/


























































































































































































































































































































Tags: приборы, устройства, аппараты с механизмами передачи или с подвижными механизмами информатика алгоритмы дискретная математика
ISBN: 5-85746-761-6
Year: 2004




Text
Т.Ч. Ху
М.Т. Шинг
КОМБИНАТОРНЫЕ
АЛГОРИТМЫ
Combinatorial
Algorithms
ENLARGED SECOND EDITION
T.C. HU
Department of Computer Science
Univerity of California, San Diego
M.T.SHING
Department of Computer Science
Naval Postgraduate School
Monterey, California
DOVER PUBLICATIONS, INC.
Mineola, New York
т.ч.ху, м.т. Шинг
комбинаторные
алгоритмы
Перевод с английского
В.Е.Алексеева, Н.Ю.Золотых,
СВ. Сорочана, В.А. Таланова,
В.Н.Шевченко, А.А.Яценко
Нижний Новгород
Издательство Нижегородского госуниверситета
им. Н.И.Лобачевского
2004
УДК 681.142.2 + 519.682.1
Ху Т.Ч., Шинг М.Т. Комбинаторные алгоритмы / Пер. с англ. —
Нижний Новгород: Изд-во Нижегородского госуниверситета им. Н.И. Лобачевского
2004. - 330 с.
ISBN 5-85746-761-6
Книга представляет собой перевод второго расширенного и дополненного
издания распространенного на Западе учебника американских математиков Т.Ч. Ху и
М.Т. Шинга.Цервое издание (1982) на русский язык не переводилось. Книга
посвящена алгер^$да* дискретной матемадаси {кратчайшие пути я потом в сетях,
динамическое прогр>аммирование, поиск с возвратом, бинарные деревья,
эвристические алгоритмы, матричное ^умножение, NP-полные задачи, локальные алгоритмы,
деревья Гомори-Ху) н может использоваться как учебник но курсу «Анализ и
разработка алгоритмов» и как справочник. Весь материал изложен в классических
традициях учебной литературы. Многие результаты на русском языке излагаются
впервые.
Для студентов, аспирантов и научных работников, специализирующихся по
дискретной математике и информатике.
Издание осуществлено при финансовой поддержке
Российского фонда фундаментальных исследований
по проекту &03-01-Ц084
рс££>и
©
©
ISBN 0-486-41962-2 (англ.)
ISBN 5-85746-761-6 (рус.)
Т. С. Ни, 1982
Т. С. Ни, Man-Tak Shing, 2002,
главы 9,10, приложение
B. Е. Алексеев, Н. Ю. Золотых,
C. В. Сорочан, В. А. Таланов,
В. Н. Шевченко, А. А. Яценко, 2004,
перевод
Оглавление
Предисловие к русскому изданию 8
Предисловие к первому изданию 11
Предисловие ко второму изданию 13
Глава 1. Кратчайшие пути в графах 15
1.1. Терминология теории графов 15
1.2. Кратчайший путь 17
1.3. Кратчайшие пути между всеми парами узлов 23
1.4. Алгоритм декомпозиции , 28
1.5. Ациклические сети 34
1.6. Кратчайшие пути в общей сети 35
1.7. Минимальное остовное дерево 38
1.8. Поиск в ширину и поиск в глубину 41
Упражнения 42
Литература 44
Ответы 47
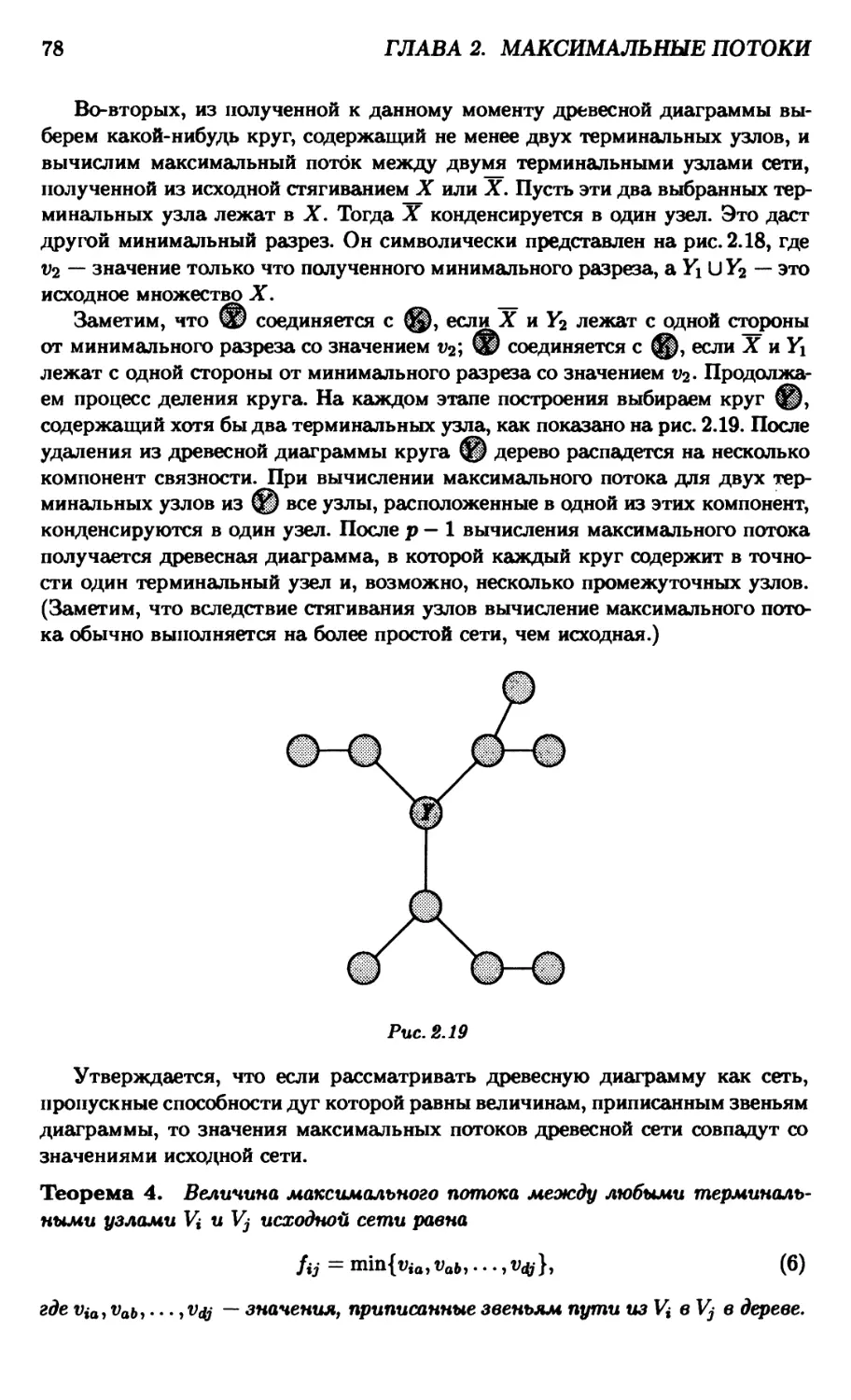
Глава 2. Максимальные потоки 48
2.1. Максимальные потоки 48
2.2. Алгоритмы нахождения максимального потока 54
2.2.1. Алгоритм Форда-Фалкерсона 55
2.2.2. Алгоритм Карзанова 61
2.2.3. МРМ-алгоритм 65
2.2.4. Анализ алгоритмов 66
2.3. Многотерминальные минимальные потоки 69
2.3.1. Реализуемость (Гомори и Ху [12]) 70
2.3.2. Анализ (Гомори и Ху [12]) 72
2.3.3. Синтез (Гомори и Ху [12]) 83
2.3.4. Многопродуктовые потоки 89
2.4. Потоки с минимальной стоимостью 90
2.5. Приложения 92
2.5.1. Множества различных представителей 93
2.5.2. PERT-метод 95
2.5.3. Оптимальное коммуникационное остовное дерево .... 99
6 ОГЛАВЛЕНИЕ
Упражнения 104
Литература 105
Ответы * 107
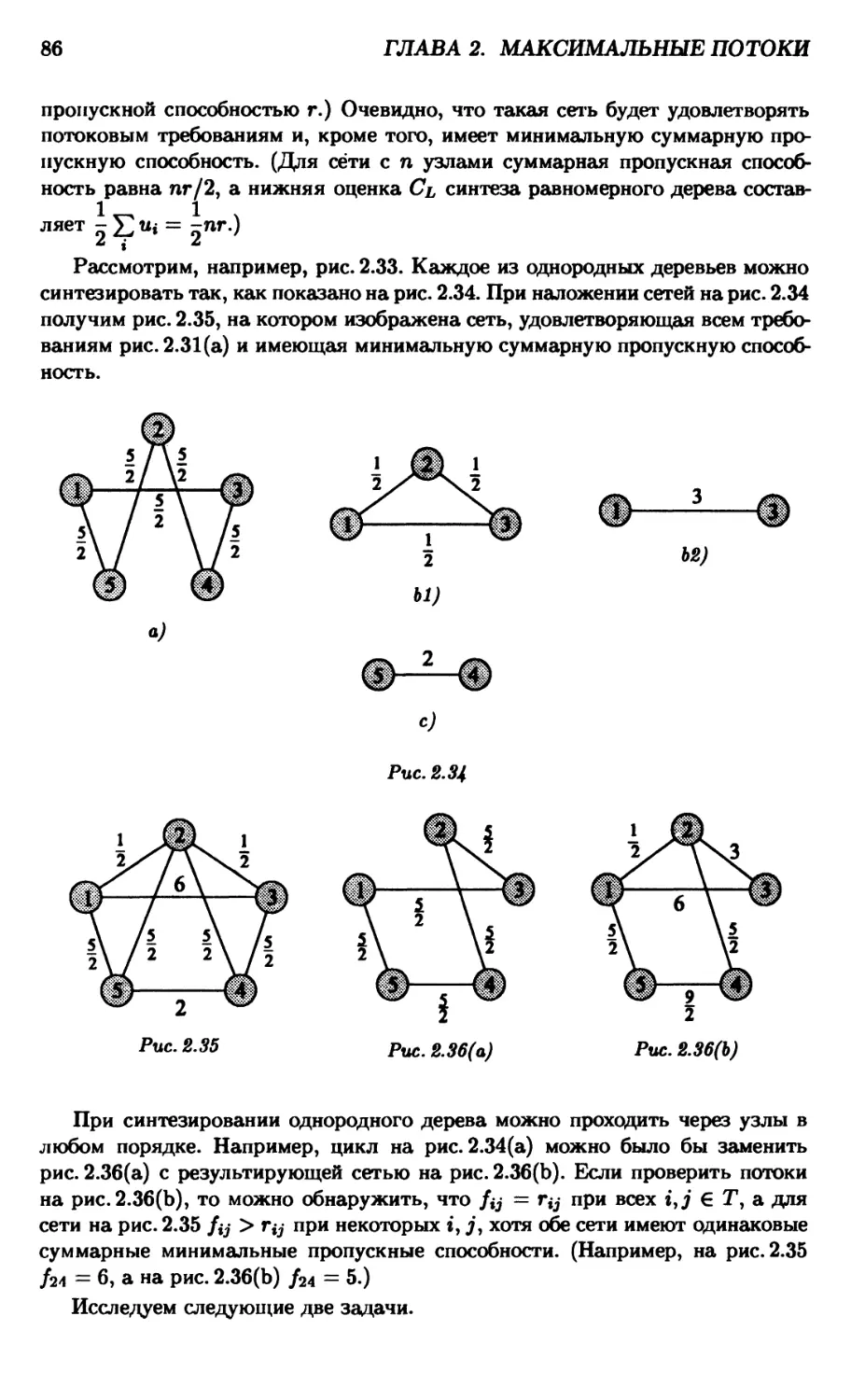
Глава 3. Динамическое программирование 109
3.1. Введение 109
3.2. Задача о рюкзаке 115
3.3. Задача о двумерном рюкзаке 123
3.4. Алфавитные деревья минимальной стоимости 129
3.5. Резюме 133
Упражнения 133
Литература 134
Ответы 135
Глава 4. Поиск с возвращением 137
4.1. Введение 137
4.2. Оценивание эффективности 143
4.3. Ветви и границы 145
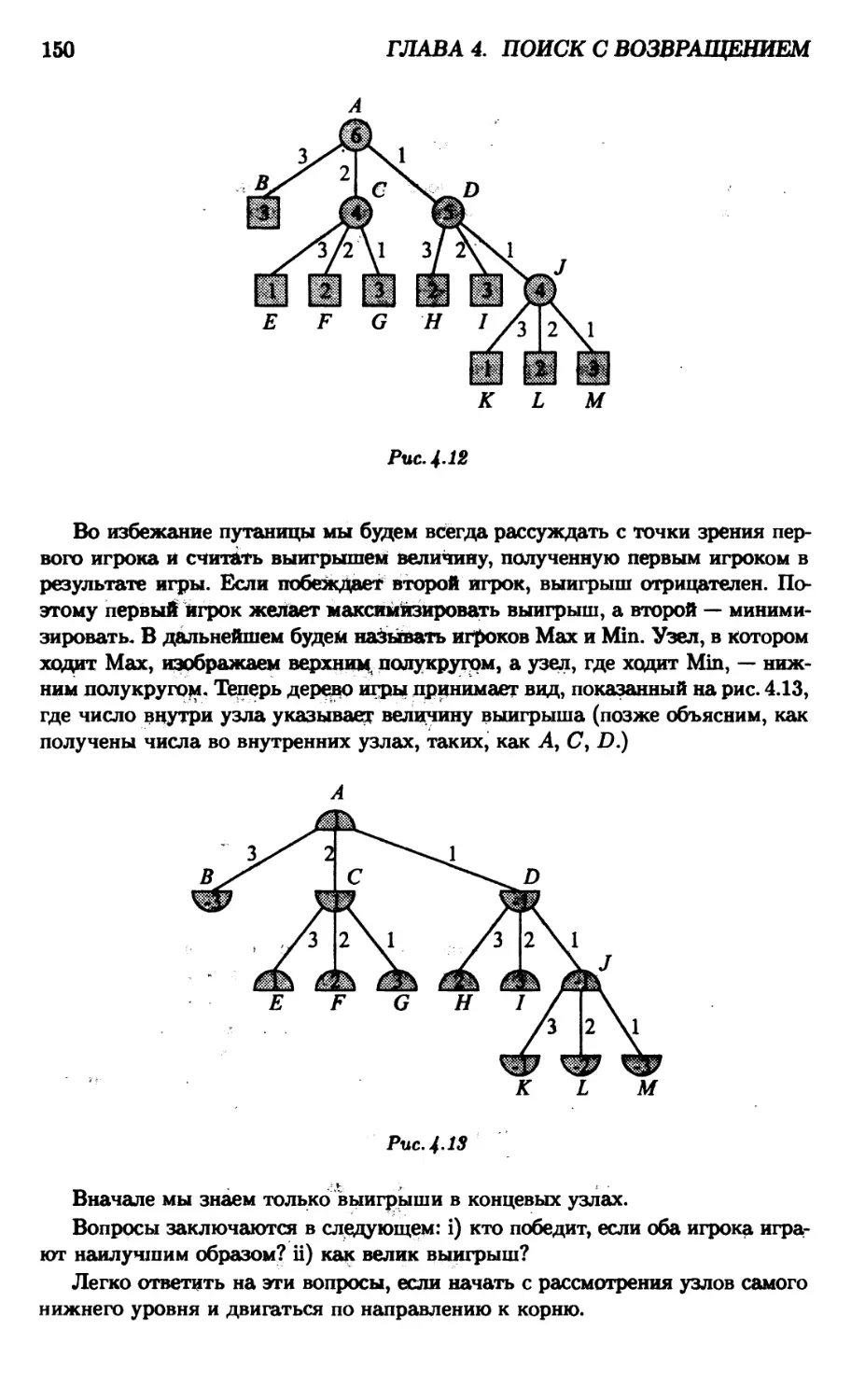
4.4. Дерево игры 149
Упражнения 154
Литература 155
Глава 5. Бинарные деревья 156
5.1. Введение 156
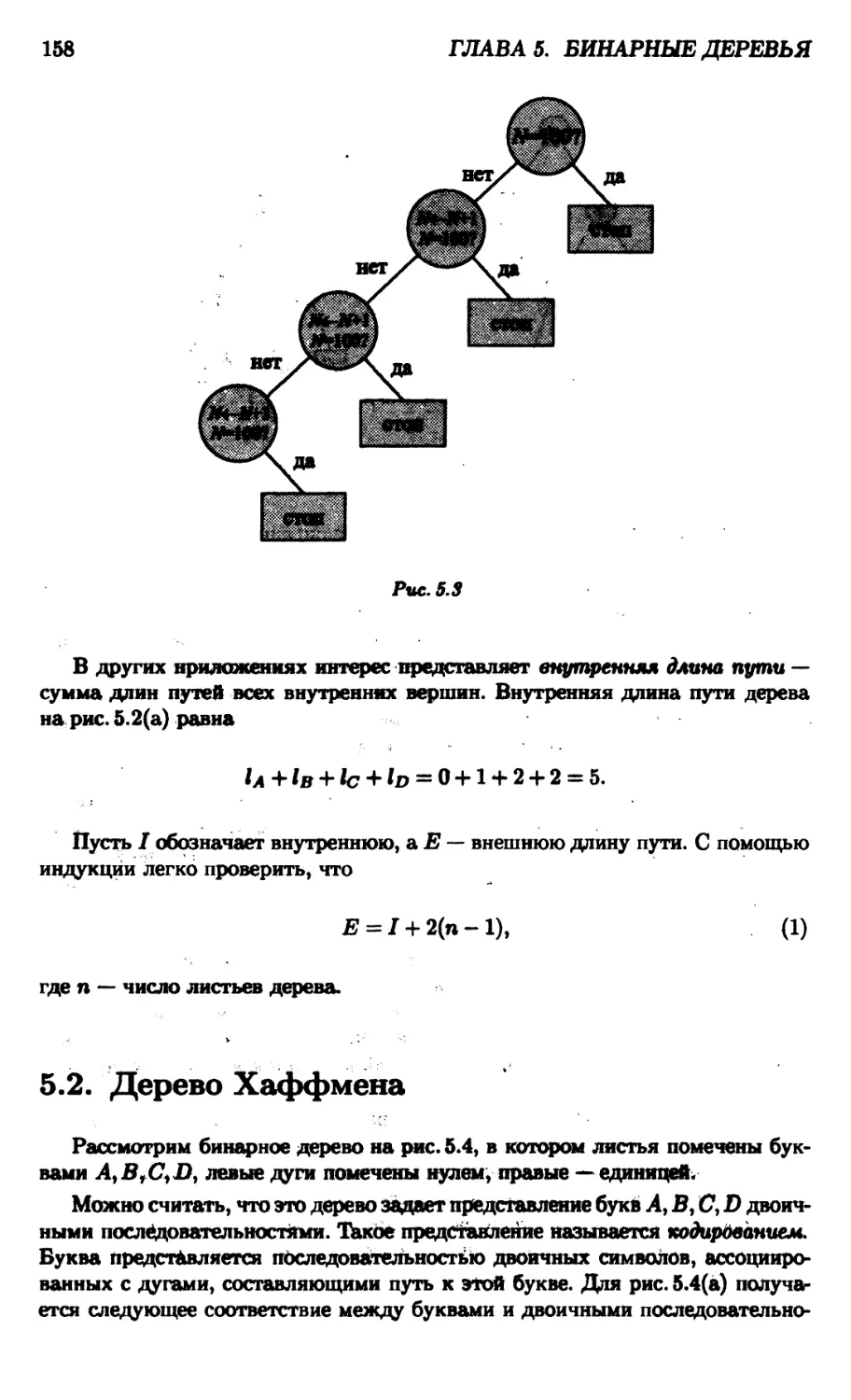
5.2. Дерево Хаффмена 158
5.3. Алфавитные деревья 164
5.4. Алгоритм Ху-Таккера 166
5.5. Допустимость и оптимальность 172
5.6. Алгоритм Гарсиа и Уочса 179
5.7. Регулярные функции стоимости 182
5.8. t-арные деревья и другие результаты 184
Упражнения 187
Литература 187
Ответы 189
Глава 6. Эвристические алгоритмы 190
6.1. Жадные алгоритмы 190
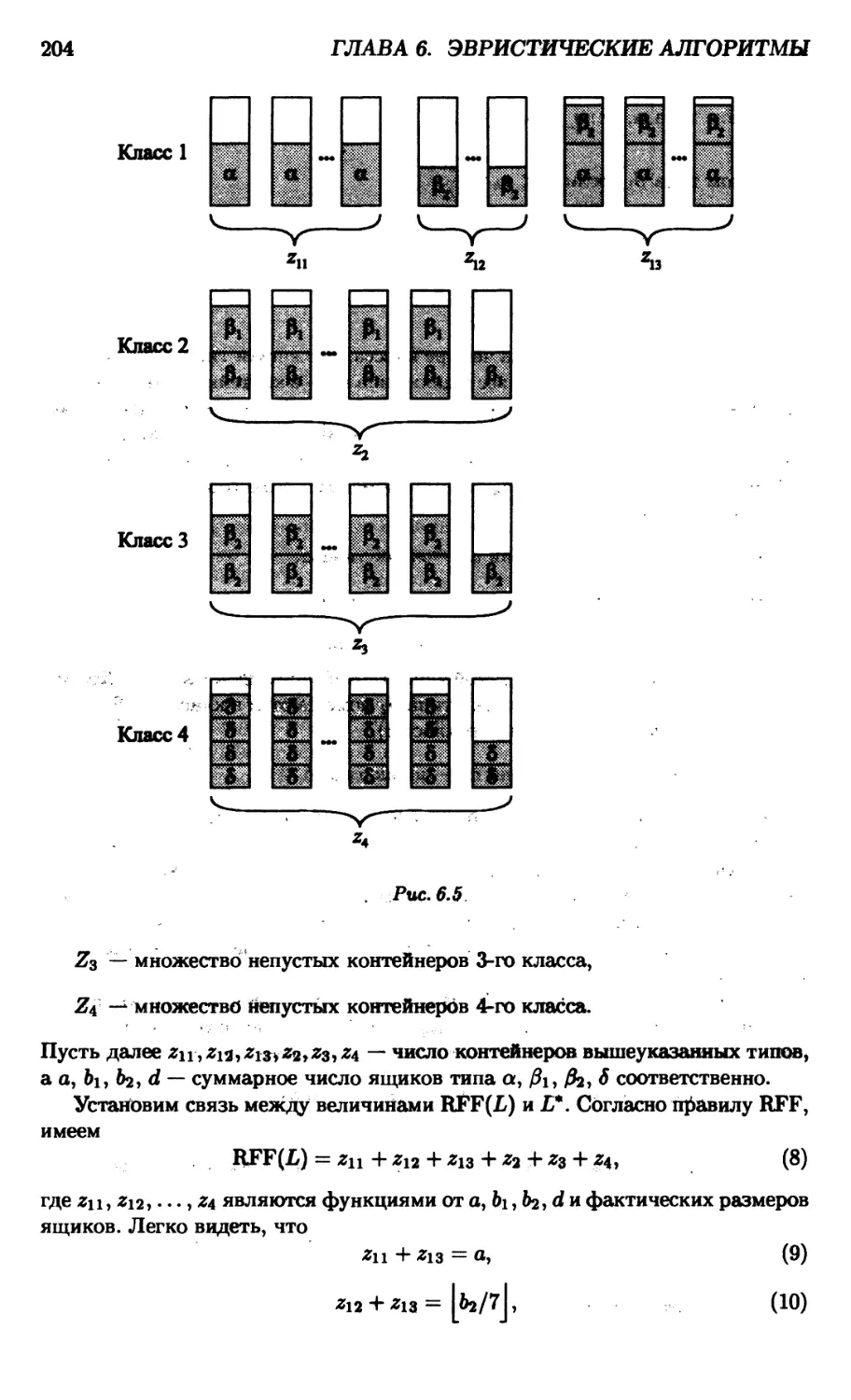
6.2. Задача об упаковке 197
6.3. Задача о составлении расписания 209
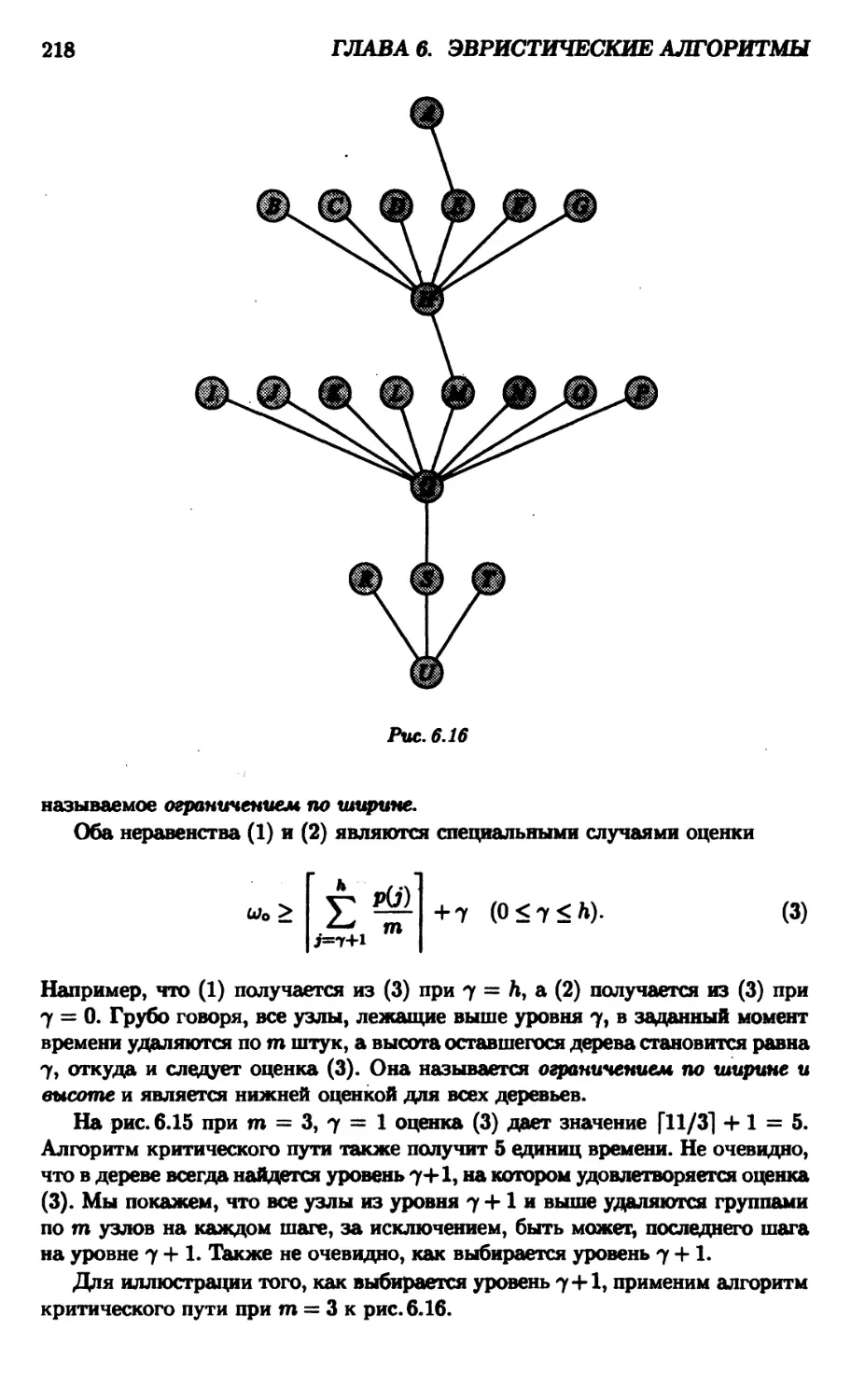
6.4. Расписание с древесными ограничениями 215
Упражнения 221
Литература 222
Глава 7. Матричное умножение 224
7.1. Алгоритм Штрассена умножения матриц 224
7.2. Оптимальный порядок умножения матриц 226
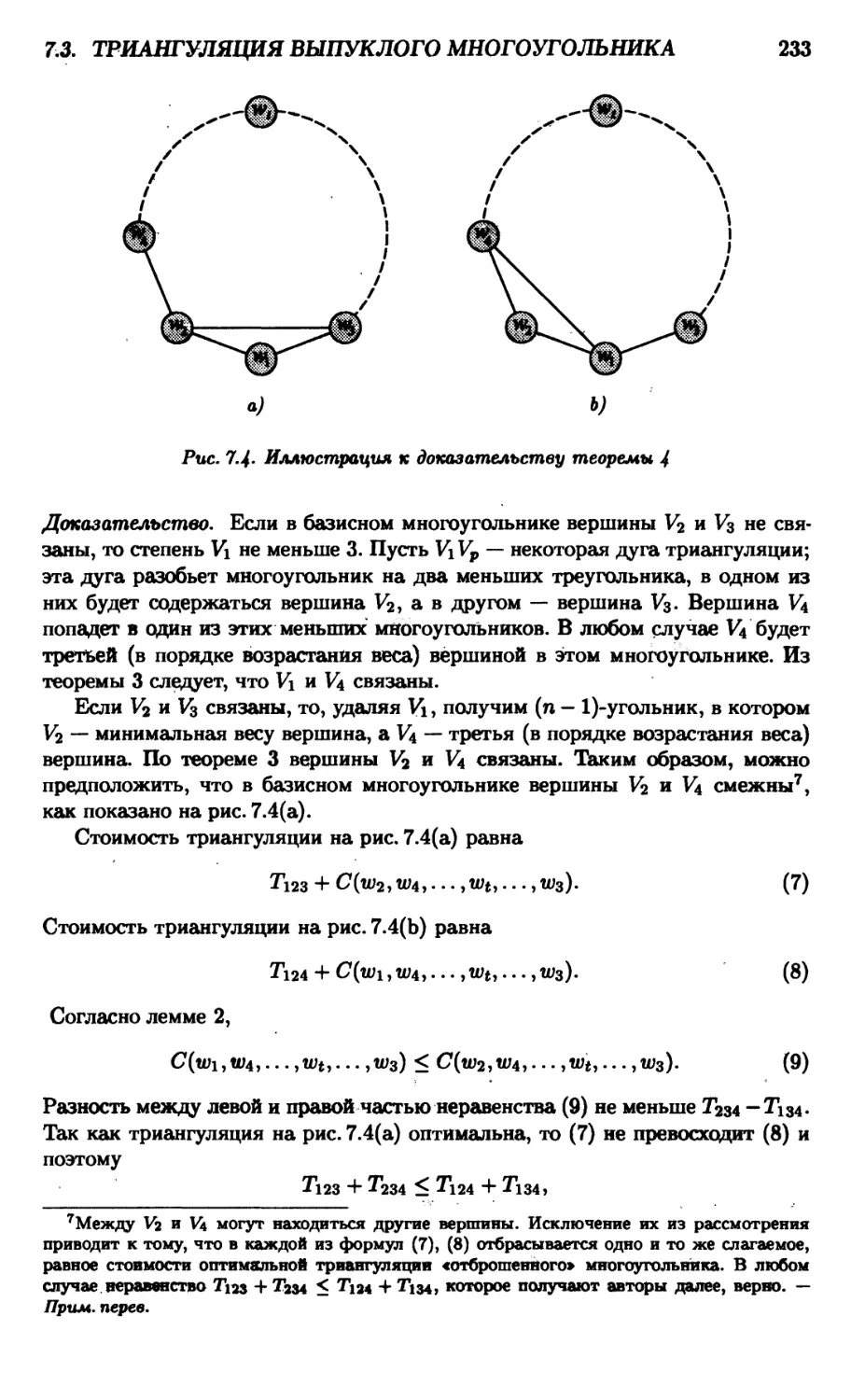
7.3. Триангуляция выпуклого многоугольника 227
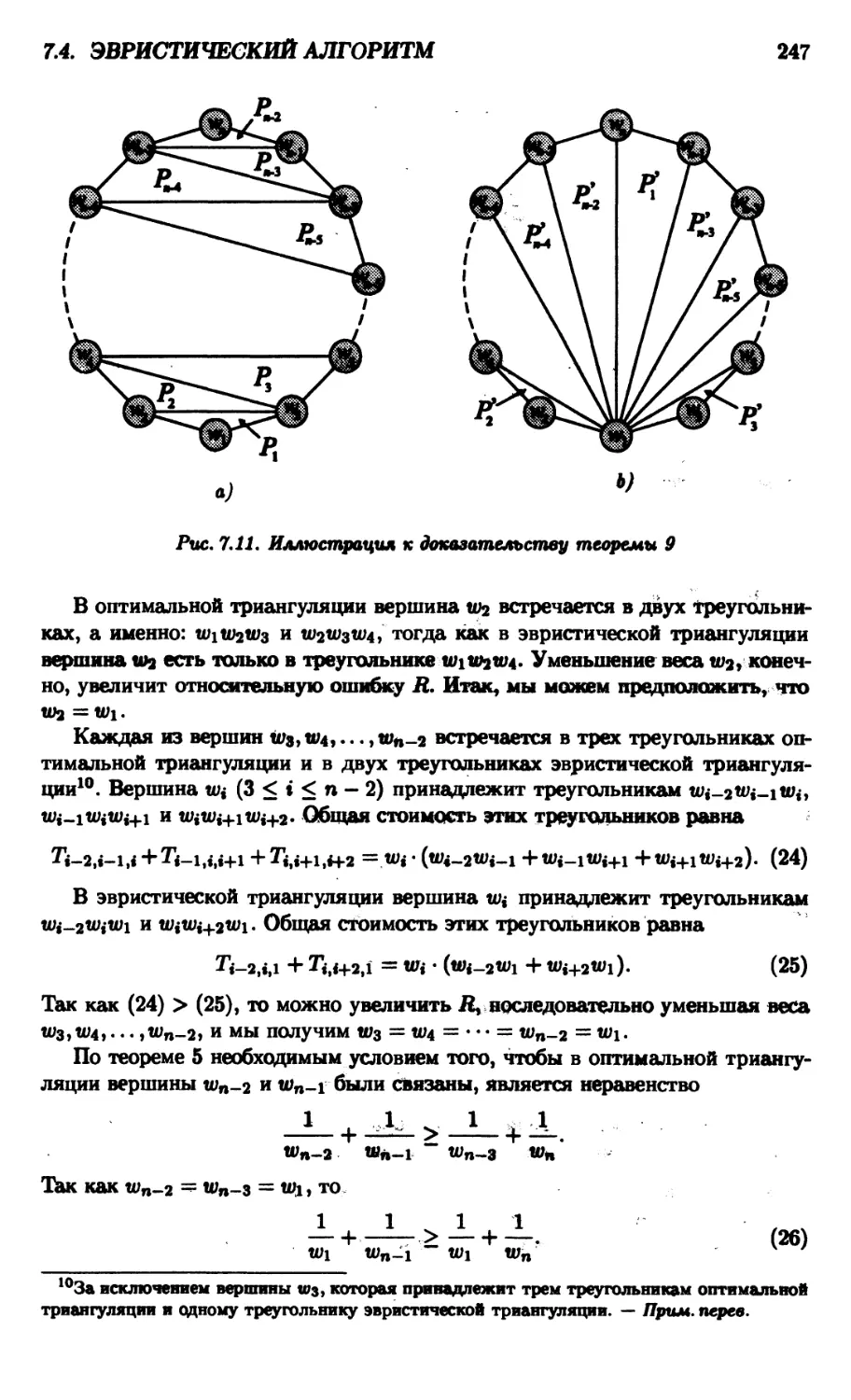
7.4. Эвристический алгоритм 238
ОГЛАВЛЕНИЕ 7
Упражнения 249
Литература 250
Ответы 251
Глава 8. JVP-полнота 252
8.1. Введение 252
8.2. Полиномиальные алгоритмы 255
8.3. Недетерминированные алгоритмы 257
8.4. JVP-полные задачи 258
8.5. Как решать JVP-полную задачу? 261
Литература 263
Глава 9. Алгоритмы локального индексирования 265
9.1. Объединение алгоритмов 265
9.2. Максимальные потоки и минимальные разрезы 268
9.3. Смежность и разделение 270
Глава 10. Дерево Гомори-Ху 277
10.1. Древесные ребра и древесные звенья 277
10.2. Стягивание 281
10.3. Доминирование 282
10.4. Эквивалентные формулировки 284
10.4.1. Оптимальное объединение компаний 284
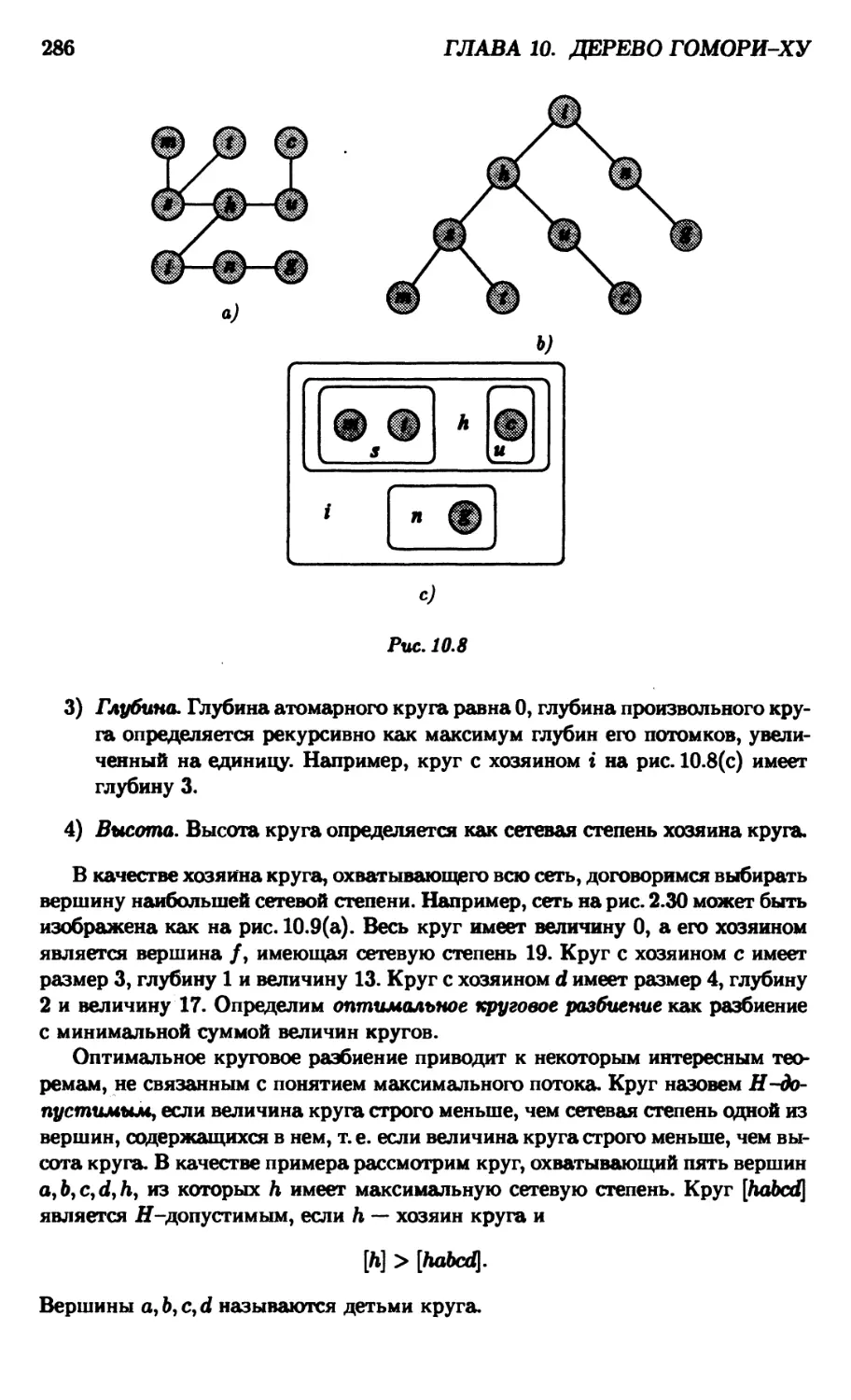
10.4.2. Оптимальное круговое разбиение 285
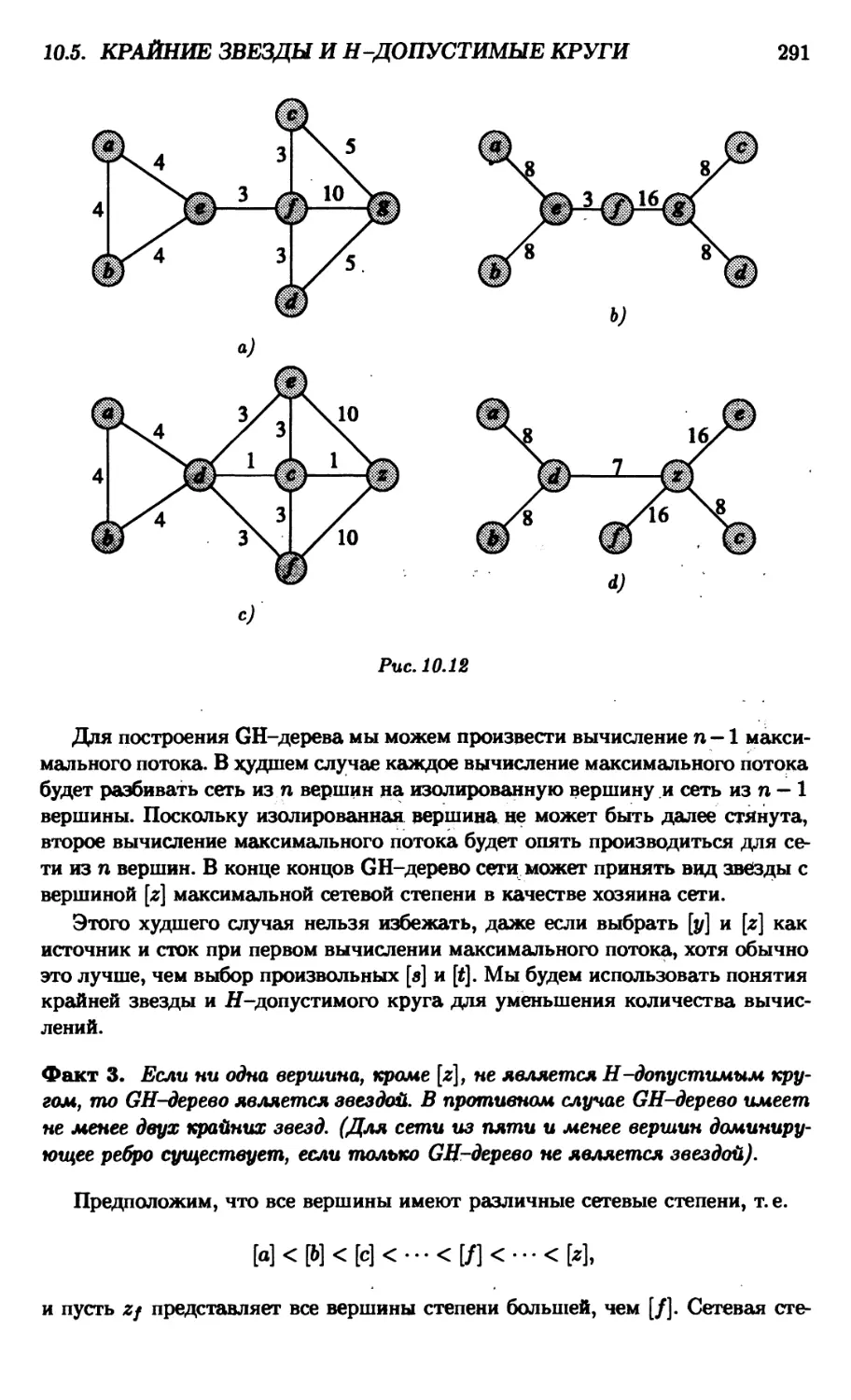
10.5. Крайние звезды и Я-допустимые круги 290
10.6. Высокоуровневый подход 295
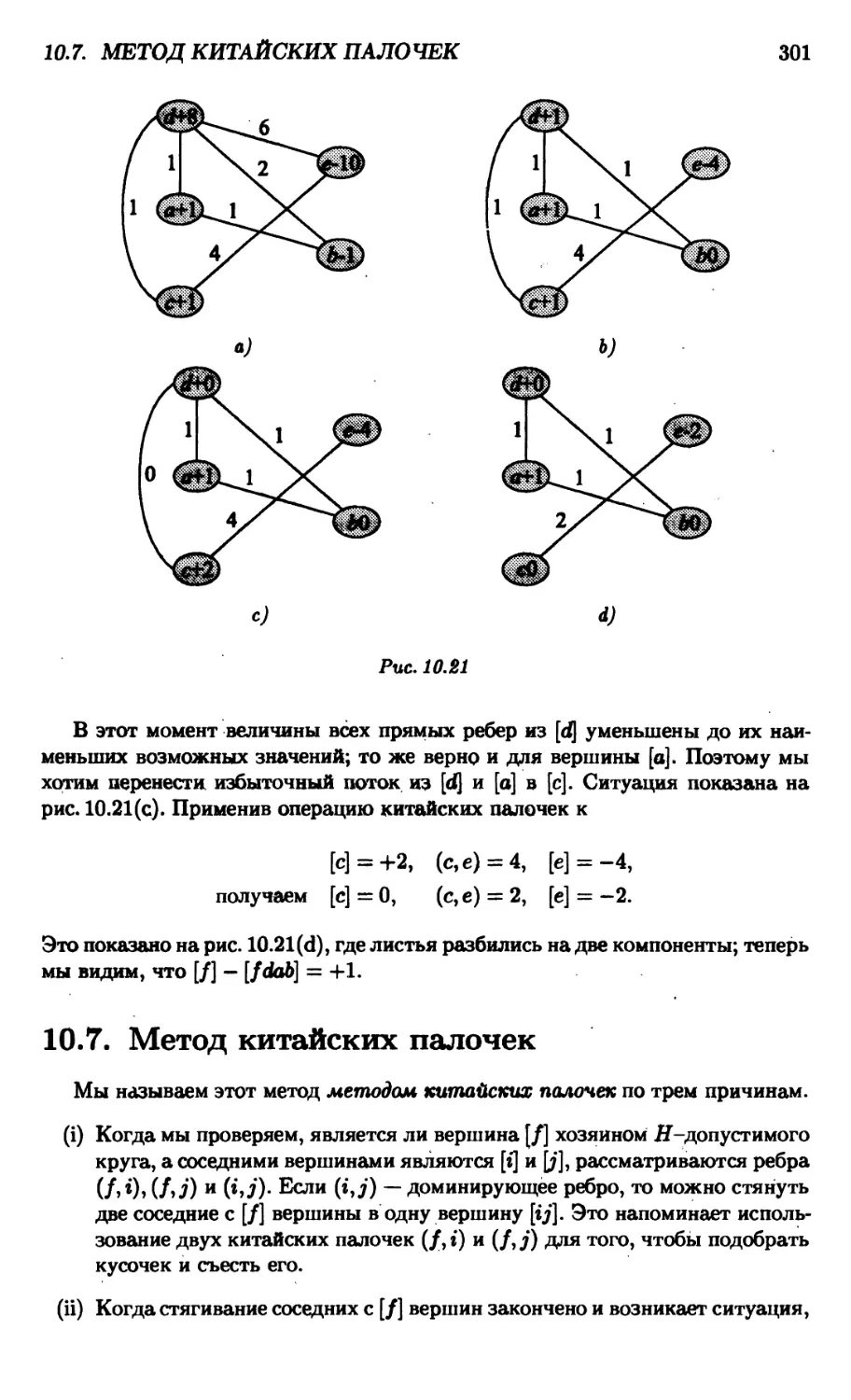
10.7. Метод китайских палочек 301
10.8. Взаимодействие между фазами 304
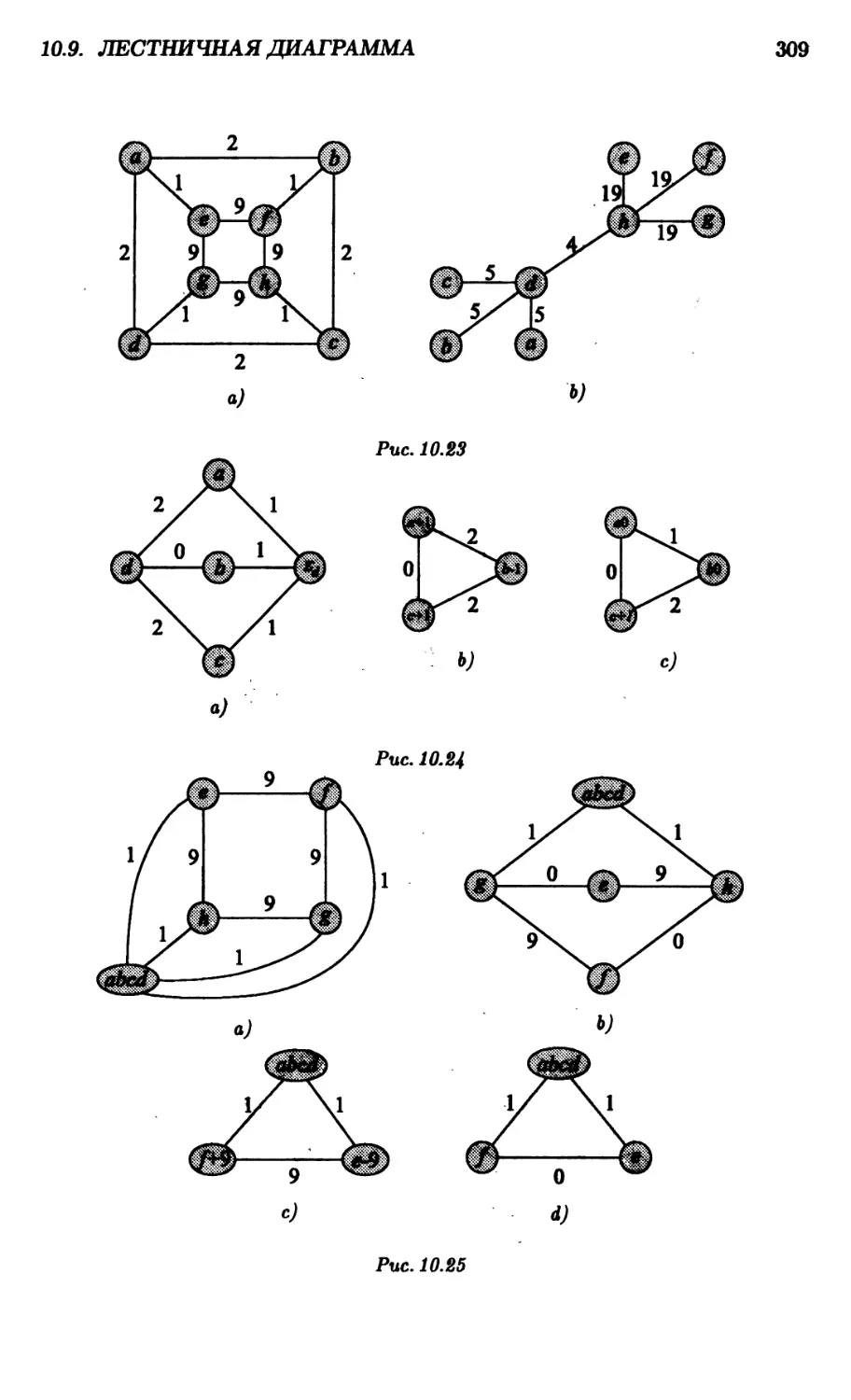
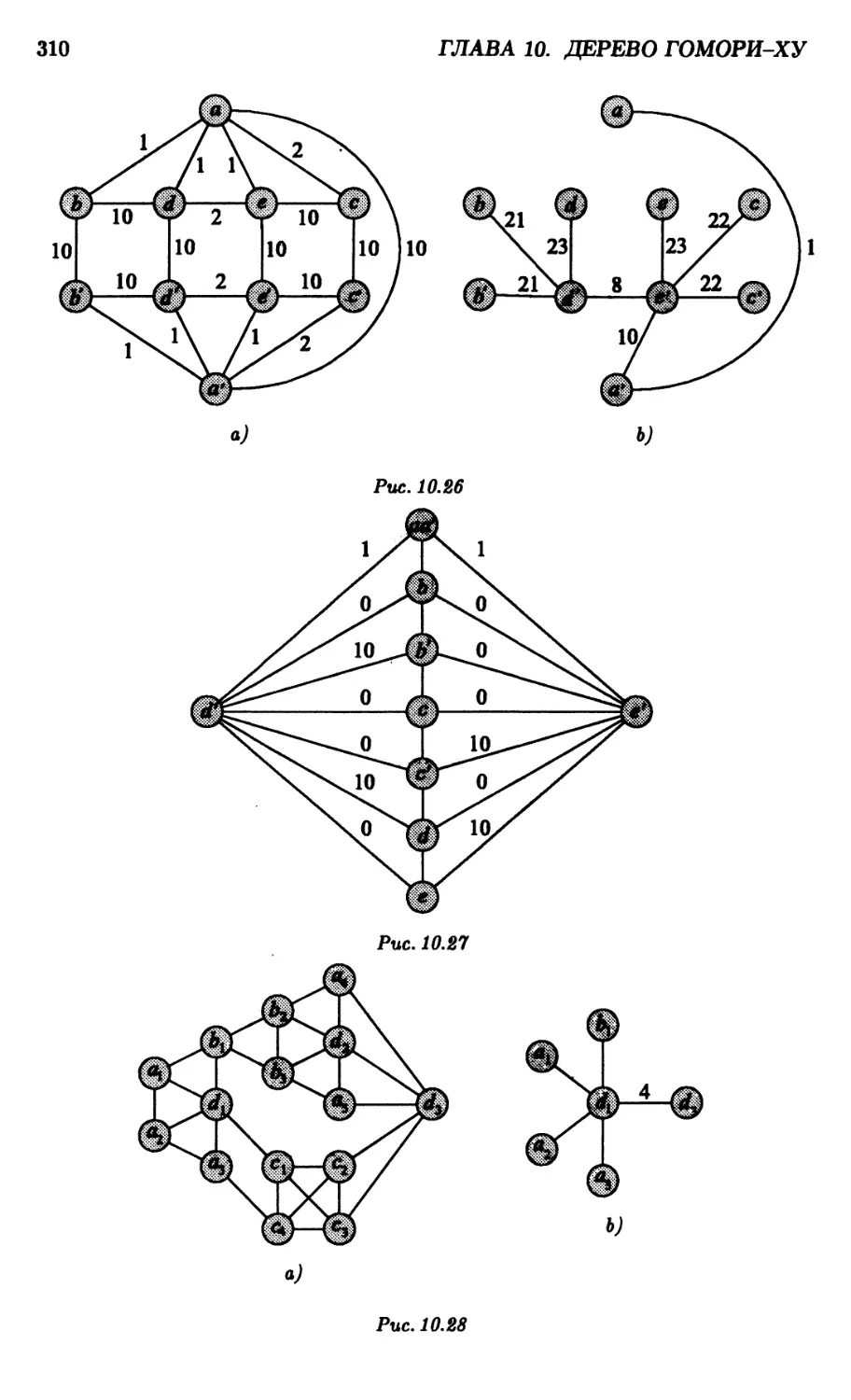
10.9. Лестничная диаграмма 306
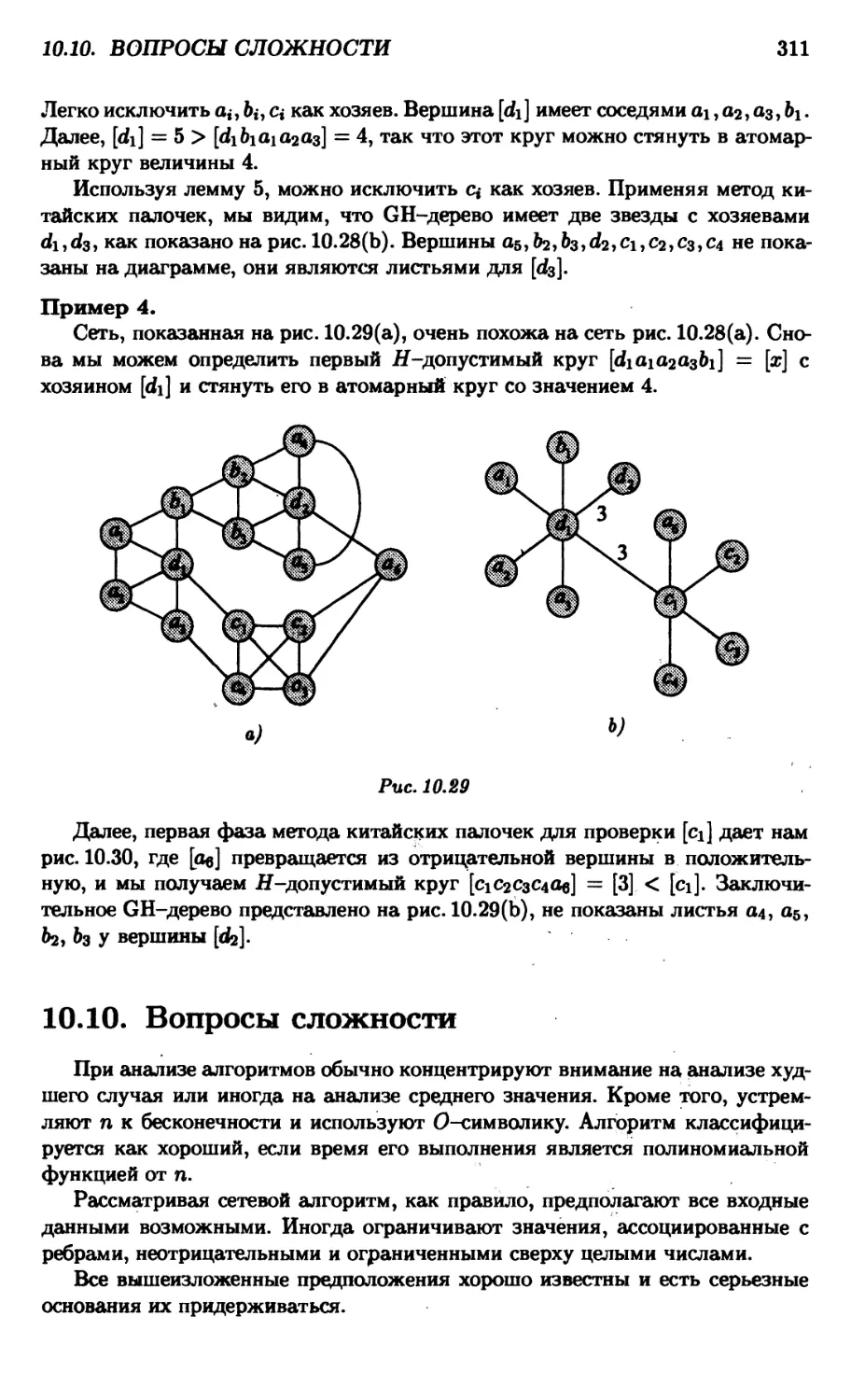
10.10.Вопросы сложности 311
Приложение А. Замечания к главам 2, 5, 6 314
АЛ. Деревья предшественников 315
А.2. Минимальная поверхность или задача о плато 316
А.З. Дополнения к главе 5 316
А.3.1. Простое обоснование алгоритма Ху-Таккера 317
А.3.2. Бинарные деревья поиска 318
А.3.3. Бинарный поиск на ленте 319
А.4. Комментарии к разделу 6.2 320
Приложение В. Сетевая алгебра 322
Литература, добавленная при переводе 324
Предметный указатель 326
Предисловие
к русскому изданию
Вниманию российского читателя предлагается перевод второго
расширенного и дополненного издания распространенного на Западе учебника
американских математиков Т. Ч. Ху и М. Т. Шинга — специалистов в области
сетевых алгоритмов и целочисленного линейного программирования. Первое
издание монографии (1982) на русский язык не переводилось.
Первый автор хорошо известен отечественному читателю по переводу его
замечательной книги «Целочисленное программирование и потоки в сетях»
[31*]1, сыгравшей большую роль в знакомстве отечественного читателя с
новыми разделами дискретной математики.
Книга посвящена алгоритмам дискретной математики и может
использоваться как учебник по курсу «Анализ и разработка алгоритмов» и как
справочник. В некоторых разделах книги принят «легкий», образный стиль
изложения с минимумом формализма (но не в ущерб математической строгости),
приводится много примеров и иллюстраций. Это мобилизует интуицию
читателя и помогает ему быстро постичь идейную суть излагаемых методов.
Несмотря на то, что на русском языке имеются разного уровня и объема
учебники, отражающие рассматриваемую тематику, например, [2*}, [3*], [20*],
[23*], [26*], [28*], данная книга отличается сбалансированным объемом,
глубиной проработки математических вопросов, отбором материала,
оригинальностью построений, обобщающих существовавшие ранее методы, хорошим
математическим языком, а главное — содержит новые математические результаты,
полученные авторами книги. Весь материал изложен в хороших традициях
учебной литературы. Содержание глав 9,10 и приложения Б не только
никогда ранее не излагалось на русском языке, но и не встречалось ни в статьях,
ни в других публикациях по-английски.
Перевод и научное редактирование выполнены на кафедре математиче-
1 Здесь и далее номер в квадратных скобках со знаком * является ссылкой на список
литературы на с. 324, добавленной при переводе. Номер в квадратных скобках без такого
знака отсылает к библиографии, размещенной в конце каждой главы. — Прим. перев.
ПРЕДИСЛОВИЕ К РУССКОМУ ИЗДАНИЮ
9
ской логики и высшей алгебры факультета вычислительной математики и
кибернетики Нижегородского государственного университета им. Н.И.
Лобачевского.
Коллектив переводчиков благодарит проф. Т.Ч. Ху за сотрудничество. Мы
искренне признательны С.А.Белову за ценные советы при переводе книги.
Именно он предложил нам перевести «one-sweep algorithm» как «алгоритм
"одним махом"». Большую помощь нам оказал М.А. Алексеев, которому мы
особенно благодарны.
Переводчики
1 июня 2004 г.
Доктору Р. Е. Гомори,
который преподавал мне
целочисленное программирование
Моему брату Дейи Ху,
который давал мне уроки английского
Памяти моей тети Ю-Фен Ху,
которая учила меня алгебре и геометрии
Памяти моих родителей,
Квонг и Мей-Юнг,
которые дали мне крылья
Моей жене Дон и моим детям
Эндрю и Лесли —
ветру для моих крыльев
Предисловие
к первому изданию
В этой книге представлены некоторые комбинаторные алгоритмы,
встречающиеся в информатике и исследовании операций. Особое внимнаие уделяется
выявлению интуитивных идей, лежащих в основе алгоритмов, и иллюстрации
их численными примерами. В отдельном руководстве описаны реализации
алгоритмов на языке PASCAL. Знакомство с линейным программированием и
сложными структурами данных не предполагается. Ббльшая часть
материала может использоваться при обучении студентов, более сложные разделы
доступны для аспирантов. Главы можно читать отчасти независимо, поэтому
преподаватель может выбрать некоторое подмножество глав для своего курса.
Книга может быть полезна и как справочник, поскольку она содержит много
информации, отсутствующей в журналах и других книгах.
Первую и вторую главы можно использовать в семестровом курсе по
теории сетей или алгоритмам на графах. В первой главе рассматриваются
некоторые задачи о кратчайших путях и излагается алгоритм разложения
больших разреженных сетей. Вторая глава посвящена потокам в сетях и содержит
много нового материала, например, алгоритмы Диница и Карзанова, ранее не
встречавшиеся в англоязычной литературе, оптимальное коммуникационное
остовное дерево и описание технологии сетевого планирования PERT в
терминах длиннейших путей и разрезов наименьшей стоимости. Во второй главе
также имеется раздел о многотерминальных потоках.
В третьей и четвертой главах рассматриваются два общих метода
оптимизации: динамическое программирование и поиск с возвращением (метод
ветвей и границ). Обе эти темы обычно детально не изучаются на
программистских факультетах. Понятие динамического программирования вводится
в третьей главе при рассмотрении специально подобранных примеров,
показывающих разнообразие решаемых этим методом задач. После решения задачи
о рюкзаке обсуждается периодическая природа ее решений. Решение
двумерной задачи о рюкзаке основано на статьях Гилмора и Гомори. Глава
заканчивается кратким обсуждением работы доктора Ф. Ф.Яо. Четвертая глава
12
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
включает в себя стандартный материал по бэктрекингу и детальное описание
а-/?-отсечения в дереве игры. В ней дается также пример применения метода
Монте-Карло для оценивания размера дерева решений.
Пятая и шестая главы содержат много нового материала, который будет
интересен специалистам в области информатики и исследования операций. В
пятой главе описаны алгоритмы Хаффмена и Ху-Таккера, включая новую
фазу перестройки, и обобщение обоих алгоритмов на регулярные функции
стоимости. Обобщение основано на статье Ху, Клейтмана и Тамаки. Здесь
также описывается и иллюстрируется конструкция Гарсиа-Уочса. В шестой
главе идет речь об эвристических алгоритмах. В ней приводится
одноточечная теорема Мэгэзина, Немгаузера и Троттера и новый алгоритм упаковки,
принадлежащий Яо. Изложение задачи теории расписаний с древесным
упорядочением работ является пересмотренной версией статьи Ху, опубликованной
в 1961 году.
Тема седьмой главы — умножение матриц. Мы излагаем два
комбинаторных результата: алгоритм Штрассена умножения двух больших матриц и
результаты об оптимальном порядке умножения цепочки матриц различных
размеров. С помощью динамического программирования последнюю задачу
можно решить за время 0(п3), однако комбинаторный подход приводит к
алгоритму трудоемкости 0(п log п). Задача нахождения оптимального порядка
умножения матриц достойна отдельной книги, но мы приводим лишь
основные теоремы и эвристический алгоритм трудоемкости 0(п) с ошибкой 15%.
В заключительной восьмой главе вводится понятие JVP-полной задачи.
Здесь преследуется цель дать читателю только интуитивное представление,
поскольку имеются книги, в которых этот предмет излагается подробно.
Автор выражает благодарность всем, кто помогал в работе над этой
книгой: Национальному фонду науки и доктору J. Chandra, доктору P. Boggs из
Научно-исследовательского центра армии США за финансовую поддержку,
докторам F. Chin, S. Dreyfus, F. Ruskey, W. Savitch, A. Tucker, M. Wachs, F. Yao
за прочтение различных частей книги, профессору L. Е. Trotter, Jr., и
профессору Andrew Yao за прочтение близкого к окончательному варианта всей
книги и множество ценных предложений, миссис Магу Deo за участие в
редактировании более ранних версий, миссис Annette Whiteman за отличный
технический набор большого числа вариантов книги, мисс Sue Sullivan за переработку
материалов в книжный формат в системе UNIX, мистеру Y. S. Кио за
подготовку предметного указателя и перечитывание частей руководства и, наконец,
в особенности, доктору Man-Tak Shing за перечитывание руководства, а также
за техническую и общую помощь в течение всей работы над книгой.
Т.Ч.Ху
Ла Хойа, Калифорния
19 октября 1981 г.
Предисловие
ко второму изданию
Пересмотренное и расширенное издание является в действительности
новой книгой, так как в нем добавлены две новые главы (9 и 10), материалы
которых никогда не публиковались. Новый материал является результатом
исследований авторов в течение последних семи лет. Девятая глава представляет
несколько хорошо известных алгоритмов в унифицированной форме,
приглашая читателя к комбинированию и изобретению новых алгоритмов. В десятой
главе рассматривается задача нахождения минимальных разрезов в сети. В
большинстве статей о потоках в сетях вначале находится поток, а затем на
основе теоремы Форда и Фалкерсона о максимальном потоке и
минимальном разрезе ищется минимальный разрез. В десятой главе целью является
нахождение п — 1 фундаментальных минимальных разрезов
неориентированной сети, т. е. дерева Гомори-Ху. Сдача рукописи девятой и десятой глав была
задержана более чем на год, и все-таки наши исследования минимальных
разрезов пока далеки от завершения. Можно надеяться, что наши результаты
будут интересны многим читателям.
Это издание имеет два новых приложения. Приложение А дополняет
материалы первых восьми глав первого издания. В приложении Б речь идет о
предмете, который мы называем сетевой алгеброй. Как в векторных
пространствах есть векторы и скаляры, в сетевой алгебре имеются циклы и ребра. В
специальном случае трех циклов и одного ребра получается двузначная
логика булевой алгебры. Из-за временных и пространственных ограничений мы
смогли только описать интуитивные идеи и проиллюстрировать их
численными примерами. Многое в этом направлении еще предстоит сделать. Авторы
надеются, что позднее они смогут написать об этом новую книгу.
Авторы приняли предложение издательства Dover, отдавая должное его
традиции издания важных классических трудов по очень низким ценам.
Многие читатели указали на ошибки (в этом издании они исправлены) и
предложили ценные замечания. Авторы выражают особую благодарность доктору
Paul A.Tucker, который проработал с ними в период с 1996 по 1999 год и
14
ПРЕДИСЛОВИЕ КО ВТОРОМУ ИЗДАНИЮ
подготовил технический отчет CS99-625 в июне 1999 года. Стоит также
отметить работу мистера Robert Ellis, который сделал оригинал-макет новых
материалов и внес важные технические предложения.
Авторы надеются, что читатели присоединятся к ним в исследованиях в
области комбинаторных алгоритмов и, в частности, сетевой алгебры и ее
приложений.
Т.Ч.Ху
М. Т. Шине
Ла Хойа и Монтерей, Калифорния
22 ноября 2001г.
Глава 1
Кратчайшие пути в графах
Нет кратчайшего пути к успеху.
1.1. Терминология теории графов
Пытаясь решить какую-нибудь проблему, мы часто рисуем граф. Граф
нередко является простейшим и наиболее ясным способом описания
системы, структуры или ситуации. Китайская поговорка «рисунок полезнее тысячи
слов» вполне оправдывается в математическом моделировании. Именно
поэтому теория графов имеет многочисленные применения в физике, биологии и
социальных науках. Большое разнообразие приложений приводит и к
разнобою в терминологии. Работы по теории графов переполнены определениями,
и каждый автор предпочитает свои собственные. Ниже мы вводим
минимальный набор интуитивно ясных определений. Применяемые здесь обозначения
и терминология близки к используемым Кнутом [18].
Граф состоит из конечного множества вершин и множества ребер,
соединяющих вершины. Мы будем изображать вершины маленькими кружками,
а ребра — линиями. Система или структура часто могут быть представлены
графом, в котором линии указывают отношения между вершинами
(элементами системы). Например, вершины могут представлять города, а ребра —
соединяющие их дороги. Мы можем также представлять вершинами людей и
соединять ребром две вершины, если соответствующие люди знакомы друг с
другом.
Читатель должен понимать, что теория графов есть теория отношений, а
не теория определений; однако без минимального числа определений не
обойтись. Вершины называют также узлами, а ребра — дугами, ветвями или
связями. Мы предполагаем обычно, что в графе G имеется п вершин, каждые
две вершины соединены не более чем одним ребром и нет ребер, соединяющих
вершину с ней самой. Вершины обозначаются через V*, а ребро, соединяющее
16
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
V{ и Vj, обозначается через е#. Две вершины смежны, если они соединены
ребром (такие вершины называют также соседними); два ребра смежны,
если оба инцидентны одной и той же вершине. Вершина имеет степень к, если
ей инцидентны к ребер.
Говорят, что последовательность вершин и ребер
(Vuei2,V2,e23,V3,... ,Vn)
образует путь из V\ в Vn. Путь можно представить только его вершинами:
(VbVa,...,V„)
или только его ребрами:
(ei2>e23>-- ->en_i>n).
Граф связен, если между любыми двумя его вершинами имеется путь.
Путь имеет длину к, если в нем к ребер. Путь называется простым, если
все вершины V\, V2,..., Vn-\, Vn различны. Если V\ = Vn, то он называется
циклом. Иначе говоря, цикл — это путь длины три или больше из
некоторой вершины в эту же вершину. Бели все вершины цикла различны, то цикл
простой. Если не оговаривается противное, то в дальнейшем «путь» будет
означать простой путь, «цикл» — простой цикл, а «граф» - связный граф.
Если ребро имеет направление (подобно улице с односторонним
движением), то оно называется ориентированным ребром. Если ребро ориентировано
от V{ к Vj, то мы не можем двигаться по этому ребру от Vj к V{. Поэтому
в определении пути мы считаем, что каждое ребро или неориентированное,
или ориентировано от V{ к У«+1* Во всех остальных определениях ориентация
ребер игнорируется. Граф называется ориентированным, если все его ребра
ориентированы, и смешанным, если некоторые ребра ориентированы, а
некоторые — нет. Цикл, образованный ориентированными ребрами, называется
ориентированным циклом (или контуром). Ориентированный граф
называется ациклическим, если в нем нет ориентированных циклов. В этом разделе
слова «граф» и «ребро» означают неориентированный граф и
неориентированное ребро.
Дерево есть связный граф без циклов. Если граф имеет п вершин, то
любые два из следующих трех условий характеризуют дерево, а третье условие
следует из них.
1) Граф G связен.
2) Граф имеет п - 1 ребер.
3) Граф не имеет циклов.
Мы будем обозначать граф G = (V,E), где V — множество узлов или
вершин, а Е — множество ребер графа. Граф G1 = (V, Е1) есть подграф графа
G = (V,E), если V'CVhE'CE.
Подграф, являющийся деревом и содержащий все вершины графа,
называется остовным деревом графа. Эти определения иллюстрируются рис. 1.1.
1.2. КРАТЧАЙШИЙ ПУТЬ
17
Рис. 1.1
Имеется три пути между Vi и Vb: (Vi, V2, V4, V5), (Vi, V4, V5), (Vi, V3, V4, Vb).
Ребра ei4, в24, ^34 и в45 образуют остовное дерево, то же верно для ребер
012, е24, ^34 и в45- Еще одно остовное дерево можно составить из ребер ei2, ei3,
ез4 и в45- Вершина V\ имеет степень 3 в графе G и степень 2 в последнем
остовном дереве. Если ребро в4ь ориентировано от V± к 1^, то по-прежнему
есть три пути из V\ вУ5, но ни одного пути из V$ в V\.
В большинстве приложений с ребрами или вершинами ассоциируются
некоторые числа. В этом случае граф называется сетью. Все определения теории
графов применимы и к сетям. В теории сетей мы обычно используем термины
«узлы» и «дуги» вместо «вершины» и «ребра».
1.2. Кратчайший путь
Одной из фундаментальных задач теории сетей является нахождение
кратчайших путей в сети. Каждой дуге сети приписано число — длина этой дуги.
В большинстве случаев длины дуг положительны, но в некоторых
приложениях они могут быть и отрицательными. Например, узлы могут
представлять различные состояния некоторой физической системы, а длина дуги еу
может означать количество энергии, поглощаемой при переходе из состояния
Vi в состояние Vj. Отрицательная длина дуги тогда означает, что энергия
излучается при переходе из V* в Vj. Если суммарная длина некоторого контура
или цикла в сети отрицательна, будем говорить, что сеть содержит
отрицательный контур.
Длина пути есть сумма длин всех его дуг. Обычно имеется много путей
между двумя вершинами V8 и V*, путь минимальной длины называется
кратчайшим путем из V, в V*.
Задача нахождения кратчайшего пути является фундаментальной и
часто входит как подзадача в другие оптимизационные задачи. В некоторых
приложениях числа, ассоциированные с дугами, представляют не дайны, а
какие-нибудь другие характеристики, и требуется найти оптимальный путь
при каком-нибудь критерии оптимальности. Но задача о кратчайшем пути
является наиболее общей задачей в классе задач об оптимальных путях.
Алгоритм нахождения кратчайшего пути обычно может быть модифицирован
для нахождения оптимальных путей при других критериях оптимальности.
Поэтому мы сосредоточимся на кратчайших путях.
Если (Vi, V2, • • •, Vk) — путь от V\ до V*, то e^i+i должно быть или
ориентированной дугой из Vi в Vi+i, или неориентированной дугой, соединяющей Vi
18
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
и Vi+i (i = 1,..., к — 1). В большинстве приложений неориентированную дугу
между Vi и Vj можно трактовать как две ориентированных дуги, одна из Vi в
Vj, другая из Vj в W Обычно рассматриваются три типа задач о кратчайшем
пути:
1) Кратчайший путь от одного узла до другого.
2) Кратчайшие пути от одного узла до всех других узлов.
3) Кратчайшие пути между всеми парами узлов.
Так как все алгоритмы, решающие задачу (1) и задачу (2), по существу,
те же самые, мы будем рассматривать задачу нахождения кратчайших путей
от одного узла до всех остальных узлов сети.
Задача нахождения кратчайшего пути корректна, если сеть не содержит
отрицательного цикла (или отрицательного контура). Заметим, что сеть
может иметь ориентированные дуги отрицательной длины и не иметь
отрицательных циклов.
Обозначим длину дуги из Vi в Vj через dij и предположим, что
dij > 0 для всех г, j, (1)
dij ф dji для некоторых г, j, (2)
dij + djk < <Uk для некоторых г, j, к. (3)
Для удобства будем считать, что dij = оо, если нет дуги из Vi в V/, и da = О
для всех г.
Условие (3) делает задачу о кратчайшем пути нетривиальной. Бели оно не
выполняется, то кратчайший путь из Vi в Vj состоит из единственной дуги
eij.
Предположим, что в сети имеется п узлов Vft, Vi,..., Vn-\ и мы хотим
найти кратчайшие пути от Vo до Vi (i = 1,2,..., п — 1). Если есть два или больше
кратчайших путей из Vo в некоторый узел, то любой из этих путей приемлем
в качестве решения.
Обычно мы хотим знать как длину кратчайшего пути, так и
последовательность его узлов.
Сделаем сначала несколько замечаний. Пусть Р* — путь из Vo в V*, Vi —
промежуточный узел этого пути. Тогда подпуть от Vo до Vi содержит меньше
дуг, чем путь Р*. Так как длины всех дуг положительны, то этот подпуть
короче, чем Р*. Сформулируем это как замечание 1.
Замечание 1. Длина пути больше, чем длина любого его подпути. (Заметим,
что это верно только если длины всех дуг положительны.)
Пусть Vi — промежуточный узел пути Р* (от V0 до Vjfe). Если Р* —
кратчайший путь, то подпуть от Vo до Vi сам должен быть кратчайшим путем. В
противном случае более короткий путь до VJ, дополненный отрезком
исходного пути от Vi до У*, составил бы путь, более короткий, чем Р*. Сформулируем
это как замечание 2.
1.2. КРАТЧАЙШИЙ ПУТЬ
19
Замечание 2. Любой подпуть кратчайшего пути сам должен быть
кратчайшим путем. (Заметим, что это не зависит от того, положительны ли длины
ДУГ.)
Замечание 3. Любой кратчайший путь содержит не более чем п — 1 дугу. (При
условии, что нет отрицательных циклов и что в сети п узлов).
На основе этих замечаний можно построить алгоритм для нахождения
кратчайших путей из V0 во все остальные узлы сети.
Представим себе, что кратчайшие пути из Vo во все остальные узлы
упорядочены в соответствии с их длинами. Для простоты изложения мы можем
переименовать узлы так, чтобы кратчайший путь в V\ был кратчайшим
среди всех кратчайших путей. Пусть пути занумерованы в порядке
возрастания их длин:
Р1<Р2<Рз<.<Рп-1.
Алгоритм найдет сначала Pi, затем Р2, и т. д., пока не будет найден самый
длинный из кратчайших путей.
Поясним идею, лежащую в основе алгоритма. Сколько дуг может быть в
пути Pi? Если Pi содержал бы более одной дуги, то он включал бы более
короткий подпуть (замечание 1). Поэтому Pi должен содержать только одну
дугу.
Если Р* содержит более чем к дуг, то он содержит по крайней мере к
промежуточных узлов. Каждый из подпутей, ведущих в промежуточный узел,
короче, чем Р*, и получается к путей, более коротких, чем Р*, что невозможно.
Поэтому кратчайший путь Р* содержит не более к дуг. Сформулируем это
как замечание 4.
Замечание 4- Кратчайший путь Р* содержит не более к дуг.
Чтобы найти Pi, нужно только рассмотреть пути из одной дуги,
минимальный среди них и будет Pi.
Чтобы найти Р2, нужно рассмотреть пути из одной и двух дуг.
Минимальный среди них будет Р2. Если Р2 — путь из двух дуг с последней дугой ej2 и
при этом j ф 1, то дуга €qj образует подпуть Р2, более кроткий, чем Р2.
Поэтому путь Р2 должен либо состоять из одной дуги, либо из двух дуг, последней
из которых является дуга ei2.
Далее мы будем приписывать узлам числа, называемые метками. Каждая
метка может быть одного из двух видов: временная или постоянная.
Постоянная метка узла — это истинное кратчайшее расстояние от начала Vo до этого
узла. Временная метка — это длина некоторого пути от начала до этого узла.
Этот путь может быть, а может и не быть кратчайшим, поэтому временная
метка является верхней оценкой истинного кратчайшего расстояния.
Приступая к поиску Pi, мы приписываем каждому узлу V{ длину дуги do*.
Эти числа называются временными метками узлов (так как позже они могут
измениться). Среди всех временных меток выбираем минимальную и
превращаем ее в постоянную. Таким образом, V\ становится помеченной постоянно.
(Постоянно помеченный узел будем называть постоянным узлом).
20
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Чтобы найти Ръ, не нужно искать все пути из двух дуг, достаточно
рассмотреть те из них, у которых первая дуга есть еоь Длины всех путей из
одной дуги приписаны узлам в качестве временных меток. Поэтому мы
можем сравнить doi (длину одной дуги) с dbi + di» (длиной пути из двух дуг) и
минимальное из этих двух значений приписать как временную метку вершине
V{. Минимум среди всех временных меток есть Рг.
Постоянная метка указывает истинное кратчайшее расстояние от Vo до V{.
Временная метка узла Vj указывает либо длину дуги eoj, либо длину пути из
Vo в постоянный узел V»*, дополненного дугой е#.
Представим себе, что все дуги сети окрашены в зеленый цвет. Когда дуга
используется в кратчайшем пути, она перекрашивается в коричневый цвет.
Таким образом, мы используем одну коричневую дугу, чтобы достичь V\,
одну или две коричневые дуги, чтобы достичь 1^, ..., не более к коричневых
дуг, чтобы достичь V*. (Цвета выбираются так, что коричневые дуги
образуют дерево, см. Упр. 2.) Мы видим, что путь P*+i не может содержать узлов с
временными метками в качестве промежуточных узлов. Поэтому мы можем
ограничить поиск путями, состоящими из последовательности коричневых
ребер, дополненной одним зеленым ребром, достигающими узла V*+i. Две или
более зеленые дуги обозначают подпуть с расстоянием меньшим, чем P*+i.
Чтобы найти путь Р*+ь содержащий одну зеленую дугу и, возможно,
несколько коричневых, мы ограничиваем поиск соседями узлов Иь Vi,..., V*.
Поиск упрощается, если применить следующее правило:
Как только узел V{ получает постоянную метку, скажем, /J, проверим для
каждого узла Vj, соседнего с узлом V{ и имеющего временную метку, верно
ли, что /J +dij меньше, чем текущая временная метка Vj. Если верно, заменим
эту временную метку значением /J + djj. Если нет, оставим временную метку
без изменения.
Чтобы найти Р*+ь достаточно найти минимальную временную метку всех
соседей узлов Vft, V\,..., V* и превратить эту метку в постоянную.
Теперь можно формально описать алгоритм и применить его к
численному примеру. Будем применять U для обозначения временного кратчайшего
расстояния и Ц для обозначения истинного кратчайшего расстояния.
Алгоритм Дейкстры.
Шаг 0. Каждому узлу V* (г = 1,2,...,п - 1) присвоить временную метку
U = db». Для удобства полагаем do» = <х>, если нет дуги, соединяющей
V0 и Vi.
Шаг 1. Среди всех временных меток выбрать /* = min/j.
»
Заменить /* на 1*к. Если нет временных меток, остановиться.
Шаг 2. Пусть V* — узел, только что получивший постоянную метку на шаге
1. Изменить временные метки соседей VJ узла VJb в соответствии со
следующим правилом:
{<<-min{{*9{;+4u}-
Перейти к шагу 1.
1.2. КРАТЧАЙШИЙ ПУТЬ
21
Рис. 1.2
Рассмотрим сеть, показанную на рис. 1.2, где числа являются длинами дуг.
Будем изображать временные метки внутри каждого узла, а когда метка
превращается в постоянную, будем помечать число звездочкой. Когда дуга
применяется в некотором кратчайшем пути, будем изображать ее жирной
линией.
Шаг 0. Все узлы получают временные метки, равные do*> а узел Vo —
постоянную метку 0. Это показано на рис. 1.3.
Шаг 1. Среди всех временных меток минимальное значение 2 имеет метка
узла V3, поэтому V3 получает постоянную метку.
Шаг 2. Узел Уз имеет соседей V2 и V&.
12 <- тт{*2,/з + d32> = min{5,2 +1} = 3.
/5 «- тш{/6>/з + d35> = min{oo,2 + 11} = 13.
Результат показан на рис. 1.4.
Шаг 1. Среди всех временных меток наименьшую метку 3 имеет узел V2>
Поэтому V2 получает постоянную метку.
Шаг 2. Соседями узла V2 являются V\, V?. (Узел V^ тоже соседний, но он стал
постоянным и поэтому исключается.)
/i «- min{fi, /5 + d21} = min{4,3 + 3} = 4.
l7 «- min{/7,/$ + d27} = min{oo,3 + 13} = 16.
Рис. 1.4
Рис. 1.5
22
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Рис. 1.6 Рис. 1.7
Шаг 1. Узел V\ получает постоянную метку 4.
Шаг 2. U «- min{/4,/J + di4> = min{12,4+ 1} = 5.
Это показано на рис. 1.5.
Шаг 1. V4 получает постоянную метку.
Шаг 2. /б <- min{/6,/2 + d46} = min{oo,5 + 6} = 11.
l7 «- min{l7Jl + d47} = min{16,5 + 9} = 14.
Шаг 1. Vq получает постоянную метку.
Шаг 2. l7 «- min{Z7,/6 + <Ы = min{14,11 + 7} = 14.
Шаг 1. V$ получает постоянную метку.
Шаг 2. l7 «- min{Z7,/5 + *т} = min{14,13 + 8} = 14.
Шаг 1. Vi получает постоянную метку.
Окончательный результат показан на рис. 1.6.
Мы вычислили кратчайшие расстояния от V0 до всех остальных узлов
сети, но не нашли кратчайших путей, на которых достигаются эти расстояния.
Ситуация подобна тому, как если было бы известно, что можно доехать из
Нью-Йорка до Лос-Анджелеса за 72 часа, но не известен маршрут,
позволяющий это сделать. Один способ проследить промежуточные узлы состоит в
следущем. Если узлу Vj приписана постоянная метка, то можно просмотреть
все соседние узлы и найти среди них тот, метка которого отличается от метки
узла Vj в точности на длину соединяющей их дуги. Таким образом мы
можем для каждого узла проследить в обратном направлении путь из начала
в этот узел. На рис. 1.7 каждому узлу приписаны два числа. Первое число —
постоянная метка, указывающая истинное кратчайшее расстояние от начала
до этого узла, второе число указывает последнюю промежуточную вершину
кратчайшего пути.
Так как алгоритм состоит из сравнений и сложений, подсчитаем
количество сравнений и сложений.
1.3. КРАТЧАЙШИЕ ПУТИ МЕЖДУ ВСЕМИ ПАРАМИ УЗЛОВ 23
Имеется п — 2 сравнений при первом проходе, п — 3 сравнений при втором
проходе и т.д., так что всего имеется (п - 2) + (п - 3) + ... + 1 = (п - 1)(п -
2)/2 сравнений на шаге 1. Аналогично, имеется (п - 1)(п - 2)/2 сложений
и столько же сравнений на шаге 2. Поэтому, трудоемкость алгоритма есть
0(п2). Так как в сети с п узлами имеется 0(п2) дуг и каждая дуга должна
быть рассмотрена хотя бы один раз, то не будет рискованным сказать, что не
существует алгоритма, требующего в общем случае O(nlogn) шагов.
В разделе 1.6 мы обсудим задачу нахождения кратчайших путей из начала
в каждый из остальных узлов для случая, когда сеть имеет отрицательные
дуги. Теперь мы обращаемся к задаче нахождения кратчайших путей между
всеми парами узлов.
1.3. Кратчайшие пути
между всеми парами узлов
В данном разделе мы рассмотрим задачу поиска кратчайших путей между
всеми парами узлов сети. Мы допускаем, что в графе могут содержаться дуги
отрицательной длины, однако запрещаем отрицательные циклы. Для
вычислительных целей мы можем рассматривать неориентированную дугу как пару
ориентированных дуг равной длины. Таким образом, отрицательная
неориентированная дуга эквивалентна отрицательному циклу, состоящему из двух
ориентированных дуг. Если существует только одна ориентированная дуга
длины d{j из узла V* в узел Vj, то мы можем считать, что существует другая
дуга из Vj в Vi с dji = оо.
Как мы уже отмечали в разделе 1.2, любой подпуть кратчайшего пути
является кратчайшим. Пусть
eij»ejk»ekl »• • •» epq
— кратчайший путь из V{ в Vq. Тогда кратчайший путь из V$ в Vj должен
представлять собой единственную дугу е^, кратчайший путь из Vj в V* — дугу
ejk и т.д. Назовем дугу е^ базисной, если она представляет собой кратчайший
путь из Vi в Vj. Из данного определения следует, что кратчайший путь состоит
только из базисных дуг. Далее, коричневые дуги, определенные в разделе 1.2,
являются базисными, однако не все базисные дуги — коричневые.
Алгоритм, который мы опишем, заменяет все небазисные дуги базисными.
Другими словами, алгоритм строит дуги, соединяющие каждую пару узлов,
не соединенную базисной дугой. Длина каждой построенной дуги равна
кратчайшему расстоянию между двумя узлами. Для данного узла Vj рассмотрим
следующую простую операцию:
dik *- min{difc, dij + djk}. (1)
Операция выполняется для каждого фиксированного j и всевозможных г и А:,
не равных j. Для трех узлов VJ, Vj и V* и трех дуг с длинами d^fc, dij и djk
данная операция сравнивает длину дуги е** с длиной пути, состоящего из двух
24
ГЛАВА I. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Рис. 1.8
дуг, с промежуточным узлом Vj. Этот случай показан на рис. 1.8. Операция
(1) называется тройственной операцией.
Для всевозможных пар узлов V* и V*, смежных с V}, выполним следующие
операции.
Если dik < dij + djk, то никаких действий не производим.
Если dik > d^ + djk, то создаем новую дугу, ведущую из V% в V* с dik =
dij +dj*.
Во-первых, фиксируем j = 1 и выполняем тройственную операцию (1) для
всех г, А; = 2,3,..., п. Затем фиксируем j = 2 и выполняем тройственную
операцию (1) для всех г, А: = 1,3,..., п. Заметим, что все новые дуги, добавленные
при j = 1, используются далее при j = 2. Мы утверждаем, что как только
все тройственные операции будут выполнены для j = п, сеть будет состоять
только из базисных дуг. Другими словами, числа, приписанные каждой
ориентированной дуге, ведущей из Vp в Vq> являются кратчайшими расстояниями
из Vp в Vq. Докажем это утверждение.
В исходной сети рассмотрим любой кратчайший путь из Vp в Vq.
Кратчайший путь должен состоять из базисных дуг этой сети. Если в результате
тройственной операции создается дуга с длиной, равной сумме длин всех
базисных дуг кратчайшего пути, то это докажет корректность алгоритма.
Рассмотрим кратчайший путь, изображенный на рис. 1.9.
При j = 1 тройственная операция создает новую дугу с с^з = <ki + di3-
При j = 2 тройственная операция никак не скажется на данном отдельном
кратчайшем пути.
При j = 3 дуга с de3 = dei + di3 Уже построена, следовательно,
тройственная операция построит дугу с deg = е*вз + ^39 = (<ki + ^13) + ^39-
При j = 4 будет построена дуга с (fee = ^24 + ^46-
Рис. 1.9
1.3. КРАТЧАЙШИЕ ПУТИ МЕЖДУ ВСЕМИ ПАРАМИ УЗЛОВ 25
Рис. 1.10
При j = 6 будет построена дуга длины
^26=^24+ ^46
= (Й24 + ^4б) + (^63 + ^39)
= Cfc4 + ^46 + d^l + d\s + ^39-
На рис. 1.9 построенные дуги изображены пунктирной линией. Числа
рядом указывают порядок, в котором эти дуги появлялись. Таким образом,
базисная дуга евз построена первой, а базисная дуга еед построена второй.
Некоторые базисные дуги, которые также будут построены в результате
тройственной операции, например, в4ъ не изображены на рисунке, так как они не
влияют на рассматриваемый кратчайший путь. Заметим, что любая из дуг,
построенная в результате тройственной операции, не может быть заменена
другой дугой или путем меньшей длины. Противное противоречило бы тому,
что исходный путь — кратчайший. Если в сети отсутствуют отрицательные
циклы, то любой кратчайший путь должен быть простым и должен состоять
не более чем из п — 1 дуг и не более чем из п — 2 различных промежуточных
узлов. Мы показали, что алгоритм работает для конкретного кратчайшего
пути, однако мы легко можем обобщить идею доказательства на случай
произвольного кратчайшего пути и дать формальное доказательство.
Приведенный алгоритм легко может быть запрограммирован на
компьютере. Длины дуг сети с п узлами могут быть заданы массивом пхп. Например,
для сети, изображенной на рис. 1.10, матрица расстояний представлена в
таблице 1.1.
При j = 1 мы сравниваем каждый элемент d^k (i ф 1, к ф 1) с di,! + d\k-
Если элемент d^k больше суммы d^i 4- di*, то элемент ё*,ъ заменяется на эту
сумму. В противном случае элемент не меняется. Таким же образом, при j = 2
мы сравниваем каждый элемент dj,* (г ф 2, к ф 2) с d^ + cfe*. Минимум из
чисел d{,k и dj,2 + cfc* становится новым значением элемента d,,*. Заметим,
что в описанных вычислениях при j = 2 мы использовали результаты,
полученные при j = 1. Для фиксированного значения j мы должны просмотреть
элементы в (п — 1) х (п — 1) матрице (диагональные элементы всегда равны
0). Каждый элемент сравнивается с суммой двух других элементов: один из
той же строки и один из того же столбца. Алгоритм завершает свою работу,
когда мы заканчиваем вычисления для j = п.
26
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Таблица 1.1
Таблица 1.2
0
1
i 00
00
4
1
0
5
1
00
оо
5
0
2
00
00
1
2
0
1
4
00
00
1
0
Выполним тройственную операцию для j = 1,2,3,4,5 и запишем только
вычисления, которые приводят к изменению в матрице расстояний. Заметим,
что все длины в неориентированной сети симметричны, поэтому достаточно
вычислить только одну из двух длин.
При j = 1
При j = 2
При j = 3
Aib «- min{d25,d2i + du} = min{oo, 1 + 4} = 5.
di3 «- min{di3,di2 + <Ьз} = min{oo, 1 + 5} = 6,
di4 «- min{di4,di2 + d^} = min{oo, 1 + 1} = 2,
d35 <- min{d35,d32 + cfcs} = min{oo, 5 + 5} = 10.
изменений нет.
При j = 4
При j = 5
di3 <- min{di3,di4 + d43} = min{6,2 + 2} = 4,
die 4- min{di6,di4 + с^б} = min{4,2 + 1} = 3,
сЬз «- min{d23,d24 + <*4з} = min{5,1 + 2} = 3,
-*- *- min{d26,d24 + ^4б} = min{5,1 + 1} = 2,
min{d36,d34 + <*4б} = min{10,2 + 1} = 3.
^35
изменений нет.
1.3. КРАТЧАЙШИЕ ПУТИ МЕЖДУ ВСЕМИ ПАРАМИ УЗЛОВ
27
Таблица 1.3
Таблица Ц
ф®фф
Ф Ф Ф ф
Заметим, что (fee изначально имело значение оо, затем 5 и, наконец, 2.
Однако дуга Ауь — 5 никогда не входила ни в один кратчайший путь. Никакая
дуга с длиной, равной сумме длин базисных дуг кратчайшего пути, не может
быть заменена дугой меньшей длины. Противное противоречило бы
предположению, что путь кратчайший. Матрица кратчайших расстояний между всеми
парами узлов представлена в таблице 1.2.
Несмотря на то, что кратчайшие расстояния между каждой парой узлов
найдены, мы еще должны найти внутренние узлы кратчайших путей.
Чтобы зафиксировать порядок, в котором появляются эти узлы, мы используем
матрицу [Р|,*], в которой элемент г-ой строки и fc-ro столбца указывает на
первый внутренний узел в пути из V* в VV Если Р^ = j, то кратчайший путь
имеет вид V*, 1^,..., V*. Далее, если Pj^ = з, то кратчайший путь имеет вид
Vi,Vj,V9,...,V*. Изначально мы полагаем Р^ = к для всех г, к. Например,
таблице 1.1 соответствует таблица 1.3.
Таким образом, предполагается, что каждая дуга — базисная (до тех пор,
пока не установлено обратное), и первым внутренним узлом на пути из V* в
Vk является сам V*.
Во время выполнения тройственной операции над таблицей 1.1 мы также
обновляем данные в таблице 1.3. Элементы таблицы 1.3 изменяются согласно
следующему правилу:
« - J Pi'"
Pi,k - <
( без :
если dik Xlij+djk,
изменения, если d^ < d# + djk-
(2)
Например, когда мы присваиваем элементу <fee значение cfei + die = 5, мы
также полагаем
Р25 = Р21 = 1-
Когда мы присваиваем элементу du значение di2+<fe4 = 2, мы также полагаем
Pi 4 =Pl2 = 2.
Когда мы присваиваем элементу die значение di4+d45 = 2, мы также полагаем
Р15 = Pi 4 = Р12 = 2.
28
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Когда мы присваиваем элементу cfes значение <fc4+ ^45 == 2, мы также полагаем
Р25 =Р24 =4.
Итак, по окончании вычислений мы имеем
Р15 =2, Р25 = 4.
Так как дуга в4б — базисная, то на протяжении всех вычислений р4б = 5.
Pi5 = 2 означает, что Ц есть первый промежуточный узел на пути из V\ в
vb.
Р2б = 4 означает, что V± есть первый промежуточный узел на пути из У^ в
Р4б = 5 означает, что Уь есть первый промежуточный узел на пути из У± в
Таким образом, мы можем выписать все промежуточные узлы на пути из
V\ в 14, ими являются Vi, V^, V4 и V^.
В общем случае, чтобы найти кратчайший путь из V8 в V*, мы находим
первый промежуточный узел p8t.
Если pgt = а, то ищем pat =?
Если pat = ft, то ищем рм =?
Эти действия завершаются, когда
Pzt = *•
Тогда Ув, Уа, И,..., Уг, Vi — узлы кратчайшего пути.
Элементы таблицы 1.3 изменяются по формулам (2) в то же самое время,
когда элементы таблицы 1.1 изменяются по формулам (1). В конце
вычислений по формулам (1), когда мы получаем таблицу 1.2 кратчайших расстояний,
мы также получаем таблицу 1.4 промежуточных узлов, вычисленную по
формулам (2).
Заметим, что несмотря на то, что,таблица 1.2 симметрична, таблица 1.4
таковой не является. Для того, чтобы получить всю таблицу 1.4, мы должны
провести все вычисления над таблицей 1.1, а не только половину вычислений,
которые мы выполнили в примере. (Например, когда мы полагаем
<кь = db\ + d\2 = 5,
мы также должны выполнить присваивания рб2 = Ры = 1-)
1.4. Алгоритм декомпозиции
Во многих приложениях сеть может быть сильно разрежена, и у нас нет
необходимости выполнять все тройственные операции, описанные в
предыдущем разделе. Мы можем рассматривать разреженную сеть как несколько
небольших сетей, перекрывающихся одна с другой, и выполнять
тройственную операцию только над элементами каждой маленькой сети. Мы можем
1.4. АЛГОРИТМ ДЕКОМПОЗИЦИИ
29
Рис. 1.11
сэкономить на вычислениях, используя алгоритм декомпозиции. Для
примера рассмотрим сеть на рис. 1.11 как две небольшие перекрывающиеся сети:
одна сеть состоит из узлов, помеченных буквами А и X, и дуг, соединяющих
эти узлы, другая сеть состоит из узлов; помеченных буквами J5 и Jf, и дуг,
соединяющих эти узлы.
Рассмотрим подмножество вершин сети и обозначим его А. Пусть X —
другое подмножество узлов. Назовем множество X разрезом для множества
Л, если оно обладает следующим свойством: при удалении из сети вершин
X вместе с инцидентными дугами сеть распадается на две или более
компоненты связности, причем одна из компонент содержит все узлы А и никаких
других. Разрез X для множества А называется минимальным разрезом, если
никакое собственное подмножество множества X не обладает этим свойством.
Очевидно, что множество всех узлов, соседних узлам множества Ау
составляет минимальный разрез для множества А. Сначала мы рассмотрим алгоритм
декомпозиции в самой простой форме, а именно, покажем, как разбить сеть
на две части. Предположим, что сеть N разбита на три множества узлов,
таких, что N — A U X U В> где X есть минимальный разрез для множества
А. Матрица расстояний для случая, когда узлам из множества А присвоены
индексы 1,2,...,|А| (через \А\ обозначена мощность множества А), а узлам
из множества X присвоены индексы \А\ + 1, \А\ + 2,..., \А\ + |Х|, показана в
таблице 1.5, где
Daa = [dij], если Vi € А и Vj € А,
Dab = [rfy], если V* € А и Vj € В и т.д.
На начальном этапе все элементы матриц Dab и Dba равны оо. Иногда
удобно использовать обозначение d^B> чтобы представить один из элементов
в Dab-
Таблица 1.5
Daa
Dxa
DBA
Dax
DXx
DRX
Dab
DXb
Dbb
30
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Введем новый термин 4 условный кратчайший путь*. Условный
кратчайший путь — это кратчайший путь при ограничении, что его узлы входят в
некоторое заданное подмножество узлов сети. Для длины кратчайшего пути
(содержащего любое количество дуг) из узла V* в узел Vj будем использовать
обозначение d\j. Для длины условного кратчайшего пути из узла VJ в узел
Vj будем использовать обозначение d^(F), где Y — подмножество узлов, из
которых можно формировать кратчайший путь. Матрицу условных
кратчайших расстояний [dyOO], для которой V* € А и Vj € J5, обозначим D*AB{Y)\
при этом d^B(Y) представляет собой один из ее элементов. Если через N
обозначена вся сеть, тогда dy(JV) = d\j. Если все элементы кратчайшего пути
принадлежат У, то
<*дл(П = «*(*)•
Пусть А означает A U X, а В означает В U X. Рассмотрим исходную сеть
как пару перекрывающихся сетей. Одна их этих сетей, А, состоит из узлов V*
(VJ € А) и дуг eij (YiyVj € А). Другая сеть, В, состоит из узлов V* (V* € В)
и дуг е*/ (V*, V\ € В). Выполним сначала тройственные операции в сети ~А. В
результате получим условные кратчайшие расстояния между любыми двумя
вершинами из А. Затем выполним тройственные операции в сети В, в которой
расстояния между узлами из X заменены условными кратчайшими
расстояниями, вычисленными для сети А. После выполнения тройственных операций
в сети В снова выполним тройственные операции в сети А. В следующих двух
теоремах заключается обоснование алгоритма разложения сети на две
перекрывающиеся части.
Теорема 1. Пусть N = A U X U В, причем X — разрез для множества А.
Тогда если условные кратчайшие расстояния D*XX(A) известны, то
кратчайшее расстояние между узлами сети В можно получить, рассматривая
только сеть В. (Заметим, что А = N — В.)
Доказательство. Если некоторый кратчайший путь в N лежит целиком в
В, тогда d^B(N) = d*BB(B), что означает, что достаточно выполнить
тройственные операции в сети В. Предположим, что найдется несколько подпутей
рассматриваемого кратчайшего пути, содержащих узлы из А. Условно это
показано на рис. 1.12(a).
Рассмотрим кратчайший путь из V\ bVq. Так как и исходный, и конечный
узлы содержатся в В и X — разрез множества В, то любой подпуть,
содержащий вершины из А, должен начинаться и кончаться в X. На рис. 1.12(a)
подпуть из V2 в V3 и подпуть из V4 J* Vb являются такими путями. Если
величины d%3(A) = d£3(N - В) и d±b(A) = dJ6(iV - В) известны, то в сети В
мы получаем две дуги: егз с расстоянием с^з(^ — В) и е^ь с расстоянием
d£b{N - В). На рис. 1.12(b) мы заменили два подпути дугами егз и в4б-
Итак, кратчайший путь из V\ в Ц состоит из подпути из V\ в 1^, дуги
в23> подпути из V3 в У4, дуги в45 и подпути из Vb в V&; этот кратчайший путь
состоит только из дуг сети В. Таким образом, достаточно рассмотреть только
сеть В. Заметим, что приведенные рассуждения не зависят от числа подпутей,
1.4. АЛГОРИТМ ДЕКОМПОЗИЦИИ
31
А
X
Гв]
А \ X \ В
а)
Ю
Рис. 1.12
содержащих узлы из А. I
Нетрудно видеть, что после того, как мы поменяем местами Л, Б и Л, Б,
теорема останется верной. Так как вначале мы выполняем тройственные
операции в А, то мы получаем только условное кратчайшее расстояние DAA(A).
К тому времени, когда В закончится, мы получим все D^-j(JV). Таким
образом, чтобы получить D^(N), мы должны выполнить тройственные операции
в А еще раз. Теперь обратимся к задаче вычисления DAB(N) и DBA(N).
Теорема 2. Пусть N = A U X U В, причем X — разрез для множества А.
Тогда1
<Глв(") = min {<TAX(N) + d*XB(JV)},
<Гва(Ю = min {dhx(N) + <TXA(N)}.
(1)
(2)
Доказательство. Чтобы добраться из узла V* € А в узел V* € J3, необходимо
посетить по крайней мере один узел Vj из X. Если взять минимум по всем Vj
из Ху тогда это в точности кратчайшее расстояние в N. I
Пусть матрица расстояний D*AX имеет размеры г х 5, а матрица
расстояний DXB(N) имеет размеры sxt. Для каждого г и А: необходимо выполнить
операцию:
<fc = min К,- + <Tjk) {Vj £X,Vi£ A, Vk € В).
(3)
Общее число сложений г х s xt, такое же общее число сравнений. Операция
(3) аналогично обычному матричному умножению с заменой х на + и + на
min. Будем называть (3) матричным минисложением2.
^од (1), (2) понимается следующее:
<,(лг) = тшЦ.(лг) + ^(лг)}, ^е л, vfce в,
ftW=jg»(<jW + <5iW}. Чел, vkeB.
— Прим. перев.
2В оригинале: minisummation. — Прим. перев.
32
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Алгоритм декомпозиции на 2 пересекающиеся сети выглядит следующим
образом.
Шаг 1. Выполнить тройственные операции для каждого элемента матрицы
/ DAA DAX \
\ Dxa Dxx ) '
В конце шага будем иметь DAA(A), DAX(A), DXA(A) и DXX(A).
Шаг 2. Выполнить тройственные операции для всех элементов матрицы
/ DXX{A) DXB \
\ DBX Dbb )
По теореме 1 в конце шага будем иметь DXX(N), DXB(N), DBX(N)
и DBB(N).
Шаг 3. Выполнить тройственные операции для всех элементов матрицы
( D\A{A) D*AX(A) \
\DXA(A) D*XX(N) J
По теореме 1 в конце шага будем иметь DAA(N), DAX(N), DXA(N)
и DXX(N).
Шаг 4. Используя (3), получаем DAB(N) и DqA(N).
Пусть матрица расстояний имет размеры п х п. Для того, чтобы найти
кратчайшие пути между всеми парами узлов прямым методом из раздела 1.3,
необходимо выполнить приблизительно п3 элементарных тройственных
операций. Теперь предположим, что мы можем разложить исходную сеть на 3
подмножества Л, X и Б, где X — разрез множества А и \А\ = щ, \Х\ = пг,
|Б| = пз, тогда для нахождения кратчайших путей между всеми парами
вершин можно использовать алгоритм декомпозиции. В этом случае требуется
(п\ + П2)3 операций на шаге 1,
(ri2 + Пз)3 операций на шаге 2,
(п\ + П2 )3 операций на шаге 3,
2(п\ • П2 • пз) операций на шаге 4.
4 1 5 506 з
Если Tii = т^п> п2 = т^п и пз = — п, то общее число операций равно т^и*,
10 10 10 1000
что составляет примерно половину всех вычислений, когда сеть
рассматривается целиком без декомпозиции.
Если сеть очень велика и слабо связана, то предпочтительнее разложить
ее на 4 пересекающиеся сети, как показано в таблице 1.6, где возможные
пропуски внутри блоков соответствовали бы элементам, равным бесконечности.
1.4. АЛГОРИТМ ДЕКОМПОЗИЦИИ
33
А
ХА
В
Хв
С
Хс
D
А
Фаа
|
\Dxaa
1_
Dba
DXba
DCa
DxcA
DDA
Xa
Daxa
Таблица 1.6
В
\Dab
\DxAxA \dxab
\Dbxa
\DXBXA
DcxA
DxcxA
Ddxa
DBb
Dxbb
DCb
DxcB
DDB
Xb
Daxb
DXAXB
Dbxb
\Dxbxb
\Dcxb
1
ФхсХв
DDXb
с
Dac
\Dxac
\Dbc
\DxbC
Dec
DxcC
DDC
Xc D
Daxc Dad
DxAxc DxAD
Dbxc DBd
DxgXc \DxBD
Dcxc \Dcd
\DxoXo \DxcD
\Ddxc Ddd
Чтобы сконструировать матрицу расстояний, подобную таблице 1.6,
выполним следующие операции. Пусть А — производное множество узлов.
Обозначим его минимальный разрез через Ха- Пусть В — минимальный разрез
для A U Ха, и Хв — минимальный разрез для A U Хл U Я. (Заметим, что
минимальный разрез для В — это Xa U Хв-) Пусть С — разрез множества
AuXaVBuXb, а Хс — минимальный разрез множества A UXaUBuXb U С.
Указанные операции необходимо продолжать до тех пор, пока требуется
дальнейшая декомпозиция. В таблице 1.6 исходная сеть разложена на 4
пересекающихся подсети: сеть А = AU-Хл, сеть В = Xa UBU-Yjg, сеть
и сеть D = Хс U D.
Теперь мы можем рассмотреть общий алгоритм декомпозиции для m
пересекающихся сетей А, В,..., G, Я.
Шаг 1. Выполнить тройственные операции последовательно наш-1 сетях
А, Я,..., G, всякий раз заменяя исходные расстояния на условно
кратчайшие расстояния, полученные для предыдущей сети. Например,
перед выполнением тройственной операции на сети В = Xa UBU Хв
матрицу DxAxA необходимо заменить на D*XaXa (А).
Чтобы применить теорему 1 к случаю нескольких перекрывающихся
сетей, отождествим А, Ха и В U Хь U • • • U Н соответственно с А, X и
В из теоремы 1. Далее, отождествим АиХлиЯ, Хв, CuXcV- • -иЯ
соответственно с А, X и В из теоремы 1. Нетрудно видеть, что в конце
шага мы получим
D\Affl,D%B(AuB\...,D*GG(AuBU''-UGy
Шаг 2. Выполнить тройственные операции последовательно наш сетях
Я,С,...,Я,А,
всякий раз заменяя расстояния в очередной сети на расстояния,
полученные для предыдущей сети. Например, DxGxG{N ~ Щ будет за-
34
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
OG0GD
а)
Ь)
Рис. 1.13
менено на D*XoXa(N). По теореме 1 в конце шага мы будем иметь
Шаг 3. С помощью операции минисложения найти кратчайшие расстояния
между всеми парами вершин, такими, в которых обе вершины из
пары не принадлежат ни одному из множеств А, В,..., G, Н. Для
матричного минисложения (3), в котором Vj € X, Ц € Л, Vk € -В, будем
использовать обозначение А ф Ха Ф В. Хотя необходимо выполнить
обе операции: А ф Ха Ф В и В ф Ха Ф А, далее для простоты будем
записывать только одну из них. Матричные минисложения должны
быть выполнены в следующем порядке:
А®ХА®(ВиХв),
(AuXAUB)®XB®(CUXc),
(A U Хл U В U Хв U С) ф Хс Ф (D U -ХЪ),
(Л U Xt U • • • U F) ф XF ф (G U XG),
(Л U Хл U • • • U F U G) ф *g ф Я.
В описанном выше матричном минисложении расстояния D*AXb(N),
полученные при первом минисложении, используются во втором.
Метод декомпозиции, описанный в данном разделе, может быть
классифицирован как метод линейной декомпозиции, так как сеть разбивается линейно
на т перекрывающихся подсетей, как показано на рис. 1.13(a). Если m
перекрывающихся сетей образует дерево, подобное изображенному на рис. 1.13(b),
тогда существует специальный порядок, в котором мы должны выполнить
тройственные операции для подсетей (см. [2], [25]).
1.5. Ациклические сети
В разделе 1.2 был предложен алгоритм нахождения кратчайших путей из
источника в каждый другой узел. В этом разделе будем интересоваться
самыми длинными путями из источника в каждый из других узлов. Эта задача о
1.6. КРАТЧАЙШИЕ ПУТИ В ОБЩЕЙ СЕТИ
35
самом длинном пути с положительными и отрицательными дугами корректна
только тогда, когда ориентированная сеть является ациклической.
Бели сеть ациклическая, то ее узлы частично упорядочены и их можно
пронумеровать так, что для каждой дуги ViVj выполняется % < j. Считаем,
что узлы уже пронумерованы таким образом (см. упражнение 6). Обозначим
источник через Vo и найдем самый длинный путь из Vo в VJ i = 1,2,..., п -1).
Обозначим через U наибольшее расстояние от Vo до VJ, тогда /о = 0, l\ = doi
и для Ik справедливо равенство
/*=тах{/,+<*,*} (j<k). (1)
з
Таким образом,
h = max{(/0 + do2)> (h + ^12)}.
/3 = max{(/0 + из), (h + d13), (h + <Ь3)},
/n_i ±= max{/j + djin-i} (j = 0,1,..., n - 2).
В равенстве (1) положим d\j = —00, если не существует направленной дуги из
Vi в Vj.
Соотношения (1) можно также использовать для нахождения кратчайших
путей из Vo в Vj в ациклической сети с отрицательными дугами, просто
заменяя в (1) максимум на минимум и полагая, что U — кратчайшее расстояние.
Для задачи о кратчайших путях в ациклической сети положим d{j = 00, если
не существует направленной дуги из Vo в Vj.
Заметим, что при вычислении /г имеются два сложения и одно сравнение,
а при вычислении /з — три сложения и два сравнения. Таким образом, общее
число сложений равно 1+2и h(n —1) = n(n—l)/2, а общее число сравнений
составляет (п—1)(п—2)/2. Оценка 0(п2) имеет место как для самого длинного
пути, так и для кратчайшего пути с отрицательными дугами. Если сеть не
является ациклической, то для нахождения кратчайших путей из источника
в каждый другой узел нужно использовать последовательные приближения.
Две техники последовательных приближений обсуждаются в разделе 1.6.
1.6. Кратчайшие пути в общей сети
Рассмотрим сеть с положительными и отрицательными дугами, в
которой нет отрицательных циклов. Нужно найти кратчайшие пути из V0 во все
остальные узлы. (Вспомним, что в алгоритме Дейкстры требуется
положительность дуг.) Так как сеть не имеет отрицательных циклов, кратчайший
путь должен быть простым путем и, следовательно, содержать не более п — \
дуг. Найдем все кратчайшие пути при помощи последовательных
приближений, где приближения первого порядка дают кратчайшие расстояния от Vo ДО
VJ, использующие только одну дугу, а приближения fc-ro порядка дают
кратчайшие расстояния от Vo до VJ (г = 1,2,... ,п - 1), использующие не более к
дуг. Аппроксимации (п —1)-го порядка дают истинно кратчайшие расстояния.
36
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Представленный здесь алгоритм является алгоритмом Форда [10] и Белл-
мана [1J. Обозначим через Й ' кратчайшее расстояние от Vo до V},
использующее не более к дуг. Пусть /j ' = doj (j = 1,2,..., n - 1). (Полагаем d\j = оо,
если нет дуги, идущей из V* в Vj).
Легко видеть, что /j — do/ U = 1> 2,..., п - 1) — кратчайшие расстояния,
использующие одну дугу. Если все lj ' (j = l,2,...,n - 1) известны, можно
рекурсивно вычислить /j ' при помощи следующего равенства.
/<*+1) = тт{/<*\ rmn(l\k) + dij)}. (1)
Для доказательства (1) рассуждаем следующим образом: кратчайший путь
в Vj, использующий не более (к + 1) дуг, в действительности может состоять
из к или менее дуг. Если это имеет место, то
j j »
что является первым слагаемым правой части (1).
С другой стороны, если кратчайший путь в Vj состоит в точности из к +
1 дуг, то пусть Vi — промежуточный узел, смежный с Vj. Таким образом,
кратчайший путь в Vj можно представить как кратчайший путь из к дуг в 1^,
за которым следует дуга е^-. Перебирая все возможные значения г, получаем
второе слагаемое правой части (1).
На самом деле вычисление (1) можно сократить. Опишем сейчас алгоритм
из [29].
Рассмотрим произвольный кратчайший путь с промежуточными узлами,
скажем,
Заметим, что индекс узлов вначале возрастает от 0 до 7, потом убывает до
2, а затем возрастает до 8. Назовем блоком всякую возрастающую либо
убывающую последовательность индексов. В примере кратчайший путь состоит
из трех блоков. Легко видеть, что любой кратчайший путь состоит не более,
чем из п — 1 блоков.
Придадим теперь новый смысл величинам /J. ': пусть /j ' —длина
кратчайшего пути из Vo в 1^, состоящего не более, чем из к блоков.
Здесь 1у может быть расстоянием кратчайшего пути из п — 1 дуг, в
котором индексы промежуточных узлов возрастают от 0 до j; то есть он содержит
только один блок. Положим
if = doj при всех j,
/j^minj/f, ^{if'+ii}} (j = l,2,...,n-l), (2)
l?* = wm{$\ nm{lf)+^} (j = n-l,...,l). (3)
1.6. КРАТЧАЙШИЕ ПУТИ В ОБЩЕЙ СЕТИ
37
В общем случае полагаем
1« = minflf-1», шп{|« + <%}} U = 1,2,...,п - 1) (ft неч.), (4)
/<*> = min (if-1*, min{/jfc) + did}\ (j = n - 1,..., 1) (* чет.). (5)
Примененим этот алгоритм к сети, изображенной на рис. 1.14, в
предположении, что все не указанные дуги имеют бесконечные длины. На рис. 1.14
последовательно показано, как получается кратчайший путь. Лежащее в
основе понятие очень напоминает тройственную операцию за исключением того,
что все пути начинаются с Vo.
Запишем только существенную информацию. (Все остальные
бесконечны.)
41)=ndn{4B,,mlii{li1) + *1:i = l,2}}
=4°\
4Ч = min{40), min {l^ + (Ц4 : i = 1,2, з}}
= 41)+<*34
= do3 +dz4,
41)=min{4°). min{41)+*7:t = l,2,...,6}}
= 4X)+d47
= do3 + ^34 + CI47,
42)=mm{41),min{42)+di7:t = 8}}
— *7 >
42) = min {#>, min {/j2) + ^ : i = 8,7, б} }
= 42)+<*75,
42) = min {4°. min {/j2) + <k2 : i = 8,7,..., з} }
=4a)+*a.
»(3) _ ,(2)
«2 — *2 >
43) = min {42\ min {43) + dis : * = 1,2,..., 7} }
=43)+<fc8
= ^03 + ^34 + ^47 + ^75 + ^52 + ^28-
Заметим, что при вычислении /j индекс j возрастает от 1 до 8 и испыты-
ваются все возможные г < j, а при вычислении г. ' индекс j убывает от 8 до
1 и испытываются все возможные i > j.
Легко видеть, что алгоритм завершит работу, если при всех j Ij + ' = г- '.
Если lj ф1\ при к = п-1 и некотором j, то существует отрицательный
38
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Рис.1.Ц
цикл.
При фиксированном j берутся либо только такие г, которые меньше, чем
j, либо те г, которые больше j. Следовательно, выполняется только
половина действий алгоритма Форда [10] или Беллмана [1]. Более того, в
представленном алгоритме можно остановиться тогда, когда при всех j справедливо
/j +1' = lj \ где к < п — 1. Заметим также, что сокращаются и требования к
размеру памяти, поскольку значение Г- можно не хранить после вычисления
3
1.7. Минимальное остовное дерево
Дана неориентированная сеть JV, нужно выбрать подмножество дуг,
образующих дерево Т, в котором существует путь между каждой парой узлов сети.
Дерево такого типа называется остовным деревом сети. Бели дугам
приписаны стоимости d*j, то стоимость остовного дерева определяется как сумма dy
по всем дугам дерева. Остовное дерево с наименьшей стоимостью среди всех
остовных деревьев называется минимальным остовным деревом. Дерево,
рассмотренное в разделе 1.2, состоит из всех дуг, задействованных в кратчайших
путях из источника. В общем случае минимальное остовное дерево отличается
от дерева кратчайших путей.
Следующие две леммы кажутся очевидными, однако их доказательства
требуют внимательного изучения.
Лемма 1. Пусть Va — произвольный узел и еах — кратчайшая дуга среди
всех дуг, смежных с Va. Тогда существует минимальное остовное дерево
Г*, содержащее дугу еах-
Доказательство. Пусть Г — минимальное остовное дерево, а А —
подмножество дуг, смежных с Уа, например, А = {еа&,еас,еа(|,еаа.}. Предположим, что
дуга еах является кратчайшей дугой, смежной с Va, но не принадлежит Т.
Поскольку Г — остовное дерево, то в Г должен быть путь из Vx в Va,
содержащий одну из дуг А, например, ead- Обозначим этот путь через (P«d,erfa),
1J. МИНИМАЛЬНОЕ ОСТОВНОЕ ДЕРЕВО 39
где PXd — путь из Vx в Vj. Заменяя ead на еаа:, получим Г*. Если еаа.
короче, чем ead, то заключаем, что Г* — остовное дерево с меньшей стоимостью.
Во-первых, в дереве Г* Va соединяется с Vx дугой еаж, а с узлом V& — путем
(ea«, Pxd)- Оставшиеся узлы V&, Vc по-прежнему связаны с Va и, следовательно,
с остальными узлами сети, значит, Г* является остовным деревом. Во-вторых,
стоимость Г* меньше, чем Г, так как еах короче, чем ead- Это противоречит
предположению о том, что Г — минимальное остовное дерево. Если дуги ead и
еах имеют одинаковые длины, то также можно заменить ead на еах и получить
минимальное остовное дерево Г*, содержащее еах- ■
Лемма 2. Если известно, что подмножество ребер, образующих поддерево
F, является частью минимального остовного дерева, то существует
минимальное остовное дерево, содержащее F, и минимальное ребро, соединяющее
F uN-F.
Доказательство. Доказательство в точности совпадает с доказательством
леммы 1, если заменить Va на F. i
По лемме 1 можно начать из произвольной вершины и выбрать
наименьшую смежную дугу. Так как известно, что только что выбранная дуга
является частью минимального остовного дерева, то можно в лемме 2 взять ее в
качестве F и выбрать наименьшую дугу, инцидентную F.
Можно продолжить выбор наименьшего ребра, инцидентного уже
выбранной компоненте. По существу, это алгоритм Прима для нахождения
минимального остовного дерева. Заметим сходство алгоритма Прима для минимального
остовного дерева с алгоритмом Дейкстры для нахождения кратчайших путей.
Снова пометим узлы, соединенные дугами в остовном дереве, постоянными
метками, а еще не соединенные узлы — временными метками.
Алгоритм Прима.
Шаг 0. Выберем произвольный узел, назовем его V\ и пометим его
постоянным значением ноль (т.е. Pi =0). Пометим все остальные узлы
временно значениями Tj, равными d\j для Vj.
Шаг 1. Среди всех временных меток выберем одну (например, Tj) с
наименьшим значением и сделаем ее постоянной. Включим дугу со значением
d{j = T{j в минимальное остовное дерево, в котором V* — постоянный
узел и Tj = dij.
Шаг 2. Пусть Vj — последний узел, только что ставший постоянным. Для
каждого временного узла V* пусть
Tk*-mm{Tk, djk}.
Если нет временных меток, то конец, иначе вернуться на шаг 1.
40
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Таблица 1.7 Таблица 1.8
фффффф ® ф Ф ф <£> Ф
0
00
1
00
3
00
00
0
00
6
00
8
1
00
0
4
2
00
00
6
4
0
6
7
3
00
2
6
0
00
оо
8
оо
7
00
0
®
ф
Ф
ф
ф
ф
0
00
1
00
3
оо
оо
0
00
6
00
8
ш
00
0
4
2
00
00
6
4
0
6
7
3
00
ш
6
0
оо
00
8
00
7
00
0
Анализ алгоритма Прима. На шаге 1 производится (п -1) + (п - 2) и h 1 =
0(п2) сравнений. На шаге 2 осуществляется (п — 2) + •'•• + 1 = 0(п2)
сравнений. Таким образом, этот алгоритм снова является алгоритмом трудоемкости
0(n2). i
Существуют другие алгоритмы [5], [28], требующие асимптотически
меньше вычислений. Смотрите рекомендуемую литературу.
Стоимость остовного дерева определяется как сумма величин dij по дугам
дерева. Остовное дерево с наименьшей стоимостью называется минимальным
остовным деревом. Аналогично можно определить максимальное остовное
дерево. Тогда алгоритм Прима можно использовать и для максимальных остов-
ных деревьев, просто заменяя минимум на максимум (здесь dij = —оо, если
нет дуги). Проиллюстрируем алгоритм Прима для сети со значениями
величин dij, указанными в таблице 1.7.
Бели данные сети представлены в матричной форме, алгоритм Прима
можно описать следующим образом:
Шаг 0. Вычеркнуть все элементы в первом столбце и пометить первую
строку.
Шаг 1. Выбрать минимальный элемент среди всех элементов в помеченных
строках, пусть, например, минимальный элемент есть dij
(вычеркнутые элементы выбирать нельзя). Если все элементы в помеченных
строках вычеркнуты, то конец.
Шаг 2. Вычеркнуть j-й столбец и пометить j-ю строку. Вернуться на шаг 1.
Если применить алгоритм Прима к таблице 1.7, то после выбора двух
элементов вычисления будуть выглядеть так, как показано в таблице 1.8
(выбранные элементы заключены в рамку).
1.8. ПОИСК В ШИРИНУ И ПОИСК В ГЛУБИНУ
41
1.8. Поиск в ширину и поиск в глубину
Во многих приложениях нужно в определенном порядке посетить все узлы
графа. Рассмотрим следующие два общих способа обхода, называемые
поиском в ширину (BFS) и поиском в глубину (DFS). BFS3 будет использоваться
в главе 2, a DFS4 — в главе 4.
Поиск в ширину. Выбираем произвольно узел графа G, назовем этот узел
Vo и затем посетим всех соседей Vo в произвольном порядке, например, это
узлы V\, У2, • • •, Vi. После посещения всех соседей Vo начать обход заново из V\
(первого посещенного соседа узла Vo) и посетить все соседние с Vi узлы,
скажем, Уц, Vi2,..., Vij, потом все узлы, соседние с V^ скажем, У21, ^2> • • • >14* •
Систематически получаем
Порядок посещений
Vo
Vl
v2
Vi
Vu
Via
Соседние узлы
Vi,Ka,...,Vi
Vii.V,,,...,^
Vm,Vm,...,V»
Va,Va,...,Vb
VnuVm,...
Vl21, Vi22,-"
На рис. 1.15 можно взять за Vo узел Va, тогда узлы можно посетить в
следующем порядке:
V., Vb, Vc, Vd, Ve, Vf,
Vo, Vi, V2, Vu, V2U vln.
Если взять в качестве Vb узел И, то можно посетить вершины в порядке
V», V„, Ve, Vd, Ve, Vf,
Vo, V,, V2, V3, V21, V„.
Заметим, что после посещения нового узла можно посетить соседей нового
узла в произвольном порядке. Здесь используется соглашение о том, что при
необходимости выбора узлы посещаются в алфавитном порядке.
Бели пометить дугу, соединяющую посещенный узел с ранее посещенным
узлом, то все эти помеченные дуги образуют остовное дерево графа G; если же
каждая дуга имеет длину 1, то остовное дерево является деревом кратчайших
путей из Vo во все остальные узлы G.
3BFS — от breadth-first-search. — Прим. перев.
4DFS — от depth-first-search. — Прим. перев.
42
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Поиск в глубину. Выбираем произвольно вершину %, а затем следуем по
ребру eoi в узел V\, потом следуем по ребру е\2 в узел V2» соседний с V\. Вообще
после посещения узла V% следуем по ребру е^ в узел Vj-, если Vj ранее еще не
был посещен. Далее применяем рекурсивно этот процесс к V} и выбираем
ребро Cjk в узел V*. Если вершина Vj уже была посещена, то возвращаемся в
V{ и выбираем другое ребро. Бели все ребра, инцидентные V{, уже выбраны и
нельзя найти ни одной новой вершины, то возвращаемся из VJ в предыдущую
вершину, за которой идет Vi, и проверяем ей инцидентные ребра.
Бели на рис. 1.15 начать с вершины Ц,, то можно посетить узлы в
следующем порядке (упорядочение определяется не единственным образом):
И, vc, va, vd, v., vf.
Дуги, следующие в новые вершины, образуют остовное дерево. Это дуги
еЬс» есо» ecdt £dti ее/*
Они показаны жирными линиями на рис. 1.16.
Читатель может сравнить два способа посещения узлов. При BFS нужно
проверить все ребра, инцидентные узлу, перед переходом к новому узлу.
Таким образом, операция последовательно выполняется веером из узлов. При
DFS переход к новому узлу осуществляется только после того, как найден
новый узел, и происходит проникновение в глубину графа. Только тогда, когда
все ребра ведут в старые вершины, идет возврат к предыдущему узлу и из
него опять возобновляется DFS.
Упражнения
1. Справедливы ли следующие утверждения? Для каждого утверждения
доказать его, если оно корректно; построить контрпример, если оно
неверно.
(i) В неориентированной сети с положительными расстояниями
кратчайшая дуга всегда принадлежит дереву кратчайших путей.
(ii) Если длины всех дуг сети различны, то существует единственное
дерево кратчайших путей из Vq во все другие узлы.
УПРАЖНЕНИЯ
43
Таблица 1.9
Го
4
5
12
00
00
оо
4
0
3
00
1
оо
00
5
3
0
1
00
оо
13
12
00
1
0
00
11
00
00
1
00
00
0
00
9
оо
00
00
11
00
0
8
оо
00
13
00
0
8
о
(Ш) Для нахождения самого длинного пути в ациклической сети
положим rfjj = к — dij, где к — достаточно большая константа, и найдем
кратчайший путь. Сработает ли это преобразование? Почему?
(iv) Разобьем сеть на две части и построим для каждой части
минимальное остовное дерево. Затем свяжем эти части кратчайшей
дугой, их соединяющей. Тогда результирующее дерево является
минимальным остовным деревом для всей сети.
(v) Возьмем п деревьев кратчайших путей с источником в каждом узле.
Тогда по крайней мере одно из них является минимальным
остовным деревом.
2. Докажите, что коричневые дуги в алгоритме Дейкстры образуют дерево,
если не учитывать направления дуг.
3. Если каждый узел так же, как и каждая дуга, имеет длину, то можно ли
найти кратчайший путь между двумя узлами? (Указание: преобразуйте
сеть.)
4. Матрица в таблице 1.9 является матрицей смежности сети. Описать
алгоритм Дейкстры в терминах матрицы и затем применить его к заданной
матрице (так же, как это было сделано для алгоритма Прима).
5. Пусть кратчайший путь между всеми парами узлов не единственен.
Какой из них будет выбран тройственной операцией? Можно ли сделать
что-нибудь для того, чтобы всегда выбирался путь с наименьшим
числом дуг? (Предполагается, что все данные целочисленные.)
6. Как пометить дуги ациклической ориентированной сети таким образом,
чтобы все ориентированные дуги шли из V* в Vj при г < j.
7. Если к сети на рис. 1.17 применить тройственные операции для
нахождения кратчайших путей между всеми парами узлов, то какой результат
получится после вычисления при j = 2?
44
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
Рие.1.17
8. Изменим тройственную операцию следующим образом:
Ргк
{Pij,
не i
если dik>dij+djk,
изменяется, если dj* < dy + dj*.
Пусть кратчайшие пути между всеми парами определяются не
единственным образом. Какой путь будет выбран такой модификацией
тройственной операции?
9. В разделе 4 предположим, что кратчайший путь между любыми двумя
узлами из X состоит из узлов, полностью лежащих в X. Упрощает ли
это алгоритм декомпозиции? (предложено Canuto и Villa)
10. Что представляет собой величина d^, если выполненить тройственные
операции при j = 1,2,..., га (га < п) и затем остановиться?
Литература
Задача о кратчайших путях рассматривается в книгах и обзорных статьях
[8], [14], [16], [23], [31].
Алгоритм Дейкстры приведен в [7]. Тройственные операции исследуются
в [6], [9], [27].
Алгоритмы декомпозиции обсуждаются в [2], [13]—[15], [20], [25], [30].
Раздел 1.6 основан на работах [1], [10], [29].
Минимальные остовные деревья рассмотрены в [5], [19], [24], [28].
Иногда представляет интерес нахождение второго кратчайшего пути или
к-ro кратчайшего пути сети. По этому предмету имеется множество статей:
см. [4], [12], [21], [22].
Для нахождения кратчайших путей между всеми парами узлов есть
алгоритм Флойда-Уоршалла трудоемкости 0(п3). В статье [26] и поправке к ней
[3] показано, как можно сократить среднее время его работы. Другим
алгоритмом для нахождения кратчайших путей между всеми парами узлов является
алгоритм Данцига [6]. Алгоритм Данцига использует индуктивный подход.
Вначале алгоритм находит условно кратчайшие пути между узлами 1,2,..., fc,
ЛИТЕРАТУРА
45
которые должны проходить только через узлы множества {1,2,..., к}. Затем
все условно кратчайшие пути перевычисляются при добавлении к этому
множеству узла к + 1. Алгоритм останавливается после добавления узла п.
Если интересоваться только кратчайшими расстояниями между всеми
парами узлов, а не самими путями, то можно получить все кратчайшие
расстояния за время 0(п2+<), см. работу [11].
1. Bellman R.E. On a Routing Problem // Quart. Applied Math. — 1958. —
Vol.15.-P.87-90.
2. Blewett W. J., Ни Т. С Tree Decomposition Algorithm for Large Networks //
Networks. - 1977. - Vol. 7, № 4. - P. 289-296.
3. Carson J.S., Law A.M. A Note on Spira's Algorithm for All-pairs Shortest
Paths Problem // SIAM J. Comput. - 1977. - Vol. 6, № 4. - P. 696-699.
4. Clarke S., Krikorian A., Rausen J. Computing the Nth Best Loopless Path in
a Network // SIAM J. Appl. Math. - 1963. - Vol. 11, №4. - P. 1096-1102.
5. Cheritonand D., Tarjan R.E. Finding Minimum Spanning Trees // SIAM J.
Computing. - 1976. - Vol. 5, №4. - P. 724-742.
6. Dantzig G. B. All Shortest Routes in a Graph // Operations Research Report
TR-66-3. - Stanford University., Nov., 1966.
7. Dijkstra E. W. A Note on Two Problems in Connection with Graphs // Numer.
Math. - 1959. - Vol. 1. - P. 269-271.
8? Dreyfus S. E. An Appraisal of Some Shortest-Path Algorithms // Oper. Res.
- 1969. - Vol. 17, №3. - P. 395-412.
9. Floyd R. W. Algorithm 97, Shortest Path // Comm. ACM. — 1962. — Vol. 5.
-P. 345.
10. Ford L.R., Jr. Network Flow Theory. — The RAND Corp. 1956.
11. Fredman M.L. New Bounds on the Complexity of the Shortest Path Problem
// SIAM J. Comput. - 1976. - Vol. 5. - P. 83-89.
12. Hoffman W., Pauley R. A Method for the Solution of the Nth Best Path
Problem // J. Assoc. Comput. Mach. — 1959. — Vol. 6. — P. 508-514.
13. Ни Т. С Decomposition Algorithm for Shortest Paths in a Network // Oper.
Res. - 1968. - Vol. 16, № 1. - P. 91-102.
14? Ни Т. С Integer Programming and Network Flows. — Addison-Wesley, 19695.
15. Hu T. C, Torres W. T. A Shortcut in the Decomposition Algorithm for Shortest
Paths in a Network // IBM J. Res. Dev. - 1969. - Vol. 13, Л*4, — P. 387-390.
53десь и далее знаком ° отмечены библиографические источники, имеющиеся на русском
языке. См. список литературы на с. 324. — Прим. перев.
46
ГЛАВА 1. КРАТЧАЙШИЕ ПУТИ В ГРАФАХ
16. Johnson D. В. Algorithms for Shortest Paths / Ph.D. Thesis. — Cornell
University, 1973.
17. Johnson E.L. On Shortest Paths and Sorting // Proc. ACM 25th Annual
Conference. - 1972. - P. 510-517.
18? Knuth D. E. Fundamental Algorithms. 2nd edition. — Addison-Wesley, 1973.
19. Kruskal J. В., Jr. On the Shortest Spanning Tree of a graph and the Traveling
Salesman Problem // Proc. AMS. - 1956. - Vol. 7. - P. 48-50.
20. Land A. H. and Stairs S. W. The Extension of the Cascade Algorithms to Large
Graphs // Management Sci. - 1967. - Vol. 14. - P. 29-33.
21. Lawler E.L. Comment on Computing the к Shortest Paths in a Graph //
Comm. of ACM - 1977. - Vol. 20, №8. - P. 603^604.
22. Minieka E., On Computing Sets of Shortest Paths in a Graph // Comm. of
ACM. - 1974. - Vol. 17. - P. 603-604
23. Murchland J. D. Bibliography of the Shortest Route Problem. — London School
of Business Studies LBS-TNT-6.2. - 1969..
24? Prim R.C. Shortest Connection Network and Some Generalization // Bell
System Technical J. - 1957. - Vol. 36. - P. 1389-1401.
25. Shier D. R. A Decomposition Algorithm Algorithm for Optimality Problems in
Tree-structured Networks // Discrete Math. — 1973. — Vol.6. — P. 175-189.
26. Spira P. M. A New Algorithm for Finding all Shortest Paths in a Graph of
Positive Arcs in Average Time 0(n2 log2 n) // SIAM J. Comput. — 1973. —
Vol. 2, ЛП.- P. 28-32.
27. Warshall S. A Theorem on Boolean Matrices // J. ACM. - 1962. - Vol. 2. -
P. 11-12.
28. Yao A. С An 0(|J5|loglog|V|) Algorithm for Finding Minimum Spanning
Trees // Information Processing Letters. — 1975. — V. 4. — P. 21-23.
29. Yen J. Y. An Algorithm for Finding Shortest Routes from All Source Nodes to
a Given Destination in General Networks // Quart. Applied Math. — 1970. —
Vol.27. -P.526-530.
30. Yen J. Y. On Hu's Decomposition Algorithm for Shortest Paths in a Network
// Oper. Res. - 1971. - Vol. 19. - P. 983-985
31. Yen J.Y. Shortest Path Network Problems // Math. Systems in Economics,
18. — Verlag Anton Hain, 1975.
ОТВЕТЫ
47
Ответы
1. (i) Неверно.
(ii) Неверно.
(iii) Не сработает, так как число дуг в самых длинных путях может быть
не одинаковым.
(iv) Неверно.
(v) Можно построить контрпример с четырьмя узлами.
3. Бели длина узла равна &, то можно добавить величину к/2 к каждой
дуге, ему инцидентной.
5. Пусть кратчайший путь имеет промежуточные узлы VJ, Vj,... Vp, среди
которых максимальный индекс задается соотношением
max{i,j,...,p} = $.
Тогда будет выбран кратчайший путь с наименьшим значением
максимального индекса.
Предположим, что все длины дуг —■ целые числа, тогда можно добавить
малое d, такое, что nd < 1.
6. Пометим все узлы, имеющие степень захода ноль, числами 1,2, —
Удалим все эти узлы вместе с исходящими из них дугами. Далее продолжаем
этот процесс.
8. Путь с наибольшим значением максимального индекса.
Глава 2
Максимальные потоки
В каждой системе есть узкое место.
2.1. Максимальные потоки
В этой главе рассматривается так называемая задача о максимальном
потоке в сети. Каждой дуге сети приписывается некоторое число. Это число
является не длиной дуги, а скорее ее шириной. Если сеть — это модель
железной дороги, а узлы представляют железнодорожные станции, то число,
приписанное дуге, может быть равно количеству путей между двумя
станциями. Если сеть моделирует трубопровод, а узлы являются сочленениями, то
это число может представлять площадь сечения трубы между двумя
сочленениями. Оно определяет наибольшее количество жидкости, которое может
пройти через дугу. Это число будем называть пропускной способностью дуги.
Пропускная способность дуги e*j обозначается через Ь#. В этом и
последующем разделах будем иметь дело не с длинами дуг, а только с их пропускными
способностями. Предполагается, что Ь# > 0 при всех i,j.
Чтобы задать сеть, необходимо указать пропускные способности всех ее
дуг. Должны быть также указаны два специальных узла, называемых
источником и стоком сети. Задача состоит в том, чтобы определить наибольшую
величину потока, который может пройти из источника в сток. Прежде всего,
необходимо точно определить, что понимается под потоком в сети, поскольку
наш ноток ведет себя не совсем так, как вода или другая жидкость. Обозначим
через Xij поток из V* в Vj через дугу eij. Для дуги имеется ограничение
О < х^ < bij. (1)
Кроме ограничения (1), потребуем, чтобы приток в каждый узел был равен
оттоку из него; т.е. поток сохраняется в каждом узле (за исключением
источника и стока). Если через V8 обозначить источник, а через Vt — сток, то
2.1. МАКСИМАЛЬНЫЕ ПОТОКИ
49
данное ограничение в узле Vj примет вид:
Yl Xii= Y1 х*к при всех i ^5> *• (2)
t к
Поскольку поток сохраняется в каждом узле, отток в источнике должен быть
равен притоку в стоке. Таким образом,
Y^xai = v = Ylx3ty (3)
* э
где v называется величиной потока.
Неориентированную дугу е# можно заменть двумя ориентированными
дугами из V{ в Vj и из Vj в V{ с одинаковыми пропускными способностями,
равными b{j. Набор значений х^, определенных для всех дуг сети и
удовлетворяющих (1)-(3), называется потоком в сети. Поток наибольшей возможной
величины называется максимальным потоком.
Имеются большие различия между потоком, определенным
соотношениями (1)-(3), и электрическим током. Ограничение (2) подобно первому закону
Кирхгофа, который говорит о том, что величина тока, входящего в узел,
равна величине тока, покидающего этот узел. Однако аналога второго закона
Кирхгофа для наших потоков нет. Также и ограничение (1) не похоже на
закон Ома — закон линейного сопротивления. Дуга не оказывает сопротивления
потоку до тех пор, пока поток не достигнет верхнего предела bij. После этого
сопротивление становится бесконечным.
Потоки в сетях широко используются во многих приложениях. Например,
каково наименьшее число дуг, которые нужно удалить для разъединения двух
заданных узлов графа? Этот вопрос является задачей теории графов, однако
его можно решить, используя понятие потока. Другие приложения
обсуждаются в разделе 2.5.
Если сеть представляет собой цепочку V8, V\, V^,..., Vn, 14, то наибольшая
величина потока, который может пройти из V8 в V* при выполнении (1)-(3),
равна
min{ftei, fti2,623, - - -, bni}. (4)
Дуга с наименьшим значением пропускной способности является «узким
местом» сети. Теперь определим понятие «узкого места» для произвольной сети.
Узкое место сети называется разрезом.
Разрез1 — это совокупность всех дуг, идущих из некоторого подмножества
узлов в его дополнение. Он обозначается через (Х,Х), где X — заданное
подмножество узлов, а X — его дополнение. Таким образом, разрез (Х,Х)
— это множество всех таких дуг eij, что либо V* € X и Vj € X, либо Vj €
X и Vi € X. Удаление всех дуг из разреза разобьет сеть на две или более
компоненты. Разрез, разделяющий узлы Va и V* — это такой разрез (-Х\Л"),
что V, е X и Vt е X.
На рис. 2.1(a) сеть изображена условно. Реальная сеть может быть такой,
как показано, например, на рисунках 2.1(b) или 2.3.
Заметим, что на с. 29 термин «разрез» использовался в другом смысле. — Прим. перев.
50
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.1(a)
Пропускная способность, или величина, с(X, X) разреза (X, X)
определяется как
5>„ гдеК- € X, Vj € X.
Заметим, что в определении разреза учитываются все дуги между
множествами X и X, тогда как при вычислении его пропускной способности подсчи-
тываются пропускные способности только дуг из X в X, а дуги из X в X
игнорируются. Поэтому в общем случае с(Х,Х) ф с(Х,Х).
Некоторые авторы определяют разрез (Х,Х) как множество дуг, идущих
из X в X, и не включают_в него множество дуг, выходящих из X в X. В
любом случае с(Х,Х) ф с(Х, X), если только сеть не состоит лишь из
неориентированных дуг.
Разрез (Х,Х), разделяющий V8 и V*, является аналогом «узкого места».
Рассмотрим произвольный разрез, отделяющий V8 от V*. Так как поток
сохраняется, величина потока, выходящего из V8, должна равняться величине
потока, входящего в V*. Вследствие ограничения (2) это_значение также равно
чистой составляющей потока через любой разрез (X, X) (т. е. разности величин
потока из X в X и из X в X). Вследствие ограничения (1) для любого разреза
(X, X) наибольшая величина потока не может превышать с(Х,Х).
Оказывается, величина максимального потока всегда совпадает с минимальной
пропускной способностью разреза, разделяющего V8 и V*. Разрез с наименьшей
пропускной способностью, разделяющий V8 и V*, называется минимальным
разрезом. (Для простоты при описании разреза иногда будем опускать фразу
«разделяющий V8 и Vt>.) Факт совпадения величины максимального потока
с пропускной способностью минимального разреза впервые был доказан
Фордом и Фалкерсоном [6]. Это центральная теорема теории потоков в сетях.
Дадим конструктивное доказательство теоремы (см. [7]), которое строит
максимальный поток и находит минимальный разрез. Доказательство
показывает, что всегда существует поток, значение которого равно пропускной
способности минимального разреза. Поскольку максимальный поток всегда
не превосходит пропускной способности произвольного разреза, в частности,
минимального разреза, то это и доказывает справедливость теоремы.
Теорема 1 (о максимальном потоке и минимальном разрезе). [6], [7]
В любой сети с целыми значениями пропускных способностей дуг величина
максимального потока из источника в сток равна пропускной способности
минимального разреза, разделяющего источник и сток.
2.1. МАКСИМАЛЬНЫЕ ПОТОКИ
51
Доказательство. Дадим конструктивное доказательство теоремы.
Если текущая величина потока равна пропускной способности
некоторого разреза, то теорема доказана. Если величина потока не равна пропускной
способности разреза, то ищем среди путей из Va в Vt такой, вдоль
которого можно послать дополнительный поток. Это увеличивает величину потока.
Продолжаем данную процедуру до тех пор, пока такого пути нельзя будет
найти. Докажем, что величина потока равна пропускной способности некоторого
разреза. Опишем систематический способ отыскания такого пути.
Начнем с произвольного множества величин х^, удовлетворяющих (1) и
(2) (например, Xij = О при всех i и j). На основе текущего потока в сети
рекурсивно определим подмножество узлов X при помощи следующих правил.
0. V, € X.
1. Если V{ € X и х^ < bij, то Vj € X.
2. Если Vi € X и Xji > 0, то Vj € X.
Все узлы, не лежащие в X, принадлежат X. Используя данные правила
определения множества -Y, рассмотрим два возможных случая.
Случай 1. Vt € X. Следовательно, для всех дуг из X в X справедливо х^ = b{j
(в силу правила 1) и не существует потока х^ через дугу из X в X (в силу
правила 2). Поэтому
jex jex jex
Следовательно, найден поток со значением, равным с(Х,Х).
Случай 2. Vt € X. Тогда существует путь из V8 в Vi» образованный дугами,
удовлетворяющими правилу 1 или правилу 2.
Обозначим этот путь
К»> • • • » У it fyji Vji • • •» Vt-
Каждая дуга в данном пути должна удовлетворять либо правилу 1, либо
правилу 2. Если дуга удовлетворяет правилу 1, т. е.
X{j < Оу,
то можно отправить дополнительный поток из V{ в Vj. Это увеличивает
величину потока вдоль дуги. Такой тип дуги называется прямой дугой.
Если же дуга удовлетворяет правилу 2, т. е.
Xji > 0,
то можно отправить поток из Vi в 1^-, фактически отменяя существующий
поток вдоль дуги. Эффект состоит в сокращении величины потока вдоль
дуги. Такой тип дуги называется обратной дугой. Данный путь по отношению
52
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.1(b)
к текущему потоку называется увеличивающим путем. Например, возьмем
сеть на рис. 2.3 (в разделе 2.2), где числа обозначают пропускные способности
дуг. Если потоки на дугах равны х8\ = #12 = х<ц = 1, а все остальные хц = О,
то e*3,e32,e2i,ei4,e4i является увеличивающим путем с обратной дугой е^\.
Предположим, что все пропускные способности являются целыми
числами, и пусть в\ — минимум среди всех разностей b{j — xij в этом пути, €2 —
минимум среди Xji в нем, а € = min{€i,€2} — целое положительное число.
Тогда можно увеличить дуговые потоки на е по всем прямым дугам пути и
уменьшить дуговые потоки на е по всем его обратным дугам. Таким образом,
величина потока уменьшается на € и новые значения х^ удовлетворяют всем
ограничениям (1) и (2). Теперь на основе нового потока можно
переопределить множество X. Если Vt все еще лежит в X, то снова увеличиваем
величину потока на некоторое е. Поскольку пропускная способность минимального
разреза — конечное число, а величина потока увеличивается по крайней
мере на единицу, то после конечного числа шагов будет получен максимальный
поток.
Теорема доказана. I
Обозначим через F8t набор неотрицательных целых чисел ##,
удовлетворяющих (1)-(3).
Следствие 1. Поток F8t максимален тогда и только тогда, когда
относительно F8t не существует увеличивающего пути.
Дадим некоторые пояснения. Величина максимального потока в любой
сети определяется единственным образом, однако может существовать
несколько потоков, дающих наибольшую величину потока. Также в сети может
существовать и несколько минимальных разрезов. Например, рассмотрим сеть на
рис. 2.1(b).
Пусть пропускная способность каждой дуги равна единице. Тогда обе дуги
^23 и e$t являются минимальными разрезами. Величина максимального
потока в точности равна 1, однако максимальным потоком может быть как х8\ =
#12 = #23 = Ж34 = #45 = #5* = 1> Т&к И Xrf = #62 = #23 = #37 = #75 = #5* = 1-
Если бы ноток был потоком воды, то равенства х8\ = #12 = #23 = #34 =
Х45 = #5* = 1 И Хм = #62 = #37 = #75 = 0 были бы НвВОЗМОЖНЫ, ПОСКОЛЬКУ
это означало бы, что некоторые трубы наполнены, а другие сухие. Этим наш
поток отличается от потока воды.
2.1. МАКСИМАЛЬНЫЕ ПОТОКИ
53
Х <
Рис. 2.2
Пусть (X, X) и (У, У) — два разреза. Будем говорить, что эти два разреза
скрещиваются, если каждое из множеств
ХпУ, Хп¥, 1пУ, Хп7
не пусто.
Теорема 2. Пусть (Х,Х) и (У, У) — минимальные разрезы. Тогда (X U
У, X U У) и (X П У, X П У) также являются минимальными разрезами.
Доказательство. Если ХсУ, тоХиУ = У, аХПУ = Х, следовательно,
(ХиУ,ХиУ)=(У,У), (ХЛУ,ХПУ) = (*,*).
Рассмотрим теперь случай, когда X (JL У и У {£ X, как показано на рис. 2.2.
Иначе говоря, данные два разреза скрещиваются. Введем четыре различных
множества следующим образом:
Q = XnY, S = XHY, Р = ХпУ, R = XnY,
где по определению V8 € Q, a V* € Л. Заметим, что
X = QuS, Х = РиЯ, y = PuQ, Y = RuS.
Пусть c(P,Q) = J^btj по всем i € P,j € Q, и аналогично для остальных
множеств.
Поскольку (Х,Х) и (Y,Y) — минимальные разрезы, а (Р U Q U S,R) и
(Q, Р U R U S) — разрезы, разделяющие V8 и V*, то должно выполняться
c(X,X) + c(y,y)<c(Pugu5,fl) + c(Q,PUflUS),
(5)
54
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
или
c(Q, Р) + c(Q, R) + с(5, Р) +■ c(S, R) + с(Р, R) + с(Р, S) + c(Q, Я) + c(Q, S)
< с(Р, R) + c(Q, R) + c(S, R) + c{Q, P) + c(Q, R) + c(Q, S),
(6)
ИЛИ
c(P,S)+c(S,P)<0. (7)
Поскольку величина c(P, S) +c(S, P) должна быть неотрицательной, то видно,
что (5) должно обращаться в равенство, т. е.
c(X,X)+c(Y,Y) = c(PuQuS,R) + c(Q,PuRuS)
или
c(X,X)+c(Y,Y)=c(XuY,Xu¥) + c(XUY,TU¥). (8)
Так как ни одно из слагаемых правой части (8) не может быть строго меньше
пропускной способности минимального разреза, то каждое из них должно ей
равняться. I
Читатель может заметить, что в общем случае c(P,S) ф c(S,P), но обе
величины с(Р, S) и c(S, Р) неотрицательны. Теорема 2 устанавливает, что если
имеются два скрещивающихся минимальных разреза, разделяющих Va и Vt ,
то существуют два других не скрещивающихся минимальных разреза.
2.2. Алгоритмы нахождения
максимального потока
В разделе 2.1 было показано, что поток является максимальным тогда и
только тогда, когда в сети не существует увеличивающего пути из Va в Vt.
Конструктивное доказательство из предыдущего раздела можно положить в
основу алгоритма, который систематически отыскивает в сети увеличивающие
пути. В действительности, самый первый алгоритм нахождения максимального
потока, принадлежащий Форду и Фалкерсону, основан на их конструктивном
доказательстве [7].
Чтобы понять алгоритм, дадим вначале численный пример для
иллюстрации некоторых понятий.
Рассмотрим рис. 2.3, на котором числа в квадратных скобках обозначают
пропускные способности дуг. Можно послать одну единицу потока вдоль пути
{V8,VUV2,Vt) и другую единицу потока вдоль пути (У„ V3,^2, Vi, КьУ*).
Суперпозиция этих двух увеличивающих путей равносильна двум
увеличивающим путям (V,, 1^, У2» Уь) и (Ve, Vi, V^ Уь). Заметим, что дуга е\2 используется
вначале для передачи потока из Vi в V2, а затем для передачи потока из Vi
в Vi. В результате поток по дуге ei2 равен нулю. Дуга е\ч является
ориентированной и может использоваться только для передачи потока из Vi в 1^.
Однако если х\ч > 0, то имеется возможность направить поток из Vi в V\, что
эквивалентно аннулированию существующего потока через эту дугу.
2.2. АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 55
Рис. 2.3
2.2.1. Алгоритм Форда-Фалкерсона
Алгоритм Форда-Фалкерсона — это систематический способ отыскания
увеличивающего пути. Алгоритм называется методом расстановки пометок
и может быть легко применен, если входные данные заданы при помощи
списков смежности. (Читатель, не знакомый со структурами данных, может не
обращать внимания на относящиеся к ним комментарии.)
Алгоритм Форда-Фалкерсона состоит из двух шагов. Первый шаг
присваивает узлам метки для поиска увеличивающего пути. Второй шаг увеличивает
поток вдоль увеличивающего пути, найденного на первом шаге. Начинаем с
нулевого значения потока (т.е. Xij = 0 при всех i,j) и повторяем шаги 1 и 2
до тех пор, пока поток не станет максимальным.
Шаг 1. Процесс расстановки пометок. Каждый узел всегда находится в одном
из следующих трех состояний.
(i) Непомеченный: узел еще не получил пометки. Вначале каждый
узел является непомеченным.
(ii) Помеченный и неотсканированный: узел помечен, но не все его
соседи являются помеченными.
(Ш) Помеченный и отсканированный: узел помечен и все его соседи
также помечены.
Узел Vj получает пометку [a,ft], состоящую из двух чисел. Число а
обозначает наибольшую суммарную величину потока, который
можно передать из V8 в Vj. Число Ь указывает последний промежуточный
узел увеличивающего пути из V8 в Vj. (Заметим сходство этих
пометок и тех, которые использовались при решении задач о кратчайших
путях в разделе 1.2.)
В начале алгоритма присваиваем узлу V, пометку [оо,з], а каждому
соседнему с ним узлу V* присваиваем пометку [Ь«,в]. Пусть у
помеченного узла V{ есть еще не помеченный сосед Vj. Тогда узлу Vj
присваиваем пометку [€(j),i], где
€(j) = min{ftei,ftij}.
56
ГЛАВА 2, МАКСИМАЛЬНЫЕ ПОТОКИ
В общем случае дополнительный поток из Vi в Vj можно отправить ,
если
Xij < bij или Xji > 0.
Предположим, что V* имеет пометку [б(<),г+], тогда Vj получает
пометку [c(j),t+], если
x{j < b^ где e(j) = min{€(i), b{j - x{j} > 0.
Узел Vj получает пометку [€(j),i~], если
Xji > 0, где e(j) = тт{б(г),х^} > 0.
Оба символа i+ и i- указывают, что V{ — последний промежуточный
узел, при этом «+» означает, что е# — прямая дуга, а «—»
означает, что ец т- обратная дуга. Заметим, что узел Vj получает пометку
только в случае, когда e(j) строго положительно.
Сначала узел V8 помечен и неотсканирован Он Станет помеченным и
отсканированным тогда, когда будут помечены все его соседи. Соседи
Va также становятся помеченными и отсканированными, когда будут
помечены все их соседи. Процесс расстановки пометок продолжается
до тех пор, пока не выполнится одно из двух условий:
(i) узел Vt помечен.
(ii) узел Vt не помечен и больше нельзя присвоить никаких новых
пометок.
В случае (ii) все помеченные узлы (отсканированные и
^отсканированные) составляют множество X, а непомеченные узлы — множество
X. Разрез (X, X) является минимальным, а текущий поток —
максимальным. Алгоритм завершает работу.
Шаг 2. Изменение потока: если узел Vt помечен, то можно проследовать
обратно из Vt в Va и изменить потоки через дуги вдоль увеличивающего
пути. Пусть [e(t), к+] - пометка узла Vi, [e(k),j~] — пометка узла V*,
a [€(j), 5+] — пометка узла Vj- Тогда добавляем e(t) к Хм и x8j и
вычитаем e(t) из Xkjy т.е. добавляем величину e(t) к потокам для прямых
дуг и вычитаем e(t) из потоков для обратных дуг.
Стираем все метки и возвращаемся на шаг 1.
Оригинальный алгоритм Форда-Фалкерсона не определяет порядок, в
котором происходит домечивание узлов или проверка помеченных и неотска-
нированных узлов. Бели следовать правилу «первый помечен — первый
отсканирован», то всегда будет использован кратчайший увеличивающий путь
(кратчайший в том смысле, что число дуг в пути наименьшее). Это
модификация Эдмондса и Карпа [4]. В литературе правило «первый помечен —
первый отсканирован» более известно как поиск в ширину (см. раздел 1.8).
2.2. АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 57
(2,/)
(U+)
Рис. 2.4
Если использовать поиск в ширину для нахождения увеличивающих путей и
применить его к сети на рис. 2.3, то получим рисунок 2.4, где числа рядом
с дугами обозначают имеющиеся потоки через дуги. (Числа в квадратных
скобках — пропускные способности дуг.)
После добавления единицы потока вдоль пути (V8, V\, V2, Vt) и расстановки
пометок получим пометки, показанные на рис. 2.5.
Используя увеличивающий путь (Vi,Vi,t^,Vi,Vi,Vi) и пометки узлов на
этом пути, добавляем единицу потока к величинам х8$> #32> #н* #4* и вычитаем
единицу из #12* После таких изменений потока получим
#*3 = #32 = #2* == 1 И Х8\ = Х\4 = XAt = 1
Если снова выполнить процесс расстановки пометок, то V, и Ц станут
помеченными, a Vi,V2,V4,Vt не будут помечены; при этом максимальный поток
равен 2, а минимальный разрез — это (X, X) = ({$,3}, {1,2,4,$}).
Дуга с пропускной способностью b%j и поток ху через эту дугу равносиль-
(М+)
Рис. 2.5
58
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
ны дуге с пропускной способностью 6J-, где
bij = bij - ХИ'
Если eji — дуга с потоком Xj% > 0, то она равносильна дуге с пропускной
СПОСОбнОСТЬЮ Ь^ = bij + Xj{.
Сеть с пропускными способностями b\j называется остаточной сетью,
порожденной существующим потоком. Дуга из V{ в Vj называется полезной,
если b'{j ф 0.
Коротко алгортим Форда-Фалкерсона можно описать следующим
образом.
1. На основе существующего потока строится остаточная сеть с
пропускными способностями Ь^.
2. В остаточной сети производим систематический поиск увеличивающего
пути и увеличиваем поток вдоль увеличивающего пути.
Если все пропускные способности дуг являются целыми числами, то поток
будет увеличиваться также на целую величину и алгоритм правильно
завершит работу. Если же пропускные способности могут быть иррациональными,
то можно построить пример, в котором алгоритм будет работать бесконечно
дол 1Ю, а величина потока будет сходиться к неверному пределу [8].
Если использовать поиск в ширину, предложенный Эдмондсом и Карпом,
то поток всегда будет увеличиваться вдоль кратчайшего увеличивающего
пути. Длиной пути называем число дуг в нем. Вначале используется
увеличивающий путь длины 1. Если не существует увеличивающих путей длины 1,
используется увеличивающий путь длины 2. Эти действия повторяются до тех
пор, пока длина кратчайшего увеличивающего пути не станет равной п — 1.
Разобьем вычисления на п—1 этапов. На каждом этапе происходит увеличение
потоков вдоль увеличивающих путей заданной длины к (к = 1,2,..., п — 1).
(В дальнейшем будет показано, что от этапа к этапу длина кратчайшего
увеличивающего пути возрастает.) В конце каждого этапа строится остаточная
сеть, порожденная существующим потоком. В начале каждого этапа имеется
остаточная сеть с пропускными способностями дуг, равными ftj..
Разобьем все узлы сети на слои. По определению, источник Va лежит в
нулевом слое. Узел V* лежит в слое к, если кратчайший путь из V8 в V{ имеет
длину к.
На рис. 2.6 показана сеть, разбитая на четыре слоя. Заметим, что узел Vt
лежит в слое 3. Следовательно, длина кратчайшего увеличивающего пути
равна 3. Поток в сети, относительно которого нет увеличивающих путей длины
3, называется тупиковым. Например, если положить на рис. 2.6 пропускные
способности всех дуг равными 1, то можно отправить единицу потока вдоль
пути (eei,ei4,e4t). Тогда не существует увеличивающего пути длины 3,
откуда заключаем, что текущий поток (величина которого равна 1) является
тупиковым, хотя величина максимального потока в этой сети равна 2.
Назовем этапом часть работы алгоритма, которая состоит в выполнении
следующих действий:
2.2. АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 59
Слой 0 Слой 1 Слой 2 Слой 3
Рис. 2.6
(i) найти остаточную сеть,
(И) разбить множество узлов на слои,
(iii) найти тупиковый поток.
Алгоритм состоит из последовательности таких этапов с ростом длины
кратчайших увеличивающих путей, причем число этапов не превосходит п — 1.
Для заданной сети предположим, что кратчайший увеличивающий путь
состоит из к дуг. Пусть N(f) — остаточная сеть, порожденная потоком /,
a N(f) - ее подсеть, состоящая только из полезных дуг, соединяющих слои
i и г + 1 (i = 0,1,2,..., к — 1). Когда использование увеличивающих путей
длины к увеличит поток настолько, насколько это возможно, образуются
новая остаточная сеть и новая подсеть, которые обозначаются N(f\) и N(f\)
соответственно. Используем запись
l(t) = *
для обозначения того, что сток Vt лежит в fc-м слое подсети N(f). Покажем,
что l(t) > к в подсети N(f\).
При разбиении узлов на слои в остаточной сети N(f) все полезные дуги
можно разбить на пять классов:
Класс А: полезные дуги, идущие из слоя i в слой г + 1.
Класс В: полезные дуги, идущие из слоя г в слой j, где j > i + 1.
Класс С: полезные дуги, идущие из слоя i + 1 в слой г.
Класс D: полезные дуги, идущие из слоя j в слой г, где j > г + 1.
Класс Е: полезные дуги, идущие из слоя $ в слой i.
В действительности класс В пуст, иначе получилось бы противоречие
определению слоев. С другой стороны, дуги из классов C,D и Е лежат в iV(/),
но не принадлежат iV(/), следовательно, эти дуги не влияют на изменения
потока.
60
■* ГЛАВА 2, МАКСИМАЛЬНЫЕ ПОТОКИ
Дуги из класса А можно использовать в увеличивающих путях, если i+1 <
fc, причем по крайней мере одна дуга в каждом увеличивающем пути
перестанет быть полезной. Пусть e^i — такая дуга. Тогда ei+i,j станет полезной
дугой в сети N(f\).
Утверждается, что кратчайший увеличивающий путь в подсети N(fx)
имеет длину не меньше к + 1, т.е. l(t) > к + 1 в JV(/i).
Если кратчайший увеличивающий путь в N(f\) не использует дугу е^+1^,
то он должен использовать Дуги только из классов А,С,£) и Е в сети N(f).
Если путь использует только дуги из А и достигает £, то это означает, что
предыдущий этап еще не завершен. Если же этот путь использует любую
одну дугу из С,£) или Е, то он должен иметь длину не менее, чем к + 1.
Если увеличивающий путь в подсети N(f\) использует дугу е*+1^, то длина
участка пути из V8 в VJ+i должна быть равна г + 1, а длина участка пути из
Vi в Vt должна быть не меньше, чем к — г. Таким образом, общая длина пути
не меньше, чем (г + 1) + 1 + (к — г) = к + 2.
Если длина увеличивающего пути от этапа к этапу возрастает, то число
этих этапов не превосходит п — 1. Предположим, что имеется m дуг. В
течение этапа существует не более т увеличивающих путей, и на поиск каждого
такого пути требуется не более, чем 0(т) шагов. Следовательно, итоговая
трудоемкость поиска составляет 0(т2) в течение этапа и 0(пт2) для всего
алгоритма Эдмондса и Карпа.
Оценка 0(пгп2) получается в предположении, что каждый увеличивающий
путь в сети N(f) ищется независимо. Можно улучшить эту оценку до
величины 0(n2m), если на каждом этапе скоординировать поиск увеличивающих
путей заданной длины. Эта улучшенная оценка принадлежит Диницу [3].
Алгоритм Диница. Вначале, используя поисков ширину, строим подсеть
N(f). После этого, применяя поиск в глубину, в N(f) отыскиваем
увеличивающие пути, достигающие Vt. Если сток Vt достигнут, то увеличиваем поток
вдоль найденного пути, корректируем пропускные способности дуг, проходя
вдоль увеличивающего пути в обратном направлении, и удаляем дуги,
пропускные способности которых стали равны нулю.
Если в процессе поиска в глубину при отыскинии увеличивающего пути
делается «шаг назад» из узла V*, то все дуги, инцидентные узлу VJ,
вычеркиваем из N(f). Поиск в глубину затрачивает время 0(п) и, поскольку в течение
этана имеется не более m увеличивающих путей, итоговая трудоемкость
алгоритма составляет 0(пт) для каждого этапа и 0(п2т) в целом. (Детальный
анализ всех потоковых алгоритмов дается в разделе 2.2.4.)
Рассмотрим сеть N(f) на рис. 2.7, в которой числа рядом с дугами
являются пропускными способностями. Если поиск в глубину находит
увеличивающий путь
V, [оо, а+], Vi [2, а+], Vq [1, i+], Vt [1, e+],
то назначаем прток xai = Xiq =% = 1и удаляем дугу e$ff из сети N(f).
Если следующий поиск в глубину находит путь
V.[oo,8+], Vp[i,s+], Vq[4,p+], Vt[l,e+],
2.2. АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 61
Рис. 2.7
то полагаем х8р = xpq = xqt = 1 и удаляем из сети дугу eqt.
Если следующий поиск в глубину находит сначала путь
V.[oo,s+], Vp[3,s+], V„[3,p+]
и делаются «шаги назад» из Vq в Vp (следовательно, вычеркивается дуга е^)
и из Vp в V8 (следовательно, вычеркивается евр), то при продолжении поиска
в глубину будет найден путь
v.[oo,e+], v;-[i,s+], Vj[i,i+], vt[ij+].
Заметим, что трудоемкость нахождения увеличивающего пути поиском в
глубину не превосходит О(п), и при каждом поиске удаляется по крайней мере
одна дуга. Алгоритм Диница на каждом этапе при построении тупикового
потока насыщает по одной дуге. Далее опишем алгоритм Карзанова, который
на каждом этапе при построении тупикового потока насыщает по крайней
мере один узел и имеет верхнюю оценку трудоемкости 0(п3).
2.2.2. Алгоритм Карзанова
Перед описанием алгоритма Карзанова необходимо прежде всего ввести
понятие предпотока в сети. Говорят, что множество х^ образует предпоток в
сети, если
(i) для каждой дуги
Zij < bij, (1)
(ii) для каждого узла Vj с входящими дугами е# и выходящими дугами е$ъ
справедливо неравенство
e«€a(Vi) eib€/?(Vi)
где a(Vj) — множество дуг, входящих в Vj, а /?(Vj) — множество дуг,
выходящих ИЗ Vj.
Узел, для которого неравенство (2) выполняется строго, называется
несбалансированным .
62
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Если каждый узел является сбалансированным, то предпоток становится
потоком в сети.
Алгоритм Карзанова состоит из нескольких этапов, на каждом из которых
ищется тупиковый поток в многослойной сети. Таким образом, общая схема
очень похожа на алгоритм Диница. Однако способ Карзанова нахождения
тупикового потока в многослойной сети имеет существенные отличия.
Напомним, что в алгоритме Диница при поиске тупикового потока в
остаточной подсети N(f) каждый раз насыщается одна дуга. В алгоритме
Карзанова при поиске тупикового потока каждый раз насыщается один узел.
Каждый этап начинается с проталкивания предпотока из Ув, а затем из слоя в
слой до тех пор, пока не будет достигнут узел V$. Затем происходит
балансировка предпотока в каждом узле. Таким образом, каждый этап состоит из
двух шагов. Первый шаг называется продвижением предпотока, а второй —
балансировкой предпотока. Эти шаги повторяются до получения тупикового
потока в остаточной подсети N(f).
Алгоритм Карзанова для нахождения тупикового потока в
многослойной сети.
Шаг 0. Построение сети N(f) на основе существующего потока.
Шаг 1. Продвижение предпотока в подсети N(f).
Шаг 2. Балансировка предпотока в подсети N(f).
Шаги 1 и 2 повторяются до тех пор, пока каждый узел, за исключением V8 и
Vt, не станет сбалансированным.
При нахождении тупикового потока в подсети N(f) на очередном этапе
назовем дугу е# закрытой, если текущую величину xij изменить нельзя. Бели
же ноток через дугу можно изменить, то эту дугу назовем открытой. Вначале
считаем, что все дуги в многослойной сети являются открытыми. В течение
второго шага некоторые дуги могут стать закрытыми, в оставшейся части
этапа потоки через эти дуги не изменятся.
Для узла Vj все дуги е^ выстраиваются в некотором порядке, например,
по возрастанию индекса к. При продвижении потока из узла Vj в следующий
слой мы всегда пытаемся передать наибольшую возможную величину потока
через первую открытую ненасыщенную дугу, потом наибольшую возможную
величину потока через вторую открытую дугу, и т.д. Таким образом, дуги в
/?(Vj) образуют очередь.
Это упорядочение дуг фиксировано в течение этапа. Поэтому обычно среди
всех открытых дуг в 0(Vj) будет несколько насыщенных дуг, одна дуга с Xjk <
bjk и несколько дуг с нулевым потоком.
Дуги в a(Vj) вначале неупорядочены, а в дальнейшем мы следим за
порядком, в котором х^ добавляются к узлу Vj. Если в ходе этапа нужно уменьшить
поток, входящий в Vj, то уменьшаем вначале самое последнее добавление;
другими словами, уменьшение величин Xij происходит по принципу «вошел
последним — вышел первым», как в стеке. Теперь можно описать детали этого
алгоритма.
2.2. АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 63
Шаг 1. Продвижение предпотока. Цель этой подпрограммы — протолкнуть
предпоток наибольшей возможной величины из источника в сток.
Начинаем процесс в источнике V8 (в слое 0) и передаем предпоток с
наибольшим возможным значением в узлы 1-го слоя, полагая x8j =
b8j для всех узлов Vj из 1-го слоя. Считаем, что предпоток передан
из слоя 0 в слой 1.
Вообще мы рассматриваем несбалансированные узлы из самого
нижнего слоя и пытаемся протолкнуть предпоток в следующий слой и
далее до Vt. Подпрограмма продвижения останавливается тогда,
когда никакой предпоток невозможно передать вперед из любого узла
Vj. Это обязательно произойдет, если дуги в 0(Vj) либо закрыты, либо
насыщены.
Шаг 2. Балансировка предпотока. Цель этой подпрограммы — сделать
несбалансированные узлы сбалансированными и эффективно
преобразовать предпотоки в регулярные потоки.
Начинаем с наивысшего слоя, содержащего несбалансированные
узлы. Для каждого такого узла Vj уменьшаем потоки, входящие в него,
по принципу «вошел последним — вышел первым» до тех пор, пока
узел не станет сбалансированным. Все дуги в a(Vj-), относящиеся к
вновь сбалансированному узлу, объявляются закрытыми. Если в
данном слое все несбалансированные узлы стали сбалансированными, то
возвращаемся на шаг 1 (даже если остались несбалансированные
узлы в низших слоях).
Заметим, что при первом выполнении шага 1 происходит продвижение
предпотока из слоя 0 в слой 1, из слоя 1 в слой 2 и т.д. до тех пор, пока
не будет достигнут узел V*, после этого переходим к шагу 2. Однако в
подпрограмме балансировки рассматривается только один слой — наивысший слой j,
содержащий несбалансированные узлы. При балансировке узлов слоя j могут
появиться несбалансированные узлы в слое j — 1. Поскольку все узлы слоев
j — 2,..., 0 уже обработаны, можно начать шаг 1 из слоя j — 1 и продвигать
наибольший возможный предпоток в сток t.
Приведем численный пример, иллюстрирующий все возможные ситуации
и поэтому весьма неблагоприятный для алгоритма Карзанова.
Рассмотрим сеть N(f) на рис. 2.8, в которой все дуги ориентированы
слева направо, а числа рядом с дугами обозначают пропускные способности (в
каждом слое первыми будут обрабатываться узлы с наименьшим индексом).
Полагаем, что в очереди дуг, исходящих из каждого узла, вначале идут дуги
с меньшим индексом. Таким образом, е\2 идет перед ехз, а в узле Vs дуга ез4
идет перед е3ь-
Шаг 1. Продвигаем предпоток из V8 в Vt. Получается предпоток, показанный
на рис. 2.9. (Первое число в квадратных скобках — это пропускная
способность дуги, а второе — поток через дугу.)
64
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Слой О
Слой 5
Рис. 2.8
Шаг 2. Уб — несбалансированный узел из наивысшего слоя, поэтому
уменьшаем #46 с 6 до 4 и объявлеем дугу е^е закрытой. Все узлы слоя 4
стали сбалансированными, поэтому переходим на шаг 1.
Шаг 1. Продвигаем предпоток из слоя 3, в котором только узел V± имеет
избыточный поток. Поскольку единственная выходящая дуга е^ закрыта,
то продвижение из узла V\ завершено, переходим к шагу 2.
Шаг 2. Теперь V* — несбалансированный узел из наивысшего слоя 3.
Уменьшаем #34 Д° нуля, так как это последнее добавление к V^ затем
уменьшаем #24 до 4 и объявляем дуги ез4 и в24 закрытыми.
Шаг 1. Избыточный поток в узле Vi продвинуть нельзя, а избыточный поток
из Vs можно продвинуть в V5» в V7» а затем в V*. Результат показан
на рис. 2.10. (Все закрытые дуги помечены символом -//к)
Шаг 2. Уменьшаем х\2 до 4, объявляем дугу е\2 закрытой и возвращаемся
на шаг 1.
Шаг 1. Избыточный поток в узле V\ продвигается через V3, V^, V? в сток V*.
Результат показан на рис. 2.11.
(Заметим, что как только дуга ез4 стала закрытой, поток через нее уже не
продвигается.)
Поток на рис. 2.11 является максимальным.
[6], 5 Г6], 6
[6], 4 ~ [6], 4
Рис. 2.9
Ш АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 65
J10].«k
[ЯЬ
[61,5^
Л6\, 4 ^,[6J,4
/СП, о
[615^ И, 5^
Рис. 2.10
\14],4
/[61,5
2.2.3. МРМ-алгоритм
Для нахождения максимальных потоков в многослойной сети Мальхот-
ра, Прамод Камар и Махешвари [24] предложили остроумную модификацию
алгоритма Карзанова. Для каждого узла Vj многослойной сети определим
потенциал потока как
mm
{ix>p»}.
т.е. как минимум из двух величин: суммы пропускных способностей дуг, вхо-
дящих в узел V}, и суммы пропускных способностей дуг, выходящих из
этого узла. Потенциал потока является наибольшей величиной потока, которую
можно передать через узел. Среди всех узлов с ненулевым потенциалом
потока в многослойной сети узел Уг с наименьшим потенциалом потока называется
опорным узлом. Бели г; — потенциал потока опорного узла, то можно
отправить v единиц потока из V8 в Vty после чего потенциал потока опорного узла
станет равен нулю.
Легко видеть, что можно отправить v единиц потока из опорного узла Vr в
сток Vt слой за слоем, так как все узлы имеют больший, чем у Уг, потенциал
потока. (Из соображений симметрии можно отправить также t> единиц потока,
из источника V, в узел Vr.) При пересылке потока через узел следует оставить
частично насыщенной не более чем одну выходящую дугу. Все насыщенные
дуги удаляются из сети. Можно удалить также опорный узел, поскольку либо
все входящие в него, либо все выходящие из него дуги являются
насыщенными.- '■-*• *-
Для нахождения опорного узла нужно п-1 сравнение. Поскольку опорный
Рис. 2.11
66
ГЛАВА 2, МАКСИМАЛЬНЫЕ ПОТОКИ
узел каждый раз удаляется, время, затрачиваемое на этап, не превосходит
0(п2). Для корректировки пропускных способностей дуг будем хранить все
выходящие дуги для каждого узла в циклическом списке. Для каждого узла
существует не более одной частично насыщенной дуги. Следовательно, общее
число корректировок пропускных способностей дуг на каждом этапе тоже
ограничено величиной 0(л2). В многослойной сети имеется не более га дуг
и каждая дуга становится насыщенной только один раз. Значит, суммарное
время, затрачиваемое на удаление дуг, есть О (га), а суммарное время работы
на этапе составляет 0(п2) + 0(т) — 0(п2). (Такая же процедура выполняется
при отправлении v единиц потока из У, в Уг.)
Так как число этапов не превосходит п — 1, получаем алгоритм поиска
максимального потока с трудоемкостью 0(п3).
2.2.4. Анализ алгоритмов
В этом разделе проанализируем обсуждавшиеся в предыдущих разделах
алгоритмы нахождения максимальных потоков.
Алгоритм Форда и Фалкерсона
Если все пропускные способности дуг являются целыми числами, то метод
расстановки пометок найдет увеличивающий путь с целочисленной
пропускной способностью, а значение максимального потока увеличится на такую же
величину. Величина максимального потока v равна пропускной способности
минимального разреза, которая является целым числом. Этому алгоритму
нужно не более v увеличивающих путей, а для поиска каждого
увеличивающего пути требуется не более 0(п2) шагов. Так как v заранее неизвестно, то
нельзя установить оценку, зависящую от т и п.
Алгоритм Эдмондса и Карна
Эдмондс и Карп предложили применять метод расстановки пометок
Форда и Фалкерсона, используя правило «первый помечен — первый
отсканировал». Это приводит к верхней оценке 0(пт2).
Чтобы это увидеть, разделим вычисление на этапы, где каждый этап
состоит в нахождения всех увеличивающих путей заданной длины. (Здесь под
длиной пути понимается число дуг в нем.)
На каждом этапе построим вначале остаточную сеть с остаточными
пропускными способностями дуг b\j, определяемыми соотношениями:
b'ij = b{j - Xij
или b'ij = \bij\ + Xji, если Xji > 0.
Это означает, что мы просматриваем каждую дугу не более двух раз, по
одному разу в каждом направлении, следовательно, итоговая трудоемкость
равна 0(т).
2Д АЛГОРИТМЫ НАХОЖДЕНИЯ МАКСИМАЛЬНОГО ПОТОКА 67
Отыскание увеличивающих путей при помощи поиска в ширину
затрачивает не более 0(т) шагов, и на каждом этапе существует не более m
увеличивающих путей. Значит, трудоемкость каждого этапа ограничена величиной
0(т2). Так как длина увеличивающих путей от этапа к этапу строго
возрастает, то число этапов не превосходит п — 1, а общее время работы ограничено
величиной 0(гап2). В общем случае 0(шп2) = 0{п5),
Заметим, что на каждом этапе мы находим тупиковый поток, а на
последнем этапе — поток с наибольшим значением.
Алгоритм Диница
Верхняя оценка трудоемкости этого алгоритма равна 0(п2т), а улучшение
обусловлено способом, при помощи которого на этапе отыскиваются
увеличивающие пути. После нахождения остаточной сети на каждом этапе, которое
затрачивает 0(т) шагов, увеличивающий путь можно найти за время
порядка 0(п).
Главное состоит в том, что при отыскании увеличивающего пути
используется поиск в глубину. Достигая узла V*, увеличиваем поток вдоль пути и
удаляем дугу, остаточная пропускная способность которой равна нулю,
Когда делается шаг назад из узла V$, то удаляются все входящие и выходящие
из Vi дуги. Таким образом, при нахождений увеличивающего пути мы
просматриваем узел не более одного раза, следовательно, общее время работы
для одного пути составляет 0(п), для всех увеличивающих путей на каждом
этапе — О(пга), а в целом трудоемкость равна 0(п2т).
Алгоритм Карзанова
Покажем, что на каждом этапе алгоритм Карзанова затрачивает 0(п2)
единиц времени. Так как число этапов не превосходит п — 1, то общая
трудоемкость составляет 0(п3).
Определим вершину как блокированную, если каждый путь из нее в сток
Vi содержит по крайней мере одну насыщенную дугу. Если вершина
блокирована, то поток через нее уже нельзя увеличить.
Лемма 1. При продвижении предпотока несбалансированная вершит
после обработки становится блокированной. Блокированная вершина остается
блокированной в течение всего этапа. ^ ^л^
Доказательство. Во время первого продвижения предпотока узел V8
становится блокированным, поскольку каждая выходящая дуга из V8 насыщена. Из
аналогичных соображений каждая несбалансированная вершина также
блокируется. Докажем лемму индукцией по числу применений шага балансировки.
Для этого покажем, что вершина, заблокированная перед балансировкой,
останется блокированной и после ее выполнения- г
Блокированная вершина Vj из наивысшего слоя не может стать неблоки-
рованной, поскольку никакой поток а^** нельзя уменьшить, а каждый путь из
Vj в Vt по определению содержит насыщенную дугу.
68
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Предположим, что в течение шага балансировки входящий Лоток узла Vj
уменьшается, а это уменьшение в свою очередь сокращает поток через
выходящую дугу блокированной вершины V% из низшего слоя.
Так как каждый путь из Щ ъЩ должен идти через блокированную
вершину Vj, то вершина Vj остается блокированной и после шага балансировки.
Пусть узел Vi из низшего слоя яри сокращении выходящего потока стал
несбалансированным. Тогда, если узел ^обрабатывается на следующем шаг
ге балансировки, то он станет сбалансированным. Каждая дуга, выходящая
из узла Vi, либо насыщена, либо закрыта. Каждый путь из V£, содержащий
закрытую дугу, должен проходить через блокированную вершину Vj.
Следовательно, V{ блокирована. I
Лемма 2. Каждая вершина проверяется на сбалансированность не более
одного раза.
Доказательство. Предположим, что балансируется вершина V*, мы
утверждаем, что с этого момента значения всех потоков на дугах в слоях, лежащих
выше Vj, не уменьшатся. Если это не так, то пусть 6^ — дуга с потоком од,
который уменьшится первым. Поскольку вершина V* уже сбалансирована к
тому времени, когда балансируется V*, единственной причиной, по которой V*
вновь будет подвергнут балансировке, может быть уменьшение выходящего
из Vk потока. Но это невозможно, так как по предположению 6<* — это первая
дуга с уменьшенным потоком. (Заметим, что потоки, входящие в узел,
заносятся в стек.) I
Лемма 3. Поток, полученный на каждом этапе, является тупиковым.
Доказательство.. Источник V9 блокируется первым, так как каждую
несбалансированную вершину можно обработать не более одного раза и поеле
обработки она останется блокированной. Следовательно, через некоторое время
все вершины станут как сбалансированными, так и блокированными. Узел V8
останется блокированным, значит, поток является тупиковым. I
Лемма 4. Трудоемкость алгоритма Карзанова построения тупиковых
потоков в многослойной cefnu ограничена величиной 0(п2).
Доказательство. В этом алгоритме есть шаги балансировки и шаги
продвижения. На шаге балансировки, если поток через дугу уменьшается, то эта
дуга становится закрытой, следовательно, суммарное число уменьшений
потока ограничено числом дуг 0{$п). Когда* лоток через дугу возрастает, она
либо насыщенная, либо ненасыщенная. Но насыщение может произойти для
каждой дуги не более одного раза, так как после любого уменьшения потока
эта дупа станет закрытой. Следовательно, число насыщений также
ограничено величиной 0(т). Ситуация, при которой поток через дугу возрастает, но
не до предельно возможного значения, может наблюдаться не более п — 1 раз
при начальном продвижении предпотока и не более п - 2 раз при
следующем продвижении, поскольку некоторый узел балансировался при начальном
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 69
продвижении предпотока и, следовательно, недоступен. Продолжая эти
рассуждения, видим, что число шагов, увеличивающих поток, но не до предельно
возможного значения, равно (п — 1) + (п — 2) Н Ь 1 = 0(п2).
Следовательно, трудоемкость алгоритма ограничена величиной 0(т) + 0(п2) = 0(п2).
Поскольку число этапов равно п, суммарное время работы алгоритма Карза-
нова составляет О (п3). I
2.3. Многотерминальные минимальные потоки
Если сеть рассматривать как коммуникационную сеть, узлы которой
представляют города, а пропускные способности дуг — пропускные способности
каналов связи, то максимальный поток из V8 в Vt можно трактовать как
максимальную скорость потока сообщений из города V8 в город V*.
Предполагается, что города, отличные от V8 и V*, служат ретрансляционными станциями
и не сообщаются между собой. В реальной жизни все города сообщаются
одновременно. В этом разделе мы будем изучать максимальные потоки между
всеми парами узлов сети. Чтобы упростить изучение математической
структуры сети, сосредоточимся на одной паре узлов в каждый момент времени. В
каждый данный момент времени только одна пара узлов служит источником
и стоком, в то время как все другие узлы являются ретрансляционными
станциями (промежуточными узлами). Таким образом, в сети с п узлами можно
выбрать п(п — 1) пар в качестве источника и стока и для каждой пары найти
максимальный поток. В этом разделе будем рассматривать только
неориентированные сети, т.е. такие, для которых by = bji при всех t,j. Требуется
вычислить (") максимальных потоков fy = fji. (Читателю нужно отличать
эту задачу от задачи нахождения одновременных максимальных потоков,
которая будет обсуждаться в разделе 2.3.4.)
Мы обсудим следующие три вопроса.
1. Условия реализуемости. Если заданы пропускные способности дуг, то
можно найти максимальные потоки для каждой из (") пар узлов.
Обозначим через fij величину максимального потока между V* и Vj. Так как
b«i = ^i, то fij = fji для всех г, j. Для всех г положим /й = оо. Значения
максимального потока можно представить в виде матрицы размера пхп,
в г-й строке и j-м столбце которой расположен элемент fij. Эта матрица
симметричная, а все ее диагональные элементы равны оо. Имеются ли
какие-нибудь соотношения между элементами матрицы, кроме fij = fji?
Если заданы элементы сети Ь^, можно заполнить матрицу ||/tj||,
вычисляя максимальные потоки, но если задана произвольная симметричная
матрица ||/у||, то будет ли существовать сеть с п узлами, для которой fij
являются этими числами? Условия на числа ||/у||, гарантирующие
существование сети, называются условиями реализуемости. Каковы
необходимые и достаточные условия для того, чтобы множество, состоящее из
п(п — 1)/2 чисел, представляло значения максимальных потоков между
парами узлов некоторой сети?
70
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
2. Анализ. Каковы значения максимальных потоков между всеми парами
узлов сети? Этот вопрос, несомненно, можно решить, выполняя
алгоритм нахождения максимального потока для каждой пары узлов, однако
можно сделать нечто лучшее.
3. Синтез. Если установить нижнюю оценку величины максимального
потока между каждой парой узлов, то можно, конечно, построить сеть,
значения максимальных потоков которой превышают нижние оценки.
Это можно сделать, присваивая произвольные достаточно большие
пропускные способности дугам между всеми парами узлов. Задача синтеза
состоит в построении такой сети, чтобы значения максимальных потоков
превышали все нижние оценки, а суммарная пропускная способность дуг
была минимальна.
Читателю следует помнить, что во всех трех задачах речь идет о
максимальном потоке для одной пары узлов в данный момент времени. После
нахождения максимального потока выбирается другая пара узлов и ищется
максимальный поток для нее, в то время как все другие узлы служат в
качестве промежуточных. Все дуги теперь становятся доступными для новых
источника и стока. Это проделывается для всех (£) пар узлов одной и той же
сети.
Такая модель называется многотерминальной сетевой потоковой
моделью.
2.3Л. Реализуемость (Гомори и Ху [12])
В неориентированной сети с пропускными способностями дуг b{j = bji
значения максимальною потока fy симметричны, т.е. fy = fa. (Для удобства
при всех % положим /ц — оо.) Справедлива следующая теорема.
Теорема 3 (Реализуемость). Для того, чтобы неотрицательные числа
f{j = fa, (г, j = 1,..., n) были значениями максимальных потоков некоторой
сети, необходимо и достаточно, чтобы при всех i,j,k выполнялось
неравенство
fik >imn{/y,/ifc}. (1)
Доказательство. Необходимость. Рассматривая V% и Vk как источник и сток
и применяя теорему о максимальном потоке и минимальном разрезе, для
разреза (Х,Х) имеем
fik=c(X,X), (2)
где Vi € X, а V* € X. Узел Vj принадлежит X или X. Если Vj € X, то (Х,Х)
— разрез, разделяющий Vj и Vk, следовательно,
fjk<c(X,X) = fik. (3)
Если Vj принадлежит X, то (Х,Х) — разрез, разделяющий V{ от Vj,
следовательно,
/«<(*,*) = /». (4)
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 71
Так как должно выполняться хотя бы одно из условий (3), (4), то получаем,
что
fik >1Шп{/у,/;к},
что и требовалось доказать.
По индукции из (1) следует, что
/ln >min{/i2,/23>..->/n-i,n}> (5)
где V\, Vi, • • • > Vn — произвольная последовательность узлов сети.
Сделаем несколько замечаний. Возьмем произвольные три узла сети и
рассмотрим значения максимальных потоков fa, fjk и fa между ними.
(Вспомним, что fij = fj{.) Утверждается, что по крайней мере два из этих значений
одинаковы. Бели бы все три значения были различными, то, подставляя
наименьшее из них в левую часть (1), получили бы противоречие. Далее,
значение потока, не равное другим двум значениям, должно быть наибольшим, в
противном случае снова получим противоречие с (1). Если бы мы начертили
п(п — 1)/2 звеньев между узлами сети с длинами звеньев, равными
значениям максимальных потоков, то в каждом треугольнике были бы две равные
стороны, а третья сторона имела бы такую же или ббльшую длину. Поэтому
(1) похоже на «неравенство треугольника», которое в значительной степени
ограничивает величины максимальных потоков сети.
Из (5) следует, что среди п(п-1)/2 величин fa = fa имеется не более п-1
различных значений потока. Этот факт можно обнаружить следующим
образом. Рассмотрим полный граф с п(п — 1)/2 ребрами, длины которых равны
значениям соответствующих максимальных потоков, и выберем ребра,
образующие максимальное остовное дерево. Утверждается, что каждая из п(п—1)/2
величин потока равна одному из (п—1) значений на ребрах дерева. Существует
единственный путь из V\ в У„, состоящий из ребер максимального остовного
дерева. Из (5) получаем, что f\n должно быть больше наименьшего или равно
наименьшему из значений на этом пути. Если оно строго больше, то можно
заменить минимальное ребро пути на f\n и получить другое остовное дерево,
суммарная величина потока которого больше, чем у исходного максимального
остовного дерева. Противоречие.
Достаточность. Она доказывается с помощью построения сети со
значениями максимальных потоков п#, удовлетворяющими (1). Чтобы ее построить,
рассмотрим числа пу, удовлетворяющие (1), в качестве длин ребер полного
графа и найдем в этом графе максимальное остовное дерево. Далее
рассмотрим сеть, имеющую такую же структуру, как и максимальное остовное дерево,
с пропускными способностями дуг b{j = riij, где п^ — заданные числа,
которые должны быть реализованы как значения потоков некоторой сети.
Утверждается, что для этой древесной сети выполняются равенства fa = rtij. Для
каждой пары узлов сети имеем
fa = тт{Ъц, bi2,..., bqj} = min{nu, П12,..., nqj} = n#,
где Ьц , 612,..., bqj — пропускные способности дуг, образующих единственный
путь из V{ bVj. Заметим, что при доказательстве достаточности условия (1)
72
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
мы показали существование древесной сети, что будет полезно в дальнейшем.
I
2.3.2. Анализ (Гомори и Ху [12])
Пусть дана сеть, показанная на рис. 2.21, тогда можно найти значения
максимальных потоков между всеми парами узлов, решив (!|) задач о
максимальном потоке. На рис. 2*29 показана другая сеть, древесного вида, тоже
с шестью узлами. Для того, чтобы найти величину максимального потока
между любыми двумя узлами древесной сети, нужно выбрать наименьшую
пропускную способность дуг единственного пути, соединяющего эти два
узла. Оказывается, что значения максимальных потоков этих двух сетей в
точности совпадают для всех соответствующих пар! Две сети будем называть
потоко-жвивалентными , если значения максимальных потоков между
всеми парами узлов одинаковы. Далее будет показано, что всякая произвольная
неориентированная сеть всегда потоко-эквивалентна древесной сети.
Кроме того, древесную сеть можно получить, решая только п — 1 задач
поиска максимального потока. Например, если рассмотреть сеть с 1000
узлами, то 1000(1000 —1)/2 = 499500 значений потока можно получить, решая 999
задач о максимальном потоке. Цель этого раздела — предложить алгоритм,
который строит древесную сеть, потоко-эквивалентную рассматриваемой
сети.
Предположим, что в Америке 1000 городов и требуется вычислить
значения максимальных потоков между столицами пятидесяти штатов. Нужно ли
решать 999 потоковых задач для того, чтобы получить 50(50 — 1)/2 = 1225
значений максимальных потоков? Оказывается, что можно найти 1225
значений максимальных потоков, решая всего лишь 50 — 1 = 49 задач поиска
максимального потока.
Задача состоит в следующем: если мы хотим найти значения
максимального потока между некоторыми узлами, а не для всех пар, то можно ли как-
нибудь уменьшить количество вычислений? Пусть нужно найти значения
максимального потока между р узлами, где 2 < р < п. Тогда вместо р(р - 1)/2
вычислений максимального потока нужно всего лишь р— 1 таких вычислений.
Кроме того, каждое из вычислений происходит на упрощенной сети.
Сначала опишем процесс, называемый стягиванием или конденсацией
множества узлов в один узел. Этот процесс преобразует подмножество узлов сети
в один узел, т. е. между каждой парой узлов данного подмножества
добавляется дуга с бесконечной пропускной способностью. (Рассмотрим сеть,
показанную на рис. 2.12.) Дуги, ориентированно связывающие узел У*, не
принадлежащий заданному подмножеству, со всеми узлами, лежащими в этом
подмножестве, заменены на единственную дугу, пропускная способность которой
равна сумме пропускных способностей соединяющих дуг.
В результате стягивания узлов V^ Vq и Vs в один узел получится сеть,
показанная на рис. 2.13.
В сети на рис. 2.12 величина максимального потока равна /27 = с(У, Y) = 4,
а минимальный разрез (У, Y) = (2|1,3,4,5,6,7,8) состоит из дуг Ьгь &23 и &2б-
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ
73
Увеличение пропускных способностей дуг, не принадлежащих
минимальному разрезу (У, У), не повлияет на величину с(У,У) и может только увеличить
пропускные способности других разрезов, разделяющих VikVj.
Следовательно, (У, У) останется минимальным разрезом, разделяющим У2 и V7.
Поэтому после вычисления величины максимального потока /27 можно, например,
конденсировать {V^V^Vs} в один узел и произвести вычисление в сети на
рис. 2.13.
При стягивании подмножества узлов получается существенно упрощенная
сеть. Это экономит немало вычислений. Докажем лемму 5, в которой
приводятся все допустимые условия для стягивания узлов. Лемма 5 — это ключ к
оставшейся части анализа.
В качестве иллюстрации предположим, что найден минимальный разрез,
разделяющий Vi € X и Vj € X. На рис. 2.14 сеть символически представлена
как диск, а разрез (X, X) обозначен сплошной линией. Если теперь
попытаться найти минимальный разрез, разделяющий Ve и V*, то минимальным
разрезом может быть (У, У), изображенный пунктирной линией, пересекающей
сплошную линию, обозначающую разрез (X, X).
Напомним, что два разреза (Х,_Х) и (YyY) скрещиваются, если каждое из
четырех множеств ХПУДПУДпУ иХП У не пусто.
Например, в сети, показанной на рис. 2.15(a), минимальный разрез,
разделяющий V{ и Vj, — это (Х,Х) = (г,а|е, fc,j), а минимальный разрез, раз-
Рис. 2.13
74
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис.2.Ц
деляющий Ve и Vjfe» — это (Y,Y) = (e,t|j,fc,a), и эти минимальные разрезы
скрещиваются.
Стягивание множества X в одну вершину на рис. 2.15(a) равносильно
увеличению пропускной способности дуги Ь{а до бесконечности. Это изменит
пропускную способность разреза (Y,Y), равную сумме Ье* + Ью- Таким образом,
если (Y,Y) — единственный минимальный разрез, разделяющий Ve и V*, то
нельзя конденсировать X в один узел.
С другой стороны, существует другой минимальный разрез
((Z,Z) = (e\i,a,j,kj),
разделяющий Ve и V*, который не скрещивается с (X, X). Теперь стягивание
X в один узел не изменит пропускную способность (Z, Z) и только увеличит
пропускную способность других разрезов. Следовательно, (Z, Z) останется
минимальным разрезом, разделяющим Ve и V*, и можно вычислить
максимальный поток /е* в сети, показанной на рис. 2.15(b), где стянуто X.
Идея стягивания узлов формализована в лемме 5. Рассматривается
произвольная сеть, показанная на рис. 2.16.
Лемма 5 (о нескрещивающихся минимальных разрезах). Пусть (X, X)
— минимальный разрез, разделяющий Vi € X и некоторый другой узел, и
пусть V€ и Vk — произвольные два узла, лежащие в X. Тогда существует
минимальный разрез (Z, Z), разделяющий Ve uVk, такой, что (Z, Z) и (X, X)
не скрещиваются.
V Ь)
Рис. 2.15
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 75
Доказательство. Предположим, что существует минимальный разрез (У, У),
разделяющий Ve и V^, который скрещивается с (Х,Х). Пусть
XnY = Q,XnY = S,
XnY = P,Xn¥=R,
как показано на рис. 2.16.
Заметим, что Ve € Р, а V* € Л.
Тогда сеть разбивается на четыре части и мы докажем, что либо (Р, Q U
Л U 5), либо (Р U Q U 5, Я) является минимальным разрезом (Z, Z), который
не скрещивается с (X, X).
Обозначим через с(Р^ Q) сумму пропускных способностей всех дуг,
связывающих части Q и Р. Тогда
с(Х,X) = c(Q,Р) + c(Q, Л) + с(5,Р) -h с(5, R).
Случай 1. Пусть V* € Q. Поскольку (Х,Х) — минимальный разрез, то
c(Q,P) + c(Q,R)+c(S,P) + c(S,R) < c(Q,P) + c(Q,R) + c(Q,S). (1)
Так как с(5, Р) > 0, то из (1) получаем
c(5,fl)<c(Q,5), (2)
с(Р, R) + c(Qf R) = с(Р, Л) + c(Q, Л), (3)
и 0<с(Р,5). (4)
Складывая (2), (3) и (4), получаем
c(P,R)+c(Q,R)+c(S,R)
< с(Р, Л) + c(Q, Л) + c(Q,S) + с(Р, S). (5)
Левая часть соотношения (5) — это величина разреза (РU Q U 5, Л),
отделяющего Ve от V* и не скрещивающегося с(Х, X), а правая часть — пропускная
способность минимального разреза (У, У). Поэтому (PuQuS, Л) и есть
искомый разрез {Z,~Z).
Рис. 2.16
76
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Случай 2. V{ € S. Аналогично можно показать, что (F, QURUS) — это разрез,
отделяющий Ve от V*, величина которого не превосходит величины разреза
(Y,7). Тогда либо (PuQuS.R), либо (P.QURUS) - искомый минимальный
разрез (Z,Z), не скрещивающийся с (Х,Х).
Лемма 5 доказана. I
Отсюда следует, что если (Х,Х) — это минимальный разрез, то при
вычислении значений максимального потока между двумя узлами из X можно
конденсировать X в один узел. (Из соображений симметрии можно то же
самое сделать для нахождения максимального потока между двумя узлами из
X.)
Лемма 5 потребуется в алгоритме, вычисляющем значения
максимального потока между всеми парами узлов сети. Существуют и другие условия,
позволяющие стягивать узлы. Одно из таких условий дает лемма 6.
Лемма 6. Пусть (X, X) — минимальный разрез, разделяющий VJ и
некоторый другой узел, и пусть V* — произвольный узел, принадлежащий 7. Тогда
существует^минимальный разрез (Z,Z), разделяющий V* и Vk, такой, что
(X, X) и (Z, Z) не скрещиваются.
Доказательство. Предположим, что существует минимальный разрез (У, У),
разделяющий К* и V*, который скрещивается с (Х,Х), и пусть
XnY = Q,Xn¥ = S,
XnY = P,Xn¥=R,
где Vk € Я, a V*jE Q (см. рис. 2.16).
Так как (X, X) — минимальный разрез, то, используя те же самые
рассуждения, получаем соотношение (5). Левая часть (5) — это величина разреза
(Р U Q U 5, Д), разделяющего V* и V*, а правая часть — пропускная
способность разреза (Y^Y). Следовательно, (Р U Q U 5,Д) — это искомый разрез
(Z,Z). I
Отсюда следует, что если (X, X) — минимальный разрез, разделяющий V{
и некоторый другой узел, и требуется найти величину /#, где V* —
произвольный узел из X, то можно конденсировать X в одну вершину.
Напомним, что цель данного раздела — вычисление максимальных
потоков между всеми парами узлов сети N, либо максимальных потоков между
узлами заданного подмножества, состоящего из р узлов этой сети. Удобно
представлять себе, что узлы — это города в США, а подмножество из р узлов
— это столицы пятидесяти штатов.
Назовем эти р узлов терминальными узлами, а оставшиеся п — р узлов —
обычными, или нетерминальными узлами. Предположим, что существует
другая сеть N\ состоящая из р узлов, в которой значения максимальных потоков
совпадают со значениями максимальных потоков между р терминальными
узлами сети N. (Говорят, что две сети с одинаковыми значениями
максимальных потоков между узлами некоторого множества узлов потоко-эквивалент-
ны друг другу относительно этого множества узлов.) Тогда можно получить
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 77
Рис. 2.18
все значения максимальных потоков для р узлов сети N'. Оказывается, что
всегда существует сеть JV7, являющаяся деревом. Описываемый ниже
алгоритм строит по сети N дерево JV7, имеющее такие же значения максимальных
потоков. Алгоритм нахождения значений максимальных потоков между р
терминальными узлами сети с п узлами состоит из двух шагов, которые
повторяются до тех пор, пока не будет построена древесная сеть N' (потоко-экви-
валентная исходной сети N относительно данных р узлов). Сеть N' можно
получить, решая р— 1 задач о максимальном потоке, в то время как
прямолинейный метод для сети N потребовал бы решения (£) задач о максимальном
потоке. Заметим, что этот алгоритм работает при всех значениях р, таких,
что 2 < р < п. Перед детальным описанием алгоритма приведем вначале его
набросок. (Читатель может опустить детальное описание и доказательство,
изучив численный пример, показанный на рис. 2.21.)
Начнем с краткой схемы алгоритма. Возьмем два терминальных узла V*
и Vj из TV, вычислим максимальный поток и найдем минимальный разрез
(X, X), для которого, Vi € X, a Vj € X. Затем нарисуем диаграмму, состоящую
из двух кругов, связанных звеном со значением v, где v — это только что
полученная величина максимального потока. В один круг поместим все узлы
из X, а в другой — все узлы из X. Это первый шаг при построении сети N'.
Когда мы решим р— 1 задачу о максимальном потоке и построим р кругов, то
диаграмма, состоящая из этих р кругов, будет потоко-эквивалентна сети N'.
На общем шаге будем вычислять максимальный поток в сети N, в которой
подмножества узлов сконденсированы в одиночные узлы. Вычисляется
максимальный поток между двумя узлами из одного круга, а результатом будет
расщепление этого круга на два круга, соединенных звеном, которому
приписывается значение, равное максимальному потоку. Таким образом,
вычисление всегда происходит на сети N или ее упрощенной форме, а получаемые
результаты отображаются на диаграмме, имеющей вид дерева. По диаграмме
принимаем решение, какую пару узлов нужно выбрать в качестве следующих
источника и стока, а также какие подмножества узлов можно конденсировать.
Теперь дадим детальное описание. Во-первых, выберем произвольным
образом два терминальных узла и вычислим максимальный поток в исходной
сети. При этом получим минимальный разрез (Х,Х), символически
представленный двумя кругами, связанными звеном, как показано на рис. 2.17. Это
первое звено древесной сети ЛГ'._Значение vi, приписанное звену, — это
величина минимального разреза (X, X). В одном круге указаны все узлы из X, а
в другом — все узлы из X.
78
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Во-вторых, из полученной к данному моменту древесной диаграммы
выберем какой-нибудь круг, содержащий не менее двух терминальных узлов, и
вычислим максимальный поток между двумя терминальными узлами сети,
полученной из исходной стягиванием X или X. Пусть эти два выбранных
терминальных узла лежат в X. Тогда X конденсируется в один узел. Это даст
другой минимальный разрез. Он символически представлен на рис. 2.18, где
V2 — значение только что полученного минимального разреза, a Y\ U Y2 — это
исходное множество X.
Заметим, что w соединяется с (Ц), если X и У2 лежат с одной стороны
от минимального разреза со значением v2; w соединяется с ^р, если X и Y\
лежат с одной стороны от минимального разреза со значением v2-
Продолжаем процесс деления круга. На каждом этапе построения выбираем круг ®,
содержащий хотя бы два терминальных узла, как показано на рис. 2.19. После
удаления из древесной диаграммы круга ® дерево распадется на несколько
компонент связности. При вычислении максимального потока для двух
терминальных узлов из © все узлы, расположенные в одной из этих компонент,
конденсируются в один узел. После р — 1 вычисления максимального потока
получается древесная диаграмма, в которой каждый круг содержит в
точности один терминальный узел и, возможно, несколько промежуточных узлов.
(Заметим, что вследствие стягивания узлов вычисление максимального
потока обычно выполняется на более простой сети, чем исходная.)
Рис. 2.19
Утверждается, что если рассматривать древесную диаграмму как сеть,
пропускные способности дуг которой равны величинам, приписанным звеньям
диаграммы, то значения максимальных потоков древесной сети совпадут со
значениями исходной сети.
Теорема 4. Величина максимального потока между любыми
терминальными узлами Vi и Vj исходной сети равна
fij = min{Vja, Vab,.. ., Vdj},
(6)
где v,a, Vob, • • •, vjj — значения, приписанные звеньям пути изУг eVj в дереве.
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 79
V'
/Y ^Ч /X \
/ *2 \ V ( <* \
I JBb J I ^Шк I
Рис. 2.20
Доказательство. Вначале докажем, что
& < min{via, vab,...,у$}, (7)
а затем
/у > min{via, va&,..., Vdj}. (8)
Заметим, что каждое звено дерева представляет разрез, разделяющий Vi
и Vj. Следовательно, значение максимального потока fij должно быть
меньше или равно каждому из значений, связанных со звеньями, откуда следует
неравенство (7).
Рассмотрим произвольный этап построения дерева, на котором звено со
значением v соединяет два круга, скажем, X и Y. Докажем, что существуют
такие терминальные узлы V* из X и Vj из У, что Д/ = v.
Это утверждение истинно, когда строится диаграмма из двух кругов,
скажем, X и X. Поскольку при построении этой диаграммы вычисляется
максимальный поток, существуют такие узлы V* € X и Vj € X, что fij = v.
Докажем, что это остается верным и при дальнейших делениях диаграммы.
Предположим, что в X выбираются узлы Va и V& и решается задача о
максимальном потоке, которая разбивает X на Yi и Y2, где Va € Yi, а Vb € Y2. Это
показано на рис. 2.20, где /a& = v1.
Если Vi € У2, то опять имеются два таких узла Vi и Vj в кругах I2 иХ,
ЧТО fij = v.
Трудность состоит в том, что Vi может принадлежать Yi. В этом случае
покажем, что foj = v.
В исходной сети
fab =v' И fij = V.
Если подмножество узлов Y\ конденсируется в один узел, а V* лежит в Yi,
то в конденсированной сети значения максимальных потоков между Va и Vb,
а также между Vi и Vj не изменятся (лемма 6). Величины максимальных
потоков в конденсированной сети будем отмечать штрихом. Тогда
fij = fij = ^
80
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
fab = fab = v'-
Заметим, что v' > v, так как (Yi, У2 U X) — разрез, разделяющий V* и Vj.
Из соотношения (5) раздела 2.3.1 следует, что в конденсированной сети
fjb > тМ//»> fiaJ'ab}
= min{i;,oo,i/}
= v (так как v' >v).
Но, согласно лемме 5, fjb = /j6, следовательно, И и 1^ — два искомых узла с
величиной максимального потока, равной величине звена, соединяющего два
круга.
Установив, что величина максимального потока между смежными
терминальными узлами равна величине соединяющего их звена, из соотношения (5)
раздела 2.3.1 для любых двух терминальных узлов, связанных рядом звеньев
дерева, получаем
fij > min{/ia, fab,..., /«#}
= mm{via,va6,.,.,i;4;}, (9)
где V{ и Vj — не смежные терминальные узлы дерева. Равенства (7) и (9)
устанавливают справедливость утверждения теоремы. i
Приведем численный пример, иллюстрирующий технику анализа.
Рассмотрим сеть на рис. 2.21, где числа рядом с дугами обозначают пропускные
способности. Предположим, что нас интересуют максимальные потоки между Vi,
V3, V4 и V5. Вначале выберем произвольно V\ и Vs и вычислим максимальный
поток. Получим минимальный разрез (Vi, V2, Ve|V3, V^, V5), значение которого
равно 13. Это показано на рис. 2.22.
Далее вычислим максимальный поток между V$ и V\ в сети, изображенной
на рис.2.23. Эта сеть получается стягиванием узлов Vi, V^ и V% на рис.2.21
в один узел. В результате получаем минимальный разрез (Vi, V2, Ve, V3, V5IV4)
со значением 14, показанный на рис. 2.24. Заметим, что
круг \$ъЩ соединяется с кругом
так как они находятся с одной стороны от минимального разреза,
разделяющего V$ и Vi. Затем найдем максимальный поток между V3 и У5» который
опять следует вычислять на сети, показанной на рис. 2.23. В результате
получим минимальный разрез (Vi, V2, Ve,V£, V4IV3) со значением 15. Это показано
на рис. 2.25.
Теперь можно остановиться, поскольку каждый круг на диаграмме
содержит только один терминальный узел. Значения потоков равны /13 = /i4 =
/15 = 13, /34 = /45 — 14 и /зб = 15. Величины максимальных потоков /13, /н,
/i5> /34, /35 и /45 в этой сети те же, что в исходной сети на рис. 2.21.
Если нас интересуют значения максимальных потоков между всеми
парами узлов, то надо продолжить этот процесс и выбрать, скажем, Vi и 1^, а
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 81
13
Рис. 2.22
13
14
Рис. 2.24
Рис. 2.23
Рис.2.25
Рис. 2.26
Рис. 2.
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Таблица 2.1
00
18
13
13
13
17
18
00
13
13
13
17
13
13
00
14
15
13
13
13
14
00
14
13
13
13
15
14
00
13
~17~|
17
13
13
13
00
затем вычислить максимальный поток в сети на рис. 2.26. В результате
получится минимальный разрез (Vi, V^l^e, V3, V^, V5) со значением 17, показанный
на рис. 2.27.
Далее выберем узлы V\ и Уч и вычислим максимальный поток в сети на
рис. 2.28. В результате получится минимальный разрез (Vi|l^, 1^, 1^, V4, Уь) со
значением 18. Он показан на рис. 2.29. Из рис. 2.29 можно легко найти
величины максимальных потоков между всеми парами узлов, которые перечислены
в таблице 2.1.
Читатель может проверить, что для всех пар узлов величины
максимальных потоков в сетях на рис. 2.21 и 2.29 одинаковы. Напомним, что две сети
с одинаковыми значениями fy потоко-эквивалентны друг другу. Если
величины максимальных потоков одинаковы для всех пар некоторого
подмножества узлов, то они потоко-эквивалентны относительного этого подмножества.
Так, сети на рис. 2.21 и 2.25 потоко-эквивалентны относительно подмножества
{Vi,V3,V4,V5}-
Описанный выше метод строит потоко-эквивалентную сеть,
являющуюся деревом. Заметим, что существует много деревьев, потоко-эквивалентных
заданной сети. Однако потоко-эквивалентное дерево, построенное выше,
обладает еще одним свойством: каждое звено дерева представляет некоторый
минимальный разрез исходной сети. Поэтому его называют деревом разрезов
Гомори и Ху (а также деревом Гомори-Ху). Дерево разрезов, состоящее из
п узлов, показывает п — 1 минимальных разрезов исходной сети, не
скрещивающихся друг с другом. На рис. 2.30 пунктирными линиями показаны п — 1
разрезов.
Дерево разрезов показывает п - 1 минимальных разрезов, определяющих
максимальные потоки между всеми парами узлов. Этот результат
сформулирован в следующей теореме.
Теорема 5 (Гомори и Ху). Любая сеть потоко-жвивалентна дереву
разрезов.
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 83
а) Ь)
Рис. 2.31
2.3.3. Синтез (Гомори и Ху [12])
В предыдущем разделе было показано, как найти величины
максимальных потоков в заданной сети. Теперь изучим обратную задачу. Пусть заданы
п(п—1)/2 чисел Гц, представляющих нижние границы максимальных потоков
между узлами V% и Vj. Какова неориентированная сеть, для которой fa > г^-,
а суммарная пропускная способность дуг минимальна?
Пусть заданы п(п — 1)/2 чисел г#. Их можно изобразить в виде
полного графа с п узлами. Если рассматривать числа г# как длины звеньев этого
графа, то можно построить его максимальное остовное дерево. Величины г^,
приписанные звеньям максимального остовного дерева, называются
доминирующими требованиями, а само это дерево называется деревом
доминирующих требований. Если рис. 2.31(a) представляет требуемые значения потоков
в сети, то на рис. 2.31(b) показано дерево доминирующих требований.
Для того, чтобы при всех i и j выполнялись неравенства fa > г* j,
необходимо и достаточно, чтобы fa > г^ для г^ € Г, где Т — дерево доминирующих
требований. Необходимость очевидна, поскольку речь идет о подмножестве
множества исходных требований. Достаточность следует из того, что Т
является максимальным остовным деревом и поэтому отсутствующие величины
r%j удовлетворяют соотношению
rip < min{rij,rjfc,...,rop}, (1)
где г^, rjk и т. д. в правой части — величины, приписанные звеньям,
образующим путь в Г из узла V* в узел Vp. В любой сети, удовлетворяющей
доминирующим требованиям, всякий поток fop автоматически должен удовлетворять
неравенствам
fip > min{/y, fa,... Jop} > min{ry,i>,.^,Гор}> rip, (2)
и, следовательно, все требования выполняются. Поэтому для удобства будем
рассматривать только доминирующие требования.
Суммарная пропускная способность дуг неориентированной сети равна
84
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Установим нижнюю оценку Сь для этой величины. Рассмотрим
произвольный узел V{ сети, удовлетворяющей доминирующим требованиям. Пусть щ =
maxr^j, т.е. щ — наибольшее'из требований на дугах, инцидентных узлу V*.
з
Для всякой сети, удовлетворяющей требованиям, должно выполняться
3
чтобы поток величины щ из узла V* был возможен. Поскольку всякая дуга
считается один раз в каждом из двух ее концевых узлов, получаем нижнюю
оценку суммарной пропускной способности дуг:
Опишем теперь процедуру синтеза (Гомори и Ху [12]) для получения сети,
удовлетворяющей заданным нижним границам. Сначала заметим, что
значения щ можно получить, рассматривая только доминирующие требования, т. е.
выбирая max гij по всем узлам, смежным с VJ, для которых г^ € Т. Рассмот-
з
рим теперь фиксированное дерево Т с требованиями г^ и нижней оценкой
Сь- Если заменить значения г^- новыми значениями г^-, то получим новую
оценку C'L. Положим г^- = т# + г'^ и найдем нижнюю оценку С£. В общем
случае имеет место неравенство
. c'1<Cl + c'l,
поскольку значения j, при которых достигаются max гij и maxr^-, могут раэ-
зз
личаться. Однако, если г# (или г^) являются однородными требованиями,
т. е. rij —г для всех дуг из Т, то
C'l = CL+C'L. (3)
Рассмотрим теперь две сети с пропускными способностями дуг, равными
соответственно b,j и Ь\^ и значениями максимальных потоков /у и /?.. Если
построить третью сеть с пропускными способностями дуг, равными Ъ"3- = b<j +
Ь\ •, то ее максимальные потоки /t" будут удовлетворять неравенствам
$>/« + /«• (4)
Пусть Г — дерево доминирующих требований, которые мы хотим
удовлетворить. Обозначим через rmin наименьшее из требований в этом дереве и
представим каждую величину г# в виде rmin + (гу - rm\n). Теперь исходное
дерево можно рассмотреть как суперпозицию двух деревьев, в одном из
которых имеются однородные требования rmin, а в другом требования равны
т%э — ^min- (Дерево с требованиями, равными r# — rmin, может состоять из
двух или более компонент, так как r%j — тт\п — 0 при некоторых i и j, либо
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 85
Рис. 2.32
можно рассматривать его как одно дерево с некоторыми требованиями,
равными нулю.) Например, дерево Т на рис. 2.31(b) можно рассматривать как
суперпозицию деревьев на рис. 2.32. Для каждой части, в которой требования
не однородны, можно продолжить процедуру декомпозиции до тех пор, пока
в каждой части требования не станут однородными. Например, деревья на
рис. 2.32 можно разложить так, как показано на рис. 2.33.
Под синтезированием дерева будем понимать построение сети со
значениями максимальных потоков, не меньшими требований в дереве. После
разложения дерева в сумму поддеревьев с однородными требованиями каждое
поддерево можно синтезировать отдельно. Если каждое равномерное поддерево
можно синтезировать так, что суммарная пропускная способность каждой
построенной подсети равняется нижней границе Cl, то суперпозиция сетей даст
сеть, которая благодаря (4) способна удовлетворить исходным требованиям,
а вследствие (3) имеет минимальную пропускную способность.
Таким образом, задача сводится к синтезированию равномерного
поддерева, т. е. поддерева со всеми требованиями, равными г. Это можно сделать,
проводя цикл через узлы и присваивая затем величину г/2 каждой дуге этого
цикла. (Если имеется только два узла, то используется единственная дуга с
с)
Рис. 2.33
86
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
пропускной способностью г.) Очевидно, что такая сеть будет удовлетворять
потоковым требованиям и, кроме того, имеет минимальную суммарную
пропускную способность. (Для сети с п узлами суммарная пропускная
способность равна пг/2, а нижняя оценка Сь синтеза равномерного дерева состав-
ляет -£tii = -пг.)
Рассмотрим, например, рис. 2.33. Каждое из однородных деревьев можно
синтезировать так, как показано на рис. 2.34. При наложении сетей на рис. 2.34
получим рис. 2.35, на котором изображена сеть, удовлетворяющая всем
требованиям рис. 2.31(a) и имеющая минимальную суммарную пропускную
способность.
а)
Ы)
Ь2)
Рис. 2.36(a)
Рис. 2.36(b)
При синтезировании однородного дерева можно проходить через узлы в
любом порядке. Например, цикл на рис. 2.34(a) можно было бы заменить
рис. 2.36(a) с результирующей сетью на рис. 2.36(b). Если проверить потоки
на рис. 2.36(b), то можно обнаружить, что /у = г^ при всех t,j € Т, а для
сети на рис. 2.35 Д/ > г^- при некоторых t, j, хотя обе сети имеют одинаковые
суммарные минимальные пропускные способности. (Например, на рис. 2.35
/24 = 6, а на рис. 2.36(b) /24 = 5.)
Исследуем следующие две задачи.
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 87
(i) Нахождение наибольшего возможного потока.
(ii) Нахождение потока, удовлетворяющего доминирующим требованиям как
строгим равенствам.
Конечно, в обоих случаях нужно, чтобы суммарная пропускная способность
была минимальной.
Рассмотрим задачу (i). Во-первых, минимальная суммарная пропускная
способность Сь определяется через величины ti*, а не через г^. Поэтому после
отыскания величин щ можно увеличить г# до значения r*j = min{ti,-,tij} без
изменения щ или нижней оценки Сь- Всякое дальнейшее увеличение значений
r*j обязательно изменит нижнюю оценку. Теперь в соответствии с процедурой,
которая будет описана позже, можно синтезировать новое дерево Г* с
результирующими максимальными потоками /?• = r*j. Утверждается, что эта сеть
N* является в определенном смысле однородно доминирующей сетью. Итог
сказанному подводит следующая теорема.
Теорема 6. Для данных требований г^ существует удовлетворяющая им
сеть N* с пропускной способностью С£ (С£ = - ]£и* J и значениями
максимальных потоков, равными
fij = rij = mmiuuUj}. (5)
Пусть N' — любая другая сеть, удовлетворяющая неравенствам f-j > г#,
суммарная пропускная способность которой равна С Тогда либо
с > съ (6)
либо flj < f^ при всех i,j. (7)
Доказательство. Предположим, что соотношение (6) не выполняется, тогда
Гц > ?ij и С < C*L. Требуется доказать, что /£ < /£. Если f[. > r^-, то при
всех % имеем ]£ Ь'^ > щ = тах^ гу. Так как х £ Ь^ = С < С£ = х £ и^ ТО в
3 2%ФЗ 2 *
действительности имеем равенство YlKj = и*- ОТС1°да следует, что
з
flj < min | JZ b'ik>£ b>3 | = min{^bиз) = fij-
Теорема доказана. I
Теперь перейдем к задаче (ii), синтезированию дерева, точно
удовлетворяющего требованиям, при минимальной суммарной пропускной способности.
Причиной появления избыточных потоков является суперпозиция сетей, у
которых минимальные разрезы по разному разбивают множество узлов.
Поэтому при синтезе однородного дерева желательно, чтобы пропускные
способности разрезов циклической сети совпадали с пропускными способностями
88
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
разрезов, представленных звеньями равномерного дерева. Например, в
циклической сети на рис. 2.34(a) разрез (Vi, V2, V3IV4, V5), разделяющий узлы У2 и
Vi, имеет пропускную способность 10, в то время как звено между V* и V± на
рис. 2.32(a) представляет разрез с пропускной способностью 5. Но пропускная
способность разреза (Vi, V%, V^|V^,.V^) в циклической сети на рис. 2.36(a) также
равна 5. Если синтезировать деревья таким образом, чтобы дерево стало
деревом разрезов построенной циклической сети, то при наложении циклических
сетей минимальные разрезы также накладываются и формируют
минимальные разрезы, а исходный доминирующий поток fiP между узлами Vi и Vp
удовлетворяет неравенству
ftp < minfoj,rjfc,...,rop}. (8)
Из неравенств (2) и (8) вытекает, что
fip = min{rij, rjfc,..., rop}, (9)
следовательно, все доминирующие требования в точности выполняются.
Для того, чтобы синтезировать циклическую сеть с однородным деревом
разрезов, требуется наличие двух дуг с пропускными способностями г/2,
соответствующими каждому звену этого дерева. Следующая процедура
расстановки пометок на основе поиска в глубину (см. раздел 1.8) строит такую
циклическую сеть из заданного дерева Т.
Шаг 1. Пометить любой из узлов Г числом 1.
Шаг 2. Проверить, существует ли какой-нибудь непомеченный узел,
смежный с текущим узлом, имеющим наибольшую среди всех помеченных
узлов пометку, равную к. Если да, то пометить его к + 1. Если
имеется более одного непомеченного узла, смежного с узлом А:, то можно
пометить к +1 любой из них. Если же непомеченных узлов, смежных
с узлом А:, нет, то проверить, есть ли непомеченный узел, смежный с
узлом к — 1. Если есть, то пометить его к + 1, если нет, то проверить
любой непомеченный узел, смежный с к — 2, и т. д.
Шаг 3. После того как все узлы Г помечены, построить цикл из узла 1 в узел
2, ..., из узла п обратно в узел 1. Получается требуемая циклическая
сеть.
На рис. 2.37 приведены два возможных помечивания дерева с п узлами при
помощи только что описанной процедуры. Для того, чтобы доказать, что эта
процедура приведет к циклической сети, дерево разрезов которой совпадает с
Г, рассмотрим любое звено Uj этого дерева, такое, как звено между V\ и V± на
рис. 2.37(a) или звено между Vi и V$ на Рис- 2.37(b). Пусть два узла,
инцидентных звену, помечены числами % и j, причем % < j. Если звено /# удаляется, то
дерево распадается на две компоненты, одна из которых содержит узел V^ а
другая — Vj. Пусть к — это наибольшая метка узла, лежащего в компоненте,
содержащей j. Тогда узел с меткой к + 1 должен принадлежать компоненте,
содержащей г. (Если к = п, то к + 1 следует заменить на 1.) Так как г < j,
2.3. МНОГОТЕРМИНАЛЬНЫЕ МИНИМАЛЬНЫЕ ПОТОКИ 89
@ ®
Щ
w ®
а) Ь)
Рис. 2.37
то узел с меткой j — 1 также должен лежать в компоненте, содержащей г.
Тогда две дуги циклической сети из j — 1 в j и из к в к + 1 соответствуют /у.
Следовательно, эта циклическая сеть будет иметь две дуги, соответствующие
звену данного дерева разрезов, пропускная способность каждой из которых
равна г/2.
2.3.4. Многопродуктовые потоки
Пусть S\ и S2 — два пункта производства, а Т\ и Т2 — два пункта
потребления. Эти пункты связаны через другие передаточные пункты дугами
с различными пропускными способностями. По сути у нас есть сеть с двумя
источниками и двумя стоками. Пусть предложения в узлах S\ и 52 равны
соответственно з\ и 52, а спросы в узлах Т\ и Т2 равны t\ и £2. Спрашивается,
можно ли точно удовлетворить предложения и спросы без нарушения
ограничений на пропускные способности дуг? Очевидно, что необходимым условием
является выполнение равенства 8\ + з^ = £i + t^. В действительности
данный вопрос можно свести к задаче о максимальном потоке. Можно создать
суперисточник S* с двумя дугами, ведущими из 5* в S\ и 52 и имеющими
пропускные способности з\ и з2. Создадим также и суперсток Г* с двумя
дугами, ведущими из Т\ и Г2 в Г*, пропускные способности которых равны £i и
£2. Теперь в новой сети можно найти максимальный поток из S* в Г*. Если
величина максимального потока равна (з\ + з2) = (*i + £2), то предложение и
спрос можно удовлетворить. Если максимальный поток меньше, чем (з\ +з2),
то существует минимальный разрез, отделяющий 5* от Г*, пропускная
способность которого меньше 3\ + з2, что означает невозможность удовлетворения
предложения и спроса.
Аналогично, любую задачу с произвольным количеством источников и
стоков можно свести к задаче с единственным источником и единственным
стоком. При этом предполагается, что все источники имеют предложения
одного рода, или существует единственный вид товара, распространяющегося по
сети. Если предложение узла S\ отличается от предложения узла 52, а
предложения из Si и 52 требуется передать соответственно в Т\ и Г2, то вопрос
о возможности этого намного сложнее. Если в сети имеется несколько товар-
90
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
ных потоков, делящих одни и те же пропускные способности дуг, то задачу
можно решить средствами линейного программирования. Для задачи с двумя
товарными потоками на неориентированной сети существуют методы,
подобные описанным выше. Об этой задаче, а также о задаче с многопродуктовыми
потоками см. [9], [16], [17].
2.4. Потоки с минимальной стоимостью
В этой главе было введено понятие пропускной способности дуги,
указывающей максимальную величину потока, который может проходить через дугу.
Зададим теперь стоимость передачи единицы потока через каждую дугу.
Поставим следующие два вопроса.
1. Какова минимальная стоимость передачи заданной величины потока из
2. Какова максимальная величина потока, который можно передать из V9
в Vt при заданном фиксированном бюджете?
Бели обозначить через с^ стоимость передачи единицы потока вдоль дуги
e«j, то задачу 1 формально можно представить в виде
mm
mz = У^СцЖц,
при условиях 5Z xv ~ Yl xik = { °» J^ *» *»
V, j = *,
0 < Xij < bij,
где v — требуемая величина потока.
Задачу 2 можно записать в виде
max г;,
при условиях Y^ CijXij < с (с — заданная константа),
Sx«"Sxi* =
0 < х^ < bij.
Если ограничения на пропускные способности дуг отсутствуют, то
величины Cij можно считать длинами дуг и найти самый дешевый (кратчайший)
путь из Va в V$, а затем отправить вдоль него требуемую величину потока.
Даже при наложении ограничений на пропускные способности дуг метод
передачи потока вдоль самого дешевого пути будет работать, если минимальная
2.4. ПОТОКИ С МИНИМАЛЬНОЙ СТОИМОСТЬЮ
91
пропускная способность этого пути больше, чем v. С другой стороны, если
минимальная пропускная способность bij < v, то эта дуга будет насыщена и
дальнейшее продвижение вдоль этого пути станет невозможным. Это
эквивалентно тому, что стоимость дуги становится бесконечной. Так возникает идея
«модифицированной стоимости», когда стоимость зависит от потока,
протекающего через дугу.
Теперь можно описать схему алгоритма решения задачи 1.
Шаг 0. Начать с нулевых значений потоков на всех дугах.
Шаг 1. Определить модифицированные стоимости с^-, порожденные
существующими потоками, следующим образом:
c*j = ^ если ° < ха < ьа>
clj = оо, если Xij = b^,
c*j = -Cji, если Xji > 0.
Шаг 2. Найти самый дешевый путь при модифицированных стоимостях с^-,
полученных на шаге 1, и передать вдоль него е единиц потока, где
€ = min{€i,€2},
€i = min среди величин (b{j — X{j)
по всем прямым дугам,
€2 = min среди величин (xji) по всем обратным дугам.
Скорректировать текущую величину потока на е единиц и вернуться
на шаг 1. (Остановиться, если текущий поток стал равен v.)
Этот алгоритм в действительности строит поток с минимальной
стоимостью величиной в р единиц для р = 1,2,..., v. Для нахождения самого
дешевого пути на шаге 2 можно использовать алгоритм поиска кратчайших путей
из раздела 1.6, в котором допускаются отрицательные длины дуг.
Применим данный алгоритм для передачи 4 единиц потока с минимальной
стоимостью в сети, показанной на рис. 2.38.
Вначале пошлем одну единицу потока вдоль пути Ув, Vi, V2, У и дуга е\ч
станет насыщенной. Остаточные пропускные способности станут равны Ь'12 =
О и &2i = 1» * модифицированные стоимости примут значения cj2 = 00 и с%х =
—3. Остаточные пропускные способности дуг и модифицированные стоимости
показаны в круглых скобках на рис. 2.39.
После передачи еще двух единиц потока получится сеть, изображенная на
рис. 2.40.
Далее мы вынуждены передать одну единицу вдоль пути Ув, У2, Vi, Vi»
после чего модифицированные стоимости станут такими, как показано на
рис. 2.41.
На рис. 2.41 указаны окончательные остаточные пропускные способности
дуг.
92
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
а) Пропускные способности Ь,7 Ь) Цены dj
Рис. 2.38
Рис. 2.39 Рис. 2.40
Заметим, что в окончательном потоке не используется самый дешевый
путь.
Для решения задачи 2 можно использовать тот же самый алгоритм за
исключением того, что всякий раз, когда суммарная стоимость достигает
бюджетного ограничения, следует останавливаться.
Легко доказать, что этот алгоритм модифицированных стоимостей
находит поток величины v с минимальной стоимостью или обеспечивает
максимальное значение потока при заданном бюджете.
Если поток в сети оптимален, то в остаточной сети нет цикла
отрицательной стоимости. С другой стороны, из отсутствия такого цикла следует, что
текущий поток оптимален. Подробности см. в [2], [17], [20].
2.5. Приложения
В этом разделе обсудим несколько приложений теории потоков в сетях.
Другие приложения можно найти в работах Форда и Фалкерсона [8], Ху [17]
Рис. 2.41
2.5. ПРИЛОЖЕНИЯ
93
и других книгах по математическому программированию. Интуитивно
величину максимального потока из V8 в Vt можно понимать как меру связанности, а
пропускную способность минимального разреза — как меру усилия,
требуемого для разделения источника и стока. Тогда теорема о максимальном потоке
и минимальном разрезе утверждает, что степень связанности равна степени
разделения.
2.5.1. Множества различных представителей
В университете работает множество профессоров, которые любят
создавать комитеты. После того, как профессоры сформировали множество
комитетов, они решают образовать комитет комитетов. Комитет комитетов состоит
из представителей, председательствующих в обычных комитетах. Действуют
следующие правила:
(i) от каждого комитета имеется в точности один представитель в комитете
комитетов,
(ii) никто в комитете комитетов не может быть представителем более одного
комитета.
Выполнимы ли эти требования? Иными словами, можно ли в каждом
комитете избрать председателя так, чтобы никакой профессор не был председателем
более одного комитета?
Чтобы сформулировать этот вопрос в терминах множеств, обозначим
V = {V\, V2,..., Vm} множество элементов,
5 = {Si, S2,..., Sn} множество подмножеств У,
где Sj состоит из элементов множества V.
Можно ли выбрать различные Vj (j = ti, • • •, in) так, чтобы существовало
взаимно однозначное соответствие между Sj и Vj? Здесь V{ (i = 1,... ,m) —
профессоры, Vj (j = ii,...,in) — председатели комитетов, a Sj (j = 1,...,n)
— комитеты.
Например, если
5! = {2,4,5}, 5b = {1,5}, S3 = {3,4}, 54 = {1,4},
то можно было бы положить, что
2 представляет S\,
1 представляет 5г,
3 представляет 5з,
4 представляет S4.
Если S\ = {1,3,4}, S2 = {1,3}, S3 = {3,4}, 54 = {1,4}, то выбрать множество
различных представителей невозможно, потому что в этом случае имеется
только три профессора 1, 3, 4 и четыре комитета.
94
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.42
Теорема, решающая вопрос о существовании, называется теоремой о
системе различных представителей и принадлежит Холлу [8]. Она является одной
из фундаментальных теорем комбинаторики.
Теорема 7 о системе различных представителей (СРП). Для
множества S = {5i,...,5n} СРП существует тогда и только тогда, когда при
всех к = 1,... ,п каждая совокупность к множеств из S содержит по
крайней мере к различных элементов.
Необходимость выполнения условий теоремы очевидна. Достаточность же
доказать не так легко. Кроме того, для того, чтобы проверить объединение
каждых к множеств из 5 (при к = 1,... ,п), нужно перечислить 2П
объединений. Даже если необходимые и достаточные условия выполняются, то данная
теорема или ее доказательство не дает процедуры для получения СРП.
Если преобразовать эту задачу в задачу о потоке в сети, то можно
предложить конструктивную процедуру, затрачивающую 0(п3) шагов. В
действительности же эту конкретную задачу можно решить за 0{п2Ъ) шагов (см. [14]).
На рис. 2.42 каждый комитет обозначен узлом, так что четырем комитетам
соответствует четыре узла в левом столбце. Каждый элемент, в свою очередь,
изображается в виде узла, и пять узлов в правом столбце представляют эти
пять элементов. Соединим Sj с V*, если Sj включает в себя Vi как элемент.
Тогда S\ = {2,4,5} будет соединен с V*i, V\ и 1^. Каждое из этих ребер — это
дуга с пропускной способностью, равной единице. Слева от узлов Sj поместим
источник 5 с дугами, имеющими пропускные способности по единице каждая,
ведущими в каждый из узлов Sj. Справа от узлов Vj поместим сток Г,
связанный с каждым Vj дугой, имеющей пропускную способность, равную единице.
Если величина максимального потока из 5 в Г равна числу комитетов, то
СРП существует, а потоковый путь автоматически выбирает представителя.
Например, потоковый путь 5 — 5г — V\ — Т означает, что V\ является
представителем 5г-
2.5. ПРИЛОЖЕНИЯ
95
2.5.2. PERT-метод
Одно из наиболее известных приложений теории потоков в сетях
называется PERT (program evaluation and review technique — метод анализа и
оценки программ)2. Эта техника используется для оптимального распределения
денежных ресурсов среди заданий проекта, при котором проект можно
завершить в кратчайшие сроки. Рассмотрим долгосрочный проект, состоящий из
множества работ. Работы частично упорядочены в соответствии с
технологическими ограничениями. Например, промывка должна производиться
раньше сушки. Будем представлять работы ориентированными дугами. Так, на
рис. 2.43 имеется пять работ, причем работа е\2 должна предшествовать
работам егз и в245 аналогично, работы е\з и егз должны завершиться до начала
выполнения работы ез4*
Рис. 243
Дря каждой индивидуальной работы имеется время нормального
завершения и абсолютно минимальное время завершения. Чем больше денег
затрачивается на работу, тем быстрее эта работа будет завершена. Задача
заключается в том, чтобы завершить весь проект как можно раньше при
фиксированном бюджете. В другой версии рассматриваемой задачи требуется завершить
весь проект до наступления определенного срока окончания с минимальной
затратой денежных ресурсов. Предположим, что у нас достаточно денег для
нормального завершения всех работ. Все дополнительные деньги следует
оптимально распределить среди работ, т. е. так, чтобы весь проект был завершен
в самый ранний срок.
На рис. 2.43 с каждой дугой (работой) ассоциированы три числа (а#, b{j, C{j)
Число aij обозначает минимальное время, b{j — время нормального
завершения, a C{j — сумма, которую нужно затратить для уменьшения времени
завершения работы на одну единицу. Так, работа ею нормально выполняется
за три дня, но при затрате на нее 3-х долларов она может быть закончена за
2 дня, а при затрате 6-ти долларов — за 1 день. (Так как минимальное время
работы ei2 составляет а\2 = 1, то на ее выполнение требуется по крайней мере
один день.)
Заметим, что дуги на рисунке образуют ациклическую сеть, а е\2, егз, ез4 —
самый длинный путь (в терминах величин bij) из V\ в 1^, который составляет
2PERT-метод разработан в 1956 году корпорацией Lockheed Air Craft, консалтинговой
компанией Booz, Allen & Hamilton и особым проектным бюро ВМС США в процессе
создания ракетного комплекса Polaris. Вскоре этот метод стал повсеместно применяться для
планирования проектов в вооруженных силах США. — Прим. перев.
96
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Затраты на дугу С.
Текущая длина
Рис. 2.44
(Ь\2 + &2з + 634) = (3 + 2 + 6) = 11 дней. Очевидно, что дополнительные деньги
следует потратить на эти работы для того, чтобы уменьшить время
завершения всего проекта, поскольку данный путь является наиболее критическим.
В литературе это называется планированием критических путей. На эту тему
имеются две фундаментальные статьи [10], [22], каждая из которых содержит
понятия из математического программирования. Работа [24] объясняет этот
алгоритм в терминах механических аналогий. Здесь изложим его в терминах
самого длинного пути.
Вначале объясним алгоритм на интуитивном уровне, а затем применим
его к сети на рис. 2.43. Для этой сети V\ является стартовым узлом, в
котором начинаются все работы, a V± — завершающий узел, в котором все работы
заканчиваются. Если в сети имеется несколько стартовых узлов, то можно
ввести новый стартовый узел V8 с дугами нулевой длины, ведущими во все
эти стартовые узлы. Поэтому можно считать, что есть только один
стартовый узел V8 и один завершающий узел Vt. Для того, чтобы сократить время
завершения проекта, нужно сократить самый длинный путь из V8 в V*. Так
как в самом длинном пути дуг много, то потратим деньги на дуги (работы) с
наименьшими значениями с#. Это бы наиболее эффективно уменьшило
длину самого длинного пути. Продолжим сокращение дуги до тех пор, пока не
выполнится хотя бы одно из условий (i) или (п).
(i) Дуга сокращена до минимального времени а^.
(И) Рассматриваемый путь не длиннее самого длинного пути.
В случае (i) берем другую дугу того же самого пути со вторым по величине
значением су. В случае (ii) есть несколько самых длинных путей. Для того,
чтобы одновременно сократить эти пути, требуется сократить дуги, лежащие
на различных таких путях. Выберем множество таких дуг так, чтобы общая
сумма величин с^- была минимальной.
В этом по существу и состоит основная идея нашего алгоритма. Иногда
дуга €{j пути Pi сокращается до минимального времени на одном из ранних
этапов. В дальнейшем сокращаются и другие дуги из Р\ и Р\ не станет самым
длинным путем, даже если дугу е# удлинить до ее исходной длины. (Заметим,
что удлинение дуги означает возможность экономии денег.)
Прежде чем применить данный алгоритм к сети на рис. 2.43, вначале
перерисуем ее так, как показано на рис. 2.44.
2.& ПРИЛОЖЕНИЯ
Рис. 2.45
Дуга, принадлежащая хотя бы одному из самых длинных путей,
называется активной, а не принадлежащая никакому из таких путей — слабой.
Активные дуги изображаем сплошными линиями, слабые — пунктирными.
Имеется три активных дуги, образующих самый длинный путь из V\ в 1^,
и так как егз имеет наименьшую стоимость Сгз, то будем уменьшать ее длину,
пока она не станет равной 1. В этот момент ехз станет активной и получится
два самых длинных пути:
в12,е2з,ез4 и в1з,ез4.
Это показано на рис. 2.45.
Для сокращения этих двух самых длинных путей имеется три
возможности:
(a) уменьшить длины е\2 и ехз, для которых с\2 + Схз = 4,
(b) уменьшить длины егз и ехз, Для которых С23 + Схз = 2,
(c) уменьшить длину ез4, для которой С34 = 3.
Заметим, что разрез (Vi,V^|V^,V^) состоит из трех дуг, но в24 неактивная.
Так как разрез, состоящий из егз и ехз, самый дешевый, то сокращаем обе эти
дуги.
Результат показан на рис. 2.46. Теперь имеется два разреза
(a) ехг и ехз, для которых сх2 + Схз = 4,
(b) вз4, ДЛЯ КОТОРОГО С34 = 3.
При уменьшении длины ез4 до 5 дуга е24 становится активной, как показано
на рис. 2.47.
Дуга, длина которой была уменьшена до минимального времени
завершения, называется жесткой. Такова дуга егз-
На рис. 2.47 имеется два разреза, стоимость каждого из которых равна 4,
а именно (схг + схз) и (сг4 + С34), и можно уменьшить длины дуг e\i и ехз ДО
значения 2, а затем уменьшить до значения 2 длины дуг е24 и ез4- В результате
получится сеть, показанная на рис. 2.48.
На данном этапе обе дуги ехз и е24 сокращены до их минимального времени
и больше не могут быть уменьшены. То же верно и для е2з. Если уменьшить
98 ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.46 Рис. 2.47
е\2 и ез4 до минимального времени, то можно увеличить длину дуги егз без
изменения длины самого длинного пути. Эта ситуация показана на рис. 2.49.
На рис. 2.49 все дуги самого длинного пути (ei2,624) являются жесткими.
Следовательно, длительность всего проекта больше нельзя уменьшить.
Стоимость (6 + 3 + 1 + 2 + 15) — это минимальная стоимость, необходимая для
уменьшения времени выполнения проекта до трех дней. В общем случае
конфигурация имеет минимальную стоимость тогда, когда самый длинный путь
состоит из активных дуг. Так, конфигурации на рис. 2.44, 2.45, 2.46, 2.47, 2.48
и 2.49 имеют минимальные стоимости при соответствующих сроках
завершения: $0 за 11 дней, $1 за 10 дней, $3 за 9 дней, $6 за 8 дней, $22 за 4 дня и
$27 за 3 дня.
Коротко алгоритм для PERT можно описать следующим образом.
1. На основе текущих длин дуг найти все самые длинные пути из V8 в Vf.
Сделать все дуги самых длинных путей активными.
2. Рассматривая величины С# для активных дуг как их пропускные
способности, найти максимальный поток из V8 в V%. (При нахождении
максимального потока получаем минимальный разрез, указывающий самый
дешевый способ для сокращения длительности всего проекта.)
3. Если дуга становится жесткой, то присваиваем ей бесконечную
пропускную способность.
4. Если на шаге 2 максимальный поток становится бесконечным, то это
означает, что дальнейшее уменьшение длительности проекта
невозможно.
5. Найти расстояние от V8 до каждого узла. Расстояние до узла V{
соответствует кратчайшему времени, за которое этот узел может быть достиг-
Рис. 2.48
Рис. 2.49
2.5. ПРИЛОЖЕНИЯ
99
Рис. 2.50 Рис. 2.51
нут. Если длина активной дуги короче разности расстояний между ее
концевыми узлами, то увеличиваем длину этой дуги. (Это эквивалентно
уменьшению стоимости.)
Поскольку данный алгоритм эквивалентен соответствующим алгоритмам
из [11], [22], [24], его доказательство здесь не приводится.
2.5.3. Оптимальное коммуникационное остовное дерево
В разделе 1.7 было введено понятие минимального остовного дерева. В
качестве типичного приложения минимальных остовных деревьев можно
рассмотреть следующую задачу: требуется связать п городов телефонными
линиями так, чтобы стоимость построения сети была минимальной. Для каждой
пары городов i и j известна стоимость d+j прокладки линии, соединяющей
эти города. Бели мы хотим связать все города, нужно по крайней мере п — 1
звено, а так как требуется минимизировать стоимость построения сети, то
необходимо найти минимальное остовное дерево.
Теперь предположим, что до построения сети для каждой пары городов
известно число телефонных звонков г^ и требуется минимизировать стоимость
связей в сети после того, как сеть будет построена. Допустим, стоимость
звонка между городами i и j равна длине телефонной линии, связывающей эти
города. Если число звонков равно г^-, то стоимость нужно умножить на г^.
Суммируя стоимости по всем парам городов, получим итоговую стоимость
связи. Чтобы минимизировать эту величину, можно было бы построить
телефонные линии вдоль кратчайших путей между всеми парами городов, а затем
наложить все кратчайшие пути для получения наилучшей сети.
В общем случае самая лучшая сеть может и не являться остовным деревом
и может состоять более чем из (п—1) звеньев, а следовательно, иметь ббльшую
стоимость построения. Для достижения компромисса между стоимостями
построения и связи мы хотим среди всех остовных деревьев выбрать дерево с
минимальной стоимостью связи. Будем называть это дерево оптимальным
коммуникационным остовным деревом.
Для формализации идеи оптимальных коммуникационных остовных
деревьев рассмотрим пример с шестью городами, расстояния между которыми
указаны на рис. 2.50.
Интенсивности звонков между этими городами указаны на рис. 2.51.
100
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.52 Рис. 2.53
Для остовного дерева, показанного на рис. 2.52, стоимость связи будет
равна
П2(2 + 2) + пз(2 + 3) + ri4(2 + 4 + 3) + • • • + г46(3 + 4) + гб6(4)
= 10(2+ 2) + 0(2 + 3) + 0(2 + 4 + 3) + -.. + 2(3 + 4) + 3(4)
= 225.
Задача нахождения оптимального коммуникационного остовного дерева
оказывается очень сложной, а предположение о том, что стоимость звонка
равна длине телефонной линии, вряд ли реалистично. Поэтому рассмотрим
специальный случай, когда все dij = 1. Иными словами, стоимость звонка
равна числу дуг в пути, связывающем данную пару городов. Даже в этом
специальном случае (когда dij = 1, а величины г# произвольные) задача об
оптимальном коммуникационном остовном дереве остается более трудной по
сравнению с задачей о минимальном остовном дереве из раздела 1.7.
Если все dij = 1, то стоимость остовного дерева на рис. 2.52 равна
Г12(2) + Г1б(1) + Г23(2) + Г2б(2) + г2б(1) + г34(3)
+ г3б(2) + г3б(1) + г4б(1) + г4б(2) + гбб(1)
= 82.
С другой стороны, стоимость остовного дерева на рис. 2.53 с такими же
значениями г# составляла бы только 77.
Докажем несколько лемм, относящихся к обсуждаемой задаче.
Лемма 7. Существует взаимно однозначное соответствие между п — 1
звеньями остовного дерева графа ип — 1 нескрещивающимися разрезами
этого графа.
Доказательство. Удалим любое звено из остовного дерева; при этом
дерево распадется на две компоненты, скажем, Т\ и Т2. Тогда удаленное звено
соответствует разрезу (Ti,T2). Применяем тот же самый процесс к одному
из деревьев 7\ или Г2. Таким образом, из любого остовного дерева получаем
множество, состоящее из п — 1 нескрещивающихся разрезов. Обратно, из
множества, состоящего из п — 1 нескрещивающихся разрезов, можно построить
остовное дерево следующим образом. Возьмем разрез (X, X); можно
нарисовать два суперузла, соединенных звеном (каждый суперузел символически
2.5. ПРИЛОЖЕНИЯ
101
. Рис. 2.54
представляет множество обычных узлов); в одном суперузле указаны имена
узлов из X, а в другом — имена узлов из X. При этом получаем одно звено
остовного дерева. Рассмотрим теперь другой разрез (Y,Y). Поскольку (Y,Y)
не скрещивается с (X,X), toYcXhYdX (или Y D Х_и Y С X); тогда
можно построить дерево с тремя суперузлами У, (X-Y) и X; как показано на
рис. 2.54. За п — 1 шагов будет построено остовное дерево с п — 1 звеньями. I
Лемма 8. Пусть даны два остовных дерева графа G, назовем одно из них
<красным>, а другое <синим*. Существует взаимно однозначное
соответствие между красными и синими звеньями, удовлетворяющее условию: для
любого синего звена Bij соответствующее красное звено Вря лежит на
пути, соединяющем V{ и Vj в красном дереве.
Перед доказательством леммы 8 проиллюстрируем ее на примере.
Напротив синего звена ## поместим список красных звеньев, образующих
путь, соединяющий V* и Vj в красном дереве. Подчеркнутое красное звено
соответствует этому синему звену By (см. рис. 2.55).
Красные звенья Синие звенья
#13
-023.
В§\
#31
#31
#14
#и
#45
#32
#16
#46
#46
#12
#26
#66
#36
#46
Доказательство. Сначала каждому синему звену ## поставим в соответ-
Красное остовное дерево
Синее остовное дерево
Рис. 2.55
102
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
ствие в качестве его образа множество красных звеньев, образующих в
красном дереве путь, соединяющий V* и Vj.
Возьмем любое подмножество синих звеньев, образующих р компонент.
Пусть число узлов в г-й компоненте равно n*, а
р
t=i
Это подмножество узлов содержит к — р синих звеньев. Образ каждой
компоненты должен быть связным и инцидентным всем узлам этой компоненты.
Рассмотрим теперь множество красных звеньев, являющееся объединением
образов данных р компонент. Это множество должно состоять из pl{< р)
компонент и быть инцидентным всем к узлам. Следовательно, оно состоит по
крайней мере из к - р' красных звеньев. По теореме 7 о множествах
различных представителей из раздела 2.5.1, в качестве образов п — 1 синих звеньев
остовного дерева можно выбрать п — 1 различных красных звеньев. I
Лемма 9. Сумма пропускных способностей п — 1 нескрещивающихся
разрезов, представленных деревом разрезов (деревом Гомори-Ху) , меньше суммы
пропускных способностей любых п - 1 нескрещивающихсл разрезов.
Доказательство. Всякое множество, состоящее из п — 1 нескрещивающихсл
разрезов, можно представить в виде остовного дерева (по лемме 7). Пусть
это остовное дерево будет красным, а дерево Гомори-Ху — синим деревом
из леммы 8. Для любого синего звена В^ существует единственное красное
звено Bpq, представляющее разрез, разделяющий в сети узлы VJ и Vj. Заметим,
что синее звено представляет минимальный разрез, разделяющий V* и Vj, а
следовательно, величина этого разреза равна значению максимального потока
fij. Так как Bpq представляет разрез, разделяющий V* и Vj, то
c(p,q) > fij = c(ij).
красное синее
Значит,
ЕФ,«) > Ec(t,j).
красные синие
Лемма доказана. i
Теорема 8. Пусть даны множество из п(п — 1)/2 требований Uj между
п узлами и остовное дерево Т на этом множестве узлов. Тогда
коммуникационную стоимость дерева Т для множества г^ можно вычислить
следующим образом:
(г) Построить сеть N, удовлетворяющую условиям Ьм = г«.
2.5. ПРИЛОЖЕНИЯ
103
(it) В сети N найти п - 1 нескрещивающихся разрезов, представленных
деревом Т.
(Ш) Сумма пропускных способностей п - 1 разрезов из (и) — это
коммуникационная стоимость дерева Т для множества величин г#.
Доказательство. Так как Лц = 1, то стоимость связи для пары узлов VpnVq
дерева Т равна величине г*,, умноженной на число звеньев пути между этими
узлами в дереве. Суммируя по (") парам узлов, получаем коммуникационную
стоимость дерева Т. С другой стороны, возьмем звено B{j дерева Г и сложим
все величины rw, в которых это звено участвует. Тогда сумма по п— 1 звеньям
из Т также дает коммуникационную стоимость дерева Т.
Если построить сеть JV, удовлетворяющую условиям Ьы = r*j, то
пропускная способность разреза (Х,Х), представленного звеном bij из Г, равна
Y^ Ъря* гда Vp € х* а Vq € X.
Это значение совпадает с количеством гм, использующих звено В^.
Суммируя по п — 1 звеньям, получаем утверждение теоремы. I
Теорема 9- При условиях dij = 1, г# > 0 оптимальнее каилсутмсацгижпое
остповное дерево Т для заданного множества величин г^ можно получить
следующим образом.
(%) Построить сеть N сЪы^гы-
(И) Для сети N построить дерево Гомори-Ху.
(Ш) Дерево Гомори-Ху, построенное на шаге (it), является оптимальным
коммуникационным деревом Т.
Доказательство. По теореме 8 коммуникационная стоимость любого остовно-
го дерева Т равна сумме п — 1 нескрещивающихся разрезов сети N с Ьы = гы.
По лемме 9 сумма пропускных способностей п — 1 нескрещивающихся
разрезов больше суммы пропускных способностей п— 1 разрезов, представленных
деревом разрезов Гомори-Ху Г*.
Следовательно, Т* — оптимальное коммуникационное остовное дерево. I
Например, если требования в сети с шестью узлами такие, как показано
на рис. 2.51, то в соответствии с теоремами 8 и 9 рассматриваем эти величины
rij в качестве пропускных способностей дуг сети. Теперь, как было описано
в 2.3.2., можно построить дерево разрезов Гомори-Ху. (На рис. 2.21
изображена та же самая сеть, что и на рис. 2.51.) Следовательно, получаем дерево
Гомори-Ху, показанное на рис. 2.53, которое совпадает с деревом на рис. 2.29.
Заметим, что коммуникационную стоимость дерева на рис. 2.53 можно
получить, суммируя значения на рис. 2.29 по всем звеньям.
18 + 17+13 + 144-15 = 77,
что было получено непосредственным вычислением.
104
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Рис. 2.56
Упражнения
1. Справедливы ли следующие утверждения? Ответ обосновать.
(i) Если пропускные способности всех дуг различны, то существует
единственный минимальный разрез, разделяющий источник и сток.
(ii) Бели пропускные способности всех дуг различны, то существует
единственное множество потоков через дуги, дающее максимальное
значение потока.
2. Доказать, что любая сеть потоко-эквивалентна дереву, имеющему
только два узла степени 1 (т. е. дереву, являющемуся цепочкой).
3. Показать, что любая сеть с четырьмя узлами, показанная на рис. 2.56,
потоко-эквивалентна относительно Уд, Vb и Vq сети с тремя узлами.
4. Предположим, что работы представлены узлами в сети PERT. Можно ли
превратить узлы в дуги так, чтобы, во-первых, сохранялось отношение
частичного упорядочения и, во-вторых, существовало взаимно
однозначное соответствие между узлами и дугами?
5. Путь из V8 в Vt с пропускными способностями дуг
(b8l,bi2, • - • ,b{j,. .. ,bkt)
называется маршрутом с максимальной пропускной способностью, если
величина
min{ftei, fti2,..., bij,..., bkt}
максимальна среди всех маршрутов из Va в Vt. Построить алгоритм для
нахождения маршрутов с максимальными пропускными способностями
между всеми парами узлов сети.
6. Построить сеть с четырьмя узлами, для которой алгоритм Форда-Фал-
керсона состоит из v итераций, где v — значение максимального потока
этой сети.
7. Возможно ли одновременное выполнение неравенств X{j > 0 и Xji > 0?
Модифицировать метод расстановки пометок так, чтобы это не
допускалось.
ЛИТЕРАТУРА
105
8. Опишем модифицированную версию метода расстановки пометок.
Присвоим узлу Vj метку [c(j),t"], если Xji > 0, где e(j) = min{e(i),Xji + by}.
Тогда после изменения потока по крайней мере одна дуга будет
насыщенной.
9. Построить такую сеть, чтобы величина тупикового потока была равна
единице, а величина максимального потока составляла бы к единиц.
10. Если пропускная способность каждой дуги равна нулю или единице, то
выполнение неравенства треугольника из раздела 2.3 является
необходимым, но не обязательно достаточным. Каково достаточное условие?
(Открытый воп]>ос)
Литература
Теорема о максимальном потоке и минимальном разрезе была доказана
Фордом и Фалкерсоном [6], [7], [8]. Поиск в ширину для нахождения
увеличивающих путей был разработан Эдмондсом и Карпом [4], а улучшенные
впоследствии алгоритмы принадлежат Диницу [3] и Карзанову [21].
Раздел 2.3 о многополюсных потоках целиком основан на статье Гомори и
Ху [12], хотя здесь освещение данной темы немного отличается от [12]. Леммы
5 и 6 следует читать внимательно. В действительности, разрез (X, X) в этих
леммах не обязан быть минимальным. Леммы 5 и 6 остаются справедливыми
и в том случае, когда не существует никакого другого разреза (Х\ X ), такого,
что
ГсХи
c(X',lt)<c(Xjt).
Разрез (Х,Х), удовлетворяющий вышеуказанному свойству, называется
локально минимальным и используется в [19]. Леммы 5 и 6 (обычно называемые
леммами о нескрещивающихся разрезах) и процесс стягивания узлов должны
иметь широкое применение в теории графов и сетей. Интересное приложение
теории потоков в сетях см. также в [26], [27].
Задача о многопродуктовых потоках в общем случае является JVP-полной
(см. главу 8), хотя подход, основанный на линейном программировании и
технике порождения столбцов, оказывается очень эффективным. Он описан в
[9], [13], [17]. Специальный случай двухпродуктовых потоков также
использует метод расстановки пометок [16].
Алгоритмы нахождения потока с минимальной стоимостью основаны на
статьях [2], [10], [15], [20], [23].
Доказательства правильности работы PERT можно найти в [11], [22], [24].
Поскольку читатель может не знать основ математического
программирования, используются интуитивные понятия «самый длинный путь» и «самый
дешевый разрез».
106
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
Раздел 2.5.3 об оптимальном коммуникационном остовном дереве основан
на работе [18]3.
1. Baratz А. Е. Construction and Analysis of Network Flow Problem which Forces
Karzanov's Algorithm to 0(N3) Running Time // M. I. T./LCS/TM-83, April
1977.
2. Busacker R.G. and Gowen P.J. A Procedure for Determining a Family of
Minimal-Cost Network Flow Patterns // ORO Tech. Report 15. — John Hopkins
Univ., 1961.
3? Dinic E. A. Algorithm for Solution of a Problem of Maximum Flow in a Network
with Power Estimation // Soviet Math. Dokl. 11. — 1970. — P. 1277-1280.
4. Edmonds J., Karp R. M. Theoretical Improvements in Algorithmic Efficiency
for Network How Problems // J. ACM. - 1972. - Vol. 19, Л*2. - P. 248-264.
5. Even S., The Max Flow Algorithm of Dinic and Karzanov: An Exposition //
M. I. T./LCS/TM-80, Dec. 1976.
6. Ford L. R., Fulkerson D. R. Maximal Flow Through a Network // Canadian
J. Math. - 1956. - Vol. 8, №3. - P. 39&-404.
7. Ford L. R., F\ilkerson D. R. A Simple Algorithm for Finding Maximal Network
Flows and an Application to the Hitchcock Problem // Canadian J. Math. —
1957. - Vol. 9, JO 2. - P. 210-218.
8? Ford L. R., Fulkerson D. R. Flows in Networks. — Princeton University Press,
1962.
9. Fulkerson D. R. Suggested Computation for Maximal Multi-commodity Network
Flows // Man. Sci. - 1958. - Vol. 5, №1. - P. 97-101.
10. Fulkerson D. R. Increasing the Capacity of a Network, the Parametric Budget
Problem // Man. Sci. - 1959. - Vol. 5, №4. - P. 472-483.
11. Fulkerson D. R. A Network Flow Computation for Project Cost Curves // Man.
Sci. - 1961. - Vol. 7. - P. 167-178
12. Gomory R. E., Ни Т. С Multi-terminal Network Rows // J. SIAM. — 1961. -
Vol.9, №4.-P. 551-570.
13. Gomory R.E., Ни Т. С Synthesis of a Communication Network // J. SIAM.
- 1964. - Vol. 12, № 2. - P. 348-369.
14. Hopcroft J. E., Karp R. M. An n25 Algorithm for Maximum in Bipartite Graphs
// SIAM J. Comput. - 1973. - Vol. 2. - P. 225-231.
15. Ни Т. С Minimum Convex Cost Flows // Navy Res. Log. Quart. — 1966. —
Vol. 13, №1. - P. 1-9.
3B дополнение к приведенным выше работам, касающимся потоков в сетях, российскому
читателю рекомендуются книги [1*], [23*]. — Прим. перев.
ОТВЕТЫ
107
16. Ни Т.С. Multi-commodity Network Flows // Орег. Res. — 1963. - Vol.11,
Л*3.-P. 344-360.
17? Ни Т. С. Integer Programming and Network Flows. — Addison-Wesley, 1969.
18. Ни Т.С. Optimum Communication Spanning Tree // SIAM J. Comput. —
1974. - Vol.3, Л*3. - P. 188-195.
19. Ни Т. С, Ruskey F. Circular Cut in a Network // Mathematics of Operations
Research. - 1980. - Vol. 5, №3. - P. 422-434.
20. Iri M. A New Method of Solving Transportation Network Problems // J. O.
R. Japan. - 1960. - Vol. 3, № 1& 2. - P. 27-87.
21? Karzanov A. V. Determining the Max Flow in a Network by the Method of
Preflows // Soviet Math. Dokl. - 1974. - Vol. 15. - P. 434-437
22. Kelley J.E., Jr. Critical Path Planning and Scheduling Mathematical Basis //
Oper. Res. - 1961. - Vol.9, Л*2. - P.296-320.
23. Klein M. A Primal Method for Minimal Cost Flows // Man. Sci. — 1967. —
Vol. 14, №3. - P. 205-220.
24. Malhotra V. M. Pramodh M. Kumar and Maheshwari S. N. An 0(v3) Algorithm
for Finding Maximum Flows in Networks // Information Processing Letters.
- 1978. - Vol. 7., №6. - P. 277-278.
25. Prager W. A Structural Method for Computing Project Cost Polygons // Man.
Sci. - 1963. - Vol. 9, №3. - P. 394-404.
26. Rao G.S. Stone H.S. and Ни Т.С. Assignment of Tasks in a Distributed
Processor System with Limited Memory // IEEE Transaction on Computers.
- 1979. - Vol. C-28, №4. - P. 291-299.
27. Schnorr C. P. Bottlenecks and Edge Connectivity in Unsymmetrical Networks
// SIAM J. Comput. - 1979. - Vol.8, №2. - P. 265-274.
28. Tarjan R. Lecture Notes on Flow Theory. — Stanford University, 1976.
Ответы
1. (i) Неверно,
(ii) Неверно.
2. Вначале построить дерево разрезов Гомори-Ху. Затем преобразовать его
в путь следующим образом. Пусть Vi, V^, Vs — узлы степени единица,
которые смежны с узлом V*. Если пропускные способности звеньев в
дереве разрезов равны Ьц, Ь»2» Ь«з> где Ьц < Ь# < Ь«з> то строим путь
через узлы Vi, Ц, V3, V* и соединяем с остатком дерева разрезов.
108
ГЛАВА 2. МАКСИМАЛЬНЫЕ ПОТОКИ
4. Иногда для сохранения отношения частичного упорядочения требуется
добавить фиктивные дуги.
5. Можно определить модифицированную тройственную операцию
следующим образом:
bik «- тах{Ь**,тш{Ьу,Ь^}}
при j = 1,2,...,п и всех г,А:, не равных j. (Сравните с тройственной
операцией из главы 1.)
Глава 3
Динамическое
программирование
Проживи оптимально сегодняшний
день, ведь сегодня первый день твоей
оставшейся жизни.
3.1. Введение
Динамическое программирование — один из подходов к решению задач
оптимизации, так же как индукция — один из методов доказательства теорем.
Динамическое программирование является одним из немногих общих
методов решения задач оптимизации и его легко можно приспособить для
решения стохастических задач. Так как данный метод весьма общий, то он может
не учитывать многих отдельных особенностей частной задачи. Обычно для
конкретной задачи удается найти специальный алгоритм, который
оказывается более эффективным, чем прямой алгоритм, основанный на динамическом
программировании.
Пример 1. Кратчайшие пути. На рис. 3.1 изображена дорожная карта, на
которой все улицы имеют одностороннее движение (слева направо). Числа,
написанные около дуг, представляют длины улиц. Задача заключается в
нахождении кратчайшего пути из узла Si (i = 1,2,3,4,5) в узел Tj (j = 1,2,3,4,5)1.
На этой частной задаче о кратчайшем пути мы проиллюстрируем идею
динамического программирования. Подход грубой силы к решению этой задачи
мог бы заключаться в нахождении всех путей из Si в 7}, сравнении длин этих
путей и выборе самого короткого. Сделаем несколько замечаний.
1 Среди кратчайших путей из 5« в 7} требуется найти путь минимальной длины, где
минимум берется по всем i = 1,..., 5, j = 1,..., 5 и всем путям из Si в Tj. — Прим. перев.
110
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Рис. 3.1
1) Предположим, что путь (S2, ^ь-Вг^С^^з) ~ самый короткий. В этом
пути найдется много подпутей, таких как (S2,4i,ft), (^4ь-В2,С2,Гз),
(А\, ft, Сг)- Каждый из подпутей должен быть сам по себе кратчайшим,
так, путь (52, А\,ft) — кратчайший путь из 52 в ft, путь (А\, ft, С2> ^з)
— кратчайший путь из Лх в Т3- Е!сли подпуть (52,^4i,ft) не является
кратчайшим, то мы можем его заменить на более короткий путь,
например, (52,^2, ft) и тем самым получить путь (52,Л2,В2,С2,1з), более
короткий, чем (S2,j4bft,C2,T3). Получили противоречие. Данное
замечание может быть суммировано в следующем предложении. Любой
подпуть оптимального пути сам является оптимальным.
2) Если мы действительно хотим попасть из Si в Tj по кратчайшему
пути, то мы должны выбрать Si для старта; однако, находясь в S*, у нас
нет необходимости знать весь оптимальный путь. Все, что мы должны
знать, — это направление движения из текущей вершины. Если бы на
протяжении всего оптимального пути стояли бы знаки, указывающие,
в каком направлении двигаться, то мы могли бы пройти шаг за шагом
весь оптимальный путь. Идея заключается не в том, чтобы описать всю
кривую, а в том, чтобы в каждой точке указать направление. В
динамическом программировании мы используем метод касательных.
3) Вместо того, чтобы стартовать из узла S*, можно стартовать из С* и
анализировать в обратном направлении. Если мы находимся в С«,
куда мы должны двигаться, вверх или вниз? Так как в каждом узле С*
есть только две возможности, то для каждого узла С* мы можем
записать «и» (для движения вверх), или «d» (для движения вниз) и можем
указать расстояние от С{ до ближайшего терминального узла Tj.
(Заметим, что не имеет значения, как мы попали в узел С*, но далее мы
3.1. ВВЕДЕНИЕ
111
d,\5 d,U
Рис. 3.2
должны двигаться оптимально.) Двигаясь назад к узлам J9*, мы снова
можем задать себе тот же вопрос. Например, в вершине В3 мы выбираем
min{4 + 3,2 + 7} = 7 (см. рис. 3.2), поэтому мы должны двигаться вверх.
Когда для всех узлов В{ все сравнения выполнены, то узлам Bt будут
приписаны метки «и», «<Ь и расстояния до ближайшей вершины Tj. Это
показано на рис. 3.2.
Принимая решение в узлах А{, у нас нет необходимости рассматривать
часть сети, которая находится справа от Bj. Именно этот факт
уменьшает объем вычислений. Переходя теперь к S*, мы снова можем
использовать тот же подход. Единственная информация, которая влияет на
выбор в узле Si, — это длина дуг, выходящих из Si и числа,
приписанные узлам Aj.
На рис. 3.2 мы видим, что возможны 2 кратчайших пути: один из узла 5з,
а другой из 5б- Оба пути легко восстанавливаются. Из 5з мы двигаемся вниз
к Лз, затем вниз к £?4, вниз к С* и, наконец, вверх к Т±. Из S& мы двигаемся
вверх к А4, затем вверх к В±, вниз к С* и, наконец, вверх к Т±.
Заметим, что в рассмотренной задаче мы определили оптимальный путь,
как путь наименьшей длины. Если бы оптимальным мы назвали путь
наибольшей длины, то для решения полученной задачи можно было бы
использовать тот же метод. Ключевым моментом в нашем случае является то, что
любой подпушь оптимального пути сам является оптимальным. Это, на
первый взгляд, очевидное утверждение может быть обобщено на многие
задачи, такие, как многоэтапные задачи принятия решений, процессы вложения
капитала и т. д. Вместо того, чтобы использовать термин путь, мы будем ис-
112
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
9 9 9 9
Рис. 3.3
пользовать термин стратегия2, что удобнее для задач принятия решений.
Исследователи, использующие динамическое программировние, называют
следующую идею принципом оптимальности.
Принцип оптимальности. Любая подстратегия оптимальной стратегии
должна быть оптимальной по отношению к ее начальному и конечному состояниям.
Обоснование очевидно. Если подстратегия не оптимальна, тогда мы можем
заменить ее лучшей с тем же начальным и конечным состоянием. Тогда общая
стратегия будет лучше, что противоречит оптимальности исходной стратегии.
Неявное предположение, которое мы делаем, заключается в том, что
стратегию можно разбить на подстратегии, такие, что из оптимальности всей
стратегии следует оптимальность любой подстратегии. Назовем путь
оптимальным, если сумма длин всех дуг (mod 10) минимальна и рассмотрим сеть на
рис. 3.3.
Любые два смежных узла соединяют две дуги. Верхняя дуга имеет
длину 1, в то время, как нижняя дуга — длину 9. Так как 1 (mod 10) меньше
9 (mod 10), то для перехода из Vs в V\, из V\ в V*i и т. д. мы должны
использовать верхнюю дугу. Тогда длина пути, использующего только верхние дуги,
равна
1 + 1 + -.+1 = 9 (mod 10),
в то время как длина пути, использующего только нижние дуги, равна
9 + Э + ---+ 9 = 81 = 1 (mod 10).
Последний путь оптимален, но он имеет неоптимальные подпути, такие, как
путь из Vs в Vi- Причина, по которой в данной ситуации динамическое
программирование не работает, заключается в том, что данная задача не может
быть разбита на подзадачи, так, что из оптимальности решения каждой
подзадачи следовала бы оптимальность решения всей задачи (см. упражнение 9).
В задаче оптимизации необходимо максимизировать или минимизировать
некоторую функцию при заданных ограничениях. Подход динамического
программирования заключается в следующем:
1) Разбить задачу на несколько подзадач. Если задача состоит в
совместном принятии нескольких решений, то подход заключается в том, чтобы
сформулировать задачу как процесс последовательного принятия
решений, в котором часть решений уже принята, а затем определить, каким
в этих условиях должно быть лучшее решение.
2В оригинале: policy — политика, курс. — Прим. перев.
3.1. ВВЕДЕНИЕ
113
2) Когда все подзадачи решены, или когда оптимальные решения частных
задач известны, можно скомбинировать эти решения, чтобы получить
оптимальное решение всей задачи. Связь между задачей и подзадачей
обычно можно определить рекурсивно функциональным уравнением.
В книгах [1], [2], [3], [14], [15] динамическое программирование
используется при решении разнообразных задач. Рассмотрим еще один пример.
Пример 2. Вложение капитала в предприятия. Необходимо
инвестировать $ 1000 в 10 предприятий. Как следует вложить деньги?
Пусть Х{ — количество денег, вложенных в г-ое предприятие, fi(x{) —
прибыль г-ro предприятия, если в него было вложено Х{ долларов. Таким образом,
задача состоит в том, чтобы вычислить
max {/i(xi) + f2(x2) + • • • + /io(sio)} ,
при ограничениях
xi + х2 + • • • + хю = 1000,
Xi > 0, целые (г = 1,2,..., 10).
Предположим, что /,(0) = 0 и все функции монотонно возрастают.
Оптимальная стратегия заключается в том, чтобы определить точную
величину Х{ для каждого из 10 предприятий. Вместо того, чтобы решать,
сколько мы должны вложить в каждое предприятие, зададимся следующим
вопросом:
Если на первые 4 предприятия уже потрачено $ 450, как мы должны
потратить остаток денег на оставшиеся 6 предприятий?
В рассматриваемой ситуации подстратегией является вложение $ 550 в 6
предприятий. Если мы не используем эти $ 550 оптимальным образом, тогда
общая стратегия не будет являться оптимальной. Заметим, что мы не знаем,
должны ли мы вкладывать $ 450 в первые 4 предприятия. Если мы знаем
решения всех подзадач такого типа, то мы можем из этих решений собрать
решение основной задачи.
Попробуем использовать эти идеи в решении небольшого примера с 4
предприятиями и $ 5, а именно;
тах{/1(х1) + /2(х2) + /з(хз) + /4(а:4)}, (1)
при ограничениях
Х\ + Х2 + Хз + #4 = 5,
Xi > 0, целые (г = 1,2,3,4).
Граничные условия имеют вид /ДО) = 0 для всех г; значения функций
приведены в таблице 3.1.
114 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Таблица 3.1
X
1
2
3
4
[5
Л(*)
11
12
13
14
15
Мх)
0
5
10
15
20
h(x)
2
10
30
32
40
h{x)
20
21
22
23
24
Так как каждая переменная принимает 6 возможных значений, наивный
подход требует проверки б4 возможностей.
Обозначим через Fk(x) максимальную прибыль, возвращаемую первыми
к предприятиями при условии, что в них вложено х долларов.
Тогда F\(x) есть максимальная прибыль первого предприятия. Так как
функция /i монотонно возрастает, то F\(x) = fi(x). Для F2(x) мы должны
определить величину х2. Остаток х—х2 необходимо потратить на первое
предприятие. Таким образом,
F2(x) = max{/2(x2) + Fi(х - х2) : 0 < х2 < х}. (2)
Если мы знаем значение F2(x) для всех х, то мы можем положить
F3(x) = max{/3(x3) + F2(x - х3) : 0 < х3 < х} (3)
и затем
F4(x) = тах{/4(х4) + F3(x - хл) : 0 < хл < х). (4)
В (1) значения всех £; должны определяться одновременно и подставляться в
fi(xi). Здесь значения Х\,х2,Хз,Х4 определяются последовательно и
подставляются в F{(x). Уравнение (2) можно записать в равносильном с точки зрения
вычислений виде:
F2(x) = max{/2(x2) + f\(x - х2) : 0 < х2 < х}.
Настоящее различие появляется в (3). У нас нет необходимости в
точности знать, откуда берется F2(x - Хз). Единственное, что необходимо знать,
— это возвращаемое число. То же самое справедливо при рассмотрении (4).
Вычисления удобно проводить, как показано в таблице 3.2.
Таблица заполнется столбец за столбцом слева направо. Для того,
чтобы заполнить новый столбец, например, F3(x), нам необходимо лишь F2(x) и
/з(х), что видно из (3).
Когда таблица будет заполнена, мы получим ^(5) = 61 и х± = 1. Это
означает, что
F3(x - хА) = F3(5 - 1) = F3(4) = 41, где х3 = 3,
F2(x -хА- х3) = F2(5 - 1 - 3) = F2(l) = 11, где х2 = 0,
Fi(x - х4 - х3 - х2) = ^(5 - 1 - 3) = Fi(l) = 11, где хх = 1.
3.2. ЗАДАЧА О РЮКЗАКЕ
115
Таблица 3.2
X
1
2
3
4
5
ад
11
12
13
14
15
xi(x)
1
2
3
4
5
ад
и
12
16
21
26
х2{х)
0
0
2
3
4
ад
11
13
30
41
43
аг3(аг)
0
1
3
3
4
ад
20
31
33
50
61
х4(х)
Итак, оптимальным решением является набор Х\ = 1, #2 = 0, х$ = 3 и #4 = 1.
Заметим, что для вычисления Fs(x) требуется х + 1 сложений и х
сравнений:
F3(x) = max
/s(0) + Fa(*-0)f ]
/з(1) + *2(*-1),
/s(«) + ft(0)
В случае суммы 6 долларов и п предприятий для вычисления Fi(x)
необходимо найти пЬ элементов. Для каждого % получаем
У^(ж + 1) = —-—- сложений,
х=1
ь
е-
6(6+1)
сравнений.
ж=1
Таким образом, всего требуется примерно пб2 операций. Обычно, функции
fi(xi) можно аппроксимировать кусочно-линейной функцией и тогда
достаточно рассмотреть только точки излома х,-.
3.2. Задача о рюкзаке
Задача минимизации или максимизации линейной функции при линейных
ограничениях называется задачей линейного программирования (ЗЛП).
Например, необходимо минимизировать
— У ^,CjXj
(1)
116 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
при ограничениях
п
£<4i*i>fc (г = 1,2,...,т), (2)
*i > 0, (3)
где Xj — неизвестные переменные, а а#, ft* и с^ — заданные константы. Если
на переменные Xj помимо неотрицательности наложено требование целочис-
ленности, то задача называется задачей целочисленного линейного
программирования (ЗЦЛП). Великое множество задач комбинаторной оптимизации
может быть сформулировано как ЗЦЛП. Таким задачам посвящены многие
книги и статьи. Раздел, изучающий эти проблемы, называют
математическим программированием.
Мы не можем обсуждать здесь весь круг проблем, возникающих в
математическом программировании. Рассмотрим только простейший тип ЗЦЛП,
а именно, целочисленную задачу с одним ограничением в (2). Такая ЗЦЛП
называется задачей о рюкзаке.
Название «задача о рюкзаке» возникает в следующей гипотетической
ситуации. Представим себе человека, который хочет взять с собой в путешествие
рюкзак. Чтобы его заполнить, он может выбирать из большого количества
вещей, каждая из которых имеет определенный вес и «ценность». Конечно,
он хотел бы взять с собой вещей с максимальной общей ценностью и общим
весом, не превышающим некоторой заранее известной границы.
Пусть Wj — вес j-ой вещи3, Vj — ценность j-ой вещи, Xj — число вещей
типа j, которые путешественник хочет взять с собой, и пусть Ь — ограничение
на суммарный вес. Задача принимает вид:
п
max^VjXj (vj > О, j = 1,2,... ,п)
3=1
при ограничениях
п
У^ WjXj <b (wj > 0, b > 0, j = 1,2,..., n),
Zj > 0, целые.
Чтобы решить эту задачу, введем новую функцию Fb{y). Пусть
к
Fk(y) = max^ VjXj (0 < к < п),
где
к
5>;*;<У (0<у<6),
i=i
3Говоря «j-ая вещь», автор имеет ввиду вещь j-ro типа. — Прим. перев.
3.2. ЗАДАЧА О РЮКЗАКЕ 117
Таблица 3.S. Значения Fk(y)
\к\у
1
2
3
4
1
0
0
0
0
2
1
1
1
1
3
1
3
3
3
4
2
3
5
5
5
2
4
5
5
6
3
6
6
6
7
3
6
8
9
8
4
7
10
10
9
4
9
10
10
"iol
5
9
11
12
следовательно, Fk(y) — максимальная ценность, которую можно получить,
используя только первые к вещей. Таким образом,
Fo(y) = 0 для всех у (0 < у < ft), так как ни одна вещь не выбрана,
Fk(0) = 0 для всех к (0 < А: < п), так как суммарный вес < 0.
Далее, F\(y) = [y/wi\v\, так как мы хотим взять вещей первого типа так
много, насколько возможно. Для произвольного Fk(y) имеем следующее
рекуррентное соотношение:
Fk{y) = max {F*_i (у), Fk(y - ад) + vk}. (4)
Обоснование заключается в следующем простом замечании: вычисление Fk(y)
подразумевает выбор вещей первых к типов, при этом fc-ая вещь используется
либо по крайней мере 1 раз, либо не используется вовсе. Если не используется,
то Fk(y) совпадает с i^-i(у). Если йещь типа к используете»но крайней мере
один раз, то ограничение на общий вес уменьшится до у — wk. Очёйидно, этот
вес мы должны использовать наилучшим образом. Максимальная суммарная
ценность при использовании первых к вещей, по определению, есть Fk(y —
wk). Заметим, что в (4) мы пишем именно F*(y — ад), а не Fk-i(y - ад), так
как fc-ую вещь можно использовать более одного раза. Подготовим таблицу
размеров п х Ь, в которой каждый элемент есть значение Fk(y) (к = 1,2,..., п;
у = 1,2,...,ft). Используя рекуррентное соотношение (4), вычислим Fk(y) в
порадке^(1),^(2),...,ад^^
(4) считаем, что
Fk (отрицательное число) = -оо.
Пример 3. Предположим, что имеется 4 типа вещей, ограничение на
суммарный вес 10 и vi = 1, v2 = 3, v3 = 5, va = 9, w\ = 2, ад = 3, ад = 4,
ад =7.
Используя (4), будем заполнять первую строку таблицы слева направо,
затем вторую строку таблицы слева направо и т. д. Результат показан в
таблице 3.3.
Заметим, что в таблице, подобной таблице 3.3, мы указыаем только
значения Fk(y), но не Xjj по которым вычисляются Fk(y). (Это подобно ситуации,
118
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
когда известны длины кратчайших путей, но не известны промежуточные
узлы, составляющие эти пути.) Чтобы найти сами х/, нам нужна другая таблица
размеров п х ft, в которой каждый элемент — это максимальный индекс
переменной Xj, использующейся в F*(y). Итак, элемент fc-ой строки, у-го столбца
этой таблицы есть
*(&>!/) = максимальный индекс переменной Xj, использующейся в Fk(y).
Таким образом, если t(fc,y) = j, то Xj > 1, т.е. j'-ая вещь используется в
Fk (у) и xq = 0 для всех q > j.
При вычислении элементов таблицы F*(j/) одновременно будем записывать
элементы г (А:, у) во вторую таблицу. Начальные условия следующие:
г(1,у) = 0, еслиЗД) = 0,
г(1,у) = 1, если^(у)^0.
В общем случае полагаем
цк ♦,) = / *(fc " г>у)> если F*-i(у) >Fk(v- u>k) + vk,
\ К если F*_i(y) < Fk(y - wk) + vk.
Для доказательства формул (4У) обратимся к (4). Если F*_i(y) > Fk(y -
iu*), тогда Xk = 0 в F*(y). Поэтому мы должны просто переписать
максимальный индекс для Ffc^i(y) как максимальный индекс для Fk(y). Это
обосновывает первую строку в правой части равенства (4;).
Если Fk-\(у) < Fk(y — Wk) + Vk, то Xk > 1 в F*(y) и мы просто записываем
к. Это обосновывает вторую строку в правой части равенства (4').
Таким образом, таблица г(&, у) хранит информацию о том, как
вычисляются элементы таблицы Fk(y). Когда обе таблицы заполнены, мы легко можем
вычислить Xj, по которым вычисляются F*(y).
Если г(к,у) = q, то xq > 1 в F*(y). Так как g-ая вещь используется по
крайней мере один раз в Fk(y), то ограничение на суммарный вес уменьшается
до у — wq и мы смотрим на элемент i(k,y — wq).
Если i(fc,y - wg) = g, то xq > 1 в F*(y - wq) (и xg > 2 в F*(y)).
Если i(k,y - wg) =p, то xp > 1 в F*(y - wg) (и xg = 1, xp > 1 в Ffc(y)).
Заметим, что элементы таблиц Fk(y) и %{к,у) вычисляются
последовательно слева направо, строка за строкой сверху вниз, как читается английский
текст. Чтобы найти значение Xj, доставляющее значение некоторого Fk(y),
мы начинаем с элемента i(fc,y'), где у' < у и у = у' + wq при %{к,у) = д.
Окончательная таблица значений г (к, у) показана на таблице 3.4.
Заметим, что при вычислении ^(10) мы в действительности вычислили
все значения Fk(y) для 1<&<4и0<у<10. Из таблицы 3.4 мы видим, что
^4(10) = 12. Из таблицы 3.4 следует, что соответствующее значение х\ есть 4,
т. е. 4-ая вещь используется по крайней мере один раз. Находим
г(4,10 - w4) = г(4,10 - 7) = г(4,3) = 2,
3.2. ЗАДАЧА О РЮКЗАКЕ 119
Таблица 3-4- Значения i(k, у)
*\У
1
2
3
4
1
0
0
0
0
2
1
1
1
1
3
1
2
2
2
4
1
2
3
3
5
1
2
3
3
6
1
2
3
3
7
1
2
3
4
8
1
2
3
3
9
1
2
3
4
10
1
2
3
4
что означает, что 2-ая вещь используется по крайней мере один раз. Далее,
имеем
i(4,3-W2) = i(4,0) = 0,
т.е. мы использовали все х$, чтобы получить ^(10) = 12. Важной чертой
проделанных вычислений является то, что при вычислении F* (у) (0 < у < ft)
мы используем только F*_i(y) (0 < у < ft). Следовательно, нет необходимости
хранить всю таблицу и мы можем стирать элемент, как только элемент под
ним вычислен. Это избавляет нас от необходимости использования больших
объемов компьютерной памяти. То же самое справедливо и для второй
таблицы, в которой нам нужна только последняя строка при вычислении значений
Xj.
Обратим внимание на величину г (4,8) = 3, откуда следует, что если
ограничение на суммарный вес 8, то мы не используем 4-ую вещь, которая имеет
самую большую ценность, отнесенную к единице веса.
Мы уже говорили, что задача о рюкзаке является простейшей ЗЦЛП с
требованием неотрицательности и целочисленности неизвестных Xj и одним
линейным ограничением. Изучим задачу о рюкзаке, в которой Xj —
неотрицательные вещественные переменные. Это даст нам некоторое понимание того,
как требование целочисленности влияет на задачу.
Если ограничения на целочисленность неизвестных Xj сняты, то задача
решается легко: найдем
Vj Vr
max— = —,
3 Wj wr
т.е. г-ая вещь есть вещь с максимальной ценностью, отнесенной к единице
веса. Заполним рюкзак r-ой вещью в количестве xr = b/wr. Затруднение
возникает, если хг не целое4. Пусть pj = vj/wj\ переставим индексы неизвестных
так, чтобы
Pi > Р2 > Рз > • • • > Рп,
где pj обозначает ценность j вещи, отнесенной к единице веса. Мы могли
бы заполнить рюкзак первой вещью, остаток заполнить второй вещью и т. д.
Этот интуитивный подход обычно дает очень хороший результат, но из-за
4Мы снова рассматриваем задачу о рюкзаке с требованием целочисленности переменных.
— Прим. перев.
120
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
требования целочисленности не всегда приводит к оптимальному решению.
Интуитивно ясно, что если Ь много больше Wi, то в оптимальном решении
х\ > 0. Для доказательства в оптимальном решении положим х\ = 0. Тогда
оптимальная ценность, конечно, не превысит fob. Однако если попытаться
заполнить рюкзак только первой вещью, мы получим зачение
I Ь I (Ь ti/Л Ъ-wi b-wx
Чтобы найти величину Ь, которая дает
VI > Pl(b-Wl) >р2&,
решим уравнение
Pi(b-wi) =p2b, откуда Ь= wu
Р1-Р2
т.е.
при 6> -w\ имеем pi(ft — W\) = p^b.
Р1-Р2
Другими словами, для достаточно большого b получаем в оптимальном
решении х\ > 1. Это означает, что
Fn(b) = vx + Fn(b - «л) для Ъ> p1w1/(p1-p2). (6)
Определим 0(b) = р\Ь "— Fn(ft); здесь 9(b) представляет разность между
оптимальными решениями в задаче о рюкзаке без требования целочисленности и
с ним. Тогда
0(Ъ - Wl) = рг(Ъ - гиг) - ЗД -т)
= pib- piW\ - (^„(Ь) - v\) (из (6) для достаточно большого Ь)
= Pib-Fn(b)
= •№)-
Это показывает, что для достаточно большого Ъ функция 9(b) периодична с
периодом «л5. Функция 0(b) определена и в случае, когда b < piW\/(p\ - рг).
Можно получить рекуррентное соотношение для функции 9(b) следующим
образом.
Очевидно, 9(b) = 0, если w\ делит Ь нацело, так как в этом случае рюкзак
заполнен полностью первой вещью с максимальной ценностью, отнесенной к
единице веса. Когда b (mod W\) /0, мы можем использовать некоторые Xj,
отличные от Х\. Так как
0{b) = Pib-Fn{b),
то максимальное значение Fn(b) дает минимальное значение 9(b). Иными
словами, мы хотим выбрать Xj так, чтобы потеря из-за требования
целочисленности была бы минимальна. Потеря вследствие выбора Xj (j ф 1) равна
5 Если р\ > Р2- — Прим. перев.
3.2. ЗАДАЧА О РЮКЗАКЕ
121
(р\ — Pj)tVj, и ограничение на суммарный вес падает до Ь — Wj. Выбор Xj
происходит в результате минимизации по всем j:
0(b) = щпЩЪ - wj) + (д, - Pj)wj}. (7)
J
Выражение (7) представляет собой рекуррентную формулу, по которой
рекурсивно вычисляются 0(b) для всех ft. Так как 0(0) = О, то, используя (7),
можно вычислить 0(6), переходя от меньших значений ft к ббльшим.
Пример 4.
vi = 18, V2 = 14, уз — 8, V4 = 4, v$ = О,
w\ ■= 15, шг = 12, гуз = 7, гУ4 — 4, г^б = 1,
Рх = 1.2, pa = 1.167, рз = 1.143, р4 = 1, ръ = 0.
Теперь
рх 18/15
• гУх = • 15 = 540.
Р* - Р2 18/15 - 14/12
Таким образом, если ограничение ft на суммарный вес превышает 540, то в
оптимальном решении наверняка Х\ Ф 0. Другими словами, мы можем
вычитать w\ из ft, пока результирующая разность все еще больше 540. Количество
вычитаний W\ из ft является нижней оценкой на величину Х\. Например, если
ft = 1000, то в оптимальном решении х\ > 30, так как 1000 — ЗОгих = 550, что
больше 540.
Заметим, что оценка 540 является только нижней оценкой. Как мы увидим
далее, оптимальное решение для ft = 1000 есть х\ — 65, Хч = 2 и хь — 1.
Чтобы получить полное представление о периодичности решения
задачи о рюкзаке, вычислим, используя (7), 0(6) для всех значений ft начиная
с ft = 0,1,2, Результат представлен в таблице 3.5. В таблице 3.5 четыре
столбца: в первом столбце находятся значения ft, во втором столбце —
соответствующие оптимальные решения (не отображены), третий столбец — это
J2wjxj (не отображено), четвертый — значения 0(b). Проверив значения 0(b)
в четвертом столбце, увидим, что 0(b) = 0(ft+15) для ft > 26. (Что показывает,
что оценка ft > 540 слишком завышена.) Из (7) получаем, что как только 0(b)
зацикливается, решение становится периодическим6.
Обсудим, как можно использовать таблицу 3.5 для всех возможных
значений bf. Рассмотрим ft = 56. Так как
ft - 2«л = 56 - 2 х 15 = 26,
то оптимальное решение для ft = 26 мы можем найти во втором столбце
таблицы 3.5 и этим решением оказывается х\ = 1, х$ = 1 и #4 = 1. Теперь мы
Периодичность функции 0(b) впервые была отмечена в [7], где получена оценка (6)
при р\ > р2 и более сложные оценки при р\ = рг > Рз и Т-Д- в [33*] (см. также [34*]
§ 3.4 п. 2) получена верхняя оценка границы периодичности, не зависящая от компонент v3
целевой функции, а именно показано, что при Ь > а(а — 1), где а = тах7- wj, справедливо
равенство 0(b) = 0(b + wi). Следуя [35*], нетрудно показать, что эта граница не улучшаема
по порядку. Для этого достаточно рассмотреть задачу о рюкзаке с параметрами п = 2,
U7] = о, гиг = о - 1, vi = 2о - 1, V2 = 2о - 3. — Прим. перев.
122 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Таблица 3.5
Значения Ь
0
1
25
26
27
40
41
42
55
Решения
1=2
9{Ь)
1.2
0.4
2.0
1.2
0.4
2.0
знаем оптимальное решение для Ь = 56: это Х\ = 3, Хз = 1 и ха = 1- (Заметим,
что решения для ft = 56 и для ft = 26 отличаются только в значении х\.)
На самом деле, мы могли бы данные из таблицы 3.5 переписать в
таблицу 3.6. В таблице 3.6 также 4 столбца. Первый столбец — это ft (mod W\).
Второй столбец содержит Wj (j ф 1) в оптимальном периодическом решении.
Третий столбец отображает величины
п
JT WjXj,
и четвертый столбец содержит значения 0(b).
Рассмотрим первый и третий столбцы в таблице 3.6. Значения в них
практически совпадают, за исключением значений, соответствующих ft (mod 15) =
3,6,9,10. Для всех других значений ft, например, ft (mod 15) = 5, оптимальное
решение есть х\ = 1, хь = 1, что видно во втором столбце, плюс надлежащая
величина Х\, т. е.
ft = Х\ -W\ +W4 + 1Уб-
Таким образом, строка ft (mod W\) = 5 дает оптимальные решения для всех
возможных ft, которые можно представить как некоторое кратное W\ плюс 5.
Для ft = 18,21,24,25 оптимальные решения даны во втором столбце. Таким
образом, для ft (mod 15) = 18,21,24,25 мы находим оптимальное решение,
просто добавляя надлежащую величину Х\. Единственные значения ft, для
которых в таблице 3.6 нет ответа, — это ft = 3,6,9,10; в этих случаях решение
необходимо вычислить отдельно.
3.3. ЗАДАЧА О ДВУМЕРНОМ РЮКЗАКЕ 123
Таблица 3.6
b (mod Wi)
о :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Xj
0
1
1,1
4,7,7
4
1,4
7,7,7
7
1,7
12,12
1,12,12
4,7
12
1,12
7,7
n
^WjXj
0
1
2
18
4
5
21
7
8
24
25
11
12
13
14
в
°
1.2
2.4
1.6
0.8
2.0
1.2
0.4
1.6
0.8
2.0
1.2
0.4
1.6
0.8
3.3. Задача о двумерном рюкзаке
В предыдущем разделе рассматривалась задача о размещении вещей в
рюкзаке, если на суммарный вес наложено ограничение. Другими словами,
рассматривался только один параметр — вес. Такой вариант задачи о
рюкзаке можно назвать задачей об одномерном рюкзаке. В данном разделе мы
рассмотрим задачу о двумерном рюкзаке, в которой каждая вещь имеет два
свойства: например, длину и вес.
Чтобы сформулировать новый вариант задачи о рюкзаке, рассмотрим
задачу о разрезании большой доски на маленькие прямоугольники заданных
размеров.
Предположим, что мы хотели бы разрезать большую доску на бруски
прямоугольной формы для продажи на рынке. Пусть цены на бруски известны.
Каким образом мы должны разрезать доску, чтобы получить максимальную
прибыль? Сформулированная задача называется задачей о раскрое. Бе
одномерный вариант является обычной задачей о рюкзаке. В данном разделе
каждая вещь характеризуется двумя параметрами: длиной и весом, и рюкзак
эквивалентен большой доске. В информатике можно рассмотреть набор
заданий, каждое из которых для выполнения требует определенного количества
времени процессора и определенного объема памяти.
Если маленький прямоугольник представляет собой задание с известным
124 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
а) Ь)
с) d)
Рис. 34
временем выполнения и известным объемом памяти, то прямоугольник
нельзя вращать, чтобы вписать его в размеры доски. С другой стороны, если мы
хотим разрезать большой кусок стекла, то ориентация маленьких
прямоугольников может быть произвольной. Далее будем предполагать, что вращать
прямоугольные куски нельзя, хотя задача о раскрое допускает произвольные
расположения маленьких кусков.
Данный вариант задачи о раскрое все равно весьма сложен, и мы
рассмотрим еще более узкую задачу. Новая задача допускает только следующие
способы раскроя:
(i) доска нарезается на горизонтальные полосы, каждая из которых затем
делится на куски вертикальными разрезами, как показано на рис. 3.4(a).
(и) дрека нарезается на вертикальные полосы, каждая из которых затем
делится на куски горизонтальными разрезами, как показано на рис, 3.4(b).
Способы раскроя, показанные на рис.3.4(а,Ь), называются двухстадийными
раскроями, так как в них вначале происходит раскрой вдоль одной
координатной оси, а затем раскрой каждого полученного куска вдоль другой
координатной оси. Шаблон, показанный на рис. 3.4(c), таковым не является, так
как не может быть получен рекурсивно с помощью разрезания большого
куска на два маленьких. Раскрой, показанный на рис. 3.4(d), также не является
таковым, так как требует более двух стадий7.
7Раскрои на рис. 3.4(а, b,d), но не на рис. 3.4(c), являются примерами так называемых
гильотинных раскроев. См., например, [25*J. — Прим. персе.
'СЛЩ^Щ
3.3. ЗАДАЧА О ДВУМЕРНОМ РЮКЗАКЕ
125
Рис. 3.5
Предположим, что нам заданы цены Vi для п прямоугольников, где U —
(горизонтальная) длина, aw* — (вертикальная) ширинаг-го прямоугольника.
Разрежем большую доску в две стадии таким образом, что общая стоимость
полученных прямоугольных кусков максимальна. Бели какой-нибудь из
прямоугольников имеет размеры, превышающие U х w^ то мы будем
предполагать, что этот прямоугольник имеет цену, равную максимальной общей
стоимости прямоугольных кусков, умещающихся в этом прямоугольнике. Другими
словами, мы не должны подравнивать размеры полученных прямоугольных
кусков под размеры Ц х W{.
Пример б. Пусть доска имеет размеры L = 14, W = 11, а для маленьких
прямоугольников имеем
Vl = $6, h =7, ил =2,
V2 = $7, /2 =5, W2 = 3,
Уз = $9, /3 = 4, ws =5.
Один из способов раскроя вначале горизонтальными разрезами, а затем
вертикальными, показанный на рис. 3.5(a), имеет общую стоимость $63, в то
время как другой способ раскроя вначале вертикальными линиями, а затем
горизонтальными, показанный на рис. 3.5(b), имеет общую стоимость $64.
Заметим, что раскрой на рис. 3.5(b) нельзя получить в две стадии:
необходим третий, «подравнивающий», этап. Однако мы не будем выполнять этот
этап, а просто оставим прямоугольники с размерами 5 х 5 и 4 х 6 как имеющие
стоимость $9 каждый.
Чтобы получить оптимальный способ раскроя вначале горизонтально, а
затем вертикально, рассмотрим задачу о разрезании доски длины 14, не
обращая внимание на ограничение по ширине. Получим задачу об одномерном
рюкзаке, а именно:
max{6xi + 7х2 + 9хз}
(1)
126 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
при ограничениях
7xi + 5х2 + 4х3 < 14,
Xi, Х2, хз > 0, целые,
где Х{ — число используемых прямоугольников 1-го типа. Если доска имеет
ширину 2, то можно использовать прямоугольники только первого типа.
Бели доска имеет ширину 3, то можно использовать прямоугольники только
первого и второго типов. Определим функции
к
Fk(x) = max^ViXi (2)
i=l
при ограничениях
к
^2Uxi<x,
Xi > 0, целые (г = 1,2,...,к).
Задача (2) может быть решена алгоритмом из предыдущего раздела.
Результат вычислений показан в таблице 3.7(a).
Заметим, что Fi(14) = 12, F2(14) = 14, F3(14) = 27. Это означает, что
доска 14 х 2 может иметь стоимость $ 12,
доска 14 х 3 может иметь стоимость $ 14,
доска 14 х 5 может иметь стоимость $ 27.
Возникает вопрос: «Сколько таких полос стоимости $12, $14 и $27 можно
получить?» Данная задача снова является задачей о рюкзаке, а именно:
max{12i/i + 14j/2 + 27у3} (3)
при ограничениях
2yi + Зу2 + 5у3 < 11,
УъУ2,Уз >0, целые.
Здесь yi представляет число полос г-го типа. (В исследовании операций
цены $ 12, $ 14 и $ 27 можно интерпретировать как теневые цены для полосы
соответствующей ширины8.)
Задачу (3) мы можем решить, определяя функции
к
С*(у)=тах]Г^7Г*у* (4)
»=1
8В линейном программировании теневые цены также называют множителями или
двойственными переменными. См., например, [31*], [9*]. — Прим. перев.
3.3. ЗАДАЧА О ДВУМЕРНОМ РЮКЗАКЕ
Таблица 3.7. Значения Fk(x) и Gk(y)
(а)
к\х
1
2
3
1
0
0
0
2
0
0
0
3
0
0
0
4
0
0
9
5
0
7
9
6
0
7
9
7
6
7
9
8
6
7
18
9
6
7
18
10
6
14
18
11
6
14
18
12
6
14
27
13
6
14
27
14
12
14
27
(Ь)
[*\*
1
2
3
1
0
0
0
2
12
12
12
3
12
14
14
4
24
24
24
5
24
26
27
6
36
36
36
7
36
38
39
8
48
48
48
9
48
50
51
10
60
60
60
HI
60
62
63
127
при ограничениях
yi > 0, целые (t = 1,2,..., fc),
где (7гЬ7г2,7Гз) = (12,14,27).
Результат вычислений (4) показан в таблице 3.7(b), а способ раскроя
стоимости $63 показан на рис. 3.5(a).
Если бы исходная доска имела размеры L = 13, W = 11, то в (4) нужно
было ИСПОЛЬЗОватЬ (7Г1,7Г2,7Гз) = (6,14,27).
В общем случае мы можем считать, что
W\ < W2 < • • • < wn.
Далее, пусть Fk(x) — максимальная стоимость полосы ширины, не
превышающей и;*. Решаем (4), где щ = ^(-Ь), a L — длина всей доски.
Аналогичным образом можно получить оптимальный раскрой,
использующий вначале вертикальные, а затем горизонтальные разрезы. Сначала
отсортируем прямоугольники по их длине:
14=!
11=4, и* =5,
v'2 = $7 ^ = 5, u>2=3>
v'3 = $6 l'3 = 7, w'3 = 2.
Задача об одномерном рюкзаке принимает вид:
max{9xi + 7x2 + 64)
(5)
128
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
при ограничениях
5a?i + Зхз + 34 < 11,
#i, #2»#з ^ 0, целые,
где х\ — число прямоугольников f-го типа в вертикальной полосе.
Задачу (5) можно решить, определяя функции
к
^(у) = тах5>& (6)
при ограничениях
к
х\ > 0, целые (г = 1,2,..., А:).
Результат вычислений (6) показан в таблице 3.8(a). Также в таблице 3.8(a)
мы видим, что вертикальные полосы 4х11,5х11и7х11 имеют стоимость
$18, $23 и $31 соответственно. Таким образом, задача принимает вид:
тах^в^ + гЗ^ + З^} (7)
при ограничениях
Vi + 5y£ + 7y£<14,
у'иУъУз >°> целые.
Здесь у\ обозначает число вертикальных полос типа г. Снова задачу (7) можно
решить, определяя функции
к
С?П*) = тах5>а/< (8)
»=1
при ограничениях
t=i
y'i > 0, целые (t = 1,2,...,к).
Результаты вычислений (8) приведены в таблице 3.8(b), а раскрой общей
стоимости $64 показан на рис. 3.5(b).
3.4. АЛФАВИТНЫЕ ДЕРЕВЬЯ МИНИМАЛЬНОЙ СТОИМОСТИ 129
Таблица 3.8. Значения F'k(x) и G'k(y)
(а)
[*\¥
1
2
3
1
0
0
0
2
0
0
6
3
0
7
7
4
0
7
12
5
9
9
13
6
9
14
18
7
9
14
19
8
9
16
24
9
9
21
25
10
18
21
30
11
18
23
31
(Ь)
,к\х
1
2
з
1
0
0
0
2
0
0
0
3
0
0
0
4
18
18
18
5
18
23
23
6
18
23
23
7
18
23
31
8
36
36
36
9
36
41
41
10
36
46
46
11
36
46
49
12
54
54
54
13
54
54
54
~й\
54
64
64
3.4. Алфавитные деревья минимальной
стоимости
Данный пример, на первый взгляд, может показаться слишком
искусственным, однако он имеет реальные приложения (см. главу 5). Пусть дана
последовательность положительных чисел, например,
4, 1, 2, 3;
поместим три пары скобок между элементами этой последовательности и
сложим:
((4 + 1)+ (2 + 3) = ((5)+ (5)) = (10).
Заметим, что получены 3 промежуточные суммы, а именно: 5, 5, 10. Сумма
промежуточных итогов равна 5 + 5 + 10 = 20. Разместим скобки иным
способом:
(4 + ((1 + 2) + 3)) = (4 + ((3) + 3)) = (4 + (6)) = (10).
Промежуточные суммы равны 3,6 и 10. Общая сумма промежуточных итогов
равна 3 + 6 + 10 = 19.
Данные примеры показывают, что сумма промежуточных итогов зависит
от того, как мы расставим скобки. Поставим следующий общий вопрос.
Пусть дана последовательность из п положительных чисел. Необходимо
так расставить скобки, чтоба сумма промежуточных итогов была
минимальной.
Эта задача допускает также графическую формулировку в виде
следующей задачи на бинарном дереве.
130
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Рис. 3.6
Пусть вес отца есть сумма весов его двух сыновей. Две вершины могут
иметь одного отца, только если они соседи в своем ярусе. Каждый способ
расстановки скобок между концевыми вершинами соответствует конкретному
дереву и наоборот. Такое дерево называется алфавитным. Ценой алфавитного
дерева является сумма весов всех его неконцевых вершин. Таким образом,
дерево на рис. 3.6(a) имеет цену 20 = 10-1-5-1- 5, а дерево на рис. 3.6(b) имеет цену
19 = 10 + 6 + 3. Для заданной последовательности концевых вершин
алфавитное дерево с минимальной стоимостью называется оптимальным алфавитным
деревом.
Рассмотрим пример с 7 концевыми вершинами. Один из способов
расстановки скобок может привести к дереву, показанному на рис. 3.7.
Сделаем несколько замечаний, подобных высказанным ранее.
(1) Если дерево на рис. 3.7 оптимально, то поддерево с корнем веса 17
должно быть оптимальным для последовательности Н Ш И И • Бели
бы существовал лучший способ группировки четырех концевых вершин
И И И Н, то мы могли бы заменить поддерево на рис. 3.7
лучшим поддеревом. Это противоречило бы тому, что исходное дерево с 7
концевыми вершинами оптимально.
(2) В задаче о кратчайшем пути мы хотели знать, в каком направлении
двигаться. Последовательность направлений определяла весь путь. В дан-
Рис. 3.7
3.4. АЛФАВИТНЫЕ ДЕРЕВЬЯ МИНИМАЛЬНОЙ СТОИМОСТИ 131
ном случае мы хотим знать, как последовательность концевых вершин
разбивается на группы. Бели мы знаем, что вначале последовательность
концевых вершин разбивается на группу из 3 вершин в левом поддереве
и группу из 4 вершин в правом поддереве, то дальше мы можем
спросить, как разделяется левое и правое поддеревья. Таким образом, знание
о последовательных разбиениях эквивалентно описанию всего дерева.
Для обозначения разбиения дерева на левое поддерево с 3 концевыми
вершинами и правое поддерево с 4 концевыми вершинами будем писать
(3,4). Начальное разбиение 7 концевых вершин может быть одним из
следующих: (1,6), (2,5), (3,4), (4,3), (5,2) и (6,1). На рис. 3.7 имеем
(3,4)-разбиение. Для левого поддерева с 3 концевыми вершинами
разбиение может быть (1,2) или (2,1). Для правого поддерева с 4
концевыми вершинами разбиение может быть (1,3), (2,2) или (3,1).
Последовательность оптимальных разбиений является описанием оптимального
дерева.
(3) В задаче о кратчайшем пути, решая задачу, мы двигались справа
налево. Сейчас мы двигаемся сверху вниз. Цена дерева с одной концевой
вершиной равна 0 по определению.
Цена оптимального дерева с двумя концевыми вершинами есть просто
сумма двух весов. В общем случае, пусть С** обозначает цену
оптимального дерева с последовательностью концевых вершин VJ,Vi+i>-- ->У* и пусть9
Щк = Щ + w*+i И 1- w*. Тогда следующие формулы можно доказать по
индукции:
Cik = пип{Су + Ci+i,* + Wik : i<j< к},
Си = 0 для всех *.
Например, цена оптимального дерева с тремя концевыми вершинами Щ Щ
Щ равна
Ci3 = min{Cii + С23, С12 + С33} + W13
= min{0 + 12,8 + 0} + 16 = 24.
Мы можем использовать (1) для вычисления цены оптимальных деревьев для
каждой тройки вершин
(4,4,8), (4,8,5), (8,5,4), (5,4,3), (4,3,5).
Как только мы узнали цену дерева с каждой возможной тройкой концевых
вершин, мы можем легко вычислить цену деревьев для каждых 4 концевых
вершин. Например, цена дерева с концевыми вершинами Ш Ш Ш1 [§1
равна
min{Cn + С24, С12 + С34, С13 + С44} + Wu
= min{0 + 29, 8 + 13, 24 + 0} + 21
= 8+13 + 21
= 42.
'Далее W{ — веса концевых вершин. — Прим. перев.
132
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Рис. 3.8
Цены всех оптимальных поддеревьев приведены на рис. 3.8.
Минимум в (1) необходим для нахождения корня бинарного дерева. Кнут
[12] заметил, что если к последовательности из п концевых вершин добавить
справа еще один лист, то корень оптимального дерева для п + 1 концевых
вершин либо не изменится, либо сдвинется вправо. Это замечание позволяет
сократить объем вычислений. Трудоемкость такого алгоритма 0(п2).
В более общей задаче функция Wik в (1) может не быть суммой весов
концевых вершин. Однако для такой общей задачи все равно существует алгоритм
с трудоемкостью 0(п2). Этот результат доказан Ф. Ф. Яо [16].
В [16] функция Wik называется инкрементирующей. Если инкрементирую-
щая функция удовлетворяет следующим условиям (2) и (3), то функция цены
dk также удовлетворяет схожим условиям: для p<q<r <s справедливо
Wvr + Wa.KWar + Wt
'pr
qa ^ "qr
wqr < WPI.
'PI1
(2)
(3)
Другими словами, из (2) и (3) следует, что функции С** удовлетворяют
неравенствам:
Орг + Сqa < Cqr + Срв,
Cqr < Cpi
Sp8l
(4)
(5)
где P<q<r<s-
Рассмотрим индекс j, на котором достигается минимум в (1). Если инкре-
ментируюшая функция задана, то j является функцией от г и А:.
Если инкрементирующие функции Wik удовлетворяют (2) и (3) и функция
цены удовлетворяет (4) и (5), то можно показать, что индекс j удовлетворяет
3.5. РЕЗЮМЕ
133
неравенству
j(»t*)<j(»t*+l)<j(*+lt*+l) ДЛЯ1<*. (6)
Заметим, что (6) дает более общий способ определения, будет ли при
добавлении справа новых концевых вершин корень оптимального дерева смещаться
вправо или останется на месте.
На основе (6) можно получить 0(п2) алгоритм для нахождения
минимального Cik в (1).
3.5. Резюме
Мы рассмотрели некоторые примеры использования динамического
программирования. Девизом динамического программирования могла бы быть
фраза: «Любая подстратегия оптимальной стратегии должна быть
оптимальной». Для решения задачи динамического программирования мы обычно
решаем все подзадачи. Это называется подходом «вверх дном». В задаче о
кратчайшем пути и задаче о вложении капитала подзадачи слабо связаны, поэтому
требуется не очень много повторений вычислений. В задаче об алфавитном
дереве минимальной стоимости все подзадачи сильно связаны и мы должны
были обработать все последовательные пары концевых вершин, тройки,
четверки и т.д. Но даже в этом случае вместо трудоемкости 0(2П) переборного
алгоритма мы получаем трудоемкость 0(п3) или 0(п4) алгоритма
динамического программирования.
Не все задачи могут быть решены с помощью динамического
программирования. В задаче о кратчайшем пути мы назвали путь оптимальным, если
длина входящих в него дуг минимальна. Динамическое программирование
нельзя было бы применить без модификаций, если вместо суммы длин дуг
рассматривалась бы сумма по модулю 10. Следующее свойство является
характерным для задач, которые можно решить с помощью динамического
программирования: целевая функция для всей задачи является суммой целевых
функций своих подзадач.
Точное необходимое и достаточное условие возможности решения задачи
с помощью динамического программирования не сформулировано.
Упражнения
1. В примере 1 мы получили кратчайшие пути из всех узлов в узлы Tj.
Измените способ решения так, чтобы можно было получить кратчайшие
пути из Si во все узлы сети.
2. Сколько сложений и сравнений требуется в алгоритме из примера 1?
3. Можно ли решить следующий вариант задачи о рюкзаке методом
динамического программирования: £ VjXj при ограничениях ]£ WjX* < ft,
#j > 0, целые.
134
ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
4. Решите пример 1 с дополнительным требованием, что каждое изменение
направления в кратчайшем пути эквивалентно прибавлению 5 единиц к
общей длине. (Указание: для каждого узла введите новую переменную,
указывающую направление пути при выходе из узла.)
5. Сформулируйте в виде ЗЛП задачу о разрезании минимального числа
больших досок стандартных размеров на заданное число
прямоугольников. См. [6], [9].
6. Задача об алфавитном дереве минимальной стоимости была впервые
рассмотрена как задача кодирования Гилбертом и Муром [5]. Сравните
метод динамического программирвоания, примененный к этой задаче, с
алгоритмом Ху-Таккера из главы 5.
7. Используйте динамическое программирование для нахождения самого
длинного пути в ациклической сети.
8. Рассмотрим произведение конечной последовательности матриц
М = Mi х М2 х • • • х Мп.
Используйте динамическое программирование, чтобы определить такой
порядок перемножения матриц, в котором общее число операций
минимально (число операций при перемножении двух матриц размеров г х s
и s х t равно r-s-t). (См. главу 7.)
9. Используйте динамическое программирование для решения задачи о
кратчайшем пути mod 10, изображенной на рис. 3.3.
Литература
По динамическому программированию есть несколько книг; см., например,
[1], [2], [4], [14], [15]. Весьма рекомендуем также две обзорные статьи [3], [10].
Разделы, посвященные задаче о рюкзаке, основаны на статьях [6], [7], [8], [9],
[11]. Раздел об алфавитном дереве минимальной стоимости основан на работах
[5], [12], [13].
1? Bellman R. Dynamic Programming. — Princeton University Press, Princeton,
N.J., 1957.
2? Bellman R., Dreyfus S. E. Applied Dynamic Programming. — Princeton
University Press, Princeton, N. J., 1962.
3. Brown K. Dynamic Programming in Computer Science. — Carnegie-Mellon
University, 1979.
4. Dreyfus S. E., Law A. M. The Art and Theory of Dynamic Programming. —
Academic Press, 1977.
ОТВЕТЫ
135
5. Gilbert E.N., Moore E.F. Variable-length Binary Encoding // Bell Systems
Tech. J. - 1959. - Vol. 38. - P. 933-968.
6. Gilmore P. С Cutting Stock, Linear Programming, Knapsack, Dynamic
Programming and Integer Programming, Some Interconnections // IBM Research
Report RC6528, May 1977.
7. Gilmore P. C., Gomory R. E. The Theory and Computation of Knapsack
Functions // Oper. Res. - 1966. - Vol. 14, No 6. - P. 1045-1074.
8. Gilmore P. C, Gomory R. E. A Linear Programming Approach to the Cutting
Stock Problem.Part 1 // Oper. Res. - 1961. - Vol.9. - P.849-859. Part II:
1963. - Vol 11. - P. 863-887.
9. Gilmore P. C, Gomory R. E. Many Stage Cutting Stock Problems of Two and
More Dimensions // Oper. Res. — 1965. — Vol. 13. — P. 94-120
10. Held M. and Karp R. M. Finite-State Process and Dynamic Programming //
SIAM J. - 1967. - Vol. 15. - P. 693-718
11? Ни Т. С Integer Programming and Network Flows. — Addison-Wesley, 1969.
12. Knuth D. E. Optimum Binary Search TVees // Acta Information. — 1971. —
Vol. 1. - P. 14-25.
13? Knuth D. E. Sorting and Searching. — Addison-Wesley, 1973.
14. Nemhauser G.L. Introduction to Dynamic Programming. — John Wiley &
Sons, 1966.
15. Puterman M. L. (ed.) Dynamic Programing and Its Application. — Academic
Press, 1977.
16. Yao F.F. Efficient Dynamic Programming Using Quadrangle Inequalities //
Proceedings of the 12th Annual ACM Symposium on Theory of Computing.
-1980. -P.429-435.
Ответы
1. Определим S(Vj) как кратчайшее расстояние от начального узла до Vj.
Например,
S(B2) = minlSHx) + 4, S(A2) + 3}.
3. Подход, используемый в примере 2, все еще работает, однако простое
рекуррентное соотношение, подобное (4) из раздела 3.2, не выполняется.
4. Определим T(Vj,d) как кратчайшее расстояние от Vj до концевого
узла Г, где d — параметр, принимающий значения 0 или 1. Значение 0
означает, что путь, выходящий из Vj, идет вниз. Таким образом,
Т(В3,0) = 2 + ппп{Г(Сз,0), 5 + Г(С3,1)},
Т(В3,1) = 4 + min{r(C2,1), 5 + Г(С2,0)}.
136 ГЛАВА 3. ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
9- Начиная с узла fc, определим
S%k = min{ (минимальная цена пути из к в Т +1) (mod 10)}.
Рекуррентная формула принимает вид:
Si = mm{SiX\ (mod 10), SJ+l (mod 10)}.
Запишем граничное условие:
Полагая % = 0,1,..., 9, получаем:
5g = 1, о8 = 0, Sg = 1, ..., Sg = 0,
•by = 0, iby = 1, ii>7 = о, ... , «Ьу = 1» • • •
И, наконец, 5g = S£ = 1.
Глава 4
Поиск с возвращением
Не со/сигайте за собой мосты:
может быть, придется отступать.
4.1. Введение
Во многих комбинаторных задачах ищутся все конфигурации,
удовлетворяющие некоторым требованиям. Например, мы можем пожелать найти все
способы расставить на шахматной доске восемь ферзей так, чтобы ни один
из них не атаковал другого. Или мы хотим найти все неотрицательные целые
числа, удовлетворяющие некоторым ограничениям. Один из подходов к
решению таких задач состоит в генерировании всех возможных конфигураций одна
за другой. Эта техника, известная как исчерпывающий поиск, обычно требует
проверки слишком большого числа случаев, что делает ее применение
непрактичным даже для очень быстрого компьютера. В большинстве приложений
благодаря особенностям задач нет необходимости в проверке всех возможных
конфигураций. Один из способов систематического поиска всех возможных
решений называется бэктрэкингом или поиском с возвращением. Подобно
динамическому программированию, эта общая техника может не выдерживать
конкуренции с алгоритмами, специально приспособленными для тех или инйх
задач. Однако бэктрэкинг, благодаря его общности, получил широкое
признание среди специалистов.
Сначала проиллюстрируем идею поиска с возвращением на примере.
Пример 1. Допустим, мы хотим разместить на шахматной доске размера
4x4 четырех не атакующих друг друга ферзей.
Так как на доске 16 клеток, то при исчерпывающем поиске необходимо
рассмотреть (146) = 1820 возможных конфигураций. Так как в каждом
горизонтальном ряду может стоять не более одного ферзя, решение можно
записать в виде последовательности (хьЯй,#3,2:4), где Xi Указь№ает позицию
138 ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Рис. 4-1
ферзя в г-том ряду. Имеется 44 = 256 таких конфигураций. Некоторые из них
удовлетворяют требованию, другие нет. Бэктрэкинг - систематический способ
перечисления всех конфигураций, удовлетворяющих требованиям.
Первым делом устанавливается взаимно однозначное соответствие между
конфигурациями и последовательностями (или векторами). В нашем
примере это очень просто. Имеется четыре позиции в каждом ряду и четыре ряда;
расстановка ферзей может быть описана вектором с четырьмя компонентами
{х\,Х2,Хз 1X4)1 где каждая переменная Х{ может принимать значения 1,2,3,4.
Значения 1,2,3,4 соответствуют четырем позициям в каждом ряду.
Например, расстановка на рис. 4.1 описывается вектором (х\, Хг, #з, #4) = (2,4, _, 1).
Чтобы перечислить все решения, воспользуемся понятием
лексикографического порядка. Вектор (х\, аъ,..., хп) лексикографически положителен,
если его первая слева ненулевая компонента положительна. Например, вектор
(0,0,1, -10, -2,100) лексикографически положителен. Вектор (&i, &2> - - - > хп)
лексикографически меньше, чем вектор (j/i, J/2, • • •, Уп)> если и только если
вектор (j/i — х\»1/2 — #2, • • • > Уп — хп) лексикографически положителен. Например,
вектор (0,0,1, -10, -2,100) лексикографически меньше (0,0,1, —1, -100, -100)
Алгоритм поиска с возвращением перебирает векторы, начиная с
лексикографически наименьшего.
В нашей задаче о шахматной доске 4x4 наименьшим вектором является
(#ъ#2,#з>#4) — (1,1,1,1), однако он не удовлетворяет условию, чтобы
ферзи не атаковали друг друга. Если перебрать векторы (1,1,1,1), (1,1,1,2),...,
(4,4,4,4), то обнаруживается, что большинство из них не удовлетворяет этому
условию. Поиск можно организовать с помощью дерева решений, как
показано на рис. 4.2.
Дерево решений имеет корень, представляющий состояние, в котором не
принимается никакого решения. Каждый из остальных узлов дерева
представляет состояние, в котором принимается решение.
На рис. 4.2 узел Уд является корнем дерева решений и считается
расположенным на нулевом уровне. Четыре узла Vb, Vc, Vb и V# (расположенные
непосредственно под Уд) находятся на первом уровне. Узлы Vp,V<3,---
находятся на втором уровне, Vq — на третьем и Vz — на четвертом. В узлах
первого уровня фиксируется значение Х\. Наличие четырех узлов на первом
уровне означает, что имеется четыре возможных значения для Х\. Выбор Vjg,
например, означает, что Х\ = 1, а выбор Vb — что Х\ = 3. Под каждым узлом
4.1. ВВЕДЕНИЕ
139
Ш
Рис. 12
первого уровня расположены четыре узла, указывающие на четыре
возможных выбора значения х2- Например, под Vb находятся узлы V>, Vg, Ун и V/,
причем Vh представляет состояние Х\ = 1 и х^ = 3. На рис. 4.2 показаны не
все узлы второго уровня. Всего имеется 16 узлов на втором уровне, 64 узла
на третьем уровне и 256 узлов на четвертом уровне.
Обычно для указания узлов в дереве используют отношение отец-сын.
Узел Уд называется отцом узлов Vb, Vc, Vd и Ve- Узел Vz является внуком
узла Vf и т.д. Каждый узел (кроме узлов четвертого уровня) имеет точно
четырех сыновей и изображен на рисунке кружком. Узлы четвертого уровня
сыновей не имеют, они изображаются квадратами и называются листьями.
Круглый узел представляет вектор, в котором некоторые компоненты еще
не определены. Квадратный узел представляет вектор, в котором все
компоненты определены. Например, узел Vz представляет вектор (1,1,1,1). Если
вектор удовлетворяет всем требованиям, он называется допустимым, в
противном случае недопустимым.
Два листа с одним и тем же отцом представляют два вектора,
отличающихся только в одной компоненте. Два листа с одним и тем же дедом
представляют два вектора, отличающихся не более чем в двух компонентах. С
другой стороны, узлы первого уровня обозначают векторы, у которых
фиксировано одно значение, а остальные компоненты пока не определены. Вектор, у
которого некоторые компоненты не определены, называется частичным
вектором. Частичный вектор Vx короче частичного вектора Vy, если количество
фиксированных компонент в Vx меньше, чем в Vy. В терминах дерева решений
узлы более высокого уровня представляют более короткие частичные
векторы. Наивысший уровень имеет корень, и он представляет вектор, у которого
ни одна компонента не фиксирована.
В терминах дерева решений бэктрэкинг есть обход дерева методом поиска
в глубину, начиная с корня (см. DFS в разделе 1.7). Из данного узла мы всегда
140
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
xi\ I I |*i| III I 1*4I
I J X2 J J J I J |*21 | J | |*2
IiZIZLJ *3 *3
I *4
PUC.4.3
PUC.4.4
PUC.4.5
движемся по самой левой еще не пройденной дуге. Если все дуги, идущие вниз
из узла Vy, уже были пройдены, возвращаемся на один уровень к отцу узла Vy,
скажем, Vx, и проверяем, все ли дуги, идущие вниз из Vx, были исследованы.
Например, узлу V# на рис. 4.2 соответствует частичный вектор (1,3, _, _),
как показано на рис. 4.3. Так как никакой выбор значения х3 не приводит к
расстановке не атакующих друг друга ферзей, то все сыновья узла Vh
представляют недопустимые векторы, поэтому мы возвращаемся в узел Vb и
выбираем путь, ведущий в У/. Предполагается, что пути из Vb в Vp и Vq уже
исследованы.
Заметим, что выбор самого левого пути равносилен выбору наименьшего
значения неопределенной компоненты.
Вначале, желая взять лексикографически наименьший вектор, мы
полагаем Xi = 1, размещая ферзя в верхнем левом углу. После этого пытаемся
выбрать наименьшее возможное значение для х2> которое не может быть
равно 1 или 2, так что наименьшее значение есть 3. Теперь мы имеем расстановку,
показанную на рис. 4.3.
Имея (xi,X2, _, _) = (1,3, _, _), мы пытаемся придать Хз наименьшее
возможное значение. Так как Хз не может теперь принимать ни одного из
значений 1, 2, 3, 4, то мы возвращаемся (backtrack), чтобы увеличить значение #2.
Полагаем х2 = 4, а затем х3 = 2. Это показано на рис. 4.4.
Имея (х\)Х%)Хъ,_) = (1,4,2,_), мы обнаруживаем, что нет подходящих
значений для х±. Поэтому необходимо вернуться, чтобы увеличить значение
Хз- Но х$ нельзя увеличить, поэтому возвращаемся, чтобы увеличить хъ- Но
Хч уже принимает максимальное значение, поэтому возвращаемся, чтобы
увеличить Xi, и полагаем Х\ = 2. После этого можно,положить Хъ = 4, хд = 1 и
Х4 = 3, что дает одно из решений задачи о четырех ферзях: (#i,X2,#3>#4) =
(2,4,1,3), оно показано на рис. 4.5.
Вдумаемся в то, что мы сделали в этом примере. Мы рассматривали
каждую расстановку на шахматной доске 4x4 как вектор, первая компонента
которого — позиция ферзя в первом ряду. Затем мы выполнили
систематический поиск всех допустимых векторов в лексикографическом порядке.
В общем случаемы ищем все последовательности (xi,X2,... ,яп),
удовлетворяющие некоторому условию Pn(xi»^2» • • •»%п)- Например, для шахматной
доски 4x4 условие Р4(#1,#2>#з>#4) состоит в том, что ни один из четырех
ферзей не дожен атаковать другого, а условие Р2 (#i, #2) - в том, что два
ферзя не атакуют друг друга. Если выполняется Р4, то выполняется Р2, а если Р2
не выполняется, то частичный вектор (#i,#2>_,_) не может быть пополнен
4.1. ВВЕДЕНИЕ
141
так, чтобы выполнялось Р*. В общих обозначениях мы имеем
Pfc+i(xi,x2,...,xfc,a;fc+i) -+A(«b«2,--.,«*) Для 0 < А; < п.
Рассмотрим общий алгоритм поиска с возвращением, предполагая, что
переменная Xi может принимать значения из множества Х{. Подразумевается,
что это множество линейно упорядочено. После того, как Х\, Хъ,..., Xk-i
фиксированы, в множестве Xk выбирается наименьшее значение х*, при котором
выполняется Pfc(xi,X2,...,Xk)- Множество таких допустимых значений Хь
будем обозначать через S*. Так как Xk упорядочено, то и Sk упорядочено. В
нашем примере значение Хч можно выбирать из множества Хч = {1,2,3,4},
но если х\ = 1, то 5г = {3,4}.
Теперь можно формально описать общий алгоритм поиска с
возвращением.
Шаг 0. Установить взаимно однозначное соответствие между
последовательностями (х\, #2, • • •, %п) и возможными конфигурациями. Пусть Xi —
множество возможных значений для Xi. При фиксированных х\, х*ъ,...
Xk-i множество допустимых значений для х* обозначается через 5*.
Мы последовательно проверяем 5* (к = 1,2,..., п).
Шаг 1. Если Sk не пусто, положить Xk равным наименьшему значению из
Sfc, которое еще не испытывалось. Если к < п, увеличить ft на 1 и
повторить шаг 1. Если к = п, выдать (xi,X2,... ,хп) как допустимый
вектор. (Если мы хотим найти все допустимые векторы, то нужно
уменьшить к на 1 и повторить шаг 1. В противном случае —
остановиться.)
Шаг 2. Если Sk пусто и к = 1, то других допустимых векторов не существует,
остановка. Если Sk пусто и к ф 1, то уменьшить А; на 1 и вернуться
на шаг 1.
Применим этот алгоритм к следующей задаче.
Пример 2. Найти все целые положительные векторы (#ь#2>#з)>
удовлетворяющие условиям:
3xi + 4ж2 + х3 < Ю, (1а)
1<#*<3, целые. (16)
Каждая из переменных xi, Хъ, #з может принимать значения 1, 2, 3,
поэтому Xi = {1,2,3} для всех г.
Дерево решений показано на рис. 4.6.
На рисунке показаны не все узлы дерева решений, в алгоритме поиска
с возвращением узлы будут посещаться в порядке Va,Vb»Vc,— Условие
Рз(х1,Х2,х3) означает здесь выполнение ограничений 3xi + 4х2 + х3 < 10
и 1 <Xi <3.
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Рис. 4 6
Условие Р2(#ъ#2) означает выполнение
3xi + 4ж2 < Ю,
1 < Xi < 3, целые, г = 1,2.
Узлы Vb, Vg, Vf соответствуют векторам
(1,1,1),
(1,1,2),
(1,1,3),
а узел Vb соответствует частичному вектору
(!,_,_)•
Первоначально для выбора Хъ имеется три возможности, но после того, как х\
зафиксировано равным 1, Si = {1}. Поэтому Vq представляет недопустимый
вектор, т.е. РгО^ъХг) = ^2(1,^2) всегда нарушается для х2 > 2. Поэтому
S3 = 0, т.е. Уя, Vb Vj предсташляют недопустимые векторы. Аналогично
узел Vk представляет недопустимый вектор и таковы же все его потомки.
Когда найден частичный вектор, не удовлетворяющий требованиям, нет
смысла пытаться расширить это частичное решение. Ранее мы заметили, что
из ложности Рк(х\,...,Xk) следует ложность P^+i (х\,..., #*,#fc+i)•
Явление, заключающееся в том, что
Pk ЛОЖНО -► Pfc+i ложно,
будем называть феноменом домино.
Заметим, что феномен домино должен иметь место для того, чтобы бэк-
трэкинг работал. Допустим, что мы хотим найти все векторы (xi,#2,2:3), УД°"
4.2. ОЦЕНИВАНИЕ ЭФФЕКТИВНОСТИ
143
влетворяющие ограничениям
3xi + 4х2 - #з < Ю,
1 < ж* < 3, целые.
Из ложности Р2(1,2) не следует ложность Рз(1>2,1).
Это один из моментов, часто упускаемых людьми, применяющими бэктр-
экинг.
Чтобы справиться с приведенной выше задачей, можно искать векторы,
(х\, Х2, х'3)» удовлетворяющие
3xi + 4х2 + х'3 < 13,
1<яь*2<3, 0<х'3<2
и затем положить хз = 3 — х'3.
4.2. Оценивание эффективности поиска с
возвращением
Прежде чем решать задачу большого размера на компьютере, мы обычно
оцениваем время работы алгоритма. Если алгоритм требует времени 0(п3) в
худшем случае, а небольшой пример для п = 10 решается за 5 минут, то мы
можем прикинуть, что для п = 100 алгоритм будет работать 5 х 1003/103 =
5000 минут.
При бэктрэкинге алгоритм обычно экспоненциален в худшем случае, но в
среднем работает гораздо лучше. Поэтому описанный выше способ
оценивания слишком пессимистичен.
Один способ оценить объем работы бэктрэкинга состоит в подсчете числа
узлов в дереве решений. В задаче о четырех ферзях \Xi\ = 4 и мы можем
использовать Х{ для оценки числа узлов в дереве:
1 + 4 + 4x4 + 4x4x4 + 4x4x4x4 = 341.
Но это очень нереалистично. Когда Х\ = 1, для х2 есть только две, а не четыре
возможности. А если х\ = 1, хъ = 3, то 5з = 0. Так что более реалистичный
путь — подсчет числа узлов на основе |5<|. Но это не так просто, поскольку \S{\
заранее не известны. Точный подсчет числа допустимых решений равносилен
полному прогону алгоритма, чего мы как раз пытаемся избежать.
Для оценивания числа узлов в дереве решений для большого примера
можно применить подход Монте-Карло. Грубо говоря, подход Монте-Карло
состоит в том, чтобы двигаться по дереву решений, выбирая значение х%
случайным образом из S{ (вместо того, чтобы выбирать наименьшее значение). Когда
путь пройден, предполагаем, что все пути в дереве (которые мы не проходили)
точно такие же, как единственный случайно выбранный путь.
Таким образом, подход Монте-Карло к бэктрэкингу состоит в следующем:
144
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Рис.17
Шаг 0. Установить взаимно однозначное соответствие между
последовательностями {х\,Х2,- ",хп) и возможными конфигурациями.
Шаг 1. Выбрать случайно значение х* из S*. Увеличить к на 1. (Если к > 3.
перейти к шагу 3.)
Шаг 2. Если S*+i не пусто, вернуться на шаг 1. Если S*+i пусто, перейти к
шагу 3.
Шаг 3. Подсчитать число узлов в дереве, предполагая, что в каждом узле
путь, который не был выбран, точно такой же, как выбранный путь.
Для иллюстрации этой идеи вернемся к шахматной доске 4x4.
Допустим, для Х\ случайно выбрано значение 1 из четырех возможных значений
(1,2,3,1), а для Х2 выбрано значение 4 из двух возможных значений (3,4),
тогда для хз единственное возможное значение есть 2. Тогда мы представляем
себе, будто дерево решений выглядит так, как на рис. 4.7.
Выбранный путь показан жирными линиями. Если бы мы выбрали зд — 3,
то 5з = 0. Так как мы не выбрали х2 = 3, то предполагаем, что эта часть
дерева выглядит точно так же, как при хъ = 4. Аналогично предполагаем, что
четыре прикорневых поддерева одинаковы. Применяя такой подход, имеем
1 + 4+4x2+4x2 = 21 узел На рис. 4.7.
Если было бы выбрано х2 = 3, мы представили бы дерево решений таким,
как на рис. 4.8, и заключили бы, что в нем 13 узлов.
Если бы мы положили х\ = 2, мы вообразили бы, что дерево решение
имеет 17 узлов и выглядит как на рис. 4.9.
Рис. 4.8
4.3. ВЕТВИ И ГРАНИЦЫ 145
Рис. 4-9 Рис. 4-Ю
Настоящее дерево решений для шахматной доски 4 х 4 показано на рис. 4.10.
Хотя подлинное дерево на рис. 4.10 не похоже ни на одно из воображаемых
деревьев, представленных на рис. 4.7, 4.8, 4.9, число узлов в нем можно
оценить довольно точно, проведя серию экспериментов. Допустим, мы дважды
получили рис. 4.7, один раз рис. 4.8 и один раз рис. 4.9. Тогда мы оцениваем
число узлов как
j - (2 х 21 + 1 х 13 + 1 х 17) = 18,
в то время как в настоящем дереве 17 узлов.
4.3. Ветви и границы
Рассмотрим вариант бэктрэкинга, известный как метод ветвей и границ.
При бэктрэкинге, когда частичный вектор не удовлетворяет ограничениям,
этот вектор и все его потомки исключаются из поиска. Если приписать
большую стоимость недопустимым векторам и нулевую стоимость допустимым
векторам, то мы должны искать вектор минимальной стоимости. Во многих
случаях частичным векторам можно естественным образом приписать
стоимости, удовлетворяющие соотношению:
СТОИМОСТЬ (Х\, Х2,.. ., Xk-l) < СТОИМОСТИ (Х\, #2, • • • yZk) (1)
для всех возможных значений переменных.
Другими словами, в дереве решений стоимость отца всегда меньше или
равна стоимости сына (сравните это с феноменом домино в разделе 4.1).
В этом случае, если мы найдем квадратный узел Ух стоимости JB, то нам
не нужно рассматривать потомков круглого узла VV, стоимость которого
превышает В, так как все потомки W имеют стоимость, большую, чем В.
Это центральная идея метода ветвей и границ. Мы не производим
ветвления в круглом узле, стоимость которого выше, чем минимальная стоимость
найденных до сих пор решений. Разумеется, эта граница обновляется, когда
находится лучшее решение.
Итак, мы обходим дерево решений методом поиска в глубину и
запоминаем решение Ух наименьшей стоимости. Когда стоимость частичного вектора
146
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Vy превышает стоимость Vxy все потомки Vy исключаются. Если находится
лучшее решение Vz, его стоимость становится новой границей.
Для задачи максимизации все делается точно наоборот. Ветвление в
круглом узле не производится, если значение в нем меньше, чем максимальное из
значений найденнных решений.
Применим метод ветвей и границ к решению задачи о рюкзаке,
обсуждавшейся в главе 3:
max{v\X\ + V2X2 + V3X3 +V4X4}
При УСЛОВИИ W1X1 + W2X2 + W3X3 + W4X4 < ft, (2)
Xi > 0, целые,
т. е. максимизируется общая ценность при условии, что общий вес ограничен
и все переменные — целые (обычно v* и од все положительны). В качестве
примера будем рассматривать задачу:
max{xi + 3#2 + 5хз + 9x4}
при условии 2a?i + Зхг 4- 4хз + 7^4 < 10 (3)
Х{ > 0, целые.
Перед применением алгоритма ветвей и границ к решению задачи о
рюкзаке необходимо обратить внимание еще на некоторые моменты.
1. Мы переупорядочим переменные так, чтобы
*>**-. (4)
Wi ОД+1
т.е. будем максимизировать
9xi + 5#2 + Зхз + Х4
при условии 7xi + 4x2 + Зхз + 2x4 < 10 . (5)
Xi > 0, целые,
(причину этого обсудим позже).
Мы не производим ветвления в узле, если нарушено ограничение на вес.
Поскольку решается задача на максимум, ветвление в узле не
производится, если его ценность меньше, чем ценность наилучшего из
найденных до этих пор допустимых решений.
Естественно определить вес узла (xi,Х2,...,х*, _,..., _) как
к
£«W,
»=1
так что если узел не удовлетворяет ограничению на вес, то все его
потомки тоже ему не удовлетверяют.
4.3. ВЕТВИ И ГРАНИЦЫ
147
Как определить ценность узла (х\, #2,...,#ь _,..., _)? Положим ее
равной
У%«*« + [ft- У]«;^}^±1, (6а)
ft
если ft — ^ гу,х^ > гу^ для некоторого) j > fc,
»=i
или
У^г;,ж<, если Ь - 5Z Wt#» < ^ для всех ^;>> *" ^)
Величина (6а) состоит из двух частей, первая из которых есть общая
ценность всех переменных с уже определенными значениями. Эти
переменные занимают вес Ylw*xi и остается только Ь - YLw*xi- Так как
переменные упорядочены в соответствии с (4), то максимальная ценность,
которая может быть достигнута при оставшемся резерве веса, есть
U-^WixA
если не учитывать, что Xk+i должно быть целым. Если ценность
каждого узла определена посредством (6а), то ценность узла есть верхняя
граница ценности всех его сыновей. Бели ценность узла меньше или равна
ценности наилучшего из полученных к текущему моменту допустимых
решений, то сыновей этого узла можно не рассматривать. Когда
Ь — 2Z w*xi < w5 Для всех 3 > *»
в рюкзак уже ничего нельзя добавить и мы записываем
к
X>i*i
*=i
как ценность узла, а сам узел объявляется листом.
Дерево решений для задачи о рюкзаке изображено на рис. 4.11. Ценность
узла, вычисленная на основе (6), написана внутри узла вверху, а общий вес —
внизу. Ветвление в узле не производится, если
(i) его общий вес превышает ограничение Ь
или
148
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Рш.411
(И) его ценность меньше иди равна ценности наилучшего из полученных до
сих пор допустимых векторов.
Заметим, что для задачи (5)
Хх = {0,1}, Х2 = {0,1,2}, Х3 = {0,1,2,3}, Х4 = {0,1,2,3,4,5}.
Вместо присваивания переменной Хк наименьшего значения из 5* будем
присваивать наибольшее.
Узлы дерева решений будут посещаться в порядке Уд, Vis,..., Va#-
В узле Vc превышено ограничение на вес, поэтому ветвление в нем не
производится. То же относится к узлам Vb^Vfe. В узле Vh мы получаем первую
границу, ценность допустимого решения. В узле Vh ветвление не
производится, так как общий вес решения равен ограничению на вес (вообще, ветвление
не производится в узлах, в которых применяется (6Ь)).
Ветвление не производится в узлах V>, Vk , Vl и Va#, так как значения
ценности в них меньше или равны текущей границе, т. е. 12.
Теперь обсудим три момента, отмеченных выше.
1. Переупорядочение переменных было сделано с тем, чтобы первый
предмет был наиболее полезным в смысле наибольшей ценности на единицу
веса.
4.4: ДЕРЕВО ИГРЫ
149
Так как ценности внутренних узлов вычисляются по (6а), ценность отца
больше или равна ценности сыновей.
2. В этой задаче узлы имеют ценности и весами мы пытаемся найти узел
с максимальной ценностью, вес которого не превосходит заданной
величины. Вес узла на уровне к определяется как
*
t=i
и если он превышает ограничение, то вес его сына тоже превышает. Если
определить ценность узла как
к
то ценность сына может быть больше, чем ценность отцдг Пр»1^том
может случиться так, что отец не превосходит по ценности лучшего из
найденных до сих пор решений, а сын превосходит; поэтому поддерево
с корнем в отцовском узле исключить из рассмотрения нельзя. Чтобы
этого избежать, мы определили ценность узла посредством (6).
3. Так как переменные упорядочены-в соответствии с (4), тЪ, если
позволить переменной х\ принимать непрерывные значения, наполнение
рюкзака предметом % всегда лучше, чём наполнение его предметом % +1.
4.4. Дерево игры
В таких играх, как крестики-нолики, ним, шашки, можно моделировать
состояния игры с помощью корневого дерева. Вместо того, чтобы
рассматривать все возможные ситуации в игре, мы можем применить идею ветвей и
границ для прогнозирования исхода игры.
Для примера рассмотрим модифицированную версию игры ним. Играют
два игрока, которые побчередно берут камни из Кучки камней. Каждый игрок
может при своем ходе взять от одного до трех камней. Побеждает игрок,
взявший все оставшиеся камни, т. е. опустошивший кучку. Выигранная сумма
равна числу камней, взятых победителем при его последнем ходе.
Пусть вначале кучка состоит из п камней. У первого игрока есть три
возможности: взять один, два или три камня. Второй игрок тоже имеет три
возможности. Поэтому игру можно описать тернарным деревом, как показано на
рис. 4.12, где предполагается, что п = 6.
На рис. 4.12 внутри узлов написано число камней в кучке. Число камней,
взятых игроком, написано рядом с дугами, так что узел В в первом уровне
показывает, что в кучке осталось 3 камня после того> как первый игрбк взял
3 камня, а узел С — что осталось 4 к&мня, если он взял два, и т. д. Очевидно,
игра закончится, когда в кучке останется три или'меньше камней. Эти узлы
вершины изображены квадратами. ч ь ч
150
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Рис. 412
Во избежание путаницы мы будем всегда рассуждать с точки зрения
первого игрока й считать выигрыше»! величину, полученную первым игроком в
результате игры. Бели побеждает второй игрок, выигрыш отрицателен.
Поэтому первый игрок желает максимизировать выигрыш, а второй —
минимизировать. В дальнейшем будем называть игроков Мах и Min. Узел, в котором
ходит Мах, изображаем верхним полукругом, а узел, где ходит Min, —
нижним полукругом. Теперь дерево игры принимает вид, показанный на рис. 4.13,
где число внутри узла указывает величину выигрыша (позже объясним, как
получены числа во внутренних узлах, таких, как А, С, D.)
Рис. 4 18
Вначале мы знаем только выигрыши в концевых узлах.
Вопросы заключаются в следующем: i) кто победит, если оба игрока
играют наилучшим образом? ii) как велик выигрыш?
Легко ответить на эти вопросы, если начать с рассмотрения узлов самого
нижнего уровня и двигаться по направлению к корню.
4Л. ДЕРЕВО ИГРЫ 151
Рис.4-Ц
Рассмотрим узел J, где в кучке осталось четыре камня и ходит Мах.
Очевидно, Мах не возьмет 1 камень, так как тогда он потеряет 3 доллара; Мах
возьмет 3 камня и потеряет 1 доллар. Поэтому, если игра придет в состояние
J, выигрыш будет — 1, и мы можем написать — 1 в узле J.
В узле D ходит Min, и он опеределенно возьмет 1 камень, так как
min{H,/, J} = min{2,3, -1} = -1.
Поэтому мы пишем — 1 в узда D.
По тем же соображениям, игрок Min возьмет 3 камня в узле С, так как
min{J5, F, G} = min{l, 2,3} = 1.
Поэтому мы пишем 1 в узле С.
Теперь в узле А игрок Мах берет 2 камня, так как
max{J5, С, D} = тах{-3,1, -1} = 1,
и мы пишем 1 в узле А
Таким образом, если оба играют оптимально, выигрыш равен 1. Другими
словами, игрок Мах всегда выигрывает.
В более сложной игре слишком утомительно рассматривать все листья,
соответствующие всевозможным окончаниям игры. Хорошо было бы иметь
возможность работать с деревом, начиная с корня, и узнавать цену игры, не
производя поиск по всем ветвям дерева. Предполагается, что оба игрока
играют оптимально. Иными словами, оба играют предельно осторожно,
предполагая, что противник очень умен (в реальном мире против хорошего и против
плохого игрока применяют разные стратегии).
Мы применим к дереву игры поиск в глубину и идею ветвей и границ для
определения цены игры.
Основная особенность здесь состоит в том, что можно применить как
верхние, так и нижние границы для отсечений в дереве игры. Под «значением»
узла будем понимать цену, соответствующую данному состоянию игры.
Рассмотрим узел Q на рис. 4.14, где ходит Мах и уже вычислено значение
для левого сына R узла Q, равное &. Узел Q мсйкет иметь много других
сыновей с различными значениями. Если эти значения меньше a, Max выберет R.
152
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Поэтому значение узла Q не меньше а и а является нижней отсекающей
границей для Q. После того, как мы узнали, что Q имеет нижнюю отсекающую
границу а, все сыновья Q будут тоже иметь нижнюю отсекающую границу а.
Пусть 5 — сын Q. Допустим, все сыновья 5 имеют значения, меньшие а, так
что значение узла S меньше а. Тогда Max в узле Q определенно выберет R.
Другими словами, нужно вычислять значения только тех сыновей узла 5, у
которых они могут оказаться больше, чем а
Итог этим рассуждениям можно подвести следующим образом:
Если значение некоторого сына Мах1 есть а, то а является нижней
отсекающей границей для значения Мах.
Если Мах имеет нижнюю отсекающую границу а, то все сыновья Max
имеют нижнюю отсекающую границу а.
Это символически изображено на рис. 4.15, где стрелки показывают, как
распространяется по дереву игры значение а.
Т U Т U
Рис. 415 Рис.116
Аналогично, если некоторый сын Min имеет значение /?, то 0 становится
верхней отсекающей границей для значения Min. Все сыновья Min тоже
будут иметь верхнюю отсекающую границу Д: Это показано симвЧхлически на
рис. 4.16.
В обозначениях рисунка 4.15, если установлено, что значение узла 5
меньше или равно а, то нет необходимости исследовать поддерево с корнем в 5.
Это называется а-отсечением. В обозначениях рисунка 4.16, если установлено,
что значение узла 5 больше или равно #, то тоже нет необходимости
исследовать поддерево с корнем S. Это называется /?-отсечением. Применяется также
термин а-Д-отсёчение.
Рассмотрим пример. На рис. 4.17 показано дерево игры, построенное без
применения а-/?-отсечений. Вначале заданы значения в концевых узлах, а
значения во всех внутренних узлах вычислены в восходящем порядке и в
заключение корень дерева получил значение 1; т.е. Мах выигрывает один доллар,
если оба игрока действуют оптимально.
Теперь построим дерево для этой игры, применяя а-/?-отсечения. Начиная
с корня Л (рис. 4.18), проходим вершины В, С, Д действуя методом поиска в
1 Здесь и далее под Мах понимается узел, в котором ходит игрок Мах. — Прим. перев.
4.4. ДЕРЕВО ИГРЫ 153
Рис. 4 17
PUC.41S
глубину. Находясь в узле D, мы видим, что его левый сын имеет значение 2,
а правый — значение 1. Так как D — узел Мшг то он получает значение 1.
После того, как £ получил значешад 1, нижняя отсекающая граница для
С есть 1 и Е тоже получает нижнюю отсекающую границу 1. Левый сын Е
имеет значение 1, поэтому 1 становится верхней отсекающей границей для Е.
Так как нижняя и верхняя отсекающие границы для Е обе равны!, то Е
получает значение 1. Итак, мы определили значение узла 2?, не рассматривая
его правого сына. Поэтому* значение правогЪ сына Е остается незаполненным.
Заметим, что истинное значение узла Е, как видно на рис. 4.17, есть -3, но
мы можем приписать ему значение 1, так как это не повлияет на значение С.
Нас ведь интересует правильное значение только в корне.
Значение С есть max{D,E} =; max{lfl} = I. Это значение становится
теперь верхней отсекающей границей для В и его потомков: F, G, Н и т. д.
Значение G = min{3,2} =-2, и это больше, чем текущая верхняя
отсекающая граница 1.
154
ГЛАВА 4. ПОИСК С ВОЗВРАЩЕНИЕМ
Напишем 2 в узле G, это будет нижней отсекающей границей для F (если
мы напишем 1 в G, то получим£ткх же самое значение в узле В). Теперь F
имеет верхнюю отсекающую границу 2 и нижнюю отсекающую границу 1,
так что значение F можно определить, не рассматривая его сыновей.
Положим значение F = 2 (когда нижняя отсекающая граница превышает
верхнюю, используем в качестве значения нижнюю границу, если это узел
игрока Мах, и верхнююv если это узел игрока Min).
Теперь Значение В = min{C,F} = min{l,2} = 1 (заметим, что мы могли
бы присвоить F значение 2 и окончательное значение В было бы тем же
самым).
Значение В есть нижняя отсекающая граница для А и всех его потомков:
J, J, AT, L, Ми т.д.
Теперь значения Сыновей if являются верхними отсекающими границами
для АГ, поэтому имеем 1 < К < -2.
Так как К является вершиной Min, то мы используем —2 в качестве
значения К.
Значение К (равное -2) есть нижняя отсекающая граница для J, который
уже имеет нижнюю отсекающую границу 1. Мы сохраняем более высокую
границу 1.
Значение J ==vaax{K,L} = max{-2,-4} = —£ Так как значение J
является верхней отсекающей границей для J, мы имеем 1 < J < —2. Так как
I — узел Min, присваиваем ему значение —2. Теперь определяется значение
узла А: тах{£, /} = тах{Г, -2} = 1. Заметим, что значение А определено без
рассмотрения узла М и его потомков.
Упражнения
1. Рассмотрите пример задачи коммивояжера с пятью городами и решите
ее с применением техники ветвей и границ.
2. Примените а-/?-отсечения к решению игры крестики-нолики.
3. В игре ним вначале имеется три кучки камней. Игрок может взять до
трех камней из любой (но только одной) кучки. Каково значение этой
игры, если вначале кучки содержат два, три и пять камней?
4. Примените бэктрэкинг для нахождения минимального числа ферзей,
которое можно расставить на шахматной доске так, чтобы каждое не
занятое поле было атаковано хотя бы одним ферзем
5. Разбиение целого положительного числа — это его представление в виде
суммы других положительных целых чисел. Например,
12 = 1 + 1 + 3 + 3 + 4=1 + 2 + 2 + 2 + 5.
Найдите все возможные разбиения числа 6 на четыре слагаемых.
ЛИТЕРАТУРА
155
Литература
Трудно проследить происхождение бэктрэкинга. Некоторые из ранних
работ на эту тему — [3], [4], [8], [13]. Большинству специалистов по исследованию
операций эта техника известна как метод ветвей и границ, так как она
применяется в основном для оптимизационных задач. Одной из первых работ по
применению метода ветвей и границ к решению задачи коммивояжера была
[9]. Общее изложение бэктрэкинга и метода ветвей и границ можно найти в
книгах [2], [5], [10], [И], [14].
Об оценивании эффективности бэктрэкинга см. [6]. Анализ о-/?-отсечений
содержится в [1] и [7]. Рекурсивную версию бэктрэкинга на графах можно
найти в [12]. ' ~ ■'* *' '<■ ; ■
1. Baudet G. М. An Analysis of the Pull Alpha-Beta Pruning Algorithm //
Proceedings of the 10th Annual ACM Symposium on Theory of Computing. — 1978.
-P. 296-313.
2. Garfinkel R. S., Nemhauser G. L. Integer Programming. — John Wiley & Sons,
1972.
3. Golomb S. W., Baumert L. D. Backtrack Programming. — J. ACM. — 1965. —
-Vol.12.-P. 516-524.
4. Hall M.H., Knuth D.E. Combinatorial Analysis and Computers. Part II //
Am. Math. Monthly. - 1965. - Vol. 72. - P. 21-28.
5. Horowitz E., Sahni S. Fundamentals of Computer Algorithms. — Computer
Science Press, 1978.
6. Knuth D. E. Estimating the Efficiency of Backtrack Programs // Math.
Computations. - 1975. - VoL 29, No 129. - P. 121-136.
7. Knuth D. E. and Moore R. W. An Analysis of Alpha-Beta Pruning // Artificial
Intelligence - 1975. - No 4, Vol. 6. - P. 293-326.
8. Lehmer D. H. The Machine Tools of Combinatorics // Applied Combinatorial
Math., edited by ВескецЬаск E. F. - Wiley, J964. - P. 5-31.
9? Little J. D.C. Murty K.G. Sweeney D. W., Karel С An Algorithm for the
Traveling Salesman Probtefcn // Oper. Res. — 1963. — Vol. 11. — P; 972-989.
10. Nijenhuis A., Wilf H. S. Combinatorial Algorithms. — Academic Press, 1975.
11? Reingold E.M. Nievergelt J., Deo N. Combinatorial Algorithms. — Prentice
Hall, 1977.
12. Tarjan R.E. Depth-First Search and Linear Graph Algorithms // SIAM J.
Comput. - 1972. - Vol. 1. - P. 146-160.
13. Walker R. J. An Enumerative Technique for a Class of Combinatorial Problems
// Proc. of Symposia in Applied Mathematics. — AMS, 1960. — Vol. X.
14. Wells M.B. Elements of Combinatorial Computing. — Pergamon Press, 1971.
Глава 5
Бинарные деревья
Будьте осмотрительны, принимал
бинарные решения в жизни.
5.1. Введение
Бинарное дерево состоит из корня и двух непересекающихся бинарных
поддеревьев, каждое из которых может быть пустым. В этой главе
предполагается, что бинарное дерево содерит по меньшей мере один узел — корень.
На рис. 5.1(a) Уд являете» корнем бинарного дерева, правое поддерево —
пустое. Левое поддерево — бинарное дерево с корнем Vb и двумя
поддеревьями, каждое из которых состоит из одного узла.
Заметим, что бинарные деревья на рисунках 5.1(a) и 5.1(b) различны, так
как у первого пусто правое поддерево, а у второго — левое.
В этой главе мы будем иметь Дело по большей части с расширенными
бинарными деревьями. Расцшрепное бинарное дерево получается из бинарного
дерева добавлением квадратных узлов, представляющих пустые поддеревья.
а) Ь)
Рис. 5.1
5.1. ВВЕДЕНИЕ
157
Рис. 5.2
Из бинарных деревьев на рис. 5.1 получаются расширенные бинарные деревья
на рис. 5.2.
В расширенном бинарном дереве круглые узлы (называемые также
внутренними узлами) имеют по два сына, а квадратные узлы (называемые
внешними узлами) не имеют сыновей. С этого момента будем применять термин
«бинарное дерево», подразумевая «расширена
Если считать, что дуги бин!фного дерев» ориентирсясаны сверху вниз, то
из корня в любой узел имеется ориентированный путь. Число дуг в иуда,
ведущем в узел V, обозначается через ty и называется длиной пути узла V.
На рис. 5.2(a) 1в = 1, 1в = 3. Длина, пути узла называется также уровнем
узла. Корень имеет нулевой уровень, и этот уровень считается наивысшим.
Узел Vi является предком узла Vj> a Vj — потомком V^ если сзгщестцует
ориентированный путь кз?Vf в Vj. Если этот путь состоит из одной Ауги,
применяются термины отец и сын. На рис. 5.2(a) узел % является предком
каждого узла. Узел Ус ~ отец узлов Ve и Vf, причем Ve — левый сын. Узел
Vq *— потомок узла Vjg, но не узла Vfc> *
Компьютерная программа может быть представлена бинарным деревом.
Внутренние узлы представляют промежуточные этапы вычислений, когда при*
нимаются решения, ведущие к двум возможным путям вычисления. Внешние
узлы представляют результаты вычислений. Например, цикл, в котором
значение параметра п увеличивается до п = 100, можно представить бинарным
деревом на рис.5.3. -SHf^•■'фЦ^.Л ^ >q^j
Корень дерева представляет старт программы, а каждый лист — выход,
соответствующий некоторым входным данным. Д?шна пути узла указывает
время, необходимое для получения данного частного результата. Бели ело
жить д^ины путей всех листьев,щ разделить на число листьев, получится
характеристика среднего времени работы щюграмъды. Внешняя длина пути
дерева определяется как сумма длин путей в<^ внеиших^ внешняя
дтона пути деревд да рис,,5.2(а) равна , ,.ф... „^ , к }, vi г у , ^
Ie + h + h + Ih + h = 3 + 3 + 3 + 3 +1 = 13.
158 ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рис. 5.8
В других приложениях интерес представляет внутренняя длина пути —
сумма длин путев всех внутренних вершин. Внутренняя длина пути дерева
на рис. 5.2(a) равна
1л +1в + к + *d = 0+14-2 + 2 = 5.
Пусть /обозначает внутреннюю, а Е — внешнюю длину пути. С помощью
индукции легко проверить, что
# = J + 2(n-l), (1)
где п — число листьев дерева.
5.2. Дерево Хаффмена
Рассмотрим бинарное дерево на рис. 5,4, в котором листья помечены
буквами А^В&Л, левые дуги помечены нулем, правые — единицей.
Можно считать, что это дерево задает представление букв А, В, С, D
двоичными последовательностями, Тйкое представление называется кодированием.
Буква представляется последовательностью двоичных символов,
ассоциированных с дугами, составляющими путь к этой букве. Для рис. 5.4(a) получат
ется следующее соответствие между буквами и двоичными последовательно-
5.2. ДЕРЕВО ХАФФМЕНА 159
Рис. 5.4
стями:
АО,
В 100,
С 101,
D 11.
Последовательность из нулей и единиц может быть однозначно
декодирована следующим образом: начиная слева, удаляем подпоследовательность,
соответствующую букве. Иначе говоря, мы отделяем левый кусок, как только
установлено его соответствие букве. Например, последовательность
100011
декодируется следующим образом:
100 0 11,
BAD.
Заметим, что в кодировании букв A,B,C,D ни один код буквы не является
началом другого. Это свойство называется свойством префикса и благодаря
ему мы применяем расширенное дерево и представляем буквы листьями, а не
внутренними узлами. Если кодирование имеет свойство префикса, нет
необходимости в пробелах между двоичными символами для декодирования.
Различные бинарные деревья соответствуют различным способам
кодирования. Дерево на рис. 5.4(b) представляет следующее кодирование:
А 00,
В 01,
С 10,
D 11.
160
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
То же сообщение BAD будет представлено как
01 00 11,
BAD.
Здесь каждая буква представлена ровно двумя символами в отличие от
предыдущего кодирования, где некоторые буквы представлялись одним символом,
а другие - тремя.
Мы хотим, чтобы при передаче сообщения на одну букву в среднем
расходовалось как можно меньше двоичных символов. Поэтому часто встречающиеся
буквы должны быть представлены короткими последовательностями, а редко
встречающиеся — длинными.
Для этого мы приписываем каждой букве V* положительный вес од,
указывающий ее относительную частоту, и определяем взвешенную длину пути
дерева как
Если буквы А, В, С, D имеют веса 4,1,2,3 соответственно, то взвешенная
длина пути дерева на рис. 5.4(a) равна
гул • 1 -+- гу« - 3 -4- «;<- • 3 -4- гУ£> -2 = 4-1-4-1-ЗЧ-2-ЗЧ-3-2 = 19.
Для дерева на рис. 5.4(b) взвешенная длина пути равна
wa2 + wb2 + wC'2 + Wd • 2 = 4-2 + 1 -2 + 2 2 + 3 • 2 = 20.
Будем называть взвешенную длину пути стоимостью дерева, так как она в
известном смысле является стоимостью кодирования.
Для заданных весов листьев бинарное дерево минимальной стоимости
называется оптимальным бинарным деревом. Алгоритм для построения
оптимального бинарного дерева предложил Хаффмен и обычно оптимальное
бинарное дерево называют деревом Хаффмена.
Опишем алгоритм Хаффмена. Пусть п букв имеют веса гиьод»-- . ,wn>
причем
wi < и>2 < ... < wn.
Заменим два узла с наименьшими весами узлом с весом w\ +W2 и рекурсивно
проделаем это для весов
U*\+W2i юз,..., wn.
В конце концов останется единственный узел с весом w\ + ti^ + ... + ги„, он
будет корнем бинарного дерева.
Применяя этот алгоритм к множеству весов 4,1,2,3, мы сначала
комбинируем два наименьших веса 1 и 2 и получаем множество из трех весов 4,3,3.
Теперь комбинируем два наименьших веса 3 и 3, получаем два веса 4,6 и
окончательно дерево выглядит, как показано на рис. 5.5. Веса написаны
внутри узлов. Заметим, что сумма весов внутренних узлов 3 + б + 10 = 19 равна
взвешенной длине пути дерева — факт, который можно доказать в общем
случае.
5.2. ДЕРЕВО ХАФФМЕНА
161
Рис. 5.5
Лемма 1. Сумма весов всей внутренних узлов равна стоимости бинарного
дерева.
Доказательство. Индукция по числу узлов. I
Большой численный пример показан на рис. 5.6(a), комбинируемые веса
подчеркнуты. Построенное дерево Хаффмена показано на рис. 5.6(Ь)„
Нетрудно доказать правильность алгоритма Хаффмена. В любом
бинарном дереве имеется внутренний узел с максимальной длиной пути. Если этот
внутренний узел V* имеет двух сыновей Va и V* не наименьших весов, то
можно поменять местами w\ и иъ с двумя сыновьями узла V*, при этом стоимость
дерева не возрастет. Затем рассматривается дерево сп-1 листом
wi +Т172,й;з, .., wn.
Поэтому завершить доказательство можно индукцией.
Если остановить процедуру Хаффмена после создания m внутренних узлов
(т < п — 1), то получится лес (л# — это совокупность деревьев1). Назовем
этот лес лесом т-суммы.
Стоимость леса можно определить как £ ш»/*; где /,• —- длины путей узлов в
деревьях леса. Например, лес 4-суммы листьев рисунка 5.6 показан на рис. 5.7.
Стоимость этого леса равна
2-2 + 2-2 + 4-1 + 2-2 + 3-2+ 61 = 28
и равна также сумме весов круглых узлов, созданных к этому моменту:
~ # + # + # + # = 28.
Лемма 2. Алгоритм Хаффмена дает лес т-суммы минимальной
стоимости для 1 < m < п - 1.
Доказательство. Доказательство проводим индукцией йо т. Ясно, что
алгоритм Хаффмена дает оптимальный лес 1-суммы. Предположим, что лемма
1 Лесом называется граф без циклов. — Прим. перев.
162
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
2, 2, 2, 3, 4, 6, 6, 7, 9, 12, 13
4, 2, 2, 4, 6, 6, 7, 9, 12, 13
4, 5, 4, 6, б, 7, 9, 12, 13
5, 8, 6, б, 7, 9, 12, 13
8, 11, S, I, 9, 12, 13
8, 11, 13, 9, 12, 13
11, 13, 17, 12, 13
13, 17, 23, 13
17, 23, 26
40, 26
66
Рис. 5.6(a)
Рис. 5.6(b)
Рие.5.7
5.2. ДЕРЕВО ХАФФМЕНА
163
верна для лесов fc-суммы, и теперь мы хотим построить оптимальный лес
(к + 1)-суммы.
В лесу (к + 1)-суммы должен быть внутренний узел V% с максимальной
длиной пути. Если сыновья этого узла не имеют минимальных весов w\ и
itf2, то можно обменять двух сыновей узла Vi с узлами w\ и и^, при этом
стоимость леса не увеличится. Поэтому новый лес (к + 1)-суммы, в котором
комбинируются w\ и гУг, также оптимален. Ясно, что этот лес (к + 1)-суммы
оптимален тогда и только тогда, когда оптимален лес fc-суммы для весов (w\ +
W2), юз» • • •»Щ- Но, по предположению индукции, алгоритм Хаффмена строит
оптимальный лес fc-суммы. i
По аналогии с бинарными деревьями можно определить Парные деревья,
в которых каждый внутренний узел имеет ровно t сыновей2.
Легко видеть, что конструкция Хаффмена при комбинировании t
наименьших узлов будет давать оптимальное Парное дерево3.
Нет явной формулы, выражающей стоимость оптимального бинарного
дерева как функцию весов листьев. Рассмотрим два множества, имеющее
одинаковое число узлов и одинаковый суммарный вес. Например, каждое из
множеств
А ={1,3,6,10},
В = {2,5,5,8}
имеет четыре узла и суммарный вес 20. Если построить дерево Хаффмена
Та для А и дерево Хаффмена Тв для В, какое из них будет иметь более
высокую стоимость? Следующая лемма отвечает на этот вопрос. Через \Тл\
обозначается стоимость дерева Гд.
Лемма 3 (об экстремальном множестве). Пусть Т — оптимальное
дерево, построенное на множестве узлов с весами Wi, Ти — оптимальное
дерево, построенное на множестве узлов с весами w\. Если выполняются
следующие условия, то стоимость Т меньше или равна стоимости Ти.
п п
0) £ wi = £ <
(И) W\ <W2 < ... < wn uw[ <w'2 < ... < w'n,
(iii) Wi + Si = W| (г = 1,..., A: — 1) и Wi - Si = ги\ (t = &,... \n), ide Si>0 для
г = 1,...,п.
Грубо говоря, эта лемма утверждает, что из двух множеств с одинаковым
суммарным весом дерево с меньшей стоимостью получается для множества,
у которого распределение весов больше отличается от равномерного.
Предполагается,; что t > 2. — Прим.перев.
3При i > 2 исключение составляет первый шаг, на котором должны комбинироваться г
узлов, где г - наибольшее число, удовлетворяющее условиям г < t и л— г делится на t - 1.
— Прим. перев.
164
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Доказательство. Предположим, что в дереве минимального веса длина пути
для wl равна 1\ (* = 1,..., п), тогда из (ii) следует, что
/;>4>...>с
Из (i) и (Ш) следует, что
*-1 п
и
*-l m
i=l i=k
Теперь
\TU\ = w[ l[ + w'2V2 + ... + w'kl'k + ... + w'nVn
= e ^/j+ом; + <ад +...+**-i!U - wi -... - ад
t=l
= E«;i/{ + /;№+* + ...**-!-**-...-*n)
t=i
t=l
> m-
I
Интуитивно план доказательства состоит в замене в дереве Ти весов w\
весами W{. В результате получается дерево Т' меньшей стоимости, чем Ти.
Так как Г — оптимальное дерево для и;,-, то \Т\ < \Т'\ < \Ти\.
5.3. Алфавитные деревья
В разделе 5.2 было показано, что бинарные деревья могут применяться
для кодирования и наилучшее кодирование определяется деревом Хаффме-
на. Интуитивная идея, стоящая за алгоритмом Хаффмена, состоит в том,
чтобы кодировать часто встречающиеся буквы короткими
последовательностями, а редко встречающиеся — длинными. Поэтому мы комбинируем две
буквы с наименьшими весами (веса соответствуют частотам появления). В
английском языке две наименее часто используемые буквы — это Q и Z, в
дереве Хаффмена у них будет общий отец.
Иногда на кодирование накладываются дополнительные ограничения.
5.3. АЛФАВИТНЫЕ ДЕРЕВЬЯ
165
/ \ / \ / \ /\
/ Л / л / л / л
abacus zoo
Рис. 5.8
Можно потребовать, чтобы алфавитный порядок букв соответствовал
порядку кодов, рассматриваемых как двоичные записи чисел. Другими словами,
при просмотре листьев дерева слева направо, Соответствующие буквы
должны появляться в алфавитном порядке. Такое дерево называется алфавитным
деревом для упорядоченной последовательности листьев. Для бинарного
дерева, в котором левым дугам сопоставлен символ 0, а правым — символ 1,
мы можем каждому листу V% поставить в соответствие число n(Vi), у
которого целая часть равна 0, а дробная часть записывается последовательностью
двоичных символов, ассоциированных с дугами пути от корня до VJ. Если
У\, Vi,..., Vn — листья алфавитного дерева, занумерованные слева направо,
то приписанные им числа удовлетворяют неравенствам п(Ц) < n(Vi+x).
Аналогично можно определить t-арное алфавитное дерево.
Заметим, что дерево Хаффмена не всегда является алфавитным: буквы С?
и Z не соседствуют в алфавитном порядке.
Алфавитное дерево представляет процедуру компьютерного поиска слова
в словаре. Приступая к поиску слеша, мы можем начать с проверки,
расположена ли его первая буква в словаре до буквы т или после. Если до т, то
можно проверить, расположена она до или после буквы /. Если же после т,
то можно проверить, расположена ли она до или после буквы 8. После того,
как первая буква найдена, та же процедура повторяется для второй и т. д. В
целом процедура поиска может быть представлена алфавитным деревом, как
показано на рис. 5.8.
Представьте себе, как трудно было бы найти слово в словаре, в котором
слова размещены случайным образом! ;Ч(
Когда веса всех слов одинаковы, оптимальный поиск состоит в том,
чтобы всегда делить множество слов пополам. Для листьев с неравными весами
можно применить тот же подход и попытаться разделить последовательность
узлов так, чтобы суммарные веса левого и правого поддеревьев были
приблизительно равны, а затем рекурсивно применить это к каждому, поддереву. К
сожалению, этот интуитивный подход не работает, как показывает следующий
пример. , ч -
Пример 1. (Контрпример к разбиению на равные веса.) Рассмотрим четыре
листа Уд, Vb, Vcs Vb с весами 4, 1, 2, 3.
Следуя интуитивному подходу, мы должны отнести листья Va и Vb к
левому поддереву, а листья Vc и Vb — к правому. Это даст алфавитное дерево,
166
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рис. 5.9
показанное на рис. 5.4(b), со стоимостью 20. Однако стоимость алфавитного
дерева на рис. 5.4(a) равна 19.
Отметим, что конструкция Хаффмена для четырех узлов Va, Vb> Vc и
Vo на рис. 5.4(a) обладает алфавитной упорядоченностью. Это не всегда так.
Если веса узлов равны wa = 1, Wb = 4, wc = 3, wo = 2, то дерево Хаффмена
не будет обладать алфавитной упорядоченностью.
Так как мы допускаем комбинирование букв только тогда, когда они
являются соседними, естественным подходом было бы комбинировать соседние
буквы с минимальным суммарным весом и продолжать это рекурсивно для
остальных п-1 букв, приписывая отцу сумму весов сыновей. К сожалению,
этот подход не работает, как видно из примера 2.
Пример 2. (Контрпример к комбинированию соседней пары минимального
веса.) Рассмотрим четыре листа Уд, Vb, Vc, Vd с весами 4, 2, 3, 4.
Минимальны! соседней парой является Vb,Vc с общим весом 5, но в оптимальном
алфавитном дереве, показанном ни рис. 5.9, Vb и Vc не имеют общего отца.
Если мы хотим построить, например, оптимальное алфавитное дерево с 26
листьями, соответствующими буквам латинского алфавита, то не так просто
определить, должна буква Н комбинироваться с G или с J. В 1959 г.
Гилберт и Мур [3] применили динамическое программирование для построения
оптимального алфавитного дерева. Их алгоритм требует времени 0(п3) и
памяти 0(п2). Он представлен в разделе 3.4. Кнут [12] улучшил оценку времени
до 0(п2). Алгоритм, который будет описан в разделе 5.4, предложен Ху и
Таккером [8], его оценки — 0(п log п) по времени и 0(п) по памяти.
5.4. Алгоритм Ху-Таккера
В задаче об алфавитном дереве задаются порядок листьев Vi,%,...,У„
и их веса w\, W2,'..., к/п. Эти последовательности называются соответственно
последовательностью узлов и последовательностью весов.
Если мы комбинируем Vi и Vj-, то их отец обозначается через VJj, его вес —
через Wij. Если комбинируются Vij и V*, их отец обозначается через V^,*. В
этих обозначениях одиночный индекс обозначает лист, а двойной или тройной
индекс — круглый узел.
5.4. АЛГОРИТМ ХУ-ТАККЕРА
167
Рис. 5.10
Если это не приведет к недоразумениям, мы будем применять Wi для
обозначения узла Vi с весом Wi. Таким образом, фраза «комбинируя узлы wi и
Wj> формируем узел Wjj> означает «комбинируя узлы V* и Vj с весами Wi и
Wj, формируем узел V%j с весом w^*.
Вообразим себе некий алгоритм, строящий оптимальное алфавитное
дерево по последовательности узлов, представленных квадратами, внутри
которых написаны веса. Допустим, мы комбинируем W{ и Wj. Тогда их отец w^
представляется кругом, внутри которого написан суммарный вес. Теперь мы
имеем п — 2 квадрата и 1 круг и делаем следующее комбинирование.
Процесс комбинирования повторяется п — 1 раз, после чего первоначальная
последовательность из п квадратов оказывается скомбинированной в один круг,
являющийся корнем алфавитного дерева.
К сожалению, нет алгоритма, который строил бы алфавитное дерево так,
как описано выше. Алгоритм Ху-Таккера сначала строит дерево, не
являющееся алфавитным, а затем преобразует его в оптимальное алфавитное дерево.
Для описания этого алгоритма необходимо ввести некоторые новые
понятия.
Два узла в последовательности узлов называются совместимой парой,
если они соседние или если все узлы между ними круглые. На рис. 5.10 узлы,
соединенные сплошными линиями, образуют совместимые нары, а пары
узлов, соединенных пунктирными линиями, не являются совместимыми.
Если скомбинировать V^ и Va с образованием V^44» то V\ V5 станут
совместимыми в новой последовательности.
Когда комбинируется пара узлов Wi и Wj, вес их отца w^ = Wi+Wj
называется весом этой пары. Пара с минимальным весом называется минимальной
парой. В последовательности узлов может быть много пар одного и того же
веса. В этом случае будем придерживаться следующего правила. Из двух пар
одинакового веса пара, имеющая самый левый узел, считается имеющей
меньший вес. Если у двух пар один и тот же левый узел, т.£. пары имеют вид
(wa,Wi) и (wa,Wj), то пара, у который правый узел расположен левее,
считается парой меньшего веса. Другими словами, пара с наименьшим индексом
имеет меньший вес, а при равенстве меньших индексов сравниваются вторые
индексы.
Применяя это правило, будем писать Wi < Wj, понимая под этим, что
Wi < Wj или W{ = Wj и Vi расположен левее Vj в последовательности узлов.
Когда мы сравниваем два веса в последовательности узлов, они теперь не
могут быть равны.
1Узел Vfc заменяется на V24, узел Va удаляется. — Прим. перев.
168
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Пара с минимальным весом среди всех совместимых пар в
последовательности узлов называется минимальной совместимой парой.
Алгоритм Ху-Таккера строит алфавитное дерево, минимизирующее £) ОД/*,
выполняя следующие шаги.
(1) Комбинирование. По данной последовательности из п узлов с весами
w\, г^2,..., wn строим последовательность из п — 1 узла, комбинируя
минимальную совместимую пару, заменяя левого сына его отцом и удаляя
правого сына из последовательности. На рисунках 5.11 и 5.12 отец
помещается непосредственно над левым сыном. Процедура слияния весов
продолжается до тех пор, пока не останется один вес. Соответствующее
дерево обозначается через Т'.
(На самом деле нет необходимости просматривать всю
последовательность, чтобы найти минимальную совместимую пару. Можно просто
скомбинировать так называемую локально минимальную совместимую
пару, это будет обсуждено позднее.)
(2) Определение уровней. Находим номер уровня U каждого листа V*
относительно корня. (Напомним, что узел с наибольшим значением U
располагается внизу дерева.)
(3) Перестройка. После того, как номера уровней /i,/2,... ,/п всех листьев
определены, просматриваем последовательность слева направо и
находим самый левый среди максимальных номер уровня, скажем, U = q.
Тогда и /j+i = q (в последовательности 1\М^ - Лп максимальные
номера уровней всегда располагаются рядом). Создаем отца пары уровня q
и назначаем этому отцу уровень q -1. Другими словами,
последовательность уровней
hMi • • • >ft-b Q1Q1U+21 • • • Лп
заменяется на
Zi,/2,...,/*_i,g - l,Zi+2,...,/n-
Затем повторяем этот прооцесс комбинирования пар максимального
уровня для новой последовательности уровней из п — 1 числа. В конце
создается корень С нулевым уровнем.
На самом деле нет необходимости находить максимальный номер уровня во
всей последовательности уровней. Следующий стековый алгоритм успешно
строит алфавитное дерево. Сначала помещаем /j, /2,..., 1п в очередь, так, что
1\ располагается в начале очереди. Затем извлекаем U по одному и помещаем
их в стек, который первоначально пуст.
Шаг 0. Стек пуст, /i, Ь,..., /п находятся в очереди.
Шаг 1. Если в стеке меньше двух элементов, перейти к шагу 2. В противном
случае проверить, равны ли значения двух верхних элементов стека.
Если они различны, перейти к шагу 2, а если равны — к шагу 3.
5.4. АЛГОРИТМ ХУ-ТАККЕРА
169
а)
Ь)
Рис. 5.11
Шаг 2. Удалить из очереди первый элемент и поместить его на вершину
стека. Перейти к шагу 1.
Шаг 3. Пусть lj — верхний элемент стека, a lj^\ — следующий элемент.
Заменить lj и Zj_i на lj — 1. Если lj — 1 = 0, остановиться, иначе перейти на
шаг 1. (Это означает, что комбинируются узлы Vj-% и 1^, а их отец
Vj-ij становится узлом уровня lj — 1.)
В последовательности весов,
местимой парой является пара
мые пары — это
«ной на рис. 5.11(a), минимальной сов-
а следующие минимальные совмести-
Заметим, что последняя совместимая пара Щ Щ разделена круглым узлом
Цр. Последовательность весов, получающаяся в результате всех этих комбини-
Рис.5.12
170 ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
#
рований, показана на рис. 5.11(b). Заметим, что на рис. 5.11(b) минимальной
совместимой парой является Щ щ|, так как они разделены только круглым
узлом @.
Если продолжить применение алгоритма к этой последовательности весов,
то получим дерева Г', показанное на рис. 5.12.
Проследив пути от корня дерева V к каждому листу, найдем номера
уровней:
вес ^гШШШШШШШшШШШ
уровень /{33554333344
В фазе перестройки сначала комбинируем Щ Щ, так как у них самый
нижний уровень. Их отец Щ находится на уровне 4 и мы будем
комбинировать щ) и Ц], так как это самая левая пара на самом нижнем уровне 4, затем
комбинируем Щ Ш > тоже находящиеся на уровне 4.
После этих комбинирований каждый из оставшихся узлов находится на
уровне 3 и их можно комбинировать пару за парой слева направо, пока не
получим дерево Т^, показанное на рис. 5.13(a). Заметим, что каждый лист
этого дерева имеет тот же уровень в дереве Т', но узлы Щ Щ не имеют в
T'N общего отца, как в Т".
В этом примере мы не применяли стековый алгоритм для перестройки
дерева, а просто последовательно рассматривали максимальные номера
уровней. Если бы применялся стековый алгоритм, то содержимое стека
изменялось бы так, как показано на рис. 5.13(b). (Читателю рекомендуется сравнить
рис. 5.13(a) с рис. 5.13(b) и самостоятельно доказать, что стековый алгоритм
работает.)
Прежде чем переходить к следующему разделу, читателю рекомендуется
выполнить несколько численных примеров на применение алгоритма Ху-Так-
кера (например, можно решить задачу из раздела 3.3).
В фазе комбинирования для того, чтобы скомбинировать минимальную
совместимую пару, мы просматривали всю последовательность весов слева
направо. На самом деле это не обязательно. Достаточно скомбинировать так
называемую локально минимальную совместимую пару. Это пара, вес которой
меньше, чем вес соседних с ней совместимых пар.
Пара узлов (wb,wc) называется локально минимальной совместимой
парой (л.м.с.п.), если выполняются условия
wa > и>с для всех узлов Уа, совместимых с V&,
юь < Wd для всех узлов Vj, совместимых с Vc.
Заметим, что когда все узлы — квадратные, пара {wj-\ , Wj) является л.м.с.п
если Wj-2 > Wj и Wj-i < Wj+u
Например, на рис. 5.11(a) пара Ш] Ш1 является локально минимальной
совместимой парой, а пара [1] Шл — минимальной совместимой парой (м.с.п).
5.4. АЛГОРИТМ ХУ-ТАККЕРА
171
Рис. 5.13
Найдя л.м.с.п., можно скомбинировать эту пару, не просматривая остальной
части последовательности весов. Аналогично на рис. 5.11(b), как только мы
обнаруживаем, что Щ fp удовлетворяют условиям л.м.с.п., мы можем их
скомбинировать, не проверяя, что происходит справа от Щ (в этом примере
И И оказываются в то же время и м.с.п.).
В последовательности весов может быть много л.м.с.п. Обязательно ли
комбинировать первую из них? Имеет ли значение порядок, в котором
комбинируются л.м.с.п.?
Оказывается, можно комбинировать любые л.м.с.п. до тех пор, пока не
останется один узел. Порядок слияния л.м.с.п. значения не имеет. В результате
всегда получится одно и то же дерево 7". Докажем следующую лемму.
Лемма 4. Пусть Va — любой узел в последовательности узлов, состоящей
из круглых и квадратных узлов, Wi — вес наименьшего узла Vi,
совместимого с Va. Если в результате комбинирования некоторой л.м.с.п. какой-нибудь
новый узел Va становится совместимым cVa, то Wi < Wd» В частности,
л.м.с.п. в последовательности узлов будет оставаться л.м.с.п., пока
комбинируются другие л.м.с.п.
Из этой леммы следует, что дерево, получаемое комбинированием л.м.с.п.,
172
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
OS0©
Рисб.Ц
не зависит от того, в каком порядке они комбинируются.
Доказательство. Рассмотрим произвольный узел Va и предположим, что вес
наименьшего узла, совместимого с Va, равен W{.
Пусть комбинируется л.м.с.п. (V^, Vc), причем Va ближе к Vb. Тогда между
Va и Vb нет квадратных узлов и хотя бы один из V&, Vc должен быть
квадратным, иначе при слиянии (V&, Vc) не появилось бы новых узлов (кроме V&c),
совместимых с Va (см. рис. 5.14).
Заметим, что ш* может находиться в любой стороне от Va. Если узел Wi
лежит справа от Va, то он должен быть круглым. Пусть Vd — узел, который
становится совместимым с Va после слияния (И,УС) (он может быть
квадратным или круглым). Тогда % должен быть совместимым с Vc в исходной
последовательности и в силу локальной минимальности пары (%,УС) имеем
Щ < Wd-
Но Wi < Wb, так как V& совместим сУав исходной последовательности, а
W{ является наименьшим совместимым с Va весом. Поэтому ь)% < ш& < Wd-
Мы доказали, что вес наименьшего узла, совместимого с любым узлом,
не может уменьшиться. Отсюда следует, что любая л.м.с.п. (Уж, Vy) останется
л.м.с.п. после слияния другой л.м.с.п., ибо Vx останется наименьшим узлом,
совместимым с Vy, и наоборот. I
Так как каждая л.м.с.п. в конечном счете будет скомбинирована, то
порядок комбинирования л.м.с.п. не важен — получаемое в результате дерево не
зависит от этого порядка.
5.5. Допустимость и оптимальность
В этом разделе мы докажем корректность алгоритма Ху-Таккера.
Напомним, что этот алгоритм состоит из трех шагов:
(1) комбинирование л.м.с.п. для получения дерева Т1;
(2) определение номера уровня U для каждого листа в 7";
(3) построение алфавитного дерева T'N по полученным /*.
Соответственно алгоритм должен удолвлетворять трем условиям:
(1) номера уровней U должны быть реализуемыми посредством
алфавитного дерева T'N (допустимость);
(2) дерево 7" должно быть оптимальным в классе деревьев, включающем
все алфавитные деревья (оптимальность);
5.5. ДОПУСТИМОСТЬ И ОПТИМАЛЬНОСТЬ
173
(3) из оптимальности Т1 должна следовать оптимальность T'N.
Так как оба дерева имеют одни и те же lj, а стоимость определяется как
53 щ1» то стоимости этих двух деревьев равны и условие (3) выполняется.
Для доказательства допустимости введем класс деревьев С и докажем, что
любое дерево из этого класса можно преобразовать в алфавитное дерево той
же стоимости.
Пусть Т — дерево, построенное для данной последовательности узлов. Для
определения принадлежности дерева Т классу С выполняются следующие
действия.
(i) Найти номер уровня каждого узла Т.
(ii) Выполнить все комбинирования в дереве, но в следующем порядке.
Сначала комбинируются пары узлов самого нижнего уровня, затем
следующего и так далее. Иначе говоря, дерево строится снизу вверх. При этом
порядок комбинирования на одном уровне не важен, но
комбинироваться должны только пары, удовлетворяющие условию (ш)э и все узлы
данного уровня должны быть скомбинированы до перехода к следующему
уровню.
(Ш) При построении, описанном в (ii), при каждом комбинировании должна
использоваться совместимая пара относительно соответствующей
последовательности узлов.
Если дерево можно построить в соответствии с правилами (i), (ii), (iii), то
Т принадлежит классу С.
Например, дерево на рис. 5.15 принадлежит этому классу, так как оно
могло бы быть построено сначала слиянием (1^,Уе), затем (14»V/), (Vde%Vcf),
(Va, Vb) и, наконец, (Vab, VdtiCf).
Заметим, что дерево Т на рис. 5.15 можно было бы построить, выполняя
сначала слияние (Уа,И)> а затем (1^,14), (V^;V/). Важно не то, как дерево
было построено, а можно ли его построить, выполняя слияние совместимых
пар уровень за уровнем снизу вверх.
Например, дерево на рис. 5.16 не принадлежит С, так как его нельзя
построить таким образом. Это дерево может быть построено слиянием
совместимых пар (Vc,Vd), (Vb,Ve), (V^V)), а затем (Vaf,Vcd) и (VafiCd,V*). Здесь
la = lc = ld = 1^ — 3 и 1ь = U = 2. В соответствии с правилами построения
сначала должны сливаться Va, Vc, Vj, V/. Можно сначала слить совместимую
пару (Ус,Vd), но тогда (Va,Vf) будет разделена квадратными узлами Vfc, Ve.
Последовательность уровней алфавитного дерева, очевидно, допускает
построение уровня за уровнем. Поэтому, класс С содержит все алфавитные
деревья. Первый шаг алгоритма Ху-Таккера не обязательна является подходящим
первым шагом для построения уровеня за уровнем.
Например, на рис. 5.12 можно было начинать построение дерева V со
слияния Щ Щ, хотя это не низший уровень. Но когда Т1 построено, его можно
построить заново уровень за уровнем снизу вверх, применяя только
совместимые пары (доказательство будет дано позже). Поэтому Т' принадлежит
классу С.
174 ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рис. 5.15 Рис. 5.16
Теорема 1. Последовательность уровней листьев любого дерева из С
реализуется алфавитным деревом.
Доказательство. Последовательность уровней реализуется, если узлы самого
нижнего уровня делятся на последовательные блоки четной длины, и после
замены пар последовательных узлов этого уровня слева направо их отцами
это же условие выполняется при каждой следующей итерации на пути вверх.
Так как каждый узел имеет брата, число узлов на уровне к должно быть
четным. Если узлы входят блоками четной длины, то их можно сливать по
два слева направо в каждом блоке, процесс повторяется рекурсивно для узлов
уровня к — 1.
Бели узлы уровня к не делятся на блоки четной длины, то должна
существовать пара узлов Уа, Vj, разделенная листом V& более высокого уровня.
Это означает, что (Уа, Vd) не совместима и противоречит предположению
о том, что дерево Т принадлежит классу С. I
Будем применять следующие обозначения:
Vi < Vj означает, что V* формируется раньше Vj (равенство указывает, что
это один и тот же узел);
Vi ~ Vj означает, что Vi и ^совместимы. Заметим, что если VJ ~ Vj и оба
они — круглые узлы, то они совместимы с одним и тем же множеством
узлов.
Если круглый узел V&c формируется раньше круглого узла Vad и узел VbC
имеет сына, расположенного между сыновьями узла Vad<> то будем говорить,
что Vad перекрещивает V&c. Отношение перекрещивания будем обозначать
через
Vbc < Vad.
Заметим, что это обозначение указывает, что Vad формируется позже VbC и что
Vbc и Vad становятся совместимыми после того, как они оба сформированы.
Например, на рис. 5.15 имеем Vde £ Vc/.
5.5. ДОПУСТИМОСТЬ И ОПТИМАЛЬНОСТЬ
175
Докажем, что алгоритм Ху-Таккера для построения Т' последовательным
комбинированием л.м.сп. удовлетворяет следующей лемме.
Лемма 5. Если Ц,с < Vad при построении V алгоритмом Ху-Таккера, то
(i) Wbc < Wad (вес узла V&c меньше веса узла Vad),
(ii) Hc,t < Vad,j (Уъс сливается раньше или одновременно с Vad),
(iii) Wbcti < wadj (вес узла, формируемого при слиянии Ц^, не превосходит
веса узла, формируемого при слиянии Vad),
(iv) 1ьс > hd (длина пути V&c не меньше чем длина пути Vad)-
Доказательство. Не теряя общности, можно предположить, что V&
находится левее Ус, a Va левее Vd. Для того, чтобы Vad перекрещивал Не»
последовательность узлов должна быть (Va, V&, Vc, Vd), (Vb, Va, Vc, Vd) или (Va, Vb, Vd, Vc).
Предположим, что эта последовательность есть Va, Vfc, Vc, Vd. Те же
рассуждения применимы и к другим последовательностям. Если имеются узлы,
расположенные между этими четырьмя узлами, то они должны быть круглыми и
они не влияют на рассуждения.
Так как (И»Н) — л.м.сп., то V& ~ Va влечет wa > гис, а Vc ~ Vd влечет
Щ <Wd, поэтому
Wbc = Wb+Wc<Wc + Wd<Wa + Wd = Wad.
Это доказывает (i).
Узлы Wbc и Wad — круглые, поэтому они совместимы с одним и тем же
множеством узлов. Из того, что wbc < wad> следует, что wbc будет первым
скомбинирован с другим узлом, скажем, W{. Поэтому VbCt% < Vadj (если wbc
комбинируется с wad<> то VbCii = Vadtj)- Это доказывает (п).
Из того, что Vbc и Vad совместимы с одним и тем же множеством узлов, и
из леммы 4 следует, что вес наименьшего узла, совместимого с V&c или Vad<>
не может уменьшиться. Это означает, что Wi < Wj, а так как wbc < wad, то
получаем (Ш).
Утверждения (И) и (iii) означают, что Ис участвует в слиянии раньше,
чем Vad, и что отец узла V&c имеет меньший вес. Аналогично устанавливается,
что его отец также участвует в сиянии раньше и что его дед имеет меньший
вес. Итерация этого утверждения приводит к выводу, что уровень V&c больше
уровня Vad- Это доказывает (iv). I
Теорема 2. Номера уровней листьев дерева V могут быть реализованы
алфавитным деревом.
Доказательство. Если узлы в Т' на любом уровне входят в блоки четной
длины, то Т' можно превратить в алфавитное дерево, как в доказательстве
теоремы 1.
Если узлы на уровне к не входят в блоки четной длины, то должна
существовать пара узлов (Va,Vd), разделенная листом V& более высокого, чем к,
уровня, т. е. 1ь < 1а- Покажем, что это ведет к противоречию.
176
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
В дереве Т" узел V& должен быть слит с другим узлом Vc до того, как V&
будет участвовать в слиянии. Поэтому узел Ц,с перекрещивается узлом Vad.
По лемме 5 1ьс > lad или 1ь > 1а (заметим, что это показывает также, что Т'
принадлежит С). I
Допустимость доказана, теперь обратимся к вопросу об оптимальности.
Введем сначала понятие обобщенной начальной последовательности.
Обобщенная начальная последовательность S* есть последовательность круглых и
квадратных узлов. По 5* строится бинарное дерево, листьями которого
являются круглые и квадратные узлы. Стоимость бинарного дерева, построенного
но 5*, определяется как J^w*/,-, ГДе wi ~~ веса круглых и квадратных узлов,
a U — номера их уровней.
Для данной последовательности S* круглые узлы, расположенные между
двумя квадратнами узлами, могут комбинироваться в любом порядке. Будем
называть такое множество круглых узлов множеством Хаффмена. Если Va и
Vb — круглые узлы из одного множества Хаффмена и wa < iu&, то для
номеров уровня в оптимальном дереве, построенном по 5*, должно выполняться
1а >1ь- Поэтому лемму 3 можно обобщить на случай оптимального бинарного
дерева, построенного по 5*.
Лемма 6. Пусть Т — оптимальное бинарное дерево, построенное по
обобщенной начальной последовательности S*, причем Wi — веса круглых
вершин, образующих множество Хаффмена. Пусть Ти обозначает
оптимальное бинарное дерево, построенное по той же последовательности S* с
заменой весов wi весами w\. Если выполняются условия:
(I) Х>< = £ <
(ii) w\ < W2 < ... < wn; w[ < и/2 < ... < w'n,
(iii) Wi + Si = и)'{ (* = 1,..., k - 1),
Wi-Si =w'{ (i = fc,...,n),
Si > 0 для г = l,...,n,
то стоимость T меньше или равна стоимости Ти.
Доказательство. Аналогично доказательству леммы 3. I
Эта лемма, как и лемма 3, не встречалась в литературе, она будет полезна
в некоторых случаях.
Класс С был введен как класс деревьев, которые могут быть построены
путем слияния совместимых пар и формируются снизу вверх уровень за
уровнем. Мы доказали также, что этот класс включает как алфавитные деревья,
так и дерево Г', создаваемое алгоритмом Ху-Таккера. Было показано также,
что Т' можно преобразовать в алфавитное дерево той же стоимости.
Теперь докажем, что Т' оптимально в классе С. Для этого введем класс С*,
включающий класс С, а затем покажем, что Т" оптимально в классе С*. Класс
С* является естественным обобщением класса С. Дерево Г, построенное по
5.5. ДОПУСТИМОСТЬ И ОПТИМАЛЬНОСТЬ
177
Рис. 5.17
обобщенной последовательности 5*, принадлежит классу С*, если существует
способ построения Т путем слияния совместимых пар снизу вверх уровень за
уровнем. Единственное различие между С* и С состоит в том, что деревья в
С* строятся по обобщенной начальной последовательности 5*, а деревья в С
— по последовательности квадратных узлов 5. Очевидно, класс С* включает
класс С, так как S есть частный случай S*. Так как, мы собираемся доказать,
что Т' является оптимальным деревом в классе С*, нас не будет интересовать,
верно ли, что любое дерево из С* может быть преобразовано в алфавитное
дерево той же стоимости.
Класс С* деревьев, строящихся по обобщенной начальной
последовательности S*, можно также охарактеризовать следующим образом:
(i) для каждого комбинирования используется совместимая пара из
последовательности S*,
(И) если Уь и Vc — узлы из S*, причем хотя бы один из них квадратный и
Уьс ~ Vady ГДе Va И Vrf — ТОЖ6 уЗЛЫ ИЗ S*, ТО he > lad-
Заметим, что условие (и) эквивалентно построению уровеня за уровнем и
что леммы 4 и 5 верны для обобщенной начальной последовательности S*.
Поэтому класс С* включает алфавитные деревья и Т", построенное по S*.
Теорема 3. Для данной обобщенной начальной последовательности S* в
классе С* существует оптимальное дерево, построенное по S*, у которого
во всех комбинированиях используются л.м.с.п.
Доказательство. Доказательство проводим индукцией по числу узлов в
последовательности S*. Предположим, что теорема верна для п - 1 и меньшего
числа узлов. Рассмотрим случай, когда в 5* имеется п узлов.
Если в классе С* нет оптимального дерева, у которого первая пара
является л.м.с.п., то выберем оптимальное дерево Т°, у которого первая пара (И> Ус)
имеет по возможности меньший общий вес. После того как пара (И>Ю
будет скомбинирована, последовательность S* будет содержать п — 1 узел и по
предположению индукции все последующие слияния можно выбрать среди
л.м.с.п. Ситуация показана на рис. 5.17.
Предположим, что V& и Vc — квадратные узлы и
Va — наименьший узел, совместимый с Ц, и лежащий слева от него,
Vd — наименьший узел, совместимый сУси лежащий справа от него,
Vx — наименьший узел, совместимый cVa я лежащий слева от него,
Vy — наименьший узел, совместимый с Vd и лежащий справа от него
178
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
(если некоторые из этих узлов не квадратные, доказательство аналогично).
Рассмотрим теперь второе слияние, которое по предположению есть л.м.с.п.
Имеется четыре возможности:
(i) Вторая пара имеет вид (V^cVi) или (Va, V&c). Так как (И>Ю не
является Л.М.С.П., ТО ДОЛЖНО ВЫПОЛНЯТЬСЯ ЛИбо Wa < Wc, Либо Wb > Wd'
Предположим, что Wb > w* (случай wa < wc аналогичен). Бели вторая
пара есть (Vba Vd), то комбинирование (Vi, Vcd) создаст дерево меньшей
стоимости, а это противоречит оптимальности Г°. Пусть второй парой
является (Va, Vbc). Так как Vc ~ Vd, то V&c ~ Vd и V* будет совместим с
любым узлом, совместимым с Не- Но юь + wc > ь)ь > tod, так что пара
{VayVbc) имеет больший вес, чем (Va, Vj), а это противоречит тому, что
{Уа^Уье) есть л.м.с.п.
(ii) Вторая пара есть (Vt,V,), л.м.сп. в последовательности 5*, и слияние
(Уи Уа) не перекрещивает %<.. В этом случае можно сначала произвести
слияние (V*, V^), в результате получится обобщенная последовательность
из п - 1 узла. Затем, по предположению индукции, можно выполнить
остальные комбинирования с использованием л.м.сп.
(iii) Вторая пара есть (Vd, Vy), она не является л.м.с.п. в исходной
последовательности S*, но становится л.м.с.п. после комбинирования (И, Ус). Так
как (Vd, Vy) не была л.м.с.п. в 5*, имеем
wc < wy. (1)
Так как (V^Vy) стала л.м.с.п. после комбинирования (И>УС)> имеем
wa>wy. (2)
Есть два подслучая:
(a) wa < Wd- Из (1) и (2) имеем wc < wy < wa, откуда следует, что
(И> Ус) есть л.м.с.п. — противоречие.
(b) Wb > Wd- Из (1) видим, что (V^V^) является л.м.с.п. Далее, при
слиянии пар (К, Vd), (V&, Vy) образуется последовательность весов,
которая приведет к построению дерева меньшей стоимости (лемма
в).
(iv) Вторая пара есть (Va, Vd), и она перекрещивает V&c. Имеется четыре
подслучая:
(a) wa > wc, Wb < Wd, тогда (И, Vc) является л.м.с.п. - противоречие.
(b) wa > wc, Wb > Wd, тогда последовательность весов wab,wCd
дает дерево меньшей стоимости, чем последовательность WbC,wad, и
wc + Wd < Wb + wc, а это противоречит тому, что вес первой пары
минимален.
(c) wa < wc, щ < Wd, тогда wa + Wb < Wb + wc, такое же противоречие,
как в случае (Ь).
5.6. АЛГОРИТМ ГАРСИА И УОЧСА
179
(d) wa < wc> Wb > Wd- Последовательность весов wab^cd даст дерево
той же стоимости, что и последовательность w^Crwad^ поскольку
he > lad- Но wa + Wb < Wb + wc> а это противоречит тому, что вес
первой пары минимален.
Итак, мы ввели классы деревьев С и С*, из которых первый является
подклассом второго. Класс С включает алфавитные деревья и дерево Г',
создаваемое алгоритмом Ху-Таккера. Мы показали, что Т" может быть
преобразовано в алфавитное дерево Г/у той же стоимости. Для доказательства
оптимальности алгоритма Ху-Таккера мы показали, что в С* существует
оптимальное дерево, которое строится слиянием л.м.с.п. Так как слияние л.м.с.п.
дает единственное дерево Г', то Т' является оптимальным деревом в С* и в
его подклассе С. I
5.6. Алгоритм Гарсиа и Уочса
В фазе комбинирования алгоритма Ху-Таккера мы последовательно
комбинируем л.м.с.п., при этом рассматриваемые пары могут быть разделены
несколькими круглыми узлами. Алгоритм Гарсиа и Уочса устраняет различие
между круглыми и квадратными узлами и располагает узлы в
последовательность так, что л.м.с.п. всегда является соседней парой. Как было замечено в
разделе 5.4, в последовательности квадратных узлов соседняя пара (tUj-i, Wj)
есть л.м.с.п. тогда и только тогда, когда
ltfj_2 > Wj И Wj-\ < Wj+i.
Опишем алгоритм Гарсиа-Уочса. Пусть Wi,W2,...,tt;j_i,ii;j,ii;j+i,...,u;n
— последовательность весов.
(i) Найти самую левую минимальную соседнюю пару, (wj_i,iuj).
(ii) Скомбинировать Wj-\ и Wj в один узел с весом Wj = Wj-\ + Wj.
(Hi) Передвинуть Wj влево, пропуская все узлы, вес которых меньше или
равен Wj. Получить новую рабочую последовательность из п — 1 узла
W1,...,WuWj,Wi+i,...,Wj-2,1Vj+l,..-,1Vn,
где W{ > Wj > тах{«;*+1,..., Wj-2}•
Этот процесс повторяется, пока в последовательности узлов не останется один
узел. Тем самым будет построено дерево Т1 в алгоритме Ху-Таккера.
Остальная часть алгоритма такая же, как в алгоритме Ху-Таккера.
На рис. 5.18 показаны последовательные шаги, получающиеся при
применении описанного алгоритма к последовательности весов, представленной на
рис. 5.11(a).
Заметим, что каждая из этих комбинаций есть самая левая л.м.с.п. в
алгоритме Ху-Таккера. Если сканировать (слева направо) л.м.с.п. в
последовательности весов, получим в точности эти комбинации.
180
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рис. 5.18
Для того, чтобы показать, что два алгоритма дают одно и то же дерево
Г', рассмотрим две последовательности (А) и (В).
(A) wi,W2,...,Wf,u£,if;i+b.
(все узлы квадратные).
,,Wj-2,Wj+l,---,Wn
(В) wi,w2,...,wuWi+i,...,Wj-2,Wj,Wj+i,...,wn
(все узлы квадратные, кроме Wj — он круглый).
Отметим, что (А) состоит из п — 1 квадрата и образуется из
последовательности, состоящей из п квадратов, после одного комбинирования в алгоритме
Гарсиа-Уочса; (В) же состоит из п — 2 квадратов и одного круга и
образуется из той же последовательности после одного комбинирования в алгоритме
Ху-Таккера. Покажем, что применение алгоритма Ху-Таккера к (А) и к (В)
даст одно и то же дерево Г', т. е. все комбинирования будут одинаковыми (если
узел wp комбинируется с «;!• в (А), то тот же узел wp будет комбинироваться
с w) в (В)).
Предполагая, что это доказано, рассмотрим две последовательности (А1)
и (В1), где (А1) состоит из п — 2 квадратов, а (В*) состоит из п — 3 квадратов и
5.6. АЛГОРИТМ ГАРСИА И УОЧСА
181
одного круга. Последовательность (А') получается из (А) после одного
комбинирования Гарсиа-Уочса, а последовательность (В1) -получается из (А) после
одного комбинирования Ху-Таккера. Точно так же можно показать, что
применение алгоритма Ху-Таккера к последовательностям (А') и (В*) даст одно
и то же дерево Т'.
Продолжая действовать таким образом, можно получить
последовательности
(А), (В), (А%(В% (А"),(В"),..., (АП-2),(1Г-2),
где (А") получается из А' в результате одного комбинирования Гарсиа-Уочса,
а (В") получается из А' в результате одного комбинирования Ху-Таккера, и
т. д. Последовательности (Л), (А'),..., (Ап~2)г— это последовательности,
порождаемые алгоритмом Гарсиа-Уочса. По существу, мы покажем, что дерево,
построенное любым числом комбинирований Гарсиа-Уочса, за которыми
следуют комбинирования л.м.с.п., будет деревом Т', определенным в алгоритме
Ху-Таккера.
Для доказательства того, что (А) и (В) дают одно и то же дерево Т",
сделаем три замечания о слиянии л.м.с.п. в последовательности (В).
Замечание 1. В подпоследовательности узлов tui,. -., «;<, Wi+i, —, ti7j—^ узел
не может подвергнуться слиянию до тех пор, пока соседний с ним справа узел
не будет подвергнут слиянию. Это следует из того, что (wj-\,wj) есть самая
левая минимальная соседняя пара.
Замечание 2. Когда подвергается слиянию ги!-, узлы Wj+i,.*.,^^ все уже
были слиты (или сливаются с Wj). Если это не так, то пусть wi будет самым
правым узлом среди ги*+1,... ,ttfj-_2, который еще не был слит. По замечанию
1, все узлы между Wi и w*j были слиты, wi совместим с любым узлом,
совместимым с круглым узлом w*j в (В), и wi <w)- Поэтому Wj не может образовывать
л.м.с.п. с другим узлом.
Замечание S. К тому моменту, когда образуется л.м.с.п., один узел которой
принадлежит множеству {iui,..., и;,*}, а другой —множеству {tUj+i,. *., tun},
узел Wj уже был подвергнут слиянию. Пусть такой л.м.с.п. будет (wx,wy),
где wx — это либо узел из {w\,..., ш*}, либо сумма некоторых узлов из этого
множества. Так как (wj-\,wj) - самая левая минимальная соседняя пара, то
W\ + W2 > W2 + W3 > • • • > ltfj_i + w^
отсюда
w\ > W3 >губ > ...,
гу2 > w* > we > —
Поэтому один из двух соседних узлов больше, чем w^. Следовательно, wx >
Wi > Wj. По замечанию 1, когда wy подвергается слиянию, все узлы между
wy и Wj уже слиты и wy ~ w*j. Но wx >Wi>w1j и это противоречит тому, что
(wx,wy) является л.м.с.п., если Wj еще не был слит.
182
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рассмотрим теперь последовательности (А) и (В). Но замечанию 3, прежде
чем w*j подвергнется слиянию в (А) или в (Б), для двух последовательностей
(А) и (В) будут выполняться одни и те же комбинирования, так как w\,..., щ
еще не вовлечены в процесс комбинирования и Wj является круглым узлом в
(В). По замечанию 2, когда w*j подвергается слиянию в (В), все узлы между
Wi и Wj+\ — круглые. Поэтому квадратный узел Wj в (А) и круглый узел
Wj в (В) совместимы с одним и тем же множеством узлов. После того, как
Wj будет слит, последовательности (А) и (В) превращаются в одинаковые
последовательности узлов.
5.7. Регулярные функции стоимости
Мы рассмотрели два алгоритма для построения оптимальных деревьев:
алгоритм Хаффмена для неалфавитного случая и алгоритм Ху-Таккера для
алфавитного случая. Стоимость дерева определялась как ^ ОД/** В задаче
кодирования функция стоимости эквивалентна средней скорости передачи
информации. В задаче поиска функция стоимости есть мера среднего числа
обращений к памяти. Бели нас интересует не среднее, а худший случай, функцию
стоимости нужно будет заменить на
maxWiU.
i
С другой стороны, если стоимость доступа к записи VJ зависит
экспоненциально от длины пути, то имеет смысл минимизировать
где t константа.
Нужен ли новый алгоритм для построения оптимальных бинарных
деревьев в случае, когда функция стоимости отличается от £ «;*/,•? Оказывается,
алгоритмы Хаффмена и Ху-Таккера можно слегка модифицировать так, что
они будут применимы ко многим функциям стоимости.
Ниже будет определен класс функций, включающий функцию J2w^i- К
любой функции из этого класса применимы модифицированные алгоритмы
Хаффмена и Ху-Таккера.
Пример 3. Для (wi,ttf2,... ,гУб) = (4,2,3,4,7) найти алфавитное дерево,
минимизирующее max w(2**).
i
Решение. Найдем совместимую пару минимального веса Щ Щ и заменим
эти два узла их отцом с весом
2тах{2,3} = 6.
Найдем совместимую пару минимального веса в последовательности узлов
IliS
5.7. РЕГУЛЯРНЫЕ ФУНКЦИИ СТОИМОСТИ 183
Рис. 5.19 Рис. 5.20
и заменим Щ Щ их отцом с весом
2-тах{4,4} = 6.
Продолжая действовать таким образом, получим дерево V на рис. 5.19.
Заметим, что вес пары (и)а,и)ь) определяется как
2-max{wa,Wb}.
В алгоритме Ху-Таккера дерево Т1 можно преобразовать в алфавитное
дерево T'Nr показанное на рис. 5.20.
Отличие состоит в назначении веса отцу, получаемому при слиянии двух
совместимых узлов. Другими словами,
Значение функции стоимости для дерева Г будем обозначать через \Т\.
Рассмотрим требования, которым должна удовлетворять функция стоимости.
Свойства регулярной функции стоимости.
Р1. \Т\ не возрастает при уменьшении любого из весов.
Р2. Для всех wa,Wb,wx
f(Wa,Wb) = f(Wb,Wa),
Wa <f(wa,Wx)y
Wa<Wb 4» f{lVa}Wx) < f{Wb,Wx)-
РЗ. Если Wb < wc и 1ь > /c> то перестановка И и К не уменьшает стоимости
дерева.
Р4. Пусть Г — дерево с п узлами, в котором сливаются Va и Vi, а Г* — дерево
с п -1 узлом, получающееся в результате слияния, причем отец узлов Va
и Vb получает вес f(wa,Wb). Существует функция 0(ttfa>w») такая, что
|т|=0(юв1ю»)+т-
184
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Р5. Функции f(warWb) и 0(wa,Wb) должны удовлетворять условиям: если
Wb < wc, то
/(/К, wb), wc) < f(f(wa, wc\ wb),
0(wa,Wb) + 9(f(wa,wb),wc) < 0(wa,wc) + 0(f(wa,wc),wb).
Грубо говоря, свойства P2-P5 гарантируют, что в дереве с тремя или
четырьмя узлами будут комбинироваться два наименьших узла, если они
совместимы. Функция \Т\ называется регулярной функцией, если существуют
такие / и 0, что выполняются условия Р1-Р5. Во всех рассмотренных выше
примерах функции стоимости были регулярными.
Легко проверить, удовлетворяет ли функция стоимости этим условиям.
Если это так, то можно применить алгоритм Ху-Таккера для построения
оптимального алфавитного дерева. Единственное отличие состоит в назначении
веса отцовскому узлу при слиянии совместимой пары. Если условие алфавит-
ности не накладывается, то оптимальное бинарное дерево может быть
построено модифицированным алгоритмом Хаффмена для данной функции
стоимости.
Ниже приводятся несколько примеров регулярных функций стоимости.
1. 9(wx,wy) = wx + wy = f(lVz,Wy),
для дерева с одним узлом \Т\ = 0.
2. 0(wx,wy) = O,
f{wXyWy) = t(wx + W„), t > 1,
\T\ = гу(корень) = J2&iwh
i
для дерева с одним узлом \Т\ равно весу этого узла.
3. e(wx,wy) =0,
f(wx,wy) = t • maz{wxyWy},
\T\ = гу(корень) = max{^ti;j},
для дерева с одним узлом \Т\ равно весу этого узла.
4. 0(wx,wy) = 0,
f(wx,wy) = max{g(wx),g(wy)}, где д — возрастающая функция и д(х) >
х для всех допустимых значений х,
для дерева с одним узлом \Т\ равно весу этого узла,
|Г| = тах^{^}.
»
Во всех этих примерах проверка регулярности тривиальна.
5.8. Парные деревья и другие результаты
Рассмотрим последовательность весов w\,..., Wj-i, Wj, tuj+i,..., wny где
W\ > W2 > • • • > Wj-i < Wj < Wj+i < ... < wn. (1)
5.8. ТАРНЫЕ ДЕРЕВЬЯ И ДРУГИЕ РЕЗУЛЬТАТЫ
185
Иначе говоря, веса сначала убывают, а затем возрастают. Такая
последовательность называется впадиной. Частными случаями впадин являются
монотонно убывающие или неубывающие последовательности.
Лемма 7. Если последовательность весов является впадиной, то
стоимость оптимального алфавитного дерева равна стоимости оптимального
дерева без условия алфавитности.
Доказательство. Предположим, что последовательность весов
удовлетворяет условию (1) и л.м.сп. есть (wj-\,wj) (или (wj-2,Wj-i))- Тогда wj_ij —
круглый узел и следующей парой минимального веса будет одна из пяти пар:
(Wj-2, Wj+i),
(^•_3, Wj-2),
К+Ъ Wj+2),
(«>j-2, «>j-l,j)>
В любом случае вновь построенный узел, назовем его wa, будет круглым
узлом.
Вообще, пусть wa < wb < •.. < wq — созданные к некоторому моменту
круглые узлы, и в этот момент слева от них имеем
W\ > W2 > ... > tl>j-2>
а справа
Wj+i < ...wn.
Тогда следующей л.м.сп. (единственной) будет одна из шести пар:
(wA, wB),
(ш,-2, U>i+l)>
(Wj_3, Wj-2),
(Ш^2, «М),
(W>t,tt>i+i).
Поэтому следующий создаваемый круглый узел Шя будет совместим со всеми
созданными до сих пор круглыми узлами.
Иначе говоря, совместимой парой минимального веса всегда будет пара
минимального веса. Так как |Г'| = \Т#\, то стоимость оптимального
алфавитного дерева будет равна стоимости дерева Хаффмена. Для других функций
стоимости доказательство такое же. i
186
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
Рис. 5.21 Рис. 5.22
Лемма 8. Существует дерево Хаффмена с
wi < W2 < • • • < t^n»
/1>/2>...>/п,
в котором узлы слева направо расположены в порядке W\,W2,...,wn.
Доказательство. Последовательность весов, расположенных в неубывающем
порядке, является частным случаем впадины. По лемме 7 стоимость
оптимального алфавитного дерева такая же, как у дерева Хаффмена. Если длины
путей не удовлетворяют неравенствам l\ > fe > ... > ln> то можно так
переставить узлы, что стоимость уменьшится, а это противоречит оптимальности
первоначального дерева. , I
Рассмотрим теперь вопрос: какие из приведенных результатов обобщаются
на тернарные и fc-арные деревья? В fc-арном дереве каждый внутренний узел
имеет к сыновей. Следующий пример показывает,что алгоритм Ху-Таккера,
в котором минимальная совместимая тройка (wa,Wb,wc) заменяется на wa +
и*ь + гус, не минимизирует J2w^i-
На рис. 5.21 показано дерево Ху-Таккера, его стоимость равна 66, но
дерево на рис. 5.22 имеет стоимость 62.
Минимальную совместимую тройку можно определить так же, как
минимальную совместимую пару. Но для локальной минимальности троек
возможны разные определения. Определим слабо локально минимальную
совместимую тройку (сл.м.с.т.) как такую, в которой один из трех узлов является
наименьшим узлом, совместимым с двумя остальными.
Для минимаксной функции стоимости, такой^как в примере 3 раздела 5.7,
можно показать, что существует конструкция «класса С», в которой все
слияния являются сл.м.с.т. Применяя следующий прием, можно добиться, чтобы
с.л.мх.т. не перекрывались, а затем можно показать, что оптимальное дерево
может быть построено с помощью тернарного аналога алгоритма Ху-Таккера.
Так как при слиянии для функции из примера 3 алгоритм дает новый
узел, вес которого в t раз больше максимального из весов его потомков, то
стоимость дерева не изменится, если веса всех потомков увеличить до
этого максимума. Теперь слияние сл.м.с.т. не может уменьшить минимальной
совместимой тройки. Поэтому алгоритм Ху-Таккера работает для тернарной
минимаксной задачи.
УПРАЖНЕНИЯ
187
Вопрос о том, допускает ли этот метод дальнейшее обобщение, остается
открытым.
Упражнения
1) Бели используется код, представленный на рис. 5.4(a), то что означает
последовательность 01111 ? Закодируйте теперь это слово кодом с
рисунка 5.4(b).
2) Докажите лемму 6.
3) Постройте оптимальные алфавитные деревья для следующих
последовательностей весов:
(i) 3, 4, 5, 6, 4, 2;
(И) 2, 6, 3, 5, 4, 4;
(Ш) 6, 4, 3, 2, 2, 5.
4) Для весов 2, 3, 4, 4, 5, 6 постройте бинарное дерево, минимизирующее
i
5) Разработайте способ построения алфавитного бинарного дерева,
минимизирующего
.maxii;j£*'.
Рассмотрите случаи (i) t > 1, (ii) t < 1.
Литература
Алгоритм построения оптимального бинарного дерева был открыт Хафф-
меном [9]. Глэсси и Карп [2] показали, что этот алгоритм может применяться
к другим видам бинарных деревьев. В этих работах бинарные деревья
рассматриваются главным образом в связи с задачей кодирования.
Гилберт и Мур [3] показали, как построить оптимальное алфавитное
дерево с использованием динамического программирования. Их алгоритм имеет
оценки 0(п3) по времени и 0(п2) по памяти.
Модифицировав процедуру динамического программирования, Кнут [12]
ускорил алгоритм Гилберта и Мура до 0(п2), но оценка памяти осталась
прежней. Ху и Таккер [8] предложили алгоритм построения оптимального
алфавитного дерева, требующий памяти 0(п). Кнут [13] дал превосходное
описание алгоритма Ху-Таккера и показал, как его можно реализовать за
время 0(п log п). Таким образом, лучшие из известных в настоящее время
оценок - O(nlogn) по времени и 0(п) по памяти. Те же оценки достигнуты в
Ш-
188
ГЛАВА 5. БИНАРНЫЕ ДЕРЕВЬЯ
работе Гарсиа и Уочса [1]. Доказательство эквивалентности двух алгоритмов
основано на предложениях И. С. Куо.
Обоснование алгоритма Ху-Таккера ([1], [4], [8]) остается длинным и
утомительным. Доказательство, приведенное в этой главе, является модификацией
доказательства из [5], где также обобщаются деревья Хаффмена и
Ху-Таккера на различные функции стоимости. Оптимальным алфавитным деревьям
посвящены также работы [6], {7], [10].
Оптимальные префиксные коды рассматриваются в [11], [14].
1. Garsia А. М., Wachs М. L. A New Algorithm for Minimal Binary Search Trees
// SIAM J. Comput. - 1977. - Vol.6. - P.622-642
2. Glassey C.R. and Karp R.M. On the Optimality of Huffman Trees // ORC
74-21, Univ. of California, Berkeley, 1974.
3. Gilbert E. N. and Moore E. F. Variable Length Binary Encodings // Bell System
Tech. J. - 1959. - Vol. 38. - P. 933-968.
4. Hu T. C. A New Proof of T-C Algorithms // SIAM J. Appl. Math. - 1973. -
Vol, 25. -P. 83-94.
5. Hu T.C. Kleitman D. J., Tamaki J.K. Binary Trees Optimum under Various
Criteria // SIAM J. Appl. Math. - Vol.37, No2. - 1979. - P.246-256.
6. Hu T. C. and Tan K. C. Path Length of Binary Search Trees // M. R. C., Report
1111, Univ. of Wisconsin, Nov. 1970.
7. Hu Т. C. and Tan К. C. Least Upper Bound on the Cost of Optimum Binary
Search Trees // Acta Informatica. - 1972. - Vol. 1. - P. 307-310
8. Hu Т. С and Tucker A. С Optimal Computer-search Trees and Variable-Length
Alphabetic Codes // SIAM J. on Appl. Math. - 1971. - Vol. 21. - P. 514-532.
9. Huffman D. A. A Method for the Construction of Minimum Redundancy Codes
// Proc. IRE 40. - 1952. - P. 1098-1101.
10. Itai A. Optimal Alphabetic Trees // SIAM J. Comput. - 1976. — Vol. 5, No 1.
-P. 9-18.
11. Karp R. M. Minimum-Redundancy Code for the Discrete Noiseless Channel //
IEEE Trans. Information Theory IT-7. - 1961. - P. 27-39.
12. Knuth D.E. Optimum Binary Search TVees // Acta Informatica. — 1971. —
Vol. 1. - P. 14-25.
13? Knuth D.E. Searching and Sorting. — Addison-Wesley, 1973.
14. Peri Y., Garey M.R., Even S. Efficient Generation of Optimal Prefix Code:
Equiprobable Words Using Unequal Cost Letters // J. ACM — Vol.22, No2.
-1975.-, P. 202-214.
ОТВЕТЫ
189
Ответы
1) ADD, 001111.
2) Положите Wi + Si = wj, тогда
£«># = ]£«;$ +а, гДе «>0.
3) Получаются деревья со следующими последовательностями уровней:
0) 3,3,2,2,3,3;
(и) 3,3,3,3,2,2;
(ш) 2,3,3,3,3,2.
4) Нужно всегда комбинировать два наибольших веса wp,wq, а их отцу
присваивать вес
5) Отцу присваивайте вес t • max{wi,Wj}, где (w{,Wj) — наименьшая (при
t > 1) или наибольшая (при t < 1) л.м.с.п. (при t < 1 л.м.с.п означает
локально максимальную совместимую пару).
Глава 6
Эвристические алгоритмы
Трудно достичь совершенства.
Обычно достаточно к нему приблизиться.
6.1. Жадные алгоритмы
Во всех предыдущих главах изучались только «оптимальные» алгоритмы
— алгоритмы, которые дают оптимальное решение задачи. Некоторые из
таких алгоритмов эффективны, а некоторые способны утомить нас своей
медлительностью. Многие алгоритмы для нахождения оптимального решения
требуют так много времени, что не могут использоваться на практике.
В действительности, многие задачи требуется решить до истечения
определенного времени. В этом случае либо используют коммерческий код, который
может не совсем соответствовать нашей задаче, либо придумывают
эвристические алгоритмы — алгоритмы, которые интуитивно кажутся хорошими и
иногда могут давать оптимальные решения. Поскольку эвристические алгоритмы
не всегда приводят к оптимальному решению, возникает два естественных
вопроса:
1) Когда эвристический алгоритм получает оптимальное решение?
2) Если эвристический алгоритм не способен получить оптимальное
решение, то какова максимальная относительная ошибка?
Для ответа на первый вопрос надо охарактеризовать входные данные и
получить необходимые и достаточные условия для работы эвристического
алгоритма. Бели он работает на большинстве входных данных или его
максимальный процент ошибки приемлем, то эвристический алгоритм можно
предпочесть алгоритму, который находит оптимальное решение, но работает
дольше.
6.1. ЖАДНЫЕ АЛГОРИТМЫ
191
Рис. 6.1
Большинство эвристически* алгоритмов основано на человеческой
интуиции, и анализировать их нелегко. Например, для шахмат, где оптимальным
решением является объявление мата королю, эвристический алгоритм может
состоять в захвате как можно большего числа фигур. Однако нельзя,
например, считать взятие пешки соперника приближением к победе, поскольку это
может обернуться поражением в конце партии. (В действительности, хорошо
известны ситуации жертвования пешки для объявления мата королю
противника.) Таким образом, этот эвристический алгоритм не обеспечивает
оптимального решения.
Тем не менее существуют задачи, в которых наилучшие действия на
каждом шаге приводят к оптимальным решениям. Например, в задаче о
минимальном остовном дереве (раздел 1.7) выбирается кратчайшая дуга, смежная
с одной из вершин построенного к началу текущего шага дерева, не
приводящая к циклу. Последовательное повторение этого шага даст в конце
минимальное остовное дерево.
В задаче о кратчайших путях из V8 в V*, показанной на рис. 6.1, видно, что
если всегда выбирать кратчайшую дугу, смежную с только что достигнутым
узлом, то результат не будет оптимальным. Подход, состоящий в выполнении
локально наилучшего действия, называется жадным методом (подходом), а
алгоритм, основанный на таком подходе, — жадным алгоритмам. Жадный
алгоритм обычно первым приходит на ум, и он иногда срабатывает. В этом
разделе изучим один из таких алгоритмов. , ,
Рассмотрим задачу, с которой мы встречаемся ежедневно, — задачу о
точном размене денег. Предположим, необходимо заплатить 36 центов. Сумму
из 36 центов можно составить из трех монет: монеты достоинством в
четверть доллара, монеты в 10 центов и монеты в 1 цент1. Предположим, что
целью является минимизация общего числа монет. Жадный алгоритм для
решение этой задачи мог бы заключаться в том, что вначале берется
максимально возможное число монет наивысшего достоинства, остаток пытаются
ликвидировать монетами следующего достоинства и т. д. В действительности,
при существующей денежной системе этот алгоритм всегда дает оптимальное
решение. Предположим теперь, что есть три типа марок достоинством,
например, в 1 цент, 9 центов и 10 центов, в то время как нужная сумма составляет
36 центов. В этом случае жадный алгоритм оптимума не дает.
*В США находятся в обращении следующие мелкие монеты: доллар, полдоллара,
четверть доллара, 10 центов, 5 центов и 1 цент. — Прим. перев.
192
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Рассмотренная задача о размене — это задача о рюкзаке из главы 3, только
максимизация заменена на минимизацию. Метод динамического
программирования (глава 3) может работать долго, поэтому применим к данной задаче
жадный алгоритм.
Для того, чтобы сделать задачу о размене более общей, будем
минимизировать суммарный вес монет, участвующих в размене. Эта задача сводится к
задаче минимизации суммарного числа монет при равенстве всех весов. Пусть
ttfi >^2> • • • > wn — веса монет,
Щ, 02,..., vn — достоинства монет.
Задача состоит в том, чтобы найти
п
МИНИМУМ 53 Wixu
При УСЛОВИЯХ Jj ViXi = у, (*/
1=1
#» > 0, целые,
где Х{ — число использований i-й монеты, а у — размениваемая сумма.
На протяжении всего раздела будем предполагать, что
(i) W{ > 0, Vi > 0, Vi — целые,
(ii) 1 = vi < v2 < • • • < vn,
(ffl) S5.>!u >.,.>«-.
Заметим, что (iii) означает, что n-я монета является наилучшей в том
смысле, что ее удельный вес, приходящийся на единицу достоинства, наименьший
среди всех монет.
Определим функцию Fk(y) как минимальный суммарный вес первых к
типов монет, участвующих в размене суммы у, т. е.
к
Fh(y) = mmJ2wiXi
*=i
* (S\
при УСЛОВИЯХ 53 vixi = У>
1=1
Xi > 0, целые.
Заметим, что
**+i(l/) = ^ min {Fk(y - «H4**+i) + w*+i**+i}, (4)
F\(y)=wi MM =wiy,
поскольку Vi = 1.
6.1. ЖАДНЫЕ АЛГОРИТМЫ
193
Смысл соотношения (4) состоит в теш, что по существу испытывается
каждое возможное значение величины хи+\ > дающее вес ti/fc+i а*+1 > а остаток будет
выплачиваться оптимально первыми к типами монет.
Определим функцию Gk(y) как суммарный вес первых к типов монет,
участвующих в размене суммы у, подсчитанную жадным алгоритмом, т. е.
<?*+i(y) = tiifc+i- • -^- +Gk(y mod vk+x).
Lu*+iJ
(5)
Первое слагаемое в правой части — это вес, использующий (к + 1)-ую
монету наибольшее возможное число раз, второе слагаемое представляет собой
жадное решение относительно оставшегося баланса. В частности,
G\(y) =w\ — = w% • у, поскольку «1 = 1,
\y\ {)
G2(y) = w2 — + w\(y mod V2).
Из условий (ii) и (iii) получаем, что
G\ (у) = Fi (у) при всех у,
G2(y) = F2(y) при всех у.
Пример 1. Пусть v\ = 1, t^ = 5, V3 = 14, V4 = 18 и iut- = 1 при всех t.
Вычислим Gi(y).
Gi(»)=wi[|J=Wi» = F1(»),
Сг(у) = t^2 71 + wi(v mod 5) = **(»)»
5 (7)
G3(y) = «13 [j^J + G2 (y mod 14),
G4(») = w4 [^J + G3 (y mod 18).
В общем случае Fi(y) < 6ч(у) и при г > 3 можно привести примеры,
когда Fi(y) < C?t(y), поскольку использование максимального числа i-й монеты
может не дать оптимального результата. Конечно, можно переименовать
монеты таким образом, чтобы выполнялось исходное предположение (ii). Если
(Ш) не выполняется и Wi/vi < Wi+i/vi+i, то при у = ы • Vi+\ жадный алгоритм
не работает.
Так как G\(y) = -Fi(y), <?2(у) = F2(y) при всех у, то возникает
естественный вопрос, когда будет выполняться равенство 6?з(у) = ^з(у)? Бели в общем
случае Gk(y) = i**(y) при всех у, то верно ли, что при добавлении (к + 1)-го
типа монет при всех у будут верны равенства Gk+i{y) = -F*+i(y)? На этот
вопрос отвечает следующая замечательная теорема [10], которая, по
существу, утверждает, что если G^+i (у) = i*i+i (у) для некоторого частного у, то
<?*+i(y) = **+i(y) ПРИ всех у.
194
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Теорема 1. Пусть при всех неотрицательных целых у и некотором
фиксированном к выполняются равенства Gk(y) = Fk(y). Пусть также vk+\ >vk
и vk+\ = pvk - £, 0 < & < Vk, где р *- некоторое положительное целое число.
Тогда следующие утверждения эквивалентны:
(a) Gk+i(y) < Gk(y) при всех положительных целых у,
(b) G*+i (у) = F*+i(у) при всех положительных целых у,
(c) Gk+\{pvk) = Fk+i(pvk),
(d) ti/fc+i + G%{6) <pwk.
Перед доказательством теоремы сделаем несколько замечаний.
Условие (а) сравнивает два жадных решения, одно с А; +1 типами монет, а
другое — с А; типами. Условие (Ъ) утверждает* что жадное решение является
оптимальным при всех значениях у. Условие (с) говорит о том, что при
некотором частном значении жадное решение и оптимальное решение совпадают,
в то время как в условии (d) только используется жадное решение при одном
частном значении 8.
Заметим, что не зависимо от величины у для вычисления значения (7* (у)
требуется только О(к) операций. Таким образом, для проверки того, верно ли,
что G*+i(y) = F*+i(y) при всех у, условию (d) нужно время порядка 0(к).
Из-за условия (с) эта теорема называется одноточечной теоремой.
Доказательство. Покажем что условия (a-d) эквивалентны. Ддя этого
докажем следующие импликации:
(а) => (Ь); (Ь) => (с); (с) => (d); не-(а) => He-(d).
(а) =^ (Ь): Пусть (а) истинно. Тогда из оптимальности F*+i(y) получаем, что
при всех у
Fk+i(y)<Gk+1(y)<Gk(y). (8)
Рассмотрим два случая:
(i) в F*+i(y) имеем a?*+i = О,
(п) в F*+i(y) имеем ar*+i > 0.
(i) Если при заданном у в F*+i (у) не используютя монеты (к + 1)-го типа,
то F^4-i(y) = Fk(y) и по условию Fk(v) = #*(у)> таким образом, из (8)
получаем
Gkiy) = Ыу) = A+ifo) < G*+1(y) < Gk(y),
откуда F*+i (у) = G*+i (у), что совпадает с (Ь).
(ii) Пусть a?*+i — это число монет (к + 1)-го типа, используемых в F*+i(y),
т. е.
F*+i (у) = w*+i - хк+х + F*(y'), (9)
где у9 — у — Vfc+iXk+i. Тогда в Fb+i(y') не используется никакая монета
(к + 1)-го типа, следовательно,
Fk+1(y') = Fk(y')=Gk(y'). (10)
6.1. ЖАДНЫЕ АЛГОРИТМЫ 195
Поскольку (8) справедливо при всех значениях у, то оно выполняется и
для частного значения у'. Заменяя у' в (8), из (10) получаем
Gk(y') = Fk+1(y'f< Gk+l(y') < Gk(y'),
откуда
Fk+1(y') = Gk+1(y'). (11)
Так как
G*+i(y' + v*+is*+i) = wk+xxk+1 + G*+i(y'),
то из (9), (11) следует, что
Fk+\{y' + v*+ix*+i) = Gfc+i(y' + v*+ix*+i),
i
т, e.
**+i(y) = GWi(») при всех у,
что совпадает с (Ь).
(b) =» (с): Пусть у принимает частное значение рик, тогда получаем
<F*+i(pt>*) = Gk+\(pvk), что совпадает с (с).
(c) =Ф> (d): Так как оптимальный вес А; +1 монет не может быть больше, чем
оптимальный вес к монет, то при всех у
Fk+i{y)<Fk(y)=Gk(y).
Пусть у = pvk- Тогда в сочетании с (с) получим, что
Gk+i(pvk) = Fk+xlpvk) < Fkipok) = Gk{poh). (12)
Оценивая обе части соотношения (12), обнаруживаем, что
ш*+1 + Gk+i(pvk - v*+i) < pwk,
откуда
Wfc+i + Gfc+it*) <pw*,
следовательно,
ш*+1+<?*(*) <jw*.
Таким образом, Gk+i(8) = G*(£), поскольку S < vk < v*+i, что совпадает с
He-(a) =^ He-(d): Пусть у — наименьшее целое число, для которого не
выполняется (а). Очевидно, что у > v*+i. Имеем
Gk(у) < Gfc+i (у) = u^+i + Gfc+i (у - v*+j).
Прибавляя к обеим частям величину G*(£), получим
Gk(6)+Gk(y) <wk+x + G*(<J) + G*+i(y-tnk+i). (13)
196
ГЛАВА 6. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Поскольку жадный алгоритм строит оптимальное решение для к монет, то
Gk(V + S) <Gk(S) +Gk(y). (14)
Так как
У + 6 = (v*+i +<*) + (»- v*+i) = P»k + (У - v*+i),
то
G*(y + S) = pwk + G*(y - v*+i). (15)
Комбинируя (13)-(15), получаем
pwk + Gfc(y - v*+i) - G*+i(y - v*+i) < wk+x + G*(£). (16)
Так как у — это наименьшее целое число, для которого (а) не выполняется,
то (а) выполняется при всех значениях у < у, в частности, при у = у — v*+i.
Это означает, что G*+i (у - Vk+i) < G*(y - v*+i). Тогда из (16) следует, что
pwk <wk+i+Gk(6),
что совпадает с не-(<1).
Теорема полностью доказана. I
Применим теорему 1 к примеру 1, в котором
vi = 1,^2 = 5,^3 = 14, V4 = 18 и W{ = 1 при всех t.
Нам известно, что
Gi(y) = Fx(y) при всех »,
G2(y) = ^2 (у) при всех *,
V3 = 14 = 3 • V2 — 1 = pv2 — 6 при р = 3,5 = 1.
Условие (d) теоремы 1 утверждает, что
и>з + G2(£) <ри>2,
т.е.
1+G2(1)<3-1,
1 + 1 < 3, что истинно.
Так как (d) выполняется, то при всех у
G3(v) = F3(y).
Далее,
va = 18 = 2 • V3 - 10 = JW3 - 5, при р = 2,5 = 10.
Далее, согласно условию (d),
tt>4 + G3(£) <рш3,
6.2. ЗАДАЧА ОБ УПАКОВКЕ
197
т.е.
1 + G3(10)<2.1,
1 + 2<21, ложь,
следовательно, условие (d) не выполнено. Жадный алгоритм не способен
получить оптимальное решение при риз = 2 • 14 = 28.
При у = 28 величина Ga{v) равна
[IHfH
в то время как F^(y) = Fs(y) равно
Заметим, что для проверки того, дает ли жадный алгоритм оптимальное
решение для п монет, требуется время порядка 0(п2).
6.2. Задача об упаковке
В последнем разделе был изучен специальный эвристический алгоритм,
известный под названием жадного алгоритма. Иногда жадный алгоритм
способен дать оптимальное решение, и была доказана теорема, которая
характеризует входные данные, на которых жадный алгоритм работает. Теперь изучим
другой тип эвристических алгоритмов, который всегда приводит к решениям,
близким к оптимальным. Попытаемся установить теоремы, которые
утверждают, что в самом худшем случае эвристическое решение будеи не очень сильно
отличаться от оптимального. Верхняя оценка максимальной относительной
ошибки дает лицу, принимающему решение, пищу для размышлений, чтобы
решить, желает ли он отказаться от поиска оптимального решения в пользу
сокращения времени работы алгоритма.
Предположим, что нам нужны деревянные бруски различной длины, а
местный цех заготовки лесоматериалов поставляет бруски стандартной
длины. Сколько стандартных брусков следует заказать, чтобы их можно было
разрезать в соответствии с нашими запросами? Эта задала называется
одномерной задачей о разрезе. Если каждый брусок интерпретировать как задание,
выполняемое процессором, а длину бруска — как время выполнения задания,
то задача превращается в задачу использования минимального числа
процессоров, необходимых для завершения всех работ в течение фиксированного
промежутка времени (стандартная длина бруска становится для каждой
машины 24 часами).
Пусть а,{ — длина i-го бруска, L = (ai, аг,..., ап) — список запросов.
Стандартный брусок обозначим через Bj.
Данная задача известна также как задача об упаковке, поскольку мы
сталкиваемся с ней, упаковывая ящики в контейнеры стандартных размеров.
Единственным ограничением на контейнер является его размер, и любой ящик
198
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
характеризуется только своим размером. Несмотря на то, что обычно размер
характеризуется тремя параметрами: длиной, шириной и глубиной (высотой),
будем иметь дело только с одним параметром. (В случае более одного парат
метра получаем многомерную задачу о разрезе, см. раздел 3.3.)
Пусть емкость каждого контейнера равна 1, а список L содержит п
элементов, 0 < а,{ < 1 при 1 < г < п. Числа 1,... ,т — это индексы контейнеров, В\
называется первым контейнером, Вт всегда обозначает последний непустой
контейнер.
Сумма величин <ц, упакованных в контейнер Bjt называется содержимым
Bj и обозначается через c(Bj). Заметим, что 1 - c(Bj) — это свободное
пространство в контейнере Bj. Назовем эту величину резервом контейнера Bj.
При заданном списке L = (ai,02,...,On) эвристический алгоритм
упаковывает
ящики а\,02,...,а% в контейнер В\, пока сц+i < 1 - c(Bi),
ящики сц+1 ,<ц+2,...,%• в контейнер В2> пока Oj+i < 1 — с(Б2),
В общем случае а* упаковывается в В{ до тех пор, пока в контейнере В{ есть
пространство для а*, и упаковывается в B*+i в противном случае. Заметим,
что в этом алгоритме как только в контейнере не остается пространства для
следующего ящика, то данный контейнер больше никогда не используется,
даже если впоследствии найдется ящик меньшего объема, который можно
поместить в этот контейнер. Данный алгоритмназывается алгоритмом *сле-
дующего подходящего*2, или NF-алгоритмом.
Пусть NF(L) — это число контейнеров, необходимых NF-алгоритму, a L*
— число контейнеров, используемых «оптимальным» алгоритмом. Тогда
максимум отношения
*<NF, = ™
характеризует наибольшую ошибку эвристического алгоритма. Поскольку это
отношение зависит от значения L*, введем также величину
r(NF) = lim max ™Ш.
Найдем верхнюю оценку величины A(NF). Возьмем произвольный контейнер
Bj (j = 1,2, »..,m—.1). Тогда справедливо неравенство
c(Bj)^c(Bj^)>l}
так как в противном случае ящики из Bj+i можно было бы уложить в Bj.
Если просуммировать эти неравенства по всему содержимому непустых
контейнеров, то получим
c(Bi) + с(Вг) + • • • + c(JBm_i) + с(Вт) > — при четном т,
т— 1
c(Bi) + с(Вг) +'•••+ с{Вт-2) + c(Bm-i) > при нечетном т.
2В оригинале: Next-Pit algorithm. — Прим. персе.
6.2. ЗАДАЧА ОБ УПАКОВКЕ
199
2N
2N -1 контейнеров
Рис. 6.2
Поскольку объем каждого контейнера равен единице, для оптимальной
упаковки потребуется по меньшей мере
•-* ш — 1 • _ _,»
L >—;г— контейнеров, откуда m < 2L* + 1,
или же
При L* -► оо получаем, что
NF(£)<2L* + 1.
r(NF) < 2.
(1)
(2)
Эта оценка показывает, что число контейнеров, получаемых NF-алгоритмами,
может превосходить величину реально требуемых контейнеров не фолее, чем
в два раза. (
Теперь укажем список, на котором NF-алгоритм достигает такого значения
отношения, как в (2). Пусть этот список состоит попеременно из компонент
1/2и1/(2#),т.е.
V2' 2JV* 2' 2N' "" ' 21'
4JV — 1 элементов
При оптимальной упаковке каждые два ящика размера 1/2 будут
упакованы в один контейнер. Для упаковки 2JV ящиков размера 1/2 потребуется
N контейнеров, а все ящики размера \/(2N) будут упакованы еще в один
контейнер, поскольку
<2*-1)х2.<1.
Таким образом, L* «/V + lv
6 другой стороны, как показано на рис. 6.2, NF-алгоритму потребуется 2N
контейнеров.
Таким образом, мы установили, что существует такой список L с
произвольно большим значением L*, удовлетворяющий неравенствам
2£* - 2 < NF(£) < 2£* +1.
200 ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Этот пример показывает, что r(NF) > 2, следовательно, из (2) получаем, что
r(NF) = 2.
Ошибка в 100%, к которой может привести NF-правило, обычно не
приемлема. Имеется три причины, по которым NF-правило приводит к такой
большой ошибке:
1. NF-правило является плохим.
2. Решение о том, чтобы положить ящик а* в контейнер, принимается не
зависимо от последующих ящиков списка.
Такой тип алгоритма называется алгоритмам реального времени, или
он-лайн алгоритмом, и используется тогда, когда компоненты списка L
доступны только один раз за все время, а назначение требуется
произвести до того момента, когда станет доступной следующая компонента.
3. Компоненты а* имеют произвольный размер. Если максимальный
размер компонент ограничен, то исполнение можно улучшить, что
показывает следующая теорема.
Теорема 2. Если размер всех компонент списка L не превосходит t (0 <
t < 1/2), то
NF(L)<^ + 1. (3)
Доказательство. Поскольку размер наибольшей компоненты не превосходит
£, то резерв каждого контейнера должен быть меньше t. Другими словами,
c(Bj) > 1 — t для всех контейнеров, за исключением, быть может, Вт.
Следовательно,
m-l »■♦
]Г c(Bj) > (m-l)(l-*), откуда L* > (m-l)(l-*), откуда NF(L) < :j—7+l.
i
Можно построить пример, в котором для некоторого списка L выполняется
неравенство
где е — положительная константа [8]. Поскольку r(NF) = 1/(1 -1) как для
верхней, так и для нижней оценок, то единственный способ улучшить
алгоритм — придумать новые эвристические правила.
Один из алгоритмов реального времени основан на правиле ^первого
подходящего^ (FF-правиле). FF-правило помещает каждый ящик в контейнер
с наименьшим номером, в котором есть пространство для размещения этого
ящика. Другими словами, помещаем а* в контейнер Bj, если при всех г < j
l-c(Bj)>ak и 1-с(В{)<ак.
3В оригинале: First-Fit rule — Прим. перев.
6.2. ЗАДАЧА ОБ УПАКОВКЕ)
201
в,
fi Л mi>*ii
в7
А
В<
В5
Рис. 6.3
Таким образом, применяя FF-правилр, мы просматриваем каждый непустой
контейнер слева направо и помещаем а* в первый подходящий контейнер.
Другое правило реального времени называется правилом «наилучшего под-
ходящего*4 (BF-правило). Согласно этому правилу, ящик а* помещается в
контейнер с наименьшим резервом. Иными словами, помещаем а* в Bj, если
при всех *, таких, что
l-c(Bi)>ak,
выполнены неравенства
0<l-c(B^-ak<l-c{Bi)-ak; ;„
Если таких j несколько, то выбираем из них наименьшее.
Если для всех непустых контейнеров 1 — с(Д) < а*, то а* помещается в
пустой контейнер с наименьшим номером.
Проиллюстрируем упаковку ящиков из списка L при помощи FF-правила,
где
L = (а1,а2,аз,а4,аб,ав,а7,а8,а9) = (0.1, 0.1, 0.6, 0.3, ОД 0.7,0.7, 0-3,0.8).
В результате потребуется пять контейнеров, как показано на рис. 6.3.
Если к данному примеру применить BF-правило; то получится тот же
самый результат.
Оба правила FF и BF являются алгоритмами реального времени, и можно
установить, что5
Доказательство неравенств (4) и (5) см* в [3J, [8].
(4)
(5)
4В оригинале: Best-Fit rule — Прим. перев.
5Величины FF(L), BF(L) и используемые далее FFD(L), BFD(L), RFF(L) определяются
по аналогии с определением величины NF(L) на с. 198. — Прим. перев.
202
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
А *1 *Ъ *4 *3
Рис. 6.4
Ошибка в 70% слишком велика, хотя для большинства списков L ошибка
будет меньше.
Рассмотрим теперь два алгоритма офф-лайн. Один из таких алгоритмов
основан на правиле епервого подходящего в порядке убывания*6 (FFD-прави-
лом). При использовании этого правила вначале происходит сортировка всех
данных списка по убыванию размеров:
а1>а2>->ап,
а затем применяется правило «первого подходящего».
Другое эвристическое офф-лайн правило называется правилом
^наилучшего подходящего в порядке убывания*1 (BFD-правилом). При его
использовании данные вначале сортируются по убыванию размерен), а затем применяется
правило «наилучшего подходящего».
Если применить FFD-правило или BFD-правило к примеру на рис. 6.3, то
получим список
L - (ai,a2,... ,ag) = (0.8,0.7,0.7,0.6,0.4,0.3,0.3,0.1,0.1)
и упаковку, показанную на рис. 6.4.
Можно установить [8] следующие оценки:
HL.<FFD(b)<HL.+4, (6)
• Hi.<BFD(L)<Hi/* + 4. (7)
Поскольку неравенства (4)-(7) по существу описывают наихудший
случай поведения рассмотренных эвристических правил, то всякое их улучшение
должно быть связано с применением более утонченных правил. Далее опишем
замечательное эвристическое правило реального времени, предложенное Яо
[13], приводящее к коэффициенту 5/3.
Во-первых, классифицируем данные в соответствии с их размерами. Ящик
а* называется
бВ оригинале: First-Fit-Decreasing rule. — Прим. перев.
7В оригинале: Best-Fit-Decreasing rule. — Прим. перев.
6.2. ЗАДАЧА ОБ УПАКОВКЕ
203
ящиком типа а, если - < а* < 1,
ящиком типа ft, если - < в* < s,
5 2
ящиком типа ft, если - < а* < -,
3 5
ящиком типа 5, если 0 < а* < -.
о
Все контейнеры разделим на четыре класса. Все ящики типа а
упаковываются в контейнеры 1-го класса, все ящики типа ft — в контейнеры 2-го класса.
Большинство ящиков типа ft (примерно 6/7 от их общего числа)
упаковываются в контейнеры 3-го класса, а оставшиеся ящики типа ft — в контейнеры
1-го класса. Все ящики типа S упаковываются в контейнеры 4-го класса.
Вначале проверяем размер а*, а затем помещаем его в соответствии с
правилом первого подходящего:
в контейнер из класса 1, если а* — ящик типа о,
в контейнер из класса 2, если а* — ящик типа ft,
в контейнер из класса 3, если а* — ящик типа ft
(исключение: каждый седьмой ящик типа ft помещаем в класс 1. Таким
образом, 7-й, 14-й,..., ящики типа ft помещаются a-jqiacc 1, а 6/7 или
более ящиков этого типа — в класс 3), 6 р
в контейнер из класса 4, если а* -^щикДгипа 6. Г
Правило «первого подходящего» можно модифицировать, если
упаковывать ящики типа ft в контейнер 1-го класса и не размещать в этих
контейнерах более одного ящика типа ft. Так как а > 1/2, то в один контейнер не
может попасть более одного ящика типа а, также мы запрещаем, чтобы в один
контейнер 1-го класса попадало более одного ящика типа ft, даже если там
есть свободное пространство. Полученная упаковка схематично изображена
на рис. 6.5.
Данное правило предложено Яо [13] и называется улучшенным правилом
^первого подходящего*. Обозначим через RFF(L) количество контейнеров,
необходимых дня упаковки: в соответствии с этим правилом. Пусть
Z\\ — множество контейнеров 1-го класса, содержащих один ящик типа
Z\2 — множество контейнеров 1-го класса, содержащих один ящик типа
Z\z — множество контейнеров 1-го класса, содержащих ящик типа а и
ящик типа ft,
Z2 — множество непустых контейнеров 2-го класса,
204
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
. Рис. 6.5
Zs — множество непустых контейнеров 3-го класса,
^4— множество непустых контейнеров 4-го класса.
Пусть далее Z\uZii,Zi$fZ2fZ3,Z4 — число контейнеров вышеуказанных типов,
a a, fti, 62, d — суммарное число ящиков типа a, /?i, #2, S соответственно.
Установим связь между величинами RPF(L) и £*. Согласно правилу RFF,
имеем
RFF(L) = zn + Z12 + *1з + z2 + z3 + 24, (8)
где гц, Zi2,..., za являются функциями от a, 61, &2) ^ и фактических размеров
ящиков. Легко видеть, что
zn +*i3 = а, (9)
*12 + *13= [Ьг/7], (10)
6.2. ЗАДАЧА ОБ УПАКОВКЕ
205
*2=[bi/2], (И)
>гз= [" (62-^12-^13)], (12)
зависимость же величины z± от d и S установить трудно. Будем использовать
следующий метод.
Если известна сумма всего содержимого контейнеров первых трех классов,
то разница между L* и данной суммой является верхней оценкой
содержимого контейнеров из Z*. Докажем, что содержимое всех контейнеров из Z± не
меньше, чем 3/4. Этот факт и верхняя оценка содержимого Z* позволяют
выразить Z* через L* и другие значения. Подставляя данное выражение в (8),
получаем связь между RFF(L) и L*.
Лемма 1. Содержимое всех контейнеров из Z±, за исключением, быть
может, двух, не меньше 3/4, т. е.
3
c(Bj)> - (npuj^i.m).
Доказательство. Пусть Bi — это первый контейнер из Z4, содержимое
которого меньше 3/4, тогда размеры всех ящиков типа S в Bi+\, В*+2,..., должны
быть больше 1/4, иначе в соответствии с правилом первого подходящего ящик
будет подходящим для контейнера В{. Если размеры всех ящиков в Bi+\, <В<+2,
..., больше 1/4 и не больше 1/3 (поскольку S < 1/3), то в каждом из
контейнеров JB^+i, ... размещается три ящика и содержимое каждого контейнера
больше 3/4 (за исключением, возможно, последнего). Иными словами, только
содержимое контейнера В% и последнего контейнера может быть меньше 3/4.
I
Теорема 3.
RFF(L)<^L* + 5.
о
Доказательство. Для того, чтобы получить требуемое неравенство,
рассмотрим три случая:
(i) *12=0,
(ii) Zu > z12 > 0,
(iii) Zi2 > Z\\ > 0.
Случай (i): Z\2 = 0.
В этом случае содержимое контейнеров из первых трех классов не меньше,
12 1
чем -а + -Ъ\ + -Ьг» а содержимое контейнеров из Z± не превосходит
206
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Используя лемму 1, получаем
**<*+t(v-\*-lb-lb). (13)
Подставляя (9) и (13) в (8), получим
RFF(L) < ±L* + io + (ъ - ^ + (*з - |fe) + 2. (14)
Заметим, что
< 1,
^з-|б2 = [f(fe-Lfe/TI)]-g*a
< f|<** - *а/7)] - !•(. + 1
< |(fc-fc/7)-|fc + 2 <16>
< 2-~ln
63
< 2.
Подставляя (15) и (16) в (14) и используя то, что а< L*, получаем
RFF(L)<|L* + 5.
«5
Случай (ii): *ц > Zi2 > 0.
Так как Z\\ > 0 и *i2 > 0, то для В{ € Zn, Б,- € Zi2 выполняется
неравенство
c(Bi) + c{Bj)>l. (17а)
Также справедливо
|<с(Д«)<1 и |<с(Д,)<|. (17Ь)
Используя (17а, 17Ь), видим, что суммарное содержимое первых трех классов
не меньше, чем
3 2 7
!*11 + g*12 + (§ + §) *з + д(2*2 -1) + з(2;гз -1)
3 2 7 4 2, <18)
> -a +-z12 + -z13 + -z2 + -z3-l,
63. ЗАДАЧА ОБ УПАКОВКЕ
207
так как zn +213 = а. Содержимое контейнеров из Za не превосходит L* — (18),
или, по лемме 1,
• „ 4/г, 3 2 7 4 2 \
(19)
~™,тч 4r, 1 7 14 1 1 „4
RFF(L) < -^ + -«+-^--^-^ + -,, + 2-
Подставляя (19) в (8), получаем, что
4_, 1 7 14
- lL +5a+15Zl2"45
4 г. ! 7 14 1 И1/!. ч1 «4
= 3L +5°+15Zl2"45Zl3"l5^ + 9 а»»-*»-*»> + 2§
^ 4rt 1 37 1_ . .
* ZL +5°+90Zl2+18b2+4
^ 4r. 1 /37 1 IV
* 3L +5a+U 7 + 18)б2 + 4"
(20)
Докажем вспомогательное утверждение.
Лемма 2.
Доказательство. При оптимальной упаковке в каждом контейнере, может
содержаться не более одного ящика типа а и одного ящика типа /fc, или два
ящика типа &, поэтому
'■ г;. ■ i(o + b).<L«,
откуда '
6a<2i*-e. (22)
Подставляя (22) в (21), получаем
1 /37 1 1 V /л_. ,
5a+(90-7 + 18J(2L-a)
/37 1 1\ ог. /1 37 1 1\
= iU-7 + i8J-2L+U-90-7-i8j°
< -L* (так как a < L*).
Лемма доказана. i
Продолжим доказательство теоремы 3. Подставляя (21) в (20), получаем
RFF(L)<j|L* + 5.
Случай (ш): Zia > *и > 0.
В этом случае неравенства (17а, 17Ь) также справедливы. Следовательно,
суммарное содержимое первых трех классов равно
2 1 (\ \\ 2/ft " 1/А
3*н + -*i2 + ( - + J 1 *i3 + -(2*2 - 1) 4- -фг3 - 1)
2 1 .1,4 2
208
ГЛАВА 6. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
(23)
4 11
< 3L* + 9°+2*12 + 5
<
Содержимое контейнеров из Z\ не превосходит
^„ 4/„ 2 1 1 4 2 \
Подставляя (23) в (8), получаем
«™„ч 4„ 1 5 2 11
RFF(L) < -L * + ya+-z12--Zi3-—z2 + -z3+4
4 г, 1 5 1
< -L * + ga+-2i2 + g-s3+4
5
lb* + io+ f ^212 + |*|)62+5 (так как ^(a + fc) < L*J
Теорема 3 доказана. I
Теперь построим пример задачи, на котором в действительности
достигается коэффициент 5/3? Упаковка ящиков типа Р\ и f}2 при использовании
правила RFF является достаточно эффективной. Ящики типа /3\
упаковываются в Z2 с заполнением не меньше 80% от оптимального, а ящики типа 02
упаковываются в Z3 с заполнением не меньше 66.67% от оптимального.
Попытаемся построить список, состоящий из ящиков типа 6, за которыми следуют
ящики типа а размера - + €, так, чтобы RFF(L) составляло бы 60% от L*.
В списке, который будет построен, имеется два сорта ящиков типа 6: те,
которые немного больше 1/4, и те, которые немного меньше 1/4, а именно,
имеются ящики размеров:
# = £+€,, (24)
Sr = \-ejy (25)
где ej = 1/47"*"2. Также есть один сорт ящиков типа а размера
Щ = \ + Ч- (26)
Рассмотрим объединенный список L = L1L2, где
b2 = (^,*|,...,*n-l>ab«2,---,Ofn,*f,^).
Оптимальная упаковка, изображенная на рис. 6.6(a), использует L* = п
контейнеров, в то время как упаковка на рис. 6.6(b), построенная по RFF-правилу,
использует
RFF(L) = ^ + 1^ + l + n=ln+l,
6.3. ЗАДАЧА О СОСТАВЛЕНИИ РАСПИСАНИЯ 209
Рис^б.б
откуда RFF(L) = |l* + i.
6.3. Задача о составлении расписания
В этом разделе рассматриваются задачи составления расписания.
Рассмотрим проект, состоящий из нескольких работ (задач), которые требуется
выполнить на некотором оборудовании (станках, машинах, процессорах). Работы
частично упорядочены в соответствии с техническими ограничениями,
например, мыть посуду нужно до того, как ее сушить* Если представлять работы
узлами, а ограничения на порядок работ — ориентированными дугами, то весь
проект может быть представлен ациклическим графом.
В данном классе задач имеется т идентичных машин i\, ft,..., Рт и п
частично упорядоченных работ Гь Г2,...., Тп. Для выполнения каждой работы
Tj требуется tj единиц времени. Задача состоит в том, чтобы назначить маг
шины на исполнение работ так, чтобы завершить весь проект за кратчайшее
время. ч v* •
Сделаем следующие предположения:
i) Все m машин одинаковы, т. е. каждая машина может выполнять любую
работу.
210
ГЛАВА 6. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
рх
А
Р,
. Г'
3
, Г*.
2
.Г».
2
■
Г<,
2
0
2
т,
9
Г5 ,
4
Г« ,
4
■
Ъ ,
4
Г« ,
4
№12
Рис. 5.7
ii) Всякий раз, когда машина не занята и есть некоторая работа, данная
машина должна начать исполнение згой работы.
Ш) Начав исполнение какой-либо работы, машина должна ее выполнить до
полного завершения.
iv) В самом начале известен список L = (2^,1^,...,!^), в соответствии с
которым работам присваиваются приоритеты8. Этот список
представляет собой некоторую перестановку всех работ. В каждый момент времени,
если машина не занята, то назначаем эту машину на исполнение
работы с наивысшим приоритетом из списка L, которую можно начать.
Если число имеющихся в наличии работ больше числа свободных машин,
то все машины назначаются на исполнение работ с наивысшими
приоритетами. В соответствии с частичным упорядочением работ, работа с
низшим приоритетом может выполняться перед исполнением работы с
высшим приоритетом. Если же машин больше, чем работ, то можно
назначить любую машину. (Для полной определенности алгоритма примем
соглашение о том, что на исполнение назначается машина с наименьшим
номером.)
На рис. 6.7 показан проект, состоящий из 9 работ. Эти работы
обозначены Т\, Гг, ..., Тр. Время выполнения каждой работы записано внутри
соответствующего узла. ТЬким образом, для завершения работы Т\ требуется 3
единицы, а дня завершения работы Т9 нужно 9 единиц времени. Ни одна из
работ Тб, Тб, Ту и Т% не может начаться до тех пор, пока не будет завершена
работа Та* С другой стороны, выполнение работ 7\, Т2, Т3 и Т4 можно начать
в любой момент времени. Имеется три одинаковых машины: Pi, Р2, Р3. Когда
будут завершены все работы, если L = (ГьТд,... ,!§)?
Поскольку есть три машины и четыре доступные работы, вначале
исполняются работы 7i, Т2, Тз с более высокими приоритетами. Назначаем машине
с наименьшим номером выполнение работы с наивысшим приоритетом. После
8Чем раньше работа встречается в этом списке, тем больший приоритет она имеет. —
Прим. перев.
6.3, ЗАДАЧА О СОСТАВЛЕНШ РАСПИСАНИЯ 211
того, как Р<2 и Рз завершат выполнение работ Г2 и Тз, останется только одна
доступная работа Т±, исполнение которой будет поручено Pi. После того, как
Pi завершит работу 2\, доступной останется только Тд, исполнять которую
будет Pi. Все назначения машин на работы представлены на рис.6.7 тремя
линиями, а суммарное время завершения составляет и = 12. Заметим, что
машина Рз остается незанятой в течение двух единиц времени, поскольку в
этот промежуток никакая работа недоступна.
Вспомним, что по предположению выполнение любой работы нельзя
прервать. Как только машина получает работу, она должна ее выполнить
полностью. Данное предположение не является обременительным. Если бы работу,
продолжительность которой равна t\ +$2, можно было прервать по истечении
времени ti, то ее всегда можно было бы преобразовать в две работы,
соединенные ориентированной дугой, длительность исполнения первой из которых
равна t\, а второй — £2« Таким образом, предполагая невозможность прерываг
ния работ, мы не уменьшаем общности. Предположение об отсутствии
времени на подготовку, состоящее в том, что машина, закончившая работу, морсет
немедленно приступить к исполнению другой работы, не очень реалистично,
однако можно объединить время на подготовку с временем исполнения.
Будем считать, что никакая машина не должна простаивать, если можно начать
хотя бы одну работу. Расписание «без простоев» приводит к многим странным
явлениям. Вот несколько из них:
У величине числа машин может привести к увеличению суммарного
времени работы. ^
Если на рис. 6.7 увеличить число машин с трех до четырех, а все другие
данные оставить без изменения, то время завершения возрастет с 12 до
15 единиц (см. рис. 6.8).
Ослабление ограничений на порядок выполнения работ может привести
к увеличению суммарного времени работы.
Бели удалкггь ориентированные дуги из Д в Г5 и из Г4 в 2в> то
получим проект, показанный на рис. 6.9, где штриховые линии соответствуют
ограничениям, удаленным из рис. 6.7. Тогда в соответствии со списком
приоритетов L = (Ti,7b,... ,Tg) весь проект займет 16 единиц времени
вместо прежних 12.
Уменьшение времени выполнения некоторых работ может привести к
увеличению времени исполнения всего проекта.
На рис. 6.10 показан, тот же самый проект, как и на рис. 6.7, за
исключением того, что времц исполнения каждой работы уменьшаю на единицу.
Можно проверить, что суммарное время завершения нового проекта
составляет и) = 13 единиц.
Нетрудно понять, что причина всех этих странных явлений объясняется
тем, что мы используем неудачный список приоритетов L. На рис. 6.11
показан пример проекта, на выполнение которого на двух машинах требуется
30 единиц времени. Если же использовать три машины, ослабить некоторые
212
ГЛАВА А ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Р, г Г' . Г» t
3 4
р2 , га, т5 -, г,
2 4 9
^ i Гз i Г« i
(0=15
Ц ■ Т<* Т'
Рис. 6.8
ограничения и уменьшить время исполнения каждой работы, то на проект
потребуется 31 единица времени вне зависимости от того, каков список
приоритетов L\
Даже если исполнение каждой работы занимает одну единицу времени,
увеличение числа машин может увеличить общее время. Это показано на
рис.6.12 для списка приоритетов L— (Ti,T2,...,Ti2).
Несмотря на эти необычные примеры можно получить несколько общих
результатов.
Теорема. Пусть имеются проект, список приоритетов L и минимальное
время и, достаточное для завершения всего проекта. Если список
приоритетов L заменить на список V, то минимальное время о/, достаточное для
завершения проекта, можно ограничить сверху:
(1)
где т — число машин.
Перед доказательством теоремы покажем, что верхняя оценка (1) является
точной (достижимой). На рис. 6.13 представлены три примера без
ограничений на порядок, на основании которых читатель может составить
представление об общая случае.
%
Т4
.>>'
т,
т,
Tf
Ъ
Рг
Рг
. г, , Г, , Г,
3 * . 9
.Тг.Ъ. Ъ ,
2 2 4
,г,, г,, Г, ,
2 4 4
0=16
т,
Рис. 6.9
6.3. ЗАДАЧА О СОСТАВЛЕНИИ РАСПИСАНИЯ
213
. *...
1 1
JS&L
Г5 .
3
3
Г, , 0 ,
3
7i
8
0
1 1
ш=13
Рис. 6.10
Pi
. 5 .
lI.
5 ,
5 ,
10
1
20
10 ,
•
09=30
4 4
4 ,
19
1
9
J3
Рис. 6.11
Р, , Г*
Й, . г,
1» . Я
Л , Г1
к . Г*
ч ■ гз
р, . п
Л tJL
»=31
. П , т9
, г. , г,
1 *? . г»
, Tii , *ft
. Г,-;Т„
. % ■
. г, .
. Я .
j-J-j
|
1
1
|
ш=3
ь
ai=4
Рис. 6.12
214
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
т=2
/>Li_J />lx I l I
/jlLlLi- рг\х\ i I
со = 2 ю' - 3
i» i 3 i pxl
т-
Рг\ 2 I1 I J>1 2 I £.
р,\ 2 i11 ^lLjlLi £.
а> = 3 a>'e5
т = 4
JJI « I /JL
^1 I LJJ P2L
/>L_J_I±J Ръ1 3 I J I
p» 3 t1» ^l1 I1 I1 I t I
a> = 4 <o'=*7
Для произвольного m справедливо a/ = I J и
Рис. 6.13
Доказательство. Для доказательства теоремы сделаем несколько замечаний.
1. В любой момент времени бездействует не более m — 1 машин.
2. Окончание каждого простоя ф совпадает с завершением работы на
другой машине. (Причина, по которой машина Р» после простоя вновь наг
чинает работать, объясняется завершением некоторой работы 7* на
машине Р*, что позволяет выполнить работу Ту Здесь из 7* выходит
ориентированная дуга в Tj.) Для обозначения того, что работа 7*
предшествует Tj, будем использовать запись 7* < 7}.
3. Если <t>j — простой машины Pj, за которым следует выполнение работы
Tj, то существует такая работа 7*, что 7* < 7}, поскольку в противном
случае исполнение работы Tj можно было бы начать раньше. Если 7*
короче ф}, то существует некоторая работа Tq < 7$, так как в противном
случае работу 7* можно было бы начать на машине Pj. Повторяя эти
рассуждения, получим упорядоченную последовательность работ,
длительность которых целиком покрывает все время простоя. Например,
на рис. 6.14 это работы
Те < 7V < Т2 < Т9 < Т1Ь < Гц < 7\2.
Обозначим множество таких работ через J*.
6.4. РАСПИСАНИЕ С ДРЕВЕСНЫМИ ОГРАНИЧЕНИЯМИ 215
Г, ф Г7 Г, Т9 Тк Г, Г4
Р, I I | I 1 I | I I
л, * I ' JV,
Рис. 0.1*
4. Время исполнения J* должно быть не больше оптимального времени
исполнения и всего множества работ J. Так как множество J* образует
упорядоченную цепочку, то
m у*' ■■*« /
< — {ты + (m - l)w)
Мы воспользовались тем, что
mi6,
поскольку в оптимальном расписании могут быть простои, и
Е*(&)
потешу что простаивать может не более т -1 машин, а также вследствие
того, что суммарное время простоя меньше и.
Теорема доказана. i
6.4. Задача о расписании
с древесными ограничениями
В предыдущем разделе мы обратили внимание читателей на многие
аномалии) появляющиеся при составлении расписания. Поэтому кажется
неправдоподобным, что для решения общей задачи составления расписания можно
найти эффективный алгоритм, строящий оптимальное решение. Однако
можно попытаться использовать следующие методы:
216
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Рис. 6.15
а), Использовать эвристический алгоритм. Такой алгоритм может
получить или не получить оптимального решения. Поэтому необходимо
описать случаи, при которых получается оптимальное решение, и оценить
величину ошибки в других случаях. Этот метод использовался в
разделе 6.1 для жадного алгоритма.
Ь) Рассмотреть специальные случаи. Например, задача об упаковке из
раздела 6.2 может рассматриваться как частный случай задачи о
составлении расписания, в которой нет упорядочения работ. Можно также
указать другие частные случаи. Например, задача с двумя процессорами
решена в [4]. Задача, в которой порядок выполнения работ описывается
деревом, решена в [7]
В этом разделе рассмотрим специальный случай, в котором порядок
выполнения работ описывается деревом и на выполнение каждой работы требуется
одна единица времени. Заметим, что среди работ нет приоритета, за
исключением ограничений на порядок. Пример дерева, описывающего возможный
порядок, см. на рис. 6.15. Заметим, что корень дерева располагается внизу на
первом уровне.
В этом разделе мы опишем алгоритм, строящий оптимальное решение
задачи составления расписания с древесными ограничениями для т процессоров
(т произвольно), и найдем формулу для нахождения минимального числа
процессоров, необходимых для выполнения работ в требуемый срок.
Используя рис. 6.15, введем несколько терминов. Узел Та называется
корнем дерева и располагается на самом низшем уровне. Узел находится на
уровне А;, если единственный путь от него до корня состоит из к — 1 дуг.
Таким образом, Тс находится на втором уровне, а Г* — на четвертом. Если
есть ориентированная дуга из Т< в!}, то Т{ называется отцом Ту Узел без
отца называется начальным узлом. На рис. 6.15 начальными являются узлы
Г/, Tj, IV, Tl, То, Th и Td- Бел» выполняется некоторая работа, то из дег
рева удаляется соответствующий узел, Таким образом, после удалений узлов
6.4. РАСПИСАНИЕ С ДРЕВЕСНЫМИ ОГРАНИЧЕНИЯМИ 217
Г/, Tj, Тк узел Те станет начальным узлом результирующего дерева. Дерево
имеет высоту Л, если максимальный уровень равен h.
Конечно же, высота дерева изменяется по мере того, как удаляются узлы.
Для описанного ниже алгоритма мы определим высоту дерева и суммарное
число начальных узлов как функцию времени.
Алгоритм заключается в удалении узлов из максимального уровня. В
неоднозначных ситуациях удаляются самые левые узлы. Так, на рис. 6.15 при
т = 3 на первом шаге будут удалены!узлы Г/, Tj, Г*, на втором шаге —
Тьу Теу Toy а на третьем шаге — 7>, Т#, ТЪ.
Очевидно, что проект, которому соответствует дерево высоты Л, нельзя
завершить за Л — 1 единиц времени вне зависимости от того, сколько имеется
доступных процессоров. Следовательно, всякий путь «©у узла из
максимального уровня до корня является критическим. Описанный алгоритм назовем
алгоритмом критического пути. Докажем, что алгоритм критического пути
строит оптимальное решение для любого древовидного графа.
Пусть р(а) — это число узлов на уровне a, s(а) — число начальных узлов
этого уровня, а с(а) — число покрытых узлов из а (покрытыми называются
узлы, имеющие отцов), тогда
р(а) = s(a) + с(а).
На рис. 6.15
р(4)=р(3) = 4;1 а(3) = с(3) = 2.
Если число процессоров зафиксировано и есть точный алгоритм удаления
узлов из дерева, то обозначим через Pt{a) и st(a) соответственно величины
р(а) и s(a) дерева, оставшегося по истечении t единиц времени. Пусть число
процессоров равно 3 и используется алгоритм критического пути. По
истечении одной единицы времени -^яосде удалзщя узлов (7/*Т^Тк).г--*1Юцучим
Pi(4) = 1. Аналогично по истечении двух единиц времени — после удаления
узлов (TiyTjyTx) и (Tl,Te,Tq) — имеем 52(3) = 2. Определим величину
St(a) = <£8t(j)
как суммарное число начальных узлов уровня а и более высоких уровней.
Тогда 5^(1) — это Общее число начальных узлов во всем дереве в момент
времени £.
Пусть ш0 — кратчайшее время завершения всех работ. Тогда
' u>o>h.; ' л (1)
Данное неравенство называете* ограничением по высоте.
Поскольку суммарное числоудаленных узлов 'не- может Превысить cj0m,
получаем неравенство * г " '
218
ГЛАВА 6. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Рис. 6.16
называемое ограничением по ширине.
Оба неравенства (1) и (2) являются специальными случаями оценки
Шо >
т
i=7+i
Pti)
т
+ 7 (0<7<Л).
(3)
Например, что (1) получается из (3) при 7 = Л, а (2) получается из (3) при
7 = 0. Грубо говоря, все узлы, лежащие выше уровня 7> в заданный момент
времени удаляются по m штук, а высота оставшегося дерева становится равна
7, откуда и следует оценка (3). Она называется ограничением по ширине и
высоте и является нижней оценкой для всех деревьев.
На рис. 6.15 при щ = 3, 7 = 1 оценка (3) дает значение Г11/3] 4-1 = 5.
Алгоритм критического пути также получит 5 единиц времени. Не очевидно,
что в дереве всегда найдется уровень 7+ h на котором удовлетворяется оценка
(3). Мы покажем, что все узлы из уровня 7 +1 и выше удаляются группами
по m узлов на каждом шаге, за исключением, быть может, последнего шага
на уровне 7 + 1- Также не очевидно, как выбирается уровень 7 + 1-
Для иллюстрации того, как выбирается уровень 7+1, применим алгоритм
критического пути при m = 3 к рис. 6.16.
6.4. РАСПИСАНИЕ С ДРЕВЕСНЫМИ ОГРАНИЧЕНИЯМИ 219
Таблица 6
Уровень
Удаление
7
Y
6
N
5
Y
4
N
3
Y
2
Y
Т1
Yj
Узлы, удаленные на последовательных шагах, можно представить в виде
цепочки
(Л,В,С), (&&£), (&i> -0. UL ЛГ.Ь), (М,&0), (Р,Я,Г), (Q), (5), (Щ,
где подчеркивание обозначает то, что узлы лежат в максимальном уровне
текущего дерева.
Заметим, что некоторые уровни содержат много узлов и не могут быть
удалены за один единственный шаг, когда данный уровень становится
максимальным уровнем текущего дерева. С другой стороны, в каком-нибудь уровне
может находиться много узлов, большинство из которых являются
начальными. Эти начальные узлы удаляются до того, как данный уровень станет
максимальным. После того, как данный уровень станет максимальным, в нем
может оказаться не более m узлов, тогда эти узлы будут удалены за один шаг.
Записав информацию о том, удаляется ли на рис. 6.16 уровень за один
шаг, когда он становится максимальным, получим таблицу 6, в которой «Y*
означает «да», a «N» — «нет».
Всегда полагаем, что 7 + 1 равно самому низкому уровню, которому
соответствует значение «N». В нашем примере 7 +1 = 4, т. е. 7 = 3. Правая часть
оценки (3) равна
+7=р+1^6+1|+з=б+з=9;
Для доказательства того, что алгоритм критического пути находит
оптимальное решение, докажем два свойства.
(i) Когда узлы удаляются пот штук за единицу времени, все они находятся
на уровне 7 + 1 или выше, за исключением последнего шага, на котором
освобождается уровень 7 + 1*
(ii) Когда высота дерева равна 7> все узлы можно удалить за у шагов.
Свойство (ii) следует из определения величины 7* Докажем (i), используя
то, что граф является деревом.
В дереве ни у какого узла не может быть более одного сына, значит, ври
последовательном удалении узлов общее число начальных узлов любого уровня
монотонно убывает, т. е.
StO)>St+1U) (* = 0,1,-.-)- (4)
В частности,
$(7 + 1)>Яи(7+1). (5)
EpU)
1=7+1
220 ГЛАВА 6. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
Если все уровни помечены меткой «N», то, очевидно, условие (i)
удовлетворяется. Если уровень а помечен меткой «Y», то
Л(а) = St{q) < т (а>7 + 1)<
Не исключено, что некоторые узлы ниже уровня 7 + 1 удаляются вместе с
узлами из максимального уровня, поскольку неравенство может выполняться
строго, т. е. pi (а) = St(a) < т. Покажем, что это может произойти только на
последнем шаге.
По предположению, если уровень 7 + 1 стал максимальным в момент
времени **, то
р*'(7 + 1)>т,
или **(7 + 1) > w>
или S? (7 + 1) >т>
откуда
St(7 + l)>m при* «С*1.
Отсюда следует, что в каждый момент времени t < if имеется не меньше
m доступных начальных узлов на уровнях выше 7- Таким образом, никакие
узлы из уровней ниже 7 + 1 не удаляются до момента времени t* - 1, где t*
— момент времени, в который высота дерева впервые стала равна у.
Следовательно, нижняя оценка (3) всегда достигается. Если же все уровни
помечены меткой «Y», то'7 — А и (3) сводится к (1).
Доказав, что алгоритм критического пути всегда находит оптимальное
решение, рассмотрим далее вопрос: сколько потребуется процессоров, если
проект должен быть завершен за Л + с шагов?
Определим величину 7* при помощи равенства
Пусть m — целое число, удовлетворяющее неравенствам
«-><»=£+:. &*?*"■ (7)
Лемма 3. Если ограничения на порядок образуют дерево высоты h, aj*,m
и с определены ьодтпошспиями (б) и (7), то т — это минимальное число
процессоров, необходимых для завершения проекта заН + с единиц времени.
Доказательство. Докажем вначале, что (т - 1) процессоров будет недостаг
точно. Заметим, что общее число узлов на уровнях от 7* +1 до ft превосходит
(т - 1)(Л - 7* + с). Если бы узлы удалялись по (т -1) штук на каждом шаге,
то по истечении Л — 7* + с шагов на уровне 7* +1 остался бы по крайней мере
УПРАЖНЕНИЯ
221
один узел. Это означает, что для завершения процесса нужно не менее 7*'Н-1
шагов, следовательно, всего потребуется не меньше, чем
(h - 7* + с) 4- (7* + 1} = Л +■« +1 шагов.
Это доказывает, что m - 1 процессоров будет недостаточно.
Убедимся теперь, что га процессоров будет достаточно. Если каждый
уровень удаляется за один шаг, то все дерево можно удалить за А шагов. Если
же за один шаг можно удалить не все уровни, то должен существовать самый
низкий уровень, который нельзя удалить за один шаг, когда этот уровень
становится максимальным. Пусть этот уровень 7 + 1-
Тогда в соответствии с алгоритмом все узлы, находящиеся на уровнях Л,
h — 1, ..., 7 •+ 1* удаляются по m штук за единицу времени. Следовательно,
суммарное время, необходимое для удаления узлов из уровня 7 + I и выше,
равно
""l h I
i=7+i j
т. е. все узлы, находящиеся на уровнях 7 + 1 и выше, удаляются за h - 7 + с
шагов* В оставшемся дереве имеем а уровней, каждый из которых можно
удалить за один шаг, а все уровни можно удалить за у единиц времени.
Следовательно, общее время составляет
(h-y + c)+y^h+c
Упражнения
1. Пусть веса всех монет совпадают, а номинальные стоимости
соответственно равны 1, 4, 7, 9. Будет ли при этих условиях работать жадный
алгоритм? Что произойдет, если номинальные стоимости изменить
соответственно на 1, 5, 14, 18?
2. Построить пример списка, на котором BF-правило работает лучше, чем
FF-правило.
3. Нарисовать граф, определяющий порядок выполнения работ на рис. 6.14.
4. В алгоритме упаковки Яо га-й ящик, типа $2 помещается в контейнер
1-го класса, где m может принимать значения 7, 8 и 9. Каким будет
наихудшее значение коэффициента, если ящиков типа & не существуете
Каким было бы значение коэффициента, если бы все ящики типа 02
помещались в контейнеры 3-го класса?
5. Обобщите алгоритм составления расписания из раздела 6.4 на случаи
кратных деревьев, входных и выходных деревьев.
(Во входном дереве у каждого узла есть не более Одного сына, а в
выходном дереве у каждого узла есть не более одного отца.)
222
ГЛАВА б. ЭВРИСТИЧЕСКИЕ АЛГОРИТМЫ
6. Прочитайте статью
Muntz R.R., Coffman E.G., Jn. Preemptive scheduling of real-time tasks on
multiprocessor systems // J. Assoc. Comput. Mach. 17, 324-338 . — 1970..
Литература
Теорему 1 можно найти в [10], ее доказательство взято из [6]. Оценки
ошибки эвристического алгоритма указаны в [10], [12]. Если записать номинальные
стоимости монет в последовательность, то теорема 1 будет описывать условие
того, что последовательность даст оптимальное решение, если ее
подпоследовательность также дает оптимальное решение. Однако есть случаи, в которых
последовательность дает оптимальное решение, а ее подпоследовательность —
нет. Такой случай изучен в [9].
Классическим трудом по алгоритму упаковки является докторская
диссертация Д. С. Джонсона [8]. В ней получено большинство оценок для правил
NF, BF, FFD и т. д. О приложениях упаковки к задачам составления
расписания со многими машинами см. [3]. Алгоритм Яо и несколько других
интересных результатов получены в [13]. Оценку эвристического алгоритма задачи о
расписании можно улучшить, если все работы имеют примерно одинаковую
продолжительность [1].
Первой работой по составлению расписания является [7]. Подробный обзор
приведен в книге [2]. Более современный обзор см. в [5]. Задача с двумя
процессорами для произвольного графа ограничений решена в [4]. Доказательство
корректности алгоритма критического пути из раздела 6.4 является новым.
Обобщение этого алгоритма описано в [11].
1. Achugbue J. О., Chin F.Y. Bounds on Schedules for Independent Tasks with
Similar Execution Times // University of Alberta Tech. Report 79-2.
2. Coffman E. G. Jr. (ed.) Computer and Job Shop Scheduling Theory. — Wiley
к Sons, 1976.
3. Coffman E.G., Garey M.R., Johnson D.S. An Application of BinPacking to
Multi-Processing Scheduling // SIAM J. Comput. - Vol.7, Nol. - 1978. -
P. 1-17.
4. Coffman E. G., Graham R. L. Optimal Scheduling for Two-Processor Systems
// Acta Informatica. - 1972. - Vol. 1. - P. 200-213.
5. Graham R. L. The Combinatorial Mathematics of Scheduling // Scientific Amer.
- 1978. - Vol. 238, No3. - P. 124-132.
6. Hu T. C, Lenard M. L. Optimality of a Heuristic Solution for a Class of
Knapsack Problems // Oper. Res. - Vol. 24, No 1. - 1976. - P. 193-196.
7? Ни Т. С Parallel Sequencing and Assembly Line Problems // Oper. Res. —
1961. - Vol.9, No6. - P.841-848.
ЛИТЕРАТУРА
223
8. Johnson D.S. Near-Optimal Bin-Packing Algorithms // MIT Report, MAC
TR-109, June 1973.
9. Johnson S. G, Kernighan B. W. Making Change with a Minimum Number of
Coins // Bell Telephone Report, Murray Hill, New Jersey.
10. Magazine M., Nemhauser G.L., Trotter L.E., Jr. When the Greedy Solution
Solves a Class of Knapsack Problems // Oper. Res. — 1975. — Vol. 23. —
P. 207-217.
11. Nett E. On Further Application of the Hu Algorithm to Scheduling Problems
// Proceedings of 1976 International Conference on Parallel Processing, Ens-
low P. H., Jr. (ed.).
12. Tien B. N., Ни Т. С Error Bounds and the Applicability of the Greedy Solution
to the Сощ-Changing Problem // Oper. Res. — Vol.25, No3. - 1977. -
P. 404-418.
13. Yao A. С New Algorithms in Bin-Packing // Stanford University Report,
STAN-CS-78-662.
Глава 7
Матричное умножение
Матричное исчисление —
арифметика высшей математики.
7.1. Алгоритм Штрассена умножения матриц
Матричное исчисление обычно рассматривается как раздел линейной
алгебры или численного анализа. В настоящей главе мы представим два
результата о матричном умножении, относящихся к комбинаторике. Первый,
принадлежащий Штрассену [15], имеет дело с умножением двух квадратных
матриц. Второй результат, принадлежащий Ху и Шингу [9]—[11], касается
оптимального порядка умножения цепочки матриц разных размеров.
Рассмотрим умножение двух 2x2 матриц:
(Сц Ci2 Л / ац а\2 \ ( Ь\\ Ь\2
С21 С22 / \ Л21 <*22 / \ ^21 &22
Элементы с# определены обычным образом:
Сц = ац6ц +012621,
Cl2 = ДцЬ12 + 012^22,
021 = Cfclftll + ^22^21,
С22 = 021&12 + Л22&22-
Заметим, что в (2) требуется 8 умножений и 4 сложения. В общем случае
для умножения двух т х т матриц требуется т3 умножений и т2(т — 1)
сложений.
Прямой способ умножения матриц использовался в течение многих лет.
Неожиданным было открытие Штрассеном [15] в 1969 г. нового способа
умножения. Для произведения (1) этот способ требует 7 умножений и 18 сложений
(1)
7.1. АЛГОРИТМ ШТРАССЕНА УМНОЖЕНИЯ МАТРИЦ
225
Сц = d\ + da
Cl2 =
c2i =
с22 = d\
-dA
d4
-d3
+ <*7,
+ <*e,
cfc + ^7,
- d$ + de.
и вычитаний обычных чисел. Если метод используется рекурсивно для двух
очень больших га х га матриц, то он требует 0(ralog27) умножений.
Чтобы представить новый способ умножения, вначале определим 7
произведений:
d\ = (an + a22)(bn + 622)?
da = (ai2 - 022X^1 + ^22),
<fe = (an - 02i)(ftn + 612),
d\ == (an + 012)622, (3)
db = (021 +022)611,
de = an(fti2 - 622),
<*7 = a22(-bn -ffei)-
Элементы c# могут быть выражены через d* следующим образом:
(4)
Легко проверить, что (2) и (4) эквивалентны и что в (3) и (4) используется
7 умножений и 18 сложений и вычитаний.
В случае умножения двух га х га матриц, где га — степень 2, каждую
матрицу можно разбить на четыре подматрицы, а именно
/ Сц Съ\^( Ап А12 \ ( Вп ВХ2 \ .
\ Сч\ Счч ) \ Ач\ Аъч J \ -B2i В22 /
и использовать приведенные выше формулы рекурсивно1.
Пусть Г (га) — время, необходимое Для умножения двух га х га матриц
приведенным алгоритмом. Из (3), (4) получаем следующее рекуррентное
соотношение:
Г(т) = 7Г(|)+18-(^)2 длят>2. (6)
Решая (6), получаем
Г(т)=0(т,0«*7) = 0(т2'81).
Результат В. Я. Пана [13] является асимптотическим улучшением результата
Штрассена2. Другие результаты, относящиеся к сложности арифметических
алгоритмов, см. в работе Винограда [16].
1Если m не является степенью двойки, то метод Штрассена предполагает окаймление
матриц нулями. Об оптимальном окаймлении см. в [37*]. — Прим. персе.
2Алгоритм, предложенный Паном, имеет трудоёмкость 0(т2781). В 1987г. был
предложен [39*] алгоритм умножения матриц с трудоемкостью 0(т237в). — Прим. перев.
226 ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
7.2. Оптимальный порядок умножения матриц
Рассмотрим произведение четырех матриц:
М = М1 X М2 X Мз X М4
[10 х 11] [11 х 25] [25 х 40] [40 х 12]
(под каждой матрицей записаны ее размеры). Так как матричное умножение
удовлетворяет ассоциативному закону, то конечный результат М не зависит от
расстановки скобок в (1). Обычный алгоритм для умножения pxq матрицы на
q х г матрицу используетрх q хг умножений. Следовательно, для выполнения
умножения (1) в порядке, показанном в (2),
М = ((Mi х М2) х М3) х М4, (2)
требуется
10 х 11 х 25 + 10 х 25 х 40 +10 х 40 х 12 = 17550 умножений.
Тогда как для выполнения умножения (1) в порядке
М = Мгх(М2х (М3 х М4)), (3)
требуется
25 х 40 х 12 + 11 х 25 х 12 + 10 х 11 х 12 = 16620 умножений.
Можно построить примеры, в которых плохой порядок умножения приводит
к намного большему числу операций, чем оптимальный порядок умножения
(см., например, [1]).
Итак, задача заключается в нахождении порядка вычисления
произведения п — 1 матриц
М = Mi х M2x...xMn_i, (4)
где Mi — матрица размера Wi х ttfi+i, такого, что общее число умножений
элементов матриц минимально. Каждый порядок умножения матриц
соответствует какому-то способу расстановки скобок вокруг п — 1 символов;
существует
(2(п-2))!
(п-2)!(п-1)!
способов расстановки п — 2 пар скобок3.
Для нахождения оптимального порядка умножения можно использовать
динамическое программирование (см. главу 3, а также [1], [6], [8], [14]). Этот
3Что равно элементу С7П_2 последовательности Каталана
с С2")' ,п_01 ч
См. далее. — Прим.перев.
7.3. ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 227
Рис. 7.1. Триангуляция шестиугольника
подход требует 0{п3) операций. Алгоритм с трудоемкостью 0(п logп) был
разработан Ху и Шингом [11], однако мы не описываем его здесь. В данной глазе
сначала мы сводим задачу об оптимальном умножении цепочки матриц к
задаче разбиения выпуклого многоугольника на непересекающиеся треугольники,
затем доказываем несколько теорем об оптимальном разбиении. На основе
этих результатов мы строим эвристический алгоритм [12] с трудоемкостью
0(h) и ошибкой, не превосходящей 15%.
7.3. Триангуляция выпуклого многоугольника
Задача умножения цепочки матриц заключается в нахождении
оптимального порядка умножения п — 1 матриц
M = MixM2x Mn_i, (1)
где Mi — Wi х Wi+i матрица. Рассмотрим задачу, на первый взгляд, не
связанную с предыдущей, — триангуляцию выпуклого многоугольника.
Пусть задан выпуклый многоугольник с п вершинами, например,
шестиугольник, изображенный на рис. 7.1. Число способов разбить этот
многоугольник на п—2 треугольников непересекающимися диагоналями, равно (п - 2)-му
числу Каталана (см., например, [7]). Таким образом, существует 2 способа
триангуляции выпуклого четырехугольника, 5 способов триангуляции выпуклого
пятиугольника и 14 способов триангуляции выпуклого шестиугольника.
Пусть вершина VJ выпуклого многоугольника имеет вес ги$. Определим
стоимость разбиения по следующему правилу. Стоимость треугольника равна
произведению весов его вершин, стоимость всего рабиения равна сумме
стоимостей треугольников, составляющих разбиение. Например, стоимость
разбиения шестиугольника, изображенного на рис. 7.1, равна
W1W2W3 + WiWsWb + W3W4We + WiWsWq. (2)
Бели стереть диагональ Vs V* и заменить ее на диагональ V\V±> тогда стоимость
нового разбиения будет равна
WlttfeWs + W1W3W4 + W\WiWe + WtWbWe. (3)
228
ГЛАВА 7. МАТРИЧДОЕ УМНОЖЕНИЕ
Для краткости вершину V{ с весом Wi будем обозначать од, выпуклый
многоугольник с п вершинами будем называть п-угольником, разбиение п-уголь-
ника на п — 2 непересекающихся треугольников будем называть
триангуляцией п-угольника.
Взаимно-однозначное соответствие между всеми способами вычисления
произведения (п — 1) матриц и триангуляциями выпуклого n-угольника
можно установить следующим образом. Для каждого многоугольника одну из его
сторон будем рисовать внизу, горизонтально; на рис. 7.1 такой стороной
является сторона ViVq. Эта сторона называется базисной. Все остальный стороны
рассматриваются по направлению часовой стрелки. Таким образом, V\Vi —
первая сторона, V2V3 — вторая сторона,..., V^Ve — пятая сторона. Первая
сторона соответствует первой матрице в цепочке, вторая сторона соответствует
второй матрице,..., базисная сторона соответствует конечному результату М
в (1). Размеры матрицы совпадают с весами вершин, которые являются
концами соответствующей стороны (напомним, что перемножаемые матрицы
должны иметь согласованные размеры). Диагонали соответствуют произведениям
подцепочек. Стоимость триангуляции совпадает с общим числом операций,
необходимым для перемножения всех матриц в цепочке в соответствующем
порядке.
Можно установить взаимно-однозначное соответствие между
триангуляциями n-угольника и алфавитными деревьями сп-1 листьями или
способами расстановки скобок в последовательности из п символов (см., например,
[5]). Легко также установить соответствие между порядками перемножения
п — 1 матриц и алфавитными бинарными деревьями или способами
расстановки скобок. Здесь мы явно установим взаимно-однозначное соответствие
между порядками вычисления произведения цепочки матриц и триангуляциями
п-угольника.
Теорема 1. Каждый порядок перемноженияп-\ матриц соответствует
триангуляции п-угольника.
Доказательство. Воспользуемся индукцией по числу матриц. Существует
лишь один способ перемножения двух матриц размеров w\ х Ш2 и од х Шз-
Это соответствует треугольнику, дальнейшее разбиение которого не
требуется. Общее число операций равно ододод» что совпадает с произведением весов
вершин треугольника. Результирующая матрица имеет размеры W\ х w3. Два
способа перемножения трех матриц: (Mi х М*) х Мз, М\ х (М2 х Мз) —
соответствуют двум способам триангуляции четырехугольника.
Предположим, что теорема справедлива для А: матриц, где А: < п - 2,
рассмотрим случай п-1 матриц. На рис.. 7.2 показан соответствующий п-угольник.
Пусть порядок перемножения определяется формулой
М = (М\ х М2 х • • • х Mp_i) х (Мр х • • • х Afn_i),
т.е. финальная матрица получается перемножением двух матриц размеров
tui х wp и wp х wn. Пусть в триангуляции n-угольника в треугольнике с
вершинами w\ и wn третья вершина — wp. Тогда многоугольник iuiiu2.. .wp —
7.3. ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 229
Рис. 7.2. Иллюстрация к доказательству теоремы 1
выпуклый, и его триангуляция соответствует некоторому порядку
перемножения матриц М1,..., Mp-i, где в произведении получается матрица размера
W\ х wp. Аналогично, триангуляция многоугольника wpWp+i ...wn
соответствует некоторому порядку перемножения матриц Mp,...,Mn_i, где в
произведении получается матрица размера wp х wn. Итак, треугольник W\Wpwn
соответствует произведению двух подцепочек, причем в произведении
получается матрица размера W\ х wn. I
Триангуляции, соответствующие (2) и (3) из раздела 2, показаны на рис. 7.5.
Теорема 2. Вычисление каждого из произведений
Mi х М2 х *., х Mn_2 хМп-и
Мп х Mi х ... х Mn_3 xAf^_2,
Мг х М3 х ... х Мп_! хМп,
где М{ — ^iampwt^a рделсеров щ х uii^i и Wn+i = Щ, требует одного и того
же минимального количества операций. (Заметим, что в первой цепочке
результирующая матрица имеет размеры W\ xwn. В последней цепочке
результирующая матрица имеет размеры од х ед. Но во всех случаях общее
число операций при оптимальном порядж умножения одно и то оке.)
Доказательство. Все циклические перестановки последовательности из п -1
матриц соответствуют одному и тому же «-угольнику и, следовательно,
соответствуют одному и тому же оптимальному разбиению. , ■
(Приведенная теорема независимо была получена в [4], но там имела
длинное доказательство.) .
Далее рассматривается только задача об оптимальной триангуляции.
Диагонали многоугольника называются дугами. Таким образом, каждая
триангуляция состоит из п — 2 треугольников, образованных п — 3 дугами и
п сторонами. В триангуляции п-уго#ьника степень вершины равна числу дуг,
инцидентных этой вершине, плюс 2 (так как каждой вершине инцидентны
еще две стороны многоугольника).
230
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
Лемма 1. В любой триангуляции п-угольника4 по крайней мере два изп — 2
треугольников образованы двумя сторонами и одной дугой, т. е. каждый из
этих треугольников имеет вершину степени 2. (Например, в триангуляции
на рис. 7.1 треугольник V\ V2V3 имеет вершину V2 степени 2, и треугольник
VtVbVe имеет вершину V$ степени 2.)
Доказательство. Каждая триангуляция n-угольника состоит из п — 2
треугольников, образованных п — 3 дугами и п сторонами. При п > 4 никакой
треугольник не может быть образован 3 сторонами. Пусть х — число
треугольников, образованных каждый 2 сторонами и 1 дугой, у — число треугольников,
образованных 1 стороной и 2 дугами, z — число треугольников, образованных
3 дугами. Так как каждая дуга встречается в двух треугольниках, то
х + 2у + 3* = 2(п - 3). (4)
Так как многоугольник имеет п сторон, то
2х + у = п. (5)
Из (4) и (5) получаем
Зх = Зг + 6.
Так как z > 0, то х > 2. I
Лемма 2. Пусть Р и Р' — два многоугольника, веса вершин которых
удовлетворяют неравенству Wi < w\ (i = l,2,...,nj, тогда стоимость
оптимальной триангуляции многоугольника Р не превышает стоимости
оптимальной триангуляции многоугольника Р'.
Доказательство. Опущено. I
Обозначим C(w\, IU2,• • • >w*) триангуляцию минимальной стоимости fc-yro-
льника с весами вершин W{. Лемма 2 утверждает, что
C(«ii,tiia»-• •»to*) < C{w'l,W2,...,w'k), если Wi <w\.
Далее до конца главы будем считать, что вершины w\, Ш2,... упорядочены
по возрастанию их веса, т. е. W\ < W2 < — Вершины шв, гиь,... не
упорядочены. Произведение трех весов iuj, Wj, Wk будем обозначать Т^*.
Для упрощения доказательств можно предположить, что все веса попарно
различны; для этого достаточно сделать е-возмущение весов. Однако и в этом
случае (все веса попарно различны) многоугольник может иметь более одной
оптимальной триангуляции. Чтобы избежать работы с такими триангуляция-
ми, будем применять следующее правило.
Пусть все вершины помечены. Будем говорить, что дуга ViVj меньше дуги
VpVq,eaiH
. г. о ^ . г , / min{i\j} = min{p,g},
mm{i,j} < min{p,g} или <
[ max{t,j}<max{p,g}.
4ТТри n > 4. — Прим. перев.
7Х ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 231
(Например, V3V9 меньше V4V5.) Каждая триангуляция n-угольника содержит
п—3 дуги, которые можно отсортировать по возрастанию, таким образом,
каждой триангуляции однозначно соответствует некоторая последовательность
дуг. Будем говорить, что триангуляция Р лексикографически меньше
триангуляции Q, если последовательность дуг триангуляции Р лексикографически
меньше последовательности дуг триангуляции Q.
Будем называть триангуляцию оптимальной, если она имеет
минимальную стоимость и среди всех триангуляции с минимальной стоимостью
является лексикографически минимальной.
Будем говорить, что две вершины связаны, если эти вершины соединяет
дуга или сторона5.
Теорема 3. В каждой оптимальной триангуляции многоугольника
вершина минимального веса V\ связана со второй (в порядке возрастания веса)
вершиной V2 и с третьей (в порядке возрастания веса) вершиной Уз. Таким
образом, в оптимальной триангуляции всегда есть дуги (или стороны) V\Vi
uVxV*.
Доказательство, Воспользуемся индукцией. Для оптимальной
триангуляции произвольного треугольника или четырехугольника теорема
справедлива. Предположим, что теорема справедлива для всякого &, где 3 < к < п — 1,
и рассмотрим оптимальную триангуляцию п-уголъника.
По теореме 1 в триангуляции найдется по крайней мере 2 вершины степени
2. Обозначим их У*, Vj. Рассмотрим 4 исчерпывающих случая.
(i) Одна из двух вершин, для определенности, У*, не совпадает ни с одной
из Vi, 1^, У3. Тогда удалим вершину У* вместе со смежными
сторонами и получим (п — 1)-угольник. В этом многоугольнике вершины Vi,
V2, V3 имеют минимальную стоимость. По предположению индукции в
оптимальной триангуляции найдутся дуги (стороны) У{Щ и V\Vs
(ii) Vi = У2, Vj = V3, т.е. каждая из вершин У2, V$ имеет степень 2. В этом
случае после удаления вершины V«g (вместе со смежными сторонами)
связаными станут вершины Vi и Vs. После удаления из исходной
триангуляции вершины Уз связаными станут вершины Vi и V^.
(iii) Vi = Vi, Vj = 1^, т.е. каждая из вершин Vi, V2 имеет степень 2. В
этом случае после удаления вершины Vi получим (п — 1)-угольник, в
котором вершины V^, V3 и V± имеют минимальный вес. По
предположению индукции в оптимальной триангуляции встречаются дуги
(стороны) 1^Уз и V2V4. Так как Vi имеет степень 2, то Уз и V* должны быть
соединены с 1^ некоторыми сторонами n-угольника. Аналогично, из
исходной триангуляции можно удалить вершину v2. В результате получим
(п — 1)-угольник, в котором Vi, Уз и V± имеют минимальный вес.
Следовательно, по предположению индукции в оптимальной триангуляции
встречаются дуги (стороны) Ух Уз vkV\V^. Так как V\ имеет степень 2, то
5Вершяны смежны, если они соединены стороной. — Прим. перев.
232
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
а) Ь)
Рис. 7.3. Иллюстрация к доказательству теоремы 3
каждая из вершин V3 и V± должна быть смежна6 V\. Однако ни в
каком n-угольнике (п > 5) вершины Vs и У± не могут одновременно быть
смежны с каждой из вершин V\ и V^.
(iv) Vi = Vi, Vj = V$. Приводя аргументы, сходные с (Ш), можно покат
зать, что в n-угольнике вершина V2 смежна cV\ и V3. Это показано на
рис 7.3(a). Тогда триангуляция на рис. 7.3Ь имеет меньшую стоимость,
так как Тда < Тод и по лемме 2
Ciwi.vjg.WyyWuw^WpyWs) < C{w^,wq,wv,wuwz,wpywz).
Так как в каждой оптимальной триангуляции всегда найдутся V\ V2 и V\ V^
то можно использовать это обстоятельство рекурсивно. А именно, при
нахождении оптимальной триангуляции заданной) многоугольника можно
разбивать его на меньшие многоугольники, повторно соединяя минимальную по
весу вершину со второй и третьей, до тех пор пока в каждом из этих
многоугольников меньшая по весу вершина не станет смежной второй и третьей.
Многоугольник, в котором V\ смежна V2 и Ц, назовем базисным.
Теорема 4.
(i) Если оптимальном триангуляция базисного многоугольника содержит
дугу или сторону У^Уз, то
1111
— + — <— + —.
Wi W4 t02 W3
(ii) Если в оптимальной триангуляции базисного многоугольника вершины
V2 и V$ не связаны, то связаны V\ и %.
*Т. е. иметь общую сторону. — Прим. иерее.
7.3. ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 233
а) Ь)
Рис. 7.4- Иллюстрация к доказательству теоремы 4
Доказательство. Если в базисном многоугольнике вершины У2 и Vs не
связаны, то степень V\ не меньше 3. Пусть V\VP — некоторая дуга триангуляции;
эта дуга разобьет многоугольник на два меньших треугольника, в одном из
них будет содержаться вершина Vi, а в другом — вершина V3. Вершина Vi
попадет в один из этих меньших многоугольников. В любом случае V4 будет
третьей (в порядке возрастания веса) вершиной в этом многоугольнике. Из
теоремы 3 следует, что V\ и V± связаны.
Если \?2 и V3 связаны, то, удаляя Vi, получим (п — 1)-угольник, в котором
У2 — минимальная весу вершина, a V± — третья (в порядке возрастания веса)
вершина. По теореме 3 вершины V2 и % связаны. Таким образом, можно
предположить, что в базисном многоугольнике вершины Vi и V± смежны7,
как показано на рис. 7.4(a).
Стоимость триангуляции на рис. 7.4(a) равна
^123 + C(w2,wt,..., wt,..., w3).
Стоимость триангуляции на рис. 7.4(b) равна
Tl24 + C(Wi, W4,. .. , Wt,.. . , W3).
Согласно лемме 2,
C(wi,W^...,Wt,...,Ws) < C(W2,tt/4,...,Wi,...,W3).
(7)
(8)
(9)
Разность между левой и правой частью неравенства (9) не меньше Г234 — Тш-
Так как триангуляция на рис. 7.4(a) оптимальна, то (7) не превосходит (8) и
поэтому
Tl23 + Г234 < Т\2А + 1\з4,
7Между Vb и Va могут находиться другие вершины. Исключение их из рассмотрения
приводит к тому, что в каждой из формул (7), (8) отбрасывается одно и то же слагаемое,
равное стоимости оптимальной триангуляции сотброшенного» многоугольника. В любом
случае неравенство Tiss + Г234 < 7*124 + Г134, которое получают авторы далее, верно. —
Прим. перев.
234
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
а) Устойчивая триангуляция Ь) Оптимальная триангуляция
Рис. 7.5. Пример, показывающий, что устойчивая триангуляция может не быть
оптимальной
что эквивалентно
1 11 1
— + — <— + —.
W\ W4 W2 W3
Теорема 5. Пусть оптимальная триангуляция п-угольника содержит два
треугольника Vx Vy Vz и Vx Vz Vw. Заметим, что вершины Vz, Vz связаны, но
не смежны. Тогда
— + — > — + —. (10)
wx wz wy ww
Доказательство. Стоимость триангуляции четырехугольника VxVyVzVw
дугой VZVZ равна
TXyz + Txzw, (11)
стоимость триангуляции четырехугольника VxVyVzVw дугой VyVw равна
J-xyw "Г -lyzw- (1^)
Из оптимальности триангуляции получаем, что (11) не больше (12), откуда
следует (10). I
Заметим, что приведенная теорема является обобщением леммы 1 из [3],
где Vy — вершина минимального веса, a,VXlVwnVz— три последовательные
вершины, такие, что ww больше wx и wz.
Триангуляция называется устойчивой, если каждый четырехугольник в
ней удовлетворяет неравенству (10).
Следствие 1. Оптимальная триангуляция устойчива, но устойчивая
триангуляция может не быть оптимальной.
Доказательство. Устойчивость оптимальной триангуляции следует из
теоремы 5. Рис. 7.5 показывает, что устойчивая триангуляция может не быть
оптимальной. I
7.3. ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 235
В любой триангуляции п-угольника каждая дуга разбивает единственный
четырехугольник. Пусть Vx,Vy,VzHVw — вершины вписанного
четырехугольника и VxVz — дуга, разбивающая этот четырехугольник. Дуга VXVZ
называется вертикальной, если выполнено (13) или (14):
min{wx,wz} < тш{ю„, ww}, (13)
(14)
J min{we',i0j} = min{wy,ww},
\max{wx,wz} < max{wy,ww}.
Дуга VXVZ называется горизонтальной, если выполнено (15)
min{wx,wx] >min{wyyti;w}y
max{wxiwz} < mox{wyjwm}.
(15)
Для краткости вертикальные (соответственно горизонтальные) дуги будем наг
зывать v-дугами (соответственно h-дугами).
Следствие 2. Каждая дуга оптимальной триангуляции является
вертикальной или горизонтальной.
Доказательство. Пусть дуга VXVZ не является ни горизонтальной, ни
вертикальной. Возможны два случая:
max{wx,wz} > max{wyiww}.
Случай 1.
min{wx,wz} >ffim{«/y)ttitl,},
с
Случай 2.
max{wx,wz} > max{tVy,ww}.
В каждом из этих случаев неравенство (10) из теоремы 5 не выполняется;
Отсюда следует, что триангуляция не устойчива и, следовательно, не может
быть оптимальной. I
Теорема в. Пусть Vx uVz — две различные вершины многоугольника, Vw
— вершина с минимальным весом среди вершин, встречающихся на пути из
Vx в Vz при движении по часовой стрелке (Vw ф Vx, Vw ф Vz), Vy — вершина
с минимальным весом среди вершин, встречающихся на пути U3VZ eVx при
движении но часовой стрелке (Vy Ф VXJ Vy ф Vz). Это показано на рис. 7.6.
Не нарушая общности, можно предположить, что тх < wz и wy < ww.
Если в оптимальной триангуляции есть h-дуга VXVZ, то
wy < wx <wz <ww.
Доказательство. Воспользуемся методом доказательства от противного.
Если wx < wy, то wx = W\ и дуга VXVZ не удовлетворяет условиям (15).
Следовательно, для того, чтобы VXVZ в оптимальной триангуляции являлась Л-дугой,
236
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
ч
\
\
®
I
I
/
/
Рис. 7.6. Иллюстрация к теореме 6
необходимо, чтобы wy < wx < wz. Так как Vy — вершина минимального веса
среди вершин, встречающихся на пути из Vz и Vx при движении по часовой
стрелке, и wx < ww, то Vy = V\.
На время предположим, что Юз < wx < wz. Из теоремы 3 следует, что
в любой оптимальной триангуляции найдутся дуги (стороны) V1V2 и ViV£,
разбивающие многоугольник на меньшие многоугольники. Если при этом Vx
и Vz попадут в разные многоугольники, то они не могут быть связаны. Не
нарушая общности, предположим, что многоугольник — базисный. Тогда по
теореме 4 в любой его оптимальной триангуляции найдется либо %%, либо
VXVA.
Если Vi» V3 связаны, то Vx и Vz принадлежат одному (п — 1)-угольнику; в
этом многоугольнике Vi является вершиной минимального веса и мы можем
повторить рассуждения. Если Vi, V4 связаны, то базисный многоугольник
снова разбивается на два меньших многоугольника, причем обе вершины Vx,
Vz оказываются в одном из них. Заметим, что этот меньший многоугольник
имеет по крайней мере п - 1 вершин, в противном случае в оптимальной
триангуляции не было бы VXVZ. Дальнейшая редукция размера многоугольника
приведет к выводу, что либо дуги VxVz не существует, либо Vx и Vz
являются второй и третьей (в порядке возрастания весов) вершинами в некотором
базисном многоугольнике Пусть в этом базисном многоугольнике вершина
Vm является вершиной с минимальным весом. Для того, чтобы VXVZ являлась
ft-дугой, необходимо, чтобы wx > wm. По теореме 4 для этого необходимо
выполнение неравенства
1111
— + — >— + —.
Wx Wz Wm Ww
Так как wx > wm, то это возможно, только если wz < ww. 1
Дугу VXVZ из теоремы 6 назовем потенциальной h-дугоИ, если ее веса
удовлетворяют условию
ю« < wz <ww.
Заметим, что приведенное неравенство слабее необходимого условия из
теоремы 6. Мы называем такие дуги потенциальными, так как только они могут
быть ft-дугами оптимальной триангуляции.
7.3. ТРИАНГУЛЯЦИЯ ВЫПУКЛОГО МНОГОУГОЛЬНИКА 237
Следствие 3. Пусть Vw — вершина максимального веса, Vx и Vz — два ее
соседа, max{wx,wz} < ww, тогда дуга VXVZ — потенциальная h-дуга.
Доказательство. Опущено. I
Следствие 4. Пусть VXVZ разделяет многоугольник на два меньших
многоугольника. Дуга VXVZ является потенциальной h-дугой тогда и только
тогда, когда веса всех вершин в одном из меньших многоугольников больше
max{Vx,Vz],
Доказательство. Утверждение следует из определения потенциальной Л-дуги
I
Многоугольник назовем верхним для ребра VXVZ, если он является
одним из меньших многоугольников, полученных разбиением исходного ребром
VXVZ, и если веса всех его вершин больше max{14, Vz}.
Две дуги называются совместимыми, если они одновременно встречают^
ся в некоторой триангуляции. В противном случае будем говорить, что дуги
скрещиваются
Предположим, что веса всех вершин в n-угольнике различны, тогда
существует (п - 1)! различных их перестановок. Например, веса на рис. 7.5(b)
10,11,25,40,12 соответствуют перестановке Wi,W2,W4,tob,to3 (где w\ < иь <
Ws < Wa < гУб)- Существует бесконечно много значений весов,
соответствующих одной и той же перестановке. Например, веса 1,16,34,77,29 также
соответствуют перестановке Wi1W21w^Wb,w^, но оптимальная триангуляция
для такого набора весов отлична от оптимальной триангуляции для набора
10,11,25,40,12. Любые две потенциальные /г-дуги из оптимальных
триангуляции, соответствующих одной и той же перестановке весов, совместимы.
Сформулируем этот замечательный факт в виде следующей теоремы.
Теорема 7. Любые две потенциальные h-дуги из оптимальных
триангуляции, соответствующих одной и той же перестановке весов, совместимы.
Доказательство. Предположим, что X\Z\, X4Z4 — скрещивающиеся
потенциальные h-дуги в разных оптимальных триангуляциях. Не нарушая общности,
будем предполагать, что х\ < z\ и X2 < z% (заметим, что х\ обозначает как
саму вершину, так и ее вес).
Так как x\Z\ и X2Z2 скрещиваются, то вершина зд должна принадлежать
одному из двух меньших многоугольников, полученных при разбиении
исходного дугой xiZi, а вершина Z2 ~ другому.
Из следствия 4 получаем, что если x\Z\ — потенциальная ft-дуга в
некоторой оптимальной триангуляции, то веса всех вершин в одном из меньших
многоугольников должны быть больше max{xi,2i}. Таким образом,
Z2 > max{a;i,zi} = z\.
Аналогично, для того чтобы X2Z2 в некоторой оптимальной триангуляции
было потенциальной h-дугой, необходимо, чтобы
Z\ > max{x2,22} = Z2-
238
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
Получили противоречие. I
Используя следствие 3 и теорему 7, можно построить все потенциальные
ft-дуги многоугольника.
Пусть VXVZ — дуга, определенная в следствии 3. Это значит, что VXVZ
— потенциальная ft-дуга, совместимая со всеми h-дугами во всех
оптимальных триангуляциях, и других потенциальных ft-дуг в ее верхнем
многоугольнике нет. Рассмотрим (п — 1)-угольник, полученный удалением Vw. В этом
(п — 1)-угольнике пусть Vw> — вершина максимального веса и Vx>, Vz* — два
ее соседа. Дуга Vz» Vz» снова является потенциальной h-дугой, совместимой со
всеми другими ft-дугами в другой оптимальной триангуляции, и других
потенциальных ft-дуг в ее верхнем многоугольнике нет. Это остается верным,
даже если Vw принадлежит верхнему многоугольнику VX>VZ>. Продолжая
далее процесс удаления вершины максимального веса, мы получим п - 3 дуги,
удовлетворяющие определению оптимальной Л-дуги.
Множество Л-дуг каждой оптимальной триангуляции является
подмножеством этих п — 3 дуг.
Процесс удаления вершин максимального веса можно превратить в
алгоритм трудоемкости 0(п). Этот алгоритм называется алгоритмом юдним
махом*8.
Алгоритм начинает работу с вершины минимального веса Vb помещает
ее в стек и рассматривает остальные вершины в порядке по часовой стрелке.
Вершины вместе с их весами помещаются в стек по следующим,правилам.
(i) Пусть Vt — вершина стека, V^-i — элемент, который находится
непосредственно под Vt, Ус — рассматриваемая вершина. Если в стеке находится
не менее двух вершин и од > tuc, то запомним V^-i Vc как потенциальную
ft-дугу, извлечем Vt из стека и поместим туда wc\ если в стеке находится
только одна вершина или Wt < t0c, то поместим wc в стек, будем
повторять этот шаг до тех пор, пока в стек не будет помещена n-ая вершина.
(и) Если в стеке более 3 вершин, то запомним ViVt-i как потенциальную
ft-дугу, извлечем Vt из стека и повторим данный шаг. Если в стеке 3 и
менее вершин, то стоп.
7.4. Эвристический алгоритм
Триангуляция, составленная полностью из v-дуг, соединяющих вершину
минимального веса со всеми остальными вершинами, называется веером. Веер
в многоугольнике W\WbWcWd... wmwn будем обозначать
Fan(wi | wb, wc, wd,..., wm, wn),
а вершину минимального веса W\ будем называть центром веера. Стоимость
веера равна
т • (wbwc + wcwd + • - • + гут«;п) = wi • (wb: wn),
8B оригинале: one-sweep algorithm. — Прим. перев.
7.4. ЭВРИСТИЧЕСКИЙ АЛГОРИТМ
239
где Wb : wn — сокращенная запись для суммы произведений от Ь)ь к wn по
часовой стрелке.
Алгоритм нахождения триангуляции, близкой к оптимальной, основан на
двух интуитивных идеях:
(i) если вершина имеет очень большой вес, то в оптимальной
триангуляции она должна быть вершиной ровно одного треугольника, т. е. иметь
степень 2;
(ii) если никакая из вершин не имеет очень большого веса, то, по-видимому,
веер с центром в вершине минимального веса должен быть близок к
оптимальной триангуляции.
Чин [3] дает достаточное условие того, что в задаче об оптимальном
порядке умножения матриц две рядом стоящие матрицы должны быть
перемножены. В теореме 8 на этой идее устанавливается достаточное условие
связанности двух вершин в оптимальной триангуляции.
Если в многоугольнике есть несколько вершин минимального веса, то
можно произвольно выбрать одну из них V\. Как только вершина V\ выбрана,
остальные вершины минимального веса можно рассматривать в порядке по
часовой стрелке. Вершина называется локально максимальной, если ее вес
больше веса каждой из двух соседних. Вершина называется локально
минимальной, если ее вес меньше веса каждой из двух соседних.
Теорема 8. [3] Пусть W\ — минимальная вершина выпуклого многоугольни-
ОД wm — локально максимальная вершина, wp, wq — ее соседи, т. е. wm > wp
uwm> wq. Если
-L + ±>±-L, (м)
Wp Wq Wi wm
то в оптимальной триангуляции многоугольника есть дуга wpwq.
Доказательство. Используем метод доказательства от противного.
Предположим, что в многоугольнике есть локально максимальная вершина и/т, для
которой выполнено неравенство (16), но дуги wpwq нет ни в одной
оптимальной триангуляции. Тогда wm является вершиной не менее двух треугольников,
не имеющих общего ребра, как показано на рис. 7.7(a) (если бы wp и wq были
связаны с вершиной, отличной от wmi то это противоречило бы
устойчивости9).
Обозначим третью вершину треугольника, содержащего wp и гутч через
wu а третью вершину треугольника, содержащего wm и wqjчерез Wj. Теперь
исходный многоугольник можно разбить на пять меньших многоугольников
°В предположении, что wp и wq связаны с вершиной ш,, отличной от шт, имеем w9 > w\
и из (16) получаем
1111
— +— > — +
wp wq w» wm
Таким образом, триангуляция с дугой wvwq лучше триангуляции с дугой wmw9. —
Прим. перев.
240
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
а) Ь) с)
Рис. 7.7. Иллюстрация к доказательству теоремы 8
Pi. Объединяя их оптимальные триангуляции, получим оптимальную
триангуляцию всёгб многоугольника. Обозначим С* стоимость оптимальной
триангуляции многоугольника Р{. Тогда стоимость оптимальной триангуляции
исходного многоугольника равна
С1 + С2 + С3 + С4 + С5, (17)
где
С2 = С(ша,...,ш^,
С3 = C(wj,...,Wi,wm),
С4 = Tipm,
Случай 1. W{ < Wj. Рассмотрим триангуляцию на рис. 7.7(b). Стоимость
триангуляции равна
CI + C5 + CJ + CS + CJ," (18)
где
С{ = С(шь...,^р) = С,ь
С^ = С(«;д,...,ш^ = С2,
C'3 = C{wj,...,Wi,wq),
С* = Tipqy
^б = -LprriQ'
Так как wm — локально максимальная вершина, то wm > wq и по лемме 2
C(wj,...,Wi,wm)>C{wj,...,wi9wq) <* С3>С'3. (19)
7.4. ЭВРИСТИЧЕСКИЙ АЛГОРИТМ
241
Из (16) получаем
1111
—+ — > — +—
Wp Wq W\ Wm
1 1 ' 1 1 , ^ V
=> 1 > h— (так как W{ > w\)
wp wq Wi wm
^ -tipm "T J-iqm ^'*ipq * -Lpqm
=» Tipm + Tjqm > Tipq + Tpqm (так как ^ < Wj),
откуда
С4+СЬ>С4 + СЬ. (20)
Из (19) и (20) имеем (18) < (17), что невозможно.
Случай 2. Wi > Wj. Рассмотрим триангуляцию на рис. 7.7(c). Стоимость
триангуляции равна
cj + cs + ci + cj + cj, (2i)
где
C{=C(uilf...ftijp) = Ci,
Cb = C(wj,...,Wi,wp),
С4 = Tjpg,
^б = Tpqm-
Так как wm —локально максимальная вершина, то wm > wp и по лемме 2
C(wj,...,wi,wm)>C(wj,...,wi,wp) & С3>С'3. (22)
Из (16) получаем
1111
— + — > — +—
Wp Wq W\ wm
I 1 1 1 , ^ ч
=*> 1 > —- + — (так как Wj >w\)
Wp Wq Wj Wm
=^ J-jpm + J-jmq > J- jpq + -Lpqm
=» Tipm + Tjmg > Tiw + Гмш (так как ^ < Wj),
откуда
c^ + cb^cj + cj. (23)
Из (22) и (23) имеем (21) < (17), что невозможно.
Приведем детали эвристического алгоритма нахождения близкой к
оптимальной триангуляции выпуклого п-угольника.
242
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
Мы начинаем с минимальной вершины, обходим границу
многоугольника по часовой стрелке и помещаем веса посещаемых вершин в стек (сначала
помещаем w\).
1. Пусть wt.— вершина стека, wt-\ — элемент, находящийся
непосредственно под wt^Wc — элемент, который нужно разместить в стеке. Если в стеке
находится две или более вершины и
тогда соединяем wt-i с wc, извлекаем из стека wt и помещаем в стек wc.
Иначе просто помещаем в стек гис. (Заметим, что из приведенного выше
неравенства следует, что щ > Щ-\ и щ > гис.) Будем повторять этот
шаг до тех пор, пока в стек не будет помещена n-ая вершина.
2. Если в стеке более 3 вершин, то соединим w\ с ttft-i, извлечем Wt и
повторим шаг, в противном случае стоп.
Заметим, что на шаге 1 отрезается вершина с достаточно большим весом,
а на шаге 2 вершина w\ соединяется со всеми вершинами, которые не были
отрезаны.
Для того, чтобы получить верхнюю оценку для относительной ошибки,
сначала докажем, что для каждого n-уголышка найдется монотонный п-угольник
с относительной ошибкой не меньше, чем у исходного n-угольника. Затем мы
докажем, что максимальная относительная ошибка достигается на
монотонном пятиугольнике.
Монотонным многоугольником называется выпуклый многоугольник с
единственной локально оптимальной и единственной фокально максимальной
вершинами. Пусть w\ — минимальная вершина в монотонном п-угольнике,
W{ — i-ая вершина, начиная от w\ в направлении по часовой стрелке, ttfj
t-ая вершина, начиная от w\ в противоположном направлении. Монотонный
n-угольник называется строго монотонным, если для всех t, таких, что 1 <
г < [n/2j, выполняется неравенство од+i > w\ > Wi или неравенство Wi~\ <
w\ <W{. Примером типичного строго монотонного базисного многоугольника
может служить многоугольник с вершинами
перечисленными в порядке обхода по часовой стрелке.
До конца раздела пусть Р обозначает выпуклый многоугольник с
минимальным числом вершин, на котором описанный выше эвристический
алгоритм допускает максимальную относительную ошибку. Тогда Р должен иметь
не менее 5 вершин, так как для любого четырехугольника приведенный
алгоритм находит оптимальную триангуляцию.
Лемма 3. Ни одна из локально оптимальных вершин многоугольника Р не
удовлетворяет неравенству (16).
7.4. ЭВРИСТИЧЕСКИЙ АЛГОРИТМ
243
Рис. 7.8
Рис. 7.9
Доказательство. Применим рассуждение от противного. Предположим, что
вершина wm многоугольника Р удовлетворяет неравенству (16), как
показано на рис. 7.8. Так как дуга wpwq есть и в оптимальной триангуляции, и в
триангуляции, производимой эвристическим алгоритмом, то мы можем
разбить Р на два меньших многоугольника Pi и Р2. Пусть С\ — стоимость оп-
тимальной триангуляции многоугольника Ри a Fi — стоимость триангуляции
многоугольника Р\ у произведенной эвристическим алгоритмом.
Относительная ошибка эвристического алгоритма для многоугольника Р
равна
где правая часть совпадает с относительной ошибкой для многоугольника Pi.
Следовательно, Pi — многоугольник с минимальным числом вершин, на
котором алгоритм делает максимальную отнрситедьную ошибку. Это
противоречит предположению, что Р — многоуго^ышк с минимальным числом вершин,
на котором алгоритм делает максимальную относительную ошибку. I
Лемма 4. Ни одна из дуг оптимальной триангуляции многоугольника Р не
является дугой веера, производимого эвристическим алгоритмом.
Доказательство. Воспользуемся рассуждением от противного.
Предположим, что дуга wiWj, показанная на рис. 7.9, встречается как в оптимальной
триангуляции, так и в веере, производимом эвристическим алгоритмом.
Мы можем разложить Р на два меньших многоугольника Pi и Р2. Пусть
стоимость оптимальной триангуляции- многоугольника Pi равна С*, а
стоимость веера, построенного в многоугольнике Р$, равна F*. Относительная
ошибка для Pi равна
Fi-Ci
Й1 =
Сг
относительная ошибка для Р2 равна
244
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
а)
Ь)
Рис. 7.10
относительная ошибка для всего многоугольника равна
п(ътгс1)+(ъ-сг) .
Пусть R\ — тах{Дь Д2} и, следовательно, R<R\. Ошибка R максимальна,
если R = Ri = Ri я Рг является базисным многоугольником с меньшим
числом вершин, чем в Д, но той же стоимости. Получили противоречие. I
Лемма 5. Пусть VxVy — h-дуга в оптимальной триангуляции
многоугольника Р. Тогда ни одна из v-дуг, принадлежащих вееру верхнего относительно
VxVy многоугольника, не является дугой оптимальной триангуляции
многоугольника Р.
Доказательство. От противного. Пусть V*Vy — Л-дуга оптимальной
триангуляции многоугольника Р. Не нарушая общности, предположим, что wx < wy.
Пусть VxVj — адуга, встречающаяся как в оптимальной триангуляции
многоугольника Р, так и в верхнем многоугольнике для дуги VxVy. Следовательно,
Р можно разбить на 3 меньших многоугольника, как показано на рис. 7.10(a).
На рис. 7.10(b) многоугольник Р можно разбить на 3 меньших многоугольника
V-дугами веера, производимого эвристическим алгоритмом. Пусть стоимость
оптимального разбиения многоугольника Р, равна С», а стоимость веера в Р/
равна i^.
Относительная ошибка триангуляции Р равна
(P/-fJ^4>JS)-(A^C2 + C73)
d 4-CV+ Сз
= № + Hi- (Pi + с2)) + да -са)
(Ci + С2) + Сз
Обозначим
Ях =
= R.
(Я+ 1*3)-(<*+<*)
Ci+C2
R3 = ^l.
7.4. ЭВРИСТИЧЕСКИЙ АЛГОРИТМ
245
Имеем R < тах{ДьДз}.
Случай 1. R\ < R&. Рассмотрим многоугольник 1% на рис. 7.10.
Относительная ошибка триангуляции Я{ равна
Wi - (wj :wy) -C(w\>Wj>...,Wy)
C(wuWj,...,wy)
>w1^wJ:Wy)-C(w,,wj wy) (ie > >
C(wx,wh...ywy)
— -^3 ""^3
= Дз > R.
Это противоречит тому, что Р — наименьший многоугольник с максимальной
относительной ошибкой.
Случай 2. Ri > Д3.
Рассмотрим многоугольник, образованный вершинами W\wxWi... wpwv, т. е
многоугольник, полученный удалением всех вершин между wp и wy. По
следствию 4 имеем
wx < wy < (остальные вершины многоугольника).
Относительная ошибка триангуляции этого многоугольника составит
(wx • (wx : wp) + Tltm) - C(wuw9,Wi,.. .rWP,wy)
C(wlyub,Wi,...,wpiwy)
> (wi - (wx : wp) + Tlpu) - {Tlxy + C(wx,Wj,... ,wp,wy))
Tixy + С(«;я, tin?:.., ti;p, «/„)
Так как
C(w*,Wi,. . . ,Wp,Wj) - CV*, W<,... ,t0p,U>t)
> wi • wp • («^ -r Wy)j
т.е. Tip,! — C^a,... ,wpiwy) > C(ti^v... ,iUp,ti;j), то относительная ошибка не
меньше
(wi • (wx : wp)+ Tlpj) - (Tlxy + C{wxywu...)wp,Wjj)
Tlxy + C(wxtwit..uwp9wj)
= (Tlxi + wt - (гц : мд)) - (Тхху + Cfru,, од,..., ну, «ц»
?i*y + C(w*, од,'..., и;р, Wj)
Это снова противоречит предположению, что Р — наименьший многоугольник
с максимальной относительнрй ошибке.
Лемма доказана. i
246
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
Лемма 6. Многоугольник Р необходимо является строго монотонным. Для
всех i, 1 < i < |n/2J, дуги Witv'if Од-iwj или дуги одги(-, од+iwj принадлежат
его оптимальной триангуляции, где од (соответственно w\) есть i-ая,
начиная с од, вершина в направлении по (соответственно против) часовой
стрелке.
Доказательство. Воспользуемся индукцией. Из теоремы 3 и леммы 4 следует,
что вершина од смежна как с од, так и с од, и одод принадлежит
оптимальной триангуляции многоугольника Р. Из теоремы 3 и леммы 5 следует, что
вершина од смежна с од, и одод принадлежит оптимальной триангуляции
многоугольника Р. Используя те же аргументы, можно показать, что
вершина од смежна с од, а од иод связаны, вершина од смежна с од, а од иод
связаны и т. д. Так как п конечно, то за конечное число шагов мы покажем,
что для 1 < i < |n/2j
(i) од <w'i<Wi+u
(ii) од и од+1 связаны с w'{.
Лемма доказана. I
Теорема 9. Многоугольник Р является строго монотонным 5-угольником.
Доказательство. Из леммы 6 следует, что многоугольник Р является строго
монотонным n-угольником, где п > 5.
Пусть од,од,... ,t0n — вершины многоугольника Р и од < од < • • • < wn.
Многоугольник Р имеет одну из следующих форм:
(i) ододод... wn-2WnWn-i • •.ОДОД, если п четно,
(ii) ододод ... wn-iWnwn-2 • •.ОДОД, если п нечетно.
Не нарушая общности, предположим, что п четно. По лемме 9
оптимальная триангуляция многоугольника Р содержит дуги од_ход и од+1ОД при
всех нечетных », таких, что 3 < % < п — 2. Это показано на рис. 7.11(a). На
рис. 7.11(b) изображен веер, полученный эвристическим алгоритмом.
Обозначим я — ,2 треугольников на рис. 7.11(a) через Pi,P2,- • • ,Рп-2-
Исключая Pi и Рп_2, каждый из оставшихся п — 4 треугольников составлен из
одной стороны и двух диагоналей. Следовательно, для каждого из этих п — 4
треугольников можно найти единственный треугольник на рис. 7.11(b), такой,
что оба будут содержать одну и ту же сторону. Многоугольник на рис. 7.11(b),
соответствующий многоугольнику Р|, обозначим Р[. Треугольники wiwn-2Wn
и w\wnwn-\ не соответствуют уже ни одному треугольнику на рис. 7.11(a).
Обозначим их Р1п_2 и Р\ соответственно. Пусть стоимость Р{ равна С,-, а
стоимость Р[ равна F[. Относительная ошибка составляет
п-2 п-2
ИП-ЦСг
R~ ^=5 •
t=l
7.4. ЭВРИСТИЧЕСКИЙ АЛГОРИТМ
247
Рис. 7.11. Иллюстрация к доказательству теоремы 9
В оптимальной триангуляции вершина од встречается в двух
треугольниках, а именно: ододод и ододод, тогда как в эвристической триангуляции
вершина од есть только в треугольнике ододод. Уменьшение веса од,
конечно, увеличит относительную ошибку R. Итак, мы можем предположить, что
од = од.
Каждая из вершин од, од,..., wn-2 встречается в трех треугольниках
оптимальной триангуляции и в двух треугольниках эвристической
триангуляции10. Вершина од (3 < t < n — 2) принадлежит треугольникам ОД-2ОД-1ОД,
од-ходод+i и WiWi+\Wi+2- Общая стоимость этих треугольников равна
7|-2,<-1,< + 7*-М,<+1 + ^+1,1+2 = ОД " (ОД-2ОД-1 + ОД-1ОД+1 + ОД+1ОД+2). (24)
В эвристической триангуляции вершина од принадлежит треугольникам
од-гОДОД и одод+гОД- Общая стоимость этих треугольников равна
Г<-2,«,1 + Г<||+2,1 = ОД • (ОД-2ОД + ОД+2ОД). (25)
Так как (24) > (25), то можно увеличить Я, последовательно уменьшая веса
ОД,ОД,. .. , Wn_2> И МЫ ПОЛУЧИМ ОД = ОД = • •. = Wn_2 = ОД.
По теореме 5 необходимым условием того, чтобы в оптимальной
триангуляции вершины wn-2 и од,_1 были связаны, является неравенство
Wn-2 ttta-1 Wn-З ОД,
Так как wn_2 = Wn-з = ОД > то
1
— +
iUX.
V)\ W„_i Wi w„
(26)
103a исключением вершины юз, которая принадлежит трем треугольникам оптимальной
триангуляции и одному треугольнику эвристической триангуляции. — Прим. персе.
248
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
Рис 7.12. Оптимальная триангуляция пятиугольника с максимальной
v вазмоэкжой ошибкой
По лемме 3 локально максимальная вершина не удовлетворяет достаточному
условию из теоремы 8:
— + —.->т— + . (27)
Из (26) и (27) получаем
Итак, для произвольного n-угольника максимальная относительная
ошибка достигается, если веса вершин удовлетворяют условиям:
шп-2 =ОД|-з = ••• ^ ОД = Wi эхлг > 1,
ti;n-i = wn = ix, *>i;
Поэтому стоимость оптимальной триангуляции равна
*V + te> + (*-4)*1,
тогда как стоимость эвристической триангуляции равна
tV + 2te3 + (n-5)s3.
Отсюда относительная ошибка составляет
to3--*3 $-1
К±
&x*+tx*r+fa^4№ # + t+(n-4)'
Следовательно, относительная ошибка обратно пропорциональна п, поэтому
R достигает своего максимального значения, когда п = 5. I
Итак, мы показали, что Р — строго монотонный пятиугольник с
оптимальной триангуляцией, показанной на рис. 7.12.
Для нахождения максимального значения R рассмотрим равенство
УПРАЖНЕНИЯ
249
Рис. 7.18. Пример триангуляции с максимальной ошибкой
и разрешим его относительно t. При заданном п наибольшая относительная
ошибка определяется равенством
t*-2t-(n-S) = 0, откуда t = 1 + у/п - 2.
Ошибка максимальна, если п = 5 и t = 1 + V3 » 0.1547, что подтверждает
гипотезу Чина [3]. На рис. 7.13 показан пятиугольник, на котором достигается
эта ошибка.
При п -4 оо получаем t ~ у/п и
В общем случае, если t задано, т. е. wn/w\ ограничено, то для каждого п
максимальную относительную ошибку можно вычислить напрямую. Например,
если t = 2, то
п + 2
Упражнения
1. Докажите следующую теорему:
Если веса вершин удовлетворяют условиям
W\ = W2 < W3 < W4 < ''' < Wn,
то любая оптимальная триангуляция n-угольника содержит треугольник
Vil^Vp для некоторой вершины Vp веса, равного гиз-
2. Докажите следующую теорему:
Если веса вершин удовлетворяют условиям
Ь)\ = W2 = • • • = Wk < Wfc+1 < W*+2 < - - - Wn (3 < * < П),
то любая оптимальная триангуляция n-угольника содержит fc-угольник
V№...Vk.
250
ГЛАВА 7. МАТРИЧНОЕ УМНОЖЕНИЕ
3. Сформулируйте задачу об оптимальной триангуляции как задачу
линейного программирования, в которой каждый столбец соответствует
треугольнику, а каждая строка — дуге.
Литература
Теория матриц является важным разделом математики, и по этой теории
написаны многочисленные монографии и учебники. Статья Штрассена [15]
содержит весьма важный и неожиданный результат. Алгоритм Пана [13]
является асимптотическим улучшением известного алгоритма Штрассена11.
Задача о цепочке матричных умножений стоит перед исследователями уже
долгое время. Для нахождения оптимального порядка умножения
используется динамическое программирование [1], [6], [8], [14].
Эвристический алгоритм был предложен в [2]. Дальнейшие улучшения
сделал Чин [3]. Эвристический алгоритм трудоемкости 0(п) основан на работе
Ху и Шинга [12]. Точный алгоритм трудоемкости O(nlogn) предлагается в
[10J, [и].
1? Aho А. V. Hopcroft J. Е. and Ullman J. D. The Design and Analysis of Computer
Algorithms. ~ Addison-Wesley, 1974. — P. 67.
2. Chandra A. K. Computing Matrix Chain Product in Near Optimum Time //
IBM Res. Report RC5626 (#24393), IBM Thomas J. Watson Research Center,
Yorktown Heights, NY, 1975.
3. Chin F. Y. An 0(n) Algorithm for Determining a Near Optimal Computation
order of Matrix Chain Product // Communication of ACM. — 1978. — Vol. 21,
No7.-P.544-549.
4. Deimel L. E.,Jr., Lampe T.A. An Invariance Theorem Concerning Optimal
Computation of Matrix Chain Products. North Carolina State Univ. Report
TR79-14.
5? Gardner M. Catalan numbers // Scientific American. — 1976. — No 6. —
P. 120-12412.
6. Godbole S. S. An Efficient Computation of Matrix Chain Products // IEEE
Trans. Computers C-22, 9 Sept. — 1973. — P. 864-866.
7. Gould H. W. Bell and Catalan Numbers. — Combinatorial Research Institute.
— Morgantown, W. Va. — June, 1977.
8. Horowitz E., Sahni S., Fundamentals of Computer Algorithms. — Computer
Science Press. — 1978. — P. 242-243.
9. Hu T. C*, Shing M. T. Computation of Matrix Chain Product // Abstracts of
AMS. - 1980. - Vol. 1, No3., Issue 3, 80T-A72. - P. 336.
1! См. примечание 2 на с. 225. — Прим. перев.
12Указанная статья в переработанном варианте вошла в книгу [6*]. — Прим. перев.
ОТВЕТЫ
251
10. Ни Т.С., Shing М.Т. Some Theorems about Matrix Multiplications // 21st
Symposium on Foundations of Computer Science. — 1980. — P. 28-35.
11. Ни Т. С, Shing M. Т. Computation of matrix chain products. I // SIAM J. on
Computing,. - 1982. - Vol. 11. - P. 362-373.
Ни Т. С. and Shing M. T. Computation of matrix chain products. II // SIAM
J. on Computing,. — 1984. — Vol. 13. — R 228-251.
12. Ни T.C., Shing M.T. An 0(n) Algorithm to Find a Near-optimum Partition
of a Convex Polygon // J. of Algorithms. — 1981. — Vol. 2, No 2. — P. 122-138.
13. Pan V. Y. New Fast Algorithms for Matrix Operations // SIAM J. Comput.
- 1980. - Vol.9, No2. - P.321-342.
14? Reingold E.M., Nievergelt J., Deo N. Combinatorial Algorithms: Theory and
Practice. — Prentice Hall, 1977. — P. 156.
15? Strassen V. Gaussian Elimination is not Optimal // Numer. Math. — 1969. —
Vol. 13.-P.354-356.
16. Winograd S. Arithmetic Complexity of Computations // CBMS-NSF regional
conference in Applied Math.'-*— SIAM publisher, 1980. — No 33.
Ответы
1, 2. См. работу Xy и Шинга [11, часть II].
3. См. Dantzig G.B. Hoffman A.J. and Ни Т.С. TViangulation (Tilings) and
Certain Block Triangular Matrices // Mathematical Programming. — Vol.
31, No. 1. - 1985. - P. 1-14.
Глава 8
iVP-цолнота
Боже, дай мне спокойствие, чтобы
смириться с задачами, которые л не
могу решить, упорство, чтобы ре-
хиать задачи, которые мне под силу,
и мудрость, чтобы отлучать первые
от вторых.
8.1. Введение
В предыдущих главах мы дали описание многих алгоритмов, решающих
разнообразные задачи. Одни из алгоритмов были весьма эффективны, другие
— очень медлительны. По-видимому, некоторые задачи просто не допускают
эффективных алгоритмов. Возникает естественный вопрос: почему?
Действительно ли, некоторые задачи по существу своему более сложные, чем другие,
или пока для их решения не найдено эффективных алгоритмов? Можно ли
классифицировать задачи по их сложности? Цель данной главы — объяснить
понятие «степень сложности задачи»1. Есть по крайней мере две причины для
классификации задач. Во-первых, если мы знаем, что задача принадлежит
классу очень сложных задач, то мы не должны сосредотачиваться на
получении оптимального решения, а можем попытаться получить приближенное
решение, верхние и нижние оценки, воспользоваться эвристиками и т. д. Во-
вторых, если задачи принадлежат одному классу, то иногда метод решения
одной из них удается преобразовать в метод решения другой. Не легко
определить, какая задача принадлежит какому классу. Две задачи могут казаться
весьма похожими, однако одна из них может быть намного сложнее другой.
Для примера рассмотрим две задачи.
Аккуратное изложение теории ЛГР-полных задач см. в книге Гэри и Джонсона [4]. В
данной главе мы излагаем эту теорию на весьма интуитивном уровне.
8.1. ВВЕДЕНИЕ
253
(i) Задано множество п попарно различных положительных целых чисел
х\, #2, • • •, #п (и четно). Необходимо разбить это множество на два
подмножества мощности п/2 каждое так, чтобы разность между суммами
элементов этих подмножеств была максимальной.
(ii) Задано множество п попарно различных положительных целых чисел
Xi,X2,... ,£„ (п четно). Необходимо разбить это множество на два
подмножества так, чтобы разность между суммами элементов этих
подмножеств была минимальной.
Задачу (i) можно решить, сортируя числа ЯьХ2,...,хп и помещая п/2
меньших чисел в первое подмножество, а п/2 больших — во второе. Данная
процедура выполнима за время O(nlogn). Другой способ.— найти медиану и
использовать ее для разбиения чисел на два множества. Известен алгоритм,
который находит fc-oe наибольшее число среди п целых чисел за время 0(п),
поэтому второй метод решения задачи (i) использует время 0(п). Так как,
надо полагать, каждый алгоритм, решающий эту задачу, должен проверить
каждое число, то 0(h) является нижней оценкой. На самом деле, мы можем
решить обобщение этой задачи, когда требуется разбить множество на
подмножества мощности к и п — к: для этого достаточно найти fc-oe наибольшее
число.
Задачу (ii) можно решить, разбивая при всех к исходное множество на
подмножества мощности кип-ки записывая суммы. Рассматривая все к,
мы, конечно же, найдем минимальную разность. Этот алгоритм использует
время, равное
Е(3=0<2">.
Конечно, для этой задачи существуют более быстрые алгоритмы, однако
никем не найден полиномиальный алгоритм или алгоритм с оценкой времени
выполнения, в которой п не появлялось бы в показателе степени.
Мы опустили несколько важных деталей. Во-первых, когда мы говорим о
задаче разбиения целых чисел £1, #2,..., х„, мы имеем в виду все возможные
значения этих чисел. Если Xi,X2,...,a?n заданы, тб мы получаем
индивидуальную задачу. Решить задачу означает решить все индивидуальные задачи.
Для конкретной индивидуальной задачи могут существовать очень
эффективные алгоритмы, но нас интересует, как алгоритм ведет себя на самых
худших входных данных. Если это не вызывает путаницы, мы будем использовать
термин «задача» вместо «все возможные индивидуальные задачи».
Во-вторых, нас интересуют «большие» задачи. Для описания задачи
необходимо закодировать входные данные, например, строкой из двоичных цифр.
Предположим, что строка имеет длину п. Тогда объем вычислений,
осуществляемых алгоритмом, есть функция /(п)2. Нас интересует асимптотическое
поведение функции/(п).
2Заметим, что время работы алгоритма на двух разных входных строках.одной длины
может быть разным, поэтому данное здесь определение функции f(n) не совсем корректно.
Под /(п) следует понимать максимальное время работы алгоритма на допустимых входных
строках длины п, где максимум берется по всем таким строкам. — Прим.перев.
254
ГЛАВА 8. NP-ПОЛНОТА
На практике мы не кодируем входные данные и не измеряем длину
строки, но в теории это необходимо делать. Во многих задачах теории графов в
качестве длины входа можно использовать число узлов или число дуг, так как
они полиномиально эквивалентны. В качестве параметра, отвечающего за
размер входных данных, можно выбирать разные величины, однако изменение
параметра не должно приводить к изменению класса сложности.
В-третьих, существуют многочисленные способы кодирования данных для
описания одной и той же задачи. Например, граф может быть задан
матрицей инцидентности «узлы-дуги» или списком всех узлов с указанием
соседних смежных узлов. Пусть входные данные закодированы, имеют длину п, и
алгоритм использует время /(п). Нам хотелось бы узнать, является ли
функция /(п) полиномиальной или экспоненциальной3. Это разбиение функций
на полиномиальные и экспоненциальные не зависит от способа кодирования:
функция /(п) никогда одновременно не будет полиномиальной для одного
разумного способа кодирования и экспоненциальной для другого разумного
способа кодирования. В этом смысле все разумные способы кодирования дают
один и тот же результат.
В-четвертых, разные компьютеры выполняют один и тот же алгоритм за
разное время. Самый простой компьютер называется машиной Тьюринга. Это
искусственный компьютер, модель абстрактной машины, которая может
писать символы на ленту, читать, стирать их и заканчивать свою работу. Кроме
этого, имеются несколько моделей машин с произвольным доступом к памяти.
Эти модели являются аналогами самых производительных современных
компьютеров. Оказывается, что если алгоритм использует экспоненциальное
время на машине Тьюринга, то он требует экспоненциального времени на любом
реальном компьютере и наоборот. Таким образом, мы можем предположить,
что у нас есть компьютер с одним центральным процессором и
неограниченной памятью.
Выделим следующие четыре класса задач в зависимости от их трудности.
1. Алгоритмически неразрешимые задачи (нерешаемые задачи). Это
задачи, для решения которых не существует алгоритма. Например,
доказано, что задача определения, остановится или нет на машине Тьюринга
заданная программа, является алгоритмически неразрешимой. В этой
книге мы не будем обсуждать задачи из этого класса.
2. Труднорешаемые задачи (вероятно, сложные задачи). Это задачи, для
решения которых, по-видимому, не существует полиномиального
алгоритма. Иными словами, для их решения, скорее всего, существуют
только экспоненциальные алгоритмы.
3. NP-задачи (NP — аббревиатура для «недетерминированные
полиномиальные»). Это класс задач, которые мы можем решить за
полиномиальное время, если угадаем, какой путь вычислений необходимо выполнить.
3Автор называет функцию полиномиальной, если ее можно ограничить сверху
некоторым полиномом, в противном случае функция называется жепоненциалъпой. Например,
согласно этому определению, функция nlogn полиномиальна, а функция nlogn
экспоненциальна. — Прим. перев.
8.2. ПОЛИНОМИАЛЬНЫЕ АЛГОРИТМЫ
255
В данном контексте должно быть странным видеть понятие
«угадывания», так как все компьютерные программы детерминированы. Грубо
говоря, этот класс включает в себя все задачи, которые имеют
экспоненциальный алгоритм, но не доказано, что они не могут иметь
полиномиального алгоритма. Это будет обсуждаться в последующих разделах.
4. Р-задачи (Р — аббревиатура для «полиномиальный»). Этот класс
включает в себя задачи, которые имеют полиномиальные алгоритмы.
Большинство людей считают, что этот класс является собственным
подклассом класса 3. Соотношение между классами Р и NP — основная тема
следующих разделов.
8.2. Полиномиальные алгоритмы
В данном разделе рассматриваются задачи, для решения которых
существуют полиномиальные алгоритмы.
Все задачи, для которых есть полиномиальные алгоритмы, составляют
класс Р. Например, задачи, требующие n log п единиц времени или п116+3п4+
7739 единиц времени, принадлежат этому классу. Сама единица времени не
фиксирована. Ею может быть, например, микросекунда или час. В обоих
случаях величина требуемого времени отличается в фиксированное (3600000000)
число раз. Есть три причины сосредоточиться цаи рассмотрении класса Р.
Во-первых, сумма и произведение многочленов являются многочленами и
поэтому суперпозиция многочленов есть тоже многочлен. Следовательно! легко
определить, является ли алгоритм полиномиальным или нет. Во-вторых,
полиномиальная функция не чувствительна к особенностям реализации.
Реализация алгоритма с использованием другой структуры данных может понизить
степень многочлена, но не найдено примерз двух реализаций одного
алгоритма, одна из которых требует полиномиального, а другая — экпоненциального
времени. В этом смысле свойство полиномиальное™ алгоритма является его
атрибутом. В-третьих, полиномиальные алгоритмы быстрее
экспоненциальных, когда задача приобретает большие размеры. Рассмотрим алгоритмы А и
В. Алгоритм А требует пб операций* а алгоритм В требует 2П операций. Если
каждая операция выполняется за микросекунду, то алгоритм А при п = 10
закончит свою работу за 0.1с, а при п = 60 — за 13 мин. С другой
стороны, алгоритм А при п = 10 закончит свою работу за 0.001с, а при п = 60
— за 366 веков. По этой причине Эдмондс назвал полиномиальные
алгоритмы хорошими. Даже «ели при малых значениях п полиномиальный алгоритм
медленнее экспоненциального, при больших я он превосходит по скорости
работы экспоненциальный. Заметим, что это справедливо, только для худшего
случая. Существуют экспоненциальные алгоритмы, которые в среднем
быстрее полиномиальных.
Мы не разбиваем класс Р на подклассы, такие, как n, nlogn, п3 и т.д.,
однако используем нотацию Ю большое», не беспокоясь о коэффициенте,
стоящем перед функцией. Читатель должен осознавать красоту всей теории и
вместе с ней ее недостатки.
256
ГЛАВА 8. NP-ПОЛНОТА
Рассмотрим задачу определения, есть ли в графе эйлеровы циклы. Граф
имеет эйлеровы циклы тогда и только тогда, когда
(i) граф связен,
(ii) степень каждой вершины четна.
'Мы не будем доказывать, что эти условия необходимы и достаточны, а
только оценим объем работы, необходимой для проверки этих двух условий.
Предположим, что граф задан пхп матрицей, в которой элементi-ой
строки j-ro столбца равен 1, если i-ая вершина смежна j-ой вершине, и 0 в
противном случае4. (Для наших целей определим элементы на диагонали равными
0.) Чтобы проверить, все ли вершины имеют четную степень, сложим
элементы каждой строки и проверим, будут ли суммы четными. Так как в графе и
вершин, то таких сумм будет п. Если просмотр каждого элемента
выполняется за одну операцию, то всего требуется п2 операций. Итак, для проверки
четности вершин требуется полиномиальное время. Чтобы проверить,
является ли граф связным, предположим, что граф задан списком смежности,
т. е. списком вершин вместе с соседями, указанными для каждой вершины. По
известной матрице смежности можно построить список смежности за время
0(п2). Затем, используя поиск в глубину, проверить граф на связность. Так
как каждая дуга будет пройдена по крайней мере два раза (ровно два раза,
если дуга принадлежит остовному дереву, и один раз, если она не принадлежит
ему), то алгоритм требует 0(т+ п), где т — число дуг. Так как m = 0(п2),
то мы снова получаем полиномиальный алгоритм в терминах числа вершин
п. Подчеркнем, что в данном случае алгоритм выдает ответ «да», если граф
имеет эйлеров цикл, или «нет», если эйлерова цикла в графе нет.
Обычно задачу формулируют так, что возможными ответами являются
«да» или «нет». Например, задачу коммивояжера нахождения кратчайшего
цикла в графе можно переформулировать следующим образом.
Имеется ли в графе цикл, длина которого меньше заданного числа В1
Если при любом В на этот вопрос можно ответить за полиномиальное
время, то легко за полиномиальное время решить задачу коммивояжера. (Легко
установить верхнюю и нижнюю границу для кратчайшего цикла, а затем
использовать бинарный поиск, испытывая разные В.)
Далее предполагается, что рассматриваются только задачи с ответами
«да» или «нет». Такие задачи называются задачами распознавания, в то время
как задачи максимизации или минимизации называются задачами
оптимизации.
Рассмотрим алгоритм как компьютерную программу. При заданных
входных данных программа выполняет различные вычисления. В зависимости от
промежуточных результатов программа выполняет другие вычисления до тех
пор, пока не будет получен ответ. Для задач распознавания таким ответом
является «да» или «нет».
Представим весь процесс вычислений в виде корневого дерева5, каждая
4Такая матрица называется матрицей смежности. — Прим. перев.
5Иногда с помощью деревьев описывают недетерминированные вычисления. Эта,
отличная от наглей, интерпретация не должна приводить к путанице.
8.3. НЕДЕТЕРМИНИРОВАННЫЕ АЛГОРИТМЫ
257
вершина представляет некоторое вычисление, а листьям приписаны
возможные ответы «да» и «нет».
Для того, чтобы алгоритм был полиномиальным, дерево должно иметь
полиномиальную высоту и, кроме этого, бремя, затрачиваемое на вычисления
в каждом узле; также должно быть полиномиальным.
Когда входные данные алгоритма известны, компьютерная программа
выполняет некоторые вычисления, по результату этих вычислений
определяется дальнейший путь вычислений. Полиномиальные алгоритмы обладают тем
свойством, что каждую траекторию вычислений можно пройти за
полиномиальное время.
Последнее свойство полиномиальных алгоритмов весьма обременительно.
Например, для задач теории графов некоторый алгоритм может использовать
полиномиальное время, если граф планарный, и экспоненциальное время в
противном случае. Представляется весьма важным выделение
полиномиальных подклассов в задачах, которые в общей постановке требуют
экспоненциального времени. Кроме того, для задач из класса Р построение более
эффективных алгоритмов или новых модификаций старых алгоритмов может
снизить время работы программы, например, с п3 до п2, п2 до nlogn. Эти
весьма важные области исследований не являются основными в данной
главе.
8.3. Недетерминированные алгоритмы
В данном разделе рассматриваются задачи из класса NP.
NP — это аббревиатура для «недетерминированный полиномиальный».
Рассмотрим понятие недетерминированного алгоритма. Для задачи
коммивояжера детерминированный алгоритм, например, поиск с возвращением,
определяет, по какой дуге следует направляться из текущего узла. Для задачи
распознавания, существует ли в графе цикл, длины меньшей Б, поиск с
возвращением неявно перебирает все циклы и дает ответ «да», если такой цикл
существует, и «нет» в противном случае.
Так как циклы перебираются один за одним и циклом с необходимым
свойством может оказаться последний, то поиск с возвращением для задачи
коммивояжера требует время 0(сп).
Недетерминированный алгоритм может правильно угадать, какая дуга из
текущей вершины должна быть следующей. Итак, если существует цикл
общей длины, меньшей В, то недетерминированный алгоритм тратит время
0(п) на вычисление суммарной длины и проверки того, меньше ли она чем
В. Таким образом, если ответ «да», то задача коммивояжера с помощью
недетерминированного алгоритма может быть решена за полиномиальное время.
Грубо говоря, если ответ «да» можно проверить за полиномиальное время,
то задачу можно решить недетерминированным алгоритмом за
полиномиальное время и задача принадлежит классу NP.
С другой стороны, если цикла длины меньшей В в графе не существует,
то для ответа «нет», по-видимому, не достаточно уметь правильно угадывать
258
ГЛАВА 8. NP-ПОЛНОТА
нужную дугу. Таким образом, задача с ответом «нет», вероятно, не
принадлежит классу NP.
Бели некоторая задача принадлежит классу Р, то дополнение к ней также
принадлежит Р. Скорее всего, аналогичное утверждение не верно для класса
NP (хотя это и не доказано).
По определению, если задача принадлежит Р, то она принадлежит NP.
Итак, класс Р является подклассом класса JVP, т. е. Р С NP. Основной вопрос
современной теории сложности — это
P = NP7
Для доказательства Р = NP достаточно показать, что для решения всякой
задачи из NP существует полиномиальный детерминированный алгоритм.
Никто еще не сделал этого. Для доказательства Р ф NP достаточно
показать, что в NP есть задача, которую детерминированным алгоритмом нельзя
решить за полиномиальное время. Никто еще не сделал и этого.
Большинство исследователей полагает, что Р ф NP. Для разрешения
этого вопроса необходим новый математический метод.
8.4. TVP-полные задачи
Задача о гамильтоновом цикле заключается в определении, есть ли в графе
цикл, проходящий через каждую вершину ровно один раз. В задаче
коммивояжера спрашивается, существует ли в графе достаточно короткий цикл,
проходящий через каждую вершину? Алгоритм для задачи коммивояжера можно
использовать для решения задачи о гамильтоновом цикле, так как вторую
задачу можно свести к первой следующим образом.
Пусть каждая дуга графа имеет длину 1, а расстояние между двумя несмеж
ными вершинами равно оо. Так как в графе п вершин, то существование цикла
длины п эквивалентно существованию гамильтонова цикла.
Заметим, что данное сведение требует полиномиального времени, а
именно, на определение расстояний между п(п — 1)/2 парами вершин. Если нам
удастся построить полиномиальный алгоритм для решения задачи
коммивояжера, то тем самым мы найдем полиномиальный алгоритм для задачи о
гамильтоновом цикле.
Будем говорить, что задача L\ сводится к задаче L2, и записывать
Li ос L2,
если любой алгоритм для 1^ можно использовать для решения задачи L\.
Подразумевается, что это сведение тратит полиномиальное время. Бели Ьч
также можно свести к Li, то говорят, что задачи Li и L2 полиномиально
эквивалентны и пишут Ь\^ Ьь-
Оба отношения ос и = транзитивны. В частности, если L\ ос L<i и Ьч ос 1$,
то L\ ос L3. Если L\ ос L2, то задача Ьч по меньшей мере так же сложна, как
и L\.
8.4. NP-ПОЛНЫЕ ЗАДАЧИ
259
Рис. 8.1
Оказывается, что в NP существует подкласс в некотором смысле самых
сложных задач (все задачи в этом подмножестве полиномиально
эквивалентны), а именно: каждую задачу из NP можно свести к любой задаче из этого
подкласса. Следовательно, если для одной из задач этого подмножества
найден полиномиальный алгоритм, то любую задачу из класса NP можно решить
за полиномиальное время.
Задачи из этого подмножества называются NP-полными* Итак, класс NP
содержит два интересных подкласса: подкласс задач, которые могут быть
решены за полиномиальное время детерминированным алгоритмом, и
подкласс задач, наиболее сложных в классе NP. Это символически изображено
на рис. 8.1.
Первая JVP-полная задача была указана в замечательной работе Кука [2].
Карп [9] указал на многие другие JVP-полные задачи.
Чтобы доказать, что Р = NP, достаточно для какой-нибудь JVP-полной
задачи найти полиномиальный детерминированный алгоритм.
Чтобы показать, что Р ф NP, достаточно для какой-нибудь задачи из
NP установить, что она не принадлежит классу Р. На самом деле, из
статьи Леднера [15] следует, что если Р ф NP, то в NP найдется задача, не
принадлежащая ни классу Р, ни классу TVP-полных задач.
Вначале выдвигались два возможных кандидата на роль таких задач. Во-
первых, задача линейного программирования, которая, однако, как показано
в [11] (см. также [1]), принадлежит классу Рг Во-вторых, задача установления
простоты числа [17], которая, как полагают, также принадлежит Р6.
Если мы найдем новую JVP-полную задачу L, то у нас есть небольшой шанс
изобрести для нее полиномиальный алгоритм. Чтобы доказать, что задача L
является iVP-полной, достаточно доказать следующие два утверждения:
(i) Задача L принадлежит классу NP.
(ii) Известная TVP-полная задача сводится к L.
Рассмотрим три стандартные JVP-полные задачи и их варианты.
1. Задача о разбиении. Существует ли в заданном числовом множестве
Xi, Х2,..., хп подмножество мощности fc, такое, что сумма чисел в этом
в3адача определения простоты числа заключается в определении, является ли заданное
число р простым. В работе [38*] для этой задачи построен детерминированный алгоритм со
сложностью 0(logI2p«poly(logp)), и тем самым показано, что задача определений простоты
числа принадлежит классу Р- — Прим. перев.
260 ГЛАВА 8. NP-ПОЛНОТА
Рис. 8.2
подмножестве равна В? Более общий вариант этой задачи —
рассматриваемая в предыдущих главах задача о рюкзаке.
2. Гамильтпоиовы циклы. Более общий вариант этой задачи — задача
коммивояжера.
За. Задача о минимальном вершинном покрытии. Во множестве вершин V
заданного графа G = (V,E) найти подмножество V С V минимальной
мощности, такое, что каждое ребро графа инцидентно по крайней мере
одной вершине из V.
Существует другой, по существу, эквивалентный, вариант задачи За:
ЗЬ. Задача о максимальном независимом множестве. Во множестве
вершин V заданного графа G = (V, Е) найти подмножество V" С V
максимальной мощности, такое, что никакое ребро графа не инцидентно двум
вершинам из V7'. Можно проверить, что V" = V — V. Например,
подмножество вершин на рис. 8.2, помеченных а, является минимальным
вершинным покрытием, а подмножество вершин, помеченных /3,
образует максимальное независимое множество.
Чтобы показать важность кодирования входных данных, рассмотрим
следующий вариант задачи о рюкзаке (задача распознавания): при заданных Wi
необходимо определить, существуют ли х^ такие, что
п
£ mxi = ft,
1=1
Xi = 0,l.
Можно построить таблицу п х Ь и решить задачу методом динамического
программирования, как показано в главе 3. Если в качестве размера входа
использовать параметры п и ft, то динамическое программирование приводит
к полиномиальному алгоритму. К сожалению, в предположении о разумности
кодирования входных данных, представление ft использует не ft, a 0(log2 ft)
цифр. С другой стороны, если ft и, следовательно, log2 ft ограничены сверху
константой, то мы получаем полиномиальный от п алгоритм. Алгоритмы,
полиномиальные при ограниченной величине коэффициентов, называются
псевдополиномиальными. Многие JVjP-полные задачи имеют
псевдополиномиальные алгоритмы, которые достаточно эффективны на практике.
8.5. КАК РЕШАТЬ NP-ПОЛНУЮ ЗАДАЧУ?
261
Для задачи о минимальном вершинном покрытии нет естественной
границы на величину каких-либо коэффициентов, и число вершин п является
хорошим параметром, характеризующим длину входа. Поэтому
псевдополиномиального алгоритма, решающего данную задачу, не существует7.
8.5. Как решать TVP-полную задачу?
Для решения новой задачи всегда хочется придумать точный
эффективный алгоритм. В книге Гэри и Джонсона [4] приведен список известных NP--
полных задачей может так оказаться, что наша задача есть в этом списке.
Что делать в этом случае? Или нашей задачи нет в списке, но мы думаем, что
она могла бы там быть. Доказательство того, что наша задача JVP-лолна, не
решает проблемы. С практической точки зрения мы должны изобрести новый
алгоритм или использовать старый, даже если задача JVP-полна. Бели
алгоритм полиномиален, но степень полинома больше 3, то этот алгоритм, скорее
всего, не достаточно эффективен. Дадим несколько советов.
1. Придумать новый алгоритм. Один из лучших примеров такого подхода
— симплекс-метод Данцига [3]. Хотя симплекс-метод не является
полиномиальным в худшем случае, он работает. Одной из главных проблем
линейного программирования является вопрос: «Почему симплекс-метод
работает так хорошо?» В формулировке задачи линейного программиро-
вания значения элементов матрицы А и векторов бис произвольны.
Вероятно, в реальных задачах Аг Ь, с удовлетворяют некоторым условиям,
делающим симплекс-метод эффективным.
2. Рассмотреть специальные случаи задачи. Мы имели дело со многими
специальными случаями этого подхода. Задача расписания с га
процессорами и п частично упорядоченными тактами времени, является
iVP-полной. Но если мы ограничимся специальным случаем, когда
ограничения представляют собой «дерево», то задачу можно решить за
линейное время, как показано в главе 6. Другой специальный случай га = 2
рассмотрен Коффманом и Грэхемом [4]. Для любой нерешенной задачи
полезно сначала рассмотреть специальные или крайние случаи, а затем
постепенно обобщать результат. Обычно новую задачу сводят к
известной, пытаясь, тем не менее, не потерять специфики задачи. Великое
множество комбинаторных задач можно свести к задачам целочисленного
линейного программирования и решать общими методами. Однако для
реальных задач эти общие методы, как правило, приводят к весьма
медленным на практике алгоритмам.
Задача о рюкзаке — это специальный случай задачи целочисленного
линейного программирования и ее эффективно можно решать с помощью
7Наряду с псевдополиномиальными алгоритмами в целочисленном линейном
программировании рассматривают квазиполиномиальные алгоритмы, т.е. алгоритмы,
полиномиальные при фиксированном числе переменных п [34*}. — Прим. перев.
262
ГЛАВА 8. NP-ПОЛНОТА
специально разработанных алгоритмов. Задачу об оптимальном
алфавитном дереве можно решать с помощью динамического
программирования, однако алгоритм Ху-Таккера, использующий особую структуру
задачи, намного более эффективен. Общий алгоритм подобен одежде
ходового размера: она подойдет всем, но не будет слишком удобна.
3. Эвристический подход. Задача о разбиении является частным случаем
задачи об упаковке, которая также JVP-полна. В главе 6 мы
использовали эвристические алгоритмы и установили оценки их точности. Чтобы
сформулировать эвристический подход для решения конкретной задачи,
обычно испытывают несколько числовых примеров, на которых
тренируют интуицию. Если эвристический алгоритм приводит к успеху только
в некоторых случаях, мы должны описать эти случаи.
На рис. 8.3 большая область представляет множество всех входных
данных, а маленький круг изображает множество тех из них, на которых
эвристический алгоритм работает.
Примером этого подхода может служить жадный алгоритм для задачи о
размене из главы 6. Когда входные данные не принадлежат маленькому
кругу, ошибка достигает своего максимума.
4. Декомпозиция задачи. Если задача большая и сложная, то ее возможно
удастся разложить на несколько подзадач и решать отдельно каждую.
После этого необходимо как-то из частных решений составить общее
решение исходной задачи. Лучший пример данного подхода —
декомпозиция задачи линейного программирования, предложенная Данцигом и
Вулфом [3]. На самом деле, большие задачи линейного
программирования решаются методом генерации строк и столбцов (обзор методов см. в
[5], [7]). В главе 2 подход декомпозиции был проиллюстрирован на
задаче нахождения кратчайших путей между всеми парами вершин большой
сети. Использование декомпозиции в динамическом программировании
приводит к методу «разделяй и властвуй».
5. Использовать общие методы. Если у нас нет времени и мы не хотим
заниматься настоящими исследованиями, можно использовать общие
подходы. Вот некоторые из них:
(i) поиск с возвращением (глава 4),
(И) динамическое программирование (глава 3),
(Ш) методы отсечений Гомори (см. [7], [8]).
Специальные модификации даже таких методов, как поиск с
возвращением, могут существенно повысить эффективность алгоритма,
например, в игре на дереве. Метод отсечений Гомори предназначен для
решения задач целочисленного линейного программирования. В некоторых
случаях он хорошо зарекомендовал себя, но при решении многих других
задач ведет себя крайне плохо.
ЛИТЕРАТУРА
263
Рис. 8.3
Вообще говоря, нет систематического метода для создания новых
комбинаторных алгоритмов. Однако мы надеемся, что наша книга пробудила у
читателя интерес к ним.
Литература
В данной главе мы дали очень краткий обзор теории JVP-подноты.
Читателю настоятельно рекомендуется прочитать книгу Гэри и Джонсона [4],
которая полностью посвящена проблеме JVP-полноты. В книге содержится
также приложение со списком известных ./VjP-полных задач и ссылками на
соответствующую литературу8. Настоятельно рекомендуем также популярную
статью Льюиса и Пападимитриу [16].
Хорошими обзорами по теории ЛГР-полноты являются работы [12], [13],
[18], [19].
Многие комбинаторные задачи можно сформулировать как задачи
линейного или целочисленного линейного программирования, см., например, [3], [7],
[8].
1. Aspvall В., Stone R.E. Khachiyan's Linear Programming Algorithm //
Computer Science Report CS-79-776. — Stanford University, 1979.
2? Cook S. A. The Complexity of Theorem-proving Procedures // Proceedings of
3rd Annual ACM Symposium on Theory о Computing. — 1971. — P. 151-158.
3? Dantzig G.B. Linear Programming and Extensions. — Princeton University
Press, 1963.
4? Garey M.R., Johnson D.S. Computers and Intractability. — Rreeman Co.,
1979.
5. Gomory R. E. Large and Non-Convex Problems in Linear Programming //
Proceedings of Symposium in Applied Math. — AMS, 1963. — Vol. XV.
6. Graham R. L. The Combinatorial Mathematics of Scheduling // Scientific
American. - 1978. - Vol. 238, No3. - P. 124-132.
8Основы теории WP-полноты излагаются в книгах [3*J, f26*] и др. — Прим. перев.
264
ГЛАВА 8. NP-ПОЛНОТА
7? Ни Т. С. Integer Programming and Network Flows. — Addison-Wesley, 1969.
8. Johnson E. L. Integer Programming. — IBM Research Report, RC7450, Dec.
26, 1978.
9? Karp R. M. Reducibility Among Combinatorial Problems // Miller R. E. and
Thatcher J.W. (eds.), Complexity of Computer Computations. — Plenum
Press, New York, 1972. - P. 85-103.
10. Karp R. M. On the Complexity of Combinatorial Problems // Networks. —
1975.-Vol. 5.-P. 45-68.
11? Khachiyan L.G. A Polynomial Algorithm in Linear Programming // Soviet
Mathematics Doklady. - 1979. - Vol. 20, No 1 - P. 191-194.
12. Klee V. Combinatorial Optimization: What is the State of the Art? // Math,
of O. R. - 1980. - Vol. 5, No 1. - P. 1-26.
13. Knuth D.E. Combinatorial Algorithms. Vol. 49.
14. Knuth D. E. Mathematics and Computer Science: Coping with Finiteness //
Stanford University Report, CS-76-541. — 1976.
15. Ladner R. E. The Computational Complexity of Provability in Systems of
Modal Prepositional Logic // SIAM J. Comput. -1977. - Vol. ,6. - P. 467-480.
16. Lewis H.R., Papadimitriou C.H. The Efficiency of Algorithms // Scientific
American. - 1978. - Vol. 238, No 1. - P. 9&-109.
17. Pratt V., Every Prime Has a Succinct Certificate // SIAM J. Comput. — 1975.
-Vol.4. -P. 214-220.
18. Tarjan R. E. Complexity of Combinatorial Algorithms // SIAM Review. —
1978. - Vol. 20, No3. - P. 457-491.
19. Weide B. A Survey of Analysis Techniques for Discrete Algorithms //
Computing Survey. - Vol.9, No4. - 1977. - P.291-313.
9 А вторы ссылаются на пока не завершенный 4-ый том монографии Кнута «Искусство
программирования». — Прим. перев.
Глава 9
Алгоритмы локального
индексирования
Если целевая функция является
суммой частичных решений, то
необходимым условием глобальной
оптимальности является локальная
оптимальность.
9.1. Объединение алгоритмов
В главе 1 были описаны некоторые алгоритмы, такие, как алгоритм
поиска кратчайшего пути, алгоритм построения минимального остовного дерева,
поиск в ширину (BFS), поиск в глубину (DFS). Эти алгоритмы могут быть
объединены в один алгоритм. Многие другие алгоритмы можно
рассматривать как частные случаи этого очень общего алгоритма. Этот общий алгоритм
называется алгоритмом локального индексирования.
Алгоритм локального индексирования последовательно присваивает
вершинам сети индексы 1,2,... ,п, выбирая каждый раз наилучшую
кандидатуру среди соседей вершин, уже получивших индексы. Выбор основан на
индивидуальном «вкладе» каждого из соседей проиндексированного множества.
Индекс, полученный вершиной, в дальнейшем не изменяется. Алгоритм
локального индексирования является, таким образом, разновидностью жадного
алгоритма, устанавливающего линейный порядок на множестве вершин.
Многие фундаментальные и полезные алгоритмы являются алгоритмами
локального индексирования. Поняв устройство алгоритма локального
индексирования, можно создавать новые алгоритмы.
Множество вершин сети будем разбивать на три подмножества:
индексированное множество J, граничное множество В и открытое множество С/. Индек-
266 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
сированное множество / состоит из вершин, получивших индекс. Граничное
множество состоит из вершин, соседствующих хотя бы с одной вершиной из J.
Открытое множество U состоит из вершин, не имеющих соседей в /. Опишем
сначала BFS и DFS в этих терминах.
Поиск в ширину (BFS).
Шаг 0. Выбрать произвольную вершину V\, присвоить ей индекс 1. Теперь
индексированное множество состоит из одной вершины. Включить
соседей v\ в граничное множество В.
Шаг 1. Пусть индексированное множество состоит из вершин vi,V2,... ,v*.
Выбрать в множестве В в качестве наилучшего кандидата вершину,
имеющую соседнюю вершину с наименьшим индексом (если таких
несколько, выбирается любая из них).
Шаг 2. Присвоить наилучшему кандидату индекс к +1. Добавить новый
элемент к множеству J. Скорректировать множества В и U. Вернуться
на шаг 1.
Поиск в глубину (DFS).
Шаг 0. Такой же, как в BFS.
Шаг 1. Такой же, как в BFS, только слово «наименьшим» заменяется на
«наибольшим».
Шаг 2. Такой же, как в BFS.
Для объединения BFS и DFS ассоциируем с каждой вершиной V{
индексированного множества вес од. Граничная вершина х, смежная, скажем, с
индексированными вершинами v\, V4, Vs, получает временную метку min{iui, wa, u>8 } •
В общем случае граничная вершина х получает временную метку
lz = minitfj,
и граничная вершина с наименьшей временной меткой получает следующее
значение индекса.
Различные способы назначения весов вершинам приводят к разным
алгоритмам локального индексирования. Например, если веса назначить так,
чтобы было w\ > W2 > ... > wn, получится DFS. Если веса назначить так,
чтобы tui < W2 < ... < гуп, получится BFS. Варьируя относительную
величину весов, можно получать разнообразные алгоритмы обхода, которые можно
рассматривать как гибриды BFS и DFS.
Алгоритм Дейкстры для нахождения кратчайшего пути тоже можно
рассматривать как алгоритм локального индексирования. Результатом работы
этого алгоритма является корневое дерево с корнем в стартовой вершине.
Алгоритм назначает вершинам индексы, указывающие порядок выбора вершин
9.1. ОБЪЕДИНЕНИЕ АЛГОРИТМОВ
267
для присоединения к дереву. Каждая вершина Vi в индексированном
множестве имеет вес ги$, равный кратчайшему расстоянию от стартовой вершины.
Переформулируем алгоритм Дейкстры как алгоритм локального
индексирования.
Алгоритм Дейкстры для нахождения кратчайшего пути.
Шаг 0. Присвоить стартовой вершине V\ индекс 1 и вес w{ = 0, добавить
эту вершину к индексированному множеству. Добавить все смежные
с V\ вершины к граничному множеству, а все остальные вершины —
к открытому множеству. Каждой вершине х в граничном множестве
присвоить временную метку lx = d\x, равную длине ребра,
соединяющего х С V\.
Шаг 1. Пусть индексированное множество состоит из вершин t^,i^,... ,v*.
Каждой вершине х в граничном множестве присвоить временную
метку
lx ~mm{wi + di,x};
Выбрать в граничном множестве В в качестве наилучшего кандидата
вершину с наименьшей временной меткой.
Шаг 2. Присвоить наилучшему кандидату индекс А: + 1 и вес Wk+i, равный
значению временной метки. Добавить эту вершину к
индексированному множеству. Скорректировать множества В и U. Вернуться на
шаг 1.
Алгоритм Прима для построения минимального остовного дерева также
может быть описан в рамках схемы алгоритма локального индексирования.
Алгоритм Прима для построения минимального остовного дерева.
Шаг 0. Выбрать произвольным образом стартовую вершину. Присвоить этой
вершине V\ индекс 1 и вес w\ — 0, добавить ее к индексированному
множеству. Добавить все смежные с v\ вершины к граничному
множеству, а все остальные вершины — к открытому множеству.
Каждой вершине х в открытом множестве присвоить временную метку
1Х ■= dla!? равную длине ребра, соединяющего х с v\.
Шаг 1. Пусть индексированное множество состоит из вершин vi,t>2,. ••,*>*•
Каждой вершине х в граничном множестве присвоить временную мет-
КУ
lx = mm{ditX}.
Выбрать в граничном множестве В в качестве наилучшего кандидата
вершину с наименьшей временной меткой.
Шаг 2. Присвоить наилучшему кандидату индекс к +1 и вес w*+i = 0.
Добавить эту вершину к индексированному множеству. Скорректировать
множества В и (/. Вернуться на шаг 1.
268 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
Отметим, что единственное различие между алгоритмами для задач о
кратчайшем пути и минимальном осговном дереве состоит в способе
вычисления временных меток граничных вершин и весов индексированных вершин.
Результатом работы алгоритма в обоих случаях является корневое дерево.
В задаче о кратчайшем пути каждая вершина в индексированном
множестве имеет вес, равный кратчайшему расстоянию до стартовой вершины. Все
вершины в индексированном множестве соединены коричневыми ребрами и,
чтобы достичь новой вершины, нужно ровно одно зеленое ребро (см. раздел
1.2). Вес индексированной вершины, инцидентной этому ребру, с добавленной
к нему длиной ребра дает верхнюю оценку длины кратчайшего пути к этой
новой вершине.
В задаче о минимальном остовном дереве общая стоимость остовного
дерева есть сумма стоимостей всех его ребер. В минимальном остовном дереве
все постоянные метки в индексированном множестве равны нулю.
Есть ли польза от представления двух алгоритмов как частных случаев
более общего алгоритма? Рассмотрим один пример.
Предположим, что вершины представляют электронные устройства и мы
хотим построить дерево наименьшей стоимости, соединяющее все эти
вершины. Стоимость создания ребра между вершинами i и j равна dij-
Минимальную стоимость построения будет иметь минимальное остовное дерево.
Допустим теперь, что вершина V\ представляет источник энергии,
питающий все остальные устройства. Тогда нам нужно дерево с наименьшими
расстояниями от v\ до каждой из остальных вершин. Такое дерево кратчайших
путей будет иметь минимальную стоимость функционирования.
Для поддержания равновесия между стоимостью построения и стоимостью
функционирования можно построить дерево, в котором достигается
компромисс между двумя стоимостями.
Предположим, имеются 12 вершин v% (t = 2,..., 13), лежащих на
окружности. Вершина vi, представляющая источник, находится в центре окружности.
Дерево кратчайших путей показано на рис. 9.1(a). Минимальное остовное
дерево показано на рис. 9.1(b), и компромиссное дерево показано на рис. 9.1(c)
(расстояния евклидовы).
Компромиссное дерево можно построить, применяя более общую формулу
вычисления меток:
lx = min{aWi + pditX}.
В алгоритме для поиска кратчайшего пути а = 1, 0 = 1. В алгоритме для
построения минимального остованого дерева а = О, 0=1. Подбирая
параметры а и /?, можно получать различные деревья, подходящие для конкретного
случая; например, можно взять а = /? = 1/2.
9.2. Максимальные потоки и минимальные
разрезы
В следующем разделе будут описаны еще два алгоритма,
укладывающихся в общую схему алгоритмов локального индексирования. Первый из них,
9.2. МАКСИМАЛЬНЫЕ ПОТОКИ И МИНИМАЛЬНЫЕ РАЗРЕЗЫ 269
Рис. 9.1
алгоритм максимальной смежности (принадлежащий Нагамочи и Ибараки),
хорошо известен. Второй, алгоритм минимального разделения, введен здесь
для иллюстрации другой разновидности процесса выбора в алгоритме
локального индексирования.
Прежде чем описать эти два алгоритма, необходимо ввести некоторые
обозначения. Наши обозначения подчиняются нескольким основным принципам
и легко запоминаются.
Ориентированная сеть G — (V, Е) состоит из множества вершии V и
множества ребер Е С V х V. Вершины обозначаются строчными буквами: t, j, и, х, у
или Vt,Vj,vi,t^ и т.д. Множества вершин обозначаются прописными
буквами: J, J,U,X,Y и т.д. Ребра обозначаются двумя инцидентными вершинами:
(hj)> («,У) или eih ei2 и т.д.
Для сетей есть два важных понятия: соединение и разделение.
Для обозначения соединения между двумя элементами будем применять
скобки и запятые, разделяя соединяемые элементы запятыми. Так, (i,j) —
ребро, соединяющее вершины % и j, (i, X) — множество ребер, соединяющих
вершину х с вершинами множества Xy(XyY) -множество ребер, у которых
один конец принадлежит множеству X, а другой — множеству Y. С каждым
270 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
ребром будет ассоциироваться пропускная способность, через c(i,j)
обозначается пропускная способность ребра (», j), а через c(X,Y) - сумма пропускных
способностей всех ребер множества X хУ. Квадратные скобки вместо круглых
применяются для обозначения разреза, т. е. множества ребер^^ удаление
которых разделяет два элемента, разделенных запятой. Так, [X, X] — это разрез,
разделяющий X и его дополнение X, a [s,t] — разрез, разделяющий вершины
s и t. Буква С перед квадратными скобками применяется для обозначения
пропускной способности или величины разреза [s,t]:
C[s,t]= £ С^Я (szx,tex).
iexjex
Верхний индекс * применяется для обозначения оптимального разреза,
разделяющего вершины s и t.
Теорему о максимальном потоке и минимальном разрезе можно
представить в виде:
*-(М) = С>,«].
X — У обозначает разность множеств X и У, т.е. множество элементов
из X, не принадлежащих У. Бели X и У не пересекаются, то X — У = X.
\Х\ обозначает мощность X. Например, если имеется п вершин и га ребер, то
|V| = п и \Е\ = га.
Для упрощения будем опускать букву с перед обозначением ребра и букву
С перед обозначением разреза. Иными словами, ребро может обозначать и
само ребро, и его пропускную способность, а разрез может обозначать как сам
разрез, так и его пропускную способность. При необходимости, во избежание
недоразумений,_будем применять буквы с и С.
Вместо [X, X] будем иногда писать просто [X] как для обозначения
разреза, так и для обозначения величины разреза. Таким образом,
[Х\ = £ c{u,v).
u€Xtv£X
Для вершины х
y€V-x
Символ объединения множеств иногда будем опускать, например:
с(АВ, XY) = с{А U В, X U У) = с(А, X) + с(А, У) + с(В, X) + с(В, У).
9.3. Максимальная смежность и минимальное
разделение
Опишем еще два алгоритма, укладывающихся в общую схему алгоритмов
локального индексирования. Алгоритм максимальной смежности
применяется для нахождения глобально минимального разреза в сети. Алгоритм
минимального разделения является двойственным к алгоритму максимальной
смежности.
9.3. СМЕЖНОСТЬ И РАЗДЕЛЕНИЕ
271
Алгоритм максимальной смежности (Нагамочи и Ибараки).
Шаг 0. Выбрать произвольно стартовую вершину v\. Присвоить ей индекс 1,
вес w\ = 0 и добавить ее к индексированному множеству. Все
смежные с v\ вершины добавить к граничному множеству, а все остальные
— к открытому множеству. Каждой вершине х из граничного
множества присвоить временную метку 1л = c(x,vi), равную пропускной
способности ребра (ar,vi).
Шаг 1. Пусть индексированное множество состоит из вершин vi,t>2, ••-,#*.
Каждой вершине х в граничном множестве присвоить временную
метку
1х = ^2с(х,ы).
iei
Выбрать в граничном множестве вершину с наибольшей временной
меткой в качестве наилучшего кандидата.
Шаг 2. Присвоить наилучшему кандидату индекс А: +1 и вес Wk+i = 0.
Добавить его к индексированному множеству. Скорректировать граничное
множество В и открытое множество U. Если \В\ ф 1 или \U\ ф 0, то
вернуться на шаг 1.
Шаг 3. Присвоить (единственной) вершине из В индекс п и вес wn = 0.
Запомнить пропускную способность разреза [vn]> С[^п] = c(t/n, V — vn).
Построить редуцированную сеть G' путем стягивания vn и vn-i • Если
в редуцированной сети больше двух вершин, повторить шаги 0-3.
Алгоритм максимальной смежности имеет много применений. Одно из них
- нахождение глобально минимального разреза в сети. Величина C[vn],
полученная на шаге 3, —- это пропускная способность потенциально минимального
разреза. Алгоритм применяется повторно к сети, в которой на одну вершину
меньше. В первой фазе имеется п вершин, во второй п — 1 и т. д. В каждой
фазе находится некоторый потенциально минимальный разрез. Настоящий
глобально минимальный разрез получается выбором наименьшего из этих
потенциально минимальных разрезов.
Для иллюстрации алгоритма максимальной смежности рассмотрим сеть
из шести вершин, показанную на рис. 9.2.
Если стартовая вершина v\ *=■ а, то наибольшее соединение с ней имеет
вершина ft, так что ft получает индекс 2: V2 = ft. Затем индексы 3,4,5,6 получают
соответственно вершины с, d, е, /. Полагаем C[f] — 6.
Этим заканчивается первая фаза. Стягиваем (е, /) и начинаем вторую
фазу на сети с пятью вершинами, показанной на рис. 9.3(a). Стартуя с v\ = а,
находим V2 = д,У$ = ft,V4 = с, V5 = d, как показано на рис. 9.3(b). Последняя
вершина d имеет разрез с C[d\ = 1 + 2 + 3 = 6.
Так заканчивается вторая фаза. Далее стартуем на новой сети с четырьмя
вершинами, показанной на рис. 9.4(a), в результате получаем величину
разреза C[h] = 7.
272 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
Рис. 9.2
Читатель может проверить, что следующие две фазы дадут величины
разрезов 6 и 11. На последней фазе сеть состоит из двух вершин. Величина
глобально минимального разреза для исходной сети равна 6.
Дадим обоснование алгоритма максимальной смежности. Пусть [X, X]
обозначает глобально минимальный разрез в сети. Имеется три случая:
(i) Разрез [vn] является глобально минимальным. Он запоминается, так что
в этом случае алгоритм работает правильно.
(И) Если обе вершины vn_i и vn принадлежат X (или X), то стягивание
ребра (vn-i, vn) не изменяет величины глобально минимального разреза.
Поэтому глобально минимальный разрез может быть найден в одной из
следующих фаз.
(Ш) Бели vn-i € X, vn € -Y, то стягивание ребра (vn_i,vn) разрушит
глобально минимальный разрез.
* Покажем, что случай (Ш) невозможен. Докажем, что любой разрез [У],
разделяющий rn_i и vn, имеет величину, большую или равную [vn]. Для
иллюстрации доказательства рассмотрим сначала сеть с 9 вершинами. Согласно
алгоритму, для v\ и i>2 должны выполняться неравенства:
с(ух, v2) > c(vi, Vj), j = 3,..., 9.
Вершина vs выбирается так, что выполняются неравенства:
c(ViV2,V3) >c(ViV2,Vj), J =4,...,9.
•;
Ь)
Рис. 9.3
9.3. СМЕЖНОСТЬ И РАЗДЕЛЕНИЕ
5
273
а)
Рис. 9.4
Идея доказательства состоит в том, чтобы взять произвольный разрез,
разделяющий tig и tig, и показать, что его пропускная способность больше, чем у
некоторого другого разреза, пропускная способность которого в свою очередь
больше, чем у некоторого третьего разреза и т. д., а последним разрезом в этой
цепочке будет [viV2V3V4VbVeVtVsiVg]. Предположим, что разрез, разделяющий
vs и vg, есть [1;11>2*>з^б1*г1>8>^41>5^9]. Тогда
c(ViV2V3VeV7VsiV4V5Vg) =
= c(ViV2V3iV4Vb) + c(v4V5,VeV7VS) + c(veV7VS,Vg) + c(viV2V3, Vg) >
> c{Vit^V3, V4) + C(V41>5, l>6*>7Ve) + c(v6V7V8, Vg) >
> c(ViVzV3,Ve) + C(V4V$, VQVlVb) + c(VeV7VSrVg) =
= c(viV2V3,Ve) + C(V4V6, V6) + c(v4Vz,V7Vs) + c{yQVlV%>Vg) >, -
> C(V\V2V3V4V5,, V6) + c(veV^V^ Vg)>
> фхV2V3V4Vb, Vg) + C(V6V7VB, Vg) -
= c(V\ V2V3V4V6^6^7^8» Vg) =
= c[Vg].
В общем случае произвольный разрез разбивает множество вершин на две
части. В каждой части индексы можно сгруппироватьв подпоследовательности
так, чтобы в каждой подпоследовательности индексы шли подряд. f
В приведенном выше примере первая часть ViV2V3VqViv% состйит<яз двух
подпоследовательностей здгдоз и щьтЩ- Вторая часть VAVbVg имеет две
подпоследовательности V4«5 и Vg. Обозначим эти подпоследовательности через
аА, ЬБ, сС, dD,... в разрезе [аАсСеЕ..., ftBdJD], где малые буквы обозначают
первые вершины подпоследовательностей. В примере а = V\,A = V2i>3»b =
V4, -В = V6, С = Ve, С = V7V8, d = Vg.
Пропускную способность произвольного разреза всегда можно записать
274 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
как сумму связей между подпоследовательностями:
с(аА, ЬВ) + фВ, сС) + с(сС, dD) + с(<ДО, е£) + с(аА, dD) + фВ, е£) +... >
> с(аА, ЬВ) + фВ, сС) + с(сС, d£>) + c(d£>, е£) + ... >
> с(аА, Ь) + фВ, с) + с(сС, dD) + c(d£>, еЕ) + ... >
> с(аА, с) + фВ, с) + с(сС, <Ш) + c(d£>, еЕ) +... =
= с(аАЬВ, с) + с(сС, dD) + c(dD, е£) + ....
Ha этом этапе аАбВ становится одной подпоследовательностью, в которой
индексы идут подряд и можно продолжить процесс:
> с(аАЪВ, d) + с(сС, d) + с(сИ), еЯ) + ... =
= с(аАЪВсС, d) + c(dDr еЕ) + ... >
> с(аАЬВсС,е) + c(dD,eE) + ... >
> фА&ВсСсДО... уУ, *) =
= Ф*).
В этом доказательстве есть три существенных момента:
(i) Пропускная способность произвольного разреза записывается в виде
суммы с(аА, ЬВ) + с(ЬВ, сС) + с(сС, dD) + c(dD, еЕ) + ..., а слагаемые,
подобные c(aA,dD)> отбрасываются.
(ii) Если г < j, то суммарное соединение между подпоследовательностью с
подряд идущими индексами и вершиной Vi всегда не меньше, чем
соединение между той же подпоследовательностью и вершиной vy, например,
с(аАуЬ) > (аА,с).
(Ш) Соединение между двумя подпоследовательностями всегда не меньше,
чем соединение между одной из них и начальной вершиной другой;
например, с(ЪВ,сС) > с(ЬВ,с).
Во всех описанных алгоритмах локального индексирования наилучший
кандидат из граничного множества определялся по индексированным
вершинам и величинам ребер, соединяющих рассматриваемую вершину с
индексированным множеством. Соединения между вершиной-кандидатом и остальными
вершинами сети игнорировались. Теперь опишем алгоритм локального
индексирования, который принимает во внимание эти соединения.
В теории графов степень вершины определяется как число инцидентных
ей ребер. В сети каждое ребро имеет пропускную способность (граф — это
частный случай, когда пропускная способность каждого ребра равна 1).
Определим сетевую степень подмножества X множества вершин как
С[Х]= £ <<«»«)•
Если c(i,j) = c(J,i), то С[Х) = С[Х].
9.3. СМЕЖНОСТЬ И РАЗДЕЛЕНИЕ
275
В главе 10 подмножество множества вершин изображается в виде круга,
охватывающего вершины подмножества. Сетевая степень подмножества — это
сумма пропускных способностей ребер, соединяющих вершины внутри круга
с вершинами вне круга. Нас интересует круг Ху у которго сетевая степень
строго меньше, чем сетевая степень вершины vx (vx € Х)> т. е.
C[vx]>C[X]=c(X,X).
В алгоритме максимальной смежности наилучший кандидат в граничном
множестве - это вершина, у которой максимальное соединение с
индексированным множеством V* = {vi, V2,..., v*}. Затем строится новое индексированное
множество V*+1 == {tfi,U2,..., t;*, v*+i} и проносе повторяется!
Теперь опишем новый алгоритм, называемый 'алгоритмом минимального
разделения. Индексированное множество I сначала состоит из одной
произвольной вершины, соседние с индексированным Множеством вершины
образуют граничное Множество В, остальные вершины — открытое множество U
(оно может быть пустым).
Этот алгоритм назван алгоритмом минимального разделения из-за того,
что сетевая степень круга, содержащего к +1 вершину (индексированное
множество из к элементов плюс новая вершина х), меньше, чем сетевая степень
круга, образованного индексированным множеством и любой другой
вершиной у.
Другими словами, вершина х выбирается так, чтобы круг [1х] имел
меньшую сетевую степень, чем круг [/у], т. е.
C[Ix] = min С[1у].
уев
Алгоритм минимального разделения.
Шаг 0. Выбрать произвольно стартовую вершину v\. Присвоить ей индекс 1,
вес w\ = 0 и добавить ее к индексированному множеству. Все
смежные с v\ вершины добавить к граничному множеству, а все остальные
— к открытому множеству. Каждой вершине х из граничного
множества присвоить временную метку lx = C[xv\]^ равную степени круга,
содержащего х и v\.
Шаг 1. Пусть индексированное множество состоит из вершин vi,V2,...,t;fc.
Присвоить каждой вершине х из граничного множества временную
метку
1ш = [1х].
Выбрать в граничном множестве вершину с наименьшей временной
меткой в качестве наилучшего кандидата.
Шаг 2. Присвоить наилучшему кандидату индекс к +1 и вес w*+i = 0.
Добавить его к индексированному множеству. Скорректировать граничное
множество В и открытое множество U. Если |Б| ф 0 или |(/| ф 0, то
вернуться на шаг 1.
276 ГЛАВА 9. АЛГОРИТМЫ ЛОКАЛЬНОГО ИНДЕКСИРОВАНИЯ
Применим алгоритм минимального разделения к сети на рис. 9.2. Если
стартовой вершиной является Ь = v\, то гъ = с, так как
С[Ъс] = 10 < С[Ъа] =* 12 < С[Щ = 13.
Если бы мы применяли алгоритм максимальной смежности, то было бы
выбрано t)2 = а, так как
с(6,а) = 5 > с(Ь,с) = 4 > c(b,d) = 2.
В алгоритме минимального разделения минимизируется величина разреза,
отделяющего вершины индексированного множества /. Стартовая вершина v\
не обязана быть вершиной наименьшей сетевой степени. Но после того, как
v\ выбрана, вершина хъ выбирается так, чтобы было [vit^] < [v\Vj]. Иными
словами, круг, охватывающий V\ и t;2, должен иметь минимальную сетевую
степень среди всех кругов, охватывающих две вершины, одна из которых v\.
В главе 10 мы будем искать круг, охватывающий множество вершин,
скажем [ai/Л], такой, что значение круга меньше, чем сетевая степень одной из
вершин внутри круга, т. е.
C[abfh] < max{C[a],C7[b],C[/],C[ft]}.
Можно ли применить алгоритм минимального разделения для поиска такого
круга? Если да, то как? Если нет, то почему?
Глава 10
Дерево Гомори-Ху
Деревья Гомори-Ху — частный
случай кластеризации, а сетевая
алгебра — обобщение булевой алгебры.
10.1. Древесные ребра и древесные звенья
Во второй главе изучались потоки в сетях, а в разделе 2.3 —
максимальные многополюсные потоки. Для сети с неориентированными ребрами все
(£) максимальных потоков можно получить, вычислив п — 1 максимальных
потоков. Сеть содержит п - 1 нескрещивающихся фундаментальных
минимальных разрезов. Если представить каждый фундаментальный
минимальный разрез звеном, то и — 1 звеньев образукуг дерево, известное как дерево
разрезов Гомори-Ху (в дальнейшем GH-дерево). Например, сеть,
изображенная на рис. 2.30, потоко-эквивалента GH-дереву, изображенному'на рис. 2.29.
Заметим, что произвольная сеть с неориентированными ребрами всегда по-
токо-эквивалентна GH-дереву. При этой звенья GH-дерева соответствуют
нескрещивающимся фундаментальным разрезам сети. Поэтому GH-дерево не
только пЬтоко-эквивалентно, но и разрезо-экЪивалентно сети.
Чтобы избежать путаницы, мы говорим, что сеть состоит из вершин и
ребер, а GH-дерево состоит из узлов и звеньев. Разрез наименьшей величины
среди п — 1 фундаментальных минимальных разрезов называется глобально
минимальным разрезом. Например, звено величины 13 на рис. 2.29
соответствует глобально минимальному разрезу сети* В этой главе вершины будут
обычно помечаться а, 6, с,..., а не va, v&, vc,..., как в предыдущих главах.
Пусть G — сеть, а Т *- ее GH-дерево. Если в Т существует звено,
соединяющее узлы i и j, то соответствующее ребро (t,j) в сети называется древесным
ребром. На рис. 2.30 ребра (vi,i>2)> (*>2>*>б)> (v6>v6), (i>5>v3) и (ьь,щ) являются
древесными.
278
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
а) Ю
Рис. 10.1
Если звено, соединяющее узлы t и j, существует, но в сети отсутствует
соответствующее ребро (г, j), то мы называем такое несуществующее ребро
виртуально древесным. Таким образом, всегда имеется п — 1 древесное ребро;
все остальные ребра называются недревесными.
Пропускная способность звена дерева, соединяющего узлы х и у,
обозначается через /(#,{/), она равна величине минимального разреза. Таким образом,
звено, соединяющее (г>5>*>б) в GH-дереве, имеет 1(щ,Уц) = 13, в то время как
древесное ребро (*>5>^б) имеет пропускную способность c(v5,i>e) = 3.
Рассмотрим сеть на рис. 10.1(a) и ее GH-дерево на рис. 10.1(b). Сетевые
степени вершин этой сети:
[va] = [а] = 14, [t*] = M = 15f И = 16,
[d\ = 18, [е] = 18, [/] = 19.
На рис. 10.1(b) для узла [а] имеется один соседний узел [с], а для узла [с]
— три соседних узла: [a], [ft] и [d\. Древесную степень узла определим как
число соседних с ним узлов в GH-дереве. Таким образом, [а] имеет древесную
степень 1, а [с] — древесную степень 3.
Если древесная степень узла равна единице, то такой узел назовем
листовым узлом или просто листом» а соответствующую вершину — листовой
вершиной. Звено, инцидентное листовому узлу, называется листовым звеном.
На рис. 10.1(b) звенья 1(с>а), /(с,ft) и /(/,е) являются листовыми звеньями.
Остальные звенья (например, i(c,d) и /(d,/) на рисунке) называются
внутренними звеньями.
Лемма 1. Максимальный поток F*(x, у) между любыми двумя вершинами
[х] и [у] не превосходит сетевых степеней этих вершин, т. е.
F*(x,y)<minM[y]}.
Доказательство, [х] и [у] являются разрезами, разделяющими вершины х и
у, поэтому пропускная способность каждого из них является верхней границей
для*1* (а?, у). I
10.1. ДРЕВЕСНЫЕ РЕБРА И ДРЕВЕСНЫЕ ЗВЕНЬЯ 279
Рис. 10.2 Рис. 10.8
Лемма 2. Если х — лист в GH-дереве, а 1(хгу) — листовое звено, то
Г(х,у) = 1(х,у) = [х]<\у].
Доказательство. Пусть 1{х^у) — звено в GH-дереве, тогда, как показано в
главе 2 (теорема 4), F*(xyy) = 1(х,у). По лемме 1
^(аг,у)<тш{И,[у]}.
Но vx является листовой вершиной, а [х] — фундаментальным
минимальным разрезом; если \у] < [х], то получается противоречие с тем фактом, что
GH-деревй разрезо-эквивалентно сети. i
Эта лемма показывает, что сетевая степень листовой вершины не
превосходит сетевой степени единственной соседней с ней вершины.
Лемма 3. Если [z] — единственная вершинах наибольшей сетевой
степенью в сети, то [z] не может быть листом GH-depeea.
Доказательство. Предположим, что [z] является листовым узлом в
GH-дереве. Тогда из леммы 2 следует, что единственный соседний с [z] узел должен
иметь сетевую степень, большую или равную степени [z], а это противоречит
тому, что [z] является единственной вершиной с наибольшей сетевой
степенью. I
Пусть неориентированная сеть имеет т ребер (п — 1 < m < п[п — 1)/2).
Среди них п — 1 древесных ребер (включая ребра с пропускной способностью
0), соответствующих звеньям GH-дерева. Оставшиеся ребра являются
недревесными.
Всего имеется 2й""1 — 1 разрезов, а нужны, по существу, только п—1 нескре-
щивающихся фундаментальных минимальных разрезов. Фундаментальный
разрез состоит из многих ребер, но только одно из них — древесное ребро.
Таким образом, если увеличить пропускную способность древесного ребра, то
это повлияет лишь на один фундаментальный разрез. € другой стороны, если
варьировать пропускную способность недревесного ребра, то это повлияет на
два или более фундаментальных разреза.
280 ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
Рис. 10.4 Рис 10.5
Найти все древесные ребра *— это значит найти все звенья или п - 1
минимальных [з, ^-разрезов. Рассмотрим сеть на рис. 10.2(a) и ее GH-дере-
во (рис. 10.2(b)). Если пропускную способность недревесного ребра (Ь,с) на
рис. 10.2(a) увеличить с 2 до 3.5, как показано на рис. 10.3(a), то получится
новое GH-дерево, изображенное на рис. 10.3(b). Если пропускную способность
недревесного ребра (Ь,с) на рис. 10.2(a) уменьшить с 2 до 0, как показано на
рис. 10.4(a), то получится новое GH-дерево, показанное на рис. 10.4(b).
Вообще говоря, GH-дерево не определяется однозначно из-за того, что пропускные
способности разрезов могут совпадать. Для устранения неоднозначности мы
всегда выбираем GH-дерево, имеющее минимальный диаметр.
Если уменьшить пропускную способность древесного ребра (ft,d) (рисунок
10.2(a)) с 5 до 0, то получится GH-дерево, приведенное на рис. 10.5(b).
Заметим, что мы могли бы выбрать для GH-дерева на рис 10.5(b) звено (a,d) с
величиной 4 вместо звена (с, d) с той же величиной. Мы выбрали
представленное GH-дерево, так как его диаметр равен 2. Если бы мы заменили звено
(c,d) звеном (a,d), полученное GH-дерево (хотя оно и было бы разрезо-экви-
валентно) имело бы диаметр -3. *
Рассмотрим сеть на рис. 10.2(a), где есть 3 древесных ребра: (а,с), (c,d)
и (ft, d). Если пропускную способность любого и& древесных ребер увеличить,
скажем, пропускную способность ребра (с, d) увеличить с 5 до 7, то вид
GH-дерева не изменится, и мы просто изменяем величину соответствующего звена
С 8 до 10.
Сформулируем это как теорему.
Теорема 1. Если пропускную способность древесного ребра (jyk) увеличить
на с > 0, то вид GH-дерева не изменится, а величина соответствующего
звена /(j, к) увеличится на е.
Доказательство. Заметим, что древесное ребро (j, к) принадлежит точно
одному из п — 1 нескрешиваюй^ихся фундаментальных минимальных разрезов.
Оно не принадлежит никакиму из остальных п — 2 фундаментальных
минимальных разрезов. Поэтому если мы заменим c(jf, к) 4- c(j, к)+€, то величины
других I*— 2 звеньев останутся прежними, только /(j,k) увеличится на е.
Таким образом, если F*(j,k) = /(j,k), то максимальный поток из j в к в новой
10.2. СТЯГИВАНИЕ
281
сети станет равным l(j, к) + е. I
Увеличение пропускной способности древесного ребра до бесконечности
равносильно созданию новой вершины, заменяющей две инцидентных этому
ребру вершины, при этом величина соответствующего звена тоже
увеличивается до бесконечности. Более формально это можно выразить следующим
образом. Пусть Gn — сеть с п вершинами, а Тп — ее единственное GH-дерево.
Пусть (j,k) ~ древесное ребро. Если мы стянем ребро (j,*) так, что
получится сеть (?n-i с п -%1 вершиной, то GH-дерево Гп_х для Gn-\ может быть
получено стягиванием соответствующего звена (j, fc) в Гя.
Замечание. Уменьшение пропускной способности древесного ребра может
изменить GH-дерево.
10.2. Стягивание
В разделе 2.3 мы описали процесс, называемый стягиванием, или
конденсацией, подмножества вершин S в одну вершину s. Это равносильно увеличению
пропускных способностей ребер, у которых оба конца принадлежат 5, до
бесконечности. Для формального описания процесса рассмотрим сеть G =с (У, £7)
с подмножеством вершин S. Тогда G/S = G1 = (V^E*) — сеть, в которой
подмножество 5 стянуто в одну вершину 8, т. е. V7 = (У - 5) IU {t;,}.
Пропускные способности ребер в G' обозначаются через d и определяются следующим
образом:
d(hj) = c(i,j), если г и j содержатся в V —JS;
*{*> s) = Е <#»*)> есди к € У -S
(в качестве примера см. рис. 2.12).
Пусть [X, X] обозначает произвольный разрез, его пропуЬкная способность
равна
С[Х,Х] = ^с(щу) (ueX,veX).
Бели обе вершины ребра (i, j) принадлежат X, то пропускная способность
разреза [Х,Х] не изменится при стягивании их в одну вершину. Можно стянуть
любое подмножество вершин 5 из X, не изменяя пропускную способность
разреза [X, ЗС]. - г
Пусть l(i,j) — звено в GH-дереве, в котором i(», j) — C*[t,j]. Это звено
Z(t,J) определяет и соединяет два поддерева Т{ и I), где i € I*, a j € Tj.'Hh
один из разрезов, представляемых звеньями Г*, не скрещивается с разрезом
C*[i,j]. Поэтому любые вершины из 7* можно стянуть. Сформулируем это
как теорему.
Теорема 2. Если S С V есть множество вершин некоторого поддерева
GH-дерева, то GH-дерево для G/S получается из GH-дерева для G заменой
этого поддерева одним узлом.
282
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
В частности, мы можем стянуть древесное ребро в одну вершину, не
изменяя фундаментальных разрезов, представленных другими п — 2 звеньями
GH-дерева (Ы. теорему 1 раздела 10.1)
10.3. Доминирование
Ребро (х, у) назовем доминирующим ребром для вершины х, если
пропускная способность этого ребра строго больше, чем сумма пропускных
способностей всех остальных ребер, инцидентных вершине х. Другими словами,
Ф,у)> £c(*,i)>
fv (1)
или с(х,у) > -[х].
Лемма 4. Если (х, у) — доминирующее ребро для х, то в GH-дереве имеется
звено (х,у).
Доказательство. Допустим, что х и у не смежны в GH-дереве. В этом случае
в маршруте, соединяющем узлы хиув GH-дереве, имеется промежуточный
узел z.
Пусть [Х,Х] — минимальный разрез, разделяющий у и z. Не теряя
общности, можно считать, что у € X, г, х 6 X. Из (1) следует, что при перемещении
х из X в X пропускная способность разреза уменьшится. Это противоречит
тому, что [Х,Х] является минимальным разрезом. I
Замечание. Доминирующее ребро является древесным ребром, но древесное
ребро может не быть доминирующим. После того, как мы нашли древесное
ребро (х,у) и стянули его, создав новую вершину з, может появиться новое
доминирующее ребро из вершины z в вершину t, поскольку условие
доминирования для t приобретает вид:
с(М) + с(1М) = Ф,0> 2ОД-
После создания новой вершины [xyi] = [zi] могут обнаружиться еще и другие
доминирующие ребра. (Если сеть содержит пять или менее вершин, то либо
существует доминирующее ребро, либо ее GH-дерево является звездой.)
Понятие доминирующего ребра для вершины х может быть обобщено до
доминирующего множества ребер. Рассмотрим все ребра, инцидентные
вершине х, и положим, что их пропускные способности равны Ci,C2... с*, где
C\>C2>">Ck-
Условие доминирования требует, чтобы существовало единственное ребро,
пропускная способность которго была бы больше половины сетевой степени
вершины х:
10.3. ДОМИНИРОВАНИЕ 283
Рис. 10.6
Более слабым является условие:
£<* > jW; (2)
т. е. сумма пропускных способностей j наибольших ребер больше, чем
половина сетевой степени вершины х. Если условие (2) выполнено, будем говорить,
что доминирующий фактор в вершине х равен /. Если существует
доминирующее ребро, то доминирующий фактор равен 1. Наибольшим значением
доминирующего фактора может быть [п/2], и оно достигается, когда все
ребра имеют одинаковые пропускные способности и граф сети является полным
графом.
В определениях доминирующего ребра и доминирующего фактора
фигурируют строгие неравенства (1) и (2). На самом деле для определения древесного
ребра, а тем самым и фундаментального минимального разреза, достаточно
знака >. Строгое неравенство нужно для того, чтобы GH-дерево строилось
однозначно (имело наименьший диаметр). Напомним, что в GH-дереве
существует два типа звеньев — листовые звенья и внутренние звенья. Листовое
звено соединяет два узла, один из которых имеет древесную степень 1.
Внутреннее звено соединяет два узла, древесная степень каждого из которых
строго больше единицы.
Рассмотрим типичное GH-дерево, изображенное на рис. 10.6, где
внутренние звенья выделены сплошными жирными линиями, а листовые звенья —
тонкими сплошными линиями. Отметим, что узлы а, ft, с, d,е, /,д, ft, t, j, fc,p, q> г
являются листьями, а инцидентные им звенья являются листовыми звеньями.
Максимальное множество листьев, имеющих общий соседний узел, взятое
вместе с этим узлом, называется звездой. Таким образом, множество {а, ft, с, в}
образует звезду, звездами являются и {/, g, w}, {d, t, е}, {ft, t, j, fc, v}, {p, g, r, x}.
Общий соседний узел для листьев звезды (имеющий древесную степень
большую, чем 1) называется хозяином звезды. Так, узел s является хозяином
для звезды {8,а,Ь,с}. Хозяин s инцидентен однму внутреннему звену (М)>
а хозяин t множества {£, d, е} инцидентен двум внутренним звеньям: (в, t) и
284
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
(t, и). Звезду назовем крайней, если ее хозяин инцидентен только одному
внутреннему звену. Таким образом, на рис. 10.6 крайними являются все звезды,
кроме [t] и [и].
GH-дерево можно представить высокоуровневой упрощенной диаграммой
(ВУ-диаграммой), как показано на рис. 10.7* На рис. Ш 7 каждая4 Звезда
представлена кружком, в котором написано имя хозяина звезды. Имея ВУ-диа-
грамму, которая состоит из всех внутренних звеньев и кружков, содержащих
листья звезд, легко построить GH-дерево, добавляя листья к их хозяевам.
© 9 ф ®
Рис. 10.7
При построении GH-дерева во второй главе вычислялись п — 1
максимальных потоков. Если бы у нас была ВУ-диаграмма, то дальнейшие вычисления
были бы не нужны. Нужно было бы просто взять вершину с наибольшей
степенью [Л] в каждом кружке ВУ-диаграммы в качестве хозяина и добавить
каждую из остальных вершин из этрго кружка в качестве листа, присвоив
листовому звену величину (Л, t) = [tJ.
10.4. Эквивалентные формулировки
Сеть есть обобщение гфафаГ, и теорема о максимальном потоке и
Минимальном разрезе является вариантом утверждения о том, что максимальная
Связность равна; минимальному разделению, понимая под связностью и
разделением соответствующие числовые характеристики. Стягивание множества
соседних вершин в одну вершину можно рассматривать как непрерывное
отображение.
Любой максимальный поток из вершины 8 в вершину t может быть разбит
на множество совместимых путевых потоков, в которых все дуговые потоки
имеют одинаковое направление.
Мы видели в разделе 2.5.3, что GH-дерево можно определить как
оптимальное дерево связи, йё используя в явном виде понятие потока. Дадим еще
два эквивалентных определения GH-дерева.
10.4.1. Оптимальное объединение компаний
Рассмотрим сеть из п вершин, которые представляют п компаний. Сетевая
степень вершины равна числу сотрудников в компании. Большой вес ребра,
соединяющего две вершины, указывает на близость сфер деятельности двух
компании.
10.4. ЭКВИВАЛЕНТНЫЕ ФОРМУЛИРОВКИ
285
Когда две компании хну объединяются в одну новую компанию г, сетевая
степень новой компании определяется как
М = Ю + Ы-2(*,у).
Теперь у нас имеется п — 1 компаний, представленных сетью из п — 1
вершин. Бели продолжить объединение компаний, то после п — 1 объединений
получим одну компанию с числом сотрудников, равным нулю.
Определим стоимость объединения компаний как min{[x],[y]}. Тогда
последовательность из п - 1 объединений, имеющая минимальную стоимость,
определяет GH-дерево.
10.4.2. Оптимальное круговое разбиение
Дерево может быть представлено многими способами (см., например,
раздел 2.3 книги Д. Кнута «Искусство программирования для ЭВМ», т. 1). Один
способ состоит в том, что сначала дерево преобразуется в корневое, а затем
для представления корневого дерева используются п вложенных или
непересекающихся кругов (на самом деле, любых замкнутых кривых). Например,
дерево на рис. 10.8(a) представлено как корневое с корнем г на рис. 10.8(b), а
затем девятью кругами на рис. 10,8(с). Имеются определенные преимущества
в изображении GH-дерева из п — 1 звена с помощью п кругов. Каждый круг
охватывает подмножество вершин и существует круг, охватывающий все п
вершин. v
Любое разбиение на круги, соответствующее некоторому Дереву,
называется правильным круговым разбиением. Правильное круговое разбиение есть
распределение п вершин сети по п кругам, охватывающих подмножества
верши^ удовлетворяющее условиям:
1) Каждый круг содержит одну или более вершин, при этом кругу
однозначно сопоставлена одна из <х>держащихся в нем вершин. Эта вершина
называется хозяином круга-
2) Если X и У — подмножества, охватываемые двумя кругами, то эти
подмножества либр не пересекаются (разобщенные), либо одно из них
включено в другое (вложенные); то есть* если \Х\ < |У |* то либо X С У, либо
ХПУ = 0. ^ * ^ ' -
Круг, содержащий ровно одну вершину, называется атомарным кругам, а.
единственная вершина является хозяином атомарного круга. Определим
некоторые характеристики круга.
1) Размер. Размер круга есть число вершин, охватываемых кругом (размер
атомарного круга равен единице).
2) Величина. Величина круга равна сумме пропускных способностей ребер,
имеющих один конец внутри круга, а другой вне круга.
286
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
а)
Ь)
г
f ' >
® ©
1 ' 1
i
L ■
N
I"
) 1
J
с;
Рис. 10.8
3) Глубина. Глубина атомарного круга равна 0, глубина произвольного
круга определяется рекурсивно как максимум глубин его потомков,
увеличенный на единицу. Например, круг с хозяином % на рис. 10.8(c) имеет
глубину 3.
4) Высота. Высота круга определяется как сетевая степень хозяина круга.
В качестве хозяина круга, охватывающего всю сеть, договоримся выбирать
вершину наибольшей сетевой степени. Например, сеть на рис. 2.30 может быть
изображена как на рис. 10.9(a). Весь круг имеет величину 0, а его хозяином
является вершина /, имеющая сетевую степень 19. Круг с хозяином с имеет
размер 3, глубину 1 и величину 13. Круг с хозяином d имеет размер 4, глубину
2 и величину 17. Определим оптимальное круговое разбиение как разбиение
с минимальной суммой величин кругов.
Оптимальное круговое разбиение приводит к некоторым интересным
теоремам, не связанным с понятием максимального потока. Круг назовем
Н-допустимым, если величина круга строго меньше, чем сетевая степень одной из
вершин, содержащихся в нем, т. е. если величина круга строго меньше, чем
высота круга. В качестве примера рассмотрим круг, охватывающий пять вершин
a,6,c,d,h, из которых h имеет максимальную сетевую степень. Круг [habcd\
является Я-допустимым, если h — хозяин круга и
[h] > [habcd\.
Вершины a>b>C)d называются детьми круга.
10.4. ЭКВИВАЛЕНТНЫЕ ФОРМУЛИРОВКИ
287
а)
Рис. 10.9
Предположим, что внутри if-допустимого круга [habcd\ выполняются
соотношения
[<Q>[dac], [d] < [date].
Тогда [d\ является хозяином if-допустимого круга [doc], а [Л] является
хозяином круга [habcd\ с двумя детьми [ft] и [doc].
Круги можно для наглядности трактовать в терминах семейных
отношений, для иллюстрации этого рассмотрим рис. 10.9(a). Вершина [с] является
хозяином Я-допустимого круга [сой], так как [с] = 16 > [cab] = 13, а [а] и [ft]
являются детьми [с]. Материнский круг [cab] имеет два дочерних атомарных
круга, a [d] является матерью [с] и бабушкой [а] и [Ь].
На рис. 10.9(a) вершина [/], будучи вершиной наибольшей сетевой
степени, является хозяином круга, охватывающего все вершины сети, так как
[/] = 19 > [fabcde] = 0. Семейные отношения могут быть описаны корневым
деревом с корнем [/].
Соответствующее GH-дерево изображено на рис. 10.9(b). Каждая вершина
помечена ее сетевой степенью (например, / имеет сетевую степень 19). Так как
оптимальное круговое разбиение эквивалентно GH-дерезу, а также дереву
оптимальной связи (см. раздел 2.5.3), у дас возникло желание охарактеризовать
оптимальные круговые разбиения с помощью теоремы» Эта теорема впервые
была опубликована Таккером, Ху и Шингом в техническом отчете CS99-625
от 17 июня 1999 г. Здесь мы даем несколько измененную версию, более
наглядную и легче доказываемую.
ТЬк как правильное круговое разбиение можно рассматривать как
корневое дерево, сосредоточим внимание на двух смежных поколениях:
материнском и дочерних кругах. Пусть хозяином материнского круга будет вершина
[h]. Дочерние круги могут быть атомарными кругами или кругами глубины
1, 2 и т. д.
Не теряя общности, разобьем дочерние круги на два подмножества, I и
J. Все вершины, которые не являются потомками [Л], конденсируются в круг,
обозначаемый z*. Это показано на рис. 10.10(a). Следующая теорема дает
необходимые и достаточные условия оптимальности кругового разбиения.
Теорема 3 (Таккер, Ху, Шинг). Перечисляемые ниже условия 1-4
являются необходимыми и достаточными для того, чтобы правильное круго-
288
ГЛАВА 10. ДЕРЕВО ГОМОРЯ-ХУ
Рис. 10.10
вое разбиение было оптимальным круговым разбиением, соответствущим
GH-дереву сети.
1. Н -допустимость. Сетевая степень [ft] хозяина материнского круга
должна быть строго больше величины этого круга, т.е [Л] > [hIJ]. Если
выразить величину круга через связи между кругами, то получим (см.
рис. 10.10(a))
[ft] - (Л,**) + (Л,/) + (К J) > (Л,**) +. (J,**) + (/,**) = [hIJ]
или (ft,JJ)>(rj,z*). U
Неравенство (1) означает, что сумма связей между хозяином и всеми
дочерними кругами должна быть строго больше, чем сумма связей
дочерних кругов с остальной частью сети, обозначенной через \z*\.
В терминах потоков: общий поток из истока [Л] в любую другую вершину
вне круга меньше [Л]. Другими словами, существует внутреннее звено,
инцидентное Я-допустимому кругу [hiJ].
Следующие три условия выводятся из сравнения дерева,
ассоциированного с pitc. 10.10(a), с другими вдзможнъп^и деревьями. Если рис. 10.10(a)
представляет оптимальную конфигурацию, то стоимость связи для
любого другого дерева должна быть больше (о стоимости связи см. раздел
2.5.3).
2. Внутренняя сме&сность. Доя любого подмножества дочерних кругов /
связь между [2] и другими вершинами в материнском круге должна быть
больше, чем связь между {/] и другими кругами, не принадлежащими
материнскому кругу, т.е:
<fc,J).+ (/,J) >(/,*•). (2)
Если условие (2) не выполняется, то можно было бы преобразовать
дерево на рис. 10.10(a) в дерево на рис. 10.10(b) и уменьшить стоимость.
Заметим, что стоимость связи для дерева на рис. 10.10(a) равна
(ft, J) 4- (ft, /) + (ft, **) + 2( J, z*) + 2(/, ж*) + 2(/, J),
10.4. ЭКВИВАЛЕНТНЫЕ ФОРМУЛИРОВКИ
289
в то время как стоимость связи для дерева на рис. 10.10(b) равна
(Л, J) + 2(М) + (М*) + 2(7,**) + (I,z*)+3(I,J),
а (2) есть разность между двумя стоимостями.
3. Внешняя смежность. Для любого круга [ J] его связь с остальными
дочерними кругами в семействе не должна быть слишком большой. В
противном случае конфигурация на рис. 10.10(c) была бы дешевле, чем на
рис. 10.10(a). Отсюда
(h,I) + (I,z*)>(I,J). (3)
Заметим, что стоимость связи для дерева на рис. 10.10(a) равна
(Л, J) + (Л,/) + (М*) + 2(J,**) + 2(I,z*) + 2(1, J),
а стоимость связи для дерева на рис. 10.10(c) равна
(Л, J) + 2(Л, J) + (ft,**) + 2(J,z*) + 3(/, г*) + (J, J).
Разность между двумя стоимостями равна (3).
4. Необратимость. Для любого круга [/] его связь с [z*] не должна быть
очень большой. В противном случае конфигурация на рис. 10.10(d) была
бы дешевле. Поэтому
{h,z') + {J,z*)>(I>z*).
Заметим, что стоимость связи для дерева на рис. 10.10(d) равна
(ft, J) + (Л, /) + 2(ft, z*) + 3( J, г*) + (/, z*) + 2(/, J)
и она должна быть больше стоимости связи для дерева на рис. 10.10(a).
Интуитивно условие 1 говорит, что хозяин должен иметь более сильные
связи со своими детьми, чем любой другой круг. Условие 2 говррит, что до*
черний круг должен быть более связан со своим семейством, чем с кругами,
не входящими в него. Условие 3 говорит, что не существует старшей сестры,
так сильно связанной с младшими сестрами, что она становится их матерью.
Условие 4 говорит, что не существует дочери, настолько сильно связанной с
внешним миром, что она становится матерью первоначального хозяина [Л].
Необходимость уже была доказана, так что эти локальные условия должны
всегда выполняться для оптимального разбиения. Для доказательства
достаточности можно показать, что любое неоптимальное разбиение должно
нарушать как минимум одно из четырех условий. Тогда, преобразуя дерево, можно
уменьшить стоимость. Подробнее см. {Таккерг Ху и Шинг].
Хотя необходимые и достаточные условия определены локально, т. е.
между материнским и дочерними кругами, эти условия не приводят
непосредственно к эффективному алгоритму. Поэтому далее мы опишем
высокоуровневый подход к задаче построения GH-дерева.
290
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
а) Ь)
Рис. 10.11
10.5. Крайние звезды и Я-допустимые круги
Напомним, что для Я-допустимого круга величина круга меньше, чем
сетевая степень одной из вершин в подмножестве, составляющем круг. В
терминах GH-дерева: звено /(»", j) является внутренним тогда и только тогда, когда
его величина строго меньше, чем сетевые степени узлов [г] и [у], т. е.
l{i,j) < min [i], [у].
Крайняя звезда является Я-допустимым кругом, в котором хозяин
принадлежит точно одному внутреннему звену, а листьями ее являются только
атомарные круги.
Возможные случаи иллюстрирует рис. 10.11(a). На этом рисунке [dab], [db]
и [da] — Я-допустимые круги, но только [db] является крайней звездой.
Внутреннее звено величины 1 инцидентно [а] и \д] в соответствующем GH-дереве.
На рис. 10.11(b) [daft) и [Ьа] — Я-допустимые круги, но только [Ьа] является
крайней звездой. Внутреннее звено величины 4 инцидентно [d\ и [д] в
соответствующем GH-дереве.
В дальнейших рассуждениях для удобства будем предполагать, что [а] <
[Ь] < [с] < • • • < [г], а [t], [j], [к] и [х] будут обозначать вершины произвольной
сетевой степени.
Факт 1. Существуют п — 1 нескрещивающихся фундаментальных
разрезов, которые однозначно соответствуют п — 1 звеньям GH-дерева.
(Замечание: разрезо-эквивалентность является более сильным условием, чем по-
токо-жвивалентность.)
Факт 2. Хозяин крайней звезды образует вместе с этой звездой
Н-допустимый круг, но не всякий Н-допустимый круг является крайней звездой.
Например, на рис. 10.12(a), [е] = 11 > [еаЬ] = 3, а [/] = 19 > [feab] = 16.
[eab] и [feab] — Я-допустимые круги, а [еаЬ] — крайняя звезда. [fecA] не
является крайней звездой, как видно из рис, 10.12(b), изображающего GH-дере-
во для сети на рис. 10.12(a). На рис. 10.12(c) [d\ = 15 > [dabc] = 13, но
[d\ = 15 > [dab] = 7. Таким образом, [dabc] — Я-допустимый круг, a [dab]
— крайняя звезда. Заметим, что (d, z) является виртуальным древесным
ребром. GH-дерево изображено на рис. 10.12(d).
10.5. КРАЙНИЕ ЗВЕЗДЫ И НЕДОПУСТИМЫЕ КРУГИ 291
Для построения GH-дерева мы можем произвести вычисление п — 1
максимального потока. В худшем случае каждое вычисление максимального потока
будет разбивать сеть из п вершин на изолированную вершину и сеть из п — 1
вершины. Поскольку изолированная вершина не может быть далее стянута,
второе вычисление максимального потока будет опять производиться для
сети из п вершин. В конце концов GH-дерево сети может принять вид звезды с
вершиной [z] максимальной сетевой степени в качестве хозяина сети.
Этого худшего случая нельзя избежать, даже если выбрать [у] и [z] как
источник и сток при первом вычислении максимального потока, хотя обычно
это лучше, чем выбор произвольных [з] и [t]. Мы будем использовать понятия
крайней звезды и Я-допустимого круга для уменьшения количества
вычислений.
Факт 3. Если ни одна вершина, кроме [z], не является Н-допустимым
кругом, то GH-дерево является звездой. В противном случае GH-дерево имеет
не менее двух крайних звезд. (Для сети из пяти и менее вершин
доминирующее ребро существует, если только GH-дерево не является звездой).
Предположим, что все вершины имеют различные сетевые степени, т. е.
М < И < И <•••<[/]<•••< м,
и пусть Zf представляет все вершины степени большей, чем [/]. Сетевая сте-
292
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
а)
Ь)
Рис. 10.13
пень [/] может быть записана как
[/] = (/,<**) + (/,*,)
где [/J есть нижняя степень [/], т. е. сумма ее связей с вершинами меньших
степеней, а [/] есть верхняя степень [/]. Тогда необходимым и достаточным
условием того, что [/] — хозяин [/abode], является следующее:
(f,abcde) > (abode, Zf),
это показывает рис. 10.13(a).
Допустим, что мы убедились, что вершины [Ь],[с], [d], [е] не могут быть
хозяевами Я-допустимых кругов, и теперь хотим проверить, является ли
вершина [/] хозяином листьев [а] и [с]. Пусть [h] — любая вершина с [h] >
max{[a],[c]}. Связи между четырьмя кругами показаны на рис. 10.13(b), где
[zm] = [bdeg... г]. Возможны следующие два случая.
(i) [/] является хозяином [fac], т.е.
[/] > [/ас], или
(/,Л) + (/,**) + (/,») > (/,Л) + (/,*•) + (Кос) + (ac,z*), или (1)
(/,ac)>(/i,ac) + (ac,z*).
(ii) [/] не является хозяином [fac], тогда
(Дос) <(Л,*с)+ («,**). (2)
Рассмотрим рис. 10.13(b) и неравенства (1) и (2) более подробно.
Из (1) получаем
(/,а) + (/, с) > (Л,а) + (Л, с) + (a,**) + (с,**),
где в правой части каждое слагаемое неотрицательно. Поэтому каждое из
следующих неравенств является необходимым условием того, чтобы [fac] был
10.5. КРАЙНИЕ ЗВЕЗДЫ И Н-ДОПУСТИМЫЕ КРУГИ
293
Рис. 10.Ц
Я-допустимым кругом:
(/,в) + (/,с)>(М) + (Л,с), (3)
(/,<»)+ (/,с)>(в,**) +(с, **), (4)
(f,a) + (f,c)>(h,a) + (c,z% (5)
(/,а) + (/,с)>(в,**) + (Л,с). (6)
Неравенство (3) легко проверить. Если соседние с [/] вершины наименьшей
степени имеют более сильные связи с другим потенциальным хозяином, то [/]
не является хозяином круга с этими вершинами. Первыми нужно проверять
те вершины, которые имеют максимальные связи с [/].
Сначала проиллюстрируем идею на численном примере, показанном на
рис. 10.14(a), где все вершины имеют одинаковую сетевую степень. Поскольку
степень каждой вершины равна 3, то любая из них может быть хозяином.
Соседними для [а] являются вершины [ft], [с] и [d] и ни одно из инцидентных
[а] ребер не является доминирующим. Далее, [а] не доминирует ни над каким
подмножеством множества {[ft], [с], И}, т. е.
(a,cd) = (e,cd),
(a,hd)<(ftd,ce/0ft),
(a, be) < (ftc,de/(/ft),
(a.bcd) <(bcd,efgh).
Таким образом, вершина [a] не может быть хозяином; по тем же причинам
им не может быть ни одна из вершин [ft], [е] или [/].
Для вершины [с], которая имеет соседние вершины [a], [d\ и [е], пусть [z*] =
[bfgh], тогда
(c,a) = (z*,a) = (ft,a),
(c,d) >(<*,**)= 0,
(c,e) = (z*,e) = (/,e).
294
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
Стянем ребро (c,d), после стягивания получаем
(cd,a) = 2>(b,a),
(cd,e) = 2>(/,e).
Действуя таким образом, в конце концов получим одну вершину [cade] с
[с] = 3 > [cade] = 2,
откуда видно, что [с] является хозяином круга [cade]. Аналогично [д]
становится хозяином круга [gbfh]. GH-дерево изображено на рис. 10.14(b).
Этот численный пример помогает обнаружить два критических пункта:
(i) если мы проверяем каждое подмножество соседних вершин, то
сложность алгоритма становится 0(2П),
(ii) в случае совпадений число вариантов возрастает.
При выводе неравенств (1) и (2) мы не использовали условия [/] < [ft] или
[/] > И, а только
[/] > max [а], [с] и [ft] > max [а], [с].
Чтобы узнать, является ли [ft] хозяином [hoc], мы проверяем неравенство
(h,ac) >(/,ос) + (ас,**),
и если [ft] не является хозяином, то
(ft,oc)>(/,oc) + (oc,z*).
Обычно сеть очень разрежена и вершина [/] имеет мало соседних вершин.
Если каждая из этих вершин имеет максимальную связь с другой вершиной
большей степени, то / не может быть хозяином. Мы сформулируем это
утверждение как лемму.
Лемма 5. Для того, чтобы вершина [f] была хозяином Н-допустимого
круга [fijk], необходимо, чтобы выполнялось хотя бы одно из условий:
(/,г)> (t,xi),
(/.i)>(j.*a).
(/,*)> (fc,x3),
где вершины хь#2,#з таковы, что {х1,Х2,#з} we пересекается с {t\j,fc} и
тт{[х1,х2,а:з]} > max{[t], [>"],[*]}.
10.6. ВЫСОКОУРОВНЕВЫЙ подход
295
Рис. 10.15
Замечание. Возможно, что (/,i) > (i,xi), но (/,j) < ij.xi) и (/,fc) < (fc,x3)
и тем не менее [fijk] является Н-допустимым кругом с хозяином [/]. Это
показано на рис. 10.15(a), где (ft,e) > (е,/), (h,ac) < (f,ac) и [ft] является
хозяином [fteac].
Для сети на рис. 10.15(a) и ее GH-дерева на рис. 10.15(b) имеем:
[/] = 27 > [/ас] = 26,
(/,oc) = 9>(ft,oc) = 3,
[ft] = 28 > [fte] = 26,
(ft,e) = 10>(/,e) = 3,
но
[ft] = 28 > [hace] = 27.
Таким образом, [ft] является хозяином круга [Лосе]; в то же время [fte] и [fac]
являются крайними звездами.
Увеличим (z*,e) и (z*,ac) на рис. 10.15(a) с 0 до 8, получим рис. 10.15(c).
Новая сеть все еще удовлетворяет условиям леммы 5, но ни [fte], ни [fac] не
являются if-допустимыми кругами.
Лемма 6- Н-допустимость — необходимое (но не достаточное) условие
для того, чтобы звезда была крайней.
10.6. Высокоуровневый подход
Для описания разреза в сети мы использовали обозначение [-Y, X], где X —
подмножество множества вершин, а X — его дополнение. Знаменитую теорему
о максимальном потоке и минимальном разрезе можно представить в виде
F*{s,t) = C*[X,X],
где з 6 X и t 6 X. При этом предполагается, что X и X порождают связные
подсети.
296 ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
При получении п - 1 фундаментальных разрезов сети необходимо конден-
сировать^Я-допустимые круги глубины 1. Если X обозначает Я-допустимый
круг, то X может не быть связной подсетью. Рассмотрим сети на рис. 10.16(a)
и 10.16(b).
а) * Ь)
Рис. юле
На обоих рисунках нужно стянуть [саб] в атомарный круг величины 2.
Локально все ребра и вершины, смежные с хозяином [с], на двух рисунках
одинаковы. Для нахождения F*(d,e) на обоих рисунках можно [cab] заменить
атомарным кругом величины 2. Это тот случай, когда Я-допустимый круг
глубины 1 не является крайней звездой, но его можно стянуть.
В сети на рис. 10.17(a), с GH-деревом, показанным на рис. 10.17(b),
Я-допустимый круг [cab] не является крайней звездой, но должен быть стянут.
Рис. 10.17
10.6. ВЫСОКОУРОВНЕВЫЙ подход
297
Сначала наметим алгоритм в предположении, что все сетевые степени
различны. Прежде чем формулировать алгоритм, проиллюстрируем его на
нескольких числовых примерах и обсудим его интуитивные основания. В
большинстве приложений на больших сетях нет нужды в предварительной
обработке сети или сортировке сетевых степеней. Нужно отметить также, что
существует много других вариантов этсйго алгоритма. Основная цель
заключается в нахождении Я-допустимого круга глубины 1, наименьшего размера и
стягивании его в атомарный круг, (U-допустимый круг может быть, а может
и не быть крайней звездой GH-дерева).
Алгоритм (предварительное обсуждение)
Предварительная обработка. Отсортируем все вершины по возрастанию
сетевой степени и будем их называть a, ft,..., z, где [а] < [ft] < • • • < [z]
(И» Ь"]> И» [xi]» [^2] по-прежнему используются для обозначения вершин
произвольной степени). Алгоритм состоит из многих фаз; в каждой фазе проверяем,
является ли некоторая вершина хозяином ff-допустимого круга глубины 1.
Если да, то стягиваем этот круг в атомарный круг. Проверяется всегда
вершина, которая не была проверена раньше.
Если ни одна из вершин [a], [ft], [с],..., \у] не является хозяином, то GH-дере-
во является звездой с центром [z]. В большинстве случаев вместо применения
алгоритма можно использовать лемму 5, чтобы убедиться, что вершина не
может быть хозяином.
Степень листа всегда меньше степени его хозяина (лемма 2). Если мы
проверяем вершину [/] как потенциального хозяина Недопустимого круга
глубины 1, то возможными листьями являются [a], [ft], [с], [d\, [е]. Все вершины со
степенями большими, чем [/]> не. могут быть листьями [/]. Для наших целей
стянем ЫуМ»"- * • VИ в ОДну вершину {zf)< -
Допустим, обнаружилось, что ло1каким-,г© причинам [с] и [е] не могут быть
листьями {/] (например, (с, г) является доминирующим ребром), и
необходимо проверить толь!«н[а],[Ь],[й| в качестве возможных листьев. Обозначим
Пусть [fabcde] — Я-дрпустимый круг. Тогда по определению имеем:
[/] > [fabcde]
= [f] +[abcde]-2(f,abcde) .
= [/] + (/> a**de) + fabcde, zf) - 2(/,abcde)
- [/] + (aftctfe,*/) - (/, abcde).
Неравенство (1) эквивалентно
(f,abcde) > (abcde,zf). (2)
Это изображено на рис. 10.13(a).
298
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
Рис. 10.18
Подобным образом, если [fabd\ — Я-допустимый круг, имеем:
[/] > [fabdi
= [f] + [abd\-2(f,abd)
= [fl + (f,abd) + (aM,cegh...z)-2(f,abd)
= [/] + (/,aW) + (aM,**) - 2(/,aM).
Неравенство (3) эквивалентно
(/,aftd)>(aW,z*). (4)
Заметим, что в неравенстве (2) связь (/, Zf) отсутствует; участвуют только
связи (/, abode) и (dbcde, z/). Подобным образом, в неравенстве (4) отсутствует
связь (/,2*); участвуют только связи (/,оМ) и (abd^z*).
Когда множество листьев известно, скажем, [a], [ft], [d], проверка
неравенства (4) становится тривиальной. Мы либо стягиваем [fobd\ в атомарный круг,
либо исключаем из рассмотрения [/], как возможного хозяина, и переходим к
следующей фазе — проверке вершины [д], имеющей следующую по величине
сетевую степень.
Здесь возникают два центральных вопроса.
(i) Как выбрать множество листьев? Мы не хотим проверять каждое
собственное подмножество из [a], [ft], [с], [d\, [е].
(ii) Если [a], [ft],..., [/] исключены как хозяева, как может эта информация
помочь нам решить, является ли [д] хозяином ff-допустимого круга?
Для начала рассмотрим численный пример, изображенный на рис. 10.18.
Имеется семь вершин [а] < [ft] < ••• < [/] < [#], и [а] = 5, [ft] = 6, [с] = 8,
[4 = 20, [е] = 22, [/] = 25, \д] = 26.
При нахождении Я-допустимого круга, охватывающего [/], мы стремимся
достичь двух целей:
10.6. ВЫСОКОУРОВНЕВЫЙ ПОДХОД 299
Рис. 10.19
(i) Чтобы величина круга, охватывающего [/], была меньше, чем степень
(и) При условии (i) круг должен иметь минимальный размер.
Первым кругом является сама [/]. При увеличении размера круга,
охватывающего [/], его величина может увеличиваться или уменьшаться и мы
останавливаемся, когда она становится меньше, чем [/]. Тот же алгоритм
можно применить, когда существует более семи вершин, стягивая все вершины,
степени которых больше [/], в [z/].
На рис. 10.19. показаны связи между [/] и потенциальными листьями и
их связи с [zf]. Связи между потенциальными листьями,временно опущены в
целях иллюстрации.
Пусть [i] — любая из вершин [а], [6], [с], [cQ, [е]. Определим
(/.о-в*/)
как избыточный поток в [г]. Вершину ft] назовем положительной вершиной,
если
(/,*)-(*,*/)> 0,
и отрицательной вершиной, если
(/.О-(*.«/)< о-
Каждый путь из [/] в [zf] на рис. 10.19 состоит из двух ребер, и всегда можно
удалить меньшее ребро и уменьшить пропускную способность большего ребра
на величину пропускной способности меньшего ребра.
Если имеются только два листа [t] и [;], то преобразованная сеть будет
выглядеть так, как на рис. 10.20, где [г] — положительная вершина с а единицами
избыточного потока, \j] — отрицательная вершина с *у единицами дефицита
потока, а /} — пропускная способность (t, j).
Возможны два случая:
300
ГЛАВАМ. ДЕРЕВОТОМОРИ-ХУ
Рис. 10.20
(i) Р < min(a,7)- Удаляем ребро 0, сеть становится несвязной, и [/г]
является Я-допустимым кругом.
(И) Р > min(a,7) = €. В пути (/,г), (t,j), (j,zf) уменьшаем пропускную
способность каждого ребра на е, в результате либо [/], либо [zf] становится
изолированной. Если [/] изолирована, то [/] не является Я-допустимым
кругом. Если [г/] изолирована, то имеем Я-дрпустимый круг с хозяином
Из трех ребер со значениями а, 0, 7 одна всегда можно удалить. Мы
называем эту операцию операцией китайских палочек.
Применяя простую идею удалений ребер, можно преобразовать рис. 10.18
в рис. 10.21(a), гд£ добавлены ребра между листьями и опущены вершины [/]
и[*/].
Заметим, что вершина [d] имеет (/, d) - (d, д) = 9 -1 = 8 единиц
избыточного потока, тогда как [е] имеет (/,е) - (е, д) = 1 -11 = -10 единиц
отрицательного потока. Ребро между положительной и отрицательной вершинами будем
называють прямым ребром, а, ребро между двумя положительными (или
двумя отрицательными) вершинами — боковым ребром (например, (a,d) и (c,d)
на рис. 10.21(a) являются боковыми ребрами, a (d,e) и (b,d) — прямые ребра).
То, что вершина [х] имеет положительную величину 8, эквивалентно
существованию ребра (/,х) = 8. Мы не рисуем ребро (/,х) = 8, так как позже
избыточный поток будет перераспределен между положительными
вершинами. Применяя вначале операцию китайских палочек к трем ребрам
(/,d) = 8, (d,e)=6, (е,9) = 10
или [d] = +8, (d,e) = 6, [е] = -10,
получаем (/, d) = 2Э (d, е) = 0, (е, (/) = 4
или [d] = +2, (d,e) = 0, [е] = -4.
Применяя операцию китайских палочек к
И =+2f (d,b) = 2, М = -1,
получаем [d\ = +1, (d,b) = 1, [Ь] = 0.
Это показано на рис. 10.21(b).
10.7. МЕТОД КИТАЙСКИХ ПАЛОЧЕК
301
с) d)
Рис. 10.21
В этот момент величины всех прямых ребер из [d\ уменьшены до их
наименьших возможных значений; то же верно и для вершины [а]. Поэтому мы
хотим перенести избыточный поток из Щ и [а] в [с]. Ситуация показана на
рис. 10.21(c). Применив операцию китайских палочек к
[с] = 4-2, (с,е) = 4, [е] = -4,
получаем [с] = 0, (с,е) = 2, [е] = -2.
Это показано на рис. 10.21(d), где листья разбились на две компоненты; теперь
мы видим, что [/] — [fddb] = +1.
10.7. Метод китайских палочек
Мы называем этот метод методом китайских палочек по трем причинам.
(i) Когда мы проверяем, является ли вершина [/] хозяином Я-допустимого
круга, а соседними вершинами являются [г] и [;'], рассматриваются ребра
(/>*)» (/>Л и (hi)- Если (i,j) — доминирующее ребро, то можно стянуть
две соседние с [/] вершины в одну вершину [ij]. Это напоминает
использование двух китайских палочек (/,г) и (/, j) для того, чтобы подобрать
кусочек и съесть его.
(ii) Когда стягивание соседних с [/] вершин закончено и возникает ситуация,
302
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
подобная изображенной на рис. 10.20 (три ребра со значениями а, /3, 7)>
то всегда остаются два ребра, подобные паре китайских палочек.
(Ш) Оба автора (Т. Ч. Ху, М. Т. Шинг) — американцы китайского
происхождения.
Опишем алгоритм китайских палочек и обсудим некоторые возможные
варианты и сокращения.
I. Сетевые степени. Вершины упорядочиваются по сетевой степени: [а] <
[Ь] <[с] < ... < [z]. Если существует доминирующее ребро для [t] из вершины
[;], то это ребро помечается как древесное. Если существует много
доминирующих ребер, начинаем с вершины, которая имеет минимум \j]. В дальнейшем
считаем, что не существует доминирующих ребер.
II. Порядок проверки. Вершины проверяются в порядке: [a], [ft], [с],..., \у]. Для
каждой вершины проверяем, не является ли она хозяином Я-допустимого
круга глубины 1. При проверке вершины [/] все вершины, сетевые степени
которых больше, чем [/], классифицируем как вершины более высокого порядка
и стягиваем их в одну вершину, обозначаемую [zf].
Начинаем с вершины, имеющей минимальную сетевую степень из ранее не
проверявшихся вершин. Данная вершина может быть проверена снова, если
был создан новый лист. Например, пусть [a], [ft], [с], [d], [е] все были проверены
и исключены из рассмотрения, как хозяева if-допустимых кругов глубины
1, и пусть мы нашли, что [fbd\ является Я-допустимым кругом глубины 1
со степенью [/ftcfl = ж, где [с] < [х] < [е]. Теперь у нас имеются вершины
[д]> Iе] > [/WL Iе!» Ь] • * •• Поскольку [/ftd], как атомарный круг, может являться
листом для [е], то мы должны вновь проверить [е], прежде чем проверять \д].
Далее классифицируем все вершины как положительные, отрицательные
или нейтральные. Вершина [х] является положительной, если (/, х) — (х, Zf) >
0, отрицательной, если (/,х) - (x,Zf) < 0, и нейтральной, если (/,х) = (x,Zf).
В худшем случае все вершины соединены между собой (т. е. граф сети есть
полный граф). В большинстве случаев необходимо просмотреть смежные только
с [/] вершины с меньшими степенями и отметить их как положительные
вершины. Аналогично все смежные с [zf] вершины считаются отрицательными.
Только если вершина [х] смежна с обеими вершинами [/] и [з/], необходимо
проверять знак разности (/,х) — (x,Zf).
III. Стягивание соседних вершин. Величина (/,х) - (x,Zf) > 0 называется
избытком потока в [х]. Образно говоря, мы хотим отправить [/] единиц
потока из вершины [/]. Если вся величина не может быть отправлена из-за малой
величины разреза или Я-допустимого круга, охватывающего
вершину-хозяина [/], то избыток потока может накапливаться внутри круга в некоторой
вершине [х]. Если [х] не смежна непосредственно с [z/], то избыток потока
— это просто пропускная способность ребра (/,х). Если [х] смежна с [z/], то
избыток потока равен (/,х) — (x,Zf). В любом случае мы можем направить
поток из [/] в [х].
10.7. МЕТОД КИТАЙСКИХ ПАЛОЧЕК
303
Пусть [*i],[*2]>-«- — положительные вершины со значениями избытка
потока РьР2,-.. • Так как эти вершины могут быть связаны между собой, то
избыток потока может быть распределен среди этих вершин при условии,
что существуют достаточные связи между ними. Мы хотели бы использовать
преимущества этой ситуации путем стягивания некоторых положительных
вершин.
Пусть [ti], [1*2],... — положительные вершины, имеющие рьРг, • • • единиц
избытка потока. Если (ti,i2) становится доминирующим ребром, мы
стягиваем эти две вершины в одну с р\ + Р2 единицами избытка потока. Точно так
же, если отрицательные вершины [jfiklft] с избытками потока q\ и ф имеют
большую связь между собой, скажем, если (ji, J2) становится доминирующим
ребром, их тоже можно стянуть в одну вершину.
IV. Разделение вершин. Рассмотрим произвольную положительную вершину
[г] с положительной величиной Pi и произвольную отрицательную вершину
\j] с в&чичиной дефицита ф, и пусть ребро, соединяющее [г] и [;'], имеет
пропускную способность fiij. В зависимости от соотношения между значениями
PuQjiPiji мы либо удаляем прямое ребро (т.е. полагаем /?# = 0), либо
переклассифицируем положительную вершину в отрицательную или
нейтральную.
Рассмотрим двудольный граф, у которго в одной доле все положительные
вершины, а в другой — все отрицательные и нейтральные. Вначале
положительные вершины.имеют величины р%, а отрицательные имеют величины qj.
Новые значения обозначаются через р{, gj, &\j •
Возможны три случая.
(i) Pij < min(pi,qj). Ребро (г,,;) удаляется, т.е.
Pi =Pi- Piji
Qj = Qj ~PiJ-
(ii) qj < min(pi,/?ij). Вершина \j] становится нейтральной и перемещается в
положительную долю, т. е.
Pi=Pi-Qji
(iii) pi < min(gj,/?tj). Вершина [г] становится нейтральной и перемещается в
отрицательную долю, т. е.
P'ij = PiJ ~ Р*
4 = 0
Qj =Qj -Pi-
304
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
В конце концов произойдет одно из следующих событий.
(i) Подмножество вершин станет не связанным с [zj]; мы имеем
if-допустимый круг. Общая сумма положительных значений равна разности между
1/1 и [fijk].
(ii) Все положительные вершины станут нейтральными и переместятся в
отрицательную часть. В этом случае [/] не является хозяином.
Заметим, что метод китайских палочек корректно находит Я-допустимый
круг, если ни один из потоковых путей не содержит потока из
отрицательной вершины в положительную вершину. В общем случае решение задачи о
потоке из [/] в [zh] может включать поток из отрицательных вершин в
положительные, но метод китайских палочек можно использовать и в этом случае
как стартовую процедуру.
10.8. Взаимодействие между фазами
Как уже говорилось, мы пытаемся найти Я-допустимый круг глубины 1
и стянуть его в атомарный круг. Если [/] — хозяин круга, то его листьями
могут быть только вершины меньшей степени. Пусть этими потенциальными
листьями являются [а], [6], [с], [d\, [е], множество всех вершин большей степени
обозначаем через z/. При проверке [/] можно учитывать только смежные с
ней вершины меньших степеней. Те несмежные вершины, которые могут со
временем стать листьями для [/], могут быть обнаружены при применении
алгоритма китайских палочек: они превращаются из отрицательных вершин
в положительные.
Когда мы проверяем вершины, не являются ли они хозяевами, в порядке
И, [Ь], [с],...,[/],... , может ли результат одной фазы помочь в следующей
фазе? Для иллюстрации используем 7 вершин. Рассмотрим следствия
соотношений
Щ < [dabd\, (1)
т. е. [dabc] не является Я-допустимым кругом с хозяином [d], и
[е] > [еаЬЫ\, (2)
т.е. [eabcd\ является Я-допустимым кругом с хозяином [е].
(1) равносильно
(d, abc) < (abc, efg) = (abc, e) + (abc, fg). (3)
(2) равносильно
(abc, fg) + (d, fg) = (abed, fg) < (e, abed) = (e, abc) + (e, d). (4)
Складывая (3) и (4), получаем
(d,abc) + (djg) < 2(e,abc) + (e,d).
(5)
10.8. ВЗАИМОДЕЙСТВИЕ МЕЖДУ ФАЗАМИ
305
Прибавляя (e,d) к обеим частям неравенства (5), получаем
(abcefg, d) < 2(е, abed) (6)
или И<2[е|. (7)
Неравенства (6) и (7) означают, что удвоенная нижняя степень вершины [е]
должна быть больше степени вершины [d\. Неравенство (7) проверить проще,
чем (6), которое включает связи (etfg) и (obed^fg).
Бели заменить неравенства (1) и (2) противоположными:
[е] < [eabcd\y '
т.е. [eabcd\ не является Я-допустимым кругом с хозяином [е], и
т.е. [dabc] является Я-допустимым кругом с хозяином [d\t
то, подобно (7), получаем
2[eJ < М- (8)
Это неравенство может быть полезным, если мы начинаем проверку с
вершины большей степени [е] и затем проверяем следующую вершину с меньшей
степенью [d\.
i Пусть [Л] — проверяемая вершина, а вершины меньших степеней разбиты
на два подмножества I я J. Все множество вершин степени большей, чем [Л],
обозначается как одна вершина Zh- *
Из теоремы 3 следуют условия того, что [Л] не является хозяином:
(!) (hJJ) < (IJ,zh)t
'(и>(М)<</, J)+ (Л'*),
(ffi) (h,J)<(I,J) + (J,zh)
для любого разбиения J, J. Условие (i) легко проверить. Условие (ii)
означает, что [Л] должно доминировать над подмножеством I , чтобы [hi] было
Я-допустимым кругом. Чтобы исключить [е] как хозяина, нам необходимо
несколько условий таких, как (9)-(13): [
(e,abcd)<(abcdjg), (9)
(e,ab)<(ob,/5)+(ab,cd), (10)
(e,cd)<(cdjg) + (cd,ab), (11)
(е,abc) <(abc, fg) + (abc, d)), (12)
M<(d,/</) + (d,afte). (13)
Если
(e,ab)>(ab,fg) + (ab,al}9 (14)
306
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
то [edb] является Я-допустимым кругом.
Заметим, что из (9) и (14) следует
(e,cd) + (ab,cd) <(«*,/(?). (15)
Неравенства (14) и (15) наводят на мысль об эффективной эвристической
процедуре нахождения разбиения /, J, а именно: -
(е,п) = тах*{(е,*) - (*, fg)} ({ii,t2, - -.} = /)»
(f9,h) = maxx{(fg,x) - (аг,е)} ({ji,j2,-. -} = J).
10.9. Лестничная диаграмма
Обычной структурой данных для представления сети из п вершин
является матрица пхп,в которой на пересечении строки t и столбца j записана
пропускная способность ребра (t, j). Для неориентированной сети матрица
симметрична, для ее хранения необходима память 0(п2).
В алгоритме китайских палочек нам могут понабиться связи (a,d), (ft,d)>
(d,e/p), [е] и т.д. Поэтому мы сконструировали специальную структуру
данных для метода китайских палочек.
Например, сеть на рис. 10.18 может быть представлена лестничной
диаграммой на рис. 10.22. Для сети из семи вершин имеется семь вертикальных
линий, каждая вертикальная линия соответствует вершине. Степень вершины
написана непосредственно под ее линией.
Имеющиеся шесть горизонтальных линий соответствуют связям между
данной вершиной и вершинами большей степени (поскольку [д] является
вершиной наибольшей степени, она не требует горизонтальной линии). Нижняя
горизонтальная линия содержит шесть направленных дуг, которым
приписаны величины:
(a, bcdefg) = 5, (a, cdefg) = 4, (a, defg) = 4,
(а, е/у) = 3, (a, fg) = 3, (а,д) = 1.
Когда эта нижняя горизонтальная линия пересекает первую вертикальную
линию, мы имеем (a, ft) = 1, что показано как направленная вниз дуга.
Аналогично все связи (a,t)> для % — ft,c,d,e,/,(/ показаны как направленные вниз
дуги с соответствующими им значениями. Таким образом, мы имеем:
(a,ft) = l, (a,c) = 0, (a,d) = l,
(а,е)=0, (а,/) = 2, (а,д) = 1.
Эти значения отражают такие факты, как
(a,bcdefg) - (a,ft) = 5 - 1 = (a,cdefg) = 4,
(a,cdefg) - (a,c) = 4 - 0 = (a,defg) = 4
10.9. ЛЕСТНИЧНАЯ ДИАГРАММА
307
10
101
16А
81
Si
5
5
4
8
5
4
12l
16
7
3
3
12
10
3
3
11
1
1
2
1
10
11
tl
ф1
51
I 1
20 22
Рис. 10.22
25
26
и так далее. Подобным же образом суммарные связи вершины [Ь] = \Ь] + [6J
отражены в направленной вниз дуге (о, Ь) = 1 и направленной вверх дуге
(b,cdefg) = 5 на вертикальной линии, соответствующей вершине [ft].
В итоге каждая вертикальная линия содержит значения [х] = \х] + [х\,
где |V| показано направленными вниз дугами на вертикальной линии и [х\
показано как одна направленная вверх дуга этой же вертикальной линии.
Если мы рассмотрим нижнюю горизонтальную линию как «первый этаж»,
который соответствует вершине [а], то горизонтальная линия «второго этажа»
соответствует вершине [6]. Второй этаж поддерживается шестью колоннами
(направленными дугами). Самая левая колонна изображена как направленная
вверх дуга, ей приписано значение (b,cdefg), а остальные колонны показаны
дугами, направленными вниз, и им приписаны значения (с, ft), (d,b), (е, 6),
Для представления сети можно использовать матрицу, в которой каждый
элемент соответствует пересечению вертикальной и горизонтальной линий и
с каждым элементом ассоциированы 4 значения, ассоциированные с дугами,
направленными вверх, вниз, влево и вправо. Требуемая память по-прежнему
составляет 0(п2). Возможны и другие структуры данных.
308
ГЛАВА т. ДЕРЕВО ГОМОРИ-ХУ
Проиллюстрируем метод китайских палочек вместе с лестничной
диаграммой на трех численных примерах.
Пример 1. В сети на рис. 10.23(a) имеется восемь вершин с
М = М = М = М<М = [/] = Ы = М-
Поскольку есть четыре вершины одинаковой сетевой степени, любая из них
может быть хозяином с остальными тремя в качестве листьев.
Если мы построим лестничную диаграмму, необходимо будет использовать
только четыре горизонтальные линии, Соответствующие a, ft, с и d, и пять
вертикальных линий, соответствующих a,ft,c,d,[e/#ft]. В соответствии с
принятыми обозначениями первой проверяется вершина [d], исходная
конфигурация представлена на рис. 10.24(a). Метод китайских палочек дает сначала
рис. 10.24(b), а затем рисЛ0.24(с), из которого видно, что [d] - [daftc] = +1
или [dabc] = [d] — 1 = 5 — 1 = 4, [dabc] становится атомарным кругом. Теперь
у нас имеется сеть из пяти вершин, показанная на рис. 10.25(a).
Применяя метод китайских палочек для проверки [j], Последовательно
получаем рис. 10.25(b), затем рис. 10.25(c) и рис. 10.25(d), который исключает [д]
как хозяина. То же получается в результате проверки fe] и [/]. Таким образом,
получаем GH-дерево, показанное на рис. 10.23(b).
Пример 2. В сети на рис. 10.26(a) благодаря наличию одинаковых сетевых
степеней вершин можно опустить некоторые повторения при вычислениях.
Эти вопросы обсуждаются в разделе 10.10 (см. с. 24 работы Padberg М.,
Rinaldi G. An efficient algoritm for the maximum capacity cut problem //
Mathematical Programming. — 1990. — Vol. 47. — P. 19-39).
В этом примере мы сначала находим доминирующее ребро из [а'] в [а],
и затем стягиваем [аа*] в атомарный круг. Используя лемму 5, можно легко
исключить [ва/]ЛЧЛ&/]Лс]Лс'] из чисда возможных хозяев. Поскольку [d\ =
[d'\ = [е] = [е1] = 23, любая из этих4 четырех вершин может быть хозяином с
другими тремя вершинами в качестве листьев (в зависимости от того, какая из
вершин проверяется первой, будет построено одно из четырех эквивалентных
GH-деревьев).
Пусть первой проверяется [<f], и пусть [е1] — вершина наивысшей
степени для метода китайских палочек, применение которого приводит к
ситуации на рис. 10.27. Поскольку [Ь] является нейтральной вершиной, а [Ь^И
— положительными вершинами со значением +10 каждая, действуя
аналогично тому, как в примере на рис. 10.18, мы можем классифицировать ft, b;,d
как положительные вершины. Остальная часть сети станет звездой с
хозяином [е1] и листьями [аа1], [dUtW], [с], [с'], [е]. Финальное GH-дерево показано на
рис. 10.26(b).
Пример 3.
В сети на рис. 10.28(a) не существует доминирующих ребер, поскольку все
ребра имеют пропускную способность 1. Мы имеем
W = 3, М = fe]= 4, [*] = 5.
10.9. ЛЕСТНИЧНАЯ ДИАГРАММА
309
\l
i
/\
2
ч 9/
Г^Ч
^И
IS
Тр
Г\1
Рис. i^.£5
^;
^
Рис. i&£{
Рис. 10.25
310
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
а)
Ь)
Рис. 10.26
Рис. 10.27
Ь)
а)
Рис. 10.28
10.10. ВОПРОСЫ сложности
311
Легко исключить а*, 6«, с* как хозяев. Вершина [d\] имеет соседями ai, а2, а3, fti.
Далее, [d\] = 5 > [diЬ^агаз] = 4, так что этот круг можно стянуть в
атомарный круг величины 4.
Используя лемму 5, можно исключить С{ как хозяев. Применяя метод
китайских палочек, мы видим, что GH-дерево имеет две звезды с хозяевами
d\,d3, как показано на рис. 10.28(b). Вершины 05,62,^3,^2,^1,02,03,04 не
показаны на диаграмме, они являются листьями для [ds].
Пример 4.
Сеть, показанная на рис. 10.29(a), очень похожа на сеть рис. 10.28(a).
Снова мы можем определить первый Я-допустимый круг [d\aia,2a3bi] = [х] с
хозяином [d\] и стянуть его в атомарный круг со значением 4.
а) Ь>
Рис. 10.29
Далее, первая фаза метода китайских палочек для проверки [с\\ дает нам
рис. 10.30, где [ае] превращается из отрицательной вершины в
положительную, и мы получаем Я-допустимый круг [схС2СзС4ав] = [3] < [с\].
Заключительное GH-дерево представлено на рис. 10.29(b), не показаны листья сц, 05,
&2> h у вершины [da].
10.10. Вопросы сложности
При анализе алгоритмов обычно концентрируют внимание на анализе
худшего случая или иногда на анализе среднего значения. Кроме того,
устремляют п к бесконечности и используют 0-<;имволику. Алгоритм
классифицируется как хороший, если время его выполнения является полиномиальной
функцией от п.
Рассматривая сетевой алгоритм, как правило, предполагают все входные
данными возможными. Иногда ограничивают значения, ассоциированные с
ребрами, неотрицательными и ограниченными сверху целыми числами.
Все вышеизложенные предположения хорошо известны и есть серьезные
основания их придерживаться.
312
ГЛАВА 10. ДЕРЕВО ГОМОРИ-ХУ
Рис. 10.30
Когда время работы алгоритма является линейной функцией от п,
естественно предположить, что существенные усовершенствования невозможны,
так как для чтения входных данных необходимо линейное время. Однако в
задаче математического программирования матрица может быть очень
большой — такой большой, что все столбцы не могут быть явно выписаны — и тем
не менее удается получить оптимальное решение очень легко за линейное или
сублинейное время. Причина заключается в том, что элементы матрицы не
являются случайными числами. Каждый столбец матрицы имеет смысл:
скажем, столбец может представлять кратчайший путь, способ укладки рюкзака
и т.д. Использование этого Для уменьшения временной сложности известно
как техника генерирования столбцов.
Если рассматривать вход компьютерной программы как независимые
переменные ж, а выход — как зависимые переменные у = /(х), то часто ищется
оптимальное значение у (максимум или минимум) по всем возможным входам х.
Это приводит к вопросу: «Как должно быть определено понятие функции?»,
Некоторые учебники определяют у = f(x) как множество упорядоченных
пар, в котором для каждого значения х существует единственное значение у.
В старых учебниках (например, у Куранта) делается упор на понятие правила
соответствия. Иными словами, каждому значению х из области определения
соответствует единственно определенное значение у, где х и у связаны каким-
нибудь законом. Бели дано значение ж, мы хотим узнать, как долго займет
процесс получения значения у — иными словами, какова трудоемкость отоб-
ражения.
Иногда для функции имеется таблица упорядоченных пар,
отсортированная по возрастанию х, но правило отображения не задано в явном виде. Каким
10.10. ВОПРОСЫ сложности
313
может быть правило отображения для следующих данных:
х = 1, у = 1996; х = 2, у = у/тг;
х = 3, у = е~'; х = 4, j/ = 1122?
Читатель, наверное, согласится, что таких функций не бывает в реальных
приложениях. В большинстве приложений правило соответствия легко
описывается и мы можем вычислить значение у как функции от х без особых
усилий. Обычно у нас также есть некоторые соображения относительно
области определения.
Что касается сети из п вершин, она может быть разреженной или очень
плотной. Может существовать много вершин с одинаковой сетевой степенью
или, возможно, все ребра имеют величину 1, и п может быть больше или
меньше 103 или 107. Подобные неформальные или грубые характеристики
сети позволяют применять различные алгоритмы лли один и тот же алгоритм с
некоторыми добавленными или удаленными частями. Ожидать от алгоритма
эффективности во всех случаях — значит желать слишком многого.
Мы предполагаем, что имеется линейный алгоритм, который определяет,
является ли данная сеть связной, и алгоритм трудоемкости 0(п2), который
находит сетевые степени всех вершин и упорядочивает их. При наличии многих
вершин одинаковой степени предполагаем, что случаи совпадения значений
разрешаются произвольным образом.
Интуиция подсказывает, что если бы мы разместили все вершины на
плоскости в соответствии с их высотами и так, чтобы пропускная способность
ребра, соединяющего две вершины, была обратно пропорциональна
расстоянию между ними, то круг с допустимым хозяином выглядел бы как холм,
окруженный рекой, с вершиной-хозяином наверху.
Некоторые леммы, теоремы, а также метод китайских палочек
способствуют лучшему пониманию. Однако мы не придумали детерминированного
алгоритма, который в худшем случае работал бы быстрее, чем лучшие потоковые
методы.
Авторы убеждены, что алгебраические обозначения, использованные при
доказательстве лемм, будут полезным инструментом. С этим инструментом
мы смогли исследовать случаи, когда величина ребра может быть
положительной или отрицательной (хотя в настоящий момент у нас нет таких конкретных
примеров или приложений).
Приложение А
Замечания к главам 2, 5, 6
В следующих книгах можно найти описание многих последних результатов
о максимальных потоках:
1. Ahuja R.K., Magnanti T.L., Orlin J. В. Network Flows. — Prentice Hall,
1993.
2. Cook W. J., Cunningham W. H., Pulleyblank W. R., Schrijver A.
Combinatorial Optimization. — Wiley, 1998.
Здесь мы прокомментируем два интересных результата:
(i) Если значения разреза определены произвольно, то для нахождения
разрезов с минимальной стоимостью, разделяющих все (£) пар узлов сети,
дереву предшественников потребуется только п — 1 обращений к
оракулу. Это является обобщением дерева Гомори-Ху, когда значение разреза
определяется как сумма пропускных способностей ребер.
(И) Технику сетевых потоков можно использовать для нахождения
минимальной поверхности (классическая задача о плато).
Более подробную информацию можно найти в работах:
[Al] Cheng С. К., Ни Т. С. Ancestor Tree for Arbitrary Multi-Terminal Cut
Functions // Annals of Operations Research. —1991. — Vol. 33. — P. 199-213.
[A2] Ни Т. С, Kahng А. В., Robins G. Optimal Robust Path Planning in General
Environments // IEEE Transactions on Robotics and Automation. — 1993.
- Vol.9, No6. - P.775-784.
[A3] Ни Т. С, Kahng А. В., Robins G. Solution of the Discrete Plateau Problem
// Proc. Natl. Acad. Sci. - 1992. - Vol.89. - P.9235-9236.
АЛ. ДЕРЕВЬЯ ПРЕДШЕСТВЕННИКОВ
315
АЛ. Деревья предшественников
В неориентированной сети с п вершинами имеется 2n_1 -1 разрезов. Пусть
значения этих разрезов заданы произвольно. Требуется найти Q) разрезов
минимальной стоимости, разделяющих все (£) пар вершин. Так как
значения разрезов определены произвольно, то можно предположить, что имеется
процедура или оракул, способные определить величины этих разрезов.
Сколько вопросов нужно задать оракулу? Ответ: п — 1. Эффективно
используя п-1 разрезов с минимальной стоимостью, можно построить бинарное
дерево с листьями (квадратными узлами), являющимися вершинами исходной
сети. Каждый круглый узел соответствует некоторому минимальному
разрезу и хранит имена двух вершин, им разделенных, а также величину этого
разреза.
Если требуется отыскать минимальный разрез, разделяющий две заданные
вершины сети, то нужно найти два листа бинарного дерева и их общего предка
(расположенного в самом низком уровне данного бинарного дерева).
Так как каждый вопрос оракулу приводит к круглому узлу, то нужно
задать только п — 1 вопросов (или выполнить п — 1 вычислений).
Очевидно, что круглый узел, расположенный в корне бинарного дерева,
соответствует глобально минимальному разрезу [X, X] заданной сети, листы
левого поддерева — вершинам из X, а листы из правого поддерева — вершинам
из X.
Вместо вопроса «каков глобально минимальный разрез?», можно только
задать вопрос «каков минимальный разрез, разделяющий вершины s и t?>
Таким образом, будем интересоваться минимальным разрезом, разделяющим
две произвольные вершины s и t, скажем,
F'(s,t) = [Х,Х].
Затем возьмем две вершины s и р из X и поинтересуемся минимальным
разрезом, разделяющим вир. Бели величина разреза равна
F'(8,p)>F*(8,t),
то узел в виде круга F*(s,p) становится левым сыном узла F*(s,t) и
продолжаем расщепление далее.
С другой стороны, если
F*(s,p)<F*(s,t),
то назначаем узел F*(s,p) корнем, a F*(s,t) становится его правым сыном.
Всегда поддерживая значение узла-отца меньшим значений двух его
узлов-сыновей, можно построить бинарное дерево предшественников. Более
подробную информацию см. в [А1].
316 ПРИЛОЖЕНИЕ А. ЗАМЕЧАНИЯ К ГЛАВАМ 2, 5, 6
А.2. Минимальная поверхность
или задача о илато
Техника сетевых потоков относится к дискретной математике, в то
время как задача о минимальной поверхности является задачей классического
анализа, и между ними нет очевидной связи. Тому, кто для вычисления
минимальной поверхности использует конечные разности, может показаться, что
конечная разность — единственное, что связывает в этой задаче
непрерывную и дискретную математику. Здесь используется не «конечная разность»,
а поток в сети. Рассмотрим реку, изображенную на рис. АЛ.
Рис.А.1
Через эту реку требуется построить мост минимальной длины. Заметим,
что вычисления могут привести к локальному минимуму, в то время как
хотелось бы получить глобальный минимум. Один из способов состоит в
измерении скорости и нахождения сечения, в котором скорость наибольшая, что
соответствует наименьшей площади сечения (в предположении отсутствия
трения и т.д.). Максимальная скорость течения соответсвует минимальному
поперечному сечению. Можно направить поток от S к Т и найти «минимальный
разрез», разделяющий 5 и Г.
Если разделить участки реки на мелкие прямоугольники и рассматривать
поток, текущий из одного прямоугольника в соседние с ним, то можно
надеяться найти подмножество прямоугольников, соответствующих
минимальному разрезу (прямую линию). Более подробную информацию см. в [A3].
А.З. Дополнения к главе 5
Здесь представлены три дополнения о бинарных деревьях.
(i) Простое доказательство корректности алгоритма Ху-Таккера,
строящего оптимальное алфавитное бинарное кодовое дерево за время 0(п log п).
(И) Будет показано, что задача построения бинарного дерева поиска может
быть преобразована в задачу построения алфавитного бинарного
кодового дерева и поэтому оптимальное бинарное дерево поиска можно
построить за время O(nlogn) вместо 0(п2).
(Ш) Для последовательности записей на ленте классический бинарный
поиск минимизирует число сравнений, а последовательный поиск мини-
А.З. ДОПОЛНЕНИЯ К ГЛАВЕ 5
317
мизирует расстояние, проходимое читающей головкой, которая вначале
находится у одного из концов ленты. Будет рассмотрен вопрос о
компромиссном дереве поиска, учитывающем оба критерия.
Для данного множества квадратных узлов с весами W{ оптимальное
бинарное кодовое дерево мнимизирует £3 wihi где Ц — уровень узла. Хорошо
известный алгоритм Хаффмена для решения этой задачи рекурсивно
комбинирует два узла наименьшего веса.
Для данной последовательности квадратных узлов оптимальное
алфавитное дерево также минимизирует £ w%h- Кроме того, оптимальное алфавитное
кодовое дерево должно удовлетворять требованию алфавитности. Алгоритм
Ху-Таккера решает эту задачу за время 0(п log п), но представленное
доказательство корректности этого алгоритма было слишком сложным. Ниже дается
набросок более простого доказательства. Основные определения даны в главе
5. Подробности читатель может найти в [А4].
[А4] Ни Т. С, Morgenthaler J. D. Optimum Alphabetic Binary Tree // Lecture
Notes in Computer Science. - 1996. - Vol. 1120. - P. 234-243.
A.3.1. Простое обоснование алгоритма Ху-Таккера
Докажем сначала несколько лемм.
Лемма 1. Если последовательность весов монотонно не убывает или
монотонно убывает, то стоимости деревьев Хаффмена и Ху-Таккера
совпадают. Более того, существует дерево Хаффмена, удовлетворяющее
требованию алфавитности (см. упражнения к разделу 2.3.4-5 вт.1 книги Д. Кнута
^Искусство программирования для ЭВМ»).
Лемма 2. Если последовательность весов является впадиной, то
стоимости деревьев Хаффмена и Ху-Таккера равны. Более того, существует дерево
Хаффмена, удовлетворяющее требованию алфавитности (см. леммы 7 и 8
в разделе 5.8).
Лемма 3. Если последовательность весов является впадиной, то круглые
узлы, создаваемые в фазе 1 алгоритма Ху-Таккера, образуют очередь с
монотонно возрастающими весами. Потомки каждого из этих круглых узлов
могут быть соединены в алфавитное бинарное дерево, удовлетворяющее
условию: если W{ < Wj, то U > lj.
Заметим, что в последовательности-впадине два наименьших узла
(круглых или квадратных) всегда совместимы. Поэтому в алгоритме Хаффмена
будут комбинироваться те же пары, что и в фазе 1 алгоритма Ху-Таккера
(см. [А4]). Для удобства введем два квадратных узла Wl и Wr веса оо,
расположенных соответственно в начале и в конце последовательности. Тогда
последовательность весов
W\ < W2 < ... < Wt > Wt+l > ...> wn
318
ПРИЛОЖЕНИЕ А. ЗАМЕЧАНИЯ К ГЛАВАМ 2, 5, б
можно рассматривать как состоящую из двух впадин:
Wl > wi < W2 < •... < wt > Wt+i > ... > wn < Wr.
Квадратный узел wt называется горой между двумя впадинами.
Из леммы 3 следует, что можно образовать две отдельных очереди — одну
для каждой впадины. Из-за горы узлы из разных впадин не совместимы
между собой. Когда наименьшие круглые узлы во впадинах станут достаточно
большими, гора будет наконец скомбинирована. С этого момента все круглые
узлы станут совместимыми. Получается слияние двух очередей. По существу,
фаза 1 в алгоритме Ху-Таккера подобна слиянию нескольких очередей, а
произвольную последовательность весов можно рассматривать как соединение
нескольких впадин.
Чтобы понять, почему последовательность уровней может быть соединена
в алфавитное дерево, достаточно рассмотреть два случая:
(1) Комбинируются два узла из одной впадины.
(2) Комбинируются два узла va и ve из разных впадин. Пусть при этом
между va и ve расположены круглые узлы Vb,vc,Vd- Каждый из них имеет
двух сыновей, скажем, уы и уьъ, vc\ и vC2, Vdi и Vd2- Когда
комбинируются va и ve, мы в действительности создаем общего отца для va и ьы>
После этого общего отца получают Vb2 и vc\, затем vc2 и Vd\. Наконец,
общего отца получают Vdi и ve.
А.3.2. Бинарные деревья поиска
В разделе 5.1 были определены бинарные деревья и показана связь
между бинарными деревьями (рис. 5.1) и расширенными бинарными деревьями
(рис. 5.2). Здесь под бинарным деревом будем понимать расширенное
бинарное дерево, оно состоит из п круглых ип + 1 квадратного узла. Пусть даны
2п + 1 вероятностей РъР2,---,Рп и <7сь<7ъ-•-,<7п, где Pi есть вероятность
того, что искомый ключ совпадает с ключом К^ находящимся в узле г, a qi —
вероятность того, что искомый ключ заключен между К{ и Ki+\. Здесь од>
-вероятность того, что искомый ключ меньше, чем К\, a qn - вероятность
того, что искомый ключ больше, чем Кп.
В бинарном дереве поиска искомый ключ сначала сравнивается с ключом,
хранящемся в корне, с применением трехвариантного сравнения <,=,>.
Затем в зависимости от результата сравнения перемещаемся в левое или правое
поддерево. Ожидаемое число сравнений выражается формулой
\*=i i=o /
где индекс Згу указывает, что применяется трехвариантное сравнение, а 0 -
стоимость трехвариантного сравнения.
В компьютере обычно применяется двухвариантное сравнение <, >,
стоимость которого меньше /?. Можно ли применять двухвариантное сравнение
А.З. ДОПОЛНЕНИЯ К ГЛАВЕ 5
319
во всех внутренних узлах? Ответ утвердительный. Рассмотрим пример на
рис. 5.2(b). Если во всех внутренних узлах применяется < и >, то невозможно
различить Кеу(А) и Key(F), когда достигнут узел F. Аналогично, если
достигнут узел #, невозможно различить Key(J5) и Key (Я). Однако в узле F можно
задать один дополнительный вопрос: «искомый ключ Key равен Кеу(А)?», а в
узле Я - один дополнительный вопрос: «искомый ключ Key равен Key (Я)?»
Таким образом, добавляя один дополнительный вопрос в каждом квадратном
узле, можно применять двухвариантное сравнение.
Применяя этот метод, мы фактически создаем п + 1 квадратный узел с
вероятностями ф>, (рг + gi), (рг + ft), • • •, (рп + Qn), а все pi в круглых узлах
заменяем нулями.
Затем можно применить алгоритм Ху-Таккера для построения
оптимального бинарного алфавитного дерева за время O(nlogn) вместо построения
оптимального бинарного дерева поиска, требующего времени (п2).
Подробности можно найти в [А5].
[А5] Ни Т.С., Tucker P. A. Optimal alphabetic trees for binary search //
Information Processing Letters. - 1998. — Vol. 67. - P. 137-140.
A.3.3. Бинарный поиск на ленте
Рассмотрим последовательность из п записей, хранящихся на ленте и
отсортированных по значению некоторого ключа. Классический бинарный
поиск рекурсивно делит ленту на отрезки равной длины до тех пор, пока не
останется одна запись. Хорошо известно, что такая процедура
минимизирует число сравнений (оно будет равно log2n). Однако при этом игнорируется
время передвижения считывающей головки (или расстояние, проходимое
считывающей головкой). Пусть с — стоимость одного сравнения, a t — стоимость
перемещения на одну запись. Можно ли минимизировать стоимость поиска с
учетом обеих этих стоимостей? Ясно, что при t = 0 следует применить
классический бинарный поиск, а при с = 0 — последовательный поиск.
Эта проблема была поставлена и решена в следующих работах.
[А6] Ни A. J. Problem 83-3 // The Journal of Algorihms. - 1984. - Vol.5. -
P. 579-580.
[A 7] Ни A.J. Mathematical selection of the optimum uniform partition search //
Computing. - 1986. - Vol.37, No3. - P.261-264.
Результат получен при следующих предположениях.
1. У всех ключей одинаковые вероятности быть искомыми.
2. Число ключей п очень велико.
3. В процессе поиска повторяется одна и таже процедура. Если сначала
лента делится на две части (т. е. р = 2), то и впоследствии всегда должно
выполняться деление на две части. Если сначала применялся
последовательный поиск (т.е. р = п), то нельзя перейти к бинарному поиску
320
ПРИЛОЖЕНИЕ А. ЗАМЕЧАНИЯ К ГЛАВАМ 2, 5, б
после, скажем, трех неудачных попыток. Можно всегда делить ленту на
10 частей (т. е. р = 10), пока не останется одна запись. Задача состоит в
том, чтобы найти оптимальное значение р — числа частей, на которые
делится лента. При р = 2 имеем классический бинарный поиск, а при
р = п — классический последовательный поиск.
Следующая формула, полученная А. Дж. Ху, дает оптимальное значение р
в зависимости от п, £, с при сделанных выше предположениях:
lnp С In у/п'
Результат может быть улучшен, если устранить предположение 3 и
потребовать определения оптимального значения р для каждого возможного п;
например, можно сначала применить несколько раз бинарный поиск, а когда п
станет меньше 30, перейти к последовательному поиску.
Чрезвычайно сложно определить точное место, в которое должна
передвигаться считывающая головка.
Например, если п — 46, то первое сравнение должно быть выполнено с 6-й
записью и лента разделена на две ленты длины 5 и 40. Бели искомой является
13-я запись, необходимо сравнивать с 6-й, 11-й, 16-й, 15-й, 14-й и 13-й, всего
получается 6 сравнений и 16+3=19 перемещений.
В [А8] описана модель оптимального гибрида бинарного и
последовательного поиска, называемая оптимальным ленточным деревом. Оптимальное
ленточное дерево не может быть описано явно, но допускает представление
бесконечной рекурсивно порождаемой последовательностью.
[А8] Ни Т.С., Wachs M.L. Binary search on a tape // SIAM J. on Comput.
1987.-Vol. 16, No 3.
A.4. Комментарии к разделу 6.2
Пусть задан список ящиков L = (ai,a2,...,an), где величина 0 < а* < 1
обозначает размер г-го ящика. Алгоритм упаковки должен упаковать все
ящики в минимальное число контейнеров размера 1. Стандартная формулировка
следующая:
1. Ящики появляются по одному в каждый момент времени, и требуется
решить, в какой контейнер требуется непосредственно поместить этот
ящик (это алгоритм он-лайн).
2. Однажды поместив ящик в контейнер, уже нельзя изъять его из данного
контейнера.
3. Эффективность алгоритма оценивается по самому худшему списку
ящиков. Этот список может быть сколь угодно длинным.
Все разработанные по настоящее время алгоритмы основаны на
следующих идеях:
А.4.
КОММЕНТАРИИ К РАЗДЕЛУ 6.2
321
1. Ящики классифицируются по размерам, как показано на с. 202, где ящик
называется ящиком типа а, если его размер больше, чем 1/2 и т. д.
Контейнеры также классифицируются по различным классам, один класс
контейнеров предназначен для больших ящиков, а другой класс
контейнеров — для маленьких ящиков.
2. Маленькие ящики можно упаковать эффективно, следовательно,
коэффициент будет мал, в то время как ящики больших и средних размеров
могут занять много пространства контейнера.
3. Пусть имеется много маленьких ящиков, следующих в списке друг за
другом, и они упаковываются в класс контейнеров, специально
предназначенный для небольших ящиков, с коэффициентом 1.2. Когда мы
снова видим в списке маленькие ящики, мы сознательно растрачиваем
определенное пространство и упаковываем их неэффективно. Данные
контейнеры отнесем к резерву на случай, если позднее появятся большие
ящики.
Таким образом, возникают два ключевых вопроса: как классифицировать
ящики и какой процент контейнеров следует назначить в резерв?
Принятая в разделе 6.2 классификация данных дает коэффициент 5/3 =
1.667. Можно классифицировать ящики по типам ai, аз, 0%, $и Аь й> $2> где
1/2 < а2 < у < ах < 1,
1/4 < ft < 1/3 < А < (1 - у) < ft < 1/2,
0 < й < 1/6 < 6г < 1/4.
Контейнеры также классифицируются по 7-ми классам, Аь Аг, Во, i?i,
В2,С\ и Сг, и происходят следующие размещения:
- все ящики типа а\ размещаются в контейнерах типа А\,
- все ящики типа а^ размещаются в контейнерах типа А2,
- все ящики типа /?о размещаются в контейнерах типа 2?о,
- большинство ящиков типа /?i размещаются в контейнерах типа В\ (0.2165
часть остается в резерве),
- большинство ящиков типа 02 размещаются в контейнерах типа В2 (0.0765
часть остается в резерве),
- большинство ящиков типа 6\ размещаются в контейнерах типа С\ (0.2805
часть остается в резерве),
- а большинство ящиков типа &ъ размещаются в контейнерах типа С?
(0.3398 часть остается в резерве).
Если взять у = 0.6225, то можно тюлучитъ самый низкий коэффициент
эффективности,' равный 1.606. Более подробную информацию см. в [A9J.
[А9] Ни Т. С, Kahng А. В. Anatomy of on-line bin packing. — Tech. Report CS
88-137, Nov. 1988.
Приложение Б
Сетевая алгебра
Вначале определим понятия, используемые в разделах 9 и 10, а затем
операции, управляющие кружками и ребрами. В заключение рассмотрим
взаимоотношение между сетевой алгеброй и булевой алгеброй.
Имеется два типа объектов, кружки (атомарные кружки равносильны
вершинам) и ребра (которые соединяют кружки). Кружок, окружающий одну
вершину, обозначается строчной буквой в квадратных скобках, например,
М» И» Мэ [у]> М. • • • э м> ы,....
Кружок, окружающий более, чем одну вершину, обозначается заглавной
буквой, и тогда принадлежность определяется особо, например,
[A],[X],[S], где А = {аиа2,а3},Х = {xux2},S = {p,tf,r,s},
или же просто перечисляем все вершины внутри данного кружка:
[aia2a3],[xix2],[wre].
Ребро, соединяющее две вершины [а] и [ft], обозначается через (a, ft).
Множество ребер, соединяющих два кружке [abc\ и [de], обозначается (abc,de),
где
(abcyde) = (a, de) + (ft, de) + (с, de)
= (a,<Q + (a,e) + (ft,d) + (ft,e) + (c,d) + (c,e).
Для неориентированных ребер (a, ft) = (ft,a), и у каждого ребра есть
неотрицательное значение, указывающее его пропускную способность.
Величина кружке определяется как сумма значений всех ему инцидентных
ребер. Для сети с конечным числом вершин С[Х] = С[Х] = с(Х,Х). Для сети
с тремя вершинами, как показано на рис. Б.1, имеем
[в] = 0, |Ь] = 1, [с] = 1.
323
Рис.В.1
Поэтому
[aft] = [а] + [ft] -2(a,ft) = 0 + 1-2-0 = 1,
[ac] = [a] + [c]-2(a,c)=0 + l-2.0 = l,
[ftc] = [ft] + [с] -2(ft,c) = 1 + 1-2-1 = 0, U
[обе] = [a] + [ft] + [c] - 2(a, ft) - 2(a, c) - 2(ft, c) = • • • = 0.
Эти четыре равенства в (1) напоминают булеву алгебру, в которой
выполняются соотношения:
0 + 1 = 1,
1+0=1- m
1 + 1 = 0, w
0 + 0 = 0,
В общем случае справедливы тождества:
[ху] = [х] + \у]-2(х,у)>
[ХУ] = [Х] + [К]-2(Х,У),
[ijk] = [г] + М + [к] - 2(tf i) - 2(г, ft) - 2(j, fc), (3)
2(Л,аЬс) = (Л,аЬ) + (Л,ас) + (Л,Ьс)>
3(Л, abed) = (Л, аЬ) + (Л, ос) + (Л, ad) + (Л, be) + (Л, М) + (Л, cd).
Типичной моделью четырех равенств из (2) являются два переключателя
света, расположенные внизу и вверху лестницы, таких, что свет зажигается
тогда и только тогда, когда в точности один из переключателей находится
в верхнем положении. Свет не горит, когда оба переключателя находятся в
одинаковом положении (т.е. оба в верхнем или оба в нижнем положении).
Если кружок с соответствующим ему значением указывает на текущее
состояние системы, то у данной системы может быть много состояний. Во
всех тождествах из (3) отсутствуют ограничения назначения ребер, которые
могут быть как положительными, так и отрицательными целыми числами.
Понятие ff-допустимого кружки могло бы использоваться во многих
других областях. Эти понятие служит для кластеризации множества элементов
независимо от того, представляют ли вершины людей, файлы данных или
электронные компоненты.
Литература
[1*] Адельсон-Вельский Г.М., Диниц Б. А., Карзанов А. В. Потоковые
алгоритмы. — М.: Наука, 1975.
[2*] Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы.
— СПб.: Вильяме, 2000.
[3*] Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ
вычислительных алгоритмов. — М.: Мир, 1979.
[4*] Беллман Р. Динамическое программирование. — М.: Изд-во иностр. лит.,
I960.
[5*] Беллман Р., Дрейфус С. Прикладные задачи динамического
программирования. — М.: Наука, 1965.
[6*] Гарднер М. Путешествие во времени. — М.: Мир, 1990.
[7*] Гасс С. Линейное программирование. — М.: Физматгиз, 1961.
[8*] Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые
задачи. — М.: Мир, 1982.
[9*] Данциг Дж. Линейное программирование, его обобщения и применения.
— М.: Прогресс, 1966.
[10*] Диниц Б. А. Алгоритм решения задачи о максимальном потоке в сети
со степенной оценкой // Докл. АН СССР. — 1970. — Т. 194, Л* 4. -
С. 754-757.
[11*} Дрейфус СБ. Обзор некоторых алгоритмов определения
кратчайшего пути // Экспресс-информация, серия «Техническая кибернетика». —
1969. - №41.
[12*) Карзанов А. А. Нахождение максимального потока в сети методом пред-
потоков // Докл. АН СССР. - 1974 - Т. 215, JM. — СЛЬ-ЬЗ.
[13*] Карп P.M. Сводимость комбинаторных проблем // Кибернетический
сборник. Новая серия. Вып. 12. — М.: Мир, 1975. — С. 16-38.
ЛИТЕРАТУРА
325
[14*] Кнут Д. Искусство программирования для ЭВМ, т. 1. Основные
алгоритмы. — СПб.: Вильяме, 2000.
[15*] Кнут Д. Искусство программирования для ЭВМ, т. 1. Основные
алгоритмы. — М.: Мир, 1976. (Третье издание: [14*])
[16*] Кнут Д. Искусство программирования для ЭВМ, т. 2. Получисленные
алгоритмы. — СПб.: Вильяме, 2000.
[17*] Кнут Д. Искусство программирования для ЭВМ, т. 2. Получисленные
алгоритмы. — М.: Мир, 1977. (Третье издание: [16*])
[18*] Кнут Д. Искусство программирования для ЭВМ, т. 3. Сортировка и
поиск. — СПб.: Вильяме, 2000.
[19*] Кнут Д. Искусство программирования для ЭВМ, т. 3. Сортировка и
поиск. — М.: Мир, 1978. (Второе издание: [18*])
[20*] Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. —
М.: МЦНМО, 1999.
[21*] Кристофидес Н. Теория графов. Алгоритмический подход. — М.: Мир,
1978.
[22*] Кук СА. Сложность процедур вывода теорем // Кибернетический
сборник. Новая серия. Вып. 12. — М.: Мир, 1975. — С. 5-15.
[23*] Липский В. Комбинаторика для программистов. — М.: Мир, 1988.
[24*] Литл Дж., Мурти К., Суини Д., Кэрел К. Алгоритм для решения задачи
о коммивояжере // Экономика и математические методы. — 1965. — Т. 1,
ЛП.- С. 94^107.
[25*] Мухачева Э. А., Рубинштейн Г.Ш. Математическое программирование.
— Новосибирск: Наука, 1977.
[26*] Пападимитриу X., Стайглиц К. Комбинаторная оптимизация. — М.:
Мир, 1985.
[27*] Прим Р. К. Кратчайшие связывающие сети и некоторые обобщения //
Кибернетический сборник. Новая серия. Вып. 2. — М.: Мир, 1961. —
С. 95-107.
[28*] Рейнгольд Э., Нивергельт Ю., Део Н. Комбинаторные алгоритмы.
Теория и практика. — М.: Мир, 1980.
[29*] Форд Л., Фалкерсон Д. Потоки в сетях. — М.: Мир, 1966.
[30*] Хачиян Л. Я. Полиномиальный алгоритм в линейном программировании
// Доклады АН СССР. - 1979. - Т. 244, Л*5. - С. 1093-1096.
[31*] Ху Т. Целочисленное программирование и потоки в сетях. — М.: Мир,
1974.
326
ЛИТЕРАТУРА
[32*] Ху Т. Параллельное упорядочивание и проблемы линии сборки //
Кибернетический сборник. Новая серия. Вып. 4. — М.: Мир, 1967.
[33*] Шевченко В.Н. О свойстве периодичности задачи о рюкзаке // Анализ
и моделирование экономических процессов. — Горький: Изд-во Горьк.
ун-та, 1981. - С. 36-38.
[34*] Шевченко В. Н. Качественные вопросы целочисленного
программирования. — М.: Физматлит, 1995.
[35*] Шевченко В. Н., Рукавишников В. В. О границе периодичности в задаче
о рюкзаке // Труды второй международной конференции
«Математические алгоритмы». — Н. Новгород: Изд-во Нижегород. ун-та, 1997. —
С.181-184.
[36*] Штрассен В. Алгоритм Гаусса не оптимален // Киб. сб., новая сер. —
М.: Мир, 1970. - Вып. 7. - С. 67-70.
[37*] Шульц М.М. Оптимальное окаймление для алгоритма Штрассена //
Журн. вычисл. матем. и матем. физ. —1977. — Т. 17, Л* 5. — С. 1296-1298.
[38*] Agrawal М., Kayal N., Saxena N. PRIMES is in P. -
Department of Computer Science & Engineering, Indian Institute
of Technology Kanpur, 2002. — 9 p. Рукопись доступна по адресу
http: //www. cse. iitk. ac. in/ueers/manindra/primality .ps
[39*] Coppersmith D., Winograd S. Matrix multiplication via arithmetic
progressions // 19th Annual ACM Symposium on Theory of Computing.
- 1987. - 1-6.
Предметный указатель
а-/?-отсечение , 152
Л-дуга , 235
v-дуга , 235
BF-правило , 201
BFD-правило , 202
BFS , 41
DFS , 41
FF-правило , 200
FFD-правило , 202
NF-алгоритм , 198
PERT , 95
Алгебра сетевая , 13 , 322
Алгоритм
«одним махом» , 238
«следующего подходящего» , 198
Гарсиа-Уочса , 179
Дейкстры , 20 , 267
Диница , 60 , 67
декомпозиции , 28
жадный , 191
Карзанова , 61 , 67
квазиполиномиальный , 261
китайских палочек , 301
критического пути , 217
локального индексирования , 265
максимальной смежности , 271
минимального разделения , 275
недетерминированный , 257
он-лайн , 200
офф-лайн , 202
Прима , 39 , 267
полиномиальный , 255
псевдополиномиальный , 260
реального времени , 200
стековый , 168
Форда-Фалкерсона , 55 , 66
Ху-Таккера , 166 , 167
Штрассена , 224
Эдмондса-Карпа , 66
эвристический , 262
Балансировка предпотока , 62
Бэктрекинг , 137
Веер , 238
Вектор частичный , 139
Вершина , 15 , 277
локально максимальная , 239
локально минимальная , 239
степень , 16
Вершины
связанные , 231
смежные , 16
соседние , 16
Внешняя длина пути , 157
Внук , 139
Внутренняя длина пути , 158
Впадина , 185
Высота дерева , 217
Граф , 15
ациклический , 16
ориентированный , 16
связный , 16
смешанный , 16
Декомпозиция , 262
линейная , 34
Дерево , 16
t-арное , 163
алфавитное , 130 , 165
бинарное , 156
оптимальное, 160
расширенное , 156
Гомори-Ху , 13 , 82 , 102 , 277
игры , 149
328
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
остовное , 16 , 38
коммуникационное , 99
минимальное , 38
разрезов , 82 , 102 , 277
решений , 138
тернарное , 149
Хаффмена , 160
Древесная степень , 278
Дуга , 15 , 229
базисная , 23
вертикальная , 235
горизонтальная , 235
обратная , 51
полезная , 58
потенциальная , 236
прямая , 51
Дуги
скрещивающиеся , 237
совместимые , 237
Задача
TVP-полная , 259
алгоритмически неразрешимая , 254
индивидуальная , 253
коммивояжера , 256 , 258 , 260
о максимальном независимом
множестве , 260
о минимальном вершинном
покрытии , 260
о минимальном остовном дереве ,
191 , 265
о разбиении , 259
о размене , 191 , 262
о разрезе , 197
о рюкзаке , 116 , 260
двумерном , 123
об упаковке , 197
оптимизации , 256
полиномиально разрешимая , 255
расписания , 261
распознавания , 256
труднорешаемая , 254
Звезда , 283
Звено , 277
Источник , 48
Кодирование , 158
стоимость , 160
Конденсация , 72 , 281
Контур , 16
Корень дерева , 156 , 216
Круг
Я-допустимый , 286
атомарный , 285
Лексикографическое сравнение , 231
Лес , 161
Лист , 139 , 278
Локально минимальная совместимая
пара (л.м.с.п.) , 170
Матрица смежности , 256
Машина Тьюринга , 254
Метод
ветвей и границ , 145
китайских палочек , 301
отсечений , 262
расстановки пометок , 55
Минисложение , 31
Многоугольник
базисный , 232
верхний , 237
монотонный , 242
Ним , 149
Ограничение по ширине и высоте , 218
Операция
китайских палочек , 300
тройственная , 24
Отец , 139 , 216
Отец узла , 157
Пара
минимальная , 167
совместимая , 167
Перекрещивание узлов , 174
Подграф , 16
Поиск
в глубину , 42 , 256 , 266
в ширину , 41 , 56 , 58 , 266
с возвращением , 137 , 141 , 257 , 262
Потенциал потока , 65
Поток
многополюсный , 69
тупиковый , 58
Поток в сети , 49
Потоко-эквивалентные сети , 72
Потомок узла , 157
Правило
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
329
«наилучшего подходящего в
порядке убывания» , 202
«наилучшего подходящего» , 201
«первого подходящего в порядке
убывания» , 202
«первого подходящего» , 200
улучшенное , 203
Предок узла , 157
Предпоток , 61
Принцип оптимальности , 112
Программирование
динамическое , 109 , 250 , 262
линейное , 115
целочисленное , 116
математическое , 116
Продвижение предпотока , 62
Пропускная способность дуги , 48
Путь , 16
кратчайший , 17
условный , 30
критический , 96 , 217
простой , 16
Разрез , 29 , 49
глобально минимальный , 277
минимальный , 29 , 50
Раскрой , 124
гильотинный , 124
двухстаднйный , 124
Ребра смежные , 16
Ребро , 15 , 277
боковое , 300
доминирующее , 282
древесное , 277
ориентированное , 16
прямое , 300
Сведение задач , 258
Свойство префикса , 159
Сеть , 17
остаточная , 58
Симплекс-метод , 261
Скрещивающиеся разрезы , 53 , 73
Список смежности , 256
Сравнение
лексикографическое , 138
Сток , 48
Сторона
базисная , 228
Стратегия , 112
Стягивание, 72 , 281 , 302
Сын узла , 157
Теорема
Гомори-Ху , 82
о максимальном потоке и
минимальном разрезе , 50
о системе различных
представителей , 94
одноточечная , 194
Триангуляция , 227
оптимальная , 231
устойчивая , 234
Узел , 15 , 277
внешний , 157
внутренний , 157
квадратный , 139 , 157
круглый , 139 , 157
начальный , 216
опорный , 65
покрытый , 217
Уровень дерева , 216
Феномен домино , 142
Функция
полиномиальная , 254
экспоненциальная , 254
Хозяин , 283
Цикл , 16
гамильтонов , 258 , 260
ориентированный , 16
простой , 16
эйлеров , 256
Числа Каталана , 226 , 227
Т.Ч. Ху, М.Т.Шинг
Комбинаторные алгоритмы
Перевод с английского
Перевод:
Редакторы перевода:
Подготовка иллюстраций:
Редактор издательства
В.Б. Алексеев, Н.Ю. Золотых,
СВ. Сорочан, А.А. Яценко
В.Б. Алексеев, Н.Ю. Золотых,
В.А. Таланов, В.Н. Шевченко
М.Г. Басова, А.Н. Микишев
Е.В.Тамберг
Формат 70 х 1081/16. Бумага офсетная. Печать офсетная.
Уч.-изд.л. 31. Усл.печ.л. 29. Тираж 400 экз. Заказ 1247
Издательство Нижегородского госуниверситета
им. Н.И. Лобачевского,
603950, Н. Новгород, пр. Гагарина, 23.
Типография ИНГУ, 603000, Н. Новгород, ул. Б. Покровская, 37.
Вниманию читателя предлагается перевод второго
расширенного и дополненного издания распространенного на Западе учебника
американских математиков Т.Ч. Ху и М.Т. Шинга. Первое издание
(1982) на русский язык не переводилось. Перевод осуществлен
сотрудниками кафедры математической логики и высшей алгебры
факультета вычислительной математики и кибернетики Нижегородского
госуниверситета им. Н.И. Лобачевского.
Книга посвящена алгоритмам дискретной математики
(кратчайшие пути и потоки в сетях, динамическое программирование, поиск
с возвратом, бинарные деревья, эвристические алгоритмы,
матричное умножение, NP-полные задачи, локальные алгоритмы, деревья
Гомори-Ху) и может использоваться как учебник по курсу «Анализ и
разработка алгоритмов» и как справочник. Весь материал изложен в
хороших традициях учебной литературы. Многие результаты на
русском языке излагаются впервые.
Для студентов, аспирантов и научных работников,
специализирующихся в области дискретной математики и информатики.
По вопросам приобретения книги
обращайтесь по адресу:
603950. г. Нижний Новгород, пр. Гагарина, 23,
Нижегородский университет им. Н.И. Лобачевского,
факультет вычислительной математики и кибернетики
Тел. (8312) 65-78-81. Факс (8312) 65-85-92
E-mail: zny@uic.nnov.ru