/





































































































Text
Уральский государственный университет им. А. М. Горького
Вл. Д. Мазуров
МАТЕМАТИЧЕСКИЕ МЕТОДЫ
РАСПОЗНАВАНИЯ ОБРАЗОВ
Учебное пособие
Екатеринбург
2010
ВВЕДЕНИЕ
Задачи распознавания образов связаны с
классификацией объектов, которая подчинена некоторой
цели. Существуют различные направления формализации
этих задач, приводящие к множеству математических
постановок. Одно из направлений использует теорию и
методы решения систем линейных неравенств. Именно это
направление, основанное на алгебраической теории линейных
неравенств, развитой С. Н. Черниковым, представлено в
данном пособии.
Распознавание образов - относительно новая область
математической кибернетики, но она интенсивно развивается,
и уже сейчас имеются многочисленные важные приложения
методов распознавания буквально во всех сферах науки и
техники, в том числе в экономике, технике, медицине,
физике, биологии, социологии и так далее. Распознавание
образов является основой искусственного интеллекта.
Общая структура курса, излагаемого в пособии, такова:
рассматриваются математические модели классификации;
вычислительные методы распознавания образов, главным
образом, итерационные методы решения систем линейных
неравенств; приложения, в том числе в математическом
программировании, экономике, технике, биологии и
медицине.
Следует подчеркнуть возрастающую роль
итерационных методов распознавания образов и
математического программирования (в частности, методов
фейеровского типа, развитых в работах И. И. Ерёмина). Это
связано с усложнением практических задач, ростом их
нестационарности, увеличением размерности.
Что касается специфики задач распознавания образов
по сравнению с традиционными для теории линейных
неравенств приложениями, то она состоит, в частности, в
3
следующем. При решении задач дискриминантного анализа
необходимо решать вопрос выбора класса разделяющих
функций: либо рассматривать всё более широкие классы,
чтобы получить в конце концов разрешимую систему
линейных неравенств, либо создавать конструкции (в том
числе комитетных) для несовместных систем неравенств.
Приспособление методов к этой специфике
осложняется тем, что разделяемые конечные множества
растут с течением времени.
Есть и другие проблемы теории распознавания образов:
- нахождение условий разделимости конечных
множеств функциями заданного класса;
- установление сходимости вычислительных методов
(в том числе методов оптимизации), включающих блоки
распознавания образов;
- исследование эффективности вычислительных
алгоритмов распознавания;
- получение оценок надежности прогноза с помощью
методов классификации.
4
Глава 1.
ОСНОВНЫЕ МАТЕМАТИЧЕСКИЕ МОДЕЛИ
РАСПОЗНАВАНИЯ ОБРАЗОВ
§ 1. Содержательный смысл задачи распознавания
образов
1.1. Общее определение
Задача распознавания образов вообще есть задача
описания и классификации (узнавания, диагностики)
объектов той или иной природы, это задача выработки
понятия о классе объектов. Другими словами, одна из задач
распознавания образов состоит в целесообразном разбиении
заданной совокупности объектов на однородные классы.
Объекты, вошедшие в один класс, должны быть «похожи»
друг на друга или близки друг к другу по некоторому
критерию «похожести» или близости. Объекты же из разных
классов должны быть достаточно различными, далёкими друг
от друга.
В соответствии с этим образ есть множество всех
объектов, сходных друг с другом в некотором фиксированном
отношении. Распознать образ объекта - значит указать, к
какому образу (классу похожих объектов) он относится.
1.2. Примеры
1. Узнавание объектов. Узнавание человеком объектов
состоит в том, что он относит их к классу сходных объектов.
Множество всех предметов, например, человек делит на
классы и каждому классу присваивает имя: «столы»,
5
«птицы», «буква «а»» и т.п. Человек распознает как
зрительные, так и звуковые сигналы.
2. Медицинская диагностика. В задаче медицинской
диагностики образом является множество всех людей,
страдающих определенным заболеванием. На материале
обследованных с верифицированным диагнозом требуется
выработать решающее правило, позволяющее отнести
очередного пациента к тому или иному образу.
3. Техническая диагностика. Установление типа
неисправности сложной технической системы является
непростой задачей. Требуется найти решающее правило,
позволяющее по набору тестов и косвенных признаков найти
вид неисправности.
Л. Классификация в биологии. Систематика является
самостоятельным разделом биологии, она непрерывно
развивается. Иерархическое разбиение живых объектов на
классы позволяет структурировать многообразие живого и
дает возможность определять место и роль каждого нового
факта.
5. Классификация в социологии. Одна из задач
социологического исследования той или иной группы
населения: разделение её на однородные в каком-либо
отношении подгруппы и выделение типопредставителей в
каждой подгруппе.
6. Типология систем. Обобщение задачи предыдущего
пункта: некоторый класс систем (сложных объектов, технико-
экономических, природных и других) требуется разбить на
однородные группы с выделением типопредставителей в
каждой группе.
6
Ί. Классификация и диагностика ситуаций. Человек
научается распознавать тип ситуации, в которой он
находится, и принимать соответствующее, заранее
заготовленное для этого типа решение. Конкретным
примером является распознавание производственных
ситуаций диспетчером, управляющим некоторым
технологическим процессом.
8. Разбиение пространства. Пусть Μ и N - выпуклые
телесные непересекающиеся многогранные множества в
пространстве /г. Следующая задача имеет многочисленные
важные применения, в частности, в математической
экономике: найти полупространство pcr" такое, чтобы рэа/,
ρπν=0. Это полупространство определяет разбиение л- на
два класса: Phr"\p.
1.3. Значение операции классификации
Классификация есть простейшая логическая операция,
однако она играет фундаментальную роль в мышлении,
поскольку является одной из основ более сложных процессов.
В связи с этим формализация мыслительных процессов,
проводимая в рамках проблемы «Искусственный интеллект»,
предусматривает прежде всего формализацию операций
классификации. Этим объясняется широкая применимость
методов распознавания образов.
Различные научные теории имеют одинаковые способы
организации знания, такие, например, как систематизация
объектов исследования (эмпирических или абстрактных). Эта
систематизация может как принимать форму простой
классификации, так и иметь более сложный вид - до
построения хорошо организованной системы. Распознавание
образов является одним из первоначальных этапов
организации данных, средством типизации и систематики.
7
1.4 Необходимость математических методов
классификации
Исследования в области распознавания образов, в
конечном счете, направлены на создание программ,
обучающихся классификации и диагностике. Почему
необходимы такие программы?
Дело в том, что обычные интуитивные методы, которые
применяет человек, оказываются неэффективными, когда
речь идет о типологии современных сложных
производственных или иных систем.
Человек хорошо распознает зрительные образы:
предметы, изображения (рисунки, чертежи), а также легко
распознает слуховые образы. Но человек испытывает
сложности при распознавании большого количества
числового материала. По числовым показателям приборов, по
таблицам трудно принять оперативное решение, если число
показателей достаточно велико.
Современная же наука вообще характеризуется
непрерывным возрастанием сложности изучаемых систем
ввиду постоянного усложнения техники и организации
производства, расширения ассортимента и сложности
выпускаемой продукции, а также необходимости более
глубокого анализа сущности природных, технических и
экономических явлений, при котором учитываются самые
слабые взаимные влияния элементов систем. При
прогнозировании ситуации и характеристик объектов с
помощью математических моделей приходится учитывать
большое число взаимосвязанных факторов в условиях, когда
доступная исследователю информация может иметь самые
разнообразные формы и быть различной по степени
детерминированности.
Большие трудности связаны с моделированием
нестационарных и плохо определенных процессов,
расплывчатых целей, нечетких ограничений. В качестве
8
примеров систем, при прогнозировании развития которых
возникают принципиально новые трудности, можно назвать
следующие:
- большие системы экономики;
- сложные производственные системы;
- экологические системы;
- социологические системы.
Так, например, если и могут быть построены
неидентифицированные модели для реальных экологических
систем, то измерения числовых параметров (таких, как
численность популяции) связаны с применением более
тонкого аппарата, чем детерминистские вычисления; они
должны проводиться на основе самонастраивающихся и
самообучающихся программ. Эффективным средством учёта
плохо формализуемых соотношений при моделировании
сложных систем является распознавание образов (РО).
Кроме того, сейчас возникла необходимость заменить
человека в оперативном управлении быстропротекающими
производственными процессами, в условиях управления
большими системами с большим числом факторов; создаются
АСУ, и нужно автоматизировать операции распознавания
объектов и ситуаций.
Существует еще один аспект, с точки зрения чистой
теории, познания законов мышления.
1.5. Схема применения методов распознавания образов
в прогнозировании
Прежде чем перейти к формальным моделям
распознавания образов коснёмся еще раз вопроса области
приложений методов классификации. Начнем с примера
применения распознавания образов в прогнозировании.
Предположим, что мы научились (с помощью ЭВМ или
других средств) распознавать тип ситуации, а следовательно,
9
и выбирать то или иное решение в некоторой конкретной
области производства. Мы в состоянии также вписать
варианты будущих ситуаций. Применяя распознавание
образов, мы можем в этом случае сделать прогноз множества
будущих решений.
Этот подход можно иллюстрировать следующим более
конкретным примером. Допустим, что имеются данные об
открытых к настоящему времени месторождениях полезных
ископаемых, служащих сырьем для металлургического
производства. Можно сформировать различные варианты
смесей материалов, получаемых из различных
месторождений, а также варианты их предварительной
подготовки как металлургического сырья. Предположим
также, что на основании накопленного опыта мы выработали
метод распознавания технологических характеристик смесей
веществ по параметрам компонентов смеси и по параметрам,
характеризующим способ подготовки. Тогда мы можем
составить прогноз сырьевой базы металлургии.
10
§ 2. Моделирование объекта классификации
2.1. Вектор состояния
Простейшая модель, применяемая в распознавании
образов, есть вектор состояния. На основе этой модели
строятся более сложные. Модель объекта, или вектор
состояния объекта, имеет вид:
*«№.....€.),
где £- вещественные числа, интерпретируемые как значения
параметров или признаков объекта.
Мы будем считать, что *=«„...,о есть вектор
пространства я\ И использовать операции сложения
векторов, умножения вектора на скаляр, а также скалярного
произведения двух векторов. Скалярное произведение
векторов хУуеяп будем означать через (х,у).
2.2. Примеры
1. Объект - машиностроительное предприятие; ζ, -
годовой объем выпускаемой продукции (в рублях); ζ2 - число
рабочих и служащих; ζ, -основные фонды; е, - количество
поставщиков; ξ5- число потребителей продукции завода.
Тогда модель объекта имеет вид:
* = «„..·,£,)€ Л5.
11
2. Объект - человек. Признаки - вопросы анкеты в
некотором социологическом обследовании. Ответ «да»
кодируется числом 1, ответ «нет» - числом 0.
2.3. Модель изображения
Один из возможных способов предоставления
изображений в виде η - мерного вектора таков. Изображение
находится на плоском экране, который разбит на
элементарные ячейки - прямоугольники. Эти элементы
просматриваются строка за строкой слева направо и сверху
вниз, и в качестве i-й координаты записывается 1, если в i-ю
ячейку попал элемент изображения, иначе записывается 0 (см.
рис. 1)
χ = (0,1,1,0,0,1,1,0,1,1,1,0,1Д 1,0)
Рис. 1.
12
§ 3. Модель дискриминантного анализа
3.1. Модель образа
Математической моделью образа (класса объектов) как
некоторого множества всех объектов, сходных друг с другом
в каком-то фиксированном отношении, является
подмножество в пространстве яя:мся\
3.2. Пример
Объекты - люди. Они моделируются 2-мерными
векторами: *=(ξ„ξ2), где ξ, - температура тела, ξ2 - количество
ударов сердца в минуту. Будем условно считать человека
здоровым, если его температура колеблется в пределах от 35
до 37°С, а пульс - от 60 до 70 ударов в минуту. Понятно, что
состояние человека не отражается полностью этими двумя
показателями, пример чисто условный. При указанных
предложениях образ «здоровые люди» имеет вид:
A/ = {JC = (f1,f2):35<f1<37, 60<ξ2<70}.
3.3. Идея обучения на прецедентах
В модели дискриминантного анализа реализуется
следующая схема обучения на примерах. Пусть мы хотим
обучить кого-нибудь отличать объекты одного рода (первого
образа) от объектов другого рода (второго образа). Мы не
пытаемся объяснить, в чем именно состоит отличие первых
объектов от других, а просто показываем конечное число
объектов того и другого вида. На основании этой информации
у обучаемого должно сформироваться правило, позволяющее
13
любой объект относить либо к первому, либо ко второму
образу.
3.4. Задача дискриминантного анализа для двух образов
Пусть имеется известное нам разбиение пространства яг
на два класса (образа): яя = лив9 апв=0.Предполагается, что
известны лишь некоторые два подмножества: л'сл, в'св. По
этим подмножествам надо составить представление
(разумеется, в общем случае лишь приближенное) о
множествах А и В.
Делается это следующим образом. Пусть выбран
некоторый класс функций
Fczf*"-/*1},
с помощью которых будем отделять множество а' от
множества в'. Требуется найти функцию /€F, такую что
/(x)>0(Vx€A/W^O(Vx€B;). (1)
При этом, на функцию / может ещё дополнительно
накладываться некоторое условие качества разделения
множеств (будем называть это условие условием
нормализации).
Задача нахождения такой разделяющей или
дискриминантной функции и есть задача дискриминантного
анализа.
Если / - решение системы (1), удовлетворяющее
условию нормализации, то мы получаем следующее
решающее правило для прогноза принадлежности
14
произвольного элемента у к тому или иному образу:
\АУ если/( ν) > 0;
[иначе В
Следовательно, приближенной модель множества л
будет {,:/оо>о}.
5.5. Пример
Рассмотрим условный пример. Обозначим через л'
конечное множество видов технологически допустимого
сырья в некотором производстве, через в' - конечное
множество видов технологически недопустимого сырья.
Каждый вид сырья пусть характеризуется двумя
параметрами: ξ, - содержание первого компонента в единице
сырья, ξ2 - содержание второго, т.е. модель каждого вида
сырья есть 2-мерный вектор *=(£„&).
ПуСТЬ Af = {(\y3);(2y\);(\y\)};Bf = {(5t\);(St2yt(2t7)}9 И F - КЛаСС
аффинных функций, т.е. /€ f <*/(*)=<*,£,+α2ξ2+/?. Составляем
систему (1):
α,+3α2+/?>0, 2α,+α2+/?>0, α, + α2 + β > 0,
5α,+α2+/?<0, 5α,+2α2+/?<0, 2α, + 7α2 + β < 0.
Одно из решений: <*, = -6, <*2 = -4, /? = 24, т.е.
/«—66-46+24.
Предположим теперь, что имеется некоторый новый
вид сырья, характеризующийся вектором (3,3). Так как
/(з,з)=-6 < о, то мы делаем прогноз, что это сырье
технологически недопустимо.
15
3.6. Геометрический смысл
Если {*:/«=о} представляет собой поверхность в /г, то
задача дискриминантного анализа заключается в построении
поверхности, разделяющей а' и в'; эта поверхность делит всё
пространство я" на два образа.
В случае, когда / - аффинная функция, /«=(<:,*)+/?,
речь идет о построении разделяющей гиперплоскости с
нормалью с.
3.7. Задача дискриминантного анализа для к образов
Пусть имеется неизвестное нам разделение
пространства /г на * образов:
RT = AlU...UAk9 A,nAj = 0 (i*j).
Известны подмножества а! с a, (/=i, ..., *).
Приведем один из способов сведения задачи
дискриминантного анализа для * образов к
последовательности задачи с двумя образами.
Построим *-ι разделяющих функций /]t..../;_,, каждая из
которых делит два множества: у; отделяет а\ от ^υ.,.υΛί; /2
отделяет а'2 от А'уи...иА'к; /;_, отделяет а'ы от л\. Таким образом,
для всякого je\J^\ решаем задачу: найти
fJeF:fJ(x)>0(4xeA'J\fJ(x)<0(4xeUA'J).
Если функции /,... ,λ_, , удовлетворяющие указанным
условиям, найдены, то классификация любого
yeR"производится согласно правилу
16
ye\
Alt если /Cv)>0; иначе
Л2, если/2(у) > 0; иначе
Л4_|э если /^,00 > 0; иначе
U
Итак, мы имеем право в дальнейшем изучать методы
только для задач дискриминантного анализа с двумя
образами.
3.8. Пример
Пусть *=«„£) есть вектор состояния сырья некоторого
производства, где ς - процентное содержание i-ro
химического компонента в единице сырья (i=l,2). Требуется
построить правило прогноза качества сырья на основании
материала наблюдений: л\ - множество, содержащее
некоторые векторы состояния хорошего сырья, л'г содержит
некоторые векторы, отвечающие среднему качеству, л\ -
аналогичное множество векторов для плохого качества
сырья. Пусть, например,
А\ - {*, = (2,4);х2 = (2,2)}, А\ = {*, = (5,2)}, А\ = {х4 = (7,1)}.
Предположим, f - класс всех линейных функций.
Решаем 2 задачи дискриминации:
1- /€F:/(x)>0(Vx€^.y;(x)<0(Vx€^U^);
2. /2€F./2(x)>0(Vx€^),/2(x)<0(Vx€^).
Одно из решений этих задач: /(*)=-2ξ, + 3ξ2, /2οο=-ξ,+5ξ2.
Пусть для прогноза представлены три вектора
СОСТОЯНИЯ СЫрЬЯ: у, = (1,3), у2 = (12,2), уу = (4,2).
17
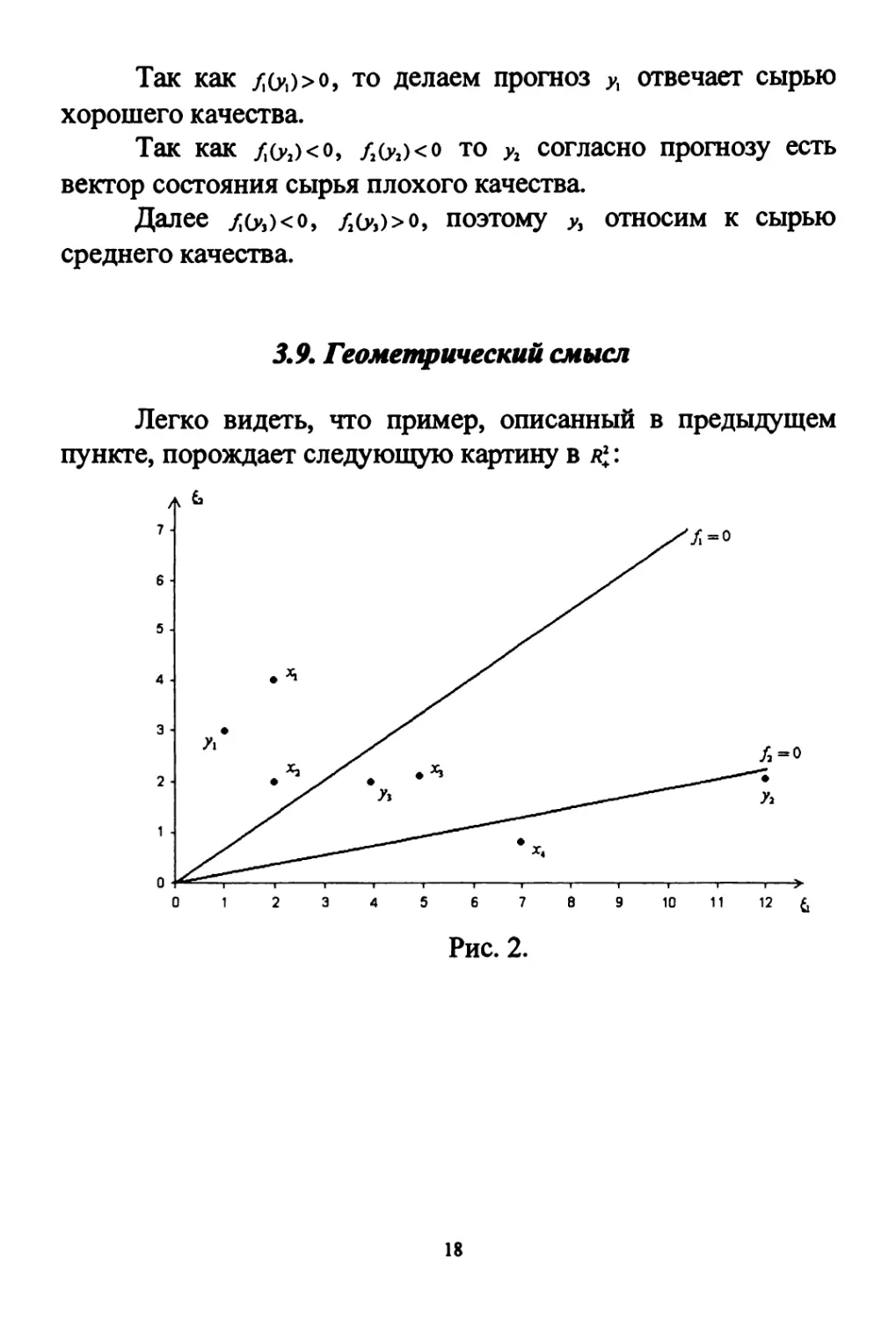
Так как /Οί)>ο, то делаем прогноз Ух отвечает сырью
хорошего качества.
Так как /(?,)< о, /2Си2)<о то Уг согласно прогнозу есть
вектор состояния сырья плохого качества.
Далее /с,)<о, /2с,)>о, поэтому у, относим к сырью
среднего качества.
3.9. Геометрический смысл
Легко видеть, что пример, описанный в предыдущем
пункте, порождает следующую картину в /ζ:
/
7 ■
6-
5 -
4 ■
3 -
2-
1 ■
0 ■
к Ь
•
Ух
* * ι
·*
1 г-
•
1
• *з
—ι г
·*.
S/,-ο
τ 1 1
/а-0
Λ
1 >
10 11 12
Рис. 2.
18
§ 4. Модель таксономии
4.1. Задача таксономии
Пусть задано конечное множество
* = {*„...дг}с/г,
и пусть к - число классов (таксонов), на которые нужно
разбить множество* :
Х = Ххи...иХк, ХкГ\Х, = <д (i*j)\ (1)
здесь χ, - /-и таксон. Число * может быть либо задано
заранее, либо должно быть определено в результате решения
задачи таксономии.
Разбиение (1) может быть осуществлено многими
способами. Если имеется функционал <р> оценивающий
качество разбиения:
причем большему значению φ соответствует лучшее
качество, то задача таксономии имеет вид:
тах{^*„ ... yXk):X = Xx\J...\JXky XiDXJ = 0 (i*j)}.
Функционал φ может учитывать качество строения
таксона *,(v,), т.е. его однородность, достаточную близость
друг к другу его элементов, и достаточную степень различия
между таксонами с различными номерами, и какие-либо
другие критерии.
19
Многие известные постановки задач таксономии
диктуются алгоритмами, реализующими их решение.
Приведем некоторые конкретные постановки.
1. Задан класс f функций /(*). Требуется найти все
максимально совместные подсистемы (μ- подсистемы) для
системы
/(xXOQtxeXlfeF (2)
Если система дх)^оо/хех1)остъ μ- подсистема системы
(2), то хх считается таксоном множества χ.
2. Пусть г(х,у) - неотрицательная функция двух
векторов хУуея\ характеризующая их «близость» друг к
другу, причем ripe, x)=0. Требуется чтобы
Vf = U, ^уеХ,\г(хуу)^Я\ V/, V/*у, V*€*„ Vy€Xj:r(x,y)>R.
3. Разбиение X на два таксона: х{сх такое, что
разделяющий хх и х\хх плоский слой наибольшей толщины
является максимально (по всем возможным х{сх) толстым.
4.2. Примеры практических задач таксономии
В качестве примеров задачи таксономии можно
привести задачи создания типологии объектов того или иного
класса (социологических групп, предприятий, технических и
природных систем и т.д.).
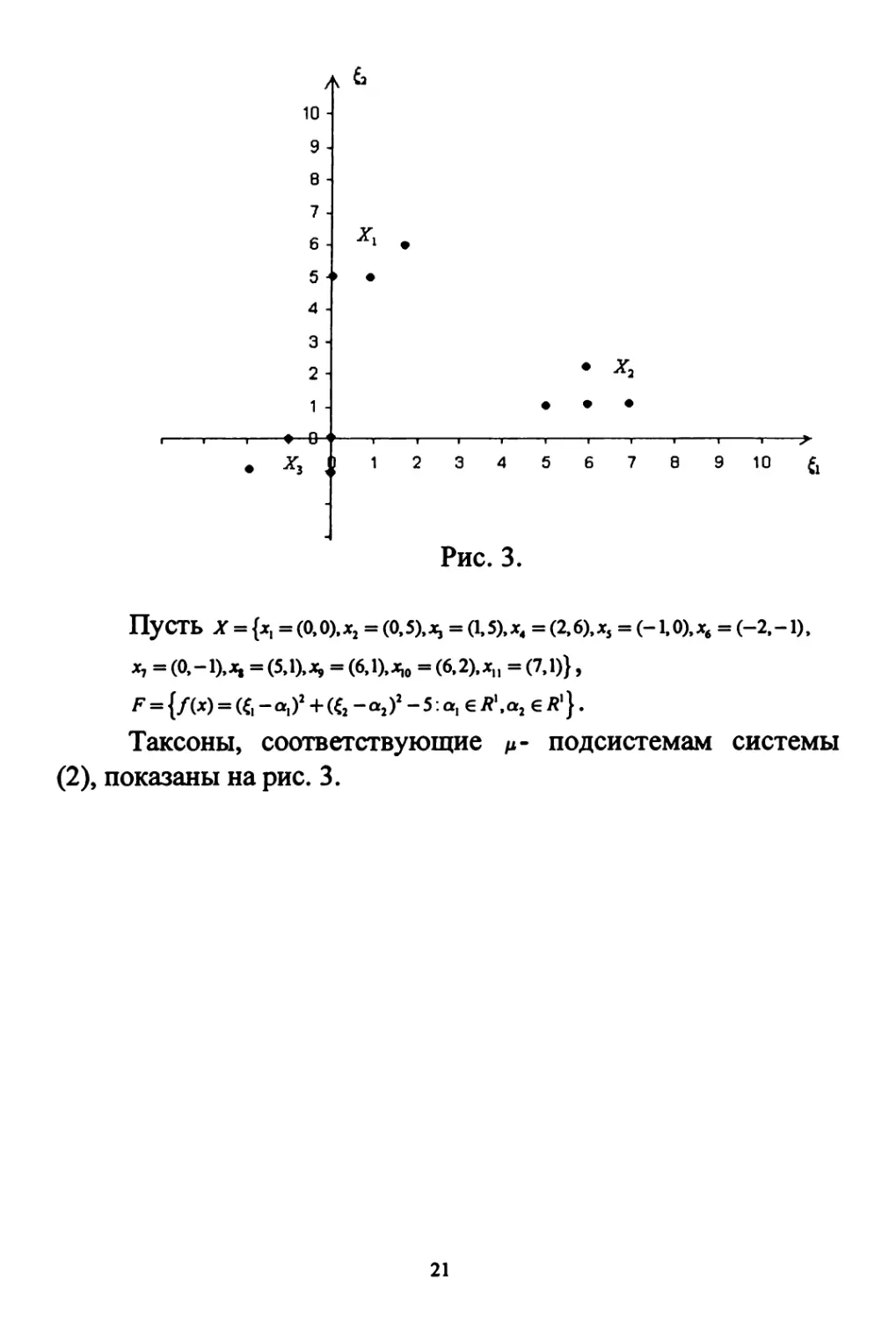
Приведем пример решения задачи в постановке 1 (см.
рис. 3).
20
10
9
θ
7
6
5
4
3
2
1
» 0 +
• χ,
• · ·
0123456789 10 ξ,
Рис. 3.
ПуСТЬ Χ = {*, = (0,0),*2 = (0.S),*, = (1,5),*4 = (2,6),*, = (-1.0),*4 = (-2.-1),
χ, = (0,-1),*, = (5,1),*, = (6,1),*,, = (6,2).*,, = (7.1)},
^{/(^(ξ,-α,ί'+β,-α,)2^:,*, €*'.<*,€*'}.
Таксоны, соответствующие μ- подсистемам системы
(2), показаны на рис. 3.
21
§ 5. Выбор признакового пространства
5.1. Постановка задачи выбора наиболее информативной
подсистемы признаков
Приведем одну из постановок. Пусть заданы а,всяп и
fc{r"->r1}9 т.е. все элементы задачи дискриминантного
анализа, Предположим также, что заданы класс допустимых
преобразований признакового пространства:
с с {/г -д'}и{/г -д2}и...и{/г -/г}
и класс допустимых преобразований множества
разделяющих функций:
φ с [f - я с {/г - д1}и{/г-1 - д1}и...и{д' - я'}}
Пусть качество дискриминации множеств А9В классом F
оценивается некоторым функционалом wa,b9f). Тогда в
общем виде задача выбора подсистемы признаков такова:
найти gcG и ^еФтакие что, ^(л,ЛЛ)принимает наиболее
возможное значение ; здесь g и φ согласованы так, что если
g6{/?"-^r},T0/;c {яг -> я'}. При этом ещё накладывается то или
иное дополнительное условие на систему признаков (часто
ограничение сверху на число используемых признаков).
Можно, например, так конкретизировать эту
постановку. Пусть /=ΰί,χ=«„...,£,)=*(/), а если j = {i„...,/,}с/, то
Пусть σ- множество всех преобразований типа
x^>x(j)<yjci), f- класс всех аффинных функций, рф - класс
ВСеХ аффиННЫХ фуНКЦИЙ, A(J) = {x(J):x€A}.
22
Одна из простейших задач выбора признаков имеет вид:
min{|j|: множества A(J) и B(J) аффинно разделимы}.
Ещё более простая постановка: min{\j\ : A(j)nb(j)=0}.
Если u(j)- качество решения задачи дискриминации при
замене А и В на A(j) и до/), то можно рассматривать задачи:
max{u>(J):\j\ = q) ИЛИ min{\j\:u>(J)>a}.
5.2. Примеры практических задач
Как сказано выше, математической моделью объекта в
распознавании образов является и-мерный вектор χ=«„...,?„).
Параметры, значениями которых являются числа {„....с,
называются признаками объекта. Для характеристики объекта
можно выбирать различные системы признаков, и задача
оценки информативности как раз состоит в нахождении
оптимальной (с точки зрения того или иного критерия
оптимальности) системы признаков.
Например, может быть поставлена задача: найти
систему признаков, измерение которых связано с
наименьшими возможными затратами, но при использовании
которых возможно разделение заданных конечных множеств
объектов с помощью функций заданного класса. Задача с
другим критерием оптимальности: выбрать подсистему,
включающую m признаков из общего их числа л, п>т,
обеспечивающую наилучшее качество разделения.
Приведем конкретный числовой пример. Пусть заданы
два множества
А и В,
дискриминацию которых нужно произвести:
Λ = {α2),(7,4),(0,-3)}, В = {(6,3),(1,5)}.
23
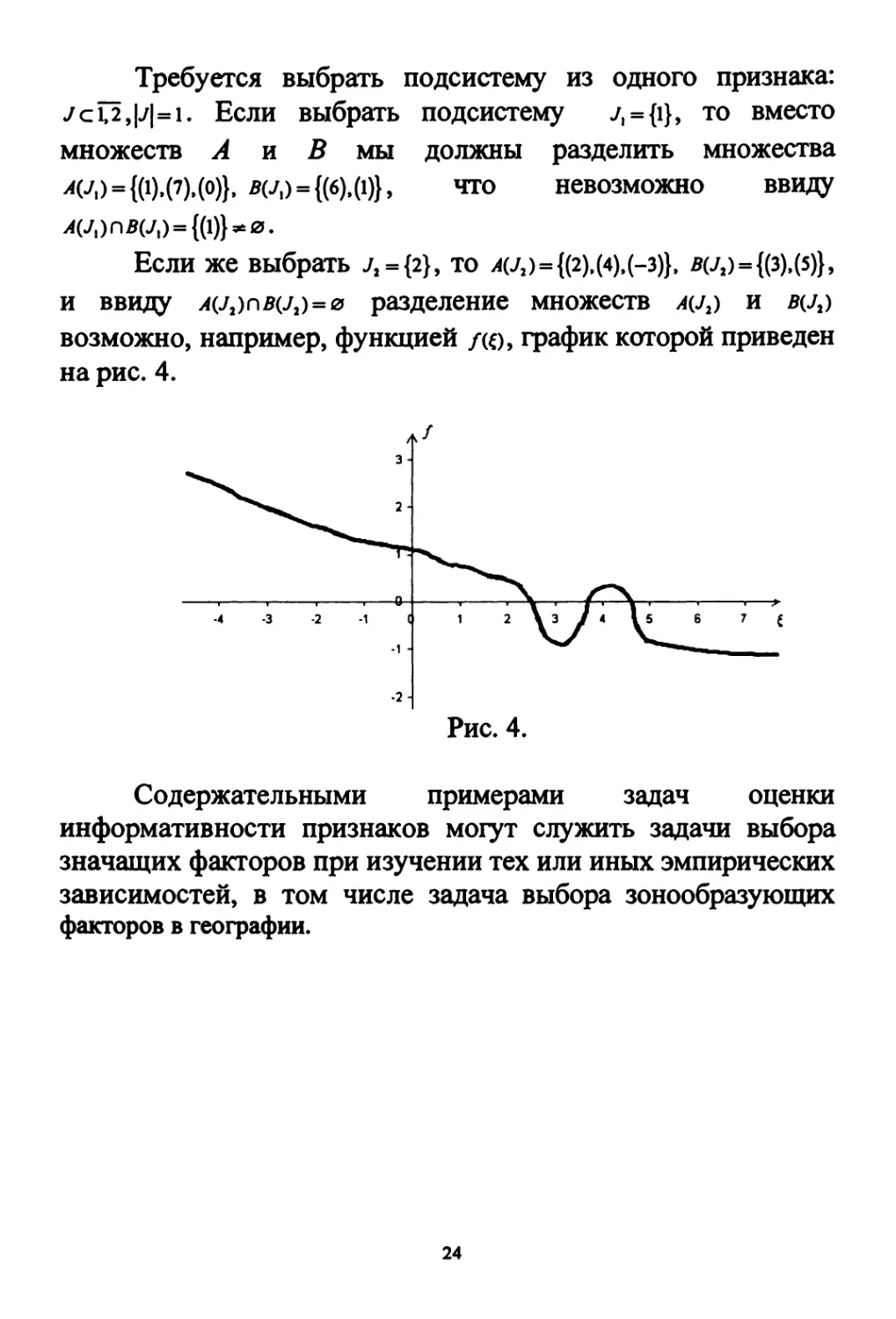
Требуется выбрать подсистему из одного признака:
Усй,|у|=ь Если выбрать подсистему ./, = {1}, то вместо
множеств А и В мы должны разделить множества
Λ0/,) = {0).(7).(ο)}, в(у,) = {(6),(1)}, что невозможно ввиду
yi(y,)nB(y,) = {(l)}^0.
Если же выбрать л = {2Ь то л(Л)={(2),(4)э(-з)}, я(Л)={(3М5)Ь
и ввиду yi(j2)nB(j2)=0 разделение множеств л(у2) и яо/2)
возможно, например, функцией /(ξ), график которой приведен
на рис. 4.
Рис. 4.
Содержательными примерами задач оценки
информативности признаков могут служить задачи выбора
значащих факторов при изучении тех или иных эмпирических
зависимостей, в том числе задача выбора зонообразующих
факторов в географии.
24
Глава 2.
ЛИНЕЙНЫЙ ДИСКРИМИНАНТНЬШ
АНАЛИЗ
§ 1. Методы дискриминантного анализа
Напомним формулировку задачи дискриминантного
анализа.
Заданы: AtBcRn; класс функций: fс{/?"->я}; условие
нормализации <p(AtBj)t/eF.
Требуется найти функцию / л-мерного вектора *,
удовлетворяющего
условиям: / € f ; Дх) > о (V* € л\ Дх) < о (Vx € в) (или может быть
уСЛОВИе Дх) ^ 0 (Vx € В)); <р(Л Bt /) - max.
Рассмотрим пока более простую формулировку:
/€F; |
/(χ)>0(ν*€Λ); (1)
Дх)<0(УхеВ).\
Зададимся следующими вопросами:
1. При каких условиях задача (1) сводится к решению
конечной системы линейных неравенств?
2. Каковы принципы выбора класса f ?
1.1 Сведение к линейным неравенствам
Ответ на первый вопрос достаточно прост. Чтобы
система (1) была конечной, казалось бы, достаточно, чтобы А
и В были конечны, нона самом деле конечности множеств А и
В вообще говоря, недостаточно для конечности системы (1),
так как есть ещё условие /€F, а задание класса f может быть
и довольно сложным.
25
Система (1) линейна в том и только том случае, когда
существует конечный набор функций /0(х),/(х),...,/.,(*)такой, что
всякая функция feF может быть представлена в виде:
λ*)=Σ>λ«+/ο«· (2)
1.2. Принципы выбора класса разделяющих функций
Перейдем к вопросу 2. Этот вопрос можно следующим
образом связать с вопросом 1. Выше уже указано, что мы
руководствуемся эвристическим принципом: чем проще
структура функции разделяющая множества А и В, тем
лучше. Поэтому если бы «простота» измерялась некоторым
функционалом φ, так что sp(/)>sp(s)означало бы, что функция
/проще функции *, можно было бы выбрать достаточно
широкий класс f (например, класс всех
полиномов) и ставить задачу в виде:
max {*>(/): / € FJ(x) > (V* € A\f(x) < (V* € В)}.
Однако это слишком сложная задача, если к тому же
учесть обстоятельство, что в реальных задачах распознавания
образов материал обучения представляет собой
последовательность, число членов которой растёт в
дискретном времени, и поэтому метод решения задачи
должен быть итерационным.
Поэтому рассмотрим другой подход. Будем
рассматривать только функции вида (2), что позволит нам
иметь дело только с системами линейных неравенств. Тогда
можно считать, что простота функций (2) = простота
наиболее сложной из /. Класс f задается так:
26
F = \
/« = Е^« + /о«:^е^/€Ф(У|€1/я)
При этом само число т может быть либо
фиксированным (f=ρ(*ι,Φ),*ι€{ι,2.....})> либо произвольным:
^=^(ф).
Будем рассматривать классы возрастающей сложности
(прих=«, оУ
*.-{« о;
фя=фя-.и{^..^:', /,«1 п)
Классу ф, соответствует класс f аффинных функций, ф2
класс fквадратичных функций,...,фя- класс f полиномов />-й
степени.
13. Требования к алгоритмам дискриминантного анализа
Проблема состоит в следующем. Желательно выбрать ι
такое, что при классе Ф,(т.е. при f = f^,)) система (1)
разрешима, а при классе ф,_, она неразрешима.
Примой подход (перебор классов ф„ф2, ...один за другим)
слишком неэкономичен; было бы желательно хотя бы уметь
использовать результаты расчетов для класса ф,_, при
переходе к классу ф, .
Несколько другой подход, позволяющий естественное
последовательное наращивание ?/ сложности разделяющего
27
класса, представляет метод комитетов, о котором будет
сказано позднее.
Хорошо было бы придумать процедуру, в которой
построение разделяющей функции сопровождалось
добавлением (по мере необходимости) новых членов вида
упр$,- Например, было бы естественным применять
процедуру, приводящую к чебышевскому приближению, и
это приближение брать как стартовое при решении
аналогичной задачи на следующем шаге расширения класса
ф,. Этот подход хорош и в случае расширяющегося материала
обучения.
Ещё один подход: использовать следующий
итерационный метод для получения кусочно-линейной
разделяющей поверхности (см. рис. 5).
стартовые точки
Рис. 5.
Каждая из стартовых точек дает начало итерационной
последовательности (получаемой методом линейной
коррекции или методом чебышевских приближений),
сходящейся к своему куску поверхности. «Свой» кусок
обучающего множества для каждой последовательностей {*;}^
определяется близостью к этой последовательности. Так, для
каждой последующей точки обучающего множества лив,
28
поступающей на вход распознающей системы, определяется
ближняя к ней из множества {*',....*;}, и относительно этой
точки делаем коррекцию.
Эта конструкция относится к классу коллективных или
размытых решений (когда вместо одной точки - множество),
как в методе комитетов. Обоснования этой процедуры пока
нет. Теперь можно перейти к изложению конкретных методов
решения систем линейных неравенств, понимая в свете
сказанного их роль в дискриминантном анализе, т.е.
анализируя их с точки зрения приспособляемости к
возможной несовместности и к возможному расширению
материала обучения.
29
§ 2. Разделяющие возможности аффинных функций
2.1. Число аффинных дихотомий
Всякому конечному множеству объектов можно ставить
в соответствие различные разбиения его на классы - в
зависимости от цели, с которой проводится классификация
объектов. Так, если на множество всех людей смотреть с
точки зрения того, какими болезнями они болеют, то они
получат одну классификацию (медицинская диагностика), а с
социальной точки зрения они будут делиться на другого рода
классы (социальная стратификация).
Поэтому каждый класс f разделяющих функций,
который мы употребляем для решения задач РО, естественно
оценивать по такому показателю: сколько разных дихотомий
одного и того же конечного множества может быть
осуществлено с помощью дискриминантных функций этого
класса.
Дихотомия множества М- разбиение множества Μ на
два класса: м = мхим1мхпм1^(д.
Введем обозначение цт,п) - число дихотомий
множества состоящего из т элементов пространства дя,
осуществимых с помощью аффинных дискриминантных
функционалов (АДФ).
Для каждого разбиения множества Μ на два
подмножества существует две различные классификации:
если Α/^Α/,υΑ/,.Α/,ηΑ/,-0, то можно считать мг первым
классом, а л/2- вторым, либо м2- первым классом, а а/,-
вторым. Поэтому 2 [число разбиений множества Μ на
два подмножества одной гиперплоскостью].
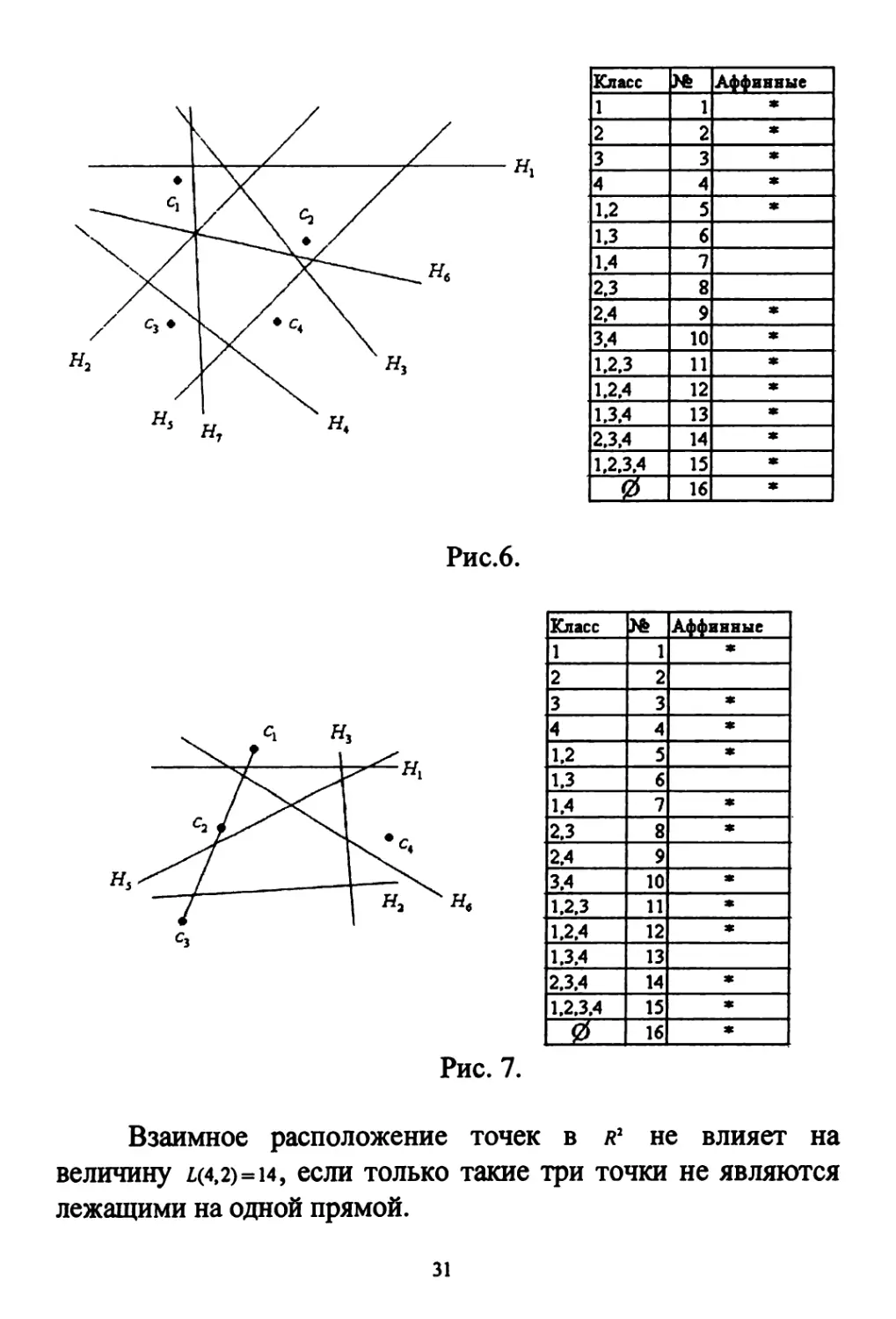
Приведем пример для /я=4, п=2 (см. рис. 6). Число всех
дихотомий равно с° + с1я + с2я+...+с; = 2я=16.
зо
Класс
1
2
3
4
I1'2
U
Μ
2,3
2,4
3,4
1.2,3
1.2,4
1.3,4
2,3,4
|l.2,3,4
Ll_
5*1
1
2
3
4
5
б
7
8
9
10
11
12
13
14
15
16
Аффинные
* I
* ι
* ι
* ι
* ι
* 1
* 1
* 1
* 1
*
*
* 1
*
Рис.6.
г, *«
Класс
1
2
3
4
1.2
1.3
1.4
2,3
2,4
3,4
1.2,3
1.2,4
1.3,4
2,3,4
11.2,3,4
UL_j
ΐϊ"1
1
2
3
4
5
б
7
8
9
10
11
12
13
14
15
16
Аффинные
* 1
* 1
* 1
* 1
* 1
* 1
* 1
* 1
* 1
* 1
* 1
* 1
Рис. 7.
Взаимное расположение точек в я2 не влияет на
величину z,(4,2)=i4, если только такие три точки не являются
лежащими на одной прямой.
31
Если, например, точки с19с29с, лежат на одной прямой
(как на рис.7), причем с2 лежит между с, и с,, то нельзя
отделить точку с2 от всех остальных. Число всех возможных
дихотомий равно 12.
2.2. Расположение точек общего вида
Определение. Расположение т точек в /г называется
расположением общего вида, если у*,* = и,...,л:Всякое
подмножество, состоящее из (*+1)-й точки, не лежит в (*-ι>-
мерном линейном многообразии.
Теорема. Если некоторые т точек в яг имеют
раСПОЛОЖеНИе ОбщеГО ВИДа, ТО Цт,л) = Цт-1,л) + Цт-1,л-1) (1)
Доказательство. Пусть яг э м = {с„...,с„}- множество
точек, имеющее расположение общего вида,
л/'={с ,с„_,};4в(/я-1,л) - число аффинных классификаций
множества м\ получаемых с помощью гиперплоскостей,
содержащих ся. Тогда число всех аффинных классификаций
а/', которые нельзя получить с помощью таких плоскостей,
раВНО L(m-\9n)-LCu(m-\tn).
Каждая из классификаций последнего вида дает только
одну классификацию множества м. А каждой классификации
множества м\ полученной с помощью плоскости проходящей
через с„, соответствуют две классификации множества м: при
одной ^относится к одному классу, а при другой - ко
второму (это делается через небольшое перемещение
плоскости. Тогда
L(mtn) = L(m-ln)-LCm(m-\tn) + 2LCm(m-\,n) = L(m-l9n)+LCm(m-\,n).
32
Покажем, что
ICe(m-l,n)=LCe(m-l,n-l). (2)
Для этого построим отрезки [c„,,c,](i = i,...,m-i). Каждые два
отрезка пересекаются только в точке ст9 так как каждые три
точки имеют расположение общего вида. Пусть Я -
гиперплоскость, пересекающая все прямые, каждая из
которых содержит какой-нибудь отрезок.
Рис.8.
Обозначим через #={</„...,</„_,} множество точек
пересечения гиперплоскости Я со своими прямыми. Число
классификаций множества Μ образуемых (л-1)- мерными
плоскостями, проходящими через точку с„,равно числу
классификаций множества ν9 образуемых (л-2)- мерными
гиперплоскостями в Я. Но Я есть (л-1)- мерное многообразие.
При этом, поскольку никакая совокупность *+ι точек,
включающая с„, не лежит в (*-ΐ) -мерном многообразии, то в Η
расположение точек общего вида. Поэтому соотношение (2)
доказано, а вместе с ним и теорема.
Замечание. Формула (1) дает возможность составить
таблицу значений Цт,п),
зз
Таблица значений Цпьп)
Ιιη/η
1
2
3
4
5
6
7
8
1
2
4
6
8
10
12
14
16
2
2
4
8
14
22
32
44
5$
3
2
4
8
16
30
52
S4
128
4
2
4
8
16
32
62
114
198
$]
2
4
8
16
32
64
126
2401
Достаточно вписать первую строку (она состоит из
чисел 2), а также столбец (2т), а затем применять формулу
(1).
34
§ 3. Метод линейной коррекции
Распознающая система имеет вид:
Материал обучения
Ί Г
Контрольная
выборки
Объекты
распознавания
Распознающая
система
ГХ
Решающее правило
Результ ат к ла ссифика ции
объектов распознавания
Рис. 9.
3.1. Алгоритм линейной коррекции
Требуется найти хея\уе#(х,с)-у>о(усеА'\(хУс)-у<о(усевг).
Введем обозначения:
(c;-l) = a;(x;y) = z;{(c;-l):c€^} = ^;{(c;-l):c€B'} = B.
Тогда надо решить систему
(α,ζ) > 0(Va € A)t(atz) < 0(Va € В)
(3)
Составим из элементов лив бесконечную
последовательность такую, что в ней каждое а ели в
встречается бесконечное число раз. Обозначим эту
последовательность через {а\а\..).
35
Выбираем *' произвольно. Строим последовательность
ι /*-ι согласно правилу
[z\ecmi (zk,ak) > О, α* € А;
ζ*.если (ζ*,α*) > 0, ак € В;
]ζ*-αα*.если (ζ*,α*)^0, α* €Β;
[ζ* Η-αα*,если (ζ\α*)< 0, ак € Λ,
где <*>о#
Этот алгоритм называется алгоритмом линейной
коррекции.
Теорема Новикова.
Теорема. Пусть множества л' и в1 аффинно разделимы.
В результате применения алгоритма линейной коррекции
возникает последовательность {**£[ такая, что 3Τ:ζτ=ζτ+Ι =,...,*т-
решение системы (3).
Доказательство. Не ограничивая общности, можно
полагать, что <*=ι и что мы решаем систему (a,z)>o(Va€/f)c
помощью следующего метода.
Из множества А составлена бесконечная
последовательность {**}~, где каждый элемент множества А
встречается бесконечное число раз. Последовательность {**}^
строим согласно соотношению
[ζ* ,если (ζ\α*\>0;
[ζ* Η- α* ,если (ζ*, α*) ^ 0.
36
Кроме того, исключим из последовательности {а*}~ те
объекты, для которых z*+1 = z*, т.е. (ζ\αέ)>ο. Пусть {ак}кш1 -
последовательность после такого исключения. Возьмем в
качестве ζ° вектор 0=(о,...,о). Тогда
ζ* = *'+... + ** (4)
Фиксируем некоторое τ такое, что (i,a)>o(Va€A).
ПОЛОЖИМ ε = ιηίη{(ζ,α):αβΑ}>0. УМНОЖИМ СКЭЛЯрНО Левую И
правую части соотношения (4) на вектор 1:
(ζ\ζ) = (^ζ) + ...+(α\ζ)^*£.
Так как по неравенству Коши4Шарцаф*|2 ^(z\z)2/|zf, то
μΐ>*νΗΤ (5)
С ДРУГОЙ СТОрОНЫ, Так Как ζ'+, = ζ'+α', ТО
|ζ>+,|2 =|ζ'|2+2(ζ^)+|α>|\ Но (ζ',α')^ο, следовательно
Сложим последние неравенства полученные для у=ι,...,*:
Полагая м=max Λα')2: а € А, получим:
|i"f<*-J/ + |if. (6)
37
Неравенство (6) противоречит неравенству (5) при
больших к, следовательно, последовательность [ак]
обрывается через конечное число номеров.
Теорема доказана.
38
§ 4. Методы линейного программирования
4.1. Симплекс-метод
Пусть в задаче дискриминантного анализа требуется
найти линейную разделяющую функцию /(x) = z,jc1h-...h-zwxw для
множеств а,В€Вг. Здесь ζ,- искомые коэффициенты
разделяющей функции. Пусть
Л = Ь = К aja):jeu]tB = {aJ^(bJi bj.jeu).
Задача дискриминантного анализа принимает вид:
Vi+ ■■•+V.>0O'€U).J цч
V.+».+V.>00"6UO.J
Рассмотрим также систему
V>+-+*>.*» >] О' е U). | . .
^ζ,Η-...H-^z^-10 €U)J
Очевидно, что если система (1) совместна, то совместна
и система (2); при этом всякое решение системы (2) является
решением системы (1).
В то же самое время решения системы (2), к которой
можно добавить линейный критерий оптимальности, имеются
стандартные методы линейного программирования, в том
числе симплекс метод которым и можно воспользоваться.
39
4.2. Методы фейеровского типа
Рассмотрим итерационные методы решения системы
линейных неравенств
Iy(x) = (cy,x)-ay<OW€U0, (О
основанные на использовании фейеровских
отображений. Будем предполагать, что |су|*о (vyeuo.
Фейеровские методы для решения систем линейных и
выпуклых неравенств разработаны и исследованы в работах
И.И. Ерёмина. Отметим, что если имеется метод получения
как угодно точного решения системы (1), т.е.Уе>о,Зх(е)=х, где
*(£)- элемент, получаемый в результате применения метода,
причем пвд1дзсКе, то на основе этого метода можно построить
метод получения точного решения систем строгих неравенств
М*)<о(у/бйо, (2)
если последняя совместна. Способ построения такого
метода, предложенный И. И. Ереминым, состоит в
следующем.
Взяв *>о, запишем следующую систему относительно
ζ = (χ;^)€Λ"+,:
Iy(z) = (cy,x)-ay.K + ^0 (VyeCm), ,3)
Замечание. Система (2) совместна тогда и только тогда,
когда совместна система (3), причем если *=(х;у)>
удовлетворяет неравенствам £,(*)<£о*=<u...,m), где о<е<б9 то
х/у - решение системы (2).
40
Следовательно, для нахождения решения системы (2)
достаточно иметь метод получений приближенных решений
системы линейных неравенств вида (1).
Доказательство. Пусть система (2) совместна и г -
некоторое её решение. Положим х'=Ух, /=
max—т~-=\» δ
j&* ctj-(cnx)
Тогда у' > δ', причем
(суэх')-ау + 6 = У[(су,х)-ау] + ^-—*^[(с,,х)-а,] + 6<0 (Vjelji), ЧТО И
a j \Cj,x)
требовалось.
Обратно, пусть (*';/) - некоторое решение системы (3):
(срх')-а,у' + 6<0,]
yf>6.
Тогда
(*τ)-ί.+7"
у'>6.
Следовательно, вектор χ = /// есть решение системы (2).
Пусть теперь о<е<$, причем для j=(xty):
Lj(z)^e О'^ОЛ m).
Тогда
(cJ,x)-aJy + 6^e<6 O = 0,l,....m);
7>6>ε\
отсюда U^ycij^i-J- (Vy€i,m), т.е. x'/y' - решение системы
(2).
Пусть 0^а/с/г. Отображение φβ{ιτ-+ /г}называется Af-
феЙерОВСКИМ, еСЛИ Vx^A/,yy€A/:[^) = y]&[||y>W-^||<||jr-yl].
41
Если множество Μ допускает хотя бы одно М-
фейеровское отображение, то оно выпукло и замкнуто. Если φ
НеПрерЫВНО, ТО V* € R\ Зх € Μ: φ* (χ) -> χ (к -> +00).
Положим далее м = {х:(\)}. Имеется множество способов
построения М-фейеровских отображений. Приведем
некоторые из них.
Функции d € {rt - r1} и е € {/г - R"} образуют разделяющую
пару для Μ если
1) 4x$Mt4y€M:{e(x\y-x) + d(x)^0;
2){y:d(y)^0} = M.
Легко доказать, что если (<*;е>- разделяющая пара для м,
то отображение
φ(χ) = χ-α—Ч-е(х),
где α €(0,2) и rf+(x)=max{о,^(х)}, является М-фейеровским.
Некоторые примеры М-разделяющих пар:
1) (/(х) = шах1у(х) = 1л(х);е(х) = сл;
2) </(*)=Σ1)(*>;«(*> - Σ с>. » где sw={у: iy« > о} и если
5(А-) = 0,ТО е(х) = 0;
3) d{x)^Lf{x)-e{x)^L){x)Cj.
y-i у-1
45. Метод нахождения чебышевсного приближения
Если множества А и В неразделимы гиперплоскостью,
то можно говорить о приближенном решении
соответствующей задачи аффинного дискриминантного
42
анализа, конкретно - о нахождении чебышевского
приближения возникающей в этой задаче систем линейных
неравенств.
На этом пути мы можем прийти к следующей
постановке.
Рассмотрим систему неравенств
-(a,jc) + U0(Va€A
(M)-U0(V6€£).
Предположим, что эта система несовместна, определим
её чебышевское уклонение:
E = mm{t>Q:-(a,x)+l<t(yaeA);(b9x)-\&(ybeB)}9 а Затем МНОЖвСТВО
М(Е) чебышевских приближений:
М(Е) = {х:-(а,х)+\^Е(Ча€АХ(Ь,х)-\^Е(ЧЬеВ)}.
Если имеется линейный критерий (с,*) качества
разделяющей функции (подлежащей минимизации), то мы
ПрИХОДИМ К Задаче min {(с, χ): χ € Μ (Ε)} .
Приведем один из алгоритмов решения этой задачи, не
использующей предварительного определения величины Е.
Положим
а(х) = max {- (α, χ) +1: а € А};
р(х) = т*х{(Ь,х)-\:ЬеВ};
7« = тах{0,а(х),^)};
ά(χ) = -argmax{-(a,jr)+l: а € А);
β(χ) = argmax{(6,x)-l: b € В].
43
Построим последовательность
произвольная точка;
если7(**) = \(**);
х* -\7(хк)Ь(хк)\Нх*)\~2 +е4с,
хк - ексу если 7(**) = О,
{*'}Ζ^«"
ГДе £4->+0, £>4=+оо, \=€4>0(У*).
Теорема. Пусть £>о. Если M(E)=*rgmin{(c,x):xeM(E)}
|α| = 1(να€Λ), |*| = 1 (V*€£),e4 =\ ^+α£>4 = οο, МНОЖеСТВа А И
КОНечНЫ, ЧИСЛО |с| ДОСТаТОЧНО МаЛО, ТО J^Jxk-M(E)\ = 0.
44
Глава 3.
МЕТОД КОМИТЕТОВ В
ДИСКРИМИНАНТНОМ АНАЛИЗЕ
§ 1. Комитетные конструкции
Как отмечено выше, задача нахождения
дискриминантной функции / такой, что
/€F,/(*)>0(V*€/0./«^0(V*€*), (1)
может не обладать решениями даже в случае апв=09
если класс f выбран недостаточно широким. Мы
сталкиваемся, следовательно, с проблемой выбора класса f .
Однако можно предложить другой метод, который
снимает эту проблему. Это метод комитетов, использующий
вместо понятия решения системы (1) некоторое его
обобщение, реализующее понятие «размытого» решения, т.е.
множества kcf, обладающего теми или иными свойствами
решения. Перейдем к конкретным определениям.
1.1. Комитет системы множеств
Определение. Пусть Φ - некоторое семейство множеств
Dj (произвольной природы): Φ ={Dj\jej}, X - некоторое
множество, и пусть ре[о,\]. р-комитетом в классе X для
семейства Φ называется конечное множество ксх такое, что
|*П£>у|>р|*|(У/€./),
45
где |а:| означает число элементов (мощность) множества
к.
Комитетом в классе X для семейства © называется
множество к с χ (не обязательно конечное) такое, что
\KnDj\>\K/Dj\(yj€J).
Замечание. Если χ η
и&
f|DyU0, то любое множество
к с χ η \f] da является /^-комитетом и комитетом.
1.2. Примеры комитетов систем множеств
Пример №1. ^ = Λ2,Α = {ατ = (ξ1,ξ2):ξ1>0},Ο2={ατ = (ξ1,ξ2):ξ2>0},
А-{*-(б.Ь):6+6<°}. МнОЖеСТВО /: = {дг, = 0Л).Дг2 = (-2,1). Д,= 0.-2)}
является 2/3-комитетом в классе Xдля семейства © = {d„d2,d,}.
Множество к является также комитетом этого семейства.
Пример № 2. Пусть X есть четырехугольник α,α^α, в я3
(см. рис. 10).
Рис. 10
Обозначим через д,...,д грани четырехугольника Х9
через к- множество {alta2taita4}. Легко убедиться в том, что /:
46
есть 3/4-комитет X для семейства <D ={DltD2tDitDt}.
Одновременно к является и комитетом.
Пример №3. Пусть X - топологическое пространство,
аеху Д - система окрестностей точки а, к = {а'}* -
последовательность, сходящаяся к элементу а.
Тогда /:- комитет в классе Jf для семейства Д
1.3. Определения и примеры комитетных конструкций
Определение, р-комитетом системы неравенств
/yW>0(Vy€/,),
//*)^0(V/€/2),
//*)=0(Υ/€/,)
(2)
в классеXназывается конечное множество ксх, являющееся
/7-комитетом системы множеств
{x:fj(x)>0} 0€/,), {x:fj(x)>0} (у€/2), {дг:/Дх) = 0} (уб/,).
Заметим, что комитет * системы (3) обладает
свойством: каждому её неравенству удовлетворяют более
половины членов комитета.
Пример. Рассмотрим систему неравенств над
пространством r1 :
ξ, >0;
(£,+i)2+te+i)2^U.J
(3)
Очевидно, что система (3) несовместна. Пусть х = я2,
/: = {х, = (ΐ;ΐ),χ2 = (0;-1),х3 = (-i,2;0,i)}. Тогда к- комитет системы (3) в
классе X.
47
Определение. /^-комитетом системы неравенств
относительно неизвестной функции /:
f(x)Z0(4x€X2)\
/(*) = 0(V*€*,)| (4)
В классе функций fс {*"->/*'}, где хх,хг,ху - известные
подмножества пространства /г, называется такое kcf, что
множество к есть р-комитет системы множеств
{/:/«>0} (jreJT.X {/:/«>0} (*€*,), {/:/(*) = (>} (*€*,).
Система (4) называется системой сопряженного вида.
Пример. Пусть яг = я1,
^ = {/(0 = f,-lg,(0 = -fH-l/2(0 = f-2,g2(0=-fH-2. /,(0 = f-3,g,«) = -fH-3....}.
Рассмотрим систему сопряженного вида:
Д2)>0,/(4)<0,/(6)>0,/(8)<0,/(10)>0.
Комитетом этой системы в классе f является
следующее множество:
Определение. Разделяющим заданные множества α,βογ
/^-комитетом функций класса X называется /?-комитет для
системы неравенств /(*) > о (ν* € Л). /(*) ^ о (Vjc € в).
Строго разделяющим называется р-комитет для
СИСТеМЫ /(jc) > 0 (Vjc € A)t f(x) < О (Vjc € В).
Пример. Рассмотрим, как делит пространство я1 на два
образа строго разделяющий множествам={(U)} и я={(2;0);(0;2)}
комитет класса линейных функций (см. рис. 11).
Строим систему /(U)>o,/(2,o)<o,/(o,2)<o, где
/«,.&)=М,+М2>т.е. у,н-^>оэ2х<о, 2уг<о.
48
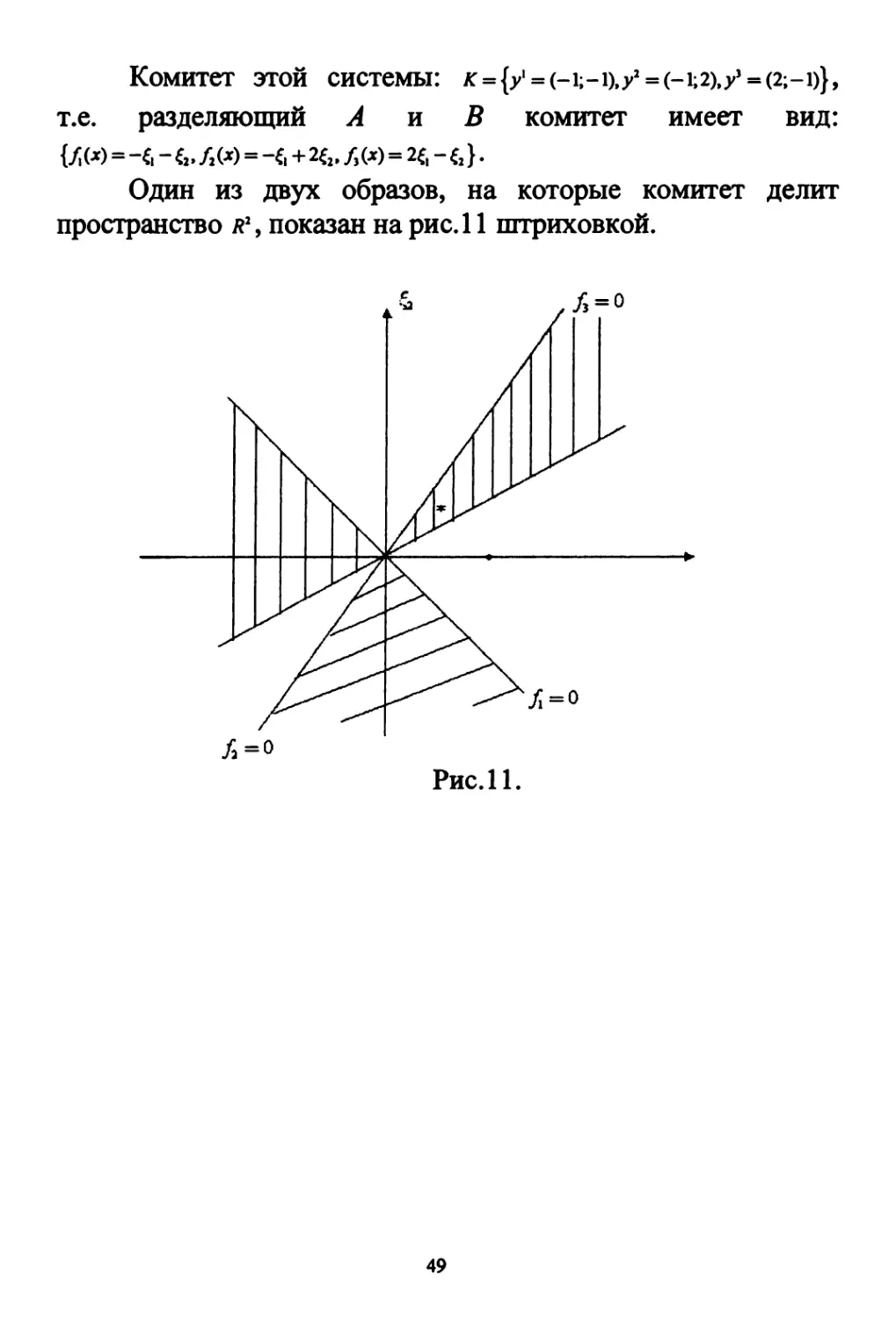
КоМИТеТ ЭТОЙ СИСТеМЫ: /Г = {У = (-1;-1),;н2 = (-1;2),;н3 = (2;-1)},
т.е. разделяющий А и В комитет имеет вид:
0!«=-6 - &. Л (*> = -f.+2f2. /,(*)=26 - ς2}.
Один из двух образов, на которые комитет делит
пространство я2, показан на рис.11 штриховкой.
/3=0
Рис.11.
49
1.4. Комитеты в распознавании образов
Рассмотрим задачу дискриминантного анализа (1).
Пусть система (1) несовместна, но существует её комитет
kcf. Тогда можно разбить /г на два образа согласно
слежующему решающему правилу:
>-элемент
первого образа, если/Cv) > 0, более,
чем для половины элементов/ € К;
иначе второго образа.
50
§ 2. Теоремы существования
2.1. Теорема существования р-комитета системы
множеств
Если всякие * множеств конечного семейства Φ
множеств: Φ ={д д,} имеют непустое пересечение, то при
к/т > ρ система Φ обладает р-комитетом.
Доказательство. Пусть α±{αΧ9...,α,}- семейство всех
пересечений вида ηη...η^,ι,*ι„(/*ιο. Пусть к - система
различных представителей для семейства А. Тогда к есть р-
комитет семейства Ф, так как 4j:\KnDJ\/\K\>c!,-_!l/ckM = k/m>p9 что и
требовалось.
2.2. Условия существования комитета линейных
неравенств
Рассмотрим конечную систему линейных неравенств
относительно χ е яг: (cJtх) > о (V/ € ΰί). (5)
Теорема. Для существования комитета системы (5)
необходимо и достаточно выполнения следующих двух
условий:
а) Нет нулевых векторов: су*о(у/€1^о, где о- нулевой
вектор;
б) Никакие два вектора ς и су при /*/ не являются
противоположно направленными друг к другу.
Замечание. Условия а) и б) вместе равносильны
следующему: если а^о и ι*у, то
с, = -Асу. (6)
51
Систему линейных однородных неравенств,
удовлетворяющую условию (6), назовем системой без
противоречий.
Доказательство теоремы.
1. Необходимость. Пусть система (5) обладает
комитетом KeRr. Докажем, что в этом случае выполняются
условия а) и б). Доказательство проведем методом от
противного: пусть хотя бы одно условие а) или б) не
выполняется. Пусть, например, не выполняется а). Тогда
3/:с,=0 И ПОТОМУ (с>эх) = 0 (Vx€/T), ЧТО ПрОТИВОреЧИТ
определению комитета. Пусть не выполняется б), т.е. для
НеКОТОрЫХ НОМерОВ / И ; И ДЛЯ НеКОТОрОГО А>0:с, = -Асу.
По определению комитета,
|{х€/Г:(с/эх)>0}|>|{х€/::(с/эх>^0}|;
|{х€/Г:(су,х)>0}|>|{х€/::(су,х)^0}|.
Т0ГДа {x€K:(cltx)>O}n{xeK:(cJtx)>0\*0.
Действительно, в противоположном случае было бы:
к/{хеК:(с19х)>0}э{хеК:(с)9х)>6\9
к/{х € К: (срх) > θ} Э {* € К: (с„х) > θ},
т.е.
{х € К: (с„х) < 0} Э {х € К: (cJtx) > θ},
{х € К: (cJtx) < 6] D [χ € К: (c,tx) > θ},
откуда
|{х€/Г:(с,,х>^0}|^|{х€/::(су^)>0}|>|{х€А::(су,х)<0}|^|{х€/::(с^х>>0}|>
> \{х € к: (cltx) ^ о}| - противоречие.
Итак, 3x€K:(cltx)>0t(cJtx)>0. НО ВВИДУ с,*-Асу,А>0, ЭТО
невозможно. Полученное противоречие окончательно
доказывает необходимость.
52
2. Достаточность. Пусть с,*-Асу при \>о и i*j. He
ограничивая общности, мы можем предполагать, что при i*j
и а>о:с/^-асу, так как в противном случае из двух неравенств
(cy,jt)>o и (с/эх)>о одно можно было бы удалить из системы (5),
не нарушив хода доказательства. Итак, мы предполагаем, что
с, *-\cj при /*у и любом числе а.
Докажем, что в этом случае
4ie\^93x' eRn :(с1%х') = 0,(с^х')*0,(1*Л (7)
Действительно, з/еГ^, если (с„х)=о, то y*/:(c/tx)=o. Пусть,
например, если (<:„*)=о, то Э1€^ж:(су.х)=о. Положим
яу = {х:(суэх)= о}. По нашему предположению, объединение
конечного числа гиперплоскостей Q#y полностью содержит
гиперплоскость //,, не совпадающую ни с одной из них, что
невозможно.
Итак, мы доказали утверждение (7). Построим
множество
/Г = {*' +£с,;-х| +сс,;х2 + ес2;-х2 +ес2;...;х" Н-ес,,;-*" + «:„},
где число е удовлетворяет условию
™*Ι(^)Γ
Легко видеть, что множество К - комитет системы (5).
Действительно, рассмотрим /-е неравенство этой системы:
(с„х)>0.
Ему удовлетворяют векторы У+ес,;-У+ес,, а из каждой
пары jc'+ec^-jc'+e^o*/) ему удовлетворяет хотя бы один
53
вектор. Следовательно, ι-му неравенству удовлетворяют 2 +
(/и-1) = (/и+1) векторов множества К - больше половины
всех 2 т членов этого множества.
Итак, теорема полностью доказана.
Рассмотрим неоднородную систему линейных
неравенств
(су.х)>ау(Уу€йо (8)
Теорема. Если [су = о] =►[<*,.<о] и [с,*о,с,*о^*^^*-^9то
комитет системы (8) существует.
Доказательство. Ввиду условия теоремы, можно
предполагать, что су = θ(γο ; тогда выполнено условие (7).
Следовательно, существует некоторый комитет К
={х\ .,*«} системы (5). Так как при достаточно большом а>о:
[(с>,х,)>о]=»[(су,адг')>а>], то множество \к={\х\.,\х'} является
комитетом системы (8).
Теорема доказана.
2.3. Оценка числа членов минимального комитета
Определение 1. Минимальным называется комитет с
наименьшим возможным числом членов.
Определение 2. Максимальной (по включению)
совместной подсистемой для системы неравенств называется
такая её совместная подсистема, которая становится
несовместной при добавлении любого нового неравенства
системы. Максимальные совместные подсистемы будем
кратко называть μ- подсистемами.
Теорема. Если комитет системы (5) существует, то
существует и минимальный комитет с числом членов ^<т.
Эта оценка является точной.
54
Доказательство. Так как комитет существует, то
выполняется условие (7). Не ограничивая общности, будем
предполагать, что среди Cj нет и одинаково направленных
векторов, т.е.
Va € Я1 :с, +ctCj*0(i*j). (9)
Покажем, что существует (лχ2)- матрица Л, для которой
VaeRl:c,A + ctCjA*O = (p,0).
Обозначим столбцы матрицы А через ueRn и veR2:
yi = («;v);cyyi = ((cy,«),(cy,v))€^
В качестве и выберем такой вектор, что (су,ы)*о(у/).
Введем обозначение: а,у = (с,,ы)/(су,и). По условию (9), <?,-<*,<?,*<>.
ТоГДа 3v € Л": (с, -а^с,,ν) * 0 (ι * J).
Найденные векторы и и ν и образуют, очевидно,
столбцы искомой матрицы Л.
Системе (5) поставим в соответствие систему
(cJA,y)>oo/je\M,yeR2 (10).
Мы показали, что если система (5) без противоречий, то
существует линейное преобразование А такое, что система
(10) также без противоречий.
Заметим, что если к = {Ух уч) - комитет системы (10), то
множество
{ухАТ у9АТ}9 где Ατ - матрица, транспонированная по
отношению к А9 является комитетом системы (5), так как
(*j*J)=(cj.yS).
Следовательно, нам достаточно доказать, что если (5) -
система над я2 без противоречий, то существует её комитет с
ЧИСЛОМ ЧЛеНОВ q^m.
Итак, предположим, что (5) - система без противоречий
над пространством я2. Покажем, что тогда, если для каждой
максимальной совместной подсистемы (μ - подсистемы)
системы (5) взять по одному решению, то полученное
множество, будет комитетом системы (5), причём число всех
55
μ - подсистем (а следовательно, и число членов этого
комитета) не больше числа всех неравенств системы.
Точнее, покажем, что при η = 2 число q всех μ-
подсистем системы без противоречий (5) нечётно: <? = 2*+ι,
причём q^my и если мы произвольно зафиксируем номер
/еП« , то число μ-подсистем, множества решений которых
лежат в полуплоскости решений / -го неравенства, равно *+ι.
Действительно, легко проверить, что число тех μ-
подсистем системы (5), множество решений которых лежат в
полуплоскости {jc:(c/,jc)>o}, равно числу μ- подсистем системы
<С'"*)=1' 1 (11)
включающих уравнение (с„х)=1. В то же время
соответствующее число для полуплоскости [x:(cJltx)<o) равно
числу тех μ- подсистем системы
Ы=-ь _ 1 (12)
(cy,*)>0(vyeW/)J
включающих уравнение (<?,.,*) = -!, множества решений
которых ограничены.
Так как система (11) в качестве множества решений
своих μ-подсистем имеет некоторое множество интервалов на
прямой, а системе (12) соответствует система внутренностей
дополнений этих интервалов, то утверждение, что ? = 2*+ι
число μ - подсистем множества решений которых лежат в /-
ой полуплоскости, равно *+ι, доказано. Тем самым доказана
и теорема.
Замечание. Оценка этой теоремы является точной в
следующем смысле: для всякого нечётного т существует
56
система т линейных неравенств вида (5), минимальный
комитет которой состоит из т членов. Соответствующие
примеры легко строятся для случая я2. В то же время для
систем большой размерности (т.е. для больших тип) обычно
число членов минимального комитета много меньше, чем /и.
В частности, легко видеть, что минимальный комитет всякой
неприводимо несовместной системы линейных неравенств
(т.е. такой несовместной системы, всякая собственная
подсистема которой совместна) состоит из трёх членов.
2.4. Существование разделяющих комитетов
Теорема. Пусть л,вея\ Для того чтобы существовал
разделяющий А и В линейный комитет, необходимо и
достаточно, чтобы
а) о^лив;
б) каждое из множеств А и В было множеством без
противоположно направленных векторов;
в) если ае а и be в, το а и ь не являлись бы одинаково
направленными векторами.
Доказательство получается непосредственным
применением теоремы о существовании комитета системы
(5)·
Теорема. Пусть л,вея\ Для того, чтобы существовал
разделяющий множества А и В комитет аффинных функций
(т.е. аффинный комитет) необходимо и достаточно
выполнения условия л η в = 0.
Доказательство. Легко убедиться, что при апв=0
система
(а.х) + у>0(ЧаеА)9 1
-(ь,х)+(-у)>оо/ЬеВ)\
57
рассматривается относительно xeRn9yeR\ является
системой без противоречий. Отсюда и следует утверждение
теоремы.
58
§ 3. Алгоритмы построения комитетов
3.1. Алгоритм с дообучением
Опишем алгоритм, который соответствует
доказательству теоремы об оценке числа членов
минимального комитета. Это один из простых алгоритмов
нахождения комитета и его преобразования при добавлении
новых неравенств, что соответствует предъявлению новых
объектов материала обучения.
Пусть задана система неравенств (она может быть
потенциально бесконечной, т.е. иметь вид
последовательности неравнеств, но для удобства изложения
мы примем, что она конечна с достаточно большим числом т
неравенств):
(cy,*)>0(Vy€U) (1)
Будем предполагать, что (1) - система без
противоречий.
Введем обозначения:
су=К ">Л
и = (т7„...эт7я),
ν = (ω„...,ω„).
Пусть вначале задано небольшое число s элементов
обучения, т.е. с,,...,*?,. При выбранных и и ν предлагаемый
алгоритм построения и преобразования комитета однородной
системы
(cy,x)>0(y/€U) (2)
состоит в следующем.
59
1. Вычисляются двумерные векторы
ίη-l п-1 \
Предполагается: и и ν таковы, что векторы d, образуют
систему без противоречий.
2. Находится комитет системы линейных неравенств
над пространством я2
(^)>0(V;€U), (3)
Состоящей из решений её μ- подсистем.
Пусть {ylt...,y,}· комитет системы (3), х=(С..£)· Тогда
легко видеть, что множество {*„ .,*„}, где*, =(£,£),
£=ъё.+"*£ (* = 1,...,л-и=и.<7) (4)
является комитетом системы (2).
3. Если в системе (2) добавляется новое неравенство
(c,+i,jc)>o, то образуем вектор
*.♦« =k+,.+.+2a^*ia^+Sa^*]= (4*.;^.л) и переходим к
следующему шагу.
4. При добавлении неравенства (dt+t,y)>o к системе (3)
возможны только следующие три случая:
а) множество {у, ущ}9 являясь комитетом системы (3),
является комитетом и системы
б)
(</,,;>) >0(Vy€U+l). (5)
В этом случае преобразовывать его нет необходимости.
60
в) множество {ylt...,y4} не является комитетом системы
(5), и хотя бы для одного элемента yk^ еЦ9 некоторая точка ζ
полупространства
{y:(d^.y)>0}
принадлежат той же μ-подсистеме системы (2), что и yk.
Тогда при условии, что вектор </J+1 не является
противоположно направленным по отношении ни к одному
вектору </„...,<*,, множество
{y-.i~i.Mz}
является комитетом системы (5);
г) в последнем из возможных случаев при условии, что
система (5) - без противоречий, множество
b.»^f;K+u^+.J)+«t+.;(^u;-^+u.)+«t*.} есть комитет
системы (5) при достаточно малом е>о.
5. По формулам (4) вычисляются новые члены
комитета системы (срх) > о w € ΰ+Ι).
3.2. Алгоритм линейной коррекции
Рассмотрим систему (1). Из множества {et}"
составляется бесконечная последовательность {gy}*^, в
которой множество {су}"ш| циклически повторяется:
* -<*.....*,=*„. gaM = с,, ..,*,„ -е.. gta+l = *,.... Комитет строится в
результате последовательности приближений. Вначале
выбирается произвольное множество *0 = {*,(0).....*,(0)}, число q
фиксировано заранее из тех или иных эвристических
61
соображений. Переход от /-го приближения к (/+1)-му
(/ = о,1,2,...) производится согласно следующему правилу.
Пусть к0 = {*,(/) хщ(о].
ВыЧИСЛЯеМ N( = ^2sign(Xj(t)tgt+l).
Затем выбираем -(|#,|+ι) векторов *до, имеющих
наименьшие по абсолютной величине отрицательные
скалярные произведения с &+|. Каждый из этих векторов
изменяется по правилу *,(/+ΐ)=χ/ο+&+,.
Этот метод не всегда приводит к нахождению комитета.
62
§ 4. Построение минимального комитета
4.1. Метод свёртывания
Метод свёртывания (исключения неизвестных) для
систем линейных неравенств, в том числе для несовместных
систем, разработан и исследован С. Н. Черниковым.
Приводимые в настоящем пункте 4.1. результаты
принадлежат С. Н. Черникову.
Рассмотрим систему линейных неравенств
(cJtx)-0J=aJa+... + aJni,-pJ<OU = l.W)
(cj>x)-0j sajA + ··· + «>£ 'β, < ° 0= "»' + l....,m)J
(1)
Определение 1. Пусть и - подпространство из /г;
со/)=
; {>Ίβ(»Ι#ι *Ь-):»в1 Л}
« = fo Vm)>OM:J2Vj(cJtx) = 0^xeU)\
[ >-» J
- некоторая конечная система порождающих элементов
конуса с(и).
Элементу у, ставим в соответствие неравенство
y-i у-1
если т*=о или г?,, =...=η^, = о при т' > о и неравенство
ί>*(^*)-Σ>Α<°>
еСЛИ т'>0 И ХОТЯ бы ОДИН ИЗ КОЭффиЦИеНТОВ %х....^т
отличен от нуля.
Система всех полученных таким образом неравенств
называется и- свёрткой системы (1). Если С (и) = {о = (О,
...,0)}, то и свёртка называется пустой.
63
Если {χ:ι = ι,....*} - базис конуса С (и\ то и -свёртка
называется фундаментальной. При u = r":u- свёртка
называется полной. Индексом ненулевого элемента конуса С
(и) называется совокупность номеров ненулевых координат
этого элемента. Индексами неравенств и -свёртки системы (1)
называются индексы соответствующих им элементов конуса
С (и).
Определение 2. Ненулевой элемент конуса С (и\
который имеет положительные координаты с номерами
у„....л+1, и нулевые остальные координаты, называются
фундаментальным элементом этого конуса, если s функций
из (сЛ.х).....(с>141,х) линейно независимы на и.
Теорема 1. Конус С (£/)имеет конечное множество
существенно различных фундаментальных элементов.
Максимальные системы существенно различных
фундаментальных элементов конуса С (и\ и только они суть
его базисы. (Два элемента конуса С (и) не являются
существенно различными, если, и только если, они
отличаются друг от друга только положительным
множителем).
Следствие. Не пустая и- свёртка системы (1) является
фундаментальной тогда и только тогда, когда она не
содержит ни одного неравенства с индексом, включающим
индекс хотя бы одного неравенства с индексом, включающим
индекс хотя бы одного из остальных её неравенств.
Определение 3. Пусть с/ис/'- два подпространства.
Если и - свёртка s системы (1) не пуста, то и'- свёртка
системы s называется повторной (им')- свёрткой системы (1).
Если система s пуста или её и' -свёртка пуста, то повторная
(U\u') -свёртка системы (1) пуста. Аналогично определяется
повторная (υ,υ',υ")-свёртка системы (1) и т.д.
Теорема 2. Любая (и-и')- свёртка системы (1) совпадает
с некоторой (u+W) -свёрткой этой системы.
64
Теорема 3. Если система (1) совместна, то для всякого
подпространства и от-.и - свёртка системы (1) совместна или
пуста. Если существует подпространство ucRn и и -свёртка
системы (1), совместная или пустая, то система (1) совместна.
Определение 4. Пусть А = {<*„...,<*„}. Каждой паре
<*,>о,ач<о соотнесём неравенство аД(с,,х)-/^-а,((с,,х)-/?,)<о,
если т'>о и хотя бы один из номеров P,q не больше т', или
неравенство а,((^*}-^)-М(с'·*}"^)*0 в противном случае.
Каждому элементу а,ел отнесем неравенство (с„х)-£<о, если
т'>о и s^mf, или неравенство (с,,*)-£^ов противном случае.
Совокупность s всех таких неравенств называется
полученной в результате а -деформации системы (1).
Теорема 4. Если х0ея%и(х0)- порождаемое элементом х0
подпространство, >4(х0)={ау=(с>эЛо):у = 1э...э/я}, то А(х0)· деформация
системы (1) есть и(х0)- свертка системы (1).
4.2. Алгоритм фундаментального свертывания
Пусть t/,=t/(e,),e, - /-Й координатный орт. Алгоритм
состоит из следующих шагов.
а) Пусть л,- столбец коэффициентов при ξ,. Произведя
4-деформацию системы (1), получим систему sn являющуюся
фундаментальной иг сверткой системы (2). Каждому
неравенству системы ^отнесем его индекс.
б) Пусть уже получена система sk- фундаментальная
(£/,+...+£/4) - свертка системы (1). Пусть аш~ столбец
коэффициентов при &+|. Произведем аш -деформацию
системы sk9 не комбинируя тех пар неравенств, объединение
индексов которых содержит индекс какого-либо третьего
неравенства системы sk. Получим систему sk+r
65
фундаментальную (£/,+...+t/4+1)-свертку системы (1). Каждому
её неравенству отнесем его индекс.
в) Если sk = 0> то полагаем sk+l = 0. Через η шагов
получим полную фундаментальную свертку системы (1).
Теорема 5. Номера неравенств несовместной системы
(1), которые входят в её произвольную минимальную
несовместную подсистему, образует индекс одного из
несовместных неравенств полной фундаментальной свертки
системы (1). Индекс каждого из несовместных неравенств
упомянутой свертки состоит из номеров неравенств,
образующих некоторую минимальную несовместную
подсистему системы (1).
4.3. Нахождение минимального комитета
Рассмотрим систему над /г:
(c,,x)>0(V;€U;) (2)
Пусть имеется некоторая подсистема системы (2):
(су,х) > О (V; €./),./cui. (3)
Множество j будем называть индексом системы (3).
Максимальная (по включению) совместная подсистема (т.е.
μ- подсистема) системы (2) есть такая совместная подсистема
(3),что если к ней добавить любое новое неравенство из
системы (2), то она станет несовместной. Минимальная (по
включению) несовместная подсистема (т.е. 1/-подсистема)
системы (2) есть такая несовместная подсистема, что если из
неё удалить любое её неравенство, то получим совместную
подсистему.
66
Теорема. Среди минимальных комитетов системы (2),
т.е. комитетов с наименьшим возможным числом членов,
существует такой, все члены которого суть решения
некоторых μ- подсистем системы (2).
Доказательство. Пусть множество к = {*„. ,*,} есть
минимальный комитет системы (2). Определим для всякого
i€U МНОЖеСТВО У,={у€1^,(су,*,.)>0}.
Рассмотрим систему (су,х) > о (ty €./,). Так как эта система
совместна, то существует μ- подсистема, индекс которой
включает у,; пусть у, - некоторе решение этой μ- подсистемы.
Легко видеть, что множество {*.···.*,} является минимальным
комитетом системы (2), все члены которого суть решения
некоторых μ- подсистем.
Теорема доказана.
Эта теорема позволяет свести задачу нахождения
минимального комитета системы (2) к двум следующим.
1. Найти все μ- подсистемы системы (2) и для каждой μ-
подсистемы найти её решение; пусть эти решения составляют
множество {*, хг).
2. Определить, сколько экземпляров каждого элемента
х, должно войти в минимальный комитет.
Задачу 2 можно решить с помощью методов
целочисленного программирования. Предположим, что
множество {*, х,} уже найдено и определим
$-{7:(с,.*)>0} Μ..».')·
Каждому s, поставим в соответствие вектор ч = (ч Ό»
ГТ1А ί+Λ если J €S,-
где ω„ = \
9 [-/, если У g Sr
Пусть ν искомое число экземпляров элемента *,,
которые должны войти в минимальный комитет. Тогда задача
нахождения минимального комитета сводится к следующей
задаче целочисленного программирования: минимизировать
(а,+ ...+\) при условиях
67
[Л,<4+... + \о;г>0 J).
[Af€{0,l,2,...}(Vi€U7).
Перейдем к задаче 1. Покажем, что все μ- подсистемы
системы (2) можно найти зная все ^-подсистемы (т.е.
минимальные несовместные). Действительно, пусть Txt...jp -
индексы всех ι/- подсистемы системы (2). Тогда ясно, что
множество s является индексом совместной подсистемы в
том и только том случае, если S не содержит Ti.
Поэтому индексы μ- подсистем можно определить как
максимальные по включению s, удовлетворяющие этому
условию.
Итак, задача свелась к нахождению всех ι/- подсистем.
Эти подсистемы можно найти методом свертывания как
следует из теоремы 5 (С. Н. Черникова), приведенной в 4.1.
Рассмотрим пример. Пусть требуется найти
минимальный комитет следующей системы линейных
неравенств:
0) δ >ο.|
(2) ξ2>οΑ
Р)-6- ξ2>οΛ
(4)-ζ+2ξ2>0,
(5) 26- ξ2>0.\
Слева от каждого неравенства записан его индекс.
Найдем фундаментальную ς-свертку:
0.3) -&>о,1
(1.4) 2ζ2>θΑ
(2) ξ2>0Λ
(3.5) -3ξ,>0,
(4,5) 36>0.)
68
Фундаментальная ς2 -свертка последней системы есть
полная фундаментальная свертка исходной системы:
(1.3.4) 0>0,
(12,3) 0>0,
(2.3.5) 0>0,
(3,4,5) 0>0.
Индексы несовместных неравенств (т.е. неравенств вида
0>0) полной фундаментальной свертки суть индексы и-
подсистем исходной системы:
7J ={1,3,4}, Г2 = {1,2,3}, Ту = {2,3,5}, Г4= {3,4,5}.
Индексы s, μ- подсистем - максимальные s, ей, 1 = 1.2,3,
удовлетворяющие условию: s 2 7; (viе й):
S, = {1,2,4,5},52 = {2,3,4},5, - {1,3,5}.
Для каждого /ей найдем *,- решение ι-й μ-
подсистемы:
дг, = (1,1); дг2 = (-2,1); х, = (1,-2).
Определим векторы ω,,υ,,υ,:
ω, =(1,1,-Ι,1,ΐ),ω2=(-Ι1,1,1,-Ι),ω, = (1,-1,1,-1,1).
Составляем задачу целочисленного программирования:
minJA, +Α, +А,: Α,ω,Η-\ω% +Α,ω, ^(1,1 ,1.1.1)Α €{0,1,2....}(Vi€Ο)} J
69
Она расписывается в виде
miniA.+Aj+A,),
Α,-λ, + Α,^Ι;
Α,+λ,-Α,^Ι;
-Α,+λ,+Α,^Ι;
Α,+λ,-Α,^Ι;
Α,-λ,+Α,^Ι;
λ, €{0,1.2,...} (ι = 1,2,3)
Решение последней задачи: а, = \=л, = ι.
Итак, один из минимальных комитетов имеет вид:
70
§ 5. Вопросы программного обеспечения
5.1. Необходимость создания пакетов программ
распознавания образов
Последнее время широкое распространение получил
новый подход к созданию высокоэффективных программных
систем обработки данных; он состоит в разработке пакетов
прикладных программ. Сущность этого подхода в том, что
большие программы и комплексы программ рассматриваются
как структуризованные системы, строящиеся из
элементарных программных единиц, называемых модулями.
Необходимость такого подхода диктуется современным
этапом развития математической технологии решения
больших прикладных задач, требованиями к качеству,
времени и надёжности решения этих задач. Н. Н. Яненко
отмечает внутренние и внешние факторы, требующие
структуризации больших программ:
Внутренние факторы программирования: требование
иерархического разбиения всего объёма работ по
программированию, их контролируемости, требование
надёжности.
Среди внешних факторов отмечаются: наличие
структуры в самих вычислительных алгоритмах,
необходимость обмена программами, необходимость
эволюции программ.
Так как методы распознавания образов нацелены на
решение прикладных задач классификации, диагностики и
управления, проблема создания пакетов прикладных
программ является актуальной и для предметной области.
Теоретические основы структуризации классов алгоритмов,
распознавания и классификации, необходимой при создании
структуризованных больших программ-пакетов, разработаны
Ю. И. Журавлёвым. В настоящее время создан ряд пакетов
71
программ распознавания и классификации. Коротко опишем
один из них.
5.2 Пакет «КВАЗАР»
Пакет прикладных программ распознавания образов
«КВАЗАР» разработан в Институте математики и механики
УНЦ АН СССР В. С. Казанцевым при участии других
сотрудников института. В основе алгоритмического
наполнения пакета лежат комитетные конструкции для
систем линейных неравенств.
Пакет представляет собой систему программ на
алгоритмическом языке ФОРТРАН - ГДР, реализующих
алгоритмы решения задач таксономии (обучение ЭВМ без
учителя) дискриминантного анализа (обучение с учителем),
отображения многомерных данных в пространство меньшей
размерности (в том числе в двумерное), выбора
информативного признакового пространства и некоторых
других задач.
Пакет написан для ЭВМ БЭСМ-6. В нём содержится
библиотека программ-модулей, в которых реализованы
некоторые алгоритмы и процедуры, а также головная
программа, имеющая блок трансляции заданий и блок
управления решением задачи. Пакет «КВАЗАР» - открытая
система: он с течением времени пополняется новыми
модулями.
С помощью пакета «КВАЗАР» решены многие
практические задачи экономики, техники, социологии,
биологии и медицины.
72
Глава 4.
ОБЗОР МЕТОДОВ ДИСКРИ1МП0ОВ^ШТНОГО
АНАЛИЗА
К настоящему времени разработано множество методов
дискриминантного анализа, их формализация и обоснование
находятся на самых различных уровнях. Многие методы
имеют лишь эвристическое основание, но оказались
полезными при решении некоторых классов практических
задач. Некоторые методы, ставшие стандартными, изучены
достаточно глубоко; к ним относятся метод оценок Ю. И.
Журавлёва, метод комитетов, метод потенциальных функций,
методы стохаотической аппроксимации и некоторые другие.
Следует отметить работы Ю. И.Журавлёва, в которых
изучается алгебраическая структура целых классов
алгоритмов. В настоящей главе кратко рассматриваются
некоторые из методов, ставших классическими и достаточно
изученных с математической точки зрения.
§ 1. Метод потенциальных функций
1.1. Геометрический смысл метода
Метод изучается в книге [8].
Будем рассматривать детерминистскую постановку.
Пусть *,>€/г. Через ки.^будем обозначать потенциал,
создаваемый точкой у в точках х. Функция к{хуУ) должна
удовлетворять следующим условиям:
a) K(xty)>o(vx,y€/?");
б)тыК(х,у)=К(у,у)\
73
в) если точка χ удаляется от Уу то значение
к (х, ^убывает.
Приведем примеры функции к(х,у). Пусть />(*,.>>)=|*->1·
ТоГДа МОЖНО, Например, ПОЛОЖИТЬ £ = ехр(-ар2)ИЛИ К = {\ + ар2)-\
где <*>о. График функции к(х,У) при фиксированном у
представляет собой «холм» с вершиной над точкой у.
Пусть AtB<zRn. Определим *,«=£*(*, я- сумму
уел
«холмов» над точками из а; кв(х) = £,к(х,у). Тогда функцию
уев
/(*) = *,(*)-*,(*) можно интерпретировать как разделяющую
для множества айв.
1.2. Итерационный процесс
Предположим, что искомая разделяющая функция /w
раскладывается в ряд по некоторой системе функций:
/m=£<wm.
I
Строим приближения /4(*ж функции /оо согласно
следующему правилу: Ш=ь/к+м=Ш+гкк(х>х^)> где
Г 0, если/А(х4+1) 2*0 и
0. если Л(хА+,)< 0 и хА+, € В;
1. если/А(хА+|)<0 и
**+ι € А\
[-1. если/ДхА+|)^0 и xk+l еВ.
Теорема (см. 8). Пусть /w-£/wW, JixoO-fX^MwO'),
««I 1-1
jnf·. <+оо. Пусть далее существует е>о, для которого
/Μι
74
Если точки хк появляются независимо с некоторой
плотностью р(х)9 то математическое ожидание по χ величины
\signf(x)-signfk(x)\ СХОДИТСЯ К НуЛЮ ПОЧТИ Наверное, ПрИ *-+оо.
75
§ 2. Методы, основанные на теории статистических
решений
Образы - некоторые бесконечные множества в
пространстве r\ Относительно этих множеств могут быть
известны те или иные вероятностные параметры или же эти
параметры могут быть оценены по конечным выборкам из
образов. Параметрические методы дискриминантного
анализа:
а) устанавливают зависимость дискриминантных
функций от параметров;
б) По материалу обучения оценивают параметры;
в) Оценки подставляют вместо параметров в
дискриминантные функции.
2.1. Задача разделения на к классов
Объекты классов появляются случайно, соответственно
к функциям плотности распределения. В качестве параметров
могут выступать:
р(х/0 - вероятность появления * в предположении, что х
принадлежит ί-му образу;
pU) - вероятность появления элемента у-го образа;
pU/x)~ вероятность, что χ принадлежит у-му образу.
(Вместо «плотности распределения» будем для
краткости писать «вероятность».)
Для разбиения яя на к образов надо построить
к функций g,(x)(i=i,. ,*) таких, что если χ принадлежит /-му
образу, то gi(x)> gj(x) (/~ л.
76
2.2. Дискриминантные функции на основе теории решений
Пусть заданы потери а (//у), когда объект у-го образа
относят к 1-му образу, и кроме того, параметры pU/χ)· Тогда
условные средние потери от отнесения к ι-му образу равны:
Поэтому правило отнесения χ к одному из А образов
таково: χ относится к ^,-му образу, где ix(i0)=minix(o.
Согласно формуле Байеса,
pOA) = P(Vy')pO')/pW. (2)
Подставим выражение для Ри/х) из (2) в (1), получим:
^(0=-ГТ Σ ^(|/у>(х/у)р(У).
Для минимизации по ι множитель — не имеет
р(*)
значения, поэтому вводим функции
'.(0= Т._Ч*НШЛри)- (3)
Предположим далее, что функция является
симметрической:
Подставим (4) в (3): мо = р(*)-р(*Л)р(0.
Так как при фиксированном х\ р(х)=const, то вместо
минимизации ιχ(ο можно минимизировать по / функцию
77
р(*/Ор«. Прологарифмировав (что не влияет на
максимизацию) получим ί-ю дискриминантную функцию:
g,W = logp(*/') + logp(i).
78
§ 3. Методы алгебры логики
3.1. Метод тупиковых тестов
Понятие теста было введено в 1956 г. С. В. Яблонским.
На основе этого понятия Ю. И. Журавлёвым и другими
разработаны тестовые алгоритмы распознавания образов,
сыгравшие большую роль в разработке теории методов
вычисления оценок.
Пусть материал обучения задан в виде таблицы Г,
строки которой - бинарные векторы состояния объектов, а
столбцы - признаки:
Векторы
х1
1
···
<
1 ···
*;
···
<
·· ·
х"
···
Признаки
1
а
···
Sm,1
···
in
···
Sm,l
···
···
Smtl
2
&
···
f1
S/n,2
• ··
£.
···
Sm,2
• · ·
S12
···
Smt2
w
U
···
^т,л
···
&
···
ζ'
···
Sin
···
ζ"
Класс
(образ)
1
···
1
···
i
··· 1
i
··· ι
k
···
* 1
Определение: Тестом таблицы Т называется
совокупность столбцов ι, /, таких, что после удаления из Τ
всех столбцов, кроме столбцов с номерами /„....ί,, получим
79
таблицу, в которой все пары строк, принадлежащих разным
классам различны. Тест ft...../,} называется тупиковым, если
никакая его истинная часть не является тестом.
Пусть Т- множество всех тупиковых тестов таблицы Τ
и ге Т9 г={|„..,/,}. Классификация любого yeR" проводится по
следующему правилу.
Если y=(vlt...tvn), то пусть *(Г)«(ц rjj. Сравним У(п с
векторами *ι4θ,...<(0»·.·,*ι4θ»···»<(Π таблицы Г. Число
совпадений У(п с векторами *;(/*),...,<ю ι-го класса обозначим
через 7,(О· Величина 7,'(θ=—Σ%(Π называется оценкой ^по *-
му классу. При этом ^относится к классу ι0, для которого
3.2. Метод анализа высказываний
Этот метод изучается в книге Горелика и Скрипкина [9].
Пусть имеются некоторые исходные высказывания А9В9С9...
Из них конструируются более сложные высказывания: а+в9
ав9 а у а-+в9а = в и т.д. истинным высказываниям
присваивается значение 1, ложным - значение 0. Таблица,
которая представляет все возможные комбинации значений
истинности некоторого набора А9В9С9... , называется
базисом.
Например, базис одного элемента:
ν\
ЩЛ
0
0
1
1
80
Базис двух элементов:
h
ψΑ
\#В
0
0
0
1
1
0
2
0
1
3
1
1
Колонки базиса рассматриваются как двоичные числа
(младший разряд - верхняя цифра), это числа от 0 до 2я-'.
Через #А обозначается изображающее число для А .Можно
найти изображающее число любой булевой функции от
А Д... по изображающим числам A JB>...
Рассматриваются задачи распознавания образов,
сводящиеся к задачам решения булевых уравнений такого,
например, типа
Х-(А + В) = Л-В-С (*)
В качестве X отыскивается такая булевая функция от
А9В,С,...9 чтобы подставив ей в (*), получить тавтологию.
Решение получается на основе использования изображающих
чисел.
3.3. Распознавание арифметических таблиц
В книге Μ. Μ. Бонгарда [10] рассматриваются, в
частности, некоторые логические методы распознавания
арифметических операций. Объект узнавания - таблица из
нескольких строк. В каждой строке - три числа: а-Мс=да,ь)9
где /- некоторая арифметическая операция. Каждой операции
/соответствует свой класс объектов (образ).
81
Следующим образом строятся признаки. Берутся
несколько простых арифметических функций МаЛс).
Признаки имеют вид:
fl, если/(а,6,с)-целое число;
' ' ' [О, если /(а,Ь,с)- дробное число;
(1, если / (а, 6, с) ^0;
0.если/(аДс)<0;
[l, если |/(*.М|>1;
[о.если \£(а,Ь,с)\<\.
Затем отбираются полезные признаки. Признак не
должен присваивать всем таблицам одно число 0 или 1.
таблицам одного класса признак должен приписывать одно и
то же число.
82
Глава 5.
МЕТОДЫ ТАКСОНОМИИ
§ 1. Метод выделения максимальных совместных
подсистем
Пусть \x\cr\ pr|<+oo. Пусть f - некоторое множество
функций, f с{дя -> я'}. Будем считать допустимой формой
таксона множество {*:/(*ко} при некотором /€F. Итак,
таксоны множества ^должны быть в виде: хп{х.Дх)^о}.
Рассмотрим систему неравенств относительно
неизвестной функции /:
f(x)^0(Vx€X\f€F. (1)
Пусть все максимальные подсистемы (μ- подсистемы)
системы (1) имеют вид: Ax)<:o(yxexJ),feFj = \t...tk. Иными
словами, множества х19...,хк суть все индексы μ- подсистем
системы (1). Из совокупности {*„...,^4}надо выбрать разбиение
{хк....,х1в}: x = (jxljtxlnxi=0(t = r).
J4
В случае, когда класс f таков, что множества {х:/(*ко} -
многомерные параллелепипеды, нахождение μ- подсистем
системы (1) может быть осуществлено с помощью методов
теории линейных неравенств. Один из таких методов для
таксономии реализован в пакете «КВАЗАР».
83
§ 2. Метод потенциальных функций
Здесь кратко изложим только геометрический смысл
метода. Пусть \x\cr" - конечное множество, которое надо
подвергнуть таксономии. Положим /(х) = ^2к(х,У).
Если множество X распадается на таксоны xlt...tx„ то
график функции /(*> представляет собой «горный ландшафт»
- вершины над множествами *„...,*,, а между множествами -
«ущелья», разделяющие таксоны.
84
§ 3. Обзор некоторых методов таксономии
3.1. Метод сфер
Изложим один из алгоритмов разработанных и
программно реализованных Н. Г. Загоруйко и другими.
Заданы: конечное множество \x\cR" и радиус
г гиперсферы. Строим шар Д(*,г), где χ - любая точка из Х9
затем множество хпв(х,г). Пусть ζ, - центр тяжести множества
хпв(х,г). Строимхпв(г19г)9 определяем z2 как центр тяжести
этого множества. Строим xnB(z2tr), находим центр тяжести ζ,
этого множества и т.д.
Этот процесс заканчивается, когда ζι+ι = ζ,. Полагаем в
качестве первого таксона xl = xnB(zX9r). Затем повторяем всё
изложенное для множества χ/χ,, получаем таксон х2 и т.д.
3.2. Метод «масок»
Пусть задано конечное множество X векторов
*=(6·····0€Λ" с координатами £€{ο,ι}. Разбиваем множество X
на таксоны х, по «сходству» элементов, т.е. по числу
совпадающих координат. В качестве порога выберем
некоторое число <*>о. Выбираем любой элемент *,ех и
запоминаем как элемент таксона хх. Выбираем произвольно
следующий элемент χ из X и сравниваем с *,. Если число
г=/·(*,*,)совпадающих координат не меньше, чем а, то векторы
считаем «похожими» и выбранный элемент χ отбрасываем.
Если же г<а,то полагаем элемент *=*2, и вектор хг
запоминаем как элемент таксона х2 и т.д. Таким образом
выделяются «маски» дс,,...,^. Далее для всех элементов
множестваXформируются «знаки». «Знак» векторах есть *-
85
мерный вектор, у-я координата которого равна 1, если /·(*,*,) ^<*,
и равна 0 в противном случае.
Все векторы с одним знаком попадают в один таксон хп
этот знак - «имя» таксона.
3.3. Прочие методы
Выше приведены наиболее простые методы
таксономии. В целом, многообразие методов достаточно
велико, и многие из этих методов связаны с весьма сложными
критериями оценки качества разбиения на таксоны. В книге
Н. В. Загоруйко [11] подробно изучается сфера методов
таксономии. В частности в ней описывается метод, в котором
реализованы критерии, выявленные в результате
исследования требований, предъявленных людьми -
экспертами к качеству разбиения на таксоны. Среди этих
требований близость точек друг к другу внутри таксона,
удаленность таксонов друг от друга, одинаковость структуры
расположения точек внутри таксона, приблизительная
одинаковость числа точек в каждом таксоне.
Рассмотрим ещё некоторые примеры методов
таксономии.
1. Метод, использующий линейные неравенства, для
разделения на два таксона. Пусть * = {*,,...,хя}. Требуется найти
jcui такое, чтобы система (*,,*)> о (vyeJ),(xy,x)<o (vy^j) была
СОВМеСТНа, И ЧТОбы \j\>a т9 α€[0,1].
2. Метод «объединения» (Э. М. Браверманна). Пусть
* = {*„. ,*„}. Пусть введена некоторая мера к(АУв)близости
между множествами А и В. Пусть хХУ...Ухк - некоторое
начальное разбиение множества X на таксоны. Надо получить
разбиение на ^множеств, t>k. На первом шаге из к
86
подмножеств получаем *-ι, объединяя в одно те два
МНОЖеСТВа X, И Хп ДЛЯ КОТОрЫХ K(XltXj) = m*xK(XptX9).
Глава 6.
МЕТОДЫ ВЫБОРА ПРИЗНАКОВОГО
ПРОСТРАНСТВА
§ 1. Оценка признаков по коэффициентам
разделяющей функции
Существует интуитивно понятное соображение, что
если классификация проводится в соответствии с линейной
дискриминантной функцией от вектора *=(£.....£,):
«•I
то величина |<*,| является некоторой оценкой
информативности /-го признака.
Именно, пусть два образа имеет вид:
Xl = {aeR" :|α|=1,(α,χ·)^θ};
где|х'|=1.
Напомним обозначения: если *=(£„...,&), j = {ϊ„...,|А}сГй, то
x(j) = (iit...tit)txl(j)={x(jy.xexl}.
ПОЛОЖИМ <Р(J) = X, (J) Π Χ2 (J).
Объем v(<p(j)) этого множества можно считать мерой
неразделимости множеств хх и х, по системе j признаков.
Приведем без доказательства теорему В. В. Андреева:
Теорема. Если ** = (£,..с) и с=(<*\* ···.<*„)> то
v(^)) = v({c€^:Fy(c)^0}), ГДв Fy(c) = ($>c) -(l-E^^-EC)·
88
Следствие. v(<P(j))=v, h-^H , где ν, - объем шара
единичного радиуса в я*.
Согласно этому следствию естественно ввести такую
оценку информативности подсистемы j признаков:
89
§ 2. Прочие методы
Пусть w(j) - некоторая мера информативности
подсистемы j признаков, jcu=/. Если
У = {|„...,|,} ω(7) = ω(|·) + ... + ω(ι,), ТО Задача
тах{ы(У):|У|^р,УсГ^} (1)
решается очень просто: нужно только найти
наибольшие по информативности ρ признаков. Если, однако,
признаки не являются независимыми, то для решения задачи
(1) в общем случае приходится просматривать с; сочетаний
признаков. При больших ρ и η с этим связан большой объем
вычислений.
Поэтому применяются методы частичного перебора, не
гарантирующие нахождения абсолютного оптимума.
Один из таких методов: метод Мерилла и Грина:
исключаем признак /,, дающий тахы(//{|}), затем из //{/}
исключаем по тому же принципу следующий признак и т.д.
Количество шагов равно л+(л-1)+.+(*-/>)«;с;.
Метод Барабаша: находим признак /,, на котором
достигается maxw(i). Затем находим /2, реализующее тахы({|„|}) и
Т.Д. ЧИСЛО ШаГОВ л+(л-1)+... + (л-р).
Метод случайного поиска с адаптацией (Лбов) состоит в
следующем. Вначале признакам присваиваются одинаковые,
равные ι/л, вероятности их употребления. В соответствии с
этими вероятностями выбираются несколько подсистем,
каждая из которых содержит ρ признаков. Для каждой
подсистемы уподсчитывается значение w(j) её
информативности. Пусть для этих подсистем:
o;(J,) = maxtj(J), o;(J2) = mintj(J).
90
Тогда для признаков входящих в у, увеличиваем
вероятность из использования, а для признаков из j2
вероятности уменьшаем. Затем вся процедура повторяется
для принятых новых значений вероятностей использования
признаков.
Метод тупиковых тестов (Ю. И. Журавлев) также
позволяет получить некоторые оценки информативности
признаков: более информативным считается признак,
вошедший в большее число тупиковых тестов.
Опишем ещё один метод, основанный на использовании
принципе двойственности в линейном программировании.
Выделим некоторые подмножества признаков:
у,сй,.... jmсΰ. Пусть материал обучения составляет
некоторое множество с с/г. Предположим, что при
использовании вместо С множества со/,) доля правильных
классификаций равна 7,. Введем обозначение:
Составим следующую таблицу:
Признак
1
...
п
Доля правильных
ответов
Частота употребления
' вариантов
Вариант
J,
аи
...
αι„
7,
£,
...
Л.
Ът
...
пт
7„
L
Ресурс (макс.частота
употребления
признаков)
1
...
1
91
Сформулируем задачу Ρ линейного программирования:
«{ς^αϊ^^1^61·11)·*^);
Она имеет смысл максимизации ожидания доли
правильных ответов при смешанной стратегии использования
вариантов подсистем признаков. Двойственная задача г
имеет вид:
min Σνί>Λ^. (ν/€ϊ^)^>ο
Координаты её оптимального вектора y=(rjt> -.5.)
естественным образом интерпретируются как оценки
дефицитности (ценности) признаков. Следовательно, для
любой подсистемы JcuJ признаков можно измерять её
информативность величиной и>с/) = £Х.
92
Глава 7.
ПРИКЛАДНЫЕ ЗАДАЧИ РАСПОЗНАВАНИЯ
ОБРАЗОВ
Задачи распознавания образов мы будем рассматривать
с точки зрения процессов автоматизации получения и
обработки данных, анализа закономерностей в массивах
информации и структуризации этих массивов.
С этой точки зрения задачи распознавания образов
могут быть разбиты на следующие группы:
1. Выделение, формирование и оценка существенных
признаков (факторов); преобразование пространства
признаков.
2. Анализ закономерностей размещения элементов
конечного множества в многомерном фазовом пространстве.
3. Разбиение пространства на классы эквивалентности,
отнесение элементов пространства к классам.
В соответствии с этим в сфере приложений методов
распознавания образов к решению практических задач
выделим следующие области:
/. Оценка ситуаций.
В этой области можно выделить задачи интерпретации
обстановки, ориентации, узнавания, диагностики.
//. Структуризация информации, организация
материала наблюдений.
Здесь отметим три группы задач:
а. Задачи классификации, разбиение совокупности
объектов, задачи районирования.
в. Запоминание информации, заполнение пробелов в
ней, обобщение опыта, его сжатие и упорядочение,
агрегирование.
93
с. Создание типологии; выделение типопредставителей,
эталонов.
///. Моделирование.
Выделим следующие группы задач:
а. Обратные задачи; идентификация моделей.
е. Построение разделяющих поверхностей,
изоповерхностей; моделирование эмпирических
зависимостей, целей и предпочтений.
с. Задачи поиска и выбора, прогнозирования,
управления, планирования, проектирования.
Далее будут приведены более или менее конкретные
примеры приложений.
§ 1· Применение методов распознавания образов для
учёта плохо формализуемых ограничений в
алгоритмах оптимального планирования
Рассмотрим задачу математического
программирования, интерпретируемую как задачу
проектирования сложного объекта. В этой модели объект
описывается его вектором состояния:*^,,...,0€ДЯ, гДе ί -
значение / - параметра состояния. Пусть показателями
качества функционирования объекта в состоянии χ будут
значения функций: fQ(x\fx(x\ ... ,/.w.
Предположим, что для нормального функционирования
объекта необходимо, чтобы
а, </,(*><£,(/ = U.*). (1)
94
Кроме того, выбор состояния χ подчинён требованию
максимизации /0(*). Получаем задачу математического
программирования
max {/,(*) :(1)}. (2)
Сформулированную модель весьма широко и успешно
применяют в решении практических задач, в том числе задач
оптимального технико-экономического планирования и
проектирования. Однако её применение в ряде случаев
наталкивается на значительные трудности. Одна из таких
трудностей состоит в том, что некоторые из ограничений (1)
могут быть плохо формализуемыми. В принятой нами
интерпретации это может означать следующее. Специалисты
по проектированию объектов рассматриваемого класса на
основании своего опыта могут выделить ряд условий,
которым должны удовлетворять параметры ?„...,£,, но не могут
записать эти условия аналитически, т.е. вид некоторых
функций /, в системе (1) им не известен.
Однако по некоторым интуитивным соображениям,
исходя из опыта, эти специалисты (будем далее называть их
экспертами) для многих векторов состояния χ = (£.....£) могут
судить о их допустимости по у-му ограничению, т.е. о
выполнении или невыполнении неравенства
Моделирование плохо формализуемых ограничений
при этих условиях может быть осуществлено с помощью
методов дискриминантного анализа. Пусть следующее
ограничение плохо формализуемо:
«, </;<*)<£ (3)
95
Предположим, что на основании опыта экспертам
известны: конечное множество мя с /г, Состоящее из
некоторых векторов х, удовлетворяющих условию (3), и
конечное множество w,c/r, содержащее векторы, не
удовлетворяющие этому условию.
Тогда можно решить следующую задачу
дискриминантного анализа: найти функцию g(x) из
некоторого класса функций σ,
разделяющую множества м, и ν,9 т.е.
g(x)>0(Vx€M,)tg(x)<0(Vx€Nt)tg€G.
Пусть ga(x) - решение этой системы. Тогда в задаче (2)
вместо ограничения (3), неизвестного нам как аналитическое
выражение, записываем ограничение &μ>ο.
Пусть, χ - оптимальный вектор получившейся задачи
оптимизации. Вектор j предъявляется для экспертизы,
которая устанавливает его допустимость или недопустимость
по ограничению (3). Если χ удовлетворяет этому
ограничению, то расширяем множество а/,, добавляя к нему
вектор χ; в противном случае χ добавляем к ый. Затем решаем
задачу дискриминации для расширения множеств мг и ν3, и
так далее.
96
§ 2. Задачи медицинской диагностики и управления
процессом лечения
Предположим, что вектор χ=(ξ,....,0 есть вектор
параметров, характеризующих состояние человека (пульс,
давление крови, температура; качественные признаки,
кодируемые числами, например, наличие или отсутствие
головной боли и т.п.). Пусть y=(vit...,*?„)- вектор состояния
окружающей среды.
С помощью методов дискриминантного анализа можно
осуществить классификацию (диагностику), ставя в
соответствие (m+л)- мерному вектору (^-({„....с..^.....^) класс
людей, страдающих соответствующим заболеванием.
Одним из классов может быть класс здоровых людей.
Обучение правилу классификации проводят на основе
материала обучения, включающего из каждого класса
некоторое конечное множество его представителей.
За этапом диагностики следует этап выбора метода
лечения. Выбираемая процедура лечения характеризуется
своим вектором параметров ζ=(<, <,). Характеристики
состояния человека после лечения зависят от векторов xtytz.
Обозначим эти характеристики через
fo(*>y>=)Ji(x>y>z) f,(x>y,z).
Каждая характеристика должна находиться в некоторых
допустимых пределах: а^/дх.**)^ o=o,u,...,g)
При этих ограничениях и при фиксированных векторах
jc=j, y=y может быть поставлена задача отыскания
процедуры - такой, что ей соответствует максимально
возможное значение показателя /0(xty,z)— .
Однако некоторые из зависимостей /у могут плохо
формализуемыми. В этом случае с помощью методов
97
дискриминантного анализа для них могут быть построены
приближённые модели, как об этом сказано в § 1.
98
Список литературы
1. Мазуров Вл. Д. О построении комитета системы
выпуклых неравенств. - Кибернетика, 1967. - №2.
2. Мазуров Вл. Д. О некоторых математических
конструкциях для распознавания образов // Нелинейное
программирование и приложения. - Свердловск, 1979.
3. Мазуров Вл. Д., Казанцев В. С, Белецкий Н. Г.,
Мезенцев СВ., Сачков Н. О. Пакет КВАЗАР
прикладных программ распознавания образов. -
Свердловск, 1979.
4. Нильсон Н. Обучающие машины. - М., 1968.
5. Черников С. Н. Свёртывание конечных систем линейных
неравенств. - ДАН УССР, 1969. - № 1.
6. Яненко Η. Η. Проблемы математической технологии. -
Тезисы доклада международной конференции
«Структура и организация пакетов программ». -
Тбилиси, 1976.
7. Журавлёв Ю. И. Об алгебраическом подходе к решению
задач распознавания или классификации. - Проблемы
кибернетики. - 1978. - № 3.
8. Айзерман Μ. Α., Браверманн Э. М., Розоноэр Л. И.
Метод потенциальных функций в теории обучения
машин.-М., 1970.
9. Горелик А. Л., Скрипкин В. А. Построение систем
распознавания. - М., 1974.
10. Бонгард М. М. Проблема узнавания. - М., 1967.
11. Загоруйко Н. Г. Методы распознавания и их применение.
-М., 1972.
12. Метод комитетов в распознавании образов // Труды
Института математики и механики УНЦ АН СССР. -
Свердловск, 1974.-Вып.6.
99
ОГЛАВЛЕНИЕ
Введение 3
Глава 1· Основные математические модели распознавания
образов 5
§ 1. Содержательный смысл задачи распознавания образов 5
§ 2. Моделирование объекта классификации 9
§ 3. Модель дискриминантного анализа 13
§ 4. Модель таксономии 19
§ 5. Выбор признакового пространства 22
Глава 2. Линейный дискриминантный анализ 25
§ 1. Методы дискриминантного анализа 25
§ 2. Разделяющие возможности аффинных функций 30
§ 3. Метод линейной коррекции 35
§ 4. Методы линейного программирования 39
Глава 3. Метод комитетов в дискриминантном
анализе 45
§ 1. Комитетные конструкции 45
§ 2. Теоремы существования 51
§ 3. Алгоритмы построения комитетов 59
§ 4. Построение минимального комитета 63
§ 5. Вопросы программного обеспечения 71
Глава 4. Обзор методов дискриминантного анализа 73
§ 1. Метод потенциальных функций 73
§ 2. Методы, основанные на теории статистических
решений 76
§ 3. Методы алгебры логики 79
Глава 5. Методы таксономии 83
§ 1. Метод выделения максимальных совместных
подсистем 83
100
§ 2. Метод потенциальных функций 84
§ 3. Обзор некоторых методов таксономии 85
Глава 6. Методы выбора признакового пространства 88
§ 1. Оценка признаков по коэффициентам разделяющей
функции 88
§ 2. Прочие методы 90
Глава 7. Прикладные задачи распознавания образов 93
§ 1. Применение методов распознавания образов для учёта
плохо формализуемых ограничений в алгоритмах
оптимального планирования 94
§ 2. Задачи медицинской диагностики и управления
процессом лечения 97
Список литературы 99
101
УДК 004.93:51
Μ139
Вл. Д. Мазуров· Математические методы распознавания образов.
Уч. пособ. 2-е изд., доп. и перераб. - Екатеринбург: Изд-во Урал,
ун-та, 2010.-101 с.
В учебном пособии излагаются основные математические
модели и методы решения задач распознавания образов
© Мазуров Вл. Д., 2010
Мазуров Владимир Данилович
Математические методы распознавания образов
Учебное пособие
Редактор Н. Алексеева
Подписано в печать 10.09.2010 Формат 60x34 1/16
Уч.издл. 7,8 Усл.печ.л. 6,4 Тираж 100 экз. Заказ 93