколько это возможно. Для крупного коллектив-
но выполняемого проекта все обычно просят докумен-
тацию и комментарии, и руководящие указания по
кодированию не должны отдаваться на расправу во имя
Листинг 3.1. Псевдокод для алгоритма отмены/развития процесса.
unsigned int count = 1;
timetypet lastcheck = -1;
/♦ time_t использовать нельзя, поскольку
разрешение в миллисекундах ие гарантировано ♦/
while (whatever)
{
if (count % 100 == 0)
{
now - timecheck ();
if (now - lastcheck > 200 миллисекунд)
{
if (передала кнопка Отмена)
{
изменить диалоговое окно на сообценне "Отмена...11;
очистить файлы temp и сделать еце что-либо, требующее выполнения;
break;
}
обновить полосу развития процесса;
lastcheck = now;
}
}
/♦ выполнять фактическую обработку здесь
каждый раз в цикле ♦/
count++;
}
Оптимизация
Глава 3
83
оптимизации. Сейчас наиболее важно, чтобы другие
программисты были способны понять ваш код так, что-
бы, когда наконец наступит время оптимизации, каж-
дый из них имел ясное представление о том, какие
функции выполняет код, а не сталкивался каждый раз
с проблемами или постоянно просил вас объяснить
смысл некоторых необычных строк кода.
И конечно, наиболее преждевременной можно счи-
тать оптимизацию, которую вы делаете без предвари-
тельного использования профиля или другого инстру-
мента измерений.
Легче сделать корректную программу
быстрой, чем быструю программу
корректной
Значительно лучше начать с разработки фрагмента кода
и попытаться улучшить его, чем разбить код на фраг-
менты, а затем пытаться собрать их вместе.
• Любые "быстрые" клавиши или изощренные опера-
торы программы, сделанные во имя оптимизации,
являются в первую очередь источником ошибок.
• Во многих (если не в большинстве) средах програм-
мирования установка компилятора на то, чтобы ге-
нерировать самый быстрый, насколько это возмож-
но, код оборачивается генерированием отладочной
информации.
• Имея корректный (но медлительный) экземпляр
кода, вы можете запустить всесторонние регресси-
онные тесты на оптимизируемых версиях этого кода
для проверки того, что процесс оптимизации не про-
дуцирует никаких новых ошибок.
Не выполняйте оптимизацию без учета
переносимости
Закон Мура был инспирирован снижением в размерах
(и соответственно увеличением числа) транзисторов на
силиконовых чипсах с течением времени. Но некоторые
достижения в компьютерной мощи с годами также про-
исходят благодаря значительным сдвигам в компьютер-
ной архитектуре. От мэйнфрейма до микро-ЭВМ, от
CISC до RISC, от пакетного режима до многопоточно-
сти — каждый этот шаг привносит новый уровень ком-
пьютерной мощи и проверен на переносимость многих
приложений.
Если вы напишете программу, переносимую на бо-
лее совершенные и скоростные компьютеры, то даже не
самая оптимальная программа может выполняться в
значительной степени быстрее, чем очень хорошо оп-
тимизированная программа, но разработанная для уста-
ревших аппаратных средств.
СПОСОБ ОПТИМИЗАЦИИ ДЛЯ ЛЕНИВЫХ
В течение нескольких лет я собрал небольшую библио-
теку личных программных утилит, которые я никогда не
оптимизировал. Все они написаны на ANSI С (с неболь-
шой примесью кое-где POSIX), являются довольно пере-
носимыми и обновляются для любых компьютеров обычно
совершенно безболезненно. Каждый раз, когда я испы-
тываю свои программы на новых аппаратных средствах,
я поражаюсь, каким мгновенно выполняемым и быстрым
становится мой старый неоптимизированный код с тече-
нием лет безо всяких усилий с моей стороны, не считая
повторной его компиляции время от времени.
Позвольте делать это компилятору
Этот совет изначально был хорош и продолжает стано-
виться еще лучше. Повышение скорости программ зави-
сит не только от аппаратных средств, но и от компиля-
торов, которые генерируют объектный код.
Просмотрите документацию по компилятору и выясни-
те, какую оптимизацию он может выполнить самосто-
ятельно, чтобы не нужно было дублировать его усилий.
Отыщите, какие переключатели или опции командной
строки нужно установить, чтобы достигнуть максималь-
ной оптимизации.
От наиболее современных компиляторов вполне
можно ожидать выполнения по крайней мере такой
оптимизации:
• Инлайнинг
• Разворачивание цикла
• Обращение цикла (на компьютерах, где это целесо-
образно)
• Редукция строгости выражения
• Удаление из цикла инварианта кода
• Назначение регистра
Резюме
Я надеюсь, что из этой главы вы узнали много нового и
полезного для себя. Мы вели речь об оптимизации не
только как о некоторых поправках кода, но рассматри-
вали выбор эффективных алгоритмов, основанный на
О-нотации, корректную реализацию этих алгоритмов и
использование профилей. Это позволяет определить
горячие точки в вашей программе, в которых была бы
уместной некоторая оптимизация, пока она не идет
вразрез с другими целями программирования, такими
как читабельность и переносимость программы.
Работа с датами
4
В ЭТОЙ ГЛАВЕ
Функции даты и времени
Ошибка тысячелетия: проблемы, связанные с датами
Полезные мелочи
Лоренс Кирби
Недавно очень драматично обсуждались вопросы, свя-
занные с датами, и особенно много волнений было вок-
руг так называемой ошибки тысячелетия. Когда вы бу-
дете читать эту главу, новое тысячелетие уже вступит в
свои права, так что для вас все эти события будут уже в
прошлом. Однако проблемы, вызванные ошибкой тысяче-
летия, остаются достаточно важными, чтобы о них знать
и научиться писать код обработки даты так, чтобы из-
бегать этих проблем. Но сначала мы посмотрим, какие
средства даты и времени обеспечиваются языком С.
Функции даты и времени
Стандартная библиотека С содержит набор функций
обработки даты и времени, объявленные в заголовке
<time.h> и показанные в листинге 4.1. В этих функци-
ях используются три типа, также объявленные в заго-
ловке: time t, struct tm и clock t.
Основные функции даты и времени
Функция time() объявлена как
time_t time(time_t * timer) ;
и дает текущую дату и время, представляемое как зна-
чение time_t. Можно либо использовать возвращенное
значение непосредственно, либо передать его указатель
переменной time_t, куда он запишет значение времени.
Если вы не передаете этот указатель переменной time t,
то вы должны передать его нулевой указатель. Перемен-
ная time t определена как арифметический тип, способ-
ный представлять время. Это означает, что она может
быть целым типом, таким как signed или unsigned, int
или long, либо типом с плавающей точкой, таким как
double. В С не специфицируется то, как переменная
time t представляет время. Переносимая программа не
должна пытаться манипулировать значениями time_t
напрямую, а должна для этой цели использовать функ-
ции стандартной библиотеки.
Обычным для компиляторов является определение
переменной time t как int или long и хранение дат, пред-
ставленных в виде секунд, начиная с 1 января 1970 г.
Последнее специфицировано стандартом POSIX, но не
требуется языком С, и лучше избегать предположений,
подобных этому, где только возможно. Даже между
системами, которые используют секунды, начиная с 1
Листинг 4.1. Функции времени языка С, объявленные в <time.h>.
timet time(time_t «timer);
double difftime(time_t timel, time_t time2);
struct tm *gmtime(const time_t «timer);
struct tm «localtime(const time_t «timer);
char *asctime(const struct tm «timeptr)
char *ctime(const timet «timer);
sizet strftime(char *s, sizet maxsize, const char «format,
const struct tm «timeptr);
timet mktime(struct tm «timeptr);
clock t clock(void);
Работа с датами
января 1970 г., могут иметься отличия, такие как вре-
менная зона (UTC —* * Coordinated Universal Time, или
местное время).
Функция difftime() объявлена как
double dif f time (time_t timel, time_t time2) ;
и вычисляет интервал между двумя значениями time_t,
давая ответ в секундах. Если время timel более позднее,
чем timel, результат будет положительным; в противном
случае результат отрицательный. Функция difftime()
позволяет измерять временной интервал в секундах,
даже когда значения time t не представлены в секундах.
Этот факт демонстрируется в листинге 4.2.
Заметьте, что код совершенно не заботится о том,
какой тип и представление имеет переменная time_t;
эти детали всегда обрабатываются функциями стандар-
тной библиотеки. Код проверяет, является ли start ве-
личиной (time_t)-l, которая является возвращаемым
значением функции time(), если время недоступно.
Программа выводит результат в два десятичных раз-
ряда. Обычно переменная time t представляет время в
полных секундах, и в этом случае нет дробной части.
Однако, если этого недостаточно, С позволяет реализо-
вать хранение информации о дробной части секунды в
переменной time t.
Полезные формы представления даты и
времени
Тип struct tm представляет дату и время разбитыми на
стандартные компоненты в соответствии с Грегорианским
календарем. В табл. 4.1 приведены элементы этого типа.
Глава 4
Таблица 4.1. Элементы типа struct tm.
Элемент Описание
int tm_sec Секунды после минут (0-60)
int tmmin Минуты после часов (0-59)
int tmhour Часы, отсчитанные от полуночи (0-23)
int tm_mday День месяца (1-31)
int tmjnon Месяц года (0(янв)-11(дек))
int trrvyear Год, начиная с 1900 г.
int tmwday День недели (О(вскр)-б(суб))
int tm_yday День года (0-365)
int tmisdst Указатель летнего времени
Названия элементов и диапазоны их изменения го-
ворят сами за себя, но здесь есть несколько дополнитель-
ных моментов:
• tm_sec заключается обычно в диапазоне 0-59, но мо-
жет принимать и значение 60 для дополнительной
секунды, которая иногда вставляется в целях сохра-
нения дней при синхронизации часов с вращением
Земли.
• tm_mon начинается не с 1 для января, а с 0. Это
часто означает, что в преобразовании даты эта вели-
чина должна быть скорректирована на 1. Посколь-
ку tm_mday начинается с 1, это не представляет ка-
кой-либо проблемы.
• tm_year представляет годы, начиная с 1900. Это оз-
начает, что год 2000 будет содержать величину 100,
имеющую более двух последних цифр года.
Листинг 4.2. Измерение временных интервалов с использованием функций timeQ и difftimeQ.
♦include <stdio.h>
♦include <stdlib.h>
♦include <time.h>
int main(void)
{
time t start, end;
start = time(NULL);
if (start == (timet)-l) {
printf("Извините, на этой системе время недоступноХп");
exit(EXITFAILURE);
}
printf("Подождите, пожалуйста, несколько секунд и нажмите клавииу ENTER/RETURN*);
fflush(stdout);
getchar();
end = time(NULL);
printf("\nThe interval was %.2f secondsXn", difftime(end, start));
return 0;
1
86
Пересмотренный язык С
Часть I
• tm_yday также начинается с 0 для 1 января. 31 де-
кабря — это 364-й либо 365-й день для високосного
года.
• tm isdst указывает, принято ли летнее время в рас-
чет для определенного времени:
tm_isdst > 0 — летнее время учитывается
tm_isdst = 0 — летнее время не учитывается
tm_isdst < 0 — информация недоступна
В языке С имеется две функции для конвертирова-
ния значения time__t в тип struct tm: это localtime() и
gmtimeO, которые объявлены как
struct tm * gmtime (const time_t * timer) ;
struct tm * local time (const time_t * timer) ;
Обе эти функции получают указатель на перемен-
ную time_t, которая содержит подлежащее конвертации
значение (тот факт, что они получают именно указатель,
является историческим нонсенсом, возможно потому,
что time_t может не всегда быть типом, гарантирующим
возможность передачи его в качестве аргумента функ-
ции). Сама переменная time_t не модифицируется, но
обе функции возвращают указатель на внутренний ста-
тический объект struct tm, содержащий соответствую-
щие значения. Различие между функциями gmtimeO и
localtime() состоит в том, что localtime() дает результат,
представленный в виде локального (местного) времени
зоны программы, в то время как gmtimeO дает резуль-
тат, представленный как GMT (или, более корректно в
наши дни, UTC).
Как управлять эффектом влияния временных зон,
которые могут значительно изменяться от одной систе-
мы к другой? Язык С даже не пытается стандартизиро-
вать это. Общий метод состоит в использовании пере-
менной TZ среды для указания информации о
временной зоне. Обычно настройка TZ является про-
блемой системного администратора, и сами С-програм-
мы не должны заботиться об этом. Стандартная библио-
тека не обеспечивает способа установки информации о
временной зоне. Все, что вы можете сделать, — это за-
дать имя текущей временной зоны (см. описание фун-
кции strftime() ниже) и определить, учитывается ли
летнее время.
Пропое строковое форматирование
времени
Функции asctime() и ctime() генерируют строку, пред-
ставляющую конкретное время в фиксированном фор-
мате, например:
Tue Feb 29 23:59:59 2000\п
— 23 ч 59 мин 59 с, вторник, 29 февраля 2000 г. Здесь
\п — обычный символ перехода на новую строку (пе-
ревода каретки). Данный символ часто доставляет не-
приятности, поскольку во многих случаях приходится
впоследствии удалять его. Функции asctime() и ctime()
объявляются следующим образом:
char * as с time (cons t struct tm * timeptr) ;
char *ctime (const struct tm *timer) ;
Эти функции одинаковы, за исключением того, что
asctimeO получает указатель на объект struct tm, в то
время как ctime(> получает указатель на объект time_t.
Функция ctime() предназначена для вывода локального
времени, и обращение ctime(timer) эквивалентно обра-
щению asctime(localtime(timer)). Листинг 4.3 демонстри-
рует использование этих функций для вывода текуще-
го времени в локальной и UTC-формах.
Функции asctimeO и ctime() возвращают указатели
на область внутренней статической памяти, которая
содержит результирующие строки. Неоднократное об-
ращение к этим функциям может переписывать один и
тот же объект, так что это важно с точки зрения окон-
чания работы со строкой перед повторным вызовом
одной из этих функций. Функция gmtimeO может воз-
вратить нулевой указатель, если конвертирование ре-
зультата в форму UTC невозможно, поэтому програм-
ма делает соответствующую проверку.
Сложное форматирование времени
Функция strftime() используется для форматирования
строки в стиле функции печати printf() (но с другими
спецификациями конвертирования) в целях обеспече-
ния гибкого способа специфицирования форматов.
Объявляется функция strftime() следующим образом:
size_t strf time (char *s, size_t maxsize,
const char * format,
const struct tm *timeptr) ;
Здесь s —* указатель на определенный вызывающей
программой массив символов, в котором будет сохране-
на результирующая строка. Переменная maxsize пред-
ставляет собой максимальное число символов, которые
функция strftime() может записать, включая символ
нуль (обычно это размер массива). Переменная format —
это строка формата, a timeptr — указатель на заполнен-
ную структуру struct tm. Функция strftime() копирует
символы из строки формата в массив, на который ука-
зывает s, конвертирует последовательности двух симво-
лов с % до полей времени. Функция возвращает число
символов, записанных в символьный массив, включая
нулевой символ. Если выходная строка окажется длин-
нее, чем maxsize, функция strftime() вернет 0 и вы ни-
чего не узнаете о содержимом массива, поскольку он
может быть записан лишь частично. В табл. 4.2 приве-
дены спецификаторы конвертирования.
Работа с датами
Глава 4
Листинг 4.3, Использование функций asctimeQ и ctimeQ для создания, простых строк даты,
linclude <stdio.h>
linclude <stdlib.h>
linclude <time.h>
int main (void)
{
time_t timeval;
struct tm *tmptr;
timeval = time(NULL);
printf("Time as local time is %s"f ctime(&timeval));
if ((tmptr = gmtime (& timeval)) == NULL)
printf("UTC time not available\n");
else
printf("Time as UTC time is %s", asctime(tmptr));
return 0;
}
Таблица 4.2. Спецификаторы конвертирования
функции strftimeQ (звездочка * указывает на
локальную специфику).______________________
Спецификатор Заменяется на
%а* Аббревиатуру названия дня недели
%А * Полное название дня недели
%Ь* Аббревиатуру названия месяца
%В* Полное название месяца
%с* Полную дату и время
%d День месяца (01-31)
%Н Час (часы на 24 часа) (00-23)
%1 Час (часы на 12 часов) (01-12)
%j День года (001-366)
%m Месяц (01-12)
%М Минуту (00-59)
%р* Обозначение АМ/РМ для часов на 12 часов
%S Секунды (00-59)
%и Номер недели (по количеству воскресений)
Название дня недели (О(вскр)-б(суб))
%W Номер недели (по количеству понедельников)
%х* Представление полной даты
%Х* Представление полного времени дня
%у Год без указания века (00-99)
%Y Полный год, включая век
%Z Название или аббревиатура временной зоны (либо пробел — в случае недоступности информации о временной зоне)
%% Одиночный символ %
Заметное место в этой таблице занимают локальные
спецификаторы (т.е. их вывод может изменяться в за-
висимости от того, учитывается регион или нет). Это
позволяет одному и тому же коду поддерживать различ-
ные форматы данных, используемые в различных реги-
онах мира. Различные местоположения могут быть ус-
тановлены с использованием функции setlocale(),
которая объявлена в библиотеке <locale,h>. Например,
в результате вызова
setlocale (LC_TIME, " " ) ;
связанные со временем части задания местоположения
программы будут установлены в соответствии с данной
средой определенной системы. Вторым аргументом
может быть символ С, определяющий среду, в которой
первоначально стартовали С-программы. Какая-либо
реализация может поддерживать другие величины для
строки, но точные ее формы определяются самой реа-
лизацией. Другие моменты относительно табл. 4.2 свя-
заны со следующим:
• Многие спецификаторы конвертирования тесно свя-
заны с конкретным элементом struct tm (например,
спецификатор %М выводит значение элемента
tm_min), но спецификаторы %j и %т изменяют зна-
чения от tm_yday до tm mon через 1 для более есте-
ственных диапазонов.
• Размеры поля для локально-определенных преобра-
зований не специфицированы. Это усложняет опре-
деление того, какой следует принять размер сим-
вольного массива для обеспечения записи в него
результата. Будьте щедры при назначении размера
буфера в случае использования этих спецификато-
ров и всегда проверяйте возвращаемое значение, что-
бы убедиться, что результат не выходит за пределы
буфера.
Пересмотренный язык С
Часть I
88
• Спецификаторы %U и %W дают номера недели. При
использовании %LJ первое воскресенье года опреде-
лено как первый день недели, т.е. 1; при использо-
вании %W первым днем недели будет первый поне-
дельник. Любой предшествующий ему день
рассматривается как принадлежащий нулевой неде-
ле. К сожалению, имеются различные способы ис-
пользования номеров недели, так что, если в вашем
конкретном приложении используются номера не-
дели, они могут не соответствовать тем, какие вам
нужны. Ниже мы рассмотрим другое определение
номеров недели.
В листинге 4.4 представлен пример программы, ко-
торая позволяет экспериментировать с форматами фун-
кции strftime(). Программа отыскивает переменную сре-
ды LOCALE и, найдя ее, устанавливает локальное время
в соответствии с этой спецификацией. Как же устано-
вить переменные среды, которые изменяются от систе-
мы к системе? Если у вас есть с этим затруднения, про-
грамму легко можно изменить для получения аргумента
среды из командной строки. Строгое использование
неправильных спецификаторов конвертирования (т.е.
не определенных в приведенной выше таблице) приво-
дит к ошибке, следствием которой может быть даже
аварийный отказ программы. Так что лучше не разре-
шать пользователю самостоятельно специфицировать
строки формата наподобие этого в реальных програм-
мах. Массив timestr в этой программе умышленно сде-
лан маленьким, чтобы вы могли увидеть эффекты, свя-
занные с формированием слишком длинной строки.
Считывание даты и времени и
манипулирование ими
Функция mktime() является, по существу, противопо-
ложностью функции localtime(). Она принимает запол-
ненный struct tm и конвертирует его в значение time_t.
Кроме того, она модифицирует элементы struct tm так,
что они оказываются в нужных диапазонах. Объявление
для функции mkthne() выглядит следующим образом:
time_t mktime(struct tm *timeptr) ;
Листинг 4,4, Экспериментирование со строками формата с помощью функции strftimeQ,
Iinclude <stdio.h>
linclude <stdlib.h>
Iinclude <locale.h>
linclude <time.h>
int main(void)
{
time_t timeval;
struct tm «tmptr;
char «localename, «category;
char format [100);
char timestr[ 30 ];
if ((localename - getenv("LOCALE")) 1= NULL) {
if ((category = setlocale(LC_TIME, localename)) == NULL)
printf ("Предупрехдение - сбой при изменении локализации\п");
else
printf("Локализация изменена на %s (%s)\n"f localename, category);
}
for (;;) {
printf("Введите строку формата strftime() или q для внхода\п");
fflush(stdout);
if (fgets(format, sizeof format, stdin) a= NULL)
break;
if (format[0] ee 'qf ББ format[l] == f\nf)
break;
timeval = time(NULL);
tmptr = localtime (& timeval);
if (strftime(timestr, sizeof timestr, format, tmptr) === 0)
printf("Массив timestr недостаточно великХп");
else
}
return 0;
printf("%s", timestr);
Работа с датами
Глава 4
Эта функция принимает указатель на объект struct
tm, который она может и считывать, и модифицировать,
и возвращает значение time t. Значение (time t)-l воз-
вращается в случае, если время в struct tm не может быть
представлено как значение time t. Все элементы, пере-
численные в табл. 4.1, используются как входные, ис-
ключая tm wday и tm_yday, которые являются просто
установками, основывающимися на значениях в других
элементах. Объект struct tm взят для представления ло-
кального времени; здесь функции mktimeO и gmtime()
не эквивалентны друг другу.
Функция mktimeO служит двум главным целям: по-
могает осуществлять ввод и кодирование дат и выпол-
нять арифметические вычисления даты. Здесь нет стан-
дарта, эквивалентного функции strftime() для чтения дат
(некоторые компиляторы поддерживают функцию
strptimeO, но это не стандарт С). Однако функции
*scanf() (т.е. scanf(), fscanf(), sscanf() плюс другие в
С99) обеспечивают разумный способ для чтения строк
даты, особенно закодированных числами. В листинге 4.5
приведен пример использования этого способа. Про-
грамма считывает строки дат из входной строки пользо-
вателя и показывает, как они интерпретируются путем
переделки строки дат с помощью функции asctime().
Элементы tm_year и tm_mon скорректированы, как
прежде отмечено, и элементу tm isdst присваивается
значение -1, указывающее, что неизвестно, учитывает-
ся или нет эффект летнего времени.
Функцию mktimeO можно использовать также для
арифметических вычислений даты. Например, если вы
запустите на выполнение код из листинга 4.5 с датой
2000/01/33 12:00:00, которая по существу соответству-
ет второму дню после 31 января 2000 г., программа
выведет следующее:
Wed Feb 02 12:00:00 2000
т.е. 12 ч 0 м 0 с, среда, 2 февраля 2000 г. Если же вы
зададите 2000/03/01 -1:00:00, то программа выведет:
Tue Feb 29 23:00:00
Листинг 4.5. Считывание строк дат.
linclude <stdio.h>
linclude <time.h>
int main(void)
{
time_t timeval;
struct tm tmval;
char inbuff[30];
for (;;) {
printf("\\пВведнте дату к время в формате ГГГ/ММ/ДД ЧЧгММхССХр");
printf("or q to quit\n");
fflush(stdout);
if (fgets(inbuff, sizeof inbuff, stdin) == .NULL)
break;
if (inbuff[0] == 'q* inbufffl] a= f\nr)
break;
if (sscanf(inbuff, "%d/ld/ld ld:%d:%d",
&tmval•tm_year, &tmval.tm_mon, Бtmval.tmjmday,
&tmval.tmhour, & tmval. tmjmin, &tmval.tm_sec) != 6) {
printf (11 Invalid date format\n");
continue;
}
tmval. tmjyear 1900;
tmval.tm_mon—;
tmval. tm_isdst = -1;
if ((timeval » mktime(&tmval)) =a (time t)-l) {
printf("Переменная timet не может представить эту дату н время\п");
continue;
}
printf("Введеннве вами дата и время являются %s", asctime(ttmval));
}
return 0;
90
Пересмотренный язык С
Часть I
т.е. 23 ч 0 м 0 с, вторник, 29 февраля 2000 г., что озна-
чает один час до начала марта 2000 г. В основном вы
можете корректировать элементы struct tm с помощью
конкретных временных интервалов, а затем вызвать
mktimeO для корректировки элементов обратно в их
корректные диапазоны. Убедитесь также, что измени-
ли летнее время (т.е. передвинули стрелки часов на один
час вперед или назад); некоторые дни будут содержать
23 или 25 часов. Если вы выполняете вычисление дня,
установите время полудня, чтобы избежать любых про-
блем, связанных с возможным переходом часа на пре-
дыдущий или последующий день.
Определение времени выполнения
программ
Последней функцией в библиотеке <time.h> является
функция clock(). В отличие от других функций, она не
имеет отношения к датам, но я упоминаю о ней здесь
для полноты общей картины. Функция clock() не опре-
деляет время "от и до"; она, скорее, предназначена для
определения времени работы CPU. Эта функция объяв-
ляется как
clock_t clock (void) ;
Заголовок <time.h> дополнительно определяет тип
clock_t и макрос CLOCKSPERSEC Функция clock()
возвращает величины, измеряющие время в единицах
(1/ CLOCKS_PER_SEC) секунд. Другими словами, для
конвертирования интервала между двумя вызовами фун-
кции clock() в секунды вам нужно разделить разницу на
CLOCKS-PER SEC Функция clock() очень полезна
для определения времени работы CPU при выполнении
той или иной программы. В листинге 4.6 демонстриру-
ется корректный подход к использованию функции
clock() для этой цели.
Наиболее важным моментом, на который следует
обратить внимание, является то, что единственное зна-
чение clock() не имеет смысла; только разница между
двумя значениями, выдаваемыми функцией clock()
представляет собой полезную величину. Это связано с
тем, что момент времени, соответствующий нулевому
возвращаемому значению, не определен. На некоторых
реализациях это время соответствует началу работы
программы, но вы не должны подразумевать это. Дру-
гие важные моменты в приведенной программе состоят
в следующем:
• Подобно time_t, переменная clock_t может быть лю-
бого арифметического типа, целой или с плавающей
точкой. Код, следовательно, делает различие между
этими типами и приводит CLOCKS_PER_SEC в тип
double, чтобы обеспечить известный тип для дели-
теля и результата.
• Функция clock() обычно определяет время с разреше-
нием в долях секунды, хотя С не требует какого-либо
специфического разрешения и оно может изменяться
в широких пределах от компилятора к компилятору
CLOCKS_PER_SEC не указывает доступного разре-
шения. Обычно значение CLOCKS PER SEC уста-
навливается равным 1000000 (один миллион), но
фактическое разрешение будет только 1/100 секун-
ды, так что возвращаемое функцией clock() значение
будет увеличено путем умножения на 10000.
• Переменная clock_t часто является 32-битовой це-
лой величиной с максимальным значением, равным
2147483647. Имейте ввиду, что при значении
CLOCKS PER-SEC, равном 1000000, вы имеете
только около 2147 секунд или просто чуть более 35
мин времени выполнения до переполнения значения
clock_t. Поэтому будьте внимательны при попытках
Листинг 4.6. Программа для определения времени выполнения кода.
linclude <stdio.h>
linclude <time.h>
int main(void)
{
clock_t start, end;
start = clock();
/* Код, время выполнения которого вы определяете, следует здесь *7
end = clock();
printf([dbl]Interval = %.2f seconds\n[dbl], (double)(end-start) /
(double)CLOCKSPERSEC);
return 0;
}
Работа с датами
Глава 4
вычислять время работы долго выполняющихся про-
грамм; на некоторой системе программа может ус-
пешно отработать, а на другой — нет.
Поскольку разрешение функции clock() может иметь
некоторые ограничения, часто даже ниже уровня мил-
лисекунд, она не в состоянии напрямую вычислять вре-
мя выполнения коротких программ. Одним из способов,
позволяющих обойти эту неприятность, является мно-
гократное выполнение короткого кода в цикле, опреде-
ление общего времени выполнения и времени един-
ственного прохода программы.
Ошибка тысячелетия: проблемы,
связанные с датами
Имеется много проблем, связанных с ошибкой тысяче-
летия (или коротко: Y2K — года 2000), но главная не-
приятность происходит с программами, которые мани-
пулируют или хранят даты с использованием только
двух последних цифр года. Как только год поменяется
с 1999 на 2000, двухцифровые даты будут представлять-
ся как изменяющиеся с 99 на 00 (т.е. номер года 99
уменьшится, вместо того чтобы увеличиться на 1). Это
может привести к неверным результатам программ,
вычисляющих временные интервалы или сортирующих
данные по датам, либо программы могут просто отобра-
жать неверную дату (например, добавлять префикс 19,
чтобы показать полный год 1900 вместо 2000). К счас-
тью, функции обработки дат в языке С нисколько не
страдают в связи с такого рода проблемами. Важным
моментом, который следует помнить, является то, что
элемент tm_year структуры struct tm представляет годы,
начиная с 1900, и не оперирует только двумя их после-
дними цифрами. Кроме того, при использовании фун-
кции strftime() применяйте спецификатор %Y, а не %у,
чтобы выводились все четыре цифры года.
Хотя функции стандартной библиотеки и не стра-
дают от Y2К-проблем, пользовательский код все еще
может столкнуться с ними. Сохранение дат как величин
time_t дает возможность избежать У2К-проблем, хотя
это может породить другие проблемы. Если вам нужно
обеспечить свой собственный формат даты, убедитесь,
что в него включены все цифры года. Имеются случаи,
когда вы можете "вылететь в трубу", если не сделаете
этого. Например, кредитные карточки обычно все еще
показывают двухцифровой год для даты истечения сро-
ка действия. Это работает, поскольку такие даты дей-
ствительны только на ограниченный период, близкий к
текущей дате. Если вам известен текущий год, можете
вычислить полный год как двухцифровой год, связан-
ный с использованием ограниченного диапазона. Лис-
тинг 4.7 демонстрирует такой подход.
Эта программа возвращает год, последние две циф-
ры которого такие же, как и в переменной yearZdig, но
который находится в пределах плюс или минус 50 лет
от текущего года, значение которого содержится в пе-
ременной yearnow. Методика такого рода может быть
полезной в случаях, когда ведется работа с существую-
щими данными, не содержащими информации о веке,
но может быть адаптирована и для случаев, когда вам
все известно об этих данных. Новые программы и фор-
маты данных обязательно должны включать информа-
цию о веке.
Наибольшая потенциальная проблема с функциями
обработки даты и времени языка С состоит в диапазо-
не дат, которые может представлять переменная time_t.
Язык С не специфицирует каких-либо минимальных
диапазонов; однако общее представление для time_t
специфицировано в стандарте POSIX и измеряет секун-
ды, начиная с 1 января 1970 г. Если переменная time_t
является беззнаковым целым типом, она не сможет
представлять даты до 1970 г. (и, возможно, даже если
она будет целым типом со знаком). Если переменная
time_t является 32-битовым целым типом со знаком, она
может представить до 2147483647 секунд после 1 янва-
ря 1970 г. Это означает, что с ее помощью можно об-
считывать даты лишь до 19 января 2038 г. Вас это бес-
Листинг 4.7. Определение полного года с использованием диапазона.
int resolve_year(int year2dig, int yearnow)
{
int result = yearnow - yearnow!100 + year2dig;
if (result >= yearnow) {
if (result > yearnow+50)
result -= 100;
} else {
if (result <= yearnow-50)
result += 100;
}
return result;
}
Пересмотренный язык С
Часть I
92
покоит? Вероятно, напрасно, но мы должны знать об
этом. Простое игнорирование проблемы приводит в
первую очередь к таким ошибкам, как ошибка тысяче-
летия. Коль скоро компиляторы развиваются, будет
возможность расширить диапазон изменения перемен-
ной time_t (например, сделав ее 64-битовой) до истече-
ния этой даты. Программы должны быть написаны так,
чтобы они были чувствительны к изменению time_t так
же, как и других стандартных типов. Самая большая
проблема здесь заключается в форматах сохраненных
данных. Сохранение дат в файлах просто как поля
time_t опасно, поскольку переменная time t может из-
меняться от компилятора к компилятору. Имеются раз-
личные возможности решения этой проблемы, включая
следующие:
• Сохраняйте даты как беззнаковые 32-битовые вели-
чины, представляющие секунды, начиная с 1 янва-
ря 1970 г. Это позволит работать с датами вплоть до
2106 г., и хотя нисколько не решает проблему, ос-
тается в значительной степени совместимым с суще-
ствующими 32-битовыми форматами.
• Для хранения значений секунд, начиная с 1 января
1970 г., отводите более широкое поле, например, 64-
битовое. Это дает эффективное решение проблемы,
хотя может выглядеть как расточительное отноше-
ние к полезному пространству.
• Для представления дат используйте другие форма-
ты, такие как текстовая строка. Хотя это и неэффек-
тивное пространство, наиболее общий формат
ГГГГММЧЧ потребует лишь 8 байтов. Это простое
и очевидное решение при использовании текстовых
файлов.
Полезные мелочи
В этом разделе описываются две функции, которые
могут быть полезными в операциях с датами и време-
нем: определение того, является ли год високосным, и
вычисление по стандарту ISO 8601 номеров недель.
Високосные годы
Один из простейших вопросов, связанных с датами,
состоит в выяснении того, является ли тот или иной год
високосным. В настоящее время наибольшее распрост-
ранение (и поддержку функций библиотеки <time.h>
языка С) получил Грегорианский календарь. Год явля-
ется високосным, если он делится на 4, исключая слу-
чаи, когда он делится на 100. Годы, делящиеся на 400,
однако, являются високосными. Вот и все правила (я
слышал разговоры о допустимых делителях 1000 и 4000,
но в настоящее время это неактуально). В частности, год
2000 был високосным; фактически годы между 1901 и
2099, делящиеся на 4, все являются високосными. Не-
который код может использовать эту упрощенную фор-
мулу, но полная формула не намного сложнее, поэто-
му нет смысла отказываться от ее использования.
Реализацию такой полной формулы демонстрирует фун-
кция is_leap():
int is_leap(int year)
{
return year %4 == 0 && (year % 100 1= 0
|| year % 400 == 0);
}
Стандарт ISO 8601: форматы дат и номера
недель
В различных частях мира используются различные оп-
ределения и форматы дат. Вероятно, наиболее класси-
ческий пример состоит в том, что в США основным
форматом даты является формат ММ/ДД/ГПТ, в то
время как в Великобритании — это формат ВВ/ММ/
ГГГГ. Так что 01/02/2000 в Великобритании — это 1
февраля, а в США — 2 января 2000 г. Имеется, однако,
международный стандарт, относящийся к датам и на-
зываемый ISO 8601. Этот стандарт определяет различ-
ные вещи, такие как стандартный формат даты и стан-
дартный номер недели. Хотя он не всегда подходит для
ежедневного использования, он обеспечивает основу
для переносимости форматов дат. Полный формат даты
стандарта ISO 8601 следующий:
ВВГГ-ММ-ДДТчч: мм: сс
где ВВ означает век, а Т — буквально буква "Т"; напри-
мер, 2000-02-29Т12:00:00 означает полдень 29 февраля
2000 г. Вы можете использовать упрощенные варианты,
такие как 2000-02-29. Очевидная особенность такого
формата состоит в том, что год и век расположены на
первом месте, и четыре цифры года делают этот фор-
мат однозначным с форматами и США, и Великобри-
тании. Это также означает (случайно), что можно про-
водить корректную сортировку дат путем обычного
сравнения строк.
Как вы помните, для вычисления номеров недель
функция strftime() имеет спецификаторы %U и %W.
Однако стандарт ISO 8601 имеет свое собственное оп-
ределение номера недели, который должен одинаково
использоваться в любой части света. В листинге 4.8
показана функция, вычисляющая недели в рассматри-
ваемом стандарте ISO 8601, а также поясняются исполь-
зуемые при этом правила.
Работа с датами
Глава 4
Листинг 4.8. Вычисление номеров недель по стандарту ISO 8601.
/****************************************************************************
* Программа weeknum_ISO8601.c Декабрь, 1999 г. Л .Кирби
*
* Вычисления номера недели в году на основе схемы стандарта ISO 8601.
* Аргументами являются следующие величины:
*
* t - указатель на структуру struct tm, в которой следующие величины должны быть
• установлены и нормализованы к специфицированным стандартным диапазонам
* (как это сделали бы стандартные библиотечные функции dmtime, localtime и mktime):
* tm_wday - день недели: 0 - воскресенье -> 6 - суббота
*
* tmyday - день года: 0 (1 января) -> 365
♦
* tm_year - год, начиная с 1900 г.
♦
* firstDOW - определяет день недели, с которой начинается неделя:
* 0 - воскресенье -> 6 - суббота. Ведели по стандарту ISO 8601
* начинаются с понедельника; в этом случае значение рассматриваемой
* переменной должно быть равным 1.
•
*******************************************************************
* Номер недели - это число между 1 и 53, включающее определение в соответствии
• со следующими правилами:
•
* 1. Подразумевается Грегорианский календарь.
• 2. Всегда имеется 7 последовательных дней с некоторым номером недели.
*
♦ 3. 4 января определяется как принадлежащее неделе 1. Аналогично неделя 1
* является первой неделей года, которая содержит, по крайней мере, 4 дня в данном году.
*
• 4. firstDOW определяет день недели, который начинает новую неделю,
• т.е. имеет отличный от предыдущего дня номер недели.
*
* 5. Номера недель увеличиваются последовательно от недели 1 до тех пор,
* пока неделя, которая определяется, не станет первой неделей следующего года.
*
♦ Это означает, что:
*
* 6. Даты до 3 января могут быть либо в неделе 1 текущего года, либо
* в неделе 52 или 53 предыдущего года.
*
* 7. Даты после 29 декабря могут быть либо в неделе 52 или 53 текущего года,
* либо в неделе 1 следующего года.
*
* XPG4 специфицирует немного отлично от правил ISO, которые выполняются,
• если определен макрос XPG4WEEKNUMS.
•
**************************************************************
*/
linclude <time.h>
Idefine isleap(year) (!((year) % 4) && (((year) % 100) || !((year) % 400)))
int veeknum_IS08601(const struct tm *t, int firstDOW)
{
const int tmpl «= firstDOW - t->tm_wday;
const int tmp2 = t->tm_yday + ((tmpl > 0) ? 3 : 10) + tmpl;
const int fourthdaynum = tmp2 % 7;
int weeknum = tmp2 / 7;
94
Пересмотренный язык С
Часть I
if (weeknum «= 0) {
lifdef XPG4WEEKNUMS
weeknum = 53;
lelse
const int yearnum = t->tm_year + (1900 % 400)-l;
weeknum = (fourthdaynum + is_leap(yearnum) >= 6) ? 53 : 52;
lendif
} else if (weeknum »= 53) {
const int yearnum = t->tm_year 4- (1900 % 400);
if (fourthdaynum > isleap(yearnum))
weeknum « 1;
}
return weeknum;
Резюме
В этой главе мы рассмотрели стандартные функции
языка С для работы с датами и временем, а также фун-
кцию clock(). Мы выяснили, как использовать их для
ввода, вывода и манипулирования датами и временем,
и выявили общие ловушки (особенно ошибку тысяче-
летия), включая проблемы, связанные с сохранением
дат и времени. Наконец, мы научились вычислять ви-
сокосные годы и коротко рассмотрели стандарт ISO
8601, особенно в связи с вычислением номеров недель.
Во всем этом нет ничего особенно сложного, но, я
надеюсь, вы теперь имеете более полное представление
о том, на что способны программы обработки дат и
времени в С, и знаете как избежать ловушек, которые
могли быть расставлены другими программистами в
прошлом.
Игры с битами и байтами
В ЭТОЙ ГЛАВЕ
Представление величин в С
Представление целых величин
Использование величин без знака в битовых операциях
Битовый сдвиг
Другие битовые операторы
Битовые массивы (битовые карты)
Подсчет битов
Зеркальное отражение битов
Битовые поля
Переносимость программ
Лоуренс Кирби
Эта глава посвящена правилам работы с битами и бай-
тами в языке С. В ней будут рассмотрены некоторые
полезные приемы с использованием битовых и байто-
вых операций, а также приведены характерные приме-
ры программ.
Рассмотрим сначала табл. 1, в которой приведены
операторы языка С для работы с битами.
Таблица 5.1, Битовые операторы С,
Оператор Описание
& Битовое И
| Битовое ИЛИ
Битовое исключающее ИЛИ
* Битовое дополнение
« Битовый сдвиг влево
» Битовый сдвиг вправо
За исключением операции дополнения все при-
веденные выше операции — бинарные, т.е. они исполь-
зуют два исходных операнда и имеют соответствующую
форму оператора присваивания. Например, выражение
а &= b эквивалентно а = а & Ь, кроме случая, когда а
вычисляется один раз.
Представление величин в С
Язык С создан для работы на двоичных (или бинарных)
компьютерах, и различные двоичные свойства проявля-
ются в нем повсюду. В частности, целочисленные типы
данных имеют сильный двоичный привкус. Возможно,
наиболее ярким проявлением этого факта являются те
максимальные и минимальные значения, которые мо-
гут принимать целочисленные величины. Действитель-
ные значение зависят от типа компьютера, но типичны-
ми максимальными значениями для типов со знаком
являются 127, 32767 и 2147483647, а для типов без знака —
255, 65535 и 4294967295. В десятичной системе счис-
ления подобные числа выглядят странно, однако это
различные степени двойки минус один. Написание та-
ких чисел в восьмеричной системе делает этот факт более
прозрачным: 0+7f, 0+7АТ, 0+7ЯПГ для величин со знаком
и 0+ff, 0+ffff, O+fttttftt — для величин без знака.
Целочисленные величины (как и величины любого
другого типа) хранятся в памяти как набор битов. Об-
щее число различных величин, которое можно предста-
вить в данном типе, ограничено содержащимся в этом
типе числом битов. Для N битов максимальным явля-
ется 2AN (2 в степени N) различных состояний. Таким
образом, один бит может представлять два состояния,
два бита могут представить четыре состояния, три бита —
соответственно восемь состояний и т.д. Для целочислен-
ных типов без знака все состояния используются для
представления положительных величин или нуля. Для
целочисленных величин со знаком число состояний
нужно разделить между положительными и отрицатель-
ными величинами. Обычно максимальное значение для
типа со знаком составляет половину максимального
значения для типа без знака.
Биты группируются в байты. Именно байты явля-
ются самыми маленькими частичками памяти, которые
можно использовать для создания объектов. Это также
и самые маленькие области памяти, к которым возмож-
на обычная адресация, исключая битовые поля, кото-
рые будут рассмотрены далее в этой главе. Байт состо-
ит из фиксированного числа битов, обычно из восьми.
Пересмотренный язык С
Часть I
96
В любой реализации языка С гарантировано наличие
хотя бы восьми битов в байте (это число может быть и
больше). Реальное число, используемое в данной реали-
зации, определяется макросом CHAR_BIT в заголовке
<limits.h>. В языке С байт — это также единица памя-
ти, отведенная для типа char.
Понятие байта широко распространено в вычисли-
тельной технике и используется как для определения
размеров памяти и дисков системы, так и для опреде-
ления скорости обмена информацией в запоминающих
и коммуникационных устройствах. Определение байта
в С не зависит от вышеупомянутых применений этого
слова, хотя обычно они соответствуют друг другу. Ког-
да в этой главе я использую термин байт, то всегда под-
разумеваю принятое в С определение. Другими слова-
ми, размер char, CHAR BIT битов, является также
самой маленькая определенной языком С единицей
адресуемости и размещения (выделения места).
Представление целых величин
Битовые операторы С & | Л ~ « и >>, а также их ва-
рианты в соединении с присваиванием &= |= Л= «—
и »= работают с исходными операндами целого типа
и дают целый результат. Поскольку данные операторы
манипулируют битами только целых величин, рассмот-
рим, каким образом представляются эти величины.
Целые величины без знака наиболее просты, они
представляются в простом двоичном формате, где каж-
дая позиция соответствует степени двойки (1, 2,4, 8 ...),
эти степени являются их весовыми коэффициентами.
Сложив весовые коэффициенты всех единичных битов,
получим значение представляемой величины.
Для целых величин со знаком все обстоит сложнее,
поскольку существует несколько способов представле-
ния отрицательных чисел. Форматы, допустимые в С,
называются "дополнение до единицы", "дополнение до
двух" и "знак-величина" (или величина со знаком, или
похожие варианты). Все эти форматы используют один
бит для определения "знака" величины, причем 0 соот-
ветствует плюсу, а 1 — минусу. Положительные числа
представляются таким же образом, как и целые величи-
ны без знака. Для отрицательных чисел эти три форма-
та предполагают различные подходы.
• Формат "знак-величина" наиболее близок к нормаль-
ному десятичному написанию чисел. Представление
отрицательного числа отличается от представления
соответствующего положительного простым прибав-
лением знакового бита.
• В формате "дополнение до единицы" отрицательные
числа получаются путем инвертирования каждого
бита соответствующего положительного числа.
• В формате "дополнение до двух", чтобы получить
отрицательное число, нужно инвертировать все биты
соответствующего положительного числа и затем
прибавить 1.
В табл. 5.2 приведены примеры представления отри-
цательных величин тремя рассмотренными способами.
Во всех примерах использован 8-битовый формат. Стар-
ший бит всегда соответствует знаковому биту, а осталь-
ные семь определяют величину.
Сделаем несколько замечаний к табл. 5.2:
• Все форматы используют одно и то же представле-
ние для положительных чисел, которое совпадает с
соответствующим представлением числа в формате
без знака.
• В форматах "знак-величина" и "дополнение до еди-
ницы" величины -0 и +0 представляются различным
образом. Для целочисленных операций это обычно
не важно, но для битовых операций, которые будут
рассмотрены дальше, имеет большое значение.
Таблица 5,2. Представление отрицательных величин в форматах целых со знаком.
Десятичная величина "Знак-величина " Дополнение до единицы” Дополнение до двух”
0 00000000 00000000 XKJU00U0
0 юоссюоо 11111111 (0АПП0О0О)
1 00009001 ХКХЮ001 00000001
-1 10000001 11111110 11111111
16 00010000 00010000 00010000
-16 10010000 11101111 11110000
127 01111111 • 01111111 01111111
-127 11111111 1COOOCOJ 10000001
128 - -
-128 - 10000000
Игры с битами и байтами
\h
Глава 5
• Формат "дополнение до двух" представляет 0 един-
ственным образом, но может представить и допол-
нительное отрицательное число (это -128 в 8-бито-
вом формате, хотя число 128 в этом формате
представить нельзя).
Из всех трех рассмотренных выше целочисленных
форматов со знаком формат "дополнение до двух" ис-
пользуется значительно чаще. Тем не менее, хорошо
хотя бы знать о существовании остальных. Фраза "об-
ратить все биты и добавить 1" звучит странно, но эта
процедура имеет некоторые приятные особенности с
точки зрения различных реализаций и использования.
Кроме случаев переполнения и переноса разряда, аппа-
ратные операции, требуемые для реализации арифме-
тики в представлении "дополнение до двух", удовлет-
воряют требованиям для реализации арифметики без
знака, когда результат представляется в форме, не пре-
вышающей по длине исходную величину. В табл. 5.3
представлены примеры сложения комбинаций битов и
соответствующие им величины, интерпретируемые в
форматах без знака и "дополнение до двух".
Как видим, одна и та же битовая комбинация может
соответствовать различным величинам, даже когда це-
лые числа представляются в одной и той же програм-
ме. В языке С тип переменной является дополнитель-
ной информацией, позволяющей полностью определить,
какую именно величину представляет та или иная ком-
бинация битов. Последний пример в таблице содержит
результат, который нельзя представить в формате без
знака. 201+211 равно 412, но девятый бит теряется, что
уменьшает результат на 256 и дает в итоге 156.
Представления целых чисел в С могут иметь "дыры",
т.е. неиспользованные биты, которые не дают вклада в
целую величину. Единственным исключением являет-
ся char без знака, в котором все биты гарантированно
участвуют в представлении числа. Сказанное выше оз-
начает, что, если длина int составляет 32 бита, это еще
не гарантирует возможность представления величин
вплоть до 2147483647. Чтобы найти реальный диапазон,
который может представлять целый тип, следует рас-
смотреть макросы *_MIN и *_МАХ, определенные в
стандартном заголовке <limits.h>_ В частности, макрос
INT—МАХ определяет наибольшую величину, представ-
ляемую типом int на конкретном компьютере.
Использование величин без знака в
битовых операциях
В предыдущем разделе было показано, что целые вели-
чины со знаком могут быть представлены в различных
форматах, обладающих различными свойствами. Чтобы
избежать возможных вызванных этим проблем, для
выполнения целочисленных операций обычно лучше
всего использовать величины без знака.
• Существование двух различных представлений 0 в
форматах "знак-величина" и "дополнение до едини-
цы" может быть источником проблем, поскольку
большинство операций в С производится в терминах
величин операндов. Имея два представления 0, ком-
пилятор может запросто конвертировать их один в
другой как угодно, что действительно очень плохо,
особенно если важное значение имеет отдельный
бит.
• Поскольку существуют различные способы представ-
ления отрицательных чисел, один и тот же набор
битов на различных системах может соответствовать
различным величинам, и при изменении отдельно-
го бита будет различным образом изменяться вели-
чина. Например, в отрицательном числе изменение
любого бита, кроме знакового, с 0 на 1 может как
' увеличить, так и уменьшить величину числа (в этом
состоит отличие формата "знак-величина" от дру-
гих). Некоторые битовые приемы, как будет пока-
зано дальше, просто не работают при определенных
представлениях величин со знаком.
Таблица 5.3. Примеры 8-битового сложения в форматах без знака и "дополнение до двух”.
Бинарное представление Величина в формате без знака Величина в формате “дополнение до двух”
00001001 9 9
+00010011 19 19
=00011100 28 28
10001001 137 -119
+00010011 19 19
=10011100 156 -100
11001001 201 -55
+11010011 211 -45
=10011100 156 -100
7 Зис.265
98
Пересмотренный язык С
Часть I
• Результат изменения именно знакового бита суще-
ственно отличается в различных представлениях —
как пример можно рассмотреть битовые комбинации
01111111 и 11111111 в табл. 5.2.
Одним словом, если в битовых операциях появля-
ются отрицательные числа, появляются и проблемы.
Конечно, можно использовать целочисленные типы со
знаком и ограничиться положительными входными и
результирующими величинами. Однако всегда безопас-
нее придерживаться типов без знака. Одно предупреж-
дение: величины типов char и short преобразуются, по
крайней мере, в int перед любыми операциями с ними.
Это значит, что, даже если операция начиналась с ти-
пом без знака, вроде unsigned char или unsigned short,
закончиться она может величинами типа int (т.е. вели-
чинами со знаком). В частности, если в операциях сдвига
изменения данных заденут знаковый бит, это может
привести к неожиданным результатам.
Битовый сдвиг
Битовый сдвиг является, возможно, одной из простей-
ших операций, осуществляемых компьютером. Ее суть
состоит в перемещении информации из каждого бита
величины в другой бит. И это позволяет выполнять
столь мощные операции, как умножение и деление.
В десятичной системе можно умножить число на 10,
добавив справа 0 или (в более общем случае) сдвинув
десятичную точку на одну позицию вправо. Можно
посмотреть на это иначе: десятичная точка остается на
месте, а все цифры числя сдвигаются влево на одну
позицию, и справа при необходимости добавляется
нуль. Таким образом, в результате сдвига влево на одну
позицию величина увеличивается в 10 раз. Эту опера-
цию можно повторить, тогда сдвиг влево на две пози-
ции приведет к умножению числа на 100, на три пози-
ции — на 1000 и т.д. В двоичной системе при сдвиге на
одну позицию число умножается на 2, а не на 10, и в
качестве множителей выступают степени двойки (2, 4,
8, 16 и т.д.).
При сдвиге влево величины без знака первый бит
рано или поздно выйдет за левый край. Такие биты от-
брасываются, и результирующая величина соответствует
уже не простому результату умножения, а ''урезанной"
версии .результата.
При сдвиге влево величин со знаком возникает до-
полнительная проблема — либо исходная величина,
либо результирующая, либо они обе могут стать отри-
цательными, поскольку сдвиг битов происходит с уча-
стием знакового бита. Ранее была показана опасность
использования битовых наборов, которые представля-
ют отрицательные величины. К сожалению, это значит,
что способ сдвига влево целого числа для умножения его
на степень двойки не всегда применим к отрицательным
числам, хотя этот способ осуществим для представле-
ний ’’дополнение до двух”.
Подобно тому, как операцию сдвига влево можно
использовать для умножения на степени 2, операцию
сдвига вправо можно использовать для деления на сте-
пени 2. Сдвигаемые за правый край биты теряются, что
соответствует отбрасыванию остатка от деления. Как и
ранее, все проходит гладко с положительными величи-
нами, чего нельзя, к сожалению, сказать об отрицатель-
ных. В дополнение ко всем проблемам представления
величин сдвиг вправо создает новую проблему: что под-
ставлять с левого края? В случае положительных чисел
ответ прост: приписываем нули, и это дает ожидаемый
результат. В случае отрицательных чисел все не так
просто. Для представлений "дополнение до единицы” и
’’дополнение до двух” компилятор может сохранить
правильность деления при добавлении слева 1. При де-
лении с остатком это вызывает округление в меньшую
сторону (к нулю) для представления ’’дополнение до
единицы” и в большую сторону (к минус бесконечнос-
ти) — для представления “дополнение до двух”. С не
определяет, к какому результату приведет сдвиг вправо
отрицательного числа; это зависит от реализации, т.е.
компилятор сам решает, 1 или 0 будут подставлены
слева. Это резко ограничивает возможность применения
операций сдвига для целых величин со знаком.
Следует заметить, что, если вы можете реализовать
умножение или деление на 2, используя способы сдви-
га, ваш компилятор тоже может это сделать. Большин-
ство компиляторов обладает достаточными средствами
оптимизации, чтобы заменить умножение на 8 сдвигом
влево на 3 позиции, если это более эффективно. Луч-
ший стиль программирования достигается ясностью:
следует выполнять умножение, когда нужно умножить,
и сдвиг — когда нужно сдвинуть биты. Тем не менее,
полезно знать, что операции умножения и деления на
одни константы могут быть более эффективными, чем
на другие. В случае умножения это даже не обязатель-
но должны быть степенями 2. Например, в выражении
х + (X « 3)
величина X умножается на 9 (поскольку 9*Х может быть
представлено как Х+8*Х). Как мы уже отмечали, боль-
шинство компиляторов могут провести подобную опти-
мизацию автоматически.
Другие битовые операторы
Практически все операции в двоичном компьютере про-
изводятся с битами. В таких процедурах, как умноже-
ние и деление, участвуют сложные процедуры. Однако
сложение и вычитание целых чисел относительно про-
сты, и на элементарном уровне это происходит так: на
Игры с битами и байтами
Глава 5
99
вход поступает некоторая совокупность битов, и на
выходе также получается совокупность битов. Есте-
ственно, они рассматриваются в понятиях величин (на-
пример (см. табл. 5.3), выражение 9+19 должно давать
в результате число 28, каким бы битовым набором это
число ни было представлено). В частности, для опера-
ций с целыми величинами без знака можно точно оп-
ределить, какие битовые операции необходимо выпол-
нить, чтобы получить правильный результат.
Рассмотрим для этого три простых случая:
• Добавление 1 (инкремент)
• Вычитание I (декремент)
• Инвертирование величины (перемена знака)
При добавлении 1 к двоичной величине изменения
начинаются с младшего бита. Если его значение было
О, оно изменяется на 1 и процесс прекращается. Если
первоначальное значение было 1, то оно изменяется на
О, и затем изменения переходят на следующий бит бо-
лее высокого порядка, т.е. осуществляется, по сути,
перенос. Этот процесс повторяется поочередно для каж-
дого бита, пока не остановится на нулевом бите или
пока не закончатся все биты. Например:
01001111
+ 1
01010000
В общем случае это выглядит так: последователь-
ность единиц, начинающаяся с бита низшего порядка,
превращается в последовательность нулей, а первый
встретившийся нуль превращается в единицу. Если ком-
бинация состоит из единиц (11111111), в результате
всегда получаются нули: 00000000.
Вычитание 1 из двоичной величины происходит
подобным же образом. Различие состоит только в том,
что процесс прекращается по достижении бита 1, а не
бита 0. При вычитании I из бита 0 происходит так
называемый заем бита из старшего разряда вместо пе-
реноса при прибавлении 1 к биту 1. Например:
...10110000
1
10101111
Таким образом, эффект уменьшения состоит в том,
что последовательность 0, начинающаяся с младшего
бита, превращается в последовательность 1, и первая
встретившаяся единица превращается в нуль. Если ком-
бинация состоит только из нулей (00000000), они все
превращаются в единицы: 11111111.
Инвертирование (т.е. изменение знака) величины
без знака звучит несуразно, но оказывается это точно
определенная операция. -X можно рассматривать как
сокращение 0-Х. В языке С существует правило, что
если результат операции с величинами без знака выхо-
дит за пределы, допустимые для типа без знака, то ре-
зультат уменьшается по модулю на МАХ+1, где МАХ —
это максимальное значение, которое может быть пред-
ставлено в этом типе. "Уменьшить по модулю" — зна-
чит, прибавить или отнять МАХ+1 столько раз, сколь-
ко необходимо, чтобы вернуть величину в допустимые
пределы. Если опять посмотреть на табл. 5.3, можно уви-
деть, что это произошло с результатом выражения
201+211. Поскольку результат (412) превосходил МАХ
(255), была вычтена величина МАХ+1 (256) и получен-
ный результат (156) оказался в допустимом диапазоне.
В табл. 5.4 приведено еще несколько подобных приме-
ров.
Таблица 5.4. Уменьшение по модулю величин
без знака.
Исходная величина Результат
0 0
255 255
256 0 (256-256)
257 1 (257 — 256)
512 0 (512 — 256 — 256)
-1 255 (-1 + 256)
-255 1 (-255 + 256)
-256 0 (-256 + 256)
Инвертируя величину, мы начинаем преобразования
с величины, находящейся в допустимых пределах (в дан-
ном случае от 0 до 255), и, инвертируя ее, получаем
результат в диапазоне от 0 до -255. Величины от -1 до -
255 находятся вне допустимых пределов для типа без
знака, поэтому полученная величина приводится к до-
пустимому диапазону путем добавления МАХ+1 (256 в
нашем случае). Заканчиваются преобразования величи-
ной -Х+256, или, в другой записи, 256-Х. В общем слу-
чае выражение -X может быть представлено как
МАХ+1-X, что верно и для 0, поскольку результат
МАХ+1 также превращается в 0. Можно переписать
выражение МАХ+1-Х как (МАХ-Х) + 1. Это важно,
поскольку МАХ является максимальной величиной,
которую можно представить переменной без знака (это
набор битов, состоящий из одних единиц). Вычитание
другой величины без знака из этой не может вызвать
никакого "заема". В результате все биты исходного числа
будут инвертированы, например:
.. .шиш
- 10010110
01101001
Пересмотренный язык С
100
Часть I
Одним словом, выражение МАХ-Х — это другой спо-
соб записи операции -X, а -X (описываемое выражение
(МАХ-Х)+1) эквивалентно (~Х)+1. Этот результат
нельзя назвать неожиданным, поскольку таким образом
определяется инвертирование в представлении ’’допол-
нение до двух". А мы уже знаем, что битовые действия
при арифметических операциях величин без знака и в
представлении "дополнение до двух" соответствуют друг
другу. В общем случае инвертирование величины без
знака на битовом уровне заключается в инвертировании
всех битов более высокого порядка, чем младший бит 1
числа. Это яснее видно на следующем примере:
х юоюооо
-х 01101111
(~Х) + 1 ошоооо
Обратите внимание на позицию, которую занимает
младший единичный бит в исходной величине X. В
результирующей величине этот бит сохраняет значение
1, все биты справа от него остаются нулями, а все биты
слева инвертируются.
Выше рассмотрены определения на битовом уровне
операций инкремента, декремента и инвертирования для
целых величин без знака. Во всех случаях ключевой
является позиция младшего бита 1 (или, в случае инк-
ремента, бита 0). Следующий наш шаг приведет к ре-
зультатам, которые будут использованы далее в этой
главе.
Рассмотрим выражение Х&-Х. Например:
х юоюооо
-X 01110000
X & “X 00010000
В результате все биты, кроме младшего бита 1, очи-
щаются. Теперь рассмотрим выражение X & (Х-1):
х юоюооо
х-1 10001111
X & (Х-1) 10000000
В результате младший бит 1 обнуляется. В табл. 5.5
представлены некоторые другие возможные комбина-
ции арифметических и битовых операторов. Наиболее
полезными являются два первых.
Таблица 5.5. Выражения для преобразований
установить/очистить с участием младшего
бита.
Выражение Результат
X & (Х-1) Младший бит 1 в X становится нулем
X & -X Все биты, кроме младшего бита 1 в X.
становятся нулями
X | (Х+1) Младший бит 0 в X становится единицей
X | ( -Х-1) Все биты, кроме младшего бита 0 в X,
становятся единицами
Ну достаточно теории; рассмотрим теперь некото-
рые примеры практического применения битовых и
байтовых операций, а приведенные выше выражения
мы используем позже.
Битовые массивы (битовые карты)
В языке С не существует никакого встроенного меха-
низма доступа к отдельным битам, которые собраны в
массив. Однако, используя битовые операции С, мож-
но с помощью нескольких простых макросов имитиро-
вать битовые массивы. Чтобы эмулировать битовый
массив, необходимо следующее:
• Структура данных, в которой может храниться би-
товый массив.
• Возможность создавать и уничтожать объекты с би-
товыми полями. Это может быть сделано либо пу-
тем прямого объявления их, либо путем создания их
динамически и использованием malloc и подобных
функций.
• Возможность привести битовый массив в определен-
ное состояние, например, очистить все биты.
• Существование способов присвоения значения (1
или 0), очистки и проверки содержимого определен-
ного бита.
В этом разделе будет показано, каким образом мож-
но удовлетворить этим требованиям, используя набор
макроопределений и определений типа. Используя фун-
кции, можно осуществить также более сложные бито-
вые операции. Следующие определения содержатся на
прилагаемом к книге CD в заголовочном файле
bitarray.h. Сначала нам потребуется структура данных,
и с этой целью используем массив целых величин без
знака для хранения битов. Известно, что целые величи-
ны без знака наиболее удобны для битовых операций,
но в пределах этого типа можно выбирать от unsigned
char до unsigned long (в языке С99 существуют и другие
варианты). Прекрасно, что нет необходимости привя-
зывать программу к одному определенному типу. Мож-
но выбрать один тип с помощью typedef, и, если по-
зднее потребуется использовать другой, можно тут же
изменить typedef, например:
typedef unsigned char BARR_ELTYPE;
Здесь выбран тип unsigned char, поскольку он явля-
ется самым простым и гарантирует использование всех
битов в каждом байте. Заметим, что это определение,
как и все последующие, имеет имя, начинающееся с
BARR_. Это позволяет легко отличать их как относя-
щиеся к операциям с битовыми массивами.
Вообще, битовый массив может потребовать больше
места в памяти, чем может предоставить одно целое
Игры с битами и байтами
Глава 5
j 101
число, поэтому общая структура данных для хранения
битового массива — это массив элементов
BARRJELTYPE. Далее мы можем определить некото-
рые полезные относящиеся к массиву величины, кото-
рые могут использоваться другими макросами, напри-
мер:
«define BARR_ELBITS (CHAR_BIT *
sizeof (BARR_ELTYPE) )
Здесь BARRELBITS определяет число битов в эле-
менте массива, т.е. число битов в объекте BARRJELTYPE
Его можно определить, умножив размер в байтах на
число битов в одном байте (CHAR_BIT, которое опре-
делено в стандартном заголовке <limits.h>). Строго го-
воря, необходимо знать число битов в типе, которые
используются для хранения величины. Поскольку все
типы, кроме unsigned char, могут содержать неисполь-
зованные биты, полученное число битов может быть
завышенным. Тем не менее, можно просто установить,
что BARR ELTYPE определяется как тип, в котором
нет неиспользованных битов, пренебрегая тем, что толь-
ко тип unsigned char обладает этим свойством:
«define BARR_ARRAYSIZE (N) ((N) +
*-»BARR_ELBITS -1) /BARR_ELBITS)
Значением BARR ARRAYSIZE (N) является коли-
чество элементов BARRJELTYPE в массиве, необходи-
мое для записи N битов информации. Оно вычисляет-
ся как результат N/BARR_ELBITS, округленный в
большую сторону, так что любой остаток от этого де-
ления продолжает оставаться в массиве. Простой спо-
соб округления в большую сторону любого целочислен-
ного выражения A/В заключается в написании (А+В-1)/В.
Этим приемом можно пользоваться, если все величины
неотрицательны и операция А+В не приводит к пере-
полнению.
Первым шагом на пути к использованию в програм-
ме битового массива является его создание. Простейший
способ — это определить в программе массив как пере-
менную. Например, для создания массива размером
SIZE битов достаточно написать:
BARRJELTYPE bitarray [BARR_ARRAYSIZE (SIZE) ] ;
Здесь BARR_ARRAYSIZE(SIZE) — это константное
выражение такой же длины, как и SIZE, которое мож-
но использовать для определения размера в объявлении
массива. Как и в случае со структурой данных любого
другого типа, может возникнуть желание создать бито-
вый массив динамически. Это можно сделать путем
вызова функции malioc. Всяческие детали этого процес-
са можно спрятать в макросе:
«define BARRJMALLOC (N) \
( (BARRJELTYPE *) malioc (BARRARRAYSIZE (N) *
wsizeof(BARR_ELTYPE)) )
Символ \ в конце первой строки — это стандартный
в языке С способ соединения строки в одну, что позво-
ляет разместить макроопределение в нескольких стро-
ках. Заметим, что объем пространства, выделяемого
mallocO, задается в байтах, поэтому нужно заказать
число элементов BARRJELTYPE в массиве, умножен-
ное на число байтов в каждом элементе BARRJELTYPE.
Нет необходимости приводить тип величин, возвраща-
емых функцией ша11ос(), и вообще, этого не стоит де-
лать, поскольку это может помешать компилятору ди-
агностировать ошибку вызова mallocO без включения
<stdlib.h>. Но в этом случае приведение типов оказы-
вается полезным, поскольку оно гарантирует, что ис-
пользующая макрос программа присвоит результат пе-
ременной подходящего типа. Вы сами можете выбирать,
использовать операцию приведения типа или нет. Что-
бы использовать этот макрос, можно написать, напри-
мер, так:
BARRJELTYPE *bitarray;
If ((bitarray = BARRMALLOC(size)) == NULL) {
/* Обрабатываем омибку выделения памяти */
}
Эта операция работает как любой обычный вызов
функции malioc; bitarray определен здесь как указатель
и возвращает значение, которое необходимо проверить
для диагностики ошибки выделения памяти. Операция
malioc требует выполнения соответствующей free-опе-
рации. Можно вызвать free непосредственно, но лучше
использовать соответствующий макрос BARR_FREE.
Это позволит создать единый интерфейс и обеспечить
гибкость в изменении внутренних деталей без необхо-
димости переписывания программы, использующей
макросы битовых массивов:
«define BARR__FREE (barr ) free (barг)
Любой битовый массив, созданный с помощью мак-
роса BARRJMALLOC, может быть уничтожен с помо-
щью макроса BARR_FREE. Чтобы можно было исполь-
зовать любой битовый массив, он должен находиться в
известном состоянии; в простейшем случае все биты
должны быть очищены. Для объявленного массива в
языке С предусмотрен простой способ в форме иници-
ализатора. Например,
BARRJELTYPE bitarray [BARR_ARRAYSIZE (SIZE) ] =
**{ О };
Эта операция приведет к инициализации массива,
содержащего нулевые биты. Если возникнет необходи-
мость очистить массив позднее или очистить массив,
созданный с помощью макроса BARJMALLOC, это
можно сделать с использованием стандартной функции
memset. Как и ранее, все подробности можно спрятать
в макроопределение:
102
Пересмотренный язык С
Часть I
fdefine BARR—CLEARARRAY(barг, N) \
memset (barr, 0, BARR_ARRAYSXZE(N) *
(EARR_ELTYPE) )
При этом требуется, чтобы вызывающая процедура
определяла размер массива в битах. Эта процедура мо-
жет очистить только весь массив целиком. Если в каче-
стве N задать число, меньшее, чем размер массива, все
равно может быть очищено больше, чем N его началь-
ных битов. Такая операция должна быть корректной, но
это уже сложнее (возможно, потребуется привлечение
некоторой функции).
Наконец, рассмотрим операции, которые и делают
битовые массивы полезными: присвоение биту значе-
ния I, его очистку (т.е. присвоение биту значения 0) и
проверку содержимого. Во-первых, определим несколь-
ко вспомогательных макросов:
idefine BARR_ELNUM(N) ( (N) / BARR—ELBITS)
Здесь BARR ELNUM определяет индекс элемента
BARR_ELTYPE, в котором содержится N-й бит.
idefine BARR_BITNUM (N) ((N) % BARR—ELBITS)
BARR_BITNUM определяет, какой бит элемента
BARR_ELTYPE содержит N-й бит. Это значение нахо-
дится в диапазоне от 0 (соответствует последнему зна-
чащему биту) до BARR_ELBITS-1.
idefine BARR—SET(barr, N) \
((barr)[BARR_ELNUM(N)] |= (RARR_ELTYPE) 1 «
^BARR—BITNUM (N) )
Макрос BARRSET устанавливает N-й бит в бито-
вом массиве barr. Единица сдвигается влево на
BARR_BITNUM(N) позиций, и проводится битовая
операция "ИЛИ” с BARR_ELNUM(N)-m элементом
битового массива, затем результат помещается в соот-
ветствующий бит. Приведение к типу (BARR-ELTYPE)
обеспечивает выполнение сдвига подходящего типа.
Например, если BARR_ELTYPE имеет тип unsigned
long, нужен сдвиг unsigned long.
idefine BARR-CLEAR (barr, N) \
( (barr) [BARR_ELNUM (N) ] &= ~ ( (BARR_ELTYPE) 1 «
' WBARR_BITNUM (N) ) )
Макрос BARR_CLEAR очищает N-й бит в битовом
массиве barr. Действие этой операции подобно дей-
ствию макроса BARR SET, за исключением того, что
очищение бита — это битовое "И" элемента
BARR_ELTYPE с инверсированной сдвинутой величи-
ной, т.е. с величиной, в которой значения всех битов,
кроме одного, который необходимо очистить, устанав-
ливаются в 1.
idefine BARRJTEST (barr, N) \
((barr)[BARR—ELNUM(N) ] & ( (BARR—ELTYPE) 1 «
*"»BARR_BITNUM (N) ) )
BARR TEST проверяет, установлен ли N-й бит в
barr. Если значение бита 1, он возвращает ненулевое
значение, в противном случае — нуль. Операция дей-
ствует подобно макросу BARR_SET, за исключением
того, что производится операция битового "И” массива
данных с маской, в которой, кроме проверяемого, все
остальные биты очищены. Битовый массив при этом не
изменяется, а полученный результат может быть ис-
пользован программой.
Результат не обязательно равен 1, если значение бита
1; это может быть любая ненулевая величина. Можно
написать макрос так, чтобы возвращалась именно еди-
ница, но это может снизить эффективность (которая и
является одной из основных причин использования
битовых массивов) без особой выгоды.
Теперь, наконец, можно легко написать макрос,
инвертирующий определенный бит в битовом массиве,
таким образом:
idefine BARR-FLIP (barr, N) \
((barr) [BARR_ELNUM (N) ] A= (BARR_ELTYPE)1 «
•**BARR_BITNUM (N) )
Здесь используется битовый оператор ’’исключающее
ИЛИ” для инвертирования N-ro бита в barr. Листинг 5.1
содержит полный список определений битового массива.
Подсчет битов
Этот раздел посвящен простой проблеме — каким об-
разом можно в целой величине подсчитать число битов
со значением 1. Для использования многих алгоритмов
в этом и в последующих разделах необходимо знать
общее число битов в целой величине. В этих алгорит-
мах будем использовать обращение к макросу
VALUE_BITS. Часто требуется знать, сколько битов
используется в переменной целого типа, что можно
определить, например, следующим образом (предпола-
гаем, что тип переменной — unsigned long):
idefine VALUE_BITS (CHAR_BIT *
wsizeof(unsigned long))
Поскольку в типе unsigned long могут содержаться
’’дыры” (неиспользуемые биты), этот факт можно при-
способить для некоторых систем. В других случаях пред-
почтительнее установить точное число битов, тогда зна-
чение VALUE—BITS может быть определено или
заменено соответствующей величиной. Можно также
вместо этого передавать величину как дополнительный
аргумент функции.
Возможно, простейший способ определения числа
единичных битов в величине — просто проверить все
биты по очереди, не являются ли они равными 1:
103
Игры с битами и байтами
Глава 5
Листинг 5.1. Определения в bitarray.h.______________________________________________________
typedef unsigned char BARR_ELTYPE;
«define BARRELBITS (CHARBIT * sizeof(BARRELTYPE))
«define BARRARRAYSIZE(N) (((N) + BARRELBITS-l) / BARR_ELBITS)
«define BARRMALLOC(N) \
((BARRELTYPE *)malloc(BARRARRAYSIZE(N) * sizeof(BARRELTYPE)))
«define BARRREALLOCfbarr, N) \
((BARRELTYPE *)realloc(barr, BARRARRAYSIZE(N) * sizeof(BARRELTYPE)))
«define BARR_FREE(barr) free(barr)
«define BARRCLEARARRAY(barr, N) \
memset(barr, 0, BARRARRAYSIZE(N) * sizeof(BARRELTYPE))
«define BARRELNUM(N) ((H) / BARRELBITS)
«define BARRBITNUM(N) ((H) % BARRELBITS)
«define BARR_SET(barr, N) \
((barr)[BARRELNUM(N)] |= (BARRELTYPE)1 « BARR_BITNUM(N))
«define BARR_CLEAR(barr, N) \
((barr)[BARRELNUM(N)] &= ~((BARRELTYPE)1 « BARRBITNUM(N)))
«define BARR_FLIP(barrf N) \
( (barr) (BARR_ELNUM(N) ] A= (BARR ELTYPE) 1 « BARRBITNUM(N))
«define BARR_TEST(barr, N) \
((barr)[BARR_ELNDM(N)) & ((BARRELTYPE)1 « BARRBITNUM(N)))
unsigned long bit__countl (unsigned long value)
{
int count = 0;
int bit;
for (bit = 0; bit < VALUE BITS; bit++) {
if (value & 1)
count++;
value »= 1;
}
return count;
}
Эта программа проверяет состояние нулевого бита
(младшего бита) и затем сдвигает все биты в value на
одну позицию вправо. После того как цикл выполнит-
ся VALUE BITS раз, все исходные биты в value прой-
дут через нулевой бит и будут проверены.
Такой подход достаточно прост и дает хорошие ре-
зультаты. Единственной причиной поиска альтернатив-
ных методов является эффективность. Во многих слу-
чаях об этом не стоит беспокоиться, поскольку времени
для осуществления проверки требуется очень мало.
Однако, если подобная процедура повторяется много
раз, общее время может оказаться значительным. Поэто-
му в общем случае полезно рассмотреть некоторые усо-
вершенствования рассмотренного подхода..
Основная сложность с bit countl состоит в том, что
цикл всегда повторяется VALUE_BITS раз. Можно сде-
лать лучше, приняв во внимание, что если величина
равна нулю или становится равной нулю, то в ней боль-
ше нет битов 1 и проверять больше нечего, поэтому
выполнение цикла следует прекратить. bit_count2 изме-
няет условия тестирования в соответствии с вышеска-
занным:
unsigned long bit_count2(unsigned long value)
{
int count = 0;
while (value Is 0) {
if (value & 1)
count++;
value »= 1;
)
return count;
}
Теперь число выполнений цикла зависит только от
позиции старшего бита 1 в исходной величине. Это осо-
бенно полезно для малых величин. Кроме того, этот
способ не зависит от величины VALUE_BITS; програм-
ма просто проверяет все биты переданной величины.
Мы уже сталкивались с методами проверки и обну-
ления младшего бита 1 в целой величине без знака.
В частности, операция X & (Х-1) очищает младший бит 1.
Можно выполнять ее таким образом, чтобы при каждом
прохождении цикла программа очищала один бит, и
нужно будет просто посчитать, сколько битов необхо-
димо очистить, чтобы обнулить величину. Такой метод
продемонстрирован в программе bit_count3:
unsigned long bi t_count3 (unsigned long value)
{
int count s 0;
while (value 1= 0) {
count++;
value value-1; /* Обнуляет
**младжий бит 1 */
)
return count;
}
104
Пересмотренный язык. С
Часть I
Здесь строка value &= value-1 представляет собой
что-то вроде ловкого трюка. Поэтому комментарий к
ней вполне уместен.
В программе bit_count4 использован способ вообще
без привлечения цикла:
unsigned long bit_count4 (unsigned long value)
{
value = (value & 0x55555555) 4- ((value »
*-l) & 0x55555555);
value = (value & 0x33333333) 4- ((value »
^♦2) & 0x33333333);
value = (value & OxOfOfOfOf) 4- ((value »
^♦4) & OxOfOfOfOf);
value = (value & OxOOffOOff) 4- ((value »
w8) & OxOOffOOff);
value = (value & OxOOOOffff) 4- ((value »
**16) & OxOOOOffff);
return (int)value;
)
Основная идея этой программы — разделить вели-
чину сначала на маленькие и затем увеличивающиеся
группы битов. Пример написан для исходных величин
фиксированного размера, составляющего 32 бита.
В первой строке используется маска 0x55555555, кото-
рой соответствует битовый набор 01010101 (это череду-
ющиеся нули и единицы). Данная операция произво-
дится собственно с самой исходной величиной и с ней
же, сдвинутой на одну позицию вправо. Таким образом,
мы начинаем с исходным битовым набором
ABCDEFGH...
а заканчиваем двумя величинами
0B0D0F0H...
0A0C0E0G. . .
которые в сумме формируют группы 2-битовых вели-
чин
|А+В|C+DIE+F|G+H|...
Каждая группа из двух битов содержит число битов
1, содержавшихся в этих двух битах первоначально.
В следующей строке используется маска 0x33333333,
которой соответствует битовая последовательность
00110011.... Сдвиг и применение маски дают в резуль-
тате две величины:
|00|C+D|00|G+H|...
..|001 A+B|00|E+F|...
которые в сумме формируют группы 4-битовых вели-
чин
|А+В+C+D|E+F+G+H|...
Заметим, что на каждом шаге слева от каждой вели-
чины находится достаточно нулей, чтобы вместить
любой возможный перенос при сложении. Процесс уве-
личения в 2 раза длины поля при каждом шаге продол-
жается до тех пор, пока не будет подсчитано полное
число битов 1 в величине value. Затем это число возвра-
щается программой.
И в последнем примере bit_count5 реализован про-
стой, но часто очень эффективный способ написания
программы с использованием таблицы преобразований:
unsigned long bit_count5 (unsigned long value)
{
static const unsigned char count_table[] - {
0flflf2rlr2r2r3flf2r2r3r2,3f3f4flf2f2f3f2f3f3f4f2f3r3r4f3f4f4r5r
1Л2,3,2ДЗ,4г2ДЗАЗА4,5,2ДЗ,4,3,4А5,3,4,4,5Л5,5,6,
If2f2f3r2r3f3r4f2f3f3r4f3,4f4f5r2f3f3f4f3r4r4f5f3f4f4f5f4f5f5r6f
2f3f3r4f3r4r4*5f3f4f4f5r4f5r5r6f3f4f4f5f4f5r5r6f4f5f5f6f5f6f6f7f
lr2f2r3*2f3r3r4r2f3r3f4f3f4f4f5r2f3f3f4f3f4f4f5f3f4r4f5f4r5f5r6f
2ДЗ,4Д4,4г5Д4,4Д4Д5,6Д4,4Д4Д5,6Д5,5,6,5,6,6,7,
2f3r3r4f3f4f4f5f3r4f4,5f4f5f5f6,3f4,4f5A5f5f6,4r5f5f6f5f6r6r7r
Зг4ДД4,5г5,6,4»5Д6,5,6г6,7,4,5г5,6Д6,6,7Д6,6,7,6,7,7,8
int count = 0;
vhile (value 1= 0) {
count +a count_table[value & Oxff];
value »= 8;
}
return count;
}
Эта таблица из 256 элементов содержит количество
битов 1 в каждом числе от 0 до 255. Программа просто
разделяет величину value на 8-битовые части и склады-
вает число битов в каждой части. Размер таблицы мож-
но установить по желанию. Например, если использо-
вать разбиение на 7-битовые части, размер таблицы
уменьшится вдвое — до 128 элементов. Однако это мо-
жет привести к большему числу повторений цикла.
Часто для решения конкретной проблемы имеется
множество способов, которые предусматривают различ-
ные компромиссы между простотой и эффективностью.
Эффективность может зависеть от ожидаемой формы
входных данных. Например, программа bit_count3 бу-
дет хорошо работать с величинами, которые содержат
мало битов 1, и плохо — если таких битов много, тогда
как программы bit_count4 и bit_count5 осуществляют ту
же работу для любых входных данных. Какая из про-
грамм окажется более эффективной — bit_count4 или
bit_count5, зависит от компилятора и системы, в кото-
рой программа будет выполняться.
Различные методы, которые были использованы в
функциях подсчета битов (побитовый анализ, операции
умножения битов, табличный поиск), применимы для
решения многих задач.
Игры с битами и байтами
1105
Глава 5
Зеркальное отражение битов
Другая простая задача состоит в том, как обратить по-
рядок всех битов в величине. Некоторые решения этой
задачи очень похожи на решения задачи подсчета би-
тов. В программе bitrevl использован простой принцип:
величина value пошагово сдвигается вправо, и на каж-
дом шаге младший бит value перемещается в младший
бит result, который пошагово сдвигается влево. В про-
грамме предполагается, что значение VALUE BITS
определено, как описывалось ранее в этой главе.
unsigned long
{
unsigned
int i;
bit^revl (unsigned long value)
long result;
result = 0;
for (i = 0; i < VALUE BITS; i++) {
result = (result «1) | (value & 1);
value »= 1;
}
return result;
1
В программе bit_rev2 продемонстрирован более лю-
бопытный принцип: соответствующие левые и правые
биты меняются местами.
unsigned long bitrev2 (unsigned long value)
{
unsigned long Ibit, rbit, mask;
из четырех битов и т.д., пока не будут переставлены
соседние группы из 16 битов. Этот алгоритм очень по-
хож на алгоритм программы bit_count4, и здесь также
предполагается, что длина данных составляет 32 бита.
Рассмотрим, как это происходит, на примере 8-битового
набора, состоящего из символов:
ABCDEFGH
Сначала, переставив соседние биты, получим:
BADCFEHG
Затем, переставив соседние пары битов, получим:
DCEAHGFE
Затем, переставив соседние группы из четырех би-
тов, получим в результате набор битов в обратном по-
рядке:
HGFEDCBA
unsigned long bit_rev3(unsigned long value)
{
value = ((value & 0x55555555) « 1) |
**( (value » 1) & 0x55555555);
value = ((value & 0x33333333) « 2) |
**((value » 2) & 0x33333333);
value = ((value & OxOfOfOfOf) « 4) |
w((value » 4) & OxOfOfOfOf);
value = ((value & OxOOffOOff) « 8) |
**((value » 8) & OxOOffOOff);
value = ((value & OxOOOOffff) « 16) |
w(value » 16);
return value;
}
for (Ibit = 1UL « (VALUEBITS-l), rbit -
W1UL;
Ibit > rbit;
Ibit »=1, rbit «= 1) {
mask s Ibit|rbit;
if ((value & mask) != 0 && (value &
^mask) != mask)
value mask;
}
return value;
1
Здесь Ibit и rbit — это 1-битовые маски, которые на-
чинаются соответственно с самого крайнего слева и са-
мого крайнего справа битов. При каждом выполнении
цикла они сдвигаются на один бит до тех пор, пока они
или встретятся, или пересекутся. Значение mask — это
результат битового ’’ИЛИ” между Ibit и rbit, т.е. межцу
теми двумя битами, которые проверяются. Если их зна-
чения одинаковы (оба равны 0 или 1), их перестановка
ничего не изменит, и соответственно никаких манипу-
ляций проводить не надо. Если их значения различны,
перестановка приведет к инвертированию их обоих, что
и выполняется в выражении value л= mask.
Программа bit_rev3 переставляет соседние биты, за-
тем соседние пары битов, после этого соседние группы
Строго говоря, если известно, что длина unsigned long
составляет точно 32 бита, то маска OxOOOOffff на после-
днем этапе не нужна. Тем не менее, никто не гаранти-
рует, что это будет иметь место в любом случае. Про-
грамма, написанная таким образом, будет работать с
32-битовыми величинами, даже если длина unsigned long
окажется больше 32 битов.
И последняя программа — bit_rev4 — демонстриру-
ет методику с использованием таблицы поиска. Эта таб-
лица содержит 256 элементов, в которых находятся ре-
зультаты битового обращения каждой 8-битовой
величины. Данная программа работает почти так же, как
и bitrevl, за исключением того, что она за один раз об-
рабатывает восемь битов вместо одного. В этом случае
длина величины, в которой обращается порядок битов,
должна быть кратна восьми.
unsigned long bit_rev4 (unsigned long value)
<
static const reverse_table[] = {
0x00,0x80,0x40 , OxcO , 0x20 fOxaO , 0x60 r6xe0 ,
0x10,0x90,0x50,OxdO,0x30,OxbO,0x70,Oxf0,
0x08,0x88,0x48,0xc8,0x28,0xa8,0x68,0xe8,
0x18,0x98,0x58,0xd8,0x38,0xb8,0x78,Oxf8,
0x04,0x84,0x44,0xc4,0x24,Oxa4,0x64,0xe4,
0x14,0x94,0x54,0xd4,0x34,0xb4,0x74,Oxf4,
106
Пересмотренный язык С
Часть I
0x0сr 0x8с 90x4с, Охсс,0x2с,Охае,0 x6 с ,Охес ,
0x1с,0x9с,0x5с9Oxdc90x3с ,ОхЬс ,0x7с,Oxf с9
0x02 90x82f 0x42,0хс2 90x22,Оха2, 0x62 90хе2 9
0x12,0x9 2 90x52,0xd2,0x32,0хЬ2,0x72,Oxf 2,
0x0а,0x8а,0x4а,Охса,0x2а,Охаа,0x6а,Охеа,
Oxla,0x9а,0x5а,Oxda,0x3а,Oxba,0x7а,Oxfа,
0x06,0x86,0x46,Охсб,0x26,Охаб,0x66,Охеб,
0x16,0x96,0x56,0xd6,0x36,ОхЬб,0x7б,Oxf6,
0х0е,0х8е,0х4е,Охсе,0х2е,Охае,Охбе,Охее,
0х1е,0х9е,0х5е,Oxde,ОхЗе,Oxbe,0х7е,Oxfе,
0x01,0x81,0x41,Oxcl,0x21,Oxal,0x61,Oxel,
0x11,0x91,0x51,Oxdl,0x31,ОхЫ,0x71,Oxf1,
0x09,0x89,0x49,0хс9,0x29,0ха9,0x69,0хе9,
0x19,0x99,0x59,0xd9,0x39,0хЬ9,0x79,Oxf 9,
0x05,0x85,0x45,0хс5,0x25,0ха5,0x65,0хе5,
0x15,0x95,0x55,0xd5,0x35,0хЬ5,0x75,Oxf5,
OxOd,0x8d,0x4d,Oxcd,0x2d,Oxad,0x6d,Oxed,
Oxld,0x9d,0x5d,Oxdd,0x3d,Oxbd,0x7d,Oxfd,
0x03,0x83,0x43,0xc3,0x23,ОхаЗ,0x63,ОхеЗ,
0x13,0x93,0x53,0xd3,0x33,ОхЬЗ,0x73,Oxf3,
OxOb,0x8b,0x4b,Oxcb,0x2b,Oxab,0x6b,Oxeb,
Oxlb,0x9b,0x5b,Oxdb,0x3b,Oxbb,0x7b,Oxfb,
0x07,0x87,0x47,0xc7,0x27,0xa7,0x67,0xe7,
0x17,0x97,0x57,0xd7,0x37,0xb7,0x77,Oxf7,
OxOf,0x8f,0x4f,Oxcf,0x2f,Oxaf,0x6f,Oxef,
0x1f,0x9f,0x5f,Oxdf,0x3f,Oxbf,0x7f,Oxff
1;
unsigned long result;
int i;
result = 0;
for (i = 0; i < VALUEBITS; i += 8) {
result = (result «8) |
** reverse_table[value & Oxff);
value »= 8;
}
return result;
Битовые поля
Структуры и объединения могут содержать элементы,
определенные как битовые поля. При определении би-
тового поля задается один из типов int, signed int или
unsigned int и, кроме того, его длина. Например, этот код
struct Bitfield {
int fieldl : 10;
signed field2 : 8;
unsigned field3 : 6;
};
определяет структуру из трех элементов, которые явля-
ются битовыми полями. Здесь fieldl — это поле типа int
длиной 10 битов, field! — поле типа signed int длиной
8 битов, a field3 — поле типа unsigned int длиной 6 би-
тов. Некоторые компиляторы, кроме int, signed int и
unsigned int, позволяют использовать и другие типы, но
этот факт не обладает свойством переносимости. Дли-
на битового поля определяется конкретным заданным
числом, а не типом.
Битовые поля, определенные как signed int или
unsigned int, заведомо либо обладают знаком (могут со-
держать отрицательные величины), либо не обладают
знаком (не могут содержать отрицательные величины).
Просто int — это в действительности тип со знаком (тот
же самый тип, что и signed int, и ведет себя во всех слу-
чаях аналогично). Однако битовое поле эффективно
представляет подобласть типа, и в случае с переменной
типа int компилятор может выбирать, захватит ли по-
добласть только положительные величины или и поло-
жительные, и отрицательные одновременно. При ис-
пользовании битовых полей предпочтительнее
использовать типы signed int или unsigned int, чем про-
сто int, тогда работа различных компиляторов будет
приводить к одному результату.
На первый взгляд битовые поля кажутся удобным
инструментом манипулирования частями целых вели-
чин. К сожалению, в языке С очень слабо определено,
каким образом компилятор располагает битовые поля.
Существует некоторая единица выделения памяти, но
компилятор может разместить битовое поле, начиная со
старших или младших битов. Если битовое поле не по-
мешается в оставшемся свободным месте слева в такой
единице, компилятор может как разделить это поле
между двумя единицами памяти, так и переместить его
полностью в другую единицу памяти, оставив в первой
неиспользованные биты. Размер единицы выделения
памяти также определяется компилятором. Он должен
быть кратен размеру байта, т.е. с помощью битового
поля нельзя создать в памяти массив из единичных би-
тов. Структура
Struct Onebit {
Unsigned bit : 1
1
займет в памяти, по крайней мере, один байт, а может
быть, и больше. Если, например, единица выделения
памяти составляет 32 бита, то структура будет иметь
длину 32 бита. Некоторые компиляторы позволяют кон-
тролировать размер единицы выделения памяти (напри-
мер, допуская использование таких типов, как unsigned
char, в битовых полях), но полностью полагаться на это
не следует.
Смысл использования битовых полей состоит в по-
лучении возможности эффективно записать некоторое
количество малых целых величин в структуру. Это про-
сто способ экономии места, который полезен при созда-
нии в памяти больших структур данных. Битовые поля
используются в некоторых операционных системах и
встроенных системах для доступа к аппаратным регис-
трам данных. Для таких приложений переносимость
менее важна. Однако использование битовых операций
языка С (возможно, с использованием некоторых мак-
росов для скрытия подробностей) может оказаться наи-
Игры с битами и байтами
Глава 5
107
лучшим подходом. В настоящее время даже программы,
жестко привязанные к аппаратной реализации, могут
перемещаться на системы других типов.
Переносимость программ
Любой объект в языке С можно рассматривать как пос-
ледовательность байтов (кроме, быть может, регистро-
вых переменных, которые не имеют адресов). Можно
получить доступ к отдельным байтам, рассматривая объект
как массив типов unsigned char; такие функции, как
memcpy, используют это свойство. Рассмотрим листинг
5.2, где отдельные байты переменной value выводятся в
том порядке, в котором они появляются в памяти.
Листинг 5.2. Представление объекта как
байтового массива.
linclude <stdio.h>
int main(void)
<
unsigned value = 0x1234;
unsigned char *ptr = (unsigned char *)&
**♦ value;
int i;
for (i » 0; i < sizeof value; i++)
printf(" %02x"f ptr[i]);
putchar('\n');
return 0;
Различные компиляторы могут представлять целые
величины различным способом; например, могут варь-
ироваться и размер байтов, и порядок байтов, и число
байтов в объекте. Могут также присутствовать неисполь-
зованные биты, которые при таком рассмотрении нео-
жиданно становятся видимыми. Поскольку в большин-
стве компиляторов длина байта составляет восемь битов
и отсутствуют неиспользованные биты, будем полагать
сейчас, что это именно так. Но даже при этом предпо-
ложении программа может выводить различные резуль-
таты, как это показано в табл. 5.6.
Таблица 5.6. Возможные результаты работы программы в листинге 5.2 в системе "байт — восемь битов".
Результат работы программы Формат int без знака
34 12 2 байта, "от младшего к старшему"
12 34 2 байта, "от старшего к младшему"
34 12 00 00 4 байта, "от младшего к старшему"
00 00 12 34 4 байта, "от старшего к младшему"
12 34 00 00 4 байта, смешанный порядок байтов
00 00 34 12 4 байта, смешанный порядок байтов
Термин "от младшего к старшему" (little endian) оз-
начает, что младший разряд в байте имеет младший
адрес, а старший разряд имеет старший адрес. "От стар-
шего к младшему" (big endian) означает, что байты рас-
положены в обратном порядке, т.е. сначала старший
разряд, а затем младший. Смешанный порядок (mixed
endian) означает комбинацию этих двух типов. Процес-
соры Intel х86, использующиеся в ПК-совместимых
компьютерах, применяют принцип "от младшего к стар-
шему", но другие, такие как Macintosh и некоторые
рабочие станции, придерживаются варианта "от старше-
го к младшему".
Из-за этого немедленно возникает проблема при
переносе двоичных данных между системами различ-
ных типов и даже в ситуации, когда программы компи-
лируются различными компиляторами или при различ-
ных установках одного и того же компилятора.
Двоичные данные, записанные одной программой, мо-
гут быть интерпретированы совершенно иначе при чте-
нии их другой программой. Возможно, наиболее про-
стой путь решения этой проблемы — полностью
избегать двоичных данных, а читать и записывать дан-
ные в текстовом формате. Таким образом можно достичь
согласования интерпретации данных различными сис-
темами. Случающиеся несогласования незначительны,
например, различные символы окончания строки обыч-
но достаточно просто конвертировать, более того, для
этого даже могут существовать необходимые программ-
ные средства.
Чтобы двоичные данные можно было использовать
в различных системах, необходимо определить внешний
формат данных, независимый от платформы или ком-
пилятора, на которых будет выполняться программа.
Этот формат должен быть определен вплоть до байто-
вого уровня. Во многих системах (например, XDR и
ASN.1) существуют определения и библиотеки, обслу-
живающие переносимый формат данных. Байты могут
быть различной величины, и с этим ничего не подела-
ешь. Язык С гарантирует, что длина байта составляет не
менее восьми битов, что является обычным миниму-
мом, принятым в большинстве систем. Значит, можно
определить байт как единицу данных, способную хра-
нить как минимум восемь битов информации; это — ве-
личина от 0 до 255. Рассмотрим следующую структуру:
struct Container {
unsigned length;
/* Вплоть до 10000 */
unsigned long capacity;
/* Вплоть до 10000000 */
unsigned char colour;
/* от 0 до 7 */
int position;
/* от -1000 до 1000 */
double weight;
1;
108
Пересмотренный язык С
Часть I
Эта структура определяет информацию о некоторого
рода контейнере. Необходимо записать эту информа-
цию в файл и затем прочесть ее в другой системе. Наи-
более простой и часто наилучший способ, позволяющий
сделать это, — записать структуру в текстовом форма-
те, возможно, в одну строку как список с разделитель-
ными запятыми. Рассмотрим простую функцию, кото-
рая получает указатель на структуру и записывает ее
строкой в текстовом файле:
int write_container (FILE *fp, const struct
Container *container)
<
return fprintfffp, "%u,%lu,%d,%d,%.2f\n",
container->length,
^container-capacity,
container-colour,
** container->position ,
container->weight);
}
Затем соответствующая функция читает строку из
текстового файла и заполняет структуру Container
int read^con tain ter (FILE *fp,
struct Container *container)
<
char buffer[100);
int colour;
if (fgets(buffer, sizeof buffer, fp) ==
NULL)
return -1;
if (sscanf(buffer, ”]%u,%lu,%d,%d,%lf”,
&container->length,
&container->capacity,
««colour,
&container->position,
&container->weight) Is 5)
return 0;
container-colour = colour;
return 1;
}
Эти функции будут записывать и читать строки типа
5000,2000000,5,-300,42.53
Необходимо очень тщательно определять внешнее
представление для написания переносимого двоичного
формата. Независимо от того, как данные хранятся в
структуре (например, длина типа int часто составляет
32 бита), мы знаем возможный диапазон их величин и
соответственно можем определить, сколько байтов не-
обходимо для их записи. Исключение составляет тип
weight, который обрабатывается несколько иначе.
В табл. 5.7 показаны размеры и сдвиги, которые будут
использованы во внешнем формате.
Таблица 5.7. Размеры полей и сдвиги для
внешнего представления struct Container.
Элемент структуры Размер в байтах Сдвиг
length 2 0
capacity' 4 2
colour 1 6
position 2 7
weight 8 9
Наконец, нам нужно определить порядок байтов, в
котором будут сохраняться величины, состоящие из
многих байтов. В этом примере порядок байтов — "от
старшего к младшему" (старший байт идет первым). В
листинге 5.3 представлены функции для записи и чте-
ния этих данных в двоичном формате.
Здесь функции работают с использованием способа
битового сдвига и операций маскирования. Рассмотрим
некоторые моменты:
• Массив unsigned char используется для хранения вне-
шних данных.
• Величины разбиваются на 8-битовые части вне зави-
симости от возможного размера байта (CHAR_BIT)
в системе. В writebin container к байтовым величи-
нам применяется маска Oxff, чтобы гарантировать
запись именно восьми битов данных.
• В readbin container байтовая величина перед сдви-
гом приводится к выходному типу, благодаря этому
операции сдвига применяются к величинам нужной
длины.
Элемент position определен как целая величина со зна-
ком. Целые величины со знаком могут иметь различные
представления ("дополнение до двух", "дополнение до
единицы", "знак-величина"), и, таким образом, програм-
ма работает только для систем, использующих одинако-
вое представление. В основном все нормально, поскольку
большинство платформ используют представление "допол-
нение до двух". Можно написать программу, которая ра-
ботает в системах с различными представлениями. Один
из путей решения этой задачи — записать все данные со
знаком как величины без знака. Когда записывающая про-
грамма должна сохранить величину со знаком, она снача-
ла превращает ее в величину без знака и затем записы-
вает эту величину. Считывающая программа читает
величину без знака и превращает ее в исходную вели-
чину со знаком.
Игры с битами и байтами
Глава 5
109
'int signed_value;
unsigned unsigned_value;
/« Перекодирует величину со знаком в диапазоне от -32767 до 32767 в величину без знака от 0 до
65535 */
unsignedvalue = signed^value >= 0
? signedvalue
: signedvalue + 65536U;
/« Перекодирует величину без знака в диапазоне от 0 до 65535 в величину со знаком в диапазоне
от -32767 до 32767 */
signed_value = unsigned_value <= 32767
? (int)unsigned_value
: (int)(unsignedvalue-32768)-32767-1;
Листинг 5,3. Запись и чтение данных контейнера struct Container как двоичных данных,
linclude <stdio.h>
linclude <stdlib.h>
int writebin_container(FILE *fp, const struct Container «container)
{
unsigned char buffer[17];
buffer]0] = (container->length » 8) & Oxff;
buffer]1] = container->length & Oxff;
buffer[2] = (container->capacity » 24) & Oxff;
buffer[3] = (container->capacity » 16) & Oxff;
buffer[4] = (container->capacity » 8) & Oxff;
buffer[5] « container->capacity & Oxff;
buffer]6] = container->colour;
buffer]?] = (container->position » 8) & Oxff;
buffer]8] = container->position & Oxff;
memcpy(&buffer]9], &container->weightv 8);
if (fwrite(buffer, 1, sizeof buffet*, fp) 1- sizeof buffer)
return -1;
return 0;
I
int readbin_container(FILE *fp, struct Container «container)
unsigned char buffer[17];
if (fread(buffer, 1, sizeof buffer, fp) 1= sizeof buffer)
return -1;
container->length = ((unsigned)buffer[0J «8) | buffer]!];
container->capacity - ((unsigned long)buffer[2] « 24) |
((unsigned long)buffer]3] « 16) |
((unsigned long)buffer[4] « 8) |
buffer[5];
container->colour = buf fer[6 J;
container->position = ((int)buffer(7] « 8) | buffer]8];
memcpy(&container->weight, &buffer]9], 8);
return 1;
}
Пересмотренный язык С
Часть I
по
Эти выражения превращают любую величину int в
величину без знака и обратно вне зависимости от того,
какой формат величин со знаком использует компиля-
тор. Величины без знака форматируются подобно чис-
лам в представлении ’’дополнение до двух". Странная
комбинация чисел в последней строке предотвращает
переполнение при операциях с величинами со знаком
(напомним, что int гарантирует представление чисел в
диапазоне от -32767 до 32767). Возможно, компилятор
сможет провести существенную оптимизацию.
Последняя проблема касается элемента weight, име-
ющего тип double. Существует большое разнообразие
представлений чисел с плавающей запятой. Если необ-
ходима максимальная переносимость, текстовый фор-
мат будет наилучшим выбором. Однако в настоящее
время многие системы используют стандартные форма-
ты, определенные в документе ANS1/IEEE-754. Соглас-
но IEEE, длина float составляет 32 бита, а длина double —
64 бита. Остаются две проблемы переносимости: размер
байта (предположим. 8 битов) и порядок байтов. Обыч-
ный порядок байтов — "от младшего к старшему” или
"от старшего к младшему". Программа, переносимая
между системами таких типов, должна быть способна ко-
пировать байты объекта с плавающей точкой в прямом или
обратном порядке. В листинге 5.3 показано копирование
в прямом порядке с использованием функции memcpy. Для
обращения порядка байтов потребуется цикл такого
типа:
For (1 = 0; i < 8; i++)
Buffer[n+i] = ((unsigned char *)
**container->weight) [7-i] ;
Процесс преобразования большой структуры во вне-
шний формат данных и из него состоит из большого
количества мелких операций. Можно улучшить поло-
жение, определив набор вспомогательных функций,
например:
/ * Кодирует величину со знаком в 2-байтовое
поле в порядке "от старшего к младшему”*/
void encode_s2(unsigned char «field, int
value)
{
unsigned uvalue = value >= 0
? value
: value + 65536U;
field[°1 ~ (uvalue » 8) & Oxff;
field[1] = value & Oxff;
1
int decodes2(unsigned char «field)
{
unsigned uvalue = ((unsigned)field[0]) |
field[l];
return uvalue <= 32767
? (int)uvalue
: (int)(uvalue-32768)-32767-l;
Резюме
Язык С поддерживает некоторые битовые и байтовые
операции низкого уровня. В этой главе представлены
некоторые полезные методы работы с битами и байта-
ми, а также даны предупреждения о возможной непе-
реносимости некоторых операций. В частности, целые
величины со знаком могут иметь несколько представле-
ний, и лучше избегать их, имея дело с битовыми опе-
рациями.
Данная глава касается также реализаций битовых
массивов, счетчиков битов и процедуры обращения би-
тов. Эти простые сами по себе операции демонстриру-
ют существенно различные подходы. В завершении этой
главы мы коснулись вопроса о том, как можно исполь-
зовать битовые и байтовые операции для создания та-
кого формата данных, который может быть доступен
одной и той же программе на различных платформах.
Хранение и извлечение данных
В ЭТОЙ ГЛАВЕ
Цели и приложения
Основные методы
Общие форматы
Усовершенствованные методы
Смежные вопросы
Стив Саммит
Всем известно, что, если при обмене информацией с
внешним миром возникает необходимость прочесть или
записать данные, используется какой-либо формат фай-
ла данных. В этой главе рассмотрены различные мето-
ды, применяемые для эффективного чтения и записи
файлов данных, и обсуждаются некоторые проблемы
выбора или разработки используемых форматов.
Данная глава начинается с общих посылок, касаю-
щихся выбора форматов файлов данных и общих спо-
собов их чтения и записи, а затем мы перейдем к рас-
смотрению более конкретных примеров. Если вам уже
известна или просто неинтересна теория, вы можете
сразу перейти к разделу "Основные методы", содержа-
щему некоторые "строительные блоки" для чтения и
записи отдельных объектов данных внутри файлов дан-
ных, или к разделу "Общие форматы", в котором пред-
ставлены примеры программ для чтения таких популяр-
ных форматов файлов, как TDF (tab-delimited fields —
поля, разделенные символами табуляции), CSV
(comma-separated values — величины, разделенные запя-
тыми) и файлы .ini (секционной инициализации).
Цели и приложения
Файлы данных имеют множество обличий. Приложе-
ние, позволяющее пользователю создавать документы,
содержащие текст, графику или что-либо еще, сохраняет
эти документы в файле данных определенного типа.
Любая программа, которой нужно сохранить ее состо-
яние между вызовами, использует для этого файл дан-
ных, и, как вы увидите дальше, конфигурационные
файлы программ тоже можно рассматривать как файлы
данных. Программы сбора данных сохраняют собран-
ные данные в некотором формате файла данных; затем
программы, манипулирующие данными, могут прочесть
их. Большинство сетевых протоколов предусматривают
передачу структурированных данных, что также мож-
но рассматривать как формат файла данных.
Разработка форматов файлов данных — достаточно
серьезный вопрос, который мы даже не будем пытать-
ся исследовать полностью. Но выбранный для исполь-
зования в файле данных формат, естественно, опреде-
ленным образом связан с программой, написанной для
его сопровождения; таким образом, формат и програм-
ма часто неразрывно связаны. Поэтому нельзя рассмат-
ривать программы записи и чтения файлов изолирован-
но, так что всюду в этой главе мы будем касаться
вопросов разработки различных форматов данных.
При выборе формата файла данных можно исполь-
зовать несколько критериев. Можно потребовать, на-
пример, чтобы файлы данных были как можно компак-
тнее или чтобы данные записывались и считывались как
можно эффективнее. Можно предпочесть, чтобы про-
грамма чтения и записи в файл была как можно проще
или чтобы вся эта работа выполнялась исключительно
существующими библиотеками. Критерием также может
служить доступная для чтения людьми форма или, на-
оборот, возможность спрятать или даже зашифровать
определенные данные. Можно потребовать, чтобы фор-
мат обладал возможностью расширения или был совме-
стим с форматом, использованным ранее. Предпочтение
можно отдать формату, который позволяет переносить
файлы данных на различные компьютеры. С другой
стороны, формат файла данных может быть просто на-
вязан нам объективной реальностью; роскошь создания
чего-либо своего собственного не всегда нам доступна.
В любом случае, даже если некоторые из этих требова-
ний противоречат друг другу, нужно искать способы
удовлетворения большинства из них.
112
Пересмотренный язык С
Часть I
Операции чтения и записи файлов данных концеп-
туально схожи между собой. Файл данных является
одним из представлений некоторых абстрактных дан-
ных, и эти же данные могут быть представлены в па-
мяти с использованием структуры данных. Процесс за-
писи файла данных является просто преобразованием
представления данных в памяти во внешнее представ-
ление при выводе данных в файл. Чтение файла данных
включает в себя обратный процесс — чтение и интер-
претацию байтов внешнего представления и реконструк-
цию представления в памяти. Далее мы увидим, что
возможности библиотеки С <stdio.h> вообще адекват-
ны всем аспектам обеих рассматриваемых задач, но, как
это часто случается, сложности начинаются на уровне
деталей.
С другой стороны, очень важно осознавать, что внут-
ренние (в памяти) и внешние представления данных,
как правило, отличаются. Процесс чтения и записи дан-
ных обычно содержит некоторые преобразования, и в
действительности всегда целесообразно спрятать дета-
ли процессов преобразования, чтения и записи в интер-
фейс, т.е. определить чтение и запись файла данных как
некие абстракции. Как мы позже увидим, можно опре-
делить структуру файла данных по принципу "точно
так же, как данные расположены в памяти", но этот
подход не имеет перспектив из-за его существенных
недостатков.
Текстовые и двоичные форматы
Существует два основных типа форматов данных. Тек-
стовые форматы представляют данные как простой
текст, в общем случае доступный пользователям. Тек-
стовые форматы разработаны таким образом, что фай-
лы можно не только структурировать и стилизовать ча-
стными программами, созданными для их чтения и
записи, но и прочитать и записать с помощью обычных
утилит текстовых файлов — текстовых редакторов, про-
грамм печати файлов и таких утилит как программа grep
в UNIX. Текстовые файлы в общем случае состоят толь-
ко из обычных печатных символов, а также пробелов,
символов новой строки и, может быть, символов табу-
ляции. В текстовом файле, например, целое число 1850
представлено четырьмя символами: 1, 8, 5 и 0, которые
расположены в файле друг за другом подобно строке
"1850". В кодах ASCII эти четыре символа имеют бай-
товые значения 0x31, 0x38, 0x35 и 0x30. Это может
показаться слишком очевидным и не требующим осо-
бого пояснения, но очень важно сравнить способы ко-
дирования данных в текстовых и двоичных файлах.
С другой стороны, в двоичном файле данных вели-
чины записываются таким способом, который во мно-
гом похож на способ хранения в памяти. Двоичные
файлы данных обычно содержат байты с произвольны-
ми величинами, не все из которых являются печатаемы-
ми символами, и попытки просмотреть или обработать
двоичный файл данных с помощью обычных утилит для
текстовых файлов приводят к полной бессмыслице.
Например, в шестнадцатиричной системе целое число
1850 представлено как ОхО73а, следовательно, представ-
ление этого числа в двоичном файле данных будет со-
держать байты с величинами 0x07 и 0x3а. На рис. 6.1
показаны побайтовые представления целой величины
1850 в текстовом и двоичном форматах.
+_ I1-' - +. +. t. +
текстовый: | 0x31 | 0x38 | 0x35 | 0x30 |
двоичный: | 0x3а | 0x07 |
РИСУНОК 6.1. Представления целой величины 1850как строки
в текстовом ASCII-файле данных и как двухбайтовой целой
величины, использующей порядок "от младшего к старшему",
в двоичном файле данных
Вопросы структурирования
Описывая двоичный формат файла данных, необходи-
мо также рассмотреть размер и байтовый порядок запи-
санных в нем объектов. Размер объекта (например, чис-
ло цифр в целой величине) часто подразумевается в
текстовом файле, но к двоичному файлу это не отно-
сится. Вернемся к целому числу 1850. Как оно записа-
но в файле данных: как два байта, как четыре байта или
как любое другое число байтов? Если проверять файл
последовательно, байт за байтом, то что будет первым —
0x07 или 0x3а? Пока эти детали не будут точно опре-
делены, невозможно достоверно читать и записывать
двоичные файлы.
Двоичные файлы данных более компактны, их мож-
но быстрее читать и записывать. Простую программу,
которая читает и записывает двоичные файлы, оказы-
вается, очень легко написать, хотя, как будет показано
далее, в простой программе существует ряд серьезных
проблем.
Большая проблема двоичных файлов состоит в том,
что их трудно сделать переносимыми. Действительно,
поскольку расположение байтов в файле данных в про-
стейшем случае идентично представлению данных в
памяти, использование простого двоичного файла огра-
ничено, ведь он жестко привязан к архитектуре компь-
ютера и, возможно, к конкретному компилятору, кото-
рый был использован при его создании. На самом деле
можно разработать переносимые форматы файлов дан-
ных, что и будет показано далее в этой главе, но про-
граммы для записи и чтения таких файлов существен-
но сложнее и не всегда столь блистательно эффективны.
Текстовые файлы данных, хотя и немного длиннее
и медленнее при чтении и записи, тем не менее, име-
113
ют ряд существенных преимуществ. Прежде всего, они
удобны для восприятия, а это уже многого стоит. Мож-
но просто посмотреть в текстовый файл данных и уви-
деть его содержимое; при этом нет надобности в спе-
циальных программах просмотра и редактирования, как
в случае с двоичными файлами. Вы можете манипули-
ровать текстовыми файлами данных, используя общие,
не требующие доработок программные средства. Тек-
стовые файлы также более удобны при отладке: если с
файлом данных что-то не так, можно просто заглянуть
в него и немедленно точно определить проблему или в
крайнем случае найти, где ошибается считывающая или
записывающая программа. Другое преимущество заклю-
чается в том, что числовые представления, которые мы
склонны использовать в текстовых файлах данных (т.е.
представления, используемые для записи целых вели-
чин или величин с плавающей запятой), автоматичес-
ки становятся нечувствительными к конкретным осо-
бенностям представлений и размеров этих типов на
различных компьютерах. Поэтому текстовые файлы
данных имеют высокий уровень переносимости.
Программа, необходимая для чтения и записи тек-
стовых файлов данных, не столь проста, как бесхитро-
стная программа для чтения и записи двоичных файлов,
но далее в этой главе вы увидите, как можно сделать ее
достаточно простой. Более того, как уже говорилось,
бесхитростные методы, применяемые для чтения и за-
писи двоичных данных, приводят к тому, что файлы
данных являются непереносимыми. Программа для чте-
ния и записи переносимых двоичных файлов данных яв-
ляется, по крайней мере, настолько же сложной, как и
программа для работы с текстовыми файлами данных.
В большинстве случаев текстовые файлы данных
совершенно адекватны и рекомендуются к использова-
нию. Если отсутствуют какие-либо особенно высокие
требования к эффективности программы, то нет необ-
ходимости тратить усилия для чтения и записи двоич-
ных файлов данных.
Вопросы разработки форматов
Время от времени вы можете наслаждаться (или нести
бремя — когда как) разработкой своих собственных
форматов файлов данных. В таких случаях можете ис-
пользовать либо метод, который кажется вам наиболее
соответствующим задаче, либо тот метод, который пред-
ставляется вам наиболее простым для чтения й записи.
Иногда, однако, формат навязывается вам окружающей
действительностью или спецификацией, и нужно раз-
гадать, каким образом корректно интерпретировать этот
существующий формат. Если вам повезет, формат бу-
дет определен в файле в терминах битов и байтов: "За-
головок сохранен в 4-байтовом поле в порядке "от млад-
шего к старшему", начиная со сдвига 120". Кроме того,
Хранение и извлечение данных
Глава 6
формат может определяться неявно конкретной про-
граммой, выполняющейся на конкретном компьютере
В этом случае для определения всех деталей формата
придется совершить определенное количество обратных
действий, а это может потребовать написания незави-
симой программы, которая могла бы читать й записы-
вать файлы, совместимые с файлами исходной програм-
мы, особенно если новая программа должна
выполняться на другом компьютере.
Очень удобно, если кроме собственно данных, фор-
мат файла данных содержит информацию, касающую-
ся самого файла данных. Например, многие файлы дан-
ных начинаются магическим числом, битовый набор
которого идентифицирует определенный сорт файла
данных и может быть использован считывающей про-
граммой для проверки того, что на входе находится
файл нужного типа. Особенно полезно, если файлы
данных содержат номер версии формата. Таким образом,
если формат файла изменялся, программа может точно
определить, какой формат файла данных используется —
новый или старый. Часто оказывается очень удобным,
особенно в случае с текстовыми файлами данных, если
файл может содержать дополнительные доступные для
чтения пользователем комментарии, которые описыва-
ют файл или собственно данные, но игнорируются про-
граммой, считывающей эти данные.
Полезно также рассмотреть такую определяющую
особенность файлов данных, как способ расположения
в них отдельных фрагментов данных; по этому призна-
ку различаются файлы фиксированного и переменного
форматов. В файле фиксированного формата определен-
ные фрагменты данных записаны в определенном по-
рядке и подразумевается, что позиция фрагмента дан-
ных, по существу, и определяет его. С другой стороны,
в файле переменного формата данные в каждом конк-
ретном случае могут располагаться в различном поряд-
ке, а некоторые данные вообще могут быть опциональ-
ными и не обязательно присутствовать в каждом файле.
Как правило, в файлах данных переменного формата
перед каждым фрагментом данных используется неко-
торого рода явный тег, чтобы недвусмысленно опреде-
лить, что представляют собой эти данные. Файлы дан-
ных переменного формата называются также файлами
данных с самоописанием.
Файлы фиксированного формата, очевидно, являют-
ся несколько менее гибкими. Если когда-либо нужно
добавить в файл новые данные, это можно сделать толь-
ко в конце файла, поскольку в противном случае все
уже существующие файлы станут недействительными,
либо написать некие программы преобразования, кото-
рые смогут иметь дело с различными вариантами.
С другой стороны, файлы переменного формата значи-
тельно более гибки — новые данные можно добавлять
8 Зак. 265
Пересмотренный язык С
114
Часть I
в любом месте и в любой момент. За это, конечно, при-
ходится платить: явно заданный тег, определяющий
фрагмент данных, занимает дополнительное место в
файле.
Текстовые файлы данных часто используют пере-
менные форматы, а двоичные файлы данных обычно
используют фиксированные форматы, но вполне воз-
можно существование текстового файла фиксированно-
го формата и двоичного файла переменного формата.
Основные методы
В этом разделе приведены базовые, низкого уровня ме-
тоды хранения отдельных объектов в файлах данных.
В дальнейшем мы будем использовать их в качестве
"строительных блоков” при написании больших частей
программы для чтения и записи целых файлов данных.
Поскольку методы чтения и записи текстовых и двоич-
ных файлов существенно различаются, они рассматри-
ваются в отдельных разделах этой главы.
Текстовые файлы
Текстовый файл является одним из немногих действи-
тельно повсеместным универсальным общим на всех
платформах объектом в вычислительной технике. По-
истине в каждой компьютерной системе существует по-
нятие "текстовый файл", и, хотя различные системы мо-
гут представлять текстовые файлы немного по-разному,
всегда можно конвертировать текстовые файлы при их
переносе на другой компьютер, даже не зная, какие
именно данные они содержат. Действительно, преобра-
зование формата текстовых файлов осуществляется в
большей или меньшей степени автоматически любой
программой, способной переносить файлы между раз-
нородными компьютерами. Поэтому в наших програм-
мах мы должны тщательно избегать всяческих специфи-
ческих для данной платформы деталей при чтении и
записи текстовых файлов. Следует использовать общую
модель текстового файла, предлагаемую языком С, и
предоставить стандартной библиотеке С и используе-
мой операционной системе заботиться о деталях, свя-
занных со спецификой конкретной платформы.
Специфика различных платформ
Основным различием текстовых файлов на различных
платформах является представление конца строки. Си-
стема UNIX обрывает строку в текстовом файле, исполь-
зуя один символ перевода строки (LF — linefeed); MS-
DOS и Microsoft Windows используют пару "перевод
каретки/конец строки" (CRLF — carriage-retum/linefeed).
Возможно, с целью отличиться, система Macintosh ис-
пользует только перевод каретки. Вне зависимости от
представления конца строки в используемой операци-
онной системе, внутри программы С новая строка все-
гда обозначается одним символом *\п'. При записи тек-
стового файла конец строки обозначается написанием
символа '\п‘, и, увидев *\п* при чтении файла, мы зна-
ем, что достигли конца строки. Стандартная библиоте-
ка С преобразует *\п' в представление конца строки,
принятое в данной операционной системе, и можно
обычно полагать, что программа переноса файлов забо-
тится о преобразовании представления конца строки, а
также других деталей формата текстового файла при
переносе файлов данных с одного компьютера на дру-
гой. Поэтому обычно при работе с текстовыми файла-
ми можно просто не обращать внимания на этот тип
особенностей различных платформ.
Различные используемые наборы символов являют-
ся еще одной зависящей от конкретной платформы про-
блемой общих текстовых файлов. Файлы данных, кото-
рые не содержат множества строк, пригодных для
чтения пользователем, не вызывают особого беспокой-
ства по поводу различий в наборах символов, и любое
преобразование (возможно, между ASCII и EBCDIC,
если в этом есть необходимость) может осуществлять-
ся внешними программами, подобными утилитам для
переноса файлов между системами. Если же файл дан-
ных действительно содержит удобные для чтения стро-
ки и особенно если строки содержат не международные
ASCII-символы, проблема различия наборов символов
может оказаться значительной. Однако полное рассмот-
рение различных международных наборов символов
выходит за рамки данной главы.
Представление данных
Основным представлением числовых данных в тексто-
вом файле является строка цифр. Строки цифр, пред-
ставляющие числовые величины, очень просто генери-
ровать, это именно то, что делает оператор printf с
форматами %d или %f. Действительно, использовать %d
в printf для создания строки цифр, которая соответствует
целому числу, настолько просто, что легко забыть, на-
сколько большая разница имеется, например, между
целым числом 1850 и строкой цифр 1 8 5 0. Именно эта
разница существенна для понимания отличий между
текстовым и двоичным форматами.
Запись в текстовые файлы данных
Запись текстовых файлов данных обычно осуществля-
ется исключительно наглядно и просто. Для записи
данных в файл используются функции printf или fprintf
в любом выбранном формате. (Некоторые примеры бу-
дут приведены далее в этой главе.) При чтении данных
существует несколько возможностей — можно попробо-
вать использовать функции scanf или fscanf логически
противоположные функциям printf и fprintf, либо мож-
Хранение и извлечение данных
Глава 6
115
но считывать текст из файла по символу или по строке
и преобразовывать выбранные числовые данные, ис-
пользуя такие функции, как atoi, atoi, atof, strtol, strtod
и, может быть, sscanf. (Функция scanf имеет заслужен-
но плохую репутацию с точки зрения пригодности ее
для устойчивой работы при интерактивном вводе дан-
ных пользователем, но функции fscanf и sscanf могут
прекрасно подойти для чтения файлов данных при ус-
ловии, что возвращаемые ими значения будут прове-
ряться).
Числовые данные
Рассмотрим, например, файл данных фиксированного
формата, содержащий в первой строке целое число, во
второй строке — число с плавающей точкой и в третьей
строке — целое число, целое число типа long int и чис-
ло с плавающей точкой, подобные приведенным ниже
123
456.789
1234 567890 123.456
Существует несколько способов чтения этих различ-
ных переменных. (В следующих ниже фрагментах про-
граммы предполагается, что переменная ifp во всех слу-
чаях содержит указатель на поток, открытый для чтения
файла данных.)
Чтобы прочесть число в первой строке, мы можем
написать:
int 11;
fscanf(ifp, "%d", 611) ;
Либо можно прочесть строку с использованием фун-
кции fgets, а затем преобразовать целое число с помо-
щью функции atoi:
fdefine MAXLIKE 100
char line[MAXLINE];
fgets(line, MAXLINE, ifp);
il = atoi (line) ;
(Естественно, для MAXLINE должна быть выбрана
значительная величина; 100 — это просто пример. Вме-
сто atoi можно использовать функции strtol или sscanf,
что и сделано в следующих примерах.)
Для чтения второй строки можно написать:
float fl;
fscanf(ifp, "%f", 6f 1) ;
Можно также прочесть эту строку, используя фун-
кцию fgets, а затем преобразовать число с помощью
функции strtod:
fgets (line, MAXLIKE, ifp) ;
fl = strtod(line, KULL);
Вместо strtod можно использовать функции atof или
sscanf.
Для считывания третьей строки можно написать:
int i2; long int 13; double f2;
fscanf (ifp, "%d %ld %lf", 612, 613, 6f2) ;
Можно также прочесть это строку с помощью фун-
кции fgets и преобразовать три числа, используя sscanf:
fgets(line, MAXLIKE, ifp);
sscanf (line, "%d % Id %lf", 612, 613, 6f2) ;
Либо, прочитав строку, преобразовать числа по од-
ному, используя функции strtol и strtod:
char *р;
i2 = strtol(line, бр, 10);
i3 = strtol (p, 6p, 10);
f2 = strtod (p, NULL);
Поскольку функции strtol и strtod могут возвращать
во втором аргументе указатель на символ, следующий
за последним преобразованным символом, можно не-
посредственно соединить вместе последовательность
преобразований нескольких соседних чисел из одной и
той же строки. Кроме того, имеется и другая опция
(описанная в разделе "Файлы, в качестве разделителей
использующие символы пробела или табуляции"), ко-
торая делит строку на разделенные пробелами "слова"
и работает с каждым компонентом отдельно.
Существует несколько вполне очевидных правил,
устанавливающих, какое из приведенных альтернатив-
ных преобразований предпочесть. Часть этих правил
зависит от личных предпочтений, часть связана с обра-
боткой ошибок (это мы еще не рассматривали), а часть
действительно произвольна. Существенным элементом
выбора является решение о том, будет ли ввод построч-
ным или будет иметь свободную форму. Функция scanf
отлично работает с вводом в произвольной форме, по-
скольку в большинстве случаев рассматривает символ
новой строки как очередной разделительный символ
пробела. Для чтения построчного ввода обычно удобно
прочитать всю строку, используя функцию fgets или
эквивалентную ей, после чего разобрать считанную стро-
ку. Эта двухшаговая стратегия особенно полезна, если
формат файла содержит необязательные или альтерна-
тивные элементы, когда необходимо четко определить
реакцию на ошибки в попытках чтения или разбора
строки путем чтения с использованием альтернативной
стратегии либо выдачи сообщения об ошибке.
В предыдущих фрагментах мы рассматривали дан-
ные типов int, long int, float и double. (Заметим, что i3
имеет тип long int, a f2 — тип double.) Из-за неявных
преобразований, осуществляемых С, можно использо-
вать формат %ff для печати величин типа float или
double, функцию strtol — для преобразования величин
типа int или long int и функцию strtod — для преобра-
зования величин типа float или double. Но, вообще, сле-
дует быть аккуратным и точно определять тип: напри-
Пересмотренный язык С
Часть I
116
мер, необходимо сочетать %d с типом int и %ld — с ти- пом long int для функций printf и scanf. Подобно этому %f соответствует типу float, a %If — типу double при ис- пользовании функции scanf. В следующей таблице представлены некоторые фор- маты, употребляемые с функциями printf и scanf, а так- же другие функции преобразования, соответствующие основным типам данных:
Тип данных формат printf Формат scanf Другие функции
char %c %c -
short int %d %hd atoi, strtol
int %d %d atoi, strtol
long int %ld %ld atol, strtol
float %e, %f, %g %f atof, strtod
double %e. %f, %g %lf atof, strtod
string %s - -
Если в файле данных нужно сохранить переменную
без знака, можно использовать форматы %и или %1п
либо функцию strtoul. Можно также использовать аль-
тернативную десятичной систему счисления, применяя
форматы %о или %х либо определив в функциях strtol
или strtoul третьим аргументом не 10, а другое число.
Строковые данные
Оперировать строками нужно еще более аккуратно.
Напечатать их можно, просто используя %s, но в фун-
кции scanf использовать формат %s можно не всегда,
поскольку при этом считывание остановится на первом
же символе пробела. Другими словами, строки, которые
могут содержать пробел, нельзя считывать, используя
только один спецификатор формата%§ с одной из scanf-
функций. Считывая из файла данных строку, которая
может содержать символ пробела, нужно либо исполь-
зовать несколько более сложный спецификатор форма-
та (обычно это %[...]), либо вообще не использовать
функции семейства scanf.
Дата и время
Дата/время является одним из типов данных, который
ставит вопрос: как сохранять их в файле данных. Язык
С определяет стандартный тип time_t для представле-
ния времени и даты, и, поскольку time t обычно (но не
всегда!) является величиной long int, может показаться
заманчивым сохранять исходную величину time t как
long int, возможно используя %ld. Однако этого не сто-
ит делать, поскольку такие действия приведут к друго-
му типу непереносимости файла данных: если когда-
либо этот файл данных будет читаться на компьютерах,
операционная система или стандартная библиотека С
которых используют различные определения time_t,
метки времени в файле данных не будут иметь смысла.
Наилучшим способом хранения дат и времени, если
придерживаться философии данного раздела, является
использование формата, не зависящего от платформы.
Для текстового файла естественно использовать недвус-
мысленный, но удобный для восприятия формат; в рас-
сматриваемом случае можно выбрать один из вариантов
стандарта ISO 8601. Ниже в качестве примера представ-
лена небольшая функция для записи величины time_t
в файл в стандарте ISO 8601 — предлагаемый комби-
нированный формат даты/времени. Вся работа выпол-
няется библиотечной функцией С strftime:
#include <stdio.h>
linclude <time.h>
void
timetprint(time t t, FILE *ofp)
{
char buff25];
struct tm *tp = localtime(&t);
strftime(buf, sizeof(buf), "%Y-%m-%dT%H:%M:%S",
wtp);
fputs(buf, ofp);
1
Эта функция запишет время 12:34:56 и дату 10 мар-
та 2000 года как 2000-03-10Т12:34:56.
Чтобы при чтении файла данных конвертировать
одну из этих строк обратно в time t, можно написать
функцию, основанную на стандартной библиотечной
функции mktime:
time_t
timetparse(char *str)
{
int y, mo, d;
Хранение и извлечение данных
Глава 6
117
int h, nr s = 0;
struct tm tm = {0};
if(sscanf(str, "%d-%d-%dT%d:%d:%d" r &mo, &d, &hr &m, &s)
< 5 && sscanf(str, "%4d%2d%2dT%2d%2d%2d",
&y, Mbo, &d, &h, fcm, &s) < 5)
return (time_t)(—1)7
tm.tm year = у - 1900; tm.tm_mon = mo - 1; tm.tm_mday = d;
tm.tm_hour = h; tm.tm_min = m; tm.tm_sec e s;
return mktime(&tm);
)
Эта функция достаточно устойчива: кроме формата,
генерируемого timetprint, может быть считано сжатое
представление с игнорированием излишней пунктуа-
ции, также допустимое в стандарте ISO 8601. В другом
случае можно пропустить секунды и полагать их рав-
ными нулю.
При таком представлении функции timetprint и
timetparse работают с локальным временем данной вре-
менной зоны. Часто, особенно в форматах обмена дан-
ными, предпочтительнее использовать не зависящее от
временной зоны время, так называемое время GMT. К
сожалению, это будет несколько сложнее, поскольку в
стандартной библиотеке С для этого нет всех необхо-
димых средств. (Можно использовать gmtime вместо
localtime в timetprint, но, к сожалению, стандартный
аналог mktime, использующий GMT, недостаточно
широко распространен.)
Смешанные форматы
Мы заканчиваем этот раздел чуть более сложным (хотя
и несколько искусственным) примером. Предположим,
мы хотим записать единичное целое число, массив,
включающий до 10 целых чисел, и такую структуру:
struct s
{
int i;
float f;
char str[20];
1;
в один файл данных, используя методы фиксированного
н изменяемого форматов. В принципе, подобное смеше-
ние таких данных очень нежелательно. Здесь мы при-
меним эти два метода исключительно для того, чтобы
продемонстрировать их одновременное использование.
Первая строка файла данных содержит слово
sampdata для определения формата файла данных и
номер версии формата. Вторая строка содержит одиноч-
ное целое число. В третьей строке расположен массив,
содержащий до 10 целых чисел, которые записаны в
одной строке и разделены пробелами. Оставшаяся часть
файла содержит элементы структуры, по одному на
строку, в начале каждой строки находится идентифи-
катор, соответствующий имени элемента структуры.
Например, весь файл данных может выглядеть следую-
щим образом:
sanpdsta 1
42
1 2 3 10 9 8
i 100
f 3.14
str Hello, world!
Цифра 1 в конце первой строки обозначает версию
формата данных №1. Массив в третьей строке в момент
записи данных в файл содержал, очевидно, шесть эле-
ментов.
Ниже приведена функция для записи такого файла.
Функция принимает в качестве аргумента поток (FILE *),
который мы предполагаем открытым для записи данных
в файл; за открытие файла отвечает вызывающая про-
грамма. Функция также принимает три порции данных
для записи. Массив а дополнен параметром па, обозна-
чающим число элементов в массиве.
void txtwrite (FILE *ofp, int i, int a[] ,
**int na, struct s *s)
{
int j;
fprintf(ofp, "sampdata %d\n", 1);
fprintf(ofp, "%d\n", i);
for(j “0; j < na; j++)
fprintf(ofp, "%d ", a(j]);
fprintf(ofp, "\n");
fprintf(ofp, "i td\n", s->i);
fprintf(ofp, "f %g\n", s->f);
fprintf(ofp, "str %s\n", s->str);
}
Функция абсолютно ясна: для записи данных в файл
в ней используется только последовательность вызовов
fprintf. Чтобы записать величины с плавающей точкой
в файл данных, подойдет формат %е или %g, но, если
нужна высокая точность, ее можно увеличить путем
использования формата %. 10g. Заметим, что соответ-
ствие между тегом в файле данных и именем элемента
структуры явно задано в вызовах fprintf в формате строк.
Пересмотренный язык С
Часть I
118
Не существует способа, позволяющего указать компи-
лятору автоматически вставлять имена элементов струк-
туры в файл данных.
Чтение данных из такого файла не намного сложнее:
выполняющая чтение функция приведена в листинге
6.1. Как и в предыдущем случае, она принимает указа-
тель на файл данных, который надо прочесть; в данном
случае — указатель на файл, открытый для чтения. Па-
раметры i и па передаются как указатели (это принятая
в С форма "передачи через ссылку"), т.е. функция мо-
жет вернуть вызывающей программе их новые значения.
(Параметр па доступен и для чтения, и для записи:
на входе в функцию он содержит значение максималь-
ного размера массива для хранения считываемых дан-
ных, а на выходе из функции — число элементов мас-
сива, считанных из файла.)
Листинг 6-1. Функция txtreadQ для чтения текстового файла данных.
♦define MAXLINE 100
♦define TRUE 1
♦define FALSE 0
int txtread(FILE * *ifp, int *i, int a[], int *na, struct s *s)
{
. char line[MAXLINE], tmpstr[10];
int j;
char *p, *p2;
if(fgets(line, sizeof(line), ifp) 3= NULL)
return FALSE;
if(sscanf(line, "tlOs td", tmpstr, Kj) != 2 ||
strcmp(tmpstr, "sampdata") 1» 0)
return FALSE; /* онибка в формате файла давних */
if(j 1= 1)
return FALSE; /* несовпадение номера версии */
if(fgets(line, sizeof(line), ifp) == NULL)
return FALSE;
*i = atoi(line);
/* читает и анализирует строку массива */
if(fgets(line, sizeof(line), ifp) яя NULL)
return FALSE;
for(j 3 0, p 3 line; j < *na Ь* *p !« '\0'; j++, рзр2)
{
a(j] = strtol(p, &p2, 10);
if(p2 =» p)
break;
}
*na 3 j;
/* осталась часть файла переменного формата */
while(fgets(line, sizeof(line), ifp) 1* NULL)
/* отделяем тег от данинх */
р я strpbrk(line, " \t");
if(р 33 HULL)
continue;
*p++ 3 '\0'; .
p += strspn(p, \t");
/* p сейчас является указателем иа давние */
/* тег отделен в начале строки */
if(strcmp(line, "i") 33 0)
s->i = atoi(p);
else if(strcmp(line, "f") яя 0)
s->f 3 atof(p);
else if(strc*p(line, "str") яя 0)
{
if((p2 3 strrchr(p, '\n')) I3 NULL)
*p2 3 '\0';
strncpy(s->str, p, sizeof(s->str));
}
/* игнорируем неопознанное поля */
}
return TRUE;
Хранение и извлечение данных
Глава 6
119
Представленная в листинге 6.1 программа также в
основном прозрачна, но стоит обратить внимание на не-
которые моменты. Функция возвращает FALSE (т.е.
нуль) при серьезных ошибках в файле данных, таких
как ошибка в номере версии. Строка, содержащая эле-
менты массива (вторая строка),-анализируется путем
повторных вызовов strtol Это дополнительная провер-
ка удаления замыкающих \п во вводимой строке, по-
скольку fgets оставит их на месте. Обработка ошибок в
этой функции не является исчерпывающей; при этом
тихо игнорируются такие возможные ошибки, как не-
числовые данные во второй и третьей строках или пло-
хо отформатированные данные в части переменного
формата. В своей собственной программе вы можете
ввести более строгую проверку ошибок.
Наиболее интересным моментом в данной програм-
ме является анализ данных переменного формата. Для
каждой строки при нахождении первого символа про-
бела в начале строки выделяется тег и оставшаяся часть
строки рассматривается как данные. Если программа не
может опознать тег, она не выдает ошибки; предпола-
гается, что неопознанный тег представляет данные, от-
носительно которых программе ничего неизвестно и
которые можно благополучно игнорировать. Разделение
тега и данных "вручную" функцией strpbrk несколько
неудобно; в разделе "Файлы, использующие раздели-
тельные символы пробела или табуляцию" будет пока-
зан более простой способ обработки данных, разделен-
ных пробелами.
Анализ данных переменного формата, выполняемый
данной программой, более устойчив, чем это нужно: тег
и данные могут разделяться произвольным количеством
символов пробела и табуляции. С другой стороны, по-
добная стратегия приводит к тому, что сохраненная
строка не может содержать символы пробела в начале
строки и будет прочитана таким же образом. Кроме того,
условие игнорирования неопознанных данных приме-
нимо не во всех случаях, так что над этим вопросом вы
можете поразмыслить сами при создании собственного
файла данных.
Еще несколько слов следует сказать об обработке
ошибок при считывании файлов данных. Поскольку
файлы данных происходят из "реального мира", следу-
ет учитывать возможность ошибок в них, и не имеет
значения, насколько вы верите, что ваша собственная
совершенная программа создает эти файлы для чтения.
Очень некрасиво со стороны программы давать сбой из-
за искаженного входного файла. Программа чтения фай-
лов данных должна проводить достаточное количество
разумных проверок, чтобы вывести содержательное со-
общение об ошибке при столкновении с неверно отфор-
матированным файлом. Если в вашей программе чтения
или проверки файла данных используются функции
scanf, основной метод проверки (который следует счи-
тать обязательным) будет состоять в проверке возвраща-
емого значения функции scanf, чтобы выяснить, все ли
ожидаемое число переменных преобразовано.
В этом разделе мы продемонстрировали вам все не-
обходимые методы для достаточно удобной записи и
чтения текстовых файлов данных. Нетрудно видеть, что
схема работы с тегированными данными в файле дан-
ных переменного формата, по сути, совпадает со схе-
мой обработки командной строки или исполняемых
командных файлов: первое "слово” в строке информи-
рует о том, что представляет собой эта строка, а осталь-
ная часть строки содержит "аргументы", рассматривае-
мые в контексте первого слова. Иными словами, чтение
и интерпретация такого вида данных требует почти та-
ких же программ, какие обычно используются для ин-
терпретации простых командных файлов и простых
конфигураций файлов типа "команда/аргумент" или
"тег/величина".
Следует тщательно проанализировать, насколько
текстовые файлы данных соответствуют перечисленным
в начале этой главы требованиям. Данные файлы, не-
сомненно, переносимы, и программы для их чтения и
записи написать не слишком сложно. Но следует при-
знать, что они обычно не столь компактны, какими
могут быть двоичные файлы, и нс всегда столь же эф-
фективны в случае чтения или записи. . Дисковое про-
странство становится все дешевле, поэтому размер файла
можно считать некритичным параметром, но скорость
ввода/вывода имеет существенное значение, особенно
для файлов больших размеров. Если важен критерий
эффективности и при этом необходимо использовать
текстовые файлы данных, возможно, имеет смысл ис-
пользовать шестнадцатеричные форматы (%х) вместо
десятеричных (%d). Это связано с тем, что различные
преобразующие функции могут осуществлять шестнадца-
теричные преобразования быстрее, чем десятеричные,
требующие деления и умножения на 10. Для чисел с пла-
вающей запятой в стандарте С99 существует новый шест-
надцатеричный формат с плавающей запятой — %а.
Другим существенным моментом при работе с боль-
шими текстовыми файдами данных (или любыми боль-
шими файлами переменного формата) является простой
поиск требуемой информации. Один из путей, позво-
ляющих избежать последовательного поиска по всему
большому файлу, — это использование индекса, кото-
рый может сохраняться как в этом же, так и в отдель-
ном файле. Подобный пример будет рассмотрен в этой
главе далее в разделе "Индексная адресация".
Двоичные файлы
Двоичные файлы мы будем рассматривать в том же
порядке, что и текстовые файлы в предыдущем разде-
120
Пересмотренный язык С
Часть I
ле. Вы обнаружите несколько схожих черт, но в основ-
ном двоичные файлы разительно отличаются от тексто-
вых, так же как и программы, которые мы напишем для
работы с ними.
При работе с двоичными файлами в первую очередь
их нужно правильно открывать. Поскольку эти файлы,
по определению, нетекстовые, нет нужды использовать
стандартную библиотеку С для преобразования симво-
лов перевода каретки или окончания строки. Нет необ-
ходимости также рассматривать символ Control-Z как
символ окончания файла в MS-DOS или Microsoft
Windows. Чтобы библиотека stdio не делала преобразо-
ваний таких символов, необходимо открывать файл в
двоичном режиме, включив символ b в строку режима
открытия файла, которая является вторым аргументом,
передаваемым функции fopen. Таким образом, чтобы
открыть файл для чтения, нужно использовать rb, а что-
бы открыть его для записи, нужно использовать wb.
В качестве отправной точки (но не в качестве реко-
мендуемой процедуры) рассмотрим сначала некоторые
упрощенные методы осуществления двоичного ввода/
вывода. Эти методы действительно просты и использу-
ют функции fread и fwrite. Обе эти функции принима-
ют указатель на некоторые данные, размер объекта дан-
ных, количество элементов данных и указатель потока.
Эти функции предназначены для прямого копирования
байтов данных из файла в память и обратно. Их можно
использовать и с текстовыми файлами, но чаще всего
они используются именно с двоичными файлами.
- Целую величину i можно записать в двоичный файл,
записав вызов следующим образом:
fwrite(£1, sizeof(int), 1, ofp) ;
Целочисленный массив агг, который содержит па
элементов, можно записать, вызвав функцию:
fwrite(arr, sizeof(int), na, ofp);
Структуру s можно записать, выполнив вызов:
fwrite(&s, sizeof(s), na, ofp);
В каждом из этих примеров sizeof используется для
вычисления в байтах размера записываемого объекта
данных; этот размер является вторым аргументом фун-
кции fwrite. Первый аргумент представляет собой ука-
затель на записываемые данные, а третий аргумент со-
ответствует количеству записываемых элементов.
Процесс чтения данных тоже очень прост. Три вы-
зова fread, соответствующие вызовам fwrite, могут вы-
глядеть таким образом:
fread(&i, sizeof(int), 1, ifp);
na = fread(arr, sizeof(int)r 10, ifp);
fread(&s, sizeof(s), na, ifp);
(Во второй строке предполагается, что размер мас-
сива агг объявлен равным 10, а переменная па предназ-
начена для хранения количества считанных элементов.)
Очень хорошо, что вызовы функций fwrite и fread
легко выполнять в программе. Но при этом плохо, что
созданные таким образом файлы имеют низкий уровень
переносимости. Поскольку расположение данных в
файле один-к-одному повторяет индивидуальную
структуру этих данных в памяти компьютера, то струк-
тура файла полностью зависит от любых особенностей
платформы. Число байтов, необходимое для записи
объектов таких типов, как int и float (как и любых дру-
гих типов), может быть различным для разных компь-
ютеров. В величинах, состоящих более чем из одного
байта, может также варьироваться порядок байтов: в
компьютерах с порядком "от старшего к младшему" байт
наивысшего порядка записывается в памяти первым и
соответственно запишется первым в файл, а в компью-
терах с порядком "от младшего к старшему" все будет
наоборот. Большинство компьютеров для отрицатель-
ных чисел используют представление "дополнение до
двух", однако теоретически возможны представления
"дополнение до единицы" и "знак-величина". Форматы
с плавающей точкой до сих пор имеют множество от-
личий: кроме размера и порядка байтов, различные ком-
пьютеры распределяют различное количество битов
для дробной части и показателя степени, а некоторые
компьютеры используют десяте- или шестнадцатирич-
ную систему счисления. Во многих машинах действи-
тельно используются форматы IEEE-754 с плавающей
запятой, но ведь не во всех. Кроме того, что касается
собственно структуры, различные компиляторы распо-
лагают различное количество заполняющих символов меж-
ду элементами, чтобы соответствующим образом выров-
нять их для более эффективного доступа. Таким
образом, в зависимости от компилятора общий размер
структуры, содержащей одни и те же элементы и в од-
ном и том же порядке, часто бывает различным для
разных компьютеров.
Различия в размере объекта, в порядке байтов, в
формате с плавающей точкой и структуре заполнения
приводят к тому, что двоичные файлы, записанные с
использованием функции fwrite на одном конкретном
компьютере и с помощью одного конкретного компи-
лятора, могут не читаться на другом. Очевидно, возник-
нут проблемы, если этот другой компьютер использует
другой размер слова или другой порядок байтов или
если компилятор на этом компьютере заполняет свобод-
ные места в структуре иным образом. Но те же самые
проблемы могут возникнуть и без переноса на другую
машину, просто при использовании другого компиля-
тора на той же машине или другой версии этого же ком-
пилятора, или даже того же самого компилятора, но при
121
вызове его с другим набором параметров. Подводя итог,
можно сказать, что если файл данных должен быть пе-
реносимым, то методы чтения и записи по типу "ах как
просто" с использованием функций (read и fwrite в об-
щем случае неприменимы.
Можно сделать так, чтобы чтение и запись двоич-
ных файлов обладали переносимостью, но при этом
необходимо осуществлять более прямой контроль запи-
си и чтения каждого отдельного байта, а не доверять
делать это компилятору. К сожалению, если записывать
и считывать файл данных побайтово, то несколько те-
ряется простота программы и те преимущества в скоро-
сти чтения/записи, которые в первую очередь и привле-
кают в двоичных файлах.
Но основной метод как раз и заключается именно в
обработке данных по одному байту. Например, предпо-
ложим, что нужно записать величину int в переносимый
файл данных. Сначала нужно выяснить, сколько бай-
тов займет эта величина в файле и в каком порядке бай-
ты будут расположены. (Это необходимо сделать, по-
скольку основная идея заключается в том, чтобы не
позволять компьютеру или компилятору делать это за
нас с вами.) Предположим, мы решили, что перемен-
ная типа int будет представлена в двух байтах файла
данных в порядке "от младшего к старшему", т.е. наи-
менее значимый байт идет первым. Тогда запись вели-
чины int можно осуществить следующим образом:
putc(x & Oxff, ofp);
putc((i » 8) & Oxff, ofp);
В выражении i & Oxff выделяется младший байт, а в
выражении (i >> 8) & Oxff — следующий старший байт.
Здесь необходимо отметить, что, во-первых, эти байты
выделяются на основе их арифметического значения, а
не их относительного (зависящего от компьютера) по-
ложения в памяти. Во-вторых, при таком подходе не
имеет значения, каков истинный диапазон значений int
на данном конкретном компьютере. Наш гипотетичес-
кий переносимый формат файла данных определяет,
что размер этой конкретной целой величины в файле
составляет два байта и — точка.
Если нужно записать двухбайтовую целую величи-
ну в порядке "от старшего к младшему", то необходимо
сделать следующие очевидные изменения:
putc((x » 8) & Oxff, ofp) ;
putc(i & Oxff, ofp);
Хотя мы постоянно говорим о проблемах переноси-
мости и хотя этот основной метод записи двоичных
файлов выглядит неплохо, необходимо признать, что он
неидеален для записи отрицательных чисел, поскольку
при этом файлу данных навязывается машинное пред-
ставление отрицательных величин ("дополнение до еди-
ницы", "дополнение до двух" или "знак-величина").
Хранение и извлечение данных
Глава 6
Резонно определить формат файла данных с использо-
ванием представления "дополнение до двух", но тогда
чтение и запись файлов на компьютерах, использующих
представления "дополнение до единицы" и "знак-вели-
чина", потребуют дополнительной программы, которая
выполняла бы необходимое преобразование.
Считывать двухбайтовые целые величины столь же
просто. Нужно только соблюдать аккуратность при чте-
нии байтов в требуемом порядке для составления их
вместе. Для чтения двух байтов в порядке "от младше-
го к старшему" можно использовать такую запись:
х = getc(ifp);
i |= getc(ifp) « 8;
А для чтения двух байтов в порядке "от старшего к
младшему" используем следующие выражения:
х = getc(ifp) « 8;
х |= getc(ifp);
Заметим здесь, что соединять эти два фрагмента в
одно выражение нельзя. Например,
х = getc(ifp) | (getc (ifp) « 8) ;
/* НЕПРАВИЛЬНО */
Действительно ли это выражение пригодно для чте-
ния целых величин "от старшего к младшему" или "от
младшего к старшему"? Ответ зависит от того, какой из
двух вызовов функции getc будет осуществлен первым,
и, в свою очередь, оказывается, что компилятор может
расположить их в любом порядке. В языке С в общем
случае не гарантируется, что выражение выполняется
слева направо.
Используя предыдущие фрагменты программ как
примеры, легко увидеть, как читать и записывать дан-
ные других типов. Вот программа для записи 4-байто-
вого целого числа i2 с использованием порядка "от
младшего к старшему":
putc(i2 & Oxff, ofp);
putc((i2 » 8) & Oxff, ofp);
putc((i2 » 16) & Oxff, ofp);
putc((i2 » 24) & Oxff, ofp);
А вот программа, считывающая это число:
12 = getc(ifp);
i2 |= (unsigned long)getc(ifp) « 8;
i2 |= (unsigned long)getc(ifp) « 16;
i2 |= (unsigned long) getc (ifp) « 24;
(Все три приведения к типу (unsigned long) нужны,
чтобы избежать потери точности и ненамеренного пе-
реноса знака в промежуточных результатах.)
До сих пор мы рассматривали целые величины, но
как в двоичные файлы данных можно записывать вели-
чины других типов? Символы должны быть записаны
как символы, строки могут быть записаны либо с ну-
лем в качестве признака окончания строки, как в С, либо
122
Пересмотренный язык С
Часть I
строке может предшествовать ее длина, сохраненная в
1- или 2-байтовой величине, либо строка может быть
приведена к фиксированному размеру. (Как мы упоми-
нали ранее, наборы международных символов могут
создавать особые проблемы для строковых данных.)
Основной способ чтения или записи структуры заклю-
чается в отдельной обработке каждого элемента с при-
менением приемов, пригодных для типа каждого эле-
мента. В общем случае мы не должны беспокоиться о
сохранении указателей в файлах данных. Так практи-
чески никогда не делают, поскольку нет никакой гаран-
тии, что данные, на которые ссылается указатель, во-
обще будут присутствовать в памяти и будут находиться
на том же месте, когда файл данных будет считываться
программой позже.
В предыдущем разделе мы упоминали о возможнос-
ти рассмотрения данных время/дата отдельно, поэтому
имеет смысл рассмотреть этот вопрос также в контек-
сте двоичных файлов. В двоичном файле даже более
заманчиво сохранять величину time_t как необработан-
ное целое число. Нов двоичных файлах делать это осо-
бенно опасно — и это кроме того, что time t вообще
может оказаться не целой величиной. Многие величи-
ны time_t, использующиеся в современных компьюте-
рах, являются 32-битовыми целыми, которые отсчиты-
вают секунды от начала некоей ’’эпохи” (1 января 1970
года для UNIX), и эти величины "закончатся” где-то
около 2040 года. Поэтому большинство компьютеров,
вероятно, будут использовать 64-битовые метки време-
ни, но в качестве наследия будет все еще множество
форматов файлов данных, отводящих метке дата/врсмя
только 32 бита. Это будет проблемой 2038 года, столь
же неприятной, как и проблема 2000 года, которую мы
недавно миновали, и на нынешних программистов бу-
дет взвалена вина происхождения этой проблемы из-за
того, что было отведено только 4 байта метке дата/вре-
мя. Для избавления ваших последователей от бремени
такой вины (и поддержания своей репутации), убеди-
тесь, что ваши форматы файлов данных не ограничи-
вают размер величин типа timet, и хотя для сегодняш-
них задач они полностью отвечают требованиям и бу-
дут соответствовать им в ближайшем будущем, но уже
очень скоро такого соответствия не будет.
Что же можно реально сделать, особенно если ком-
пьютеры, на которых мы работаем сейчас, по-прежне-
му используют 32-битовую временную метку? Одной из
возможностей является заказ большего, чем необходи-
мо. количества байтов в файле данных, и написание
программ чтения и записи таким образом, чтобы их
работоспособность автоматически сохранялась при пе-
реносе их на компьютеры, где величина time_t занима-
ет больше 32 битов. Например, поле длинной 6 байтов
содержит 48 битов, или 248 секунды, что больше девяти
миллионов лет. Запись такого расширенного формата
мы покажем далее в этом разделе.
Возможно, наиболее тонкого подхода требует сохра-
нение в двоичных файлах данных величин с плавающей
точкой. Недостаточно определить только размер и по-
рядок следования байтов, так как само понятие "поря-
док байтов" в данном случае не столь же прозрачно, как
для целых величин. Различные компьютеры использу-
ют совершенно разные форматы для величин с плава-
ющей запятой, в этих форматах предусмотрено различ-
ное количество битов для представления экспоненты и
дробной части. Хотя форматы 1ЕЕЕ-754 широко рас-
пространены, они не универсальны. По аналогии с толь-
ко что показанным для целых величин подходом мож-
но использовать подробно определенный формат
величин с плавающей точкой и процедуру преобразо-
вания между этим форматом и машинным форматом
при чтении и записи. Как это сделать, используя фор-
мат IEEE-754, будет видно из следующего примера.
Собрав воедино все эти идеи, покажем, как можно
записывать и читать двоичную версию файла данных,
использованного в качестве примера в разделе "Тексто-
вые файлы". (Напомним, что в этом файле находятся
магическое число, номер версии, целая величина, мас-
сив целых чисел и структура.) Ниже приведена функ-
ция для записи таких данных в двоичный файл данных:
void binwrite(FILE *ofp, int i, int a[], ^nt na» struct s *s)
{
int j;
putint(12543r ofp); /* магическое число */
putc(lr ofp); /* номер версии */
putint(ir ofp);
putint(naf ofp);
for(j e 0; j < na; j++)
putint(a[j], ofp);
putc('i'r ofp); putint(s->if ofp);
putc('f'r ofp); putfloat(s->f, ofp);
putc('s'r ofp); fwrite(s->str, 1, 20, ofp);
Хранение и извлечение данных
Глава 6
123
При записи текстового файла данных для выполне-
ния основной работы можно было использовать функ-
цию fprintf из стандартной библиотеки. Что касается
переносимых двоичных файлов данных, то здесь ситу-
ация складывается не так удачно. Можно переложить
основную часть работы на собственные функции putint
и putfloat, которые мы сейчас вам покажем.
Чтение двоичных файлов производится аналогично:
int binread(FILE *ifpf int *if int a(}r int *nar struct s *s)
{
int x, x2, j, j2, tag;
if(1getint(&xv ifp) 11 x !« 12543) /♦ магическое число */
return FALSE;
if((x = getc(ifp)) == EOF || x 1= 1) /* номер версии ♦/
return FALSE;
getint(i, ifp);
getint(&x, ifp);
for(j я j2 « 0; j < x; j++)
{
getint(&x2, ifp);
if(j2 < *na) a(j2++] « x2;
}
♦na = j2;
/♦ осталась часть переменного формата ♦/
while((tag » getc(ifp)) 1» EOF)
{
switch(tag)
{
case 'i':
getint(£s->i, ifp);
break;
case ' f':
getfloat(&s->f, ifp);
break;
case 's':
fread(s->str, 1, 20, ifp);
break;
/♦ неопознанные поля игнорируются ♦/
}
}
return TRUE;
Здесь снова основную работу выполняют функции
getint и getfloat.
Функции putint и getint достаточно просты в напи-
сании; все детали работы функции putint полностью
видны, а для функции getint нужно только добавить
небольшой код для проверки на ошибки.
void putint (int i, FILE *ofp)
{
putc(i £ Oxff, ofp);
putc((i » 8) & Oxff, ofp);
}
int getint(int *ipr FILE *ifp)
{
int i;
int c;
if((c « getc(ifp)) == EOF) •
return FALSE;
i “ c;
if((c - getc(ifp)) «« EOF)
return FALSE;
i Iя c « 8;
♦ip « i;
return TRUE;
А сейчас обратимся к данным с плавающей точкой.
Ниже приведена упрощенная реализация функции для
записи переменных С с плавающей точкой в переноси-
мый двоичный файл данных. Эта функция записывает
четыре байта в единичный формат IEEE-754, причем
младший байт идет первым.
Пересмотренный язык С
124]
Часть I
void putfloat(float f, FILE *ofp)
{
double mantf;
unsigned long manti;
int e, s = 0;
mantf = frexp(f, be);
if (mantf < 0)
{ s = 1; mantf = -mantf; }
manti = Idexp (mantf, 24);
manti 4= "(IL « 23);
/* затираем неявную начальную единицу */
manti |= ((unsigned long)s «31) |
((unsigned long)(e+126 & Oxff) «
^23);
putc(manti & Oxff, ofp);
putc((manti » 8) & Oxff, ofp);
putc((manti » 16) & Oxff, ofp);
putc((manti » 24) & Oxff, ofp);
Суть данной реализации функции putfloat заключа-
ется в использовании библиотечной функции С frexp из * s
<math.h>, которая разделяет число с плавающей точ-
кой на дробную часть и показатель степени в экспонен-
те. Дробная часть возвращается в виде числа с плаваю-
щей точкой из диапазона от 0 до 1. Затем она передается
в другую функцию из библиотеки <math.h> — Idexp —
для умножения ее на 22\ в результате чего дробная часть
сдвигается влево на 24 бита, и ее можно рассматривать
как целое число. Поскольку бит старшего порядка в нор-
мированной ненулевой дробной части всегда равен 1,
форматы IEEE-754 не сохраняют его, поэтому мы очи-
щаем этот бит. Мы располагаем биты показателя степе-
ни и знака на соответствующих позициях и в конце за-
писываем четыре байта.
Данная версия функции putfloat не является полной,
поскольку она не манипулирует ни ненормированны-
ми числами, ни бесконечными величинами. На Web-
сайте издательства ’’ДиаСофт" содержится более полная
реализация этой функции.
Ниже приведена реализация парной функции
getfloat для чтения данных:
int getfloat(float *fp, FILE *ifp)
{
unsigned char buf[4];
unsigned long mant;
int e, s;
if(fread(buf, 1, 4, ifp) 1= 4)
return FALSE;
mant = buf[0 ];
mant [= (unsigned long)buf[l] « 8;
mant (unsigned long)(buf[2] & 0x7f) « 16;
e = ((buf[3] & 0x7f) « 1) | ((buf(2] » 7) & 0x01);
s = buf[3] 6 0x80;
mant |= (IL « 23); /* восстановление лидирующей единицы */
♦fp = Idexp(mant, e-127-23);
if(s) *fp =
return TRUE;
Здесь также используется библиотечная функция С
frexp, в данном случае — для восстановления показате-
ля степени и дробной части. Приведение к типу
(unsigned long) при построении переменной mant сде-
лано по причинам, рассмотренным ранее при чтении
4-байтовых целых чисел, т.е. для того, чтобы избежать
потери точности и ненамеренного переноса знакового
бита. Данная версия getfloat, так же как и putfloat, яв-
ляется упрощенной: она не оперирует ненормированны-
ми числами и не всегда возвращает корректно округлен-
ный результат. Полная реализация этой функции нахо-
дится на Web-сайте издательства "ДиаСофт". На том же
компакт-диске есть программа для чтения и записи ве-
личин языка С типа double в формате IEEE-754 double.
Возвращаясь к вопросу о сохранении дат и времени,
рассмотрим приведенную ниже функцию, которая за-
писывает величину time_t в двоичный файл как 6-бай-
товую целую величину в порядке "от младшего к стар-
Хранение и извлечение данных
Глава 6
125
тему". Это очевидный аналог функции putint, исполь-
зующий цикл д ля расширения размера величины time t
до шести байтов:
void puttime (time_t t, FILE *ofp)
{
int i;
for(i == 0; i < 6; i++)
{
putc(t & Oxff, ofp);
t »= 8;
}
)
Далее представлена соответствующая функция для
чтения time_t:
int gettime (time_t *tp, FILE *ifp)
{
timet t;
char buf[6);
int i;
if(freadfbuf, 1, 6, ifp) 1= 6)
return FALSE;
t = buf[5];
/* вероятно, затрагивается знак */
for(i « 5-1; i >= 0; i—)
t = (t « 8) | (buffi] & Oxff);
*tp s t;
return TRUE;
I
Обе эти функции работают корректно, когда длина
величины time_t составляет 32 бита или более. (Здесь
используется явное, хотя и безобидное предположение,
что величина timejt имеет знак, как это бывает в боль-
шинстве UNIX-систем.) При использовании этих фун-
кций по-прежнему стоит позаботиться о переносимос-
ти своих файлов данных на различные операционные
системы, которые используют различные "эпохи” или
отображения time_t, но, в конце концов, вы не должны
ограничивать метку времени в своих файлах данных 32
битами.
За исключением предыдущих примеров функций
fread и (write, все представленные в данной главе про-
граммы имеют достаточно высокий уровень переноси-
мости. Однако следует отметить, что чтение и запись
двоичных файлов данных побайтово трудоемко и эф-
фективность его меньше максимально возможной, осо-
бенно если размер и порядок байтов данных, которые
записываются или считываются, не совпадает с внут-
ренним форматом используемого компьютера. Закон-
чим мы данный раздел упоминанием о двух компро-
миссных подходах, которые могут быть значительно
эффективнее.
Если нужно считать или записать большое количе-
ство расположенных рядом целых чисел одинакового
размера и если можно каким-либо образом гарантиро-
вать, что размер одного из целочисленных типов дан-
ных С совпадает с размером данных в файле, то в этом
случае можно прочесть или записать все целые величи-
ны сразу, используя функции fread или (write, и пере-
ставлять байты только по необходимости. Например,
массив агт, содержащий 2-байтовые целые величины,
можно записать с помощью программы, подобной при-
веденной ниже:
fifdef BIGENDIAN
swap2bytes(arr , па);
Iendif
fwrite(arr, 2, na, ofp);
где функция swap2tnto представляет собой что-то вроде
void swap2bytes (void *buf, size_t n)
{
unsigned char *p = buf, top;
size__t i;
for(i = 0; i < 2 * n; i += 2)
tmp = p[i);
p[i] = p[i+l|;
p[i+l] = tmp;
}
I
Чтобы применять этот метод, необходимо быть уве-
ренным в том, что используемый тип данных С имеет
подходящий размер. Было бы заманчиво предположить,
что тип short int гарантирует надежное функциониро-
вание в случае двух байтов, а тип long int — в случае
четырех байтов. Однако становятся все более популяр-
ными 64-битовые компьютеры, в которых длина long int
составляет 8 байтов. (Предположение о том, что
sizeof(short int) == 2, выполняется негарантированно,
хотя, если уж полагаться на случай, это, возможно,
более безопасный вариант.) Поэтому необходимо ис-
пользовать правильно выбранные typedef с определени-
ями, зависящими от конкретных используемых компь-
ютера или компилятора. В новом стандарте С99
заголовок <inttypes.h> определяет несколько типов фик-
сированного размера, которые вполне пригодны для
этой цели.
Далее, чтение массива очень похоже на его запись:
n = fread(arr, 2, na, ifp);
lifdef BIGENDIAN
if(n > 0)
swap2bytes(arr, n);
ffendif
И при чтении, и при записи у этого метода есть тот
недостаток, что программа по-прежнему не является
абсолютно переносимой. Это значит, что при ее ком-
пиляции необходимо будет убедиться, что выбранный
тип данных полностью соответствует размеру целой ве-
личины в файле и макрос препроцессора BIGENDIAN
установлен правильно ~ определен или не определен,
в зависимости от того, какой порядок байтов использу-
126
Пересмотренный язык С
Часть I
ется компьютером. Стиль программирования, требую-
щий, чтобы подобные установки (размер типа, порядок
байтов и т.д.) были точно определены, полностью про-
тивопоказан для поддержания переносимости, поэтому
его следует избегать.
Другой аспект переносимого определения двоичных
файлов (т.е. независимого определения порядка байтов,
как части формата файла данных) состоит в том, что
если файл данных и записывается, и считывается на
компьютерах с "неправильным порядком", данные, в
конце концов, будут переставлены два раза. Можно
минимизировать лишние перестановки за счет усложне-
ния процедуры: при записи файлов данных всегда ис-
пользовать внутренний порядок байтов записывающе-
го компьютера, но при этом помечать файл данных
таким образом, чтобы считывающая программа знала,
какой именно порядок байтов использован в данном
конкретном файле, и в соответствии с этим проводила
или не проводила перестановку. Например, если была
записана постоянная 2-байтовая величина 0x0102 или
4-байтовая величина 0x01020304 где-нибудь в заголов-
ке, а при считывании файла программа прочитала их как
0x0201 или 0x04030201, то становится понятно, что при
считывании данных необходимо делать перестановку,
в противном случае можно читать данные без конвер-
тирования, и тогда программа будет выполняться быс-
трее.
Недостаток такого подхода состоит в его дополни-
тельной сложности. В худшем случае каждая програм-
ма должна содержать два набора функций чтения из
файла: набор быстро выполняемых функций чтения
данных при порядке, свойственном этому компьютеру,
и набор более медлительных функций с конвертирова-
нием порядка байтов. При этом подходе мы все еще не
освобождаемся от проблемы хранения размеров целых
чисел и по-прежнему должны побеспокоиться о пра-
вильном решении этой задачи.
Общие форматы
В предыдущих разделах были рассмотрены форматы
файлов данных, разработанные нами для наших соб-
ственных целей. При этом требовалось лишь, чтобы
созданная именно для этого конкретного случая про-
грамма, считывающая файлы данных, могла прочесть
то, что было записано другой специально созданной
программой записи файлов данных. В этом разделе об-
суждаются вопросы записи файлов в общих, удовлетво-
ряющих промышленным стандартам форматах, которые
могут читаться другими программами, и написания
программ для чтения файлов общих форматов, записан-
ных другими программами.
Файлы, в качестве разделителей
использующие символы пробела или
табуляции
Возможно, наиболее общеупотребительным и широко
применяемым, особенно в среде UNIX, является тексто-
вый формат с колонками цифр, разделенных пробела-
ми. Очень полезно было бы написать обслуживающую
программу, которая может оперировать разделенными
пробелами полями, поскольку, в конце концов, она
будет более полезной во многих случаях, чем собственно
чтение файлов данных.
Одной из частей такой обслуживающей программы
является приведенная ниже функция, разделяющая
строку пробелами на серию "слов". Эта функция выпол-
няет работу, подобную той, которую выполняет биб-
лиотечная функция strtok, но с другим интерфейсом.
linclude <stddef.h>
linclude <ctype.h>
int getvords(char *line, char *words[],
int maxwords)
{
char *p = line;
int nwords = 0;
while(1)
{
while(isspace(*p)) p++;
if(*p ®= r\0') return nwords;
words[nwords++] = p;
while(!isspace(*p) *p != '\0') p++;
if(*p == '\0') return nwords;
if(nwords >= maxvords) return nwords;
♦p++ = '\0';
}
1
Данная функция разделяет текстовую строку на ме-
сте, вставляя символы *\0’, и помещает указатель на
начало каждого слова в массив, переданный из вызыва-
ющей процедуры. Таким образом, words[0] будет ука-
зателем на первое слово, words[l] — на второе слово и
т.д. Если файл данных состоит из трех колонок — це-
лое число, число с плавающей точкой и строка, — его
можно прочесть в массив структур, используя эту про-
грамму, при этом структура определяется так же, как и
в разделе "Текстовые файлы" (см. ранее в этой главе).
Idefine MAXLINE 100
Idefine MAXARRAY 50
struct s sarray[MAXARRAY];
char line[MAXLINE];
char *pr *words[3);
int nw, na = 0;
struct s s;
Хранение и извлечение данных
Глава 6
127
while(fgets(line, sizeof(line), ifp) 1= NULL)
{
if(*line == 't') continue;
nw = getwords(line, words, 3);
if(nw < 3) continue;
if(na >= MAXARRAY) break;
s.i = atoi(words[0]);
s.f = atof(words[1]);
if((p = strrchr (words[2], '\n')) != NULL)
*p « '\0';
strncpy(s.str, words[2], sizeof(s.str));
sarray[na++] = s;
В эту программу привнесено также несколько тон-
костей: строки, начинающиеся с символа #, рассматри-
ваются как комментарии и пропускаются; пропускают-
ся также пустые строки.
Как упоминалось ранее, при записи строк в тексто-
вые файлы часто нужно проявлять осторожность, если
строки могут содержать пробелы или другие разделите-
ли текста. Что касается данного примера, то что про-
изойдет, если одна из строк будет содержать пробел в
третьей колонке? Будет ли это выглядеть как четвертая
колонка? В этом случае можно использовать следующую
(осознанную) уловку в реализации функции getwords:
если в передаваемом из вызывающей процедуры масси-
ве words недостаточно места для сохранения всех реаль-
но находящихся в строке слов, то "лишние" слова не
разделяются, а все они помещаются в последний эле-
мент массива words вместе с разделяющими их пробе-
лами. Передавая третьим аргументом в функции
getwords число 3, мы гарантируем, что строка из "тре-
тьего" слова — независимо от того, есть в ней пробел
или нет — будет содержаться в words[2] и, следователь-
но, в s.str.
Функция getwords может быть полезной не только
для чтения колонок данных в файле; она является пре-
красным дополнением к набору средств любого про-
граммиста. Например, можно переписать последний
цикл функции txtread из раздела "Текстовые файлы",
используя функцию getwords для разделения тега и соб-
ственно данных в каждой строке части файла перемен-
ного формата.
while (fgets (line, sizeof (line) , ifp) ?= NULL)
{
nw - getwords(line, words, 2);
if(nw < 1)
continue;
if(strcmp(words(0}, "i") == 0)
s->i = atoi(words[1J);
else if(strcmp(words[0], "f") == 0)
s->f = atof(words[1J);
else if(strcmp(words[0], "str") == 0)
{
if((p2 = strrchr(words[l], '\n')) != NULL)
♦p2 = '\0';
strncpy(s->str, wordsf1], sizeof(s->str));
)
/* неопознанные поля игнорируются */
Если упорядочивать колонки, разделенные произ-
вольными символами пробела, то нельзя допустить су-
ществование любых пробелов внутри произвольных
колонок. (Трюк, использованный в предыдущем приме-
ре, можно применять только для последней колонки.)
Другой подход заключается в выборе только одного
конкретного разделителя и использовании его в единич-
ном экземпляре для отделения каждой колонки. Очень
часто в качестве разделителя выбирают символ табуля-
ции; текстовые файлы данных, содержащие разделен-
ные символами табуляции поля, часто называют TDF
(tab-delimited field). Если проводить строгую политику
отделения каждой колонки только символом табуляции,
то тогда внутри любой колонки можно допустить суще-
ствование других пробелов. При этом также оказывает-
ся возможным обрабатывать пробелы в начале и в кон-
це колонок и даже пустые колонки.
Ниже приведена функция, разделяющая строку на
колонки более жестко с использованием только одного
разделителя, который передается как параметр. Основ-
ную работу выполняет функция strchr из библиотеки
<string.h>; все остальное — лишь регистрация данных.
finclude <string.h>
int getcolsfchar *line, char «words!],
wint maxwords, int delim)
{
char *p = line, *p2;
int nwords = 0;
while(*p != '\0')
{
words(nwords++) = p;
if(nwords >= maxwords)
return nwords;
p2 = strchr(p, delim);
if(p2 == NULL)
break;
*p2 = '\0';
p = p2 + 1;
}
return nwords;
)
Использование функции getcols эквивалентно ис-
пользованию getwords; они могут легко заменять друг
друга в зависимости от того, какое именно разделение
на колонки требуется.
Теперь перейдем от проблем чтения к записи; ниже
приведена общая функция для записи данных в жестко
разделенный файл. (Здесь также конкретный выбран-
ный разделитель передается в качестве параметра).
128
Пересмотренный язык С
Часть I
void writecols(char *cols[J, int ncols,
WFILE *ofpr int delim)
{
int i;
char *p;
for(i = 0; i < ncols; i++)
{
for(p = colsfi); *p 1= '\0'; p++)
{
if(*p != delim && *p != '
}n')
putc(*pf ofp);
else putc(' *r ofp);
}
putc(i < ncols-1 ? delim : '\n\
wofp);
)
1
Эта функция принимает массив строк и записывает
их все в одну линию, используя конкретный раздели-
тель. Она проводит двойную проверку отсутствия в стро-
ках выбранного разделителя, поскольку находящиеся в
строке разделители собьют правильное размещение ко-
лонок. Если какая-либо строка содержит разделитель,
то все разделители в строке заменяются пробелами.
(Программа также проверяет наличие символов новой
строки в строках, которые еще сильнее собьют правиль-
ное размещение колонок.)
Величины, разделенные запятыми
Другой популярный формат файлов данных содержит
величины, разделенные запятыми; такие файлы извес-
тны как CSV-файлы (CSV — comma-separated values).
Подходя к задаче несколько упрощенно, можно читать
и записывать CSV-файлы с помощью функций getcols
и writecols из предыдущего раздела, определив в каче-
стве разделителя символ запятой. Но функции getcols и
writecols не содержат механизма взятия в кавычки —
предложенного для CSV-файлов способа решения про-
блемы полей, содержащих разделитель. В данном слу-
чае не учитывается возможность того, что поле величи-
ны может содержать запятую. Если одно из разделен-
ных запятой полей заключено в двойные кавычки, то
предполагается, что запятая внутри этого поля являет-
ся не разделителем, а частью поля данных. Поскольку
двойные кавычки используются как специальный сим-
вол, нужно отслеживать возможность того, что поле
может содержать двойные кавычки как смысловой сим-
вол. В файлах CSV эта проблема решается удвоением
литеральных (смысловых) двойных кавычек; когда счи-
тывающая CSV-файл программа анализирует поле с
двойными кавычками, удвоенные двойные кавычки
превращаются в просто двойные, но при этом продол-
жается чтение того же поля.
(Заметим, что соглашение об удвоенных двойных
кавычках отличается от способа помещения двойных
кавычек в строку, который используется в С. В этом
языке, конечно, для помещения двойных кавычек в
строку, ограниченную двойными кавычками, использу-
ется последовательность символов перехода \")
Анализ CSV-файлов не столь прост, как анализ в
предыдущем разделе файлов, разделенных пробелами.
Ниже приведена функция, разделяющая строку текста
запятыми на некоторые величины. Так же, как и в слу-
чае с функциями getwords и getcols из предыдущего
раздела, здесь предполагается, что вызывающая про-
грамма сама считывает текст, который передается как
строка. Функция возвращает отдельные величины как
указатели на элементы в исходной строке. (Единствен-
ное отличие состоит в том, что, поскольку удвоенные
двойные кавычки в полях, ограниченных двойными
кавычками, должны быть превращены просто в двойные
кавычки, символы иногда могут перемещаться в буфе-
ре строки; недостаточно просто написать завершающие
разделители \0, как это делают функции getwords и
getcols.)
linclude <stddef.h>
csvburst(char *line, char *arr[], int narr)
{
char *p;
int na = 0;
char prevc = /* для распознавания первого поля */
char *dp = NULL;
int inquote = FALSE;
for(p « line; *p != '\0'; prevc = *pr p++)
{
if(prevc == 'fcfc 1inquote)
{
/* начинаем новое поле */
if (dp 1= NULL)
♦dp = '\0'; /* завершаем предыдущее */
Хранение и извлечение данных
Глава 6
129
if(na >- narr)
return па;
агг(па++] = р;
dp = р;
if(*p == '•')
{
inquote = TRUE;
continue; /* пропускаем кавычки */
}
}
if (inquote && *p == '"')
{
/* двойные кавычки превращаются в одинарные; */
/* в противном случае кавычки прекращают чтение в данном режиме ♦/
if(*(p+D 1=
inquote = FALSE;
р++; /♦ пропускаем первые кавычки */
}
if(*p 1= || inquote)
*dp++ = *p;
}
if (dp 1= NULL)
♦dp = '\0';
if(na < narr)
arr[na] = NULL;
return na;
Хотя на первый взгляд программа кажется несколь-
ко запутанной, на самом деле она выполняет всего лишь
три функции:
• Копирует величины, используя присвоение *dp++ =
*р, в текущую сканируемую величину. (Использо-
вание двух указателей обеспечивает при необходи-
мости возможность сдвига символов, когда преобра-
зуются кавычки в кавычках.)
• Осуществляет поиск разделенных запятыми вели-
чин; после их обнаружения записывает \0 для окон-
чания предыдущей величины и начинает новую.
• Выполняет поиск двойных кавычек как в начале, так
и внутри величины. В начале величины кавычки
включают "режим кавычек" для этой величины. Внут-
ри величины кавычки либо являются первыми из уд-
военных кавычек, обозначающих литеральные ка-
вычки, либо выключают "режим кавычек".
Ниже приведена соответствующая функция для за-
писи строки величин, разделенных запятыми, в тексто-
вый файл. Подобно функции writecols из предыдущего
раздела, она проверяет наличие специальных символов
и при необходимости заключает поле в кавычки.
9 Зак. 265
linclude <stdio.h>
linclude <string.h>
void csvwrite (char *arr[}r int narr, FILE *6fp)
{
int i;
for(i = 0; i < narr; i++)
{
if(strpbrk(arr[i], "r\"\n") == NULL)
fputs(arr[i], ofp);
else {
char *p;
putc('"'r ofp);
for(p = arr[i]; *p != '\0'; p++)
{
if(*p ==
fputs("\"\""r ofp);
else if(*p == '\n')
putc(' ofp);
else putc(*p, ofp);
}
putct'-'r ofp);
}
putc(i < narr-1 ? : '\n'r ofp);
)
}
Стандартная библиотечная функция strpbrk возвра-
щает значение, отличное от значения NULL, если (в
130
Пересмотренный язык С
Часть 1
данном случае) записываемая строка содержит запятую,
двойные кавычки или символ новой строки.
В качестве демонстрации работы этих двух функций
ниже приведен фрагмент программы, которая копиру-
ет один CSV-файл в другой, выбирая при этом опреде-
ленные колонки. Массив selcols содержит номера выб-
ранных колонок; в данном примере нужно извлечь
колонки под номерами 1, 3 и 5.
int selcols[] = (1, 3, 5};
int nselcols = 3;
char line[MAXLINE], *p;
char *arr1[MAXCOLS], *arr2[MAXCOLS];
int na, i;
while(fgets(line, sizeof(line)r ifp) !- NULL)
{
if((p = strrchr(line, '\n')) != NULL)
*p = '\0';
na = cs vbur st (line, arrl, MAXCOLS);
for(i = 0; i < nselcols; i++)
{
if(selcols[i] < na)
arr2[i] = arrl[selcols[ij ];
else arr2[i] =
}
csvwrite(arr2, nselcols, ofp);
}
Файлы ini
Файл .ini также является широко распространенным
форматом файла данных. Файл .ini представляет собой
текстовый файл, содержащий набор конфи1урационных
переменных, возможно, разделенный на секции,, при
этом каждая секция содержит конфигурационные пере-
менные для различных подсистем внутри программы
или (особенно это касается Windows-систем) для раз-
личных программ. Например, файл
[А]
Ь=1
с=2
[В]
Ь=2
d=3
содержит конфигурационные переменные для двух ва-
риантов или подсистем, А и В. В листинге 6.2 представ-
лена функция для выбора конфигурационной перемен-
ной из файла .ini. Функция принимает три параметра:
имя файла .ini, имя секции и имя конфигурационной
переменной, или ’’ключ". Функция открывает файл,
находит требуемую секцию и внутри этой секции на-
ходит ключ. В случае возникновения каких-либо про-
блем (например, если файл не может быть открыт или
не может быть найдена требуемая секция или ключ)
функция возвращает значение NULL.
Поскольку для поиска имени секции и имени пере-
менной используется С-функция strncmp, для этих
имен существует различие между строчными и пропис-
ными буквами. Обычно, однако, имена в .ini-файлах не
различают строчные и прописные буквы. Можно снять
чувствительность функции csvburst к регистру букв, за-
менив один или оба вызова strncmp вызовом других
функций, нечувствительных к регистру, таких как
stmicmp или stmcasecmp, которые доступны в качестве
приложений во многих системах.
Содержащаяся в листинге 6.2 программа демонстри-
рует основной метод чтения таких файлов. В реальной
же ситуации, если возникает необходимость считать
несколько конфигурационных переменных, предпочти-
тельнее не открывать файл и не искать секцию для каж-
дой переменной в отдельности. На Web-сайте ’’Диа-
Софт” находится расширенная версия функции inifetch,
которая не предполагает столь частого повторения опе-
рации открытия файла и поиска в нем.
Усовершенствованные методы
До сих пор мы рассматривали только запись файлов
данных и их чтение, но ничего не говорили об обнов-
лении файлов данных. В общем случае невозможно об-
новить файл данных "на месте", поскольку модель вво-
да/вывода в языке С в соответствии с базовой моделью
ввода/вывода, обеспечиваемой практически всеми опе-
рационными системами, не предоставляет возможнос-
ти вставки или удаления байтов из середины файла.
Поэтому обновить файл данных можно, только перепи-
сав его. Для этого обычно выполняются такие операции:
записываются измененные данные во временный файл,
и, когда процесс записи успешно завершен, уничтожа-
ется исходный файл данных, а его имя присваивается
временному файлу.
Можно перезаписать некоторое количество байтов в
середине текстового файла, и это позволяет обновить
файл данных, если размер (в байтах) предназначенной
для записи новой информации равен размеру старой ин-
формации, которую она заменит. В этом разделе рассмот-
рены вопросы перезаписи данных с двумя различными
целями: для обновления данных и для построения
встроенного индекса, позволяющего легко находить за-
писи в файле данных переменного формата.
Обновление записей
Время от времени при чтении файла данных возни-
кает необходимость найти определенную запись и за-
менить некоторыми новыми данными. В нижеследу-
ющем фрагменте программы продемонстрировано,
как это делается. Предположим, что указатель на файл
fp открыт на файл данных, который содержит множе-
ство последовательных записей наших трехэлементных
структур (int, float, string), записанных один за другим
с помощью функций putint, putfloat и fwrite для стро-
131
Хранение и извлечение данных
Глава 6
Листинг 6.2. Получение конфигурационной переменной из файла .ini.
linclude <stdio.h>
linclude <string.h>
Idefine MAXLINE 1000
char *
inifetch(const char «file, const char «sect, const char «key)
{
FILE *fp;
static char line[MAXLINE};
char *p, *retp = NULL;
int len;
if((fp = fopen(file, "r")) == NULL)
return NULL;
/* поиск секции */
len = strlen(sect);
while((p = fgetsfline, MAXLINE, fp)) 1= NULL)
{
if(*line != *[•)
continue;
if(strncmp(&line[l), sect, len) == 0 &K
line[1+len] == ' ]')
break;
}
if(p != NULL) /* она найдена */
{
/* поиск ключа */
len = strlen(key);
while (fgetsfline, MAXLINE, fp) != NULL)
{
if(«line == '[')
break;
if(strncmp(line, key, len) == 0 &&
line [len] == '=')
{
retp s &line[len+l);
if((p « strrchr(retp, '\n')) != NULL)
♦p = '\0';
break;
}
}
}
fclose(fp);
return retp;
>
ки. Другими словами, используется схема фиксирован-
ного формата так, как использовалась функция fwrite
для целой структуры или для массива структур; здесь
не используется функция binwrite, показанная ранее в
этой главе. Поскольку рассматривается двоичный файл
и мы собираемся читать его и записывать в него, то
указатель fp должен быть открыт с использованием ре-
жима г+Ь или эквивалентного ему.
struct s s;
long int offset;
while(l)
<
offset = ftell(fp);
if(!getint(&s.i, fp))
break;
getfloat(&s.f, fp);
132
Пересмотренный язык С
Часть I
fread(s.str, 1, 20, fp);
if(s.i == 3)
{
strcpy(s.str, "changed");
fseek(fpf offset, SEEKSET);
putint(s.i, fp);
putfloat(s.f, fp);
fwritefs.str, 1, 20, fp);
break;
Поскольку каждая запись сделана с помощью фун-
кций putint, putfloat и fwrite, прочесть их можно, выз-
вав соответственно функции getint, getfloat и fread. Пе-
ред чтением каждой записи вызывается функция ftell для
записи текущего сдвига в файле. Когда найдена иско-
мая запись, мы обновляем строковую величину в копии
нашей структуры в памяти, вызываем функцию fseek,
чтобы найти точку, откуда была считана запись, и за-
писываем измененную запись в файл. В нашем приме-
ре обновляемой записью является запись, в которой
элемент i типа int имеет значение 3.
Здесь следует обратить внимание на два важных
момента. Одним из них является использование функ-
ции fseek; в режимах г+ и w+ явный поиск — это один
из способов, позволяющих информировать библиотеку
stdio о том, что имеет место переключение из режима
чтения в режим записи. В нашем случае, конечно, вы-
полнение поиска для определения места, из которого
была считана изменяемая запись, оказывается вполне
естественным.
Второй момент заключается в том, что в действи-
тельности мы не можем ни вставить, ни удалить инфор-
мацию, а только переписать ее. Как уже говорилось,
вообще невозможно вставить или удалить данные, не
переписывая весь файл. В некоторых случаях можно
достичь эффекта, подобного удалению данных, без их
переписывания, а изменив лишь запись таким образом
(опять-таки, не изменяя ее длины), чтобы она содержа-
ла некий бит или иной флаг, определяющий запись как
уничтоженную. Хотя запись по-прежнему остается на
месте, но, если все программы считывания файла напи-
саны так, что запись, отмеченная как уничтоженная,
игнорируется, она будет невидимой. Другая возмож-
ность заключается в том, что, если файл данных ис-
пользует свой собственный индекс для эффективного
произвольного доступа, можно записать новую копию
обновленной записи куда-либо в файл, обновив указы-
вающий на нее индекс и сделав старые, замещенные
данные недоступными. Пример такого индекса (хотя и
без использования его для обновления данных таким
образом) будет рассмотрен далее.
Индексная адресация
Ранее мы упомянули, что одним из способов повыше-
ния эффективности работы с файлами переменного
формата является индексация. Нашим последним при-
мером будет текстовый файл данных переменного фор-
мата, подобный последнему примеру в разделе "Двоич-
ные файлы”, но в данном случае содержащий множество
записей. Первая часть файла — легко читаемые индек-
сы, позволяющие быстро находить полные записи в
этом файле. Поскольку сдвиг каждой записи относи-
тельно начала файла неизвестен до тех пор, пока запись
не будет записана, позднее необходимо возвращаться и
вписывать в индексы величины сдвигов.
Ниже показан пример программы записи в файл.
Вначале создается фиктивный индекс, далее при сохра-
нении записей ведется учет сдвига относительно нача-
ла файла для каждой из них путем вызова функции ftell
и сохранения результата ее работы во временной струк-
туре index. Далее идет возврат к началу файла, и индек-
сы записываются повторно, но теперь уже эти индексы
содержат реальные сдвиги относительно начала файла,
сохраненные вместо записанных при первом проходе.
Фиктивные индексы содержат строки, состоящие из
нулей, и их длина известна, поскольку они записыва-
ются функцией fprintf по форматам %06d и %0151d. Это
позволяет точно сохранить реальные индексы на их
местах.
struct s data [MAXARRAY];
int na;
struct index
int key;
long int offset;
struct index ix[MAXARRAY];
/* записываем фиктивный индекс */
for(i = 0; i < na; i++)
fprintf(ofp, "%06d %0151d\n", 0, 0L);
fprintf(ofp, "[end of index]\n\n");
for(i « 0; i < na; i++)
{
ix[i].key = data[i].i;
ix[i].offset = ftell(ofp);
fprintf(ofp, "i %d\n", data[i].i);
fprintf(ofp, "f %g\n", data[i].f);
fprintf(ofp, "str %s\n\n", data[i].str);
}
rewind(ofp);
for(i = 0; i < na; i++)
fprintf(ofp, "%06d %0151d\n", ix[i].key,
*-*ix[i) .off set);
Хранение и извлечение данных
Глава 6
133
Далее приведена программа для чтения индексов,
предшествующая поиску отдельных записей. Список
индексов начинается с начала файла и заканчивается
записью ’’[end off index]”.
na = О ;
while(fgets(line, sizeof(line), ifp) 1= NULL)
{
if(strncmp(line, [dbl][end of[dbl], 7) = 0)
break;
nw = getwords(line, words, 3);
if(nw == 2)
{
ix[na].key = atoi(words[0]);
ix[na].offset = atoi(words[1]);
na++;
}
И в завершение этого раздела продемонстрируем
набросок программы для поиска и чтения определенной
записи. Предполагается, что список индексов уже счи-
тан и сохранен в массиве ix предшествующей програм-
мой. Искомая запись должна соответствовать целой ве-
личине, находящейся в переменной seekval:
struct index *ixp = NULL;
for(i = 0; i < na; i++)
{
if(ix[i].key == seekval)
{
ixp = &ix[i];
break;
1
1
if(ixp «= NULL)
return; /* не найдено ♦/
fseek(ifp, ixp->offset, SEEKSET);
while(fgets(line, sizeof(line), ifp) Is NULL)
{
nw = getwords(line, words, 2);
if(nw “» 0)
break;
if (Stroup(words[0), "i") =e 0)
s.i = atoi (words [1));
else if(strcmp(words[0], "f") == 0)
s.f = atof (wordsfl ]);
else if(strcmp(words[0], "str") == 0)
{
char *p2 = strrchr(words[l], f\nr);
if(p2 !« NULL)
*p2 = '\0';
strncpy(s.str, words[l], sizeof(s.str));
}
Полученный из индекса сдвиг относительно нача-
ла файла содержит информацию о том, где начинается
искомая запись, поэтому программа переходит к указан-
ному сдвигу и начинает чтение. Первая встретившаяся
пустая строка определяет конец записи.
Смежные вопросы
Настоящая глава посвящена главным образом разработ-
ке и воплощению ваших собственных файлов данных,
но в основном программистский мир более не нужда-
ется в новых форматах файлов данных. Уже существу-
ют определенные форматы, одни из них специфичны,
другие могут использоваться достаточно широко, при
этом они могут сопровождаться уже написанными биб-
лиотеками для манипулирования данными. Может ока-
заться проще выбрать и изучить один из них, а не со-
здавать свой собственный. Этот раздел содержит ссылки
на многие из таких форматов и на некоторые другие
ресурсы, относящиеся к общим форматам файлов дан-
ных. (К сожалению, руководство по этим форматам и
рассмотрение программ для их чтения и записи выхо-
дят за рамки данной главы.)
Пересмотренный язык С
Часть I
134
Страница по иерархическому формату данных (HDF —
hierarchical data format) находится в Internet по адресу
http://hdf.ncsa.uiuc.edu/.
Страница по общему формату данных (CDF —
common data format) находится по адресу http://
nssdc.gsfc.nasa.gov/cdf/cdf_hom.html.
Проект netCDF (network Common Data Form — род-
ственник формата CDF) находится по адресу http://
www.unidata.ucar.edu/packages/netcdf/index.html
Формат внешнего представления данных (XDR —
External Data Representation) от фирмы Sun описан в RFC
1014 и RFC 1832.
Базовые правила кодирования (BER — Basic
Encoding Rules) описаны вместе с сопутствующими воп-
росами записи абстрактного синтаксиса ASN.l (Abstract
Syntax Notation) в стандартах Х.409 и ISO8825.
Если вас интересуют форматы сжатых файлов дан-
ных, отлично подойдет список FAQ (frequntly asked
question — ответы на часто задаваемые вопросы) по
сжатию Jean-loup Gailly, доступный через Internet в
обычном архиве списков FAQ.
Что касается графических форматов, чудесной ссыл-
кой является созданный Джеймсом Мюрреем (James D.
Murray) список FAQ по графическим форматам файлов
(Graphics File Format FAQ) по адресу http://
www.ora.com/centers/gff-fag/index.htm.
Огромный архив информации по форматам файлов
всех типов находится в Internet на странице http://
www.wotsit.org/.
ПРИМЕЧАНИЕ
Приведенные данные были актуальны в марте 2000 г.,
когда была написана эта глава, но ко времени прочтения
ее вами некоторые из них могли измениться. Обновлен-
ные ссылки можно найти на домашней странице и стра-
нице опечаток этой книги по адресу http://
users.powernet.co.uk/eton/unleashed/errata/index.html.
И в завершение этой главы отметим, что если вам
необходимо быстро осуществить доступ к большому
массиву данных, если вы действительно собираетесь
вставлять или удалять данные или если у вас имеется
огромное количество данных, стоит рассмотреть воз-
можность сохранения их в настоящей базе данных, а не
в простом файле данных.
Резюме
В этой главе показано, как создавать, записывать и счи-
тывать форматированные файлы данных — как тексто-
вые, так и двоичные. Двоичные файлы данных меньше,
и их можно быстрее читать и записывать, в то время как
текстовые файлы гибче и вполне пригодны для практи-
ческого использования (благодаря своей доступности
для чтения).
С одного компьютера на другой переносимы только
тщательно разработанные файлы данных. Они облада-
ют такими свойствами, как встроенный номер версии,
что дает возможность работать с ними без ошибок даже
при расширении программ и форматов файлов данных.
Хорошо написанные программы для чтения файлов
данных должны проверять номер версии файла и дру-
гие структурные подробности в процессе его чтения и
выводить полезные сообщения об ошибках.
В общем случае в файле данные представляются
иначе, чем в памяти компьютера. Следовательно, при
чтении и записи файлов данных обычно выполняются
некоторые преобразования формата данных. И хотя
темой данной главы является чтение и запись файлов
данных, большинство приемов для чтения, записи и
кодирования структурированных данных могут исполь-
зоваться для таких задач, как чтение конфигурационных
файлов или реализация сетевых протоколов.
Текстовые файлы данных обычно записываются с
помощью функции fprintf и считываются комбинацией
функций чтения, таких как fgets, и функций преобра-
зования, таких как strtol. Единственными стандартны-
ми функциями, подходящими для чтения и записи дво-
ичных файлов данных, являются fread и fwrite, но обычно
в результате их работы получаются непереносимые фай-
лы данных, поэтому приходится создавать собственные
обслуживающие функции (включая putint и getint) для
удобного чтения и записи в двоичный файл различных
типов данных с сохранением переносимости.
В завершение мы показали вам, как записывать и
считывать некоторые общеизвестные форматы файлов
данных, такие как TDF, CSV и INI. Теперь вы знаете,
как обновлять записи в определенном месте файла дан-
ных и как создавать индекс для быстрого поиска запи-
сей в файле данных переменного формата.
Исправление кода программ
7
В ЭТОЙ ГЛАВЕ
Обратимся к диагностике
Поиск и исправление распространенных ошибок
Программные средства отладки
Планируем успех, предвидя неудачи
Процесс отладки
Кошмар программиста
Ричард Хэзфилд
Программирование по своей природе является очень
сложным процессом, требующим напряженной ум-
ственной деятельности. Можно даже сказать, что это
самый трудоемкий вид интеллектуальной работы. По-
этому, как бы хорошо ни была написана программа,
вполне объяснимо, что в ней могут встречаться ошиб-
ки. Ведь известно, что не ошибается только тот, кто
ничего не делает. Опыт подсказывает, что чем позже
ошибка замечена, тем дороже обойдется ее исправле-
ние. Это можно очень просто продемонстрировать. Если
ошибка выявлена на стадии тестирования при сдаче в
эксплуатацию, то необходимо не только исправить про-
1рамму, но и повторить всю серию тестов для проверки
правильности сделанного исправления. Очевидно, если
ошибка выявлена еще на стадии разработки, проводить
повторные тесты нет необходимости. С точки зрения
экономии следует применять такую стратегию разработ-
ки программ, которая позволяла бы выявлять ошибки
как можно раньше в процессе разработки.
В этой главе будут рассмотрены некоторые способы
раннего выявления ошибок. Начнем рассмотрение с
диагностики компилятора. Затем проанализируем неко-
торые общие характеристики отладочных программ.
Мы разработаем также библиотеку для поиска ошибок
в программе и рассмотрим несколько общих типов оши-
бок. Заканчивается глава действительно кошмарной
программой, содержащей множество типичных про-
граммистских ошибок.
Обратимся к диагностике
Первой линией обороны в борьбе с ошибками (кроме,
разумеется, собственного интеллекта) является компи-
лятор. Все компиляторы С стандарта ANSI при столк-
новении с нарушением ограничительного условия или
синтаксической ошибкой должны вывести хотя бы одно
диагностическое сообщение. Ниже приведен пример
нарушения ограничения:
typedef struct FOO
{
unsigned int i: 1;
unsigned int j: 1;
} FOO;
FOO foo;
unsigned int *p;
p = fifoo.j;
Нарушение ограничительного условия здесь заклю-
чается в том, что операнд в операторе & не может быть
битовым полем, так что компилятор должен выдать
диагностическое сообщение. Не буду приводить здесь
пример синтаксической ошибки, без сомнения, вы уже
видели их тысячи.
Компилятор может собрать много разнообразной
информации в процессе обработки вашей программы,
но он не должен сообщать вам ее. К счастью, хорошие
компиляторы собирают намного больше диагностичес-
кой информации, чем можно было бы ожидать. Это
очень полезно, поскольку позволяет повысить качество
программы даже в процессе ее написания.
Некоторые думают, что программа пишется полно-
стью за один присест до первой компиляции. Это мо-
жет быть оправдано в системах с разделением времени
типа больших вычислительных машин, в которых ком-
пиляция осуществляется довольно долго. Это особенно
верно, если программа большая и содержит много мо-
дулей, управление компиляцией которых осуществля-
ется системой сопровождения версий. Это может зани-
мать циклы процессора и влиять на машинные
136
Пересмотренный язык С
Часть I
мощности, доступные другим пользователям. Конечно,
следует разрабатывать программу задолго до первого
обращения к компилятору независимо от доступных
аппаратных средств. Однако, если вы начинаете разра-
ботку кода на автономном компьютере, лучше компи-
лировать регулярно. Таким образом, можно исправлять
опечатки в процессе набора кода программы, что менее
утомительно, чем делать это в процессе большого очи-
стительного сеанса редактирования в конце.
Более того, некоторые современные встроенные ре-
дакторы имеют свойство, которое называется "заверше-
ние кода”, — они запрашивают у автора каждый аргу-
мент функции и предлагают выбор полей структуры,
имя которой только что было набрано. Это свойство
очень экономит время, вносит некий дух тривиальнос-
ти в задачу программирования и является даже забав-
ным, особенно когда работает неправильно. Нередко
база данных "завершение кода" строится при компиля-
ции. Поэтому частая компиляция позволяет экономить
время и усилия по поиску прототипов функции и опи-
сания структуры.
Нет ничего нового в этом мире. Несомненно, вы
часто попадаете в ситуацию, когда сталкиваетесь с про-
блемой, которая смутно напоминает подобную ошиб-
ку, встретившуюся год или больше назад. Но это вос-
поминание не очень поможет, если вы не помните,
каким образом смогли исправить ее в последний раз!
Хорошо бы записывать свои ошибки и способы их уст-
ранения, что я вам настоятельно рекомендую делать
Это позволит вам не напрягать лишний раз свои ум-
ственные способности.
Как нужно использовать предупреждения
Диагностика компилятора существует для того, чтобы
помочь вам. Большинство компиляторов выводит диаг-
ностические сообщения двух типов — ошибки и пре-
дупреждения. Очень немногие программисты принуж-
дают компилятор построить программу, даже если она
содержит ошибки. Однако я встречал множество про-
граммистов, которые сдают программу в эксплуатацию,
даже если при ее компиляции генерируется очень мно-
го предупреждений.
Разумно помнить, что каждое предупреждение вы-
водится с одной очень простой целью — помочь вам на-
писать лучшую программу. Возможно, простейший спо-
соб стать лучшим программистом — это начать обращать
внимание на каждое предупреждение, прослеживать
причину каждого предупреждения и долго и напряжен-
но думать, как сделать программу более надежной.
Иногда пропускать предупреждения очень соблазни-
тельно. Если вы помните, стандарт ANSI позволяет ком-
пилятору выводить диагностику по его усмотрению до
тех пор, пока он корректно компилирует программу.
Поэтому неудивительно, что некоторые компиляторы
выдают диагностические сообщения по поводу про-
граммы, о которой вы думали, что в ней все в полном
порядке. Например, для программы, представленной в
листинге 7.1, компилятор Borland выдаст диагностичес-
кое сообщение.
Листинг 7.1. Генерирование компилятором
диагностического сообщения.
linclude <stdio.h>
linclude <string.h>
int main (void)
{
sizet len = 0;
char buffer[1024] = {0};
if(fgets(buffer, sizeof buffer, stdin) 1=
'-♦NULL)
{
len = strlen(buffer);
printf("The input string is %u bytes
'"*long.\n",
(unsigned)len);
}
return 0;
}
При компиляции этой программы компилятором
Borland C++ 5.2 выводится следующее сообщение:
Warning foo. с 6 ... • len1 is assigned a value
that is never used in function main
т.е. "Переменной ’len' присвоено значение, которое ни-
когда не используется в функции main()"
Вообще, я склонен инициализировать все перемен-
ные при определении. Существуют аргументы "за” и
"против" такого стиля программирования (этот вопрос
обсуждается в главе 2, и, несомненно, одним из возра-
жений против такого стиля как раз является то, что он
продуцирует такие предупреждения!
Это предупреждение действительно досаждает мне.
Я точно знаю, что оно означает и почему появляется,
и я моту понять, как оно может принести пользу кому-
нибудь, чей стиль программирования отличается от
моего. Неприятно, что если эти предупреждения про-
сто игнорировать, то в каждой написанной программе
их будет несколько штук. Проблема состоит в том, что
эти "безвредные" предупреждения имеют свойство на-
капливаться до такого состояния, когда из общей мас-
сы трудно выделить предупреждения, которые действи-
тельно заслуживают внимания.
Вероятно, можно попытаться использовать специ-
фические для конкретного компилятора указания
(pragma), чтобы убрать вывод предупреждений, но та-
кие указания, как правило, создают намного больше
Исправление кода программ
Глава 7
137
лроблем, чем решают. Например, указание компилято-
ру Borland C++ убрать данное предупреждение выгля-
гит так:
({pragma warm -aus
Это указание подавляет выдачу предупреждения, но
против такого образа действий имеется три возражения.
Во-первых, нужно либо вводить и убирать вывод сооб-
щения для каждой функции, либо принять, что дей-
ствительно бесполезное присвоение никогда не будет
отмечено. Во-вторых, указания специфичны для каж-
дого компилятора по определению. Теоретически
предполагается, что компилятор игнорирует неопознан-
ные указания, но на практике это не всегда так. Что,
если данное указание означает что-то совсем другое для
другого компилятора? Указание привязывает програм-
му к конкретному компилятору, а это плохо для пере-
носимости. Для моей работы переносимость является
обычным требованием, поэтому такое решение непри-
емлемо. В-третьих, использование указаний компилято-
ру создает плохой прецедент. Ваши менее пунктуальные
сотоварищи, увидев такой пример в вашей программе,
могут начать убирать предупреждения тем же способом —
и, таким образом, воцарится хаос.
Я могу, конечно, использовать другой компилятор,
и на протяжении многих лет я именно так и делал.
Сложность с компилятором Borland в том, что, хотя он
несовершенен с любой точки зрения, но является одним
из лучших компиляторов для PC, и сейчас я двигаюсь
скорее к нему, чем от него.
Или я могу написать что-то вроде следующего:
void sink (void *р, int i)
{
if(i > 0)
sink(p, 0);
}
и вызвать эту функцию таким образом:
size__t len = О;
char bufferf1024];
sink(&len, 0);
if(fgets(buffer, sizeof buffer, stdin) !=
'-♦NULL)
{
len = strlen(buffer);
/* ... */
Но это можно сделать немного позднее. Сначала вы
можете вызвать функцию sink() для каждой перемен-
ной, которую собираетесь использовать, но едва ли это
хороший пример использования программных ресурсов,
даже если условно скомпилировать sink() вне готовой
программы.
Другой возможный путь решения проблемы — из-
менить стиль программирования, что фактически и про-
исходит. Это не было сознательным решением, но я
заметил, что начал менее придирчиво относиться к ини-
циализации переменных при определении, с тех пор как
стал чаще использовать компилятор Borland.
Если когда-нибудь вам удастся найти стиль про-
граммирования, при котором для любой программы все
компиляторы С стандарта ANSI на наиболее придирчи-
вом уровне предупреждений вообще не выводят предуп-
реждения, весь мир будет очень вам благодарен.
Использование более одного компилятора
Различные реализации могут продуцировать сколько
угодно диагностических сообщений (при обязательной
диагностике синтаксических ошибок и нарушений ог-
раничительных условий), правильно компилируя кор-
ректный код. Использование более одного компилято-
ра может помочь вам определить проблему в своей
программе. Конечно, при этом требуется, чтобы про-
грамма была переносимой, что наиболее вероятно толь-
ко при написании программ с использованием стандар-
та ANSI С.
Использование как минимум двух компиляторов,
если это возможно, может иногда помочь убедить кого
угодно (обычно вас самих), что конкретная проблема
заключается в вашей программе и что это не ошибка
компилятора. В конце концов, очень сомнительно, что
два конкурирующих создателя компиляторов допусти-
ли совершенно одинаковые ошибки. Кроме того, очень
вероятно, что один компилятор снисходительнее дру-
гого. Например, в стандарте ANSI компилятор может
инициализировать локальную переменную как NULL,
0 или 0.0 по своему усмотрению. Если ваш любимый
компилятор позволяет это, а ваш второй компилятор
нет, то программа может вести себя совершенно по-раз-
ному в зависимости от того, какой компилятор исполь-
зуется. (Если это происходит, ваша программа, несом-
ненно, содержит ошибку, и в этом случае использование
второго компилятора избавит вас от излишних затруд-
нений на стадии тестирования.) Более того, стандарт
допускает и более ощутимые различия между компиля-
торами: например, INT MAX (наибольшее число, ко-
торое можно хранить в типе int) должно быть не менее
32767, часто оно составляет 2147483647, но может при-
нимать и другие значения. Таким образом, использова-
ние различных компиляторов помогает высветить про-
блемы совместимости в вашей программе.
Выбор уровня предупреждений
Если мы согласны, что предупреждения полезны, то,
очевидно, имеет смысл выводить все предупреждения,
которые только может выдать компилятор для любой
части программы. Некоторые программисты придержи-
ваются противоположного мнения. Их интересует толь-
138
Пересмотренный язык С
Часть I
ко компиляция, поэтому они устанавливают уровень
предупреждений так, чтобы полностью исключить их!
Но, в конце концов, такая страусиная политика им не
поможет. Сгоревший телефонный счет не означает, что
вы не должны платить деньги телефонной компании,
это означает только, что вы не знаете, сколько именно
вы должны. Точно так же, убрав вывод предупрежде-
ний, вы не устраняете вызывающую их проблему. Если
существуют какие-либо проблемы в программе, то чем
раньше мы об этом узнаем, тем лучше. Установки ваше-
го компилятора следует сделать настолько придирчивы-
ми и строгими, насколько это возможно. Если есть ус-
тановка ’’вечно всем недовольный”, используйте ее.
Некоторые авторы рекомендуют использовать ключ,
имеющийся во многих компиляторах, при использова-
нии которого все предупреждения представляются как
ошибки, но я не захожу столь далеко. Кроме того, не-
которые компиляторы генерируют предупреждения
там, где многие из нас склонны говорить скорее о воп-
росах стиля. Более того, бывают ситуации, когда надо
написать быстро довольно тривиальную программу,
которую и используешь-то один раз. При этом скорость
ее написания важнее совершенства программы (если
она, конечно, вообще работает), и было бы досадно
обращаться к опциям компилятора дважды: сначала —
чтобы выключить режим "считать предупреждения
ошибками", а затем — чтобы включить его снова. Но,
несомненно, при написании законченного программно-
го продукта можно использовать максимально строгий
из доступных уровень предупреждений.
Если вы решаете игнорировать предупреждения, то
должны опираться на знания, а не на неведение. Язык
С предполагает вашу уверенность в том, что вы знаете,
что делаете. Не стоит не обращать внимания на предуп-
реждения. Тщательно изучайте каждое предупреждение.
Если, уже сделав это, вы убеждены, что понимаете при-
чину предупреждения и действительно знаете, что в
этом случае с программой все в порядке, а предупреж-
дение — это только благонамеренная "утка", и готовы
доказать это членам вашей команды, — ну что ж, про-
пускайте такое предупреждение. Разумно при этом со-
проводить программу упоминанием о возникающем
предупреждении вместе с ясным объяснением, почему
вы решили все так и оставить. Если впоследствии ока-
жется, что данное решение было неверным, то тот, кто
будет приводить программу в порядок, будет иметь, по
крайней мере, ключ, который поможет ему начать про-
цедуру отладки. Этим "кем-то” можете оказаться и вы.
Использование установок ANSI
Было бы слишком наивно предполагать, что каждый
читатель данной книги строго придерживается стандарта
ANSI С. Однако, если вы пишете программы, которые
будут выполняться более чем в одной системе, то, по
всей вероятности, вы будете стремиться к ANSI-про-
грамме, и в этом случае установки опций ANSI С в ва-
шем компиляторе особенно важны. Современные ком-
пиляторы могут предупредить вас о непереносимых
конструкциях всех типов, если вы сообщите им об этой
необходимости.
Эта книга не рассматривает конкретные платформы
или компиляторы. Тем не менее, ниже приведены ANSI-
ключи (при максимально высоком уровне выдачи пре-
дупреждений) для наиболее популярных компиляторов
на микрокомпьютерах:
• BORLAND C++ 5.2: bcc32 -A -w foo.c
• Microsoft Visual C++ 5.0/6.0: cl -Za -W4 foo.c
• GNU C/Delorie C: gcc -W -Wall -ansi -pedantic foo.c
Метод "сверху-вниз"
Из-за плохого синтаксиса компилятор может запутать-
ся до такой степени, что может вывести 30, 50 или даже
100 ложных сообщений об ошибке просто потому, что
вы забыли закрыть фигурной скобкой цикл while() или
набрали двоеточие вместо точки с запятой в конце опе-
ратора. По этой причине, а также потому, что я имею
дело с относительно быстродействующей машиной, я
стараюсь исправлять несколько ошибок за один раз,
начиная каждый раз сверху списка. У меня наиболее
часто появляется сообщение unknown identifier (неизве-
стный идентификатор), так как я обычно не объявляю
переменные до тех пор, пока полностью не решу, как
буду (и буду ли вообще) использовать их. Мне случа-
лось исправлять до 50 unknown identifier за один проход.
Если, однако, я вижу ошибки, подобные следующим:
For statement missing ; in function main
- в операторе функции main пропущена ;
Function should return a value in function
main
- функция должна возвращать значение в функцию
main
'i' is assigned a value that is never used in
function main
— переменной ’i’ присваивается значение, не
используемое в функции main
то я знаю, что допустил одну из тех ошибок, которую
производят сногсшибательный эффект на компилятор.
Суть в том, что эта пропущенная точка с запятой вмес-
те с пропущенными круглыми или фигурными скобка-
ми — прекрасный способ одурманить компилятор. С
этой точки зрения разумно перейти к практике исправ-
ления только одной ошибки за один раз. Если в рассмат-
риваемом случае я проигнорирую первое сообщение, то
буду ломать голову над двумя другими. Это не удиви-
Исправление кода программ
Глава 7
139
тельно, поскольку диагностика по сути своей склонна
к ложным выводам. Поэтому в такой ситуации лучше
всего исправить сначала первую ошибку, а затем отком-
пилировать программу снова.
Между прочим, данное явление присуще не только
языку С. Много лет назад мой друг жаловался на то, что
его компилятор COBOL вывел более 3 тыс. сообщений
об ошибках, когда в одном месте своей программы сде-
лал орфографическую ошибку в слове ENVIRONMENT.
После исправления этой ошибки число сообщений
уменьшилось до более управляемой величины (300).
Ваш друг Lint
Много лет назад, пытаясь ускорить компиляцию, кто-
то решил вынести средства анализа качества програм-
мы из компилятора С и поместить их в отдельную ути-
литу. Эта отдельная утилита была названа lint, и идея
заключалась в том, что вы быстро компилируете свою
программу до тех пор, пока она худо-бедно работает, а
затем используете lint, чтобы выявить в программе оп-
лошности и избавиться от них.
Эта стратегия, возможно, была ошибочной. Отделе-
ние процесса окончательной доводки программы от
процесса ее создания может привести некоторых про-
граммистов к мысли о недостаточной важности ошиб-
коустойчивости программы. Это, однако, дает вожделен-
ный эффект ускорения процесса разработки.
Современные компиляторы в последние годы исполь-
зовали значительное повышение скорости работы с тем,
чтобы вновь вернуть основные функциональные воз-
можности lint компилятору. Это действительно хорошее
изменение. Тем не менее, некоторые lint-программы
невероятно привередливы и поэтому могут сообщить вам
много такого о вашем программном коде, о чем, как вам
казалось, вы знали и раньше. Я лично использую про-
1рамму lint, называемую LCLint, которая легально дос-
тупна на Wold Wide Web; это одна из самых злобных lint,
которые я только встречал. Рассмотрим пример ее вы-
вода Но сначала я приведу часть текста, чтобы вы по-
няли, насколько эта программа придирчива:
flnclude <stdio.h>
int main(void)
<
printf("Hello world\n");
return 0;
}
Что вообще может быть не так в этой программе?
Сейчас посмотрим. Ниже приведен вывод программы
LCLint с использованием установки +strict:
bello.c: (in function main)
jhello.c:5:3: Вызываемая функция printf может
получить доступ к состоянию файловой
системы, но список глобальных переменных не
содержит глобальных переменных fileSystem.
Вызываемая функция использует внутреннее
состояние, но список глобальных переменных,
который был проверен, не содержит
переменные internalstate ( -internalglobs
запретит выдачу этого сообщения).
hello.c:5:3: При вызове функции printf
возможно недокументированное изменение
состояния файловой системы : printf("Hello
word\n")
Сообщение о недокументированной модификации
файловой системы (примененное к
неопределенной функции при выставленном
modnomod) (-modfilesys запретит выдачу
этого сообщения)•
Проверка закончена, в коде обнаружено 413
ошибок
(Я не привожу остальных 411 найденных ошибок,
и все в stdio.h! Многие ошибки относятся к неисполь-
зуемым константам или прототипам функций.) Сниже-
ние в программе LCLint уровня серьезности ошибок от
+strict до +checks приводит к уменьшению проблем в
stdio.h до каких-нибудь пустяковых 230 и к отсутствию
проблем в hello.c.
Хорошая программа lint действительно повышает
качество ваших программ, если вы сумеете подобрать
установки, которые будут достаточно строгими, но в то
же время не обескураживающе суровыми. Для LCLint
я использую уровень +checks, который, как я понимаю,
находится где-то посередине между простой проверкой
синтаксиса и педантизмом +strict. (Очевидно, ребята из
LCLint готовы что-нибудь предложить вам, если вы
ухитритесь написать реальную программу, которая во-
обще не вызывает сообщений на уровне +strict Это —
вызов для вас.)
Разумнее всего придерживаться золотой середины.
Если обращать хоть какое-то внимание на вывод lint (а
если этого не делать, то зачем тогда вообще ее исполь-
зовать?), то всегда обнаружатся какие-то изъяны ваше-
го стиля программирования. Если вы начинаете их ис-
правлять, вывод lint становится менее пространным;
обычно это соответствует действительному повышению
качества программы, что и является основной целью,
конечно.
Существует определенный тип программистов, ко-
торые любят выискивать ошибки в программах других
(хорошо, хорошо, признаюсь!). Программа lint прекрасна
для придирщиков, и некоторые люди пользуются ею как
оружием (например, в Usenet). Как это ни странно, та-
кое оружие приносит большую пользу "жертве", если
этот человек достаточно мудр, чтобы не страдать от
унижения в связи с прилюдным анатомированием его
программы и чтобы осознать, что это — возможность
стать лучшим программистом.
Пересмотренный язык С
Часть I
140
Я не агитирую именно за LCLint — просто так по-
лучилось, что я ее использую. Но я действительно сто-
ронник вообще программ lint; и настоятельно рекомен-
дую выбрать какую-нибуд^\ из них, подходящую для
вашей конкретной платформы, и использовать ее для
всех новых исходных кодов (и\для старых тоже, если у
вас есть достаточно времен^, энергии и энтузиазма,
чтобы вернуться назад и исправить их).
Поиск и исправление
распространенных ошибок
Давайте четко разграничим тестирование и отладку. Обе
процедуры сложны и требуют мастерства, обе необхо-
димы и при этом очень сильно отличаются друг от дру-
га. Рассмотрим пару рабочих определений.
Тестирование — это искусство вывести программу из
строя, когда вы думаете, что она работает.
Отладка — это искусство исправить программу, о
которой вы думаете, что она не в порядке.
(Я создал эти определения сам и недавно со смешан-
ным чувством обнаружил более или менее идентичные
определения в "Практике программирования" Кернигана
и Пайка (The Practice of Programming, Kemighan и Pike).
Ничто не ново в этом мире.)
Когда вы закончили (или думаете, что закончили)
первый вариант любой нетривиальной программы, мо-
жете держать пари, что она не в порядке. Верно сказа-
но, что в каждой нетривиальной программе есть хотя бы
одна ошибка. Таким образом, отладка происходит как
до тестирования, так и после него. И это, конечно, ите-
рационный процесс.
Данная глава посвящена отладке, а не тестированию,
но я скажу несколько слов о тестировании. Самому дей-
ствительно нельзя протестировать собственную про-
грамму. Если ваша организация достаточно велика, те-
стированием должен заниматься независимый человек,
который мало или вообще не принимает участия в про-
цессе создания программы. Сложно оценить собствен-
ную программу объективно. Естественно, вы гордитесь
собственной программой, верите, что в ней нет ошибок,
и думаете, что она готова к эксплуатации. (А если это
не так, то зачем ее тестировать?) Поэтому вы не настро-
ены проанализировать ее отстраненно, не правда ли?
И пока не будет доказано, что программа выдержала не-
зависимую проверку, она действительно не готова для
реального использования. Независимый испытатель
подвергнет ее намного более тщательному тестирова-
нию, чем вы когда-либо сможете сделать это сами.
Естественно, проверка профаммы продолжится и в
то время, когда она будет реально использоваться — в
этом случае уже не тестирующим, а реальными пользо-
вателями. Чем более тщательным было начальное тес-
тирование, тем более длительным будет использование
программы.
Не слишком приятно услышать от тестирующего о
неадекватных действиях программы, поэтому имеет
смысл потратить время и самому убедиться, что все в
порядке. Конечно, если программа только что написа-
на, в ней обязательно есть ошибки (если только это не
действительно тривиальная программа, наличие ошибок
в которой очень маловероятно). Поэтому стоит повто-
рить выполнение программы несколько раз и удостове-
риться, что она в полной мере отвечает своему назна-
чению. Это кажется очевидным, однако далеко не все
программисты так поступают. Некоторые отправляют
программы в систему управления версиями, даже не
компилируя их. Они сами напрашиваются на неприят-
ности, и неприятности не заставят себя ждать. (Я это
точно знаю, поскольку (стыд мне и позор!) и сам так
делал.)
Когда вы впервые запустите свою программу, то,
вероятно, сразу заметите некоторые ошибки или неточ-
ности. Запишите их. Записывайте все неадекватности,
которые заметите, независимо от того, неожиданны они
или планировались заранее. Естественной реакцией яв-
ляется исправление первой же оплошности. Сделав это,
однако, вы можете забыть об остальных замеченных
проблемах, а они могут быть не столь явно видны при
последующих выполнениях программы. Записывая их,
вы обеспечиваете себе шанс проверить всё потенциаль-
но проблематичные места.
Этот процесс состоит из N итераций. Прогнать про-
грамму, записать все ошибки и неточности, которые
были замечены, исправить программу, снова прогнать
ее...
Когда же можно остановиться? Когда вы устраните
все проблемы, конечно. Это не означает, что в вашей
про1рамме уже нет ошибок, это только означает, что она
готова к тестированию.
Минуточку. Если вы внимательно читали, то долж-
ны были заметить фразу "исправляем программу". Как
вы будете исправлять ее? Особенно, как вы идентифи-
цируете и исправите неуловимые изъяны?
Наилучшая стратегия — разделяй и властвуй. Дей-
ствительно, знать, где проблемы нет, почти так же хо-
рошо, как и знать, где она есть, особенно если вы мо-
жете сразу выделить большие области, которые не могут
быть причиной проблемы.
Здесь очень выручает модульное построение про-
граммы. Программу, созданную в виде большой спутан-
ной массы спагетти, полную переходов goto, глобаль-
ных переменных и вызовов Iongjmp(), намного труднее
отладить, чем тщательно разработанную модульную
программу. Если программа разбита на модули, каждый
из которых отвечает за какой-то определенный аспект
Исправление кода программ
Глава 7
141
работы программы, намного легче локализовать пробле-
му, чем если ответственность за один и тот же процесс
разделена между несколькими функциями или даже
исходными файлами.
Модульное построение программы имеет и другие
преимущества. Например, если вы изолируете непере-
носимую часть программы в отдельные модули и обес-
печите связь с ними только через хорошо определенные
интерфейсы, то перенести программу на другой компь-
ютер будет сравнительно просто.
После того как вы определили, в каком модуле, ско-
рее всего, заключается проблема, следует обратиться к
исходному коду. Вероятно, таким образом определяет-
ся местоположение 90% всех ошибок. Но не слишком
задерживайтесь на этом. Если вы не можете найти ошиб-
ку в исходном коде за пару минут, значит, вы действи-
тельно не знаете, где она. Следите за временем. Если вы
не можете найти ошибку, выполняя прогонку в течение
двух или, может быть, трех минут и используя сообще-
ния об ошибках, не тратьте зря время — используйте
более методичный подход. В любом случае попробуй-
те сначала случайный подход, но не слишком на него
полагайтесь.
Если вам не повезло сразу найти причину сложнос-
тей, то каким же образом локализовать проблемную
зону?
Во-первых, попробуйте воспроизвести ошибку спе-
циально. Если сможете это сделать, получите важную
информацию о природе ошибки. Но и в противном слу-
чае вы можете рассчитывать на получение не менее важ-
ной информации.
Если ошибка воспроизводится при известном набо-
ре исходных данных, попробуйте слегка изменить этот
набор. Ошибка не устранена? В данном случае оба воз-
можных ответа также принесут полезную информацию.
Если вы можете воспроизвести ошибку множеством
способов, вы очень близки к обнаружению причины
сложностей. При каком минимальном изменении во
вводимых данных ошибка не будет проявляться? Если
вы это выяснили, возможно, вы на правильном пути в
поиске ошибки.
Бывает, кажется, что только одна вводимая величи-
на вызывает сложности? Некоторые соблазняются сле-
дующим способом исправления такой проблемы:
foo = bar (baz) ;
if (baz == 9)
foo = 13.4;
Для этого так называемого исправления существует
технический термин "bodge” — это плохо. Программист
убирает симптом, а не его причину. Настоящая пробле-
ма заключается, вероятно, в функции Ьаг(), следова-
тельно, нужно проверить эту функцию, найти настоя-
щую причину ошибки и устранить ее.
Когда вы установили набор вводимых данных, вы-
зывающий ошибку, а также немного отличающийся
набор данных, который ее не вызывает, можете строить
гипотезы. Не старайтесь ограничиться только одной
гипотезой. Наступает очередь бумаги и ручки (или тек-
стового редактора и ваших пальцев). Попытайтесь при-
думать 5-10 возможных причин ошибки, не пытаясь
оценить их при этом.
Когда список гипотез составлен, вы можете опреде-
лить условия однозначной проверки каждой гипотезы. Это
может включать только проверку вашего исходного кода,
или потребуется создать новый тестовый вариант.
' Можно ограничить рабочий объем, особенно при
тестировании больших систем с большим количеством
вводных данных, выделив сомнительный модуль и по-
местив его в специально написанную тестовую програм-
му. Такая программа обычно состоит из функции
main(), подозрительной подпрограммы, все остальное
должно быть сокращено до минимума. Таким образом
вы сможете сконцентрироваться только на проблемной
подпрограмме. Очевидно, значительно менее удобно,
если существует множество глобальных переменных
или других немодульных конструкций, и это еще одно
основание для использования модульного стиля.
Наступает время для выполнения программы в по-
шаговом режиме или проверки трассировочных файлов.
С хорошими современными отладчиками вы легко до-
беретесь до нужного модуля, используя функциональ-
ные возможности пошагового выполнения с заходом и
без захода в подпрограммы. Если вместо этого вы ис-
пользуете файлы трассировок, то воспользуйтесь скани-
рующими утилитами типа grep, чтобы добраться до
приблизительно нужного места.
Основная идея состоит в том, чтобы, закрыв глаза
на поведение программы, определить первое место, где
происходит что-то не то. Один из способов сделать это —
установить контрольную точку где-то посередине про-
граммы, выполнить программу до этой точки и прове-
рить состояние переменных. Если все выглядит нор-
мально, установите контрольную точку дальше на три
четверти текста программы и продолжите ее выполне-
ние. Если не все в порядке, остановите отладку, по-
ставьте контрольную точку на четверти текста програм-
мы и снова запустите ее. Это простое применение
принципа двойного прерывания. Если ваша программа
содержит миллион строк, аккуратный выбор конт-
рольных точек позволит уменьшить число итераций
примерно до двадцати, чтобы приблизительно иденти-
фицировать строку, вызывающую проблему.
СПРОСИ ДРУГА ИЛИ МЕДВЕЖОНКА ТЕДДИ
Избавьтесь от ощущения, что вы должны решить пробле-
му за один присест или полностью самостоятельно. Иногда
перерыв в работе творит чудеса. Если вы закончили ра-
Пересмотренный язык С
142
Часть I
бочий день, так и не найдя ошибки, а решение пробле-
мы пришло вам в голову в машине по дороге домой, то
вы знаете цену отстранения от проблемы. (Этот метод
применим не только к отладке программ. Это хорошо
известная техника решения кроссвордов, а также боль-
шинства других проблем.)
Консультация ваших коллег также может быть полезна при
выяснении будущего вашей программы. Сам процесс
объяснения проблемы другому человеку в деталях, дос-
таточных для того, чтобы он мог помочь вам, часто мо-
жет быть хорошим толчком и для вашего ума. Если ря-
дом нет подходящего человеческого существа,
используйте любимого плюшевого медвежонка. И это
помогает! Достаточно даже, если вы убедите себя хотя
бы на время, что ваш собеседник слушает и понимает
вас. Его роль чисто символическая. Он не должен ниче-
го говорить.
Моего игрушечного медвежонка зовут Клинт. Если вы
чувствуете себя глупо, разговаривая с бессловесным
плюшевым медвежонком, найдите запасные очки (подой-
дут солнцезащитные) и наденьте их на медвежонка. Те-
перь вы разговариваете с (явно) умным плюшевым мед-
вежонком, и это существенно меняет дело. Я не знаю
почему, но эта методика работает. Мой хороший друг,
которому я это предложил, хохотал над самой идеей, но
я убедил его попробовать. У него не было плюшевого
мишки, но у него был игрушечный слон, который в солн-
цезащитных очках выглядел достаточно круто. Теперь слон
является неотъемлемой частью его отладочной страте-
гии. Почему? Потому что помогает.
Этот метод, конечно, срабатывает не всегда. Если вы не
можете решить свои проблемы таким способом и хоти-
те проконсультироваться с живыми людьми, прекрасно.
Мы все делаем это, и это не признание несостоятель-
ности, а только еще одно средство достижения цели.
Чтобы свести к минимуму время, которое ваши коллеги
тратят на помощь вам, полезно написать маленькую про-
грамму, воспроизводящую проблему. Сделайте копию
кода и уберите из нее все посторонние и несуществен-
ные части. Когда это сделано, запустите полученную про-
грамму снова и убедитесь, что ошибка воспроизводится.
Этот процесс упрощения может сам по себе помочь выя-
вить причину проблемы. Если этого не произойдет, вы,
по крайней мере, облегчите своим коллегам задачу по-
нимания и затем (надеемся) решения проблемы.
Когда вы локализуете проблему до конкретной стро-
ки либо, возможно, до конкретного цикла или конкрет-
ной функции, то в большинстве случаев сразу же опре-
делите суть этой проблемы, а ее устранение часто
оказывается очень простым делом.
К сожалению, не существует алгоритма поиска оши-
бок. Нет такого руководства, просто следуя которому
шаг за шагом, вы гарантированно найдете ошибки про-
граммирования. Тем не менее, многие ошибки очень
типичны. Рассмотрим некоторые наиболее распростра-
ненные из них, придерживаясь лозунга "знай своего
врага". Далее в этой главе мы рассмотрим ошибки с точ-
ки зрения диагностики. А сейчас наша цель — рассмот-
реть наиболее общие причины ошибок.
Ошибки завышения (или занижения)
значения на единицу
char *strdup(char *s)
{
return strcpy(malloc(strlen(s))f s);
}
Этот код демонстрирует множество проблем. Во-
первых, он вторгается в пространство имен реализации.
Кроме того, он использует возвращаемое функцией
malloc значение без предварительной проверки того, что
запрос на размещение был удовлетворен, и беззаботно
предполагает, что s не равно NULL. В 97 случаях из 100
(да, я сделал такой подсчет) ни одна из этих проблем
не приведет к сбою программы. Но здесь есть и другая
проблема. Для s выделено недостаточно места. Это про-
исходит из-за того, что функция strlen возвращает чис-
ло символов в строке, не учитывая символ нуль в ее
конце. Поэтому strcpy изменяет область памяти, не при-
надлежащую программе. Это классическая ошибка за-
нижения числа на единицу (off-by-one error). Вот при-
мер еще одной аналогичной ошибки:
int CalсТоtai(int *arr, size_t numelems)
{
size_t i;
int total = 0;
for(i = 0; i <= numelems; i++)
{
total += *arr++;
}
return total;
Ошибка здесь заключена в операторе сравнения уп-
равляющего оператора цикла. Там должно быть <, а не
<=. Вы можете подумать, что это очевидная ошибка.
И это действительно так. Ну почему же тогда мы так ча-
сто делаем ее?!
Ошибки нарушения границы
Время от времени мы работаем не столько с объектами,
сколько с отношениями между ними, и при этом осо-
бенно предрасположены к ошибке нарушения границ.
Например, если нужно вычислить сумму разностей меж-
ду соседними элементами массива, можно написать
что-то вроде:
int CalcDiffSum (int *arr, size_t numelems)
{
int Sum = 0;
size_t i;
for(i = 0; i < numelems; i++)
{
Sum += *arr - *(arr + 1);
1
Исправление кода программ
Глава 7
143
return Sum;
}
Проблема заключается в операторе условия цикла.
Он выглядит нормально, не так ли? Но, конечно, это не
так. Должно быть написано
for(i = 0; i < numelems - 1; 1++)
Чтобы в максимальной степени предотвратить ошиб-
ки, следовало бы проверить значение numelems еще до
цикла и убедиться, что оно не равно 0 или 1.
Это один из вариантов ошибки нарушения границы.
Все ошибки нарушения границ являются ошибками за-
вышения или занижения значения на единицу, обрат-
ное неверно. К сожалению, эти конкретные ошибки
почти неизменно приводят к использованию не при-
надлежащей программе памяти, поэтому они часто яв-
ляются причиной кажущегося случайным поведения
программы.
Бесконечные циклы
Зная о том, что циклы входят в арсенал средств профес-
сионального (и даже начинающего) программиста, вы
будете удивлены тем, насколько часто возникает пута-
ница в циклах. Все мы знаем, что наши циклы должны
завершаться в определенный момент. Но часто они этого
не делают. Вот один довольно хитроумный пример:
void WriteCharасterSet(char *filename)
{
unsigned char ch;
FILE *fp = fopen(filename, "wbe);
for (ch = 0; ch < 256; ch++)
{
fwrite(£ch, 1, 1, fp);
}
fclose(fp);
}
Это достаточно типичный черновой код, который
многие программисты пишут за несколько секунд для
выполнения небольшой, четко поставленной задачи. Вы
можете использовать эту подпрограмму, чтобы получить
таблицу EBCDIC или расширенную ASCII-таблицу,
подходящую для просмотра в шестнадцатеричном ре-
дакторе, для визуального определения места отдельно-
го символа в упорядоченной последовательности. Но эта
подпрограмма не работает. Не будем обращать внима-
ния на полное отсутствие проверки ошибок в этой про-
грамме (оставим так, как есть), а сконцентрируемся на
цикле.
Он выглядит достаточно невинно, но в действитель-
ности эта программа будет выполняться (теоретически)
бесконечно на платформах, где CHAR_BIT составляет
8 (это верно для большинства реализаций). Принимая,
что CHAR_BIT равно 8, получаем, что тип unsigned char
принимает значения от 0 до 255. Когда ch равно 255 и
выполняется операция ch++, то ch получает значение
256, которое приводится к диапазону конкретного типа
данных (это не случай переполнения, вызванного нео-
пределенным поведением; подобное приведение опре-
делено стандартом для типов без знака). Таким образом,
значение ch изменятся с 256 на 0 (поскольку 256%256
равно 0), и выполнение цикла продолжается. Реально
выполнение программы может прекратиться, когда диск
будет полностью заполнен. Если, конечно, вам повезет.
Присваивание вместо сравнения
Это противная ошибка. В языке С каждое выражение,
определенное иначе, чем void, имеет свое значение,
которое может быть использовано в других выражени-
ях. Это может привести к следующей проблеме:
NODE *AddNode (NODE *root, char *data)
{
diff = strcmp(data, root->data);
if(diff > 0)
{
if(root->left = NULL)
{
root->left » malioc(sizeof *root->left);
/* ... */
Хорошо видно, что это конкретное дерево будет
стремиться стать меньше травинки всю оставшуюся
жизнь. Проблема заключается в знаке равенства, кото-
рый фактически является оператором присваивания.
Программист хотел набрать ==, но пропустил один знак
=. Это бывает очень часто.
Такую ошибку в большинстве случаев можно пре-
дотвратить путем простой перестановки членов. Для
проверки равенства с точки зрения компилятора совер-
шенно безразлично, в каком порядке расположены ар-
гументы. Если с двух сторон находятся переменные, вам
остается только аккуратно набирать нужное количество
знаков =. Если же с одной стороны находится констан-
та, то вы можете кое-что сделать для предотвращения
рассматриваемой ошибки.
Почему бы не приучить себя помещать константу в
операторе сравнения слева? В таком случае, если вы
пропустите один из знаков =, вам гарантирована лишь
ошибка компиляции (нельзя присваивать значение кон-
станте).
В нашем примере мы могли бы написать:
if(NULL « root->left)
{
/* ... */
Здесь сделана та же опечатка, но в этом случае код
просто не будет компилироваться. Лучше’ найти ошиб-
ку на стадии компиляции, чем в процессе выполнения
программы, и я уверен, вы со мной согласитесь.
Пересмотренный язык С
Часть I
144
Те, кто использует компиляторы, предостерегающие
против использования операторов присваивания внут-
ри операторов if() и while(), часто говорят, что лучше
писать ясный код и верят, что компилятор предупре-
дит об опечатке, а также утверждают, что (root->left ==
NULL) легче читать, чем (NULL == root->left).Te же,
кто регулярно использует более одного компилятора,
меньше в этом уверены. Некоторые компиляторы про-
сто не выполняют проверку такого рода.
Переполнение буфера
Начинающие С-программисты быстро понимают, что
так делать нельзя:
linclude <stdio.h>
linclude <string.h>
int main(void)
{
char *b ;
strcpy(s, "Hello world!");
printf("%s\n", s);
return 0;
}
поскольку s, конечно, не указывает на область памяти,
отведенную программе. Здесь можно внести исправле-
ние, сделав s массивом из 13 или большего числа сим-
волов.
А как насчет этого?
linclude <stdio.h>
int main(void)
{
char s[13 ];
printf ("Please type in your name\n");
gets(s);
printf("Your name is %s\n", s);
return 0;
1
Эта программа содержит нерегулярную ошибку. Все
прекрасно работает, если пользователь не вводит более
12 символов. Но как вы можете контролировать пользо-
вателя? Никак. Если он введет имя из 50 символов, у вас
будут большие проблемы. И даже если он введет имя из
13 символов, у вас все равно будут большие проблемы.
Функцию gets() нельзя использовать безопасно.
Вместо нее рекомендуется функция fgets(), но даже она
не является панацеей, поскольку вы должны позабо-
титься о согласовании среднего аргумента с размером
буфера. Хотя функция fgets() определенно более ошиб-
коустойчива, чем gets(), она все равно не может творить
чудеса; аргументы действительно необходимо получать
правильно.
Конечно, иногда переполнение буфера происходит
более хитроумными способами, как это показано в ли-
стинге 7.2.
Листинг 7.2. Перепслнение буфера.
linclude <stdio.h>
linclude <string.h>
int main(void)
{
char Name[12];
char First[12];
char Second[12];
printf("First name?\n");
fgets(First, sizeof First, stdin);
printf("Last name?\n");
fgets(Second, sizeof Second, stdin);
strcat(Name, First);
strcat(Name, ");
strcat(Name, Second);
printf("Full name: %s\n". Name);
return 0;
Первая проблема здесь состоит в том, что Name не
инициализируется, и, таким образом, в результате вы-
зова strcat может переполниться буфер. Вам может по-
везти: первый байт strcat может оказаться равным 0, и
тогда все будет в порядке (пока). Вам может повезти еще
больше: первые несколько байтов strcat могут оказать-
ся печатными символами, такими как ”XzR3kg59ED",
после которых идет 0. В этом случае ваша программа
будет работать относительно пристойно, к тому же ее
вывод ясно покажет, что там есть ошибка, и даст вам
шанс исправить ее перед передачей программы на тес-
тирование.
Вторая проблема состоит в том, что в массиве Name
недостаточно места для некоторых возможных комби-
наций данных, вводимых в массивы First и Second. На-
пример, имя ’’Winston Churchill”, не переполняя ни
First, ни Second, переполнит массив Name при копиро-
вании в него.
Нарушение границ массива
Переполнение буфера — это частный случай наруше-
ния границ массива. Массивы в С можно разделить на
два типа. К первому типу принадлежат массивы, грани-
цы которых определяются в процессе компиляции, раз-
мер массивов второго типа определяется во время вы-
полнения программы с использованием таких
подпрограмм, как malloc, для выделения памяти.
(В новом стандарте С99 введен синтаксис для мас-
сивов переменной длины, но я предполагаю, что вы пока
используете компилятор С89.)
В листинге 7.3 показан пример простого нарушения
границ массива фиксированной длины.
Исправление кода программ
Глава 7
145
Листинг 7.3. Нарушение границ массива фиксированной длины,
linclude <stdio.h>
int main(void)
{
char CharacterSet[128] ~ {0}; /* инициализируем все элементы массива в 0 */
int ch;
int i;
while((ch = getcharf)) != EOF)
{
++CharacterSet[ch];
}
printf([dbl]Char Frequency\n[dbl]);
printf([dbl]— ---\n[dbl]);
for(i = 0; i < sizeof CharacterSet; i++)
{
printf([dbl]%3d %d\n[dbl]f i, CharacterSet[i]);
}
return 0;
У этой программы достаточно интересная история.
Сначала она была написана для системы, использующей
ASCII. Она была протестирована в этой системе с ис-
пользованием файла, который содержал только ASCII-
символы (в диапазоне от 0 до 127). Позднее она была
перенесена на систему, использующую EBCDIC. Ник-
то не заметил, что программа предполагает, что в фай-
ле используется 7-битовый набор ASCII-символов. В
системах EBCDIC тип char обычно является типом без
знака (будет ли "избитый" char со знаком или без зна-
ка — это особенности реализации), поскольку EBCDIC —
это 8-битовый набор символов. Конечно, при первом же
введенном символе произойдет останов программы.
Ошибка заключается в нарушении границ массива,
но причина ее в неверном предположении отноститель-
но используемого набора символов.
Недостающие аргументы
Прототип, в языке С, аккуратно позаимствованный из
C++, прошел длинный путь к обеспечению того, что
операторы вызова вашей функции имеют нужное чис-
ло аргументов. К сожалению, прототип не может по-
мочь при использовании функций с переменным коли-
чеством параметров. Ну хорошо, это немного помогает.
Это значит, что существует проверка типа возвращаемой
функцией величины и тех типов, которые описаны в
прототипе. Но, как только достигается многоточие,
проверка по прототипу прекращается.
Ниже приведена одна из моих любимых ошибок:
linclude <stdio.h>
int main(void)
10 Зак. 265
{
char *s = "string";
int d = 42;
double f - 3.14;
printf("String is %sf int is %df double is
»-»%f\n’);
return 0;
1
Согласен, это грубая ошибка. Но компилятор не
может (или, по крайней мере, совершенно не обязан)
обнаружить ее. Несомненно, это не является недостат-
ком информации в прототипе. Компилятор должен
полагаться на специальные знания о функции printf,
чтобы выделить данную проблему. Более того, вполне
возможно, что формат строки наследуется (действитель-
но, в реальных программах наследование формата стро-
ки достаточно обычно), и в таком случае компилятор
не способен обнаружить эту ошибку.
Почему это моя любимая ошибка? Возможно пото-
му, что я делаю ее очень часто. Эту ошибку легко сде-
лать, особенно когда торопишься. К счастью, ее доволь-
но легко обнаружить, и ее вывод неизменно приводит
в замешательство. Как-то я сумел вывести вместо стра-
хового платежа только в £30 (это около $50) в месяц
такую сумму страхования, которая может довести до
банкротства любую отдельную нацию в мире, если бу-
дет когда-либо востребована.
Указатели
Я твердо верю, что истинного С-программиста можно
легко узнать по его отношению к указателям. Тот, кто
любит язык С, любит и указатели. Тот, кто не любит
указатели, никогда не сможет полюбить и С, как бы он
Пересмотренный язык С
Часть I
146
ни старался. С-программисты любят указатели потому,
что они так просты и, несмотря на это, так могуществен-
ны. Те, кто чувствует отвращение к указателям, дума-
ют, что они излишне усложнены. Одно можно сказать
определенно: ошибки, связанные с указателями, труд-
нее всего обнаружить и исправить.
Если мы имеем представление об указателях, то,
скорее всего, столкнемся с проблемой указателей, если
недостаточно тщательно продумали условия окончания
выделенной области. Тот, кто не разбирается в указа-
телях, может, конечно, столкнуться с проблемами бо-
лее или менее в любое время.
Рассмотрим обычную ошибку новичка, представлен-
ную в листинге 7.4, где программист использует память,
для него не отведенную.
Листинг 7.4, Ошибка распределения памяти.
linclude <stdio.h>
linclude <stdlib.h>
int main(void)
{
char «filename;
FILE *fp;
int Result « EXITSUCCESS;
int i;
printf("This program calculates perfect squares.\n");
printf("Please enter a filename for the output:\n");
fgets(filename, 13, stdin);
fp = fopen (filename, "w");
if(fp 1= NULL)
{
fprintf(fp, "Perfect squares\n");
for(i = 0; i < 100; i++)
{
fprintf(fp, "%2d %4d\n", i, i * i);
}
fclose(fp);
}
else
{
printf("Couldn't open file %s\n", filename);
Result = EXITFAILURE;
}
return Result;
Кроме неверного предположения относительно того,
что имя файла может содержать только 13 символов, и
отсутствия проверки возвращаемого функцией fgets()
значения, эта программа еще и использует пространство,
ей не отведенное. Переменная filename — это указатель.
Она не инициализирована, и, следовательно, ее значе-
ние представляет собой ’’мусор". Функция fgets() ника-
ким образом не может определить, что ей передан бес-
смысленный адрес, и запишет 13 символов данных в 13
байтов, начиная с этого бессмысленного адреса. Что
получится в результате? Этого сказать нельзя. Вполне
возможно, что программа все равно будет работать, но
это, конечно, совсем не обязательно. Это яркий пример
неопределенного поведения программы.
Ошибка того же рода имеет место, когда память
корректно распределена, затем освобождена и после
этого используется снова. Как только вы освободили
память, она немедленно становится недоступной для
вас и обращение к ней приводит к неопределенному
поведению. Следующий фрагмент кода иллюстрирует
такую ошибку:
while (p->Next ! = NULL)
{
free(p);
free(p->Data);
p = p->Next;
)
Я обнаружил этот код в ежемесячном пакете про-
грамм, которые использовались больше года. Програм-
ма содержала постоянный источник проблем, и меня
попросили пройтись по ней частым гребнем, посколь-
ку с ней, очевидно, было что-то не так. Это только одна
Исправление кода программ
Глава 7
147
из многих найденных мною ошибок. Исправление этой
одной было наибольшим достижением уже хотя бы
потому, что оператор не мог запустить пакет опять пос-
ле выполнения этой программы.
Неверное представление, приводящее к этой ошиб-
ке, имеет такой смысл: "Я только что освободил эту
область памяти. Записанные в ней величины данных не
могли измениться за те несколько микросекунд, кото-
рые прошли до моего обращения к ним, поэтому все
должно быть в порядке. Сейчас они мне по-прежнему
доступны". Это неверно. Когда вы освобождаете память,
это происходит навсегда, начиная именно с данного
момента. Если вы хотите снова обратиться к этим дан-
ным, не освобождайте прежде занимаемую ими память.
Если для какой-либо другой цели вам снова нужна па-
мять, вызовите функцию mallocO снова.
Другая ошибка, связанная с указателями, заключа-
ется в неоднократном освобождении памяти. Приходят
на ум две стратегии предотвращения этой ошибки. Пер-
вая: мы можем присвоить значение NULL указателю
Листинг 7.5. Полная утечка памяти.
linclude <stdio.h>
linclude <stdlib.h>
linclude <time.h>
после освобождения области памяти, на которую он
указывает. Стандарт ANSI гарантирует, что обращение
free (NULL) ;
вполне безвредно. Поэтому, установив указатели в
NULL, мы предотвращаем повреждение, которое может
произойти при последующей передаче их функции
free(). Это полезная предосторожность, но вы можете
посчитать ее слишком слабой формой защиты. Вторая
стратегия подразумевает более надежный подход, но он
должен быть введен на стадии разработки программы.
Программа должна освобождать память в нужном мес-
те. и это нужное место должно быть только одно.
В идеале модуль, в котором память распределяется, дол-
жен отвечать и за ее освобождение.
Менее опасной, чем рассмотренные, но все-таки
существенной является проблема так называемой утеч-
ки памяти. Это звучит как серьезная аппаратная пробле-
ма, но на самом деле это просто небрежность в освобож-
дении ненужной памяти. Листинг 7.5 демонстрирует
хороший пример утечки памяти.
int main(void)
{
clock_t startt end;
unsigned long count = 0;
start = clock();
I
while(mallocf1024))
{
++count;
if(count % 16 == 0)
{
end = clock();
printf("%7f CPU seconds: %d kilobytes allocated\n"f
(double)(end - start) / CLOCKSPERSECf
count);
}
}
printf("Out of memory (no more kilobytes).\n");
return 0;
1
Может быть, поучительно действительно запустить
эту программу со всеми утечками просто для того, что-
бы проверить, насколько эффективно работает ваша
программа, когда операционная система находится в
условиях недостатка памяти. После этого вам, возмож-
но, придется перезагрузить свой компьютер — это за-
висит от вашей операционной системы. Помните, что
утечки памяти влияют не только на ваш процесс; они
могут уменьшить время и объем памяти, доступные для
других процессов, выполняемых на том же компьюте-
ре в то же время.
Многие С-программисты считают, что указатели и
массивы — это одно и то же. Они действительно име-
ют много общих свойств, но это не одно и то же. Пута-
148
Пересмотренный язык С
Часть I
ница с указателями и массивами может стать причиной
ошибок. Например:
int GetLoginNameFromUser (char *buffer)
{
int Result = 0;
if(fgets(bufferf sizeof buffer, stdin) ==
^NULL)
{
Result = -1;
}
return Result;
Сложность этой ошибки заключается в том, что все
выглядит корректно. Конструкция вызова fgets будет
прекрасно работать, только если buffer — это массив
char. Это не так. Наиболее длинное имя пользователя,
которое можно прочесть таким способом, имеет
sizeof(char*) -1 байтов.
Что произойдет, если изменить параметр следующим
образом?
int GetLoginNameFromUser (char buffer [100])
/* ... */
Это не поможет! Переменная buffer по-прежнему
является указателем на char, потому что компилятор
превратил ее из массива в указатель. Если вы сомневае-
тесь, запустите такую программу:
#include <stdio.h>
int foo(char *p)
{
return (int)sizeof(p);
}
int bar(char s[100])
{
return (int)sizeof(s);
}
int main(void)
{
char baz[100];
printf("sizeof char[100] in main() = %d\n",
(int)sizeof baz);
printf("sizeof char * in foo() = %d\n",
**foo(baz));
printf("sizeof char[100] in bar() = %d\n",
bar(baz));
return 0;
}
Вывод этой программы ясно демонстрирует два мо-
мента: массивы — это не указатели, и массивы превра-
щаются в указатели, когда передаются как параметры в
функцию.
Иногда очень сложно содержать указатели в поряд-
ке. Если указатель указывает не на то место, которое пла-
нировалось, это может поставить вас в трудное положе-
ние. Чаще всего неправильное указание имеет место в
группах связных структур с динамическим выделением
памяти (связные списки и все родственные им струк-
туры). В ходе дальнейшего обсуждения я буду говорить
о связных списках, но основные принципы примени-
мы к любым подобным структурам данных, таким как
очереди, стеки и деревья.
Проблемы возникают, когда программист неверно
учитывает все возможные перестановки, когда добавляет
новый элемент в список (или друхую структуру дан-
ных), уничтожает элемент, ищет элемент или переме-
щает его. Рассмотрим перестановку двух элементов в
двунаправленном связном списке. Ваша стратегия пере-
становки должна принимать во внимание каждую из
следующих возможностей: один из элементов находит-
ся в конце списка; оба элемента находятся в одном или
в другом конце списка; элементы расположены рядом;
элементы не расположены рядом; элементы расположе-
ны через один элемент.
Это все варианты, которые вы должны рассмотреть
для двунаправленного связного списка. Более сложные
структуры данных требуют более сложного анализа ва-
риантов. Циклический сдвиг ветви дерева, например,
при удалении вершины в двоичном дереве требует бо-
лее тщательного рассмотрения.
Если не будет проведен корректно и тщательно по-
добный анализ вариантов, вполне могут возникнуть
проблемы. Поиск и исправление этих ошибок потребу-
ет кропотливой "детективной” работы. Приведенный
ниже метод занимает много времени, но, по крайней
мере, известно, что он работает. С помощью отладчика
или трассировочного кода определяем значения указа-
телей и затем можем создать изображение структуры
данных на бумаге. Используя прямоугольники для обо-
значения отдельных блоков данных и стрелки для обо-
значения указателей, мы можем визуализировать то, что
действительно происходит в программе. Если мы име-
ем ясное представление о том, что должно происходить
в программе, этот метод всегда даст лучшую информа-
цию о проблеме и способах ее устранения. К сожале-
нию, это трудоемкий и очень медленный метод, похо-
жий на прохождение односвязного лабиринта. Держась
все время рукой за стену, вы проходите все изгибы это-
го лабиринта и, если вы старательны и терпеливы, то
рано или поздно доберетесь до конца. Мы часто можем
сократить работу, идентифицируя заранее относитель-
но небольшой набор проверочных данных, который до-
стоверно воспроизводит ошибку.
В этом методе наибольшую сложность представляет
человеческий фактор. Когда вы проверите около сотни
различных присвоений указателей, вам это надоест, и
существует весьма реальный соблазн броситься вперед
с ничтожным шансом заметить ошибки и неточности.
Терпение — это добродетель.
149
Программные средства отладки
Если бы только существовала программа, которая мог-
ла бы отладить вашу программу! Но такой программы
нет (по крайней мере, пока еше нет). Лучшее, чем мы
сейчас располагаем, — это программа, собирающая ин-
формацию, которая поможет вам отладить свою про-
грамму. Программные средства отладки так называют-
ся в основном ради красного словца: они не выполняют
никакой отладки, ее делаете вы. Несмотря на это, сред-
ства отладки действительно чрезвычайно полезны, они
дают вам верную информацию для определения пробле-
мы (если только вы можете определить, какая именно
информация вам нужна.)
Существует два типа программных средств: те, что
пишете вы, и те, которые написаны другими. Это от-
носится и к средствам отладки. Рассмотрим оба этих
типа.
Коммерческие отладчики
Хорошие отладчики — это находка, они могут сделать
вашу жизнь удивительно легкой. Если вы никогда не
пользовались отладчиком, выберите какой-нибудь из них
и научитесь им пользоваться. Хороший отладчик должен
предоставлять как минимум такие возможности:
• Устанавливать и убирать контрольные точки (точки
прерывания)
• Выполнять программу до текущей позиции курсора
• Выполнять программу в пошаговом режиме
• Предоставлять возможность выбора, заходить внутрь
функций или нет
• Показывать значения выбранных переменных
• Показывать стек текущих вызовов
В продаже есть много отличных отладчиков кроме
тех, которые включены в популярные коммерческие
компиляторы. Научитесь эффективно их использовать,
и вы сбережете многие тысячи часов своего времени.
Хотя лучший отладчик в мире не заменит умствен-
ных усилий, разумное использование хорошего отлад-
чика является, возможно, наилучшим методом отладки.
Макросы трассировки
Когда не было диалоговых отладчиков, мы повсюду в
своих кодах вставляли операторы вывода. Если тщатель-
но выбрать и расставить операторы вывода, они дей-
ствительно принесут пользу. Тем не менее, мы были
очень рады, когда наконец появились диалоговые отлад-
чики.
Иногда отладчики по самой своей сути не могут
помочь в решении проблемы. Это особенно касается
Исправление кода программ
Глава 7
программ реального времени, имеющих дело с событи-
ями в реальном масштабе времени. Например, рассмот-
рим программу, посылающую пакеты на асинхронный
TCP/IP-сокет. Вы не знаете и пытаетесь выяснить, по-
чему программа посылает слишком быстро слишком
много пакетов по низкоскоростному каналу связи. По-
шаговое выполнение вашего исходного кода — медлен-
ный процесс, даже если вы делаете это так быстро, как
только можете, по сравнению со скоростью выполнения
программы вне отладчика. Поэтому при пошаговом
выполнении этого TCP/IP-кода все работает прекрасно.
Когда программа выполняется в нормальном режиме,
вообще ничего не работает. В данной ситуации необхо-
дима внутренняя информация о состоянии программы,
когда она выполняется с реальной скоростью вне отлад-
чика. В подобных ситуациях мы возвращаемся к трас-
сировочным кодам.
Что нам нужно от трассировочного кода? Мы опре-
деленно не хотим включать трассировочный код в ко-
нечную версию программного продукта. Вероятно, мы
напишем достаточно длинный трассировочный код (чем
короче, конечно, тем лучше, но сначала он наверняка
будет длинным). Если наша программа запускается из
командной строки, трассировочный код будет мешать
конечному пользователю в случае, если он будет ис-
пользовать стандартный поток вывода или стандартный
поток ошибок. Если ваша программа использует GUI
(графический пользовательский интерфейс), то может
даже не оказаться подходящего стандартного выходного
потока, которым можно было бы воспользоваться для
вывода! Если же мы поместим его в файл (это наилучший
выбор), пройдет не так много времени, и трассировоч-
ные файлы заполнят весь носитель данных пользовате-
ля. Следовательно, необходимо, чтобы трассировочный
код можно было легко убрать и так же легко вернуть на
место. Эта звучит как задание для условной компиля-
ции. Мы не хотим использовать свои обычные макро-
сы отладки — требуется возможность включать и вык-
лючать трассировочный код независимо от других
отладочных подсистем.
Мы хотим, если получится, отделить трассировоч-
ный код от стандартного выходного потока и стандарт-
ного потока ошибок. Поэтому мы будем использовать
файл.
Будем ли мы использовать все время один и тот же
файл? Нет. Имеет смысл использовать возможность
сравнивать трассировочные файлы, полученные при
разных проходах программы. В идеале имя файла дол-
жно выбираться автоматически и для каждого прохода
программы должно быть разным. Один из предлагаемых
способов — связать имя файла с датой и временем.
Желательно, чтобы трассировочный код можно
было легко использовать. Хотелось бы также отслежи-
150
Пересмотренный язык С
Часть I
вать текущее значение отдельной переменной, иметь
возможность выводить одновременно значения несколь-
ких переменных и определять собственный формат
строки. К этрму можно добавить, что неплохо было бы
иногда попробовать написать специфический трассиро-
вочный код.
Будет действительно полезно, если в каждое отла-
дочное сообщение будут включены имя файла и номер
строки. Тогда, цросто взглянув на трассировочный файл,
мы будем знать, какая функция порождает выходное
сообщение.
И наконец, трассировочный код должен быть яс-
ным, понятным и по возможности кратким. Мы хотим,
чтобы его наличие как можно меньше влияло на про-
грамму, и не хотим слишком загромождать простран-
ство имен. Поэтому не следует использовать глобальные
переменные, также рекомендуется ограничиться малым
числом функций.
Ниже представлен набор трассировочных макросов
и функций, удовлетворяющий всем выше перечислен-
ным требованиям (он есть и на Web-сайте издательства
"ДиаСофт"). Я знаю, что это надежный и испытанный
набор, поскольку сам использовал его в нескольких
проектах. Я постарался исключить все ошибки. Может
быть он даже вообще не содержит ошибок! (Если там
ошибка все-таки есть, то, скорее всего, в коде, работа-
ющем с датой. Перефразируя Петера ван дер Линдена
(Peter van dcr Linden), можно сказать: тот, кто думает,
что программная обработка дат проста, никогда этого не
делал.) Для этой книги я переименовал этот набор в
CFollow (беглый поиск по Web-страницам позволил
исключить более очевидные названия, поскольку они
уже использованы). Сначала — заголовок в листинге 7.6.
Листинг 7-6. Заголовок трассировочных макросов.______________________________________________
♦ifndef CFOLLOWH____
♦define CFOLLOWH____
♦define CFOLLOWMAXLINE 100000L /* Максимальное число строк, которое может быть записано в
* трассировочном файле. */
/* По умолчанию трассировка отключена. Для включения ее вы можете изменить Hf 0 на Hf 1
* (ниже), но лучже использовать возможность компилятора задать ♦define в командной строке.
* Обычно -DCFOLLOWON будет верно, но для ванего компилятора это может быть иначе. */
*/
♦if 0
♦define CFOLLOWON___
♦endif
♦ifdef CFOLLOWON____
/* S для строки */
♦define S_FOLLOW(svar) CFollow(___FILE__,\
LINE ,\
0,\
♦svar"e[%s]",\
svar)
/*А для массива (или символа, не обязательно терминированного) */
♦define A_FOLLOW(avar, bytes) CFollow(___FILE__,\
__LINE__,\
0,\
♦avar"(first %d bytes) e[%*.*s]",\
(int)bytes,\
(int)bytes,\
(int)bytes,\
avar)
/* I для Int */
♦define I_FOLLOW(ivar) CFollow(_FILE____, \
_LINE___,\
0,\
♦ivar"s[%d]",\
ivar)
/* U для Unsigned int */
♦define U_FOLLOW(uvar) CFollow(___FILE__,\
151
Исправление кода программ
. Глава 7
LINE ,\
ОД
luvar"=[%u)"Д
uvar)
/* HI для sHort Int */
Idefine HIFOLLOW(sivar) CFollow(____FILE__Д
___LINE_Д
0Д
lsivar"=[%hd]"Д
sivar)
/* HU для sHort Unsigned int*/
Idefine HU_FOLLOW(suvar) CFollow(___FILE__Д
_LINE_,\
0,\
lsuvar"=[%huj",\
suvar)
/* LI для Long Int */
Idefine LI_FOLLOW(Ivar) CFollowf____FILE__t\
_LINE_, \
0Д
llvar"=[%ld]"Д
Ivar)
/* LU для Long Unsigned int */
Idefine LU FOLLOW(ulvar) CFollowf___FILE__Д
___LINE__,\
0Д
lulvar"=[%lu]"Д
ulvar)
/* D для Double */
Idefine DFOLLOW(dvar) CFollow(____FILE__Д
___LINE__Д
0Д
|dvar"=(%f] Д
dvar)
/* В для булевых значений (истина/ложь) */
Idefine BFOLLOW(cond) CFollow(_FILE_____Д
1_LINE_,\
ОД
"Condition "Icond" = %s",\
(cond) ? “TRUE" : "FALSE")
/* P для указателей */
Idefine P_FOLLOW(ptr) CFollow(____FILE__,\
LINE Д
0Д
"Pointer "Iptr" = %p",\
(void *)(ptr))
/* F для формата, определенного пользователем, целый суффикс показывает количество
*дополнительных аргументов */
*/
Idefine FFOLLOWO(s) CFollow(____FILE__Д
___LINE_Д
ОД
s)
Idefine FFOLLOWl(format, a) \
CFollow(__________________________________FILE_,\
____LINE_,\
0,\
format,\
a)
Idefine FFOLLOW2(format, a, b) \
CFollow(__________________________________FILE___,\
LINE ,\
o,\
format,\
152
Пересмотренный язык С
Часть I
а, Ь)
♦define FF0LL0W3(format, а, b, с) \
CFollowf__FILE__,\
__LINE__,\
0,\
format,\
а, Ь, с)
♦define F_F0LL0W4(format, а, b, с, d) \
CFollow(__FILE__,\
_LINE___, \
0,\
format,\
a, b, c, d)
♦define F_F0LL0W5(format, a, b, c, d, e) \
CFollow(__FILE_,\
__LINE__,\
0,\
format,\
a, b, c, d, e)
i
♦define CF_CODE(code) code
♦define CF_FUNCIN(flincname) CFollow(____FILE___, \
______________________________________LINE__,\
1Д
"Function %s() entry point.
♦funcname)
♦define CF_FUNCOUT(funcname, typespec, rval) \
CFollow(__FILE_____________________________,\
_LINE_,\
-1Л
"Function %s() returns [%"ltypespec"]
♦funcname,\
rval)
♦define CFOLLOW CLOSEDOWN CFollow(NULL, 0, 0, NULL)
void CFollow(char «FileName,
int LineNumber,
int DepthModifier,
char *Formatstring,
...);
♦else
♦def ine S FOLLOW(svar)
♦define A_F0LL0W(avar, bytes)
♦def ine I FOLLOW(ivar)
♦define UFOLLOW(uvar)
♦define HIFOLLOW(sivar)
♦define HU_FOLLOW(suvar)
♦define LI_FOLLOW(Ivar)
♦define LUFOLLOW(ulvar)
♦define DFOLLOW(dvar)
♦define BFOLLOW(cond)
♦define P FOLLOW(ptr)
♦define FFOLLOWO(s)
♦ define F_FOLLOW1(format, a)
♦ define F_FOLLOW2(format, a, b)
♦ define FFOLLOW3(format, a, b, c)
♦ define F_FOLLOW4(format, a, b, c, d)
♦ define F FOLLOW5(format, a, b, c, d, e)
♦ define CFCODE(code) /*нет программы! */
♦ define CF_FUNCIN(funcname)
Исправление кода программ
Глава 7
153
♦define CF_FUNCOUT(funcname, typespec, rval)
♦define CFOLLOWCLOSEDOWN
Iendif /* * Трассировочные операторы включены или выключены */
♦endif /* CFOLLOWH___*/
А теперь — исходный код в листинге 7.7.
Листинг 7.7. Код трассировочного макроса.
♦include <stdio.h>
♦include <stdarg.h>
♦include <time.h>
♦include <string.h>
♦include "cfollbw.h"
/*
* GetOutputFileName():
/* Эта функция создает имя файла для использования функцией fopen. Она статическая, поэтому не
* будет загромождать ване пространство имен. */
*
* Данная функция, хотя н удовлетворяет стандарту ANSI для подпрограмм, является зависящей
* от реализации, поскольку создает имя файла. Созданные имена файлов прекрасно подходят для
* таких систем, как:
*
* MS-DOS Windows Unix
* Linux AmigaDOS TOS (Atari ST)
*
* но при работе с ней на других системах у вас могут возникнуть проблемы. Если вы используете
* MVS, предлагаю вам просто использовать обычное DDNAME в качестве имени файла и управлять
* собственно именем файла через JCL. При работе с другими системами вы, возможно, захотите
* подправить аргументы функции sprintf, чтобы получить формат, соответствующий вайей системе.
*
* Если вана реализация использует 32-битовую переменную time_t, начиная с 1/1/1970, данный код
* работает вплоть до 2038 года. После этого, надеюсь, вы будете использовать 64-битовую time_t
* и поэтому проведете новую компиляцию. */
*/
static void GetOutputFileName(char *OutFileName)
<
time_t CurrentTime;
struct tm Now;
long DaysSincel999;
long ¥earsSincel999;
time(&CurrentTime);
memcpy(&Now, localtime(fcCurrentTime), sizeof Now);
YearsSincel999 = (long)(Now.tmyear - 99);
DaysSincel999 = YearsSincel999 * 365 +
(YearsSincel999 + 3) / 4;
/* 2100, 2200 и т.п. - не являются високосными годами */
if(YearsSincel999 > 100)
{
DaysSincel999 -= YearsSincel999 % 100;
}
/* 2400, 2800 и т.п. - високосные годы */
if(YearsSincel999 > 400)
154
Пересмотренный язык С
Часть I
{
DaysSincel999 +« YearsSincel999 % 400;
DaysSincel999 += Now.tm_yday + 1;
/* Гарантируем, что число содержит не более четырех цифр */
DaysSincel999 %= 10000;
sprintf(OutFileName,
"C%041d%02d%01d.%01d%02d",
DaysSincel999,
Now.tm_hour,
Now.tmmin / 10,
Now.tm_min % 10,
Now.tm_sec);
}
void CFollow(char * InFileName,
int LineNumber,
int DepthModifier,
char * Formatstring,
...)
static FILE *fp = NULL;
static long Counter = 0;
static int Depth = 0;
const int Tabwidth = 4;
static char OutFileName[FILENAMEMAX] =
int i;
static int CounterWidth = 0;
long cwloop;
va_list ArgList;
if(DepthModifier < 0)
{
Depth += DepthModifier;
va_start(ArgList, Formatstring);
if(NULL == fp)
GetOutputFileName(OutFileName);
- fp = fopen(OutFileName, "w");
if(NULL == fp)
{
/* Мы не можем записывать в файл. С неохотой используем stdout. */
fр = stdout;
CounterWidth - 0;
for(cwloop = 1;
cwloop <= CFOLLOWMAXLINE;
cwloop *= 10L)
{
++CounterWidth;
}
if(NULL s= Formatstring)
{
155
Исправление кода программ
Глава 7
if(fp 1- stdout)
{
fclose(fp);
}
}
else
{
if(Counter < CFOLLOWMAXLINE)
{
fprintf(fp,
-%0*ld %12s (%5d) : ",
CounterWidth,
++Counter,
InFileName,
LineNumber);
for(i = 0; i < Tabwidth * Depth; i++)
fprintf(fp, " ");
}
vfprintf(fp, Formatstring, ArgList);
fprintf(fp, "\n");
fflush(fp);
if(DepthModifier > 0)
{
Depth +“ DepthModifier;
vaend(ArgList);
/* конец cfollov.c ♦/
Ha Web-сайте издательства "ДиаСофт" вы найдете
простую управляющую программу, которая проиллюстри-
рует использование каждого приведенного макроса. Сто-
ронники совершенства заметят, что вызов макроса
CFOLLOW_CLOSEDOWN для закрытия трассировоч-
ного файла в конце функции main() — хорошая идея.
Макросы для отслеживания отдельных переменных
достаточно просты. Они используют оператор препро-
цессора #, чтобы превратить имена переменных в стро-
ки. Это позволит вам освободиться от лишнего набора
символов. Было бы приятно иметь возможность вклю-
чить общий макрос типа fprintf. Если мы используем
printf, это было бы сделать достаточно просто, хотя код
при этом будет выглядеть странно. Я могу объяснить это
проще, показав, что имеется в виду:
fdefine PRINT (х) printf х
Это можно использовать следующим образом:
/* ... некоторый КОД ....*/
PRINT(("foo = %s, bar = %d, baz - %f", foo,
wbar, baz));
/* ... код продолжается . .. */
Странность состоит в том, что здесь мы вынуждены
использовать две круглые скобки, что действительно
выглядит несколько необычно. К сожалению, это необ-
ходимо, поскольку макросы стандарта С89 не могут
принимать переменное число параметров. (Макросы
С99 могут это делать, но я не могу полагаться на то, что
у вас уже установлен компилятор С99.)
Проблема в том, что мы используем трассировочный
файл, а не stdout. Мы можем использовать этот метод
для fprintf только в том случае, если подготовили к ис-
пользованию указатель на файл для функции трассиров-
ки. Но я не люблю так делать, поскольку это будет ока-
зывать влияние на пространство имен пользователя и
поэтому продуцирует потенциальную ошибку.
Поэтому я неохотно отказался от данной идеи и
вместо этого использую набор макросов, принимающих
все большее и большее число аргументов. Это работает
неплохо, хотя, конечно, вы должны так же строго обес-
печить соответствие между форматом строки и осталь-
Пересмотренный язык С
156
Часть I
ными аргументами, как и при использовании fprintf
обычным способом. Препроцессор проследит за исполь-
зованием нужного числа аргументов в макросе, что нео-
жиданно, но весьма приветствуется.
Иногда удобно ввести трассировочные циклы. Если,
например, мы хотим вывести все содержимое массива,
было бы хорошо использовать для этого цикл. Без со-
мнения, и в этом случае мы предпочтем трассировоч-
ный код. Поэтому я предлагаю простой макрос
CF_CODE, который позволит заключить в него следу-
ющий код:
CF_CODE({)
CF_CODE( int i);
CF_CODE( for(i = 0; i < 10; 1++))
CF_CODE( F_FOLLOW2("arr[%d] = [%d]\n"f i,
warr[i]);)
CF_CODE(})
Вы можете написать еше проще:
tifdef CFOLLOW_ON_
{
int i;
for(i = 0; i < 10; i++)
FFOLLOW2 Carried] = [%d]\n"f i,
*>arr[i]);
#endif
Выбор за вами.
Оказалось, что при написании программ, поведение
которых асинхронно (например, программ Windows для
сокетов), очень полезны макросы CF_FUNCIN и
CF_FUNCOUT, поскольку можно определить, какие
функции вызываются и в каком порядке! Вы подумае-
те, что это слишком элементарная информация, но
здесь можно неожиданно легко ошибиться. Эти макро-
сы очень помогли мне в понимании таких программ.
Более того, они используют переменную Cfollow()
DepthModifier на входе в функцию и выдают ее при
выходе из этой функции. Если вы запомните функцию
с этими макросами "от головы до хвоста", то выходной
трассировочный файл читать будет намного легче.
Я установил максимальное число выводимых строк,
равное 100 тыс. Если вам на выходе нужно больше,
сначала подумайте, как вы собираетесь реально исполь-
зовать всю эту информацию. Если вам действительно
необходимо такое большое число трассировочных
строк, просто измените соответствующее определение
#define константы CFOLLOW_MAXLINE на cfollow.h.
Планируем успех, предвидя неудачи
Уровень ошибок в программных проектах тревожно
высок. Успех может измеряться в таких понятиях, как
бюджет, дата выпуска или качество реализации. Боль-
шинство проектов не удовлетворяют ни одному из пе-
речисленных критериев. Поэтому мы не можем сказать,
что мы никогда не делаем ошибок. Если вы будете из-
начально предполагать, что ошибки будут иметь место,
то сможете планировать свой ответный удар и таким
образом уменьшить их воздействие. Существует множе-
ство полезных методов для возможно более раннего
обнаружения ошибки: правильный выбор цели, макети-
рование, чувствительные стратегии тестирования, экс-
пертная оценка, итеративные методологии разработки,
модульное строение программ, процедуры управления
их изменениями, а также материальное стимулирование
программистов, создающих надежные программы, и т.д.
Все эти методы важны, но ни один из них не относит-
ся исключительно к программированию на языке С,
поэтому мы не будем их здесь рассматривать. Если вы
хотите прочесть больше об общем качестве программ,
я настоятельно рекомендую прекрасную книгу Стива
Мак-Коннела (Steve McConnell) "Совершенный код”
(Code Complete). А в следующих разделах этой главы
будет рассказано о том, как мы планируем достичь ус-
пеха в программировании на С, используя методы, ко-
торые предвидят неудачи и тем помогают нам избежать
их. Рассмотрим только отладочные коды и операторы
контроля — два наиболее полезных метода в нашем ар-
сенале.
Отладочный код
Иногда желательно, чтобы наша программа давала ин-
формацию, помогающую при ее отладке. Пользователям
эта информация никогда не понадобится, она полезна
скорее для программистов. Наши трассировочные мак-
росы являются достаточно типичным примером отла-
дочного кода, но они ни в коем случае не являются
только примером.
Мы обычно управляем отладочным кодом, исполь-
зуя условную компиляцию, определяя макрос, когда
нужна отладка, и не определяя его в противном случае.
Это хорошо, но жаль, что нет стандартного макроса,
который все мы могли бы использовать для подобной
работы. Однако в некотором смысле существует такой
стандартный макрос, правда, он имеет противополож-
ный смысл: NDEBUG. Макрос assert() (который будет
рассмотрен далее) исключается препроцессором, если
определен NDEBUG. Таким образом, мы можем напи-
сать следующий отладочный код:
#ifndef NDEBUG
DebugDumpList(fcRoot);
#endif
Я никогда не участвовал в проекте, где бы это ис-
пользовалось. Большинство людей предпочитают ис-
пользовать свой собственный макрос. Конечно, это тоже
неплохо.
Исправление кода программ
Глава 7
157
Керниган и Пайк (Kemighan, Pike) не придержива-
ются метода tfifdef DEBUG, считая, что это сделает те-
стирование более проблематичным. Вместо этого они
рекомендуют следующее:
enuxn { DEBUG = 0 };
if(DEBUG)
printf(. . . .
Они утверждают, что многие компиляторы не созда-
ют программу для операторов отладки, если DEBUG
установлен в значение 0, но, тем не менее, проводят
проверку синтаксиса (удобство, которое вы теряете,
выполняя условное компилирование). Когда я столк-
нулся с такой точкой зрения, то не нашел в стандарте
ANSI С никаких гарантий того, что компилятор не бу-
дет и не должен создавать код для недоступных облас-
тей программы. Этот метод может хорошо работать на
вашем компиляторе (в этом случае, конечно, используй-
те его). Тем не менее, если необходимым требованием
является переносимость (а так и должно быть в книге,
посвященной языку С вообще, а не UNIX С, или С для
больших компьютеров, или DOS С), то мы знаем, что
при условной компиляции не генерируется код для
недоступных ветвей программы, поэтому я рекомендую
выполнять именно ее.
Даже если вы никогда раньше не использовали от-
ладочный код, вы почувствуете к нему вкус с помощью
макросов CFolIow. Но разработку программы можно
упростить не только путем использования трассировоч-
ного кода. Некоторые программисты создают целые
отладочные подсистемы, которые они включают во все
новые проекты. CFolIow — один из таких примеров,
другие мы рассмотрим в главе, посвященной управле-
нию памятью.
При работе с кодом отладки важнее всего помнить,
что это должен быть дополнительный код, а не суще-
ственная часть программы. Интуитивно понятно, что
хороший отладочный код часто приводит к большей
машинной занятости (получение дополнительной ин-
формации всегда требует времени, неважно, сколько
именно). Более того, он часто использует ресурсы, спе-
цифичные для системы или сети, в которых он созда-
вался (оригинальная версия CFolIow была написана на
компьютере с операционной системой Windows 95, но
она всегда записывала свои трассировочные файлы в
UNIX, который, случалось, работал рядом в локальной
сети). Мы не можем в программе оставлять трассиро-
вочный код; перед эксплуатацией программы его сле-
дует удалить. Поэтому необходимо обеспечить, чтобы
Одновременно не был удален собственно смысловой
код.
Какой именно код отладки вы напишете для себя?
Наиболее широко используется трассировочный код, но
в голову приходит и множество других возможностей.
В хорошо структурированном окружении может ока-
заться полезным, если при каждом выполнении про-
грамма будет вносить запись в базу данных, сохраняя
такие детали, как номер версии программы, дата, вре-
мя, ID компьютера и пользователя, аргументы команд-
ной строки, имя файла данных для теста, рабочие харак-
теристики и тысячи других полезных вещей. Конечно, это
не может быть сделано только в ANSI С, поэтому я не буду
вдаваться в подробности. Но представьте себе созданные
таким образом удобства, когда, например, для того,
чтобы сравнить эффективность различных версий про-
граммы, достаточно просто выполнить SQL-запрос в
автоматически созданной базе данных. Полезность от-
ладочного кода ограничена только требованиями здра-
вого смысла и вашим воображением.
Использование операторов контроля
Операторы контроля проверяют логику вашей програм-
мы. Идея состоит в вызове функции assert() с услови-
ем, которое должно выполняться, если программа ра-
ботает так, как задумано. Если условие не выполняется,
assert() останавливает выполнение программы. Макрос
assert() используется исключительно для отладки, и
если NDEBUG определен при наличии <assert.h>, то
assert() удаляется препроцессором. Поэтому он не вли-
яет на эффективность программы при эксплуатации.
Это прекрасная идея! Таким образом, вы можете
проводить все виды тестов внутри кода для выяснения
того, написан ли код так, как вы задумали. Используй-
те все преимущества такой возможности, и вы не пожа-
леете.
ASSERT() - ЭТО НЕ ВСЕГДА БЕСПРОИГРЫШНЫЙ ВЫБОР
В своем недавнем проекте я вставил в исходный код не-
сколько операторов контроля и других специфичных для
отладки вещей. В должное время код был передан на
тестирование системы, и наши отладочные макросы были
выключены. Люди, устанавливающие и проводящие ком-
пиляцию JCL, не были С-программистами и не определи-
ли NDEBUG (а эту работу компилятор не может сделать
за вас). В результате все операторы контроля остались
на месте! К счастью, это не имело большого значения,
поскольку мой код не удалось скомпилировать. Конечно,
определение NDEBUG позволило все исправить.
Не используйте assert() для проверки корректности
своих данных. Он может только проверять логику про-
граммы. Например, рассмотрим следующий код:
char *р;
р = malloc(len);
foomem(p);
/* ... */
I
158
Пересмотренный язык С
Часть I
void foomem(char *р)
{
assert(р ! = NULL);
dosomethingwith(p);
}
Это пример совершенно разумного использования
assert. Ясно, что функция foomem() производит неко-
торые действия с переданным ей буфером, и предпола-
гается (при эксплуатации), что указатель на буфер ве-
рен. Все в порядке, поскольку тот, кто вызывает malioc,
проверяет возвращаемое значение, вплоть до того, что
отсутствие проверки может быть расценено как ошиб-
ка. Так, если программа тестируется при величине len,
равной 4 млрд, мы можем быть относительно уверены,
что возникнет ошибка контроля, прекратится выполне-
ние программы с кратким сообщением на stderr (обыч-
но с полной информацией об имени исходного файла
и номере строки, в которой находится оператор конт-
роля).
Для чего точно нельзя использовать assert() — так это
для проверки корректности данных. Ошибка контроля
обычно означает следующее: программист допустил
логическую ошибку, которая несколько смягчается тем
фактом, что он побеспокоился о контроле логики про-
граммы. Применительно к данным это звучит как бес-
смыслица. Если входные данные вызывают проблемы
для программы, это касается того человека, который
отвечает за ввод данных в программу. В нижеследующем
коде assert() применяется неверно:
#include <stdio.h>
linclude <assert.h>
int main(void)
{
char buff[32];
printf("Type your name\n");
assert(NULL 1= fgets(buff, sizeof buff,
stdin));
printf("Your name is %s\n", buff);
return 0;
1
Здесь есть несколько проблем. Во-первых, assert() —
это макрос, и нехорошо вызывать функции внутри круг-
лых скобок макроса, чтобы не вычислять аргумент дваж-
ды. Во-вторых, исключительной глупостью является
заключение смысловой части программы внутри опера-
тора контроля — если NDEBUG будет определен, эта
часть программы будет полностью удалена! В-третьих,
оператор контроля использован для того, чтобы опре-
делить, использовал ли пользователь некоторые комби-
нации клавиш, сигнализирующие операционной систе-
ме об окончании ввода данных (например, Ctrl+Z в
DOS и Ctrl+D в UNIX), и таким образом ухитрился не
ввести данные. Такое использование оператора контроля
не имеет ничего общего с корректностью или некоррек-
тностью логики программы и потому недопустимо.
КОНТРОЛЬ РАБОТОСПОСОБНОСТИ МОДУЛЕЙ ПРОВЕРКИ
КОРРЕКТНОСТИ ДАННЫХ
Сказав все это, необходимо упомянуть, что существует
сценарий, в котором можно использовать assert!) для
проверки корректности данных, и именно там, где дан-
ные действительно должны быть проверены.
Программы нуждаются в данных. Эти данные должны
откуда-то появляться, только самые ограниченные про-
граммы содержат в себе все необходимые данные. По-
этому в большинстве случаев данные привносятся извне.
Если вы сторонник модульного строения программ, у вас,
вероятно, разгорелись глаза. Разве не прекрасно создать
один модуль, единственной обязанностью которого будет
получение корректных данных от пользователя? Этот
модуль будет нести ответственность за корректность вво-
димых данных. (Как вариант, можно использовать два
совместно работающих модуля: один собирает данные и
передает их другому на проверку.)
Это пример хорошего дизайна. Если проверкой коррек-
тности вводимых данных занимается только один модуль,
то в других модулях нет нужды предусматривать что-либо
для проверки этих данных. Модуль проверки корректно-
сти данных можно представить себе защитным кольцом
вокруг сердцевины программы. В совершенном мире
модуль проверки корректности данных может проверять
данные только один раз, так что внутренние подпрограм-
мы (которые могут вызываться много раз) могут дове-
рять полученным данным. Это дает огромный выигрыш в
производительности.
К сожалению, мы живем в несовершенном мире. Никто
не может гарантировать, что в поверяющем модуле нет
ошибки, не правда ли? Надеюсь, в один прекрасный день
это случится. Пока же глупо писать программу, подоб-
ную следующей:
double CalcMetresPerSecond(double miles,
^double hour)
{
return miles * 0.447 / hour;
1
И что будет, если наша программа проверки корректно-
сти данных содержит ошибку, которая позволит перемен-
ной hour принимать значение 0.0?
Если нет модуля проверки корректности данных, необхо-
димо добавить такую проверку:
if (fabs (hour) > DBL_MIN)
/* ... */
Но у нас есть модуль проверки корректности данных;
просто мы ему пока еще не верим. Но однажды мы ему
поверим, а пока мы хотим реально располагать спосо-
бом проверки данных на стадии отладки в предположе-
нии, что, когда программа будет подготовлена к прода-
же, модуль проверки корректности будет исправлен. Если
же он не в порядке, мы хотим это знать.
Используя проверочный оператор assert!) таким образом:
assert(fabs (hour) > DBL_MIN) ;
Исправление кода программ
Глава 7
159
мы решим все эти проблемы. Мы повысим надежность
отладочного кода, мы будем предупреждены, если про-
грамма проверки корректности данных содержит ошиб-
ку, и у нас есть простой способ убрать проверку при
компиляции.
Есть небольшой подводный камень в макросе
assert(); его аргумент должен быть целым выражением.
Строго говоря, в С89 такой код:
int foo (char *bar)
{
assert(bar);
/* ... */
}
вызывает неопределенное поведение! Однако следую-
щий код:
int foo (char *bar)
{
assert(bar ! = NULL);
/* ... */
}
верен, поскольку операторы сравнения возвращают це-
лый результат (в данном случае 0, если операнды рав-
ны между собой, и 1 — если не равны). В С99 это не
является проблемой, поскольку в assert() может быть
передано выражение скалярного типа, такого как ука-
затель.
Использование операторов контроля в
процессе компиляции
Иногда вы не хотите ждать периода выполнения про-
граммы, но хотите (при определенных условиях) вы-
явить ошибки на стадии компиляции. Например, вы
можете использовать два заголовка проекта (например,
foo.h и bar.h), причем оба они содержат структуры, воз-
можно, struct FOO и struct BAR. Для вашего кода важ-
но, чтобы они имели одинаковый размер — еще вы зна-
ете, что они подвергаются постоянной независимой
модификации. Корректно ли они обновлялись, сохра-
нялось ли соответствие размеров? Вот один из путей,
позволяющих выяснить это:
char dummy [sizeof (FOO) == sizeof (BAR) ? 1 : -1];
Поскольку вы вынуждены использовать sizeof, вы не
можете сделать это во время предварительной обработ-
ки, но это можно сделать в процессе компиляции, по-
скольку в действительности значение sizeof вычисляет-
ся именно в это время. Ясно, что, если размеры структур
различны, надо объявить массив с отрицательным чис-
лом элементов, который недопустим и вызовет диагно-
стическое сообщение. Это скорее изящный трюк (пора-
зительно, чего только не найдешь в Usenet!), хотя и с
несколько ограниченной областью применения; вы,
вероятно, никогда не будете его использовать. Тем не
менее, он всегда в вашем распоряжении.
Процесс отладки
Чтобы отладить программу, надо знать, что она долж-
на делать, исследовать ее действительное поведение и
определить, чем оно отличается от ожидаемого. Если мы
можем классифицировать ошибки по их влиянию на
программу, это поможет выяснить причину различий
между действительным и ожидаемым ее поведением.
Что должно происходить
Чтобы исправить программу, нужно иметь четкое пред-
ставление о том, какие функции она выполняет и как
Если бы вы хорошо поняли поведение своей програм-
мы, то могли бы написать ее без ошибок и вам не нуж-
но было бы ее отлаживать. Таким образом, отладку
можно рассматривать как углубление знаний о своей
собственной программе. Тем не менее, пока вы не бу-
дете точно знать, что и как должна делать программа,
успех ваших отладочных действий маловероятен.
Что происходит на самом деле
Простой прогон программы может дать некоторое по-
нимание проблем, возникающих в коде. Может быть,
что-нибудь выглядит не совсем нормально. Может
быть, возникает большая пауза между двумя выводами
там, где вы совсем этого не ожидаете, или же програм-
ма выполняется слишком быстро. Важны любые наме-
ки на то, что что-то не так. Внимательное наблюдение
за программой поможет понять разницу между тем, что
вы ожидаете от программы, и тем, что реально получа-
ете.
Если это вообще возможно, установите все вводы в
свою программу из файла. (Прекрасно подойдет для
этого поток stdin.) Затем вы можете автоматизировать
прогоны программы. Не будет необходимости вручную
вводить данные, и вы всегда сможете переопределить
свой ввод из файла. (Это допускается не во всех, но во
многих операционных системах.) Сделав это, вы смо-
жете заняться наблюдением и обдумыванием програм-
мы, а не тратить время на снабжение ее данными.
Определение места поломки
Выполнение программы в пошаговом режиме (или чте-
ние трассировочных файлов) является простейшим спо-
собом, позволяющим выявить место появления первых
симптомов, но симптом — это не причина, а только
результат. Для поиска причины нужно определить ме-
сто возникновения первого симптома, хотя бы просто
для сокращения области поиска причины. Суть заклю-
Пересмотренный язык С
Часть I
160
чается в том, чтобы найти симптом, и затем поискать
рядом непосредственную причину. Например, мы ви-
дим, что printf записывает несуразицу в выходной по-
ток. В конце концов, мы отслеживаем его в отладчике
и находим, что это вывод строки. Может ли указатель
на символ иметь значение NULL? Поэтому мы добав-
ляем некоторый трассировочный код (или запрашива-
ем в отладчике значение указателя) и определяем, что
это не NULL. Но, тем не менее, выводятся явно иска-
женные данные. Проверка подпрограммы показывает,
что данный указатель передается в текущую функцию
как параметр. Следующий шаг — посмотреть в стеке, где
эта функция вызывается. Двигаясь таким образом в об-
ратном направлении, мы сможем достаточно быстро
определить причину искажения данных. Не позволяй-
те ошибкам запугивать вас. Их можно отследить, и в
этом состоит их уязвимость.
Не обязательно постоянно отслеживать выполнение
каждой отдельной строки кода. Используйте возможно-
сти отладчика и устанавливайте точки прерывания в тех
местах кода, до которых ваша программа может выпол-
няться без помех. Затем можно прейти к пошаговому
режиму и отслеживать значения переменных, начиная
с этой точки. В некоторых отладчиках предусмотрена
опция "выполнить до курсора", при этом ваша програм-
ма выполняется с нормальной скоростью и останавли-
вается в месте текущего расположения курсора, как если
бы там была помещена временная точка прерывания.
Это полезное сокращение, особенно если вы углубились
во множество вложенных циклов, которые не хотите
проходить во всех деталях. Просто поместите курсор
после цикла и используйте клавишу или комбинацию
клавиш, соответствующих команде "выполнить до кур-
сора".
РАСПЕЧАТКА СЦДРЖИУЮГО (ДАМП) ОПЕРАТИВНОЙ ПАМЯТИ
Некоторые операционные системы обеспечивают распе-
чатку содержимого (снятие дампов) оперативной памя-
ти, если программа выполняется настолько неверно, что
заслуживает вмешательства самой операционной систе-
мы. Если снятие дампов памяти доступно, обычно суще-
ствуют инструменты для их интерпретации. Например,
разработчики программ, работающие под Linux, могут
использовать GNU-отладчик gdb. Если вы получили дамп
памяти в Linux, а программа скомпилирована с включен-
ной отладочной информацией (-д), вы, используя gdb,
можете точно определить строку, которая вызвала сня-
тие дампа памяти. Если имя вашей выполняемой програм-
мы crash и дамп памяти был снят в файл под названием
coredump, можно просто набрать:
gdb crash coredump
Это очень полезная лазейка, если ваша реализация под-
держивает такую возможность.
Когда вы найдете место возникновения ошибки, то
сможете исправить код. Если вы не можете этого сде-
лать, значит, вы недостаточно хорошо изучили свою
программу, и в таком случае имеет смысл переписать ее,
используя более простой (возможно, более нудный)
путь.
Успех отладки полностью определяется вашим по-
ниманием программы. Если вы прекрасно изучили свою
программу, она не будет иметь ошибок. Но, чтобы про-
вести отладку, вы не должны ждать появления ошибок.
Почему бы не выполнить в пошаговом режиме новую
программу сразу после ее написания? Это хороший
способ проверить тот факт, что ваша программа следу-
ет намеченной путеводной нити выполнения, и выявить
проблемы на ранней стадии, еще до того, как они мо-
гут стоить вам реальных денег.
Типы ошибок
Если вам удалось откомпилировать программу, то ка-
кие-то проблемы в ней могут реально возникнуть толь-
ко по двум причинам: либо программа не следует ваше-
му техническому заданию, либо она не смогла успешно
завершиться (вследствие некоторых ошибок обращения
к памяти, нарушения прав доступа или нарушения об-
щей защиты, из-за ошибки пользовательского приложе-
ния или аварийного останова). Учитывая наши текущие
цели, работающий код нас совершенно не интересует,
так что мы спокойно можем забыть об этом и сосредо-
точиться на ошибках логики приложения и на ошибках
аварийных отказов.
К счастью, ошибки логики приложения очень лег-
ко исправить, конечно, если вы хорошо понимаете, в
чем состоит техническое задание. Ошибки аварийных
отказов сложнее, поскольку вызвавшая их причина ред-
ко бывает ясна с первого взгляда.
АРХИВ ЖАРГОНА
Архив Жаргона — это занимательная и ценная хакерская
древняя и современная лексика. Он восходит к 1975 году
и был начат Рафаэлем Финкелем (Raphael Finkel) из уни-
верситета Стенфорда (Stanford University). Этот архив в
некоторой степени базируется на словаре Пита Самсона (Pete
Samson), который был создан в 1959 году. В нем рассмот-
рены тысячи жаргонных словечек, используемых в хакер-
ских кругах, включая многие любимые мною перлы.
Если я расскажу вам, где найти этот Архив, то, листая
его, вы потратите время, которое могли бы использовать
для полезного труда; подумайте, можете ли вы позво-
лить себе это?
Ну ладно, запускайте окно просмотра Web-страницы по
адресу http://www.tuxedo.org.
Либо, если вы принадлежите к тем странным людям,
которым нравится тратить деньги, закажите его в мест-
ном книжном магазине:
The New Hecker's Dictionary 3rd Edition, compiled by Eric S
Raymond, published by The AMT Press, ISBN 0-262-68092-0.
161
Архив Жаргона содержит четыре смешных названия
для различных типов ошибок, все они названы в честь
известных ученых (Нильса Бора, Вернера Гейзенберга,
Бенуа Мандельброта и Эрвина Шредингера). Они клас-
сифицированы скорее по их симптомам, чем по причи-
нам, их вызывающим. Если вы поняли, что где-то есть
ошибка, намного вероятнее, что вы знаете симптом, а
не причину, поэтому это действительно вполне полез-
ная классификация. Рассмотрим каждый из них и изу-
чим некоторые методы поиска различных причин, их
вызывающих.
Ошибки Бора (Bohr Bugs)
Ошибка Бора — это ошибка, имеющая простую (хотя,
возможно, неизвестную) причину. Если причина обна-
ружена и удалена или внесены изменения нужным об-
разом, ошибка пропадает. Такие детерминистические
ошибки проще всего найти и исправить. К счастью,
большинство ошибок попадает именно в эту категорию.
Например, оператор вывода с неверным текстом сооб-
щения относится к детерминистическим ошибкам. Если
вы хотели набрать
puts("This is correct.");
а в действительности набрали
puts("This is incorrect.”);
то в результате получаете детерминистическую ошибку.
НЕМНОГО О САМИХ ОШИБКАХ
Возможно, наиболее известной ошибкой Бора в истории
была моль Грея Мюррея Хоппера (Grace Murray Hopper).
Сразу после второй мировой войны Хоппер работал на
вычислительной машине Mark II для военно-морских сил
США. 9 сентября 1947 г. техник обнаружил на Mark II
моль, застрявшую между контактами одного из реле в
машине и вызвавшую сбой в работе. Инцидент был опи-
сан в регистрационном журнале как "первый реальный
случай найденного бага" (игра слов: баг, bug — ошибка,
в дословном переводе — жук. — Примеч. пер.). (Хоппер,
правда, заметил, что моли в это время там не было, но
история считает, что была, поэтому традиционно это
ассоциируется с ней.) Насколько мне известно, сам
жучок и регистрационный журнал находятся сейчас в
Смитсоновском музее истории американской техники
(Smithsonian's History of American Technology Museum).
Описанная история широко известна, но многие ошибоч-
но считают, что слово "bug" возникло в результате это-
го инцидента. Это не так. Термин "bug" был в употреб-
лении уже по крайней мере 100 лет и, очевидно, широко
использовался уже на ранней стадии эпохи телеграфии.
Если вы считаете, что ошибка такого рода никогда не
может произойти у вас, хорошенько подумайте. Заме-
тили ли вы, что в последние годы для вставки плат в
разъем расширения PC необходимо отломить заглушку?
Если вы поставили в компьютер новою карту, а позже
убрали ее, на тыльной стороне вашего компьютера ос-
Исправление кода программ
Глава 7
танется отверстие. Я никогда не находил моль ни в од-
ной из своих машин, но пауки часто вызывают проблемы
(этим, возможно, объясняется отсутствие моли). Я живу
в надежде, что в один прекрасный день они обнаружат
мировую паутину World Wide Web (здесь снова игра
слов: World Wide Web — всемирная паутина. — Примеч.
пер.) и исчезнут из моей жизни навсегда.
Ошибки Бора — это чаще всего простые ошибки ло-
гики приложений, простые ошибки на единицу, обыч-
но не связанные с границей массива, опечатки, приво-
дящие к правильному коду (например, = вместо ==),
случайно закомментированные части программы и дру-
гие приземленные вещи.
Ошибки Гейзенберга (Heisenbugs)
Гейзенбаг — это прекрасное название для рассматрива-
емого здесь класса ошибок, и я бы хотел быть его авто-
ром. Каламбур очень удачен; я не физик, но, насколь-
ко я помню, принцип неопределенности Гейзенберга
(несколько вольно пересказанный) звучит приблизи-
тельно так: нельзя наблюдать явление, не изменив его.
Это довольно досадно для квантовой физики, как я
полагаю, но для программистов это настоящий кошмар.
Ваша программа не работает. Хорошо, используем от-
ладчик. Вы знаете, что она не работает, поэтому акку-
ратно работаете в пошаговом режиме. Она работает.
Отлично! Вы вновь запускаете ее вне отладчика. Она не
работает. Ох! Вы опять прогоняете ее под отладчиком,
но уже без пошагового режима. Она работает. Ага! Она
работает только тогда, когда вы пытаетесь выследить
ошибку! (Ошибка Гейзенберга часто возникает у про-
граммистов, использующих чрезмерное количество вос-
клицательных знаков.)
Без сомнения, вы с этим сталкивались. Приходят в
голову два вопроса:
• Почему это происходит?
• Что я могу с этим сделать?
Ошибка Гейзенберга оказывается обычно нарушени-
ем памяти того или иного типа: либо какой-то указатель
указывает не на то, на что следует, либо неверен какой-
нибудь индекс массива.- Если мы затрагиваем область
памяти (неважно, для чтения или для записи), нам не
отведенную, мы вызываем неопределенное поведение
программы. Проблема с неопределенным поведением
состоит в том, что мы не можем определить его, поэто-
му не следует удивляться ничему из того, что делает
наша программа. Печально, но это так. А сейчас рас-
смотрим пример неинициализированного указателя:
char *р;
и результат действия такого оператора:
11 Зак. 265
162
Пересмотренный язык С
Часть I
strcpy(р, q) ;
где q — некоторый допустимый указатель, указываю-
щий на сравнительно длинную строку. Компилятор
выделит некоторую область памяти для указателя р так
же, как он выделяет память для любой другой перемен-
ной. Содержимое, находящееся по адресу, на который
указывает переменная р, может быть произвольным.
Каковы шансы на то, что р указывает на безопасную
область памяти? Их вычислить нельзя. Возможно, р
указывает на безопасную область, а может быть, и нет.
Точно сказать нельзя.
Ошибка Гейзенберга возникает, если р не указывает
на безопасную область памяти, вызывая ошибку выпол-
нения программы. Поэтому вы запускаете отладчик, что
приводит к перемещению данных в памяти, и в резуль-
тате этого р начинает указывать на совершенно безобид-
ное место.
Что же мы можем с этим сделать? Первая линия
обороны строится путем инициализации всех указате-
лей в NULL при определении, что уже стало для меня
привычкой. Это единственный вопрос, где я не согла-
шаюсь на компромиссы с компилятором. Если я за это
получаю предупреждение, то оставляю все как есть.
Инициализация переменных типа int при определении
может быть не столь важна по сравнению с компиля-
цией без предупреждений, но для указателей это жиз-
ненно важно, независимо от того, есть предупреждения
или нет.
Если этого недостаточно, приходит время использо-
вать отладчик или, если программа работает в реальном
времени, трассировочный код.
Как обычно, первый шаг состоит в определении
симптомов. Как показывает мой собственный опыт, нет
ничего необычного в том, что проблема обнаружится в
стандартной библиотечной функции, часто одной из
семейства printf. Некоторые реализации содержат ис-
ходные коды для стандартной библиотеки, и вас может
смутить, когда в процессе отладки вы окажетесь в сере-
дине исходного кода функции printf. Но правило оста-
ется тем же самым — мы двигаемся назад по програм-
ме. Стек позволит определить место, откуда printf
вызывается вашим собственным кодом, и далее вниз по
коду — с терпением и вниманием. (Когда я первый раз
попал под отладчиком в исходные тексты printf, я за-
циклился на возможности ошибки в printf. Это стоило
мне нескольких бесцельно потерянных часов; я нару-
шил первое правило отладки: "Подозревай компилятор
в последнюю очередь!")
Если вы отлаживаете сложную структуру данных,
такую как объектное дерево, то, вероятно, придете к
необходимости отслеживания каждой операции присва-
ивания указателя и сравнения, как описано ранее в этой
главе. Это долгая и неблагодарная работа, но она дей-
ствительно приносит результаты.
Ошибка Мандельброта (Mandelbugs)
Некоторые ошибки кажутся совершенно случайными.
Лежащие в их основе причины представляются непос-
тижимо сложными, как легендарное множество Ман-
дельброта, в честь которого они и названы. Кажется, что
вы не можете последовательно воспроизвести ее. Про-
грамма работает в течение только 70% времени (для
конкретных входных данных) или работает только вне
отладчика (в противоположность ошибки Гейзенберга),
или выдает ложные результаты в среду, или работает
только на компьютере Джоя, или прерывает выполне-
ние только на Катином компьютере.
Наиболее раздражающей является ошибка Мандель-
брота, при которой прекращается даже выполнение
программы. Это особенно расстраивает, когда вы знае-
те, что ваша программа прекрасно работает на другой
платформе. Я недавно начал переносить сетевую биб-
лиотеку с Windows на Linux. Первый модуль, который
я попытался перенести, был модулем для работы с дво-
ичными деревьями. Я написал управляющую програм-
му для тестирования библиотеки деревьев и проверил
ее на Windows-компьютере. Все работало превосходно.
Я скопировал ее на Linux-компьютер и снова откомпи-
лировал. Возникла ошибка недопустимого обращения к
памяти и создан файл дампа памяти. Я не мог понять
этого. Казалось, что все это не имеет никакого смысла.
Не имея опыта работы с программой отладки gdb, я
добавил некоторый трассировочный код. В программе
по-прежнему происходила ошибка недопустимого об-
ращения к памяти, без единой строчки вывода. Поэто-
му я дописал оператор контроля в main () как самую
первую строку в программе. И опять ошибка недопус-
тимого обращения к памяти и — никаких данных на
выходе!
Когда оказываешься в такой ситуации, естественно,
предполагаешь, что какая-то часть программы работает
правильно, а в чем-то есть ошибка. Поэтому можно
начать с пустой функции main и добавлять за один раз
определенную ее часть, проводя затем проверку. В кон-
це концов, мы внесем ошибку, из-за которой останав-
ливается программа. Это локализует ошибку. Либо мож-
но начать с полной программы, убирая модули,
функции, строки^ В определенный момент программа
начнет работать, в том смысле, что будет выполняться
без ошибки неверного обращения к памяти. И это так-
же может помочь в решении проблемы. Обе эти стра-
тегии не содержат риска до тех пор, пока у нас есть
резервная копия программы.
Исправление кода программ
Глава 7
163
Когда мы обнаружим сегмент программы, в котором,
как нам кажется, находится ошибка, мы вернемся к
упорной детективной работе.
Ошибка Шредингера (Schroedinbugs)
Может быть, с небольшой натяжкой, но существуют
несомненные случаи ошибки Шредингера. В знамени-
том умозрительном эксперименте Шредингера "Кот"
гипотетический кот помещается в закрытую коробку
при обстоятельствах, которые приводят к удивительно-
му выводу — кот оказывается живым и мертвым в одно
и то же время.
Заглянув в коробку, мы сводим две возможности к
одной определенности. Шредингер придумал этот умоз-
рительный эксперимент для демонстрации того, что он
считал неотъемлемо присущим квантовой теории.
Ошибка Шредингера — это так называемая ошибка,
находящаяся в состоянии спячки. Программа служит в
течение многих лет. Затем кто-то находит ошибку, чи-
тая старый, пожелтевший листинг исходного кода. И в
этот момент программа перестает работать и начинает
работать снова, только когда ошибка исправлена. Сам
факт нахождения ошибки превращает две возможности —
есть ошибка или ее нет — в твердую уверенность, что
она есть.
Звучит невероятно, не так ли? Но, как я уже гово-
рил, есть совершенно достоверные такие случаи. Я не
суеверен, и я не могу найти рациональное объяснение
этому. Я предполагаю, что либо ошибка находилась в
мало используемой части программы, либо влияла на
вывод программы несущественным образом; ошибка
была в программе все время, но никто ее не замечал.
Когда вы выявили ошибку в листинге и начали искать
отклонения в поведении программы, вы найдете их.
Истинная ошибка Шредингера интересна, но труд-
на в исследовании. По определению, вы знаете, где в
коде присутствует ошибка, поэтому вопрос заключает-
ся только в ее исправлении.
Сопровождение старых кодов вообще может оказать-
ся сложной задачей. Если у вас есть исходные тексты,
это всегда преимущество. Меня как-то пару лет назад
попросили подготовить аналитическое сообщение о
возможности преодоления проблемы 2000 года в неко-
ей важной внутрифирменной программе, исходный код
Которой был потерян. Это оказалось намного более
^ложным делом, чем следовало бы, что явилось прямым
результатом отсутствия исходного кода.
Вы не слишком преуспеете в исправлении старого
кода, если для этого у вас нет нужных средств. Реше-
ние таких проблем требует изобретательности и боль-
шого внимания. Но вы можете сделать так, чтобы ваша
Программа, сейчас совершенно новая, через какое-то
время не создавала сложностей при ее сопровождении.
Как сделать так, чтобы сопровождающий вашу програм-
му специалист любил вас и через десять лет, а не про-
клинал ваше имя? Убедитесь, что следующие вещи на-
дежно сохранены и при необходимости будут доступны
такому специалисту:
• Компьютер, работающий под управлением нужной
операционной системы
• Компилятор, который был использован первона-
чально, — никогда не выбрасывайте CD со старыми
компиляторами!
• Список опций этого компилятора и ключей, кото-
рые были использованы
• Исходный код вместе с заголовочными файлами
• Вся доступная документация
• Тестовые сценарии, условия, данные
• Ожидаемые результаты тестов
Имея все это, квалифицированный сотрудник не
будет иметь реальных проблем при сопровождении ва-
шего кода.
Кошмар программиста
Чтобы закончить данную главу, я хотел бы предложить
вашему вниманию бриллиант среди программ, создан-
ный Эдмундом Стефен-Смитом (Edmund Stephen-
Smith), консультантом из Новой Зеландии, и приведен-
ный здесь с его разрешения. Представленная в листинге
7.8 программа компилируется (предупреждения есть, но
нет ошибок). Игра заключается в том, чтобы посчитать
ошибки. Эдмунд написал эту программу как тест для
собеседования. Большинство людей смогли найти в ней
четыре или пять ошибок. Какое количество сможете
выловить вы? Играйте честно; не читайте замечаний
после текста программы до тех пор, пока не определи-
те это число сами.
(Числа с левого края введены исключительно для
удобства при ссылках на строки кода и не являются его
частью. Версия этого кода на Web-сайте издательства
"ДиаСофт" не содержит этих чисел.)
Перед тем как читать дальше, постарайтесь найти в
этом тексте как можно больше ошибок. И сколько же
вы их нашли? А сколько нашел я? Я не уверен, что
выловил все возможные ошибки, но вот мой список:
В начале исходного кода пропущено включение биб-
лиотек <stdlib.h> и <string.h> (для функций malloc и
strcpy). Это две ошибки, и, по крайней мере, одна из них
приведет к неопределенному поведению программы.
В строке 4 содержится довольно недобросовестная
попытка перестановки. Трудно сказать, сколько здесь
ошибок. Во-первых, точка с запятой в конце — вероят-
164
Пересмотренный язык С
Часть I
Листинг 7.8. Считаем ошибки,
1 linclude <stdio.h>
2 linclude <assert.h>
3
4 I de fine SWAP(x, y) xA= yA= x;
5
6 int
7 main()
8 {
9 char *s="uvwxyz";
10 char *t;
11 unsigned long a, b, c;
12 int i;
13
14 printf("String: %s (%d entries).\n"
15 "Change which character to '1'? ", s,
16 strlen(s));
17 scanf("%d", &a);
18
19 assert((0 <= a) 66 (a < strlen(s)));
20 sfa]= *lr;
21
22 printf("Original changed to %s\n", s);
23 printf("Reverse which range of characters (from-to)? ",
24 b, c);
25
26 scanf("%lu%lu", &a, 6b);
27 assert(a<=b);
28
29 t= malioc(strlen(s+1));
30
31 strcpy(t, s);
32 for (i=b; i<(b+c)/2; i++)
33 SWAP(t[b+i], t[c-i]);
34
35 printf("Result of reverse is %s -> %s\n", s, t);
36 return 0;
37 }
но, плохая идея, но не это главное. Во-вторых, ошибка
заключается в том, что дважды примененный XOR не
обменивает значения двух переменных. И наконец, если
мы исправим это, добавив XOR в том же стиле, то по-
лучим неопределенное поведение, причины которого —
в двукратной модификации переменной между двумя
последовательными точками. Признаем лучше весь вы-
зов сплошной ошибкой, третьей в нашем подсчете. Луч-
шим решением будет следующее:
#define SWAP(x, у) do {unsigned long tmp;\
tmp = x;\
x = y;\
у = tmp;} while(0)
Разделение int main() на две строки выглядит стран-
но, но это разрешено.
В обращении к printf, начинающемся в 14-й строке
кода, строка формата разделена на две строки. Это хо-
рошо — они будут сцеплены. Но возвращаемое strlen
значение противоречит спецификатору %d в строке
формата: оно должно быть типа int, тогда как функция
strlen возвращает в действительности тип size_t. Поэто-
му требуется приведение результата к типу Int. Лучше
вместо этого в строке формата использовать специфи-
катор %и. Но даже при этом результат нужно привести
к типу unsigned int, поскольку нет гарантии, что пере-
менная size_t принадлежит к типу unsigned int. Она
может иметь тип long int, например. Это уже четыре
ошибки.
В строке 17 кода scanf принимает в качестве аргу-
мента адрес переменной а, которая принадлежит к типу
unsigned long, поэтому формат строки должен быть %1и.
Это уже пять ошибок.
Поскольку возвращаемое функцией scanf значение
не проверяется, нет гарантии того, что значение а оп-
ределено. Поэтому его нельзя безопасно использовать в
последующем вызове assert (если только NDEBUG не
определен). Это уже шесть ошибок. В строке 20 про-
грамма модифицирует один из элементов строкового
Исправление кода программ
Глава 7
165
массива, на который указывает s. Это приведет к нео-
пределенному поведению. Семь ошибок.
В вызове функции printf, начинающемся на 23-й
строке текста, аргументы Ъ и с излишни. Я не собира-
юсь считать это ошибкой, но это может помешать вы-
зову.
В 26-й строке переменные а и Ъ передаются в фун-
кцию scanf, но проверка последующей части кода по-
казывает, что подразумевались Ъ и с. Это логическая
ошибка. Таким образом, имеем восемь ошибок. Будем
предполагать для дальнейшего анализа, что мы испра-
вили эту строку. Не проверяется также значение, воз-
вращаемое scanf, но я не собираюсь еще раз засчитывать
эту ошибку.
При виде оператора контроля в строке 27 я был край-
не удивлен. Конечно, должна быть проверкаЬ<==0. Если
уж мы проверяем это, мы должны также проверить
c<strien(s). Ошибочная проверка увеличивает счет оши-
бок до девяти.
В 29-й строке аргументом malloc являетсяБ strien(s+l),
а в действительности должен быть strlen(s)+l. Десять
ошибок.
Строка 30 содержит трудную для определения ошиб-
ку. Строка пуста! Конечно, она должна содержать про-
верку того, что вызов malloc действительно выделяет
необходимую память. Одиннадцать ошибок.
Задание цикла в 32-й строке и тело этого цикла в 33-
й строке полностью неверны. Это классический случай
(в реальной программе), когда программист старается
быть очень искусным, но у него это не получается.
Лучше было бы определить два счетчика цикла: первый,
возрастающий от значения Ь, и второй, убывающий от
значения с, и использовать проверку Ъ<с. Двенадцать
ошибок.
И наконец, пространство, выделяемое функцией
malloc, вообще не используется в программе. Вы долж-
ны согласиться с тем, что это не является ошибкой,
поскольку память должна быть очищена для нас в лю-
бом случае, т.е., строго говоря, это не ошибка.
Итого я насчитал двенадцать ошибок. Вы, может
быть, насчитаете еще больше, если будете строже, чем
я. Сколько я всего пропустил?
Эта программа — яркий пример плохого стиля. Вы
можете включить нечто подобное в процесс собеседо-
вания, проводимый вами с претендентами на работу по
программированию или отладке программ.
Резюме
В этой главе было рассмотрено несколько полезных
стратегий отладки. Мы обсудили такие идеи, как днев-
ник ошибок, многострадальный медвежонок и отладоч-
ные коды, а также классифицировали некоторые общие
ошибки по их причинам и симптомам. Вы получили
новую библиотеку CFollow отладочных кодов, которая
может вам помочь.
Отладка — сложное дело; в этом нет сомнений. Но
настойчивость и усердие, а также немного мастерства
позволят выявить и исправить любую ошибку в програм-
ме. Наиболее важный урок заключается в правиле "Не
сдаваться". Это позволит исправить ошибку. Мы толь-
ко должны найти способ, как это сделать.
Управление памятью
8
В ЭТОЙ ГЛАВЕ
Управление памятью
Общие ошибки использования памяти
Сбои функции выделения памяти
Успешное выполнение функции calloc
Занимаемся контролем
Ричард Хэзфилд
Эта глава посвящена не только реализации функций
управления памятью в С (malloc, calloc, realloc и free),
но и способам их надежного и эффективного исполь-
зования. Мы рассмотрим также вопросы выделения и
освобождения памяти в целях предотвращения утечек
памяти в программах.
Управление памятью
Память — это дефицитный ресурс. Как бы ни был ве-
лик ее объем, нам всегда может понадобиться еще боль-
ший. В наше время многозадачных операционных сис-
тем и "раздутых” приложений требования к размеру
памяти компьютеров возрастают экспоненциально. Каж-
дый раз в сети Usenet кто-нибудь задает вопрос: "Как я
могу запросить более 2 Гб памяти?" Обычно в ответ
можно услышать следующее: "Вы уверены, что вам нуж-
ны эти два гигабайта? Возможно, вам следует пересмот-
реть свой проект”. Это вполне естественный ответ, по-
скольку для большинства вычислительных задач
достаточно намного меньшего объема памяти.
Более того, физические размеры компьютеров
уменьшаются. Все больше приложений втискивается в
миниатюрные ящички, многие из которых меньше ва-
шей руки. Существует физический предел для количе-
ства чипов RAM, находящихся в компьютере. Пробле-
ма нехватки памяти может быть смягчена успехами в
миниатюризации технологических решений, но не сто-
ит на это расчитывать. Поэтому не следует полагать, что
объем памяти компьютеров будет постоянно расти.
Программисты должны использовать память мудро
и экономно. Как и в случае любого сообща используе-
мого дефицитного ресурса, следует быть внимательным
к другим людям при запросе памяти у системы, посколь-
ку одновременно с нашей программой могут выполнять-
ся и другие, а мы часто не в состоянии оценить важ-
ность нашей программы для пользователя по сравнению
с другими. Конечно, следует использовать такой объем
памяти, какой требуется, но не следует запрашивать
больше необходимого без очень серьезной причины (как
мы увидим в дальнейшем, вполне может понадобиться
немного больше памяти, чем это необходимо для рабо-
ты программы).
Общие ошибки использования памяти
Использование незаказанной памяти
Эта книга не для начинающих. Поэтому этот малень-
кий раздел вы можете и не читать. Прискорбно, но есть
такие С-программисты, которые имеют многолетний
опыт использования языка, зарабатывают значительные
суммы (часто за работу в качестве консультантов), но
до сих пор не видят ничего дурного в таком коде:
char *р;
strcpy(p, "Hello world.”);
Должен с сожалением признать, что я знаю некото-
рых таких программистов персонально. Данный раздел
написан как раз для них. А теперь сосредоточьтесь,
потому что это действительно важно. Указатели пред-
назначены для сохранения и доступа к местоположению
объектов. Это не значит, однако, что они рождаются,
зная, где расположены объекты, но они должны указы-
вать на фактическое местоположение объектов.
Иногда мы используем указатели на char так, как
если бы они были массивами char, а иногда использу-
ем массивы char так, как если бы это были указатели на
char. Но указатели и массивы неэквивалентны. Указа-
Управление памятью
Глава 8
167
тел и — это не массивы, а массивы — это не указатели.
Так получилось, что они являются синтаксически эк-
вивалентными формальными параметрами при объявле-
нии функции, исключительно из-за того, что компиля-
тор сводит представление массива к представлению
указателя, а это может привести к некоторой путанице.
Крайне важно уделять достаточное внимание тому,
как ваша программа и стандартная библиотека исполь-
зуют память. Например, функция типа strcpy, будучи
описанной как получающая char * в качестве первого
аргумента, в действительности должна принимать адрес
первого элемента массива char, достаточно большого для
сохранения копии исходной строки, определенной во вто-
ром аргументе. Просто передать неинициализированную
переменную char* (или, как я однажды увидел в Web-
сети, адрес одного символа!) не слишком хорошо.
А вот другой пример неправильного использования
памяти, извлеченный прямо из конференции Usenet
(слегка отредактированный, чтобы скрыть личность
виновного), в данном случае — с участием sprintf. Воп-
рос был такого рода: ”У меня есть массив char, и я хо-
тел бы добавить величину int к этому массиву, что-ни-
будь типа: int d=42; char*s=”some text"+d;. Очевидно,
это не будет работать, но существует ли способ, позво-
ляющий сделать это?” Ниже приведен ответ, пришед-
ший яркой вспышкой озарения.
Пытались ли вы сделать так:
int d = 42;
char *s;
sprintf (s, "some text %d", d) ;
Этот фрагмент выдает полное фундаментальное не-
понимание того, как используется память. Указатель s
не инициализирован. У него нет конкретного значения
(его значение не определено). Он не указывает на что-
нибудь законное или полезное. Нет заказанной облас-
ти памяти, в которую функция sprintf может коррект-
но записать вывод.
ПРИМЕЧАНИЕ
Если уж мы говорим о sprintf, может быть, стоит заме-
тить, что следующая обычная конструкция
sprintf(mystring, "%s%d%s%f", mystring, j,
otherstring, d) ;
приводит к неопределенному поведению программы,
поскольку компилятор может проводить запись в mystring
в таком порядке, в каком хочет, возможно, начиная с
конца выражения. А может сделать и по-другому.
Если вы действительно хотите сделать это, то в качестве
области для временного хранения используйте другую
строку.
sprintf(thirdstring, "%s%d%s%f", mystring, j,
otherstring, d) ;
strcpy(mystring, thlrdstring);
Итак, каким же образом следует выделять память
для строки? Ниже приведены два возможных способа:
char s[13];
strcpy(s, "Hello world.");
char *p;
p = malioc(13);
if(p 1= NULL)
{
strcpy(p, "Hello world.");
/* здесь осуществляйте необходимые
операции со строкой */
free(p);
}
Следует заметить, что для использования функции
strcpy необходимо написать #include <string.h>, а для
использования функций malioc и free нужно написать
#include <stdlib.h>.
В примере с функцией sprintf наш предполагаемый
эксперт из Usenet должен был бы предусмотрительно
определить, какой объем памяти потребуется для ре-
зультирующей строки, включая и место для символа
окончания строки, и заказать, по крайней мере, имен-
но такой объем памяти (в данном примере требуется 13
байтов).
Рассматриваем функцию gets() как
вредную
Есть функция, для гарантированно надежного исполь-
зования которой вы никогда не сможете заказать доста-
точный объем памяти, это — gets(). Эта функция, по-
просту говоря, — ожидающая своего времени ошибка.
Хуже того, во многих системах возможно использова-
ние программы с функцией gets() для получения неза-
конного доступа к системе. Печально известный Internet
Worm (вирус Червь Internet. — Прим. науч, ред.) основан
как раз на такой атаке на gets().
Функция gets() принимает в качестве своего един-
ственного аргумента указатель на char. Начиная от этой
величины char, функция, возможно, заполняет память
данными из stdin до тех пор, пока не достигнет новой
строки, в этот момент функция gets(), возможно, окан-
чивает строку нулем и возвращает управление вызыва-
ющей программе. И если каким-то чудом stdin содер-
жит символ новой строки среди первых N символов, где
N — размер переданного буфера, тогда вы можете ис-
ключить все слова возможно из данного предложения —
именно для этого конкретного вызова функции. Одна-
ко, если символ новой строки не встретится достаточ-
но рано, функция gets() начнет использовать память, к
168
Пересмотренный язык С
Часть I
которой она не должна прикасаться, что приводит к
неопределенным результатам.
В системах со стековой организацией (другими сло-
вами, в большинстве систем) довольно легко задать
функции gets() такую входную строку, при которой
будет умышленно перезаписан адрес возврата в стеке и
подставлен адрес враждебной агрессивной программы.
Что может сделать такая агрессивная программа? В дей-
ствительности все, что захочет кракер. А это уже пря-
мая угроза безопасности вашей системы. Никогда не
используйте gets()! (Почти такая же строка аргументов
применима для scanf() при чтении строки данных, раз-
ница между этими двумя функциями заключается в
том, что функцию scanf() при осторожном обращении
можно использовать корректно.) Возьмите себе за пра-
вило использовать вместо gets() функцию fgets().
Ошибки при сохранении адреса
При вызове функции распределения памяти необходи-
мо записывать возвращаемое ею значение. Вы уже зна-
ете это, не правда ли? Код, имеющий примерно следу-
ющий вид:
strcpy(malloc(13), "Hello world.");
имеет совсем не тот тип, какой бы вы хотели. (Если в
этот момент вы начали довольно хихикать, трепещите.
Я видел исходный код промышленной программы, не
сильно отличающийся от приведенного. Если вы не
поняли шутки, то в действительности вам следовало бы
очень испугаться.)
Это не значит, однако, что необходимо все время
сохранять указатель, указывающий на данный адрес.
Например:
char *р;
int i;
р - malloc(N);
if (p != NULL)
{
for(i = 0; i < N; i++)
{
*p++ = '\0';
/* ... */
Это выглядит небезопасно, поскольку мы заказали
память, а затем изменили значение указателя, который
сохранял базовый адрес этой выделенной области памя-
ти. В действительности, однако, это совершенно безо-
пасно, поскольку все, .что необходимо сделать для воз-
вращения исходного значения, — это прокрутить назад
указатель: p-=N;. (В качестве альтернативного вариан-
та можно просто присвоить некоторой другой перемен-
ной значение, которое имел указатель р перед началом
цикла.) Я не утверждаю, что это хороший способ напи-
сания программы, но он хотя бы не является неверным.
В качестве другого примера того, что я имею в виду,
рассмотрим двусвязный список:
typedef struct doublelist
{
struct doublelist *next;
struct doublelist *prev;
struct FOO payload;
} doublelist;
Для создания этого списка вы начнете с doublelist*
которому присвоите результат вызова malloc. Результа-
ты последующих вызовов malloc для дальнейших свя-
зей в списке будут присвоены различным экземплярам
указателей next и prev. Поскольку можно использовать
эти указатели для перемещения к любому элементу в
списке, то, пока у вас есть указатель на любое место в
списке, нет никакой необходимости сохранять исход-
ный указатель.
Отсутствие проверки возвращаемых
значений
Самое неприятное в процедуре выделения памяти то,
что она не всегда работает, поэтому мы должны прове-
рять значение, возвращаемое malloc, calloc или realloc
при каждом вызове функции. Если действительно про-
изошел сбой, мы должны предпринять необходимые
действия. (Более подробно об этом поговорим позже.)
Нужно помнить, что в случае сбоя все эти функции
возвращают NULL. Первое, что вы делаете после заказа
памяти, — записываете что-нибудь в эту область памя-
ти. Запись в ячейку по указателю NULL является зап-
рещенной операцией. (Ранее в этой книге были рассмот-
рены последствия неопределенного поведения
программ, поэтому я не буду снова заострять ваше вни-
мание на всех тех ужасных вещах, которые могут при
этом произойти.)
Следовательно, если вы не сравниваете величину,
возвращаемую функцией заказа памяти, с NULL, то с
точки зрения абстрактной машины С последующее по-
ведение вашей программы будет совершенно неопреде-
ленным и непредсказуемым.
Некоторые люди опускают проверку на ошибки
функции mallocO, поскольку считают, что достигаемый
отбрасыванием проверки выигрыш в эффективности
перевешивает соответствующую потерю надежности.
Это выглядит так, как если бы вы, выезжая за город по
сельской дороге, слишком быстро выскакивали из-за
хорошо знакомого угла, поскольку никогда раньше не
встречали здесь кого-нибудь, кто бы двигался по дру-
гой дороге. Понятно, что однажды вы пожалеете о та-
ком легкомыслии.
Отсутствие запасного указателя для realloc
В листинге 8.1 содержится небольшой кошмарик для вас.
169
Листинг 8.1. Недопустимое использование
функции realloc.
char *ReadTextFile(FILE * f p)
{
size_t size = 0;
size t len;
char *p » NULL;
char buffer[128];
while(fgets(buffer, sizeof buffer, fp))
{
len = strlen(buffer);
p « realloc(p, size + len);
strcpy(p + size, buffer);
size +== len;
}
return p;
Эта функция считывает файл в память. Однако мо-
жет случиться, что выделенной области памяти недо-
статочно для считывания всего файла. В этом случае хо-
рошо было бы позволить пользователю отредактировать
фрагменты файла, которые могут быть считаны, и со-
хранить их под разными именами, или использовать ка-
кой-либо другой аналогичный подход. К сожалению,
пользователь даже не получит такого шанса, поскольку
программа позволяет возвращаемой величине, которая в
случае ошибки заказа памяти равна NULL, переписать
информацию, сохраненную в р-адресе исходного буфера.
В листинге 8.2 показан намного лучший способ,
позволяющий сделать это.
Листинг 8.2. Правильное использование функции
realloc.
char *ReadTextFile(FILE *fp, int *Error)
<
size_t size = 0;
size t len;
char *p = NULL;
char *q;
char buffer[128];
♦Error = 0;
while(fgetsfbuffer, sizeof buffer, fp))
{
len = strlen(buffer);
q = realloc (p, size + len);
if(q 1= NULL)
{
p = q;
strcpyfp + size, buffer);
size += len;
}
else
{
♦Error = 1;
}
Управление памятью
Глава 8
}
return p;
}
Эта функция возвращает указатель на максимально
возможную копию в памяти входного файла (или
NULL, если самый первый заказ памяти не удался). В
случае неполного прочтения она присваивает перемен-
ной, содержащей информацию об ошибках, ненулевое
значение. Здесь нет утечки памяти (хотя, конечно, вы-
зывающая функция ответственна за освобождение па-
мяти в соответствующее время).
Использование памяти, которая не
выделена
Я не знаю почему, но многие программисты думают,
что можно делать так:
while (р != NULL)
{
free(p);
р « p->next;
}
Их рассуждения выглядят примерно следующим
образом: "Я знаю, на что указывал р перед вызовом
free(), и я не сделал ничего, чтобы изменить его; все,
что делает функция free(), всего лишь изменяет некий
список. Присвоение произошло через наносекунду или
около того после вызова free(), поэтому у системы не
было времени использовать эту область памяти каким-
либо другим образом. Эта область по-прежнему мне
доступна для получения указателя next; поэтому я так
и делаю”.
Трудно оспаривать позицию такого рода, особенно
когда (во многих случаях) эти Программисты могут по-
казать вам, что их рассуждения корректны (даже если
это и не так). Но мы должны это сделать. Тому, кто
страдает аллергией на аналогии, следует пропустить два
следующих абзаца.
Это немного похоже на покупку и затем последую-
щую продажу дома. Когда вы приобрели его, вы може-
те делать с ним все, что хотите. Можете разместить в
нем все что угодно и жить в нем вполне счастливо так
долго, как вам хочется, вплоть до того момента, когда
вы его продадите.
Когда вы продали дом, у вас уже нет права жить в
нем. У вас нет даже права зайти в него. У вас может быть
запасной ключ (аналог указателя р), но это ничего не
значит. Это уже не ваш дом. Как только вы передали
документ на право собственности новому владельцу, вы
ни по какой причине не имеете права находиться в
доме. Если вы случайно забыли нечто чрезвычайно важ-
ное для вас на чердаке, можете попытаться вернуться и
забрать это, но права на такое действие вы не имеете.
Пересмотренный язык С
Часть I
170
В некоторых странах владелец, застав вас в доме, может
даже пристрелить вас на месте (несколько экстремаль-
ный вариант неопределенного поведения). Намного
безопаснее удостовериться, что вы сохранили все вам
необходимое, перед передачей права собственности.
Это только иллюстрация, и, как сказал Бьерн Стра-
уструп (Bjame Stroustrup), ’’доказательство путем анало-
гии является обманом”. Если это не удовлетворило вас,
обратитесь к разделу 7.20.3 стандарта С, в котором го-
ворится: ’’значение указателя, который указывает на
освобожденную область, неопредслено". Другими сло-
вами, обращение к освобожденной области памяти при-
водит в результате к неопределенному поведению. То же
самое можно сформулировать иначе: вы не можете га-
рантировать определенность поведения своей програм-
мы, и теоретически она может заставить компьютер
производить любое действие, доступное ему физичес-
ки. включая и различные возможности отправления
сообщений по электронной почте вашему начальнику,
чем я в действительности не хотел бы вас тревожить.
Ниже приведено решение вышеупомянутой голово-
ломки, при котором не возникает вызывающей ужас
угрозы неопределенного поведения.
Т *q; /* того же типа, что и р*/
while(р != NULL)
{
q = p->next;
free(p);
p = q;
}
Подобные проблемы возникают в функциях такого
типа:
char *BuildPhoneNumber(int code, int num)
{
char telno[16];
sprintf(telno, "(%05d) %d", code, num);
return telno;
}
Переменная telno является локальной переменной
функции BuildPhoneNumber(). Поэтому нельзя рассчи-
тывать на определенность ее содержимого после выхо-
да из функции.
Чтобы решить эту небольшую головоломку, либо
сделайте telno переменной типа static, либо передайте
ее в массив char достаточного размера, либо динамичес-
ки закажите память и верните указатель на эту область
памяти (не забудьте освободить ее, когда она будет уже
не нужна).
Восстановление памяти операционной
системой
В стандарте С ничего не сказано о том, что происходит
с динамически заказанной памятью, которая осталась
таковой к моменту завершения программы. В конце
концов, программа может быть написана на С, но ведь
нет никаких требований относительно того, что вызы-
вающая программа должна быть написана на С, не так
ли? То, что произойдет сразу после завершения про-
граммы, написанной на С, выходит за пределы стандар-
та С. Существует распространенное мнение, что опера-
ционная система освободит память, которая была
использована программой, когда эта программа завер-
шит свою работу. Для многих операционных систем это
верно; в действительности это почти верно для опера-
ционных систем наиболее общего использования. Но
стандарт С не дает никаких гарантий того, что это так.
Хорошей программистской практикой является при-
вычка убирать за собой, если можно так выразиться, т.е.
оставлять после себя компьютер в том же состоянии, в
каком он был до вашей работы с ним. Возвращение
динамически заказанной памяти является частью этого
процесса. Если этот аргумент убедил вас, значит, вы
всегда были убеждены в этом, а если это не так, то я
сомневаюсь, что изменил сейчас ваше мнение. Поэто-
му позвольте мне перейти к более прагматичной при-
чине, по которой необходимо всегда очищать память, —
речь пойдет о повторном использовании кода.
Хорошие программы используются повторно. Иног-
да целая программа преобразуется в библиотечную под-
программу. Когда я работал в компании по страхованию
жизни, то приложение по планированию накоплений
(несколько тысяч строк кода), которое я помогал раз-
рабатывать, превратилось в библиотечную подпрограм-
му. Оно было программой, а стало функцией (или ско-
рее целым набором функций, с одной функцией в
качестве точки входа), и эта функция стала вызываться
множество раз во время одного прохода головной про-
граммы. К сожалению, это приложение заказывало па-
мять, но не освобождало ее, когда она была уже не нуж-
на. И то, что было совершенно приемлемо для многих
людей, когда приложение было программой, стало клас-
сическим примером утечки памяти после превращения
в библиотечную подпрограмму. Понятно, что оно было
исправлено. Также понятно, что можно было бы сохра-
нить много времени и, следовательно, денег, если бы с
самого начала программа разрабатывалась с учетом пра-
вильного освобождения памяти.
Планируйте возможность повторного использования
своего кода. Освобождайте память, когда заканчиваете
ее использовать. Коллеги будут считать вас педантом,
но когда-нибудь парни, сопровождающие вашу про-
грамму в течение 10 лет, будут очень хорошо к вам от-
носиться. Они, конечно, все равно будут обзывать вас
(все программисты сопровождения делают это), но при-
меняемые ими эпитеты не будут столь неприятными, а
это многого стоит.
Управление памятью
Глава 8
171
Сбои функции выделения памяти
Это обычный код для обработки ошибок:
р = malloc (bytes) ;
if(p == NULL)
{
printf("Can't allocate enough memory.
Aborting.\n");
exit(EXITFAILURE);
)
Для "студенческого” кода это совсем неплохо. Про-
верка необходима, поскольку может произойти сбой в
функции malloc. На практике в корректно написанном
студенческом коде очень редко происходит сбой при
выделении достаточного объема памяти, поскольку тре-
буемое количество стремится к нескольким сотням бай-
тов и при каждом конкретном запуске программы за-
прашивается всего несколько таких блоков (разве что
профессор пребывает в отвратительном расположении
духа). Если даже добросовестный студент решает про-
вести "тяжелые испытания" своего приложения, потре-
бовав от него использовать больше памяти, чем оно
может получить, он, вероятно, будет удовлетворен ре-
зультатом вызова printf. Его программа преждевремен-
но завершится из-за ошибок проектирования.
ПРИМЕЧАНИЕ
Не только студенты могут избежать этого. Для тех, кто
плохо изучал С в колледже, с помощью Usenet или ис-
пользуя другие возможности, становится традиционным
прекращение выполнения приложения при возникновении
сбоя в распределении памяти. Можно предположить, что
восстановление работоспособности программы после
ошибки выделения памяти скорее оставляется в качестве
упражнения для аспирантов, чем тщательно изучается как
естественное требование к реальной программе. И нуж-
но, чтобы студент понимал, что exit (EXIT_FAIL.URE); в
действительности должно читаться как сокращение от
"Вставьте здесь ваш механизм восстановления работос-
пособности программы".
В реальном мире жизнь не так проста. Представьте,
что вы целый час работаете над документом, когда ваш
любимый текстовый редактор вдруг пытается выделить
20 или 30 байтов для нового шрифта, терпит неудачу,
пишет краткое оправдание в stdout и прекращает свою
работу. Никакой возможности отменить действие, выз-
вавшее требование выделения памяти, никакой возмож-
ности сохранить свою работу, только сухое сообщение —
"никакой трагедии, не беспокойтесь, пока!" (если вам
повезет), и часовая работа идет коту под хвост. Долго
ли такой текстовый редактор будет оставаться вашим
любимым?
Что можно сделать в случае сбоя? Во многом это,
конечно, зависит от приложения, но мы можем сделать
несколько общих заключений в точном соответствии с
природой наших требований к памяти.
Проанализируйте требования памяти
Действительно ли требующаяся нам память должна
быть одним цельным блоком? Если ответ отрицатель-
ный, то, возможно, мы сможем выполнить два запроса.
Когда вы вызываете malloc(), он старается найти один
блок свободной памяти, достаточно большой, чтобы
удовлетворить ваше требование. Если он может найти
достаточно большой блок, он возвращает указатель на
него. Если не может, то возвращает NULL. Запрашивая
два меньших блока, вы облегчаете malloc() жизнь, и
действительно может оказаться, что он справится с дву-
мя вашими требованиями.
Используйте меньше памяти
Не запрашиваем ли мы объем памяти, превосходящий
необходимый? Это, конечно, не всегда плохо, если вы
ищете постоянный компромисс между размером и ско-
ростью. Например, у нас может быть динамический
буфер, размер которого иногда надо менять; может
иметь смысл заказать значительно больше памяти, чем
необходимо при изменении размера. Сделав так, мы
уменьшим количество вызовов функции realloc, и эф-
фективность нашей программы пострадает намного
меньше, чем в противном случае. Некоторые заходят так
далеко, что утверждают: следует удваивать размер бу-
фера при каждом запросе, как показано в листинге 8.3:
Листинг 8.3. Минимизируем число вызовов realloc.
static char *buffer = NULL;
static size_t bufsize = 0;
while(strlen(s) >= bufsize)
{
p = realloc(buffer, bufsize * 2);
if(p 1= NULL)
{
bufsize *= 2;
buffer = p;
else
{
printf("er.•.now what?\n");
}
}
Существуют границы области применения стратегии
корректировки в случае ошибки выделения памяти.
Кроме всего прочего, вполне может оказаться, что раз-
мер буфера уже почти достаточен. Листинг 8.4 демон-
стрирует, каким образом мы можем попытаться восста-
новить работу после такого сбоя.
172
Пересмотренный язык С
Часть I
Листинг 8.4. Восстановление работы после сбоя
realloc.
static char ‘buffer = NULL;
static sizet bufsize = 0;
size_t len = strlen(s) + 1;
while(len > bufsize)
{
p = realloc(buffer, bufsize * 2);
if(p ! = NULL)
{
bufsize *= 2;
buffer = p;
}
else
{
p = realloc(buffer, len);
if(p ’= NULL)
{
bufsize = len;
buffer = p;
}
else
{
/* Что произойдет дальше, очень
сильно зависит от самого приложения */
printf("What we need here is a
design decision!\n");
}
}
}
Этот код уже лучше. Он пытается восстановить ра-
боту после сбоя при выделении памяти, но по-прежне-
му остается без ответа вопрос о том, что произойдет в
случае появления второй ошибки. Возможно, будет
правильно либо освободить всю память и сообщить
вызывающей функции, что ничего не получилось, либо
использовать дополнительный параметр — указатель на
переменную состояния — и с ее помощью сообщать,
что не все данные могут быть корректно сохранены из-
за ограничений памяти, но часть, которая может быть
сохранена, теперь доступна. Что окажется верным, за-
висит от приложения. Здесь важнее всего отметить, что
решение о прекращении работы приложения должна
принимать не вспомогательная функция. Такое решение
должно приниматься на уровне приложения, а не на
уровне вспомогательной функции. Это связано с тем,
что вспомогательные функции, если они действитель-
но полезны, могут быть использованы во множестве
приложений различных типов, от которых могут требо-
ваться различные реакции на ошибку.
Используйте буфер фиксированной длины
Рассмотрим простую программу, которая копирует
файл из одного места в другое. Если размер исходного
файла может быть определен заранее (возможно, с ис-
пользованием таких зависящих от реализации расшире-
ний, как filelength(), которые имеются во многих хоро-
шо известных компиляторах), то программа может
выделить нужное количество байтов, считать исходный
файл в этот буфер и записать его из этого буфера. Про-
сто и быстро. Если это не получается, не беда. Програм-
ма не должна полагаться на динамический буфер.
В самом худшем случае она может работать с буфером,
состоящим только из одного байта. Кроме того, она
почти наверняка может использовать маленький авто-
матический буфер — массив типа unsigned char.
Я недавно написал программу, которая обрабатывает
текстовые файлы, проводя элементарные "поиск и за-
мену". Мне был нужен большой буфер, но, если нуж-
но, я мог проделывать операции и с буфером меньшего
размера. Я определил маленький буфер и величину
char*. Я пытался динамически заказать 8 Кб памяти.
Если это не получалось, попытка повторялась для вдвое
уменьшенного объема памяти, и процесс уменьшения
запрашиваемого объема памяти вдвое продолжался до
тех пор, пока либо происходило выделение требуемого
объема, либо запрашиваемый объем памяти становил-
ся меньше размера автоматически выделяемого буфера.
В таком случае я отказывался от этой процедуры и пе-
реходил к использованию автоматического буфера. Из-
лишне говорить, что до сих пор моя функция всегда
могла выделить 8 Кб с первой попытки. Но если это
когда-нибудь не получится, я всегда готов к такой си-
туации!
Выделяйте резерв на случай аварийной
ситуации
Ваша программа может быть построена таким образом,
что вы не сможете обеспечить ее отказоустойчивость в
случае сбоя выделения памяти, поскольку для этого
необходимо выделить память (!), что в данный момент
сделать невозможно. Это проблемы проектирования
программы. Если вы сталкиваетесь с такой ситуацией,
рассмотрите возможность перепроектирования програм-
мы таким образом, чтобы программа выделяла память,
необходимую для удачной обработки ошибки в начале
работы, когда предположительно памяти имеется в изо-
билии. Верно, что эта память может не понадобиться до
тех пор, пока не будет необходимости устранить сбой,
но также верно и то, что именно в начале работы про-
граммы наиболее вероятно получить заказанную память —
не стоит ждать, пока будет слишком поздно. Это еще
один пример запроса памяти, которая, строго говоря,
вам может и не понадобиться, но которую вы захватыва-
ете во имя надежности своей программы.
Управление памятью
Глава 8
173
Использование дискового пространства
У вас есть возможность использовать другие виды запо-
минающих устройств в качестве дополнения к основной
памяти. Многие операционные системы стандартно
используют такую виртуальную память. При недостат-
ке RAM они находят некоторую область памяти, кото-
рая кажется ненужной в этот момент и записывают ее на
диск, создавая свободное пространство для вашего запро-
са. Если ваша операционная система делает это, малове-
роятно, что вы столкнетесь с отказом при динамическом
выделении памяти, разве что ваша программа слишком
требовательна или ошибка столь велика, что разрушает
подсистему выделения памяти в приложении.
НАГРУЖАЕМ WINDOWS
Когда пару лет назад я тестировал некоторую програм-
му управления памятью, я заставил Windows NT выделить
мне 1,5 Гб памяти, используя множество сравнительно
небольших выделений в цикле. Время освобождения их
заняло более 90 минут!
Если ваша операционная система не предоставляет
виртуальную память, то сравнительно просто сделать
это самому. Все, что при этом вам нужно, — создать
большой файл на основном запоминающем устройстве,
будь то жесткий диск, магнитная лента или перезапи-
сывающийся CD-ROM. Я буду предполагать, что вы ис-
пользуете жесткий диск; с точки зрения нашего обсуж-
дения почти или вообще нет никакой разницы между
дисками, магнитными лентами, перезаписывающимися
CD-ROM и желтыми листочками для записей с липучкой.
Какой величины должен быть файл, зависит частич-
но от размера вашего диска, а частично от объема тре-
буемой памяти. К счастью, пространство на диске на-
много дешевле, чем RAM, поэтому вы, скорее всего,
получите столько пространства на диске, сколько вам
нужно.
Идея проста. Прежде всего закажите буфер подхо-
дящего размера в начале выполнения программы, ког-
да свободно больше всего памяти. Затем, если происхо-
дит сбой выделения памяти, найдите блок динамически
выделенной памяти, в котором вы какое-то время не
нуждаетесь, и запишите его в файл на диске. Потом вы
можете вновь использовать эту память для другой цели.
Когда вам понадобится исходное содержимое буфера,
его можно прочесть из файла. (Если вам еще нужны
более новые данные, можете записать их в другую часть
файла перед загрузкой в буфер старых исходных дан-
ных.) Может оказаться необходимым написать управ-
ляющие функции, которые будут осуществлять для вас
эти операции. Их так просто написать, и в настоящее
время настолько мало операционных систем, не исполь-
зующих виртуальную память, что я даже не привожу
здесь для вас соответствующие коды.
Использование одной или нескольких из приведен-
ных выше стратегий приведет к тому, что вы никогда
не потеряете данные из-за ограничений памяти.
Успешное выполнение функции calloc
Функция calloc, как я привык считать, изумительна.
Она не только выделяет память удобными прямоуголь-
ными блоками, пригодными для массивов, но и иници-
ализирует все элементы этих массивов со значением
нуль.
Я имел именно такое представление об этой функ-
ции. Но оно было неправильным, по крайней мере, в
отношении указанных аспектов поведения функции
calloc. Взять хотя бы мое смутное представление о не-
коей "прямоугольной" памяти, которое появилось у
меня под влиянием двух аргументов функции calloc
(длины и ширины, так сказать). Но я упоминаю здесь об
этом только потому, что встречал некоторых людей,
имеющих такое же неверное представление. Если вы
один из них, то знайте, что память организована не так.
Лучше всего представлять ее длинным рядом библио-
течных ящичков с нарисованными на боках маленьки-
ми восьмеричными или шестнадцатеричными числами.
Важнее другое неверное (и более опасное) представ-
ление: функция calloc необязательно инициализирует все
элементы массива со значением нуль. Хуже того, она,
возможно, будет их обнулять, но может и не обнулять
элементы, поэтому у нее больше шансов поймать несве-
дущих, чем у многих других ловушек С.
С целыми величинами (char и различными вариан-
тами int) все в порядке, независимо от того, со знаком
они или без. Их значения будут равны нулю. И может
быть, все будет в порядке с указателями и величинами
с плавающей точкой (float, double и long double). Но
может быть, и нет. Язык С не гарантирует, что величи-
на, содержащая только нулевые биты, является пред-
ставлением нулевой величины и для указателей
(NULL), и для величин с плавающей точкой (0.0). Так
часто бывает, но вы никогда не можете быть уверены,
что это действительно так. Это не тот факт, который я
хотел бы обсуждать в деталях именно сейчас, особенно
потому, что этот вопрос больше касается типов данных,
чем проблем управления памятью, поэтому ограничим-
ся этим предупреждением. Если для вас важна перено-
симость программы, не доверяйте функции calloc ини-
циализацию своих переменных со значением нуль. Если
элементами вашего массива являются указатели или
величины с плавающей точкой (либо вы создаете мас-
сив структур или объединений, которые содержат вели-
чины с плавающей точкой или указатели), проводите
инициализацию самостоятельно, в цикле.
В действительности можно также использовать
malioc. Если ваши структуры велики, это может пока-
174
Пересмотренный язык С
Часть I
заться огромным неудобством. Заметим, однако, что
нетрудно найти рациональный способ за счет дополни-
тельного экземпляра вашей структуры:
FOO f = {О};
FOO *р;
р = malloc(n * sizeof *р);
if(p 1= NULL)
{
for(i = 0; i < N; i++)
P[i] =
}
Мы обычно предпочитаем, чтобы те функции, ко-
торые выполняет этот код, выполняла функция calloc.
В этом коде приносится в жертву эффективность ради
ясности и краткости. Если вы хотите сжать код вплоть
до самого последнего байта, то, вероятно, предпочтете
использовать вместо этого обычный метод.
Занимаемся контролем
Контроль — вот чем в действительности является уп-
равление памятью. Чтобы память работала на вас, не-
обходимо точно знать (или иметь возможность опреде-
лить) местоположение каждого блока памяти,
заказанного вашей программой, чтобы вы смогли когда
нужно обратиться к этой памяти (и смогли корректно
освободить ее после использования). Вы также должны
знать размер каждого блока для уверенности, что вы не
осуществляете запись в не выделенную вам память.
Несколько лет назад я работал над программой, ко-
торая заказывала и перезаказывала большой объем па-
мяти, и столкнулся с фактом утечки памяти. Я хотел
снизить вероятность того, что программа не сможет
выполнить свое задание из-за ошибки распределения
памяти. Чтобы обеспечить себе гарантию корректного
использования памяти, я написал промежуточные фун-
кции для вызова функции malloc и ей подобных функ-
ций и для отслеживания всех случаев выделения и ос-
вобождения памяти. Я также пытался сделать эти
функции более полезными, чем их эквиваленты из биб-
лиотеки С. Например, все они поддерживают издавна
используемое мной соглашение о возврате величины int,
при этом ее значение, равное 0, соответствует успеш-
ному вызову. Определенным улучшением была и про-
межуточная функция для realloc. Я хотел, чтобы мне
никогда не нужно было помнить об использовании за-
пасного указателя, как это приходилось делать при воз-
вращении кода возникшей ошибки (оставляя нетрону-
тым исходный указатель). Чтобы достичь столь
волшебного результата (как я тогда считал), я должен
был передавать указатель на указатель в каждую функ-
цию выделения памяти.
Отслеживание памяти заключалось в записывании
информации о выделении памяти в бинарное дерево
вместе с информацией _FILE_ и _LINE_. В качестве
первичной информации я сохранял собственно указа-
тель и использовал его как ключ.
Я не принял во внимание, что при запросе операци-
онная система начинала выделение памяти с низших
адресов, увеличивая возвращаемый адрес на некоторую
величину при каждом новом выделении. В результате
мое бинарное дерево стало выглядеть скорее как унар-
ный телеграфный столб — наиболее дорогостоящая
симуляция сортированного списка. Эффективность ра-
боты программы резко снизилась.
Чтобы справиться с проблемой низкой эффективно-
сти, я применил ко всему набору функций условную
компиляцию. Они будут включены в программу, толь-
ко когда я этого захочу. В противном случае использу-
ются более простые функции окончательного кода. Та-
ким образом, я могу осуществлять контроль над
памятью в процессе разработки, ликвидировать утечки
и затем вновь скомпилировать программу для сдачи в
эксплуатацию. Я мирился с медленной работой прило-
жения в процессе разработки ради гарантии надежнос-
ти работы окончательного кода.
Поразительно, но программа работала. Я разработал
приложение, и, после того как было продано аж нуль
его копий (!), код канул в небытие.
Я извлек его на свет несколько дней назад, полный
сознания того, что мой код достаточно хорош для этой
книги, и надежды, что эта превосходная библиотека
принесет реальную пользу всему человечеству. К мое-
му большому удивлению, этот код был и близко не так
хорош; он потребовал от меня очень много работы для
того, чтобы привести его к должному виду. Прежде все-
го. он был столь же переносим, как и угольная залежь.
Я был испуган. Поскольку невероятно, чтобы я мог
написать код настолько плохо, мне оставалось только
предположить, что он испортился. Уверен, вы понима-
ете, что я имею в виду. Когда вы в следующий раз ужас-
нетесь, глядя на код, написанный вами несколько лет
назад, вспомните меня.
СОВЕТ
Если вам важна переносимость кода, действительно сто-
ит использовать более чем один компилятор. Если это
только возможно, компилируйте и тестируйте свой код
под управлением более чем одной операционной систе-
мы. Мне нравится использовать Windows и Linux в каче-
стве обычных операционных систем, хотя мне случалось
использовать OS2 и OS390 (мэйнфреймовская операцион-
ная система). Выполнение вашей программы на мэйнф-
реймовской машине действительно позволит проверить
вам, верное ли вы имеете представление о переносимо-
сти!
175
Как бы там ни было, я проделал необходимую ра-
боту и представляю вам исправленный исходный код.
Библиотека включает в себя заголовочный файл
(memtrack.h) и файл с исходным кодом (memtrack.c).
Файл memtrack.c представляет собой простую управля-
ющую программу. Показывая, как контролировать па-
мять, я, кроме того, буду все время обращать ваше вни-
мание на мои ошибки (и исправление их), частично,
чтобы вас позабавить, но в основном в надежде на то,
что вы, мой благосклонный читатель, извлечете пользу
из моих ошибок и не сделаете таких же сами.
Заголовочный файл для осуществления
контроля над памятью
В листинге 8.5 описывается интерфейс.
Листинг 8.5. Заголовочный файл для
осуществления контроля над памятью.
Iifndef MEMTRACKH__
Idefine MEMTRACKH__
Здесь уже есть моя самая первая ошибка. Да, уже!
В моем первоначальном исходном коде этот контроль
включения имел вначале два символа подчеркивания
(_MEMTRACK_H__), что выглядело действительно
круто, но на деле оказалось нарушением соглашения о
пространстве имен.
Idefine MEMTRACK__FILENAME ’’MEMTRACK.TXT"
Ошибка номер два. В данном случае ошибка состо-
ит в построении программы. Вместо того чтобы позво-
лить пользователю определить имя регистрационного
файла при выполнении, я использовал жестко заданное
имя для этого файла. Я не стал изменять построение
программы (поскольку это включало бы и радикальные
изменения в интерфейсе, которые не имеют ничего
общего с управлением памятью), но я перенес тексто-
вую строку в заголовочный файл, где ее легче найти,
если вы захотите ее изменить.
Следующий шаг —.определение количества имен
функций, которые фактически являются директивами
препроцессору. В зависимости от того, будем ли мы
контролировать память или нет, они будут заменены
именами отслеживающих или неотслеживающих фун-
кций.
Имена важны. Я долго и мучительно думал, разум-
но ли назвать эти макросы malloc, realloc и т.п. Если бы
я сделал это, тогда код пользователя-программиста выг-
лядел бы куда более прилично и с этой точки зрения
достигалось бы некоторое преимущество. С другой сто-
роны, это может затушевать использование программы
отслеживания памяти, что действительно было бы пло-
хо. К тому же пришлось бы создавать отдельные заго-
Управление памятью
Глава 8
ловочные файлы для этих макросов, поскольку иначе
они будут конфликтовать с вызовами стандартных биб-
лиотечных функций malloc и т.п. в самих исходных
кодах контроля памяти. Более того, эти имена макро-
сов будут конфликтовать с прототипами в <stdlib.h>,
что может вызвать самые различные осложнения. По-
этому я использовал другие имена. Я решил назвать мак-
росы xmalloc, xrealloc и т.п. Поскольку эти имена уже
достаточно популярны как неофициальные расшире-
ния, я решил использовать описательные имена с ис-
пользованием букв верхнего и нижнего регистров. В
этом случае маловероятен конфликт с именами уже
существующих популярных функций.
#ifdef MEMTRACK
Idefine AllocMemory(size) \
DebugAllocMemory(size, ___FILE__, ___LINE_)
Idefine AllocCopyString(s) \
DebugAllocCopyString(s, __FILE__, ___LINE_)
Idefine ReAllocMemory(p, newsize) \
DebugReAllocMemory(p, newsize, _FILE , ___LINE_)
Idefine ReleaseMemory(p) \
DebugReleaseMemory(p, FILE , LINE )
Idefine MEMTRKMEMALLOC 1
Idefine MEMTRK_MEMFREE 2
Idefine MEMTRKREPORT 3
Idefine MEMTRKDESTROY 4
lifndef TYPMEMTRKMSG
Idefine TYPMEMTRKMSG
typedef int MEMTRKMSG;
#endif
Перед функциями, осуществляющими контроль над
памятью, стоят четыре задачи. Мы хотим регистриро-
вать выделение памяти, убирать устаревшие записи об
этом (когда память освобождается), обеспечить сообще-
ние по запросу и уничтожить все записи (по окончании
работы программы). У меня была и пятая задача,
MEMTRK INIT, но она приводила к излишнему услож-
нению кода приложения, поэтому я ее отбросил. Фун-
кция TrackMemoryO использует эти константы в опе-
раторе switch().
Здесь переменная typedef представляет интерес.
В языке С до сих пор нет директивы #ifntypedef, отсут-
ствие которой я нахожу весьма досадным фактом. На-
пример, нет ничего необычного в typedef int BOOL.
Именно потому, что это обычно, велики шансы столк-
новения между двумя определениями типа с тем же
самым именем в заголовочных файлах двух различных
библиотек утилит. (Для данного конкретного случая в
новом стандарте С99 есть тип _Воо1, но принцип оста-
ется тем же и для других общих типов, определяемых
176
Пересмотренный язык С
Часть I
пользователем. У меня были сложности с парой особен-
но неясных определяемых пользователем типов, когда
я участвовал в корпоративных разработках.) Существу-
ет один способ, позволяющий обойти проблему, кото-
рую могло удачно решить применение #ifntypedef, если
бы такой оператор только существовал: включение за-
щиты в стиле заголовочного файла вокруг каждого
typedef. К сожалению, исправлять все наши определе-
ния typedef таким способом слишком дорого. И хотя я
начал это делать, достаточно очевидно, что это не вой-
дет у вас в привычку. Тем не менее, я оставил охран-
ный код на месте на тот случай, если это покажется вам
хорошей идеей и вы захотите ее использовать. Если это
не так, просто забудьте о ней.
Сейчас мы переходим к очень важному типу ALIGN.
Посмотрите сначала на код, а затем я объясню.
#ifndef TYP-ALIGN
♦define TYPALIGN
typedef union
{
long 1; /* в C99 попробуйте вместо этого
использовать intmax_t * /
unsigned long lu;
double f;
long double If;
void *vp;
void (*fp)(void);
} ALIGN;
#endif
Первая версия этой библиотеки сохраняла копии
указателей, возвращаемых различными функциями ди-
намического заказа памяти, в двоичном дереве. Чтобы
найти в двоичном дереве нужное место для записи ука-
зателя, было необходимо сравнить относительные вели-
чины указателей. Поскольку многие операционные си-
стемы присваивают адреса в возрастающем порядке, по
крайней мере на некоторое время этот метод, вполне
вероятно, приведет к дереву более тонкому, чем шари-
ковая ручка на диете. Конечно, мы можем решить эту
проблему, выполнив какие-либо преобразования указа-
телей в целые величины и хешируя эти величины для
получения лучшего дерева.
Но более серьезная и существенная проблема заклю-
чается в сравнении указателей. Вполне допустимо для
С-программы, если два указателя, имеющие различные
битовые наборы, указывают на один и тот же объект.
Они могут представлять тот же объект, даже если их
значения различны. Печально известная сегментная
организация виртуальной памяти ранних процессоров
Intel 80x86 — это типичный пример подобной странно-
сти. Для этих процессоров битовые наборы 0х1004(ЮА0
и ОхЮООООЕО относятся к одному и тому же адресу.
Интуитивно это понять трудно, но это именно так. Мы
можем преобразовать указатель в целую величину (воз-
можно, через массив unsigned char) и сохранить ее в
качестве ключа. Но мы не можем гарантировать того, что
пользовательская программа вернет тот же битовый на-
бор для освобождения указателя, который мы переда-
ли сразу после выделения памяти.
И мы не можем пожать плечами и заявить, что не
собираемся беспокоиться о поддержании любых плат-
форм с нелинейной адресацией. Это книга о С, а не о
С для платформ с линейной адресацией} Поэтому мы дол-
жны найти лучшее решение.
Хорошо, если нет возможности подходящим обра-
зом сравнивать указатели, нельзя ли вместо этого срав-
нивать что-нибудь другое? Что, если мы присвоим уни-
кальное значение каждому выделению памяти и
используем эту величину как ключ дерева?
Проблема, связанная с этой идеей, заключается в
том, что для обеспечения относительно твердой гаран-
тии уникальности каждого случая выделения памяти,
возможно, лучше всего присваивать индекс, который
будет возрастать при каждом выделении. Здесь все в
порядке (достаточно надолго), за исключением того,
что это приводит к чрезвычайно неэффективной струк-
туре дерева. Как мы можем обойти эту проблему?
Одним из возможных решений, как я говорил ранее,
является хеширование. Если мы можем разработать спо-
соб, позволяющий исказить ключ предсказуемым (или,
по крайней мере, воспроизводимым) образом, то это
может дать нам намного более пышное и широкое де-
рево. Тогда код для балансировки дерева не понадобит-
ся нам на протяжении еще нескольких глав в этой кни-
ге. Более того, мы не должны даже сохранять
хешированные величины. Можно просто снова вычис-
лить их, когда они нам понадобятся, если только най-
дем способ сохранения собственно ключа. Это особен-
но полезно, если мы заканчиваем выполнение
программы, используя не одну хеш-величину.
СОВЕТ
Помните, что алгоритм хеширования должен быть искус-
но разработан для конкретного 'набора данных и в соот-
ветствии с вашими конкретными требованиями. Вы, воз-
можно, захотите (или вынуждены) иметь несколько или
даже много корзин. Не исключено, что существует ог-
раничение на количество коллизий (пересечение элемен-
тов), допустимое для заданного числа элементов входных
данных. В нашем случае мы вообще не допускаем кол-
лизии, и обычно хорошо, если их количество не превы-
шает некоторую разумную величину. Что значит "разум-
ная величина", зависит от приложения.
Как вы можете узнать, каково количество коллизий и
используются ли все доступные корзины? Стоит написать
программу, которая бы считывала некоторый блок дан-
ных и выводила схему заполнения хеш-таблицы. Тогда
после получения этой информации ее можно было бы
использовать для реализации количественного подхода к
алгоритму хеширования.
Управление памятью
Глава 8
177
Для сохранения ключа необходима память. Так по-
лучается, однако, что нам нужен новый ключ именно
тогда, когда мы все равно запрашиваем память. Поэто-
му все, что необходимо сделать, — это заказать неболь-
шой объем дополнительной памяти, в которую и запи-
сать значение ключа для данного распределения памяти.
Однако для нашего кода вызова будет не слишком
удобно пропускать старый ключ при использовании
динамически выделенной памяти, особенно если это
еще зависит от того, определен ли MEMTRACK. Воз-
вращаемый нами указатель должен указывать область
памяти, расположенную сразу за дополнительно заре-
зервированной для ключа областью. Но какой объем
памяти мы должны отвести для ключа? Зависит ли это
от того, сколько запросов памяти мы будем делать?
Это может показаться странным, но размер ключа не
является основным вопросом. Наиболее важным явля-
ется гарантирование того, что в программу пользовате-
ля возвращается указатель, который пригоден для сохра-
нен ия данных любого типа. Если это не так, код
пользователя-программиста может закончиться наруше-
нием работы с памятью и при этом в его коде будет
сохраняться видимость полного порядка. А это плохо,
поэтому мы должны гарантировать, что указатель на
область памяти, который мы возвращаем пользователю-
программисту, подойдет для всего, что он захочет с ним
делать. Чтобы это обеспечить, мы сохраняем наш ключ
в переменной union, содержащей большие типы данных —
и чем они больше, тем лучше. Типы вроде char будут,
вероятно, недостаточно большими, но и long int, и long
double, и указатели на функцию являются потенциаль-
ными кандидатами на их применение, поэтому просто
используем объединение union из них всех (и несколь-
ких других). Следовательно, выбираем тип ALIGN.
Будет проще сохранять тип unsigned long, который до-
статочно велик для счетчика распределения памяти.
Между прочим, нужно упомянуть, что мы не наме-
рены использовать в union более одного поля. Мы ис-
пользуем union только для того, чтобы заставить ком-
пьютер организовать память так, как мы хотим, —
наиболее гибким образом.
Теперь нам нужен тип для описания деталей запро-
са. Мы хотели бы сохранить адрес, возвращаемый
пользователю, объем заказанной памяти и, что наибо-
лее существенно^ место в исходном коде пользователя-
программиста, в котором происходит распределение
(имя файла и номер строки). Вооруженный этой инфор-
мацией, пользователь-программист сможет найти утеч-
ки памяти. Мы не хотим сохранять ключ в данной
структуре, потому что реально он не имеет никакого
отношения к этим данным — он представляет собой
только число, помогающее нам находить эти данные.
Это могут быть любые данные.
«xfndef TYP_PAYLOAD
tdefine TYPPAYLOAD
typedef struct PAYLOAD
{
void *Ptr;
size_t Size;
char «FileName;
int LineNumber;
} PAYLOAD;
ftendxf
Для нас было бы достаточно удобно, если бы что-
либо из этой информации можно было использовать в
качестве уникального ключа. Однако это исключено.
Мы уже выясняли, почему не подходит наиболее мно-
гообещающий кандидат void *Ptr. Но можно рассмот-
реть и другие варианты. Подумайте, например, об ис-
пользовании LineNumber вместо других переменных.
Теперь давайте заканчивать. Напишем тип структу-
ры, которая может быть узлом в двоичном дереве. Спе-
шу сказать, что это не претендует на демонстрацию
двоичного дерева. Код для работы с деревом, исполь-
зующийся здесь, как вы видите, очень прост. Здесь,
например, нет балансировки.
«define MEM_LEFTCHILD О
«define MEMRIGHTCHILD 1
«define MEMMAXCHILDREN 2
«ifndef TYPMEMTREE
«define TYPMEMTREE
typedef struct MEMTREE
{
struct MEMTREE * ChiId[MEM_MAX_CHILDREN1;
unsigned long Key;
PAYLOAD Payload;
} MEMTREE;
«endif
(Ради экономии места я убрал прототипы функций
из этого листинга, но, конечно, вы можете найти их на
Web-сайте издательства ’’ДиаСофт".)
Определение интерфейса заканчивается определе-
нием того, что произойдет, если константа
MEMTRACK не будет определена.
«else
«define AllocMemory malloc
«define AllocCopyString CopyString
«define ReAllocMemory realloc
«define ReleaseMemory free
«define TrackMemory(a, b, c, d, e, f)
«endif
«endif
12 3uc265
Пересмотренный язык С
Часть I
178
Реализация библиотеки контроля памяти
Но довольно об интерфейсе. Теперь посмотрим, как в
действительности работает программа. В листинге 8.6)
демонстрируется реализация:
Листинг 8.6. Исходный текст библиотеки контроля
памяти.
linclude
linclude
linclude
linclude
<stdio.h>
<stdlib.h>
<string.h>
<time.h>
linclude <assert.h>
linclude "memtrack.h"
Функция strdup() не входит в стандартную библио-
теку ANSI С. Тем не менее, она широко используется.
Поскольку функция strdupO традиционно реализована
во многих компиляторах в качестве средства заказа об-
ласти памяти для строки с последующим копировани-
ем строки в эту область, я счел разумным включить
способ проверки заказа памяти функциями типа
strdup(). К сожалению, я не могу использовать имя
strdup() для этой функции, поскольку это нарушило бы
стандартное соглашение о "будущих реализациях", ко-
торое резервирует для использования в будущем все
внешние идентификаторы, начинающиеся с букв str,
после которых следуют буквы нижнего регистра.
Эта функция не контролирует вызываемое распре-
деление памяти, но это необходимый неотслеживаю-
щий аналог отслеживающей версии.
char *CopyString(char *InString)
{
char *p = NULL;
if(InString 1= NULL)
{
p = malloc(strlen(InString) + 1);
if (NULL 1= p)
{
strepy(p , InString);
}
}
return p;
}
lifdef MEMTRACK
/* Отслеживающие версии */
Всякий раз, когда происходит распределение памяти,
необходимо записать этот факт. Путем выделения несколь-
ких дополнительных байтов мы получаем достаточно ме-
ста для сохранения нашего ключа. Фактическая обработ-
ка ключа осуществляется функцией TrackMemory().
Функция DebugAlIocMemoryO является почти пол-
ной заменой функции malloc(). Она требует два допол-
нительных параметра: FileName и LineNumber Однако
использующий библиотеку программист не должен бес-
покоиться об этом, поскольку для функции эти пара-
метры определяются маской-макросом.
void *DebugAllocMemory(size__t Size,
char *FileName,
int LineNumber)
{
void *ptr;
char *p;
ptr - malloc(Size + sizeof(ALIGN));
if(ptr != NULL)
{
TrackMemory(MEMTRKMEMALLOC,
0/
ptr,
Size,
FileName,
LineNumber);
Дополнительная память должна быть незаметной для
вызывающей функции, поэтому необходимо заказывать
на sizeof(ALIGN) байтов больше, чем возвращает функ-
ция malloc. Но нельзя выполнять арифметические опе-
рации с указателями неполного типа (указатели типа
void). Чтобы обойти это ограничение, используется вре-
менный указатель типа char *, и, таким образом, мы
можем найти соответствующий адрес.
р = ptr;
р += sizeof(ALIGN);
Ptr = р;
}
return ptr;
}
char *DebugAllocCopyString(char *String,
char *FileName,
int LineNumber)
{
char *p = NULL;
int Errorstatus = 0;
size_t Length = strlen(String) + 1;
p = malloc(Length + sizeof(ALIGN));
if(0 == Errorstatus)
{
strepy(p + sizeof(ALIGN), String);
TrackMemory(MEMTRKMEMALLOC,
0,
Р/
Length,
FileName,
LineNumber);
p += sizeof(ALIGN);
}
Управление памятью
Глава 8
179
return р;
1
Нельзя непосредственно вызывать наш вариант функ-
ции strdup(), потому что он не закажет достаточно памя-
ти для ключа, сохраняемого функцией TrackMemory().
Мы можем сделать нечто подобное с помощью
но мне кажется более понятным в этом случае просто
реорганизовать копию программы, которая включает
возможность отслеживания. (Изначально это было сде-
лано для malloc, calioc и realloc, но я обнаружил, что
мсяу сократить исходный код на некоторое количество
строк, удалив из кода не выполняющие отслеживание
версии оболочек этих функций без потери функцио-
нальности).
Перепроектирование функции realloc
Следующая задача — это отслеживание всех вызовов
функции-оболочки realloc. Эта функция, подобно дру-
гим функциям-оболочкам, в качестве первого парамет-
ра получает тип void**. Это действительно хорошая
мысль. Вместо того чтобы покорно использовать интер-
фейс, предоставляемый функцией realloc, я могу улуч-
шить его. В конце концов, мне совершенно понятно, что
ни комитет ANSI, ни Деннис Ричи (Dennis Ritchie),
никто другой не занимались разработкой функции
realloc настолько тщательно, как должны были бы де-
лать. Так как же ее улучшить?
Я могу передавать адрес старого указателя, а не его
значение, и обновлять его в функции-оболочке тогда и
только тогда, когда вызов функции realloc был удачен.
Эта функция будет возвращать не указатель, а целую
величину, зависящую от удачности выполнения данной
функции, как я это делаю в моей обычной практике.
Таким образом, ошибка ptr=realloc(ptr,newsize) будет
устранена навсегда! Я был очень рад этой идее и потра-
тил немного времени на ее программирование. Пожалуй,
этот код работает неплохо.
Как я обнаружил, перекомпилируя и перепроверяя
программу для этой книги, это непереносимый метод.
В то время как вы можете присвоить указатель на лю-
бой объект указателю void* без потери информации, это
не обязательно выполняется для указателя void**! Этрт
код хорошо работал с компилятором, которым я тогда
пользовался, и это лучшее, что можно сказать. Чтобы
Заставить его работать в ANSI С, необходимо выполнять
приведение типов в вызове, наподобие этого:
OidltWork = RaallocMemory (& (void *)р, newsize)*;
Иногда приведение типа необходимо (как в данном
примере), но результат его всегда выглядит крайне не-
привлекательно. Если функция спроектирована таким
Образом, что при вызове всегда или почти всегда необ-
ходимо выполнять приведение типа аргументов этой
функции, вы должны серьезно задуматься над правиль-
ностью своего проекта.
Серьезно задумавшись над этим, я пришел к выво-
ду, что ошибся. У меня не было никакого желания пи-
сать &(void*) всюду в исходных текстах программ. По-
этому я рассмотрел некоторые другие возможности.
Одной из них была идея помешать указатель в струк-
туру. Неприятность этой идеи заключалась в том, что я
должен был поместить указатель в структуру, передать
структуру в качестве параметра, получить указатель из
структуры в функции-оболочке, выполнить распределе-
ние памяти, обновить указатель и позволить вызываю-
щей функции опять получить указатель, как если бы он
реально использовался. Все это очень долго и утоми-
тельно, особенно для пользователя-программиста.
Я всегда пытаюсь избегать выполнения такой большой
работы и предпочитаю, чтобы ее выполняла библиоте-
ка, когда это возможно. Однако я решил добиться луч-
шего дизайна, а не кротко скопировать метод ANSI.
В конце концов, я добился реализации метода, хо-
рошо защищенного "от дурака". Или почти защищенно-
го. Это значит, что предполагается некоторое доверие
к вызывающей функции: если функция будет прини-
мать обычный void*, то проблема приведения типа бу-
дет устранена. Конечно, тот факт, что С всегда переда-
ет параметры по величине, означает, что я не смогу
эффективно обновлять указатель, поэтому необходимо
возвращать из функции указатель, а не предполагавший-
ся код возврата. Но это не вызывает проблем, так как
для сообщения об ошибке можно возвращать NULL.
Понятно, что это взваливает на программиста бремя
использования дополнительного указателя в случае не-
удачного вызова, но я считаю это небольшой платой за
более надежный метод.
Я отступил на шаг, чтобы полюбоваться собствен-
ной работой, и обнаружил, что я заново воплотил про-
ект ANSI С функции realloc. Можно сражаться и даль-
ше, но наступает время принять неизбежное, поэтому
я бросил это занятие; оказалось, что кто бы ни проек-
тировал realloc, он знал, что делает. Вот такой урок для
чрезмерно старательного и заносчивого выдумщика.
Возвращение к предыдущему проекту
realloc
Вот как в результате после серии попыток была реали-
зована функция-оболочка:
void *DebugReAllocMemory (void *p01dMem,
sizet NewSize,
char *FileName,
int LineNumber)
{
void *NewPtr = NULL;
int ItWasntNull = 0;
char *p;
180
Пересмотренный язык С
Часть I
ALIGN KeyStore;
if(pOldMem 1= NULL)
{
ItWasntNull = 1;
Если в функцию передан ненулевой указатель, мы
считаем, что указатель содержит адрес памяти, ранее
заказанный с помощью функции-оболочки из этой биб-
лиотеки. Вообще, если программист заказывал память
другими средствами, то он не использует эту библио-
теку. Таким образом, мы можем использовать ключ из
байтов, находящихся непосредственно перед передан-
ным в функцию адресом.
р = pOldMem;
р -= sizeof(ALIGN);
memcpy(&КеуStore.lu, p, sizeof(ALIGN));
}
NewPtr = realloc(p01dMem,
NewSize +
(NewSize >0 ?
sizeof(ALIGN) :
0));
if (NULL 1= NewPtr)
{
if(ItWasntNull)
{
Стандарт С гарантирует, что функция realloc кор-
ректно скопирует данные (в случае необходимости) из
старого блока в новый, поэтому это не совсем то же, что
вызов функции free после вызова функции malioc. Как
бы там ни было, с точки зрения контроля памяти, все
сводится к тем же самым операциям, поэтому вот как
была написана эта функция. В результате во многих
обстоятельствах эта функция дважды вызывает функ-
цию TrackMemory.
TrackMemory (MEMTRK__MEMFREE,
KeyStore.lu,
NULL,
0,
FileName,
LineNumber);
}
if(NewSize > 0)
{
TrackMemory(MEMTRKMEMALLOC,
0,
NewPtr,
NewSize,
FileName,
LineNumber);
p = NewPtr;
p += sizeof(ALIGN);
NewPtr = p;
}
}
return NewPtr;
)
Целью упражнения было выяснить, всегда ли осво-
бождается память, которая была заказана. Необходимо
отслеживать освобождение памяти так же, как отслежи-
вается ее заказ. Эта функция является простой проме-
жуточной функцией для free, которая вначале вызыва-
ет ТгасМетогу для сообщения ей об освобождении
памяти.
void DebugReleaseMemory(void *pSource,
char *FileName,
int LineNumber)
{
char *p;
ALIGN KeyStore;
iffpSource != NULL)
{
p = pSource;
p -= sizeof(ALIGN);
memcpy(&KeyStore.lu, p, sizeof(ALIGN));
TrackMemory(MEMTRKMEMFREE,
KeyStore.lu,
NULL,
0,
FileName,
LineNumber);
free(p);
}
Проектирование хеш-ключей
Как мы уже установили, указатели на тип void делают
невозможным использование ключей дерева, поэтому
вместо них будут использоваться хешированные индек-
сы. Эти индексы сохраняются с заказанной памятью и
передаются в MemTrkCmp, откуда, в свою очередь, они
передаются функциям hashl и hashZ.
Эти две функции очень похожи. Различие заключа-
ется в константах. Первая функция спроектирована с
расчетом на сбалансированное дерево. Я преднамерен-
но воздержался от совершенной балансировки дерева,
поскольку это отвлечет нас от главной цели этой гла-
вы, заключающейся в обсуждении вопросов управления
памятью. (Если вас интересует балансировка деревьев,
обратитесь к главе 12.) Поэтому функция hashl долж-
на дать нам относительно неплохо сбалансированное
дерево без того, чтобы слишком глубоко в этом разби-
раться. К сожалению, это значит, что многие значения
ключей дублируются. Я потратил много времени на
поиск константы, которая дала бы мне достаточно уни-
кальных ключей и хорошо сбалансированное дерево, но
Управление памятью
Глава 8
181
не нашел ни одной, которую счел бы достаточно хоро-
шей. Вот почему я решил использовать две хеш-функ-
ции.
Наша вторая программа хеширования улаживает все
коллизии, вызванные первым алгоритмом, и базирует-
ся на предположении, что не более чем 2147483647 за-
казов памяти выполняется в процессе выполнения лю-
бого теста. Я считаю, что это разумное предположение.
(Если программа будет заказывать в среднем тысячу
блоков памяти в секунду, то исчерпание нашей уникаль-
ной хеш-величины произойдет через три недели.) Для
библиотеки, которую предполагается реально исполь-
зовать, этот вопрос необходимо рассмотреть более тща-
тельно. Поскольку это отладочная библиотека, я чув-
ствую себя достаточно безопасно. Однако, если ваши
требования более жесткие, воспользуйтесь таким при-
близительным планом модификации: добавьте третью
хеш-функцию и используйте ее, если первых два хеш-
алгоритма не смогли различить два ключа. Убедитесь,
что константы, которые вы используете для третьей
хеш-функции, достаточно велики и что они являются
взаимно простыми по отношению к существующим.
unsigned long hashl (unsigned long value)
{
return ((value * 179424601UL + 71UL) % 167UL);
unsigned long hash2(unsigned long value)
<
return ((value * 179424673UL + 257UL) %
**2147483647UL);
>
Функция MemTrkCmp просто сравнивает два клю-
ча, хешируя их и сравнивая значения. Она может, ко-
нечно, сравнивать два ключа непосредственно, но это
даст нам ужасно неэффективное дерево.
int MemTrkCmp (unsigned long keyl,
unsigned long key2)
<
int diff = 0;
unsigned long hvl, hv2;
hvl = hashl(keyl);
hv2 - hashl(key2);
if(hvl > hv2)
{
diff = 1;
}
else if(hvl < hv2)
{
diff = -1;
}
else
{
hvl = hash2(keyl);
hv2 = hash2(key2);
if(hvl > hv2)
diff = 1;
}
else if(hvl < hv2)
diff = -1;
}
else
(
Если это предположение когда-нибудь окажется
неверным, я очень удивлюсь. Единственный способ,
позволяющий достичь этого, заключается в запуске те-
ста продолжительностью три с половиной недели, ко-
торый заказывает тысячу блоков в секунду, и в этом
случае вы можете рассмотреть третью хеш-функцию,
как я предложил ранее.
assert(keyl == key2);
}
}
return diff;
Сообщения о текущих заказах памяти
При окончании выполнения программы (или в любой
момент в процессе ее выполнения) может возникнуть
желание посмотреть, какой объем памяти был заказан
и какой объем не был освобожден. Эта функция выво-
дит информацию об одном распределении памяти.
int MemPrintAllocs (const PAYLOAD *pl, void *p2)
{
FILE *fp = p2;
fprintf(fp,
"\n%8p allocated %7u byt%s
“at Line %5d of File %s.“,
pl->Ptr,
(unsigned int)pl->Size,
pl->Size == 1 ? "e " s "es",
pl->LineNumber,
pl->FileName);
return 0;
)
Теперь рассмотрим функцию TrackMemory, которая
реально выполняет отслеживание. Прежде всего необ-
ходимо отметить, что мы передаем ей либо значение
ключа, либо указатель. В идеале мы предпочли бы в
обоих случаях передавать значение ключа, поскольку
ключ дает нам способ найти соответствующее место в
дереве. Но если мы записываем, что память была толь-
ко что заказана, то ключа еще не существует. Задачей
этой функции является определить значения ключа.
Поэтому, когда мы записываем оператор распределения
памяти, мы работаем с указателем. Если мы записыва-
Пересмотренный язык С
182
Часть I
ем оператор освобождения памяти, ключ известен, по-
этому мы используем его.
Эта функция использует достаточно много статичес-
ких переменных. Я не являюсь приверженцем статичес-
ких переменных и использую их здесь вынужденно.
Я бы предпочел, чтобы пользовательский код содержал
структуру, в которой находилась бы необходимая ин-
формация, и передавал эту структуру в функцию по
необходимости, посредством функций выделения памя-
ти. К сожалению, программист, использующий библио-
теку, возможно, не побеспокоится о передаче структур,
содержащих информацию о выделении памяти, в фун-
кции заказа памяти. Более того, эта структура не будет
необходима, когда MEMTRACK не определен. Необхо-
димость учитывать эти сложности на уровне пользова-
теля-программиста приводит к невыносимым сложно-
стям при использовании данной библиотеки. Поэтому
используются статические переменные, хотя они не
являются потокочувствительными. Пожалуйста, запом-
ните это, если вы программируете многопоточные при-
ложения.
Вы также заметите, что я инициализировал все ста-
тические переменные нулевыми значениями. Посколь-
ку для статических переменных С делает это сам, та-
кая предосторожность может быть отнесена либо к
предосторожностям по поводу будущих изменений спе-
цификаций сохранения, либо к зарождающейся пара-
нойе. Вам решать.
int TrackMemory(MEMTRK_MSG Msg,
unsigned long Key,
void * Ptr,
int Size,
char * FileName,
int LineNumber)
int Errorstatus = 0;
static FILE *fp = NULL;
static unsigned long MemTrackldx = 0;
PAYLOAD EntryBuiIder ® {0};
MEMTREE *NodePtr = NULL;
unsigned long ThisKey = 0;
PAYLOAD *EntryFinder = NULL;
ALIGN KeyStore = {0};
static MEMTREE *МешТгее = NULL;
static int IveBeenlnitialised = 0;
static unsigned long MaxAlloc = 0;
static unsigned long CurrAlloc = 0;
time_t tt = {0};
struct tm *tmt = NULL;
if(1IveBeenlnitialised)
{
Прежде всего необходимо открыть файл, в который
мы будем записывать сообщения о выделении памяти.
Я опять должен кое в чем вам признаться. При первом
написании этого кода я открывал файл в режиме ”wt",
подразумевая "создать текстовый файл". Я знал, что с
использованием "w” можно добиться того же результа-
та, но хотел достичь совершенства. В действительности
же я достиг непереносимости. Так что не используйте
"wt", подразумевая "w”.
Наш указатель на файл сообщений о заказах памя-
ти является хорошим примером того, что не всегда не-
обходимо отказываться от выполнения программы, если
запрос какого-либо ресурса терпит неудачу. Поскольку
сейчас мы работаем с тестовой библиотекой, а не с ра-
бочей системой, то имеем некоторую свободу. Мы мо-
жем не только изменить место вывода, но даже черкнуть
сообщение в stderr, давая возможность пользователю
узнать, что у нас есть проблемы.
fp = fopen(MEMTRACK_FILENAME, "w") ;
if (NULL == fp)
{
fprintf(stderr,
"Can't create file %s\n",
MEMTRACKFILENAME);
fprintf(stderr,
"Using stdout instead.\n");
fp = stdout;
}
IveBeenlnitialised = 1;
Мы хотели бы сохранять информацию о расположе-
нии в коде строю/, в которой осуществляется заказ памя-
ти. Наши промежуточные макросы дают информа-
цию _FILE_ и _LINE_, что вполне нам подходит.
Сохранение копии имени файла может вызвать зна-
чительное увеличение расхода ресурсов. Это вполне
можно пережить, но такой необходимости нет. До тех
пор пока мы не попытаемся изменить его содержимое,
мы можем вполне успешно направить указатель
FileName на адрес, представленный _FILE_.
EntryBuilder. FileName = FileName;
EntryBuilder.LineNumber = LineNumber;
switch(Msg)
{
case MEMTRK_MEMALLOC:
А сейчас мы создадим сообщение о выделении па-
мяти. В эту процедуру входит сохранение адреса ново-
го блока памяти (с точки зрения программиста-пользо-
вателя, а не с нашей, т.е. нужно учесть дополнительный
блок, используемый нами для своих целей), размер бло-
ка и ключ (определенный по индексу, который увели-
чивается при каждом выделении памяти).
EntryBuilder.Ptr =
^sizeof(ALIGN);
EntryBuilder.Size =
(char *)Ptr +
Size;
183
ThisKey = MemTrackIdx++;
KeyStore.lu = ThisKey;
memcpy(Ptr, AKeyStore, sizeof
KeyStore);
i f(NULL == AddMemNode(AMemTree ,
ThisKey,
AEntryBuilder))
{
fprintf(fp,
"ERROR in debugging code - "
"failed to add node to memory tree.\n");
fflush(fp);
}
else
{
Успешно добавив новое сообщение о выделении па-
мяти в дерево, мы можем проконтролировать выделение
памяти другим способом. Можно подсчитать количество
байтов, выделенное пользователю, а также максималь-
ный объем памяти, выделенной в определенный момент.
CurrAlloc += Size;
if(CurгAlloc > MaxAlloc)
<
MaxAlloc = CurrAlloc;
}
}
break;
case MEMTRKMEMFREE:
NodePtr = FindMemNode(MemTree, Key);
if(NULL 1= NodePtr)
{
EntryFinder = ANodePtr->Payload;
CurrAlloc -= EntryFinder->Size;
if(CurrAlloc < 0)
{
fprintf(fp,
"ERROR: More memory released "
"than allocated!\n");
fflush(fp);
}
DeleteMemNode(AMemTree, Key);
}
else
/* Попытка освободить блок, который
никогда не был выделен */
fprintf(fp,
"Attempted to free unallocated "
"block %p at Line %d of File %s.\n".
EntryBuiIder.Ptr,
EntryBuiIder.LineNumber,
EntryBuiIder.FileName);
fflush(fp);
}
Управление памятью
Глава 8
break;
case MEMTRKREPORT:
fprintf(fp,
"\nMemory Tracker Report\n");
fprintf(fp,
"-----------\n\n”) ;
Наше сообщение создается достаточно легко; это не
требует особых усилий. Пользователю было бы удобно,
если бы мы включили в сообщение информацию о дате
и времени. И мы делаем это (убедившись, конечно, что
функция localtime не возвращает ошибку).
tt = time (NULL) ;
tmt = localtime(Att);
if(tmt ! = NULL)
char timebuffer[64] - {0};
strftime(timebuffer,
sizeof timebuffer,
"%B:%M:%S %Z on %A %d %B %Y",
tmt);
fprintf(fp, "\n%s\n\n", timebuffer);
}
fprintf(fp,
"Current Allocation: %lu byt%s.\n",
CurrAlloc,
CurrAlloc == 1 ? "e" : "es");
fprintf(fp,
"Maximum Allocation: %lu byt%s.\n",
MaxAlloc,
MaxAlloc == 1 ? "e" : "es");
fprintf(fp,
"Nodes currently allocated:\n\n");
Чтобы определить, не остались ли выделенными
какие-либо области памяти, мы проходим в обратном
направлении по всему дереву, посещая все узлы. Каж-
дый узел соответствует заказанной, но не освобожден-
ной области памяти.
WalkMemTree (MemTree, MemPrintAllocs, fp) ;
if(CurrAlloc == 0)
{
fprintf(fp, "None! (Well done!)");
}
fprintf(fp, "\n");
fflush(fp);
break;
case MEMTRKDESTROY:
DestroyMemTree(AMemTree);
Я не знаю, заметили ли вы, что в регистрационный
файл записывается достаточно много информации, но
нет проверки работы оператора fprintf. Позаботимся об
184
Пересмотренный язык С
Часть I
этом сейчас, вызвав ferror, и тогда мы получим инфор-
мацию о любых проблемах, возникающих при выводе:
if(ferror(fp))
fprintf(stderr, "Error writing to
^log file.\n");
}
fclose(fp);
* break;
default:
break;
}
return Errorstatus;
}
/* Здесь для краткости пропущены функции
двоичного поиска по дереву; вы найдете их в
этом месте программы в файле memtrack.c на
Web-сайте издательства "ДиаСофт" */
Итак, мы все сделали. Остается только рассмотреть
собственно библиотечные функции для работы с дере-
вьями.
Ладно, здесь я немного лицемерю. Именно библио-
течные функции для работы с деревьями и доставили
мне больше всего хлопот в этой главе. Первоначально
написанные мною функции для работы с деревьями
были непереносимыми и не слишком соответствовали
тем изменениям, которые я ввел для доведения качества
кода до пригодного к опубликованию уровня. Я пере-
писал их с немалой помощью Бена Пфаффа (Ben Pfaff)
и Чеда Диксона (Chad Dixon) (но все имеющиеся в них
ошибки — мои собственные). Сейчас эти функции мне
очень нравятся. Я не привожу здесь исходные коды,
потому что эта глава посвящена проблемам управления
памятью, а не деревьям! Конечно, вы можете найти мой
код для работы с деревьями на CD-ROM, но, пожалуй-
ста, не используйте его в качестве основы для собствен-
ной библиотеки работы с деревьями. Для этого куда
больше подходят реализации Бена для работы с дере-
вьями red-black и AVL.
Просматривая весь материал, относящийся к этой
книге, на Web-сайте издательства "ДиаСофт", вы най-
дете также управляющую программу, которая заказыва-
ет большой объем памяти и затем освобождает ее. Про-
водите компиляцию после определения переменной
MEMTRACK, если вы хотите контролировать память,
и не определяйте ее — в противном случае.
Резюме
Корректное использование памяти является существен-
ной частью программирования на языке С. В этой гла-
ве мы подробно рассмотрели многие ошибки управле-
ния памятью, способы восстановления при сбоях
выделения памяти и разработали программу поиска
утечек памяти.
По мере того как приложения становятся все более
сложными, правильное управление памятью становит-
ся все более и более затруднительным. Однако, когда в
нашем распоряжении есть разумный набор средств для
ее осуществления, задача перестает быть сложной. Она
даже может превратиться в забаву!
Моделирование и контроллеры
В ЭТОЙ ГЛАВЕ
Общее представление о конечных автоматах
Пример выключателя света
Превращение конечного автомата в код
Применение моделирования и контроллеров
Важные аспекты безопасности в использовании контроллеров
Моделирование простого компьютера
Мэтью Ватсон
Контроллеры окружают нас повсюду. Перед появлени-
ем компьютеров механизмы управления реализовыва-
лись на аппаратном уровне. В настоящее время с появ-
лением дешевых микропроцессоров повсеместными
стали программные контроллеры.
В конце двадцатого столетия человечество было
удивлено тем, что грузоподъемники, автомашины и ото-
пительные системы необходимо проверить на отсут-
ствие проблемы 2000 года. Язык С часто выбирают в
качестве языка программирования встроенных контрол-
леров из-за скорости выполнения и компактности кода.
Представьте себе работающую в реальном времени си-
стему, вроде системы управления воздушным движени-
ем, написанную на COBOL и предназначенную для
работы в пакетном режиме!
В настоящей главе будут рассмотрены следующие
вопросы:
• Что такое конечный автомат и как его использовать.
• Как преобразовать диаграммы состояния в коды, на-
писанные на С.
• Как моделировать элементы реального мира. Мно-
гие реальные прикладные программы используют
свойства конечных автоматов.
• Почему контроллеры жизненно важны и что проис-
ходит, если с ними что-то не в порядке.
• Как моделируются более сложные сценарии.
Общее представление о конечных
автоматах
Конечный автомат (finite state machine, FSM), или ав-
томат с конечным числом состояний, как следует из его
Названия, — это модель, имеющая конечное число со-
стояний. В любой момент времени механизм находит-
ся в определенном состоянии. Когда автомат получает
входной сигнал, он может перейти в другое состояние,
как показано на рис. 9.1.
Как обычно говорят, причиной перехода из одного
состояния в другое является входной сигнал. Входной
сигнал не всегда вызывает такой переход, например,
автомат может всегда находиться в определенном состо-
янии.
Конечный автомат часто является наилучшей моде-
лью многих реальных машин. В качестве примеров мож-
но назвать грузоподъемники, светофоры и торговые ав-
томаты, для которых существует дискретный набор
состояний и входных сигналов.
Конечные автоматы полезны для разработки про-
грамм, поскольку помогают формализовать систему.
Они также помогают при сопровождении и дальнейшем
расширении, обеспечивая точную модель поведения
системы. Это может быть только на пользу! При разра-
ботке программных средств часто код достигает такой
степени сложности, что программист уже не понимает
точно, почему программа работает. На этой стадии не
совсем понятны взаимосвязи и трудно точно составить
представление о состояниях, через которые проходит
система. Использование FSM позволяет разобраться в
этом.
РИСУНОК 9.1. Диаграмма перехода автомата из одного
состояния в другое.
Пересмотренный язык С
Часть I
186
Пример выключателя света
В качестве чрезвычайно простого примера рассмотрим
выключатель света. У этого автомата есть только два
возможных состояния: включен и выключен (рис. 9.2).
Мы назовем эти состояния So и Sr Возможны два вход-
РИСУНОК 9.2. Выключатель света имеет только два
возможных состояния.
Конечный автомат молено изобразить схематически,
как показано на рис. 9.3, или с помощью таблицы, как
показано в табл. 9.1.
РИСУНОК 9.3. Диаграмма состояний FSM выключателя света.
Как вы видите на диаграмме, переход из состояния
So (свет выключен) в состояние S, (свет включен) про-
исходит, когда автомат получает входной сигнал 1Г
Аналогично переход из S, в So происходит, когда авто-
мат получает входной сигнал 10.
Таблица 9.1. Таблица перехода выключателя из
одного состояния в другое.
Входной сигнал
Состояние 'о 1.
So So S,
s, So S,
Как правило, диаграммы нагляднее и проще для
понимания, чем таблицы переходов состояний. Одна-
ко таблица переходов из одного состояния в другое
полезна при написании кода на С.
Превращение конечного автомата
в код
Теперь, когда у нас есть таблица переходов, мы можем
написать код, представленный в листинге 9.1.
Листинг 9.1. LST9_1.C — конечный автомат
выключателя света.
/* Пример выключателя света: два состояния
(включен или выключен); два различных
входных сигнала (включить, выключить) */
enum state { OFF,
ON
В
enum input { SWITCHOFF,
SWITCH-ON
};
int main()
{
enum state LightState;
enum input Lightinput;
Lightstate = OFF;
Lightinput = SWITCH-ON;
switch( LightState )
/* Свет в настоящее время выключен */
case OFF:
switch( Lightinput )
case SWITCH_OFF:
break;
case SWITCHON:
LightState = ON;
break;
}
break;
/* Свет в настоящее время включен */
case ON:
switch( Lightinput )
{
case SWITCHON:
break;
case SWITCHOFF:
LightState = OFF;
break;
1
break;
}
return 0;
На первый взгляд код кажется выходящим за преде-
лы необходимого — такое количество строк только для
Моделирование и контроллеры
Глава 9
187
того, чтобы изменить состояние! Тем не менее, этот код находится в определенном состоянии, входной сигнал
хорошо иллюструет общий принцип. Когда автомат обрабатывается в соответствии с состоянием, как пока-
зано в листинге 9.2.
Листинг 9.2. LST9 2.C — альтернативная реализация конечного автомата выключателя света.
/* Пример выключателя: два состояния (включен или выключен);
два различных входных сигнала (включить, выключить) */
enum state { OFF = 0,
ON
};
епшп input { SWITCH OFF = О,
SWITCHON
};
Idefine NUMSTATES 2
Idefine NUMINPUTS 2
int main()
{
enum state Lightstate;
enum input LightInput;
enum state TransTable[NUM STATES] [NUM INPUTS] = { { OFF, ON },
{ OFF, ON } };
LightState = OFF;
Lightinput = SWITCHON;
LightState = TransTable[ LightState ][ Lightinput ];
return 0;
В другой альтернативной реализации для представ-
ления переходов можно было бы использовать двумер-
ный массив.
Применение моделирования и
контроллеров
Моделирование связано с контроллерами, но эти два
метода подходят к проблеме с противоположных сто-
рон. Моделирование обычно выполняется для имита-
ции функциональных возможностей существующего
контроллера. Этот метод дает результат, поскольку по-
зволяет экономить денежные средства.
В таких отраслях промышленности, как нефтяная,
газовая и химическая (очистительные заводы), неболь-
шое повышение эффективности на одном заводе дает
возможность сберечь миллионы долларов.
Важные аспекты безопасности в
использовании контроллеров
Устройства, ранее контролируемые аппаратными сред-
ствами и управляемые человеком, в настоящее время
находятся под контролем программных средств. В слу-
чае с торговыми автоматами и им подобными машина-
ми особенно беспокоиться не стоит. Однако, что может
случиться, если программные средства управляют раке-
тами, самолетами или атомными электростанциями?
В следующем разделе показаны некоторые ошибки
программирования.
Обычные ошибки программирования
У каждого, кто достаточно долго писал программы, есть
свой набор историй о грубых ошибках. Любой, кто пи-
шет программы в группе или поддерживает код, напи-
санный другим программистом, вскоре находит соб-
ственный "Сборник самых веселых ошибок
программиста". Например, в табл. 9.2 приведено не-
сколько классических примеров.
Таблица 9,2. Классические ошибки,
Пример Ошибка
if (х=3) Условный переход происходит всегда.
Должно быть if (х==3)
if (х == 3): В конце не должно быть точки с запятой;
у=4; у-4 выполняется всегда
х=3; Переменной х не присваивается значение 3,
хотя выражение вполне законно для языка С.
Попробуйте!
Пересмотренный язык С
188
Часть I
В этом плане С чрезвычайно неумолимый язык.
Другие языки программирования скорее удерживают вашу
руку, а С предоставляет веревку, чтобы повеситься.
Конечно, есть много возможностей минимизировать
вероятные ошибки. Написание if(3==x) позволит выя-
вить случайную ошибку if(3=x), поскольку невозмож-
но присвоить какое-либо значение числу 3. Помогают
и анализ кода, и тщательное тестирование, и хорошая
методология программирования.
В некоторых случаях программные средства наноси-
ли людям ущерб. В описанном ниже случае программ-
ные средства явились прямой причиной смерти паци-
ентов. Каждый, кто занимается программным
обеспечением, должен знать об этой трагической исто-
рии.
Рассказ о Therac-25
Therac-25 был медицинским линейным ускорителем,
спроектированным и построенным в начале 80-х. Он
был установлен в 11 госпиталях США и Канады.
Therac-25 позволял лечить пациентов с опухолями,
разрушая эти опухоли определенными дозами радиа-
ции. Therac-25 имел два режима работы: электронный
режим для лечения поверхностных тканей и фотонный/
рентгеновский — для лечения более глубоких тканей.
В обоих режимах использовался один и тот же пучок
энергии при различных уровнях мощности. В режиме
радиационного облучения луч действовал с мощностью,
приблизительно в 100 раз большей, чем в режиме элект-
ронного облучения. Это происходило из-за того, что
между источником луча и пациентом помещался спе-
циальный фильтр, вызывавший появление рентгено-
вских лучей.
Очевидно, что режимы и уровни мощности являются
взаимно исключающими. Если фильтр для рентгено-
вского режима не находится на месте, то пациент по-
лучает значительную дозу радиации. В предшествую-
щих линейных ускорителях для предотвращения такой
случайности существовали аппаратные средства блоки-
ровки. В Therac-25 программные средства обеспечива-
ли безопасность.
К сожалению, в некоторых случаях рентгеновский
фильтр не находился на месте, что приводило к суще-
ственной передозировке радиации и смерти пациентов.
Ошибка заключалась в отсутствии учета скорости меха-
нических элементов машины, когда оператор мог по
несчастной случайности выставить радиационный ре-
жим облучения, который определяет высокий уровень
мощности. Оператор мог затем изменить режим, уста-
новив электронный. Однако из-за времени, необходи-
мого для движения механических частей, исправление
оператора было отработано до того, как механические
части закончат свое движение.
В результате уровень энергии оставался высоким, а
рентгеновский фильтр не был установлен. Вторая ошиб-
ка была найдена позднее. Лечение могло быть продол-
жено при установке значения некоторой переменной
равным нулю. Это означало, что установлены и режим
облучения (фильтры), и мощность облучения. Эта пе-
ременная увеличивалась при каждом вызове конкретной
подпрограммы при установке параметров лечения. Од-
нако переменная записывалась только в одном байте
(восемь битов), а подпрограмма вызывалась часто. Это
приводило к переполнению переменной, и ее значение
становилось равным нулю. Если оператор начинал ле-
чение в тот момент, когда происходило переполнение,
работала полная энергия пучка без всяких фильтров.
Вы можете найти полный, детальный доклад о
Therac-25, написанный Ненси Левенсон (Nancy
Levenson) из Вашингтонского университета (University
of Vashington) в журнале IEEE, Vol. 26, No. 7, Juli 1993.
Мораль этой истории
Найдите время подумать о своем подходе к написанию
программ и помните, что большинство программистов,
возможно, создают свой код таким же образом. Учиты-
вайте, что этот код пилотирует самолеты, лечит паци-
ентов и управляет ракетами.
Моделирование простого компьютера
В известном смысле компьютер можно считать усовер-
шенствованным конечным автоматом. У него есть раз-
личные состояния и входные сигналы, которые опре-
деляют переход из одного состояния в другое. В
качестве более сложного примера моделирования созда-
дим модель простого компьютера с упрощенным 8-би-
товым процессором.
Этот компьютер будет использовать классическую
фон-неймановскую архитектуру. Он имеет общую па-
мять для команд и данных (рис. 9.4) и арифметико-ло-
гическое устройство (ALU — Arithmetic Logic Unit).
Память
Для простоты данный компьютер будет иметь 65536
байтов памяти. Вы, может быть, не знаете, что в языке
С один байт не обязательно равен восьми битам! По
стандарту ANSI он определен в библиотеке <limits.h>
как CHAR BIT битов. Гарантируется, что CHARBIT
составляет, по крайней мере, восемь битов, но может
быть и больше. В большинстве компьютеров это дей-
ствительно восемь битов, но важно не считать это само
собой разумеющимся. Однако в нашем последующем
моделировании один байт будет равен восьми битам.
Моделирование и контроллеры
Глава 9
j 189
Регистры
Арифметико-логическое
устройство
0x0000
OxFFFF
Адресное пространство
РИСУНОК 9.4. Архитектура моделируемого компьютера.
Регистры
Наш компьютер имеет четыре регистра (табл. 9.3). Та-
ким образом, мы обеспечиваем минимальный уровень
сложности.
При моделировании компьютера число команд бу-
дет минимальным. Тем не менее, даже с ограниченным
числом команд мы можем смоделировать основные
принципы работы всех компьютеров.
Но ничто не стоит на месте, а развивается обычно
по принципу "от простого — к сложному". Так, первый
процессор обладал очень ограниченным набором команд.
Позднее стали создаваться процессоры со все большим и
большим набором команд (в чипе CISC — Complex
Instruction Set Chip). Оборотной стороной этого было то,
что большинство программистов использовали только ма-
лую часть всех команд и наличие многих команд приво-
дило к снижению общей эффективности. Был введен
чип RISC (Reduced Instruction Set Chip), который имел
(точно так же, как и первый процессор) ограниченный
набор команд. Разница заключалась в том, что эти но-
вые чипы были способны выполнять небольшое число
своих команд за короткий промежуток времени. Это
оказалось возможным, поскольку небольшое количество
команд означает более высокую эффективность чипа.
Таблица 9.3. Регистры моделируемого компью-
тера.________________________________________
Регистр Описание
Регистр А 8-битовый регистр общего назначения
Регистр В 8-битовый регистр общего назначения
Регистр Счетчик команд. Это регистр файлов только
счетчика для считывания (с точки зрения
команд пользователя)
Регистр .Здесь хранится состояние арифметических
состояния операций; это основа для разрешения команд
устройства переходов
В табл. 9.4 размер адреса ячейки памяти составляет
16 битов (два байта), и размер непосредственно полу-
чаемых постоянных данных составляет восемь битов
(один байт).
Таблица 9,4. Набор команд моделируемого компьютера.
Команда Аргумент Описание
LOADA Адрес ячейки памяти Загружает содержимое памяти в регистр А
LOADB Адрес ячейки памяти Загружает содержимое памяти в регистр В
LOADAI 8-битовая константа Устанавливает регистр А равным 8-битовой константе
LOADBI 8-битовая константа Устанавливает регистр В равным 8-битовой константе
NOP Пустая команда для этого шага
STOREA Адрес ячейки памяти Записывает в память содержимое регистра А
STOREB Адрес ячейки памяти Записывает в память содержимое регистра В
ADDA 8-битовая константа Добавляет 8-битовую константу к содержимому регистра А
ADDB 8-битовая константа Добавляет 8-битовую константу к содержимому регистра В
COMPAI 8-битовая константа Сравнивает регистр А с константой и устанавливает состояние регистра состояний устройства
COMPBI 8-битовая константа Сравнивает регистр В с константой и устанавливает состояние регистра состояний устройства
BLT Адрес ячейки памяти Программа переходит на данный адрес, если регистр состояния <0
BGT Адрес ячейки памяти Программа переходит на данный адрес, если регистр состояния >0
JUMP Адрес ячейки памяти Программа безусловно переходит на данный адрес
PRINTA Выводит содержимое А на консоль в шестнадцатеричном формате
BREAK Указывает системе прекратить выполнение
Пересмотренный язык С
190
Часть I
Этот список содержит большинство (в отношении
функциональных возможностей) основных команд, ис-
пользуемых во многих 8-битовых процессорах. Хотя с
точки зрения современных стандартов это и простые
команды, но их реализация была достижением в техно-
логии микропроцессоров 70-х годов.
Построение С-кода
Сейчас поговорим немного о проектировании. Модель
должна обладать следующими функциональными воз-
можностями:
• Читать файлы кода ассемблера и собирать их в па-
мяти
• Выполнять программу в памяти
• Выполнять программу пошагово, по одной команде
за один раз
• Проверять содержимое регистров
• Проверять содержимое памяти (шестнадцатеричный
дамп)
• Дисассемблировать содержимое памяти (переводить
на язык ассемблера)
Для этой модели мы используем интерфейс коман-
дного типа (а не интерфейс на основе меню).
Считывание ассемблерного кода
Листинг ассемблера будет сформирован с помощью ко-
манд из табл. 9.4, а также комментариев и меток. Ассем-
блер для модели будет несколько символическим (так,
будем использовать JUMP Label, а не JUMP OxOOF), так
что пользователь, пишущий на ассемблере, не будет
беспокоиться о вычислении сдвигов адреса и т.п. (лис-
тинг 9.3).
Листинг 9-3. LST9_3.ASM — пример листинга
ассемблера-
* Это комментарий, игнорируйте меня
:Loopl
LOADAI 0
ADDA 1
COMPAI 9
ВЫ Loopl
END
Комментарий следует пропустить. Когда встречает-
ся метка, ее адрес в памяти должен быть записан в таб-
лицу символов для дальнейшего обращения к ней. Каж-
дая встретившаяся команда должна быть введена в
память. Мы добавим то ограничение, что ссылки на
метки могут быть только обратными, т.е. ссылками толь-
ко на те метки, которые были описаны (листинг 9.4).
Листинг 9.4. LST9j4.C — определения типа.
typedef enum {NONE, IMMEDIATE, ADDRESS)
OPERANDTYPE;
typedef struct
{
char* InstructionName;
OPERANDTYPE Operand;
unsigned char MachineCode;
} INSTRUCTION;
Существует два возможных способа анализа данных.
Первый заключается в анализе каждой строки: сравне-
ние полученной строки с именами команд:
if ( О = strcmp (Token, "LOADB"))
Можно также хешировать Token каким-либо мето-
дом, гарантирующим уникальность области команд, и
выполнять переключение по хеш-индексу. Нам следу-
ет написать несколько строк кода для обработки каж-
дой команды. Этот подход дает максимальную гиб-
кость, потому что каждая команда может иметь
произвольно заданные ассоциирующиеся с ней опера-
ции. Недостатком в данном случае является то, что
очень похожие операции выполняются для каждой ко-
манды, и, таким образом, почти идентичный код пи-
шется и обслуживается во многих местах.
Второй подход заключается в поддержке списка ко-
манд в таблице данных и написании кода для прохода
по таблице. Это означает, что объем кода, который нуж-
но написать и сопровождать, будет меньше.
Необходимость описанного сейчас выбора часто
встречается при написании программ на С. Программи-
сты часто обнаруживают, что они вынуждены выбирать
между гибкостью различных программ для различных
сценариев, что приводит к дублированию кода, и более
общим решением с меньшей гибкостью, но приводящим
к меньшему объему кода для написания и сопровожде-
ния.
В общем случае проще написать меньше кода и под-
держивать больше данных, чем наоборот. Однако это не
всегда верно — наилучший метод может быть выбран на
основании опыта. Рассмотрим листинг 9.5.
В листингах 9.4 и 9.5 определены таблицы данных
для списка команд. Таблица команд является трехэле-
ментной структурой: имя команды, тип команды и код,
который будет помещен в память (листинг 9.6).
Листинг 9.6 демонстрирует анализ входного ассем-
блерного файла. Каждая строка состоит либо из метки,
либо из команды с необязательными комментариями.
Если встречается метка, она вносится в символьную таб-
лицу вместе с адресом памяти, которую она занимает.
Моделирование и контроллеры
Глава 9
191
Листинг 9.5. LST9_5.C — список команд.
static INSTRUCTION InstructionTable[] = {"LOADA", ADDRESS, LOADA,
"LOADB", ADDRESS, LOADB,
"LOADAI", IMMEDIATE, LOADAI,
"LOADBI", IMMEDIATE, LOADBI,
"NOP", NONE, NOP,
"STOREA", ADDRESS, STOREA,
"STOREB", ADDRESS, STOREB,
"ADDA", IMMEDIATE, ADDA,
"ADDB", IMMEDIATE, ADDB,
"COMPAI", IMMEDIATE, COMPAI,
"COMPBI", IMMEDIATE, COMPBI,
"BLT", ADDRESS, BLT,
"BGT", ADDRESS, BGT,
"JUMP", ADDRESS, JUMP,
"PRINTA", NONE, PRINTA
-BREAK", NONE, BREAK };
Листинг 9.6. LST9 6.C — синтаксический разбор листинга ассемблера.
while (NULL 1= fgets (Line, MAXLINE, Fp ))
<
LineNo++;
if ( '*• == Line[0] || == Line[0] || '\n' == Line[0] )
{
/*отбрасывание комментариев */
continue;
}
/«проверка строки */
Token = strtok (Line, Seps);
if (NULL == Token)
continue;
}
/* проверяем, не метка ли это, и если это так, то добавляем ее в таблицу символов */
if == Token[0])
{
Token++;
Insert_Token (Token, SymbolTable, MemLocation);
}
else
{
/* компонуем лексему в памяти */
Instruction = Findinstruction (Token);
Memory [MemLocation] = Instruction.MachineCode;
MemLocation++;
if (IMMEDIATE == Instruction.Operand ||
ADDRESS -= Instruction.Operand)
{
/* получение операнда */
Token - strtok (Line, Seps);
if (NULL == Token)
printf("Error\n");
break;
}
}
192
Пересмотренный язык С
Часть I
/* нам необходнмо ввести один дополнительный байт в память */
if ( IMMEDIATE == Instruction.Operand)
{
Memory [MemLocation] = strtol (Tokenf NULL, 16);
MemLocation++;
}
/* нам необходимо ввести два дополнительных байта в память */
if ( ADDRESS == Instruct!on.Operand)
{
Symbol = FindToken (Token);
/* машина поддерживает расположение "от старшего к младшему" */
Memory [MemLocation] = (Symbol.Location » 8) & OxFF;
MemLocation++;
Memory [MemLocation] = SymbolLocation SOxFF;
MemLocation++;
}
}
}
Начальная ячейка памяти определяется пользовате-
лем (по умолчанию используется шестнадцатеричное
0x100).
Каждая команда занимает в памяти один байт. Ко-
манда может иметь необязательный операнд, который
может занимать один байт (это касается типов
IMMEDIATE) или два байта (это касается типов
ADDRESS). Команда с операндом типа NONE в дей-
ствительности вообще не имеет операндов и поэтому
занимает всего только один байт.
Ожидается, что ADDRESS является символом мет-
ки. Если символ еще не встречался, это отмечается как
ошибка.
Версия функции strdupO эффективно реализует
вставку в символьную таблицу. Эта функция присут-
ствует во многих компиляторах С, хотя и не является
ANSI-функцией. Однако она настолько полезна, что
многие программисты имеют собственные ее версии на
случай, если она отсутствует в компиляторе. Заметьте,
что не нужно приводить тип возвращаемой величины.
Многие С-программисты пишут следующее:
х = (TYPE*) malloc ( n * sizeof (TYPE) );
Однако malloc возвращает тип void*, таким образом,
нет необходимости осуществлять его приведение. Более
того, приведение может быть опасно, поскольку оно
может замаскировать тот факт, что вы забыли написать
#mclude<stdlib.h>, приведением возвращаемого по умол-
чанию типа int В этом состоит главное различие между
С и C++, в котором возвращаемая из malloc величина
должна быть приведена.
Выполнение программы
Теперь реально начинается моделирование. В основном
это означает поддержание четырех регистров А, В, PC
(счетчик команд) и SR (состояния устройства), чтение
из памяти и запись в память. Мы действительно соби-
раемся ’’сыграть в компьютер”. И опять существует вы-
бор: либо для управления программой использовать таб-
лицу данных, либо использовать заготовленный код для
каждой команды. В данном случае заранее заготовлен-
ный код, возможно, является лучшим выбором.
Пользователь определяет стартовый адрес (шестнад-
цатеричный) первой командой. Это означает просто по-
мещение этого адреса в регистр счетчика команд. Ко-
манда загружается в регистр счетчика команд,
декодируется (с помощью выражения switch), и затем
выполняется требуемая операция.
В текущем состоянии нашего компьютера процесс
моделирования остановится при обнаружении команды
BREAK либо при обнаружении неизвестной команды.
Конечно, в большинстве настоящих 8-битовых микро-
процессоров это вызовет неопределенное поведение с
произвольно-неопределенным внутренним состоянием.
Пошаговое выполнение команд
Возможность пошагового выполнения команд весьма
полезна и на уровне языка ассемблера, и для языков бо-
лее высокого уровня. К счастью, благодаря модульно-
му строению нашей программы, мы получаем эту фун-
кциональную возможность практически без
дополнительных усилий. И при обычном, и при поша-
говом выполнении программы используются общие
функции, поэтому можно минимизировать объем дуб-
лирующегося кода.
Проверка содержимого регистров
Просто выведите на печать содержимое регистров А, В,
счетчика команд и состояния устройства.
Моделирование и контроллеры
Глава 9
193
Проверка содержимого памяти
Другая простая функция. Она выводит на печать содер-
жимое памяти, 8 байтов в каждой выходной строке. Это
даст начальный и конечный адреса.
Дисассемблирование содержимого памяти
В действительности это действие, обратное первому
(считыванию файла и компоновке его в памяти). При
заданных начальном и конечном адресах функция де-
кодирует команды, находящиеся в памяти. Это может
быть полезно для проверки адреса перехода, при том,
что метка указывает на этот адрес. Например, строка
JUMP LABEL
трансформируется в
JUMP 1F0A
Собираем все вместе
Теперь все функции могут быть соединены вместе с
помощью простого синтаксического анализатора коман-
дной строки, который использует strtok. Если вы не
используете постоянно библиотечную функцию strtok
стандарта ANSI, то это прекрасная возможность позна-
комиться с ней поближе. Вы найдете се в библиотеке
<string.h>.
Резюме
Эта глава даст вам возможность получить информацию
о конечных автоматах и диаграммах состояния, которая
позволит вам осуществлять программирование простых
примеров. Здесь рассказывается также об использовании
метода моделирования в промышленности.
Читатель познакомится с программами, которые
используют контроллеры, и узнает, какой вред они
могут нанести. Как пример более сложного моделиро-
вания рассматривается моделирование простого фон-
неймановского компьютера.
Вы теперь знаете, насколько разнообразно можно
использовать язык С в моделировании реальных прило-
жений и, более того, как программы на С действитель-
но могут управлять реальными объектами.
13 Зак. 265
Рекурсия
10
В ЭТОЙ ГЛАВЕ
Что такое рекурсия
Как использовать рекурсию
О рекурсии подробнее
Практическое применение рекурсии
Питер Сиба
"Чтобы понять рекурсию, сначала нужно понять рекур-
сию." Как ни шутливо звучит это выражение, суть его
от этого не меняется. Эта глава поможет вам преодолеть
начальные трудности и приступить к использованию
рекурсии. Вы не только получите представление о том,
что такое рекурсия, но и сможете взять на вооружение
предложенные способы осмысления соответствующих
программ, что поможет вам понять, в каких именно
случаях рекурсия будет верным решением проблемы.
Примеры кодов в этой главе, в отличие от примеров
во многих других главах этой книги, не слишком при-
годны для повторного использования. Нет необходимо-
сти в библиотеке или других вспомогательных кодах
рекурсии для использования в других рекурсивных алго-
ритмах. Приведенные коды в основном ориентированы на
то, чтобы дать вам практический опыт использования ре-
курсии. С этой целью приведены и рассмотрены класси-
ческие примеры, а также диагностические сообщения,
которые позволяют понять, как работают соответству-
ющие алгоритмы. (Единственным исключением являет-
ся реализация функции, которая есть в некоторых биб-
лиотеках С, хотя она и не определена в стандарте. Эта
функция достаточно полезна в контексте рассматрива-
емых вопросов рекурсии, поэтому она включена в биб-
лиотеку.)
В этой главе будут рассмотрены следующие вопросы:
• Как реализовать рекурсивный алгоритм. Это доста-
точно легко в С, но дополнительное объяснение не
помешает.
• В чем состоит суть действия рекурсии. Мы рассмот-
рим примеры различных рекурсивных алгоритмов,
включая и совершенно неэффективные.
• Некоторые обычные ловушки рекурсивных кодов.
Не все задачи следует реализовывать с помощью ре-
курсии, некоторые рекурсивные реализации чрезвы-
чайно неэффективны.
Что такое рекурсия
Очень просто описать рекурсию, но очень трудно
объяснить, в чем же состоит суть ее действия. Описа-
ния в этой главе вначале могут показаться бессмыслен-
ными: для понимания необходимо время. Мы поигра-
ем с некоторыми примерами. Нс следует ожидать, что
с самого начала они покажутся вам совершенно разум-
ными. Действительно, рекурсивные колы могут быть
достаточно сложными для понимания и могут давать
множество неожиданных побочных эффектов. С этой
точки зрения нет ничего неожиданного в том. что мно-
гие программы, участвующие в Международном кон-
курсе самых запутанных кодов на С (International
Obfuscated С Code Contest), являются рекурсивными
(даже слишком).
ПРИМЕЧАНИЕ
Международный конкурс самых запутанных кодов на С,
как видно из названия, это ежегодное состязание, в ко-
тором принимают участие авторы наиболее причудливых
кодов для выполнения самых обычных задач. Вы можете
найти этот Web-сайт по адресу WWW.ioccc.org.
Проще говоря, рекурсия — это процесс вызова фун-
кцией самой себя. В С это действительно делается очень
просто. Вы всегда знаете, как написать программу, в
которой функция вызывает другую функцию, как по-
казано в наиболее популярной программе, написанной
на С:
#include <stdio.h>
int
main(void) {
195
printf("hello, world!\n");
return 0;
}
В некоторых языках нужно проделать много допол-
нительной работы, чтобы вызвать функцию, если это
приведет к вызову ею самой себя, пусть даже и непря-
мому. В С этого нет. Вот один совершенно тривиальный
пример:
unsigned int
recurse_n_times(unsigned int n) {
if (n == 0)
return 0;
else return recurse_n_times (n - 1) + 1;
>
Эта функция возвращает свой аргумент. Но какой
мучительный путь она проходит! Если в нее передает-
ся число, которое больше нуля, функция вызывает себя
это число раз, только чтобы возвратить величину, изна-
чально переданную ей.
Это не особенно реалистичный пример — никто в
действительности нс включит такой код в реальную
программу, — но он показывает, насколько просто реа-
лизовать рекурсию в С. Вам попросту не нужно реали-
зовывать рекурсию, она является особенностью языка.
Не рассматривая С, можно сказать, что рекурсия —
это процесс ответа на вопрос ответом на более простой
вариант этого же вопроса. Чем это определение может
помочь нам? Если есть сложная задача, но ее легко мож-
но разбить на более простые задачи, а каждую из них —
еще на более простые задачи, то, в конце концов, мож-
но решить даже самую сложную задачу без особых уси-
лий.
И это действительно так. К сожалению, может ока-
заться сложно понять суть этой простой концепции.
Поэтому рассмотрим некоторые примеры.
Факториалы: традиционный пример
Давайте начнем с традиционного короткого примера —
факториала. (Мы будем обращаться к нему позднее,
поэтому будьте внимательны, иначе вы не сможете ра-
зобраться с более сложными примерами, в которых мы
будем ссылаться на этот.)
Для тех, кто не сталкивался с этим понятием рань-
ше, поясню, что факториал х (пишется как х/) — это
целое число х, умноженное на х-7, умноженное на х-2, —
и так до тех пор, пока счет не дойдет до х=7. Иначе это
можно записать так:
х!=ис*(х-1) ’
за исключением
0!=1
(И как побочный эффект 1!=1*0! также будет равно 1.)
Рекурсия
Глава 10
Например, 4! это 4*(3!), что, в свою очередь, равно
4*(3*(2!)), а это — 4*(3*(2*(1!))). Данная величина рав-
на (4*3*2* 1), или 24. Значение 5/сводится к 5*4!, или
]20. Как вы видите, величина п! определяется через
другие факториалы. Это подходит для рекурсивной ре-
ализации, приведенной в листинге 10.1.
Листинг 10.1. Функция, вычисляющая факториал.
01 long factorial(int х) {
02 if (х == 1)
03 return 1;
04 return x * factorial(x - 1);
05 }
Как работает этот код? Давайте посмотрим, что про-
исходит с factorial(4) в пошаговом режиме. (Если вы
никогда не проводили трассировку кода вручную, то
сейчас для этого наступил прекрасный момент; это сде-
лает рекурсию намного более понятной.) Все начина-
ется с вызова factorial(4).
Вызвав функцию factorial(4), мы начинаем со стро-
ки 1. Переходим к строке 2, в которой х не равен 1,
поэтому переходим к строке 4, где возврашаем
4*factorial(x-l). Для вычисления этой величины нуж-
но вычислить factorial(3).
Начинаем функцию factorial(3) со строки 1. Снова
х не равен 1, следует вернуть factorial(2), умноженный
на 3. Это значит, что начинает выполняться следующий
вызов функции.
Начинаем factorial(2) со строки 1. Снова в строке 2
х не равен 1, поэтому возврашаем удвоенный
factorial(l). Для этого вызываем factorial(l) В данном
случае х равен 1, поэтому возвращаем 1.
Возвращаемся к строке 4 функции factorial(2), по-
лученное значение 1 умножаем на 2 и передаем резуль-
тат назад.
Возвращаемся к строке 4 функции factorial(3), по-
лученное значение 2 умножаем на 3 и передаем резуль-
тат назад.
Возвращаемся к строке 4 функции factorial(4), по-
лученное значение 6 умножаем на 4 и получаем окон-
чательный результат (24), который является значением,
возвращаемым в вызывающую функцию.
Мы получили его! Точно, это число было приведе-
но ранее, и, таким образом, можно убедиться, что код
верен. (Авторы не делают ошибок.)
Что же в действительности здесь происходило? Да-
вайте введем понятие, которое вы, вероятно, слышали
раньше, — стек. В действительности стек — это любая
структура данных, которая позволяет вводить в нее ве-
личины и затем вынимать из стека последнее введенное
значение. В языке С обычно думают о последователь-
ности функций, вызывающих другие функции по по-
рядку в стеке. (В одних компьютерах фактически суще-
196
Пересмотренный язык С
Часть I
ствует специальная область памяти, которая называет-
ся стеком и используется для хранения переменных с
автоматическим выделением памяти и возврата этих зна-
чений. Другие компьютеры осуществляют это иным
образом, но не стоит беспокоиться — эти структуры все-
гда работают как стек.)
Рекурсия в С использует преимущество неявного рас-
пределения ресурсов в стеке для управления вызовами
вложенных функций. Вы не должны специально запра-
шивать память для сохранения промежуточных резуль-
татов вычислений, а также называть переменные — вы
просто пишете определения и получаете желаемый ре-
зультат.
Вернемся к примеру factorial(n). Обратите внимание,
что получается слишком много величин, которые необ-
ходимо где-то сохранять, — множителей, которые ис-
пользуются в цепочке возвратов в конце каждой опера-
ции. Каждый оператор
return n*factorial(п-1);
сохраняет локальное значение п в стеке. Вся прелесть в
том, что неважно, как много уровней обращения имеет
функция, не нужно явно создавать переменные типа
"П5", "пб", и "п7", не нужно объявлять некоторый гро-
мадный массив или заказывать память с помощью
mallocQ. Достаточно просто организовать вызов функ-
цией самой себя и позволить компьютеру самому бес-
покоиться о деталях. (Далее будет показано, что код
может выглядеть так, как будто вы заказываете массив
сами.)
Часто серия вызовов функций от начала программы
(например, main()) до данной текущей точки называется
стеком вызовов, а число вызываемых функций — глуби-
ной, или глубиной стека.
Числа Фибоначчи: другой традиционный
пример
Последовательность Фибоначчи является другим попу-
лярным примером. Хотя это не совсем чистый пример,
внимательно прочтите этот раздел, перед тем как при-
ступить к написанию кода подобного рода. В последо-
вательности Фибоначчи каждый член является суммой
двух предыдущих. Начинается все с пары единиц, а
затем последовательность выглядит таким образом: 1,1,
2, 3, 5, 8, 13, 21, 34, ... Давайте рассмотрим формаль-
ную рекурсивную их реализацию в листинге!0.2.
Листинг 10.2. Последовательность Фибоначчи.
int fib(int х) {
if (х == 1 || х == 2)
return 1;
return fib(x - 2) + fib(x - 1);
}
С точки зрения математики это точно и корректно;
на самом деле математики любят описывать функции
именно так. Однако, возвращаясь к С, можно сказать,
что это неправильное употребление рекурсии. Почему?
Предположим, вы вызываете fib(9). Первое, что делает
функция, — вычисляет fib(7), которое, в свою очередь,
требует вычисления fib(6) и fib(5). Когда заканчивает-
ся вычисление fib(7), функция вычисляет fib(8). Что
значит вычислить fib(8)? Сначала вновь вычисляется
fib(6), затем вновь вычисляется fib(7), для чего, конеч-
но, необходимо вновь вычислить также fib(6). Таким
образом, громадное количество дополнительного време-
ни тратится на вычисление результатов, которые уже
вычислены. Детально мы проанализируем это позднее,
но надо осознавать, что данный алгоритм действитель-
но неприемлем с точки зрения эффективности. (Если
все, что вы хотите, — это описать последовательность
Фибоначчи, то, конечно, этот код прекрасно подойдет
для этого.)
ПРИМЕЧАНИЕ
Если вы прямо сейчас хотите рассмотреть еще несколь-
ко примеров рекурсивных алгоритмов, обратитесь к гла-
ве 13. А более сложный пример приведен в главе 19.
(Синтаксический разбор в действительности является од-
ним из лучших примеров, но сам синтаксический анали-
затор представляет собой значительную часть кода, по-
этому не будем дублировать его здесь.)
Как использовать рекурсию
Начиная говорить об использовании рекурсии, мы пред-
полагаем, что вы читали (или прочтете) главу 3, в ко-
торой речь идет об анализе эффективности. Здесь бу-
дут использоваться общеизвестные термины, а на более
специальных терминах останавливаться особо не будем,
поскольку они рассмотрены в других главах.
Первое, что нужно сделать при написании рекурсив-
ного алгоритма, — убедиться в том, что вам действи-
тельно нужно написать рекурсивный алгоритм. Иногда
лучше не писать с самого начала именно рекурсивный
код. Рекурсия — это изящный метод, но стоит попро-
бовать применить и другие.
Для многих рекурсивных алгоритмов характерен
подход по принципу 'разделяй и властвуй". На каждом
уровне рекурсии вы будете все более и более прибли-
жаться к решению той или иной проблемы. Однако не
всегда это именно так.
Сначала освойтесь с тем, что вы пытаетесь сделать.
Как решать какую-либо проблему? Если в первую оче-
редь вы думаете о выделении стека для хранения про-
межуточных результатов, то вполне вероятно, что вы
имеете дело с рекурсивной операцией.
197
Пример использования: двоичный поиск
Примером разумного использования рекурсии являет-
ся алгоритм двоичного поиска. Этот алгоритм прини-
мает сортированный массив и находит в массиве задан-
ную величину (если она там есть). Алгоритм работает
следующим образом. Выполняется сравнение среднего
значения в массиве с ключом поиска. Если это искомое
значение, процесс заканчивается. Если ключ больше
среднего значения, поиск продолжается в части масси-
ва "над" средним значением; в противном случае следу-
Рекурсия
Глава 1CL
ет осуществлять поиск "под" ним. В конечном счете
приходим к массиву из одного элемента; если это не ваш
ключ, значит, вашего ключа в этом массиве нет.
Итак, каким образом можно запрограммировать этот
процесс? Давайте предположим, что мы работаем с це-
лыми числами; задаем массив целых величин, размер
массива и искомое значение. Что нужно возвращать? Я
предпочитаю возвращать указатель на искомый элемент
массива либо нулевой указатель, если величина не най-
дена. Таким образом, функция должна выглядеть при-
мерно так, как код, приведенный в листинге 10.3.
Листинге 10.3. Функция поиска.
01 /* Поиск: нахождение "ключа", если он есть в элементах а[0]...a[asize-l] */
02 int *
03 search(int а[], int asize, int key) {
04 int mid = asize / 2;
05
06 /* Проверяем разумность значении аргументов */
07 if (а == NULL || asize == 0) {
08 return NULL;
09 }
10 if (key > a [mid]) {
11 /* Ключ больше среднего элемента */
12 return searchfa + mid + 1, asize - (mid + 1), key);
13 }
14 if (key < a [mid]) {
15 /* Ключ меньне среднего элемента */
16 return search(a, mid, key);
17 }
18 /* Ни больше, ни меньше - значит, равен! */
19 return &a[mid];
20 }
Как эта программа работает? Если делается попыт-
ка поиска в массиве, состоящем из нуля элементов, то
возвращаем нулевой указатель; в таком массиве не с чем
сравнивать. Если передается нулевой указатель, про-
грамма поиска скорее любезно сообщит об ошибке, чем
попытается получить значение объекта, на который
указывает данный указатель. После этого остается три
возможности:
Во-первых, можно найти ключ; в таком случае мы
возвращаем указатель на него.
Во-вторых, ключ может быть больше среднего эле-
мента. В этом случае начинаем с элемента, следующего
за средним. Поскольку элементы с [0] по [mid] массива
исключаются, оставшаяся часть массива содержит на
(mid+1) элементов меньше, чем исходный массив. (Пе-
ред тем как принять это предположение, продумайте все
возможные варианты. Что случится, если mid является
максимальным элементом в массиве? В этом случае все
сработает как следует, но всегда подобные вещи надо
проверять.)
В-третьих, ключ может оказаться меньше среднего
элемента массива. В этом случае остается mid элемен-
тов слева (т.е. сверху, от [0] до [mid-1]). Этот факт был
причиной ошибки в моей программе до этапа ее тести-
рования; не подумав, я решил вновь вычитать величи-
ну mid+1 из размера массива. Это подходит для масси-
вов с нечетным количеством элементов, но. если массив
имеет четное количество элементов, это приводит к
тому, что пропускается элемент, находящийся непос-
редственно перед исходным. Вновь обращаю ваше вни-
мание: проверяйте граничные условия. В этом случае
проще понять, как mid используется в качестве размера
массива. Поскольку в С элементы массива имеют номе-
ра от 0 до п-1, то, если элемент a[mid] находится сразу
же за пределами массива, значит, массив содержит [mid]
элементов.
Теперь проследим за реальным выполнением про-
граммы. В коды, которые можно найти на Web-сайте
издательства "ДиаСофт", включен трогательно простой
пример программы; файл должен называться search.c.
Нашли? Хорошо. Мы собираемся проследить за двоич-
198
Пересмотренный язык С
Часть I
ным поиском в массиве. Для удобства читателей, не име-
ющих доступа к Web-сайту издательства "ДиаСофт",
этот массив приведен здесь:
int а[]={ О, 2, 4, 5, 7, 9, 10, 12}
Заметим, что массив уже отсортирован. Этот метод
поиска неприменим, если массив не отсортирован! Он
может повести себя самым непредсказуемым образом и
не привести к успеху. Программа не принесет никаких
особых разрушений, но алгоритм поиска может оказать-
ся нс очень эффективным вплоть до того, что програм-
ма может сообщить об отсутствии искомой величины в
массиве, даже если она в массиве есть.
Что будет, если мы будем искать, скажем, 8? (Слы-
шу хор ваших голосов: "Мы не найдем его!”) Хорошо,
это верно, мы не найдем его. Но давайте посмотрим на
рис. 10.1.
Начнем выполнение search() с такими аргументами:
массивом, приведенным выше, величиной asize, равной
8, и ключом key, также равным 8. В строке 4 вычисля-
ем величину mid, которая равна asize/2, или 4. Провер-
ка разумности задания массива в строке 7 в данном слу-
чае для нас неактуальна: мы передаем массив, и он не
пустой. Сравниваем величину ключа со "средним"
объектом массива. В данном случае a[mid] равно 7, по-
этому мы попадаем внхтрь тела оператора if в строке 10.
Строка 12 имеет следующий вид:
return search (а + mid + 1, asize - (mid + 1),
**key) ;
Здесь a+mid+l — это адрес первого после a [mid]
элемента. Поскольку a[inid] и все элементы перед ним
исключены из рассмотрения, остается меньшая на
(mid+1) элементов область поиска. Это приводит нас на
следующий уровень поиска.
int а[] = { 0, 2, 4, 5, 7, 9, 10, 12 };
[0 2 4 5 7 9 10 12]
mid
0 2 4 5 7 [9 10 12]
mid
0 2 4 5 7 [9] 10 12
mid
0 2 4 5 7 9 10 12
РИСУНОК 10.1. Поиск последовательно уменьшающихся частей
массива.
На этом уровне имеется массив из трех элементов:
ог 9 до 12. Поскольку новая величина asize равна 3, ве-
личина mid равна 1. (Обратите внимание, что посколь-
ку используется целочисленная арифметика, округле-
ние производится в меньшую сторону. Поэтому
некоторые коды выглядят асимметричными.) И снова
осуществляется проверка передаваемого массива, и вы-
полняется сравнение key со средним элементом, кото-
рым является число 10. В данном случае ключ меньше
10, поэтому мы проходим первую проверку и заходим
в тело следующего оператора if в строке 14. В этом слу-
чае вызов функции выполняется из строки 16. Мы на-
чинаем с начала массива в том же самом месте, но при
новом вызове search() в нем существуют элементы с но-
мерами только "перед" mid.
Теперь у нас есть массив из одного элемента, начи-
ная с 9. Величина asize равна 1, поэтому величина mid
равна 0. Это значит, что осуществляется поиск в "нуле-
вом" элементе массива: есть только один элемент. Срав-
ниваем величину key (по-прежнему равную 8) с этим
элементом. 8 меньше 9, поэтому пытаемся повторить
тот же поиск, но с величиной asize, равной нулю.
В данном случае в результате проверки массива вы-
дается ошибка. Больше нет элементов для поиска, по-
этому возвращается нулевой указатель.
При поиске на более высоком уровне (в массиве из
одного элемента) возвращается нулевой указатель, гак
же как при поиске на следующем уровне (в массиве из
трех элементов).
В конечном счете в результате исходного поиска в
целом массиве возвращается тот же нулевой указатель.
Процесс закончен! Мы определили, что величина 8 от-
сутствует в данном массиве.
Обратите внимание, что каждый поиск проводится
во вдвое меньшем массиве, чем предыдущий. Вот поче-
му двоичный поиск эффективен; поэтому также разум-
но реализовать его в виде рекурсивной функции.
Это случай, так сказать, естественного применения
рекурсии. На каждой стадии при вызове search() выпол-
няется то же самое, что и на самом верхнем уровне, —
осуществляется поиск ключа в массиве известного раз-
мера. Поэтому мы можем применять ту же логику ко все
мгьшим и меньшим частям данных — до тех пор пока
нс достигнем конца.
ПРИМЕЧАНИЕ
Так называемое естественное применение может ока-
заться не самым подходящим; это очевидный способ
написания кода для двоичного поиска, но он не всегда
позволяет достигнуть оптимальной эффективности. Это
лишь хороший пример, но необязательно хорошее про-
ектное решение.
Пример вычисления факториала в начале данной
главы нс имеет такого же смысла. Почему? Частично
потому, что мы ничего реально не делаем на каждом
уровне рекурсии, а просто снова и снова повторяем
некоторые действия без разбиения материала, с которым
работаем. (Об этом речь пойдет далее в этой главе, ког-
да будет рассматриваться преобразование рекурсивных
реализаций в итерационные.)
Рекурсия
Глава 10
199
Как не следует использовать рекурсию
Сдержанность часто является наилучшей стратегией.
Существуют ситуации, в которых рекурсия, хотя и ка-
жется изначально хорошим решением, но таковым в
действительности не является. Вычисление последова-
тельности Фибоначчи является прекрасным примером
этого. Хотя эта задача действительно имеет рекурсивные
черты, заключающиеся в том, что каждый член полу-
чается в результате решения меньшего варианта этой же
задачи, но каждая такая задача решается повторно не-
сколько раз.
Рассмотрим программу fibl.c. Функция fib() имеет
встроенный счетчик, поэтому можно определить, какое
количество вычислений производится. Перед выполне-
нием этой программы сделайте некоторые оценки. Как
вы думаете, сколько вызовов fib() понадобится для вы-
числения fib(10)?
Как видите (если вы запустили тестовую програм-
му), количество вызовов быстро возрастает с ростом
аргумента. Поэтому эта задача, вероятно, не подходит
для рекурсивной реализации. (Позднее мы рассмотрим
способы се реализации без этой проблемы.) Если вы
терпеливы, попробуйте вычислить fib(40) или что-ни-
будь подобное, но знайте, что это потребует достаточ-
но много времени. (К тому моменту когда вы будете
читать этот материал процессоры, конечно, будут бо-
лее быстродействующими, во всяком случае по сравне-
нию с моим. Поэтому, чтобы яснее почувствовать задер-
жку, вам может понадобиться вычислить fib(50).)
Существует и другая причина, которая не позволя-
ет использовать рекурсивные решения для некоторых
задач, но се труднее определить точно. Некоторые про-
блемы логически просто не являются рекурсивными.
Возможно, вы сможете приспособить для их решения
и рекурсивный алгоритм, но такой алгоритм всегда бу-
дет несколько уродливым.
"Уродливый". Да, это действительно точный, техни-
чески верный термин. К сожалению, после многочис-
ленных бесед с другими программистами (и даже с не-
сколькими непрограммистами), я понял, что
большинство из нас в действительности не имеют чет-
кого набора правил для выбора наиболее эффективной
методики. Хорошая рекурсия подобна настоящему про-
изведению искусства; вы понимаете, что я имею в виду.
Вот один пример: кто-то написал в конференцию
Internet считывающую ввод программу, которая реали-
зована рекурсивно. Она выглядит таким образом:
void
read_input(void} {
if (read_line()) {
put—lineinbuffer(};
readinput(};
}
Мне это кажется неверным. Почему? Потому что
новый вызов read inputO — это не решение части про-
блемы более высокого уровня; это решение совсем дру-
гой проблемы, точно такой же, как и первая. Так что в
этом случае приходится говорить об итерации, а не о
рекурсии. Даже пример с последовательностью Фибо-
наччи не выглядит так путанно, как этот код. Функцию
read_input(), вероятно, следует написать таким образом:
void
readinput(void) {
while (readline())
putlineinbuffer();
}
Обратите внимание, что здесь не создается гигантс-
кий стек вызовов для длинного входного файла. Труд-
но точно определить, почему это имеет значение, осо-
бенно если известно, что входной файл невелик. По
мере приобретения собственного опыта у вас разовьет-
ся определенное чутье на это. Просто будьте вниматель-
ны к задачам, которые в действительности не становятся
проще при использовании рекурсии.
ПРИМЕЧАНИЕ
Как говорилось ранее, вызовы функций реализованы с
использованием стека некоторого типа. Не существует
переносимого способа, позволяющего контролировать
размер стека или даже просто определить, что при сле-
дующем вызове функции произойдет сбой из-за перепол-
нения стека. При выходе за область стека операционная
система, вероятно, остановит выполнение программы —
если вам повезет. При нормальных вызовах функции вы
вообще можете не беспокоиться о переполнении стека.
Но переполнение возможно в случае рекурсивных алго-
ритмов, которые могут достигать нелепой глубины, как
в предыдущем примере считывания ввода.
Это обычно не касается алгоритмов наподобие двоичной
сортировки, поскольку, даже если массив состоит из
четырех биллионов элементов, глубина стека будет только
log2n=32.
О рекурсии подробнее
Теперь после общего обзора рассмотрим некоторые де-
тали. Прочитав до конце этот раздел, вы поймете в чем
состоит суть действия рекурсии.
Одним из наиболее важных моментов, о котором
следует знать, является то, что часто компилятор тво-
рит истинные чудеса, чтобы сделать рекурсивную про-
грамму более эффективной. Поэтому знание реальной
работы того или иного алгоритма не подскажет вам, что
фактически происходит внутри центрального процессо-
ра. Это только поможет понять, что вы делаете и в чем
можете ошибаться.
Пересмотренный язык С
Часть I
200
Еще один пример: Евклидов алгоритм
Добавим еще пару примеров к нашей коллекции и про-
анализируем их. Сначала рассмотрим Евклидов алгоритм
для поиска наибольшего общего делителя двух чисел.
Маленькая математическая подробность: наибольший
общий делитель двух чисел — это наибольшее целое чис-
ло, на которое делятся оба эти числа без остатка. При-
мер реализации представлен в листинге 10.4.
Листинг 10.4. Евклидов алгоритм.
int
gcd(int х, int у) {
if (х < у) {
return gcd(y, x);
} else if ((x % y) != 0) {
return gcd(y, x % y);
} else {
return y;
}
}
Поскольку оба числа должны делиться на получен-
ное число без остатка, не имеет значения, в каком по-
рядке они передаются, но для данного алгоритма нуж-
но знать, какое число больше. Поэтому перед
собственно рекурсивной частью мы рекурсивно вызы-
ваем функцию gcd() с измененным порядком аргумен-
тов. Возможно, это глупо; можно просто написать сле-
дующий код, чтобы поменять эти числа местами:
if (к < у) {
int tmp;
tmp = х;
х = у;
у = tmp;
}
Однако большой разницы здесь нет. Хотя такое ис-
пользование рекурсии не слишком изящно, но код по-
лучается короче в написании, и совершенно понятно,
что при этом не добавляется множество уровней рекур-
сии в нашем алгоритме. Теперь можно быть уверенным,
что х больше у.
Теперь рассмотрим два возможных варианта. В пер-
вом случае х делится на у, тогда у является наибольшим
общим делителем, иначе при делении будет получать-
ся остаток. Ничего страшного: в этом случае понятно,
что наибольший общий делитель меньшего числа и ос-
татка является и наибольшим общим делителем боль-
шего и меньшего чисел. Поскольку мы знаем, что оста-
ток (х%у) обязательно меньше у, то при таком вызове
функции gcd(y, х%у) первый аргумент гарантированно
больше второго. Итак, будем использовать рекурсию.
Версия программы, представленная на Web-сайте
издательства "ДиаСофт", немного сложнее, но ее основ-
ной задачей является лишь показать, какова глубина
рекурсии при вызове gcd(). Это поможет вам увидеть,
кяк в действительности работает рекурсивный алгоритм.
Пример вывода представлен в листинге 10.5.
Листинг 10.5. Глубина рекурсии.
two numbers? 25 15
calling gcd(25, 15):
remainder 10, calling gcd(15, 10)
remainder 5, calling gcd(10, 5)
remainder 0, returning 5
returning 5
returning 5
Можете определить, насколько этот вывод соответ-
ствует вашим ожиданиям. Попробуйте выполнить эту
программу для нескольких комбинаций исходных чи-
сел; вы заметите, что глубина рекурсии редко бывает
очень большой.
"Хвостовая рекурсия"
Теперь давайте вернемся к более раннему "факториаль-
ному'* примеру. Этот пример не слишком удобен для
рекурсии; в действительности это итерационная задача.
Начнем с рассмотрения простой версии, скопированной
в основном из начала этой главы. Однако здесь добав-
лена переменная count для контроля числа уровней ите-
раций. (Проницательный читатель уже знает, каким оно
будет.)
Пример "работает" прозрачно (здесь нет никакого
роста в геометрической прогрессии, как при вычисле-
нии рядов Фибоначчи), но не содержит принципа под-
гонки как при двоичном поиске или при вычислении
наибольшего общего делителя. Проблема заключается в
том, что программу вычисления факториала нельзя раз-
делить на меньшие части — необходимо пройти весь
стек до конца.
Это подводит нас к определению 'хвостовой"рекур-
сии — особого случая, когда единственный вызов рекур-
сивной функции находится в конце этой же функции.
(На самом деле можно заметить, что пример вычисле-
ния наибольшего общего делителя принадлежит к тому
же типу, но это не столь очевидно при такой реализа-
ции.)
Исключение "хвостовой" рекурсии
В действительности многие современные компиляторы
С обладают достаточно развитыми оптимизационными
возможностями и способны исключить такую рекурсию,
сохраняя некоторую непротиворечивость Некоторые
компиляторы не могут этого делать, тогда эта обязан-
ность ложится на вас. Исключение "хвостовой" рекур-
сии включает преобразование функции из вызывающей
саму себя в функцию, которая, немного обработав пс-
Рекурсия
Глава 10
201
ременные, возвращается к началу. Неясно? Тогда давай-
те рассмотрим нерекурсивное вычисление факториала.
Эта функция похожа на предыдущую, только она
никогда не вызывает сама себя; она переходит в свое
начало. Я использовал goto вместо явного цикла, чтобы
привлечь внимание к тому факту, что компилятор не
всегда воспринимает такой цикл так же, как он воспри-
нимает операторы for и while. Определенно будущий
читатель вашего кода будет рассматривать это отличным
образом. (В действительности обычно используется
цикл, но сейчас рассматривается пример, а нс эксплуа-
тирующийся код.)
Можно заметить, что неожиданно исчезает реальный
вопрос о глубине рекурсии; мы накапливаем величины,
пока не произойдет некое событие. Конечно, можно
определить итерацию, но, поскольку при каждой ите-
рации не выделяется новая область памяти, глубина ее
не настолько важна.
То же самое можно сделать и в других функциях.
Например, посмотрите программу gcd2.c на Web-сайте
издательства ’’ДиаСофт”. Такие же изменения сделаны
в функции ged — используется goto вместо вызова фун-
кцией самой себя. Это даст тот же результат, но при
этом величина будет возвращена не через всю цепочку
вызовов, а непосредственно в вызывающую функцию.
Мы снова заменяем глубину рекурсии итерациями.
Код, который вызывал сам себя несколько раз, сейчас
просто несколько раз проходит через цикл (в данном
примере — то же самое число раз).
Конечно, это не коды для реального использования.
Программист, сопровождающий такой код, нс похвалит
вас, если вы будете таким образом использовать goto.
Вместо этого у вас, вероятно, появится желание напи-
сать правильную итерационную версию этой програм-
мы. Поэтому давайте посмотрим на такие итерационные
версии.
Если исключить использование переменой count, то
можно сказать, что функция для вычисления фактори-
ала имеет практически тот же самый размер, что и рань-
ше (листинг 10.6).
Листинг 10.6. Измененная функция для
вычисления факториала.
long
factorial(int х) {
long accumulator ~ 1;
while (x > 1) {
accumulator *= x—;
}
return accumulator;
}
Можно заметить, что алгоритм по-прежнему выпол-
няет те же функции: если х больше единицы, происхо-
дит умножение х на факториал (х-1). Однако в этом
случае умножение происходит тут же, без погружения
в цепочку вложенных вызовов factorial().
Многие компиляторы создают для этих двух вари-
антов программы практически одинаковый код, кото-
рый выполняет одни и те же функции.
Еще раз о последовательности Фибоначчи
Теперь уберем рекурсию из примера с последователь-
ностью Фибоначчи. Наша первая версия немного неук-
люжа, но в ней нет рекурсии. Не стесняйтесь попробо-
вать ее сами и оценить ее эффективность. Версия,
представленная в листинге 10.7, намного быстрее рекур-
сивной.
Листинг 10.7. Первое исправление программы для
вычисления последовательности Фибоначчи.
01 int
02 fib(int х) {
03 int i, *a, r;
04
05 if (x < 3)
06 return 1;
07
08 a = malloc(x * sizeof(int));
09
10 if (la)
11 return -1;
12
13 a[l] » a[0] = 1;
14 for (i = 2; i < x; ++i) {
15 a[i] = a[i - 1] + a[i - 2];
16 }
17
18 r = a[x - 1];
19 free;
20 return r;
21 )
Здесь следует сделать несколько замечаний. Преж-
де всего вы заметите в коде особое внимание к гранич-
ным условиям. В действительности первый вариант это-
го кода содержал ошибку в одном из этих условий.
Условие проверялось — х меньше 2, а не меньше 3.
Я думал, что граничные условия верны, но забыл, что
граничные условия также проверяются при немедлен-
ном возврате. Вы также заметите, что выполняется про-
верка возвращаемого функцией malloc() значения.
В некоторых кодах-примерах такая проверка не делает-
ся —- и напрасно.
Суть логики этой программы следующая. Мы выде-
ляем достаточно памяти для массива, который содержит
первые х членов последовательности. Присваиваем зна-
чения первым двум членам, а значения остальных оп-
ределяем в цикле. Закончив это, сохраняем возвращае-
мое значение (строка 18), поскольку нужно освободить
Пересмотренный язык С
Часть I
202
память (строка 19). и затем возвращаем значение, кото-
рое было в массиве.
Это пригодная к реальному использованию версия,
но не очень приятно выполнять заказ всей этой памя-
ти, когда каждое число реально используется не более
двух раз. Поэтому принимаем окончательную версию:
вместо того чтобы выделять память для всех чисел,
выделим се только для трех чисел — для тех двух чи-
сел, которые складываем, и для результата сложения.
Новая версия приведена в листинге 10.8.
Листинг 10.8. Окончательная версия функции для
вычисления последовательности Фибоначчи.
01 int
02 fib(int х) {
03 int i, a[3];
04
05 if (x < 3)
06 return 1;
07
08 a[l] = a[0] = 1;
09 for (i — 2; i < x; ++i) {
10 a[2] » a[0] + a[l];
11 a[OJ = a[l];
12 a[l] = a[2];
13 }
14
15 return a[2];
16 }
Поскольку массив исключен, отпадает также необ-
ходимость создания копии последнего элемента масси-
ва после окончания операций с массивом. С другой сто-
роны, у нас есть две дополнительные копии при каждой
итерации, когда мы "вращаем” величины в маленьком
массиве. При такой организации проблема решается
значительно быстрее, чем в исходной версии, и с ис-
пользованием значительно меньшего объема памяти,
чем любая другая версия. Это уже не так плохо!
Сейчас посмотрим, как все это работает. Покажем,
как осуществляется отслеживание массива при выпол-
нении программы (табл. 10.1). Мы начинаем при усло-
вии х=6.
В данном примере функция возвращает значение 8.
Обратите внимание, что при каждой итерации до-
бавляется только один дополнительный проход цикла,
будь то третья или шестая итерация. Сравните с рекур-
сивной реализацией этой функции, в которой для х=3
осуществляется три вызова, для х=5 — девять, для х=6 —
пятнадцать вызовов. Таким образом, от геометрической
зависимости времени обработки (при которой каждое
следующее число требует в 1.6 раза больше вычислений,
чем предыдущее) мы пришли к линейной. Это значи-
тельное улучшение!
Таблица 10.1. Трассировка функции для вычис-
ления последовательности Фибоначчи._________
aJ0[ «[1] «[2] I Где мы находимся
1 1 N/A 2 исходные установки
1 1 2 2 вычисление а[2]
1 2 2 2 перемещение величин в массиве, "вращение"
1 2 2 3 ++i
1 2 3 3 вычисление а[2]
2 3 3 3 перемещение величин в массиве
2 3 3 4 ++i
2 3 5 4 вычисление а[2]
3 5 5 4 перемещение величин в массиве
3 5 5 5 ++i
3 5 8 5 вычисление а[2]
5 8 8 5 перемещение величин в массиве
5 8 8 6 ++i
К сожалению, остается открытым вопрос о том, ког-
да следует использовать рекурсию. Итак, использовать
рекурсию имеет смысл, если вы не можете выполнить
работу, используя рабочую область фиксированного
размера — другими словами, когда вам нужен неявный
стек. Даже для последовательности Фибоначчи можно
сделать все необходимое, используя только три сохра-
няемые величины. При работе с более сложными за-
дачами (такими, как синтаксический анализ) иногда
бывает невозможно заранее определить, насколько глу-
боким будет ваш анализ.
Конечно, можно перейти к итеративному подходу,
но отслеживать заказы памяти для всех переменных
будет очень трудно. Это тот случай, когда рекурсия
действительно удобна: если необходимо выделять па-
мять для новых переменных при каждой итерации, ком-
пилятор просто сделает это за вас. Это та область, в
которой С — действительно удобный язык; компилятор
также легко обеспечивает вызов функцией самой себя,
как и вызов одной функции другой.
Рекурсия часто используется в ситуациях "разделяй
и властвуй", это касается, например, таких операций,
как сортировка или обход деревьев. В некоторых из этих
случаев может быть использован итерационный подход,
но рекурсивный код при этом может быть достаточно
простым для понимания, чтобы смириться с более низ-
кой его эффективностью.
Рекурсия
Глава 10
203
Непрямая рекурсия
Поскольку в С легко вызывать одну функцию из дру-
гой, возможна непрямая рекурсия. Функция может не
прямо вызывать себя, она может вызвать другую функ-
цию, та, в свою очередь, следующую и т.д. — так мож-
но в конце концов прийти к вызову исходной функции.
Это не распространенный подход, но вполне возмож-
ный. Вообще, это может произойти только в более
сложных ситуациях. Например, реализация синтакси-
ческого анализатора может привести к некоторой не-
прямой рекурсии.
Обычно непрямая рекурсия специально не рассмат-
ривается. Однако нужно помнить, что непрямая рекур-
сия все равно остается рекурсией, потому что в рекур-
сивных кодах могут существовать ловушки, присущие
только рекурсивным кодам, и в них можно угодить, даже
если рекурсия в коде непосредственно не очевидна.
(Обратите внимание на пример strtok() в следующем
разделе. Подумайте о том, что случится, если вы не
сможете даже понять, как вы возвращаетесь к сегменту
кода, использующему strtok()!)
Рекурсия и время существования данных
Одним из самых приятных моментов при использова-
нии рекурсивных кодов в С является то, что рекурсия
’’происходит прямо сейчас”. Нет необходимости прила-
гать специальные усилия для объявления функций,
специально отмечая их рекурсивность; компилятор по-
заботится об этом сам.
К сожалению, компилятор нс может всегда делать
все, что вы хотите. В С длительность хранения большин-
ства объектов определяется автоматически; имеется в
виду, что они возникают при входе в блок, в котором
они определены, и прекращают свое существование при
выходе из этого блока.
Например, так ведут себя аргументы функций: при
вызове функции копии се аргументов хранятся в опре-
деленной области памяти, и при возврате из функции
это пространство автоматически освобождается. Вы не
можете управлять этим — такова особенность языка.
Однако статические объекты ведут себя иначе.
В примерах программ вы могли заметить, что некото-
рые переменные объявлены вне рекурсивных функций.
При рекурсивном вычислении наибольшего общего де-
лителя depth определяется как глобальная переменная
И характеризуется статической длительностью хране-
ния. Так, если каждому вызову функции gcd() соответ-
ствуют свои значения х и у, при всех вызовах исполь-
зуется общая переменная depth.
Это приводит в результате к обычной ловушке; фун-
кции, использующие объекты со статической продол-
жительностью хранения, могут не очень хорошо рабо-
тать в сочетании с рекурсией. Например, рассмотрим стан-
дартную библиотечную функцию strtok(). Эта функция
имеет часть статических данных, связанных с нею, —
строку, которая будет продолжать поиск, если вы пе-
редадите нулевой указатель. Рассмотрим представлен-
ную в листинге 10.9 функцию, которая выглядит впол-
не правдоподобно и которая разбивает входные строки
на лексемы.
Листинг 10.9. Простая программа для разбиения
на лексемы.
void
tok(char *s, char *delim) {
char *tmp;
tmp = strtok(s, delim);
while (tmp) {
printf("token: %s\n", tmp);
tmp ~ strtok(NULL, delim);
}
}
Откомпилируйте эту программу, находящуюся на
Web-сайтс издательства "ДиаСофт”, или напишите соб-
ственный кол. Это не очень сложно и поможет вам уви-
деть, как просто анализировать простой ввод. Код дос-
таточно прямолинеен — никаких уловок. Вполне
невинный, правда? Теперь сделаем его немного более
интересным. Если он сталкивается с числом (последо-
вательностью цифр и запятых), желательно, чтобы он
выводил набор чисел отдельно.
Это должно быть просто! У нас уже есть программа
для разбиения на лексемы. Используя заданный разде-
литель, попробуем код tok2.c (листин! 10.10), в кото-
рый мы добавили простой рекурсивный вызов.
Логика здесь достаточно проста: если мы получаем
лексему, полностью состоящую из цифр и запятых и она
содержит запятую, мы разделяем лексему, используя
запятую в качестве разделителя. (Если запятых нет во-
обще, значит, она уже была разбита, а если мы получа-
ем что-то отличающееся от цифр и запятых, значит, это
какой-то другой тип слова.)
Рассмотрим пару простых тестов, где такой способ
работает. Вводим foo 123,456 и получаем лексемы foo,
123, 456. А теперь скажите, разве рекурсия не мощный
метод?
Давайте рассмотрим строку чуть посложнее: задаем
123,456 foo. Мы ожидаем лексемы 123, 456 и foo.
К сожалению, мы получим только 123 и 456. Рекурсив-
ные вызовы заставляют strtok() идти, так сказать, по
своим следам; внутренний буфер, используемый
strtok(), переписывается '’внутренним” вызовом tok(), и
таким образом при ’'внешнем" вызове теряется содержи-
мое переменной.
204
Пересмотренный язык С
Часть I
Листинг 10.10. Ошибочная попытка добавления дополнительной возможности.
01 void
02 tok(char *s, char *delim) {
03 char *tmp;
04
05 tmp = strtok(s, delim);
06 while (tmp) {
07 /* Длина исходной подстроки, содержащей только символы из второго аргумента */
08
09
10 if (strspn(tmp, [dbl]0123456789,[dbl]) == strlen(tmp) &&
11 strchr(tmp, *,')) {
12 tok(s, [dbl],[dbl]);
13 } else {
14 printf([dbl]token: %s\n[dbl], tmp);
15 1
16 tmp = strtok(NULL, delim);
17 }
18 }
Проследим за выполнением программы. Начнем сна-
чала:
tok(”123,456 foo”, " ") ;
В строке 05 устанавливаем tmp, указывающим на ”Г
в начале строки. В то же самое время функция strtok()
сохраняет указатель на Т в начале foo и заменяет об-
ласть памяти перед ней нулевым байтом. Позднее мы
ожидаем, что strtok(NULL, " ”) возвратит указатель на
"Г.
Теперь заходим в цикл в строке 06. Первое, что мы
делаем, — проверяем, содержит ли строка (tmp) только
числа и запятые и содержит ли она хотя бы одну запя-
тую. Она содержит запятую, поэтому происходит но-
вый вызов функции tok с этой строкой и запятой в ка-
честве разделителя — так, как если бы мы написали:
tok (”123,456”/’,”) ;
Начинается новый вызов. Сначала определяем зна-
чение новой переменной tmp (помните, что, поскольку
это переменная с автоматическим выделением памяти,
это не та же самая переменная tmp, которая использу-
ется при "внешнем” вызове ). Вновь (мы по-прежнему
находимся в строке 05, но в более глубоком вызове)
используем strtok() для разделения строки. Возвращается
указатель на ”1”, и при изменении запятой на нулевой
байт устанавливается внутренний указатель на ”4”, что-
бы можно было, продолжать поиск.
Заходим в цикл в строке 06. Сейчас строка, на ко-
торую указывает tmp, не содержит запятой, поэтому
выводим ее (строка 14). Выведя текущую лексему, пе-
реходим к строке 16, где происходит вызов
strtok(NULL, *’,”); таким образом можно разделить
сколько угодно полей с запятыми в качестве разделите-
лей. Таких полей больше нет, поэтому strtok() опреде-
ляет значение своего внутреннего следующего указате-
ля как нулевой указатель, чтобы показать отсутствие
полей (и то, что при следующем вызове ничего не вер-
нется). Затем возвращается указатель на ”4”.
Возвращаемся к началу цикла. Цикл продолжается,
поскольку trap не является нулевым указателем. Здесь
опять нет запятой, поэтому выводим содержимое tmp.
Теперь при следующем вызове strtok() tmp устанавли-
вается равным нулевому указателю, поскольку разбор
строки ”123,456”, с которой мы начинали, закончен.
Поэтому возвращаемся к началу цикла, но, поскольку
tmp равно нулю, цикл завершается и мы возвращаемся
к вызову более высокого уровня.
Вернувшись, вновь достигаем строки, в которой
происходит вызов strtok() для определения значения
tmp. Если вы вернетесь к месту кода непосредственно
перед повторным вызовом tok(), то вспомните, что мы
ожидаем получить указатель на Т из ”foo". К сожале-
нию, буфер, в котором функция strtok() хранила его.
был переписан в процессе другого вызова tok()l Вместо
указателя на Т получаем нулевой указатель. Цикл за-
вершен, и мы возвращаемся в вызывающую программу,
не обрабатывая оставшуюся часть строки. Вот так-то!
Что здесь не так? Поскольку strtok() имеет только
один указатель и он не сохраняется при рекурсивных
вызовах tok(). наша "правдоподобная" рекурсивная фун-
кция реально не работает так, как мы этого ожидали!
Проблема в том, что при использовании подобной
рекурсивной функции необходимо убедиться, что вы-
зов не зависит от статических данных, которые могут
быть искажены, или что вы сохранили такие данные.
К сожалению, действительно трудно сделать такое
с помощью strtok(), поскольку нет возможности досту-
па к ее внутреннему буферу. Некоторые системы пред-
лагают расширение strsep(), функциональные возмож-
Рекурсия
Глава 10
205
ности которого подобны возможностям функции
strtokO, но strsep() не использует статический буфер. К
сожалению, эта функция не входит в стандарт С, но она
входит в библиотеки С для различных бесплатных
UNIX-подобных систем, поэтому вы всегда можете по-
лучить копию либо использовать работающую подоб-
ным образом функцию, представленную на Web-сайте
издательства "ДиаСофт”.
Пример корректной реализации программы tok2
представлен под именем tok3.c. Эта программа исполь-
зует функцию, эквивалентную берклиевской функции
strsep(), под новым именем sepstr(). Предлагаю вам ис-
пользовать эту функцию в своих программах; она, в
принципе, эквивалентна стандартной, хотя, возможно,
не столь изящна, как ее аналог в берклиевской версии
стандартной библиотеки С. Почему она называется
sepstr, а не strsep? Потому что в стандарте С зарезерви-
рованы все имена, начинающиеся с str и с последующи-
ми прописными буквами, для использования в реали-
зациях, и действительно многие системы предоставля-
ют функцию strsep(). (Известно, что она включена в
некоторые дистрибутивы Linux и во все системы на
платформе 4.4BSD, такие как BSD/OS или NetBSD.)
Вообще, это показывает способ создания функции,
которую можно использовать рекурсивно. Убедитесь,
что у нее нет "внутреннего состояния", которое может
проявиться. Она должна полностью полагаться на пе-
ременные с автоматическим выделением памяти и на
свои аргументы и возвращать те значения, которые вам
необходимо знать для последующего обращения к ней.
На тот случай, если у вас нет доступа к Web-сайту
издательства "ДиаСофт", пример реализации sepstr()
представлен в листинге 10.11.
Листинг 10.11. Функция sepstr().
char * *
sepstr(char **s, char *delim) {
char *ret;
sizet n;
/* Проверка разумности аргументов*/
if (is || !*s || 1delim)
return NULL;
/* Мы возвращаем указатель на текущее значение s */
ret = *s;
/* Сначала определяем, сколько символов из содержимого ' *s' не находится в 'delim' -
* обозначим это число 'п'.
* Если (*s)[n] является нулевым байтом, то вся строка не содержит ни одного символа из
* delim; в противном случае найден первый разделитель */
n * strcspn(*s, delim);
if ((*s)[n]) {
(*s)[n] = *\0';
/* Увеличиваем s, чтобы он указывал на символ, следующий за первым разделителем */
*s += (n + 1);
} else {
/* Больше нет строк, которые нужно вернуть, */
*s = NULL;
}
/* и мы возвращаем сохраненный указатель на старое содержимое *s. */
return ret;
}
Эта функция обладает несколько необычным для
библиотечной функции интерфейсом — она возвраща-
ет пользователю две величины. Во-первых, необходим
адрес только что найденной лексемы, а во-вторых —
адрес следующей лексемы, поскольку нужно знать, от-
куда начинать снова. Способ, который предполагает ис-
пользование sepstr(), заключается в том, что пользова-
тель обеспечивает место для хранения указателя; и
вместо строки передается адрес указателя, так что мо-
жет быть возвращен новый указатель. Это звучит путан-
но, но метод действительно легко использовать; вы орга-
низуете передачу в цикле одного и того же указателя,
пока его содержимое не становится нулевым. Посколь-
ку это действительно хороший интерфейс, я скопиро-
вал его.
Прежде всего функция sepstr() проводит проверку
состоятельности аргументов, и, если аргументы являют-
ся нулевыми указателями или первый указатель указы-
206
Пересмотренный язык С
Часть I
вает на нулевой указатель, функция не может сделать
ничего полезного, поэтому она также возвращает нуле-
вой указатель. Помните, что оператор логического ИЛИ
в языке С подобен короткому замыканию; если при
первой же проверке обнаружена несостоятельность ар-
гументов, вторая проверка даже не начинается. Поэто-
му безопасно проверять *s, когда известно, что s нс яв-
ляется нулевым указателем. После проведения этих
проверок сохраняем возвращаемое значение. Вне зави-
симости от того, что произойдет, возвращаемая лексе-
ма всегда будет начинаться с начала строки.
После этого нужно применить функцию strcspn(),
чтобы определить, в какой части строки не использу-
ются символы из delim. Ее имя происходит от словосо-
четания complement span (дополнительный диапазон);
она возвращает длину начальной подстроки до первого
аргумента, который определяет диапазон (т.е. полнос-
тью состоит из элементов, отсутствующих во втором
аргументе). Если первый символ после этого диапазона
не является нулевым байтом, значит, это символ, кото-
рый был найден в строке с разделителями; поэтому мы
устанавливаем нулевое значение байта, а указатель, пе-
реданный пользователем, устанавливаем на следующий
байт. В противном случае символов из набора раздели-
телей не найдено; нет следующей лексемы, поэтому мы
определяем пользовательский указатель на строку как
нулевой указатель. В любом случае мы возвращаем най-
денную лексему (листинг 10.12).
Листинг 10.12. Переписанная функция tok() с
использованием sepstr().
void
tok(char *sr char *delim) {
char *tmp;
tmp = sepstr(&s, delim);
while (tmp) {
if (strspn(tmp, -0123456789,") ==
wstrlen(tmp) &&
strchr(tmp, ',')) {
tok(tmp, ",");
} else {
printf("token: %s\n", tmp);
tmp = sepstr(&s, delim);
}
Использовать sepstr() очень легко. Ее особенность
состоит в том, что вы не передаете нулевой указатель,
чтобы сообщить ’’продолжать работать с этой строкой”.
При каждом вызове функции вы сообщаете, с какого
места нужно начинать, и она начинает работу с этого
места. Если вы скомпилируете программу в системе,
которая содержит функцию strsepQ в стандартной биб-
лиотеке, то увидите, что достаточно поставить ее на
место sepstr(), и больше ничего не надо менять. (Если
только вам не попадется система, в которой функция
strsep() будет совсем не такой, как в других системах.
Это может звучать неправдоподобно, но изредка такое
происходит в расширениях языка.)
Практическое применение рекурсии
Рекурсии целесообразно применять в задачах, которые
можно разбить на множество меньших подобных задач.
Но если эти меньшие задачи будут существенно отли-
чаться друг от друга, вероятно, итерация окажется по-
лезнее рекурсии. Иногда лучшим способом является
комбинация: рекурсивный алгоритм разбивает задачу на
части, с которыми работает итерационный код.
Классическим примером использования рекурсии
является, вероятно, синтаксический анализ. Проще го-
воря, синтаксический анализ по своей природе являет-
ся рекурсивной задачей. Рассмотрим анализ выражения
на языке С: вы анализируете выражение наподобие
”x+(y+z)", анализируя при этом выражение такого
типа: ”х+<выражение>”, а затем анализируете второе
выражение, используя тот же метод. (Более подробно
синтаксический анализ рассмотрен в главе 19.) Поиск
часто организовывается рекурсивно, особенно если ис-
ходные данные отсортированы. (Ранее был рассмотрен
пример двоичного поиска.) Заметим, что не всякий
поиск проводится в фиксированном известном масси-
ве. Рассмотрите проблему поиска удачного хода при
игре в шахматы. Он часто реализуется в виде рекурсив-
ной процедуры: шахматная программа проводит поиск
по дереву ходов, и каждый ход занимает один уровень
стека.
Сортировка также обычно осуществляется рекурсив-
но, хотя не все сортировочные алгоритмы используют
рекурсию. Быстрая сортировка, один из наиболее изве-
стных сортировочных алгоритмов, обычно рассматри-
вается как рекурсивная функция, хотя можно втиснуть
ее и в итерационный шаблон.
Итак, рекурсия имеет смысл тогда, когда вы плани-
руете выделять память для каждого уровня решаемой
проблемы. Попробуйте свои силы. Не бойтесь написать
рекурсивную версию, которая сначала будет крайне
неэффективной. Если она действительно так плоха,
возможно, вы найдете способ ее улучшить, но работа с
рекурсивным решением может помочь вам в понимании
проблемы. Эффективность следует рассматривать во
вторую очередь; сначала получите работающий алго-
ритм и поймите его, затем посмотрите, нужно ли его
улучшить.
Рекурсия
Глава 10
207
Резюме
В этой главе вы узнали, что такое рекурсия, как она
действует и для решения каких проблем ее можно ис-
пользовать. Были рассмотрены примеры, демонстриру-
ющие суть действия рекурсии, а также примеры неце-
лесообразного использования рекурсии. Мы показали
пару ловушек, которые существуют в рекурсивных ко-
дах. Теперь вы сможете сделать разумный выбор меж-
ду рекурсией и итерацией в конкретных задачах. Если
вы хотите больше узнать об этом, попробуйте написать
несколько тестовых программ, и посмотреть, как они
работают. Конечно, также рекомендуется обратиться к
стандартной литературе, такой как книга Кнута (Knuth)
"The Art of Computer Programming".
Если у вас появится желание подробнее ознакомить-
ся с концепцией рекурсии, включая некоторые неком-
пьютерные ситуации, в которых она проявляется, про-
читайте книгу Дугласа Хофстадтера (Douglas Hofstadter)
"Godel, Escher, Bach". Чем лучше вы познаете суть ре-
курсии, тем эффективнее сможете использовать ее в
программировании.
Если вы хотите еще поразмышлять о рекурсии, вот
вам задача. Я доказал, что использовать рекурсивную
функцию для чтения входных данных нецелесообраз-
но, а для синтаксического анализа это самый подходя-
щий метод. Если ваша рекурсивная анализирующая
программа вызывает функцию для чтения входных дан-
ных, это хорошо или плохо? Если плохо, то чем этот спо-
соб действительно отличается от рекурсивного чтения
входных данных? Я задавал эти вопросы некоторым дос-
таточно опытным программистам и получил очень инте-
ресные ответы. Задайте эти вопросы своим друзьям.
Организация данных
ЧАСТЬ
В ЭТОЙ ЧАСТИ
Простые абстрактные структуры данных
Поиск по двоичному дереву
ш
Методы быстрой сортировки
Деревья
'-I?;? *1
Разреженная матрица
Работа с графами
Простые абстрактные структуры
данных
В ЭТОЙ ГЛАВЕ
Массивы
Односвязные списки
Двусвязные списки
Циклические списки
Стеки
Очереди
Очереди по приоритету
Двусторонние очереди (деки)
Разнородные структуры и объектные деревья
Ричард Хэзфилд
Однажды я попросил коллегу написать программу, ко-
торая удаляла бы повторяющиеся строки из некоего
текстового файла. Его программа работала, но плохо.
Она работала крайне медленно — намного медленнее,
чем можно было ожидать. Фактически эта программа
была нужна не на длительный срок, а всего лишь на не-
сколько дней, но было необходимо, чтобы она работа-
ла быстро.
Поэтому мне пришлось посмотреть эту программу.
Она считывала одну строку из входного файла и запи-
сывала ее в выходной файл. Каждую последующую
строку входного файла эта программа затем сравнивала
с каждой уже записанной строкой выходного файла.
Если все эти сравнения давали отрицательный резуль-
тат, программа записывала данную строку в выходной
файл. Этот метод имел два достоинства. Во-первых, он
несомненно давал правильный результат. Строки выход-
ного файла сохраняли свой первоначальный порядок —
требование, которое, должен признаться, я забыл ука-
зать.
Но программа была крайне медлительной. Пробле-
ма с самим алгоритмом заключалась в его временной
сложности, равной О(п2), в результате чего он становил-
ся совершенно неэффективным при работе уже со срав-
нительно скромными объемами данных. Чтобы обрабо-
тать всего лишь несколько сотен строк, этой программе
требовалось не менее двух минут. Но некоторые наши
файлы имели длину несколько тысяч строк, и для их
обработки вполне могло потребоваться несколько часов
или даже дней.
Все кончилось тем, что я написал свою собственную
версию программы, которая считывала все входные дан-
ные в двоичное дерево, присоединяя к каждой строке
ее номер; ключом являлся сам текст. Тот факт, что дан-
ные считывались в это дерево, исключал повторяющи-
еся строки. Затем я просто копировал это дерево в дру-
гое дерево и на сей раз ключом был номер строки. Таким
образом, выполняя обход этого второго дерева, я мог
записать все строки в выходной поток в правильном
порядке. Время, необходимое для обработки таким спо-
собом типичного входного файла, составляло менее
одной секунды.
Очевидно, что этот алгоритм был лучше, хотя для
него требовался объем памяти, почти в 2 раза превыша-
ющий размер исходного файла. К счастью, это не со-
ставило проблемы в случае с теми конкретными данны-
ми, с которыми мы имели дело. Проблемой это могло
стать, только если количество данных было бы слиш-
ком велико, и тогда первый алгоритм оказался бы без-
надежно медлительным. Тогда нам пришлось бы искать
другое решение, например, присоединить к строкам их
номера, выполнить для этих строк дисковую сортиров-
ку слиянием и фильтрацию, а затем еще одну сортиров-
ку слиянием, чтобы снова разместить строки в правиль-
ном порядке.
Для работы моего алгоритма требовалась еще соот-
ветствующая структура данных. Когда выше я писал
’’считывала все входные данные в двоичное дерево”, то
предполагал, что двоичное дерево уже существует. Без
соответствующей структуры данных этот алгоритм не
имеет смысла и его нельзя выразить в виде кода про-
граммы. Это свидетельствует о том, что для многих ал-
горитмов требуются хорошо известные и относительно
простые структуры данных.
14 Эйс 265
Организация данных
Часть II
210
В настоящей главе рассматривается большинство
классических структур данных, но деревья не входят в
это число, потому что они заслуживают отдельной гла-
вы (фактически даже нескольких глав). Здесь будут
описаны способы обобщения понятий классических
структур данных, с тем чтобы отделить структуру дан-
ных от реальных данных. Действительно, ведь должна
же существовать возможность составить список поку-
пок, не объясняя списку, что такое печеные бобы, или
печеным бобам — что такое списки. Мы коснемся так-
же понятия инкапсуляции (объединения данных с их
функциональным назначением), но не подумайте, по-
жалуйста, что эта глава об объектно-ориентированном
программировании (ООП). Это не так. Тем не менее,
некоторые принципы ООП исключительно хорошо под-
ходят для проектирования структур данных на языке С,
поэтому было бы легкомысленно не использовать их
там, где это возможно. (Если не утверждается иное,
слово объект в данной главе означает, как это опреде-
лено в языке С, просто поименованную область памя-
ти, такую как переменная. См. The С Programming
Language, 2nd edition, Kernighan and Ritchie, c. 197.)
Для большинства рассматриваемых в этой главе
структур данных мы представим подпрограммы, кото-
рые могут служить основой ваших собственных библио-
тек. Они не являются законченными библиотеками, но
они достаточно подробны и надежны для того, чтобы с
их помощью вы легко могли приступить к созданию
своих собственных библиотек, не уступающих по каче-
ству библиотекам промышленного изготовления.
ПРИМЕЧАНИЕ
Конечно, эти библиотеки написаны для программистов, а
не непосредственно для пользователей. Пользователи
будут работать с приложением, в котором используется
та или иная библиотека. Поэтому пользователями нашей
библиотеки будут фактически программисты. В дальней-
шем тексте я пытался это пояснить, используя, когда
необходимо, термин пользователь-программист.
Во всех рассматриваемых случаях мы преднамерен-
но избегаем использования переменных, областью ви-
димости которых является весь файл, будь то статичес-
кие (типа static) или внешние (типа extern) переменные.
Мы избегаем также статических переменных, областью
видимости которых является функция. Вместо этого
совместное использование данных осуществляется ис-
ключительно посредством механизма передачи парамет-
ров. Это нс только соответствует принципам грамотно-
го проектирования, но также означает, что можно иметь
более одного экземпляра структуры данных. Избегая вне-
шних и статических переменных, мы в качестве допол-
нительного преимущества получаем более высокий уро-
вень безопасности потоков.
Давайте же теперь начнем с наиболее знакомой,
мощной и в значительной степени недооцениваемой
структуры данных — с массива.
Массивы
Массив — это не просто структура данных; это также
механизм языка, который позволяет адресовать множе-
ство подобных объектов в простом цикле. Массивы зас-
луживают пристального изучения по той причине, что
принципы работы с ними могут быть использованы для
реализации любой классической структуры данных.
Вас может удивить тот факт, что массивы, состав-
ляя одно из основополагающих понятий языка С, под-
робно рассматриваются в книге, которая самым опре-
деленным образом предназначена не для начинающих.
Однако фактом остается и то, что многие профессио-
нальные С-программисты плохо разбираются в масси-
вах и, следовательно, не могут в полной мере исполь-
зовать предоставляемые ими возможности.
Поскольку в массиве можно хранить объекты любого
рода, включая указатели на функции (но не сами функ-
ции), программист имеет возможность обрабатывать лю-
бую группу объектов индивидуально (МуАггау[0]), в
цикле (МуАггаур]) или коллективно (МуАггау).
В языке С имеется две разновидности массивов —
массивы фиксированного размера и массивы перемен-
ного размера. В С99, новом стандарте ANSI С, был вве-
ден новый синтаксис для массивов переменного разме-
ра, но здесь не будет рассматриваться этот вопрос; ко
времени написания этих строк не было ни одного ком-
мерческого компилятора, соответствующего стандарту
С99. Поэтому здесь речь пойдет о синтаксисе стандар-
та С89.
"Обычные" массивы
Когда мы учимся программировать на языке С, наше
первоначальное знакомство с массивами осуществляет-
ся, как правило, посредством синтаксиса, описывающе-
го массив фиксированной длины:
#define MAX_ORDER_ENTRIES 16
ORDER_LINE OrderLine[MAX_ORDER_ENTRIES] = {0} ;
В результате в производственных программах часто
используются именно такие массивы. Иногда такие
программы работают прекрасно, но если мы не будем
внимательными, то можем излишне ограничить пользо-
вателей. Массив OrderLine не позволяет пользователю
вводить в заказ более 16 позиций (items). Мы часто го-
ворим себе: "Если этого будет недостаточно, то можно
просто увеличить размер MAX_ORDER_ENTRIES и
перекомпилировать программу". Но конечные пользо
ватели вряд ли имеют доступ к исходному коду, не го
Простые абстрактные структуры данных
Глава 11
211
воря уже о том, умеют ли они вообще компилировать
программы. Таким образом, на вас возлагается задача
сопровождения и модификации этой программы всякий
раз, когда пользователю будет мешать произвольно ус-
тановленное ограничение размера массива. А это достав-
ляет лишние неудобства вашим заказчикам.
Одномерные массивы фиксированного размера
Одномерные массивы, несомненно, являются самыми
распространенными. Нет необходимости рассматривать
их здесь очень подробно, поскольку они относительно
просты. Но все же следует, по-видимому, напомнить,
что язык С не позволяет программисту передавать мас-
сив в функцию. Что можно передать в действительнос-
ти, так это значение указателя на первый элемент мас-
сива. Даже если вы объявляете, что в функцию
передается массив, компилятор внутренне преобразует
синтаксис массива в синтаксис указателя. Тем не менее,
общепринято говорить о "передаче массива в функцию".
Когда вы встречаетесь с такой фразой, пожалуйста,
имейте в виду, что, строго говоря, она неправильна и
является просто удобным сокращением при описании
действительного положения вещей.
Нам часто приходится передавать такие массивы в
функции. Поскольку нам известна размерность одномер-
ного массива и его фиксированный размер, мы склон-
ны также передавать эту информацию в вызываемую
функцию. Например:
int GetOrders (ORDERJLTNE
Order Ar ray [MAX_ORDER__ENTRIES] )
{
size t i;
int GotAnOrder = 1;
for(i = 0; (i < MAX_ORDER_ENTRIES) &&
^GotAnOrder; i++)
{
GotAnOrder = GetOneOrder((OrderArray[i]);
}
return -i;
I
Этот код работает. Но в функцию GetOrders() пере-
дается внутренняя информация о массиве, которая ей
на самом деле не требуется. Если мы решаем изменить
значение константы MAX_ORDER__ENTRIES, то это не
представляет никакой проблемы, так как мы были дос-
таточно разумны и использовали директиву #define, а не
"магическое число". Но что нужно было бы сделать,
если бы мы занимались поисками ошибки и решили
временно использовать массив меньшего размера? Сле-
довало бы помнить, что необходимо изменить код в двух
местах, а также не забыть затем восстановить его. Оче-
видно, было бы разумнее посылать эту информацию в
функцию GetOrders() во время выполнения.
int GetOrders (ORDER LINE
OrderArray [MAX_ORDER_ENTRIES] f
sizet MaxEntries)
{
size t i;
int GotAnOrder = 1;
for(i = 0; i < HaxEntries (( GotAnOrder;
wi++)
{
GotAnOrder = GetOneOrder((OrderArray[ i ]);
}
return -i;
}
Этот код уже лучше. Здесь все еще остается пробле-
ма, связанная с фиксированным размером массива, но
мы пока не будем ею заниматься.
Поскольку компилятор знает размер типа
ORDER__LINE (предполагается, что этот размер сооб-
щается ему каждый раз с помощью какого-нибудь под-
ходящего определения typedef) и поскольку он знает
базовый адрес массива, он может вычислить адрес лю-
бого объекта внутри массива. В результате можно сокра-
тить объявление параметров массива, как это показано
ниже:
int GetOrders (ORDER_LINE OrderArray [] ,
size_t HaxEntries)
Это фактически полностью эквивалентно такому
объявлению:
int GetOrders(ORDER_LINE *OrderArray,
size__t HaxEntries)
Пожалуйста, поймите меня правильно! Массивы —
это не указатели, а указатели — не массивы. Тем не ме-
нее, "как формальные параметры в определении функ-
ции", эти два на вид разные объявления массива
OrderArray являются идентичными (см. K&R, с. 99-100).
Двумерные массивы фиксированного размера
При переходе к двумерным массивам объявление пара-
метров немного усложняется. С помощью объявления
#define MAX-AGE 130
fdefine NUMGENDERS 2
double Loading[HAX_AGE] [NUM—GENDERS] = {0};
мы хотели бы передать в функцию элементы массива
Loading таким образом, чтобы функция могла модифи-
цировать эти элементы. Вот чего делать нельзя:
void PopulateLoadingArray (double **Loading,
size_t MaxAge,
size_t NumGenders)
{
size t Age, Gender;
for (Age = 0; Age < MaxAge; Age++)
{
for (Gender = 0; Gender < NumGenders;
’•* Gender++)
212
Организация данных
Часть II
{
Loading[Age][Gender] = CalcLoading(Age,
wGender);
}
}
1
Мы не можем этого делать, так как только по инфор-
мации, предоставленной функции PopuIateLoadingArrayO,
компилятор не может установить, как вычислить адре-
са элементов массива. Можно сделать это самостоятель-
но, используя запись с указателями:
void PopulateLoadingArray (double **Loading,
size_t MaxAge,
size_t NumGenders)
sizet Age, Gender;
for (Age = 0; Age < MaxAge; Age++)
{
for(Gender - 0; Gender < NumGenders;
wGender++)
{
**(Loading + Age * MaxAge + Gender) =
CalcLoading(Age, Gender);
}
}
}
Но это выглядит крайне непривлекательно! Дей-
ствительно ли это правильный код? Не пришлось ли вам
просматривать его дважды, чтобы удостовериться в
этом? Хотели бы вы сопровождать такой код? Я бы
тоже не хотел.
Если вместо этого вновь вернуться к записи с помо-
щью массивов, то код станет намного яснее. Можно
исправить функцию PopuIateLoadingArrayO (имеется в
виду предыдущий код), просто изменив объявление
функции:
void PopulateLoadingArray (double Loading []
[NUM_GENDERS] ,
size_t MaxAge,
size__t NumGenders)
Обратите внимание, что нужно указывать размер
всех индексов в массиве, за исключением самого край-
него слева (который является необязательным). Это дает
компилятору достаточно информации для того, чтобы
определить требуемые адреса в массиве.
Есть способ, позволяющий упростить передачу масси-
ва в функцию, который заключается в том, чтобы приве-
сти массив к типу struct, как показано в листинге 11.1.
Листинг 11.1. Передача массива в функцию.
linclude <stdio.h>
typedef struct ARRAY_INT_4_6
{
int array[4][6];
} ARRAY—INT—4—6;
int SumArray (ARRAY_INT_4_6 *);
int main(void)
{
ARRAYINT46 Array =
{
{
{ 1, 2, 3, 4, 5, 6 },
{ 2, 3, 4, 5, 6, 7 },
1 3, 4, 5, 6, 7, 8 },
1 4, 5, 6, 7, 8, 9 }
}
};
int Total;
Tota1 = SumArray(&Array);
printf(“Total is %d\n“, Total);
return 0;
}
int SumArray(ARRAY INT-4-6 *a)
{
size_t outer, inner;
int Total = 0;
for(outer = 0;
outer < sizeof a->array /
sizeof a->array[0 ];
outer++)
<
for(inner = 0;
inner < sizeof a->array[0] /
sizeof a->array[0][0];
inner++)
{
Total += a->array[outer][inner];
}
)
return Total;
}
Преимущества этого метода состоят в том, что он
упрощает синтаксис объявления параметров и, как по-
казано в листинге, позволяет внутри функции вычислять
размеры массива в каждом измерении. Недостаток же
метода заключается в том, что он привязывает функцию
к конкретному размеру массива, затрудняя применение
этой функции в более общих случаях. Но, как уже от-
мечалось, массивы фиксированного размера всегда бу-
дут доставлять нам проблемы, что бы мы ни делали.
Следовательно, приводить такой массив к типу struct
или нет — это главным образом вопрос стиля програм-
мирования.
Здесь хотелось бы сделать краткое отступление: с
массивами, имеющими два и более измерения, мы час-
то работаем с использованием вложенных циклов. Я.
например, очень часто делаю одну и ту же ошибку:
Простые абстрактные структуры данных
Глава 11
213
копирую и вставляю внешний цикл во внутренний и
при этом забываю обновить все элементы оператора
управления циклом:
for(i = О; 1 < OUTER; 1++)
{
for(j = 0; j < INNER; i++)
{
total += array
}
Такая проблема будет возникать реже, если исполь-
зовать имеющие смысл имена счетчиков циклов, так как
в этом случае возможная ошибка будет, очевидно, бо-
лее заметной.
N-мерные массивы фиксированного размера
Двух измерений достаточно для удовлетворения почти
всех потребностей. Даже в трехмерных (3D) графичес-
ких программах мы можем записать координаты вершин
любой фигуры с помощью двумерного (2D) массива.
В этом случае каждая из трех строк представляет одно
пространственное измерение, а каждый столбец — три
координаты одной точки. Тогда каждая ячейка массива
будет представлять смещение данной точки от некоего
базиса в данном измерении. Таким образом, следующий
двумерный массив
int Cube[3][8] =
{
{ 0, 1, 1, 0, 0, 1, lf 0 },
{ 0, 0, 1, 1, 0, 0, 1, 1 },
{ 0, 0, 0, 0, 1, 1, 1, 1 }
>;
представляет вершины трехмерного куба с единичной
стороной. Таким способом мы можем даже представлять
фигуры, имеющие четыре или более измерения; для
этого просто необходимо увеличить число строк в дву-
мерном массиве.
Тем не менее, бывают ситуации, когда необходимо
использовать более двух измерений. В этих случаях
можно было бы просто расширить наш ’’двумерный”
синтаксис и задать все индексы (за исключением само-
го крайнего слева, который при желании можно опус-
тить) в формальном объявлении параметров массива.
Как мы упоминали ранее, использование массивов
фиксированного размера может приводить к различным
ограничениям. В последующих разделах этой главы
будет рассмотрено гораздо более гибкое понятие — ди-
намически распределяемый массив переменной длины.
Массивы переменного размера
Массивы переменного размера предоставляют програм-
мисту гораздо больше потенциальных возможностей,
Чем массивы фиксированного размера. Однако в данном
случае возможности предоставляются не только для
создания гибких, удобных и полезных программ, но,
увы, также и для совершения ошибок. Здесь будут рас-
смотрены методы, позволяющие реализовывать масси-
вы переменного размера безопасно и надежно.
Одномерные массивы переменного размера
Одномерные массивы переменного размера создаются на
самом деле просто. Если вам требуется массив из N
объектов типа Т, то вот как это делается:
#include <stdlib.h>
/* ... */
T *p;
p - malloc (N * sizeof *p);
if(p 1= NULL)
{
/* Теперь у нас есть массив, и мы можем
записывать в него информацию */
}
Как видите, этот код иллюстрирует тот факт, что в
С-программах не следует избегать применения функ-
ции malloc, поскольку это может сделать незаметным
случайный пропуск файла <stdlib.h>.
Изменение размеров массива — уже не такое простое
дело, но и не очень сложное. Нам потребуется еще один
указатель — снова типа ’’указатель на данные типа Т":
#include <stdlib.h>
T *tmp;
tmp = realloc(p, NewNumElems * sizeof *p);
if(tmp != NULL)
{
/* Изменение размеров массива прошло
успешно */
р = tmp;
}
else
{
/* Изменение размеров массива не
выполнилось, р по-прежнему указывает на
старые данные */
}
Обратите внимание на использование второго ука-
зателя. Это необходимо всякий раз, когда вызывается
функция realloc. Многие программисты просто исполь-
зуют тот же самый указатель р, предполагая, что все
будет в порядке. Но если их надежды не оправдаются,
они не только не получат дополнительную память, ко-
торую запрашивали, но и потеряют ту, которую имели
до этого, так как их единственный указатель на нее, р,
теперь будет иметь значение NULL!
Организация данных
Часть II
214|
Изменение размеров массива — это очень полезная
возможность, которая может придать нашим програм-
мам гораздо большую гибкость.
Однако не следует забывать, что после окончания
работы с массивом необходимо в соответствующий мо-
мент освободить выделенную для него память.
Двумерные массивы переменного размера
Вот где работа с массивами становится действительно
увлекательной! Я могу без предварительной подготов-
ки создать массив М * N объектов типа Т тремя различ-
ными способами. В примере кода программы использо-
вался тип int, но можно заменить его любым другим
типом данных.
Первый из этих трех методов требует меньше всего
памяти, но обеспечивает относительно медленный до-
ступ к элементам массива. Идея метода заключается в
имитации массива фиксированного размера. Выделяем
sizeof(T) * М * N байтов и к отдельному элементу мас-
сива А [х] [у] можем обращаться по адресу А + N * х + у.
Помните, что компилятор сам позаботится о размере
каждого элемента массива (если, конечно, мы не зада-
дим void *), поэтому нам не придется задавать его. Наш
последний (см. выше) эксперимент с программой
PopuIateLoadingArrayO достаточно хорошо иллюстриру-
ет этот метод адресации, так что не будем повторно
приводить здесь этот код.
Изменение размеров такого массива — дело доволь-
но хитрое, так как приходится осуществлять сложные
манипуляции с данными, если мы не хотим потерять
информацию, которая уже хранится в массиве.
Во втором методе, так же как и в первом, для мас-
сива выделяется единый блок памяти. Однако на этот
раз блок будет больше — мы запрашиваем дополнитель-
ную память для М указателей на объекты Т, и общий
объем требуемой памяти оказывается равным
sizeof (Т) * М * N + sizeof (Т *) * М. Первые
sizeof (Т *) * М байтов мы резервируем для совокупно-
сти указателей на тело основного массива, что позволяет
использовать запись А [х] [у]. Это менее очевидно, по-
этому в листинге 11.2 приведен полностью работающий
пример соответствующей программы.
Листинг 11.2. Двумерный массив переменного размера.
linclude <stdio.h>
linclude <stdlib.h>
typedef int T;
T **Allocate(size_t mr sizet n)
{
T **a;
T *p;
'size_t Row;
a e malioc(m * n * sizeof **a + m * sizeof *a);
if(a 1= NULL)
{
for (Row = 0r p e (T *)a + m; Row < m; Row++f p += n)
{
a [Row] = p;
}
)
return a;
int main(void)
T **array;
int i;
int j;
int total = 0;
int row 4;
int col « 7;
array = Allocate(rowr col);
if(array 1 = NULL)
{
/* Заполнение массива */
Простые абстрактные структуры данных
Глава 11
215
for(i = 0; i < row; i++)
for(j = 0; j < col; j++)
array[i][j] = i + j;
/* Обращение к массиву */
for(i = 0; i < row; i++)
for(j = 0; j < col; j++)
total += array[ij[j);
printf("Total is %d\n", total);
free(array);
return 0;
Как видим, "начинка" функции AllocateO оказыва-
ется довольно внушительной. Кроме того, как для мас-
сива переменного размера, не так-то просто изменить
его размер! Его можно изменить, но для этого необхо-
дим обслуживающий код, сохраняющий данные масси-
ва. Можно довольно легко изменить размеры блока, но
при этом придется весьма сложным образом пересылать
в памяти данные массива. В листинге 11.3 показан код
программы, изменяющей размеры блока. Обратите вни-
мание на то, что следует сообщить функции как старый
размер массива, так и новый.
Листинг 11,3. Изменение размеров двумерного массива с указателями в заголовочном блоке,
linclude <stdlib.h>
typedef int T;
T **Reallocate(T **OldP,
size t oldm,
size t oldn,
size t newm,
size t newn)
{
T **NewP = NULL;
T *p;
size t Row;
/* Вам необходимо больше памяти? */
if(newm * newn * sizeof **NewP + newm * sizeof *NewP >
oldm * oldn * sizeof **OldP + oldm * sizeof *OldP)
{
/* Да, поэтому давайте ее получим */
NewP = reallocfOldP,
newm * newn * sizeof **NewP +
newm * sizeof *NewP);
}
else
{
NewP = OldP;
}
if (NewP 1= NULL)
{
/* Теперь нам опять придется создавать таблицу указателей */
for (Row = 0, р = (Т *)NewP + newm;
Row < newm;
Row++, p += newn)
{
NewP[Row] - p;
}
}
return NewP;
}
2161
Организация данных
Часть II
Можно попробовать модифицировать эту функцию
так, чтобы она сохраняла максимальное количество дан-
ных исходного массива. Но я не буду этого делать.
В третьем методе используется такой же объем па-
мяти, как и во втором, однако не требуется, чтобы па-
мять была выделена одним целым блоком. Кроме того,
этот метод облегчает изменение размеров массива.
Сначала мы выделяем блок памяти для размещения
М указателей на данные типа Т. Затем в цикле проходим
этот массив и на каждом этапе цикла выделяем блок па-
мяти, достаточный для размещения N объектов типа Т.
Это означает, что мы больше не можем освобождать
память за один вызов. Необходимо в цикле проходить
массив указателей, освобождая память, занимаемую
каждым элементом, а затем освобождать память, зани-
маемую самим массивом указателей. (Можно написать
простую функцию, которая будет выполнять эту зада-
чу.) С другой стороны, если используются очень боль-
шие массивы, можно особенно не волноваться относи-
тельно того, успешно ли будет выделена память, так как
она больше не должна представлять собой один целый
блок. Конечно, по-прежнему необходимо проверять,
успешно ли была выделена память, но риск неудачи зна-
чительно снижается.
Рис. 11.1 должен помочь вам представить все это
более отчетливо.
Массив
Г*
С элементов типа Т
I
array [0]
array [1]
array [2]
array [г-2]
array [r-1]
array [0] [0] | array [0] [1 j [ ........ [array |q [c-2]|array (0J [<M]|
array [1] [0J | array [1Ц1 j [ .......... [array [1J [c-2]|array [1] [c-1]|
array [2] [0] | array И [1] [ ........... [array [2] [c-2]|array [2] [c-1]|
________»|array[r-2] [0] [array [r-2][1]| . [array [r-2][c-2]|array [r-2][c-lj|
—^{array [rl] [Ol|array [r-1}[1]| ..... [array [r-1][c-2]|array [r-1] (c-1]|
РИСУНОК 11.1. Двумерный массив переменного размера.
В листинге 11.4 показано, как мы собираемся реа-
лизовать этот массив.
Этот массив является очень гибким с точки зрения
изменения его размера. Можно добавлять (или удалять)
строки, делать более длинными все строки или только
некоторые из них (что даст нам структуру данных, из-
вестную как невыровненный массив (ragged array)).
Листинг 11.4. Двумерный массив переменного
размера.
linclude <stdio.h>
linclude <stdlib.h>
typedef int T;
void Release(T **ar size_t m)
{
size_t Row;
f or (Row = 0; Row < n; Row++)
{
if (a[Row] 1= NULL)
{
free(a[Row]);
}
}
free;
T **Allocate(size_t mr size_t n)
{
T **a;
size_t Row;
int Success = 1;
a = nalloc(n * sizeof *a);
if(a 1= NULL)
{
for (Row = 0; Row < m; Row++)
{
a[Row] = malloc(n * sizeof *a[Row]);
if(NULL == a[Row])
Success = 0;
1
}
/* Если любое внутреннее выделение памяти
закончится аварийно, нам следует произвести
очистку
*/
if (1 1= Success)
{
Release(a, m);
a = NULL;
}
}
return a;
)
int main(void)
{
T **array;
int i;
int j;
int total = 0;
int row = 4;
int col = 7;
array = Allocate (row, col);
if (array != NULL)
Простые абстрактные структуры данных
217
Глава 11
{
/* Заполнение массива */
for(i = 0; i < row; i++)
for(j = 0; j < col; j++)
array[i][j] = i + j;
/* Обращение к массиву */
for(i = 0; i < row; i++)
for(j = 0; j < col; j++)
total += array[i] [ j ];
printf("Total is %d\n", total);
Release(array, row);
}
return 0;
}
Такая гибкость исключительно полезна — особенно
возможность иметь строки разной длины. Например,
если бы мы писали программу текстового редактора, то
можно было бы считывать в память весь файл целиком
(при условии, что имеется достаточно памяти). При
этом одна строка текста соответствовала бы одной стро-
ке массива и между строками массива не было бы не-
использованных участков памяти.
Листинг 11,5. Считывание в память текстового файла.
Для иллюстрации вышесказанного напишем про-
грамму, которая будет делать именно это — считывать
в память текстовый файл. Предположим, что текстовый
файл состоит из разумного числа строк текста, отделен-
ных друг от друга символами новой строки С\п’). Это
может соответствовать символу перевода строки (ска-
жем, в системе UNIX), символу возврата каретки (на
компьютерах Macintosh), комбинации этих двух симво-
лов (DOS/Windows) или чему-нибудь совершенно ино-
му. Нет никакой необходимости писать для этого код,
так как, когда мы открываем файл в текстовом режиме,
стандартная библиотека выполнит всю необходимую
трансляцию. Единственным условием является то, что
формат текстового файла должен быть родным для той
операционной системы, в которой будет выполняться
эта программа.
Начнем с функций для массива строк. (Полный код
листинга 11.5 находится на Web-сайте издательства
"ДиаСофт” и содержит операторы включения и прото-
типы, которые здесь для краткости опущены.) Прежде
всего попытаемся создать массив строк. Для этого сна-
чала выделим память для массива указателей, а затем на
каждый указатель выделим память, необходимую для
размещения строки.
char **AllocStrArray(sizet NumRows, sizet Width)
<
char ** Array = NULL;
size t Row;
int Success - 1;
/* Выделение 0 байтов - это ве великая идея, а логическая ошибка.
*/
assert(NumRows > 0);
assert(Width > 0);
/* Ba тот случай, если выделение нулевой памяти не будет перехвачено при тестировании, мы
проверим это здесь.
*/
if(NumRows > 0 && Width > 0)
{
Array = malioc(NumRows * sizeof *Array);
if (Array != NULL)
{
for (Row = 0; Row < NumRows; Row++)
{
Array[Row] = malioc(Width * sizeof *Array[Row]);
if ( NULL == Array [ Row])
{
Success « 0;
}
else
{
/* Сделаем строку пустой, что почти всегда будет правильным и никогда не может быть
неправильным.
*/
Array[Row][0] = '\0';
}
218
Организация данных
Часть II
}
/* Если любая из операции внутреннего выделения памяти завершится аварийно, следует
выполнить очистку.
*/
if(1 1= Success)
{
FreeStrArray(Array, NumRows);
Array я NULL;
}
return Array;
Если вся память полностью не может быть выделе-
на, то программа выполняет ее очистку (вызывая фун-
кцию FreeStrArrayO) и возвращает значение NULL.
Здесь заранее предполагается, что существует функция
FreeStrArrayO, и вот она к вашим услугам. Как и мож-
но было ожидать, она представляет собой простой цикл.
void FreeStrArray (char **Array, size_t
NuinRows)
{
size_t Row;
if (Array 1= NULL)
{
for(Row e 0; Row < NuinRows; Row++)
{
if (Array[Row] !s NULL)
{
free (Array [Row]);
}
}
free(Array);
}
)
Изменение размеров одной строки является очень
простым делом. Необходимо знать номер этой строки
и новый ее размер.
int ResizeOneString(char **Array,
size t Row,
sizet NewSize)
{
char *p;
int Success = 1;
assert(Array != NULL);
p = realloc(Array]Row], NewSize);
if(p 1= NULL)
{
Array[Row] = p;
}
else
{
Success = 0;
}
return Succes s;
)
Обратите внимание, как аккуратно вызывается фун-
кция realloc(). Используя дополнительный указатель,
мы гарантируем, что первоначальный указатель не бу-
дет потерян, даже если выделение памяти закончится
неудачно.
Конечно, необходимо будет иметь возможность до-
бавлять (или удалять) строки. Чтобы эта функция уда-
ляла строки, в параметре NumRowsToAdd просто нуж-
но передать отрицательное число.
int AddRowsToStrAxray (char ***ArrayPtr,
size t OldNumRows,
int NumRowsToAdd,
size_t InitWidth)
{
char **p;
int Success * 1;
int Row;
int OldRows;
OldRows = (int)OldNumRows;
if(NumRowsToAdd < 0)
{
for (Row - OldRows - 1;
Row >= OldRows + NumRowsToAdd;
Row-)
{
free](*ArrayPtr) [Row]);
}
}
p = realloc(*ArrayPtr,
(OldRows + NumRowsToAdd) *
sizeof(**ArrayPtr));
if(p != NULL)
{
♦ArrayPtr « p;
for(Row = OldRows;
Success && Row < OldRows +
NumRowsToAdd;
Row++)
{
219
(«ArrayPtr}[Row] « malloc(InitWidth);
if((«ArrayPtr)(Row) != NULL)
{
(*ArrayPtr)[Row][0] = '\0';
}
else
{
Success = 0;
}
}
}
else
{
Success = 0;
}
return Success;
}
В этом коде имеется два интересных момента. Во-
первых, если мы удаляем строки, то нет необходимос-
ти заходить в цикл, который выделяет память для но-
вых строк. Это предотвращается условием цикла.
Во-вторых, обратите внимание на использование круг-
лых скобок, например, в случае (*Аггау) [Row]. Если
опустить здесь скобки, то это приведет к катастрофи-
ческим последствиям, так как скобки [] имеют более
высокий приоритет, чем *.
Теперь у нас имеется весь требуемый код, но было
бы полезно иметь еще функцию, которая устанавливает
размер каждой строки массива точно равным числу бай-
тов, необходимых для размещения строки текста. Мож-
но было бы возразить, что небольшое количество избы-
точных байтов не имеет никакого значения,„но в
некоторых случаях это важно. Эту функцию использо-
вать не обязательно^ но на всякий случай создадим ее.
int ConsolidateStrArray(char ««ArrayPtr,
size_t NumRows)
Простые абстрактные структуры данных
Глава 11
{
sizet Row;
sizet Len;
int NumFailures == 0;
for (Row == 0; Row < NumRows; Row++)
{
/* Если эта библиотека использовалась
правильно, то ви один указатель на строку
не должен иметь значение NULL, поэтому
именно так нам и следует полагать.
*/
assert(ArrayPtr[Row] != NULL);
Len = 1 + strlen(ArrayPtr[Row]);
if(0 == ResizeOneStringfArrayPtr, Row,
Len))
{
++NumFailures;
}
}
return NumFailures;
)
При наличии всех этих функций код (программы)
для чтения файла в память будет удивительно коротким.
Можно просто в цикле считывать каждую строку фай-
ла в соответствующую строку массива. Если файл ока-
жется длиннее, чем первоначально предполагалось,
можно просто добавить в массив строки. То же самое
касается строки файла. Если она окажется длиннее, чем
ожидалось, то можно изменить размер соответствующей
строки массива. В этом случае мы вполне можем обна-
ружить, что наш буфер недостаточно велик для того,
чтобы можно было за один раз считать полностью всю
строку с помощью функции fgets(). Поэтому нужно
добавить небольшой код, чтобы быть уверенным в том,
что вся строка считана полностью, а не лишь несколь-
ко ее первых байтов:
int ReadFile(char *Filename,
char ***Array,
int «NumRows)
<
char Buffer[DEFAULTLINELEN] = {0};
char «NewLine = NULL;
FILE *fp;
int Error = 0;
int Row « 0;
sizet NumBlocks;
«NumRows e 0;
«Array = AllocStrArray(LINESPERALLOC,
DEFAULTLINELEN);
if(NULL != «Array)
fp = fopen (Filename, "г");
if(fp 1= NULL)
{
«NumRows = LINES_PER_ALLOC;
NumBlocks = 1;
220
Организация данных
Часть II
/* Число байтов, которое считывает функция fgets(), не больше, чем размер буфера,
включая завершающий нуль (zero terminator) и символ новой строки, если он присутствует среди
этих байтов. Поэтому мохет потребоваться считывать более длинные строки. Для этого будем
вызывать функцию fgetsf) снова и снова - до тех пор, сока не встретим символ новой строки.
*/
while(0 == Error &&
NULL != fgetsfBuffer, sizeof Buffer, fp))
{
NewLine = strchr(Buffer, r\n');
if(NewLine NULL)
{
♦NewLine = ' \0';
}
/* Эта функция strcat использует функцию AllocStrArray(), инициализирующую строки
"пустыми строками".
*/
strcat((*Array)[Row], Buffer);
if (NewLine != NULL)
{
/* Присутствовал символ новой строки, так что следующая строка является новой.
*/
NumBlocks - 1;
++Row;
if(Row >= *NumRows)
{
/* Добавить другие строки LINESPER ALLOC. Если это не срабатывает, прекратить.
*/
if(0 AddRowsToStrArray(Array,
♦NumRows,
LINESPERALLOC,
DEFAULTLINELEN))
{
Error « ERR ROWS NOT ADDED;
}
else
{
♦NumRows += LINESPERALLOC;
}
}
}
else
{
++NumBlocks;
/♦ Создать на этой строке место для дополнительных данных. ♦/
if(0 ==
ResizeOneString(*Array,
Row,
NumBlocks * DEFAULTLINE LEN))
{
Error = ERRSTRINGNOTRESIZED;
}
}
}
fclose(fp);
if (0 =*= Error && «NumRows > Row)
{
i f(0 «« AddRowsToStrArray(Array,
♦NumRows,
Row - *NumRows,
0))
{
Error = ERRALLOCFAILED;
}
♦NumRows = Row;
Простые абстрактные структуры данных
Глава 11
221
}
else
{
Error = ERR_FILE_OPEN_FAILED; /* Невозможно открыть файл */
}
}
else
{
Error = ERRALLOCFAILED; /* Невозможно выделить память */
}
if(Error != 0)
{
/* Если первоначальное выделение памяти закончилось аварийно, указатель *Аггау будет иметь
значение NULL. Функция FreeStrArray() соответствующим образом обрабатывает эту возможную
ситуацию.
*/
FreestrArray(*Array r *NumRows);
♦NuinRows = 0;
}
else
<
ConsolidateStrArray(*Arrayr *NumRows);
return Error;
Обратите внимание, что каждый раз, когда нам не
хватает места, мы за один раз выделяем память нс для
одной строки, а для блоков новых строк. Таким образом
мы пытаемся уменьшить число вызовов функции
realloc(). Выделение памяти может быть дорогостоящей
операцией, так что выделение памяти блоками позво-
ляет повысить скорость работы данной программы. К
сожалению, этого нельзя гарантировать во всех реали-
зациях, так как они отличаются друг от друга; но это
разумное эмпирическое правило.
Теперь требуется только связать все это вместе с
помощью ведущей функции main(), чтобы проиллюст-
рировать, как эта программа может применяться на
практике. Рассмотрим пример с очень простым прило-
жением, которое записывает каждую строку файла в
стандартный поток вывода в обратном порядке. Для
краткости я опустил заголовки. В полном виде код мож-
но найти на Web-сайте издательства ’ДиаСофт”:
int main(int argc, char **argv)
{
char **array = NULL;
int rows;
int thisrow;
int error;
if(argc > 1)
{
error ~ ReadFile(argv[l], (array, (rows);
switch(error)
{
case 0:
for(thisrow = rows - 1; thisrow >= 0; thisrow—)
{
printf("%s\n", array[thisrow]);
}
FreeStrArray(array, rows);
break;
case ERRSTRINGNOTRESIZED:
222
Организация данных
Часть II
case ERRALLOCFAILED:
case ERR_ROWS_KOT_ADDED:
puts("Insufficient memory.");
break;
case ERR_FILE_OPEN_FAILED:
printf("Couldn't open %s for reading\n"r argvfl]);
break;
default:
printf("Unknown error1 Code %d.\n", error);
break;
}
}
else
puts("Please specify the text file name.");
}
return 0;
Обратите внимание, что функция выделения памя-
ти для массива строк вызывается через функцию
ReadFile(), а функция FreeStrArrayO — непосредствен-
но из функции main(). Хорошая ли это идея? Многие
программисты думают, что было бы лучше написать
функцию такого же уровня, что и функция ReadFile(),
которая отвечала бы за освобождение памяти, выделен-
ной через функцию ReadFile(). Это проектное решение
требует серьезного рассмотрения, а я не чувствую себя
достаточно сильным в этом вопросе, поэтому воздер-
жусь от рекомендаций.
N-мерный массив переменного размера
Заканчивая рассматривать двумерные массивы и пере-
ходя к N-мерным, первым делом отметим, что N-мер-
ные массивы представляют собой простое расширение
двумерных массивов с дополнительными уровнями кос-
венной адресации, каждый из которых требует отдель-
ного массива указателей. Чтобы кратко проиллюстри-
ровать это, напишем простую функцию, выделяющую
память для пятимерного массива типа Т (листинг 11.6).
Поскольку в примере для двумерного массива уже было
показано, как осуществлять полную проверку ошибок,
повторять здесь этот код не будем. Конечно, производ-
ственная библиотечная программа должна включать
этот код.
Вас может неприятно поразить то, каким неизящным
является данный код программы. Вы думаете, что ре-
курсивная функция была бы намного элегантнее? Вов-
се нет. Проблема заключается вот в чем: какой тип ука-
зателя следовало бы использовать в рекурсивной
функции? Стандарт ANSI не гарантирует, что для лю-
бого Т sizeof(T *) == sizeof(T **).
Если бы это было большой проблемой, мы бы на-
шли какое-нибудь решение. Но это вовсе не такая уж
значительная проблема, поскольку на практике редко
требуется применять многомерные массивы (фактичес-
ки их применяют намного чаше, чем следовало бы).
Если вы обнаружите, что используете многомерные
массивы лишь по привычке, то пересмотрите проект
вашей программы.
Массивы указателей
Конечно, при условии соблюдения всех ограничений,
накладываемых конкретной реализацией языка, масси-
вы можно использовать для хранения любых объектов,
включая объекты любых размеров. Однако иногда лучше
хранить не сами объекты, а указатели на эти объекты.
Сохраняя в массивах указатели вместо объектов, мы
приобретаем ряд преимуществ. Во-первых, если для
хранения объектов требуется память не в виде единой
области, то вероятность получить запрашиваемую па-
мять возрастает. Во-вторых, легче изменять порядок
расположения объектов. Если, например, требуется сор-
тировать массив, можно гораздо более эффективно менять
местами указатели на объекты, чем сами объекты; можно
также намного быстрее разделить массив на две или
более части, просто копируя указатели, а не объекты.
Однако эти преимущества будут только в том слу-
чае, если объекты имеют намного большие размеры, чем
указатели. Нет никакой особой пользы от массива типа
int *, каждый элемент которого указывает на один эле-
мент данных типа int Как мы увидим, это условие спра-
ведливо и для структур данных других видов.
Массивы указателей на функции
Одна из самых полезных целей применения массивов
заключается в том, чтобы хранить в них указатели на
функции. Бьярн Строуструп (Bjarn Stroustrup), созда-
тель языка C++, пишет, что "массив указателей на фун-
Простые абстрактные структуры данных
Глава 11
223
Листинг 11.6. Пятимерный массив.
linclude <stdlib.h>
typedef int T;
T *****Alloc5DArrayOfT(size_t mr
size__t n,
sizet p,
sizet q,
size_t r)
{
T *****Аггау = NOLL;
int Success - 1;
size_t a, br cr d;
Array =
malioc(m * sizeof *Array);
for(a == 0; a < m; a++)
{
Array[a] =
malioc(n * sizeof *Array[0]);
for(b = 0; b < n; b++)
{
Array[a][bl =
malioc(p * sizeof *Array[0][0]);
for(c = 0; c < p; c++)
{
Arrayfa][b][c] =
malioc(q * sizeof *Array[0)[0][0]);
for(d = 0; d < q; d++)
{
Array[a][bl[cj[d] =
malioc(r * sizeof *Array[0][0][0](0]);
}
}
}
}
return Array;
кции бывает полезным очень часто. Например, систе-
ма меню для моей программы-редактора, в основе ра-
боты которой лежит использование мыши, реализова-
на с помощью массивов указателей на функции,
представляющие различные операции”. И хотя реали-
зация этой идеи может оказаться весьма сложной, сама
идея является очень простой. Каждая операция реали-
зуется с помощью одной функции (или, если более точ-
но, с помощью одной интерфейсной функции, которая
сама вызывает другие функции для выполнения ими
своих задач). И каждое меню в программе-редакторе
представлено массивом указателей на эти функции.
Эта методика могла бы также использоваться для
создания цикла, в котором осуществляется обращение
к ряду функций. Это может показаться бессмысленным
(почему бы нс развернуть цикл и не вызывать функции
явно?), но если учесть, что внутри цикла мы могли бы
менять функции, на которые указывают указатели, то
станет очевидно, что это действительно мощный меха-
низм.
Возможности здесь безграничны. Однако мы проил-
люстрируем эту методику на примере очень простого и
распространенного применения массива указателей на
функции в качестве конечного автомата. Не будем здесь
вдаваться в излишние подробности, так как конечные
автоматы рассматриваются в другой главе этой книги.
Обычно конечные автоматы являются детерминистичес-
кими, но здесь у нас конечный автомат с небольшим
отличием: это автомат с произвольным перемещением.
Как показано в листинге 11.7, в программе имеется пять
состояний — вверх, вниз, вправо, влево и стоп. При вы-
полнении каждого действия последующее состояние
определяется случайным образом.
Листинг 11.7. Применение массива указателей на
функции.
linclude <stdio.h>
linclude <time.h>
linclude <stdlib.h>
int Random( int i)
224
Организация данных
Часть II
double d;
d = rand() / ((double )RAND_MAX + 1.0);
d *= i;
return (int)d;
}
int go leftfint *xr int *y)
{
—*x;
printf("Going left!\n");
return Random(5);
}
int gorightfint *x, int *y)
++*x;
printf("Going right!\n");
return Random(5);
)
int go_down(int *x, int *y)
{
—*y;
printf("Going down!\n");
return Random(5);
}
int go_up(int *x, int *y)
++*y;
printf("Going up!\n");
return Random(5);
}
int stop(int *xr int *y)
{
printf("End of the road: (%d, %d)\n"f *xr *y);
return -1;
}
int main(void)
{
int paction[ ]) (int *, int *) =
{
go_leftr go_right, go_down, go_up, stop
};
int state = 0;
int x = 0;
int у = 0;
srandf(unsigned)time(NULL));
do
{
printf("Currently at (%d, %d)\n"r xf y);
state = (*action[state])(&xr &y);
} while(state ! = -1);
return 0;
Наше объявление массива указателей на функции
является относительно простым, поэтому воздержимся
от определения каких-либо новых типов. Однако, если
требуется указывать на функции более сложных типов
(например, они сами принимают указатели на функции
в качестве аргументов), то синтаксис может стать опре-
деленно пугающим. В этих ситуациях следовало бы
использовать спецификатор typedef, чтобы упростить
код посредством промежуточных типов.
При компиляции этой программы я получаю четы-
ре сообщения об ошибках; все они предупреждают о
неиспользуемых переменных. Это цена, которую при-
ходится платить за сохранность типов. Все объекты в
массиве должны быть одного и того же типа. Посколь-
ку требовалось создать прототипы полностью для всех
функций, пришлось сделать так, чтобы все функции
имели один и тот же тип. Фактически каждой функции
(за исключением stop()), требуется только одно целое
число. Но первым двум требуется, чтобы это было х, а
двум другим — чтобы это было у. Функции stop() тре-
буются оба эти числа
Проблема различающихся списков аргументов обыч-
но возникает в подобных ситуациях, когда требуется
трактовать функции одинаковым образом.
Одно из возможных решений, как уже было сказа-
но, — добавить дополнительные аргументы так, чтобы
все функции были одного типа. Другой способ заклю-
чается в том, чтобы отказаться от сохранности типов и
объявлять все функции как имеющие тип int(), т.е. как
функции с неопределенным списком параметров, воз-
вращающие значение типа int. Это не позволяет компи-
лятору осуществлять проверку по прототипу и означа-
ет, что массив можно использовать для указания на
другие виды функций. Однако при этом устраняется
важное средство безопасности, — так что следует хоро-
шо подумать, прежде чем приступать к выполнению тех
или иных действий.
Еще одно решение состоит в использовании записи
с пропуском, допускающей после первого аргумента
столько аргументов, сколько требуется. Оно не намного
лучше, чем объявление функций в качестве имеющих тип
int(), поскольку опять-таки компилятор не имеет возмож-
ности проверять заданные функции по прототипу.
Наконец, можно было бы просто передавать всем
необходимым функциям указатель на некоторую струк-
туру (скрытую под обозначением void *) и внутри каж-
дой функции приводить его к указателю на структуру
соответствующего типа. Однако это противоречит духу
(но не букве) проверки по прототипу. Вопрос сохран-
ности типов в целом заключается в том, чтобы не по-
зволять передавать (в функцию), скажем, параметр типа
int и трактовать его по ошибке как тип double. А такое
бесцеремонное использование типа void * нарушает
правила безопасности. (Можно было бы уменьшить
риск, всегда добавляя к структуре тег типа (type tag).
Более подробно об этом будет рассказано дальше.)
Ни одно из этих решений не является по-настояще-
му удовлетворительным. Если только нам не повезет
особенно крупно и не потребуется указывать в массиве
только на функции, которые действительно будут иметь
один и тот же тип, обязательно придется искать комп-
ромисс в вопросе сохранности типов и, следовательно,
особо тщательно проверять свой код.
225
Массивы разнородных объектов
Требование, чтобы все элементы массива имели один и
тот же тип, может показаться слишком ограничиваю-
щим. Было бы очень хорошо, если бы можно было хра-
нить в одном массиве объекты разных видов, не правда
ли? Если бы можно было трактовать группу родствен-
ных, но разных объектов как единое целое, сохраняя в
то же время способность работать с ними индивидуаль-
но в соотвествии с их типами, то такая возможность
обеспечила бы огромную гибкость.
Реализовать это вполне возможно, причем относи-
тельно легко. При этом мы неизбежно рискуем сохран-
ностью типов, но можно в какой-то степени уменьшить
этот риск, применяя теги типов. Сначала объявляется
структура с тегом типа и указатель на этот объект. При
необходимости можно также сохранить в этой структуре
указатель на функцию, что позволит вкусить все пре-
лести инкапсуляции (листинг 11.8).
Листинг 11.8. Массив объектов.
typedef struct HETEROBJECT
{
int tag;
void *obj;
int (*func)();
} HETEROBJECT;
Простые абстрактные структуры данных
Глава 11
Сразу же видно, что для маленьких объектов наклад-
ные расходы весьма значительны. Вряд ли было бы це-
лесообразным такое решение, если бы большинство
объектов были очень маленькими.
Обратите также внимание на то, что, поскольку мы
отказались от проверки типов в инкапсулированной
функции, большинство хороших компиляторов выдаст
при компиляции предупреждающие сообщения. К этим
сообщениям нельзя относиться пренебрежительно. Как
указывалось в предыдущих разделах, есть способы, по-
зволяющие от них избавиться, но эти уловки устраня-
ют только предупреждающие сообщения, а не саму
проблему. Это похоже на попытку погасить пожар,
выключая пожарную сирену. Так что будем обращать
внимание на предупреждающие сообщения, убеждать-
ся, что опасность, о которой они предупреждают, на
этот раз отсутствует и осторожно продвигаться дальше.
Чтобы гарантировать, что мы не получим повторя-
ющиеся типы, будем-использовать для тегов перечис-
ляемый тип. INVALID_TAG — это первый тег перечис-
ляемого типа, и по умолчанию ему присваивается
значение 0. В результате такое объявление
HETEROBJECT Bag [6] = {0} отмечает каждый эле-
мент массива как недействительный (на данный мо-
мент). Конечно, вскоре после этого объявления мы при-
своим тегу соответствующее значение.
Кроме того, чтобы упростить инициализацию мас-
сива, создадим небольшую вспомогательную функцию:
епшп
<
INVALID_TAG,
FOOTAG,
BARTAG,
BAZTAG
} TAG;
typedef struct FOO
{
char data;
char foo[80];
} FOO;
typedef struct BAR
<
char bar[80];
long data;
} BAR;
typedef struct BAZ
<
double data_a;
char baz(80];
double data_b;
> BAZ;
Void BagInsert(BETEROBJECT *bag,
size_t Item,
int Tag,
void «Address,
int («Function) ())
15 Зак. 265
Организация данных
Часть II
226
{
bag[Item].tag - Tag;
bag[Item].obj = Address;
bag[Item]•func - Function;
}
int DoFoo(FOO *foo)
{
printf("%s [%c]\n", foo->foo, foo->data);
return 0;
}
int DoBar(BAR *bar)
{
printf("%s [%ld]\n", bar->barf bar->data);
return 0;
}
int DoBaz(BAZ *baz)
{
printf("%s [%f, %f]\n", baz->baz, baz->data_a, baz->data_b);
return 0;
}
int main(void)
{
FOO fa = {'a', "I'm the first foo"}; FOO fb = {'b', "I'm the second foo"}; BAR ba = {"I'm the first bar", 6 }; BAR bb « {"I'm the second bar", 42 };
BAZ za = { 1.414, BAZ zb = { 2.718, BETEROBJECT Bag[6] "I'm the first baz", 1.618 }; "I'm the second baz", 3.141 } » {0};
int i; Baginsert(Bag, 0, BARTAG, &bb, DoBar);
Baginsert(Bag, I, BAZ TAG, &za, DoBaz);
Baginsert(Bag, 2, BAR TAG, &ba, DoBar);
Baginsert(Bag, 3, FOOTAG, &fb, DoFoo);
Baginsert(Bag, 4, BAZ TAG, &zb, DoBaz);
Baginsert(Bag, 5, FOO-TAG, &fa, DoFoo);
for(i = 0; i < sizeof Bag / sizeof Bag[0]; i++)
{
(*Bag[i].func)(Bag[i].obj);
}
return 0;
Можно было бы применить более формальный под-
ход и предоставить вам полную библиотеку, но здесь
мало что можно стандартизировать. Нельзя гарантиро-
вать, что возвращаемый указатель на функцию типа int
подойдет для ваших целей. Возможно, вы предпочли бы
совсем не применять указатели на функции (оператор
выбора внутри главного цикла for с успехом заменил бы
их в этом несколько искусственном примере). И кроме
вспомогательной функции Baglnsert(), которая вам,
может быть, подойдет, а может быть, и нет, другой ре-
альной потребности в библиотеке функций нет; синтак-
сис простого массива будет в самый раз.
Здесь мы видели, как можно использовать теги для
хранения в одном и том же массиве различных видов
данных. Эта же самая методика будет использоваться в
кодах программ, представленных в оставшейся части
настоящей главы. Однако теперь, когда вы знаете, как
применять теги, больше не будем приводить примеры
их использования. При необходимости код программы
обрабатывает их соответствующим образом. Если в
структуре данных вы всегда используете объекты одного
конкретного вида, не беспокойтесь о теге; чтобы удов
летворить компилятор, просто передайте в качестве зна
чения тега, скажем, нуль.
Простые абстрактные структуры данных
Глава 11
227
Конечно, эти теги не обеспечивают такую сохран-
ность типов, как, например, шаблон языка C++. Ни
один компилятор не сообщит, что вы использовали в
структуре данных неправильный тег. (С другой стороны,
шаблоны языка C++ для каждого отдельного типа
(объекта) создают новый комплект объектного кода, и
некоторые считают это неэкономным.) В настоящей
главе будем твердо придерживаться указателей на неиз-
вестные типы (объектов), а ответственность за правиль-
ность использования типов возложим на плечи пользо-
вателя-программиста. Так, вообще-то, и должно быть.
Одни думают, что вопрос сохранности типов является
решающим, другие полагают, что это смирительная
рубашка, а третьи считают, что сохранность типов дол-
жна быть своего рода дорожным указателем, а не тю-
ремной камерой. Хорошая библиотека обслужила бы
запросы всех этих видов пользователей-программистов.
Я большой поклонник спецификатора typedef. Мно-
гие С-программисты думают, что спецификатор typedef—
это ненужная вещь, которая только затемняет инфор-
мацию, требуемую программисту для нормального вы-
полнения работы.. Согласны ли вы с этой точкой зре-
ния — зависит от того, как вы понимаете задачу
программирования.
Рассматривать язык С как своего рода переносимый
язык ассемблера вовсе не бессмысленно — вы загружа-
ете числа в память, выбираете их во время выполнения
вычислений и затем выгружаете из памяти результат.
Язык С является языком достаточно низкого уровня и
способствует такому виду программирования.
С другой стороны, одинаково правомочно считать,
что любая новая проблема может через некоторое вре-
мя снова где-нибудь возникнуть, и на этот случай сле-
дует подготовить план. Поэтому попытаемся сделать
свой код повторно используемым. Подобным образом
поступают все С-программисты, даже если такая зада-
ча заключается только в том, чтобы найти старую про-
1рамму, взять из нее необходимый исходный код и вста-
вить его в новую программу. Конечно, они будут его
дорабатывать, чтобы слегка изменить требуемым обра-
зом, и в конце концов получат несколько десятков не-
много отличающихся версий одного и того же кода!
Оказывается, что код легче использовать повторно,
если он написан таким образом, что скрывает основные
детали подзадачи, решаемой данной программой. Ког-
да я пишу программу-клиент TCP/IP, для меня неваж-
но, является ли объект типа SOCKET сложной струк-
турой или объектом типа int (как оно и есть в
действительности). В это время меня интересует толь-
ко следующее: объявить объект, правильно его иници-
ализировать и передать в соответствующие функции.
Такая абстракция данных тесно связана с функциональ-
ной абстракцией, которая обеспечивается в стандартной
библиотеке языка С. Я не говорю, что мы должны быть
слепыми в отношении того, что происходит внутри
библиотек. Но не нужно фокусировать внимание на
том, как они работают, каждый раз при их использова-
нии. Чем чище интерфейс, тем лучше. Ключевое слово
typedef помогает хранить низкоуровневые детали интер-
фейса библиотеки в таком месте, откуда их можно при
необходимости извлечь, но в месте, которое можно и
проигнорировать.
Конечно, с этой идеей можно зайти слишком дале-
ко и, в конце концов, прийти к языку C++. Тем не
менее, разумный уровень абстракции может помочь
сконцентрироваться на важном, поверить в то, что наши
библиотеки работают правильно и заняться собственно
своей работой — писать приложения, в которых исполь-
зуются эти библиотеки.
В оставшейся части этой главы будут рассматривать-
ся классические структуры данных. Чтобы сделать зна-
чение каждой структуры данных и правила ее исполь-
зования кристально ясными, спецификатор typedef
использовался всего лишь в нескольких случаях.
Односвязные списки
Односвязный список — это способ соединения объек-
тов таким образом, когда каждый объект указывает на
следующий объект в этом списке. Порядок расположе-
ния объектов зависит от приложения, и обычно это
просто порядок, в котором программа встречает данные.
Списки особенно полезны тогда, когда порядок элемен-
тов в них не играет роли. Если требуется упорядочить
список по некоторому ключу так, чтобы можно было
осуществлять в нем поиск отдельного элемента, то луч-
ше использовать более упорядоченную структуру дан-
ных, такую как динамически распределяемая область
памяти (рассматривается далее в настоящей главе) или
дерево (см. главу 12).
Списки особенно полезны в тех случаях, когда дан-
ные в памяти необходимо запоминать сразу же, а мы
заранее не знаем, сколько данных можем получить, или
когда требуется переставлять данные произвольным
образом.
Можно просто реализовать односвязный список,
используя массив, как показано в листинге 11.9.
Этот список связан таким образом, что, если пере-
числять книги в порядке списка, то они будут распола-
гаться в алфавитном порядке их авторов. (Это произ-
вольное решение, цель которого — проиллюстрировать
упорядочение списка. На практике простые списки, как
правило, не годятся для сортировки данных, поступа-
ющих в произвольном порядке. Для этой цели лучше
подходят двоичные деревья.)
228
Организация данных
Часть II
Листинг 119. Односвязный список на основе массива,
linclude <stdio.h>
typedef struct ITEM
{
char Title[30];
char Author[30];
int Next;
} ITEM;
int main(void)
{
ITEM List[] =
{
{"UNIX Unleashed", "Burk and Borvath", 2},
{"Algorithms in C", "Sedgewick", 9},
{"Builder Unleashed", "Calvert", 10},
{••C++ Unleashed", "Liberty", 12},
{"Linux Unleashed", "Busain and Parker", 8},
{"Teach Yourself BCB", "Reisdorph", 1},
{"Data Structures & Algorithms", "Lafore", 3},
{"DOS Programmers Reference", "Dettmann & Johnson", 11},
{"C Programming Language", "Kernighan & Ritchie", 6},
{"C++ Programming Language", "Stroustrup", 13},
{"C: Bow to Program", "Deitel & Deitel", 7},
{"C : A Reference Manual", "Barbison & Steele", 15},
{"The Standard C Library", "Plauger", 5},
{"C Programming FAQs", "Summit", 14.},
{"Expert C Programming", "van der Linden", -1},
{"C Unleashed", "Beathfield & Kirby", 4}
int Current = 0;
while(Current != -1)
{
printf("Read %s, by %s.\n".
List[Current].Title,
List[Current].Author);
Current - List[Current].Next;
return 0;
Ключ к пониманию связанного списка находится в
строке, где переменной Current присваивается новое
значение, которым является индекс следующего элемен-
та списка. Чтобы закончить список, требуется некое
"сигнальное" значение; в данном случае выбрано -1, но
это может быть любое значение, недопустимое в каче-
стве значения индекса. (Если последний элемент спис-
ка содержит индекс первого элемента, то мы имеем
циклический список. Более подробно об этом будет
рассказано далее.)
Хотя можно, как выяснилось, реализовать связанные
списки с помощью массивов, это немного необычный
способ. Если массив заполняется полностью, то при
поступлении новых элементов необходимо перераспре-
делить для массива (оперативную) память. Если нам
требуется добавить новый элемент в начало списка,
нужно либо передвинуть все элементы на одну позицию
вперед, чтобы освободить место, либо ввести новую
переменную, указывающую какой элемент находится в
начале списка.
Кроме того, в определение данных была встроена
информация о том, что они являются частью списка.
Действительно ли нужно делать это? Разве нельзя иметь
список элементов, которые не содержат такую инфор-
мацию? Это было бы очень полезно при наличии оп-
ределенных ранее и не содержащих такой информации
структур (данных), которые теперь необходимо сохра-
нить в списке. Например, разве нельзя иметь список
объектов типа struct tm?
Простые абстрактные структуры данных
Глава 11
229
Ответ на последний вопрос уже известен. При рас-
смотрении массивов можно было убедиться в том, на-
сколько легко встроить в структуру указатель, который
может указывать на любой объект. В результате можно
разделить понятие списка и понятие данных приложе-
ния и рассматривать их по отдельности. Тогда становит-
ся возможным и даже желательным написать комплект
библиотечных (под)программ для управления связан-
ным списком, состоящим из... ничего!
Ответ на первый вопрос очень прост. Хотя структу-
ра данных не может содержать экземпляр самой себя
(чем бы это все закончилось?), она может содержать
указатель на экземпляр самой себя. Если используется
этот указатель, чтобы указывать на следующий элемент
в списке, можно быстро и просто создавать списки, а
также добавлять новые элементы в любое место спис-
ка, в том числе и в начало. Потребуется “сигнальное”
значение для обозначения конца списка, и значение
NULL подходит для этой цели превосходно. Рис. 11.2
поможет вам представить все это более отчетливо.
Указатель ВШИТ на односвязный список,
принадлежащий приложению
NULL
РИСУНОК 11.2. Односвязный список с тремя элементами.
Отделение самого списка от элементов (данных),
находящихся в этом списке, имеет еще одно важное
преимущество. Когда требуется сохранить список на
диске или другом внешнем носителе, можно сохранять
только данные без информации о самом списке. Если
бы информация о структуре списка была встроена в
структуру данных приложения, пришлось бы осторож-
но прокладывать путь через эту структуру, сохраняя на
диске только выбранные элементы и опуская указате-
ли списка. Конечно, можно было бы также записать и
информацию о списке, но это потребовало бы излиш-
него расхода внешней памяти. К тому же пришлось бы
быть весьма осторожным при считывании информации
с внешнего запоминающего устройства назад в оператив-
ную память, так как мы бы считывали указатели, содер-
жащие неверную информацию, которую пришлось бы
аккуратно исправлять. Не следует делать жизнь такой
запутанной.
Чтобы придать списку, насколько это возможно,
общий характер, не будем полагать, что в списке хра-
нятся объекты одного и того же типа. Поэтому будем
применять поле тега. Кроме того, может быть полезно
сохранять в структуре размер элемента, на который
указывает указатель. (Эта информация может потребо-
ваться приложению, а может и нет. Но пусть список
будет более гибким.) Полный исходный код для лис-
тинга 11.10 можно найти на нашем CD-ROM в файлах
sllist.h и sllist.c; тестовый драйвер хранится в файле
sllistmn.c.
Прежде всего требуется подходящая структура дан-
ных.
Листинг 11.10. Простая библиотека односвязного
списка.
typedef struct SLLIST
{
int Tag;
struct SLLIST *Next;
void *Object;
size_t Size;
} SLLIST;
Здесь мы имеем указатель на следующий элемент
списка, указатель на сами данные, поле тега и размер
(которые не используются в самом коде связанного
списка; они там присутствуют только для удобства
пользователя-программиста).
Добавление элементов
Новый элемент можно поместить в начале, в конце или
где-нибудь в середине списка Начнем с функции, до-
бавляющей элемент где-то в середину списка; две дру-
гие функции являются фактически частными случаями
данной функции. При первом добавлении осуществля-
ется определение списка. Чтобы начать список, просто
определяем указатель на SLLIST, присваиваем ему зна-
чение NULL и передаем его в одну из функций Add.
Чего не нужно делать в вызывающем коде — так это
объявлять экземпляр структуры SLLIST; нам просто
требуется указатель. Функции Add сами получают не-
обходимую память, а функции удаления полагаются на
свою способность освобождать память, занимаемую
элементом. Если они делают это по отношению к эк-
земпляру SLLIST, для которого не была выделена па-
мять посредством функции malioc (или realloc, или
calloc), то результат не определен. Вот краткое напоми-
230
Организация данных
Часть II
нание — если освобождается память, не выделенная
ранее одним из этих способов, то во время выполнения
реализация имеет полную свободу действий, включая,
а не исключая, освобождение львов из клеток в зоопар-
ке через дорогу. Это может привести к путанице, пре-
дотвратить которую способна только работа над кодом
программы.
При втором добавлении начинаем построение спис-
ка. Каждый элемент списка указывает на следующий
элемент, а указатель последнего элемента имеет значе-
ние NULL.
int SLAdd (SLLIST **Item,
int Tag,
void *Object,
sizet Size)
{
SLLIST *NewItem;
int Result = SLSUCCESS;
assert(Item != NULL);
if(Size > 0)
{
Newltem = malloc(sizeof *NewItem);
if(Newltem NULL)
{
NewItem->Tag = Tag;
NewItem->Size = Size;
NewItem->Object « malloc(Size);
if(NewItem->Object != NULL)
{
memcpy(NewItem->Object, Object,
Size);
/* Обработать пустой список */
if(NULL == *Item)
{
Newltem->Next = NULL;
♦Item = Newltem;
}
else /* Вставить сразу после
текучего элемента */
{
NewItem->Next = (*Item)->Next;
(*Item)->Next = Newltem;
}
}
else
{
free(Newltem);
Result « SLNOMEM;
}
}
else
{
Result = SLNOJIEM;
}
}
else
{
Result = SLZEROSIZE;
}
return Result;
}
Если для сохранения этого объекта недостаточно
памяти, завершаем работу безопасным способом, осво-
бождая память, которую выделили для структуры
SLLIST, так что для нового элемента память совсем не
выделяется. Такие обслуживающие действия обязатель-
ны, однако они имеет тенденцию значительно увеличи-
вать размеры кода по сравнению с простой реализаци-
ей. Наградой за это будет возможность использовать
этот код со значительной долей уверенности, что он
выдержит работу в самых разных приложениях.
Данная функция вставляет элемент в список после
того элемента, адрес которого ей передается. Хотелось
бы также иметь возможность вставлять новый элемент
перед тем элементом, адрес которого передается в фун-
кцию. Эту задачу выполняет следующая функция. Од-
нако для односвязных списков это сопряжено с опре-
деленными трудностями. Можно сделать это только в
начале списка, так как невозможно добраться до преды-
дущего элемента, чтобы изменить его указатель Next.
Фактически мы даже не знаем, действительно ли пользо-
ватель-программист предоставил первый элемент спис-
ка! Мы должны этому верить. Не знаю как вам, но мне
не по душе доверять своим пользователям-программи-
стам, пусть даже они прекрасные люди и, несомненно,
точно знают, что делают (большей частью). Я бы пред-
почел быть абсолютно уверенным в том, что мой код
будет работать безотказно. При всем сказанном мы до-
веряем пользователям-программистам каждый раз, когда
пишем библиотечную функцию, принимающую указа-
тель на данные типа char *. Можно проверить его на
значение NULL, но нельзя, например, гарантировать,
что указатель инициализирован или что для работы
функции выделено достаточно памяти.
int SLFront(SLLIST **Item,
int Tag,
void *Object,
size_t Size)
{
int Result = SL_SUCCESS;
SLLIST *p = NULL;
assertfltem 2- NULL);
Result = SLAdd(&p, Tag, Object, Size);
if(SLSUCCESS == Result)
{
p->Next = *Item;
♦Item = p;
}
return Result;
}
231
Отметим тот приятный факт, что, несмотря на все
связанные с этой функцией проблемы, она короткая,
так как удалось повторно использовать код функции
SLAdd().
Если пользователь-программист дает нам адрес эле-
мента, находящегося внутри списка, то в результате мы
получим расщепленный список. У этого списка будет
два начала, один из которых — только что добавленный
элемент. Какой бы заманчиво новаторской ни казалась
эта идея расщепленного списка, она полна опасностей
и лучше о ней не вспоминать.
При работе с двусвязными списками эта проблема
исчезает (более подробно об этом речь пойдет далее),
так как по своей природе они позволяют перемещаться
по списку в обратном направлении.
Добавлять элементы в начало списка выгодно, так
как это выполняется быстро. Однако иногда в прило-
жении может потребоваться поместить новые элемен-
ты в конец списка.
int SLAppend(SLLIST **Item,
int Tag,
void *Object,
size_t Size)
{
int Result = SLSUCCESS;
SLLIST *EndSeeker;
assert(Item != NULL);
if(NULL == *Item)
{
Result = SLAdd(Item, Tag, Object, &ze);
else
{
EndSeeker = *Itern;
while(EndSeeker->Next 1= NULL)
{
EndSeeker = EndSeeker->Next;
}
Result = SLAdd(&EndSeeker, Tag, Object,
^*Size);
}
)
У нас нет другого выбора, кроме как последователь-
но, от элемента к элементу, перемещаться по списку в
поисках последнего элемента (узла), что для длинных
списков делает эту операцию весьма дорогостоящей. Но
если говорить строго, это на самом деле неверно. Вы-
бор есть. Можно создать управляющую структуру, со-
держащую указатели на начало и конец этого списка.
Это позволило бы обеспечить, чтобы функция SLFront()
Не вызывалась ни для каких других элементов, кроме
Первого элемента списка. Однако это немного усложни-
ло бы данную модель, и здесь не будет рассматривать-
ся это направление, особенно потому, что и без того
ясно, как модифицировать предлагаемый код.
Простые абстрактные структуры данных
Глава 11
Обновление элемента списка
Иногда требуется модифицировать данные, хранящие-
ся на определенной позиции. Это легко сделать, ис-
пользуя следующий код:
int SLUpdate (SLLIST *Item,
int NewTag,
void *NewObject,
sizet NewSize)
{
int Result « SLSUCCESS;
void *p;
if(NewSize > 0)
{
p = realloc(Item->Object, NewSize);
if (NULL != p)
{
Itexn->Ob ject = p;
memmove(Item->Object, NewObject,
^NewSize);
Item->Tag = NewTag;
Item->Size = NewSize;
}
else
{
Result = SLNOMEM;
}
}
else
{
Result = SLZEROSIZE;
}
return Result;
}
Как видите, мы позволяем пользователю-программи-
сту предоставлять не только другие данные, но и совер-
шенно иной объект, имеющий новый тег и новый раз-
мер. У пользователя-программиста нет никакой особой
необходимости сохранять в списке объекты только од-
ного типа. Разумно используя теги, можно управлять
большим числом объектов разного вида, находящихся
в одном и том же списке. Это может принести значи-
тельную выгоду в нетривиальных приложениях, где
работа с разнородными элементами выполняется оди-
наково. Возможность заменить объект одного типа
объектом другого типа позволяет повысить уровень гиб-
кости кода.
Отыскание данных
Как пользователь-программист получает доступ к дан-
ным, хранящимся в отдельном элементе списка? Он мог
бы просто разыменовать указатель Object структуры
SLLIST, но было бы лучше, чтобы он этого не делал,
так как в результате его код становится тесно связанным
с нашей конкретной реализацией односвязного списка.
232
Организация данных
Часть II
(Нельзя запретить ему делать это, не усложняя в огром-
ной степени код, и такое решение затруднило бы
пользование библиотекой, от чего пострадали бы
пользователи-программисты, соблюдающие правила.)
Однако, если предоставить простой механизм, обеспе-
чивающий ему доступ к данным более объектно-ориен-
тированным способом, то можно обоснованно ожидать,
что он будет поступать подобающим образом.
void *SLGetData(SLLIST *Itern,
int *Tagr
size_t *Size)
{
void *p - NULL;
if(Item != NULL)
{
if(Tag 1= NULL)
{
♦Tag « Item->Tag;
}
if(Size 1= NULL)
{
♦Size - Item->Size;
1
p - Item->Object;
}
return p;
)
Можно было бы возвратить копию данных, но тог-
да на пользователя-программиста легла бы ответствен-
ность за освобождение занимаемой этой копией памя-
ти, после того как он закончит с ней работать. А мы
стараемся облегчать его работу, а не затруднять. Одна-
ко это означает, что нам придется доверить ему распо-
ряжаться указателем на данные.
Если вы поклонник языка C++, то могли бы в этом
месте принять самодовольный вид. Тогда вспомните,
что скрытность данных в любом объекте C++ может
быть нарушена, если осуществить приведение их к типу
char *.
Удаление элемента
Элемент удаляется из списка достаточно просто в том
случае, если требуется только освободить память. Од-
нако это не все, что нужно сделать. Проблема заключа-
ется в целостности списка. Можно легко удалить эле-
мент, стоящий после того, который нам указан. Но
поскольку у нас нет указателя на предыдущий элемент,
можно удалить тот, что указан, и одновременно обес-
печить, чтобы список остался правильно связанным.
Лучшее, что можно сделать, — это вернуть указатель на
следующий элемент и верить, что пользователь-про-
граммист сам правильно свяжет список. Конечно, такая
ситуация далеко не идеальна. Опять-таки, при работе
с двусвязными списками эта трудность просто исчезает.
SLLIST *SLDeleteThis(SLLIST *Item)
{
SLLIST *NextNode = NULL;
if(Item != NULL)
{
NextNode - Item->Next;
if(Item->Object != NULL)
{
free(Item->Object);
}
free(Item);
}
return NextNode;
}
void SLDeleteNextfSLLIST *Item)
{
if (Item != NULL && Item->Next != NULL)
{
Item->Next = SLDeleteThis(Item->Next);
)
)
Здесь снова можно повторно использовать код, что-
бы свести к минимуму его дублирование.
Уничтожение списка
Необходимо иметь возможность полного уничтожения
списка после окончания работы с ним. Это относитель-
но просто:
void SLDestroy(SLLIST **List)
{
SLLIST *Next;
if(*List != NULL)
{
Next ® *List;
do
{
Next = SLDeleteThis(Next);
} while(Next NULL);
♦List - NULL;
1
)
У меня был соблазн сделать эту функцию рекурсив-
ной. Однако это было бы ошибкой. Если бы список
состоял из нескольких тысяч элементов, то реализации
функции на основе стека вполне могло бы не хватить
ресурсов и она закончилась бы аварийно. Кроме того,
функция с итерационным решением почти наверняка
работает более быстро.
Проход по списку
Последняя функция в библиотеке односвязного списка
дает возможность выполнять некоторые операции сра-
зу над всеми элементами списка. Для этого позаимству-
ем прием, применяемый в стандартных библиотечных
Простые абстрактные структуры данных
|233
Глава 11
функциях qsort и bsearch, частью списка параметров
которых являются указатели на функции. Функции
SLWalk требуется указатель на функцию, принимаю-
щую три параметра: тег. указатель на объект некоторо-
го типа и указатель на структуру, содержащую аргумен-
ты (если аргументы не требуются, этот последний
указатель может иметь значение NULL). Тег позволяет
создать внутри функции какой-нибудь оператор выбо-
ра на тот случай, если потребуется иметь дело с разны-
ми видами объектов. Функция SLWalk просто проходит
последовательно по всем элементам списка, вызывая для
каждого из них эту функцию и передавая в нее тег,
объект и аргументы. В функции SLWalk предполагает-
ся, что в случае успешного выполнения вызванная фун-
кция возвращает 0. Если какой-нибудь вызов этой фун-
кции завершится аварийно (она возвратит ненулевое
значение), функция SLWalk прекратит проход по эле-
ментам списка. Она возвратит результат самого после-
днего вызова (который, если при проходе где-нибудь не
произойдет ошибка, будет результатом вызова для пос-
леднего элемента списка).
int SLWalk(SLLIST *List,
int(*Func)(intr void *, void *),
void *Args)
{
SLLIST *ThisItem;
int Result = 0;
for(ThisItem = List;
0 == Result && This Item != NULL;
ThisItem = ThisItem->Next)
{
Result « (*Func)(ThisItem->Tag,
Thi sItem->Object,
Args);
}
return Result;
)
Вот и все. Теперь у нас есть все необходимое, что-
бы облегчить работу с односвязными списками. Итак,
как пользоваться этой библиотекой? Давайте посмот-
рим, как это делается, на примере программы тестово-
го драйвера.
Тестовый драйвер
Вот короткий пример. Вы увидите, что когда мне тре-
буется выбрать элемент внутри списка, приходится ис-
пользовать временную переменную. Это потому, что я
не решаюсь перемещать указатель к началу списка (про-
блема, которая будет решена далее путем использова-
ния двусвязных списков):
linclude <stdio.h>
linclude <stdlib«h>
linclude <assert.h>
linclude "sllist.h"
typedef struct BOOK
{
char Title[30J;
char Author[30);
} BOOK;
typedef struct FIELDINFO
{
int Titlewidth;
int AuthWidth;
} FIELDINFO;
int PrintBook(int Tag, void *Memoryf void *Args)
{
BOOK *b « Memory;
FIELDINFO *f = Args;
assert(Tag == 0);
printf("Read %*sr by %*s\n"r
f->TitleWidth,
b->Titler
f->AuthWidth r
b->Author);
return 0;
234!
Организация данных
Часть II
int main(void)
BOOK Воок[] =
{
{"Expert С Programming", "van der Linden"},
{"C Programming FAQs", "Summit"},
{"C++ Programming Language", "Stroustrup"},
{"Algorithms in C", "Sedgewick"},
{"Teach Yourself BCB", "Reisdorph"},
{"The Standard C Library", "Plauger"},
{"C++ Unleashed", "Liberty"},
{"Data Structures & Algorithms", "Lafore"},
{"C Programming Language", "Kernighan & Ritchie"},
{"Linux Unleashed", "Busain and Parker"},
{"C Unleashed", "Beathfield & Kirby"},
{"C : A Reference Manual", "Barbison & Steele"},
{"DOS Programmers Reference", "Dettmann & Johnson"},
{"C: Bow to Program", "Deitel & Deitel"},
{"Builder Unleashed", "Calvert"},
{"UNIX Unleashed", "Burk and Borvath"}
};
SLLIST *List = NULL;
SLLIST *Removed = NULL;
BOOK *Data;
FIELD INFO Fidinfo » { 30, 30};
size_t NumBooks = sizeof Book / sizeof Book[0];
size_t i;
/* Заполнить список */
for(i = 0; i < NumBooks; i++)
{
if(SLSUCCESS !=
SLFront(&List, 0, Book + i, sizeof(BOOK)))
{
puts("Couldn't allocate enough memory.");
SLDestroy(&List);
exit(EXITFAILURE);
}
}
/* Распечатать список */
SLWalk(List, PrintBook, &FldInfo);
/* Удалить одни элемент */
Removed - List;
for(i = 0; i < NumBooks / 2; i++)
{
Removed = Removed->Next;
}
Data = SLGetData(Removed->Next, NULL, NULL);
printf("XnRemoving title %s\n\n", Data->Title);
SLDeleteNext(Removed);
/* Распечатать список еце раз, чтобы подтвердить удаление */
SLWalk(List, PrintBook, &FldInfo);
/* Уничтожить список */
SLDestroy(&List);
return 0;
Простые абстрактные структуры данных
Глава 11
235
Применение структуры FIELDJNFO в нашем коде
носит довольно искусственный характер; информация,
которую она содержит, доступна в структуре BOOK.
Все, что требуется сделать, — воспользоваться операто-
ром sizeof Однако с помощью этой структуры иллюст-
рируется механизм применения параметра Args.
Двусвязные списки
Итак, использование односвязных списков сопряжено
с рядом проблем, большая часть которых вызвана тем,
что невозможно возвращаться к началу списка. Все эти
трудности можно решить путем добавления указателей
возврата. При добавлении этих связей в односвязный
список он становится двусвязным.
Двусвязный список отличается от односвязного тем,
что элемент этого списка содержит не только указатель
на следующий элемент, но и указатель на предыдущий
элемент. Это увеличивает накладные расходы, связан-
ные со структурой списка, но они почти всегда окупа-
ются, так как повышают мощь, уровень гибкости и на-
дежность приложения. На рис. 11.3 показано, как
устроен двусвязный список.
Указатель DLUST на двусвязный список, принадлежащий приложению
NULL
РИСУНОК TL3. Двусвязный список из трех элементов
Что касается точности рисунка, то здесь я пошел на
компромисс (в действительности все указатели Prev и
Next должны указывать на базовый адрес структуры, а
не куда-то в ее середину), чтобы более ясно проил-
люстрировать логику списка. Мы можем перемещаться
с помощью указателей вдоль всего списка и при жела-
нии можно вполне законно ссылаться на какой-нибудь
элемент Item в этом списке, используя запись
Item->Next->Prev или даже Item->Next->Prev->
Prev->Prev->Next->Next (Но только при условии, что
все элементы, входящие в это довольно странное выра-
жение, действительно существуют. Если любое из этих
подвыражений принимает значение NULL, код рабо-
тать не будет.)
Ранее было показано, как можно использовать мас-
сивы переменного размера для хранения текстового
файла в оперативной памяти, и тогда было высказано
предположение, что можно было бы использовать этот
вид структуры данных при написании программы тек-
стового редактора. Однако этот подход чреват различ-
ными проблемами. Таким способом можно легко читать
файл, но при попытке отредактировать его сразу же
возникнут трудности. Если, например, пользователь
нажимает на клавишу Return, то он ожидает, что в ре-
дактируемом файле будет начата новая строка. Это оз-
начает, что в массив должна быть вставлена новая стро-
ка — и не в конце (это было бы пустяковой задачей), а
где-то в середине. Поскольку мы имеем массив указа-
телей, все, что необходимо сделать, — создать новую
строку в конце и изменить все указатели на одну пози-
цию посредством функции memmove. Но эта функция
будет вызываться каждый раз, когда пользователь нажи-
мает клавишу Return. Было бы бучше, если бы можно было
вставить новую строку на место, не передвигая все вокруг.
Эта проблема решается с помощью двусвязного списка.
Исходный код для этой библиотеки (листинг 11.11)
находится на Web-сайте издательства "ДиаСофт" в фай-
лах dllist.h и dllist.c.
Создание двусвязного списка
Для создания двусвязного списка требуется только один
элемент. Имея соответствующую структуру данных (ко-
торая, как видите, практически идентична структуре
SLLIST и отличается только одним дополнительным
указателем Prev):
Листинг 11.11. Библиотека двусвязного списка.
typedef struct DLLIST
{
int Tag;
struct DLLIST *Prev;
struct DLLIST «Next;
void *Object;
size_t Size;
} DLLIST;
можно написать простую функцию, которая создает
новый элемент с указателями Prev и Next, имеющими
значение NULL.
DLLIST «DLCreate(int Tag, void «Object, size_t
Size)
{
DLLIST «Newltem;
236
Организация данных
Часть II
Newltem - malloc(sizeof *NewItem);
if(Newltem != NULL)
{
NewItem->Prev = NewItem->Next » NULL;
Newltem->Tag = Tag;
NewItem->Size = Size;
NewItem->Object = malloc(Size);
if(NULL ! = NewItem->Object)
{
memcpy(NewItem->Object, Object, Size);
}
else
{
free(Newltem);
Newltem = NULL;
}
}
return Newltem;
}
Пользователь-программист, если хочет, может выз-
вать эту функцию для создания первого элемента спис-
ка, но это не обязательно. Различные функции Add вы-
зовут ее, когда это будет необходимо.
Прежде чем вплотную заняться (под)программами
вставки для двусвязных списков, рассмотрим несколь-
ко простых навигационных функций, которые впослед-
ствии позволят сэкономить время.
DLLIST *DLGetPrev(DLLIST *List)
{
if(List 1= NULL)
{
List = List->Prev;
}
return List;
}
DLLIST *DLGetNext(DLLIST *List)
{
if(List != NULL)
{
List = List->Next;
}
return List;
}
DLLIST *DLGetFirst(DLLIST *List)
{
if(List 1= NULL)
{
while(List->Prev != NULL)
{
List = DLGetPrev(List);
}
}
return List;
}
DLLIST *DLGetLast(DLLIST *List)
{
if(List != NULL)
{
while(List->Next 1= NULL)
{
List - DLGetNext(List);
}
}
return List;
}
Во многих функциях требуется вставлять некоторый
элемент в список, где этот элемент уже существует.
Например, элемент мог быть только что создан с помо-
щью функции DLCreate(), и теперь нужно вставить его
на соответствующее место. Весь код указателей можно
было бы поместить в каждую функцию, где он требу-
ется. Но имеет смысл выделить его в отдельную функ-
цию. При необходимости пользователь-программист
может вызывать ее непосредственно, но в большинстве
случаев это ему не потребуется. На самом деле у нас
будут две такие функции: одна, чтобы вставлять новый
элемент перед существующим элементом, и другая, что-
бы вставлять его после существующего элемента. По-
скольку эти функции очень похожи, приведем здесь
только одну из них.
int DLInsertBefore (DLLIST *ExistingItem,
DLLIST *NewItem)
{
int Result = DLSUCCESS;
if(Existingltem != NULL && Newltem != NULL)
{
NewItem->Next = Existingltem;
NewItem->Prev = ExistingItem->Prev;
ExistingItem->Prev = Newltem;
if(NewItem->Prev != NULL)
{
NewItem->Prev->Next = Newltem;
}
}
else
{
Result = DLNULLPOINTER;
}
return Result;
}
ПРИМЕЧАНИЕ
Часто требуется выполнять какие-либо действия, неваж-
но какие, либо перед существующим элементом, либо
после него, поэтому у многих функций имеется две раз-
новидности. Их можно было бы объединить, добавив до-
полнительный параметр; существуют аргументы за и про-
тив каждого из этих способов. Здесь выбран способ,
который наиболее ясно отображает суть дела.
В списке имеется четыре разных места, куда можно
добавить новый элемент, — в начало списка, в конец, а
237
также перед данным элементом и после него. Если спи-
сок короткий, некоторые из этих мест могут совпадать,
но, как мы увидим, это не имеет значения.
Вставка элемента в начало списка
Чтобы вставить элемент в начало списка, необходимо
сначала найти начало списка. (Мы могли бы предполо-
жить, что пользователь-программист указывает именно
начало списка, но лучше все-таки быть уверенным, чем
предполагать.) Для этого можно использовать функцию
DLGetFirst().
int DLPrepend(DLLIST **Item,
int Tag,
void *Object,
size t Size)
{
int Result = DLSUCCESS;
DLLIST *p;
DLLIST *Start;
assert(Item != NULL);
p = DLCreate(Tag, Object, Size);
if(p != NULL)
{
if(NULL == *Item)
{
♦Item = p;
}
else
{
Start = DLGetFirst(*Item);
DLInsertBefore(Start, p);
}
}
else
{
Result = DL__NO_MEM;
}
return Result;
}
Вставка элемента в конец списка
Чтобы вставить элемент в конец списка, необходимо
только вызвать функцию DLGetNext(), которая возвра-
щает указатель на последний элемент списка. Код фун-
кции DLAppend(), которая добавляет элемент в конец
списка, очень похож на код функции DLPrepend(), и
его повторение здесь не имеет смысла (он находится на
Web-сайте издательства ’’ДиаСофт").
Вставка элемента внутрь списка
Когда требуется вставить элемент не в начало и не в
Конец списка, а куда-нибудь в другое место, вот тут-то
МЫ и начинаем зарабатывать свой хлеб. В этом случае
Простые абстрактные структуры данных
Глава 11
придется позаботиться о четырех указателях, таких как
указатели Prev и Next нового элемента, указатель Next
предшествующего элемента и указатель Prev последую-
щего элемента. Поскольку большой список можно по-
лучить только начиная с маленького списка, некоторые
из этих элементов могут отсутствовать, поэтому необ-
ходимо быть осторожным со значениями NULL этих
указателей.
После того как будет задан существующий элемент
списка, можно будет вставить новый элемент перед ним
или после него. Допустимо как одно, так и другое, и
трудно выбрать одно из двух, не зная особенностей и
специфики приложения. Поэтому мы реализовали оба
варианта. (Они очень похожи, и здесь показан только
один из них.)
int DLAddAfter(DLLIST **Item,
int Tag,
void *Object,
size t Size)
{
int Result = DLSUCCESS;
DLLIST *p;
assett(Item != NULL);
p - DLCreate(Tag, Object, Size);
if(p != NULL)
{
if(NULL == *Item)
{
♦Item - p;
}
else
{
DLInsertAfter(*Item, p);
}
}
else
{
Result = DLNOMEM;
}
return Result;
}
Обновление и поиск данных
Функции DLUpdate() и DLGetData() обеспечивают та-
кой же самый способ доступа к данным, как и в случае
с односвязными списками. Если не считать, что эти
функции принимают указатель типа DLLIST *, а не
SLLIST *, то можно сказать, что они идентичны фун-
кциям SLUpdate() и SLGetData().
Извлечение элемента из списка
Иногда бывает необходимо убрать элемент из списка,
не удаляя его (т.е. не освобождая его память). Напри-
мер, может потребоваться переслать элемент из одного
238
Организация данных
Часть II
списка в другой. Такую операцию несложно выполнить,
но при этом на пользователя-программиста возлагается
ответственность закончить должным образом эту работу.
DLLIST *DLExtract(DLLIST *Item)
{
if(Item != NULL)
{
if(Item->Prev 1 = NULL)
{
Item->Prev->Next = item->Next;
}
if(Item->Next != NULL)
{
Item->Next->Prev = Item->Prev;
}
}
return Item;
}
Удаление элемента списка
При удалении элемента из односвязного списка возни-
кали проблемы с целостностью списка. С двусвязным
списками такой трудности нет, и для удаления элемента
требуется только одна функция, а не две. Вот она:
void DLDelete(DLLIST *Itern)
{
if(Item != NULL)
{
DLExtract(Item);
if(Item->Object != NULL)
{
free(Item->Object);
}
free(Item);
}
}
Эта функция вызывает, в свою очередь, функцию
DLExtract() для связывания списка перед освобождени-
ем памяти, ранее занимаемой элементом.
Как поменять элементы местами
В некоторых случаях требуется поменять местами не-
которые элементы списка. Например, может понадо-
биться отсортировать список по ключу, зависящему от
данных. Этот обмен относительно прост, за исключе-
нием одного неудобного случая, когда два меняемых
местами элемента являются соседними. Необходимо
обязательно проверить, так ли это. Если да, то самое лег-
кое решение — просто убрать из списка один из них, а
затем снова вставить на соответствующее место.
int DLExchange(DLLIST *ItemA, DLLIST *ItemB)
{
int Result = DLSUCCESS;
DLLIST *t0;
DLLIST *tl;
DLLIST *t2;
DLLIST *t3;
if(ItemA 1= NULL && ItemB 1= NULL)
{
if(ItemA->Next == ItemB)
{
DLExtract(ItemA);
DLInsertAfter(ItemB, ItemA);
}
else if(ItemB->Next == ItemA)
{
DLExtract(ItemB);
DLInsertAfter(ItemA, ItemB);
}
else
{
to = ItemA->Prev;
tl = ItemA->Next;
t2 = ItemB->Prev;
t3 = ItemB->Next;
DLExtract(ItemA);
DLExtract(ItemB);
if(t2 1= NULL)
{
DLInsertAfter(t2, ItemA);
}
else
{
DLlnsertBefore(t3, ItemA);
if(tO 1= NULL)
{
DLInsertAfter(tO, ItemB);
}
else
{
DLInsertBefore(tl, ItemB);
}
}
}
else
{
Result = DL_NULL_POINTER;
}
return Result;
}
Подсчет числа элементов
Как узнать, сколько элементов имеется в списке? Очень
просто (кстати, здесь иллюстрируется, как правильно
применять функции DLGetPrev() и DLGetNext()):
int DLCount(DLLIST *List)
{
int Items = 0;
DLLIST *Prev = List;
DLLIST *Next = List;
Простые абстрактные структуры данных
Глава 11
239
if(List != NULL)
{
++Iterns;
while((Prev = DLGetPrev(Prev)) 1= NULL)
{
++Iterns;
}
while((Next = DLGetNext(Next)) ! = NULL)
++Items;
}
}
return Items;
}
Вырезание и вставка
Возможность разбивать списки на части и затем объе-
динять их снова новыми и интересными способами
была бы очень полезной во многих видах приложений.
Делать это совсем нетрудно, если только у вас есть ос-
новные представления о том, как работать с указателя-
ми. Но здесь затрагиваются вопросы проектирования
программы. Как, например, задать в программе раздел
списка, который требуется вырезать? Какой способ
выбрать? Тот ли, который подразумевает принцип ’’на-
чать здесь и вырезать N элементов”? Или другой, суть
которого заключается в следующем: "вырезать от этого
элемента и до этого"! А может быть, какой-то иной?
Выбор способа зависит от приложения. Например, для
программы моделирования, по-видимому, подойдет
первый способ, тогда как для текстового редактора —
второй. Все эти вопросы ведут к интересным упражне-
ниям, поэтому не будем лишать вас удовольствия само-
стоятельно во всем разобраться. По этой причине я не
включил сюда соответствующий код. Если вам потре-
буется исследовать эту идею более глубоко, используйте
функции DLExtract() и DLInsertAfter().
Вот для начала код, позволяющий вставлять один
список в конец другого. С полным основанием можно
ожидать, что пользователю-программисту потребуется
соединять вместе два списка, и данный интерфейс до-
пускает несколько возможностей. Используя уже напи-
санные ранее функции, получаем простой, радующий
глаз код.
void DLJoin(DLLIST *Left, DLLIST *Right)
<
if (Left ! = NULL && Right ! = NULL)
{
Left = DLGetLast(Left);
Right = DLGetFirst(Right);
Left->Next = Right;
Right->Prev - Left;
>
Уничтожение всего списка
Процесс уничтожения всего списка очень прост, и, что
интересно, для этого не нужен первый элемент списка.
Подойдет любой элемент. Поскольку в списке имеется
двойная связь, можно перемещаться от того места, ко-
торое указано, вперед и назад до тех пор, пока не на-
толкнемся на указатель со значением NULL. С помо-
щью функции DLGetFirst() можно было бы
переместиться в начало списка, но более эффективно
удалить сначала часть списка, расположенную до пере-
данного нам элемента, а затем — после него, особенно
если переданный указатель находится на некотором рас-
стоянии от начала списка.
void DLDestroy(DLLIST **List)
{
DLLIST *Marker;
DLLIST *Prev;
DLLIST *Next;
if(*List »= NULL)
{
/* Сначала уничтожить все предпествуюцие
элементы */
Prev = (*List)->Prev;
while(Prev 1= NULL)
{
Marker = Prev->Prev;
DLDelete(Prev);
Prev = Marker;
}
Next = *List;
do
{
Marker = Next;
DLDelete(Next);
Next = Marker;
} while(Next != NULL);
♦List = NULL;
Проход по списку
Для полноты в библиотеку включена функция
DLWalk(). Но так как она мало чем отличается от фун-
кции SLWalk(), не будем приводить ее здесь. Един-
ственным различием между ними является то, что фун-
кция DLWalk() сначала отыскивает первый элемент
списка, а затем последовательно проходит через все
элементы.
Тестовый драйвер
Чтобы проиллюстрировать гибкость двусвязного спис-
ка, давайте возьмем короткий отпуск. Конечно, нам
потребуется тщательно спланировать маршрут, чтобы
включить в него основные курорты мира. Начнем с
240
Организация данных
Часть II
очень обширного маршрута, а затем будем постепенно
произвольно урезать список до тех пор, пока в нем не
останется только одно место. Для экономии места я
сократил код (включая проверку кое-каких ошибок и
большую часть файлов включения!), но на Web-сайте
издательства "ДиаСофт” можно найти полный исход-
ный код вместе с файлом cityloc.text, который содержит
широту и долготу трехсот крупных городов. Он также
содержит небольшое количество деревень (в которых нет
международных аэропортов). Элементы этого файла
разделяются запятыми.
/* Стандартные заголовки файла вырезаны */
linclude "dllist.h"
♦define PI 3.14159265358979323846
typedef struct CITY
{
char Nation[30];
char CityName[25];
double Latitude;
double Longitude;
} CITY;
int CompCities (const void ‘pl, const void *p2)
{
const CITY *cl = pl, *c2 = p2;
return strcmp(cl->CityName, c2->CityName);
}
int ParseCity(CITY *c, char *Buffer)
{
char ‘Token;
char *endp;
Token = strtokf Buffer, ",\n");-
strcpy(c->Nation, Token);
Token = strtok(NULL, ",\n");
strcpy(c->CityName, Token);
Token = strtok(NULL, ",\n");
c->Latitude = strtod(Token, fcendp);
Token = strtok(NOLL, ",\n");
c->Latitude += strtod(Token, fcendp) / 60.0;
Token = strtok(NULL, ",\n");
if('S' == toupper(*Token))
{
c->Latitude *= -1.0;
}
c->Latitude *= PI;
c->Latitude /= 180.0;
Token = strtok(NULL, ",\n");
c->Longitude = strtod(Token, &endp);
Token = strtok(NULL, ",\n");
c->Longitude += strtod(Token, fcendp) / 60.0;
Token = strtok(NULL, ",\n");
if('E' == toupper(‘Token))
{
c->Longitude *= -1.0;
)
c->Longitude *= PI;
c->Longitude /= 180.0;
return 1;
}
/* Вычислить расстояние между двумя точками на
земной поверхности (точность составляет
примерно +/- 30 миль).
*/
int CalcGreatCircleDistance(CITY ‘Cityl, CITY
*City2)
{
return (int)(3956.934132687 *
acos((sin(Cityl->Latitude) *
sin(City2->Latitude)) +
((cos(City1->Latitude) *
cos(City2->Latitude)) *
((cos(Cityl->Longitude) *
cos(City2->Longitude)) +
(sin(Cityl->Longitude) *
sin(City2->Longitude))))));
}
int Random(int n)
double d;
d = rand() / (RANDMAX + 1.0);
d *= n;
return (int)d;
/* Тестовый файл cityloc.txt может быть передан
как argv[l]. */
int main(int argc, char *argv[])
{
DLLIST ‘List - NULL;
DLLIST ‘Safe » NULL;
CITY ‘City = NULL;
CITY ThisCity = {0};
CITY ‘TempCity = NULL;
CITY ‘First;
CITY ‘Second;
long TotalDistance;
int Distance;
int i;
int j;
int k;
int NumCities = 0;
int MaxCities = 0;
char Buffer[80] = {0};
FILE *fp = NULL;
srand((unsigned)time(NULL));
if(argc > 1)
241
{
fp = fopen(argv[l], "г");
/* Здесь вырезана проверка опибок */
}
else
{
puts("Please specify a cities file.");
exit(EXITJFAILURE);
}
while(NULL Is fgets(Buffer,
sizeof Buffer,
fp))
{
if(ParseCity(fcThisCity, Buffer))
{
if(++NumCities >= MaxCities)
{
++MaxCities;
Maxcities *= 3;
MaxCities /= 2;
Tempcity = realloc(City,
MaxCities * sizeof *TempCity);
/* Здесь вырезана проверка опибок */
City = TempCity;
}
memcpy(City + NumCities - 1,
fcThisCity,
sizeof *City);
}
}
fclose(fp);
TempCity = realloc(City, NumCities * sizeof
♦TempCity);
if(NULL == TempCity)
{
puts("Something odd is happening, realloc
returned");
puts ("NULL for a /reduction/ in
storage.");
else
<
City = TempCity;
}
j = Random(NumCities - 6) 4- 6;
/* Создать произвольный список городов */
for(i = 0; i < j; i++)
k = Random(NumCities);
if(DLSUCCESS != DLAddAfter(«List,
0,
City + k,
sizeof *City))
{
Простые абстрактные структуры данных
Глава 11
/* Здесь вырезана проверка опибок */
}
}
Safe = List;
while(j > 1)
{
TotalDistance = 0;
First = DLGetData(List, NULL, NULL);
while(DLGetNext(List) 1= NULL)
{
List = DLGetNext(List);
Second = DLGetData(List, NULL, NULL);
Distance =
CalcGreatCircleDistance(First,
Second);
printf("%s - %s : %d miles.\n".
First->CityName, Second->CityName,
Distance);
TotalDistance += Distance;
First = Second;
}
printf("Total distance for this route:
%ld miles.\n",
'TotalDistance);
if(j > 2)
{
printf("— Removing one city —\n");
}
k = Random (j - 1);
for(i = 0; i < k; i++)
{
List = DLGetPrev(List);
}
DLDelete(List);
List = Safe;
—j;
}
/* Уничтожить список */
DLDestroy(«List);
free(City);
return EXITSUCCESS; *
}
Этот код иллюстрирует способ добавления элемен-
тов в список и удаления их оттуда. Он также показыва-
ет (что очень важно), как можно проходить весь спи-
сок (traverse)* в любом направлении.
16 Эк 265
Организация данных
Часть II
242
Циклические списки
Циклические списки — это одно- или двусвязные спис-
ки, которые, если можно так выразиться, гоняются за
своим собственным хвостом: А указывает на В, В ука-
зывает на С, С указывает на D, D указывает на Е и Е
указывает на А. Они лучше всего подходят для цикли-
ческих данных. Например, рассмотрим расписание дви-
жения поездов с 24-часовым периодом (расписание
повторяется каждые 24 часа). Если в 9 часов вечера кли-
ент спрашивает, какие поезда будут отправляться в бли-
жайшие 6 часов, то он, по-видимому, хотел бы услы-
шать не только о том поезде, который отправляется в
21:38. но и о том, который отправляется в 01:19. Цик-
лический список прекрасно подходит для этой задачи.
Из-за его циклической природы в нем отсутствуют пер-
вый и последний элементы. Поэтому полезно ввести
понятие текущей позиции, через которую выполняют-
ся все операции (это хорошо видно на рис. 11.4). Если
нужный элемент находится не на текущей позиции, то
мы можем как бы поворачивать список до тех пор, пока
не получим элемент, который требуется. Обычно за
один раз приложение поворачивает список на один эле-
мент, но при необходимости может поворачивать и на
большее число элементов. Эти вращения осуществляют-
ся очень быстро, так как в действительности данные в
памяти не пересылаются — требуется только присвоить
новое значение указателю. На рис. 11.4 показано, как с
помощью указателей списка образуется кольцо, при
этом каждый элемент списка хранит указатель на дан-
ные приложения.
Заглавный узел
Заглавный узел никоим образом не играет существен-
ной роли в циклическом списке, но он может в огром-
ной степени упростить код программы. В некоторых ре-
ализациях циклического списка указатель последнего
элемента направлен на заглавный узел. Это может дать
обратный эффект и усложнить код. По-видимому, для
последнего элемента как-то более естественно указывать
на первый элемент, в истинно циклическом стиле.
Мы будем использовать заглавный узел (листинг
11.12) для минимизации накладных расходов пользова-
теля-программиста на отслеживание текущего элемен-
та Все, что требуется, — позаботиться о заглавном узле.
РИСУНОК 11.4. Циклический список.
Простые абстрактные структуры данных
|243
Глава 11
а циклический список позаботится о себе сам. Заглав-
ный узел позволяет также хранить дополнительную
информацию, связанную не с отдельным элементом
списка, а со списком в целом. Мы воспользуемся этим,
чтобы хранить счетчик числа элементов в списке.
Листинг 11.12. Библиотека циклического списка.
typedef struct CL_ITEM
{
int Tag;
struct CL ITEM *Prev;
struct CLITEM *Next;
void *Object;
size t Size;
} CLITEM;
typedef struct CLIST
{
CLITEM *CurrentItem;
size_t Numitems;
} CLIST;
Чтобы применять эти библиотеки одно- и двусвяз-
ного списков, необходимо объявить указатель на неко-
торый элемент списка и присвоить ему значение NULL.
Наш заглавный узел немного иной; в коде своего при-
ложения будем определять сам экземпляр заглавного
узла, а не указатель на него. Чтобы обеспечить правиль-
ную инициализацию заглавного узла, нужно определить
его следующим образом:
CLIST Clist = {О};
Эта инициализация гарантирует, что CLisLCurrentltem
будет иметь значение NULL, a CList.Numltems — 0.
ПРИМЕЧАНИЕ
Для этой же самой цели невозможно использовать
memset, так как нельзя гарантировать, что ваш компью-
тер будет представлять значение NULL совокупностью
исключительно нулевых битов.
Вставка первого узла
Первый узел — это особый случай, так как он будет
указывать на самого себя. Определить, является ли узел
первым, — задача простая. Требуется только проверить
Поле Numltems структуры CLIST.
Вставка последующих узлов
Относительно последующих узлов приходится решать,
В какое место списка их вставлять. Одна вполне разум-
ная стратегия заключается в том, что новый узел добав-
ляется в конец списка. Хотя где конец циклического
Списка? Пожалуй, конец списка — это элемент, на ко-
торый указывает указатель Prev текущего элемента. Это
определение не хуже любого другого, и мы будем его
применять; следовательно, вставлять новый элемент
будем после этого последнего элемента, так чтобы ука-
затель Prev текущего элемента был нацелен теперь на
новый элемент.
Рассмотрим добавление в список второго элемента.
Требуется добавить его как Current->Prev->Next. Сей-
час, когда в списке только один элемент, Current->Prev
указывает на Current! Поэтому в действительности на
новый элемент будет указывать и Current->Next, и
Current->Prev! Однако, если мы примем во внимание
циклическую природу данной ситуации, то увидим, что
это правильные действия.
Вот код, вставляющий в список новые элементы:
int CLAddltem(CLIST *List,
int Tag,
void *Object, >
size_t Size)
{
CLITEM *Newltem;
int Result = CLSUCCESS;
assert(List ! = NULL);
Newltem - CLCreatefTag, Object, Size);
if(NULL == Newltem)
{
Result = CLNOMEM;
}
else
{
++List->NumIterns;
if(NULL -- List->CurrentItem)
{
/* Это первый элемент списка, поэтому
он указывает на себя в обоих направлениях.
*/
List->CurrentItem = Newltem;
List->CurrentItem->Next = Newltem;
List->CurrentItem->Prev = Newltem;
}
else
{
/* Поместим этот элемент сразу хе
перед текущим элементом
*/
NewItem->Prev = List->CurrentItem->Prev;
NewItem->Next = List->CurrentItem;
List->CurrentItem->Prev->Next = Newltem;
List->CurrentItem->Prev = Newltem;
}
}
return Result;
}
Как видите, в этом коде вызывается функция
CLCreate(), которая здесь не показана, но которая на-
ходится на Web-сайте издательства ’’ДиаСофт” в файле
cllist.c. Ее задача заключается в создании нового узла,
который затем добавляется в список с помощью функ-
ции CLAddItem().
244
Организация данных
Часть II
Восстановление и обновление данных
Если мы ограничимся восстановлением только элемен-
та, находящегося на текущей позиции, то сделать это
можно просто. Необходимо только возвратить указатель
на данные текущего элемента. Обновление данных тоже
является очень легким делом. В данной главе уже рас-
сматривалась общая идея; чтобы увидеть исходный код,
загляните в файл cllist.c на Web-сайте "ДиаСофт”.
Вращение списка
Эффективное вращение списка является интересным
упражнением по оптимизации. Поскольку список цик-
лический, у него есть некоторые общие свойства с ариф-
метическими операциями по модулю. Пусть нам требу-
ется повернуть список на Р мест и в списке имеется N
элементов. Первая оптимизация, которую можно выпол-
нить, — уменьшить Р таким образом, чтобы оно нахо-
дилось в диапазоне от 0 до N-1. Для этого нужно ис-
пользовать операцию деления по модулю языка С.
Однако сначала убедитесь в том, что число Р не явля-
ется отрицательным. Если же оно отрицательное сле-
дует преобразовать его в положительное. Это можно
сделать, не нарушая смысла числа Р, путем добавления
к нему числа, кратного числу N.
Чтобы получить соответствующее кратное М, мож-
но сделать так:
м = (N — 1 — P)/N
Здесь учитывается тот факт, что результатом цело-
численного деления является целое число.
Прибавляем к Р следующее число:
р = р + (М * N)
В результате этой операции число Р станет положи-
тельным, причем "чистый" результат запроса на враще-
ние не изменится. Разумеется, это делается только в том
случае, если Р отрицательное. Теперь можно уменьшить
Р по модулю N, чтобы поворачивать список на мини-
мальное число мест. Если, конечно, не считать, что это
может быть и не минимальное число!
Для нашей следующей оптимизации используется
тот факт, что перемещение по кругу вперед на Р мест —
это то же самое^ что и перемещение на N — Р мест на-
зад. Поэтому, если Р > N/2, можно повернуть список
на N — Р мест назад, вместо того чтобы поворачивать
на Р мест вперед. Вот этот код:
void CLRotate (CL I ST *List, int; Places)
{
int Multiple;
int i;
assert(List 1= NULL);
if(List->NumIterns > 0)
{
if(Places < 0)
{
Multiple = (List->NumItems - 1 -
Places) /
List->NumIterns;
Places += Multiple * List->NumItems;
}
Places %= List->NumIterns;
if(Places > (int)List->NumIterns / 2)
{
Places = List->NumItems - Places;
for(i = 0; i < Places; i++)
(
List->CurrentItem = List->CurrentItem->Prev;
}
}
else
{
for(i = 0; i < Places; i++)
(
List->CurrentItem = List->CurrentItem->Next;
)
}
}
Удаление узлов
Поскольку мы договорились, что будем адресовать спи-
сок только посредством элемента, расположенного на
текущей позиции, удаление элементов должно быть
совсем простым делом и, действительно, так оно и есть.
Маленькая проблема возникает только тогда, когда эле-
мент, который необходимо удалить, является един-
ственным в списке:
int CLDelete(CLIST *List)
{
int Deleted = 0;
CLITEM *PrevItem;
CLITEM *ThisItem;
CLITEM *NextItem;
assert(List != NULL);
if(List->NumItems > 0)
{
Deleted = 1;
ThisItern = List->CurrentItem;
free(ThisItem->Object);
Nextltem = ThisItem->Next;
Prevlten = ThisItem->Prev;
if(1 == List->NumIterns)
{
List->CurrentItem = NULL;
}
else
{
Простые абстрактные структуры данных
। 245
Глава 11
List->CurrentItem = Nextitem;
NextItem->Prev = Prevltem;
PrevItem->Next = NextItern;
}
free(ThisItem);
—List->NumIterns;
}
return Deleted;
1
Мы возвратили целое число, чтобы указать, дей-
ствительно ли элемент был удален. Это делает функцию
CLDestroyO тривиальной. Это один из тех редких слу-
чаев, когда оператор continue используется как способ
документирования того факта, что я действительно стре-
мился к тому, чтобы оператор управления циклом вы-
полнил всю работу. Любой оптимизирующий компиля-
тор, достойный этого звания, удалит оператор continue.
void CLDestroy(CLIST *List)
{
assert(List 1= NULL);
while(CLDeletefList))
{
continue;
}
}
Проход по списку
Поскольку точно известно, сколько элементов имеется
в списке, проход по списку может быть сделан в про-
стом цикле:
int CLWalk(CLIST *List,
int(*Func)(int, void *f void *),
void *Args)
<
CLITEM *ThisItem;
int Result = 0;
int i;
assert(List I- NULL);
for(ThisItem = List->CurrentItem, i = 0;
0 == Result &&
i < (int)List->NumItems;
Thisltem = ThisItem->Next, i++)
{
Result = (*Func)(ThisItem->Tag,
ThisItem->Object,
Args);
}
return Result;
}
Решение задачи Иосифа
Самым лучшим примером структуры циклических дан-
ных для нашей демонстрационной программы будет
структура из задачи Иосифа.
Согласно легенде, еврейский историк Флавий
Иосиф (Flavius Josephus) (37 н. э. — ок. 100 н. э.) был
вовлечен в сражение между евреями и римлянами и
прятался в пешере еще с 40 людьми. Пещера была ок-
ружена римскими воинами. Казалось неизбежным, что
людей Иосифа обнаружат и захватят в плен. Для боль-
шинства из находившихся там смерть была более почет-
ной, чем плен, и группа решила совершить самоубий-
ство следующим образом: все становились в круг,
начинали считать людей по кругу и убивали каждого
третьего до тех пор, пока не оставался один человек,
который должен был убить себя сам. В отличие от ос-
тальных, Иосифу и его другу идея плена нравилась
больше; они быстро (и, подозреваю, лихорадочно) вы-
числили, где им стать в круге, чтобы остаться двумя
последними.
Вообще, задача Иосифа состоит в исключении каж-
дого К-го элемента группы, первоначально состоящей
из N элементов, до тех пор, пока не останется только
один или (если, вы хотите быть абсолютно точным) два
элемента. Циклический список хорошо подходит для
решения этой задачи:
(include <stdio.h>
(include <stdlib.h>
(include <string.h>
(include <time.h>
(include "clist.h"
int main (void)
<
char *lntro(l =
{
The Josephus Problem",
246
Организация данных
Часть ii
"Рассмотрим круг из N элементов. Если удалить К-й элемент, то останется N - 1 элементов.
"Если эту процедуру повторять, то действительно останется только один элемент. Какой?
"Ответ дает эта программа.
NULL
В
char **Text;
char buffer[32];
char *endp;
CLIST Circle = {0};
int Result = EXIT_SUCCESS;
unsigned long N;
unsigned long K;
unsigned long i;
for(Text = Intro; *Text 1= NULL; ++Text)
{
puts(*Text);
}
puts("\nHow many items in the ring?");
if(NULL == fgets(buffer, sizeof buffer, stdin))
{
puts("Program aborted.");
exit(EXIT_FAILURE);
}
N = strtoul(buffer, &endp, 10);
if(endp == buffer || N == 0)
{
puts("Program aborted.");
Result = EXITFAILURE;
}
else
{
puts("Count how many items before removing one?");
if(HULL == fgets(buffer, sizeof buffer, stdin))
{
puts("Program aborted.”);
exit(EXlTFAILURE);
}
К = strtoul(buffer, &endp, 10);
if(endp «« buffer || К == 0)
<
puts("Program aborted.");
Result = EXITFAILURE;
}
}
for(i = 0; EXITSUCCESS Result && i < N; i++)
{
if(CLSUCCESS !=
CLAddltem(^Circle,
0,
&i,
sizeof i))
{
printf("Insufficient memory. Sorry.\n");
Result = EXITFAILURE;
}
}
Простые абстрактные структуры данных
Глава 11
247
if(EXITSUCCESS == Result)
{
while(Circle.Numitems > 1)
{
CLRotate(&Circle, K);
printf("Removing item %lu.\n",
*(unsigned long *)CLGetData(&Circle,
NULL,
NULL));
CLDelete(^Circle);
/* Если удалить один элемент, то текущем станет следующий за ним. Это сбивает нап счет
* на единицу, поэтому повернем круг назад на один узел (элемент).
*/
CLRotate(fcCircle, -1);
}
printf("The last item is %lu.\n",
*(unsigned long *)CLGetData(&Circle,
NULL,
NULL));
}
CLDestroy(bCircle);
return Result;
}
Ну хорошо, нам в повседневном программировании
не требуется решать много задач, подобных задаче
Иосифа! Однако понятие циклического списка точно
так же применяется и в других видах моделирования,
например, в программном обеспечении, устанавливаю-
щем последовательность проигрывания музыкальных
произведений, и даже в подпрограммах квантования
времени операционной системы.
Стеки
Все структуры данных, представленные в этой главе,
широко используются в прикладном и системном про-
граммном обеспечении по всему миру, но, пожалуй, ни
одна из них не используется так часто, как стек, кото-
рый (заслуженно или нет) стал почти синонимом согла-
шений по передаче параметров в современных языках.
Но что такое стек? Давайте посмотрим.
По своей внутренней природе, стек — это просто
список, но список, который подчиняется двум прави-
лам. Первое правило заключается в том, что новые эле-
менты можно помещать только на вершину стека; это
называется занесением (pushing) элемента. Второе прави-
ло состоит в том, что вы можете брать элементы только
с вершины стека; это называется извлечением (popping).
В краткой форме эти правила содержатся в акрониме
(сокращении) LIFO (Last In, First Out — последним
Пришел, первым ушел). Эту идею иллюстрирует рис.
11.5. Стеки часто используются компиляторами для от-
слеживания функций и их параметров — так часто, что
многие программисты говорят о ’’помещении аргумен-
тов в стек’’, как будто компиляторы всегда используют
стеки для хранения аргументов. Этот трюизм, подобно
многим другим, не является абсолютно верным — на-
пример, многие оптимизирующие компиляторы поме-
щают аргументы в регистры, если это позволяет повы-
сить производительность.
первым и будет NULL
считываться
последним
РИСУНОК 115. Стек.
Однако не надо быть разработчиком компиляторов,
чтобы понять, что стеки весьма полезны. Стекй приме-
248
Организация данных
Часть II
няются в калькуляторах с обратной польской записью
(Reverse Polish Notation) при анализе и вычислении вы-
ражений и во множестве прикладных задач. В качестве
примера программы рассмотрим одну такую задачу.
Большинство стеков, которые мне встречались в
кодах программ, были реализованы плохо. Код почти
неизменно был написан как часть приложения, а не как
автономная, повторно используемая библиотека. (По-
вторное использование кода — это Священный Грааль
языка C++. Поклонники этого языка постоянно пыта-
ются найти примеры повторного использования кода,
но, похоже, никак не могут их найти. С другой сторо-
ны, приверженцы языка С в течение многих лет повтор-
но используют коды программ, делая это без особого
шума; у них просто нет никакой потребности громко
кричать об этом. Но по какой-то непонятной причине
эта блестящая история повторного использования про-
грамм, по-видимому, не включает в себя стеки, по край-
ней мере, если судить по моему опыту. Программисты
обычно реализуют стек как статический массив, облас-
тью действия которого является файл. Поэтому как
функция push(), так и функция рор() могут иметь дос-
туп к стеку. Это хорошее сокрытие данных, но плохая
абстракция. Такая методика ограничивает применение
функций доступа только одним стеком (если только
авторы программ не приложили огромных усилий).
Более того, массив привязан к одному типу данных.
Если требуется хранить в стеке переменные какого-ни-
будь другого типа, необходимо написать новый набор
функций.
И наконец, стек не является безразмерным, он под-
чиняется ограничениям, накладываемым компьютером
и операционной системой. Но, помимо этого, размер
стека ограничивается некоторым произвольным макси-
мумом, устанавливаемым разработчиком во время напи-
сания кода. Сначала кажется, что это хорошая идея, но
в конечном счете каждый раз приходится убеждаться,
что это не так, поскольку любые произвольно наклады-
ваемые ограничения обречены на то, что рано или по-
здно возникнет необходимость их нарушить.
При проектировании общей библиотеки стека хоте-
лось бы решить эти проблемы. К сожалению, нелегко
обеспечить сокрытие данных без использования стати-
ческих переменных, а мы как раз и не хотим их исполь-
зовать, так как они нарушают безопасность потоков (это
объясняется в основном тем, что в стандарте ANSI С
отсутствует поддержка потоков).
Поскольку стек — это просто частный случай спис-
ка, имеет смысл использовать часть кода, уже написан-
ного для списка. В данном примере нет особой необхо-
димости в двусвязном списке, поэтому уменьшим
накладные расходы для нашего стека, используя одно-
связный список. Этот список мы приведем к структуре
нового типа STACK и адрес этой структуры передадим
в функции, которые будут осуществлять занесение и из-
влечение данных.
Создание стека
Наш стек очень простой (листинг 11.13).
Листинг 11.13. Создание стека.
typedef struct STACK
{
lifndef NDEBUG
int Checklnitl;
fendif
SLLIST *StackPtr;
sizet Numltems;
lifndef NDEBUG
int Checklnit2;
fendif
} STACK;
Поле Numltems присутствует здесь исключительно
для удобства. Мы также определили пару отладочных
полей, которые используются в операторах контроля
Обратите внимание, что, поскольку используется
структура SLLIST, до собственно определения стека
должен быть выполнен оператор #include "sllist.h”. На
выбор предлагается три варианта.
Во-первых, отказаться от использования структуры
SLLIST и вновь написать требуемые нам функции. Как
полноправный член ассоциации ленивых программис-
тов я бы хотел избежать дополнительной работы, свя-
занной с этим.
Во-вторых, можно было бы включить заголовочный
файл sllist.h в заголовочный файл stack.h. Мне не нра-
вится этот вариант. По моему мнению, вложение заго-
ловочных файлов — это плохая идея.
И в-третьих, можно настоять на том, чтобы в каж-
дый транслируемый модуль, в который пользователь-
программист включил файл stack.h, был включен и
файл sllist.h, причем перед файлом stack.h. Этот вари-
ант мне тоже не нравиться, потому что он, по-видимо
му, откладывает дополнительную работу на "потом"
(никогда не заставляйте себя выполнять какую-нибудь
одну и ту же работу каждый день в течение многих лет.
если можете сегодня сделать это раз и навсегда).
Ни один из этих вариантов не является идеальным
(по крайней мере, с моей точки зрения пуриста), поэто
му придется пойти на компромисс и принять не самое
совершенное решение. Первый вариант определенно нс
подходит, так как С-программисты используют кол
повторно при каждой возможности. Третий вариант, по
видимому, очень трудоемкий и имеет еще один недо
статок — он ведет к тому, что прикладные программы
Простые абстрактные структуры данных
249
Глава 11
будут зависеть от библиотеки стека, повторно исполь-
зующей структуру SLLIST. В настоящий момент эта
идея кажется прекрасной, но, возможно, через год мы
кое-что усовершенствуем, и тогда все эти прикладные
программы придется перекомпилировать и перекомпо-
новывать, а это плохо. (Если мы изменяем содержимое
структуры STACK, то это подразумевает необходимость
перекомпиляции всех программ, использующих функ-
ции из библиотеки стека.) Необходимость редактиро-
вать при этом и прикладной код была бы весьма неже-
лательной и потенциально дорогой. Однако если мы
просто включаем файл sllist.h в файл stack.h, то избега-
ем этой проблемы и ограждаем пользователя-програм-
миста от ненужной информации о том, что в реализа-
ции стека используется код списка.
Поэтому с некоторой неохотой выбираем второй
вариант — включаем sllist.h в stack.h, но, по крайней
мере, мы испытываем удовлетворение от сознания того,
что это лучший из трех вариантов.
При наличии определения структуры остается толь-
ко соответствующим образом определить экземпляр
данной структуры в коде приложения. Это очень про-
сто:
STACK Stack = (О);
4»
В результате этого определения указатель на стек
инициализируется значением NULL, а переменная
Numltems — нулем. Если NDEBUG не определена, то
контрольные поля также инициализируются нулем.
(Если NDEBUG определена, то эти поля будут обрабо-
таны препроцессором и исчезнут.)
Занесение элементов
Занесение элементов также выполняется очень просто.
Необходимо только вызвать функцию SLFront(), опре-
деленную в коде библиотеки односвязного списка:
Ant Stackpush (STACK * Stack,
int Tag,
void *Object,
size t Size)
<
int Result = STACKPUSHFAILURE;
int ListResult;
assert(Stack 1= NULL);
assert (0 == Stack->CheckInitl && 0 ==
wStack->CheckInit2);
ListResult = SLFront(&Stack->StackPtr, Tag,
^Object, Size);
if(SLSUCCESS == ListResult)
{
Result = STACKSUCCESS;
++Stack->NumItems;
}
return Result;
Это было сделано с чудесной легкостью — пришлось
только вызвать код, который был написан раньше. Как
можно было заметить, был определен новый набор мак-
росов контроля ошибок в коде стека, так как мы не хо-
тим, чтобы пользователи-программисты были вынужде-
ны писать код, зависящий от того, что в определении
стека была использована структура SLLIST. Операто-
ры контроля не гарантируют правильную инициализа-
цию стека (в частности потому, что они исчезают, если
NDEBUG определена), но они дают нам разумную сте-
пень защиты от случайной небрежной инициализации.
Извлечение элементов
Процесс извлечения элементов так же прост, как про-
цесс их занесения. Код уже написан более чем наполо-
вину. Нам приходится решать две задачи: первая — из-
влечь объект из стека таким образом, чтобы
вызывающее их приложение могло получить эти дан-
ные, и вторая — удалить данные из стека.
Проблема здесь заключается в ответственности. Ког-
да элемент заносится в стек, библиотечный код выде-
ляет для него память. (Память выделяется кодом одно-
связного списка, но суть вопроса в том, что она не
выделяется пользователем-программистом.) Следова-
тельно, библиотечный код должен нести ответствен-
ность и за освобождение памяти, занимаемой элемен-
том. Но, наверное, пользователь-программист не
извлекал бы элемент из стека, если бы не хотел полу-
чить эти данные, а он не может их получить, если мы
только что освободили память, занимаемую этим эле-
ментом. (Тот, кто думает, что это можно сделать, дол-
жен тратить меньше времени на написание неработаю-
щих программ и больше — на чтение стандарта.)
Для решения этой проблемы требуется, чтобы
пользователь-программист передавал нам указатель на
область памяти, достаточную для запоминания данного
объекта. Мы скопируем объект в эту область памяти, а
затем освободим память, занимаемую нашей копией эле-
мента. Предполагается, что пользователь-программист
знает, какой объем памяти требуется для сохранения
верхнего элемента стека.
int StackPop(void *Object, STACK *Stack)
{
size_t Size; •
void *p;
int Result = STACKSUCCESS;
assert(Stack 1= NULL);
assert(0 == Stack->CheckInitl && 0 ==
Stack->CheckInit2);
250
Организация данных
Часть II
if(Stack->NumItems > 0)
{
р = SLGetData(Stack->StackPtr, NULL, (Size);
if(p 1= NULL Object 1= NULL)
{
memcpy(Object, p. Size);
}
else
{
Result = STACKPOPFAILURE;
}
Stack->StackPtr = SLDeleteThis(Stack->StackPtr);
—Stack->NumIterns;
}
else
{
Result = STACKEMPTY;
}
return Result;
}
Обращение к первому элементу
Рассматривая процесс извлечения элемента из стека, я
случайно упустил из внимания важную проблему.
Я сказал: "Предполагается, что пользователь-програм-
мист знает, какой объем памяти требуется для сохране-
ния верхнего элемента стека". Но я не сказал, как он
может это узнать. Вот функция, которая обеспечивает
доступ пользователя-программиста ко всей требуемой
информации:
void *StackGetData(STACK *Stack, int *Tag,
**size__t *Size)
{
assert(Stack 1= NULL);
assert(0 == Stack->CheckInitl && 0 ==
**Stack->CheckInit2);
return SLGetData(Stack->StackPtr, Tag,
wSize);
}
Подсчет числа элементов в стеке
Пожалуй, единственное свойство стека, которое мы еще
не рассмотрели, — это число элементов в нем. Его лег-
ко сосчитать:
size_t Stackcount(STACK *Stack)
{
assert(Stack 1= NULL);
assert(0 == Stack->CheckInitl && 0 ==
b*Stack->CheckInit2);
return Stack->NumIterns;
I
Сохранение природы стека
Важно не заниматься обманом, добавляя или удаляя
другие элементы, кроме верхнего. Это связано с тем, что
принцип работы стека широко известен. Если обслужи-
вающий программист ожидает, что обычные правила
стека будут соблюдаться, то это нельзя назвать неразум-
ным. Если вы придерживаетесь парадигмы L1FO, то это
гарантирует, что ваш код будет более понятным. Когда
требуется добавлять элементы в середину или на дно
стека (или извлекать их оттуда), лучше вместо стека
использовать связанный список.
Если пользователь-программист обновляет стек стро-
го в соответствии с инструкциями изготовителя (т.е.
только посредством "официальных" интерфейсных фун-
кций StackPush и StackPop), то данный библиотечный
код не будет нарушать правил LIFO.
Пример стека: программа проверки
синтаксиса HTML
Чтобы проиллюстрировать работу нашей библиотеки
стека, напишем элементарную программу проверки
синтаксиса HTML. Эта программа должна подтверж-
дать, что для каждого открывающего тега HTML име-
ется соответствующий закрывающий тег. Для этого мы
просто считываем весь файл в оперативную память (по-
вторно используя функцию ReadFile, которая была опи-
сана ранее в настоящей главе) и проверяем каждую
строку на наличие открывающих и закрывающих тегов
(тег заключен между символами < и >, а перед закры-
вающим тегом стоит символ /). Каждый раз, встречая
новый тег, первым делом нужно проверить, не являет
ся ли он одним из тех тегов, которые не требуется зак-
рывать (некоторые теги HTML, например <hr>, отно-
сятся к этой категории). Если не является, то можно
заносить его в стек. Когда встречается закрывающий тег.
мы извлекаем предыдущий тег из стека и сравниваем с
найденным. Если эти два символа < и > не относятся к
одному тегу, значит, делаем вывод, что в сценарии
HTML имеется синтаксическая ошибка. Здесь недоста-
точно места, чтобы показать исходный код полностью:
его можно найти на компакт-диске. А ниже приводит-
ся функция main():
int main(int argc, char *argv(])
{
STACK Stack = {0};
char Filename [FILENAME—MAX] = {0};
char *HTMLTag = NULL;
char *Temp = NULL;
size—t CurrSize = 0;
251
Простые абстрактные структуры данных
Глава 11
char *р; /* find < */
char *q; /* find > */
char **array = NULL; /* файл HTML */
int Count = 0;
int Error;
int rows;
int thisrow;
int Status = EXITSUCCESS;
if(argc > 1)
{
strepy(Filename, argv[l]);
}
else
{
printf("HTML syntax checker\n");
printf ("Please type in the name of the file\n”);
printf("to check or EOF (AZ in DOS/Win, AD\n");
printf("in Unix) to quit: ");
fflush(stdout);
if(NULL == fgets(Filename, sizeof Filename, stdin))
printf("Exiting program.\n”);
Status = EXITFAILURE;
}
else
{
p = strchr(Filename, '\n');
if (NULL != p)
{
*p = '\0';
}
}
}
if(EXITSUCCESS =« Status)
{
Error = ReadFile(Filename, barray, brows);
if(Error 1= 0)
{
printf("Couldn't read file %s.\n", Filename);
Status = EXIT_FAILURE;
}
else
{
printf(”\nChecking file %s\n\n". Filename);
for(thisrow = 0;
EXIT_SUCCESS == Status bi thisrow < rows;
thisrow++)
{
p = strchr(array(thisrow), '<');
while (EXIT SUCCESS == Status && p != MULL)
{
•q » strpbrk(p + 1, "\t >\n");
if (NULL == q)
{
252
Организация данных
Часть II
printf("Syntax error, line %d"
(no tag closure).\n", thisrow);
++Count;
}
else
{
if(q - p > (int)CurrSize)
{
CurrSize = q - p;
Temp = realloc(BTMLTag, CurrSize);
if (Temp 1= NULL)
{
BTMLTag = Temp;
}
else
{
printf("Memory loss.Xn");
Status = EXITFAILURE;
}
}
memcpy(BTMLTag, p + 1, q - 1 - p);
BTMLTag[q - 1 - p] = '\0';
Downstring(BTMLTag);
}
if(p[lj != '/')
{
if(1Exempt(BTMLTag))
{
if(STACKSUCCESS 1= StackPush(fcStack,
0,
BTMLTag,
q - pB
{
printf("Stack failure: %s on line %d\n",
BTMLTag,
thisrow);
Status = EXITFAILURE;
}
}
}
else
{
Temp = StackGetData(&Stack,
NULL,
NULL);
if(0 != strcmp(BTMLTag + 1, Temp))
{
printf("%s closure expected,"
" %s closure found on line %d.\n".
Temp,
BTMLTag,
thisrow);
++Count;
}
StackPop(NULL, &Stack);
}
p = strchr (p + 1, '<');
Простые абстрактные структуры данных
253
Глава 11
printf("%d syntax errorfes found.Xn",
Count,
Count == 1 ? : "s");
FreeStrArray(array f rows);
StackDestroy(&Stack);
return Status;
Чтобы протестировать этот код программы, я опро-
бовал его работу со всеми страницами своего Web-сай-
та. Сначала я подумал, что в коде имеется "жучок”, так
как программа выдавала сообщения о нескольких син-
таксических ошибках HTML в готовых страницах, ко-
торые уже в течение некоторого времени работали на
Web (всегда в первую очередь подозревайте свой код, а
уже потом чей-то еще!). Но я ошибался. При дальней-
шем исследовании выяснилось, что в этих Web-страни-
цах действительно имелись ошибки. Так что это на са-
мом деле полезная демонстрационная программа.
Очереди
Наиболее полезными структурами данных являются те,
которые можно легко представить в уме. Хороший при-
мер таких структур — стек; каждый может представить
себе стопку коробок (чем стек, по сути, и является). Так
же легко можно представить себе очередь, и это пре-
имущество делает ее одним из мощных инструментов
программиста.
В основных чертах очереди похожи на стеки, но
подчиняются другому набору правил, известному как
FIFO (First In, First Out — первым пришел, первым
ушел). При таком режиме можно добавлять элементы
только в конец очереди и удалять элементы только из
начала очереди. Эта очередь функционирует точно так
же, как и обычная очередь в магазине или на почте (рис.
11.6).
Очереди часто используются при моделировании.
В качестве очень яркого примера представьте, что вы пи-
шите программу моделирования супермаркета. Очере-
NULL очереди. Новые элементы будут
помещаться после этого элемента.
РИСУНОК 11.6. Очередь.
254
Организация данных
Часть II
ди идеально подходят для моделирования цепочки лю-
дей, ожидающих, когда их обслужит кассир. Очереди
могут быть также полезными в системном программи-
ровании. Например, многозадачные операционные си-
стемы хранят события и сообщения в очереди или,
чаще, во множестве очередей — по одной для каждого
текущего процесса.
Программировать библиотеку очереди с помощью
односвязного списка не так удобно, как стек, но это
можно осуществить. Хитрость заключается в том, что
используются два указателя: один на начало очереди, а
другой — на ее конец.
Конечно, можно сэкономить несколько байтов па-
мяти, реализуя очередь с одним указателем — но толь-
ко за счет того, что вам придется последовательно про-
ходить через всю очередь каждый раз, когда потребуется
считать какой-нибудь элемент. Это требует О(п) опера-
ций вместо 0(1), и если очередь большая, то займет
много времени. Кроме того, можно предположить, что
необходимый дополнительный код займет больше мес-
та, чем будет сэкономлено на указателе для одной оче-
реди; в конце концов, код программы не может хранить-
ся в нулевом количестве байтов. Однако если бы мы
писали приложение с тысячами или миллионами оче-
редей, то могли бы прийти к мнению, что такая опти-
мизация памяти (и связанное с ней снижение произво-
дительности) — это стоящая идея.
Создание очереди
В качестве очереди будем использовать структуру дан-
ных, показанную в листинге 11.14.
Листинг 11.14. Создание очереди.
typedef struct QUEUE
{
lifndef NDEBUG
int Checklnitl;
fendif
SLLIST *HeadPtr;
SLLIST *TailPtr;
size_t Numltems;
lifndef NDEBUG
int Checklnit2;
fendif
} QUEUE;
Мы ожидаем, что пользователь-программист будет
правильно определять экземпляр очереди QUEUE, та-
ким же образом, как и в коде стека STACK:
QUEUE Queue = {О} ;
Добавление элементов в очередь
Здесь возможны два сценария: добавление элемента в
пустую очередь или в очередь, которая содержит, по
крайней мере, один элемент. В обоих случаях наша за-
дача — просто обеспечить, чтобы указатели были в по-
рядке.
int QueueAdd(QUEUE *Queue ,
int Tag,
void *Object,
size t Size)
{
int Result = QUEUEADDFAILURE;
int ListResult;
assert(Queue 1= NULL);
assert(0 == Queue->CheckInitl && 0 ==
**Queue->CheckInit2);
ListResult = SLAdd(&Queue->TailPtr, Tag,
^Object, Size);
if(SLSUCCESS == ListResult)
{
if(0 == Queue->NumIterns)
{
Queue->HeadPtr = Queue->TailPtr;
}
else
{
Queue->TailPtr = Queue->TailPtr->Next;
}
Result = QUEUESUCCESS;
++Queue->NumItems;
}
return Result;
}
Из этого листинга видно, что указатель начала все-
гда указывает на первый элемент списка, а указатель
конца — на последний элемент.
Удаление элементов из очереди
При удалении элементов возможны те же две ситуации,
что и при их добавлении: либо первый элемент списка —
это единственный оставшийся элемент, либо нет. Если
речь идет о первом варианте, то необходимо присвоить
указателю конца значение NULL. Кроме того, перед
нами стоит та же самая проблема, что и в случае со сте-
ком: разрешить пользователю-программисту доступ к
данным, память под которые мы собираемся освобож-
дать. Поэтому, пожалуй, не будет ничего удивительно-
го, если мы примем аналогичное решение.
int Queu*Reaove (void *Object, QUEUE *Queue)
{
size_t Size;
void *p;
int Result = QUEUESUCCESS;
Простые абстрактные структуры данных
Глава 11
255
assert(Queue 1= NULL);
assert(0 == Queue->CheckInitl && О ==
***Queue->CheckInit2);
if(Queue->NumIterns > 0)
{
p = SLGetData(Queue->HeadPtr, NULL,
,-*&Size);
if(p 1= NULL)
{
memcpy(Object, p. Size);
}
else
{
Result = QUEUEDELFAILURE;
}
Queue->HeadPtr = SLDeleteThis(Queue->HeadPtr);
—Queue->NumItems;
if(0 == Queue->NumIterns)
{
Queue->TailPtr = NULL;
}
}
else
{
Result = QUEUE_EMPTY;
}
return Result;
Излишне говорить, что нам требуется также функ-
ция QueueGetData(), которая находится на Web-сайте
издательства "ДиаСофт". (Во всех отношениях она
идентична функции StackGetData().)
Сохранение природы очереди
Как и при работе со стеками, мы не должны занимать-
ся обманом и при работе с очередями. Понятие очере-
ди является еще более простым, чем понятие стека,
поэтому следует придерживаться правила FIFO.
Прикладная библиотека работы с
очередями
Этой библиотекой очередей действительно легко
Пользоваться, так как в ней имеется только две основ-
ные функции: одна добавляет элемент в очередь, а дру-
гая удаляет его. Поэтому не будем здесь приводить при-
мер исходного кода, использующего библиотеку
Очереди. Однако на компакт-диске вы найдете (в фай-
ле queuemn.c) программу, в которой моделируется оче-
редь в супермаркете. Покупатели прибывают в очередь
С рядом товаров, которые они хотят купить. Когда кас-
сир освобождается, они подходят к нему, чтобы он их
Обслужил. Пользователь управляет числом работающих
кассиров, и идея заключается в том, чтобы максималь-
но увеличить прибыль, используя минимально необхо-
димое число кассиров (и не более того — кассирам, по
понятным причинам, необходимо платить зарплату).
Очереди по приоритету
Мы уже начали рассматривать упорядоченные структу-
ры данных, такие как стек и очередь. Иногда, когда в
структуру данных заносятся новые данные, ее прихо-
дится переупорядочивать. Классическим примером
структуры, к которой предъявляется такое требование,
является очередь по приоритету.
Очередь по приоритету — это структура данных, ко-
торая облегчает хранение элементов данных в порядке
приоритета. Чаще всего они используются в приложе-
ниях планировки задач. Другой сферой их применения
являются многозадачные операционные системы. Они
функционируют в соответствии с очень простым пра-
вилом: первым пришел, наибольшим ушел (First In,
Largest Out) или, если хотите: первым пришел, наимень-
шим ушел (First In, Smallest Out) — все зависит от того,
как вы определяете приоритет.
Имеется несколько способов реализации очереди по
приоритету, наиболее понятным из которых является
сортированный список. Идея заключается в том, чтобы
взять простой список и вставить новый элемент на то
место в списке, которое определяется приоритетом этого
элемента. Поиск соответствующего места производится
по некоторому ключу приоритета.
Это простая и привлекательная идея. Но она также
обладает серьезным изъяном. При малом числе элемен-
тов данный метод функционирует прекрасно, но, по
мере того как список растет, метод начинает "пробук-
совывать". Временная сложность отсортированного
списка равна O(N2), и можно использовать намного
лучший способ, чем этот. Какой?
Как это часто бывает, на выручку приходит самая
полезная в истории программирования справочная книга
Искусство программирования Дональда Е. Кнута (the Art
of Computer Programming by Donald E. Knuth) — един-
ственная книга такого рода. В томе III Поиск и сорти-
ровка (Sorting and Searching) автор рассматривает очере-
ди по приоритету и демонстрирует алгоритм, который
называется пирамидальная сортировка (heapsort). По
определению автора, массив элементов К является пи-
рамидой, или частично упорядоченным полным бинар-
ным деревом (heap), если ключи элементов используют-
ся для упорядочения этих элементов таким образом, что
1 <= | j/2 | < j <= N, K[j/2J >= КЩ. Вполне естествен-
но, что пирамидальная сортировка превращает массив
в пирамиду. В рассматриваемой книге также описан
метод, позволяющий сохранять массив отсортирован-
ным при добавлении или удалении элементов.
Организация данных
256
Часть II
На рис. 11.7 ключами для объектов являются про-
стые целые числа, причем большее число указывает на
более высокий приоритет. Сплошные линии обознача-
ют связи через указатели (pointer relationship) (напри-
мер, объект, хранимый в элементе 0 пирамиды содер-
жит указатель на объект с ключом 317). Пунктирные
линии указывают на логические взаимосвязи. Поэтому
ясно видно, что пирамида является разновидностью
дерева.
ИНДЕКС
ОБЪЕКТ
не на прямую связь через
указатель. Каждый ключ
имеет более высокий
приоритет, чем любой из
двух ключей, которые
расположены справа от
него и с которыми у него
имеется неявная
логическая связь.
Листинг 11.15. Создание очереди по приоритету.
typedef struct BEAPELEMENT
{
int Tag;
size t Size;
void *Object;
} HEAPELEMENT;
typedef struct HEAP
{
sizet Count; /* Число элементов в
пирамиде. * /
sizet MaxCount; /* Число элементов, для
которых выделена память. */
HEAPELEMENT *Неар; /* Элементы пирамиды */
} HEAP;
РИСУНОК 11.7. Пирамида.
Поскольку пирамиды являются такими запутанны-
ми (проверьте в исходном коде, если не верите!), идея
по поводу библиотеки будет особенно полезна. До кон-
ца карьеры вам больше никогда не потребуется писать
код для пирамид, так как ниже следует носящая абсо-
лютно общий характер библиотека пирамиды, которая
позволяет обрабатывать все и любые виды объектов
вместе или по отдельности (при условии, что их мож-
но сравнивать друг с другом каким-либо способом).
Исходный код, представленный здесь, в значительной
мере создан на основе кода GNU Бэна Пфаффа (Ben
Pfaff), однако я адаптировал его для объектов любого
вида.
Создание очереди по приоритету
Определим две структуры данных: управляющую струк-
гуру пирамиды и элемент пирамиды. Они показаны в
листинге 11.15.
Как видите, в структуре HEAP будет храниться общая
информация о пирамиде. Строго говоря, пирамида
представляет собой массив структур HEAP ELEMENT,
вот почему указатель на них также называется Heap
HEAP *HeapCreate (size__t MaxCount)
{
HEAP *Heap - malioc(sizeof *Beap);
if(Heap != NULL)
{
Heap->Count = 0;
Heap->MaxCount = MaxCount;
Heap->Heap « malioc(Heap->MaxCount *
sizeof *Heap->Heap);
if(Heap->Heap == NULL)
{
free(Heap);
Heap - NULL;
}
}
return Heap;
}
Требуется обеспечить, чтобы пользователь-програм-
мист не был стеснен ненужными ограничениями. По-
этому, исходя из первоначального предположения о
вероятном числе элементов, которые нам могут потре-
боваться, динамически выделяем для пирамиды опре-
деленный объем памяти, который при необходимости
можем изменить.
Добавление элементов в очередь по
приоритету
Вот где начинает становиться страшновато. Алгоритм
Кнута воспроизведен здесь во всем его великолепии.
int Heapinsert(HEAP *Неар t
int Tag,
size_t Size,
void *Objectr
BEAPCOMPARE Comp)
{
int if j;
Простые абстрактные структуры данных
Глава 11
257
int Done = 0;
int Okay = 1;
void *NewObject = NULL;
assert (fieap != NULL);
NewObject = malloc(Size);
if(NULL == NewObject)
{
Okay = 0;
}
else
{
memcpy(NewObject, Object, Size);
if(Okay && fieap->Count >= Eeap->MaxCount)
{
Beap->Eeap = realloc(Heap->Heap,
2 * Heap->MaxCount *
sizeof *fieap->fieap);
if(Беар->Беар 1= NULL)
{
Eeap->MaxCount *= 2;
}
else
{
Okay = 0;
free(NewObject);
}
if(Okay)
{
/* Алгоритм Кнута 5.2.3-16. Шаг 1. *7
j = Eeap->Count + 1;
while(!Done)
{
/* Шаг 2. */
i = j / 2;
/* Шаг 3. */
if (i == 0 || (*Comp) (Heap->Heap[i -
^*1) .Object,
Eeap->Heap[i - Ij.Tag,
Object,
Tag) <= 0)
{
Heap->Heap[j - Ij.Tag = Tag;
Heap->fieap[j - IJ.Size = Size;
Heap->Heap[j - 1].Object = NewObject;
Eeap->Count++;
Done = 1;
}
else
{
/* Шаг 4. */
Eeap->Eeap[j - 1] = Eeap->Heap[i - 1];
3 = i;
}
}
}
return Okay;
}
Здесь требуется осветить некоторые детали данной
реализации. Во-первых, может оказаться, что памяти,
выделенной для пирамиды, недостаточно для того, что-
бы вставить в пирамиду новый элемент. В таком случае
следует просто увеличить в 2 раза объем памяти, выде-
ленный для пирамиды. Если наше первоначальное пред-
положение было обоснованным, то такое вряд ли про-
изойдет более одного раза.
Во-вторых, мы имеем дело с объектами, которые
требуется сравнивать. Значительную часть времени эти
объекты могут быть численно несравнимыми. Поэтому
необходимо, чтобы пользователь-программист обеспе-
чил какой-нибудь способ сравнения объектов. Точно с
такой же проблемой сталкиваются стандартные библио-
течные функции qsort и bsearch, поэтому позаимству-
ем у них решение, а именно: указатель на функцию
сравнения. Желательно, чтобы эта функция сравнения
работала примерно так же, как и функция qsort, за ис-
ключением того, что она может иметь дело с объекта-
ми разных типов, и это следует иметь в виду. Все пре-
красно до тех пор, пока сравнение объектов имеет смысл.
Поэтому в функцию сравнения требуется передавать
теги (tags). В результате получается функция типа ука-
затель на функцию, принимающая два указателя на void,
два на int и возвращающая тип int. Все это достаточно
утомительно и заслуживает своего собственного специ-
фикатора typedef, так что мы имеем:
typedef int (*HEAP__COMPARE) (const void *Left,
int LeftTag,
const void *Right,
int RightTag);
Заметьте, что при вызове указателя на функцию
используется запись (*foo)(), а не просто foo(). Оба вида
записи законны, и некоторые программисты предпочи-
тают последнюю, так как они полагают, что в этом слу-
чае их крд выглядит проще — действительно, достой-
ная цель. Однако я хотел бы видеть звездочку,
поскольку она напоминает, что я имею дело с указате-
лем на функцию, и удерживает от поиска тела несуще-
ствующей функции foo().
Удаление элементов из очереди по
приоритету
При вставке каждого элемента для него осуществляет-
ся поиск соответствующего места в пирамиде. Следова-
тельно, при удалении элемента нужно было бы просто
убирать его из пирамиды. К сожалению, все не так про-
сто. Необходима гарантия, что при этом пирамида со-
хранит свою целостность. Вот как обеспечить такую
гарантию:
Организация данных
Часть II
258
int HeapDelete(HEAP *Heapf
int *pTagr
size_t *pSizer
void *pObjectf
HEAPCOMPARE Comp)
{
/♦ Алгоритм Кнута 5.2.ЗВ-19. */
int rf if j;
int Done;
int KeyTag;
void *KeyObject = NULL;
void *01dItem;
if (Heap->Count == 0)
return -1;
if(pTag != NULL)
{
♦pTag = Heap->Heap[0].Tag;
}
if(pSize != NULL)
{
♦pSize = Heap->Heap[O].Size;
}
if(pObject != NULL)
{
memcpy(pObject,
Heap->Heap[0].Object r
Heap->Heap[0].Size);
OldItem = Heap->Heap[0].Object;
KeyTag = Heap->Heap[Heap->Count - l].Tag;
KeyObject = Heap->Heap[Heap->Count - 1].Object;
r = Heap->Count - 1;
j = i;
Done - 0;
while(1Done)
{
i = j;
j *= 2;
if (j > r)
{
Done = 1;
}
else
{
if (j 1= r)
{
if((*Comp)(Heap->Heap[j 7 1].Object,
Heap->Heap[j - Ij.Tag,
Heap->Beap[j ].Object r
Heap->Heap[j ].Tag) > 0)
{
}
1
if((*Comp)(KeyObject,
KeyTag r
259
Простые абстрактные структуры данных
Глава 11
Веар->Веар[j - 1].Object ,
Beap->Beap[j - IJ.Tag) <== 0)
{
Done = 1;
}
else
{
Beap->Beap[i - 1] = Beap->Beap[j - 1];
}
Beap->Beap[i - 1].Object = Keyobject;
Beap->Beap[i - IJ.Tag = KeyTag;
free(Oldltern);
-Heap->Count;
return 0;
}
Ha Web-сайте издательства "ДиаСофт" можно най-
ти вспомогательные функции, необходимые для полно-
ты библиотеки очереди по приоритету.
Приложение с очередью по приоритету
Вот простая программа отображения списка. Можете
модифицировать ее для своих собственных целей (од-
нако, надеюсь, что вам не придет в голову баллотиро-
ваться на пост президента на этой неделе). На этот раз,
чтобы сэкономить в главе побольше места, я удалил все,
за исключением функции main(); но, разумеется, на
Web-сайте издательства "ДиаСофт" находится вей про-
грамма полностью:
int main(void)
(
TASK Tasklist[] =
<
{"Run for president", 30},
{"Wash the dog", 20},
{"Take children to school", 15},
{"Write a sonnet", 16},
{"Mow the lawn", 7},
{"Drink coffee", 6},
{"Do Usenet", 7},
{"Read a good book", 17},
{"Check email", 4},
{ "Buy flowers ", 1},
{"Install new OS", 9},
{"Pour coffee", 5}
};
TASK ThisTask = {0};
sizet NumTasks - sizeof Tasklist / sizeof TaskList(O);
size__t i;
REAP *Beap;
int BadCount;
Beap - BeapCreate(8);
if(NULL != Beap)
<
260
Организация данных
Часть II
for(i = 0; i < NumTasks; i++)
{
Heapinsert(Heap,
0,
sizeof TaskList[0],
TaskList + i,
CompareTasks);
}
/* Теперь давайте убедимся, что это действительно пирамида. */
printf("Is this a heap?\n");
BadCount = EeapVerify(Heap, CompareTasks, stdout);
if(BadCount > 0)
{
printf("Number of errors: %d\n", BadCount);
}
else
{
puts("Good heap.");
}
puts("Here's a heap dump.");
HeapDump(Heap, PrintTasks, stdout);
while(HeapGetSize(Heap) > 0)
{
HeapDelete(Heap,
NULL,
NULL,
&ThisTask,
CompareTasks);
printf("Time to %s\n", ThisTask.JobName);
1
HeapDestroy(Heap);
}
return 0;
Двусторонние очереди (деки)
Слово deque (произносится "лек”) — это довольно сим-
патичный неологизм в программировании; он происхо-
дит от выражения double-ended queue (двусторонняя
очередь), точно описывающего свой смысл. Устоявше-
гося акронима (сокращения), описывающего принцип
действия деков и подобного тем, что имеются для сте-
ков и очередей, нет. Самое лучшее, что я смог приду-
мать, — это FOLIFOLO (First or Last In, First or Last
Out — первым или последним пришел, первым или пос-
ледним ушел). Трудно надеяться, что этот акроним за-
воюет награду "Лучший акроним года". Как бы там ни
было, правила просты: можно добавлять и удалять эле-
менты с любой стороны дека, но нельзя добавлять или
удалять элементы в любом другом месте дека (рис. 11.8).
Значение NULL
РИСУНОК 11.8. Дек.
Простые абстрактные структуры данных
Глава 11
261
Ну теперь это должно быть для вас знакомо! Код
программы показан в листинге 11.16.
Листинг 11-16. Создание дека.
typedef struct DEQUE
<
lifndef NDEBUG
int Checklnitl;
fendif
DLLIST *BeadPtr;
DLLIST *TailPtr;
size_t Numltems;
lifndef NDEBUG
int ChecklnitZ;
fendif
} DEQUE;
Как видите, в качестве основы мы собираемся ис-
пользовать двусвязный список. Односвязный список в
данном случае непрактичен, так как пришлось бы по-
следовательно перебирать его элементы каждый раз при
удалении элемента из конца списка. По тем же самым
причинам, которые уже рассматривались ранее в насто-
ящей главе, в файл deque.h встроен необходимый опе-
ратор включения.
Добавление элемента в начало дека
Поскольку большую часть работы выполняет код дву-
связного списка, код для добавления элементов будет
довольно коротким:
Int DequeAddAtFront(DEQUE *Deque,
int Tag t
void *Object,
size t Size)
i
int Result = DEQUEADDFAILURE;
int ListResult;
assert(Deque 1- NULL);
assert(0 == Deque->CheckInitl && 0 ==
^♦Deque^ChecklnitZ);
ListResult = DLAddBefore(&Deque->BeadPtr,
Tag,
Object,
Size);
if(DL-SUCCESS == ListResult)
{
if(0 == Deque->NumIterns)
{
Deque->TailPtr = Deque->BeadPtr;
}
else
{
Deque->HeadPtr = Deque->HeadPtr->Prev;
}
Result » DEQUESUCCESS;
++Deque->NumIterns;
}
return Result;
}
Добавление элементов в конец дека
Неудивительно, что код для добавления элементов в
конец дека в какой-то степени симметричен предыду-
щему коду. Вот та часть кода, которая отличается от
предыдущей функции:
/* ... */
ListResult - DLAddAfter(&Deque->TailPtr,
Tag,
Object,
Size);
if(DLSUCCESS == ListResult)
{
if(0 == Deque->NumIterns)
{
Deque->HeadPtr = Deque->TailPtr;
}
else
{
Deque->TailPtr = Deque->TailPtr->Next;
}
/* ... */
Удаление элементов из начала дека
Удалять элемент из начала дека не очень сложно, но,
чтобы сохранить адрес нового начала, придется исполь-
зовать временный указатель:
int DequeRemoveFromFront (void *Object, DEQUE
*Deque)
{
size_t Size;
void *p;
DLLIST *Temp;
int Result = DEQUESUCCESS;
assert(Deque 1= NULL);
assert(0 == Deque->CheckInitl && 0 ==
w*Deque->CheckInit2);
if(Deque->NumIterns > 0)
<
p = DLGetData(Deque->BeadPtr, NULL,
**&Size);
if(p 1= NULL)
{
if(Object 1= NULL)
{
memcpy(Object, p. Size);
}
Temp = Deque->BeadPtr->Next;
DLDelete(Deque->BeadPtr);
Deque->BeadPtr = Temp;
262
Организация данных
Часть II
—Deque->NumIterns;
if (0 == Deque->NumIterns)
{
Deque->TailPtr - NOLL;
}
}
else
{
Result = DEQUEDELFAILURE;
}
1
else
{
Result = DEQUEEMPTY;
}
return Result;
)
Удаление элементов из конца дека
Симметрия дека, опять-таки, в исходном коде для уда-
ления элемента из конца дека очень хорошо видна. Вот
часть кода, отличная от предыдущего:
/* ... */
р = DLGetData(Deque->TailPtr, NULL, SSize);
if (р != NULL)
{
if (Object 1= NULL)
{
memcpy(Object, p, Size);
1
Temp » Deque->TailPtr->Prev;
DLDelete(Deque->TailPtr);
Deque->TailPtr = Temp;
—Deque->NumIterns;
if(0 == Deque->NumIterns)
{
Deque->HeadPtr = NULL;
/♦ ... */
Сохранение природы дека
Еще раз обратите внимание на важность соблюдения
парадигмы (принципа функционирования) дека. Если
мы начнем вставлять или удалять элементы в середине
дека (а делать это нетрудно), то можно решить какую-
то сиюминутную проблему, связанную с написанием
программы, но при этом поставить под вопрос проект
всей программы в целом. И в- первую очередь возника-
ет вопрос: правильным ли было решение создавать дек?
К тому же зддача сопровождения программы становит-
ся более трудной. Если вам требуется список, исполь-
зуйте список, а не дек.
Дек автомобилей
Некоторые счастливчики могут позволить себе перево-
зить свои автомобили на большие расстояния по желез-
ной дороге. Автомобили загоняются на автовоз с обеих
сторон и стоят там до тех пор, пока поезд не прибудет
к месту назначения. Было бы неразумно ставить в се-
редину автовоза автомобили, перевозимые на короткие
расстояния! Было бы идеально, если бы все автомоби-
ли, перевозимые на дальние расстояния, стояли в сере-
дине автовоза, а по краям стояли автомобили, перево-
зимые на короткие расстояния.
Автовоз — это хороший пример дека, поскольку ав-
томобили как с одной, так и с другой стороны могут
заезжать на него или съезжать только поочередно. Мож-
но, конечно, поднимать их краном, но гораздо проще,
когда они заезжают и съезжают сами.
Для этого автомобили необходимо сортировать.
В главе 13 Дэн Корбит (Dann Corbit) утверждает, что
никогда нельзя пользоваться функцией qsort. Надеюсь,
он простит меня за то, что я применяю ее здесь. Имей-
те в виду, что функция qsort необязательно является ре-
ализацией алгоритма Quicksort (быстрая сортировка).
В стандарте требуется только, чтобы функция qsort сор-
тировала данные, но не определено как. (Правда, по-
ставщики, которые реализуют функцию qsort с помо-
щью алгоритма Bubble Sort (пузырьковая сортировка),
вряд ли продадут много копий своего компилятора.)
Как бы там ни было, будем использовать функцию qsort,
так как можно быстро написать код ее вызова, не отвле-
каясь'от темы нашего примера, которая заключается в
том, чтобы продемонстрировать работу функций из
библиотеки дека.
В приведенном примере (листинг 11.16) автомоби-
ли грузятся на автовоз в Дувре (на юго-восточном по-
бережье Англии). Некоторые автомобили отправляют-
ся аж в Шотландию. Как нам обеспечить, чтобы они
доехали туда с минимальным объемом погрузочно-раз-
грузочных работ? Вот как:
int main(void)
{
DEQUE Transporter = {0};
char *City[NUM_CITIES] =
{
"London"f
"Watford"r
"Luton"t
263
Простые абстрактные структуры данных
Глава 11
"Milton Keynes",
"Northampton",
"Leicester",
•Derby",
"Chesterfield",
"Sheffield",
•Leeds",
"Newcastle",
"Edinburgh"
I»
size_t NumCities = sizeof City / sizeof CityfOJ;
CAR LeftCar(LNUMCARS) = {0};
CAR RightCar(RNUMCARSJ = {0};
CAR *Car;
int i;
srand((unsigned)time(NULL));
for(i = 0; i < LNUMCARS; i++)
{
RandomiseCar(LeftCar 4- i);
}
for(i = 0; i < RNUM_CARS; i++)
{
RandomiseCar(RightCar 4- i);
qsort(LeftCar,
LNUMCARS,
sizeof LeftCar[0],
CompareCarsByDest);
qsort(RightCar,
RNUMCARS,
sizeof RightCar[0],
CompareCarsByDest);
puts("Welcome to Dover- The automatic car-loading");
puts("process is about to begin.\n");
for(i = 0; i < LNUM CARS; i++)
{
if(DEQUE SUCCESS ! = DequeAddAtFront(^Transporter,
0,
LeftCar 4- ir
sizeof LeftCar[i]))
{
puts("Car crash? Insufficient memory.");
exit(EXITFAILURE);
}
printf("%s, bound for %s, added at front.\n",
LeftCar(i].RegNumber,
City)LeftCar[i]-Destination));
for(i = 0; i < RNUM CARS; i++)
{
if(DEQUESUCCESS ! = DequeAddAtBack(fcTransporter,
Or
RightCar 4- i r
sizeof RightCarfi]))
{
264
Организация данных
Часть II
puts("Crunch1 Insufficient memory.");
exit(EXITFAILURE);
>
printf("%sf bound for %s, added at back.Xn",
Rightcar[i].RegNumber t
City[Rightcar[i].Destination]);
printf("Okay, we're on our way to %s!\n"f CityfO]);
for(i - 0;
DequeCount(&Transporter) > 0 i < NUM_CITIES;
i++)
{
puts("Deedle-dee-DEE, Deedle-dee-DAH...");
printf("Okay, we've arrived at %s.\n", City[i]);
Car = DegueGetDataFromFront(&Transporter, NULL, NULL);
if(Car == NULL)
{
puts ("We seem to have run out of cars,");
puts("so I guess the journey is over.");
exit(0);
while(Car != NULL &&
DequeCount(&Transporter) > 0 &&
Car->Destination == i)
{
printf("Unloading %s from front.\n", Car->RegNumber);
DequeRemoveFromFront(NULL, ^Transporter);
Car = DegueGetDataFromFront(bTransporter, NULL, NULL);
1
Car = DequeGetDataFromBackf&Transporter, NULL, NULL);
while (Car != NULL &&
DequeCount(bTransporter) > 0
Car->Destination == i)
{
printf("Unloading %s from back.\n", Car->RegNumber);
DequeRemoveFromBack(NULL, ^Transporter);
Car = DequeGetDataFromBack(^Transporter, NULL, NULL);
1
if(i < NUMCITIES - 1)
{
printf("All done, so we're off to %s!\n",
City[i + 1));
printf("That's it - journey's end.\n");
return 0;
Как видите, я сократил напечатанный исходный
код; весь исходный код целиком можно найти на Web-
сайте издательства ’’ДиаСофт" в файле dequenm.c.
В этом примере были использованы функции чтения
DequeGetDataFromFront и DequeGetDataFromBack, что-
бы перед удалением данных из дека проверять, действи-
Простые абстрактные структуры данных
Глава 11
265
тельно ли эти данные необходимо убрать. Это необяза-
тельно, если заранее известно, что данные будут уда-
ляться независимо от их содержания. В этом случае мы
передаем в функцию Deque Remove From Front или
DequeRemoveFromBack адрес объекта соответствующе-
го размера. Однако, если используются объекты сме-
шанных типов, то потребуется взглянуть на данные хотя
бы для того, чтобы определить, данные какого типа
находятся на данном конце дека.
Разнородные структуры и объектные
деревья
Реальный мир очень сложен, и его трудно моделировать.
Всю нашу жизнь нельзя аккуратно разложить по масси-
вам, циклическим спискам или стекам. Однако если
использовать классические структуры данных в комби-
нации друг с другом, то можно осуществить моделиро-
вание реальных объектов на соответствующем уровне
сложности.
Что такое ’'соответствующий уровень сложности"?
Мы не хотим, чтобы код программы был чересчур
сложным, но он должен описывать реальность настоль-
ко точно, насколько это необходимо для решения сто-
ящей перед нами задачи. "Упрощать вещи следует ров-
но настолько, насколько это возможно, и не более того”, —
говорил Эйнштейн. Иногда для решения сложных про-
блем приходится разрабатывать моделирующие програм-
мы с высоким уровнем сложности. Тем, кто говорит: "В
языке С этого нельзя сделать", в действительности сле-
довало бы говорить более точно: "В языке С этого нельзя
сделать легко".
Например, рассмотрим сортировочную станцию на
железной дороге. Какая структура данных подойдет для
ее описания? Массив не подойдет. Список тоже не по-
дойдет. Похоже, ни одна классическая структура дан-
ных, даже деревья, не дает возможности описать сор-
тировочную станцию адекватно. Единственной более
или менее подходящей структурой данных для модели-
рования сортировочной станции был бы, по-видимому,
граф, но и он не полностью адекватен.
Но кто сказал, что можно использовать только одну
структуру данных?
Что такое тупик, как не стек? Что такое боковой
путь, если не дек? Главные пути, которые отличаются
от боковых путей тем, что имеют точки пересечения с
другими главными путями, представляют собой дву-
связные списки. Даже поворотная платформа может
быть классически описана как циклический список.
И конечно же, если требуется, можно создавать масси-
вы всех этих структур данных.
Таким образом, используя комбинацию большого
числа структур данных различных типов можно создать
^соответствующий уровень сложности, необходимый для
решения какой бы то ни было задачи, стоящей перед
нами в данное время. Это не значит, что можно было
бы легко написать программу моделирования сортиро-
вочной станции. Но можно немного облегчить себе
жизнь, разбивая задачу на решаемые подзадачи, а затем
соответствующим образом объединяя вместе решения
этих подзадач. В этом и заключается суть программи-
рования.
Резюме
Естественно, что выбор алгоритма определяет выбор
структуры данных. Так же естественно, что диапазон и
сложность (мощность) структур данных, доступных
программисту, оказывает влияние на выбор алгоритма.
Многие программисты полагают, что классические
структуры данных и алгоритмы являются старомодны-
ми и их необходимо учить в колледже только для того,
чтобы сдать экзамены. На самом же деле реальный мир
трещит по швам от переполняющих его практических
приложений для списков, очередей и т.д.
Повторное использование кодов программ облегча-
ет нашу жизнь. Создав набор солидных библиотек для
работы с классическими структурами данных, можно
сэкономить массу времени. Возможно, вы без всякой
модификации будете применять библиотеки, представ-
ленные в настоящей главе. А может быть, вы адаптиру-
ете их для своих нужд или напишете свои собственные.
Каким бы путем вы ни пошли, не отказывайтесь от
преимуществ, которые мощный набор библиотек дает
для работы с основными абстрактными типами данных.
Мы только начали исследовать организацию дан-
ных. В этой части книги будут еще рассмотрены важ-
ные методы, позволяющие хранить информацию таким
способом, что она может быть быстро извлечена. Здесь
же имеется множество деревьев, которые только и ждут
желающих по ним "полазить".
Поиск по двоичному дереву
В ЭТОЙ ГЛАВЕ
Анализ алгоритмов поиска
Двоичные деревья
Сбалансированные двоичные деревья
12
Бэн Пфафф
Даже если у вас не очень большой опыт программиро-
вания, вы, наверное, обратили внимание на важность
понимания алгоритмов, связанных с поиском. Необхо-
димость проведения поиска возникает при написании
самого разного рода программ, начиная от компилято-
ров и интерпретаторов и заканчивая системами обработ-
ки текстов и графическими редакторами. Многие про-
граммы тратят значительную часть времени на
проведение поиска. Поэтому есть смысл более подроб-
но изучить алгоритмы поиска.
В этой главе мы сначала в общих чертах опишем
различные алгоритмы поиска, а затем более подробно
остановимся на двоичных поисковых деревьях, посколь-
ку это один из эффективных способов хранения данных
и их поиска в линейном списке. Рассмотрим также про-
стое несбалансированное двоичное дерево поиска и наи-
более часто используемые типы сбалансированного дво-
ичного поискового дерева: AVL-дерево и red-black
(красно-черное) дерево. По ходу рассмотрения создадим
библиотеки на языке С для работы с каждым из этих
типов двоичных поисковых деревьев.
Анализ алгоритмов поиска
Линейный поиск является наиболее очевидным методом
поиска в списке. По этой методике поиск начинается с
начала списка и каждый его элемент сравнивается с
искомым элементом. Если таким образом будет найден
нужный элемент, то поиск считается успешно завершен-
ным. Если же достигнут конец списка, а необходимый
элемент не найден, поиск считается завершенным не-
удачно.
Скорость линейного поиска обратно пропорциональ-
на количеству элементов, которые в данном списке срав-
ниваются с искомым элементом. Если элементы распо-
ложены случайным образом, то скорость линейного
поиска будет обратно пропорциональна количеству эле-
ментов в списке. При осуществлении поиска элемента,
которого вообще нет в списке, сравнение будет произ-
ведено со всеми его элементами. Если в списке содер-
жится большое количество элементов, такой алгоритм
поиска будет выполняться очень медленно.
Скорость описанного выше простого линейного ал-
горитма поиска можно повысить двумя путями. Напри-
мер, можно в конец списка поместить копию искомого
элемента (сигнальную метку). В этом случае мы будем
знать, что в списке есть искомый элемент, поэтому нет
необходимости на каждом этапе проверять, достигнут
конец списка или нет. Когда искомый элемент будет
найден, необходимо проверить, является ли найденный
элемент сигнальной меткой или он действительно был
в списке.
Другим методом повышения скорости линейного
поиска является использование упорядоченного спис-
ка, в котором элементы расположены в порядке по воз-
растанию. В этом случае при отсутствии в списке ис-
комого элемента не нужно будет проводить его
сравнение с каждым элементом списка: если первый
элемент списка больше искомого элемента, значит, пос-
ледний отсутствует в списке.
Двоичный поиск
Но если список уже отсортирован, лучше использовать
другой метод поиска. Вместо того чтобы начинать с
начала списка, начинаем с середины. Если средний эле-
мент списка является искомым элементом, это просто
великолепно: мы попали на него с первой попытки.
В противном случае необходимо определить, средний
элемент больше или меньше искомого элемента. Пред-
положим, что средний элемент больше искомого. В этом
Поиск по двоичному дереву
Глава 12
j 267
случае мы знаем, что искомый элемент находится во
второй части списка, если он вообще есть в списке.
При использовании такого алгоритма за один этап
мы сократили объем поиска в 2 раза. Дальнейший по-
иск можно проводить с помощью этого же алгоритма.
С каждым шагом мы все больше приближаемся к иско-
мому элементу, уменьшая на каждом этапе количество
сравниваемых элементов в списке примерно вдвое.
В конце концов, либо искомый элемент будет найден,
либо количество элементов в списке уменьшится до
нуля, что будет означать отсутствие искомого элемента
в списке.
В качестве примера рассмотрим игру ’’Угадай число".
В этой игре игрок загадывает число, скажем, между 1 и
15, а компьютер пытается его угадать. После каждой
попытки компьютера игрок говорит, соответствует ли
ответ компьютера загаданному, а если нет, то уточня-
ет, больше или меньше загаданного выданное компью-
тером число.
Предположим, игрок загадал число 10. Первая по-
пытка компьютера будет 8, среднее число между 1 и 15,
которое меньше загаданного. Теперь компьютер знает,
что загаданное число находится между 9 и 15, поэтому
следующей его попыткой будет число 12. Игрок сооб-
щает, что это число больше загаданного, т.е. загаданное
число находится в пределах между 9 и 11. Средним
элементом этого диапазона будет число 10 — эта сле-
дующая попытка компьютера окажется верным ответом.
По сравнению с линейным поиском двоичный по-
иск оказывается гораздо быстрее. На каждом этапе ко-
личество возможных элементов сокращается вдвое, т.е.
в списке из п элементов максимальное количество эта-
пов будет примерно равно количеству операций деле-
ния п на 2, пока полученный результат не станет мень-
ше единицы. В математике это значение называется
логарифмом по основанию 2 от числа п или просто log2n.
Следовательно, двоичный поиск является алгоритмом
порядка O(log2n).
Добавление и удаление элементов из
отсортированной таблицы
Если вы внимательно прочитали то, о чем говорилось
выше, то вероятно, заметили, что при рассмотрении
алгоритма двоичного поиска начали появляться предпо-
ложения. В линейном поиске необходимо было просто
идти по списку на один элемент за один шаг, а в дво-
ичном поиске приходится постоянно прыгать по спис-
ку. В примере игры ’’Угадай число” мы последователь-
но переходили к элементам 8, 12 и 10.
Это ограничивает структуры данных, которые могут
быть использованы в качестве списка. Связанный спи-
сок не подходит по той простой причине, что переход
от одного элемента к другому занимает много времени.
Проше воспользоваться массивом, поскольку в массиве
легко получить доступ к любому элементу.
Массивы удобны для проведения двоичного поиск,
если нет необходимости в добавлении и удалении эле-
ментов. Если такая необходимость есть, то для массива
это будет проблемой, поскольку вставка или удаление
элемента в середине массива означает, что все последу-
ющие элементы придется передвигать в памяти, а это
довольно медленная операция. Нельзя просто добавить
элементы в конец массива, поскольку для проведения
двоичного поиска массив должен быть отсортирован.
Точно так же элементы не могут быть удалены из сере-
дины списка без образования "дыр’’.
Следовательно, ни массив, ни связанный список не
подходят для реализации структуры данных, предназ-
наченных для двоичного поиска, если есть необходи-
мость во вставке и удалении элементов. Требуется но-
вая структура данных, которая называется двоичным
деревом.
Двоичные деревья
Преимущество двоичного дерева состоит в том, что при
двоичном поиске на каждом следующем этапе поиска
должны быть проанализированы только два возможных
направления. Двоичное дерево в каждом элементе со-
держит указатели на эти два направления. На рис. 12.1
показан пример игры ’’Угадай число”.
РИСУНОК 12.1. Двоичное дерево игры "Угадай число".
Двоичное дерево — это структура, состоящая из
нуля или большего количества узлов, каждый из кото-
рых содержит некоторое значение (например, одно из
чисел в игре "Угадай число"), а также указатели на ле-
вое и правое поддеревья. Один или оба указателя на эти
поддеревья могут иметь значение NULL. Ненулевые
поддеревья сами являются двоичными деревьями. Таким
образом, двоичные деревья являются рекурсивными
структурами.
Двоичное дерево поиска — это двоичное дерево с од-
ним дополнительным свойством: для каждого узла х все
узлы в левом поддереве х, если оно ненулевое, содер-
жат значения, которые меньше значения узла х, а все
узлы в правом поддереве содержат значения, которые
Организация данных
Часть II
268
больше значения узла х. Двоичное дерево игры "Угадай
число” является двоичным деревом поиска. В этой гла-
ве мы будем рассматривать только двоичные деревья
поиска, поэтому для удобства они иногда будут назы-
ваться либо двоичными деревьями, либо просто дере-
вьями, даже если это и не совсем верно.
Далее, имеет смысл ввести еще несколько понятий.
В двоичном дереве поиска каждый узел является роди-
тельским узлом, или просто родителем, двух своих под-
деревьев. Соответственно узлы поддеревьев являются
дочерними узлами. Узел, у которого нет дочерних узлов,
называется листом, а узел, у которого нет родителя, или,
чаще, узел в вершине дерева — корнем своего дерева.
Пустое дерево — это дерево без узлов.
Обратите внимание, что двоичные деревья с одним
и тем же содержимым могут иметь различные структу-
ры. Сравните, например, рисунки 12.2 и 12.1. На обо-
их рисунках изображены двоичные деревья поиска,
которые содержат целые числа от 1 до 15, но эти дере-
вья имеют различную структуру.
РИСУНОК 12.2. Еще одно дерево, содержащее целые числа от 1
до 15. Сравните структуру этого дерева со структурой
дерева, показанного на рис. 12.1.
Структура для узла в языке С
Довольно теории. Перейдем к вопросу о том, какие за-
дачи можно решать для двоичных деревьев. Начнем с их
узлов.
Просмотрев еще раз определение узла, можно напи-
сать на языке С определение аналогичной структуры,
приведенное в листинге 12.1.
Листинг 12.1. bin.c — узловая структура для
двоичного дерева.
31 struct bin_node {
32 int data;
33 struct binnode *left;
34 struct binnode *right;
35 };
Обратите внимание на точное соответствие абстрак-
тного определения двоичного дерева и структуры, со-
здаваемой в этом листинге: struct bin node содержит
значение data: указатель на левое поддерево — left и
указатель на правое поддерево — right.
Для целей, которые поставлены в этой главе, значе-
ние узла будет иметь тип int. Расширение приведенно-
го примера кода для использования значений другого
типа мы оставляем для самостоятельной проработки
читателю.
Структура в языке С для дерева
Кроме отслеживания отдельных узлов, необходимо
иметь возможность работать со всем деревом. В боль-
шинстве случаев эта задача сводится к отслеживанию
корневого узла дерева, что позволяет легко передать это
дерево для обработки функциям. Но иногда бывает не-
обходимо хранить и другую информацию о дереве.
С этой целью проще всего определить еще одну струк-
туру для самого дерева и поместить в нее указатель на
его корень и дополнительную информацию. Например,
38 struct bin_tree {
39 struct bin_node *root;
40 int count;
41 };
Здесь переменная root определена как указатель на
узел. Данную переменную можно было бы объявить как
сам узел, но это усложнило бы некоторые операции.
Вообще, корень легче объявить как указатель.
Поле count содержит дополнительную информацию
о самом дереве. В некоторых случаях необходимо знать
количество узлов в дереве. Для этого удобнее обновить
значение count, а не пересчитывать каждый раз количе-
ство узлов в дереве.
Операции
Это действительно волнующая часть. Теперь, когда из-
вестно, почему данные представляют в виде двоичного
дерева и каким образом представить его на языке С,
можно написать код, который будет выполнять различ-
ные операции. Итак, приступим.
Создание
Создать пустое двоичное дерево очень просто. Прежде
всего необходимо с помощью функции malloc() выде-
лить память под структуру struct bin tree. Если функ-
ция mallocO завершится неудачно, вызывающей про-
грамме в качестве предупреждения будет возвращен
нулевой указатель. Можно было бы выдать сообщение
об ошибке и закончить выполнение программы или
освободить неиспользованную память и еще раз попы-
таться выделить ее под двоичное дерево либо исполь-
зовать какую-то другую стратегию. Если выделение
памяти прошло успешно, инициализируется новое де-
Поиск по двоичному дереву
Глава 12
269
рево и вызывающей программе возвращается указатель
на это дерево.
45 struct bin__tree *bin_create (void)
46 {
47 struct bin tree *tree = malloc(sizeof
*tree);
48 if (tree == NULL)
49 return NULL;
50 tree->root = NULL;
51 tree->count = 0;
52 return tree;
53 }
Поиск
Само по себе пустое двоичное дерево бесполезно. Те-
перь, когда код для создания пустого двоичного дерева
написан, необходимо наполнить его данными. Оказы-
вается, что первым шагом при вставке узла (и при мно-
гих других операциях с двоичным деревом) является
поиск узла с таким же значением, поэтому перед опе-
рацией вставки узла рассмотрим процесс поиска по дво-
ичному дереву.
57 int bin_search(const struct bin_tree
4*tree, int item)
58 {
59 const struct bin node *node;
60
61 assert(tree != NULL);
62 node « tree->root;
63 for (;;) {
64 if (node == NULL)
65 return 0;
66 else if (item == node->data)
67 return 1;
68 else if (item > node->data)
69 node = node->right;
70 else
71 node = node->left;
72 }
73 }
Здесь мы объявили функцию bin_search(), которая
будет осуществлять поиск значения item по дереву tree.
Если значение item присутствует в дереве, эта функция
возвращает ненулевое значение, если же такого значе-
ния в дереве нет, функция возвращает нуль.
Функция bin_search() начинает свою работу с про-
верки аргументов (строка 61). Это очень важный мо-
мент, особенно для функций, которые делают опреде-
ленные предположения о своих аргументах (т.е.
практически для всех функций). В нашем примере не-
обходимо убедиться, что tree является структурой
bin tree. Хотя мы не можем точно это проверить, тем
не менее, можем проверить, не является ли tree просто
нулевым указателем.
Обратите внимание, что в данном случае нужно
было бы написать !=NULL, хотя при проверке указа-
телей в операторах if и while и в некоторых других это
не обязательно. Многие компиляторы одинаково будут
воспринимать и assert(tree), и assert(tree!=NULL), но
поведение программы в случае первой проверки будет
неопределенным. Поэтому лучше обезопасить себя, чем
потом сожалеть.
Собственно поиск по двоичному дереву следует сра-
зу за проверкой аргументов. Для поиска используется
алгоритм, который был подробно описан в начале этой
главы. Начинается поиск с корня дерева (строка 62).
На каждом этапе процесса поиска нужно проверять,
все ли узлы просмотрены (строка 64). Если все, значит,
искомого элемента в дереве нет, и тогда в качестве пре-
дупреждения вызывающей программе возвращается 0
(строка 65). Если текущий узел не последний, значение
этого узла сравнивается со значением item. Если эти два
значения равны, возвращается 1, таким образом вызы-
вающая программа узнает об успешном нахождении
значения item (строки 66 и 67).
Если значение item больше значения узла, то оно
должно находиться в правом поддереве (если оно вооб-
ще есть в дереве), поэтому мы переходим в правое под-
дерево и повторяем весть процесс (строки 68 и 69). Если
значение item меньше значения узла, то оно должно
находиться в левом поддереве, поэтому мы переходим
в левое поддерево и опять повторяем весть процесс
(строки 70 и 71).
Давайте рассмотрим поведение функции bin_search()
для предельного случая, когда дерево пустое. Всегда есть
смысл проверять поведение программ в таких гранич-
ных случаях, поскольку неаккуратные программисты
иногда упускают их из виду и потом возникают ошиб-
ки. Как бы то ни было, в нашем примере ошибок не
будет: если дерево tree пустое, то tree->root будет ну-
левым указателем и функция bin search() возвратит 0
при первом же проходе цикла.
Вставка
Как было сказано в предыдущем разделе, вставка узла
в двоичное дерево является просто продолжением опе-
рации поиска. Отличие заключается лишь в том, что,
если искомого элемента в дереве нет, мы добавляем в
дерево новый узел в то место, на котором он должен
быть.
78 int bin__insert (struct bin_tree *tree, int
^item)
79 {
80 struct bin_node *nodef **new;
81
82 assert(tree != NULL);
83 new = 6tree->root;
84 node = tree->root;
85 for (;;) {
86 if (node == NULL) {
270
Организация данных
Часть II
87 node = *new = malioc(sizeof *node);
88 if (node != NULL) {
89 node->data = item;
90 node->left = node->right = NULL;
91 tree->count++;
92 return 1;
93 }
94 else
95 return 0;
96 }
97 else if (item == node->data)
98 return 2;
99 else if (item > node->data) {
100 new = fcnode->right;
101 node = node->right;
102 }
103 • else {
104 new = &node->left;
105 node = node->left;
106 }
107 }
108 }
Здесь объявляется функция binjnsert(), которая в
качестве аргументов принимает двоичное дерево и эле-
мент, который необходимо вставить. Функция
bin_insert() возвращает 1, если элемент успешно был
вставлен в дерево, 2 — если элемент с таким же значе-
нием уже есть в дереве (двоичное дерево поиска, по
нашему определению, не может содержать в разных
узлах несколько одинаковых значений), и 0 — если эле-
мента в дереве нет и вставка невозможна из-за ошибки
при выделении памяти.Таким образом, вызывающая
программа может проверить успешность выполнения
операции вставки по возвращаемому функцией
bin_Jnsert() значению.
Как и ранее, здесь node указывает на текущий узел.
Новая переменная new — это двойной указатель, ука-
зывающий на. указатель, по которому мы попали в узел
node. Это очень важный момент, поэтому при рассмот-
рении кода всегда следует о нем помнить.
В начале функции мы проверяем, не является ли tree
нулевым указателем, затем инициализируем node значе-
нием .корня дерева и присваиваем переменной new ад-
рес указателя на корень дерева (строки 82-84).
Основной цикл функции (строки 85-105) повторя-
ется по одному разу для каждого уровня дерева. При
этом выполняются проверки, аналогичные тем, которые
производятся в функции bin_search().
Наибольшее различие функций bin insert() и
bin_search() заключается в их поведении при попадании
на нулевой указатель, когда элемента item в дереве нет.
Нам необходимо добавить элемент в нужную точку
дерева, заменяя ^нулевой указатель, с помощью которо-
го Мф1. попали в данную точку дерева, новым узлом,
содержащим элемент item. К счастью, известно, где
находиться нулевой указатель, поскольку для его отсле-
живания используется переменная new. Мы просто вы-
деляем память под новый узел и сохраняем его в *new,
проверяя успешность выделения памяти (строки 87 и 88).
Кроме того, для обеспечения более легкого доступа
нужно сохранить новый узел в node. Мы инициализи-
руем новый узел значением item и устанавливаем зна-
чения указателей поддеревьев нового узла равными
NULL (строки 89 и 90). И наконец, увеличиваем на 1
счетчик элементов дерева и возвращаем значение 1, го-
ворящее о том, что новый узел был успешно вставлен
(строки 91 и 92).
Здесь программный код прохождения по дереву не-
сколько изменен по сравнению с кодом для поиска. Это
было необходимо для сохранения значения переменной
new и возвращения значения, которое используется в
случае, если элемент item найден. В остальном код фун-
кции bin_insert() соответствует коду функции
bin_search().
Удаление
Теперь, когда у нас есть код для создания двоичного
дерева и вставки в него элементов, нам понадобится
функция для удаления элементов из дерева. Процесс
удаления элементов несколько сложнее, чем процесс
вставки. Давайте рассмотрим этот код.
112 int bin_delete (struct bin_tree *tree, int
^item)
113 {
114 struct bin node **qf *z;
115
116 assert(tree 1= NULL);
117 q - 6tree->root;
118 z = tree->root;
119 for (;;) {
120 if (z == NULL)
121 return 0;
122 else if (item == z->data)
123 break;
124 else if (item > z->data) {
125 q = 6z->right;
126 z = z->right;
127 }
128 else {
129 q = 6z->left;
130 z = z->left;
131 }
132 }
133
134 if (z->right == NULL)
135 *q - z->left;
136 else {
137 struct binnode *y = z->right;
138 if (y->left == NULL) {
139 y->left = z->left;
140 *q = y;
141 }
142 else {
143 struct binnode *x = y->left;
144 while (x->left 1= NULL) {
Поиск по двоичному дереву
Глава 12
271
145 у = х;
146 х = y->left;
147 }
148 y->left = x->right;
149 x->left = z->left;
150 x->right = z->right;
151 *q = x;
152 }
153 154 }
155 tree->count-;
156 free(z);
157 return 1;
158 } i.-
Мы объявляем функцию bin_delete(), которая в ка-
честве аргументов принимает двоичное дерево tree и
значение item, которое необходимо удалить. Функция
bin_delete() возвращает 0, если значения item в дереве
нет, и 1 — если значение item было успешно удалено.
(Функция, в принципе, не может завершиться неудач-
но, поэтому в ней не предусмотрено определенного
возвращаемого значения на случай неудачи.)
Цикл в начале функции (строки 119—132) должен
показаться вам знакомым. Это тот же алгоритм поиска
в двоичном дереве, который мы реализовали уже дваж-
ды, но здесь node переименован на z, a new на q.
Кроме того, если значение item найдено, вместо выпол-
нения вставки элемента цикл просто завершается (с
помощью оператора break).
После завершения цикла мы знаем наверняка, что
значение item уже присутствует в дереве tree, посколь-
ку это и есть условие завершения цикла. Кроме того, z
указывает на узел, который необходимо удалить, a q —
на указатель, с помощью которого мы попали в узел z.
Теперь, чтобы решить, каким образом можно удалить
узел из дерева, необходимо проанализировать значение
z. Возможны три различных случая, два из которых
достаточно просты, а третий несколько сложнее. Каж-
дый из этих случаев представлен на рис. 12.3 и рассмат-
ривается ниже.
Случай 1 (рис. 12.3 а, строки 134 и 135 предыдуще-
го кода). Узел z не имеет правого дочернего узла, сле-
довательно, узел z можно заменить его левым дочерним
узлом. Мы просто заменяем указатель на z (*q) указа-
телем на левый дочерний узел узла z. Если узел z не
имеет и левого дочернего узла, значение *q заменяется
на нулевой указатель, что тоже не представляет ника-
ких затруднений. Вот и все, что требуется сделать в этом
случае.
Случай 2 (рис. 12.3 Ь, строки 137—141). Узел z име-
ет правый дочерний узел, но тот не имеет левого дочер-
него узла. Правый дочерний узел узла z получает левое
поддерево узла z, а затем заменяет собой сам узел z. Мы
заменяем z на у, устанавливая значение *q. Кроме того,
чтобы не потерять левое поддерево узла z, нужно ско-
пировать указатель на него в у.
Случай 3 (рис. 12.3 с, строки 142—151). В оставшемся
случае узел z заменяется на дочерний узел х, а затем х
удаляется, поскольку у него нет левого дочернего узла.
Мы знаем, что у z есть правый дочерний узел и что у
правого дочернего узла есть левый дочерний узел, ко-
торый мы сохраняем в х. Далее цикл проходит по ука-
зателю на левый дочерний узел узла х до тех пор, пока
не наткнется на узел без левого дочернего узла (строки
144—147). В этом случае х становится наследником узла z
в дереве tree, т.е. х содержит минимальное значение в де-
реве tree, которое больше значения узла z. Таким образом,
узел у оказывается родительским узлом для узла х.
272
Организация данных
Часть II
Почему х является преемником z? Порассуждаем
логически. Все узлы в левом поддереве узла z содержат
значения, которые меньше значения узла z, поэтому
преемник узла z должен быть из правого поддерева узла
z. Поскольку в двоичном дереве при перемещении вле-
во значения уменьшаются, то, чтобы найти наименьшее
значение, необходимо переходить к левым поддеревь-
ям до тех пор, пока все левые поддеревья не закончат-
ся. Не имеет смысла переходить на правое дерево, по-
скольку правый дочерний узел всегда содержит
значение, превышающее значение родительского узла.
Теперь узел х является преемником узла z, а узел у
является родительским узлом для узла х. Чтобы эффек-
тивно удалить узел z, необходимо его заменить на узел
х и свести задачу удаления z к задаче удаления предше-
ствующего узла х. Узел х не имеет левого дочернего узла
(иначе он не был бы преемником узла z), поэтому его
удаление не представляет никаких сложностей.
Сначала узел х удаляется из дерева путем замены
указателя на левое поддерево узла у (который указыва-
ет на х) указателем на правое поддерево узла х (строка
148). Далее поддеревья узла х заменяются поддеревья-
ми узла z и указатель *q устанавливается на узел х, а не
на z (строки 148—151). На этом процедура удаления за-
вершается.
После удаления количество узлов в дереве уменьши-
лось на единицу, поэтому значение счетчика
tree->count уменьшается на 1 (строка 155). Переменная
t больше не используется, поэтому мы ее высвобожда-
ем (строка 156). И наконец, функция bin delete() воз-
вращает вызывающей программе значение, соответству-
ющее успешному удалению узла (строка 157).
В заключение рассмотрим предельный случай: что,
если удаляемый узел оказывается единственным узлом
дерева? В этом случае искомым узлом будет z. Он бу-
дет обнаружен при первом же прохождении цикла, и
цикл завершится. Поскольку узел z является листом (т.е.
у него нет правого поддерева), мы можем рассматривать
случай 1 (см. ранее) и никаких проблем не возникает.
Упорядоченное рекурсивное прохождение
Одним из преимуществ двоичных поисковых деревьев
по сравнению с другими структурами представления
данных является то, что в двоичном дереве легко полу-
чить доступ к данным в упорядоченном (отсортирован-
ном) виде. В таких структурах как хеш-таблицы для это-
го необходимо каждый раз выполнять медленную и
дорогостоящую сортировку.
Рекурсия является наиболее простым методом напи-
сания программ для распечатки сортированного спис-
ка значений всех узлов двоичного дерева поиска. Такой
алгоритм основан на самой структуре двоичного дере-
ва. Для каждого узла справедливо утверждение о том,
что значение этого узла больше значений узлов в его
левом поддереве и меньше значений узлов в его правом
поддереве. Следовательно, для распечатки содержимо-
го дерева в отсортированном виде необходимо сначала
распечатать содержимое его левого поддерева, затем зна-
чение его корня и, наконец, содержимое его правого
поддерева.
Но каким образом распечатывать поддеревья? По-
мните, поддеревья двоичного дерева сами являются дво-
ичными деревьями, поэтому их содержимое необходи-
мо распечатывать таким же образом, как и содержимое
всего дерева: сначала содержимое левого поддерева, за-
тем значение корня, а затем содержимое правого под-
дерева. Другими словами, поддеревья распечатываются
рекурсивно — так же, как и корень.
Прямо по этому описанию можно напиейть функ-
цию:
162 static void walk(const struct bin_node
w*node)
163 {
164 if (node == NULL)
165 return;
166 walk(node->left);
167 printf("%d ", node->data);
168 walk(node->right);
169 }
Функция walk() в качестве аргумента принимает
указатель на узел node двоичного дерева поиска. Функ-
ция распечатывает в отсортированном виде содержимое
дерева, корнем которого является узел node.
Обратите внимание, что walk() является первой на-
шей функцией, которая в качестве аргумента принима-
ет указатель на узел. Но это не совсем то, что требует-
ся. При написании библиотеки функций лучше не
ожидать от пользователя знания внутреннего содержи-
мого библиотеки в большей мере, чем это необходимо.
Это принцип скрытия информации или абстракции. По
этой же причине функция walk() объявлена как static,
что не позволит просмотреть код функции вне файла,
в котором она объявлена. Ниже приведен код более
удобной открытой (public) функции для прохождения
двоичного дерева, которая в качестве аргумента прини-
мает указатель на дерево, а не на узел.
Код этой функции довольно прост. Если node явля-
ется нулевым указателем, то печатать нечего (строки
164 и 165). В противном случае печатается левое под-
дерево узла node (строка 160), затем значение самого
узла (строка 167), а после этого правое поддерево (стро-
ка 168), как было описано выше.
Теперь определим открытую функцию, которая бу-
дет использовать функцию walk():
172 void bi n_walk (const struct bin__tree *tree)
173 {
174 assert(tree != NULL);
Поиск по двоичному дереву
Глава 12
273
175 walk(tree->root);
176 }
Эта функция не требует объяснений. Она проверя-
ет, не является ли аргумент tree нулевым, и вызывает
функцию walk(), которая и выводит элементы двоично-
го дерева на печать.
Упорядоченное итеративное прохождение
Рекурсия представляет собой простейший способ реа-
лизации упорядоченного прохождения двоичного дере-
ва, но во многих случаях рекурсия бывает неудобна.
Предположим, например, что необходимо написать фун-
кцию tree_sum(), которая бы вычисляла сумму элементов
двоичного дерева поиска. Если бы модифицировать фун-
кцию bin_walk() в функцию bin_walk_action(), которая
будет вызываться для каждого узла, то можно получить
примерно такой код:
static void sum_walk_function(int value, void
♦sum)
{
*(int *) sum += value;
}
int tree_sum(struct bin_tree *tree)
{
int sum = 0;
bin_walk_action(tree, bsum);
return sum;
1
Такой метод имеет несколько недостатков. Во-пер-
вых, в нем используются две функции для выполнения
работы, которая, по логике, требует лишь одной функции,
что усложняет понимание программы. Во-вторых, пере-
дача данных между tree_sum() и sum_walk function()
усложнена. В третьих, передача данных опасна, по-
скольку она требует преобразования типов, которого
избегают большинство осторожных программистов.
Альтернативный метод прохождения двоичного де-
рева поиска исключает указанные недостатки. Функцию
tree_sum() можно записать в следующем виде:
int tree_sum(struct bin_tree *tree)
{
struct biniterator iter;
int sum = 0, addend;
bin_for_each_init(biter);
while (bin_for_each(tree, biter, baddend))
sum += addend;
return sum;
В этой функции преодолены многие недостатки ее
предыдущей версии. Она не требует использования двух
функций, вся логика сосредоточена в одном месте, и нет
необходимости в запутанной и опасной передаче данных.
Теперь, когда мы убедились в полезности функции
итеративного прохождения двоичного дерева, давайте
перейдем к написанию такой функции. Для краткости
и простоты не будем добиваться полной дееспособнос-
ти функции bin_for_each(), как в приведенном выше
коде.
Можно было бы просто разработать метод итератив-
ного прохождения дерева, но, возможно, более полез-
но будет исключить рекурсию в рекурсивном методе,
который уже был рассмотрен. Рассмотрим код функции
walk(), которая была приведена в предыдущем разделе:
if (node = NULL)
return;
walk(node->left);
printf("%d ", node->data);
walk(node->right);
Обратите внимание, что последний рекурсивный
вызов функции walk() не производит никаких действий
после выхода из функции. Это называется концевой ре-
курсией. которую всегда можно заменить переходом на
начало функции после всех необходимых изменений
аргументов функции. Поэтому в качестве первого шага
исключения рекурсии перепишем код в следующем
виде:
for (;;) {
if (node == NULL)
return;
walk(node->left);
printf(" %d ", node->data);
walk(node->right);
}
Остался только один рекурсивный вызов, исключить
который гораздо сложнее. Подумайте о том, что на са-
мом деле происходит при вызове walk(tree->left): сохра-
няется текущее значение node, далее оно заменяется на
node->left, а затем выполнение функции начинается
сначала. Если значение node равно NULL и выполнение
функции завершается, то предыдущее значение node
восстанавливается и выполнение возобновляется с опера-
тора, который следует непосредственно после вызова.
Этот процесс можно имитировать и без вызова
walk(tree->left), если мы сами будем сохранять и вос-
станавливать значение node. Для этой цели идеально
подойдет представление данных в виде стека. (Факти-
чески многие программы, написанные на С, неявно
используют стек для отслеживания вызовов функций.)
Реализовать такой стек очень просто:
struct bin_node *stack[32];
int count = 0;
for (;;) {
while (node != NULL) {
stack[count++] = node;
node = node->left;
18 Зак. 265
274
Организация данных
Часть II
if (count == 0)
return;
node = stack[-count];
printf(*%d "f node->data);
node = node->right;
}
Здесь stack является массивом указателей на узлы,
которые составляют содержимое стека, a count — коли-
чество указателей в стеке на данный момент времени.
(Следовательно, если count больше нуля, верхним ука-
зателем в стеке является stack[count-l].)
Новый код в цикле выполняет явное сохранение
текущего значения node. Если значение node ненулевое,
оно сохраняется в стеке, а значение node заменяется
значением node->left, после чего выполнение функции
начинается сначала. Если значение node нулевое, фун-
кция восстанавливает предыдущее значение node и вы-
полнение продолжается. При отсутствии предыдущих
значений node, на что указывает пустой стек, можно
считать, что задача выполнена и функция завершает
свою работу.
Теперь у нас есть замена для функции walk(). Од-
нако, если вы четко следите за всеми нашими рассуж-
дениями, то, может быть, заметили, что нет необходи-
мости разбивать задачу прохождения дерева на две
функции. Мы без труда можем объединить измененную
функцию walk() с функцией bin walk() и в результате
получить функцию bin_traverse():
180 void bin__traverse (const struct bin_tree
***tree)
181 {
182 struct binnode *stack(32);
183 int count;
184
185 struct binnode *node;
186
187 assert(tree != NULL);
188 count = 0;
189 node = tree->root;
190 for (;;) {
191 while (node != NULL) {
192 stack [count++] = node;
193 node = node->left;
194 }
195 if (count == 0)
196 return;
197 node = stack [-count ];
198 printf("%d ", node->data);
199 node = node->right;
200 }
201 }
Обратите внимание, что на практике такой реализа-
ции следует избегать, за исключением случаев, когда
высота дерева ограничена и меньше размера стека.
В реальной программе выделение памяти под стек сле-
дует производить динамически и при необходимости
расширять стек.
Уничтожение дерева
В конце концов настает момент, когда дерево становит-
ся ненужным. В таком случае его следует уничтожить.
При этом необходимо уничтожить каждый узел дерева
и саму его структуру. Уничтожение всех узлов дерева
можно выполнить с помощью еще одной рекурсивной
функции. На этот раз нужно убедиться, что мы не по-
лучим доступа к уничтоженному узлу. Для этого про-
ще всего выполнить обратное прохождение, в отличие
от прямого прохождения, которое осуществляется в
функциях avl_walk() и avl_traverse(). При обратном
прохождении мы сначала рекурсивно выполняем дей-
ствие над каждым поддеревом узла, а затем над самим
узлом. Это легко реализуется следующим образом:
204 static void destroy(struct bin_node *node)
205 {
206 if (node == NULL)
207 return;
208 destroy(node->left);
209 destroy(node->right);
210 free(node);
211 }
Сначала функция destroy() проверяет, равен ли ука-
затель node на узел, который необходимо уничтожить,
значению NULL. Если равен, то никаких действий не
выполняется и функция завершается (строки 206 и 207).
В противном случае функция destroy() вызывает рекур-
сивно саму себя для левого и правого поддеревьев, а
затем высвобождает сам указатель node (строки 208-210).
Проще было бы иметь возможность уничтожить де
рево без знания его внутренней структуры. Кроме того,
требуется уничтожить не только узлы, но и структуру
bin tree. Поэтому введем вспомогательную функцию,
которая вызывает функцию destroy():
214 void bin_destroy (struct bin_tree *tree)
215 {
216 assert(tree != NULL);
217 destroy(tree->root);
218 free(tree);
219 }
Счетчик
При определении структуры bin_tree6bm введен элемен i
count, который используется для отслеживания количс
ства узлов дерева. До сих пор не было предложено ни
какого метода доступа к этой информации наряду с
прямым доступом к элементам структуры struct
bi ntгее. Требовать от пользователей библиотеки знания
’’внутренностей" структуры нецелесообразно, особенно
если библиотека будет использоваться не только в коле
для которого она непосредственно была предназначен?
Лучше, если пользователь будет считать библиотек;,
"черным ящиком".
275
Давайте напишем простую функцию, которая будет
определять количество узлов в указанном двоичном де-
реве:
222 int bin count (const struct bin tree *tree)
223 {
224 assert(tree 1= NULL);
225 return tree->count;
226 }
Этот код не требует объяснений.
Анализ
В начале этой главы причиной рассмотрения двоично-
го дерева была названа низкая скорость поиска по спис-
ку. Теперь необходимо еще раз более точно оценить
скорость поиска по двоичному дереву, чтобы убедить-
ся, что оно действительно обеспечивает ту скорость, на
которую мы рассчитывали.
В примере игры "Угадай число" на каждом уровне
дерева всегда было два возможных варианта выбора. Это
означает, что количество возможностей уменьшается на
каждом этапе вдвое. Именно это и требовалось.
Но что произойдет, если на каждом уровне будет не
по два возможных варианта выбора? Тогда количество
возможностей не будет уменьшаться вдвое на каждом
этапе, поскольку при этом исключается только одна
возможность (тот элемент, с которым производилось
сравнение). Эффективность в этом случае приближает-
ся к эффективности линейного поиска, при котором на
каждом этапе исключается только одна возможность.
Для удобства дальнейшего обсуждения введем не-
сколько дополнительных терминов. Высотой дерева
будем называть максимальное количество узлов, по ко-
торым можно пройти, начиная с корня дерева, если
разрешено переходить только от родительского узла к
дочернему, но не наоборот. Согласно этому определе-
нию, высота листа равна 1, а высота узла, который не
является листом, равна I плюс высота самого высокого
поддерева этого узла.
Максимальное время поиска по двоичному дереву
зависит от его высоты. Если высота дерева равна 5, тог-
да для определения того, содержится ли искомый эле-
мент в дереве, требуется в наихудшем случае выполнить
пять сравнений. Двоичное дерево с п узлами будет иметь
высоту не менее logjW, а максимальная высота может
оказаться равной п, если дерево сконструировано не-
брежно.
Поскольку максимальное время поиска зависит от
высоты дерева, желательно иметь дерево с минимальной
высотой. Давайте рассмотрим, как строится нормальное
двоичное дерево, а затем посмотрим, каким образом оно
Может выродиться в связанный список, и проанализи-
руем стратегии минимизации высоты дерева.
Поиск по двоичному дереву
Глава 12
Формирование двоичного дерева случайным
образом
В начале этой главы был рассмотрен метод построения
двоичного дерева из сортированного списка. В резуль-
тате такого подхода мы всегда получали двоичное де-
рево минимальной высоты. Но это достаточно редкий
случай. В реальной жизни всегда придется добавлять и
удалять узлы. Если бы такая возможность не требова-
лась, можно было бы просто использовать сортирован-
ный список, поскольку с ним легче работать.
Предположим, что мы начинаем с пустого двоичного
дерева, в которое добавляем узлы до тех пор, пока де-
рево не будет содержать все необходимые данные. Пред-
положим, что добавление узлов осуществляется случай-
ным образом. Что это будет означать для функции
bin_insert()? На каждом этапе вероятность тогр, что зна-
чение добавляемого элемента будет больше или мень-
ше значения узла, составляет по 50%. Это означает, что
вставка узла со случайным значением в двоичное дере-
во произойдет в случайном месте в нижней части дере-
ва. Поэтому вставка элементов в двоичное дерево слу-
чайным образом должна привести к созданию дерева, по
которому можно будет провести быстрый поиск, по-
скольку не происходит '’накопления” узлов в каком-
либо месте дерева.
Удаление узлов из дерева случайным образом также
позволяет сохранить высоту дерева близкой к минималь-
ной. Это несколько менее очевидно, поскольку функ-
ция bin_delete() рассматривает три различных случая, но
можете быть уверены, что приведенное утверждение
справедливо.
Вам, может быть, будет недостаточно этих неофи-
циальных утверждений. Тогда почитайте книги The Art
of Computer Programming, Vol. 3 или Introduction to
Algorithms, ссылки на которые приведены в приложении
В. Обе этих книги дают доказательства того, что встав-
ка в двоичное дерево и удаление из двоичного дерева
случайным образом приводит к тому, что высота дере-
ва стремится к минимальной. Математические выклад-
ки, которые использовались в этих книгах, здесь не
будут рассматриваться, хотя они и не очень сложные.
Формирование двоичного дерева не случайным
образом
Что происходит, когда значения вставляются в двоич-
ное дерево не случайным образом? Тогда дерево может
выродиться в связанный список. Например, рассмотрим
рис. 12.4 а как пример того, что происходит в самом
худшем случае, когда значения вставляются в отсорти-
рованном порядке. Образование зигзагообразного дере-
ва, показанного на рис. 12.4 Ь, менее вероятно, но на-
столько же плохо для проведения по нему поиска.
РИСУНОК 12.4. Два вида вырожденного двоичного дерева.
Какого-либо одного простого решения указанной
проблемы, не существует. Если ваше приложение будет
вставлять элементы в двоичное дерево преимуществен-
но в отсортированном порядке, то простое двоичное
дерево лучше нс использовать. Вместо этого рекоменду-
ется использовать одну из "сбалансированных" древо-
видных структур, которые будут рассмотрены во второй
части этой главы, или выбрать какую-либо другую
структуру представления данных.
На практике многие приложения вполне могут ис-
пользовать простое двоичное дерево, которое проще
сбалансированного дерева. Крайний случай вырождения
двоичного дерева в связанный список случается не так
уж часто. Определите, какая структура будет лучше
подходить для вашего приложения, и используйте эту
структуру.
Передовые методы
Существует несколько способов организации двоично-
го дерева, но до сих пор в данной главе рассматривался
только один из них. Имеет смысл рассмотреть и неко-
торые другие методы. В последующих разделах речь
пойдет об указателях на родительские узлы и последо-
вательной обработке двоичных деревьев.
Указатели на родительские узлы
При написании функции avl traverse(), предназначен-
ной для итеративного прохождения двоичного дерева,
нам приходилось в стеке хранить узлы, к которым не-
обходимо было вернуться, поскольку не было другого
способа прохождения по дереву в обратном направле-
нии. Неплохо было бы, если бы мы могли найти на-
следника узла, не отслеживая его родительский узел.
Тогда не пришлось бы организовывать стек, поскольку
можно было бы без труда переходить от узла к его на-
следнику.
Одним из путей решения указанной проблемы яв-
ляется хранение в каждом узле еще одного дополнитель-
но указателя, указывающего на родительский узел дан-
ного узла. Если это не корневой узел, то указатель на
родительский узел будет ненулевым.
Для этого придется изменить структуру struct
bill—node. Процесс изменения, как видно из листинга
12.2, является довольно простым.
Листинг 12.2. pbin.c — структура узла для
двоичного дерева с указателями на родительские
узлы.
31 struct pbinnode {
32 int data;
33 struct pbin_node *left;
34 struct pbin_node *right;
35 struct pbinnode *parent;
36 };
Назовем измененную структуру узла struct pbinnode.
Кроме того, аналогично структуре bin-tree, можно
объявить структуру pbin_tree. В качестве примера ис-
пользования поля field напишем функцию, которая бу-
дет находить наследника данного узла в двоичном де-
реве с указателями на родительские узлы:
194 static struct pbin_node *successor(struct
**pbin_node *x)
195 {
196 struct pbinnode *y;
197
198 assert(x != NULL);
199 if (x->right 1= NULL) 1
200 у = x->right;
201 while (y->left != NULL)
202 у = y->left;
203 }
204 else {
205 у = x->parent;
206 while (y != NULL && x == y->right) {
207 x = y;
208 у = y->parent;
209 }
210 }
211
212 return y;
Здесь pbin_successor() в качестве аргументов прини-
мает указатель х на узел и возвращает наследника узла.
Если указанный узел содержит максимальное значение,
содержащееся в дереве, функция возвращает NULL.
Случай 1 (строки 199—203). Если узел х имеет пра-
вый дочерний узел, то его наследником будет минималь-
ное значение в правом поддереве. Сравните этот код с
кодом для случая 3 в bin_delete(). Обратите внимание,
что указатели на родительские узлы пока не использу-
ются.
Случай 2 (строки 204—210). Этот случай немного
сложнее. В качестве примера рассмотрим определение
последователя узла 7 или узла 11 на рис. 12.1. Для это-
Поиск по двоичному дереву
Глава 12
277
го случая легче мыслить в обратном порядке. Если у х
есть наследник у, то х является предшественником у.
При необходимости найти предшественника у, нужно
было бы использовать минимальное значение левого
поддерева узла у. Аналогично, чтобы найти наследника
узла, требуется найти минимальное значение в его пра-
вом поддереве. Для этого от узла у следует двигаться в
направлении вниз и влево, а затем вправо до тех пор,
пока не закончатся правые поддеревья.
Этот путь можно пройти в обратном направлении,
двигаясь вверх и влево до тех пор, пока имеется такая
возможность, а затем сделать один шаг вверх и вправо.
Обратите внимание, что на каждом этапе есть только
один путь, по которому можно идти вверх. Поэтому мы
просто анализируем, в каком направлении двигаемся, и
если это был шаг вправо, то процесс необходимо завер-
шить. Процесс также завершается, если больше нет уз-
лов, поскольку это говорит о том, что х представляет
собой элемент дерева с максимальным значением.
Как можно было убедиться, указатели на родитель-
ские узлы облегчают процесс прохождения двоичных
деревьев, но они усложняют и снижают скорость встав-
ки элементов в дерево и удаления элементов из дерева,
поскольку необходимо обновлять большее количество
полей. Кроме того, дерево с указателями на родительс-
кие узлы занимает больше места в памяти, чем обыч-
ное двоичное дерево.
Все рассмотренные ранее функции для работы с
обычным двоичным деревом могут быть написаны и для
дерева с указателями на родительские узлы. Для крат-
кости коды этих функций не приводятся в тексте кни-
ги, но их можно найти в файле pbin.c на Web-сайте из-
дательства ’’ДиаСофт”.
Ссылки
Указатели на родительские узлы являются одним из
способов упрощения прохождения по двоичному дере-
ву; другим способом является использование ссылок.
Идея ссылок основана на том, что в двоичном дереве
узлы с пустыми левыми или правыми поддеревьями
поля поддеревьев содержат нулевые указатели. В двоич-
ном дереве со ссылками указатели поддерева, которые в
другом случае были бы нулевыми, используются для
хранения указателей на другие части дерева.
В частности, потенциально нулевые указатели на
левое и правое поддеревья используются как указатели
соответственно на предшественника и наследника узла.
Такие потенциально нулевые указатели называются
ссылками. В этом разделе не ссылочные указатели будут
называться связями.
Левая ссылка узла, которая содержит минимальное
значение в дереве, является нулевым указателем. То же
самое относится и к правой ссылке узла, которая содер-
жит максимальное значение в дереве. Эти указатели
будут единственными нулевыми указателями в дереве.
Несомненно, будет необходимо различать обычные
связи и ссылки. В результате в структуру каждого узла
вводятся два дополнительных бита, которые позволят
отличить связь от ссылки.
На основании приведенного описания можно объя-
вить структуру такого узла, как это показано в листин-
ге 12.3.
Листинг 12.3. tbin.c — структура узла для
двоичного дерева со ссылками.
31 struct tbinnode {
32 int data;
33 struct tbin node Heft;
34 struct tbinnode *right;
35 unsigned l_thread:l;
36 unsigned r_thread:l;
37 };
В приведенной выше структуре l_thread устанавли-
вается равным 0, если left является связью, и 1 — если
ссылкой. То же самое относится и к r_thread. I thread
и r thread объявлены как битовые поля шириной в один
бит, т.е. каждое из этих полей занимает один бит. Если
нет жестких ограничений на объем занимаемой памя-
ти, то более эффективным вариантом было бы объявить
эти поля как char, поскольку компиляторы плохо оп-
тимизируют битовые поля.
Давайте напишем функцию, которая будет находить
наследника узла в дереве со ссылками.
282 static struct tbin__node *successor(struct
**tbin_node *x)
283 {
284 struct tbinnode *y;
285
286 assert(x != NULL);
287
288 у = x->right;
289 if (x->r_thread == 0)
290 while (y->l_thread == 0)
291 у = y->left;
292 return y;
293 }
Как и ранее, здесь возможны два случая. Случай 1
(строки 288-291) аналогичен первому случаю для фун-
кции pbin_successor(). Если узел имеет правое поддере-
во, осуществляется поиск минимального значения в этом
поддереве. Обратите внимание, что вместо проверки
указателей на неравенство NULL, в функции осуществ-
ляется проверка того, являются ли указатели связями.
Случай 2 (строка 288) даже проще предыдущего: если
указатель right узла является ссылкой, он указывает на
наследника. (Мы всегда начинаем с перехода вправо,
поэтому и в первом и во втором случаях используется
строка 288.)
Организация данных
Часть II
278
Дерево такого вида является деревом с полными
ссылками. Можно также определить понятие двоично-
го дерева с правыми ссылками, в котором пустые правые
указатели на дочерние узлы каждого узла заменяются
ссылками, а левые не заменяются. В дереве с полными
ссылками можно написать функцию predecessor(), ана-
логичную функции successor(), но для дерева с правы-
ми ссылками нельзя написать такую эффективную фун-
кцию. Преимуществом двоичного дерева с правыми
ссылками является то, что операции изменения дерева
будут проводиться быстрее, чем для дерева с полными
ссылками, поскольку нет необходимости следить за
левыми ссылками.
Двоичное дерево со ссылками может занимать не-
сколько меньший объем памяти, чем дерево с указате-
лями на родительские узлы. Оба этих подхода предпо-
лагают решение одних и тех же задач при прохождении
дерева и оба требуют большего времени для выполне-
ния вставок и удалений узлов, чем в случае обычного
двоичного дерева. Двоичное дерево со ссылками требу-
ет несколько меньшего времени на прохождение дере-
ва. Остановиться на каком-либо варианте сложно. Если
вам необходимо будет использовать дерево, то просто
выберите то дерево, которое вы лучше всего понимае-
те, и реализуйте его.
Функции для выполнения всех необходимых опера-
ций над двоичным деревом со ссылками приведены в
файле tbin.c на Web-сайте ’’ДиаСофт”. В тексте книги
для экономии места эти функции не приводятся.
Сбалансированные двоичные деревья
Когда проводился анализ эффективности различных
типов двоичных деревьев, было отмечено, что, если
элементы вставляются в двоичное дерево в отсортиро-
ванном виде, эффективность двоичного дерева стремит-
ся к эффективности связанного списка. Напомним, что
этот недостаток не так легко исключить.
Но путь все же есть, хотя и не совсем простой. Пос-
ле каждой операции изменения дерева можно проводить
балансировку дерева, которая позволяет минимизировать
его высоту. При этом поиск по двоичному дереву будет
требовать минимального времени. Балансировка позво-
ляет также ускорить операции вставки и удаления уз-
лов, которые тоже требуют проведения поиска.
К сожалению, пока нет способа проведения быст-
рой балансировки дерева до его минимальной высоты
Тем не менее, балансировка является очень эффектив-
ным методом, и о ней не стоит забывать. Мы не можем
провести балансировку дерева до его минимальной вы-
соты, но, задав критерий ’’разбалансированности" дерева
перед проведением очередной балансировки, можно
приблизиться к этой минимальной высоте. В этом слу-
чае, хотя мы и не получаем дерева с минимально воз-
можной высотой в каждый момент времени, тем не
менее, находимся близко к минимуму.
AVL-дерево и дерево red-black задаются различными
наборами критериев, в соответствии с которыми дере-
во считается сбалансированным. В следующем разделе
будет сначала рассмотрено AVL-дерево, а затем дерево
red-black. Для каждого из этих типов сбалансированно-
го дерева мы укажем критерии проведения балансиров-
ки, определим структуры их узлов и напишем функции
для вставки и удаления узлов. Хотя коды функций для
выполнения других операций и не приводятся в книге,
они включены в файлы avl.c и rb.c на Web-сайте изда-
тельства "ДиаСофт".
В последующих разделах рассмотрены вопросы
вставки и удаления узлов в сбалансированном дереве, но
со сбалансированным деревом лучше всего работать с
помощью карандаша и бумаги. Попытайтесь нарисовать
дерево, затем вставить в него или удалить узел. После
выполнения этих операций при необходимости прове-
дите балансировку. Изучите, каким образом эти опера-
ции выполняет приведенный код, и сравните получае-
мые результаты. Такой тип обучения не заменит
никакое описание.
AVL-дерево
AVL-дерево является одним из наиболее давно извест-
ных и наиболее популярных типов сбалансированных
двоичных деревьев поиска. Термин AVL содержит пер-
вые буквы из фамилий изобретателей этого типа дере-
ва — русских математиков Г. М.Адельсона-Вельского и
Е.МЛандиса.
В AVL-дереве коэффициент сбалансированности узла
определяется как высота правого поддерева узла минус
высота его левого поддерева. Чтобы двоичное дерево
было AVL-деревом, необходимо, чтобы коэффициент
сбалансированности был в пределах от —1 до +1. Та-
ким образом, каждая часть AVL-дерева будет "почти
сбалансированной”, поскольку левое и правое поддере-
вья каждого узла имеют почти равную высоту.
Двоичное дерево с п узлами, если оно полностью
сбалансировано, имеет высоту со значением 1о^(л+1).
округленным вверх до ближайшего целого числа. С дру-
гой стороны, AVL-дерево с п узлами всегда имеет высо-
ту между log2(w+l) и 1.44041og2(n+2)—0.328 (доказатель-
ства этого факта приведены в книге The Art of Computer
Programming, Vol, 3, ссылка на которую имеется в при-
ложении В). Так что условие сбалансированности AVL-
дерева не всегда дает полностью сбалансированное де-
рево, тем не менее, высота сбалансированного
AVL-дерева достаточно близка к высоте полностью сба
лансированного дерева.
Поиск по двоичному дереву
Глава 12
279
Мы легко можем создать структуру узла AVL-дере-
ва на языке С (листинг 12.4).
Листинг 12.4. avl.c — структура узла AVL-дерева.
31 struct avl_node {
32 struct avlnode *link[2];
33 int data;
34 short bal;
35 };
В эту структуру внесено несколько изменений по
сравнению со структурами узлов, которые использова-
лись ранее. Давайте более подробно рассмотрим эти
изменения. Раньше у нас были связи left и right, теперь
в структуру узла avl_node введен массив link, состоящий
из двух указателей: link[0] соответствует указателю left,
a link[ 1] — указателю right. Это позволяет упростить
хранение ссылок на один из дочерних узлов данного узла —
можно просто хранить 0 или 1 и использовать эти зна-
чения в качестве индекса массива link.
Кроме того, link стал первым элементом структуры.
На это есть своя причина. Стандарт ANSI С гарантиру-
ет, что указатель на структуру является указателем на
его первый элемент и наоборот, разумеется, если выпол-
няется соответствующее преобразование типов. В неко-
торых примерах кода, приведенных ниже, мы будем
считать, что указатель root структуры avl_tree является
структурой avl node, а не указателем на структуру
avlnode, каковым он объявлен. В таких случаях нуж-
но будет оценить только первый элемент массива link.
Как следствие, можно просто взять адрес элемента root,
преобразовать его в тип avl node* и использовать ре-
зультат.
И последнее изменение — добавление переменной
bal, которая используется для отслеживания коэффици-
ента сбалансированности. Она всегда должна иметь зна-
чение — 1, 0 или 1. В приведенном коде переменная bal
имеет тип short, но она может иметь и меньший тип со
знаком, например signed char, или даже быть битовым
Полем со знаком.
Структура avl tree в точности соответствует струк-
туре bin_tree. Большая часть функций bin_*(), которые
выполняют различные операции над двоичным деревом,
могут использоваться в их первоначальном виде, необ-
ходимо только заменить bin_tree и bin node на avl tree
И avl_node соответственно. Исключение составляют
функции, которые вносят в дерево изменения, посколь-
ку теперь необходимо изменять значение bal и произ-
водить при необходимости балансировку дерева. В на-
шем случае это функции вставки и удаления узлов.
В следующем разделе рассматривается реализация этих
функций для AVL-дерева.
Вставка
Вставка узла в AVL-дерево намного сложнее, чем встав-
ка узла в простое двоичное дерево поиска. Процесс
вставки узла можно разбить на четыре этапа.
1. Поиск. Этот этап аналогичен первому этапу при
вставке узла в обычное двоичное дерево поиска.
Кроме того, при продвижении вглубь дерева требу-
ется отслеживать дополнительную информацию.
2. Вставка. Вставляем в дерево новый узел.
3. Пересчет коэффициентов сбалансированности. Коэф-
фициенты сбалансированности узлов, находящих-
ся выше нового узла, изменились. Заменяем их но-
выми значениями.
4. Ротация. Если вставка нового узла приводит к не-
сбалансированности дерева, то для поддержания
сбалансированности нужно перенести некоторые
узлы. Этот процесс называется ротацией.
А теперь рассмотрим код:
92 int avl_insert (struct avl_tree *tree, int
‘-♦item)
93 {
94 struct avl node **v, *w, *xr *y, *z;
95
96 assert(tree != NULL);
97 v = &tree->root;
98 x = z = tree->root;
99 if (x == NULL) {
100 tree->root = new_node(tree, item);
101 return tree->root != NULL;
102 }
103
104 for (;;) {
105 int dir;
106 if (item == z->data)
107 return 2;
108
109 dir = item > z->data;
110 у = z->link(dir];
111 if (y — NULL) {
112 у = z->link[dir] = new node (tree, item);
113 if (y == NULL)
114 return 0;
115 break;
116 }
117
118 if (y->bal 1= 0) {
119 v « &z->link[dir];
120 x = y;
121 }
122 z = y;
123 }
124
125 w = z = x->link[item > x->dataj;
126 while (z != y)
127 if (item < z->data) {
128 z->bal = -1;
129 z = z->link[0J;
Организация данных
Часть II
280
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
else {
z->bal = +1;
z » z->link[l];
if (item < x->data) {
if (x->bal 1= -1)
x->bal-;
else if (w->bal == -1) {
♦v = w;
x->link[0] = w->link[1];
w->link[l] = x;
x->bal = w->bal = 0;
1
else {
assert(w->bal == +1);
*v = z = w->link[l];
w->link[l] ® z->link[0];
z->link[0] = w;
x->link(0] « z->link[l];
z->link[l] = x;
if (z->bal == -1) {
x->bal = 1;
w->bal = 0;
}
else if (z->bal == 0)
x->bal = w->bal = 0;
else {
. assert(z->bal +1);
x->bal = 0;
w->bal - -1;
1
z->bal = 0;
У
У
else {
if (x->bal 1= +1)
x->bal++;
else if (w->bal == +1) {
*v = w;
x->link[l] = w->link[0];
w->link(0] = x;
x->bal == w->bal = 0;
У
else {
assert(w->bal == -1);
*v = z = w->link[0J;
w->link[0] ® z->link[l];
z->link[l] = w;
x->link[lj = z->link[0];
z->link[0] ® x;
if (z~>bal == +1) {
x->bal = -I;
w->bal = 0;
У
else if (z->bal == 0)
x->bal = w->bal = 0;
else {
assert(z->bal == -1);
x->bal = 0;
w->bal = 1;
У
193 z->bal » 0;
194 }
195 }
196 return 1;
197 }
Начинаем с объявления нескольких переменных и
обработки особого случая вставки в пустое AVL-дерево
(строки 94—102). Легче обработать этот особый случай
отдельно, а не пытаться включить его в общий алгоритм.
Функция new__node() является вспомогательной фун-
кцией, которая выделяет память под структуру avl_node.
Если она завершается успешно, она инициализирует
значение item нового узла, устанавливает указатели на
дочерне узлы на NULL, устанавливает значение поля
bal равным 0, увеличивает поле count структуры tree на
единицу и возвращает новый узел. В противном случае
она возвращает нулевой указатель.
Код в строках 104—123 производит поиск и вставку
узла в AVL-дерево. Он аналогичен соответствующему
коду функции bin_insert(), но имеет и некоторые осо-
бенности. Переменная z используется для отслеживания
текущего узла. Если узел z содержит то же самое значе-
ние, что и новый узел, который необходимо вставить,
выполнение функции завершается (строки 106 и 107).
В противном случае dir получает значение индекса в
массиве z->link дочернего узла z, который будет теку-
щим на следующем этапе (строка 109). Если item боль-
ше, чем z->data, itern>z->data содержит значение 1, что
означает правый дочерний узел, в противном случае
item меньше и item<z->data содержит значение 0, что
означает левый дочерний узел.
Переменная у получает значение следующего теку-
щего узла, которым является дочерний узел узла z на
стороне dir (строка 110). Если у содержит нулевой ука-
затель, то это и будет точкой, в которую нужно вста-
вить новый узел. Новый узел создается функцией
new_node(); он вставляется как дочерний узел узла z и
присваивается указателю у. На этом цикл завершается
с помощью оператора break (строки 111—116). Если па-
мять под новый узел не может быть выделена, функция
завершается неудачно (строки 113 и 114).
Узел х используется для отслеживания последнего
пройденного узла с ненулевым коэффициентом сбалан-
сированности, a v содержит указатель, с помощью ко-
торого мы пришли в х (строки 118—121). х — это точ-
ка, в которой нам может понадобиться провести
балансировку. Если коэффициент сбалансированности
узла равен нулю, то при вставке нового узла под дан-
ным узлом может измениться значение коэффициента
сбалансированности на +1 или -1, но при этом не по-
требуется проводить операцию балансировки.
Вставка нового узла у приводит к изменению коэф-
фициента сбалансированности для узлов, находящихся
выше этого узла. Строки 125—134 обновляют значения
Поиск по двоичному дереву
Глава 12
281
коэффициентов сбалансированности для узлов, находя-
щихся между х и у. Коэффициенты сбалансированнос-
ти всех этих узлов перед выполнением функции были
равны нулю, поскольку х указывает на узел с ненуле-
вым коэффициентом сбалансированности, который бли-
же всего находится к у по дереву- от корня. И все эти
коэффициенты сбалансированности после выполнения
операции будут отличными от нуля, поскольку при
вставке у увеличивается высота дерева.
После пересчета коэффициентов сбалансированно-
сти узлов, находящихся между х и у, необходимо изме-
нить коэффициент сбалансированности самого узла х.
Удобнее всего разделить все возможные варианты на два
случая: у находится в левом поддереве узла х (строки
136—166), и у — в правом поддереве узла х (строки 166—
195). Эти случаи аналогичны, поэтому рассмотрим код
только для первого случая.
Если коэффициент сбалансированности узлах равен
+1 или 0, то это простой случай: можно просто помес-
тить в x->bal новое значение коэффициента сбаланси-
рованности (строка 138) и на этом закончить.
Если же коэффициент сбалансированности узла х
равен -1, значит, левое поддерево было уже выше пра-
вого, а мы еще увеличили его высоту. Следовательно,
для сохранения сбалансированности дерева необходи-
мо провести его балансировку. Сделать это можно дву-
мя путями. На рис. 12.5 представлены обе возможнос-
ти. Обратите внимание, что на рисунке коэффициенты
сбалансированности показаны внутри узлов, а поддере-
вья обозначены прописными буквами над их относи-
тельной высотой. Новый узел вставляется bw, в резуль-
тате коэффициент сбалансированности узла х
становится равным -2, а это недопустимое значение для
AVL-дерева.
Случай 1 (рис. 12.5 а, строки 139—144). Коэффици-
ент сбалансированности узла w — левого дочернего узла
узла х — равен -1, как показано в левой части рисунка.
Код выполняет правую ротацию узлов w и х, перемещая
узел w на место узла х. Узел х становится правым до-
черним узлом узла w, а последний становится левым
дочерним узлом узла х. После такого преобразования
высота дерева остается такой же, как и до вставки узла
у, и AVL-дерево остается сбалансированным. Результат
ротации приведен в правой части рисунка.
Случай 2 (рис. 12.5 6, строки 145-163). Коэффици-
ент сбалансированности узла w равен +1. В этом слу-
чае мы выполняем двойную ротацию', сначала левую ро-
тацию узлов у и w, а затем правую ротацию узлов у и х
(строки 147-151).
Этот случай имеет три подслучая, которые отлича-
ются значениями коэффициента сбалансированности
правого дочернего узла узла w. На рисунке представлен
только один случай. В зависимости от этих подслучаев
определяются значения коэффициентов сбалансирован-
ности после выполнения двойной ротации. Более под-
робно эти подслучаи можно рассмотреть по коду (стро-
ки 152-162).
После проведения балансировки выполнение функ-
ции завершается (строка 196).
РИСУНОК 12.5. Случаи, в которых при вставке узла в AVL-
дерево требуется проведение балансировки.
Удаление
Операция удаления узла в AVL-дереве также несколь-
ко сложнее аналогичной операции для простого двоич-
ного дерева. Кроме того, она даже сложнее, чем встав-
ка узла. Как и в случае вставки узла, процесс удаления
узла разделим на отдельные этапы:
1. Поиск. Производим поиск по дереву и находим узел,
который необходимо удалить. В процессе поиска
отслеживаем узлы, по которым осуществлялось про-
движение, и эти данные будут необходимы для вы-
полнения последующих этапов.
2. Удаление. Узел удаляется. Обновляем список прой-
денных узлов в соответствии с изменениями в де-
реве.
3. Балансировка. Производим пересчет коэффициентов
сбалансированности и при необходимости проводим
балансировку.
А теперь приступим к рассмотрению кода.
201 int avl_delete (struct avl__tree *tree, int
witem)
202 {
203 struct avlnode *ap[32J;
204 int ad[32];
Организация данных
Часть II
282
205 int к = 1; 269 w = ap[k];
206 270 if (ad[k] == 0) {
207 struct avl_node **yf *z; 271 if (w->bal == -1) {
208 272 w->bal = 0;
209 assert(tree ! = NULL); 273 continue;
210 274 }
211 ad[0] = 0; 275 else if (w->bal == 0) {
212 ap[0] = (struct avlnode *) 6tree->root; 276 w->bal = 1;
213 277 break;
214 z = tree->root; 278 }
215 for (;;) { 279
216 int dir; 280 assert(w->bal == +1);
217 if (z == NULL) 281
218 return 0; 282 x » w->link[l];
219 if (item == z->data) 283 assert(x 1= NULL);
220 break; 284
221 285 if (x->bal > -1) {
222 dir = item > z->data; 286 w->link f1J = x->link[0];
223 ap[k] » z; 287 x->link[0] = w;
224 ad[k++] = dir; 288 ap[k - l]->link[ad[k - 1]] = x;
225 z = z->link[dir]; 289 if (x->bal == 0) {
226 } 290 x->bal = -1;
227 291 break;
228 tree->count-; 292 }
229 у = &ap[k - l]->link[ad[k - 1]]; 293 else
230 if (z->link[l] »« NULL) 294 w->bal - x->bal = 0;
231 *y « z->link[0J; 295 )
232 else { 296 else {
233 struct avlnode *x = z->link[l]; 297 assert(x->bal == -1);
234 if (x->link[0] == NULL) { 298 z = x->link[0];
235 x->link[0] = z->link[0]; 299 x->link[0] = z->link[l];
236 *У = x; 300 z->link[l] = x;
237 x->bal = z->bal; 301 w->link[l] = z->link[0];
238 ad[k] = 1; 302 z->link[0] = w;
239 ap[k++] = x; 303 if (z->bal == +1) {
240 } 304 w->bal = -1;
241 else { 305 x->bal = 0;
242 struct avl_node *w « x->link[0]; 306 }
243 int j « k++; 307 else if (z->bal ~ 0)
244 308 w->bal = x->bal = 0;
245 ad[k] = 0; 309 else {
246 ap[k++] = x; 310 assert(z->bal == -1);
247 while (w->link[0] != NULL) { 311 w->bal = 0;
248 x = w; 312 x->bal = +1;
249 w = x->link[0J; 313 }
250 ad[k] = 0; 314 z->bal = 0;
251 ap[k++] = x; 315 ap[k - l]->link[ad[k - 1]] - z;
252 } 316 }
253 317 }
254 ad[j] = 1; 318 else {
255 ap[j] * w; 319 assert(ad[k] == 1);
256 w->link[0] = z->link[0]; 320 if (w->bal == +1) {
257 x->link[0] = w->link[l]; 321 w->bal = 0;
258 w->link[1] = z->link[1]; 322 continue;
259 w->bal = z->bal; 323 }
260 *y = w; 324 else if (w->bal == 0) {
261 } 325 w->bal = -1;
262 } 326 break;
263 327 }
264 free(z); 328
265 assert(k > 0); 329 assert(w->bal == -1);
266 while (-k) { 330
267 struct avl_node *wf *x; 331 x = w->link[0J;
268 332 assert(x != NULL);
Поиск по двоичному дереву
Глава 12
283
333
334 if (x->bal < +1) {
335 w->link[0] » x->link[l];
336 x->link[ll = w;
337 ap[k - l]->link(ad[k - 1Ц = x;
338 if (x->bal == 0) {
339 x->bal = +1;
340 break;
341 }
342 else
343 w->bal = x->bal = 0;
344 }
345 else if (x->bal == +1) {
346 z = x->link[l);
347 X“>link[l] = z->link[0];
348 z->link[0] = x;
349 w->link[0] = z~>link[l];
350 z->link[l] » w;
351 if (z->bal == -1) {
352 w->bal = 1;
353 x->bal = 0;
354 }
355 else if (z->bal == 0)
356 w->bal = x->bal = 0;
357 else {
358 assert(z->bal =« 1);
359 w->bal = 0;
360 x->bal = -1;
361 }
362 z->bal = 0;
363 ap[k - 1J->link[ad[k - 1]] = z;
364 }
365 }
366 }
367
368 return 1;
369 }
Строки 214—226 могут показаться вам знакомыми.
Все, что мы делаем, — производим поиск по дереву,
сравнивая значение каждого пройденного узла z со зна-
чением item. Пройденные узлы помешаются в стек, при
этом узлы хранятся в массиве ар[], а направления, по
которым осуществлялось продвижение, — в массиве
ad[] (строки 223 и 224). Когда искомое значение item
будет найдено, цикл завершится (строки 229 и 220).
Теперь переходим к этапу удаления (строки 228—
264). При удалении узла в AVL-дереве возможны те же
три случая, что и при удалении узла в простом двоич-
ном дереве, но в AVL-дереве они усложняются необхо-
димостью отслеживания списка узлов, которые находят-
ся выше удаляемого узла.
Вначале с помощью стека указателей узлу у присва-
ивается указатель, по которому мы пришли в узел z
(строка 229). Первый случай (строки 230 и 231) полно-
стью соответствует случаю удаления из простого двоич-
ного дерева, а второй случай (строки 233—240) лишь не-
много сложнее. Обратите внимание, что нам приходится
копировать коэффициент сбалансированности узла z в
X и добавлять х в стек узлов.
Третий случай (строки 241—261) несколько сложнее.
В процессе прохождения дерева при поиске наследни-
ка узла z (строки 247—252) необходимо держать прой-
денные узлы в стеке (строки 250 и 251). И еще один мо-
мент: поскольку узел х заменяется узлом w, нужно
также в стеке заменить х на w (строки 254 и 255).
Переходим к этапу балансировки (строки 265—366).
Он осуществляется почти так же, как при вставке узла
в AVL-дерево, но иногда приходится выполнять не-
сколько ротаций.
Цикл выполняется до тех пор, пока в стеке есть узлы.
В начале каждого цикла w присваивается верхний узел
стека (строка 269). Элемент ad[k] содержит индекс мас-
сива w->link[] поддерева, из которого был удален узел.
Как и при вставке, при удалении возможны два сим-
метричных случая. Рассмотрим вариант, когда ad[k]
равно 0 (строки 270—317), т.е. узел удаляется с левого
поддерева узла w.
Возможны два простых случая. Если коэффициент
сбалансированности узла w равен -1, то удаление узла
из левого поддерева узла w приводит к тому, что оно ста-
новится более сбалансированным и новый коэффици-
ент сбалансированности будет равен 0 (строки 271—274).
Однако это означает, что полная высота w уменьшилась,
поэтому может потребоваться проведение балансиров-
ки дерева, в котором w является дочерним узлом. Ис-
пользуя continue, мы переходим на следующую итера-
цию в цикле.
Если же коэффициент сбалансированности узла w
равен 0 (строки 275-278), удаление узла из левого под-
дерева узла w приводит к тому, что его правое поддере-
во становится длиннее левого, т.е. коэффициент сбалан-
сированности становится равным +1. Полная высота
дерева не изменяется, поэтому в дальнейшем изменении
дерева нет необходимости. С помощью break выходим
из цикла. На рис. 12.6 приведены более сложные слу-
чаи, которые требуют выполнения ротации. На этом
рисунке используются те же обозначения, что и на пре-
дыдущем. В каждом случае узел удаляется из левого
поддерева узла w, коэффициент сбалансированности
которого равен +1, и это приводит к тому, что новый
коэффициент сбалансированности становится равным
+2 — недопустимому значению для AVL-дерева.
Случай 1 (рис. 12.6 а, строки 285—288, а также 293
и 294). Коэффициент сбалансированности узла х, кото-
рый является правым дочерним узлом узла w, равен +1.
Правая ротация узлов х и w приводит к полной сбалан-
сированности. Цикл продолжается.
Случай 2 (рис. 12.6 д, строки 285—292). Коэффици-
ент сбалансированности узла х равен 0. При выполне-
нии левой ротации AVL-дерево возвращается в сбалан-
сированное состояние. После выполнения ротации
коэффициент сбалансированности узла х будет равен
-1, а узла w — +1. Цикл заканчивается.
Организация данных
284
Часть II
введена Гибалсом (Gibals) и Седжвиком (Sedgewick) в
1978 г.
В дереве red-black каждый узел ассоциируется с оп-
ределенным цветом: красным или черным. Баланс дос-
тигается путем упорядочения узлов определенным об-
разом с учетом их цвета. Точные правила выглядят
следующим образом:
1. Красные узлы могут иметь только черные дочерние
узлы.
2. Все пути от узла до любого листа, расположенного
ниже в дереве, содержат одно и то же количество
черных узлов.
Кроме того, корневым узлом дерева red-black в этой
главе для простоты кода всегда будет черный узел
В общем случае корневым узлом дерева red-black может
быть узел любого цвета.
Высота данного узла по черным узлам — это количе-
ство черных узлов на пути от данного узла до листа, не
считая сам узел.
Высота дерева red-black с п узлами составляет от
log/w+l) до 21og2(w+1).
Для отслеживания цвета узлов можно использовать
перечисляемые типы, как показано в листинге 12.5.
Листинг 12.5. rb.c — использование
перечисляемых типов для отслеживания цвета
узлов дерева red-black.
31 enum colox {
32 RBRED,
33 RB BLACK
34 };
РИСУНОК 12.6. Случаи, в которых при удалении узла U3AVL-
дерева требуется проведение балансировки.
Случай 3 (рис. 12.6 с, строки 296-316). Коэффици-
ент сбалансированности узла х равен —1, что для вос-
становления баланса требует проведения двойной рота-
ции. Коэффициент сбалансированности левого
дочернего узла узла х перед ротацией может быть лю-
бым, что требует рассмотрения трех возможных случа-
ев. Этот код аналогичен коду, который используется для
выполнения двойной ротации при вставке узла в AVL-
дерево.
Обратите внимание, что случаи 1 и 2 напоминают
случай 1 для вставки, а случай 3 — случай 2 для встав-
ки. Это можно увидеть, сравнив, например, рисунки
12.6 а и 12.6 b с рис. 12.5 а и рис. 12.6 с с рис. 12.5 Ь.
После этого выполнение функции завершается.
Дереве red-black
Дерево red-black является более новой формой сбалан-
сированного дерева, чем AVL-дерево. Первоначально
оно было разработано Байером (Bayer) в 1972 г. под
названием ’’симметричное двоичное В-дерево". Терми-
нология, которая используется в настоящее время, была
На основе enum color можно создать структуру узла
дерева red-black:
37 struct rb_node {
38 struct rb_node *link[2];
39 int data;
40 enum color color;
41 };
Структура rb_node аналогична структуре для узча
AVL-дерева. Вместо коэффициента сбалансированнос-
ти она содержит элемент color, который может иметь
одно из значений: RB RED — для красного узла и
RBBLACK — для черного узла, color можно было объя-
вить и как целый тип, например, short int или char, либо
даже как битовое поле без знака
Как и в случае с AVL-деревом, для работы с дере-
вом red-black можно адаптировать большинство функ-
ций, которые используются для простого двоичного
дерева. Исключение при этом также составляют функ-
ции, которые вносят в дерево изменения. В последую-
щих разделах рассматриваются функции вставки и уда-
ления узлов в дереве red-black.
Поиск по двоичному дереву
Глава 12
285
Вставка
Без лишних прелюдий рассмотрим код, который встав-
ляет узел в дерево red-black.
100 int rb_insert(struct rb_tree *tree, int
••item)
101 {
102 struct rbnode *ap[48];
103 int ad[48];
104 int ak;
105
106 struct rbnode *x, *y;
107
108 assert(tree != NULL);
109 if (tree->root == NULL) {
110 tree->root = new_node(tree, item,
‘-RBBLACK);
111 return tree->root != NULL;
112 }
113
114 ad(0] = 0;
115 ap[0] - (struct rbnode *) &tree->root;
116 ak = 1;
117
118 x = tree->root;
119 for (;;) {
120 int dir;
121
122 if (item == x->data)
123 return 2;
124 dir - item > x->data;
125
126 apfak] = x;
127 adfak++] = dir;
128 у = x->link[dir];
129 if (y == NULL) {
130 x = x->link[dir] = newnode (tree,
'-♦item, RBRED);
131 if (x == NOLL)
132 return 0;
133 break;
134 }
135 x = y;
136 }
137
138 while (ap[ak - l]->color == RBRED)
139 if (ad[ak - 2] == 0) {
140 у = apfak - 2]->link[l];
141 if (y ! = NULL 66 y->color ==
'-RBRED) {
142 ap[-ak]->color = y->color =
^-RBBLACK;
143 ap[-ak]->color = RBRED;
144 }
145 else {
146 if (adfak - 1J == 1) {
147 x = apfak - 1];
148 у = x->linkflj;
149 x->link[l] = y->link[0];
150 y->linkf0] = x;
151 apfak - 2]->link(0] = y;
152 }
153 else
154 у = apfak - 11;
155 156 х = apfak - 2];
157 x->color = RBRED;
158 y->color = RBBLACK;
159 160 x->link[0] = y->link[l];
161 y->link[l] = x;
162 apfak - 3]->linkfadfak -
163 164 break;
165 }
166 }
167 else {
168 у - apfak - 2]->linkf0];
169 if (y != NULL 66 y->color
^*RB_RED) {
170 ap[-ak]->color - y->color =
^*RB BLACK;
171 apf-ak]->color = RBRED;
172 }
173 else {
174 if (adfak - 1] == 0) {
175 x = apfak - 1];
176 у = x->linkf0];
177 x->link[ 0 J = y->linkfl];
178 y->link[l] = x;
179 apfak - 2]->linkfl] = y;
180 }
181 else
182 183 у = apfak - 1|;
184 x = apfak - 2];
185 x->color = RBRED;
186 187 y->color = RBBLACK;
188 x->linkfl] = y->linkfOJ;
189 y->linkf0] = x;
190 apfak - 3]->linkfadfak - 3]]
191 break;
192 }
193 194 }
195 196 tree->root->color = RBBLACK;
197 198 } return 1;
В начале функции объявляем некоторые вспомога-
тельные переменные (строки 102—106). Далее для уп-
рощения общего алгоритма обрабатывается особый слу-
чай вставки в пустое дерево (строки 109—112).
В этой части кода используется вспомогательная
функция new_node(), которая выделяет память и ини-
циализирует новую структуру rbjnode. Значения item и
color устанавливаются в соответствии с требованиями
вызывающей функции, оба указателя на дочерние узлы
устанавливаются равными NULL, значение count увели-
чивается на 1, и возвращается новый узел. Если память
не может быть выделена, new_node() возвращает нуле-
вой указатель.
286
Организация данных
Часть II
Строки 118—136 знакомы вам по поиску по двоич-
ному дереву и по вставке нового узла. Кроме того, каж-
дый пройденный узел для последующего использования
при балансировке записывается в стек (строки 126 и
127).
Первоначально новый узел х считается красным.
Рассмотрим правила для дерева red-black, которые при
этом могут быть нарушены. Вставка красного узла не
нарушает правило 2, поскольку она не изменяет коли-
чество черных узлов ни на одном из путей. Но это мо-
жет нарушить правило 1: если родительский узел узла
х красный, то вставка красного узлах не разрешается и
нам придется вносить изменения в структуру.
Цикл в строках 138—193 повторяется до тех пор,
пока не будет удовлетворено первое правило. В начале
каждой итерации мы считаем, что узел х является крас-
ным, так же как его родительский узел ар[ак-1]. (В дей-
ствительности х в цикле отсутствует. При необходимо-
сти данные по этому узлу можно взять из стека.)
На каждой итерации нужно определять, какие изме-
нения необходимо внести, чтобы удовлетворить прави-
лу 1. Далее мы вносим эти изменения и, если требует-
ся проводить еще какие-либо изменения, переходим на
следующую итерацию либо, если правило 1 удовлетво-
ряется, завершаем цикл.
Как и раньше, здесь возможны два симметричных
случая. Рассмотрим случай, обрабатываемый в строках
139—166, при котором дочерний узел узла х является
левым дочерним узлом своего родительского узла. Сна-
чала мы считаем, что узел у является правым дочерним
узлом родительского узла родительского узла узла х
(строка 140). (у может быть нулевым указателем, т.е.
родительский узел родительского узла узла х не имеет
правого дочернего узла.)
Все три возможных случая приведены на рис. 12.7.
На рисунке черные узлы залиты черным цветом, а крас-
ные оставлены незалитыми. Для удобства узлы, не обо-
значенные в коде программы, на рисунке отмечены как
а и Ь. Поддеревья обозначены прописными буквами.
В каждом случае красный узел вставляется в левое под-
дерево узла а в качестве дочернего узла другого красно-
го узла, что нарушает правило 1.
Случай 1 (рис. 12.7 а, строки 141—144). Если узел у
существует и является красным, можно просто изменить
цвет узлов b и у на черный, а цвет узла а — на красный.
Обратите внимание, что это позволяет сохранить высоту
дерева с корнем в родительском узле родительского узла
узла х по черным узлам, не нарушая правила 2. Однако
существует возможность того, что узел а является до-
черним узлом красного узла. Для обработки такого слу-
чая предназначен цикл. Поэтому после замены узла х
на родительский узел узла а снова осуществляется про-
ход по циклу. (Как и в предыдущем случае, х присут-
ствует неявно, его значение не переприсваивается.)
РИСУНОК 12.7. Случаи, в которых при вставке узла в дерево
red-black требуется проведение балансировки.
На рисунке показан только случай, когда узел х яв-
ляется правым дочерним узлом узла Ь, но он соответ-
ствует и случаю, когда узел х является левым дочерним
узлом узла Ь.
Случай 2 (рис. 12.7 Л, строки 146—152). Если узел х
является правым дочерним узлом своего родительского
узла, выполняем левую ротацию. Это переводит случай
2 в случай 3, который будет рассматриваться ниже.
Независимо от того, проводилась ротация или нет, кол
устанавливает, что родительским у!лом узла х будет у
(строки 148 и 154).
Случай 3 (рис. 12.7 с, строки 156-164). Узел х яв-
ляется правым красным дочерним узлом своего роди-
тельского красного узла у, который, в свою очередь, яв-
ляется левым дочерним узлом черного узла а.
Выполняем правую ротацию. Обратите внимание, что
действия, которые предпринимаются в случаях 2 и 3.
позволяют сохранить высоту дерева по черным узлам,
удовлетворяя правилу 2, при этом восстанавливается
условие 1 и разделяются два красных узла. Поскольку
правило 1 удовлетворяется, цикл завершается.
Поиск по двоичному дереву
Глава 12
287
И последний этап — устанавливаем черный цвет для
корневого узла (строка 195). Это всегда можно сделать,
поскольку это не приводит к нарушению правил.
Удаление
Теперь рассмотрим процедуру удаления узла. Начнем с
листинга.
202 int rb_delete (struct rb_tree *tree, int item)
203 {
204 struct rbnode *ap[48];
205 int ad[48];
206 int k;
207
208 struct rb node *wr *xf *yf *z;
209
210 assert(tree != NULL);
211
212 ad[0] = 0;
213 ap[0] = (struct rbnode *) &tree->root;
214 k = 1;
215
216 z = tree->root;
217 for (;;) {
218 int dir;
219
220 if (z == NULL)
221 return 0;
222
223 if (item == z->data)
224 break;
225 dir = item > z->data;
226
227 ap[k] = z;
228 ad[k++] = dir;
229 z - z->link[dir];
230 }
231 tree->count-;
232
233 if (z->link[0] NULL || z->link[l] ==
^*NULL) {
234 у = z;
235
236 x = y->link[0];
237 if (x == NULL)
238 x « y->link[l];
239 }
240 else {
241 ap[k] = z;
242 ad[k++] = 1;
243 у = z->link[l];
244
245 while (y->link[0) != NULL) {
246 ap[k] = У;
247 ad[k++] = 0;
248 у = y->link[0J;
249 }
250
251 x « y->link[l];
252 z->data = y->data;
253 }
254 ap[k - l]->link[ad[k - 1]] = x;
255
256 if (y->color == RB_RED) {
257 free(y);
258 return 1;
259 260 }
261 262 free(y);
263 while (k > 1 fcfc (x == NULL 11 x->color ==
'-RB BLACK))
264 if (ad[k - 1] == 0) {
265 266 w = ap[k - l]->link[l];
267 if (w->color == RBRED) {
268 w->color = RB_BLACK;
269 270 ap[k - l]->color - RB_RED;
271 ap[k - l]->link[l] = w->link[0];
272 w->link[0] = ap[k - 1];
273 274 ap[k - 2]->link[ad[k - 2]] = w;
275 ap[kj - ap[k - 1];
276 ad[k] = 0;
277 ap[k - 1] = w;
278 279 k++;
280 w = ap(k - l]->link[l];
281 282 }
283 if ((w->link[0) == NOLL ||
»w->link[0]->color == RBBLACK)
284 && (w->link[l] == NOLL ||
'"•w->link[l]->color == RBBLACK)) {
285 w->color = RB-RED;
286 x = ap[k - 1];
287 k-;
288 }
289 else {
290 if (w->link[l] == NOLL ||
4 *w->link[l ]->color == RB BLACK) {
291 w->link[0]->color = RBBLACK;
292 w->color = RB_RED;
293
294 у = w->link[0];
295 w->link[0] =* y->link[l];
296 297 y->link[l] = w;
298 w = ap(k - l]->link[l] = y;
299 300 }
301 w->color = ap[k - l]->color;
302 ap[k - l]->color = RBBLACK;
303 304 w->link[1]->color = RBBLACK;
305 ap[k - l]->link[l] = w->link[0];
306 w->link[0] = ap[k - 1];
307 308 ap[k - 2]->link[ad[k - 2]] = w;
309 x = tree->root;
310 break;
311 }
312 }
313 else {
314 w = ap[k - l]->link[0];
Организация данных
Часть II
288
315 if (w->color == RBRED) {
316 w->color = RBBLACK;
317 ар [к - l]->color - RBRED;
318
319 ар[к - l]->link[O] - w->link[l];
320 w->link[l] « dp[k - 1];
321 ар[к - 2]->link[ad[k - 2]] = w;
322
323 ap[k] = ap[k - 1];
324 ad[k] = 1;
325 ap[k - 1] = w;
326 k++;
327
328 w = ap[k - l]->link[0|;
329 }
330
331 if ((w->link[0] == NULL ||
'“♦w->link[ 0 ]->color == RBBLACK)
332 && (w->link[l] == NULL ||
*-*w->link[ 1 ]->color == RBBLACK)) {
333 w->color = RBRED;
334 x = ap[k - 1);
335 k-;
336 }
337 else {
338 if (w->link[O] == NULL ||
'"•w->link[0]->color == RBBLACK) {
339 w->link[l]->color = RBBLACK;
340 w—>color = RB RED;
341
342 у = w->link[l];
343 w->link[l] = y->link[0J;
344 y->link[0] - v;
345
346 w = ap[k - l]->link(0] = y;
347 }
348
349 w->color - ap[k - l]->color;
350 ap[k - l]->color = RBBLACK;
351 w->link[0]->color = RBBLACK;
352
353 ap[k - lJ->link[0] = w->link[l];
354 w->link[l] = ap[k - 1];
355 ap[k - 2]->link[ad[k - 2]] = w;
356
357 x = tree->root;
358 break;
359 }
360 }
361
362 if (x ’= NULL)
363 x->color = RBBLACK;
364
365 return 1;
366 }
Функция гЪ_delete() начинается, как и предыдущие
функции, которые были рассмотрены, с объявления
локальных переменных, организации стека и проверок
(строки 204-210).
Код в строках 212—230 аналогичен соответствующе-
му коду для функций avi_delete() и rb_insert(): он про-
изводит поиск по дереву. Текущее значение узла z срав-
нивается со значением item, узлы, по которым осуще-
ствляется продвижение, заносятся в стек. Если значе-
ние item найдено, цикл завершается. При выходе из
цикла z является узлом, который необходимо удалить,
ра[к-1] является родительским узлом узла z и т.д.
Методика, которая используется для удаления узла
в функции rb delete(), немного отличается от методи-
ки, применяемой в функциях avl_delete() и bin_delete(),
поэтому рассмотрим ее более подробно.
Если узел z имеет меньше двух дочерних узлов, то
указатель на этот узел в его родительском узле заменя-
ется указателем на левый дочерний узел узла z, если
таковой имеется. Если левый дочерний узел узла z от-
сутствует, то указатель на узел z в его родительском узле
заменяется указателем на правый дочерний узел узла z
(строки 233—239). Следовательно, если узел z является
листом, он заменяется нулевым указателем.
В противном случае для поиска наследника узла z
используется у, при этом посещенные узлы заносятся в
стек (строки 240—253). Поскольку наследник узла z не
может иметь левого дочернего узла, его можно легко
удалить, заменив правым дочерним узлом (если таковой
имеется). Эти данные копируются в z (строка 252).
Такая методика отличается от использованной ранее, в
которой для перемещения наследника удаленного узла
производились операции над указателями, а не копиро-
вание полей данных.
Удаляемым узлом является узел у (строка 254). Если
у — красный узел, то его можно удалить, не нарушая
правила 1. Функция успешно завершается (строки 256-
259). В любом случае память, выделяемая под у, выс-
вобождается функцией free() (строки 257 и 261).
Теперь необходимо откорректировать свойства дере-
ва red-black. Только что был удален черный узел, поэто-
му правило 2 нарушено и требуется это исправить. На
данном этапе узел х является корневым узлом дерева, ко-
торое имеет на один черный узел больше, чем оно дол-
жно иметь, а стек содержит все родительские узлы это-
го узла вплоть до самого корневого узла всего дерева.
В цикле проверяется, является ли х красным узлом.
Если это условие выполняется, цикл завершается, по-
скольку мы можем просто заменить цвет на черный. Мы
также выходим из цикла, если, судя по значению к.
изменения проведены по всему дереву и дерево снова
соответствует всем правилам дерева red-black.
Как и раньше, возможны два симметричных случая.
Рассмотрим только случай, когда х является левым уз-
лом своего родительского узла (строки 264—312). Пер-
вым делом будем считать, что w является правым дочер
ним узлом родительского узла узла х (строка 265), а
затем рассмотрим каждую из четырех возможностей, как
показано на рис. 12.8.
Поиск по двоичному дерев)
Глава 12
289
На рис. 12.8 черные узлы залиты черным цветом, а
красные оставлены незалитыми. Узлы, залитые серым
цветом, могут быть либо черными, либо красными.
Узлы, не обозначенные в коде функции, для удобства
отмечены как о, b и с. Поддеревья обозначены пропис-
ными буквами.
Случай 1 (рис. 12.8 а, строки 267-281). С этим слу-
чаем, когда узел w — красный, легче справиться, пре-
образовав его к одному из трех других случаев, а не раз-
решая его напрямую. Преобразование выполняется за
счет левой ротации w на место, занимаемое узлом а, и
обновления стека. Обратите внимание, что такое пре-
образование не изменяет высоты дочерних поддеревьев
по черным узлам.
РИСУНОК 12,8. Случаи, в которых при удалении узла из дерева
red-black требуется проведение балансировки.
Случай 2 (рис. 12.8 Ь, строки 283-288). Если узел w
не имеет красного дочернего узла (узлы b и с могут быть
черными либо вообще отсутствовать), то его цвет мож-
но просто заменить на красный. Это позволяет убрать
один черный узел из правого поддерева родительского
узла узла х, соответствующий черному узлу, удаленно-
му в х. Таким образом восстанавливается правило 2 для
поддерева. Тем не менее, по-прежнему требуется про-
водить изменения вверх по дереву, поскольку высота
всего дерева по черным узлам изменилась. Поэтому цикл
выполняется до тех пор, пока стек будет содержать узлы.
Случай 3 (рис. 12.8 с, строки 290-299). Если узел
b — красный, а узел с — черный или отсутствует, то,
выполняя правую ротацию w и обменивая цвета узлов
w и Ь, можно преобразовать этот случай в случай 4.
Случай 4 (рис. 12.8 J, строки 301-310). Узел w име-
ет правый красный дочерний узел. Выполняем левую
ротацию и изменяем цвета некоторых узлов. В резуль-
тате высота левого поддерева увеличивается по черным
узлам, удовлетворяя правило 2. Мы присваиваем корень
дерева tree узлу х, что обеспечивает черный узел в кор-
не дерева, и выходим из цикла.
Если х не является нулевым указателем, цвет узла х
устанавливается черным, как это требуется по условию
цикла (строки 362 и 363). На этом выполнение функ-
ции завершается.
Сравнение AVL-дерева и дерева red-black
AVL-дерево и дерево red-black сравнимы по своим свой-
ствам. Некоторые замечания:
• Операции вставки и удаления для AVL-дерева и де-
рева red-black являются О(1о^л)-операциями.
• Вставка в AVL-дерево требует не более одной рота-
ции, но удаление может потребовать до log2n рота-
ций. С другой стороны, вставка в дерево red-black
может требовать двух ротаций, но удаление требует
не более трех._
• Максимальная высота AVL-дерева для дерева из п
узлов меньше максимальной высоты дерева red-black
для одного и того же количества узлов.
Кроме сравнения различных типов сбалансирован-
ных деревьев будет полезно провести сравнение сбалан-
сированных деревьев с некоторыми другими хорошо
известными структурами данных:
• Хеш-таблицы в среднем дают эффективность поряд-
ка 0(1) для поиска, вставки и удаления. Однако воз-
можны граничные случаи, которые снижают эффек-
тивность до О(л) для п элементов. Разработка
подходящей хеш-функции может оказаться доволь-
но сложным делом и занять много времени. Кроме
того, хеш-таблицы сложно пройти в порядке возра-
стания их элементов.
19 Змс. 265
290
Организация данных
Часть II
• Списки с пропусками для рассматриваемых здесь опе-
раций дают такую же эффективность, как и двоич-
ное дерево. Кроме того, они позволяют повысить
скорость итерации по узлам с целью хранения узлов
в памяти в отсортированном виде. Списки с пропус-
ками, так же как и хеш-таблицы, имеют граничные
случаи. Но, тем не менее, можно снизить вероят-
ность этих случаев до уровня, которым можно пре-
небречь. Списки с пропусками являются довольно
новым изобретением, поэтому они не так хорошо
известны, как остальные методы.
• Для дерева 2~3Ч пирамидального дерева и других ти-
пов многопутевых деревьев характерно ветвление в
каждом узле дерева на два и более поддерева. Все эти
типы деревьев имеют недостатки, которые в общем
случае делают их менее эффективными, чем сбалан-
сированное дерево, но они имеют свои цели приме-
нения, например, хранение и поиск по дисковым
архивам данных.
И последнее замечание. Всегда помните, что AVL-
дерево и дерево red-black, как и обычное двоичное де-
рево, могут содержать указатели на родительские узлы
или ссылки.
Резюме
В этой главе рассмотрены основы работы с двоичным
деревом. Вначале был описан процесс линейного поис-
ка, а затем процесс двоичного поиска по отсортирован-
ному списку. Мы обнаружили, что двоичные деревья
являются более эффективной альтернативой для ис-
пользования их с болыш/ми, динамически меняющими-
ся списками. Подробно было рассказано о целом ряде
алгоритмов, предназначенных для выполнения измене-
ния двоичного дерева и проведения поиска, и представ-
лена их реализация на языке С. Кроме того, рассмот-
рены преимущества и недостатки двоичного дерева с
указателями на родительские узлы и двоичного дерева
со ссылками. Описаны два типа сбалансированных дво-
ичных деревьев — AVL-дерева и дерева red-black, кото-
рые за счет некоторого усложнения исключают гранич-
ные случаи, характерные для обычного двоичного
дерева. И наконец, приведено короткое сравнение
свойств и достоинств двоичного дерева и некоторых
других типов структур данных.
Методы быстрой сортировки
В ЭТОЙ ГЛАВЕ
Классификация данных
Основы сортировки
Эффективные методы сортировки
Методы сортировки слиянием
13
Дэн Корбит
В этой главе будут рассмотрены методы сортировки.
Вначале мы определим основные термины и алгоритмы,
а затем перейдем к рассмотрению принципов работы
соответствующих алгоритмов. Кроме того, приведем
исходные коды наиболее часто используемых алгорит-
мов. И наконец, рассмотрим составные алгоритмы, в
которых реализовано множество эффективных методов
и которые можно использовать для сортировки больших
объемов данных. Некоторые идеи, рассматриваемые в
этой главе, нигде раньше не рассматривались, поэтому
могут представлять особый интерес для читателя.
Классификация данных
Сортировка представляет собой классификацию данных.
При наличии неупорядоченных данных, самое первое,
что необходимо сделать, — провести их классификацию.
В наше время быстрого развития компьютерных систем
И появления высококлассной магистрали передачи ин-
формации можно находить и хранить такие объемы
Информации, о которых раньше и помыслить было
Нельзя. Большой объем неупорядоченных данных сам
По Себе не имеет высокой ценности. Чтобы данные при-
обрели определенный смысл, их необходимо классифи-
Цировать по какой-либо важной или ключевой характе-
ристике. Чем выше уровень упорядоченности данных,
тем выше их ценность, поскольку по этим данным мож-
но ответить на большее количество вопросов. "Да, объе-
мы ^продаж возросли, но в каком регионе уровень про-
даж, самый высокий, а в каком самый низкий? Какой
агент имеет самый высокий уровень продаж? Какое
Оборудование увеличивает объем продаж, а какое обо-
рудование слабо влияет или вообще не влияет на объем
ПроДаж? Какая система обучения наиболее эффектив-
на?* и т.п. Мы можем ответить на эти вопросы и без
сортировки, но с сортировкой получим ответы гораздо
быстрее. А время, как известно, — деньги. При наличии
двадцати миллионов неупорядоченных записей полу-
чить ответ на вопросы, касающиеся этих записей, бу-
дет практически невозможно. Если же провести класси-
фикацию этих данных, то можно будет оперативно
ответить на такие и многие аналогичные вопросы.
Стивен Скина (Steven S. Skiena) в книге The Algorithm
Design Manual пишет следующее:
• Сортировка является тем базовым блоком, на осно-
ве которого строятся многие другие алгоритмы. Изу-
чив методы сортировки, можно смело приступить к
решению других задач.
• Исторически сложилось так, что компьютеры тратят
больше времени на сортировку, чем на что-либо
другое. Четвертую часть времени работы универсаль-
ных вычислительных машин занимает сортировка
[Knu73bJ. И хотя неизвестно, справедливо ли это
утверждение в отношении малых компьютеров, тем
не менее, на практике сортировка остается наиболее
широко распространенным алгоритмом.
• Сортировка является наиболее изученной задачей в
теории вычислительных машин и систем. Известны
буквально десятки различных алгоритмов, большин-
ство из которых имеют определенные преимущества
в определенных ситуациях. Чтобы убедится в этом,
предлагаю читателю просмотреть книгу [Knu73b], в
которой представлены примеры интересных алго-
ритмов сортировки и проведен их анализ.
• Большинство интересных идей, которые использу-
ются в разработке алгоритмов, появились в контек-
сте задач сортировки (например, "разделяй и вла-
ствуй", структуры данных и рандомизированные
алгоритмы).
Организация данных
Часть II
292
ПРИМЕЧАНИЕ
[Knu73b] — это ссылка на книгу The Art of Computer
Programming, Volume 3: Sorting and Searching, D.E. Knuth,
Addison-Wesley, Reading MA, 1973.
Типы алгоритмов сортировки
Ниже приведен перечень наиболее общих алгоритмов,
которые используются в различных приложениях:
• Внутренняя сортировка — это алгоритм, который в
процессе сортировки использует только оператив-
ную память (ОЗУ) компьютера и который применя-
ется во всех случаях, за исключением однопроход-
ного считывания данных и однопроходной записи
отсортированных данных.
• Внешняя сортировка — это алгоритм, который при
проведении сортировки использует внешнюю па-
мять, как правило, жесткие диски (в старых систе-
мах — магнитную ленту) и обычно выполняет не-
сколько считываний и записей. Внешняя сортировка
разработана для обработки списков данных, которые
не помещаются в ОЗУ.
Тип сортировки (внутренняя или внешняя) опреде-
ляется не физическими параметрами, а алгоритмом.
Алгоритм внутренней сортировки может использо-
вать виртуальную память и большую часть времени
работать с диском, а при внешней сортировке в не-
которых случаях все данные могут быть загружены
за один проход.
• Сортировка сравнением — это алгоритм сортировки,
который для размещения элементов в заранее опре-
деленном порядке использует сравнение ключей.
• Дистрибутивная сортировка — это алгоритм сорти-
ровки, который оперирует непосредственно с неко-
торыми характеристиками ключей.
• Сортировка на месте — это алгоритм сортировки, ко-
торый требует лишь незначительного фиксированно-
го объема памяти для завершения сортировки.
• Устойчивая сортировка — это алгоритм, который
обеспечивает сохранение первоначального порядка
элементов с равными ключами. Неустойчивую сор-
тировку всегда можно преобразовать в устойчивую,
добавляя ключи, например, первоначальное положе-
ние в списке.
Когда выполнять сортировку
Если перед вами встала задача сортировки, то первое,
что нужно решить для себя, — писать функцию сорти-
ровки или нет. В большинстве случаев ответ будет от-
рицательным. Для больших объемов данных, которые
используются для получения ответов на повторяющие-
ся вопросы, удобнее пользоваться базами данных. Ком-
пании, которые занимаются разработкой баз данных,
потратили сотни тысяч или даже миллионы долларов на
определение наиболее эффективных путей упорядоче-
ния данных. Кроме того, может оказаться, что перед
вами стоит задача выбора, а не сортировки. Выбор яв-
ляется более простой операцией, чем сортировка. Од-
нако иногда все же придется писать функции сортиров-
ки. Может быть, вы работник компании, которая
занимается разработкой баз данных, и вам предстоит
создать фантастический способ оперативной сортиров-
ки данных, например, в случае, когда пользователь дает
команду на сортировку данных, которые не имеют ука-
зателя (индекса). Может быть, вы работаете над созда-
нием драйвера для графической платы и вам необходи-
мо упорядочивать многоугольники по многим
измерениям. Поскольку очевидно, что данная операция
должна проводиться за минимально возможное время,
работа с базой данных исключается. Имеется множество
других факторов, преимуществ и недостатков, которые
обязательно нужно взвестить, перед тем как принять
решение о написании функции сортировки. Предпола-
гая, что вы все-таки решили писать функцию сортиров-
ки, давайте рассмотрим основы того, что для этого бу-
дет необходимо.
Основы сортировки
По своей сути сортировка является просто математичес-
кой операцией над наборами данных. В конце концов,
сортировка выполняется либо путем извлечения, либо
путем разделения. Представьте себе два набора данных
одинакового объема. Первый набор называется неупо
рядоченным, а второй — упорядоченным. Первый на-
бор может быть в какой-либо степени упорядоченным,
но не обязательно. Для создания упорядоченного набо
ра можно брать последовательно в нужном порядке эле-
менты из первого набора и переносить их во второй на
бор. Этот процесс продолжается до тех пор, пока
первый набор не окажется пустым, а второй — запол
ненным. Такой процесс представляет собой пример сор
тировки путем извлечения. Пузырьковая сортировка,
сортировка методом выбора и сортировка методом вста
вок являются типичными примерами сортировки, вы
полняемой именно таким образом.
На рис. 13.1 показано, каким образом при сортиров
ке способом извлечения отдельный элемент неупорядо
ченного набора перемещается в упорядоченный набор
мы извлекаем элемент из неупорядоченного набора и
добавляем его в упорядоченный набор. При этом, как
правило, на каждом этапе процесса сортировки прихо
дится просматривать или перемешать большую часы,
элементов неупорядоченного или упорядоченного (или
того и другого) набора.
Методы быстрой сортировки
Глава 13
293
Б сортировке способом извлечения элементы
С целью сортировки можно также разделить неупо-
рядоченный набор на две части. Для этого существует
несколько способов. Можно выбрать один элемент и
разделить набор на две части: на элементы, которые
меньше выбранного, и те, которые больше его, или на
"победителей" и "побежденных". Если продолжить та-
кое разделение, то в конце концов получится упорядо-
ченный набор. Методы быстрой и пирамидальной сор-
тировки основаны именно на таком принципе.
На рис. 13.2 показано, как на каждом этапе неупо-
рядоченный набор разделяется на два поднабора. Таким
образом, мы разбиваем задачу на все меньшие и меньшие
подзадачи до тех пор, пока делить будет уже нечего.
При желании можно разделить исходный набор дан-
ных не на две, а на большее количество частей. Если мы
знаем, что собой представляют данные, можем разби-
вать набор на любое количество поднаборов. Блочная
сортировка и сортировка с подсчетом подразумевают
именно такой подход. Может показаться, что для уско-
рения сортировки лучше разбивать набор на большее
количество поднаборов, но это не всегда справедливо.
Представьте себе набор данных, состоящий только из
трех элементов. Будем ли мы производить сортировку
способом извлечения или разбивкой на два или на ты-
сячу поднаборов — это практически не повлияет на ко-
личество шагов сортировки. Но такие простые операции,
как извлечение, легче выполнять, чем разделение.
Сортировка способом разделения на большое коли-
чество поднаборов будет отличаться количеством под-
наборов N, на которое мы одновременно разбиваем на-
бор. На рис. 13.3 на каждом этапе сортировки
неупорядоченный набор разделяется на N = 9 подна-
боров. Как видно, в этом случае неупорядоченный на-
бор разделяется на искомые поднаборы гораздо быст-
рее, чем при разделении на две части — буквально за
один этап.
Обратите внимание, что нам требуется, по крайней
мере, N ячеек. Но если выбрать слишком большое чис-
ло N, можно получить много пустых ячеек, что приве-
дет к напрасной трате времени на их анализ.
Организация данных
Часть II
294
В сортировке способом разделения на два ftoofape на каждом шаге мы
разбиваем неупорядоченный набор на две части. Это типичная стратегия
‘разделяй и властвуй", которая используется для упрощения сложных задач.
На этом шаге мы разбиваем >«уъчм^^>нный набор на два поднабора, которые
будут примерно по половине элементов первоначального набора
Элементы группируются по величине таким образом, что меньшие элементы
попадают в левый поднабор, а большие - в правый.
РИСУНОК 13.2. Сортировка способом разделения на два поднабора.
В нижней части рис. 13.3 показано, что если продви-
гаться от более значащей цифры к менее значащей, то
метод разделения на группы может оказаться неустой-
чивым. Если же продвигаться в обратном направлении,
то метод разделения на группы обязательно должен
быть устойчивым, иначе процедура не будет работать.
Именно по этой причине для цифровой поразрядной
сортировки в убывающем порядке часто выполняется
сортировка подсчетом. Сортировка подсчетом является
устойчивым алгоритмом.
BinO Bini Bin2 Bin 3 Bin 4 Bin5 Bin6 Bin7 Bin8
РИСУНОК 13.3. Сортировка способом разделения на поднаборы N.
Методы быстрой сортировки
Глава 13
|295
Алгоритмы порядка 0(п2)
Рассмотрим в первую очередь внутреннюю сортировку,
начиная с алгоритмов порядка О(п2).-Возможно, чтобы
вы понимали, что оптимальность не является прямым
следствием высокой скорости работы. Может показать-
ся, что время проведения сортировки обратно пропор-
ционально числу N, т.е. зависит от N линейно. Действи-
тельно, если объем набора данных достаточно велик, то
предыдущее утверждение вполне справедливо. Но по-
мните, что О-нотация говорит только об асимптотичес-
ком поведении алгоритмов, а не о действительной их
эффективности. Казалось бы, не совсем логично, но
алгоритмы порядка О(п2) для сортировки небольших
наборов данных оказываются более оптимальными. Это
очень важно, поскольку алгоритмы с лучшими О-нота-
циями часто разбивают большие наборы данных на
маленькие наборы, а затем используют алгоритмы по-
рядка О(п2). Так, если сортируется десять миллионов
элементов, алгоритм может разбить этот набор на мил-
лион наборов по десять элементов в каждом. Как вы
можете догадаться, в этом случае полное время сорти-
ровки может определяться эффективностью алгоритма
порядка О(п2).
Алгоритмы, которых следует избегать
Давайте начнем не с того, какой алгоритм порядка (Хи2)
лучше использовать, а с рассмотрения алгоритмов, ко-
торых следует избегать, и причин такой тактики.
Сортировка методом выбора
Метод выбора является, наверное, самым очевидным
методом сортировки. В качестве примера предположим,
что я даю вам пять чисел 100, 8, 2, 20 и 9 и прошу рас-
положить их в порядке возрастания. Не сомневаюсь, что
вы расположили эти числа в следующем порядке: 2, 8,
9, 20, 100, но как вы получили этот ответ? Вероятнее
всего, вы просто выбрали самое маленькое число, затем
следующее самое маленькое и т.д. Сортировка методом
выбора производится путем многократного поиска в
неупорядоченном наборе минимального значения и
переноса найденного значения в упорядоченный спи-
сок. Сортировка методом выбора (как и любая другая)
начинается с неупорядоченного набора данных. Посте-
пенно мы создаем упорядоченный набор, размер кото-
рого увеличивается с уменьшением размера неупорядо-
ченного набора. Алгоритм находит минимальный
элемент в неупорядоченной части набора, а затем про-
изводит перестановку элементов, перемещая найденный
элемент в конец упорядоченной части набора.
Идея метода сортировки выбором заключается в
том, что при каждой перестановке данных элемент пе-
ремещается прямо в необходимое место. Сначала мы
находим наименьший элемент в наборе и заменяем пер-
вый элемент в наборе найденным элементом. Затем
находим следующий минимальный элемент и ставим
его на второе место. Далее продолжаем описанный про-
цесс до полной сортировки набора. Этот метод потому
и называется сортировкой методом выбора, что он ос-
нован на выборе минимального элемента в еще неупо-
рядоченной части набора данных.
Двунаправленная сортировка методом выбора (кото-
рая иногда называется сортировкой перемешиванием)
является вариантом сортировки методом выбора, в ко-
тором на каждом этапе находятся как минимальный, так
и максимальный элементы, которые затем перемещают-
ся на соответствующие позиции. Поиск минимального
и максимального элементов особым способом может
позволить повысить эффективность сортировки. Вмес-
то того чтобы сравнить уже найденные минимальный
и максимальный элементы с каждым элементом неупо-
рядоченного списка, сравниваем элементы неупорядо-
ченного набора между собой по два элемента за один
раз. Затем сравниваем минимальный элемент с меньшим
элементом из двух, а максимальный элемент — с боль-
шим элементом из двух. Таким образом, вместо четы-
рех сравнений по два неупорядоченных элемента мож-
но обойтись тремя сравнениями. Хотя сортировка
методом выбора — превосходный способ выполнения
сравнений, тем не менее, это неэффективный метод
сортировки. Не используйте его.
Сортировка методом выбора является чуть ли не
самым плохим алгоритмом в отношении количества
сравнений (порядка О(п2)), но очень эффективным в
отношении количества перестановок (порядка О(п))
Это достоинство иногда используется в качестве аргу-
мента при выборе сортировки методом выбора для ра-
боты с большими объемами данных. Не используйте
этот метод. Скорость сортировки методом выбора в об-
щем случае примерно равна скорости пузырьковой сор-
тировки, а при выполнении сортировки с использова-
нием указателей, а не сортировки самих элементов
объем данных не имеет значения. В общем, никогда не
используйте сортировку методом выбора. Она полезна
для понимания метода пирамидальной сортировки, но
сортировка методом выбора очень неэффективна.
Пузырьковая сортировка
Пузырьковая сортировка — это метод, в котором в не-
упорядоченном наборе сравниваются и при необходи-
мости переставляются два соседних элемента. Таким
образом, элемент поднимается (как пузырек воздуха в
воде) вверх по списку до тех пор, пока не встретится
элемент с меньшим значением. Если пройден весь на-
бор и не сделано ни одной перестановки, то данные
считаются отсортированными и выполнение алгоритма
завершается.
Организация данных
Часть II
296
Можно также выполнять двунаправленную пузырь-
ковую сортировку (которую иногда называют сортиров-
кой перемешиванием). Первая итерация проходит так
же, как и в стандартной пузырьковой сортировке, а вто-
рая итерация проходит снизу вверх. Восходящая итера-
ция позволяет большим элементам "утонуть" только на
один уровень, а меньшим элементам "всплывать” быст-
рее. Это является преимуществом только в том случае,
если большая часть малых элементов в исходном спис-
ке расположена внизу списка. Как в отношении коли-
чества сравнений, так и в отношении количества пере-
становок пузырьковая сортировка является алгоритмом
порядка О(п2). Наилучший эффект достигается в слу-
чае, когда список почти отсортирован и малые элемен-
ты в конце списка отсутствуют. И Седжвик (Sedgewick),
и Кнут (Knuth) не зря осмеивают метод пузырьковой
сортировки как алгоритм порядка О(п2) и в отношении
количества сравнений, и в отношении количества пере-
становок. По этой же причине он часто приводится в
книгах по программированию для начинающих и в за-
даниях на самостоятельную проработку. Но вы лучше
не используйте метод пузырьковой сортировки. Он про-
сто никуда не годится.
ДОРОГОЙ УРОК
А теперь пришло время рассказать страшную историю.
В 1989 г. я работал над большим проектом по созданию
программного обеспечения для одной большой корпора-
ции. Эта корпорация занималась созданием интерфейс-
ного программного пакета для своей библиотеки. База
данных была организована на базе SQL-сервера, а биб-
лиотечный пакет назывался Dynix Marquis. Сотрудники
Dynix разработали интерфейс только для OS/2, а корпо-
рация, на которую я работал, не собиралась инсталли-
ровать OS/2 на девять тысяч компьютеров. Я занимался
написанием синтаксического анализатора правил библио-
теки ALA, которые описывают порядок проведения пред-
варительной обработки строк так, чтобы запросы могли
находить все строки единым образом. Я нашел чей-то код
и увидел, что этот код выполняет внешнюю пузырьковую
сортировку библиографий, поскольку пользователи мог-
ли запрашивать литературу множеством самых различных
способов.
Я воскликнул: "Это же пузырьковая сортировка!" Но мне
ответили, что даже Кнут говорит, что в определенных
случаях можно выполнять и пузырьковую сортировку.
Наборы данных невелики, а операции, производимые над
этими наборами, довольно сложны. Алгоритм пузырько-
вой сортировки очень легко реализовать и отладить. По-
пробуйте протестировать такую программу на различных
запросах, и вы увидите, что скорость вполне приемлема
и соответствует требованиям проекта.
Эта программа была протестирована на большом коли-
честве запросов и позволила убедиться, что все выше
сказанное справедливо. А может быть, я просто думал,
что справедливо. Оказалось, что разработчики использо-
вали компьютеры 486-й серии с объемом ОЗУ 16 Мб,
что на тот момент времени было чуть ли не пределом
совершенства. Большинство пользователей использовали
компьютеры 386-й серии с объемом ОЗУ 4 Мб. Даже на
таких компьютерах программа, основанная на пузырько-
вой сортировке, удовлетворяла требованиям проекта, но
уже на грани возможного. Многие пользователи жало-
вались на скорость работы. Но можно представить себе,
что при экспоненциальном росте во времени производи-
тельности вычислительной техники скорость работы про-
граммы должна все более и более возрастать. Но, как
ни странно, справедливо обратное утверждение. Дело в
том, что объем библиотеки тоже рос по экспоненциаль-
ному закону. Поэтому, скажем, при запросе "Показать
все видеофильмы о С или C++, отсортированные по дате"
в 1989 г. было бы получено всего восемь фильмов, но к
1994 г. было бы уже около 800 фильмов. В конце кон-
цов, корпорация заменила эту систему какой-то другой
системой с гораздо меньшими возможностями. Пузырько-
вая сортировка погубила проект стоимостью в один миллион
долларов. К тому времени в рамках пакета Dynix Marquis был
создан интерфейс под управлением Windows, но старый ин-
терфейс был намного богаче, и мне его очень не хвата-
ло (я был одним из постоянных пользователей системы).
Итак, не выполняйте пузырьковую сортировку. Никогда и
ни при каких обстоятельствах. Существуют намного бо-
лее эффективные методы. А вероятность нанести реаль-
ный ущерб при выполнении пузырьковой сортировки
слишком велика. Может быть, вы думаете, что объем
данных будет не настолько велик, чтобы увидеть разни-
цу, но это слишком опасное предположение. Откровен-
но говоря, сортировка с двоичными вставками ничуть не
сложнее пузырьковой сортировки. Пузырьковая сортиров-
ка — это само зло. Такие люди, как Джон Бентли (Jon
Bentley), Плагер (P.J. Plauger), Роберт Седжвик (Robert
Sedgewick) или Дональд Кнут (Donald Knuth), может быть,
и знают, в каких случаях использовать эти неэффектив-
ные методы сортировки, но большинство из нас — про-
стые смертные, поэтому держитесь от этих методов
подальше.
Эффективные методы сортировки
Теперь, когда мы знаем, что не следует выполнять сор
тировку методом выбора и пузырьковую сортировку,
давайте рассмотрим наиболее эффективные алгоритмы
порядка О(п2) — сортировку методом вставок и другие
подобные методы.
Сортировка методом вставок
Чтобы понять принцип работы некоторых алгоритмов
сортировки, давайте проведем серию мысленных экспе
риментов, в которых будет участвовать вымышленная
семья Джонс. Любые связи с реальными или вымышлен
ными людьми (включая семью моей матери) являются
простым совпадением. Для начала позвольте предста
вить вам членов семьи Джонс. Отца зовут Роско Ричард,
но все называют его Дик. Мать зовут Реа, но отец на
зывает ее Мад. Дочерей зовут (от старшей к младшей)
Мэрилин, Карен, Анита (Нита), Джуди и Вики. Дик по
своей натуре шутник.
Методы быстрой сортировки
{297
Глава 13
Однажды сестры Джонс сидели на ступеньках перед
домом и завтракали. На завтрак они сделали яичницу,
но никто из них не любил желтка. Поэтому они отде-
ляли желтки и выбрасывали их.
Дик выглянул в окно. "Опять играетесь с едой!
Смотрите у меня!". Затем он пошел и взял очки. Они
были настолько сильными, что в них за фут уже нельзя
было ничего увидеть. (Дик взял очки просто потому, что
в них девушки выглядели смешными и они усложняли
любое занятие. Но очки позволяют провести аналогию
с компьютерами, поскольку компьютеры могут иссле-
довать только один или два элемента за один раз. Они
не могут, как мы, сразу просмотреть весь набор и най-
ти одинаковые элементы.) В этих очках все, что нахо-
дится дальше одного фута, было просто размытым пят-
ном. "Так, девушки, — сказал Дик, — время сортировать
носки, но тот, кто будет сортировать, должен надеть эти
очки, а тот, кто без очков, не должен говорить, куда
положить носок".
В семье Джонс носят носки разных размеров. У Дика
размер носков 10, у Реи — 8, у Мэрилин — 7, у Карен —
6, у Ниты — 5, у Джуди — 4, а у Вики — 3. Для про-
стоты они носят только белые носки. В этом случае им
не приходится искать пару к носку и ничего страшно-
го, если один носок потеряется. Но поскольку носки
имеют разные размеры, их необходимо отсортировать
по длине. Мэрилин придумала способ сортировки нос-
ков (рис. 13.4).
Сортировка методом линейных вставок
1. Взять носок из корзины.
2. Взять носок на полу (если на полу есть носки) и
проверить, меньше ли его размер размера носка в
руках.
3. Если размер носка из корзины меньше размера нос-
ка, взятого с пола, передвинуть все носки на полу,
освободив место для нового носка.
4. Положить носок на только что освобожденное на
полу место.
5. Если в корзине еще остались носки, перейти к п. 1
и продолжать до тех пор, пока корзина не станет
пустой.
Более формально этот алгоритм представлен в лис-
тинге 13.1.
РИСУНОК 13.4. Сортировка носков.
Этот метод довольно эффективен для сортировки
носков. Поскольку у каждого члена семьи по семь пар
носков, то всего имеется 7 человек *7 пар *2 носка/
пара=98 носков.
Давайте вычислим, сколько времени в среднем нам
понадобится на сортировку носков. Количество носков
«а полу начинается с 1 и заканчивается на 98. Посколь-
ку для каждого носка выполняются одни и те же опе-
рации, то пункты 1—5 будут выполнены ровно 98 раз.
Вспомним, что объем отсортированного списка начина-
ется с 1 и заканчивается на 98. В некоторый произволь-
ный момент времени "Г для определения точки встав-
ки нам придется просмотреть половину носков (в сред-
нем) и переместить половину всех носков.
Следовательно, количество операций (в среднем) будет
следующим:
Сравнение: 0+1 + 1.5+2+2.5+...+49=2425.5 (прибли-
зительно (п2)/4, т.е. 2401).
Количество перемещенных носков будет в среднем
точно таким же — 2425,5.
298
Организация данных
Часть II
Листинг 13,1. Сортировка методом линейных вставок._____________________________________________
/*
Простая сортировка методом линейных вставок. Сортировка с двоичными вставками лучие, а
сортировка методом Велла еце лучие.
*/
void LINEARINSERTION (Etype a[]f unsigned long n)
{
unsigned long ir
Etype tmp;
for (i = 1; i < n; i++) /* найти точку вставки */
for (j = i; j > 0 && GT(a[j - 1], a[j]); j—) {
/* Переместить все элементы дальне и вставить текучий элемент. */
tmp = a[j];
a[j] = a[j - 1];
a[j - 1] = tmp;
}
}
Поскольку девушки смогут осмотреть или перемес-
тить один носок примерно за одну секунду, то сорти-
ровка займет примерно 4851 секунду (1 час 20 минут).
Интересно, что если перемещения и сравнения требу-
ют примерно одного и того же времени, то выполнение
сортировки займет то же самое время. Это вызвано тем,
что, если мы раньше найдем место, куда нужно подло-
жить носок, нам придется переместить большее коли-
чество носков. А если мы найдем нужное место позже,
придется переместить меньшее количество носков. Если
носок нужно положить на первое место, то придется
переместить все носки, если же носок нужно положить
на последнее место, мы вообще не делаем перемеще-
ний.
’’Отлично, теперь очередь Карен". Дик берет все
носки и кладет их назад в корзину и тщательно пере-
мешивает. Девушки понимают, что им снова придется
сортировать носки.
"Но нам потребуется на все больше пяти часов", —
пожаловалась Нита.
"У меня есть идея", — говорит Джуди.
’’Какая?" — поинтересовались Мэрилин. Может
быть, если бы Джуди высказала свою идею раньше, сор-
тировка носков не заняла бы так много времени.
"Тут требуется воображение, — ответила Джуди. —
Если мы посмотрим на носки на полу, то увидим, что
они находятся уже там, где и должны быть. Самый
маленький находится слева, а самый большой — спра-
ва Сначала мы поставим Вики возле самого маленько-
го носка, а Мэрилин — возле самого большого. Начнем
с носка, находящегося между Мэрелин и Вики. Если
носок, взятый из корзины, будет больше, чем носок на
полу, мы поставим Вики рядом с носком на полу, по-
скольку Вики самая маленькая. Далее будем считать,
что носок возле Вики самый маленький, и посмотрим
на носок, который лежит посередине между нашими
самым маленьким и самым большим носками. Если
носок, взятый из корзины, будет не больше, чем носок
на полу, мы поставим Мэрилин рядом с носком на полу,
поскольку Мэрилин самая большая. Далее будем счи-
тать, что носок возле Мэрилин самый большой и по-
смотрим на носок, который лежит посередине между
нашими самым большим и самым маленьким носками.
Если продолжать такую сортировку дальше, то нам при-
дется проверить лишь несколько носков".
Сортировка с двоичными вставками
1. Мэрилин и Вики стоят у кучи носков, Мэрилин
возле большего носка, а Вики — возле меньшего.
2. Карен берет носок из корзины.
3. Карен смотрит на носок на полу, который находит-
ся посередине между Вики и Мэрилин (если там
есть носок).
4. Если носок в руке Карен больше, чем носок на
полу, нужно переставить Вики к носку на полу, на
который смотрит Карен. В ином случае следует по-
ставить туда Мэрилин.
5. Повторять пункты 2, 3, 4 до тех пор, пока Мэре-
лин и Вики стоят на одном и том же месте.
6. Карен перемещает все носки на полу вниз (по спис-
ку), освобождая место на полу для нового носка.
7. Карен кладет этот новый носок на только что осво
бодившееся место.
8. Если в корзине еще есть носки, Карен переходит к
п. 1 и продолжает всю процедуру до тех пор, пока
корзина не станет пустой.
В листинге 13.2 приведена реализация этого метода
сортировки на С.
Методы быстрой сортировки
Глава 13
299
Листинг 13.2. Сортировка с двоичными вставками.
/*
Это простои алгоритм сортировки с двоичными вставками. Сортировка с двоичными вставками в
среднем намного быстрее сортировки методом линейных вставок, а сортировка методом Велла еце
быстрее. Вы, может быть, сами пожелаете протестировать сортировку с двоичными вставками и
сортировку методом Велла, но я подозревав, что на больиинстве систем сортировка методом Велла
будет быстрее.
*/ void INSERTIONSORT(Etype array[], unsigned long count)
{
unsigned long partition; /* Конец нового сегмента */
long beg; /* Поиск начинается здесь (эта переменная перемечается к ipg) */
long ipg; /* Текучая точка вставки (посередине между beg и end)
' long end; /* Поиск заканчивается здесь */
Etype temp; /* Переменная предназначена для временного хранения одного
элемента массива */
/* По определению, сортируется один элемент. Формируем все больмие и больжие упорядоченные
сегменты до тех пор, пока весь массив не будет отсортирован. */
for (partition = 1; partition < count; partition+4-) {
/* двоичный поиск точки вставки */
beg ~ ipg = 0; /* Первый элемент отсортированной части массива - это
элемент 0 */
end = partition - 1;/* Последним уже отсортированным элементом является
элементарный сегмент, равный 1 */
/* Без этой проверки цикл завериился бы только в случае, если элемент с таким
значением уже отсортирован */
while (end >• beg) {
/* Точка вставки посередине между началом и концом */
ipg - ((end 4- beg) » 1); /* Предупреждение. Мы ие можем сортировать
массивы с количеством элементов >(MAX_LONG)/2 */
/* Однако эту сортировку можно выполнять ТОЛЬКО для небольних сегментов */
/* Мы вставляем элемент, который находится в конце сегмента */
/* Он еце не отсортирован, ио весь массив левее него ухе отсортирован. */
if (GT(array[ipg], array[partition]))
end = ipg - 1;
else
beg = ++ipg;
}
/* Предоставить место в array[ipg] для arrayfi] */
/* Он ухе может быть на своем месте */
if (partition 1= (unsigned long) ipg) {
temp = array[partition]; /* Сохранить новый элемент, который мы
собираемся вставить */
/* Переместить данные от точки вставки вниз. Функцию memcpy() использовать
нельзя */
memmove(barray[ipg + 1], &arгay[ipg],
(partition - ipg) * sizeof(Etype));
array[ipg] - temp; /* Вставить новый элемент в нужное место */
}
У
return;
)
Количество сравнений:
0+l+log2(2)+...+log2(98)=512.5 (приблизительно
0.79*n*log2(n) или 0.79*648.24 = 512.11 для п=98).
Количество перемещений будет таким же, как и при
сортировке методом линейных вставок, — 2425,5.
Общее количество операций в среднем гораздо мень-
ше, чем при сортировке методом линейных вставок:
всего около 2938 сравнений и перемещений. Для сор-
тировки двоичными вставками количество сравнений не
зависит от первоначальной упорядоченности носков.
Организация данных
Часть II
300
К счастью, количество сравнений очень невелико. Тем
не менее, количество перемещений, которое равно ко-
личеству перемещений при сортировке методом линей-
ных вставок, существенно снижает скорость этого ме-
тода. Если бы нам приходилось перемещать все носки,
то работы было бы не меньше, чем раньше. Но если
перед началом сортировки список уже был отсортиро-
ван, нам вообще не придется перемещать элементы. В
данном случае мы просто добавляем носок в конец спис-
ка. Поэтому общее количество ^операций может быть
всего 512,5. Следовательно, сортировка носков займет,
скорее всего, около 49 минут, хотя, если носки уже
были отсортированы, то можно справиться и за 8,5
минут.
Очевидно, что сортировка двоичными вставками
гораздо эффективнее сортировки методом линейных
вставок. Для малых массивов данных (около 20 элемен-
тов) сортировка двоичными вставками является, навер-
ное, единственным алгоритмом, который следовало бы
использовать. Он намного лучше сортировки методом
линейных вставок. Но в метод вставок можно внести
еще одно усовершенствование.
Сортировка методом Шелла
До изобретения быстрой сортировки сортировка мето-
дом Шелла была наиболее оптимальным методом сор-
тировки с точки зрения сложности. Теперь это уже не
так, но сортировка методом Шелла все еще является
хорошим алгоритмом для небольших наборов данных.
Метод Шелла является обобщением метода вставок.
Этот алгоритм, разработанный Дональдом Шеллом
(Donald Shell), основан на том, что сортировка методом
вставок выполняется очень быстро на почти отсортиро-
ванном массиве данных. Он также известен как сорти-
ровка с убывающим шагом, В отличие от сортировки ме-
тодом вставок, при сортировке методом Шелла весь
массив не сортируется одновременно: массив разбива-
ется на отдельные сегменты, которые сортируются раз-
дельно с помощью метода вставок.
Для некоторой длины шага h будем считать, что
массив состоит из h отдельных сегментов. Каждый сег-
мент содержит примерно п, деленное на h, элементов.
После того как все сегменты отсортированы, массив
разделяется на меньшее количество сегментов (т.е. длина
шага уменьшается), и процесс повторяется до оконча-
тельной сортировки всего массива, когда h будет равно
1. Интересно, что если длина последнего шага равна 1,
то можно использовать любую последовательность длин
шагов. Тем не менее, некоторые значения длины шагов
имеют преимущества перед другими. Наилучшую пос-
ледовательность длин шагов еще предстоит найти. Хотя
принцип сортировки методом Шелла довольно прост,
его формальный анализ затруднен. Для сортировки
Шелла О-нотация точно неизвестна, но известно, что
при разумном выборе последовательности длин шагов
h он имеет порядок сложности, близкий к О(п’4/3)). За-
чем нужна сортировка методом Шелла? Выполнение
этого метода сортировки обусловлено наличием не-
скольких больших элементов в массиве данных, кото-
рый необходимо отсортировать. Иногда самый большой
элемент может стоять на первом месте. В таком случае
сортировка методом вставок на каждом шаге будет пе-
ремещать этот элемент на одну позицию правее (ниже).
Максимальный элемент будет перемещаться n—1 раз.
Но это еще не самое плохое. Иногда рядом с ним нахо-
дятся другие большие элементы. Они так же, как и мак-
симальный элемент, будут перемещаться в конец мас-
сива. В некоторых очень редких случаях все элементы
располагаются в массиве в обратном порядке (хуже не
придумаешь) Вот это действительно проблема для сор-
тировки методом вставок!
Именно в таком случае помогает сортировка мето-
дом Шелла. Предположим, что в некоторый момент
времени шаг h равен 10, т.е. фактически на данном эта-
пе мы выполняем сортировку методом вставок каждого
десятого элемента массива. Элементы в нашем h-под-
массиве будут перемещаться на одну позицию за один
шаг в этом подмассиве, но в самом массиве это десять
позиций, т.е. мы нашли способ, с помощью которого
можно перемещать большие элементы в 10 раз быстрее,
чем при сортировке методом вставок. Еще лучше сор-
тировка методом Шелла подходит для почти упорядо-
ченного массива. По сравнению с обычным методом
вставок метод Шелла обладает значительными преиму-
ществами. Но, несмотря на все свои достоинства, сор-
тировка методом Шелла тоже эффективна только в слу-
чае небольших наборов данных. Реализация метода
Шелла приведена в листинге 13.3.
Имейте в виду, что существуют специальные спосо-
бы оптимизации для случаев, когда количество элемен-
тов меньше пяти. Это позволяет ускорить метод всего
на несколько процентов, но это уже много. Сортировка
методом Шелла будет выполняться для многих задач, в
которых количество элементов в массиве данных не-
большое, а также в других методах сортировки, в кото-
рых используется метод Шелла. Поэтому любую воз
можность даже незначительного ускорения этого метода
необходимо тщательно рассмотреть.
Быстрая сортировка
Теперь перейдем к следующему заданию для сестер
Джонс. Я не могу вам сказать, что они натворили на сей
раз, это не совсем удобно. Достаточно только сказать,
что и тут не обошлось без очков. Как бы там ни было.
Дик придумал еще одно наказание. Когда девушки уви
дели Дика с очками, они сказали: "Мы знаем, снова
Методы быстрой сортировки
Глава 13
301
носки". "Нет. Я придумал кое-что другое". Дик любит
играть в покер. Он часто играет со своими друзьями из
Департамента дорог. Обычно он выигрывает намного
больше, чем проигрывает, и уже собрал большую кол-
лекцию мелочи. Он принес галлонную банку, полную
монет. "Отсортируйте вот это и не забудьте про очки.
Правила остаются теми же. Только тот, кто носит очки,
может сортировать монеты. Другие должны молчать".
"Да тут их тысячи! Может даже сотни тысяч! С на-
шими методами сортировки носков мы не справимся и
за день!" — расстроилась Мэрилин. И тут Ните пришла
в голову великолепная идея: "Мы поделим их пополам".
"Я принесу пилу”, — сказала Вики.
"Нет, нет. Ничего такого не нужно. Мы просто раз-
делим все монеты на несколько кучек".
Метод быстрой сортировки
1. Высыпать все монеты в одну кучу.
2. Взять из кучи одну монету.
3. Если монета имеет большой номинал, положить ее
в другую кучу справа.
4. Если монета имеет небольшой номинал, положить
ее в третью кучу слева.
Листинг 13,3, Сортировка методом Шелла.
/*
** Последовательность длин шагов h в этой версии метода Желла взята из Handbook of Algorithms
** and Data Structures in Pascal and C, Gaston Gonnet, Ricardo Baeza-Yates, Addison Wesley;
** ISBN: 0201416077
** У меня эта последовательность дает лучшие результаты, чем у Седжвика (Sedgewick) при полной
** оптимизации. Для вас оптимальная последовательность длин шагов может быть другой, поэтому
** советуй попробовать воспользоваться и последовательностью, предложенной Седжвиком. Задача
** определения оптимальной последовательности длин шагов h еще не решена. Вы можете провести
** сортировку всех комбинаций последовательных шагов при количестве элементов не более 20,
** поскольку именно в этой области сортировка методом Шелла имеет очень большое преимущество.
** Если вам удастся найти какую-то хорошую последовательность, ваше имя может стать известным.
*/
void SHELLSORT(Etype array[], sizet count)
{
size_t i,
inc,
i;
Etype tmp;
switch (count) {
case 0:
case 1:
return;
case 2:
INSERTTWO(array);
return;
case 3:
INSERTTHREE(array);
return;
case 4:
INSERTFOUR(array);
return;
default:
for (inc = count; inc >0;) {
for (i = inc; i < count; i++) {
j = i;
tmp = array [i];
while (j >= inc && (LT(tmp, array[j - inc]))) {
array(j) = array[j - inc];
j -= inc;
}
arrayfj] • tmp;
} /* Вычислить следующий шаг h */
inc = (size t) ((inc > 1) && (inc < 5)) ? 1 : 5 * inc / 11;
}
}
>
302
Организация данных
Часть II
5. Перейти к п. 2 для каждой кучи, пока во всех ку- танется по одной монете, все монеты окажутся пол-
чах не окажется по одной монете. Поскольку кучи ностью упорядоченными,
монет с большим номиналом находятся сплава, а с n
mvnvi v wuiDinnm пи nncuiv , Реализация этого алгоритма на С приведена в лис-
меныним номиналом — слева, то, когда в кучах ос- тинге |з 4
Листинг 13.4. Примитивная быстрая сортировка.
/*
Примитивная быстрая сортировка. Этот алгоритм неэффективен для обцих цепей. Не используйте его.
*/
void QSORTB(Etype * A, int 1, int г)
{
int loc;
if (1 < r) {
int i = 1,
j = r?
Etype tmp,
pivot = A[l);
/* Разделить кучи на сегменты */
for (;;) {
while ((A[j] >= pivot) && (j > 1))
j—;
while ((A[i] < pivot) && (i < r))
if (i < j) {
tmp = A[i];
A[ij = A[j);
A(j] = tmp;
} else {
loc = j;
break;
}
}
/* Рекурсия*/
QSORTB(Af 1, loc);
QSORTB(Af loc + 1, r);
}
}
Именно это девушки и сделали. Сортировка заняла
довольно много времени — почти пять часов, но это не
так уж плохо, если принять во внимание, какое коли-
чество монет им пришлось отсортировать и притом ис-
пользовать эти глупые очки.
Недостатки метода быстрой сортировки
Для данных со случайным начальным распределением
метод быстрой сортировки подходит просто идеально,
но для некоторых часто встречающихся распределений
он совсем не годится. Как объясняет Джон Бентли (Jon
Bentley) в "Software Exploratorium: History of Heapsort”
(Unix Review. Vol. 10, 8, August, 1992), многие популяр-
ные реализации метода быстрой сортировки имеют не-
достатки, которые для многих часто встречающихся рас-
пределений данных снижают эффективность до
порядка О(п2). К таким часто встречающимся распре-
делениям относятся, например, уже упорядоченные
данные, данные, упорядоченные в порядке убывания,
или данные, увеличивающиеся от концов к середине. В
таких случаях сортировка полумиллиона элементов
вместо нескольких минут требует нескольких недель.
Примитивный метод быстрой сортировки настолько
опасен, что его можно использовать разве что в целях
обучения. После того как вы поймете простой алгоритм,
в него можно внести небольшие изменения, которые
сделают этот алгоритм намного более эффективным.
Сортировка методом Синглтона
Алгоритм 347 Ассоциации по вычислительной технике
(АСМ) является намного более экономичным вариан-
том простого метода быстрой сортировки. Вернемся к
семье Джонс и посмотрим, чем они занимаются.
Естественно, когда Дик вернулся к дочерям, он был
очень удивлен, когда увидел, что они отсортировали все
монеты. Реа сказала, что она все время была в комнате
с девушками и они не нарушали правил. ’’Хорошо,
сказал Дик. — Теперь очередь следующей”.
Методы быстрой сортировки
Глава 13
[зоз
"Так мы никогда не закончим!” — застонала Джуди.
"Давайте посмотрим, что мы сделали не так, — ска-
зала Мэрилин. — Я заметила, что иногда мы берем пен-
ни, а пенни — самая маленькая монета. Но мы можем
просто не брать пенни, поскольку в куче могут быть
только пенни. Почему бы нам просто не перемешать
кучу и не выбрать из нее несколько монет другого дос-
тоинства? А затем мы будем брать среднюю из них и
разделять монеты на кучи с ее использованием".
Нита добавила: "Я заметила, что иногда в куче бы-
вают только одинаковые монеты, т.е. она уже отсорти-
рована. Почему бы нам сначала не просмотреть быстро
всю кучу — а вдруг ее не нужно будет сортировать?"
А у Реи была идея еще лучше: "Я заметила, что вы
тратите слишком много времени на маленькие кучи.
Почему бы вам для сортировки маленьких куч не ис-
пользовать те же методы, которые вы использовали при
сортировке носков? Я ручаюсь, вы сэкономите уйму
времени".
И вот что они сделали.
Алгоритм сортировки методом Синглтона (модифици-
рованный метод быстрой сортировки)
1. Высыпать все монеты в одну кучу.
2. Посмотреть, не отсортирована ли уже куча. Если
нет, то:
3. Перемешать кучу и взять из нее несколько монет.
Взять среднюю монету из выбранных.
4. Если монета имеет большой номинал, положить ее
в кучу справа.
5. Если монета имеет небольшой номинал, положить
ее в кучу слева.
6. Если куча маленькая, использовать метод сортиров-
ки двоичными вставками. Иначе:
7. Перейти к п. 2 для каждой кучи, пока во всех ку-
чах не будет по одной монете. Поскольку кучи мо-
нет с большим номиналом находятся справа, а с
меньшим номиналом — слева, то, когда в кучах ос-
танется по одной монете, все монеты окажутся пол-
ностью упорядоченными.
ПРИМЕЧАНИЕ
Листинг алгоритма 347 довольно объемистый. Вы може-
те найти реализацию этого алгоритма в файле allsort.h на
Прилагаемом к книге CD-ROM.
В семье Джонс бывают не только наказания. Иног-
да бывает и веселье. Они играют на музыкальных ин-
струментах, и иногда Дик играет на гармонике или на
аккордеоне, а Реа — на фортепьяно. Они играют ста-
рые известные песни, а девушки поют.
Пирамидальная сортировка
Однажды семья Джонс решила провести турнир по
шашкам. Все знали, что лучший игрок — Дик, поэтому
в первом туре он не играл. Что касается всех остальных,
то они пытались свести самых старших игроков (и, воз-
можно, самых хороших) с самыми молодыми (и, воз-
можно, самыми плохими). Реа играла с Вики, Мэрилин —
с Джуди, а Карен — с Нитой. Как и ожидалось, выиг-
рали Реа, Мэрилин и Карен (хотя Карен пришлось не-
мало потрудиться). В следующем туре Карен играла с
Диком, а Реа — с Мэрилин. Дик, как и ожидалось, вы-
играл, а Мэрилин преподнесла первую неожиданность.
Ко всеобщему удивлению, она вышла победителем и
финальной игры. Причиной, по которой настоящие
турниры часто проводятся именно по такой схеме, яв-
ляется определение наилучшего игрока (на сегодняш-
ний день). Лучшие игроки перемещаются вверх по спис-
ку. По терминологии вычислительной техники такая
структура называется пирамидой (или кучей — может,
потому, что турниры могут принести кучу удоволь-
ствий).
Проведение турнира эквивалентно операции постро-
ения пирамиды. Пирамида обладает несколькими инте-
ресными свойствами. Одно из свойств, которые мы
могли заметить, состоит в том, что необходимо провес-
ти всего несколько игр, чтобы определить, кто являет-
ся сильнейшим игроком. Эффективность пирамиды
равна O(n*log(n)) подобно эффективности метода быс-
трой сортировки. А второе свойство — глубина кучи
всегда невелика. Фактически она составляет ceil(lQg(n)),
или, говоря другими словами, высота пирамиды при-
близительно соответствует высшему битовому разряду
в количестве элементов в пирамиде. Так, например,
если в пирамиде находится 220 элементов, то высота
пирамиды будет составлять ровно 20. Кроме того, пи-
рамиды очень просты и имеют еще одно замечательное
свойство: с пирамиды легко взять верхний элемент.
В нашем случае турнира по шашкам это будет Мэри-
лин. Мы также можем убирать элементы из пирамиды
и добавлять в нее новые элементы, выполняя неболь-
шое количество операций. При этом пирамида останется
отсортированной.
Существует много методов организации пирамид.
Одни из них более эффективны, другие — менее. Есть
даже пирамиды, которые дают эффективность порядка
0(1) для всех операций, кроме операции удаления ми-
нимального элемента в пирамиде, которая имеет эффек-
тивность порядка O(log(n)). Тем не менее, не рекомен-
дуется использовать эти пирамиды. Причина состоит в
том, что указанная эффективность проявляется лишь
асимптотически (т.е. при очень большом количестве
элементов), но для просто больших массивов данных
Организация данных
304
Часть II
(для которых мы должны были бы выполнять пирами-
дальную сортировку) эти пирамиды не дают такой эф-
фективности, как более простые алгоритмы. Так как же
нам выполнять сортировку с помощью пирамид? Мы
могли бы сформировать пирамиду, а затем выбирать
верхний элемент до тех пор, пока пирамида не окажет-
ся пустой. Но такая сортировка так же неэффективна,
как и быстрая сортировка. А те случаи, в которых быс-
трая сортировка не срабатывает, случаются настолько
нечасто, что реализовывать пирамидальную сортиров-
ку становится нецелесообразно.
Если рассмотреть общий случай поведения методов
быстрой и пирамидальной сортировки, то (в среднем)
метод пирамидальной сортировки окажется гораздо
медленнее. Вот какой вред может нанести проведение
пирамидальной сортировки. Представьте себе специаль-
ную таблицу, которую раздали 40000 сотрудникам.
В таблице содержится информация о сотрудниках.
Иногда нам приходится находить сотрудника по име-
ни или по фамилии, или, может быть, мы будем по-
мнить номер его телефона и забудем его имя, а нам
хотелось бы назвать его по имени, когда он поднимет
трубку. Сотрудник должен иметь возможность упоря-
дочить данные в таблице в любой последовательности,
которая ему необходима. Для этого может понадобить-
ся сортировка. Если эти 40 тыс. сотрудников будут ис-
пользовать таблицу два раза в неделю и время пирами-
дальной сортировки будет составлять 10 секунд вместо
2 секунд при использовании быстрой сортировки, то за
год это составит 40 тыс. сотрудников * 2 раза в неделю ♦
52 недели в году * (10 — 2) секунд = 33,28 млн поте-
рянных секунд. В сутках 86400 секунд, т.е. мы потеря-
ем 385 человеко-дней. Маленькая восьмисекундная раз-
ница выливается в один человеко-год. Добавьте к этому
чувство разочарования от десятисекундного ожидания,
и вы поймете, что это может сказаться и на производи-
тельности. И хуже всего, если это ожидание будет раз-
дражать сотрудников, они могут вообще отказаться от
использования этого инструмента. Инструменты на-
правлены на повышение продуктивности, но при пло-
хой реализации они могут даже быть причиной сниже-
ния производительности труда.
Тем не менее, мы не оставим пирамиды без внима-
ния. Как мы убедимся позже, в форме очереди по при-
оритету пирамиды (или кучи) чрезвычайно полезны
для сортировки. Будем использовать очередь по приори-
тету (которая является не чем иным, как пирамидой, в
которой мы в основном будем снимать верхний элемент
и вставлять и убирать другие элементы) для комбини-
рования различных методов.
Сортировка подсчетом
После очередного плохого поведения сестер возвраща-
емся к нашей банке с мелочью. Но на этот раз Дик при-
нес пятигаллонное ведро, до краев заполненное моне-
тами.
"Мы больше никогда не увидим солнечного света", —
пожаловалась Вики.
На этот раз, перед тем как что-либо предпринять,
они долго сидели и думали. "С тем же успехом мы мог-
ли бы отсортировать целую ванну мелочи, — сказала
Мэрелин. — Мы никогда их не отсортируем".
И тут Карен пришла идея: "Банки! Нам потребует-
ся много банок!" "Зачем?" — спросила Джуди.
"Тот, кто будет сортировать монеты, будет просто
называть нужную банку, а остальные будут подносить
эту банку, — ответила Карен. — Это не нарушает пра-
вила, поскольку тот, кто носит очки, кладет монету в
нужную банку и говорит остальным, что они должны
делать".
Мэрилин увидела одну проблему: "Хорошо, у нас
есть много банок, но банки какого размера нам нужны?
У нас есть еще одно пятигаллонное ведро и несколько
галлонных ведер, много банок объемом в кварту и мно-
жество маленьких банок".
"Я об этом уже думала, — ответила Карен. — Мы
сначала пересчитаем монеты. Затем для тех монет, ко
торых больше всего, мы используем емкости побольше,
а для тех монет, которых меньше всего, можно будет
использовать и маленькие банки".
И вот что они сделали (рис. 13.5).
Алгоритм сортировки подсчетом
1. Пересчитать все монеты в куче по типу.
2. Распределить ведра в соответствии с количеством
монет.
3. Для каждой монеты, оставшейся в куче, назвать
ведро, в которое необходимо положить монету.
4. Бросить монету в ведро и перейти к п. 3.
Удивительно, но этот метод оказался настолько бы
стрым, что сортировка заняла даже меньше времени, чем
сортировка галлонной банки монет.
Даже Дик был удивлен: "Три часа сорок пять мину i
на сортировку шести галлонов монет!? Мад, они, навср
ное, нарушали правила?"
"Тут сложно сказать — да или нет, но я бы сказала
что нет, они не нарушали правил".
"Хорошо, — сказал Дик. — Тогда я позову Волтера”
Волтер играет в покер всю свою жизнь. И ему в на
следство от отца досталась немалая коллекция моно.
часть которой была унаследована им еще от деда. Пос-
ле короткого телефонного звонка пришел Волтер с боль
шим мешком, набитым монетами.
Методы быстрой сортировки
Глава 13
305
РИСУНОК 13.5. Сортировка монет.
’’Вот теперь посмотрим, сколько времени вам по-
надобится”.
И снова, перед тем как приступить к сортировке,
сестры решили посидеть и подумать. ’’Есть какие-ни-
будь идеи?" — спросила Вики, но ответа так и не полу-
чила.
Но тут Реа сказала: "Дик, сделай мне, пожалуйста,
доску".
’’Конечно, Мад. Какую доску?"
’’Доску с отверстиями. По одному отверстию для
каждого размера монет. Даже для тех старых монет в два
цента и для золотых монет в двадцать долларов. Для
всех монет, которые у нас есть".
"Хорошо, я буду через пять минут".
Когда Дик вернулся с доской, он спросил, для чего
Рее нужна эта доска.
"Для начала в сарае я возьму трубки".
Через десять минут Реа вернулась с тачкой, запол-
ненной кусками труб разных размеров и форм, рулоном
липкой ленты и несколькими мешками. Еще через пят-
надцать минут она соорудила какое-то устройство, ко-
торое выглядело как коллекция волынок. С помощью
ленты она соединила один конец трубки с отверстием
в доске соответствующего размера, а второй конец она
соединила с мешком. На доске возле каждого отверстия
она написала номиналы монет и передала это устрой-
ство Мэрилин. А работало это устройство следующим
образом (рис. 13.6).
Алгоритм сортировки методом множественных вставок
1. Взять из кучи монету, пока куча не окажется пус-
той.
2. Посмотреть, к какому отверстию в доске монета
подходит.
3. Опустить монету в нужное отверстие.
4. Перейти к п. 1.
Заметили ли вы, что для каждой монеты выполня-
ется только одна операция? И вам даже не нужно пе-
ред сортировкой пересчитывать все монеты. В некото-
ром роде мы все еще пользуемся принципом "разделяй
и властвуй", но разделяем сразу на большое количество
частей. По сути, для разделения мы выполняем хеши-
рование, но не простое хеширование, а "волшебное".
Мы выбрали такое уникальное хеширование, которое
позволяет сразу привести данные в порядок.
На первый взгляд кажется, что таким способом мож-
но сортировать все что угодно. Но помните, нам при-
шлось выполнить подготовительные операции, в пер-
вую очередь, создать устройство для сортировки?
Назовем его функцией соответствия. Такие функции
соответствия придется строить для каждого типа дан-
ных, которые необходимо отсортировать методом мно-
жественных вставок. Есть и еще одна проблема — па-
мять. В решении девушек использовались мешки,
размера которых хватало для размещения в них монет.
Но в вычислительной технике, если требуется отсорти-
ровать миллион элементов, понадобится миллион меш-
ков. Это было бы слишком расточительно. Вместо это-
го можно использовать структуру типа связанного
20 Зак. 265
Организация данных
Часть II
306
списка. При этом для каждого элемента понадобится
место для хранения по крайней мере одного указателя.
Если количество элементов действительно очень вели-
ко (слишком велико для хранения их в памяти), может
быть, придется ограничивать количество элементов,
которые могут быть отсортированы одновременно. По-
скольку поиск и чтение на диске занимает намного
больше времени, чем работа с памятью, выгоднее хра-
нить в памяти максимально возможное количество эле-
ментов.
РИСУНОК 13.6. Сортировка монет методом множественных
вставок.
В общем случае быстрые методы проявляют свою
эффективность только в случае больших наборов дан-
ных. Поэтому можно воспользоваться тем же приемом,
который использовался в методе быстрой сортировки.
Если набор данных действительно огромен, можно сор-
тировать большие части этого набора с помощью мето-
да множественных вставок, а затем, когда набор будет
разбит на более мелкие части, можно выполнить сор-
тировку методом Синглтона (которая, в свою очередь,
автоматически переходит в метод двоичных вставок).
Одним словом, для каждой работы будем использовать
нужный инструмент.
Метод сортировки подсчетом является устойчивым
двухпроходным методом, который работает непосред-
ственно с ключами. На первом проходе подсчитывают-
ся вхождения каждого ключа в массив смешений, а за-
тем подсчитывается промежуточная сумма, и каждая
точка смещений оказывается точкой вставки нового эле-
мента. При втором проходе элемент переносится в его
окончательное положение в соответствии с точкой сме-
щения для этого ключа. В сортировке методом подсче-
та предполагается, что ключи являются целыми числа-
ми от 0 до к, где к — константа. Часто выбирается
k=UCHAR_MAK В этом случае за один приембудет
Обрабатываться один символ данных. Такой выбор со-
вершенно произволен. Вполне можно принять
k=USHRT_MAX, но тогда потребуется гораздо больше
дополнительной памяти и много времени может уйтить
на просмотр пустых ведер. Эффективность сортировки
методом подсчета равна O(n+k), или О(п), если к име-
ет порядок О(п). Это позволяет получить очень высо-
кую скорость сортировки для элементов из О1раничен-
ного диапазона. Обратите внимание, что данный метод
перекрывает нижний предел "оптимальности", который
имеет порядок O(n*log(n)). Это не противоречит утвер-
ждению о том, что оптимальный метод сортировки тре-
бует n*log(n) сравнений, поскольку сортировка методом
подсчета не основана на проведении сравнений. Сорти-
ровка методом подсчета сама по себе не так уж и по-
лезна, поскольку не часто приходится сортировать дан-
ные длиной в один символ.
Например, необходимо провести сортировку четы-
рех элементов. Первый байт первого элемента равен 7,
второго элемента — 0, третьего элемента - 5 и четвер-
того — 4. В нашем массиве вхождений получим следу-
ющее:
1, 0, 0, 0, 1, 1, О, 1
Прибавляя содержимое текущего приемника к со-
держимому всех предыдущих приемников, вычисляем
смещения:
О, 1, 1, 1, 1, 2, 3, 3, 4
Далее, если при вставке данных в целевой массив
встречается число 0, его смещение будет равно 0, чис-
ло 4 получит смещение 1, число 5 — смещение 2 и т.д.
Таким образом, мы можем определить место каждого
элемента.
Восходящая поразрядная сортировка
При восходящей поразрядной сортировке (Least
Significant Digit radix-sorting — Поразрядная сортиров-
ка начиная с самого младшего разряда. — Прим, науч
ред.) перемещение выполняется справа налево по одно-
му символу (или приемнику) за шаг. Метод восходящей
поразрядной сортировки использовался в механических
сортировочных машинах для сортировки карточек сшс
до изобретения компьютеров. Для каждой цифры или
Методы быстрой сортировки
Глава 13
[307
символа имеется контейнер. Содержимое этого контей-
нера вычисляется таким же образом, как и в сортиров-
ке методом подсчета. На каждом последующем прохо-
де на основании текущего символа определяется, в
какой контейнер переместить запись. Этот процесс по-
вторяется для каждого символа в ключе от менее зна-
чащего к более значащему. Данный метод работает толь-
ко потому, что метод сортировки подсчетом устойчив.
Но мы не используем такой метод. Можно было бы ис-
пользовать метод сортировки слйянием, который тоже
является устойчивым, но на практике это никогда не де-
лается. Поразрядная сортировка выполняется в случае,
когда ключи маленькие или когда количество элемен-
тов просто огромно. Для огромного количества элемен-
тов сортировка слиянием будет неэффективна, или, по
крайней мере, не так эффективна, как сортировка под-
счетом.
Ускоренная восходящая поразрядная сортировка
Поскольку заранее известно, сколько мы будем делать
проходов, можно было бы подсчитать все ведра одно-
временно. Предположим, у нас есть восьмисимвольный
ключ и наши ведра содержат один символ. Если не под-
считать все символы одновременно, то придется сделать
восемь проходов для подсчета и восемь проходов для
распределения символа по ведрам. Если же подсчитать
их одновременно, нужно будет выполнить только один
проход для подсчета и восемь проходов для распределе-
ния символа. Если ключи достаточно длинные, то таким
образом мы сэкономим много времени. При этом требу-
ется довольно умеренный объем дополнительной памя-
ти, поскольку необходим только один набор счетных
контейнеров для обработки каждого элемента ключа.
Нисходящая поразрядная сортировка
При нисходящей поразрядной сортировке (Most
Significant Digit radix-sorting — Поразрядная сортиров-
ка начиная со старшего разряда. — Примеч. науч, ред.)
перемещение осуществляется слева направо, а не спра-
Ва налево, как было в предыдущем случае. Это означа-
ет, что теперь нельзя подсчитать все контейнеры одно-
временно. Но зато мы получили одно преимущество:
теперь можно сортировать только те части исходного
набора данных, которые нуждаются в сортировке. Если,
например, весь набор состоит из одного символа, сор-
тировка пройдет за один проход. При восходящей по-
разрядной сортировке пришлось бы обрабатывать все
контейнеры. Говоря другими словами, мы тратим вре-
мя только на обработку значащих символов ключа.
Если, например, мы имеем ключ длиной 256 символов,
То очень маловероятно, что для выполнения сортиров-
ки придется просматривать весь ключ слева направо.
Еше одним существенным преимуществом нисходящей
поразрядной сортировки является то, что она не требу-
ет устойчивых алгоритмов сортировки, как восходящая
поразрядная сортировка. Это означает, что можно ис-
пользовать методы быстрой сортировки, сортировки
Шелла или любой другой алгоритм сортировки.
В последнее время были разработаны новые усовер-
шенствованные алгоритмы поразрядной сортировки,
например, адаптивная поразрядная сортировка и пораз-
рядная сортировка вперед, которые в настоящее время
проходят тестирование. Неплохо в этой области пора-
ботал Стефан Нильсон (Stefan Nilsson).
Поразрядная сортировка произвольных типов
данных
Наверное, в любой книге по. сортировке вы прочтете,
что поразрядную сортировку нельзя использовать про-
извольным образом подобно сортировке сравнением. Но
это не так. Поразрядная сортировка, которая основана
на сортировке подсчетом, является совершенно отдель-
ным видом сортировки. Каким образом производится
сортировка в методах, основанных на сортировке срав-
нением? Мы используем функцию сравнения, которая
сообщает, что один из элементов больше, меньше или
равен другому элементу. Но чтобы обработать эту ин-
формацию, необходимо иметь представление о значи-
мости битов. Например, в числах с плавающей точкой
самый значащий бит — это бит знака, за которым сле-
дует бит знака экспоненты. Затем идет бит экспонен-
ты, а далее — мантисса. В числах типа unsigned short
более значащий бит находится перед менее значащим
Каким образом можно передать эту информацию фун-
кции сравнения? Мы просто вводим функцию разделе-
ния данных, которая возвращает биты, выстроенные в
порядке значимости. Эта функция в поразрядной сор-
тировке является аналогом функции сравнения в сор-
тировках сравнением. Поскольку в языке С есть лишь
небольшое количество фундаментальных типоЬ данных,
создать для них функцию разделения данных — не та-
кая уж сложная задача.
Опасности алгоритмов с линейной функцией
времени
Алгоритмы с линейной функцией времени опасны при
использовании с большими ключами. Предположим, что
нужно отсортировать записи, ключи которых имеют
длину 256 символов. Может оказаться, что первые сим-
волы всех ключей одинаковы. Это не так уж невероят-
но, как можно подумать. Представьте себе отчет, в ко-
тором записи группируются по отделениям компании.
У нас может быть ключ ’ Amalgamated Computer
Consulting — Восточное отделение", с которого будут
начинаться все записи. Это означает, что мы потеряем
много времени на подсчет и распределение всех этих
Организация данных
Часть II
308
байтов. А теперь рассмотрим некоторые короткие клю-
чи. Представьте себе, что длина ключа составляет 24
символа. Поскольку время поразрядной сортировки
пропорционально длине ключа, алгоритму восходящей
поразрядной сортировки потребуется п*25 проходов. Но
если использовать метод сортировки порядка n*log(n),
то log(n) здесь будет больше, чем 25. Поскольку 2й рав-
но 33554432, скорости поразрядной сортировки и ме-
нее "оптимальной" сортировки порядка O(n*log(n)) срав-
няются при сортировке 33554432 элементов. Другими
словами, линейные алгоритмы сортировки неэффектив-
ны даже при средней длине ключа. Можно, конечно,
выбрать гибридную стратегию или использовать пораз-
рядную сортировку только для ключей небольшой дли-
ны (листинги 13.5 и 13.6).
Листинг 13.5. Нисходящая поразрядная сортировка.
/*
Нисходящая поразрядная сортировка. Основана на описании, приведенном в "Algorithms in С" Robert
Sedgewick, ISBN:0-201-31452-5.
Здесь был введен оператор CHUNK, аналогичный оператору сравнения в методах сортировки
сравнением. Этот оператор выполняет все преобразования, необходимые для расположения битов в
порядке их значимости.
*/
lifndef RADIX MISSING
tdefine bin l+count[A]
void RADIXMSD(Etype a[], long 1, long r, unsigned w)
{
if (w > KEYSIZE || r <= 1)
return;
if (r - 1 <= LargeCutoff * COST) {
IQSORT5(a + 1, r - 1 4 1);
return;
} else {
long i,
Ъ
count [ R 4 1] = {0};
Etype *b = malloc((r -141)* sizeof(Etype));
/* Если выделение памяти завершится неудачно, выполнить стандартное сравнение */
if (b == NULL) {
IQSORT5(a + 1, г - 1 + 1);
return;
}
/* Перейти к следующему контейнеру */
for (i = 1; i <= г; i++) {
count[CHUNK(а + i, w) 4 1J++;
}
/* Для определения смещения сложить с содержимым предшествующих контейнеров */
for (j = l; j < R; з++)
countfj] 4= count[j - 1];
/* Распределить в соответствии с положением контейнеров */
for (i = 1; i <= г; i++) {
b[count[CHUNK(а + i, w)]++] = a[ij;
}
/* Перенести назад в исходный массив */
for (i = 1; i <= г; i++)
a[i] = b[i - 1];
free;
/* Обработать следующий элемент ключа для первого контейнера */
RADIXMSD(a, 1, bin(O) - 1, w 4 1);
for (3 = 0; j < R - 1; j44) {
/* Обработать следующий элемент ключа для остальных контейнеров */
RADIXMSD(a, bin(j), bin(j + 1) - 1, w + 1);
Методы быстрой сортировки
[309
Глава 13
Восходящая поразрядная сортировка представлена в листинге 13.6.
Листинг 13.6. Восходящая поразрядная сортировка.
/*
Восходящая поразрядная сортировка. Основана на описании, приведенном в •Algorithms in С" Robert
Sedgewick, ISBN:0-201-31452-5.
Здесь был введен оператор CHUNK, аналогичный оператору сравнения в методах сортировки
сравнением. Этот оператор выполняет все преобразования, необходимые для расположения битов в
порядке их значимости.
В функции также присутствует оператор CHUNKS, который одновременно перестраивает биты всех
данных в порядке их значимости.
*/
void RADIXLSD(Etype а[], long 1, long r, size_t keysize)
{
int i,
Dr
Etype *b;
if (r - 1 <« LargeCutoff * COST) {
IQSORT5(a + 1, r - 1 + 1);
return;
}
/* Для длинных ключей восходящая поразрядная сортировка слинком неэффективна */
if (KEYSIZE > 8) {
RADIXMSD(a, 1, г, 0);
return;
} else {
unsigned long cnts[R + 1][8] * {0};
b * malloc((r - 1 + 1) ♦ sizeof(Etype));
/* Если выделение памяти завериится неудачно, выполнить стандартное сравнение */
if (b == NULL) {
IQSORT5(a + 1, г - 1 + 1);
return;
}
/* Пересчитать все контейнеры */
for (i « 1; i <= г; i++)
CHUNKS(а + i, cnts);
for (v « KEYSIZE - 1; v >« 0; w—)
/* Для определения смещения сложить с содержимым предиествувщих контейнеров */
for (j « 1; j < R; j++)
cnts[j][w] += cnts[j - l][vj;
for (w « KEYSIZE - 1; w >= 0; w—) {
long count[R + 1] =
{0};
/* Распределить в соответствии с положением контейнеров */
for (i « 1; i <= г; i++) {
b[cnts[CHUNK(&a[i], w)][w]++] = a[i];
}
/* Перенести назад в исходный массив */
for (i » 1; i <® г; i++)
a[i] = b[ij;
}
free;
1
Организация данных
Часть II
310
Методы сортировки слиянием
Предположим, мы не можем поместить все данные в
память, как бы ни старались. В таком случае придется
проводить сортировку по частям, а затем соединять от-
дельные части в единое целое. Для этого используется
методика, которая называется слиянием.
Для понимания принципа слияния сначала рассмот-
рим простой пример, а затем приведем пару примеров
использования этого принципа. В качестве основного
метода сортировки наборов данных любого размера для
слияния отдельных наборов данных будем пользовать-
ся очередью по приоритету.
Сортировка двоичным слиянием
Самым простым для понимания является двоичное сли-
яние (слияние двух наборов данных, которое иногда
называют просто слиянием).
Алгоритм двоичного слияния
I. Из двух упорядоченных списков (неважно, как они
были упорядочены) извлечь по одному элементу и
-выбрать меньший из них.
2. Повторять п. 1 до тех пор, пока один из списков не
станет пустым.
3. Переписать оставшиеся элементы (если таковые
имеются) второго списка в результирующий список,
поскольку эти элементы уже отсортированы.
В листинге 13.7 приведен пример неэффективного,
но понятного двоичного слияния.
Недостатки сортировки методом двоичного
слияния
Метод двоичного слияния обладает только одним пре-
имуществом — он устойчив. Сортировка слиянием тре-
бует дополнительного объема памяти, пропорциональ-
ного количеству сортируемых элементов. Если
выделение памяти пройдет неудачно, будет применять-
ся метод быстрой сортировки, который не является ус-
тойчивым. Другими словами, нельзя быть уверенным в
устойчивости процесса сортировки. А в некоторых слу-
чаях метод вообще не будет работать. Кроме того, при
его использовании необходима дополнительная память,
и работает он медленнее метода быстрой сортировки.
Майк Ли (Mike Lee) написал алгоритм сортировки сли-
янием, который работает гораздо эффективнее приве-
денного выше, но все равно до быстрой сортировки ему
еще далеко (упомянутый алгоритм сортировки слияни-
ем можно найти на Web-сайте по адресу http://
www.ontek.com/mikey/flogger.tar.uu). И этот метод так-
же требует дополнительной памяти. Скорость сортиров-
ки слиянием можно повысить несколькими способами.
Можно разделить большие наборы данных на части и
за счет этого уменьшить количество сравнений. Можно
попробовать за счет хитроумных операций с памятью
снизить потребности в дополнительной памяти до не-
которого постоянного значения. Но полученный в ре-
зультате всех этих ухищрений алгоритм будет все рав-
но хуже метода быстрой сортировки.
Сортировка слиянием с делением на
секции
А сейчас давайте поговорим о потоке данных. Какими
свойствами он обладает? Известно, что значения посту-
пающих данных либо увеличиваются, либо уменьшают-
ся, либо остаются постоянными. Это называется три-
хотомией (хорошее слово для тех, кто его уже знает).
Как бы там ни было, предположим, что сначала мы пос-
ледовательно просматриваем все данные. Пока данные
не меняют направление своего изменения (постоянно
увеличиваются или уменьшаются), вносим их в теку-
щую секцию. Так, если данные увеличиваются или ос-
таются неизменными, вносим их в возрастающую сек-
цию, а если данные уменьшаются или остаются
неизменными, — в убывающую секцию. Нам необходи-
мо только два типа секций. Но можно обойтись и од-
ной возрастающей секцией, если данные постоянно уве-
личиваются, или одной убывающей секцией, если
данные постоянно уменьшаются. Но все-таки более ве-
роятно, что потребуются обе секции. Это напоминает
’’естественное слияние", которое использовал фон Ней-
ман. Фон Нейман следил только за увеличивающимися
последовательностями. Пользуясь таким принципом, в
некоторых случаях мы будем получать секции размером
1 (если, например, данные уже были отсортированы в
убывающем порядке). Используя оба вида секций, не-
трудно найти все упорядоченные участки в потоке дан-
ных. Для данных, отсортированных в убывающем по-
рядке, можно получить только убывающую секцию. Но
каким образом можно объединить эти уже упорядочен-
ные в возрастающем и/или убывающем порядке после-
довательности в одну упорядоченную последователь-
ность?
Очевидно, что для получения упорядоченной пос-
ледовательности нужно выбирать данные из начал воз-
растающих последовательностей и из концов убывающих
последовательностей. Для объединения двух последова-
тельностей в одну можно также использовать простой
метод слияния. Затем объединим две уже объединенные
последовательности в одну и повторим этот процесс до
получения одной результирующей последовательности.
Если к=(полный размер последовательности)/(средний
размер секции), то для получения результирующей пос-
ледовательности потребуется только k/2+k/4+...+1 ша-
гов слияния. Это выглядит достаточно эффектно. Но
давайте вернемся к очереди по приоритетам.
311
Методы быстрой сортировки
Глава 13
Листинг 13.7. Сортировка слиянием.
/*
** Приведенные ниже функции реализуют неэффективный, но понятный метод двоичного слияния. №
** просто соединяем два набора упорядоченных данных
*/
void
MMERGE (Etype А[], Etype B[), sizet 1, sizet n, size_t r)
{
size_t i = 1;
size_t j = m + 1;
sizet k = 1;
/* Вставить минимальный элемент в массив В */
while ((i <® m) && (j <= г))
{
if (LT (A[iJ, A[j]))
B[k++] = A[i++];
else
B[k++] = A[j++);
}
/* Скопировать остаток (если таковой есть) */
while (i <= m)
{
B[k++1 = A[i++];
>
while (j <= r)
{
B[k++] = A[j++J;
>
/* Переписать элементы в исходный массив */
for (k = 1; k <= г; k++)
{
A[k) = B[k];
>
}
/* Вспомогательная функция */
void
MSORT (Etype Al), Etype B[], size t 1, size t r)
{
size_t m;. /* Середина */
if (1 < r)
{ /* Разбивать задачу на две до получения одного элемента */
/* Делим секцию на две, проводим сортировку и слияние */
m » ((1 + г) » 1);
MSORT (А, В, 1, ш);
MSORT (А, В, m + 1, г);
MMERGE (А, В, 1, ш, г); /* Отдельный элемент отсортирован */
}
}
/*
Это действительно неэффективный метод сортировки слиянием. Пожалуйста, не используйте его. Он
приводится только для учебных целей.
♦/
void
MERGESORTB (Etype А[ ], size t count)
<
Etype *B;
if ((В = malioc(count * sizeof (Etype))))
{
MSORT (A, B, 0, count-1);
free;
}
else /* Будем надеяться, что выделение памяти пройдет неудачно и мы воспользуемся более
эффективным методом сортировки. */
IQSORT5(A, count);
I
312
Организация данных
Часть II
Поскольку данные сортируются отдельными блока-
ми (все данные не помещаются в памяти), у нас будет
список файлов, в которых будут содержаться отсорти-
рованные блоки. Если поместить в очередь по приори-
тетам все списки в возрастающем порядке, а затем вы-
бирать верхний элемент очереди до тех пор, пока она
не станет пустой, то мы отсортируем все элементы за
один этап. ’’Произошло чудо!” — закричите вы (надеюсь,
не вслух). Способ, предусматривающий работу с очере-
дью по приоритетам, и способ слияния двух списков в
основном аналогичны, но имеют существенное отличие.
При одновременной сортировке двух списков, которые
не помещаются в памяти, придется постоянно работать
с диском. При использовании очереди по приоритетам
мы будем делать следующее.
Алгоритм сортировки слиянием с делением на секции,
использующий очереди по приоритетам
1. Сканируя данные или открывая уже упорядоченные
последовательности, записанные на диске, форми-
руем секции.
2. Вставляем наименьший элемент каждой секции в
очередь по приоритетам.
3. Удаляем из очереди минимальный элемент и запи-
сываем его на диск.
4. Если при удалении минимального элемента из сек-
ции секция не освободилась, то переносим следу-
ющий элемент из этой секции в нашу очередь.
5. Переходим к п. 3.
Очевидно, что? этот метод позволяет производить
считывание и запись за одиц проход независимо от того,
сколько требуется файлов для'получения окончательно
упорядоченной последовательности. Это очень ценное
свойство. Раньше большие файлы сортировались с по-
мощью метода, который называется выбором с замеще-
нием. Выбор с замещением — медленный алгоритм, но
он может работать с последовательностями удвоенной
длины. Поскольку метод двоичного слияния для сорти-
ровки данных требует выполнения большого числа опе-
раций записи и считывания, удвоение длины последо-
вательностей дает положительный эффект, даже если
сам алгоритм неудачен. Теперь, когда у нас есть очередь
по приоритетам, можно считать, что мы нашли ему
достойную замену.
Но здесь есть одна проблема. Давайте рассмотрим
наихудший случай. При сканировании данных мы об-
наруживаем, что они увеличиваются-уменыпаются-уве-
личиваются-уменьшаются... так что длина всех секций
оказывается равной 2. В этом случае мы сталкиваемся
даже с двумя проблемами. Во-первых, данные о секци-
ях требуют много памяти. Необходимо отмечать нача-
ло и конец каждой секции и указывать, какая это сек-
ция: возрастающая или убывающая. Скорее всего, эти
данные будут состоять из двух значений типа unsigned
long и одного значения типа char. Если ключи имеют
малую длину, то вспомогательные данные будут зани-
мать слишком много памяти. И это еще не все — при
малых размерах секций наш алгоритм ведет себя как
обычная пирамидальная сортировка. А мы уже знаем,
что пирамидальная сортировка в среднем намного хуже
быстрой сортировки.
Сортировка слиянием по принципу
"нарезания печенья"
Для решения именно этой проблемы предлагается но-
вый метод, который назвывается "нарезание печенья”
(cookie-cutter). Предположим, мы начинаем сканирова-
ние данных, и по результатам предварительного анали-
за узнаем, что данные будут разбиты на слишком боль-
шое число секций. Давайте разобьем данные на
небольшие сегменты одинакового размера ("печенье") и
отсортируем их с помощью какого-либо другого мето-
да сортировки. Если размер последнего сегмента будет
меньше других, просто оставим его для последующей
сортировки. Таким образом, мы получим большое ко-
личество секций одинакового размера и упорядочен-
ных в одном направлении. Теперь для объединения
отдельных сегментов можно использовать другой алго-
ритм слияния. Наш алгоритм выглядит следующим об-
разом:
Алгоритм слияния по принципу "нарезания печенья"
1. Разделить массив на небольшие сегменты размером
t=n/k, где п — размер массива, к — некоторый раз-
мер, удобный для хранения данных в файлах.
2. Провести сортировку данных в отдельных файлах
с помощью других методов сортировки, например,
метода Шелла.
3. Выполнить алгоритм слияния с делением на сек-
ции.
Реализация приведенного алгоритма на языке С по-
казана в листинге 13.8.
А теперь давайте объединим все в одно целое. Мы
хотим написать процедуру сортировки данных для об-
щего случая, которую можно было бы использовать для
сортировки любых данных.
Первая задача — протестировать алгоритмы.
На рисунках 13.7—13.10 приведены графики произ-
водительности различных алгоритмов сортировки.
313
Методы быстрой сортировки
Глава 13
Листинг 13.8. Алгоритм слияния с делением на секции.
/*
* * Данная функция предназначена для разбивки данных на секции.
* * Это конечный автомат с двумя состояниями. Возрастающая секция - 1, убывающая секция - 0.
**
* * Так выглядит значительно усовершенствованная версия моего кода. Больная часть
* * усовершенствований внесена Канг Су Гатлином (Kang Su Gatlin).
*/
int PARSCAN(Etype * arrayf unsigned long n, partition ps[]f long max^par)
{
unsigned long i;
char direction;
long pcount = 0;
ps[pcount].start = 0;
ps]pcount].ascending - GE(array]l]f array(O));
for (i = 1; i < n; i++) {
direction = GE(array[i)f array[i - 1]);
if (ps[pcount].ascending 1= direction) {
ps[pcount].end = i - 1;
pcount++;
if (pcount > max_par)
return -max_par;
ps[pcount].start « i;
if (i == n - 1)
ps[pcount].ascending = 1;
else
ps[pcount].ascending e GE(array]i + 1], array]i]);
}
}
ps]pcount].end = n - 1;
pcount++;
return pcount;
♦* Удалить минимальный элемент из секции.
♦/
Itype PDELETEMIN(partition * p, char *endf Etype data]])
{
Etype e;
if (p->start < p->end) {
♦end = 0;
} else {
♦end = 1;
if (p->start > p->end)
puts("Error! Deletion from empty partition");
if (p->ascending) {
e = data[p->start++];
} else {
e = data]p->end-];
return e;
)
/♦
*♦ Взять минимальный элемент из секции.
*/
Itype PGETMIN(partition p. Etype data]])
(
Etype e;
Организация данных
Часть II
314
if (р.ascending) {
е = data[р.start];
} else {
е = datafp.end];
}*
return е;
}
/*
** Этот метод Велла работает с секциями данных, а не с элементами данных.
*/
void PSHELLSORT(partition array!], size_t count, Etype * data)
{
size_t i,
inc,
j;
partition tmp;
Etype etmp;
for (inc = count; inc >0;) {
for (i = inc; i < count; i++) {
j = i;
tmp = array [i];
etmp - PGETMIN(tmp, data);
while (j >~ inc && (LT(etmp, PGETMIN(array[j - inc], data)))) {
array!j] e array!j - inc];
j -= inc;
}
array!j] - tmp;
} /* Вычислить следующий mar h. */
inc = (size t) ((inc > 1) && (inc < 5)) ? 1 : 5 * inc / 11;
}
}
/* Нормализовать секцию, удалив первый элемент или изменив его приоритетность и переместив на
* нужное место.
*/
void PNORMALIZE(partition * array, size_t count, Etype data[])
{
long beg; /* Поиск начинается здесь (эта переменная движется к ipg) */
long ipg; /* Текучая точка вставки */
long end; /* Поиск заканчивается здесь */
partition temp; /* Временно сохранить partition */
long i;
Etype McGuffin = PGETMIN(array!0], data);
/* Может быть, нам и не придется ничего делать (я оптимист). */
if (count <2 || LE(McGuffin, PGETMIN(array!1], data)))
return;
/* Двоичный поиск точки вставки */
beg = ipg = 1; /* Первый элемент отсортированной части массива - это элемент 0 */
end ~ count - 1; /* Последний элемент отсортированной части массива - это элемент
partition */
/* Без этой проверки цикл завержился бы только в случае, если элемент с таким значением
уже отсортирован */
while (end >= beg) {
/* Точка вставки посередине между началом и концом */
ipg = ((end + beg) » 1);
if (GE(PGETMIN(array!ipg], data), McGuffin))
end = ipg - 1;
315
Методы быстрой сортировки
Глава 13
else
beg = ++ipg;
}
/* Предоставить место в data[ipg] для data[0] */
temp = array[0]; /* Сохранить новый элемент, который мы собираемся вставить */
for (i = 0; i < ipg; i++)
array[i] = array[i 4 1];
array[ipg - 1] = temp; /* Вставить новый элемент в нужное место */
return;
>
/* Этот метод сортировки слиянием можно назвать полезным. Во реальной ценностью обладает версия
с операциями ввода/вывода */
void MERGE_SORT(
Etype а[],
unsigned long count,
partition * pset,
unsigned long maxpar
)
{
long pcount;
Etype *alternate = NULL;
unsigned long current = 0;
unsigned long increment - 0;
/* Пытаемся разбить данные на секции */
pcount = PARSCAN(a, count, pset, maxpar);
/* Если количество секций слишком велико, используем метод "нарезания печенья". */
if (pcount < 0) {
unsigned long j;
increment « count / (max par) + 1;
if (increment < SmallCutoff)
increment ~ SmallCutoff;
for (j = 0; j < count; j += increment)
IQSORT5(&a[j], increment);
if (count % increment)
IQSORT5(&a[count - (count % increment)], count % increment);
/* He нужно проводить сканирование. Секции могут быть вычислены напрямую.
*/
pcount = PARSCAN(a, count, pset, maxpar);
}
if (pcount == 1) {
if (pset[0].ascending)
return;
else {
REVERSEARRAY(a, pset[0].start, pset[0].end);
return;
}
1
if ((alternate = malloc(count * sizeof(Etype)))) {
/* После этого нага все секции будут упорядочены в возрастающем порядке */
PSHELLSORT(pset, pcount, а);
{
char end = 0;
Etype e;
while (current < count) {
e ~ PDELETEMIN(pset, tend, a);
alternate[current++] = e;
if (end) {
pset++;
pcount-;
} else {
316
Организация данных
Часть II
PNORMALIZE(pset, pcount , а );
}
}
}
memcpy(a, alternate, count * sizeof(Etype));
free(alternate);
} else
IQS0RT5(ar count); /* Конец устойчивого метода. */
РИСУНОК 13.7. Математический анализ алгоритмов сортировки. Теоретическая производительность в наихудшем случае. Точка
пересечения.
Эти графики получены на основании математичес-
ких вычислений и дают довольно полную картину по-
ведения алгоритмов сортировки. Но, тем не менее, не-
обходимо провести тестирование алгоритмов на своем
компиляторе. Производительность алгоритмов сорти-
ровки может отличаться на разных компиляторах. По-
этому необходимо знать, каким образом каждый алго-
ритм ведет себя в различных условиях. Необходимо
протестировать алгоритмы на различных структурах
наборов данных, поскольку в реальных условиях дан-
ные могут иметь самые разнообразные последователь-
ности. И, кроме того, необходимо проверить алгорит-
мы на реальных данных. Это вызвано тем, что в
реальных условиях могут иметь место такие структуры,
о которых мы даже не подозреваем. В листинге 13.9
представлена программа, предназначенная для проведе-
ния тестирования различных алгоритмов сортировки.
Методы быстрой сортировки
Глава 13
[317
РИСУНОК 13.8. Математический анализ алгоритмов сортировки. Теоретическая производительность в наихудшем случае
РИСУНОК 13.9. Математический анализ алгоритмов сортировки. Теоретическая средняя производительность при малом
количестве элементов вблизи начала координат.
Организация данных
Часть II
318
РИСУНОК 13.10. Математический анализ алгоритмов сортировки. Теоретическая средняя производительность при малом
количестве элементов.
Листинг 13.9. Тестирование алгоритмов сортировки.
linclude <limits.h>
linclude <float.h>
linclude <stdio.h>
linclude <stdlib.h>
linclude <time.h>
linclude <assert.h>
linclude <string.h>
linclude <math.h>
linclude "inteltyp.h"
linclude "distribs.h"
linclude "genproto.h"
linclude "mtrand.h"
Iifdef WIN32
Idefine CDECL ____cdecl
lelse
Idefine CDECL
lendif
Iifdef ASSERT
lundef ASSERT
lendif
Iifdef DEBUG
Idefine ASSERT(x) assert((x))
lelse
Методы быстрой сортировки
Глава 13
319
♦define ASSERT(x)
fendif
static const char *dlist[] =
{
"constant",
"five",
"perverse",
"ramp",
"random",
"reverse",
"sorted",
"ten",
"trig",
"twenty",
"two",
NULL
};
/*
** Функции для определения времени работы другой функции
** ПРЕДУПРЕЖДЕНИЕ. Значения статических переменных изменяются, поэтому программа BE
“ ДОПУСКАЕТ повторного вхождения!
«« Be используйте этот код в многопоточных программах!
*/
static clockt с start,
enow;
static time t start,
now;
static const double dclocksper sec = CLOCKS PER SEC;
void reset_timer()
{
start = time(NULL);
c_start = clock();
}
double dTotal = 0;
double elapsed_time_since_reset(const char «message)
{
double delta;
double fract;
now = time (NULL);
enow « clock();
delta - difftime(now, start);
fract = (enow - cstart) / dclockspersec;
if (delta > 10000) {
if («message)
printf("%s:%g\n", message, delta);
dTotal += delta;
} else {
if («message)
printf("%s:%g\n", message, fract);
dTotal += fract;
}
start = now;
cstart = enow;
return delta;
>
Void dup(int la[], double da[], int count)
<
int i;
for (i = 0; i < count; i++)
da[i] = (double) la[i);
>
Организация данных
Часть II
320
«define MAX PAR 100
int CDECL gmain(int argc, char **argv)
{
int k;
double dt[512];
int it[512);
long COUNT = 1000000L;
long pmin, pmax;
sizet стах = COUNT;
unsigned long cycles = 0;
long iterations;
sizet count;
sizet pass;
char pausef 3];
int which = 0;
int sorttype;
int iseed = 7;
int *iarray;
double ♦darray;
double bd = 0, hd = 0, sd = 0, id - 0, qd = 0, Id = 0, pd = 0, md = 0;
double bi = 0, si = 0, hi = 0, ii = 0, qi = 0, li = 0, pi = 0, mi = 0;
partition pset[MAX_PAR] = {0};
enum distributiontype d - constant;
if (argc >1) {
COUNT = atoi(argv[l]);
if (COUNT < 1) {
putspCount must be >= 1");
exit(EXITFAILURE);
}
}
iarray = malloc(COUNT * sizeof(int));
darray = malloc(COUNT * sizeof(double));
if (liarray || !darray) {
puts("Error allocating arrays for sort tests.");
exit(EXITFAILURE);
}
if (argc > 1) {
pmin = atol(argv[2]);
pmax - atol(argv[3]);
} else {
pmin = 2;
ртах = стах;
}
mtsrand(4357U);
printf("pmin = %ld, ртах = %ld\n", pmin, pmax);
printf("Sort type (n) Batch Shell Insert "
Методы быстрой сортировки
Глава 13
” Quick RadixL RadixM Reap Merge\n");
for (pass = pain; pass <- pmax;) {
lifdef DEBUG
iterations = 1;
♦else
iterations = /* (long) (le3 / (log(pass))); */ 1;
lendif
if (iterations < 1)
iterations = 1;
lifdef _DEBUG
printf("pass = %ld, iterations = %ld\n", pass, iterations);
lendif
count - pass;
while (d < unknown) {
lifdef DEBUG
printf("type=%s, element count = %ld, interations = %ld\n",
dlistfwhich], count, iterations);
lendif
for (sorttype = 0; sorttype < 5; sorttype++) {
cycles++;
make_distrib(darray, iarray, pass, d);
if (count <= 64) {
memcpy(dt, darray, count * sizeof dt[0]);
memcpy(it, iarray, count * sizeof it[0]);
switch (sorttype) {
case 0:
lifdef DEBUG
if ((cycles + 1) % 2000 == 0)
putchar('i');
lendif
for (к = 0; к < iterations; k++) {
memcpy(dt, darray, count * sizeof dt[0]);
memcpy(it, iarray, count * sizeof it[0]);
reset-timer();
InsertionSort-Si(it, count);
ii += elapsed_time_since-reset(");
reset_timer();
InsertionSort_d(dt, count);
id += elapsed_time_since_reset("");
if (!ArrayIsDefinitelySorted_si(it, count - 1))
puts("NOT SORTED");
if (!ArrayIsDefinitelySorted_d(dt, count - 1))
puts("NOT SORTED");
1
break;
case 1:
lifdef -DEBUG
if ((cycles + 1) I 2000 == 0)
putchar('b');
lendif
for (к = 0; к < iterations; k++) {
memcpy(dt, darray, count * sizeof dt[0]);
memcpy(it, iarray, count * sizeof it[0]);
reset_timer();
Batchersi (it , count);
bi += e lapsed_time_since_r eset (" ");
reset_timer();
Batcherd(dt, count);
bd +« elapsedtimesince_reset (" ");
if (IArrayIsDefinitelySorted-Si(it, count - 1))
puts("NOT SORTED");
if (IArraylsDefinitelySorted_d(dt, count - 1))
21 3ml 265
322
Организация данных
Часть II
puts("NOT SORTED");
I
break;
case 2:
lifdef DEBUG
if ((cycles + 1) % 2000 — 0)
putchar('s');
lendif
for (к = 0; к < iterations; k++) {
memcpy(dt, darray, count * sizeof dt[0]);
memcpy(it, iarray, count * sizeof it[OJ);
reset_timer();
Shellsort_si(it, count);
si += elapsed_time_since_reset("");
reset_timer();
Shellsort_d(dt, count);
sd += elapsed_time_since_reset("");
if (JArraylsDefinitelySortedsi(it, count - 1))
puts("NOT SORTED");
if (JArraylsDefinitelySorted_d(dt, count - 1))
puts("NOT SORTED");
1
break;
1
>
switch (sorttype) {
case 0:
for (k - 0; к < iterations; k++) {
make_distrib(darray, iarray, pass, d);
reset timer();
Iqsort5_si(iarray, count);
qi += elapsed_time_since_reset( "");
reset_timer();
Iqsort5_d(darray, count);
qd += elapsed_time_since_reset (" ");
if (JArraylsDefinitelySorted_si( iarray, count - 1))
puts(“NOT SORTED");
if (JArraylsDefinitelySorted_d(darray, count - 1))
puts("NOT SORTED");
1
break;
case 1:
for (к = 0; к < iterations; k++) {
make_distrib(darray, iarray, pass, d);
reset_timer();
RadixLsd_si(iarray, 0, count - 1, 0);
li += elapsed_time_since_reset (" ");
reset_timer();
RadixLsd_d(darray, 0, count - 1, 0);
Id += elapsed_time_since_reset("");
if (JArraylsDefinitelySorted_si(iarray, count - 1))
puts("NOT SORTED");
if (1ArrayIsDefinitelySorted-d(darray, count - 1))
puts("NOT SORTED");
1
break;
case 2:
for (k = 0; к < iterations; k++) {
makedistrib(darray, iarray, pass, d);
resettimer();
heapsort_si(iarray, count);
hi += elapsed_timesince_reset("");
reset_timer();
heapsort_d(darray, count);
Методы быстрой сортировки
Глава 13
323
hd += elapsed_time_since_reset(;
if (1ArrayIsDefinitelySortedsi(iarray, count - 1))
puts("NOT SORTED");
if (!ArrayIsDefinitelySorted_d(darray, count - 1))
puts("NOT SORTED");
)
break;
case 3:
for (к = 0; к < iterations; k++) {
make_distrib(darray, iarray, pass, d);
reset_timer();
mergesort_si(iarray, count, pset, MAX_PAR);
pi += elapsedtime_since_reset("");
resettimer();
mergesort_d(darray, count, pset, MAX—PAR);
pd += elapsed_timesince_reset("");
if (!ArrayIsDefinitelySorted_si(iarray, count - 1))
puts("NOT SORTED");
if (!ArrayIsDefinitelySorted_d(darray, count - 1))
puts("NOT SORTED");
)
break;
case 4:
for (к = 0; к < iterations; k++) {
make_distrib(darray, iarray, pass, d);
resettimer();
RadixMsd_si(iarray, 0, count - 1, 0);
mi += elapsed_time_since-reset("");
reset-timer();
RadixMsd_d(darray, 0, count - 1, 0);
md += elapsed_timesincereset(*");
if (1ArrayIsDefinitelySorted-Si(iarray, count - 1))
puts("NOT SORTED");
if (IArrayIsDefinitelySorted_d(darray, count - 1))
puts("NOT SORTED");
)
)
)
which++;
d++;
)
which = 0;
d = constant;
printf("Integral sorts %91u %5.1f %5.1f %5.1f "
“ %5.1f %5.1f %5.1f %5.1f %5.1f\n",
pass, bi, si, ii, qi, li, mi, hi, pi);
printf("Double sorts %91u %5.1f %5.1f %5.1f "
" %5.1f %5.1f %5-lf %5.1f %5.1f\n",
pass, bd, sd, id, qd, Id, md, hd, pd);
bi = si = ii = qi = li = mi = hi = pi = 0;
bd = sd = id = qd = Id = md = hd = pd = 0;
if (pass < 64)
pass++;
else
pass = pass * 2;
}
free(darray);
free(iarray);
printf("Press enter to continue.\n");
fgets(pause, sizeof pause, stdin);
return 0;
Организация данных
Часть II
324
Для получения точного времени следует использо-
вать профилировщик. Многие компиляторы содержат
профилировщики; можете также приобрести отдельный
профилировщик, например, Vtune.
Для каждого типа данных, который мы будем сор-
тировать, создаем объект сортировки. Объект сортиров-
ки будет иметь функцию сравнения (обязательно) и
функцию распределения (если возможно). К счастью,
у нас будут обе эти функции. Кроме того, у нас будет
массив указателей на функции, которые (указатели)
будут расположены в соответствии с производительно-
стью алгоритмов для массивов данных определенного
размера. Независимо от размера массива данных мы
будем производить сортировку с довольно высокой эф-
фективностью. Для некоторых массивов данных мож-
но иметь даже несколько указателей на функции, по-
скольку для различных типов данных мы можем
использовать различные алгоритмы. Затем максималь-
но загружаем память данными. Проводим их сортиров-
ку и записываем во временный файл. Продолжаем этот
процесс до тех пор, пока не будут отсортированы все
данные. Далее с помощь очереди по приоритетам объе-
диняем все файлы в один выходной файл.
Алгоритм "молниеносная сортировка"
I. Прочитать часть данных, которая помещается в ОЗУ
(не в виртуальной памяти).
2. Отсортировать эту часть и записать на диск. Сор-
тировка производится методом, оптимальным для
данного размера массива.
3. Если исходный файл не исчерпан, перейти к п. 1.
4. Вставить начала всех временных файлов в очередь
по приоритетам и выполнить слияние до исчерпа-
ния всех временных файлов.
Реализация указанного алгоритма на языке С при-
ведена в листинге 13.10.
Листинг 13.10. "Молниеносная сортировка".
/*
** это тестовый драйвер для сортировки слиянием, о которой вы никогда не слыяали. Теперь можно
** объединять произвольное количество файлов за один проход. Этот метод можно еще более
** улучмить, но в программе прекрасно отражен сам принцип метода.
*/
linclude <stdio.h>
linclude <string.h>
linclude <stdlib.h>
linclude <math.h>
linclude <float.h>
linclude "inteltyp.h"
linclude "distribs.h”
linclude "genproto.h"
linclude "mtrand.h"
linclude "barproto.h"
/*
** Этот набор состоит из 40 млн элементов, но вы можете выбрать любое другое число.
*/
static const unsigned long max_buffer = 40000000L;
♦define MAX_STR_LEN 8192 /* можете заменить это число на любое другое */
♦define MAXLINES 1500000 /* максимальное число строк во входном файле */
static char «backup[MAXLINES]; /* Массив для хранения секций входных данных «/
static FILE *fout; /* выходной файл */
/*
Считать из stdin и создать массив с одним элементом в строке. Возвратить количество строк.
*/
/* Вала операционная система может иметь определенные ограничения */
♦define MAXTEMPFILES 256
/* Сколько имеется секций? */
static int count = 0;
325
Методы быстрой сортировки
Глава 13
/* Этот объект определяет наы вабор упорядоченных секции */
/* Будем производить сортировку по частям. Отсортированные части описаны ниже. */
static fileset fset(MAX_TEMP_FILES] = {0}; /* около 2 млн */
/* Считать следующий элемент из файлового набора */
int fgetitem(fileset * р)
<
char *рс;
pc = fgets(p->buffer, sizeof(p->buffer>, p->fin);
lifdef DEBUG
if (Ipc) {
if (!feof(p->fin))
puts(strerror(errno));
}
lendif
p->empty = (pc == NULL);
return p->empty;
}
/*
** Удалить из файлового набора минимальный элемент и указать конец файла
*/
char *fdeletemin( fileset * р, char *end)
{
if (p->empty 11 p->fin == NULL) {
puts("error! deletion from empty fileset*);
exit(EXIT_FAILURE);
}
p->empty = *end = fgetitem(p);
return p->buffer;
}
/*
* * Выполнить сортировку списка файловых наборов методом Велла. Это не сортировка данных в
* * файле. Мы сортируем сами файлы по значению их минимального элемента (который будет первым
* * элементом, поскольку используем ухе упорядоченные поднаборы исходных данных.
*/
void fshellsort(fileset fset[], size_t count)
(
size_t i,
inc,
j;
fileset tmp;
char *etmp;
for (inc = count; inc >0;) {
for (i = inc; i < count; i++) {
j = i;
tmp = fset[i];
etmp = tmp.buffer;
while (j >= inc && (It (etmp, fsetfj - inc] .buffer))) {
fset[j] = fset[j - inc];
j -= inc;
}
fset[j] = tmp;
} /* вычислить следующий маг h */
inc = (size_t) ((inc > 1) && (inc < 5)) ? 1 : 5 * inc / 11;
}
/*
♦* чтобы набор остался упорядоченным после удаления элемента, необходимо провести нормализацию.
** Вормализация требует выполнения O(log(q)) операций, где q - количество файловых наборов
326
Организация данных
Часть II
** [а не количество элементов данных].** q is the number of filesets [NOT the number of data
*/
void fnormalize(fileset * fset, size_t count]
{
long beg; /* поиск начинается здесь (эта переменная движется к
значению ipg) */
long ipg; /* текущая точка вставки */
long end; /* поиск заканчивается здесь */
fileset temp; /* переменная для временного хранения одного файла */
long i;
char *mcguffin = fset[0].buffer;
/* Может быть, нам и не придется ничего делать (я оптимист). */
if (count < 2 || le(mcguffin, fset[l].buffer))
return;
/* Двоичный поиск точки вставки */
beg = ipg = 1; /* первый элемент отсортированной части массива - это
элемент 0 */
end = count - 1; /* последний элемент отсортированной части массива - это
элемент fileset */
/* Без этой проверки цикл завершился бы только в случае, если элемент с таким значением
уже отсортирован */
while (end >= beg) {
/* Точка вставки предположительно находится посередине между началом и концом */
ipg = ((end + beg) » 1);
if (ge(fset[ipg].buffer, mcguffin))
end = ipg - 1;
else
beg = ++ipg;
}
/* предоставить место в data[ipg] для data[0] */
temp = fset[0J; /* сохранить новый элемент, который мы собираемся вставить*/
for (i = 0; i < ipg; i++)
fset[i] = fset[i + 1J;
fset[ipg - 1] = temp; /* вставить новый элемент в нужное место */
return;
}
/*
* * Строка больме или эквивалентна другой строке?
*/
int ge(char *1, char *r)
{
return (strcmp(l, r) >= 0);
}
/*
* * Строка меньме или эквивалентна другой строке?
*/
int le(char *1, char *r)
{
return (strcmp(l, r) <= 0);
>
/*
* * Строка строго меньше или эквивалентна другой строке?
*/
int lt(char *1, char *r)
{
return (strcmp(l, r) < 0);
}
Методы быстрой сортировки
Глава 13
327
/*
** Считать из файла блок строк.
*/
static int
char *file_name,
char *lines[],
int maxlines,
size t * offset
)
{
int
size_t
static size_t
char
static FILE
static char
readlines(
nlines = 0
size;
limit;
«newline;
*in_file;
«basep,
«cur;
if («offset == 0) {
if (!(in_file = fopen(filename, "rb"))) {
perror(file_name);
exit(EXlTFAILURE);
}
fseek(in_file, 0, SEEKEND);
size = ftell(in_file) + 10000;
limit = size - «offset > max_buffer ? max buffer : size - «offset;
fseek(in_file, «offset, SEEKSET);
if (I (basep = callocf (limit + 1), 1)))
return -1;
}
fseek(in_file, «offset, SEEKSET);
cur = basep;
while (fgetsfcur, limit - (cur - basep), infile)) {
lines[nlines] = cur;
if ((newline = strchr(lines(nlines], '\n'))) {
cur = newline + 2;
} else {
puts("warning - text in file should end in newline");
cur[strlen(cur)] = '\n';
cur[strlen(cur)] = 0;
cur += strlen(cur) + 1;
}
nlines++;
if (nlines == maxlines || limit - (cur - basep) < MAX STR LEN) {
«offset = ftell(in_file);
break;
)
1
if (feof(infile))
«offset = 0;
return nlines;
}
/*
** Записать поднабор исходных данных, которые содержатся в массиве t.
*/ 1
▼oid writelines(char *t(], int nlines, FILE * fout)
<
int i;
for (i = 0; i < nlines; i++)
fprintf(fout, ”%s“, t[i]);
>
Организац ия данных
Часть II
328
/*
** тестовый драйвер
*/
int main(int argc, char *argv[])
{
int nlines;
int i;
char end = 0;
char *e;
size_t offset = 0;
char *name;
int savecount;
fileset *fs я fset;
mtsrand(4357U);
if (argc 1= 3) {
fprintf(stderr, "Usage: %s inputfile output_file\n", argv[0]);
return 1;
}
fout = fopen(argv[2], "wb");
if (fout == NULL) {
printf("Count not open %s\n", argv[2]);
exit(EXITFAILURE);
}
fprintf(stderr, "\nFile: %s\n", argv[l]);
do {
/* Считать блок из исходного файла. */
if ((nlines = readlines(argv(l], backup, MAXLINES, toffset)) >= 0) {
/* Отсортировать этот блок */
Iqsort5_str(backup, nlines);
fifdef DEBUG
if (1ArrayIsDefinitelySorted_str(backup, nlines)) {
puts("rats");
exit(EXITFAILURE);
}
tendif
/* Записать отсортированный блок на диск */
if ((папе - tmpnam(NULL)) 1= NULL) {
strcpy(fset[count].filename, name);
fset[count].fin - fopen(fset[count].filename, "wt");
writelines(backup, nlines, fset[count].fin);
count++;
} else {
puts("error creating output file");
exit(EXITFAILURE);
}
}
/* Цикл до исчерпания файла */
} while (offset > 0);
/* Сбросить на диск все открытые файлы */
fflush(NULL);
/* Закрыть временные файлы (открытые в режиме записи) и открыть их в режиме считывания.
** Затем взять первый элемент.
*/
for (i = 0; i < count; i++) {
fclose(fset[i].fin);
fset[i].fin = fopen(fset[i].filename, "rt");
fseek(fset[i].fin, 0, SEEKSET);
fgetitem(&fset[i]);
}
/* Выполнить сортировку секций методом Пелла. Если количество секций слитком велико, может
** быть, вместо метода Пелла лучше выполнить быструю или поразрядную сортировку.
*/
329
Методы быстрой сортировки
Глава 13
fshellsort(f set, count);
savecount = count; /* Запомнить количество секций */
/* Объединить секции с использованием очереди по приоритетам */
while (count >0) {
е = fs[0]-buffer;
fprintf(fout, "%8И, fs[0]-buffer);
fdeletemin(f s, fiend);
if (end) {
fs++;
count—;
fnormalize(f s, count);
/* Сбросить на диск все открытые файлы */
fflush(NULL);
/* Закрыть и удалить все временные файлы */
for (i = 0; i < savecount; i++) {
fclose(fset[i J.fin);
if (remove(fset[ij.filename) 1= 0) {
printf("unable to delete file %s\n“, fsetfi]-filename);
puts(strerror(errno));
return 0;
}
Причиной, по которой этот метод настолько ценен,
является то, что время проведения дисковых операций
ввода/вывода составляет большую часть времени сорти-
.ровки. Согласно данному методу, нам приходится:
• Прочитать файл по частям за один проход.
• Записать отсортированные части за один проход.
• Считать отсортированные части с использованием
очереди по приоритетам.
• Записать объединенные данные.
При этом приходится производить чтение и запись
два раза, независимо ни от размера исходного файла, ни
от объема доступной памяти. Если бы мы использова-
ли обычный метод слияния, нам бы пришлось выпол-
нять операции считывания/записи множество раз. Если,
например, генерируется восемь файлов, то для их со-
здания понадобится один проход считывания/записи.
Затем пришлось бы производить считывание/запись
восьми файлов для получения четырех файлов. После
этого снова пришлось бы производить считывание/за-
пись четырех файлов для получения двух файлов и,
наконец, считывание/запись двух файлов для получе-
ния выходного упорядоченного файла. Если бы у нас
было несколько сотен файлов, пришлось бы выполнять
огромное количество операций считывания/записи.
Именно поэтому часто используется метод выбора с
замещением. Метод выбора с замещением — довольно
медленный алгоритм, но в среднем он позволяет в 2 раза
уменьшить количество операций считывания/записи.
Но, имея метод слияния с помощью очереди по приори-
тетам, метод выбора с замещением можно не использо-
вать.
ПРИМЕЧАНИЕ
Интерфейсы моих функций выследят несколько непривычно.
Вы, наверное, обратили внимание, что некоторые функ-
ции совсем не похожи на функции. Например,
* * Можете мне не верить, во это полннй текст
* * функции для сортировки массивов строк.
* * Строка Idefine ETYPE_STRING заставит
* * allsort.h сформировать функции для работы с
* * массивом строк.
* * Зачем такие сложности, когда можно просто
* * использовать функцию сравнения?
* * Потому что интерфейс функции qsort()
* ♦ довольно медленный. Нан метод несколько
* * сложнее, но выигрыл в скорости стоит того.
*/
Idefine ETYPE_STRING
finclude "allsort.h"
А где же собственно код? В этой функции создается что-
то типа шаблона в языке C++. Причиной использования
такого метода, а не интерфейса (например, функции
qsort())f является значительное увеличение скорости.
Интерфейс функции q$ort() требует, чтобы для переста-
новки элементов использовалась функция memcpyl), по-
скольку неизвестен размер элементов. Такой ложный
шаблон позволяет работать более эффективно и есте-
ственно.
Организация данных
Часть II
330
Резюме
Сортировка, как и многие другие задачи, решаемые
вычислительной техникой, является сочетанием искус-
ства и науки. Для определения оптимального метода
необходимо немного поэкспериментировать. Интерфейс
функции qsort(), определенной в библиотеке <stdlib.h>,
имеет один недостаток, связанный с обращением к фун-
кции memcpy(). Но можно ввести простой шаблон, ко-
торый позволяет устранить недостатки интерфейса фун-
кции qsort() за счет некоторого увеличения объема кода.
Опыт показывает, что при работе с небольшими фай-
лами не следует переходить на алгоритм сортировки
методом линейных вставок: сортировка двоичными
вставками дает большую скорость, а сортировка мето-
дом Шелла дает еще большую скорость. Поэтому для
небольших файлов лучше всего использовать не метод
линейных вставок, а метод Шелла. При очень малых
размерах файлов скорость сортировки можно повысить
за счет применения специальных методов. Для больших
файлов в большинстве приложений наиболее оптималь-
ным, скорее всего, будет метод быстрой сортировки,
который зарекомендовал себя лучше, чем сортировка
слиянием или пирамидальная сортировка.
С помощью некоторых модификаций можно до-
биться безопасного использования метода быстрой сор-
тировки в любых случаях. Эти модификации включа-
ют вероятностный выбор медианы, проверку прямой и
обратной упорядоченности секций, переход при малых
размерах секций на метод Шелла и выполнение сорти-
ровки малой секции перед сортировкой большой сек-
ции. Некоторые из этих модификаций часто встречают-
ся в библиотеках функций сортировки, но во многих
случаях одна или даже несколько модификаций могут
быть опущены, что может привести к снижению эффек-
тивности сортировки, а иногда и к опасности выполне-
ния такой сортировки. Это крайне неприятно, посколь-
ку сортировка является одной из наиболее важных и
часто используемых операций, выполняемых вычисли-
тельной техникой.
Часто говорят, что поразрядная сортировка не под-
ходит для сортировки произвольных данных. Но, ис-
пользуя шаблон, аналогичный шаблону, применяемому
в сортировке сравнением, можно добиться выполнения
поразрядной сортировки для любых данных. Все, что не-
обходимо, — найти функцию распределения наиболее
значащих битов в секциях. Даже обобщенный метод по-
разрядной сортировки не является панацеей, поскольку
большие размеры ключей снижают эффективность пораз-
рядной сортировки до уровня стандартных методов сор-
тировки сравнением, например, быстрой сортировки.
И наконец, дисковые методы сортировки часто ис-
пользуют методы множественного слияния. Это явля-
ется серьезной ошибкой, поскольку метод, основанный
на использовании очереди по приоритетам, намного
более эффективен. Даже метод выбора с замещением
уступает методу очереди по приоритетам. Метод, осно-
ванный на использовании очереди по приоритетам,
объединяет все файлы за один проход.
Как известно, в любом правиле (включая приведен-
ные) есть исключения. Но все-таки правило работает
гораздо чаще, чем исключения из него. Всегда имеет
смысл рассмотреть несколько вариантов. Каждый из
описанных здесь методов может быть усовершенствован.
Искренне надеюсь, что некоторые читатели этой кни-
ги не только усовершенствуют эти методы, но и поде-
лятся своими идеями с другими.
Деревья
14
В ЭТОЙ ГЛАВЕ
Скотт Флурер
Структура данных типа дерево
Использование деревьев
Сравнение деревьев с двоичными древовидными структурами и хеш-таблицами
Описанные в предыдущей главе структуры данных
отлично работают и очень удобны в применении. Од-
нако существует и другая древовидная структура дан-
ных, которая иногда оказывается полезной и позволяет
более эффективно решать многие проблемы, особенно
те, для решения которых необходимо осуществление
поиска. Такая древовидная структура данных известна
как дерево (trie).
В этой главе описывается структура данных типа
дерево. Вначале я объясню, что представляет собой де-
рево, и покажу его основные свойства. Затем мы рас-
смотрим несколько листингов, реализующих такую
структуру данных, и исследуем вопрос о том, кд к этот
программный код можно приспособить для нужд кон-
кретного приложения. И наконец, в этой главе мы про-
ведем сравнение структуры данных типа дерево с дру-
гими древовидными структурами.
Структура данных типа дерево
Для иллюстрации описываемого подхода к организации
данных рассмотрим простую задачу: требуется очень
быстро найти слово в компьютеризированном словаре.
Для начального поиска выбирается первая буква слова,
скажем "S", и рассматриваются только те слова, кото-
рые начинаются с буквы "S". Если в словаре оказывает-
ся более одного слова, начинающегося с этой буквы,
выделяем следующую букву в слове, скажем "Г, и рас-
сматриваем только те слова в словаре, которые начина-
ются с букв "St". Этот метод просмотра букв искомого
слова продолжается до тех пор, пока не наберется ко-
личество букв, достаточное для его однозначной иден-
тификации с заданным словом.
Поиск данных в дереве выполняется точно так же.
Ключ, по которому осуществляется поиск, разбивается
на части (в предыдущем примере это были различные
буквы, составляющие заданное слово), затем последо-
вательно используется каждая такая часть для опреде-
ления ветви дерева, по которой следует двигаться даль-
ше. В этом и состоит отличие рассматриваемой
методики от поиска в двоичном дереве (tree), описан-
ном в главе 12: для более быстрого осуществления по-
иска выбираются отдельные биты ключа, вместо того
чтобы сравнивать полный ключ с ключом, находящим-
ся в узле дерева.
Формально структура типа дерево может состоять из
нуля или более узлов. Узел дерева может нс иметь от-
ветвлений, и в этом случае он называется листом. Узел
может иметь несколько других дочерних узлов, и тогда
будем называть его поддеревом. Каждый добавленный к
узлу дерева лист имеет соответствующий ключ. Необ-
ходимо, чтобы ключ в каждом листе указывал путь к
этому листу. Требуется также, чтобы у поддерева было
как минимум два листа.
ПРИМЕЧАНИЕ
Если в природе у дерева растут листья, то у нашего с вами
дерева тоже должны быть листья. Я имею в виду, что игру
слов в этом тексте не следует воспринимать слишком
серьезно.
Рассматриваемый подход имеет несколько отличий
от более традиционного поиска в двоичном дереве. Во-
первых, необязательно, чтобы каждый узел имел толь-
ко два подузла (дочерних узла). Если мы выберем сра-
зу N битов ключа одновременно и используем все их
для поиска следующего узла, то поиск ускорится, по-
скольку при этом размерность дерева снижается до 2\
Разумеется, если вы увеличиваете степень N, то так же
резко увеличивается размер каждого узла, поэтому при-
дется искать компромисс между временем поиска и тре-
буемым для этого объемом памяти.
Организация данных
Часть II
332
Одна из особенностей такого дерева состоит в том,
что его форма определяется только ключами, которые
оно содержит на данный момент. Функция поиска ска-
нирует ключ так, чтобы однозначно идентифицировать
его среди всех других ключей в дереве, и ничего более.
Это означает, что, в отличие от большинства других
структур данных, не затрачивается время на переупо-
рядочение дерева путем вставки и удаления — нет не-
обходимости в программировании вычурной логики.
В каких случаях применяются деревья
Деревья удобно применять для точного сопоставления.
Следует, однако, обратить внимание на несколько важ-
ных моментов:
• Деревья склонны к использованию большего объе-
ма памяти, чем другие структуры данных, посколь-
ку у каждого поддерева имеется полная таблица ука-
зателей к подузлам. Для сравнения: в бинарном
дереве содержится не более двух указателей к подуз-
лам. Конечно, применяя деревья, вы можете сокра-
тить размер требуемой памяти путем уменьшения
одновременно используемого для поиска количества
битов в ключе, но это также снизит скорость поис-
ка на дереве.
• Обслуживание дерева, вообще, несколько сложнее,
чем обслуживание других структур данных, таких
как двоичные деревья или хеш-таблицы. Но в то же
время оно не так запутано, как в том случае, если
речь идет, например, о дереве AVL.
• В деревьях ключи рассматриваются как последова-
тельности битов. Это означает, что, даже если по-
лучены точные поразрядные совпадения, поиск мо-
жет не дать результатов. Одно из неочевидных
следствий этого состоит в том, что нужно быть осо-
бенно внимательным, когда ключ представляется
структурой. Язык С позволяет вставлять заполнение
после членов структуры, и такое заполнение может
не иметь постоянного значения. Если вы действи-
тельно желаете использовать структуру в качестве
ключа, нужно модифицировать объект key walker
(определенный далее в этой главе) так, чтобы, спус-
каясь по различным членам структуры, избегать не-
поименованных включений.
Использование деревьев
А теперь давайте приступим к исследованию реализа-
ции дерева и посмотрим, как она работает. Прежде чем
речь пойдет об алгоритмах, поговорим о том, как выг-
лядят структуры данных и как они работают вместе.
Если имеется указатель к узлу, можно не беспокоиться
о том, является этот узел листом или поддеревом, до тех
пор, пока не придет время с ним работать. Мы будем
создавать листья и поддеревья определенных структур.
Обычно указатели на различные структуры несовме-
стимы. Однако можно создать первый элемент каждой
структуры одного и того же типа. Затем С позволит нам
переключить указатель на структуру к указателю на
первый член, и тогда указатели на листья и поддеревья
станут совместимыми. Кроме того, если первый член
дает сведения о типе структуры, определяется сам этот
член, а затем — тип структуры. Итак, структура будет
выглядеть следующим образом:
enum trie_node__type { TRIE_LEAF, TRIE_SUBTRIE };
typedef enum trie_node__type *trie_pointer;
Здесь trie__pointer — указатель на некоторый тип
узла. Все листья обозначаются как TRIE LEAF в каче-
стве содержимого первого члена, все поддеревья обозна-
чаются как TRIE SUBTR1E. Таким образом, мы опре-
делили два типа узлов; альтернативные реализации
очень часто определяются по-другому.
Далее, начиная с определения дерева, поддерево
соотносится с префиксом ключа, который делится, по
крайней мере, на два отдельных ключа Затем функция
поиска в дереве должна выявить, какому узлу подходит
следующий символ, который является указателем на
массив nextjevel. Поскольку мы должны иметь возмож-
ность обрабатывать случай, когда один ключ фактичес-
ки является префиксом другого, необходимо устано-
вить, что произойдет, если окончание ключа —
exactmatch — указывает на один или более листов. По-
лезно также знать параметр count — количество ключей,
для которых этот узел является префиксом: это упро-
щает функцию удаления. Итак, структура нашего узла
будет иметь такой вид:
«define LOG_TRIE_BRANCH_FACTOR 4
♦define TRIEBRANCHFACTOR
(1«LOG_TRIE_BRANCH_FACTOR)
struct trie subtrie {
enum trienodetype type; /* TRIE_NODE */
struct trie_leaf *exact_match;
int count;
trie_pointer nextlevel[TRIEBRANCHFACTOR];
};
Здесь мы определили LOG TRIE_BR4NCH FACTOR
как число битов в ключе, которое считывается для каж-
дого поддерева, a TRIE_BRANCH__FACTOR является
результирующим фактором в каждом поддереве. Их
можно изменять для регулирования скорости поиска и
использования деревом памяти.
Аналогично для листа устанавливается уникальный
ключ, и если поисковая программа находит его, значит,
найденный ключ — единственно возможный для лис-
та. Таким способом отыскивается лист, и его ключ од-
нозначно определяет местоположение этого листа Ког-
333
Деревья
Глава 14
да программа поиска обнаруживает ключ, необходимо
убедиться, что нашелся именно тот ключ (поскольку
возможно несовпадение ни с одним ключом в дереве).
Для этого используются поля key и len_key. Они фак-
тически указывают на копию ключа, которую мы раз-
местили в памяти, так что этот модуль не нуждается в
сопровождении. Кроме того, нужно помнить, что про-
грамма вставки должна выполнить обратный ход, ког-
да введен новый ключ, для этого используется поле
result. С того момента, когда приложение потребует кон-
кретный тип поля result, создается поле типа
type result, которое мы определим позже как typedef,
когда будем знать, какой тип требует приложение. Это
выглядит следующим образом:
struct trie_leaf {
enum trie node type type; /* TRIELEAF */
unsigned char *key;
s ize_t 1en_key;
trieresult result;
};
Необходимо также определить объект для полного
дерева. Кроме того, должен быть известен корень дере-
ва (т.е. узел, соответствующий пустому префиксу). Та-
ким образом, получим объявление:
struct trie {
trie_pointer root;
В
Создание и разрушение
Первое, что нужно сделать, — создать наше дерево.
Программа создания дерева оказывается достаточно
простой:
struct trie *trie_create (void)
{
struct trie *trie = mallocf sizeof(*trie )
)7
if (trie) {
trie->root = 0;
}
return trie;
1 •
В этом примере показано, что дерево размещается в
памяти, и, если все складывается благополучно, дерево
обнуляется.
Программа разрушения дерева и очищение всей ис-
пользуемой им памяти оказывается несколько сложнее.
Сначала рекурсивная программа в цикле освобождает
Всю Память, занимаемую узлом и всеми его подузлами.
Эта Структура в данном модуле вызывается несколько
раз: получаем основной указатель, сопоставляем его
С типом узла, а затем обрабатываем объект, основанный
на этом типе. При необходимости удалить лист из па-
мяти используется специальная подпрограмма; ее при-
менение возможно также и в других местах программы.
А если требуется удалить поддерево из памяти, удаля-
ется текущий узел, все его листья и подузлы. Ниже
показано, кок можно удалить узел:
static void destroy_jaode (trie_jpointer node)
{
if (node == 0)
return;
switch (*node) {
case TRIELEAF: {
struct trie_leaf *p = (struct
^♦trieleaf * )node;
destroyleaf(p);
break;
}
case TRIESUBTRIE: {
struct trie_subtrie *p = (struct
**trie_subtrie*)node;
int i;
destroy leaf(p->exact_match);
for (i=0; i<TRIE_BRANCH_F ACTOR; i++)
destroy node(p->next_level[i J);
free(p);
break;
}
default: assert(0);
}
}
static void destroyleaf(struct trie_leaf
*-**leaf)
{
if (leaf) {
free(leaf->key);
free(leaf);
)
}
Такая процедура обработки узла является общим
элементом и других различных процедур обработки
дерева. Известен указатель либо на trie_subtrie, либо на
triejeaf, но пока неясно, на что именно. Поэтому пе-
реключаемся на поле типа узла и в зависимости от того,
на чем он основан, обрабатываем поддерево или лист.
После выполнения этих операций программа удале-
ния всего дерева из памяти становится проще. Как толь-
ко удаляются образующие дерево узлы, из памяти сра-
зу удаляется и само дерево:
void trie^destroy (struct trie *trie)
{
if (trie) {
destroynode(trie->root);
free(trie);
}
}
Выделение битов
Определение направления поиска в дереве осуществля-
ется путем выделения битов из ключа. Таким же обра-
334
Организация данных
Часть II
зом биты выделяются и при операциях вставки и уда-
ления ключа. Итак, соберем объект для выполнения
этой работы. Назовем этот объект key_walker (дослов-
но — ’’прогуливающийся по ключу”. — Примеч. пер.),
поскольку он действительно ’’гуляет" по выделенным
битам ключа, и создадим макрос initialize_walker для
запуска объекта по ключу и макрос extract_next — для
выделения следующего набора битов. Для выделения N-
го набора битов из ключа используется также макрос
extract_at_offset. Эти макросы, создаваемые для исполь-
зования в программе поиска, обеспечивают быструю
поисковую работу всего модуля.
Обычно такие функциональные возможности офор-
мляются в виде функции, которая вызывалась бы из
нескольких различных мест программы. Функции по-
нять легче, чем макросы, легче производить их отлад-
ку, и в результате возникает меньше хлопот. Однако
поиск во всем дереве должен выполняться быстро, и при
правильном их использовании макросы часто работают
лучше, чем функция. Исходя из этих соображений,
будем использовать именно макросы.
Определенный нами объект key__walker представля-
ет ключ как массив символьных переменных unsigned
char фиксированной длины. Некоторые приложения
используют объект key walker для получения значи-
тельно большей информации о фактической структуре
ключа.
В нашем случае указанные выше макросы можно
легко написать, если каждый набор выделяемых битов
является массивом переменных unsigned char, как это
показано в листинге 14.1.
Здесь элемент key указывает на следующий байт
ключа, а элемент len дает количество оставшихся слева
байтов — при приближении их к нулю мы получим сиг-
нал о достижении конца ключа.
Однако не всегда желательно иметь набор как мож-
но большего числа битов. При выделении хотя бы вось-
ми битов требуется значительный размер поддеревьев.
Кроме того, в некоторых компиляторах тип unsigned
char занимает в памяти значительно больше, чем восемь
битов, за счет чего еще больше увеличивается коэффи-
циент загрузки используемого пространства.
Таким образом, нужно обеспечить альтернативную
схему реализации, которая сможет итеративно выделять
биты из конкретных переменных unsigned char, состав-
ляющих ключ. К счастью, выбирать реализацию мы
можем позволить препроцессору:
♦define LEVEL_PER_UCHAR ((CBAR_BIT+TRIE_LOG_BRANCB_FACTOR-1)
TRIE_LOG_BRANCH_FACTOR)
typedef struct keywalker {
const unsigned char *key;
size_t len;
int bit_offset;
} key_walker;
♦define initialize_walker(walker, key, len_key) \
(void) ( \
(walker).key = (key), \
(walker).len = (len_key), \
(walker).bitoffset = -TRIELOGBRANCHFACTOR \
)
♦define extract_next(walker) \
((walker).len == 0 ? -1 : \
((walker).bitoffset >= CHARBIT-TRIELOGBRANCHFACTOR ? \
(((walker).len -= 1) ? ((walker).bit_offset=0, \
*++(walker).key & (TRIEBRANCHFACTOR-l)) : -1) : \
((walkerJ.bitoffset += TRIELOGBRANCHFACTOR, \
(♦(walker).key » (walker).bitoffset) \
& (TRIEBRANCHFACTOR-l))))
♦define extract_atoffset(key, lenkey, offset) \
((len_key)*LEVEL_PER_UCHAR <= (offset) ? -1 : \
((((^ey)[ (Offset) /LEVELPERJJCBAR ]) » \
(TRIELOGBRANCHFACTOR*((offset)%LEVEL_PERJJCHAR))) \
& (TRIEBRANCHFACTOR-1)))
Эти макросы выглядят устрашающе, но на самом
деле они не так уж сложны. Элемент key по-прежнему
указывает на следующий байт ключа, а элемент len дает
число его байтов слева. Однако теперь bit_plTset дает
набор битов (минус TRIELOGBRANCHFACTOR).
и нужно сдвинуть этот байт для получения следующе-
го набора. При выполнении макроса extract__next снача-
ла проверяется отсутствие ключа (если len равно нулю).
335
Деревья
Глава 14
Листинг 14.1. Выделение битов ключа.
typedef struct key_walker {
const unsigned char *key;
size t len;
} key_walker;
Idefine initialize_walker(walker, key, len_key) \
(void)( \
(walker).key = (key), \
(walker).len = (len_key) \
)
Idefine extract_next(walker) \
((walker) .len == 0 ? -1 s ((walker) .len -= 1, *(walker) .key++))
Idefine extract_at offset(key, len_key, offset) \
((lenkey) <= (offset) ? -1 : ((key)[offset]))
Затем уточняется, выделен ли последний набор битов
из текущего байта, и если да, то осуществляется пере-
ход к следующему байту. Если количество битов в этом
байте больше, чем необходимо, то bit offset переходит к
следующему набору битов и выделяет их. Набор битов
всегда извлекается из одной переменной unsigned char. Это
избавляет от такой нежелательной ситуации, когда нуж-
но получить следующую группу битов из ключа, а окон-
чание ключа оказывается в середине этой группы.
Поиск
Для поиска по конкретному ключу (который фактичес-
ки является основой дерева) мы начинаем с корневого
ухга и выделяем биты из ключа, чтобы определить тре-
буемое направление движения по дереву. Поиск продол-
жается до тех пор, пока мы не попадем на пустой ука-
затель NULL (это означает, что дальше ничего нет) или
На лист (это означает, что данный конкретный лист
является результатом поиска) либо пока не исчерпают-
ся биты ключа. В последнем случае с того места, где
закончились эти биты, выполняем поиск в поддереве и
проверяем, существует ли лист, который в точности
соответствует условиям поиска. Объединяя вместе все
сказанное выше, получим программный код, представ-
ленный в листинге 14.2.
Сканирование по ключу и индексирование различ-
ных поддеревьев продолжается до тех пор, пока не за-
кончатся биты ключа или не закончится поддерево.
В этот момент проверяется наличие узла и устанавли-
вается, верен ли найденный ключ. Разумеется, нужна
другая программа для определения того, является ли
этот ключ верным и какое значение получено — конеч-
ное или значение ’’not found" (не найден). Выполнять эту
процедуру будем в главной поисковой программе, несмот-
ря на то что делать это необходимо в двух местах и код
процедуры придется повторить дважды. Если мы хотим
несколько повысить скорость поиска, программный код
следует преобразовать в следующий макрос:
tatic trieresult compare_leaf( const struct trie_leaf *leaf,
const unsigned char *key, sizet len_key )
if (lleaf || len_key != leaf->len_key ||
0 1= memcmp( key, leaf->key, lenkey)) {
return 0;
} else
return leaf->result;
Вставка
Конечно, поиск значений не будет работать как следу-
ет, пока мы не сможем вставлять эти подлежащие по-
иску значения. Объявим функцию trie__insert, которая
вудет выполнять вставку в дерево узла, ключа (и его
размер) для поиска и переменную, которая будет воз-
вращаться, если ключ найден.
Теперь следует разработать программу, которая бу-
аст вставлять лист в узел. Для этого требуются узел, лист
и средство для выделения битов из ключа, по которому
осуществляется операция вставки. Нужно также уметь
определять подробный путь вглубь узла, в который
выполняется вставка. Здесь потребуется обработка ис-
ключительных ситуаций, так как успешное завершение
операции вставки по пустому указателю невозможно.
После того как мы получим такую программу, останет-
ся только разместить в памяти наш лист (т.е. нашу ко-
пию ключа, на который ссылается лист) и вставить его
в корневой узел, как это показано в листинге 14.3.
336
Организация данных
Часть II
Листинг 14.2. Поиск в дереве.
trie_result trie_search(const struct trie *trie,
const unsigned char *key, size_t len_key)
{
trie_pointer node;
key_waIker wa 1ker;
const struct trie_leaf *leaf;
if (trie == 0)
return 0;
initialize_walker(walker, key, len_key);
node = trie->root;
for (;;} {
const struct trie_subtrie *q;
int n;
if (Inode) {
return 0;
}
if (*node 1= TRIESUBTRIE)
break;
q - (const struct trie_subtrie*)node;
n = extractnext(walker);
if (n < 0) {
return compare_leaf( q->exact_match, key, len_key );
} else {
assert ( n < TRIEBRANCHFACTOR );
node = q->next_level[n];
1
assert( *node «= TRIE_LEAF );
leaf = (const struct trie_leaf*)node;
return compare_leaf( leaf, key, len_key );
Листинг 14.3. Вставка ключа в дерево.
int trie_insert(struct trie *trie, const unsigned char *key, size_t len_key,
trieresult result) {
if (trie) {
trie_pointer p;
key_walker walker;
struct trie_leaf *leaf;
leaf = malioc( sizeof( *leaf ) );
if (Ileaf)
return 0;
leaf->key = malioc( len_key > 0 ? len_key : 1 );
if (!leaf->key) {
free(leaf);
return 0;
1
memcpy( leaf->key, key, len_key );
leaf->type = TRIELEAF;
leaf->len_key = len_key;
leaf->result = result;
initialize_walker( walker, key, len_key );
p = insert_node( trie->root, &walker, 0, leaf );
337
Деревья
Глава 14
if (P) {
trie->root = p;
return 1;
1
destroy leaf( leaf );
1
return 0;
1
А теперь, очевидно, нужно написать программу для
вставки листа. Чтобы успешно вставлять лист в узел, не-
обходимо уметь обрабатывать три случая: когда узел
пуст, узел является листом и узел заполнен. Первый
случай — самый простой. Когда лист добавляется к пу-
стому узлу, ясно, что если поиск достиг этой части
структуры дерева, то найденный лист — это конечная
точка поиска. В таком случае этот лист можно считать
узлом, как показано в листинге 14.4.
Листинг 14.4, Вставка листа в узел._______________________________________________
static trie_pointer insert_node( triepointer old_node, key_walker «walker, [srl
int level,
struct trieleaf «leaf )
{
if (!old_node) {
return (trie_pointer)leaf;
Вставка листа в заполненный узел несколько слож-
нее. При прохождении до конца ключа будем считать,
что установилось полное соответствие. (В случае запол-
ненного узла программа сообщит об ошибке; ваше при-
ложение может как-то иначе обрабатывать ситуацию в
случае уже существующего ключа.) Если доступны ка-
кие-то еще биты ключа, лист вставляется в узел на сле-
дующем уровне. При этом нужно убедиться, что обра-
ботка ошибок вставки выполняется правильно.
switch (* *old_node) {
case TRIESUBTRIE: {
struct trie_subtrie *node = (struct trie subtrie*)old node;
int n;
n = extract_next( «walker );
if (n < 0) {
/*
* Если мн вняли из клича, то устанавливаем его полное соответствие,
* если это еце не сделано
*/
if (node->exact_match) {
return 0;
}
node->exact match = leaf;
} else {
!*
* Следующий n-й набор битов - рекурсивный вызов insert_node для
* вставки листа в узел n-го уровня next_level
*/
assert( n < TRIEBRANCHFACTOR );
if (node->next_level(nJ) {
trie pointer next_level = insert_node( node->next_level[n],
walker, level+1, leaf );
if (1nextlevel) {
return 0;
Зис.265
338
Организация данных
Часть II
}
node->next_level[п] = nextlevel;
} else
node->next_level[n] = (triepointer)leaf;
}
/*
* В любом случае, если мы достигли этого места, значит, лист вставлен успеино.
*/
node->count += 1;
return (triepointer)node;
}
Наиболее сложная ситуация возникает при вставке пользовавшись имеющейся программой (которую мы
листа в другой лист. Но можно обойти ее, представив сейчас пишем) для вставки нового листа в только что
существующий лист в виде полного узла и затем вое- преобразованный узел. Такой подход дает нам следую-
щую программу:
case TRIELEAF: {
struct triesubtrie *new_node;
struct trieleaf *previous_leaf = (struct trie leaf*)old node;
triepointer result;
int i, n;
newnode = malloc ( sizeof ( *newnode ));
if (Inewnode) return 0;
new_node->type » TRIESUBTRIE;
new_node->exact_match = 0;
for (i=0; i<TRIE_BRANCH_FACTOR; i++)
new_node->next_level[i J = 0;
n = extract at offset( previous_leaf->key, previous_leaf->len key,
level );
if (n < 0) {
new_node->exact_match = previousleaf;
} else {
assert( n < TRIEBRANCHFACTOR );
new_node->next level[nJ = (trie_pointer)previous_leaf;
}
new_node->count = 1;
result = insert_node( (trie_pointer)new_node, walker, level, leaf );
if (1result) {
free(new_node);
return 0;
}
return result;
}
default:
assert(O);
return 0;
Удаление
Время от времени возникает необходимость удалять
узлы из структуры дерева. С этой целью прежде всего
создается программа для удаления листа из узла. Так же,
как и ранее, сопоставляется тип узла. Обрабатывая слу-
чай, когда узел легко превращается в лист, проверяем,
соответствует ли ключ удаляемому листу, и, если это
так, лист удаляется и указатель устанавливается в
NULL. Программа удаления листа представлена в лис-
тинге 14.5.
339
Деревья
Глава 14
Листинг 14.5. Удаление листа из структуры дерева._______________________________________________
static int delete_node( triepointer * *node, key walker *walker,
const unsigned char *key, sizet len_key )
{
if (!*node)
return 0;
switch (**node) {
case TRIE_LEAFs {
struct trie_leaf *p = (struct trieleaf*)*node;
if (lenkey 1= p->len_key 11 0 1= memcmp( key, p->key, lenkey ))
return 0;
destroy_leaf(p);
♦node = 0;
return 1;
Случай, когда узел является полным, немного более
сложен. Сначала проверяются следующие биты ключа,
чтобы выяснить, где может находиться требуемый лист.
Затем удаляется лист из подузла и обрабатывается си-
туация обнаружения конца ключа:
case TRIESUBTRIE: {
struct trie_subtrie *p = (struct triesubtrie*)*node;
int n;
n = extract_next( *walker );
if (n < 0) {
if (p->exact_match == 0)
return 0;
assert( lenkey == p->exact_match->len_key &&
0 ~ memcmp( key, p->exact_match->key, len key ) );
destroyleaf( p->exact_match );
p->exact-inatch = 0;
} else {
if (!delete_node( &p->next_level[nj, walker, key, len key ))
return 0;
}
Однако теперь нам нужно проверить, можно ли
уменьшить структуру дерева, свернув соответствующее
Поддерево. Для этого используется индекс количества
узлов: мы будем сворачивать поддерево, если на нем
остался только один подчиненный лист. Если это так,
то узел заменяется листом. После проведения этой опе-
рации программный код будет выглядеть так: осуществ-
ляется поиск ключа (который является либо точным
ключом, либо ключом следующего уровня, поскольку
некоторые подузлы уже были свернуты), узел удаляет-
ся из памяти и заменяется оставшимся листом:
p->count -= 1;
assert( p->count >0 );
if (p->count == 1) {
trie_pointer leaf;
int i;
/*
♦ Необходимо свернуть узел. К счастью, известно, что
* подуровни также должны быть свернуты, и можно просканировать
♦ всех потомков для непустого подузла
*/
leaf = (trie_pointer)p->exact_match;
340
Организация данных.
Часть II
for (i=0; i<TRIE_BRANCH_FACTOR; i++)
if (p->next_level[ij) {
assert( leaf == 0 );
leaf = p->next_level [ i ];
}
/-* Нужно найти потомка, который должен быть листом */
assertf leaf 1=0 );
assert( *leaf == TRIELEAF );
/* Можем использовать этот лист в качестве нового узла, удалив из памяти старое
поддерево */
free(p);
♦node = leaf;
}
return 1;
default:
assert(O);
return 0;
После получения этой программы написать про- проще — стоит лишь удалить лист из корня, как это по-
грамму для удаления листа из полного дерева становится казано в листинге 14.6.
Листинг 14.6. Удаление листа из дерева.
int trie_delete( struct trie *trie, const unsigned char *key, size_t lenkey )
{
if (trie) {
keywalker walker;
initialize_walker( walker, key, lenkey );
return delete_node( fctrie->root, (walker, key, len_key );
}
return 0;
Возможные модификации структуры типа
дерево
В зависимости от конкретных требований своего прило-
жения вы можете осуществлять самые различные модифи-
кации представленного выше программного кода. Можно
варьировать величину LOG_TRIE_BRANCH_FACTOR
для изменения соотношения между временем поиска и
объемом требуемой памяти. Ниже приведен список не-
которых идей, которые вы можете реализовать для сво-
его конкретного приложения:
• Ваше приложение может никогда не иметь ключа,
который бы являлся префиксом другого ключа. На-
пример, приложение может делать все ключи оди-
наковой длины. В этом случае вы можете ограни-
читься элементом данных exact_match и всю логику
подчинить этому элементу.
• Предыдущая обработка показала, что попытка вста-
вить уже существующий ключ приводит к ошибке.
В этом случае в зависимости от потребностей при-
ложения вы можете либо просто проигнорировать
вставку ключа, либо обновить результат поиска. Для
реализации обоих этих случаев можно модифициро-
вать программу insert_node. Заметим, однако, что
сделать это не так просто, как может показаться;
проще всего добавить программный код для сравне-
ния двух листьев (при попытке вставить новый лист
в существующий) и обработки возможных ситуаций.
• Один из методов экономии рабочего пространства
(памяти) состоит в модификации формата узла.
Можно свернуть все узлы с количеством листьев
менее N в специальный формат, имеющий список
соответствующих листьев. Когда программа поиска
обнаруживает один из таких специальных узлов, она
осуществляет последовательное сканирование спис-
|341
Деревья
Глава 14
ка в поисках соответствия. Это может позволить
сберечь большой объем памяти, поскольку в обыч-
ном дереве большинство участков памяти распола-
гается на более низких уровнях — именно на тех,
которые вполне можно свернуть.
• Еще более радикальная модификация для эконо-
мии пространства (которая, возможно, менее эффек-
тивна; если вам требуется ее осуществить, значит,
вы, вероятно, уже попробовали сделать модифика-
цию, описанную в предыдущем абзаце) состоит в
изменении формата узла в целях использования
двухуровневой таблицы. Первый уровень такой
таблицы представляет собой массив значений
TRIE_BRANCH_FACTOR переменных unsigned
char. Для индексации в массив указателей исполь-
зуется некоторое значение. Хитрость здесь состоит
в том, что вы распределяете лишь столько входов во
второй массив, сколько имеется отдельных входов;
так что все указатели NULL имеют только один
определенный для них вход. Поскольку большинство
указателей обычно обнулены и на большинстве ком-
пиляторов занимают несколько больше пространства,
чем переменные unsigned char, то в результате мы по-
лучаем значительную экономию памяти. Узел с коли-
чеством NumChildren узлов-потомков на следующем
уровне использует TRIE_BRANCH_FACTOR*
(NumChildren+l)* sizeof(TriePointer) байтов вместо
TRIE_BRANCH_FACTOR* sizeof(TriePointer) бай-
тов. При этом программа вставки становится не-
сколько более замысловатой, особенно если вам нуж-
но обрабатывать случай, когда у вас имеется
отдельный потомок UCHAR_MAX.
• С другой стороны, можно дать несколько рекомен-
даций по ускорению выполнения программы поис-
ка. Вы можете определить статический узел
TRIE_NULL, который используется для индикации
того факта, что по данному префиксу листья отсут-
ствуют (в текущей реализации для такой индикации
используется явное обнуление). Путем замены всех
случаев нулевых указателей на обособленный узел
вы можете исключить из программы trie_search про-
верку указателя на нулевое значение, заменив ее
проверкой типа узла, если окончание поиска совпа-
дает с неузловым значением. На многих централь-
ных процессорах обслуживание всех возможных вет-
вей оказывается несколько накладным, так что
указанные замены могут позволить вам сэкономить
большое количество времени.
Иной подход к попытке выиграть в скорости поис-
ка ценой увеличения требуемого для этого простран-
ства состоит в изменении определения дерева так,
чтобы листья всегда встречались в позиции, которую
дает полное расширение ключа. Например, лист на
символьном дереве, соответствующий "АВС", всегда
можно найти, следуя сначала по ветви "А", затем по
ветви "В", и наконец, по ветви "С". Такой подход
очень экономит время, поскольку, когда программа
поиска выходит на какой-либо лист, отпадает необ-
ходимость в повторной проверке того, является ли
полученное совпадение истинным, — если вы ого-
ворили путь для получения листа, то полученный
ключ обязан быть правильным. Одно предупрежде-
ние: если вы используете длинные ключи, такая
методика может "съедать" большой объем памяти.
• Путем еще более радикальных изменений вы може-
те также расширить дерево для осуществления по-
иска в плохо определенных структурах. Примером
сопоставления в плохо определенной структуре мо-
жет служить проверка соответствия входного набо-
ра одной из строк "АВ*", "А*В" или "*ВС", где *
может быть любым символом.
Для обеспечения таких плохо определенных соот-
ветствий необходимо выполнить несколько модифика-
ций, которые включают:
• модификацию формата узла листа для того, чтобы
могли быть сопоставлены несколько различных
структур. Вы можете решать, какая структура дол-
жна быть создана с соответствием во время вставки;
• модификацию формата узла так, чтобы узел сопро-
вождался конкретным списком потенциально соот-
ветствующих ему листьев на конкретном уровне. Это
означает, что теперь дерево уже не имеет в точнос-
ти древовидную структуру, но вместо этого конкрет-
ный узел может иметь указатели из нескольких ро-
дительских узлов (такая структура называется вып-
рямленный ациклический граф).
ПРИМЕЧАНИЕ
Более детально выпрямленный ациклический граф и дру-
гие типы графов рассматриваются в главе 16.
• модификацию программ вставки и удаления для об-
работки этой измененной структуры данных. В ча-
стности, если программы требуют изменить указа-
тель путем добавления или удаления листа, они
должны проверять, существует ли уже этот конкрет-
ный узел, и, если это так, снова использовать его.
Скажу откровенно, что такая проблема будет возни-
кать не очень часто и, как вы поняли, потребуются не-
которые усилия для того, чтобы правильно ее решить.
Тем не менее, если вам необходимо выполнять поиско-
вые операции очень быстро, структура типа дерево яв-
ляется одной из немногих ваших альтернатив.
342
Организация данных
Часть II
Сравнение деревьев с двоичными
древовидными структурами и
хеш-таблицами
Деревья (trie) можно использовать и для решения тех же
типов проблем, какие решают двоичные древовидные
структуры (tree) и хеш-таблицы. Ниже показано, как
деревья соотносятся с этими более традиционными
структурами данных:
• Деревья выполняют поиск на дереве за время 0(1),
в худшем случае — в зависимости от фиксированной
длины ключа. Хеш-таблицы могут делать это в сред-
нем за время 0(1), но их время в худшем случае бу-
дет значительно большим. Структура типа двоичное
дерево, которая содержит п элементов, потребует
для поиска O(log(n)) времени.
• В противоположность хеш-таблицам, деревья могут
быть быстро просмотрены по порядку хранящихся
в них элементов. Для этого потребуется модифици-
ровать объект key walker так, чтобы он в первую
очередь просматривал наиболее значимый бит клю-
ча. Конечно, двоичное дерево может выполнять не
только это, но даже больше.
• Деревья склонны к использованию значительно
большего объема памяти, чем двоичные деревья или
хеш-таблицы. Последние две структуры расходуют
память пропорционально числу узлов внутри этих
структур данных. Деревья, в отличие от этого, зани-
мают пространство пропорционально количеству
узлов, умноженному на количество элементов, кото-
рые должны быть проверены на равенство среднему
значению перед тем, как вы получите соответствие,
и на размер каждого поддерева. Если вы используе-
те много ключей с длинными общими префиксами,
это может вылиться в значительный объем памяти.
Вам действительно необходимо изучить особеннос-
ти своих данных, прежде чем сделать вывод о том,
подходит ли вам структура типа дерево.
Резюме
В этой главе мы рассмотрели основы работы со струк-
турами данных типа дерево. Вначале было дано опре-
деление дерева, рассказано о том, как выполняется поиск
в нем, а также описаны некоторые его фундаментальные
свойства. Затем мы реализовали дерево в виде программ-
ного кода и обсудили различные способы модификации
такой реализации. Был также представлен сравнитель-
ный анализ свойств и достоинств деревьев с некоторы-
ми другими структурами данных.
Разреженная матрица
В ЭТОЙ ГЛАВЕ
Что такое разреженная матрица
Почему данные могут быть разреженными
Когда используется разреженная матрица
Построение разреженной матрицы
Прохождение разреженной матрицы
Вильям Фишбурн
В этой главе рассматривается одна из наиболее совер-
шенных из когда-либо изобретенных структур данных.
Разреженная матрица — это экономичная структура для
хранения данных, разнесенных по обширной логи-
ческой области. Разреженная матрица аналогична
стандартному массиву, но объединяет в себе универ-
сальность списков и деревьев, сохраняя при этом про-
странственную конфигурацию, характерную для мас-
сивов. Разреженные матрицы используются для
хранения сравнительно небольшого объема данных,
которые располагаются в большой области данных. Ре-
ализация разреженных матриц связана со значительны-
ми издержками, и это делает их все более непрактич-
ными по мере заполнении области данных значимыми
величинами. Таким образом, существует хорошо опре-
деленный набор задач, для решения которых использу-
ется структура данных типа разреженной матрицы.
Построение разреженной матрицы представляет со-
бой фактически процесс объединения нескольких мно-
госвязных списков. Эти связанные списки формируют
логический массив значений, в котором хранятся толь-
ко ненулевые значения. Ввиду логической сложности
связей между списками существует необходимость со-
здания функций, которые облегчают прохождение мас-
сива, снимают эту сложность с основных направлений
программирования и инкапсулируют свою функцио-
нальность внутри библиотеки. И наконец, будут рас-
смотрены вопросы практического использования этой
библиотеки.
Что такое разреженная матрица
Перед тем как начать подробно рассматривать вопросы
построения разреженной матрицы, важно понять ее
Природу. Разреженная матрица — это сложная структура
данных, которая для своего поддержания требует тща-
тельной организации. Разреженная матрица имитирует
массив, но не требует дополнительной памяти для раз-
мещения пустых ячеек. Хотя разреженная матрица, как
правило, не бывает полной, тем не менее, на рис. 15.1
показан полностью заполненный массив размером 6x6.
Это не просто массив другого типа
ПРИМЕЧАНИЕ
В этой части термины "стандартный массив" и "массив
языка С" очень часто взаимозаменяемы. Когда-то исполь-
зование термина "стандартный массив" означало массив,
описанный в стандартных библиотеках языка С. Но сегод-
ня этот термин приобрел и другой смысл, означая соот-
ветствие правилам, установленным признанной организа-
цией по созданию стандартов. Поэтому термин "стандар-
тный массив" был заменен термином "массив языка С”.
Еще один устаревший термин — "массив языка Цаскаль" —
использовался для описания массивов языка С/’посколь-
ку в С массивы хранились так же, как и в языке Паскаль.
Исторически Паскаль использовался в учебных заведени-
ях, с ним было знакомо огромное количество програм-
мистов, так что термин "массив языка Паскаль" был по-
нятен многим. С течением времени Паскаль стал все
меньше и меньше использоваться в учебных заведениях,
поэтому термин "массив языка Паскаль" выходит из упот-
ребления. Именно по этой причине этот термин в тек-
сте данной главы не используется.
Разреженная матрица имеет несколько следующих
отличий от стандартного массива:
• Метод физического хранения
• Метод доступа
• Скорость доступа
В следующих подразделах подробно рассматривает-
ся, в чем заключаются эти отличия.
Организация данных
Часть II
344
РИСУНОК 15.1. Полная разреженная матрица размером 6x6
Метод физического хранения
Как правило, массив языка С хранится в виде последо-
вательности значений. В одномерном массиве (напри-
мер, a[depth]) величина depth является глубиной масси-
ва, которая представляет собой количество смещений
между начальным элементом массива и его конечным
элементом минус один. Так, например, четвертый элемент
одномерного массива смешен на величину трех элементов
массива. Графически это показано на рис. 15.2.
а[0] а(11 а[2] а!3]
Размер I
элемента —>1
массива увеличенный в 3 раза размер
------------- элемента массива
Многомерный массив несколько сложнее. Он может
храниться различными способами в зависимости от ре-
ализации языка С, но, как правило, дополнительные
измерения, общая сумма которых определяет размерность
массива, хранятся со сдвигом друг относительно друга.
Таким образом, чтобы найти положение элемента а[1][3]
в двумерном массиве элементов, необходимо найти ука-
затель на начало массива а(Ц, а затем перейти через три
размера элемента, как это показано на рис. 15.3.
Следовательно, объем памяти, который необходим
для хранения традиционного массива, можно вычислить
как произведение длин каждого измерения массива,
умноженное на размер одного элемента. Отсюда следу
ет, что необходимый для хранения стандартного мае
сива объем памяти возрастает геометрически при у вс
личении размерности массива. Кроме того, объем
памяти возрастает арифметически при увеличении ко
личества элементов в одном измерении.
РИСУНОК 15.2. Определение положения четвертого элемента в
стандартном массиве а размером 1+4.
Разреженная матрица
Глава 15
345
а[0][0] а[0][1] а[0][2] а[0][3] а[1][0] а[1][1] а[1Ц2] а[1][3]
Размер
элемента
массива
Размер элемента массива
умноженный на количество
элементов в измерении
Увеличенный в 3 раза
размер элемента
массива
РИСУНОК 15.3. Определение положения четвертого элемента во втором измерении стандартного массивам размером 2x4.
В отличие от стандартного массива, в разреженной
матрице хранятся только элементы с ненулевыми зна-
чениями. Как будет показано далее, с каждым измере-
нием разреженной матрицы связаны заголовки и указа-
тели, но объем памяти, который необходим для
хранения разреженной матрицы, линейно зависит от
количества ячеек с ненулевыми значениями, независи-
мо от изменения количества измерений или длины каждо-
го измерения} Этот факт является основным свойством
разреженной матрицы, которое делает ее ценным сред-
ством анализа больших систем данных, содержащих
малое количество значений.
Метод доступа
В стандартном языке С массив является встроенным
компонентом. Массив вводится зарезервированными
символами [], которые используются для доступа к эле-
ментам массива. Поскольку разреженная матрица не
является составной частью языка С, для доступа к эле-
ментам такой матрицы необходимо пользоваться специ-
альными функциями. Это в определенной степени ус-
ложняет код, в котором используются разреженные
матрицы, по сравнению с кодом, использующим стан-
дартные массивы.
Скорость доступа
Поскольку стандартный массив языка С основан на
смещении его элементов относительно начальной точ-
ки, скорость доступа к произвольному элементу масси-
ва очень высока. С другой стороны, разреженная мат-
рица, по сути, является совокупностью связанных
списков, поэтому доступ к определенной ячейке требует
ирохождения по нескольким указателям. Таким обра-
зом, время доступа к произвольной ячейке в разрежен-
ной матрице является переменной величиной, которая
Зависит от количества связей, по которым необходимо
Пройти для достижения требуемой ячейки. В общем
случае разреженная матрица имеет меньшую скорость
доступа, чем стандартный массив соответствующего
размера.
Заголовочные списки
Как уже было сказано, разреженная матрица представ-
ляет собой совокупность связанных списков. Одна из
частей этой совокупности определяет размерность мас-
сива. Для каждого измерения в разреженной матрице
имеется одна структура заголовочного списка. Каждый
заголовочный список состоит из элементов заголовоч-
ного списка, которые представляют один определенный
экземпляр измерения, заполненный данными. Заголо-
вочные списки являются двусвязными списками, что
позволяет двигаться по ним как в одном, так и в дру-
гом направлении. На рис. 15.4 представлен элемент за-
головочного списка.
РИСУНОК 15.4. Элемент заголовочного списка.
Для примера рассмотрим двумерную разреженную
матрицу размером 6x6, которая показана на рис. 15.1.
Предположим, что только два узла матрицы — 1Щ4] и
12ЦЗ| — содержат некоторые значения. В этом случае у
нас будут заголовочные списки строк Строка 2 и Стро-
ка 3, которые соответствуют второй и третьей строкам
матрицы, и заголовочные списки столбцов Столбец 4 и
Столбец 5, которые соответствуют третьему и четвер-
Организация данных
Часть II
346
тому столбцам матрицы. Поскольку все остальные стро-
ки и столбцы не содержат никаких значений, в разре-
женной матрице они не представлены. Так, например,
при запросе значения, содержащегося в узле [ОДО], бу-
дет получен 0 (как уже говорилось, считается, что не-
занятые узлы разреженной матрицы содержат значение
0), и при этом даже не будет выполняться просмотр
данных, поскольку в соответствующем заголовочном
списке нет ни строки, ни столбца с такими номерами.
Узлы матрицы
Следующим элементом разреженной матрицы являет-
ся совокупность связанных списков, которые служат
узлами матрицы. Узлы содержат данные, которые хра-
нятся в разреженной матрице. Базовая структура узла
показана на рис. 15.5. Обратите внимание, что в струк-
туре на этом рисунке не показаны все подробности.
Более детально структура узла будет рассмотрена в пос-
ледующих разделах.
Продолжая рассмотрение примера, приведенного в
предыдущем разделе, можно сказать, что разреженная
матрица в нашем случае будет содержать только два
значения узлов. Узел НЦ4] будет указывать на заголов-
ки для Строки 2 и Столбца 5, а указатели узла будут
указывать сами на себя. Узел [2]|3| будет указывать на
заголовки для Строки 3 и Столбца 4, а указатели этого
узла, как и в предыдущем случае, будут указывать сами
на себя. Разреженная матрица для данного примера
приведена на рис. 15.6.
Размерность
Размерность разреженной матрицы определяется коли-
чеством заголовочных списков, которые составляют
матрицу. Очень часто разреженные матрицы имеют
постоянную размерность, но в этой главе будет рассмат-
риваться построение матрицы размерностью N. По-
скольку каждый заголовочный список является отдель-
ным элементом, построение матрицы размерностью N
никоим образом не отражается на структурах заголовоч-
ных списков. Однако каждый узел должен указывать на
соответствующие заголовки, поэтому переменное коли-
чество указателей внесет некоторое интересное ’’иска-
жение" в реализацию разреженной матрицы переменной
размерности. Кроме того, необходимо, чтобы в каждом
измерении узлы указывали на предыдущий и последу-
ющий соседние узлы. И опять же, переменное количе-
ство пар указателей усложняет реализацию такой раз-
реженной матрицы.
Поскольку при рассмотрении большего количества
измерений существует тенденция к еще большему раз-
режению данных, имеет смысл разработать такую реа-
лизацию разреженной матрицы, которая бы позволяла
строить матрицу произвольной размерности. Кроме
того, при увеличении размерности матрицы растет л
объем памяти, сэкономленной за счет использования
разреженной матрицы.
РИСУНОК 15.5. Элемент узла.
Разреженная матрица
Глава 15
347
Заголовочные связи
РИСУНОК 15.6. Разреженная матрица размером 6x6 с двумя узлами.
Почему данные могут быть
разреженными
Если бы у нас была библиотека функций для работы с
разреженными матрицами, то ее можно было бы ис-
пользовать только для разреженных наборов данных.
Почему? Все преимущества разреженной матрицы ос-
нованы на том, что данные разрежены. Если данные не
разрежены, то использование разреженных матриц мо-
жет принести больше вреда, чем пользы. Работа с раз-
реженной матрицей для многих программистов значи-
тельно сложнее, чем со стандартным массивом.
Поэтому, если набор данных не разрежен, большинство
программистов не возьмут на себя труд по реализации
разреженной матрицы, а будут использовать стандарт-
ные массивы. Кроме того, скорость работы также мо-
жет оказаться проблемой. Иногда использование разре-
женной матрицы значительно усложняет решение
поставленной задачи по сравнению с решением той же
задачи с помошью стандартных массивов. И наконец,
экономия памяти, которая является главной причиной
использования разреженных матриц, быстро сводится на
нет, если набор данных все менее разрежен.
Что такое разреженные данные
Традиционно считается, что разреженные данные — это
данные, которые в основном содержат нулевые, или
пустые, значения. В некоторых случаях разреженность
данных может быть очевидной. Рассмотрим, например,
нанесение на карту всех видимых на небе звезд. Очевид-
но, что на ночном небе будет гораздо больше пустого
пространства, чем звезд, видимых невооруженным гла-
зом (в противном случае ночное небо было бы очень
ярким). Несмотря на то что количество видимых звезд
очень велико (настолько велико, что вы даже можете
подумать, что такие данные не разрежены), тем не ме-
нее, они распределены по огромной площади. Таким
образом, количество видимых звезд по сравнению с
количеством мест, которые могли бы быть заняты ви-
димыми звездами, может служить примером разрежен-
ных данных.
Разреженность данных определяется не количеством
данных, а отношением занятых позиций данных к ко-
личеству всех возможных позиций. Такое отношение
определяет разреженность данных. Для обоснования
использования разреженной матрицы для данных той
или иной степени разреженности необходимо оценить
скорость работы и сложность кода, а также объем сэко-
номленной при этом памяти.
348
Организация данных
Часть II
Сложность кода
По своей природе разреженные матрицы, как уже гово-
рилось, являются сложными структурами данных. Если
стоящая проблема достаточно проста, то не имеет смыс-
ла усложнять ее решение за счет использования разре-
женной матрицы. Кроме того, если перед нами не сто-
ит задача экономии памяти, использование разреженной
матрицы также ничем не будет обосновано. Програм-
мист должен сравнить гибкость, обеспечиваемую ис-
пользованием разреженной матрицы, со сложностью (и
увеличением размера кода) ее использования.
Следует также учитывать и возможность повторно-
го использования кода. Создание и использование биб-
лиотеки функций для работы с разреженными матри-
цами — не такая уж простая задача. Не все
программисты могут сопровождать, а тем более изме-
нять код, разработанный для разреженных матриц. Это
делает код очень сложным для понимания и модифи-
цирования неопытными программистами. Очевидно,
что для облегчения повторного использования и сопро-
вождения код должен быть по возможности прост. Ис-
пользовать разреженные матрицы просто потому, что
это возможно, нецелесообразно.
Но существуют операции, выполнение которых дей-
ствительно упрощается при использовании разреженной
матрицы. Это особенно актуально при поиске значений
в матрице с последующим изменением этих значений в
соответствии со значениями соседних ячеек. Приложе-
нием, которое почти идеальным образом подходит для
использования разреженных матриц, является игра
"Жизнь Конвея" (Conway). Это приложение часто мож-
но увидеть в многочисленных экранных заставках, по-
этому в настоящей главе мы не будем касаться вопро-
сов реализации этого приложения. Тем не менее,
короткое рассмотрение принципа игры поможет понять,
каким образом разреженная матрица может упростить
ее реализацию.
ИГРА "ЖИЗНЬ КОНВЕЯ"
Игра ’’Жизнь Конвея", придуманная Джоном Конвеем
(John Н. Conway), — это совсем не игра, а аппарат ис-
следований по клеточному автомату (одно из направле-
ний в проблеме искусственной жизни), которые были
опубликованы в Scientific American в апреле 1970 г. Игра
очень проста и имеет очень легкие для понимания пра-
вила. Игра ведется на сетке (обычно двумерной), кото-
рая является жизненным пространством всех клеточных
автоматов. На сетку наносится начальная (как правило,
случайная) конфигурация, которая далее развивается во
времени. Правила, по которым клетки живут и умирают,
следующие
Количество занятых Процесс
соседних клеток
0 Смерть
1 Смерть
2 Выживание
3 Выживание или рождение
4 Смерть
5 Смерть
6 Смерть
7 Смерть
8 Смерть
Игра "Жизнь Конвея" в основном используется для обу-
чения студентов использованию разреженных матриц,
поскольку она идеально подходит под определение раз-
реженных данных. Как правило, связанные с клеточными
автоматами задачи очень хорошо соответствуют требо-
ваниям к данным, которые должны использоваться в раз-
реженной матрице.
В игре "Жизнь Конвея" клетка считается живой, если
ее значение равно 1. Игра обычно ведется на двухмер-
ной матрице, но она не ограничена двумя измерения-
ми. Матрица заполняется начальной конфигурацией
(которая может быть случайной) единиц, произвольным
образом расположенных в матрице. Каждое "поколение"
в игре появляется в результате прохождения через мат-
рицу. Ячейки, которые содержат единичные значения,
могут потерять эти значения в зависимости от количе-
ства соседей (слишком много соседей — клетка "умира-
ет" от перенаселенности, слишком мало соседей — клет-
ка "умирает" от голода). Кроме того, клетки могут
вызывать появление новой клетки (оптимальное коли
чество соседей вызывает рождение клетки).
В экранных заставках игровая доска, как правило,
состоит из 640x480 ячеек, т.е. всего получается 307200
ячеек. В некоторых экранах размер доски может состав-
лять 1280x1024 ячеек, т.е. 1310720 ячеек. Имейте в
виду, что популяция является динамичной и количество
активных клеток может состоять от 15 и до нескольких
тысяч. Поскольку изменения всегда происходят внутри
одной ячейки активной клетки, при стандартной реа
лизации массива обработка сотен тысяч пустых ячеек
может и не потребоваться. В реализации же разрежен
ной матрицы определить "живые" клетки и проводит ь
операции вокруг них не так уж сложно. Игра "Жизнь
Конвея" является ярким примером того, кок разрежен
ная матрица может упростить реализацию сложной за
дачи.
Экономия памяти
Если данные действительно разрежены, то разреженная
матрица дает значительную экономию памяти по сран
нению со стандартным массивом, поскольку в разрежен
Разреженная матрица
Глава 15
349
ной матрице хранятся только активные данные. Допол-
ните.! ьный объем памяти, связанный с реализацией
разреженной матрицы, довольно легко оценить. Каждый
заголовок содержит четыре указателя. Каждый узел со-
держит указатели в количестве Зхразмерность (где раз-
мерность — количество измерений в матрице). На ос-
нове этого можно вычислить требуемый дополнитель-
ный объем памяти:
Об,ьем памяти= (используемые_заголовки * 4 *
размер_указателя) +
(используемые_узлы * 3 *
размерность * размер_указателя)
Рассмотрим двумерную матрицу с 100 заголовочны-
ми значениями в каждом измерении. Предположим, что
в этой матрице хранится не более 250 целых чисел. Каж-
дый заголовок в действительности использует не более 70
возможных значений заголовка. Если размер целых чисел
составляет 4 байта и длина указателей составляет столько
же, тогда требуемый дополнительный объем памяти со-
ставит 7120 байтов. 250 значений требуют 250x4 байтов,
т.е. 1000 байтов. Таким образом, для размещения дан-
ных в разреженной матрице потребуется в сумме 8120
байтов. При размещении тех же данных в стандартном
массиве понадобилось бы 100x100x4=40000 байтов.
Следовательно, в нашем примере разреженная матрица
позволяет уменьшить объем памяти для размещения
данных почти в 5 раз.
ПРИМЕЧАНИЕ
Имейте в виду, что приведенный пример является про-
сто приблизительной оценкой, поскольку мы еще подроб-
но не рассматривали структуры элементов заголовочно-
го списка и узлов разреженной матрицы. Наша оценка
основана на данных, приведенных в предыдущих разделах
главы, которые предназначены для оценки дополнитель-
ного объема памяти, требуемого для реализации разре-
женной матрицы. Более точные оценки дополнительного
объема памяти будут приведены далее в этой главе.
Когда используется разреженная
матрица
После того как вы получили представление о природе
разреженной матрицы и природе данных, которые иде-
ально подходят для представления их в виде разрежен-
ной матрицы, наступило время рассмотреть случаи, в
которых следует использовать разреженную матрицу.
Существует довольно большое количество типов задач,
решение которых сводится к действиям над разрежен-
ной матрицей. Некоторые из этих типов будут рассмот-
рены ниже. Кроме того, существуют целесообразные и
нецелесообразные операции над разреженной матрицей.
В этом разделе не приводится полный перечень всех
случаев, в которых использование разреженной матри-
цы целесообразно. Здесь приведены скорее указания
и отправные точки в определении целесообразности
использования разреженной матрицы в конкретных слу-
чаях. Рассмотрев некоторые указанные области приме-
нения разреженной матрицы, можно оценить целесооб-
разность использования разреженной матрицы для
каждого определенного приложения.
Типы задач
Как уже говорилось, наиболее подходящим приложени-
ем для реализации его с помощью разреженной матри-
цы является игра ’’Жизнь Конвея". Существуют и дру-
гие типы задач, которые рекомендуется решать с
использованием разреженной матрицы. В то время как
игра "Жизнь Конвея’’ представляет собой специфичес-
кую задачу в области клеточных автоматов, в настоящем
разделе будут рассмотрены некоторые другие, более
общие задачи, которые рекомендуется решать с исполь-
зованием разреженной матрицы.
Направленный граф
Граф показывает связь между узлами. Направленный
граф показывает не только то, как узлы связаны, но и
то, в каком направлении они связаны. В некоторых слу-
чаях существует также возможность задать "вес” связи
между узлами, который определенным образом харак-
теризует природу связи.
Хорошим примером направленного графа является
карта дорог. Города или пересечения дорог будут узла-
ми графа, а дороги, которые соединяют узлы, будут
связями. Весами могут быть расстояния между узлами.
Направление связи будет иметь смысл, если некоторые
из дорог имеют одностороннее движение. Логическая
схема такой карты показана на рис. 15.7.
РИСУНОК 15.7. Карта — пример направленного графа с весами
связей.
Организация данных
Часть II
350
Направленные графы могут быть представлены в
виде двумерной разреженной матрицы (одно измерение
для отправной точки связи, а второе — для ее конечной
точки), в каждом измерении которой содержатся назва-
ния городов. Другими словами, строки будут отправной
точкой пути, а столбцы — конечной его точкой. Вес пути
(или расстояние между городами) будет представлен зна-
чением, хранящимся в узле разреженной матрицы.
Маршруты между городами являются направленны-
ми за счет расположения городов в разных измерениях
(строка, столбец). Каждый город считается упорядочен-
ной парой, вследствие чего обращение к маршруту (Го-
род 4, Город 2) не обязательно дает то же значение, что
(Город 2, Город 4). В нашем примере маршрут (Город 4,
Город 2) равен 14, а вызов (Город 2, Город 4) вообще
даст ошибку (нет такого маршрута).
Поскольку в разреженной матрице довольно легко
увеличить размер каждого измерения (добавить или
убрать города) и матрица не содержит данных о ком-
бинации городов, которые не соединены прямыми мар-
шрутами (например, Город 4 и Город 5), то разрежен-
ная матрица является достаточно эффективным (с точки
зрения требуемой памяти) методом представления кар-
ты дорог. Конечно, такую простую карту, как карта в
нашем примере, не имеет смысла представлять в виде
разреженной матрицы, но представление карты даже
средней сложности обеспечит существенную экономию
памяти по сравнению с традиционным массивом.
Заголовки разреженной матрицы позволяют прохо-
дить разреженную матрицу быстрее, чем многосвязные
списки, на которых обычно строятся направленные гра-
фы. Таким образом, в зависимости от приложения раз-
реженная матрица может обеспечить значительные пре-
имущества по сравнению с более традиционными
подходами.
Сгруппированные данные
Данные, сгруппированные вместе в несколько групп на
большом пространстве и связанные между собой, явля-
ются еще одним типом задач, которые легко решаются
при использовании разреженной матрицы. Поскольку в
разреженной матрице хранятся только существующие
данные, пустые пространства между элементами не
имеют никакого значения.
Рассмотрим задачу мониторинга стока воды на боль-
шой территории, которая служит водосбором для реки
или озера. Вблизи озера или реки объем воды будет
довольно большим, что приведет к тому, что практичес-
ки все ячейки, которые представляют эту область, бу-
дут содержать значения. Вдали от озера или реки точ-
ки данных будут растягиваться в линию, по мере того
как все притоки будут отслеживаться в направлении к
их источникам. На внешних границах представляемой
области лишь очень немногие ячейки будут содержать
значения. В общем случае данные будут группировать-
ся вокруг основных районов стока воды в озеро или в
реку.
Эффект сгруппированности данных чрезвычайно
важен для такого типа картографирования. Кроме того,
очень важно иметь возможность просмотреть область
водосбора и определить основные источники воды, что
упростит охрану водной среды или позволит следить за
состоянием водосбора. Используя разреженную струк-
туру, можно вычислить плотность отдельных групп и
определить объемы воды на территории большой пло-
щади, не выполняя вычислений с участем ячеек, в ко-
торых сток воды отсутствует.
Многосвязные узлы
Графы, которые содержат определенный тип многосвяз-
ных узлов, также удобно представлять в виде разрежен-
ных матриц. Если можно считать, что граф имеет по-
слойные связи между узлами, то каждый слой такого
графа можно считать элементом дополнительного изме-
рения. Ранее в этом разделе мы рассматривали направ-
ленный граф с весами связей. Это был двумерный ме-
тод работы с многосвязными узлами. Тем не менее,
существует целый класс задач, которые имеют множе-
ственные двумерные решения и которые можно пред-
ставить в виде трехмерной разреженной матрицы.
Траектории полетов самолетов принадлежат именно
к такому типу. Траектории полетов чрезвычайно слож-
ны и могут содержать множество измерений. Три наи-
более важные из них — это город отправления, город
назначения и время. Дополнительные измерения могут
включать номер рейса, номер самолета и количество
проданных билетов. Работая только с тремя указанны-
ми выше измерениями, можно использовать город от-
правления в качестве одного заголовка, город назначе-
ния — в качестве другого, а время — в качестве третьего.
Таким образом, полеты между городами находятся в
разных временных слоях.
Как правило, многосвязные узлы хранятся в неко-
торой древовидной структуре.
Однако иногда древовидные структуры бывают не-
эффективны. Например, в нашем случае очень сложно
было бы выбрать верхний элемент дерева. Кроме того,
встает вопрос, каким образом проходить дерево? По
времени, по городу назначения или отправления? Мат-
рица позволяет проходить данные так, как желает
пользователь. Более того, степень разреженности дан-
ных о полетах (в очень редких случаях каждый город
соединен со всем другими городами прямым полетом и
крайне редко все самолеты находятся в воздухе одно-
временно) делает целесообразным использование разре-
женных матриц и позволяет экономично использовать
ресурсы.
Разреженная матрица
Глава 15
|351
Целесообразные операции
Кроме структур данных, характерных для определенно-
го типа задачи, существуют операции, которые сами по
себе могут оправдать использование разреженной мат-
рицы. Очевидно, что функции для работы со стандарт-
ными массивами, которые характерны и для разрежен-
ной матрицы, являются целесообразными операциями.
В настоящем разделе рассмотрены и другие целесооб-
разные операции.
Обход графов
Обход графа начиная с известной точки и поиск извес-
тной конечной точки является естественным примене-
нием разреженной матрицы. Структура связных спис-
ков разреженной матрицы очень напоминает структуры,
которые используются для работы с графами, и, кроме
того, в заголовке разреженной матрицы хранится ин-
формация о начальной и конечной точках. В случае
направленного графа выполнить обход очень просто.
Для ненаправленного графа обход несколько сложнее,
Поскольку кратные узлы разреженной матрицы необхо-
димо будет обходить для каждого узла графа.
Параллельные операции над узлами
Если над каждой ячейкой со значением необходимо
выполнить одну и ту же операцию, то для передачи
значений группе параллельных процессоров можно ис-
пользовать структуру разреженной матрицы. Посколь-
ку разреженная матрица содержит только ячейки со
значениями, процессору не может быть передана ячей-
ка без значения. Если строка с названиями (или заго-
ловочный список) столбцов передается процессору, то
прохождение осуществляется эффективным образом
только по ячейкам со значениями. Если понадобится
значение соседней ячейки, его можно получить по свя-
зи, не прибегая к вычислению индексов. По этим при-
чинам разреженные матрицы часто используются при
необходимости проведения интенсивных инженерных
вычислений на параллельных процессорах.
Мономиальные матрицы
Диагональная матрица — это двумерная матрица, все
элементы которой, за исключением диагональных эле-
ментов с левого верхнего угла до правого нижнего, рав-
ны 0. Очевидно, диагональная матрица является разре-
женной во всех случаях, за исключением тривиальных
(когда матрица вообще нулевая).
Мономиальная матрица является разновидностью
диагональной. Можно сказать, что это диагональная
Матрица, в которой переставлена местами одна пара
строк. Мономиальные матрицы часто используются для
выполнения исключения метода Гаусса.
Метод Гаусса — это метод решения системы N ли-
нейных алгебраических уравнений с N неизвестными.
В этой главе не будет рассматриваться исключение ме-
тода Гаусса.
Поскольку одним из многочисленных приложений
разреженной матрицы является решение систем уравне-
ний, важно иметь возможность эффективно хранить и
выполнять операции над диагональными и мономиаль-
ными матрицами.
Простые операции над матрицами
Основные операции над матрицами включают сложе-
ние, вычитание, умножение, обращение и преобразова-
ние к ступенчатой форме (которое выполняется с помо-
щью исключения метода Гаусса). Эти простые операции
над матрицами выполняются достаточно просто, несмот-
ря на сложность реализации разреженной матрицы. Все
указанные операции рассмотрены в главе 18.
Помимо указанных стандартных операций, выпол-
няемых над матрицами, существуют и другие простые
операции: поиск определенных значений и прохожде-
ние матрицы для определения локальных и глобальных
минимумов и максимумов, — для которых целесообраз-
но использовать разреженную матрицу.
Операции, которых следует избегать
Помимо возможностей разреженной матрицы и типов
операций, которые можно производить над разрежен-
ной матрицей, необходимо рассмотреть и типы опера-
ций, которые значительно усложняются при использо-
вании разреженной матрицы. В этом разделе описаны
некоторые операции, выполнение которых при пред-
ставлении данных в виде разреженной матрицы значи-
тельно усложняется.
Если при выполнении какой-то задачи возникают
сложности, это еще не значит, что эту задачу вообще
нельзя решить или не следует решать. Тем не менее,
имеет смысл рассмотреть операции, выполнение кото-
рых затрудняется при использовании разреженной мат-
рицы, а также причины этих затруднений, чтобы про-
граммист мог сделать обоснованный выбор. В одних
случаях сложностей просто нельзя избежать, а в других
можно применить другой, более целесообразный под-
ход, который становится очевидным при рассмотрении
недостатков разреженной матрицы. Такие случаи мож-
но легко выделить.
Сложные операции над матрицами
Сложные операции, выполняемые над матрицами,
включают вычисление собственных значений, транспо-
нирование матрицы, вычисление определителя матри-
цы и тензорный анализ. Вас может несколько удивить,
что такая основная операция, как вычисление опреде-
Организация данных
352
Часть II
лителя матрицы, относится к разряду сложных. В дей-
ствительности вычисление определителя включает пе-
ремножение значений, связанных по диагонали (в двух
измерениях). В разреженной матрице нет связей по
диагонали, поэтому определение значений, находящих-
ся на диагонали, достаточно сложно и требует много
времени.
Диагональные матрицы- содержат значения только на
своей диагонали. В чем же разница по сравнению с про-
сто разреженной матрицей? Диагональная матрица со-
держит только одно ненулевое значение в каждой паре
строка/столбец. Это позволяет легко распознать диаго-
нальную матрицу, даже несмотря на то, что значения
расположены по диагонали. Но это не относится к вы-
числению определителя матрицы, когда диагональные
элементы умножаются в определенном порядке.
Все эти операции требуют многократного прохож-
дения массива данных, и ни одна из них не получает
никакого преимущества от того, что в массиве имеются
нулевые значения. Таким образом, если вы предпола-
гаете выполнять эти типы операций, то, если на это нет
особой необходимости, не представляйте структуру
данных в виде разреженной матрицы.
Обращение матрицы
Обращение матрицы является особым случаем не по
причине самого процесса обращения матрицы, а по
причине процесса определения принципиальной воз-
можности обращения конкретной матрицы. Как прави-
ло, сначала вычисляется определитель, и только в слу-
чае, если он не равен нулю, обращение матрицы
возможно. Невозможность обращения матрицы можно
определить и другими способами, но эти способы мо-
гут быть неэффективными, особенно для больших мат-
риц. Поэтому при необходимости выполнения опера-
ции обращения матрицы разреженную матрицу лучше
не использовать.
Поиск "нулевых” значений
В общем случае поиск значений, которых нет, считает-
ся достаточно сложной задачей. Это относится и к раз-
реженным матрицам.
ПРИМЕЧАНИЕ
В языке С между значениями NULL и 0 имеется разли-
чие. "Нулевое" значение заключается в кавычки, чтобы
его можно было отличить от значения NULL. "Нулевое"
значение в этом разделе фактически означает отсутствие
значения. В разреженных наборах данных многие значе-
ния во многих ячейках просто отсутствуют (именно по-
этому данные и являются разреженными). В разрежен-
ной матрице пустая ячейка возвращает значение 0. Таким
образом, поиск пустых ячеек в разреженной матрице
(т.е. "нулевых" значений, а не значений NULL) эквивален-
тен поиску значений 0.
Если по какой-либо причине необходимо найти ’’ну-
левые” значения, т.е. значения 0, то для выполнения
такой операции разреженная матрица оказывается не
самой лучшей структурой представления данных. Это
справедливо по целому ряду причин, из которых мы
рассмотрим лишь несколько:
• Если данные разрежены, результат поиска “нуле-
вых” значений будет давать большее значение, чем
размер самой разреженной матрицы, по которой про-
изводился поиск!
• Поиск "нулевых" значений означает, что необходи-
мо будет интерполировать позиции внутри разре-
женной матрицы, которые находятся между суще-
ствующими позициями. Это довольно сложный и
утомительный процесс программирования, в кото-
ром можно наделать много ошибок.
• Поиск необходимо проводить как по узлам, так и по
заголовкам, поскольку могут отсутствовать целые
заголовки.
• Эффект от экономии памяти за счет использования
разреженной матрицы, как правило, сводится на нет
из-за увеличения времени выполнения операции по-
иска.
Не следует забывать, что разреженные матрицы
были придуманы для облегчения работы с редкими
ненулевыми значениями в матрице при игнорировании
ее "нулевых" значений. Действительно, если целью ис-
пользования разреженной матрицы является игнориро-
вание "нулевых" значений, то имеет ли смысл приме-
нять такую структуру для поиска этих "нулевых"
значений?
Построение разреженной матрицы
Наконец-то мы добрались до сути этой главы! Теперь,
когда мы разобрались с концепцией разреженной мат-
рицы и рассмотрели ее преимущества и недостатки, пора
перейти к процессу построения таких матриц.
Реализация разреженной матрицы, которая будет
представлена далее, позволяет динамически определять
N-мерную матрицу. Большинство реализаций разрежен-
ных матриц предназначено для двух- или трехмерных
матриц (но не для двух- и трехмерных). Приведенная
реализация может быть модифицирована для построе
ния матриц именно таких размерностей, но, в принци
пе, она предназначена для создания матриц любых раз
мерностей.
Следует с самого начала иметь в виду, что обеспс
чение возможности работы с матрицами произвольной
размерности значительно усложняет реализацию. Тем нс
менее, можно надеяться, что такая реализация будет
более полезна для вас хотя бы только потому, что она
Разреженная матрица
Глава 15
353
является более сложной, а упростить ее можно без осо-
бых усилий. Так что пристегните ремни, мы начинаем!
Поскольку, как правило, выделение памяти проис-
ходит динамически, необходимо иметь функции, кото-
рые бы могли высвобождать выделенную ранее память
перед очередным выделением памяти под указатели на
разреженную матрицу. Поэтому в данном разделе будет
рассмотрен вопрос создания и удаления компонентов
разреженной матрицы.
Структура данных для самой разреженной матрицы
проста и не требует объяснений:
typedef struct sparse—matrix {
SPHDRELEMENT *hdr_stack;
int error_no,
• dimensions,
*hdr_ranges;
} SPARSE—MATRIX;
Здесь hdr_stack указывает не на один указатель за-
головочного списка, а на стек указателей заголовочно-
го списка, по одному указателю для каждого измерения.
Аналогично указатель hdrjranges указывает не на один
диапазон, а на стек нижних и верхних пределов пози-
ций элементов в каждом измерении. Переменная
dimensions представляет собой количество измерений
(размерность) разреженной матрицы. Значение перемен-
ной еггог_по устанавливается при возникновении той
или иной ошибки. Возможные значения переменной
errorjno приведены в табл. 15.1.
Таблица 15,1. Значения переменной errorjio.
Значение Описание
О Нет ошибки
1 Нехватка памяти
2 Испорчена заголовочная связь
3 Испорчена узловая связь
4 Ниже минимального значения dimensions
5 Выше максимального значения dimensions
6 Ошибочное измерение
7 Вставка прошла неудачно
8 Значение не найдено
9 Недостаточная размерность
10 Список узлов не пуст
Номера ошибок и их описания приведены в файле
sparse.h, который находится на Web-сайте издательства
"ДиаСофт”.
Указатели стека будут рассмотрены в последующих
разделах.
Построение заголовочных списков
В разреженной матрице заголовочный список исполь-
зуется для задания компонентов измерения. Для каж-
дого измерения имеется заголовочный список, и каж-
дый такой список может иметь любое требуемое
количество компонентов. Каждый компонент заголовоч-
ного списка называется элементом заголовочного списка.
В стандартных массивах элементы являются целы-
ми числами от 0 до величины "длина измерения — 1".
Так, например, трехмерный стандартный массив с че-
тырьмя элементами в каждом измерении объявляется
следующим образом:
int my—array [4] [4] [4] ;
Этот массив в каждом измерении будет иметь эле-
менты 0—3.
В N-мерном разреженном массиве при его создании
необходимо указать только количество измерений. Сле-
довательно, элементы заголовочного списка могут быть
указаны явно (особенно если заголовок содержит сим-
вольные данные) или неявно (путем вставки значений
в разреженную матрицу).
Каждый заголовочный список хранится в структу-
ре SPARSE—MATRIX. Списки в структуре располага-
ются один поверх другого. Чтобы найти заголовочный
список, относящийся к определенному измерению,
необходимо просто к указателю на стек добавить ве-
личину (dimension-1), т.е. на единицу меньшую но-
мера измерения. Это действие выполняет функция
sp_get_header_list, которая возвращает указатель
SPHDRELEMENT, а ей в качестве аргументов пере-
даются указатель SPARSE MATRIX и номер требуемо-
го измерения. В приведенном ниже примере определя-
ется заголовок второго измерения разреженной матрицы
my_matrix:
linclude <sparse.h>
8Р_HDR_ELEMENT *header_requested;
8PARSEMATRIX thematrix;
int thedimension;
thedimension = 2;
beaderrequested = sp_get_header_list(4the_matrix, thedimension);
if (headerrequested «« (SPHDRELEMENT *)NULL)
23 Зег 265
354
Организация данных
Часть II
if(the matrix.errorno 1= SP_NOERR)
fprintf(stderr, sp_get_header_list: Error %d on request for dimension header %dn* ,
matrix.error_no, thedimension);
exit(matrix.errorno);
else
fprintf(stdout, " No values currently in the sparse matrixn" );
else
fprintf(stdout, ” Successfully retrieved the header for dimension %d" ,
thedimension);
Обычно вызывать эту функцию напрямую не требу-
ется, но она часто используется в библиотеке функций
для работы с разреженной матрицей, которая будет рас-
сматриваться в оставшейся части этой главы.
Определение элементов заголовочного списка
Структура языка С, которая используется для представ-
ления элемента заголовочного списка, несколько слож-
нее, чем мы считали до сих пор. Иногда бывает полез-
но задать массивы, которые в качестве значений
измерения содержат строки символов. В стандартном
массиве языка С для этого используются только пере-
числяемые типы.
Поскольку данная глава посвящена разработке очень
гибкой реализации разреженной матрицы, которая до-
пускает многократное использование, элементы заголовоч-
ного списка содержат указатели на тип данных, опреде-
ленный пользователем, который, в свою очередь,
определяет элемент заголовочного списка. Если пользова-
тель не указывает тип данных, по умолчанию будет при-
нят целый тип. Хотя может случиться так, что пользова-
тель пожелает иметь данные разных типов в разных
измерениях, тем не менее, реализация такой разреженной
матрицы не будет рассматриваться в этой книге. Таким
образом, элементы заголовочного списка могут иметь толь-
ко один указанный пользователем тип данных:
SP_HEADER_DATA Структура для SP_.HEADER.DATA
имеет следующий вид:
typedef struct sp__header_data {
int header label;
} SP_HEADER_DATA;
Если структура SP_HEADER_DATA устанавливает-
ся пользователем, то он должен определить и перемен-
ную SPHDUD.
Это можно сделать, вставив перед объявлением
структуры SP_HEADER_DATA пользователя следую-
щую строку:
ftdefine SPHDUD
Использование этой переменной вместо переменной,
установленной по умолчанию, показано в файле
sparse.h, находящемся на Web-сайте "ДиаСофт”.
Кроме того, структура элемента заголовочного спис-
ка содержит порядковый номер. Таким образом, элемент
заголовочного списка имеет следующую структуру:
typedef struct sp_hdr_element {
struct sp_hdr_element *previous, «next;
struct sp node «first, «last;
int sequence;
SPHEADERDATA «detail;
} SP_HDR_ELEMENT;
Указатели previous и next используются для построе-
ния двусвязного списка для заголовочного списка. Указа-
тели first и next используются для построения двусвязно-
го списка для узлов разреженной матрицы, которые
находятся в данном измерении. Указатель detail исполь-
зуется для задания пользователем типа данных заголовка.
Статическое или динамическое выделение памяти?
Существует возможность выделения памяти под заго-
ловки заранее, если максимальная размерность заголов-
ка известна и определение требуемого дополнительно-
го объема памяти не является проблемой. Такой тип
выделения памяти называется статическим, и это озна-
чает, что при выполнении программы общий размер
матрицы не изменяется.
Программы, приведенные в настоящем разделе,
обеспечивают гибкость библиотеки функций для рабо-
ты с разреженными матрицами путем динамическою
выделения памяти. Однако этот процесс имеет свои
355
недостатки. Поскольку память выделяется динамичес-
ки, существует вероятность того, что используемая па-
мять не будет высвобождена требуемым образом, что
приведет к ее утечке. Кроме того, необходимо будет
отслеживать возвращаемые значения всех функций,
которые могут использоваться для выделения памяти,
на случай, если объем памяти недостаточен или выде-
ление памяти проходит неудачно по какой-либо другой
причине. Поэтому описанный выше тип данных разре-
женной матрицы включает поле ошибки, значение ко-
торого устанавливается в случае возникновения ошиб-
ки при работе с элементами матрицы. Каждая функция
перед началом работы должна обнулить поле ошибки,
чтобы предотвратить возвращение номера ошибки, воз-
никшей при выполнении предыдущей функции.
Односвязные или двусвязные списки?
В этой реализации разреженной матрицы используют-
ся двусвязные списки, что облегчает прохождение мат-
рицы в любом направлении. Поскольку списки являют-
ся дважды связанными и круговыми, они никогда не
будут содержать связи NULL. Обнаружение связи NULL
означало бы, что в процессе создания разреженной мат-
рицы произошла ошибка.
Использование двусвязного списка в заголовочном
списке особенно ценно, поскольку часто при работе с
матрицей бывает необходимо пройти между элемента-
ми заголовка в разных направлениях. Необходимость
пройти вдоль всего измерения для того, чтобы вернуться
назад, может негативно сказаться на эффективности,
особенно в случае больших размеров измерений. По-
Разреженная матрица
Глава 15
скольку основополагающим принципом разреженной
матрицы является небольшое количество данных по
сравнению с доступным для них пространством, ис-
пользование в заголовочных списках двусвязных спис-
ков представляется особенно целесообразным.
Использование односвязных списков может значи-
тельно сократить требования к дополнительной памя-
ти. Тем не менее, в общем случае требуемый объем до-
полнительной памяти составляет незначительную часть
от объема памяти, занимаемого данными, даже при
использовании двусвязных списков. И хотя двусвязные
списки усложняют сопровождение каждого списка, луч-
ше сразу рассмотреть более сложный случай; его упро-
щение оставляю вам в качестве задания для самостоя-
тельной проработки.
Добавление новых измерений
Перед вставкой данных в разреженную матрицу можно
добавить произвольное количество измерений. После
того как данные будут вставлены в матрицу, возмож-
ность добавления измерений уже не будет иметь смыс-
ла. Матрица не сможет определить соответствие ново-
го значения измерения уже существующим данным.
Для добавления в существующую разреженную
матрицу нового измерения используется функция
sp_add_header_dimension. Эта функция возвращает ука-
затель SPARSE_MATRIX, а в качестве аргументов
принимает указатель SPARSEMATRIX, добавляемое
измерение, а также нижний и верхний пределы добав-
ляемого измерения. В приведенном ниже примере в раз-
реженную матрицу my matrix вставляется второе изме-
рение:
tinclude <sparse.h>
SPARSEMATRIX thejmatrix, *matrix_ptr;
int the dimension, dim_min, dimmax;
thedimension = 2?
dimmin = 0;
dim max - 5000;
atrixptr = fithe_matrix;
atrixptr = sp_add_header dimension(fcthe_matrix,
thedimension,
dim_min, dimmax);
if (the_matrix.error_no 1= SP_NOERR)
fprintf(stderr, “ spaddheaderelement: Error %d received trying to add dimension %dn“ ,
the matrix. error_no, the_dimension);
return(the_matrix.error_no);
При добавлении заголовка в существующую матри-
цу необходимо выполнить операцию вставки элемента
в поле sp hdr stack структуры SPARSE MATRIX. Ал-
горитм процесса вставки приведен ниже (проверка па
раметров не приводится):
356
Организация данных
Часть II
Если новое измерение больве, чем количество
измерении в существующем массиве, нужно
выполнить следующее:
Перераспределить стек заголовочных ^дисков
Инициализировать элементы стека заголовков
Скопировать старый стек заголовков в новый
стек
Перераспределить стек для вставки элементов
диапазона размера заголовка
Инициализировать элементы стека диапазона
Скопировать элементы старого стека диапазона
в новый стек
Освободить память, занимаемую старым стеком
диапазона и старым стеком заголовков
Выделить память под новую область данных
заголовка
Присвоить только что созданному указателю
адрес области данных заголовка
Инициализировать указатели нового заголовка,
чтобы они указывали сами на себя
Установить порядковый номер равным
минимальному значению
Вставить новые значения пределов
Возвратить матрицу SPARSE_MATRIX
Код данной функции можно найти в файле sparse.c
на Web-сайте '’ДиаСофт”. Часть кода, соответствующая
приведенному алгоритму, показана ниже:
/* Проверка того, находится ли номер нового измерения внутри диапазона существующих измерении
матрицы */
if (dim > sp-dimensions)
{
/* Попытка выделить память под новый стек заголовков соответствующего размера */
newhdrstack = (SPHDRELEMENT *)malloc(sizeof(SPHDRELEMENT)*dim);
if (newhdr stack == (SPHDRELEMENT *)NULL)
{
sp->error_no = SP_MEMLOW;
return(sp);
}
/* попытка выделить память под новый стек пределов соответствующего размера */
new_rng_stack = (int *)malloc(sizeof(int)*dim*2);
if (newrngstack »» (int *)NULL)
<
free(newhdrstack);
sp->error_no = SPMEMLOW;
return(sp);
}
/* Скопировать значения старого стека заголовков в новый стек */
(void *)memcpy((void *)newhdrstack, (void *)(sp->hdr_stack),
sizeof (SP HDR-ELEMENT) * (sp-dimensions));
/* Скопировать значения старого стека пределов в новый стек */
(void *)memcpy((void *)new_rng_stack, (void *)(sp->hdr_ranges),
sizeof(int) * (sp-dimensions) * 2);
/* Инициализировать новые элементы */
for (currdim = 0; currdim < dim; curr_dim++)
{
newheader = (SP_HDR_ELEMENT *)(newhdrstack + curr_dim);
new_header->previous = new_header;
new_header->next = newheader;
new_header->first = (SP_NODE *)NULL;
new_header->last = (SP NODE *)NULL;
if (curr dim >= sp-dimensions)
{
new_header->sequence = 0;
newrng - (int *)(new_rng_stack + (2 * curr dim));
*new_rng = 0;
new_rng ++;
*new_rng = 0;
}
new header-detail = (SPHEADERDATA *)NULL;
}
Разреженная матрица
Глава 15
/* Вставить новые значения */
sp->dimensions = dim;
free(sp->hdr_ranges);
free(sp->hdr_stack);
sp->hdr_ranges = new_rng_stack;
sp->hdr_stack = newhdrstack;
}
/* Вставить данные no добавленному измерению */
newheader = (SPHDREbEMENT *)(sp->hdr_stack + (dim - 1));
newhe ad e resequence = dimmin;
newrng = (int *)(sp->hdr_ranges + (2 * (dim - 1)));
*new_rng = dim_min;
newrng ++;
*new_rng = dimmax;
В приведенной части наибольший интерес представ-
ляет вызов функции malloc, которая выделяет память
под заголовочные списки и пределы.
Добавление элементов заголовочного
списка
После определения измерений и аккуратного выделе-
ния под них памяти в массиве в существующий заголо-
вочный список можно вставить или присоединить со-
ответствующие элементы заголовочного списка. Нет
необходимости выполнять эту функцию вручную сра-
зу после создания разреженной матрицы, поскольку эти
элементы заголовочного списка добавляются явным
образом при вставке в разреженную матрицу нового
узла, который ранее не имел заголовка.
Еще одной причиной добавления элементов заголо-
вочного списка является заполнение поля данных заго-
ловочного списка значениями, заданными пользовате-
лями.
Вставка
Элементы заголовочного списка могут быть вставлены
в произвольном порядке. Следовательно, вставка эле-
мента заголовочного списка подразумевает, что список
уже может содержать значения по любую сторону от
вставляемого элемента. Поскольку нулевой элемент
вставляется по умолчанию при создании измерения, в
списке будет, по крайней мере, один элемент. Процесс
вставки узла в двусвязный список уже рассматривался,
поэтому код функции для вставки элемента заголовоч-
ного списка не приводится, но его можно найти в фай-
ле sparse.c на Web-сайте издательства ’’ДиаСофт".
Вставка элемента заголовочного списка осуществля-
ется с помощью функции sp ins header element. Фун-
кция возвращает модифицированную матрицу
SPARSE-MATRIX. Аргументами функции являются
матрица SPARSE_MATRIX, измерение, в которое
вставляется заголовок, порядковый номер измерения и
указатель на данные SP_HEADER_DATA В приведен-
ном примере вставляется заголовок третьего элемента во
втором измерении разреженной матрицы my_matrix:
linclude <sparse.h>
SPARSE MATRIX thematrix, *matrix_ptr;
int the_dimension, the_sequence;
SPHEADERDATA *thedetail = (SPHEADERDATA *)NULL;
thedimension = 2;
thesequence = 3;
matrixptr = sthe_matrix;
matrix_ptr = sp_ins_header_element(&the_matrix, the_dimension,
thesequence, the_detai1);
if (the_matrix.error_no != SP_NOERR)
<
fprintf(stderr, [dbl]sp_ins_header_element: Error %d received trying to add header element
td\n[dbl],
thematrix.error_no, thesequence);
return(the_matrix.error_no);
)
Организация данных
Часть II
358
Присоединение
Присоединение элемента заголовочного списка к дву-
связному списку — это то же самое, что вставка элемен-
та в двусвязный список. Однако для односвязного спис-
ка присоединение будет несколько отличаться от
вставки, поэтому имеет смысл написать отдельную про-
грамму для присоединения элемента заголовочного
списка. Это упражнение оставляю вам для самостоя-
тельной проработки — не беспокойтесь, здесь потребу-
ется внести лишь незначительные изменения в програм-
му вставки sp_insjieader_element
Удаление элемента заголовочного списка
Поскольку память под элементы заголовочного списка
выделяется с помощью функции malioc, во избежание
утечки памяти необходимо, чтобы эти элементы были
правильно удалены. Удаление выполняется с помощью
функции free и путем перестройки структуры связей
двусвязного списка. Из практических соображений
структура связей, как правило, изменяется перед осво-
бождением памяти, занимаемой элементом заголовоч-
ного списка. В некоторых случаях бывает полезно иметь
такой элемент списка, чтобы указатель этого элемента
можно было переназначить непосредственно перед уда-
лением элемента. Алгоритм этой функции приведен
ниже (проверка параметров не приводится):
Получить заголовочный список для требуемого
измерения
Вайти в заголовочном списке требуемый
порядковый номер
Если требуемый порядковый номер не найден,
вернуть разрехенную матрицу, поскольку
удалять нечего
Если элемент заголовочного списка связан с
узлами,
вернуть разрехенную матрицу с сообщением об
ошибке
Установить значение указателя на следующий
элемент предыдуцего элемента равным
значении указателя на следующий элемент
текущего элемента
Установить значение указателя на предыдущий
элемент следующего элемента равным значению
указателя на предыдущий элемент текущего
элемента
Высвободить память, занимаемую данными
заголовка
Высвободить память, занимаемую элементом
заголовочного списка
Возвратить матрицу
Исходный код функции sp del header element при-
веден в файле sparse.c на Web-сайте издательства ’’Диа-
Софт". Часть кода, соответствующая приведенном}
выше алгоритму, представлена ниже:
/* Вайти удаляемый заголовок ♦/
list_top = sp_get_header_list(sp, dim);
if (sp->error_no SPNOERR)
{
return(sp);
}
/* Точно известно, что удаляемое значение не является первым значением, поэтому ищем
следующие значения */
oldheader = list_top;
do
{
oldheader = old_header->next;
}
while ((old_header->sequence < seq) &&
(old header 1 * list-top));
/* Если old_header не содерхит искомого порядкового номера, значит, в матрице нет элемента с
таким значением */
if (oldheader->sequence != seq)
{
return(sp);
}
/* Убеждаемся, что заголовок не связан с узлами */
if ((old-header->first 1= (SP_NODE *)NULL) ||
(old—header->last 1= (SPNODE *)NULL))
{
sp->error_no = SP-HFULL;
return(sp);
Разреженная матрица
Глава 15
,359
}
/* Изменить указатели предыдущего узла */
old_header->previous->next = old_header->next;
/♦ Изменить указатели следующего узла */
old_header->next->previous = old_header->previous;
/♦ Высвободить память */
free(old_header->detail);
free(oldheader);
return(sp)*
ПРЕДУПРЕЖДЕНИЕ
Очень важно, чтобы переменные SP__HEADER_ELEMENT
удалялись именно таким образом, а не просто путем
изменения значения указателя. При изменении значения
указателя поле стека в SP__HEADER_ELEMENT останется
выделенным и неразыменованным. Это может привести
к потере доступной для программы памяти, и в конеч-
ном счете потерянные указатели займут все доступное
пространство.
Восстановление связей
Последняя часть кода, приведенного в предыдущем раз-
деле, восстанавливает двусвязный список в месте уда-
ления элемента заголовочного списка. При вставке и
удалении элементов списка необходимо поддерживать
его целостность. Это означает, что необходимо восста-
новить указатели предыдущего и последующего элемен-
тов, чтобы в списке не было "дыр".
Связи с узлами не рассматриваются, поскольку если
в матрице остаются узлы, связанные с удаляемым эле-
ментом, то этот элемент удалить невозможно. Узлы при-
шлось бы переприсваивать новому элементу заголовочно-
го списка, что вообще не имело бы никакого смысла.
Такйм образом, если удаляемый элемент заголовочного
списка содержит указатели на узлы, то этот элемент нельзя
удалить и функция sp del header element возвращает
сообщение об ошибке.
Память
Поскольку память под разреженную матрицу выделяет-
ся динамически, при добавлении компонентов матри-
цы память берется из некоей "кучи". Необходимо, что-
бы при удалении компонентов матрицы или всей
матрицы выделенная память возвращалась в "кучу",
иначе она не будет доступна для других выделений
внутри программы. В конечном счете вся доступная
Память будет заполнена и выполнение программы пре-
кратится. Вследствие этого очень важно иметь функ-
цию, которая бы возвращала память, динамически вы-
деленную под какие-либо структуры данных, назад в
*кучу".
Нужно также отметить, что если при попытке вы-
делить память из "кучи" она оказывается недоступной,
то функции, которые строят разреженную матрицу,
возвращают ошибки. Связанные с памятью ошибки,
описание которых приведено в табл. 15.1, следует про-
верять после каждого выделения памяти. Примеры та-
ких проверок можно найти в кодах функций построе-
ния разреженных матриц.
Построение списка узлов матрицы
Итак, в нашей разреженной матрице есть заголовки, но
нет места, где можно было бы разместить сами данные.
Можно построить N-мерную разреженную матрицу, но
она будет бесполезна, если в нее нельзя поместить дан-
ные. Для этого необходимо ввести узлы. Узел содержит
данные, связанные со значениями (величинами), кото-
рые вставляются в разреженную матрицу.
Хотя вам могло показаться, что структуры заголовков
довольно просты, тем не менее, структуры узлов являют-
ся N-двусвязными списками, т.е. содержат двойные свя-
зи в N направлениях по N измерениям разреженной мат-
рицы. Как и в предыдущем случае, при этом решающую
роль играют стеки связей.
Извлечение списка узлов, как правило, выполняет-
ся с помощью элемента заголовочного списка. Таким
образом, передавая функции spjget node list матрицу
SPARSE-MATRIX, измерение и порядковый номер за-
головочного элемента, мы получим список узла. Алго-
ритм получения списка узла приведен ниже:
Извлечь заголовочный список
Провести поиск порядкового покера в
заголовочном списке
Если порядковый номер найден,
вернуть указатель элемента заголовка на
первый узел,
иначе
вернуть NULL
Единственной сложной частью этого алгоритма яв-
ляется поиск порядкового номера в заголовочном спис-
ке. Поскольку заголовочный список упорядочен по по-
рядковым номерам, возникает желание продвигаться по
списку до тех пор, пока не встретится порядковый но-
360
Организация данных
Часть II
мер, который больше искомого порядкового номера
При таком подходе возникает одна проблема — если все
порядковые номера в списке меньше искомого, поиск
будет идти по круговому списку бесконечно. Таким
образом, необходимо проверять, не достигнут ли верх
списка, и, если достигнут, а искомый порядковый но-
мер не найден — останавливать поиск.
СОВЕТ
При поиске в двусвязном списке в разреженной матри-
це имеет смысл отслеживать первый элемент заголовоч-
ного списка (или начальную точку поиска), чтобы не про-
ходить список бесконечно.
Код функции spgetnodejist, которая извлекает
список узла, можно найти на Web-сайте издательства
"ДиаСофт”. Ниже приводится часть кода, которая реа-
лизует приведенный выше алгоритм:
/* Извлечь заголовочный список данного измерения */
header_list = sp_get_header_list(sp, din);
if ((sp->error_no 1= SPNOERR) ||
(headerlist = (SPEDRELEMENT *)NULL))
{
return((SPNODE *)NULL);
1
/* Поиск в заголовочном списке требуемого порядкового номера */
headerelement = header_list;
while ((header_element->next->sequence < seq) &&
(header_element->next 1= headerlist))
{
headerelement = header_element->next;
}
/♦ Если header element не является искомым порядковым номером, значит, такового в списке нет */
if (header_element->sequence != seq)
{
return((SPNODE *)NULL);
1
else
{
return(header_element->first);
}
Хотя теперь мы имеем возможность извлекать спис-
ки узлов, тем не менее, сам процесс создания узлов мат-
рицы еще не был рассмотрен.
Создание узлов матрицы
Списки узлов матрицы связаны с элементами заголовоч-
ного списка, как показано на рис. 15.1 и указано в ал-
горитме и коде, приведенным в предыдущем разделе
Структура узла матрицы тоже обманчиво проста:
typedef struct sp_node {
SPEDRELEMENT * *hdr_stack;
struct sp_node **dimension_stack;
int value;
) SP_NODE;
В этом коде hdrstack в структуре SPJNODE отли-
чается от hdr stack в структуре SPARSE_MATRIX. Они
имеют одинаковые наименования, поскольку структу-
ра данных одна и та же. hdrjstack является стеком ука-
зателей SP_HDR_ELEMENT, по одному указателю для
каждого измерения. Эти указатели указывают на эле-
менты заголовочного списка, которые связаны с данным
узлом.
Поле dimension_stack используется для хранения
указателей двусвязного списка каждого измерения. Как
и другие стеки в разреженной матрице, dimension_stack
указывает не на одну структуру SPJNODE, а на две
структуры в каждом измерении. Сначала идет указатель
на следующий узел, а затем указатель на предыдущий
узел в данном измерении. Измерения хранятся в упо-
рядоченном виде (по порядку).
Поле value содержит значение, связанное с узлом.
Статическое или динамическое выделение памяти
под узлы?
Существует возможность выделять память под узлы за-
ранее, если известно максимальное количество узлов и
возможно требуемый дополнительный объем памяти нс
является проблемой. Такой тип выделения памяти на-
зывается статическим. Это означает, что при выполне-
Разреженная матрица
Глава 15
361
нии программы количество узлов не изменяется. Хотя
статическое выделение памяти и имеет смысл для заго-
ловков, тем не менее, для узлов статическое выделение
практически не используется Редкими исключениями
могут быть диагональные матрицы, которые использу-
ются в программе многократно. Однако в общем случае
статическое выделение памяти под узлы разреженной
матрицы не используется.
Программы, приведенные в настоящей главе, обес-
печивают гибкость библиотеки функций для работы с
разреженными матрицами путем динамического выде-
ления памяти. Однако этот процесс имеет и свои недо-
статки. Йоскольку память выделяется динамически,
существует вероятность того, что используемая память
не будет высвобождена требуемым образом, что приве-
дет к ее утечке. Кроме того, необходимо будет отсле-
живать возвращаемые значения всех функций, которые
Могут использоваться для выделения памяти, на случай,
если объем памяти недостаточен или выделение памя-
ти проходит неудачно по какой-либо другой причине.
Поэтому описанный выше тип данных разреженной
матрицы включает поле ошибки, значение которого
устанавливается в случае возникновения ошибки при
работе с матрицей. Каждая функция перед началом
работы должна обнулить поле ошибки, чтобы предот-
вратить возвращение номера ошибки, возникшей при
выполнении предыдущей функции.
Связь с элементами заголовочного списка
В каждом измерении каждый узел содержит ссылку на
один элемент заголовочного списка. В этом случае име-
ется возможность начать с некоторого узла и пройти
значения соседних узлов в этом измерении. Несмотря
на то что узлы напрямую связаны друг с другом, узлы,
которые находятся рядом в одном измерении, могут
быть значительно удалены друг от друга в другом изме-
рении.
Ссылки на элементы заголовочного списка хранят-
ся в поле hdrjsrack структуры SP NODE. В стеке каж-
дому измерению соответствует один элемент, и измере-
ния располагаются упорядоченно. Вставка элементов в
этот стек осуществляется так же, как в стек hdr_srack
структуры SPARSEMATRIX.
Односвязные или двусвязные списки?
В этой реализации разреженной матрицы используют-
ся двусвязные списки, что облегчает прохождение мат-
рицы в любом направлении. Поскольку списки являют-
ся двусвязными и круговыми, они никогда не будут
содержать связей со значением NULL. Обнаружение
связи NULL означало бы, что при создании разрежен-
ной матрицы произошла ошибка.
Использование двусвязного списка в списке узла
имеет очень большое значение. Очень редко приложе-
ние, для которого целесообразно применять разрежен-
ные матрицы, не получает никаких преимуществ от
возможности быстрого прохождения по соседним узлам
одного измерения. Так, например, в игре ’’Жизнь Кон-
вея” приходится постоянно перемещаться между сосед-
ними узлами и выполнять вычисления. При использо-
вании же односвязного списка в некоторых случаях для
возвращения на один узел назад пришлось бы проходить
весь список.
Если вы решите реализовать список узла на основе
односвязного списка, рассмотрите возможность исполь-
зования обратных указателей и применения рекурсии
при прохождении связей, что несколько снижает нега-
тивный эффект от использования связей только одного
направления.
Вставка новых измерений
После того как в разреженную матрицу вставлены узлы,
количество измерений матрицы изменить нельзя. Пред-
ставьте себе двумерный граф, содержащий только одну
точку (3,5). А теперь предположим, что этот граф стал
трехмерным. Где в третьем измерении будет лежать
наша единственная точка? Можно принять, что все
имеющиеся в графе точки будут находиться в третьем
измерении в положении 0, т.е. в нашем случае (3,5,0),
но это просто неэффективное использование третьего
измерения.
ПРЕДУПРЕЖДЕНИЕ
После вставки значений узлов в разреженную матрицу в
нее нельзя вставить новые измерения. Это становится
вполне очевидным, если рассмотреть, что происходило
бы с узлами при добавлении нового измерения. Какое
положение в этом новом измерении занимали бы узлы?
Представьте, что двумерная матрица стала трехмерной.
Будут ли имеющиеся узлы находиться в одном положе-
нии вдоль третьего измерения? Будут ли они находиться
в точке 0 третьего измерения? На эти вопросы нельзя
ответить однозначно.
Но это не говорит о том, что нельзя добавить эле-
менты заголовочного списка. В действительности эле-
менты заголовочного списка добавляются неявно при
создании узла, для которого в конкретном измерении не
было элемента заголовочного списка. Это означает, что
вставка первых нескольких узлов займет несколько боль-
ше времени, чем вставка последующих узлов, посколь-
ку при вставке узлов придется вставлять и один или
несколько элементов заголовочного списка.
Вставка узлов матрицы
Узлы матрицы добавляются путем указания порядково-
го номера элемента заголовочного списка, который
362
Организация данных
Часть II
представляет собой положение узла в разреженной мат-
рице. Этот упорядоченный набор чисел, или кортеж,
должен соответствовать количеству измерений в разре-
женной матрице. Поскольку матрица может иметь N
измерений, кортеж, который представляет положение
узла в матрице, также должен иметь N измерений. Что-
бы иметь возможность вставлять в матрицу узлы, необ-
ходимо найти способ хранения кортежей.
Структура, которая используется для хранения кор-
тежей, может показаться вам очень знакомой:
typedef struct sp__tuple {
int *seq_stack, dimensions;
} SPJTUPLE;
Поле dimensions содержит количество измерений,
которое должен представлять кортеж. Поле seq stack
представляет собой указатель на стек порядковых номе-
ров в порядке расположения измерений. Поскольку, по
своей сути, это стек, для работы с ним используются
функции sp_tuple_dim и sp_addtuple. Структура кор-
тежей должна удаляться с помощью функции
sp del tuple. Использование стеков уже обсуждалось в
главе 11 и в этой главе, поэтому код указанных функ-
ций рассматриваться не будет, но их можно найти на
Web-сайте издательства "ДиаСофт”.
После задания кортежа можно приступить к встав-
ке узлов.
Вставка
Первым шагом при вставке узла является проверка су-
ществования узла. Если узел, который мы пытаемся
вставить, уже существует в матрице, то, может быть,
пользователь просто попытается изменить значение это-
го узла. Таким образом, первым шагом является провер-
ка существования узла. Алгоритм поиска узла выглядит
следующим образом:
Проверить, находятся ли значения, передаваемые
в кортеже, внутри пределов данного
измерения
Получить список узлов, который связан с первым
значением измерения
Для каждого измерения в кортеже найти
соответствующий указатель элемента
заголовочного списка
Поместить элемент заголовочного списка в
стек
Сравнить полученный стек со значениями стека
hdr_stack
Если найдено совпадение,
возвратить узел.
Иначе
возвратить NULL
Как правило, предполагается, что в алгоритмах про-
водятся все необходимые проверки параметров. В при-
веденном алгоритме проверка того, находятся ли значе-
ния, передаваемые в кортеже, внутри пределов данного
измерения, настолько важна, что этот этап был явно
включен в код.
Поскольку к первому измерению кортежа доступ
получить очень легко и это необходимо, чтобы взять
какую-то точку в качестве начальной, то из разрежен-
ной матрицы извлекается список узла именно первого
измерения. На данном этапе узлы в списке содержат
указатель на стек заголовков, который, в свою очередь,
является стеком указателей на элементы заголовочного
списка. С другой стороны, кортеж содержит стек поряд-
ковых номеров, которые соответствуют элементам заго-
ловочного списка. Хотя, в принципе, оба стека указы-
вают на одно и то же, их нельзя сравнивать напрямую.
Сначала необходимо преобразовать один стек в другой
и только потом сравнивать их. Таким образом, на сле-
дующем этапе производится преобразование стека по-
рядковых номеров кортежа в стек элементов заголовоч-
ного списка.
После преобразования стека кортежа можно прово-
дить прямое сравнение нового стека и стека, храняще-
гося в узлах. Такое сравнение выполняется путем пря-
мого побитового сравнения элементов памяти.
При обнаружении в стеках совпадения возвращает-
ся первый узел, для которого найдено совпадение. По-
скольку в точности с кортежем может совпадать только
один узел, то если такое совпадение найдено, значит,
это и есть требуемый узел.
Код, который реализует этот алгоритм, приведен в
листинге 15.1. Программу sp retrieve node можно най-
ти в файле sparse.c на Web-сайте "ДиаСофт”.
Еще раз подчеркивая важность проверки параметров
и предполагая, что некоторые функции кода будут не-
понятны без всех объявлений переменных, приведем
полный код функции вставки узла.
Узлы в матрицу можно вставлять в произвольном
порядке. Таким образом, вставка узла означает, что мат-
рица уже может содержать узел в каком-либо другом
измерении, которое содержит один или несколько эле-
ментов заголовочного списка. Однако в некоторых слу-
чаях требуемый элемент заголовочного списка может
отсутствовать, поэтому в качестве меры предосторожно-
сти делается попытка вставить требуемый элемент за-
головочного списка. В таком случае, если требуемый
элемент заголовочного списка отсутствует, он будет
создан, а если существует, новый элемент не создается.
Поскольку вставка узла влечет за собой вставку этого
узла в большое число двусвязных списков, имеет смысл
рассмотреть алгоритм, предназначенный для выполне-
ния такой вставки.
Разреженная матрица
Глава 15
363
Листинг 15.1. Извлечение узла разреженной матрицы.
/********************************************************* *♦*
** SPRETRIEVENODE **
** **
** Извлекает узел разреженной матрицы. **
** **
** ВХОДНЫЕ ДАННЫЕ: *♦
** sp - Разреженная матрица, в которую будет **
*♦ вставляться узел. **
** tuple - Кортеж, который используется для **
♦* указания положения узла. * «
♦ * **
** ВЫХОДНЫЕ ДАННЫЕ: **
♦* SPARSEMATRIX * - Указатель на модифицированную **
разреженную матрицу **
** * *
*« ПОБОЧНЫЕ ЭФФЕКТЫ: **
♦♦ При возникновении опибки поле error по « *
** разреженной матрицы может получить номер опибки. * *
** Если возникла ошибка, устанавливается значение **
** этого поля и возвращается указатель NULL. Таким **
образом, если возвращается указатель NULL, **
** необходимо проверить значение поля errorno **
** соответствующей матрицы. **
*• ПРИМЕЧАНИЯ: **
************************************************************/
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude [dbl]sparse.h[dbl]
SPNODE *sp_retrieve_node(SPARSE MATRIX *sp, SP_TUPLE *tuple)
/* SPARSEMATRIX *sp - Разреженная матрица, из которой будет извлекаться узел */
/* SPTUPLE «tuple - Кортеж, который используется для указания положения узла */
{
SPNODE «newJList, «nodepos;
SPEDRELEMENT **new_hdr_list, *hdr_pos, *hdr_list;
int currdim, *curr_seq, node_found=0;
/« Если разреженна матрица пуста, узел нельзя извлечь «/
if (sp -« (SPARSE MATRIX *)NULL)
{
return((SP NODE *)NULL);
sp->error_no = SP_NOERR;
/* Если кортеж пуст, узел нельзя извлечь */
if (tuple == (SPTUPLE *)NULL)
{
sp->error_no = SPBADDIM;
return((SP NODE *)NULL);
1
/* Убедиться, что количество измерений в кортеже соответствует количеству измерений в
разреженной матрице */
if (sp->dimensions 1= tuple->dimensions)
{
sp->error_no - SP_BADDIM;
return((SPNODE *)NULL);
364
Организация данных
Часть II
/* Проверить правильность задания кортежа ♦/
for (curr__dim = 0; curr_dim < sp->dimensions; curr_dim++)
{
curr_seq = (int ♦)(tuple->seq + (curr_dim));
if ((*curr_seq < spgetrange_min(sp, cfirr dim + 1)) ||
(sp->error no != SPNOERR))
{
sp->error_no = SPDLOW;
return((SP_NODE *)NULL);
}
if ((*curr_seq > sp_get__range_max(sp, currdim + 1)) ||
(sp->errorno != SPNOERR))
{
sp->error__no = SPDHIGH;
return((SP_NODE *)NULL);
}
}
/* Получить список узла первого измерения */
newlist = sp_get_node_list(sp, (int)l, ♦(tuple->seq));
if ((newlist =« (SPJNODE *)NULL) ||
(sp->error_no != SP_NOERR))
<
return((SPNODE *)NULL);
}
/* Построить стек заголовков */
new_hdr_li st =
(SPEDRELEMENT **)malloc(sizeof(SPEDRELEMENT *) *
sp->dimensions);
if (new_hdr_list == (SPEDRELEMENT **)NULL)
{
sp->error_no = SPMEMLOW;
return((SPNODE *)NUL£);
}
/* Для каждого измерения в кортеже найти соответствующий элемент заголовочного списка */
for (curr_dim = 0; curr_dim < sp->dimensions; curr_dim++)
{
/* Получить порядковнй номер, соответствующий данному измерению */
curr__seq = ((int *)(tuple->seq + (curr__dim)));
/* Получить элемент заголовочного списка */
hdrjpos = sphdrlistelementget(sp, currdim + 1,
♦curr_seq);
if ((hdr_pos == (SPEDRELEMENT *)NULL) ||
(sp->error_no I = SPNOERR))
{
free(new_hdr_list);
return((SPNODE *)NULL);
}
/* Вставить этот заголовок в список */
♦((SPEDRELEMENT ♦♦)(newhdrlist + (currdim))) «
hdrpos;
}
/♦ Поиск совпадающего кортежа в списке узла ♦/
nodepos = new__list;
node__found e 1;
i f (memcmp ((void ♦) node_pos->hdr_stack,
(void ♦) new__hdr__list,
(sizeof(SPEDRELEMENT ♦) ♦ sp->dimensions)))
{
Разреженная матрица
Глава 15
365
do
{
/* Первый указатель в dimensionstack указывает на следующий узел в первом измерении, и,
поскольку это то, что нам надо, можем использовать приведенный ниже код */
nodepos - *(node_pos->dimension_stack);
node found = !memcnip( (void *)node_pos->hdr_stack,
(void *)new_hdr_list,
(sizeof(SPHDRELEMENT *) *
sp->dimensions));
}
while ((nodepos != newlist) && (!node found));
free (new_hdr__list);
if (nodefound)
{
return(nodepos);
}
else
(
return((SPNODE *)NULL);
}
}
Вставка узла является довольно сложной операцией,
поэтому анализ алгоритма для лучшего его понимания
будет разбит на несколько частей. Первое, что необхо-
димо определить, — нужно ли вставлять узел. Если узел
уже существует, то попытка вставки может быть всего
лишь попыткой изменить значение этого узла. Рассмот-
рим сначала этот простой случай:
Если увел уже существует,
вставить переданное значение в поле значения
узла
Для проверки существования узла используется фун-
кция sp retrieve node, которой передаются матрица
SPARSEMATRIX и кортеж положения нового узла:
/* Попытка извлечь узел, если он уже
существует */
newnode == sp_retrieve_node( sp, tuple);
if (sp->error_no != SPJNOERR)
return(sp);
/* Если узел существует, просто обновить
его значение */
if (newnode != (SPNODE *)NULL)
new_node->value « nodeval;
return(sp);
Чаще всего узла в матрице нет, поэтому будет необ-
ходимо найти место, куда его нужно вставить. Необхо-
димо также начать строить указатели, которые будут
содержаться в узле. Кроме того, если требуемый эле-
мент заголовочного списка отсутствует, следует создать
и его. Все это можно сделать одновременно, пользуясь
следующим алгоритмом:
Выделить память под стек заголовков
Цикл по всем измерениям:
Извлечь из кортежа порядковый номер данного
измерения
Попытаться вставить элемент заголовочного
списка
Получить элемент заголовочного списка,
который соответствует этому измерению и
порядковому номеру
Записать указатель на элемент заголовочного
списка в узловой стек hdr__stack
Реализация этого алгоритма приведена ниже:
/* Поскольку узла не существует, проверяем существуют ли все необходимые заголовки, и если
заголовков нет, вставляем их. При этом строим стек заголовочного списка, требуемый для
узла */
newhdrstack = (SPHDRELEMENT **)malloc
(sizeof(SP HDR ELEMENT * ) *
(sp->dimensions - 1));
for (curr dim = 0; curr_dim < sp->dimensions; curr_dim++)
<
/* Установить текущий порядковый номер равным порядковому номеру в стеке кортежа,
соответствующего текущему измерению */
366
Организация данных
Часть II
curr_seq - (int *)(tuple->seq + (curr dim));
/* При необходимости вставить элемент заголовочного списка */
spres = sp_ins_header_e lenient (sp, curr__dim + 1,
♦currjeq,
(SPEEADERDATA *)NULL);
if (sp->error_no != SPNOERR)
{
free(newhdrstack);
return(sp);
}
/* Получить указатель на элемент заголовочного списка */
headerpos = sp_hdr_list_element_get (sp, curr__dim + 1,
*curr seq);
if ((headerpos == (SPEDRELEMENT *)NULL) ||
(sp->error_no != SP_NOERR))
<
free(newhdr_stack);
return(sp);
}
*(newhdrstack + (currdim)) = header pos;
Теперь самое время создать новый узел и структуру
dimension_stack. Структуру dimension_stack нужно ини-
циализировать указателем на новый узел, чтобы в слу-
чае, если новый узел является первым узлом в разрежен-
ной матрице, указатели были сконфигурированы
соответствующим образом. Этот процесс понять не-
сложно. Намного труднее понять последнюю часть про-
цедуры.
Проходя по всем измерениям, необходимо устано-
вить указатели узла на другие узлы и вставить узел в
двусвязный список каждого измерения. Все это произ-
водится в одном цикле. Алгоритм для выполнения пе-
речисленных функций имеет следующий вид:
Цикл по каждому измерению:
Получить элемент заголовочного списка,
связанный с новым узлом для данного
измерения
Получить список узла, связанный с элементом
заголовочного списка
Если список узла пуст,
Вставить в список новый узел;
Иначе
Цикл по всем другим измерениям:
Получить порядковый номер из кортежа
для текущего измерения
Пока порядковый номер узла в списке
узлов меньые порядкового номера из кортежа
и не пройден весь список, то
Перейти к следующему узлу в списке
Если порядковый номер узла в списке
узлов больые порядкового номера из кортежа
Записать указатель на узел из списка
узлов в новое поле следующего узла для
данного измерения
Записать указатель на узел из списка
узлов предыдущего узла в новое поле
предыдущего узла для данного измерения
Записать новый узел в предыдущий
узел узла в списке
Записать новый узел в следующий узел
узла перед текущим узлом в списке
Результат работы этого цикла зависит от порядка
узлов в списке узлов. Порядок узлов в списке узлов на-
чинается с первого измерения и заканчивается измере-
нием N. Таким образом, при поиске узлов, пока поиск
идет в порядке возрастания номеров измерений, значе-
ния порядковых номеров узлов будут возрастать. Код,
который выполняет функцию, описываемую предыду-
щим алгоритмом, выглядит следующим образом:
/* Вставить узел в списки узлов, связанные с каждым элементом заголовочного списка */
for (curr dim = 0; curr dim < sp->dimensions; curr_dim++)
{
/* Получить элемент заголовочного списка, соответствующий данному измерению */
header_pos = *(SPEDRELEMENT **)(new_node->hdr_stack +
currdim);
/* Получить список узлов, соответствующих этому элементу заголовочного списка */
nodehead « header_pos->first;
367
Разреженная матрица
Глава 15
/* Список узлов упорядочен в порядке возрастания порядковых номеров измерений слева
направо, поэтому проходим список начиная с первого измерения кортежа до тех пор, пока не
найдем требуемое положение в списке */
node_pos = node_head;
backtotop = 0;
pos_found = 0;
/* Если в этом списке не было других узлов, то автоматически получим первое положение */
if (nodepos == (SPNODE *)NULL)
{
pos_found = 1;
header_pos->first = new_node;
header_pos->last = newnode;
}
for (sub dim = 0;
(suhdim < sp->d intensions) && (!pos_found) fcfc
(!backto_top);
sub_dim++)
{
/* Пропустить текущее измерение, поскольку по умолчанию все узлы в списке соответствуют
текущему измерению * /
if (sub_dim 1= currdim)
{
/* Получить из кортежа порядковый номер для данного измерения */
currseq = (int ♦)(tuple->seq + (sub_dim));
/* Поиск элемента, который равен или больше порядкового номера узла ♦/
next sub dim = 0;
do
{
/* Get the sequence number for this node in this
sub-dimension */
nodeseq = ((SPHDRELEMENT *)*
((node_pos->hdr_stack) +
(subdim)))->sequence;
/* Если этот порядковый номер измерения больше порядкового номера из кортежа, то
новый узел необходимо вставить перед текущим узлом */
if (nodeseq > *curr_seq)
{
poS-found = 1;
J
else
/* Если этот порядковый номер измерения равен порядковому номеру из кортежа, то
необходимо проверить следующее измерение */
i f(node—seq == * curr_seq)
{
next-Sub_dim = 1;
}
else
{
/* Если этот порядковый номер измерения меньше порядкового номера из кортежа,
то проверить' следующий узел */
nodepos - sp_nextnode(sp, curr_dim+l,
nodepos);
if (sp->error__no 1= SPNOERR)
f ree(newhdrstack);
free(newnode);
free(nodestack);
368
Организация данных
Часть II
return(sp);
}
backtotop = (nodepos == nodehead);
}
}
}
while ((!back_to_top) && (Iposfound)
(!next_sub_dim));
}
}
/* Если найден узел, который больше текущего узла, установить указатели */
if (nodepos 1= (SPNODE *)NULL)
{
/* Теперь nodepos указывает на узел, который должен стоять после текущего узла.
Поскольку этот узел должен стоять после текущего узла в двусвязном списке, установить в
стеке указатель на следующий узел */
nextnode = nodepos;
*((SP NODE * *)(new_node->dimension_stack +
(2 * currdim))) =
next_node;
/* Указатель на предыдущий узел соответствует указателю на предыдущий узел старого узла */
prevnode - spprevious_node(sp, curr dim+1, nodepos);
if ((sp->error_no 1= SPNOERR) ||
(prevnode «» (SPNODE *)NULL))
{
f гее(newhdrstack);
free(new_node);
free(nodestack);
returnfsp);
}
*((SP NODE * *)(new_node->dimension stack +
(2 * curt-dim) + 1)) - prev_node;
/* Вставить узел в существующую структуру связей */
* ((SP-NODE * *) (prev_node->dimension__stack +
(2 * curr_dini))) - new_node;
*((SP_NODE * *)(next_node->dimension_stack +
(2 * curt-dim) + 1)) = new node;
>
/* При необходимости обновить первый и последний указатели */
if (node-pos =« node head)
{
/* Если проверен весь список, то node_pos должен быть последним узлом в заголовке */
if (back_to_top)
{
headerpos->last = new_node;
header_pos-’>first « next_node;
}
else
{
/* Если новый узел меньше узла в заголовке, то nodepos должен быть первым узлом в
заголовке */
header_pos->first = neW-Bode;
headet-POS“>last = prevnode;
}
}
}
Разреженная матрица
Глава 15
369
Узел в разреженную матрицу вставляется с помощью
функции sp_ins_node. Эту функцию можно найти в
файле sparse.c на Web-сайте издательства "ДиаСофт". В
качестве аргументов функция sp_ins_node принимает
структуру SPARSE-MATRIX, кортеж, описывающий
положение узла, и значение, которое должно быть на-
значено узлу.
Присоединение
Присоединение узлов к разреженной матрице аналогич-
но вставке в случае использования двусвязных списков.
Использование в качестве списка узлов односвязного
списка с требуемым количеством обратных указателей
значительно усложнило бы код. Если вы не используе-
те односвязные списки, то присоединение узлов ничем
не будет отличаться от вставки узлов.
Удаление узлов матрицы
Удаление узла матрицы является более простой операци-
ей, чем вставка узла в матрицу. Основным назначением
функции sp_del„node является восстановление связей,
разрушенных при удалении узла. В качестве аргументов
функция принимает структуру SPARSE_MATRIX и
структуру кортежа SP_TUPLE, которая определяет по-
ложение узла в матрице. После того как узел будет най-
ден, необходимо вокруг этого узла восстановить связан-
ный список. И наконец, все связи заголовков, которые
указывают на удаляемый узел, должны быть перенап-
равлены.
При проведении всех этих изменений указателей
необходимо помнить, что узлы следует удалять только
с помощью функции удаления, а не функции free. При
вызове функции free память не разыменовывается (сте-
ки в узле строятся с помощью функции malioc) и дву-
связный список остается разорванным.
ПРЕ/М1РЕЖДЕНИЕ
Для удаления структуры, построенной с помощью функ-
ции malioc, всегда используйте функцию удаления, что
гарантирует высвобождение всей памяти.
Восстановление связей
Функцию удаления sp_del_node можно найти в файле
sparse.c на Web-сайте издательства "ДиаСофт". Функция
для восстановления связей вокруг удаляемого узла ис-
пользует следующий алгоритм:
Извлечь удаляемый узел
Цикл ио всем размерностям:
Установить указатель на следующий узел
предыдущего узла равным указателю на
следующий узел удаляемого узла
Установить указатель на предыдущий узел
следующего узла равным указателю на
предыдущий узел удаляемого узла
Если этот узел является единственным узлом
в заголовочном списке, то
Установить первый и последний указатели
элемента заголовочного списка равными NULL
Если этот узел является первым указателем
элемента заголовочного списка, то
Установить первый указатель элемента
заголовочного списка равным указателю на
следующий узел удаляемого узла
Если этот узел является последним указателем
элемента заголовочного списка, то
Установить последний указатель элемента
заголовочного списка равным указателю на
предыдущий узел удаляемого узла
ПРИМЕЧАНИЕ
Очень важно помнить, что указатели на списки узлов в
элементе заголовочного списка для каждого измерения
должны обновляться при любом изменении списка узлов.
Это легко забыть, учитывая количество указателей, с
которыми приходится работать, так что будьте внима-
тельны, ведь эти указатели будут часто использоваться и
не должны устаревать: Если список узлов обновляется,
а указатели элемента заголовочного списка нет, то по-
пытка прохождения списка узлов может оказаться неудач-
ной. Если заголовочные списки при удалении узлов (осо-
бенно это касается первых узлов в списках) не
обновляются, то попытка получить доступ к списку узлов
будет неудачной.
Код, который реализует описанный алгоритм, при-
веден ниже (проверка правильности параметров не при-
водится):
/* Извлечь удаляемый узел */
del_node = sp_retrieve_node(sp, tuple);
if ((del_node == (SPNODE *)NULL) ||
(sp->error_no != SPNOERR))
{
return;
)
/♦ Переставить указатели вокруг удаляемого узла в существующих списках в каждом измерении */
for (curr_dim = 0; curr__dim < sp->dimensions; curr_dim++)
{
nextnode = *((SP_NODE **)(del_node->dimension_stack +
(2 * currdin)));
24 Эйс. 265
370
Организация данных
Часть II
prevnode « *((SP_NODE **)(del_node->dimension_stack +
(2 * currdim) + 1>);
/* Установить указатель на следующий узел узла prevnode на узел next node */
*((SP_NODE * *)(prev_node->dimension_stack +
(2 * currdim))) = nextnode;
/* Установить указатель на предыдущий узел узла next node на узел prevnode */
*((SP_NODE * *)(next_node->dimension_stack +
(2 * curr dim) +1)) = prevnode;
/* Изменения могут повлиять на указатели в заголовке */
header = *(SP EDR ELEMENT * *)(del_node->hdr_stack +
curr_dim);
/* Если это последний узел в списке, то установить первый и последний указатели в
заголовке равными NULL */
if ((nextnode == prevnode) && (next_node = del node))
{
header->first = (SPNODE *)NULL;
header->last = (SPNODE *)NULL;
}
else
{
/* Исправить первый указатель, если del_node был первым в списке */
if (header->first «= jdel node)
{
header->first = nextnode;
}
/* Исправить последний указатель, если delnode был последним в списке ♦/
if (header->last == delnode)
{
header->last = prev_node;
}
}
После восстановления связей память, занимаемая
связанными с узлом структурами и самим узлом, мож-
но освободить. Функция не возвращает никаких значе-
ний, поскольку ей нечего возвращать.
Прохождение разреженной матрицы
Теперь, когда мы построили разреженную матрицу,
можно начать выполнять с ней некоторые операции.
Наиболее важные операции — это перемещение по мат-
рице и извлечение значений. Для целей этого раздела
матрица будет считаться двумерной, как обычная таб-
лица или плоский граф. Трехмерную матрицу предста-
вить себе несколько сложнее, а четырехмерную матри-
цу и матрицу с более высокими размерностями
вообразить себе просто невозможно. Однако основные
принципы, характерные для двух измерений, можно без
труда распространить на три и большее количество из-
мерений.
Перемещение по строкам
Многие приложения требуют перемещения по строкам
данных и выполнения определенных операций. Струк-
тура разреженной матрицы, которая была построена в
этой главе, содержит структуры заголовочных списков,
позволяющие упростить эти операции. Извлекая эле-
мент заголовочного списка, связанного с требуемой
строкой, пользователь может получить первый узел
списка узлов для этой строки. Затем вы можете пройти
по списку узлов (по круговым ссылкам) до достижения
последнего узла в списке (также содержащегося в эле-
менте заголовочного списка).
Перемещение по столбцам
Перемещение по столбцам аналогично перемещению по
строкам. Начинать следует с элемента заголовочного
списка, находящегося во втором измерении, а не в пор*
вом. Как и при перемещений по строкам, пользователе
Разреженная матрица
Глава 15
371
выбирает требуемый элемент заголовочного списка, а
затем с помощью первого и последнего указателей пе-
ремещается по списку узлов.
Перемещение по упорядоченным парам
Перемещение по упорядоченным парам основано на
создании структуры кортежей. Кортеж хранит положе-
ние узла в виде упорядоченной пары. В кортеже в виде
стека хранятся порядковые номера, соответствующие
положению узла в измерении в порядке возрастания
номеров измерений. После того как кортеж создан, с
помощью функции sp retrieve node можно найти тре-
буемый узел. Чтобы убедиться, что узел извлечен без
ошибок, очень важно не забыть проверить поле ошиб-
ки в структуре SPARSE MATRIX Если получено зна-
чение NULL и операция прошла без ошибок, значит,
просто с данной упорядоченной парой не связано ни-
какое значение.
Проверка диапазонов
Проверка диапазонов (или пределов) осуществляется в
функции sp_retrieve_node. Такая проверка имеет два
важных момента. Во-первых, количество измерений в
кортеже проверяется по количеству измерений в разре-
женном массиве. Далее, каждый элемент в кортеже про-
веряется по минимальному и максимальному значени-
ям для каждого измерения в массиве. Пример кода,
который выполняет эту функцию, приведен ниже:
/* Проверить, соответствует ли количество измерений в кортеже количеству измерений в разреженной
матрице * /
if (sp->dimensions 1= tuple->dimensions)
sp->error_no = SP-BADDIM;
return((SP NODE *)NULL);
/* Проверить, правильно ли указан кортеж! */
for(curr_dim « 0; curr_dim < sp->dimensions; curr_dim++)
currseq « (int *)(tuple->seq + (sizeof(int) * curr_dim));
if ((‘currseq < sp_get_range_min(sp, curr_dim + 1)) ||
(sp->error_no 1= SPJNOERR))
sp->error__no = SPDLOW;
return((SPNODE *)NULL);
if ((*curr_seq > sp_get_range_max(sp, curr dim + 1)) ||
(sp->error_no ! = SP_NOERR))
sp->error_no = SPDBIGB;
return((SPNODE *)NULL);
В каждой функции, которая получает доступ к раз-
реженной матрице с использованием кортежей, долж-
на выполняться такая проверка пределов.
Резюме
В этой главе был рассмотрен процесс создания N-мер-
ной разреженной матрицы. Определена роль разрежен-
ных структур данных в программировании и указаны
сильные и слабые стороны таких структур. Разработа-
но большое количество функций, которые создают раз-
реженную матрицу и выполняют с нею различные опе-
рации. При разработке этих функций были рассмотрены
различные их варианты и подчеркнута важность управ-
ления памятью. И наконец, здесь описаны методы до-
ступа к элементам разреженной матрицы.
Работа с графами
16
В ЭТОЙ ГЛАВЕ
Определение графов
Циклические и ациклические графы
Представление графов
Алгоритмы поиска кратчайшего пути
Минимальные остовные деревья
Оптимизация: последнее замечание
Ян Вудс
Графы предоставляют программистам очень полез-
ные инструменты. Это мощная абстракция, описываю-
щая множество реальных проблем, которые очень труд-
но или вообще невозможно смоделировать иначе.
Транспортные системы, компьютерные сети и World Wide
Web — это лишь небольшое количество реальных сис-
тем, которые легко можно представить в форме графов.
В этой главе описываются некоторые простые эле-
менты теории графов, рассматриваются приложения, к
которым ее можно применить, а также вопросы реали-
зации и использования этой теории на практике.
Определение графов
Графы — это просто коллекция (набор) точек (вершин).
которые соединяются между собой ребрами. Когда две
вершины соединяются ребром, говорят, что это смеж-
ные вершины. Графы обычно лучше, чем полная абст-
ракция, представляют объекты, поскольку ребра и вер-
шины имеют вполне реальные аналоги. Например,
можно сказать, что каждая вершина — это железнодо-
рожная станция, а ребра — железнодорожные пути меж-
ду станциями.
Более формально граф определяется как набор вер-
шин V и ребер Е, которые составляют сам граф. Каж-
дое ребро определяется парой смежных вершин (v,w),
где v и w являются элементами множества V вершин.
Ребра могут также иметь приписываемые им издер-
жки (или затраты, или веся). Это числовое значение,
зависящее от того, насколько "трудно" передвигаться по
ребру. Такое значение может характеризовать время,
расстояние, затраты или какие-либо другие параметры,
которые могут быть выражены числом. Подобные зна-
чения используются, когда осуществляется выбор опти-
мального маршрута от одной вершины до другой.
Степень вершины — это число выходящих из нее ре-
бер. Полустепенью захода вершины считается количество
трактов, входящих в вершину. Данные значения явля-
ются основой некоторых алгоритмов, которые будут
рассматриваться в настоящей главе далее.
Подграф — это граф, сформированный из некоторых
вершин и ребер другого графа. В подграфе могут быть
представлены только вершины и ребра, представленные
в оригинальном графе. Любое подмножество вершин и
ребер графа G является подграфом G.
Путь представляет собой последовательность вер-
шин, которая описывает маршрут вдоль ребер между
вершинами графа. Под издержками пути понимается
сумма издержек пройденных на этом пути ребер.
Граф на рис. 16.1 представляет простой Web-сайт.
Каждая вершина — это страница, а каждое ребро -
гипертекстовое соединение между страницами. Это ори-
ентированный граф: когда вы щелкаете (кнопкой мыши)
на связи, нет необходимости заботиться об обратной
связи с предыдущей страницей.
Граф представляет реальную информацию. Сам граф —
это абстракция чего-то реального: вершины и ребра
могут выступать в качестве реальных объектов или со-
стояний. Все, что включает дискретные состояния с
соединениями между ними, может быть представлено
в форме графа.
Обычно легко обнаружить сходство некоей системы
с графом. И дорожные карты, и компьютерные сети, и
электронные схемы соединений — все они имеют гра
фоподобные свойства. Основное правило заключается в
следующем: если что-то похоже на граф, значит, это и
есть граф!
Работа с графами
Глава 16
373
РИСУНОК ЛЬЛ. Граф простого Web-сайта.
Ориентированные графы
Ориентированный граф — это просто граф, в котором
ребра между вершинами имеют направление (рис. 16.2).
Каждое ребро — это один путь от вершины-источника
до вершины назначения. Ребро определяется как соеди-
нение между парой вершин. В ориентированном графе
очень важен порядок пары — обычно ребро (v,w) про-
ходится только от v до w. Ориентированные ребра изоб-
ражаются со стрелками, показывающими направление,
В котором соединены вершины.
РИСУНОК 16.2. Ориентированный граф.
Неориентированный граф
Неориентированный граф имеет ребра, которые можно
проходать из любых двух вершин, между которыми эти
ребра лежат (рис. 16.3). Другими словами, неориенти-
рованное ребро (v,w) предполагает, что есть ребро (w,
V). Ребро в неориентированном графе не помечается
стрелкой, демонстрируя таким образом, что по такому
ребру можно двигаться в любом направлении. Полусте-
пень захода вершины в неориентированном графе — это
то же самое, что и ее степень.
РИСУНОК 16.3. Неориентированный граф
Неориентированные графы являются полными, если
каждая вершина в графе имеет ребра ко всем другим
вершинам, как показано на рисунке 16.4.
РИСУНОК 16.4. Полный неориентированный граф
Связанные графы
Неориентированный граф является связанным, когда
есть путь, использующий любое количество ребер, от
любой вершины ко всем другим вершинам. Пример на
рис. 16.5 демонстрирует именно такой граф.
РИСУНОК 16.5. Неориентированный связанный граф
Организация данных
Часть II
374
Для ориентированных графов все это немного слож-
нее. Когда, как в случае с неориентированным связан-
ным графом, есть путь от любой одной вершины ко всем
другим вершинам, граф можно описать как сильно свя-
занный (рис. 16.6).
РИСУНОК 16.6. Ориентированный сильно связанный граф.
Ориентированный граф можно описать также как
слабо связанный. Ориентированный слабо связанный
граф не имеет пути от любой одной вершины к другим,
но когда направление ребер игнорируется (т.е. если он
трактуется как неориентированный граф), то граф ока-
зывается связанным (рис. 16.7).
РИСУНОК 16.7. Ориентированный слабо связанный граф.
Графы, которые не являются неориентированными
связанными или ориентированными графами, которые
сильно или слабо связаны, описываются просто как
несвязанные графы.
Насыщенные и разреженные графы
Важными свойствами графов являются их насыщен-
ность и разреженность. Граф, в котором каждая верши-
на связана только с небольшой частью представленных
в графе вершин, называется разреженным. А граф, в
котором каждая вершина соединяется со значительным
количеством других вершин, называется насыщенным.
Для известных графов легко определить, насколько
они насыщены или разрежены. Это можно сделать, если
рассмотреть среднюю степень вершин. В динамически
построенном графе это сделать значительно труднее.
Степень насыщенности или разреженности графа вли-
яет на удобство хранения его в памяти и на время вы-
полнения любых работающих с ним алгоритмов. Про-
гнозирование того, рассматривать 1раф насыщенным или
разреженным, зависит от того, что граф будет представ-
лять. Реальные сети обычно являются разреженными.
ПРИМЕЧАНИЕ
Для получения более детальной информации по разре-
женным матрицам просмотрите главу 15.
Собираясь использовать граф, необходимо опреде-
лить хотя бы предположительно, насколько он будет
насыщенным. Если используются списки смежных вер-
шин, то для хранения насыщенного графа потребуется
больше памяти. Если граф кажется насыщенным, то
более эффективно хранить его как матрицу смежности
Циклические и ациклические графы
Цикл представляет собой путь, который начинается и
заканчивается в одной и той же вершине. Если граф
имеет цикл, то говорят, что это циклический граф. Про-
тивоположностью ему является ациклический граф, т.е.
граф без циклов. И ориентированные, и неориентиро-
ванные графы можно описать как циклические и как
ациклические. Неориентированные графы, которые нс
содержат каких-либо циклов, называются деревьями
(рисунки 16.8 и 16.9). Циклы известны также под на-
званием контуры.
Контур Эйлера — это цикл, в котором каждое ребро
графа проходится только один раз. Для поиска таких
циклов имеется метод, который предполагает выполне-
ние поиска в глубину. Многие знакомы с такими цик-
лами: обычно они используются как простые голово-
ломки, в которых требуется нарисовать что-либо, нс
отрывая ручки от бумаги. Аналогично путь Эйлера — это
путь, который проходит по каждому ребру только один
раз, но который начинается и заканчивается не в одной
и той же вершине. Решение для поиска контуров или
путей Эйлера в графе будет рассмотрено далее в этой
главе.
Представление графов
Представление графа в виде структуры данных очень
зависит от того, насколько он будет насыщенным. Су
шествует два основных подхода: матрицы смежности и
списки смежных вершин. Ни один из этих подходов не-
применим для графов .
Для насыщенных графов матрица смежности ис
пользует значительно меньше памяти, чем список смсж
ных вершин того же графа. Для разреженных графов,
наоборот, список смежных вершин более эффективен.
Следовательно, важно иметь возможность предска
зать, насколько насыщенным или разреженным будем
граф, перед тем как его представить.
Работа с графами
Глава 16
375
РИСУНОК 16.8. Неориентированный циклический граф.
РИСУНОК 16.9. Неориентированный ациклический граф.
Матрицы смежности
Для представления графа можно использовать матрицу
смежности (adjacency matrix). Это просто двумерный
массив со строкой и столбцом для каждой вершины.
Ребра между вершинами получаются путем манипули-
рования содержимым массива.
Для создания ребра (v,w), имеющего вес с, нужно
просто записать: M|v,w]=c. Ребро с бесконечным весом
эквивалентно отсутствию ребра. Обычно M[v,vj равно
О, т.е. такое ребро не имеет веса. Другими словами, нет
затрат при продвижении от некоторой вершины к самой
себе (рис. 16.10).
Списки смежных вершин
Списки смежных вершин (adjacency list) — это динамичес-
кий вариант представления графа. Такой вариант более
Эффективен для разреженных графов, поскольку сохра-
няются только ребра, представленные в графе. Вся вы-
деленная память используется только для представле-
ния ребер.
Для каждой вершины в графе имеется связанный с
нею список. Каждый элемент связанного списка пред-
ставляет одно ребро и хранит вес этого ребра и соответ-
ствующую вершину. При добавлении к вершине ново-
го ребра в связанный список добавляется новый элемент
(рис. 16.11). Эта технология подобна использованной
для разреженных массивов.
На Web-сайте издательства ’’ДиаСофт" находится
библиотека графов, которая включает оба эти представ-
ления. Одна из целей библиотеки состоит в том, чтобы
дать возможность одному и тому же коду работать с
любым из указанных представлений. Все примеры ко-
дов в этой главе работают с каким-либо одним представ-
лением, пока та или иная операция имеет смысл толь-
ко для конкретного типа графа.
РИСУНОК 16.10. Пример графа и
его матрица смежности.
РИСУНОК 16.11. Пример графа и
его список смежных вершин.
Организация данных
Часть II
376
Структура Graph является структурой верхнего уров-
ня, которая определяет граф в библиотеке. Эта струк-
тура отслеживает все существующие в графе вершины
и ребра независимо от того, представлен граф матрицей
смежности или списком смежных вершин.
struct Graph
{
int NumVertices;
struct Graphvertex ** Vertices;
struct GraphSpec * Private;
/«внутреннее значение */
};
Здесь имеется две функции, которые относятся толь-
ко к этой структуре.
struct Graph * MakeGraph (enum GraphType T) ;
Данная функция создает новый пустой граф и воз-
вращает указатель на структуру Graph или NULL, если
память не может быть выделена для ее размещения.
Единственный ее параметр определяет способ представ-
ления графа: List для списков смежных вершин или
Matrix — для матрицы смежности.
int FreeGraph(struct Graph * G) ;
Данная функция освобождает память, выделенную
для структуры Graph, включая все вершины и ребра,
которые в нее добавлены.
Вершины представляются с использованием струк-
тур struct Graph Vertex. Эти структуры могут хранить
тег, который имеет тип int или void*. Вершины графа
обычно представляют реальные вещи, и значение тега
позволяет каждую вершину связать с информацией о
том, что она представляет.
int AddVertex (struct Graph * G) ;
Структура Graph без вершин совершенно бесполез-
на. Эта функция добавляет одну вершину в структуру
графа и возвращает значение индекса или код ошибки,
значение которого меньше нуля. Возвращаемый индекс
затем используется для идентификации вершины в гра-
фе. Возвращаемый индекс является действительным,
только если с тех пор, как он впервые был установлен,
вершины не удалялись. Ниже приведены фрагменты
кода на языке С, показывающие, как можно создать граф
и вершину, а также установить значение тега.
int i;
struct Graph * G;
G=MakeGraph(List);
if (1G>
{
/* Недостаточно памяти для создания
структуры графа */
}
i-AddVertex(G);
if (i<0)
{
/* Ошибка при добавлении вершины */
}
G->Vertices[i]->Tag.Nun-42;
int Removevertex (struct Graph * G, int Index) ;
Необходимо также иметь возможность удалять вер-
шины. Любое ребро, которое входит или выходит из
удаленной вершины, тоже нужно удалить. Когда уда-
ляется одна вершина, другие вершины получают новые
индексы, так что в графе не остается "дыры" на месте
вновь удаленной вершины.
int ConnectVertex (struct Graph * G,
wint Source, int Destination, int Cost);
Данная функция добавляет ориентированное ребро,
имеющее заданный вес, от исходной вершины к верши-
не назначения. Это ребро — единственный путь от ис-
точника к месту назначения. Неориентированное реб-
ро можно создать, просто добавив одно ребро от Source
к Destination, а затем второе ребро от Destination к
Source. При соединении новым ребром вершин Source
и Destination, которые уже имеют ребро между собой,
изменяется вес предыдущего ребра в параметре Cost.
int Disconnectvertex (struct Graph * G,
*»int Source, int Destination) ;
Эта функция удаляет ребро между Source и
Destination. В неориентированном графе надо также не
забыть удалить ребро от Destination к Source.
Большинство алгоритмов, которые можно приме-
нить к графам, требуют некоторых исследований ребер
между вершинами. Способ, которым представляются
ребра, зависит от того, как представлен граф. Матрицы
смежности и списки смежных вершин хранят ребра
совершенно разными способами. Эти функции обеспе-
чивают возможность исследования надлежащим образом
списка ребер для обоих представлений. Они работают
одинаково для матриц смежности и списков смежных
вершин, а также позволяют одной и той же функции
оперировать с обоими представлениями.
Структура EdgeScan содержит информацию об од-
ном ребре, а также информацию, требуемую функци-
ей EdgeScanNext() для размещения следующего ребра
в списке.
struct EdgeScan
{
struct Graph * G;
int Cost;
int Source;
int Dest;
Работа с графами
Глава 16
! 377
union
{
void * Ptr;
int Index;
} Internal; /* используется для
записи положения */
);
int EdgeScanStart(struct Graph * G, int Index,
struct EdgeScan * EScan);
Эта функция инициализирует структуру EdgeScan
при подготовке списка ребер для отдельной вершины,
определенной своим индексом.
int EdgeScanEnd(struct EdgeScan * EScan);
Данная функция проводит операцию сканирования
ребра к его концу, освобождая любые источники в
структуре EdgeScan. Как только проводится эта опера-
ция, содержимое структуры EdgeScan становится боль-
ше недействительным.
int EdgeScanNext(struct EdgeScan * EScan);
Эта функция извлекает информацию для следующе-
го ребра (или первого, если функция EdgeScanStart
только что вызвана) и устанавливает элементы структу-
ры EdgeScan. Если последнее ребро уже возвращено
таким образом, то возвращается значение >0. При ус-
пешном завершении функции возвращается 0.
Приведенный ниже фрагмент кода показывает, как
исследовать список ребер конкретной вершины.
/♦ G — это граф, содержащий несколько вершин
с ребрами между ними */
struct EdgeScan Е;
EdgeScanStart(G,i,&Е);
while (EdgeScanNext(4E)==0)
{
/* Здесь выполняются какие-либо действия
над элементами Е */
)
EdgeScanEnd(&Е);
Топологическая сортировка
Ориентированные ациклические графы можно исполь-
зовать для представления событий или состояний, ко-
торых можно надлежащим образом достигнуть, как по-
казано на рис. 16.12. Обычно такие графы применяют
для сети заданий, которая используется для определе-
ния требуемого порядка выполнения нескольких задач.
Перед выполнением очередной новой задачи все пред-
варительные условия (т.е. предыдущие задачи) должны
быть выполнены.
Вершины такого графа в основном предназначены
не для того, чтобы пометить его в порядке, в котором
их требуется обходить. Порядок обхода описывает то-
пологическая сортировка. Обычно определенный поря-
док не бывает уникальным.
Выполнить топологическую сортировку графа до-
вольно просто. Вершина без входящих ребер является
правильной корневой вершиной. Эта вершина и любые
выходящие из нее ребра затем удаляются из графа. Пос-
ле этого мы ищем другую вершину без входящих ребер.
Если такая вершина не найдена, значит, граф содержит
цикл и его нельзя подвергнуть топологической сорти-
ровке. Порядок, в котором выбираются корневые вер-
шины, и является результатом сортировки.
Примененный таким образом этот алгоритм оказы-
вается неразрушающим и эффективным, когда структу-
ры данных используются эффективно.
РИСУНОК 16.12. Сеть заданий.
Организация данных
Часть II
378
Корневая вершина имеет полустепень захода, рав-
ную 0. При удалении корневой вершины полустепень
захода всех смежных вершин уменьшается на 1, при
этом потенциально создаются новые корневые верши-
ны. Наиболее трудоемкой частью такого алгоритма явля-
ется поиск корневых вершин. Линейный поиск вершин
будет очень медленным, так как его требуется делать
каждый раз, когда удаляется очередная вершина.
Более эффективный подход состоит в использова-
нии очереди вершин с полустепенями захода, равными 0.
Как только ребра удаляются и создаются новые корневые
вершины, их можно добавлять к очереди. Порядок, в ко-
тором новые вершины добавляются в очередь, также
является результатом топологической сортировки.
Во-первых, нам необходимо создать таблицу полу-
степеней захода каждой вершины (листинг 16.1). Это
можно сделать, если просто просмотреть место назна-
чения каждого ребра в графе и увеличивать значение
счетчика на единицу. Для этого потребуется выполне-
ние Е (количество ребер в графе) итераций.
Теперь можно просмотреть таблицу для поиска вер-
шин, которые можно использовать в качестве первого
корня. Любые вершины с полустепенью захода, равной
0, добавляются в очередь. Для реализации данного под-
хода создадим очередь с помощью массива. Этот мас-
сив используется для хранения новых просмотренных
корневых вершин и для возвращения результата.
Листинг 16.1. Построение таблицы полустепеней захода вершин.
void InitIndegreeTable(struct Graph * G, int * itable)
{
/*
Построение таблицы полустепеней захода из графа G, которая должна иметь размер, по крайней
мере, G->NumVertices
*/
int i;
struct EdgeScan E;
for (i=O;i<G->NumVertices;i++) {
EdgeScanStart(G,i,&E);
while (EdgeScanNext(4E)==0)
{
itable[E.Dest]++;
EdgeScanEnd(&E);
int TopologicalSort(struct Graph * G, int ** sorted)
{
/*
Выполнение топологической сортировки графа G, создание массива целых чисел G->NumVertices и
возвращение его как сортированного в *sorted.
Если сортировка проила успеино, возвращается 0, а в случае оиибки возвращается значение <0
(GRAPHBADPARAM, GRAPHOUTOFMEN , GRAPH_BADGRAPH)
*/
int first, last, i;
int * queue;
int * itable;
struct EdgeScan E;
if (!G || 1 sorted) return GRAPH BADPARAM;
queue=malloc(sizeof(int)*G-»iumVertices);
itable=malloc(sizeof(int)*G->NumVertices);
if (Iqueue || 1itable)
{
free(queue);free(itable);
return GRAPHOUTOFMEM;
}
InitIndegreeTable(G,itable);
Работа с графами
Глава 16
379
last=O;first=O;
/* Поиск вернин с полустепенью захода, равной 0 */
for (i=0;i<G->NumVertices;i++)
{
if (itable[i]==0) Enqueue(i);
/* Пока по-прежнему имеются вернины с полустепенью захода, равной 0... */
while (last!=first)
{
Dequeue(i);
EdgeScanStart(G,i,&E);
while (EdgeScanNext(&E)==0)
{
itable[E.Dest]—;
if (itable[E-Dest]==0) Enqueue(E.Dest);
}
EdgeScanEnd(fcE);
free(itable);
/* Если у нас нет выведенных из очереди G->NumVertices элементов, значит, получен циклический
граф */
if (first!=G->NumVertices)
fгее(queue); return GRAPH_BADGRAPH;
}
*sorted=queue;
return 0;
Такая реализация, как видно, требует для выполне-
ния O(V+E) итераций. Это несколько расточительно,
потому что много времени тратится на построение таб-
лицы полустепеней захода, поиск первых корневых вер-
шин и добавление их в очередь. Добавление полустепе-
ней захода каждой вершины в структуру данных графа
позволяет уменьшить время работы этого алгоритма за
счет использования немного большего объема памяти и
некоторого снижения скорости при добавлении или уда-
лении ребер.
Паросочетание
Одной из наиболее общих проблем, которые решаются
с использованием графов, является паросочетание эле-
ментов одного множества с элементами другого, отлич-
ного от него множества. Для упрощения этой пробле-
мы данные моделируются с использованием
специальных графов. Двудольным (bipartite graph) назы-
вается граф, в котором вершины разделены на два от-
дельных множества А и В — таких, что ребра соединя-
ют каждую вершину в А с каждой вершиной в В. Ребра
представляют некоторое взаимоотношение между дву-
мя множествами типа "va похоже на vb" или "va превра-
щается в vb".
Паросочетание — это некоторый граф, соединяю-
щий множество А с множеством В. Количество паросо-
четаний зависит от представленных данных. Допусти-
мыми могут быть не все возможные ребра, поскольку
ребро представляет взаимоотношение между вершина-
ми двух множеств. Максимальное паросочетание — это
сочетание, которое соединяет наибольшее количество
вершин в множестве А с наибольшим количеством вер-
шин в множестве В.
Например, наш проект содержит определенное ко-
личество различных задач, каждая из которых требует
различных навыков. Таким образом, у нас в команде
будет определенное количество людей с различными
навыками, необходимыми для работы над этим проек-
том. Проблема состоит в том, чтобы обеспечить выпол-
нение каждой задачи так, чтобы каждый человек из
персонала работал только над той задачей, которая со-
ответствует его квалификации. Это и будет максималь-
ным паросочетанием.
Каждый член команды (множество А) и каждое за-
дание, требующее выполнения (множество В), представ-
ляются как вершины. Хотя оба множества Moiyr быть
представлены вершинами одного двудольного графа,
они являются индивидуальными множествами и на
Организация данных
Часть II
380
диаграмме показаны в виде двух столбцов. Добавляют-
ся также ребра от членов команды к заданиям, для вы-
полнения которых они имеют соответствующую квали-
фикацию (рис. 16.13).
Алгоритм работает с использованием начального
паросочетания, которое первоначально может быть нео-
птимальным. Работа алгоритма начинается с изучения
всех вершин в множестве А для определения того, какая
из них не имеет ребер. Если такая вершина найдена, она
помечается (рис. 16.14). Если нет, значит, полученное
паросочетание является оптимальным. В приведенном
примере начальное паросочетание имеет только одну
вершину в множестве А без каких-либо ребер. Это
"Стив", и он помечается с помощью звездочки.
Для каждой вновь помеченной вершины V есть не-
помеченная вершина в множестве В, у которой при на-
чальном паросочетании не было ребра и которая поме-
чается с помощью вершины V. Когда это выполняется
первый раз, каждая вершина, помеченная звездочкой
(любая вершина в множестве А, которая не имеет ре-
бер), классифицируется как вновь помеченная.
РИСУНОК 16.13. Двудольный граф персонала и заданий.
Теперь выполним подобные операции над вновь
домеченными вершинами в множестве В. Для каждой
вновь помеченной вершины V есть непомеченная вер-
шина в множестве А, к которой ведет ребро при началь-
ном паросочетании и которая помечается с помощью V
(рисунки 16.15 а —16.15 е). Эти два шага повторяются до
Тех пор, пока нельзя будет пометить еще одну вершину.
РИСУНОК 16.14. Начальное паросочетание.
Если имеется помеченная вершина в множестве В,
но при начальном паросочетании нет входящего в нее
ребра, значит, паросочетание не является оптимальным.
Если же получено оптимальное паросочетание, то мож-
но на этом остановиться.
РИСУНОК 16.15 а. Первая стадия нанесения меток.
Работа с графами
Глава 16
381
РИСУНОК 16.15 Ь. Вторая стадия нанесения меток.
РИСУНОК 16.15 с. Третья стадия нанесения меток.
Альтернативный путь можно найти, если проходить
вершины начиная с вершины во множестве В, которая
помечена, но не при начальном паросочетании (рис.
16.16). Путь проходит от вершины к своей метке и за-
канчивается, когда достигнута непомеченная вершина.
Максимальное паросочетание можно получить с
использованием начального паросочетания и альтерна-
тивного пути. Решение достигается тогда, когда все реб-
ра в начальном паросочетании не лежат на альтернатив-
ном пути и все ребра на альтернативном пути при
начальном паросочетании отсутствовали (рис. 16.17).
Хорошим способом реализации этого алгоритма яв-
ляется использование пары стеков и пары таблиц. Сте-
ки используются для эффективного определения вновь
помечаемых вершин. Элементы считываются из одно-
го стека, а вновь помеченные вершины просто записы-
ваются в другой стек. Два стека используются потому,
что необходимо провести различие между вновь поме-
ченными вершинами множества А и множества В. Таб-
лицы используются для хранения начального паросоче-
тания и для отметки каждой вершины.
Достаточно подходящее начальное паросочетание
Можно получить, если добавить столько ребер, сколько
возможно (табл. 16.1). Близкое к оптимальному началь-
ное паросочетание позволяет быстро найти действитель-
но оптимальное решение. Первый подход, позволяющий
это сделать, состоит в линейном выборе каждой вершины
В графе и добавлении ребра от этой вершины к любой
другой вершине, которая еще не имеет своего входящего
В нее ребра. В большинстве случаев это потребует Е (ко-
личество ребер в графе) итераций. Вероятно, это будет
наиболее близкое к оптимальному паросочетание.
Создание трехмерной модели
Создание звуковой модели
РИСУНОК 16.15 d. Четвертая стадия нанесения меток.
Пометка вершин выполняется с помощью стеков.
Таблица для хранения меток инициализируется таким
образом, что каждая вершина сначала не помечена. Рас-
сматривается начальное паросочетание, и каждое реб-
ро в наборе А, которое не связано с другой вершиной,
записывается в первый стек и помечается некоторым
нулевым значением.
Организация данных
Часть II
382
РИСУНОК 16.17. Максимальное паросочетание.
Создание трехмерной модели
Стив
Стив
Джон
Ян
Сначала вершины списываются из первого стека, а
связанные вершины, которых не было в начальном па-
росочетании без меток, записываются во второй стек и
помечаются. Затем вершины списываются из второго
стека и связанные вершины, которые были в начальном
паросочетании без меток, записываются в первый стек
и помечаются.
Это продолжается до тех пор, пока не опустошатся
оба стека. Теперь больше нельзя ничего помечать (табл.
16.2). В худшем случае в один из стеков записывается
почти каждая вершина. На практике это зависит от вы-
бора начального паросочетания и графа. Ближайшее к
максимальному начальное паросочетание требует обра-
ботки нескольких вершин.
Затем начальное паросочетание можно изучить для
непомеченных вершин в наборе В, к которым не ведут
ребра. Используя таблицу меток, можно найти путь
(табл. 16.3). Простой, но несколько неэффективный
подход состоит в следовании пути и создании новой
таблицы, содержащей только путь.
Создание звуковой модели
РИСУНОК ЛЬЛЬ. Альтернативный путь
Таблица 16.1. Начальное паросочетание.
Вершина Назначение Вершина Назначение
Джон Создание трехмерной модели Создание трехмерной модели Джон
Аарон Создание искусственного интеллекта Создание искусственного интеллекта Аарон
Стив ничего Создание звуковой модели Ян
Пол Модели Модели Пол
Ян Создание звуковой модели Уровни ничего
Работа с графами
Глава 16
383
Таблица 16.2. Результаты нанесения меток.
Вершина Назначение Вершина Назначение
Джон Создание трехмерной модели Создание трехмерной модели Стив
Аарон Создание искусственного интеллекта Создание искусственного интеллекта Стив
Стив Создание звуковой модели Джон
Пол Модели
Ян Создание звуковой модели Уровни Ян
Таблица 16.3. Альтернативный путь.
Вершина Назначение Вершина Назначение
Джон Создание трехмерной модели Создание трехмерной модели Стив
Аарон -1 Создание искусственного интеллекта -1
Стив Создание трехмерной модели Создание звуковой модели Джон
Пол -1 Модели -1
Ян Создание звуковой модели Уровни Ян
Теперь легко найти максимальное паросочетание.
Для этого нужно сравнить таблицу начальных паросо-
четаний и таблицу пути. Там, где целевая вершина в
таблице пути равна -1, указанное в начальном паросо-
четании ребро добавляется в решение. Там, где целевая
вершина в таблице пути отличается от соответствующей
вершины в начальном паросочетании, также добавляет-
ся ребро (табл. 16.4, см. также рис. 16.17). Все эти реб-
ра являются неориентированными.
Таблица 16.4. Максимальное паросочетание.
Вершина Назначение Вершина Назначение
Джон Создание звуковой модели Создание трехмерной модели Стив
Аарон Создание искусственного интеллекта Создание искусственного интеллекта Аарон
Стив Создание трехмерной модели Создание звуковой модели Джон
Пол Модели Модели Пол
Ян Уровни Уровни Ян
Глубинный поиск
Большинство полезных операций, которые можно вы-
полнить на графах, требуют осуществлять поиск вершин
В графе, следуя по ребрам. Обычно это делается спосо-
бом, немного похожим на исчерпывающий поиск по де-
ревьям.
Глубинный поиск (DFS — dept-first search) в графе,
по существу, очень похож на обход в заданном поряд-
ке, используемый в деревьях. Выбирается корневая вер-
шина и выполняется обработка корня. Затем каждая
смежная с корнем вершина рекурсивно обрабатывается
таким же образом. Различие состоит в следующем: нам
нужно убедиться, что уже просмотренная вершина не
будет посещаться позже. Для этого нужно использовать
таблицу осмотренных вершин. Смежная вершина пере-
дается рекурсивной функции, только если она еще не
исследовалась. Приведенный ниже код представляет
собой шаблон для глубинного поиска. Несмотря на то
что код успешно проходит по дереву глубинного поис-
ка в графе, он не выполняет никакой обработки.
void GenericDepthFirstSearchfstruct Graph * Grint Index,int * Visited)
<
/* Visited указывает на массив целых чисел из G->NumVertices элементов и принимает значение О
перед первым вызовом
*/
struct EdgeScan EScan;
Организация данных
Часть II
384
Visited[Index]=true;
/* Здесь выполните обработку! */
EdgeScanStart(G,Index,&EScan);
while (IEdgeScanNext(&EScan))
{
if (!Visited[EScan.Dest]) DepthFirstSearch( Gf EScan.Dest, Visited);
}
EdgeScanEnd(&EScan);
Время работы глубинного поиска в графе обычно имеет
порядок, равный О-нотации соответствующего алгоритма
поиска. Для определения того, была ли вершина назначе-
ния уже просмотрена, изучается каждое ребро.
В действительности глубинный поиск повторяет
древовидную структуру при движении по графу. На
рис. 16.18 показан возможный глубинный поиск. Непре-
рывные линии — это ребра, которые отслеживаются при
глубинном поиске. Прерывистые линии — это ребра,
которые исследованы, но не пройдены, поскольку це-
левая вершина уже была посещена. Глубинный поиск
начинается с вершины v0, которая имеет одно выходя-
щее ребро, идущее к вершине vk Затем мы проходим
ребро от v, к v3. Ребро от v3 к v0 рисуем как прерывистую
линию, потому что вершина v0 уже посещена и это ребро
изучено, но не пройдено. Получившееся дерево можно
легко увидеть, если проигнорировать непройденные реб-
ра (прерывистые линии). Поиск по дереву продолжает-
ся до тех пор, пока не будут посещены все вершины.
РИСУНОК 16.18. Прохождение по дереву в графе с
использованием DFS.
Проблема, связанная с приведенной выше универ-
сальной функцией глубинного поиска, состоит в том,
что в несвязанном неориентированном графе или сла-
бо связанном ориентированном графе будут определен-
ные вершины, до которых поиск не дойдет. Кроме того,
с точки зрения программного обеспечения передача пе-
ременной Visited при первом обращении и предположе-
ние о том, что память под нее выделена и ей присвое-
но значение, могут быть далеки от действительности.
Обе эти проблемы можно решить с помощью интерфей-
сной функции-оболочки.
Эта функция верхнего уровня размещает Visited и
выполняет вызов функции, которая, в свою очередь,
фактически выполняет глубинный поиск. Когда функ-
ция возвращает результат, то каждая вершина в дереве,
начиная с корневой, оказывается обработанной. Если
граф является связанным, все вершины получают отмет-
ку об их посещении.
Если граф не является связанным (или сильно свя-
занным), можно провести другой глубинный поиск с по-
мощью интерфейсной функции-оболочки, начиная с
непосешенной вершины. Это можно сделать столько
раз, сколько потребуется, пока не будут посещены все
вершины.
Эта операция может стать очень трудоемкой. Худ-
ший способ ее выполнения заключается в том, чтобы
провести линейный поиск Visited, каждый раз начиная
с тех вершин, которые имеют индекс 0. Даже если граф
является связанным, потребуется V итераций, чтобы
убедиться, что не осталось непосещенных вершин. Су-
ществует два простых усовершенствования для решения
этих проблем.
Первое — в дополнение к массиву Visited проводить
подсчет вершин, которые посещены. Функция глубин-
ного поиска могла бы увеличивать этот счетчик. Теперь
интерфейсная функция-оболочка может легко прове-
рить тот факт, что каждая вершина посещена. Это уве-
личивает время выполнения на связанных графах до
порядка О(Е).
Второе усовершенствование применяется для умень-
шения времени выполнения, если речь идет об очень не-
связанных графах. Вместо того чтобы каждый раз пере-
устанавливать счетчик в 0 и просматривать массив
Visited для поиска посещенных вершин, счетчик перво-
Работа с графами
Глава 16
385
начально устанавливают в 0. Для последующего обра-
щения к функции глубинного поиска счетчик не пере-
устанавливается, и поиск непосещенных вершин про-
должается со следующего индекса после предыдущей
корневой вершины. Это значит, что даже в худшем слу-
чае этой проверки (когда в графе нет связей) потребу-
ется только V итераций, т.е. максимальное время выпол-
нения будет иметь порядок O(V+E).
Можно привести два простейших примера примене-
ния глубинного поиска. Это определение того, являет-
ся ли граф связанным (или сильно связанным — для
ориентированных графов) и имеется ли путь между
двумя вершинами. Первая задача — определение связ-
ности — решается путем простой модификации универ-
сальной функции-оболочки глубинного поиска. Функ-
цию глубинного поиска, показанную в листинге 16.2,
вызывать можно только один раз. После возвращения
этой функцией результата каждая вершина будет посе-
щена и граф окажется связанным, либо будут непосе-
щенные вершины, и тогда граф окажется несвязанным.
При использовании этой технологии по отношению к
ориентированным графам функция возвращает истину
в случае, если они сильно связаны. Слабо связанные и
несвязанные ориентированные графы этот тест не вы-
держивают.
Определение того, имеется ли путь между двумя
вершинами, с использованием глубинного поиска —
тоже довольно простая операция. Во многих ситуациях
полезно знать, имеется ли путь от вершины и к вершине
v. Использование глубинного поиска позволяет выпол-
нить эту операцию за время, меньшее, чем определен-
ное О-нотацией алгоритма. Алгоритм поиска кратчай-
шего пути можно использовать для определения
следующего: если имеется путь от вершины и к верши-
не v, но его прохождение требует много времени, то он
плохо подходит для этой простой задачи.
Листинг 16.2. Глубинный поиск,
/* Реализация глубинного поиска для определения того, имеется ли путь (любой длины) от S к D.
Переменная Visited требуется для предотврацення неограниченного движения по циклу. Она должна
быть равна sizeof(int)*NuberOfVertices и инициализирована с помощью нулей перед первым
выполнением.
*/
int AVC_Inner(struct Graph * G, int S, int Drint * Visited)
{
int retval;
struct EdgeScan EScan;
retval=0;
Visited[S]=l;
EdgeScanStart(G, S,&EScan);
while (EdgeScanNext(&EScan)==O && retval-=0)
{
if (EScan.Dest==D) retval=0;
else if (!Visited[EScan.Dest]) retval=AVC_Inner(G,EScan.Dest,D,Visited);
}
EdgeScanEnd(&EScan);
return retval;
>
int AreVerticesConnectedfstruct Graph * Grint Source, int Dest)
(
int * Visited;
int i, retval;
if (!G || Source<0 || Dest<0 ||
Source>=G->NuinVertices | | Dest>=G->NumVertices) return GRAPB BADPARAM;
Visited=malloc(sizeof(int)*G->NumVertices);
if (!Visited) return GRAPEOUTOFMEM;
for (i=O;i<G->NumVertices;i++) Visited[i]=0;
retval=AVC_Inner(G,Source,Dest,Visited);
free(Visited);
return retval;
>
25 Зе. 265
Организация данных
Часть II
386
Для инициализации структуры Visited используется
функция-оболочка. Функция глубинного поиска позволяет
использовать и как корень. Затем передается целевая вер-
шина Как и каждая посещенная функцией глубинного
поиска вершина, она сравнивается с v. В наихудшем слу-
чае время выполнения этого метода имеет порядок
О (Е), что типично для функций глубинного поиска.
Для этой задачи можно также выполнять поиск в
ширину. При таком поиске целевые вершины добавля-
ются в очередь. Смежные вершины добавляются в ко-
нец этой очереди. Это тоже занимает время порядка
О(Е). На практике при выполнении такого поиска вряд
ли можно получить заметное преимущество по сравне-
нию с глубинным поиском. Если вершины и и v нахо-
дятся близко друг к другу, то поиск в ширину для оп-
ределения положения v можно выполнить за меньшее
количество итераций, чем при глубинном поиске. Об-
ратное тоже верно.
Нерекурсивный глубинный поиск
Рекурсивная функция неидеальна во многих случаях.
Для глубокой рекурсии можно использовать множество
выполняемых стеков. Компилятору также необходима
дополнительная память для считывания и записи сво-
их параметров на каждом уровне; чем больше инфор-
мации передается, тем больший размер стека требует-
ся. В большинстве случаев издержки невелики, так что
вполне можно применять простую рекурсивную реали-
зацию. В случаях, когда размер стека ограничен или
глубина рекурсии очень велика, имеет смысл вообще не
использовать рекурсию. Глубинный поиск, как и любую
рекурсивную функцию, можно выполнять без обраще-
ния функции к самой себе.
Это достигается путем использования стека в основ-
ной памяти. Множество архитектур компьютеров име-
ют специфические возможности для доступа к одному
или нескольким стекам. Операционные системы и про-
граммы, которые запускаются на них, используют эти
особенности. Такие стеки обычно ограничены в разме-
рах и намного меньше, чем общая доступная память.
Написать переносимый код не так просто, как может
показаться, потому что это требует хорошего понима-
ния ограничений большинства платформ. Вот один та-
кой случай: одни системы позволяют использовать ог-
ромные стеки, а другие — нет. Это ограничение,
конечно, можно обойти, если реализовать в основной
памяти свой собственный стек.
Значительную обеспокоенность вызывает то, что
при использовании очень больших графов с огромным
количеством вершин стек программы может перепол-
ниться. Некоторые сочетания современных компилято-
ров и операционных систем вообще не имеют очень
больших стеков. Количество рекурсий перед перепол-
нением стека может быть намного меньше 80 тыс. или
намного больше нескольких миллионов. На более ста-
рых системах (типа 16-битовой MS-DOS и похожих
платформах) стек может быть ограничен менее чем 3-4
тыс. глубинных рекурсий в зависимости от количества
передаваемых аргументов. Общий объем памяти на
большинстве систем достаточен для содержания стека,
состоящего из миллиона элементов, что намного боль-
ше, чем размер стека, доступный программе.
Стеки могут быть реализованы просто и эффектив-
но, а основная память обычно больше по сравнению с
доступным программным стеком. Поиск выполняется
путем записи в стек индекса каждой вершины, смежной
с текущей. Следующий корень выбирается просто пу-
тем считывания вершины из стека. Если стек пуст, то
выбирается новый еще не посещенный корень и поиск
продолжается, пока не будут посещены все вершины.
Приведенная ниже функция — это шаблон для выпол-
нения глубинного поиска с использованием структуры
данных стека вместо рекурсии. Эта функция почти
ничего не делает, только осуществляет проход по дере-
ву глубинного поиска.
void Stack_DFS(struct Graph * G)
{
int V;
int * Visited;
struct EdgeScan E;
struct Stack * S;
InitStack(S);
Visited=nalloc(sizeof (int) *G->NumVertices);
if (IVisited) return;
for (V=O;V<G->NumVertices;V++)
Visited[V]=0;
for (V=0;V<G->NumVertices;V++)
{
do {
if (VisitedfV]) continue;
VisitedfV]=l;
/* Обработку вернины V выполните здесь */
Edgescanstart(GfVr&E);
while (EdgeScanNext(fcE)-=O)
{
if (!Visited[E.Dest])
Push(E.Dest,S)
}
if (IsEDpty(S)) V=-l;
else V=Pop(S);
} while (V!=-l);
}
free(Visited);
FreeStack(S);
Работа с графами
Глава 16
387
Сильно связанные компоненты
Слабо связанные ориентированные графы содержат
сильно связанные подграфы. На эти подграфы ссыла-
ются как на сильно связанные компоненты графа. Ори-
ентированный граф, имеющий только один сильно свя-
занный компонент, является сильно связанным.
Можно локализовать сильно связанные компоненты
ориентированного графа или определить, является ли
он сильно связанным, выполнив для этого два глубин-
ных поиска.
Первый поиск выполняется на графе G. Каждая вер-
шина нумеруется в порядке обхода. Всякий раз, когда
достигается тупик, продолжается поиск какой-либо
непосещенной вершины и индексация продолжается с
этого места. На рис. 16.19 показаны результаты поиска —
глубинный остовный лес и соответствующая нумерация
вершин графа G.
РИСУНОК 16.19. Граф G и его остовный лес как результат DFS
Затем граф G трансформируется для создания ново-
го графа Gt путем изменения направления каждого реб-
ра. Глубинный поиск в Gt проводится начиная от вер-
шины с самым маленьким номером, заданным в
Предыдущем поиске. При достижении тупика поиск на-
чинается от вершины с наименьшим номером — и так
до тех пор, пока не будут посещены все вершины.
Каждое дерево глубинного остовного леса, которое
найдено при поиске в Gt (рис. 16.20), является сильно
связанным компонентом.
РИСУНОК 16.20. Граф Gt и его остовный лес как результат DFS.
Для двух сильно связанных вершин должен быть
путь от вершины и к вершине v и от вершины v к вер-
шине и в графе Сив графе Gt. Глубинный остовный
лес для G и G, определяет эти пути в обоих случаях.
При глубинном поиске в G нумеруются вершины и
создается глубинный остовный лес. Каждый сильно свя-
занный компонент должен находиться в одном и том же
глубинном остовном дереве. Кроме того, если существует
путь от вершины и к вершине v, то и просматривается
раньше v, и поэтому и имеет меньший номер, чем v.
Прохождение ребра в G, от вершины и к вершине v —
то же самое, что и перемещение от v к и в графе G.
И снова создается глубинный остовный лес, и каждая
вершина в сильно связанном компоненте должна нахо-
диться в одном и том же глубинном остовном дереве.
Но здесь есть небольшое различие.
Глубинный поиск в Gt начинается с вершины с наи-
меньшим номером. Если после этого мы дошли до вер-
шины в том же глубинном остовном дереве, то стано-
вится ясно, что в G есть не только путь от вершины и к
Организация данных
Часть II
388
вершине v, но и от вершины и к вершине v в Q. Граф
Gt — это перегруппированный граф G, поэтому должен
быть путь от вершины и к вершине v и от вершины v к
вершине и в G (обратное реверсирование направления
ребра, перемещенного в Gt). Однако и и v должны быть
сильно связанными.
Это означает, что глубинный остовный лес в графе
G, определяет все сильно связанные компоненты в гра-
фе G.
Определение путей и контуров Эйлера
Путь Эйлера проходит по каждому ребру в графе толь-
ко один раз. Контур Эйлера проходит каждое ребро в
графе тоже один раз, а также начинается и заканчива-
ется в одной и той же вершине (рис. 16.21). Многие уже
знакомы с концепцией следующей простой головолом-
ки — нарисовать какое-то очертание без отрыва ручки
от бумаги.
Если серьезно, то поиск путей и контуров Эйлера
имеет более практичное применение. Их можно исполь-
зовать для проложения маршрута по каким-либо реаль-
ным сетям таким образом, что каждое ребро будет про-
ходиться в точности один раз. Существуют некоторые
свойства, которыми должен обладать граф, чтобы в нем
имелся путь или контур Эйлера.
РИСУНОК 16.21. Граф, который имеет путь Эйлера, и сам этот
путь.
Для существования контура Эйлера каждая верши-
на в графе должна иметь некоторую степень. Если лю-
бая вершина имеет нечетную степень, то сформировать
контур Эйлера невозможно. В каждую вершину долж-
ны входить и из нее выходить только еще не пройден-
ные ребра. Этого никогда не случится с вершиной, име-
ющей нечетную степень, потому что в нее можно войти,
а выйти нельзя, поскольку все выходящие ребра уже
пройдены.
Чтобы получить путь Эйлера, в графе должно быть
точно две вершины с нечетной степенью. Путь должен
начинаться и заканчиваться в вершине с нечетной сте-
пенью, потому что только эти вершины можно посетить
дополнительное (для входа) количество раз.
Теперь очевидно, что для графа требуются ограни-
чения. Граф не должен быть связанным. Однако этот
граф должен содержать только один связанный подграф.
Если граф содержит больше одного связанного подгра-
фа, то он не может иметь путей или контуров Эйлера,
так как некоторые ребра никогда не будут пройдены.
Любой граф, который удовлетворяет указанным ус-
ловиям, должен иметь путь Эйлера или контур Эйле-
ра. Такой граф называется эйлеровским.
Определение пути или контура Эйлера можно про-
вести с использованием методики, похожей на глубин-
ный поиск. Следующий алгоритм используется для
поиска контура Эйлера, но его можно немного изме-
нить, чтобы он позволял также находить путь Эйлера в
любом графе, который удовлетворяет приведенным
выше условиям.
На рисунках 16.22—16.25 показан пример выполне-
ния такого алгоритма. Работа алгоритма заключается в
локализации циклов в графе с использованием похожей
на глубинный поиск методики. Эти циклы затем мож-
но скомбинировать для образования одного цикла, ко-
торый проходит по всем ребрам в графе, — цикла Эй-
лера. Алгоритм можно описать как последовательность
следующих действий:
1. Инициализировать список циклов.
2. Выполнять глубинный поиск, пока все ребра не
будут удалены из графа. Добавить текущий номер
вершины в текущий путь. Пройти ребро, образован-
ное в процессе поиска, и удалить его. Если ребер
для просмотра больше нет, то добавить текущий
путь в список циклов, а затем продолжить поиск
непройденных вершин, начиная с первой вершины.
3. Объединить пути и циклы вместе для формирова-
ния контура Эйлера.
Рассмотрим подробнее этот алгоритм. Глубинный
поиск начинается с вершины v0 и на последующих итс-
Работа с графами
Глава 16
389
рациях посещаются вершины и v3. После v3 достига-
ется v0, и полученный цикл считается найденным. За-
тем цикл v0, v4, v3 и v0 сохраняется.
РИСУНОК 16.23. Ребра графа, по которым проходит путь
0~+1-*4-+3-+О, удаляются.
Затем глубинный поиск продолжается с первой вер-
шины, которая имела выходящее из нее ребро. В нашем
случае это вершина vb При глубинном поиске может
быть найден цикл vB v2, v4, v5, v4, v7, v6, v3,-vb который
добавляется в список циклов. Рис. 16.24 демонстриру-
ет граф без второго найденного цикла.
Следующий этап глубинного поиска начинается с вер-
шины v5; при этом обнаруживается цикл v5, v7, v8, v5. На-
чиная с этого момента, мы больше не найдем непросмот-
ренных ребер. Таким образом, получилось три цикла.
РИСУНОК 16.24. Граф с удаленными ребрами по пути
1-*2-*5-*4-*7-*6-*3-+1.
Полный цикл можно получить, если вставить най-
денные циклы один в другой. Цикл, который начина-
ется и заканчивается в вершине, можно вставить в дру-
гой цикл или путь на место этой вершины. В нашем
случае цикл v„ v2, v5, v4, v7, v6,. v5, v0 можно вставить в
Цикл v0, vn v4, v3, v0 на место вершины v,. To же самое
можно сделать с оставшимся циклом для получения
полного контура Эйлера.
Этот же алгоритм с небольшими поправками мож-
но использовать также для поиска пути Эйлера. Разни-
ца состоит в результате первого этапа поиска. Любой
граф, удовлетворяющий условиям для контура Эйлера,
после первого этапа поиска создает цикл. Чтобы найти
путь Эйлера, первый поиск надо провести, начиная с
одной из двух вершин с нечетными степенями. Резуль-
татом такого поиска будет путь от первой вершины с
нечетной степенью ко второй. Все последующие этапы
поиска дают циклы, которые можно вставить в первый
путь таким же образом, как и в случае с контуром Эй-
лера.
РИСУНОК 16.25. Найденный контур Эйлера.
Эффективная реализация этого алгоритма может
оказаться немного громоздкой. Потенциальную пробле-
му представляют неориентированные графы из-за обыч-
ного способа их представления. Хотя в графе ребро яв-
ляется единственным объектом, оно представляется как
два ориентированных ребра, одно из которых идет от и
к v, а другое — от v к и.
Прохождение матрицы смежности или списка смеж-
ных вершин для проверки ребер в соответствии с этим
алгоритмом требует много времени. Желательно всегда
передвигаться по списку ребер только вперед. Когда
ребро просматривается, его можно либо удалить, либо
поместить за указатель ребра этой вершины, и тогда оно
больше никогда не будет просматриваться.
Это, безусловно, справедливо для ориентированных
ребер; после того как ребро передается, оно больше
никогда не исследуется. Неориентированные графы
немного усложняют этот алгоритм, поскольку мы дол-
жны учитывать тот факт, что каждое ребро представле-
но в виде двух направленных ребер. Это значит, что
изучить неориентированное ребро можно дважды, про-
двигаясь вперед и назад по каждому ребру и получая
неправильные результаты. Для решения этих проблем
разумно использовать структуры данных.
Задача коммивояжера
Задача коммивояжера (TSP — Travelling Salesperson
Problem) встречается каждый день в различных формах,
хотя не все люди на самом деле что-либо продают.
Коммивояжер посещает множество городов, и при этом
он начинает и заканчивает свое путешествие у себя
дома. Цель состоит в поиске цикла наименьшей длины.
Организация данных
390
Часть II
Это проблему можно представить в виде графа. Го-
рода будут вершинами, а дороги от одного города к
другому — ребрами. Затраты на прохождение ребра мо-
iyr представлять собой деньги, расстояние, время или
определенную комбинацию этих параметров.
Задачу TSP можно решить, если найти циклы Га-
мильтона (Hamiltonian cycles) в графе, который представ-
ляет некую реальную сеть. Цикл Гамильтона — это
цикл, который проходит только один раз через каждую
вершину, а затем возвращается к первоначальной вер-
шине. Оптимальным решением TSP будет цикл Гамиль-
тона наименьшей длины в графе.
Решение задачи TSP, представленной в виде графа,
оказывается довольно банальным. Метод грубой силы
предназначен для определения всех возможных циклов
Гамильтона и сравнения их длин. Решением будет цикл
с наименьшими общими затратами. Этот подход гаран-
тирует, что найдено действительно оптимальное реше-
ние, но имеется один существенный недостаток.
Проблема этого метода состоит в том, что время,
необходимое для получения решения, значительно пре-
вышает срок жизни человека, которому требуется ре-
зультат. Для полного графа с V вершинами существует
(V-l)!/2 возможных циклов Гамильтона. При использо-
вании графа с 25 вершинами и компьютера, выполня-
ющего алгоритм со скоростью миллиард перестановок
за секунду, для получения решения может потребовать-
ся около 10 миллионов лет.
К счастью, для практических целей требуется всего
лишь приближенная аппроксимация. Результат не дол-
жен быть идеальным — он просто должен быть доста-
точно хорошим. Приближенная аппроксимация может
выполняться значительно быстрее и скорее возвращать
результат для его использования.
Сначала требуется быстро создать аппроксимацию,
которую позже можно будет усовершенствовать. Все,
что нужно, — это построить цикл . Гамильтона или что-
либо близкое к нему, с самой короткой длиной. Поиск
такого цикла не очень практичен, но мы можем полу-
чить близкий к требуемому цикл за довольно короткий
срок. Все полные графы являются гамильтоновыми: они
всегда имеют, по крайней мере, один цикл Гамильто-
на. Неполные графы не всегда могут быть гамильтоно-
выми. Для упрощения проблемы и возможности приме-
нения нашего алгоритма к негамильтоновым графам
необходимо трансформировать исходный граф в пол-
ный. Этим мы гарантируем, что найденный цикл будет
циклом Гамильтона.
Полный граф из исходного можно сделать путем
добавления ребер между одной вершиной и всеми ос-
тальными вершинами с затратами, равными длине крат-
чайшего пути между ними. Правильным бы было ис-
пользовать алгоритм кратчайшего пути Флойда (Floyd),
а таблицу результатов использовать для создания ново-
го полного графа. Рис. 16.26 демонстрирует исходный
граф и созданный на его основе полный граф.
РИСУНОК 16.26. Исходный граф и созданный на его основе
полный граф.
Начальный цикл можно найти с использованием так
называемого алгоритма "ближайшего соседа". Начиная
с "домашней" вершины, в начальный цикл добавляется
вершина "ближайшего соседа", которая еще не посеще-
на. Как только будут посещены все вершины, цикл за-
вершается, следуя по ребру к "домашней” вершине. На
рис. 16.27 показаны результаты выполнения алгоритма
"ближайшего соседа" на примере полного графа, начи-
ная с "домашней" вершины v0.
Длина этого начального цикла Гамильтона должна
быть больше или равной длине оптимального цикла
Гамильтона. Найденный цикл будет близок к длине
оптимального цикла Гамильтона, но маловероятно, что
это в точности будет он.
Теперь, когда у нас есть цикл, достаточно близкий
к циклу Гамильтона с минимальной длиной, можно
усовершенствовать только что найденный цикл. Это
делается путем изменения цикла в соответствии с на-
бором правил, а затем сравнения длины вновь создан-
ного цикла с длиной предыдущего.
РИСУНОК 16.27. Результат выполнения алгоритма "ближайшего
соседа".
Хорошую аппроксимацию или даже точный цикл
можно найти, управляя ребрами более короткого цик-
Работа с графами
Глава 16
|391
ла. Разъединение пары ребер так, чтобы цикл разделялся
на два пути (более чем из одной вершины) и другое
соединение этих ребер — вот верный механизм измене-
ния найденного более короткого цикла. Для любой та-
кой пары ребер существует только одна комбинация,
которая позволяет создать цикл, отличающийся от пре-
дыдущего. Если один или несколько из вновь созданных
циклов имеют более низкие общие затраты, чем преды-
дущий, то он становится исходным, и этот процесс
повторяется со следующей парой ребер этого цикла до
тех пор, пока больше нельзя будет делать перестановок
ребер.
По окончании мы должны получить цикл, который
должен иметь большие, но близкие к реальному опти-
муму общие затраты, или иметь точный оптимум зат-
рат. На рис. 16.28 показаны циклы, полученные при
первом проходе. Номер в квадратике возле каждого цик-
ла — это общая их длина. Только один новый цикл
имеет общую длину, которая меньше, чем оригиналь-
ная. При втором проходе ни один из циклов не улуч-
шается и алгоритм заканчивается на цикле v0 —> v3 —>
v4^ Vj -> v2 -» v0, который имеет общую длину 15.
Найденный цикл имеет другой контекст по сравне-
нию с исходным графом, однако это полный граф, со-
зданный на основе оригинального графа. Теперь требу-
ется создать цикл и поместить его назад в контекст
оригинального графа. При использовании в оригиналь-
ном графе каждый элемент цикла является самым ко-
ротким путем между двумя вершинами, а не списком
просмотренных вершин. Другими словами, это значит,
что цикл v0 v3 —> v4 —> Vj -> v2 —> v0 в контексте ори-
гинального графа является самым коротким путем от v0
до v3, за которым следует самый короткий путь от v3 до
v4, за которым, в свою очередь, следует самый корот-
кий путь от v4 до v, и т.д. В этом примере все получен-
ные пути имеют длину в одно ребро, однако это не обя-
зательно будет справедливо для всех графов.
Для большинства целей эта технология позволяет
получить приемлемо точные результаты за небольшое
время. Приложения такого алгоритма применяются не
только для путешествующих коммивояжеров и опреде-
ления оптимальных маршрутов доставки грузов.
Алгоритмы поиска кратчайшего пути
Одним из принципов использования теории графов яв-
ляется поиск наилучшего из нескольких маршрутов.
Такой маршрут определяется путем подсчета пути с
наименьшими затратами между вершинами в графе.
Выражаться затраты могут по-разному: в цене за биле-
ты, в расстоянии в милях, какими-либо единицами из-
мерения времени или в чем-либо еще, что можно чис-
ленно определить. Важным моментом является то, что
можно определить, насколько хороши соединения меж-
ду двумя вершинами. В алгоритмах поиска кратчайше-
го маршрута чем меньше затраты, тем лучше маршрут.
Множество проблем в реальном мире решаются пу-
тем определения кратчайшего маршрута. Очевидными
РИСУНОК 16.28. Полученные циклы.
392
Организация данных
Часть II
являются проблемы, связанные с самым коротким вре-
менем, расстоянием или ценой, которые необходимы
для перемещения из одного места на другое. Определе-
ние самого короткого маршрута можно применить ко
всему, что представляется в виде графа.
Алгоритм Дийкстры: единственный
источник
В алгоритме Дийкстры (Dijkstra) рассчитываются общие
затраты на кратчайший маршрут от любой единствен-
ной вершины в графе ко всем остальным вершинам.
Алгоритм выполняется как определенная последователь-
ность действий. На каждой итерации определяются
наименьшие общие затраты на одну вершину.
Алгоритм Дийкстры: итерации
Для каждой вершины в графе сохраняются два значе-
ния. Общие затраты на путь от стартовой вершины к
каждой вершине используются для отслеживания зат-
рат на наилучший маршрут, а в конце алгоритма — для
получения реальных затрат на кратчайший маршрут.
Для прохождения этого маршрута для каждой верши-
ны предыдущая вершина сохраняется в кратчайшем мар-
шруте, с тем чтобы позже ее можно было использовать
для перемещения обратно по этому маршруту. Пошаго-
вая реализация алгоритма Дийкстры выглядит следую-
щим образом:
1. Первоначально стартовая вершина дает общие зат-
раты 0. Все остальные вершины имеют бесконечные
общие затраты. Для всех вершин создается преды-
дущая вершина. Начальной вершиной будет V —
текущая вершина.
2. Пометить V как посещенную.
3. Скорректировать общие затраты всех вершин, смеж-
ных с V, как еще не посещенные. Если общие зат-
раты V плюс затраты на движение по ребру к смеж-
ной вершине меньше, чем общие затраты на
смежную вершину, то маршрут через V имеет мень-
шие затраты, чем найденные до сих пор. Установить
новые общие затраты смежной вершины и устано-
вить V как вершину, которая стоит на пути перед
смежной вершиной.
4. Непосещенную вершину с минимальными общими
затратами выбрать в качестве текущей вершины V.
5. Повторять все шаги, начиная с шага 2, пока не бу-
дут посещены все вершины.
По окончании алгоритма предыдущую вершину как
элемент таблицы можно использовать для перемещения
обратно по кратчайшему маршруту от любой вершины.
Рисунки 16.29—16.36 и таблицы 16.5—16.12 демон-
стрируют работу алгоритма Дийкстры. На диаграммах
те вершины, которые уже посещены, — имеют черный
цвет, а непосещенные вершины остаются светлыми.
Цифры возле каждой вершины представляют маршрут
к этой вершине с наименьшими затратами на данный
момент. После посещения вершины общие затраты от
начала не изменяются. Здесь v, — начальная вершина.
Первый граф (рис. 16.29) показывает положение
после выполнения шага 1. Общие затраты на путь для
стартовой вершины устанавливаются равными 0, а
для остальных вершин — равными бесконечности.
Таблица 16.5. Алгоритм Дийкстры — стадия 1.
Посещенные вершины Общие затраты Предыдущие вершины
1 нет 0 нет
2 нет оо нет
3 нет оо нет
4 нет оо нет
5 нет оо нет
6 нет оо нет
7 нет оо нет
После первой итерации определяются общие затра-
ты на V! и корректируются общие затраты на v2 и v3.
РИСУНОК 1&3Q. Алгоритм Дийкстры — диаграмма стадии 2
Работа с графами
Глава 16
393
Таблица 16.6. Алгоритм Дийкстры — стадия 2.
ч Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 нет 1 Vi
3 нет оо нет
4 нет 2 Vi
5 нет оо нет
6 нет оо нет
7 нет оо нет
Среди непосещенных вершин выбирается вершина с
минимальными общими затратами (v2). Она помечает-
ся как посещенная, и корректируются общие затраты на
v3 и v5.
РИСУНОК 16.31. Алгоритм Дийкстры — диаграмма стадии 3.
Таблица 16.7. Алгоритм Дийкстры — шаг 3.
ч Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 V,
3 нет 6 Ч
4 нет 2 Vi
5 нет 4 Ч
6 нет оо нет
7 нет оо нет
Затем выбирается v4. Поскольку v, уже посещена,
обновляется только v6.
Таблица 16,8. Алгоритм Дийкстры — шаг 4.
Выбирается вершина v6, и обновляется значение зат-
рат на v7. Маршрут от v6 к v3 имеет меньшие затраты (5),
чем определенный ранее маршрут (6). Общие затраты
на v3 обновляются, и v6 устанавливается как предыду-
щая вершина в маршруте.
РИСУНОК 16.32. Алгоритм Дийкстры — диаграмма стадии 4
РИСУНОК 16.33. Алгоритм Дийкстры — диаграмма стадии 5.
Таблица 16.9. Алгоритм Дийкстры — стадия 5.
ч Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 Vi
3 нет 5 ve
4 да 2 Ч
5 нет 4 Ч
6 да 3 v4
7 нет 6 ve
После этого выбирается v5. Смежная вершина v7 не
обновляется, потому что маршрут через v5 не имеет
улучшений по сравнению с ранее найденным.
Ч Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 Ч
3 нет 6 ч
4 да 2 Vi
5 нет 4 v2
6 нет 3 v4
7 нет оо нет
РИСУНОК 16.34. Алгоритм Дийкстры — диаграмма стадии 6.
Организация данных
Часть II
394
Таблица 16.10. Алгоритм Дийкстры - стадия 6.
ч, Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 Vi
3 нет 5 v6
4 да 2 Vi
5 да 4 V2
6 да 3 V4
7 нет 6 v6
Таблица 16.12. Алгоритм Дийкстры — стадия 8.
Hi Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 Vi
3 да 5 v6
4 да 2 Vi
5 да 4 V2
6 да 3 V4
7 да 6 v6
Выбирается v3, но, так как обе смежные вершины
уже были посещены, они просто помечаются как посе-
щенные без влияния на другие вершины.
Таблица 16.11. Алгоритм Дийкстры — стадия 7.
ч, Посещенные вершины Общие затраты Предыдущие вершины
1 да 0 нет
2 да 1 Vi
3 да 5 V6
4 да 2 Vi
5 да 4 V2
6 да 3 V<
7 нет 6 V6
И наконец, помечается как посещенная вершина v7.
Больше не осталось непосещенных вершин — алгоритм
завершен.
РИСУНОК 16.35. Алгоритм Дийкстры—диаграмма стадии 7.
РИСУНОК 16.36. Алгоритм Дийкстры — диаграмма стадии &
Теперь табл. 16.12 содержит кратчайший маршрут от
стартовой вершины v1 ко всем другим вершинам в гра-
фе. Кратчайший маршрут можно проследить от любой
вершины с использованием информации о предыдущей
вершине, содержащейся в таблице. Например, кратчай-
ший маршрут от V! к v3 по таблице — это v„ v4, v6, v3 с
общими затратами, равными 5.
Выполнение алгоритма Дийкстры
Первое, что требуется сделать, — обеспечить соответ-
ствующие значения для хранения нужной в процессе
работы информации. Структура Dijkstra_Row содержит
всю информацию, которая необходима во время рабо-
ты алгоритма, а в конце содержит информацию, необ-
ходимую для отслеживания найденных путей. Пример
в листинге 16.3 демонстрирует размещение и инициа-
лизацию такой таблицы.
Каждая вершина посещается один раз (для связан-
ных графов), и для поиска вершины, которая имеет
минимальные затраты, сканируется весь список вер-
шин. Это означает, что необходимо V итераций, где V —
это количество вершин в графе. В случае с разреженны-
ми графами данное значение может быть меньше.
При использовании алгоритма Дийкстры нужно по-
мнить, что для больших разреженных графов очень
много времени занимает итерация всей таблицы. Пра-
вильнее было бы использовать приоритетную очередь.
После посещения каждой вершины ее смежная вер-
шина вставляется в приоритетную очередь. Очередь
предполагает, что элементы удаляются в порядке воз-
растания их общих затрат.
Точно так же функции структуры очередности имеют
большое влияние на эффективность алгоритма. Для обыч-
ной приоритетной очереди существует два подхода.
При первом подходе используется приоритетная
очередь, в которой не допускается повторение одной и
той же вершины. Когда в эту очередь добавляется ранее
присутствовавшая вершина, минимальные затраты этих
двух вершин принимаются во внимание, а другие не учи-
тываются. В основном алгоритме вершины просто удаля-
ются из очереди в нужном порядке без повторений. Обыч-
но поиск в очереди необходим для определения того,
представлена ли уже в ней новая вершина. В листинге 16.4
реализована эта технология для разреженных графов.
395
Работа с графами
Глава 16
Листинг 16.3. Алгоритм Дийкстры и функция InitResults.
int InitResults(struct DijkstraRow ** Results, int NuinRows)
{
int i;
struct Dijkstra_Row * ptr;
ptr=malloc(sizeof(struct DijkstraRow) * NuinRows);
if (Iptr) return GRAPHOUTOFMEM;
for (i=0;i<NumRows;i++)
{
ptr[i].TotalCost=GRAPH_NOTCONNECTED;
ptr[i].Previous=-1;
ptr(i].Visited=FALSE;
У
*Results=ptr;
return 0;
>
int Dijkstra Simple(struct Graph * G, int Source,
struct Dijkstra_Table * Table)
(
int V; /* V - это индекс текущей вернины */
int С; /* С используется на этапе 4, поиск вервины с минимальными затратами */
int i;
struct DijkstraRow * Results;
struct EdgeScan E; /* содержит информацию о ребре */
i=InitResults((Results, G->NumVertices);
if (i) return i;
Results[Source].Total=0; /* Ear 1 */
Results [Source] .Previous—1; /* предыдущего узла нет */
V=Source;
do {
Results [V] .Visited=TRUE; /* Ear 2 */
EdgeScanStart(G, V, (E); /* Ear 3 */
while (EdgeScanNext((E)==O)
{
if (ResultsfE.Dest].Visited) continue;
if (E.Cost<0) return GRAPHJBADGRAPH;
if (Results[V].Total + E.Cost < ResultsfE.Dest].Total )
{
Results[E.Dest].Total = Results[V].Total + E.Cost;
Results[E.Dest].Previous=V;
}
}
EdgeScanEnd((E);
V—1; /* Ear 4 */
C=GRAPH_NOTCONNECTED;
for (i=0;i<G->NumVertices;i++)
{
if (1 Results[i] .Visited (( Results[i] .TotaKC)
{
V=i;
C=Results[i].Total;
}
}
} while (V!=-l);
396
Организация данных
Часть II
Table->G=G;
Table->Source=Source;
Table->Results=Results;
return 0;
Листинг 16.4. Алгоритм Дийкстры для разреженных графов,_______________________________
int Dijkstra_Sparse(struct Graph * G, int Source, struct DijkstraTable * Table)
{
int V; /* V - это индекс текущей вершины */
int i;
struct PQueue Q;
struct DijkstraRow * Results;
struct EdgeScan E; /* содержит информацию о тракте */
PQInitialise(bQ);
InitResults(^Results, G->NumVertices);
Results[Source],Total=0; /* Ear 1 */
Results[Source],Previous=-l; /* предыдущего узла нет */
V=Source;
do {
Results[V].Visited-TRUE; /* lar 2 */
EdgeScanStart(G, V, &E); /* Ear 3 */
while (EdgeScanNext(&E)==O)
{
if (Results[E.Dest].Visited) continue;
if (E.Cost<0) return GRAPHBADGRAPH;
if (Results[V].Total + E.Cost < Results[E.Dest]-Total )
{
Results[E.Dest].Total = Results[V].Total + E.Cost;
Results[E.Dest].Previous=V;
PQ_Enqueue(&Q,Results[E.Dest].Total,E.Dest);
}
}
EdgeScanEnd(&E);
V=PQ_Dequeue(&Q); /* Bar 4 */
} while (V!=-l);
Table->G=G;
Table->Source=Source;
Table->Results~Results;
return 0;
}
При втором подходе используется очередь, которая
допускает повторение одной и той же вершины. В этом
случае каждый раз, когда вершина удаляется из очере-
ди, требуется проверить, была ли она ранее посещена.
Это делается просто с помощью цикла, который удаля-
ет вершины из очереди, пока все вершины в ней не бу-
дут посещены или не будет найдена непосещенная.
Так в чем же разница? Второй подход лучше исполь-
зовать при сравнительно больших значениях N — коли-
честве элементов в очереди, которое потенциально ста-
новится все больше по мере увеличения в графе ребер.
Это приравнивается к использованию большей памяти
за счет переменных, участвующих в размещении и ос-
вобождении каждого элемента очереди. При первом
подходе используется значительно меньше памяти.
Первый подход обычно работает быстрее даже при
поиске по представленной очереди. Число ребер в гра-
фе потенциально очень большое, и издержки добавле-
Работа с графами
Глава 16
397
Ния, перемещения и исследования каждого элемента в
очереди зачастую больше, чем при поиске в очереди.
Структура данных, используемых как приоритетная
очередь, имеет большое значение во время выполнения
задачи. При простой реализации связанного списка по-
лучаются неприемлемые результаты, в каждом поиске
выполняется V итераций, требующих времени выпол-
нения порядка СЦУ2). Хотя это то же самое, что и про-
стая описанная ранее реализация, она будет выполнять-
ся дольше, поскольку поддержка связанного списка
занимает больше времени.
Использование двоичной динамической памяти мо-
жет позволить значительно снизить время, необходимое
для разреженных графов. Операции в динамической
памяти обычно выполняются за время порядка O(log N)
и снижают время выполнения алгоритма Дийкстры до
порядка O(V log V). Однако реализация поиска в дво-
ичной динамической памяти может занять много вре-
мени, и любые выгоды, полученные от ее использова-
ния, теряются в этих дополнительных издержках. Дру-
гие структуры динамической памяти, при которых
операции поиска немного сложнее, будут иметь значи-
тельно меньшие издержки.
Алгоритм Дийкстры имеет значительные недостат-
ки, которые ограничивают его применение. Например,
он не работает, когда в графе имеются ребра с отрица-
тельными затратами. Рассмотрим рис. 16.37.
Когда используется этот алгоритм, то кратчайший
маршрут от Vj к v2 определяется как vp v3, v2 с общими
затратами, равными 3. В действительности кратчайший
маршрут — это V], v3, v4, v2 с общими затратами, равны-
ми -4.
Происходит ошибка, так как алгоритм предполага-
ет, что общие затраты на достижение вершины будут по-
стоянно увеличиваться. После посещения вершины
предполагается, что больше нет других путей, которые
он может достигнуть с минимальными затратами. Это
справедливо только для ребер с положительными зат-
ратами. Любой маршрут возвращается к уже посещен-
ной вершине, которая должна иметь общие затраты, пре-
восходящие или равные затратам на ранее найденном
Пути.
РИСУНОК 16.37. Граф, имеющий ребро с отрицательными
затратами.
Все сказанное выше не касается ребер с отрицатель-
ными затратами. В таком графе должен быть путь об-
ратно к уже посещенной вершине, который имеет зат-
раты, меньшие, чем ранее найденные. Однако решение
есть: алгоритм Беллмана-Форда (Bellman-Ford).
Алгоритм Беллмана-Форда:
централизованные ребра с
отрицательными затратами
Алгоритм Беллмана-Форда очень похож на алгоритм
Дийкстры. Основное их различие состоит в том, что ал-
горитм Дийкстры предполагает, что вы никогда не бу-
дете возвращаться к уже посещенной вершине, а алго-
ритм Беллмана-Форда не имеет такого предположения.
Существует две примечательные проблемы. Первая
заключается в том, что данный алгоритм занимает боль-
ше времени, чем алгоритм Дийкстры. В алгоритме Дий-
кстры каждая вершина обрабатывается только один раз.
В отличие от него, алгоритм Беллмана-Форда потенци-
ально может посещать каждую вершину V-1 раз (напри-
мер, в полном графе).
Вторая проблема — это особенности графа, который
имеет один или более циклов с отрицательными значе-
ниями затрат. В таких графах может случиться так, что
алгоритм никогда не завершится. Он просто будет нео-
граниченно работать в цикле. С небольшими усилиями
эту проблему все же можно преодолеть.
Рассмотрим вершину, смежную со всеми другими
вершинами, как некоторую вершину полного графа.
Когда алгоритм запускается, центральная вершина бу-
дет ставиться в очередь около V-1 раз, где V — это ко-
личество вершин в графе. Когда же цикл работает с этой
вершиной, то она будет ставиться в очередь намного
чаще, чем V-l раз. С учетом этого условия (что верши-
на ставится в очередь более V-1 раз) требуется создать
функцию для выхода. В такой ситуации невозможно
работать с этим алгоритмом, и поэтому мы не получим
результатов, которым можно было бы доверять.
Для вершин, являющихся частью цикла, кратчай-
ший маршрут между ними становится неограниченно
отрицательным, так как можно вечно передвигать цикл,
чтобы получить путь со все меньшими и меньшими зат-
ратами. Любой путь, который можно создать и который
содержит вершину в цикле с отрицательными затратами,
будет также иметь неограниченно отрицательные затра-
ты. Будет лучше просто не учитывать любые результа-
ты, найденные в графе с отрицательными циклами, так
как на практике они не имеют большого значения.
В практических ситуациях ребра с отрицательными
затратами (и тем более циклы с отрицательными затра-
тами) чрезвычайно редки. В качестве примера возьмем
граф, представляющий сеть железных дорог, в которой
затраты на ребро — это реальные затраты на путеше-
398
Организация данных
Часть II
ствие в долларах. В этом контексте ребро с отрицатель- го определенного маршрута. Почти во всех других жиз-
ными затратами будет там, где железнодорожная ком- ненных ситуациях, представляемых с помощью графов,
пания платит своим пассажирам за использование это- ребра с отрицательными затратами не возникают. Лис-
тинг 16.5 демонстрирует алгоритм Беллмана-Форда.
Листинг 16.5. Алгоритм Беллмана-Форда.
int Bellman(struct Graph * G, int Source, struct DijkstraTable * Table)
{
int V; /* V - это индекс текущей вернины */
int i;
struct PQueue Q;
struct Dijkstra_Row * Results;
struct EdgeScan E; /* содержит информацию о ребре */
PQ_Initialise((Q);
i=InitResults((Results , G->NumVertices);
if (i) return i; /* сообщить о любой онибке */
Results[Source].Total=0; /* lar 1 */
Results[Source].Previous--!; /* предыдущей вернины нет */
V=Source;
do {
Results[V].Visited++; /* lar 2 */
if (Results[V].Visited==G->NumVertices) return GRAPH_BADGRAPH;
/* если есть посещенная вернина, одна для каждой вернинн, то мы должны быть в
отрицательном цикле. Возвратить оннбку для предотвращения неограниченного цикла
*/
EdgeScanStart(G, V, (Е); /* lar 3 */
while (EdgeScanNext((E)--O)
{
if (Results[V).Total + E.Cost < Results!E.Dest].Total )
{
Results[E.Dest].Total = Results[V].Total + E.Cost;
Results[E.Dest].Previously;
PQEnqueue((Q,Results[E.Dest]•Total,E.Dest);
}
}
EdgeScanEnd((E);
V=PQ_Dequeue((Q); /* lar 4 */
} while (V!=-l);
Table->G=G;
Table->Source=Source;
Table->Results-Results;
return 0;
Алгоритм Флойда: все пары вершин
Алгоритм Флойда (Floyd) подсчитывает кратчайший
путь между всеми парами вершин в графе, но не так, как
показано ранее. Этого можно достичь, запуская исход-
ный алгоритм кратчайшего пути V-1 раз и упорядочи-
вая результаты. В случае с алгоритмом Дийкстры это
происходит приблизительно за V3 итераций. То же са-
мое справедливо и в случае с алгоритмом Флойда.
Различие состоит в том, насколько тяжело выполнять
каждую итерацию. Алгоритм Флойда реализуется до-
вольно просто, потому что каждая итерация занимает
совсем немного времени. Почти во всех случаях это го-
раздо проще, чем выполнять множество централизован-
ных функций поиска кратчайшего пути.
Предположим, что у нас есть путь между вершина-
ми у, и Vj, на котором посещается определенное коли-
Работа с графами
Глава 16
399
чество промежуточных вершин. Можно представить
этот путь, составляя список последовательных вершин,
который выглядит следующим образом: v,, i0, in i2... ir,
Vj. D[u,v] — это кратчайший путь между двумя верши-
нами. c[u,v] — это затраты прямого ребра от и к v, рав-
ные затратам некоторого ребра, если и и v — смежные
вершины, или равные бесконечности, когда и и v не
являются смежными.
В алгоритме Дийкстры для поиска кратчайшего пути
D[u.v] между двумя вершинами рекурсивно применяется
правило:
D[u,v]=min(D[u,v], В[и,Ц+с[1п,у])
Другими словами, минимальные затраты от и к v -
это затраты на кратчайший найденный путь либо зат-
раты на промежуточные вершины плюс ребра, соединя-
ющие промежуточные вершины на пути к v. Передви-
гаясь по вершинам, используемым в качестве
промежуточных, можно подсчитать кратчайший путь ко
всем вершинам. Это то, что делает алгоритм Дийкстры
"централизованным", — и никогда не изменяется.
Алгоритм Флойда основывается на тех же правилах,
однако работает по-другому. Как и алгоритм Дийкстры,
он на каждом этапе подсчитывает кратчайший путь,
проводя итерации переменных по правилу. Отличие
состоит в способе проведения такого подсчета.
Вместо выполнения поиска пути к промежуточной
вершине мы обрабатываем путь от и к v как два от-
дельных пути, разделенных некоторой промежуточной
вершиной ik. Теперь нас больше интересует путь от к
v, чем просто определение того, есть ли ребро от вер-
шины in к вершине v.
При выполнении алгоритм Флойда длину неизвест-
ных путей можно определить исходя из длины путей,
которые уже известны. После подсчета кратчайшего
пути между и и v его можно использовать для опреде-
ления проходящих через v путей от и ко всем другим
вершинам.
Первоначально известные кратчайшие маршруты —
это ребра в графе. Более короткие пути определяются в
процессе работы алгоритма. Массив, используемый для
хранения текущих известных кратчайших путей, пер-
воначально идентичен матрице смежности в графе.
Выберем промежуточную вершину к. Для каждой
пары вершин (i,j) применяется правило:
D[iJ]=min(D[i,j], D[i,k]+ D[k,jJ)
С использованием каждого значения к изучается
Каждый возможный путь между двумя вершинами и осу-
ществляется поиск кратчайшего из них. Следующий
Пример показывает, как этот алгоритм работает на прак-
тике.
Вместо того чтобы представлять результаты как мат-
рицу смежности, при реализации используется более
общий способ хранения. Рис. 16.38 и табл. 16.13 демон-
стрируют результаты, представленные в наиболее дос-
тупном для понимания виде.
Первая колонка таблицы — это список всех возмож-
ных путей, которые могут существовать в рассматрива-
емом графе. Следующая колонка — это начальные зна-
чения затрат на этих путях, а каждая последующая
колонка — затраты после обработки каждого значения
к. Затраты, выделенные жирным шрифтом, — мини-
мальные затраты, рассчитанные для определенного зна-
чения к, т.е. текущие затраты пути i —»j больше, чем
пути i —» к+к —» j.
РИСУНОК 16.38. Алгоритм Флойда.
Таблица 16.13. Алгоритм Флойда.
Путь Начальное значение к=0 к=1 к=2 к=3
v0-»v0 0 0 0 0 0
v0-> v1 -1 -1 -1 -1 -1
v0->v? оо оо 1 1 1
v0->v3 2 2 2 2 2
Vi —> v0 ©о оо ОО 6 6
Vi ->V, 0 0 0 0 0
Vi->v2 2 2 2 2 2
V, ->v3 ©о ©о оо 5 5
v2->v0 4 4 4 4 4
V2-> Vi ©о 3 3 3 3
v2->v2 0 0 0 0 0
v2-»v3 3 3 3 3 3
v3->v0 оо оо оо 7 7
v3—*v. 1 1 1 1 1
V3-»V2 ©о оо 3 3 3
V3 -> V3 0 0 0 0 0
Сначала в качестве промежуточной используется
вершина v0. Для каждого i и j мы используем правило
для определения того, является ли путь от i до j, кото-
Организация данных
400
Часть II
рый использует промежуточную вершину, короче, чем
текущий. В нашем примере определяется, что путь
v2 -»v, короче, чем полученный при использовании v0
в качестве промежуточной вершины. Другими слова-
ми, путь v2-~> v0-> V! длиннее, чем кратчайший путь
v2 » vb определенный ранее.
Во время следующей итерации, когда к=1, выпол-
няется та же самая операция. Однако на этот раз полу-
чается, что пути —> V] —> v2 и v3 —> v, —> v2 короче, чем
определенные ранее пути v0 —> Vj и v3 —> v2 соответствен-
но. После того как использованы все значения к, окон-
чательными значениями являются длины кратчайших
путей. В листинге 16.6 реализован алгоритм Флойда.
Можно также определить фактический путь, а не
только его длину между любой парой вершин. Это не-
намного сложнее, чем алгоритм Дийкстры. Требуемая
информация — это значение к, являющееся кратчай-
шим путем. Отсюда можно разделить каждый путь на
два, причем первый заканчивается и второй начинает-
ся в промежуточной вершине. Эту же операцию можно
применить для каждого пути, пока не будут полностью
разделены все пути: путь — это направление от и к v без
каких-либо промежуточных вершин.
Например, можно найти путь v3 —> v0. Просмотрев
таблицу, определяем, что кратчайший путь v3 -> v0 ис-
пользует v2 как промежуточную вершину для кратчай-
шего пути к=2. Теперь путь будет v3 —> v2 —> v0. Приме-
няем ту же логику для v3 —> v2. Кратчайший путь
использует вершину Vj в качестве промежуточной. Таким
образом, получаем кратчайший путь v3 —» Vj —> v2 —> v0.
Дальнейшие действия показывают, что каждую
часть маршрута нельзя больше разделить, потому что нет
соответствующего значения к.
При такой технологии путь разбивается так, как
если бы он был двоичным деревом. Рис. 16.39 нагляд-
но демонстрирует, как разделяется путь v3 v0. Это ут-
верждение справедливо для любого пути.
РИСУНОК 16.39.Путъч3-Ъ v0.
Алгоритм Флойда дает корректные результаты и для
графов с ребрами, имеющими отрицательные затраты.
Если встречаются циклы с отрицательными затратами,
алгоритм не будет работать бесконечно, но полученные
результаты не будут достоверными. Это состояние мож-
но определить, изучив пути от каждой вершины назад
к ней самой. Если обнаружится отрицательный цикл,
то затраты пути назад к вершине после окончания ра-
боты алгоритма будут иметь отрицательное значение.
Обычно расстояние от любой вершины обратно к ней
самой равно 0.
Итак, для выполнения алгоритма Флойда требуется
V3 итераций, как и при выполнении алгоритма Дийкст-
ры для каждой вершины. Различие состоит во времени,
которое требуется для выполнения каждой итерации.
Реализация алгоритма Флойда имеет очень плотный
внутренний цикл. Хорошо оптимизирующий компиля-
тор сделает из него исключительно быстро выполняе-
мый код. Реализации алгоритма Дийкстры обычно име-
ют более сложный внутренний цикл, поэтому каждая
итерация занимает больше времени.
В действительности предшествующая реализация не
так эффективна, как можно было бы ожидать. Это связано с
выбранным значением GRAPH NOTCONNECTED, кото-
рое используется в случае несвязанного графа и задается
равным INT_MAX (в файле graphs.h на Web-сайте изда-
тельства ’’ДиаСофт"). При добавлении величины
INT-МАХ к самой себе обычно происходит переполнение.
В ANSI/ISO С переполнение переменной вызывает нео-
пределенное поведение программы. На практике это
приводит к случайным результатам в неориентирован-
ных графах, являющихся несвязанными, и в ориенти
рованных графах, которые не являются сильно связан-
ными. На большинстве компьютерных систем вершины,
к которым нет пути, дают очень близкие значения, но
не равные GRAPH_NOTCONNECTED
Выполнение проверки предотвращает это перепол-
нение, но только за счет ухудшения характеристик ал
горитма. Внутренний цикл настольно сжат, что такая
проверка значительно увеличивает время выполнения
алгоритма. Но существуют способы предотвращения
этого.
Один из таких способов, состоит в том, чтобы сдс
лать граф связанным (или сильно связанным в случае с
ориентированным графом). После этого проверка нео
бязательна, так как есть условие защиты, благодаря ко
торому переполнение больше не может произойти.
Второй способ — не использовать GRAPH NOT
CONNECTED, но выбрать значение, которое при удва
ивании не вызовет переполнения (т.е. INT_MAX>2*n)
Любые общие затраты для графа будут меньше п, ш»
крайней мере наполовину меньше, чем значение для
самого длинного пути в графе.
Работа с графами
Глава 16
401
Листинг 16.6. Алгоритм Флойда.
int Floyd(struct Graph ♦ G,struct Floyd_Table * Table)
/* Алгоритм Флойда используется в целях подсчета кратчайшего марирута для всех пар вервии,
в случае успеха возвращается 0, или значение <0, если произошла ошибка (GRAPH_OUTOFMAN,
GRAPH_B ADPARAM). При передаче графа, содержащего цикл с отрицательными затратами, получаются
фиктивные результаты, а не результат ошибки в сегментации, в начальных циклах и т.п.
*/
{
int i,j,k;
/* Для каждой пары вершин i и j определяется кратчайший маршрут D[i,j]. D[i,j] определяется
как минимум D[i,j] и марирута через каждую промежуточную вершину к, т.е. используется правило
min(D[i,j], D[i,k]+ D[k,j])
*/
struct FloydResult ** R;
struct EdgeScan EScan;
if (1G || ITable || !G->NumVertices) return GRAPHBADPARAM;
/* Создать двумерный массив результатов */
R=MakeResults(G->NumVertices);
if (!R) return GRAPHOUTOFMEM;
/* Инициализировать таблицу результатов */
for (i=O;i<G->NumVertices;i++)
EdgeScanStart(G,i,bEScan);
while (EdgeScanNext(&EScan)==0)
{
R[i][EScan.Dest].Total=EScan.Cost;
}
EdgeScanEnd(SEScan);
1
for (k=O;k<G->NumVertices;k++)
for (i=O;i<G->NumVertices;i++)
for (j=0;j<G->NumVertices;j++)
{
/* Поскольку на практике GRAPHNOTCONNECTED - это INTMAX, требуется убедиться, что не
произойдет переполнения */
if (R[i][kJ.Total==GRAPHJiOTCONNECTED 11 R[k][j].Total==
GRAPHNOTCONNECTED) continue;
if (R[i)[j].Total > R[i][k].Total + R[k][j].Total)
{
R[i][j]-Total=R[i][k].Total + R[k][j].Total;
R[i)(j]•Previous=k;
)
}
Table->G=G;
Table->Results=R;
return 0;
Функции на Web-сайте издательства "ДиаСофт" и
представленные здесь разработаны в наиболее общем
•Иде, чтобы их можно было использовать с любыми
разумными графами, и поэтому проверка не проводит-
ся. Если работоспособность алгоритма — главная про-
блема, это предположение можно отбросить и сделать
другие допущения.
При попытке найти кратчайший путь для всех пар
насыщенных графов хорошая реализация алгоритма
Флойда предпочтительнее (по скорости выполнения),
чем многократное применение алгоритма Дийкстры.
Для разреженных графов алгоритм Дийкстры с исполь-
26 Зак. 265
Организация данных
Часть II
402
зованием двоичной пирамиды (см. главу 11) будет ра-
ботать с менее заметно возросшей скоростью.
Теоретически существует технология, основанная на
алгоритме Флойда, которую лучше всего использовать
для больших разреженных графов. Этот алгоритм про-
веряет каждую возможную промежуточную вершину
для каждой пары вершин в графе. Для разреженных
графов количество определенных путей между парами
сравнимо с количеством возможных пар.
Во время выполнения алгоритма Флойда на бумаге
становится ясно, что необходимо работать только с из-
вестными вершинами. Просто если ребро у -> vk неиз-
вестно (имеет бесконечные затраты), то любой путь от
v4 —» vk —» Vj будет бесконечен без возможности каких-
либо улучшений. Эти же рассуждения можно приме-
нить ко второй части пути vk —> v?
Идею известных путей можно использовать для
уменьшения количества необходимых итераций. Слож-
ность состоит в реализации такого алгоритма. Очевид-
но, он будет работать медленнее, чем при нормальной
реализации алгоритма Флойда, поскольку процессору
требуется время для поддержания различных необходи-
мых структур данных.
Минимальные остовные деревья
Остовное дерево — это дерево, полученное из ребер
неориентированных графов, которые соединяют все
существующие вершины. Минимальным остовным де-
ревом называется дерево, имеющее наименьшие общие
затраты (сумма затрат каждого используемого ребра).
Только связанные графы могут иметь минимальные
остовные деревья.
Такие деревья часто используются для решения про-
блем особого рода. Представьте себе установку WAN
(глобальной сети) между определенным количеством
отдаленных друг от друга мест. Цель — найти кабель
самой короткой длины, соединяющий вместе все тре-
буемые места. Эту сеть можно описать графом, верши-
нами которого являются связываемые места, а ребрами
между ними — возможные кабельные связи с затрата-
ми, определенными по отношению к расстоянию или
их стоимости (рис. 16.40). Минимальное остовное де-
рево такого графа будет решением данной проблемы,
так как оно имеет наименьшие общие затраты по реб-
рам, соединяющим все вершины.
Любое остовное дерево имеет ребра в количестве
V-1, это минимальное число ребер, соединяющих V вер-
шин. Добавив ребро в остовное дерево, мы создадим
цикл, и это будет уже не дерево. Удаляя ребро внутри
цикла, можно удалить цикл и сделать его снова дере-
вом. Общие затраты ребер дерева уменьшаются, если
затраты удаленного ребра больше, чем затраты вновь до-
бавленного ребра.
РИСУНОК 16.40. Граф и его минимальное остовное дерево.
Остовное дерево имеет минимальные затраты, ког-
да при добавлении одного ребра и удалении другого
уменьшаются общие затраты ребер в дереве.
Обычно для создания минимального остовного де-
рева графа используются два способа. Первый представ-
ленный здесь способ — алгоритм Крускала (Kruskal).
Этот алгоритм создает дерево путем добавления ребер
в порядке связанных с ними затрат. Второй способ —
алгоритм Прима (Prim), который строит дерево путем
добавления в него вершин на каждой стадии.
Алгоритм Крускала
Этот алгоритм создает дерево графа, на каждой итера-
ции добавляя в дерево ребро, пока все вершины не ста-
нут связанными. Любое ребро, которое приводит к фор-
мированию цикла, игнорируется. На рис. 16.41 показано
минимальное остовное дерево на каждой стадии для
графа, пример которого дан на рис. 16.40. Алгоритм
Крускала можно представить следующим образом:
1. Создать структуру данных для хранения дерева во
время его построения. Эта структура содержит все
вершины, которые существуют в графе, без соеди-
няющих их ребер.
2. Просмотреть все ребра в графе в порядке их стоимо-
сти. Выбрать первое (с минимальными затратами)
ребро.
3. Выбрать следующее ребро из списка.
4. Если текущее ребро не образует цикл, то оно добав
ляется в дерево.
5. Повторить все действия, начиная с п. 3, пока вес
вершины в дереве не станут связанными.
Работа с графами
Глава 16
403
Часть реализации этого алгоритма, занимающая са-
мое большое количество времени на вычисления, — это
способ, которым выбираются ребра. Графы обычно хра-
нятся таким образом, что трудно создать список ребер
для всего графа. Оба представленных способа страдают
от этой проблемы, однако они имеют преимущества с
других точек зрения.
Хорошим решением было бы создание приоритетной
очереди ребер. Операция вывода из очереди автомати-
чески дает ребро с наименьшими затратами, которое не
было изучено. После этого действия 3—5 выполняются
самое большее за Е итераций, где Е — количество ре-
бер в графе. Способ, по которому реализуется очередь,
занимает очень много времени.
Один подход решения этой проблемы состоит Ъ ис-
пользовании двоичной динамической памяти — отчас-
ти сложной, но эффективной структуры данных. Время,
за которое приоритетные очереди обычно выполняют
одну операцию постановки в очередь с использовани-
ем двоичной динамической памяти в качестве базовой
структуры данных, имеет порядок O(log N), т.е. полное
время на построение приоритетной очереди ребер име-
ет порядок О(Е log Е).
РИСУНОК 16.41
Стадии алгоритма Крускала.
Листинг 16.7. Алгоритм Крускала.
int KruskalUndirected(struct Graph * G,struct Graph ** TreePtr)
<
/* Граф G изучается для создания нового графа, который является минимальным остовным деревом,
а структура Graph *, обозначенная указателем TreePtr, принимает новое значение.
В случае успеха возвращается значение 0, в случае оиибки - значение <0 (GRAPH_BADRAM,
GRAPH-OUTOFMEN)
*/
int i, j, numadded;
struct Graph * Tree;
struct PEdgeQueue * Q;
struct EdgeScan EScan;
if (!G || 1 TreePtr) return GRAPHBADPARAM;
404
Организация данных
Часть II
PEQ_Initialise(Q);
Tree=MakeGraph(List);
if (ITree) return GRAPHOUTOFMEM;
/* Наги 1 и 2: расположение ребер в графе по затратам, а также дублирование вершин графа G в
Tree (только потому, что быстрее работает один цикл, выполняющий две задачи, чем два цикла,
выполняющие одну задачу
*/
for (i=O;i<G->NumVertices;i++)
(
j=AddVertex(Tree);
if (j<0)
{
/* Ошибка. Очистить и возвратиться */
PEQFree(Q);
FreeGraph(Tree);
return j;
}
Tree->Vertices[j]->Tag=G->Vertices[i]->Tag;
EdgeScanStart(G,i,fcEScan);
while (1EdgeScanNext(fcEScan))
{
/* Установить EScan так, чтобы противоположное ребро не повторялось, поскольку мы
работаем только с неориентированными ребрами. В таком случае можно использовать только
половину необходимой памяти и отслеживать любое ребро только один раз. Затраты - это время
на обработку.
*/
if (EScan.Source>EScan.Dest) SWAP(EScan.Source,EScan.Dest,int);
if (PEQEnqueue(Q,&EScan))
{
/* Ошибка - не хватает памяти. Очистить и возвратиться. */
PEQFree(Q);
FreeGraph(Tree);
return GRAPBOUTOFMEM;
}
}
EdgeScanEnd(&EScan);
numadded=0;
/* лаг 3, выбрать следующее ребро из списка */
while (numadded<G->NumVertices-1 && !PEQ_Dequeue(Q,&EScan))
{
/* Наг 4, если текущее ребро не образует циклов, оно добавляется в дерево */
if (1AreVerticesConnected(Tree,EScan.Source,EScan.Dest))
{
/* Если не существует пути от источника к месту назначения, то текущее ребро при
добавлении не образует цикла */
j=ConnectVertex(Tree,EScan.Source,EScan•Dest,EScan.Cost);
if (1 j) j=ConnectVertex(Tree,EScan.Dest,EScan.Source,EScan.Cost);
if (j)
{
/* Произошла ошибка, очистить и возвратиться */
PEQFree(Q);
FreeGraph(Tree);
return j;
}
Работа с графами
Глава 16
405
numadded++;
}
}
*TreePtr=Tree;
PEQFree(Q);
return 0;
Алгоритм Прима
Алгоритм Прима (Prim) создает минимальное остовное
дерево путем добавления единственного ребра (а также
вершин) в дерево после определенного количества ите-
раций. Вершины в графе разделяются на два набора:
один, являющийся частью дерева, а другой — нет. Во
время каждой итерации ребро с минимальными затра-
тами связывает любую вершину, являющуюся частью
решения, с любой вершиной, которая еще не добавле-
на в это решение. Это происходит до тех пор, пока в
решение не будут добавлены все вершины, другими
словами, пока не будет выбрано V-l ребер.
Может показаться, что этот алгоритм похож на ал-
горитм Дийкстры. Но разница в том, что алгоритм При-
ма сохраняет ребра с минимальными затратами, в то
время как алгоритм Дийкстры сохраняет пути с мини-
мальными затратами. Алгоритм Прима можно описать
следующим образом:
1. Выбрать корневую вершину V.
2. Пометить V как посещенную.
3. Для каждой смежной с V вершины установить зат-
раты кратчайшего ребра.
4. Выбрать непосещенную вершину с наименьшими
затратами ребра в качестве текущей вершины V и
добавить связывающее ребро в остовное дерево.
5. Повторить все шаги, начиная со второго, пока не
будут посещены все вершины.
Таблицы 16.14—16.21 и рис. 16.42 демонстрируют
алгоритм Прима. На рис. 16.42 показано минимальное
остовное дерево на каждой стадии для графа, показан-
ного на рис. 16.40.
Таблица 16.14. Алгоритм Прима — стадия 1.
v„ Посещенные вершины Затраты ребра Предыдущая вершина
0 нет оо нет
1 нет оо нет
2 нет оо нет
3 нет оо нет
4 нет оо нет
5 нет оо нет
6 нет оо нет
Таблица 16.15. Алгоритм Прима — стадия 2.
Посещенные вершины Затраты ребра Предыдущая вершина
0 да оо нет
1 нет 8 v0
2 нет 6 V0
3 нет оо нет
4 нет 7 нет
5 нет ОО V0
6 нет оо нет
Таблица 16.16. Алгоритм Прима — стадия 3.
ч. Посещенные вершины Затраты ребра Предыдущая вершина
0 да оо нет
1 нет 3 v^
2 да 6 V,
3 нет оо нет
4 нет 5 v2
5 нет 7 Vo
6 нет ОО нет
Таблица 16.17. Алгоритм Прима — стадия 4.
Посещенные вершины Затраты ребра Предыдущая вершина
0 да оо нет
1 да 3 v2
2 да 6 Vo
3 нет 2 Vi
4 нет 5 V2
5 нет 7 Vo
6 нет оо нет
Таблица 16.18. Алгоритм Прима — стадия 5.
V„ Посещенные вершины Затраты ребра Предыдущая вершина
0 да оо нет
1 да 3 v2
2 да 6 v0
3 нет 2 Vi
4 нет 5 v2
5 нет 7 Vo
6 нет ОО нет
Организация данных
Часть II
406
Таблица 16.19. Алгоритм Прима — стадия 6.
ч, Посещенные вершины Затраты ребра Предыдущая вершина
G да сю нет
1 да 3 v2
2 да 6 v0
3 да 2
4 да 5 V2
5 нет 1 v4
6 нет 2 V4
Таблица 16.20. Алгоритм Прима — стадия 7.
4, Посещенные вершины Затраты ребра Предыдущая вершина
0 да ос нет
1 да 3 v2
2 да 6 v0
3 да 2 Vi
4 да 5 v2
5 да 1 v4
6 > нет 2 V4
Таблица 16.21. Алгоритм Прима — стадия 8.
4, Посещенные вершины Затраты ребра Предыдущая вершина
0 да сю нет
1 да 3 v2
2 да 6 v0
3 да 2 Vi
4 да 5 V2
5 да 1 V4
6 да 2 V4
Несмотря на то что алгоритм Прима похож на алго-
ритм Дийкстры, он не страдает от некоторых проблем,
присущих алгоритму Дийкстры. Операция, выполняе-
мая алгоритмом Прима, не будет отличаться от опера-
ции алгоритма Дийкстры, если присутствуют ребра с
отрицательными затратами. Циклы с отрицательными
затратами более не представляют проблемы: в резуль-
тате работы алгоритма (имеется в виду дерево) цикла не
создается, значит, алгоритм не может входить в беско-
нечный цикл.
Сходство этих алгоритмов отражается и на их реа-
лизации. Все проблемы реализации и работоспособнос-
ти, характерные для алгоритма Дийкстры, присущи и ал-
горитму Прима. Реализация алгоритма Прима для
неориентированных графов представлена в листинге 16.8.
Самое длительное время выполнения алгоритма
Прима имеет порядок (XV2). При работе с разреженны-
ми графами его можно уменьшить, если использовать
приоритетную очередь вершин. С использованием дво-
ичной динамической памяти в качестве основной струк-
туры очереди можно уменьшить время выполнения при
работе с разреженными графами до порядка О(Е log V).
При использовании алгоритма Прима для несвязан-
ных графов некоторые вершины не будут посещаться.
В таком графе невозможно построить минимальное ос-
товное дерево, но в то же время для каждой связанной
части графа можно создать лес, состоящий из минималь-
ных остовных деревьев.
РИСУНОК 16.4Z
Стадии алгоритма Прима.
407
Работа с графами
Глава 16
Листинг 16.8. Алгоритм Прима.
int Prim Undirected(struct Graph * G,struct Graph ** TreePtr)
<
/* Граф G изучается для создания нового графа, который является минимальным остовным деревом,
а структура Graph *, обозначенная указателем TreePtr, принимает новое значение.
В случае успеха возвращается значение 0, в случае оиибки возвращается значение <0
(GRAPH-BADRAM, GRAPHOUTOFMEN)
*/
struct Graph * Tree;
struct PrimWorking * W;
struct EdgeScan EScan;
int NumVisited, V, i, j, lowest;
if (!G || !TreePtr) return GRAPBBADPARAM;
Tree=MakeGraph(List);
if (ITree) return GRAPBOUTOFMEM;
W-malloc(sizeof(struct PrimWorking)*G->NumVertices);
if (!W)
{
FreeGraph(Tree);
return GRAPBOUTOFMEM;
};
for (i=0;i<G->NumVertices;i++)
{
W[i].Visited=FALSE;
W[i].LowestCost=GRAPH_NOTCONNECTED;
W[i].Prev=-l;
j=AddVertex(Tree);
if (j<0>
{
/* Онибка, очистить и возвратиться */
FreeGraph(Tree);
free(W);
return j;
>
Tree->Vertices(j]->Tag=G->Vertices[i]->Tag;
NumVisited-0;
/* Дерево - пустой граф. Посещенный массив целых чисел длиной G->NumVertices вначале
обновляется */
/* Наг 1, выбрать корневую вернину */
V=0;
for (;;)
<
/* lar 2, пометить вернину V как посещенную */
W[V].Visited=TRUE;
NumVisited++;
if (NumVisited“G->NumVertices) break; /* Мы закончили */
/* Bar 3, для каждой вернины, смежной с V, установить затраты кратчайнего ребра */
EdgeScanStart(G,V,ЬEScan);
while (!EdgescanNext(&EScan))
408
Организация данных
Часть II
{
if (EScan.Cost<W[EScan.Dest]•LowestCost)
{
W[EScan•Dest]•LowestCost=EScan.Cost;
W(EScan.Dest).Prev=V;
}
}
EdgeScanEnd((EScan);
/* lar 4, выбрать вервину с ребром, имеющим минимальные затраты, которая еще не была
посещена, и добавить ребро в минимальное остовное дерево.
*/
lowest=GRAPH_NOTCONNECTED;V=-l;
for (i=O;i<G->NumVertices;i++)
{
if (W[i).Visited) continue;
if (V==-l) V=i;
if (W[i).LowestCost<lowest)
{
lowest=W[i].LowestCost;
V=i;
}
>
if (W[V].Prev!=-l)
{
i=ConnectVertex(TreefVfW[V].Prev,W[V].LowestCost);
if (!i) i=ConnectVertex (Tree, W(V] .Prev, V,W[V] .LowestCost);
if (i)
{
/* Произошла оиибка, исправить и возвратиться */
free(W);
FreeGraph(Tree);
return i;
}
}
/* Первое 'V=i' в предыдущем цикле используется для сохранения индекса вериины, которая еце
не посещена. Это четко работает в случае, когда все посещенные неровны не имеют каких-либо
ребер к иепосеценным вернинам (т.е. граф является иеорнеитированным). Если граф
неориентированный, то V устанавливается как иепосещениая вернина, следовательно, создается не
минимальное остовное дерево, а минимальный остовный лес. Если же граф ориентирован, то V
будет индексом вернины, имеющей ребро с минимальными затратами.
*/
}
free(W);
*TreePtr=Tree;
return 0;
Оптимизация: последнее замечание
Графы, как структуры данных, являются довольно
сложными, и могут легко стать очень большими. При
работе с такими усложненными структурами тратится
много времени. Ключом к оптимизации является видо-
изменение структур данных, используемых для демон-
страции графа таким образом, чтобы уменьшить коли-
чество итераций общих алгоритмов.
При работе с алгоритмами, занимающими много
времени на вычисления (например, с алгоритмами сор-
тировки или поиска), выбор подходящих структур дан-
ных позволяет повысить их эффективность, однако
обычно это касается алгоритмов, которые имеют значи-
Работа с графами
Глава 16
409
тельно улучшенные характеристики. Для любого алгорит-
ма, работающего с графами, количество итераций (а сле-
довательно, и времени на выполнение) во многом зависит
от скорости исследования структур данных графа.
Во-первых, необходимо выяснить, — является ли
граф насыщенным или разреженным. Это во многом
зависит от того, для чего он был разработан. Как пра-
вило, чем больше структура данных (имеется в виду
использование структурой физической памяти), тем
больше времени займет выборка и полное выполнение
задачи. Чем больший объем памяти задействован в про-
цессе, тем больше времени потребуется на ее обследо-
вание, в результате чего неизбежно увеличивается время
работы алгоритма. Выбор представления, использующе-
го наименьший объем памяти, позволяет в значитель-
ной степени уменьшить время выполнения алгоритма.
Во-вторых, нужно определить, можно ли данную
структуру данных применить к алгоритмам, которые ис-
пользуются в вашем частном приложении. Если, напри-
мер, у вас есть граф, который часто, но не сильно об-
новляется, то можно значительно уменьшить время
выполнения, если просто поддерживать список ребер,
требующих изменения, и добавлять или удалять их.
Не существует строгих правил при оптимизации
алгоритмов работы с графами. Основной подход — сде-
лать часто требуемые данные легкодоступными, а един-
ственный способ, позволяющий добиться этой цели, —
правильное использование структур данных.
Резюме
В этой главе были рассмотрены некоторые элементы
теории графов, технологии представления графов в ка-
честве структуры данных, а также продемонстрирова-
ны алгоритмы, которые можно использовать практичес-
ки. Библиотека графов, применяемая во всех примерах
кода, достаточно гибка, так что ее можно использовать
во всех приложениях, за исключением тех, в которых
главным критерием является время выполнения.
Дополнительные
тематические разделы
ЧАСТЬ
Шифрование
Встроенные системы
ЯГ til-'
В ЭТОЙ ЧАСТИ
Матричная арифметика
Обработка цифровых сигналов
Синтаксический анализ и вычисление
выражений
Создание программных инструментальных
средств
Генетические алгоритмы
Мёжплатформенная разработка:
программирование коммуникационных средств
Написание CGI-приложений на С
Арифметика произвольной точности
Обработка естественных языков
С
Взгляд в будущее: С99
Параллельная обработка
ЖШ...... ...
Матричная арифметика
В ЭТОЙ ГЛАВЕ
Что такое матрица
Простые операции матричной арифметики
Реализация матричной структуры в языке С
Инициализация матриц из массивов
Извлечение матрицы из файла
Запись объектов MATRIX T в stdout или в другой файл
Полная реализация суммирования и транспонирования
Сложные концепции матриц
Решение линейных алгебраических уравнений
Дальнейшие направления работы
Другие подходы
Сэм Хоббс
В этой главе речь пойдет о матрицах, будут рассмотре-
ны примеры их использования и алгоритмы матричной
арифметики, а также исследованы вопросы управления
матрицами с. использованием языка С. Вы узнаете, как
выполнять суммирование, вычитание, умножение, ин-
вертирование (обращение) и транспонирование матриц,
а также как вычислять определители и решать линей-
ные (первой степени) алгебраические уравнения (вклю-
чая исправление возможных ошибок). И не волнуйтесь,
если вдруг какие-либо из перечисленных понятий вам
покажутся слишком сложными. В этой главе все опи-
сывается очень доходчиво, шаг за шагом, рассматрива-
ется каждая операция, подробно рассказывается о том,
как их выполнять и математически, и на языке С. А ко-
нечной целью главы является создание библиотеки мат-
риц, которую можно будет использовать прямо в С-про-
граммах для различного рода приложений.
ПРИМЕЧАНИЕ
Библиотека матриц, разработанная в этой главе, как и
любые другие такого рода библиотеки, имеет свои ог-
раничения. Расчет огромных разреженных матриц или
решение систем, содержащих тысячи уравнений, находит-
ся за пределами возможностей этой библиотеки.
Что такое матрица
Матрица — это прямоугольный массив чисел, который
можно логически представить на языке С следующим
образом:
double а[3][4]
Матрицы можно использовать для упрощения пред-
ставления задач линейной алгебры (систем уравнений)
и преобразований координат. Алгоритмы и операции,
используемые для выполнения матричной арифметики,
не требуют выполнения сложных математических вы-
числений. (Для манипулирования огромными матрица-
ми или почти вырожденными матрицами существуют
определенные тематические разделы, которые довольно
сложны. В этой главе упоминаются некоторые из них, но
они не покажутся вам недоступными или слишком слож-
ными.) Основное внимание мы уделим реализации
практических решений проблем с использованием мат-
ричной арифметики на языке программирования С.
ПРИМЕЧАНИЕ
Вырожденными (или сингулярными) называются матрицы,
которые нельзя инвертировать (обратить). Инверсия, — это
некий эквивалент деления в арифметике действительных
чисел (об этом будет подробно рассказано далее). По-
пытка инвертирования вырожденной матрицы аналогична
попытке деления на нуль.
Все основные матричные операции просты; в дей-
ствительности. за исключением инициализации пере-
менных и установки циклов, основные расчеты в язы-
ке С можно реализовать с помощью единственной
строки кода для каждой такой операции.
ПРИМЕЧАНИЕ
Практические вопросы инициализации переменных, уста-
новки циклов, управления памятью и обнаружения оши-
бок повышают уровень сложности программ, однако про-
граммист не должен бояться матричной арифметики. Ее
412
Дополнительные тематические разделы
Часть III
основы просты и понятны; Проблемы даже средней слож-
ности можно решить без труда. Действительно сложные
вопросы могут потребовать присутствия в команде раз-
работчиков специалиста по численному анализу, посколь-
ку в данной главе эти вопросы не обсуждаются.
Операции вычисления определителей и инвертиро-
вания матриц более сложны, однако существуют про-
стые и понятные методы проведения этих операций и
их реализации на языке С. Кроме того, при вычислении
обратной матрицы (что часто делается при решении сис-
тем линейных алгебраических уравнений) основной про-
блемой является распространение (накопление) ошибок.
(Вопросы распространения и устранения ошибок будут
рассмотрены в этой главе далее.)
Наиболее сложная часть работы матричной арифме-
тики на языке программирования С — это реализация
деталей проекта. Имеется в виду инициализация пере-
менных, определение структур и компонентов языка,
которые используются для представления матрицы,
управление памятью (включая обработку временных
переменных), передача сложных структур в качестве
аргументов, а также использование указателей для эф-
фективной адресации отдельных элементов матрицы.
Простые операции матричной
арифметики
Стандартной математической нотацией (записью) для
представления матрицы с помощью абстрактного сим-
вола является выделенная курсивом прописная буква
(например, А), которая представляет прямоугольный
массив чисел с типичным элементом а., находящимся
v
в строке / и в колонке (столбце) j. Поскольку мы гово-
рим о том, как реализовывать матричную арифметику
с использованием языка программирования С, то, есте-
ственно, будем просто ссылаться на элемент a[i][j], ко-
торый используется в языке С для стандартного пред-
ставления двумерного массива.
Несмотря на то что множество матриц, которые ис-
пользуются, например, для решения уравнений, явля-
ются квадратными (например, матрица 2x2 или 3x3),
матрица, вообще, — это прямоугольный массив чисел,
и он не обязательно должен быть квадратным.
Можно сложить две матрицы с одинаковыми прямо-
угольными размерами и получить новую матрицу с теми
же размерами. Например, при сложении двух матриц
3x4, получаем новую матрицу 3x4. Элементы новой
матрицы — это просто сумма соответствующих элемен-
тов двух складываемых матриц (в системе обозначений
языка С):
sum_ab[x][j]=a[x][j]+b[x][j];
(при реализации эго выражение должно быть заключе-
но в соответствующие циклы for). Таким же образом
выполняется вычитание:
dxf_ab[x] [j]=a[x] (j]-b(x] [j] ;
Сложение и вычитание должны быть вам знакомы.
Следующей простой операцией с матрицами явля-
ется транспонирование; буквально это означает пере-
становку элементов из рядов в колонки. Символически
операция транспонирования записывается с помощью
верхнего индекса Т (А7) и читается как транспонирован-
ная матрица А. Для квадратных матриц в результате
транспонирования матрица просто ’’перебрасывается"
через главную диагональ. В общем же случае транспо-
нированная матрица MxN — это матрица NxM (рис.
17.1).
РИСУНОК 17.1. Результат транспонирования матрицы MxN —
новая матрица NxM.
В системе обозначений языка С транспонирование
записывается следующим образом:
a_transpose[x] [j]=a[j] [х] ;
Поскольку операция транспонирования является
частью многих арифметических операций, выполняе-
мых над матрицами, рассмотрим ее реализацию. Биб-
лиотека матриц будет содержать также функцию для
умножения матрицы на постоянное число. Это общая
операция для матриц, однако нет необходимости ее
подробно рассматривать в этой главе.
Есть еще два термина, которые нам потребуются при
обсуждении матричной арифметики. Первый — диаго-
нальная матрица (diagonal matrix) (рис. 17.2), которая
является квадратной матрицей с нулевыми внедиаго-
нальными элементами.
РИСУНОК 172.
Диагональная матрица.
а11 0 0 0
0 а22 0 0
0 0 а33 0
0 0 0 а44
Второй термин — треугольная матрица (triangular
matrix) (рис. 17.3), т.е. квадратная матрица с нулевыми
поддиагональными элементами (она называется верхней
треугольной матрицей, поскольку ненулевые элементы
находятся в ее верхней половине) или наддиагональны-
ми элементами (в данном случае это нижняя треуголь
ная матрица, поскольку ненулевые элементы находят-
ся в нижней половине матрицы).
413
Нихняя
треугольная = = >
матрица
~3 О О О~
7 8 0 0
6 7 11 О
3 8 9 10
Верхняя
треугольная ==>
матрица
3 7 6 3
0 8 7 8
О О 11 9
О О О 10
РИСУНОК 17.3. Треугольная матрица.
В этой главе треугольные матрицы используются не
слишком часто, но они очень важны при проведении
различного рода исследований, поэтому их описанию
следует уделить некоторое внимание. Верхние треуголь-
ные матрицы также рассматриваются в разделе "Опре-
делители и норма Евклида" далее в этой главе.
Реализация матричной структуры в
языке С
Возникает очевидный вопрос: "Что может быть проще?"
Прямоугольный массив действительно прост (как было
сказано в самом начале этой главы):
double а[М] [N] ;
где М и N — это литеральные константы (возможно,
заданные оператором макроопределения, например
tfdefine М 3). И если вы не против того, чтобы встро-
ить детали матричной арифметики в свой код для вы-
полнения любой операции, то можно использовать
именно этот подход. В некоторых ситуациях это может
быть единственно правильный подход. Другой подход
состоит в использовании глобальных переменных (или,
если их необходимо скрыть, статических переменных),
достаточно больших, чтобы можно было охватить мак-
симальные размеры любой матрицы, предназначенной
для работы. Затем ваша подпрограмма будет работать
только с частью этих переменных. Например, если вы
собираетесь работать с несколькими матрицами разме-
рами 2x2, 4x4 или более (но не больше 10x10), то мож-
но объявить определенное количество глобальных мас-
сивов размером 10x10 и выполнять все расчеты в этих
массивах (естественно, при этом подходе можно опре-
делять функции для выполнения поставленной задачи)
Однако, если вы хотите написать функции, которые
бы выполняли матричные операции так, чтобы детали
были скрыты и можно было работать с матрицами про-
извольного размера, не задаваясь целью заблаговремен-
но выяснять их количество, нужно задать соответству-
ющую структуру в языке С, которая бы могла вмещать
такую матрицу.
Существует ряд практических вопросов. Язык
ANSI С 1990 г. — это язык реализации для матричной
библиотеки. Этот стандарт позволяет объявлять масси-
вы только с использованием числовых констант. Это
означает, что правильно будет задавать матрицу а[3] [4],
Матричная арифметика
Глава 17
а не матрицу а[ш][п], где тип рассчитываются во вре-
мя выполнения программы.
ПРИМЕЧАНИЕ
Новый стандарт ANSI 1999 г. по языку программирования
С позволяет объявлять массивы с помощью переменных,
рассчитываемых во время выполнения. Некоторые ранние
компиляторы также предоставляли такую возможность
при использовании нестандартного расширения. Однако
множество компиляторов до сих пор этого не обеспечи-
вают. В целях установки совместимости и с ранним стан-
дартом языка С, и с существующими компиляторами
языка С, которые все еще не позволяют использовать
рассчитываемые во время выполнения переменные, биб-
лиотека матриц реализует матричную арифметику вне
зависимости от этой особенности.
Арифметика указателей и индексы
массива
Одним из первых вопросов, о которых следует поду-
мать, является арифметика указателей, на которой ос-
нована реализация массивов в языке С. Когда вы задае-
те двумерный массив типа приведенного ранее, можете
передать название массива как аргумент функции, од-
нако информация о размерах массива автоматически не
передается. Затем, когда вы для описания массива ис-
пользуете систему обозначений двойной квадратной
скобкой, компилятор не имеет возможности адресовать
отдельные его элементы. Самый простой способ, позво-
ляющий это сделать, — учитывать следующие условия:
• Двумерный массив хранится "построчно".
• Арифметика указателей и арифметика индексов мас-
сива идентичны.
На языке С выражение a[i] можно записать в экви-
валентной форме как *(a+i). Когда компилятор авто-
матически отслеживает размеры двумерного массива, вы-
ражение a[i][j] эквивалентно выражению:
*(a+i*numrows+j)
Операторы языка С
double а[4]={1,2,3,4} ;
И
double а[2][2] = {{1,2},{3,4}} ;
обращаются к одной и той же внутренней памяти ком-
пьютера.
Самым простым решением по передаче массива фун-
кции является передача адреса первого элемента масси-
ва (т.е. &а[0] для одномерного массива или &а[0][0] —
для двумерного), и после этого можно работать с индек-
сами в самой функции. Аналогично, если нужно размес-
тить двумерный массив, просто размещайте одномерный
массив и отдельно выполняйте арифметику индексов.
Дополнительные тематические разделы
414
Часть III
Другими словами, можно написать код, который
будет иметь один из двух видов. Первый:
index = О;
for ( i = 0; i < rows; i++) {
for ( j = 0; j < cols; j++) {
a[index] = 0.0;
index++;
}
}
Вычисление переменной index, если начать co зна-
чения 0 и постепенно увеличивать его на 1, позволяет
избежать проблемы выполнения сложной арифметики
путем использования преимуществ построчного хране-
ния массива. При этом первый элемент следующей стро-
ки хранится в памяти сразу вслед за последним элемен-
том текущей строки. Такой подход практически полезен
в том случае, когда расчеты отдельного элемента одной
матрицы зависят только от отдельного элемента другой
матрицы. (Это справедливо при сложении и вычитании
матриц.)
Вторая общая форма кода включает фактическое
явное вычисление индекса:
for ( i = О; х < rows; i++) {
for ( j = 0; j < cols; j++) {
a[mdx(i,j)J = 0.0;
}
}
где mdx() — это макрос или функция:
int mdx( int i, int j) {
return i*rows+j;
}
ПРИМЕЧАНИЕ
mdx(l — это просто аббревиатура индекса матрицы. По-
скольку эта функция (которая реализуется как статичес-
кая функция, Используемая только внутри самой библио-
теки матриц) применяется довольно часто, важно сделать
ее название коротким. Определение ее как функции
было использовано во время разработки для упрощения
отладки и тестирования программ. После завершения
разработки функция mdx() была заменена эквивалентным
макросом.
сы, чтобы дать возможность использовать условные
математические обозначения даже в самом рабочем коде.
К сожалению, когда-нибудь этот дополнительный шаг
также приведет к затруднениям. Библиотека матриц
реализует условные обозначения языка С, в котором
первым элементом является [0] [0]. В этой главе исполь-
зуются и условные обозначения языка С при рассмот-
рении рабочего кода, и условные математические обо-
значения, когда речь идет о математике или уравнениях.
ПРИМЕЧАНИЕ
В связи с тем что на практике иногда индекс массива
начинается с 1 вместо 0, получается очень сомнитель-
ный код С. Это может вызывать недоумение у опытных
С-программистов, которые ожидают, что первый элемент
массива будет иметь индекс 0. Если по какой-то причи-
не это абсолютно необходимо, нужно снабдить код со-
ответствующими комментариями, поясняющими это раз-
личие. Например, рассмотрите возможность адресации
с помощью функциональной нотации так, чтобы индекс
был заключен в круглых скобках, а не в квадратных. Как
правило, этот подход очень нежелательно использовать
в С, и его следует избегать для удобства дальнейшего
сопровождения кода.
В то же время использование условных обозначений
языка С при реализации кода мало влияет на конечно-
го пользователя программы, основное внимание кото-
рого сосредоточено на результате, а не на скрытых де-
талях (т.е. не на том, например, как проводятся сами
расчеты).
Структура MATRIX_T матричного типа
Общим подходом в С является описание структуры
struct, которую можно разместить динамически и кото-
рая позволяет хранить всю информацию, необходимую
для проведения расчетов матриц, внутри структуры. Для
этого нужно задать количество строк и колонок (разме-
ры матрицы), а также значения элементов самой мат-
рицы. (Отдельные значения, например а^, называются
элементами матрицы А.) Концептуально мы хотели бы
иметь структуру, изображенную на рис. 17.4.
Что такое начальный индекс
Другой вызывающей затруднения проблемой является
противоречивость понятия начального индекса. Первый
элемент двумерного массива в С — это а[0][0], в то
время как математическим условным обозначением пер-
вого элемента двумерной матрицы является аП. Рано или
поздно кто-нибудь забудет это различие (вполне воз-
можно, это будете вы, когда начнете программировать
или реализовывать программу). Некоторые другие биб-
лиотеки матриц пересчитывают в явном виде все индек-
РИСУНОК 17.4.
Обычная структура матричного типа.
Introws
_lntco/s__
а11 а12
а21 а22
Однако необходим еще один дополнительный уро-
вень косвенных переменных (чтобы иметь возможность
динамического размещения массива, размер которого до
начала выполнения неизвестен). Тогда мы используем
структуру, показанную на рис. 17.5.
Матричная арифметика
Глава 17
415
РИСУНОК 175.
Структура матричного типа
с динамическим размещением
массива.
introws;
intco/s;
arrayp*
а00 а01
а10 а11
По терминологии, принятой в С, основной матрич-
ный тип можно определить как
typedef struct {
int rows;
int cols;
double *val;
} MATRIX_T;
Когда массив динамически размещен, то указатель
на val, основываясь на размере матрицы, будет указы-
вать на динамически размещенный массив переменных
типа double (размещенных в то же время, что и сама
структура, с учетом значений переменных rows и cols).
Учитывая все вышесказанное, давайте начнем насто-
ящую реализацию набора подпрограмм обработки мат-
риц с динамическим выделением и освобождением па-
мяти для структуры MATRIX_T, как показано в
листинге 17.1.
Этот листинг находится в начале файла m__matrix.c,
который имеется на Web-сайте издательства "ДиаСофт".
Функция m_new() сначала размещает массив Tunadouble
соответствующего размера. Если при этом происходит
ошибка, немедленно возвращается NULL. Затем разме-
щается и инициализируется сама структура MATRIX_T.
Если при размещении происходит ошибка, то ранее
размещенный массив типа double освобождается, после
чего возвращается NULL. В противном случае мы по-
лучим размешенную структуру MATRIXT с инициа-
лизированными переменными rows и cols и значениями
для переменных массива типа double. Функция ш_Ггее
освобождает размещенную ранее структуру MATRIX T
и связанный с нею массив переменных типа double.
Кроме того, код ошибки устанавливается равным посто-
янной ALLOCFAIL, определенной в tfdefined.
ПРИМЕЧАНИЕ
Ниже приведен соответствующий способ объявления ука-
зателей структуры MATR!X_T:
MATRIX_T *а = NULL; /* NULL вызывает
инициализацию
/* указателей, обнаруженных в */
/* коде обнаружения оиибок в */
/* библиотеке работы с матрицами */
а = m_new(3,4);
Листинг 17.1, Реализация матрицы с динамическим выделением памяти.
/* Размещение новой матрицы, элементы не инициализируются */
MATRIXT *
m_new(int nrows, int ncols)
{
double *temp;
MATRIXT *m = NULL;
if ((temp = malloc(nrows * ncols * sizeof(double)))
== NULL) {
mmerrcode = ALLOCFAIL;
return NULL;
}
if ((m = malloc(sizeof(MATRIXT))) == NULL) {
mmerrcode = ALLOCFAIL;
free(temp);
return NULL;
}
m->rows = nrows;
m->cols - ncols;
m->val = temp;
return m;
I
/* Освобождение матрицы */
void
_free(MATRIX_T ♦ m)
<
if ( m == NULL) return;
/* Это не оиибка; используется для восстановления в других подпрограммах библиотеки матриц */
free(m->val);
free(m);
D
416
Дополнительные тематические разделы
Часть III
Обработка ошибок
Основным вопросом при проведении различного рода
сложных расчетов в С (и во многих других языках про-
граммирования) является устранение ошибок. Попыта-
емся установить значение ошибки, которое програм-
мист может проверить (листинг 17.2). Это можно
сделать с использованием статической переменной
mmerrcode, которую можно установить, переустановить
или проверить с помощью функций m_setter(),
m_resetter() и errcode(). Имеется также функция
m_errmsg(), которая возвращает строку описания.
ПРИМЕЧАНИЕ
Использование статических переменных с областью види-
мости файла (типа mmerrcode) создает потенциальную
проблему. В этом случае имеется обычный способ об-
работки требований по сохранению режима ошибки.
Проблема состоит в том, что такое использование ста-
тических переменных не вызывает ошибок, если вы ко-
дируете потоки, однако это приводит к неправильному
значению переменной mmerrcode для одного потока,
поскольку ее значение установлено в другом потоке. Если
вы кодируете потоковое приложение, которое использует
матричную библиотеку, то вам потребуется модифици-
ровать эту библиотеку, чтобы найти другой способ, по-
зволяющий отслеживать коды ошибок.
Листинг 17.2. Обработка ошибок.
static int mmerrcode = 0;
void
m_seterr(int errcode)
{
mmerrcode - errcode;
}
void
mreseterr(void)
{
mmerrcode = 0;
}
const char *
m_errmsg(int errcode)
{
switch (errcode) {
case RMISMATCB:
return "row mismatch";
case CMISMATCH:
return "column mismatch";
case NOTSQUARE:
return "not a square matrix**;
case ALLOCFAIL:
return "allocation failure";
case FILEREADFAIL:
return "file read failure";
case ROWPARSEFAIL:
return "row parse failure";
case COLPARSEFAIL:
return "column parse failure";
case RCMISMATCB:
return "row-column mismatch";
case INDEXOUTOFRANGE:
return "index out of range";
case LENMISMATCH:
return "length mismatch";
case NULLARG:
return "NULL argument";
default:
return NULL;
}
}
int
m_errcode(void)
{
return mmerrcode;
}
Другие принципы проектирования
матричной библиотеки
Написание непротиворечивой библиотеки требует со-
здания серии проектных решений.
Какой вид условных обозначений будет использо-
ваться для возвращения значений и передачи аргумен-
тов? Матричная библиотека передает указатели на
структуры MATRIX_T для результата и аргументов.
Обычно возвращаемое значение — это указатель
MATRIX_T на результат. Это поддерживает такой стиль
написания кода, который, по крайней мере, минималь-
но похож на стиль написания уравнений. Например,
сумму матриц можно закодировать следующим образом:
result=m_add(result, а, Ь) ;
Модифицирован будет только ’’результирующий"
аргумент. ’’Вводимые" аргументы изменены не будут.
Идеально, если пользователю матричной библиотеки не
нужно писать код, в котором ’’результирующий” аргу-
мент был бы таким же, как и один из "вводимых" аргу-
ментов. В некоторых случаях это будет давать коррект-
ные результаты, но не всегда на них можно опираться.
Будет ли распределение памяти в основном контро-
лироваться библиотекой или вызывающей программой?
Необходимо, чтобы распределение памяти находилось
под прямым контролем вызывающей программы. Вре-
менные переменные будут назначаться и освобождать-
ся только в случае крайней необходимости.
Должна ли библиотека разрешать программистам
выполнять прямой доступ или осуществлять модифи-
кацию содержимого структур данных, либо все-таки
должны быть функции, позволяющие безопасно рабо-
тать под контролем библиотеки? Функции доступа не-
обходимы для возвращения количества строк, столбцов
и значений отдельных элементов, а также для установ
ки значений отдельных элементов.
417
ПРИМЕЧАНИЕ
В сущности, невозможно запретить программисту выпол-
нять прямой доступ к внутренним элементам структур
данных. Однако при наличии функций, которые дают воз-
можность безопасно осуществлять такие операции, про-
граммист может отказаться от самостоятельного выпол-
нения таких опасных задач.
Какие специализированные подпрограммы ввода/
вывода необходимы для обеспечения целей матричной
библиотеки? Это функций для размещения структур
MATRIX-T, для запуска их из файлов, из одно- или
двумерных массивов или для того, чтобы приравнять их
единичной матрице. Функции для вывода включают в
себя функцию для распечатывания результатов в stdout
или для записи в файл значений в формате CSV (comma-
separated values — значения, разделяемые запятой).
Кок называть (именовать) функции или перемен-
ные? Как правило, общие функции имеют префикс т_.
Статические переменные имеют префикс mm. Статичес-
кие функции называются описательно, но не имеют
специального префикса.
Матричная арифметика
Глава 17
Общепринято, что названия переменных должны
быть осмысленными. Например, для описания строк
индекс row более предпочтителен, чем i. При условных
обозначениях функций матричной библиотеки частич-
но используются осмысленные названия. Однако в мате-
матической литературе по матрицам очень распростране-
но использование однобуквенных индексов типа i, j и к,
поэтому вполне естественно, что и в матричной библио-
теке используются такие же однобуквенные индексы.
Инициализация матриц из массивов
Матричная библиотека имеет две функции для иници-
ализации структуры M_MATRIX из массивов: одну —
для задания из одномерных массивов, а другую — из
двумерных массивов. Как сказано ранее, внутреннее
представление для одно- и двумерных массивов с оди-
наковым общим количеством элементов — одно и то же.
В результате функции для инициализации матриц из
двумерных массивов просто подсчитывают общее коли-
чество элементов и вызывают функцию для инициали-
заций матриц из одномерного массива. Листинг 17.3 де-
монстрирует обе эти функции.
Листинг 17.3. Инициализация массивов.
MATRIXT * m_assign_arr2(MATRIX_T * af int nrows, int ncols, double *arr)
{
int len;
if (a == NULL) {
mmerrcode = NULLARG;
return a;
}
if (nrows 1= a->rows) {
mmerrcode = RMISMATCB;
return a;
}
if (ncols 1= a->cols) {
mmerrcode = CMISNATCH;
return a;
}
len = nrows * ncols;
return m__assign_arrl(af len, arr);
}
MATRIX-T * m_assign—arrl (MATRIX__T * a, int alen, double *arr)
{
int i, j, index;
if (a == NULL) {
mmerrcode - NULLARG;
return a;
}
if (alen != a->rows * a->cols) {
mmerrcode = LENMISMATCH;
return a;
}
index = 0;
for (i = 0; i < a->rows; i++) {
for (j = 0; j < a->cols; j++) {
a->val[index] = arr[index];
index++;
}
}
27 Зак. 265
418
Дополнительные тематические разделы
Часть III
Код определения ошибок в этих функциях доволь-
но типичен. Сделайте проверку, чтобы убедиться, что
ни один из аргументов-указателей структуры
MMATRIX не имеет значения NULL. Убедитесь так-
же, что количество строк и столбцов согласовывается с
аргументами.
Извлечение матрицы из файла.
Одной из наиболее сложных операций является началь-
ный ввод инициализированной структуры M MATRIX
из файла. Функция m_fnew() — это функция матрич-
ной библиотеки, предназначенная для размещения и
инициализации объектов M MATRIX из файлов.
Довольно удобно, когда в файлы данных встроены
комментарии (для которых в этой главе используется
расширение .mat). Комментарии — это строки, которые
начинаются с символа #. Затем задаются данные мат-
рицы на строке, которая для четырехстрочной матри-
цы читается как ’’строк,4". Аналогично для матрицы из
пяти столбцов данные столбцов задаются на строке от-
дельно как ’’столбцов,5". Заметьте, что здесь нет пробе-
лов перед или после запятой. После этого на последу-
ющих строках задаются значения элементов матрицы,
разделенные запятыми. Строки комментариев могут
быть вставлены в любое место файла. Строки файлов с
расширением .mat считываются отдельно с помощью
функции m_getline(), игнорирующей строки коммента-
риев. Последующие строки могут содержать данные для
другой матрицы. Вызывающая программа отвечает в
основном за открытие и закрытие файла, содержащего
данные матрицы.
ПРИМЕЧАНИЕ
Функция m_getlineO позволяет использовать статическую
символьную переменную массива line с областью види-
мости файла. Это имеет такие же недостатки, как и при
использовании статической переменной mmercode, кото-
рая рассматривалась ранее. Поскольку m__getline() —
единственная функция, использующая line, существует
меньшая вероятность появления проблемы, однако код не
является реентерабельным. Поскольку переменная line
имеет номинальную длину 4096 символов, то при исполь-
зовании статической переменной для функции m_gettineO
стек можно сделать меньше. Если важна реентерабель-
ность кода, можно определить максимальную действи-
тельно необходимую длину и внутренне объявить пере-
менную line для функции m_getline().
Синтаксический разбор данных строк и столбцов, а
также значений элементов данных проводится с помо-
щью функции strtok() из стандартной библиотеки.
ПРИМЕЧАНИЕ
Функция strtokfl имеет репутацию довольно коварной
функции, но для этой цели она подходит идеально. Син-
таксический разбор такой строки на отдельные поля од-
нозначен, поскольку в данных нет пустых полей (это одна
из задач, с которой функция strtokO не справляется).
Использование StrtokO также делает код нереентерабель-
ным. Рекомендуем программистам, которым необходи-
мо проводить простой синтаксический разбор строк, вни-
мательно прочитать документацию по функции strtokO.
Это, несмотря на ее плохую репутацию и ограничения,
прекрасный инструмент для использования этой функции
в нормальных обстоятельствах. (Что касается плохой ре-
путации, то причинами ее стали ситуации, сходные с той,
когда начинающий плотник говорит: "Молотки опасны. Я
поранил палец, когда первый раз попытался воспользо-
ваться молотком". А попробуйте вбить гвоздь без молот-
ка. С другой стороны, молотки, в сущности, бесполез-
ны, если захочешь ввернуть шурупы. В своей работе
пользуйтесь соответствующим инструментом.)
Другим потенциальным недостатком использования фун-
кции strtokO в функции m_fnew(| является то, что пользо-
ватели воздерживаются от применения strtokO в коде,
который неоднократно обращается к StrtokO*
Пример файла матричных данных показан в лис-
тинге 17.4.
Листинг 17.4. Пример файла матричных данных.
I Это строка комментария
I Другая строка комментария
rows,2
cols,3
1.1,2.О,3.0
4.6,5.3,9.1
I Далее следует установка данных другой
I матрицы
rows,3
cols,2
1.1,2.5
3.0,4.2
4.О,5.1
Функции m_fnew() и m_getline() показаны в листин-
ге 17.5.
Матричная арифметика
Глава 17
419
Листинг 17.5. Размещение и инициализация матрицы из файла,
char *
m_getline(FILE * fp)
{
do {
if (!fgets(line, LINELEN, fp)) {
mmerrcode = FILEREADFAIL;
return NULL;
}
} while (*line == '#');
return line;
MATRIX! *
m_fnew(FILE * fp)
<
int i, j, rows, cols, index;
char *tck;
char *lineptr;
MATRIX! *a;
/* Задать количество строк */
if (!m_getline(fp)) { return NULL;}
if (!(tok = strtok(line, ",?))) {
mmerrcode = ROWPARSEFAIL;
return NULL;
}
if (strcmp(tok, "rows")) {
mmerrcode = ROWPARSEFAIL;
return NULL;
}
if (!(tok = strtok(NULL, ","))) {
mmerrcode = ROWPARSEFAIL;
return NULL;
}
rows = atoi(tok);
if (Irows) {
mmerrcode ~ ROWPARSEFAIL;
return NULL;
}
/* Задать количество столбцов */
if (Imgetline(fp)) { return NULL;}
if (!(tok = strtok(line, ","))) {
mmerrcode = COLPARSEFAIL;
return NULL;
}
if (strcmpftok, "cols")) {
mmerrcode = COLPARSEFAIL;
return NULL;
if (!(tok = strtok(NULL, ","))) {
mmerrcode = COLPARSEFAIL;
return NULL;
}
cols = atoi(tok);
if (!cols) {
mmerrcode = COLPARSEFAIL;
return NULL;
}
/* Разместить новую матрицу */
if (!(a « m_new(rows, cols)))
return NULL; /* функция m_fnew() выполняет проверку омибки в
* m new */
420
Дополнительные тематические разделы
Часть III
index = 0;
for (i - 0; i < rows; i++) {
if (!m_getline(fp)) {
m__free;
return NULL;
}
lineptr = line;
for (j « 0; j < cols; j++) {
if (!(tok = strtok(lineptr, ","))) {
mfree;
return NULL;
}
a->val[index] = atof(tok);
index++;
lineptr = NULL; /* аргумент NULL передается функции strtok() после первой
передачи */
}
}
return а;}
Запись объектов MATRIX T в stdout
или в другой файл
Запись матричных объектов в выходной поток обеспе-
чивают две очень простые функции. Первая из них —
это m_printf(), которая посылает сформатированный
выходной поток в файл stdout. Вторая — m_fputcsv, за-
писывает матричный объект в файл в формате CSV. Эти
функции показаны в листинге 17.6.
Листинг 17,6. Функции вывода результатов.
void
m_printf(char *label, char *format, MATRIX T * a)
{
int i, j;
if (a == NULL) {
printf("m_printf NULL argument error\n");
return;
}
printf("%s\n", label);
printf("rows = %d, cols - %d\n", a->rows, a->cols);
for (i = 0; i < a->rows; i++) {
for (j = 0; j < a->cols; j++) {
printf(format, a->val[mdx(a,i,j)));
}
printf("\n");
}
void
m_fputcsv(FILE * fp, MATRIXT * a)
{
int i, j;
char *sep;
char commaf] =
char nocommaf] =
if (a == NULL) {
mmerrcode = NULLARG;
return;
}
fprintf(fp, "rows,%d\n", a->rows);
fprintf(fp, "cols,%d\n", a->cols);
for (i = 0; i < a->rows; i++) {
sep = nocomma;
Матричная арифметика
Глава 17
421
for (j = 0; j < a->cols; j++) {
fprintf(fp, "%s%f, sep, a->val[mdx(a,i,j)]);
sep = comma;
}
fprintf(fp, "\n");
}}
Функция m_printf() принимает аргументы для над-
писей и для числового формата элементов, позволяя
программисту контролировать формат отображения
данных.
Функция m fputcsv менее гибка в этом отношении.
Она использует по умолчанию числовой формат %f.
Если это вам неудобно, то данную функцию можно
легко изменить. При этом в формате важно убирать
лидирующие пробелы. Единственным недостатком этих
функций является метод проверки того, что в рядах
чисел нет лидирующих или замыкающих запятых. Это
делается с помощью предшествующей каждому значе-
нию строки sep (которая содержит либо comma, либо
nocomma).
Полная реализация суммирования и
транспонирования
В листинге 17.7 показан пример кода для реализации
суммирования и транспонирования матриц.
Листинг 17.7. Суммирование и транспонирование матриц.
MATRIXJT *
m_add(MATRIX_T * sum, MATRIX T * a, MATRIX T * b)
{
int i, j, index;
if (sum == NULL || a == NULL || b == NULL) {
mmerrcode = NULLARG;
return sum;
}
if (a->rows 1= b->rows) {
m_seterr(RMISMATCH);
return sum;
}
if (sum->rows 1= b->rows) {
mseterr(RMISMATCH);
return sum;
}
if (a->cols != b->cols) {
mseterr(CMISMATCH);
return sum;
}
if (sum->cols != b->cols) {
mseterr(CMISMATCH);
return sum;
}
index = 0;
for (i = 0; i < sum->rows; i++) {
for (j = 0; j < sum->cols; j++) {
sum->va1[index J =
a->val[index] + b->val[index];
index++;
}
}
return sum;
MATRIX_T ♦
transpose(MATRIXT * trans, MATRIXT * a)
<
int i, j;
if (trans == NULL II a == NULL) {
Дополнительные тематические разделы
Часть III
422
mmerrcode = NULLARG;
return trans;
}
if (trans->rows != a->cols) {
mmerrcode = RCMISMATCE;
return trans;
}
if (trans->cols != a->rows) {
mmerrcode = RCMISMATCE;
return trans;
}
for (i = 0; i < a->rows; i++) {
for (j = 0; j < a->cols; j++) {
trans->val[mdx(trans, j, i)] =
a->val[mdx(a, i, j)];
}
}
return trans;
Как предварительно было сказано, основные опера-
ции производятся в одной строке кода, хотя при ини-
циализации, обнаружении ошибок и установке циклов
используется намного больше строк кода. Две суще-
ственные строки кода, начинающиеся с sum->val и
trans->val, скрыты во втором уровне циклов for.
Чтобы ни на что не отвлекаться и лучше понять, как
выполняются основные операции с матрицами, в боль-
шинстве приведенных ниже листингов полный код об-
наружения ошибок не показан. В полном объеме этот
код можно найти в файле m matrix.c на Web-сайте из-
дательства "ДиаСофт*'. Код в функциях для суммиро-
вания и транспонирования довольно типичен для вы-
полнения проверок на наличие ошибок. Коды для
вычитания и умножения на константу также не пока-
заны в листингах, а включены в полную библиотеку
матриц, находящуюся на Web-сайте "ДиаСофт".
Сложные концепции матриц
Основные операции — обработка ошибок, размещение
матриц и их ввод/вывод — теперь завершены. С помо-
щью более сложных операций в этой главе проводятся
расчеты определителя и инвертирование матрицы.
Сложная математика матриц
Первоначальная мотивация (по крайней мере, внутрен-
не) при изучении арифметики матриц — решение сис-
тем уравнений. Одиночное линейное уравнение — это
основа линейной алгебры. На рис. 17.6 показано оди-
ночное линейное уравнение и его решение.
РИСУНОК 17.6. __ _ ь
Решение простого SX — Ь или X — q
линейного уравнения.
Это решение получено путем умножения обеих ча-
стей основного уравнения на 1/а или аг1, т.е. просто на
обратную величину числа а. Фактически промежуточ-
ный шаг для получения решения можно написать так,
как показано на рис. 17.7.
РИСУНОК17.7. _ ь
Промежуточный шаг для 8“^ах = X = а~^Ь = —
решения простого линейного
уравнения.
Это самое простое линейное уравнение не имеет
практического применения при работе с матрицами.
Однако при работе с системой уравнений, имеющих
несколько неизвестных (рис. 17.8), терминология мат-
риц становится особенно полезной.
РИСУНОК 17.8.
Система линейных уравнений.
а11 X! + а12 х2 — Ц
®21 + а22 х2 = ^2
Математики переписывают уравнения, изображен-
ные на этом рисунке, как произведение матриц, т.е. в
виде одного матричного уравнения (рис. 17.9).
РИСУНОК 17.9.
Система линейных уравнений
в матричной форме.
а11 а12 Х1 1^1
а21 а22 х2 I Ь2
или
Ах = Ь
На рис. 17.9 А — это матрица размером 2x2, хи b —
матрицы размером 1x2, или векторы.
Как и для первого уравнения (только с одним неиз-
вестным), решение этого матричного уравнения может
быть записано так, как показано на рис. 17.10.
Матричная арифметика
Глава 17
423
x= A-1b
где А’1 - это обратная матрица А.
РИСУНОК 17.10. Решение системы линейных уравнений с
использованием записи в форме матриц.
Этот пример — пока только,мотивация. Он просто
подготавливает вас к пониманию таких вещей, как ум-
ножение матриц и единичная матрица.
На рис. 17.10 А — это матрица 2x2, а х и Ь ~ матри-
цы 1x2 (или векторы).
Умножение матриц
Ранее рассмотренный мотивационный пример матрич-
ного уравнения, изображенный на рисунках 17.8 и 17.9,
Ах=Ь
содержит определение произведения матриц. Этот при-
мер демонстрирует умножение матрицы Л размером 2x2
на матрицу х размером 2x1. Вообще, произведение не
ограничено одним столбцом (как Ь). Количество столб-
цов левой матрицы А в произведении должно быть та-
ким же, как и количество строк в правой матрице х.
Элементы произведения — это сумма элементов строк
матрицы Л, умноженных на элементы столбцов матри-
щ>1 х. Математически умножение матриц в общем виде
представлено на рис. 17.11.
п
?СУНОК17Л1 product,. = £aikbkj
Умножение матриц. 4 J
На рис. 17.11 а — это матрица MxN, b — матрица
NxP, а результат умножения product — матрица МхР.
На языке С это записывается следующим образом
(пренебрегая всеми внешними циклами и инициализа-
циями):
product[1] [j] = 0.0;
for (k = 0; k < COLS; k++) {
product[i][j] += a[i][k]*b[k][j];
)
При умножении матриц очень важно знать, что про-
изведение АВ — это не то же самое, что произведение
ВА (хотя существует ряд исключений). Математики
скажут, что умножение матриц не коммутативно, и
должно быть ясно, что, поскольку умножать можно
только прямоугольные матрицы одинакового размера,
определенное ранее произведение АВ не означает, что
определено и произведение ВА. Например, может быть
определено произведение матрицы 3x4 (как множимо-
го) на матрицу 4x5, но не наоборот.
Код матричной библиотеки для умножения матриц
приведен в листинге 17.8.
Листинг 17.8. Умножение матриц.
MATRIXT *
m_mup(MATRIX_T * prod, MATRIXT * a,
MATRIX_T * b)
{
int i, j, k;
if (prod == NULL || a == NULL ||
b == NULL) {
mmerrcode = NULLARG;
return prod;
if (prod->rows != a->rows) {
mmerrcode = RMISMATCH;
return prod;
}
if (prod->cols != b->cols) {
mmerrcode = CMISMATCB;
return prod;
if (a->cols != b->rows) {
mmerrcode = RCMISNATCH;
return prod;
for (i = 0; i < a->rows; i++) {
for (j = 0; j < b->cols; j++) {
prod->val[mdx(prod,i,j)];
for (k = 0; k < a->cols; k++)
{
prod->val[mdx(prod,i,j)] +=
a->val[mdx(a,i,k)] * b->val[mdx(b,k,j)];
}
}
}
return prod;}
Единичная матрица
Единичная матрица определяется как квадратная мат-
рица с нулевыми значениями внедиагональных элемен-
тов и единичными значениями диагональных элемен-
тов. Единичная матрица обычно изображается с
помощью символа 1. Пример такой матрицы размером
3x3 показан на рис. 17.12.
"1 0 б"
РИСУНОК 17.12. /=010
Единичная матрица. 0 0 1
Единичная матрица при умножении на другую мат-
рицу (соответствующего размера) дает в результате ту
же самую (другую) матрицу. Иначе говоря, единичная
матрица — матричный арифметический эквивалент
обыкновенного числа 1, по крайней мере, в отношении
умножения. Единичная матрица — это одно из важных
исключений при умножении матриц, поскольку
АМА
Дополнительные тематические разделы
Часть III
424j
Надо заметить, что запись в матричной форме (или
матричная нотация) иногда может быть недостаточно
наглядна, когда в ней фигурирует единичная матрица.
Например, если в предыдущем уравнении матрица А
изображается как квадратная, то понятно, что единич-
ная матрица / будет иметь такой же размер, как и мат-
рица А. Но если А не квадратная, а, скажем, матрица
mxn, то в матричной нотации предполагается, что I в
выражении AJ — это матрица пхп, в то время как I в
выражении IA — это матрица mxm. Это довольно слож-
но понять теоретически, а практически это просто оз-
начает, что единичная матрица может быть любого раз-
мера, который необходим для получения тождества.
Чтобы сделать такую нотацию более точной (когда
это важно), можно использовать альтернативную за-
пись, например J — для обозначения единичной мат-
рицы размером пхп.
Иногда (особенно в инженерной терминологии) еди-
ничная матрица называется унитарной и обозначается
как U,
Одна из функций языка С, включенная в матричную
библиотеку под названием m_assignjdentity(), задает
значения элементов единичной матрицы в массив, пе-
редаваемый как аргумент (и как результат).
Определители и нормы Евклида
Одним из наиболее важных разделов арифметики мат-
риц является инверсия, или обращение, матриц, но,
перед тем как к ней приступить, следует рассказать о
детерминантах, или определителях. В достаточно общей
(и очевидно не математической) форме определитель —
это измерение величины квадратной матрицы (и толь-
ко квадратной — неквадратные матрицы не имеют оп-
ределителей). Если детерминант матрицы равняется
нулю, это означает, что матрица неинвертируема (не
может быть обращена). Если же детерминант очень бли-
зок к нулю, то имеется большая вероятность, что мат-
рица плохо обусловлена, а это означает, что обратная
матрица, вероятно, будет имеет большую унаследован-
ную ошибку, которая получится в результате расчета.
Смысл определителя, равного нулю, математически
точен, однако при написании программ, которые вы-
полняют численный анализ с использованием чисел с
плавающей десятичной точкой (в любом С-представле-
нии: двойное, длинное двойное число или любой дру-
гой тип данных с плавающей точкой), существует ре-
альная возможность того, что в расчетах вместо очень
маленького ненулевого числа мы получим число, кото-
рое в точности будет равно 0.
Смысл определителя как некоей величины можно
лучше понять в контексте нашего вспомогательного
уравнения Ах=Ь. Решение этого уравнения (совершен-
но естественным способом) будет таким, как показано
на рис. 17.13.
const::b
РИСУНОК 17.13. хч __________1
Решение с помощью определителя. detA
В этой главе для решения систем уравнений не ис-
пользуется подход, изображенный на рис. 17.13, одна-
ко в большинстве учебников по линейной алгебре и
матрицам рассказывается о решении уравнений имен-
но таким методом. (После этого авторы учебников этот
метод не используют, поскольку он малоэффективен.)
На рис. 17.14 изображен другой подход к решению си-
стемы уравнений.
Матрица А размером 2x2 имеет определитель, равный величине:
**11 322— ai232l
Матрица А размером 3x3 имеет определитель, равный величине:
+ а„ + а13- а13 аЕ - а„ а* - а„
РИСУНОК 17.14. Подсчет определителя матрицы.
Большие матрицы имеют определители, состоящие
из намного более сложных сумм и разниц произведений
их элементов. Чем пытаться считать определители с
использованием такого сложного набора определений
(которые также Moiyr быть очень неэффективными), в
этой главе для упрощения расчетов используются неко-
торые известные свойства определителей.
Определитель треугольной (или диагональной) мат-
рицы — это произведение ее диагональных элементов,
как показано на рис. 17.15.
ПРИМЕЧАНИЕ
В верхней части примера треугольной матрицы использу-
ются числа х, у и z (рис. 17.15). Определители таких
матриц не зависят от конкретных значений х, у и z.
РИСУНОК 17.15.
Определитель треугольной
(или диагональной) матрицы —
это произведение ее
диагональных элементов.
2
det О
х у
3 z = 2*3*4 = 24
0 0 4
Если любая строка матрицы умножается на констан-
ту, определитель новой матрицы — это константа, ум-
ноженная на определитель исходной матрицы (рис
РИСУНОК 17.16. Определитель матрицы в случае, если ее
строка умножается на константу.
Матричная арифметика
Глава 17
425
ПРИМЕЧАНИЕ
Для непосредственного вычисления определителей мат-
ричная библиотека не использует свойство умножения
строки на константу, а умножает на константу сам оп-
ределитель. Однако далее в этой главе определитель
тоже косвенно вычисляется в процессе обращения мат-
риц, и далее будет использоваться это его свойство.
Если две строки матрицы переставляются, то опре-
делитель матрицы, полученной в результате такой пе-
рестановки, имеет то же абсолютное значение, что и
оригинальная матрица, но знак определителя меняется
на противоположный (рис. 17.17).
‘о 0 4*" ~2 X у"
det 0 3 Z = (-1)*det 0 3 Z = (-1)»2*3*4 = -24
2 X У_ 0 0 4
РИСУНОК 17.17. Определитель матрицы, в которой
переставлены две строки.
Если одна строка прибавляется или вычитается из
другой строки матрицы, то определитель не меняется
(рис. 17.18).
Используя эти свойства, можно преобразовать квад-
ратную матрицу в треугольную или диагональную мат-
рицу, для которой можно легко посчитать определитель.
~2 X У ”2 X У
det 0 3 Z = det 0 3 Z = 2*3*4 = 24
_0 0 4_ _0+2 0+х 4+у
РИСУНОК 17.18. Если одна строка прибавляется или
вычитается из другой строки матрицы, то определитель не
меняется.
Пример вычисления определителя с использовани-
ем этого метода приведен в табл. 17.1. Числа первой
строки добавляются или вычитаются из оставшихся
строк до получения нулей в каждом первом столбце,
кроме первой строки. Затем числа из второй строки
добавляются или вычитаются из оставшихся нижних
строк до получения нулей в каждом втором столбце под
диагональю. По окончании этой процедуры вы получи-
те верхнюю треугольную матрицу. Этот метод известен
как метод исключения Гаусса (Gaussian elimination). Оп-
ределитель такой матрицы — это произведение ее диа-
гональных элементов. Конкретный элемент на диагона-
ли, с которым вы работаете, чтобы устранить
поддиагональные элементы, называется ведущим элемен-
том (pivot element).
ПРИМЕЧАНИЕ
Существует соблазн игнорировать сложные термины типа
гауссова исключения. Гаусс был известным математиком,
который разработал этот метод для расчета определи-
телей (и соответственно для решения линейных уравне-
ний). Эта терминология настолько распространена, что вы
можете использовать ее в любом разговоре о линейной
алгебре, даже если не имеете о ней никакого представ-
ления. Однако, как и во многих других элементах мате-
матики, это просто общепринятое название.
Таблица 17.1. Гауссово исключение.
Исходная матрица
1.00 2.00 3.00 4.00
5.00 6.00 7.00 8.00
1.00 4.00 5.00 7.00
2.00 3.00 -3.00 4.00
строка 0: перестановка строк
5.00 6.00 7.00 8.00
1.00 2.00 3.00 4.00
1.00 4.00 5.00 7.00
2.00 3.00 -3.00 4.00
строка 0, столбец 0:
получение нулей в поддиагональных элементах столбца
5.00 6.00 7.00 8.00
0.00 0.80 1.60 2.40
0.00 2.80 3.60 5.40
0.00 0.60 -5.80 0.80
строка 1: перестановка строк
5.00 6.00 7.00 8.00
0.00 2.80 3.60 5.40
0.00 0.80 1.60 2.40
0.00 0.60 -5.80 0.80
строка 1, столбец 1:
получение нулей в поддиагональных элементах столбца
5.00 6.00 7.00 8.00
0.00 2.80 3.60 5.40
0.00 0.00 0.57 0.86
0.00 0.00 -6.57 -0.36
строка 2: перестановка строк
5.00 6.00 7.00 8.00
0.00 2.80 3.60 5.40
0.00 0.00 -6.57 -0.36
0.00 0.00 0.57 0.86
строка 2, столбец 2:
получение нулей в поддиагональных элементах столбца
5.00 6.00 7.00 8.00
0.00 2.80 3.60 5.40
0.00 0.00 -6.57 -0.36
0.00 0.00 0.00 0.83
Результат
det - 76.00
Дополнительные тематические разделы
Часть III
426
Существует соблазн проигнорировать возможность
перестановки строк. Если вы это сделали, то рано или
поздно, выполняя эти операции, вы столкнетесь с мат-
рицей, которая имеет нуль на диагонали и не позволит
вам работать с треугольной матрицей (по крайней мере,
без перестановки строк). Пример такой матрицы разме-
ром 3x3 изображен на рис. 17.19.
РИСУНОК 17.19.
Пример матрицы, показывающий
необходимость перестановки строк.
“о о Г
1 1 1
J 2 2
Матрица на рис. 17.19 имеет определитель, равный
-1, но ее нельзя представить в форме диагональной или
треугольной матрицы без перестановки строк.
Еще одна причина перестановки строк — это увели-
чение точности. Если ведущий элемент — это элемент
в столбце с максимальным абсолютным значением, то
при расчете определителя точность будет выше. Когда
выполняется перестановка строк для того, чтобы поме-
стить максимальный элемент из нижней (поддиагональ-
ной) половины матрицы в положение ведущего элемен-
та, то такой метод называется гауссово исключение с
частичной максимизацией ведущего элемента (Gaussian
elimination with partial pivot maximization).
В матричной библиотеке имеется функция m__det()
для расчета определителя. Вспомогательные функции
swaprows() и set_Iow_zero() используются соответствен-
но для перестановки указанной и ведущей строк и при-
бавляет или вычитает числа ведущей строки, чтобы
получить каждый элемент под диагональю в соответ-
ствующем столбце равным нулю.
Код приведен в листинге 17.9; фактическое тести-
рование на сингулярность проводится с использовани-
ем концепции нормализованного определителя (normalized
determinant), о котором будет рассказано в следующем
разделе.
Листинг 17.9. Вычисление определителя,
double
mdet(MATRIXT * * a, double epsilon)
{
/* Рассчитывает определитель матрицы с использованием гауссова исключения с частичной
* максимизацией ведущего элемента */
/* Код проверки на ошибки не показан */
int row, col, swap, sign;
double pivot, e__norm, det;
e_norm = m_e_norm;
det = 1.0;
sign = 1;
/* Разместить "черновую" матрицу для работы */
if (!(t = m__new(a->rows, a->cols))) return 0.0;
t = m_assign(t, a);
/* Для каждой строки */
for (row = 0; row < t->rows; row++) {
/* Найти в столбце под диагональю наибольший элемент */
swap = maxelementrow(t, row);
/* Переместить строки для помещения наибольшего элемента на место ведущего элемента */
if (swap != row) {
sign = -sign;
swaprows(t, row, swap);
}
/* Умножить текущее значение определителя на ведущий элемент */
pivot = t->val[mdx(t, row, row)];
det *= pivot;
if ((fabs(det) / e_norm) < epsilon) {
return 0; /* потенциально единичная матрица */
)
/* Вычесть числа ведущей строки из каждой строки под диагональю, чтобы получить нули
* на месте всех поддиагональных элементов ведущего столбца */
col = row;
set__low__zero (t, col);
)
mfree(t);
if (sign < 0)
Матричная арифметик;
Глава 17
[427
det = -det;
return det;
}
static void
set_low__zero(MATRIX_T * t, int col)
{
int if j;
double pivot, factor;
pivot = t“>val[mdx(t, col, col)];
for (i = col + 1; i < t->rows; i++) {
factor = t“>val[mdx(t, i, col)] / pivot;
for (j ® col; j < t->cols; j++) {
t“>val[mdx(t, i, j)] -=
factor * t->val[mdx(t, col, j)];
}
}
}
static void
swaprows(MATRIX T * t, int row, int swap)
{
int j;
double temp;
for (j = 0; j < t“>cols; j++) {
temp = t“>val[mdx(t, row, j)];
t“>val[mdx(t, row, j)] = t->val[mdx(t, swap, j)];
t->val[mdx(t, swap, j)] = temp;
}}
Одним из проектных принципов матричной библио-
теки является то, что передаваемые функциям аргумен-
ты остаются неизмененными (за исключением тех, ко-
торые дают реальные результаты). Второй принцип —
это минимизировать использование временных перемен-
ных. Этот конфликт между проектными принципами
приводит к тому, что надо размещать и освобождать
временную структуру MATRIX_T как часть процесса
вычислений в функции m_det().
Норма Евклида и нормализованный определитель
Если определитель матрицы равен 0, значит, матрица
сингулярна. Если определитель близок к нулю, то мат-
рица, вероятно, будет плохо обусловленной и вычисле-
ния матрицы, вероятно, будут ошибочными. Посколь-
ку вычисления чисел с плавающей точкой имеют
тенденцию к потере точности, полезно делать провер-
ку на их близость к нулю. Сложность состоит в том, что
диагональная матрица 3x3 с диагональными элемента-
ми порядка 10’6 имеет определитель порядка КУ18, в то
время как диагональная матрица 3x3 с диагональными
элементами порядка 1000 имеет определитель порядка
1 000 000 000 (или 109). Даже если две матрицы прак-
тически эквивалентны, не следует полагать, что вычис-
ления, в которых используются матрицы или их опре-
делители, должны приводить к менее точным
результатам только потому, что одна из них имеет оп-
ределитель, на 27 порядков по величине меньший, чем
определитель другой матрицы. Фактическое определе-
ние того, насколько определитель близок к нулю, зави-
сит от абсолютных величин элементов матрицы.
ПРИМЕЧАНИЕ
Этот пример различий в значении определителей был
придуман сознательно. (Поэтому это довольно необыч-
ный пример.) Вычисления диагональных матриц в любом
случае незатруднительны, но есть другие, более серьез-
ные случаи применения недиагональных матриц. Любая
пара похожих матриц с элементами, умноженными на
общие коэффициенты, которые отличаются на большую
величину, будут страдать от очевидного подобного несо-
ответствия, что не имеет ничего общего со свойствами
каждой из этих матриц.
Один способ определения близости определителя к
нулю состоит в сравнении абсолютного значения опре-
делителя с абсолютным значением наибольшего элемен-
та. Если значение определителя меньше значения такого
элемента, то матрица, вероятнее всего, будет плохо
обусловленной.
Болес систематический подход состоит в использо-
вании евклидовой нормы матрицы, которая, по опреде-
лению, равна корню квадратному из суммы квадратов
каждого элемента матрицы (рис. 17.20). Функция язы-
ка С m ejiorm предназначена для. расчета нормы Евк-
лида. Затем определяется нормализованный определи-
тель как абсолютное значение определителя, деленное
на норму Евклида. Если это значение намного меньше
428
Дополнительные тематические разделы
Часть III
1, то матрица будет плохо обусловленной. Нормализо-
ванный определитель дает возможность более объектив-
но представить, насколько определитель близок к нулю
и является ли матрица плохо обусловленной. Этот метод
хорошо работает в большинстве случаев, однако пользо-
ватель должен знать, что иногда даже этот подход может
давать обманчивые результаты. В этих случаях может быть
полезна проверка по норме Евклида обратной матрицы
(хотя этот способ не реализован в нашей матричной
библиотеке, прилагаемой к этой книге).
|det(A)|
РИСУНОК1720. I" : <<1
f rows cols
Норма Евклида, < / £ £ а-
\ j=i j=i
ПРИМЕЧАНИЕ
Термины Евклидовы нормы и нормализованный опре-
делитель — это немного необычные названия; и опять же,
это не должно вас пугать. Это точная терминология,
которая используется специалистами, но не так широко,
как другая терминология, о которой было упомянуто
ранее.
И даже эту проверку надо выполнять с некоторой
осторожностью. Стандарт языка С требует, чтобы тип
double имел, по крайней мере, 10 значащих цифр.
В зависимости от конкретной матрицы значение норма-
лизованного определителя будет иметь порядок не ме-
нее 10‘9 (1014 — для компиляторов в стандартах IEEE),
и по-прежнему имеется возможность аккумулирования
ошибок, которые возникают в результате того, что мат-
рица плохо обусловлена. Реальная ситуация сильно за-
висит от диапазона изменения значений элементов мат-
рицы и от того, как происходит распространение
ошибки в каждом конкретном случае. На практике, воз-
можно, было бы лучше делать различные тесты, осно-
ванные, насколько это возможно, на нормализованном
определителе без рутинных ручных расчетов. В функ-
ции языка С для расчета матриц текущее произведение
ведущих элементов, которое в конечном итоге становит-
ся значением определителя, сопоставляется с аргумен-
том сравнения — ипсилон, который передается этой
функции. Если в какой-то момент текущее произведе-
ние, разделенное на норму Евклида, будет меньше, чем
ипсилон, расчет прекращается и возвращается нулевое
значение определителя.
ПРИМЕЧАНИЕ
Стандарт ANSEC 1990 г. требует, чтобы переменные с
плавающей точкой имели, по крайней мере, 6 значащих
цифр и чтобы двойные и длинные двойные числа имели,
по крайней мере, 10 значащих цифр. Далее, предпола-
гается, что компиляторы, реализующие стандарт IEEE-754
(по представлению чисел), должны иметь двойные чис-
ла, по крайней мере, с 15 значащими цифрами.
Ах= Ь или Ах= 1b
А-1 Ах = А-11ЬилиХ= А"1Ь
Обратная матрица
Процесс вычисления обратной матрицы очень похож на
процесс вычисления определителя. Обратная матрица
А определяется как матрица А1, которая при умноже-
нии на А дает единичную матрицу (рис. 17.21). Это еще
одно исключение из свойств умножения матриц.
РИСУНОК 1721 .
_ АА-^ — А“1А= I
Свойства обратной матрицы.
Вернемся к нашей системе линейных уравнений,
заданных в матричной форме (рис. 17.22).
Для решения этого матричного уравнения, если нам
известна матрица А1, умножаем обе части уравнения на
А~г. Результат показан на рис. 17.23.
Итак, если вы выполняете таким же образом умно-
жение строки, перестановку строк и исключение вне-
диагональных элементов для А и /, то можете одновре-
менно преобразовывать А в /и Iв А1. Если вы будете
сохранять текущее произведение диагональных элемен-
тов (перед тем как они трансформируются в 1), то по-
лучите определитель более или менее легко.
РИСУНОК 1722
Распознавание неявной
единичной матрицы
с правой стороны уравнения.
РИСУНОК1723.
Решение линейного уравнения
с помощью обратной матрицы.
Различия между этим процессом и вычислением
определителя состоят в том, что элементы над и под
диагональю заменяются нулями. Этот процесс называ-
ется исключением Гаусса-Джордана (Gauss-Jordan
elimination). К тому же очень важно максимизировать
ведущие элементы. (Фактически это то, что называется
частичной максимизацией ведущего элемента. Полная
максимизация включает перестановку также столбцов.
Однако в результате перестановки столбцов получает-
ся вычисленная обратная матрица с перемешанным
порядком следования столбцов. Лучше выполнять час-
тичную максимизацию, которая базируется только на
использовании перестановки строк, чем заниматься
сложным делом устранения ”перемешанности" резуль-
татов. К тому же дополнительная точность, достигаемая
при полной максимизации ведущих элементов вместо
частичной, обычно незначительна.)
В листинге 17.10 представлен код С для реализации
кода обращения матрицы (и его вспомогательных фун-
кций). Здесь также выполняется тест для нормализован-
ного определителя: если его значение меньше, чем за-
данное для сравнения, то определитель приравнивается
к нулю и функция инверсии возвращается. В табл. 17.2
показаны результаты шагов, выполняемых при обраще-
нии матрицы.
429
Матричная арифметика
Глава 17
Листинг 17.10. Обращение матрицы.
MATRIXT *
m_inverse(MATRIX_T * v, MATRIXT * a,
double *det, double epsilon)
{
/* Рассчитывает обращенную матрицу с использованием исключения Гаусса-Джордана с частичной
оптимизацией ведущего элемента */
int row, col, swap, sign;
double pivot, enorm;
MATRIXT *t = NULL;
/*** Код проверки оиибки не показан ***/
e_norn = menori;
♦det = 1.0;
sign = 1;
/♦ Разместить "черновую" матрицу для инвертирования */
t = m_new(a->rows, a->cols);
t ® m_assign(t, a);
/♦ Установить целевую матрицу для единичной матрицы ♦/
v = m_assign_identity(v);
for (row = 0; row < t->rows; row++) {
/* Найти в колонке под диагональю наибольжий элемент ♦/
swap - maxelementrow(t, row);
/♦ Переместить строки для помещения наибольшего элемента на место ведущего элемента ♦/
if (swap != row) { sign = -sign; }
swaprows2(t, v, row, swap);
}
/♦ Разделить каждый элемент ведущей строки на ведущий элемент, чтобы получить единицу
на месте ведущего элемента */
pivot = t->val(mdx(t, row, row)];
♦det *= pivot;
if ((fabs(*det) / enorm) < epsilon) {
return v; /♦ потенциально сингулярная матрица ♦/
}
t = m_muprow(row, 1. / pivot, t); /
v = m__muprow(row, 1. / pivot, v);
/♦ Вычесть числа ведущей строки из каждой строки для получения нулей на месте всех
элементов ведущего столбца, кроме элемента в ведущей строке ♦/
col = row;
set_col_zero(t, v, col);
}
m__free(t);
if (sign < 0)
♦det = -*det;
return v;
}
static void
et col_zero(MATRIX_T * t, MATRIX T * v, int col)
(
int i, j;
double pivot, factor;
pivot = t->val[mdx(t, col, col)];
for (i = 0; i < t->rows; i++) {
if (i == col) {
continue;
}
factor = t->val[mdx(t, i, col)] / pivot;
for (j - 0; j < t->cols; j++) {
t->val[mdx(t, i, j)] -=
430
Дополнительные тематические разделы
Часть III
factor * t->val[mdx(t, col, j)];
v->val[mdx(v, ir j)] -=
factor * v->val[mdx(v, col, j)];
}
}
}
static void
swaprows2(MATRIX-T * t, MATRIX_T * v, int row, int swap)
{
int j;
double temp;
for (j = 0; j < t->cols; j++) {
temp = t->val[mdx(t, row, j)];
t->val[mdx(t, row, j)] = t->val[mdx(t, swap, j)];
t->val[mdx(t, swap, j)] = temp;
temp - v->val[mdx(v, row, j)];
v->val[mdx(v, row, j)J = v->val[mdx(v, swap, j)];
v->val[mdx(v, swap, j)] = temp;
}
}
В табл. 17.2 показан пример промежуточных и окон-
чательных результатов по предыдущему листингу.
Таблица 17.2. Обращение матрицы шаг за
шагом.
строка 2: перестановка строк
Оригинальная матрица и единичная матрица
1.00 2.00 3.00 4.00 ** 1.00 0.00 0.00 0.00
5.00 6.00 7.00 8.00 0.00 1.00 0.00 0.00
1.00 4.00 5.00 7.00 ** 0.00 0.00 1.00 0.00
2.00 3.00 -3.00 4.00 ** 0.00 0.00 0.00 1.00
1.00 0.00 -0.14 -0.71 ** 0.00 0.29 -0.43 0.00
0.00 1.00 1.29 1.93 ** 0.00 -0.07 0.36 0.00
0.00 0.00 -6.57 -0.36 ** 0.00 -0.36 -0.21 1.00
0.00 0.00 0.57 0.86 ** 1.00 -0.14 -0.29 0.00
строка 2, столбец 2: получение нулей в столбце
строка 0: перестановка строк
1.00 0.00 0.00 -0.71 ** 0.00 0.29 -0.42 -0.02
0.00 1.00 0.00 1.86 ** 0.00 -0.14 0.32 0.20
0.00 0.00 1.00 0.05 ** 0.00 0.05 0.03 -0.15
0.00 0.00 0.00 0.83 ** 1.00 -0.17 -0.30 0.09
5.00 6.00 7.00 8.00 ‘ 0.00 1.00 0.00 0.00
1.00 2.00 3.00 4.00 ‘ 1.00 0.00 0.00 0.00
1.00 4.00 5.00 7.00 ‘ 0.00 0.00 1.00 0.00
2.00 3.00 -3.00 4.00 0.00 0.00 0.00 1.00
строка 3, столбец 3: получение нулей в столбце
Результаты: окончательная единичная и обращенная
матрицы
строка 0, столбец 0: получение нулей в столбце
1.00 1.20 1.40 1.60 АА 0.00 0.20 0.00 0.00
0.00 0.80 1.60 2.40 ** 1.00 -0.20 0.00 0.00
0.00 2.80 3.60 5.40 АА 0.00 -0.20 1.00 0.00
0.00 0.60 -5.80 0.80 строка 1: ” 0.00 -0.40 перестановка строк 0.00 1.00
1.00 1.20 1.40 1.60 АА 0.00 0.20 0.00 0.00
0.00 2.80 3.60 5.40 АА 0.00 -0.20 1.00 0.00
0.00 0.80 1.60 2.40 АА 1.00 -0.20 0.00 0.00
0.00 0.60 -5.80 0.80 АА 0.00 -0.40 0.00 1.00
1.00 0.00 0.00 0.00 ** 0.86 0.14 -0.68 0.05
0.00 1.00 0.00 0.00 АА -2.25 0.25 1.00 0.00
O.Q0 0.00 1.00 0.00 АА -0.07 0.07 0.05 -0.16
0.00 0.00 0.00 1.00 АА 1.21 -0.21 -0.37 0.11
Повторим еще раз, эта функция размещает и осво-
бождает временные переменные во избежание модифи-
кации аргументов, отличных от результата. Вспомога-
тельные функции setcol_zero() и sawprows2() являются
аналогами вспомогательных функций, используемых
при расчете определителей. Обе эти функции работа-
ют и в процессе инвертирования матрицы, и при окон-
чательном ее обращении.
строка 1, столбец 1: получение нулей в столбце
1.00 0.00 -0.14 -0.71 ** 0.00 0.29 -0.43 0.00
0.00 1.00 1.29 1.93 0.00 -0.07 0.36 0.00
0.00 0.00 0.57 0.86 1.00 -0.14 -0.29 0.00
0.00 0.00 -6.57 -0.36 ** 0.00 -0.36 -0.21 1.00
Решение линейных уравнений
При решении системы линейных уравнений самый про-
стой подход позволяет написать код, который реализует-
ся, пока идет расчет обратной матрицы и умножение на
известный вектор правых частей системы (рис. 17.24).
431
РИСУНОК1724.
Решение систем А . А 1.
Ах= b => х = А“’Ь
линейных уравнении
с обращением матрицы.
Имеются несколько более прямолинейные методы
решения систем линейных уравнений (как говорилось в
разделе, посвященном определителю). Их основное пре-
имущество заключается в том, что они позволяют легко и
непосредственно исправлять возможные ошибки.
Функция языка С для решения систем линейных
уравнений представлена в листинге I7.ll.
Поскольку мы хотим получить от этой функции
решение системы линейных уравнений, то по оконча-
нии расчета вычисленная обратная матрица нас боль-
ше не интересует. Функция назначает и освобождает
временную структуру MATRIX T для хранения обрат-
ной матрицы. К тому же она вызывает функцию
m inverse(), которая также размещает и освобождает
временные переменные.
Распространение ошибок при матричных
вычислениях
Все ошибки при операциях, в которых используются
числа с плавающей точкой, — это результат нашей не-
аккуратности. Целые значения, представленные как
значения с плавающей точкой, представляются точно
(если они имеют представимый диапазон и точность
используемого типа значений с плавающей точкой),
однако большинство других чисел не имеют точного
представления. Представления числа 1/3 с десятью (или
пятнадцатью) значащими цифрами для обычных целей
будет вполне достаточно, пока выполняется несколько
операций умножения, деления, сложения и вычитания
разнообразных чисел.
Листинг 17.11. Решение систем линейных уравнений.
Матричная арифметика
Глава 17
Ошибки в числах с плавающей точкой накапливают
и могут маскировать правильные результаты при про-
ведении таких расчетов, как инвертирование (обраще-
ние) матрицы. Например, при вычитании двух почти
одинаковых чисел в полученном результате теряется
точность. Таким же образом при сложении и вычитании
двух чисел, которые отличаются на порядок величины,
очень близкой к используемой компилятором базовой
точности, тоже теряется точность. В главе 24 подробно
рассказывается о распространении ошибок в числах с
плавающей точкой.
ПРИМЕЧАНИЕ
Например, если максимальная точность чисел составля-
ет четыре значащие цифры, то разница между 100,0 и
99,95 может (в зависимости от того, как эта операция
выполняется математической библиотекой) давать 0 или
0,1; однако ни то, ни другое нас не устраивает. (Конеч-
но, можно сделать так, чтобы конкретная математичес-
кая библиотека могла хранить дополнительны цифры точ-
ности для внутренних расчетов и возвращать результат
0,05, однако и здесь нет гарантии требуемой точности;
и вообще, такие библиотеки являются редкостью.) Кро-
ме того, сумма 100,0 и 0,01 равна 100,0 при точности
только в четыре значащие цифры. Ситуация улучшается,
когда компилятор в стандартах ANSI использует, по край-
ней мере, 10 или 15 значащих цифр. Однако, в конце
концов, любое определенное ограничение количества
значащих цифр дает ошибки или в точности или в коли-
честве значащих цифр, получаемых в результате расче-
тов, в которых используются числа с плавающей точкой.
Излишне говорить, что в матричных вычислениях (и в
большинстве других расчетов, в которых используются
значащие цифры для деления, умножения, сложения и
вычитания) мы получим преимущество от использования
произвольно задаваемой или увеличенной точности при
расчетах определителей и обращении матриц.
MATRIXT *
m_solve(MATRIX_T ♦ х, MATRIXT ♦ a, MATRIXT ♦ b,
double eps ilon)
{
/* Решает линейное уравнение Ax=b относительно x с обращением матрицы• Примечание: явного кода
проверки нет (исключение составляет анализ ошибок размещения); все потенциальные ошибки
проверяются в вызываемых функциях */
MATRIXT »ainv = NULL;
double det = 0.0;
if ((ainv = m_new(a->rows, a->cols)) == NULL) {
return x;
}
if ((ainv = m_inverse(ainv, a, &det, epsilon)) == NULL)
return x;
x = m_mup(x, ainv, b);
m_free(ainv);
return x;
>
432
Дополнительные тематические разделы
Часть III
Исправление ошибок при решении систем
линейных уравнений
Если есть подозрение о наличии существенных ошибок
в решении системы линейных уравнений, можно при-
менить простой итерационный подход к исправлению
этих ошибок.
ПРИМЕЧАНИЕ
Значительность ошибки зависит от того, кто ее оценива-
ет. В одних случаях 2% точности (или меньше) будет
более чем достаточно. В других случаях даже 10 или 15
значащих цифр точности, гарантированных стандартом С,
может быть недостаточно, даже если не происходит
распространения ошибок.
Полученный в результате расчета вектор х, возвра-
щаемый функцией m_solve(), не является точным реше-
нием. Подставляя х обратно в исходное матричное урав-
нение, мы получим новый вектор правых частей
системы Ь', отличающийся от первоначального Ь.
Чтобы понять метод исправления ошибок, будем
считать, что вектор х — это точное необходимое нам
решение и / - полученный результат численного ре-
шения системы. Когда х' подставляется обратно в ис-
ходное матричное уравнение, результатом будет вектор
Ь', который отличается от b (рис. 17.25).
Ах* =Ь’
Вычтем это уравнение из исходного и получим
результат:
А(х-X*) =Ь-Ь'или A*xadj =b-b'
РИСУНОК 17.25. Исправление ошибки при решении линейного
уравнения.
Однако если поправка xadj к х известна (а ее можно
посчитать непосредственно путем умножения А7 на b-b'),
то правильным решением х Ъухеч следующее: x+xadj.
Это исправление ошибки не даст точного решения
для х, пока рассчитываемое значение xadj и разница
известного b и рассчитываемого Ь будет давать ошибку
по той же причине, по которой дает ошибку первона-
чально рассчитываемое значение х. Имеет смысл мно-
гократно применять этот метод, однако само присут-
ствие ошибок не позволяет получить необходимую нам
величину. Итерации эффективны до тех пор, пока аб-
солютное значение (в некотором смысле) xadj уменьша-
ется. В результате тестов на поиск убывающего значе-
ния величины ошибки можно получить максимальное
абсолютное значение элемента xadj или евклидову нор-
му xadj. Может оказаться достаточно одной или двух
итераций, хотя для уточнения результата можно и их
продолжать. В конце концов, в процессе произойдет
ошибка, вызванная дальнейшим уточнением.
Этот процесс реализует функция С m_ecsolve().
Итерации продолжаются до тех пор, пока убывает евк-
лидова норма. (В этой функции для избежания некон-
тролируемых вычислений жестко закодировано ограни-
чение в 10 итераций. На практике 10 итераций никогда
не понадобятся, однако если необходимо увеличить
этот предел, цикл for объединяют с пределом, указан-
ным в комментарии.) Код этой функции приведен в
листинге 17.12.
ПРИМЕЧАНИЕ
Множество специалистов полагают, что одной или двух
итераций достаточно для этой технологии исправления
ошибок. Однако применение этой технологии не прине-
сет никакого вреда до тех пор, пока не будет достигнут
какой-нибудь специфический критерий (типа уменьшения
евклидовой нормы). Можно также использовать и другие
критерии, например, уменьшение максимального абсо-
лютного значения величины xadj.
Технологии исправления ошибок могут быть полезны и при
работе с маленькими матрицами, однако особую выгоду
от использования исправления ошибок можно получить
при работе с матрицами размером 10x10 и больше.
Как и в случае функции m_solve(), для функции
m_ecsolve() обратная матрица не является частью ее
результата, поэтому размещается временная переменная
для использования ее в самой функции. Пока вызыва-
ется функция обращения матрицы, проводится даль-
нейшее косвенное размещение временных переменных
структуры M-MATRIX. Несколько других временных
переменных сначала размещаются для хранения проме-
жуточных результатов, а в дальнейшем освобождаются.
ПРИМЕЧАНИЕ
Если вы не изучали внимательно листинг, приведенный для
функции m__ecsolve(), то сделайте это сейчас. Обычно
при программировании на структурированном языке при-
менения оператора goto избегают. Есть такое выраже-
ние: "НапиСать '‘макаронный" (с использованием только
вложенных один в другой блоков. — Примеч. науч, ред.)
код". Это можно сделать на любом языке программиро-
вания. Тогда вы можете спросить, зачем в функции
m__ecsolve|) используется оператор goto? Чтобы функция
могла очистить свое предыдущее распределение памяти
в случае возникновения ошибки при распределении, а
часть кода выявления ошибки распределения включает код
для каждой проверки, которая имеет, по крайней мере,
пять обращений к функции m_free(). Тем не менее, эти
же обращения выполняются и в конце функции. В этом
случае использование оператора goto действительно со
кращает код и упрощает очистку распределенной памя
ти при возникновении ошибки. Следует ли избегать исполь
зование оператора goto? Конечно, но, если он позволяс!
упростить код, можно отступить от этого запрещения.
433
Матричная арифметика
Глава 17
Листинг 17.12. Исправление ошибок при решении систем линейных уравнений.
MATRIXT ♦
mecsolve(MATRIX Т ♦ х, MATRIXT ♦ a, MATRIXT * Ь,
double epsilon)
{
/* Решает линейное уравнение Ах=Ь относительно х с обращением матрицы и итеративным исправлением
ошибок */
MATRIXT *ainv = NULL;
MATRIX T *bprime = NULL;
MATRIX T *adj = NULL;
MATRIXT *newx = NULL;
MATRIXjr *newadj = NULL;
MATRIX T *err = NULL;
int iteration;
double adjenorm, newadjenorm, det;
if (!(ainv = m_new(a->rows, a->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
if (!(bprime = m_new(b->rows, b->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
if (!(adj = m__new(x->rows, x->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
if (!(newx = m_new(x->rows, x->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
if (!(newadj = m_new(adj->rows, adj->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
if (!(err = m_new(x->rows, x->cols))) {
mmerrcode = ALLOCFAIL;
goto ending;
}
/* рассчитать первое решение, включая расчет первой поправки */
ainv = id inverse(ainv, a, &det, epsilon);
x = m_mup(x, ainv, b);
bprime - m_mup(bprime, a, x);
err = m_sub(err, b, bprime);
adj = mmupfadj, ainv, err);
adjenorm = menorm(adj);
/♦ Итеративно рассчитать новые решения, пока точность увеличивается, но сделать не более
чем 10 итераций во избежание проведения неконтролируемых вычислений */
for (iteration = 0; iteration < MMAXITERATIONS; iteration++) {
newx = m_add(newx, x, adj);
bprime = m_mup(bprime, a, newx);
err = m_sub(err, b, bprime);
newadj = m_mup(newadj, ainv, err);
newad jenorm = menorm (newad j);
/* Эта проверка выполняется для того, чтобы увидеть следующее: если не произошло
улучшение решения по сравнению с решением, вычисленным на предыдущей итерации, то выполняется
оператор else, чтобы выйти из цикла, а если результат улучшился, то итерация выполняется еще
раз ♦/
if (newadjenorm < adjenorm) { /* значение все еще уточняется */
adjenorm = newadjenorm;
х = massign(x, newx);
adj = m__assign(adj, newadj);
28 Зак. 265
434
Дополнительные тематические разделы
Часть III
} else {
break;
}
}
ending:
m__free(err);
m_free(newadj);
mfree(newx);
mfree(adj);
m_f ree(bprime);
mfree(ainv);
return x;}
На этом заканчивается так называемая техническая
часть повествования. Далее читатель найдет ряд реко-
мендаций и советов по усовершенствованию матричной
библиотеки, и узнает, какое еще существующее про-
граммное обеспечение можно при этом использовать.
Дальнейшие направления работы
Разработанная в этой главе матричная библиотека — это
хорошая базовая библиотека, однако существует множе-
ство возможных вариантов ее совершенствования. Не-
которые из них описаны здесь и помогут всем желаю-
щим осуществить задуманное.
• Расширьте библиотеку, чтобы охватить другие мат-
ричные функции, такие как eigenvalues, eigenvectors,
cofactor и т.д.
• Измените алгоритм, который использовался для ин-
вертирования матриц. Возможное предложение —
алгоритм, использующий нижние и верхние треу-
гольные матрицы. Этот метод позволяет уменьшить
количество сложений и умножений и в конечном
счете сократить распространение ошибок при расче-
те.
• Реализуйте прямой алгоритм для решения систем
линейных уравнений, а не с использованием обра-
щения матрицы. Хороший подход — это метод ис-
ключения Гаусса, который используется для вычис-
ления определителей и который продуцирует
(внутренне) верхнюю треугольную матрицу, исполь-
зуемую для получения решений снизу вверх.
• 'Явно передавайте или используйте глобальные пе-
ременные для их временного хранения в m_det(),
m_inverse(), m_solve и т.д.
• Создавайте резервы для функции обработки ошибок
и обеспечьте обработку ошибок по умолчанию.
В качестве альтернативы измените условие возврата
значения, чтобы всегда возвращать код ошибки и
возвращать результаты путем модификации аргу-
ментов результата.
• Оптимизируйте арифметику индексного исчисления
для расширения возможностей реализации.
• Используйте новые возможности для динамическо-
го размещения двумерных массивов, чтобы сделать
описания элементов более естественными. В качестве
альтернативы замените динамическое размещение
одним из следующих методов, перечисленных на
Web-сайте FAQ по адресу comp.lang.c и предназна-
ченных для выполнения тех же самых действий.
• Перепишите библиотеку так, чтобы можно было при
расчетах с плавающей точкой использовать числовой
тип, отличный от типа удвоенной точности. Будет
особенно просто выполнить это для чисел одинар-
ной точности или длинных чисел удвоенной точно-
сти. Другие возможности включают любые числовые
типы, которые поддерживают четыре основные
арифметические операции (сложение, вычитание,
умножение и деление). Примеры, которые вы може-
те реализовать очень просто, включают числа с фик-
сированной точкой, комплексные или рациональные
числа (относительно просто). Арифметика произ-
вольной точности до некоторой степени трудна
(прежде всего потому, что процесс задания основ-
ных операций весьма сложен).
• Вообще, перепишите библиотеку так, чтобы можно
было использовать арифметические подпрограммы
для других числовых типов путем передачи в мас-
сив указателей функции для необходимых матема-
тических операций. Заметьте, что, хотя это дает в
результате очень общую библиотеку, может про-
изойти значительное снижение эффективности в
зависимости от того, как вновь заданный числовой
тип обрабатывает временные переменные.
• Перепишите библиотеку для использования разре-
женных массивов. (Разреженные массивы описаны
в главе 15.)
• Перепишите библиотеку для использования разре-
женных массивов общего числового типа (таких, как
значения произвольной точности).
435
• Используйте полностью альтернативный подход и
найдите коммерческую или свободно доступную
библиотеку и реализуйте ее для использования на
своей платформе.
Другие подходы
Есть свободно доступный пакет, который называется
Unpack* написанный много лет назад на языке
FORTRAN. Он во многом является эталоном для рас-
четов по линейной алгебре. Если вы имеете доступ к
компилятору языка FORTRAN и ваш компилятор язы-
ка С поддерживает вызываемый объектный код, напи-
санный на других языках, то можно реализовать набор
интерфейсных функций-оболочек и прямо обращаться
к подпрограммам пакета Unpack.
Существует множество других коммерческих или
свободно доступных пакетов, которые можно исполь-
зовать в расчетах по линейной алгебре (BLAS и LAPACK —
только две из них). Возможно, наилучшим подходом для
выяснения текущего состояния в рассматриваемой об-
ласти является выполнение исследования в книжной
библиотеке, проведение поиска по Internet с помощью
словосочетаний типа "линейная алгебра" либо привле-
чение каких-либо групп новостей Usenet, которые за-
нимаются этим предметом.
Матричная арифметика
Глава 17
Резюме
В этой главе были рассмотрены основные идеи простой
арифметики матриц и пути реализации этих идей в
матричной библиотеке ANSI С.
Были описаны основные проектные принципы и
рассказано о сложении и вычитании матриц, а также об
их транспонировании и инверсии. Для этого был ис-
пользован метод расчета определителя квадратных мат-
риц и способ определения относительной (или норма-
лизованной) абсолютной величины определителя.
Читатель узнал, как использовать матричную библио-
теку (в частности, функцию инверсии матриц) для по-
иска решения систем линейных уравнений.
Поскольку бывают врожденные погрешностй (или
ошибки), происходящие при инверсии матрицы, суще-
ствуют и врожденные ошибки при поиске решения си-
стемы уравнений. Матричная библиотека используется
также для итеративного уточнения решения.
Функция m_ensolve(), реализующая решение с ис-
правлением ошибок решений линейных уравнений,
является примером того, как использовать матричную
библиотеку. Кроме того, файл m test.c на Web-сайте
издательства "ДиаСофт" содержит код проверки для
матричной библиотеки с примерами использования
многих из пользовательских функций в этой библиоте-
ке.
Обработка цифровых сигналов
В ЭТОЙ ГЛАВЕ
Применение С к явлениям реального мира
Сжатие данных
Выявление и исправление ошибок
Алгоритмы управления PID
Специализированные процессоры цифровых сигналов
Джек Клейн
В этой главе описаны некоторые методы, применя-
емые в программах С для обработки сигналов, поступа-
ющих из внешнего мира, а не из файлов или с устройств
ввода пользователя.
Оцифровка здесь описывается не очень подробно.
Стандарт языка С не определяет никаких способов вза-
имодействия с устройствами, которые выполняют зада-
чу преобразования реальных сигналов в цифровые зна-
чения, пригодные для обработки программами.
В различных системах эти способы будут различны. По-
этому процесс считывания аналоговых сигналов в неко-
тором конкретном устройстве может не соответствовать
подобному процессу, выполняемому на ПК. В этой гла-
ве дано общее описание природы данных, позволяющее
понять приведенные примеры программ.
Применение С к явлениям реального
мира
С развитием компьютерной индустрии компьютеры
становятся все меньше по размеру, мощнее и дешевле.
В связи с этим постоянно расширяется сфера их при-
менения. Сегодня они используются в таких областях,
о которых совсем недавно не могло быть и речи. Часто
их применение связано с обработкой реальных физичес-
ких данных.
Учитывая огромную популярность языка С для всех
видов программирования, легко догадаться, что этот
язык может использоваться во множестве приложений
интерфейсов для реальных физических процессов. Не
говоря уже о его популярности при решении общих
задач, язык С широко используется для программиро-
вания специализированных микропроцессоров и микро-
контроллеров, которые часто применяются во встроен-
ных системах. Термин встроенные системы служит для
описания компьютеров, встроенных внутрь устройств,
которые значительно отличаются от типичных настоль-
ных компьютеров.
Компьютеры, по крайней мере те, которые могут
быть запрограммированы на С, являются цифровыми,
но процессы, происходящие в реальном мире, носят
аналоговый характер. Звук, температура, скорость, ос-
вещенность, вес и многие другие характеристики реаль-
ного мира проявляются в виде постоянно изменяющихся
непрерывных величин, а не точных числовых значений.
Первый шаг в цифровой обработке сигналов состо-
ит в преобразовании обрабатываемой аналоговой харак-
теристики в одно или более числовых значений, пред-
ставляющих ее величину. Этот процесс называется
оцифровкой.
Первоначально термин цифровая обработка сигналов
был синонимом цифрового анализа и фильтрации сиг-
налов. Эти процессы предполагают выполнение таких
операций, как быстрое преобразование Фурье, преобра-
зование Лапласа, свертка и других методов математичес-
кой обработки. Такие методы по-прежнему широко
применяются во многих научных и инженерных при-
ложениях.
Но данная книга посвящена программированию на
С, а не математической теории анализа. Вместе с тем
программирование на С широко используется во всех
видах компьютеризованных систем, имеющих дело с
оцифрованными данными, всевозможными способами
получаемыми из реального мира.
В настоящей главе представлено несколько прило-
жений реализованных на С интерфейсов к оцифрован-
ным реальным физическим сигналам, причем основное
внимание уделяется стандартным методам программи-
рования на С, а не связанной с этим математической
теории.
437
Следует отметить, что в значительной части приме-
ров кода, представленных в этом разделе, очень широ-
ко используются операторы языка С побитовой обработ-
ки и сдвига. Если вы не знакомы с этими особенностями
языка, то, прежде чем приступать к работе с кодом,
обратитесь к главе 5.
Сжатие данных
Сжатие данных — одна из ключевых технологий совре-
менной сети Internet. За исключением кода HTML са-
мих Web-страниц, почти все передаваемые по сети
WWW данные являются сжатыми в том или ином фор-
мате. В табл. 18.1 приведены лишь некоторые из фор-
матов сжатия, которые можно встретить в WWW.
Таблица 18.1. Некоторые распространенные
типы сжатых файлов.
Тип файла Данные
GIF Графические данные
PNG Графические данные
JPEG Графические данные
MPEG Звуковые и видеоданные
AVI Звуковые и видеоданные
PDF Текстовые и графические данные
MP3 Музыкальные данные
ZIP Любые данные
GZ Любые данные
Некоторые из новейших Web-технологий, такие как
Web Cams (Web-камеры), реальный звук и видеотранс-
ляции, основываются на сжатии в реальном времени
аудио- и видеоданных на компьютере-источнике и рас-
паковке их на компьютере-приемнике.
ГРИ1УЕЧАНИЕ
Прекрасным источником информации о множестве раз-
личных форматов файлов, в том числе графических и
сжатых, является коллекция файловых форматов програм-
мистов Вотсита (Wotsit’s Programmer’s File Format
Collection) на Web-сайте, расположенном по адресу
http://www.wotsit.org.
Сжатие данных выполняется и для экономии дис-
кового пространства, и для сокращения времени пере-
дачи. Сжатые данные занимают меньше места на жест-
ких дисках, лентах резервного копирования и других
носителях. Кроме того, для их копирования или пере-
дачи требуется меньше времени, что способствует эко-
номии времени при передаче или получении данных по
коммуникационным линиям с ограниченной пропуск-
ной способностью, например, при использовании мо-
дема для подключения к Internet.
Обработка цифровых сигналов
Глава 18
Алгоритмы сжатия основываются на распознавании
последовательностей и повторений в исходных несжа-
тых данных. Если данные одновременно шифруются и
сжимаются, то обычно конечный файл имеет меньшие
размеры, если сжатие выполняется до шифрования. Это
связано с тем, что при шифровании удаляются -после-
довательности и повторения, наличие которых в конеч-
ном файле и обусловливает эффективность алгоритмов
сжатия.
Типы сжатия
Все форматы сжатия можно разделить на два типа: без
потерь и с потерями.
• Сжатие без потерь является полностью обратимым.
При распаковке сжатого представления данных ре-
зультат оказывается точным дубликатом исходных
данных перед сжатием. Важно помнить, что ника-
кие методы сжатия без потерь не могут гарантиро-
вать уменьшение размера любого произвольного
фрагмента данных. Любой алгоритм может натолк-
нуться на такой наихудший вариант входных дан-
ных, когда сжатых данных в действительности ока-
зывается больше, а не меньше исходных.
• Сжатие с потерями не является полностью обрати-
мым. При распаковке сжатого таким образом пред-
ставления данных результат оказывается лишь апп-
роксимацией исходных данных, а не побитовым их
дубликатом.
В настоящее время оба типа сжатия широко исполь-
зуются в различных целях.
При сжатии данных для создания резервной копии
на ленте, диске CD-ROM или диске Zip требуется сжа-
тие без потерь. Если из резервной копии нельзя создать
точный дубликат исходного файла, то резервное копи-
рование вообще теряет смысл. Аналогично при загруз-
ке из Internet сжатого файла, который содержит образ
выполняемой программы, необходимо иметь возмож-
ность восстановить точную копию оригинала, а в про-
тивном случае программу выполнить не удастся.
Сжатие с потерями часто выполняется по отноше-
нию к аудио- и видеоданным для достижения больших
коэффициентов сжатия. При этом учитывается ограни-
ченность наших органов чувств, особенно их неспособ-
ность различать очень небольшие изменения цвета, яр-
кости, высоты звука или его громкости.
Все форматы сжатия можно разделить еще на два
типа: адаптируемые и фиксированные.
• Адаптируемые алгоритмы сжатия адаптируются к
действительным обрабатываемым ими данным. При-
меняемый тип кодирования (без потерь или с поте-
рями) изменяется исходя из последовательностей и
438
Дополнительные тематические разделы
Часть III
повторений, присутствующих в данных, которые
подлежат кодированию. Эти алгоритмы могут обес-
печить наибольшие обшие коэффициенты сжатия
для произвольных форматов данных.
• Фиксированные алгоритмы сжатия основываются на
предварительно сделанных допущениях относитель-
но данных, которые должны быть закодированы.
При применении к любым произвольным форматам
данных эти алгоритмы не обеспечивают таких вы-
соких коэффициентов сжатия, как адаптируемые
алгоритмы. Но при применении к тому типу дан-
ных, для которого они были разработаны, эти алго-
ритмы часто могут обеспечить более высокие коэф-
фициенты сжатия, чем адаптируемые методы общего
назначения.
Наиболее часто используемые алгоритмы
сжатия
Вероятно, любому из читателей этой книги доводилось
отправлять или получать хотя бы один факс. Стандарт
Group 3 Digital Facsimile был создан рабочей группой
Comite Consultatif International Telephonique et Telegraphique
(CCITT) International Telecommunications Union (ITU) в
1983 г. Это привело к настоящей революции в облас-
ти факсимильных аппаратов, произошедшей в течение
80-х и начала 90-х гг.
Передача факсимильных сообщений регулируется
двумя стандартами CCITT. Один из них, Т.4, описыва-
ет формат кодирования и сжатия данных изображений
при передаче факсимильных сообщений. Второй стан-
дарт, CCITT, используемый при передаче факсимиль-
ных сообщений, рассматривается далее в этой главе.
Формат кодирования факсов Т.4 может служить хо-
рошей иллюстрацией некоторых концепций (и их реа-
лизации) в коде, используемых для программирования
алгоритмов сжатия на языке С. Это широко используе-
мый реальный стандарт, а не искусственный пример.
Кроме того, он объединяет два важных метода, которые
применяются во многих типах алгоритмов сжатия:
сквозное кодирование и фиксированное кодирование
Хаффмана (Huffman). И наконец, это формат сжатия без
потерь, и поэтому, если правильно реализовать подпрог-
раммы кодирования и декодирования, можно закодиро-
вать, а затем декодировать файл и получить в точности
те же данные, которые были вначале. Это позволяет
экспериментировать с кодом стандарта Т.4, используя
простые файлы двоичных данных и не прибегая к ре-
альному использованию факсимильного аппарата или
телефонной линии.
Обычно факсимильные аппараты ежедневно выпол-
няют в реальном времени кодирование и декодирование
по стандарту Т.4 реальных видеосигналов, полученных
из документов, которые они сканируют, передают и
принимают или воспроизводят. Многие функции про-
токола Р.4 предназначались для того, чтобы обеспечить
разработку сравнительно недорогих факсимильных ап-
паратов в те времена, когда процессоры были значитель-
но более дорогими и менее производительными, а па-
мять — более дорогостоящей, чем в настоящее время.
Факсимильный аппарат мог иметь всего несколько ты-
сяч байтов памяти. В то время как для современного
типичного настольного компьютера это не имеет осо-
бого значения, память — дефицитный ресурс в типич-
ных встроенных системах, таких как самостоятельный
факсимильный аппарат. В примерах программ кодиро-
вания и декодирования по протоколу Т.4 будут проил-
люстрированы некоторые технологии, которые позво-
ляют сократить объем используемой памяти в подобных
приложениях.
Факсимильное изображение
Все факсимильные изображения сканируются при од-
ном и том же разрешении по горизонтали. Каждая го-
ризонтальная строка сканирования имеет длину 215 мм
+/— \% и состоит из 1728 пикселов при разрешении по
горизонтали, равном приблизительно восьми пикселам
на миллиметр или 200 пикселам на дюйм. Каждая стро-
ка сканируется слева направо по пикселам.
Стандарт Group 3 определяет два разрешения: стандар-
тное и повышенное. Разрешение по вертикали выбирает-
ся из этих двух разрешений. При стандартном разрешении
выполняется сканирование 3,85 горизонтальных строк на
миллиметр (приблизительно 98 сканируемых строк на
дюйм), в то время как при повышенном разрешении
используется вдвое более высокое разрешение — выпол-
няется сканирование 7,7 строк на миллиметр (прибли-
зительно 195 строк на дюйм). Факсимильные аппараты,
в которых в качестве единиц измерения чаще всего ис-
пользуются дюймы, а не метрические единицы, могут
выполнять сканирование или печать с разрешением,
равным 200 пикселам на дюйм по горизонтали и 100
или 200 — по вертикали без необходимости каких-либо
настроек.
Стандартные факсимильные аппараты могут рабо-
тать с листами метрического размера А4 или общепри-
нятого в США размера 8,5 х 11 дюймов. Стандартная
номинальная длина листов формата А4 составляет 297
миллиметров. Это дает приблизительно 1143 сканиру-
емые строки на страницу при стандартном разрешении
или около 2287 строк — при повышенном разрешении.
Обычно из-за наличия областей обрезки сканера и
принтера передаются не все возможные сканируемые
строки. Как правило, типичные аппараты передают oi
1000 до 1100 сканируемых строк при стандартном раз-
решении или от 2000 до 2200 строк — при повышен-
ном разрешении.
439
Для понимания кодирования и сжатия информации
по стандарту Т.4 прежде всего необходимо понять, как
изображение страницы выглядит для факсимильного
аппарата в процессе сканирования. Воспользуемся не-
большим фрагментом из самой известной программы на
языке С — "Hello World" — и взглянем на него глазами
факсимильного аппарата. На рис. 18.1 показано, как
слово "Hello", напечатанное и сканированное или визу-
ализированное с повышенным разрешением шрифтом
размером 9 пунктов, выглядит для факсимильного ап-
парата или программы.
РИСУНОК 18.1. Слово "Hello", отображенное шрифтом
размером 9 пунктов при повышенном разрешении факса.
Пока давайте предположим, что этот текст располо-
жен в верхнем левом углу страницы, которую мы соби-
раемся отправить в качестве факса, а остальная часть
страницы представляет собой совершенно пустой белый
лист бумаги. Две верхние сканируемые строки являют-
ся полем и полностью пусты, как и два крайних левых
столбца, даже в тех строках, которые содержат тексто-
вые пикселы.
Преобразование изображения в
закодированный поток
Каждая сканируемая строка изображения факсимильно-
го изображения содержит точно 1728 пикселов, каждый
из которых может быть черным или белым. Поскольку
существует только два возможных значения пиксела, он
может быть представлен одним битом, равным 1 для
белого или 0 — для черного цвета. Это означает, что вся
сканированная строка может быть сохранена в 216 сим-
вольных значениях без знака, каждое из которых хра-
нит значение восьми пикселов. Стандарт языка С тре-
бует, чтобы символьное значение без знака содержало,
по меньшей мере, восемь битов и чтобы не было ника-
ких представлений недопустимых битовых последова-
тельностей или "ловушек". Таким образом, в символе без
Обработка цифровых сигналов
Глава 18
знака можно без проблем хранить любую комбинацию
битов 1 и 0, представляющих белые и черные пикселы.
Даже если конкретная реализация имеет типы симво-
лов, содержащие более восьми битов, в каждом символь-
ном значении без знака удобно хранить восемь битов дан-
ных, поскольку такие устройства, как UART,
используемые при передаче факсимильных сообщений,
как правило, одновременно принимают по восемь битов.
Обычно для оцифровки изображений в сканерах
факсимильных аппаратов и других цифровых видеоус-
тройствах, таких как настольные сканеры и цифровые
камеры, используются устройства Charge Coupled Devices
(CCD — устройства накопления заряда). В факсимиль-
ных аппаратах особенно часто используется устройство,
называемое контактным сканером изображения (Contact
Image Scatter — CIS), разработанное специально для
факсов, но являющееся всего лишь специальным типом
CCD. Для каждого пиксела в изображении устройство
CCD выводит аналоговый сигнал в виде напряжения,
пропорционального яркости пиксела. Этот сигнал мо-
жет быть передан устройству, называемому аналого-циф-
ровым преобразователем (АЦП), которое генерирует циф-
ровое значение, пропорциональное аналоговому
напряжению. Программа может считать цифровое сло-
во, соответствующее яркости каждого пиксела, сравнить
его с предопределенным пороговым значением и ре-
шить, является ли пиксел белым или черным. Для ска-
нирования может также использоваться устройство, на-
зываемое компаратором, которое имеет два аналоговых
входа и один выход цифрового сигнала. К входам под-
водятся напряжения, представляющие порог яркости и
аналоговые сигналы яркости пикселов с устройства
CCD. Выходной цифровой сигнал имеет значение 1 или
О в зависимости от того, какое входное напряжение
выше. По существу, компаратор становится однобито-
вым АЦП, и при этом требуется меньше операций об-
работки и менее дорогостоящие схемы, чем при исполь-
зовании действительного АЦП и программного
сравнения яркости каждого пиксела.
В примере кода, рассматриваемого в этом разделе и
помещенного на Web-сайт издательства "ДиаСофт", не
рассматриваются специфичные для конкретного обору-
дования детали считывания и оцифровки пикселов
изображения. Вместо этого предполагается, что во вход-
ном файле каждой сканированной строке соответству-
ет 216 символьных значений без знака типа unsigned
char, каждое из которых соответствует восьми пикселам.
Бит 7 (0X80) первого символьного значения без знака
представляет самый первый (верхний левый) пиксел
изображения. Бит 6 (0X40) представляет второй пиксел,
бит 7 второго байта массива — девятый пиксел и т.д. до
бита 0 (0X01) заключительного (216-го) символьного
значения без знака unsigned char, представляющего зна-
чение самого последнего, правого пиксела изображения.
Дополнительные тематические разделы
440
Часть III
Можно было бы передавать изображение факси-
мильного сообщения в виде простых двоичных скани-
рованных строк, как описано выше, — по 216 октетов
(восьмерок) на строку, что при стандартном разрешении
соответствовало бы 246888 октетам или 1975104 битам
при максимальном количестве сканированных строк
страницы размера А4, равном 1143. При типичной ско-
рости передачи данных факса, равной 9600 бит/с (би-
тов в секунду) для передачи изображения потребовалось
бы приблизительно 205 секунд или почти 3,5 минуты.
Даже при скорости передачи, равной 14400 бит/с, обес-
печиваемой в более современных факсимильных аппа-
ратах, время передачи все же составило бы около 137
секунд или приблизительно 2,15 минуты. Для повышен-
ного разрешения все указанные значения пришлось бы
удвоить.
Действительное время передачи по факсу типичной
машинописной страницы при скорости передачи, рав-
ной 9600 бит/с, составляет около 30 секунд, т.е. при
кодировании по протоколу Т.4 изображение сжимает-
ся приблизительно до 288 тыс. битов, или 36 тыс. ок-
тетов. Даже при том, что не все возможные сканирован-
ные строки используются в действительности, при
сжатии машинописной страницы количество октетов в
среднем уменьшается с 216 до 36 на сканированную
строку, что дает коэффициент сжатия, приблизитель-
но равный 6.
Формат кодирования
Если вернуться к рис. 18.1, можно увидеть, что первая
и вторая сканированные строки не будут содержать ни-
чего, кроме белых пикселов. Каждый из 216 символов
без знака в массиве, представляющем сканированные
данные, будет содержать значение OxFF. Первые изме-
нения проявятся лишь в третьей сканированной строке —
первой, содержащей символьные данные. Содержимое
массива сканированных данных для этой сканирован-
ной строки приведено в табл. 18.2.
Таблица 18.2. Данные сканированного изобра-
жения для третьей строки текста "Hello".
Смещение символьной переменной без знака Содержимое (в двоичной форме) Содержимое (в шест- надцатеричной форме)
0 11000011 ОхСЗ
1 11000111 0хС7
2 11111111 OxFF
3 11111111 OxFF
4 00000001 0x01
5 11111110 OxFE
6 000000111 0x07
Все остальные 299 символьных значений unsigned
char содержат OxFF для остальной части пустой белой
сканированной строки.
Первый шаг при кодировании каждой сканирован-
ной строки — это вычисление текущей длины. Начиная
с самого левого пиксела каждой сканированной строки,
выполняется подсчет количества последовательных бе-
лых пикселов в строке до конца строки или до первого
встреченного черного пиксела. Пикселы в строке мож-
но описать сериями чисел, представляющих количество
пикселов одного цвета, за каждым из которых следует
символ W для белых пикселов (white) или В — для чер-
ных (black).
Первые две сканированные строки, образующие вер-
хнее поле над текстом, содержат 1728 белых пикселов
и могут быть представлены как 1728W. Первые 7 сим-
волов без знака unsigned char третьей сканированной
строки, приведенной в табл. 18.2, в которой сканер ви-
дит верхние части буквы ИН" и двух букв "Г, можно
было бы описать следующим образом:
2W, 4В, 4W, ЗВ, 19W, 7В, 8W, 6В, 3W
Поскольку все остальные 1672 пиксела в строке яв-
ляются белыми и могут быть представлены всеми еди-
ничными битами в остальных 209 символах unsigned
char в массиве, действительное кодирование всей этой
сканированной строки выглядит следующим образом:
2W, 4В, 4W, ЗВ, 19W, 7В, 8W, 6В, 1675W
Именно эти изменяющиеся последовательности че-
редующихся белых и черных пикселов действительно
кодируются и передаются. Сканированная строка фак-
са всегда начинается с последовательности белых пик-
селов, поэтому, если сканируется строка, которая начи-
нается с черного пиксела, первая последовательность
этой строки представляется как 0W.
В качестве действительного формата для кодирова-
ния изменяющихся последовательностей выполняется
модифицированное кодирование Хаффмана. В общем
случае кода Хаффмана закодированные данные состо-
ят из значений фиксированного размера (типа симво-
лов), а коды переменной длины (которые в протоколе
факса Т.4 называются "кодовыми словами") присваива-
ются таким образом, что наиболее часто встречающие-
ся значения представлены наиболее короткими кодовы-
ми словами, а реже встречающиеся — более длинными.
В коде факса Т.4 кодовые слова представлены как име-
ющие переменную длину, поэтому и исходные данные
и закодированные выходные данные представляют со-
бой строки битов переменной длины. Как и во всех
типах кодирования Хаффмана, все кодовые слова дол-
жны быть уникальными. Никакое кодовое слово нс
может начинаться с той же последовательности битов,
что и более короткое кодовое слово.
Обработка цифровых сигналов
Глава 18
441
Обратите внимание, что, несмотря на выражение
"кодовые слова", коды Т.4 имеют переменную длину от
2 до 13 битов и никак не связаны с размером слов про-
цессора или с каким-либо иным значением фиксирован-
ной длины.
Одним из возможных способов присвоения кодовых
слов последовательностям пикселов было бы наличие
1729 кодовых слов для каждой возможной последова-
тельности белых пикселов длиной от 0 до 1728 и 1728
кодовых слов — для последовательностей черных пик-
селов. Это привело бы к очень длинным кодовым пос-
ледовательностям и ограничило бы достижимую степень
сжатия. Вместо этого в стандарте Т.4 определен двуху-
ровневый подход к кодированию последовательностей
пикселов.
Этот подход несколько напоминает концепцию,
используемую в представлении десятичных чисел, ког-
да цифры от 0 до 9 используются для представления
сотен или тысяч с основанием 10. Аналогично при ше-
стнадцатиричном представлении цифры от 0 до 9 и
символы от А до F используются для представления
значений с основанием 16.
В протоколе Т.4 предусматривается кодирование с
основанием 64. Существует 64 кодовых слова, называе-
мых "оконечными кодовыми словами", каждое из кото-
рых представляет черные и белые пикселы и указывает
последовательности длиной от 0 до 63. Эти слова при-
ведены в табл. 18.3. Когда последовательность пикселов,
длина которой попадает в этот диапазон, встречается в
сканированной строке, соответствующее кодовое слово
добавляется к коду сканированной строки.
Таблица 18.3. Оконечные кодовые слова кода
факса Т.4 для последовательностей пикселов
длиной от 0 до 63.
Последовательность Белое кодовое слово Черное кодовое слово
0 00110101 0000110111
1 000111 010
2 0111 11
3 1000 10
4 1011 011
5 1100 0011
6 1110 0010
7 1111 00011
8 10011 000101
9 10100 000100
10 00111 0000100
11 01000 0000101
12 001000 0000111
13 000011 00000100
14 110100 00000111
15 110101 000011000
Последовательность Белое кодовое слово Черное кодовое слово
16 101010 0000010111
17 101011 0000011000
18 0100111 0000001000
19 0001100 00001100111
20 0001000 00001101000
21 0010111 00001101100
22 0000011 00000110111
23 0000100 00000101000
24 0101000 00000010111
25 0101011 00000011000
26 0010011 000011001010
27 0100100 000011001011
28 0011000 000011001100
29 00000010 000011001101
30 00000011 000001101000
31 00011010 000001101001
32 00011011 000001101010
33 00010010 000001101011
34 00010011 000011010010
35 00010100 000011010011
36 00010101 000011010100
37 00010110 000011010101
38 00010111 000011010110
39 00101000 000011010111
40 00101001 000001101100
41 00101010 000001101101
42 00101011 000011011010
43 00101100 000011011011
44 00101101 000001010100
45 00000100 000001010101
46 00000101 000001010110
47 00001010 000001010111
48 00001011 000001100100
49 01010010 000001100101
50 01010011 000001010010
51 01010100 000001010011
52 01010101 000000100100
53 00100100 000000110111
54 00100101 000000111000
55 01011000 000000100111
56 01011001 000000101000
57 01011010 000001011000
58 01011011 000001011001
59 01001010 000000101011
60 01001011 000000101100
61 00110010 000001011010
62 00110011 000001100110
63 00110100 000001100111
Дополнительные тематические разделы
442|
Часть III
Если последовательность пикселов оказывается
длиннее 63, как. например, пустая белая строка, состо-
ящая из 1728 пикселов, используется второй набор ко-
довых слов. Они называются "составными кодовыми
словами", и каждое составное кодовое слово использу-
ется для последовательности черных или белых пиксе-
лов, кратной 64, причем для каждого цвета использу-
ется другой набор кодов. Когда составное кодовое слово
встречается в коде, передаваемом по факсу, сразу за ним
всегда следует оконечное кодовое слово для этого же
цвета. Составные коды приведены в табл. 18.4.
Таблица 18.4. Составные кодовые слова кода факса Т.4 для последовательностей пикселов длиной от 64 до 1728.
Последовательность Белое кодовое слово Черное кодовое слово
64 11011 0000001111
128 10010 000011001000
192 010111 000011001001
256 0110111 000001011011
320 00110110 000000110011
384 00110111 000000110100
448 01100100 000000110101
512 01100101 0000001101100
576 01101000 0000001101101
640 01100111 0000001001010
704 011001100 0000001001011
768 011001101 0000001001100
832 011010010 0000001001101
896 011010011 0000001110010
960 011010100 0000001110011
1024 011010101 0000001110100
1088 011010110 0000001110101
1152 011010111 0000001110110
1216 011011000 0000001110111
1280 011011001 0000001010010
1344 011011010 0000001010011
1408 011011011 0000001010100
1472 010011000 0000001010101
1536 010011001 0000001011010
1600 010011010 0000001011011
1664 011000 0000001100100
1728 010011011 0000001100101
Для завершения кодирования изображения факса в
коде Т.4 требуется еще только одно кодовое слово —
кодовое слово конца строки EOL. Оно представляется
последовательностью битов 000000000001 и имеет не-
сколько специальных свойств.
Вначале рассмотрим последовательность битов это-
го слова. Она начинается с 11 ведущих нулей, которые
никогда не появляются нигде, кроме конца сканирован-
ной строки. Если вы внимательно просмотрите другие
кодовые слова в табл. 18.4, то увидите, что ни одно из
них не начинается более чем с шести последовательных
нулей и не заканчивается более чем тремя нулями. Та-
ким образом, максимально возможное количество нулей
в любых двух последовательных кодовых словах не
может быть больше девяти.
Второе специальное свойство кода EOL — возмож-
ность его расширения дополнительными нулевыми би-
тами. Перед конечным битом 1 кодового слова EOL
может присутствовать любое количество дополнитель-
ных битов 0. Внутри или между любыми другими ко-
довыми словами никаких дополнений не допускается.
Теперь можно вернуться к трем верхним сканиро-
ванным строкам рис. 18.1 и посмотреть, как выполня-
ется действительное кодирование. Давайте изменим
приведенную выше форму записи, добавив букву "Т"
для оконечных (terminating) или "М" — для составных
(make-up) кодовых слов. Каждая из первых двух полно-
стью пустых строк содержит по одной последователь-
ности 1728 белых пикселов. Поскольку 1728 больше 64
и кратно 64. каждая из этих пустых строк может быть
описана как
1728WM, 0WT, EOL
Таким образом, за белым составным кодовым словом
010011011, представляющим 1728 белых пикселов, сле-
дует белое оконечное кодовое слово 00110101, за кото-
рым следует кодовое слово EOL 000000000001. Посколь-
ку коды переменной длины следуют друг за другом без
учета границ более высокого уровня, конечный код для
каждой из первых двух сканированных строк выглядит
следующим образом:
010011011 00110101 000000000001
Другими словами, сканированная строка, состоящая
из 1728 пикселов, сведенная к 1728 битам единиц и
нулей, в соответствии с протоколом Т.4 кодируется 29
битами, что дает коэффициент сжатия, равный почти
60 (1728:29)! Во многих факсимильных аппаратах и
компьютерных программах факсов часто используется
дополнение строки для получения целых октетов путем
добавления ведущих нулей к кодовому слову EOL:
010011011 00110101 000000000000001
Теперь коэффициент сжатия оказывается равным
точно 54 (или 1728:32)!
Пустая строка, состоящая из всех белых пикселов,
имеет наибольший коэффициент сжатия. Средняя ма-
шинописная или печатная страница содержит доволь-
но много пустых белых сканированных строк между
Обработка цифровых сигналов
443
Глава 18
строками текста, поэтому они значительно влияют на
общий коэффициент сжатия при передаче типичного
факса.
Теперь третья строка изображения, показанного на
рис. 18.1, с помощью двухуровневого описания может
быть выражена следующим образом:
2WT, 4ВТ, 4WT, ЗВТ, 19WT, 7ВТ, 8WT, 6ВТ,
1664WM, 11WT,EOL
а закодированный поток битов приобретает вид:
000111 011 1011 10 0001100 00011 10011 0010 011000
000000000001
После добавления двух дополняющих нулевых би-
тов к кодовому слову EOL, с тем чтобы строка завер-
шалась на границе октета, поток приобретает следую-
щий вид:
000111 011 1011 10 0001100 00011 10011 0010 011000
00000000000001
С использованием дополнения коэффициент сжатия
составляет 1728:56, что все еще больше 30.
Каждая передача страницы факса начинается с пе-
редачи одной последовательности EOL, сразу за кото-
рой следует первая сканированная строка. Каждая ска-
нированная строка в передаваемом сообщении факса
кодируется кодом переменной длины, описанным в
таблицах 18.3 и 18.4, и передается в виде непрерывно-
го потока битов без учета границ октетов или каких-
либо иных границ. В потоке отсутствуют какие-либо
стартовые, стоповые, биты проверки четности,ил и ка-
кие-либо другие дополнительные биты. Каждая скани-
рованная строка завершается кодовым словом EOL, со-
стоящим, по меньшей мере, из 11 последовательных
битов 0. Это позволяет синхронизировать приемник с
передатчиком в случае ошибок передачи, так как любая
последовательность, состоящая более чем из девяти
последовательных битов 0, будет частью последователь-
ности EOL. Сразу за каждой сканированной строкой, за
исключением последней, идет начальное кодовое сло-
во следующей строки без учета границ октетов, хотя оно
может быть началом нового октета, если предыдущая
строка естественным образом закончилась по границе
октета или была соответствующим образом дополнена
нулями, как во втором из приведенных выше примеров.
За последней сканированной строкой страницы сле-
дует шесть последовательных кодовых слов EOL — без
каких-либо кодовых слов пикселовых данных между ними,
которые указывают на достижение конца страницы.
Еще один нюанс
Прежде чем можно будет приступить к кодированию и
декодированию данных в формате факса Т.4, нужно
учесть еще одно, последнее обстоятельство. Кодовые
слова Т.4 описываются потоком битов, следующих слева
направо, причем первый, самый крайний слева бит каж-
дого кодового слова идет сразу за последним, самым
крайним справа битом предыдущего кодового слова.
Эти биты должны передаваться от отправителя получа-
телю именно в этом порядке — слева направо. Однако
в факсимильных аппаратах и факс-модемах использу-
ются стандартные устройства последовательного порта,
и когда 8-битовый октет записывается в передатчик та-
кого устройства, он передается в виде последовательно-
го потока, начиная с младшего (самого крайнего спра-
ва) и заканчивая старшим (самым крайним слева) битом.
Чтобы проиллюстрировать это, давайте вернемся к
кодированию пустой белой строки, кодовое слово EOL
которой дополнено двумя битами 0 до границы октета:
010011011 00110101 000000000000001
Сказанное можно проиллюстрировать, разделив
строку на 8-битовые октеты:
01001101 10011010 10000000 00000001
Если бы значения этих четырех октетов были записа-
ны в передатчик стандартного последовательного устрой-
ства одно за другим, то последовательный результирую-
щий поток битов во времени имел бы следующий вид:
10110010 01011001 00000001 10000000
Последовательность октетов сохранилась бы, но
порядок битов в каждом октете был бы изменен на об-
ратный. Приложения, предназначенные для кодирова-
ния двоичных данных в соответствии с протоколом Т.4
и для декодирования Т.4 обратно в двоичные данные,
будут "на лету" выполнять это изменение порядка сле-
дования битов.
Программа сжатия 1.4: encode.c
На Web-сайте "ДиаСофт" содержится полный исход-
ный код стандартной программы на языке С, которая
считывает двоичные данные из файла цепочками по 216
символов без знака, обрабатывает младшие восемь би-
тов в качестве пикселов сканированной строки и гене-
рирует код Т.4 для каждой сканированной строки, пос-
ле чего записывает его в другой двоичный файл.
Программа состоит из единственного файла исходного
кода encode.c. В целях экономии места в книге большая
часть содержимого этого файла здесь не приводится.
Заголовок fax.h определяет некоторые числовые кон-
станты, чтобы избежать жесткого кодирования чисел в
исходном коде. На Web-сайте "ДиаСофт" содержится
также программу decode.c, которая выполняет обратную
операцию и преобразует закодированное кодом Т.4
представление страницы факса в исходное двоичное
представление сканированного изображения. Содержи-
мое файла fax.h выглядит следующим образом:
Дополнительные тематические разделы
Часть III
444
♦define PIXELS_PER_ROW
♦define PIXELSPEROCTET
♦define OCTETSPERROW
♦define MAXIMUMROWS
♦define T4BUFFERSIZE
♦define EOLLENGTH
♦define OCTET_MASK
1728
8
(PIXELSPERROW /
PIXELS_PER_OCTET)
1024
1024
12
Oxff
Программа encode.c определяет тип данных для хра-
нения и использования кодовых слов Т.4, а также че-
тыре массива констант этого типа, по одному для бе-
лого и черного оконечных кодовых слов и белого и
черного составных кодовых слов. Вот как выглядит оп-
ределение типа данных:
typedef struct
{
unsigned char code length;
unsigned char bit_pattern;
} T4_ENCODE;
Таблицы подстановок для всех кодовых слов пред-
ставляют собой четыре массива структур T4ENCODE.
На первый взгляд содержимое этих структур может
показаться непонятным. Оба члена структуры имеют
тип unsigned char, что гарантирует наличие в них вось-
ми битов и возможность хранения значений в диапазо-
не от 0 до 255. Хранение нужного количества битов
кодового слова, которое всегда составляет от 2 до 13, в
члене code_length не создает никаких проблем. Но сами
кодовые слова Moiyr содержать до 13 битов, и все же мы
представляем их членом bitpattern. В соответствии со
стандартом языка С это необходимо делать при исполь-
зовании любого процессора, использующего компиля-
тор С, а не только на какой-либо отдельной платфор-
ме, где данные типа unsigned char могут содержать 13
или более битов.
Чтобы выяснить, как это можно сделать, давайте
снова обратимся к таблицам 18.3 и 18.4. Даже при том,
что некоторые кодовые слова используют 9, 10, 11, 12
или 13 битов, все единичные биты попадают в число
правых восьми битов. Все биты, расположенные перед
последними восьмью битами в более длинных кодовых
словах, являются нулевыми. Независимо от размера
значения типа целого без знака, хранящегося в после-
довательности битов, его фактическое числовое значе-
ние меньше 255, поскольку ведущие нули не оказыва-
ют никакого влияния. Следовательно, значение любого
кодового слова можно хранить в переменной типа
unsigned char. Фактически, даже если платформа и ком-
пилятор предоставляют более восьми битов в unsigned
char, только младшие восемь битов используются про-
граммами кодирования и декодирования Т.4. Если при-
сутствуют какие-либо старшие биты, они совершенно
не используются.
Ниже приведены первые несколько строк из про-
граммы encode.c, которые содержат массивы таблиц
подстановок:
static cost T4_ENCODE white__terminate [ ] =
{
{ 8, ОХАС}, /* 0 белых пикселов */
{ 6r 0XE0}, /* 1 белый пикселов */
{ 4, 0XE0}, /* 2 белых пикселов */
{ 4, 0X10}, /* 3 белых пикселов */
Если сравнить эти строки с первыми несколькими
кодовыми словами для последовательностей белых пик-
селов, приведенными в табл. 18.3, вероятно, это вызо-
вет недоумение. Хотя выше пояснялось, как каждое
кодовое слово может храниться в значении типа unsigned
char, члены bitpattern в элементах массива кажутся
вообще не соответствующими представленным в табли-
це. Это связано с тем, что записи таблицы уже преоб-
разованы в соответствии с порядком передачи битов
последовательным устройством.
На рис. 18.2 показаны два примера того, как были
получены табличные значения: один пример для кодо-
вого слова, содержащего менее восьми битов, и другой —
для слова, которое содержит более восьми битов. В стро-
ке А кодовое слово для последовательности 1011 четы-
рех белых пикселов помещено выровненным по право-
му краю в четырех младших битах октета (unsigned
char). В строке В старшие биты октета дополнены 0
битами. В строке С порядок следования восьми битов
изменен на обратный, и это значение используется для
члена bit_pattern. Если вы обратитесь к программе
encode.c, то увидите, что членом bit_pattern для
white_terminate[4] является 0xD0.
В строке D показано составное кодовое слово для
последовательности 512 черных пикселов 000001101100.
В строке Е показан остаток октета после отбрасывания
всех битов старше восьми младших, которые всегда яв-
ляются 0. В строке F порядок следования оставшихся
восьми битов снова изменен на обратный, в результате
чего член bit ^pattern для black_makeup[7] (содержащий
кодовое слово для этой последовательности пикселов)
инициализируется значением 0x36.
Функция main()
Функция main() в файле encode.c — простой драйвер
для кода, который действительно выполняет сжатие.
Эта функция анализирует ар!ументы командной стро-
ки для отыскания двух имен файлов: одного — для
входного файла, содержащего двоичные данные пиксе-
лов, которые необходимо закодировать, и второго — для
выходного файла, который будет содержать результат,
закодированный в соответствии с протоколом Т.4, Фай-
лы открываются в двоичном режиме.
Обработка цифровых сигналов
Глава 18
445
ШПЛИНТЕ]
РИСУНОК 182.
Кодирование кодовых слов
Т.4 8-битовыми значениями.
С
D
Е
0 0 0 0 0
О | О I О I О | О I О I 1 | 1 I О I 1 I 1 | О I О I
Кроме того, эта функция определяет буфер, размер
которого достаточен для хранения вывода Т.4, генери-
руемого в результате сканирования любой возможной
строки. Поскольку используемые кодовые слова явля-
ются фиксированными, можно легко вычислить макси-
мальную длину возможной выходной закодированной
строки. Наихудшим случаем является сканированная
строка, содержащая чередующиеся белые и черные пик-
селы. Код для одного белого пиксела содержит шесть
битов, а для одного черного — три бита. Таким обра-
зом, каждая комбинация одного белого и одного черно-
го пикселов генерирует девять битов кодовых слов.
Строка из 1728 пикселов может содержать 864 пары че-
редующихся пикселов, приводя к 7776 битам кодовых
слов (927 октетам). Если строка начинается с черного
пиксела, необходимо добавить начальное 8-битовое ко-
довое слово. И наконец, два байта кодового слова EOL
доводят общее количество октетов до 975. В файле fax.h
размер буфера T4BUFFERSIZE определен равным
1024, но во встроенной системе с ограниченным объе-
мом памяти можно использовать именно 975 байтов.
Функция EncodePage()
Функция main() вызывает функцию EncodePage(), пе-
редавая ей два указателя FILE: указатель на массив и
копию имени выходного файла для сообщений об
ошибках. Эта функция представлена в листинге 18.1.
Функция EncodeUne()
Функция EncodePage() вызывает функцию EncodeLine()
до MAXIMUM ROWS (максимальное количество строк)
раз или пока не будет достигнут конец входного файла в
процессе попытки считывания из него 216 значений типа
unsigned char (листинг 18.2). Эта функция записывает за-
кодированную кодом Т.4 версию каждой строки в выход-
ной файл и возвращает целое значение, указывающее на
успешность операции. Она может возвращать 0 или поло-
жительное число, равное количеству сгенерированных и
записанных сканированных строк, либо значение стандар-
тного макроса EOF языка С, которое является отрицатель-
ным целым числом — в случае ошибки.
Функция CountPixelRun()
Функция EncodeLine() вызывает функцию CountPixelRiin()
(листинг 18.3) для поочередного извлечения последова-
тельностей белых и черных пикселов из двоичного ис-
ходного файла изображения. Эта функция возвращает
либо число в диапазоне между 0 и 1728, указывающее
длину найденной последовательности указанного цве-
та, либо EOF, если входной файл завершается на сере-
дине сканированной строки. В процессе извлечения
последовательностей пикселов функция сохраняет те-
кущее значение общего количества пикселов, остаю-
щихся в сканированной строке, всегда передавая его
функции CountPixelRun(). Это необходимо потому, что
входной файл содержит необработанные двоичные дан-
ные без каких-либо символов-ограничителей, указыва-
ющих концы сканированных строк.
446
Дополнительные тематические разделы
Часть III
Листинг 18.1 Функция EncodePage().
static int
EncodePage(FILE *fin, FILE ♦tout,
unsigned char *buff,
char *output_name)
{
int size;
int scan_lines;
sizet written;
/* Записывает в файл обязательное начальное кодовое слово EOL */
if (sizeof EOL 1= fwrite(EOL, 1, sizeof EOL, fout))
{
printf(wrerr , outputname);
return EOF;
}
for (scan lines = 0; scan_lines< MAXIMUM ROWS; )
{
size = EncodeLine(buff, fin);
if (size < 0)
{
break;
}
++scan_lines;
written = fwrite(buff, sizeof *buff, size, fout);
if ((int)written 1= size)
{
printf(wrerr, outputname);
return EOF;
}
}
/* Записывает обязательные весть последовательных кодовых слов EOL для указания конца
страницы */
if (sizeof EOF 1= fwrite(EOP, 1, sizeof EOP, fout))
{
printf(wrerr, outputname);
return EOF;
}
return scan_lines;
Листинг 18.2. Функция EncodeLineQ.
int
EncodeLine(unsigned char *t4_out, FILE *fin)
{
int scan_count e PIXELS_PER_ROW;
int runcount;
unsigned char *t4_ptr = t4_out;
PIXELBITS color = WHITEPIXEL;
while (scan count > 0)
<
runcount = CountPixelRun(color, scan_count, fin);
if (runcount == EOF)
{
return EOF;
}
447
Обработка цифровых сигналов
Глава 18
if (color == BLACKPIXEL)
{
if (runcount > 63)
{
t4_ptr = Outputcodeword(
black_makeup + (run_count / 64) - 1,
t4_ptr);
t4_ptr = OutputCodeWord(
black_terminate + (run_count % 64) ,
t4_ptr);
color = WHITEPIXEL;
}
else
{
if (run_count > 63)
{
t4_ptr = OutputCodeWord(
white makeup + (run_count / 64) - 1,
t4_ptr);
}
t4_ptr = OutputCodeWord(
whiteterminate + (run count % 64),
t4_ptr);
color = BLACKPIXEL;
scan_count -= run_count;
t4ptr = OutputCodeWord(NULL, t4_ptr);
return (int)(t4_ptr - t4_out);
1
Затем функция EncodeLine() вызывает функцию
OutputCodeWord() для сохранения кодовых слов для
каждой последовательности в буфере, переданной ей
функцией EncodePage(). Если последовательность со-
держит более 63 пикселов, для ее кодирования требу-
ются и составное и оконечное кодовые слова.
В случае ошибки ввода или вывода функция
EncodeLine() возвращает EOF; иначе она возвращает
целое значение, указывающее количество байтов сгене-
рированного кода. В последней строке значение, вычис-
ленное путем вычитания двух указателей в массиве
Выходного буфера, преобразуется в int. Это желательно
потому, что разность между двумя указателями в языке
С имеет тип ptrdiff_t, определенный в библиотеке
<stddef.h>, и должна быть равна или больше значения
типа int. При необходимости компилятор автоматичес-
ки преобразует это значение в int, что всегда будет де-
латься без переполнения, поскольку, как мы уже зна-
ем, наибольшее генерируемое значение не превышает
975. Но подобное преобразование типа лучше выпол-
нять явно.
Листинг 18,3, Функция CountPixelRunQ,
static int
CountPixelRun(PIXEL_BITS wanted, int maximum,
FILE *fin)
{
int run_count = 0;
int input;
static int rawpixels = 0;
static int bits_used = 8;
static int EOFflag « 0;
for ( ; ; )
{
if (bitsused >= PIXELSPEROCTET)
{
if (maximum >~ 8)
if (EOFflag)
{
return EOF;
}
else if ((input = fgetc(fin)) == EOF)
{
EOFflag = 1;
break;
}
rawpixels = input & OCTETMASK;
448
Дополнительные тематические разделы
Часть III
bits_used = 0;
}
else
{
break;
1
}
if (wanted == (rawpixels & PIXEL_TEST))
{
++run_count;
++bits_used;
—maximum;
raw_pixels «= 1;
}
else
{
break;
}
1
return run_count;
}
Функция CountPixeiRunO получает значение
PIXEL_BITS, указывающее цвет искомой последова-
тельности, количество остающихся пикселов в текущей
сканированной строке и указатель на входной файл для
считывания данных. Поскольку последовательность
пикселов может начинаться и заканчиваться в любом
месте без учета границ октета, функция CountPixeiRunO
сохраняет некоторые постоянные данные в статических
переменных.
Переменная raw_pixels типа unsigned int хранит со-
держимое последнего октета, полученного из входного
файла путем обращения к функции в случае, если пос-
ледовательность пикселов заканчивается в середине ок-
тета. По умолчанию эта переменная инициализируется
значением 0, поскольку она имеет статический харак-
тер, но явная инициализация служит напоминанием об
этом факте.
Переменная bitS-Used подсчитывает количество пик-
селов, уже извлеченных из rawjixels. Когда значение
bits_used достигает значения PIXELS-PER_OCTET,
определенного в fax.h равным 8, это означает, что
все пикселы в октете использованы и из входного
файла необходимо выполнить считывание другого
октета. Инициализация этой переменной значением
PIXEIJSPEROCTET вынуждает функцию CountPixeiRunO
считывать из входного файла первый октет при пер-
вом к ней обращении.
И наконец, флаг EOF_flag используется функцией
CountPixeiRunO для напоминания о том, что она уже
получила сообщение об ошибке во время считывания
входного файла. Когда обращение к функции fgetc()
впервые возвращает EOF, этот флаг устанавливается и
текущая последовательность прерывается, после чего
накопленное значение счетчика последовательностей
возвращается функции EncodeLine(). Если EncodeLine()
снова вызывает функцию CountPixeiRunO, она просто
возвращает EOF.
Локальная переменная input определена как перемен-
ная типа int со знаком для приема значения, возвращае-
мого функцией fgetcO- Если бы использовалась перемен-
ная raw_pixels типа unsigned int, программа могла бы
правильно распознавать EOF не во всех версиях языка С.
Фактически используемый алгоритм подсчета после-
довательностей проверяет старший использованный бит в
raw_pixels, выполняя побитовую операцию AND (логичес-
кое И) с перечислимой константой PIXEL_MASK, име-
ющей значение 0x80, и сравнивая результат с требуемым
аргументом PIXEL—BITS, который имеет значение 0x80
для белых пикселов или 0 — для черных. До тех пор
пока результат такого сравнения дает истину (TRUE),
последовательность продолжается и raw—pixels сдвига-
ется влево на один бит для помещения следующего бита
в проверяемую позицию.
Функция OutputCodeWord()
Следующая функция, OutputCodeWord() (листинг 18.4),
иллюстрирует тот факт, что вставка последовательнос-
ти битов произвольной длины в выходной поток гораз-
до проще распознавания произвольных последователь-
ностей битов во входном потоке. Поскольку длина
выходной последовательности битов известна, функция
OutputCodeWord() может обрабатывать ее фрагментами,
размер которых может достигать размера полного окте-
та, в зависимости от длины и выравнивания. Длина
входной последовательности неизвестна, пока не будут
прочитаны все ее биты. Можно создать код, в котором
во время считывания весь октет проверяется на предмет
совпадения цвета всех его пикселов с текущим цветом.
Это позволило бы сэкономить время при подсчете пос-
ледовательностей белых пикселов (вспомните о нали-
чии всех этих белых сканированных строк), но не при
обработке последовательностей черных пикселов, по-
скольку в типичных документах, передаваемых по фак-
су, восемь и более последовательных черных пикселов
встречаются нс столь уж часто.
Функция OutputCodeWord() вызывается функцией
EncodeLine() по-разному для вывода кодового слова для
последовательности пикселов и для вывода кодового
слова EOL. В первом случае код аргумента указывает
причину этого. Если кодом является NULL, значит,
должно генерироваться кодовое слово EOL. В противном
случае код указывает на одну из структур Т4—DECODE,
и выводится кодовое слово, содержащееся в этой структу-
ре. Так или иначе, функция OutputCodeWord() возвраща-
ет целевой указатель, полученный ею сразу по заверше-
нии работы, причем к этому времени его значение может
быть увеличено один или два раза.
Обработка цифровых сигналов
Глава 18
[449
Листинг 18.4. Функция OiitpiitCodeWord().
static unsigned char
♦Outputcodeword(const T4ENCODE *coder unsigned char *t4 ptr)
{
int length;
static int freebits = 8;
static unsigned long current_output - 0;
/♦ Если аргументом указателя является NULL, выполняется вывод кодового слова EOL */
if (NULL == code)
{
currentoutput &= OCTET_MASK;
current—output »= free_bits;
*t4_ptr++ = (unsigned char)(current-Output & OCTET-MASK);
if (free bits < 4)
{
*t4—ptr++ - 0;
}
*t4—ptr++ = 0x80;
freebits = PIXELS_PER_OCTET;
current-Output = 0;
}
/* в противном случае выводится кодовое слово, хранящееся в структуре */
else
{
length = code->code_length;
current—output | =
((unsigned long)code->bit_pattern « length);
while (length >= fгев-bits)
{
current_output »= fгев-bits;
*t4ptr++ = (unsigned char)(current—output & OCTET-MASK);
length -= fгев-bits;
freebits « PIXELSPEROCTET;
}
if (length 1= 0)
{
current-Output »= length;
fгев-bits -= length;
}
}
return t4_ptr;
}
Для хранения информации между обращениями
функция OutputCodeWord() нуждается также во внут-
ренних статических переменных. Поскольку кодовое
слово может завершаться, заполняя октет лишь частич-
но, то во время возврата из функции переменная
current_output может быть заполнена частично, поэто-
му для сохранения значения она должна быть статичес-
кой. Значение free_bits определяет количество битов
следующего кодового слова, которые еще должны быть
помещены в переменную currentoutput.
Операция вставки кодового слова произвольной дли-
ны, начиная с произвольного пограничного бита, иллю-
стрируется шаг за шагом на рис. 18.3. В данном случае
показано добавление 13-битового кодового слова к пяти
остающимся битам предыдущего кодового слова.
Отображение действительных символов 1 и 0 для
позиции каждого бита затрудняет различение исполь-
зованных и неиспользованных битов или битов нового
кодового слова и битов, оставшихся от предыдущего
слова. Поэтому на рисунке делается отход от фактичес-
кого битового содержимого и используется другая фор-
ма записи. Буква X указывает бит в переменной
current_output, оставшийся от предыдущего вставленно-
го кодового слова, независимо от того, является ли в
действительности бит равным 1 или 0. Аналогично бук-
ва Y представляет бит нового кодового слова, который
29 Зак. 265
должен быть вставлен, независимо от его фактического
значения. Символ 0 на рисунке указывает бит, который
изначально является 0 и не является частью вывода. И
наконец, дефис (-) означает бит, не имеющий значения,
который уже перемещен в выходной буфер памяти и
будет отброшен. Вертикальная линия на рисунке пока-
зывает расположение младшего октета, содержащего
самые младшие биты переменной current_output.
Предположим, что freejbits содержит значение 3, т.е.
три правых бита переменной current_output не имеют
значения, а левые пять битов содержат биты предыду-
щего кодового слова. Содержимое кодового слова мож-
но представить как ХХХХХ—. Все биты, предшеству-
ющие младшим восьми, равны 0. Это показано в строке
А на рисунке. Штриховые линии (- -) слева указывают
на то, что в переменной присутствуют и другие биты
0, поскольку переменная current output имеет тип
unsigned long и фактически содержит, по меньшей мере,
32 бита.
В строке В показан член bit_pattern структуры
Т4—ENCODE — октет, хранящийся в переменной типа
unsigned char и содержащий восемь битов. Если конк-
ретная реализация типа unsigned char содержит более
восьми битов, все старшие биты являются нулями.
Любой или все биты, расположенные слева от верти-
кальной черты, могут не существовать.
В следующих трех строках кода полностью развора-
чивается новое кодовое слово и вставляется в перемен-
ную current_output:
length = code->code__length;
currentoutput | =
((unsigned long) code->bit_pattern « length) ;
Эта операция показана в строках В, С и D. Первый
шаг в вычислении выражения состоит в преобразовании
типа члена bit_pattem в unsigned long. Преобразование
типа значения из более узкого в более широкое заклю-
чается в заполнении старших битов нулями, поэтому
сразу по завершении преобразования типа промежуточ-
ное значение полностью соответствует показанному в
строке В.
Применение круглых скобок приводит к тому, что
следующей должна выполняться операция левого сдви-
га. В нашем примере значение типа unsigned long сдви-
гается влево на 13 мест, и результат этой операции по-
казан в строке С. Сдвиг влево всегда приводит к сдвигу
битов 0 справа, независимо от того, имеет или не име-
ет знак сдвигаемое значение. В процессе этого пять пос-
ледних битов нового кода, которые все являются бита-
ми 0, создаются заново, а все кодовое слово сдвигается
за пределы первых восьми битов временного значения,
оставляя все восемь младших битов равными 0.
Заключительный шаг вычисления выражения состо-
ит в выполнении побитовой включающей операции OR
(логическое ИЛИ) по отношению к временному длин-
ному значению без знака и значению current output.
Поскольку current_output содержит биты 0 во всех раз-
рядах, которые старше младшего октета, а временное
значение содержит все биты 0 в младшем октете, резуль-
тат логического объединения очевиден; он показан на
рисунке в строке D.
Теперь мы добрались до цикла, начинающегося с
while (length >= free__bits)
Поскольку длина length равна 13, а неиспользован-
ный вывод — только 3, при первом вычислении усло-
вия тело цикла выполняется. Строка
current_output »= fхее__bits;
сдвигает значение current_output на три позиции; ре-
зультат этой операции показан в строке Е. Поскольку
currentoutput имеет тип без знака, сдвиг вправо всегда
приводит к сдвигу битов 0 слева. Теперь младший ок-
тет текущего вывода полностью заполнен восьмью би-
тами кодовых слов и может быть сохранен в выходном
буфере. В строке
Обработка цифровых сигналов
Глава 18
451
*t4_jptr++ = (unsigned char) (current_output &
OCTETMASK);
выполняется эта задача и выходной указатель увеличи-
вается для указания на следующую ячейку выходного
буфера, которую нужно заполнить. Побитовое логичес-
кое И с переменной OCTET MASK, определенной как
Oxff, обеспечивает использование только младших вось-
ми битов unsigned char. В реализациях с 8-битовыми
символьными переменными это делать не обязательно,
но в результате наша программа становится совмести-
мой с платформами, на которых используются более
широкие символы. Преобразование типа в unsigned char
не требуется, поскольку OCTET_MASK уже гарантиру-
ет соответствие переменной диапазону unsigned char, но
явное преобразование типа при присвоении более узко-
го типа — всегда рациональное действие, которое пре-
дотвращает появление предупреждений компилятора и
компоновщика.
Как только восемь битов перемешены в выходной
буфер, они больше не нужны и не имеют значения, как
показано в строке F на рис. 18.3.
Последние две строки в теле цикла
length -= free_bits ;
freejbits = PIXELS_PER_OCTET
Здесь мы всего лишь сдвинули биты переменной
free bits (в данном случае 3 бита) новой последователь-
ности в младший октет, поэтому вычитаем 3 из общей
длины, чтобы для обработки осталось 10 битов. По-
скольку теперь все биты в младшем октете не имеют
значения и доступны для использования, устанавлива-
ем free_bits равным значению PIXELS PER OCTET,
которое определено равным 8.
Поскольку length (равное 10) больше, чем free bits
(равное 8), тело цикла while выполняется во второй раз.
currentoutput сдвигается вправо на free_bits (т.е. на 8)
позиций, приводя к строке G на рисунке. В процессе
этого все не имеющие значения биты, которые уже
были сохранены в выходном буфере, сдвигаются за
пределы правой границы переменой current_output и
исчезают. Младший октет заполняется восьмью новы-
ми битами, поэтому он снова сохраняется в выходном
буфере, а его содержимое помечается как не имеющее
значение в строке Н. И наконец, цикл вычитает free bits
(равное 8) из length (равного 10), оставляя значение
length равным 2. Значение free_bits снова устанавлива-
ется равным 8.
Условие цикла while вычисляется в третий раз, но
теперь значение length (равное 2) не больше и не равно
значению freejbits (равному 8), поэтому тело цикла
пропускается. Выполнение достигает условного выраже-
ния
if (length != 0)
В данном случае значение length равно 2, поэтому
тело этого выражения выполняется.
{
current__output »= length;
freebits -=length;
1
В строке I на рисунке переменная current_output
сдвигается влево на два бита, и это значение 2 вычита-
ется из free bits, давая значение, равное 6 и указываю-
щее, что в младшем октете остается 6 не имеющих зна-
чения битов, которые должны быть замешены битами
из следующего кодового слова.
Интерес представляет также обработка этой функ-
цией кодового слова EOL, когда параметром кода явля-
ется NULL. Протокол Т.4 не требует, чтобы сканиро-
ванные строки заканчивались и новые сканированные
строки начинались точно по границе октета. Но такое
совпадение — очень распространенная практика, по-
скольку она упрощает управление буфером для записи
в файл, как это имеет место в данной программе, или
для пересылки на последовательное устройство, как это
делается в факсимильных аппаратах.
Преобразование закодированного потока в
изображение
Декодирование страницы, закодированной в соответ-
ствии с протоколом Т.4, в двоичные пикселы — более
сложная задача, чем ее кодирование. Вообще, это утвер-
ждение справедливо по отношению к большинству ал-
горитмов сжатия и многим методам шифрования. В слу-
чае же кодирования Т.4 это обусловлено, в частности,
следующими причинами:
• Во время кодирования известно, что каждая необра-
ботанная строка сканирования состоит ровно из 216
октетов, содержащих 1728 битов, представляющих
пикселы изображения. При декодировании точная
длина любой строки неизвестна до тех пор, пока не
будут обнаружены кодовые слова, дополняющие ее
до 1728 битов, и заключительное кодовое слово
EOL.
• В правильном изображении может присутствовать
любая произвольная последовательность пикселов.
Не существует никаких недопустимых или непра-
вильных значений, поэтому никакая проверка на
наличие ошибок здесь не требуется. Но не каждая
последовательность произвольных битов представля-
ет правильный закодированный в соответствии с
протоколом Т.4 образ. Фактически существует гораз-
до больше неправильных последовательностей, чем
правильных, поэтому программа декодирования дол-
жна выполнять значительный объем проверок на
предмет наличия ошибок.
Дополнительные тематические разделы
452
Часть III
Программа распаковки Т.4 decoder
На Web-сайт "ДиаСофт" помещен полный исходный
код стандартной программы С, которая считывает зако-
дированные в соответствии с протоколом Т.4 данные из
файла и записывает их декодированный двоичный об-
раз в другой файл. Если начать с созданного надлежа-
щим образом файла двоичного образа, закодировать его
программой кодирования и декодировать результат с
помощью программы декодирования, то ее вывод будет
идентичен исходному двоичному файлу. За исключени-
ем того же заголовка fax.h, который использовался в
программе кодирования, программа decode.c содержит
только стандартные заголовки С и реализована в виде
единого файла исходного кода.
Как и ранее, тип структуры данных для представ-
ления кодовых слов Т.4 определяется в начале файла,
но и тип структуры, и организация массивов таблицы
подстановок значительно отличаются от определенных
в программе кодирования. Структура определяется сле-
дующим образом:
typedef srtuct
{
unsigned char bitpattern;
unsigned char runlength;
} T4_DECODE;
Давайте взглянем на первый массив, содержащий
некоторые из этих структур:
static const T4__DECODE
{
{ 0x07, 0x02 >, /*
{ 0x08, 0x03 }, /*
{ 0х0В, 0x04 }, /*
{ 0х0С, 0x05 }, /*
{ 0х0Е, 0x06 }, /*
{ 0x0F, 0x07 }, /*
}
t4_white_04 [ ] =
2 белых пиксела */
3 белых пиксела */
4 белых пиксела */
5 белых пикселов */
6 белых пикселов */
7 белых пикселов ♦/
Прежде всего, можно заметить, что в члене
bit_pattem порядок битов в кодовых словах не изменен
на обратный и что слова не выровнены по левому краю.
Вместо этого они хранятся в том же виде, в каком
представлены в таблицах 18.3 и 18.4, и выравниваются
по правому краю. Это значительно упрощает код срав-
нения с шаблоном, поэтому перед поиском в таблицах
подстановки выполняется изменение порядка битов
слева — направо.
В ходе рассмотрения таблиц подстановки програм-
мы кодирования было объяснено, кок кодовые слова
длиной до 13 битов могут без потерь храниться в вось-
ми битах: поскольку все старшие биты являются 0, они
не влияют на числовое значение.
С другой стороны, член runjength должен содер-
жать любое возможное значение от 0 до 1728 включи-
тельно в восьми битах, которые могут непосредственно
представлять значения лишь до 255. Это достигается за
счет того, что для каждого цвета существует только 91
отдельное кодовое слово, и поэтому в действительнос-
ти требуется только 91 отдельное значение. Первый
очевидный шаг реализации этого — использование зна-
чений от 0 до 63 для представления текущих длин око-
нечных кодов. Составные кодовые слова могут быть
представлены путем использования нескольких методов.
Примененный в этой программе метод учитывает то
обстоятельство, что длина составных кодовых слов все-
гда кратна 64 без остатка. Если длину кодовых слов
разделить на 64, результатом будет значение от 1 до 27
включительно. Чтобы можно было различить значение
1, представляющее кодовое слово для последовательно-
сти из 64 пикселов, и i, представляющее единственный
пиксел, член run_length для составных кодов объединя-
ется со значением 0x80 побитовой операцией логичес-
кого ИЛИ.
Таким образом, оконечные кодовые слова для пос-
ледовательностей от 0 до 63 пикселов имеют значения
члена runjength в диапазоне от 0x00 до 0x3f, а состав-
ные коды для последовательностей от 64 до 1728 пик-
селов (от 1x64 до 27x64) имеют значения в диапазоне
от 0x81 до 0x9b.
В программе для настольного компьютера в целях
хранения фактического значения каждой длины после-
довательности можно использовать переменную типа
короткого целого (short int), но для экономии памяти
подобное представление также, вероятно, можно было
бы использовать и во встроенных системах.
Структуры T4_DECODE разделяются на большее
количество массивов, чем структуры T4 ENCODE в
программе кодирования. Существуют отдельные масси-
вы для всех кодовых слов одинаковой длины для каж-
дого цвета. В каждом массиве структуры хранятся в
порядке возрастания числовых значений кодовых слов.
Алгоритм декодирования использует также другой
тип данных. Определение типа и часть массива приве-
дены ниже:
typedef struct
{
const T4DECODE *token;
int searchlength;
} CODETABLE;
Обработка цифровых сигналов
Глава 18
453
static const CODE_TABLE codetablef12][2] =
{
{
{ t4_black_02, sizeof t4_black_02/sizeof *t4_black_02 },
{ NULL , 0 }
{
{ t4_black_03f sizeof t4_black_03/sizeof *t4_black_03 },
{ NULL , 0 }
b
{
{ t4_black_04f sizeof t4_black_03/sizeof *t4_black_03 }r
{ t4_white_04, sizeof t4_white04/sizeof *t4_white_04 }
b
По мере того как программа бит за битом создает
потенциальное кодовое слов из входного файла, из этого
массива выбирается структура CODE TABLE для соот-
ветствующего цвета и длины кодового слова.
И наконец, в программе определяются два перечис-
лимых типа данных: одно — представляющее цвета пик-
селов, второе — для выражения значений, которые мо-
гут быть найдены вместо кодового слова, указывающего
последовательность пикселов:
typedef enum
{
BLACK_WANTED,
WHITEWANTED
} PIXELWANTED;
typedef enum
{
T4_EOF = -1,
/* встретился конец входного файла */
T4EOL = -2,
/* найдено кодовое слово конца строки */
Т4_ INVALID = -3
/* недопустимое протоколом Т.4 кодовое
слово */
} T4-RESULTS;
Функция main()
В этой программе функция main() также является про-
стым драйвером. Она определяет буфер вывода, кото-
рый будет содержать полную строку двоичных данных
пикселов. Декодирование полностью противоположно
кодированию в том смысле, что точный размер каждой
строки вывода известен, но длина строки ввода должна
быть определена. Функция main() анализирует также
аргументы командной строки для получения имен ис-
ходного и выходного файлов и открывает оба эти фай-
ла в двоичном режиме. Два указателя FILE и указатель
на буфер данных передаются функции DecodePage().
Функция DecodePage()
Функция DecodePage(), показанная в листинге 18.5,
содержит код для обработки как отдельной строки, так
и целой страницы. Программа не имеет отдельной фун-
кции DecodeLine(), аналогичной функции EncodeLine()
в программе кодирования, поскольку это усложнило бы
распознавание последовательности конца страницы.
Листинг 18.5, Функция DecodePageQ.
int
DecodePage(FILE *fin,
FILE *fout,
unsigned char * const buff)
{
PIXELWANTED wanted; /* найденный в настоящий момент цвет */
int pixel_run; /* длина последовательности текущего цвета */
int eop-COunt = 0; /* используется для распознавания конца страницы */
int faxlines; /* счетчик декодированных строк */
int pixel—count; /* общее количество пикселов в текущей строке */
int total_run; /* общее количество пикселов в текущей последовательности */
unsigned char *out_ptr; /* указатель в область буфера вывода */
/* Первым кодовым словом в файле должно быть EOL */
pixel-run = GetPixelRun (WHITE-WANTED, fin);
if (pixel-Гип 1= T4-EOL)
454
Дополнительные тематические разделы
Часть III
puts("missing initial EOL");
return EOF;
}
/* Считывание, декодирование и вывод закодированных сканированных строк одной вслед за другой */
for (fax_lines = 0; fax lines < MAXIMUM ROWS; )
{
wanted - WEITE_WANTED; /* строки начинаются с белых последовательностей */
out_ptr = buff; /* вывод начинается сначала */
pixel_count = 0; /* в новой строке пикселы отсутствуют */
do ’
{
pixelrun = GetPixelRun(wanted, fin);
if (pixel run >= 0)
{
eopcount =0; /* последовательности пикселов после последнего EOL */
if ((total jrun - pixel run) > 63)
{
/* Если количество только что декодированных пикселов в последовательности больпе
63, последовательность является составным кодом и за ней всегда следует оконечный код для
этого хе цвета. Поэтому функция GetPixelRun вызывается снова с этим же цветом для получения
общей длины последовательности */
pixel_run = GetPixelRun(wanted, fin);
if (pixel run >= 0)
{
total_run += pixelrun;
1
else
{
puts("decode: make-up code missing");
return EOF;
}
1
/* Перед вставкой новой последовательности пикселов в буфер вывода необходимо
удостовериться, что длина последовательности не превысит допустимое количество пикселов для
одной строки, поскольку это могло бы привести к записи вне области памяти, выделенной для
буфера, и неопределенному поведению */
if ((pixelcount += totalrun) > PIXELSPERROW)
L
puts("decode: line too long");
return EOF;
1
else
{
/* Новая последовательность пикселов поместится в буфере, поэтому ее можно вставить */
outptr - Outputpixels(total_run, wanted, out_ptr);
/* Поскольку последовательности белых и черных пикселов чередуются, теперь следует
искать цвет, противоположный цвету последней последовательности */
if (wanted »» WHITE_WANTED)
{
wanted = BLACKWANTED;
1
else
{
wanted = WEITEWANTED;
}
}
}
} while (pixel_run >= 0);
/* Функция GetPixelRun() возвратила значение, которое не представляет последовательность
пикселов; репение о следующих действиях принимается исходя из этого конкретного значения */
455
Обработка цифровых сигналов
Глава 18
switch (pixelrun)
{
case T4_E0F:
puts("decode: unexpected end of file");
return EOF;
case T4E0L:
/* Обнаружение кодового слова EOL корректно в двух случаях: после декодирования
кодовых слов в точности для 1728 пикселов */
if (PIXELSPERROW == pixelcount)
{
++fax_lines;
fwrite(buff, 1, OCTETS_PER_ROW, fout);
++eop_count;
}
/* ...и после декодирования пикселов 0 после предлествуюцего кода EOL, поскольку несть
последовательных кодов EOL в строке без каких-либо иных пикселов между ними сигнализирует о
конце страницы */
else if (0 == pixel count)
{
if (++eop_count >= б)
{
return faxlines;
}
}
/* Если кодовое слово EOL обнаружено после ряда пикселов, количество которых меньле
1728, это является опибкой */
else
{
puts("decode: invalid line length");
return EOF;
}
break;
case T4INVALID:
/* Если функция GetPixelRun() обнаруживает последовательность битов, которая не
соответствует ни одному из кодовых слов Т.4 ... */
puts("decode: invalid t.4 code");
return EOF;
default:
/* то в целях безопасности выполняется действие, определенное по умолчанию... */
puts("decode: program error");
return EOF;
}
}
return fax_lines;
Удостоверившись, что файл содержит обязательное
начальное кодовое слово EOL, функция DecodePage()
выполняет цикл для каждой сканированной строки до
тех пор, пока не декодирует MAXIMUM_ROWS строк
или не обнаружит последовательность символов, сигна-
лизирующую о конце страницы, или пока не встретит
ошибку.
В цикле для каждой строки функция вызывает фун-
кцию GetPixelRun(), которая поочередно ищет последо-
вательности белых и черных пикселов. Когда для неко-
торого цвета возвращается составной код, функция
DecodePage() снова вызывает функцию GetPixelRun()
для этого же цвета, чтобы получить следующий оконеч-
ный код. Значения обоих кодов объединяются и пере-
сылаются функции OutputPixels() в качестве единой
последовательности.
В процессе декодирования последовательностей пик-
селов функция DecodePage() сохраняет текущее значе-
ние счетчика общего количества пикселов в текущей
строке. Длина каждой новой последовательности срав-
нивается с текущим общим количеством, чтобы гаран-
тировать невозможность превышения допустимого ко-
личества пикселов в строке PIXELS PER ROW в
результате ошибочного ввода. Если бы такое произош-
ло и была вызвана функция OutputPixels(), запись мог-
ла бы быть выполнена вне границ массива буфера вы-
456
Дополнительные тематические разделы
Часть III
вода, приводя к неопределенному поведению. Если об-
щая длина последовательностей, определенная для ска-
нированной строки, превышает допустимую длину,
программа останавливается с выводом сообщения об
ошибке.
Когда сканированная строка начинается с черного
пиксела, функция DecodePage() не проверяет наличие
последовательностей белых пикселов нулевой длины.
Она просто передает значение функции OutputPixels(),
которая ничего не делает, если ей передана последова-
тельность пикселов любого цвета нулевой длины.
Переменная eop_count используется для распознава-
ния последовательности конца страницы, состоящей из
шести последовательных кодовых слов EOL без каких-
либо иных пикселов данных между ними. Ее значение
увеличивается при каждом обнаружении последователь-
ности EOL и сбрасывается обратно в нуль при извлече-
нии любых пикселов данных. Если значение eopcount
достигает шести, страница завершается.
Обнаружив допустимую последовательность пиксе-
лов соответствующего цвета, функция GetPixelRun()
возвращает значение между 0 и 1728. Отрицательные
возвращаемые значения в случае обнаружения последо-
вательностей, не являющихся последовательностями
пикселов, определены в перечне T4RESULTS.
Если функция pixel run получает от функции
GetPixelRun() отрицательное значение, никакая часть
остального кода внутри цикла do...while() не выполня-
ется и цикл завершается, поскольку условие while() ока-
зывается ложным. В этом случае перечислимое значе-
ние обрабатывается оператором switch().
Если функция DecodePage() выполняется успешно,
она возвращает число декодированных и сохраненных
в main() строк. В противном случае функция возвраща-
ет последовательность сообщений EOF, указывающих
на наличие ошибки. Фактически функция завершается
при первой же ошибке, что, вероятно, будет вызывать
нарекания пользователей реального факсимильного ап-
парата. Возможно, лучшим подходом был бы просмотр
закодированного потока на предмет наличия, по край-
ней мере, 11 последовательных битов 0, указывающих,
что следующий прибывающий единичный бит сигнали-
зирует о конце строки (EOL). Во многих случаях допу-
стимо, чтобы одна или несколько сканированных строк
были утеряны при сохранении основной части изобра-
жения страницы.
Функция GetPixelRunf)
Функция GetPixelRun(), приведенная в листинге 18.6,
вызывается с параметром PIXEL WANTED, указываю-
щим найденный цвет, и указателем на входной файл;
эти же аргументы она прямо передаст функции
GetNextBit(). Функция GetPixelRun() инициализирует
несколько перечисленных ниже переменных.
Переменная code_word устанавливается в 0, посколь-
ку никакие биты еще не были считаны из входного
файла и помещены в эту переменную. Переменная bits,
которая представляет длину code word, также устанав-
ливается в 0.
Кодовые слова для черных пикселов, могут содер-
жать любое количество битов от 2 до 13. Но длина ко-
довых слов для белых пикселов находится в пределах
между 4 и 9 битами, поэтому функция GetPixelRun()
устанавливает для переменных minbits и max bits зна-
чения, соответствующие текущему цвету пиксела.
Затем функция GetPixelRun() входит в свой основ-
ной цикл, который продолжается до тех пор, пока не
будет распознано кодовое слово или не встретится
ошибка.
Листинг 18-6. Функция GetPixelRunQ.
static int
GetPixelRun(PIXELWANTED color, FILE *fin)
{
unsigned int codeword = 0;
int bits = 0;
int pixel_run, nextbit, minbits, maxbits;
const T4—DECODE *t4p;
/* Параметр искомого цвета обрабатывается в качестве булевого значения, BLACK_WANTED указывает
черный цвет, а любое другое значение - белый */
if (BLACKWANTED == color)
{
minjbits = 2; /* минимальная длина кодового слова для черных пикселов */
max_bits =13; /* максимальная длина кодового слова для черных пикселов ♦/
}
else /* выполняется поиск WHITEPIXEL */
{
color = WHITE-WANTED;
457
Обработка цифровых сигналов
Глава 18
minbits =4; /* минимальная длина кодового слова для белых пикселов */
max_bits =9; /* максимальная длина кодового слова для белых пикселов */
}
for ( ; ; ) /* до момента обнаружения кодового слова или онибки */
{
do
{
/* Поскольку цикл do...while содержит проверку в конце, он всегда выполняется, по
меньпей мере, один раз, поэтому функция GetNextBit() будет всегда вызываться при каждом
прохождении цикла, даже если длина создаваемого кодового слова больпе минимального значения */
if ((nextbit = GetNextBit(fin)) == T4EOF)
{
return T4EOF;
}
else
{
codeword = (codeword «1) | nextbit;
}
} while (++bits < minbits);
/* Как только кодовое слово становится достаточно длинным, его необходимо сравнить с EOL */
if (bits >= EOL LENGTH && code word == 1)
{
return T4EOL;
}
/* Если максимальная длина уже достигнута и кодовое слово не является EOL, все следующие
биты, вплоть до EOL, должны быть нулевыми */
if (bits > maxjbits)
{
if (code word 1= 0)
{
return T4INVALID;
}
}
else if (NULL 1= (t4p =
code_table[bits - 2][color].token))
/* Это условие должно размещаться в конструкции else if, указанной над ним, посколькуг
если bits > max bits, обращение к массиву code_table будет выполняться вне области массива,
приводя к неопределенному поведению */
{
t4p = bsearchf&codeword, t4p,
codetable[bits - 2][color]•searchlength,
sizeof *t4p, T4Compare);
if (NULL t4p)
{
pixelrun = t4p->run_length;
/* в этом месте программы упаковка составных кодов в символьные переменные без знака
отменяется и длина последовательности снова разворачивается до своего полного значения */
if (pixel_run & 0x80)
{
pixel_run &= “0x80;
pixel_run «= 6;
return pixelrun;
}
}
}
}
458
Дополнительные тематические разделы
Часть III
Первоначально цикл do...while() в верхней части основ-
ного цикла будет вызывать функцию GetNextBit() дваж-
ды для последовательностей черных и четыре раза —
для последовательностей белых пикселов. Возвращаемые
биты сдвигаются в переменную code_word справа. Как
только количество битов в code_word становится равным
значению min_bits, цикл прерывается. При каждом до-
полнительном выполнении внешнего цикла цикл
do...while() будет добавлять по одному биту к перемен-
ной code word, даже если значение bits уже больше или
равно значению min_bits.
Затем выполняется проверка на наличие кодового
слова EOL. Если 11 или более нулевых битов уже со-
браны в переменную code_word, заключительный еди-
ничный бит, завершающий последовательность EOL,
делает условие истинным и возвращается перечислимое
значение T4JEOL.
Если последовательность EOL не выявлена, выпол-
няется проверка на наличие ошибочных входных дан-
ных. Если количество битов в code_word уже превыша-
ет значение maxbits (9 для белых или 13 для черных
пикселов), единственным допустимым случаем является
последовательность части кодового слова EOL — извле-
чение строки нулей, предшествующих заключительно-
му единичному биту. Если длина code word уже пре-
вышает значение max bits для текущего цвета и его
значение не равно 0, функция GetPixeIRun() выявляет
недопустимую последовательность Т.4 и возвращает
значение ошибки.
Если в ходе выполнения программы этот тест про-
ходит, значит, code__word содержит допустимую длину
кодового слова для текущего цвета. Параметры цвета и
длины объединяются для обеспечения доступа к мас-
сиву code table, определяя указатель на первый элемент
массива структур CODE_TABLE, которые содержат все
допустимые кодовые слова текущей длины для текущего
цвета. Все кодовые слова имеют длину, равную, по
меньшей мере, 2, поэтому массив code_table начинает-
ся с пары элементов, в которой элемент длины кодово-
го слова равен 2. Это достигается при использовании
величины bits-2 в качестве значения индекса.
После профилактической проверки того, что указа-
тель T4_DECODE не является нулевым (NULL), фун-
кция GetPixelRiin() использует этот указатель и член
search_Iength для вызова стандартной библиотечной
функции bsearchO в целях просмотра упорядоченного
массива на предмет равенства значения bit_pattern те-
кущему значению code_word.
Если bsearch() возвращает значение совпадения, фун-
кция GetPixelRun() по седьмому биту проверяет, представ-
ляет ли член runjength структуры Т4_DECODE длину
простого оконечного кодового слова (от 0 до 63) или
длину составного кодового слова. Если это значение
соответствует длине составного кодового слова, функ-
ция распаковывает его (слово) в обычное целое значе-
ние, диапазон которого составляет от 64 до 1728. Пос-
ле этого функция возвращает длину последовательности.
Функция T4Compare()
Эта очень короткая функция имеет дескриптор соответ-
ствия функции обратной связи, необходимый для функ-
ции bsearch(). Первый параметр pointer to void — это
псевдоним указателя на переменную code_jword в фун-
кции GetPixeIRun(). Второй параметр — псевдоним эле-
мента массива T4 DECODE, содержашего кодовые сло-
ва для соответствующего цвета с длиной, равной
codeword.
static int T4C-,«^>are (const void *x, const void *y)
{
return *(int *)x - (int)((T4DECODE *)y)->
bit_pattern;
}
Перед переадресацией необходимо выполнить пре-
образование типов указателей для указываемых ими
данных. Для переменной code_word, которая в действи-
тельности имеет тип unsigned int, значение всегда поло-
жительно и меньше 4096, поэтому обращение к ней
посредством указателя на signed int совершенно одно-
значно и приводит к такому же значению типа signed int.
Для второго указателя выполняется явное преобразова-
ние типа в указатель на структуру T4_DECODE, исполь-
зуемый для обращения к члену bit_pattern, а затем тип
значения преобразуется в signed int.
Тип обоих значений преобразуется в signed int, а не
unsigned int, поэтому единственная операция вычитания
может генерировать точное возвращаемое значение. Без
преобразования типа на некоторых сравнительно ред-
ко встречающихся платформах эти значения могли бы
привести к значениям типа целых без знака, и вычита-
ние двух значений типа unsigned int никогда не приво-
дило бы к отрицательному результату.
Функция GetNext Bit()
Функция GetNextBit(), приведенная в листинге 18.7, ра-
ботает почти также, как часть функции CountPixeiRunO в
программе кодирования. Она поддерживает статические
переменные, содержащие октет, который последним
был считан из входного файла, и число уже извлечен-
ных из октета битов. Именно в этой функции в програм-
ме декодирования выполняется преобразование поряд-
ка следования битов слева направо. Функция
GetNextBit() сдвигает октет слева направо и всегда воз-
вращает крайний справа бит. Функция GetPixelRun()
сдвигает переменную code word влево и перемещает
возвращаемый бит справа.
459
Обработка цифровых сигналов
Глава 18
Листинг 18.7. Функция GetNextBitf).
static int
GetNextBit(FILE * f in)
{
static int bitsused = PIXELSPEROCTET;
static unsigned int t4_in;
int input;
/* Проверка наличия оставшихся битов в текущем октете */
if (bitsused >= PIXELSPEROCTET)
{
/* Если битов больме не осталось, осуществляется получение нового октета из исходного файла */
if ((input = fgetc(fin)) == EOF)
<
return T4_EOF;
1
else
{
/* После получения нового октета выполняется маскирование восьми младмих битов */ */
t4_in = input & OCTETMASK;
/* Никакие биты из этого октета еще не использовались */
bitsused = 0;
}
}
else
{
/* Если в текущем октете остаются биты, выполняется сдвиг последнего бита с правой стороны
октета и помещение следующего бита в позицию 0 */
t4_in »= 1;
}
++bits_used; /* использование бита и его учет */
return t4_in & 1; /* возвращение бита 0 октета */
Функция OutputPixels()
Функция OutputPixeIs(), приведенная в листинге 18.8,
получает цвет, значение счетчика и указатель на буфер
вывода, в котором необходимо сохранить результаты.
Поскольку функция работает с потоками битов пере-
менной длины, которые не обязательно начинаются и
заканчиваются по границе октета, она хранит статичес-
кие внутренние переменные для текущего частично за-
полненного октета и числа свободных битов, которые
в нем еще доступны.
Работа этой функции подобна работе функции
OutputCodeWordO в программе кодирования и вновь
подтверждает, что вставка последовательности битов
известной длины в выходной поток гораздо проще, чем
извлечение последовательностей неизвестной длины из
входного потока.
Генерирование символов
Если вы когда-либо получали факс, то, вероятно, обра-
щали внимание на заголовок в верхней части каждой его
страницы. Обычно такие заголовки содержат название
организации отправителя и номер телефона, к которо-
му подключен его факсимильный аппарат. Часто так-
же присутствует номер страницы сообщения. Даже если
остальная часть страницы искажена, заголовок отобра-
жается ясно и четко.
Эти заголовки генерируются непосредственно фак-
симильным Аппаратом или программой передачи фак-
симильных сообщений. Они не являются частью изоб-
ражения страницы, загруженной в сканирующее
устройство, поэтому остаются ровными и неискаженны-
ми, даже если бумага подается с перекосом или нерав-
номерно.
Заголовки генерируются на основе информации,
введенной пользователем в факсимильный аппарат или
в программу во время начальной установки. Факсимиль-
ный аппарат кодирует эти строки в коды Т.4 и переда-
ет их перед передачей действительного содержимого
страницы.
Невозможно генерировать коды Т.4 непосредствен-
но из текстовых строк или даже из отдельных битовых
последовательностей, используемых для каждого сим-
вола. В связи со способом кодирования последователь-
ностей белых и черных пикселов вся строка текста дол-
жна быть преобразована в пикселы эквивалентной
сканированной строки.
460
Дополнительные тематические разделы
Часть III
Листинг 18.8. Функция OutputPixels().
static unsigned char
♦Outputpixels(int length,
PIXEL WANTED wanted,
unsigned char *out_ptr)
{
unsigned int mask;
static int outbitsleft = PIXELS PER OCTET;
static unsigned int pixelout = 0;
if (BLACKWANTED == wanted)
{
mask = 0;
}
else
{
mask - Oxff;
while (length >= outbitsleft)
{
pixel out «= outbits left;
*out_ptr++ = (unsigned char)(pixelout
| (mask » (PIXELSPEROCTET - outbits_left)));
pixelout = 0;
length -= outbitsleft;
outbitsleft = PIXELSPEROCTET;
}
if (length)
{
pixelout «= length;
pixelout | =
mask » (PIXELSPEROCTET - length);
outbitsleft -= length;
return out_ptr;
Ha Web-сайте "ДиаСофт” находится файл исходно-
го кода textlbin.c, который считывает простые тексто-
вые файлы ASCII и генерирует двоичные файлы изоб-
ражений, эквивалентные получаемым в результате
печати текста на бумаге шрифтом фиксированного раз-
мера в 10 пунктов и сканирования его факсимильным
аппаратом. В генераторе символов используется расши-
ренный набор символов для текстового режима PC, по-
этому он имеет графические представления для всех
символов с номерами от 0 до 255.
Выходные файлы — это необработанные двоичные
изображения, кодируемые 216 символьными перемен-
ными без знака для каждой сканированной строки, в
младших битах каждой из которых хранится по восемь
пикселов. Эти файлы могут использоваться в качестве
исходных для программы encode.c. Подробная инфор-
мация приведена в файле chapl8.txt на Web-сайте "Диа-
Софт".
На нашем компакт-диске имеется также "поощри-
тельная" программа lj300.c. Она считывает двоичный
файл, аналогичный создаваемым программами decode.c
или textlbin.c, и генерирует двоичный файл для печа-
ти изображения на принтере типа Laser Jet или совмес-
тимом с ним, с графическим разрешением, равным 300
DPI. Если вы используете принтер другого типа, позво-
ляющий печатать графические изображения, этот файл
можно применять в качестве отправной точки в процес-
се преобразования изображений для используемого
вами принтера.
Чтобы действительно напечатать изображение на со-
вместимом принтере, нужно знать, как выполняется
пересылка необработанного двоичного файла непосред-
ственно на принтер без преобразования его драйвером
принтера операционной системы. Более подробные све-
дения приведены в файле chapl8.txt на Web-сайте "Диа-
Софт".
Обработка цифровых сигналов
Глава 18
461
Выявление и исправление ошибок
Дорогостоящую с точки зрения денег и трудозатрат
информацию необходимо надлежащим образом хра-
нить, получать и отправлять, иначе при возникновении
непредвиденных ситуаций можно утерять важные дан-
ные, если вовремя не позаботиться о создании резерв-
ных копий. Информация в цифровой или любой дру-
гой форме характеризуется высокой степенью
организованности и низкой степенью энтропии. Но в
соответствии с физическими законами энтропия всегда
повышается, если только для предотвращения этого
процесса не затрачивается энергия.
В этом разделе речь пойдет об использовании языка
С для выполнения задачи выявления и исправления
неизбежных ошибок при хранении или передаче дан-
ных. Чтобы снова и снова не повторять выражение ’’хра-
нение и передача данных", в дальнейшем для описания
любой ситуации, когда в данные могут вкрасться ошиб-
ки, будем использовать термин "обработка данных" (data
handling).
Борьба с хаосом
Враги ваших данных никогда не дремлют. Электричес-
кие помехи и даже солнечные пятна постоянно пыта-
ются помешать их передаче. Жесткие диски и другие
носители информации иногда оказываются не в состо-
янии возвратить хранящиеся на них данные. В реаль-
ном мире невозможно гарантировать полную безопас-
ность и сохранность данных во время их хранения или
передачи. Однако при использовании соответствующих
технологий вероятность повреждения данных может
быть снижена до очень малого значения.
Для этого используются две различные, но тесно
связанные между собой идеи: выявление и исправление
ошибок. Выявление ошибок предполагает распознава-
ние того, что данные, принятые в результате передачи
или полученные из хранилища, были изменены или
повреждены. Исправление ошибок, которое обязатель-
но требует сначала выявления ошибок, объединяет ме-
тоды распознавания того, какими данные должны быть,
и восстановления их исходного состояния.
Например, при получении в электронном сообщении
от другого С-программиста текста "Hello Worle" легко
догадаться, что он, скорее всего, имел в виду "Hello
World” и что ошибка имела место либо при передаче,
либо она была простой опечаткой. Выявив такую ошиб-
ку, ее можно исправить почти мгновенно.
Однако большинство проблем являются более слож-
ными. Давайте рассмотрим годовые финансовые отче-
ты крупной корпорации, пересылаемые в фирму, кото-
рая занимается их учетом. Отчеты могут содержать
миллионы байтов данных, многие из которых хранят-
ся в двоичном виде в электронных таблицах. Вначале
они сжимаются, затем шифруются для обеспечения
безопасности. Внешне конечный поток данных вообще
не имеет ничего общего с фактической информацией,
и единственный ошибочный бит может сделать невоз-
можной расшифровку и распаковку данных в пригод-
ную для использования форму.
Избыточность
Ключом к выявлению и исправлению ошибок служит из-
быточность — добавление дополнительной информации
сверх минимально необходимой для передачи нужных
данных. Пример "Hello World" уже характеризуется значи-
тельной избыточностью. В строке присутствуют только
восемь различных символов - "Н", "е", "I", "о", "W", "г”,
"d" и символ пробела. Поскольку три бита могут содержать
восемь различных комбинаций, можно было бы присво-
ить 3-битовые замещения для символов в приведенной выше
последовательности. Если договориться, что будут использо-
ваться только эти восемь символов, и определить их кодиро-
вание, строку "Hello World" можно было бы заменить циф-
ровой строкой 0000010Ю0Ю0111111000111010110,
требующей только 33 битов вместо, по меньшей мере,
88 битов, занимаемых 11 символами.
Далее, ошибка при передаче могла бы изменить пос-
леднее 3-битовос представление символа с кода для
символа "d" на код для символа "е", что привело бы к
строке 0000010100100111111000111010001. Конечно,
глядя на эту строку битов, нельзя сразу сказать, что
информация была искажена. После декодирования
ошибка все же может быть распознана, но только бла-
годаря тому, что переданная фраза является очень ко-
роткой и очень знакомой.
Когда сложные данные хранятся или передаются в
форме, которую нельзя непосредственно распознать, то
на основе самих этих данных нельзя установить, что
они были искажены. Однако в некоторых случаях это
возможно. Например, изменение одного-двух битов в
двоичном представлении числа с плавающей точкой
может привести к сбою процессора при дальнейшей
обработке или к очевидной ошибке вычислений, но это
не обязательно.
Если ошибки возможны в двоичных данных, сохра-
ненных в виде символов без знака, при обращении к
данным из программы, написанной на С, нельзя пола-
гаться на использование исключительных состояний или
ловушки, поскольку любая комбинация битов в сим-
вольной переменной без знака является вполне допус-
тимым значением.
Существует много способов добавления избыточно-
сти для обработки данных, обеспечивающей выявление
ошибок и, возможно, их исправление. Рассмотрим не-
462
Дополнительные тематические разделы
Часть III
которые из наиболее часто используемых методик, на-
чиная с самых ранних.
Простейший способ добавления избыточности для
любой обработки данных — дублирование. Фактичес-
ки именно этот способ лежит в основе создания резер-
вных копий. Такая технология вполне подходит для дол-
говременного хранения данных, но значительно меньше —
для обмена и обработки особо важных данных в реаль-
ном масштабе времени.
Давайте рассмотрим процесс дублирования, выпол-
няемый при обмене данными. Вместо одной копии
файла в электронном виде выполняется отдельная от-
правка двух копий. Обе копии сравниваются, и если они
полностью совпадают, то с высокой степенью вероят-
ности можно заключить, что обе они верны.
Но что означает их несовпадение? Скорее всего,
одна из них верна, а другая содержит ошибки, но ка-
кая именно? Что делать — подбрасывать монету?
Хорошо, давайте отправим три отдельные копии.
Если все три копии идентичны, то с очень высокой сте-
пенью вероятности можно считать, что все они верны.
Если две копии совпадают, а третья — нет, вывод .оче-
виден: неверна третья копия. Конечно, если все три
копии оказываются различными, мы возвращаемся к
исходной проблеме.
Проблема выполнения дублирования при обмене
данными заключается в том, что оно обходится очень
дорого с точки зрения времени и пропускной способ-
ности линии связи.
Четность
На заре развития компьютеров данные в основном были
текстовыми, а текст в большинстве случаев имел фор-
мат ASCII. Размеры слов в большинстве компьютеров
были кратны восьми битам или, по меньшей мере, мог-
ли передаваться на 8-битовые периферийные устрой-
ства. Стандартные интерфейсы, такие как параллельные
порты принтера, последовательные коммуникационные
UART (Universal Asinchronous Recei ver/Transmitter — уни-
версальный асинхронный приемопередатчик. — Примеч.
науч, ред.) и многие другие были разработаны для того,
чтобы данные могли считываться или записываться на
них цепочками по восемь битов, или октетами.
Одной из самых ранних технологий выявления оши-
бок была проверка четности, которая быстро была реа-
лизована в аппаратуре UART. Весь набор символов
ASCII охватывает диапазон значений от 0 до 127.
В принятой в языке С форме записи шестнадцатирич-
ных значений им соответствовали значения от 0x00 до
0x7F. Старший бит всегда был 0 и никогда не изменял-
ся. Если бы каким-либо образом содержимое этого пос-
леднего бита устанавливалось, исходя из значений ос-
тальных семи битов, можно было бы выявить ошибку,
изменившую значение одного из битов.
Применительно к двоичным значениям слово чет-
ность используется для .описания количества единичных
битов в двоичном значении.
Октет, который содержит двоичное значение 0x1,
содержит восемь битов 00000001. Как видите, октет
содержит единственный единичный бит, а поскольку 1 —
нечетное число, говорят, что этот октет является нечет-
ным. Обратите внимание, что нечетность или четность
никак не связана с тем, является ли четным или нечет-
ным числовое значение октета. Октет, который содер-
жит четное десятичное число 2, в двоичном представ-
лении выглядит как 00000010 и является нечетным.
Предположим, что мы можем принять соглашение
о том, что при обработке текста ASCII с использовани-
ем по одному октету для каждого символа будет выпол-
няться проверка младших семи битов дня определения
того, четное или нечетное количество единичных битов
они содержат. Затем будем устанавливать неиспользуе-
мый старший бит так, чтобы весь 8-битовый октет имел
определенную четность (т.е. был четным или нечет-
ным). Фактически выбор проверки четности или нечет-
ности не имеет никакого значения до тех пор, пока все
придерживаются одного общего соглашения.
Как проверить и установить четность? Это достаточ-
но просто выполнить аппаратно, и многие устройства
UART и некоторые процессоры, такие как процессоры
серий Intel х86, могут делать это. Но сделать это мож-
но без труда и в программе, написанной на С. Доста-
точно просто использовать побитовый оператор XOR
(исключающее ИЛИ) для совместного комбинирования
всех битов один за другим. Если конечный результиру-
ющий бит равен 1, значит, последовательность .битов
имеет нечетный признак четности. Если он равен 0, то
последовательность имеет четный признак четности.
Простая программа, представленная в листинге 18.9
(и содержащаяся на Web-сайте "ДиаСофт**), иллюстри-
рует проверку и установку четности в языке С. В про-
грамме выполняется проверка младших семи битов зна-
чения, а затем восьмой бит устанавливается таким
образом, чтобы все восемь битов имели четный признак
четности.
Половина цифровых значений окажется неизменен-
ной, а вторая половина будет содержать лишний бит.
При выполнении проверки четности может быть
выявлена любая ошибка в одиночном бите. Четыре
младших бита кода ASCII для цифры 0 являются нуле-
выми. Если бы в результате ошибки при обработке дан-
ных любая из них изменилась на 1, результатом было
бы значение 0x31, 0x32, 0x34 или 0x38. Каждое из этих
значений — код ASCII для другой цифры, но, как вид-
но из предыдущего вывода программы, ни одно из них
не имеет соответствующего признака четности.
463
Обработка цифровых сигналов
Глава 18
Листинг 18.9. Программа Parity.c, которая добавляет четный признак четности к символам, считанным
из stdin.
linclude <stdio.h>
linclude <string.h>
unsigned int even_parity(unsigned int ch)
int temp = 0;
int count;
/* Усечение символа ASCII до семи битов */
ch &= 0x7f;
/* Установка значения temp равным 0 для четного признака четности или 1 - для нечетного
признака */
for (count = 0; count < 8; ++count)
temp *= ((ch » count) & 1);
}
if (temp)
{
ch |= 0x80;
}
return ch;
}
int main(void)
{
char buff[22];
char *cp;
for ( ; ; )
printf([dbl]\nEnter up to 20 characters: [dbl]);
fflush(stdout);
if (fgets(buff, sizeof buff, stdin) == NULL ||
buff [0] == '\n')
puts([dbl]Goodbye![dbl]);
return 0;
}
/* Удаление из строки символа новой строки, если он присутствует */
if ((ср = strchr(buff, '\n')) 1= NULL)
{
*ср = '\0';
}
for (ср = buff; *ср 1= '\0г; ++ср)
{
printf([dbl]%02Х is %02Х with even parity\n[dbl],
*cp & 0x7f, evenjparity(*cp & 0x7f));
}
}
1
Если вы запустите эту программу и в ответ на при- щий вывод, при условии что ваша система использует
Глашение введете цифры от 0 до 9, то увидите следую- набор символов ASCII:
464
Дополнительные тематические разделы
Часть III
Enter up to 20 characters: 0123456789
0x30 is 0x30 with even parity
0x31 is OxBl with even parity
0x32 is 0xB2 with even parity
0x33 is 0x33 with even parity
0x34 is 0xB4 with even parity
0x35 is 0x35 with even parity
0x36 is 0x36 with even parity
0x37 is 0xB7 with even parity
0x38 is 0xB8 with even parity
0x39 is 0x39 with even parity
Фактически система, использующая признак четно-
сти, будет выявлять некоторое нечетное количество
ошибок в битах: три, пять или семь. Предположим, что
все три младших бита кода ASCH для 0, т.е. 0x30, из-
меняются на 1. Результатом этого является 0x37, что
соответствует 7 в коде ASCII, но он имеет неправиль-
ный признак четности. В данном случае осуществляет-
ся только выявление ошибок без какой-либо возможно-
сти их исправления, поскольку ошибка четности
свидетельствует только об изменении нечетного коли-
чества битов, но не о том, сколько и какие именно биты
были изменены.
Недостаток метода с использованием бита четности
в том, что он не может выявлять любые четные коли-
чества ошибочных битов. Предположим, что два млад-
ших бита 0 в результате ошибки изменяются. 0x30 пре-
вращается в 0x33, что соответствует 3 в коде ASCII,
причем ошибка не отображается.
Таким образом, использование бита четности само
по себе является слабым средством. Можно было бы
предположить, что вероятность двух ошибок в одном
октете сравнительно низка, но в некоторых ситуациях,
особенно при определенных условиях помех во время
передачи, возможно лавинообразное накопление оши-
бок, когда искажаются несколько следующих один за
другим битов. Такие ситуации встречаются еще доста-
точно часто в некоторых приложениях, например, для
обмена данными через последовательные интерфейсы.
Контрольные суммы
Один из методов включения проверки ошибок в данные —
создание контрольных сумм. При этом используется
возможность рассмотрения данных в качестве массива
символьных переменных без знака в памяти либо пото-
ка символьных переменных без знака при записи или
считывании из потоков, которыми могут быть файлы на
диске или коммуникационные каналы. Кроме того,
символьные переменные без типа в С имеют всего лишь
тип короткого целого, т.е. являются числами. Следова-
тельно, к потоку можно добавлять любое их количе-
ство, и до тех пор, пока используются типы без знака,
результат будет всегда однозначно определен.
Простая программа, представленная в листинге 18.10
(хранящаяся на Web-сайте "ДиаСофт" в файле
checkline.c), иллюстрирует метод вычисления конт-
рольных сумм.
Листинг 18.10. Программа Checkline.c, которая выполняет вычисление контрольных сумм для строк,
считанных из stdin.
linclude <stdio.h>
linclude <string.h>
int main(void)
{
char buff[100];
unsigned int count, sum;
char * *nl;
for ( ; ; )
I
printf("Enter a string: ");
fflush(stdout);
if ( fgets(buff, sizeof buff, stdin) == NULL
|| buff[0] == '\n')
{
return 0;
}
if ((nl = strchr (buff, '\n')) != NULL)
*nl = '\0';
for (count = 0, sum = 0; buff [count] != '\0r; ++count)
{
sum += (unsigned char)buff[count];
}
printf(“The checksum of \“%s\“ is %u decimal, %X hex\n“,
buff, sum, sum);
}
465
Если запустить эту программу в системе, в которой
используется набор символов ASCII, то в ответ на при-
глашение ввести фразу "Hello World" на экране должно
отобразиться следующее:
Enter a string: Hello World
The checksum of "Hello World" is 1052
'-♦decimal, 41C hex
Одним из возможных способов добавления возмож-
ности выявления ошибок к файлу было бы считывание
символьных переменных без знака по одной и сумми-
рование полученных значений. Затем нужно было бы
дописать дополнение вычисленного значения в качестве
дополнительного байта к концу файла. Позднее можно
было бы снова проверить файл путем считывания по
одному байту (включая последний добавленный байт
контрольной суммы) и суммирования. Если результат
не равен 0, значит, файл был поврежден. Но равенство
результата 0 еще не гарантирует сохранность данных.
Давайте снова запустим программу checkline.c, но на
этот раз в ответ на приглашение введем строку "Некто
World". При условии, что в вашей системе использует-
ся набор символов ASCII, вывод будет выглядеть сле-
дующим образом:
Enter a string: Некто World
The checksum of "Некто World" is 1052
'"•decimal, 41C hex
Получение такого, казалось бы, странного результа-
та связано с тем, что в коде ASCII числовое значение
"к” на единицу меньше, а значение "т" на единицу боль-
ше значения "1". В результате общая сумма остается не-
изменной.
Теперь введите строку "Hello Wrold" — обратите вни-
мание на перестановку местами символов "г” и "о" в слове
"World". Даже если используемым набором символов яв-
ляется не ASCII, контрольная сумма будет такой же, как
для строки "Hello World", несмотря на то, что числовые
значения будут отличаться от приведенных.
Enter a string: Hello Wrold
The checksum of "Hello World" is 1052
'"♦decimal, 41C hex
Как видим, простая контрольная сумма тоже явля-
ется не очень надежным средством выявления ошибок.
Контроль, осуществляемый с помощью
избыточного циклического кода
Гораздо более мощный метод выявления ошибок —
контроль с помощью избыточного циклического кода
(cyclic redundancy check), который обычно сокращенно
называют CRC. Существуют алгоритмы CRC, которые
используют 8, 16 или 32 бита. Вычисление CRC осно-
вывается на математической концепции полиномиаль-
Обработка цифровых сигналов
Глава 18
него деления. Чтобы понять и использовать этот код,
не требуется понимания этой концепции или даже озна-
комления с ней. В реальной реализации этого метода ис-
пользуются всего лишь побитовые операторы сдвига ло-
гического И применительно к целым типам без знака.
Любой из вас, кого воспоминания о школьном кур-
се алгебры не приводит в содрогание, вероятно, вспом-
нит полиномиальные уравнения. Например, уравнение
второй степени для параболы имеет форму у= ах2+Ьх+с.
Здесь значения а, b и с называют коэффициентами, а
сам полином имеет вторую степень, поскольку наивыс-
шей степенью аргумента х является вторая.
Возникает вопрос, какое отношение все это имеет к
потокам битов? Давайте начнем со скромного символа
А в коде ASCII, числовое значение которого составляет
0x41 или 01000001, как в 8-битовом октете. Это значе-
ние можно рассматривать в качестве полинома, все ко-
эффициенты которого равны либо I, либо 0 в зависи-
мости от битов в строке. Таким образом, октет,
содержащий А в коде ASCII, можно считать полиномом
седьмой степени:
Ох7 + lx6 + Ох5 4- Ох4 4- Ох3 4- Ох2 4- Ох1 + 1х°
Естественно, любой член с коэффициентом, равным
0, также равен 0 и может быть опущен; таким образом,
полиномиальное представление символа А упрощается до
1х6 + 1х°
Поскольку наивысшей остающейся степенью х яв-
ляется х6, то это — полином шестой степени. Подобные
рассуждения справедливы и для строк битов любой
длины, а не только для таких типов, как char или long.
Если переданное сообщение содержит 10 октетов, оно
содержит 80 битов и может рассматриваться в качестве
представления полинома 79-й степени при условии, что
первым битом сообщения является 1.
Другим важным свойством полиномов является то,
что один полином можно разделить на другой с обра-
зованием частного и остатка. Именно этот остаток час-
то называют "CRC". Если делимый полином имеет сте-
пень л, длина остатка равна п битов. Это означает, что
сам делитель должен содержать «4-7 битов — на один
больше длины остатка.
Еще одно очень полезное свойство алгоритмов CRC
состоит в том, что если вычислить CRC для данного
потока данных, а затем в надлежащем порядке добавить
вычисленное значение CRC к генератору CRC, то ре-
зультат будет равен 0. Генератор (программа, которая
передает или сохраняет данные) будет вычислять зна-
чение CRC для всего потока данных, а затем присоеди-
нять вычисленное значение к концу потока. Потреби-
тель (приемник или получатель данных) вычисляет
CRC для всего потока и вычитает его из CRC, создан-
ного генератором. Если результат равен 0, значит, CRC
совпадают.
30 Зак. 265
466
Дополнительные тематические разделы
Часть III
Проверка CRC может быть реализована побитово, и
именно так она была первоначально включена в такое
оборудование, как контроллеры дисков и платы сетевых
интерфейсов, которые имеют дело с последовательны-
ми потоками данных, передаваемыми по одному биту.
Этот метод обработки одного бита за другим может
быть воспроизведен в программе, но, как иллюстриру-
ют примеры сжатия Т.4, обработка по одному биту
малоэффективна.
Все алгоритмы с использованием CRC — полностью
детерминированные. Для любого заданного текущего
значения бита после обработки следующего бита суще-
ствует только два возможных новых значения, в зави-
симости от того, равен он (новый бит) 0 или 1. После
обработки следующих двух битов существует только
четыре возможных новых значения, в зависимости от
того, являются ли они 00, 01, 10 или 11. Поскольку
октет может содержать только 256 значений, можно
сгенерировать таблицу подстановок, содержащую 256
записей, и выполнить несколько операций побитового
сдвига логического И в целях генерирования нового
значения. Это необходимо для добавления битов окте-
та к CRC за один раз вместо выполнения восьми повто-
рений для обработки по одному биту.
Существует несколько широко используемых вари-
антов метода CRC, наиболее распространенными из
которых, вероятно, являются CRC-CCITT (16-битовый
CRC), CRC16 и CRC32. Все эти варианты имеют обыч-
ную и обратную реализации. Это связано с тем, что
последовательные устройства передают вначале млад-
шие биты, так же как в процессе кодирования и деко-
дирования факсимильных сообщений по протоколу Т.4.
Кроме ширины, алгоритмы CRC различаются по
начальному значению, по необходимости использова-
ния заключительного значения операции исключающего
ИЛИ, по используемому полиному и по тому, требует-
ся ли изменение порядка следования битов или нет. Два
часто используемые 16-битовые алгоритма CRC — CRC-
CCITT и CRCI6 — различаются почти по всем этим па-
раметрам.
• CRC-CCITT использует значение CRC, равное
0x1021 (в действительности — 0x11021, поскольку
для получения 16-битового значения остатка CRC
требуется 17-битовое значение, но старший бит все-
гда равен 1, поэтому он просто подразумевается).
Этот алгоритм инициализирует генератор значени-
ем Oxffff и не обращает порядок следования битов в
октетах данных или в конечном значении. Алгоритм
не требует выполнения заключительной операции
исключающего ИЛИ указанного значения с конеч-
ным остатком CRC.
• CRC16 использует значение CRC, равное 0x8005 (в
действительности — 0x18005). Этот алгоритм иници-
ализирует генератор значением 0 и обращает порядок
следования битов в октетах данных и в конечном ос-
татке CRC, но также не требует заключительной опе-
рации исключающего ИЛИ.
Две наиболее популярные подпрограммы CRC ис-
пользуют значения генераторов CRC, значительно от-
личающиеся одно от другого. Выбор подходящего зна-
чения требует кропотливого математического анализа
возможных ошибочных последовательностей и выходит
далеко за возможности большинства программистов и
рядовых математиков. В часто используемых форматах
применяются хорошо подобранные значения, которые
оправдали себя за долгие годы их использования.
Есть преимущество инициализации генератора зна-
чением, отличным от 0, как это делается в CRC-CCITT,
но не делается в CRC16. Если начать со значения 0,
последовательность начальных битов 0 любой длины
(если генерирование выполняется побитово) или все
октеты 0 не оказывают никакого влияния на это значе-
ние. Генерируемое значение CRC остается равным 0 до
тех пор, пока во входном потоке не появятся ненулевые
данные. Если бы фактические данные начинались с пос-
ледовательности нулевых битов или октетов и их было бы
один, несколько, слишком мало или слишком много,
алгоритм CRC16 никогда не выявил бы проблему.
CCITT в названии CRC-CCITT в действительности
означает ту же организацию, которая управляет стан-
дартом протокола факсимильных сообщений Т.4, а так-
же еще одним стандартом, используемым при передаче
факсов — Т.30. Ранее мы отмечали, что закодированные
данные всей страницы факса передаются в виде непре-
рывного потока битов, без кодов начала, конца или ка-
кого-либо выявления/исправления ошибок.
Отправляющие и принимающие устройства факсов
также обмениваются данными перед отправкой изобра-
жения первой страницы, между страницами, если их
больше одной, и после отправки последней страницы. Они
делают это, отправляя друг другу специально сформати-
рованные пакеты с использованием протокола, называе-
мого HDLC (High-level Data Link Control — Управление
компоновкой данных высокого уровня), и каждый пакет
включает в себя 16-битовый код CRC, сгенерированный
с использованием алгоритма CRC-CCITT (также назы-
ваемого HDLC).
Функция CRCCCITT()
В листинге 18.11 показана функция CRCCCITT() из
программы crcccitt.c (на Web-сайте "ДиаСофт"), в ко-
торой используется реализация таблицы подстановок
Обработка цифровых сигналов
|467
Глава 18
Листинг 18.11. Функция CRCCC1TT().
unsigned short
CRCCCITT(unsigned char *datar sizet length,
unsigned short seed, unsigned short final)
sizet count;
unsigned int crc = seed;
unsigned int temp;
for (count = 0; count < length; ++count)
{
temp = (*data++ * (crc » 8)) & Oxff;
crc = crc_table[temp] * (crc « 8);
}
return (unsigned short)(crc * final);
}
Здесь crc table — массив констант, состоящий из
256 значений типа unsigned short. Переменная temp в
действительности необязательна, поскольку без нее все
генерирование нового значения CRC можно было бы
выполнить в единственной строке кода, но ее исполь-
зование упрощает прослеживание текста программы.
Обратите внимание, что начальное значение seed и
значение для выполнения заключительной операции
исключающего ИЛИ с результатом передаются в каче-
стве параметров. Алгоритм CRC-CCITT начинается со
значения OxfffT и не выполняет завершающей операции
исключающего ИЛИ, поэтому всегда передается значе-
ние, равное 0. Эти параметры были помещены в про-
грамму потому, что рассматриваемый код может быть
приспособлен к другим 16-битовым алгоритмам CRC
путем простого изменения содержимого массива
crc_table и передачи других параметров.
Возможность передачи конкретного значения такой
“затравки” также полезна, когда по соображениям эко-
номии используемой памяти или процессорного време-
ни необходимо, чтобы блок данных обрабатывался по
частям, а не весь сразу. Подобная ситуация могла бы
возникнуть в 16-разрядной среде процессора Intel х86,
если бы блок данных занимал более одного сегмента
объемом 64 Кб. Первое обращение к функции сгс!6() в
качестве “затравки” будет передавать значение Oxffff
указателя на начало данных и длину, показывающую,
какой именно объем данных был доступен в данный
момент. При последующем обращении, когда доступен
больший объем данных или процессорное время, зна-
чение, возвращенное при предыдущем обращении, пе-
редастся обратно и генерирование CRC продолжается,
обеспечивая такой же результат, как если бы обработка
выполнялась непрерывно.
Функция main()
Функция main() в листинге 18.12 — простой небольшой
тестовый драйвер, который служит для демонстрации
эффектов использования алгоритма CRC-CCITT. Он
принимает единственный параметр командной строки —
имя существующего файла, который он открывает в дво-
ичном режиме. Программа выполняет весь вывод в stdout.
Она считывает первые 256 байтов из памяти в 258-байто-
вый массив и вызывает функцию CRCCCITT() для вы-
числения значения CRC, которое она отображает на
экране. Программа также сохраняет 16-битовый CRC в
двух последних переменных типа unsigned char в буфе-
ре младшим октетом вперед, хотя программа может ра-
ботать на процессорах, использующих любую последо-
вательность октетов. И в заключении она снова
вызывает функцию CRCCCITT() с параметром длины,
равным 258 (исходные данные плюс CRC), и снова ото-
бражает результат.
Предлагаю вам поэкспериментировать с этой про-
граммой, создав две идентичные копии файла, содержа-
щего, по меньшей мерс, 256 байтов. Теперь измените
один бит в любом из первых 256 байтов в любом фай-
ле. Запустите эту программу для оригинала и для изме-
ненной копии и посмотрите, к чему может привести
изменение одного бита.
Исправление ошибок: коды Гамминга
Все обсуждаемые до сих пор методы были предназна-
чены для выявления ошибок. Если во время обработки
данные повреждаются, бит четности, контрольные сум-
мы или CRC могут предупредить об этом, но не обес-
печивают никакого указания, где именно в потоке воз-
никла ошибка и как ее можно исправить.
Если данные находятся в хранилище или были пе-
реданы, можно прибегнуть к другой резервной копии
или повторить передачу. Но что произойдет при отказе
жесткого диска на высоконадежном сервере, работаю-
щем круглосуточно семь дней в неделю, на котором
данные сохраняются постоянно? Потеря информации о
заказах или учетной информации, даже полученной за
несколько часов перед тем, как было выполнено резер-
вное копирование, может нанести огромный финансо-
вый ущерб.
Существуют методы, которые помогают нс только
распознавать ошибки, но и обеспечивают достаточный
объем информации для восстановления данных. Наибо-
лее популярным из таких методов является использо-
вание кодов Гамминга (Hamming). Эти коды использу-
ют несколько битов четности, сгенерированных особым
образом.
Коды Гамминга создают сравнительно большую из-
быточность. Различные коды Гамминга обозначаются
заключенной в круглые скобки комбинацией двух чи-
сел, разделенных запятой. Имеющая наименьшее прак-
тическое значение версия обозначается (7,4). В общем
случае такое двузначное представление обозначают как
Дополнительные тематические разделы
Часть III
468
(c,d), где d — исходное количество битов данных в сло-
ве данных, а с — количество битов в закодированном
слове, включая биты четности Гамминга. Количество
битов четности Гамминга р равно с — d. В случае коди-
рования Гамминга (7,4) три бита четности (р) добавля-
ются к четырем битам данных (d), давая общую длину
закодированного слова (с), равную семи битам.
Все коды Гамминга должны соответствовать соотно-
шению
d + р + 1 <= 2Р
При любом количестве битов четности р существу-
ет 2Р возможных комбинаций этих битов. Иначе гово-
ря, в случае (7,4) с тремя битами четности существует
восемь возможных комбинаций трех битов четности.
В соответствии с приведенным соотношением количе-
ство комбинаций битов четности должно быть, по мень-
Листинг 18.12. функция main() для CRCCCITT().
шей мере, на единицу больше общего числа битов в за-
кодированном слове.
Рассмотрим код Гамминга (12,4), поскольку он име-
ет несколько важных областей применения. Для каждо-
го 8-битового октета генерируется четыре бита четнос-
ти Гамминга, или контрольных бита. Два октета с
контрольными битами помещаются в трех октетах, что
удобно для хранения или передачи посредством стан-
дартных 8-битовых периферийных устройств.
На рис. 18.4 показан метод визуализации 8-битово-
го октета, объединенного с его четырьмя контрольны-
ми битами в код Гамминга. Исходные восемь битов дан-
ных распределяются по конечному 12-битовому
результату, причем контрольные биты Гамминга встав-
ляются в определенные позиции. В основе 12-битового
результата лежит перенумерация, представляющая пол-
ное закодированное слово в виде битов от С1 для млад-
Idefine TEST SIZE 256
int main(int argc, char **argv)
FILE *fin;
size_t how_many;
unsigned short the_crc;
unsigned char buff [TEST_SIZE + 2];
if (argc < 2)
<
puts([dbl[usage: crcccitt filename[dbl]);
return EXITFAILURE;
}
else if (NULL == (fin = fopen(argv[l], [dbl]rb[dbl])))
<
printf([dbl]crcccitt: can't open %s\n[dbl], argv[l]);
return EXITFAILURE;
)
howmany = fread(buff, 1, TEST_SIZE, fin);
fclose(fin);
if (howjmany 1= TEST_SIZE)
<
printf([dbl]crcccitt: error reading %s\n[dbl], argv[l]);
return EXITFAILURE;
}
thecrc = CRCCCITT(byff, TESTSIZE, Oxffff, 0);
printf([dbl]Initial CRC value is 0x%04X\n[dbl], thecrc);
buff [TESTSIZE] = (unsigned char)((the_crc » 8) & Oxff);
buff [TEST_SIZE + 1] = (unsigned char)(the_crc & Oxff);
thecrc = CRCCCITT(buff, TESTSIZE + 2, Oxffff, 0);
printf([dbl]Final CRC value is 0x%04X\n[dbl], thecrc);
return EXITSUCCESS;
}
Обработка цифровых сигналов
Глава 18
>469
шего бита до С12 для старшего бита. Эта визуализация
помогает понять кодирование и проверку кодов Гаммин-
га. Реальные обрабатываемые биты необязательно дол-
жны физически размещаться таким же образом.
С12С11 СЮ С9 С8 С7 С6 С5 С4 СЗ С2 С1
РИСУНОК 18.4. Визуализация кодов Гамминга (12,4).
Для применения метода Гамминга, предназначенно-
го для выявления и исправления ошибок, четыре конт-
рольных бита вычисляются для каждого октета и пере-
даются или сохраняются с данными не обязательно в
том порядке, который показан на рис. 18.4. Когда дан-
ные и их контрольные биты принимаются или считы-
ваются, данные снова используются для вычисления
контрольных битов. Каждый набор из четырех конт-
рольных битов обрабатывается как двоичное число, со-
держащее значение между 0 и 15. Два контрольных бита
объединяются операцией исключающего ИЛИ. В слу-
чае отсутствия какой-либо ошибки это дает результат,
равный 0. Если происходит ошибка в одном бите, ре-
зультирующее значение является номером ошибочного
бита. Результат, равный 1, 2, 4 или 8, показывает, что
ошибка произошла в С1, С2, С4 или С8, т.е. один из
битов Гамминга является ошибочным. Любое другое
значение указывает на ошибку в бите данных.
Существует несколько различных способов генери-
рования четырех контрольных битов Гамминга для 8-
битового октета. Простейший из них — использование
таблицы подстановок, состоящей из 256 значений, про-
индексированных числовыми значениями октета. Ко-
нечно, необходимо использовать какой-либо другой
метод для вычисления значений, которые будут поме-
щены в таблицу в самом начале. Поскольку биты Гам-
минга предполагают использование контроля четности,
можно предположить, что при этом используется опе-
ратор исключающего ИЛИ, и это действительно так.
Биты Гамминга для конкретного октета могут гене-
рироваться бит за битом с использованием следующих
формул:
Hl = D6 л D4 л D3 л D1 л D0
Н2 = D6 л D5 л D3 л D2 л D0
НЗ = D7 л D3 л D2 л D1
Н4 = D7 л D6 л D5 л D4
Более простой метод — использование позиционного
алгоритма. Взгляните на заново обозначенные позиции
битов на рис. 18.4, где биты пронумерованы от С1 до
С12. Начните со значения Гамминга, равного 0, и про-
верьте каждый бит данных в исходном октете. Если бит
равен 1, выполните операцию исключающего ИЛИ для
номера "С" этого бита и значения Гамминга.
Оба этих метода присутствуют в функциях програм-
мы hamming.c (на Web-сайте "ДиаСофт”), хотя они и не
используются, поскольку программа содержит также
заранее определенную таблицу кодов Гамминга (листинг
18.13).
Программа запрашивает допустимое значение окте-
та (от 0 до 255) и количества битов (от 0 до 7). При вводе
пустой строки в ответ на любой запрос она завершает
свою работу. После проверки введенных данных про-
грамма инвертирует указанное число битов во введен-
ном значении. Она получает код Гамминга для исход-
ного и измененного значений и объединяет их
операцией исключающего ИЛИ. Результат этой опера-
ции используется для индексирования таблицы исправ-
лений, которая связывает номера Ci с битами в октете
данных. Значение корректировки объединяется исклю-
чающим ИЛИ с "поврежденным” октетом для восста-
новления исходных данных.
Технология RAID
В начале обсуждения кодов Гамминга мы упоминали
случай отказа жесткого диска на сервере, хранящем осо-
бо важные данные. Любой дисковод — слабое место
компьютера, и вопрос заключается лишь в том, "когда”,
а не "если" он откажет. Если диск отказывает прежде,
чем хранящиеся на нем данные будут скопированы или
зарезервированы на какой-либо иной носитель, эти дан-
ные теряются.
Одна из технологий, используемых для исправления
последствий возможного отказа жесткого диска, — это
технология RAID (Redundant Array of Independent Disks —
Массив независимых дисков с избыточностью). Суще-
ствуют различные уровни технологии RAID, одни из
которых обеспечивают защиту данных, в то время как
другие этого не делают.
Одна из технологий RAID называется отражением
диска. Сервер содержит два идентичных диска, управ-
ляемых параллельно либо специальным устройством в
компьютере, либо программным драйвером на уровне
операционной системы, прозрачным для прикладной
программы, которая сохраняет особо важные данные
Одни и те же данные записываются параллельно на оба
диска. Если один диск отказывает, все данные остают-
ся неповрежденными на втором диске.
470
Дополнительные тематические разделы
Часть III
Листинг 18.13. Программа Hamming.c, иллюстрирующая использования кодов Гамминга.
int main(void)
{
unsigned long value;
unsigned long modified;
long thejbit;
int ham;
int mod ham;
char buff[50];
for ( ; ; )
<
printf("Enter a value between 0 and 255 in C notation: ");
f flush j( stdout);
if (NULL == (fgets(buff, sizeof buff, stdin)))
break;
}
else if (*buff f\nr)
{
break;
value = strtoul(buff, NULL, 0);
if (value > 255)
{
puts("Value too large");
continue;
printf("Enter the bit (0 - 7) to change: ");
fflush(stdout);
if (NULL -= (fgets(buff, sizeof buff, stdin)))
{
break;
}
else if (*buff == '\nr)
{
break;
}
thebit = strtol(buff, NULL, 0);
if (thejbit >7 || the bit < 0)
{
puts("Bit number out of range");
continue;
}
ham = hamming[value];
modified = value * (1 « thejbit);
mod_ham = hamming[modified];
printf("Original value 0x%02X Bamming Code 0x%X\n“,
value, ham);
printf("Modified value 0x%02X Bamming Code 0x%X\n",
modified, modjiam);
printf("Exclusive OR of the Bamming Codes is 0x%X\n",
ham * mod_ham);
printf("Correction mask is 0x%02X\n",
4 corrections[ham * mod ham]);
4 printf("Corrected value is 0x%02X\n\n",
modified * corrections [ham * mod_ham]);
}
printf("\nGoodbye\n");
return 0;
Обработка цифровых сигналов
Глава 18
471
Если вспомнить о концепции передачи двух копий
данных, может возникнуть вопрос, как при отражении
диска удается избегать аналогичных проблем? Когда
диск отказывает, то часто он становится нечитабельным,
и поэтому не возникает никакого сомнения относитель-
но того, какой диск вышел из строя. Даже если такой
диск отвечает на запросы, контроллеры дисков автома-
тически вычисляют CRC для записываемых данных, а
затем повторно вычисляют и сравнивают их при считы-
вании. Таким образом, в общем случае не возникает
никаких проблем с определением отказавшего диска,
когда считываемые данные не совпадают.
Однако, когда один диск отказывает, система боль-
ше не располагает защитой, предоставляемой техноло-
гией отражения. Если она должна продолжать функци-
онировать, то новые данные сохраняются только на
оставшемся диске. Если второй диск отказывает преж-
де, чем первый отказавший диск будет заменен и будет
выполнено повторное отражение дисков, то данные
будут потеряны.
Существуют другие уровни RAID, которые исполь-
зуют более двух дисков и коды Гамминга для восстанов-
ления данных. В наиболее сложных реализациях фак-
тически генерируется код Гамминга (7,4) для каждого
4-битового полубайта данных и используется до семи
дисков, по одному для каждого бита данных и для каж-
дого бита Гамминга. Технология размещения единого
значения данных на нескольких дисках называется
распределением (striping).
Существуют промежуточные уровни, которые обес-
печивают большую безопасность при отказе диска, чем
простое отражение диска, и требуют меньших затрат,
чем подход с использованием семи дисков.
Давайте рассмотрим систему, которая использует
код Гамминга (12,8). Имеется 12 битов закодированных
данных, которые могут быть распределены по трем
полубайтам по четыре бита каждый. Эти три полубай-
та могут быть распределены по трем различным дискам.
Во время отказа диска система может использовать от-
ражение на двух остальных дисках для защиты новых
данных до тех пор, пока третий диск не будет заменен.
Может показаться, что естественным было бы раз-
делить данные октета на его четыре старших и четыре
младших бита. Каждый из этих 4-битовых полубайтов
сохранялся бы на одном из двух дисков, а 4-битовый код
Гамминга — на третьем. К сожалению, этот подход не-
приемлем: если диск, на котором хранится старший
полубайт, откажет, невозможно будет однозначно вос-
становить его на основании только младшего полубай-
та и битов Гамминга.
Во всяком случае, существует 35 различных спосо-
бов разделения 8-битового октета на два 4-битовых по-
лубайта. Двенадцать из них обеспечивают нужное ка-
чество: при наличии любого полубайта и четырех би-
тов кода Гамминга они могут воссоздать отсутствующий
полубайт данных и восстановить исходные данные.
Одна из этих 12 комбинаций показана на рис. 18.5.
РИСУНОК 18.5. Распределение данных с использованием кодов
Гамминга.
Алгоритмы управления PID
Она из причин потребности в программах для захвата,
оцифровки и обработки внешних сигналов состоит в
необходимости управления физическими процессами,
которые эти сигналы представляют. Одна из наиболее
широко используемых технологий программирования в
системах управления — это алгоритм PID во всем его
множестве разновидностей и вариантов.
Все механизмы управления, от простого выключа-
теля освещения до наиболее сложного автоматизирован-
ного оборудования, могут быть отнесены к одной из
двух категорий: замкнутому контуру и разомкнутому
контуру. Эти категории проиллюстрированы на рис.
18.6. Управление по замкнутому контуру получило свое
название благодаря замкнутой цепи обратной связи,
показанной на правой схеме. Выходной управляющий
сигнал проходит от контроллера к управляемому про-
цессу. Входной сигнал обратной связи передается от
процесса к управляющему устройству, замыкая контур.
Управление по разомкнутому контуру, показанное на
левой схеме, получило свое название в связи с отсут-
ствием в контуре цепи обратной связи.
Существует совершенно иной метод разделения всех
механизмов управления на другие две категории в зави-
симости от природы выходного сигнала управляемого
ими механизма. Этими категориями являются управле-
ние постоянно изменяющимися процессами и управле-
ние состоянием включено/выключено. При управлении
постоянно изменяющимся процессом выходной сигнал
устройства управления может изменяться от нуля до
некоторого максимального значения или в некоторых
случаях от некоторого отрицательного минимального
значения до некоторого максимального положительно-
Разомкнутый контур Замкнутый контур
го значения, проходя через нуль. При управлении со-
стоянием включено/выключено используются только
две настройки: ’’полностью включено" или ’’полностью
выключено”.
Названные две категории непосредственно никак не
соотносятся одна с другой. Возможны все четыре ком-
бинации систем управления: разомкнутый контур вклю-
чен ия/выключения, разомкнутый контур непрерывно-
го выходного сигнала, замкнутый контур включения/
выключения и замкнутый контур непрерывного выход-
ного сигнала. Наибольший интерес представляет четвер-
тая категория — замкнутый контур непрерывного вы-
ходного сигнала.
В табл. 18.5 приведены некоторые используемые в
терминологии управления термины и их определения.
Таблица 18.5. Определения терминов, используемых в управлении.
Термин управления Определение
Переменная процесса Преобразованный в цифровую форму сигнал обратной связи, представляющий реальный физический процесс, которым нужно управлять.
Контрольное значение Входное значение для механизма управления, которое указывает желательное значение переменной процесса.
Выходной сигнал Значение, которое вычисляется устройством управления и пересылается какому-либо физическому механизму, который оказывает влияние на управляемый процесс.
Ошибка Разность между контрольным значением и переменной процесса в каждый конкретный момент времени. Цель алгоритма управления — все время поддерживать ошибку максимально приближенной к нулю.
Интервал или такт Почти все алгоритмы управления учитывают временной фактор. Переменная процесса определяется во время каждого интервала (или каждого такта), а алгоритм вычисляет новое значение выходного сигнала.
Помеха Изменение внешних факторов, отличное от изменения выходного сигнала устройства управления, которое влияет на переменную процесса. Например, перемещение вверх- вниз по склону было бы помехой для устройства автоматического управления автомобилем, пытающегося поддерживать постоянную скорость.
Коэффициент передачи Входные и выходные сигналы устройства управления могут иметь весьма различающиеся масштабы. Например, ввод контрольного значения, равного 10 мА, может вызывать выходной сигнал, равный 1 А. Коэффициент передачи — простая скалярная константа, позволяющая непосредственно сравнивать различные уровни сигналов.
Коэффициент усиления Общий термин, применяемый к общему коэффициенту передачи контроллера по отношению к отдельным членам, образующим алгоритм управления. Устройство управления, которое создает выходной сигнал, равный 1 А, при входном сигнале, равном 10 мА, имело бы общий коэффициент усиления, равный 100. Любой коэффициент усиления может быть равен 0, и в этом случае он не оказывает никакого влияния на выходной сигнал, или же он может быть больше, меньше или равен единице.
Обработка цифровых сигналов
Глава 18
473
Термин управления Определение
Коэффициент пропорциональности Буква "Р" в названии PID означает "Proportional” (пропорциональный). При каждом прохождении по контуру текущая ошибка (разность между переменной процесса и контрольным значением) умножается на коэффициент пропорциональности для вычисления члена пропорциональности (Р), который участвует в вычислении выходного сигнала.
Интегральный коэффициент "I" в названии PID означает "Integral" (интегральный). Этот термин относится к вычислениям, а не к программированию на языке С. В течение заданного интервала времени ошибка суммируется, или интегрируется, и эта сумма умножается на интегральный коэффициент для получения интегрального члена (I), который участвует в вычислении выходного сигнала.
Производный коэффициент "D" в названии PIDозначает "Derivative" (производный) — еще один вычислительный термин. В теории управления он имеет такое же, как и в математике, значение — скорость изменения функции. В данном случае скорость изменения ошибки от одного интервала времени к другому является производной, и это значение умножается на производный коэффициент для получения производного члена (D), участвующего в вычислении нового выходного значения.
Смещение Смещение — это постоянный член, добавляемый к вычисленному значению выходного сигнала и не зависящий от контрольного значения или сигнала обратной связи переменной процесса.
Запаздывание Некоторые управляемые процессы не имеют временного запаздывания между изменением выходного сигнала и соответствующим изменением переменной процесса, или, по крайней мере, изменение полностью завершается до начала следующего интервала. Примерами этого могут служить громкость звука или яркость света, когда управляемые электронные устройства реагируют очень быстро. Однако большинство управляемых физических процессов, таких как перемещение, температура, давление и многие другие, характеризуются значительной инерцией. Для полного изменения переменой процесса после изменения выходного сигнала требуется некоторое время.
Время бездействия Этот термин связан с запаздыванием, но отличается от него. В некоторых системах из- за расстояния между звеньями или других факторов изменение выходного сигнала может в течение некоторого времени вообще не приводить ни к каким изменениям переменой процесса. Со временем изменение выходного сигнала начинает оказывать влияние Программа pidloop на Web-сайте "ДиаСофт” не имитирует время бездействия.
Коэффициент ускорения Во многих ситуациях управления требуется максимально быстро привести переменную процесса к контрольному значению. В других ситуациях важно, чтобы переменная процесса изменялась с заданной скоростью, называемой коэффициентом ускорения. Коэффициент ускорения может быть положительным при увеличении значения переменной процесса и отрицательным — при его уменьшении.
Запирание Этот термин — частный случай понятия "трение покоя". Из физики известно, что трение между покоящимися объектами больше, чем между объектами, перемещающимися друг относительно друга (так называемое "сухое трение" — Примеч. науч. ред.). Влияние запирания на систему заключается в том, что она становится нелинейной при очень малых уровнях выходного сигнала. Если исходным является состояние покоя, изменения в переменной процесса вообще будут отсутствовать до тех пор, пока выходной сигнал не достигнет некоторого минимального уровня. Программар1с11оор на Web-сайте "ДиаСофт" не имитирует запирание.
Упреждающая поправка Алгоритм использует упреждающую поправку, когда предполагается наличие некоторого эффекта, который, безусловно, увеличит ошибку, и в этом случае алгоритм заблаговременно изменяет выходной сигнал для предотвращения или уменьшения этой ошибки. Каждая упреждающая поправка представляет собой другой тип коэффициента усиления.
Упреждающая поправка на ускорение Этот член упреждающей поправки иногда используется в алгоритмах управления при
наличии изменения контрольного значения, мгновенного или постепенного, с определенным коэффициентом ускорения. Если текущий выходной сигнал поддерживает приемлемое значение ошибки при текущем контрольном значении, то, чтобы члены Р, 1 и D смогли среагировать, ошибка должна увеличиться. Величина изменения контрольного значения умножается на коэффициент упреждающей поправки на ускорение и применяется к выходному сигналу немедленно, чтобы выходной сигнал изменился прежде, чем ошибка возрастет.
Дополнительные тематические разделы
Часть III
474
Таблица 18.5. Определения терминов, используемых в управлении.
Термин управления Определение
Упреждающая поправка на скорость Упреждающая поправка на скорость — это модифицированная форма определенного ранее смещения. Она вычисляется путем умножения контрольного значения на постоянный коэффициент, но по-прежнему остается независимой от сигнала обратной связи, поступающего от переменной процесса.
Упреждающая поправка на трение Эта упреждающая поправка иногда используется в системах с достаточно большим значением запирания, которое в обычных условиях заметно влияет на переменную процесса. В общем случае эта поправка реализуется в виде дополнительного члена, добавляемого к выходному сигналу, когда значение переменной процесса находится в области, в которой запирание приводит к наибольшей нелинейности.
Время сохранения состояния Некоторые механизмы, управляемые выходным сигналом устройства управления, не могут работать с частотой, превышающей определенное значение, или даже могут быть повреждены, если будут изменять свое состояние слишком быстро. Примером может служить компрессор холодильника или кондиционера воздуха. Такое поведение характерно для механизмов, которые могут находиться только в состояниях включения или выключения и которые не изменяют своего состояния постоянно. Время сохранения состояния — это время, выраженное в интервалах или тактах, по истечении которого выходной сигнал может быть снова изменен.
Коэффициент холостого хода Иногда природа управляемого процесса диктует максимальную скорость изменения выходного сигнала устройства управления. Примерами могут служить коробка передач, которая может выйти из строя при слишком быстром изменении скорости, превышающем допустимое значение момента вращения, или устройство управления движением транспортного средства с пассажирами, когда слишком резкое изменение скорости приводило бы к неприятным рывкам.
Программа pidloop.c
Сам по себе алгоритм управления заключается в диф-
ференцировании и вычислении значений на основании
измерений переменной процесса и ошибки и последу-
ющего умножения этих значений на соответствующие
коэффициенты усиления для получения произведений.
Затем произведения суммируются для вычисления но-
вого значения выходного сигнала.
Члены, определенные в табл. 18.5, одновременно
используются не во всех системах управления. Факти-
чески одновременно все эти члены будут использоваться
лишь в некоторых системах. Тем не менее, можно со-
здать общую программу, которая будет учитывать все
возможные члены. Установка коэффициента для любо-
го члена равным нулю предотвращает какое-либо его
влияние на выходной сигнал.
Файл исходного кода pidloop.c помещен на Web-сай-
те "ДиаСофт”. Большинство определенных в этом файле
функций относятся к имитатору, они выполняют синтак-
сический анализ входной командной строки и выполня-
ются в однопроходном интерактивном или автоматичес-
ком режиме. Только функция ComputePIDO и часть
функции main() действительно являются частью соб-
ственно алгоритма управления.
В файле pidloop.txt на Web-сайте "ДиаСофт” пояс-
няется, как запустить программу pidloop после ее созда-
ния в интерактивном режиме или посредством сцена-
риев. Компакт-диск содержит также сценарии для всех
используемых примеров (файлы с расширением .pid).
Если выполнять указания, приведенные в текстовом
файле, и использовать примеры, то изменение этих
сценариев или создание новых в целях эксперимента не
должно вызвать затруднений.
Для простоты во всех сценариях предполагается, что
выходной сигнал может изменяться от -100 до +100%
и что коэффициент передачи между выходным сигна-
лом и переменной процесса постоянен.
Если вывод выходных значений программы pidloop
в виде графика затруднителен, можно поэксперименти-
ровать с изменением коэффициентов упреждающей
поправки и запаздывания, отмечая результирующее из-
менение значения среднеквадратичной ошибки. Чем
меньше среднеквадратичное значение, тем меньше сред-
няя ошибка.
Структура PIDPARAMS
Структура PID_PARAMS в листинге 18.14 содержит
все переменные для собственно цикла PID, а также не-
сколько переменных, связанных с имитацией, которые
для удобства сгруппированы в единый блок.
Листинг 18.14. Структура PID_PARAMS из
программы pidloop.c.
typedef struct
{
double p_gain; /* коэффициент
пропорциональности 'P* */
475
double i_gain; /* интегральный
double dgain; коэффициент 'I' */ /* производный
double acc_ff; коэффициент 'D' */ /* упреждающая поправка
double fri_ff; на ускорение 'А' */ /* упреждающая поправка
double vel_ff; на трение 'F' */ /* упреждающая поправка
double hold; на скорость 'V' */ /* время сохранения
double bias; состояния выходного сигнала 'Н' */ /* смещение *В' */
double accel; /♦коэффициент ускорения 'R'*/
double setpt; /«контрольное значение *S * */
double trans; /*коэффициент передачи 'Т'*/
double lag; /* запаздывание изменения
double min; / выходного сигнала *1/ */ * минимальное значение
double max; / выходного сигнала 'N' */ * максимальное значение
double cycles; выходного сигнала 'М' */ /* счетчик повторения
double slew; циклов 'Y' */ /* минимальный коэффициент
} PIDPARAMS; холостого хода 'W' */
Переменные области видимости файла
Переменные this target и next_target используются в
вычислениях PID, но они определены в области види-
мости файла (листинг 18.15), чтобы их можно было
использовать при выводе результатов имитации. Пере-
менные event_index и rms_error относятся только к
имитации.
Листинг 18.15. Переменные области видимости
файла из pidloop.c.___________________
static int eventindex =0;
static double event_target =0;
static double event-target =0;
static double rmS-error =0;
Функция ComputePID()
Функция ComputePIDO в листинге 18.16 содержит пол-
ную реализацию алгоритма управления, в котором при-
меняется большинство из часто используемых техноло-
гий.
В первой части кода обрабатываются ускорение и
замедление. Если текущее целевое значение переменной
процесса не равно контрольному значению, то на каж-
дой итерации оно изменяется путем добавления или
вычитания значения ускорения, пока не станет равным
конечному контрольному значению. Это значение со-
Обработка цифровых сигналов
Глава 18
храняется в переменной next_target, а разность между
ним и текущим целевым значением вычисляется и со-
храняется в переменной accel.
Значение this_error вычисляется путем вычитания
текущего значения переменной процесса PV из значе-
ния thiS-target Производная ошибки (скорость измене-
ния ошибки) вычисляется в deriv путем вычитания зна-
чения last_eiTor из значения thiS-еггог. Это же значение
добавляется также к изменяющемуся суммарному зна-
чению интегральной ошибки в переменной integral.
На этом завершаются все вычисления, основываю-
щиеся на текущем и прошлом значениях переменной
процесса.
При вычислении this_output каждое из этих значе-
ний умножается на соответствующий коэффициент, а
произведения складываются. Если значение любого из
коэффициентов установлено равным 0, соответствую-
щий член не влияет на общую сумму.
Затем функция выполняет сравнение ограничений с
новым значением this_output Если коэффициент холо-
стого хода указан, он ограничивает величину, на кото-
рую значение ttiis__output может отличаться от значения
last-output независимо от всех остальных факторов.
Если имеются абсолютное максимальное и минималь-
ное значения выходного сигнала, необходимо сравнить
значение ttiis_output с ними и принудительно ограни-
чить рамками допустимого диапазона.
Дополнительные проверки позволяют убедиться, что
значения last_output и last-error обновлены результата-
ми текущего вычисления и будут доступны при следу-
ющем повторении цикла.
Функция GetCurrentPV()
Эта функция выполняет минимальную имитацию сис-
темы отклика второго порядка, имеющую инерционное
запаздывание. Она имитирует аппаратно-зависимые
функции применения вычисленного значения выходно-
го сигнала к некоторому устройству, выжидающему
истечения всего заданного интервала времени, считы-
вающему переменную процесса с другого аппаратного
устройства и выполняющему возврат в функцию main()
как раз к моменту начала следующей итерации. Работа
функции достаточно проста, и она иллюстрирует ими-
тацию инерции посредством использования параметра
запаздывания. Функция приведена в листинге 18.17.
Чтобы разобраться в работе этой функции, давайте
проследим за кодом с момента первого его вызова пос-
ле запуска программы с ненулевым значением выход-
ного сигнала. Новое значение выходного сигнала добав-
ляется к статической переменной build—up, которая была
равна 0 и поэтому теперь равняется значению выходно-
го сигнала.
476
Дополнительные тематические разделы -
Часть III
Листинг 18.16. Функция ComputePID() из файла pidloopx.
static double
ComputePID(double PV)
{
/* Для хранения информации между повторениями цикла требуются три статические переменные */
static double static double integral lasterror lastoutput « 0.0; = 0.0; = 0.0;
static double
double thiS-вггог;
double this_output;
double accel;
double deriv;
double friction;
/* Требуемым значением PV для этой итерации является значение, вычисленное в качестве
значения nexttarget во время предыдущего выполнения цикла */
this_target = nexttarget;
/* Проверка ускорения и вычисление нового целевого значения PV для следупщего выполнения
цикла */
if (params, а с cel > 0 && this_target != params, setpt)
{
if (this_target < params.setpt)
{
next_target += params.accel;
if (next-target > params.setpt)
{
next—target = params, setpt;
}
}
else /* params.target > params.setpoint */
{
next_target -= params.accel;
if (next target < params.setpt)
{
nexttarget = params, setpt;
}
}
}
else
{
next-target = params.setpt;
}
/* Ускорение - это разность между целевым значением PV при данном выполнении цикла и этим
значением при следующем выполнении цикла */
accel = next-target - this_target;
/* Ожибка для текущей итерации - это разность между текущим целевым значением и текущим
значением PV */
thiS-вггог = thiS-target - PV;
/* Производная - это разность между ошибками текущей и предыдущей итераций */
deriv = thiS-вггог - last_error;
/* Очень простой способ определения того, существует ли фактор трения, который необходимо
компенсировать во время следующей итерации; если текущее значение PV равно 0, а целевое
значение для следующей итерации не равно 0, запирание может представлять проблему */
friction = (PV == 0.0 && next-target != 0.0);
/* Новая ошибка добавляется к интегральной поправке */
integral +® this-target - PV;
477
Обработка цифровых сигналов
Глава 18
/* Квадратичная отибка накапливается в переменной rmserror для создания отчета в конце
работы программы, она не участвует в вычислениях цикла PID */
rms_error += (this_error * this_error);
/* Теперь, когда все переменные члены вычислены, они могут быть умножены на соответствующие
коэффициенты, а результирующие произведения могут быть просуммированы */
this_output = params.pgain * this_error
+ params.igain * integral
+ params.d_gain * deriv
+ params.accff * accel
+ params.vel_ff * next_target
+ params.friff * friction
+ params.bias;
lasterror = thiserror;
/* Сравнение с коэффициентом холостого хода, ограничивающим скорость изменения выходного
сигнала */
if (0 ! = params .slew)
{
if (this_output - last_output > params.slew)
{
thisoutput = lastoutput + params.slew;
}
else if (last_output - this_output > params.slew)
{
this_output = last_output - params.slew;
}
1
/* Теперь выполняется сравнение с абсолютными ограничениями */
if (thisoutput < params.min)
{
thi soutput = params.min;
}
else if (thisoutput > params.max)
{
this_output = params.max;
}
/* Сохранение нового значения выходного сигнала, которое будет использоваться в качестве
старого значения выходного сигнала во время следующей итерации цикла */
return last_output = this_output;
}
Листинг 18.17. функция GetCurrentPVQ из файла pidloop.c.
static double
GetCurrentPV(double output)
{
static double buildup
double value;
= 0.0;
build_up += output;
value = build_up * (1 - params.lag) * params.trans;
buildup *= params.lag;
return value;
}
Параметр запаздывания, значения которого лежат в
диапазоне от 0 до 1, теперь используется для вычисле-
ния доли значения build_up, применяемой к значению
PV немедленно, и доли, применение которой к буду-
щим итерациям запаздывает из-за инерции. Если зна-
чение params.lag равно 0, все значение build_up приме-
няется немедленно, поскольку имитация ведет себя по-
добно системе без инерции. Если значение paramsJag
478
Дополнительные тематические разделы
Часть III
равно 1, никакая часть выходного сигнала вообще ни-
когда на применяется к значению PV, которое навсегда
останется равным 0.
При следующей итерации новое значение выходно-
го сигнала добавляется к остатку значения build_up и
снова делится на составляющие в соответствии со зна-
чением paramsJag.
Пропорциональное управление:
коэффициент Р
Коэффициент Р в вычислении управляющего сигнала
генерирует выходной сигнал, пропорциональный теку-
щей ошибке. Это кажется вполне логичным — когда
ошибка велика, выходной сигнал требует большего из-
менения; когда ошибка мала, требуется меньшее изме-
нение. Недостаток чисто пропорционального управле-
ния заключается в том, что при достижении состояния,
когда контрольное значение равно нулю, умножение
нуля на коэффициент Р дает нулевое значение выход-
ного сигнала.
Действительно, существует три возможных резуль-
тата применения чисто пропорционального управления:
• Если коэффициент Р мал, значение переменной про-
цесса будет стремиться к контрольному значению,
но никогда его не достигнет, все время оставаясь
меньше.
• Если коэффициент Р слишком велик, значение пе-
ременной процесса будет осциллировать (колебать-
ся) вокруг контрольного значения.
• Если значение коэффициента Р находится в соответ-
ствующих пределах, значение переменной процес-
са вначале превысит значение контрольной перемен-
ной, а затем будет осциллировать; но амплитуда
колебаний будет затухать, и со временем значение
переменной процесса установится несколько ниже
контрольного значения.
На всех приведенных в этом разделе графиках
сплошная линия представляет контрольное значение, а
штриховая — переменную процесса PV. Прежде чем
анализировать результаты, рассмотрите ту часть кода и
данных программы, которая действительно выполняет
имитацию PID. Вертикальная ось представляет полное
значение PV, выраженное в процентах, а горизонталь-
ная ось — количество выполненных циклов, ассоции-
руемое с временем.
Результаты выполнения программы pidloop со сце-
нарием step.pid приведены на графике рис. 18.7. Вначале
значения всех коэффициентов устанавливаются равны-
ми нулю. Контрольное значение устанавливается рав-
ным 20, и смещение также равно 20. Эта конфигурация
действует подобно функционированию системы в режи-
ме ручного управления и по истечении периода време-
ни, определяемого запаздыванием, значение выходно-
го сигнала устанавливается равным 20.
РИСУНОК 18.7. Превышение контрольного значения при
использовании только коэффициента пропорциональности.
Как только выходной сигнал стабилизируется, сту-
пенька, равная 10% полного диапазона, генерируется
изменением контрольного значения до 30, а коэффици-
ент Р активизируется при установке этого значения рав-
ным 1.9. Выходное значение изменяется типичным для
чисто пропорционального управления образом, внача-
ле скачкообразно с появлением колебаний, которые
постепенно затухают, и наконец устанавливается ниже
контрольного значения.
Попробуйте изменять параметр запаздывания и ко-
эффициент Р в сценарии step.pid. чтобы выяснить, ка-
кое влияние они оказывают на выходное значение уп-
равляемого сигнала.
Интегральное управление: коэффициент I
Член коэффициента 1 может удерживать значение вы-
ходного сигнала равным контрольному значению, как
только оно достигнуто. Хотя применение вычислитель-
ного термина “интегральный" предполагает сложные
вычисления, он имитируется в управлении PID путем
добавления текущей ошибки к изменяющемуся суммар-
ному значению. При этом никаких сложных вычисле-
ний не требуется.
Независимо от конкретного используемого значения
коэффициента I, значение переменной процесса сначала
превысит контрольное значение, а затем выполнит не-
сколько колебательных движений, прежде чем устано-
вится окончательно.
На рис. 18.8 представлен график результатов выпол-
нения программы pidloop со сценарием ionly.pid. Коэф-
фициент I обусловливает затухающие колебания значе-
ния переменной процесса, которое затем постепенно
устанавливается почти в точности равным контрольно-
му значению.
Обработка цифровых сигналов
Глава 18
479
1001--------------------------------------------------
90----------------------------------------------------
80----------------------------------------------------
70 ---- ----------------------------------------------
t *
60 —4-------=±—= =^= == ===== -11 =
»
50 --!------------------------------------------------
I
40 --1------------------------------------------------
।
30 —t-------------------------------------------------
»
20 —--------------------------------------------------
t
i
10 -i-------------------------------------------------
t
о ----------------------------------------------------
0 2 4 6 8 10 12 14 16 18 20
РИСУНОК 18.8. График процесса при использовании только
коэффициента /.
В алгоритме PID часто используются измененные
варианты интегрального члена I, когда его накопленное
интегральное значение обнуляется (если коэффициент
Р сам по себе обеспечивает достижение выходным сиг-
налом максимального или минимального значения)
либо когда максимальное абсолютное значение интег-
рала ограничивается.
Производный член: коэффициент D
При правильном применении производный член умень-
шает превышение контрольного значения и последую-
щие осцилляции. Если вычертить ошибку переменной
процесса на каждом интервале времени, на котором
выполнялось вычисление PID, можно в каждый момент
времени получить производную изменения ошибки. Как
и в случае с интегралом, сложные математические фун-
кции можно легко аппроксимировать. Поскольку про-
изводная — это скорость изменения функции, а в дан-
ном случае — функции ошибки во времени, то ее
приближенно можно вычислить путем вычитания ошиб-
ки предыдущего интервала из ошибки текущего интерва-
ла и деления полученной разности на величину интерва-
ла. Полученный таким образом результат используется
в качестве аппроксимации производной.
Результат добавления коэффициента D к интеграль-
ному управлению иллюстрируется на рис. 18.9. Он был
получен при выполнении программы pidloop по сцена-
рию id.pid. По мере того как интегральный коэффици-
ент повышает значение переменной процесса по на-
правлению к контрольному значению, ошибка
уменьшается. В результате отрицательный производный
коэффициент добавляется к смещенной части положи-
тельного интегрального коэффициента, способствуя
уменьшению наступающего со временем превышения
контрольного значения. Среднеквадратичная ошибка
уменьшается от значения 14,36 в сценарии ionly.pid до
13,59 в сценарии id.pid.
100 90
80
70
АЛ •
OV 50 7 t — — —
40
30
20 t
Ю 1
6
С ) 2 4 6 8 10 12 14 16 18 РИСУНОК 18.9. График, иллюстрирующий применение коэффициентов / и D. 20
Член D в алгоритме PID часто исключают из вычис-
лений во время ускорения или при изменении конт-
рольного значения.
Объединение всех коэффициентов. PID
На рис. 18.10 показан результат выполнения сценария
pid.pid, объединяющего все три коэффициента, благо-
даря которым алгоритм PID и получил свое название.
Среднеквадратичная ошибка была уменьшена до 8,43,
и из графика видно, что амплитуда колебаний оказы-
вается значительно меньше, а установка конечного (кон-
трольного) значения происходит быстрее.
100 90
80
70
60 50
40
ол
«зи ол
4CV
IV о
с ) f » 10 15 20 25 30 35 40 45 50
РИСУНОК 18.10. График изменения переменной процесса при
использовании полного алгоритма управления PID.
Профили
До сих пор в примерах различных компонентов алго-
ритма PID предполагалось, что начальное значение пе-
ременной процесса на некоторую величину отличается
от контрольного значения и что требуемым результатом
является максимально быстрое достижение выходным
Дополнительные тематические разделы
| 4801
Часть III
сигналом контрольного значения и стабилизация его на
этом уровне. Но это не всегда так. Бывают случаи, ког-
да требуется точное управление изменениями перемен-
ной процесса.
Давайте рассмотрим случай управления температу-
рой внутри химического аппарата, в котором протека-
ет реакция. Если температура повышается слишком
медленно, время расходуется непродуктивно и, возмож-
но, результат реакции также оказывается неудовлетво-
рительным. Если температура повышается слишком
быстро, в реакторе может повыситься давление и выз-
вать опасность аварии.
Еще один тип управления, при котором важна ско-
рость изменения переменной процесса, — это управле-
ние движением. Например, при управлении движени-
ем лифта во избежание травм пассажиров требуется
осуществлять управление его ускорением. Еще один
пример — согласование нескольких видов перемещения.
Рассмотрим механическое устройство, вырезающее де-
тали из заготовок. Для вырезания двумерных форм та-
кое устройство имеет два мотора по координатам X и
Y. Для выполнения прямого разреза под углом 45 гра-
дусов оба мотора должны с равным ускорением разви-
вать одинаковую скорость, а затем одинаково замедлять-
ся. Если один из моторов ускоряет или замедляет
движение быстрее, чем другой, разрез не будет прямым.
При управлении движением очень часто требуется
переместиться из одного положения в другое, причем
заданная скорость должна быть достигнута с заданным
ускорением. При достижении точки, расположенной на
заданном расстоянии от точки назначения, движение
замедляется с тем же ускорением, которое использова-
лось для достижения заданной скорости, обеспечивая
плавную остановку в конечном положении.
Если вычертить график такого изменения скорости
во времени, то в результате получим трапецию, кото-
рую часто называют профилем скорости движения. (Та-
кие профили могут иметь не только трапециевидную,
но самую разнообразную форму. — Примеч. науч, ред.)
Такой профиль показан на рис. 18.11, хотя в ими-
таторе для начала торможения использовалось заданное
время, а не заданное положение движущейся точки. Для
получения этого графика программа была выполнена по
сценарию acel 1.pid, в котором используются те же па-
раметры, что и при получении предыдущего графика.
Программа имитирует ускорение, равное 3% от те-
кущего значения скорости, до достижения скорости,
равной 70% от максимальной. В указанное время дви-
жение замедляется с замедлением, равным 3% (или с
ускорением, равным -3%), до полной остановки точки.
Среднеквадратичная ошибка оказалась равной прибли-
зительно 1,69.
Упреждающие поправки
Все исследованные до сих пор алгоритмы были реактив-
ными. Они оказывали действие после возникновения
ошибки. Даже производный член, который ограничива-
ет превышение контрольного значения, вычисляется на
основании двух последних значений ошибки.
Давайте рассмотрим систему, находящуюся в ста-
бильном состоянии со значением переменной процес-
са, равным контрольному значению. Оба эти значения
могут быть нулевыми или какими-либо другими по-
стоянными значениями. Когда приходит время уско-
рить систему, на каждой итерации контрольное значе-
ние повышается на некоторую величину. Поскольку
ответ системы на изменение контрольного значения
запаздывает, после первого интервала времени появля-
ется ошибка, которая на последующих интервалах уве-
личивается. Поскольку величина изменения конт-
рольного сигнала системе управления известна, она
(система) может предвидеть изменение результирующей
ошибки и на каждом интервале времени предпринять
упреждающее действие для уменьшения или даже пол-
ного исключения будущей ошибки.
На этом основывается применение упреждающей
поправки на ускорение. Приведенный на рис. 18.11
профиль начинается при значениях переменной про-
цесса и контрольном значении, равных нулю, затем
применяется ускорение, равное 3%. Поскольку на пер-
вом интервале ошибка по-прежнему отсутствует, выход-
ной сигнал и переменная процесса остаются равными
нулю в течение текущего цикла. На следующей итера-
ции трехпроцентное ускорение проявляется полностью
в появлении ошибки. Обычный алгоритм PID коррек-
тирует эту ошибку, но на следующей итерации скорость
увеличиваются еще на 3%, создавая дополнительную
ошибку.
Обработка цифровых сигналов
Глава 18
481
Упреждающая поправка на ускорение добавляет член
к вычисленному значению выходного сигнала, исходя
из примененного ускорения, прежде чем это ускорение
приведет к появлению ошибки.
Другой пример упреждающей поправки — упрежда-
ющая поправка на скорость. Эта поправка улучшает
ответ переменной процесса на изменения контрольно-
го значения, будь то отдельные скачки или управляе-
мое ускорение.
При обычном управлении PID интеграл строится до
тех пор, пока его значение не становится в точности
равным значению, необходимому для поддержания
выходного сигнала на уровне контрольного значения с
учетом коэффициента I. Когда контрольное значение
изменяется и устройство управления пытается реагировать
на это, построенный интеграл сопротивляется изменению,
пытаясь сохранить старое контрольное значение до тех
пор, пока накопленные значения ошибок не настроят его
(интеграл) на новое контрольное значение.
Предупредительное уменьшение интегрального ко-
эффициента может улучшить ответ процесса на изме-
нения контрольного значения. Однако, если вместо
коэффициента I нс используется никакой другой коэф-
фициент, он будет увеличивать время, требующееся для
установления значения переменной процесса.
Упреждающая поправка на скорость замещает часть
коэффициента I. Она вычисляется путем умножения
самого контрольного значения на некоторый множи-
тель. Подобно упреждающей поправке на трение, эта
поправка применяется к новому контрольному значе-
нию при выполнении изменения для предвосхищения
и попытки исключения будущей ошибки.
График на рис. 18.12 — это результат выполнения
сценария acceIZ.pid. В этом сценарии используется то
же самое значение ускорения и конечное контрольное
значение, что и в сценарии accell.pid, но в нем добав-
лены упреждающие поправки на ускорение и скорость,
а интегральный коэффициент уменьшен для их компен-
сации.
На графике почти невозможно разглядеть штрихо-
вую линию переменной процесса, маскируемую сплош-
ной линией контрольного значения. При этом среднеквад-
ратичная ошибка, равная 1,69 в сценарии accell, снижается
приблизительно до 0,168 — почти на порядок!
Прочие модификации и
эксперименты с PID
Ни в одном из приведенных ранее примеров сценариев
не используется параметр упреждающей поправки на
трение — небольшое значение, добавляемое к очень
низким уровням значений переменной процесса для
компенсации запирания, — поскольку имитатор не под-
держивает эффекта запирания.
РИСУНОК 18.12. Профиль скорости движения при
использовании алгоритма управления с упреждающими
поправками.
Попробуйте изменять значения в различных файлах
сценариев и посмотрите, как такие изменения влияют
на результаты. Небольшие изменения, особенно в пара-
метре запаздывания, могут оказывать большое влияние.
Если вы используете текстовый редактор, который под-
держивает режим выделения и копирования столбцов,
и программу электронных таблиц, которая может вы-
черчивать графики, то сможете без труда просмотреть
получаемые результаты в графическом виде. Первона-
чально я использовал именно этот подход, но для со-
здания оригиналов графиков в этой книге использовал-
ся другой метод.
В состав материалов на Web-сайте "ДиаСофт” вклю-
чена программа script.c, которая использовалась в каче-
стве инструмента, помогающего в создании графиков.
Она считывает выходной файл, захваченный програм-
мой pidloop, и генерирует текстовый файл, содержащий
сценарий AutoCAD. Этот сценарий не полностью соот-
ветствует материалу, изложенному в этой книге, но он
помещен на Web-сайт "ДиаСофт" в качестве отправной
точки на тот случай, если у читателей имеется програм-
ма создания графиков, которая может выполнять такие
сценарии.
Специализированные процессоры
цифровых сигналов
Вычислительная часть любого приложения цифровой
обработки сигналов может быть запрограммирована на
стандартном языке С и выполнена на любой платформе,
которая имеет доступный стандартный компилятор С. Но
процессоры общего назначения, применяемые в настоль-
ных компьютерах, не обеспечивают максимальной произ-
водительности этих вычислений, в то время как тип про-
цессора, получивший название Digital Signal Processor
(процессор цифровых сигналов — DSP), делает это.
31 Зак. 265
Дополнительные тематические разделы
Часть III
482
Ниже описаны некоторые специализированные
свойства аппаратных средств DSP, которые делают их
в высшей степени эффективными при вычислениях,
связанных с цифровой обработкой сигналов. Однако не
все DSP обладают всеми описанными ниже свойствами.
Инструкция МАС
Инструкция MAC (Multiply Accumulate — накопление
произведений) — отличительное свойство DSP. Многие
алгоритмы обработки сигналов выполняют суммирова-
ние вычисленных произведений, подобно вычислению
нового значения выходного сигнала в программе pidloop.
В обычном процессоре для каждого такого шага потре-
бовались бы, по меньшей мере, две инструкции. Вна-
чале два члена, такие как значение и коэффициент, ум-
ножаются один на другой, а затем их произведение
добавляется к изменяющейся итоговой сумме. DSP име-
ет инструкцию МАС, которая на одном этапе перемно-
жает два значения и добавляет их произведение к акку-
мулятору.
Суммирование квадратов
Накопление текущей суммы квадратов значений — еще
одна распространенная технология кода DSP, как это
имеет место в вычислении среднеквадратичной ошиб-
ки в программе pidloop. Многие DSP имеют единствен-
ную инструкцию, которая за одно действие получает
квадрат значения и добавляет или вычитает его из зна-
чения аккумулятора.
Индексация массивов
Часто процессоры DSP работают с большими массива-
ми выборочных совокупностей данных — как одномер-
ными, так и двумерными. Часто им требуется обращать-
ся к элементам в определенном, непоследовательном
порядке. Например, к массиву выборки из 1024 элемен-
тов может требоваться доступ в следующем порядке:
элемент 0, элемент 512, элемент 1, элемент 513 и т.д.
Многие DSP имеют для этого специальные аппаратные
функции индексирования. Специальные регистры заб-
лаговременно загружаются значениями приращения для
индексирования, и после каждого использования задан-
ное значение добавляется к индексу.
Кольцевые буферы
Часто DSP работают с потоками данных, которые, по
крайней мере, временно хранятся в кольцевых буферах
памяти. В обычном языке С для реализации кольцево-
го движения индекс нужно было бы увеличивать, затем
проверять его на предмет достижения конца массива, а
затем снова сбрасывать в нулевое значение и т.д. Мно-
гие DSP имеют специальные аппаратные функции для
обработки этого закольцовывания на аппаратном уровне.
Арифметические операции с насыщением
Во многих приложениях большой массив данных нуж-
дается в изменении путем умножения, деления, сложе-
ния или вычитания одного и того же значения для каж-
дого элемента. Если значения принадлежат к одному из
типов целых значений со знаком, переполнение или
отрицательное переполнение приводит к неопределен-
ному поведению. Если значения имеют тип целого без
знака, поведение вполне определено, но оказывается не
таким, как требуется. Во всех этих случаях желательно,
чтобы при переполнении результату присваивалось
минимальное или максимальное значение. В обычных
процессорах это должно выполняться программой, но
многие DSP имеют специальные инструкции выполне-
ния арифметических операций с насыщением, которые
решают эту задачу на аппаратном уровне.
Циклы переполнения нуля
Зачастую вычисления DSP сопряжены с циклической
обработкой больших массивов данных. Благодаря спе-
циальным вычислительным инструкциям подобные
циклы часто состоят из единственной инструкции, та-
кой как МАС. Многие DSP имеют специальный регистр
циклов. Когда инструкция загружает значение в этот
регистр, следующая инструкция при условии, что она
является повторяемой, повторяется нужное количество
раз с максимальной скоростью.
Множество адресных областей и шин данных
В обычных процессорах, подобных Pentium или Power
PC, существует только одна шина данных. Все инструк-
ции и данные поступают в процессор по ней. В то же
время DSP часто имеют две или три отдельные шины
данных, например, одну для области памяти кода для
загрузки инструкций и две — для области памяти дан-
ных для одновременной загрузки операндов.
Большие внутренние области памяти
DSP используют те же достижения в технологии полу-
проводников, что и обычные процессоры, в том числе
чипы памяти большой емкости. Вместо того чтобы ис-
пользовать подобную память в качестве кэша, DSP ис-
пользуют ее в качестве фиксированной памяти, содер-
жащей код и данные для обеспечения максимально
быстрого выполнения.
Почему в настольном компьютере не
используется DSP
При выполнении определенных типов вычислений про-
цессоры DSP обладают гораздо более высокой произво-
дительностью, чем обычные процессоры типа Pentium
или Power PC. В связи с этим может возникнуть вопрос,
Обработка цифровых сигналов
Глава 18
483
почему они не используются в настольных компьюте-
рах? Дело в том, что их оптимизация для ряда случаев
применения ведет к повышению стоимости. Транзисто-
ры, используемые для реализации функций DSP, не
обеспечивают многие общие функции, требующиеся
настольным операционным системам и приложениям.
Ограничения многозадачности
Современные процессоры обладают такими аппаратны-
ми функциями, как аппаратные менеджеры памяти, под-
держивающие виртуальную память и защиту памяти для
выполнения нескольких задач и потоков. DSP не имеют
такого аппаратного обеспечения и вообще не очень под-
ходят для обеспечения режима многозадачности.
Ограниченные типы данных
Как правило, DSP имеют единственный тип для пред-
ставления действительных чисел — тип с фиксирован-
ной или плавающей точкой. В 32-разрядных DSP этим
типом, как правило, является 32-разрядный тип, ана-
логичный типу одинарной точности IEEE 754, который
в большинстве современных процессоров используется
в качестве типа с плавающей точкой реализациями язы-
ка С. В некоторых случаях действительный тип несов-
местим с IEEE и требует преобразования к типу IEEE.
Большинство процессоров DSP не поддерживают более
длинный тип с плавающей точкой и фактически не от-
вечают требованиям стандартных типов double и long
double языка С.
Ограниченный доступ к памяти
Большинство DSP адресуют ячейки памяти только од-
ного размера. 32-разрядный DSP имеет 32-разрядные
регистры и считывает, записывает и работает с 32-раз-
рядными словами. В нескольких наиболее распростра-
ненных семействах 32-разрядных DSP типы char, short,
int и long являются 32-разрядными значениями, опре-
деляемыми в одних и тех же диапазонах, а байт в С
также содержит 32 бита. Если для экономии места в 32-
разрядном слове сохранить четыре символа, DSP при-
шлось бы считывать слово и выполнять побитовые опе-
рации для изменения значения одного символа в строке.
Отсутствующие инструкции
Несмотря на высокую производительность вычислитель-
*ных функций DSP, в них отсутствуют некоторые аппа-
ратные инструкции, необходимые для эффективной
трансляции многих часто выполняемых программных
задач. Например, в большинстве DSP отсутствует инст-
рукция деления. Деление должно выполняться подпрог-
раммой на программном уровне.
Расширения DSP в процессорах общего
назначения
Несмотря на то что DSP не подошли бы для запуска
современных настольных операционных систем, подоб-
ных Windows или Linux, и их приложений, некоторые
из их функций находят применение в более распрост-
раненных процессорах.
Вероятно, наиболее известными примерами могут
служить расширения ММХ и SIMD компании Intel для
последних процессоров семейства Pentium. Возможно,
менее известны инструкции AltiVec компании Motorola,
включенные в процессоры Power PC. Все эти инструк-
ции основываются на операциях типа SIMD (Single
Instruction, Multiple Data — один поток инструкций,
множество потоков данных), в которых специальный
регистр содержит до четырех значений типа целого или
типа с плавающей точкой одинарной точности, и одна
инструкция выполняет одну и ту же операцию со все-
ми четырьмя значениями одновременно. Все эти инст-
рукции используют такие особенности DSP, как выпол-
нение арифметических операций с насыщением, и
повышают производительность компьютера при выпол-
нении таких аудиовизуальных задач, как проигрывание
фильмов DVD или музыки MP3, и других приложений.
Процессоры для встроенных приложений управления
также не являются исключением. Во многих встроенных
системах для выполнения их задач используются обыч-
ные процессоры и либо DSP, либо специализированное
оборудование, т.е. они используют преимущество интег-
рации функций DSP в главный процессор.
е Один из членов семейства контроллеров серии
MCS96 производства компании Intel, часто используе-
мый во встроенных автоматических приложениях, име-
ет дополнительный 32-разрядный аккумулятор и спе-
циальные новые инструкции для его применения.
Та же технология, которая позволяет настольным
процессорам параллельно выполнять несколько опера-
ций с целыми значениями и значениями с плавающей
точкой, позволяет новейшим процессорам, предназна-
ченным для применения во встроенных системах, на
одном чипе совмещать все функции DSP с функциями
стандартного процессора.
Резюме
В этой главе были исследованы некоторые концепции
цифровой обработки сигналов с точки зрения програм-
мирования на С, а не с точки зрения математики. Рас-
смотрены примеры, с которыми каждый С-программист
встречается при использовании компьютера. При вы-
полнении загрузки с жесткого диска, выходе в Internet
и открытии Web-сраницы, содержащей всего одно гра-
Дополнительные тематические разделы
484
Часть III
фическое изображение, компьютер осуществляет управ-
ление PID для выполнения операций с жестким диском,
выявления и исправления ошибок в переданных и при-
нятых данных и распаковки данных для воспроизведе-
ния графического изображения.
Язык С предоставляет все инструментальные сред-
ства и функции, необходимые для выполнения любой
задачи обработки сигналов — от операций логического
И побитового сдвига низкого уровня, используемых при
сжатии и обработке ошибок, до сложных вычислений
с плавающей точкой в таких приложениях, как алгорит-
мы управления PID.
И в заключение был рассмотрен специализирован-
ный процессор цифровых сигналов, для чего большин-
ство программистов на С не создают программы непосред-
ственно. Вы узнали, чем такой процессор отличается от
более знакомых процессоров настольных компьютеров.
Было показано, как ценой снижения общей производи-
тельности большинства других операций, используемых
в программах более общего назначения, компромиссы
в конструкции процессора DSP способствуют повыше-
нию производительности при выполнении некоторых
специализированных вычислений в процессе обработ-
ки сигналов.
Синтаксический анализ и
вычисление выражений
В ЭТОЙ ГЛАВЕ
Постановка задачи
Формулировка решения
Польская нотация
Преобразование из обычной формы в форму
обратной польской нотации
Преобразование из формы польской нотации
в оценочную функцию
Синтаксический анализ ошибочного ввода
При написании программ на языке С мы формируем
некоторые выражения, которые должны подчиняться
определенным правилам, для того чтобы их можно
было понять. Тс выражения, которые не соответствуют
этим правилам, считаются ошибочными и не являются
частью языка С. Об этом, например, свидетельствуют
сообщения компилятора С об ошибках, и в таких слу-
чаях требуется изменить ошибочные операторы.
В этой главе будут рассмотрены вопросы написания
выражений, т.е. их синтаксическая нотация (запись). Вы
узнаете, каким образом можно написать транслятор, ко-
торый читает синтаксическое определение, после чего
выполняет синтаксический анализ ввода согласно этому
определению. Это код, который приводит введенный
текст в соответствие установленным правилам и выда-
ет сообщения, когда такое соответствие отсутствует.
В программе на языке С могут встретиться операто-
ры, содержащие следующие выражения:
х+=х*д* ((р[О] *д+р[1]) *д+р[2] ]) /
( ( (q[0] *g+q(l] ) *g+q(2] ) *g+q[3] ) ;
или
ps (L3]=ps [L3]«l I ps[L4]»15;
или
sexp=lexp<SHRT_MIN?SHRT_MIN: lexp<SHRT_MAX? (short) lexp:
^SHRT_MAX;
которые должны оцениваться в строго определенном
порядке. Правила, задающие этот порядок, позволяют
понять эти выражения независимо от того, насколько
неясными они кажутся на первый взгляд. Правила для
синтаксического анализа таких выражений являются
частью спецификации языка С и включают в себя пра-
вила синтаксиса (т.е. то, что можно написать) и прави-
ла семантики (т.е. смысл написанного).
Ян Келли
Итак, чтобы написать какое-либо выражение, необ-
ходимо применить указанные выше правила, чтобы
получить эти выражения в правильной форме. Если же
выражение не согласуется с правилами, то оно оказы-
вается недопустимым и не может быть использовано.
Однако существует огромное число допустимых выра-
жений, которые, тем не менее, необходимо разгадать и
понять их смысл.
Постановка задачи
Давайте попробуем создать часть компилятора. Это
простой синтаксический анализатор выражений, кото-
рый будет выбирать в качестве входных данных неко-
торый текст, основываясь на том предположении, что
это — выражение. А в качестве выходного результата он
будет выводить следующее:
• Описание формы выражения (его синтаксиса) либо
сообщения об ошибке
• Фрагмент кода, который, будучи встроенным в под-
ходящую программную среду, позволит вычислить
это выражение.
Кроме того, к обработке ошибок, согласованию во
времени и точности выполняемых операций синтакси-
ческого анализа предъявляются следующие требования:
• Обработка ошибок. Здесь придется бороться с по-
пыткой ввода недопустимых выражений (т.е. пред-
ставленных в неправильной форме) и формировать
осмысленные сообщения об ошибках. Компилятор,
который просто указывает на оператор, содержащий
ошибку, и выдает невразумительное или бесполез-
ное сообщение, вряд ли вообще уместен.
• Согласование во времени. Синтаксический анализатор
и генератор кода должны выполнять свою задачу в
486
Дополнительные тематические разделы
Часть III
течение приемлемого времени. По мере увеличения
длины выражений нагрузка на компиляторы возра-
стает. Однако время, которое требуется компилято-
ру для обработки выражений, не должно возрастать
вместе с увеличением длины выражения по экспо-
ненциальному закону (что в действительности про-
исходило в некоторых первоначальных вариантах
компиляторов). В идеальном случае компиляция
второго выражения, которое в 2 раза длиннее пер-
вого, не должна превышать по времени компиляцию
первого выражения более чем в 2 раза, поскольку
согласование этого процесса во времени должно по
возможности подчиняться линейному закону.
• Точность. Несмотря на то что обнаруживать ошиб-
ки необходимо, это отнюдь не означает, что пра-
вильные выражения требуется отмечать как непра-
вильные или неправильные выражения как
правильные. На самом деле требуется создать код
для вычисления выражения, который соответствовал
бы настоящему смыслу этого выражения. Ведь код,
который всегда дает результат 42, вряд ли принесет
большую пользу.
После того как будет получен код для обработки
выражений, станут более понятны способы написания
отдельных частей компиляторов, а также причины, по
которым иногда код компилируется довольно долго, а
сообщения компиляторов об ошибках оказываются со-
вершенно неясными и иногда просто раздражают.
Формулировка решения
Прежде всего необходимо рассмотреть правила, которые
описывают синтаксис (т.е. то, что можно написать) и
процесс синтаксического анализа (т.е. выяснение смыс-
ла написанного).
Синтаксическая нотация
В рамках определения языка С, будь то стандарт ANSI
или полное определение этого языка по Кернигану и
Ричи (K&R), имеются правила, которые описывают
синтаксис, а также смысловые описания различных
правил. Правила синтаксиса написаны в формальной
нотации. Например:
выра жен ие-умножения:
выражение-приведения -т иное
выражение-умножения * * выражение-приведения-типов
выражение-умножения / выражение-приведения-типов
выражение-умножения % выражение-приведения-типов
выражение-сложения:
выражение-умножения
выражение-сложения + выражение-умножения
выражение-сложения — выражение-умножения
На обычном языке бинарный оператор ♦ означает
умножение, бинарный оператор / означает получение
частного, а бинарный оператор % — получение остат-
ка от деления первого операнда на второй; если второй
операнд равен 0, тогда результат не определен.
Такая нотация (запись) нередко называется нор-
мальной формой или формой Бэкуса-Наура (БНФ —
Backus-Naur Form). Она впервые была использована при
описании языка Algol 60. БНФ допускает несколько
различных способов записи, однако далее в этой главе
будет использована нотация, несколько отличающаяся
от той, какая используется в определении K&R.
Каждое правило синтаксиса имеет свое имя (пате).
Оно записывается в первой строке с последующим дво-
еточием. В каждой последующей строке указывается
альтернатива (alternate). Каждая альтернатива состоит
из последовательности элементов, которые, в свою оче-
редь, являются либо символьной строкой (это означа-
ет, что каждый символ должен присутствовать в анали-
зируемом элементе), либо именем (это означает, что во
входных данных должно присутствовать некое описа-
ние анализируемого элемента). Имена всегда выделяют-
ся курсивом.
Иногда рядом с именем располагается нижний ин-
декс . Этот индекс означает, что данный элемент яв-
°Р*
ляется необязательным. Он появляется один раз либо
вообще отсутствует.
Иногда возникает так много альтернатив, что все они
записываются в одной строке, причем после имени и
двоеточия следует фраза one of (одно из). Ниже приве-
дены некоторые примеры правил из определения K&R:
parameter-declaration:
declaration-specifiers declarator
declaration -specifiers abstract-declarator^
unary-operator: one of
type-specifier: one of
void char short int long float double signed
unsigned struct-or-union-specifier enum-specifier typedef-
name
Как можно заметить, иногда (в частности, в приве-
денном выше определении type-specifier (описатель типа))
такая запись позволяет разделить одну строку на две
или более строки, причем это отнюдь не означает пре-
доставление какой-либо альтернативы.
Итак, можно сказать, что эта запись означает следу-
ющее.
• Каждый элемент, выделенный курсивом, представля-
ет в данном синтаксисе что-то еще.
• Каждый элемент представляет в чистом виде само-
го себя.
487
• Альтернативы представлены таким образом, что они
либо размещаются в отдельных строках, либо для
этого используется фраза one of которая размещает-
ся после узлового имени.
• Нижний индекс opt означает, что данный элемент яв-
ляется необязательным.
О понимании синтаксиса
Один из способов, позволяющих понять выражение,
состоит в том, чтобы взять копию определения K&R и
построить с ее помощью синтаксическую диаграмму
выражения. Если начать анализ с выражения
Ь * с2 + xyz
то можно было бы рассуждать следующим образом. Это
выражение состоит из пяти отдельных обозначений:
трех идентификаторов Ь, с2 и xyz, а также двух бинар-
ных арифметических операторов: * и +. При этом зна-
чение b умножается на значение с2, а произведение этих
значений складывается со значением xyz.
В этом рассуждении использовалось следующее:
• Лексические правила, позволяющие распознавать,
например, Ь, с2 и xyz в качестве идентификаторов,
а * и + — в качестве операторов
• Правила семантики, позволяющие интерпретировать
+ в качестве оператора сложения, а * в качестве опе-
ратора умножения.
• Правила старшинства, позволяющие полагать, что
операция умножения связывает операнды друг с дру-
гом “теснее*’, чем операция сложения, и поэтому она
выполняется прежде сложения.
Все эти правила должны быть реализованы в разра-
батываемом нами коде. Для этого нужно рассмотреть,
каким образом правила каждой из упомянутых выше
категорий могут быть представлены и затем реализова-
ны в коде.
Правила синтаксиса
Правила синтаксиса получаются довольно длинными.
Автору этих строк удалось составить подмножество пра-
Синтаксический анализ и вычисление выражений
Глава 19
вил для языка С. Это подмножество не содержит выра-
жений присваивания или перечислимых констант и
позволяет использовать весьма ограниченный набор
типов имен в выражениях приведения типов. В них так-
же имеются ограничения на типы целочисленных кон-
стант и опущен оператор поразрядного отрицания. Тем
не менее, они содержат все основные элементы выра-
жения на С. Именно это подмножество правил будет
использовано при написании примера кода, рассматри-
ваемого в этой главе.
Синтаксическое обозначение, использованное в
этом подмножестве правил, оказывается более компак-
тным, чем описанное выше обозначение БНФ, приме-
няемое в официальном определении (K&R) данного
языка. В этом обозначении альтернативы разделяются
вертикальной чертой (|), а не размещаются в отдельных
строках. Определяемое имя отделяется от своего опре-
деления двумя двоеточиями и знаком равенства (::=), а
не одним лишь двоеточием, причем каждое правило
завершается знаком диеза (#). Выделенные курсивом
слова обозначают имена синтаксических классов, а взя-
тые в кавычки (а иногда и специально выделенные по-
лужирным шрифтом) символы представляют собствен-
но символы (называемые также терминальными символами
(terminal characters)). Нижний индекс (означающий
необязательный элемент) в данном случае не использу-
ется, а вместо него применяется обозначение empty (пу-
стой элемент). В данном представлении синтаксиса вы-
ражений были реализованы некоторые рекомендации
по реализации из параграфа А13 определения K&R.
Читателю придется привыкнуть к синтаксису, выра-
жаемому в разных формах записи БНФ. В любой из этих
форм нет ничего таинственного, однако все формы дол-
жны непременно выражать ссылки на другие описания
синтаксиса, терминальные символы и альтернативы.
Между прочим, применяемая здесь компактная форма
БНФ оказывается намного ближе к первоначальной
форме, использовавшейся в отчете по языку Algol 60
(Algol 60 Report), так что для ее применения имеется
хорошее историческое обоснование:
empty ::= #
primary-expression identifier | constant | ( expression ) #
identifier ::= letter identifier-tail it
identifier-tail ::= letter identifier-tail | digit identifier-tail | identifier-tail | empty it
constant::— integer-constant | character-constant | floating-constant it
character-constant ::— "L" small-character-constant | small-character-constant it
small-character-constant single-character"" | ""'escaped-character"" it
digit ::= "0" | “Г | “2" | “3" | “4“ | “5“ | "6“ | *7“ | “8“ | "9" it
octal-digit ::= "0“ | “1" | “2" | “3“ | “4“ | “5" | "6" | ”7” it
optional-octal-digit::~ octal-digit | empty it
488
Дополнительные тематические разделы
Часть III
hex-digitdigit | upper-hex-digit | lower-hex-digit |
upper-hex-digit ::= "А” | "В” | "С" | "D” | "Е“ | "F’ #
lower-hex-digit ::= V | "Ь" | "с" | ”<Г | "е" | Г #
escaped-character ::= "\" escape-sequence #
escape-sequence ::= ”iT | "t" | V | V | V | ’’(Г | V | и\" | "?" | | octal-digit
optional-octal-digit optional-octal-digit | "х" hex-digit hex-digit it
integer-constantdigit integer-constant | digit #
floating-constant ::= integer-part fraction-part E-part exponent F-part it
integer-part integer-constant | empty it
fraction-part ::= point integer-part | empty it
point ::= It
E-part"e” | "E" | empty it
F-part T | F* | T | ”L" | empty it
exponentoptional-sign integer-constant | empty it
optional-sign "+" | | empty it
postfix-expression primary-expression | postfix-expression "++" \ postfix-expression " #
unary-expression postfix-expression | "++" unary-expression | unary-expression | unary-operator cast-expression it
unary-operator ::= | 7" it
cast-expression ::= unary-expression it
multiplicative-expression cast-expression | multiplicative-expression cast-expression | multiplicative-expression ”/" cast-
expression | multiplicative-expression "%" cast-expression it
additive-expression ::= multiplicative-expression | additive-expression "+" multiplicative-expression | additive-expression
multiplicative-expression it
shift-expression ::= additive-expression | shift-expression "«" additive-expression | shift-expression "»" additive-expression it
relational-expression shift-expression | relational-expression "<" shift-expression | relational-expression ">"shift-expression |
relational-expression "<=" shift-expression | relational-express ion ">=" shift-expression it
equality-expression relational-expression | equality-expression "B” relational-expression | equality-expression '^"relational-
expression it
AND-expression equality-expression | AND-expression "<&" equality-expression it
exclusive-OR-expression AND-expression | exclusive-OR-expression ""'AND-expression it
inclusive-OR-expression exclusive-OR-expression | inclusive-OR-expression "\" exclusive-OR-expression it
logical-AND-expression ::= inclusive-OR-expression | logical-AND-expression "&&" inclusive-OR-expression it
logical-OR-expression logical-AND-expression | logical-OR-expression "\\"logical-AND-expression it
expression logical-OR-expression it
Класс single-character (одиночный символ) формально
не определен. Он включает любом одиночный печатае-
мый символ, отличный от одинарных кавычек, двойных
кавычек, вопросительного знака или обратной косой
черты. К подобным символам относятся все прописные
и строчные буквы, цифры, а также знаки , . it $ | % Л &
* 0 @ I ~ # , - <> и / (косая черта).
В контексте рассматриваемого кода не допускаются нео-
тображаемые символы в коде ASCII, для которых не
предусмотрены явные управляющие последовательно-
сти, хотя некоторые компиляторы и допускают их на-
личие в строках либо выраженными в виде символьных
констант.
Класс letter (буква) также формально не определен,
однако он означает любую прописную и строчную букву
от а до z или от А до Z.
Следует также заметить, что по крайней мере син-
таксические классы expression (выражение), cast expression-
expression (выражение приведения типов), unary operator
(унарный оператор), postfix-expression (постфиксное выра-
жение), type-name (имя типа) и constant (константа) в
рассматриваемом синтаксисе отличаются от официаль-
Синтаксический анализ и вычисление выражений
Глава 19
489
ных определений С, которые оказываются более обшир-
ными, и если бы они использовались, то соответствующий
код получился бы намного длиннее. Расширение такого
кода до полных определений не вызывает особых затруд-
нений, однако ограниченный объем настоящей книги не
позволяет этого сделать. Кроме того, класс identifier (иден-
тификатор) не может начинаться с символа подчерки-
вания. Он должен начинаться с буквы. Кроме того, из
этого синтаксиса удалены массивы и указатели.
Такой (сокращенный) синтаксис также предполага-
ет предварительное удаление всех лишних пробелов из
анализируемого текста таким образом, чтобы он не со-
держал символов пробела, новой строки, табуляции,
перевода формата или комментариев.
Синтаксический анализ (без рассмотрения ошибок)
Во время анализа строки символов, которая, как пред-
полагается, может оказаться выражением, необходимо
иметь возможность разделить ее на подстроки, чтобы
было ясно, где идентификатор, где выражение сложе-
ния и т.д. В качестве примера рассмотрим следующее
выражение:
b*c2+xyz
Если пронумеровать каждый из этих символов сле-
дующим образом:
О b
1
2 с
3 2
4 +
5 х
6 у
7 z
то в процессе синтаксического анализа получилась бы
информация, приведенная в табл. 19.1.
Таблица 19.1. Простая таблица синтаксического анализа.
Номер по порядку Элемент синтаксиса Русская транскрипция Начальный Конечный Начало Конец синтаксиса
символ символ синтаксиса
1 Identifier идентификатор 0 0 0 0
2 Identifier идентификатор 2 3 0 0
3 Identifier идентификатор 5 7 0 0
4 Primary-expression основное выражение 0 0 1 1
5 Primary-expression основное выражение 2 3 2 2
6 Pri mary-expression основное выражение 5 7 3 3
7 Postfix-expression постфиксное выражение 0 0 4 4
8 Postfix-expression постфиксное выражение 2 3 5 5
9 Postfix-expression постфиксное выражение 5 7 6 6
10 Unary-expression унарное выражение 0 0 7 7
11 Unary-expression унарное выражение 2 3 8 8
12 unary-expression унарное выражение 5 7 9 9
13 cast-expression выражение приведения типов 0 0 10 10
14 cast-expression выражение приведения типов 2 3 11 11
15 cast-expression выражение приведения типов 5 7 12 12
16 multiplicative-expression выражение умножения 0 0 13 13
17 multiplicative-expression выражение умножения 0 3 16 14
18 multiplicative-expression выражение умножения 5 7 15 15
19 additive-expression выражение сложения 0 3 17 17
20 additive-expression выражение сложения 0 7 19 18
21 shift-expression выражение сдвига 0 7 20 20
22 relational-expression выражение отношения 0 7 21 21
23 equality-expression выражение равенства 0 7 22 22
24 AND-expression выражение И 0 7 23 23
25 exclusive-OR-expression выражение исключающего ИЛИ 0 7 24 24
26 inclusive-OR-expression выражение включающего ИЛИ 0 7 25 25
27 logical-AND-expression выражение логического умножения 0 7 26 26
28 logical-OR-expression выражение логического сложения 0 7 27 27
29 expression выражение 0 7 28 28
490
Дополнительные тематические разделы
Часть III
На рис. 19.1 представлена диаграмма синтаксичес-
кого анализа. Подобные диаграммы могут быть также
нарисованы в виде древовидных структур (рис. 19.2).
Оба указанных рисунка служат графическим представ-
лением табл. 19.1.
Несмотря на то что дерево, приведенное на рис. 19.2,
оказывается намного проще для понимания, чем при-
веденная выше таблица, тем не менее в рассматривае-
мом здесь примере кода предпочтение будет отдавать-
ся получению именно подобной таблицы.
b 1 4 7 10 13 16
17 19
с_2 _5 _8 _11_14_
2.
20 21 22 23 и т.д.
РИСУНОК 19.1. Синтаксис выражения.
х /
у 3 6 9 12 15 18
z.
РИСУНОК 192.
Простое дерево
синтаксического анализа.
Методы синтаксического анализа
Существует несколько следующих методов синтаксичес-
кого анализа:
• нисходящий синтаксический анализ, выполняемый ме-
тодом рекурсивного спуска (top-down recursive descent),
• метод столкновения изолированных участков (island
collision),
• метод LALR,
• метод простого предшествования (simple precedence)
и многие другие. Некоторые из указанных выше мето-
дов описаны в классической книге Principles of Compiler
Design ("Принципы проектирования компиляторов") Аль-
фреда В. Ахо (Alfred V. Aho) и Джеффри Д. Улльмана
(Jeffry D. Ullman), выпущенной в 1977 году в изда-
тельстве Addison-Wesley. Рассматриваемый здесь метод
представляет собой модифицированный нисходящий
синтаксический анализ, выполняемый методом рекур-
сивного спуска с предварительным просмотром и на-
чальным лексическим анализом.
При восходящем синтаксическом анализе (bottom-up
parsing) просмотр начинается с наименьших частей син-
таксиса, т.е. тех частей, которые в большей степени
соответствуют входному тексту, а затем постепенно из
более простых структур создаются более сложные.
Примерно такой порядок анализа приведен в табл. 19.1.
В этом случае рассуждение начинается со следующего
предположения: "После этой буквы следует другая бук-
ва. Возможно, это идентификатор. Это идентификатор,
после которого следует знак умножения, а затем еще
один идентификатор, поэтому это может быть выраже-
ние”, и так рассуждение продвигается далее в направ-
лении "выражения", которое мы собственно и пытаем-
ся распознать. Если во входном тексте имеется ошибка
и он не соответствует возможному синтаксису, тогда
этот факт обнаруживается как можно ранее и обычно
расценивается как весьма близкий к ошибке в тексте.
При нисходящем синтаксическом анализе (top-down
parsing) просмотр начинается с той части синтаксиса,
которую требуется в конечном счете распознать (что и
является конечной целью анализа), а затем мы посте-
пенно переходим ниже в направлении отдельных сим-
волов текста. Иногда такой подход означает просмотр
всего входного текста только для того, чтобы обнару-
жить несоответствие, после чего приходится возвра-
щаться назад и выбирать другую альтернативу. Нисхо-
дящий синтаксический анализ может занять намного
больше времени, чем восходящий анализ, однако такие
синтаксические анализаторы намного проще написать.
Если в анализируемом тексте имеется ошибка, то уве-
ренности в этом не будет до тех пор, пока нс будут
испробованы все возможные варианты анализа, причем
зачастую нет ни малейшего намека на местонахождение
ошибки в операторе.
Можно воспользоваться преимуществом простоты
написания и избежать недостатка медленного выполне-
ния, введя в анализ два следующие свойства: лексичес-
кий анализ и предварительный просмотр. Лексический
анализ скорее подобен некоторому восходящему син-
таксическому анализу. При этом выбираются синтакси-
ческие классы и принимается решение о том, что они
настолько распространены и легко распознаваемы бе-
зотносительно к контексту, что имеет смысл проанали-
зировать прежде всего именно их. Это означает, что
поиск таких элементов, как идентификатор, осуществ-
ляется только один раз.
Когда в правиле синтаксиса имеется несколько аль-
тернатив, они могут быть опробованы в любом поряд-
ке. Наилучшим используемым порядком является тот,
при котором сначала опробуется наиболее длинная из
всех возможных альтернатив. Например, если анализи-
руется условное выражение (conditional-expression), тогда
имеет смысл выполнить предварительный поиск в тек-
сте вопросительного знака. Если таковой имеется, тог-
да следует опробовать сначала вторую альтернативу и
вернуться к первой альтернативе только в том случае,
если вторая не даст желаемого результата. Если же воп-
росительный знак отсутствует, тогда следует опробовать
491
сначала первую альтернативу, а если и она не даст же-
лаемого результата, тогда уже становится ясно, что оп-
робование второй альтернативы не имеет смысла.
К каждой альтернативе может быть добавлено две
разреженные таблицы типа "Должно содержать" и "С
чего может начинаться". В таблице "Должно содержать"
указывается, что именно следовало определить как
встретившееся в следующем тексте на предыдущих эта-
пах синтаксического или лексического анализа, если
данная конкретная альтернатива даст желаемый резуль-
тат. Таким образом, для второй альтернативы условно-
го выражения в таблице "Должно содержать" будет, по
крайней мере, указано, что в последующем тексте дол-
жны присутствовать символы "?" и
Таблица "С чего может начинаться" также представ-
ляет собой разреженный массив, причем в нем указы-
ваются тс символы и синтаксические классы, которые
могут встретиться в начале любой альтернативы. Это
означает, что альтернативу можно быстро обойти, если
первые несколько символов указывают на вероятность
того, что данная альтернатива не даст желаемого ре-
зультата. Таблица "С чего может начинаться" в равной
степени полезна и при восходящем синтаксическом
анализе. Она может быть создана автоматически из са-
мого синтаксиса так же, впрочем, как и таблица "Дол-
жно содержать". Соответствующий код находится в
файле СЫ9Раг2.с на Web-сайте "ДиаСофт".
Семантика
Реализуемая здесь семантика заключается просто в ге-
нерировании фрагмента кода для вычисления выраже-
ния, также написанного на С. Однако код на языке С
будет совершенно отличаться от исходного выражения
и эмулировать простой код ассемблера для воображае-
мого центрального процессора (ЦП). Описание языка
ассемблера для настоящего ЦП можно найти в книге
Assembly Language for the PC ("Язык ассемблера для ПК")
Джона Соча (John Socha) и Питера Нортона (Peter
Norton), которая позволит яснее понять, почему автор
этих строк выбрал именно такие, а не другие команды
этого языка. В рассматриваемом здесь воображаемом ЦП
имеется два аккумулятора (accumulator), в которые мож-
но загружать значения и из которых можно эти значе-
ния извлекать и выполнять над ними арифметические
операции. Кроме того, в этом ЦП имеется упрощенный
стек (stack), представляющий собой большой массив,
доступ к которому будет возможен только по элемен-
ту, индекс которого находится в индексном регистре. А
в качестве индексного регистра (index) служит простая
переменная типа int, начальное значение которой, как
известно, равно нулю.
Все остальные переменные относятся к типу double.
Операции, которые при этом допускается выполнять
Синтаксический анализ и вычисление выражений
Глава 19
перечислены в табл. 19.2 (некоторые из них отмечены
двойным вопросительным знаком как сомнительные).
Использование сомнительных операций приводит к
генерированию более короткого кода, хотя абсолютной
необходимости в этом нет. В конце вычисления требу-
ется, чтобы первый аккумулятор содержал полученное
значение, тогда как значение индексного регистра опять
должно быть равно нулю.
В качестве примера применения только указанных
выше операций рассмотрим вычисление следующего
выражения:
Ь * с2 + xyz
которое в итоге даст следующий код:
А1 = Ь;
А2 = с2;
Al = А1 * А2;
А2 = xyz;
Al = Al + А2;
Для вычисления более сложного выражения, воз-
можно, потребуется стек. Например, для вычисления
выражения
(а * Ь + с * d) / (е + f)
потребуется следующий код:
А1 = а;
А2 « Ь;
Al = А1 * А2;
stack[index++] = Al;
Al = с;
A2 = d;
Al = Al * A2;
A2 = stack[index—];
Al = Al + A2;
stack[index++] - Al;
Al = e;
A2 = f;
Al = Al + A2;
stack[index++l = Al;[sr]
A2 = stack[index—];[sr]
Al = stack[index—];[sr]
Al = Al / A2;[sr]
Для вычисления других выражений, возможно, по-
требуется применение методов и команд перехода. Так,
выражение
(a>b) ? с + d : е * f
может быть представлено в виде следующего кода:
А1 = е;
А2 = f;
Al = Al * а2;
stack[index++] = Al;
Al = c;
Дополнительные тематические разделы
492
Часть III
А2 - d;
Al = Al + A2;
stack[index++] = Al;
Al = a;
A2 = b;
if (A1>A2) goto LI;
Al « stack[index—];
A2 = stack[index—);
goto L2:
LI:
A2 = stack[index—];
Al - stack[index—];
L2:
Правила старшинства и порядок
вычисления
Примеры выражений, результаты трансляции которых
приведены выше, ясно показывают, что операции в дан-
ном случае должны выполняться в совершенно ином
порядке, чем это указано в исходном выражении. Этот
порядок зависит от правил старшинства, применяемых
в языке С, а также от тех операций, которые могут вы-
полняться в окончательном варианте ЦП (в данном слу-
чае в воображаемом процессоре).
Определенный порядок вычислений совершенно
естественно возникает в результате анализа синтаксиса.
Способ написания синтаксиса позволяет группировать
вместе те элементы, которые теснее связаны друг с дру-
гом. Порядок вычисления операций одной и той же
степени связности (операндов) устанавливается в соот-
ветствии с таблицей порядка старшинства операций,
приведенной на с. 53 второго издания книги K&R. Из
этой таблицы следует, например, что операторы умно-
жения вычисляются слева направо, а оператор условия
?: — справа налево.
Чтобы придать всему этому какой-то смысл, нередко
используется так называемая польская нотация (Polish
notation), которая рассматривается в следующем разделе.
Польская нотация
Польская нотация (или форма записи) означает напи-
сание арифметических выражений без всяких скобок.
Если исследовать операции, возможные в рассматрива-
емом здесь воображаемом процессоре, то можно заме-
тить, что в них (так же, впрочем, как и в операциях,
выполняемых реальным процессором) вообще отсут-
ствуют скобки.
Краткая историческая справка
Польский математик и логик Ян Лукашевич печатал в
1920 г. свою докторскую диссертацию на старой немец-
кой пишущей машинке, у которой было не две клави-
ши переключения регистра, а три: строчные буквы и
знаки препинания, прописные буквы, а также все скоб-
ки и другие специальные символы. Вместо того чтобы
Таблица 19.2. Операции, допустимые в воображаемом ЦП.
Операция Описание
label: Действие отсутствует — это лишь место для размещения метки goto
А1 = constant; А2 = constant; А1 = name; А2 - name; name = А1; лате = А2; Загрузить значение constant в аккумулятор 1 Загрузить значение constant в аккумулятор 2 Загрузить содержимое переменной лате в аккумулятор 1 Загрузить содержимое переменной лате в аккумулятор 2 (??) Сохранить содержимое аккумулятора 1 в переменной лате Сохранить содержимое аккумулятора 2 в переменной лате (??)
А1 = А2; А2 = А1; А1 = А1 op А2; Скопировать содержимое аккумулятора 2 в аккумулятор 1 (??) Скопировать содержимое аккумулятора 1 в аккумулятор 2 (??) Выполнить операцию ор над содержимым аккумуляторов 1 и 2, разместив результат в аккумуляторе 1 К допустимым операциям относятся следующие: +,-,*,/»%, |, & и "
А1 = op А1; Выполнить унарную операцию ор над содержимым аккумулятора 1. К допустимым операциям относятся следующие: — и !
А1 = stack[index--J; Извлечь верхний элемент стека и поместить его в аккумулятор 1
А2 = stack[index—]; stack[index++] = А1; stack[index++] = А2; goto label , if (A1 op A2) goto label Извлечь верхний элемент стека и поместить его в аккумулятор 2 Поместить в стек содержимое аккумулятора 1 Поместить в стек содержимое аккумулятора 2 (??) Передать управление по метке label Передать управление по метке label, если операция отношения ор дает истинный результат, Операциями отношения могут быть следующие: !=, >= <=, > и <
Синтаксический анализ и вычисление выражений
493
Глава 19
вынужденно использовать все три клавиши переключе-
ния регистра (старая, с грохотом работавшая пишущая
машинка часто заедала при переключении регистров),
Лукашевич изобрел запись, которая не требовала при-
менения скобок. Для этого обычная запись операнд опе-
ратор операнд была заменена на запись оператор операнд
операнд. Таким образом, обычная запись А + В превра-
тилась в запись + АВ.
Примеры обычной и обратной польской
нотации
В польской нотации довольно сложные выражения,
требующие многочисленных скобок в обычной форме
записи, сводятся к простым строкам, которые для не-
опытного глаза, однако, кажутся не столь уж просты-
ми. Так, выражение
(а * (с + d) + (е + f) * g) / (j + i)
в польской нотации превращается в следующее выраже-
ние:
/ + *a + cd* + efg + ji
Порядок записи оператор операнд операнд мог бы
быть в равной степени и следующим: операнд операнд
оператор. Это означает, что оператор может быть раз-
мещен и после операндов, а не перед ними. Это так
называемая обратная польская нотация (Reverse Polish
notation). Например, приведенное выше выражение в
обратной польской нотации будет выглядеть следую-
щим образом:
acd + * ef +g * + ji + /
I vwva wu wi.
Польская нотация иногда еще называется префиксной
нотацией, а обратная польская нотация — постфиксной
нотацией. Обычная же запись называется инфиксной
нотацией.
Преимущества польской нотации
Несмотря на то что обратная польская нотация отнюдь
не очевидна, она весьма близка к тому порядку, кото-
рый требуется для фактического вычисления выраже-
ний в рассматриваемом здесь воображаемом процессо-
ре. Так, выражение
а * Ь + с
превращается в обратной польской нотации в следую-
щее выражение:
а Ь * с +
Используя команды воображаемого процессора, это
выражение можно интерпретировать следующим обра-
зом:
Загрузить а в аккумулятор А1
Поместить в стек содержимое аккумулятора А1
Загрузить Ь в аккумулятор А1
Поместить в стек содержимое аккумулятора А1
Извлечь из стека и поместить в аккумулятор А2
Извлечь из стека и поместить в аккумулятор А1
Выполнить умножение
Поместить в стек содержимое аккумулятора А1
Загрузить с в аккумулятор А1
Поместить в стек содержимое аккумулятора А1
Извлечь из стека и поместить в аккумулятор А2
Извлечь из стека и поместить в аккумулятор А1
Выполнить сложение
В программном коде это будет выглядеть следующим
образом:
А1 = а;
s tack[index++] = Al;
Al = b;
stack[index++] = Al;
A2 = stack[index—];
Al = stack[index—];
Al = Al * A2;
stack[index++] = Al;
Al = c;
stack[index++] = Al;
A2 = stack[index—];
Al = stack[index—];
Al = Al + A2;
В данном случае использованы допустимые коман-
ды, которые не отмечены двойным вопросительным
знаком в табл. 19.2.
Преобразование из обычной формы в
форму обратной польской нотации
Обычная и обратная польская запись может быть полу-
чена в результате синтаксического анализа конкретно-
го выражения. Если нарисовать дерево этого анализа,
тогда его можно представить в виде воздушного шара
вокруг дерева, из которого медленно откачивается воз-
дух, в результате чего шар окутывает ствол, ветви, бо-
лее мелкие веточки и листья дерева (рис. 19.3).
РИСУНОК 193.
Обычная и обратная польская
запись может быть получена
в результате синтаксического
анализа.
Если последовать по контуру оболочки этого вооб-
ражаемого воздушного шара, то можно проследить все
дерево. При этом каждая точка, в которой имеется ветвь,
встретится неоднократно. Так, например, если начать
обход приведенного выше дерева с его вершины (кор-
ня) и направиться влево, то порядок, в котором будут
494
Дополнительные тематические разделы
Часть III
встречаться узлы дерева, окажется следующим: + * а *
Ь* + с +. Если записать в этой последовательности имя
узла, когда оно встретится в первый раз при перемеще-
нии к этому узлу вниз по дереву (например, +*abc),
тогда получится обычная польская запись. Если же за-
писать имя этого узла, когда оно встретится в последний
раз при перемещении от этого узла вверх по дереву,
тогда получится обратная польская запись: ab*c+. Эта
древовидная форма служит основанием для получения
обеих нотаций. Анализ обычной польской нотации по-
казывает, что ее можно было бы назвать порядком сле-
дования ’’потомков после предков”, тогда как в резуль-
тате анализа обратной польской нотации ее можно было
бы назвать порядком следования ’’предков после потом-
ков". У них имеются и следующие более формальные
названия: обход в прямом порядке и обход в обратном
порядке соответственно.
Такое описание оказывается вполне пригодным не-
зависимо от того, насколько сложным оказывается вы-
ражение или его анализ.
Упрощенный вариант
Рассматриваемый здесь механизм синтаксического ана-
лиза должен подразумевать следующее
• Чтение синтаксиса выражений, которые подлежат ’
синтаксическому анализу, и создание внутренних
структур, которые бы позволяли осуществить син-
таксический анализ.
• Выполнение синтаксического анализа выражения в
соответствии с тем синтаксисом, который дает при-
емлемый результат.
Одним из способов создания механизма синтакси-
ческого анализа является компиляция синтаксиса в про-
грамму. Недостаток такого.способа состоит в его негиб-
кости. Так, если в синтаксисе обнаружится ошибка, то
программа должна быть изменена. Здесь же применяется
способ, предполагающий чтение синтаксиса, а это озна-
чает, что еог можно без труда изменить, не прибегая к
соответствующей модификации программы. Более элеган-
тная реализация компилятора с записью синтаксиса в
коде приведена в книге Algorithms + Data Structures —
Programs ("Алгоритмы и структуры данных для создания
программ") Никлауса Вирта (Niklaus Wirth), выпущен-
ной в 1976 г. издательством Prentice Hall. В этой книге
приведен прекрасный пример написания программ,
ясно показывающий, почему синтаксис не должен на-
ходиться в самом коде!
Чтение синтаксиса
В коде, находящемся в файлах Chl9Pars.c и Chl9Pars.h
на Web-сайте "ДиаСофт”, предполагается, что синтак-
сис написан в соответствии со следующим правилами:
• Каждое определение синтаксиса состоит из одной
"строки” (завершающейся знаком диеза и символом
новой строки)
• Каждое определение синтаксиса начинается преж-
де всего с имени описываемого синтаксического
класса.
• Всякое следующее после имени определение синтак-
сиса состоит из одной или более альтернатив, при-
чем каждая альтернатива отделена от последующей
вертикальной чертой.
• Каждая альтернатива состоит из последовательнос-
ти элементов.
• Элемент представляет собой имя (т.е. имя некото-
рого синтаксического класса), символьную строку,
имя процедуры в круглых, фигурных или квадрат-
ных скобках.
• Каждый явный символ или символьная строка,
предполагаемые в анализируемых входных данных,
заключены в двойные кавычки с применением тех
же правил, которые используются в стандартной для
языка С нотации для обозначения обратной косой
черты, вопросительного знака, кавычек и т.д.
Такая нотация аналогична использованной в табл.
19.1, однако она получается еще более краткой.
В результате чтения синтаксиса создается ряд соот-
ветствующих структур. Каждое правило синтаксиса
позволяет получить структуру следующего вида:
• Указатели на значения NULL, обозначающие конец
цепочек. Кроме того, при чтении всего синтаксиса
просматриваются структуры для заполнения следу-
ющих таблиц:
• Таблица синтаксических имен. Каждому опреде-
лению синтаксиса (т.е. строке) из входного син-
таксиса в этой таблице соответствует одна пози-
ция. В каждой такой позиции записываются имя
синтаксической единицы и указатель на голов-
ной элемент, который определяет данную едини-
цу. В процессе построения таблицы используется
также ряд признаков (флагов). Индекс (номер стро-
ки) каждой позиции таблицы представляет собой
номер, который впоследствии используется для
обращения к данному определению синтаксиса.
Эта таблица состоит из MAX_SYNTAXJTEMS
элементов, где MAX SYNTAX ITEMS — это
максимальное число определений синтаксиса,
поддерживаемых данной программой.
• Таблица "Должно содержать”. В этой таблице вы-
деляется одна позиция для каждой альтернати-
Синтаксический анализ и вычисление выражений
Глава 19
495
вы синтаксиса. Длина каждой такой позиции
составляет 256 + MAX_SYNTAX_ITEMS эле-
ментов. Каждый элемент представляет собой
единственное значение типа char, которое равно
(двоичному) 0 или (символьному) значению Y.
При этом значение 0 свидетельствует о том, что
эта альтернатива не должна содержать данный
конкретный символ или синтаксическую едини-
цу, а значение Y указывает обратное. Если пер-
вые 256 элементов таблицы представляют симво-
лы, тогда остальные ее элементы представляют
синтаксические единицы.
• Таблица "С чего начинается”. В этой таблице вы-
деляется одна позиция для каждой альтернативы
синтаксиса и еще одна позиция — для каждого го-
ловного элемента синтаксиса. Длина каждой такой
позиции составляет 256 + MAXJSYNTAXJTEMS +
MAX_ALTERNATE_ITEMS элементов, где
MAX_ALTERNATE-ITEMS — это максималь-
Листинг 19.1. Чтение определения синтаксиса.
ное число поддерживаемых альтернатив во всех
правилах синтаксиса вместе взятых. Каждый эле-
мент представляет собой единственное значение
типа char, которое равно (двоичному) 0 или (сим-
вольному) значению Y. Как и в таблице 'Долж-
но содержать", в данном случае указанные выше
значения означают, что та или иная альтернати-
ва или головной элемент может или не может на-
чинаться с данного конкретного символа (для
первых 256 элементов таблицы) либо с синтак-
сической единицы (для остальных элементов таб-
лицы).
Код распределения и построения синтаксического
дерева (листинг 19.1) является зеркальным отображени-
ем кода, который освобождает это дерево. Это означа-
ет, что для каждой процедуры, которая размещает часть
синтаксического дерева, существует соответствующая
процедура, которая освобождает ту же самую часть этого
дерева.
linclude
linclude
linclude
linclude
<stdio.h>
<stdlib.h>
<string.h>
<ctype.h>
lifndef TRUE
Idefine TRUE 1
lendif
lifndef FALSE
Idefine FALSE 0
lendif
Idefine SYNTAXLINELIMIT 1024
Idefine MAXSYNTAXITEMS 128
Idefine MAXALTERNATEITEMS 1024
Idefine MAXROUTINENAMES 30
Idefine SYNTAXNAMELENGTH 32
Idefine ROUTINENAMELENGTH 16
Idefine PARSEBUFFERLENGTH 4096
struct sSyntaxHead;
struct sSyntaxAlt;
struct sSyntaxBody;
struct sSyntaxHead* SyntaxRoot;
struct sSyntaxHead {
char SyntaxName (SYNTAXNAMELENGTH+l];
struct sSyntaxHead* pNextHead;
struct sSyntaxHead* pPreviousHead;
struct sSyntaxAlt* FirstAlternate;
int iSyntaxNumber;
int iStartsWith;
int iMustContain;
int (*LexRoutine) ( void* );
int ilsLexical;
);
Дополнительные тематические разделы
496
Часть III
struct sSyntaxAlt {
struct sSyntaxBody* ThisBody;
struct sSyntaxAlt* NextAlt;
struct sSyntaxAlt* PreviousAlt;
struct sSyntaxBead* ParentBead;
int iSyntaxNumber;
int iAlternateNumber;
int iStartsWith;
int iMustContain;
struct sSyntaxBody {
struct sSyntaxBody* NextBody;
struct sSyntaxBody* PreviousBody;
struct sSyntaxAlt* ParentAlt;
struct sSyntaxBead* BodyBead;
char* Bodycontents;
int (*BodyCheck) ( void* );
int (*LexCheck) ( void* );
int (*CodeGenerate) ( void* );
int iSyntaxNumber;
int iAlternateNumber;
int iStartsWith;
int iMustContain;
int Readsyntax ( struct sSyntaxBead** pRoot )
{
extern char *_sys_errlist[ ];
int iStatus = TRUE;
fSyntaxFile = fopen ( sSyntaxFileName, "r" );
if (fSyntaxFile==NULL)
{
/* Ошибка: невозможно открыть файл синтаксиса */
iStatus = FALSE;
return iStatus;
while (Ifeof(fSyntaxFile))
{
iStatus - ProcessSyntaxLine ( );
if ( *pRoot «» NULL )
{
*pRoot = SyntaxTable[0].pSyntaxPointer;
fclose(fSyntaxFile);
return iStatus;
int FindSyntaxName ( char* SyntaxName )
{
int iReturn = 0;
int i;
int j;
j = iNextSyntax;
if (j>0)
{
for (i=0;((iReturn==0)&&(i<iNextSyntax));i++)
Синтаксический анализ и вычисление выражений
497
Глава 19
if (strcmp(SyntaxName,SyntaxTable[i].SyntaxName)==0)
{
iReturn = i;
1
}
}
if (iReturn==O)
{
iReturn = CreateSyntaxTableEntry ( SyntaxName );
}
return iReturn;
}
int CreateSyntaxTableEntry (char* pSyntaxName)
{
int iStatus;
strepy(SyntaxTable[iNextSyntax].SyntaxName,pSyntaxName);
SyntaxTable[iNextSyntax].pSyntaxPointer = NULL;
SyntaxTable[iNextSyntax].iMustContain = 0;
SyntaxTable[iNextSyntax].iStartsWith - 0;
iStatus = iNextSyntax;
iNextSyntax++;
return iStatus;
>
void FreeWholeSyntax ( void )
{
int i;
for (i=0; (KiNextSyntax); i++)
{
if ( SyntaxTable[i].pSyntaxPointer!=NULL )
{
FreeSyntaxHead ( SyntaxTable[i].pSyntaxPointer );
SyntaxTable[i].pSyntaxPointer = NULL;
}
}
return;
}
int GetSyntaxName ( char* SyntaxLine, int* j )
{
struct sSyntaxHead* pNewSyntaxHead;
char SyntaxName[SYNTAXNAMELENGTH+l];
int i;
int m;
int iMySyntaxNumber;
strepy(SyntaxName,;
m = 0;
for (i=0; (m==0); i++)
{
if (isidchar(SyntaxLine[i + *j]))
{
Sy ntaxName [ i ] = SyntaxLine[i + *j];
SyntaxName[i + 1] = '\0';
}
else
{
32 Зак. 265
498
Дополнительные тематические разделы
Часть III ~
m = i;
*3 += i;
}
}
iMySyntaxNumber = FindSyntaxName ( SyntaxName );
if (SyntaxTable[iMySyntaxNumber].pSyntaxPointer==NULL)
{
pNewSyntaxBead = malloc ( sizeof (struct sSyntaxHead) );
SyntaxTable[iMySyntaxNumber].pSyntaxPointer « pNewSyntaxBead;
strcpy (pNewSyntaxBead->SyntaxName , SyntaxName);
pNewSyntaxBead->iSyntaxNumber = iMySyntaxNumber;
pNewSyntaxEead->iStartsWith = 0;
pNewSyntaxBead->iMustContain = 0;
pNewSyntaxBead->FirstAl ternate = NULL;
pNewSyntaxBead->LexRoutine = NULL;
pNewSyntaxBead->iIsLexical = FALSE;
pNewSyntaxBead->pNextBead = NULL;
if (iMySyntaxNumber>0)
{
pNewSyntaxBead->pPreviousBead =
SyntaxTablef iMySyntaxNumber-1].pSyntaxPointer;
(SyntaxTable(iMySyntaxNumber-l].pSyntaxPointer)->pNextHead =
pNewSyntaxBead;
}
else
{
pNewSyntaxBead->pPreviousBead = NULL;
}
}
return iMySyntaxNumber;
int isidchar ( char testchar )
{
int iStatus;
if ((isalpha(testchar))||(isdigit(testchar)||(testchar=='-')))
iStatus = TRUE;
else
iStatus = FALSE;
return iStatus;
}
int Getldentifier ( char* InputBuffer, char* Identifier, int* j )
{
int iStatus = FALSE;
int i = 0;
while ((isidchar ( * (InputBuffer+*j))) && (i<ROUTINE_NAME_LENGTB))
{
Identifier[i++] = *(InputBuffer+*j);
iStatus = TRUE;
}
Identifier[ij = '\0';
return iStatus;
}
int GetLexName ( char* SyntaxLine, char* Identifier, int* j, int iMySyntaxNumber )
499
Синтаксический анализ и вычисление выражений
Глава 19
int iMyLexNumber = -1;
while (SyntaxLine[*j]==' '}
(*j)++?
if ((SyntaxLine[*jJ==r{') || (SyntaxLine!*j]=='(')
|| (SyntaxLine!*j]=='['))
{
(*j)++;
iMyLexNumber = Getldentifier ( SyntaxLine, Identifier, j );
while ((SyntaxLine[*j]==' ') || (SyntaxLine!*j)=='\t'))
{
}
if (strncmp(&SyntaxLine[*jJ,":L:=",4)==0)
{
SyntaxTable (iMySyntaxNumber ]. pSyntaxPointer->iIsLexical = TRUE;
(*j)+M;
}
else
{
SyntaxTableIiMySyntaxNumber].pSyntaxPointer->iIsLexical = FALSE;
(*j)+=3;
return iMyLexNumber;
int GetRoutinePointer ( char* pszRoutineName, int (**FoundRoutine) (void*) )
{
int iStatus = FALSE;
int i;
*FoundRoutine = NULL;
for (i=0;(i<-globMaxName);i++)
{
if (strcmp(pszRoutineName, RoutineNameTable[i].sNameBody ) == 0)
{
*FoundRoutine = RoutineNameTable(i].BodyRoutine;
iStatus = TRUE;
return iStatus;
}
return iStatus;
}
int GetNewSyntaxHead ( struct sSyntaxBead** ppNewSyntaxHead ,
char* Identifier )
{
int iStatus = TRUE;
*ppNewSyntaxHead = malioc(sizeof(struct sSyntaxBead));
(*ppNewSyntaxBead)->SyntaxName[0] ='\0';
(*ppNewSyntaxHead)->FirstAlternate = NULL;
(*ppNewSyntaxHead)->iStartsWith = 0;
(«ppNewSyntaxHead)->iMustContain = 0;
(*ppNewSyntaxHead)->LexRoutine = NULL;
(*ppNewSyntaxHead)->iIsLexical - FALSE;
(*ppNewSyntaxHead)->pNextHead = NULL;
500
Дополнительные тематические разделы
Часть III
(*ppNewSyntaxBead)->iSyntaxNumber = iNextSyntax/*++*/;
if (iNextSyntax>0)
{
(*ppNewSyntaxBead) ->pPreviousBead =
SyntaxTable[iNextSyntax-1].pSyntaxPointer;
if ((SyntaxTable[iNextSyntax-1].pSyntaxPointer)1=NULL)
{
(SyntaxTable[iNextSyntax-1].pSyntaxPointer)->pNextBead =
♦ppNewSyntaxBead;
}
}
else
{
(*ppNewSyntaxfeead)->pPreviousBead = NULL;
}
if (strcmp(Identifier,"")==O)
{
(*ppNewSyntaxBead)->LexRoutine = NULL;
(*ppNewSyntaxBead)->iIsLexical = FALSE;
}
else
{
GetRoutinePointer ( Identifier,
& ((* ppNewSyntaxBead)->LexRoutine) );
(*ppNewSyntaxBead)->iIsLexical = TRUE;
}
return iStatus;
int ProcessSyntaxLine ( void )
{
int iStatus = TRUE;
char* pC;
struct sSyntaxBead* pNewSyntaxBead;
char Lexldentifier[ROUTINENAMELENGTB+l];
int j=0;
int iMyLexNumber;
int iMySyntaxNumber;
pNewSyntaxBead = pRootSyntax;
pC = fgets(SyntaxLine, SYNTAXLINELIMIT, fSyntaxFile );
if (pC!=NULL)
{
iMySyntaxNumber = GetSyntaxName ( SyntaxLine, &j );
pNewSyntaxBead = SyntaxTable[iMySyntaxNumber].pSyntaxPointer;
Lexldentifier[0] = '\0';
iMyLexNumber - GetLexName ( SyntaxLine, Lexldentifier, &j,
iMySyntaxNumber );
iStatus = GetAlternates ( &j, pNewSyntaxBead );
} /* Конец оператора "if/then", во входной строке имеются какие-то данные */
return iStatus;
}
void FreeSyntaxBead ( struct sSyntaxBead* pFreeBead )
struct sSyntaxAlt* pFreeAlt;
while ( pFreeBead!=NULL )
{
pFreeAlt = pFreeBead->FirstAlternate;
501
Синтаксический анализ и вычисление выражений
Глава 19
FreeAlternates ( SpFreeAlt );
free ( pFreeBead );
pFreeBead = NULL;
}
return;
int GetAlternates ( int* jf struct sSyntaxBead* pNewSyntaxBead )
{
int iStatus = TRUE;
struct sSyntaxAlt* pNewAlternate = NULL;
struct sSyntaxAlt* pPreviousAlternate;
while (( iStatus == TRUE ) && ( *j != 0 ))
{
pPreviousAlternate = pNewAlternate;
pNewAlternate = malloc ( sizeof ( struct sSyntaxAlt ) );
if (pPreviousAlternate!=NULL)
{
pPreviousAlternate->NextAlt = pNewAlternate;
pNewAlternate->PreviousAlt - pPreviousAlternate;
}
else
{
pNewAlternate->PreviousAlt « NULL;
}
pNewAlternate->NextAlt = NULL;
iNextAlternate++;
AlternateTable[iNextAlternate].pAlternatePointer = pNewAlternate;
AlternateTable[iNextAlternate].iSyntaxNumber = iNextSyntax;
AlternateTable[iNextAlternate].iStartsWith = 0;
AlternateTable]iNextAlternate].iMustContain = 0;
pNewAlternate->iAlternateNumber = iNextAlternate;
pNewAlternate->iSyntaxNumber = iNextSyntax;
if (pPreviousAlternate==NULL)
{
pNewSyntaxBead->FirstAlternate - pNewAlternate;
}
else
{
pPreviousAlternate->NextAlt = pNewAlternate;
}
iStatus = GetOneAlternate ( j , pNewAlternate );
} /* Конец цикла "while", успешное получение альтернатив */
return iStatus;
}
int GetOneAlternate ( int* j, struct sSyntaxAlt* pNewAlternate )
{
int iStatus = TRUE;
int i;
struct sSyntaxBody* pPreviousBody;
struct sSyntaxBody* pNewBody = NULL;
i = 0;
while (( i == 0 ) && ( iStatus ==* TRUE ))
{
SkipSpaces ( j );
if ((SyntaxLine[*j]=='|') |l (SyntaxLine]* Л=='#')
|| (SyntaxLinef*j]=='\n') |j (SyntaxLine]*j]=='\0'))
{
502
Дополнительные тематические разделы
Часть III
i = 1;
if ((SyntaxLine[*j]=='#') || (SyntaxLine[*j]=='\0'))
{
iStatus = FALSE;
}
else
{
iStatus = TRUE;
}
} /* Конец оператора "if/then", завершение альтернативы */
else
{
pPreviousBody = pNewBody;
pNewBody = malioc ( sizeof ( struct sSyntaxBody ) );
i f (pPreviousBody==NULL)
{
pNewAlternate->ThisBody » pNewBody;
pNewBody->PreviousBody « NULL;
else
{
pNewBody->PreviousBody = pPreviousBody;
pPreviousBody->NextBody = pNewBody;
}
pNewBody->NextBody = NULL;
pNewBody->BodyContents = NULL;
pNewBody->BodyCheck = NULL;
pNewBody->LexCheck = NULL;
pNewBody->CodeGenerate = NULL;
pNewBody ~>iSyntaxNumber = iNextSyntax;
pNewBody->ParentAlt = pNewAl ternate;
pNewBody->iStartsWith = 0;
pNewBody->iMustContain = 0;
iStatus = GetSyntaxItem ( j, pNewBody );
if (1iStatus)
{
i = 1;
iStatus = TRUE;
}
}
} /* Конец цикла "while", получение элементов синтаксиса в пределах этой альтернативы */
return iStatus;
void FreeAlternates ( struct sSyntaxAlt** pFreeAlt )
{
struct sSyntaxAlt* pNextAlt;
struct sSyntaxBody* pFreeBody;
while (*pFreeAlt1=NULL)
{
pNextAlt = (*pFreeAlt)->NextAlt;
pFreeBody = (*pFreeAlt)->ThisBody;
FreeSyntaxItem ( (pFreeBody );
free ( *pFreeAlt );
*pFreeAlt = pNextAlt;
*pFreeAlt - pNextAlt;
return;
503
Синтаксический анализ и вычисление выражений
Глава 19
int GetSyntaxItem ( int* j, struct sSyntaxBody* pNewBody )
{
int iStatus = TRUE;
int i;
int k;
int 1;
int m;
int n;
char Identifier [ROUTINENAMELENGTH+l ];
int («RoutineAddress) (int*, int*);
switch (SyntaxLine[* j]) {
case ' (':
(*j)++;
iStatus = Getldentifier ( SyntaxLine , Identifier , j );
(*□)++;
iStatus = GetRoutinePointer ( Identifier, (RoutineAddress );
pNewBody->BodyCheck = RoutineAddress;
break;
case ' [':
(*j)++;
iStatus = Getldentifier ( SyntaxLine , Identifier , j );
(*□)++;
iStatus = GetRoutinePointer ( Identifier, (RoutineAddress );
pNewBody->CodeGenerate = RoutineAddress;
break;
case ' {':
iStatus = Getldentifier ( SyntaxLine , Identifier , j );
(*1H+;
iStatus ~ GetRoutinePointer ( Identifier, (RoutineAddress );
pNewBody->LexCheck = RoutineAddress;
break;
case
к = *j + 1; /* Индекс первого символа в строке */
m = 0;
n = 0;
for (i=k; (m~0) ;i++)
{
if (((SyntaxLine[i]=='\"') (( (SyntaxLine[i+1]!=f\V))
|| (SyntaxLine[i]=='\n') || (SyntaxLine[iJ=='\0'))
{
m = i; /* Индекс заверваюцих кавычек */
(*j) += n + 2;
}
n++;
}
1 - m - k;
pNewBody->BodyContents - malloc(sizeof(char) * (1 + 1));
strepy (pNewBody->BodyContents, “ ");
strncat(pNewBody->BodyContents,SyntaxLine+k,(1));
pNewBody->iSyntaxNumber - 0;
pNewBody~>BodyHead = NULL;
break;
default:
if (isalpha(SyntaxLine[*j]))
{
k - GetSyntaxName ( SyntaxLine, j );
pNewBody->iSyntaxNumber = k;
}
else
{
iStatus - FALSE;
}
504!
Дополнительные тематические разделы
Часть III
break;
};
return iStatus;
}
void FreeSyntaxItem ( struct sSyntaxBody** pFreeBody )
{
struct sSyntaxBody* NextSyntaxBody - NULL;
while (*pFreeBody1=NULL)
{
NextSyntaxBody = (*pFreeBody)->NextBody;
if (((*pFreeBody)->BodyContents)!=NULL)
{
free((*pFreeBody)->BodyContents);
free ( *pFreeBody );
♦pFreeBody = NextSyntaxBody;
*pFreeBody = NextSyntaxBody;
Teturn;
}
void Skipspaces ( int* j )
{
while (isspace(SyntaxLine[*j]) && (SyntaxLine[*j]!=,\n'))
{
(*□> ++;
}
return;
}
Приведенный в листинге 19.1 код для чтения опре-
деления синтаксиса не поддерживает лексический ана-
лиз и не строит таблицы "Должно содержать" и "С чего
начинается". Такой код создается достаточно просто.
Синтаксический анализ выражения
В примере синтаксического анализатора, приведенном
в файлах ChPars.c и ChPars.h на Web-сайте "ДиаСофт",
предполагается, что подлежащие чтению выражения
уже находятся в файле. Каждое выражение читается и
анализируется, а код, генерируемый в конце успешно-
го анализа, записывается в выходной файл. Если вам
требуется иная форма вывода, то и ее легко изменить.
Синтаксический анализатор размещает один указа-
тель в начале выражения, а другой — на вершине абст-
рактного (вероятного) синтаксического дерева. Затем он
пытается сопоставить символы, на которые указывает
первый указатель, с правилами синтаксиса, на которые
указывает второй указатель. Правила синтаксиса в ко-
нечном счете приводят к отдельному элементу, который
содержит указатель на символьную строку. Эта символь-
ная строка может совпадать или не совпадать с входны-
ми символами. Если она совпадает с ними, значит об-
наружено (возможное) синтаксическое соответствие, и
тогда можно попробовать перейти к следующему эле-
менту синтаксиса. Если же она не совпадает с входны-
ми символами, то данное правило не подходит, и по-
этому опробуется следующая альтернатива. Если это
последняя альтернатива, тогда придется подняться на
один уровень вверх по дереву и опробовать следующую
альтернативу на этом уровне. В конечном счете мы воз-
вращаемся к вершине абстрактного синтаксического
дерева, либо обнаружив полное совпадение (положи-
тельный результат) либо определив, что входные дан-
ные неверны (отрицательный результат).
Вот вкратце и весь принцип действия синтаксичес-
кого анализатора. А теперь обратимся к примеру. Допу-
стим, что мы пытаемся сопоставить синтаксическое имя
element (химический элемент), для которого имеются сле-
дующие определения синтаксиса:
Синтаксический анализ и вычисление выражений
Глава 19
505
elementmetal | non-metal #
metal A-metal | C-metal | N-melal it
A-metal ::= "A" A-metal-end it
C-metal"C" C-metal-end it
N-metal ::= "N" N-metal-end it
non-metal ::= A-non-metal | C-non-metal | N-non-metal it
A-non-metal"A" А-non-metal-end it
C-non-metal ”C" C-non-metal-end it
N-non-metal .*:= "N" N-non-metal-end it
A-metal-end "u" | "g" it
C-metal-end "o” | | "r" a
N-metal-end"i" it
A-non-metal-end 'b" it
C-non-metal-end 1" | empty it
N-non-metal-end"e" | empty it
Это дает возможность распознавать следующие ме-
таллы: золото (Au), серебро (Ag), кобальт (Со), медь
(Си) и никель (Ni), а также следующие неметаллы: ар-
гон (Аг), хлор (С1), углерод (С), неон (Ne) и азот (N).
Допустим, что имеется следующий входной поток:
Au
Тогда синтаксический анализатор начинает свою
работу с такого вопроса: "Это химический элемент?”
Затем синтаксический анализатор задает вопрос:
"Это металл?"
Далее ставится еще один вопрос: "Это А-металл?"
Чтобы быть А-металлом, этот химический элемент
должен начинаться на букву А...
Пожалуй, демонстрация такого примера займет мно-
го места на бумаге. Поэтому ради краткости каждая
синтаксическая диаграмма будет записана в виде одной
строки. А ответ на каждый вопрос будет выровнен по
началу вопроса, но на другой строке. Символ во вход-
ных данных, на который указывает конечный указатель,
будет выделен полужирным шрифтом, а символ, на ко-
торый указывает начальный указатель, будет выделен
курсивом. Таким образом, все сказанное выше теперь
имеет следующий вид:
Химический элемент Aw
Металл Aw
A-металл Aw
A Au
Да, это A Aw
Конец анализа A-металла Ли
и Ли
Ли
Да, это и
Да, это конец анализа A-металла Ли
Да, это A-металл Ли
Да, это металл Ли
Да, это химический элемент Ли
Анализ был проделан довольно быстро и просто.
В итоге оказалось, что это золото. А теперь допустим,
что имеются следующие входные данные:
Си
Соответствующий ряд вопросов и ответов окажется
несколько длиннее: Химический элемент Cw
Металл Cw
А-металл Cw
А Cw
Нет, не А Cw
Нет, не А-металл Cw
С-металл Cw
С Cu
Да, это С Cw
Конец анализа С-металла Cu
о Cu
Нет, это не о Cu
и Cu
Да, это и Cu
Да, это конец анализа С-металла Cu
Да, это С-металл Cu
Да, это металл Cu
Да, это химический элемент Cu
Как видно, начальный и конечный указатели пере-
мещались вперед и назад в пределах входных данных,
и, прежде чем был найден правильный ответ, было со-
здано и исключено несколько возможных вариантов
синтаксического анализа. Итак, медь также обнаруже-
на. Если построить цепочку, подобную приведенным
выше, для анализа азота (N), путь к правильному отве-
ту окажется намного длиннее и сложнее.
А теперь допустим, что имеются следующие вход-
ные данные:
Cs
Цепочка для анализа этих входных данных будет
иметь следующий вид:
Химический элемент
Металл
А-металл
А
Cs
Cs
Cs
Cs
Дополнительные тематические разделы
Часть III
506|
Нет, не А Cs
Нет, не A-металл Cs
С-металл Cs
С Cs
Да, это С Cs
Конец анализа С-металла Cs
...(Далее следуют строки анализа на несоответствие
о, и или г)...
о Cs
Нет, это не конец анализа Cs
С-металла
Нет, это не С-металл Cs
N-металл Cs
Нет, это не конец анализа Cs
С-неметалла
Нет, это не С-неметалл Cs
N-неметалл Cs
N Cs
Нет, это не N Cs
Нет, это не N-неметалл Cs
Нет, это не неметалл Cs
Нет, это не химический элемент Cs
В итоге было проанализировано все синтаксическое
дерево и совпадение не обнаружено, поскольку этот
синтаксис не предполагает наличие цезия.
Из этого анализа также стало ясно, что на каждой
его стадии необходимо запоминать начальный и конеч-
ный указатели. Это означает, что при распознавании
каждого фрагмента синтаксиса необходимо знать пер-
вый и последний символы, с которыми этот фрагмент
совпадает. Таким образом, когда обнаруживается ошиб-
ка, становится известно, как далеко придется вернуть-
ся, чтобы совершить еще одну попытку. При этом име-
ется также возможность указать пользователю, какие
именно фрагменты выражения и как именно были рас-
познаны.
Упрощенный синтаксис выражений
Рассматриваемый ниже упрощенный синтаксис приве-
ден на рис. 19.1. Это полный синтаксис, который мы
используем на протяжении данной главы. Он упрощен
здесь потому, что время лексического анализа пока еще
не наступило, а кроме того, здесь не будут рассмотре-
ны варианты типа "С чего может начинаться" и "Долж-
но содержать". Таким образом, процесс синтаксического
анализа любых элементов, с которых могут начинаться
другие альтернативы, будет повторяться несколько раз.
Следовательно, каждый идентификатор, например, бу-
дет повторно проанализирован несколько раз, прежде
чем будет найден подходящий его контекст. Такой под-
ход отнюдь не обязательно эффективен, однако он уп-
рощает понимание.
Интуитивные правила обычного языка
Каждое правило синтаксиса имеет простую интерпре-
тацию на обычном языке. В частности, "выражение сло-
жения — это выражение умножения или выражение
сложения, за которым следует знак плюса и выражение
умножения, либо выражение сложения, за которым
следует знак минуса и выражение умножения". Эту же
фразу можно выразить следующим образом:
additive-expression ::= multiplicative-expression | additive-
expression "+" multiplicative-expression | additive-expression
**-” multiplicative-expression it
Увы, эти выражения ничем не напоминают те фра-
зы, которыми мы живо обмениваемся в повседневном
общении. Тем не менее, они ясны и просты. А теперь
самое время опять обратиться к рис. 19.1, чтобы вспом-
нить синтаксис предложений (сокращенный), который
мы стремимся получить.
Строгие правила С
Код, находящийся в файлах Chl9Pars.c и Chl9Pars.h на
Web-сайте "ДиаСофт", содержит простой механизм син-
таксического анализа. Этот код состоит из следующих
трех частей: управляющей части, которая открывает
файлы, формирует запросы на загрузку абстрактного
синтаксиса, читает анализируемые выражения и иници-
ирует синтаксический анализ и генерирование кода;
загружающей синтаксис части, которая устанавливает
управляющие структуры для синтаксического анализа;
а также части, выполняющей анализ и генерирующей
код.
В рассматриваемом примере кода предполагается,
что абстрактный синтаксис находится в конкретном
файле, имя которого явно указано в коде (очевидно,
здесь могут быть внесены изменения в соответствии с
потребностям конкретной среды.) Кроме того, предпо-
лагается, что анализируемые выражения и выходной
результат тоже располагаются в файлах, имена которых
явно указаны в коде. И это положение тоже можно из-
менить с учетом конкретной среды.
В данном случае устанавливаются следующие две
основные структуры: структура абстрактного синтаксиса
(т.е. того, что может быть распознано) и структура кон-
кретного синтаксического анализа (т.е. того, что факти-
чески было распознано).
Структура абстрактного синтаксиса соответствует
содержимому табл. 19.1 в том отношении, что каждое
507
правило выражается связанной древовидной структурой.
У каждого узла этой структуры имеется свое имя (эк-
вивалентное левой части правила синтаксиса), а также
одна или несколько альтернатив (соответствующих ле-
вой части правила синтаксиса и разделенных вертикаль-
ными чертами). Каждая альтернатива указывает на це-
почку элементов. А каждый элемент представляет собой
указатель на синтаксический узел (именованный эле-
мент) либо на символьную строку. В пределах этих эле-
ментов существуют и другие элементы, которые будут
рассмотрены далее в этой главе.
Структура конкретного синтаксического анализа
представляет собой единственное дерево. Каждый из его
узлов указывает на один конкретный узел абстрактного
синтаксиса и альтернативу в пределах этого узла. Кро-
ме того, каждый узел содержит последовательность (це-
почку) элементов. А каждый элемент представляет со-
бой указатель на другой конкретный узел либо на вполне
определенную символьную строку.
logical-OR-expression ::== logical-AND-expression | logical-
OR-expression "||" logical-AND-expression it
expression ::= logical-OR-expression it
Действие синтаксического анализатора начинается с
установки начального указателя на первый символ во
входном буфере и конечного указателя на значение
NULL (которое означает, что он ни на что не указыва-
ет). Синтаксический анализатор затем пытается сопос-
тавить содержимое входного буфера с корневым синтак-
сическим правилом из дерева абстрактного синтаксиса.
В данном случае синтаксический анализатор начинает
свою работу с анализа элемента expression (выражение).
Первой (и единственной) альтернативой элемента
expression является выражение logical-OR-expression
(выражение логического сложения). При этом синтак-
сический анализатор строит конкретный узел синтакси-
ческого анализа элемента expression, а затем еще один
узел для выражения logical-OR-expression Первой аль-
тернативой выражения logical-OR-expression является
выражение logical-AND-expression (выражение логичес-
кого умножения). Далее синтаксический анализатор
продолжает построение более конкретных узлов синтак-
сического анализа. В конечном счете синтаксический
анализатор достигает конца входного буфера либо эле-
мента абстрактного синтаксиса, который просто не со-
впадает с содержимым входного буфера. Если синтак-
сический анализатор достигает конца выражения и в то
же время конца всех ожидающих обработки элементов
абстрактного синтаксиса, то синтаксический анализ
оказывается успешным. В этом случае осуществляется
переход к этапу генерирования кода.
Однако, если распознавания не произошло или име-
ются дополнительные элементы абстрактного синтакси-
Синтаксический анализ и вычисление выражений
Глава 19
са, ожидающие обработки и еще не распознанные, тог-
да анализ завершается неудачно. В этом случае синтак-
сический анализатор вынужден отменить свое последнее
решение и сделать альтернативный выбор. Последним
является такое решение синтаксического анализатора,
при котором из абстрактного синтаксиса была выбрана
конкретная альтернатива. При этом самый нижний эле-
мент отвергается, соответствующий узел синтаксичес-
кого анализа исключается и опробуется следующая аль-
тернатива абстрактного синтаксиса. Этот процесс
перемещения вверх и вниз по деревьям продолжается до
тех пор, пока анализ определенно не потерпит неудачу
(т.е. когда возможных альтернатив уже больше нет и
совпадение не обнаружено) либо окажется успешным.
Приведенное выше описание может показаться вам
несколько суховатым, поэтому обратимся к конкретно-
му примеру. Допустим, что входной буфер содержит
такое выражение:
abc + xyz 6
Тогда синтаксический анализатор попытает выпол-
нить следующее:
expression
logical-OR-expression (Р alternate)
logical-AND-expression (Р alternate)
inclusive-ОR-expression (P alternate)
exclusive-OR-expression (Iя alternate)
AND-expression (Iя alternate)
equality-expression (Iя alternate)
relational-expression (P alternate)
shift-expression (P alternate)
additive-expression (P alternate)
multiplicative-expression (P alternate)
cast-expression (P alternate)
unary-expression (1st alternate)
postfix-expression (P alternate)
primary-expression (P alternate)
identifier (Iя alternate)
На этом этапе был проанализирован элемент identifier
(идентификатор), начинающийся в принятом здесь оп-
ределении с элемента letter (буква), после которого сле-
дует элемент identifier-tail (хвост идентификатора).
identifier ::= letter identifier-tail it
identifier-tailletter identifier-tail | digit identifier-tail |
identifier-tail | empty it
Класс letter совпадает с начальной буквой а, и для
определения следующего элемента (identifier-tail) началь-
ный указатель перемещается для указания на букву Ъ во
508
Дополнительные тематические разделы
Часть III
входном буфере. Итак, синтаксический анализ продол-
жается следующим образом:
letter (Ъ)
identifier-tail (1st alternate)
letter (Ъ)
identifier-tall (1st alternate)
letter fc)
identifier-tail (1st alternate)
letter
На этом этапе появляется ошибка. Начальный ука-
затель указывает на символ ”5”, который определенно
не является буквой (letter). Поэтому эта ветвь исключа-
ется вплоть до того места, в котором был сделан после-
дний выбор, и вместо нее опробуется вторая альтерна-
тива. Таким образом, конец приведенного выше
синтаксического анализа получается следующим:
letter ('а)
identifier-tail (1st alternate)
letter (Ъ)
identifier-tail (1st alternate)
letter fc)
identifier-taii t Г* nhemnte)
letter
identifier-tail (2,d alternate)
digit ('5)
Зачеркнутые строки здесь и далее обозначают неко-
торые ложные пути, которым последовал синтаксичес-
кий анализатор, пытаясь добраться до правильного ре-
шения.
Следующим элементом синтаксиса опять является
элемент identifier-tail, который не принес желаемого ре-
зультата ни в первой альтернативе (поскольку знак "+"
не является буквой (letter)), ни во второй альтернативе
(поскольку знак не является цифрой (digit)). А вот
в третьей альтернативе анализ приносит положительный
результат (пустой элемент (empty))'.
letter fa')
identifier-tail (1st alternate)
letter (Ъ)
identifier-tail (Г alternate)
letter (c)
identifier-fail f f* ahrmrfe)
letter
identifier-tail (2,d alternate)
digit ('5')
identifier’fori f Л* iTlfemnfr)
"letter
identifier’Mil (2* rtffernnfe)
digit
identifier-tail (3rd alternate)
empty
А теперь рассмотрим следующий предполагаемый
элемент синтаксиса, который относится к остальной
части выражения primary-expression (основное выражение).
В конечном счете синтаксический анализ приведет к
созданию структуры, описанной в табл. 19.3.
Рекурсия
Во всем рассматриваемом здесь процессе выполняются
рекурсивные процедуры, т.е. такие процедуры, которые
вызывают сами себя косвенно или явно. В рекурсии,
собственно, нет ничего плохого, однако при ее выпол-
нении непременно необходимо избежать бесконечной
рекурсии, которая может возникнуть довольно просто.
Рассмотрим следующий синтаксис только с одним пра-
вилом:
alpha : := alpha "b" | "а" #
Здесь alpha — это строка, состоящая из одной бук-
вы а и еще одной буквы Ь. При просмотре входного бу-
фера синтаксический анализатор задается следующим
вопросом: "Это alpha?"- и решает опуститься на один
уровень, чтобы еще раз задать вопрос: "Это alpha?” за-
тем он рекурсивно опускается еще на один уровень,
опять задает вопрос: "Это alpha?”— и решает, что... ну
и так далее.
Чтобы избежать подобного рода порочной рекурсии
(left recursion), приведенное выше правило можно было
бы переписать в виде пары следующих правил:
alpha :.= alphahead 'b" #
alphahead "a" alphahead > | V' #
В этой паре правил регламентируется тот факт, что
в каждой ветви нужно проверить, по крайней мере, один
символ во входном буфере, прежде чем будет принято
решение об успешном или неудачном завершении ана-
лиза. Таким образом, подобный синтаксис никогда не
приведет к бесконечной рекурсии.
Как же быть с намного более длинными выражени-
ями, написанными на языке С? Может ли анализ с ис-
пользованием такого синтаксиса вообще привести к бес-
конечной рекурсии? На первый взгляд ответ на этот
вопрос не вполне очевиден, и, хотя синтаксис можно
исследовать на предмет возможных опасных ветвей,
вероятно, в синтаксическом анализаторе должны быть
такие средства, которые всякий раз будут предупреж-
дать о возникновении подобной нежелательной ситуа-
ции. Если такое предупреждение появляется, это может
Синтаксический анализ и вычисление выражений
1509
Глава 19
иметь два последствия. Во-первых, оно препятствует чение неопределенного времени, а во-вторых, оно пре- бесполезной работе синтаксического анализатора в те- дупреждает пользователя об ошибке в исходном синтак- сисе. Таблица 19.3. Синтаксический анализ исходного выражения.
Имя анализируемого элемента Русская транскрипция Часть выражения
expression выражение abc5 + xyz6
logical-OR-expression (1st alternate) выражение логического сложения (первая альтернатива) abc5 + xyz6
logical-AND-expression (1st alternate) выражение логического умножения (первая альтернатива) abc5 + xyz6
inclusive-OR-expression (1st alternate) выражение включающего ИЛИ (первая альтернатива) abc5 + xyz6
exclusive-OR-expression (1st alternate) выражение исключающего ИЛИ (первая альтернатива) abc5 + xyz6
AND-expression (1st alternate) выражение И (первая альтернатива) abc5 + xyz6
equality-expression (1sl alternate) выражение равенства (первая альтернатива) abc5 + xyz6
relational-expression (1st alternate) выражение отношения (первая альтернатива) abc5 + xyz6
shift-expression (1st alternate) выражение сдвига (первая альтернатива) abc5 + xyz6
additive-expression (2nd alternate) выражение сложения (вторая альтернатива) abc5 + xyz6
additive-expression (1st alternate) выражение сложения (первая альтернатива) abc5
multiplicative-expression (1st alternate) выражение умножения (первая альтернатива) abc5
cast-expression (1sl alternate) выражение приведения типов (первая альтернатива) abc5
unary-expression (1st alternate) унарное выражение (первая альтернатива) abc5
postfix-expression (1st alternate) постфиксное выражение (первая альтернатива) abc5
primary-expression (1st alternate) основное выражение (первая альтернатива) abc5
identifier (1sl alternate) идентификатор (первая альтернатива) abc5
letter буква а
identifier-tail (1st alternate) хвост идентификатора (первая альтернатива) Ьс5
letter буква b
identifier-tail (1st alternate) хвост идентификатора (первая альтернатива) с5
letter буква с
identifier-tail (2nd alternate) хвост идентификатора (вторая альтернатива) 5
digit цифра
identifier-tail (3rd alternate) хвост идентификатора (третья альтернатива)
empty пустой элемент 5
+ +
multiplicative-expression (1sl alternate) выражение умножения (первая альтернатива) xyz6
cast-expression (1sl alternate) выражение приведения типов (первая альтернатива) xyz6
unary-expression (1sl alternate) унарное выражение (первая альтернатива) xyzp
postfix-expression (1s* alternate) постфиксное выражение (первая альтернатива) xyz6
primary-expression (1st alternate) основное выражение (первая альтернатива) xyz6
identifier (1s* alternate) идентификатор (первая альтернатива) xyz6
letter буква X
identifier-tail (1SI alternate) хвост идентификатора (первая альтернатива) yz6
letter буква z
identifier-tail (2nd alternate) хвост идентификатора (первая альтернатива) 6
digit цифра 6
identifier-tail (3rd alternate) хвост идентификатора (третья альтернатива) пустой элемент
Дополнительные тематические разделы
Часть III
510
Для обнаружения бесконечной рекурсии в процес-
се ввода нового заголовка (узла) в дерево анализа на
каждом этапе синтаксический анализатор может снова
попытаться найти среди всех предыдущих узлов такой,
узел, имя и значения которого совпадают с теми, на
которые указывают входной и выходной указатели.
Если такой узел имеется, то, возможно, придется вер-
нуться в то же самое состояние, которое соответствует
предыдущему этапу процесса анализа, и установить
состояние ошибки.
Рекурсивные правила могут быть скрытыми. Рас-
смотрим следующий синтаксис:
alpha ::= alphahead "b" | betahead "с" #
alphahead ::= betahead "a” | "b" alphahead #
betahead alphahead "b" | "a" betahead #
Можно ли здесь сразу же заметить рекурсию? Она
присутствует в последней паре правил. Когда синтак-
сический анализатор пытается определить, соответству-
ет ли что-нибудь элементу alphahead\ он прежде всего
задает вопрос: "Это betahead!” Чтобы определить это, он
задает вопрос: "Это alphahead!”., а чтобы определить
последнее, он задает вопрос: Это betahead!” и т. д.
Даже если эти альтернативы поменять местами, ре-
курсия все равно останется:
alpha ::= alphahead "b" | betahead "с" #
alphahead ::= "b" alphahead | betahead "a" #
betahead ::= "a" betahead | alphahead "b" #
Если синтаксическому анализатору предоставляется
буфер, содержащий лишь символ с, он задает вопрос: "Это
alphahead (первая альтернатива)*!”- и, чтобы определить
это, анализирует первый символ и обнаруживает, что это
не Ь. Следовательно, вместо этого он задает такой воп-
рос: "Это alphahead (вторая альтернатива)*!” А чтобы
определить это, она задает вопрос: "Это betahead (пер-
вая альтернатива)?” Таким образом, синтаксический
анализатор просматривает первый символ и обнаружи-
вает, что это не а, и тогда заменяет предыдущий воп-
рос следующим: Это betahead (вторая альтернатива/!”
Чтобы ответить на этот- вопрос, синтаксический анали-
затор задает вопрос: "Это alphahead (первая альтернати-
ва)?”- и, таким образом, возвращается туда, откуда он
начал свой анализ.
Ошибки в синтаксисе
Похоже, что дело принимает еще более скверный обо-
рот. Обратил ли читатель внимание на то, что в двух
последних примерах правил синтаксиса имеется еще
одна серьезная ошибка? На самом деле не существует
такой символьной строки, которая этим правилам соот-
ветствует. Оба определения, alphahead и betahead, мо-
гут вообще оказаться бесконечными, даже в абстракт-
ном смысле. Каким же образом можно гарантировать
отсутствие подобной ошибки в намного более сложном
синтаксисе выражений, написаных на языке С?
Вероятно, читателю будет приятно узнать, что, когда
гарантируется отсутствие бесконечных рекурсивных
путей во всем синтаксисе, рекурсия должна всегда быть
конечной. Поэтому гарантия отсутствия бесконечной
рекурсии в синтаксисе приобретает весьма важное зна-
чение. В коротком синтаксисе это можно определить на
глаз. А для более длинного синтаксиса существуют ин-
струментальные средства, которые способны проверять
качество синтаксиса.
Нетрудно проверить, что каждое используемое имя
определено (описано), однако при написании синтакси-
са, в котором можно легко совершить ошибку, очень важ-
но ее исключить. В равной степени просто (и важно)
проверить тот факт, что имя не определено дважды.
Простой синтаксический анализатор на С
Простой синтаксический анализатор, приведенный в
листинге 19.2, строит дерево синтаксического анализа,
исходя из заданных входных данных и прочитанного
определения синтаксиса. Процедура синтаксического
анализа носит рекурсивный характер и принимает сле-
дующие три аргумента: указатель на часть входного
буфера, которая представляет интерес в настоящий
момент, узел абстрактного синтаксиса, попытка сопос-
тавления с которым предпринимается, а также родитель-
ский (предыдущий) узел дерева синтаксического анали-
за, который уже построен. Если последний аргумент
представляет собой указатель на значение NULL, зна-
чит, это начало синтаксического анализа, и в таком слу-
чае необходимо распределить новый корневой элемент
синтаксического анализа.
Листинг 19.2. Простой синтаксический анализатор.
struct sParseNode;
struct sParseNode {
struct sParseNode*
struct sParseNode*
struct sParseNode*
struct sParseNode*
struct sSyntaxBead*
ParentParse;
NextParse;
PreviousParse;
ThisParse;
ThisBead;
Синтаксический анализ и вычисление выражений
Глава 19
511
struct sSyntaxBody*
int (*CodeGenerate)
int iFirstChar;
int iLastChar;
};
ThisBody;
( void* );
struct sSyntaxTableElement {
char SyntaxName [ SYNTAX_NAME_LENGTH+1 ];
struct sSyntaxBead* pSyntaxPointer;
int iStartsWith;
int iMustContain;
};
struct sAlternateTableElement {
struct sSyntaxAlt* pAlternatePointer;
int iSyntaxNumber;
int iStartsWith;
int iMustContain;
};
struct sRoutineNameTableElement {
char sNameBody [ROUTINE_NAME_LENGTB+1 ];
int (*BodyRoutine) ( void* );
/* -------------------------- Определение глобальных переменных --------------------------- */
struct sSyntaxBead* pRootSyntax;
struct sParseNode* pRootParse;
struct sRoutineNameTableElement RoutineNameTable[MAX ROUTINENAMES];
struct sSyntaxTableElement SyntaxTable [MAXSYNTAXITEMS];
struct sAlternateTableElement AlternateTable [MAXALTERNATEITEMS];
int globLabel;
int globMaxName;
int iNextSyntax;
int iNextAlternate;
char SyntaxLine[SYNTAXLINELIMIT+1];
char ParseBuffer[PARSE_BUFFER_LENGTB+l];
FILE * fSyntaxFile;
char sSyntaxFileName[257];
FILE * flnputFile;
char sInputFileName[257];
FILE * fOutputFile;
char sOutputFileName[257];
/* ----------------------- Конец определения глобальных переменных ------------------------ */
/* ------ Прототипы---------------------------------------------------*/
int Readsyntax ( struct sSyntaxBead* * pRoot );
int FindSyntaxName ( char* SyntaxName );
int ProcessSyntaxLine ( void );
void FreeWholeSyntax ( void );
int GetNewSyntaxEead ( struct sSyntaxBead** ppNewSyntaxBead,
char* Identifier );
int CreateSyntaxTableEntry (char* pSyntaxName);
void FreeSyntaxBead ( struct sSyntaxBead* pFreeBead );
int GetAlternates ( int* jf
struct sSyntaxBead* pNewSyntaxBead );
int GetOneAlternate ( int* jf
struct sSyntaxAlt* pNewAlternate );
void FreeAlternates ( struct sSyntaxAlt** pFreeAlt );
int GetSyntaxItemf int* j,
struct sSyntaxBody* pNewBody );
Дополнительные тематические разделы
5121
Часть III
void FreeSyntaxItem ( struct sSyntaxBody** pFreeBody );
void SkipSpaces ( int* j );
int GetSyntaxName ( char* SyntaxLine, int* j );
void RemoveSpaces ( char* InputBuffer );
int TryMatchParse ( char** ppInputBuffer, int* k, struct sSyntaxBody* pSyntaxP, struct sParseNode** ppParseBody )
int GetNewParseBody ( struct sParseNode* pParentBead, struct sParseNode* pPreviousBody struct sParseNode** ppNewBody );
int BuiIdNewParseBody ( struct sParseNode* pParentBead, struct sParseNode* pPreviousBody struct sParseNode** ppNewBody, int iFirstChar, int iLastChar );
int Parse ( char** ppInputBuffer, int* k, struct sSyntaxBead* pRootS, struct sParseNode** ppRootP );
int GenerateOutputCode ( struct sParseNode* pRootP );
int GetNextSyntax ( struct sSyntaxBody** ppSyntaxP );
int SkipNextSyntax ( struct sSyntaxBody** ppSyntaxP );
void PrintSyntaxTree ( void );
int isidchar ( char test char );
int Getldentifier ( char* InputBuffer, char* Identifier, int* j );
int GetLexName ( char* SyntaxLine, char* Identifier, int* j, int к );
int ProcessOutputNode ( struct sParseNode** ppParseBead, struct sParseNode** ppParseBody )
int GetRoutinePointer ( char* pszRoutineName, int (**FoundRoutine) (void*) );
int parletter ( void* );
int pardigit ( void* );
int paroctal ( void* );
int parchar ( void* );
int gencomparison ( char* pszComparator );
int genlt ( void* );
int genie ( void* );
int gengt ( void* );
int genge ( void* );
int geneq ( void* );
int genne ( void* );
int genAND ( void* );
int genOR ( void* );
int genXOR ( void* );
int genLAND ( void* );
int genLOR ( void* );
int genoperate ( char* pszOperator );
int genadd _ ( void* );
int gensubtract ( void* );
int genmutiply ( void* );
int gendivide ( void* );
int genmodulus ( void* );
void SetupRoutineNames ( void );
void Removespaces ( char* InputBuffer )
{
513
Синтаксический анализ и вычисление выражений
Глава 19
int in,out,b!nSpaces;
blnSpaces = FALSE;
out = 0;
for (in=0;((in<PARSE_BUFFER_LENGTH)&& (InputBuffer[in]!='\0'));in++)
{
if (blnSpaces)
{
if (!isspace(InputBuffer[in]))
InputBuffer[out++] = InputBuffer[in];
blnSpaces = FALSE;
}
}
else
{
if (isspace(InputBuffer[in]))
{
blnSpaces = TRUE;
InputBuffer[out++] - '
}
else InputBuffer[out++] = InputBuffer[in];
}
} /* Конец цикла “for/in" анализа входного буфера */
InputBuffer[out] = '\0';
}
int parletter ( void* one )
{
int iStatus;
if (isalpha(*(char*)one))
{
iStatus=TRUE;
}
else
iStatus = FALSE;
return iStatus;
}
int pardigit ( void* one )
{
int iStatus;
if (isdigit(♦(char*)one))
{
iStatus=TRUE;
}
else
iStatus = FALSE;
return iStatus;
}
int paroctal ( void* one )
{
int iStatus;
if ((isdigitf*(char*)one)) && (*(char*)one!=='8')
&& (*(char*)one!='9'))
{
33 Зак.265
Дополнительные тематические разделы
514
Часть III
iStatus=TRUE;
>
else
iStatus = FALSE;
return iStatus;
int parchar ( void* one )
{
int iStatus;
if ((*(char*)one=='\ " ) || (*(char*)one=a='\\')
|| (*(char*)one=='\?') || (*(char*)one=='\"'))
{
iStatus = FALSE;
}
else
iStatus=TRUE;
return iStatus;
int BuiIdNewParseBody ( struct sParseNode* pParentEead,
struct sParseNode* pPreviousBody,
struct sParseNode *♦ ppNewBody ,
int iFirstChar,
int iLastChar )
{
int iStatus;
iStatus = GetNewParseBody ( pParentHead, pPreviousBody, ppNewBody );
if (iStatus==TRUE)
{
(*ppNewBody)->iFirstChar - iFirstChar;
(*ppNewBody)->iLastChar = iLastChar;
}
return iStatus;
int GetNewParseBody ( struct sParseNode* pParentEead,
struct sParseNode* pPreviousBody,
struct sParseNode** ppNewBody )
{
int iStatus - TRUE;
*ppNewBody = malloc(sizeof (struct sParseNode));
if ((*ppNewBody)!=NULL)
{
(* ppNewBody) ->ParentParse = pParentEead;
(*ppNewBody)->NextParse = NULL;
(♦ppNewBody)->PreviousParse = pPreviousBody;
if (pPreviousBody!-NULL)
{ -
pPreviousBody->NextParse = * ppNewBody;
}
(*ppNewBody)->ThisParse - NULL;
(*ppNewBody)->iFirstChar = 0;
(*ppNewBody)“>iLastChar = -1;
}
else
{
Синтаксический анализ и вычисление выражений
Глава 19
515
return iStatus;
int TryMatchParse ( char** ppInputBuffer,
int* k,
struct sSyntaxBody* pSyntaxP,
struct sParseNode** ppParseBody )
{
int iStatus = TRUE;
int iBodyStringLength;
int kLocal;
struct sParseNode* pNewParse = NULL;
char *pInputBuffer;
if (pSyntaxP->BodyContents!=NULL)
{
iBodyStringLength = strlen(pSyntaxP->BodyContents);
if ((iBodyStringLength + к)>PARSE_BUFFER_LENGTH)
{
iStatus = FALSE;
return iStatus;
}
plnputBuffer = *ppInputBuffer;
if (strncmpf *pInputBuffer+k,pSyntaxP->BodyContents,
iBodyStringLength)1=0)
{
iStatus = FALSE;
return iStatus;
}
} else {
pNewParse = NULL;
kLocal = *k;
if (IBuildNewParseBody ( *ppParseBody, NULL, (pNewParse, kLocal, -1))
{
iStatus « FALSE;
return iStatus;
}
if((pSyntaxP->BodyHead)!=NULL)
iStatus = Parse ( (plnputBuffer, (kLocal, pSyntaxP->BodyHead,
(pNewParse );
else
iStatus = TRUE;
*k = kLocal;
return iStatus;
}
int Parse ( char** ppInputBuffer,
• int* k,
struct sSyntaxBead* pRootS,
struct sParseNode** ppRootP )
{ int iStatus = FALSE;
int iWorkStatus = TRUE;
int bNextExists = FALSE;
struct sSyntaxBody* pSyntaxP « NULL;
struct sSyntaxBody** ppSyntaxP = (pSyntaxP;
struct sParseNode* pParseBody = NULL;
struct sParseNode** ppParseBody « (pParseBody;
516
Дополнительные тематические разделы
Часть III
if ((*ppRootP)==NULL)
{
*ppRootP = malloc(sizeof (struct sParseNode));
if ((*ppRootP)==NULL)
{
iStatus = FALSE;
return iStatus;
}
(*ppRootP)->ParentParse = NULL;
(*ppRootP)->NextParse = NULL;
(*ppRootP)->PreviousParse = NULL;
(*ppRootP)->ThisEead = pRootS;
(*ppRootP)->ThisBody = NULL;
(*ppRootP)->ThisParse = NULL;
(*ppRootP)->CodeGenerate = NULL;
(*ppRootP)->iFirstChar = 0;
(*ppRootP)->iLastChar = -1;
}
else
{
}
pSyntaxP = pRootS->FirstAlternate->ThisBody;
ppSyntaxP = &pSyntaxP;
bNextExists = (pSyntaxP!=NULL);
while (bNextExists && iWorkStatus)
{
if (pSyntaxP==NULL)
{
iStatus ~ TRUE;
return iStatus;
} /* На этом синтаксический анализ завершается */
bNextExists = TRUE;
iWorkStatus = TryMatchParse ( ppInputBuffer, k, pSyntaxP,
ppParseBody );
if (iWorkStatus)
{
bNextExists = GetNextSyntax ( ppSyntaxP );
}
else
{
iWorkStatus = SkipNextSyntax ( ppSyntaxP );
}
if ((*ppSyntaxP)I=NULL)
{
pSyntaxP = *ppSyntaxP;
}
} /* Конец цикла "while" проверки наличия еце одного узла */
iStatus = iWorkStatus;
return iStatus;
int GetNextSyntax ( struct sSyntaxBody** ppSyntaxP )
{
int iReturn = FALSE;
*ppSyntaxP = (*ppSyntaxP)->NextBody;
if ((*ppSyntaxP)!=NULL)
iReturn = TRUE;
return iReturn;
517
Синтаксический анализ и вычисление выражений
Глава 19
int SkipNextSyntax (struct sSyntaxBody** ppSyntaxP )
{
int iReturn = FALSE;
if (((*ppSyntaxP) ->ParentAlt->NextAlt) 1 =NULL)
{
*ppSyntaxP = (*ppSyntaxP)->ParentAlt->NextAlt->ThisBody;
}
if ((*ppSyntaxP)!=NULL)
iReturn = TRUE;
return iReturn;
}
void PrintParseTree ( struct sParseNode* plnput, int depth )
{
struct sParseNode* pParseNode;
int newDepth;
newDepth = depth+1;
pParseNode ~ plnput;
While (pParseNode!=NULL)
{
if (pParseNode==NULL)
return;
sp(depth); printf("At :%p: points :%p:%p:%s:\n",pParseNode,
pParseNode->ThisBead,pParseNode->ThisBody,
pParseNode->ThisHead->SyntaxName);
sp(depth); printf(" :%p:%p:%p: :%p:%p:%p:\n",
pParseNode->ParentParse, pParseNode->NextPar se,
pParseNode->PreviousParse,
pParseNode->ThisParse,pParseNode->ThisHead,
pParseNode->ThisBody);
if (pParseNode->ThisParse!=NULL)
{
PrintParseTree ( pParseNode->ThisParse, newDepth);
}
pParseNode = pParseNode->NextParse;
}
return;
}
void PrintSyntaxTree ( void )
{
struct sSyntaxHead* pSyntaxHead;
struct sSyntaxAlt* pSyntaxAlt;
struct sSyntaxBody* pSyntaxBody;
int iHead = 0;
int iAlt = 0;
int iBody = 0;
int i = 0;
/* Начать с корневого головного элемента синтаксиса */
pSyntaxHead = pRootSyntax;
printf ( "----------------—START-----------------------\n" );
/* Проверить в цикле все головные элементы синтаксиса */
while ((pSyntaxHead!-NULL) && (iHead<20))
{
iHead++;
printf("Head name :%s: address :%p:",pSyntaxHead->SyntaxName,
pSyntaxHead);
printf("\n");
printf("Syntax counter in head :%d:\n",pSyntaxHead->iSyntaxNumber);
printf("First Alternate in Head :%p:\n",pSyntaxHead->FirstAlternate);
Дополнительные тематические разделы
518
Часть HI
pSyntaxAlt = pSyntaxHead->FirstAlternate;
iAlt = 0;
while ((pSyntaxAlt!=NULL) 66 (iAlt<10))
{
iAlt++;
printf(" Start of alternate :%p:"rpSyntaxAlt);
printf(•\n");
printf(" Alternate counter :%d:\n",
pSyntaxAlt->iAlternateNumber);
printf(" Syntax Counter in Alternate :%d:\n",
pSyntaxAlt->iSyntaxNumber);
printf(" Body pointer in Alternate :%p:\n",
pSyntaxAlt->ThisBody);
/* Проверить в цикле все альтернативы данного головного элемента синтаксиса */
/* Проверить в цикле все основные элементы для данной альтернативы */
pSyntaxBody = pSyntaxAlt->ThisBody;
iBody - 0;
while ((pSyntaxBody!=NULL) 66 (iBody<20))
{
printf(" Start of body :%p:"fpSyntaxBody);
printf("\n");
printf(" parent alt :%p:\n"fpSyntaxBody->ParentAlt);
printf(" Body Contents :%p:\n",pSyntaxBody~>BodyContents);
if (pSyntaxBody~>BodyContents 1=NULL)
printf(" == :%p: s%ss\n"fpSyntaxBody->BodyContents,
(pSyntaxBody->BodyContents));
printf(" Syntax Head :%p:\n",pSyntaxBody->BodyHead);
printf(" Syntax Number :%d: alternate :%d:\n",
pSyntaxBody~>iSyntaxNumber , pSyntaxBody->iAlternateNumber);
printf(" End of body :%p:\n",pSyntaxBody);
pSyntaxBody = pSyntaxBody->NextBody;
iBody++;
} /* Конец цикла проверки основных элементов */
printf(" End of alternate :%p:\n",pSyntaxAlt);
pSyntaxAlt « pSyntaxAlt->NextAlt;
} /* Конец цикла проверки альтернативы */
printf("End of Head %s\n",pSyntaxHead->SyntaxName);
pSyntaxHead = pSyntaxHead-> pNextHead;
} /* Конец цикла проверки головного элемента синтаксиса */
printf ("---------------TABLES----------------------\n" );
printf("iNextSyntax=:%5.5d: iNextAlternate=:%5.5d:\n",iNextSyntax r
iNextAlternate);
for (i=0;(i<iNextSyntax);i++)
{
printf("%5.5d :%p: :%s:\n",i,SyntaxTable[iJ.pSyntaxPointer,
SyntaxTable[i].SyntaxName);
}
printf (" ....................................\n");
for (i=0;(i<iNextAlternate);i++)
{
printf("%5.5d :%p: :%5.5ds\n"fi,AlternateTable[i].pAlternatePointer,
AlternateTable[i].iSyntaxNumber);
1
printf ("------------------END------------------------\n")f-
return;
oid SetupRoutineNames ( void )
{
strcpy(RoutineNameTablef 0].sNameBody,"genadd");
RoutineNameTable[0]•BodyRoutine = genadd;
strcpy(RoutineNameTable[1].sNameBody,"gensubtract");
RoutineNameTable[1].BodyRoutine = gensubtract;
strcpy(RoutineNameTablef2].sNameBody,"genmultiply");
RoutineNameTable[2]-BodyRoutine = genmultiply;
519
Синтаксический анализ и вычисление выражений
Глава 19
strcpy(RoutineNameTable[3].sNameBody,"gendivide");
RoutineNameTable[ 3 ].BodyRoutine = gendivide;
strcpy(RoutineNameTable[ 4 ].sNameBody ,"genmodulus");
RoutineNameTable[ 4 ].BodyRoutine = genmodulus;
strcpy(RoutineNameTable[ 5 ].sNameBody ,"genmolt");
RoutineNameTable[5].BodyRoutine = genlt;
strcpy(RoutineNameTable[ 6 ].sNameBody ,"genie");
RoutineNameTable[6J.BodyRoutine = genie;
strcpy(RoutineNameTable[7].sNameBody,"gengt");
RoutineNameTable[ 7 ].BodyRoutine = gengt;
strcpy(RoutineNameTable[ 8 ].sNameBody ,"genge");
RoutineNameTable[ 8 ].BodyRoutine = genge;
strcpy(RoutineNameTable[9].sNameBody,"geneq");
RoutineNameTable[9].BodyRoutine = geneq;
strcpy(RoutineNameTable[10].sNameBody t"genne");
RoutineNameTable[10].BodyRoutine = genne;
strcpy(RoutineNameTable[11].sNameBody ,"genAND");
RoutineNameTable[11].BodyRoutine = genAND;
strcpy(RoutineNameTable[12 J.sNameBody,"genOR");
RoutineNameTable[12].BodyRoutine = genOR;
strcpy(RoutineNameTable[13].sNameBody,"genXOR");
RoutineNameTable[13].BodyRoutine = genXOR;
strcpy(RoutineNameTable[14].sNameBody,"genLAND");
RoutineNameTable[14].BodyRoutine = genLAND;
strcpy(RoutineNameTable[15].sNameBody,"genLOR");
RoutineNameTable[15].BodyRoutine = genLOR;
strcpy(RoutineNameTable[16].sNameBody,"parletter");
RoutineNameTable[16).BodyRoutine = parletter;
strcpy(RoutineNameTable[17].sNameBody,"pardigit");
RoutineNameTable[17].BodyRoutine = pardigit;
strcpy(RoutineNameTable[18].sNameBody,"paroctal");
RoutineNameTable[18].BodyRoutine = paroctal;
strcpy(RoutineNameTable[19].sNameBody,"parchar");
RoutineNameTable[19].BodyRoutine = parchar;
strcpy(RoutineNameTable[20].sNameBody,"genid");
RoutineNameTable[20].BodyRoutine = NULL;
strcpy(RoutineNameTable[21].sNameBody,"genconst");
RoutineNameTable[21].BodyRoutine = NULL;
strcpy(RoutineNameTable[22].sNameBody,"genplusplus");
RoutineNameTable[22].BodyRoutine ~ NULL;
globMaxName = 22;
return;
}
int main ( int argc, char * argv[])
{
int iStatus = EXITSUCCESS;
int bGoodSyntax = FALSE;
int bGoodParse = FALSE;
int bGoodOutput = FALSE;
int к =0;
char* p = NULL;
char* pParseBuffer= NULL;
printf("Parser; Version 1.0 20000325.20:47\n");
iNextSyntax = 0; /* Специальное обнуление элемента */
iNextAlternate =0; /* Специальное обнуление элемента */
SyntaxTablef0].SyntaxName]0] = ' \0';
SyntaxTable[0].pSyntaxPointer - NULL;
SyntaxTable[0].iStartsWith = 0;
SyntaxTable [0). iMustContain ~ 0;
520
Дополнительные тематические разделы
Часть III
AlternateTable!0].pAlternatePointer = NULL;
AlternateTable[0].iSyntaxNumber = 0;
AlternateTable!0].iStartsWith = 0;
AlternateTable!0]-iMustContain = 0;
pRootSyntax = NULL;
pRootParse = NULL;
fSyntaxFile = NULL;
strcpy(s SyntaxFileNamet"Syntax.txt");
flnputFile = NULL;
strcpy(sInputFileName, "Testinput,txt");
fOutputFile = NULL;
strcpy(SOutputFileName,"GeneratedCode.txt");
SetupRoutineNames ( );
globLabel = 0;
bGoodSyntax = Readsyntax ( &pRootSyntax );
flnputFile = fopen(slnputFileName,"r");
i f (fInputFile==NULL)
{
iStatus ~ EXITFAILURE;
return iStatus;
}
fOutputFile = fopen(sOutputFileName,"w");
if (fOutputFile==NULL)
{
iStatus = EXITFAILURE;
return iStatus;
}
while (!feof(flnputFile))
{
p = fgets(ParseBuffer,PARSEBUFFERLENGTB , flnputFile);
if(p!=NULL)
{
RemoveSpaces(ParseBuffer);
/* LexicalAnalyse!ParseBuffer) */
к = 0;
pParseBuffer = &ParseBuffer[0];
bGoodParse = Parse ( fcpParseBuffer, &k, pRootSyntax, fcpRootParse );
if (bGoodParse)
{
bGoodOutput = GenerateOutputCode ( pRootParse );
}
} /* Конец оператора "if/then", новая строка для анализа найдена */
} /* Конец цикла "while" чтения входного файла выражений */
if (fSyntaxFile!=NULL)
{
fclose(fSyntaxFile);
}
if (flnputFile!=NULL)
{
fclose(flnputFile);
}
if (fOutputFile!=NULL)
{
fclose(fOutputFile);
}
return iStatus;
521
В листинге 19.2 приведен основной код синтаксичес-
кого анализатора. Более подробные комментарии к нему
даны в файлах Chl9Pars.c и Chl9Pars-h, находящихся
на Web-сайте ’'ДиаСофт". Этому коду может потребо-
ваться много времени для обнаружения ошибки во вход-
ных данных, а также для поиска правильного пути син-
таксического анализа правильных входных данных. В
нем не используются таблицы "Должно содержать" и "С
чего начинается". Добавить соответствующий код вам
будет нетрудно.
Полная версия
Теперь, когда известно, каким образом может быть вы-
полнен синтаксический анализ выражения, осталось
рассмотреть еще два следующих вопроса: как сделать
синтаксический анализ эффективным и что можно
сформировать в качестве выходного результата.
Эффектность синтаксического анализа в данном слу-
чае означает необходимость указать те элементы, кото-
рые могут быть просмотрены на этапе предварительно-
го лексического анализа. Если вернуться к примеру
синтаксического анализа выражения
abc5 4- xyz 6
то можно заметить, что при этом был опробован, при-
чем неоднократно, элемент identifier (идентификатор).
Если бы подобные лексемы identifier были обнаружены
на этапе предварительного анализа, тогда их не потре-
бовалось бы повторно анализировать в каждой альтер-
нативе. В рассматриваемой здесь нотации вместо обо-
значения ::= может быть использовано обозначение :L:=
каждого элемента, предварительно обработанного при
лексическом анализе. Таких элементов должно быть не
так уж и много при условии, что они заложены в син-
таксисе достаточно глубоко во избежание многочислен-
ных повторений их рассмотрения анализатором.
Формирование выходного результата означает, что
необходимо предпринять ряд действий, связанных с
каждым анализируемым элементом. В используемой
здесь нотации можно ввести в квадратных скобках имя
функции, написанной на языке С (например, [паше]),
для обозначения вызова функции, которая сформирует
по завершении синтаксического анализа выходной ре-
зультат, соответствующий данной конкретной ветви
проведенного анализа.
Иногда синтаксическое правило может быть лучше
выражено или более эффективно реализовано с помо-
щью конкретной функции, вызываемой для применения
этого правила. Если имя функции, написанной на язы-
ке С, указывается в фигурных скобках (например,
{паше}) непосредственно после определения этого име-
ни, то будет применяться именно эта лексическая фун-
кция, написанная на С, вместо обычного механизма
синтаксического анализа.
Синтаксический анализ и вычисление выражений
Глава 19
Возможно, полезным окажется также введение дру-
гих сокращенных процедур, вызываемых во время син-
таксического анализа. Они могут быть указаны в круг-
лых скобках (например, (паше», однако такой способ
здесь не демонстрируется. Подобные процедуры могут
быть использованы в обход обычного синтаксического
анализа в особых местах синтаксиса, где не требуется
применять в полную силу обычные возможности более
медлительного синтаксического анализатора. Такую
возможность следует рассматривать только в том случае,
если время выполнения кода синтаксического анализа-
тора играет первостепенную роль.
Таким образом, можно было бы получить следую-
щий синтаксис:
identifier :L:= letter identifier-tail it
identifier-tail {lexidtail} ::= letter identifier-tail \ digit
identifier-tail | identifier-tail | empty it
additive-expression ::= multiplicative-expression | additive-
expression "+" multiplicative-expression [genadd} | additive-
expression multiplicative-expression #
Следует заметить, что каждая функция, которая
вызывается из этого синтаксиса, должна быть доступна
для применения в синтаксическом анализаторе.
Такие функции служат в качестве дополнения к
обычной синтаксической нотации. Безусловно, они яв-
ляются не только средствами генерирования выходно-
го кода в результате синтаксического анализа, но и
удобным способом записи, описанным здесь и проде-
монстрированным в коде на Web-сайте "ДиаСофт".
Полный синтаксис выражений
Приведенный ниже синтаксис реализован в коде, нахо-
дящемся в файлах СЫ9Раг2.с и Chl9Par2.h на нашем
CD-ROM, а сам синтаксис находится в файле
ExpSynt2.txt.
empty ::= #
primary-expression ::= identifier [genid] | constant [genconst]
| "(" expression ")" it
identifier :L:= letter identifier-tail it
identifier-tail {lexidtail} letter identifier-tail | digit
identifier-tail | " "identifier-tail | empty it
letter (parletter) :L:= "x" #
single-character (parchar) :L:— ’x" #
constantinteger-constant | character-constant [floating-
constant it
character-constantT" small-character-constant | small-
character-constant it
small-character-constant :L:— "'"single-character"'" |
'""escaped-character"'" it
522
Дополнительные тематические разделы
Часть III
digit (pardigit) :L:= '0"| "Г'| ’2"| '3"| '4"| '5"| Ъ"| 7м
|'8"|'9"#
octal-digit (paroctal) :L:= '0" | 7" | '2W | 3" | '4" | 3й |
"6"| 7"| '8"| '9й#
optional-octal-digitoctal-digit | empty #
hex-digit digit | upper-hex-digit | lower-hex-digit |
upper-hex-digit ::= "N" | В" | 'C" | D" | 'E" | T" #
lower-hex-digit V | Ъ" | V | 'И " | V | Г #
escaped-character {lexescchar} :L:= *\" escape-sequence it
escape-sequence Ъ" | V | V" | ’b” | Tr*| ЧТ | "a" | VI
7 й | '***| octal-digit optional-octal-digit optional-octal-digit
| V' hex-digit hex-digit #
integer-constant flexintcon] :L:~ digit integer-constant | digit it
floating-constant {lexflpcon} :L:= integer-pan fraction-part
E-part exponent F-part it
integer-constantNL digit integer-constant | digit it
integer-part integer-constantNL | empty it
fraction-part point integer-part | empty it
point* * #
E-part ::= Г | *EW | empty it
F-part T | T" | V | IT | empty it
exponent ;;= optional-sign injeger-constant | empty it
optional-sign | | empty it
postfix-expression primary-expression | postfix-expression
"++"[genplusplus] | postfix-expression [genminusminus]
it
unary-expression ::=postfix-expression | [genplusplus] "++"
unary-expression | [genminusminus] unary-expression |
unary-operator cast-expression [genunary] it
unary-operator" | 7" it
cast-expression unary-expression it
multiplicative-expressioncast-expression | multiplicative-
expression "*" cast-expression [genmultiply] | multiplicative-
expression */" cast-expression [gendivide] | multiplicative-
expression "%" cast-expression [genmodulus] it
additive-expression multiplicative-expression | additive-
expression "+" multiplicative-expression [genadd] | additive-
expression "- " multiplicative-expression [gensubtract] it
shift-expression ::= additive-expression \ shift-expression
additive-expression [genleftshift] | shift-expression ”»"
additive-expression [genrightshift] it
relational-expression shift-expression | relational-
expression "<"shift-expression[genlt] | relational-expression
”>” shift-expression [gengt] | re/aftottaZ-expression "<=”
shift-expression [genie] | relational-expression ">=" shift-
expression [genge] it
equality-expression relational-expression | equality-
expression *'==" relational-expression [geneq] | equality-
expression relational-expression [genne] it
AND-expression equality-expression | AND-expression
equality-expression [genAND] it
exclusive-OR-expression AND-expression [exclusive-OR-
expression AND-expression [genXOR] a
inclusive-OR-expression exclusive-OR-expression |
inclusive-OR-expression exclusive-OR-expression[genOR]
it
logical-AND-expression inclusive-OR-expression |
logical-AND-expression "&&" inclusive-OR-expression
[genLAND] it
logical-OR-expression logical-AND-expression | logical-
OR-expression "\\" logical-AND-expression[genLOR] it
expression ::= logical-OR-expression it
Приведенные выше определения классов letter (бук-
ва) и single-character (одиночный символ) полностью опи-
раются на реализованные в коде процедуры, причем
правые части этих определений представляют отнюдь
не то, что они означают в действительности.
Интуитивные правила обычного языка
Каждое соответствующее правило синтаксиса было до-
полнено вызовом процедуры, которая призвана внедрять
код конкретного арифметического оператора. В местах
расположения вызовов процедур указывается, что перед
выполнением соответствующей операции все подвыра-
жение должно быть проанализировано. Каждый опера-
тор применяется, начиная с нижней части дерева син-
таксического анализа (т.е. с наиболее удаленной от
корня точки) вверх в направлении корня. На самом деле
операторы применяются в описанном выше порядке
следования "предков после потомков" (называемом так-
же обходом в обратном порядке).
Для каждого подвыражения имеется одна конкрет-
ная точка, в которой вызывается вычисляющая его фун-
кция. Появление более одной точки приводит к внедре-
нию лишнего кода, что, возможно, нет так уж критично,
хотя может привести к снижению эффективности. Этот
предмет здесь глубоко не рассматривается, поэтому те,
кого интересуют вопросы написания компиляторов с оп-
тимизацией. должны обратиться к другим источникам.
К лексическим элементам, которые не требуется
всякий раз повторно анализировать, относятся следую-
щие: identifier (идентификатор), small-character-constant
(небольшая символьная константа), escaped-character (уп-
равляющий символ), digit (цифра), integer-constant (целочис-
ленная константа) и floating-constant (константа с плава-
ющей точкой). Вследствие того что первая часть
Синтаксический анализ и вычисление выражений
Глава 19
523
элемента floating-constant (т.е. integer-part (целая часть))
может быть подобна элементу integer-constant, поиск
этой пары лексических элементов должен выполняют-
ся в следующем порядке: floating-constant, а затем integer-
constant. Этот синтаксис был изменен таким образом,
чтобы отразить наличие двух разных видов элемента
integer-constant того, что используется в лексическом
анализе, и того, что лежит в основе другого определе-
ния (integer-constantNL), для которого лексический ана-
лиз не требуется.
Строгие правила языка С
Различные процедуры, имена которых теперь обозначе-
ны в синтаксисе, должны быть известны синтаксичес-
кому анализатору. По мере загрузки синтаксического
дерева выполняется сопоставление идентификаторов с
известным списком, а затем в синтаксическом дереве
размещаются указатели на реальные процедуры. Если
процедура неизвестна, тогда может быть выдано сооб-
щение об ошибке. В этом случае в рассматриваемом
примере кода размешается простой указатель на значе-
ние NULL. Соответствующий код находится в файлах
Chl9Pars.c и Chl9Pars.h на Web-сайте "ДиаСофт”.
Преобразование из формы польской
нотации в оценочную функцию
Форма польской нотации выражения существует в син-
таксическом анализе в виде дерева. Ранее уже было по-
казано, каким образом в результате просмотра дерева
может быть сформирована запись в форме обычной или
обратной польской нотации. Часть такого анализатора,
генерирующая код, осуществляет просмотр дерева в по-
рядке следования "предков после потомков", применяя
процедуры генерирования кода в каждом содержащем зап-
рос узле. Запросы на генерирование кода размещаются в
конце соответствующих альтернатив, так что они оказы-
ваются последними элементами, встречающимися при
обработке ветви. Это придает особое значение приме-
нению обратной польской нотации. Характер каждой
процедуры генерирования кода определяется видом
обрабатываемого оператора.
Описание процесса обычным языком
Прежде всего осуществляется чтение абстрактного син-
таксиса и создание внутреннего описания абстрактно-
го синтаксиса (т.е. того, что можно написать). Затем
выполняется первый вариант синтаксического анализа
каждой строки реальных входных данных (т.е. обнару-
жение того, что фактически было написано) и генери-
рование соответствующего кода. При этом осуществля-
ется просмотр дерева синтаксического анализа и при-
менение операций генерирования кода в порядке сле-
дования обратной польской нотации. Действия
различных процедур описаны в табл. 19.4.
Приведенный в табл. 19.4 код не столь эффективен
по сравнению с тем кодом, который может быть сгене-
рирован. Например, в окончательной последовательно-
сти может неоднократно встретиться следующая пара
команд:
stack[index++] = Al;
Al = stack [index—] ;
которая всегда может быть оптимизирована. Этого мож-
но добиться благодаря организации простого взаимодей-
ствия между процедурами генерирования кода либо
второго прохода сгенерированного кода, при котором
удаляются лишние кодовые пары. В настоящих компи-
ляторах выполняется не только это, но и оптимизация
циклов, исключение общих подвыражений, правильная
организация использования регистров для сокращения
числа обращений к памяти и т.д.
Пример кода для некоторого процесса
В коде, приведенном в листинге 19.3, показаны неко-
торые процедуры генерирования кода. В этом примере
синтаксический анализатор и генератор кода на самом
деле не вычисляют выражения самостоятельно. Для
этого достаточно заменить приведенные в данном при-
мере процедуры генерирования кода соответствующи-
ми процедурами вычисления выражений. Этот код вне-
дряется в том же порядке,, в котором он будет
вычисляться, поэтому вместо внедрения команд после-
дние будут просто выполняться в вычисляющем вари-
анте этого синтаксического анализатора.
Синтаксический анализ ошибочного
ввода
Возможно, читатель вводит данные идеально, не делая
ошибок, и поэтому синтаксическому анализатору его
выражений обработка ошибок не потребуется. А вот
автор этих строк вводит данные неуверенно, пропуская
скобки, делая опечатки, размещая знак плюса перед
целыми числами и по забывчивости создает операторы
типа "!>" ("не больше"). Поэтому синтаксическим ана-
лизаторам его выражений требуется обработка ошибок,
чтобы сообщить о месте их совершения при написании
выражения.
Дополнительные тематические разделы
Часть III
524
Таблица 19.4. Процедуры генерирования кода.
Процедура генерирования кода Действие Описание
X[genid] A1 = x;stack[lndex++] = Al; Загрузить содержимое идентификатора в регистр А1 и поместить его в стек
X[genconst] A1 = x;stack[index++] - A1; Загрузить константу в регистр А1 и поместить ее в стек
[genplusplus] A1 = stack[index++];A2 = 1;A1 = = A1 + A2;stack[index++] = A1; Прибавить 1 к верхнему элементу стека
[genminusminus] Al = stack[index-];A2 = 1;A1 = = A1 — A2;stack[index++] = A1; Вычесть 1 из верхнего элемента стека
[genmultiply] A1 = stack[index-];A2 = - stack[index~];A1 = A1 * A2; Умножить два верхних элемента стека. Этот код весьма похож на код других арифметических операций. Так, для выполнения операций [genadd], [gensubstruct] и [genmodulus] над одним символом достаточно заменить команду stack[index++] = А1
[genlt] A1 = stack[index-];A2 = = stack[index—];if(A1 < A2) goto M2;A1 = O;goto L2;M2:A1 = 1;L2: Определить, является ли один элемент стека меньше другого. Следует заметить, что другие операции сравнения — [gengt], [genie], [geneq] и [genne] — выполняются аналогичным образом. Для этого необходимо лишь изменить оператор сравнения
t [genunary]; A1 = stack[index-];A1 = tAI; stack[index++] = A1; Применить унарный оператор t к верхнему элементу стека
[genAND] Al = stack[index-];A2 = = stack[index—];A1 = A1 & A2; stack[index++] = A1; Применить оператор AND к двум верхним элементам стека. Этот код аналогичен коду других логических операций: [genOR], [genXOR], [genLAND] и [genLOR]. На самом деле этот код также весьма похож на код, внедренный для арифметических операций
Листинг 19.3. Некоторые процедуры генерирования кода,
int GenerateOutputCode ( struct sParseNode* pRootP )
{
int iStatus = TRUE;
struct sParseNode* pParseSead;
struct sParseNode* pParseBody;
pParseSead = pRootP;
pParseBody = pParseBead->ThisParse;
while ((pParseBead!=NULL) && (iStatus==TRUE))
{
iStatus = ProcessOutputNode ( fcpParseBead, (pParseBody );
}
return iStatus;
int ProcessOutputNode ( struct sParseNode** ppParseBead,
struct sParseNode** ppParseBody )
{
int iStatus = TRUE;
if {(«ppParseBody)==NULL)
{
if (/*((*ppParseBead)->ThisBody!=NULL) && */
(((*ppParseBead)->CodeGenerate)!=NULL))
{
(*ppParseHead)->CodeGenerate ( NULL );
}
525
Синтаксический анализ и вычисление выражений
Глава 19
}
else
{
♦ppParseBody - (*ppParseBody)->NextParse;
}
if((*ppPars eBody)!=NULL)
{
♦ppParseHead = (*ppParseBody)->ParentParse;
}
else
{
♦ppParseHead = NULL;
}
return iStatus;
int gencomparison ( char* pszComparator )
{
int iStatus = TRUE;
fprintf(fOutputFile,"Al = stack[index—];\n");
fprintf(fOutputFile,"A2 = stack[index—];\n");
fprintf(fOutputFile,"if (Al %s A2) goto M%4.4d;\n",
pszComparator,++globLabel);
fprintf(fOutputFile,"Al - 0;\n");
fprintf(fOutputFile,"goto L%4.4d;\n",globLabel);
fprintf(fOutputFile,"M%4.4d:\n",globLabel);
fprintf(fOutputFile,"Al = l;\n");
fprintf(fOutputFile,"L%4.4d:\n",globLabel);
return iStatus;
int genlt ( void* one )
{
int iStatus;
iStatus = gencomparison("<");
return iStatus;
}
int gengt ( void* one )
{
int iStatus;
iStatus = gencomparison(">");
return iStatus;
}
int genie ( void* one )
{
int iStatus;
iStatus = gencomparison("<=");
return iStatus;
}
int genge ( void* one )
{
int iStatus;
iStatus - gencomparison(">=");
return iStatus;
}
int geneq ( void* one )
{
int iStatus;
526
Дополнительные тематические разделы
Часть III
iStatus = gencomparison("==");
return iStatus;
}
int genne ( void* one )
{
int iStatus;
iStatus = gencomparison("!=");
return iStatus;
}
int genoperate ( char* pszOperator )
{
int iStatus - TRUE;
fprintf(fOutputFile,"Al = stack[index—];\n");
fprintf(fOutputFile,"A2 = stack[index—];\n");
fprintf(fOutputFile,"Al = Al %s A2;\n",pszOperator);
fprintf(fOutputFile,"stack[index++] = Al;\n");
return iStatus;
}
int genadd ( void* one )
{
int iStatus;
iStatus = genoperate("+");
return iStatus;
}
int gensubtract ( void* one )
{
int iStatus;
iStatus = genoperate;
return iStatus;
}
int genmultiply ( void* one )
{
int iStatus;
iStatus = genoperatef"*");
return iStatus;
}
int gendivide ( void* one )
{
int iStatus;
iStatus » genoperatef"/");
return iStatus;
}
int genmodulus ( void* one )
{
int iStatus;
iStatus = genoperate("%");
return iStatus;
}
int genAND ( void* one )
{
int iStatus;
iStatus - genoperate("&&");
527
Синтаксический анализ и вычисление выражений
Глава 19
return iStatus;
}
int genOR ( void* one )
{
int iStatus;
iStatus = genoperatef"II");
return iStatus;
}
int genXOR ( void* one )
{
int iStatus;
iStatus - genoperate("*");
return iStatus;
}
int genLAND ( void* one )
{
int iStatus;
iStatus = genoperate("&");
return iStatus;
}
int genLOR ( void* one )
{
int iStatus;
iStatus = genoperate("|");
return iStatus;
}
void sp(int depth)
{
int i;
for (i=O;i<depth;i++)
printf(" ");
return;
}
Аристотель говорил, что правильное рассуждение
конечно, однако существует бесконечное число спосо-
бов неправильного рассуждения. При синтаксическом
анализе возможны любые ошибки, однако самое луч-
шее, чего можно добиться в автоматизированном син-
таксическом анализаторе, — это указать на первую об-
наруженную ошибку и дать пользователю возможность
самостоятельно ее исправить. При обработке ошибок
приходится допускать, что входной текст близок к пра-
вильному выражению на данном языке. Ведь нельзя же
в самом деле ожидать, что компилятор языка С будет
выдавать осмысленные сообщения об ошибках, если
предоставить ему программу на COBOL или текст ро-
мана Finnegans Wake ("Поминки по Финнегану”}.
Нисходящий синтаксический анализатор определя-
ет ошибку только в том случае, когда он достигает кон-
ца входных данных, причем это не дает ни малейшего
преставления о том, где именно была совершена ошиб-
ка. Восходящий синтаксический анализатор нередко
может более точно указывать местонахождение ошиб-
ки во входных данных, однако это происходит отнюдь
не всегда. Что касается синтаксиса выражений, напи-
санных на языке С, то в этом случае благоразумное
предположение о местонахождении ошибки может быть
сделано. Если же входные данные представлены на та-
ком языке, как, например, FORTRAN IV, то найти ме-
сто совершения ошибки будет непросто в силу конст-
рукции самого языка.
Один из способов, позволяющих сделать обработку
ошибок в синтаксическом анализаторе более полезной,
состоит в разделении входных данных при первоначаль-
ном проходе на подвыражения, которые могут быть
определены в результате лексической проверки. Что
касается языка С, то при первом проходе могут быть
попарно сгруппированы квадратные и круглые скобки,
а затем вызван отдельный процесс синтаксического ана-
лиза содержимого, заключенного в каждую пару таких
скобок.
528
Дополнительные тематические разделы
Часть III
Более подробные сведения об обработке ошибок
приведены в рекомендованной выше книге "Принципы
проектирования компиляторов"Альфреда В. Ахо и Джеф-
фри Д. Улльмана.
Итак, внимательно пишите код и пользуйтесь син-
таксическим анализом!
Резюме
В этой главе была рассмотрена альтернативная (и более
старая) форма БНФ, а также были показаны некоторые
ее расширения, способствующие созданию более эффек-
тивных синтаксических выражений.
Был приведен пример транслятора, который читает
синтаксис языка, а затем анализирует его, выдавая вы-
ходной семантический результат или его интерпрета-
цию. Это один из наиболее распространенных приме-
ров транслятора. И наконец, здесь было показано, что
даже пример кода, приведенный в этой книге, способен
анализировать отнюдь не все. Поэтому дальнейшее изу-
чение синтаксического анализа вы, при необходимос-
ти, будете осуществлять самостоятельно.
Создание программных
инструментальных средств
В ЭТОЙ ГЛАВЕ
Характеристики хороших программных средств
Библиотеки кодов
Фильтры и инструменты общего применения
Автоматическое генерирование тестовых данных
Генераторы кода
Ричард Хэзфилд
Существует три вида программных инструментальных
средств:
• Те, которые мы создаем для других людей
• Те, которые другие создают для нас
• Те, которые мы создаем для себя
Мы все создаем инструменты для других людей. Для
наших пользователей эти программы являются инстру-
ментами, которые призваны облегчить их работу.
В то же время мы все используем инструменты, со-
зданные для нас другими людьми: операционные сис-
темы, компиляторы, компоновщики, профайлеры, си-
стемы управления реляционными базами данных,
анализаторы кодов, текстовые редакторы, системы уп-
равления версиями и так далее.
В этой главе речь пойдет о третьем виде инструмен-
тов — о тех, которые мы создаем для себя, чтобы облег-
чить свою работу по созданию инструментов для дру-
гих людей. Поэтому под термином ’’программные
инструментальные средства’’ (software tools) будут под-
разумеваться именно такие инструменты.
Иногда трудно объяснить менеджеру проекта, на-
сколько выгодно создавать такой инструмент, который
конечный пользователь никогда не увидит и производ-
ство которого может оказаться сравнительно дорогим.
Тем не менее, разработка такого программного обеспече-
ния может привести к реальному снижению себестоимо-
сти всего проекта в более или менее короткие сроки.
НУЖНЫЕ ИНСТРУМЕНТЫ СОЗДАВАЙТЕ САМИ
Года два назад я работал над проектом Year 2000. Пер-
вым моим заданием была оценка инструмента Y2K от
поставщика специальных программных средств. Мы потра-
тили около двух недель, пытаясь заставить этот инстру-
мент делать то, что нам надо, но он делал лишь то, для
чего был разработан, а это определенно не было связа-
но с проблемой 2000 г.!
Этот продукт (необычная форма программы grep) боль-
ше других подходил для наших целей. Он стоил около
(25000 (или почти $40000) за копию, а нам требовалось,
по крайней мере, пять копий. Я решил, что можно быс-
трее и дешевле написать инструмент, лучший чем Y2K.
Именно это и было сделано. Сначала мы нашли DOS-вер-
сию grep (сейчас это нетрудно). Затем написали на языке
С несколько программ форматирования данных, прими-
тивный генератор кодов для создания командного файла
под управлением DOS, содержащий множество (сотни!)
обращений к функции grep, и внешний интерфейс на
Visual Basic. Был написан также другой генератор кодов,
который выходные данные из grep переформатировал как
операторы #pragma message, заданные как источники
сообщения "Hello world". Каждое сообщение имело точ-
но такой же формат, как и предупреждающее сообще-
ние компилятора Visual C++ 1.5. И наконец, была создана
программа обмена информацией между Visual Basic и
Visual C++ 1.5, которая автоматически при нажатии кла-
виш посылает команды на загрузку и компиляцию сгене-
рированного файла. Затем Visual C++ выводит содержи-
мое всех операторов #pragma message в окне вывода.
Поскольку операторы имеют собственный формат пре-
дупреждения, реакция на них была такая же, как если
бы они сами являлись предупреждениями. Итак, при двой-
ном щелчке на кнопке grep можно было исследовать код
в контексте проблем, связанных с использованием двух-
цифровых полей года.
Конечно же такой программный инструмент никогда не
смог бы составить коммерческой конкуренции инструмен-
ту, который мы оценивали. Но его создание не было
просто забавой. Мы действительно хотели получить ин-
струмент, который бы в точности отвечал нашим требо-
ваниям. (Недавно я узнал, что наш клиент до сих пор
использует этот инструмент для других целей, сэкономив
при этом немало денег.)
34 Зак. 265
Дополнительные тематические разделы
Часть III
530
Я никогда не встречал кого-нибудь, кто бы входил
в команду программистов конкретно с целью написания
инструментов для остальной части команды. Но смысл
ясен: никто вместо нас не создаст нужные нам инстру-
менты.
Характеристики хороших
программных средств
Свои инструменты следует писать не быстро, а правиль-
но. Конечно, для этого могут потребоваться определен-
ные ресурсы программирования. Но игра стоит свеч —
хорошие инструменты можно использовать снова и сно-
ва. Давайте поговорим о том, как создавать хорошие
программные средства.
Интерфейс пользователя
Поскольку созданные нами инструменты не предназна-
чены для широкого использования, они не обязательно
должны быть ’’красивыми". Они даже не должны быть
основаны на GUI. В действительности для основных
инструментов зачастую лучше обеспечить простой ин-
терфейс типа командной строки. Во-первых, это намно-
го упростит их использование в комбинации с конвей-
ерами и фильтрами, а во-вторых, я могу написать
программу в ANSI С и буду уверен, что вы поймете ее
с первого взгляда. Гораздо сложнее будет ее понять, если
мне придет в голову использовать библиотеку GUI, с
которой вы незнакомы. Все инструменты, которые были
разработаны в этой главе, предназначены для работы в
среде командной строки, но в то же время их легко
можно модифицировать для использования в GUI-про-
граммах.
Когда разрабатывается новый программный инстру-
мент, то хотелось бы думать, что пользователь знает,
для чего предназначен этот инструмент, особенно если
вы предполагаете использовать его самостоятельно. Но
представьте себе, что шесть месяцев назад в конце пер-
вой фазы проекта вы создали инструмент, с помощью
которого, скажем, производили тестирование. Это был
очень полезный инструмент. С тех пор он не использо-
вался. Скоро заканчивается вторая фаза проекта, и вам
снова потребуется этот инструмент. Вспомните ли вы,
как он работает?
Во избежание этой проблемы создайте свое "прави-
ло правой руки", по которому все инструменты, кото-
рые вы создаете, должны включать стандартный способ
проведения ненавязчивого напоминания о том, как им
пользоваться. Один способ заключается в том, чтобы во
все такие программы добавить переключатель -h (или,
если вам нравится, -?), который интерпретируется как
просьба о помощи. Другой способ — это введение не-
которого рода аргумента командной строки с заданным
по умолчанию значением (например, argc==l), при ко-
тором бы выводился короткий список инструкций по
работе с программой.
Насколько это возможно, ориентируйте программу
на работу со стандартным вводом/выводом. Хорошо,
если требуется манипулировать двоичными файлами, но
с текстовыми файлами может возникнуть много специ-
фичных для конкретного проекта проблем. Использо-
вание стандартного ввода/вывода позволит получить
довольно большое преимущество от конвейеров и филь-
тров для объединения инструментов в новые созидатель-
ные формы.
КАК ЗАСТАВИТЬ ИНСТРУМЕНТЫ РАБОТАТЬ ВМЕСТЕ
Несколько лет назад, когда я работал в страховой ком-
пании в Великобритании над новой большой деловой сис-
темой расценок, мне поручили проверить, отвечают ли
make-файлы современным требованиям. Звучит это до-
вольно просто, но таких файлов было множество, и все
они были просто огромны!
Все начиналось с решения задач вручную, но я постоян-
но находил способы, с помощью которых можно было
автоматизировать некоторые из наиболее рутинных аспек-
тов работы. Со временем я закончил работу и получил
маленькую строку инструментов — всего около десятка
инструментов. Все они использовали стандартный ввод/
вывод, и в результате я смог связывать их вместе в од-
ной длинной строке, наподобие следующей:
а < makefile |b|c|d|e|f|g|h|
i | j > reportfile
Это позволило сэкономить много времени и значительно
ускорило выполнение моих задач, хотя и выглядело очень
необычно. В принципе, можно было бы немного пере-
делать стандартный ввод/вывод. Но смысл, надеюсь, по-
нятен. Простые инструменты, разработанные для совмес-
тной работы, позволяют существенно упростить работу.
На этой идее основано большинство инструментов UNIX.
Ошибкоустойчивость
Теоретически, крайне необходимо, чтобы ваши инстру-
менты были такими же устойчивыми в отношении по-
явления ошибок, как и промышленные программы. На
практике, однако, этот совет часто не принимается во
внимание. Если вы такой же, как и множество других
программистов, то хотя бы сделаете ошибкоустойчи-
вость программ пропорциональной количеству раз ее
использования.
При кодировке одноразового файла, возможно, вы не
будете делать проверки рабочих битов функции
malloc(), если только это не вошло у вас в привычку.
Возможно, это и преувеличение, но всегда проверяйте
значение, возвращаемое функцией fopen(), и выводите
как можно более содержательное сообщение, если это
531
значение неверно. Это позволит сэкономить много ва-
шего времени.
Гибкость
Чем более гибкими являются инструменты, тем боль-
ше вероятность того, что их можно будет повторно ис-
пользовать для других целей. С другой стороны, для
этого придется потратить больше времени, а это может
оказаться для вас проблемой. Но если у вас есть время
решить простую проблему, то расширьте ее, а затем
напишите программу для решения этой обобщенной
проблемы. Вы поймете, что это один из наиболее ин-
тересных и полезных аспектов создания инструментов.
Простота
Достижение этой цели в некоторой мере состоит в кон-
фликте с достижением гибкости. Здесь нужен компро-
мисс. Более простая программа, скорее всего, будет
использоваться один или два раза. Программа считает-
ся гибкой, если в будущем ее можно будет использовать
лишь с небольшими изменениями. Если вы сможете
написать простую и гибкую программу, это будет дей-
ствительно выигрышная комбинация.
Переносимость
Все лучшие программы в конечном счете переносятся
на другие платформы. Чем ближе ваш программный ин-
струмент к ANSI С, тем будет проще перенести его на
другой компилятор или на другую операционную сис-
тему. Если проблема состоит в существенной неперено-
симости, то попробуйте разбить ее на две задачи, одна
из которых переносима, а вторая — нет. Например, если
требуется определить количество строк в каждом фай-
ле дерева каталогов, то можно написать программу счи-
тывания такого дерева, которая записывает все соответ-
ствующие имена файлов в отдельный файл (без
необходимости считывания самих файлов). Можно так-
же написать вторую программу, которая будет считы-
вать этот файл как входной. Затем его можно перенес-
ти с использованием функции fopen(), которая в свою
очередь работает с каждым названием файла, ничего не
зная о всей структуре директории. Это позволяет дей-
ствительно очень просто перенести программу в другие
рабочие среды, поскольку для этого нужно будет толь-
ко переписать первую программу. Кроме того, некото-
рые операционные системы обеспечивают команды на
уровне интерфейса пользователя для работы с файло-
выми системами. Это довольно неплохо, поскольку оз-
начает. что по крайней мере для этих операционных
систем вообще не потребуется переписывать эту часть
инструмента.
Создание программных инструментальных средств
Глава 20
Библиотеки кодов
Повторное использование кодов — это обязательное ус-
ловие продуктивного программирования. В простейшем
случае мы снова используем коды каждый раз, когда
обращаемся к функции printf() или strcpy(). Можно за-
даться целью собрать коллекцию полезных операций за
время всей своей карьеры. К сожалению, мы не всегда
утруждаем себя упорядочением этих операций для
облегчения их повторного использования. Очень часто,
когда встречаются знакомые проблемы, мы думаем про
себя: "Точно, я делал что-то подобное несколько меся-
цев назад". Затем идем и ищем исходный код старой
программы, копируем нужную ветвь программы, встав-
ляем ее в новую программу и просто ждем, пока эти
программы выполняют то, что требуется.
Но так не должно быть. Любая реализация С позво-
ляет создавать библиотеки полезных подпрограмм и
связывать эти библиотеки с приложениями. Технология
компоновки и связывания в различных версиях компи-
лятора С выполняется по-разному, но это всегда мож-
но сделать. Проверьте документацию локальной версии
для получения информации по поводу построения биб-
лиотек.
Здесь нам поможет осторожное программирование.
Как правило, если мы попытаемся решить проблему в
более общем виде, чем это может сделать специфичес-
кое приложение, то можно намного облегчить свою ра-
боту в будущем, а сейчас придется потратить лишь не-
много времени. Если это войдет в привычку, то процесс
написания программ не покажется вам долгим, так как
у вас уже будет серьезная коллекция полезных про-
грамм, которые можно многократно использовать. Та-
ким образом, можно гораздо быстрее создавать инстру-
менты. (Небольшой пример: файловый фильтр.
Используя библиотеку двоичного дерева, можно филь-
тровать текстовый файл для дублирования строк за три
шага: считать stdin в настроенное на текст дерево, ско-
пировать во второе настроенное на количество строк
дерево и записать второе дерево в stdout. Работа сдела-
на. Исходная программа содержит лишь около 15 строк
небиблиотечных кодов.)
Переменные с областью видимости файла — это
главное препятствие для повторного использования про-
грамм. Большинство функций связаны с программой, в
которой они находятся, и их труднее вырезать и встав-
лять в другую программу. Это одна из причин, по ко-
торой вообще не рекомендуется использовать перемен-
ные с областью видимости файла (независимо от того,
являются они static или extern).
Отдельно следует упомянуть об организации биб-
лиотек. Хорошие редакторы связей (компоновщики)
связывают библиотечный код в программу, разрешая
Дополнительные тематические разделы
Часть III
532
доступ только тем подпрограммам, которые действи-
тельно используются данной программой. Такой подход
дает два реальных связанных между собой преимуще-
ства. Во-первых, окончательная программа оказывает-
ся меньше, чем если бы в нее встроили всю библиоте-
ку. Во-вторых, это значит, что выполнение программы
имеет преимущество из-за небольшого размера кода, так
как небольшие программы менее подвержены загрузкам
и разгрузкам памяти (свопированию) менеджером памя-
ти операционной системы. Это процесс, который иног-
да значительно увеличивает время выполнения. Мы
можем помочь компоновщику, размещая насколько это
возможно по нескольку функций в каждом исходном
файле. Идеально, когда в исходном файле содержится
только одна функция. Это связано с тем, что очень труд-
но корректно извлечь код из объектного файла на фун-
кциональном уровне (рассмотрите, например, случай,
когда функция использует переменные с областью дей-
ствия файла), поэтому компоновщик имеет склонность
выбирать из библиотеки целые объектные файлы.
ПРИМЕЧАНИЕ
На Web-сайте "ДиаСофт” каждая функция не выделена
в отдельный файл, чтобы не заставлять вас работать с
несметным количеством новых исходных файлов. Но в то
же время, нам нелегко было принять такое решение.
Фильтры и инструменты общего
применения
Лучшие инструменты — это те, которые можно много-
кратно использовать, даже если они выполняют самые
простые функции. Ниже приведено краткое описание
некоторых из наиболее часто используемых инструмен-
тов общего назначения.
Преобразование символов табуляции в
символы пробела
Многие программисты на языке С имеют особое отно-
шение к введению отступов. Одни настаивают на том,
что табуляция — это зло, другие твердо убеждены в ее
необходимости. Скорее всего, правильны оба мнения.
Однако некоторые среды (особенно в мире мэйнфрей-
мов) представляют проблемы для исходного кода, со-
держащего символы табуляции, поэтому будет полезно
иметь способ конвертировать эти символы в пробелы и
наоборот. Создать такой инструмент очень просто, по-
этому не стоит даже приводить здесь его исходный код.
Вы можете также найти утилиту преобразования табу-
ляция-пробел в коллекции фрагментов кода Боба Сто-
ута (Bob Stout’s Snippets collection) по адресу: http://
www.snippets.org (прекрасная подборка универсальных
инструментов С. Однако если вы заинтересовались про-
блемой преобразования табуляция-пробел, то, наверное,
найдете занимательным написать собственную програм-
мку, которая делает такого рода преобразование.
Преобразование из EBCDIC в ASCII
Да, EBCDIC до сих пор используется на многих Web-
сайтах. Большинство эмуляторов терминала имеют ути-
литу конвертирования, которая производит необходи-
мые преобразования между ASCII и EBCDIC, когда
необходимо передавать файлы между мэйнфреймовской
платформой и платформой PC или UNIX. Однако не-
трудно представить случай, когда вам захочется сделать
это самому. Например, если создается универсальный
Web-браузер, то, возможно, будет полезно выполнять
ваши собственные преобразования. Прекрасно работа-
ющую конверсионную программу можно также найти
в коллекции Боба Стоута. На Web-сайте "ДиаСофт”
имеется таблица преобразования ASCII-EBCDIC (в
файле ascebc.txt), которая хранится в удобном для ва-
ших программ формате (CSV) и которую можно исполь-
зовать, если вы решитесь создать свой собственный
инструмент преобразования. Будет лучше, если в такой
программе использовать беззнаковый тип unsighned char.
На мэйнфреймовской платформе по умолчанию тип char
является беззнаковым (unsighned), так как EBCDIC —
это 8-битовый код. ASCII — это только 7-битовый код,
и обычно он представлен типом sighned char, но сим-
волы ASCII по-прежнему могут на полных основаниях
храниться в переменных типа unsighned char. Дальней-
шее сравнение различий показывает, что не все коды
EBCDIC имеют эквиваленты в ASCII, поэтому нужно
тщательно рассмотреть, каково будет соответствующее
поведение программы преобразования EBCDIC-ASCII,
которая встречает символ EBCDIC, не имеющий экви-
валента в ASCII и заданный конкретными условиями
вашего проекта.
Просмотр выходных данных
В рабочих средах, обеспечивающих командную строку,
наиболее естественно перенаправить выходные данные
программы в файл. Но некоторым людям нравится на-
блюдать, что происходит во время работы программы.
Например, в MS-DOS с помощью команды dir вызыва-
ется список директорий, который можно легко исполь-
зовать для получения списка файлов для ввода в про-
грамму. Для этого нужно просто перенаправить
выходной поток в файл (например, dir * . c/b>clist).
Хотя более удобно, если одновременно можно видеть
выходные данные; для этого в MS-DOS нет возможно-
сти. Но можно написать простую программу, которая
приводит к получению желаемого эффекта, как пока-
зано в листинге 20.1.
533
Листинг 20.1. Разделение выходных данных
программы на два потока,
linclude <stdio.h>
void tee (FILE *fp)
{
char buffer[2048];
while(fgets(buffer, sizeof buffer, stdin))
{
fprintf(stdout, "%s", buffer);
if(NULL != fp)
{
fprintf(fp, "%s", buffer);
}
}
}
int main(int argc, char *argv[])
{
FILE *fp = NULL;
if(argc > 1)
{
fp = fopen(argv[ 1 ], "w");
if(NULL == fp)
{
fputs("Error opening output stream.",
stderr);
}
}
tee(fp);
if (NULL 1= fp)
{
fclose(fp);
}
return 0;
Программа в листинге 20.1 копирует стандартный
ввод в стандартный вывод и в то же время записывает
его в файл, название которого содержится в argv[l]
(если такой есть). Программа настолько проста и полез-
на, что даже трудно понять, почему компания Microsoft
не включила ее в MS-DOS как стандартную утилиту.
Как бы то ни было, эта программа позволяет путем мо-
дификации команды dir (например, dir * . c/b | tee clist)
сразу же просмотреть результаты и спрятать их в файл.
(Пользователи UNIX, естественно, предпочитают ис-
пользовать is вместо dir, а пользователи MVS при этом,
возможно, сокрушаются, так как большинство их инст-
рументов работают в пакетном режиме, вне пределов
видимости.) Между прочим, это только один пример
применения — можно найти множество других спосо-
бов получить выгоду из этой простой программы.
Простой разделитель строк
Некоторые среды устанавливают ограничения на длину
строк, что делает перенос кода более болезненным, чем
Создание программных инструментальных средств
Глава 20
бы этого хотелось. Например, не будет ничего необыч-
ного, если исходные файлы мэйнфреймовских про-
грамм хранятся в библиотечном наборе данных (БНД)
с длиной записи 80 битов (вот почему мэйнфреймовс-
ких программистов иногда обвиняют в "80-колончатом
мышлении”). В результате мэйнфреймовский документ
стандартов кодирования С-проектов часто настоятель-
но требует, чтобы строки были не длиннее, чем 80 ко-
лонок, или даже в некоторых случаях 72 колонки. Это
позволяет просматривать весь исходный код в редакто-
ре ISPF, который для вашего комфорта и удобства ото-
бражает восьмиразрядные номера строк. Это хорошо,
если код пишется на той же самой платформе, потому
что редактор не позволяет забывать о таком ограниче-
нии. Однако, если код уже существует на другой плат-
форме и требуется его перенести, то шансы на успех
увеличиваются, когда существуют строки кода, которые
превышают допустимый предел. В таких случаях пра-
вильное решение — это отредактировать исходный код
в форму, удобную для переноса. Это способ средней
трудоемкости. Хотя проще было бы быстро проверить
существующий исходный код — может быть, он будет
работать даже если его не модифицировать при переносе
на новую платформу. Возможно, теперь вы захотите из-
бавиться от утомительных преобразований, особенно
если тест на переносимость показал, что требуется про-
извести много преобразований, перед тем как програм-
ма будет правильно работать на новой платформе. В
таких случаях редактирующая ваш код программа-ока-
жет необходимую помощь. (UNIX-программисты ис-
пользуют для этой цели intent и, скорее всего, перей-
дут прямо в конец этого листинга.)
Листинг 20.2 показывает, как может работать такая
программа.
Листинг 20.2. Простая программа разделения
строк.
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
void help(void)
{
char *helpmsg[] =
{
"limn",
"Usage: limn <n>",
"Example: limn 72",
"Copies standard input to standard
output,",
"ensuring that no line exceeds n
characters",
Tin length. Longer lines are split,
and a",
"terminating \\ character is added to
the",
534
Дополнительные тематические разделы
Часть Ш
"line at the split point, n must be at
least 3."
};
size t if j = sizeof helpmsg /
sizeof helpmsg[0];
for(i = 0; i < j; i++)
{
puts(helpmsg[ i ]);
}
}
int main(int argc, char **argv)
{
int status = EXITSUCCESS;
char *endp;
int thischar;
size t lim;
size_t currline = 0;
if(argc <2 || strcmp(argv[ 1 ]f == 0)
{
help();
Status = EXITFAILURE;
}
else
{
lim = (sizet)strtoul(argvf1], &endp,
10);
if(endp == argv[lj || lim < 3)
{
help();
printf(-\nlnvalid arg %s\n", argv[l]);
status = EXITFAILURE;
}
else
{
while((thischar = getchar()) 1= EOF)
{
if(thischar == '\n')
{
currline « 0;
}
else if(++currline == lim)
{
putchar( '\V);
putchar('\n');
currline = 1;
}
putchar(thischar);
}
}
)
return status;
Чтобы увидеть, насколько неизящно это решение,
давайте попробуем осуществить фильтрацию исходно-
го файла С (такого, как сама эта программа) с аргумен-
том командной строки, равным 10. Ниже приведен
фрагмент результата вывода.
int main(\
int агдсг\
char **a\
rgv)
<
int sta\
tus = EXI\
TSUCCESS
7
char *e\
ndp;
int thi\
schar;
size_t \
lim;
size t \
currline \
= 0;
Как видите, ничего хорошего. Конечно, при ограни-
чении 80 это не выглядит так плохо, как при значении
10, но все равно это не самый лучший способ.
Если у вас есть достаточно времени, можете пере-
писать эту программу для разделения строк в более под-
ходящих местах. Использование строковых литералов
немного усложняет такую задачу, но позволяет получать
вполне корректные результаты.
СОВЕТ
Можно разделять строковые литералы на порции. Напри-
мер, строка
"The system has detected that you pressed a
key - press [RESET] to effect this chance"
превращается в строку
"The system has detected" "that you pressed a
key — press [RESET]" "to effect this
chance".
Теперь эту строку можно разделить между кавычками,
которые вставлены по-новому и которые не должны быть
разделены запятыми.
Поиск и замена байтов
Я полагаю, что этот раздел главы явился следствием
моих усилий в мэйнфреймовском С-программировании;
я разработал несколько инструментов специально с це-
лью переноса исходных кодов с PC на мэйнфрейм. Если
вы когда-нибудь использовали мэйнфреймовский тек-
стовый редактор, то поймете, почему я предпочтитаю
писать коды на PC!
Создание программных инструментальных средств
Глава 20
535
В некоторых терминальных программах эмуляции
символы квадратных скобок [ и J не поддерживаются.
Символы ОхВА и ОхВВ — это эквиваленты EBCDIC
символов ASCII 0x5В (левая кка. (ротная скобка) и 0x5D
(правая квадратная скобка). Однако на практике эти
значения зачастую (в зависимости от установок вашей
терминальной эмуляции) не работают, потому что ком-
поновщик отбрасывает их как недопустимые символы.
Для С-программистов это представляет определенную
проблему. Одним из решений, если это можно так на-
звать, является использование вместо скобок триграфов.
Например:
char MyArray??(??) = "Hello world";
char YourArray??(100??) = (О);
Этот метод работает, но код довольно трудно про-
читать.
Как только встречается триграф, EBCDIC загружа-
ет пару символов, которые компоновщик трактует как
если бы они были [ или ]. Коды EBCDIC для двух сим-
волов в форме вопросительного знака - это OxAD и
OxBD.
Было бы неплохо, если бы можно было написать
программу для конвертирования всех квадратных ско-
бок в С-программе в значения ASCII, которые при кон-
вертировании файла в EBCDIC становятся значениями
EBCDIC и которые наводят компилятор на мысль, что
квадратные скобки в коде действительно являются та-
ковыми.
Не правда ли, было бы неплохо также, если бы мож-
но было написать программу для конвертирования лю-
бого произвольно выбранного значения байта в файле
в некоторые другие, указанные нами значения?
Я назвал эту программу sandra. Это не женское имя,
название означает просто Search AND ReplAce (поиск и
замена). Эту программу можно найти на Web-сайте
"ДиаСофт” под названием sandra.c. Но будьте осторож-
ны: как вы видите, в sandra отсутствует проверка ввода.
Взгляните, например, на функцию HexToInt() (листинг
20.3).
Листинг 20.3, Поиск и замена байта,
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude <ctype.h>
int BexToInt(char *s)
{
int IntVal = 0;
char Hex[) = "0123456789ABCDEF";
char *p = NULL;
while(*s 1= '\0')
{
IntVal «= 4;
p = strchr(Hex, toupper(*s));
if (NULL 1= p)
{
IntVal |= (p - Hex);
}
else
{
printf("Can't convert hex value %s.\n"r
s);
exit(EXIT_FAILURE);
}
++s;
}
return IntVal;
I
Если использовать эту программу осторожно, то она
будет прекрасно работать. К сожалению, при непра-
вильном вводе (т.е. когда строка не распознается как
имеющая шестнадцатиричный формат) она что-то не-
разборчиво пишет в выходной поток и завершает рабо-
ту. Это делает нереальным включение функции
HexToInt() в библиотеку кодов. Очень стыдно, потому
что это довольно полезная программка. К счастью, ее
очень легко исправить — просто нужно дописать допол-
нительный параметр: указатель на значения ошибки или
указатель на объект, в котором может быть сохранен
результат (оставьте возвращаемое значение свободным
для использования его в качестве кода ошибки).
Но это не единственная проблема рассматриваемой
программы. Вы видите ошибку? Если задается достаточ-
но большая строка ввода, то она переполняет перемен-
ную IntVal, что приводит к неопределенному поведению
программы. (Этого можно избежать, изменив тип пере-
менной IntVal на unsighned int. Выдача неправильного
результата не прекратится, если передается чрезмерно
длинная строка, но он будет, по крайней мере, предска-
зуемо неправильным.)
Когда создаются программные инструментальные
средства для собственного использования, то можно не
доводить их до совершенства, другое дело — промыш-
ленный код. Запомните: неопределенное поведение
программы может коснуться не только ваших пользова-
телей, но и вас самих.
Давайте просмотрим остальную часть программы.
Наши проблемы еще не закончились...
void Sandra (char *filename, int in, int out)
{
FILE *fp = NULL;
unsigned long count = 0;
unsigned char c;
fp = fopen(filename, "r+b");
if(NULL == fp)
{
printf("Can't open file %s for
update.\n", filename);
Дополнительные тематические разделы
536
Часть III
exit(EXITFAILURE);
}
while(fread(&с, 1, 1, fp))
if(с == (unsigned char)in)
{
c = (unsigned char)out;
fseek(fp, -IL, SEEKCUR);
count++;
if(l != fwrite (&c, 1, 1, fp))
{
puts("Can't write to file.");
fclose(fp);
exit(EXITFAILURE);
}
if(EOF == fflush(fp))
{
puts("fflush failed.");
fclose(fp);
exit(EXIT_FAILURE);
I
I
}
fclose(fp);
printf("The byte was replaced %lu time%s.\n",
count,
count == 1UL ? "" : "s");
}
Эта функция тоже имеет свои недостатки. К счас-
тью, на этот раз они незначительны.
Во-первых, название функции будет не настолько
описательным, как, скажем, SearchAndReplaceByte().
Присвоенные функциям и переменным вычурные на-
звания сначала всегда кажутся невинно веселыми. Че-
рез шесть месяцев после этого на практике вы можете
и не вспомнить, каково же все-таки назначение этой
функции. Теперь вы предупреждены, поэтому не вините
меня, если седые волосы у вас все-таки появятся.
Вторая проблема похожа на проблему с функцией
HexToInt(): она тесно связана с конкретным приложе-
нием, как и функция HexToInt().
Обратите также внимание на вызов функции fflush().
В языке С между операциями считывания данных из
потока и затем их записи в поток требуется обращение
к функции размещения файла (к одной из следующих:
fseek, fgetpos или rewind). Если вы записываете данные
в поток, а затем считываете из него, то между этими
двумя операциями должны вызвать функцию размеще-
ния файла fflush(). Если этого не сделать, программа
активизирует неопределенное поведение, и не надо
удивляться, когда она произведет форматирование ва-
шего жесткого диска или сделает вообще нечто из ряда
вон выходящее.
Л Один из технических рецензентов этой книги, ис-
пользуя Turbo C++ в режиме ANSI С под управлением
Windows 98, понял, что эта программа не работает, как
нужно и прилежно заменил fflush() на fseek(fp, 0L,
SEEK_CUR). Это рациональный обходной путь, но он
не понадобится, если использовать по-настоящему
ANSI-ориентированный компилятор.
И наконец, давайте рассмотрим функцию main().
Важный момент здесь — это поведение программы, ког-
да добавляется несколько аргументов. ANSI не гаранти-
рует, что argv[0] содержит название программы. Для
конкретной С-реализации будет абсолютно правильным
снабдить программу значением argc, равным 0. В этом
случае argv[0] будет NULL. Если же ваша операцион-
ная система всегда обеспечивает значение argc, равное,
по крайней мере, 1 и вас не заботит выпрос переноси-
мости, то для вас это не является проблемой.
int main(int argc, char *argv[])
{
if(argc < 4)
{
printf("Usage: %s filename searchbyte
replacebyte\n",
argc > 0 ? argv[0J : "sandra");
}
else
{
Sandra(argv[l], BexToInt(argv[2]),
BexToInt(argv[3 J));
}
return 0;
}
Теперь переписывание программы sandra с целью
придания ей большей ошибкоустойчивости станет для
вас простым упражнением. Возможно, это полезно сде-
лать, если вы используете более одной платформы и
особенно если работаете на мэйнфреймовских системах.
Шестнадцатиричные данные
Многие С-программисты считают, что данные лучше
хранить в текстовых файлах. Их легко создавать и мо-
дифицировать с помощью текстовых редакторов, легко
читать и легко переносить с одной операционной сис-
темы на другую. Двоичные файлы более громоздки.
Часто бывает невозможно их прочитать, так как они
содержат непечатаемые символы. Их также довольно
трудно правильно модифицировать, и они очень не-
удобны для переноса, поскольку различные операцион-
ные системы используют различные стратегии выравни-
вания и даже различную последовательность байтов.
Тем не менее, иногда приходится использовать двоич-
ные данные, хотя бы потому, что мы приступили к
проекту слишком поздно для того, чтобы влиять на
проектные решения по хранению данных. В этом слу-
чае очень полезно выводить шестнадцатиричные выход-
ные данные двоичного файла в stdout, т.е. получать
шестнадцатиричный дамп.
537
Несколько довольно полезных утилит уже выполня-
ют это. К сожалению, они имеют тенденцию показы-
вать шестнадцатиричные результаты вывода в формате
из шестнадцати колонок. Хорошо, если ваши записи
имеют длину, кратную 16 байтам. Но, как правило, это
не так.
Поэтому давайте напишем собственную утилиту (ли-
стинг 20.4). По умолчанию установим длину строки
равной 16 байтам, поскольку это дает приемлемо разум-
ный вывод на 80-колоночный экран. Однако мы обес-
печим и возможность изменения длины строки, чтобы
колонки могли иметь требуемую ширину. Я позаботил-
ся, в частности, о том, чтобы сделать этот код макси-
мально переносимым, поэтому его можно запускать
довольно безопасно на любой платформе, даже на та-
ких, на которых один байт имеет 32 бита. Создавая
инструменты для множества платформ, позаботьтесь об
их переносимости и приложите к этому все усилия
Листинг 20.4. Шестнадцатиричный дамп.
linclude
linclude
linclude
linclude
linclude
<stdio.h>
<stdlib.h>
<string.h>
<ctype.h>
<limits.h>
/* Функция help() берется из книжного текста.
См. файл hd.c */
int BexDumpfchar «Filename, size t Width)
{
int Status = EXIT SUCCESS;
FILE «InFilePtr;
В языке С тип char определен имеющим такой же
размер, как и один байт. Большинство систем имеют 8-
битовые байты. В действительности это так широко рас-
пространено, что многим программистам трудно пове-
рить, что возможен другой размер байтов. Тем не менее,
существуют архитектуры, которые используют 16- и
даже 32-битовые байты. Если вы захотите отобразить
каждый шестнадцатиричный разряд (гексит) в байте, то
важно знать, какое количество гекситов следует отобра-
жать. Это можно довольно просто подсчитать. Если
имеется CHAR_BIT битов в одном байте (задается в
библиотеке <limits.h>) и четыре бита для гексита (это
всегда истинно), то CHAR_BIT/4 гекситов будут тре-
бовать для своего представления один байт. Уже лучше!
Но в действительности не требуется, чтобы CHAR__BIT/4
было кратно 4, поэтому фактически перед делением на
4 к CHAR_BIT необходимо добавить три бита. Напри-
мер, если CHAR-BIT равно 9 или 10 или 11, то двух
Создание программных инструментальных средств
Глава 20
гекситов недостаточно. Однако (CHAR_BIT+3)/4 гек-
ситов уже будет достаточно.
int BexitsPerByte - (CBARBIT + 3) / 4;
unsigned char «TextBuffer;
unsigned char «BexBuffer;
sizet BytesRead;
sizet ThisByte;
size_t BexBuffWidth;
InFilePtr = fopen(Filename, "rb");
if(NULL == InFilePtr)
{
printf("Can't open file %s for
reading.\n",
Filename);
Status = EXITFAILURE;
}
else
<
BexBuffWidth = Width *
(BexitsPerByte + 1);
TextBuffer = malloc(Width + 1);
if(NULL == TextBuffer)
{
printf("Couldn't allocate %u bytes.\n",
(unsigned) (Width 4- 1));
Status = EXITFAILURE;
}
else
{
BexBuffer = malloc(BexBuffWidth 4- 1);
if(NULL =« BexBuffer)
{
printf("Couldn't allocate %u bytes.\n",
(unsigned) (BexBuffWidth 4- 1));
Status = EXITFAILURE;
}
else
{
Здесь Width байтов обрабатываются одновременно.
Сохраняя действительно прочитанное количество бай-
тов (которые получились при указании размера блока,
равного 1, и подсчета Width), можно обработать после-
дние несколько байтов файла, который не кратен в точ-
ности указанной ширине, в том же цикле, что и основ-
ную часть данных файла.
while ( (BytesRead = fread(TextBuffer,
1,
Width,
InFilePtr)) > 0)
{
for(ThisByte = 0;
ThisByte < BytesRead;
ThisByte4-4-)
{
538
Дополнительные тематические разделы
Часть III
/* Вставить шестнадцатиричный код в
шестнадцатиричный буфер с соответствующим
сдвигом */
sprintf((char *)(HexBuffer +
ThisByte *
(BexitsPerByte + 1)),
"%0*X ",
HexitsPerByte,
(unsigned) TextBuffer [ThisByte] ) ;
По вполне очевидным причинам мы не хотим выво-
дить непечатаемые символы. Общее соглашение состо-
ит в отображении на их местах некоторых других сим-
волов, вроде точки поэтому сделайте это тоже.
if(91sprint(TextBuffer[ThisByte]))
{
TextBuffer[ThisByte] =
}
}
TextBuffer[ThisByte] = '\0';
printf("%-*.*s | %s\n",
HexBuffWidth,
HexBuffWidth,
HexBuffer,
TextBuffer);
}
if(terror(InFilePtr))
{
printf("Warning: read error on
file %s.\n".
Filename);
Status » EXITFAILURE;
}
/* release memory resource */
free(HexBuffer);
}
/* release memory resource */
free(TextBuffer);
}
/♦ release file resource */
fclose(InFilePtr);
}
return Status;
int main(int argc, char **argv)
{
int Status = EXITSUCCESS;
size_t NumChars - 16;
char ♦EndPointer;
int FilenameArg = 1;
if(argc < 2 || strcmp(, argv[l]) == 0)
<
Help();
Status = EXITFAILURE;
1
else
{
if(memcmp(argv[l], "-c", 2) == 0)
{
FilenameArg = 2;
NumChars = (sizet)strtoul(argv[l] + 2,
fcEndPointer,
10);
При преобразовании из строкового в цифровой фор-
мат всегда используйте семейство функций strtox:
strtod(), strtol(), stroul() и т.д.. Они дают намного боль-
ше информации о преобразовании, чем atoi() или atof().
В частности, они сообщают, каким был первый символ,
который нельзя преобразовать.
if (EndPointer == argv[l] 4-2 || NumChars < 1)
<
Help();
puts("\nlnvalid or missing argument.");
Status = EXITFAILURE;
}
}
}
if(EXIT_SUCCESS == Status)
{
Status = HexDump(argv[FilenameArg], NumChars);
}
return Status;
)
Более развернутая программа шестнадцатиричного
дампа может включать размер заголовочной записи как
дополнительный, возможно необязательный аргумент и
отображать группы байтов либо по отдельности, либо
все вместе. Таким образом, если заголовочная запись
будет иметь размер, отличный от других записей, это
не будет препятствовать получению их в таком виде, как
мы хотим. Если эта модификация окажется полезной,
можете спокойно использовать ее в своем исходном коде.
Автоматическое генерирование
тестовых данных
Тестирование является "любимой ненавистью” каждо-
го программиста. Отладка, несмотря на негативное со-
держание, действительно может быть увлекательной.
В этом есть дух вызова, тайны, требующей раскрытия,
и множество разработчиков получают огромное удовлет-
ворение, когда дефект наконец устраняется. Но в то же
время тестирование действительно надоедает. При тес-
тировании не должно быть никаких сюрпризов, пото-
му что теоретически все ошибки найдены. Полностью
Создание программных инструментальных средств
Глава 20
539
завершенное тестирование предполагает до крайности
многочисленное повторение прогонов программы. Од-
нако если это нужно делать, так почему бы не попы-
таться сделать это немного проще и быстрее? Если мы
сможем автоматизировать, по крайней мере, некоторые
задачи, связанные с тестированием, то можно сохранить
много времени и работа будет не так скучна.
Один из аспектов тестирования, который относит-
ся к автоматизации, — это генерирование тестовых
(контрольных) данных. Подумайте, насколько ввод те-
стовых данных может быть раздражающе долгим и уто-
мительным. Можно ли сэкономить немного времени на
наборе данных на клавиатуре? Если мы сможем напи-
сать программу, которая продумывает вместо нас тес-
товые данные, то можно значительно сэкономить вре-
мя, которое тратится на рутинные процессы.
Написание вспомогательных приложений
для тестирования
Лучшим способом автогенерирования тестовых данных
является написание программы, которая производит
файл или файлы, которые приложение сможет легко
прочитать. Чтобы это сделать, имеет смысл написать
приложение таким образом, чтобы оно могло считывать
файл контрольных данных и использовать их тем же
способом, что и "живые" данные. Может быть, наше
приложение будет в обычном порядке принимать вво-
димые данные прямо от пользователя, возможно с по-
мощью графического API-интерфейса. В зависимости от
приложения желательно было бы проверять под-
программы ввода данных отдельно, в то время как
считывание файла автоматически сгенерированных кон-
трольных данных в приложение выполняется исключи-
тельно для тестирования базовых алгоритмов. С другой
стороны, может оказаться необходимым использовать
коммерческий инструмент тестирования для управле-
ния интерфейсом пользователя. В последнем случае
можно разработать генератор тестовых данных таким
образом, чтобы он производил файлы таких данных,
которые смог бы прочитать основной инструмент тес-
тирования. Таким образом, можно выполнить все про-
верки за один цикл и совсем без какого-либо ручного
вмешательства. Если это для вас не проблематично и
формат наших файлов доступен для вас, то можно по-
рекомендовать формат CSV.
Если вам не приходилось встречаться с CSV, сооб-
щаю, что это аббревиатура от comma-separated values
(значения, разделенные запятой), которая означает, что
список значений разделяется запятыми (за исключени-
ем запятых, заключенных в кавычки, — в этом случае
они считываются как часть строки, разграниченной ка-
вычками). Такой формат очень прост для генерирова-
ния и относительно легок для считывания (с использо-
ванием функции strtok() или некоторым подобным об-
разом). Более того, считывать и писать файлы в формате
CSV могут большинство программ табличных вычисле-
ний. Однако если требуется получить данные автома-
тически, но в то же время с некоторыми улучшениями
фожно добавить несколько специальных тестов, кото-
рые не производит наш генератор, отредактировать су-
ществующие тесты и т. п.), то нужно просто загрузить
файл в крупноформатную таблицу, на месте отредакти-
ровать его и заново сохранить. Если же под рукой нет
подходящей крупноформатной таблицы, то для быст-
рой очистки данных можно использовать текстовый ре-
дактор (хотя это не так просто, поскольку текстовый ре-
дактор вряд ли расположит данные в форме таблицы).
Другое преимущество считывания файлов тестовых
данных в формате крупноформатной таблицы заключа-
ется в том, что для проверки результатов можно исполь-
зовать возможности любой современной программы таб-
личных вычислений. Мы создаем файлы в формате CSV.
Загружаем вводимые данные в крупноформатную таб-
лицу и записываем формулы для расчета ожидаемых
результатов. При тестировании программы можно затем
сравнить эти результаты с теми, которые были получе-
ны в крупноформатной таблице. Если в результате тес-
тирования программы получается выходной файл в
формате CSV, это просто замечательно, потому что
путем электронного сопоставления можно сравнить ре-
зультаты с теми, которые приведены в крупноформат-
ной таблице, — это огромная экономия времени! Сле-
дует добавить, что в случае, если вы примете это
предложение, не приписывайте сразу все несовпадаю-
щие результаты проверяемой программе, так как ошиб-
ка может находиться в табличной формуле. Эту ошиб-
ку можно найти путем тщательной проверки и самой
программы, и табличных формул, а возможно (и это
даже лучше) путем пересчета правильного результата
каким-нибудь другим способом.
Как ваше приложение реагирует на сбой? Может,
оно саморазрушается, унося с собой дефектные данные
и отображая множество сообщений об ошибках и сбо-
ях? А может быть, оно обеспечивает некоторый способ
для записи ошибки, а затем спокойно переходит к сле-
дующему набору данных?
Не всегда можно избежать эффекта лавинного обра-
зования ошибок. Иногда действительно требуется оста-
новить процесс обработки ошибок. В большинстве слу-
чаев, конечно, мы этого не делаем. Если круглосуточная
работа банка данных в национальном информационном
центре остановилась из-за того, что какой-то клерк в
Манчестере набрал в номере счета 3 вместо 2, то грош
цена такому банку. Теперь приходится писать програм-
мы, которые, насколько это возможно, позволяют ис-
правлять ошибки. Если мы сможем создать такую про-
Дополнительные тематические разделы
Часть III
540
грамму, она, конечно, поможет при тестировании. Если
же нет, то нужно разработать программу для поиска не
более чем одной проблемы за один ее тестовый прогон.
Разработка тестовых данных
При написании генераторов тестовых данных требует-
ся выяснить все полезные критерии для таких данных.
В основном требуется проверить их на ошибки заниже-
ния, переполнения, деления на нуль и т.п. В то же вре-
мя выполнение заурядного теста, на данных которого
программа работает нормально, говорит о том, что вы
"не против свидания, но жениться не хотите". Все-таки
стоит потратить немного времени на то, чтобы сделать
тестовые данные более полными, и удостовериться, что
программа будет осуществлять тестирование тщательно.
Автоматические генераторы тестов лучше использо-
вать для ординарных случаев, но если вам повезет, то
его можно будет применить и в некоторых особых слу-
чаях. Если при этом приложение даст сбой, это будет
даже лучше (в плохом всегда ищите хорошее). А вооб-
ще, в особенных случаях действительно следует прове-
сти ручную работу по вводу реальных тестовых данных.
Написание кода генерирования тестовых
данных
Написать программу генератора всесторонних тестовых
данных довольно сложно, если не сказать невозможно,
поэтому и не будем пробовать. Вместо этого выберем
относительно простое гипотетическое приложение, ко-
торое обрабатывает журнал транзакций, состоящий из
шифра документа, даты, названия счета и результата.
Как можно сгенерировать тестовые данные для этой
программы?
Нетрудно создать относительно правдоподобные
данные. Этот несуществующий обработчик журнала
транзакций ожидает ввода шифров документов в фор-
мате АА9999/аа (т.е. две большие буквы, четыре числа,
слэш и три маленькие буквы, например "BD4392/rjh").
Для облегчения сортировки лучше всего представить
даты в международном формате дат yyyy/mm/dd (напри-
мер, 2000/06/28). Затем требуется указать название сче-
та (так как это бизнес, то требуются настоящие дело-
вые названия), а также результат транзакции — два
десятичных разряда. Если транзакция состоит в расхо-
довании, то результат должен быть отрицательным.
В противном случае результат будет положительным.
Здесь очень помогут случайные числа. (Конечно,
стандартная библиотека С не производит случайных
чисел — они просто псевдослучайны. Но в то же время
они случайны в достаточной мере, чтобы можно было
работать с ними, поэтому все равно воспользуемся ими
и тоже назовем "случайными", даже если это, строго
говоря, не так. Случайные числа дают действительно
случайные данные. Это конечно хорошо, но тоже свя-
зано с проблемами. Что, если позже потребуется пере-
строить файл с теми же данными, что и в прошлый раз?
В языке С значения, которые дает функция rand(),
основываются на начальной величине, которая запуска-
ет внутреннюю реализацию какого-нибудь алгоритма
генерирования псевдослучайных чисел. Начальную ве-
личину можно выбрать самостоятельно и просто пере-
дать ее функции srand(). Если передается постоянное
значение, то вы всегда получите от этой функции тот
же самый результат. Если вместо этого передается слу-
чайное значение, то каждый раз будут получаться раз-
ные результаты. (Как можно получить случайное зна-
чение для передачи его функции srand()? Очень просто:
srand(time(NULL)).)
Основной механизм для примера генератора тесто-
вых данных передает функции srand() постоянное или
случайное значение в зависимости от параметра коман-
дной строки. Здесь этот механизм не показан, но его
можно найти на Web-сайте "ДиаСофт" в файле
datagen.c.
Затем мы применим пару функций для генериро-
вания случайных чисел R двойной точности в диапазо-
не 0.0<=R<1.0 и целых чисел в диапазоне 0<=R<N.
Многие для получения случайных целых чисел в задан-
ном диапазоне используют оператор % (например,
rand() % N). Это приемлемо, если генератор случайных
чисел, используемый в этой программе, действительно
хороший. Большинство из них посредственны, так как
не всегда числа случайны в разрядах битов нижних
уровней настолько, насколько это требуется. Техноло-
гия, показанная в листинге 20.5, значительно лучше,
поскольку располагает более значимые биты в разрядах
более высокого уровня; многие коммерческие генерато-
ры случайных чисел делают почти то же самое.
Листинг 20.5. Генерирование случайных тестовых
данных.
double RandDbl(void)
{
return rand() / ((double)RAND MAX 4- 1.0);
}
int Randlnt(int n)
{
return (int)(n * RandDbl());
}
Теперь мы готовы к генерированию некоторых дан-
ных. В следующей функции нет ничего сложного, но
следует обратить внимание на один или два момента.
Во-первых, как вы видите, здесь задается пара указате-
лей на алфавит (один для больших и один для малень-
Создание программных инструментальных средств
Глава 20
541
ких букв). Если ваша система использует ASCII, то мож-
но получить случайную букву алфавита с использова-
нием простого выражения, такого как Randlnt(26)+’A*.
В противном случае работайте на системе, которая ис-
пользует другие (например, EBCDIC). Указанная здесь
технология применяется для всех кодовых таблиц (но
не во всех языках; для простоты используйте обычный
26-буквенный английский алфавит).
Чтобы ввод исходных данных сделать нагляднее и
проще, можно задать пару массивов для хранения двух
элементов типичного названия компании. Реальная ре-
ализация программы, возможно, будет считывать дан-
ные из файла, и они будут иметь сравнительно более
широкий диапазон. Технология при этом остается той
же — мы комбинируем два этих элемента наугад для
получения нормального разброса названий компаний.
int GenerateData(FILE *fp, size__t MaxRecs)
{
char ‘Lower = "abcdefghijklmnopqrstuvwxyz
char ‘Upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ
char *Name[] =
{
"Arrow",
"Complete",
"Eagle",
Gilbert",
"Ingenious",
"Kludgit & Runn",
"Mouse",
"Objective",
"Quality",
"Systemic",
"Underwater",
"Wannabee",
"Bizarre",
Drastic",
Fiddleyew",
Havago",
"J Random Loser",
Lightheart",
"Neurosis",
"Paradigm",
"Runaway",
"Terrible",
"Value",
"YesWeWill"
char'‘Business[ ] =
{
"Advertising",
"Computers",
"Engineering",
"Garage",
"Industries",
"Knitwear",
"Mills",
Office Cleaning"
"Questionnaires",
"Systems",
"Upholstery",
"Waste Disposal",
};
"Building",
"Deliveries",
Foam Packing",
Hotels",
Janitorial",
"Laser Printers",
"Notaries",
,"Printers",
"Radio",
"Talismans",
"Van Hire",
"Yo-yos"
size t NumNames = sizeof Name /
sizeof Name[0);
sizet NumBuses = sizeof Business /
sizeof Business[O];
time t date time t;
struct tm date = {0};
struct tm *pd;
size t ThisRec;
datetime_t = time(NULL);
pd = localtime(fcdatetimet);
if(pd != NULL)
{
memcpy(fcdate, pd, sizeof date);
}
else
Чего действительно нужно избегать — так это гене-
рирования непреднамеренно плохих тестовых данных.
При обращении к функции localtime() нет никаких га-
рантий, что мы получим правильную дату. Следует
учесть это и установить альтернативную дату. Выберем
1 января 2000 года как основную дату для использова-
ния в экстренной ситуации. Но в обычных случаях бу-
дем использовать текущую дату.
{
date.tmmday = 1;
date.tmmon = 0;
date.tmyear = 100;
}
fprintf(fp,
"Reference,Date,Account,Amount\n");
for(ThisRec = 0; ThisRec < MaxRecs;
ThisRec++)
{
fprintf(fp,
"%c%c%04d/%c%c%c,".
Upper[RandInt(26)],
Upper[Randlnt(26)],
Randlnt(10000),
Lower[Randlnt(26)],
Lower[Randlnt(26)],
Lower[Randlnt(26)]);
fprintf(fp,
"%d/%02d/%02d,",
date.tm year + 1900, /* NB: NOT
a Y2K bug! */
date.tmmon + 1,
date.tmmday);
fprintf(fp, "%s ",
Name[Randlnt(NumNames)]);
fprintf(fp, "%s Ltd,",
Business[Randlnt(NumBuses)]);
Чтобы получить правдоподобный диапазон варьиро-
вания дебетов и кредитов, мы выбирали случайное чис-
ло и вычитали из него меньшее число. Таким образом,
можно быть абсолютно уверенным, что одни числа бу-
дут положительными, а другие отрицательными. Однако
за короткий промежуток времени маловероятно полу-
чить 0,00; этот вид исключительного тестирования сле-
дует добавить вручную
542
Дополнительные тематические разделы
Часть III
fprintf(fp,
-%.2f\n-r
(RandDbl() * 5000.0) - 2250.0);
*
if(Randlnt{2) == 0)
{
Периодически дату нужно изменять. Выберем уве-
личение даты на 1 на основе результата подбрасывания
монеты (RandInt(2)==0), но, если хотите, можете на-
угад добавить N дней. Можно даже для проверки пра-
вильности подпрограмм сортировки сделать так, чтобы
дата изменялась в обратную сторону.
Технология изменения даты достаточно проста, но
довольно интересна, потому что она позволяет исполь-
зовать функцию mktime(), которая рассматривалась в
главе 4. Эта функция конвертирует struct tm в перемен-
ную которая имеет очевидный смысл. Интерес-
но то, что при конвертировании функция mktime() упо-
рядочивает данные, следовательно, нам это делать нс
придется. Нужно просто добавить 1 к числу дней и по-
зволить функции mktime() рассортировать тс случаи, в
которых при добавлении единички к числу дней полу-
ченное число превышает нормальное количество дней
в рассматриваемом месяце.
ОШИБКА Y2.038K
На некоторых системах функция представлена внут-
ренне как long int, при этом различие между двумя пос-
ледующими значениями составляет одну секунду
и это значение составляет время с даты примерно 30-
летней давности (вполне возможно, с 1 января 1970 г.).
(Стандарт ANSI не утверждает, что это так, но и не зап-
рещает этого.) На таких системах, включая те, которые
я использую наиболее часто, представляемые перемен-
ной time_t дни буквально сочтены. Такого рода реализа-
ция с использованием начальной даты 1/1/1970 будет
приводить к переполнению переменной time_t в январе
2038 года. При использовании такой системы, если делать
достаточно записей с помощью функции GenerateDatall,
можно получить довольно странные результаты. (Каково
же решение? Приобретите новый компилятор с более
чувствительной стратегией по отношению к time_t. Но
перед тем как его купить, уточните этот момент!)
++date. tmmday;
datetimet = mktime(fcdate);
if(datetimet 1 - (timet)-1)
{
pd = localtime(&date_time t);
if(pd 1= NOLL)
{
memcpy(&date, pd, sizeof date);
}
}
}
}
return 0;
}
Как видите, процесс создания инструмента автома-
тического генерирования тестовых данных очень про-
сто, несмотря на возникающие иногда препятствия (та-
кие, как проблема с данными). А теперь обратим
внимание на кое-что более серьезное!
Генераторы кода
Если автоматизировать производство, по крайней мере,
некоторого программного обеспечения, то можно сэко-
номить много времени. Кроме того, написание генера-
торов кода - это один из наиболее увлекательных ас-
пектов разработки программного обеспечения.
Квины
Проще всего объяснить, что такое генераторы кода,
можно с использованием понятия квин (но это не озна-
чает, что квин проще всего написать). Квин — это про-
грамма, которая генерирует собственный исходный код
в качестве выходных данных. Можно назвать ее само-
документируюшейся программой. Вот один из самых
известных квинов, который скопирован из файла Jargon
File:
char* f ="char
♦f=%c%s%c;main(){printf(f,34,f,34,10)
main(){printf(f,34,f,34,10);}
He знаю, кто первым написал эту программу. Но,
боюсь, что этот человек имеет извращенный вкус. Вам
действительно стоит запустить эту программу, чтобы
посмотреть, что имеется в виду. Код можно найти на
Web-сайте ’’ДиаСофт" (в файле quine.c). (Кстати, этот
код работает только на компьютерах, которые исполь-
зуют ASCII.)
В этом коде введен обрыв строки для того, чтобы
удовлетворить требованиям к длине строк в этой кни-
ге, но я не имел в виду квин. Он самостоятельно час-
тично усовершенствуется при первоначальном запуске
программы, и, если перенаправить вывод результатов в
файл, то можно получить нормальный квин.
Поскольку эта программа не имеет прототипов для
многоликой функции printf(), она избегает неопределен-
ного поведения, однако, думаю, стоит извиниться за
этот явный программистский трюк. Если в запасе у вас
есть хотя бы часок и вы не прочь потрудиться, можете
попробовать написать свой собственный квин.
Теперь, когда вы знаете, что такое квин, объясню,
для чего он все-таки нужен. Итак, когда следует разра-
батывать генераторы кода?
Когда есть смысл генерировать код
Несмотря на очевидное мастерство, квин довольно при-
митивен. Он знает только то, что требуется вывести
Создание программных инструментальных средств
Глава 20
543
данные; он не использует какие-нибудь входные дан-
ные для определения своих действий. Но ведь нам тре-
буется генерировать полезный код. Если результат все-
гда один и тот же, то генератор кода не потребуется;
проще будет самому написать необходимую программу.
Нередко генераторы кода используются для написа-
ния готовых программ. Они решают одну из самых по-
вторяющихся проблем либо в самой программе, либо в
большой коллекции программ. Позвольте привести при-
мер. Несколько лет назад я работал над большим меж-
платформенным проектом, который разрабатывался для
использования в средах Microsoft Windows (версия 3.1,
если вы еще помните) и MVS (мэйнфреймовская опе-
рационная система). Программа должна была иметь
возможность разделения на два модуля: модуль досту-
па к базе данных и расчетный модуль. Мы написали и
отладили расчетный код (но не модуль базы данных) на
PC, но его нужно было проверить на мэйнфреймовской
машине, на которой отладочные возможности были
отчасти примитивными. Поэтому, когда при тестирова-
нии обнаруживалась ошибка, она становилась для нас
проблемой.
Выход из этого положения прост, но его довольно
трудно было осуществить. Если бы можно было как-
нибудь перехватить данные после того, как они прошли
через модуль доступа к базе данных, и направить их в
PC, то их можно было бы подать в расчетный модуль
PC-версии и там их исправить.
Какое же решение мы приняли? Генератор кода! Был
написан код для считывания заголовочного файла мо-
дуля (где, к моему неудовольствию, определены прак-
тически все переменные) и создан исходный код, в ко-
тором можно хранить названия и значения каждой
отдельной интересующей нас переменной. Это было не-
много сложно. Легче было написать подпрограммы для
загрузки информации в файл (в текстовом формате,
конечно, потому что две платформы не используют одну
и ту же последовательность байтов) и для считывания
информации из файла после того, как ее перенесли на
PC. Итак, как только вводилась новая переменная, нуж-
но было просто снова запускать генератор кода для
выбора этой переменной и включать ее в выходной код,
который затем перекомпилировать и снова подключать
к процессу.
В более поздних, но очень простых проектах мои
коллеги создали генератор кода, который считывает
спецфайлы КОБОЛ а и переводит их в заголовочные
файлы С. Какие бы манипуляции ни производились с
этими спецфайлами на мэйнфреймовской машине, нуж-
но было лишь снова запустить генератор кода, так как
биты С-программы используют такое же описание дан-
ных, как и биты КОБОЛ а.
В обоих описанных случаях автоматизация програм-
мирования позволила значительно сэкономить время и
усилия. Кроме того, в обоих этих случаях генератор
кода считывал исходный код так, что он выполнял свою
работу. Такая операция называется синтаксическим раз-
бором,, и поскольку она уже подробно рассматривалась
в главе 19, здесь мы не будем повторяться.
В связи с тем, что требуется написать синтаксичес-
кий анализатор как часть приложения генерирования
кода, мы хотели бы , насколько это возможно, сохра-
нить свою работу по синтаксическому разбору для бу-
дущего. Поэтому давайте разработаем синтаксический
анализатор для программы, которая будет производить
программу синтаксического разбора. Надеюсь, это не
звучит слишком запутанно! Позвольте объяснить.
Когда я начинаю писать программу, то первый шаг
делаю почти автоматически. Мои пальцы, как говорит-
ся, сами набирают нужные символы:
#include <stdio.h>
int main(void)
{
return 0;
}
Возможно, это не слишком много, но это хорошее
начало, и можно спокойно продолжать работать. Теперь
нужно подумать, что потребуется для записи информа-
ции в командной строке. Быстро отредактируем ее по
порядку, добавим int argc или char*argv[] (или char
**argv) в объявлении функции main(). После этого
предстоит выполнить утомительную задачу — синтак-
сический разбор аргумента командной строки. Требуется
проверить, имеется ли достаточное количество аргумен-
тов и не слишком ли их много, выяснить, представля-
ют ли аргументы тот тип данных, который ожидается?
А что можно сказать по поводу переключателей? Это не
трудная работа, но довольно кропотливая, не так ли?
Было бы прекрасно, если бы для создания требуе-
мого кода можно было запустить генератор кода. Тот,
кто использует UNIX, в этом месте может сказать ’’Нуж-
но использовать функцию getopt()!". По этому поводу
следует сделать три замечания. Во-первых, эта функция
не является одной из функций ANSI С, и это не гаран-
тирует, что ее можно использовать на всех платформах.
Четыре наиболее часто используемых мною С-компи-
лятора — это gcc (Linux), gcc (DJGPP), Microsoft Visual
C++ (в режиме С) и Borland C++ (тоже в режиме С).
Последние два довольно широко распространенных
компилятора не поддерживают функцию getopt(), на-
сколько я выяснил после обширного и обстоятельного
поиска, выполненного преимущественно путем обраще-
ния к файлам помощи этих систем). Во-вторых, getopt()
не очень хорошо выполняет поставленную задачу; толь-
ко ее использование представляет само по себе доволь-
544
Дополнительные тематические разделы
Часть III
но интенсивный процесс. И в-третьих, страница
manpage (из документации UNIX) для функции getopt()
на моей Linux-системе во входе Bugs сообщает: ’’Эта
manpage-страница перепутана”. Ну вот, пожалуй, и все.
Нет, то, что действительно требуется — это програм-
ма, которая сама будет писать биты командной строки
моей программы и позволит легко работать со всеми
указанными пользователем данными. Хотелось бы за-
дать примерно следующее:
int AppliestionMain (char ♦infile, char
♦outfile, int optflag)
{
/* ... */
}
и позволить генератору кода позаботиться обо всем осталь-
ном. Конечно, аргументы функции ApplicationMain()
будут разными в разных программах. Это неудобно. Мо-
жет ли в решении этой проблемы помочь сам генератор
кода?
Да, может. Но для этого следует найти способ, с
помощью которого можно было бы сообщать, что нуж-
но сделать для каждой программы, причем этот способ
должен реализоваться проще (для пользователей гене-
ратора кода), чем сам процесс написания кода. Чтобы
такой способ сделать эффективным, потребуется напи-
сать новый язык. Это нс так страшно, как кажется по-
началу. Например, форматирующая строка функции
printf() фактически является языком, но мы так приуче-
ны использовать этот язык, что не часто задумываемся
о том, что это действительно язык.
Разработка грамматики и синтаксиса
входных данных
Для генератора кода потребуются данные, если вами
движет что-то более чем простая любознательность.
Однако требуется каким-то образом провести синтакси-
ческий разбор входного потока. Насколько точно это
будет сделано, очень зависит от природы приложения
и особенно от того, будет ли проводиться контроль над
входной спецификацией. При написании, скажем, ути-
литы преобразования кода на языке Pascal в код на С у
нас нет такой возможности; сначала требуется провес-
ти синтаксический разбор кода на Pascal в порядке,
указанном в спецификации. Однако, если есть возмож-
ность задать входную грамматику, то нужно это сделать.
Поскольку мы собрались написать генератор грам-
матического анализатора командной строки, то для него
можно выбрать собственный синтаксис - мы же не
строим синтаксис существующего языка.
Что же нужно сообщить генератору кода? Давайте
этот вопрос упростим и ограничимся списком перемен-
ных типа long, double или char *. Ими нетрудно управ-
лять. Так как переключатели довольно полезны, доба-
вим также возможность работы с простыми (включить/
выключить) переключателями.
Вот пример грамматики в приближенной форме Бэ-
куса-Наура (Backus-Naur Form):
infile:
specifier
infile specifier
specifier: one of
switchspecifier
doublespecifier
longspecifier
stringspecifier
switchspecifier:
-identifier
doublespecifier:
identifier D
longspecifier:
identifier L
stringspecifier:
identifier S length
identifier:
letter
identifiertail letter
identifiertail:
letterorunderscore identifiertail
digit identifiertail
letterorunderscore
digit
letterorunderscore:
letter
letter: one of
ABCDEFGHIJKLMNOPQRST
U V W X Y Z
abcdefghi jklmnopgrst
u v w x у z
digit: one of
0123456789
length:
1 to 255
Из приведенного текста видно, что код механизма
синтаксического разбора генератора позволяет прини-
мать из входного потока четыре различных вида специ-
фикаторов:
• -foo означает, что foo — это произвольный переклю-
чатель. Если он указывается конечным пользовате-
лем, то он равен 1, в противном случае его следует
установить равным 0. Такая поддержка переключа-
Создание программных инструментальных средств
Глава 20
[545
телей является несколько ограниченной, но, в кон-
це концов, мы же хотим все упростить.
• bar L означает, что параметр bar имеет тип long int
и он обязателен. (Только переключатели не обяза-
тельны.)
• baz D означает, что baz — это тип double.
• quux S 35 означает, что quux является строкой, ко-
торая по длине не может превышать 35 байтов (без
учета символа конца строки).
Можно обеспечить любое количество спецификато-
ров, хотя нужно помнить, что соответствующая реали-
зация не обязана поддерживать списки параметров фун-
кций более чем с 127 параметрами. Но такого их
количества должно быть достаточно.
Если мы задали генератору кода входные данные
этого примера, мы хотели бы использовать их для про-
изводства кода, который считывает и понимает строку
argv и передает нам информацию из argv в форме вызо-
ва функции:
int ApplicationMain (int foo, long bar, double
baz, char * *quux)
Мы собираемся написать программу, которая дол-
жна проводить разбор введенных данных, поэтому она
должна производить код для синтаксического разбора и
обрабатывать результаты таким образом, чтобы можно
было использовать вводимые данные в нашей програм-
ме. Наверное, после этих слов вы почувствовали легкое
головокружение. Действительно, генераторы кода час-
то вносят путаницу в наши мысли, но думаю, это сто-
ит того, чтобы воспользоваться выполняемым ими объе-
мом работ и их очевидной мощью и гибкостью.
Простой синтаксический анализатор
Для полного синтаксического разбора нашей граммати-
ки требуется провести множество различных проверок,
поэтому сфокусируем внимание на высокоуровневых
аспектах грамматики. Мы определенно не собираемся
проверять какой-либо из введенных спецификаторов.
Просто прочитаем их и примем на веру. Можно считать,
что, как только они попадают в компилятор С, то сра-
зу же подтверждается их правильность. Не будем делать
также различия между функциями FileName (разрешен-
ный спецификатор С) и Fil$name (не является таковым).
Для реализации синтаксического анализатора будем
использовать конечный автомат (или КА). Этот конеч-
ный автомат очень прост и имеет только четыре состо-
яния — Get Variable (получить переменную), Get Туре
(получить тип), Get Length (получить длину) и Stop (ос-
тановиться), как показано в листинге 20.6.
Листинг 20.6. Простая программа, производящая
синтаксический разбор.
linclude
linclude
linclude
linclude
<stdio.h>
<stdlib.h>
<string.h>
<assert.h>
linclude “dllist.h“
Минуточку — название библиотеки "dllist.h" в ка-
вычках? Да, мы собираемся снова использовать коды,
которые разработали ранее в этой книге. Где-то же нуж-
но хранить наши переменные. Порядок переменных
очень важен, и обязательно нужно несколько раз про-
смотреть список переменных, чтобы сделать двусвязный
список более подходящим. Поэтому следует снова най-
ти и использовать библиотеку, которая была разработа-
на в главе 11.
# de fine INDENT_2
Idefine INDENT!
Idefine MAX_IDENT_LEN 32
Idefine MAXSTRLEN 255
Idefine LINESPERSCREEN 23
Idefine BOOL 'B'
Idefine DOUBLE 'D'
Idefine LONG 'L'
Idefine STRING 'S'
/* Аргументы типа 'В' - это переключатели,
* которые находятся в состоянии либо
* “включено*1, либо “выключено*1, поэтому для
* них не требуется задавать тип данных или
* длину.
*/
Idefine NONSWITCHTYPES "DLS“
Idefine GET_VARIABLE 'V'
Idefine GET_TYPE 'T'
Idefine GET LEN 'L'
Idefine STOP 'S'
Idefine SWITCH_CHAR
Эти группы макросов позднее будут использовать-
ся генератором кода.
Константы MAXJDENT.LEN и MAX_STR_LEN
ограничивают размер имен спецификаторов и строчных
аргументов соответственно. Ограничения выбираются
произвольно; при необходимости их можно легко регу-
лировать.
Константа LINES_PER_SCREEN используется ге-
нератором Help(). BOOL и ему подобные типы пред-
ставляют в нашей грамматике индикаторы типов В, D,
L и S. Типы BOOL (необязательные переключатели,
35 Эмс.265
546
Дополнительные тематические разделы
Часть III —
имеющие состояния "включено" или "выключено") не-
удобны для работы, так как они не похожи на другие
три типа. Решение разработать грамматику таким обра-
зом принято просто с тем, чтобы показать, что и с та-
кой громоздкой грамматикой можно работать, если де-
лать это осторожно. Может быть, вы сможете
усовершенствовать грамматику и соответственно отре-
дактировать синтаксический анализатор.
Теперь поговорим о хранении данных. Синтаксичес-
кий анализатор должен помещать полученную инфор-
мацию в некоторого рода контейнер. Для этого потре-
буется довольно простая конструкция.
typedef struct ARGUMENT
{
char Name[MAXIDENTLEN];
int Type;
size t Len; /* for strings */
} ARGUMENT;
int Parseinput(DLLIST **ArgList,
FILE «InStream,
FILE «LogStream)
{
int Status = EXITSUCCESS;
ARGUMENT Arg = {0};
char InBuff[256];
char «VarName;
char «VarType;
char «VarLen;
char «EndPtr;
const char Delimsf] = " ,\t\n";
char «Data;
char «NextToken;
int HaveData = 0;
int State = GET_VARIABLE;
Здесь запускается наш конечный автомат. Первое его
состояние - это GET_VARIABLE. При этом перемен-
ная HaveData приравнивается 0, так как пока еше не
были считаны какие-либо данные из входного потока.
while(EXIT-SUCCESS — Status &&
State 1= STOP)
{
fprintf(LogStream,
"Status report: Data? %s\n",
HaveData ? "Yes" : "No");
Для упрощения отладки в файл регистрации встав-
лено несколько строк таким образом, чтобы можно
было легко следить за работой конечного автомата. Они
изъяты из этого листинга (кроме той строки, которую
мы только что там видели), но их по-прежнему можно
найти на Web-сайте "ДиаСофт" в исходном коде
(genergc.c).
Если к этому моменту нет каких-либо данных (на-
пример, в самом начале цикла), то следует их откуда-
то получить, для чего используем функцию fget(). Это
довольно живучая функция, которая не позволит пере-
полнить входной буфер. Эта функция обычно оставля-
ет '\п' в конце выходных данных (исключение состав-
ляют случаи, когда объем данных превышает
пространство для их хранения), но мы можем просто
вставить *\п* в строку ограничителей разметки.
if(HaveData)
{
Data = fgets(InBuff, sizeof InBuff,
InStream);
if (Data 1= NULL)
{
fprintf(LogStream,
"Status report: Got data
%s\n",
InBuff);
BaveData = 1;
NextToken = InBuff;
)
else
{
Если данные найдены, значит, все в порядке. Если
же нет, то нужно рассмотреть нашу грамматику. Един-
ственное место, откуда можно без помех вырезать дан-
ные, находится между спецификаторами, т.е. там, где
можно найти идентификатор переменной. Однако если
программа находится в каком-либо другом состоянии
(не в состоянии GET_VARIABLE), то мы получим син-
таксическую ошибку и нам придется остановить конеч-
ный автомат.
if (State »= GET_yARIABLE)
{
Status = EXITFAILURE;
)
State = STOP;
Запомните, первым состоянием конечного автома-
та, которое нам встретится при нормальных обстоятель-
ствах, будет GET_VARIABLE. Если в случае, когда нет
данных, этим состоянием окажется STOP, то механизм
конечного автомата немедленно остановится. Передавая
автомату пустой поток входных данных (можно попы-
таться передать, например, файл нулевой длины), мы
получим программную оболочку, которая во многом
походит на пустую оболочку ракушки-улитки. Такое
экспериментирование ясно и наглядно указывает, какие
части генератора кода основываются на вводимых дан-
ных. Обычно, однако, начальным состоянием является
GET_VARIABLE.
switch (State)
{
case STOP:
break;
547
case GET_VARIABLE:
VarName = strtok(NextToken, Delims);
NextToken = NULL;
При получении маркера от буфера данных для луч-
шей работы функции strtok() требуется знать, происхо-
дит ли пополнение буфера. Поэтому здесь использует-
ся функция NextToken, которая указывает на буфер
новых данных или никуда не указывает, в зависимости
от того, имеется ли действительно в данный момент
новая информация. Функция NextToken при получении
новых данных снова указывает на буфер данных в на-
чале цикла.
Если при разметке произойдет сбой, переменная
HaveData устанавливается в нуль. Таким образом фор-
мально регистрируется ошибка в начале цикла, который
после этого получит некоторые дополнительные данные
для своей работы.
if (VarName == NULL)
{
HaveData = 0;
}
else
{
if(VarName[0] == SWITCHCHAR)
{
if(strlen(VarName + 1) > MAX_IDENT—LEN)
{
Status = EXITFAILURE;
State = STOP;
}
else
{
strcpy(Arg.Name, VarName +
1); /
Arg.Type * BOOL;
Arg. Len = 0;
Здесь немного неуклюжий синтаксис. Нужно отдель-
но провести проверку переменных переключателя. Если
такая переменная найдется, следует проверить, не имеет
ли она слишком длинное название, а затем с использо-
ванием функции DLAppend() добавить ее в двусвязный
список переменных.
Когда будет найдена переменная-переключатель,
состояние изменяться не будет, так как вся переменная
работает с одним маркером.
if (DL_SUCCESS != DLAppend (ArgList,
О,
&Arg,
sizeof Arg))
{
Status = EXITFAILURE;
State = STOP;
}
}
}
else
{
Создание программных инструментальных средств
Глава 20
if(strlen(VarName) > MAXIDENTLEN)
<
Status = EXITFAILURE;
State = STOP;
}
else
{
Если же переменная не является переключателем, то
нужно, во-первых, сохранить копию имени перемен-
ной, а во-вторых, изменить состояние конечного авто-
мата с GET_VARIABLE на GETJTYPE.
Между прочим, в структуре аргумента требуется
функция strcpy(). Когда происходит событие появления
спецификатора типа в отдельной строке ввода, название
переменной переписывается с помощью функции fget(),
поэтому такое событие нужно по возможности перехва-
тить.
strcpy (Arg. Name, VarName) ;
State = GETJTYPE;
)
)
}
break;
case GET-TYPE:
VarType = strtok(NextToken, Delims);
NextToken = NULL;
if(VarType == NULL)
{
HaveData = 0;
}
else
{
После получения с помощью функции strtok() типа
требуется подтвердить его правильность. Это должна
быть строка, содержащая только один ненулевой сим-
вол — один из "D", "S" или "L". Если это не так, значит
произошла ошибка и следует остановить процесс.
if (VarType[lJ != '\0' ||
Strchr(NONSWITCH-TYPES,
VarType[0]) == NULL)
{
State - STOP;
Status = EXITFAILURE;
else
{
Итак, тип передан на проверку и можно продол-
жить. Сохраняем тип в структуре и устанавливаем дли-
ну переменной равной 0. Если это переменная типа
строка, то устанавливаем состояние GET_LEN, с тем
чтобы в следующий раз длину установленной по умол-
чанию переменной можно было переписать в следую-
щем цикле. С другой стороны, можно немедленно до-
бавить переменную в список. Теперь, когда мы готовы
к работе со следующей переменной, можно снова уста-
новить состояние GET_VARIABLE.
548
Дополнительные тематические разделы
Часть III
Arg.Type - VarType[ 0 ];
Arg.Len = 0;
if(VarType(O) == STRING)
{
State = GET—LEN;
}
else
{
if(DL—SUCCESS I = DLAppend(ArgList,
0r
&Arg,
sizeof Arg))
{
Status = EXITFAILURE;
State = STOP;
}
else
{
State = GETVARIABLE;
}
}
}
}
break;
case GET—LEN:
VarLen = strtok(NextToken, Delims);
NextToken = NULL;
if(VarLen == NULL)
{
BaveData = 0;
}
else
{
Arg.Len = (size_t)strtoul(VarLen, fcEndPtr, 10);
if(EndPtr == VarLen ||
Arg. Len == 0 | j
Arg.Len > MAXSTRLEN)
{
State = STOP;
Status = EXIT-FAILURE;
}
else
Конвертируем длину строки в цифровой формат и
проверяем ее на удовлетворение основным ограничени-
ям (действительно ли длина строки представляет чис-
ло между 1 и MAX_STR_LEN?). Если все правильно,
можно немедленно добавить строку в список перемен-
ных с использованием функции DLAppend() и продол-
жать "охотиться" за следующей переменной, установив
состояние GET_VAR1ABLE.
{
if(DL_SUCCESS != DLAppend(ArgList,
О,
(Arg,
sizeof Arg))
{
Status = EXITFAILURE;
State « STOP;
}
else
<
State = GETVARIABLE;
}
}
}
break;
default:
/* D */
Если мы встретились c default:, то появилась про-
блема, поскольку состояния конечного автомата конт-
ролируются изнутри; поэтому неизвестное состояние
характеризует нарушение программы:
assert(О); /♦ Эта программа нарушена ♦/
State = STOP;
State = EXITFAILURE;
break;
}
}
return Status;
}
Когда эта функция заканчивает свою работу, дву-
связный список будет содержать некоторое количество
дескрипторов (описаний) переменных. Более сложная
грамматика должна приводить в результате к более
длинной функции. Такая функция может даже дать
более детализированные дескрипторы переменных. Но
она по-прежнему выдает список. Позднее этот список
будет использоваться в генераторе кодов.
Образец вывода генератора кодов
Если имеется пример вгида файла, который мы хотим
получить, то можно яснее представить свою конечную
цель. В этом случае можно предвосхитить выходной
результат работы программы, которую мы хотим напи-
сать. Однако это не всегда возможно, хотя общее реше-
ние довольно простое. Нужно просто вставить имею-
щийся пример в текстовый редактор, затем сделать
несколько копий этого примера и немного их изменить
соответствующим образом. Изменения выполняются с
помощью некоторого значения для генератора кодов,
который вы хотите написать; он будет должным обра-
зом выполнять эти изменения вместо вас.
То, что нам требуется — это результирующий файл.
Легко забыть, что это именно выходной файл, поскольку
он выглядит точно так же, как исходный код, только
созданный С-программой. Давайте рассмотрим этот
выходной результат и укажем точные особенности, ко-
торые имеют большую важность для генерирования
кода. На этой стадии нас не будет слишком заботить,
какую работу должен выполнять результирующий код.
Первое, на что нужно обратить внимание в листин-
ге 20.7, — это код с комментариями, указывающими на
549
его происхождение. Насколько это важно, мы увидим
позднее. Не забудьте, что необходимо добавить коммен-
тарии к сгенерированному коду, и в целом они не на-
столько важны, как в обычном коде. Но если в сгене-
рированном коде только один комментарий, то пусть он
сообщает следующее: "Это сгенерированный исходный
код”.
Листинг 20.7. Результат генерирования исходного
кода.
/* argproc.с */
/* Автоматически сгенерированный файл. Этот
* файл вручную не модифицируйте. Вместо этого
* измените genargs.с и регенерируйте файл.
*/
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
Idefine SWITCHCHAR ' -'
typedef struct ARG
{
int internal;
char InFile[256];
char OutFile[256];
char LogFile[256];
char HelpFile[256]
} ARG;
Это пример выполнения программы, которая рабо-
тает с двумя входными файлами, двумя выходными
файлами и с необязательным переключателем, подава-
емыми на ее вход. Точное содержимое структуры ARG
(которая, если помните, построена автоматически) бу-
дет варьировать в зависимости от инструкций, заданных
генератору.
Автоматическое создание абстрактных типов данных —
это типичное использование генераторов кода. Обычно
эти абстрактные типы данных предназначены для ис-
пользования программистом. В этом частном случае
переменные ARG предназначены только для использо-
вания их генерированным кодом.
int GetAxgs(int argc, char **argv, ARG *argp)
{
int ThisArg;
int CompArg;
if(argc <- 4)
{
return -1;
}
if(argc > 6)
{
return -2;
}
Создание программных инструментальных средств
Глава 20
Жестко запрограммированные здесь значения 4 и 6
специфичны для этого приложения. В общем, "магичес-
кие числа" этого вила представляют собой неудачную
практику программирования, потому что делают про-
грамму более сложной для внесения изменений. Одна-
ко причин, по которым приходилось бы изменять эти
магические числа, в действительности нет, кроме тех
случаев, когда требуется изменить параметр синтакси-
са в программе или когда это должно повлечь за собой
регенерацию кода (и, таким образом, автоматическое
обновление этих чисел). Во всяком случае, будет отно-
сительно просто нейтрализовать эти осложнения, если
возникнет определенная причина для беспокойства.
for(ThisArg = 1, CompArg = 0; ThisArg < argc;
ThisArg++)
{
if(argv(ThisArgJ[0] == SWITCHCHAR)
<
if(strcmp("-internal", argv[ThisArg]) == 0)
{
argp->internal = 1;
}
else
{
printf("Unknown switch %s\n",
argv[ThisArg]);
return ThisArg;
}
}
else
{
В этом месте программы видно, что код размещен
четко и его легко можно прочесть. Конечно, можно
предположить, что если мы не собираемся редактиро-
вать код, он может быть и нечитабельным. Это действи-
тельно так, но четкий код имеет неоспоримые преиму-
щества, когда вы пытаетесь отладить сам генератор кода
switch (CompArg)
{
case 0:
{
if(strlen(argv[ThisArg]) > 255)
{
return ThisArg;
)
strcpy(argp->InFile, argv[ThisArg]);
break;
}
case 1:
{
if(strlen(argv[ThisArg]) > 255)
<
return ThisArg;
}
strepy(argp->OutFile, argv[ThisArg]);
break;
case 2:
{
550
Дополнительные тематические разделы
Часть III
if(strlen(argv[ThisArg]) > 255)
{
return ThisArg;
}
strcpy(argp->LogFile , argv[ThisArg]);
break;
}
case 3:
{
if(strlen(argv[ThisArg]) > 255)
{
return ThisArg;
}
strcpy(argp->HelpFile, argv[ThisArg]);
break;
}
}
++CompArg;
-}
}
return 0;
1
Блок switch здесь довольно интересен. Давайте по-
лучше рассмотрим операторы case. Каждый из них
объявляет локальную область видимости с использова-
нием скобок { и }, даже если они не требуются синтак-
сисом case. Почему? Причина может заключаться в сти-
ле программирования. Одни программисты заключают
свои блоки в фигурные скобки из эстетических сообра-
жений, а другие это делают, чтобы можно было исполь-
зовать проверку соответствия фигурных скобок про-
граммным редактором и таким образом упростить
нахождение пути для операторов switch, которые име-
ют большие блоки case. В представленном случае для
установки скобок есть (если вы забыли каламбур) хо-
рошая, солидная и совершенно невидимая причина.
Этот пример выходного кода предназначен для при-
ложения, которому в качестве аргументов требуются
только один переключатель и несколько строк. Другие
приложения могут требовать аргументов long или double.
В этом случае выходной код выполняет обращение к
функциям преобразования (strtol или strtod), которым
необходим адрес переменной char *. Можно просто
объявить его в области видимости функции, но на не-
которых компиляторах это может означать получение
предупреждения в выходных данных (вроде тех, кото-
рые мы рассматриваем), если переменная не использу-
ется. Вместо этого будем использовать локальную об-
ласть видимости и при необходимости объявим
переменную char * в локальной области видимости.
Можно было бы не применять локальную область ви-
димости в тех блоках case, которые этого не требуют.
В то же время правильно выполненные локальные об-
ласти видимости не будут вызывать диагностических со-
общений, даже если эти области излишни, поэтому их
удаление слишком затрудняло бы работу генератора
кода. Готовы ли вы иметь дело с дополнительным объе-
мом выходного кода, в основном определяется тем, на-
сколько долгим и трудным вы хотите сделать процесс
разработки генератора кода.
int ApplicationMain(int internal,
char * InFile,
char * OutFile,
char * LogFile,
char * HelpFile);
void Help(void);
int main(int argc, char **argv)
{
int Status;
int ArgResult;
ARG ArgList = {0};
ArgResult = GetArgs(argc, argv, SArgList);
if(ArgResult != 0)
{
Help();
Status = EXITFAILURE;
}
else
{
/* Вызов вашей программы... */
Status -
(ApplicationMain(ArgList.internal,
ArgList.InFile,
ArgList.OutFile,
ArgList.LogFile,
ArgList.HelpFile) == 0)
?
EXITSUCCESS •
EXITFAILURE;
)
return Status;
}
Теперь можно увидеть, как все детали стыкуются друг
с другом. Функция main() обращается к GetArgs(), кото-
рая заполняет структуру ArgList, а затем вызывает функ-
цию ApplicationMain(), которая передает каждую индиви-
дуальную составляющую этой структуры как отдельный
аргумент. Понятно, что прототип App!icationMain() бу-
дет различным в разных приложениях, потому что эле-
менты структуры ArgList каждый раз будут разными.
И еще более понятно, что генератор кода может обра-
ботать этот прототип для своих целей и последователь-
но, на по-программной основе записать этот прототип
в его выходной файл (сгенерированный С-программой).
Если функция GetArgs() возвращает ненулевое зна-
чение, программа вызывает функцию Не1р() и завершает
выполнение. Генератор кода тоже продуцирует функ-
цию Не1р(), но здесь мы ее не приводим. Она содержит
большое количество вызовов функции printf() вперемеж-
Создание программных инструментальных средств
Глава 20
551
ку с вызовами функции fgets(). чтобы сделать справоч-
ные сообщения более легкими для чтения. Эту часть
процесса можно упростить. Мы будем снабжать гене-
ратор кода текстовым файлом, содержащим текст, ко-
торый будет вставлен в Не1р(), так почему мы не мо-
жем просто систематизировать его содержание так,
чтобы файл помощи был доступен во время выполне-
ния программы? Проблема с таким решением состоит
в том, что файл помощи предполагается доступным во
время выполнения. А что если это не так? Встраивая
файл в генерируемый код, мы гарантируем, что текст
всегда, когда потребуется, будет доступен.
Управление сопровождением
Если вам потребуется внести изменения в выходной
результат генератора кода, всегда изменяйте сам гене-
ратор, а не результирующий код. Если же вы измените
результирующий код, то эти изменения потеряются,
когда генератор будет запущен в следующий раз. Вот
почему так важно при работе с генератором кода поме-
тить файл с указанием его происхождения и ясным и
недвусмысленным сообщением "Не модифицировать!"
Однажды я включил комментарий, который, по моему
мнению, был наиболее изящным: "Пожалуйста, не из-
меняйте код, пока вы действительно не будете вынуж-
дены это сделать; лучше измените генератор, если есть
время". Естественно, многие решили, что им-таки дей-
ствительно очень нужно изменить сам код и, конечно,
позже в связи с этим у меня возникли большие затруд-
нения. Нужно писать четко и официально Автомати-
чески сгенерированный код можно изменять только
путем изменения самого генератора, а не путем беспо-
лезных манипуляций.
К сожалению, когда бы я категорично что-либо ни
заявлял, сразу появляется некоторая исключительная
ситуация, показывающая, что я не прав. В частном слу-
чае этого генератора кода и других, которые продуциру-
ют шаблонные листинги, будет лучше изменить исход-
ный код в частном порядке, если и только если
используется переключатель -internal. Этот переключа-
тель в генерируемом коде строит скелетную функцию
ApplicationMainO, предназначенную для создания шаб-
лона, который можно самостоятельно заполнить. В этом
частном случае весь смысл переключателя состоит в
том, что можно использовать генератор для простой,
одноразовой программы, которая полностью хранится
в одном трансляционном модуле. На самом деле при ре-
дактировании сгенерированного кода у вас нет выбора —
действительно, куда вы поместите выполняемые функ-
ции? Если вы не укажете переключатель -internal, ске-
летная функция не будет сгенерирована; это предпо-
лагает, что вы будете переводить эту функцию в
какой-то другой трансляционный модуль.
Простой генератор кода
Написанную на С программу на высоком уровне мож-
но разделить на три части: директивы препроцессора,
определение типов и функции. У нас есть две функции,
предназначенные для генерирования, поэтому генера-
тор кода будет состоять из четырех элементарных про-
цедур: одной — для директив препроцессора, одной —
для определения типов и двух — для функций.
Функция WriteHeaderO отвечает за директивы препро-
цессора. Ее первая задача состоит в том, чтобы пометить
результирующий код его именем файла вместе с предуп-
реждением о том, что код сгенерирован автоматически.
Для этого, естественно, функция WriteHeaderO исполь-
зует синтаксис комментария.
После этого нужно просто написать несколько опе-
раторов #include и #define. Требуемый точный состав
этих операторов будет разным в различных генераторах.
Вполне-может оказаться, что вы вообще не захотите
использовать какой-либо из операторов include, напри-
мер, когда требуется сгенерировать заголовочный файл.
Может быть, вы захотите распечатать файл argproc.c
с Web-сайта "ДиаСофт" и всегда иметь его при себе при
изучении кода в листинге 20.8, который генерируется
файлом argproc.c.
Листинг 20.8. Подпрограмма генерирования
заголовка,
int WriteHeaders(FILE «OutStream, char
^♦OutFile)
{
fprintf(OutStream, •/* %s */\n", OutFile);
fprintf(OutStream,
"/* automatically generated file. Do not\n");
fprintf(OutStream,
" * modify this file by hand. Change\n");
fprintf(OutStream,
" * genargs.c and regenerate the file\n");
fprintf(OutStream,
* instead.\n");
fprintf(OutStream,
’ */\n");
fprintf(OutStream, "linclude <stdio.h>\n");
fprintf(OutStream, "linclude <stdlib.h>\n");
fprintf(OutStream, "linclude <string.h>\n\n");
fprintf(OutStream,
"Idefine SWITCHCHAR '%c'\n\n",
SWITCHCHAR);
return EXIT_SUCCESS;
}
Директивы препроцессора просты — одна функция
fprintfO следует за другой. Следующая стадия — это ге-
нерирование кода typedef. Поскольку у нас есть все эле-
менты структуры двусвязного списка, то сравнительно
552
Дополнительные тематические разделы
Часть III
легко создать тип ARG. Для этого нужно организовать
обычный цикл по списку.
Особенно следует позаботиться о двух моментах в
случае использования константы STRING. Первое, что
надо сделать — это выделить для STRING большее зна-
чение, чем то, которое хранится синтаксическим ана-
лизатором, для размещения символа конца строки. Во-
вторых, указанное значение содержится в переменной
size_t. Хотя это целый тип без знака, однако мы не знаем
точно, какого он вида, поэтому перед передачей его
функции fprintf() нужно выполнить приведение типа.
Пользователи мэйнфреймовских машин в зависимо-
сти от того, насколько полноценно их программное
обеспечение эмуляции терминала, могут заменять
-diar%s[%u];\n- на ‘char %s??(%u??);\n".
int WriteTypedef(FILE «OutStream, DLLIST «ArgList)
{
ARGUMENT «Arg;
fprintf(OutStrearn, "typedef struct ARG\n{\n");
while(ArgList)
{
Arg = DLGetData(ArgList, NULL, MULL);
fprintf(OutStrearn, ");
switch(Arg->Type)
{
case BOOL:
fprintf(OutStream, "int %s;\n", Arg->Name);
break;
case LONG:
fprintf(OutStream, "long %s;\n", Arg->Name);
break;
case DOUBLE:
fprintf(OutStream, "double %s;\n", Arg->Name);
break;
case STRING:
fprintf(OutStream, "char %s[%u];\n",
Arg->Name,
(unsigned)(Arg->Len + 1));
break;
ArgList = DLGetNext(ArgList);
fprintf(OutStream, "} ARG;\n\n");
return EXITSUCCESS;
Теперь нужно написать код для генерирования фун-
кции GetArgs(). Здесь следует обращать особое внима-
ние на детали, хотя в этом нет ничего сложного. Преж-
де всего следует отметить, что CountBools() — это
просто вспомогательная функция, которая подсчитыва-
ет количество произвольных аргументов командной
строки в списке переменных, переданных с помощью
параметра ArgList. Код для CountBools() здесь не при-
водится, но его можно найти на Web-сайте "ДиаСофт”
в файле genargc.c.
int WriteFunction(FILE «OutStream, DLLIST
«ArgList)
{
DLLIST «Start;
ARGUMENT «Arg;
int CompArgs;
int OptArgs;
int ThisArg;
int ThisCompArg;
char «Indent = INDENT2;
OptArgs ~ CountBools(ArgList);
Создание программных инструментальных средств
Глава 20
553
CompArgs = DLCount(ArgList) - OptArgs;
Start = DLGetFirst (ArgList) ;
Нашей первой задачей является генерирование оп-
ределения функции. Он будет передан argc и argv из
функции mam() вместе с указателем на структуру ARG.
Как только станет известно, что имеются обязательные
аргументы CompArgs необязательные аргументы
OptArg, несложно будет сгенерировать код для опреде-
ления того, достаточно ли аргументов и не слишком ли
их много. Рассмотрев в первую очередь эти вопросы, мы
можем сконцентрироваться на более глубоких задачах
проверки самих аргументов.
fprintf(OutStrearn,
"int GetArgs(int argc,"
" char **argv, ARG *argp)\n");
fprintf(OutStrearn, "{\n"); fprintf(OutStrearn, int ThisArg;\n");
fprintf(OutStream, " int CompArg;\n");
fprintf(OutStrearn, "\n");
fprintf(OutStream, " if(argc <= %d)\n", CompArgs);
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
fprintf(OutStream, "
ThisArg <
fprintf(OutStream, •
return -1;\n* *);
if(argc > td)\n*, CompArgs + OptArgs + 1);
return -2;\n");
for(ThisArg - 1, CompArg = 0;"
argc; ThisArg++)\n");
{\n");
Необязательные аргументы требуют специальной
обработки, но только если некоторый необязательный
аргумент специфицирован в грамматике; следовательно,
значение OptArgs должно быть больше 0. Следующий
код будет вставлять в генерируемый код последователь-
ную проверку каждого необязательного аргумента.
if(OptArgs > 0)
{ !
fprintf(OutStream, " if(argv[ThisArg][0] «= •
* "SWITCH__CHAR)\n");
fprintf(OutStream, " {\n ");
do
{
Arg = DLGetData(ArgList, NULL, NULL);
if(Arg->Type == BOOL)
{
fprintf(OutStream,
"if(strcmp(\"%c%s\",“
argv[ThisArg]) == 0)\n",
SWITCHCHAR,
Arg->Name);
fprintf(OutStream, " {\n");
fprintf(OutStream,
argp->%s = l;\n",
Arg->Name);
fprintf(OutStream, }\n");
fprintf(OutStream, else ");
}
ArgList = DLGetNext(ArgList);
} while(ArgList != NULL);
Дополнительные тематические разделы
Часть III
554
Поскольку неопознанные аргументы будут обраба-
тываться с помощью else, имеет смысл использовать син-
таксис конструкции if.../ else if.../ else if.../ else, с кото-
рой легко производить итерации. Даже при отсутствии
определенного по умолчанию условия, это, скорее все-
го, будет самое мудрое решение, даже если такая кон-
струкция завершится пустым блоком else {}.
fprintf(OutStream, "\n");
fprintf(OutStream, " {\n");
fprintf(OutStream,
" printf(\"Unknown switch "
"%%s\\n\", argv[ThisArg]);\n");
fprintf(OutStream, " return ThisArg;\n");
fprintf(OutStream, " }\n");
ArgList = Start;
fprintf(OutStream, " }\n");
fprintf(OutStream, " else\n");
fprintf(OutStream, " {\n");
Indent = INDENT—4;
В самом начале сгенерированной функции GetArgs()
указатель Indent был установлен на строковый литерал,
содержащий два пробела. Если необязательных аргумен-
тов нет, указатель по-прежнему будет указывать на этот
литерал. Если такие аргументы есть, то указатель будет
перенаправлен на строковый литерал, содержащий че-
тыре пробела, для предотвращения выделения текста
отступами. Это может показаться негативным моментом
стиля кодировки, но такая операция значительно упро-
щает работу и позволяет легко читать код.
Завершив рассмотрение необязательных аргументов,
перейдем к обязательным. Если известно, в каком по-
рядке они появляются, можно использовать switch для
перехода прямо в код для обработки любого из обяза-
тельных аргументов.
fprintf(OutStream/ ”%s switch(CompArg)\n",
Indent);
fprintf(OutStream, "%s {\n", Indent);
for(ThisArg = 0, ThisCompArg - 0;
ThisCompArg < CompArgs;
ThisArg++)
{
Arg = DLGetData(ArgList, NULL, NULL);
if(Arg->Type ! = BOOL)
<
fprintf(OutStream,
"%s case %d:\n".
Indent,
ThisCompArg);
fprintf(OutStream,
"%s {\n".
Indent) ;
В этой главе мы уже обсуждали ложное с первого
взгляда открытие фигурной скобки. Если имеется аргу-
мент типа long или double, то потребуется новая пере-
менная char *EndPtf, которая будет использоваться
strtol или strtod. А почему бы не использовать функции
atoll() и atof(), которые не требуют этого дополнитель-
ного указателя? Да потому что они не могут обнаружить
различия между 0 (или 0.0) и случайным нечисловым
текстом. Необходимо, чтобы возвращалось сообщение
об ошибке, если аргумент невозможно правильно кон-
вертировать.
switch (Arg->Type)
{
case LONG:
fprintf(OutStream,
“%s char *EndPtr;\n",
Indent);
fprintf(OutStream,
"%s argp->%s = "
strtol(argv[ThisArg]"
", fcEndPtr, 10);\n",
Indent,
Arg->Name);
fprintf(OutStream,
"%s if(EndPtr =="
" argv[ThisArg])\n".
Indent);
fprintf(OutStream,
"%s {\n",
Indent);
fprintf(OutStream,
“%s return ThisArg;\n".
Indent);
fprintf(OutStream,
"%s }\n".
Indent) ;
Очень долго мы генерируем только код функцио-
нальных фрагментов. Теперь нужно создать код, кото-
рый будет должным образом работать и который вклю-
чает генерирование кода проверки ошибок.
break;
case DOUBLE:
fprintf(OutStream,
"%s char *EndPtr;\n",
Indent);
fprintf(OutStream,
"%s argp->%s = strtod"
"(argv[ThisArg], fcEndPtr);\n",
Indent,
Arg->Name);
555
fprintf(OutStream,
"%s if(EndPtr
"== argv[ThisArg])\n".
Indent);
fprintf(OutStream,
"%s {\n",
Indent);
fprintf(OutStream,
"%s return ThisArg;\n".
Indent);
fprintf(OutStream,
"%s )\n"f
Indent);
break;
case STRING:
Строковый тип не вызывает подобных проблем кон-
вертирования. Однако в дальнейшем может появиться
другая проблема — это проблема хранения. Нужно убе-
диться, что строка поместится в структуре ARG, для
которой передан указатель. К счастью, всегда можно
получить максимальную длину строки, поэтому можно
просто вызвать stflenO для выполнения проверки и срав-
нить возвращаемое значение с допустимой длиной. Если
все хорошо, то можно использовать функцию strcpy() для
копирования данных пользователя в нашу структуру.
fprintf(OutStream,
"%s if(strlen(argv"
"[ThisArg]) > %d)\n",
Indent,
Arg->Len);
fprintf(OutStream,
"%s {\n",
Indent);
fprintf(OutStream,
"%s return ThisArg;\n".
Indent);
fprintf(OutStream,
"%s }\n".
Indent);
fprintf(OutStream,
"%s strcpy(argp->%s, "
"argv[ThisArg]);\n",
Indent,
Arg->Name);
break;
default:
/* Неподдерживаемый тип, уже определен. */
assert(O);
break;
}
fprintf(OutStream,
"%s break;\n".
Indent);
fprintf(OutStream,
Создание программных инструментальных средств
Глава 20
"%s }\n",
Indent);
++ThisCompArg;
}
ArgList = DLGetNext(ArgList);
}
fprintf(OutStream, "%s }\n". Indent);
fprintf(OutStream, "\n");
fprintf (OutStream, "%s i+CompAxg;\n” ,
Indent) ;
Независимо от того, имеются необязательные аргу-
менты или нет, теперь мы приближаемся к точке общ-
ности кода; поэтому можно закончить оператор if() зак-
рытием фигурной скобки и, наконец, забыть об Indent.
if(OptArgs > О)
{
fprintf(OutStream, "
}
}\n");
fprintf(OutStream, }\n");
fprintf(OutStream, " return 0;\n");
fprintf(OutStream, "}\n\n");
return EXITSUCCESS;
}
До сих пор все операторы fprintf() были относитель-
но простыми. Теперь они становятся немного более
сложными в основном потому, что мы будем распеча-
тывать операторы printf(), а это означает, что мы натол-
кнулись на проблему символов перехода.
Посмотрите на это простое выражение: printf(”Hi\n*');.
Если необходимо вывести это выражение на экран или
на другое стандартное устройство вывода, то в строке
нужно расположить три управляющих символа, напри-
мер:
printf("printf(\"Hi\\n\");\n");
Это выглядит несколько одиозно, но ничего не по-
делаешь. Вы всегда можете столкнуться с чем-то нео-
бычным, когда пишете программу для написания дру-
гих программ.
int WriteMain (FILE *OutStream,
FILE *HelpStream,
DLLIST *ArgList,
int InternalApp)
{
DLLIST *Arg;
ARGUMENT *Data;
Самый легкий способ, позволяющий сгенерировать
функцию main(), - это определить массив указателей
на текст, который будет печататься. Затем можно про-
сто итерировать эти указатели, последовательно печа-
556
Дополнительные тематические разделы
Часть III
тая текст. Такая работа выполняется почти для всей
функции main(). Однако в ее коде есть четыре места, в
которых этого будет недостаточно. В трех из них выпол-
няется работа с прототипом, обращением и (если спе-
цифицирован указатель -internal) с телом функции
ApplicationMain();. В четвертом месте генерируется фун-
кция Не1р(). Чтобы можно было использовать простую
технологию для большинства выходных результатов и
настраивать коды для обработки исключений, в неко-
торых строковых литералах в массиве указателей ис-
пользуется метка-заполнитель. Я выбрал заполнитель %
для места, где должен работать прототип, Л — для об-
ращения к функции,! — для функции Не1р() и & — для
тела функции (если указан -internal). Таким образом,
переключение на MainText[i][O] позволит обрабатывать
эти специальные случаи со значениями, задаваемыми
по умолчанию путем простого обращения к функции
fprintf().
char *MainText[] =
{
"%", /* Напилите прототип для функции
ApplicationMain() ♦/
void Help(void),
"int main(int argc, char **argv)",
int Status;",
int ArgResult;",
" ARG ArgList == {0};",
" ArgResult = GetArgs(argc, argv,
(ArgList);",
" if(ArgResult != 0)",
• Г,
- Help();",
" Status » EXITFAILURE;",
•
else",
" {"r
" /* Вызов вашей программы... */",
"*", /* Напилите функцию вызова для
ApplicationMain() */
" return Status;",
void Help(void)",
"{"г
-I-,
"fc", /* Напишите тело функции для
ApplicationMain() */
NULL
В
int i;
int j;
char buffer[MAXSTRLEN];
char *p;
for(i = 0; MainText[i] != NULL; i++)
<
switch(MainText[i][0])
{
case ' ! ' :
Вот первый специальный случай — функция Нс1р().
Это действительно довольно просто. Информация счи-
тывается из вспомогательного файла, предусмотренно-
го пользователем, затем разбирается новая строка (если
она представлена), и помещает содержимое этого фай-
ла в оператор printf(). При более искусной реализации
можно написать код определения массива char * для
функции Не1р() таким же образом, как и для функции,
генерирующей Не1р(), и добавить код цикла для распе-
чатывания. Если вы тоже хотите это сделать, можете
изменить наш код.
Если выводится много результатов функции Не1р(),
нужно убедиться, что их отображение приостанавлива-
ется через каждые несколько строк, чтобы пользователь
мог следить за ними и нажимал Enter, если он готов про-
должать просмотр.
/* Генерирование функции Не1р() */
fprintf(OutStream, " char buffer!8);\n\n");
j = 0;
while(fgets(buffer, sizeof buffer, Helpstream))
{
p = strehr(buffer, '\nr);
if(p 1= NULL)
{
♦p = *\0';
}
fprintf(OutStream,
" printf(\"%s\\n\");\n",
buffer);
if (j == LINESPERSCREEN)
{
fprintf(OutStream,
fprintf(stderr, \"Press ENTER to"
continue...\\n\");\n");
fprintf(OutStream,
" fgets(buffer, sizeof buffer,
"stdin);\n");
j = 0;
}
break;
case ' %:
case ’ & ’ :
557
Понятия "прототип функции" и "определение фун-
кции" настолько близки, что можно ими оперировать,
в основном, одинаково. Различия незначительны. Во-
первых, не нужно генерировать тело функции, если не
был специфицирован флажок -internal. Во-вторых, в
прототипе точка с запятой требуется, а в описании
функции — нет. В-третьих, необходимо, чтобы тело
функции придерживалось описания, а не прототипа.
Используя if(), можно легко учитывать каждое из этих
различий.
Если бы можно было гарантировать, что пользова-
телю всегда будет требоваться внутреннее тело функции,
отдельный прототип не потребовался бы. Мы могли бы
просто определить функцию перед main(), и она бы дей-
ствовала как ее собственный прототип. Но если пользо-
ватель потребует наличия функции ApplicationMain()
внутри генерированного кода, он столкнется с некото-
рыми ограничениями; я не думаю, что немного более
простой код мог бы оправдать эти ограничения.
if (MainText[i] [0] = ’S')
{
if (!InternalApp)
<
break;
}
fprintf(OutStream,
"/* Write, or call, your"
application here.\n“);
fprintf(OutStream,
" * ApplicationMain must"
" return int. 0 indicates\n");
fprintf(OutStream,
" * success. Any other value "
"indicates failure.");
fprintf(OutStream,
" */\n\n");
}
/* Генерирование прототипа */
fprintf(OutStream, “int
ApplicationMain(");
j = 0;
Нам снова требуется сделать цикл по списку аргу-
ментов — на этот раз для продуцирования прототипа и
определения функции для ApplicationMain(). В дальней-
шем мы встретим еще один такой же цикл.
Для обеспечения переносимости каждый параметр
после первого разместим в отдельной строке. Стандарт
ANSI С требует "покладистых" компиляторов для под-
держания хотя бы 127 параметров в обращении к фун-
кции; он не требует поддержания исходных строк дли-
ной более чем 509 символов (по крайней мере, стандарт
С89, а многие программисты все еще используют стан-
дарт С89). С тех пор как длина параметров стала состав-
лять как минимум шесть символов каждый (три для int,
Создание программных инструментальных средств
Глава 20
один для пробела, один для запятой и один для иден-
тификатора с возрастанием до двух, когда уже исполь-
зованы все односимвольные идентификаторы), невоз-
можность расчленять параметры на отдельные строки
привела к появлению строк длиной более 700 символов.
Правильно работающий компилятор С89 мог на всех
основаниях отказаться компилировать такой исходный
код. Вот почему теперь стало необходимым разделять
параметры на отдельные строки.
Заметьте, что переменная j используется для отсле-
живания того, является ли текущий аргумент первым.
Если это так, то не следует ставить запятую — это при-
ведет к синтаксической ошибке при компилировании
пользователем сгенерированного кода.
for(Arg = ArgList;
Arg 1= NULL;
Arg - DLGetNext(Arg))
{
Data = DLGetData(Arg, NULL, NULL);
switch(Data->Type)
{
case BOOL:
fprintf(OutStream,
"%sint ",
j == 0 ?
", \n "
break;
case LONG:
fprintf(OutStream,
"tslong ",
j == 0 ?
break;
case DOUBLE:
fprintf(OutStream,
"tsdouble ",
j == 0 ?
", \n
" ");
break;
case STRING:
fprintf(OutStream,
"%schar * ",
j == 0 ?
MM
", \n "
break;
default:
fprintf(stderr,
"program error in fun"
“ction WriteMain()\n");
assert(O);
break;
}
++j;
558
Дополнительные тематические разделы
Часть III
fprintf(OutStream, "% s"t Data->Name);
}
fprintf(OutStream,
")%s\n",
MainText[i][0] == '%' ?
if(MainText[i][0] == '&')
{
fprintf(OutStream, "{\n return 0;\n)\n\n");
}
break;
Обратите внимание, как заканчивается этот блок
case. Если генерируется прототип, то блок заканчива-
ется точкой с запятой, в противном случае — телом фун-
кции (конечно, только если оно требуется — проверка
этого содержится в начале блока case).
Теперь самое время генерировать обращение к фун-
кции. Это нужно сделать независимо от того, имеется
ли тело функции или нет. (Как следствие, тело функ-
ции требуется написать где-то в другом месте, когда еще
не определен указатель -internal, иначе эта программа
никогда не будет правильно компоноваться.)
На этот раз не стоит волноваться насчет типа пере-
менной ~ нужно только указать ее имя, присоединен-
ное к имени структуры, и точечный оператор.
case * * *:
/* Генерирование обращения к функции */
fprintf(OutStream,
" Status =
(ApplicationMain(");
j = 0;
for(Arg = ArgList;
Arg != NOLL;
Arg = DLGetNext (Arg))
{
Data = DLGetDatafArg, NULL, NULL);
fprintf(OutStream, "%sArgList.%s",
j == 0 ?
",\n
r
Data->Name);
++j;
}
fprintf(OutStream,
") =» 0) ?\n
EXITSUCCESS "
":\n
EXIT_FAILURE;\n") ;
break;
default:
fprintf(OutStream, "%s\n",
MainTextfi));
break;
}
}
return EXITSUCCESS;
}
Теперь мы имеем весь код, необходимый для гене-
рирования результирующего файла. С этой целью нуж-
но связать фрагменты кода вместе, а для этого, в свою
очередь, требуется функция, которая выполняла бы
следующее:
• Принимала аргументы командной строки для флага
internal и имен четырех необходимых файлов — фай-
ла грамматики, результирующего файла, системно-
го журнала (для синтаксического анализатора) и
вспомогательного файла.
• Открывала при необходимости файлы для чтения и
записи.
• Вызывала функцию синтаксического анализатора и
функции генерирования кода.
Здесь эта функция отредактирована путем замены
кода обработки файлов и анализа аргументов коммен-
тариями, а полный исходный код находится на Web-
сайте "ДиаСофт”.
int ApplicationMain(int internal,
char * InFile,
char * OutFile,
char * LogFile,
char * HelpFile)
{
int Status;
DLLIST ‘ArgList = NULL;
FILE *fpln, *fpOut, ‘fpLog, ‘fpHelp;
/* Код для открытия всех четырех файлов
вставить сюда. */
Status = Parseinput(KArgList, fpln, fpLog);
if(EXITSUCCESS == Status)
{
DLWalk(ArgList, WalkArgs, fpLog);
Status - WriteHeaders(fpOut, OutFile);
}
if(EXITSUCCESS == Status)
{
Status = NriteTypedef(fpOut, ArgList);
}
if(EXITSUCCESS == Status)
{
Status ~ WriteFunctionffpOut, ArgList);
}
if(EXIT-SUCCESS == Status)
{
Status = WriteMain(fpOut, fpHelp,
ArgList, internal);
}
Создание программных инструментальных средств
[559
Глава 20
/* Код для закрытия всех четырех файлов
вставить сюда. */
DLDestroy(&ArgList);
return Status;
)
Вы, наверное, не удивитесь, когда узнаете, что эта
функция называется main(). На практике, однако, я
убедился, что процесс программирования проверки пра-
вильности командной строки очень утомителен, поэто-
му для получения кода проверки аргументов здесь ис-
пользовался генератор кода. (Если хотите сделать
по-другому, используйте результат этой программы для
помощи вам в ее написании.)
Эту программу нетрудно использовать. Несколько
примеров входных файлов находятся на Web-сайте ’’Диа-
Софт”, поэтому вы можете сами сгенерировать несколько
исходных кодов, чтобы увидеть, как все это работает.
Увидев реально работающую программу генерирова-
ния кода, думаю, вы согласитесь, что здесь нет ничего
слишком сложного в части, касающейся С. Кропотли-
вая и тяжелая работа связана только с проектировани-
ем. Когда вы хорошо разберетесь в этом, то поймете, что
генератор кода пишет сам себя в буквальном смысле.
Резюме
В этой главе подчеркнута важность создания программ-
ных инструментов как поддисциплины программирова-
ния, рассмотрены некоторые характеристики полезных
программных инструментальных средств, изучены пути
создания более действенных библиотек кодов и обсуж-
дены аспекты проектирования нескольких фильтров
командной строки. По ходу дула мы написали несколь-
ко программ, которые, надеюсь, вы будете часто ис-
пользовать в своей работе.
Кроме того, были исследованы способы автомати-
ческого генерирования тестовых данных для упрощения
зачастую громоздких процессов крупномасштабного
тестирования.
И наконец, разрабатывая полезные инструменты, вы
получили возможность довольно глубоко проникнуть в
"черную магию’’ генерирования кода и подробно изу-
чить процесс разработки синтаксического анализатора
командной строки. Создавать генераторы кода удиви-
тельно приятно. Как говорил один известный хакер:
"Я не хочу писать программы, я хочу писать програм-
мы, которые сами пишут другие программы".
Генетические алгоритмы
В ЭТОЙ ГЛАВЕ
Понятие генетического алгоритма
Генетическая структура
Операции мутации
Рекомбинация
Отбор
Вскрытие “черного ящика”
Оптимизация
Пример приложения: генетический биржевой консультант
Майк Райт
В этой главе представлена нетрадиционная модель про-
граммирования на основе генетики и эволюции, а не
классической математики. Прежде всего рассмотрим
преимущества и недостатки предлагаемого генетическо-
го подхода. Генетические алгоритмы прекрасно реша-
ют множество проблем, с которыми плохо справляют-
ся традиционные алгоритмы.
Затем перейдем к описанию компонентов таких про-
грамм и их организации. Исследуем также различные
способы кодирования данных на генетическом уровне,
а затем основные эволюционные операции, включаю-
щие мутацию, рекомбинацию и отбор.
После подробного анализа представленных генети-
ческих алгоритмов будет рассказано, как лучше выпол-
нять эти программы. Четкость и оптимизация — вот
наиболее важные составляющие успеха.
И наконец, полученные знания вы сможете приме-
нить в своей работе по созданию реального приложения
генетической концепции — генетического биржевого
консультанта. Дальнейшее развитие генераций генети-
ческого биржевого консультанта позволит программе
выдавать очень хорошие предложения по поводу того,
какие акции более предпочтительны для предпринима-
теля, а какие — менее.
Понятие генетического алгоритма
Генетический алгоритм решает проблемы путем приме-
нения принципов теорий естественной эволюции жи-
вых организмов. Среда программы имитирует природу,
позволяя подмножеству наиболее приспособленных
организмов жить и размножаться за счет менее приспо-
собленных. Вместо действительных организмов популя-
ция программы состоит из генетически кодированных
решений. Более сильное решение создает другое, немно-
го отличающееся дочернее решение, в то время как бо-
лее слабые решения ’’умирают" и заменяются потомка-
ми "выживших" решений. Как и в природе, потомки
"выживших" представителей похожи на своих предше-
ственников и зачастую наследуют их преимущества, и
свое дальнейшее существование основывают на них.
После появления каждого поколения естественный от-
бор становится все более жестким. Полученные в резуль-
тате такого отбора индивидуумы становятся все силь-
нее и сильнее.
Генетические алгоритмы предоставляют следующие
уникальные преимущества использования эволюцион-
ной модели:
• Система наследования является довольно гибкой.
Это позволяет предназначенный для одной цели код
использовать для другой цели. Большая часть обра-
ботки данных и логики универсально применимы
для любой проблемы. На самом деле, если у вас воз-
никли небольшие затруднения, то границы пробле-
мы часто можно модифицировать, причем запускать
эволюционный процесс заново не требуется.
• Если используемая последовательность прерывает-
ся или неизвестна продолжительность ее действия,
то для решения этих проблем имеется множество
способов. Время от времени можно проводить оцен-
ку объединенной популяции для поиска лучшего те-
кущего поколения.
• Проблемы, которые трудно осмыслить, зачастую ре-
шаются с приемлемой эффективностью по генети-
ческому алгоритму. Поэтому следует сравнивать
между собой решения, проводить их анализ и выби-
рать наилучшее из них.
• Процессы эволюции очень хорошо регулируются в
больших параллельных системах. Чем больше попу-
Генетические алгоритмы
Глава 21
561
ляция, тем быстрее она развивается. Подмножество
индивидуумов может развиваться независимо друг от
друга, затем они разделяются, дублируются и с
очень небольшими ограничениями вновь соединя-
ются.
• Полученные решения могут сильно отличаться от
тех, которые ожидаются. Может существовать ши-
рокое многообразие корректных решений, и иногда
для того, чтобы их найти, выполняется случайный
поиск. Это приводит к новым революционным (или
эволюционным!) подходам, когда программа нахо-
дит совершенно новое лучшее решение. Творческие
процессы хорошо моделируются генетическими ал-
горитмами, в которых используются похожие стадии
осмысливания, повторного применения результата,
его оценки и усовершенствования (в эволюционной
терминологии называемые мутацией, рекомбинаци-
ей и отбором).
Ниже приведен список терминов, часто используе-
мых в структурах и алгоритмах генетических данных:
• Ген — секция генетического кода, которая представ-
ляет единственный параметр для потенциального
решения.
• Аллель — значение, хранимое в гене.
• Хромосома — набор генов, достаточных для полного
описания возможных решений для программы. Ука-
зывает единственную точку в области решений.
• Геном —- все хромосомы индивидуального организма.
• Генотип — значения генома.
• Область проблем— область всех возможных проблем-
ных случаев, каждый из которых имеет свой неза-
висимый параметр, задающий другое измерение.
• Область решений — похожа на область проблем, но
заданную параметрами решения, а не проблемными
параметрами. Каждая точка в области решений пред-
ставляет допустимое, но, скорее всего, условно оп-
тимальное решение указанной проблемы.
Генетическая структура
Ген является фундаментальной структурой генетичес-
ких данных. Ген — это просто секция генетического
кода, представляющая единственный параметр потен-
циального решения. Гены могут иметь любой размер, но
обычно не более одного бита длиной.
СОВЕТ
В генетическом коде следует представлять только пара-
метры решения. Другие переменные, включая парамет-
ры проблемной области, не должны быть представлены.
Для представления аллелей в генах можно исполь-
зовать любую схему. Наиболее общим является исполь-
зование двоичного кода Грея, так как эволюционные
операторы, особенно предназначенные для мутации,
получении постоянно увеличивающихся изменений,
кажутся более эффективными в кодах Грея, чем в пос-
ледовательных кодах. Коды Грея, названные в честь
открывшего их Фрэнка Грея (Frank Gray), представля-
ют собой любые цифровые упорядоченные системы, в
которых все соседние целые числа в числовом представ-
лении отличаются в точности на одну цифру. Такое
представление полезно для генетических приложений,
поскольку небольшие изменения, например при мута-
ции, обычно предназначены для получения только не-
больших изменений в значении. В табл. 21.1 приведе-
ны примеры двоичного кода Грея из трех битов в
сравнении со стандартно упорядоченной двоичной пос-
ледовательностью.
Таблица 21.1. Пример двоичного упорядочения
кода Грея.
Код Грея Последовательный код
ООО 000
001 001
011 010
010 011
110 100
111 101
101 110
100 111
Хотя коды Грея имеют много интересных свойств,
наиболее привлекательным для генетических систем
является их цифровая близость. Чтобы свести к мини-
муму нежелательные эффекты случайности, нужно под-
держивать изменяемые значения близкими друг другу.
Большие изменения значения менее желательны, чем
небольшие числовые изменения при выполнении коди-
рования Грея.
Прямое и обратное преобразование простых кодов
Грея очевидно (листинг 21.1).
Листинг 21.1. Преобразование кода Грея в
обычное двоичное представление.
unsigned int bin_to_Gray(unsigned int n)
{
return n * (n » 1);
}
unsigned int Gray_to_bin(unsigned int n)
{
int i;
for(i=0; (1 « i) < sizeof (n) * CHAR_BIT; i++)
36 Зак. 265
562
Дополнительные тематические разделы
Часть III
{
n *= n » (1 « i);
}
return n;
}
Гены сгруппированы в хромосомы. Одиночная хро-
мосома содержит достаточное количество генов для
полного описания решения и независимой оценки с
точки зрения пригодности решения. В большинстве
случаев каждая отдельная популяция содержит только
одну хромосому. Вторичные хромосомы можно исполь-
зовать для хранения временно неиспользуемых возмож-
ностей или других данных, прямо не относящихся к
основной проблеме.
Структуры хромосом могут значительно различать-
ся. Плоские, одномерные, имеющие постоянный размер
битовые или символьные массивы — вот самые простые
хромосомные структуры, причем для большинства при-
ложений их вполне достаточно. Более сложные хромо-
сомы можно построить с использованием многомерных
массивов, деревьев и даже хеш-таблиц. Такие структу-
ры в основном предназначены для управления, если они
лучше отражают область решений.
Полная совокупность хромосом индивидуумов со-
ставляет геном организма. Геномы свободно использу-
ют очень простые структуры, довольно сложные струк-
туры или что-нибудь среднее для организации
составляющих их хромосом. Природа использует хоро-
ший простой метод: просто связывает все вместе в один
длинный массив (или два дублированных массива для
ДНК).
Как определить, что нужно для организации гене-
тических данных? В первую очередь следует рассмот-
реть операции, которые необходимо выполнить с эти-
ми данными. Геном копируется, комбинируется с
другими геномами, мутирует, сращивается и оценива-
ет свое состояние, чтобы определить, насколько хоро-
шо решена конкретная проблема. Возможно, геном не
потребуется искать или демонстрировать. Необходимо
рассмотреть также данные, которые будет хранить ге-
ном. Они различны для разных реализаций и проблем-
ных целей. Иногда частное кодирование не совсем под-
ходит для определенных структур. А иногда одного
скалярного целого числа достаточно для кодирования
всего генома. Для большей эффективности и логичес-
кой ясности каждый ген, каждая хромосома и каждый
геном должны быть разработаны таким образом, чтобы
каждое возможное расположение и порядок лежали в
уникальной точке области решений, а не в какой-либо
другой. Удаление заведомо "неправильных решений" из
области решений может также значительно упростить
выполнение задачи. Если значение х может быть опти-
мальным только в диапазоне от 0 до 10, то не задавайте
диапазон значений х от 0 до 100. При этом, конечно,
вы должны быть уверены, что хорошо знаете х, так как
вы можете нечаянно исключить некоторые неочевидные
хорошие решения. Конечным пунктом рассмотрения
является эволюционный процесс. Нужно убедиться, что
генетическая структура в процессе эволюции может
эффективно рекомбинироваться. Дочерние хромосомы
должны наследовать как можно больше преимуществ от
своего (своих) родителя (родителей). Если генетическая
структура делает это с трудом или вовсе не делает, то
генетические алгоритмы быстро имитируют деградацию
и начинают случайное блуждание в области решений.
В некоторых случаях сама проблема делает генетичес-
кое наследование нежелательным. При возникновении
таких проблем данный подход не позволяет получить
полное решение.
Операции мутации
В связи с тем что обновленный генетический материал
не смешивается ни теперь, ни потом, популяция дей-
ствительно может страдать от застоя (стагнации). По-
степенно популяция заполняется множеством очень
простых генотипов. Поддержание определенного отно-
шения нескольких поколений к множеству индивидуу-
мов уменьшает стагнацию, но это недостаточно общее
решение. Генетический дрейф популяции приходит к
застою, поскольку в организмах из поколения в поко-
ление перемешиваются одни и те же наборы генов.
Даже естественный отбор может вести к стагнации,
поскольку самые приспособленные организмы стремят-
ся заменить менее приспособленные. В экстремальных
условиях, например, когда только небольшой процент
популяции выживает и порождает каждое поколение,
это может привести к единообразию и останется толь-
ко один высший генотип.
Операции мутации предназначены для удержания
популяции от стагнации, аккуратно добавляя некоторые
случайные элементы в некоторые хромосомы Иногда
при генетическом дрейфе или естественном отборе уда-
ляются критичные аллели, необходимые для получения
более мощных организмов. Мутации предоставляют
популяции возможность экспериментировать с целыми
оригинальными аллелями, вместо того чтобы просто
пытаться создавать больше комбинаций аллелей из су-
ществующих генотипов.
Мутации должны проводиться в меру. Слишком большое
количество мутаций устраняет преимущества, полученные
в результате наследования и эволюции. Мутации — это яд
для генетического алгоритма, если только они не вводят-
ся малыми дозами.
Генетические алгоритмы
Глава 21
563
Рекомбинация
Рекомбинация — это процесс создания нового поколе-
ния из старого. Имеется множество способов, позволя-
ющих сделать это. Единственным требованием являет-
ся то, что строятся новые хромосомы и что в дочерних
хромосомах заменяются некоторые характеристики,
унаследованные ими от родителей.
Единственные родители
Перестановка аллелей внутри одной и той же хромосо-
мы имеет такой же эффект, как и в случае простой му-
тации. Этот способ рекомбинации включает только пе-
рестановку позиций генов аллелей, например изменение
АВС на АСВ. Дочерние вариации редко сохраняют пре-
имущества от такого типа наследования. Технологии
рекомбинации, которые включают более, чем одного
родителя, более эффективны для получения высших
генотипов.
Скрещивание генов
Скрещивание генов — это очень простая технология
рекомбинации. Дети берут аллели более чем из одной
родительской хромосомы, случайно выбирая родителя,
который обеспечит следующий аллель. Дочерние гены
по-прежнему в точности отображают гены родителей
(аллели не изменяют своего положения), но комбина-
ция представляет собой смесь аллелей каждого родите-
ля. Например, комбинируя таким образом родительские
последовательности АВС и XYZ, можно создать восемь
различных дочерних комбинаций: ABZ, AYC, AYZ,
ХВС, XBZ, XYC и две оригинальные родительские пос-
ледовательности.
На смешивание могут быть наложены ограничения.
Например, можно потребовать, чтобы большая часть
аллелей поступала от более благополучного родителя
(родителей). Если соединить вместе одну сильную и две
слабые хромосомы, то лучше получить необходимые
аллели от единственного сильного родителя, чем от двух
слабых. Другой возможностью является требование,
чтобы каждый родитель привносил равное количество
аллелей.
Скрещивание генов наиболее эффективно, когда оно
выполняется на относительно независимых генах.
Скрещивание последовательностей генов
Это наиболее общая технология копирования ценных
последовательностей аллелей от каждого родителя. Точ-
ки сращивания выбираются на дочерней хромосоме и
разделяются между родителями. ABCD пересекается с
WXYZ, и в результате получается восемь возможных
дочерних комбинаций в зависимости от того, какая точ-
ка сращивания выбрана и какой родитель получает ка-
кую сторону: ABYZ, AXYZ, WXYD, WXCD, WBCD и две
оригинальные родительские последовательности. Этот
метод рекомбинации более стабилен, поскольку полез-
ные характеристики намного лучше переходят в следу-
ющее поколение и такие наследники в большей степе-
ни походят на своих родителей. Однако скрещивание
последовательностей оставляет меньше вариантов, чем
скрещивание отдельных генов.
ПРЕДОСТЕРЕЖЕНИЕ
Точки сращивания нужно выбирать на границах генов.
Разрезая отдельные аллели надвое, можно уничтожить
полезные характеристики.
Объединение генов
Дочерние хромосомы могут наследовать аллели, кото-
рых не было в каком-либо родителе, но которые созда-
ются путем комбинации самих аллелей. Для объедине-
ния аллелей можно использовать несколько операций,
например, исключающее ИЛИ, усреднение и т.п. Для
генов, которые представляют непрерывные параметры,
объединение значительно расширяет поиск оптималь-
ного значения.
ПРИМЕЧАНИЕ
Объединение генов не выполняется для дискретных зна-
чений. Если комбинирование двух аллелей для получения
одной уникальной аллели не имеет смысла для конкрет-
ного гена, следует исключить этот ген из процесса. Не-
которые хромосомы разрабатываются такими, что они
содержат только дискретные значения, и в этом случае
объединение бесполезно.
Отбор
Поскольку каждое новое поколение должно содержать
геномы, превосходящие аналогичные геномы в преды-
дущих поколениях, более пригодные хромосомы дол-
жны включаться более часто, чем менее пригодные.
Один простой метод включает только несколько лучших
организмов в фазе репродукции и позволяет полностью
умереть низшему геному. Такой отбор можно сделать
строгим, с использованием так называемого ’’жесткого”
выбора, который позволяет убедиться, что низшие орга-
низмы всегда умирают, а высшие всегда выживают.
Отбор можно сделать вероятностным, с использовани-
ем "мягкого" выбора. В результате такого отбора неко-
торые более предпочтительные хромосомы могут уми-
рать в надежде на то, что менее приспособленные
родители произведут исключительного потомка.
Дополнительные тематические разделы
Часть III
564
ПРВДОСГЕРЕЖВМЕ
Если позволить слишком многим геномам выжить и уча-
ствовать в создании следующего поколения, это может
привести к очень быстрой стагнации.
Каждый геном-член популяции — сначала требует-
ся ранжировать по функции пригодности. Это просто
позволяет определить, насколько хорошо каждое гене-
тически кодированное решение удовлетворяет проблем-
ной цели. Из-за необходимости сравнения нескольких
кандидатов друг с другом функция пригодности долж-
на возвращать точные, окончательно сформированные
характерные оценки решений, а также легко их ранжи-
ровать и сравнивать друг с другом: Всегда легче рабо-
тать с единственным значением пригодности, но все-
таки некоторые проблемы можно уменьшить лишь до
нескольких таких значений.* Например, программа по-
иска наилучших из возможных рабочих мест выдаст вам
несколько вариантов высокооплачиваемой работы, при-
чем в одном случае вам покажется удобным месторас-
положения офиса, а в другом больше понравится сама
работа. Однако, скорее всего, будет неудобно иметь
программу, которая принимала бы решение о том, как
конвертировать все эти критерии в один критерий ’’луч-
шая работа". В этих случаях функция пригодности по-
лучает множество значений, которые приблизительно
равноправны, например, когда одна хромосома нашла
хорошо оплачиваемую работу, а другая нашла среду, в
которой лучше работать. Только когда все значения
пригодности являются значениями высшего порядка,
можно без опаски рассматривать такую хромосому как
более предпочтительную перед другими.
Разработчик должен определить, как работать с вы-
жившими родителями каждого поколения. Поколение
должно либо служить как активная пунктуация, полно-
стью регенерирующая популяцию за каждый цикл,
либо определенным образом отбирать индивидуумов,
которые смогут выжить в следующих поколениях. Эти
стратегии называются соответственно стратегией запя-
той и стратегией плюса. Отсутствие возможности роди-
телю конкурировать со своим потомком часто записы-
вается как (родитель, потомок), что означает смерть
родителя и его замену потомком, в то время как запись
(родитель + потомок) указывает на объединение роди-
теля и потомка в той же самой популяции в качестве оп-
понентов, равных друг другу, и потенциальных пар.
Стратегия плюса обычно выполняется лучше, но ре-
зультаты использования стратегии запятой более полез-
ны для оценки эффективности технологий отбора и ре-
комбинации.
Иногда гены внутри популяции сводятся к един-
ственному значению. Все или большая часть хромосом
имеют одно и то же значение аллеля для генов. Очень
часто это довольно полезно, так как указывает наилуч-
шие аллели для этих генов, однако иногда реализуется
сильный, но ошибочный оптимум. Мутация действи-
тельно держит популяцию в пределах желательной ста-
бильности, но после этого эволюция не может продол-
жать улучшение популяции обычными способами.
Воспроизводство большей разновидности без потери
необходимых преимуществ стабильности и прогрессив-
ного усовершенствования называется видообразованием.
Разделение популяции на подмножества, в которых ге-
номы мигрируют редко или вообще не мигрируют, при-
водит к развитию разновидностей (видов). Одно под-
множество может потерять жизнеспособность, а другое
может продолжать эволюцию. Случайное производство
одного или нескольких чужих организмов может позво-
лить преодолеть застой, и популяция будет развивать-
ся дальше. Иногда два подмножества развиваются в двух
различных отношениях, и один чужой геном из более
улучшенного подмножества может быстро размножить-
ся и стать доминирующим над более слабым, создавая
две неожиданно очень похожих особи. Самый мягкий
способ представления чужих геномов — это скрещива-
ние чужого(их) организма(ов) с одним или более посто-
янными обитателями. Это смягчает влияние, оказыва-
емое новоприбывшими.
Виды можно изолировать с помощью похожих, но
не идентичных проблемных областей. Иногда хромосо-
мы более быстро эволюционируют, когда сталкивают-
ся с проблемой, которая только немного отличается от
реальной. После решения измененной проблемы обыч-
но необходима только небольшая эволюция для преоб-
разования решения в похожую проблему. Эти неболь-
шие генетические изменения необходимы, чтобы
незначительная конкретизация в измененной проблеме
наследовалась из существующей резидентной популя-
ции, постоянно работающей над основной проблемой
для нескольких поколений.
Вскрытие "черного ящика"
Генетические алгоритмы реализуются легко. Интуитив-
но они имеют смысл. Программисты, которые понима-
ют, как это сделать, тем не менее, знают только не-
сколько деталей вышеуказанных теоретических основ.
Математика, на которой зиждятся генетические алго-
ритмы, не так проста, и ее нелегко понять. Поскольку
большинство программистов заботятся только о выпол-
нении алгоритма, чтобы получить максимальную выго-
ду, и не думают о подтверждении или полном понима-
нии принципов, существует широко распространенная
тенденция, в результате которой отбор решений проис-
ходит эмпирически. Иными словами, если программа
работает, значит, ее результаты можно использовать. В
основном это правильно, но, когда программа ведет себя
Генетические алгоритмы
Глава 21
565
не так, как надо, недостаток глубокого понимания ал-
горитма может стать большой проблемой.
Рассматривайте генетические функции в программе
как исключительно экспериментальные. Сделайте так,
чтобы переменные управления можно было легко изме-
нять, причем попробуйте использовать различные стра-
тегии. Опишите массив статистических данных как эк-
спериментальные данные. Опишите состояние
популяции, успех рекомбинации, количество уникаль-
ных индивидуумов, количество поколений и т.п. Попро-
буйте описать обширные обзоры и выводы так же, как
несколько примеров близких индивидуумов, подвергаю-
щихся различным операциям. Если можно, то попытай-
тесь сделать свою экспериментальную программу инте-
рактивной, чтобы можно было легко изучить влияние
каждого параметра управления на работу программы.
Запомните: намного легче получить корректную ра-
боту отдельной простой функции, чем всей программы.
Правильное выполнение генетических алгоритмов зави-
сит от нескольких взаимосвязанных операций. Очень
плохо то, что причину неправильного поведения мож-
но определить, только исследовав конечный результат.
Например, сообщение "Моя популяция очень хаотич-
на" — это не очень конкретный симптом. Выясните, для
чего разработана каждая функция, а затем проверьте,
действительно ли она выполняет свою задачу.
Для целей управляемости сделайте исходный код
настолько простым, насколько это возможно. Исполь-
зуйте длинные, содержательные идентификаторы. Ме-
тафоры используйте последовательно. Названия типа
"mu" и "lambda" не помогут так, как "родители" и "по-
томки". Если метафора далее не помогает, оставьте ее.
Может быть, вы предпочитаете употреблять термин
"ДНК" вместо "геном"— пожалуйста. Если вы представ-
ляете себе мутацию как бурю, то можете спокойно
переименовать переменную "mutation factor” на пере-
менную "inches_of_precipitation”. В сообществе компь-
ютерной науки предпочитают генетические и эволюци-
онные метафоры, однако можно использовать и другие.
Если вам не нравится использовать слова "аллель" и "ге-
нотип", не используйте их. Однако все же попытайтесь
использовать некоторые виды метафор, потому что это
упрощает способ задания каждому элементу уникально-
го, осмысленного названия. Если вы имеете дело с не-
сколькими различными операциями, попробуйте дать
каждой из них свое собственное имя. Не нумеруйте их
и не давайте названия типа "RepOp27", так как их мож-
но перепутать друг с другом, и это заставит кого-нибудь
просмотреть весь код, чтобы понять значение этих опе-
раций. И, самое главное — вводите достаточное коли-
чество комментариев для объяснения того, что и зачем
вы делаете, часто ссылаясь на метафоры.
Оптимизация
Случайные поиски довольно медлительны. Чем более
они случайны, тем более медленно они выполняют
поиск. Генетические алгоритмы — это класс техноло-
гий случайного поиска. К счастью, генетические алго-
ритмы имеют несколько необычных свойств, которые
хорошо приспособлены для определенных форм опти-
мизации.
Параллелизм
Генетические алгоритмы хорошо работают параллель-
но. Один из способов такой работы заключается в том,
чтобы каждый процесс развивал независимое подмно-
жество. Периодически между подмножествами проис-
ходит обмен представленными геномами, для того что-
бы обнаруженные преимущества одного процесса
можно было использовать для ускорения развития дру-
гого процесса. Это создает множество параллельных
видов, причем все с одной и той же конечной целью.
Существуют также способы, позволяющие парал-
лельно развивать одни и те же виды. Процесс эволюции,
потенциально состоящий из нескольких операций му-
тации, рекомбинации и отбора, можно разделить по
длине, причем каждый процесс предназначается для
одной операции, выполняемой вдоль конвейера. Про-
цесс можно также разделить поперек, т.е. разделить
популяции на независимые сегменты для множества
операций, например, для оценки пригодности и мута-
ции. После этого каждое поколение воссоединяется.
Поиск эффективных генетических
операторов
Каждая проблема и каждая реализация имеют различ-
ный набор оптимальных операторов. Иногда использо-
вание только двух родителей в последовательном скре-
щивании является лучшим вариантом, в то время как в
других случаях лучше подходит мутация поиска экст-
ремума. Тестируя популяции с помощью различных
операций и с различными управлениями, можно опре-
делить, что более пригодно для работы над данной про-
блемой.
Запомните также, что генетические алгоритмы созда-
ют очень хорошие универсальные оптимизаторы. В ка-
честве альтернативы статистической оптимизации по-
иска для развития эволюционной стратегии можно
использовать мета-эволюционные функции. Адекват-
ность стратегии определяется тем, как быстро совершен-
ствуется популяция. Генотип представляет решение
доступных операций. Это происходит так же просто, как
один бит для каждого гена может включать и выклю-
чать операции.
Дополнительные тематические разделы
Часть III
566
Разделение проблемной области
Генетические алгоритмы работают намного быстрее
при поиске маленьких составных областей решений, чем
с одной большой объединенной областью решения. Не
объединяйте несколько небольших областей решения в
одну. Это может казаться заманчивым, но почти навер-
няка потребует больше времени для решения множества
проблем за один раз, чем если бы это делалось незави-
симо.
Пример. Мистер Рич хочет получить наиболее рос-
кошный автомобиль для передвижения по городу. Ему
требуется нанять более опытного водителя и приобре-
сти очень дорогую машину. Поскольку мы можем при-
нять к рассмотрению любого водителя, который может
управлять любым автомобилем, то эти две проблемы
требуется разделить. Одна и та же популяция не долж-
на затруднять поиск комбинации лучших водителей и
лучших машин. Должна быть указана каждая популя-
ция: одна — для поиска шофера и одна — для поиска
машины.
В большинстве экстремальных ситуаций такое раз-
деление проблемы сужает область решения до удвоен-
ного квадратного корня от объединенной проблемы.
Вместо миллиона возможностей требуется искать толь-
ко две тысячи. Проблему нужно разделить на как мож-
но большее число подпроблем. Однако, если подпроб-
лемы действительно взаимосвязаны, например, когда
каждый шофер водит автомобиль по-разному и это оп-
ределяет пригодность решения, то проблему нельзя
подходяще разделить на меньшие проблемы.
Отклонение произошедших неудач
Программа может содержать запись каждой последую-
щей субоптимальной хромосомы, поэтому если одна и
та же хромосома генерируется всегда заново, то ее надо
немедленно уничтожить. Это может сохранить немно-
го времени, так как генетические алгоритмы заведомо
не имеют гарантий того, что один и тот же эволюцион-
ный путь не будет пройден несколько раз. При этом
следует проявлять известную осторожность, чтобы не
исключить хорошие пути развития высших комбина-
ций. Обычно очень бедная хромосома не приводит к
таким результатам, к каким приводит более пригодная
хромосома. Естественно, что хорошие хромосомы обыч-
но более предпочтительны для создания наиболее про-
дуктивного потомства, чем плохие.
Исправление ошибок
Некоторые приложения направляют довольно большую
долю ресурсов на обнаружение и/или коррекцию оши-
бок. Программы связи, в частности, имеют дело с ошиб-
ками при соединении, проблемами трафика и ошибка-
ми устройств. Многократное использование генетичес-
ких алгоритмов уменьшает или снимает необходимость
этих мер предосторожности, потому что средства ис-
правления ошибок уже встроены в них. Генетические
программы являются существенно безразличными к
нескольким ошибочным геномам, пропавшим или запоз-
давшим геномам, повторяющимся копиям геномов и т.п.
Если эти геномы "в основном нормальные”, то пробле-
мы обычно даже не замечаются. Даже если часть про-
граммы, не связанная с развитием, немного поврежде-
на (например, когда оценка пригодности не совсем верна
или когда игнорируется небольшая часть кода рекомби-
нации), то алгоритм будет продолжать функциониро-
вать почти так же хорошо, как если бы ошибок не было
совсем. В отличие от большинства других приложений,
генетические алгоритмы достаточно гибки, и ошибки
становятся лишь маленькой помехой, а не критичным
фактором для системы. Появляющиеся ошибки имеют
тенденцию убывать параллельно с построением субоп-
тимальных решений.
Неполные решения и изменение
ограничений на ресурсы
Иногда скорость работы программы становится критич-
ным фактором. На работающих в реальном времени
системах проблемы нужно решать в заданные времен-
ные интервалы, иначе могут возникнуть непредвиден-
ные ситуации. Путем повышения скорости поиска наи-
более подходящих решений генетические алгоритмы
обеспечивают правильный ответ на сделанный запрос.
Они не гарантируют, что полученное решение будет
хорошим, но предлагают лучшее решение из найденных
за данное время. Если требуется немедленный ответ, то
подойдет и тот лучший, который был найден. Если
позднее появится способ, позволяющий заменить это
решение, то будет готово и другое намного лучшее ре-
шение. Текущую популяцию даже можно "заморозить"
и сохранить, чтобы позднее использовать для дальней-
шей эволюции.
Может произойти так, что потребуется решить про-
блему, а доступные ресурсы для выполнения этой за-
дачи непрерывно изменяются. Генетические алгоритмы
легко приспосабливаются к размеру популяции для
полного заполнения доступной области памяти. Чем
больше становится доступной память, тем большие попу-
ляции могут использоваться. Даже если память, исполь-
зованная генетическим алгоритмом в процессе эволюции,
переполняется, то потеря геномов не становится фаталь-
ной проблемой. Если время работы CPU сокращается,
то с решением, представляющим лучшие результаты,
всегда можно работать. Даже с очень ограниченной па-
мятью и временными ограничениями генетические ал-
горитмы могут давать довольно неплохие решения, хотя
567
очевидно, что они лучше работают, когда ресурсы бо-
гаты.
Использование метафор
Метафоры очень помогают в понимании, они даже
могут направить исследование в новое русло. Модель
Матушки Природы часто работает хорошо. Некоторые
из наиболее фундаментальных основ являются универ-
сальными, работающими одинаково хорошо и для бак-
терий, и для компьютерных программ. Другие аспекты
неуниверсальны. Как в современном самолетостроении
используют металл вместо перьев, программист должен
отказаться от элементов природной генетики и эволю-
ции, так как стали доступными более усовершенство-
ванные технологии. Природа могла бы быть хорошим
началом, обеспечивающим ощутимые доказательства
жизнеспособности, но это не означает, что природные
методы — наилучшие или даже более интересные. Ре-
активный самолет может летать выше и быстрее, чем
любая птица, летучая мышь или насекомое. Текущие
исследования в области эволюционных алгоритмов уже
отделились от оригинальной природной модели и ис-
пользуют более новые и более мощные идеи.
Пример приложения: генетический
биржевой консультант
Биржевой маклер приносит пользу, продавая часть ак-
ций по цене, которая больше их покупной стоимости.
На наиболее общем уровне биржевой маклер должен ре-
шить, когда требуется купить пакет акций, когда его
продать, а когда попридержать акции, приобретенные
ранее.
Биржевой анализ — это хороший пример примене-
ния генетического алгоритма, поскольку довольно час-
то происходит так, что трудно точно определить, какие
факторы более полезны для предугадывания будущих
цен на акции, и, вероятно, существует много одинако-
во хороших, но не обязательно очевидных решений.
Иногда биржевые цены кажутся довольно правдивыми
для конкретного набора, а иногда кажется, что они
выбраны совершенно случайно. С использованием гене-
тических алгоритмов можно выработать приблизитель-
но оптимальное решение и определить, когда лучше
покупать акции, а когда их лучше продавать.
ПРИМЕЧАНИЕ
Полный пример программы не включен в эту главу, од-
нако ее можно найти на Web-сайте издательства "Диа-
Софт" вместе с недавними данными по биржевым ценам.
Генетические алгоритмы
Глава 21
Анализ проблемы
Входные данные представляют собой двумерный мас-
сив истории изменения цен за год. Каждая колонка со-
ответствует уникальному символу тикера названия ак-
ций, а каждый ряд —• последующему дню. Результатом
работы программы будет рекомендация для каждой ко-
лонки — покупать, удерживать или продавать. В лис-
тинге 21.2 определяются эти структуры.
Листинг 21.2. Типы входных и выходных данных
генетического биржевого консультанта
/* Тип данных, используемых для ввода */
typedef struct
{
unsigned int price[NUMSTOCKS}[BISTORYLENGTB];
} history_t;
/* Тип данных, используемых для вывода */
typedef enum
{
SELL = -1,
HOLD = 0,
BUY = 1
} recommendation_t;
Генетическая структура
Решение требует только рекомендации, однако функ-
ция пригодности требует, чтобы каждая хромосома
была закодирована внутри ее плана для выработки ре-
комендаций исходя из истории динамики цен. Нам не
нужна просто рекомендация купить, продать или по-
придержать что-нибудь — мы должны сделать ту опе-
рацию, которая получила наиболее выгодную рекомен-
дацию. Все, что нужно сделать, — спроектировать
хромосому, которая бы являлась генератором рекомен-
даций.
Хромосомы фиксированной длины реализуются про-
ще всего, и нам, возможно, не потребуется даже пере-
менной номеров генов, поэтому нужно убедиться толь-
ко, что мы имеем фиксированное количество генов.
Рекомендации можно получить путем сравнения
текущей цены с текущей средней ценой за акцию с ис-
пользованием генетически кодированных покупок и
продаж. Каждая хромосома содержит только два гена:
один описывает цену, пропорционально текущей сред-
ней цене, когда срабатывает рекомендация о покупке,
и второй, который просто описывает цену, когда сра-
батывает рекомендация о продаже. Когда не срабаты-
вает рекомендация покупки или продажи, генерирует-
ся рекомендация об удержании акций.
Поскольку каждый ген — это просто целое значение,
то для них можно выполнить кодирование Грея.
568
Дополнительные тематические разделы
Часть III ~
Генетические структуры, используемые генетичес-
ким биржевым консультантом, масштабируемым от
индивидуальных генов до целых популяций, описаны
в листинге 21.3.
Листинг 21.3. Генетические структуры и
структуры ввода для генетического биржевого
консультанта.____________________________________
typedef unsigned int gene_t;
typedef struct
{
gene_t buy_price;
gene_t sellprice;
} chromosome_t;
typedef struct
{
chromosome!
individual[SPECIESPOPULATION};
} species_t;
typedef struct
{
species t species[NUM STOCKS];
} population_t;
Определение пригодности
Нам необходимо получать самые лучшие рекомендации,
которые позволили бы заработать большую сумму де-
нег. Это требование можно определить как систему ге-
нерирования рекомендаций, которые обеспечивали бы
максимальную прибыльность в применении к доступ-
ным историям динамики цен. Следовательно, генотип
считается наиболее пригодным, когда создает план ре-
комендаций, который, если ему следовать ежедневно,
будет приводить к наиболее выгодному результату.
После этого есть все основания верить генотипной сис-
теме в том, что вырабатываемые ею рекомендации дей-
ствительно являются бесценными. Мы будем использо-
вать единственное, со знаком значение пригодности,
представляющее выгоду созданного генотипа, применя-
емого каждый день на данных по истории динамики
цен. Описание всего этого на языке С приведено в ли-
стинге 21.4.
Листинг 21.4. Функция, отвечающая за
* определение того, насколько хорошо каждый
организм участвует в биржевой торговле.
long fitness(
/* Обсуждаемая хромосома */
chromosome_t* с,
/* Исторические цевы «/
unsigned int* history
)
long total_price = 0;
long avgprice;
Long price;
long shares = 0;
Long cash = 0;
unsigned int t;
for(t = 0; t < HISTORY—LENGTH; t++)
{
price = history[t);
total_price += price;
avgprice = total_price / (t + 1);
/* Рассматриваемая цена по отвоиевию
к средней */
price -= avg_price;
/* Приведение цены в процентное
соотношение */
price » price * 100 / avg_price;
if(-price >= (long)Gray_to_bin(c->
wbuy_price))
{
/* Купить другой пакет */
++shares;
cash -= (long)history[t];
}
else if(price >= (long)Gray_to_bin(c->
wsell_price))
{
/* Продать другой пакет */
—shares;
cash += (long)history[t];
}
}
/* Наличные деньги за вычетом удержаний
ва чистую стоимость сравнения */
cash += shares * (long)history[t-1];
return cash;
}
Процесс выбора
Поскольку каждая акция имеет похожие, но потенци-
ально независимые факторы, влияющие на их цену, то
нужно назначить виды для каждого символа тикера ак-
ции. Миграция позволит обнаружить любые существен-
ные преимущества и станет распространяться далее,
пока можно поддерживать необходимые индивидуаль-
ные преимущества. Каждый символ, тикера акции полу-
чит рекомендацию от специального экспертного орга-
низма, развивающегося только для этого символа, и все
же эти организмы будут совместно работать друг с дру-
гом, обмениваясь полезными идеями с соседними суб-
популяциями, которые предназначены для других ак-
ций.
Генетические алгоритмы
Глава 21
569
Каждое подмножество популяции будет иметь фик- ’’стратегия плюса", позволяющая родительским геноти-
сированный размер. В каждом поколении новые гено- пам неограниченно выживать из поколения в поколе-
типы заменяют старые. В листинге 21.5 используется ние.
Листинг 21.5. Простая функция выбора для принятия решения о том, кому "жить”, а кому "умирать".
unsigned int select_survivors(
/* Существующие особи */
species_t const* before,
/* Выкивине организма */
species_t* after,
/* Значение пригодности каждого организма */
long* fit
)
{
unsigned int i;
unsigned int j;
long record;
long temp;
/* Копирование 1/4 наиболее выгодных после [] */
for(i = 0; i < SPECIES POPULATION / 4; i++)
{
record = i;
for (j = i+1; j < SPECIES POPULATION; j++)
{
if(fit[j] > fit[record])
{
record = j;
}
}
/* Использование значений пригодности */
temp = fit[record];
fit[record] » fit[i);
fit[i) = temp;
after->individual[i] = before->individual[record J;
}
return i;
}
Инициализация популяции
Начнем с внутренней случайной популяции в каждой сес-
сии. Листинг 21.6 содержит функции инициализации.
Листинг 21.6. Оба гена хромосомы получают случайные значения.
void initialize_chromosome(chromosome_t* с)
{
c->buy_price = bin_to_Gray(rand() % MAXPRICE);
c->sell_price = bin_to_Gray(rand() % MAXPRICE);
}
void initialize_species(species_t* s)
{
int i;
for(i = C; i < SPECIES POPULATION; i++)
{
initializechromosome(&s->individual[i]);
Дополнительные тематические разделы
Часть III
}
570
void initializepopulation(population_t* p)
{
int i;
/* Отдельный вид для каждой акции */
for(i = 0; i < NUM STOCKS; i++)
{
initializespecies(&p->species[i]);
}
Стратегия мутации
Для этой задачи будем использовать только легкую му-
тацию. Будет достаточно простой случайной побитовой
переброски (листинг 21.7).
Поскольку теперь есть несколько генов, для произ-
водства потомства нужно одновременно скомбиниро-
вать только двух родителей. Выбор родителей можно
сделать случайным (листинг 21.8).
Листинг 21.7. Побитовая переброска между простейшими функциями мутации.
void mutate_gene(gene_t* g)
{
/* Переброска произвольного бита в гене */
♦g А= 1 « г and () % (sizeof (genet) * CHARBIT);
void mutate_chromosome(chromosome_t* c)
{
switch(rand() & 1)
{
case 0:
mutate_gene(&c->buy_price);
break;
case 1:
mutategene(&c->sell_price);
break;
}
void mutatespecies(speciest* s)
{
unsigned int i;
for(i = 0; i < SPECIES POPULATION; i++)
/* Мутирует только одна хромосома при каждом значении MUTATION_FACTOR */
if (rand() % MUTATION FACTOR == 0)
{
mutate_chromosome(fcs->individual[ i ]);
}
}
Стратегия рекомбинации
Каждый ген может быть логически объединен с таким
же геном другой хромосомы, поэтому надо этим вое-
пользоваться и сделать так, чтобы гены встретились где-
нибудь посередине. В этом случае имеет смысл и про-
стое скрещивание.
571
Генетические алгоритмы
Глава 21
Листинг 21.8. Функции рекомбинации, отвечающие за создание новых организмов из старых.
void mate_genes(
gene_t* parent_l,
genet* parent_2f
gene_t* child
{
switch(rand() % 3)
{
case 0:
/* Наследовать от первого родителя */
♦child = *parent_l;
break;
case 1:
/* Наследовать от второго родителя */
♦child = *parent_2;
break;
case 2:
/* Наследовать от обоих родителей */
♦child = *parent_l + *parent_2 » 1;
break;
}
}
void mate_chromosomes(
chromosome_t* parent_l,
chromosome_t* parent_2f
chromosome_t* child
)
{
mate_genes(
fcparent__l->buy_price f
*parent_2->buy_price,
achild->buy_price
);
mate_genes(
fcparent_l->sell_pricef
fcparent_2->sell_pricef
fcchild->sell_price
}
void recombine(
species_t* s,
unsigned int numsurvivors
)
{
unsigned int i;
unsigned int parent_l;
unsigned int parent_2;
/* Пополнить видовую популяцию детьми */
for(i = num_survivors; i < SPECIES_POPULATION; i++)
{
/* Выбрать двух случайных родителей из выживыих */
parent_l = rand() % num_survivors;
parent_2 = rand() % num_survivors;
/♦ Создать ребенка от двух родителей */
mate_chromosomes(
fcs->individual[parent_l],
fcs->individual[parent_2],
*s->individual[i]
}
}
Дополнительные тематические разделы
Часть III
572
Результаты и умозаключения
Популяция, состоящая из сотни организмов, последова-
тельно находит наилучшие возможные значения меньше
чем за пятьдесят поколений. Из-за простоты хромосом
все, кроме самых больших, изменений в рекомбинации
не имеют видимого эффекта.
Этот довольно простой алгоритм кажется вполне
адекватным для поиска хороших портфелей акций в
биржевой торговле. Он позволяет быстро найти наилуч-
шее значение пригодности, и его можно использовать
для исследования больших областей решений, за пре-
делами простых операций покупки-продажи. Исполь-
зование более комплексных стратегий оценки пригод-
ности, типа совпадения с шаблоном займет больше
времени, но в результате будут получены более опти-
мальные рекомендации.
Резюме
В этой главе приведена замечательная концепция ис-
пользования генетики и эволюции для решения проблем
различной степени сложности. Мы увидели, что, хотя
генетические алгоритмы не решают чистых, поставлен-
ных "с нуля” проблем, подобных сортировке целых
чисел, они очень удобны для разрешения тех затрудни-
тельных ситуаций, которые появляются в реальном
мире. Неверные исходные данные, изменяющие ресурс-
ные ограничения, изменяющие цели, а также сами цели,
которые довольно трудно определить, не нарушают эво-
люцию настолько драматично, как это происходит в
обычных алгоритмах.
Наиболее необычные метафоры зачастую приводят
к самым интересным решениям. Несмотря на то что эво-
люция животного мира не относится к компьютерным
программам, мы, программисты, можем извлечь из этого
много хороших уроков. Например, простой генетичес-
кий алгоритм прекрасно справляется с такой трудной
проблемой, как биржевой анализ.
Межплатформенная разработка:
программирование
коммуникационных средств
В ЭТОЙ ГЛАВЕ
Планирование переноса
Абстрактные слои
Сокеты
Межплатформенное приложение
Чед Диксон
В этой главе рассматриваются вопросы, которые волну-
ют всех программистов в определенный момент их ка-
рьеры. Речь идет о разработке межплатформенных при-
ложений. Сначала нужно определить, что составляет
платформенную специфику кода и почему она имеет
негативный характер. Читатель узнает, какие механиз-
мы участвуют в написании сетевых приложений для
использования со стеками TCP/IP. Будут рассмотрены
две общеизвестные среды — Microsoft и UNIX. Затем
будут описан абстрактный процесс, различные методы
а также представлен исходный код для использования
в собственных приложениях. А в заключении будет рас-
сказано о том, как создавать приложения клиент-сервер,
и, что самое главное, как их сделать более переносимы-
ми.
Планирование переноса
Работа программистов состоит в решении реальных
проблем, при этом не имеет особого значения, какой
компьютер используется. Например, нет существенно-
го преимущества в разработке алгоритма наибольшего
общего делителя специально для компьютеров Amiga.
Целесообразно использовать давно имеющийся алго-
ритм Евклида, который может быть реализован для ра-
боты на любых компьютерах.
В этом отношении очень помогают стандарты. Если
мы пишем С-программы в соответствии со стандарта-
ми ANSI С, то можем быть уверены, что они будут ра-
ботать на любом компьютере, которому доступен
ANSI С-компилятор. Такое написание программ обыч-
но представляет собой довольно простой процесс. Как
утверждают Керниган и Ричи, "С не привязан к како-
му-то особенному оборудованию или системе, и мож-
но легко писать программы, которые будут работать без
изменений на любом компьютере, который поддержи-
вает С”.
Преимуществ написания переносимых кодов в соот-
ветствии со стандартами множество. Например, перено-
симую программу требуется написать только один раз.
Это ускоряет разработку. Код легче сопровождать, так
как программистам сопровождения нужно знать толь-
ко базовый язык, поскольку им не придется сталкивать-
ся с проблемами, которые потребовали бы знания всех
расширений, относящихся к одной реализации. Твердо
укоренившаяся в ANSI С основа кода более стабильна,
а поведение кода легче понять, чем основу кода, изо-
билующую ориентированными на реализацию расшире-
ниями.
Однако иногда бывает не так все просто. Програм-
ма оперирует не только алгоритмами, но и ресурсами
типа аппаратных средств, для которых нет стандартно-
го интерфейса. Бывают случаи, когда нет другой альтер-
нативы, как только отважиться на применение каких-
либо расширений. Это является серьезным шагом и
потенциально приведет в дальнейшем к огромному
объему работы. Любую полезную программу нужно
уметь переносить за один день. Чем больше код зави-
сит от расширения компилятора, тем сложнее будет
выполнить эту задачу. Другие программисты не пред-
принимают такого шага наобум. По возможности сле-
дует писать переносимый код и только в случае край-
ней необходимости — непереносимый. А иногда такие
случаи возникают.
Это может вызвать удивление, однако некоторые
наиболее любимые нами функции являются действи-
тельно непереносимыми. Неопытные программисты,
работающие в средах DOS и Windows, должны пони-
мать, что функции getch(), kbhit(), clrscr() и им подоб-
ные представляют собой часть языка С, и неудобно,
574
Дополнительные тематические разделы
Часть III
когда они переносят код на другой компилятор, возмож-
но, в другой операционной системе. Многим UNIX-
программистам трудно поверить, что в ANSI не упоми-
нается функция bzero(). И все знают, что strdupO и
stricmpO — это стандартные функции С. На самом деле,
конечно, это не так.
Когда мы работаем с аппаратными средствами, то
часто вынуждены писать непереносимые коды. Одна-
ко при этом можно максимально сократить проблемы,
связанные с переносом этого кода в другую рабочую
среду. Выходом из сложившейся ситуации является
принцип "разделяй и властвуй". Разделив программу на
переносимую и непереносимую части, можно, когда
придет время, уменьшить объем необходимых исправ-
лений. Изолирование непереносимого кода в собствен-
ных модулях означает, что для каждой новой платфор-
мы необходимо будет переписать только эти модули.
Абстрактные слои
Абстрактный слой — это функция или группа функций,
задачей которых является изоляция приложения от
функций, к которым обычно идет обращение (рис. 22.1).
Например, программист может вместо обращение к
функции getch() из его приложения выбрать обращение
к GetKey(). Затем он пишет GetKeyO так, чтобы она
вызывала функцию getch() вместо него. GetKeyO — это
абстракция. Сама по себе эта функция не выполняет
никаких действий (или, по крайней мере, почти ника-
ких). Она просто передает задание функции getch().
Однажды программа будет перенесена на систему, ко-
торая не поддерживает функцию getchO, но ничего не
произойдет — нужно будет только перекодировать фун-
кцию GetKeyO, а не все приложение. Приложение про-
сто обращается к GetKeyO и нисколько не заботится о
том, как GetKeyO получает событие нажатия клавиши,
если такое событие действительно получено. Таким
образом, исходное приложение остается полностью
переносимым. Необходимо только перекодировать аб-
страктные функции для каждой платформы.
Преимущества абстрактных слоев и наилучший спо-
соб их написания становятся действительно понятны-
ми при использовании их в относительно больших про-
граммах. Это обычно оправдывает автора в том, что он
не работает со всеми деталями вручную. Для разнооб-
разия давайте теперь особенно тщательно рассмотрим
реальную проблему, включающую непереносимый код,
и выясним, можно ли сделать код переносимым (или,
по крайней мере, более переносимым).
Практическая задача, которую мы собираемся ре-
шить, связана со средствами коммуникации. Как мож-
но написать программу, которая бы общалась с другой
программой, выполняемой на другом компьютере?
И как при этом свести к минимуму сложности, возни-
кающие при переносе программ в другую среду?
РИСУНОК 22.1. Изолирование библиотечных функций с помощью
абстрактных слоев.
Перед тем как взяться за проблему переносимости,
давайте решим первую проблему, связанную с техноло-
гией коммуникаций.
Это очень обширная тема, так что во всей полноте
рассмотреть ее будет сложно. Наша цель —- написать две
программы, которые будут способны запускаться на
различных компьютерах, связанных между собой. Что-
бы у вас все получилось без сучка и задоринки, найди-
те список дополнительной литературы по этой теме в
приложении В, и по возможности воспользуйтесь пред-
ложенной литературой.
Сокеты
Чтобы получить программы, общающиеся друг с дру-
гом, мы будем использовать библиотеку средств комму-
никации, известную как сокеты Беркли (Berkeley
Sockets). Это не просто библиотека, а целая система
понятий. Основная идея похожа на идею телефонии.
Имея телефон и отверстие в стене, с которым соединен
вывод телефона, я могу позвонить любому человеку в
мире, который, тоже имеет телефон. Мне не требуется
знать, как звук моего голоса доходит до моего абонента
или как его голос доходит до меня. Все что мне нужно
знать, — это как говорить в это отверстие в стене, кото-
рое обычно называется сокетом. Сокеты Беркли в боль-
шей или меньшей мере основываются на этой идее.
Internet предлагает два основных протокола переда-
чи, каждый из которых используется по-своему. Самый
простой протокол — это UDP (User Datagram Protocol,
пользовательский протокол дейтаграмм — независимых
от других пакетов транспортируемых массивов данных. —
Прим. науч. ред.). В большинстве случаев этот протокол
называется также IP (Internet-протокол). Другим меха-
низмом передачи является TCP (Transmission Control
Protocol — протокол управления передачей). Их общей
аббревиатурой является TCP/IP. Чем же они отличают-
ся, какой из них и при каких обстоятельствах лучше
использовать?
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
TCP/IP — это двунаправленный протокол управле-
ния потоком на основе соединений. Этот протокол га-
рантирует последовательное осуществление надежного
(без ошибок) управления потоком данных. Каждый
пакет распознается с использованием последовательно-
сти чисел внутри заголовка пакета. Проверка ошибок
проводится с помощью алгоритма CRC (Ciclic
Redundancy Code — контроль, осуществляемый с помо-
щью циклического избыточного кода) в пакете. Это га-
рантирует, что пакет будет доставлен по назначению
неповрежденным.
Протокол UDP — полная противоположность TCP.
Для поддержания механизма передачи он требует боль-
ших усилий. Это просто означает, что пакеты могут
прибывать беспорядочно, с ошибками и, в конце кон-
цов, могут вообще не прибыть. И хотя надежность TCP
не дается бесплатно, издержки UDP довольно значи-
тельны. Применение сокетов TCP, как правило, назы-
вается трехступенчатым установлением связей (3-Way
Handshake). В этом процессе ведущий компьютер, обыч-
но называемый клиентом, отсылает серверу (компью-
тер, принимающий требование клиента) запрос на под-
тверждение (АСК). Затем сервер начинает устанавливать
ресурсы, необходимые для поддержания присоединен-
ного сокета. Он отвечает на АСК подтверждением и
синхронизированным запросом. Этот пакет отсылается
как ACK/SYN. Компьютер-клиент принимает этот па-
кет и отвечает на него некоторое время для завершения
трехступенчатого установления связей. Окончательный
пакет содержит подтверждение на получение предыду-
щего пакета и синхронизирует (SYN) ответ. Как толь-
ко пакет прибывает на сервер — установка сессии счи-
тается завершенной. Затем каждый хост начинает
отсылать и получать данные.
Протокол UDP не имеет концепции сессии или со-
единения, поэтому действия TCP не являются необхо-
димыми для сокетов UDP. Дейтаграммный сокет может
отсылать и получать данные от любого компьютера в
любое время. Без уведомлений и проверки ошибок это
может происходить, естественно, довольно быстро, осо-
бенно на низкоскоростных WAN-линиях глобальной
сети.
Обычно TCP/IP сравнивают с системой электронной
почты. TCP соответствует зарегистрированной почте.
Когда вы отсылаете пакет по почте зарегистрировав его,
он гарантированно прибудет неповрежденным и в таком
же состоянии, в каком был отправлен. Если по какой-
то причине пакет не прибыл, то об этом вам будет со-
общено, чтобы можно было решить проблему и попы-
таться установить связь снова.
С другой стороны, UDP более похож на открытку.
Когда вы посылаете почтовую открытку, то используе-
те не лучший способ пересылки сообщения. Она может
быть доставлена в целости и сохранности. Может при-
быть разорванной. Может прибыть на шесть месяцев
позже срока отправки или, наконец, может потеряться
в почтовой системе и никогда не прибыть. Чтобы оп-
ределить, какой метод является более подходящим для
вашей программы, необходимо рассмотреть природу
используемых данных. Действительно ли каждый оди-
ночный байт, а на самом деле каждый бит критичен?
Можете ли вы позволить себе потерять какие-либо дан-
ные?
Когда вы работаете с финансовыми или навигаци-
онными системами, то ответ на второй вопрос однозна-
чен: "Нет”. Но бывают случаи, когда ответом может быть
"Да".
Как насчет прямого воспроизведения видео? В пер-
вую очередь при передаче видео обращают внимание на
скорость. Самое главное — быстро, насколько это воз-
можно, передать данные реального видео, чтобы обес-
печить плавную передачу кадров. Если один из пиксе-
лов кадра неправилен и будет просматриваться
значительно медленнее секунды, то будет ли это замет-
но? Наверное, нет.
Возможно, иногда потребуется выполнить полную
проверку ошибок TCP, а иногда понадобится скорость
UDP. Выбор за вами. Сокеты Беркли полностью поддер-
живают оба этих протокола.
Библиотека сокетов широко используется на систе-
мах UNIX. Компания Microsoft выполнила ее немного
другим способом — она работает с конечным результа-
том — Winsock. IBM также имеет версию библиотеки
сокетов, доступную для мэйнфреймовских систем. К
сожалению, все эти версии немного отличаются друг от
друга. Это и является проблемой. О том, как мы ее ре-
шим, будет рассказано далее в этой главе. А теперь да-
вайте рассмотрим два различных букета сокетов —
UNIX и Widows.
ПРИМЕЧАНИЕ
Если вы хотите написать код на платформе IBM или Мас,
то придется немного поработать, однако, думаю, вы
будете рады услышать, что концепция абстрактного слоя
так же актуальна и полезна и в этом случае.
Первый пример конкретного случая, для которого
будет задействован механизм передачи TCP, связан с
розничными магазинами, принадлежащими одной ком-
пании. В этой сети есть главный офис и несколько под-
чиненных офисов. В конце каждого дня каждому ком-
пьютеру подчиненных офисов необходимо пересылать
общую сумму продаж в компьютер головного офиса.
В свою очередь, компьютер головного офиса посылает
компьютерам подчиненных офисов общую сумму про-
576
Дополнительные тематические разделы
Часть III
даж за предыдущий день по всем подчиненным магази-
нам. (Сейчас не будем учитывать вопросы безопаснос-
ти этих операций.)
Сначала мы получим решение для UNIX, а затем
разработаем решение для Widows. Эти решения очень
похожи, но не идентичны. Затем будет показано, как
можно упростить процесс подключения, написав абст-
рактный слой для непереносимых частей программы.
Сокеты, использующие TCP под
управлением UNIX
Требуется написать две программы: сервер (программу,
которую мы хотим запустить на компьютере головного
офиса) и клиент (по одной копии которой будут уста-
новлены на каждом подчиненном компьютере). Начнем
с сервера.
Программа UNIX-сервера
Работа сервера в основном заключается в ожидании. Он
должен знать, когда клиент хочет подсоединиться к
нему, должен принимать каждое соединение, управлять
сеансом связи с клиентом и прерывать соединение, ког-
да сеанс связи завершен.
IP-адрес — это 32-битовая величина без знака (в
настоящее время в медленном процессе она обновляет-
ся до 128-битовой), которая однозначно идентифици-
рует компьютер в сети. Конечно, этой сетью может быть
Internet, вот почему необходим такой большой иденти-
фикатор. Для контакта с сервером клиенту нужно знать
IP-адрес этого сервера. Однако серверу заблаговремен-
но не требуется знать IP-адрес клиента. (Клиент сам
сообщит его.)
ПРИМЕЧАНИЕ
Новый 128-битовый IP-адрес для следующего поколения
Internet-протокола называется IPv6 или IP ng (Internet
Protocol, Next Generation). Co временем он заменит 32-
битовый IP-адрес четвертой версии, которую мы сейчас
используем.
Поскольку на компьютере головного офиса может >
быть запущено более одной работающей в сети програм-
мы. Нам необходим метод, с помощью которого можно
проводить различия между программами так чтобы,
когда пакет данных прибывает на компьютер, основная
система знала, для какого компьютера он предназначен.
Для реального примера можно рассмотреть самый обыч-
ный Internet-сервер. Как правило, такая машина запус-
кает любую или все из следующих программ: обслужи-
вание электронной почты, Web-сервера HTTP, сервера
FTP (File Transfer Protocol— Протокол передачи фай-
лов), чат-серверов, электронные коммерческие услуги и
многие другие. Это можно сделать с использованием IP-
адресов компьютеров, однако затем необходимо убе-
диться, что данные будут доставлены по назначению.
Самый простой способ — назначить каждому пакету
данных определенный номер, который идентифициру-
ет программу, для которой предназначен пакет. Этот
номер называется номером порта.
Требуется выбрать номер порта, который, скорее
всего, не будет конфликтовать с программами, запуска-
емыми на нашем компьютере. Номера портов хранятся
в 16-битовом целом числе без знака, поэтому имеется
значения для работы в диапазоне от 0 до 65535. Все
числа в диапазоне от 0 до 1023 предназначены для ре-
зерва, однако их нельзя использовать для этой конкрет-
ной программы (в действительности на многих компь-
ютерах, использующих UNIX, вообще невозможно
использовать эти номера, даже для предназначенной для
них цели, если не зарегистрироваться в корневом ката-
логе системы). Когда выбирается номер порта или со-
кета для использования, следует проверить существую-
щую базу стандартов (оформленную в серию
документов, известную как Requests for Comments, или
RFC (запросы комментариев), чтобы убедиться, что
выбранный номер сейчас не используется другим изве-
стным приложением. За некоторыми исключениями,
почти за все номера идет борьба. Все, что требуется
сделать, — это выбрать номер, с помощью которого мы
сможем убедиться, что нет двух программ на одном
компьютере, которые ждут получения данных через
один и тот же порт в одно и то же время. Это локаль-
ная проблема управления компьютером. Нашему кли-
енту необходимо знать номер порта, с которого будет
прослушиваться сервер. С этой целью для сервера нуж-
но каждый раз использовать один и тот же номер пор-
та. Выберем 1091 в качестве номера порта для нашего
приложения на тех основаниях, что это такое же слу-
чайное число, как и любое другое, и оно не использу-
ется другими приложениями, локализованными в этой
сети.
В листинге 22.1 приведен полный исходный код для
UNIX-сервера.
Листинг 22.1. Исходный код для TCP UNIX-
сервера.
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.b>
linclude <signal.h>
linclude <sys/tine.h>
linclude <sys/select.b>
linclude <sys/types.h>
linclude <sys/socket.h>
linclude <netinet/in.b>
Как видите, необходимо вставить довольно много
заголовочных файлов, чтобы написать программу не-
Межплатформенная разработка: программирование коммуникационных средств
‘577
Глава 22
большого сервера. Первые четыре файла просто требу-
ются для этой индивидуальной программы, а оставши-
еся пять работают с библиотекой сокетов. Библиотека
sys/time.h используется функцией select(), sys/select.h
необходима для макросов select() и гибких дисков FD*,
sys/types.h — для макроса htons(), sys/socket.h поддер-
живает прототипы для функций сокетов (вроде recv())
и, наконец, netinet/in.h определяет структуры для вы-
зовов сокетов.
volatile sig_atomic_t done;
void inthandler(int Sig)
<
done = 1;
}
int CbeckForData(int sockfd)
{
struct timeval tv;
fd_set read_fd;
tv.tv_sec=0;
tv.tv_usec=O;
FD_ZERO(Sreadfd);
FDSET(sockfd , fcreadfd);
if(select(sockfd+1, &read_fd,NULL,
NULL, fctv)== -1)
{
return 0;
}
if(FD_ISSET(sockfd, fcreadfd))
{
return 1;
}
return 0;
ПРИМЕЧАНИЕ
Спецификация описателя volatile инструктирует компиля-
тор не делать никаких допущений относительно содержи-
мого переменных при оптимизации. Например, в коде:
volatile int i;
i=5;
этот описатель предупреждает компилятор, чтобы он не
заменял эти три инструкции на
i=7;
поскольку тогда значение i по крайней мере теоретичес-
ки, могло бы быть изменено другим фактором без кон-
троля компилятора.
Эта небольшая программка представляет собой се-
тевой эквивалент функции kbhit(). Тот, кто слышал об
этой функции (кстати, эта функция не является функ-
цией ANSI С), знает, что она используется для опреде-
ления того, ожидается ли информация о нажатии кла-
виш в буфере клавиатуры, без извлечения этой
информации. Используя функцию сокетов Беркли
selectO, функция CheckForData() определяет, имеются
ли данные, ожидающие извлечения, но на самом деле
она не извлекает эти данные.
совет
В действительности функция select!) просто отслеживает
дескрипторы файлов. В среде UNIX значение 0 дескрип-
тора файла рассматривается как stdin. Поэтому, пере-
давая это значение функции select!), можно перевести
его в буквенный эквивалент функции kbhift).
{
int sockfd=0;
int new_fd=0;
struct sockaddr_in my_addr;
struct sockaddrin their_addr;
socklen_t sin_size=0;
char data[255]={0};
char *endp;
FILE *fp;
char Filename [FILENAME_MAX] = DEFAULT_FILE_NAME;
unsigned long currenttotal = 0;
unsigned long newtotal = 0;
В среде UNIX почти каждый объект трактуется как
файл. Если вы знакомы с UNIX, то, наверное, уже зна-
ете об этом. Достаточно сказать, что сокет UNIX не
отличается от сокета Widows и имеет присоединенный
к нему дескриптор файла. Этот дескриптор можно за-
писывать и считывать из данных ввода/вывода. Пере-
менная sockfd — это своеобразный дескриптор файла,
и мы будем использовать ее для отслеживания одного
из сокетов (вообще-то, будут использоваться два соке-
та), который будет следить за новыми соединениями.
Когда получен запрос на новое соединение, для его
приема будет использоваться new_fd. Структура
my_addr содержит информацию о локальном сервере, а
their_addr —- это структура, содержащая информацию
об адресе нашего клиента.
Перед тем как действительно приступить к установке
сокета, необходимо провести небольшую уборку на
уровне приложения. Запомните, что мы собирались
сообщить всем клиентам общую сумму продаж за- вче-
рашний день. Поэтому нужно найти вчерашний файл
(если повезет, он будет в файле под названием argv[l]),
открыть его и скопировать номер.
if (argc < 2)
{
printf("No file specified.
Using \"%s\"\n",
DEFAULTFILENAME);
}
else
{
strcpy(Filename, argv[l]);
}
fp = fopen(Filename, "r");
37 Эмс. 265
578
Дополнительные тематические разделы
Часть III
if(fp 1= NULL)
{
if(NULL 1= fgets(data, sizeof data, fp))
{
currenttotal = strtoul(data, &endp, 10);
1
fclose(fp);
}
else
{
printf("Couldn't read file %s\n".
Filename);
)
Чтобы пользователь мог легко остановить програм-
му сервера, с помощью функции signal() установим
обработчик прерываний. Строго говоря, единственное,
что позволяет стандарт ANSI С сделать в обработчике
сигналов (с учетом переносимости), — изменить значе-
ние переменной sig atomic t. Так и сделаем. Модифи-
цируемая переменная — одна из тех, которые управля-
ют циклом. Когда программа прерывается, переменная
принимает значение 1, которое завершает цикл при сле-
дующем проходе.
if(signal(SIGINT, SIG_IGN) ?= SIG_IGN)
{
signal(SIGINT, inthandler);
1
if(signal(SIGTERM, SIGIGN) 1= SIGIGN)
signal(SIGTERM, inthandler);
)
Теперь можно приступить к установке сокета. Что-
бы получить информацию о том, как использовать со-
кет, обратимся к структуре my addr. Будем использо-
вать семейство значений AF_INET, которое обычно
означает, что будет использоваться домен Internet (се-
тевая передача TCP/IP).
INADDRANY — это значение, которое означает: "Я
очень счастлив сообщить об этом сокете любому IP-ад-
ресу на планете”.
Функция htons() (вообше-то, это макрос) заверяет,
что информация о номере порта хранится в сети в по-
байтовом порядке (старший байт, младший байт) неза-
висимо от того, какова на самом деле локальная архи-
тектура: ”от старшего к младшему” (вначале сохраняется
наиболее старший байт, как в семействе IBM 370, PDP-
90, в микропроцессорах Motorola и множестве RISC-
машин с сокращенным набором команд) или ”от млад-
шего к старшему” (вначале сохраняется младший байт,
как в PDP-11, VAX и других компьютерах, использую-
щих процессоры Intel).
Далее открывается сокет с помощью функции
socket(). Эта функция возвращает дескриптор файла для
выполнения последующих обращений к библиотечным
функциям сокетов.
SOCK STREAM указывает, что предпочтительно
этот сокет должен использовать механизм передачи
TCP, а не UDP.
my_addr. sin^family = AF__INET;
my addr.sinaddr.saddr = INADDRANY;
myaddr.sin port = htons(1091);
memset(my_addr.sin_zero, 0, sizeof
**my_addr.sin_zero);
if ((sockfd = socket(AFINET, SOCKSTREAM,
^0)) == -1)
{
printf("Unexpected error on
*-* socket ()\n");
return EXITFAILURE;
}
Теперь, когда сокет открыт, будем использовать его
для установления связи. Для этого присоединим его к
соответствующему порту, который мы уже установили
в структуре my_addr. Если сервер этого не делает, то
клиент не сможет подсоединиться.
Когда сервер подключен, он может начинать прини-
мать сообщения клиентов. Для этого, как нетрудно до-
гадаться, нужно вызвать функцию listen(). Первый ар-
гумент этой функции — дескриптор файла, который
указывает, какой сокет прослушивается. Второй аргу-
мент указывает, сколько клиентов будет поддерживать
система в очереди на соединение (т. е. насколько боль-
шой журнал заказов мы хотим создать).
if (bind (sockfd,
(struct sockaddr *)&my_addr,
sizeof(struct sockaddr))== -1)
{
printf("Unexpected error on bind()\n");
return EXITFAILURE;
}
if(listen(sockfd, 4) =« -1)
{
printf("Unexpected error on
wlisten()\n");
shutdown(sockfd,2);
return EXITFAILURE;
)
Функция accept() (с которой мы еще встретимся)
блокируется. Это означает, что она будет ожидать, пока
будет перенаправлена просьба о соединении перед воз-
вращением управления нашей программе. Вот для чего
нужна наша собственная функция CheckForData(); нуж-
но только вызвать функцию accept(), если ожидается
полезный прием.
Межплатформенная разработка: программирование коммуникационных средств
579
Если accept() все-таки вызывается, то это означает,
что есть ожидающий обработки пакет. Поскольку каж-
дое принятое и прочитанное соединение закрывается,
то должно появиться новое соединение. Кроме того, мы
не позволяем старым соединениям существовать доста-
точно долго, чтобы иметь возможность получить второй
пакет. Так что функция accept() даст нам новый деск-
риптор сокета для использования с этим новым соеди-
нением. Затем этот дескриптор сокета можно исполь-
зовать для передачи функции recv(), а буфер — для
извлечения фактически поступивших данных.
После обращения к функции recv() мы получаем
данные от сокета. Для этого требуется знать, какой со-
кет проверить, где расположены данные и каков объем
принимаемых данных. Последний параметр, для опре-
деленных флагов в этом случае не нужен. Значение О
позволит функции recv() использовать значения, при-
нятые по умолчанию, которые для нашего примера
приложения вполне пригодны.
while(?done)
{
if(0 1= CheckForData(sockfd))
{
sin size = sizeof(struct sockaddr_in);
if((new_fd = accept(sockfd,
(struct sockaddr *)fctheir_addr,
fcsinsize)) == -1)
{
printf("Unexpected error on
*-*accept()\n");
continue;
}
memset(data, 0, sizeof data);
if(recv(new fd, data, sizeof data, 0)
{
printf("Unexpected error on
wrecv( )\n");
}
else
{
newtotal += strtoul(data, &endp, 10);
printf("Received data: %s\n", data);
}
И наконец, посылаем ответ обратно клиенту. Фун-
кция send() синтаксически похожа на функцию recv().
После того как данные отосланы, нам больше не тре-
буется общаться с клиентом, поэтому нужно закрыть
временный сокет.
sprintf(data, "%lu\n", currenttotal);
if (send(new_fd, data, sizeof data, 0) = -1)
<
printf("Unexpected error on
^*send( )\n");
}
Глава 22
shutdown (new_f d, 2);
}
)
Весь описанный процесс продолжается столько вре-
мени, сколько необходимо. Нажав Ctrl+C, пользователь
подает сигнал программе, что нужно остановиться.
В этом месте обработчик сигналов устанавливает пере-
менную контроля цикла для того, чтобы цикл завершил
следующий тест. В данный момент можно закрыть про-
слушивающий сокет и записать данные в выходной
файл.
shutdown(sockfd,2);
printf("User requested program to
*-*halt.\n");
fp = fopen(Filename, "w");
if(fp 1= NULL)
<
fprintf(fp, "%lu\n", newtotal);
fclose(fp);
}
else
printf("Couldn't write total %lu to file
w%s\n",
newtotal.
Filename);
}
return EXITSUCCESS;
)
Вот и все. Как видите, код предельно короткий (а
самое главное — более или менее переносимый ) и дает
этой программе возможность общения с другими ком-
пьютерами почти по всему миру.
Сама по себе эта программа бесполезна — требует-
ся клиент для общения.
UNIX-программа клиента
Написать программу-клиент немного более сложно, так
как требуется сообщить клиенту, где находится сервер.
Это можно сделать с использованием службы имен до-
менов DNS (Domain Name Service). Мы сообщаем DNS-
имя компьютера, работающего с программой-сервером
(обычно называемое именем хоста), а затем получаем
IP-адрес компьютера. Если у вас нет службы DNS или
если ваш компьютер не установлен для ее использова-
ния, то вместо нее используйте файл хостов, содержа-
щий список имен хостов и их соответствующих IP-ад-
ресов.
В листинге 22.2 показана реализация клиента. За-
метьте, что здесь добавлен новый заголовок netdb.h, у
которого есть прототип для функции gethostbyname().
Пока что это очень похоже на код сервера. Един-
ственным отличием является то, что вместо
INADDR.ANY для IP-адреса будет использоваться ад-
рес, возвращаемый функцией gethostbyname().
580
Дополнительные тематические разделы
Часть III
Листинг 22.2. Исходный код для UNIX-клиента TCP.
linclude <stdio.h>
linclude <stdlib.h>
linclude <errno.h>
linclude <string.h>
linclude <netdb.h>
linclude <netinet/in.h>
linclude <sys/socket.h>
int Random(int n)
return (int)(n * (rand() / (1.0 + (double)RANDMAX))); }
int main(int argc, char *argv(])
{
int sockfd=0;
char data(255]={0};
struct hostent *he;
struct sockaddr_in theiraddr;
srand(time(NULL));
if (argc < 2)
{
fprintf(stderr,"usage: application hostname\n");
return EXITFAILURE;
}
if((he = gethostbyname(argv[lj)) == NULL)
{
printf("Error with gethostbyname()\n");
return EXITFAILURE;
>
if ((sockfd = socket (AFINET, SOCKSTREAM, 0)) == -1)
{
printf("Error with socket()\n");
return EXITFAILURE;
}
theiraddr.sin_family = AFINET;
theiraddr.sinport - htons(1091);
theiraddr.sinaddr = ‘((struct in addr *)he->h_addr);
memset(their_addr.sin zero,
Or
sizeof theiraddr.sinzero);
Следующее отличие: здесь не используются функ-
ции listen() и accept(). Это функции сервера. Вместо них
будет использоваться функция connect() для соединения
с сервером.
if(connect(sockfd,
(struct sockaddr *)Stheiraddr,
sizeof(struct sockaddr)) -- -1)
printf("Error with connect()\n");
return EXITFAILURE;
}
sprintf(data,
"%lu Branch %d",
(unsigned long)Random(10000),
Random(lOO));
if(send(sockfd, data, sizeof data, 0) — -1)
printf("Error with send()\n");
return EXITFAILURE;
}
memset(data, 0, sizeof data);
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
581
if (recv(sockfd, data, sizeof data, 0) == -1)
{
printf("Error with recv()\n");
return EXITFAILURE;
}
printf("Received: %s\n", data);
shutdown(sockfd, 2);
return EXIT_SUCCESS;
He так уж и плохо, не правда ли? Но опять же, этот
код в определенной степени непереносим. Ни эта про-
грамма, ни программа для сервера никогда не компили-
руются в типичном компиляторе под управлением
Windows. Как же это сделать в Windows?
Сокеты, использующие TCP под
управлением Windows
Программы сокетов Windows используют библиотеку
Winsock, которая очень похожа, но, увы, не идентична
сокетам Беркли. К сожалению, в книге нет места для
описания всех различий. Но, по крайней мере, мы мо-
жем разработать сервер и клиент под управлением
Windows. Поэтому без дальнейших предисловий давай-
те приступим к рассмотрению программы сервера.
Windows-программа сервера
Как видно из листинга 22.3, Windows обычно все дела-
ет по-своему. Наличие функций WSAStartup() и
WSACkanup() — это, возможно, наиболее очевидные
отличия от кода UNIX. Кроме того, Windows-версия ис-
пользует различные заголовочные файлы и имеет огром-
ное количество различных типов — SOCKET, WORD и
т. д., — которые мы должны использовать для своего
рода зашиты от будущих изменений в основной библио-
теке.
Листинг 22.3. Исходный код для TCP-сервера, работающего под управлением Windows.
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude <winsock.h>
linclude <signal.h>
Idefine DEFAULTFILENAME "sales.dat"
volatile sigatomic t done;
void inthandler(int Sig)
{
done = 1;
1
int CheckForData(int sockfd)
{
struct timeval tv;
fd set read fd;
tv.tv sec=0;
tv.tvusec=0;
FD_ZERO((read—fd);
FD—SET(sockfd, firead_fd);
if(select(sockfd+1, Sreadfd,NULL, NULL, fctv)== -1)
{
return 0;
}
if(FD_ISSET(sockfd, fireadfd))
{
return 1;
return 0;
}
int main(int argc, char **argv)
WORD
WSADATA
SOCKET
wVersionRequested = MAKEWORD(1,1);
wsaData;
sock;
Дополнительные тематические разделы
582|
Часть III
SOCKET newsock;
SOCKADDRIN myaddr;
char data[255]= {0};
char *endp;
FILE *fp;
char Filename[FILENAMEMAX] = DEFAULTFILENAME;
unsigned long currenttotal = 0;
unsigned long newtotal = 0;
if(argc < 2)
{
printf("No file specified. Using \"%s\"\n",
DEFAULTFILENAME);
}
else
{
strcpy(Filename, argv[l]);
}
fp = fopen(Filename, "r");
if(fp != NULL)
<
if(NULL != fgets(data, sizeof data, fp))
{
currenttotal = strtoulfdata, &endp, 10);
}
fclose(fp);
else
<
printf("Couldn't read file %s\n". Filename);
}
if(signal(SIGINT, SIGIGN) != SIGIGN)
{
signal(SIGINT, inthandler);
}
if(signal(SIGTERM, SIGIGN) 1= SIGIGN)
{
signal(SIGTERM, inthandler);
}
myaddr.sinfamily = AFINET;
myaddr.sinaddr.s addr = INADDRANY;
myaddr.sinport = htons(1091);
WSAStartup(wVersionRequested, (wsaData);
if(wsaData.wVersion != wVersionRequested)
{
printf("\n Wrong version of WinsockXn");
return EXITFAILURE;
}
if((sock = socket(AFINET, SOCKSTREAM, 0)) ==
INVALIDSOCKET)
{
printf("Unexpected error on socket()\n");
return EXIT FAILURE;
}
if(bind(sock,
(LPSOCKADDR)(myaddr,
sizeof (struct sockaddr)) == SOCKET__ERROR)
{
printf("Unexpected error on bind()\n");
583
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
shutdown(sock,2);
return EXITFAILURE;
}
if (listen(sock, SOMAXCONN) == SOCKETERROR)
{
printf(“Unexpected error on listen()\n•);
shutdown(sock, 2);
return EXIT_FAILURE;
}
while(Idone)
{
if(0 1= CheckForData(sock))
{
new sock = accept(sock, NULL, NULL);
if(new_sock == INVALIDSOCKET)
{
printf(“Unexpected error on accept()\n“);
}
memset(data, 0, sizeof data);
if (recv(new_sock, data, sizeof data,0) =e
SOCKETERROR)
{
printf(“Unexpected error on recv()\n“);
memset(data, 0, sizeof data);
if (recv(new_sock, data, sizeof data,0) =*= SOCKET ERROR)
{
printf(“Unexpected error on recv()\n“);
}
else
{
newtotal += strtoul(data, lendp, 10);
printf("Received data: %s\n“, data);
}
sprintf(data, "%lu", currenttotal);
if (send(new_sock, data, sizeof data,0) SOCKET_ERROR)
{
printf(“Unexpected error on send()\n“);
shutdown(new_sock,2);
}
shutdown(sock, 2);
WSACleanup();
printf(“User requested program to halt-\n“);
fp = fopen( Filename, “w“);
if(fp != NULL)
{
fprintf(fp, “%lu\n“, newtotal);
fclose(fp);
else
{
printf("Couldn't write total %lu to file %s\n“,
newtotal,
Filename);
}
return EXITSUCCESS;
}
Дополнительные тематические разделы
584
Часть III
Это могло бы быть намного хуже. Код Windows до-
статочно похож на код UNIX, поэтому абстрактный
слой просматривается относительно легко. Но так бы-
вает не всегда. Например, если мы написали програм-
му Windows полностью в GUI вместо консольного при-
ложения, то слою выделения придется управляться не
только с кодом сокета, но и со всей GUI-концепцией
Windows. Это сделать не так просто.
Windows-программа клиента
Теперь, когда мы увидели родную программу ТСР-сер-
вера, работающего под управлением Windows, в листин-
ге 22.4 приведем программу клиента.
Листинг 22.4. Исходный код для TCP-клиента под управлением Windows
linclude <stdio.h>
linclude <string.h>
linclude <time.h>
linclude <winsock.h>
int Random(int n)
{
return (int)(n * (rand() / (1.0 + (double)RANDMAX)));
int main(int argc, char *argv[])
{
WORD wVersionRequested = MAKEWORD(1,1);
SOCKADDR_IN theiraddr;
WSADATA wsaData;
SOCKET sockfd;
LPHOSTENT he;
char data[255]={0};
int nRet=0;
srand(time(NULL));
if (argc < 2)
{
printf("usage: application hostname\n“);
return EXIT_FAILURE;
}
nRet = WSAS tar tup (wVersionRequested,
(wsaData);
if (wsaData.wVersion Is wVersionRequested)
{
printf("\n Wrong version of Winsock\n“);
return EXIT-FAILURE;
}
he = gethostbyname(argv[1]);
if (he == NULL)
{
printf(“Error in gethostbyname().\n“);
return EXIT-FAILURE;
}
sockfd = socket(AF—INET,
SOCK-STREAM,
IPPROTO—TCP);
if (sockfd == INVALIDSOCKET)
{
printf(“Error on call to socket()\n“);
return EXIT-FAILURE;
I
their-addr.sin_family = AF_INET;
585
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
theiraddr.sin_addr = ♦((LPINADDR)*he->haddrlist);
theiraddr.sinport = htons(1091);
nRet - connect(sockfd,
(LPSOCKADDR)itheiraddr,
sizeof(struct sockaddr));
if (nRet == SOCKETERROR)
{
printf ("Error on connect() An");
return EXITFAILURE;
}
sprintf(data, "%lu Branch %d",
(unsigned long)Random(10000),
Random(lOO));
nRet = send(sockfd, data, strlen(data), 0);
if (nRet == SOCKETERROR)
{
printf("Err on send()\n");
return EXITFAILURE;
}
meinset(data, 0, sizeof data);
nRet = recv(sockfd, data, sizeof data, 0);
if (nRet == SOCKETERROR)
{
printf("Error on recv()\n");
return EXITFAILURE;
}
printf("Received: %s\n", data);
shutdown(sockfd,2);
WSACIeanup();
return EXITSUCCESS;
Межплатформенное приложение
Трудности, связанные с этой программой, состоят в
том, что ее придется написать дважды, по одному разу
для каждой платформы. Но не стоит по этому поводу
волноваться. Ведь это очень простая и маленькая про-
грамма. Но если речь идет о большой и сложной про-
грамме, то переписать все для новой платформы будет
гораздо сложнее и может занять много времени.
Существует два возможных решения этой проблемы.
Можно "напичкать" код директивами препроцессора
#ifdef либо написать абстрактный слой.
Сначала давайте исследуем условный вариант ком-
пиляции.
Использование препроцессора в качестве
инструмента переноса
Идея условной компиляции состоит в том, чтобы ука-
зать некоторые уникальные директивы, определяемые
каждым компилятором, для которого планируется на-
писать код. В этом случае требуется только провести раз-
личие между Windows и UNIX. Если используется пос-
ледняя версия компилятора Microsoft или Borland С, то
можно относительно безопасно предположить, что
-WIN32 уже определена. (Вас беспокоит слово "отно-
сительно"? Оно беспокоит и меня.)
В листинге 22.5 приведен пример использования пре-
процессора для создания межплатформенной версии сер-
веров, продемонстрированных в предыдущих листингах.
Не правда ли, это выглядит крайне непривлекатель-
но? Хуже того, все это трудно проследить и, более того,
трудно сопровождать. Если вы сделаете изменение, то
разница окажется настолько большой, что придется
делать это изменение в двух местах.
А что, если вы написали код, который должен бу-
дет работать на трех компиляторах? Или на пяти? Или
на девяти? Представьте себе, как будет выглядеть такой
код. К счастью, есть способ, позволяющий сделать все
это лучше.
586
Дополнительные тематические разделы
Часть III
Листинг 22.5. Использование препроцессорных директив в качестве инструмента переноса,
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude <signal.h>
lifdef WIN32
linclude <winsock.h>
lelse
linclude <sys/time.h>
linclude <sys/select.h>
linclude <sys/types.h>
linclude <sys/socket.h>
linclude <netinet/in.h>
lendif
Idefine DEFAULT_FILE_NAME "sales.dat"
volatile sig_atomic_t done;
void inthandlerfint Sig)
{
done = 1;
}
int CheckForDatafint sockfd)
{
struct timeval tv;
fd_set readfd;
tv.tv_sec=0;
tv.tv_usec=O;
FD_ZERO(Sread f d);
FD_SET(sockfd , fcreadfd);
if(select(sockfd+1, bread_fd,NULL, NULL, itv)==* -1)
{
return 0;
}
if(FD_ISSET(sockfd, breadfd))
{
return 1;
}
return 0;
}
int main(int argc, char **argv)
{
lifdef WIN32
WORD wVersionRequested = MAKEWORD(1,1);
WSADATA wsaData;
SOCKET sock;
SOCKET new_sock;
SOCKADDRIN myaddr;
lelse
int sock=0;
int new_sock=0;
struct sockaddrin my_addr;
struct sockaddr_in their_addr;
socklent sin_size=0;
lendif
587
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
char data[255]= {0};
char *endp;
FILE *fp;
char Filename[FILENAMEMAX] = DEFAULTFILENAME;
unsigned long currenttotal = 0;
unsigned long newtotal = 0;
if(argc < 2)
{
printf("No file specified. Using \"%s\"\n",
DEFAULTFILENAME);
}
else
{
strepy(Filename, argv[l]);
fp = fopen (Filename, "r");
if(fp 1= NULL)
<
if(NULL != fgets(data, sizeof data, fp))
{
currenttotal = strtoul(data, &endp, 10);
}
fclose(fp);
}
else
{
printf("Couldn't read file %s\n", Filename);
}
if(signal(SIGINT, SIGIGN) ! = SIGIGN)
{
signal(SIGINT, inthandler);
}
if(signal(SIGTERM, SIGIGN) != SIGIGN)
{
signal(SIGTERM, inthandler);
}
my_addr.sin_family = AFINET;
my_addr.sin addr.saddr = INADDRANY;
myaddr.sin port = htons(1091);
lifdef _WIN32
WSAStartup(wVersionRequested, &wsaData);
if (wsaData.wVersion != wVersionRequested)
{
printf("\n Wrong version of Winsock\n");
return EXITFAILDRE;
}
if ((sock = socket(AFINET, SOCKSTREAM, 0)) ==
INVALID-SOCKET)
lelse
memset(my addr.sin zero, 0,sizeof myaddr.sin_zero);
if ((sock = socket (AFINET, SOCKSTREAM, 0)) == -1)
lendif
588
Дополнительные тематические разделы
Часть III
{
printf("Unexpected error on socket()\n");
return EXITFAILURE;
}
lifdef WIN32
if (bind(sock, (LPSOCKADDR)&iny_addr, sizeof (struct sockaddr)) ==SOCKET_ERROR)
lelse
if (bind(sockr(struct sockaddr *)&my addr, sizeof(struct sockaddr))== -1)
lendif
<
printf("Unexpected error on bind()\n");
shutdown(sock,2);
return EXIT_FAILURE;
}
lifdef WIN32
if (listen(sock, SOMAXCONN) == SOCKETERROR)
lelse
if (listen (sock, 4) == -1)
lendif
printf("Unexpected error on listen()\n");
shutdown(sock, 2);
return EXIT_FAILURE;
}
while(Idone)
{
if(0 ! = CheckForData(sock))
{
lifdef WIN32
new sock = accept(sock, NULL, NULL);
if (newsock == INVALIDSOCKET)
lelse
sin size = sizeof(struct sockaddrin);
if((newsock = accept(sock,
(struct sockaddr *)
btheiraddr,&sin size)) ==* -1)
lendif
{
printf("Unexpected error on accept()\n");
lifndef WIN32
memsetfdata, 0, sizeof data);
lendif
lifdef WIN32
if(recv(newsock, data, sizeof data, 0) ==SOCKET_ERROR)
lelse
if(recv(new_sock, data, sizeof data, 0) “ -1)
lendif
{
printf("Unexpected error on recv()\n");
}
else
{
newtotal += strtoulfdata, bendp, 10);
printf("Received data: %s\n", data);
}
589
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
sprintf(data, “%lu“, currenttotal);
lifdef WIN32
if (send(new_sock, data, sizeof data, 0) == SOCKET^ERROR)
lelse
if (send(new sock, data, sizeof data, 0) == -1)
lendif
{
printf(“Unexpected error on send()\n“);
}
shutdown(new sock, 2); }
}
shutdown(sock , 2);
lifdef WIN32
WSACleanupf);
lendif
printf(“User requested program to halt.\n“);
fp = fopen(Filename, “w“);
if(fp != NULL)
<
fprintf(fp, "%lu\n“, newtotal);
fclose(fp);
}
else
{
printf(“Couldn't write total %lu to file %s\n“,
newtotal,
Filename);
}
return EXITSUCCESS;
Написание абстрактного слоя
Абстрактный слой изолирует платформно-зависимые
функциональные возможности и типы данных от пере-
носимого кода в отдельный модуль (или модули). Плат-
формно-зависимые модули затем переписываются спе-
циально для каждой платформы. Для этого следует
написать новый заголовочный файл, который содержит
специальные переменные typedef и #define, вместе с
прототипами функций для функций абстрактного слоя
(необходимо понимать, что эти прототипы функций
должны быть идентичными на всех целевых платфор-
мах). Сам модуль приложения включает этот новый
заголовок и будет связан с каждым соответствующим
платформно-зависимым модулем.
Назовем наш слой выделения CUPS ("С Unleashed
Portable Sockets", переносимые сокеты раскрепощенного
С). Неплохо, правда?
В листинге 22.6 показана UNIX-версия cups.h.
Листинг 22.6. Заголовок для UNIX-версии библиотеки переносимых сокетов.
/♦ Это UNIX-версия cups.h ♦/
lifndef CUPSB____
Idefine CUPS_H___
linclude
linclude
linclude
linclude
linclude
linclude
linclude
<sys/types.h>
<netinet/in.h>
<sys/socket.h>
<sys/time.h>
<sys/select.h>
<netdb.h>
<stdlib.h>
Idefine CUPSSBUTDOWNRECEIVE 0
Idefine CUPSSBUTDOWNSEND 1
Idefine CUPSSBUTDOWNBOTB 2
590
Дополнительные тематические разделы
Часть III
typedef struct CUPSINFO
{
int Dummy; /* Структурный нуль: Windows требует init info, a UNIX-нет. */
} CUPSINFO;
typedef struct CONNECTION
{
int address length;
struct sockaddr in my addr; -
struct sockaddr_in their addr;
struct hostent «he;
socklen_t sinsize;
int Socket;
} CONNECTION;
Эта структура CONNECTION является ключом для
абстрактного слоя. Она содержит экземпляры всех
структур данных, которые потребуются для UNIX-вер-
сии кода. Это нужно для того, чтобы можно было пе-
реместить любую трассировку сокетов Беркли из исход-
ного кода слоя приложения. Инкапсуляция данных
сокетов Беркли в структуре означает, что, хотя основ-
ная парадигма сокетов остается, мы больше не зависим
от различных аспектов сокетов Беркли на слое прило-
жения.
void CUPSInit(CUPS_INFO *plnfo);
int CUPSStartup(CUPS_INFO *plnfo);
int CUPSGetHostByName(CONNECTION «Connection, char *);
int CUPSConnectfCONNECTION «Connection);
int CUPSCheckForData(CONNECTION «Connection);
int CUPSInitTCPConnection(CONNECTION «Connection,
unsigned long Address,
unsigned short Port);
int CUPSInitUDPConnection(CONNECTION «Connection,
unsigned long Address,
unsigned short Port);
int CUPSBind(CONNECTION «Connection);
int CUPSListen(CONNECTION «Connection);
int CUPSShutDown(CONNECTION «Connection,
int ShutdownType);
int CUPSAcceptConnection(CONNECTION «NewSocket,
CONNECTION «ServerConnection);
int CUPSRecv(CONNECTION «Connection,
char «data,
size_t size);
int CUPSRecvFrom(CONNECTION «Connection,
char «data,
size t size);
int CUPSSendTo(CONNECTION «Connection,
char «data,
size_t size);
int CUPSSend(CONNECTION «Connection,
char «data,
size_t size);
int CUPSShutdownClientCohnection(CONNECTION «Connection,
int ShutdownType);
int CUPSCleanup(CUPS_INFO «Cupslnfo);
lendif
Вооружившись заголовком, можно написать UNIX- дет перенесен в среду UNIX, и его можно компилиро-
версию cups.h (листинг 22.7). Этот исходный файл бу- вать только в компиляторе С под управлением UNIX.
591
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
Листинг 22.7, UNIX-версия библиотеки переносимых сокетов,_____________________________________
/* Библиотека переносимых сокетов CUPS для UNIX */
linclude “cups.h“
void CUPSInit(CUPSINFO «plnfo)
{
/* Суррогатная функция; функциональные возможности не требуются UNIX. */
return;
}
int CUPSGetHostByName(CONNECTION «Connection, char «Host)
{
int Result=0;
if((Connection->he=gethostbyname(Bost)) == NULL)
{
Result = 1;
}
return Result;
int CUPSStartup(CUPSINFO *plnfo)
{
return 0;
}
int CUPSInitTCPConnection(CONNECTION «Connection,
unsigned long Address,
unsigned short Port)
{
int Result = 0;
if(!Connection->he)
{
Connection->my_addr.sin_family = AF_INET;
Connection->my_addr.sinaddr.saddr = Addres s;
Connection->my_addr.sinport « htons(Port);
Connection->sin_size = (j;
}
else
{
Connection->their_addr.sin family = AFINET;
Connection->their_addr.sin_port = htons(1091);
Connection->their addr.sin addr =
*((struct inaddr*)Connection->he->h_addr);
memset(Connection->their_addr.sinzero,
0,
sizeof Connection->their_addr.sinzero);
}
Connection->Socket = socket(AF_INET, SOCKSTREAM, 0);
if(Connection->Socket == -1)
{
Result « 1;
}
return Result;
}
int CUPSInitUDPConnectionfCONNECTION «Connection,
unsigned long Address,
unsigned short Port)
int Result
0;
592
Дополнительные тематические разделы
Часть III
Connection->address_length = sizeof(struct sockaddr);
if(!Connection->he)
{
Connection->my_addr.sin_family = AF_INET;
Connection->myaddr.sin_addr.s_addr = Address;
Connection->my addr.sinport = htons(Port);
Connection->sin size - 0;
}
else
<
Connection->their_addr.sin_family = AF_INET;
Connection->their_addr.sin port ® htons(Port);
Connection->their_addr.sinaddr =
*((struct inaddr *)Connection->he->h_addr);
memset(Connection->their_addr.sin_zero,
0,
sizeof Connection->their_addr•sinzero);
}
Connection->Socket = socket(AF_INET, SOCKDGRAM, 0);
if(Connection->Socket == -1)
{
Result = 1;
}
return Result;
}
int CUPSConnect(CONNECTION «Connection)
{
int Result « 0;
if (connect(Connection->Socket,
(struct sockaddr *)bConnection->their_addr ,
sizeof(struct sockaddr)) ==-l)
{
Result = 1;
}
return Result;
int CUPSCheckForData(CONNECTION «Connection)
{
struct timeval tv;
fdset readfd;
tv.tvjsec=0;
tv.tv_usec=0;
FD_ZERO(bread fd);
FD_SET( Connect ion-r>Socketf bread fd);
if(select(Connection->Socket+l,
bread_fd,
NULL,
NULL,
btv)== -1)
return 0;
if(FDISSET(Connection->Socket, breadfd))
{
return 1;
}
return 0;
}
int CUPSBindfCONNECTION «Connection)
{
int Result = 0;
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
593
if(bind(Connection->Socket,
(struct sockaddr *)&Connection->my_addr,
sizeof(struct sockaddr)) == -1)
{
Result = 1;
}
return Result;
1
int CUPSListen(CONNECTION «Connection)
{
int Result « 0;
if(listen(Connection->Socket, 4) == -1)
{
Result = 1;
1
return Result;
}
int CUPSShutdown(CONNECTION *Connection, int ShutdownType)
<
if(ShutdownType != CUPSSHUTDOWNRECEIVE &&
ShutdownType ! = CUPSSHUTDOWNSEND)
{
ShutdownType == CUPSSHUTDOWNBOTH;
1
shutdown(Connection->Socket, ShutdownType);
return 0;
1
int CUPSAcceptConnection(CONNECTION «NewSocket,
CONNECTION «Serverconnection)
{
int Result = 0;
«NewSocket ® «ServerConnection;
NewSocket->Socket = accept(ServerConnection->Socket,
(struct sockaddr *)
&ServerConnection->
their_addr,
&ServerConnection->sin_size);
if(NewSocket->Socket == -1)
{
Result = 1;
}
return Result;
}
int CUPSRecv(CONNECTION «Connection,
char «data,
size t size)
{
int Result = 0;
if(recv(Connection->Socket ,
data,
(int)size,
0) == -1)
{
Result = 1;
1
return Result;
}
38 Зек. 265
594
Дополнительные тематические разделы
Часть III
int CUPSRecvFrom(CONNECTION «Connection,
char «data,
size_t size)
<
int Result - 0;
if(recvfrom(Connection->Socket,
data,
size,
0,
(struct sockaddr *)SConnection->their_addr,
&Connection->address length) == -1)
{
Result = 1;
1
return Result;
}
int CUPSSendTo(CONNECTION «Connection,
char «data,
sizet size)
<
int Result = 0;
if(sendto(Connection->Socket,
data,
size,
0,
(struct sockaddr *)bConnection->their_addr,
sizeof(struct sockaddr)) == -1)
{
Result - 1;
}
return Result;
}
int CUPSSend(CONNECTION «Connection,
char «data,
size t size)
<
int Result = 0;
if(send(Connection~>Socket,
data,
(int)size,
0) =~ -1)
{
Result « 1;
}
return Result;
}
int CUPSShutdownClientConnection(CONNECTION «Connection,
int ShutdownType)
{
if(ShutdownType != CUPS SHUTDOWN RECEIVE £&
ShutdownType !» CUPSSHUTDOWNSEND)
{
ShutdownType = CUPSSHUTDOWNBOTH;
}
shutdown(Connection->Socket, ShutdownType);
return 0;
}
int CUPSCleanup(CUPS_INFO «CupsInfo)
{
return 0;
}
Межплатформенная разработка: у«чтхлммь» * • ание коммуникационных средств
595
Глава 22
Возможно, самым однозначным аспектом этого на-
бора функций является то, что некоторые из них не вы-
полняют никаких действий. Зачем же тогда написаны эти
кажущиеся бесполезными функции? Windows-версия кода
требует выполнения действий запуска и очистки, даже
если для UNIX-версии в этом нет необходимости. Тем
не менее, слой приложения будет обращаться к каким-
либо функциям запуска и очистки, даже если для UNIX
такие действия не требуются, и эти функции-манеке-
ны оказываются самым простым решением.
Другой важный момент состоит в том, что некото-
рые функции в CUPS вообще не используются нашим
приложением. Они предназначены для использования
в UDP-приложениях. Хотя мы все-таки оставили для
них место, на Web-сайте издательства "ДиаСофт” вы
найдете программу-сервер преобразования температуры
и соответствующую программу-клиент, которые ис-
пользуют абстрактный слой CUPS.
Windows-версии этих двух файлов похожи, но, ес-
тественно, не идентичны. В листинге 22.8 показана
Windows-версия cups.h.
Листинг 22.8. Заголовок для Windows-версии библиотеки переносимых сокетов.
lifndef CUPSH___
idefine CUPS В
linclude <stdarg.h>
linclude <time.h>
linclude •winsock.h"
Idefine CUPSSBUTDOWNRECEIVE 0
Idefine CUPSSHUTDOWNSEND 1
Idefine CUPSSHUTDOWNBOTH 2
Idefine CUPSMAXOUT 256
typedef struct CUPS INFO
<
WORD VersionRequested;
} CUPSINFO;
typedef struct CONNECTION
{
int address length;
SOCKADDRIN myaddr;
SOCKADDRIN theiraddr;
SOCKET Socket;
LPHOSTENT he;
} CONNECTION;
/* Прототипы идентичны UNIX-версии. Их можно найти на компакт-диске в Windows-файле cups.h.
* Здесь они пропущены, но место для них оставлено.
♦/
lendif
Windows-версия cups .с является нашей следующей
задачей. Различий будет немного, но те, которые суще-
ствуют, являются причиной проблем, которые мы по-
пробуем разрешить. В листинге 22.9 представлен пол-
ный исходный код.
Библиотека CUPS является основой, на которой
можно писать предыдущие приложения. Просто нужно
в нашей архитектуре скомпилировать их в объектный
код с корректным файлом cups.c.
Давайте посмотрим, как будет выглядеть такое прило-
жение. В листинге 22.10 показан тот же самый сервер,
который был написан ранее, но теперь с использовани-
ем библиотеки CUPS, чтобы выделить непереносимые
функциональные элементы из начального исходного
кода приложения. Вопрос в том, для какой среды пред-
назначен этот исходный файл — Windows или UNIX?
А есть ли новшества? Конечно. Преимущество ис-
пользования библиотеки CUPS состоит в том, что этот
файл может работать в обеих архитектурах, описанных
в этой главе, — в UNIX и в Microsoft Windows.
Давайте еще раз посмотрим, как работает библиоте-
ка CUPS (листинг 22.11), на сей раз — в программе-
клиенте.
596
Дополнительные тематические разделы
Часть III
Листинг 22.9. Windows-версия библиотеки переносимых сокетов.
/* Библиотека переносимых сокетов CUPS для Windows */
linclude "cups.h"
void CUPSlnitfCUPS INFO *plnfo)
{
pInfo->VersionRequested = MAKEWORD(1, 1);
}
int CUPSStartup(CUPS_INFO *plnfo)
{
int Result = 0; /* 0 = success */
WSADATA ws aData;
WSAStartup(pinto->VersionRequested, &wsaData);
if(wsaData.wVersion != plnfo->VersionRequested)
{
Result = 1;
}
return Result;
}
int CUPSGetHostByName(CONNECTION «Connection,
char «Host)
{
int Result=0;
if((Connection->he=gethostbyname(Host)) == NULL)
{
Result = 1;
}
return Result;
int CUPSInitTCPConnection(CONNECTION «Connection,
unsigned long Address,
unsigned short Port)
{
int Result = 0;
if(1Connection->he)
{ .
Connection->my_addr.sin_family = AFINET;
Connection->my_addr.sin_addr.saddr = Address;
Connection->myaddr.sin port = htons(Port);
}
else
{
Connection->their_addr.sin family = AFINET;
Connection->their_addr.sinaddr =
*((LPINADDR)*Connection->he->h addrlist);
Connection->their addr.sin_port = htons(Port);
}
Connection->Socket = socket(AF_INET, SOCKSTREAM, 0);
if(Connection->Socket == INVALIDSOCKET)
{
Result = 1;
}
return Result;
1
int CUPSInitUDPConnection(CONNECTION «Connection,
unsigned long Address,
unsigned short Port)
597
Межпяатформенная разработка: программирование коммуникационных средств
Глава 22
int Result = 0;
Connection->address_length = sizeof(struct sockaddrin);
if(IConnection->he)
{
Connection->my_addr.sin_family = AFINET;
Connection->my_addr.sinaddr.saddr = Address;
Connection->my_addr.sinport = htons(Port);
}
else
<
Connection->their_addr.sin_family = AFINET;
Connect!on->theiraddr.sinaddr =
*((LPINADDR)*Connection->he->h_addr_list);
Connection->their_addr.sinport = htons(Port);
}
Connection->Socket = socket(AFINET, SOCKDGRAM, 0);
if(Connection->Socket == INVALIDSOCKET)
{
Result = 1;
}
return Result;
int CUPSConnectfCONNECTION «Connection)
{
return connect(Connection->Socket,
(LPSOCKADDR)&Connection->their_addr,
sizeof (struct sockaddr));
}
int CUPSBind(CONNECTION «Connection)
{
int Result = 0;
if(bind(Connection->Socket,
(LPSOCKADDR)&Connection->my_addr,
sizeof(struct sockaddr)) == SOCKETERROR)
Result = 1;
}
return Result;
int CUPSListenfCONNECTION «Connection)
{
int Result = 0;
if(listen(Connection->Socket, SOMAXCONN) ==
SOCKETERROR)
<
Result = 1;
}
return Result;
int CUPSShutdown(CONNECTION «Connection, int ShutdownType)
{
if(ShutdownType != CUPSSHUTDOWNRECEIVE &&
ShutdownType != CUPSSHUTDOWNSEND)
{
ShutdownType = CUPSSHUTDOWNBOTH;
}
shutdown(Connection->Socket, ShutdownType);
return 0;
1
598
Дополнительные тематические разделы
Часть III
int CUPSAcceptConnection(CONNECTION «NewSocket,
CONNECTION *ServerConnection)
{
int Result = 0;
«NewSocket = «Serverconnection;
NewSocket“>Socket = accept(ServerConnection->Socket,
NULL, NULL);
if(NewSocket->Socket == INVALIDSOCKET)
{
Result = 1;
}
return Result;
int CUPSRecv(CONNECTION «Connection,
char «data, sizet size)
{
int Result = 0;
if(recv(Connection->Socket,
data, (int)size, 0) == SOCKETERROR)
{
Result = 1;
}
return Result;
int CUPSRecvFrom(CONNECTION «Connection,
char «data, size_t size)
{
int Result = 0;
if(recvfrom(Connection->Socket, data, size, 0,
(struct sockaddr «)&Connection->their_addr,
&Connection->address_length) == SOCKETERROR)
{
Result 1;
}
return Result;
int CUPSSend(CONNECTION «Connection,
char «data, sizet size)
{
int Result = 0;
if(send(Connection->Socket, data,
(int)size, 0) == SOCKETERROR)
{
Result « 1;
}
return Result;
}
int CUPSSendTo(CONNECTION «Connection,
char «data, size_t size)
{
int Result ж 0;
if(sendto(Connection->Socket,
. data,
size,
0,
(struct sockaddr *)bConnection->their_addr,
(int) sizeof (struct sockaddr)) ==
SOCKETERROR)
{
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
Result = 1;
}
return Result;
599
int CUPSShutdownClientConnection(CONNECTION «Connection,
int ShutdownType)
{
if(ShutdownType != CUPSSEUTDOWNRECEIVE &&
ShutdownType ! = CUPSSEUTDOWNSEND)
{
ShutdownType = CUPSSEUTDOWNJBOTE;
}
shutdown(Connection->Socket, ShutdownType);
return 0;
int CUPSCleanup(CUPS_INFO *CupsInfo)
{
WSACleanupf);
return 0;
}
int CUPSCheckForDatafCONNECTION «Connection)
{
struct timeval tv;
fd set read_fd;
tv.tv_sec=0;
tv.tv_usec=O;
FD_ZERO(&read_fd);
FD SET(Connection->Sockett fcreadfd);
iff select(Connection->Socket+1, bread fd,
NULL, NULL, &tv)== -1)
{
return 0;
}
if(FDISSET(Connection->Socket, fcreadfd))
{
return 1;
}
return 0;
Листинг 22.10. Межплатформенное приложение-сервер, использующее библиотеку CUPS.
/* Приложение (программа-сервер)
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude <signal.h>
linclude "cups.h"
Idefine DEFAULTFILENAME "sales.dat"
volatile sig_atomic_t done;
void inthandler(int Sig)
{
done = 1;
int main(int argc, char **argv)
600
Дополнительные тематические разделы
Часть III
CUPSINFO Cupslnfo = {0};
CONNECTION Serverconnection = {0};
CONNECTION ConnectionToClient = {0};
char data[255) = {0};
char *endp;
FILE *fp;
char Filenamef FILENAME J4AX] = DEFAULTFILENAME;
unsigned long currenttotal = 0;
unsigned long newtotal = 0;
if(argc < 2)
{
printf("No file specified. Using \"%s\"\n",
DEFAULTFILENAME);
}
else
{
strcpy(Filename, argv(lj);
}
fp = fopen(Filename, "r");
if(fp 1= NULL)
{
if(NULL ! = fgets(data, sizeof data, fp))
{ currenttotal = strtoul(data, &endp, 10);
}
fclose(fp);
}
else
{
printf("Couldn't read file %s\n", Filename);
}
if(signal(SIGINT, SIGIGN) != SIGIGN)
{
signal(SIGINT, inthandler);
}
if(signal(SIGTERM, SIGIGN) != SIGIGN)
{
signal(SIGTERM, inthandler);
}
stand(time(NULL));
CUPSInit(&CupsInfo);
if(CUPSStartup(&CupsInfo) !- 0)
{
printf("Initialization failed.\n");
fgets(data, sizeof data, stdin);
return EXITFAILURE;
}
if(0 != CUPSInitTCPConnection(&ServerConnection,
INADDRANY, 1091))
{
printf("Call to socket() failed\n\n");
return EXITFAILURE;
}
if(0 != CUPSBind(&ServerConnection))
601
Межплатформенная разработка: программирование коммуникационных средств
Глава 22
{
printf("Can't bind().\n");
return EXITFAILURE;
}
if(0 ! = CUPSListen(&Serverconnection))
{
printf("Unexpected error while calling listen().\n");
CUPSShutdown(bServerConnection, CUPSSBUTDOWNBOTB);
return EXITFAILURE;
}
while(Idone)
if(0 != CUPSCheckForData(^ServerConnection))
{
if(0 != CUPSAcceptConnectionf&ConnectionToClient,
fcServerConnection))
{
printf("Unexpected error on accept()\n");
}
else
{
memset(data, 0, sizeof data);
if(0 ! = CUPSRecv(&ConnectionToClient,
data, sizeof data))
{
printf("Unexpected error on recv()\n");
}
else
{
newtotal += strtoul(data, &endp, 10);
printf("Received data: %s\n", data);
}
sprintf(data, "%lu\n", currenttotal);
if(0 ! = CUPSSendf&ConnectionToClient,
data, sizeof data))
{
printf("Unexpected error on send()\n");
}
CUPSShutdownClientConnection(&ConnectionToClient,
CUPS_SEUTDOWN_BOTE);
}
}
CUPSShutdown(& ServerConnection, CUPS_SEUTDOWN_BOTE);
CUPSCleanup(&CupsInfo);
printf("User requested program to halt.Vn");
fp « fopen( Filename, "w");
if(fp !« NULL)
{
fprintf(fp, "%lu\n", newtotal);
fclose(fp);
}
else
{
printf("Couldn't write total %lu to "
"file %s\n", newtotal. Filename);
}
return 0;
602
Дополнительные тематические разделы
Часть III
Листинг 22.11. Межплатформенное приложение-клиент, использующее библиотеку CUPS,
linclude <stdio.h>
linclude <stdlib.h>
linclude <string.h>
linclude "cups.h1*
int Random (int n)
{
return (int)(n * (rand() / (1.0 + (double)RAND_MAX)));
int main(int argc, char *argv[J)
{
CUPSINFO Cupslnfo = {0};
CONNECTION Clientconnection « {0};
char data[255]={0};
if (argc 1= 2)
{
printf("usage: application hostname\n");
return EXITFAILURE;
}
stand(time(NULL));
CUPSInit(&CupsInfo);
if(CUPSStartupf&CupsInfo) != 0)
{
printf("Initialization failed.\n");
fgets(data, sizeof data, stdin);
return EXITFAILURE;
)
if (CUPSGetBostByName(&ClientConnection, argvflj) != 0)
{
printf("Failure to resolve Hostname. %s\n", argvflj);
return EXITFAILURE;
}
if(0 != CUPSInitTCPConnection(bClientConnection,
INADDRANY, 1091))
{
printf("Error on call to socketf).\n");
return EXITFAILURE;
}
if (0 1= CUPSConnect(&ClientConnection))
<
printf("Error on connect().\n");
return EXITFAILURE;
}
sprintf(data, "%lu Branch %d",
(unsigned long)Random(10000),
Random(lOO));
if(0 1= CUPSSend(fcClientConnection, data, sizeof data))
{
printf("Unexpected error on send()\nM);
}
memset(data, 0, sizeof data);
Межплатформенная разработка: программирование коммуникационных средств
603
Глава 22
if(0 != CUPSRecvf&ClientConnection, data, sizeof data))
{
printf("Unexpected error on recv()\n");
}
printf("Received: %s\n", data);
CUPSShutdown(fcClientConnectiont CUPSSHUTDOWNBOTH);
return EXITSUCCESS;
Резюме
В этой главе были раскрыты некоторые возможности
написания сетевых TCP/IP-приложений на различных
компьютерах. После тщательного исследования внут-
реннего процесса был предложен относительно перено-
симый способ написания одного приложения, которое
компилируется и запускается на многих системах.
Если вы ничего не знали о сетевом программирова-
нии до того, как прочитали эту главу, то теперь имеете
об этом вполне отчетливое представление. Наиболее
важный урок, который можно извлечь из этой главы,
вообще не имеет ничего общего с сетевым программи-
рованием. Оказывается, с использованием абстрактно-
го слоя не только теоретически, но и практически мож-
но упростить процесс переноса программ. Это не всегда
простая задача, но, в конце концов, мы получаем суще-
ственные преимущества от устойчивости базового кода
и облегчения его сопровождения.
Написание CGI-приложений на С
В ЭТОЙ ГЛАВЕ
Что такое CGI
Основы CGI
Методы ввода данных в HTML
Среда CGI
Получение данных
Синтаксический разбор строки запроса
Пример приложения: поиск прототипа функции
Вопросы безопасности
Чед Диксон
В настоящей главе рассмотрен единый шлюзовой интер-
фейс, или, как его часто называют, CGI (Common
Gateway Interface). Читатель узнает, как создавать ди-
намические Web-страницы с использованием стандар-
та HTML (HyperText Markup Language, язык гипертек-
стовой разметки) и языка программирования С. Полезно
будет ознакомиться с CGI-утилитами и научиться ис-
пользовать их в CGI-приложениях. Кроме того, на кон-
кретном примере описан процесс создания приложения
и рассмотрена его работа на Web-сервере. И наконец,
особое внимание будет уделено вопросам безопасности,
связанным с созданием CGI-приложений, и предложе-
ны методы по предотвращению возможного неправиль-
ного использования данной технологии.
Что такое CGI
В недалеком 1990 г. Тим Бернерс-Ли (Tim Berners-Lee),
специалист по вычислительной технике в Исследова-
тельской лаборатории физики элементарных частиц
(CERN), перевернул весь мир, хотя, наверное, и не
собирался этого делать. Перед ним стояла задача найти
ну* и обеспечения быстрого и эффективного обмена
информацией между учеными в области физики высо-
ких энергий. Решение, которое он нашел, стало извест-
но как всемирная паутина (World Wide Web, или WWW,
или просто Web). Создание протокола передачи гипер-
текста (HTTP) и языка HTML явилось той вехой, ко-
торая определила саму сущность WWW.
Протокол HTTP не рассматривается в данной кни-
ге. Достаточно лишь сказать, что протокол HTTP ис-
пользуется Web-браузерами для доступа к HTML-стра-
ницам. HTML представляет собой довольно простой
язык разметки, который используется браузерами для
форматирования Web-страниц. Это не язык программи-
рования. Он облегчает вывод на экран текста и рисун-
ков, но имеет незначительные вычислительные возмож-
ности. В частности, он не может изменять текст и ри-
сунки, которые отображает на экране. Но он может
отображать формы, воспринимать данные, вводимые в
формы и вызывать программы для обработки этих дан-
ных. Программы обработки могут генерировать HTML-
страницу, которая возвращается Web-браузеру и выво-
дится на экран. Возникновение единого шлюзового
интерфейса сыграло очень важную роль в дальнейшем
развитии WWW.
Несомненно, CG1 наиболее часто используется для
поиска в сети www. В типичном поисковом сервере
пользователь задает строку поиска. CGI-приложение
выполняет запрос базы данных и возвращает пользова-
телю результаты поиска в формате HTML. CGI может
использоваться и для выполнения множество других
задач, среди которых преобладают гостевые книги, счет-
чики и формы электронной почты.
CGI-приложение — это выполняемая программа,
которая хранится на Web-сервере. Она предназначена
для запуска не локальным пользователем, а процессом
Web-сервера. CGI-программа получает входные данные
либо со стандартного входного потока, либо из пере-
менных среды. Она обрабатывает эти данные соответ-
ствующим образом и генерирует в стандартном выход-
ном потоке HTML-страницы. Web-сервер считывает
выходные данные CGI-программы и передает их брау-
зеру пользователя, который выводит их на экран конеч-
ного пользователя. Такое использование стандартных
входного и выходного потоков должно запасть в душу
любого С программиста. Язык программирования С
особенно хорошо подходит для CGI-программирования
(хотя теоретически можно применять любой другой
язык, который способен обеспечить доступ к стандарт-
Написание CG1-приложений на С
605
Глава 23
ному входному и выходному потокам и к среде главной
вычислительной машины, называемой далее хост-маши-
ной). Более того, можно (и даже желательно) писать
CGI-программы на полностью переносимом языке стан-
дарта ANSI С. В некоторых случаях используются базы
данных SQL, в которых отдельные части программ не
будут переносимыми, но можно обойтись и без исполь-
зования таких баз данных. Все CGI-коды в настоящей
главе написаны на ANSI С.
РИСУНОК 23.1. CGI-процесс.
Перед написанием реальной CGI-программы необ-
ходимо усвоить довольно большой объем информации.
Но это не так уж трудно, а само программирование на
С не представляет никаких трудностей, если у вас уже
есть базовые знания по работе с CGL
Основы CGI
Написание и использование CGI-программ в первую
очередь, конечно, предполагает наличие среды разработ-
ки С. Но это еще не все. Понадобится также Web-cep-
вер. Для проверки работоспособности и тестирования
CGI-программ вы можете использовать сервер вашего
Intemet-провайдера. Если нет, не волнуйтесь. В Internet
имеются бесплатные, высококачественные программы
Web-сервера, которые можно при необходимости запу-
стить на своем компьютере.
Не менее важным является знание основ языка
HTML. Если вы не знакомы с HTML, то сейчас как раз
подходящее время восполнить этот пробел в знаниях.
К сожалению, данная задача выходит за рамки нашей
книги. По HTML существует довольно большое коли-
чество учебников, и, конечно, в самой сети WWW мож-
но найти множество сайтов, посвященных HTML. Язык
HTML достаточно прост в изучении. Вы сможете по-
стичь его основы за несколько минут, а если посвятите
этому пару дней, то смело можете считать себя почти
экспертом. Автор настоящей главы предполагает, что вы
имеете некоторое представление о HTML. Тем не ме-
нее, ниже рассматриваются специальные теги, которые
будут использоваться в приводимых примерах. А теперь
приступим.
Методы ввода данных в HTML
В HTML имеется несколько различных механизмов вво-
да данных, большинство из которых знакомо любому
человеку, который использовал современные операци-
онные системы с графическим интерфейсом пользова-
теля. Для формирования вводимых пользователем ис-
ходных данных имеются выпадающие списки,
радиокнопки, кнопки выбора, поля ввода текста, мно-
гострочные поля ввода текста и кнопки управления.
Тег <FORM>
Для получения данных от пользователя в HTML исполь-
зуется концепция формы. Форма HTML начинается с
тега <FORM> и заканчивается тегом </FORM>. (Теги
HTML нечувствительны к регистру, и в тексте книги
они набраны прописными буквами только для того,
чтобы их выделить.) Все, что находится между двумя
указанными тегами, будет считаться частью формы.
Формы могут содержать не только текст и рисунки, но
и элементы управления. Тег <FORM> может иметь два
атрибута, которые нам необходимо рассмотреть:
METHOD и ACTION.
Атрибут METHOD играет важную роль при обра-
ботке Web-сервером вашего запроса. Он может поддер-
живать любой метод, который поддерживает данная
версия HTTP. Например, для HTTP 1.0 это методы
GET, POST и HEAD, для HTTP 1.1 кроме указанных
доступны методы PUT, TRACE и DELETE. Рассмотрим
только два метода — GET и POST, которые по своей
сути очень похожи. Оба метода являются запросами к
браузеру на передачу CGI-процессу данных пользова-
теля, но работают они немного по-разному (более под-
робно принципы их работы будут описаны далее в этой
главе).
Атрибут ACTION сообщает процессу Web-сервера,
что он должен сделать с данными, предоставленными
ему пользователем через форму HTML. Рассмотрим
простой пример:
<FORM METHOD=POST ACTION=/cgi-bin/proto.cgi>
По тегу видно, что атрибут ACTION ссылается на
файл proto.cgi в каталоге cgi-bin. Таким образом опре-
деляется приложение, которое будет выполнять какие-
то действия с входными данными и выдавать какие-то
выходные данные, а также указывается его местополо-
жение. Файл должен являться исполняемой CGI-npo-
граммой. На Windows NT Server исполняемая CGI-про-
грамма, вероятнее всего, будет иметь расширение .ехе,
а не xgi.
606
Дополнительные тематические разделы
Часть III
Тег <INPUT>
Теги <INPUT> являются основными тегами, использу-
ющимися в формах. Этот тег сообщает браузеру, что мы
хотим получить от пользователя какие-то данные. Теги
<INPUT> имеют несколько атрибутов, из которых наи-
более часто используются NAME, VALUE и TYPE.
Атрибут NAME используется для присваивания дан-
ным имени, которое можно было бы распознавать. На-
пример, если мы хотим, чтобы пользователь ввел свой
возраст, то такие данные можно назвать AGE. По сути,
это имя переменной, которое используется (как и лю-
бое имя переменной в С) для обозначения определен-
ного значения, имеющего определенный смысл. При
передаче пользователем формы Web-серверу в запросе
будет содержаться *AGE=23" (или любое другое значе-
ние, введенное пользователем). (Строки запроса будут
рассмотрены далее.) Атрибут NAME, как вы увидите,
может также выполнять еще одну функцию: он может
использоваться для группировки элементов управления,
например, радиокнопок или кнопок выбора.
Атрибут VALUE позволяет установить значение по
умолчанию для поля в форме. Таким образом, можно
заранее заполнить некоторые поля в форме значения-
ми, которые редко изменяются, или просто для отобра-
жения этих значений в качестве примера.
Атрибут TYPE предоставляет множество интересных
возможностей. Он используется для указания ожидае-
мого типа данных пользователя. Ниже более подробно
рассматривается каждый тип.
Тип TEXT используется в том случае, когда пользо-
ватель должен ввести одну текстовую строку в свобод-
ном формате. Данный тип имеет дополнительные атри-
буты SIZE и MAXLENGTH. Для установки значения по
умолчанию с типом TEXT может использоваться опи-
санный выше атрибут VALUE.
Вот пример получения от пользователя названия
города:
<INPUT TYPE=TEXT NAME=City SIZE=10
**MAXLENGTH=15 VALUE=Home>
В приведенной строке создается поле ввода текста с
именем City, для которого значение, принятое по умол-
чанию, равно Ноше. Длина поля будет составлять 10
символов, воспринимаемая длина данных — 15 симво-
лов (при необходимости браузер будет прокручивать
поле). Если вы думаете, что 15 символов будет недоста-
точно, можете изменить это значение по своему усмот-
рению.
Тип PASSWORD очень похож на тип TEXT с един-
ственном различием: для того чтобы скрыть вводимые
данные от любопытных глаз, в поле текста вместо сим-
волов будут отображаться звездочки. Вот пример ис-
пользования типа PASSWORD:
<INPUT TYPE-PASSWORD NAME=Password SIZE=10
**MAXLENGTH=15>
Если вы считаете, что такая возможность маскиров-
ки вводимых данных обеспечивает безопасность, не
торопитесь с выводами. Данные, защищенные типом
PASSWORD, передаются как простой текст. Браузер
просто не отображает данные в форме, но, тем не ме-
нее, данные передаются Web-серверу в незашифрован-
ном виде. Поэтому не считайте тип PASSWORD сред-
ством защиты с помощью пароля.
Тип HIDDEN кажется лишним, но на самом деле он
довольно полезен. Своей способностью содержать тек-
стовую строку он несколько напоминает тип TEXT, но
принцип его работы несколько иной. Браузер не отобра-
жает для пользователя содержимого поля типа HIDDEN,
и пользователь ничего не знает о наличии на странице
такого поля (если, конечно, он не просмотрит исход-
ный HTML-код, что совсем несложно сделать).
Если пользователь не может даже видеть поле, не
говоря уже об изменении его содержимого, то зачем
тогда нужно такое поле? Каждое открытие Web-страни-
цы считается новым посещением независимо от пре-
дыдущих случаев ее посещения. Тип HIDDEN можно
использовать для сохранения данных между посещени-
ями. Он может использоваться при проверках правиль-
ности и для задания пользовательских опций. Напри-
мер, если мы хотим указать CGI-приложению, по какой
базе данных производить поиск, можно сделать следу-
ющее:
<INPUT TYPE^HIDDEN NAME=DBCHOICE
**VALUE=PROGRAMMING>
Для создания радиокнопок используется тип
RADIO. Можно также создать группы радиокнопок
внутри формы, устанавливая одинаковый для всех ра-
диокнопок в группе атрибут NAME. В группе может
быть выбрана только одна кнопка. Если требуется, что-
бы одна из радиокнопок была выбрана по умолчанию,
то для нее необходимо установить атрибут CHECKED.
Пример использования типа RADIO приведен ниже.
1) Cream <INPUT TYPE=RADIO NAME=WhiteOpt
**VALUE=C CHECKED>
2) Milk <INPUT TYPE=RADIO NAME=WhiteOpt
**VALUE=M>
3) Black CINPUT TYPE=RADIO NAME=WhiteOpt
**VALUE=B>
В данной части программы создается группа радио-
кнопок Option с первой радиокнопкой, выбранной по
умолчанию. При передаче CGI-приложению данных,
установленных по умолчанию, переменная WhiteOpt
будет иметь значение С. Радиокнопки будут располо-
жены в одну линию с подписями (в нашем случае это
целые числа 1, 2 и 3), находящимися слева от радио-
607
кнопки. Их можно расположить и так, как это обычно
делается, — в отдельных строках с подписями справа:
<INPUT TYPE=RADIO NAME=WhiteOpt VALUE=C
**CHECKfeD>l) Cream <P>
<INPUT TYPE=RADIO NAME»WhiteOpt VALUE=M>2)
'-♦Milk <P>
<INPUT TYPE=RADIO NAME=WhiteOpt VALUE=B>3)
*»Black
Тег P начинает новую строку. Он не требует ответ-
ного тега </Р> закрытия строки, поскольку начало но-
вой строки обязательно является концом старой.
Радиокнопки используются для выбора одной аль-
тернативы из небольшого списка взаимно исключающих
друг друга альтернатив. Если список достаточно длин-
ный, использовать радиокнопки не совсем удобно, по-
этому в таком случае вместо них лучше использовать
выпадающие списки. Процесс создания выпадающих
списков будет рассмотрен далее в этой главе.
Тип CHECKBOX очень похож по синтаксису на тип
RADIO. Он используется для создания простых пере-
ключателей "включено/выключено". Переключатели
тоже можно объединять в группы, но и в таком случае
возможность одновременного включения (выключения)
нескольких переключателей в одной группе сохраняет-
ся. Конечно, объединять переключатели в группы со-
всем не обязательно.
Если мы используем атрибут CHECKED, то будет
установлен переключатель, и, чтобы отказаться от ука-
занной опции, пользователь должен выключить его. Если
атрибут CHECKED не используется, то для выбора
указанной опции пользователь должен сам установить
переключатель.
Атрибут VALUE определяет текст, который будет
передан вместе с именем переключателя, если переклю-
чатель установлен. Если при передаче формы Web-сер-
веру переключатель не был установлен, браузер не бу-
дет передавать Web-серверу никаких данных,
касающихся состояния переключателя. В приведенном
ниже примере создаются три логически независимых
переключателя, два из которых установлены по умол-
чанию:
Sugar <INPUT TYPE=CSECKBOX NAME=Sugar
**VALUE=Yes CHECKED>
Cookie <INPUT TYPE» CHECKBOX NAME»Cookie
*~VALUE=Yes>
Chocolate <INPUT TYPE= CHECKBOX KAME=Choc
**VALUE=Yes СЙЕСХК1»
Снятый переключатель не возвратит никакого зна-
чения. Если бы форма приведенного примера была пе-
редана CGI-приложению со значениями, принятыми по
умолчанию, то приложение получило бы следующие
данные: Sugar=Yes и Choc=Yes.
Написание CGI-приложении на С
Глава 23
Переключатели можно объединить в группу путем
простого присвоения всем переключателям одного и
того же имени. Обратите внимание, что при объедине-
нии переключателей в группу по имени CGI-приложе-
нию будет передаваться одно поле для каждого установ-
ленного переключателя, поэтому приложение должно
иметь возможность обрабатывать данные такого вида.
Пример использования переключателей, объединенных
в группу, может выглядеть следующим образом:
Sugar <INPUT TYPE=CHECKBOX NAME=Sweet VALUE=Su
'**CHECKED>
Cookie <INPUT TYPE» CHECKBOX NAME» Sweet
**VALUE=Co>
Chocolate <INPUT TYPE= CHECKBOX NAME= Sweet
'-*VALUE=Ch CHECKED>
Если эти данные будут передаваться Web-серверу без
изменения, то CGI-программа получит два поля, и оба
с именем Sweet: Sweet=Su и Sweet=Ch.
<INPUT TYPE="RESET">
Тип RESET дает браузеру задание вывести на экран
кнопку, при щелчке на которой всем элементам внутри
структуры <FORM> </FORM> будут присвоены зна-
чения, приведенные в HTML-описании этой формы.
<INPUT TYPE=”SUBMIT’’>
Тип SUBMIT дает задание браузеру вывести на эк-
ран управляющую кнопку, при щелчке на которой бу-
дут выполнены действия, указанные в параметре
ACTION тега FORM.
Теш <SELECT> и <OPTION>
Тег SELECT путем создания предварительно заполнен-
ного выпадающего списка опций предоставляет меха-
низм одновременного отображения нескольких оп-
ций, из которых можно выбрать только одну. Чтобы
задать список опций, используется тег OPTION. Для
форматирования выпадающего списка может исполь-
зоваться атрибут SIZE, а для установки значения по
умолчанию — атрибут SELECTED. Ниже приведен
пример использования тега SELECT:
<SELECT NAME=Color SIZE=3>
<OPTION VALUE=Red>Red
<OPTION VALUE»Blue SELECTED>Blue
<OPTION VALUE=Green>Green
</SELECT>
Таким образом на нашей Web-странице будет созда-
но окно списка со значениями Red, Blue и Green в ка-
честве опций. Значением, принятым по умолчанию,
будет Blue.
Если вы хотите, чтобы в окне списка пользователь
мог выбрать несколько опций, то в теге SELECT необ-
ходимо указать MULTIPLE:
608
Дополнительные тематические разделы
Часть III
<SELECT NAME=Color SIZE=3 MULTIPLE»
Это позволит пользователю выбирать одновременно
несколько пунктов в списке. В большинстве графичес-
ких Web-браузеров это можно сделать путем выбора
пунктов при нажатой клавише Ctrl. В текстовом Web-
браузере lynx выбор нескольких пунктов из списка осу-
ществляется с помощью клавиши Enter. При использо-
вании атрибута MULTIPLE следует иметь в виду, что
Web-сервер получит несколько (т.е. нуль и более) зна-
чений одной и той же переменной.
Тег <TEXTAREA>
Тег TEXTAREA создает многострочное поле ввода тек-
ста, в которое пользователь может ввести большой объем
данных. Этот тип отличается от типа TEXT тем, что с
помощью атрибутов COLS и ROWS можно установить
количество столбцов и строк, которые будут отобра-
жаться на экране.
Тег TEXTAREA, кроме того, позволяет с помощью
атрибута WRAP, значение которого можно устанавли-
вать равным OFF, VIRTUAL или PHYSICAL, произво-
дить автоматический переход на новую строку. Значе-
ние OFF указывает, что автоматический переход на
новую строку не производится, а строки передаются
Web-серверу в том же виде, в каком они были введены
пользователем. Значение VIRTUAL свидетельствует о
том, что автоматический переход на новую строку бу-
дет производиться только на экране, а Web-сервер бу-
дет получать данные в виде одной строки. Значение
PHYSICAL свидетельствует о том, что автоматический
переход на новую строку будет производиться не толь-
ко на экране, но в таком же виде будет передаваться
Web-серверу.
CTEXTAREA NAME=Feedback ROWS=5 COLS=80
*-*WRAP=VIRTUAL>
</TEXTAREA>
В данном примере браузеру дается задание отобра-
зить на экране пользователя поле ввода текста высотой
5 строк и шириной 80 столбцов. Автоматический пере-
ход на новую строку будет осуществляться только на
экране, а Web-серверу будет отсылаться одна непрерыв-
ная строка.
Пример HTML-формы входных данных
Давайте закрепим только что полученные знания по
HTML-формам на простом примере, который в даль-
нейшем мы используем для создания нашего первого
CG1 -приложения.
<нтщ>
<HEAD>
<TITLE>
ANSI С Standard Library Function
Prototypes
</TITLE>
</HEAD>
<BODY>
<PRE>
<FORM METEOD="POST"' ACTION="/cgi-bin/
** proto. cgi">
Please type in the name of the function
whose prototype you wish to see.
<INPUT TYPE="text" NAME="function"
b*SIZE="20">
<BR>
<INPUT TYPE="submit*>
</FORM>
</PRE>
</BODY>
</HTML>
В приведенном примере задано простое поле ввода
текста, в которое пользователь может ввести имя функ-
ции языка программирования ANSI С. После этого CGI-
программа отобразит прототип указанной функции. Как
именно это происходит, рассмотрим далее в этой главе.
Среда CGI
При передаче HTML-формы Web-серверу данные, име-
ющиеся в форме, передаются CGI-программе, указан-
ной в атрибуте ACTION тега FORM. Web-сервер созда-
ет совокупность переменных среды и предоставляет их
CGI-программе. Эти переменные среды предоставляют
разработчикам CGI-программ достаточно большой
объем полезной информации.
Что подразумевается под термином "переменная
среды"? Представьте себе базу данных, в которой хра-
нятся переменные и значения, управляемые операци-
онной системой. Стандартная библиотека ANSI С име-
ет функцию getenv(), которая может осуществлять
поиск по базе данных. Вы даете этой функции имя пе-
ременной, а она возвращает значение (или NULL, если
переменная не найдена), связанное с указанным именем.
Вот и все. Прототип функции getenv() находится в биб-
лиотеке stdlib.h и выглядит следующим образом:
char *getenv(const char *name) ;
Помните, что переменные среды можно только счи-
тывать! Функция getenv() возвращает указатель на саму
переменную среды. Если необходимо изменить данные,
которые выдает функция getenv(), то. нужно сделать
копию этих данных и изменять только эту копию. Вот
пример кода, который выполняет указанные действия:
finclude <stdlib.h>
linclude <string.h>
Написание CGl-приложенийна С
Глава 23
|6О9
I* Этот код может напомнить вам функцию
* stdup(), поддерживаемую многими
* компиляторами; однако stdup() не входит в
* стандартную библиотеку ANSI С. Поэтому, для
* того чтобы код был полностью переносимым,
* приходится что-то придумывать» Эта функция
* возвращает NULL, если строку нельзя
* скопировать или для копии недостаточно
* памяти. В противном случае она возвращает
* указатель на копию.
* Примечание. После успешного завершения
* функции необходимо с помощью функции fхее()
* освободить память, выделенную под указатель
* функцией DupStringQ.
*/
char *DupString(const char *s)
{
char *Dup = NULL;
if(s != NULL)
{
Dup = malloc(strlen(s) 4 1);
if(Dup != NULL)
{
strcpy(Dup, s);
}
}
return Dup;
)
Перед тем как Web-сервер запускает CGI-приложе-
ние, он устанавливает целый ряд очень полезных пере-
менных среды. Они описываются далее. В каждом аб-
заце приведен пример соответствующей переменной,
полученной в результате дампа переменной среды, ко-
торый можно выполнить с помощью команды SET опе-
рационной системы MS-DOS, и приведено типичное
значение этой переменной.
AUTH.TYPE
Если сервер поддерживает аутентификацию пользователя
и сценарий защищен, то тип используемой аутентифика-
ции передается с помощью переменной AUTH_TYPE.
Такая аутентификация абсолютно не зависит от CG1-
процесса.
AUTH_TYPE=Basic
CONTENTJ.ENGTH
Если атрибут ACTION установлен равным POST, то эта
переменная будет содержать размер данных в байтах в
стандартном входном потоке. В противном случае ей
будет присвоено значение NULL. Имейте в виду, что,
хотя значение атрибут ACTION само по себе числовое,
но, тем не менее, оно хранится в строковой перемен-
ной. Поэтому само это числовое значение можно полу-
чить с помощью функций atoi(), atol(), strtoIQ или
strtoulO в зависимости от того, какая функция вам боль-
ше нравится. (Если вы не доверяете своему Web-серве-
ру в части предоставления надежной среды, то лучше
всего, наверное, использовать функцию strtol() или даже
strtoul(),что позволит вам самостоятельно проверить
правильность результата.)
CONTENT_LENGTH=32
CONTENT_TYPE
Этот конкретный тип MIME в явной форме информи-
рует пользователя о точном формате его данных. Из
приведенного ниже примера видно, что данные пред-
ставлены в закодированном виде. Знание формата дан-
ных позволяет гораздо легче производить синтаксичес-
кий анализ ожидаемых данных.
CONTENT_TYPE=application/x-www-form-urlencoded
GATEWAY-INTERFACE
Переменная GATEWAY-INTERFACE указывает версию
CGI, которую поддерживает Web-сервер. Формат этой
переменной имеет вид СС1/<номер версии>.
GATEWAY_INTERFACE= CGI/1.1
HTTPACCEPT
Web-браузеры могут устанавливать параметры типов
кодировки MIME, которые они принимают. Элементы
в списке разделяются запятыми. В следующем примере
приведен формат тип/подтип, тип/подтип:
HTTP_ACCEPT=image/gif, image/jpeg, image/pjpeg,
*♦*/*
НИР-CONNECTION
Браузер клиента открывает TCP-сеанс с Web-сервером.
Данная переменная содержит тип соединения.
HTTP_CONNECTION=keep-alive
НИР-HOST
Данная переменная будет содержать хост-имя сервера. Это
может быть просто вымышленное имя компьютера.
HTTP_HOST=www.zog.com
НПР-REFERER
Данная переменная содержит URL-адрес источника
ссылки, с которого была вызвана CGI-программа.
HTTP—REFERER=h ttp: //www. zogsearch. com/cgi-bin/
**query?keyword=sheep&where=f arming
HnP_USER_AGENT
Зная значение переменной HTTP-USER_AGENT, мы
можно определить тип браузера, используемого конеч-
ным пользователем. Это позволяет создавать страницы,
содержание которых зависит от типа используемого
39 Зек. 265
610
Дополнительные тематические разделы
Часть III
браузера. Переменная имеет следующий формат: про-
граммное обеспечение/библиотека версии/версия. Зна-
чения переменной для некоторых часто используемых
браузеров приведены ниже.
Для Internet Explorer 3.02 значение переменной
HTTP_USERAGENT равно:
HTTP_USER_AGENT=Mozilla/2.0 (compatible; MSIE
* ♦3.02; Update а; АК; Windows 95)
Для IE4:
HTTP_USER_AGENT=Mozilla/4.0 (compatible; MSIE
* *4.01; Windows NT)
Для Netscape 4.04:
HTTP_USER_AGENT=Mozilla/4.04 C-NE (Win95; I)
PATHJNFO
Клиент (как правило, браузер) имеет возможность че-
рез переменную PATH INFO передавать дополнитель-
ную информацию, касающуюся места нахождения при-
ложения. Местонахождение CGI-приложения можно
задать по его виртуальному пути, за которым следует
дополнительная информация. Эта дополнительная ин-
формация передается переменной PATHJNFO.
PATH_INFO=/cgi-bin/proto. cgi
PATH-TRANSLATED
Сервер предоставляет версию значения переменной
PATHJNFO, транслированную в переменную
PATH JTRANSLATED. в которой логические имена за-
менены физическими. Вполне возможно, что Wcb-cep-
вер поддерживает несколько доменов на одном компь-
ютере. Переменная РАТНТ RAN SLATED дает
системный путь, а не относительный. Вот два примера:
PATH_TRANSLATED=/usr/home/www.zog.com/cgi-bin/
* *proto. cgi
PATH_TRANSLATED=C s\iis\www.zog-com\cgi-
* *bin\proto. exe
QUERY_STRING
Если в теге FORM атрибут METHOD установлен рав-
ным GET, то Web-сервср поместит объединенные дан-
ные из формы в переменную QUERY_STRING. Если
использовалось значение POST, то функция
getenv("QUERY_STRING”) возвратит указатель NULL,
давая CG1-программе указание о том, что она должна
взять данные из стандартного потока данных. (Для луч-
шего понимания различия между этими двумя значени-
ями см. описание переменной REQEST METHOD.)
QUERY_STRING=func ti on=memse t
REMOTE.ADDR
Если требуется IP-адрес браузера, который вызывает
нашу программу, то его можно найти в переменной
REMOTE__ADDR.
REMOTE__ADDR=192.168.10.25
REMOTE_HOST
Эта переменная содержит хост-имя компьютера, кото-
рый делает запрос. Если правильное доменное имя не-
доступно клиенту, функция getenv() возвращает значе-
ние NULL.
REMOTE_HOST=a2x46.iwl.net
REMOTEJNDENT
Это поле показывает идентификатор пользователя. Оно
доступно не всегда, а в зависимости от того, поддержи-
вает ли компьютер клиента IDENT RFC (Requests for
Comments). RCF 931 поддерживает идентификацию и
автоматическую аутентификацию. В основном RFC
используется для автоматического входа па FTP-сервер
и проверки пользователя IRC (Internet Relay Chat). Если
клиент поддерживает данную функцию, то переменная
будет содержать имя пользователя.
REMOTE_INDENT=dixonc
REMOTE.USER
Переменная REMOTE-USER связана с переменной
AUTH TYPE. Если сервер поддерживает аутентифика-
цию пользователя и сценарий защищен, то переменная
REMOTE_USER содержит имя пользователя, под ко-
торым он был аутентифицирован.
REMOTE_USER=dixonc
REQUEST-METHOD
Эта переменная содержит атрибут METHOD, который
был установлен в теге FORM.
REQUEST_METHOD=POST
SCRIPT_NAME
Эта переменная содержит имя самой CGI-программы и
аналогична argv[O] в обычной программе на С. Это, как
правило, значение, которое дается атрибуту ACTION в
теге FORM на самой HTML-странице. Благодаря это-
му мы имеем замечательную возможность выдавать
ссылку из программы на саму себя, что бывает необхо-
димо, когда пользователь хочет запустить программу
несколько раз подряд. Далее будет приведен пример
использования этой возможности.
SCRIPT_NAME=/cgi-bin/proto. cgi
Написание CG1'•приложений на С
Глава 23
611
SERVER.NAME
Переменная SERVER_NAME может содержать либо
действительное имя, либо доменное имя-псевдоним,
либо IP-адрес сервера. Значение этой переменной ис-
пользуется для указания относительных URL-ссылок.
Например, следующее значение дает хост-имя сервера:
SERVER_NAME=cgi.zog.com
SERVER_PORT
Большинство HTTP-серверов используют порт 80, но
это ни в коей мере не является требованием. Довольно
часто серверы либо по соображениям безопасности, либо
вследствие необходимости поддержки нескольких серве-
ров на одном компьютере используют и другие порты.
Переменная SERVER_PORT сообщает CGI-прило-
жению номер порта, который использовался для уста-
новления соединения с ним.
SERVER_PORT=80
SERVER_PROTOCOL
Переменная SERVER-PROTOCOL очень похожа на
переменную GATEWAY-INTERFACE. Она содержит
версию Web-сервера и протокол, которого он придер-
живается.
SERVER_PROTOCOL=HTTP/1.1
SERVER.SOFTWARE
Переменная SERVER-SOFTWARE содержит информа-
цию об имени и версии Web-сервера.
SERVER_SOFTWARE=Apache/l.3.6 (Unix) (Red Hat/
** Linux)
Получение данных
При рассмотрении тега FORM был упомянут атрибут
METHOD. Этот атрибут определяет, какой из двух со-
вершенно различных методов использует Web-сервер
при передаче данных CGI-приложению. Вспомните,
что два возможных значения атрибута METHOD — это
GET и POST.
Если значение атрибута METHOD установлено рав-
ным GET, то Web-сервер вызовет процесс, указанный в
атрибуте ACTION, и для задания значения переменной
среды QUERY—STRING будет использовать данные
формы. Кроме того, он будет отображать строку данных
в адресной строке браузера, как если бы это был URL-
адрес, что может быть проблемой, если, скажем, ваши
данные содержат пароль. Это является особенностью не
какого-то отдельного браузера, а особенностью самого
HTTP-протокола. Более того, существует ограничение
на количество символов в URL-адресе. Это ограничение
накладывается уже самим используемым браузером. Для
одних браузеров оно составляет 8192 байта, для других —
всего 255 байтов, но важным является то, что такое ог-
раничение существует.
К счастью, есть превосходная альтернатива. Устано-
вив значение атрибута METHOD равным POST, мож-
но указать Web-серверу передавать данные CGI-прило-
жению через стандартный входной поток данных.
Кроме того, Web-сервер передаст CGI-приложению в
переменной CONTENT-LENGTH точное количество
байтов, которое должно быть принято приложением.
Такой метод передачи не накладывает ограничений на
объем передаваемых данных. И еще одним преимуще-
ством этого метода является то, что метод POST не ото-
бражает строку запроса в адресной строке браузера, как
это делает метод GET. Тем не менее, не следует считать
этот метод абсолютно безопасным, он просто более бе-
зопасен, чем метод GET. Данные все еще передаются от
браузера Web-серверу в открытом (незакодированном)
виде.
Первое, что должно сделать CGI-приложение, — оп-
ределить, где брать данные. Для этого мы просматриваем
значение переменной среды REQLEST METHOD, кото-
рое будет, как известно, иметь значение либо GET, либо
POST.
Если установлен метод GET, то данные необходи-
мо брать из переменной среды QUERY_STRING. Если
установлен метод POST, то по содержимому перемен-
ной CONTENT-LENGTH нужно определить объем дан-
ных, которые требуется считать. После этого можно вы-
делить необходимый объем памяти для размещения этих
данных (для этого подойдет функция malloc()) и прочи-
тать указанный объем данных из входного потока.
Рассмотрим исходный код, который выполняет опи-
санную выше процедуру (листинг 23.1). Вы наверняка
заметите, что в этом коде используется несколько мак-
росов. Эти макросы определены в файле cgLh, который
находится на Web-сайте издательства "ДиаСофт".
Этот исходный код находится в файле cgi.c.
Вы, возможно, заметили, что в приведенной функ-
ции нет ничего, что ограничивало бы ее использование
только одним приложением. Остается выяснить, будет
ли она работать со всеми CGI-программами, написан-
ными на С. Будет. Работоспособность функции даже не
зависит от метода передачи данных, будь то GET или
POST. Поэтому вам не придется писать собственную
функцию, можете просто взять ее с Web-сайта издатель-
ства "ДиаСофт".
612
Дополнительные тематические разделы
Часть III
Листинг 23.1. Функция ReadCGIData, которая
осуществляет считывание входных данных CGI-
программы с входного потока.
char ‘ReadCGIData(int *Error)
{
char ‘Buffer = NULL;
char ‘RequestMethod = NULL;
char ‘ContentLength = NULL;
char ‘CGIData = NULL;
size t Size = 0;
♦Error = CGISUCCESS;
RequestMethod = getenv("REQUESTMETHOD");
if(NULL == RequestMethod)
{
♦Error = CGINULLREQMETHOD;
}
if(0 == ‘Error)
{
if(strcmp(RequestMethod,"GET") == 0)
{
/* GET */
CGIData = getenv("QUERYSTRING");
if(NULL == CGIData)
{
♦Error = CGINOQUERYSTRING;
}
else
{
Buffer = DupString(CGIData);
if(NULL == Buffer)
{
♦Error = CGINOMEMORY;
}
}
}
else if(strcmp(RequestMethod,"POST") 0)
{
/* POST */
ContentLength - getenv("CONTENTLENGTH");
if(NULL ~= ContentLength)
{
♦Error = CGIBADCONTENTLENGTH;
}
if(0 == ‘Error)
{
Size = (size_t)atoi(ContentLength);
if (Size <= 0)
{
♦Error = CGIBADCONTENTLENGTH;
}
}
if(0 == ‘Error)
{
++Size;
Buffer = malloc(Size);
if(NULL =- Buffer)
{
♦Error = CGINOMEMORY;
}
else
{
if(NULL == fgets(Buffer, Size,
'-•stdin))
{
♦Error = CGINODATA;
free(Buffer);
Buffer = NOLL;
}
}
}
else
{
♦Error = CGIUNKNOWNMETHOD;
>
return Buffer;
Синтаксический разбор строки запроса
Функция ReadCGIData возвращает указатель на копию
строки запроса, переданной Web-сервером CGI-прило-
жению. Строка запроса представляет собой текст, кото-
рый содержит все данные с формы. Она имеет формат
переменная=значение, и если в строке присутствует несколь-
ко элементов данных, то они отделяются символом ампер-
санда & (например, переменная=значение&переменная=зна-
чение). Имя переменной будет зависеть от значения
NAME, которое использовалось в HTML-форме.
Кроме того, в строке запроса можно заметить неко-
торые странные символы. Например,
mes sage=this+is+a+tes t &message2=wow+%21
Давайте более подробно рассмотрим эти данные и
формат данных. Как вы, несомненно, помните, при ис-
пользовании метода GET передачи данных строка зап-
роса передается как URL-адрес. Поэтому строка запро-
са должна удовлетворять правилам написания
URL-адресов. Например, в строке не должно быть про-
белов или знаков пунктуации. Представьте себе адрес
http://w!Aw.$%.com. Он просто не будет работать. Но
что делать, если мы хотим передать CGI-приложению
именно такой набор символов? Способность Web-сер-
вера кодировать данные позволяет это сделать.
Необходимо решить две отдельные задачи по деко-
дировке (хотя их можно решать и параллельно). Пер-
вая — преобразовать символ "+" в символ " " (пробел),
а вторая — преобразовать шестнадцатиричные символы
в их ASCH-эквиваленты. Такие символы представлены
в виде %хх, где % — специальный символ, который ука-
зывает, что следующие далее символы нужно обрабаты-
вать особым образом, хх — это шестнадцатиричное зна-
чение, которое необходимо представить в формате
613
ASCII. Например, %21, т.е. 0x21 в шестнадцатиричном
виде, соответствует десятичному значению 33, что со-
ответствует символу "1".
ПРИМЕЧАНИЕ
Если вы разработчик универсальных программ, то, навер-
ное, уже начинаете проявлять нетерпение. А как насчет
расширенного двоично-десятичного кода и других упоря-
доченных кодовых таблиц? А что произошло с переноси-
мым программированием? Просто HTTP использует ASCII,
и другого варианта просто нет. ASCII фактически явля-
ется алфавитом Web-сети.
Приведенное описание может показаться немного
сложным. Тут уместно вспомнить пословицу, которая
гласит, что лучше один раз увидеть, чем сто раз услы-
шать. Поэтому давайте лучше посмотрим на исходный
код, приведенный в листинге 23.2.
Листинг 23.2. CGIHexToAscii — преобразование
шеснадцатиричных данных в формат ASCII.
int CGIHexToAscii(char *s)
{
/* В случае ошибки установить значение
Error не равным нулю. */
int Error = 0;
/* Будет очень удобно, если все
шестнадцатиричные цифры будут содержаться в
непрерывной упорядоченной строке.
*/
static const char *Еех = "0123456789ABCDEF";
/* Эта переменная будет использоваться для
хранения смещения в строке Hex.
*/
unsigned int Ascii - 0;
/* Это просто запасной указатель. Будем
перемещать его по списку и использовать для
указания на текущий адрес, по которому
будут записываться символы.
*/
char *р;
/* не равен NULL, если найдена
действительная шестнадцатиричная цифра. */
char *Match;
/* Для каждого символа в строке...*/
for(p = s; lError && *s != '\0'; s++)
{
/* Это шестнадцатиричная цифра? */
if(*s == '%')
{
/* Да. Оставляем р, переносим s на
первый байт кодировки.
*/
s++;
Написание CGI-приложений на С
Глава 23
/* Символ должен быть в строке Вех,
если его там нет, значит, в данных есть
ошибка.
*/
if ((Match = strchr(Hex, *s)) != NULL)
{
/* Теперь можно вычислить старший
полубайт эквивалента символа в кодировке
ASCII.
*/
Ascii = (unsigned int)(Match - Hex);
/* А теперь то же самое для младшего
полубайта.
*/
s++;
if((Match = strchrfHex, *s)) !=
NULL)
{
/* Убрать старший полубайт. */
Ascii «= 4;
Ascii |= (unsigned int)
(Match - Hex);
/* Теперь можно обновить строку.
Обратите внимание, что для каждого
шестнадцатиричного символа в данных р
отстает от s на два символа.
*/
*р++ = (char)Ascii;
}
else
{
Error = 1;
}
}
else
{
Error = 1;
}
}
/* Если это не шестнадцатиричный символ,
может, это символ 4-, который должен стать
пробелом?
*/
else if(*s == '+')
{
*р++ = •
}
/* Нет? Тогда просто копируем символ. */
else
{
*р++ = *s;
}
}
if(!Error)
{
/* Не забываем в конце строки поставить
нуль. */
*р = '\0';
}
return Error;
Дополнительные тематические разделы
614
Часть III
Как и предыдущий, этот код можно найти на Web-
сайте издательства ’’ДиаСофт” в файле cgi.c, и вам не
придется писать его самому.
Если вы думаете, что этой функции передается вся
строка запроса, то вы ошибаетесь. Вспомните, что дан-
ные представлены в виде пар переменная-значение, раз-
деленных символом амперсанда. Если амперсанд явля-
ется частью данных пользователя (и преобразуется
браузером в шестнадцатиричный вид), то преобразова-
ние всей строки в формат ASCII было бы неправильным
решением. Имеет смысл сначала перед каждой парой
переменная=значение поставить маркеры, а затем декоди-
ровать каждую пару.
Кроме того, необходимо Подумать о хранении пере-
менных и их значений. Первое, что приходит в голову, —
это список. Поэтому нашей первой задачей будет фор-
мирование структуры данных, которую можно органи-
зовать в виде связанного списка. Вот часть файла cgi.h:
typedef struct CGI_LIST
{
char ‘Variable;
char ‘Value;
struct CGILIST ‘Next;
} CGI_LIST;
Ничего сложного, это довольно простой односвяз-
ный список. Мы продвигаемся по строке запроса, раз-
бивая ее символами амперсанда, декодируем ее, разде-
ляя переменные и значения (при этом в качестве
разделителя переменной и значения используется сим-
вол "=”). К сожалению, мы не знаем, какой объем па-
мяти выделить под значение и под переменную. Пер-
вый способ, позволяющий определить это, — двигаться
по строке до первого символа ’*=”, затем вернуться на
начало строки и произвести само копирование данных.
Однако это не очень эффективно.
Оказывается, это делать не обязательно. Достаточ-
но просто поместить переменную Variable и значение в
одно место памяти (на место переменной). Далее пере-
мещаем указатель по символам значения Value до тех
пор, пока не встретится символ устанавливаем зна-
чение, на которое указывает указатель, равным нулю
(\0) и переводим указатель на следующую позицию.
Пока мы помним, что Value указывает на местоположе-
ние переменной Variable, а не на местоположение Value
(и не попытаемся по ошибке дважды освободить память
с помощью функции free()), все будет работать без про-
блем. Такое решение выгладит достаточно аккуратным.
В листинге 23.3 приведена функция, которая стро-
ит список указанным способом.
Листинг 23.3. Функция CGICreateList, которая осуществляет создание и заполнение связанного списка
данными пользователя.
CGILIST ‘CGICreateList(char ‘Data)
{
/‘ Основной указатель списка */
CGILIST ‘CGIList;
/* Указатель на текущую позицию в списке */
CGILIST ‘Currltem = NULL;
/* Если получена даже небольшая ошибка, очистить список и выйти из программы
*/
int Error = 0;
/* Одно поле. Разделено на лексемы с использованием ' = ' */
char ‘Field;
/* Выделить память под корневой узел */
CGIList = malioc(sizeof ‘CGIList);
if(CGIList != NULL)
{
/* Перевести указатель в начало списка */
Currltem = CGIList;
/* Получить первое поле. Поскольку функция strtok изменяет свои аргументы, то в случае,
если строка запроса хранилась в переменной среды (метод GET), ее нельзя использовать
напрямую, именно поэтому мы делаем копию.
*/
Field ~ strtok(Data, "i\n");
if(NULL == Field)
{
}
Error » 1; /* Данные отсутствуют! */
615
Написание CGI-приложений на С
Глава 23
/* Для каждого поля */
while(0 == Error && Field != NULL)
{
/* Преобразовать закодированные символы (например, %21 в '!') */
if(CGIHexToAscii(Field) != 0)
{
Error = 1;
}
else
{
/* Устанавливаем значения по умолчанию. Мы не можем использовать memset, поскольку в
стандарте ANSI не оговорено, что в двоичном виде NULL во всех разрядах содержит нули.
*/
CurrItem->Value = NULL;
CurrItem->Next = NULL;
/* Для сохранности скопировать данные поля */
CurrItem->Variable = DupString(Field);
if(NULL == CurrItem->Variable)
{
Error = 2;
}
else
{
/* Начать c Variable */
CurrItem~>Value = CurrItem->Variable;
/* Продолжаем, пока не встретим ' = ' */
while(*CurrItem->Value 1= '\0' &&
*CurrItem->Value 1= '=')
{
++CurrItem->Value;
}
if('\0' «= *CurrItem->Value)
{
Error = 3;
}
else
{
/* В конце Variable вставляем нуль */
*CurrItem->Value = '\0';
/* Указать на первый байт величины */
++CurrItem->Value;
}
}
.}
if(0 == Error)
{
/* Получить следующий маркер */
Field = strtok(NULL, "&\n");
if (Field != NULL)
{
/* Выделить память под следующий узел */
CurrItem->Next = malloc(sizeof *CurrItem->Next);
if(NULL == CurrItem->Next)
{
Error = 1;
}
else
{
Currltem » CurrItem->Next;
}
}
Дополнительные тематические разделы
Часть III
616
}
}
/* В случае ошибки удалить весь список */
if(Error != 0)
{
CGIDestroyList(CGIList);
CGIList = NULL;
}
}
return CGIList;
Код, приведенный в листинге 23.3, строит связан-
ный список, в котором каждый узел представляет одну
переменную и соответствующее ей значение. Признаком
конца списка является значение NULL. В таком списке
могут содержатся переменные с одинаковыми именами,
следовательно, у нас не будет проблем, если для радио-
кнопок или выпадающих списков будет установлено
MULTIPLE.
Кроме того, потребуется код для удаления списка.
К счастью, он довольно прост:
void CGIDestroyList (CGI_LIST *List)
{
CGILIST *Next = NULL;
while(List ! = NULL)
{
Next = List->Next;
if(List->Variable 1= NULL)
{
free(List->Variable);
}
/* Обратите внимание, что функция free не
используется для освобождения Value,
поскольку она все равно указывает на
Variable
*/
free(List);
List - Next;
}
}
Пример приложения: поиск прототипа
функции
Весь код, который был приведен в этой главе, абсолют-
но не зависел от конкретного CG 1-приложения, и его
можно использовать в любом таком приложении. Теперь
наступило время рассмотреть само приложение. Если
вы помните, приложение должно позволять пользова-
телю производить писк прототипа любой функции
стандартной библиотеки языка программирования ASNI
С. Если пользователь захочет, он сможет просмотреть
номер версии CGI-приложения, набрав в строке поис-
ка слово version. В любом случае будет лучше, если для
повторного поиска пользователю не придется возвра-
щаться на предыдущую страницу. Поэтому наше CG1-
приложение будет не только выводить на экран прото-
тип указанной функции или номер версии, но и новую
форму, с помощью которой пользователь сможет про-
должить поиск по библиотеке функций С.
Чтобы сделать процесс программирования для наше-
го читателя как можно более приятным, мы позаботи-
лись, чтобы все функции в приложении, за исключени-
ем только одной функции, специфичной для данного
приложения, выполнялись с помощью одной функции
Арр(). Можете считать, что точкой входа в CGI-про-
грамму является функция Арр()< (Конечно, это не так,
и в самом имени Арр() нет никакого специального смыс-
ла, просто выбрано такое имя. Можно назвать программу
по своему усмотрению, при этом, естественно, необхо-
димо будет внести необходимые изменения в main().)
Если вы захотите создать другое CGI-приложение, про-
сто перепишите одну функцию Арр(). Ну и, конечно,
можете использовать любые вспомогательные функции.
В приведенном примере в листинге 23.4 используется
только одна такая функция.
Как видно из листинга, для создания выходного
потока необходимо всего лишь вызвать printf. Web-бра-
узер возьмет стандартный выходной поток и передаст
его браузеру пользователя, как если бы пользователь
потребовал передачи обычной Web-страницы (в неко-
тором роде оно так и есть).
Вспомогательная функция GetPrototype() возвращает
кодированный прототип функции вместе с соответству-
ющим заголовочным файлом и в некоторых случаях
полезные советы. Она возвращает NULL, если она не
нашла данных о функции с указанным именем. Нет
необходимости приводить листинг функции
GetPrototypeO в данной главе. Его можно найти на Web-
сайте издательства "ДиаСофт" в файле proto.c. По сво-
ей сути это просто поисковая таблица. "Настоящее"
CGI-приложение может иметь возможность произво-
дить поиск по текстовому файлу или по базе данных
SQL, но для простоты, переносимости и (возможно)
повышения скорости выполнения функция
GetPrototypeO держит все данные в памяти.
Все, что требуется знать, — как объединить весь этот
код с функцией main() (листинг 23.5), но мы к этому
готовы.
617
Написание CGI-приложений на С
Глава 23
Листинг 23.4. Функция Арр — ориентированный на приложение код для отображения прототипов
функций стандартной библиотеки ANSI С.____________________________________________________________
void App(CGI_LIST *List)
{
char *Proto = NULL;
int GettingVersionlnfo = 0;
char *VersionInfo =
"C Unleashed CGI Demo vl.05";
char *ScriptName = getenv("SCRIPTNAME");
/* Мы ожидаем, что в списке будет только один элемент, поэтому давайте его используем.
*/
if(strcmp(List->Valuef "version") == 0)
{
GettingVersionlnfo = 1;
}
printf("<HTML>\n");
printf(" <HEAD>\n");
printf(" <TITLE>\n ");
if(GettingVersionlnfo)
{
printf("Version information for CGI Demo\n");
}
else
{
printf("Function prototype for %s", List->Value);
}
printf(" </TITLE>\n");
printf(" </HEAD>\n");
printf(" <BODY>\n");
if(GettingVersionlnfo)
{
printf("<Hl>Version information for CGI Demo<Hl>\n");
printf ("<PXPxE2>%s</E2>\n", Versioninfo);
)
else
{
printf (" <ElxB>%s</Bx/Elxp>\n", List->Value);
Proto = GetPrototype(List->Value);
if(NULL == Proto)
{
printf("<I>%s not found. Please"
" check spelling.</I>\n",
List->Value);
}
else
{
printf("<I>%s</I>\n", Proto);
}
}
if(ScriptName != NULL)
{
printf(" <BR>\n");
printf(" <FORM METBOD=\"POST\""
" ACTIONS\"%s\">\n",
ScriptName);
printf (" <BRXER><BR> \ n " );
618
Дополнительные тематические разделы
Часть III
printf(" <CENTER>\n");
printf(" <FONT SIZE=4>\n");
printf(" Next search:\n");
printf(" <BR>\n<BR>\n");
printf(" Please type in the name "
"of the function\n");
printf(" whose prototype you"
" wish to see.\n");
printf(" </FONT>\n" };
printf(" <BR><BR>\n");
printf(" <INPUT TYPE=\"text\" NAME="
"\"function\" SIZE=\"20\">\n");
printf(" <BR><BR>\n");
printf(" <INPUT TYPE=\"submit\">\n");
printf(" </CENTER>\n");
printf(" </FORM>\n");
printf(" </BODY>\n");
printf("</HTML>\n");
Листинг 23.5. Функция mainQ — точка входа нашего CGI-приложения.
int main(void)
{
CGILIST *List = NULL;
char *CopyOfQueryString = NULL;
int ErrorCode = 0;
/* Следующая строка обязательна согласно требованиям протокола HTTP. Она не будет появляться
на вамей HTML-странице.
*/
printf("Content-Type: text/html\n\n");
CopyOfQuerystring = ReadCGIData(&ErrorCode);
if(NULL == CopyOfQueryString)
{
switch(ErrorCode)
{
case CGINULLREQMETHOD:
printf("No CGI request method "
"could be identified.\n");
break;
case CGIUNKNOWNMETHOD:
printf("Unsupported CGI request method.\n");
break;
case CGINOQUERYSTRING:
printf("No CGI query string found.\n");
break;
case CGINOMEMORY:
printf("Memory allocation failure.\n");
break;
case CGIBADCONTENTLENGTB:
printf("Missing or invalid CONTENT_LENGTH.\n");
break;
case CGINODATA:
printf("No CGI input data could be found.\n");
break;
default:
619
Написание CGI-приложений на С
Глава 23
printf("Unknown CGI Error.\n");
break;
}
/* Мы не можем продолжать, поэтому выходим. */
return EXITFAILURE;
}
List = CGICreateList(CopyOfQueryString);
/* Сработало это или нет, у нас больме нет необходимости в CopyOfQuerystring, поэтому
освобождаем ее.
*/
free(CopyOfQueryString);
if(NULL == List)
{
printf("Can't parse CGI data.Xn");
return EXITFAILURE;
}
/***************************
* *
* Здесь вызывается ваме *
* CGI-приложение! *
* *
***************************/
Арр(List);
/* Не забываем очистить память */
CGIDestroyList(List);
return 0;
Приведенный код находится на Web-сайте издатель-
ства "ДиаСофт" в файле proto.c.
Вы, наверное, думаете: в чем же загвоздка? Все ка-
жется слишком простым. Поверьте, никакой загвоздки
нет, все действительно очень просто. Вспомогательный
код уже написан, и для написания CGI-приложения
вам требуется только заменить функцию Арр() своей
собственной функцией.
На рисунках 23.2 и 23.3 показано наше CGI-прило-
жение в работе.
Рис. 23.2 демонстрирует, как отображается HTML-
форма и каким образом она запрашивает данные.
На рис. 23.3 представлены результаты работы CGI-
приложения, выводимые браузером Internet Explorer.
Вопросы безопасности
При написании CGI-программ необходимо рассмотреть
несколько вопросов, касающихся безопасности. Вообще,
в самом CGI-процессе нет "дыр", которые можно было
бы использовать. Большинство проблем возникает
вследствие плохого программирования.
Запуск внешних процессов
CGI-процесс имеет тот же идентификатор ID процес-
са, что и Web-сервер. Это могло бы привести к некото-
рым компромиссам, касающимся уровня безопасности,
если бы конечный пользователь имел возможность да-
вать команды нашему серверу.
Давайте рассмотрим конкретный пример. У нас есть
форма, которая работает в качестве ping-сервера. Ее
единственная задача — получить из HTTP-формы адрес
хоста или IP-адрес и попытаться проверить доступность
адресата, выдавая при этом результаты на экран.
<FORM METHOD=”POST” ACTION=" /cgi-bin/ping. cgi”>
<INPUT TYPE=TEXT NAME=host>
</FORM>
Теперь предположим, мы разбираем строку запроса
и извлекаем данные, которые соответствуют данным,
введенным в HTML-форму, и присваиваем их перемен-
ной char *name. Что для этого нужно сделать?
char cmd[250]s{0};
sprintf(end, "/bin/ping -c4 %s", name);
system(emd);
Дополнительные тематические разделы
620
Часть III
Это то, что нам нужно, и выглядит довольно обосно-
ванно, но, увы, пользователь слишком хитер. Что слу-
чится, если он введет в форму следующую строку:
"www. mcp. com; cat%20/etc/passwd"
Данная строка будет запущена с помощью команды
system() как ping -с4 127.0.0.1 ;cat /etc/passwd.
(шестнадцатиричное число %20 соответствует в ASCII
пробелу.)
Допустим, что данный сервер работает под управле-
нием UNIX. В UNIX символ заставляет оболочку за-
пускать следующую команду, а следующая команда в
нашем случае отправит уязвимые данные назад через
Web-браузер.
Наша CGI-программа может выполнять любую ко-
манду, которую даст владелец сервера, создавая таким
образом угрозу для безопасности.
Совершенно ясно, что вряд ли вам придется писать
ping-сервер. Тем не менее, написание серверов даты и
времени — вполне обычное дело, и для получения даты
и времени можно пользоваться не только функциями
time() и localtime(), но и system(). А некоторые CGI-
программы для отправки своих выходных данных по
электронной почте вызывают функцию sendmail. И если
system() используется непродуманно, то именно в таком
месте и открывается брешь в безопасности.
Исходный HTML-код не является секретом
Почти любой браузер позволяет пользователю просмот-
реть наш HTML-код и/или сохранить его в файле. Эта
информация может быть полезна для взломщика в его
попытках нарушить нашу безопасность. Давайте
возьмем обычное CGI-приложение, выполняющее от-
правку электронной почты Web-мастеру.
<INPUT TYPE=HIDDEN NAME=sendto
wVALUE=webmaster @mcp. com>
Какие данные мы раскрываем в данной строке? Во-
первых, выходные данные будут переданы по адресу
webmaster@mcp.com. А во-вторых, пользователь может
изменить указанный адрес. Это относится ко всему на-
шему HTML-коду. Взломщик может сохранить наш
HTML-документ на своем локальном диске и отредак-
тировать его. Теперь код будет содержать значение
VALUE=me@badsite.com, Когда он запустит данный
код, то передаст новые данные CGI-приложению и
электронная почта пойдет по адресу, который указал
взломщик. Даже если это не приносит больше никако-
го вреда, тем не менее, мы только что потенциально
открыли ворота для рассылки электронной рекламы.
Теперь рассмотрим другую возможность. Предполо-
жим, мы пишем на CGI базу данных и наша HTML-
страница содержит имена базы данных и таблицы, к
которым необходимо обращаться. Можно даже указать
имя учетной записи и пароль, которые используются для
соединения с базой данных. Предположим, мы пошли
таким путем:
<INPUT TYPE=HIDDEN NAME-db VALUE=2000ql>
<INPUT TYPE=HIDDEN NAME=table VALUE=sales>
На самом деле это довольно обычный подход. Мы
указали имя базы данных и имя таблицы — данные,
которые должны храниться в секрете. Это дает взлом-
щикам (любопытным, вредным или злонамеренным)
возможность использовать тактику грубой силы для
получения доступа к базе данных. Что случится, если
они сохранят HTML-код, отредактируют его и попро-
буют произвести поиск со следующими значениями
<INPUT TYPE=HIDDEN NAME=db VALUE=2000q2>
или co значениями текущего года и квартала? Получат
ли они доступ к еще не открытым данным? Все зави-
Написание CGl-приложенийна С
Глава 23
621
сит от вашей реализации, но вполне возможно, что по-
лучат. Это и является одной из возможностей взлома,
на которую следует обратить внимание в первую оче-
редь.
Как же можно обеспечить безопасность CGI-прило-
жений?
На самом деле все довольно просто. Всегда считай-
те, что каждый блок данных содержит ошибки или даже
является атакой на ваш сервер. Поэтому всегда все про-
веряйте.
Не используйте метод GET для отправки данных на
сервер, пока не будете вполне убеждены в том, что пе-
редаваемая информация не нарушает безопасности.
Помните, что вся строка запроса QYERYJSTRING бу-
дет выводится в адресной URL-строке браузера клиен-
та, и если подглядывание через плечо может принести
вред вашему CGI-приложению, то для отправки данных
используйте метод POST.
Всегда следите за тем, какие данные раскрываете в
своем HTML-коде. Имейте в виду, что даже скрытые
значения могут быть изменены и использованы против
вас.
Для кодировки уязвимых данных используйте про-
токол защищенных сокетов (Secure Sockets Layer, SSL)
или протокол защищенной передачи гипертекстов
(Secure HTTP, SHTTP).
Рассматривайте все так, как если бы это был откры-
тый код. Любой вызов системного приложения необхо-
димо проверять, чтобы убедиться, что он не несет по-
тенциальной опасности. Не думайте, что ваш код
является секретом только потому, что его будет видеть
только персонал вашей компании. Внутренние взлом-
щики — вполне обычное дело в компьютерном бизне-
се. Сможет ли ваша компания выдержать направленную
атаку взломщика, вооруженного внутренними данными,
полученными от обиженного (или бывшего) работника
вашей компании.
Давайте будем осторожными.
Резюме
В этой главе рассмотрено программирование в среде
единого шлюзового интерфейса (CGI). Детально описан
процесс создания динамических Web-страниц с исполь-
зованием стандартных языков программирования
HTML и С. Предоставлены утилиты, которые можно
использовать во всех CGI-приложениях. Приведен при-
мер приложения, и его работоспособность проверена на
Web-сервере. Кроме того, подробно рассмотрены потен-
циальные возможности нарушения безопасности, свя-
занные с программированием CGI-приложений, и пред-
ложены методы предотвращения неправильного
использования технологии CGI.
Арифметика произвольной
точности
В ЭТОЙ ГЛАВЕ
Распространение ошибок при выполнении арифметических операций
Переполнение, потеря значимости и деление на нуль
Порядок выполнения операций
Размеры целых чисел
Размеры чисел с плавающей точкой
Никогда не делайте предположений относительно среды выполнения кода
Примеры высокой и низкой точности
Различные методы представления сверхвысокой точности
Пример кода для действий над строкой символов
Дробные числа
Общие арифметические функции
Использование стандартных типов
Выбор представления сверхточных чисел
Вычисление числа е с точностью до десяти тысяч знаков после точки
Ян Келли
Доктор Джонсон спросил одну женщину, сколько ей
лет. После того как она сказала, что ей двадцать пять с
четвертью, он заметил, что ответ был очень точным,
хотя в его точности можно было усомниться, но в лю-
бом случае такая точность не имеет практически ника-
кого значения. При вычислениях вы имеете дело с под-
держанием определенной точности (количество цифр
после точки) с известной вероятностью (того, что эти
цифры верны).
В этой главе рассказывается, каким образом можно
определить точность полученных результатов вычисле-
ний и как написать код для проведения вычислений с
очень высокой точностью. Для этого необходимо знать
причины возникновения арифметических ошибок и то,
как избежать этих ошибок. Кроме того, в данной главе
приведены примеры кода, которые иллюстрируют не-
сколько различных способов представления чрезвычай-
но точных значений (до 10000 цифр после точки) и
проведения простых арифметических операций над та-
кими числами. И наконец, предлагаются советы по ис-
пользованию каждого из этих способов в зависимости
от конкретной ситуации.
Математики имеют привычку давать некоторым
странным числам имена, например, пи, гамма, алеф-
нуль, или С-нуль. Есть такое число, которое математи-
ки называют е. На рис. 24.1 показано, как оно вычис-
ляется (не пугайтесь этой формулы).
РИСУНОК 24.1
Иррациональное число.
Формулу с рис. 24.1 можно также представить в та-
ком виде:
1+1/1!+1/2!+1/3!+1/4!+1/51+1/6!+...
или, что то же самое,
1 +1/1+ 1/( 1*2)+1/(1 *2*3)+1/(1 *2*3*4)+
1 /(1 *2*3*4*5)+1 /(1 *2*3*4*5*6)+...
а приближенное значение е составляет 2.718.
Число е — это иррациональное число, поскольку нет
таких двух целых чисел а и Ь, для которых е=а/Ь, т.е.
его нельзя представить в виде отношения. Прочитав эту
главу, вы, может быть, придете к выводу, что сами ма-
тематики, которые думают о таких вещах, тоже ирра-
циональны. Иррациональное желание автора состоит в
том, чтобы увидеть, как выглядят первые десять тысяч
знаков после точки числа е. В листинге 24.1 приведена
короткая программа, которая вычисляет и выводит на
экран значение числа е.
Арифметика произвольной точности
Глава 24
623
Листинг 24.1. Вычисление значения числа е.
linclude <stdio.h>
int nainfint argc, char * argv[])
{
double dResult;
double dWork;
int i;
dResult = 1.0;
dWork - 1.0;
for (i=l;(i<20);i++)
{
dWork /= i;
dResult += dWork;
}
printf("e = %f\n",dResult);
return 0;
}
Программа в листинге 24.1 (и на Web-сайте издатель-
ства "ДиаСофт” в файле СН24е.с) при запуске ее с
Microsoft MSVC 4.2 под управлением Windows NT дает
результат 2.718282. После нескольких простых изменений
в формате команды printf, заменив %f на %32.20f, та же
программа в той же вычислительной среде дает результат
2.71828182845904550000 (или 2.71828182845904553500
для более поздней версии того же компилятора). Но на-
сколько этот результат верен?
Увы, к сожалению, этот результат «вверен. Он до-
вольно точен, но только до 15 цифр после точки, что
очень далеко от заветных десяти тысяч. Все те нули в
конце полученного результата абсолютно неинформа-
тивны. Даже если изменить тип переменных dWork и
dResult с double на long double, нельзя получить боль-
шей точности (в данной среде). Почему так происхо-
дит?
Распространение ошибок при
выполнении арифметических
операций
Следует иметь представление о некоторых возможных
источниках ошибок, возникающих в арифметических
операциях. Их очень много. Необходимо также учиты-
вать ограничения, которые накладываются способом
представления чисел в компьютере, и влияние арифме-
тических операций на точность результата. Кроме того,
нужно учитывать скорость, пределы изменения резуль-
тата, точность и безопасность.
Ошибки сложения и вычитания
Конечно, сложение и вычитание являются довольно
точными операциями. Для целых чисел вышесказанное
почти правда, но не совсем, поскольку, например, при
сложении очень больших чисел получаемый результат
не может быть представлен типом int или long int. А для
нецелых чисел это совсем неправда, поскольку суще-
ствует ограничение на точность представления в ком-
пьютере чисел с плавающей точкой. Поэтому последние
несколько битов результата можно поставить под со-
мнение.
Но сколько битов являются сомнительными? Если
у вас есть два числа А и В и вы хотите получить значе-
ние А + В, то необходимо иметь ввиду, что число А в
компьютере представляется в виде А ± а, где а — ошиб-
ка числа Д а В представляется в виде В ± Ь, где b —
ошибка числа В. В результате сложения получается ре-
зультат А + В ± (а + Ь), следовательно, при сложении
ошибки складываются.
Ошибки могут быть как положительными, так и от-
рицательными. Поскольку они являются ошибками, то
мы не знаем, завышено наше представление или зани-
жено. Известно только то, что представленные числа
находятся в определенном диапазоне и ширина этого
диапазона определяется величиной ошибки. Следова-
тельно, если А' — компьютерное представление числа А,
то мы знаем, что число А находится где-то в диапазоне
(А'-а/2, А'+ а/2).
Та же формула точности вычислений справедлива и
для вычитания. Если нужно вычислить значение А - В,
то в действительности мы получим А - В ± (а + Ь). Да,
ошибки складываются и в данном случае. Даже если
одно из исходных чисел является абсолютно точным,
вы все равно в результате получите ошибку из-за неточ-
ности другого числа.
В приведенном примере вычисления числа е каждое
последовательное сложение'значений переменной
dWork для получения результата dResult несколько уве-
личивает общую ошибку результата.
Если аппаратное обеспечение вашего компьютера не
совсем совершенно, то существует еще и вероятность
того, что последний бит или несколько последних би-
тов результата в некоторых случаях будут просто оши-
бочными. Это может дать достаточно большую общую
ошибку. Если вы думаете, что этого не случится, заме-
чу, что в своей книге The Standard С Library Плогер (P.J.
Plaugcr) указывает, что на некоторых компьютерах Cray
при выполнении простой операции сложения чисел с
плавающей точкой теряются четыре последних бита. На
IBM System 390 при каждой операции сложения чисел
с плавающей точкой можно потерять до трех битов.
Ошибка умножения
Умножение еще больше влияет на точность вычислений,
чем сложение или вычитание Если вы хотите вычис-
лить А*В, то в действительности вычисляете
624
Дополнительные тематические разделы
Часть III
(А ± а)*(В± Ь) и получаете А*В ±(А*Ь + В*а + а*Ь). Это
выглядит крайне непривлекательно! Но что это значит?
В качестве примера представьте себе, что значение
А равно 5.3, но имеет ошибку ±1.0x1024, а значение В
равно 6.9 и имеет немного большую ошибку ±2.0х10-24
Мы получим результат 36.57 ± (5.3*2.0*10 24+6.9*1.0*10‘24+
+1.0*2.0*10'24*10"24). Последнее произведение этого вы-
ражения можно не учитывать ввиду его малости —
2.0*10-48. Это сводит ошибку вычисления к 17.5*1 О'24.
Данное значение намного больше ошибок исходных
чисел. И, как и в предыдущем случае, даже если одно
из исходных чисел является абсолютно точным, вы все
равно в результате получите ошибку из-за неточности
другого числа, только на этот раз ошибка получится
гораздо больше.
Ошибка деления
Ошибка при делении возникает примерно так же, как
и при умножении. Так, если вы хотите вычислить А/В,
то получите результат (A/В) ± 5, где ошибка ±5, по
крайней мере, не меньше значения (А*Ь + В*а). Точная
формула для вычисления ошибки деления даже длин-
нее формулы вычисления ошибки умножения. Более
подробный анализ этой ошибки можно найти в книге
The Art of Computer Programming Дональда Кнута (Donald
Knuth), том 2, глава 4.
Следовательно, если выполняется сложение, вычи-
тание, умножение или деление двух чисел, которые
представляются с некоторыми ошибками, то и резуль-
тат будет содержать ошибку, которая может быть на-
много больше ошибок исходных чисел. Если вам пове-
зет, ошибка может оказаться меньше. Но при написании
кода не надейтесь на удачу, всегда нужно предполагать,
что ошибка возрастает.
Может быть, вы считаете, что числа, с которыми вы
имеете дело, не содержат никакой ошибки. Но в дей-
ствительности существует лишь небольшое количество
таких нецелых чисел, которые компьютер может пред-
ставить без ошибки. Числа 1/2, 1/4, 1/8, 1/16 и т.д. по-
падают в их список. Но 1/3, 1/5, 1%, 5/7 — практичес-
кие все числа, с которыми приходится иметь дело, —
могут быть только приближенно представлены в виде
числа с плавающей точкой.
Выводы по размерам ошибок
Если над двумя значениями (а ± е) и (b ±f), где е и /—
ошибки значений а и Ъ, выполняется арифметическая
операция, то минимальную ошибку результата можно
вычислить по формулам, представленным в табл. 24.1.
Таблица 24.1. Ошибки арифметических опера-
ций
Операция Ошибка операции
+ тах(е + f, rep)
тах(е + f, rep)
* тах((е * v) + (f * a), rep)
I тах((е * f) + (f * a), rep)
В табл. 24.1 rep — точность типа результата или про-
межуточного типа, который использовался для получе-
ния результата, в зависимости от того, точность какого
типа ниже (больше ошибка). Ошибка, получаемая в
результате выполнения любой арифметической опера-
ции, всегда больше ошибок исходных чисел.
Переполнение, потеря значимости и
деление на нуль
Есть ошибки, существование которых заложено в самих
арифметических операциях. Кроме того, есть ошибки,
причиной которых является диапазон чисел, которые
могут быть представлены внутри компьютера. Суще-
ствуют минимальное и максимальное числа, которые
могут быть представлены. Что означают максимальное
и минимальное числа в данном контексте?
Максимальное число — это наибольшее положитель-
ное число, которое может быть представлено в компь-
ютере, т.е. число, наиболее удаленное от нуля в поло-
жительную сторону. Существует также наибольшее по
модулю отрицательное число, т.е. максимальное отри-
цательное (минимальное) число, которое можно пред-
ставить, или число, наиболее удаленное от нуля в от-
рицательную сторону. Если при вычислениях результат
выходит за диапазон максимальных чисел, будет полу-
чена ошибка переполнения.
Минимальное число — это наименьшая величина,
которая может быть представлена, т.е. величина, очень
близкая к нулю, но не равная нулю. Если результат
вычислений находится ближе к нулю, чем минималь-
ное число (как положительное, так и отрицательное),
будет получена ошибка потери значимости. При вычис-
лении числа е с точностью до десяти тысяч знаков пос-
ле точки, мы наверняка выйдем за границу потери зна-
чимости.
Некоторые арифметические операции дают резуль-
тат, который не имеет никакого смысла. Если поделить
число на очень маленькую величину, результат будет
очень большим. Поделив очень большое число на очень
маленькое, можно получить ошибку переполнения.
Если поделить любое число на нуль, результат невоз-
можно будет представить ни в одной системе исчисле-
ния — попытка представить бесконечность ни к чему
Арифметика произвольной точности
Глава 24
625
не приведет, и будет получена ошибка деления на нуль.
Математикам, наверное, интересно узнать, как называ-
ется такая бесконечность: алеф-нуль или С-нуль. Всем
же остальным будет интересно знать, как заставить ком-
пьютеры выдавать правильные результаты.
Порядок выполнения операций
В абстрактной математике не имеет значения, в какой
последовательности выполнять вычисления — резуль-
тат будет одним и тем же. Так, например, A-B+C-D+E-
Г всегда равно A+C+E-B-D-F и всегда равно (А+С+Е)-
(B+D+F), а (А*В)/С всегда равно (А/С)*В. Но порядок
выполнения вычислений на компьютере имеет значение —
мы помним, что каждая арифметическая операция по-
своему влияет на точность получаемого результата, и
один порядок вычислений может привести к потере
значимости или существенному увеличению пропорци-
ональной ошибки, в то время как другой не приведет к
этому.
Например, рассмотрим вычисление по формуле А-
В+С, причем мы знаем, что А и В всегда близки по ве-
личине. Это означает, что вычитание В из А даст вели-
чину, малую по сравнению с А и В, и, следовательно,
пропорциональная ошибка полученного результата бу-
дет значительно больше ошибок исходных величин.
Поэтому, если мы будем производить вычисление по
формуле (A-BJ+C, то будем складывать величину (А-В),
имеющую большую ошибку, с величиной С. Если бы
вычисления производились по формуле (А+С)-В, то
операция вычитания производилась бы над числами,
более удаленными друг от друга, чем в первом случае,
и, следовательно, пропорциональная ошибка была бы
не такой большой.
В качестве еще одного примера рассмотрим форму-
лу A-B+C-D+E-F, в которой А и В очень близки по ве-
личине, а С и D, а также Ей F просто близки по вели-
чине. Увеличение пропорциональной ошибки будет
справедливо для каждой из трех пар. Поэтому, если
проводить вычисления по формуле (A-B)+(C-D)+(E-F),
пропорциональная ошибка возрастет за счет всех трех
пар. Однако если порядок сделать следующим:
(A+C+E)-(B+D+F), то неизбежное увеличение ошибки
происходит только один раз.
Для умножения и деления лучше сначала выполнять
операцию умножения, а только потом деление, посколь-
ку в таком случае возникающая ошибка будет меньше,
т.е. используйте формулу (А *В)/С\ а не (А/С) *В.
Размеры целых чисел
В С имеется несколько типов, которые предназначены
для хранения целых чисел: char, short int, int и long int.
Стандарт С четко не устанавливает, сколько битов дол-
жен содержать каждый из этих типов, но он устанавли-
вает некоторое минимальное их количество. Так, тип
char должен содержать, по крайней мере, 8 битов. Тип
short int должен быть не короче, чем char, и иметь ми-
нимум 16 битов, int должен быть не короче, чем short
int, и, как и short int, иметь минимум 16 битов, long int
должен быть не короче, чем int, и иметь, по крайней
мере, 32 бита. Он может быть длиннее, но стандарт не
говорит, что он должен быть длиннее.
Еще один не указанный в стандарте момент — ка-
кому типу соответствует тип char: unsigned char или
signed char. Он может соответствовать как одному, так
и другому. Тем не менее, стандарт указывает, что тип
int соответствует типу signed int, а тип long int — типу
signed long int. Если вы все же хотите, чтобы тип char
соответствовал типу signed char, объявите его как signed
char. Аналогично, если нужно, чтобы тип char соответ-
ствовал типу unsigned char, объявите его как unsigned
char.
Как правило, вы обнаружите, что длина типа char
составляет 8 битов, типа short int — 16 битов, а типа
long int — 32 бита, но полагаться на это не следует. Если
автор компилятора пожелает, чтобы длина типа char
была равна 11 битам, а типов short int, int и long int —
по 67 битов, то это будет точно соответствовать всем
требованиям стандарта С. Но все же, скоре всего, ока-
жется, что длина char составляет 16 битов, short int и
int — 32 бита, a long int — 64 бита. На компьютерах Cray
тип char имеет длину 8 битов, типы short int, int и long
int — по 64 бита.
Количество битов определяет максимальное значе-
ние (наиболее удаленное от нуля), которое может со-
держаться в данном типе. Для 8-, 16- и 32-битовых це-
лых чисел без знака эти значения равны 255, 65535 и
424967295 соответственно, для 8-, 16- и 32-битовых
целых чисел со знаком положительные значения равны
127, 32767 и 2147483647, а 64 бита дают впечатляющее
значение 9223372036854775807; отрицательные значе-
ния равны -128, -32768 и -2147483648 и, конечно же,
-9223372036854775808.
Отрицательные числа могут быть не равны приведен-
ным, они могут быть такими же, как положительные
числа, но со знаком минус. Это зависит от того, в ка-
ком виде они представлены: в виде дополнения до двух
(обычная форма) или в виде дополнения до единицы (в
настоящее время используется редко, но, тем не менее,
возможно и такое представление).
Примеры обоих вариантов представления чисел при-
ведены в табл. 24.2.
40 Зак. 265
626
Дополнительные тематические разделы
Часть III
Таблица 24.2. Представление отрицательных чисел в виде дополнения до единицы ulb виде
дополнения до двух.
Рассмотрим десятичное число +105, которое в 8-битовом двоичном представлении (как правило, signed char) равно
01101001, и представим число -105:
Дополнение до единицы Дополнение до двух
Правило для получения отрицательных чисел: Правило для получения отрицательных чисел: “Поменяйте значения битов на противоположное”, “Поменяйте значения битов на противоположное и таким образом, 01101001 становится 10010110 добавьте единицу”, таким образом, 01101001 сначала становится 10010110 и после добавления единицы получим 10010111 Рассмотрим десятичное число 1, которое в 8-битовом двоичном представлении равно 00000001: Дополнение до единицы Дополнение до двух
-1 соответствует 11111110 -1 соответствует 11111111 Рассмотрим число 0, которое в 8-битовом двоичном представлении равно 00000000: Дополнение до единицы Дополнение до двух
-0 соответствует 11111111, т.е. существует как +0, так и -0 Меняем значения битов на противоположное, получаем 11111111 и добавляем единицу, получаем 00000000 (переход в следующий разряд игнорируется), т.е. -0 и +0 представлены одним и тем же числом
Одним из последствий использования представления
в виде дополнения до единицы является то, что суще-
ствуют как положительный нуль, так и отрицательный,
которые имеют различное представление. При дополне-
нии до единицы наиболее удаленное от нуля отрица-
тельное число имеет ту же величину (но противополож-
ного знака), что и наиболее удаленное от нуля
положительное число. Таким образом, для 8-битовых
целых чисел без знака пределы изменения равны -127
и +127. Еще одним недостатком является то, что по
последнему биту нельзя определить, какое это число:
четное или нечетное.
Представление в виде дополнения до двух дает толь-
ко один нуль (что более соответствует реальности).
Кроме того, оно позволяет представлять отрицательное
число, большее по величине, чем положительное чис-
ло, при одном и том же количестве битов. Таким обра-
зом, для 8-битовых целых чисел без знака пределы из-
менения равны -128 и +127.
Точность операций над целыми числами
Целые числа — это удобные числа. Они начинаются с
нуля и идут в положительную и отрицательную сторо-
ны с шагом, равным единице. Любая операция над це-
лыми числами, если ее результат не вызывает ошибки
переполнения, абсолютно точна. Вот и все.
Хотя нет, не все.
Если никакая часть из серии операций, включаю-
щих сложение, вычитание и умножение, не вызывает
ошибки переполнения, то все в порядке. Но если в се-
рии операций есть деление, будьте осторожны.
Числа 2 и 3 являются целыми, но 2, деленное на 3
(2/3), не является целым числом. Кроме того, так уж
получается, что ответ нельзя точно представить в дво-
ичном представлении, поэтому только само представле-
ние такого числа в компьютере уже вносит некоторую
ошибку. Таким образом, что же можно сказать о коде,
приведенном в листинге 24.2 (и на Web-сайте издатель-
ства "ДиаСофт” в файле Ch24inti.c), в котором деление
числа 2 на число 3 производится несколькими различ-
ными способами?
Листинг 24.2. Деление целых чисел.
linclude <stdio.h>
int main (int argc, char * argv[])
{
int iTwo = 2;
int iThree « 3;
int iA;
double dB;
double dC;
double dD;
iA = iTwo / iThree;
dB = iTwo / iThree;
dC = (double) iTwo / iThree;
dD = (double) (iTwo / iThree);
printf("ia = %d dB=%f dC=%f
dD-%f\n",iA,dB,dC,dD);
return 0;
}
Арифметика произвольной точности
Глава 24
627
Поскольку целая часть результата деления равна
нулю, неудивительно, что и значение iA равно нулю. Но
все ли остальные значения будут равны 0.6666667?
Для получения значения 0.666666... необходимо
сделать некоторые преобразования, т.е. метод представ-
ления чисел необходимо изменить с типа int (целое
число) на тип double (число с плавающей точкой). В
языке С определены несколько правил преобразования
типов, кроме того, некоторые свои правила может иметь
и компилятор. Точные правила преобразования типов
приведены в книге The С Programming Language (K&R).
Эти правила сводятся к следующим действиям:
Если один из операндов имеет тип long double, пре-
образовать другой операнд в тип long double.
Если один из операндов имеет тип double, преобра-
зовать другой операнд в тип double.
Если один из операндов имеет тип float, преобразо-
вать другой операнд в тип float.
В противном случае...
(Более подробно эти правила рассмотрены в указан-
ной книге K&R.)
Подобные правила преобразования типов при вы-
полнении арифметических операций зависят от самого
вычисляемого выражения. В программе примера, при-
веденного в листинге 24.2, эти правила могут быть не-
сколько иными в зависимости от расстановки скобок и
от того, включает ли компилятор в рассмотрение левую
часть в операции присвоения при определении границ
выражения. В случае компилятора MSVC Release 4.2
под управлением Windows NT 4.0 приведенная програм-
ма давала следующие результаты:
1А=0 dB=0.000000 dC=0.666667 dD=0.000000
Результаты работы программы показывают, что если
в процессе вычислений результат приводился к типу int,
то деление числа 2 на 3 дает 0. Следовательно, рассмат-
ривая выражения
1A=xTwo/xThxee;
И
хВ=хТwo/xThxee;
можно увидеть, что в правой части выражения содер-
жатся только значения типа int. Поэтому оно вычисля-
ется как int, давая нуль, а затем это целое значение пре-
образуется в тип, которому принадлежит переменная
результата. Даже несмотря на то что переменная dB в
этом примере имеет тип double, ответом все равно бу-
дет нуль.
Выражение
dC= (double) xTwo/xThxee;
в правой части имеет одну переменную типа int и одну
переменную типа double. Приведение (double) позволя-
ет преобразовать значение переменной iTwo в тип double
до выполнения операции деления. Поэтому результатом
этого выражения является 0.666667.
Но как объяснить то, что выражение
dD= (double) (xTwo/xThree) ;
тоже дает в ответе нуль? Мы же преобразовали его к
типу double?
Да, мы его привели к double, но фактически был
преобразован тип самого результата, т.е. тип выражения
в скобках. Это выражение, которое содержит только
значения типа int, преобразуется в тип double после вы-
полнения операции деления. Но, как видно из получа-
емого ответа, это уже слишком поздно: операция деле-
ния над целыми числами дает целое число нуль,
который потом преобразуется в тип double и присваи-
вается левой части выражения.
Преобразования типов long и int
Язык программирования С позволяет присваивать зна-
чения переменных типа int переменным типа long int.
Такое присвоение является вполне обычным и не дол-
жно вызывать никаких ошибок. Но, кроме того, С по-
зволяет присваивать значения переменных типа long int
переменным типа int, а такое присвоение может вызвать
некоторые ошибки. Хороший компилятор предупреж-
дает о возможности возникновения ошибок при выпол-
нении такого присвоения, поэтому обращайте внимание
на все предупреждения.
Размеры чисел с плавающей точкой
Для представления нецелых чисел в компьютерах ис-
пользуется формат, который известен как формат с пла-
вающей точкой. Аппаратные средства вычислительных
машин будут поддерживать один или несколько разме-
ров чисел с плавающей точкой, которые могут варьиро-
ваться от 16 битов (возможен, но применяется редко),
32 бита (встречается наиболее часто), 64 бита (исполь-
зуется все чаще), 128 битов и т.д. На некоторых компь-
ютерах размер чисел с плавающей точкой может соот-
ветствовать некоторому промежуточному значению,
например, 80 или 96 битов.
Представление чисел с плавающей точкой
В компьютере число с плавающей точкой представля-
ется в виде двух или трех полей:
• знак (который не всегда присутствует)
• экспонента (которую иногда называют характерис-
тикой)
• значение (которое иногда называют мантиссой)
628]
Дополнительные тематические разделы
Часть III
Мантиссу можно считать дробной частью, представ-
ленной в двоичном виде. Самый значащий бит имеет
значение 2 *, или 1/2, следующий бит — 22, или 1/4, и
т.д. Экспонента представляет собой степень основания Ь,
на которую необходимо умножить мантиссу, чтобы
получить требуемое значение. Если с — значение харак-
теристики (которая является целым числом), а т —
значение мантиссы (которая всегда меньше единицы),
то значение числа с плавающей точкой равно m*tf.
Ну и что это значит? Предположим, что в данном
примере основание равно 16. Именно такое значение
выбрали инженеры при разработке компьютера, и вы не
можете изменить это число. Следовательно, в рассмат-
риваемом случае значение числа с плавающей точкой
будет равно /л*/#, т.е. число 112.0 будет представлено
в виде двоичной дробной части .11100000 и экспонен-
ты 2, поскольку 112.0=(7/16)*162. Число 112.25 будет
представлено в виде двоичной дробной части (мантис-
сы) .11101000 и экспоненты 2.
Основание числа с плавающей точкой может быть
равно 2, 8 или 16. Если вы пользуетесь IBM 390, то
основание равно 16. Если вы используете процессор
типа Intel х86, то основание равно 2. То, что основание
соответствует степени числа 2, теоретически никак не
обосновано и всегда выбирается таковым исключитель-
но по соображениям практичности. Если вы эксперт по
разработке аппаратного компьютерного обеспечения, то
можете ради развлечения заложить основание 37, даже
если таким основанием никто не будет пользоваться.
Если значения трех полей — знака, экспоненты и са-
мой величины — являются положительными целыми чис-
лами s, е и v соответственно, то выражаемое ими число с
плавающей точкой будет представлено в форме:
(-l)s* b(eM>* O.v или (-l)s* b<e*M)* l.v
где М — значение, выражаемое самым значимым битом
поля экспоненты, а b —основание экспоненты. Следо-
вательно, для IBM число с плавающей точкой представ-
ляется в виде:
(-l)s* 16(е 64)* O.v
а стандартный формат IEEE (стандарт Института ин-
женеров по электротехнике и электронике):
(-l)s* 2<е,28>* l.v
Максимальная точность
Каждая часть представления числа с плавающей точкой
имеет свою длину, т.е. определенное количество битов,
составляющих соответствующее поле. Число битов в
поле мантиссы определяет, насколько точно можно
представить число. Количество битов в поле характери-
стики (экспоненты) определяет ширину диапазона
представляемых чисел.
Олин из форматов чисел с плавающей точкой в IBM
System 390 (и аналогичных вычислительных машинах)
состоит из 1 бита на поле знака, 7 битов на поле экспо-
ненты и 24 битов на поле мантиссы. Основание числа
с плавающей точкой составляет 16, что означает, что вы
можете гарантировать точность только 21 бита из 24
(этот момент будет рассмотрен в следующем разделе
"Нормализация"). Поэтому максимальная точность
представляемых чисел будет единица, деленная на 221,
т.е. на число, чуть превышающее два миллиона.
7 битов поля экспоненты (характеристики) интер-
претируются как 8-битовое число со знаком, поэтому
диапазон экспоненты составляет от -64 до +63. Это дает
числа от минимального 16 64 до максимального 16+63, или
приблизительно от 8.6x10 78 до 7.2х10+75. Поскольку
мантисса может иметь любое дробное значение почти
от 1 до 1/16, то минимальное число составляет в дей-
ствител ьности 5.4х 10’79.
Если формат имеет больше битов в каждом поле, то
можно получить более высокую степень точности (при
большем количестве битов в мантиссе) и шире диапа-
зон представляемых чисел (при большем количестве
битов в характеристике).
С ошибкой переполнения мы впервые столкнулись
при рассмотрении целых чисел. Для чисел с плавающей
точкой ошибка переполнения возникает при попытке
представить число, которое больше по величине, чем
максимальная экспонента, которую можно представить.
В случае с форматом IBM System 390 переполнение
возникает при попытке представить значение, которое
по величине превышает плюс-минус 7.2х10+78.
Теперь можно рассмотреть новый тип ошибки —
ошибки потери значимости. Она возникает, если мы
пытаемся представить число, которое находится ближе
к нулю, чем минимальная экспонента, которую можно
представить. На IBM System 390 потерю значимости
вызывает число, которое по величине меньше числа
плюс-минус 5.4x10'79. Такого типа ошибки нет в цело-
численной арифметике: числа, ближайшие к нулю, —
это +1 и -1, которые легко представить.
В арифметике чисел с плавающей точкой есть еще
один тип ошибок, которого нет в целочисленной ариф-
метике, — потеря точности. Неважно, что мы делаем, но
если числа, над которыми мы производим арифметичес-
кие операции, имеют мантиссу длиной 24 бита, точность
не может быть выше, чем 1, деленная на 2+2\ а на прак-
тике, возможно, и того хуже — 1, деленная на 2+21.
В рассматриваемом примере вычисления числа е с
точностью до десяти тысяч знаков после точки нам на-
верняка придется иметь дело с дробными числами, на-
ходящимися ближе к нулю, чем числа, которые могут
быть представлены с помощью экспоненты длиной 7,
63 или даже 1023 бита. Мы определенно получим
629
ошибку потери значимости (если длина нашей экспо-
ненты меньше 32 тыс. битов) и потерю точности (если
длина экспоненты меньше 32 тыс. битов).
Нормализация
Число 0.001953125 (или 1/512) может быть представле-
но несколькими способами:
16 2х1/2
16 >х1/32
16°х1/512
16^x1/8192
и Т.Д.
Из всех этих представлений первым приведено пред-
ставление, в котором мантисса максимальна. Если по-
смотреть на это значение в двоичном виде, то можно
увидеть, что в первом представлении количество веду-
щих нулей минимально. Такое значение называется нор-
мализованным. Вообще, нормализованным представлени-
ем любого числа с плавающей точкой является то, в
котором количество ведущих нулей минимально, а, сле-
довательно, количество значащих битов мантиссы мак-
симально. Если основание числа равно 16, то значение,
по крайней мере, одного бита в старшем полубайте (в
четырех битах) равно 1. Если основание числа равно 8,
то значение, по крайне мере, одного бита из трех стар-
ших равно 1; если же основание числа равно 2, то зна-
чение самого старшего бита должно быть равно 1.
Операции над числами с плавающей точкой могут
давать как нормализованные, так и ненормализованные
результаты. В общем случае вы должны предполагать,
что результат является нормализованным, но необходи-
мо учитывать, что можно потерять несколько битов
точности. Например, если основание числа равно 16, то
следует считать, что каждая операция над числами с
плавающей точкой приведет к потере, по крайней мере,
Арифметика произвольной точности
Глава 24
трех битов точности. В действительности некоторые
операции приводят к потере меньшего количества би-
тов, но всегда лучше предполагать наихудший вариант.
Точность операций над числами с
плавающей точкой
Какова же действительная точность операций над чис-
лами с плавающей точкой?
На современных вычислительных машинах при про-
ведении вычислений может производится расширение
мантиссы, поэтому аппаратное обеспечение в действи-
тельности не теряет того количества битов точности,
которое указывалось ранее, но вы не можете полагать-
ся на то, что у вас в данном отношении современное
аппаратное обеспечение. Лучше просто выяснить это.
Каким образом?
Определение точности чисел с плавающей
точкой
Существует много интересных фактов, касающихся
представления чисел в конкретной среде, которые было
бы полезно знать.
В стандартном языке С определено большое коли-
чество констант, значения которых приведены в библио-
теках <float.h> и <limits.h>. Эти значения неодинако-
вы для разных компьютеров и компиляторов, так что
необходимо быть осторожным при обращении к ним по
именам. Никогда не предполагайте в своем коде, что вы
знаете эти числа. Пример программы в листинге 24.3 (и
на Web-сайте "ДиаСофт** в файле Ch24cnst.c) показы-
вает, каким образом можно вывести список этих значе-
ний в той среде, в которой вы работаете.
Эти значения точно указывают, как представлены
числа в вашей среде. Значения констант приведены в
таблицах 24.3 и 24.4.
Листинг 243. Каким образом создать список стандартных арифметических пределов,
linclude <stdio.h>
linclude <limits.h>
linclude <float.h>
int main (int argc, char* argv[])
{
printf(" Characters and integers:\n");
printf("CBAR_BIT=%d CBAR_MAX=%d CHAR_MIN=%d\n“,
CBARBIT,CHARMAX,CBARMIN) ;
printf("INT_MAX=%d INT_MIN=%d\n",INTMAX,INTMIN);
printf("LONG_MAX=%ld LONG_MIN=%ld\n",LONG_MAX,LONGMIN);
printf("SCBAR_MAX=%d SCBAR_MlN=%d\n",SCBAR_MAX,SCHARMIN);
printf("SERT_MAX=%d SHRT_MIN=%d\n",SHRTMAX,SBRTMIN);
printf("UCBAR MAX=%d OINT_MAX=%u OLONG_MAX=%ul OSBRT_MAX=%d\n",
UCHARMAX,OINTMAX,ULONGMAX,USHRTMAX);
printf(" Floating point:\n");
printf("FLT_ROUNDS=%d FLT_RADIX=%d FLT_MANT_DIG=%d FLT_DIG=%d\n",
630
Дополнительные тематические разделы
Часть III
FLTROUNDS,FLTRADIX,FLT_MANT_DIG,FLTDIG);
printf("FLT_MIN_EXP=%d FLT_MIN_10_EXP=%d\n",FLTMINEXP,
FLT_MIN_10_EXP);
printf("FLT_MAX_EXP=%d FLTJ4AX_10_EXP=%d\n",FLTMAXEXP,
FLT_MAX_10_EXP);
printf("FLT_MAX=%e FLTEPSILON=%e FLT_MIN=%e\n"rFLTMAX,
FLT_EPSILON,FLT_MIN);
printf(" Double precision:\n");
printf("DBL_MANT_DIG=%d DBLDIG=%d\n“,
DBL_MANT_DIG,DBL_DIG);
printf("DBL_MIN_EXP=%d DBLMIN10_EXP=%d\n",DBLMINEXP,
DBLMINlOEXP);
printfj"DBL_MAX_EXP=%d DBL_MAX_10_EXP=%d\n",DBLMAXEXP,
DBLMAX10EXP);
printf("DBL_MAX=%e DBL_EPSILON=%e DBL_MIN=%e\n",DBLMAX,
DBL_EPSILONrDBL_MIN);
printf(" Long Double precision:\n");
printf(-LDBL J4ANT_DIG=%d LDBL_DIG=%d\n",
LDBL_MANT_DIG,LDBL_DIG);
printf("LDBL_MIN_EXP=%d LDBL_HIN_10_EXP=%d\n",LDBLMINEXP,
LDBLMINIOEXP);
printf("LDBL_MAX_EXP=%d LDBL_MAX_10_EXP=%d\n",LDBLMAXEXP,
LDBLMAX10EXP);
printf("LDBLJ4AX=%e LDBL_EPSILON=%e LDBL_MIN=%e\n",LDBLMAX,
LDBLEPSILON,LDBLJ4IN);
return 0;
}
Таблица 24.3, Пределы точности для целочисленной арифметики.
Имя Значение
CHAR_BIT CHARMAX Число битов в типе char. Должно быть не менее 8. Максимальное целое значение для типа char. Должно быть не менее 127. Может соответствовать значению SCHAR_MAX или UCHAR.MAX, но какому именно, зависит от среды.
CHAR.MIN Минимальное целое значение для типа char. Должно быть не менее -127. Может соответствовать значению SCHAR_MIN или UCHAR. MIN, но какому именно, зависит от среды.
INT.MAX INT.MIN LONG.MAX Максимальное значение для типа signed int. Должно быть не менее 32767. Минимальное значение для типа signed int. Должно быть не менее -32767. Максимальное значение для типа long int. Должно быть не меньше чем INT_MAX и не менее 2147483647.
LONG_MIN Минимальное значение для типа long int. Должно быть не меньше чем INTMIN и не менее -2147483647, хотя может быть и дальше от нуля.
SCHAR.MAX SCHAR.MIN SHRT_MAX SHRT-MIN UCHAR_MAX USHRT_MAX Максимальное значение для типа signed char. Должно быть не менее 127. Минимальное значение для типа signed char. Должно быть не менее -127. Максимальное значение для типа short int Должно быть не менее 32767. Минимальное значение для типа short int. Должно быть не менее -32767. Максимальное значение для типа unsigned char. Должно быть не менее 255. Максимальное значение для типа unsigned short int. Должно быть не менее 65535 и не меньше чем SHRT-MAX.
UINT-MAX Максимальное значение для типа unsigned int. Должно быть не менее 65535 и не меньше чем USHRT-MAX.
ULONG_MAX Максимальное значение для типа unsigned long int. Должно быть не менее 4294967295 и не меньше чем UINT-MAX.
Арифметика произвольной точности
Глава 24
|631
Таблица 24.4. Пределы точности для арифметики чисел, с плавающей точкой.
Имя Значение
FLT_ROUNDS Модель округления чисел с плавающей точкой при сложении: -1 — не определена. 0 — к нулю, 1 — к ближайшему, 2 — к положительной бесконечности, 3 — к отрицательной бесконечности.
FLTRADIX Экспонента в представлении чисел с плавающей точкой. Это может быть значение 2 или 16. а также любое другое значение, которое заложили инженеры. Должно быть не менее 2.
FLT_MANT_DIG DBLMANTDIG LDBL_MANT_DIG FLT_DIG DBLDIG LDBLDIG FLT_MIN_EXP DBL_MIN_EXP LDBL_MIN_EXP FLT_MIN10_EXP DBL.MIN JO-EXP LDBL_MIN10_EXP FLT_MAX_EXP DBLMAXEXP LDBL_MAX_EXP FLT_MAX_10_EXP DBL_MAX_10_EXP LDBL.MAX_10_EXP FLT.MAX DBL.MAX LDBL.MAX Количество цифр основания в представлении чисел с плавающей точкой (float, double, long double). Точность в десятичных позициях в представлении чисел с плавающей точкой (float, double, long double). Должно быть, по крайней мере, 6 для float и 10 для double и long double. Минимальная экспонента в представлении чисел с плавающей точкой с основанием FLT_RADIX (float, double, long double). Минимальная экспонента в представлении чисел с плавающей точкой с основанием 10 (float, double, long double). Максимальная экспонента в представлении чисел с плавающей точкой с основанием FLT_RADIX (float, double, long double). Максимальная экспонента в представлении чисел с плавающей точкой с основанием 10 (float, double, long double). Максимальное нормализованное число с плавающей точкой (float, double, long double). Это максимальное (наиболее удаленное от нуля) число, которое может быть представлено. Должно быть не менее 1Е+37.
FLT-EPSILON DBL-EPSILON LDBLEPSILON FLT_MIN DBL.MIN LDBL-MIN Минимальная значимая разница между 1 и значением, которое меньше 1, представленная в виде числа с плавающей точкой (float, double, long double). He должно превышать IE-5 для float и 1E-9 — для double и long double. Минимальное нормализованное число с плавающей точкой (float, double, long double). Это наименьшее количество (ближайшее к нулю), которое может быть представлено. Должно быть не более 1Е-37.
Описание, приведенное в таблицах 24.3 и 24.4, не-
много отличается от официального описания рассмат-
риваемых констант; их точное описание можно найти
в самом стандарте. Но, тем не менее, приведенное опи-
сание вполне подходит для практического использова-
ния.
В каждой среде (конкретный компилятор С на кон-
кретной вычислительной машине, на которой установ-
лена конкретная операционная система) каждой указан-
ной константе соответствует определенное значение.
Значения могут очень сильно отличаться от минималь-
ных значений, приведенных в таблицах 24.3 и 24.4. В
таблицах 24.5-24.8 приведены примеры значений неко-
торых констант для пяти различных сред на одной и той
же вычислительной машине.
632
Дополнительные тематические разделы
Часть III
Таблица 24.5. Примеры пределов для целых
чисел.
Имя Значение
char_bit 8
char_max 127
charmin -127, -128
ucharmax 255
uchar_min -255, -256
schar_max 127
schar_min -128
shrtmax 32767
shrt_min -32767, -32768
int_max 2147483647, 32767
int_min -2147483647, -2147483648, -32767, -32768
long_max 2147483647
long_min -2147483647, -2147483648
ushrt_max 65535
uint_max 4294967295, 655351
ulong_max 4294967295, 655351
Таблица 24 .6. Примеры пределов для чисел с
плавающей точкой типа float.
Имя Значение
flt_rounds 1
flt_radix 2
flt_mant_dig 24
flt_dig 6
flt_min_exp -125
flt_min_10_exp -37
flt_maxexp 128
fltmaxlOexp 38
flt_max 3.404823е+38
flt_epsilon 1.192093е-07
1.175494е-38
Таблица 24.7. Примеры пределов для чисел с
плавающей точкой типа double.
Имя Значение
dbl_mant_dig 53
dbl_dig 15
dbl_min_exp -1021
dblmin10_exp -307
dbl_max_exp 1024
dbl_jnax_10_exp 308
dbl_max 1.797693e+308
dbl_epsilon 2.220446e-16
dbl_min 2.225074e-308, 0
Таблица 24.8. Примеры пределов для чисел с
плавающей точкой типа long double.____
Имя Значение
ldbl_mant_dig 53,64
ldbl_dig 15, 18, 19
ldbl_min_exp -1021.-16381
ldbl_min_10_exp -307,-4931
Idblmaxexp 1024, 16384
ldbl_max_10_exp 308, 4932
ldbl_max 1 797693e+308, NaN
ldbl_epsilon 2.220446e-16, 2.121398e-314, 5.342539e-318,1.618855e-319
ldbl_min 2.225074e-308, 3.464203e-310, 5.284429e-315, 7.588354e-320
Все пять сред работали на одном и том Лее процес-
соре Intel, но под управлением разных операционных
систем, а также при использовании разных компилято-
ров С и библиотек периода выполнения. При одной
комбинации значение константы DBL MIN оказалось
даже равным 0.0, что является практически невозмож-
ным значением. Символ "NaN" в этих таблицах озна-
чает "Not A Number" (не является числом), т.е. с исполь-
зованием стандартных методов значение не может быть
представлено.
Никогда не делайте предположений
относительно среды выполнения кода
Если результат не является точной двоичной дробью
(как это обычно и бывает), вполне вероятно, что про-
изводится некоторое округление. Не предполагайте, что
округление будет производиться по тем правилам, ко-
торые вы изучали в школе ("Если последняя цифра
меньше пяти, округляйте вниз, если последняя цифра
пять или больше пяти, округляйте вверх"). Существу-
ют четыре метода округления, один из которых может
использоваться в вашей конкретной среде. Различные
компиляторы и различные библиотеки времени выпол-
нения вполне могут использовать на одном и том же
компьютере различные протоколы. Хотя это и не опре-
деляется возможными значениями константы
FLTJROUNDS, но, тем не менее, один из методов ок-
ругления может состоять в том, чтобы всегда округлять
до четного или всегда округлять до нечетного. Такое ок-
ругление является попыткой избавиться от некоторой
свойственной школьному методу округления тенденции
округлять вверх. Более подробно с поучительными при-
мерами ухода (дрейфа) точности это рассмотрено в упо-
минавшейся ранее книге Кнута.
Арифметика произвольной точности
Глава 24
633
Уход наблюдается в том случае, когда округление в
сериях вычислений приводит к постепенному все боль-
шему смещению вычисленного значения от действитель-
ного. Например, если Л=0.55555555, а #=1.0, то впол-
не возможно, что А+В будет округлено до 1.5555556.
Если из полученного числа вычесть В, то получится
значение, немного отличающееся от значения А, с ко-
торого мы начинали: 0.5555556. Следовательно, (А+В)—
В—А не будет нулевым. Поэтому цикл
int i ;
double А=0.55555555;
double B=1.0;
double С-0.0;
for (i=0;(i<32000);i++)
{
С = ((С + (A + В)) - В) - 0.55555555;
}
может в результате дать некоторое ошибочное значение.
Чтобы определить, будет ли уход оказывать влияние
при вычислениях определенных значений, можете по-
экспериментировать в своей среде со значениями Л и В.
Еще несколько примеров для оценки ухода можно най-
ти на Web-сайте издательства "ДиаСофт” в файле
Ch24Drift.c.
Отрицательные числа не всегда
представляются в виде дополнения до
двух
Часто мы полагаем, что отрицательные числа могут быть
представлены в виде дополнения до двух. Но это пред-
положение не всегда справедливо. На некоторых ком-
пьютерах отрицательные числа могут быть представле-
ны в виде дополнения до единицы. Следовательно, мы
также часто предполагаем, что диапазон представляемых
чисел с отрицательной стороны длиннее на единицу,
чем с положительной стороны, что тоже не всегда спра-
ведливо. Если вы просмотрите приведенные в примерах
возможные значения констант INT MAX и INT_MIN,
то увидите, что в некоторых случаях INT_MIN=
(INTJMAX+1), а иногда INT_MIN=-INT_MAX. По-
этому не делайте в своем коде никаких предположений,
касающихся представления отрицательных чисел: тиль-
да ( ) означает замену значений битов на противопо-
ложные, а знак минуса (-) означает изменение знака
числа на противоположный. Любой код, который дела-
ет различие между этими операторами, будет зависи-
мым либо от аппаратного обеспечения, либо от среды.
Представления "от старшего к младшему"
и "от младшего к старшему"
В каком порядке биты хранятся внутри компьютера?
Рассмотрим десятичное число 4660. В шестнадцатирич-
ном представлении ему соответствует 1234. Если в кон-
кретной среде тип short int имеет длину 16 битов и мы
помещаем данное значение в переменную типа short int,
то можно ли ожидать, что где-то в памяти компьютера
находятся два последовательных байта, младший из
которых имеет значение 12, а старший — 34?
Увы, нет. На некоторых типах вычислительных ма-
шин значения будут храниться в виде 12 | 34, а на не-
которых — в виде 34 | 12. Эти представления называ-
ются от младшего к старшему и от старшего к младшему
(соответственно big-endian и little-endian по книге "Путе-
шествия Гулливера Джонатана Свифта).
А как насчет больших чисел, которые занимают 32
бита? Если в вашей среде тип long int занимает 32 бита
и вы устанавливаете значение переменной типа long int
равным 305419896, то каким образом это значение бу-
дет храниться в памяти компьютера? Указанное значе-
ние в шестнадцатиричной форме имеет вид 12345678,
и в зависимости от архитектуры вычислительной маши-
ны возможны следующие варианты:
12 | 34 | 56 | 78
34 | 12 | 78 | 56
78 | 56 | 34 | 12
Порядок внутри байтов не изменяется, изменяется
порядок только пар байтов или порядок всех четырех
байтов. Поэтому никогда не пишите код, который свя-
зывает адреса в памяти со значениями, за исключени-
ем разве что объема памяти, который занимают эти зна-
чения. Например, никогда не пытайтесь получить
младший байт переменной типа long int путем измене-
ния указателя и извлечения четвертого значения типа
char. В некоторых случаях вы получите не то, что ожи-
даете, и это зависит от самого компьютера.
Примеры высокой и низкой точности
Одно из занятий, которое математики считают развле-
чением, — это вычисление чисел с огромным количе-
ством знаков после точки. С каждым годом количество
известных знаков после точки числа л становится все
больше и больше. Для вычисления числа р недостаточ-
но прости взять длину окружности и поделить на ес
диаметр. Мы знаем значение числа р до многих сотен
(нет, тысяч) миллионов знаков после точки. Мы также
знаем значение числа е до многих миллионов знаков
после точки, хотя (для этой главы) полезнее будет вы-
числить его, а не посмотреть в справочнике.
При проведении физических измерений нам очень
повезет, если мы получим точность хотя бы с десятью
знаками после точки, а часто приходится иметь дело
даже с меньшей точностью. Можно определить рассто-
яние до Луны в любой момент времени с точностью
Дополнительные тематические разделы
Часть III
634
порядка 10 см, что соответствует точности чуть выше,
чем 1/1010, т.е. некоторые значения мы знаем довольно
точно. Точность составляет десять знаков после точки.
Известно, что количество молекул в 12 граммах уг-
лерода составляет около 6.02217*1023, но это число об-
ладает точностью только до 1/106, т.е. ошибка состав-
ляет, по крайней мере, единицу в одном миллионе.
В этом случае точность составляет только пять знаков.
В полдень 1 июня 1995 г. население Европы, по
некоторым оценкам, составляло 498 миллионов, но это
число известно только с точностью до трех миллионов, что
хуже, чем 1/100. Здесь точность — только два знака.
Расстояние от Земли до созвездия Андромеды со-
ставляет, по разным оценкам, от 2 до 5 миллионов све-
товых лет, т.е. между 1.9*1022 и 4.7*1022 метров, при этом
ошибка составляет 250%.
Различные методы представления
сверхвысокой точности
Поскольку размеры целых чисел и точность чисел с
плавающей точкой ограничиваются аппаратно, то необ-
ходимо найти какой-то другой способ представления
сверхточных чисел.
Обычно мы просто записываем на бумаге длинную
строку цифр. Мы легко можем умножать двузначные
числа и даже перемножать 100-значные числа (хотя и с
большими усилиями).
Но каким образом можно представить длинную
строку цифр в программе?
Строки целых чисел
Когда мы пользуемся карандашом и бумагой, то можем
записать строки целых чисел с использованием цифр
012345678и9. Этот набор изначально возник
вследствие того биологического факта, что люди име-
ют десять пальцев. Но десять ничем не отличается от
любого другого целого числа, которое больше единицы, —
можно было бы выбрать любое другое число. Мы выб-
рали десять просто для удобства. Другие народы для
своей системы исчисления выбрали другие основания.
Так, в древней Греции, где люди ходили в открытых
сандалиях, основанием системы исчисления было чис-
ло 20 (это отразилось на том, как в наше время во фран-
цузском языке выражаются числа между 50 и 100), а в
Вавилоне основанием было число 60.
Мы используем позиционную нотацию (запись, или
представление). В числе 532 двойка имеет значение две
единицы, значение цифры 3 — три десятка, а значение
цифры 5 — пять, умноженное на десять, умноженное
на десять (сотни).
Десятичное представление
В обычном десятичном представлении мы используем
десять различных символов, упорядоченных по значи-
мости (справа налево), начиная с единиц (10°), затем
следуют десятки (101), затем сотни (102), затем тысячи
(Ю3) и т.д.
Для тех, кому интересны существующие разговор-
ные языки, арабские цифры, которые мы используем,
в арабском написании пишутся справа налево. Младшая
цифра числа все так же располагается справа, а старшая —
слева. Когда мы читаем последовательность цифр в тек-
сте, то, для того чтобы узнать, какое значение имеет
старшая цифра, нужно начать просмотр с конца (с
младшей цифры) числа, а затем вернуться к старшей
цифре. Быстро скажите вслух число 968374215. Навер-
ное, вы начали отсчет с конца и подсчитали, что 9 оз-
начает ’’девятьсот миллионов”, а не ’’девяносто милли-
онов" или "девять миллиардов”.
Заметили вы это или нет, но девятка имеет в 10 раз
выше порядок, чем следующая шестерка (поскольку 9
расположена левее 6 и мы пользуемся десятичной сис-
темой счисления), это очевидно.
Шестнадцатиричное представление
Если бы при счете мы пользовались как пальцами рук,
так и пальцами ног, за исключением больших пальцев,
то мы бы имели 16 цифр. Тогда можно было бы исполь-
зовать позиционную систему исчисления, которая при
чтении справа налево дала бы количество единиц (16°),
количество чисел 16 (161), количество чисел 256 (162),
количество чисел 4096 (163) и т.д. в тяжело запомина-
ющейся, но логически абсолютно верной последова-
тельности.
Это было бы шестнадцатиричное представление. Для
его использования нам необходимо 16 различных цифр,
в качестве которых приняты 0, 1,2, 3, 4, 5, 6, 7, 8, 9,
А, В, С, D, Е и F.
Может быть, все это не стоит так подробно обсуж-
дать, поскольку вы и без того все хорошо знаете, как-
никак в языке С команда printf имеет символы управ-
ления форматом для десятичного (%d), восьмеричного
(%о) и шестнадцатиричного (%х) представлений. Про-
сто в данном разделе обосновывается тот факт, что в
качестве основания может использоваться любое число,
которое больше единицы. А как насчет использования
какого-нибудь очень большого числа?
Представление с основанием 32768
Можно использовать представление с основанием
32768. Это потребует использования 32768 различных
символов, и каждая позиция будет обозначать количе-
ство единиц (32768°), количество чисел 32768 (327681),
количество чисел 1073741824 (327682) и т.д. В языке С
Арифметика произвольной точности
Глава 24
635
для этой цели идеально использовать массив типа short
int.
Поскольку людям не очень просто воспринимать
числа, представленные в системе счисления с таким
основанием, то вместо него можно использовать осно-
вание 10000, тогда каждый элемент массива будет со-
держать в точности по четыре десятичные цифры чис-
ла, которое мы представляем, что будет удобно при
распечатке и/или чтении таких значений. Можно так-
же использовать массив типа long int, полагаясь на то,
что элемент такого массива может содержать значение,
которое не меньше 2147483647, и выбрать в качестве
основания число 1000000000 (один миллиард). Каждая
позиция будет состоять из девяти десятичных цифр.
Ниже будет приведен код, который в качестве осно-
вания при представлении чисел использует 10000.
Строки символов
Теперь можно вернуться к десятичному представлению,
‘но на этот раз будем представлять числа как строки
символов (char), точно так же, как мы их записываем.
Это означает, что функции сложения, вычитания и т.п.
должны будут работать только с одним разрядом и сами
заботиться о "переносе" и "заеме" со следующего разря-
да, точно так же, как это делаем мы при выполнении
арифметических операций вручную. \
Пример кода для действий над
строкой символов
Хотя нельзя всегда рассчитывать на использование таб-
лицы символов ASCII (например, на вашем компьюте-
ре может использоваться EBCDIC (расширенный дво-
ично-десятичный код обмена информацией)), тем не
менее вы можете рассчитывать на последовательность
символов от 'О’ до ’9', причем ’0‘ в этой последователь-
ности идет перед ’9'. Поэтому, если переменная с име-
ет тип char и вы знаете, что она содержит цифру, тогда
(с - ’О’) — десятичное значение этой цифры. По край-
ней мере, такое представление гарантируется языком С.
Сложение
Если мы установили предел точности, скажем, 12 тыс.
цифр, то необходимо следующим образом объявить
переменные, которые будут содержать цифры:
«define MAX_PRECISION 12000
char aSample[MAX_PRECISION+l] ;
Для выполнения сложения необходимо позаботит-
ся о переносе в следующий разряд. Предположим, что
необходимо вычислить сумму двух чисел. В этом помо-
жет следующая функция:
«define MAX_PRECISION 12000
int cAdd ( char * aOne, char * a Two,
char * aThree )
{
int iStatus = 0;
int carry = 0;
int i - 0;
int j = 0;
for (i=MAX_PRECISION-1; (i>=0) ;i—)
{
j = *(aOne+i) + *(aTwo+i) +
carry - '0' - 'O';
carry = j / 10;
j = j % 10;
*(aThree+i) = j + 'O';
}
return iStatus;
}
Более подробно приведенная функция описана в
файле Ch24Add.c на Web-сайте издательства "ДиаСофт".
Аналогично можно распространить представление
чисел до представления их с помощью массивов типа
int, в которых первый элемент каждого массива указы-
вает, сколько еще элементов содержит данный массив,
т.е. массивы могут иметь разные размеры.
Умножение
По коду, приведенному в листинге 24.4, видно, что
умножение намного сложнее сложения: Комментарии
(обширные!) по приведенному коду можно найти в
файлах Ch24AOK.c и Ch24AOK2.c на Web-сайте изда-
тельства "ДиаСофт". Такой метод умножения можно
разбить на четыре этапа:
1. Перемножить пару цифр.
2. Перемножить две строки цифр.
3. Выделить память.
4. Нормализовать результат.
Под словом "цифра" подразумевается "цифра систе-
мы счисления с основанием 10000” — значением, кото-
рое больше, чем количество пальцев на руках.
Причиной, по которой необходимо отдельно рас-
смотреть "простое” перемножение одного слова на дру-
гое, является то, что произведение может быть длиннее
операндов. Так, например, число 9876 (которое пред-
ставляет одну "цифру" в системе счисления с основанием
10000), умноженное на 4567 (которое тоже представляет
одну "цифру" в системе исчисления с основанием
10000), дает 45103692, которое состоит из двух "цифр"
- "4510” и "3692".
636
Дополнительные тематические разделы
Часть III
Листинг 24.4. Умножение в системе счисления с основанием 10000.
linclude <stdlib.h>
Idefine BASE 10000
Idefine SQRTBASE 100
Idefine INT int
int pairMultiply ( INT iOne, INT iTwo, INT * pAnswer)
{
INT iStatus = 0;
INT iOneTop = 0;
INT iOneBot « 0;
INT iTwoTop = 0;
INT iTwoBot = 0;
INT iAnsTop = 0;
INT iAnsBot = 0;
if (iOne>SQRT_BASE)
{
iOneTop = iOne / SQRTBASE;
iOneBot *= iOne % SQRTBASE;
}
else
{
iOneTop - 0;
iOneBot = iOne;
}
if (iTwo>SQRT_BASE)
{
iTwoTop = iTwo / SQRTBASE;
iTwoBot = iTwo % SQRTBASE;
}
else
{
iTwoTop = 0;
iTwoBot = iTwo;
}
iAnsBot - (iOneBot * iTwoBot) 4-
(iOneBot * iTwoTop * SQRTBASE) +
(iOneTop * iTwoBot * SQRTBASE);
iAnsTop = (iOneTop * iTwoTop);
if (iAnsBot>BASE)
{
iAnsBot = iAnsBot % BASE;
iAnsTop = iAnsTop + (iAnsBot / BASE);
}
pAnswer[ 0 ] = iAnsTop;
pAnswer[ 1 ] - iAnsBot;
return iStatus;
int aMultiply ( INT * aOne, INT * a Two, INT ** a Answer)
{
int iStatus = 0;
int i = 0;
int j « 0;
int к = 0;
int m = 0;
INT * pint;
INT ** pplnt = &plnt;
INT w[2];
Арифметика произвольной точности
Глава 24
637
if ((aOne==NULL) || (aTwo==NULL) || (aAnswer==NULL))
iStatus = 1;
else
{
i = abs(aOne[0]) + abs(aTwo[0]) + 1;
j = aAllocate(i, pplnt);
if (j!=0)
iStatus = 1;
else
{
for (k=abs(aTwo[0]);(k>0);k—)
{
for (j=abs(aOne[0]); (j>0); j—)
{
в = pairMultiply ( aOne[j], aTwo[k], w);
plnt[i + 1 - к - j] += w[l];
plnt[i - к - j] += w[0];
1
}
if (((aOne[0]>0)££(aTwo[0]<0))
|| ((a0ne[0]<0)&£(aTwo[0]>0)))
pInt[0] = - pInt[0];
m = aNormalise (pplnt, aAnswer);
if (ml=0)
iStatus = 1;
}
}
return iStatus;
}
int aNonnalise ( INT ** aUnNormal, INT ** aNormal )
{
int iStatus = 0;
int i = 0;
int j = 0;
int к = 0;
int m = 0;
int s = 1;
if ((aUnNormal==NULL) 11 (aNormal==NULL)
|| ((*aUnNormal)==NULL))
iStatus = 1;
else
{
♦aNormal = *aUnNormal;
к = abs((*aUnNormal)[0]);
if ((*aUnNormal)[0]<0)
s = -1;
if (k>0)
j = (*aUnNormal) [ 1 ];
m = 0;
for (i=l;((j==O)££(i<=k));i++)
{
j = (*aUnNormal) [ i ];
m++;
}
}
if (m>0)
{
к = abs((«aUnNormal)[0]) - m;
j = aAllocate(k, aNormal);
for (i=l;(i<(k+l));i++)
Дополнительные тематические разделы
Часть III
638
{
j = i + m;
(*aNormal) [ j ] = (*aUnNormal) [ i ];
}
if (s<0)
(*aNormal)[0] = - (*aNormal)[0 ];
free(*aUnNormal);
*aUnNormal = NULL;
}
}
return iStatus;
}
int aAllocate ( int iCount, INT ** aAnswer )
{
int iStatus = 0;
INT * pint = NULL;
int i в 0;
pint = calloc ( sizeof (INT), iCount 4- 1);
if (pInt==NULL)
{
iStatus = 1;
return iStatus;
}
else
{
for (i=l;(i<=iCount);i++)
plntfi] = 0;
*plnt » iCount;
}
if (aAnsverl-NULL)
*aAnsver = pint;
return iStatus;
Дробные числа
Ни в одном коде, представленном в данной главе и ка-
сающемся работы с большими числами, не учитывалась
возможность работы с нецелыми числами. От целых
чисел числа с плавающей точкой отличаются только тем,
что они требуют еще и знания положения десятичной
точки.
Перед сложением и вычитанием операнды необходи-
мо выровнять, т.е. добавить ведущие или конечные нули,
чтобы количество цифр в обоих операндах было одина-
ковым и десятичная точка располагалась в одном месте. А
при последующей нормализации ведущие и конечные
нули будут удалены в результирующем числе.
Умножение и деление можно производить так же,
как и в случае целых чисел, только после выполнения
операции перед нормализацией необходимо определить
положение десятичной точки. Метод определения по-
ложения десятичной точки будет рассмотрен в следу-
ющем разделе.
Положение десятичной точки при
умножении
Если мы перемножаем два числа, первое из которых
содержит а цифр перед десятичной точкой и b цифр —
после десятичной точки (т.е. общая длина числа состав-
ляет (а+b) цифр), а второе число содержит с цифр пе-
ред десятичной точкой и d цифр — после десятичной
точки (т.е. общая длина числа составляет (c+d) цифр),
то произведение будет содержать (b+d) цифр после точ-
ки. Таким образом, для определения количества цифр
после точки в произведении мы просто складываем ко-
личество цифр после точки в двух операндах.
Положение десятичной точки при делении
При делении положение десятичной точки определить не
так просто, как при умножении. Если производится опе-
рация деления над числами а.Ь и с.d (см. раздел по опре-
делению десятичной точки при умножении), то из пер-
вых (а+b—с—d) цифр результата (до нормализации) (b—d)
из них будут находиться после десятичной точки.
639
Общие арифметические функции
В файлах CH24Abad.c и СН24АОК.С на Web-сайте из-
дательства ’’ДиаСофт” содержатся программы для вы-
полнения четырех основных арифметических операций
над сверхбольшими целыми числами. Первый файл
(CH24Abad.c) содержит верный, но неполный код, ко-
торый предлагается вам для самостоятельной доработ-
ки в качестве упражнения в целях рассмотрения возни-
кающих при этом проблем. В файле СН24АОК.С
приведено полное решение всех этих проблем.
Описания имеющихся в этих программах функций
приведены в табл. 24.9.
Арифметика произвольной точности
Глава 24
В четырех функциях, приведенных в табл. 24.9, ис-
пользуются несколько вспомогательных функций, опи-
сание которых приведено в табл. 24.10.
В файле СН24АОК2.С повторены все представлен-
ные выше функции и, кроме того, имеется возможность
работы с числами с десятичной точкой (т.е. с нецелы-
ми числами).
Во всех указанных файлах функции aAdd, aSubtract,
aMultiply, aDivide, cascMultily, cascDivide и aDivNormalize
выделяют память, которую пользователь должен освобо-
дить.
Файл ChSafe.c содержит набор функций для выпол-
нения простых арифметических операций над типом
double. Описание этих функций приведено в табл. 24.11.
Таблица 24.9. Арифметические операции над большими целыми числами.
Имя функции Описание функции
aAdd aSubtract Складывает большое число (слагаемое) с другим большим числом и выделяет память под сумму. Вычитает большое число (вычитаемое) из другого большого числа (уменьшаемого) и выделяет память под разницу.
aMultiply aDivide Умножает большое число (множимое) на другое большое число и выделяет память подпроизведение. Делит большое число (делимое) на другое большое число (делитель) и выделяет память под частное. Комментарии в коде описывают способ вычисления остатка.
Таблица 24.10. Вспомогательные функции, которые используются в функциях для выполнения
арифметических операций над большими числами.
Имя функции Описание функции
pairMultiply Умножает слово на слово и получает результат в виде пары (массива) слов. Память под все операнды должна быть выделена пользователем заранее.
cascMultiply oneDrvide Умножает большое число на слово и выделяет память под произведение. Делит слово на слово, представляя частное и остаток в виде массива. Память под все операнды должна быть выделена пользователем заранее.
pairDhride Делит пару слов (массив) на слово, представляя частное и остаток в виде массива. Память под все операнды должна быть выделена пользователем заранее.
cascDivide aDivNormalize aNormalize Делит большое число на слово и выделяет память под частное. Остаток не вычисляется. Выполняет нормализацию после деления, выделяет память под нормализованный ответ. Нормализует большое число, выделяет память под ответ и освобождает память, которая была выделена под аргумент.
Таблица 24.11. Функции для выполнения простых арифметических операций над типом double.
Имя функции Описание функции
flpSafeDhrideSensitive Делит делимое, заданное с определенной точностью, на делитель, заданный с определенной
flpSafeDivide точностью, дает частное, вычисляя его точность и выдавая при необходимости сигнал об ошибке. Делит делимое на делитель, дает частное. Для выполнения вычислений вызывает функцию flpSafeDhrideSensitive.
flpSafeMultiplySensitive Умножает множитель, заданный с определенной точностью, на другой множитель, также
flpSafeMultiply заданный с определенной точностью, дает произведение, вычисляя его точность, выдает при необходимости сигналы об ошибках. Умножает множитель на другой множитель, дает произведение. Для выполнения вычислений вызывает функцию flpSafeMultiplySensitive.
Дополнительные тематические разделы
Часть III
640
Имя функции Описание функции
flpSafeAddSensitive Складывает слагаемое, заданное с определенной точностью, с другим слагаемым, также заданным с определенной точностью, дает сумму, вычисляя ее точность, выдает при необходимости сигналы об ошибках.
flpSafeAdd Складывает слагаемое с другим слагаемым, дает сумму. Для выполнения вычислений вызывает функцию flpSafeAddSensitive.
flpSafeSubtractSensitive Вычитает вычитаемое, заданное с определенной точностью, из уменьшаемого, заданного с определенной точностью, дает разность, вычисляя ее точность, выдает при необходимости сигналы об ошибках. Для выполнения вычислений вызывает функцию flpSafeAddSensitive.
flpSafeSubtract Вычитает вычитаемое из уменьшаемого, дает разность. Для выполнения вычислений вызывает функцию flpSafeSubtractSensitive.
flpcmp Сравнивает два числа с плавающей точкой с наибольшей доступной для данного типа точностью.
flpSetEquivalent Если переменные, данные в качестве аргументов, равны с некоторой точностью числу и (ипсилон, обычно обозначает предел точности), то значения обеих переменных устанавливаются равными большему по модулю значению. Если значения переменных не равны, функция возвращает FALSE.
Названия некоторых переменных внутри указанных
функций основаны на английской терминологии:
Addend плюс Addend равно Sum ’
Minuend минус Subtrahend равно Difference
Multiplicand умножить на Multiplicand равно Product
Numerator деленное на Denominator равно Quotient
(и Remainder)
Все функции принимают аргументы в одной и той же
последовательности. Функции flpSafeAdd, flpSafeSubtract,
flpSafeMultiply и flpSafeDivide принимают два аргумента
и возвращают результат выполнения операции. Все резуль-
таты и аргументы имеют тип double. Поэтому вместо
double dA, dB, dC;
dA = dB + dC;
можно записать
double dA, dB, dC;
dA - flpSafeAdd ( dB, dC ) ;
Функции flpSafeAddSensitive, flpSafeSubtractSensitive,
flpSafeMultiplySensitive и flpSafeDivideSensitive также
принимают одну и ту же последовательность аргумен-
тов, которая гораздо длиннее, чем для указанных выше
функций. Возвращаемое значение является результатом
выполнения операции. Функции имеют по семь аргу-
ментов:
е Первый операнд, тип double.
е Точность первого операнда, тип double. Если это зна-
чение равно нулю, то считается, что первый операнд
содержит неизвестную ошибку.
• Второй операнд, тип double.
• Точность второго операнда, тип double.
• Указатель на переменную типа double, которая по-
лучит точность результата операции. Если значение
указателя NULL, то указатель игнорируется.
• Флаг типа int, который указывает, будет ли данная
функция вызывать функцию raise вывода сообще-
ния об ошибках. Если его значение равно нулю,
предупреждение об ошибках выводиться не будет.
• Указатель на переменную типа int, которая получит
значение ошибки, сообщение о которой должно быть
вызвано. Этот указатель используется только в слу-
чае, если шестой аргумент равен нулю, указывая на
то, что в действительности предупреждение об
ошибке выводиться не будет.
Точным эквивалентом выражения
dA=fIpSafeAdd(dB, dC) ;
является выражение
dA=flpSafeAddSensitive(dA, 0.0, dC, 0.0, NULL,
0, NULL);
Две оставшиеся функции — это функции сравнения
диапазонов flpcmp и установки эквивалентных значений
flpSetEquivalent.
Функция flpcmp в качестве аргументов принимает
три параметра. Первый и третий имеют тип double, а
второй — строка символов. Эта строка содержит опера-
тор сравнения — один из операторов ==, !=, >, <, <=
или >=. Функция filpcmp выполняет операцию сравне-
ния первого и третьего аргументов и возвращает значе-
ние типа Boolean. Тем не менее, сравнение производится
с некоторой определенной точностью: два значения
считаются равными, если величина их разницы не пре-
вышает некоторого значения COMPARE_EPSILON
(смысл переменной €OMPARE_LPSILON (число £ был
описан ранее).
Арифметика произвольной точности
Глава 24
641
Функция flpSetEquivalent в качестве аргументов тре-
бует двух параметров, каждый из которых является ука-
зателем на тип double. Если аргументы равны между
собой (что определяется функцией flpcmp), то значение
параметра с меньшим абсолютным значением будет
установлено равным значению параметра с большим
абсолютным значением.
Использование стандартных типов
Если нам нельзя отходить от встроенных типов float,
double и long double, то каким образом мы можем убе-
диться, что операции выполняются с требуемой точно-
стью, т.е. каким образом можно определить точность
полученного после выполнения операции результата? В
файлах Ch24Safe.c и Ch24Safe.c на Web-сайте издатель-
ства ’’ДиаСофт” содержится полный набор функций для
выполнения арифметических операций над значения-
ми типа double. Эти функции можно без труда распро-
странить на тип long double. Коды функций приведены
в листинге 24.5, но присутствующие в файлах на Web-
сайте "ДиаСофт” комментарии в этом листинге не при-
водятся.
Листинг 24.5. Функции для выполнения арифметических операций над значениями типа double с
заданной точностью,
linclude <stdio.h>
linclude <siqnal.h>
linclude <math.h>
linclude <limits.h>
linclude <float.h>
linclude <string.h>
linclude "Ch24Safe.h”
lifndef TRUE
Idefine TRUE (0==0)
lendif
lifndef FALSE
Idefine FALSE (l==0)
lendif
/* Для flpcmp() требуется макрос-константа */
Idefine COMPAREEPSILON DBLEPSILON
/* ARITBMETACCEPTPRECISION - это предел допустимой точности после любой арифметической
операции. Установлен равным одному проценту (0.01), но его можно заменить любым другим
значением. Должен иметь тип long double (отсюда и L в конце): */
Idefine ARITBMETACCEPTPRECISION (0.OIL)
Idefine ARITBMET_DENOMINATOR_ZERO SIGILL
Idefine ARITHMETPRECISIONBAD SIGINT
Idefine ARITBMETBEYONDRANGE SIGFPE
double flpSafeDivideSensitive (
double flpNumerator,
double flpNumeratorPrecision,
double fIpDenominator,
double flpDenominatorPrecision,
double * pfIpResultPrecision,
int RaiseError, int * pErrorRaised )
{
double flpReturnValue = 0.0;
double flpZero = 0.0;
double flpLocalResultPrecision = 0.0;
double flpLocalNumPrecision - 0.0;
double flpLocalDenomPrecision = 0.0;
long double flpLocalReturnValue = 0.0;
if ( pfIpResultPrecision 1= NULL )
{
flpLocalNumPrecision=DBL_EPSILON * fabs( flpNumerator );
if ( DBL_EPSILON > flpLocalNumPrecision )
flpLocalNumPrecision = DBLEPSILON;
if ( flpNumeratorPrecision > flpLocalNumPrecision )
flpLocalNumPrecision = flpNumeratorPrecision;
Дополнительные тематические разделы
Часть III
642j
flpLocalDenomPrecision z DBL_EPSILON *
fabs( flpDenominator );
if ( DBLEPSILON > flpLocalDenomPrecision )
flpLocalDenomPrecision = DBL_EPSILON;
if ( flpDenominatorPrecision > flpLocalDenomPrecision )
flpLocalDenomPrecision = flpDenominatorPrecision;
flpLocalResultPrecision = ( flpLocalNumPrecision *
fabs ( flpDenominator ) )
4- ( flpLocalDenomPrecision *
fabs ( fIpNumerator ) );
if ( flpLocalResultPrecision < DBL_EPSILON )
flpLocalResultPrecision = DBLEPSILON;
*pfIpResultPrecision = flpLocalResultPrecision;
}
if ( pErrorRaised 1= NULL )
♦pErrorRaised = 0;
if ( flpcmp ( fIpNumerator, ==“, flpZero ) )
return ( fIpReturnValue );
if ( flpcmp ( flpDenominator, “==“, flpZero ) )
<
if ( pf IpResultPrecision != NULL )
*pfIpResultPrecision = DBLMAX;
if ( pErrorRaised 1= NULL )
♦pErrorRaised « ARITBMET DENOMINATOR ZERO;
if ( RaiseError )
raise ( ARITBMETDENOMINATORZERO );
fIpReturnValue * DBLMAX;
return ( fIpReturnValue );
}
flpLocaIReturnValue = (long double) fIpNumerator /
(long double) fIpDenominator;
if ( flpLocalResultPrecision < DBLEPSILON *
fabs ( flpLocalReturnvalue ) )
flpLocalResultPrecision = DBLEPSILON *
fabs ( flpLocalReturnValue ) ;
if ( fabs ( flpLocalReturnValue ) > DBLMAX )
{
if ( pfIpResultPrecision 1= NULL )
*pfIpResultPrecision = DBLMAX;
if ( pErrorRaised 1= NULL )
♦pErrorRaised = ARITEMETPRECISIONBAfr;
if ( flpLocalReturnValue < 0.0L )
fIpReturnValue = - DBL MAX;
else fIpReturnValue = DBLMAX;
if ( RaiseError )
raise ( ARITHMETPRECISIONBAD );
return ( fIpReturnValue );
} .else {
fIpReturnValue = fIpLocalReturnValue;
if ( pfIpResultPrecision 1= NULL )
♦pfIpResultPrecision - flpLocalResultPrecision;
if ( flpLocalResultPrecision >
( fabs ( flpReturnValue ) > DBL EPSILON ?
( fabs ( flpReturnValue ) *
ARITHMETACCEPTPRECISION ) : DBLEPSILON ) )
{
if ( pErrorRaised 1= NULL )
♦pErrorRaised = ARITHMETBEYONDRANGE;
if ( RaiseError )
raise ( ARITHMETBEYONDRANGE );
Арифметика произвольной точности
Глава 24
643
}
return ( fIpReturnValue );
}
double fIpSafeDivide (double fIpNumerator,
double flpDenominator)
{
double fIpReturnValue = 0.0;
fIpReturnValue = flpSafeDivideSensitive (fIpNumerator, 0.0,
flpDenominator, 0.0,
NULL, FALSE, NULL);
return (fIpReturnValue);
}
double flpSafeMultiplySensitive (
double flpFirstMultiplicand,
double flpFirstMultiplicandPrecision,
double fIpSecondMultiplicand,
double fIpSecondMultiplicandPrecision,
double * pflpResultPrecision,
int RaiseError, int * pErrorRaised )
{
double fIpReturnValue = 0.0;
double flpZero = 0.0;
double fIpLocalResultPrecision = 0.0;
double flpLocalFirstPrecision = 0.0;
double fIpLocalSecondPrecision = 0.0;
long double fIpLocalReturnValue = 0.0;
if ( pflpResultPrecision 1= NULL )
<
flpLocalFirstPrecision = DBLJEPSILON *
fabs( flpFirstMultiplicand );
if ( DBLJEPSILON > flpLocalFirstPrecision )
flpLocalFirstPrecision = DBLEPSILON;
if ( flpFirstMultiplicandPrecision >
flpLocalFirstPrecision )
flpLocalFirstPrecision=fIpFirstMultiplicandPrecision;
fIpLocalSecondPrecision = DBLEPSILON *
fabs( fIpSecondMultiplicand );
if ( DBLEPSILON > fIpLocalSecondPrecision )
fIpLocalSecondPrecision = DBLEPSILON;
if ( fIpSecondMultiplicandPrecision >
flpLocalSecondPrecision )
fIpLocalSecondPrecision =
fIpSecondMultiplicandPrecision;
flpLocalResultPrecision - ( flpLocalFirstPrecision
* fabs ( fIpSecondMultiplicand ) )
4- ( flpLocalSecondPrecision
* fabs ( flpFirstMultiplicand ) );
if ( flpLocalResultPrecision < DBLEPSILON )
flpLocalResultPrecision - DBLEPSILON;
♦pflpResultPrecision = flpLocalResultPrecision;
}
if ( pErrorRaised != NULL )
♦pErrorRaised = 0;
if ( flpcmp ( flpFirstMultiplicand, o.O j
|| flpcmp ( f IpSecondMultiplicand, ==", 0.0 ) )
{
if ( pflpResultPrecision Is NULL )
<
if ( flpFirstMultiplicandPrecision >
fIpSecondMultiplicandPrecision )
♦pflpResultPrecision =
Дополнительные тематические разделы
644
Часть III
flpFirstMultiplicandPrecision;
else *pfIpResultPrecision =
fIpSecondMultiplicandPrecision;
}
return ( flpReturnValue );
}
if ( pfIpResultPrecision Is NULL )
{
*pfIpResultPrecision = ( ( flpFirstMultiplicandPrecision
* fabs ( fIpSecondMultiplicand ) )
4- ( f IpSecondMultiplicandPrecision
* fabs ( fIpFirstMultiplicand ) ) );
}
flpLocalReturnValue = (long double) fIpFirstMultiplicand *
(long double) fIpSecondMultiplicand;
if ( flpLocalResultPrecision < DBLEPSILON
* fabs ( flpLocalReturnValue ) )
flpLocalResultPrecision = DBLEPSILON
* fabs ( flpLocalReturnValue ) ;
if ( fabs ( flpLocalReturnValue ) > DBL_MAX )
{
if ( pfIpResultPrecision 1- NULL )
*pfIpResultPrecision = DBLMAX;
if ( pErrorRaised 1= MULL )
♦pErrorRaised = ARITHMETPRECISIONBAD;
if ( flpLocalReturnValue < 0.0L )
flpReturnValue = - DBLMAX;
else flpReturnValue - DBLMAX;
if ( RaiseError )
raise ( ARITHMETPRECISIONBAD );
return ( flpReturnValue );
} else {
flpReturnValue = flpLocalReturnValue;
if ( pfIpResultPrecision 1= NULL )
♦pfIpResultPrecision = flpLocalResultPrecision;
if ( flpLocalResultPrecision >
( fabs ( flpReturnValue ) > DBLEPSILON ?
( fabs ( flpReturnValue )
* ARITBMETACCEPTPRECISION ) s DBLEPSILON ))
<
if ( pErrorRaised !- NULL )
♦pErrorRaised = ARITHMETBEYONDRANGE;
if ( RaiseError )
raise ( ARITHMETBEYONDRANGE );
}
}
return ( flpReturnValue );
}
double flpSafeMultiply (double fIpFirstMultiplicand,
double fIpSecondMultiplicand)
<
double flpReturnValue = 0.0;
flpReturnValue ~ fIpSafeMultiplySensitive (
fIpFirstMultiplicand, 0.0,
fIpSecondMultiplicand, 0.0,
MULL, FALSE, NULL);
return (flpReturnValue);
}
double fIpSafeAddSensitive ( double fIpFirstAddidand,
double flpFirstAddidandPrecision,
double flpSecondAddidand,
double fIpSecondAddidandPrecision,
double * pfIpResultPrecision,
Арифметика произвольной точности
Глава 24
645
int RaiseError,
int * pErrorRaised )
{
double flpReturnValue = 0.0;
double flpZero = 0.0;
double flpLocalResultPrecision = 0.0;
double flpLocalFirstPrecision - 0.0;
double flpLocalSecondPrecision - 0.0;
long double flpLocalReturnValue = 0.0;
if ( pfIpResultPrecision 1= NULL )
{
flpLocalFirstPrecision = DBLEPSILON
* fabs( flpFirstAddidand );
if ( DBL_EPSILON > flpLocalFirstPrecision )
flpLocalFirstPrecision = DBLEPSILON;
if ( fIpFirstAddidandPrecision > flpLocalFirstPrecision )
flpLocalFirstPrecision = fIpFirstAddidandPrecision;
flpLocalSecondPrecision = DBLEPSILON
* fabs( fIpSecondAddidand );
if ( DBLEPSILON > flpLocalSecondPrecision )
flpLocalSecondPrecision = DBL_EPSILON;
if ( fIpSecondAddidandPrecision >
flpLocalSecondPrecision )
flpLocalSecondPrecision = fIpSecondAddidandPrecision;
flpLocalResultPrecision = flpLocalFirstPrecision
4- flpLocalSecondPrecision ;
if ( flpLocalResultPrecision < DBLEPSILON )
flpLocalResultPrecision = DBL EPSILON;
*pfIpResultPrecision = flpLocalResultPrecision;
}
if ( pErrorRaised 1- NULL )
«pErrorRaised = 0;
flpLocalReturnValue = (long double) flpFirstAddidand +
(long double) fIpSecondAddidand;
if ( flpLocalResultPrecision < DBLEPSILON
* fabs ( flpLocalReturnValue ) )
flpLocalResultPrecision = DBLEPSILON
* fabs ( flpLocalReturnValue ) ;
if ( fabs ( fIpLocalReturnValue ) > DBL MAX )
{
if ( pfIpResultPrecision != NULL )
♦pfIpResultPrecision = DBLMAX;
if ( pErrorRaised 1- MULL )
♦pErrorRaised « ARITHMETPRECISIONBAD;
if ( fIpLocalReturnValue < 0.0L )
flpReturnValue = - DBLMAX;
else flpReturnValue = DBLMAX;
if ( RaiseError )
raise ( ARITHMETPRECISIONBAD );
return ( flpReturnValue );
} else {
flpReturnValue - fIpLocalReturnValue;
if ( pf IpResultPrecision 1= NULL )
♦pfIpResultPrecision = flpLocalResultPrecision;
if ( flpLocalResultPrecision >
( fabs ( flpReturnValue ) > DBLEPSILON ?
( fabs ( flpReturnValue )
* ARITHMETACCEPTPRECISION ) : DBLEPSILON ))
{
if ( pErrorRaised 1= NULL )
♦pErrorRaised « ARITHMETBEYONDRANGE;
if ( RaiseError )
raise ( ARITHMETBEYONDRANGE );
646
Дополнительные тематические разделы
Часть III
}
}
return ( fIpReturnValue );
}
double flpSafeAdd (double fIpFirstAddidand,
double flpSecondAddidand)
{
double fIpReturnValue = 0.0;
fIpReturnValue = flpSafeAddSensitive (
fIpFirstAddidand, 0.0,
fIpSecondAddidand, 0.0,
NULL, FALSE, NULL);
return (fIpReturnValue);
}
double flpSafeSubtractSensitive (
double flpFirstSubtrahend,
double fIpFirstSubtrahendPreci sion,
double flpSecondSubtrahend,
double fIpSecondSubtrahendPrecision,
double * pflpResultPrecision,
int RaiseError, int * pErrorRaised )
{
double fIpReturnValue = 0.0;
fIpReturnValue = flpSafeAddSensitive ( flpFirstSubtrahend,
fIpFirstSubtrahendPrecision,
- fIpSecondSubtrahend,
fIpSecondSubtrahendPrecision,
pflpResultPrecision,
RaiseError, pErrorRaised );
return (fIpReturnValue);
}
double flpSafeSubtract (double flpFirstSubtrahend,
double flpSecondSubtrahend)
{
double fIpReturnValue я 0.0;
fIpReturnValue = flpSafeSubtractSensitive (
flpFirstSubtrahend, 0.0,
flpSecondSubtrahend, 0.0,
NULL, FALSE, NULL);
return (fIpReturnValue);
}
int flpcmp( double dA, char *sCond, double dB )
{
int iStatus = -1;
int iEqual = -1;
int iALargerThanB я -1;
double dBig, dAbsDiff, dDelta;
dBig = fabs( ( fabs( dA ) > fabs( dB ) ) ? dA : dB );
dDelta = dBig * COMPAREEPSILON;
dAbsDiff = fabs( dA - dB );
iEqual = ( dAbsDiff <= dDelta ) ? TRUE : FALSE;
iALargerThanB = dA > dB;
if ( 0 яя strcmp( sCond, "яя" ) )
iStatus = iEqual;
else if ( 0 == strcmpf sCond, "!=" ) )
iStatus я IiEqual;
else if ( 0 str cap ( sCond, <" ) )
iStatus - ( IiALargerThanB ) || iEqual;
else if ( 0 == str cup ( sCond, ">=" ) )
iStatus = iALargerThanB 11 iEqual;
Арифметика произвольной точности
Глава 24
647
else if ( 0 == strcmp( sCond, "<" ) )
iStatus = ( 1 iALargerThanB ) £& ( liEqual );
else if ( 0 == strcmp( sCond, •>• ) )
iStatus = iALargerThanB && ( liEqual );
else
raise( SIGILL );
return iStatus;
}
int flpSetEquivalent( double *dA, double *dB )
{
int iStatus = FALSE;
iStatus = flpcmp( *dA, ==", *dB );
if ( TRUE == iStatus )
<
if ( fabs( *dA ) > fabs( *dB ) )
*dB = *dA;
else
*dA = *dB;
1
return iStatus;
}
В данных функциях при выполнении каждой опе-
рации вычисляется точность получаемого результата.
Следует отметить, что, даже если операнды не содер-
жат ошибок, вполне вероятно, что ошибку будет содер-
жать результат. Кроме того, функции выдают предуп-
реждения при возникновении ошибки переполнения,
деления на нуль (или на число, близкое к нулю) и не-
допустимой потери значимости.
При использовании стандартных типов они сами по
себе не позволяют повысить точность получаемых ре-
зультатов. Если вы действительно хотите получать зна-
чения с заданной точностью, вам совершенно необхо-
димо обобщить методы вычислений.
Выбор представления сверхточных
чисел
Выбор средств для представления чисел с высокой точ-
ностью зависит от конкретных потребностей. Всегда
продумайте, какая точность вычислений вам нужна и чем
вы готовы заплатить за требуемую точность. В данной гла-
ве было предложено несколько вариантов такого представ-
ления чисел высокой точности и приведены примеры фун-
кций для работы с ними. В приведенной в конце главы
программе вычисления числа е используется еще один
метод. Каждый метод имеет свои недостатки, касающи-
еся скорости работы, расширяемости, простоты коммер-
ческого использования, допустимого диапазона чисел и
т.д. К сожалению, не существует какого-либо одного
оптимального варианта, который можно было бы ис-
пользовать во всех случаях для представления чисел с
высокой точностью.
Это одна из тех областей создания программ, в ко-
торых перед принятием решения необходимо до конца
продумать все последствия принятого решения. Желаю
удачи!
Вычисление числа е с точностью до
десяти тысяч знаков после точки
В листинге 24.6 приведен пример программы для вычис-
ления числа е с точностью до десяти тысяч знаков пос-
ле точки. Обратите внимание, что в программе содер-
жится несколько констант. Их описание приведено в
табл. 24.12. В качестве упражнений можно сделать сле-
дующее:
• Модифицировать приведенную программу для рабо-
ты с массивами значений типа long int, а не с мас-
сивами значений типа int. Это займет примерно
столько времени, сколько требуется для закипания
чайника.
• Написать функцию LongMultiply, аналогичную фун-
кции LongDivide, которая бы умножала массив зна-
чений типа long int на одно значение типа long int.
Это займет примерно столько времени, сколько вам
требуется, чтобы выпить чашечку кофе.
• Написать функцию aLongMultiply, которая бы умно-
жала два больших числа, содержащиеся в массиве типа
long int. Здесь вам будет необходимо определить раз-
мер результирующего числа, а следовательно, и раз-
мер массива, в который будет помещаться результат.
За это время можно будет выпить уже несколько
чашек кофе.
Дополнительные тематические разделы
Часть III
648
• Написать функцию aLongDivide, которая бы дели- ла два больших числа, содержащихся в массиве типа long int Это уже не так просто, поэтому на Web-сай- те издательства "ДиаСофт" в файле Ch24AOK.c даны Таблица 24.12. 1 ления числа е. Сонстанты в программе вычис-
Имя константы Описание константы
некоторые подсказки (возможно, ошибочные), а в NUMBERJBASE Основание нашего представления
файлах Ch24AOK,c и Ch24AOK2.c приведено реше- ние. Если вы не захотите пользоваться приведенны- DIGSJNBASE чисел Количество десятичных позиций в
ми подсказками, то выполнение этого задания мо- жет стоить вам целого бассейна кофе и большого NUMBER-WIDTH числе NUMBER_BASE-1 Количество элементов в массиве,
расстройства. lUMIT представляющем число Максимальное количество итераций в цикле проведения вычислений
Листинг 24,6, Программа вычисления числа е с точностью до WOOD знаков после десятичной точки,
/* Комментарии к этой программе приведены на Web-сайте "ДиаСофт” в файле Ch24BigE.c */
linclude <stdio.h>
linclude <limits.h>
Idefine ILIMIT 3300
/* ПРЕДУПРЕЖДЕНИЕ. Достоверность выполнения различных действий с числами с таким основанием
ограничена. */
lif (INT_MAX>(ILIMIT*100000))
Idefine NUMBERBASE 100000
Idefine DIGSINBASE 5
lelse
Idefine NUMBERBASE 10
Idefine DIGSINBASE 1
lendif
lif (DIGSIN_BASE==5)
Idefine NUMBERWIDTH 2001
lelse
Idefine NUMBERWIDTH 10001
lendif
int LongDivide ( int * Numerator, int * Denominator,
int * Answer );
int LongAdd ( int * iFirst, int * iSecond, int * iAnswer );
int main(int argc, char * argv[])
{
int aResult[NUMBERWIDTH+l];
int aWork[NUMBER_WIDTH+1];
int i;
int j;
aResult[0] = NUMBERWIDTH;
aResult[l] = 1;
aWorkfO] = NUMBERWIDTH;
aWorkfl] = 1;
for (i=2;(i<=NUMBER_WIDTH);i++)
{
aResult[i] « 0;
aWork[i] = 0;
for (i=l;(i<ILIMIT);i++)
{
j s LongDivide ( aWork, &i, aWork );
if (j<=0)
i • ILIMIT + 1;
LongAdd ( aWork, aResult, aResult );
}
649
Арифметика произвольной точности
Глава 24
printf("е - ");
printf("%1.Id.",aResult[l]);
for (i=2;(i<NUMBER_WIDTH);i++)
{
lif (DIGS_IN_BASE==5)
printf("%5.5d ",aResultfi]);
lendif
I if (DIGSINBASE==1)
printf("%1.Id"faResult(i]);
if ((i % 5)==1)
printf(" ");
lendif
if ((i I 10)==0)
{
printf("\n");
if ((i % 100)==0)
printf("\n");
}
}
printf("\n");
return 1;
}
int LongDivide ( int * Numeratorf int * Denominator,
int * Answer )
{
int iStatus = 0;
int j = 0;
int к = 0;
int m = 0;
int d = 0;
d = «Denominator;
Answer[0] = Numerator!0];
for (j=l;(j<=Numerator[0]);j++)
{
if (k>0)
m в Numerator! j] + (k * NUMBER BASE) •
else
m = Numerator!j];
Answer!j] = m / d;
if (Answer!]] 1=0)
iStatus = 1;
к = m % d;
}
return iStatus;
}
int LongAdd ( int * iFirst, int * iSecond, int * iAnswer )
{
int iStatus • 0;
int i = 0;
int 3 = 0;
int к = 0;
int m = 0;
i = iFirst!0];
к = 0;
for (pi;(j>0|;j-)
{
if (iFirst!j]1=0)
iStatus = 1;
m = iFirst]j] + iSecond!3] i- k;
к = 0;
Дополнительные тематическиеразделы
Часть III
650
while (m>=NUMBER_BASE)
{
m -= NUMBERBASE;
к += 1;
}
iAnswerfjJ = n;
return iStatus;
Какой же ответ мы получим в результате выполне-
ния приведенной программы? Начало ответа приведе-
но ниже, а полностью он содержится на Web-сайте из-
дательства "ДиаСофт" в файле Ch24BigE.c.
е = 2.71828 18284 59045 23536 02874 71352 66249 77572 47093
69995 95749 66967 62772 40766 30353 54759 45713 82178 52516
64274 27466 39193 20030 59921 81741 35966 29043 57290 03342
95260 59563 07381 32328 62794 34907 63233 82988 07531 95251
01901 15738 34187 93070 21540 89149 93488 41675 09244 76146
06680 82264 80016 84774 11853 74234 54424 37107 53907 77449
92(169 55170 27618 38606 26133 13845 83000 75204 49338 26560
29760 67371 13200 70932 87091 27443 74704 72306 96977 20931
01416 92836 81902 55151 08657 46377 21112 52389 78442 50569
53696 77078 54499 69967 94686 44549 05987 93163 68892 30098
79312 77361 78215 42499 92295 76351 48220 82698 95193 66803
31825 28869 39849 64651 05820 93923 98294 88793 32036 25094
43117 30123 81970 68416 14039 70198 37679 32068 32823 76464
80429 53118 02328 78250 98194 55815 30175 67173 61332 06981
12509 96181 88159 30416 90351 59888 85193 45807 27386 67385
89422 87922 84998 92086 80582 57492 79610 48419 84443 63463
24496 84875 60233 62482 70419 78623 20900 21609 90235 30436
99418 49146 31409 34317 38143 64054 62531 52096 18369 08887
07016 76839 64243 78140 59271 45635 49061 30310 72085 10383
75051 01157 47704 17189 86106 87396 96552 12671 54688 95703
50354 02123 40784 98193 34321 06817 01210 05627 88023 51930
33224 74501 58539 04730 41995 77770 93503 66041 69973 29725
08868 76966 40355 57071 62268 44716 25607 98826 51787 13419
51246 65201 03059 21236 67719 43252 78675 39855 89448 96970
96409 75459 18569 56380 23637 01621 12047 74272 28364 89613
42251 64450 78182 44235 29486 36372 14174 02388 93441 24796
35743 70263 75529 44483 37998 01612 54922 78509 25778 25620
92622 64832 62779 33386 56648 16277 25164 01910 59004 91644
99828 93150 56604 72580 27786 31864 15519 56532 44258 69829
46959 30801 91529 87211 72556 34754 63964 47910 14590 40905
86298 49679 12874 06870 50489 58586 71747 98546 67757 57320
56812 88459 20541 33405 39220 00113 78630 09455 60688 16674
00169 84205 58040 33637 95376 45203 04024 32256 61352 78369
51177 88386 38744 39662 53224 98506 54995 88623 42818 99707
73327 61717 83928 03494 65014 34558 89707 19425 86398 77275
47109 62953 74152 11151 36835 06275 26023 26484 72870 39207
64310 05958 41166 12054 52970 30236 47254 92966 69381 15137
32275 36450 98889 03136 02057 24817 65851 18063 03644 28123
14965 50704 75102 54465 01172 72115 55194 86685 08003 68532
28183 15219 60037 35625 27944 95158 28418 82947 87610 85263
98139 55990 06737 64829 22443 75287 18462 45780 36192 98197
13991 47564 48826 26039 03381 44182 32625 15097 48279 87779
96437 30899 70388 86778 22713 83605 77297 88241 25611 90717
66394 65070 63304 52795 46618 55096 66618 56647 09711 34447
40160 70462 62156 80717 48187 78443 71436 98821 85596 70959
10259 68620 02353 71858 87485 69652 20005 03117 34392 07321
13908 03293 63447 97273 55955 27734 90717 83793 42163 70120
Арифметика произвольной точности
651
Глава 24
50054 51326 38354 40001 86323 99149 07054 79778 05669 78533
58048 96690 62951 19432 47309 95876 55236 81285 90413 83241
16072 26029 98330 53537 08761 38939 63917 79574 54016 13722
36187 89365 26053 81558 41587 18692 55386 06164 77983 40254
35128 43961 29460 35291 33259 42794 90433 72990 85731 58029
09586 31382 68329 14771 16396 33709 24003 16894 58636 06064
58459 25126 99465 57248 39186 56420 97526 85082 30754 42545
99376 91704 19777 80085 36273 09417 10163 43490 76964 23722
29435 23661 25572 50881 47792 23151 97477 80605 69672 53801
71807 76360 34624 59278 77846 58506 56050 78084 42115 29697
52189 08740 19660 90665 18035 16501 79250 46195 01366 58543
66327 12549 63990 85491 44200 01457 47608 19302 21206 60243
30096 41270 48943 90397 17719 51806 99086 99860 и т.д<
Резюме
В данной главе рассмотрены способы, с помощью ко-
торых при использовании стандартного языка С мож-
но добиться высокой точности арифметических вычис-
лений и создать программы для выполнения операций
над числами, содержащими большое количество цифр.
Кроме того, было рассказано, каким образом (иногда со-
вершенно неожиданным) возникают и распространяют-
ся ошибки. И в качестве заключительного примера было
вычислено число е с несерьезной точностью — всего
лишь до десяти тысяч знаков после десятичной точки.
Несерьезной? И число е, и число п уже известны с точ-
ностью до сотен миллионов знаков после точки, и, если
вы хотите уметь делать то же самое, то вам необходимо
изобрести свои методы представления чисел со сверх-
высокой точностью. Удачи вам!
Обработка естественных языков
2
В ЭТОЙ ГЛАВЕ
Синтаксис и семантика естественных языков
Сложности ввода естественных языков
Сложности вывода естественных языков
Ян Келли
В английском языке можно создать выражения, для
понимания которых существуют определенные прави-
ла. Выражения, которые не подчиняются этим прави-
лам, считаются ошибочными и не являются частью
английского языка. То же самое можно сказать и в от-
ношении арифметических выражений в языке С, о ко-
торых шла речь в главе 19. Но мы не можем повернуть
время вспять и изменить существующие выражения
английского языка, если они не подчиняются нашим
правилам. Поэтому нужно либо изменить наши прави-
ла, либо каким-либо образом обрабатывать возникаю-
щие ошибки. И одним из путей исторического разви-
тия английского языка было возникновение время от
времени курьезных выражений, которые не подчиняют-
ся существующим правилам, но, тем не менее, являют-
ся частью английского языка или становятся его частью.
Существует множество компьютерных систем, кото-
рые в качестве входных данных принимают естествен-
но-языковой ввод. В настоящей главе рассмотрены ме-
тоды, которые могут использоваться при обработке
естественных языков. Английский язык — это есте-
ственный язык, и большая часть примеров будет при-
ведена именно на английском языке. Но этот язык ни-
чем не отличается от других естественных языков,
например, русского, французского, немецкого, суахи-
ли, тамильского, китайского, арабского, урду или испан-
ского языков. Все эти языки относятся к разряду слож-
ных, как, впрочем, все естественные языки.
Компьютерные системы, которые имеют дело с ес-
тественными языками, также могут быть сложными. В
данной главе рассматриваются как простые системы
(например, командные процессоры), так и очень слож-
ные (например, системы машинного перевода). Вы уз-
наете, что означает термин "обработка естественных
языков" и какие существуют методы обработки, кото-
рые могут быть применимы на вычислительной маши-
не. В главе производится сравнение английского языка
с синтаксисом и семантикой алгоритмического языка и
рассматривается написание кода на С, предназначенно-
го для обработки естественных языков.
Синтаксис и семантика естественных
языков
Как и алгоритмические языки, естественные языки об-
ладают понятиями синтаксиса и семантики: что можно
сказать и что сказанное значит Но синтаксис естествен-
ных языков намного сложнее синтаксиса алгоритмичес-
ких языков и намного более гибок. Семантика естествен-
ных языков зависит от реального мира, а не от
искусственного мира, в котором все можно измерить.
Например, в данный момент я набираю текст этой гла-
вы на портативном компьютере. Я сижу в поезде. На-
против меня сидит высокий, начинающий лысеть мо-
ложавый человек со светлыми волосами. Он
сосредоточенно читает книгу в мягком переплете, сло-
жив ее вдвое и не заботясь о сохранности ее корешка.
В газетах часто встречаются такие описания, и мы
считаем их правильными. Теперь вы можете представить
себе, хотя и не совсем точно, этого человека. Вы не
знаете его точного возраста, вы не можете быть увере-
ны в том, какая у него прическа (но вы знаете кое-что
о его прическе), вы знаете, что он что-то делает с кни-
гой (ни размера, ни цвета которой вы не знаете). Каж-
дый читатель представит себе образ этого человека по-
разному, и этот образ будет отличаться от реального
человека, сидящего напротив меня. Каждая система,
выполняющая обработку естественного языка, должна
уметь справляться с такими неточностями и при необ-
ходимости исправлять их. Один политик как-то жало-
Обработка естественных языков
Глава 25
653
вался, что его умышленные двусмысленные выражения
были потеряны при переводе. Программы могут и не
иметь двусмысленностей, но данные для этих программ
могут их иметь.
Синтаксис естественных языков
Можно ли составить полную описательную граммати-
ку такого языка, как английский? Нет, нельзя. Можно
составить и написать описательную грамматику неко-
торых частей английского языка, на котором говорят
(или пишут) в отдельных районах. Но полная грамма-
тика должна позволять использование таких выражений
как, "Mistah Kurtz — he dead" (Джозеф Конрад), и в то
же время указывать, что такие выражения употреблять
не следует. Наблюдения за разговорным языком (в от-
личие от более официального письменного языка) по-
казывают, что большую часть часть выражений, кото-
рые мы употребляем, в действительности нельзя назвать
полными выражениями, и они могут быть понятны
только из контекста. "Хотите кофе? Передайте мне,
пожалуйста,... спасибо,... с сахаром или без?"
В IV веке (или в VI, а может быть, и в каком-то дру-
гом — по этому вопросу ведется много научных споров)
до нашей эры Панини (Panini) записал синтаксис язы-
ка санскрит (и первая буква п в его имени должна пи-
саться с точкой под ней). Возможно, вы не говорите на
санскрите, если, конечно, не решили изучать индуист-
ские религиозные тексты или индоевропейскую линг-
вистику, но в то давнее время санскрит был широко
распространенным языком. Грамматика Панини более
всего соответствует полному описанию естественного,
разговорного языка. Для описания языка необходимо
иметь систему синтаксических обозначений, и Панини
разработал такую систему. Она не так уж отличается от
нормальной формы Бэкуса (BNF) — очень мощная и
очень неудобная.
В школе вы, наверное, изучали английские суще-
ствительные, прилагательные и глаголы, а также пути
определения подлежащего и сказуемого в предложении.
Вам известны такие термины, как "единственное чис-
ло" и "множественное число", "будущее время" и "при-
даточное предложение". Вы также, может быть, знаете,
что предложение в английском языке строится, как
правило, по принципу "подлежащее-глагол-дополне-
ние". Но встречали ли вы когда-нибудь диаграмму сле-
дующего вида:
которая разбирает один возможный вариант синтакси-
са предложения The cat sat on the mat.(Kor сидел на ков-
рике)? Эта диаграмма в точности соответствует диаграм-
ме на рис. 25.1.
Обе диаграммы показывают, что предложение состо-
ит из подлежащего, за которым следует сказуемое; ска-
зуемое состоит из глагола, за которым следует предлож-
ная группа; именная группа состоит из артикля, за
которым следует существительное и т.д.
Существуют другие модели языка, но лингвисты все
еще не договорились, какая из моделей наиболее на-
глядна или какая наиболее полезна. Например, анализ
зависимостей дает схему, показанную на рис. 25.2.
Так что не существует единственно правильного ва-
рианта синтаксического разбора английского предложе-
ния. Все зависит от ваших предпочтений и в конечном
счете от цели проведения синтаксического анализа.
РИСУНОК 25.1. Синтаксис английского языка для простого предложения.
Дополнительные тематические разделы
Часть III
654
РИСУНОК 25.2. Анализ зависимостей простого предложения.
Отличия от алгоритмических языков
Такой язык, как С (Кобол, Фортран или Ада), в значи-
тельной мере определяется своим синтаксисом. Синтак-
сис известен заранее, и известно также, что он полон и
верен. Такие языки, £ак английский (французский,
арабский или тамильский), расширяются и изменяют-
ся, и никакая организация не может решить, какой син-
таксис верен.
Если вы говорите на американском варианте англий-
ского языка, нужно надеяться (hopefully), вы поймете
то, что я сейчас сказал. Если же вы говорите на британ-
ском варианте английского языка, вам, может быть,
будет резать слух американское использование слова
hopefully в предыдущем предложении. Но такое "амери-
канское использование” в некоторых случаях становит-
ся и "британским использованием". В естественных язы-
ках появляются не только новые слова, но и новые пути
использования этих слов.
Пример правил для подмножества английского
языка
В табл. 25.1 приведены простые грамматические прави-
ла для небольшого подмножества английского языка.
Эти правила позволяют создать много предложений, в
которых используются слова из набора boy girl dog cat
table chair old young green heavy intelligent living kisses hits puts
gives runs barks sits talks lies decays glows never soon on by with
to the a no every. Грамматика представлена в сжатой, пер-
воначальной версии нормальной формы Бэкуса, кото-
рая рассматривалась в главе 19.
Таблица 25.1. Первая грамматика.
Синтаксические правила
предложение:—подлежащее сказуемое #
подлежащее: :=именная-группа #
сказуемое: :=глагольная-группа | глагольная-группа дополнения обстоятельства #
дополнения: :=прямое-дополнение | косвенное-дополнение | прямое-дополнение обстоятельства косвенное-дополнение #
глагольная-группа: :=обстоятельства глагол обстоятельства #
обстоятельство: :=наречие обстоятельства | наречие | пусто #
прямое-дополнение::=именная-группа #
косвенное-дополнение::=предлог именная-группа #
именная-группа::=определитель прилагательные существительное #
прилагательные::=прилагательное прилагательные | прилагательное | пусто #
пусто::= #
артикль: :="the" | "а” | "по" | "every” #
существительное::=”Ьоу” | "girt" | "cat" | "dog” | "table” | "chair” #
прилагательное::="old" | "young" | "green" | "heavy" | "intelligent" | "living" #
наречие: :="never" | "soon" #
предлог::="оп" | "by" | "with" | "to” #
глагол: :="kisses” | "puts" | "gives" | "runs" | "lies" | "barks” | "sits" | "talks" | "hits" | "decays" | "glows" #
Обработка естественных языков
Глава 25
Грамматические правила, приведенные в табл. 25.1,
позволяют создавать такие предложения, как/Ле boy kisses
a girl, a dog never barks, the boy soon gives a heavy cat to a
young girl. Эти предложения обычны и корректны, они
верны с точки зрения английского языка. Но приведен-
ные правила позволяют создавать и такие странные
предложения, как the green dog kisses a young table, a heavy
chair barks, every old chair soon lies on the green cat. Эти
предложения верны с точки зрения грамматики англий-
ского языка, но маловероятны с точки зрения реально-
го мира (собаки не зеленые, стулья не лают). Но, с дру-
гой стороны, это неплохо, что грамматика позволяет
использовать такие предложения: в конце концов, в
каких-нибудь странных обстоятельствах они могут ока-
заться полезными.
Кроме того, приведенные грамматические правила
допускают использование таких предложений, как every
heavy green heavy green green green heavy heavy young old cat
barks with a table. Это предложение неверно. Чрезвычай-
но трудно придумать такие обстоятельства, при кото-
рых данное предложение будет иметь смысл, а предло-
Таблица 25.2. Более ограничивающая грамматика.
Синтаксические правила
жение по girl soon never puts soon never уже абсолютно вне
всякого понимания, но, тем не менее, по приведенным
грамматическим правилам оно возможно. Получается,
что это неправильная грамматика?
Нет, правильная.
Приведенные выше предложения на самом деле
вполне соответствуют правилам английского языка, а
причиной, по которой они считаются ошибочными,
является то, что в этом реальном мире у нас никогда бы
не возникла необходимость в их использовании. Эти
предложения являются следствием наблюдений за этой
вселенной (’’реальным миром”), но не за всеми возмож-
ными вселенными. Полезные обстоятельства, может
быть, не так легко придумать, но это не означает, что
они невозможны. С другой стороны, приведенная грам-
матика не позволяет сказать то, что действительно не-
возможно в английском языке, например, barks green with
puts. Для такого предложения нельзя придумать интер-
претации ни в одной вселенной.
В табл. 25.2 приведены более жесткие грамматичес-
кие правила, которые еще более ограничивают количе-
ство возможных предложений.
предложение::=личное-подлежащее личное-сказуемое | одушевленное-подлежащее одушевленное-сказуемое |
неодушевленное-подлежащее неодушевленное-сказуемое #
подлежащее::=именная-группа #
личное-подлежащее::=личная-именная-группа#
одушевленное-подлежащее::=одушевленная-именная-группа #
неодушевленное-подлежащее::=неодушевленная-именная-группа #
сказуемое::=глагольная-группа | глагольная-группа дополнения обстоятельства #
личное-сказуемое::=личная-глагольная-группа | личная-глагольная группа-дополнения обстоятельства #
одушевленное-сказуемое: :=одушевленная-глагольная-группа | одушевленная-глагольная-группа дополнения обстоятельства #
неодушевленное-сказуемое::=неодушевленная-глагольная-группа | неодушевленная-глагольная-группа дополнения
обстоятельства #
дополнения::=прямое-дополнение | косвенное-дополнение | прямое-дополнение обстоятельства косвенное-дополнение #
глагольная-группа::=обстоятельства глагол обстоятельства #
личная-глагольная-группа::=обстоятельства личный-глагол обстоятельства #
одушевленная-глагольная-группа::=обстоятельства одушевленный-глагол обстоятельства #
неодушевленная-глагольная-группа::=обстоятельства неодушевленный-глагол обстоятельства #
обстоятельства::=наречие обстоятельства | наречие | пусто #
прямое-дополнение::=именная-группа #
косвенное-дополнение: :=предлог именная-группа #
личная-именная-группа::=определитель личная-часть #
одушевленная-именная-группа::=определитель одушевленная-часть #
неодушевленная-именная-группа::=определитель неодушевленная-часть #
именная-группа::=определитель личная-часть | определитель одушевленная-часть | определитель неодушевленная-часть #
личная-часть:: =личные-прилагательные личное-существительное #
одушевленная-часть::=одушевленные-прилагательные одушевленное-существительное #
656
Дополнительные тематические разделы
Часть III
неодушевленная-часть::=неодушевленные-прилагательные неодушевленное-существительное #
прилагательные::=прилагательное прилагательные | прилагательное | пусто #
личные-прилагательные::= личное-прилагательное личные-прилагательные | личное-прилагательное | пусто #
одушевленные-прилагательные: “одушевленное-прилагательное одушевленные-прилагательные | одушевленное-прилагательное |
пусто #
неодушевленные-прилагательные::=неодушевленное-прилагательноенеодушевленные-прилагательные | неодушевленное-
прилагательное | пусто #
общие-прилагательные::=общее-прилагательное общие-прилагательные | общее-прилагательное | пусто #
пусто::= #
артикль::="the" | "а” | ’’по" | "every” #
неодушевленное-существительное::-ЧаЬ1е” | "chair” #
одушевленное-существительное::="саГ | "dog" | личное-существительное #
личное-существительное::="Ьоу" | "girl" #
существительное::=неодушевленное-существительное | одушевленное-существительное #
общее-прилагательное ::="old" | "young" | "heavy" #
личное-прилагательное: :=общее-прилагательное | одушевленное-прилагательное | "intelligent” #
одушевленное-прилагательное: :=общее-прилагательное | "living" #
неодушевленное-прилагательное::=общее-прилагательное | "green" #
прилагательное::=общее-прилагательное | личное-прилагательное | неодушевленное-прилагательное #
наречие: :="never" | "soon" #
предлог::=”оп” | "by" | "with” | "to" #
o6iunn-maron::="stands" | "lies" #
неодушевленный-глагол::=’Ч1есаув" | "glows" | общий-глагол #
одушевленный-глагол::="Ьагкз" | "sits" | "puts" | "runs" [ общий-глагол #
личный-глагол::="И5ве8" | "gives" | "talks" | "sits" | "puts" | "runs" | общий-глагол #
глагол::=неодушевленный-глагол | одушевленный-глагол | личный-глагол #
Грамматические правила, приведенные в табл. 25.2,
все еще позволяют составлять предложения типа the boy
kisses a girl, a dog never barks и the boy soon gives a heavy cat
to a young girl. Но они не позволяют использовать пред-
ложения, в которых содержится что-то вроде green cat
или green dog только boy или girl может быть подлежа-
щим при talks и kisses так что фраза типа the green table
glows, приемлема, а фраза типа a dog glows — нет. Мож-
но сказать: the dog runs, но нельзя сказать: the table runs.
При расширении грамматические правила, приведен-
ные в этой таблице становятся громоздкими, и вскоре
приходится думать о других методах их представления.
К тому же, приведенные грамматические правила слиш-
ком жесткие, а ведь в некоторых случаях (хотя и ред-
ко) мы хотим поговорить о green dog (о зеленой собаке).
Поэтому, может быть, не следует использовать грамма-
тику один раз, а делать несколько проходов по есте-
ственно-языковым входным данным, объявляя отдель-
ные структуры более или менее допустимыми в
зависимости от наших знаний о реальном мире и от
степени сочетаемости отдельных слов.
Кроме того, в нашей грамматике задан полный сло-
варный состав. Такой подход неприменим для широкого
распознавания естественного языка: необходимо иметь
словари, которые могут содержаться в файлах, куда
можно добавлять новые слова. Каждая словарная статья
должна содержать информацию о той или иной части
речи (существительное, прилагательное, наречие и т.д.),
о том, является ли словарная статья личной, одушевлен-
ной или неодушевленной или принадлежит к какому-
либо другому классу.
Распознавание контекста
Грамматические правила, приведенные в табл. 25.2,
включают в себя некоторые характеристики семантики.
Для естественных языков это неизбежно. Мы попыта-
лись включить в нашу грамматику некоторые возмож-
ности по распознаванию контекста. Ноам Чомски (Noam
Chomsky) разделил грамматику на четыре группы:
Грамматика типа 3 — регулярная, или конечно-авто-
матная грамматика
Грамматика типа 2 — фразо-структурная, или грам-
матика непосредственных составляющих, или некон-
текстная грамматика
Грамматика типа 1 — контекстная грамматика
Грамматика типа 0 — общая грамматика
Обработка естественных языков
Глава 25
[б57
Грамматика большинства алгоритмических языков
является грамматикой типа 2, т.е. неконтекстной грам-
матикой, хотя некоторая чувствительность к контексту
может быть встроена в механизм интерпретации (семан-
тический элемент) компиляторов (например, в С опе-
ратор j=34000; обычно предполагает, что переменная j
не должна иметь тип short int). Грамматика естествен-
ных языков принадлежат, по крайней мере, к типу —
1, контекстная грамматика. С одной стороны, чувстви-
тельность к контексту является результатом нашего зна-
ния реального мира, а с другой — просто связана с са-
мим языком. Некоторые аналитики утверждают, что
грамматика естественных языков принадлежит к типу
О — общая грамматика.
Если взглянуть на запрещенные выражения, приве-
денные в табл. 25.3, то можно увидеть, что знание ре-
ального мира не является достаточной причиной для
объявления какой-либо лингвистической структуры
ошибочной.
Смешивание словарного состава (словаря) и грамма-
тики в единую структуру приводит к меньшей прозрач-
ности как словаря, так и грамматики. Одна из возмож-
ных методик —грамматика выражается в простом виде
(как показано в табл. 25.1), но к терминам в словаре
добавляются два типа маркеров. Первый тип маркеров —
простые грамматические категории: boy и table являют-
ся существительными, green и intelligent — прилагатель-
ными. Второй тип маркеров указывает, какого рода ха-
рактеристиками обладает данный термин и в какой
степени. Так, например, boy и table являются одушевлен-
ными и личными, cat и dog — одушевленными, a table —
неодушевленным; глаголы talks и kisses являются личны-
ми в большой степени и одушевленными — в. меньшей.
Далее, синтаксический анализатор может быть устроен
таким образом, чтобы он предпочитал объединение слов
с совпадающими свойствами, т.е. он объединяет личные
глаголы с личными подлежащими или (в меньшей сте-
пени) с одушевленными подлежащими, неодушевлен-
ные прилагательные — с неодушевленными существи-
тельными и т.д.
Другой тип анализа, который проводился над боль-
шими частями текста, был направлен на определение
того, какие слова чаще всего употребляются в сочета-
нии. Например, слово table часто употребляется со сло-
вом leg, но не так часто со словом chlorine. Такие табли-
цы совместимости очень полезны в тех случаях, когда
есть сомнения в правильности обрабатываемого текста
на естественном языке или когда необходимо опреде-
лить, какое именно значение имеет данное слово в дан-
ном контексте. Более подробно эти вопросы рассмотре-
ны в разделе "Машинный перевод".
Грамматика алгоритмических языков четко установ-
лена, и ее границы хорошо известны. Всегда можно
определить, является ли в определенном алгоритмичес-
ком языке данное выражение возможным или нет. Но в
естественных языках границы возможного постоянно
изменяются, и в любой период времени существуют
выражения, которые находятся "на грани возможного",
поэтому бывает сложно определить, являются ли они
частью языка или нет. Системы обработки естественных
языков должны уметь справляться с такими сложностя-
ми и делить входные данные не на "хороший язык" и
"плохой язык", а на входные данные, которые система
может обработать, и на другие входные данные
С помощью синтаксического анализатора, рассмот-
ренного в главе 19, можно получить дерево анализа ан-
глийских предложений, основанного на любом наборе
рассмотренных выше грамматических правил. Однако
код для вычисления выражений необходимо будет из-
менить на более подходящий код для системы обработ-
ки естественных языков. Вы сами должны определить-
ся с семантикой вводимых данных.
Таблица 25,3. Запрещенные выражения.
Запрещенное выражение Причина
The green dog (зеленая собака) Знание реального мира: собаки не бывают зеленого окраса. Но я могу покрасить собаку в зеленый цвет. Это возможно.
The boys has spoken (мальчики поговорили) Знание лингвистики: the boys является множественным числом, a has spoken требует подлежащего в единственном числе.
Colorless green ideas sleep furiously (бесцветные зеленые идеи бездействуют неистово) Знание реального мира: трудно представить какой-либо мир, в котором данное предложение будет иметь смысл. Но если предложение интерпретировать как “unexciting ecological concepts do nothing very much, with a great deal of noise” (неинтересные экологические концепции практически не работают, зато поднимают много шума), тогда в нашем реальном мире такое предложение будет иметь смысл. Это запрещенное выражение Чомски приводит как один из примеров грамматического выражения, не являющегося частью языка.
Man flies to the Moon (человек летит на Луну) Знание реального мира: это совершенно невозможно. Ой! В 1969 году наши знания о реальном мире изменились. Теперь это предложение стало возможным.
42 Зак. 265
658
Дополнительные тематические разделы
Часть III
Семантика естественных языков
The cat sat on the mat. Lots of cats do that, everybody knows.
And nothing strange comes of it. But once cat sat on the mat
and something strange did come of it.
(Кот сидел на коврике. Масса котов делают это,
каждый знает. И ничего странного с ними не про-
исходит. Но один раз кот сидел на коврике и с ним
произошло нечто странное) (Джоан Эйткен "The Cat
Sat on the МаГ из "Stories for Under-Fives")
Но какой смысл несет этот текст?
Когда вам встречается такое простое предложение
как The cat sat on the mat, вы говорите: "Я знаю, что это
значит’*, но действительно ли вы знаете? Прежде всего,
очень многое зависит от цели предложения. Было ли
целью приведенного предложения указать, что в опре-
деленный момент времени в реальном мире отдельная
особь вида fe/is felis села на небольшой коврик у двери?
Или предложение является просто примером для ребен-
ка, который еще учится читать, но, тем не менее, мо-
жет понять смысл прочитанного? Или оно было выб-
рано просто из-за повторяющегося ассонанса звуков at?
Для человека смысл предложения легче понять из
контекста. Смысл цитаты из восхитительной детской
сказки Джоан Эйткен, приведенной в начале этого раз-
дела, не ограничивается ее буквальным смыслом, она,
кроме того, служит литературным источником, который
могут понять даже маленькие дети. Еше одним контек-
стом, в котором приведено данное предложение, явля-
ется иллюстрация методик синтаксического разбора.
Иногда бывает сложно определить смысл одного-
единственного слова, не говоря уже о предложении.
Часто слова имеют несколько значений. Например, сло-
во table может быть реальным существительным (вещь,
которая идет в комплекте со стульями), абстрактным
существительным (table of elements — таблица элемен-
тов), прилагательным (Table Mountain — горное плато)
или глаголом, означающим вынесение предложений на
рассмотрение. В этом последнем контексте значение
слова table очень отличается по смыслу, вкладываемо-
му в данное слово по разные стороны Атлантики. Кро-
ме того, глагол table может означать “помещать в мас-
сив (таблицу)" (table these figures). Какое именно значение
имеет слово table и к какой части речи оно принадле-
жит, можно определить только из контекста. И это спра-
ведливо для очень большой части английских (и не
только) слов.
В таких предложениях, как Time flies like an arrow
(Время летит подобно стреле) и Fruit flies like an apple
(Плод падает подобно яблоку), мы знаем, что слъьъflies
и like имеют различные значения. Это вытекает из на-
шего знания реального мира и лексики, т.е. мы знаем,
что в английском языке существует такое понятие, как
fruit fly (плодовая мушка) (поэтому эти два слова стоят
вместе, fly является существительным, a fruit — прила-
гательным, описывающим существительное), но в анг-
лийском языке нет такого понятия, как time fly.
При разработке и создании компьютерных систем
необходимо подумать: "Для чего нам нужны входные и
выходные данные системы обработки естественных язы-
ков? Что мы ожидаем от системы?” И на основании
ответов на эти вопросы можно создать узкоспециализи-
рованную грамматику подмножества английского язы-
ка (испанского, валлийского, чироки, японского и т.д.),
которая подходит для нашей системы.
В алгоритмическом языке каждый оператор имеет
четко определенное значение. В естественных языках
значение может варьироваться в широких пределах.
Перед созданием системы компьютерной интерпрета-
ции естественного языка мы всегда должны задать себе
вопрос: "Что мы ожидаем от системы?" Осуществляем
ли мы поиск команд, описаний, выдаем информацию
или анализируем авторство?
Если в качестве примера взять самую простую сис-
тему обработки естественных языков — систему, кото-
рая осуществляет выбор из ограниченного количества
выражений (например, анализатор команд компьютер-
ной системы), то для такой системы семантика языка
будет довольно простой. Если рассмотреть очень боль-
шую систему, например систему машинного перевода,
то для такой системы семантика будет очень сложной.
Сложности ввода естественного языка
Лично я предпочел бы разговаривать со своим компью-
тером. Моя жена говорит мне, что я на самом деле гово-
рю со своим компьютером, но я бы хотел, чтобы ком-
пьютер меня понимал и мог отвечать мне. Но можем ли
мы в наше время получить возможность естественно-
языкового ввода в компьютер или машинную систему?
Команды обработки
Вы, вероятно, знакомы и с другими алгоритмическими
языками помимо С. Это могут быть языки сценариев
команд UNIX или языки управления других систем
(JCL в MVS, командные файлы MS-DOS и т.д.). Набор
возможных команд очень ограничен: удаление файлов,
запрос о свободном месте на диске, создание каталогов,
запрос на возникновение определенных событий в оп-
ределенные моменты времени и т.п. Для представления
таких команд можно выбрать небольшое подмножество
английского языка. Так, вместо
cd /home/syzygy
Is -1 *.c
rm test.c
rm *.tmp
Обработка естественных языков
Глава 25
{659
можно было бы "сказать" или набрать на клавиатуре:
Go to directory syzygy under home under the root directory.
Show me the names and details of all files of type little C.
Delete the file test dot little C. Delete all files of type little
Tee Em Pee.
Эти же команды могут на некоторых системах выг-
лядеть следующим образом:
cd \home\syzygy
dir *.c
erase test.c
erase *.tmp
Это позволяет пользователю не изучать более лако-
ничные командные языки, которые отличаются от си-
стемы к системе. К сожалению, английский язык на-
много более витиеватый, чем командные языки.
Игры
Go north. Take rod. Put bird in cage. Flight dragon with sword.
Эти команды знакомы всем, кто играл в Adventure (иног-
да эту игру называют Colossal Cave). Другие игры (на-
пример, Zork) позволяет вводить даже более сложные
команды. Некоторые из многопользовательских сетевых
игр обладают еще более широкими возможностями по
обработке естественных языков.
В игре четко определены границы возможного, и
весь язык, который используется в игре, относится толь-
ко к этому миру. Большая часть вводимых пользовате-
лем команд представляют собой команды действий (сде-
лай что-то: go, take, flight), за которыми следует прямое
дополнение (объект, над которым производится дей-
ствие: bird, dragon), а иногда и косвенное дополнение
(объект, в (на) котором или с помощью которого про-
изводится действие: in cage, with sword).
Обработка команд не представляет особых сложно-
стей: если игрок говорит eat banana, а в данный момент
у него нет banana или игра не поддерживает действие
eat, то игрок просто получает сообщение, что его коман-
да осталась непонятой (и, возможно, при этом он уви-
дит гнома, который бросает в него топор).
Синтаксис игры с естественно-языковым интерфей-
сом, как правило, очень ограничен, и при обработке не
приходится сталкиваться с многозначностью: bear будет
обозначать только медведя, a table всегда будет столом.
Машинный перевод
Совершенно другой задачей является машинный пере-
вод, т.е. использование компьютера для перевода с од-
ного естественного языка на другой. На вход системы ма-
шинного перевода может подаваться текст любой степени
сложности, в котором может идти речь практически о
чем угодно, а на выходе желательно получать адекват-
ный (возможно, не совсем элегантный) и корректный
перевод. Если система машинного перевода не может
обработать текст, то у нее нет возможности, как в игре
Colossal Cave, бросить в вас топор. Синтаксис системы
машинного перевода чрезвычайно сложен.
Системы машинного перевода начали разрабатывать-
ся еще со времен создания первых электронных вычис-
лительных машин, и в настоящее время имеется не-
сколько таких систем. Эти системы, как правило,
используются большими компаниями и организациями,
такими как Европейская комиссия, компания Ford
Motor, ВВС США и НАСА. Но иногда они используют-
ся и отдельными пользователями. Существуют Web-сай-
ты, которые могут давать перевод Web-страниц на ос-
новные европейские языки.
Наиболее успешно системы машинного перевода
работают с информационными текстами, но плохо ра-
ботают со стилистическими или идиоматическими тек-
стами. Например, следующие предложения довольно
легко поддаются машинному переводу: Use the 15 mm.
open-end spanner to remove the topmost nut.; The control-flow
statements of a language specify the order in which computations
are performed.; Draw ellipse with horizontal diameter dl and
vertical diameter d2, with left edge at current position. Но сле-
дующие предложения перевести будет гораздо сложнее:
How sweet the moonlight sleeps upon this bank (Шекспир); No
time like the present (народи.); After us the deluge (Мария
Антуанетта); Give him a flea in his ear (народн.); But where
are the snows of yesteryear? (Виллон); Go down the shop and
get us half a pigs head, with two eyes, to see us through the week
(Лондон Кокни).
Почему последние предложения сложнее перевести?
Рассмотрим предложение Give him a flea in his ear (Дай-
те ему блоху в ухо). Оно не имеет никакого отношения
ни к блохам (flea), ни к ушам (ear), оно означает отру-
гайте его. Это идиоматическое выражение. Но если это
предложение перевести дословно на французский язык,
то, невзирая на его идиоматический смысл в английс-
ком языке, мы получим другую, французскую идиому,
которая означает прошепчите ему. Поэтому система ма-
шинного перевода, осуществляющая перевод данного
предложения с английского языка на французский, дол-
жна знать эту идиому в английском языке и соответству-
ющую ей идиому во французском языке. Теперь рас-
смотрим предложение Go down the shop ] to see us through
the week (Спуститесь в магазин и принесите половину
свиной головы с глазами, чтобы увидеться через неде-
лю). Это предложение основано на двух значениях сло-
ва "see": видеть и продержаться.
Словарь системы машинного перевода должен быть
особенно богат, поскольку в нем должны быть не толь-
ко отдельные слова, но и идиомы и термины, состоя-
щие из нескольких слов. Так, например, словарь должен
содержать слово magnetic, слово tape и слово unit, но он
660
Дополнительные тематические разделы
Часть III
должен содержать и термин magnetic tape unit. Слово
magnetic переводится на французский язык как
magnutique, tape — как utape, a unit — как unitu. но тер-
мин magnetic tape unit (лентопротяжное устройство, маг-
нитофон) переводится на французский язык как
durouleur.
Возможная длина термина не ограничивается:
myocardial infarction — это единый термин, состоящий из
двух специальных слов; magnetic tape unit — это жаргон-
ный термин, состоящий из трех, сравнительно широко
употребляемых слов. Нейл Томкинсон (Neil Tornkinson)
(в статье Reflections on English Usage журнала Language
Monthly за июль 1984) цитирует слова Reserve Band
guaranteed Atlas Aircraft Corporation Limited bearer U.S. dollar
ten year Certificates как единый термин — эквивалент
одного слова — в том контексте, в котором он исполь-
зовался.
Количество терминов в языке даже большее, чем
количество слов, и, кроме того, есть уже упоминавши-
еся идиомы. Идиома — это устойчивое выражение, зна-
чение которого невыводимо из значений составляющих
его компонентов. Состоящие из одного слова идиомы
представляют собой многозначные слова, или метафо-
ры. Идиомы, состоящие из нескольких слов, могут быть
метафорами, которые еще существуют, например: w
have not closed the door on negotiations (мы не хлопнули
дверью на переговорах), или которые уже исчезли из
языка, например: closing the stable door after the horse has
bolted (закройте плотнее дверь после того, как лошадь
будет стреножена). Английское выражение pig in a poke
соответствует русскому выражению кот в мешке, но
выражение let the cat out of the bag (выпустите кота из
мешка) имеет совершенно другой смысл. И беда ждет
переводчика эвфемизма tired and emotional (усталый и
эмоциональный), который не знает, что на самом деле
он означает (в английских газетах) пьяный.
Определить , что переводить, а что оставить без пе-
ревода, также бывает сложно, и особую проблему в этом
смысле представляют имена собственные. Jean-Loup
Chiflet указывает, что по-английски его имя John
Wolfwhistle, Dr. Peter Toma, который руководил исследо-
ваниями в Джоржтауне по созданию рабочей системы
машинного перевода, был удивлен, прочитав свое имя
как Dr. Peter Divided into [several] volumes. Toma — это
старая, достаточно редкая, но реальная форма француз-
ского глагола tomer, который означает ’’делить на [не-
сколько] томов".
Сложность представляет также определение того,
какие части входных данных являются идиомами, а
какие —- нет. Например, тот, кто kicks the bucket очень
редко бьет ногой по емкости для переноски жидкости;
как раз перед этим он on his last legs (по-английски), но
beating the garlic (по-французски). Ответственность не
лежит буквально на ваших плечах, это просто метафо-
ра, a pain tn the neck не всегда указывает на дискомфорт
в шейных позвонках. Русское выражение на улице боль-
шое движение дословно переводится на английский как
on street large motion, но на литературном английском это
будет there is a lot of traffic in the street.
Выбор правильного значения многозначных слов и
словосочетаний в некоторых случаях требует знания
темы текста (если в тексте говорится о мебели, то table
будет столом; если в тексте говорится о финансовом
состоянии, то table будет таблицей чисел), а в некото-
рых случаях выбор правильного значения зависит от
грамматических форм предложений (в одном предложе-
нии может быть только один глагол, следовательно, bear—
глагол, а в другом предложении есть два возможных
глагола, но только одно подлежащее, следовательно, bear —
существительное).
По машинному переводу написано много книг.
Я рекомендую в качестве хорошего вводного источни-
ка книгу Machine Translation, Ten Years On, eds. Douglas
Clarke and Alfred Vella, Cranfield University Press, 1998,
и превосходную книгу Machine Translation, Past, Present,
Future W.J. Hutchins, Ellis Horwood, 1986.
В настоящее время существует огромное количество
систем машинного перевода (Globalink, Metal, Systran,
AppTek, PC-Transfer, PARS, SPANAM/ENGSPAN,
ATLAS, Transcend, LOGOS и Eurotra). Еще больший
список вы можете найти в сети Internet .
Увидеть систему машинного перевода Systran в действии
можно на Web-странице http://babelfish.altavista.com/.
На http://www.t-mail.com/ работает безымянная систе-
ма машинного перевода. По адресам http://www.lim.nl/
eamt/ (и на Web-страницах организаций-филиалов) и
http://bcs.org.uk/nalatran/nalatran.html приведена ин-
формация по некоторым другим системам и их теоре-
тическим основам, а также много другой полезной ин-
формации.
Эквивалентность
При больших объемах обрабатываемых текстов на есте-
ственном языке сравнение проводить трудно. Функция
strcpy языка С указывает только на посимвольную эк-
вивалентность. Но мелочи часто приводят к ошибкам:
иногда мы используем неверную грамматику, вставля-
ем ненужные слова или пропускаем нужные. Система
обработки естественных языков должна с этим справ-
ляться. Поэтому сравнение строк в системе обработки
естественных языков должна давать в результате не боль
ше/равно/меныие, а степень эквивалентности строк. Од-
ним методом является назначение каждой позиции сим-
вола коэффициента значимости (веса), причем первые
позиции имеют большую значимость. А дальше сам
пользователь решает, принять ли ему ответ больше нуля/
нуль/меньше нуля или учитывать абсолютное значение.
661
Листинг 25.1. Сравнение строк.
linclude <string.h>
int strlikefchar *s, char *t)
{
int i;
int j;
int r = 0;
int w = 16384;
r = strcpy(s,t);
if (r==0)
return r;
if (r<0)
w = -w;
j = min(strlen(s)rstrlen(t));
for (i=0; (i<j); i++)
{
if (s[i|==t[ij)
r += w;
w = w / 2;
}
return r;
Это алгоритм нечеткого сравнения. Далее в этой
главе в разделе "Синтаксический разбор естественно-
языкового ввода" будет рассказано об использовании
нечетких синтаксических анализаторов.
Искусственный интеллект
Джон Маккарти (John McCarthy), изобретатель языка
программирования LISP, в 1956 г. впервые ввел термин
искусственный интеллект. С тех пор сам этот термин и
понятие, им обозначаемое, являются предметом многих
дискуссий. Вот несколько мнений относительно искус-
ственного интеллекта:
• Искусственный интеллект невозможен. Только чело-
веческие существа (или другие существа, у которых
есть душа) могут обладать интеллектом, машины не
могут иметь души, и поэтому они не думают. Искус-
ственный интеллект можно сравнить с пластиковы-
ми цветами, которые несут только внешнее подобие
оригинала, но не обладают его свойствами.
• Машину можно заставить думать. Искусственный ин-
теллект можно также уподобить вертолету, который,
по сути, является искусственной птицей: его полет ре-
ален, даже несмотря на то, что внешний вид вертоле-
та и принцип полета отличаются от птичьего.
• Искусственный интеллект, наконец, подобен со-
зданному человеком искусственному озеру, которое
по всем своим свойствам и внешнему виду идентич-
но природному. Они отличаются только по своему
происхождению, но после прошествия некоторого
периода времени это различие не будет иметь ника-
кого значения. Искусственный интеллект — это про-
сто следующий шаг в естественном развитии все
Обработка естественных языков
Глава 25
более специализированных и приспособленных
форм жизни на Земле.
Каждое из этих мнений (и многие другие) исполь-
зовались в качестве обоснований для следующих выво-
дов:
• Исследования в области искусственного интеллек-
та были признаны в худшем случае безвредными, а
в лучшем способными принести пользу.
• Бессмысленными и обреченными на неудачу.
• Самой важной задачей, которую должно решать лю-
бое цивилизованное общество.
• Недопустимыми, так как они являются порождени-
ем греха.
Независимо от того, можно заставить машины ду-
мать или нет, исследования в области искусственного
интеллекта дают больше простора для работы машин.
Мы узнаем все больше и больше, и границы искусст-
венного интеллекта раздвигаются все дальше и дальше.
Лично я считаю, что искусственный интеллект имеет
непосредственное отношение к компьютерам, о которых
мы еще ничего не знаем. Хорошо известная компьютер-
ная диалоговая модель ELIZA является примером того,
что раньше считали искусственным интеллектом, но
теперь она всего лишь забавная игрушка.
Понимание речи требует высокого уровня интеллек-
та (отдельные примеры приведены в разделе "Распозна-
вание речи" далее в этой главе), и, несомненно, искус-
ственный интеллект будет играть немалую роль в
обработке естественных языков.
Установление авторства
Стилистический анализ разговорного языка отличается
от того, что обычно пишут в словарях. Например, если
вы владеете английским языком, то знаете, наверное,
что основное значение английского глагола to see связа-
но с действием, выполняемым глазами (смотреть, ви-
деть). Но, скорее всего, вы не догадываетесь, что этот
глагол употребляется в значении to understand (пони-
мать) в 3 раза чаще, чем во всех других значениях. По-
этому при проведении синтаксического разбора и пере-
воде мы должны указать компьютеру наиболее часто
используемые значения слов.
В тексте можно сосчитать общее количество слов и
составить таблицу использования наиболее часто ис-
пользуемых слов. Количество вхождений определенных
слов будет варьироваться от автора к автору. На осно-
вании такого анализа невозможно гарантировать, что все
тексты одного автора дадут одни и те же значения вхож-
дений для одних и тех же наиболее часто встречающих-
ся слов, но с достаточно высокой степенью увереннос-
ти можно сказать, что вследствие определенного образа
Дополнительные тематические разделы
Часть III
662
мышления отдельного автора его наиболее часто упот-
ребляемые слова будут одними и теми же.
Отношение количества вхождений наиболее часто
употребляемых слов к общему количеству слов являет-
ся достаточно точным показателем авторства. Этот ме-
тод используется в качестве основы для определения
авторства. Например, анализ Посланий от Павла на язы-
ке оригинала (греческом) показал, что они написаны
разными авторами (что было известно уже давно).
Определение отношений количества вхождений оп-
ределенных слов не говорит о содержании текста, но
имеет смысл спросить, в каком соотношении эта пара
(или тройка) слов входят в лексикон. И это может дать
некоторое представление о существовании терминов,
состоящих из нескольких слов, в которых рассматрива-
емые слова разделены.
Если вы хотите написать код, который производит
подсчет слов в тексте и выдает частоту их вхождения,
прочитайте раздел "Морфология" далее в этой главе.
Может быть, вы захотите сгруппировать подобные сло-
ва, например, а и ап будут считаться одним словом так
же как love, loves, loved и loving.
Листинг 25.2. Формирование случайного текста.
Электронные игрушки
На прошлое Рождество мне подарили игрушку Ферби
(Furby). Это привлекательная говорящая электронная
игрушка. Она реагирует на звук и свет, может опреде-
лить, когда она находится вверх ногами или когда ее
гладят, щекочут или кормят. Ферби можно кормить
только воображаемой едой, нажимая ложкой на язык.
Моя Ферби говорит по-английски (немного). Я знаю,
что есть Ферби, говорящие по-испански и по-французс-
ки, и нет никакой принципиальной причины, по которой
она не могла бы говорить на любом другом языке.
Язык, на котором говорит Ферби, достаточно гибок
и основан на словаре, который состоит примерно из ста
слов, нс все из которых являются английскими. Эти
слова объединяются в словосочетания С течением вре-
мени длина словосочетаний растет — структура пред-
ложений усложняется.
В листинге 25.2 приведен код, которые формирует
случайный, но, тем не менее, синтаксически правиль-
ный английский текст.
linclude
linclude
linclude
linclude
<stdio.h>
<string.h>
<stdlib.h>
<time.h>
char* pRandWord ( char* WordListf], int ListLength, int NullChances)
{
char* pReturn = NULL;
int iMaximum;
int iFound;
iMaximum = ListLength + NullChances;
iFound = rand() % iMaximum;
. if (iFound<ListLength)
pReturn = WordListfiFoundJ;
return pReturn;
)
void WordListf char* WordListf], int ListLength)
{
int iProbNull;
char* pW;-
iProbNull = ListLength;
pW = WordListf0];
while (pW!=NULL)
{
pW = pRandWord (WordListr ListLengthr iProbNull);
iProbNull += iProbNull;
if (pW!=NULL)
printf ("Js "rpW);
}
)
663
Обработка естественных языков
Глава 25
int main (int argc, char* argv[J)
{
int i = 0;
int j = 0;
char* pW;
char *Nouns[] = { "table", "chair", "boy", "girl", "dog", "cat",
"bottle", "clarinet", "candle", "sofa", "father", "mother",
"television", "telephone", "flower", "book", "cup" };
int CountNouns = 17;
char *Verbs[] = { "eats", "kisses", "loves", "orders", "sees",
"understands", "takes", "answers", "moves", "ignores" };
int CountVerbs = 10;
char «Adjectives!] = { "tall", "small", "pretty", "flat", "tuneless",
"different", "green", "plastic", "delicate", "pompous" };
int CountAdjectives = 10;
char «Determiners[] = { "a", "the", "no", "every"
int CountDeterminers = 4;
char «Adverbs[] = { "quickly", "slowly", "twice", "evenly", "thus" };
int CountAdverbs = 5;
timet th is time;
thistime = time(NULL);
srand (thistime);
pW = pRandWord (Determiners, CountDeterminers, 0);
printf("%s ",pW);
WordList(Adjectives, CountAdjectives);
pW = pRandWord (Nouns, CountNouns, 0);
printf("%s ",pW);
WordList(Adverbs, CountAdverbs);
pW = pRandWord(Verbs, Countverbs, 0);
printf("%s ",pW);
pW = pRandWord (Determiners, CountDeterminers, 0);
printf("%s ",pW);
WordList(Adjectives, CountAdjectives);
pW = pRandWord (Nouns, CountNouns, 0);
printf("%s.\n",pW);
return 0;
}
Распознавание речи
Моя жена говорит, что телефон в моей машине — это
игрушка. Он узнает мой голос, когда я прошу его на-
брать определенные телефонные номера. Мы так при-
выкли к распознаванию речи, что часто не задумываем-
ся над тем, насколько это сложно. Если кто-то
обращается к вам на языке, на котором вы говорите, вы
без труда можете разбить поток звуков на отдельные
слова и фразы и понять смысл сказанного. Однако, если
вы слушаете разговор на незнакомом языке, вы даже не
можете угадать, где кончается одно слово и начинается
другое. Насамомделемыговоримнепрерывнымпотокомзву-
ков. Подумайте о трудностях, которые рассматривают-
ся в последующих разделах.
Обработка звука
В каждом языке есть свои звуки. Единственным звуком,
который существует во всех естественных языках, яв-
ляется звук А. Мы может произвести не одну сотню
других звуков. В каждом языке существует от 12 до 60
различных звуков — это небольшая часть из всех воз-
можных звуков. В английском языке используется око-
664
Дополнительные тематические разделы
Часть III
ло 45 звуков. Эти звуки называются фонемами. Написан-
ные буквы являются только приближением этих звуков.
Распознавание фонем
Чтобы распознать произносимые звуки, необходимо
иметь модель звуков языка. Эта модель будет отличать-
ся даже в самых похожих по своей природе языках и в
различных диалектах одного и того же языка. Американ-
ский акцент очень сильно отличается от южно-англий-
ского, но говорящие с разными акцентами люди хоро-
шо распознают соответствующие звуки.
Чтобы показать, насколько важен акцент, рассмот-
рим стандартное австралийское произношение слова
"basin" (бассейн), которое точно соответствует стандар-
тному американскому произношению слова "bison" (би-
зон). Любая система обработки речи, которая нс может
справиться с такими вариациями, будет бесполезной.
Рассмотрим предложение The cat sat on the mat. Ка-
кие фонемы присутствуют в данном предложении?
В этом предложении имеются следующие фонемы:
[qskatsatbn qsmat], или /q/ /з/ /к/ /а/ /t/ /s/ /а/ /t/ /Ь/ /
n//q//3//m//a//t/.
Что это значит? Символы, которые выглядят не со-
всем так, как обычные буквы, являются символами IPA
(Международного фонетического алфавита). Данная кни-
га написана о языке программирования С, поэтому, если
вы хотите просмотреть полный перечень символов IPA и
их значений, обратитесь к книгам по лингвистике (или
изучите предисловия к большим словарям). Но смысл
приведенной странной строки символов прост: "за зву-
ком /th/ следует звук /ег/, далее идет звук Д/" и т.д.
Для анализа звуков языка можно записать большой
объем разговорного языка и проанализировать записи
или в книгах по лингвистике найти результаты уже
проведенных анализов.
Сандхи
В разговоре мы в зависимости от контекста несколько
изменяем основные звуки. Рассмотрим для примера
слово "sit". Это слово содержит три фонемы: [sit]. Теперь
рассмотрим слово "down". Оно состоит из четырех фо-
нем [down]. Но при произнесении слов sit down конеч-
ное "t" слова sit и начальное "d" слова down объединя-
ются в дин звук "d”, т.е. в действительности
произносится [sidown] или sid-down. Такое изменение
звуков называется сандхи (sandhi). (Это санскритский
термин.) Любая система распознавания речи должна
иметь хотя бы базовые знания о правилах сандхи раз-
говорного языка. Эти правила будут различны в различ-
ных языках.
Распознавание слов
Казалось бы, после разделения звукового потока на от-
дельные фонемы и после применения правил сандхи
для данного языка распознавание слов будет уже не-
сложной задачей.
Увы, нет. В распознавании слов есть свои сложнос-
ти, среди которых — определение начала и окончания
слова и морфология.
Во фразе six sailors seek cattle для получения правиль-
ной комбинации система должна быть способна откло-
нить варианты sick sailor see cat le и six sail or sea-cat le.
В данном случае мы знаем, что 1е не является английс-
ким словом, и это знание позволяет правильно проана-
лизировать поток звуков. А как насчет фразы: Can he be
famous?, которая состоит точно из тех же звуков, что и
фраза canny beef a mouse. В действительности разница
есть — она в ударении. Первый слог слова famous нахо-
дится под ударением, а в слове mouse под ударением
находится все слово. И хотя вы об этом, может быть, и
не догадываетесь, но, тем не менее, ударение имеет
очень большое значение для понимания речи.
Морфология
Рассмотрим английское слово "love" (любовь). Оно яв-
ляется основой для образования слов loves, loved, lovely,
и п lovingly, unloved, lover и т.д. "Дополнительные части",
которые добавляются к слову "love", называются морфе-
мами, а раздел грамматики, который рассматривает
структуру слов, называется морфологией.
В каждом естественном языке имеются свои прави-
ла образования морфем и сопряжения слов. В этом от-
ношении английский язык довольно прост. Для обра-
зования множественного числа добавляется "s" (cat,
cats), для образования прошедшего времени — "ed" (love,
loved), "ing" добавляется для образования прилагатель-
ного или причастия от глагола (love, loving), "ly" — для
образования наречия от прилагательного (delicious,
deliciously). В других языках для сопряжения слов име-
ется очень большое количество морфем. Если бы сло-
варь содержал все возможные формы слов, он был бы
огромным. Мы привыкли находить корень слова и по
корню определять значение слова. Такой же процесс
можно использовать в компьютерных словарях, но при
этом необходимо производить морфологический анализ.
Иногда морфологические изменения можно произ-
водить по определенным правилам, но в некоторых слу-
чаях приходится пользоваться словарем. Рассмотрим
листинг 25.3, в котором сделана попытка генерирования
форм английских глаголов. Рассмотрим, как глагол to
open звучит в предложении / open this book. Можно ска-
зать Yesterday I opened this book и I have opened this book и
I am opening this book.
Обработка естественных языков
665
Глава 25
Листинг 25.3. Морфологические изменения.
linclude <stdio.h>
linclude <string.h>
void MorphVerbl(char* verb)
{
printf("%s %sed %sed
*-»%sing\n",verb,verb,verb,verb);
return;
}
int main(int argc, char* agv[])
{
MorphVerbl("open");
MorphVerbl("love");
return 0;
}
При работе программы над словом love в результате
получаем лишние буквы е. Эту ошибку можно испра-
вить, проверяя последний символ глагола: если после-
дний символ е, добавляем только J, если последний
символ не е, добавляем ed, а при добавлении ing конеч-
ную е необходимо убрать. Это учтено в листинге 25.4.
Эта программа будет производить правильные мор-
фологические изменения для глаголов to open и to love,
но для глагола to tap ответ будет содержать ошибку. Мы
должны добавить правило, согласно которому, если гла-
гол заканчивается на одну согласную, перед которой
стоит одна гласная, то согласная удваивается — tap,
tapped. Если же перед конечной согласной стоят две
гласные, то согласная не удваивается — clean, cleaned.
Это правило учтено в листинге 25.5.
Листинг 25.4. Морфологические изменения, вторая попытка.
linclude <stdio.h>
linclude <string.h>
void MorphVerbl(char* verb)
{
int Lengthverb;
int EPosition;
Lengthverb = strlen(verb);
EPosition = Lengthverb - 1;
if (verb[EPosition J=='e')
printf("%s %sd %sd %*.*sing\n",verb,verb,verb,
EPosition,EPosition,verb);
else printf("%s %sed %sed %sing\n",verb,verb,verb,verb);
return;
}
int nain(int argc, char* agv[J)
{
MorphVerbl("open");
MorphVerbl("love");
MorphVerbl("tap");
return 0;
Листинг 25.5. Морфологические изменения, третья попытка.
linclude <stdio.h>
linclude <string.h>
int isVowel (char cTestLetter)
{
int iReturn = 0;
if ((cTestLetter=='a') || (cTestLetter==fe')
|| (cTestLetter=='i') || (cTestLetter==* о')
(cTestLetter=='u'))
iReturn = 1;
return iReturn;
}
void MorphVerbl(char* verb)
{
int Lengthverb;
int LastPosition;
LengthVerb = strlen(verb);
LastPosition = LengthVerb - 1;
Дополнительные тематические разделы
666
Часть III
if (verb[LastPosition]=='e')
printf("%s %sd %sd %*.*sing\n",verb,verb,verb,
LastPosition,LastPosition,verb);
else if ((!isVowel(verb[LastPosition]))
&& ( isVowel(verb[LastPosition-1]))
&& (!isVowel(verb[LastPosition-2])))
printf(”%s %s%ced %s%ced %s%cing\n”,verb,
verb,verb[LastPosition],
verb,verb[LastPosition],
verb,verb[LastPosition]);
else printf("%s %sed %sed %sing\n",verb,verb,verb,verb);
return;
int main(int argc, char* agv[])
{
MorphVerbl("open");
MorphVerbl("love");
MorphVerbl("tap");
MorphVerbl("clean");
MorphVerbl("look");
MorphVerbl("see");
return 0;
В результате работы этой программы мы получим
правильные ответы для глаголов love, tap, clean и look,
но формы глагола to open будут ошибочными (виной
этому — наше последнее правило). И что еще хуже, мы
не можем придумать алгоритм, который бы правильно
образовывал формы глаголов to see (see, saw, seen, seeing)
и to shake (shake, shook, shaken, shaking) и других непра-
вильных и сильных английских глаголов. В таких слу-
чаях придется пользоваться словарем.
Распознавание выражений
Теперь рассмотрим выражения, т.е. одно разговорное
предложение или команду. Вы уже поняли, что необ-
ходимо иметь некоторую систему, дающую возмож-
ность голосового ввода (здесь необходимо определить-
ся с соответствующим аппаратным и программным
обеспечением для обработки звука). Нужно разделить
входной звуковой поток на фонемы и внести изменения
в соответствии с правилами сандхи. Следует просмот-
реть словарь языка, убрать все неопределенности и
представить для обработки последовательность слов
(или, скорее всего, список возможных последовательно-
стей слов). Все это представляет собой достаточно слож-
ную задачу, значительная часть которой еще плохо изу-
чена. И неудивительно, она не так часто встречается.
После ввода выражений их необходимо обработать,
но чтобы окончательно решить, ’’что было сказано на
самом деле”, эту стадию обработки вполне можно со-
четать со стадией ввода.
Наиболее простые системы имеют узкие границы
возможных входных данных. Например, мой автомо-
бильный телефон воспринимает только номера и очень
ограниченный набор команд, состоящих из одного или
двух слов.
Обработка выражений
Если система является игрой, то игра продолжается.
Если система работы с естественными языками — ко-
мандный процессор (телефона или компьютера), то
команда преобразуется во внутренний формат операци-
онной системы или машины и выполняется. Если это
система перевода речи (такие системы создаются для
перевода речи при проведении международных теле-
фонных разговоров), то на основании входных данных
производится перевод. Независимо от назначения сис-
темы существует вероятность того, что система будет
работать без ошибок, равно как и того, что она будет
работать с ошибками.
Обработка ошибок
Метод обработки ошибок зависит от назначения систе-
мы и от этапа, на котором возникла ошибка. Это дале-
ко не ново — системы обработки естественных языков
в этом отношении аналогичны любым другим компью-
терным системам.
Ошибки Moiyr происходить на этапе распознавания
входных данных, например, вследствие сильного шумо-
вого фона, нераспознаваемого акцента или использова-
ния слов, которых нет в словаре. Ошибки могут быть в
самой команде. Например, пользователь может либо
дать указание удалить несуществующий файл или файл,
который нельзя удалить, либо попросить сделать за-
Обработка естественных языков
667
Глава 25
прещенное действие, либо дать недостаточно информа-
ции для выполнения команды, либо в игре просит вы-
полнить недопустимое действие и т.п. Каждую из этих
ошибок следует обрабатывать с учетом назначения си-
стемы. Можно, например, произвести поиск похожего
корректного выражения, предложить свой вариант, от-
клонить команду или выполнить какое-либо другое со-
ответствующее действие.
Распознавание текста
Очень важно иметь как можно более полное представ-
ление о распознавании текста, так как большинство
систем обработки естественных языков принимают ввод
в письменном виде. Такой ввод имеет громадные пре-
имущества хотя бы только потому, что система точно
уверена в правильности распознавания входных данных
(хотя ошибок в обработке все еше хватает). К таким
системам предъявляются не столь жесткие требования
по распознанию входных данных, за исключением слу-
чаев, когда текст поврежден или ошибочен. Все мы зна-
комы с программами проверки орфографии, которые
пытаются разобраться в смысле набранного нами тек-
ста. В листинге 25.1 был приведен пример алгоритма
нечеткого сравнения строк, который определяет скорее
не эквивалентность строк, а их подобие.
Существуют алгоритмы такого типа и для более
сложного синтаксического анализа предложений, кото-
рые не соответствуют грамматическим правилам, но
близки (при использовании определенных значений
входящих в него слов) к правильному предложению.
Синтаксический анализ естественно-
языкового ввода
В главе 19 приведен пример синтаксического анализа-
тора. Можно ли расширить такого рода анализатор для
работы с естественно-языковым вводом, и если да, то
какие изменения необходимо внести?
Не существует единственно верного метода проведе-
ния синтаксического анализа естественно-языкового
ввода, каждая система в зависимости от назначения
использует свой набор грамматических правил. Для
систем машинного перевода синтаксический анализ
должен быть достаточно глубоким, для игры анализ
может быть совсем простым. Многочисленные Web-
страницы, посвященные машинному переводу, позво-
ляют оценить, насколько сложен процесс синтаксичес-
кого анализа. Но для простоты в последующих разделах
мы будем считать, что разрабатываем синтаксический
анализатор для компьютерной игры. Поэтому анализа-
тор будет довольно простым и будет иметь маленький
словарь. В нашем случае словарь не обязательно должен
быть внешним, он может быть частью грамматики.
Методы синтаксического анализа
Как и в алгоритмических языках, для синтаксического
разбора естественно-языкового ввода существует не-
сколько методов. Одна грамматическая и лингвистичес-
кая модель может быть реализована несколькими мето-
дами.
Как правило, мы считаем, что анализ должен про-
ходить сверху вниз, но окончательное дерево анализа не
всегда строится именно таким образом, его можно по-
строить и снизу вверх. Это относится и к анализу алго-
ритмического языка, и к анализу естественно-языково-
го ввода. Анализаторы для анализа сверху вниз легче
создавать, но работают они медленнее, а анализаторы
для анализа снизу вверх сложнее создать, но работают
они быстрее
Для обработки естественно-языкового ввода можно
создать так называемые синтаксические анализаторы
столкновения островов. Отдельные составляющие есте-
ственно-языкового ввода можно легко разбить на бло-
ки, по сути, на слова. Можно провести лексический
анализ каждого слова и снабдить его синтаксическими
данными. Затем взять по два или три отдельные блока
и проанализировать их на наличие синтаксических бло-
ков более высокого уровня. В случае успеха мы продол-
жаем собирать все большие и большие подгруппы до тех
пор, пока не получим одну группу, которая и будет
являться результатом анализа всего блока входных дан-
ных. Процесс такого анализа можно представить в виде
возникновения в море неизвестности небольших остро-
вков определенности, которые становятся все больше и
больше, соседние островки соединяются в большие ос-
трова, как бы сталкиваются, отсюда и название столк-
новение островов
Нечеткий синтаксический анализ
Мы уже увидели разницу между четким сравнением эта
строка эквивалентна той и нечетким сравнением эта
строка подобна той. Анализаторы, которые используют-
ся в компиляторах, производят четкое сравнение соот-
ветствия синтаксису. Анализаторы систем обработки
естественных языков должны позволять производить
нечеткое, вероятностное сравнение соответствия син-
таксису языка. Одним из путей обеспечения такой воз-
можности является замена всех четких сравнений нечет-
кими. Таким образом, мы не спрашиваем, является ли
это слово существительным, мы спрашиваем, похоже ли
данное слово на существительное с заданной степенью дос-
товерности?
Каждый блок входных данных можно анализировать
несколько раз. Первый раз анализ производится на ос-
новании четкого сравнения. Если анализ проходит не-
удачно, требуемую степень достоверности снижают и
повторяют анализ. Такой процесс может проводиться
668
Дополнительные тематические разделы
Часть III
сколько угодно раз. В первый раз определяется это пред-
ложение, в следующий раз — это очень похоже на предло-
жение, далее — это немного похоже на предложение и т.д.
Сложности вывода естественных
языков
Результаты работы программы могут включать рисун-
ки (изображения), распечатки (текст), звук или дей-
ствия (управление процессом). Распечатки и звук дол-
жны выводиться в естественно-языковой форме.
Самым простым естественно-языковым выводом
является выбор одной или нескольких фраз, которые
являются частью самой программы. Именно к таким
выходным данным мы привыкли: сообщения компиля-
тора об ошибках, сообщения о состоянии системы, за-
головки таблиц. Но, конечно, под естественно-языко-
вым выводом понимается совсем другое.
При формировании предложения вы не берете одно
из предложений, которые уже знаете. Вы берете слова,
которые знаете, и собираете их в выбранную структу-
ру, необходимым образом изменяя слова, и получаете
предложение, которое, может быть, никогда раньше не
произносили и больше никогда не произнесете. Боль-
шинство предложений, которые мы произносим, мы
больше никогда не повторяем. Именно такой мы пред-
ставляем себе систему с естественно-языковым выводом —
эта система, которая может формировать выражения,
пользуясь словарем и грамматическими правилами, из-
меняя необходимым образом слова, причем в некото-
рых случаях эти изменения могут быть довольно слож-
ными.
Если мы возьмем маленький словарь, состоящий из
слов banana cream mustard like he, и захотим сказать, что
кто-то в прошлом имел склонность к употреблению
фруктов с молочным кремом, то можем составить сле-
дующее:
кто-то like (в прошедшем времени) что-то
кто-то= he like (в прошедшем времени) что-то =
(banana, cream)
he like (в прошедшем времени) banana and cream
Здесь придется вводить новые слова, заменяя
(banana, cream) на banana and cream. Слово and не тре-
буется для передачи смысла, который мы вкладываем в
рассматриваемое предложение, использование этого
слова обусловлено требованиями синтаксиса английско-
го языка. Теперь получилось:
he like (в прошедшем времени) banana and cream
Но еще необходимо сделать два изменения форм
слов. Первое вызвано необходимостью использования
прошедшего времени. Поэтому заменяем like на liked.
Второе изменение вызвано тем, что для выражения об-
щих случаев в английском языке часто используется
форма множественного числа, поэтому banana становит-
ся bananas. Таким образом, получаем
Не liked bananas and cream
А теперь подумайте, как сказать о том, что кто-то
имел противоположный вкус, т.е. не любил есть фрук-
ты с этой имеющей резкий запах желтой приправой
(горчица, mustard). Тогда предложение может иметь вид:
кто-то отрицание like (в прошедшем времени) что-то
кто-то= he отрицание like (в прошедшем времени)
что-то = (banana, mustard)
he отрицание like (в прошедшем времени) (banana,
mustard)
Теперь мы можем заменить (banana, mustard) либо на
banana and mustard, либо на banana with mustard. По-
скольку предложение отрицательное и этот "кто-то"
ненавидел эти два продукта вместе, а не по отдельнос-
ти, то лучше, наверное, выбрать banana with mustard (но
это не является обязательным, просто это более веро-
ятный вариант). Таким образом,
he отрицание like (в прошедшем времени) banana with
mustard
he отрицание like (в прошедшем времени) bananas
with mustard
В некоторых языках следующим шагом было бы
he not like (в прошедшем времени) banana with mustard
но в английском языке это было бы ошибкой. Нужно
вставить глагол "to do" в определенной форме:
he do not like (в прошедшем времени) banana with
mustard
и в этом примере для получения прошедшего времени
следует изменить не глагол like (как это было в преды-
дущем примере), а глагол do. Получаем следующее
предложение:
he did not like bananas with mustard
Как видите, изменения не так уж просты. Более того,
они будут отличаться от языка к языку. Если вы дума-
ете по-итальянски, то, может быть, удивляетесь, зачем
англичане для получения отрицательного предложения
добавляют один дополнительный глагол; если же вы
думаете по-французски, то, может быть, удивляетесь,
каким образом англичане обходятся без заключения
отрицаемого глагола в "вилку". Если вы занимаетесь
написанием программ, представьте себе, насколько
сложной может быть организация естественно-языково-
го вывода.
669
Вывод звука
Вывод звука намного легче распознавания звука. Тем не
менее, это не такая уж простая задача, поскольку тре-
бует использования нескольких средств. Прежде всего
необходимо иметь средство, которое будет выбирать,
что выводить (формирование выражений). Далее систе-
ма должна решить, какие слова ей использовать (форми-
рование слов), создавая правильные формы выбранных
слов (морфология). Затем по контексту нужно выбрать
произношение и расстановку,ударений, что, кроме того,
включает применение правил сандхи, и сделать выход-
ной текст распознаваемым путем выбора скорости, вы-
соты звука и обработки возникающих ошибок.
Доктор Маргарет Мастерман (Margaret Masterman)
утверждает, что вся речь может быть проанализирова-
на на основе дыхательных групп. Дыхательная группа —
это набор слогов, которые произносятся без пауз меж-
ду ними, т.е. на одном дыхании. Такие наборы доволь-
но небольшие и, как правило, содержат нс более 20 сло-
гов. Предложения могут быть гораздо длиннее и
состоять из нескольких дыхательных групп. Если пау-
зы между группами отсутствует, понимание усложня-
ется. Если паузы между группами расположены непра-
вильно, понять сказанное иногда бывает очень сложно.
Превосходным примером последнего являются слова,
начиная с If w offend, it is with our good will из произведе-
ния Шекспира "Сон в летнюю ночь. Эти слова написа-
ны со знаками пунктуации, которые показывают акте-
ру, каким образом разбить предложение на дыхательные
группы, что полностью (и комически) изменяет смысл
сказанного:
Our true intent is. All for your delight.
We are nor here. That you should here repent you.
Эти слова становятся довольно скучными, если их
разбить на правильные дыхательные группы:
Our true intent is all for your delight.
We are nor here that you should here repent you.
Система вывода звука должна позволять разбить
предложения на правильные дыхательные группы, ина-
че она тоже исказит истинный смысл.
Обработка естественных языков
Глава 25
Вывод текста
Процесс вывод текста тоже является довольно сложным.
Мы привыкли к определенному стилю документов, и
различного рода программы обработки текстов помога-
ют нам добиться требуемого стиля. Так, например, в
системах машинного перевода необходимо не только
передать смысл текста, но и четко указать заголовок,
тело текста и подчеркнуть, на какие слова и фразы в
тексте оригинала обращалось особое внимание (выделе-
ние полужирным шрифтом или курсивом). При сохране-
нии стиля текста очень важно использовать правила
переноса и перехода на новую строку, которые харак-
терны для данного языка и для данного текста.
Резюме
Многочисленные исследования показывают, что распоз-
навание и обработка естественно-языкового ввода будет
одним из следующих значительных достижений в обла-
сти вычислительной техники. Многие переводчики
никак не дождутся того дня (не такого уж, кстати, и
далекого), когда их смогут заменить электронные пере-
водчики. Мы еще нс достигли того момента, который
предвидел Гуд (I.J. Good) в 1962 г., когда сказал, что
сверхинтеллектуальные компьютеры будут последним
изобретением, которое понадобится человеку, потому
что, когда компьютеры достигнут уровня интеллекта
человека, они возьмут всю работу по изобретательству
на себя. Но мы недалеки от этого момента — он насту-
пит еще при жизни многих читателей этой книги.
Пока еще слишком рано говорить о том, будут ли
даны искусственному интеллекту право голосования и
другие моральные права, хотя это не так уж и бессмыс-
ленно. Сейчас мы можем создать интеллект лишь на
уровне интеллекта таракана. Но кто знает, если науч-
но-технический прогресс и дальше будет развиваться с
такой невероятной скоростью, как сегодня, то, может
быть, появление первой машины, обладающей уровнем
интеллекта человека, уже не за горами.
Шифрование
В ЭТОЙ ГЛАВЕ
Оценка рисков нарушения безопасности
Почему не следует создавать новых алгоритмов шифрования
Выбор алгоритма шифрования
Реализация шифрования
Майк Райт
По-видимому, ни один из типичных компонентов про-
граммы не содержит так много скрытых проблем, как
компоненты, отвечающие за безопасность. Так называ-
емые бреши в системе защиты данных, в отличие от
функциональных ограничений, неточностей в выдава-
емых результатах или даже проблем с совместимостью,
являются практически незаметными. И вполне обычной
может быть ситуация, когда разработчик программно-
го продукта так и не обратил на них внимания. Эти
бреши затем могут быть обнаружены и преданы глас-
ности более опытными пользователями в самых разных
целях.
Поэтому каждый разработчик программного обеспе-
чения должен обладать определенными знаниями, до-
статочными для обеспечения требуемого ему уровня бе-
зопасности.
Язык С является идеальным языком для осуществ-
ления шифрования, поскольку его многие понимают, он
очень мобилен и высокоэффективен. Эти три его атри-
бута имеют очень большое значение для программ шиф-
рования.
В данной главе рассматриваются вопросы создания
безопасных компьютерных систем. Поскольку не суще-
ствует такого понятия, как безопасность среднего уров-
ня (может быть только две крайности — “пан или про-
пал”), глава полностью ориентирована на самую
надежную из доступных нам технологий. Здесь рассмат-
риваются все этапы обеспечения безопасности: плани-
рование, разработка и окончательное осуществление.
Разъясняются термины, используемые при описании
шифрования, и рассматриваются все требования для
обеспечения безопасности высокого уровня. Предлага-
ются способы решения часто встречающихся проблем,
и особо рассматриваются области, в которых многие
программисты делают наиболее досадные ошибки. Ос-
новное внимание уделяется тому, каким образом осу-
ществляется шифрование. При этом описываются не ка-
кие-то малоизученные новые или тривиальные реше-
ния, а надежные проверенные методики, которые
используются в настоящее время.
Оценка рисков нарушения
безопасности
Шифрование используется главным образом для защи-
ты данных от нежелательного доступа. Если единствен-
ной угрозой безопасности являются некомпетентные
пользователи, ненадежные устройства или другие ситу-
ации, не связанные со злыми намерениями, не следует
использовать шифрование. Существуют другие решения
для обеспечения целостности данных, удаления повто-
ряющихся комбинаций и т.п., которые не рассчитаны
на намеренное вторжение. Эти решения зачастую более
производительны, а иногда и более эффективны.
Выявите угрозу
Точно решите, кого вы боитесь. Совершенно неизвест-
ные, непредсказуемые взломщики непобедимы. Разбей-
те угрозы по осмысленным группам в соответствии с
намерениями, ресурсами и другими подобными крите-
риями. Для некоторых приложений потенциальной уг-
розой можно считать каждого пользователя.
Оцените ресурсы взломщика
Далее необходимо оценить ресурсы каждого взломщи-
ка. Сколько времени и денег они имеют? Насколько
мощными вычислительными средствами они обладают?
Имеют ли они доступ к ключам (например, к открыто-
му ключу в системах с двумя ключами)? Могут ли они
Шифрование
Глава 26
671
поддерживать связь с законными пользователями и мо-
гут ли они убеждением, силой, с помощью обмана или
воровства получить доступ к имеющимся у них сведе-
ниям?
При оценке ресурсов потенциальных взломщиков
лучше переоценить их, чем недооценить. С развитем
технологий для получения одного и того же результата
необходимо все меньше и меньше ресурсов. Вычисли-
тельные средства дешевеют, появляются и распростра-
няются новые, более совершенные алгоритмы, обработ-
ка данных и связь требуют все меньше времени,
появляются все более опытные специалисты. Это хоро-
шо можно проследить по тому факту, что широко из-
вестный алгоритм DES (стандарт шифрования данных)
уже считается недостаточным даже для очень коротко-
го периода, и его быстро заменили гораздо более мощ-
ными алгоритмами. Даже так называемые “случайные”
взломщики в настоящее время имеют доступ к мощным
вычислительным средствам и специализированному,
очень эффективному программному обеспечению, что
позволяет им в течение всего нескольких часов получить
незаконный доступ к сообщениям, для взлома которых
еще до недавнего времени требовалась работа “всех ком-
пьютеров мира на протяжении времени, превышающе-
го возраст Вселенной”.
Определите, какова может быть цель
взлома
После определения ресурсов каждого взломщика необ-
ходимо подумать, какие цели может преследовать
взломщик. Зачем ему взламывать вашу систему? На-
сколько решительным он может быть? Что именно он
ищет? Не поддавайтесь соблазну предположить, что его
цель будет серьезной. Иногда взломщики могут взламы-
вать программы просто ради забавы или из-за плохого
настроения. Только подумайте, сколько компьютерных
вирусов было написано без какой-либо пользы для про-
граммиста, а только ради причинения ущерба и из-за
риска наказания по закону.
Определитесь с оружием и тактикой
взломщиков
Следующим пунктом в оценке безопасности является
определение возможных путей взлома. Этот вопрос не-
обходимо рассмотреть досконально. Если не исключе-
на возможность, что взломщик может причинить ущерб,
используя определенный подход или инструментарий,
то этот подход и инструментарий должны быть в вашем
списке. Попытайтесь поставить себя на место потенци-
ального взломщика и решите, каким бы способом вы
взломали собственную программу. Может показаться
заманчивым просто успокоиться и решить, что взлом
невозможен, но попытайтесь быть более изобретатель-
ным. Иногда бывает полезным предположить, что не-
которые меры безопасности сняты или что некоторые
правила изменены. Если взломщик сможет легко обой-
ти некоторые из правил или предположений, на кото-
рые вы рассчитываете, то можете оказаться, что ваша
система очень уязвима. Имейте в виду, например, что
ни в коем случае нельзя открывать все секреты. Пароли
можно угадать. Операционная система или другая про-
грамма может делать копии ваших данных, о которых
вы даже не задумываетесь, например, данных в осво-
бождаемой памяти, резервных копиях и файлах подкач-
ки. Имея возможность сократить количество неизвест-
ных секретов даже на самую малость, взломщик, может
быть, сможет найти недостающие сведения с использо-
ванием грубой силы.
Узнайте своих пользователей
Очень часто одной из самых явных угроз безопасности
являются... пользователи вашей системы. Они иногда
пользуются очень широкими правами доступа, но при
этом не имеют достаточно такта или знаний оптималь-
ной безопасности системы. Если вы не знаете уровня
пользователей, считайте их “чайниками”. Даже если
ваши пользователи не имеют злого умысла, тем не ме-
нее, они могут сделать то, что негативно отразится на
безопасности системы. Лучше предположить, что мно-
гие из пользователей не будут следовать вашим указа-
ниям по доброй воле. Если не потребовать обязатель-
ного периодического изменения пароля, то они,
несмотря на ваши инструкции, до скончания века бу-
дут использовать в качестве пароля кличку своего до-
машнего любимца. Вот такие они, ваши пользователи.
Если их поведение может негативно сказаться на безо-
пасности системы, особенно если это может затронуть
не только того одного пользователя, но и других, то
необходимо предусмотреть меры, которые все же зас-
тавят их следовать вашим инструкциям.
Сосредоточьтесь на самом слабом звене
Важность следующего правила нельзя переоценить: в
первую очередь всегда обращайте внимание на самое
слабое звено. Систему нельзя сделать более безопасной,
устранив брешь, которой не пользуется ни один взлом-
щик. Если все ваши пользователи помещают пароли на
своих Web-страницах, то для вас не имеет смысла улуч-
шать алгоритм шифрования. Сначала исправьте то, что
легче всего взломать. Тщательно оцените список взлом-
щиков и текущую конфигурацию своей системы, это
позволит выявить то звено, которое может легко быть
использовано взломщиком. Взломщики будут делать
примерно то же: они сначала оценят вашу систему, най-
дут самые слабые места, которые можно использовать,
672
Дополнительные тематические разделы
Часть 111
и выберут одно из них. Они сдадутся только тогда, ког-
да убедятся, что даже самое слабое место очень трудно
использовать.
Почему не следует создавать новых
алгоритмов шифрования
Хорошие алгоритмы шифрования попадаются нечасто.
Их очень трудно придумать, и, даже когда создан но-
вый алгоритм, его обычно быстро патентуют и накла-
дывают различные ограничения на его экспорт, что ус-
ложняет или вообще исключает его использование
другими пользователями.
Такое невеселое положение вдохновило программи-
стов на разработку собственных алгоритмов шифрова-
ния, которые порой давали поразительные результаты.
Поскольку довольно большое число программистов
имеют дело в основном с характеристиками программы,
которые можно отследить (например, с копией памяти
во время выполнения программы), они часто не уделя-
ют должного внимания безопасности шифрования. Они
думают, что всего после нескольких мгновений разду-
мий над возможными слабыми местами их алгоритмы,
взятые “с потолка”, могут обеспечить должный уровень
безопасности. Очень самонадеянные программисты
даже будут сравнивать свои наивные алгоритмы с алго-
ритмами, популярными в настоящее время, и иногда
заявлять, что их уровни безопасности эквивалентны.
Что плохого в новых шифрах
А проблема в следующем: ошибки в шифрах вряд ли
могут быть обнаружены людьми, не имеющими отно-
шения к криптографии. Бессмысленный текст очень
легко создать. Большинство последовательностей псев-
дослучайных чисел на первый взгляд кажутся вполне
случайными. Результат работы плохого алгоритма шиф-
рования выглядит так же, как результат работы очень
хорошего алгоритма.
При этом ошибка является практически невидимой.
В то время как результат работы ошибочного алгорит-
ма сортировки будет очевидно неверным, результат
ошибочного алгоритма шифрования выглядит вполне
нормально. Мы ждем бессмыслицы и получаем бес-
смыслицу.
Рассмотрим следующий простой алгоритм:
char encrypt (char р)
{
return
}
Такой алгоритм часто будет выдавать бессмыслен-
ный результат. И, вероятнее всего, к нему трудно бу-
дет подобрать ключ, но любой злоумышленник сможет
взломать такой алгоритм. Он не более безопасен, чем
простое правило Кесаря “сдвига йа три”. В более слож-
ных алгоритмах может использоваться стандартная биб-
лиотека С, например:
void encrypt (char* р, unsigned key)
<
srand(key);
while(*p)
{
*p++ rand();
}
Этот алгоритм безопаснее, чем предыдущий, но не
намного. Этот алгоритм с некоторыми изменениями
наиболее часто используется в “доморощенных” алго-
ритмах шифрования. Первая проблема в том, что фун-
кция rand() не гарантирует генерирования случайных
чисел: в действительности она предназначена для гене-
рирования псевдослучайных чисел. Случайные числа
являются абсолютно безопасными, в то время как псев-
дослучайные содержат обнаруживаемые повторяющие-
ся последовательности. Кроме того, в качестве началь-
ного числа используется только одно значение unsigned
int. Перебор всех возможных значений займет всего
одну-две минуты даже на плохом компьютере. Поэто-
му сообщения можно легко расшифровать и вычислить
ключ, выполняя элементарный криптоанализ. Данный
алгоритм не состоит использовать также потому, что
различные реализации функции rand() делают эту про-
грамму непереносимой (на другие платформы). Все
другие реализации библиотеки будут, скорее всего, не-
совместимыми с авторской и не смогут правильно рас-
шифровывать зашифрованные сообщения.
Держите внешние границы на виду
Иногда программист, надеясь достигнуть более высоко-
го уровня безопасности, держит в секрете сам алгоритм
шифрования. Это ничем не лучше, чем отказаться от
установки факелов вдоль внешних стен вашей крепос-
ти в надежде, что нападающие споткнутся в темноте.
Есть только одна ситуация, в которой это может быть
полезным, — когда взломщики не имеют доступа к коду
даже в двоичной форме и когда используемый алгоритм
исключительно слабый, а злоумышленник неопытный.
Любой взломщик среднего уровня сможет определить
алгоритм по двоичному выполняемому файлу практи-
чески независимо от того, настолько он хорошо спря-
тан. Анализа одного только зашифрованного текста бу-
дет достаточно для определения или даже для прохода
используемого алгоритма, особенно при плохом алго-
ритме шифрования. Вы всегда должны держать подход
к своей крепости хорошо освещенным, чтобы можно
было увидеть подкрадывающихся незваных гостей. По-
Шифрование
Глава 26
673
мните, что им только на руку искать в темноте дыры в
стенах. Лучники не могут стрелять в нападающих, ко-
торых они не видят, и строители не могут устранить
дефект, который они так и не обнаружили.
Практика хранения исходного кода в секрете не
одобряется. Это исключает его анализ и критику дру-
гими. Даже наиболее уважаемые и опытные специали-
сты по криптографии открывают свои алгоритмы для
всеобщей оценки перед их использованием. Посторон-
ние люди часто быстро находят недостатки, которые
разработчик упустил из виду. Новые точки зрения име-
ют очень важное значение, а взломщики всегда имеют
другую точку зрения, поскольку они не разработчики
системы. Хранение алгоритма в секрете дает взломщикам
именно это преимущество. Секрет должны составлять
ключи, а не алгоритм. Если ваш шифр полагается на
секретность алгоритма, то вам необходимо переделать
систему безопасности, поскольку она очень уязвима.
Подумайте, сколько времени и других ресурсов на-
правлено на разработку хорошего алгоритма шифрова-
ния. Если секретный алгоритм может стать известным
более чем одному человеку, то вся секретность алгорит-
ма подвергается риску быть раскрытой взломщиком.
Любая утечка информации может разрушить весь ваш
секрет. Если какая-нибудь значительная часть алгорит-
ма полагается на его секретность, то необходимо сроч-
но разработать совершенно новый алгоритм, даже если
ключи находятся в безопасности. Это довольно непри-
ятная ситуация.
Сложность - это не безопасность
Вы можете попробовать сделать алгоритм более безопас-
ным путем добавления нескольких сдвигов и простых
чисел, добавления таблиц замещения и, может быть,
путем использования большого количества независимых
операций, сбивающих с толку. Тогда алгоритм становит-
ся настолько сложным, что его безопасность будет га-
рантирована. К сожалению, это может помочь только в
редких случаях. Если вы планируете просто сбить
взломщика с толку, добавляя операции, наличие кото-
рых можно объяснить только преднамеренным услож-
нением, то с таким подходом вы ничего не добьетесь.
Вы можете ввести самого себя в заблуждение до такой
степени, что решите зашифровать свой собственный
алгоритм или сделать его настолько неэффективным,
что ни один разумный человек не решится провести
полный поиск ключей. Но потенциальный взломщик
может все-таки найти одну и ту же повторяющуюся
последовательность в одних и тех же местах. Исполь-
зование неоправданных или слабо обоснованных опе-
раций можно сравнить с заклинанием камней, из кото-
рых сделаны стены вашей крепости. Если вы не знаете,
к чему может привести такое заклинание, то не можете
гарантировать, что оно принесет больше пользы, чем
вреда. Многие неоправданные операции представляют
собой всего лишь несколько простых и быстро выпол-
няемых операций, которые и не требуют того, чтобы
взломщик определял их точную последовательность. И
тогда для него не составит труда расшифровывать ваши
сообщения даже быстрее, чем это сможете сделать вы.
Тяжело видеть, что стены крепости рушатся неприяте-
лем с меньшими усилиями, чем открываются ворота для
союзника.
Не считайте, что только люди с высоким уровнем
интеллекта смогут взломать ваш “доморощенный” ал-
горитм шифрования. Если вы программируете на С, зна-
чит, уже можете похвастаться своими умственными
способностями. Любой алгоритм шифрования, который
вы изобрели, может гарантировать защиту от любого
человека, за исключением, может быть, только секрет-
ных агентов правительства, правильно? Нет, неправиль-
но. Вы, может быть, удивитесь, когда увидите инстру-
менты, которыми пользуются случайные взломщики.
Программы общего назначения можно бесплатно ска-
чать из Internet, некоторые из них взламывают наибо-
лее простые алгоритмы шифрования, даже не требуя
ввода каких-либо данных. А вооружившись нескольки-
ми угаданными словами незашифрованного текста и
одной из дружественных пользователю рассчетных про-
грамм, даже ваша младшая сестра в течение нескольких
минут сможет взломать любые плохо зашифрованные
сообщения.
Если вы действительно намерены разработать соб-
ственный алгоритм шифрования, вам понадобится боль-
ше информации, чем приведено в настоящей главе.
Специалисты по криптографии должны набраться тер-
пения для того, чтобы разработать приличный алгоритм;
они должны много читать и тренироваться взламывать
свои собственные алгоритмы. Умножьте время, которое
вам потребовалось для изучения языка С, примерно на
десять и узнаете, сколько времени вам понадобится для
того, чтобы стать специалистом по криптографии.
Криптография — это не простое развлечение, она тре-
бует хорошего знания математики и логики.
Выбор алгоритма шифрования
Большинство программистов используют уже существу-
ющие алгоритмы шифрования.
На самом деле имеется довольно небольшой список
таких алгоритмов. В этой главе будут описаны только
некоторые из них, но они довольно надежны. Большин-
ство из приведенных алгоритмов являются или могут
быть сделаны так называемыми надежными алгоритма-
ми, которые Moiyr подпадать под действие ограничений
на экспорт. Так что перед передачей их за границу про-
смотрите соответствующие законы.
43 Зак. 265
674
Дополнительные тематические разделы
Часть III
Шифрование может использоваться для различных
целей. Хотя назначение всех алгоритмов — скрытие
информации от взломщиков, тем не менее, существует
несколько способов обеспечения секретности, и каждый
способ имеет свою область применения. Необходимо
четко представлять требования своей системы по безо-
пасности и выбрать наиболее подходящее решение.
Шифрование с одним ключом
Шифрование с одним ключом в настоящее время обес-
печивает большую безопасность и скорость, чем шиф-
рование с двумя ключами, при одинаковых размерах
ключей. Оно наиболее полезно, когда существует толь-
ко один пользователь, что не требует распространения
открытых ключей. Поскольку для шифрования и де-
шифрования используется один и тот же ключ, то при
необходимости включения дополнительных пользовате-
лей могут возникнуть проблемы. Шифрование с одним
ключом является наиболее часто используемой формой
шифрования и обеспечивает конфиденциальность. Оно
также обеспечивает определенный уровень аутентифи-
кации, поскольку пользователю, не имеющему ключа,
довольно сложно подделать зашифрованное сообщение.
Алгоритмы шифрования с одним ключом подразде-
ляются на блочные и поточные. Как следует из их на-
званий, блочные алгоритмы шифрования предназначе-
ны для работы с блоками данных определенного разме-
ра, а поточные — для шифрования непрерывного пото-
ка данных. Как правило, поточные шифры более
гибкие, но менее безопасные, чем блочные. В основе по-
точного шифрования заложена идея генерирования хо-
рошей последовательности псевдослучайных чисел (с
использованием ключа в качестве начального значения)
и объединения этой последовательности с открытым
текстом.
Одним из широко используемых алгоритмов поточ-
ного шифрования является алгоритм RC4, разработан-
ный компанией RSA Data Security, Inc. Первоначально
он был защищен как коммерческая тайна компании, но
впоследствии получил широкую известность. Алгоритм
RC4 не запатентован, но само название “RC4” являет-
ся торговой маркой компании RSA Data Security, Inc.
Популярность этого алгоритма в значительной степени
объясняется его простотой (листинг 26.1). Он исполь-
зует только 2064 бита состояния без заранее определен-
ных констант и считается достаточно безопасным. Мо-
жете, не задумываясь, выбирать этот алгоритм, если
хотите получить высокую производительность и доста-
точно высокий уровень безопасности и если не хотите
иметь дело с такими усложнениями, как размеры бло-
ков, большие таблицы и сложные операции.
Листинг 26.1 Функция шифрования/дешифрования, выполняемого с помощью алгоритма RC4,
typedef struct
{
byte_t table[256];
byte_t index[2];
} RC4_key_t;
/* Вызывается перед вифрованнем/дешифрованием */
void RC4_setup_key(
byte_t const key_text[],
size t len,
RC4_key_t* key)
{
int i;
byte t temp, e;
/* Инициализация таблицы ключей */
for(i - 0; i < 256; i++)
{
key->table[i] = i;
}
/* Инициализация индексов */
key->index[0] = 0;
key->index[l] = 0;
/* Подготовка таблицы ключей */
for(i = 0f e = 0; i < 256; i++)
{
/* Поиск индекса e */
e += keytext[i%len] + key->table[i];
lllu*4»«кмие
Глава 26
675
/* Обмен значениями */
temp = key->table[ i ];
key->table[i J = key->table[ e ];
key->table[e] = temp;
}
}
/* Вифрование/дешифрование можно выполнять с помоцью этой функции */
void RC4_encrypt(
bytet const plaintexts,
bytet ciphertext[],
size_t len,
RC4 key_t* key)
{
int i;
byte_t temp;
for(i = 0; i < len; i++)
{
/* Обновление индексов */
key->index(1] += key->table[++key->index[O]];
/* Обмен элементов таблицы */
temp = key->table[key->index[0]];
key->table[key->index[O]] = key->table[key~>index[l]];
key->table[key->index[1]] = temp;
/* Создание зашифрованных данных */
ciphertextfi] =
plaintextfi] Л
key->table[
key->table(key->index[0 J] +
key->table(key->index(l]]
1;
}
Существует большое количество алгоритмов блочно-
го шифрования. Ниже приведены несколько наилучших
и наиболее популярных:
• DES (Data Encryption Standard — Стандарт шифро-
вания данных): официальный алгоритм шифрования
Национального института стандартов и технологий
(NIST) для несекретных данных с 1976 по 1997 гг.,
который имел название FIPS 46. Этот алгоритм в
значительной степени устарел. Ключи длиной 64
бита (эффективная длина — 56 битов) слишком малы
для использования в настоящее время. Тем не менее,
DES до сих пор используется в алгоритме Triple-DES
— намного более безопасном алгоритме. В мире, на-
верное, нет ни одного столь полно изученного ал-
горитма.
• Triple-DES: как следует из его названия, для шиф-
рования данных Triple-DES использует тройной ал-
горитм DES и три различных ключа. Этот алгоритм
намного безопаснее обычного алгоритма DES, но го-
раздо медленнее. Одни программисты предпочита-
ют использовать его как более безопасную альтерна-
тиву алгоритму DES, учитывая объем материалов,
посвященных DES, а другие по той же причине из-
бегают его использования из-за боязни секретных
недомолвок в его описании и существования специ-
ального оборудования для его взлома.
• Blowfish: шифр, разработанный Брюсом Шнейером
(Bruce Schneier) из компании Counterpane Systems.
Этот алгоритм не запатентован, авторские права на
него не защищены, и он доступен бесплатно для
всех пользователей. Алгоритм Blowfish — популяр-
ный алгоритм шифрования, который обеспечивает
хорошую безопасность и высокую скорость работы.
• CAST (назван по именам его разработчиков Charlisle
Adams и Stafford Tavers): безопасный алгоритм шиф-
рования, популяризованный последними версиями
PGP (Pretty Good Privacy). Хотя и запатентован ком-
панией Northern Telecom Ltd., тем не менее, его
можно свободно использовать без специального раз-
решения и без оплаты.
Дополнительные тематические разделы
676!
Часть III
• Rijndael (назван по именам его разработчиков Vincent
Rijmen и Joan Daemen): этот алгоритм позволяет
производить быструю смену ключей, что делает его
привлекательным для приложений, которые выпол-
няют шифрование или дешифрование с использова-
нием различных ключей. Кроме того, он обеспечи-
вает высокую скорость и безопасность. Алгоритм не
запатентован.
• Serpent: этот алгоритм имеет низкую скорость, но
зато дает высокий уровень безопасности. Он не тре-
бует большого объема памяти и может хорошо про-
тивостоять направленным атакам.
• Twofish: алгоритм, представленный компанией
Counterpane Systems — разработчиком алгоритма
Blowfish. Как и Blowfish, алгоритм Twofish не запа-
тентован, авторские права на него не защищены, и
он доступен бесплатно для всех пользователей.
Twofish очень безопасен и имеет очень высокую
скорость работы. Алгоритм в высокой степени гибок,
и его можно модифицировать для выполнения оп-
тимизации по размеру/времени и для использования
с несколькими ключами.
Подробное описание и примеры исходных кодов
этих алгоритмов приведены в книге Applied Cryptography —
Protocols, Algorithms, and Source Code in С Брюса Шнейе-
pa (Bruce Schneier). Это великолепный справочник по
криптографии для С-программистов. Ниже приведены
два Web-адреса, с которых можно начать поиск исход-
ных кодов:
http://www.counterpane.сот/http://www/pgpi.org
Шифрование с двумя ключами
Шифрование с двумя ключами основано на использо-
вании двух ключей: открытого и секретного. Этот ме-
тод не гарантирует высокий уровень безопасности, по-
скольку ключи более легко могут попасть ко многим
пользователям. Открытый ключ можно свободно распро-
странять, и даже не только среди дружественных
пользователей, а секретный ключ не нужно распрост-
ранять вообще, даже среди дружественных пользовате-
лей. Такая возможность чрезвычайно полезна для неко-
торых приложений, особенно для сетевых, которые
используются для связи через незащищенные каналы.
Методики, связанные с шифрованием с двумя ключа-
ми, используются также для создания цифровых под-
писей.
Поскольку безопасное шифрование с двумя ключа-
ми сложнее разработать, и оно является сравнительно
новой концепцией, существует не так уж много действи-
тельно уникальных алгоритмов. В настоящее время
широко используются только три основных принципа:
использование дискретных логарифмов, разложение на
множители и эллиптические кривые. Приведенные
ниже и большинство других существующих алгоритмов
используют один из этих трех принципов.
• Diffie-Hellman (назван по именам своих разработчи-
ков): система обмена ключами основана на дискрет-
ных логарифмах в финитных полях, созданных
большими простыми числами. Этот алгоритм был
первой предложенной системой и в настоящее вре-
мя используется очень широко. Он положен в осно-
ву нескольких других систем шифрования, включая
Х0.42 — стандартную систему ANSI (Национально-
го института стандартизации США).
• RSA (назван по именам разработчиков Rivest, Shmir
и Adleman): полная двухключевая система, выполня-
ющая как распространение ключей, так и создание
цифровых подписей. Система основана на сложно-
сти разложения больших целых чисел на простые
множители.
• DSS (Digital Signature Standard — Стандарт цифро-
вых подписей): модифицированный алгоритм созда-
ния цифровых подписей, разработанный Элом Га-
малом (El Gamal). Обеспечивает только выполнение
операций над цифровыми подписями и обычно ис-
пользуется с системой Diffie-Hellman.
• ЕСС (Elliptic Curve Cryptosystem — Криптосистема,
основанная на эллиптических кривых); новая мно-
гообещающая идея, предложенная независимо друг
от друга Коблитцем (Koblitz) и Миллером (Miller).
Методика по своей сути аналогична методике сис-
темы Diffie-Hellman, но она предусматривает ис-
пользование эллиптических кривых на финитном
поле, а не обычных дискретных логарифмов. Этот
метод, возможно, дает большую безопасность при
меньших размерах ключей, но он изучен не так под-
робно, как другие часто использующиеся системы.
Одностороннее хеширование
Хеширование также часто ассоциируется с шифровани-
ем и особенно с цифровыми подписями. Хотя хеширо-
вание несколько отличается от шифрования, тем не
менее, оно защищает открытый текст от просмотра.
В отличие от обычного шифрования, хеширование не
связано с ключами, и по одному только зашифрованно-
му тексту (который называется профилем сообщения)
очень тяжело получить открытий текст.
Хеширование широко используется и в других при-
ложениях, которые абсолютно не связаны с обеспече-
нием безопасности данных, например, в хеш-таблицах.
Хеширование, выполняемое для обеспечения безопас-
ности, как и другие виды этого метода основывается на
равномерном распределении результатов. Хеширование,
Шифрование
Глава 26
677
обеспечивающее безопасность, отличается от других
видов хеширования тем, что выполняется в одном на-
правлении. Из хешированных данных очень сложно
получить исходные данные или найти другие данные,
которые после хеширования дадут тот же результат.
Управление национальной безопасности США в ка-
честве части Стандарта безопасного хеширования раз-
работало SHA-1 (Secure Hash Algorithm-1 — Алгоритм-
1 безопасного хеширования). Хотя SHA-1 — достаточно
сложный алгоритм, тем не менее, он является наилуч-
шим вариантом для приложений, которые требуют хе-
ширования.
SHA-1 дает 160-битовый профиль сообщения и ра-
ботает с блоками, имеющими фиксированную длину
512 битов (листинг 26.2). Поскольку он требует разбивки
входного сообщения на блоки фиксированной длины,
то часто приходится дополнять блоки незначащей ин-
формацией. SHA-1 имеет особую и достаточно необыч-
ную функцию заполнения, которая добавляет к биту,
равному 1, много нулей и вставляет целое число дли-
ной 64 бита.
Листинг 26.2. Функция заполнения алгоритма
SHA-1.
void SHA_l_pad_msg(
uint32_t* * padded,
uint64_t numblocks,
bytet const* unpadded,
uint64t len
)
{
uint64_t zeros;
uint64_t extralen;
uint64_t p_len;
uint64_t i;
bytet* bptr;
bptr = (byte_t*)padded;
plen = num_blocks * 64;
extra_len = p_len - len;
memset(bptr + len, 0, extralen);
memcpy(padded, unpadded, len);
zeros = extra_len - 8;
if(zeros > 0)
{
-zeros;
for(i = 0; i < zeros; i++)
{
bptrfplen - i - 9] = 0;
}
b_ptr[p_len - i - 9] = 0x80;
}
/* Преобразование из представления "от
младшего к старшему" */
native byte_order(padded, len/4+1);
/* Закончить длиной сообщения */
padded[numblocks * 16 - 2] = len » 29;
padded[numblocks * 16 - 1] = len « 3;
}
К счастью, SHA-1 имеет лишь несколько “магичес-
ких” констант и только три функции перестановки. Сам
алгоритм довольно прост: каждый блок для обработки
подается на вход основной функции хеширования, а
профиль сообщения — это сумма профилей каждого
блока (листинг 26.3).
Листинг 26.3. Реализация алгоритма SHA-1.
/*
* Объявить тип SHA_1_F как указатель на
* функцию, работающую с тремя 32-битовыми
* словами.
*/
typedef uint32t (*SHA_1_F)(
uint32_t a,
uint32t b,
uint32_t c);
uint32_t SHA_l_F0(
uint32_t a,
uint32_t b,
uint32_t c)
{
return с * a & (b л c);
/* Такие хе функции для Fl() и F3() */
uint32_t SHA_1_F1F3(
uint32_t a,
uint32_t b,
uint32_t c)
{
return а л b л c;
uint32_t SHA_1_F2(
uint32_t a,
uint32_t b,
uint32_t c)
{
return a & b | c & (a | b);
}
uint32_t SHA_l_rot(uint32_t x, int n)
{
return x « n | x » 32-n;
void SHA_l_main(
uint32_t const msg[16],
uint32_t digest[5])
uint32 t const K[4]
678
Дополнительные тематические разделы
Часть III
{
0х5А827999,
0x6ED9EBAl,
0x8FlBBCDC,
0xCA62ClD6
};
/* Функции SBA1F */
SHA1F const FJ4] « {
&SHA1F0,
6SHA_1_F1F3,
6SHA1F2,
6SBA1F1F3
};
uint32_t table[80];
uint32_t offset[5];
uint32_t temp;
int i, j;
/* Инициализация сдвига */
for(i * 0; i < 5; i++)
{
offset[i] = digest[i];
}
/* Инициализация таблицы */
for(i = 0; i < 16; i++)
{
table!!] = msg[i];
}
for(; i < 80; i++)
{
table[i] =
SHAlrot(
table[i - 3] *
table[i - 8] *
tableti - 14] *
table[i - 16],
1
);
/♦ Вычисление сдвига профиля */
for(j = 0, i = 0; j < 4; j++)
{
for(; i < j * 20 + 20; i++)
{
temp -
SHA_1_rot(offset[0], 5) +
(*F[jl)(offset[l], offset[2], offset[3]) +
offset[4] +
table[i] +
K[ jl;
offset!4] = offset!3];
offset!3] = offset!2];
offset12] « SHA_l_rot(offset[1], 30);
offset!1] = offset[0];
offset!0] = temp;
}
}
/* Обновление профиля */
for(i = 0; i < 5; i++)
{
digest[i] += offset!!];
}
/* В случае ошибки возвратить 0 */
int SHA_l_full(
byte_t const* msg,
uint64_t len,
uint32_t digest[5]
)
{
uint32_t const origin!5] =
{
0x67452301,
0XEFCDAB89,
0x98BADCFE,
0x10325476,
0XC3D2E1F0
};
uint 3 2_t* padded;
uint 6 4_t num_blocks;
uint64_t i;
/* Дополнить сообщение до 512-битового блока
*/
num_blocks = (len + 8) * 8 / 512 + 1;
padded - (uint32_t*)malloc(
numblocks * 64
);
if (padded == NULL)
{
err no - ENOMEM;
return 0;
}
SEA_l_pad_nsg(padded, numblocks, msg, len);
/* Инициализация профиля */
for(i = 0; i < 5; i++)
{
digest!i] = origin!!];
}
/* Хеширование профиля каждым блоком */
for(i = 0; i < num_blocks; i++)
{
SHA l main(padded + i * 16, digest);
}
free(padded);
return 1;
Реализация шифрования
Даже после выбора алгоритма необходимо тщательно
реализовать выбранным алгоритм, чтобы защита, обес-
печиваемая алгоритмом, не свелась на нет плохой реа-
лизацией. Существует много вариантов реализации, в
которых можно наделать большое количество ошибок.
Шифрование
Глава 26
679
Режимы работы
Программы шифрования могут использоваться в одном
из нескольких возможных режимов. Каждый режим
определяет набор выполняемых нал открытыми или
зашифрованными данными операций до и после само-
го шифрования. Эти операции служат для обеспечения
еще более высокого уровня безопасности, чем может
обеспечить сам алгоритм. Даже самые мошные алгорит-
мы шифрования почти ничего не стоят, если их исполь-
зовать в слабом режиме.
В FIPS 81 (федеральный стандарт по обработке ин-
формации) и в ANSI ХЗ. 106-1983 (стандарт Националь-
ного института стандартизации США) описаны четыре
режима работы. Было предложено несколько нестандар-
тных режимов работы, но не рекомендуется пользоваться
ни одним из них, если у вас нет на то особой причины.
При описании каждого режима будут использовать-
ся перечисленные ниже имена. Вместо обозначений пе-
ременных, состоящих только из одной буквы (как это
бывает во многих справочных пособиях) будем исполь-
зовать полные имена, поскольку так их значение будет
более понятно:
• BLOCKSIZE — число битов в каждом блоке. Обыч-
но находится в пределах от 64 до 256 битов.
• ELEMENTSIZE — для режимов с обратной связью
размер в битах каждого элемента текстового масси-
ва. Как правило, является константой и не изменя-
ется от сообщения к сообщению. ELEMENTSIZE
может иметь значение от 1 до BLOCKSIZE.
• block_t — тип каждого блока. Все блочные алгорит-
мы шифрования устанавливают размер блока и воз-
можные размеры блока. Блоки являются просто не-
прерывными последовательностями битов
фиксированного размера. Блок подается на вход и
выдается на выходе функции блочного шифрования.
• element_t — тип элементов текстового массива в ре-
жимах с обратной связью. Каждая переменная
element_t имеет длину ELEMENTSIZE. В общем
случае, когда ELEMENTSIZE==BLOCKSIZE,
element_t равен block—t.
• plaintext [] — массив блоков, подлежащих шифрова-
нию. Каждый элемент массива является уникаль-
ным блоком и имеет тип block—t (или element—t в
режимах с обратной связью). Эта информация защи-
щена от взломщиков.
• ciphertext [] — массив зашифрованных блоков, так-
же имеющих тип block_t (или element_t в режимах
с обратной связью). Такой массив является исход-
ным для дешифрования и выходным после шифро-
вания. Эта информация защищена от взломщиков
путем шифрования.
• key — секретный ключ, который используется для
шифрования и дешифрования сообщений. Размер клю-
ча определяется алгоритмом и/или размером блока.
• origin — вектор инициализации. Это значение тре-
буется для большинства режимов для начала шиф-
рования или дешифрования. Значение origin всегда
имеет тип block_t и должно быть уникальным.
• encrypt() — основная функция шифрования. В каче-
стве аргумента принимает один блок открытого тек-
ста и ключ, возвращает один блок зашифрованною
текста. Эта функция реализована в соответствии с
выбранным алгоритмом шифрования (DES, Twofish
и т.д.).
• decrypt() — основная функция дешифрования, про-
тивоположная по своему действию функции
encrypt(). В качестве аргумента принимает один
блок зашифрованного текста и ключ, возвращает
один блок открытого текста.
Режим кодовой электронной книги
Режим кодовой электронной книги (Electronic Code Book
Mode, ECB) является наименее безопасным, но наиболее
простым режимом реализации (листинг 26.4). Поскольку
при такой реализации выполняется небольшое количество
операций, эта реализация является также наиболее быст-
рой и наименьшей по размеру, к тому же ресурсы, требу-
емые данной реализацией, незначительны по сравнению
с ресурсами, требуемыми функцией шифрования. Режим
кодовой электронной книги не используется, когда требу-
ется высокий уровень защищенности. Его следует исполь-
зовать только для проведения тестов, проверки правиль-
ности реализации алгоритма шифрования и т.п. и
никогда не использовать в конечном продукте.
Режим сцепления шифрованных блоков
Режим сцепления шифрованных блоков (Cipher Block
Chaining Mode, CBC) — более защищенный режим, но
тоже довольно простой (листинг 26.5). В этом режиме
проводится операция логического исключающего ИЛИ
блока открытого текста с последним блоком зашифро-
ванного текста, и это гарантирует, что одинаковые бло-
ки открытого текста не приведут к получению одина-
ковых блоков зашифрованного текста.
Режим обратной связи по выходу
Два режима обратной связи по выходу (Output Feedback
Mode, OFB) сложнее двух предыдущих режимов (лис-
тинг 26.6). Обратите внимание, что в режимах обратной
связи функция decrypt() не используется. Для шифро-
вания и дешифрования используется функция encrypt().
В некоторых случаях это позволяет сэкономить место
и упростить отладку, поскольку вместо двух сложных
функций используется только одна.
680
Дополнительные тематические разделы
Часть III
Листинг 26.4. Режим кодовой электронной книги.
void encryption(
blockt const plaintext!],
block t ciphertext[],
size_t len,
keyt key)
int i;
for(i = 0; i < len; i++)
{
ciphertext[i] » encrypt(plaintext[i], key);
}
void decryption!
blockt const ciphertext[],
block_t plaintext[],
size_t len,
key_t key)
int i;
for(i = 0; i < len; i++)
{
plaintext!!] = decrypt(ciphertext[i], key);
}
Листинг 26.S. Режим сцепления шифрованных блоков.
void encryption!
blockt const plaintext!],
blockt ciphertext!],
size_t len,
keyt key,
blockt origin)
{
int i;
ciphertext[0] - encrypt!plaintexts ] * origin, key);
for(i = 1; i < len; i++)
{
ciphertext!!] -
encrypt(plaintext!!] * ciphertext!! - 1], key);
}
void decryption!
block_t const ciphertext!],
blockt plaintext!],
size_t len,
key t key,
blockt origin)
{
int i;
plaintext!0] - decrypt(ciphertext[0], key) * origin;
for(i = 1; i < len; i++)
{
plaintext[i] =
decrypt(ciphertext[i], key) * ciphertext[i - 1];
}
681
Листинг 26.6. Режим обратной связи по выходу.
void encryption(
block t const plaintext!],
blockt ciphertext[],
size t len,
key_t key,
blockt origin)
{
int i;
blockt temp;
temp » origin;
for(i = 0; i < len; i++)
{
temp « encryptftemp, key);
ciphertextfi] = plaintext!!] * temp;
}
}
void decryption!
blockt const ciphertext[],
blockt plaintext[],
size t len,
key_t key,
blockt origin)
int i;
blockt temp;
temp - origin;
for(i - 0; i < len; i++)
{
temp = encrypt!temp, key);
plaintext!!] = ciphertext!!] * temp;
}
ПРИМЕЧАНИЕ
Режим обратной связи по выходу, приведенный в листин-
ге 26.6, предполагает, что значение BLOCKSIZE равно
значению ELEMENTSIZE. Стандарт позволяет использовать
режим обратной связи с другими размерами элементов,
но во всех случаях это будет и сложнее, и менее безо-
пасно.
Режим шифрованной обратной связи
Режим шифрованной обратной связи (Cipher Feedback
Mode, CFB) аналогичен режиму обратной связи по вы-
ходу, но в качестве обратной связи использует не метод
многократного шифрования вектора инициализации неза-
висимо от текста, а зашифрованный текст (листинг 26.7).
ПРИМЕЧАНИЕ
Запомните, что блоки определяются алгоритмом шифро-
вания как входной и выходной параметры функций
encrypt!) и decrypt!), а элементы — это составляющие
Шифрование
Глава 26
текста. В режимах, описанных выше, текст просто состоял
из блоков и различие между элементами и блоками не
проводилось, но в более сложных режимах с обратной
связью это различие может иметь значение.
Когда значение ELEMENTSIZE равно значению
BLOCKSIZE, все становится гораздо проще, исключая
необходимость в отдельном типе element t и использо-
вании сдвига и одной временной переменной (листинг
26.8). Но обратите внимание, что, в отличие от режима
с обратной связью по выходу, использование значений
ELEMENTSIZE, не равных BLOCKSIZE, не приводит
к снижению безопасности, а только к усложнению кода.
Рекомендуется использовать режим шифрованной
обратной связи при ELEMENTSIZE==BLOCKSIZE.
Это — решение среднего уровня сложности, позволяю-
щее выполнять быстрое шифрование/дешифрование с
помощью только одной функции encrypt(). При ис-
ключении необходимости использования функции
decrypt() уменьшается количество сложных функций,
что упрощает отладку.
Изменение значения ELEMENTSIZE на какое-либо
другое число, нс равное BLOCKSIZE, усложняет зада-
чу и значительно снижает скорость работы. Аппаратная
реализация при этом также имеет меньшую скорость,
хотя и не настолько, как в случае с программной реа-
лизацией, поскольку операции с битами в аппаратных
средствах производятся более эффективно.
Все четыре стандартных режима (электронной кни-
ги, сцепления шифрованных блоков, обратной связи по
выходу и шифрованной обратной связи) всесторонне
изучались на протяжении целого ряда лет. Режим элек-
тронной книги признан небезопасным по слишком мно-
гим причинам, которые даже нет смысла перечислять.
Три остальных режима гораздо безопаснее.
В режиме обратной связи по выходу функция
encrypt() может выполняться заранее или одновремен-
но с получением открытого или зашифрованного тек-
ста. Поскольку эта операция, как правило, достаточно
медленная, то такое преимущество может обеспечить
значительное повышение скорости работы программы.
Пожалуйста, обратите внимание, что для начала рабо-
ты необходимо иметь ключ и вектор инициализации.
Порядок байтов
Практически все функции, связанные с шифрованием,
работают с многобайтовыми блоками, которые исполь-
зуются в качестве целых чисел. Для обеспечения фун-
кциональной совместимости различных реализаций
необходимо обратить особое внимание на преобразова-
ние данных из представления в виде блоков целых чи-
сел в представление в виде последовательностей битов
и наоборот.
682
Дополнительные тематические разделы
Часть III
Листинг 26.7. Режим шифрованной обратной связи.
void encryption!
element_t const plaintext!]f
element! ciphertext[],
size t len,
key_t key,
block t origin)
{
int i;
block! temp;
temp = origin;
ciphertext!0] »
plaintext[0] *
encrypt(temp, key) » BLOCKSIZE - ELEMENTSIZE &
(1 « ELEMENTSIZE) - 1;
for(i » 1; i < len; i++)
{
temp = temp « ELEMENTSIZE | ciphertext[i - 1];
ciphertext[ i ] =
plaintext!i] *
encrypt(temp, key) » BLOCKSIZE - ELEMENTSIZE &
(1 « ELEMENTSIZE) - 1;
void decryption!
element! const ciphertext!],
element! plaintext[],
size_t len,
key_t key,
block! origin)
<
int i;
block t temp;
temp - origin;
plaintext[0] -
ciphertext[0] *
encrypt(temp, key) » BLOCKSIZE - ELEMENTSIZE &
(1 « ELEMENTSIZE) - 1;
for(i » 1; i < len; i++)
{
temp = temp « ELEMENTSIZE | ciphertext[i - 1);
plaintext!!] =
ciphertext!!] *
encrypt(temp, key) » BLOCKSIZE - ELEMENTSIZE &
(1 « ELEMENTSIZE) - 1;
Листинг 26.8. Режим шифрованной обратной связи при ELEMENTSIZE==BLOCKSIZE.
void encryption!
blockt const plaintext!],
block! ciphertext[],
size_t len,
key t key,
block t origin)
int i;
Шифрование
Глава 26
683
ciphertext[0] = plaintext[О] А encrypt(origin, key);
for(i « 1; i < len; i++)
{
ciphertext[i] =
plaintext[i] A encrypt(ciphertext[i - 1], key);
}
void decryption!
blockt const ciphertext[],
blockt plaintext[],
size t len,
key_t key,
block_t origin)
{
int i;
plaintext[0] = ciphertext[0] A encrypt(origin, key);
for(i » 1; i < len; i++)
{
plaintext[i] =
ciphertext[i] * encrypt(ciphertext[i - 1], key);
}
СОВЕТ
При необходимости проведения операций с битами нуж-
но использовать только целые числа без знака. Бит зна-
ка будет только мешать.
Стандартным представлением порядка байтов де-
факто стал порядок “от младшего к старшему”
(“ABCD”), т.е. самый старший байт предшествует, всем
младшим байтам. В представлении “от младшего к стар-
шему” 32-битовое значение OxOAOBOCOD будет пред-
ставлено последовательностью четырех байтов ОхОА,
0x0В, ОхОС и OxOD именно в приведенном порядке.
Некоторые процессоры (среди которых и весьма попу-
лярные Intel 80x86) используют другой порядок байтов,
что может потребовать проведения соответствующих
преобразований.
Если необходимо добиться некоторой функциональ-
ной совместимости, то все блоки необходимо трансли-
ровать в представление “от младшего к старшему” и
обратно. Часто даже проверка правильности работы
реализации для получения правильного тестового ре-
зультата требует соответствующего порядка байтов.
Ниже приведена простая функция, иллюстрирую-
щая преобразование сообщения 32-битового блока из
представления “от младшего к старшему”:
void native_byte__order (
uint32t* msg,
sizet num_blocks)
{
bytet* b_ptr;
while(numblocks-)
{
bptr = (bytet*)(msg + numblocks);
msg[num_blocks] =
(uint32_t)b_ptr[0] « 24 |
(uint32t)bptr[l] «16 |
(uint32_t)b_ptr[2] « 8 |
(uint32__t) b_ptr [ 3 ];
}
)
При обратном преобразовании выходное сообщение
преобразуется обратно в представление “от младшего к
старшему”:
void big__endian(
uint32_t* msg,
size_t num_blocks)
{
bytet* bptr;
uint32_t temp;
while(numblocks-)
{
bptr « (bytet*)(msg + numblocks);
temp = msg[num_blocks];
b_ptr(0] - temp » 24;
b_ptr[l] = temp » 16;
b ptr[2] = temp » 8;
b_ptr[3] = temp;
}
Дополнительные тематические разделы
Часть III
684
Обеспечение аутентичности открытого
ключа
В криптосистемах с двумя ключами тот факт, что взлом-
щик знает открытый ключ, как правило, не вызывает
никаких проблем. Однако при некоторых обстоятель-
ствах взломщик может перехватить передачу также от-
крытого ключа и подменить оба ключа другими ключа-
ми. Если взломщик сможет убедить пользователя, что
тот получил открытый ключ от дружественного пользо-
вателя, то взломщик может выдать себя за этого пользо-
вателя и получать все сообщения, предназначенные для
дружественного пользователя, и сможет подделать лю-
бое сообщение от этого пользователя. Поэтому пользо-
вателям такой системы необходимо средство для под-
тверждения аутентичности (подлинности) их открытых
ключей.
Одно решение состоит в создании официальных
органов. Каждый пользователь получает открытые клю-
чи всех надежных официальных органов каким-либо
защищенным путем (как правило, не через протокол),
поэтому пользователи могут быть уверены, что откры-
тые ключи официальных органов являются подлинны-
ми. Следовательно, любой пользователь, желающий
получить ключ, который будет ассоциироваться с дан-
ным пользователем, может обратиться к одному из офи-
циальных органов и после предоставления доказа-
тельств, что личность пользователя соответствует
личности владельца ключа, получить сертификат. Сер-
тификат представляет собой просто цифровую подпись,
которая несет идентифицирующую информацию, свя-
занную с открытым ключом.
Слишком высокая скорость шифрования
Безопасное шифрование является относительно медлен-
ной операцией. И это, похоже, навсегда останется спра-
ведливым. Сделать небезопасный алгоритм шифрования
медлительным очень легко, но сделать очень хороший
алгоритм быстрым — это совершенно другая задача
Безопасные алгоритмы шифрования для получения
сложного результата часто выполняют сложные опера-
ции или повторяют одни и те же операции по несколь-
ку раз.
Алгоритмы шифрования, как и любые другие алго-
ритмы, можно оптимизировать. Используя заранее вы-
численные таблицы, выполняя параллельную работу,
повторно используя промежуточные состояния и дру-
гие методики, можно значительно повысить производи-
тельность алгоритмов. Однако часто бывает так, что эти
простые методы оптимизации производительности
нельзя применить к безопасному алгоритму шифрова-
ния. Например, безопасный алгоритм шифрования не
может получить больших преимуществ за счет парал-
лельного выполнения, поскольку в большинстве случа-
ев безопасность обеспечивается именно благодаря пос-
ледовательному выполнению операций.
Будьте осторожны при повышении производитель-
ности за счет снижения уровня безопасности. Несомнен-
но, шифрование с более низким уровнем безопасности
может быть выполнено гораздо быстрее, чем шифрова-
ние с более высоким уровнем безопасности, но сниже-
ние уровня безопасности при этом часто недооценива-
ется. Если вы уверены, что некоторый алгоритм
обеспечивает достаточно высокий уровень безопаснос-
ти, можете попробовать провести его оптимизацию и
повышать его быстродействие до тех пор, пока резуль-
тат работы алгоритма или сам алгоритм не изменятся
таким образом, что это может поставить под угрозу бе-
зопасность данных. Если некоторые способы оптими-
зации представляют очевидную угрозу безопасности, то
снижение безопасности, вызываемое применением не-
которых других способов, может быть не так очевидно.
Так, например, изменение порядка выполнения опера-
ций может иметь катастрофические последствия, если
это изменение каким-либо образом влияет на получае-
мые результаты. Убедитесь, что вы получаете результат,
который соответствует требуемому, что ваш метод ге-
нерирования ключей верен и т.д. Если вы больше про-
граммист, чем специалист по криптографии, не изоб-
ретайте новых алгоритмов, новых режимов работы и не
изменяйте существующие.
Некоторые алгоритмы шифрования были специаль-
но разработаны таким образом, чтобы повысить их ус-
тойчивость к длительным и мощным атакам. Путем
многократного выполнения программы взломщик по
длительности выполнения операций или по требуемым
для этого ресурсам может более точно угадать значение
ключа. Например, возведение в степень при больших
значениях показателя степени занимает гораздо больше
времени, чем возведение в степень при небольших зна-
чениях этого показателя. Любая операция, длительность
которой зависит от значений операндов, подвергается
длительным атакам. Имейте этот факт в виду при оп-
тимизации кода, если такие атаки представляют угрозу
вашей программе.
Помните, что низкая скорость, свойственная алго-
ритмам шифрования, оказывает положительное влияние
на его защищенность от использования грубой силы,
если взломщик просто перебирает все возможные вари-
анты. Если вам попался очень быстрый алгоритм, спро-
сите сами себя, сколько времени потребуется на его
взлом с использованием грубой силы. В некоторых слу-
чаях всего несколько итераций (в пределах нескольких
миллиардов) будет достаточно для взлома всего сообще-
ния или ключа. Только тот факт, что алгоритм исполь-
зует 256-битовый ключ, не значит, что взломщик дол-
685
жен будет перебрать все возможные комбинации 256
битов. Высока вероятность того, что быстрый алгоритм
потому и быстрый, что он выполняет мало функций,
обеспечивая либо очень низкий уровень защиты, либо
вообще не обеспечивая ее. Самый быстрый метод шиф-
рования и самый незащищенный — это просто
ciphertextfi] ^plaintext [i].
Слишком высокий уровень безопасности
Как ни странно, можно выполнять шифрование со
слишком высоким уровнем безопасности. Когда уровень
безопасности считается слишком высоким? Когда вы не
совсем понимаете, что делаете или как это должно быть
сделано. Простое копирование кода является одним из
путей создания слабых мест. Необходимо изучить при-
меры использования сильных алгоритмов шифрования,
попытаться их понять и только после этого приступать
к их реализации. Кое-кто, может быть, будет разочаро-
ван тем, что без понимания сильных алгоритмов шиф-
рования нельзя будет эффективно их реализовать.
Программисты могут найти превосходно сделанные
алгоритмы, намного превосходящие любой алгоритм,
который они могут создать сами. Вы можете не пони-
мать отдельных его характеристик, но, тем не менее,
пользоваться его преимуществами. Однако программа
остается ограниченной для вас из-за непонимания ее.
Если в алгоритм необходимо внести изменения в соот-
ветствии с требованиями конкретной ситуации, то, не
имея четкого представления о работе алгоритма, вы не
сможете внести эти изменения или даже не будете по-
дозревать, что нужно вносить какие-либо изменения.
Если не понять преимуществ данного алгоритма, то
можно реализовать его настолько плохо, что он нс бу-
дет обеспечивать должного уровня безопасности, кото-
рую он может обеспечить в принципе.
Если вы не знаете, какой алгоритм выбрать — более
слабый, который вы понимаете, или более сильный,
которого вы нс понимаете, — попробуйте более подроб-
но рассмотреть сильный алгоритм и убедитесь, что его
не так уж сложно изучить. Любой другой выбор приве-
дет к потенциально низкому уровню безопасности.
Представьте себе, что вы не умеете плавать и прыгаете
с очень высокой скалы. С одной стороны находится
море глубиной 60 метров, а с другой — залив глубиной
по щиколотку. Если, прыгнув в залив, вы останетесь
живы, то наверняка погибнете, прыгнув в море из-за
неумения плавать. Поэтому в данном случае лучше сна-
чала научиться плавать, а потом прыгать в глубокую
воду.
Если у вас нет ни времени, ни возможности изучить
сильный алгоритм самому, пусть хотя бы кто-нибудь, кто
знает этот алгоритм, просмотрит вашу реализацию. В та-
ком случае вы сможете избежать некоторых ошибок.
Шифрование
Глава 26
Просто добавьте "соли"
В любые секретные данные, которые обрабатываются
любой функцией безопасности в целях их шифрования,
хеширования или с любой другой целью, сначала необ-
ходимо добавить “соли”. “Соль” — это уникальное зна-
чение, добавляемое к секретным данным для того, что-
бы результирующую последовательность нельзя было
повторить. Главное требование к такой “соли” — это ее
уникальность. Можно использовать случайные числа,
временные метки, индексы или другие значения, кото-
рые можно сделать уникальными. Константа не может
быть хорошей “солью”, поскольку она будет уникаль-
ной только при первом использовании. Каждый стан-
дартный режим шифрования, за исключением просто-
го режима кодовой электронной книги, для его
первоначальных данных требует, по крайней мере, од-
ного блока “соли”.
Зачем используется “соль”? Если не добавлять
“соль”, то данные могут поддаваться атакам, использу-
ющим избыточность зашифрованных данных. Если
взломщик сможет найти несколько повторяющихся бло-
ков или сопоставить зашифрованный и открытый тек-
сты, он может легко взломать вашу систему. Нет необ-
ходимости искать ключ, если взломщик знает, что текст
“We have been discovered!” (“Мы обнаружены!”) в за-
шифрованном виде всегда представляется как
OxABCDEF 123456. Он будет знать, что при каждом
вхождении этого блока использовалось одно и то же
сообщение, и может начать составлять словарь всех со-
общений, которые вы используете. При добавлении
“соли” усложняются практически все методы крипто-
графического анализа.
Необходимо следить за тем, чтобы одни и те же дан-
ные никогда не шифровались с использованием одного
и того же ключа и чтобы одни и те же данные, зашиф-
рованные с использованием одного и того же ключа, в
зашифрованном виде были различны. Совсем не обяза-
тельно, чтобы “соль” держалась в секрете. Даже если
взломщик знает, какое значение вы использовали, тем
не менее, пока используются уникальные значения,
“соль” выполняет свою работу. Хотя сохранение “соли”
и ключа в секрете более безопасно, однако часто не
оправдывает себя. Помните, что “соль” должна быть
уникальна для каждого сообщения, поэтому хранение
ее вместе с ключом менее эффективно, чем использо-
вание разового ключа (т.е. случайного ключа, который
используется только один раз, а затем заменяется дру-
гим случайным ключом). Большинство реализаций со-
вместно с зашифрованным сообщением дают “соль” в
открытом виде (незашифрованном). Такая практика
допустима. Использовать открытую “соль” намного
более безопасно, чем вообще не использовать ее. Скры-
тая “соль” обеспечивает еще более высокий уровень
Дополнительные тематические разделы
Часть III
686
безопасности, но если вы сможете это сделать, то смо-
жете сделать и больший ключ, поскольку больший ключ
дает более высокий уровень безопасности, чем скрытая
“соль”.
Постоянство памяти
С такими широко используемыми средствами, как кэш,
виртуальная память и автоматическое создание резерв-
ных копий по копиям секретных данных в незащищен-
ных местах, взломщики более легко могут найти кон-
фиденциальные данные.
Для защиты данных от взлома таким путем необхо-
димо принять специальные меры. Нужно представить
себе наихудший вариант работы программы. Предполо-
жите, что данные времени выполнения вашей програм-
мы копируются в незащищенный файл подкачки и что
при межпроцессном взаимодействии может осуществ-
ляться обмен открытыми данными через Internet. Кро-
ме того, представьте, что системные вызовы и их аргу-
менты можно отследить и что ваша программа может
быть запушена в эмулированной среде, которая не пол-
ностью поддерживает все меры безопасности, и т.п.
Самая простая мера предосторожности — не хранить
уязвимые данные дольше, чем это необходимо. Удаляйте
данные сразу после их использования. Избегайте пере-
дачи уязвимых данных через внешние библиотеки кол-
лективного доступа. Будьте очень осторожны в том,
какая информация передается пользователю. Данные,
предназначенные для одного пользователя, могут пере-
даваться через сотни потоков, ни один из которых не
гарантирует секретности. Так, например, функция
printf() скопирует данные в поток stdin, который, в свою
очередь, может быть перенаправлен через целый ряд
внешних потоков, включая конвейеры, файлы и соке-
ты, и проходить в процессе передачи через 50 других
компьютеров в открытом виде. Не надейтесь, что ваши
пользователи будут достаточно умны, чтобы выявить
опасность, поскольку о взломах они обычно узнают из
новостей, но даже тогда не верят.
Попытайтесь не упустить из виду данные, которые
должны держаться в секрете. Значения промежуточных
переменных, данные по генерированию случайных чи-
сел и т.п. могут значительно облегчить работу взломщи-
ка. Если данные больше вам не нужны и они каким-
либо образом связаны с обеспечением безопасности
программы, уничтожайте их сразу же после использо-
вания. Не просто используйте функции free() или
fclose(), а устанавливайте значения равными констан-
там, и, таким образом, их предыдущие значения уже не
будут существовать.
В поисках помех
Взломщики не должны иметь возможность просто уга-
дать ключи шифрования. Безопасность шифрования
зависит от случайности его ключей. Единственный путь
сделать так, чтобы взломщики не смогли угадать клю-
чи, — это выбирать ключи совершенно случайным об-
разом. С уменьшением степени случайности выбора
ключей снижается их эффективность и они легче под-
даются взлому даже при использовании простого пере-
бора вариантов. Вероятность того, что ключ будет иметь
определенное значение, должна быть не более вероят-
ности того, что ключ будет иметь любое другое возмож-
ное значение. (Некоторые алгоритмы имеют несколько
очень слабых ключей, которые должны исключаться в
процессе генерирования ключей.) Хотя в настоящее
время широко используются генераторы псевдослучай-
ных чисел (например, стандартная функция rand()),
тем не менее, действительно случайные числа не так
просто генерировать.
Генератор псевдослучайных чисел принимает одно
предположительно случайное число и расширяет его до
большого количества значений, которые имеют слож-
ную повторяющуюся структуру. Структура должна быть
достаточно сложной, чтобы ее было трудно обнаружить
и получаемые значения казались случайными. Псевдо-
случайные числа — не очень хорошая замена действи-
тельным случайным числам. Например, генерирование
256-битового ключа, выбираемого с помощью генерато-
ра псевдослучайных чисел на основании 8-битового
значения, приводит к тому, что 256-битовый ключ име-
ет эффективную длину 8 битов, поскольку фактически
неизвестны только эти 8 битов. Генерирование псевдо-
случайных чисел с использованием в качестве началь-
ного значения псевдослучайных чисел приводит толь-
ко к получению более псевдослучайных чисел с
начальным значением, которое использовалось для ге-
нерирования первой последовательности псевдослучай-
ных чисел.
Некоторые аппаратные средства сделаны так, что
они позволяют во время работы программы получать
действительные случайные числа. Будьте осторожны
при использовании таких случайных чисел, поскольку
совершенно случайными они могут казаться лишь на
первый взгляд. Только тот факт, что приложение вызы-
вает эти значения случайным образом, еще не значит,
что они достаточно случайны для использования их при
шифровании. Недостоверные или непредсказуемые по-
токи данных не во всех случаях являются действитель-
но случайными потоками.
Большинство программ требуют ввода случайного
значения пользователем. Точное время возникновения
некоторых событий, например значение миллисекунд
Шифрование
Глава 26
687
при запуске программы, может вполне использоваться
в качестве источника случайных данных небольшого
объема. Сбор большего объема случайных данных, осу-
ществляемый таким путем, может занять много време-
ни и вызвать раздражение у пользователя. Но такой вид
источника случайных данных не подходит, когда есть
вероятность, что взломщик может угадать время, в ко-
торое произошло то или иное событие. Например, не
смысла определять время нажатий на клавиши, если
взломщик может перехватить эти события.
Очень плохое решение, которое часто используют,
— это просьба ввести случайные данные самому пользо-
вателю. Пользователи — очень плохие генераторы слу-
чайных чисел. Они, как правило, считают, что все, что
придет им в голову, является случайным и не подлежит
угадыванию, а затем используют придуманные данные
повторно. Хотя некоторым пользователям нравится воз-
можность выбора своего пароля, они почти всегда не-
правильно используют эту возможность, выбирая для
более легкого запоминания паролей существующие сло-
ва или другие данные, которые легко угадать. Хеширо-
вание (или перефразирование) пароля пользователя
помогает не всегда. Случайные данные, введенные
пользователем, имеют такое плохое качество, что для
получения хорошего случайного значения требуется
проделать еще много работы.
Искусство криптографии и теория вычислительных
машин развились настолько, что надежное шифрование
требует большего объема случайных данных, чем рядо-
вой пользователь может запомнить. Обычный взрослый
человек знает примерно 200 тыс. слов, включая имена.
Выбор случайным образом одного слова из этих 200 тыс.
даст меньше 18 битов данных. Следовательно, алгоритм
DES требует более трех слов, а 256-битовый ключ ал-
горитма AES — более 14 слов. Современные системы
шифрования с двумя ключами требуют больших клю-
чей для обеспечения одного и того же уровня безопас-
ности, чем системы с одним ключом, а это означает, что
пользователю в некоторых случаях пришлось бы запо-
минать последовательность более сотни действительно
случайных слов. Однако некоторые не всегда помнят
даже телефонные номера. Вывод один — только пользо-
ватели с исключительно развитой памятью могут ис-
пользовать сильное шифрование, а иначе надежное
шифрование потребует не только памяти человека, но
и средств записи данных, например, компьютерных
дисков.
Чем меньше, тем лучше
Независимо от качества шифрования, уровень безопас-
ности всегда можно повысить за счет генерирования
меньшего объема зашифрованного текста. Большинство
атак взлома требуют или облегчаются при наличии для
анализа большого объема зашифрованного текста. Даже
после взлома сообщения некоторого объема взломщик
предпочитает взломать еще большее сообщение.
Необходимо часто менять ключи, чтобы объем дан-
ных, зашифрованных с помощью одного уникального
ключа, был небольшим. Не генерируйте и не храните
несколько ключей одновременно для последующего
использования. Чем дольше хранится ключ, тем боль-
ше вероятность того, что его найдут. При необходимо-
сти использования нового ключа сгенерируйте его с
использованием новых случайных данных. При отсут-
ствии необходимости в старом ключе всегда полностью
удаляйте его, приравнивая его значение к константе.
Поскольку шифрование с двумя ключами, как пра-
вило, выполняется медленнее и для обеспечения уров-
ня безопасности, равного уровню безопасности шифро-
вания с одним ключом, требуются большие ключи,
предпочтение следует отдать совместному использова-
нию этих двух видов шифрования. Метод шифрования
с двумя ключами может использоваться только для
шифрования ключа системы шифрования с одним клю-
чом, что потенциально делает сообщение более безопас-
ным, а его обработку — более быстрой, ч£?л использо-
вание только метода шифрования с двумя ключами.
Другая очень полезная методика, которую следует
применять, — это сжатие данных перед их шифровани-
ем. Сжатие имеет несколько преимуществ. Оно позво-
ляет удалить повторяющиеся структуры и уменьшить
объем зашифрованного текста, в результате чего умень-
шается объем сообщения, доступный взломщику для
анализа. Кроме того, меньшее количество блоков дан-
ных дает возможность ускорить процессы шифрования
и дешифрования. И, разумеется, меньший объем зашиф-
рованного текста можно более эффективно хранить и
передавать.
Не оставляйте подсказок
Иногда суть сообщения является не единственной цен-
ной частью сообщения. Иногда содержание сообщения
можно определить даже по времени его передачи, по его
длине, по отправителю, получателю и подругой доступ-
ной информации. Любые свойства сообщения, которые
могут представлять какую-либо ценность для взломщи-
ка, должны быть защищены или, если это возможно,
удалены. По возможности перенесите уязвимую вспо-
могательную информацию (например, тему) в зашиф-
рованную часть сообщения. Если это невозможно, за-
шифруйте поля по отдельности. При использовании
только одного ключа всегда лучше иметь одно большое
поле зашифрованных данных, чем несколько отдельных
зашифрованных полей меньшего размера.
Если ценность представляет время отправления,
необходимо производить отправку периодически. Если
688
Дополнительные тематические разделы
Часть III
важное сообщение должно быть получено не более чем
через одну минуту после его отправки, отсылайте каж-
дую минуту ложные сообщения, и, таким образом, не
будет возможности выявить среди ложных сообщений
действительное. Создавайте ложные сообщения таким
образом, чтобы их нельзя было отличить от действи-
тельного, делайте все сообщения близкими по размеру
и по содержанию. Если длину и содержание сообщения
нельзя определить заранее, то просто с помощью слу-
чайных значений придайте им случайный характер.
Каждый получатель должен принять и, возможно, по
индексу или по подписи отличить действительное со-
общение от ложных. Это предотвратит возможность
замены взломщиком ложных сообщений.
Другой вариант — время передачи можно скрыть,
если передать сообщение с достаточно длинной, случай-
ной задержкой по времени. Конечно, это замедляет
получение сообщения получателем.
Анонимность также можно обеспечить за счет пери-
одического обмена большими ложными или бессмыс-
ленными сообщениями между всеми пользователями, а
действительными сообщениями можно обмениваться
только при необходимости.
Маскировка информации
Самое большое преимущество, которое может получить
взломщик, — это обнаружить объект взлома. Поэтому
самый лучший вариант зашиты — держать потенциаль-
ных взломщиков в полном неведении о сообщениях.
Маскировка информации становится действительно
полезной, когда она выполняется совместно с обычным
шифрованием. Взломщик, обнаруживший только скры-
тый зашифрованный текст, скорее всего, не будет пред-
принимать попыток взлома, думая, что данные слиш-
ком случайны, чтобы иметь какой-либо смысл. Для
маскировки информации становится необходимым, что-
бы зашифрованный текст был не только защищен от
несанкционированного преобразования в открытый
текст, но и был смешан с вспомогательными данными
и контекстом. В таком случае зашифрованный текст
гораздо легче упустить из виду, и смешивание может
повлиять на выбор алгоритмов взлома.
Наиболее очевидной стратегией маскировки инфор-
мации является скрытие информации в таком месте, где
ни один потенциальный взломщик не будет ее искать.
Используя этот подход, можно скрыть сообщения до-
вольно большой длины. Часто информация скрывается
в невыделенной памяти, включая память на жестких
дисках, кодируется под документы (как правило,
HTML или XML), хранится в неиспользуемых, резерв-
ных или игнорируемых заголовочных полях, особенно
часто в полях комментариев, хранится на диске в сек-
торах с нетрадиционным доступом или в секторах, мар-
кированных как испорченные.
Реже используется хранение данных поверх других
данных, когда оба сообщения занимают одно и то же
пространство. Многие форматы настолько гибки, что
небольшие изменения в файле не приводят к измене-
нию интерпретации этого файла. Например, компиля-
торы языка С игнорируют пустые места в исходном
коде, поэтому ввод сообщения в исходный файл на С
не будет замечен компилятором. Добавляя всего по 0 —
3 позиции к концу каждой строки исходного кода, мож-
но спрятать 2 бита на строку, что, возможно, будет не
замечено самим программистом, который тщательно
просматривает файл. Даже взломщики, которые пыта-
ются обнаружить зашифрованные сообщения, вряд ли
будут тщательно просматривать открытый файл исход-
ного кода. Скрывая одно сообщение в другом, вы по-
лучаете еще одно преимущество: можете зашифровать
само несущее сообщение. В этом случае даже можно
дать взломщику дезинформацию, если он сумеет взло-
мать несущее сообщение. После взлома сложного за-
шифрованного сообщения взломщики будут так рады
увидеть сообщение, что они и не подумают, что в этом
сообщении скрывается другое. А если и подумают, то
скрытое сообщение будет выглядеть настолько случай-
ным, что совсем не будет казаться сообщением, а толь-
ко игрой их воображения.
Поскольку незамеченными могут пройти только не-
большие правдоподобные изменения, несущее сообще-
ние бывает, как правило, намного больше заложенного
в нем скрытого сообщения. Большинство специалистов
по маскировке информации часто для маскировки дан-
ных используют большие файлы, например, файлы
изображений или звуковые файлы. Эти файлы обеспе-
чивают объем, достаточный для передачи простых со-
общений. Изменения в младшем байте каждого кадра
или пиксела вполне могут пройти незамеченными.
Последние штрихи
Последним этапом в создании любого приложения для
шифрования должен быть его взлом. Вы сами должны
взломать свое приложение хотя бы один раз. Возьмите
на себя роль взломщика и найдите уязвимые места.
Если это слишком сложно, попытайтесь несколько об-
легчить свою задачу, считая, что пользователи не сле-
дуют вашим инструкциям, снижая эффективность или
вообще убирая алгоритм шифрования, и т.д. Иногда
существующие недостатки становятся более очевидны-
ми, когда в программу вносятся различного рода ухуд-
шения.
После того как волнение от взлома собственной про-
граммы утихнет, передайте ее коллегам, пусть они по-
пробуют ее взломать. Если они не смогут этого сделать,
по крайней мере, попросите их предложить свои идеи
и указать на возможные проблемы. Дайте им соответ-
Шифрование
Глава 26
689
ствующий исходный код, чтобы они могли видеть, как
работает программа.
Затем после устранения всех недостатков, которые
будут обнаружены после неоднократного взлома вашей
программы, поиграйте в игру под названием “а что,
если...”. Спросите себя, что именно произойдет, если
программа будет каким-либо образом дискредитирова-
на. Предположите, что у вас есть злонамеренные и глу-
пые пользователи. Представьте, что кто-то возьмет ваш
исходный код и распространит его троянскую версию.
Определите, каким образом один серьезный недостаток
сможет повлиять на всю программу. Не смотрите на это
свысока и не исключайте все возможности. Если вы
пользуетесь системой шифрования, значит, вы готовы
к попытке взлома и должны знать, что произойдет, если
взлом будет успешным. Необходимо принять соответ-
ствующие меры — такие, чтобы один успешный взлом
не разрушил и не ослабил всю систему.
Вы должны постараться не только ограничить мак-
симальные размеры провала в системе безопасности, но
и разработать план безопасного восстановления после
возникновения проблем. Вопросы, варьирующиеся от
утери пароля или повреждения файла ключей до пол-
ной потери работоспособности системы, должны быть
тщательно продуманы еще до полной готовности моде-
ли безопасности. Если оставить их на потом, то это
может позволить взломщику выяснить все другие меры
безопасности, просто сравнивая сбойную систему с вос-
становленной после повреждений. Очень часто бывает,
что взлом систем с достаточно высоким уровнем безо-
пасности возможен, если заставить систему восстанав-
ливаться после возникшей проблемы или просто выдать
себя за пользователя, у которого возникли проблемы и
который нуждается в помощи.
И наконец, после завершения разработки програм-
мы не давайте обещаний, которых вы не в состоянии
выполнить. Не хвастайтесь неприступностью програм-
мы. Очень немногие программисты считают себя безуп-
речными, будьте осторожнее, если вы причисляете себя
к таковым. Просто и честно опишите слабые места, что-
бы пользователь мог правильно к ним приспособиться.
Пользователи не любят, когда им навязывают ложное
чувство безопасности. Подробно опишите, какой алго-
ритм и каким образом вы используете, укажите источ-
ник случайных данных и другую необходимую инфор-
мацию. Скрытие этой информации практически не
служит защитой для программного обеспечения, а ее
раскрытие повышает вероятность того, что проблемы
можно будет обнаружить гораздо раньше и что опытные
пользователи будут доверять вашему продукту. В таком
случае они посоветуют неопытным пользователям ис-
пользовать эту программу, и, таким образом, все пользо-
ватели будут иметь доверие к вашей программе.
Резюме
Итак, основным языком программирования для шифро-
вания является язык С. Другие языки программирова-
ния кажутся либо слишком высокоуровневыми, либо
слишком низкоуровневыми для создания программ
шифрования.
Почти каждое современное приложение должно ка-
ким-либо образом быть связано с обеспечением безопас-
ности. Люди все более ориентируются на зарабатывание
денег с использованием программного обеспечения и
передачи очень важной информации программному
обеспечению. Теперь вы знаете, почему для программи-
стов становится все более важным иметь четкое пред-
ставление о вопросах безопасности и методиках обес-
печения безопасности, таких как шифрование данных.
Без четкого понимания этих вопросов будет невозмож-
но обеспечить конфиденциальность электронных дан-
ных, аутентификацию и электронную коммерцию.
В этой главе дана оценка и произведена классифи-
кация угроз безопасности. В некоторых случаях наи-
большую угрозу представляют сами пользователи, безо-
пасность которых вы пытаетесь обеспечить. Были
рассмотрены типичные ошибки, которые могут быть
допущены при разработке новых алгоритмов шифрова-
ния, если не уделить должного внимания вопросам
криптографии.
В число основных тем этой главы также входят: со-
временное состояние криптографии, алгоритмы шифро-
вания, их назначение и применение.
И наконец, особенно подробно рассмотрена часть
работы по обеспечению безопасности, о которой боль-
шинство программистов забывают: реализация деталей.
Поэтапно описан процесс создания действительно бе-
зопасной системы — начиная от выбора различных ре-
жимов шифрования и заканчивая выбором источника
помех. Представлены также некоторые методы обеспе-
чения еще более высокого уровня безопасности данных
после их шифрования, например, такие как маскиров-
ка данных и удаление их после использования.
44 Зак. 265
Встроенные системы
В ЭТОЙ ГЛАВЕ
Программирование встроенных систем на языке С
С-программирование встроенных систем и стандарт ANSI С
RTOS — операционные системы реального времени
Система RTEMS как типичный пример RTOS
Стефан Уилмс
Всякий раз, когда речь идет о том, что микропроцессор
куда-то встраивается, мы имеем дело со встроенной
системой. Процессор и его периферия подгоняются к
приложению и внедряются в него. С персональными
компьютерами и рабочими станциями происходит все
наоборот: приложение приспосабливается к данной
системе с данной периферией и устройствами ввода/
вывода. Возьмем в качестве примера современную сти-
ральную машину. У нее имеется дисплей, на котором
(в виде текста) отображается информация о том, что
машина в настоящий момент делает, кнопки, с помо-
щью которых машине задается та или иная команда ре-
гуляторы для установки операционных параметров, таких
как температура воды или скорость вращения центрифу-
ги. Это типичный пример встроенной системы:
• она не выглядит как настольный компьютер, но все
же имеет скрытый внутри компьютер
• компьютер приспособлен к дизайну машины
• она имеет совершенно необычные устройства ввода/
вывода
• система разработана исключительно для выполне-
ния, программное обеспечение создано вне системы.
К другим примерам встроенных систем относятся
автомобильные аудиосистемы со встроенным искателем
маршрута или высокотехнологичные самолеты наподо-
бие новых моделей аэробусов. И если вы когда-либо
пробовали слишком быстро ехать по скоростной трас-
се, а на информационном дисплее вашего автомобиля
появляется ’’Система перегружена”, вы знаете, что где-
то здесь должен быть встроенный компьютер.
Если вы спросите, является ли каждый объект, уп-
равляемый микропроцессором, встроенной системой,
включая персональные компьютеры и мэйнфреймовские
системы, то энтузиасты ответят: "Да, конечно", хотя
это, безусловно, является преувеличением и не вполне
соответствует действительности. Вообще, термин встро-
енная система (Embedded system дословно переводится как
внедренная система. — Примеч. пер.) трудно определить
точно, но можно и по-другому взглянуть на предыду-
щий список. Компьютер приспосабливается для весьма
специфического использования, поэтому стандартные
компоненты, такие как монитор, клавиатура и мышь,
имеют самый разнообразный вид и модификацию.
Во встроенных системах используются любые дос-
тупные программируемые аппаратные средства. В одних
используются микропроцессоры, разработанные специ-
ально для встроенных систем, такие как Hitachi серии
SH, в то время как в других — обычные микропроцес-
соры, известные в мире персональных компьютеров, на-
пример, Intel 80x86, Motorola 680x0 или процессор
PowerPC. Каждая встроенная система по-своему уни-
кальна, но процессор является их главным общим ком-
понентом. Он устанавливает базовый язык программи-
рования (ассемблер) и оказывает некоторое влияние на
архитектуру периферии и интерфейсы с другими уст-
ройствами.
Анализ минимальных потребностей для встроенных
систем показывает, что мы имеем дело с самой простей-
шей компьютерной системой. В первую очередь необ-
ходим процессор, небольшой объем постоянной памя-
ти для хранения выполняемой программы и соединение
с машиной или другим объектом, которым мы предпо-
лагаем управлять. Добавьте сюда традиционную элект-
ронную схему (блок питания, кварц и т.п.) — и вы по-
лучите то, что требуется. Процессор самостоятельно
обеспечивает оперативную память (например, регист-
ры). Все остальное добавляется только при необходи-
мости, например:
Встроенные системы
Глава 27
691
• RAM
• контроллеры прерываний
• устройства отображения памяти
• последовательные и параллельные порты
• системная шина для подсоединения более сложной
периферии.
В зависимости от задач, для решения которых пред-
назначается микропроцессор, производитель может ре-
шить либо разрабатывать и изготовлять свою собствен-
ную компьютерную систему из упомянутых выше
компонентов, либо обратиться к полуфабрикатным ком-
пьютерным модулям, которые он может использовать.
Имеется огромный рынок полуфабрикатных внедряе-
мых модулей с целым рядом очевидных преимуществ,
включая такие, как:
• стандартизация, обеспечивающая массовое произ-
водство
• отсутствие необходимости доводки и тестирования
сложной компьютерной схемы
• поддержка при добавлении аппаратных средств и
развитии программного обеспечения.
Основной целью является придание гибкости даже
простому, маленькому, а также мощному компьютерно-
му модулю, который фирма может приспособить к сво-
ему продукту.
В этой главе будут рассмотрены ключевые аспекты
разработки платформно-независимого программного
обеспечения и его связь с программированием встроен-
ных систем на языке С:
• Подготовка к работе: компилятор и инструменталь-
ные средства
• Подготовка программы к выполнению: код програм-
мы запуска
• Обеспечение обратной связи: базовые средства вво-
да/вывода
Программирование встроенных систем
на языке С
Большинство современных встроенных систем програм-
мируются либо на ассемблере, либо (в большинстве
случаев) на С. В языке С гармонично сочетаются воз-
можности программирования низкого уровня со свой-
ствами языка высокого уровня. Необходимость низко-
уровневого программирования (т.е. программирования,
тесно привязанного к аппаратным средствам) диктует-
ся рудиментарной природой встроенных систем. Свой-
ства языка высокого уровня главным образом повыша-
ют читабельность и модифицируемость программного
кода.
В настоящее время язык С стал стандартным языком
программирования встроенных систем. Компиляторы С
доступны для каждого микропроцессора и каждого полу-
фабрикатного модуля встроенной системы, где они фор-
мируют интегральную часть пакета разработки программ-
ного обеспечения для модуля. Если вы разрабатываете
свою собственную систему, то можете либо получить
компилятор С для микропроцессора от производителя
этого процессора, либо использовать компилятор GNU-
С, если ваш процессор поддерживает его. Бесплатный
GNU-проект поддерживает широкий спектр рассматри-
ваемых процессоров и включает больше чем просто ком-
пилятор GNU-C: редактор связей, библиотечный ме-
неджер и широкий набор инструментов разработки
программного обеспечения — все это является частью
проекта. Фактически множество С-компиляторов, рас-
пространяемых производителями процессоров или
встраиваемых модулей, основаны именно на компиля-
торе GNU-C.
Вне зависимости от того, какой компилятор исполь-
зуется, программирование встроенных систем всегда
означает разработку платформно-независимого про-
граммного обеспечения. Ваша система разработки про-
граммного обеспечения обычно будет значительно от-
личаться от целевых аппаратных средств, которые будут
выполнять создаваемую вами программу. В некоторых
случаях такое различие может быть незначительным, но
результат будет тот же — вы не сможете выполнить
программу для встроенной системы на платформе, ко-
торую для нее создаете. Кроме кросс-компилятора не-
обходим также набор кросс-инструментов разработки
программного обеспечения.
Подготовка к работе
Проще всего подготовка к разработке программного
обеспечения для встроенной системы выполняется при
наличии полного набора кросскомпилятора и инстру-
ментальных средств от компании, изготовившей процес-
сор или встраиваемый модуль. В этом случае вы полу-
чите инструкцию по установке базовой системы,
инсталляции инструментов и т.п. В конце концов, ваша
базовая система будет готова для производства про-
грамм, которые будут затем выполняться целевыми ап-
паратными средствами.
Компилятор GNU-C (сокращенно GCC) и его ин-
струментальные средства (BINUTILS) являются типич-
ной альтернативой в том случае, если комплект про-
граммного обеспечения для вашей аппаратуры
недоступен. GNU был перенесен в широкий спектр
целевых процессоров и процессорных архитектур. Ком-
пилятор, инструменты и списки поддерживаемых глав-
692
Дополнительные тематические разделы
Часть III
ных (хост-систем) и целевых систем можно найти по
адресу http://www.gnu.org.
Основным требованием является наличие хост-сис-
темы с существующим С-компилятором, способным
создавать программы для этой системы. Первым делом
следует распаковать исходный код инструментов
B1NUTILS и приспособить их для целевой системы.
Таким образом будут созданы ассемблер (компонующая
программа), редактор связей, библиотечный менеджер
для объектных файлов и сгруппированы другие инст-
рументы. Все пакеты программного обеспечения GNU
используют один и тот же трехэтапный механизм фор-
мирования программного обеспечения:
1. Конфигурирование исходного кода для данных
типов главной и целевой систем и директории хост-
системы. При этом будут созданы необходимые
make-файлы.
2. Использование утилиты МАКЕ для построения
программы (или программ) из исходного кода. Ре-
зультирующая программа будет выполняться на
хосте, но будет поддерживать и целевые аппаратные
средства.
3. Инсталляция программ, созданных для директории
хост-системы, путем повторного использования
МАКЕ.
После формирования инструментов BINUTILS нуж-
но распаковать исходный код GCC и встроить, выпол-
няя для этого все ту же трехэтапную процедуру. После
этого у вас уже должен быть работающий кросс-компи-
лятор С и работающий набор инструментальных средств
разработки.
Запуск программы встроенной системы
Одной из главных проблем, связанных со встроенными
системами, является перенос программы из хост-систе-
мы во встроенную, где она должна выполняться. Основ-
ная методика запуска программ одинакова для большин-
ства микропроцессоров: когда включается питание или
нажимается кнопка RESET, процессор входит в неко-
торое исходное состояние и начинает выполнять коман-
ды из конкретных заранее определенных адресов памя-
ти. По этим адресам памяти должна быть доступна
текущая программа, соответствующий загрузчик или
запускающая программа-стартер. Кроме того, програм-
ма должна включать весь код, требуемый для инициа-
лизации процессора и всех используемых им аппарат-
ных средств.
Простейший подход для обеспечения (наличия)
программы по адресу, где процессор ожидает ее найти,
состоит в использовании заменяемых или программи-
руемых модулей памяти типа ROM, PROM, EPROM,
EEPROM и т.п. Такие модули памяти представляют
собой постоянные запоминающие устройства (ПЗУ)
для хранения программ. Программа выполняется пу-
тем подключения модуля в его сокет (гнездо) на
встроенной системе и подключения питания. Модуль
EEPROM и его более современный вариант Flash-
ROM более предпочтительны, поскольку они могут
быть перепрограммированы на месте, без необходи-
мости их отключения, путем использования специаль-
ной электронной схемы. Это, следовательно, не-
сколько ослабляет аспект постоянства памяти модуля.
Действительно, такая схема может быть зашита таким
образом, что программа сможет перезаписывать мо-
дуль EEPROM в процессе выполнения, например, для
сохранения информационного параметра или для
внутреннего обновления самой программы. На слу-
чай, если вам незнакомы использованные выше акро-
нимы для модулей ПЗУ, ниже приведен короткий
список с расшифровкой их смысла:
• ROM — Read Only Memory — постоянное запоми-
нающее устройство (ПЗУ)
• PROM — Programmable ROM — программируемое
ПЗУ (ППЗУ)
• EPROM — Erasable PROM — допускающее стирание
ППЗУ
• EEPROM — Electrically EPROM — электрически
стираемое ППЗУ
• Flash-ROM — современный вариант EEPROM, в ко-
тором целые блоки памяти очень быстро могут быть
очищены и перезаписаны; другие преимущества
включают более быстрый доступ для чтения и боль-
шую емкость памяти на меньшем чипе.
Использование таких чипов представляет собой наи-
более типичный способ хранения программ во встроен-
ной системе. Системы, в которых для хранения про-
граммного кода используются жесткие диски,
исключительно редки. Что еще остается сделать перед
тем, как запустить программу, — это записать программу
на чипы. Переносные чипы требуют подключения к
специальному программирующему устройству (про-
грамматору) и установки за(перепрограммированного
чипа обратно во встроенную систему. Современные
модули EEPROM и Flash-ROM могут быть перепрог-
раммированы непосредственно внутри системы. Для
этого необходимо, чтобы существующее программное
обеспечение включало специальный маршрутизатор для
оперирования свойствами аппаратных средств в целях
стирания и перезаписи содержимого памяти чипа. Но-
вая программа, записываемая на EEPROM или Flash-
ROM, может быть получена, в частности, из базовой
системы посредством коммуникационного соединения.
693
Если встроенная система имеет достаточный объем
RAM и фиксированное коммуникационное подключе-
ние к подходящей хост-системе, можно реализовать
альтернативный и более динамичный подход. Модуль
(EEP)ROM содержит лишь простейшую программу на-
чальной загрузки, которая использует коммуникацион-
ное соединение для запроса из базовой системы требу-
емой программы на выполнение; соответствующий
программный код через коммуникационное соединение
загружается в RAM, и последним действием начально-
го загрузчика будет запуск программы на выполнение.
В предыдущем разделе описана наиболее фундамен-
тальная (базовая) форма встроенной программы, при
которой программа должна инициализировать процес-
сор и все аппаратные средства перед выполнением ими
главной задачи. Другими словами, программные сред-
ства должны обеспечивать множество очень важных и
сложных функциональных возможностей еще до того,
как выполнять даже простейшие задачи. Но это не яв-
ляется главной проблемой. Для большинства микропро-
цессоров базовая программа инициализации доступна
через Internet. Поиск в Internet или исследования в со-
ответствующих группах новостей Usenet могут сберечь
для вас время и усилия. С большинством аппаратных
средств ввода/вывода ситуация аналогична: если они не
слишком необычны, вам удастся найти исходный код,
который либо уже делает то, что вам нужно, либо мо-
жет послужить хорошим базовым примером.
Наконец, я приведу несколько примеров, когда си-
туация с программным обеспечением оказывается даже
менее критичной. Еще раз повторим, полуфабрикатный
модуль встраиваемой системы имеет наибольшее пред-
ложение. Если такой модуль обеспечен всей необходи-
мой поддержкой, он поступает с полным набором кор-
ректируемого кода запуска и с дополнительными
библиотеками ввода/вывода для доступа ко всем функ-
циям аппаратных средств. Некоторые системы могут
иметь модули BIOS (Basic Input Output Software — Ба-
зовое программное обеспечение ввода/вывода. — При-
меч. пер.) либо, по крайней мере, устройство PROM на-
чальной загрузки. Модуль BIOS представляет собой вид
встроенной библиотеки программ для системы. Он со-
держит базовый код запуска и дополнительную, но
очень примитивную поддержку ввода/вывода. Модуль
PROM начальной загрузки обладает меньшей функци-
ональностью: он обеспечивает главным образом базовую
инициализацию процессора и обычно минимальный
механизм для загрузки программы из устройства ввода,
наподобие последовательного порта, сетевого соедине-
ния или запоминающего устройства.
Встроенные системы
Глава 27
Базовые средства ввода/вывода
Программа, не имеющая доступа к каким-либо сред-
ствам ввода/вывода, абсолютно бесполезна. Она не мо-
жет получать входные данные, а значит, не может вос-
принимать результаты своей работы или подчиняться
внешним командам. Аппаратные средства ввода/вывода
необходимо подсоединять к процессору таким образом,
чтобы процессор мог управлять ими. По существу, един-
ственный способ, позволяющий связать микропроцес-
сор с его окружением, состоит в считывании или изме-
нении содержимого ячеек памяти. Процессоры с
устройствами ввода/вывода непосредственно на чипе
составляют исключение: они будут иметь инструкции
ассемблера для использования этих устройств.
Аппаратные средства с отображением памяти про-
граммируются путем записи кодовых комбинаций би-
тов или байтов в ячейки памяти. Чтобы сделать это на
языке С, нужно присвоить адрес памяти переменной-
указателю. Предположим, например, что необходимо
установить бит 3 по адресу 0x80004242:
unsigned char *adr=0x80004242; /* Это только
демонстрационный пример адреса */
*adr=*adr|0x04;
Программный код, подобный приведенному, пишет-
ся для конкретного компилятора и конкретного аппа-
ратного средства. Во-первых, адрес памяти будет, ско-
рее всего, неверным для любой системы, кроме той, для
которой этот код был написан. Во-вторых, концепция
присвоения целых значений переменным-указателям в
языке С обусловлена определением специфического
компилятора. На одних С-компиляторах это может
быть запрещено, а на других может потребоваться спе-
циальный синтаксис. В предыдущем примере исполь-
зован наиболее общий синтаксис, используемый боль-
шинством С-компиляторов.
Для большинства аппаратных средств во встроенных
системах потребуется список адресов памяти, связанных
с этими аппаратными средствами, и детальное описа-
ние того, что можно прочитать по этим адресам и что в
эти адреса будет записываться. Главная проблема про-
граммирования встроенных систем состоит в том, что
такое описание, как правило, чрезвычайно сложно. Даже
очевидные простейшие задачи, такие как использование
последовательного порта, требуют для их выполнения
очень сложных функций. Вообще, программирование
аппаратных средств напрямую через интерфейс распре-
деленной памяти является очень сложным делом. Это
ответ на вопрос, почему наличие даже простейшего
программного обеспечения поддержки обеспечивает
огромное преимущество, и этого не следует недооцени-
вать.
Дополнительные тематические разделы
Часть III
694
Давайте рассмотрим простой практический пример
программирования выводного устройства отображения
памяти: семисигментный дисплей, наподобие тех, ко-
торые используются в цифровых циферблатах электрон-
ных часов. В нем имеется семь строк для каждой циф-
ры, которые могут переключаться в положение вкл/выкл
по отдельности и формируют цифру ”8”, если все они
включены одновременно. В нашем примере дисплей
содержит, скажем, четыре цифры и двоеточие между
первой и второй парами цифр. Такой дисплей выглядит
примерно так:
Каждая цифра отображается одним байтом в памя-
ти. Биты 0-6 каждого байта управляют семью сегмен-
тами; бит 7 не используется. Здесь пятый управляющий
байт предлагает две простые функции: бит 0 включает
и выключает дисплей, бит 1 включает и выключает дво-
еточие между парами цифр. Напишем пример основной
функции драйвера, которая изменяет содержимое дис-
плея путем выполнения следующих действий:
• выключение дисплея
• установка нового содержимого
• включение дисплея снова.
/*
* * setDisplayContents
**
* * digits : the bytes to write to the four
digits in the display
* * byte 0 is the rightmost digit
* * colon : flag for controlling the colon: 0
= off, 1 = on
**
* * Macro DISPLAY_BASE_ADR is used to obtain
the display base
* * address. The offset 0 is assumed to be the
display control
** register. Offsets 1 to 4 are assumed to be
the digits 1 to
** 4 (rightmost to leftmost respectively).
*/
void setDisplayContents( unsigned char
digits!4], int colon )
unsigned char «display = DISPALYBASEADR;
int i;
/* switch display off */
display!0] &= OxFE;
/* write the 4 digits */
for ( i=0 ; i < 4 ; i++ )
display!i+1] » digits!!];
/* set the colon status */
if ( colon == 0 )
display!0] OxFD;
else
display[0] |= 0x02;
/* switch display back on */
display!0] |== 0x01;
Функции setDisplayContentsO даже не нужно знать,
как будут выглядеть комбинации битов. Она выполня-
ет лишь элементарную функцию драйвера. Функция
более высокого уровня логики, назовем ее displayTime(),
могла бы использовать функцию setDisplayContentsO
для отображения на дисплее значения фактического
времени, например, ”12:00". Если вам интересно, как
будет выглядеть функция displayTime(), заметим, что это
зависит от аппаратного обеспечения. Такая функция
должна знать, как биты позиций в цифровом байте со-
относятся (корреспондируют) с линиями числа. Без
таблицы, которая показана ниже, функция
setDisplayContentsO бесполезна:
о
6 I I 1
- 2
5 | | 3
4
Функция типа следующей:
int displayTime(int hours, int minutes,
int colon);
хорошо отражает высокоуровневое окончание пользова-
тельского интерфейса. Ее можно использовать без зна-
ния специфики аппаратных средств, и она приспособ-
лена к хорошо определенной задаче.
Рассмотренный пример показывает, как управлять
выводным устройством и создавать для него функции
драйвера. Чтение с вводного устройства выполняется с
помощью аналогичных базовых операций доступа к
памяти. Например, в руководстве по эксплуатации од-
ной из моих карт дигитайзера Шифратор, или устрой-
ство ввода графической информации. — Примеч. науч,
ред.) указывается, что в результате считывания конкрет-
ного адреса FIFO DATA ADR будет получен нижний
элемент аппаратной памяти FIFO (First In First Out —
концепция хранения данных "первым вошел — первым
вышел" — Примеч. пер.), в которой дигитайзер хранит
результаты оцифровки строки аналогового ввода в ре-
гулярных интервалах. Другой адрес FIFO_STAUS_ADR
может быть считан для получения информации о состо-
янии аппаратной FIFO. Отдельные биты соответству-
ют указаниям на то, что память FIFO свободна, напо-
ловину заполнена или переполнена. Ниже приведен
Встроенные системы
Глава 27
695
короткий простой пример того, как эти адреса можно
использовать для получения новой входной информа-
ции:
int readFifо ( unsigned char *pData )
int status;
status » «((unsigned char*)FIFO_STAUS_ADR);
if ( (status & 0x03) 0 )
♦pData « «((unsigned
char*)FIFO_DATA_ADR);
return status & 0x03;
}
Печать сообщений и отладка программ
Отладка программ для встроенных систем представля-
ет собой довольно сложную задачу, в основном посколь-
ку в них редко имеются устройства для отображения
текста или средства для соединения с интерактивным
отладчиком. Интерактивные отладчики на уровне ис-
ходного кода являются лучшими инструментами для
отладки программного обеспечения, но они требуют
очень сложного механизма для взаимодействия с испол-
няемой программой. В случае типичной встроенной
системы либо вообще нет способа использовать отлад-
чик, либо этот способ очень сложен. Если система дос-
таточно мощная для поддержки RTOS (Real Time
Operating System — операционная система реального
времени. — Примеч. пер.) и если такая RTOS поддержи-
вает отладку, можно найти способ доступа к отладке
централизованными средствами даже на уровне исход-
ного кода С.
Вывод сообщений на некий терминал или экран яв-
ляется наиболее популярным способом отладки про-
грамм, и довольно часто это единственно возможный
путь. Если встроенная система не имеет дисплея, то,
безусловно, потребуется какое-либо аппаратное сред-
ство для соединения с хост-системой. Без такой комму-
никационной поддержки отладка становится очень тру-
доемкой и нужно будет задействовать какой-либо
доступный аппаратный механизм вывода данных.
Способность отправлять данные хост-системе озна-
чает способность посылать ей текст. Весьма часто пос-
ледовательный интерфейс во встроенной системе дос-
тупен и может быть использован для отправки данных
базовой системе. Программа-получатель на хост-систе-
ме нуждается в приеме входящего текста и отображении
его на экране подходящим образом. Из личного опыта
могу сказать, что с использованием чуть большего, чем
простой функции printf() можно отладить даже более
сложные параллельные приложения реального времени.
В ситуациях, когда нет шансов обратиться к тексту
функций вывода, отладка становится сложнее. Нужно
найти какую-нибудь оптическую или акустическую
обратную связь для генерирования основной обратной
связи протекания программы. Примеры таких ситуаций
включают:
• код запуска программы
• функции органов прерываний
• высококритичные ко времени функции
В таких случаях обычно используют, если есть воз-
можность, динамик или светодиод либо семисегмент-
ный дисплей. Если же ни одно из этих средств недоступ-
но, остается подсоединить к встроенной системе
осциллограф, чтобы поймать изменения в конкретных
ячейках памяти или ввода/вывода.
С-программирование встроенных
систем и стандарт ANSI С
После всех этих дискуссий о том, почему программи-
рование встроенных систем оказывается столь завися-
щим от конкретных аппаратных средств, вас может об-
радовать заголовок этого раздела. Здесь будет
подробнейшим образом рассказано, почему встроенные
системы программируются на очень низком аппаратно-
ориентированном уровне, в то время как стандарт ANSI
С (American National Standard for Information for C —
Американский национальный информационный стан-
дарт для программирования на С. — Примеч, науч, ред.),
по определению, является в высшей степени аппарат-
но-независимым языком программирования.
При ближайшем рассмотрении оказывается, что
ANSI С может стать очень важной частью написания
программного обеспечения для встроенных систем.
Быстрые, сложные и мощные вычислительные аппарат-
ные средства с каждым годом (если не месяцем) стано-
вятся все более дешевыми, и это решительно повышает
доступную вычислительную мошь встроенных систем.
Программное обеспечение для встроенных систем боль-
ше выгадывает от преимуществ стандарта ANSI С в том
случае, если речь идет о значительном объеме аппарат-
но-независимой обработки. Наличие мощного процес-
сора будет автоматически способствовать повышению
производительности аппаратно-независимой обработки
в системе.
Взглянем с другой стороны на пример, приведенный
в предыдущем разделе. Все аппаратные зависимости для
установки семисегментного дисплея инкапсулированы
в простую функцию setDisplayContents(). Более объем-
ная и сложная функция displayTime() может быть пол-
ностью написана на языке ANSI С.
Стандарт ANSI С представляет две концепции на-
писания соответствующего С-компилятора: базовая и
свободная реализация. Термин базовая реализация
(hosted implementation) означает, что ею поддерживается
696
Дополнительные тематические разделы
Часть III
полный стандарт, в то время как свободная реализация
(freestanding implementation) поддерживает подмноже-
ство стандарта, в котором в основном отсутствуют воз-
можности ввода/вывода библиотеки <stdio.h>. Но даже
свободная реализация будет поддерживать все языковые
конструкции, такие как выражения, типы данных или
функции, таким же образом, как это описывает стандарт
ANSI С.
Абстракция и инкапсуляция являются ключевыми
аспектами использования ANSI С во встроенных сис-
темах. Зависимости от аппаратных средств и системно-
ориентированный код должны быть выделены и инкап-
сулированы в простые низкоуровневые функции
драйвера, составляющие базовый интерфейс для досту-
па к аппаратным средствам. Высокоуровневый код
ANSI С для доступа к аппаратным средствам будет ис-
пользовать только интерфейс драйвера. Если эта кон-
цепция реализуется последовательно и если в основу
построения хорошего интерфейса драйвера положено
некоторое планирование, то перенесение программно-
го обеспечения на новую систему ограничивается лишь
переносом на новые аппаратные средства интерфейса и
функций драйвера.
Перенесение программного обеспечения на встроен-
ную систему — далеко не то же самое, что постоянные
изменения в аппаратных средствах. Этот процесс может
происходить не так быстро, как можно было бы ожи-
дать. Может быть, вы только хотите использовать но-
вую, более производительную модель процессора или
добавить новое устройство, которое будет оказывать
влияние на распределение памяти, либо использовать
новый, более мощный контроллер прерываний. Воз-
можностей для существенных и второстепенных изме-
нений имеется множество, и каждое такое изменение
будет оказывать большее или меньшее влияние на со-
ответствующие функции интерфейса.
Если вы последовательно проводите концепцию,
состоящую в обеспечении всех аппаратных устройств
низкоуровневым интерфейсом драйвера, то вы факти-
чески реализуете концепцию выбора: какую использо-
вать современную операционную систему. Сходство
было настолько поразительным, что вызвало удивление
многих программистов и заставило их задуматься,
нельзя ли это превратить в понятие (концепцию) про-
стейшей операционной системы для встроенных систем.
Таким образом и родились операционные системы ре-
ального времени RTOS.
RTOS - операционные системы
реального времени
Главной целью для операционных систем реального
времени RTOS являются встроенные системы. RTOS
служат в основном для удовлетворения нужд встроен-
ных приложений, возникающих в реальном времени.
Они призваны придать как можно больше вычислитель-
ной мощи активным задачам, а сама по себе RTOS по-
требляет очень мало ресурсов. Системы RTOS предла-
гают стандартизированный интерфейс на уровне
функций с аппаратными средствами встроенной систе-
мы, редуцируя таким образом задачу переноса прило-
жений встроенной системы в задачу переноса операци-
онной системы RTOS. Наконец (и это еще не все),
RTOS реализуют такие свойства высокоуровневых опе-
рационных систем, как многозадачность, многопоточ-
ность и межпроцессная коммуникация, с использовани-
ем стандартизированного интерфейса функций. Они
имеют также интегрированную поддержку отладки для
RTOS-приложений.
Непосредственная связь с аппаратными средствами
часто приводит к очень строгим условиям синхрониза-
ции, которые должны быть выполнены. Прерывания
аппаратных средств должны быть связаны как можно
быстрее, т.е. немедленно, либо устройства должны стре-
миться попадать в фиксированные интервалы с очень
высокой точностью. Здесь высокая точность — ключе-
вой аспект. Обычные операционные системы, такие как
Windows или UNIX, не могут гарантировать конкретное
и точное время ответа для прерываний или таймеров
аппаратных средств. RTOS, с другой стороны, опреде-
ляет, что для конкретной цели системы это гарантиру-
ет отклик на прерывание в пределах, например, 12 мик-
росекунд. Для большинства операций RTOS вы
получаете гарантированное максимальное время выпол-
нения или ответа. Обычно операции RTOS выполняют-
ся настолько быстро и эффективно, насколько это воз-
можно для потребления минимума процесс(ор)ного
времени.
Функции интерфейса RTOS позволяют получить
доступ к таким важным свойствам аппаратных средств,
как аппаратные таймеры, контроллеры прерываний, а
также к памяти или осуществлять коммуникацию через
последовательный порт. Если RTOS перенесена в кон-
кретную целевую систему и если ее аппаратные сред-
ства доступны, то доступ к ним можно получить через
приложение стандартным способом. Приложение ста-
новится значительно меньше зависимым от аппаратных
средств и может программироваться на более высоком
логическом уровне.
Многозадачность и процессная коммуникация пред-
ставляют собой центральные свойства любой современ-
ной операционной системы. Их очень сложно реализо-
вать, и внутри RTOS они снижают эффективность
работы в реальном времени. Если вы захотите реализо-
вать эти свойства для данных аппаратных средств, то
вашей собственной маленькой, самостоятельно написан-
ной операционной системе придет конец.
Встроенные системы
Глава 27
697
В целом это большой плюс — иметь доступную
RTOS для данной встроенной системы. С точки зрения
всех свойств, которые предоставляют системы RTOS,
почти всегда стоит приложить усилия для перенесения
такой RTOS на данные аппаратные средства, если она
не была перенесена ранее. Популярные RTOS оборудо-
ваны портами для самых разнообразных платформ ап-
паратных средств. Такие порты включают коммутаци-
онные панели популярных встроенных систем, важные
архитектуры аппаратных средств и микропроцессоры
типичных встроенных систем. Если вы достали полу-
фабрикатный модуль встроенной системы и для этого
модуля доступна RTOS, остается только подстроить его
для своих целей, либо он станет частью среды разработ-
ки программного обеспечения, которая поставляется с^
модулем.
Если ваши целевые аппаратные средства поддержи-
ваются на уровне типа процессора или аппаратной ар-
хитектуры, то нужно самостоятельно перенести части
исходного кода RTOS для адаптации се к конкретной
аппаратной компоновке. Поскольку для RTOS такой
перенос представляет собой стандартную процедуру,
она должна быть хорошо задокументирована, а суще-
ствующие порты служат примерами для добавления
новых портов. RTOS создана как гибкая и переносимая
операционная система. Перенос ее на новые аппарат-
ные средства предусмотрен ее проектом. Поэтому, как
уже было сказано, это обязательно следует сделать,
поскольку переделка предоставляемых RTOS функций
будет стоить вам значительно больших затрат.
Система RTEMS как типичный пример
RTOS
Система RTEMS (Real Time Executive for Military
Systems — Управляющая программа реального времени
для военных систем. — Примеч. пер.) представляет со-
бой типичный пример мощной и гибкой RTOS. Перво-
начально разработанная для армии США, она реализо-
вана с ориентацией на основное применение во
встроенных системах и в средах реального времени.
Операционная система RTEMS свободно доступна и
основана на бесплатных инструментальных средствах
разработки программного обеспечения GNU. Инстру-
менты GNU представляют собой специально спроекти-
рованные инструментальные средства разработки про-
граммного обеспечения кросс-систем, с помощью
которых хост-система используется для создания при-
ложений для различных целевых систем. RTEMS пол-
ностью использует эту концепцию добавляя свой соб-
ственный целевой тип "rtems" для всех поддерживаемых
RTEMS целей.
Центральная Web-страница для RTEMS находится
по адресу http://www.rtems.com.
Ниже приведен список возможностей, которые под-
держивает RTEMS и которые должна поддерживать
хорошая система RTOS:
• Поддержка гомогенных и гетерогенных микропро-
цессорных систем
• Многозадачность
• Упреждающее планирование, управляемое событи-
ями и основанное на приоритетах
• Монотонное планирование с учетом нестандартных
ситуаций
• Взаимодействие между задачами и синхронизация
• Приоритетное наследование
• Управление ответными прерываниями
• Динамическое распределение памяти
• Поддержка большого количества процессоров и кон-
кретных встроенных коммутационных панелей
• Высокий уровень подстройки к изменению пользо-
вательских конфигураций
• Высокий уровень подстройки к расширению круга
пользователей
• Реентерабельная библиотека ANSI С (допускающая
повторный вход из выполняемой программы)
• Поддержка POSIX
• Реализация стека TCP/IP и сокетов BSD
Этот список показывает преимущества использова-
ния RTOS, подобных RTEMS. Большинство этих воз-
можностей достаточно сложны для реализации, особен-
но если говорить об использовании их в реальном
времени. Управление под RTEMS требует очень незначи-
тельных ресурсов. Эта система будет занимать примерно
от 60 до 120 Кб в зависимости от количества возможнос-
тей, которые будут использоваться приложением.
Все аппаратно-зависимые части RTEMS инкапсули-
рованы в так называемый пакет BSP (Boards Support
Package — Пакет поддержки панелей. — Примеч. пер.).
Перенос RTEMS на новые целевые аппаратные средства
сводится к написанию нового пакета BSP для целевой
аппаратуры — либо на основе универсального шаблона,
либо путем адаптации существующего подобного BSP.
Пакет включает драйверы устройств всех аппаратных
средств для реализации набора хорошо определенных
функций интерфейса, и, таким образом, добавляется
уровень абстракции, который делает приложение более
аппаратно-независимым.
698
Дополнительные тематические разделы
Часть III
Резюме
В этой главе представлены базовые концепции встроен-
ных систем — они представляют весьма тонкие и спе-
цифические элементы программируемых аппаратных
средств, и каждая из них по-своему совершенно уни-
кальна. Очень важный шаг в программировании встро-
енных систем состоит в получении хорошей среды раз-
работки программного обеспечения с надежной
поддержкой отладки. Предпочтительным и наиболее
общим языком программирования является С, и боль-
шинство полуфабрикатных модулей встроенных систем
включают С-компилятор и набор инструментальных
средств разработки.
В случае более крупных и более производительных
систем для получения мощной и гибкой среды выпол-
нения приложений могут использоваться конкретные
операционные системы реального времени.
Параллельная обработка
28
В ЭТОЙ ГЛАВЕ
Основные концепции
Компьютеры и параллельная обработка
Параллельная обработка в С
Стефан Уилмс
В этой главе рассказывается о параллельной обработке
и приводятся некоторые примеры ее выполнения в сре-
де языка С. Первый раздел этой главы является введе-
нием в предмет параллельной обработки.
Основные концепции
Параллельная обработка — это одновременное выпол-
нение программ. Давайте сначала рассмотрим пример.
Если у одного рабочего мытье автомобиля занимает один
час, то двое рабочих смогут вымыть два автомобиля за
одно и то же время, т.е. за один час. Двое рабочих мо-
гут вымыть один автомобиль примерно за полчаса.
Смысл этого примера состоит в том, что при наличии
вдвое большего количества рабочих можно достичь
вдвое большей производительности. И действительно,
одна из главных целей параллельной обработки состо-
ит в повышении общей производительности. Примене-
ние этого понятия к компьютерам привело бы нас к
простой закономерности, что увеличение количества
компьютеров и программ, работающих над одной и той
же проблемой, уменьшит время, необходимое для ее
решения. На самом деле это не так просто, как может
показаться.
Представьте себе теперь не двоих, а девятерых или
даже десятерых мойщиков автомобилей. Получили ли
бы мы время мойки одного автомобиля, равное одной
десятой времени его мойки одним мойщиком? Навер-
ное, нет, поскольку имеется ограничение на максималь-
ное количество человек, которые, в принципе, могут
эффективно вымыть один автомобиль. И здесь главное
правило состоит в том, чтобы придерживаться макси-
мальной степени распараллеливания, которая может
быть применена к данной задаче. Чтобы проиллюстри-
ровать еще один аспект параллельной обработки (рас-
параллеливания), приведем такой пример. Десять чело-
век могут быть эффективно задействованы для мытья
десяти машин параллельно, но только при условии по-
стоянного поступления на конвейер предназначенных
для мытья автомобилей, чтобы поддерживать занятость
рабочих. И здесь тоже, как видно, эффективность рас-
параллеливания зависит от типа проблемы.
В соответствии с тем, о чем мы сейчас говорили, име-
ется два основных способа параллельной обработки:
• Распараллеливание в глубину, при котором несколь-
ко рабочих работают над одним участком проблемы,
прежде чем перейти к другому ее участку.
• Широкая параллельная обработка, когда несколько
рабочих работают над несколькими участками про-
блемы независимо друг от друга.
Обе эти концепции могут быть скомбинированы для
формирования нового понятия наподобие производ-
ственной линии. Каждому рабочему предназначается
одна конкретная подзадача, которую он выполняет на
каждом отдельном участке проблемы. Когда рабочий
заканчивает решение своей подзадачи, он переходит на
следующий участок. Если применить эту концепцию к
примеру с мойкой автомобилей, то такой подход может
означать, что первый рабочий моет только крышу, вто-
рой — только окна и двери, третий — капот и бампер и
т.д. Рассмотренный пример также демонстрирует дру-
гой важный аспект параллелизации типа производствен-
ной линии (называемой также конвейеризацией}: значи-
мость порядка выполнения. Для достижения желаемых
результатов отдельные этапы процесса должны выпол-
няться в правильной последовательности. Например,
мойка крыши автомобиля после мытья окон — это да-
леко не лучший вариант.
Дополнительные тематические разделы
Часть III
700
Компьютеры и параллельная
обработка
В случае с компьютерами вы встретитесь с двумя типа-
ми параллелизма: фактической и имитированной парал-
лельной обработкой. Фактическая параллельная обра-
ботка требует наличия нескольких микропроцессоров,
которые в состоянии осуществлять связь друг с другом
и совместно использовать общий набор данных. При
имитированной параллельной обработке используется
только один процессор для обработки нескольких про-
грамм, выполнение которых лишь кажется параллель-
ным. Для разделения времени обработки между парал-
лельно выполняемыми программами используется
циклический (или карусельный) механизм (round robin).
В этом случае имеется некий диспетчер, обычно в фор-
ме операционной системы, который выделяет опреде-
ленное время для обработки каждой программы в пос-
ледовательности одна за другой. Действительный режим
имитированной параллельной обработки называется
также приоритетным многозадачным режимом. Парал-
лельно выполняемые программы называются задачами,
и приоритетность здесь означает, что операционная
система следует расписанию независимо от задачи. За-
дача активизируется, разрешается к выполнению в те-
чение определенного отрезка времени и возвращается в
состояние бездействия до тех пор, пока планировщик,
сделав круг, не вернется к ней. Для отражения важнос-
ти той или иной задачи часто используются приорите-
ты. Задачи с более высоким приоритетом получают
больший отрезок времени для выполнения или чаще
активизируются.
Вы можете спросить себя: "Почему такой паралле-
лизм называется имитированной многозадачностью?"
Операционная система и планирование добавляют об-
работке еще большую значимость. Итак, для такого
названия имеется несколько важных причины:
• Операционная система использует механизм распи-
сания для выполнения системных сервисных служб
как набор параллельных задач, и, таким образом, со-
здается высокий уровень модуляризации.
• Операционная система использует расписание для
выполнения программ, запущенных параллельно
множеством пользователей, так что разделение вре-
мени обработки между пользователями производит-
ся на основе равенства их приоритетов.
• Программа может использовать параллелизм для до-
стижения высокой степени модуляризации путем
разделения сложной проблемы на простейшие под-
проблемы, как, например, в простом случае с мыть-
ем автомобилей в предыдущем разделе. Простейшие
подпроблемы должны быть достаточно независимы-
ми, чтобы их можно было выполнять параллельно.
• Программа может выполнять параллельную обработ-
ку с целью использования мощных диспетчерских
свойств операционной системы. Часто более слож-
ные программы реализуют свойства, которые пред-
полагают реализацию параллельных свойств. Напри-
мер, вспомним текстовый процессор, который
считывает ввод пользователя и одновременно прове-
ряет его орфографию, или представим себе програм-
му, которая получает входные данные, обрабатыва-
ет их и отправляет или сохраняет полученные
результаты. Эти программы следуют своему соб-
ственному расписанию, гарантирующему, что вход-
ные данные не потеряются, особенно если они мо-
гут возвращаться с различной скоростью, но никогда
не гарантирующему, что обработка данных займет
столько времени, сколько нужно. Использование
параллельных задач и разрешение операционной си-
стеме создавать расписание — это наиболее опти-
мальный вариант, позволяющий программисту сбе-
речь огромные усилия в ходе реализации сложных
программ планирования.
• Программа с хорошо спланированным распараллели-
ванием, как показано в предыдущем пункте, стано-
вится высокомасштабируемой с точки зрения фак-
тически параллельных аппаратных средств. Если
программа состоит из независимых параллельных
задач с хорошо разработанными интерфейсами для
передачи информации и данных от одной задачи к
другой, то такая программа может стать в значитель-
ной мере независимой безотносительно к тому, вы-
полняются все задачи одним процессором или эти
задачи распределены между несколькими процессо-
рами. Добавление большего числа аппаратных
средств будет способствовать ускорению выполнения
программы без необходимости изменять саму эту
программу.
Приоритетная многозадачность
Приоритетная многозадачность как концепция — это
более чем только наличие планировщика для распреде-
ления времени CPU между параллельными задачами.
Другими аспектами, которые подразумеваются в пред-
шествующем списке, являются инкапсуляция и вирту-
ализация. Каждая задача путем надлежащей разработ-
ки может предполагать дтя своего выполнения наличие
всего процессора. Операционная система должна быть
уверена, что задачи не будут конфликтовать друг с дру-
гом. Концепция требует, чтобы все задачи имели дос-
туп ко всем аппаратным ресурсам ("видели" их), задей-
ствованным операционной системой. Таким образом.
Параллельная обработка
Глава 28
701
операционная система может выполнять множество за-
дач, причем все задачи могут безопасно предполагать,
что они имеют неограниченный доступ ко всем аппа-
ратным средствам.
Еще одно слово о планировании и приоритетной
многозадачности: они привязаны к операционной сис-
теме, которая в большинстве случаев является действи-
тельно корректной. Современные микропроцессоры
обычно имеют встроенную поддержку многозадачнос-
ти, но операционная система должна контролировать и
реализовывать этот механизм, хотя имеется несколько
предположительно редких исключений. Некоторые
микропроцессоры сочетают свойство встроенной при-
оритетной многозадачности с планированием аппарат-
ных средств. Такие микропроцессоры не нуждаются в
операционной системе для реализации многозадачнос-
ти. Хорошим примером может служить процессор
INMOS Transputer. Тем не менее, везде далее в книге мы
будем ссылаться на операционную систему как на глав-
ного планировщика. Специальные аппаратные средства,
подобные процессору Transputer, обычно относятся к
области встроенных систем, описанных в главе 27.
Кооперативная многозадачность
Для полноты общей картины упомянем также о коопе-
ративной многозадачности, на которую иногда ссыла-
ются как на "мужицкую многозадачность". Приоритет-
ная многозадачность представляет для операционной
системы достаточно сложную проблему — прежде все-
го, она требует значительных административных издер-
жек. Кооперативная многозадачность представляет со-
бой более простой подход к распараллеливанию. Ее
концепция состоит в том, что текущая программа про-
должает выполняться до тех пор, пока управление не
вернется к операционной системе, после чего система
переключается на выполнение следующей программы.
Программа может вернуть управление либо самостоя-
тельно путем вызова специальной перепланирующей фун-
кции, либо непроизвольно, если операционная систе-
ма прерывает любой вызов функции операционной
системы в целях перепланирования. Очевидная невы-
годность такого подхода состоит в том, что любая про-
грамма может монополизировать ресурсы CPU, редко
передавая или вообще никогда не передавая управление.
Вот почему такая мультизадачность называется коопе-
ративной — этот метод может быть использован только
в случае, если все программы сотрудничают друг с дру-
гом. Одной-единственной не сотрудничающей с други-
ми программы достаточно, чтобы эффективно блокиро-
вать операционную систему. Например, система
Windows 3.x использует кооперативную многозадач-
ность. Единственная задача, которая не вернула управ-
ление операционной системе, может "заморозить" вы-
полнение всех других задач. Операционные системы
Windows 9х и Windows NT используют приоритетную
многозадачность.
Межпроцессная коммуникация
Разделение программы на параллельные задачи требу-
ет, чтобы эти задачи совместно использовали данные
или обменивались ими для работы по направлению к
одной общей цели. При многозадачности отдельные
задачи не должны зависеть от степени предположения
относительно того, что каждая из них выполняется на
своем собственном процессоре. Таким образом, совме-
стное использование данных перестает быть вопросом.
Многопоточность является концептуальным решением
для параллельных программ, которые требуют совмес-
тного использования данных. С другой стороны, для
обмена данными и информацией параллельные задачи
используют коммуникационные связи.
Межпроцессная коммуникация — это основной ме-
ханизм, который при мультизадачности реализуется
операционной системой. Коммуникационный канал
может выглядеть как однонаправленная связь между
двумя задачами для отправления или получения дан-
ных. Ради ясности лучше иметь для конкретных целей
выделенные каналы. Давайте в качестве примера рассмот-
рим основную задачу обработки данных. Эта задача явля-
ется частью большой программы и должна обрабатывать
некоторым специфическим способом входящие данные,
перед тем как отправить их какой-нибудь другой задаче.
Типичный набор коммуникационных каналов включает:
• Канал для приема данных, поступающих на обра-
ботку.
• Канал для отправки данных на последующую обра-
ботку.
• Канал для получения управляющих команд (таких,
как параметры обработки или команды запуска и ос-
танова). Этот канал обычно связан с управляющей
задачей, ответственной за управление потоком дан-
ных и обработкой данных в большом приложении
обработки данных.
• Канал для отправки сообщений, команд подтверж-
дений, информации о течении процесса или состо-
янии либо для возврата управляющему процессу со-
общений об ошибках. Здесь могут быть
использованы несколько выделенных каналов, если
это улучшит общий дизайн программы.
Потоки, многопоточность и синхронизация
Отдельные задачи предполагают высокий уровень неза-
висимости вплоть до того, что их можно помещать в
702
Дополнительные тематические разделы
Часть III
различные процессы, но при этом нужно учитывать
следующее:
• Они имеют мало общего, и для обмена данными не-
обходимо использовать достаточно сложные меха-
низмы.
• Они представляют скорее статический механизм для
параллельной обработки.
Для обоих этих факторов имеется альтернатива,
называемая потоками (threads). Потоки совместно ис-
пользуют одну и ту же область в памяти, занятую дан-
ными и программным кодом, и их легко можно запус-
кать и останавливать в пределах одной задачи.
Представим себе поток как функцию, которая, будучи
вызванной, выполняется параллельно с вызывающей
функцией. Потоки представляют параллельные субком-
поненты задачи. Недостатком этого является, конечно,
то, что потоки вынуждены выполняться в той же самой
среде, в которой выполняется породившая их задача.
Другими словами, поток нельзя разместить на другом
процессоре или выполнять с другими опциями много-
задачности.
Потоки можно рассматривать как логические компо-
ненты задачи, и они действительно очень похожи на
функции. Если программная логика задачи указывает
какие-то вещи, которые происходят параллельно, пото-
ки могут представлять этот параллелизм и эффективно
использовать мощь планирования параллельности опе-
рационной системой. Например, представьте себе зада-
чу, которая должна принять входные данные через два
канала, обработать эти данные и отправить результат
через третий выходной канал данных. В результате по-
лучим задачу, состоящую из четырех каналов:
• Принимающий поток для первого канала входных
данных, который помещает поступающие данные в
буфер.
• Принимающий поток для второго канала входных
данных, размещающий поступающие данные в том
же буфере, который использует другой принимаю-
щий поток, или во второй отдельный буфер входных
данных.
• Поток обработки данных, который принимает вход-
ные данные из входного буфера (или буферов), об-
рабатывает их и результат обработки размещает в
выходном буфере данных.
• Отправляющий поток, который принимает выход-
ные данные из буфера выходных данных и отправ-
ляет их через выходной канал.
Такая концепция предусматривает способность по-
токов разделять и совместно использовать данные и
фактически рассчитана на использование потоков для
реализации полного отделения коммуникационных ка-
налов от обработки данных. Возможность разделения
данных между множеством потоков приводит к пробле-
ме синхронизации доступа к этим данным.
Два потока, осуществляющих запись в один и тот же
объект в памяти, будут, скорее всего, конфликтовать
между собой. В случае использования буфера оба пото-
ка могут сделать запись в один и тот же слот буфера,
что приведет к катастрофической путанице в данных.
Решением этой проблемы является так называемая син-
хронизация доступа: разделение объектов памяти так,
чтобы они были доступны одновременно только одно-
му потоку. При этом потоки должны иметь возможность
определить, доступен ли в данный момент буфер для
записи в него или чтения из него, для резервирования
доступа к буферу в течение всего времени, пока пото-
ки используют его.
Механизм синхронизации сам по себе должен быть
потокобезопасным. Другими словами, представим себе
два потока, и оба они одновременно запрашивают раз-
решения на запись. В этом случае механизм синхрони-
зации должен предотвратить получение обоими пото-
ками информации о том, что буфер доступен для
записи. Такой тип синхронизации называется семафо-
ром, а однозначно доступный объект обычно называет-
ся ресурсом. Семафоры в основном используются для
синхронизации параллельного доступа к таким одно-
значно (или единственно) доступным ресурсам. Ис-
пользованию семафоров удовлетворяют две основные
операции:
• Ожидание доступности (открытия) семафора. Сема-
фор зарезервирован (закрыт) для ожидающей зада-
чи. Как только он становится доступным, открыва-
ется доступ к соответствующим ресурсам, но только
после того, как будет возвращена функция резерви-
рования семафора, не ранее.
• Закрытие семафора для текущей задачи после того,
как соответствующий ресурс ей более не требуется.
Для обеспечения эффективной многопоточности се-
мафор не должен быть зарезервированным для других
задач дольше, чем это абсолютно необходимо, посколь-
ку эти задачи уже могут ожидать его открытия.
Параллельная обработка в С
Язык программирования ANSI-С, как уже говорилось,
не поддерживает системно-ориентированных свойств, а
параллельная обработка является именно таким свой-
ством.
Свойства каждой операционной системы или набо-
ра инструментальных средств разработки программно-
го обеспечения имеют свою собственную концепцию
для поддержки параллельного программирования. С-
Параллельная обработка
Глава 28
703
программистам эти свойства доступны с использовани-
ем специальных функций поддержки операционной
системы и специального набора вызываемых функций
языка С. Функции, структуры данных и другие опре-
деления формируют интерфейс API (Application
Programmer's Interface) параллельного программирова-
ния. В этом разделе используется один конкретный
интерфейс API а качестве примера для демонстрации
того, как такой API можно использовать для реализации
основных свойств параллельного программирования в С.
Для формирования своих примеров исходного кода я
использую набор инструментов INMOS ToolSet. Может
быть, этот API не очень широко распространен, но он
очень прост, и его легко использовать в реализации ба-
зовых и усовершенствованных концепций параллельно-
го программирования.
В этом разделе демонстрируются следующие кон-
цепции:
• Многозадачность
• Многопоточность
• Межпроцессная коммуникация
• Синхронизация процесса
Многозадачность в С
Задачи, как указывалось, представляют собой независи-
мые параллельные программы. Каждая задача форми-
рует отдельную программу на свой собственный манер
и, следовательно, имеет свою собственную функцию
main(). В большинстве операционных систем ее созда-
ние и запуск не требуют специальных усилий. Систе-
ма сама поддерживает запуск программ в параллельном
режиме. Например, в GUI-ориентированной системе
для запуска любого количества программ вам нужно
просто щелкать кнопкой мыши, и все эти программы
будут выполняться как параллельные задачи. Межпро-
цессная или в данном случае межзадачная коммуника-
ция является тем, что специально создает набор задач.
Коммуникация из отдельных задач формирует большую
программу, имеющую одну общую цель. Поскольку этот
аспект очень важен, он будет рассмотрен в разделе
"Межпроцессная коммуникация" далее в этой главе.
Наличие командной оболочки операционной систе-
мы, которая поддерживает запуск задач, означает, что
также можно использовать С для запуска задач изнут-
ри программы путем простой передачи соответствую-
щей команды оболочки в функцию system(). Например,
в UNIX при вызове этой функции программа, называе-
мая hello, запускается как параллельная задача и немед-
ленно возвращается оболочка bash:
system( "&hello");
В следующей строке кода выполняется то же самое
в операционной системе Windows:
system ( "start /ш hello.exe " ) ;
Чаще всего скрипты оболочки используются для за-
пуска всех задач большого распараллеленного приложе-
ния для операционной системы. Специальные среды
программирования, однако, часто формируют исключе-
ние, особенно если на целевых аппаратных средствах
отсутствует операционная система или если операцион-
ная система является специальной реализацией для
встроенных систем. В таких системах для запуска задач
приложения используются специальные механизмы.
Одни из них для запуска задач поддерживают специаль-
ные функции, другие используют специальные встро-
енные инструменты для комбинирования задач в целях
формирования одной программы.
Система INMOS ToolSet, которая будет в основном
использоваться для исходного кода рассматриваемых
здесь примеров, принадлежит второй категории. Аппа-
ратные средства и программное обеспечение требуют,
чтобы все задачи для всех процессоров формировали
одиночные двоичные файлы. Для создания задач как
отдельных программ (называемых связанными модулями)
используются компилятор и редактор связей, а инстру-
мент конфигурирования и отбора используется для
объединения задач в единый двоичный файл вместе с
информацией о том, какие задачи выполняются на ка-
ком процессоре и каково их назначение для взаимной
коммуникации. Загрузчик и пускатель программы бу-
дут копировать результирующий двоичный файл на це-
левые аппаратные средства и обрабатывать распределе-
ние задач и процедуру запуска.
Многопоточность в С
Многопоточность более тесно связана с С-программи-
рованием, чем многозадачность. Для создания и запус-
ка С-функций как параллельных потоков требуется
хорошо определенный интерфейс функции. Поскольку
такой интерфейс не поддерживается стандартом ANSI-
С, каждая среда программирования обеспечивает свой
собственный интерфейс. Общая их концепция, поло-
женная в основу всех систем, обычно одинакова или, по
крайней мере, их концепции очень сходны. Однако
программист должен исследовать специфические дета-
ли для каждой системы заново. Для представления этих
базовых концепций будем использовать синтаксис ин-
терфейса INMOS ToolSe.
Предположим, что потоки представлены некоей
структурой данных, называемой Process, и что некото-
рая функция, которую мы собираемся запустить как
поток, должна, по крайней мере, иметь указатель на
Process в качестве первого параметра. Кроме того, име-
704
Дополнительные тематические разделы
Часть III
ются функция РгосА11ос() для создания процесса из ного процесса. Рассмотрим в листинге 28.1 простой при-
функции и функция ProcRimO — для запуска создан- мер программы, которая для печати произвольного ко-
личества приветствий использует поток.
Листинг 28.1. Использование потока для печати приветствий,
linclude <stdio.h>
linclude <process.h> /* Расширения языка С для использования потоков */
void MyFirstProcess( Process *р, int numberOfHellos, int *pFinished )
{
int i;
for ( i=0 ; i < numberOfHellos ; i++ )
{
printf( "'Hello World' number %d from process %p\n", i, p );
}
*pFinished = 1;
}
int main( void )
{
int finished = 0;
Process *procHello;
procHello = ProcAlloc( MyFirstProcess, /* функция потока */
1000, /* количество стеков памяти */
2, /* номера аргументов */
5, /* первый аргумент */
«finished ); /* второй аргумент */
if ( procHello 1= NULL )
{
ProcRun( procHello );
while ( finished == 0 )
{
printf( "main is waiting ...\n" );
}
printf( "mains end of thread detected\n" );
ProcAllocClean( procHello );
}
else
{
printf( "ERROR: unable to allocate process\n" );
}
return 0;
Размещение потока требует спецификации стека
памяти для функции потока и несколько фактичес-
ких аргументов в дополнение к Process*, следующе-
му за значениями аргументов для передачи функции
потока. Неравный NULL указатель потока означает,
что размещение потока было успешным. Целая пере-
менная finished здесь используется для того, чтобы по-
казать один (по общему признанию, простой и эле-
ментарный) способ для main(), позволяющий
определить, когда процесс procHello достиг своего
окончания. Она также показывает, как main() поддер-
живает выполнение параллельно с MyFirstProcess.
Функция ProcAUocClearO освобождает всю память, от-
веденную для MyFirstProcess. Эта программа выводит
следующее:
main is waiting . . .
'Hello World' number 1 from process 8000c374
main is waiting ... 'Hello World' number 2 from process 8000c374
main is waiting ... 'Hello World' number 3 from process 8000c374
main is waiting ... 'Hello World' number 4 from process 8000c374
main is waiting ... 'Hello World' number 5 from process 8000c374
main is waiting ...
main: end of thread detected
Параллельная обработка
Глава 28
|Т05
Межпроцессная коммуникация в С
Коммуникационные каналы могут быть использованы
в любом месте, где задачи или потоки обмениваются
данными. Они формируют главный механизм обмена
данными для задач, в то время как потоки могут выби-
рать, использовать им каналы или разделенные для со-
вместного использования данные. Преимуществом ком-
муникационных каналов является автоматически
встроенная синхронизация. Когда данные получены,
они могут быть обработаны немедленно, поскольку яв-
ляются полной копией отправленных данных.
Для представления коммуникационной связй меж-
ду параллельными процессами система INMOS ToolSet
использует тип данных Channel (канал). Этот каналь-
ный тип всегда однонаправленный; это означает, что он
имеет один фиксированный посылающий конец и один
фиксированный принимающий конец. Двунаправленная
коммуникация требует двух выделенных однонаправ-
ленных связей Channel. В этом случае имеются две про-
стые функции, которые обрабатывают отправку и по-
лучение данных через Channel:
int ChanOut( Channel *pOutChan, void
***pDataToSend, int numBytesToSend ) ;
int Chanin( Channel *pInChan, void
***pStoreHere, int numBytesToReceive ) ;
Обе функции будут возвращать значения, когда опе-
рация будет завершена. Система ToolSet реализует пол-
ностью синхронизированную канальную коммуника-
цию через тип Channel. Когда функция ChanOut()
возвращает значение, получатель может безопасно по-
лагать, что данные были получены успешно и в полном
объеме. Хотя это может быть иначе для других сред
программирования. Другие системы могут иметь фун-
кцию отправки, которая возвращает значение, как толь-
ко все данные уже находятся в пути, но это не обяза-
тельно говорит о том, что они прибыли по назначению.
Процесс получения экземпляров Channel для осуще-
ствления коммуникации осуществляется по-разному
для задач и для потоков. В следующем разделе рассмат-
риваются эти два аспекта.
Канальная коммуникация для задач
Главная проблема для задач состоит в том, как получить
экземпляры Channel для осуществления коммуникации
с другой задачей. Будучи независимыми программами,
задачи не используют совместные данные и не могут
передавать информацию друг другу. Обычно эта пробле-
ма решается с помощью поддержки со стороны опера-
ционной системы или среды разработки программного
обеспечения. Одно общее решение, поддерживаемое
многими операционными системами, называется кон-
вейером. Задачи запрашивают коммуникационный ка-
нал от операционной системы, а система отслеживает,
когда два запроса соответствуют друг другу, и обеспе-
чивает между соответствующими задачами прямую
связь.
Система INMOS ToolSet в большей степени является
статической. Она обеспечивает статическое распределе-
ние задач по процессорам во время сборки программы
через конфигурационный текстовый файл. Специфи-
ческие коммуникационные связи между задачами явля-
ются дополнительным важным свойством конфигураци-
онного файла. Для соединения двух задач можно
использовать команды, подобные следующим:
connect taskl. da tai при t to task2.dataOutput;
Здесь taskl, taskl, datalnput и dataOutput — это име-
на, определенные программистом в других местах кон-
фигурационного файла. Внутри задачи имеется специ-
альная функция, называемая getparam(), для получения
каналов (и других параметров) из программной конфи-
гурации:
Channel *myInputChannel;
/* ... */
myInputchannel - (Channel*)getparam(1);
Число 1 здесь просто указывает, что первый пара-
метр в конфигурации задачи используется в качестве
указателя канала.
Каналы, как только они получены, в задачах и по-
токах используются единообразно. Следующий раздел
включает несколько примеров программного кода, ил-
люстрирующего использование метода канальной ком-
муникации.
Канальная коммуникация для потоков
В пределах задачи каналы при необходимости могут
быть созданы динамически и переданы далее в функ-
ции и потоки как обычные аргументы функции. Сис-
тема INMOS ToolSet обеспечивает специфическую фун-
кцию ChanAlloc() для размещения канала. А функцию
ChanFree() можно использовать для удаления или об-
новления канала, после того как он был использован.
Комбинируя эти две функции с функциями ChanOut()
и Chanln(), описанными выше, можно получить основ-
ные функциональные возможности для реализации
мощной канальной коммуникации. Листинг 28.2 демон-
стрирует использование канальной коммуникации.
45 Зак. 265
706
Дополнительные тематические разделы
Часть III
Листинг 28.2. Использование канальной коммуникации,
linclude <stdio.h>
linclude <stdlib.h>
linclude <process.h> /* Расширения языка С для использования потоков и каналов */
/*
* * Этот поток будет добавлять 2 к целой величине, получаемой через входной
* * канал, и отправлять результат через выходной канал.
* * Получение числа 0 будет заканчивать поток.
*/
void AddTwoProc( Process *р, Channel *input, Channel *output )
{
int number = 1;
while ( number != 0 )
{
Chanin( input, (number, sizeof(int) );
printf( "AddTwoProc: received number %d\n", number );
if ( number 1= 0 )
{
number += 2;
}
ChanOut( output, (number, sizeof(int) );
>
printf( "AddTwoProc: end of thread reached\n" );
}
int main( void )
{
int i, newValue;
Process *procAddTwo = NULL;
Channel *chanToThread = NULL;
Channel *chanFromThread 3 NULL;
/*
** Упрощенное размещение и ошибка выполнения: попытайтесь разместить
** все элементы и проверьте успешность такого размещения.
*/
chanToThread = ChanAlloc();
chanFromThread = ChanAlloc();
procAddTwo = ProcAlloc( AddTwoProc, 1000, 2,
chanToThread, chanFromThread);
if ( chanToThread =- NULL 11 chanFromThread == NULL
| | procAddTwo =e NULL )
{
printf( "ERROR: allocting data failed\n" );
return EXITFAILURE;
}
/* start the thread */
ProcRun( procAddTwo );
for ( i = 10 ; i >= 0 ; i— )
{
ChanOut( chanToThread, (i, sizeof(int) );
Chanin( chanFromThread, (newValue, sizeof(int) );
printf( "main: send %d and received %d\n", i, newValue );
}
return EXITSUCCESS;
}
Параллельная обработка
707
Глава 28
Ниже приведен вывод этой программы:
Here * s the
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
main: send
AddTwoProc:
AddTwoProc:
main: send
program output:
received number 10
10 and received 12
received number 9
9 and received 11
received number 8
8 and received 10
received number 7
7 and received 9
received number 6
6 and received 8
received number 5
5 and received 7
received number 4
4 and received 6
received number 3
3 and received 5
received number 2
2 and received 4
received number 1
1 and received 3
received number 0
end of thread reached
0 and received 0
В этом примере программы используются распреде-
ленные каналы как параметры для функции AddTwoProcO,
и коммуникация осуществляется в main(). Однород-
ность канальной коммуникации также позволила бы вы-
полнить реализацию, в которой получение каналов про-
изводится с помощью функции getparamO и отдельная
задача коммутирует с потоком AddTwoProc(). Заметьте,
что обращения к функциям ChanFreeO и РгосА11оС1еап()
для краткости были опущены. Подразумевается также,
что по окончании программы каналы освобождаются ав-
томатически.
Синхронизация доступа к данным в С
Потоки могут легко совместно использовать доступ к
одним и тем же объектам данных. Для предотвращения
коллизий потоки должны синхронизировать доступ к
этим совместно используемым объектам данных. Посмот-
рим на код в листинге 28.1 с другой точки зрения. Оба
потока, main() и MyFirstProcess(), претендуют на доступ
к переменной finished, объявленной в jnainO- Указатель на
finished передается в поток MyFirstProcessO, в резуль-
тате чего в эту переменную фактически записывается
новое значение. В этом конкретном случае синхрониза-
ция не выполняется, да она и не требуется. Один по-
ток лишь записывает в переменную некоторое значение,
а другой лишь считывает его.
Если же два потока должны делать запись в одну и
ту же переменную параллельно, то планировщик пото-
ков решил бы, скорее, на случайной основе, какое зна-
чение доступно в какое время. Давайте вернемся к при-
меру, который рассматривался выше: представьте себе
два потока, добавляющие объекты данных в один совме-
стно используемый буфер. Такой буфер может содер-
жать, например, массив для хранения объектов данных
в определенной последовательности и располагать счет-
чиком, указывающим на следующий доступный индекс
массива для его хранения следующего объекта данных.
Сохранение объекта данных выполняется в три этапа:
1. Проверка наличия свободного места в буфере.
2. Сохранение объекта данных в массиве на свобод-
ном в данный момент месте.
3. Увеличение на единицу счетчика занятого простран-
ства.
Давайте рассмотрим упрощенную реализацию на С
этого алгоритма:
int AddDataToBuffer( Buffer *pBuf, Data *pData )
{
int returnCode = 0; /* код, заданный по
умолчаиив для успешной операции */
if ( pBuf->location < pBuf->maximum )
{
pBuf->dataArray[pBuf->location] = *pData;
pBuf~>location += 1;
}
else
returnCode = -1;
return returnCode;
}
А теперь подумаем, что случится, если два потока
попытаются выполнить указанные выше три этапа по-
чти в одно и то же время. Фатальная коллизия между
доступами к данным может произойти на каждом эта-
пе. Например, если один поток лишь начинает этап 2 в
то время, когда другой поток только закончил этап 2,
но еще не выполнил этап 3, первый поток будет пере-
писывать элементы данных, записанных вторым пото-
ком, поскольку второй поток еще не успел увеличить на
единицу счетчик занятого пространства.
Приведенный ниже код показывает, как могли бы
выглядеть эти два потока:
/*
** Упрощенное получение и сохранение потока: здесь нет конечного состояния
** и обработка оыибок совершенно элементарна
*/
Дополнительные тематические разделы
Часть III
708
void RecAndStoreProc( Process *p, Channel *pRecChan, Buffer *pBuf >
{
int returnCode;
Data dataObject;
while ( 1 )
{
/* Получен один объект данных */
Chanin ( pRecChan, &dataObject, sizeof(dataObject) );
/* Попытка сохранить объект данных в буфере */
returnCode = AddDataToBuffer( pBuf, (dataObject );
if ( returnCode != 0 )
{
printf( "ERROR: buffer store failed => data object lost\n" );
}
}
}
Механизм синхронизации требует зарезервировать
доступ к буферу перед фактическим доступом к нему.
Концепция семафоров, рассмотренная в начале этой
главы, четко представляет то, что необходимо для ре-
шения этой проблемы. Все среды параллельного про-
граммирования имеют свои собственные реализации
семафоров, но основной механизм должен обеспечи-
ваться средой программирования. Более важно то, что
семафоры гарантированно работают безотказно. Систе-
ма INMOS ToolSet предлагает следующие функции для
поддержки семафоров:
Semaphore *SemAlloc( int initialstate );
void SemFree( Semaphore *pSemaphore );
void SemWait( Semaphore *pSemaphore );
void SemSignal ( Semaphore *pSemaphore ) ;
Первые две функции просто размещают и освобож-
дают объекты типа Semaphore. Семафоры могут иметь
два состояния: резервирование (значение 1) и доступ
(значение 0), и каждое из этих состояний можно уста-
новить с помощью переменной initialstate. Функция
SemWait() будет ждать, пока данный семафор будет
доступен, и зарезервирует доступ к тому семафору, с
которым он работает. Функция SemSignal() будет осво-
бождать доступ к семафору, таким образом помечая его
как доступный.
Если принять, что структура данных Buffer имеет
компонент типа Semaphore*, называемый pAccessSync,
то для получения полностью безопасной синхрониза-
ции параллельных потоков нужно просто изменить
функцию AddDataToBuffer(), как это сделано ниже:
/*
* * Пример определения типов данных "Data" и
"Buffer".
*/
typedef int Data;
typedef struct buffers
{
Data dataArray[100];
Semaphore *pAccessSync;
int location;
int maximum;
} Buffer;
/*
* * Добавление нового объекта данных в буфер и
* * использование семафора для синхронизации
* * параллельного доступа к буферу.
*/
int AddDataToBuffer( Buffer *pBuf, Data *pData
)
{
int returnCode = 0; /* код, заданный по
умолчанию для успешной операции */
/* резервирование доступа к буферу */
SemWait( pBuf->pAccessSync );
if ( pBuf->location < pBuf->maximum )
{
pBuf->dataArray[pBuf->location] = *pData;
pBuf->location += 1;
}
else
returnCode = -1;
/* освобождение доступа к буферу перед
возвратом */
SemSignal( pBuf->pAccessSync );
return returnCode;
}
709
Резюме
Эта глава охватывает основные концепции параллель-
ной обработки в режимах многозадачности и многопо-
точности. Многозадачность описывает раздельные па-
раллельные программы, в то время как потоки
представляют собой параллельные субкомпоненты об-
щего потока. Задачи являются принципиально незави-
симыми и могут выполняться на различных процессо-
рах, в то время как потоки совместно используют среду
породившей их задачи.
Параллельная обработка
Глава 28
Коммуникационные каналы обеспечивают удобный
и синхронный путь для обмена данными между зада-
чами и потоками. В случае нескольких задач имеется
лишь незначительная возможность совместно использо-
вать данные или она отсутствует вообще, в то время как
потоки безусловно могут совместно использовать дос-
туп к объектам данных.
Если объекты данных разделяются между потоками,
должен использоваться механизм синхронизации в фор-
ме семафоров для уверенности в том, что параллельный
доступ к одному и тому же объекту данных не приве-
дет в результате к неожиданным коллизиям.
Взгляд в будущее: С99
29
В ЭТОЙ ГЛАВЕ
Новое в стандарте С99
Потерянные возможности
Изменения по сравнению с С89
Питер Сибеч
В двадцатом веке вскоре после изобретения безлошад-
ных повозок был изобретен язык программирования С.
Первая формальная стандартизация, которая заверши-
лась в 1989 г., предоставила стандарт С, с которым зна-
комо большинство программистов и который является
темой данной книги. Однако работа над стандартом С
продолжалась, и, в конце концов, был разработан стан-
дарт С9Х. Поскольку стандарт ISO был формально при-
нят в конце 1999 г., то в настоящее время стандарт С
известен как С99. Его официальное название — ISO/
IEC 9899:1999. В этой главе предыдущий по хроноло-
гии стандарт будет называться С89ч а текущий — С99.
К сожалению, с точки зрения С99 большинство ком-
пиляторов пока не переведены на этот язык. Поэтому,
чтобы компиляция проходила по возможности без про-
блем, в этой главе будет представлен минимальный
объем кода.
Новый стандарт намного больше предшествующего,
поэтому здесь будут отражены не все изменения, а толь-
ко те, которые могут заинтересовать программиста сред-
ней квалификации.
В этой главе будут рассмотрены следующие вопросы:
• совершенно новые свойства и свойства стандартной
библиотеки, которые можно использовать
• совершенно новые свойства, которые, скорее всего,
не будут использоваться
• свойства, которые могут вызвать ошибку при компи-
ляции на компиляторах С99
• свойства, которые могут неожиданным образом по-
влиять на поведение вашей программы
Данная глава не является пособием по С99. Если вы
хотите больше узнать о стандарте С99, поищите книги,
посвященные именно этой теме.
Новое в стандарте С99
Нового здесь очень много. В С появилось несколько
новых типов, ряд новых стандартных функций и ряд
новых синтаксических особенностей для представления
часто использующихся конструкций. Эти особенности
мы для удобства разобьем на группы
Большинство новых свойств в С99 были введены на
основании опыта работы в предшествующих стандартах.
По большей части комитет стандартизировал существу-
ющую практику в компиляторах С, а не вводил новые
возможности. Новые возможности вводились на основании
опыта создания компиляторов или в качестве более эффек-
тивных версий функций, которые были внесены в спеш-
ке. (Например, в С99 правила преобразований целых
типов, особенно в отношении типа long long, намного
проще, чем были ранее.)
Множество изменений в С99 просто являются по-
пыткой упростить или исправить предшествующий
стандарт. При подаче жалоб (отчетов о дефектах), ка-
сающихся стандарта С89, многие просто получали от-
веты с обещаниями о том, что указанные недостатки
будут учтены в последующих версиях стандарта С. И
большинство из них действительно были учтены в стан-
дарте С99.
Новые типы
В С99 есть целый ряд целых типов, булевый тип, 64-
битовый целый тип и новые комплексные арифмети-
ческие типы. В него также введены массивы перемен-
ной длины и структуры, в которых последний элемент
имеет переменный размер.
Взгляд в будущее: С99
Глава 29
711
Базовые типы
В стандарт С99 введен новый тип _Воо1, который яв-
ляется булевым типом. Как правило, требуется вклю-
чить в программу файл <stdbool.h> и ссылаться на него
как на bool. Единственной причиной, по которой этот
тип не назван bool, является тот факт, что существую-
щие коды имеют макросы с такими именами. Булев тип
обладает всеми необходимыми возможностями: преоб-
разование в __Воо1 дает значение (1) для любого значе-
ния, не равного нулю, и (0) — в противном случае. Это
не изменяет существующего правила языка С, согласно
которому, если значение выражения равно нулю, то в
операторах if, while и for оно будет иметь значение
"ложь".
ПРИМЕЧАНИЕ
Макрос, который определяет, что bool соответствует
__Воо1, не присутствует ни в одном старом заголовочном
файле, поскольку это могло бы повлиять на работоспо-
собность существующего кода; необходимо явно потре-
бовать это новое свойство.
В С99 введены три новых комплексных типа, соот-
ветствующие трем типам с плавающей точкой, которые
вам известны. Комплексные типы позволяют произво-
дить различного рода сложные вычисления. По той же
причине, по которой bool назван Bool, ключевое сло-
во, которое вводит комплексный тип, — это -Complex
или просто complex, если вы включили в состав своей
программы файл <complex.h>. В заголовочном файле
<complex.h> также определено значение I, которое со-
ответствует математической константе Л Например:
#include <complex.h>
complex float f={l, 0};
f*=I; // теперь f содержит {0, 1};
И последнее: в С99 значительно расширены цело-
численные типы. Наиболее интересный из новых типов —
тип long long. Его название несколько противоречит
самому языку (обычно спецификатор типа не исполь-
зуется два раза, или, по крайней мере, не имеет двой-
ного действия), но существующая практика закрепила
за ним это название. Этот тип уже присутствует в це-
лом ряде компиляторов и представляет собой целый тип
"длиной не менее 64 бита". Обратите внимание на то,
что этот тип должен поддерживаться всеми платформа-
ми, но на многих платформах скорость выполнения
кода будет гораздо ниже, чем с использованием 32-би-
тового или меньшей длины типов.
Введение типа long long вызывает проблемы во мно-
гих существующих программах. Они могли быть напи-
саны так, что любой целый тип можно преобразовать в
long и напечатать с помощью %ld. Однако в системах, в
которых тип long long длиннее типа long, это неприем-
лемо. Влияние такой особенности, как полагают, будет
ограниченным, но, тем не менее, появилась необходи-
мость в наличии гарантированно максимального цело-
го типа, поэтому в С99 введен целочисленный тип мак-
симальной длины — intmaxt. Этот тип должен
существовать на всех системах, и его длина не должна
быть меньше длины любого другого типа. Аналогично
в С99 теперь имеется тип intptr_t — целый тип, кото-
рый может содержать указатель, если таковой имеется.
Некоторые платформы не будут иметь типа, достаточ-
но большого для представления произвольных значений
указателей; в таком случае тип intptrt на них отсутству-
ет. В команде printf появился новый флаг формата, ко-
торый соответствует типу intmax t. Он будет рассмот-
рен далее в этой главе в разделе "Новые свойства
стандартной библиотеки".
В стандарт С99 введено также большое количество
типов, названия которых выглядят как intAM, например
int64_t, int32_t и т.д. Это "точные" типы. Так, тип
int32 t имеет ровно 32 бита. Однако некоторая конкрет-
ная система может не поддерживать все эти типы. Боль-
шинство систем будут поддерживать только те типы, для
которых имеете^ соответствующая аппаратная поддер-
жка. Поэтому вы, как и ранее, не можете написать пе-
реносимый код, который использует 32-битовый цело-
численный тип, но можете написать код, который и без
#ifdef будет использовать целочисленный 32-битовый
тип, если он поддерживается платформой.
Кроме вышеуказанных типов точной длины, суще-
ствует ряд типов с названиями, имеющими вид
int_least32_t. Эти типы позволяют использовать типы
большей длины, чем типы, обеспечиваемые данной
системой. Так, тип int32 t имеет длину 32 бита, а тип
intjeast32_t может иметь длину 36 или даже 128 битов.
Имеются также "быстрые" типы, например, int_fast32 t,
которые представляют самый быстрый тип длиной не
менее N битов, поддерживаемый в данной среде.
В отдельных реализациях могут поддерживаться и
другие целочисленные типы, хотя стандарт устанавли-
вает, что максимальным целочисленным типом должен
быть тип intmax_t. Количество дополнительных типов
может быть довольно большим, но предполагается, что
эти типы будут соответствовать размерам слов или ти-
пам, которые используются в системных интерфейсах
(например, возможному диапазону размеров файлов или
аргументу конкретного системного вызова).
Для поддержки всех этих новых целочисленных
типов коренным образом изменились правила преобра-
зования типов. Теперь они выражаются в обобщенном
виде, а не явно ссылаются на типы, оговоренные в стан-
дарте. В общем случае выражение приводится к типу,
который имеет самую большую длину.
Дополнительные тематические разделы
Часть III
712
Такое большое количество целочисленных типов
было введено для того, чтобы дать возможность про-
граммистам для часто используемых типов применять
стандартные имена. В целом ряде существующих про-
грамм имеются вложенные конструкции #ifdef, которые
вводят "32-битовый целочисленный тип" или "целочис-
ленный тип длиной не менее 32 бита". Теперь это де-
лает сам компилятор. Быстрые типы и типы с ограни-
чением минимальной длины введены для того, чтобы
дать возможность программистам, которые не предъяв-
ляют таких жестких требований, использовать типы,
которые удовлетворят их потребности, не полагаясь на
популярный 8-битовый байт.
Производные типы
В стандарте С99 появилось три новых объявления, свя-
занных с массивами: массив переменной длины, пере-
менные члены структур и несколько поистине уникаль-
ных способов преобразования элементов "массива” в
функции.
Массивы переменной длины изменяют целый ряд
представлений о языке С. Наиболее поразительным для
опытного программиста будет их взаимодействие с опе-
ратором sizeof. Поскольку размер массива может ме-
няться в процессе работы программы, оператор sizeof,
который определяет длину массива переменной длины,
больше не является константой. Это также означает, что
аргумент оператора sizeof будет вычисляться в тех слу-
чаях (и только в тех случаях), в которых он не вычис-
лялся бы, если бы в аргументе не было массива пере-
менной длины.
Массивы переменной длины являются на удивление
мощным инструментом. Однако имеются и отдельные
недостатки. Одним из таких недостатков является то,
что использование выражений, вычисляющих длину
массива, может иметь побочные эффекты. Вы можете с
уверенностью считать, что в таком случае ваши буду-
щие пользователи вас не похвалят.
Массивы переменной длины нельзя использовать
везде. Например, элементы структуры не могут быть
массивами переменной длины. Однако объявления
структуры также имеют новую форму, которая может
быть "переменной". Многие программисты старшего
поколения, наверное, помнят один трюк со структурой.
Он имел следующий вид:
struct foo{
int len;
char data[l];
};
Программист выделял под структуру больше памя-
ти, чем ожидалось, а затем использовал данные так, как
если бы они были массивом большей длины. Комитет
по С отметил, что такое использование является непра-
вильным, хотя и не предложил другой альтернативы. Но
в С99 такая возможность предусмотрена. В С99 приве-
денная выше часть программы будет выглядеть следу-
ющим образом:
struct foo{
int len;
char data[);
);
При этом размер структуры будет определяться так,
как если бы последний элемент отсутствовал. Однако
если вы выделите дополнительную память, ее можно
будет использовать через этот последний элемент
Новые свойства стандартной библиотеки
В С99 значительно возрос объем стандартной библио-
теки. Вам будет интересно просмотреть раздел стандар-
та, касающийся стандартной библиотеки, или докумен-
тацию по компилятору, когда она станет доступной.
Введен целый ряд функций для работы с типами с пла-
вающей точкой, большая часть которых предназначена
для подсказки компилятору о том, что определенная
оптимизация допустима или желательна.
Стандарт имеет много новых функций, которые об-
легчают написание устойчивого, легко сопровождаемо-
го кода. Например, новая функция snprintf() позволяет
программисту указывать максимальное количество сим-
волов, которые могут быть записаны в одну строку. Как
и раньше, функция возвращает количество символов,
которое она напечатала бы, если бы было достаточно
места, что позволяет перед выделением места под стро-
ку узнать требуемый для нее размер памяти. Эта функ-
ция пришла из 4.4BSD, поэтому все системы, исполь-
зующие BSD, уже поддерживают эту функцию, как,
возможно, и большинство реализаций Linux.
Новый стандарт включает заголовочный файл
<tgmath.h>, в котором содержатся некоторые серьезные
функции для работы с числами с плавающей точкой.
Любая функция в библиотеке <math.h>, которая при-
нимает аргумент типа double (или несколько таких ар-
гументов), при включении <tgmath.h> становится
"обобщенной", т.е., если в качестве аргумента ей пере-
дать значение типа float, результат будет иметь тип float,
а если ей передать значение типа long double, то резуль-
тат будет иметь тип long double. То же самое относится
и к функциям для работы с комплексными числами,
объявленными в файле <complex.h>.
Функция printf имеет новый флаг, соответствующий
типу intmax t. Для этого типа имеется спецификатор
формата %jd. Теперь есть возможность выдать на печать
любое целое число со знаком, которое только может
использоваться в программе, написанной на С:
printf("%jd\n", (intmaX—t) n) ;
Взгляд в будущее: С99
Глава 29
713
(Если вас удивляет, что этот спецификатор не на-
зван как-нибудь более наглядно, например, %md, пояс-
ним, что существующая реализация использует %ш в ка-
честве расширения.)
Добавлен комплект взаимосвязанных функций
vscanf, vfscanf и vsscanf. Эти функции работают так же,
как и функции семейства scanf, но в качестве аргумен-
та принимают одно значение vs list, а не переменное
количество аргументов. Эти функции присутствовали в
целом ряде библиотек С, поэтому вы уже могли ими
пользоваться.
Семейство функций printf получило несколько но-
вых спецификаторов форматов (включая %а и %А для
шестнадцатиричных констант с плавающей точкой).
Спецификатор %lf теперь является синонимом специ-
фикатора %f, поскольку это рекомендовано во многих
книгах по С. Новые спецификаторы появились и у фун-
кции strftime.
Это далеко не полный перечень новых особеннос-
тей стандартной библиотеки С99, но он дает некоторое
представления о нововведениях.
Новые (и расширенные) ограничения
Стандарт С99 расширил и изменил много ограничений,
к которым привыкли программисты. Изменение, кото-
рое лично мне нравится больше всего, касается ограни-
чения на количество символов, по которому различают-
ся внешние идентификаторы. Раньше это ограничение
было равно шести символам с учетом регистра, а теперь
с учетом регистра значащими являются 31 символ.
Было расширено много других ограничений. Вооб-
ще, теперь компиляторы будут обеспечивать несколь-
ко более широкую среду, чем раньше. Строки могут
быть длиннее, вложенность может иметь большую глу-
бину, а объекты и выражения могут быть сложнее. В
некоторых случаях и сейчас можно столкнуться с дей-
ствием ограничений, но уже не так часто, как раньше.
Единственным ограничением, которое может не понра-
виться многим программистам, является то, что макси-
мальный размер объекта не должен превышать 65535
байтов (вместо 35767 байтов в стандарте С89). Правда
с помощью команды malloc можно всегда выделить
больший объем, но команда malloc может не сработать.
Новый синтаксис
Самые большие изменения, наверное, произошли в син-
таксисе. Теперь можно легко выполнять те функции,
которые раньше выполнить было просто невозможно.
В этом разделе рассмотрены различные изменения, ка-
сающиеся того, что можно писать и как это можно пи-
сать.
Набор символов
Во-первых, изменился набор символов. И изменился
существенно. Некоторые из этих изменений уже были
частью стандарта. Они были введены в поправках к
стандарту в 90-х годах. Однако поддержка расширенных
идентификаторов и строк (в основном касающаяся сим-
волов национальных языков и других символов) явля-
ется новым свойством.
Примерно в 1995 г. поправка 1 (которая в стандарте
называется AMD1) официально включила в существую-
щий стандарт С "широкие" символы, диграфы и альтер-
нативные варианты написания отдельных операторов.
Введение "широких" символов является попыткой
сделать различие между минимальным доступным объе-
мом памяти (char) и содержимым набора символов (ко-
торый может быть гораздо больше).
Альтернативные варианты написания отдельных
операторов будут доступны, если включить в програм-
му заголовочный файл <iso646.h>, что позволит, на-
пример, вместо && использовать and. Это сделано для
удобства использования в системах, в которых ранее
использовавшиеся символы было неудобно набирать.
Аналогично диграфы были введены для обеспечения
возможности набора символов (например, {}), набор
которых в некоторых системах затруднен. В отличие от
триграфов, диграфы являются только маркерами. Они
замещаются символами, для замены которых они пред-
назначены, и играют ту же синтаксическую роль.
Например, вместо
Int main (void) {return 0; }
можно написать
int main (void) <%return 0%>
но оператор
puts("<%%>");
не даст вам фигурные скобки.
В С99 введена поддержка универсальных имен сим-
волов — речь идет о символах, взятых из универсаль-
ного набора. Можно просто игнорировать эту возмож-
ность, если вам никто не пришлет код, в котором
используется эта кодировка. Эта возможность, в прин-
ципе, нужна для создания имен идентификаторов, сим-
волов или строковых констант, которые могут содержать
произвольные символы из национальных наборов сим-
волов. Универсальные имена символов могут записы-
ваться либо в виде \uxxxx, либо в виде \Uxxxxxxxr. Пер-
вый вид определят 16-битовый символ (с помощью
четырех шестнадцатиричных цифр), а второй — 32-
битовый символ (с помощью восьми шестнадцатирич-
ных цифр). Но в таком виде представляются не все сим-
волы. В настоящее время такие символы обозначают
714
Дополнительные тематические разделы
Часть III
несколько символов в именах внешних идентификато-
ров. Четыре шестнадцатиричные цифры считаются как
шесть символов, а восемь шестнадцатиричных цифр —
как 10 символов. (Или, по крайней мере, могут таковы-
ми считаться. Некоторые реализации более эффектив-
ны.) В будущих версиях стандарта универсальные сим-
волы будут всегда считаться одним символом.
Синтаксис препроцессора
Препроцессор также получил несколько новых неболь-
ших функций. Одна из наиболее желаемых — возмож-
ность задания макросов переменной длины. В С99 мак-
рос переменной длины выглядит примерно следующим
образом:
idefine PERR( format, . ..) fprintf(stdderr,
—format, VA ARGS______)
Это теперь исключит наиболее часто встречаемый в
сети Usenet вопрос.
Новый язык имеет новую форму pragma, которая
предназначена для использования в расширениях макро-
сов. Она выглядит следующим образом: PragmaC’flTgy") —
и, как правило, соответствует #pragma args. Обратите
внимание, что аргументы заключаются в кавычки.
Добавлены новые предопределенные макросы, боль-
шинство из которых будут использоваться в будущих
тестах. (Чтобы определить, поддерживает ли реализа-
ция соответствующую функцию, можно проверить,
определен макрос или нет.)
Теперь препроцессор производит все вычисления в
типе intmax_t, а не в типе long.
Список аргументов макроса теперь может быть пу-
стым. В расширении макроса вместо аргумента не бу-
дет ничего вставляться. Например:
idefine Р (х) х ii printf
//расширяется до fprintf(stdout, "hello, world!\n");
P(stdout, "hello, world!\n");
// расширяется до printf("hello, world!\n");
// - но неверно в C89
P()(stdout, "hello, world ?\n");
В C89 вызов макроса P() привел бы к ошибке, по-
скольку макрос требует наличия аргумента. В С99 ар-
гумент может опускаться.
И наконец, то, чего вы так долго ждали: вставка
комментариев с помощью символов //. Это делается
точно так же, как в C++, и многие, если не все, ком-
пиляторы, использующиеся в настоящее время, уже
поддерживают комментарии такого вида.
Объявления
Наиболее существенное изменение в объявлениях в С99
касается их места расположения. Теперь объявления
могут находиться в любом месте кода. В общем случае
в любом месте, где можно разместить оператор, можно
разместить и объявление. (Единственным исключени-
ем является то, что операторы могут иметь перед собой
метки, а объявления — нет.) Кроме того, переменная
может быть объявлена (и, если нужно, инициализиро-
вана) в первой строке оператора for. В этом случае об-
ласть видимости переменной ограничивается телом
цикла. Например:
for (int i=l; i<=10; ++i) {
printf("Простой пример, [line %d]\n", i);
}
// Здесь переменная i уже не определена
Составные литералы являются временными объяв-
лениями. В С99 для создания (и даже для инициализа-
ции) объекта уже не нужно объявлять переменную.
Можно просто поставить имя типа перед списком, зак-
люченным в скобки. Это выглядит как преобразование
типов, хотя и отличается от преобразования типов по
своей сути. Так, например, если есть объявление
struct bar {int а, b, с; char *s;}:
struct bar valuel, value2;
то в C89 значения должны вноситься в структуру по
одному:
valuel .а = О ;
valuel.b = 1;
valuel.с = 3;
valuel.s = "twenty three";
В С99 все значения можно внести в структуру одно-
временно:
value2=(struct bar) {0, 1, 3, "двадцать три”};
а не инициализировать каждый элемент по отдельности.
Приведенный ниже пример не обладает высокой
переносимостью, но является хорошей иллюстрацией
того, для чего можно использовать составные литералы.
В системе UNIX при вызове select в качестве аргумен-
тов используются целое значение, три указателя на мас-
сивы целых чисел и указатель на struct timeval Многие
программисты используют функцию select как простой
способ обеспечения небольшой задержки, скажем, ме-
нее чем на секунду. Ниже приведен пример такого ис-
пользования select в С89 (в среде UNIX):
void millisleep(int n) {
struct timeval t;
t.tvsec = 0;
t.tvusec = n * 1000;
select (0, 0, 0r 0, St);
I
В C99 можно написать:
void millisleep (int n) {
select(0, 0, 0, 0, &((struct timeval) {0,
'-*n*1000>));
}
Взгляд в будущее: С99
Глава 29
[715
В некоторых системах функция select изменяет свой
последний аргумент на время, оставшееся до заверше-
ния паузы. Приведенный код будет работать в любом
случае, хотя и не всегда будет давать время до заверше-
ния паузы.
Это свойство становится еще более мощным при
использовании его совместно с выделенными инициа-
лизаторами, которые будут рассмотрены далее.
В стандарте С99 также вводится концепция ’’ограни-
ченных указателей" (restricted pointers). Тот, кто помнит
предшествующий стандарт, с ужасом подумает о специ-
фикаторе noalias, который встречался в проекте преды-
дущего стандарта. Однако restrict по-существу отлича-
ется от noalias.
Основное назначение ограниченных указателей —
обеспечение дополнительной информации для компи-
ляторов о потенциальном совмещении имен, что позво-
ляет компиляторам более эффективно оптимизировать
программы. Если при определении функции вы счита-
ете, что не имеет смысла передавать функции два ука-
зателя, указывающие на одно и то же место, то при
объявлении этих указателей можно использовать специ-
фикатор restrict. Если взять некоторую программу и
удалить из нее restrict, она все равно будет работать.
Однако если вы вводите restrict, то фактически подтвер-
ждаете, что определенные объекты действительно име-
ются, и это может вызвать неопределенное поведение
программы.
О существовании спецификатора restrict необходи-
мо знать главным образом потому, что некоторые фун-
кции в стандартной библиотеке объявлены с использо-
ванием ключевого слова restrict. Это означает, что вы не
можете передавать этим функциям несколько указате-
лей, указывающих на один и тот же объект. Более под-
робно об этом можно прочитать в стандарте.
В С99 введен еще один новый спецификатор: inline.
Этот спецификатор может применяться только к фун-
кциям. Его имеет примерно такое же назначение, как в
C++. В языке С inline считается только подсказкой, от
компилятора никогда не требуется, чтобы вызов функ-
ции заменялся ее кодом. Во многих компиляторах уже
поддерживается спецификатор inline, поскольку он ис-
пользуется и в C++. Существуют небольшие различия
в особенностях спецификатора inline в С и C++, но для
большинства задач эти различия можно игнорировать и
использовать inline просто в качестве подсказки компи-
лятору о том, что данная функция должна быть макси-
мально быстрой. Следует знать, что замена вызова фун-
кции ее кодом не всегда увеличивает скорость. Можно
найти примеры программ, которые работают медленнее,
если функции объявлены со спецификатором inline.
В С99 спецификаторы могут повторяться. Это свой-
ство было введено из-за того, что программисты хоте-
ли использовать volatile в typedef, а далее объявлять
объект volatile определенного типа. Поэтому специфи-
каторы типа теперь можно дублировать; использование
третьего и большего количества спецификаторов не ока-
зывает никакого эффекта.
И наконец, ключевое слово static в С99 получило
еще одно значение. Если параметр функции является
массивом, то размер массива может иметь специфика-
торы типа. Если один из них — спецификатор static, то
любой передаваемый функции указатель должен указы-
вать на массив с количеством элементов не меньше ука-
занного. Например,
void foo(int a[static 10]);
объявляет функцию, первый аргумент которой — это
указатель, по меньшей мере, на 10 значений типа int.
Это не был бы новый стандарт С, если бы он не прида-
вал нового значения слову static.
Инициализация
Изменены несколько аспектов инициализации перемен-
ных. Один аспект (отчасти из-за составных литералов) —
опущено требование о том, что инициализаторы состав-
ных данных (массива, структуры и объединения) дол-
жны быть константами.
В С99 также введены выделенные инициализаторы,
которые указывают, для какого элемента составных дан-
ных предназначен инициализатор. Теперь можно ини-
циализировать отдельный элемент массива, структуры
или даже массива структур. Например, если есть струк-
тура
struct foo{
int a, b;
};
то се можно инициализировать следующим образом:
struct foo f={.b=3;};
что эквивалентно
struct foo f={0, 3);
И что особенно удобно, теперь не обязательно ини-
циализировать элементы в указанном порядке и пере-
писывать инициализаторы при добавлении новых эле-
ментов, при изменении их порядка или при каком-либо
другом изменении объявления структуры. Пока поля,
которые вы пытаетесь инициализировать, существуют,
код будет работать без ошибок. Значения полей, кото-
рые не инициализированы явно, равны нулю, как это
и было раньше.
Выделенные инициализаторы также позволяют ини-
циализировать отдельный элемент объединения, а не
только первый именованный элемент (что исключает
еще один часто встречающийся в сети Usenet вопрос).
716
Дополнительные тематические разделы
Часть III ~
Эти свойства можно также использовать совместно
с составными литералами. Например, в предыдущем
примере (с использованием select) можно написать:
select(0, 0, 0, 0, &((struct
** timeval){.ty_usec=n*1000)));
Теперь можно ставить запятую в конце списка зна-
чений типа enum. Это позволит упростить написание
вашими программами других программ и удовлетворя-
ет общему правилу, которое во многих случаях предус-
матривает использование дополнительных запятых в
конце списка.
Другие новые свойства
Каждая функция имеет неявную переменную__func__,
которая представляет собой строку, содержащую имя
функции. Это свойство поддерживается целым рядом
компиляторов (хотя конкретное его написание может
различаться). Оно полезно в основном для процесса
отладки. В некоторых реализациях похожее свойство
доступно за счет использования макроса препроцессо-
ра, но версия, которая принята в стандарте, является
идентификатором, и ее нельзя использовать в препро-
цессоре.
Теперь стало возможным записывать значения с пла-
вающей точкой в шестнадцатиричном виде. И это не
шутка. Выглядит это следующим образом:
float f=0x2.fpl0;
Здесь ”р" вводит экспоненту, которая записывается
в десятичном виде и представляет двоичную экспонен-
ту. Это представление соответствует способу представ-
ления чисел с плавающей точкой в вычислительной ма-
шине, в котором количество битов представляемого
значения и двоичная экспонента задают шкалу. Если ра-
нее вы не испытывали недостатка в таком свойстве, то
и теперь вы, наверное, редко будете им пользоваться.
Теперь существуют стандартные указания трансля-
тору — т.е. то, что вы можете поместить в директиву
#pragma, которая имеет одно и то же значение во всех
компиляторах. Все стандартные указания начинаются с
STDC.
Введена новая спецификация для арифметики IEEE
в С. Не все реализации поддерживают это свойство, но
если поддерживают, то существует стандартная специ-
фикация проверки доступности арифметики IEEE (с
помощью специальных макросов, о которых шла речь
ранее).
Потерянные возможности
Прежде всего мы потеряли возможность неявного объяв-
ления переменных типа int. Программы, в которых
предполагается, что переменные без объявления типа
имеют тип int, будут ошибочными. Неявное объявление
все еще допустимо в стандарте С89, но многие компи-
ляторы уже выдают предупреждения о таком объявле-
нии. Если вы иногда грешите неявным объявлением, то
настал час расплаты. Это также означает, что static i;
больше не будет соответствовать объявлению static int
i;, теперь это будет синтаксической ошибкой.
Теперь нельзя возвращать значение из функции,
объявленной как void, или не возвращать значение из
функции, имеющей тип, отличный от void.
Описание main теперь более четко указывает, что
тип int возвращаемого значения обязателен. Члены ко-
митета ранее считали, что это было достаточно очевид-
но, но широкое использование в книгах по С void
main(void) показало, что существующее описание недо-
статочно четко определяет тип main. Некоторые реали-
зации до сих пор позволяют использовать помимо двух
указанных дополнительные формы main (одной — с ар-
гументами и одной — без аргументов). Однако только
две указанные выше формы считаются переносимыми.
В С89 подтверждалось (в отчетах о дефектах), что
тип long является самым большим целым типом. В С99
это ошибочно. Дебаты в Usenet по этому поводу все еще
продолжаются.
Не все предложения, которые были внесены, были
отражены в стандарте. Две функции для работы со стро-
ками strap и srtsep не были исключены.
Однако по большей части свойства добавлялись, а не
удалялись. Это звучит замечательно до тех пор, пока вы
не попытаетесь денек поносить с собой полную распе-
чатку стандарта.
Изменения по сравнению с С89
В язык С было внесено очень много незначительных
изменений. Главным образом они никак не повлияют на
существующие программы. Более того, предполагается,
что компиляторы должны выдавать предупреждения о
возможных неприятностях, вызванных изменениями, и
о том, каким образом данная реализация интерпрети-
рует сам язык. В большинстве случаев в условиях ново-
го стандарта языка существующие программы будут
продолжать компилироваться и работать, как и ожида-
лось.
Чаще всего изменения приводят к замене идиом
стандарта С89 на идиомы стандарта С99. Было внесено
минимальное количество изменений, которые повлия-
ют на коды существующих программ, и такие измене-
ния, где это возможно, вызовут предупреждения или
сообщения об ошибках.
В стандарт внесены новые разъяснения, и исправле-
ны имевшие место ошибки. Многие определения в стан-
Взгляд в будущее: С99
Глава 29
717
дарте С89 имели нежелательный скрытый смысл или
неточно выражали смысл, который в них закладывал-
ся. В некоторых случаях в стандарте С99 рассмотрены
граничные условия, которые не были рассмотрены в
стандарте С89. Например, теперь, если функция
tmpnam не может сгенерировать подходящее имя, то она
возвращает указатель NULL. Ранее это было возможно
только после ТМР_МАХ вызовов функции tmpnam.
Правила совмещения имен были в значительной мере
переработаны.
В стандарте С99 изменены определения "зависяще-
го от реализации", "неустановленного" и "неопределен-
ного" поведения. Границы между ними были несколь-
ко перенесены и установлены более четко. Это не
должно оказать никакого влияния на работу большин-
ства программ, несмотря на внесенные изменения. На-
пример, теперь в стандарте полностью оговорено усло-
вие деления отрицательных целых чисел с тем, чтобы
в различных реализациях округление могло произво-
диться как вниз, так и вверх.
В стандарте С89 довольно пространно говорилось о
неопределенном поведении программ. Так, например,
попытка получить доступ к объектам, не имеющим
определенного значения, могло привести к неопределен-
ному поведению. В С99 для разъяснения такого пове-
дения вводится понятие "представление прерывания"
(trap representation). Представление прерывания — это
последовательность битов, которые при интерпретации
в виде данного типа не дают никакого значения. Если
доступ к данным осуществляется с помощью функции
lvalue с типом, для которого эти данные являются пред-
ставлением прерывания, то это приведет к неопределен-
ному поведению. Другими словами, это означает, что
определенные данные не могут принадлежать к опре-
деленному типу. Например, некоторая последователь-
ность битов может не быть интерпретирована как float.
В общем случае значение одного типа может быть пред-
ставлением прерывания для любого другого типа. Кро-
ме того, если значение объекта не определено (напри-
мер, не инициализировано), то, возможно, оно является
представлением прерывания. Поэтому, когда вы объяв-
ляете указатель, но не инициализируете его, неопреде-
ленное поведение может вызвать не только попытка
разыменовать указатель, но даже попытка обратиться к
указателю, скажем, преобразовать его к другому типу,
выдать его на печать или присвоить его значение дру-
гому указателю. Символьные типы не имеют представ-
лений прерывания, поэтому можно получить доступ к
любым данным как к последовательности битов, не
опасаясь представлений прерывания.
Само понятие представления прерывания не изме-
няет принципа работы языка, а служит только для луч-
шего понимания стандарта, но, тем не менее, оно бу-
дет сюрпризом для людей, которые не знали, что про-
стое считывание неопределенного значения может выз-
вать разгрузку оперативной памяти и другие неприят-
ности. Не обращайтесь к неинициализированной памяти —
и вы будете иметь меньше проблем.
Если main объявлена с типом возвращаемого значе-
ния int (как и должно быть в переносимом коде), то
завершение main без возврата значения эквивалентно
возвращению значения 0. Многие неаккуратные про-
граммисты привыкли возвращать случайные значения.
Теперь этот недостаток устранен.
Стандарт четко указал, что только приведенные в
стандарте точные строки режимов (для fopen) имеют
определенные значения. Некоторым программистам
могло показаться, что текст стандарта С89 предполага-
ет, что за строкой режима мог следовать дополнитель-
ный текст (особенно это касается записи ЧгГ, иногда
встречающегося в книгах в качестве обозначения "тек-
стового режима" на некоторых системах; в стандартном
С это будет просто "г", поскольку текстовый режим
установлен по умолчанию). Но стандарт С99 либо вно-
сит изменения, либо более четко описывает назначение,
в зависимости от того, что вас интересует.
В целом изменения, как правило, безвредны, но на
всякий случай полезно иметь и более старый компиля-
тор, если на первых порах у вас возникнут какие-либо
проблемы.
Резюме
Стандарт С99 внес значительные изменения в язык про-
граммирования С. Эти изменения не менее серьезны,
чем разница изменения между языком, описанным в
книге The С Programming Language Кернигана и Ричи
(Kernighan и Ritchie) издания 1978 г., и языком, опи-
санным в стандарте ISO 1989 г. В такой короткой главе
невозможно рассказать обо всех изменениях. Поэтому
здесь были рассмотрены самые интересные. Не ждите,
что переход на новый стандарт произойдет за одну не-
делю. Пройдет некоторое время, пока вы привыкнете к
новым свойствам ну и, наверное, сделаете массу оши-
бок при работе с новым стандартом. Наслаждайтесь
процессом обучения.
Наиболее полным источником информации по но-
вому языку на сегодняшний день является стандарт.
К тому времени, когда вы будете читать эту книгу, на-
верное, будет возможно на Web-сайте ISO приобрести
технические условия на язык С в формате PDF. Про-
цесс принятия стандарта национальными организация-
ми (например, Национальным институтом стандартизации
США, ANSI) может занять длительное время, но началь-
ные реализации уже начинают появляться. В скором вре-
мени компилятор gcc уже будет поддерживать (а, возмож-
Дополнительные тематические разделы
Часть III
718
но, уже поддерживает) большую часть новых свойств, ого-
воренных в стандарте. Многие свойства в стандарте С99
соответствуют свойствам компилятора gcc.
Web-сайт по FAQ (часто задаваемые вопросы) Сти-
ва Саммита (Steve Summit) в группе новостей
comp.Iang.c в сети Usenet дает значительный объем
вводной информации по С99. Рекомендую вам прочесть
эту информацию. На момент написания книги этот FAQ
находился по адресу:
http: //www. eskimo. com/-scs/C-f aq/top. htxnl
Информацию по стандарту С также можно найти в
сети Usenet в группе новостей по адресу comp.std.c, где
рассматриваются различные воплощения стандарта ISO.
Информация имеет несколько эзотерический характер,
но если у вас есть сложный вопрос, то это самый под-
ходящий источник информации.
Комитет по С до сих пор проводит заседания, и ве-
дутся отдельные разговоры о стандарте СОХ, который
будет создан в будущем, вероятно, в течение десяти лет.
Если вы хотите принять участие в них — пожалуйста.
Членство открыто для всех заинтересованных лиц, и
комитет будет рад, если в работе будет участвовать как
можно большее количество людей. Официальная домаш-
няя страница комитета на момент написания книги
находилась по адресу:
http: //anubxs. dkuug.dk/JTCl/SC22/WG14/
Приложения
IV
ЧАСТЬ
Общедоступная лицензия GNU
В ЭТОМ ПРИЛОЖЕНИИ
Условия копирования, распространения и модификации
Отсутствие гарантийных обязательств
Как применять указанные условия к своим новым программам
Условия копирования,
распространения и модификации
Настоящая Лицензия применима к любой программе
или другой работе, содержащей уведомление, помещен-
ное владельцем авторских прав, в котором говорится,
что эту программу разрешается распространять в соот-
ветствии с условиями этой Общедоступной лицензии.
Термин "Программа” относится к любой такой програм-
ме или работе, а термин "работа, основанная на Про-
грамме" означает либо Программу, либо любую произ-
водную работу, находящуюся под защитой закона об
авторских правах, т.е. работу, содержащую Программу
или се часть, точную или с изменениями копию и/или
переведенную на другой язык. (В дальнейшем перевод
входит в термин "модификация”). Каждый получатель
лицензии в дальнейшем именуется "вы".
Деятельность, не связанная с копированием, распро-
странением и модифицированием, не подпадает под
действие данной Лицензии. Использование Программы
ничем не ограничивается, а результаты работы Програм-
мы подпадает под действие настоящей Лицензии толь-
ко в том случае, если их содержание составляет рабо-
ту, основанную на самой Программе (вне зависимости
от того, были ли они получены в результате использо-
вания Программы).
Справедливость вышесказанного зависит от того, что
выполняет сама Программа.
1. Вы можете копировать и распространять точные ко-
пии исходного кода Программы в том виде, в кото-
ром вы его получили, на любом носителе информа-
ции при условии, что на каждой копии на видном
месте будет напечатано соответствующее сообщение
об авторских правах и отказ от гарантийных обяза-
тельств. Не изменяйте уведомления, касающиеся
данной Лицензии и отсутствия любых гарантийных
обязательств. Передайте всем получателям Програм-
мы вместе с Программой копию настоящей Лицен-
зии.
Вы можете брать плату за саму физическую переда-
чу копии и можете взять на себя любые гарантий-
ные обязательства в обмен на получаемую плату.
2. Вы можете модифицировать свою копию или копии
Программы или любой ее части, таким образом фор-
мируя работу, основанную на Программе, и копи-
ровать и распространять такие модификации или ра-
боты на основании Раздела 1 данной Лицензии при
условии выполнения всех приведенных ниже усло-
вий:
а) Вы должны указать, что вы модифицировали фай-
лы, и указать даты всех изменений.
Ь) По условиям настоящей Лицензии вы должны
бесплатно обеспечить лицензией любую работу, ко-
торую вы распространяете или публикуете, которая
полностью или частично содержит или основана на
Программе или на ее части.
с) Если модифицированная программа работает в
интерактивном режиме, то при ее запуске она дол-
жна выдавать сообщение, включающее уведомления:
об авторских правах, об отсутствии гарантийных
обязательств (или о гарантийных обязательствах,
если вы берете на себя какие-либо обязательства), о
том, что пользователи могут распространять про-
грамму в соответствии с указанными условиями, и
о том, как пользователи могут просмотреть копию
настоящей Лицензии. (Исключение: если сама по
себе Программа интерактивна, но не выдает указан-
ного сообщения, то вашей работе, основанной на
Общедоступная лицензия GNU
[721
Приложение А
Программе, также не обязательно выдавать такое
сообщение).
Приведенные требования применяются к модифи-
цированным работам в целом. Если отдельные час-
ти этой работы не основаны на Программе и сами
по себе могут считаться независимой и отдельной
работой, то настоящая Лицензия и ее условия не
относятся к таким частям, если вы распространяете
их как отдельные работы. Но в случае, если вы рас-
пространяете эти же части в качестве части работы,
основанной на Программе, такое распространение
должно соответствовать условиям настоящей Лицен-
зии; условия Лицензии распространяются на всю
такую работу в целом и, следовательно, на каждую
ее часть независимо от автора.
Назначением данного раздела является не требова-
ние своих прав и не оспаривание ваших прав на пол-
ностью созданную вами работу, а использование пра-
ва контроля за распространением производных или
коллективных работ, основанных на Программе.
Кроме того, простое сочетание на одном носителе
информации Программы (или работы, основанной
на Программе) и работы, не основанной на Програм-
ме, не приводит к попаданию последней под дей-
ствие настоящей Лицензии.
3. Вы можете копировать и распространять Програм-
му (или работу, основанную на ней, согласно раз-
делу 2) в виде объектных файлов или в виде выпол-
няемых файлов по условиям, указанным в разделах
1 и 2, если вы при этом выполняете следующее:
а) Обеспечиваете ее полным машинно-считываемым
исходным кодом, который должен распространять-
ся по условиям разделов 1 и 2 на средствах переда-
чи информации, которые используются для распро-
странения программного обеспечения, или
Ь) Обеспечиваете ее письменным предложением,
действительным, по крайней мере, три гола, пере-
дать третьей стороне по цене, не превышающей цену
физического распространения исходного кода, пол-
ную машинно-считываемую копию соответствующе-
го исходного кода, который распространяется в со-
ответствии с условиями разделов 1 и 2 на средствах
передачи информации, которые используются для
распространения программного обеспечения, или
с) Обеспечиваете ее информацией, которую вы по-
лучили в качестве предложения по распространению
соответствующего исходного кода. (Этот вариант
возможен только для некоммерческих работ и толь-
ко в случае, если вы получили программу в объект-
ном коде или в виде выполняемых файлов с пред-
ложением в соответствии с подразделом (Ь>
настоящего раздела).
Исходный код используется для внесения в него
изменений. Для выполняемых файлов полный ис-
ходный код означает весь исходный код всех моду-
лей, плюс соответствующие файлы определений
интерфейса, плюс сценарии, которые используют-
ся для управления процессом компиляции и уста-
новки выполняемых файлов. Однако, как особое
исключение, распространяемый исходный код мо-
жет не включать то, что распространяется с основ-
ными модулями (компилятором, ядром и т.п.) опе-
рационной системы, в которой работает данный
выполняемый модуль, если этот компонент не рас-
пространяется с выполняемым модулем.
Если распространение выполняемых или объектных
модулей осуществляется путем предложения по по-
лучению копии из указанного источника, то такое
же предложение по доступу к исходному коду, на-
ходящемуся в том же источнике, считается распро-
странением исходного кода, даже если третьи лица
не обязаны копировать исходный код совместно с
объектным кодом.
4. Вы не можете копировать, модифицировать, лицен-
зировать и распространять Программу иначе, чем так,
как указано в настоящей Лицензии. Любая такая по-
пытка копировать, модифицировать, лицензировать и
распространять Программу является незаконной и
автоматически прекращает действие ваших прав,
обеспечиваемых настоящей Лицензией.
Однако лица, которые получили от вас копии или
права в соответствии с настоящей Лицензией и в
этом случае будут сохранять свои права, пока они
действуют согласно всем требованиям Лицензии.
5. От вас не требуется принятие настоящей Лицензии,
поскольку вы ее не подписываете. Однако больше
никакой документ не дает вам разрешения на моди-
фицирование или распространение Программы или
основанных на ней работ. Эти действия запрещены
законом, если вы не принимаете условия Лицензии.
Поэтому, модифицируя или распространяя Про-
грамму (или любую работу, основанную на Про-
грамме), вы подтверждаете принятие вами настоя-
щей Лицензии и всех ее условий на копирование,
распространение и модифицирование Программы
или работ, основанных на Программе.
6. При распространении Программы (или любой рабо-
ты, основанной на Программе) получатель автома-
тически получает лицензию от первоначального об-
ладателя лицензии на копирование, распространение
и модифицирование Программы согласно условиям
настоящей Лицензии. Вы можете не накладывать
никаких дополнительных ограничений на использо-
вание получателем прав, указанных в настоящей
46 Зак. 265
Приложения
Часть IV
722
Лицензии. Вы не отвечаете за принятие Лицензии
третьими лицами.
7. Если, как следствие решения суда, обвинения в на-
рушении патентного права или по какой-либо иной
причине (не относящейся к вопросам патентования),
на вас наложены ограничения (решение суда, дого-
воренность и т.д.), которые нарушают условия Ли-
цензии, то они не освобождают вас от условий Ли-
цензии. Если вы не можете распространять
Программу, одновременно выполняя и обязательства
по настоящей Лицензии и все другие обязательства,
тогда, как результат, вам запрещается распростра-
нять Программу.
Если какая-либо часть настоящего раздела не выпол-
няется или не может быть выполнена вследствие ка-
ких-либо обстоятельств, то должна применяться ос-
тавшаяся часть раздела и раздел в целом должен
применяться в других обстоятельствах.
Целью настоящего раздела является не поощрение к
нарушению патентного права или других прав соб-
ственности или оспаривание законности таких прав.
Единственной целью настоящего раздела является
защита целостности системы распространения от-
крытого программного обеспечения, которая реали-
зована на основе общедоступных лицензий. Многие
люди сделали щедрые вклады в целый ряд программ,
которые распространяются благодаря этой системе,
в надежде на постоянное использование системы.
Автор/жертвователь сам решает, через какую систему
распространять свое программное обеспечение, а по-
лучатель лицензии не может иметь такого выбора.
Этот раздел предназначен для четкого объяснения
того, что считается следствием оставшейся части Ли-
цензии.
8. Если распространение и/или использование Про-
граммы ограничено в некоторых странах либо па-
тентами, либо интерфейсами, защищенными автор-
скими правами, то первоначальный владелец
авторских прав, который дает Программе настоящую
Лицензию, может указать географические ограниче-
ния на действие Лицензии, которые исключают эти
страны, т.е. распространение разрешается только в
тех странах, которые не входят в список исключен-
ных. В таком случае настоящая Лицензия считается
включающей указанные ограничения, как если бы
они фактически были включены в Лицензию.
9. Фонд бесплатно распространяемых программ может
время от времени опубликовывать переработанные
и/или новые версии Общедоступной лицензии. Та-
кие новые версии будут аналогичны настоящей Ли-
цензии по характеру, но могут отличаться в деталях,
которые касаются новых проблем.
Каждой версии присваивается отличительный но-
мер. Если в Программе указан номер настоящей вер-
сии Лицензии, которая применима для данной вер-
сии и для последующих версий, вы можете по
своему усмотрению выполнять условия либо этой
версии, либо любой последующей версии, опубли-
кованной Фондом бесплатно распространяемых про-
грамм. Если в Программе не указан номер версии
Лицензии, вы можете пользоваться любой версией,
когда-либо опубликованной Фондом бесплатно рас-
пространяемых программ.
10. Если вы включаете части Программы в другие от-
крытые программы, условия распространения кото-
рых отличаются, попросите разрешения у автора.
Для получения разрешения на распространение про-
граммного обеспечения Фонда бесплатно распрост-
раняемых программ, охраняемого авторским правом,
пишите в Фонд бесплатно распространяемых про-
грамм; мы иногда делаем исключения. Наше реше-
ние будет основано на достижении двух целей: со-
хранение статуса открытого программного
обеспечения всех работ, основанных на нашем от-
крытом программном обеспечении, и содействие в
обмене и использовании программного обеспечения
в целом.
Отсутствие гарантийных обязательств
11. ПОСКОЛЬКУ ПРОГРАММА ЗАПАТЕНТОВАНА
КАК БЕСПЛАТНАЯ, ТО НЕТ НИКАКИХ ГАРАН-
ТИЙНЫХ ОБЯЗАТЕЛЬСТВ В ПРЕДЕЛАХ, РАЗРЕ-
ШЕННЫХ ДЕЙСТВУЮЩИМИ ЗАКОНАМИ.
ЕСЛИ ОТДЕЛЬНО НЕ УКАЗАНО, ТО ОБЛАДАТЕ-
ЛИ АВТОРСКИХ ПРАВ И/ИЛИ ДРУГИЕ ЛИЦА
ПЕРЕДАЮТ ПРОГРАММУ "КАК ЕСТЬ" БЕЗ КА-
КОЙ-ЛИБО ГАРАНТИИ, НИ ПРЯМОЙ, НИ ПОД-
РАЗУМЕВАЕМОЙ, ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИ-
ВАЯСЬ ПОДРАЗУМЕВАЕМЫМИ ГАРАНТИЯМИ
ПО ГОДНОСТИ К ПРОДАЖЕ И ПРИГОДНОСТИ
ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ. ВЫ БЕРЕТЕ НА
СЕБЯ ВЕСЬ РИСК, КАСАЮЩИЙСЯ КАЧЕСТВА
И ХАРАКТЕРИСТИК ПРОГРАММЫ. ЕСЛИ ОКА-
ЖЕТСЯ, ЧТО ПРОГРАММА ИМЕЕТ НЕДОСТАТ-
КИ, ВСЕ ЗАТРАТЫ ПО ОБСЛУЖИВАНИЮ, РЕ-
МОНТУ И ВНЕСЕНИЮ ИСПРАВЛЕНИЙ ЛЯГУТ
НА ВАС.
12. НИ В КАКИХ СЛУЧАЯХ, ЕСЛИ ЭТО НЕ ТРЕБУ-
ЕТ СООТВЕТСТВУЮЩИЙ ЗАКОН ИЛИ НЕ СО-
ГЛАСОВАНО ПИСЬМЕННО, ВЛАДЕЛЕЦ АВТОР-
СКИХ ПРАВ ИЛИ ЛЮБОЕ ДРУГОЕ ЛИЦО,
КОТОРОЕ МОЖЕТ МОДИФИЦИРОВАТЬ И/
ИЛИ РАСПРОСТРАНЯТЬ ПРОГРАММУ КАКУКА-
Общедоступная лицензия GNU
723
Приложение А
ЗАНО ВЫШЕ, НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ
ЗА ВАШИ УБЫТКИ, ВКЛЮЧАЯ ВСЕОБЩИЕ,
СПЕЦИАЛЬНЫЕ, ПОБОЧНЫЕ И КОСВЕННЫЕ
УБЫТКИ, ВЫЗВАННЫЕ ИСПОЛЬЗОВАНИЕМ
ИЛИ НЕВОЗМОЖНОСТЬЮ ИСПОЛЬЗОВАНИЯ
ПРОГРАММЫ (ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИ-
ВАЯСЬ ПОТЕРЯМИ ДАННЫХ, НЕТОЧНОЙ ИН-
ТЕРПРЕТАЦИЕЙ ДАННЫХ, ПОНЕСЕННЫМИ
ВАМИ ПОТЕРЯМИ ИЛИ ПОТЕРЯМИ ТРЕТЬИХ
ЛИЦ ЛИБО НЕСПОСОБНОСТЬЮ ПРОГРАММЫ
РАБОТАТЬ СОВМЕСТНО С ДРУГИМИ ПРОГРАМ-
МАМИ), ДАЖЕ ЕСЛИ ВЛАДЕЛЕЦ АВТОРСКИХ
ПРАВ ИЛИ ДРУГОЕ ЛИЦО БЫЛО ОСВЕДОМЛЕНО
О ВОЗМОЖНОСТИ ТАКИХ УБЫТКОВ.
КОНЕЦ УСЛОВИЙ ЛИЦЕНЗИИ
Как применять указанные условия к
своим новым программам
Если вы разрабатываете новую программу и хотите сде-
лать ее полезной для широкой общественности, то наи-
лучшим путем достижения этого является распростра-
нение вашей программы как открытого программного
обеспечения, которое может распространяться и изме-
няться согласно условиям, указанным выше.
Для этого вставьте приведенные ниже сообщения в
свою программу. Удобнее всего вставить их в начало
каждого файла исходного кода, в этом случае наиболее
эффективно подчеркивается отсутствие лицензии, и
каждый файл должен иметь, по крайней мере, строку
"copyright" и ссылку на место, где можно найти полный
текст сообщения:
<Строка, в которой содержится имя программы и
коротко описано ее назначение>
Copyright (с) 19уу <имя автора>
Эта программа является открытой, вы можете рас-
пространять ее и/или модифицировать согласно усло-
виям Общедоступной лицензии GNU, опубликованной
Фондом бесплатно распространяемых программ, версии
2 или (по вашему усмотрению) более поздней версии.
Эта программа распространяется в надежде, что она
окажется полезной, но она НЕ ИМЕЕТ НИКАКОЙ
ГАРАНТИИ, даже подразумеваемой гарантии ПО
ГОДНОСТИ К ПРОДАЖЕ и ПРИГОДНОСТИ ДЛЯ
ОПРЕДЕЛЕННОЙ ЦЕЛИ. Более подробная информа-
ция приведена в Общедоступной лицензии GNU.
Вместе с данной программой вы должны были по-
лучить копию Общедоступной лицензии GNU; если вы
ее не получили, пишите по адресу Free Software
Foundation, Inc., 675 Mass Ave., Cambridge, MA 02139,
USA.
Кроме того, включите в текст свой электронный и
почтовый адрес.
Если программа интерактивна, сделайте так, чтобы
она при запуске выводила небольшое сообщение при-
мерно следующего содержания:
Gnomovision версия 69, Copyright (с) 19уу имя ав-
тора
Gnomovision распространяется БЕЗ КАКОЙ БЫ ТО
НИ БЫЛО ГАРАНТИИ; для получения более подроб-
ной информации наберите 'show w'.
Это открытое программное обеспечение, и вы може-
те распространять его в соответствии с определенными
условиями; для получения более подробной информа-
ции наберите 'show с'
Гипотетические команды show w и show с должны
выводить соответствующие части Общедоступной лицен-
зии. Конечно, вы можете использовать любые другие ко-
манды или даже использовать мышь или меню — любой
вариант, который подходит для вашей программы.
Кроме того, ваш работодатель (если вы работаете
программистом) или представитель вашего учебного
заведения, если вы где-то учитесь, должен подписать
"отказ от авторских прав" на программу. Вот пример
"отказа", измените только имена:
Настоящим Yoyodyne, Inc. отказывается от всех ав-
торских прав на программу Gnomovision, написанную
Джеймсом Хакером.
<подпись Тай Куна> 1 апреля 1989 г.
Тай Кун, вице-президент
Общедоступная лицензия запрещает использовать
вашу программу в программах, защищенных авторски-
ми правами. Если ваша программа является библиоте-
кой подпрограмм, вы можете рассмотреть компоновку
своей библиотеки с программами, защищенными автор-
скими правами. Если вы захотите это сделать, исполь-
зуйте Общедоступную Лицензию GNU для Библиотек
вместо этой Лицензии.
Избранная библиография
В ЭТОМ ПРИЛОЖЕНИИ
Книги
Сетевое программирование
Ресурсы Internet
Что находится на CD-ROM
В этом приложении приведен перечень книг и ресурсов,
предложенных авторами данной книги для получения
дополнительной информации по программированию на
языке С.
Книги
The Algorithm Design Manual, Steven S. Skiena, Springer-
Verlag New York, Inc., ISBN 0-387-94860-0
Algorithms in C Parts 1-4, Fundamentals, Data Structures,
Sorting, Searching 3rd Edition, Robert Sedgewick, 1997 ISBN
0-201-31452-5
The Art of Computer Programming Volume 1, Donald E
Knuth, Addison-Wesley, ISBN 0-201-89683-4
The Art of Computer Programming Volume 2, Donald E
Knuth, Addison-Wesley, ISBN 0-201-89684-2
The Art of Computer Programming Volume 3, Donald E
Knuth, Addison-Wesley, ISBN 0-201-89685-0
C: A Reference Manual, 4th Ed., Harbison & Steele, Prentice
Hall, ISBN 0-13-326224-3
C: How to Program, 2nd Ed., Deitel, H.M. & Deitel, P.J.,
Prentice Hall, ISBN 0-13-226119-7
C Programming: A Modern Approach, K. N. King, W. W.
Norton & Company, Softcover ISBN 0-393-96945-2
C Programming FAQs, Steve Summit, Addison-Wesley,
ISBN 0-201-84519-9
The C Programming Language, 2nd Ed., Brian W Kemighan
and Dennis M Ritchie, Prentice Hall, ISBN 0-13-110362-8
C Traps and Pitfalls, Andrew Koenig, Addison-Wesley,
ISBN 0-201-17928-8
Code Complete, Steve McConnell, Microsoft Press, ISBN 1-
55615-484-4
Data Structures and Algorithm Analysis in C, Mark Allen
Weiss, Addison-Wesley, ISBN 0-201-49840-5
Data Structures Using C, Aaron M. Tenenbaum, Yedidyah
Langsam, Moshe J. Augenstein, Prentice-Hall, Englewood
Cliffs, NJ, 1990 (ISBN 0-13-199746-7).
Expert C Programming, Peter van der Linden, Prentice Hall,
ISBN 0-13-177429-8
Introduction to Algorithms, Thomas H. Cormen et al., MIT
Press’ ISBN 0-262-03141-8
The New Hacker's Dictionary, Eric S Raymond, MIT Press,
ISBN 0-262-68092-0
The Practice of Programming, Brian W Kemighan and Rob
Pike, Addison-Wesley, ISBN 0-201-61586-X
The Standard C Library, P.J. Plauger, Prentice Hall, ISBN
0-13-131509-9
Sorting and Sort Systems, Harold Lorin, Addison-Wesley,
ISBN 0-201-14453-0
Сетевое программирование
Перечисленные книги касаются не только программи-
рования на С, но они позволят вам расширить свои зна-
ния. Код в этих книгах, как правило, приведен на язы-
ке С.
TCP/IP Illustrated, W. Richard Stevens
Published by Addison-Wesley
Volume HemJDetails the TCP/IP protocols
ISBN 0201633469
Volume 21em]Details the TCP/IP stack in 4.4BSD-Lite
ISBN 020163354X
Volume 3[em]Details many TCP/IP Services
ISBN 0201634953
725
UNIX Network Programming, W. Richard Stevens, Prentice
Hall, Volume l[em]Networking APIs: Sockets and XT I, ISBN
013490012X
Windows Sockets Network Programming, Bob Quinn and Dave
Shute, Addison-Wesley, ISBN 0201633728
Ресурсы Internet
Анализ сортировки методом Шелла Роберта Седжвика
(Robert Sedgewick):
http: //www. cs. princeton. edu/~rs/talks/
shellsort.ps
Домашняя страница Стефана Нильсона (Stefan Nilsson)
(поразрядная сортировка):
http://www.nada.kth.se/~snilsson/
Страница Карима Ратиба (Karim Ratib) (целый рад ал-
горитмов):
http: //www2. iro. umontreal. ca/~ratib/code
Информация Ли Киллафа (Lee Killough) по приоритет-
ным очередям:
http: //members. xroom. с ого/killough/heaps. html
Следующая часть Web-сайтов будет полезна, если вы
хотите больше узнать о сетевом программировании:
Проблемная группа проектирования Internet является
авторитетным источником RFC (Request for Comments),
Избранная библ
Приложение В
FYI (For Your Information) и другой информации, каса-
ющейся TCP/IP.
http://www.ietf.org/
Домашняя страница Агентства по выделению имен и
уникальных параметров протоколов:
http://www.iana.org/
Домашняя страница общественной проблемной группы
Internet:
http://www.istf.isoc.org/
Домашняя страница Общества Internet:
http://www.isoc.org/
Домашняя страница Совета по архитектуре Internet:
http: //www. iab. org/
Группа проектирования и планирования Internet:
http: //www.iepg.org/
Usenet
Обсуждение ANSI C: comp.lang.c
Работа в сети: comp.protocols.tcp-ip и alt.winsock, обе эти
группы новостей просто превосходны.
Перед отправкой своего вопроса, пожалуйста, просмот-
рите сначала FAQ группы новостей.
Предметный указатель
А
Адрес разряда байта 107
от младшего к старшему 107
от старшего к младшему 107
смешанный порядок 107
Алгоритм
347 302
CRC 575
RC4 674
SHA-1 677
"ближайшего соседа" 390
блочного шифрования 675
сжатия 437
адаптируемый 437
фиксированный 438
управления PID 471
шифрования с двумя ключами 676
Аллель 561
Анализ
лексический 490
Аналоговые сигналы 436
Ациклический граф 341
Б
Берклиевская функция 205
Бинарная операция 95
Бит четности Гамминга 468
В
Ведущий элемент 426
Вес ребра графа 372
Весовые коэффициенты битов 96
Видообразование 564
Временные зоны 86
Выпрямленный ациклический граф 341
Г
Ген 561
Геном 562
Граф
ациклический 341
двудольный 379
Грегорианский календарь 92
Группы новостей 32
направление запроса 33
д
Данные 437
дублирование 462
избыточность 467
сжатие 437
Двоичное дерево со ссылками 277
Двойный указатель 270
Двудольный граф 379
Деревья
многопугевые 290
Дескриптор файла 577
Диаграмма состояний FSM 186
Дигитайзер 694
Дрейф точности 632
Дублирование данных 462
Дыхательная группа 669
3
Замкнутый контур непрерывного выходного
сигнала 472
Зоны
временные 86
И
Идиома 660
Избыточность данных 461
Избыточный циклический код 465
Инвертирование 99
величины 99
Индекс
хешированный 180
Индексный регистр 491
Инициализация 715 .
Интерфейс командного типа 190
Исключение Гаусса-Джордана 428
Искусственный интеллект 661
К
Календарь
грегорианский 92
Карусельный механизм 700
Код
трассировочный 149
Кодирование
Грея 567
Хаффмана 438, 440
Коды Грея 561
Компаратор 439
Компилятор GNU-C 691
Конвейеризация 699
Контур Эйлера 374, 388
Кортеж узла в матрице 362
Коэффициент сбалансированности узла
278
Куча 303
Л
Латентность 82
Лексический анализ 490
Лексема 203
Лес
остовный . 387
Линейный поиск 266
М
Макрос 60
Максимальное паросочетание 379
Максимальные значения для типов 95
Мантисса 627
Массив 147, 166
невыровненный 216
Матрица 412
диагональная 412
треугольная 412
элемент 414
ведущий 426
Международный стандарт дат 92
Метод
выбора с замещением 329
исключения Гаусса 425
множественных вставок 305
Механизм
карусельный 700
управления 471
Многозадачность 700
имитированная 700
кооперативная 701
приоритетная 700
Многопоточность 701, 703
Многопутевые дереш 290
Модули ПЗУ 692
Мпрфплоги 664
Н
Наибольший общий делитель 200
Невыровненный массив 216
Неопределенное поведение программы
146, 161
Номер порта 576
Нормализованный определитель 426
Нотация 634
позиционная 634
О
О-нотация 65, 67
алгоритмы 65
программы 67
Октет 462
Операция
бинарная 95
Определитель 426
нормализованный 426
Остовный лес 387
Отражение диска 469
Оцифровка 436
П
Пакет 435
BSP 697
Unpack 435
Пакетирование 80
Передача массива в функцию 211
Переменная среды 608
Повторное использование кода 170
Подграф 372
Поиск
линейный 266
Полосы развития процесса 81
Полустепень заход а графа 372
Польская нотация 492
Порядок записи в память 120
от младшего к старшему 120
от старшего к младшему 120
Поток 701, 702
Правила кодирования 134
Предметный указатель 1 *7 *7 I
Представление прерывания 717 Стандарт
Признак четности 462 ANSI 695
Проверка четности 462 Group 3 Digital Facsimile 438
Производительность 79 POSIX 84
Протокол 574 программирования 35
HTTP 604 Стек 195,247
TCP/IP 575 глубина 196
UDP 574 Степень вершины графа 372
57, для коммуникации 80 Т
Профиль скорости движения 480 Таблица переходов 186
Путь Тег 113
графа 372 HTML 250
Эйлера 374 типов 225
р Терминальные символы 487
Распараллеливание 699 Термины, используемых в управлении
Реализация 695 472
базовая 695 Тестирование 140
свободная 696 Технология RAID 469
Рекурсия 508 отражение диска 469
порочная 509 распределение 471
Ротация узлов 281 Типы 710
С базовые 711 новые 710
С99 31 . производные 712
Свойства аппаратных средств DSP 482 Трассировочный код 149
Семантика 491 Трешинг 65
Семафор 702, 708 Трихотомия 310
Сжатие данных 437 У
алгоритмы сжатия 437 сжатие без потерь 437 Удаление повторяющихся строк 209
сжатие с потерями 437 Указатель 28, 147, 166
Сигнал Уровни RAID 471
аналоговый 436 Установление связей
Символ трехступенчатое 575
терминальный 487 Утечка памяти 147, 355
Синтаксический анализатор столкновения Ф
островов 667 Синтаксический Форма Бэкуса-Наура 486
анализ 206 Формат 96, 113
разбор 543 версии 113
Синхронизация 701 доступа 702 дополнение до двух 96 дополнение до единицы 96 знак-величина 96
Сокеты Беркли 574 кодирования факсов Т.4 438
Сортировка с убывающим шагом 300 переменной 113
Составное кодовое слово 442 фиксированный 113
Стагнация 562
Искусство программирования на С
728
Формат файлов 111
CSV 111
TDF 111
Формат данных 134
netCDF 134
графический 134
иерархический 134
общий 134
Функция
берклиевская 205
навигационная 236
соответствия 305
X
Хеширование 676 '
Хешированные индексы 180
Хромосома 562
ц
Цикл
режима работы 80
Гамильтона 390
Ч
Четность
признак 462
Ш
Шифрование 670
с одним ключом 674
Э
Эквивалентность 660
Экспонента 627
Элемент
ведущий 426
заголовочного списка 353
матрицы 414
Эффективность программ 62
Я
Язык 604
HTML 604
Иностранные термины
АСМ 302
ANSI С 26, 29
ANSI Х3.106-1983 679
API 703
BER 134
BINUTILS 691
BSP 697
CCD 439
CIS 439
CRC 465
CRC-CCITT 466
CRC16 466
DFS 383
DSP 481
ELIZA 661
FIFO 253, 694
FIPS 81 679
FOUFOLO 260
FTP 576
HDLC 466
INMOS ToolSet 703
IPA 664
ISO 8601 92
UFO 249
RFC 576
RTOS 696
SHTTP 621
SIMD 483
SSL 621
TSP 389
UART 462
UTC 85
Искусство I
программирования на |
Фундаментальные алгоритмы,
структуры данных и примеры
приложений
Подробно рассмотрены
Широкий спектр реальных бизнес-
приложений
Полное описание последнего ANSI-
стандарта языка
Управление производительностью
приложений и теория оптимизации
Стандарты программирования
Абстрактные структуры данных
Создание инструментальных средств для
разработчиков
Цифровая обработка сигналов
Методика синтаксического разбора и
вычисления выражений
Реализация алгоритмов генной инженерии
Создание коммуникационных приложений
Особенности реализации алгоритмов
шифрования данных
Организация параллельной обработки
данных
Разработка распределенных и клиент-
серверных приложений
Концепции и реализация CGI-приложений
Написание функций матричной алгебры
Реализация алгоритмов сортировки,
поиска и обработки древовидных
структур
Особенности создания систем
искусственного интеллекта и трансляция
синтаксических конструкций естественных
языков
Управление памятью и рекурсия
Поразрядная обработка данных
Об авторах
Ричард Хэзфилд — разработчик
программного обеспечения и владелец
компании Eton Computer Systems Ltd.
Ричард является автором многочисленных
программ для страховых компаний,
лечебных учреждений, банков и
авиакомпаний.
Лоуренс Кирби — дипломированный
специалист Кэмбриджского университета,
имеет опыт программирования на С свыше
10 лет. Лоуренс является соучредителем
компании Netactive Systems Ltd, которая
специализируется на коммуникациях и
информации для финансового рынка.
s книга-почтой интернет-магазин
www.dlasoft.klev.ua
КАТЕГОРИЯ ►
Программирование
$ЛМ»
PUBLISHING
ОБОЛОЧКА ►
С
books@diasoft.kiev.ua
УРОВЕНЬ
Начинающий Средний Мастер Экспер
[7TTW издательство
DiaSoft
Украина, Киев