/
































































































































































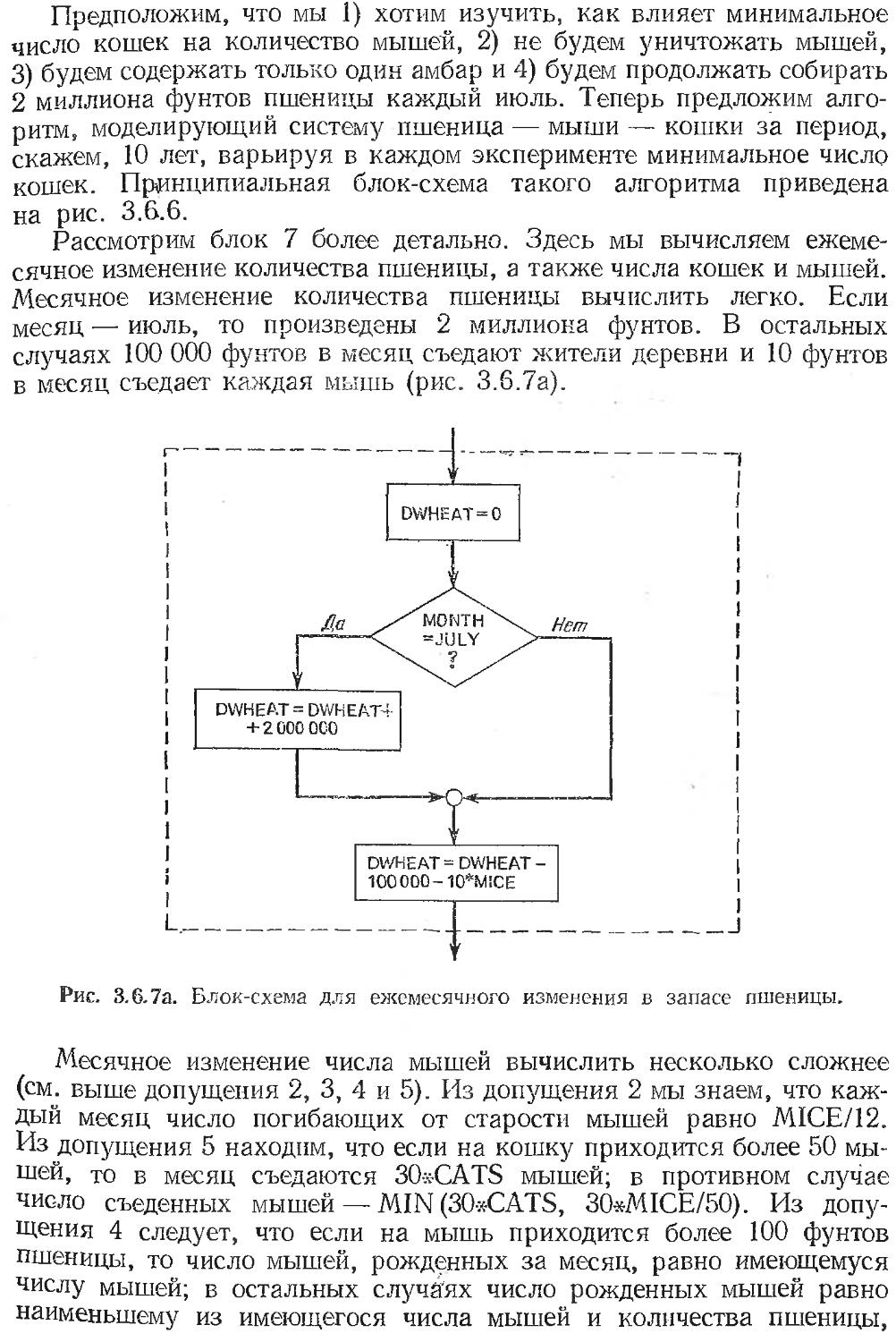
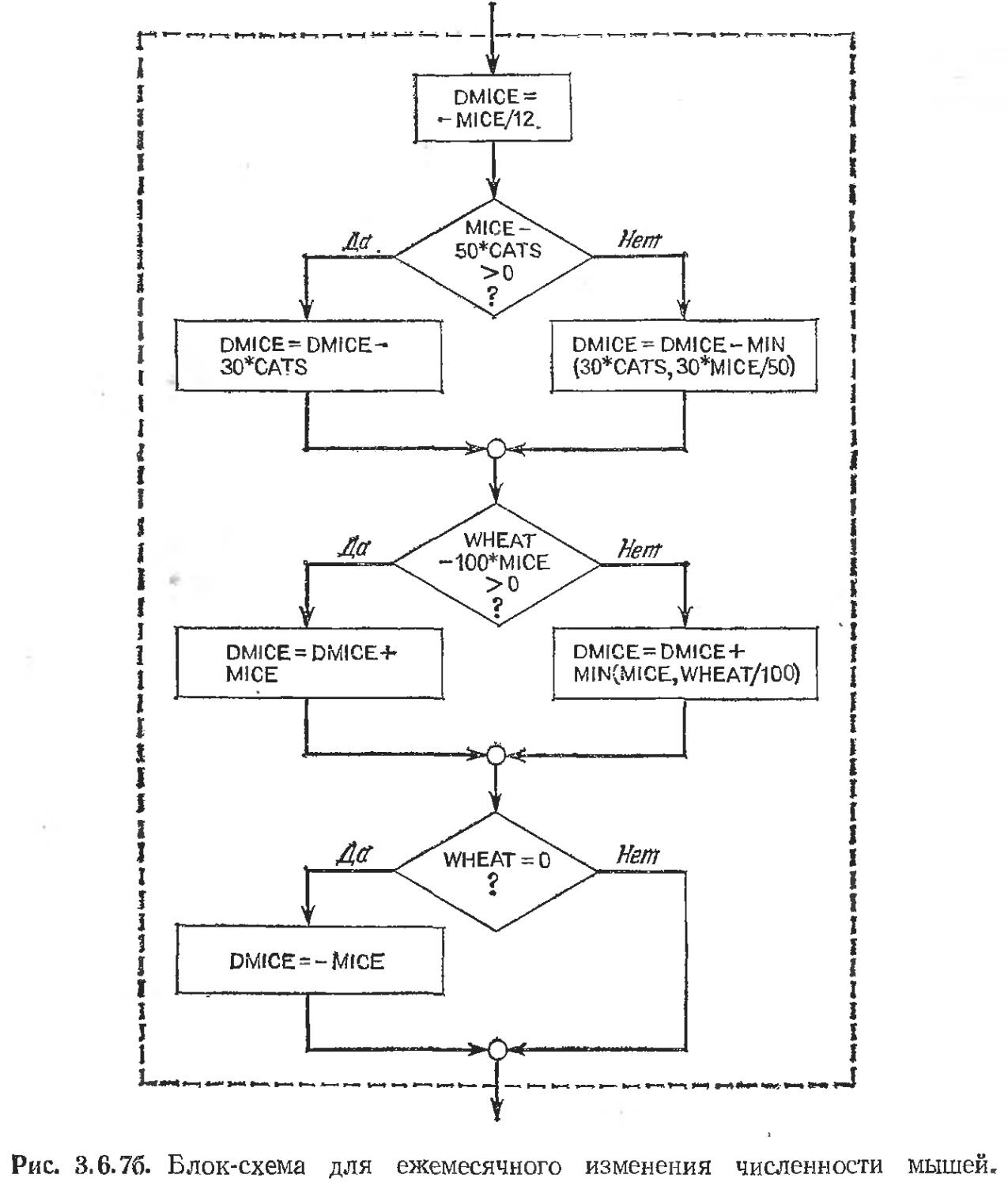














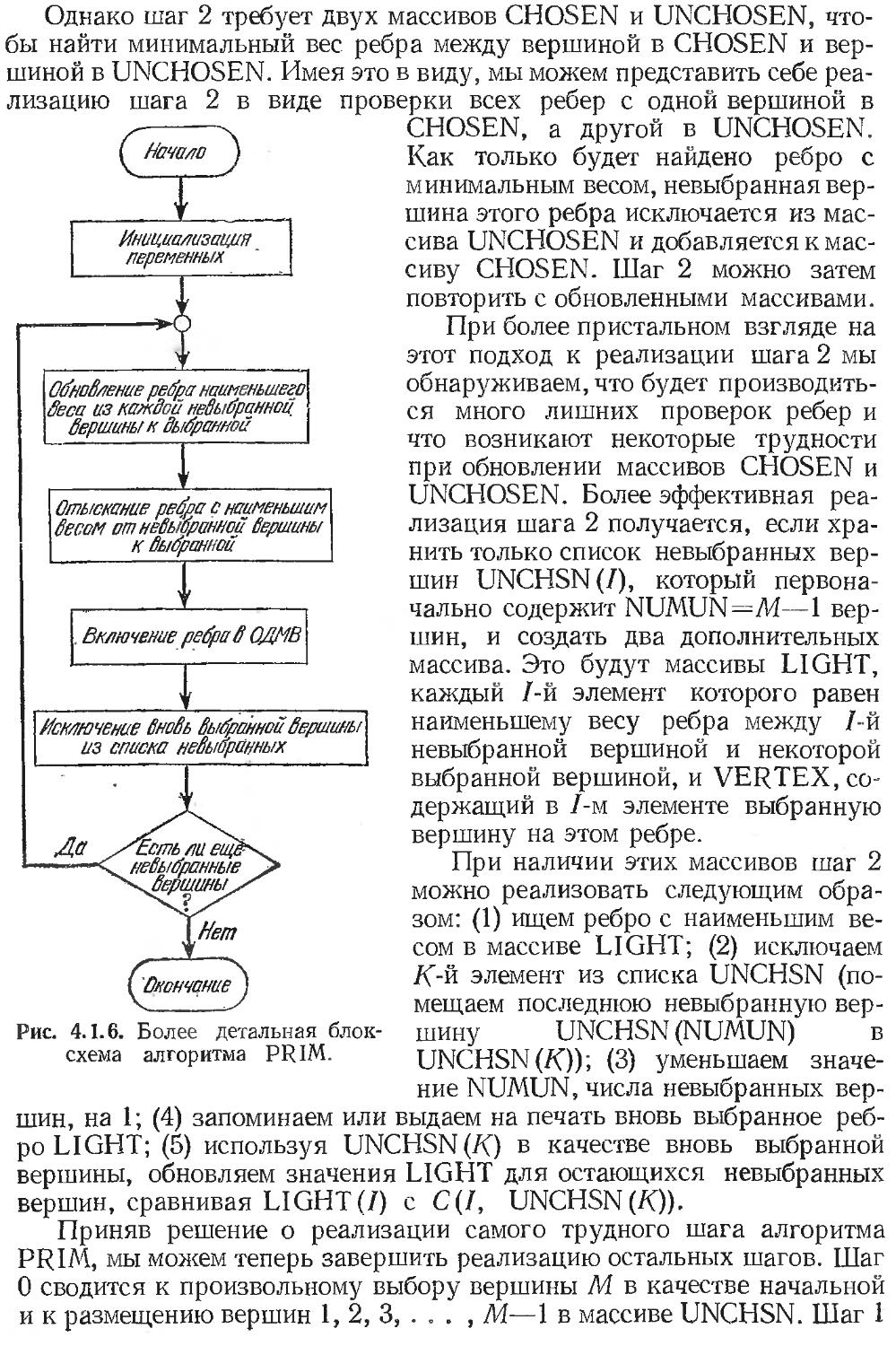














































































































































































Text
ОГЛАВЛЕНИЕ
От редактора перевода....................................................... 5
Предисловие.......................................................... 7
Глава 1. Полное построение алгоритма................................... 14
1.1. Введение...................................................... 14
1.2. Алгоритмы..................................................... 14
1.3. Основные этапы полного построения алгоритма................... 16
Глава 2. Некоторые основные приемы и алгоритмы......................... 30
2.1. Структурное программирование сверху-вниз и правильность программ 30
2.2. Сети.......................................................... 47
2.3. Некоторые структуры данных................................... 66
2.4. Элементарные понятия теории вероятностей и статистики......... 85
Глава 3. Методы разработки алгоритмов.................................... 106
3.1. Методы частных целей, подъема и отрабатывания назад.........
3.2. Эвристики...................................................
3.3. Программирование с отходом назад............................
3.4. Метод ветвей и границ.......................................
3.5. Рекурсия....................................................
3.6. Моделирование...............................................
106
113
125
131
145
163
Глава 4. Полный пример........................................ 181
4.1. Построение алгоритма для отыскания остовного дерева минимального веса............................................................
4.2. Проверка программ.........................................
4.3. Документация и обслуживание...............................
181
197
216
Глава 5. Алгоритмы машинной математики..............................
222
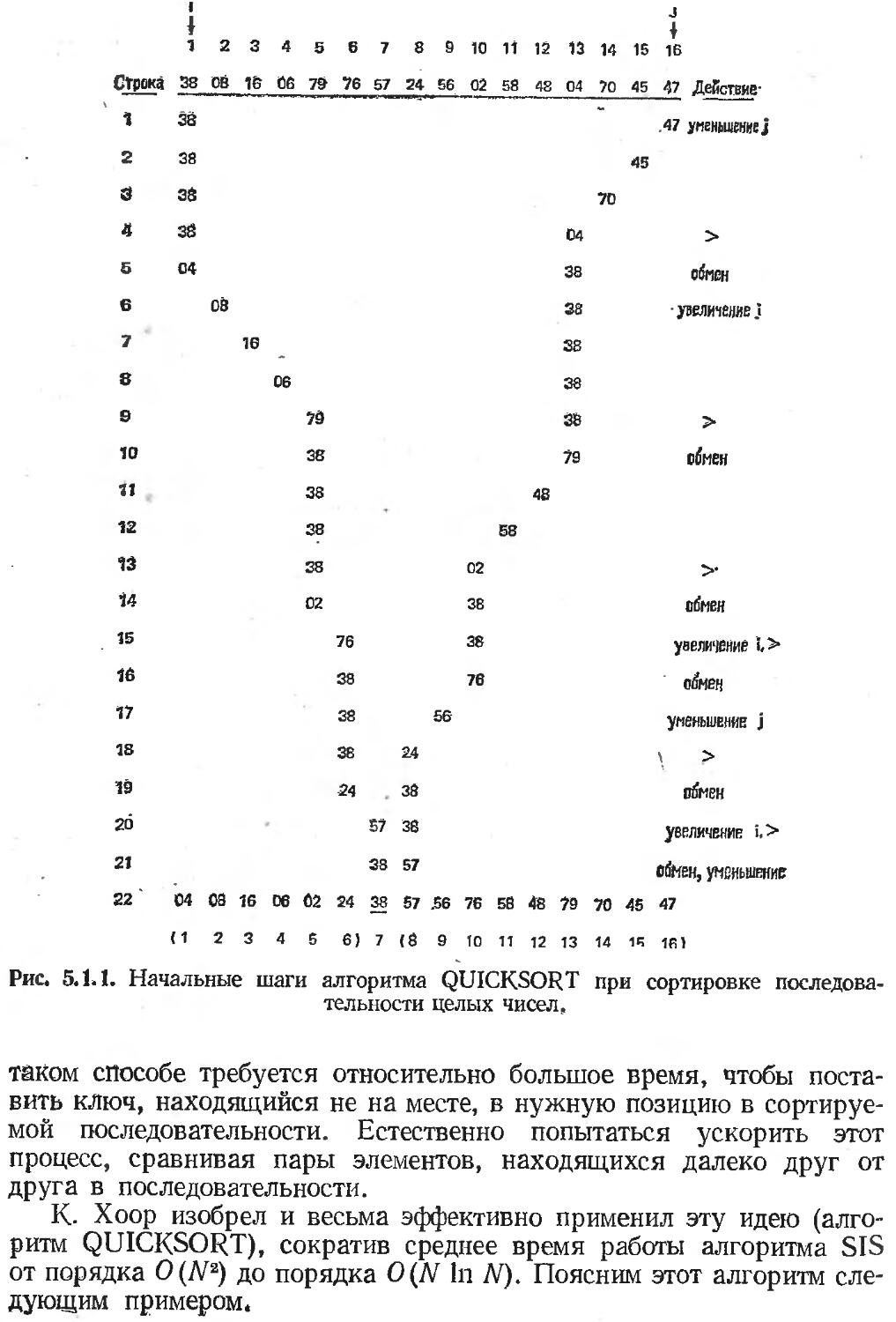
5.1. Сортировка..........................
5.2. Поиск...............................
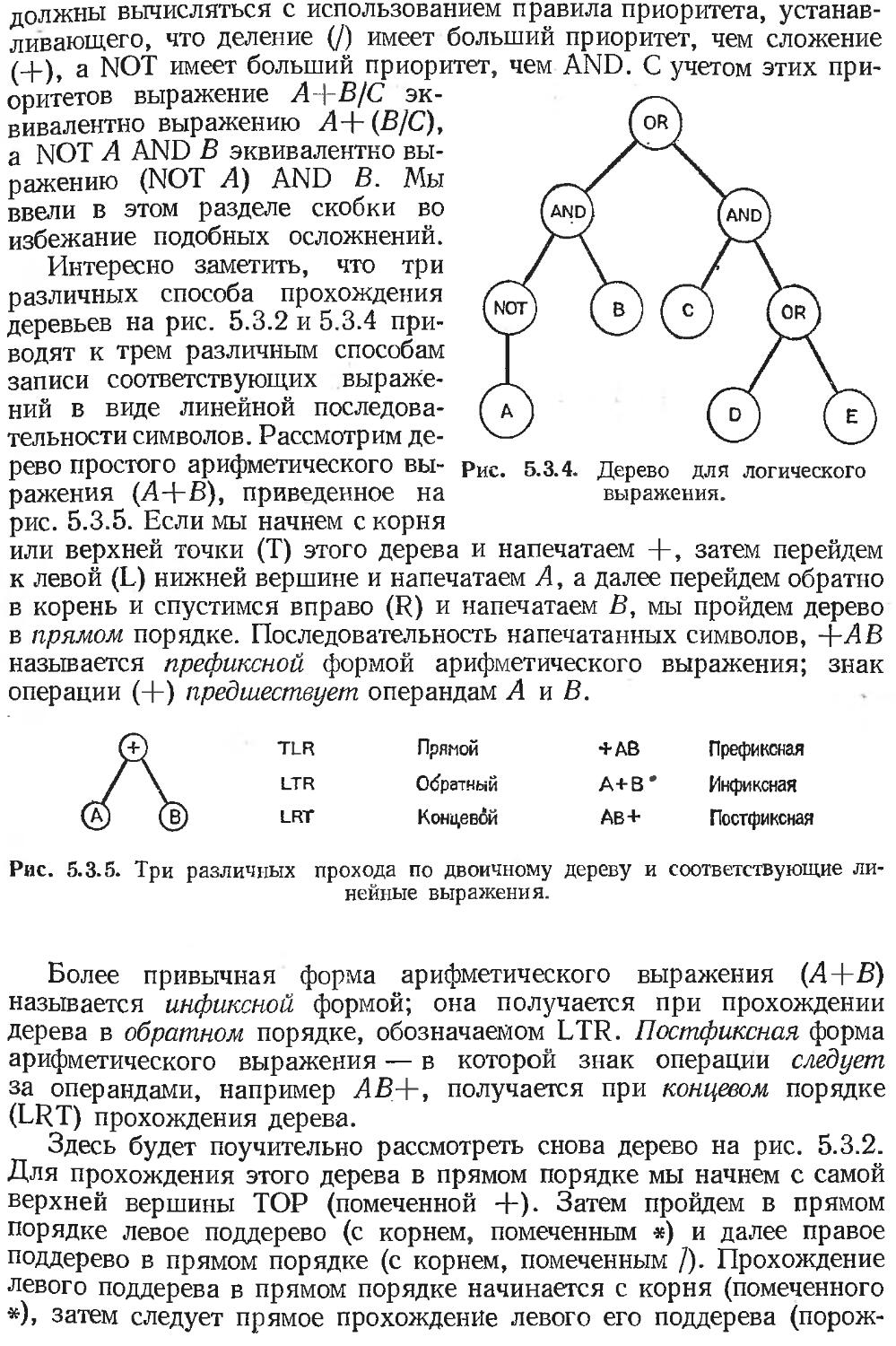
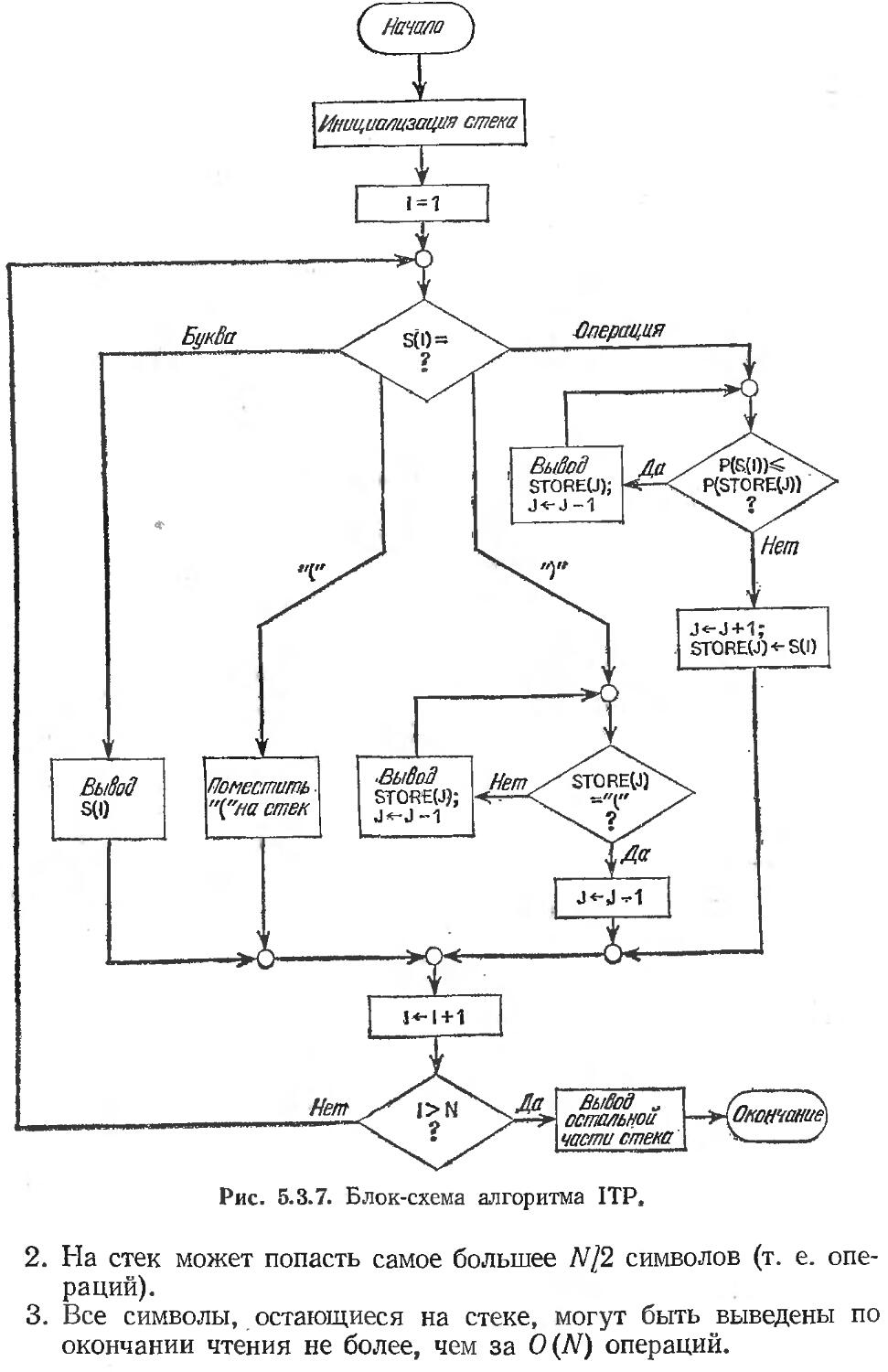
5.3. Арифметические и логические выражения
5.4. Страничная организация памяти . . . . ,
5.5. Параллелизм.........................
223
241
255
266
283
Глава 6. Математические алгоритмы.................................. 297
6.1. Игры и комбинаторные головоломки.......................... 297
6.2. Кратчайшие пути......................................... 309
6.3. Вероятностные алгоритмы................................... 320
Глава 7. Дополнительные замечания и ссылки......................... 338
Приложение А. Соглашения, принятые для описания алгоритмов......... 352
Приложение Б. Множества и некоторые основные алгоритмы на множествах . 357
Предметный указатель............................................... 361
С. ГУДМАН
С.ХИДЕТНИЕМИ
ВВЕ/ЕНИЕ
В PA3PABOW
И АНАЛИЗ
АЛГОРИТМОВ
Перевод с английского
Ю. Б. Котова
Л. В. Сухаревой
Л. В. Ухова
под редакцией
В. В. Мартынюка
ИЗДАТЕЛЬСТВО «МИР»
МОСКВА 1981
ББК 22.19
Г 93
УДК 681.142.2
Гудман С., Хидетниеми С.
Г 93 Введение в разработку и анализ алгоритмов.— М.: Мир, 1981. 368 с.
Монография американских авторов, посвященная общим принципам решения задач на ЭВМ, разработке и анализу алгоритмов. Подробно описываются основные этапы решения задач, даются конкретные примеры, иллюстрирующие теоретические выводы и упражнения (общим числом более 300). По тематике книга пересекается с .«Искусством программирования» Д. Киута (М.: Мир, т. 1—3, 1976—78), но рассчитана иа первоначальное знакомство с предметом.
Для пользователей ЭВМ и студентов, изучающих программирование.
20204___022
Г 041(01)—81' 22—81 ’ ч- Е 2405000000
ББК 22.19
6Ф7.3
Редакция литературы по математическим наукам
© 1977 by McGraw-Hill, Inc. All rights reserved © Перевод на русский язык, «Мир», 1981
ОТ РЕДАКТОРА ПЕРЕВОДА
Алгоритм представляет собой строгую систему правил, определяющую последовательность действий над некоторыми объектами. Следуя такой системе правил как инструкции, различные исполнители будут действовать одинаково и получат одинаковые результаты. В частности, алгоритмом является всякая последовательность действий, выполнение которой можно поручить вычислительной машине. Таким образом, подготовка и решение задачи на ЭВМ сводятся к разработке, описанию и выполнению алгоритма.
В предлагаемой книге излагается с привлечением многочисленных и представительных примеров комплекс общих методов организации решения задач, относящихся к различным областям знания. Последовательно проводится выделение основных этапов решения задачи (постановка, выбор модели, разработка алгоритма, проверка его правильности, реализация алгоритма, анализ алгоритма и его сложности, проверка программы и документация).
Несомненным достоинством книги является то, что при сравнительно небольшом объеме она покрывает обширный фактический материал, причем благодаря продуманной методике и живому, непринужденному стилю авторам, как правило, удается наглядно излагать нетривиальные математические результаты. Методически удачным представляется выбранный авторами язык для полуформального описания алгоритмов — в рамки стандартных синтаксических- конструкций с использованием алголоподобных служебных слов заключаются неформальные фразы на естественном языке. В ряде случаев алгоритмы доведены до программ на Фортране.
Книга будет ценным пособием для студентов, работа которых связана с использованием ЭВМ. Для тех студентов, которые специализируются по программированию, она может послужить вводным курсом при подготовке к изучению более обширных монографий, в частности многотомного труда Д. Кнута «Искусство программирования для ЭВМ». В методическом и терминологическом плане данная книга находится в определенной близости с более специальным исследованием А. Ахо, Дж. Хопкрофта и Дж. Ульмана «Построение и ана
лиз вычислительных алгоритмов», перевод которого опубликован издательством «Мир» в 1979 году.
При переводе мы, как правило, сохраняли в алгоритмах английские идентификаторы, чтобы у читателей не возникало затруднений при сопоставлении этих алгоритмов с приводимыми программами на Фортране.
Авторское предисловие, гл. 1, 3, разд. 5.1, а также приложения А и Б перевела Л. В. Сухарева. Гл. 2 перевел Л. В. Ухов. Гл. 4, 5 (кроме разд. 5.1) и 6 перевел Ю. Б. Котов. В переводе гл. 7 участвовали все три переводчика.
В. В. Мартынюк
ПРЕДИСЛОВИЕ
Учебные программы по вычислительной математике и программированию обычно содержат следующие типичные курсы (возможно, под несколько иными названиями): 1) введение в программирование, чаще всего на основе Фортрана, Бэйсика или ПЛ/1; 2) программирование на языке ассемблера; 3) структуры данных; 4) дискретные структуры; 5) организация машины; 6) численные методы; 7) обзор языков программирования; 8) обработка финансовой и административной информации; 9) прикладное программирование и 10) системное программирование. В этой книге мы предлагаем курс разработки и анализа алгоритмов.
В начальном курсе программирования особое внимание обычно уделяется таким темам, как работа ЭВМ, подготовка и перфорирование данных, синтаксис языка программирования, кодировка программы, ввод/вывод, элементарные аспекты и применения структур данных, понятия подпрограммы и функции, отладка программы, разработка относительно простых программ, некоторые понятия машинного языка, а также примеры прикладных программ. Существует несколько дополнительных разделов программирования, которые не рассматриваются ни в начальном курсе, ни сколь-нибудь подробно в других студенческих курсах по вычислительной математике и программированию. К числу этих разделов относятся:
1. Полная подготовка, от начала до конца, достаточно сложной задачи для решения на ЭВМ.
2. Такие методы разработки алгоритма, как метод частных целей, наискорейшего подъема, отхода назад и работы в обратном направлении, ветвей и границ, рекурсия и эвристика.
3. Эффективная и правильная реализация перечисленных алгоритмов.
4. Правильность алгоритма и программы (то, что часто заставляет задумываться, правильно ли выглядит распечатка?).
5. Критерии эффективности и сложности алгоритма, вопросы общей эффективности.
6. Проверка программы, включающая тесты на правильность, сложность и общее поведение программы.
7. Более изощренный математический аппарат (включающий, например, теорию вероятностей), требующийся при разработке и анализе достаточно сложных программ.
В этой книге рассматриваются все указанные аспекты программирования.
Хотя курс разработки, и анализа алгоритмов, конечно, содержит в значительном объеме программирование, он не был задуман как просто второй (или третий) курс программирования. Поэтому некоторые разделы, которые можно отнести к разработке и анализу алгоритмов, здесь не рассматриваются; эти разделы включают вопросы ввода/ вывода, методы отладки, оптимизацию компиляторов и работу с библиотечными программами. Эта книга служит как бы мостом между практическими, ориентированными на программирование курсами и более теоретическими, математически ориентированными курсами по вычислительной математике и программированию. Подобная ориентация курса, а также учебный характер представленных алгоритмов объясняют их выраженный математический оттенок.
Схема на стр. 10 показывает, как можно включить курс разработки и анализа алгоритмов в типичный учебный план по специальности «вычислительная математика». В известной степени мы рассматриваем этот курс как замену курса «введение в дискретные структуры», который содержится в учебной программе 68 АСМ (Сотт АСМ, март 1968). Хотя рассматриваемый нами материал имеет полноценное математическое содержание, его уровень ниже, он имеет менее теоретический, менее формальный характер, чем введение в дискретные структуры, а его приложения к вычислительной математике более очевидны.
Математический аппарат, применяемый при разработке и анализе алгоритмов, содержит вводные сведения из теории сетей (графов), комбинаторики, теории вероятностей и статистики. Эти разделы рассматривались не сами по себе, а скорее в плане использования для алгоритмических приложений. Для установления правильности некоторых алгоритмов или их свойств на протяжении всей книги приводятся доказательства, многие из которых опираются на метод математической индукции. Мы не задавались целью научить студентов доказывать теоремы, но надеемся, что они смогут следовать логике доказательств.
Мы полагаем также, что предмет, рассматриваемый в этой книге, играет центральную роль в вычислительной математике и программировании. Помимо того что этот материал может послужить основой первого теоретического курса учебной программы, он имеет близкое отношение к курсам по структурам данных, языкам программирования, прикладному программированию и численному анализу.
В принципе студент, прошедший односеместровый курс математического анализа, начальный курс программирования и хорошо владеющий понятиями комбинаторики и теории множеств на уровне средней школы, вполне подготовлен для чтения этой книги. Средства анализа используются не часто, но его знание в известной степени свидетельствует о математической зрелости. Мы обнаружили, что материал несколько трудноват для большинства студентов второго курса и, по-видимому, больше соответствует уровню третьего или четвертого курса.
Так как составление и проверка программы являются важной частью процесса создания алгоритма, мы включили в книгу тексты машинных программ. Хотя некоторые коллеги могут не согласиться с нашим выбором, мы решили дать все программы на Фортране — по той простой причине, что это единственный язык программирования, который известен почти всем. Похоже, что любое другое решение либо накладывает дополнительные требования на подготовку читателя, либо делает книгу настолько объемной, что ее основное содержание оказывается размытым.
Выбранная нами форма представления алгоритмов — это нечто среднее между стилем пошагового описания алгоритма с большим количеством комментариев, который популяризовал Кнут в первых трех томах Искусства программирования, и алголоподобным форматом, который в настоящее время часто используется в литературе. Такие конструкции, как do-while и if-then-else, регулярно применяются в их обычном смысле. Были приложены определенные усилия, чтобы не отступать от принципов структурного программирования. В приложении А собраны правила и условные обозначения, употребляемые в этой книге для изложения алгоритмов.
В первой главе в основном содержится качественное описание понятия алгоритма и описание основных шагов процесса полного построения алгоритма. К сожалению, ограниченный объем книги не позволяет описать большинство алгоритмов с такой степенью подробности. В последующих главах некоторые шаги построения алгоритмов оставлены в качестве упражнений.
Во второй главе излагаются некоторые принципы и средства, полезные для разработки и анализа алгоритмов. В ней также рассмотрены элементарные понятия структурного программирования, теории сетей (графов), структур данных, теории вероятностей и статистики. Для полноты в конце книги дано приложение, посвященное теории множеств и элементарным методам доказательств. Была сделана попытка во всей главе и приложениях сохранить «алгоритмический оттенок» и везде, где только возможно, для иллюстрации основных понятий вводились новые алгоритмы.
По поводу элементарных понятий теории вероятностей и статистики, изложенных в гл. 2, следует сделать некоторое пояснение. Многие интересные и важные вопросы разработки и анализа алгоритмов по своей природе вероятностные; например, имеются веские доводы в пользу того, что наиболее эффективным критерием качества алгоритма является его средняя или ожидаемая производительность. С другой стороны, мы осознаем, что многие студенты сталкиваются с трудностями при изучении теории вероятностей и статистики. По этой причине книга составлена так, что преподаватель может почти безболезненно опустить материал, носящий вероятностный характер.
В третьей главе рассмотрены некоторые полезные приемы разработки алгоритмов, в каждый раздел' главы включены по крайней мере одна новая задача и (пли) алгоритм.. В гл.. 4 полностью построен
алгоритм нахождения остовного дерева минимального веса. Зтот алгоритм иллюстрирует некоторые простые процедуры проверки программ.
В гл. 5 и 6 содержатся примеры и приложения, большинство которых подкрепляет идеи, выдвинутые в первых четырех главах. Преподаватели могут выбирать материал из этих глав в зависимости от интересов и математического уровня аудитории, длительности курса и т. д. Гл. 7 построена как справочник.
В книгу включены почти 300 упражнений. Они весьма различны по трудности, многие из них носят экспериментальный характер и допускают дальнейшее развитие. Упражнения представляют собой важную часть книги, и мы надеемся, что преподаватели найдут время для обсуждения наиболее интересных и трудных задач на занятиях. Заметим, что, чем больше звездочек (*) стоит перед упражнением, тем выше его трудность. Упражнения с пометкой «Ь» отличаются значительной трудоемкостью. Некоторые упражнения «озаглавлены», чтобы показать охв§т определенных тем или понятий. Преподаватели могут образовывать группы из двух-трех студентов для выполнения наиболее громоздких и трудных заданий, в особенности тех, которые требуют большой работы с программами.
Было бы трудно перечислить всех, кого мы хотим поблагодарить, кто вложил в эту книгу силы и время. Многие прочли ее и высказали свои замечания, конструктивную критику и одобрение. Прежде всего мы благодарим Диану Гудман, нашу машинистку и главного «корректора». Дане Ричардс принадлежит более половины разд. 6.1, Брусу Чартресу мы обязаны экологической моделью в разд.З.б.В число тех, кто внес наиболее значительный вклад, входят Линвуд Фергюсон, Ричард Арментраут и Клей Пендерграст. Мы благодарим Арта Флека, Гарольда Стоуна, Кена Боумана, Вэйн Медисон, а также анонимного читателя за их полезные замечания. Издательство «Моутон Паблишере» любезно разрешило нам заимствовать около 12 рисунков и несколько страниц текста в разд. 2.2. Диана Спрессер, Санди Митчелл и Дженнифер Уорд помогли с упражнениями и корректурой книги. Наконец, но не меньше, чем остальных, мы хотели бы поблагодарить слушателей нашего курса по разработке и анализу алгоритмов, которые на протяжении последних трех лет охотно выступали в роли «подопытных кроликов».
Никакая книга подобного рода не может быть совершенно свободной от опечаток. Несмотря на усилия многих людей, несомненно, в тексте остались ошибки. Мы будем благодарны, если читатели доведут их до нашего сведения.
С. Гудман
С. Хидетниеми
Глава I. Полное построение алгоритма
1.1. Введение
Для начала следовало бы рассказать о том, чего мы хотим достичь. В своей теоретической и практической деятельности вы будете иметь дело с задачами, для решения которых потребуются знания в области математики и программирования. Для этого часто нужно будет построить алгоритм. Цель нашей книги — помочь вам научиться 1) поставить задачу, 2) построить работающий алгоритм, 3) реализовать алгоритм как машинную программу и 4) оценить эффективность алгоритма.
Такую цель легче сформулировать, чем реализовать. Мир программирования усеян останками программ, которые когда-то считались готовым продуктом, но впоследствии оказались неправильными, неэффективными, непонятными или непригодными по какой-то другой причине. Возможно, простейшее объяснение этого факта заключается в том, что ЭВМ — относительно новый и сложный инструмент, и требуется время для того, чтобы научиться хорошо им пользоваться. Не так легко овладеть ЭВМ как мощным инструментом для решения задач, особенно математических.
Цель этой главы — сделать первую попытку объяснить понятие полного построения алгоритма, основными этапами которого являются:
1. Постановка задачи.
2. Построение модели.
3. Разработка алгоритма.
4. Проверка правильности алгоритма.
5. Реализация алгоритма.
6. Анализ алгоритма и его сложности.
7. Проверка программы.
8. Составление документации.
Остальные главы книги посвящены детальному изучению и иллюстрации этих фундаментальных этапов. Пока мы ограничимся кратким обсуждением алгоритмов (разд. 1.2) и этапов, ведущих к их полному построению (разд. 1.3).
1.2. Алгоритмы
Каждый, кто решал задачи с помощью ЭВМ, имеет некоторое интуитивное представление о значении слова «алгоритм». Кое-кто даже утверждает, что это одно из важнейших понятий вычислительной математики. «Официальное» определение из последнего (1971) издания
Оксфордского словаря английского языка гласит, что «algorithm» — это ошибочное написание слова «algorism», в свою очередь algorism считается более или менее синонимичным алгебре и арифметике, и это определение датируется девятым веком. Очевидно, современное употребление термина пока еще ограничено кругом людей, связанных с ЭВМ.
Попытаемся сначала выразить наши интуитивные соображения. Мы можем нестрого определить алгоритм как однозначно трактуемую процедуру решения задачи. Процедура — это конечная последовательность точно определенных шагов или операций, для выполнения каждой из которых требуется конечный объем оперативной памяти и конечное время. Дополнительно потребуем, чтобы алгоритм работал конечное время для любых входных данных.
Одно из неудобств этого определения состоит в том, что термин «однозначная трактовка» весьма неоднозначен. «Однозначен» для кого? Или по отношению к чему? Поскольку ничто не является абсолютно ясным или абсолютно неясным, должен быть указан, хотя бы неявно, исполнитель. Алгоритм вычисления производной кубического полинома может быть вполне ясен тем, кто знаком с анализом, но для прочих он может оказаться совершенно непонятным. Таким образом, следует также указать вычислительные возможности исполнителя.
Существуют и другие трудности с определением. Может случиться, что алгоритм заведомо существует для конкретной задачи, но его трудно или невозможно описать в некоторой заданной форме. Человечество разработало эффективный алгоритм завязывания шнурков на ботинках. Многие дети с пятилетнего возраста могут зашнуровывать свои ботинки. Но дать чисто словесное описание такого алгоритма без картинок и демонстрации — очень трудно (попробуйте).
Очевидно, что в нашем определении есть некоторые недостатки. Можно избежать большинства этих недостатков, определив «математические машины» с очень точно указанными возможностями. Тогда мы скажем, что алгоритм — это некоторая процедура, которая может выполняться такой машиной. Подобные попытки определения алгоритма очень глубоки и трудны математически, и они слишком негибки для наших целей.
Нам хотелось бы сохранить некоторую гибкость и интуитивную привлекательность первого определения и в то же время, хотя бы частично, устранить некоторые из его неопределенностей. Это легко сделать, описав «типичный» современный компьютер и язык общения с ним и определив затем алгоритм как процедуру, которая может быть реализована на этом компьютере при помощи данного языка.
Этот компьютер будет иметь неограниченную память с произвольным доступом, в которой могут храниться действительные и целые числа, а также логические константы. В одном слове этой памяти можно хранить произвольное конечное число, и можно извлечь любое слово за фиксированное, постоянное время (это удобное предположение, может быть, немного нереалистично, но на практике это почти
так). Такой компьютер может выполнять хранимую программу, которая состоит' из допустимой последовательности команд, охватывающих все стандартные арифметические операции, операции сравнения, переходы и т. д. Обычно мы будем считать,, что .каждая такая команда выполняется за единицу времени. Простыми описаниями часть памяти может быть организована в одно-, двух- и трехмерные массивы (матрицы). Мы будем пользоваться языком Фортран в качестве модели возможностей нашей машины, когда нужно будет что-то конкретизировать.
По сути дела мы утверждаем, что только тогда имеется алгоритм для решения задачи, когда можно написать программу для ЭВМ, решающую эту задачу. Это спорный вопрос. Программы на описанном выше компьютере не могут зашнуровывать ботинки. Среди точно определенных шагов не содержатся шаги, необходимые для завязывания шнурков. Имеются весомые аргументы в пользу того, что мы на самом деле оперируем ограниченным понятием алгоритма. Человек, как машина, способен выполнять множество тонких операций, которые лежат за рамками возможностей нашего типичного компьютера. Однако ограниченное определение — это как раз то, что нам требуется в данной книге.
Следующий пример алгоритма иллюстрирует уровень детализации, согласующийся с нашим определением. В приложении А содержится подробное обсуждение правил и условных* обозначений, использованных в книге для описания алгоритмов.
Рассмотрим простую задачу нахождения максимального числа в списке из N действительных чисел 7? (1), 7? (2), . . ., 7? (А). Основная идея алгоритма заключается в том, чтобы перебирать по очереди все числа списка и запоминать наибольшее до сих пор встретившееся число. К тому моменту, когда весь список будет проверен, запомнится наибольшее число. Попробуйте нарисовать блок-схему этого алгоритма прежде, чем читать дальше.
Запись А<-В означает оператор присваивания, т. е. переменной А присваивается текущее значение В.
Algorithm МАХ. Даны N действительных чисел в одномерном массиве 7? (1), 7? (2).7? (А), найти такие М и J, что
M=R(J) = max 7? (7<).
1 <K<7V
В случае когда два или более элементов R имеют наибольшее значение, запоминается наименьшее значение J.
Шаг 0. [Установка в начальное состояние, или инициализация] Set Мч—7?(1); and А-1.
Шаг 1. [М=1?] If 7V=1 then STOP fi Д
1J В этом алгоритме fi и od используются соответственно для обозначения конца конструкций if и do. Более детально это будет обсуждаться в разд, 2,1.
Шаг 2. [Проверка каждого числа] For ДЧ-2 to N do шаг 3 od; and STOP.
Шаг 3. [Сравнение] If M<ZR (Л) then set M-*-R (A); and fi (теперь M — наибольшее число из проверенных, а К — его номер в массиве).
Алгоритм МАХ не закодирован на каком-то языке, а записан в форме, которую легче воспринять; он выражен в виде шагов, которые легко реализуются в каждом общепринятом языке программирования. От такого представления нетрудно перейти к кодовой форме. Однако так бывает не всегда. Некоторые алгоритмы слишком сложны, чтобы перейти за один шаг от предварительного словесного описания к кодам машины. Может потребоваться ввести по крайней мере один промежуточный этап разработки.
1.3. Основные этапы полного построения алгоритма
Теперь мы кратко рассмотрим основные этапы, перечисленные в конце разд. 1.1. Прежде всего определим назначение каждого этапа и выясним, как эти этапы объединяются в единое целое.
Постановка задачи
Прежде чем мы сможем понять задачу, мы должны ее точно сформулировать. Это условие само по себе не является достаточным для понимания задачи, но оно абсолютно необходимо.
Обычно процесс точной формулировки задачи сводится к постановке правильных вопросов. Перечислим некоторые полезные вопросы для плохо сформулированных задач:
Понятна ли терминология, используемая в предварительной формулировке?
Что дано?
Что нужно найти?
Как определить решение?
Каких данных не хватает и все ли они нужны?
Являются ли какие-то имеющиеся данные бесполезными?
Какие сделаны допущения?
Возможны и другие вопросы в зависимости от конкретной задачи. Часто после получения полных или частичных ответов на некоторые из вопросов их приходится ставить повторно.
Пример. Джек — агент по продаже компьютеров (коммивояжер); на его территории 20 городов, разбросанных по всему Техасу. Компания возмещает ему только 50% стоимости деловых автомобильных поездок. Джек вычислил, сколько ему будет стоить переезд на машине
между каждыми двумя городами на его территории. Ему, естественно, хотелось бы снизить свои дорожные расходы.
Что дано? Исходная информация задана в виде перечня городов на территории Джека и соответствующей матрицы стоимостей, т. е. двумерного массива с элементами сц, равными стоимости переезда из города I в город /. В данном случае матрица стоимостей имеет 20 строк и 20 столбцов.
Что мы хотим найти? Мы хотим йомочь Джеку снизить его дорожные расходы. Это звучит несколько туманно. Действительно, вопрос о том, каким будет решение, выглядит неуместным. Обдумав ситуацию, мы придем к выводу, что ничего не можем сделать без дополнительной информации от Джека. Имеет ли Джек в одних городах больше покупателей, чем в других? Если да или если есть какие-то особые покупатели, то Джек, возможно, захочет посещать какие-то города чаще. Могут быть и такие города, в которые- Джек специально не поедет, а заедет туда, когда окажется в соседнем городе. Другими словами, нам надо знать больше о приоритетах Джека и учитывать предпочтения при составлении графика поездок.
Поэтому мы возвращаемся к Джеку и требуем у него дополнительную информацию. Он сообщает, что хотел бы иметь маршрут, начинающийся и оканчивающийся в его базовом городе и проходящий по одному разу через все остальные города на его территории. Следовательно, нам требуется список городов, содержащий каждый город только один раз, за исключением базового города, который стоит в списке первым и последним. Порядок городов в этом списке представляет собой маршрут, по которому Джек должен объезжать города на своей территории. Сумма стоимостей проезда между каждыми двумя последовательными городами списка — это общая стоимость маршрута, представленного списком. Мы решим задачу Джека, если представим ему список с наименьшей возможной общей стоимостью.
Это хорошая исходная постановка задачи. Мы знаем, что мы имеем и что хотим найти.
Построение модели
Задача четко поставлена, теперь нужно сформулировать для нее математическую модель. Это очень важный шаг в процессе решения, и его надо хорошо обдумать. Выбор модели существенно влияет на остальные этапы в процессе решения.
Как вы можете догадаться, невозможно предложить набор правил, автоматизирующих стадию моделирования. Большинство задач должно рассматриваться индивидуально. -Тем не менее существует несколько полезных руководящих принципов. Выбор модели — в большей степени дело искусства, чем науки, и, вероятно, эта тенденция сохранится. Изучение удачных моделей — это наилучший способ приобрести опыт в моделировании.
Приступая к разработке модели, следует задать по крайней мере два основных вопроса:
1. Какие математические структуры больше всего подходят для задачи?
2. Существуют ли решенные аналогичные задачи?
Второй вопрос, возможно, самый полезный во всей математике. В контексте моделирования он часто дает ответ на первый вопрос. Действительно, большинство решаемых в математике задач, как правило, являются модификациями ранее решенных. Большинство из нас просто не обладает талантом Ньютона, Гаусса или Эйнштейна, и для продвижения вперед нам приходится руководствоваться накопленным опытом.
Сначала нужно рассмотреть первый вопрос. Мы должны описать математически, что мы знаем и что хотим найти. На выбор соответствующей структуры будут оказывать влияние такие факторы, как: 1) ограниченность наших знаний относительно небольшим количеством структур,’ 2) удобство представления, 3) простота вычислений, 4) полезность различных операций, связанных с рассматриваемой структурой или структурами.
Сделав пробный выбор математической структуры, задачу следует переформулировать в терминах соответствующих математических объектов. Это будет одна из возможных моделей, если мы можем утвердительно ответить на такие вопросы, как:
Вся ли важная информация задачи хорошо описана математическими объектами?
Существует ли математическая величина, ассоциируемая с искомым результатом?
Выявили мы какие-нибудь полезные отношения между объектами модели?
Можем мы работать с моделью? Удобно ли с ней работать?
Пример. Возвращаемся к задаче агента по продаже компьютеров, рассмотренной ранее в этом разделе. Начинаем с постановки задачи, данной в конце примера.
Решали ли мы ранее аналогичные задачи? В математическом смысле, вероятно, нет. Однако все мы сталкивались с задачами выбора пути по дорожным картам или в лабиринтах. Можем ли мы прийти к удобному представлению нашей задачи наподобие карты?
Очевидно, нужно взять лист бумаги и нанести на нем по одной точке, соответствующей каждому городу. Мы не собираемся изображать точки так, чтобы расстояние между каждой парой точек, соответствующих городам i и /, было пропорционально стоимости проезда c}j. Расположим точки любым удобным способом, соединим точки i и / линиями и проставим на них «веса» сц
Схема, которую мы только что изобразили,— это частный случай известного в математике графа, или сети. В общем случае сеть — это множество точек (на плоскости) вместе с линиями, соединяющими некоторые или все пары точек; над линиями могут быть проставлены веса.
Для простоты предположим, что у Джека только пять городов, для которых матрица стоимостей показана на рис. 1.3.1, а. Тогда сетевая модель может быть изображена, как на рис. 1.3.1, б. Предположим также, что стоимость проезда из города i в город / такая же, как и из / в i, хотя это и необязательно.
Что мы ищем в задаче? В терминах теории сетей список городов (который мы ранее описали) определяет замкнутый цикл, начинающийся с базового города и возвращающийся туда же после прохождения каждого города по одному разу. Такой цикл соответствует неотрывному движению карандаша вдоль линий сети, которое проходит через каждую точку только один раз и начинается и оканчивается в одной и той же точке. Обход такого рода назовем туром. Стоимость тура определяется как сумма весов всех пройденных ребер. Задача решена, если мы можем найти тур с наименьшей стоимостью.
На рис. 1.3.1, б обход 1—5—3—4—2—1 есть тур со стоимостью 5+2+1+4+1 = 13. Является ли он туром с минимальной стоимостью?
Рассмотренная задача известна в литературе как задача коммивояжера; она стала в какой-то мере классической. Это один из наиболее известных примеров таких задач, которые очень легко поставить и промоделировать, но очень трудно решить. Время от времени мы будем возвращаться к этой задаче в целях иллюстрации.
Разработка алгоритма
Как только задача четко поставлена и для нее построена модель, мы должны приступить к разработке алгоритма ее решения. Выбор метода разработки, зачастую сильно зависящий от выбора модели,
может в значительной степени повлиять на эффективность алгоритма решения. Два разных алгоритма могут быть правильными, но очень сильно отличаться по эффективности. В одном из следующих разделов этой главы обсуждаются критерии эффективности.
Пример. Вернемся к коммивояжеру из предыдущего раздела. Постановка задачи и модель, описанные ранее, наводят на мысль о следующем алгоритме.
Сначала произвольно перенумеруем п городов целыми числами от 1 до и, присваивая каждому городу свой номер. Базовому городу приписываем номер п. Заметим, что каждый тур однозначно соответствует перестановке целых чисел 1,2,..., п—1. Действительно, каждый тур соответствует единственной перестановке, и каждая перестановка соответствует единственному туру. Такое соответствие называется взаимно-однозначным. Таким образом, для любой данной перестановки мы можем легко проследить соответствующий тур на сетевой модели и в то же время вычислить стоимость этого тура.
Можно решить задачу, образуя все перестановки первых n—1 целых положительных чисел. Для каждой перестановки строим соответствующий тур и вычисляем его стоимость. Обрабатывая таким образом все перестановки, запоминаем тур, который к текущему моменту имеет наименьшую стоимость. Если мы находим тур с более низкой стоимостью, то производим дальнейшие сравнения с этим туром.
Algorithm ETS (Исчерпывающий коммивояжер). Решить задачу коммивояжера с N городами, последовательно рассматривая все перестановки из N—1 положительных целых чисел. Таким образом мы рассмотрим каждый возможный тур и выберем вариант TOUR с наименьшей стоимостью MIN. Алгоритм ETS требует в качестве входных данных число городов N и матрицу стоимостей С.
Шаг 0. [Инициализация, т. е. установка в начальное состояние] Set TOUR^-0; and MIN-«-oo.
Шаг 1. [Образование всех перестановок] For /-*-1 to (N—1)! do through шаг 4 od; and STOP.
Шаг 2. [Получение новой перестановки] Set Р<-1-я перестановка целых чисел 1, 2, . . ., N—1. (Заметим, что здесь нужен подалгоритм.)
Шаг 3. [Построение нового тура] Строим тур Т (Р), соответствующий перестановке Р; and вычисляем стоимость COST (Т (Р)). (Заметим, что здесь нужны два других подалгоритма.)
Шаг 4. [Сравнение] If COST (P(P))<MIN then set TOUR«-<-T(P); and MINx-COST (7 (P)) fi.
Алгоритм ETS — неплохое первое приближение к точному алгоритму. Ему недостает некоторых важных подалгоритмов, и он недо
статочно близок к окончательной программе. Эти недостатки будут устранены позже.
Похоже, что существует тенденция: программисты затрачивают относительно небольшое время на стадию разработки алгоритма при создании программы. Проявляется сильное желание как можно быстрее начать писать самое программу. Этому побуждению не надо поддаваться. На стадии разработки требуется тщательное обдумывание, следует также уделить внимание двум предшествующим и первым трем следующим за стадией разработки этапам. Как и следует ожидать, все восемь основных этапов, перечисленных в разд. 1.1, нельзя рассматривать независимо друг от друга. В особенности первые три сильно влияют на последующие, а шестой и седьмой этапы обеспечивают ценную обратную связь, которая может заставить нас пересмотреть некоторые из предшествующих этапов.
Правильность алгоритма
Доказательство правильности алгоритма — это один из наиболее трудных, а иногда и особенно утомительных этапов создания алгоритма.
Вероятно, наиболее распространенная процедура доказательства правильности программы — это прогон ее на разных тестах. Если выданные программой ответы могут быть подтверждены известными или вычисленными вручную данными, возникает искушение сделать вывод, что программа «работает». Однако этот метод редко исключает все сомнения; может существовать случай, в котором программа не сработает.
Мы предложим следующую общую методику доказательства правильности алгоритма. Предположим, что алгоритм описан в виде последовательности шагов, скажем, от шага 0 до шага tri. Постараемся предложить некое обоснование правомерности для каждого шага. В частности, может потребоваться лемма об условиях, действующих до и после пройденного шага. Затем постараемся предложить доказательство конечности алгоритма, при этом будут проверены все подходящие входные данные и получены все подходящие выходные данные.
Пример. Алгоритм ETS настолько прост, что его правильность легко доказать. Поскольку проверяется каждый тур, должен быть проверен и тур с минимальной стоимостью; как только до него дойдет очередь, он будет запомнен. Он не будет отброшен — это может случиться только в том случае, если существует тур с меньшей стоимостью. Алгоритм должен закончить работу, так как число туров, которые нужно проверить, конечно. Подобный метод доказательства известен как «доказательство исчерпыванием»; это самый грубый из всех методов доказательства.
Подчеркнем тот факт, что правильность алгоритма еще ничего не говорит о его эффективности. Исчерпывающие алгоритмы редко бывают хорошими во всех отношениях.
Реализация алгоритма
Как только алгоритм выражен, допустим, в виде последовательности шагов и мы убедились в его правильности, настает черед реализации алгоритма, т. е. написания программы для ЭВМ.
Этот существенный шаг может быть довольно трудным. Во-первых, трудность заключается в том, что очень часто отдельно взятый шаг алгоритма может быть выражен в форме, которую трудно перевести непосредственно в конструкции языка программирования. Например, один из шагов алгоритма может быть записан в виде, требующем целой подпрограммы для его реализации. Во-вторых, реализация может оказаться трудным процессом потому, что перед тем, как мы сможем начать писать программу, мы должны построить целую систему структур данных для представления важных аспектов используемой модели. Чтобы сделать это, необходимо ответить, например, на такие вопросы:
*
Каковы основные переменные?
Каких они типов?
Сколько нужно массивов и какой размерности?
Имеет ли смысл пользоваться связными списками?
Какие нужны подпрограммы (возможно, уже записанные в памяти)?
Каким языком программирования пользоваться?
Конкретная реализация может существенно влиять на требования к памяти и на скорость алгоритма.
Другой аспект построения программной реализации — это программирование сверху-вниз. Объяснение этого понятия будет дано в разд. 2.1, а пока укажем, что программирование сверху-вниз — это подход к разработке и реализации, который состоит в преобразовании алгоритма в такую последовательность все более конкретизированных алгоритмов, что окончательный вариант представляет собой программу для ЭВМ.
Сделаем одно важное замечание. Одно дело — доказать правильность конкретного алгоритма, описанного в словесной форме. Другое дело — доказать, что данная машинная программа, предположительно являющаяся реализацией этого алгоритма, также правильна. Таким образом, необходимо очень тщательно следить, чтобы процесс преобразования правильного алгоритма (в словесной форме) в машинную программу «заслуживал доверия».
Советуем читателю снова рассмотреть алгоритм ETS в свете обсуждения в данном подразделе и постараться построить его по этапам, как было предложено, пока вы не получите машинную программу.
Анализ алгоритма и его сложности
Существует ряд важных практических причин для анализа алгоритмов. Одной из них является необходимость получения оценок или границ для объема памяти или времени работы, которое потребуется алгоритму для успешной обработки конкретных данных. Машинное время и память — относительно дефицитные (и дорогие) ресурсы, на которые часто одновременно претендуют многие пользователи. Всегда следует избегать прогонов программы, отвергаемых системой из-за нехватки запрошенного времени, которое указывается на рабочей карте. Поразительно, скольким программистам приходится слишком дорогим способом выяснять, что их программа не может обработать входные данные раньше, чем через несколько дней машинного времени. Лучше было бы предугадать такие случаи с помощью карандаша и бумаги для того, чтобы избежать ненужных прогонов. Хороший анализ способен выявить узкие места в наших программах, т. е. разделы программы, на которые расходуется большая часть времени (см. упр. 1.3.16).
Существуют также важные теоретические причины для анализа алгоритмов. Хотелось бы иметь некий количественный критерий для сравнения двух алгоритмов, претендующих на решение одной и той же задачи. Более слабый алгоритм должен быть улучшен или отброшен. Желательно также иметь механизм для выявления наиболее эффективных алгоритмов и замены устаревших. Иногда невозможно составить четкое мнение об относительной эффективности двух алгоритмов. Один может в среднем лучше работать, к примеру, на случайных входных данных, в то время как другой лучше работает на каких-то специальных входных данных. Хотелось бы иметь возможность делать аналогичные выводы о сравнительных достоинствах двух алгоритмов.
Важно также установить абсолютный критерий. Когда можно считать решение задачи оптимальным? Иными словами, когда наш алгоритм настолько хорош, что невозможно (независимо от наших умственных способностей) значительно его улучшить?
Пусть А — алгоритм для решения некоторого класса задач, ап — размерность отдельной задачи из этого класса. Во многих задачах в этой книге п — просто скаляр, равный числу вершин графа. В общем случае п может быть массивом или длиной вводимой последовательности. Определим fA (п) как рабочую функцию, дающую верхнюю границу для максимального числа основных операций (сложения, сравнения и т. д.), которые должен выполнить алгоритм А для реше-‘ ния любой задачи размерности п. Будем пользоваться следующим критерием для оценки качества алгоритма А. Говорят, что алгоритм А полиномиальный, если fA(n) растет не быстрее, чем полином от п, Б противном случае алгоритм А экспоненциальный. Этот критерий основан на времени работы в худшем случае, но аналогичный критерий может быть также определен для среднего времени работы. «Экс
периментальная» основа для этого критерия качества заключается в том, что, по-видимому, последовательные или параллельные машины более или менее способны воспринимать полиномиальные алгоритмы для больших задач, а на экспоненциальных алгоритмах они довольно быстро «задыхаются».
Следующее обозначение стандартно во многих математических дисциплинах, в том числе и в анализе алгоритмов. Функцию f(n) определяют как О [g(n)l и говорят, что она порядка g(n) для больших п, если
Это
ДЛЯ
lim = constant =+0.
П^-ео g<P)
обозначается, как f (n)=O[g(n)]. Функция h(n) является о[z(n)l больших n, если
Иш -*Д = 0.
П->ео «(«)
символы произносятся соответственно, как «О большое» и «о ма-
Эти
лое». Интуитивно, если f(n) есть О[^(н)], то эти две функции, по существу, возрастают с одинаковой скоростью при и->оо. Если [(п) есть o[g(n)], то g(n) возрастает гораздо быстрее, чем f(n).
Пример.
(а) Полином f (/г)=2«в-|-6/г4Ч-6п2+18 есть О(пъ), так как
lim + 6п3 +18 g
п-
Он представляет собой о (и5’1), о(еп) и о(2'г). Действительно, он является «о малым» от любой функции, возрастающей быстрее, чем полином пятой степени.
(б) Функция f(n)=2n есть о (п!), так как lim 4- = 0.
П\
Однако 2П есть О(2п+1) и о(5п-1).
(в) Функция f (/г)=10001Лг есть о(п).
Итак, алгоритм полиномиальный, если fA(n)=O LPft(n)l или fA(n)— =о [Pk(n)], где Pk(n) — некоторый полином от переменной п произвольной фиксированной степени k. В противном случае алгоритм является экспоненциальным.
Конечно, хотелось бы провести возможно более точный анализ, т. е. знать как можно больше о функции fA(n). Мы бы лучше представили себе действие алгоритма А, если бы знали, что fA(и)=2,5 п2+ +3,7 п—5,2, чем если бы нам было известно только, что fA(n)=O(ri?). Такие детальные сведения об алгоритме могут быть получены только из конкретной реализации. Точные коэффициенты fA(n) в общем слу
чае зависят от реализации; характеристика 0(п2) обычно свойственна алгоритму, т. е. не зависит от различных особенностей реализации.
Важно также знать, насколько плохо работает экспоненциальный алгоритм. Существует много важных задач, для которых в настоящее время известны только экспоненциальные алгоритмы. Одна из них —• задача коммивояжера, другие описаны в разных разделах книги. Эти задачи необходимо решать ввиду их практической значимости. Раз уж известны только экспоненциальные алгоритмы, то хотелосьбы пользоваться наиболее эффективными из них. Очевидно, что алгоритм, решающий задачу размерности п за 0(2") шагов, предпочтительнее алгоритма, решающего ее за 0(п!) или 0(п") шагов.
Пример. Рассмотрим ранее описанный алгоритм ETS. Сразу можно сделать вывод, что это экспоненциальный алгоритм с оценкой по крайней мере О (о!). В задаче с п городами алгоритм ETS требует от нас исчерпывающе перечислить перестановки первых п—1 положительных целых чисел. Число таких перестановок (п—1)1. Даже если требуется только один шаг для каждой такой перестановки (грубая недооценка — см. упр. L3.5), эта часть алгоритма все же потребует 0[п—1)!] шагов. Как только представлена перестановка, как в шаге 1 алгоритма ETS, можно найти соответствующий тур и его стоимость за 0(п) шагов (см. упр. 1.3.6). Поэтому любая верхняя граница для общего времени работы должна быть по крайней мере 0(м!).
Предположим, что у нашего коммивояжера 20 городов и что у нас есть феноменальный подалгоритм алгоритма ETS для шага 1, который генерирует новую перестановку только за один шаг. Предположим также, что мы имеем быстродействующую машину, которая выполняет каждый элементарный шаг (например, сравнение, сложение, поиск элемента матрицы) за 10-7 с. Тогда, так как 201^2-1018, решение нашей задачи с использованием алгоритма ETS займет немногим меньше 70 веков.
Конечно, это довольно сильно подрывает наше доверие к алгоритму ETS. В гл. 3 мы увидим, как можно получить перечисляющие алгоритмы для отыскания сносных, но не обязательно оптимальных решений для больших задач за приемлемое время.
Именно теперь уместно подчеркнуть, что к этапам, перечисленным в конце разд. 1-1, не нужно относиться как к чему-то незыблемому. Скорее они представляют собой руководящие принципы. Некоторые шаги могут выполняться одновременно с другими, некоторые могут быть даже пропущены. Если есть хорошая модель, то, вероятно, нет необходимости строить другую. Порядок шагов не стоит считать раз и навсегда заданным. Конечно, нельзя доказать правильность алгоритма до того, как он разработан, но, может быть, лучше провести некоторый анализ процесса разработки алгоритма прежде, чем его реализовывать. Это тем более так, если есть повод предположить, что алгоритм будет экспоненциальным (как в нашем примере). Некий анализ на стадии разработки может подсказать, как сделать
алгоритм более эффективным. И наконец, этапы процесса построения могут быть с выгодой пересмотрены после того, как они уже считаются завершенными. Например, фазы анализа и проверки могут обеспечить ценную обратную связь с этапами разработки и реализации.
Получение для заданного алгоритма функции типа «верхняя граница» в худшем случае попадает под рубрику «анализ алгоритма». Интересно также исследовать все возможные алгоритмы, решающие тот же тип задач, и определить, какой из них лучше относительно данного критерия. Такой анализ очень труден и попадает под рубрику «сложность вычислений».
Проверка программы
Программа написана, настает время эксплуатировать ее. Как мы все очень хорошо знаем, эксплуатации программы предшествует отладка. После того как исправлено множество синтаксических, логических ошибок и ошибок перфорирования, программу, наконец, можно прогнать на простом примере (таком, который может быть проверен вручную). Что же дальше?
Процесс проверки программы должен включать в себя значительно больше, чем было указано выше. Было бы преувеличением сказать, что проверка программы в вычислительной математике аналогична экспериментированию в естественных науках, но думается, что между этими процессами есть что-то общее. Проверка программы может быть охарактеризована как экспериментальное подтверждение того факта, что программа делает именно то, что должна делать. Проверка программы является также экспериментальной попыткой установить границы использования алгоритма (программы).
Все мы можем сделать ошибки при доказательстве и при переводе правильного алгоритма в программу. Каждый может забыть или не учесть некоторый частный случай задачи. Недостаточно доказать правильность алгоритма. Окончательная программа должна быть тщательно проверена и оттестирована. Мельчайшие особенности вашей операционной системы могут вызвать для некоторых входных данных такое действие какой-то части вашего алгоритма, о котором вы не подозревали. Программа должна быть проверена для широкого спектра допустимых входных данных. Этот процесс может быть продолжительным, утомительным и сложным.
Как выбрать входные данные для тестирования? На этот вопрос невозможно дать общего ответа. Для любого алгоритма ответ зависит от сложности программы, имеющегося ресурса времени, а также от персонала, занимающегося проверкой, числа вводов (т. е. вариантов входных данных), для которых можно установить правильность выводов, и т. д. Обычно множество всех вводов огромно, и полная проверка практически невозможна. Мы должны выбрать множество вводов, которые проверяют каждый участок программы. Надо обяза
тельно достаточно полно проверить случаи, которые с большой ве-роятностыо встретятся в практике. Редко можно гарантировать правильность программы, но мы можем и должны провести соответствующую проверку, чтобы быть достаточно уверенными в этом.
Дальнейшая проверка также необходима для того, чтобы установить качество алгоритма. Анализ, описанный в предыдущем разделе, не всегда надежен. Сделанные в ходе анализа упрощающие допущения должны быть экспериментально проверены. Многие большие, сложные алгоритмы трудно или невозможно математически исследовать. В таких случаях особенно важно проверить алгоритм в действии, трудоемкости, так как это единственная возможность оценить его качество.
Опыт показывает, что анализ среднего функционирования алгоритма более ценен и трудоемок, чем анализ наилучшего и наихудшего случаев. Если возможен анализ худшего случая, то очень важно экспериментально установить, работает ли алгоритм значительно лучше в среднем, чем в худшем случае.
Аналитический и экспериментальный анализ дополняют друг друга. Аналитический анализ может быть неточным, если сделаны слишком сильные упрощающие допущения. В этом случае могут быть получены только грубые оценки. С другой стороны, получить достаточное экспериментальное подтверждение для гарантий какой-либо статистической достоверности может оказаться невозможным или непрактичным. Экспериментальные результаты, особенно когда используются случайно сгенерированные данные, могут оказаться слишком односторонними. Чтобы получить достоверные результаты, нужно там, где это возможно, провести как аналитическое, так и экспериментальное исследование.
Программы следует тестировать также для того, чтобы определить их вычислительные ограничения. Многие программы для некоторых входных данных работают хорошо, а для других плохо. Желательно, чтобы характеристика работы алгоритма «плавно» менялась от хорошей к плохой при переходе от входных данных, на которых алгоритм хорошо работает, к входным данным, для которых это не так. Алгоритм ETS хорошо работает для и очень плохо для м^15. К сожалению, в данном случае переход не плавный, и алгоритм имеет тенденцию плохо работать в промежуточных случаях. Желательно пользоваться как аналитическими, так и экспериментальными методами, чтобы охарактеризовать те входные данные, которые считаются или «хорошими», или «плохими». Например, предположим, что у нас есть алгоритм, который в худшем случае имеет трудоемкость О (и!), а его средняя трудоемкость О (и3). Было бы очень удобно, если бы мы могли охарактеризовать входные данные для нашего алгоритма другим параметром а, а затем установить, какие комбинации (п, а) требуют экспоненциального времени работы, а для каких комбинаций задача может быть решена за полиномиальное время. Ясно, что если средняя характеристика — порядка О (и3), то должно быть меньше вводов, требующих экспоненциального времени. Если бы эти вводы можно
было распознать, то их можно было бы избежать. К сожалению, данная область исследований еще не достигла такого уровня, при котором мы можем выявлять такие вводы, но к этому надо стремиться.
Документация
На самом деле этап документации не является последним шагом в процессе полного построения алгоритма. В частности, он не заключается в том, чтобы добавить карты с комментариями, когда вы закончили все остальное. Процесс документации должен переплетаться со всем процессом построения алгоритма, и особенно с этапами разработки и реализации.
Трудно читать чужую программу в коде. Наиболее очевидный мотив для документации — дать возможность людям понять программы, которые написаны другими. Конечно, лучший способ — это составить программу настолько понятно, чтобы она сама себя поясняла. Но это невозможно осуществить ни для каких программ, кроме простейших; и программа в коде должна быть дополнена другими формами пояснений. Обычно для этого используются карты с комментариями.
Но в действительности это только надводная часть айсберга. Документация включает в себя всю информацию и помогает объяснить, что делается в программе, т. е., в частности, блок-схемы, описания ступеней в вашем построении сверху-вниз, вспомогательные доказательства правильности, результаты тестирования, детальные описания формата и требований к вводу/выводу и т. д. В разд. 4.3 проводится более детальное обсуждение документации. В настоящий момент предлагаем вам золотое правило: оформляйте ваши программы в таком виде, в каком вам хотелось бы видеть программы, написанные другими.
Упражнения 1.3
1.3.1. Решение задачи коммивояжера. Найдите оптимальное решение задачи коммивояжера, изображенной на рис. 1.3.1, применив алгоритм ETS из данного раздела.
1.3.2. Факториалы (проверка). Каково наибольшее целое положительное N, такое, что М! уложится точно в одно слово вашей ЭВМ? Предскажите аналитически свой ответ прежде, чем выходить на машину. Хорошо подумайте. Какие ухищрения можно использовать, чтобы втиснуть в слово как можно большее число?
1.3.3. Кодирование— декодирование (полное построение). Один элементарный шифр состоит в том, чтобы поставить буквы алфавита во взаимно-однозначное соответствие с буквами пересортированного алфавита. Например, если соответствие следующее: Алфавит: ABCDEFGHIJKLMNOPQRSTUVWXYZ Буквы кода: MTJCZEOKLNSUXYADFBWVG Н I Р R Q,
тогда слово CODE будет зашифровано как JACZ.
Постройте, реализуйте, проверьте и оформите документацией алгоритм, для которого код является вводом и который кодирует и декодирует произвольные записи.
1.3.4. Перестановки (доказательство). Покажите, что число перестановок первых п целых положительных чисел равно nl .
1.3.5. Генератор перестановок (полное построение). Полностью постройте алгоритм, генерирующий все перестановки первых п целых положительных чисел. Подойдет ли ваш алгоритм для шага 2 алгоритма ETS?
1.3.6. Построение туров (разработка). Постройте подалгоритм для построения туров в шаге 3 алгоритма ETS.
1.3.7. Число туров коммивояжера (доказательство). Покажите, что если матрица стоимостей С в задаче коммивояжера с п городами симметрична, т. е. Сц=Сцрля всех i и /, то число разных туров равно (п—1)1/2. Два тура считаются разными, если им не соответствуют в точности одинаковые последовательности городов.
1.3.8. Алгебра сложности.
(а) Покажите, что f(n)=3.7nE-|-100.8n+106 имеет порядок О (и2) при п-> оо.
(б) Покажите, что f(/i)=2n/I00 -100 имеет порядок О(2П) при со.
(в) Покажите, что п! имеет порядок О(пп) при п-+- со.
(г) Покажите, что 2П возрастает при п—> оо быстрее,' чем любой полином от п конечной степени.
1.3.9. Предположение в задаче коммивояжера (модель и разработка). Рассмотрим матрицу стоимостей С задачи коммивояжера с п городами. Если мы выберем п элементов из С таким образом, что в точности один элемент будет выбран из каждой строки и каждого столбца, будут ли отрезки пути, соответствующие этим элементам, образовывать тур?
1.3.10. Римские цифры (полное построение). Постройте алгоритм, преобразовывающий произвольное положительное целое число, записанное в арабских цифрах, в систему римских цифр и наоборот.
1.3.11. Стороны треугольника (полное построение). Для произвольной тройки чисел (х, у, г) полностью постройте алгоритм, определяющий, существует ли треугольник Т со сторонами х, у и г.
*1.3.12. Перестановки (сравнение алгоритмов). Разработайте и реализуйте два разных алгоритма для генерирования случайных перестановок.'Сравните их эффективность.
*1.3.13. Факториалы (разработка). Разработайте алгоритм, вычисляющий значение функции F(ri)=m, где т — число знаков, содержащихся в десятичной записи п!
1.3.14. Экспоненциальные функции (сложность). Разработайте алгоритм, который будет определять, сколько времени потребуется вашей ЭВМ для выполнения 2П, пп и и! элементарных операций, для п=1, 2, 3, . . . , 50.
*1.3.15. Экспоненциальные функции (сложность). Разработайте алгоритм для вычисления G(m, n)=k, где k определяется следующим образом: nk~r^.m\<.nh. Вычислите некоторые значения G(tn, п).
L1.3.16. Программный профиль (сложность, проверка). Профиль программы для данного ввода — это, по существу, гистограмма, показывающая, сколько раз выполняется каждый оператор программы во время ее работы.
Реализуйте алгоритм МАХ из разд. 1.2. Для Л'=20 создайте входной массив равномерно распределенных на отрезке [0, 100] чисел, используя датчик случайных чисел. Постройте усредненный профиль для вашей программы, основанный на испытании 50 вводимых наборов.
Глава 2. Некоторые основные приемы и алгоритмы
Есть несколько основных приемов, которыми должен уметь пользоваться каждый, кто разрабатывает и анализирует алгоритмы. В этой главе мы представим некоторые фундаментальные теоретические положения и алгоритмы из четырех различных областей: структурное программирование сверху-вниз, сети, структуры данных и вероятность и статистика. Материалом этих разделов мы будем пользоваться на протяжении всей книги.
2.1. Структурное программирование сверху-вниз
и правильность программ
Математическая функция f: X-+Y может быть определена как правило, которое каждому элементу х из некоторого множества X, называемого областью определения, ставит в соответствие (единственное) значение у из некоторого множества Y, называемого областью значений. Конкретную функцию f из данного множества X в данную область У можно полностью описать одним из двух способов: либо приведя таблицу упорядоченных пар [х, f(x)], указывающих для каждого аргумента х^Х значение функции /(х); либо указав правило вычисления или набор правил (т. е. алгоритм), который позволяет для значения х вычислять значение /(х). Второй способ необходим тогда, когда область определения функции X является либо бесконечным, либо очень большим конечным множеством.
Первое, что требуется от алгоритма, это правильно реализовывать данную функцию f: X-^Y. Другими словами, каждый алгоритм служит для определения функции a: X'-YY' из множества X' допустимых исходных данных в область Y' возможных результатов. Алгоритм является правильной реализацией функции f, если Х<=Х' и Y^Y' и если
f(x)=a(x) для каждого х^Х.
Второе это то, что от алгоритма требуется такая реализация функции, чтобы время и требуемые усилия для вычисления произвольного значения f(x)=a(x) были по возможности наименьшими.
Далее от алгоритма требуется (и это требование становится все более весомым) такая реализация, чтобы она была легка для понимания, проста для доказательства правильности и удобна для модификаций в случае изменения спецификаций функции.
Последнее требование важно главным образом потому, что по мере того, как алгоритмы становятся все более и более сложными, соот
ветственно растет трудность понимания, как они работают, исправления обнаруженных в них ошибок, доказательства их правильности и при необходимости правильного внесения в них изменений. В последние годы обратили внимание на то, что от 50 до 100% времени программист тратит на решение задач по исправлению, эксплуатации и модификации программ. Пытаясь помочь программистам, индустрия программного обеспечения предлагает более систематичные подходы к программированию, т. е. предлагает методики, использование которых уменьшает вероятность ошибок в программах, упрощает их понимание и облегчает модификацию.
На сегодняшний день самой популярной методикой, по-видимому, следует считать структурное программирование сверху-вниз. В данном разделе мы введем основные идеи этой методики и проиллюстрируем ее на примере.
Структурное программирование
Наше объяснение структурного программирования мы начнем с определения блок-схемы. Блок-схема — это ориентированная сеть, вершины которой могут быть одного из трех типов, представленных на рис. 2.1.1.
Функциональная вершина используется для представления функции f: X-+Y. Предикатная вершина используется для представления функции (или предиката) р: Х->-{Т, F}, т. е. логического выражения, передающего управление по одной из двух возможных ветвей. Объединяющая вершина представляет передачу управления от одной из двух входящих ветвей к одной выходящей ветви.
Структурная блок-схема — это блок-схема, которая может быть выражена как композиция из четырех элементарных блок-схем, изображенных на рис. 2.1.2. Сравнительно просто доказать, что любая программа для вычислительной машины может быть «представлена» блок-схемой. Как было показано Бомом и Якопини, верно (хотя далеко не очевидно) и то, что любая блок-схема может в свою очередь быть представлена структурной блок-схемой. Из этого результата немедленно следует, что для разработки любого алгоритма достаточно четырех элементарных блок-схем, приведенных на рис. 2.1.2.
Когда структурная блок-схема служит как представление программы, В интерпретируется как булевское выражение, а 51 и 52 интерпретируются как программные операторы (или процедуры).
_ Блок-схемы на рис. 2.1.2, а, б, в и г называют структурами управления программы. Схема на рис. 2.1.2, а называется композицией и записывается в виде do 51; 52 od (или просто 51; 52). Схема на рис. 2.1.2, б называется выбором (или альтернативой) и записывается в виде if В then 51 else 52 fi (символ fi можно опускать при записи этой конструкции; он является признаком окончания конструкции if). Блок-схемы на рис. 2.1.2, виг называются итерацией (или по-зторением) и записываются соответственно как while В do 51 od и
Рис. 2.1.1. Типы вершин на блок-схеме: (а) функциональная вершина, (б) предикатная вершина, (е) объединяющая вершина.
Рис. 2.1.2. Четыре элемента
структурной блок-схемы,
Рис. 2.1.3. Блок-схема для оператора if В then S1.
do SI while В od (употребление символа od также необязательно).
Следует отметить, что часто употребляемый упрощенный оператор if В then S1, блок-схема которого приведена на рис. 2.1.3, представляет собой частный случай оператора if - then-else.
Важная особенность заключается в том, что каждая из этих четырех программных структур управления имеет один вход и один выход. Отсюда следует, что у любой блок-схемы, составленной из этих элементов, также будет один вход и один выход. На рис. 2.1.4 в качестве иллюстраций приводится несколько примеров структурных блок-схем, построенных из данных элементов; лингвистически эти блок-схемы могут быть описаны следующим образом:
СО И В then do S1; S2 cd
else if C then S3
else 34 fi fi
(^) If В then if C then do SI; S2 cd
else while D do S3 od ft
else do 84; S5; 86 od fi
Обратите внимание на то, что в предыдущих блок-схемах совершенно отсутствует оператор goto.
Строго говоря, под структурным программированием понимается процесс разработки алгоритмов с помощью структурных блок-схем.
а 6
Рис. 2.1.4. Две структурных блок-схемы.
Однако в более широком плане структурное программирование допускает большее разнообразие элементарных структур управления, чем те, которые были предложены Бомом и Якопини (т. е. те, которые
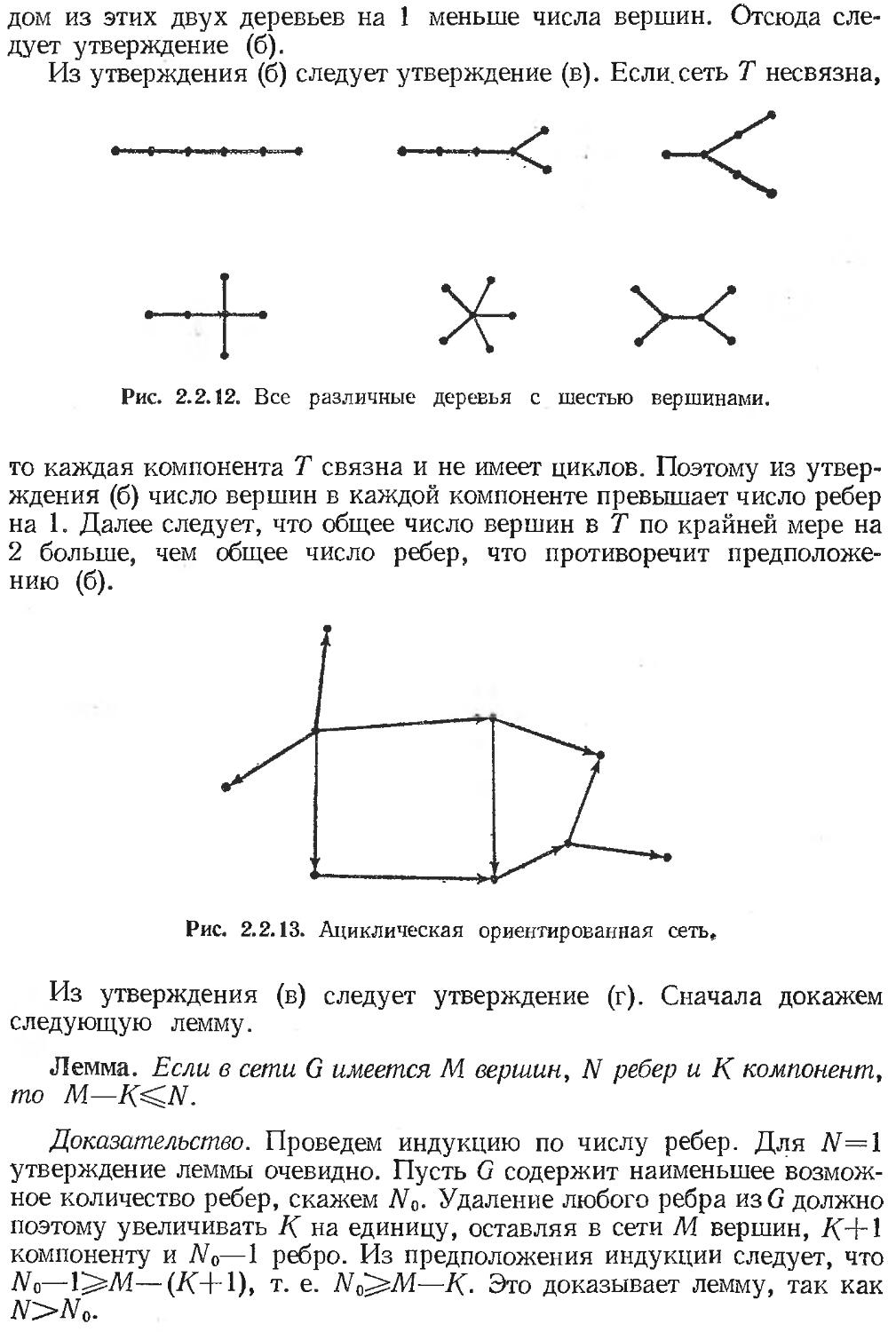
изображены на рис. 2.1.2). Дело в том, что, хотя эта совокупность структур управления достаточна для построения любой программы для вычислительной машины, само построение не обязательно окажется простейшим или наиболее естественным. Проиллюстрируем это на некоторых примерах.
Первый пример (рис. 2.1.5) соответствует ситуации, обрабатываемой на Фортране оператором COMPUTED GO ТО. Лингвистически
Рис. 2.1.5. Блок-схема для оператора case,
эту блок-схему можно выразить в виде case i of SI; S2; . . .; Sm to
что эквивалентно
if i=l then SI else
if i=2 then S2 else
if i=m then Sm fi . . . fi fiT)
Вторая запись по сравнению с первой выглядит менее естественно.
Второй пример (рис. 2.1.6) соответствует ситуации, когда необходимо преждевременно завершить выполнение итераций, или цикла DO, вводя дополнительный выход. Один из возможных лингвистических операторов для блок-схемы на рис. 2.1.6 имеет вид
while В do SI; if С then S2
else goto OUT fi od
Хотя более строгие формы структурного программирования исключают применение оператора goto, блок-схемы, в которых оператор
х) Строго говоря, если i не равно ни одному значению 1, 2, , , . , т, то данный оператор пропускается, Это не отражено на рис, 2.1.5,
goto используется достаточно аккуратно, могут сохранить свойство структурных блок-схем: один вход и один выход.
Еще один пример простой неструктурированной блок-схемы, часто
встречающийся в программировании, приведен на рис. 2.1.7, а. На рис. 2.1.7, б указан один из способов структурирования этой блок-схемы, хотя получаемый результат и нельзя считать вполне естественным. Заметим, что лингвистический оператор для неструктурированной блок-схемы на рис. 2.1.7, а требует применения оператора goto. Например,
k: SI; if В then S2; goto k fi
тогда как лингвистический оператор для структурированной блок-схемы на рис. 2.1.7, б его не содержит. Например,
do SI; while В do S2; SI od od
Вообще говоря, структурное программирование определяет процесс разработки алгоритмов в терминах «квазиструктури-рованных» блок-схем, в которых элементарные структуры управления являются, как правило, структурами Бома и Яко-пини. Впрочем, допускаются и другие структуры «простого типа» при условии, что они обладают свойством «один вход и один выход».
Рис. 2.1.6. Блок-схема для преждевременного окончания цикла.
Программирование сверху-вниз и правильность программ
Как отмечалось в разд. 1.3, программирование сверху-вниз — это процесс пошагового разбиения алгоритма на всё более мелкие части с целью получить такие элементы, для которых можно легко написать конкретные команды. На рис. 2.1.8 этот процесс иллюстрируется для случая блок-схемы на рис. 2.1.4, б.
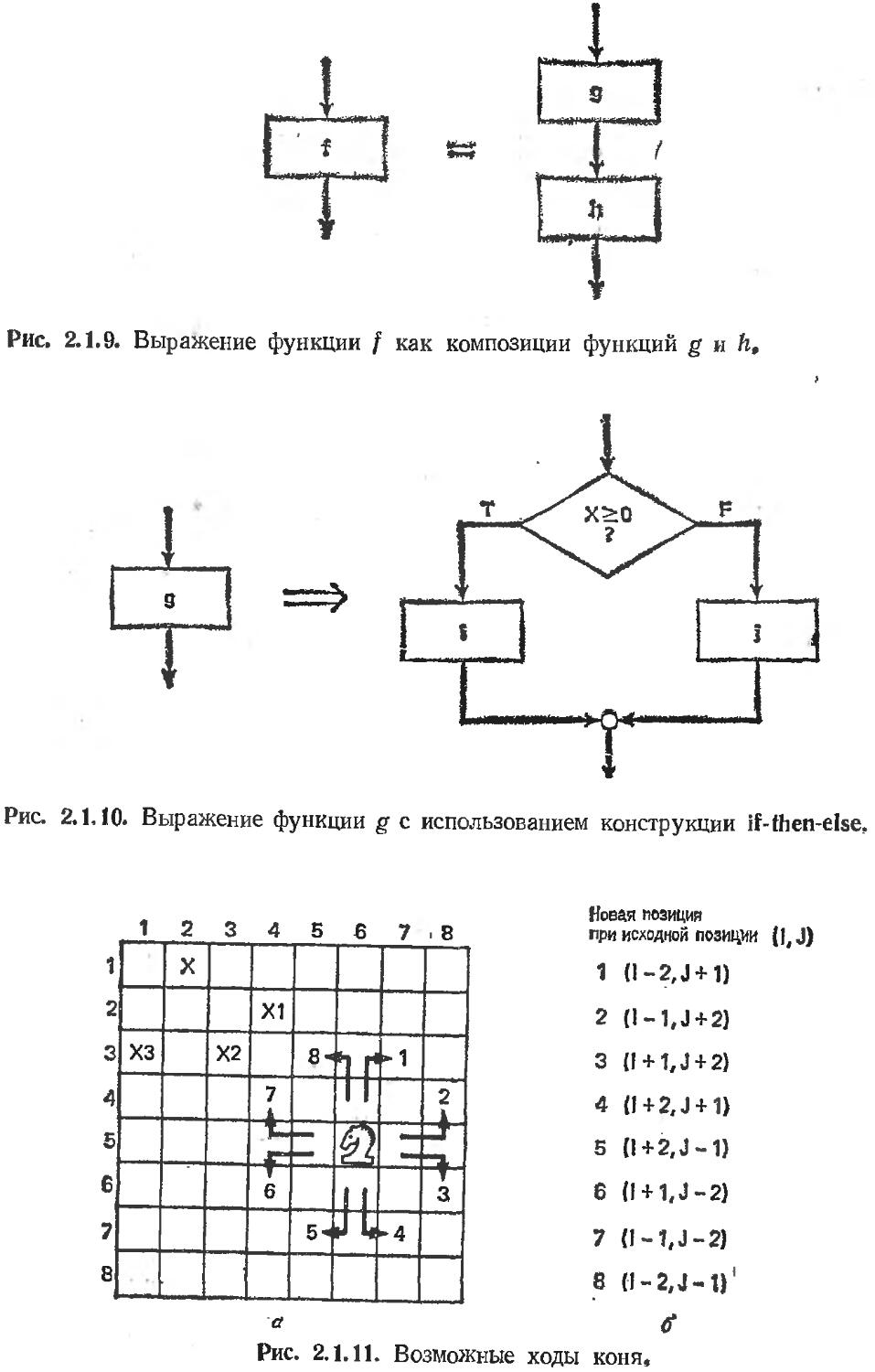
Структурное программирование сверху-вниз — это процесс программирования сверху вниз, ограниченный использованием структурных блок-схем. Идея весьма проста. Предположим, что требуется разработать алгоритм для некоторой конкретной функции f. Пусть далее можно доказать, что f есть композиция двух других (надо полагать, более простых) функций g и h, т. е. f(x)=h(g(x)), как показано на рис. 2.1.9. Тогда проблема разработки алгоритма для f сводится к проблемам разработки алгоритмов для g и h.
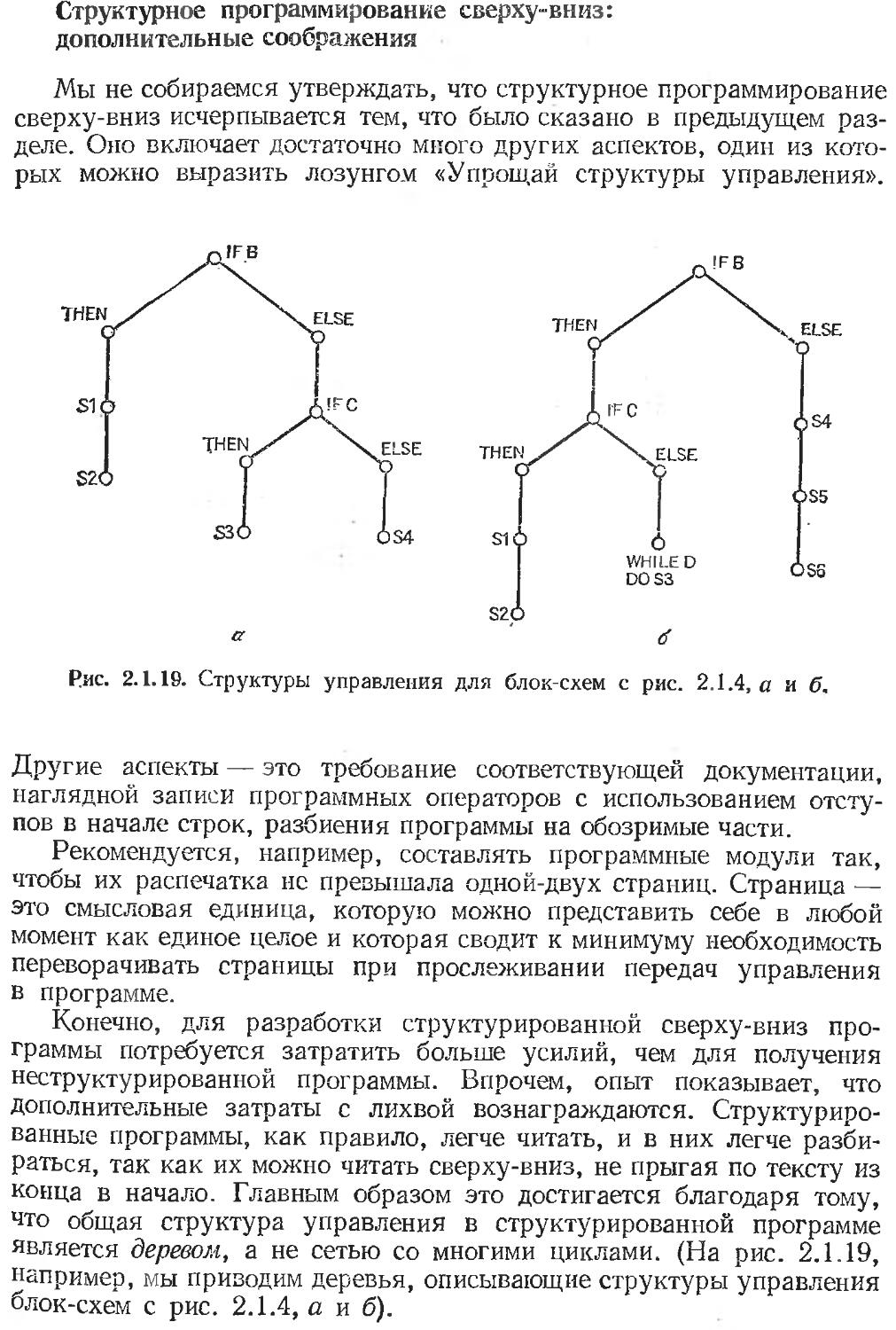
Пусть далее можно доказать, что функция g равна некоторой функ
ции i, когда заданный параметр х неотрицателен, или равна некоторой другой функции j, когда х отрицателен. Тогда алгоритм для вычисления g можно выразить в форме конструкции if-then-else (рис. 2.1.10).
Рис. 2.1.7. (а) Неструктурированная блок-схема; (б) эквивалентная структурированная блок-схема.
Поэтому, если алгоритмы для функций i и j построены, то правильный алгоритм для функции g строится автоматически.
Разработанные таким методом «сверху-вниз» алгоритмы обладают в некотором смысле свойством правильности, встроенной в них шаг за шагом. В связи с этим в них, как правило, меньше ошибок, и их правильность доказывается легче.
В структурном программировании сверху-вниз на каждом шаге процесса разработки спрашивается, нельзя ли текущую функцию (подфункцию) выразить как композицию двух (или более) других функций, т. е. функций типа do SI; S2 od, if-then-else, do-while или while-do. Конкретный пример поможет нам выразить эти идеи яснее.
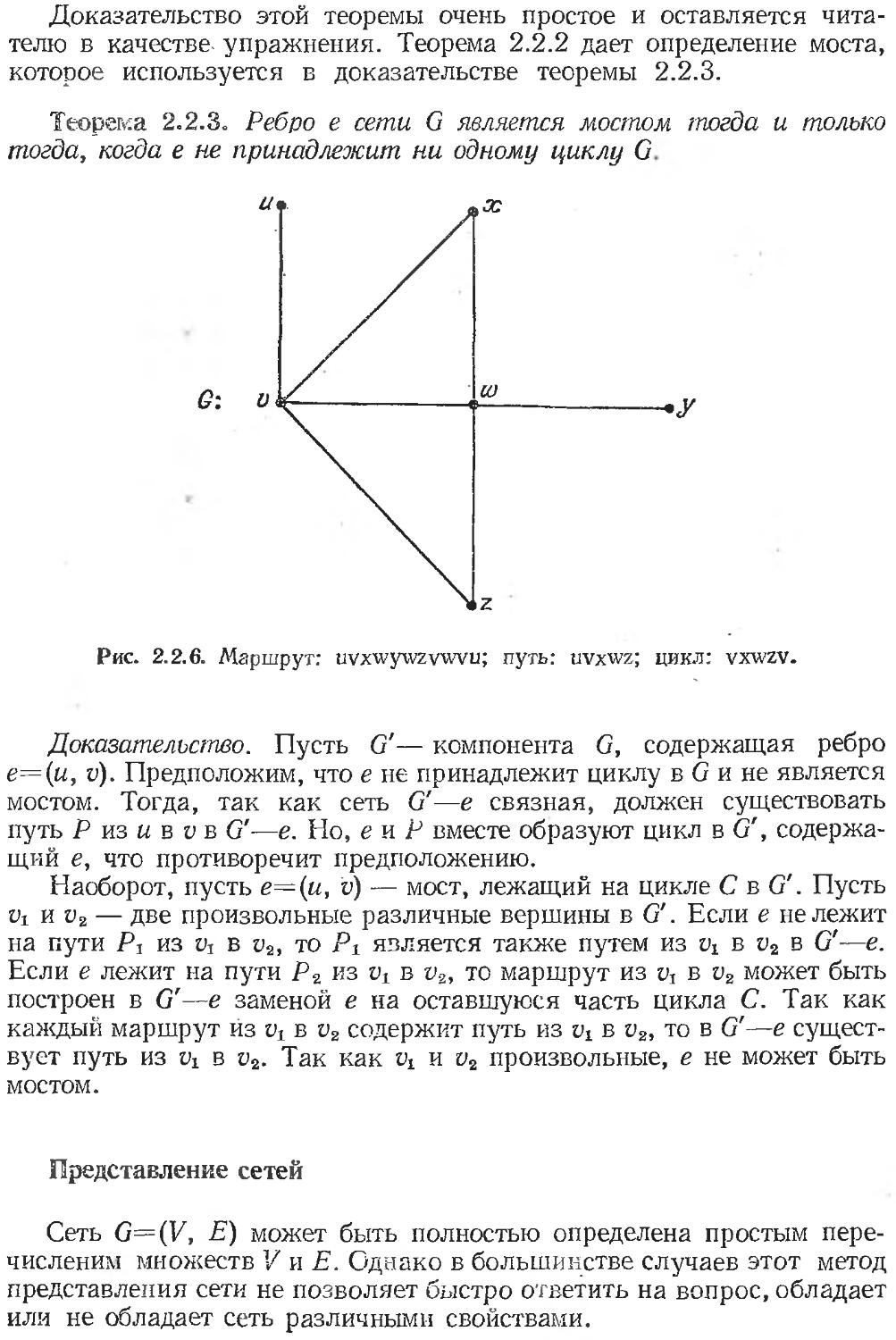
Тур коня
В шахматах конь может пойти из заданного поля (положения) на одно из самое большее восьми других полей, как показано на рис. 2.1.11. Так как конь не может сойти с доски, то из произвольного поля он не всегда может пойти на все восемь полей. Например, из поля
Рис. 2.1.8. Процесс разработки по методу «сверху-вниз» для блок-схемы на рис. 2.1.4, б.
л —(1, 2) он за один ход может перейти на поля XI, Х2, ХЗ, которые показаны на рис. 2.1.11, а.
2.1.9. Выражение функции f
как композиции функций g и h.
Рис. 2.1.10. Выражение функции g с использованием конструкции if-then-else.
Новая позиция
При ИСХОДНОЙ ПОЗИЦИИ (1,3)
1 (I—2,3 + 1)
2 (1-1, J + 2)
3 (1 + 1.3 + 2)
4 (1+2,3 + 1)
5 (I+2,3-1)
6 (1 + 1,3-2)
7 (1-1,3-2)
8 (1-2,3-1)'
<5*
Рис. 2.1.11. Возможные ходы коня,
Рассмотрим следующий вопрос: может ли конь, начав с некоторого поля шахматной доски, сделать последовательно 63 хода таким образом, чтобы побывать на каждом поле ровно один раз? Такой маршрут называется туром коня.
Не имея никакой математической теории, которая помогла бы
1
2
3
4 Б
6
7
8
1 2 3 4 5 6 7 8
22 19 24 17 14 5 10 7
25 16 21 32 11 8 13 4
20 23 18 15 3 6 9
29 26 31 33 12 2
40 37 28 35 44 [г
27 30 39 34
38 41 36 45 43
46 42
Рис. 2.1.12. Произвольный путь коня из поля (5, 6).
нам быстро ответить на этот вопрос, единственное, что мы можем сделать, это, по-видимому, обратиться к перебору всех возможных маршрутов коня на шахматной доске. Но число маршрутов, как свидетельствует комбинаторика, практически неисчерпаемо.
Можно попытаться воспользоваться вычислительной машиной и с ее помощью справиться с комбинаторным взрывом при поиске тура коня. Поэтому сделаем попытку построить алгоритм на основе какой-нибудь интуитивной процедуры, генерирующей последовательность маршрутов коня на шахматной доске, в надежде, что среди них окажется и нужный нам маршрут.
Рассмотрим произвольный маршрут из произвольного поля, например (5, 6) (рис. 2.1.12); целое N указывает на М-е поле, входящее в пройденный путь. Очевидно, что в этом примере после сорок пятого хода на поле (8, 2) конь может пойти только на поле, на котором он уже был, либо сойти с доски. Возможно, более методичный подход позволит получить более длинный маршрут.
Рассмотрим следующую простую стратегию. Начать с произвольного поля. Из заданного поля попытаться пойти сначала на поле 1, как указано на рис. 2.1.11, б (т. е. на два поля вверх и на одно вправо). Если это сделать нельзя, попытаться пойти на поле 2; при неудаче — на поле 3 и т. д. по часовой стрелке. При достижении положения, из которого невозможно пойти ни на одно из перечисленных восьми полей, не сходя с доски или не посещая какое-то поле второй раз, прервать маршрут и зафиксировать (или распечатать) результаты.
Ориентируясь на эту схему, начнем разработку такого алгоритма методом сверху-вниз. Начнем с одного-единственного оператора:
создать возможный тур коня (рис. 2.1.13, а). Это должно включать построение пути и затем распечатку результата (рис. 2.1.13, б). Построение пути сводится к выбору начальной позиции (рис. 2,1.13, в) и затем построению маршрута из этой позиции.
Здесь у нас есть достаточно хороший способ выбора начальной позиции, например считывая два целых числа (/, J), принимающих значения от 1 до 8. Мы также видим, что распечатка результатов предполагает распечатку целых значений, которые хранятся в соответствующем шахматной доске массиве (BOARD (7, J)). Поэтому теперь нам нужно сосредоточиться на том, как построить путь, начинающийся в поле (/, J).
Из того факта, что целые числа хранятся в массиве BOARD (/, J), следует необходимость присвоить всем элементам массива начальные значения, равные 0 (рис. 2.1.13, г). Таким образом, ход на поле (/, J) возможен при BOARD (/, J)=0. Далее, выход за пределы доски можно обнаружить, проверив принадлежность значений I и J отрезку значений целых чисел [1, 8].
Выход за пределы доски можно обнаружить также и по другой схеме (рис. 2.1.14). Добавим по два дополнительных ряда полей к каждому краю массива BOARD и занесем в каждое новое поле некоторое начальное значение, например 99. Тогда попытка выйти за пределы доски обнаруживается по ненулевому значению рассматриваемого поля.
Закончив с присваиванием начальных значений массиву BOARD, вернемся опять к задаче построения тура из произвольного поля (/, J). Мы должны попытаться разбить этот этап на последовательность меньших этапов, сводящихся к операторам if-then-else, do-while или while-do.
Здесь мы начинаем ощущать, что нам не обойтись без основного цикла, в котором некоторый индекс, скажем Д, пробегает множество всех возможных полей, на которые можно пойти с поля (/, J). Движе-ние коня приостанавливается, когда А>8. Из этого следует разбиение обсуждаемого этапа, представленное на рис. 2.1.15, а.
При попытке пойти на новое поле из поля (/, .7) может произойти одно из двух: либо ход возможен, и тогда мы заменяем значение (/, J) на новое, присваивая К значение 1, либо ход невозможен, и тогда значение Д увеличивается на 1 (рис. 2.1.15, б).
Остается еще определить значение К для поля (/, J). Для этой цели создается специальная таблица (рис. 2.1.16), в которой указываются модификации значений I и J для определения поля К. Теперь мы можем завершить построение нашей окончательной структурированной блок-схемы, которая приведена на рис. 2.1.17.
Реализация этого алгоритма на Фортране приведена на следующем рисунке (рис. 2.1.18). В качестве упражнения напишите и пропустите на машине программу для этого алгоритма и проверьте, можно ли
Построить путь
СозЗоть~ Возможный тур коня
а
_______1____
Распечатать результаты
0
Выбрать начатое no/ie^J)
Построить путь излоля(1,Р)
Распечатать результаты
6
Рис. 2.1.13. Разработка алгоритма возможного тура коня методом сверху-вниз.
99 99 99 99 99 99 99 99 99 99 99 99
99 99 99 99 99 99 99 99 99 99 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 9С 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 0 0 0 0 0 0 0 0 99 99
99 99 99 99 99 99 99 99 99 99 99 99
99 99 99 99 S9 99 99 99 99 99 99 99
Рис. 2.1.14. Первоначальная конфигурация на доске.
a
Рис. 2.1.15. Продолжение разработки алгоритма «тур коня» методом сверху-вниз.
К 1-перемещение J-перемещение
1 -2 + 1
2 -1 +2
3 +1 +2
4 +2 +1
5 +2 -1
6 +1 -2
7 -1 -2
8 -2 -1
Рис. 2.1,16. Таблица модификации значений / и J для хода на новое поле К.
Рис. 2.1.17. Окончательная блок-схема алгоритма «тур коня».
с его помощью фактически найти тур коня. Или модифицируйте алгоритм и найдите тур коня с помощью какой-либо другой стратегии. Уверяем вас, что это сделать можно!
с с с с с с с с с с с с с с с с с с с с
PROGRAM KNIGHT (OUTPUT.INPUT«TAPE3a:XNPUT«TAPFG^GU»PUTJ
ПРОГРАММА СТРОИТ ТУР КОНЯ. СТРАТЕГИЯ ПЕРЕМЕЩЕНИЯ НА СЛЕДУЮЩУЮ ПОЗИЦИЮ-ПО ЧАСОВОЙ СТРЕЛКЕ.
НАЧАЛЬНАЯ ПОЗИЦИЯ СЧИТЫВАЕТСЯ.
ОПИСАНИЕ ПЕРЕМЕННЫХ
B3ARD(X,J> =N ОЗНАЧАЕТч ЧТО ПОЛЕ В СТРОКЕ I
И СТОЛБЦЕJ БЫЛО Ы~ЫМ ПОЛЕМ В ТУРЕ КОНЯ.
=О~НА ПОЛЕ ЕЩЕ НЕ ХОДИЛИ.
= 99~ ПОЛЕ НАХОДИТСЯ ВНЕ ДОСКИ (ЧТОБЫ УДЕРЖАТЬ КОНЯ В ПРЕДЕЛАХ ДОСКИ).
IKOVE(K)
JROVECK)
К-ОЕ ПОЛЕ, НА КОТОРОЕ МОЖЕТ ДОЙТИ
КОНЬ С ДАННОГО ПОЛЯ.
I.J ТЕКУЩЕЕ ПОЛОЖЕНИЕ КОНЯ.
INEXT.JNEXT ВОЗМОЖНОЕ СЛЕДУЮЩЕЕ ПОЛЕ ДЛЯ ХОДА.
INTEGER BOARD(12*12 3 . IMOVF. (в 3 < JNOVE(в 3
DATA IMOVE(lBlMOVEf2>oIROVE(3)ilHOVE<%)eIHOVE(SMIIWE(feU
+ lMOVE(7)elM0VE(a>/-2«-l«l»2»2«l»-l«-2/
DATA JMOVE(1 >, JMOvE(23 « JWOVC(33. JROVE(%3 v JfiOyE(53«*Ж«уЕC61 ♦
♦ jM0VE(7)«JH0VE(6>/i,2e2«l»-le«‘2»-2(-l/'
C
С ВЫБРАТЬ НАЧАЛЬНУЮ ПОЗИЦИЮ с
READ(5.10003 XINlTtJINIT 1000 FORHAT(2I2> c С ИНИЦИАЛИЗИРОВАТЬ ДОСКУ С
DO 200 I s 1*12 DO 100 J = 1*12 BOARD(I«J> = 0 IF ( I -LT. 3 o0Ro у oGTe 10 .OR.
♦ J ЛТ. 3 .CR. j .GT. 10 3 DOAROd.J) = 99
100 continue 200 CONTINUE c С ИНИЦИАЛИЗИРОВАТЬ ПЕРЕМЕННЫЕ, с I
к - 1 BoARDCIlNlTtJINIT) s 1 I = UNIT J = JINIT N = 2
C С ПРОВЕРИТЬ, HE ОКОНЧЕН ЛИ ТУР. С
300 IF ( К .GT. 8 3 GOTO 500
С ’ ПРОВЕРИТЬ, МОЖНО ЛИ СДЕЛАТЬ ХОД КА ПОЛЕ К
с
INEXT = UIM0VEIK3
JNEXT = J*JMOVE(K3 С
IF ( BOARD(INEXTfJHEKT) .ME. О » CC?O <££JO
С ТОГДА(ПОЙТИ НА НОВОЕ ПОЛЕ И ПОДУЧИТЬ НОВОЕ ЗНАЧЕНИЕ(М)
С
BOAROCINEXT.JNEXT3 s N N a N*1 J = JNEXT I = XNEXT К = 2. GOTO 300 c С ИНАЧЕ (испытать следующее поле)
с *>0о к = К*1 GOTO 300 с С ТУР закончен^ распечатать доску и ЧИСЛО ходов с 500 N = N-1
w:lTE!6«S000>((BOePD(I,J>«J=3,10>4=3>10>iN
2000 FORMAT(SHIBOARO IS<//.0(fiJ10/>• //•1;H THERE WEREsIStSHHOVESl STOP eno
Рис. 2.1.18. Реализация алгоритма «тур коня» на Фортране. (Текст в операторе
2000: «Доска: ...было ...ходов».)
Структурное программирование сверху-вниз: дополнительные соображения
Мы не собираемся утверждать, что структурное программирование сверху-вниз исчерпывается тем, что было сказано в предыдущем разделе. Оно включает достаточно много других аспектов, один из которых можно выразить лозунгом «Упрощай структуры управления».
Другие аспекты — это требование соответствующей документации, наглядной записи программных операторов с использованием отступов в начале строк, разбиения программы на обозримые части.
Рекомендуется, например, составлять программные модули так, чтобы их распечатка нс превышала одной-двух страниц. Страница — это смысловая единица, которую можно представить себе в любой момент как единое целое и которая сводит к минимуму необходимость переворачивать страницы при прослеживании передач управления в программе.
Конечно, для разработки структурированной сверху-вниз программы потребуется затратить больше усилий, чем для получения неструктурированной программы. Впрочем, опыт показывает, что Дополнительные затраты с лихвой вознаграждаются. Структурированные программы, как правило, легче читать, и в них легче разбираться, так как их можно читать сверху-вниз, не прыгая по тексту из конца в начало. Главным образом это достигается благодаря тому, что общая структура управления в структурированной программе является деревом, а не сетью со многими циклами. (На рис. 2.1.19, например, мы приводим деревья, описывающие структуры управления блок-схем с рис. 2.1.4, а и б).
По этой причине такие программы иногда называют программами со структурой дерева.
Прежде чем окончить наше обсуждение структурного программи-
рования сверху-вниз, хотелось бы сделать несколько предостереже-
Рис. 2.1.20. Структурированная блок-схема глубины вложения три.
ний. Во-первых, этот метод разработки алгоритмов не гарантирует отсутствие ошибок в программе. Опыт показывает, например, что, когда глубина вложения структур управления равна трем или более трех, вероятность совершения ошибки возрастает очень сильно. На рис. 2.1.20 приведен пример структурированной блок-схемы с глубиной вложения три. Аналогичная ситуация возникает и в случае, когда модули становятся очень длинными.
Второе предостережение связано с термином «программирование без
goto», которое иногда используется как характеристика структурного программирования. Чем бы ни было структурное программиро-
вание, это ни метод программирования, запрещающий использование операторов goto, ни процесс преобразования неструктурированной программы в программу без операторов goto. Помимо того что само по себе это не приводит к структурированной программе, текст про-
граммы становится менее понятным.
Упражнения 2.1
2.1.1. Находит ли программа KNIGHT (КОНЬ) тур коня из произвольного начального поля? Со всех начальных полей?
2.1.2. Разработайте следующую эвристику для решения задачи тура коня. Начать с произвольного поля шахматной доски и перейти на поле, из которого на следующем ходе можно пойти на наименьшее (наибольшее?) число полей. Продолжать процедуру до тех пор, пока есть ходы или пока не найден тур коня.
2.1.3. Можно ли с помощью эвристики из упр .2.1.2. найти тур коня из произвольного начального поля?
2.1.4. Каково различие между понятием «правильности программы», о котором мы говорили в этом разделе, и понятием правильности алгоритмов в разд. 1.3?
2.1.5. Рассмотрите все языки программирования, с которыми вы знакомы, и упорядочите их с точки зрения пригодности для структурного программирования,
*L2.1.6. Заново рассмотрите некоторые задачи из упражнений к гл. 1, включающие написание программ. Переделайте алгоритмы в соответствии с требованиями структурирования сверху-вниз. Сравните и сопоставьте старые и новые версии этих программ. На основании полученных результатов сформулируйте преимущества и недостатки метода структурирования сверху-вниз в программировании,
2.2. Сети1)
Тот факт, что сети — это одно из самых полезных математических средств, подтверждается тем, что они применяются во многих областях самого различного направления; сюда входят химия, физика, строительство и электротехника, исследование операций, психология,
Рис. 2.2.1. (а) Остовные деревья и электрические сети; (б) представление органических соединений: метионин (без атомов Н).
социология, лингвистика и много разделов математики (включая численный анализ, теорию матриц, теорию групп, топологию, дискретные вероятностные процессы, теорию игр и комбинаторику). Более того, сети, и в частности деревья, являются, по-видимому, наиболее часто используемыми математическими структурами в вычислительной математике. Сети и деревья используются при изучении структур данных, в компиляции, языках программирования, операционных системах, теории вычислений, сортировке, теории поиска и искусственном интеллекте. На рис. 2.2.1 и 2.2.2 приведены некоторые примеры использования сетей в качестве моделей. В этом разделе мы представим основы теории сетей, обсудим различные способы представления сетей в памяти вычислительной машины и сформулируем некоторые алгоритмы определения элементарных свойств сетей.
-1) В программистском мире нет единого мнения о том, какой из двух терминов «граф» или «сеть» более употребителен. Мы выбрали термин «сеть», так как он, по-видимому, чаще встречается в прикладных областях.
((C + D) *В + А)
Рис. 2.2.2. Некоторые применения деревьев в вычислительной математике: (а) таблицы символов; (6) арифметические выражения; (в) подмножества множеств и вложенные структуры; (г) деревья сортировки (здесь представлено английское предложение: The words in this sentence have been alphabetically sorted as a rooted binary tree — слова в этом предложении были отсортированы по алфавиту как двоичное корневое дерево); (o') игровые деревья; конкретное дерево для игры НИМ,
Основные понятия
Сеть G=(V, Е) состоит из конечного множества V=V(G) М вершин (Л4^1) и конечного множества E=E(G) TV неупорядоченных пар различных вершин (и, v) (М>0), называемых ребрами G. Сеть Gi=(Vi, Ег) на рис. 2.2.3, а состоит из семи вершин Vi{t, и, v, w, х, у, z} и семи ребер Ei={(u, v), (v, w), (w, x), (w, z), (z, v), (v, x), (w, y)j.
Очень важно понять, что сеть может быть изображена многими различными способами', например, сети, приведенные на рис. 2.2.3, б и в, те же, что и на рис. 2.2.3, а. Это следует из определения сети (убедитесь сами). В конце этого раздела задача, состоящая в том, чтобы
Рис. 2.2.3. Три способа изображения неориентированной сети.
определить, представляют ли два чертежа одну и ту же сеть, будет рассмотрена более подробно.
Две вершины и и v являются смежными, если в G существует ребро (и, п); в противном случае и и v независимы. Про ребро (и, v) также говорят, что оно инцидентно вершинам и и v.
Обратите внимание на то, что ребра состоят, как мы сказали, из неупорядоченных пар различных вершин. Таким образом, ребра не-ориентированы в том смысле, что ребра (и, v) и (v, и) считаются одним и тем же ребром. Более того, ребра вида (и, и), называемые петлями, не допускаются. Мы также не разрешаем наличия в сети мультиребер, Т- е. двух или более копий данного ребра. Если в конкретных применениях рассматриваются и мультиребра, то сеть называется мульти-сетью (рис. 2.2.4).
Если мы изменим наше определение так, чтобы сеть состояла из конечного множества вершин и множества упорядоченных пар [и, п] различных вершин, то получим определение ориентированной сети-, см. рис. 2.2.5, где V(G3)={u, v, w, х, у, z} и E(Gs)={[u, v], [о, w],
Рис. 2.2.5. Ориентированная сеть.
[v, х], [х, w\, [&у, у], [щ, z], [г, о]}. При работе с ориентированной сетью G=(V, Е) элементы V обычно называют узлами, а элементы Е — дугами.
Если [и, о] — дуга ориентированной сети, то мы говорим, что и — левый сосед v, a v — правый сосед и.
Очень часто в практических применениях желательно приписывать ребрам или дугам сети веса для того, чтобы моделировать такие величины, как время, расстояние или стоимость. Взвешенная сеть — это такая сеть, ребрам или дугам которой поставлены в соответствие действительные числа.
Множество соседей вершины v N (v) это множество вершин, смежных с v, т. е. W(о)={п| (и, и) £Е}. Так, множество соседей вершины v на рис. 2.2.3, а состоит из вершин и, х, w и г. Степень вершины V, обозначаемая как dv или deg (и), равна числу вершин в N (у), т. е. dv=deg(w)=|/V(n)|. Таким образом, если вершины в Gi на рис. 2.2.3 расположить в порядке w, v, х, г, и, у, t, то их соответствующие степени есть 4,4,2,2,1,1,0, т. е. <4,=4, do=4, dx=2 и т. д.
Вершина v называется тупиковой -вершиной, если deg(o)=1; если deg (с)=О, то говорят, что v — изолированная вершина. На рис. 2.2.3, а вершины и и у тупиковые, а вершина t изолированная.
Теорема 2.2.1. Пусть G — сеть с М вершинами vlt v2, . . ., vM и N
ребрами. Тогда
м
2 dz = 2M.
1 = 1
Доказательство теоремы немедленно следует из того, что каждое ребро добавляет 1 к степени каждой из его двух вершин и поэтому добавляет 2 к сумме степеней всех вершин.
Следствие 2.2.1. В каждой сети G число вершин нечетной степени четно.
Доказательство этого следствия оставляется читателю в качестве упражнения.
Как пример использования следствия 2.2.1 рассмотрим группу из k человек, которую мы представим k вершинами V={vi, v2, . . ., vk}. Если два человека и Vj знакомы друг с другом, то будем говорить, что для них существует ребро (иг, vj). Из следствия 2.2.1 следует, что в любой группе число людей, которые знакомы с нечетным числом других людей, четно.
Сеть G'=(V', Е') является подсетью сети G=(V, Е), если V'sV и Е’^Е. Если V'=V, то говорят, что G'— остовная подсеть G. Если u^V, то G—v обозначает подсеть, вершины которой есть V—{и}, а ребра — все ребра в Е, не инцидентные v, т. е. G—v получается из G вычеркиванием v и всех инцидентных v ребер. Аналогично для ребра е=(и, v) G.E, G—е обозначает подсеть, получаемую из G удалением е, но не и и ц; G-\-e обозначает подсеть, получаемую добавлением е к G.
Маршрут в сети G=(V, Е) из вершины щ в вершину ип — это (конечная) последовательность вершин W=ut, и2, . . ., ип, таких что (иг, ui+1)£E(G) для каждого!, l^i^n—1. Маршрут W замкнут, если wi=«nJ в противном случае маршрут W открыт. Маршрут называется путем, если ни одна вершина (и, следовательно, ни одно из ребер) не появляется в W более одного раза. Цикл — это замкнутый маршрут ui, и2, . . ., un, Ui, для которого u^Uj, если иДр Рис. 2.2.6 иллюстрирует введенные термины.
Сеть G связная тогда и только тогда, когда для любых двух вершин и и v из G существует путь из и в v, в противном случае говорят, что G несвязная. В несвязной сети G максимальные связные подсети называются компонентами G.
Некоторые связные сети можно сделать несвязными, удалив одну-единственную вершину или ребро. Говорят, что вершина v является разделяющей вершиной сети G, если у G—v больше компонент, чем У G. Ребро е является мостом в G, если у G—е больше компонент, чем у G. На рис. 2.2.6 w — разделяющая вершина и (да, у) — мост.
Теорема 2.2.2. Ребро е связной сети G является мостом тогда и только тогда, когда существуют две вершины Vi и v2, такие, что е принадлежит каждому пути из щ в v2.
Доказательство этой теоремы очень простое и оставляется читателю в качестве упражнения. Теорема 2.2.2 дает определение моста, которое используется в доказательстве теоремы 2.2.3.
Теорема 2.2.3. Ребро е сети G является мостом тогда и только тогда, когда е не принадлежит ни одному циклу G.
Рис. 2.2.6. Маршрут: uvxwywzvwvu; путь: uvxwz; цикл: vxwzv.
Доказательство. Пусть G'— компонента G, содержащая ребро е=(и, и). Предположим, что е не принадлежит циклу в G и не является мостом. Тогда, так как сеть G'—е связная, должен существовать путь Р из и в v в G'—е. Но, е и Р вместе образуют цикл в G', содержащий е, что противоречит предположению.
Наоборот, пусть е=(и, v) — мост, лежащий на цикле С в G'. Пусть щ и v2 — две произвольные различные вершины в G'. Если е не лежит на пути Pi из Hi в u2, то Pi является также путем из в в G'—е. Если е лежит на пути Р2 из щ в п2, то маршрут из v, в и2 может быть построен в G'—е заменой е на оставшуюся часть цикла С. Так как каждый маршрут из щ в и2 содержит путь из v± в и2, то в G'—е существует путь из Vi в v2. Так как гу и v2 произвольные, е не может быть мостом.
Представление сетей
Сеть G=(V, Е) может быть полностью определена простым перечислении множеств V и Е. Однако в большинстве случаев этот метод представления сети не позволяет быстро ответить на вопрос, обладает или не обладает сеть различными свойствами.
Можно также представить сеть в виде (в известном смысле произвольной) картинки. Хотя визуальное представление иногда полезно при выявлении свойств заданной сети, оно не применимо для больших сетей и мало пригодно при работе с вычислительной машиной.
Имеется много разнообразных методов представления сети в памяти вычислительной машины. Какого-то одного лучшего метода
1 2 3 4 5
1 0 10 11
2 10 111
A(G): 3 0 1 0 0 1
4 110 0 0
5 1110 0
Рис. 2 2.7. Представление в форме матрицы смежности.
нет; лучшее представление зависит от решаемой задачи. При этом следует быть чрезвычайно осторожным, так как выбор конкретного представления может существенно повлиять на скорость и эффективность работы алгоритма.
Матрица смежности. Любая сеть G~(V, Е) с М вершинами может быть представлена матрицей размера МхМ при условии, что вершинам G приписаны некоторые (произвольные) метки. Если вершины G помечены метками щ, vz, . . ., щл, то матрица смежности A (G) определяется следующим образом:
A (С)=1а„1,
где Gjj=l, если щ смежна с щ1); а^-О в противном случае.
На рис. 2.2.7 приведена сеть и ее матрица смежности. Заметим, что для неориентированной сети G A (G) всегда будет симметричной матрицей (0, 1) с нулями на диагонали. Заметим также, что степень вершины vt равна числу единиц либо в i-й строке, либо в i-м столбце 4(G).
Матрица инцидентности Второй метод представления сети использует матрицу инцидентности 1(G). Если вершины G помечены (произвольно) метками щ, v2, . . ., щл, а ребра — метками е1г ег, . . ., eN, то
х) Если G — взвешенная сеть, то элемент равен весу ребра между вершинами i и /.
матрица инцидентности MXN определяется следующим образом: /(G)=[fey],
где Ьц=1, если щ инцидентна ер, Ьц=0 в противном случае.
На рис. 2.2.8 приведена матрица инцидентности / (G) сети G с рис. 2.2.7.
Заметим, что каждый столбец в I (G) содержит ровно две единицы и что никакие два столбца не идентичны. Заметим также, что число
а b с d е f g
1 1 1 0 0 0 10
2 10 10 10 1
1(G): з oooiooi
4 0 0 0 0 1 1 0
5 0 1 1 1 0 0 0
Рис. 2.2.8. Представление в форме матрицы инцидентности.1
единиц в i-й строке равно степени dt для vt в G. Матрица инцидентности полезна для решения различных сетевых задач, касающихся циклов. С другой стороны, матрица инцидентности требует больше памяти (MX.N, т. е. порядка М3 слов) и использует ее менее эффективно, поскольку (М—2)хМ слов заполнены нулями.
Векторы смежности. Вместо представления сети матрицами (0, 1) можно воспользоваться матрицей, в которой элементы соответствуют непосредственно меткам щ, vz, . . ., vM, приписанным вершинам G. В такой матрице i-я строка содержит вектор, компонентами которого являются все вершины, смежные с Vj. Порядок элементов в таком векторе, называемом вектором смежности, обычно определяется порядком, в котором представлены ребра в G (например, порядок ввода в программу). На рис. 2.2.9 мы приводим сеть G, список ребер G в случайном порядке и представление G в форме векторов смежности. Размер матрицы, содержащей векторы смежности, никогда не превышает MXD, где D — максимальная степень вершины из G.
Векторы смежности особенно удобно представляют сеть, когда задача может быть решена за небольшое число просмотров каждого ребра в G.
Ниже приведена небольшая программа на Фортране, которую можно использовать (с незначительными модификациями в операторе READ) для представления в форме векторов смежности сети с рис. 2.2.9, а, причем порядок ребер указан на рис. 2.2.9, б.
С
С
С
4 1 3 5 2 4
1 2
S 2 1 5 2 3
2
3
4
5
4 2 5 0
4 15 3
5 2 0 0
12 0 0
3 2 10
Рис. 2.2.9. Представление в форме векторов смежности.
МЫ ПРЕДПОЛАГАЕМ, ЧТО ЭЛЕМЕНТАМ МАССИВОВ
NETW(I, J) И DEGREE (I) ПРИСВОЕНЫ
С НАЧАЛЬНЫЕ ЗНАЧЕНИЯ 0
С
С ПРОЧЕСТЬ ЧИСЛО ВЕРШИН М И
С ЧИСЛО РЕБЕР N
С
READ( )М, N
С
С ПРОЧЕСТЬ РЕБРА (U, V) ИЗ G
С
DO 1 K=l, N
READ ( ) U, V
DEGREE (U) =DEGREE (U)-|-I NETW (U, DEGREE (U)) = V DEGREE (V) = DEGREE (V)+l NETW (V, DEGREE (V)) = U
1 CONTINUE
Еще одно полезное представление сети, с помощью списков смежности, обсуждается в разд. 2.3.
Воспользуемся некоторыми из рассмотренных нами сейчас понятий при разработке алгоритма определения связности сети и идентификации ее компонент, в случае когда сеть не связна. Такой алгоритм может оказаться очень полезной подпрограммой для более сложных процедур.
Главная идея алгоритма CONNECT (связывание) очень проста. Интуитивно хотелось бы свести компоненту к одной вершине. Это может быть сделано в процессе последовательного сведения, когда все смежные с данной вершины «сливаются» с ней. Вершина v сливается
с соседней вершиной и при удалении ребра (и, и), и отождествлении v с и. Одна результирующая вершина, обозначаемая через и, является смежной для каждой вершины, которая была смежной для и и/или v перед слиянием. Эта операция проиллюстрирована на рис. 2.2.10.
Рис. 2.2.10. Процесс сведения (о) перед и (б) после слияния v с и.
Процедура будет состоять из выбора начальной вершины и слияния с ней соседней вершины. Эта операция повторяется до тех пор, пока у По не останется смежных вершин. К этому моменту сведенная таким образом сеть будет состоять либо из одной вершины о0, и в этом случае первоначальная сеть G была связной, либо у нас будет выделена одна из компонент G. Во втором случае выбирается новая начальная вершина и процедура повторяется. Таким образом можно выделить все компоненты.
Algorithm CONNECT (СВЯЗЫВАНИЕ) для определения связных компонент произвольной сети G. Переменная С — счетчик числа компонент.
Шаг 0. [Инициализация] Set Н G; and С 0.
Шаг 1. [Получение очередной компоненты] While Я+0 do through шаг 5 od; and STOP.
Шаг 2. [Выбор в Н вершины Vo]
Set Vo ч- произвольная вершина из Н.
Шаг 3. [Слить вершины с Vo] While Vo смежна по крайней мере с одной вершиной U в И do шаг 4 od.
Шаг 4. [Слияние] Пусть U — смежная с Vo вершина в И. Set Н результирующая сеть после слияния U с Vo. (В этом цикле следует вести учет всех вершин, слитых с Vo. Для простоты здесь эту операцию учета мы опускаем.)
Шаг 5. [Удаление Уо] Set Н+-Н—Vo; and С-«-С+1.
Блок-схема для алгоритма CONNECT приводится на рис. 2.2.11. Доказательство правильности, реализация и анализ этого алгоритма оставлены в качестве упражнения.
Деревья
Дерево—это неориентированная связная сеть без циклов. Любая сеть без циклов называется лесом, а ее связные компоненты — деревьями. На рис. 2.2.12 приводятся все различные деревья с шестью вершинами. Весь рисунок можно считать лесом, состоящим из 36 вершин и 6 компонент.
Ориентированная сеть является деревом тогда и только тогда, когда она дерево с дугами, рассматриваемыми как неориентированные ребра Ациклическая ориентированная сеть не обладает ориентированными циклами. Ориентированная сеть на рис. 2.2.13 ациклична, но не является деревом. Следующая ниже теорема дает несколько других описаний деревьев.
Теорема 2.2.4. Пусть Т — сеть с Л1^2 вершинами. Тогда все следующие утверждения эквивалентны (т. е. если верно одно, то верны и все остальные)-.
(а) Т — дерево. Иначе говоря, Т связно и не имеет циклов.
(б) В сети имеется М—1 ребро и нет циклов.
(в) В сети Т имеется М—1 ребро и Т связна.
(г) Сеть Т связна, и каждое ее ребро — это мост.
(д) Любые две вершины в Т соединяются единственным путем.
(е) В сети Т нет циклов, но добавление любого нового ребра создает ровно один цикл.
Доказательство. Из утверждения (а) следует утверждение (б). Так как Т не содержит циклов, удаление любого ребра разбивает Т на два дерева. Это следует из того факта, что ребро есть мост тогда и только тогда, когда оно не содержится ни в одном цикле (теорема 2.2.3). Индукцией по М легко
Рис. 2.2.11. Блок-схема для алгоритма CONNECT (СВЯЗЫВАНИЕ).
показать, что число ребер в каж-
дом из этих двух деревьев на 1 меньше числа вершин. Отсюда следует утверждение (б).
Из утверждения (б) следует утверждение (в). Если.сеть Т несвязна,
Рис. 2.2.12. Все различные деревья с шестью вершинами.
то каждая компонента Т связна и не имеет циклов. Поэтому из утверждения (б) число вершин в каждой компоненте превышает число ребер на 1. Далее следует, что общее число вершин в Т по крайней мере на 2 больше, чем общее число ребер, что противоречит предположению (б).
Рис. 2.2.13. Ациклическая ориентированная сеть,
Из утверждения (в) следует утверждение (г). Сначала докажем следующую лемму.
Лемма. Если в сети G имеется М вершин, N ребер и К компонент, то М—ДДД\'.
Доказательство. Проведем индукцию по числу ребер. Для N—1 утверждение леммы очевидно. Пусть G содержит наименьшее возможное количество ребер, скажем No. Удаление любого ребра изС должно поэтому увеличивать Д на единицу, оставляя в сети М вершин, /С+1 компоненту и No—1 ребро. Из предположения индукции следует, что До—1>М—(/С+1), т. е. Д0^Д1—Д. Это доказывает лемму, так как Д>Д0.
Из утверждения (в) и доказанной леммы путем сведения к проти-воречию получаем утверждение (г), так как /(=1 и удаление любого ребра оставляет М — 2 ребра и М. вершин.
Из утверждения (г) следует утверждение (д). Каждая пара вершин соединяется по крайнёй мере одним путем, так как сеть Т связна. Если каждая пара вершин соединяется двумя или более различными путями, то любые два таких пути образуют цикл; отсюда следует противоречие, так как никакое ребро в таком цикле не может быть мостом по теореме 2.2.3.
Из утверждения (д) следует утверждение (е). Если Т содержит цикл, то любые две вершины в этом цикле должны быть связаны по крайней мере двумя путями. Если к Т добавляется ребро I, то в Т-\-1 между тупиковыми вершинами / будут существовать два пути [ребро / и единственный путь, задаваемый утверждением (д)]. Это единственный цикл в Т-\-1, потому что любой другой цикл также должен был бы содержать ребро I. Отсюда следовало бы существование двух вершин в Т, между которыми имеется по крайней мере два различных пути,— противоречие с утверждением (д).
Из утверждения (е) следует утверждение (а). Предположим, что сеть Т несвязна. Если мы добавим к Т ребро, которое соединяет вершины в двух компонентах, то цикла создать нельзя; это противоречит утверждению (е). Поэтому Т должна быть связна, и теорема.2.2.4 доказана.
Следствие 2.2.4. Каждое дерево с Л43>=2 вершинами имеет по крайней мере две тупиковые вершины.
Доказательство непосредственно следует из теорем 2.2.1 и 2.2.4.
Дерево, у которого одна вершина выделяется среди всех других, называется корневым деревом-, выделенная вершина называется корнем дерева. Как правило, корневые деревья изображаются так, что корень оказывается наверху, а все остальные вершины — ниже его, на уровнях, соответствующих расстоянию от корня. Иллюстрация приведена на рис. 2.2.14, а. Мы будем предполагать, что каждое дерево с корнем имеет по крайней мере три вершины. Максимальный уровень любой вершины в дереве с корнем известен как высота дерева.
Среди наиболее широко используемых математических структур употребляется один специальный класс корневых деревьев, известных как двоичные корневые деревья. С ними нам часто придется встречаться в этой книге. Двоичное корневое дерево — это корневое дерево, у которого степень корня равна 2, а степень всех остальных вершин 1 или 3. Одно такое дерево приведено на рис. 2.2.14, б.
Теорема 2.2.5. Пусть Т — двоичное корневое дерево, у которого М вершин, высота L и Q тупиковых вершин. Тогда
(а) М нечетно-,
Уровень
О
1
2
3
4
Уровень
О
1
2
3
4
5
Рис. 2.2.14. (г/) Корневое дерево высоты 4; (б) двоичное корневое дерево высоты 5.
в)
(Г)
м < IS 2' ;
i=0
[log2(M+ 1)- .
Доказательство теоремы оставлено в качестве упражнения.
Остовное дерево для сети G есть остовная подсеть, являющаяся деревом. На рис. 2.2.15 приведены взвешенная сеть G и некоторые из ее остовных деревьев с их весами. Сколько у сети остовных деревьев? Легко показать следующее.
Теорема 2.2.6. Сеть G связна тогда и только тогда, когда она содержат остовное дерево.
Изоморфизм
Этот раздел мы завершим кратким рассмотрением следующей важной задачи. Если у нас есть два представления сети, то, как узнать, не описывают ли они одну и ту же сеть?
Очевидно, сначала нужно определить, что подразумевается, когда мы говорим, что «две сети одинаковы». Две сети G и G' изоморфны, если существует взаимно-однозначное соответствие между вершинами G и G', такое, что две вершины и и v смежны в G тогда и только тогда, когда в G' смежны соответствующие им вершины. Точнее, G=(E, Е) изоморфна G' = (V', Е’)— это записывается в виде G^G',— если существует взаимно-однозначная функция h из V в V’, обладающая тем свойством, что (u, v)£E тогда и только тогда, когда (/i(u), h(v))£E'.
Проблема определения, являются ли две сети изоморфными, неожиданно оказывается трудной. Для произвольных сетей все известные алгоритмы, гарантирующие правильный ответ, экспоненциальные.
Фактически даже для небольших сетей эту задачу решить нелегко. Все три сети на рис. 2.2.16 изоморфны друг другу. Если вам это кажется очевидным, попытайтесь определить, какие сети изоморфны друг ДРУГУ (если такие есть) из приведенных на рис. 2.2.17.
Итак, проблема изоморфности очень трудна, как можно к ней подступиться? Хотя может и не оказаться возможным разработать алгоритм изоморфизма, являющийся полиномиальным в худшем случае, попытаемся сделать нечто полезное.
Рис. 2.2.16. Три изоморфные сети.
Начнем с совершенно очевидного замечания. Из определения следует, что если сети G и G' изоморфны и изоморфизм h найден, то любая вершина v степени d в G должна отображаться на вершину v'=h(v) в G' той же самой степени.
Рис. 2.2.17.
Что если мы попытаемся построить на этом наблюдении процедуру исчерпывающих проб и ошибок? Рассмотрим, например, две сети G и д': у каждой 10 вершин и каждая вершина степени 3. Любая из возможных взаимно-однозначных функций h из V в V будет удовлетворять указанному выше ограничению на степень; имеется 10! таких функций. Поэтому для решения вопроса об изоморфности G и G' нам нужно было бы испытать каждую из 10! возможных функций, чтобы найти одну, удовлетворяющую требованию изоморфизма.
Перед лицом этого комбинаторного взрыва исследователи часто отказываются от поиска эффективного алгоритма изоморфизма и взамен этого строят простые процедуры, от которых ожидается хорошая работа в большинстве случаев. Предпочитают также алгоритмы изоморфизма, пригодные для специальных классов сетей, появляющихся в некоторых приложениях.
Инвариантом сети G называется параметр, имеющий одно и то же значение для всех сетей, изоморфных G. Среди самых очевидных инвариантов отметим следующие:
1. Число вершин.
2. Число ребер.
3. Число компонент.
4. Последовательность степеней, т. е. список степеней всех вершин в убывающем порядке значений.
В контексте данной книги эв/шстш/ес/шйал гор итм обладает следующими двумя свойствами.
1. Он находит, как правило, хорошие, хотя и не обязательно оптимальные, решения.
2. Его легче и быстрее реализовать, чем любой из известных точ-‘ ных алгоритмов (т. е. алгоритмов, гарантирующих оптимальное решение).
Более полное рассмотрение таких алгоритмов можно найти в разд. 3.2. Эвристики для решения задач изоморфизма обычно состоят в попытках показать, что две рассматриваемые сети не изоморфны. Для этого составляется список различных инвариантов в порядке, определяемом сложностью вычисления инварианта. Затем последова тельно сравниваются значения параметров сетей. Как только обнаруживаются два различных значения одного и того же параметра, приходят к заключению, что данные сети неизоморфны.
К сожалению, не известно множества инвариантов, которое позволило бы этой процедуре установить за полиномиальное время, что сети изоморфны. Такое множество (неизвестно, будет ли оно когда-нибудь найдено) называется кодом сети. По существу, эвристический алгоритм рассматриваемого типа сводится к сравнению неполных кодов двух сетей. Конечно, рассмотрение большего числа инвариантов увеличивает вероятность правильного заключения об изоморфизме при совпадении всех значений параметров, но в общем случае ничего не гарантирует. Например, для двух пятивершинных сетей на рис. 2.2.18 все четыре из перечисленных выше инвариантов совпадают, но эти сети не изоморфны.
Рассмотрим теперь пример достаточно сложной эвристики, работающей с матрицей смежности A (G). Сама по себе матрица смежности не является инвариантом, хотя если G и Gx изоморфны, то при некотором переупорядочивании столбцов и строк /1(G) мы получаем A(Gt). Если у сетей G и Gx М вершин, то поиск нужной последовательности перестановок строк и столбцов требует в худшем случае О (/И!) операций. Впрочем, описываемая ниже полиномиальная процедура справ-
ляется вроде бы достаточно хорошо с задачей отсеивания неизоморф ных сетей.
Вычисляется Л2(С;) для i=l, 2. Затем переставляются строки и столбцы Д2(С1) и A-(G2} так, чтобы элементы на главной диагонали оказались в нисходящем порядке. Если Gx и G2 изоморфны и все диаг нальные элементы различны, то при этой перестановке должны по. читься идентичные матрицы. Если нет, то данные две сети не мо
Рис. 2.2.19.
быть изоморфными. Если матрицы идентичны, можно продолжить проверку с A^fGt), . . . , Ak(Gi) для i=l, 2. Значение k определяется имеющимся бюджетом машинных ресурсов. Если все из проверенных матриц совпадают, то весьма правдоподобно, но не обязательно истинно, что Gi и G2 изоморфны.В дальнейшем эту процедуру мы будем называть методом СПС (сравнение порядков смежности).
Окончательная формулировка алгоритма, использующего метод СПС, и некоторые другие вопросы, касающиеся этого метода, оставляются читателю в качестве упражнения. В упр. 2.2.25 содержится важная теоретическая интерпретация элементов возведенной в степень матрицы смежности.
На рис. 2.2.19 работа метода СПС проиллюстрирована на примере двух сетей с рис. 2.2.18. Факт неизоморфности Gx и G2 становится ясным достаточно рано на основании следующего:
1) переупорядоченные матрицы Д2(Сг) не совпадают по элементам вне главной диагонали и 2) не равны диагональные элементы Л3(Сг). Как для Д2(СХ), так и для Д2(С2) переупорядочение выполнено заменой строк и столбцов 2 и 3. Обратите внимание на перемещение элементов, стоящих на пересечении пар строк — столбцов.
Упражнения 2.2
2.2.1. Изобразите все неизоморфные сети с пятью вершинами. Их 34.
2.2.2. Изобразите все неизоморфные деревья с восемью вершинами. Их 23.
2)2.3. Докажите теорему 2.2.1 методом математической индукции.
У.&4. Докажите следствие 2.2.1.
Тй-2:5. Алгоритм СВЯЗЫВАНИЕ (правильность). Проверьте правильность алгоритма СВЯЗЫВАНИЕ.
Д2.2.6. Алгоритм СВЯЗЫВАНИЕ (реализация, проверка). Реализуйте и проверьте алгоритм СВЯЗЫВАНИЕ. Один интересный способ реализовать операцию слияния использует матрицу смежности и операцию двоичного ИЛИ (см. приложение Б). Для слияния вершины ty с вершиной щ просто добавьте строку R (/), соответствующую Vj, к строке, соответствующей V;, используя форму двоичного сложения ИЛИ. Затем добавьте столбец С(/) к столбцу C(i) и занесите нуль в диагональный элемент Строки R(i). После удаления R(j) и С (у) результирующая матрица будет представлять сеть после слияния.
2.2.7. Алгоритм СВЯЗЫВАНИЕ (анализ). Используя реализацию из упр. 2.2.6, арризведите анализ сложности алгоритма СВЯЗЫВАНИЕ.
5.2.8. Алгоритм ПРОВЕРКА ДЕРЕВА (разработка). Воспользуйтесь алгоритмом СВЯЗЫВАНИЕ при разработке алгоритма ПРОВЕРКА ДЕРЕВА, определяющего, звтчется ли данная сеть деревом.
%2.Ь. Разделяющие вершины и мосты (доказательство). Докажите следующие две Горемы (критерии).
Теорема. Вершина v связной сети G является разделяющей вершиной тогда и только тогда, когда существуют две вершины пх и v2, где v, пх и v2 — различные вершины, такие что v принадлежит каждому пути из пх в п2.
Теорема 2.2.2. Ребро е связной сети G является мостом тогда и только тогда, когда существуют две вершины пх и и2, такие, что е принадлежит каждому пути из vx в v2.
L2.2.10. Представление преобразования (разработка, реализация). Разработайте и реализуйте алгоритм, который преобразует матрицу смежности в матрицу инцидентности и наоборот.
*2.2.11. Двудольные сети (доказательство). Сеть G=(V, Е) называется двудольной, если V можно разбить на два непересекающихся подмножества Кх и V2, такие, что каждое ребро в Е соединяет вершину в Vx с вершиной в К2. Докажите, что сеть двудольная тогда и только тогда, когда каждый цикл содержит четное число ребер. 2.2.12. Полные двудольные сети. Двудольная сеть (см. определение в упр. 2.2.11) называется полной, если для любых ы£Кх и v^V2, (и, п)£1Л Пусть Кт г1 обозначает единственную полную двудольную сеть, где |Vx|=m и |К2|=п. Выведите формулу для числа ребер в Kmin-
2.2.13. Изобразите две неизоморфные сети с шестью вершинами, имеющие одинаковые последовательности степеней.
*2.2.14. Как можно было бы использовать представление в форме характеристического вектора, введенное для множеств (см. приложение Б), чтобы сэкономить память при представлении сетей? Какими недостатками обладают ваши предложения? 2.2.15. Полные сети. Сеть с М вершинами называется полной и обозначается через Км, если каждые две вершины смежные. Такие сети использовались при моделировании задачи о коммивояжере. Покажите двумя различными способами, что число ребер в /Qu задается формулой
2.2.16. Перерисуйте Къ и К31 3 (см. упр. 2.2.12 и 2.2.15) так, чтобы в каждой сети имелось только одно пересечение ребер, т. е. только одно пересечение в точке, не являющейся вершиной сети.
* L2.2.17. Алгоритм РАЗДВЕР (полная разработка). Полностью постройте алгоритм, который находит все разделяющие вершины в данной сети.
* *2.2.18. Реализуемая последовательность степеней (доказательство). Невозрастающая последовательность положительных чисел называется реализуемой, если существует сеть, для которой эта последовательность является последовательностью степеней. Докажите, что последовательность dlt d2, ... , d^ (где d1’^d2^. . .^dyn^O) реализуема тогда и только тогда, когда последовательность d2—1, d3—1, . . . , d^l+1, d-di + fr i реализуема.
* *2.2.19. Алгоритм РЕАЛИЗУЕМОСТЬ (разработка). Разработайте алгоритм, основывающийся на теореме из упр. 2.2.18, который определяет, является ли конечная последовательность положительных целых чисел реализуемой.
* 2.2.20. Какие из сетей на рис. 2.2.17 изоморфны?
* *L2.2.21. Метод СПС (разработка, реализация). Разработайте и реализуйте подпрограмму для метода СПС. Что вы сделаете, когда два или более из диагональных элементов будут иметь одинаковые значения?
* *L2.2.22. Эвристика изоморфизма (разработка, реализация, проверка). Разработайте, реализуйте; и проверьте эвристический алгоритм для обнаружения изоморфизма. Ограничьтесь сетями не более чем с 12 вершинами.
* 2.2.23. Инварианты. Попытайтесь составить список из 10 или больше сетевых инвариантов.
* 2.2.24. Докажите теорему 2.2.5.
* *2.2.25. Докажите следующую теорему. Если А — матрица смежности невзвешенной сети G и V(G)= {с'7, о2, . . . , ом ), то (!> /)'й элемент матрицы А'1, где /г>1,— это число различных маршрутов из ty в V,- длины п в G (считайте, что у каждого ребра длина равна единице).
2.2.26. Докажите теорему 2.2.6.
2.3. Некоторые структуры данных
В гл. 1 мы высказали утверждение о том, что выбор структур данных может существенно повлиять на скорость и эффективность реализованного алгоритма. В этом разделе мы введем несколько структур данных (связанные списки, стеки и очереди) и процедуры для работы с ними, которые часто оказываются полезными.
Рассмотрим преимущества и недостатки использования массивов. Среди преимуществ отметим следующие:
1. Массивы помогают объединять множества данных в осмысленные группы.
2. Имена массивов с индексами минимизируют потребность в слежении за многими элементами данных с различными именами.
3. Использование индексов обеспечивает непосредственный и автоматический доступ к любому элементу в массиве.
4. Индексация позволяет также производить с помощью циклов DO и FOR автоматическую, быструю и эффективную обработку всех данных или выделенных подмножеств данных, хранимых
в массивах. эту обработку входит инициализация, поиск, хранение и модификация.
Недостатки массивов не так очевидны. Лучше всего массивы годятся для данных, значения которых не изменяются, порядок которых (важен он или не важен) также не изменяется. Если порядок элементов в массиве подвергается изменению, то каждый раз, когда порядок меняется, перестановка элементов требует очень много времени.
Рис. 2.3.1. Переорганизация линейного списка.
Рассмотрим, например, TV-элементный массив CSIOO(TV), в котором содержатся лексикографически упорядоченные имена студентов, слушающих в данный момент курс программирования CS100 (рис. 2.3.1, а). Если студенты ГРАНТ и РУЗВЕЛЬТ перестают посещать курс, а новый студент ДЖЕФФЕРСОН добавляется, то нам бы хотелось получить новый список слушателей, приведенный на рис. 2.3.1, б. Подумайте о трудности и стоимости написания и выполнения программы, которая смогла бы перестроить массив CS100 в соответствии с этими изменениями. С другой стороны, связанный список представляет собой структуру данных, которая требует дополнительной памяти, но позволяет легко вносить такие изменения.
Связанные списки
На рис. 2.3.2, а массив CS100 преобразован из одномерного в двумерный массив CS100L. В столбце 1 массива CS100L по-прежнему содержатся фамилии студентов, зачисленных на курс CS100, хотя, как
явствует из рис. 2.3.2, б, теперь уже не требуется, чтобы эти фамилии были упорядочены по алфавиту. В столбце 2 массива CS100L содержатся неотрицательные целые числа, называемые связями или указателями, значениями которых являются номера строк массива, содержащих фамилию следующего студента (в алфавитном порядке) в текущем
CS100L ИНФО 1 СВЯЗЬ 2 CSlOOt ИНФО 1 СВЯЗЬ 2
1 ADAMS 2 1 ADAMS 2
2 BUCHANAN 3 2 BUCHANAN 4 *
ИСКЛЮЧИТЬ 3 GRANT 4 3 №
4 HARRISON 5 4 HARRISON 5
Б JACKSON 6 Б JACKSON 11 *
6 KENNEDY 7 6 KENNEDY 7
7 LINCOLN 8 7 LINCOLN 9 *
ИСКЛЮЧИТЬ в ROOSEVELT 9 8 //////////77/7// % ROOSEVELT7/^ ж
9 TRUMAN 10 9 TRUMAN 10
10 WASHINGTON 0 10 WASHINGTON 0
11 ДОБАВИТЬ 11 JEFFERSON 6 4
a 6
Рис. 2.3.2. Переорганизация связанного списка.
списке. Звездочкой (*) мы отметили те указатели, значения которых изменились в связи с удалением фамилий GRANT и ROOSEVELT и добавлением JEFFERSON. Заметим, что на рис. 2.3.2, б:
ADAMS указывает на BUCHANAN [CS100L (1, 2)=2 и
CS100L(2, 1)=BUCHANAN].
BUCHANAN указывает на HARRISON [CS100L(2, 2)=4
и CS100L(4, 1)=HARRISONL
JACKSON указывает на JEFFERSON.
JEFFERSON указывает на KENNEDY и т. д.
Массив CS100L(/, J) размера МХ2 работает как линейный связанный список. Линейный связанный список — это конечный набор пар, каждая из Которых состоит из информационной части INFO (ИНФО) и указующей части LINK (СВЯЗЬ). Каждая пара называется ячейкой. Если мы хотим расположить ячейки в порядке сц, ci2, . . . . . . , Cin, то СВЯЗЬ (tj)=ij+i для /= 1, .... п—1, а СВЯЗЬ(г‘п)=0 и указывает на конец списка.
На рис. 2.3.3, а приведена стандартная диаграмма линейного связанного списка; на рис. 2.3.3, б приведена диаграмма связанного списка с рис. 2.3.2, б. Заметим, что GRANT и ROOSEVELT отсутствуют в списке на рис. 2.3.3, б, хотя они присутствуют на рис. 2.3.2, б как
заштрихованные элементы. При реализации связанных списков участвует переменная FIRST (ПЕРВЫЙ) или HEAD (ГОЛОВА), значение которой есть адрес первой ячейки списка (рис. 2.3.3, а).
Как было указано выше, одно из главных преимуществ связанных списков заключается в том, что можно легко удалять и добавлять элементы списка. Далее мы приводим два алгоритма, которые можно использовать при выполнении модификаций, требуемых для преобразования рис. 2.3.2, а в 2.3.2, б.
Рис. 2.3.3. Диаграммы линейных связанных списков.
Первый алгоритм будет удалять заданный элемент из связанного списка. Этот процесс иллюстрируется на рис. 2.3.4, где мы ищем ячейку Ct, у которой ИНФО(1)=ТРИ, передвигая указатели PREV и PTR до тех пор, пока такая ячейка не найдена. Затем мы заменяем значение СВЯЗЬ в ячейке, на которую указывает PREV, на значение СВЯЗЬ в ячейке, на которую указывает PTR. Далее следуют блок-схема (рис. 2.3.5), формальное описание и реализация (рис. 2.3.6) этого алгоритма.
Algorithm DELETE (УДАЛЕНИЕ). Удаляется ячейка ct, у которой INFO (i)=VALUE из связанного списка, первая ячейка которого задается переменной FIRST.
Шаг 1. [Выбор первой ячейки] Set PTR FIRST; PREV 0.
Шаг 2. [Ячейка пуста?] While PTR=/=0 do шаг 3 od.
Шаг 3. [Это она?] If INFO (PTR)=VALUE then [Это первая ячейка?]
if PREV=0 then [удалить спереди]
set FIRST ^-LINK(PRT); and STOP
else [удалить изнутри]
set LINK(PREV)*-LTNK(PTR); and STOP fi
else [Выбор следующей ячейки]
set PREV^-PTR; PTR ч-LINK(PTR) fi.
Шаг 4. [He в списке] НАПЕЧАТАТЬ «ЗНАЧЕНИЕ НЕ В СПИСКЕ»;
and STOP.
Рис. 2.3.4. Удаление ячейки из связанного списка.
Следующий алгоритм будет вносить в связанный список новую ячейку. Предположим, что в списке ячейки упорядочены в порядке возрастания содержимого" поля ИНФО (INFO). Этот алгоритм аналогичен алгоритму DELETE (УДАЛЕНИЕ) в том отношении, что при выполнении операции внесения используются указатели PREV и PTR.
На рис. 2.3.7 проиллюстрирован процесс внесения, причем мы предполагаем, что
ОДИН < ДВА < ТРИ < ЧЕТЫРЕ
На рис. 2.3.8 и 2.3.9 приведены блок-схема и реализация следующего алгоритма:
Algorithm INSERT (ВНЕСЕНИЕ). Внести новую ячейку ROW (РЯД), где INFO (ROW)=VALUE, в упорядоченной связанный список, первая ячейка которого задается в FIRST (ПЕРВЫЙ).
Шаг 1. [Выбор первой ячейки] Set PTR FIRST; PREV <- 0. Шаг 2. [Ячейка пуста?] While PTR^O do шаг 3 od.
Начала
1 Выйрать первую ячейку
Шаг 3. [Предшествует ли новая ячейка выбранной?! И VALUE^INFO(PTR) then [вносится спереди?!
if PREV=0 then [внести новую ячейку спереди] set FIRST ч-ROW;
LINK(ROW) ч- PTR; and STOP
else [внесли новую ячейку внутрь] set LINK(PREV) ч-
ч- ROW; LIN К (ROW)
PTR; and STOP fi
else [Выбрать очередную ячейку]
set PR EV-c-PTR; PTRLINK (PTR) fi.
Шаг 4. [Список пуст?] If PREV=0
then [внести новую ячейку как единственную ячейку в списке] set FIRST «-ROW; LINK (ROW)«-0; and STOP else [внести новую ячейку в конец списка]
set LINK(PREV)«-ROW; LINK(ROW)«-0; and
STOP fi.
Списки смежности
В одном из эффективных способов представления сети G=(V, Е) используются связанные списки смежности. Это представление сильно напоминает векторы смежности (см. разд. 2.2), но, как правило, тре-
* SUBROUTINE DELETE IFIRST.INFO.LINK.VALUE» INTEGER INFO(SOO).LINKC500».FIRST.VALUE.PREv.PTR C С ВЫБОР первой ячейки G
PTR S FIRST PREV s О c С ПРОВЕРКА, HE ПУСТА ЛИ ЯЧЕЙКА. V
5. IF t НТК «НЕ» 0 J СОТО 20
Ю URlTEtS.IOOOI
jooq рокпдтаан value not du list»
RETURN c С ПРОВЕРКА, НУЖНАЯ ДИ ЯЧЕЙКА G
20 IF I INFO(PTR) «НЕ» VALUE I GOTO 60 1C С ТОГДА (ЭТО ПЕРВАЯ ЯЧЕЙКА?)
IF < PREV »NE. 0 J СОТО Stf с ТОГДА (УДАЛИТЬ СПЕРЕДИ)
^tgi FIRST S J.1NKIPTR»
RETURN c С ИНАЧЕ (УДАЛИТЬ ИЗНУТРИ}
SO LINK(PREV) » tINKiPTRI
RETURN C
« ВЫБОР СЛЕДУЮЩЕЙ ЯЧЕЙКИ £0 PREV = PTR
PTR = LIKK(pTRJ СОТО 5 c
ENO
Рис. 2.3.6. Реализация алгоритма DELETE.
Рис. 2.3.7. Внесение ячейки в связанный список.
бует меньше памяти. На рис. 2.3.10, в приведено представление сети G с рис. 2.3.10, а в форме связанного списка. Это представление зависит как от разметки вершин vlt v2, . . ., vM, так и от порядка, в котором задаются ребра G (случайное упорядочение ребер приведено на рис. 2.3.10, б).
Чтобы определить, какие вершины являются смежными для данной вершины при представлении в форме связанного списка, мы должны следовать указателям в столбце с названием NEXT. Например, для того чтобы найти вершины, смежные с вершиной 3, мы определяем, что NEXT(3)=12. Проверяя двенадцатую строку, мы видим, что ADJ (12)=4, т. е. вершина 3 смежна вершине 4. Мы также видим, что NEXT (12)=7. Так как ADJ (7)=1, вершина 3 смежна с вершиной 1...
Начало
Выбрать первую ячейку
Рис. 2.3.8. Блок-схема алгоритма INSERT (ВНЕСЕНИЕ).
И*наконец, так как NEXT (7)=0, вершина 3 не смежна ни с какой другой вершиной.
Это представление требует 2(Л4-1-2А) слов памяти, где М — число вершин и А — число ребер в G. Заметим, что 2М этих слов ADJ (1), . . . , ADJ (М) и М слов, для которых NEXT (0=0, имеют значение, равное 0. Впрочем, первые М слов массива ADJ могут быть использованы для хранения полезной информации о вершинах vlr v2> . . . , v^. Например, в них можно запоминать значения степеней dt для Vt.
ООП ПП'О ООО ОПП ППО ОПП ООО 000 ПОП ООО
SUBROUTINE INSERT (FIRST,INFO,LINK,ROW,VALUE)
INTEGER INFO(5001 «LINK(500),FIRST,ROW,VALUE,PREV,PTR
ВЫБОР ПЕРВОЙ ЯЧЕЙКИ.
РТР = FIRST PREV = 0
ПРОВЕРКА, ПУСТА ЛИ ЯЧЕЙКА.
5 IF ( PTR .NE. 0 ) GOTO 40 ТОГДА (ПУСТ ЛИ. СПИСОК)
10 IF С PREV .NE. 0 ) GOTO 30
ТОГДА (ВКЛЮЧЕНИЕ ЯЧЕЙКИ КАК ЕДИНСТВЕННОЙ В СПИСКЕ)
20 FIRST = ROW
LINK(ROW) = 0 RETURN
ИНАЧЕ (добавление ячейки в конце списка)
30 LINK(PREV) = Row
LINK(ROW) = 0 RETURN
ПРОВЕРИТЬ, ПРЕДШЕСТВУЕТ ЛИ НОВАЯ ЯЧЕЙКА ВЫБРАННОЙ
40 IF ( VALUE .GT. INFO(PTR) ) GOTO 60
ТОГДА (ВНОСИТСЯ ЛИ ОНА СПЕРЕДИ)
50 IF ( PREV .NE. О ) GOTO 70
ТОГДА (ДОБАВИТЬ ЯЧЕЙКУ СПЕРЕДИ)
60 FIRST = ROW
HNK(ROW) = PTR RETURN
ИНАЧЕ (ДОБАВИТЬ ЯЧЕЙКУ ВНУТРЬ)
70 LINK(PREV) = ROW
LINK(ROW) = PTR RETURN
ВЫБОР НОВОЙ ЯЧЕЙКИ
80 PREV = PTR PTR = LINK(PTR) GOTO 5
END
Рис. 2.3.9. Реализация алгоритма INSERT (ВНЕСЕНИЕ).
ADJ NEXT
15
19
12
18
17
3 С
1 0
1 0
4 6
5 0
2 0
4 7
3 8
1 10
2 9
5 13
4 11
2 16
4 14
в
Рис. 2.3.10. Представление сети в форме связанного списка.
На рис. 2.3.11 приведен фрагмент программы на Фортране, с помощью которого можно получить списки смежности на рис. 2.3.10, в по ребрам, заданным в порядке, указанном на рис. 2.3.10, б.
Стековые списки и стеки
Мы увидели, что (линейные) связанные списки — это эффективная структура данных для моделирования ситуаций, в которых подвергаются изменениям упорядоченные массивы элементов данных. В частности, это справедливо для случая, когда модификациями являются главным образом внесение элементов в середину массивов или удаление элементов из середины массива. Когда модификации касаются лишь начала и конца, необходимость в связанных списках исчезает, и становятся достаточными простые линейные (одномерные) массивы.
В качестве примера рассмотрим следующую задачу. Во всех компиляторах с языков программирования требуется узнавать, является
ли произвольное выражение правильно построенным. В частности, нужно определять, правильно ли расставлены в выражении скобки. Например, последовательность
()(()()) представляет правильную последовательность скобок, а ()((()())
неправильную (есть лишние левые скобки). В более широком математическом контексте в арифметическом выражении обычно встречаются также квадратные скобки [ ] и фигурные скобки { }.
DO 1 I = 1.100 ADJ(I) = О NEXT(I) = О 1 CONTINUE С С ВВОД ЧИСЛА ВЕРШИН Р
С
READ<5.1000)P 2000 F0RNAT(2J3> С
I = Р+1 . ‘ С С ВВОД РЕБЕР (M.N) ДЛЯ G
С 100 READ(5tlOOO)MiN
С С ЕСЛИ М ОТРИЦАТЕЛЬНО,
С БОЛЬШЕ РЕБЕР НЕТ
IF ( М .LT. 0 > GOTO 200 С
ADJ(I> = N NEXT(I) = NEXTCH». NEXT(H) = J I = 1+1 ADJ(I) = И NEXT(I) = fJEXT(N> NEXT(N) = X I = 1+1 C с ВВОД НОВОГО РЕБРА
С
GOTO 100 с с ПРОДОЛЖЕНИЕ ПРОГРАММЫ
200 •
Рис. 2.3.11. Фрагмент программы для представления сети в форме связанного списка.
Предположим, что вас попросили разработать алгоритм определения того, что произвольная последовательность круглых, квадратных и фигурных скобок является правильно построенной. Что мы понимаем под правильно построенной последовательностью? Обычное определение состоит в следующем:
1. Последовательности ( ), I ] и { } являются правильно построенными.
2. Если последовательность х правильно построенная, то правильно построены и последовательности (х), [х] и {х}.
3. Если последовательности х и у правильно построенные, то такова же и последовательность ху.
4. Правильно построенными являются лишь те последовательности, правильность которых следует из конечной последовательности применений правил 1, 2 и 3.
Это определение определяет правильно построенные последовательности конструктивно. Например, следующие последовательности являются правильно построенными:
Элемент
Последовательность
Образована с помощью правил
а ( ) 1
б [( )] 2 и я
в {[( )]} 2 и б
г {[( )]}{ } 1, 3 и в
д ({[( )]}{ }) 2 и г
е [ ]({[( )]}{ }) 1, 3 и д
ж {[ ]({[( )]}{ })} 2 и е
Обычно, чтобы установить, являются ли выражения такого типа
правильно построенными, используют стековую память (или просто
стек), которая представляет собой бесконечную в одну сторону после-
довательность слов памяти, как изображено на рис. 2.3.12.
Вершина
Рис. 2.3.12. Диаграмма стековой памяти.
Для запоминания элемента данных в стеке элемент заносят в верхнее слово ТОР (ВЕРШИНА), сдвигая тем самым вниз (по одному слову) все другие слова, хранящиеся в стеке (совершенно аналогично тому, как в столовой складывают подносы в стопку). Выбор элементов данных из стека возможен лишь считыванием по одному за раз из слова ТОР, причем все остальные элементы данных сдвигаются вверх.
Мы не имеем права выбирать элементы данных внутри стека. (В столовой мы обычно не выбираем двадцатый поднос из стопки подносов.) Иногда термин «стек» обоз
начает стековую память, когда нам разрешено считывать элементы, находящиеся ниже слова ТОР, но не разрешается изменять их значения или добавлять новые элементы ниже слова ТОР.
Покажем на примере, как стековая память помогает нам легко определить, является ли такая последовательность, как £={[ ] ({[( )П{ })}. правильно построенной. Элементы g будем обозначать Xi, х2, . . . , Хп, где хг есть одна из скобок {, }, (, ), [ или ]. Элементы {, ( и [ назовем ЛЕВЫМИ символами; скажем, что Xi — левый партнер Xj, если хг—[ и х;=], или хг=( и xj=), или Xi={ и Х;=}.
Algorithm WELLFORMED (ПРАВИЛЬНО ПОСТРОЕННАЯ). Определяет, является ли произвольная последовательность символов хрсг. . .xN, где каждый xt — одна из скобок {, }, (, ), [, или ], правильно построенной.
Шаг 0. [Инициализация] Set ТОР ч- 0; / -«- 1.
Шаг 1. [Читается последовательность слева направо]
While do through шаг 3 od.
Шаг 2. [Записывается в стек ЛЕВЫЙ символ]
If хг ЛЕВЫЙ символ then [записывается хг] else [выбирается символ из стека] if ТОР левый партнер
then выбрать элемент ТОР из памяти else НАПЕЧАТАТЬ «НЕПРАВИЛЬНО ПОСТРОЕННАЯ»; and STOP fi fi.
Шаг 3. [Прочесть следующий символ] Set I -е- /+1.
Шаг 4. [Память пуста?] If ТОР=0 then PRINT «ПРАВИЛЬНО ПОСТРОЕННАЯ»;
else PRINT «НЕПРАВИЛЬНО ПОСТРОЕННАЯ» fi; and
STOP.
Применим теперь алгоритм ПРАВИЛЬНО ПОСТРОЕННАЯ к последовательности
SF={ []({[()]} { } ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
На рис. 2.3.13 приведено содержимое стека, соответствующее операциям чтения элементов изg слева направо. Целое значение над Z-й конфигурацией стека указывает на то, что в данный момент' читается хгй символ.
Для реализации стека на Фортране мы возьмем одномерный массив STORE [описанный как STORE (Л4)1 и целую переменную с именем ТОР. Всегда, когда нам нужно поместить на вершину стека элемент А(/), мы выполняем следующие простые команды:
ТОР=ТОР+1
IF (TOP. GT. М) GO ТО 100 STORE (ТОР) = X (I) GO ТО 200
100 PRINT «ПЕРЕПОЛНЕНИЕ СТЕКА»
200
CONTINUE
Рис. 2.3.13. Конфигурации стековой памяти при работе алгоритма WELL-FORMED (ПРАВИЛЬНО ПОСТРОЕННАЯ).
Далее для выбора элемента выполняются следующие команды:
IF (TOP. EQ. 0) GO ТО 300
X(I) = STORE(TOP)
ТОР = ТОР —1
GO ТО 400
300 PRINT «СТЕК ПУСТ»
400 CONTINUE
Очереди
В стековой памяти для внесения и удаления элементов можно пользоваться только словом ТОР. В очереди элементы добавляются с одного конца, а выбираются с другого. Эти элементы обычно называются началом (FRONT) и концом (REAR) очереди. Термин «очередь» вы
бран потому, что эти структуры данных часто используются для моделирования обслуживающих линий, например люди в очереди к парикмахеру, автомобили у светофора, очередь заданий операционной системы.
Рис. 2.3.14. Реализация
очереди с использованием линейного массива,
Для моделирования очереди, как правило, используют линейный массив [например, QUEUE (500)] и две целые переменные FRONT и REAR, которые указывают на первые и последние элементы очереди соответственно. Вначале REAR^FRONT, но когда к очереди добавится свыше 500 элементов, то, по-видимому, некоторые записи будут удалены из начала очереди. Если это так, то, чтобы не допустить переполнения массива, мы присваиваем REAR=1 и продолжаем заполнять очередь с начала массива. Впрочем, REAR никогда не должен перегонять FRONT.
На рис. 2.3.14 показано то, что называется ситуацией одна очередь — одно обслуживание. В этом примере емкость очереди 5, конкретные клиенты помечены метками от А до Н, первый ожидающий в очереди клиент обслуживается за три единицы времени, после чего он покидает очередь. В момент Т=0 очередь пуста, и значения FRONT (F) и REAR (F) равны нулю. В момент Т — 1 прибывает А, ждет 3 единицы времени и покидает очередь в момент Т=4. Клиенты В, C,D, Е, G и Н прибывают в моменты времени 2, 3, 4, 7, 8 и 9 соответственно. С ждет 4 единицы, прежде чем продвинуться в начало очереди, и покидает ее в момент 7'=10. Когда прибывает G, в момент Т=8, конец очереди находится в массиве в положении 5. Здесь мы помещаем G в положение 1 очереди и присваиваем R = 1. Когда в момент Т=9 прибывает Н, в R засылается 2, в этот момент очередь полностью заполнена. Теперь конец очереди сравнялся с ее началом, и, пока С не покинет очередь, в нее становиться нельзя.
Подпрограмма QADD (рис. 2.3.15) добавляет элемент VALUE к очереди. Предполагается, что, когда очередь пуста, FRONT = REAR= =0. Процесс удаления элемента из очереди аналогичен. Подпрограмма QDELET (рис. 2.3.16) выполняет эту работу; при удалении из оче
реди последнего элемента программа присваивает величинам FRONT и REAR значения, равные 0. В разд. 3.6 очереди будут рассмотрены с точки зрения моделирования.
SUBROUTINE QAOO (QUEUE.N.FRONT.REARtVALUE) INTEGER QUEUE(N).FRONT.REAR.value c С ПРОВЕРКА, ПУСТА ЛИ ОЧЕРЕДЬ.
IF < REAR ,NE, 0 > GOTO 20 C
С ТОГДА (ДОБАВИТЬ ПЕРВЫЙ ЭЛЕМЕНТ)
. 10 FRONT = 1 REAR = 1 GUEUE(l) = VALUE ’ RETURN
С ПРОВЕРКА, REAR=N?
C
20 IF ( REAR ,NE. N ) GOTO 40 C
С ТОГДА (УСТАНОВИТЬ ЗНАЧЕНИЕ REAR=0) С
30 REAR = О С С ПЕРЕДВИНУТЬ REAR.
С
40 REAR = REAR+1 С
С ПРОВЕРКА, НЕ ПЕРЕПОЛНИЛАСЬ ЛИ ОЧЕРЕДЬ.
IF ( REAR .НЕ. FRONT ) GOTO 60 С С ТОГДА С 50 WRITE(6(1000)
1000 F0RMAT(14H QUEUE IS FULL)
REAR s REAR-J IF ( REAR ,EQ. 0 ) REAR x N RETURN
c
С ИНАЧЕ (ДОБАВИТЬ К REAR) С 60 QUEUE(REAR) = VALUE RETURN END ;
Рис. 2.3.15. Подпрограмма, добавляющая к очереди один элемент. (Текст в операторе 1000: «Очередь полна».)
Деревья
Линейные массивы можно также использовать для компактного представления деревьев определенного вида. Пусть Т — дерево с М вершинами, в котором вершины помечены целыми числами 1,2,... , М. Говорят, что дерево Т рекурсивно помечено (или рекурсивное), если каждая вершина с меткой больше 1 смежна ровно с одной вершиной, у которой метка имеет меньшее значение. На рис. 2.3.17 приведены примеры рекурсивного дерева 7\ и нерекурсивного дерева Т2.
SUBROUTINE QDELET (QUEUE,N.FR0Nt,REAR,VALUE» INTEGER QUEUE(N)«FRONT,REAR,VALUE
c
С ПРОВЕРКА, ПУСТА ЛИ ОЧЕРЕДЬ.
IF ( REAR .NE. 0 J GOTO 20 c С ТОГДА c
10 URITE(6,1OOOJ
10QO FORMAT(15H QUEUE' IS ЕМРТТ»
RETURN
c
с проверка: остался ТОЛЬКО ОДИН ЭЛЕМЕНТ?
с
20 IF С front .NE. REAR > СОТО *0 с с ТОГДА (УСТАНОВИТЬ ПУСТУЮ ОЧЕРЕДЬ) с
30 VALUE = OUEUEVFROnTJ REAR = о RETURN
С
С УДАЛИТЬ ИЗ ОЧЕРЕДИ ЭЛЕМЕНТ И ПЕРЕДВИНУТЬ-
С Front
АО VALUE = QUEUE(FRONT) FRONT = FRONT+1
С
С ЕСЛИ FRONT >N, ТО УСТАНОВИТЬ FRONT-1.
С
IF ( FRONT .GT. N 1 FRONT = 1 RETURN
C END
Рис. 2.3.16. Подпрограмма, удаляющая из очереди один элемент. (Текст в операторе
1000: «Очередь пуста»).
Рис. 2.3.17. Рекурсивное дерево Т± и нерекурсивное дерево Т2.
На примере линейного массива ДЕРЕВО показано, как компактно можно представить рекурсивное дерево Тг, ДЕРЕВО (I)—J обозначает, что вершина I смежна вершине J.
123456789 10
0111245451 TREE
Упражнения 2.3
2.3.1. Какие структуры данных вы использовали бы для каждого из следующих множеств данных: (а) план посадочных мест; (б) таблица среднего роста как функции веса, пола и возраста; (в) множество всех подмножеств М элементов; (г) колода карт; (д) множество k людей и отношение X знаком с Y; (е) игра в шашки; (ж) л=3,14159... ; (з) организационная иерархия; (и) множество значений одной случайной переменной? Заметьте, что вам может понадобиться хранить кое-какую дополнительную информацию (например, потенциальное применение данных, желаемая точность л), поэтому не торопитесь с ответом для некоторых множеств данных.
2.3.2. Большие целые. Напишите программу для работы с очень большими целыми числами, т. е. целыми числами, для которых недостаточен размер машинного слова. Более конкретно, вы могли бы попытаться вычислить большое число из ряда Фибоначчи или значение факториала.
L2.3.3. Железнодорожная станция. Разработайте и реализуйте на вычислительной машине функционирование небольшой сортировочной железнодорожной станции. Поезда будут прибывать в соответствии с некоторым расписанием. Вагоны прибывающих поездов должны быть перераспределены и сформированы в отбывающие поезда, уходящие в различные пункты назначения в соответствии с другим расписанием. Могут прибывать также пустые вагоны, принадлежащие другим железным дорогам. Последние нужно комплектовать и периодически возвращать владельцам.
2.3.4. Рассмотрите некоторые преимущества и недостатки использования связанных линейных списков в сравнении с последовательными линейными списками. Обратите особое внимание на вопросы объема памяти, добавления, удаления и доступа к элементам списка.
2.3.5. Напишите две подпрограммы, которые будут (а) удалять и (б) добавлять элемент в хорошо упорядоченный массив CSIOO(N). Сравните их скорость и эффективность с подпрограммами DELETE и INSERT для связанных списков.
2.3.6. Напишите подпрограммы, которые будут (а) добавлять элемент в начало связанного списка, (б) добавлять элемент в конец связанного списка и (в) распечатывать содержимое всех ячеек связанного списка.
2.3.7. Перестановки (стеки). Пусть целые 1, 2, 3, 4 прибывают в естественном порядке на вход стека. Рассмотрев все возможные последовательности операций занесения в стек и выборки из стека, определите, какие из 24 возможных перестановок можно получить на выходе. Например, перестановку 2314 можно получить, применив такую последовательность действий: занести 1, занести 2, выбрать 2, занести 3, выбрать 3, выбрать 1, занести 4, выбрать 4.
2.3.8. Перестановки (деки). Дек (очередь с двумя входами) — это линейный список, для которого все операции внесения, удаления и доступа можно производить с любого конца списка. Измените упр. 2.3.7 для дека.
2.3.9. Моделирование (очереди). Напишите программу, моделирующую линию ожидания емкостью в 10 человек, если для обслуживания клиента и удаления его из очереди требуются 2 единицы времени, Вероятность появления одного нового клиента в
течение 1 единицы времени равна р, где 0<р<1. В течение единицы времени никогда не появляются два и более клиентов. Последите за переполнением очереди как за функцией от р.
2.3.10. Замкнутые связанные списки. На рис. 2.3.18 приведен пример замкнутого связанного списка. Можете ли вы придумать какое-либо применение для этой структуры данных. Попытайтесь реализовать одну из ваших идей.
2.3.11. Работа со связанными списками. Разработайте алгоритмы, выполняющие для списков с одной связью следующее:
(а) Преобразование связанного списка в замкнутый связанный список (см. упр, 2.3.10).
(б) Обьединение двух списков, в каждом из которых ячейки INFO упорядочены лексикогр афически.
(в) Преобразование связанного списка в последовательный список (обычный одномерный массив).
2.3.12. Упакованное десятичное представление. Разберитесь, что имеется в виду, когда говорят «упакованное десятичное представление целых чисел» (см. [77], стр. 37). Каковы преимущества и недостатки этого представления?
*L2.3.13. Шах. Напишите программу, которая будет считывать шахматную позицию и определять, не находится ли один из королей под шахом. Можно затем попытаться определить, не является ли шах матом.
2.3.14. Переполнение стека. Нужно попытаться разместить два стека в одном фиксированном блоке памяти, организованном как интервал последовательных адресов. Как следовало бы расположить стеки, чтобы минимизировать трудности, возникающие в связи с переполнением,
**L2.3.15. Кроссворды. Напишите программу составления кроссвордов. Предположим, что исходными данными является конфигурация 6x6 (некоторое расположение пустых и заполненных квадратов) и список слов, состоящих из шести или менее букв. Результатом должно быть расположение этих слов, образующее общепринятый кроссворд, или сообщение о том, что такая конфигурация невозможна.
*2.3.16. Рекурсивные деревья. Разработайте алгоритм построения единственного пути в рекурсивном дереве Т между произвольно заданными вершинами и и о, используя компактное линейное представление на рис. 2.3.17. Указание- Можно построить алгоритм, просматривающий это представление справа налево один раз,
2.4. Элементарные понятия теории вероятностей и статистики
Очень много важных задач содержат в той или иной степени неопределенность. Представляющие интерес величины заранее непредсказуемы, а имеют случайный, характер, который должен быть отражен в любой корректной модели. Модели такого типа называются вероятностными.
В данном разделе мы будем рассматривать некоторые понятия из теории вероятностей и статистики. Ниже кратко описаны некоторые применения этого аппарата к разработке и анализу алгоритмов.
1. Анализ средней трудоемкости алгоритма. Предположим, что У нас есть алгоритм (алгоритм S), оптимизирующий (в некотором смысле) порядок выполнения заданий на вычислительной машине. К числу важнейших факторов, определяющих время работы алгоритма, относятся общее число (N) и типы заданий, ожидающих выполне
ния. Если все задания простого типа, то алгоритм S может построить расписание за время 0(N). Но если все задания очень сложные, то алгоритм S требует O(7V3 4) времени. Предположим, что между этими
Рис. 2.3.18.
крайними случаями имеется 12 различных типов заданий и что пакеты, как правило, содержат смесь из заданий различных типов. Насколько хорош наш алгоритм? Чтобы ответить на этот вопрос, нам нужно знать, каково среднее, представительное множество заданий. Затем мы должны решить, насколько хорошо работает алгоритм в среднем. Отсюда следует необходимость точно определить, что такое «среднее». Возможно, что худший случай О (Л/4) для операционной системы неприемлем; например, может оказаться, что вся система будет бездействовать в ожидании, пока подпрограмма не составит расписание. Если худший случай встречается редко и средняя трудоемкость алгоритма равна О (№/*), то можно использовать алгоритм S в операционной системе. С другой стороны, если средний режим О (Л/4), мы, по-видимому, будем вынуждены применить какой-то другой быстрый, грубый, эвристический алгоритм, не гарантирующий оптимального расписания. На этом примере отчетливо виден ряд важнйх моментов, связанных с анализом алгоритмов.
2. Моделирование. Одним из самых важных применений вычислительной машины является ее использование в качестве средства проведения управляемых экспериментов на сложных реальных системах за короткое время и при относительно низких затратах. Для этого строят алгоритм, моделирующий реальную систему. Во многих отношениях это крайнее средство. К моделированию прибегают, как правило, когда задачи безнадежно превышают наши аналитические возможности и сочетают в себе трудоемкость и неопределенность. В сущности, все серьезные модели вероятностны.
3. Вычислительная статистика. Вычислительную машину часто используют для обработки и анализа статистической информации. Необходимо разрабатывать и анализировать алгоритмы, выполняющие статистические вычисления аккуратно и эффективно.
4. Алгоритмы принятия решений. Вычислительная машина становится все более популярной в мире коммерции и государственного управления как помощник при решении важных вопросов. Все задачи
в этой области существенно включают процесс принятия решений в условиях неопределенности.
Рассмотрим, например, следующую задачу. В текущий момент правительство поддерживает ряд административных и обслуживающих агентств. В условиях катастрофического уменьшения бюджета некоторое число агентств необходимо упразднить или сильно ограничить их в средствах. Имеется огромный объем данных, относящихся к прошлой, настоящей и будущей деятельности этих агентств. Как принять решение? Один из самых обещающих количественных методов разрешения таких проблем известен как теория статистических решений Байеса. К сожалению, в этой теории совершенно отсутствуют хорошие вычислительные алгоритмы. В настоящее время ее полезность ограничивается относительно простыми задачами.
5. Генерация случайных чисел. Почти во всех предыдущих приложениях теории вероятностей и статистики требуется средство внесения в данные неопределенности. Хотелось бы, если возможно, делать это с помощью механизма, внутреннего по отношению к самой вычислительной машине, избегая дорогостоящей и потребляющей много времени внешней активности. Разработка и анализ хороших алгоритмов генерации случайных данных — это серьезная самостоятельная проблема.
Мультипроцессорные системы
Начнем с простой задачи. Имеется мультипроцессорная система с пятью идентичными процессорами. На этой системе нужно пропустить большую сложную программу. Программа требует трех из пяти процессоров и не может быть загружена, если число свободных процессоров меньше трех. Какова вероятность того, что мы сможем загрузить программу в тот момент, когда мы готовы работать с ней?
Каждая вероятностная модель формулируется в терминах эксперимента. Эксперимент — это любое точно определенное действие. В нашем примере эксперимент состоит в том, чтобы определить, сколько в системе свободных процессоров. С каждым экспериментом мы можем связать множество исходов. Пометим наши пять процессоров целыми числами от 1 до 5. Один возможный исход эксперимента может быть тогда обозначен вектором с 5 компонентами (1,0, 1,0, 0), что означает состояние системы, когда процессоры 1 и 3 заняты, а процессоры 2, 4 и 5 свободны. Если система находится в этом состоянии, то программа будет принята. Множество всех возможных исходов называется пространством элементарных событий эксперимента. Используя 5-компонентное представление, можно увидеть, что в нашем мультипроцессорном эксперименте имеется 25 элементов пространства элементарных. событий. Ниже все они явно перечислены:
5, = (0,0,0,0,0) 5г=(1.0,0,0,0) s3=(0,1,0,0,0) S4=(0,0,1,0,0) S5=(о, 0,0,1,0) 56=(0,0,0,0,1) ®7=(1.1,0,0,0) $8= (1,0,1,0,0) 5э=(1,0,0,1,0) 510= (1,0,0,0,1) 5ц = (0,1,1,0,0)
51г = (0,1,0,1,0) 5,3= (0,1,0,0,1) 5,4= (о, 0,1,1,0) Sis=(0,0,1,0,1) 51в=(0,0,0,1,1) Si7=(0,0,1,1,1)
S13 = (O,1,0,1,1) 51э = (0,1,1,0,1) 52о = (0,1,1,1,0) 521 =(1,0, 0, 1,1) 5гг= (1.0,1,0,1)
52з=(1,0,1,1,0) 524 = (1,1,0,0,1) 5гз=(1,1,0,1,0) 52з=(1,1,1,0,0) 527=(О,1,1,1,1) 52з=(1,0,1,1,1) 529=(1,1,О,1,1) 5so = (1,1,1,0,1) 5з, = (1,1,1,1,0) 5й-(1,1,1.1,1)
Пусть S={si, s2, s3, . .} — пространство элементарных событий эксперимента. Предположим на время, что S содержит конечное или бесконечное счетное число элементов. Событие — это любое подмножество пространства элементарных событий. Обычно событие словесно выражается в терминах эксперимента, а затем переводится на язык подмножества S. Рассмотрим, например, следующее событие: заняты по крайней мере четыре процессора. В терминах S это событие состоит из всех исходов, которые представляют состояния системы, когда используются четыре или пять процессоров, т. е.
£={(0, 1, 1, 1, 1), (1, 0, 1, 1, 1), (1, 1, 0, 1, 1), (1, 1, 1, 0, 1), (1, 1,
1, 1, 0), (1, 1, 1, 1, 1)}=
{$27’ $28> $29. $30, Set, S32}.
Единичный акт эксперимента называется испытанием. Пусть Е — событие, определенное в пространстве S. Если исход испытания эксперимента принадлежит Е, то мы говорим, что событие Е произошло. При каждом испытании может иметь место только один исход s в S. Однако тем самым произойдет каждое событие, включающее s.
События могут быть сформированы из других событий с помощью стандартных операций над множествами: объединения, пересечения и дополнения. Если
Ei = событие, состоящее в том, что заняты по крайней мере четыре процессора,
и Е2 = событие, состоящее в том, что заняты самое большее четыре процессора,
то Е3 = Et П Ез= событие, состоящее в том, что заняты в точности четыре процессора =
{(0, 1, 1, 1, 1), (1, 0, 1, 1, 1), (1, 1, 0, 1, 1), (1, 1, 1, 0, 1), (1, 1, 1, 1, 0)}=
{$27, $28> $29’ $30» $31}-
При чтении П читается как и, и как или и дополнение как не.
Если £i и £2 — любые два непересексиощихся события (т. е. Ei п f) £2=0), то они называются несовместными. Если £х и £2 — несов
местные события, то невозможно, чтобы при одном и том же испытании произошли оба события. В рассматриваемом примере, если
£i — процессор 1 занят и Е2 = процессор 1 свободен,
то £i п£2=0- Проверьте это, явно перечислив все элементы £i и £2.
Теперь мы готовы начать обсуждение вероятности. Сначала попытаемся сформулировать стандартное интуитивное понятие вероятности с помощью нашего нового словаря. Нас интересует вероятность того, что данное событие случится в результате эксперимента S- Эксперимент S повторяется N раз, причем N — большое число. Каждое испытание дает исход из S. Этот исход либо в £, и в этом случае событие £ произошло, либо нет. Предположим, что событие £ произошло п раз в N испытаниях. В этом случае мы склонны определить вероятность события £ как
Р(Е) = ±.
Данное число можно интерпретировать как относительную частоту появления события £ при выполнении эксперимента S', в этом сущность частотной интерпретации вероятности.
Очень важно понять, что частотная интерпретация не является существенной частью теории вероятностей, хотя она и очень популярна и полезна на практике. Теория вероятностей построена на формальной аксиоматической базе, которую не следует отбрасывать как бесполезную абстракцию чистой математики. Аксиоматическая теория определяет все правила, используемые при подсчете вероятности. Как мы увидим, эта теория обладает фундаментальными слабостями, и частотная интерпретация дает один из возможных способов справиться с этими слабостями.
Пусть S — пространство элементарных событий эксперимента S-Пусть Р — связанная с S мера вероятности, которая ставит в соответствие некоторым событиям Es.S действительное число £(£), называемое вероятностью события Е. Эти вероятности должны удовлетворять трем основным правилам (называемым аксиомами)'.
I P(£)^sO для любого £sS;
II £(£)=!;
Ill P(£1u£2)=P(£i)+£(£2)> если Ei и £2 несовместны, т. е. если £i п £2=0.
Как только этим «некоторым» событиям приписываются вероятности, согласующиеся с перечисленными тремя аксиомами, становится возможным (в принципе) вычислять вероятность любого другого события, определенного на S, пользуясь приписанными вероятностями и тремя аксиомами.
По-видимому, самый трудный аспект в построении вероятностных моделей — это установление вероятностей событий. Общая теория не
говорит нам, как для данной конкретной задачи решить, какие выбрать события и какие им приписать числа. Этот выбор целиком оставляется человеку, анализирующему задачу. Обычно вероятности устанавливаются на базе эксперимента и частотной интерпретации. Другой широко распространенной схемой является схема равновероятного распределения, которая описана в следующем разделе. Очень важно понять, что этот выбор при моделировании может сильно повлиять (и влияет!) на полезность самой модели. Теория нейтральна; она будет давать предсказания независимо от выбора конкретных значений. Но, если выбор значений сделан недостаточно точно, предсказания станут неверными и не будут отражать поведение моделируемой задачи из «реального мира».
Вернемся к нашей мультипроцессорной задаче. Предположим, что надежные экспериментальные данные показывают, что каждое из 32 состояний пространства S с равной вероятностью может быть фактическим состоянием системы (исходом) в любом испытании. Поэтому перед испытанием у нас нет оснований предпочитать какое-либо одно состояние другому. Отметим, что все 32 элемента в S взаимно исключают друг друга *). Используя метод индукции и аксиомы II и III, легко показать покажите!), что
P(S)=P(S1)+P(s2)+. . .+P(s3I)+F(s32)=l 2>.
Так как каждое состояние равновероятно, то
P(Sl)=P(s2)=. . ,=F(s32)=1/32.
Итак, основные значения вероятностей установлены.
Теперь мы можем решить нашу мультипроцессорную задачу. Какова вероятность того, что мы сможем загрузить нашу программу, когда она готова к выполнению? Интересующее нас событие — это
Е = свободны три или более процессоров.
В терминах элементов множества S
Е {sj, s2, . . . , Sj6, s10}.
Следовательно,
P (£) = F (Sj U s2 U ... USi„) =
= P (Si) + P (s2) + •. + P (s16) =
_1 ,_L, , LL=16 = 1
32^’32 ‘ ’ ‘32 32 2 ’
Таким образом, нам, по-видимому, удастся загрузить программу в половине попыток, учитывая, что мы пользуемся моделью с равными
х) Напомним, что s17D.s18=(0, 0, 1, 1, l)f](0, 1, 0, 1, 1)=0Г, а не (0, 0, 0, 1, 1). Это не характеристические векторы (см. приложение Б); не забывайте их интерпретацию.
2) Заметьте, что S=3iUs2U- • -Us3iUs;i2-
вероятностями и частотной интерпретацией конечного результата. Если система работает в более тяжелом режиме и состояниям s27, . . . ..., s32 соответствуют большие вероятности, чем состояниям st, ..., s26, то теория предскажет меньшие шансы на успех.
Очень заманчиво всегда подходить к решению вероятностных задач, используя основную процедуру, описанную в этом примере. Сформулируем ее:
1. Идентификация пространства элементарных событий S.
В этой книге S будет часто содержать конечное число элементов. Пытайтесь выбирать S так, чтобы все его элементы были несовместными и в совокупности исчерпывающими, т. е. чтобы никакие два события не могли произойти одновременно и чтобы при каждом испытании происшедшее событие входило в множество Sх).
2. Присваивание вероятностей. Присвойте вероятности элементам S. Это присваивание должно согласовываться с аксиомами I, II и III. Пространство S должно состоять из конечного числа несовместных и в совокупности исчерпывающих элементов. Поэтому вероятности должны быть присвоены элементам S таким образом, чтобы сумма всех присвоенных значений равнялась 1. (Почему сумма должна быть равна 1?)
3. Идентификация событий решения. Переведите искомое решение на язык событий из S.
4. Вычисление искомых вероятностей. Используя правила вычисления (аксиомы I, II и III и другие правила из упражнений), подсчитайте искомые вероятности.
Хотя вывод большинства формул для подсчета вероятностей оставляется в качестве упражнений, есть одно настолько важное правило, что мы должны обсудить его очень подробно. Оно известно как формула условной вероятности. Пусть Е и F — два события, определенные в пространстве S, и пусть Р (Е) и Р (F) — вероятности, соответствующие этим событиям. Пусть P(E\F) обозначает вероятность события Е при условии, что произошло событие F. Как правило, Р (Е)^=Р (E\F). Как только мы знаем, что событие F произошло, вычисление вероятности Е зависит уже не от всего пространства S; теперь нам нужно рассматривать только те элементы S, которые обусловливают выполнение события F. Все это учитывается автоматически в формуле
Р (Е ] F) — ~]гцлр~ (имеет смысл, только когда Р (F) =# 0).
Проверим формулу условной вероятности на нашем мультипроцессорном примере. Предположим, что на пути в машинный зал для за-
J) Более формально, множество подмножеств А±, ... , Ап в S состоит из несовместных и в совокупности исчерпывающих подмножеств, если ЛгПД/=0 для всех »=#/, и U A'p=S.
f=i
пуска программы мы встретили друга, который сказал нам, что он только что занял своей программой первый процессор и что программа будет работать очень долго. Он ничего не сказал о состоянии остальных четырех процессоров. Какова теперь вероятность того, что мы сможем загрузить свою программу? Пусть
Е = событие, состоящее в том, что нам удается загрузка, т. е. что свободны три или более трех процессоров;
F = событие, состоящее в том, что процессор 1 занят.
Если событие F произошло, то мы знаем, что система должна находиться в одном из следующих 16 состояний: s2, s7 — Si0, s2f — s2„, s28 — s32. Каждое из этих 16 состояний по-прежнему равновероятно; иначе говоря, у нас нет оснований предпочесть какое-то одно состояние всем остальным. Поэтому вероятность того, что предстоящее испытание будет иметь некоторый конкретный исход из этого множества, равна 1/16,’ т. е. P(SilF)=^ для i=2, 7—10, 21—26 и 28—32. В этом ограниченном пространстве исходы s2, s„ s8, sB и Si0 означают появление события Е. Следовательно, по аксиоме III
Р(Е|Е) = Р(82]Е) + Р(87|Е) + Р(88|Е) + Р(89|Е) + Р(8хо]Е)=А.
Чтобы воспользоваться формулой условной вероятности, рассматриваем полное пространство S. Тогда
E' = {si> s2, ..., Sfe};
^ = {82, 8, —Sjg, S2i S2C, S28 S32};
£nF = {s2, s7, Sg, s9, Sj0J;
P(£nF) = P(s2) + P(s7) + F(s8) + F(se) + P(si0) (аксиома 111) = ^;
P (П = P (S2) + P (S7) + . • • + p (s10) + P (Sti) + ... + P (s26) +
+ P (s28) + ...+P (s82) (аксиома III) = i|;
и
5
p (F \ Р\ = LCLd. 32 5
1 ' P(f) if, 16-
32
А что, если появление события F никак не связано с ожидаемым появлением Е? Тогда
P(E) = P(E|F).
Но Р(Е|Е) = -^йО-,
поэтому Р (Е) = —, или Р (Е Q F) — Р (Е) • Р (F).
Если события Е и F таковы, что вероятность их совместного появления
равна произведению вероятностей их раздельного появления, то говорят, что эти события независимы. Эта формула легко обобщается на случай трех или более взаимно независимых событий, т. е. если множества Ai, . . . , Ап таковы, что
P(At Г) Aj)=P(Ai)-P(Aj) для любых i^j, то Р(Л1ПЛ2П. . .ПДП)=Р(А)Р(Д2). . .Р(ДП).
В большинстве задач имеется возможность определить одну или более действительных величин, которые задают информацию в более удобной форме, чем явное описание событий. Например, целочисленная функция
X — число свободных процессоров
сообщает нам все, что мы хотим знать в нашем мультипроцессорном эксперименте. Искомая конечная вероятность может быть выражена как Р (Х>3) и равна вероятности того, что значение X больше или равно 3. Обратите внимание на то, что X в действительности является функцией, область определения которой есть пространство S, а область значений — множество {0, 1, 2, 3, 4, 5}. Любая такая функция из пространства (и определенной на нем вероятностной меры) задачи на множество действительных чисел называется случайной переменной. Фактически все серьезные вычисления вероятностей выполняются в терминах случайных переменных.
Определение вероятностей на области значений случайной переменной называется распределением. В нашем мультипроцессорном примере, предполагая, что элементы S равновероятны, мы имеем
Р(Х = 0)=1,
Р(Х-1)=^.
P(X-2) = g,
Р(Х=3)=12,
/>(Х=4)=А,
Р(Х = 5)=±.
Чтобы понять, как вычисляются эти значения, рассмотрим Р(Х=4)=Р (имеются в точности четыре свободных процессора)
= р (б2 и S3 и S4 и 86 и 86) =
= Р (s2) + Р (S3) + р (s4) + Р (s5) + Р (86) =!
32^32^32^32^32 32
Случайная переменная, область значений которой состоит из счет-ного числа возможных значений, называется дискретной. Если случайная переменная Y должна принимать одно из значений yi, yz, . . . , то
Р(У=^г)>0 при t=l, 2, ... ;
Р (У—у)=0 для всех остальных значений у.
Дискретные распределения этого вида называются массовыми функциями вероятности. Так как переменная Y должна принимать в эксперименте одно из значений yit массовая функция должна удовлетворять отношению
i
Иначе говоря, с вероятностью 1 (т. е. уверенностью) переменная Y должна равняться одному из допустимых значений (заметим, что Y не может равняться двум разным значениям одновременно). Легко проверить, что данная массовая функция вероятности случайной величины удовлетворяет этому условию.
Математическое ожидание, или среднее значение, или среднее, случайной переменной Y определяется как
E[Y]^yiP(Y=yi).
i
Согласно частотной интерпретации вероятности, среднее есть среднее значение случайной величины, во время наблюдения за которой было проведено большое число испытаний. В нашем примере
£(Х)=^(0)+^(1)+2(2)+^(3)+^(4)+^(5)-|=2.5.
Отметим, что среднее не обязательно принадлежит области значений случайной переменной. Любая функция от случайной переменной G(Y) также является случайной переменной (почему?), математическое ожидание которой задается формулой
д[О(У)] = 2о(^)Р(У=^.)1). (О
Пусть опять переменная X обозначает число свободных процессоров. Если случайная переменная G характеризует дефицит процессоров, т. е. равна числу процессоров, которых нам не хватает для того, чтобы запустить нашу программу, то
3, если X = О,
2, если Х=1,
1, если Х — 2,
. О, если Х = 3.
х) Эту формулу часто называют «законом стихийного статистика», так какова нередко вводится как определение (как сделали и мы) «стихийным» статистиком, забывающим, что эта формула может быть выведена.
Согласно равенству (1), получаем
E[G(X)] = 3[P(G = 3)] + 2[P (G^2)] + l[P(G=l)] + 0[P(G = 0)] = = 3 [Р(Х = 0)] + 2 [Р (X = 1)] + 1 [Р (X = 2)] + 0 [Р (Х>3)]-
Польза понятия математического ожидания увеличивается, когда фактическое значение, принимаемое случайной переменной, как правило, мало отличается от среднего. Одной из мер этого отличия является так называемая дисперсия случайной переменной. Пусть Y — случайная переменная со средним ц —Е (Y). Тогда дисперсия Y, обозначаемая как var [У], определяется следующим образом:
var [У] = Е [(У- р)2] = £ (у{ - р)2 Р (У = у,-). (2)
Здесь мы воспользовались формулой математического ожидания для функции от случайной переменной. Стандартное отклонение случайной переменной определяется как
а[У] = |Ууаг[У].
Для случайной переменной X в нашем примере
var [Х]=(0-2.5)- (я) +(* - 2-5)’ (я) + (2-2.5)- (g) +
+ (3 - 2.5)- (g) + (4- 2.5)- ( ’ j + (5-2.5)- (g) 1.25,
и о[Х]=1.12.
Сортировка методом прямого включения
Этот раздел мы завершим анализом математического ожидания, или среднего, для трудоемкости одного простого алгоритма сортировки.
Сортировка методом прямого включения работает со списком неупорядоченных положительных целых чисел (обычно называемых ключами), сортируя их в порядке возрастания. Это делается примерно так же, как большинство игроков упорядочивают сданные им карты, поднимая каждый раз по одной карте. Покажем работу общей процедуры на примере следующего неотсортированного списка из восьми целых чисел:
27 412 71 81 59 14 273 87.
Отсортированный список создается заново; вначале он пуст. На каждой итерации первое число неотсортированного списка удаляется из него и помещается на соответствующее ему место в отсортированном списке. Для этого отсортированный список просматривается, начиная с наименьшего числа, до тех пор, пока не находят соответствующее
место для нового числа, т. е. пока все отсортированные числа с меньшими значениями не окажутся впереди него, а все числа с большими значениями — после «его. Следующая последовательность списков показывает, как это делается:
Итерация О
Итерация 1
Итерация 2
Итерация 3
Итерация 4
Итерация 5
Итерация 6
Итерация 7
Неотсортированный 412 71 81 59 14 273 87
Отсортированный 27
Неотсортированный 412 71 81 59 14 273 87
Отсортированный 27 412
Неотсортированный 71 81 59 14 273 87
Отсортированный 27 71 412
Неотсортированный 81 59 14 273 87
Отсортированный 27 71 81 412
Неотсортированный 59 14 273 87
Отсортированный 27 59 71 81 412
Неотсортированный 14 273 87
Отсортированный 14 27 59 71 81 412
Неотсортированный 273 87
Отсортированный 14 27 59 71 81 273 412
Неотсортированный 87
Отсортированный 14 27 59 71 81 87 273 412
В следующем алгоритме заводится только один список, и переорганизация чисел производится в старом списке.
Algorithm SIS (Сортировка Прямым включением)Отсортировать на старом месте последовательность целых чисел 7(1), /(2), . . . , I (N) в порядке возрастания. ,
Шаг 1. [Основная итерация]
For J 2 to N do through шаг 4 od; and STOP.
Шаг 2. [Выбор следующего целого] Set A'-e-Z(J); and
L<- J— 1.
Шаг 3. [Сравнение с отсортированными целыми] While /«
</(L) AND L>1 do set /(£+!)+-/(£); and L+-L—1 od.
Шаг 4. [Включение] Set Z(L+1)/С.
Блок-схема алгоритма SIS приводится на рис. 2.4.1.
Оценим теперь среднее число сравнений, необходимых для сортировки случайных данных методом прямого включения. В качестве упражнения мы оставляем определение максимального и минимального числа требуемых сравнений.
Пусть N — число подлежащих сортировке ключей. Рассмотрим 7-й проход по циклу на шаге 1. В начале этого прохода первые I ключей неотсортированного списка ранее были правильно упорядочены, и теперь мы собираемся включить (i+l)-H ключ в список из I отсортированных ключей. Имеется i—1 «промежутков» между отсортированными ключами и еще две позиции на концах списка, что в сумме дает
Рис. 2.4.1. Блок-схема алгоритма
SIS.
i‘+l возможных позиций для следующего ключа. Предположим, что новый ключ с равной вероятностью l/(i+1) может быть помещен в любой из этих промежутков. Пусть Xt — случайная переменная, равная числу сравнений, требуемых для помещения ключа i+1 в правильную
позицию на этом проходе. Тогда
£[*/]= 1 (т^т)+2(тЬ)+з(тЬ) + -+7Тг+7ТТ=
= -^[1+2 + 3+...+(i-l) + f + i] =
~ t-p 1 + уру (используем формулу Гаусса)'=
=^- + —
2 т i+ 1
Заметим, что, когда нужная позиция находится на дальнем конце, выполняется только i сравнений. Так как имеется N ключей, в цикле на шаге 1 выполняется N—1 итераций. Если случайная переменная У обозначает общей число сравнений при сортировке, то
У — A'i + Х2 + ... + Адг-!-
Используя результат из упр. 2.4.11, получим
е[У]=£[Хх]+£[Х2]+ • • +£[ХЛг_1] =
= (±+±А (+... + ==
2 Т 2 У'Д 2 ' 3 J 2 N )
= у [1 + 2+ • • • +(^— 1)]+ [y + yH- • • • Ч—д/—] 1=3
/V —1 2V-1
ЧЕ'+Етгг-
i= 1 i=1 1
<см- УПР- 2-4.10)=.
=?+т-^, к 1
где HN=y\^- называется Л^-м гармоническим числом1). f=l 1
Таким образом, среднее число сравнений, требуемых алгоритмом SIS для сортировки N ключей, приблизительно равно №/4> а средняя сложность равна 0(№). С помощью аналогичного анализа можно обнаружить, что среднее число перемещений I (L+1) / (L) также
О(№).
Алгоритм SIS не является очень хорошим алгоритмом сортировки, хотя, впрочем, он один из простейших и наиболее удобных для реализаций. В разд. 5.1 будут изучены более сложные алгоритмы сортировки со средней сложностью и сложностью в худшем случае O(N log N).
На примере сортировки методом прямого включения мы продемонстрировали простой вероятностный анализ сложности. Далее в книге мы будем часто прибегать к подобному анализу.
J) Когда W—> оо, HN приблизительно равно In A,+0,577+0(l//V).
ЧтоОы показать основное различие между вероятностным и стати-стическим подходом, вернемся к нашему анализу ожидаемой трудоемкости алгоритма SIS. По заданному или предполагаемому распределению сортируемых элементов мы вычислили ожидаемое число сравнений, выполняемых при сортировке N ключей. При этом мы воспользовались определениями и правилами вычисления из теории вероятностей. Таким образом, заданное распределение было использовано для предсказания поведения алгоритма. Этот тип анализа характерен для большинства вероятностных моделей.
Во многих отношениях статистические задачи «обратны» вероятностным задачам. Наблюдается поведение системы и делается попытка вывести заключения о лежащем в основе неизвестном распределении случайных величин, которые описывают функционирование системы. Определим случайную переменную Y, которая равна для любой случайной последовательности N целых чисел числу сравнений, требуемых алгоритмом SIS для сортировки этой последовательности. Каждое применение алгоритма SIS к случайной последовательности целых чисел дает, таким образом, выборку Y. Хотя нам и не известно распределение У, мы можем взять несколько выборок, вычислить среднее Y от этих полученных экспериментальным путем чисел и принять Y как оценку математического ожидания Y (т. е. использовать Y для аппроксимации Е [У]). Следовательно, для вывода заключений о случайной переменной используются полученные из наблюдений значения.
Не представляется возможным дать общие рекомендации относительно того, какая из форм анализа лучше. На практике они должны дополнять друг друга. В нашем примере мы сделали предположение о распределении и затем смогли вычислить Е [У] вероятностными методами. То есть мы предположили, что (7+1)-й ключ с равной вероятностью может оказаться помещенным в любую из позиций на концах или внутри отсортированного списка из i элементов. Верно ли это предположение для «реальных» данных? С другой стороны, статистическая оценка для Е [У] может оказаться плохой из-за того, что наблюдаемая выборка была в некотором смысле «непредставительной». Если нам сдали случайным образом четыре карты и все они оказались тузами, будем ли мы считать, что вся колода состоит только из тузов? Если провести оба анализа — сравнить статистическую оценку У с выведенным значением Е [У] — и значения окажутся близкими, будут основания считать, что мы кое-что знаем о средней трудоемкости алгоритма. Если они сильно отличаются, возникает причина для беспокойства.
Продолжим обсуждение оценок и статистического анализа алгоритмов в несколько более общих терминах. Нас интересует ожидаемая или средняя трудоемкость некоторого алгоритма А на множестве возможных исходных данных D. Множество D очень велико, и алгоритм А достаточно сложен. Рассмотрим обработку алгоритмом А некоторых случайным образом выбранных из D исходных данных как экспери
мент, который определяет случайную переменную 1, время работы алгоритма А. Распределение Т неизвестно. Для наших целей не требуется обязательно статистически оценивать все распределение Т. Будет достаточно оценить значения некоторых свойств распределения, а именно математическое ожидание и дисперсию.
Общая процедура оценки свойства 6 распределения следующая. Возьмем ряд наблюдений (Xi, Х2, . . . , Хп) за интересующей нас случайной переменной X. Построим функцию F (Хи Х2, ... , Хп), область определения которой есть множество наблюдений, а область значений — множество возможных значений свойства 6. Такая функция называется оценкой 6 и сама представляет собой случайную переменную (почему?).
Как мы выбираем конкретную функцию в качестве оценки? Поскольку имеется много возможностей выбора, следует дать некоторый критерий, гарантирующий выбор хорошей оценки. Интуитивно самый очевидный критерий состоит в выборе для оценки такой функции F, собственное распределение х) которой сильно концентрируется вокруг истинного значения 6. Рассмотрим три конкретные характеристики хороших оценок, которые отражают это интуитивное требование.
Случайная переменная F является несмещенной оценкой 0, если Е [F]=0. Существуют очень простые несмещенные оценки для математического ожидания и дисперсии любой случайной переменной. Оценка
п
Х(Х1? .... x„)=lyix,.
i= 1
является несмещенной оценкой математического ожидания Е [X]. Это следует из
Е[Х] = Г =
L J
п
= £[х/] (см‘ УПР- 2.4.11)
i=l
— [X] (почему?)
= Д[Х].
Так как var [X] определяется через Е [X] (см. уравнение (2) и упр-2.4.12), выбранная для var [X] оценка будет зависеть от того, знаем ли мы Е [X] или Е [X] должно быть оценено. Если значение Е [X] известно, то оценку
п
G(Xb ..., Х„) = 1£(Х1—Е[Х]Г
i=i
естественно подсказывает определение var [X]. Легко установить, что
х) Напоминаем, что F — случайная переменная!
оценка G не смещена:
B[G]=£
1=1
п
=4 Е (X [Х’Я-2Е [X,.] Е [X] | (£ [Х])=) =
= -- пЕ [X2] - п (Е [X])2 = var [X].
При этом используются результаты упр. 2.4.12. Если значение Е [X] неизвестно, как обычно и бывает, то оценка
п
..., XJ = -±rX(X,.-X)2
1=1
является несмещенной оценкой для var [X]. Доказательство этого оставлено в качестве упражнения.
Согласующаяся оценка G(Xlt . . . , Х„) свойства 6 — это оценка, значение которой будет как угодно близко к 6 с вероятностью, приближающейся к 1, когда ц->оо. Более формально, G(Xj, . . . , Хп) является согласующейся оценкой для 6, если
lim Р {| G (Хп .. ., Х„) — 61 < е} = 1 для любого е > 0. п -> со
Согласующаяся характеристика отражает наше интуитивное ожидание того, что, чем больше выборка, тем она более надежна. Это интуитивное предположение математически подтверждается одним из самых важных результатов в теории вероятностей.
Теорема 2.4.1. (слабый закон больших чисел). Пусть Xj, ... , Хп — независимые случайные переменные и (а) £'[Хг]=лге, (б) var [X J=<72 для i=l, 2, . . . , п. Если
.....=
i— 1
то для любого е>0
lim Р{|Х—т|<е}=1. П —> со
Более сильная формулировка этой теоремы позволяет опустить условие (б) конечности дисперсии. Из закона больших чисел немедленно следует, что X — согласующаяся оценка математического ожидания случайной переменной.
Несмещенная оценка с минимальной дисперсией — это несмещенная оценка, дисперсия которой наименьшая среди всех несмещенных оценок или, возможно, среди всех несмещенных оценок определенного рода. Дисперсию часто можно рассматривать как меру точности оцен
ки. Чем меньше дисперсия, тем больше шансы, что значение оценки будет близко к значению свойства, которое она оценивает. Таким образом, малая величина дисперсии является желательной характеристикой оценки.
Пример. Время работы динамически выполняемого алгоритма измеряется с помощью двух системных часов. Показания первых часов Ти вторые часы регистрируют время Т2. Те и другие часы неточны в связи с наличием шумов в системе. Но природа шума такова, что каждые часы с равной вероятностью дают отклонения в большую и меньшую сторону на одну и ту же величину. Поэтому
Е [7\]=£ [Та!=Т = истинное время работы.
Таким образом, и первые, и вторые часы несмещенные, но известно, что их точность различна, т. е.
var [TipAvar [Т2].
Предположим, что var [7\]<?var [Т2].
Какую из величин, 7\ или Т2, следует принять для оценки Г? Почему бы не использовать и те и другие часы для получения некоторого взвешенного среднего? Соответственно пусть
H(Tlt Ta)=s7\+(l-s)7\
при некоторой константе O^Cs^l, которая пока что не определена. Ясно, что оценка Н(1\, Т2) несмещенная, так как
Е [H]=sE [7\]+(1— s)E [7\] (см. упр. 2.4.11) = s£+(l— s)T=T. Константа s будет выбрана так, чтобы получить оценку с наименьшей возможной дисперсией среди всех оценок, записанных в форме простого взвешенного среднего от Л и Т2.
Чтобы найти значение s, которое минимизирует var [Я], поступаем следующим образом, прибегая к стандартному приему дифференциального исчисления:
var[^] = s2var[T1] + (l — s)2var[T2] (см. упр. 2.4.13);
var [Я] = 2s var [7\] + (—2 -J- 2s) var [Га] = 0;
var [7\] = s var [7\] + s var [7\];
Уаг[72]
var I^il + var [T"2] '
Нетрудно проверить, что это значение s действительно минимизирует var [Я].
Не удивляет ли то, что мы не берем значение s= 1, т. е. что для оценки Т мы не пользуемся только 7\? В конце концов, var [7\]<;var [ST2], и поэтому у первых часов большая точность, чем у вторых. Но тогда не учитывается важный факт, что Т2 — также несмещенная оценка, й ее значение содержит информацию о времени работы Т. Конечно,
более точные часы должны учитываться с большим весом. Так ли об-стоит дело при нашем выборе s? Если var [7\]=var [Т"2], то придает ли наш выбор обоим часам равные веса?
Упражнения 2.4
2.4.1. Перерешайте всю мультипроцессорную задачу для случая шести процессоров и программы, которой необходимы четыре процессора. Снова воспользуйтесь равновероятным распределением. Вычислите Е [X] и var [X], где случайная переменная X равна числу свободных процессоров.
2.4.2. Какова вероятность получить в точности 7 выпадений «орла» при 12 бросаниях «правильной» монеты?
2.4.3. Пусть в мультипроцессорной задаче G(X)=X2, где X — случайная переменная, массовая функция вероятности которой приведена на стр. 93. Вычислите Е [G] и var [G],
2.4.4. Сортировка прямым включением (анализ). Каково максимально и минимально возможное число сравнений, затрачиваемых алгоритмом SIS для сортировки N ключей?
2.4.5. Если все возможные упорядочения N ключей равновероятны, какова вероятность того, что ключи уже будут отсортированы до начала работы алгоритма SIS?
2.4.6. Игрок полагает, что его стратегия игры в рулетку первоклассная. Он наблю-дает-за появлением черных и красных номеров. Если появляются подряд пять красных (черных) номеров, он поставит 10 долларов на черный (красный) номер при следующем запуске рулетки. Он рассчитывает на то, что вероятность появления подряд шести красных (или черных) номеров очень мала. Проанализируйте эту стратегию.
2.4.7. Если Е — произвольное событие в любом пространстве элементарных событий S, покажите, что Р(Е)^1.
*2.4.8. Если Е и F — два произвольных события, покажите, что
Р (Е U П= Р (Е)+Р (F)—P (Е П F).
2.4.9. Покажите, что Р(0)=0, где q — пустое множество,
2.4.10. Докажите тождество
Оно применялось при анализе алгоритма SIS.
*2.4.11. Если Х1( . . . , Хп—случайные переменные с совместной массовой функцией Р(х1г х2, ... , x„)=P(X1=Xi, Х2=х2, .... Х„=х„) и если аъ . . . , ап — произвольные константы, покажите, что
Е [а1Х1-)~а2Х2-(~. . .-j-anX^—a^E [XJ+. . .~j~anE [Xj.
2.4.12. Если X—произвольная дискретная случайная переменная, то покажите,
var [Х]=Е [X2]-(Е [X])2.
2.4.13. Покажите, что для любой случайной переменной X и константы а
var [aX]=a2var [X].
*2.4.14. Два самолета летят из города X в город Y. У первого самолета два мотора, в случае аварии он может продолжать полет на одном моторе. У второго самолета четыре мотора, в случае аварии ои может продолжать полет па двух моторах. Все шесть моторов идентичны, вероятность выхода из строя во время полета для каждого мотора равна р. Предположим, что работа каждого мотора не зависит от состояния остальных. На каком бы самолете вы предпочли лететь? Рассмотрите все значения р в области 0<р<1.
2.4.15. Бросаются четыре одинаковые кости с равновероятным исходом. Какова вероятность, что не выпадет ни одной пятерки?
2.4.16. Пусть S— пространство элементарных событий, и пусть {£], ... , Fn}—• множество событий, которые в S несовместимы и в совокупности исчерпывающие, Если Е — произвольное событие, покажите, что
Е= U (£Г)Л)-«=1
2.4.17. Используя результат упр. 2.4.16, покажите, что
Р (£) = Р (Е | F-) Р
t i = 1
*2.4.18. Еше раз рассмотрите алгоритм МАХ из разд. 1.2. Предположим, что каждое упорядочение N чисел равновероятно. Пусть случайная переменная Y обозначает положение наибольшего числа. Вычислите £ [К] и var [У].
*2.4.19. Какова вероятность того, что случайно выбранный тур в задаче о коммивояжере для N 1 ородов будет оптимальным? Какие вам нужно сделать предположения при решении этой задачи?
*2.4.20. Независимые случайные переменные. Две случайные переменные Хг и Х2 независимы, если
Р(.¥д<а и Х2<Ь) Р(Хг<а)-Р(Х2<ц) для всех а и Ь.
Покажите, что если Xt и Х2 независимы, то
£ 1Х1Х2]=£ [XJ-£lX2].
**2.4.21. Алгоритм SIS (анализ). Как и ранее при обсуждении сортировки методом прямого включения, пусть случайная переменная Y равна числу сравнений, необходимых для сортировки N ключей с помощью алгоритма SIS. Вычислите var [У]. Предположите, что все Х{ •— независимые случайные переменные.
*2.4.22. Биномиальное распределение. Рассмотрим п испытаний в эксперименте, в котором вероятность «успеха» равна р. Пусть случайная переменная X фиксирует число успехов в п испытаниях. Предположим, что исход любого испытания не влияет на исход любого другого испытания. Покажите, что массовая функция вероятности для X задается формулой
P(X = k)=^nk^ pk(l — p)n~k, k = 0,l,...,n.
Вычислите £ [X] и var [X].
*2.4.23. Пусть G— сеть с N вершинами, ребра которой выбираются случайно в соответствии со следующей схемой. Для каждой пары вершин i и / ребро (г, /') принадлежит G с вероятностью р независимо от i и / и не принадлежит G с вероятностью 1—р. Каково ожидаемое число ребер в G? Генерируемые таким образом сети называются p-случайными сетями.
*2.4.24. Геометрическое распределение. Пусть вероятность успеха любого испытания в эксперименте равна р, Каждое испытание не зависимо от любого другого испытания.
Будем продолжать эксперимент до тех пор, пока не получим в испытании первый успех. Пусть случайная переменная X равна числу испытаний до первого успешного испытания включительно. Какова массовая функция вероятности для X? Вычислите Е [X] и var [X].
2.4.25. Сортировка методом прямого включения (сложность, проверка). Реализуйте алгоритм SIS в форме программы на вычислительную машину. Нужно случайным образом сгенерировать (как?) множества из 20 неотсортированных ключей и зафиксировать число сравнений, произведенных при сортировке каждого множества. Пусть у — среднее этих значений. Сравните Y со значением Е [К], полученным при анализе метода сортировки прямым включением.
*2.4.26. Покажите, что оценка
п
s^Xlt ..., Хп)=-±-гУ (Х,--Х)3 1=1
является несмещенной оценкой для var [X].
2.4.27. Убедитесь, что при пашем выборе s в примере из.последней части разд. 2.4 значение var [г/] действительно минимально.
Глава 3. Методы разработки алгоритмов
Каждый, кто занимается разработкой алгоритмов, должен овладеть некоторыми основными методами и понятиями. Всем нам когда-то впервые пришлось столкнуться с трудной задачей и задать вопрос: с чего начать? Один из возможных путей — просмотреть свой запас общих алгоритмических методов для того, чтобы проверить, нельзя ли с помощью одного из них сформулировать решение новой задачи. Цель этой главы — построить и пояснить несколько фундаментальных методов разработки алгоритмов и решения задач.
В разд. 3.1 содержится краткое описание трех основных методов решения задач. По крайней мере один из этих методов в некотором смысле лежит в основе многих процедур и алгоритмов, обсуждаемых в последующих главах книги. В разд. 3.3 и 3.4 рассмотрены два общих метода решения больших комбинаторных задач — метод отхода и метод ветвей и границ. Рекурсия, инструмент, который может в значительной степени упростить логическую структуру многих алгоритмов, представлена в разд. 3.5. В разд. 3.2 и 3.6 изучаются два широко используемых «житейских» метода: эвристика и имитация. Видимо, в больших, сложных прикладных программах эти два метода используются чаще, чем все остальные вместе взятые.
3.1. Методы частных целей, подъема
и отрабатывания назад
Как разработать хороший алгоритм? С чего начать? У всех нас есть печальный опыт, когда смотришь на задачу и не знаешь, что делать. В этом разделе кратко описаны три общих метода решения задач, полезные для разработки алгоритмов.
Первый метод связан со сведением трудной задачи к последовательности более простых задач. Конечно, мы надеемся на то, что более простые задачи легче поддаются обработке, чем первоначальная задача, а также на то, что решение первоначальной задачи может быть получено из решений этих более простых задач. Такая процедура называется методом частных целей.
Этот метод выглядит очень разумно. Но, как и большинство общих методов решения задач или разработки алгоритмов, его не всегда легко перенести на конкретную задачу. Осмысленный выбор более простых задач— скорее дело искусства или интуиции, чем науки. Более того, не существует общего набора правил для определения класса задач, которые можно решить с помощью такого подхода. Размышление над
любой конкретно задаче начинается с постановки вопросов. Частные цели могут быть установлены, когда мы получим ответы на следующие вопросы:
1. Можем ли мы решить часть задачи? Можно ли, игнорируя некоторые условия, решить оставшуюся часть задачи?
2. Можем ли мы решить задачу для частных случаев? Можно ли разработать алгоритм, который дает решение, удовлетворяющее всем условиям задачи, но входные данные которого ограничены некоторым подмножеством всех входных данных?
3. Есть ли что-то, относящееся к задаче, что мы не достаточно хорошо поняли? Если попытаться глубже вникнуть в некоторые особенности задачи, сможем ли мы что-то узнать, что поможет нам подойти к решению?
4. Встречались ли мы с похожей задачей, решение которой известно? Можно ли видоизменить ее решение для решения нашей задачи? Возможно ли, что эта задача эквивалентна известной нерешенной задаче?
В сущности, все попытки решить задачу изоморфизма сетей (см. разд. 2.2) тем или иным образом используют метод частных целей. Это особенно характерно для попыток решить задачу путем нахождения (полного) множества инвариантов сети, такого, что две сети изоморфны тогда и только тогда, когда значения инвариантов из этого множества одни и те же для обеих сетей. Алгоритм изоморфизма в разд. 2.2 можно рассматривать как ориентированный на последовательность частных целей.
Второй метод разработки алгоритмов известен как метод подъема. Алгоритм подъема начинается с принятия начального предположения или вычисления начального решения задачи. Затем начинается насколько возможно быстрое движение «вверх» от начального решения по направлению к лучшим решениям. Когда алгоритм достигает такую точку, из которой больше невозможно двигаться наверх, алгоритм останавливается. К сожалению, мы не можем всегда гарантировать, что окончательное решение, полученное с помощью алгоритма подъема, будет оптимальным. Этот «дефект» часто ограничивает применение метода подъема.
Название «подъем» отчасти происходит от алгоритмов нахождения максимумов функций нескольких переменных. Предположим, что f(x, у) — функция переменных х и у и задача состоит в нахождении максимального значения f. Функция f может быть представлена поверхностью (имеющей холмы и впадины) над плоскостью ху, как на рис. 3.1.1. Алгоритм подъема может начать работу в любой точке z0 этой поверхности и проделать путь вверх к вершине в точке zj. Это значение является «локальным» максимумом в отличие от «глобального» максимума, и метод подъема не дает оптимального решения.
Вообще методы подъема являются «грубыми». Они запоминают не-
которую цель и стараются сделать все, что могут и где могут, чтобы подойти ближе к цели. Это делает их несколько недальновидными.
Как показывает наш пример, алгоритмы подъема могут быть полезны, если нужно быстро получить приближенное решение. Этот вопрос будет исследован дальше в разд. 3.2.
Третий метод, рассматриваемый в этом разделе, известен как
Рис. 3.1.1. Подъем к локальному максимуму.
отрабатывание назад, т. е. начинаем с цели или решения и движемся обратно по направлению к начальной постановке задачи. Затем, если эти действия обратимы, движемся обратно от постановки задачи к решению. Многие из нас делали это, решая головоломки в развлекательных разделах воскресных газет.
Давайте постараемся применить все три метода этого раздела в довольно трудном примере.
Задача о джипе
Мы хотели бы пересечь на джипе 1000-мильную пустыню, израсходовав при этом минимум горючего. Объем топливного бака джипа 500 галлонов, горючее расходуется равномерно, по 1 галлону на милю. В точке старта имеется неограниченный резервуар с топливом. Так как в пустыне нет складов горючего, мы должны установить свои собственные хранилища и наполнить их топливом из бака машины. Где расположить эти хранилища? Сколько горючего нужно залить в каждое из них?
Подойдем к этой задаче с помощью метода отрабатывания назад. С какого расстояния от конца мы сможем пересечь пустыню, имея запас горючего в точности на k баков? будем задавать этот вопрос для &=1, 2, 3, . . . , пока не найдем такое целое п, что п полных баков позволят пересечь всю 1000-мильную пустыню.
Для ответ равен 500 милям, как и показано на рис. 3. .2. Можно заправить машину в точке В и пересечь оставшиеся 500 миль пустыни. Ясно, что это наиболее отдаленная точка, стартуя из которой
о-г-юсОйш
S00' миль
В--
О миль
А
Рис. 3.1.2. Задача о джипе: пересечение пустыни из Л в С.
можно преодолеть пустыню, имея в точности 500 галлонов горючего.
Мы поставили перед собой частную цель, потому что не смогли бы решить сразу исходную задачу. Мы не задаем- вопрос: сколько топлива нужно машине, чтобы преодолеть заданную дистанцию? Вместо этого задаем более простой, но родственный вопрос: какое расстояние можно проехать на заданном количестве топлива? Ответить на первый вопрос становится возможным, когда ответом на второй является: не меньше 1000 миль.
Предположим, что &=2, т. е. имеется два полных бака (1000 галлонов). Будем рассматривать этот случай, опираясь на результат для&=1. Данная ситуация иллюстрируется на рис. 3.1.2. Каково максимальное значение xlt такое, что, отправляясь с 1000 галлонами горючего из точки 500—х1г можно перевезти достаточно горючего в точку В, чтобы завершить поездку, как в случае /г=1.
Один из способов определения приемлемого значения Xi состоит в следующем. Заправляемся в точке 500—Xi, едем х} миль до В и переливаем в хранилище все горючее, кроме Xi галлонов, которые потребуются для возвращения в точку 500—х^ В этой точке бак становится пустым. Теперь наполняем второй полный бак, проезжаем хг миль до В, забираем в В горючее, оставленное там, и из В едем в С с полным баком. Общее пройденное расстояние состоит из трех отрезков по хг миль и одного отрезка ВС длиной 500 миль. Мы должны израсходовать каждую каплю топлива, чтобы сделать значение хх как можно большим. Поэтому Xi находим из уравнения
3x1+500=1000 (галлонов);
его решение: Xi=500/3. Таким образом, два бака (1000 галлонов) позволяют нам проехать
B2 = 500 + Xj
Заметим, что исходная предпосылка является недальновидной и грубой. Когда имеются в распоряжении k баков горючего, мы просто стараемся продвинуться назад как можно дальше от точки, найденной, для k—1 баков.
Рассмотрим k—З. Из какой точки мы можем выехать с 1500 галлонами топлива так, что машина сможет доставить 1000 галлонов в точку 500—Xj? Возвращаясь к рис. 3.1.2, мы ищем наибольшее зна
МИЛЬ.
чение х2, такое, что, выезжая с 1500 галлонами топлива из точки 500—Xi—х2, мы можем доставить 1000 галлонов в точку 500—хт. Мы выезжаем из точки 500—Xt—х2, доезжаем до 500—xt, переливаем все горючее, кроме х2 галлонов, и возвращаемся в точку 500—лу—х2 с пустым баком. Повторив эту процедуру, мы затратим 4х2 галлонов на проезд и оставим 1000—4х2 галлонов в точке 500—Xi. Теперь в точке 500—Xi—х2 осталось ровно 500 галлонов. Заправляемся последними 500 галлонами и едем в точку 500—xi, израсходовав на это х2 галлонов.
Теперь мы находимся в точке 500—хъ затратив на проезд 5х2 галлонов топлива. Здесь оставлено в общей сложности 1500—5х2 галлонов. Это количество должно быть равно 1000 галлонам, т. е. х2=500/5. Из этого заключаем, что 1500 галлонов позволяют нам проехать
D3 = 500 + Xi + *2 = 500 f 1 + 4-+ тй миль.
Продолжая, индуктивно процесс отрабатывания назад, получаем, что п баков горючего позволяют нам проехать Dn миль, где 0,-600(1 + 4 + 1+...+^).
Нужно найти наименьшее значение п, при котором D,^ 1000-Простые вычисления показывают, что для п=7 имеем D7=977,5 мили, т. е. семь баков, или 3500 галлонов, топлива дадут нам возможность проехать 977,5 мили. Полный восьмой бак — это было бы уже больше, чем нам надо, чтобы перевезти 3500 галлонов из точки А в точку, отстоящую на 22,5 мили (1000—977,5) от А. Читателю представляется самостоятельно убедиться в том, что для доставки 3500 галлонов топлива к отметке 22,5 мили достаточно 337,5 галлона. Таким образом, для того чтобы пересечь на машине пустыню из Л в С, нужно 3837,5 галлона горючего.
Теперь алгоритм транспортировки горючего может быть представлен следующим образом. Стартуем из А, имея 3837,5 галлона. Здесь как раз достаточно топлива, чтобы постепенно перевезти 3500 галлонов к отметке 22,5 мили, где мы в конце концов окажемся с пустым баком и запасом горючего на семь полных заправок. Этого топлива достаточно, чтобы перевезти 3000 галлонов к точке, отстоящей на 22,5+500/13 миль от А, где бак машины будет опять пуст. Последующие перевозки приведут нас к точке, отстоящей на 22,5+ 500/13+ +500/11 миль от Л, с пустым баком машины и 2500 галлонами.
Продолжая таким образом, мы продвигаемся вперед благодаря анализу, проведенному методом отрабатывания назад. Вскоре мы окажемся у отметки 500(1—1/3)=1000/3 миль с 1000 галлонами топлива. Затем мы перевезем 500 галлонов в В, зальем их в бак машины и доедем без остановки до С. Рис. 3.1.3 иллюстрирует весь этот процесс.
Для тех, кто знаком с бесконечными рядами, заметим, что Dn
есть n-я частная сумма нечетного гармонического ряда, поскольку этот ряд расходится, алгоритм. дает возможность пересечь любую пустыню. Как можно модифицировать этот алгоритм для того, чтобы оставить достаточно горючего в различных точках пустыни для возвращения в Л?
Т^бакоВ Абака Ъ'бака 2 бака 1 бак
^1.ЬгаЛ 2000 гал 1500 гак 1000 гол 500 гаг
Рис. 3.1.3. Схема решения задачи о'джипе.
500
>вС
Возникает вопрос, можно ли проехать 1000 миль, затратив меньше чем 3837,5 галлона горючего. Оказывается, что нельзя. Доказательство этого факта довольно сложно. Однако можно высказать следующий, довольно правдоподобный довод. Очевидно, мы действуем наилучшим образом для &=1. При /г=2 мы используем наш план для k=l и затем вводим в действие второй бак горючего для того, чтобы оказаться как можно дальше от В. Исходная предпосылка для k баков заключается в том, что мы знаем, как действовать наилучшим образом в случае с k—1 баками, и отодвигаемся как можно дальше назад с помощью /г-го бака.
Следующие четыре раздела так или иначе основываются на трех общих методах, рассмотренных здесь. В сущности, эти методы используются на протяжении всей книги, хотя мы не будем каждый раз явно указывать на это.
Упражнения 3.1
3.1.1. Взвешивание монет (подъем). Имеется 25 золотых монет. Все они одного веса, за исключением одной монеты с дефектом, которая весит меньше остальных. Разработайте алгоритм, определяющий дефект за три взвешивания. Каково максимальное число монет, для которых можно определить монету с дефектом не больше чем за три взвешивания на весах с чашками?
3.1.2. НеотградуироваКные сосуды (отрабатывание назад). Имеются неотградуиро-ванные 5-галлонный и 3-галлонный сосуды. Нужно отмерить ровно 4 галлона жидкости. Разработайте алгоритм для этой процедуры. Предполагается, что есть очень большой резервуар с жидкостью.
*3.1.3. Задача разрезания бумаги (частные цели). На рис. 3.1.4 показан греческий крест, составленный из пяти одинаковых квадратов. Делая только два прямых разреза, разрежьте крест так, чтобы можно было сложить его части в прямоугольник, одна сторона которого в два раза длиннее другой.
3.1.4. Разбиение круга (подъем). На какое максимальное число частей может быть разделен круг четырьмя прямыми линиями?
3.1.5. Десятичный — восьмеричный—двоичный перевод (частные цели). Разработайте и реализуйте алгоритм для перевода десятичных чисел в двоичные и наоборот. В качестве подцели примите перевод в восьмеричные числа.
, 3.1.6. Игра (отрабатывание назад). Три человека играют
в игру, в которой один выигрывает, а другие два проигрывают. Каждый проигравший дает выигравшему сумму, раввую количеству денег, которое было у выигравшего в начале игры. Были сыграны три игры, каждый игрок выиграл один раз, у 1-го игрока оказалось 4 доллара, у 2-го — 20 долларов, у 3-го — 6 долларов. Сколько денег бы-—-— ----- ло у каждого игрока в начале игры?
*L3.1.7. Магические квадраты (постановка задачи и ре-_____________ шение). Магический квадрат размерности п — это матрица пхп, содержащая первые и2 положительных целых чи-Рис. 3.1.4. Греческий сел. Эти числа расположены так, что их суммы в каждой крест. строке, столбце и вдоль двух главных диагоналей равны
одному и тому же значению С.
(а) Сформулируйте алгебраическую задачу, решение которой даст магический квадрат для я=3. Постарайтесь решить полученную систему уравнений без применения ЭВМ.
(б) Разработайте алгоритм нахождения магических квадратов для п=3 и «=4. Эта процедура не обязательно должна основываться на вашей алгебраической модели. Реализуйте, проверьте и проанализируйте алгоритм на ЭВМ. Можно ли его использовать для больших значений п?
*3.1.8. Ханойская башня (отрабатывание назад, частные цели). Рис. 3.1.5 иллюстрирует древнюю игру, известную под названием Ханойской башни. Игра начинается, когда п дисков разного диаметра расположены по возрастанию диаметров на одном из трех стержней. Цель игры — по одному перенести диски, чтобы они в конечном счете были расположены в том же порядке на другом стержне. Не разрешается класть диск большего диаметра на диск меньшего диаметра.. Разработайте алгоритм, который проделывает эту процедуру за 2';—1 операций, где под операцией подразумевается перемещение диска с одного стержня на другой. Стержни, по существу, являются запоминающими устройствами типа стека, и переставлять можно только верхний диск в пирамиде.
3.1.9. Каннибалы и миссионеры. Следующая задача является классической, и для ее решения можно воспользоваться любым из трех основных методов, рассмотренных в этом разделе. Три миссионера и три каннибала находятся на одном берегу реки; лодка может перевезти двух человек. Все они хотят перебраться через реку. Нельзя допустить, чтобы на одном берегу находилась группа миссионеров с более многочисленной группой каннибалов. Разработайте процедуру, позволяющую всем шестерым перебраться через реку.
3.2. Эвристики
Эвристический алгоритм, или эвристика, определяется как алгоритм со следующими свойствами:
1. Он обычно находит хорошие, хотя не обязательно оптимальные решения.
2. Его можно быстрее и проще реализовать, чем любой известный точный алгоритм (т. е. тот, который гарантирует оптимальное решение).
Понятия «хороший» и «обычно» в свойстве 1 меняются от задачи к задаче. Например, если для решения задачи все известные точные алгоритмы требуют нескольких лет машинного времени, то мы можем охотно принять любое нетривиальное приближенное решение, которое может быть получено за разумное время. С другой стороны, имея быстрое, близкое к оптимальному решение, мы можем стремиться все же к точному решению.
Хотя не существует универсальной структуры, которой можно описать эвристические алгоритмы, многие из них основываются или на методе частных целей, или на методе подъема. Один общий подход к построению эвристических алгоритмов заключается в перечислении всех требований к точному решению и разделении требовайий на два класса, например:
1. Те, которые легко удовлетворить.
2. Те, которые не так легко удовлетворить.
Или
1. Те, которые должны' быть удовлетворены.
2. Те, по отношению к которым мы могли бы пойти на компромисс.
Тогда цель построения алгоритма — создать алгоритм, гарантирующий выполнение требований 1-го класса, но не обязательно 2-го. Это не означает, что для удовлетворения требований 2-го класса не делается никаких попыток, это просто означает, что не может быть дано никаких гарантий, что они будут' удовлетворены.
Часто очень хорошие алгоритмы должны рассматриваться как эвристические. Например, предположим, что мы построили быстрый алгоритм, который, кажется, работает на всех тестовых задачах, но мы не можем доказать, что алгоритм правильный. Пока не дано такое доказательство, алгоритм следует рассматривать как эвристику.
В качестве примера рассмотрим следующий «грубый» алгоритм решения задачи коммивояжера из разд. 1.3.
Algorithm GTS (коммивояжер). Построить приближенное решение TOUR со стоимостью COST для задачи коммивояжера с N городами и матрицей стоимостей С, начиная с вершины U.
Шаг 0. [Инициализация] Set TOUR <-0; COST <-0; VU’, помечаем U — «использована», а все другие вершины — «не использована». (Вершина V — положение на сети в данный момент.)
Шаг 1. [Посещение всех городов] For К<- 1 to N—1 do шаг 2 od.
Шаг 2. [Выбор следующего ребра] Пусть (V, W) — ребро с наименьшей стоимостью, ведущее из V в любую неиспользованную вершину IU; set TOUR TOUR+ + (V, №); COST<-COST+C(V, W); помечаем W — «использована»; and set V IU.
Шаг 3. [Завершение тура] Set TOUR TOUR+ (V, 1); COST <-COST+ +C(V, 1); and STOP.
На рис. 3.2.1, а изображена сеть с рис. 1.3.1; рис. 3.2.1, б — е
Рис. 3.2.1. Иллюстрация алгоритма GTS.
иллюстрируют построение тура коммивояжера алгоритмом GTS, начинающегося с вершины 1; пройденные вершины обозначены черным квадратиком, а непройденные — кружком.
Алгоритм GTS дает тур со стоимостью 14, а в гл. 1 мы нашли тур со стоимостью 13. Ясно, что алгоритм GTS не всегда находит тур с минимальной стоимостью.
Обычно грубые алгоритмы очень быстры и интуитивно привлекательны, но, как мы заметили, они не всегда работают J). Нам повезло,
*) То есть не всегда дают оптимальное решение задачи.— Прим, ред.
и мы смогли легко найти контрпример для алгоритма GT . днако не всегда можно легко показать, что грубый алгоритм не работает. Разумеется, если мы считаем, что наш грубый алгоритм работает всегда, то мы должны доказать, что это так.
Алгоритм GTS основан на идее подъёма. Цель — найти тур с минимальной стоимостью. Задача сведена к набору частных целей — найти на каждом шаге «самый дешевый» город, чтобы посетить его следующим. Алгоритм не строит плана вперед; текущий выбор делается безотносительно к последующим выборам.
Оптимальное решение задачи коммивояжера имеет два основных свойства:
1. Оно состоит из множества ребер, вместе представляющих тур.
2. Стоимость никакого другого тура не будет меньше данного.
Алгоритм GTS рассматривает свойство 1 как «обязательное», или «легкое», требование, а свойство 2 — как «трудное», относительно которого можно пойти на компромисс.
Пример с пятью городами на рис. 3.2.1 сразу показывает, что алгоритм GTS не гарантирует свойство 2. Однако на шаге 2 делается некоторая попытка снизить стоимость тура Т.
Конечно, для алгоритма GTS легко написать программу, но является ли он быстрым? Для произвольной задачи коммивояжера с п городами требуется 0(п2) операций, чтобы прочесть или построить матрицу стоимостей С. Поэтому нижняя граница сложности любого алгоритма, способного дать нетривиальное возможное решение этой задачи, равна 0(п2). Нетрудно проверить, что для любой разумной реализации шагов 1—3 требуется не больше, чем 0(п2), операций. Поэтому алгоритм GTS настолько быстрый, насколько возможно.
По-видимому, алгоритм GTS — это хороший эвристический алгоритм. Конечно, понятие «хороший» относительно. Поскольку алгоритм ETS (исчерпывающий коммивояжер) слишком неэффективен (см. разд. 1.3), эпитет «хороший» может просто указывать на тот факт, что алгоритм GTS — наилучший из имеющихся для больших (в разумных пределах) значений п.
Качество алгоритма GTS может быть значительно улучшено простой модификацией. Самым плохим свойством алгоритма является то, что выбор ребер очень низкой стоимости при выполнении шага 1 на ранних или средних стадиях работы алгоритма может привести к выбору очень дорогих ребер в заключительной стадии. Один из способов предостеречься от этого — применять алгоритм для каждого из р^п разных, случайно выбранных, начальных городов. Другая модификация может состоять в повторении алгоритма для того же самого начального города, но надо начинать со второго по дешевизне ребра и затем, быть может, вернуться к прохождению самых дешевых ребер для последующих вершин. Возможны и другие вариации. Затем можно выбрать наименьший из рассмотренных туров. Или лучше: сохранять только самый дешевый тур из до сих пор найденных и
отбрасывать частично построенные туры, стоимости которых уже превышают стоимость текущего самого дешевого тура. Конечно, сложность модифицированного алгоритма, который мы назовем GTS2, может достигать порядка 0(рп2).
Algorithm GTS2 (грубый коммивояжер, версия 2). Образовать туры из разных начальных городов для задач коммивояжера
с N городами. Последовательно строятся Р туров и запоминается лучший из до сих пор найденных туров. В качестве ввода для алгоритма требуются значения N, Р, матрица стоимостей С и Р начальных городов {Vi, У2, • Vp}-
Шаг 0. [Инициализация] Set К. <- 0; COST ч-оо; and BEST ч-0. (Переменная К отсчитывает число до сих пор использованных начальных городов; BEST служит для запоминания лучшего из до сих пор найденных туров, стоимость которого равна COST.)
Шаг 1. [Начало нового тура] Do through шаг 3 while К<Р od; and STOP.
Шаг 2. [Образование нового тура] Set К. К+1; and CALL GTS (Ед-). (Оператор CALL GTS(VA) заставляет алгоритм GTS построить тур с городом VK в качестве начального. Тур Т (К) со стоимостью С (К) построен.)
Шаг 3. [Обновление лучшего тура] If C(K)<COST then set BEST-*-T(К); and COSTC(K) fi.
Рис. 3.2.2. Иллюстрация алгоритма GTS2.
Реализация алгоритма GTS2 с подалгоритмом GTS не представляет труда. Алгоритм GTS2 должен передавать текущее значение COST алгоритму GTS. Если в процессе выполнения подпрограммы стоимость частично построенного тура больше или равна COST, то возвращается значение С(К) = °о-
Что получится, если применить алгоритм GTS2 к задаче с пятью городами, показанной на рис. 3.2.2? Возьмем р=3, а в качестве начальных городов — три вершины с нечетными номерами.
Начиная с вершины 1, находим следующие ребра:
(1, 2) со стоимостью 25,
(2, 3) со стоимостью 17 [замечаем, что (2,1) дает нежелательный подтур],
(3,5) со стоимостью 1,
(5,4) со стоимостью 10 (это ребро мы вынуждены выбрать как единственно возможное на данном этапе),
(4,1) со стоимостью 9.
Общая стоимость полученного тура равна 62.
Начиная с вершины 3, находим следующие ребра:
(3,5) со стоимостью 1,
(5,2) со стоимостью 8 [замечаем, что (5,3) дает нежелательный подтур],
. (2,1) со стоимостью 5,
(1,4) со стоимостью 31,
(4,3) со стоимостью 24.
Общая стоимость этого тура равна 69.
Наконец, начиная с вершины 5, находим:
(5,3) со стоимостью 7,
(3,4) со стоимостью 6,
(4,1) со стоимостью 9,
(1,2) со стоимостью 25,
(2,5) со стоимостью 25.
Здесь общая стоимость равна 72.
Этот маленький пример показывает, как повторное применение эвристического алгоритма с некоторыми модификациями при каждом повторении может компенсировать его слабые места. Это похоже на взятие выборки для определения среднего значения случайной переменной. Чем больше выборка, тем больше мы имеем информации и тем лучшую получаем оценку. Однако в данном случае у нас нет теоретического результата, аналогичного закону больших чисел, который гарантирует сходимость к истинному значению.
В оставшейся части этого раздела будет описан чрезвычайно простой, но удивительно эффективный эвристический алгоритм.
Предположим, что у нас есть множество п одинаковых процессоров, обозначенных Pi, . . ., Рп, и т независимых заданий Ju . . Jт, которые нужно выполнить. Процессоры могут работать одновременно, и любое задание можно выполнять на любом процессоре. Если задание загружено в процессор, оно остается там до конца обработки. Время обработки задания Jt известно, оно равно tt, i=l, . . ., т. Наша цель — организовать обработку заданий таким образом, чтобы
выполнение всего набора заданий было завершено как можно быстрее. Прежде всего построим модель.
Как действует эта система процессоров и заданий? Каково расписание ее работы? Расписанием просто является упорядоченный список заданий L. Система работает следующим образом: первый освободившийся процессор берет из списка следующее задание. Если одновременно освобождаются два или более процессоров, то выполнять очередное задание из списка будет процессор с наименьшим номером. Предполагается, что время, необходимое для загрузки задания в машину, равно нулю. Процессор будет обрабатывать задание до полного завершения, а затем, если список не исчерпан, получит следующее задание.
Предположим, что имеется три процессора и шесть заданий с Zi=2, /2=5, £3=8, 4=1, и Рассмотрим расписание L= (J2, J5, Ji, Je, Js)- В начальный момент времени Т=0, Рх начинает обработку J2, Р2 начинает J5, а Р3 начинает Ji. Процессор Р3 заканчивает Ji в момент времени Т=2 и начинает обрабатывать задание J4, пока Pi и Р2 еще работают над своими первоначальными заданиями. При Т=3 Р3 опять заканчивает задание J4 и начинает обрабатывать задание J6, которое завершается в момент Т=4. Тогда он начинает последнее задание J3. Процессоры Рх и Р2 заканчивают задания при 7=5, но, так как список L пуст, они останавливаются. Процессор Р3 завершает выполнение J3 при Т—12. Рассмотренное расписание проиллюстрировано на рис. 3.2.3 временной диаграммой, известной как схема Ганта. Очевидно, что расписание не оптимально. У процессоров Pi и Р2 велико время бесполезного простоя. Расписание L* — — (J3, J a, J3, J i, Ji, J в) позволяет завершить все задания за 7* =8, что должно быть оптимумом, так как никакое расписание не может
Рис. 3.2.3. Схема Ганта для расписания L.
позволить завершить все задания за меньшее время, чем требуется для выполнения самого длинного задания.
Обозначим через Lo оптимальное расписание, а через соответствующее кратчайшее время завершения всех заданий. Построение £„ — это трудная задача, требующая сложных методов, таких, как метод ветвей и границ (см. разд. 3.4).
Рассмотрим следующий, очень простой эвристический алгоритм. Обозначим через L* расписание выполнение заданий, в котором задание с наибольшим временем обработки стоит первым, затем в порядке убывания времени обработки стоят остальные задания, последним стоит задание с самым маленьким временем обработки. Эвристический алгоритм создает расписание L*, перечисляющее задания в порядке убывания времени их обработки (при совпадении времен порядок выбирается произвольно).
Возвращаясь к предыдущему примеру, видим, что L*=(J3, J2, J6, Ji, J*, J в)- Расписание L* завершает все задания за время Т*=8, как показано на рис. 3.2.4. Таким образом, в этом примере эвристический алгоритм построил оптимальное расписание.
Рис. 3.2.4. Схема Ганта для оптимального расписания L*.
Конечно, наивно было бы думать, что такой простой эвристический алгоритм является точным. Действительно, легко придумать задачу, для которой он нс дает оптимального решения. На рис. 3.2.5 показан пример для двух процессоров и 4=3, 4=3, /3=2, 4=2, 4=2. На рис. 3.2.5, а показано расписание L*, а на рис. 3.2.5, б — оптимальное расписание.
Для этого эвристического алгоритма получается очень полезный результат. Как и раньше, обозначим через Т* время завершения всех заданий в задаче с п процессорами при использовании эвристического
алгоритма с расписанием работ, упорядоченных в порядке убывания времени обработки. Пусть Те обозначает время завершения этих заданий при использовании оптимального расписания. Можно доказать тогда, что
т* 4 1
То 3 Зп ’
При помощи этого результата можно получить верхнюю границу ошибки, если мы пользуемся
этим эвристическим алгоритмом, не
Ц> = (-1-ь J3»J4»J2»J5) То = 6
L* = т*=7
а
Рис. 3.2.5. Неоптимальное эвристическое расписание L* и оптимальное расписание
желая затрачивать усилий, на поиск оптимального расписания. Для п=2, и эта максимальная ошибка достигается, как по-
казано на рис. 3.2.5. Для большого числа процессоров максимальная ошибка может достигать 33%.
Точные верхние оценки эвристических алгоритмов на самых плохих случаях получить трудно. Такие оценки известны фактически для очень малого числа эвристических алгоритмов.
Теперь рассмотрим другой тип задач по составлению расписания для многопроцессорных систем. Вместо вопроса о быстрейшем завершении набора заданий фиксированным числом процессоров теперь ставим вопрос о минимальном числе процессоров, необходимых для завершения данного набора заданий за фиксированное время Ти. Конечно, время То будет не меньше времени выполнения самого трудоемкого задания.
Эта задача составления расписания эквивалентна следующей задаче упаковки. Пусть каждому процессору Ps соответствует ящик В} размера То. Пусть каждому заданию Jt соответствует предмет размера ti, равного времени выполнения задания Jt, i=l, . . ., п. Теперь для решения задачи по составлению расписания нужно построить алгоритм, позволяющий разместить все предметы в минимальном количестве ящиков. Конечно, нельзя заполнять ящики сверх их объема Те и предметы нельзя дробить на части.
Рассмотрим множество предметов, показанных на рис. 3.2.Ь. Их пять: два из них имеют размер 3 и три — размер 2. Какое требуется минимальное число ящиков размера 4, чтобы поместить в них все предметы? Ответ показан на рис. 3.2.6, где заштрихованные участки обозначают пустые места в ящиках.
Для решения этой задачи существует несколько простых эвристических алгоритмов. Каждый из них может быть описан в нескольких строках. Рассмотрим четыре таких алгоритма:
Н1 (первое попавшееся размещение для заданного списка, First Fit, FF). Пусть L — некоторый порядок предметов. Первый предмет из L кладем в ящик Вг. Второй предмет из L кладем в Blt если он туда помещается. В противном случае кладем его в следующий ящик В2. Вообще очередной предмет из L кладем в ящик Bt, куда этот предмет поместится, причем индекс i ящика наименьший среди всех возможных. Если предмет не помещается ни в один из k частично заполненных ящиков, кладем его в ящик Вк+1. Этот основной шаг повторяется, пока список L не будет исчерпан.
Н2 {первое попавшееся размещение с убыванием, First Fit Decreasing, FFD). Этот алгоритм отличается от алгоритма FF тем, что список L упорядочен от больших предметов к меньшим.
НЗ (лучшее размещение для заданного списка, Best Fit, BF). Пусть L — заданный порядок заданий. Основной шаг тот же, что и в FF, но очередной предмет кладется в тот ящик, где остается наименьшее неиспользованное пространство. Таким образом, если очередной предмет имеет размер 3 и есть четыре частично заполненных ящика размера 6, в которых осталось 2, 3, 4 и 5 единиц незаполненного пространства, тогда предмет кладется во второй ящик, и тот становится полностью заполненным.
Н4 (лучшее размещение с убыванием, Best Fit Decreasing, BFD). Этот алгоритм такой же, как и BF, но L упорядочен от больших предметов к меньшим.
Для этой задачи упаковки было найдено несколько хороших верхних оценок. Одна из лучших, принадлежащая Грэхему, выглядит
б
Рис. 3.2.7. Пример, в котором эвристический алгоритм первого попавшегося размещения с убыванием дает наихудшее возможное соотношение: Nppp/NB=ll/9.
следующим образом. Пусть NB — минимальное число необходимых ящиков, полученное при помощи точного алгоритма. Если TVFFD обозначает приближенное решение, найденное алгоритмом FFD, тогда для любого е>0 и достаточно большого NB
N FFD И । „
9- + е-
Таким образом, алгоритм FFD дает решение, которое не может быть хуже оптимального более чем на 23%. Это гарантированная оценка; для любой конкретной задачи ошибка может быть намного меньше.
Нелегко построить пример, на котором эвристический алгоритм FFD работает наихудшим возможным образом. Прежде чем читать дальше, попытайтесь немного поэкспериментировать. Представим один такой «плохой случай». Пусть е>0 — произвольно выбранное, но маленькое положительное действительное число. Предположим,
что все ящики размера 1 и что нужно упаковать следующие предметы:
1 .
6 предметов размера у+е, 1 .
6 предметов размера
12 предметов размера —2е,
6 предметов размера -^+2е.
На рис. 3.2.7, а показана оптимальная упаковка, использующая No= =9 ящиков. Очевидно, что эта упаковка оптимальна, так как все 9 ящиков полностью заполнены. Если для решения этой задачи применить эвристический алгоритм FFD пункта Н2, получим упаковку, показанную на рис. 3.2.7, б, использующую A^FFF)=11 ящиков.
Задачи упаковки могут быть удивительно обманчивы. Например, если нужно упаковать в ящики размера 1000 предметы размеров £==(760, 395, 395, 379, 379, 241, 200, 105, 105, 40), то эвристический алгоритм Н2 потребует для этого NFFD=3 ящика. Это на самом деле оптимальное решение (проверьте это). Давайте уменьшим все размеры на одну единицу, что приводит к списку L'=(759, 394, 394, 378, 378, 240, 199, 104, 104, 39). Теперь эвристический алгоритм FFD дает 7Vffd=4. Это, очевидно, не оптимальное и совершенно неожиданное решение. Почему этот пример не нарушает результата 11/9?
Обратим внимание на другую аномалию. Применяя эвристический алгоритм Н1, упакуем L=(7, 9, 7, 1, 6, 2, 4, 3) в ящики размера 13. Находим, что /VFF=3, как показано на рис. 3.2.8, а; очевидно, что этот результат оптимальный. Уберем предмет размера 1, что приводит к списку L’= (7, 9, 7, 6, 2, 4, 3). Теперь, как показано на рис. 3.2.8, б, /Vff=4.
Другие примеры аномалий у эвристических алгоритмов для задач составления расписаний даны у Грэхэма [41].
Упражнения 3.2
L3.2.1. Алгоритм GTS2 (реализация). Напишите программу для алгоритма GTS2. Проведите экспериментальный анализ среднего результата.
3.2.2. Алгоритм GTS2. Алгоритм GTS2 использует несколько городов в качестве «начального» города.. Что, если коммивояжер имеет единственный начальный город, скажем тот, в котором он живет. Означает ли это, что он не может использовать тур, полученный алгоритмом?
*3.2.3. Эвристический алгоритм для задачи коммивояжера (разработка). Предположим, что в симметричной задаче коммивояжера мы нашли тур (не обязательно оптимальный). Выбираем произвольно в этом туре два несмежных ребра, допустим (i, /) и (k, I). Предполагая, что данные четыре города встречаются в порядке i, j, k, I (меж-ДУ ! ч k находятся другие города), мы можем преобразовать текущий тур в новый, исключая ребра (i, /) и (k, I) и заменяя их ребрами (i, k) и (/, I). Заметим, что в новом тУре некоторые ребра, может быть, придется проходить в обратном направлении.
Примените это преобразование для построения эвристического алгоритма в задаче коммивояжера.
*L3.2.4. Сравнение эвристических алгоритмов (проверка). Проведите сравнительную проверку алгоритма GTS2 с вашим алгоритмом из упр. 3.2.3. Прогоните оба алгоритма на одних и тех же тестовых задачах. Сравните найденные стоимости туров, а также
Рис. 3.2.8. Аномалия при использовании эвристического алгоритма первого попавшегося размещения; упаковка становится хуже, когда убран предмет.
* 3.2.5. Эвристический алгоритм для задачи об укладке рюкзака (разработка, анализ). Имеется рюкзак объема V и неограниченный запас каждого из N различных видов предметов. Каждый предмет вида i имеет известные объем V; и стоимость тр i=l, ... , N. В рюкзак можно положить целое число различных предметов. Нужно упаковать рюкзак так, чтобы общая стоимость упакованных предметов была наибольшей, а их общий объем не превосходил V. Форма предметов в задаче не рассматривается.
Разработайте и проанализируйте грубый эвристический алгоритм для задачи об упаковке рюкзака.
* *3.2.6. Задача покрытия множества (разработка, анализ). S — множество элементов. для любого i=l, . . . , п—это множество из п множеств, каждое из
которых состоит из элементов S. Задача состоит в нахождении наименьшего числа множеств из ff, таких, что объединение этих множеств содержит все элементы множества S. Эта задача известна как задача минимального покрытия множества.
Разработайте эвристический алгоритм, дающий возможное решение этой задачи. Проанализируйте работу, необходимую. для реализации этого эвристического алгоритма.
* 3.2.7. Тур коня (модель, разработка). Снова рассмотрим эвристический алгоритм поиска тура для коня из разд. 2.1. Разработайте другой эвристический алгоритм для этой же задачи.
3.3. Программирование с отходом назад
Метод разработки алгоритма, известный как программирование с отходом назад, можно описать как организованный исчерпывающий поиск, который часто позволяет избежать исследования всех возможностей. Этот метод особенно удобен для решения задач, требующих проверки потенциально большого, но конечного числа решений.
Задача о велосипедном замке
В качестве примера рассмотрим комбинационный замок для велосипеда, состоящий из набора N переключателей, каждый из которых может быть в положении «вкл» или «выкл». Замок открывается только при одном наборе положений переключателей, из которых не менее LW2J (целая часть от N/2) находятся в положении «вкл». Предположим, что мы забыли эту комбинацию, а нам надо отпереть замок. Предположим также, что мы готовы перепробовать (если необходимо) все комбинации. Нам нужен алгоритм для систематического генерирования этих комбинаций. Если проигнорировать условие |_ N/2 J , то для замка существует 2Л' возможных комбинаций. (Покажите, что это так.) Неплохие шансы найти правильную комбинацию могут быть при A^IO. Однако условие |_ N/2 J позволит отбросить (или лучше не генерировать) многие комбинации.
Промоделируем каждую возможную комбинацию вектором из N нулей и единиц. На i-м месте будет 1, если i-й переключатель находится в положении «вкл», и 0, если i-й переключатель — в положении «выкл». Множество всех возможных М-векторов хорошо моделируется с помощью двоичного дерева (см. разд. 2.2). Каждая вершина /г-го уровня этого дерева будет соответствовать определенному набору первых k компонент М-вектора. Две ветви, идущие вниз из вершины этого уровня, соответствуют двум возможным значениям (/?+ 1)-й компоненты в М-векторе. У дерева будет N уровней. Рис. 3.3.1 на примере М=4 поясняет основную конструкцшб.
Условие, заключающееся в том, что число переключателей в положении «вкл» должно быть не меньше |_ M/2 J , позволяет нам не образовывать части дерева, которые не могут привести к правильной комбинации. Например, рассмотрим вершину 00 на рис. 3.3.1. Так как правая ветвь (к ООО) не может привести к допустимой комбинации, нет нужды ее формировать. Если какие-то вершины, следующие за рассматриваемой вершиной, не удовлетворяют ограничению задачи, то эти вершины не надо рассматривать. В данном случае никакие из
вершин, находящихся внутри пунктирных линий, не нужно исследовать и даже формировать.
Теперь, воспользовавшись этой моделью двоичного дерева, можно изложить процедуру отхода назад для образования только тех комбинаций, в которых по крайней мере |_ ^/2 J переключателей находятся в положении «вкл». Алгоритм сводится к пересечению дерева.
Рис. 3.3.1. Двоичное дерево, представляющее TV-векторы из нулей и единиц.
Двигаемся вниз по дереву, придерживаясь левой ветви, до тех пор, пока это возможно. Достигнув конечной вершины, опробуем соответствующую комбинацию. Если она не подходит, поднимаемся на один уровень и проверяем, можем ли мы спуститься опять по другой ветви. Если это возможно, берем самую левую из неисследованных ветвей. Если нет, отходим вверх еще на один уровень и пытаемся спуститься из этой вершины. Перед спуском проверяем, можно ли удовлетворить условие об |_ N]2 J включенных переключателях в последующих вершинах. В ситуации, изображенной на рис. 3.3.1, этот алгоритм просмотрит следующую последовательность вершин:
1
11
111
1111 Проверка этой комбинации.
111 Отход, так как НИ — конечная вершина.
1110 Спуск по единственной непросмотренной ветви вниз, проверка этой комбинации.
111 Снова отход.
11 Отход дальше, так как из 111 все ветви просмотрены.
ПО Спуск по единственной непросмотренной ветви.
1101 Проверка комбинации.
110 Отход из 1101.
1100 Проверка комбинации.
ПО Отход из 1100.
11 Отход, так как все ветви просмотрены.
1 Отход, так как все ветви просмотрены.
10 Спуск по единственной непросмотренной ветви.
101 Спуск по самой левой непросмотренной ветви.
1011 Проверка комбинации.
101 Отход.
1010 Проверка комбинации.
101 Отход.
10 Отход.
100 Спуск по единственной непросмотренной ветви.
1001 Проверка комбинации.
100 Отход.
10 Отход; заметим, что мы не опускаемся к 1000, так как эта вершина нарушает условие о том, что должно быть по крайней мере две единицы.
1 Отход.
Корень Отход.
0 Спуск по единственной непросмотренной ветви.
и т. д.
Алгоритм останавливается, когда мы возвращаемся к корню и не остается непросмотренных ветвей.
Этот простой пример иллюстрирует основные свойства, общие для всех алгоритмов с отходом назад. Если можно сформулировать задачу так, что все возможные решения могут быть образованы построением Дивекторов, тогда ее можно решить при помощи процедуры с отходом.
Задача — головоломка «8»
Рис. 3.3.2. иллюстрирует так называемую головоломку «8». В коробке 3x3 находятся восемь подвижных квадратов, одно место — пустое (обозначенное х). Любой занумерованный квадрат, прилегающий к пустому месту, можно передвинуть на это место, при этом пустое место окажется в позиции, занимаемой до этого занумерованным квадратом. Например, на рис. 3.3.2, а квадрат 3 можно передвинуть на место, обозначенное х, пустое место окажется в позиции, занимаемой до этого квадратом 3, как показано на рис. 3.3.2, б. Попытаемся найти последовательность передвижений, которая преобра-
зует конфигурацию, изображенную на рис. .3. , а, в конфигурацию, показанную на рис. 3.3.2, в.
Рис. 3.3.2. Головоломка «8»,
тем не менее эффективную ЛЛвекторную структуру. Каждая вершина дерева будет соответствовать конфигурации головоломки. Корень (на уровне 0) будет соответствовать исходной конфигурации (рис. 3.3.2, а), от него будут отходить ветви, ведущие к вершинам уровня 1, каждая из которых будет соответствовать конфигурации, полученной одним передвижением из исходной. Вершины, непосредственно следующие за любой вершиной дерева, будут упорядочены слева направо по направлению, в котором движется пустая клетка. Самая левая конфигурация будет соответствовать движению пустой клетки влево, остальные конфигурации будут соответствовать движениям пустой клетки вверх, вниз и направо. На рис. 3.3.3 показаны первые два
tfpSHb
УроВешЛ
Рис. 3.3.3. Построение дерева отходов для головоломки «8».
уровня нашего дерева. Заметим, что передвижение пустой клетки наверх из исходной конфигурации невозможно.
Вершины уровня k соответствуют всем конфигурациям, которые можно достичь за k ходов из корневой конфигурации. Не теряя при этом никаких возможных путей к желаемой конфигурации, мы не будем допускать, чтобы непосредственно следующая за какой-либо
вершиной конфигурация повторяла непосредственно предшествующую. Например, рассмотрим самую правую вершину уровня 1 на рис. 3.3.3. Эта вершина могла бы иметь две последующие, соответствующие передвижениям пустого квадрата влево и вниз. Но передвижение влево повторит корневую конфигурацию и не приблизит нас к окончательному состоянию.
Таким образом, элементы /V-векторов, соответствующие конфигурациям, должны удовлетворять условию, состоящему в том, что (/?4-1)-й элемент должен получаться из /г-го одним ходом и (/?+1)-й элемент не может быть таким же, как (/г—1)-й. Каково значение N? Глубина дерева N означает максимальное число ходов, которые мы собираемся рассматривать на пути от исходной конфигурации к конечной. Так как мы не представляем себе, сколько ходов может потребоваться, N должно быть выбрано на основании нашего запаса терпения или машинного времени. Например, если N=7, то процедура покажет, может ли быть получена окончательная конфигурация не более чем за семь передвижений из исходной конфигурации.
Теперь мы подготовлены к тому, чтобы воспользоваться процедурой с отходами для головоломки «8». Как и в задаче с велосипедным замком, постараемся всегда двигаться влево вниз по дереву поиска. Рис. 3.3.4 иллюстрирует дерево отходов. Номера, стоящие рядом с конфигурациями, показывают порядок генерации вершин в процедуре. Окончательная конфигурация в вершине 20 может быть достигнута через три передвижения от исходного состояния. Продолжите в качестве упражнения процедуру с отходами, чтобы получить конфигурацию, изображенную на рис. 3.3.2, г.
В наихудшем случае алгоритмы с отходами экспоненциальные, ибо может оказаться необходимым исчерпывающий поиск на множестве решений с экспоненциальным числом элементов. В ранее рассмотренной задаче о велосипедном замке может быть 2N вершин на уровне N, так как поиск бинарный. Процедура с отходами, отбрасывающая 99% потенциально возможных решений, является все еще экспоненциальной, потому что 2Л71ОО растет экспоненциально при N—>оо.
Программирование с отходом часто называют «методом на крайний случай», так как можно привести аргументы, показывающие, что оно всего лишь на один уровень эффективнее «лобовых» методов полного перебора. Следует, конечно, искать более эффективные методы, но такое пожелание легче высказать, чем осуществить. Программирование с отходом — важный инструмент, которым должен уметь пользоваться каждый программист.
Упражнения 3.3
3.3.1. Пример с головоломкой «8». Продолжите процедуру с отходами, продемонстрированную на головоломке «8», с целью получить конфигурацию, показанную на рис. 3.3.2, г. Поиск ведите не дальше седьмого уровня дерева.
Уровень 7
Рис. 3.3.4. Дерево отходов, построенное для получения конфигурации в вершине 20.
L3.3.2. Пример с головоломкой «&> (реализация). Дайте полное формальное описание алгоритма с отходами для головоломки «8». Напишите программу и примените ее в упр. 3.3.1.
*3.3.3. Задача восьми ферзей (разработка). Покажите, что максимум восемь ферзей могут быть расположены на стандартной шахматной доске 8x8 таким образом, что ни один ферзь не бьет другого. Разработайте алгоритм с отходами, в явном виде создающий такую конфигурацию.
-L3.3.4. Задача восьми ферзей (реализация). Реализуйте алгоритм в упр. 3.3.3.
**3.3.5. Алгоритмы с отходами (общая формулировка). Попытайтесь дать детальную, общую, теоретико-множественную формулировку основной структуры, характерной для всех алгоритмов с отходами.
***3.3.6. Алгоритмы с отходами (анализ). Обычно почти невозможно провести очень точный анализ ожидаемой трудоемкости алгоритма с отходами. Как можно грубо оценить среднее время работы алгоритмов с отходами? Охарактеризуйте сильные и слабые стороны этих способов оценки. Опробуйте их на реальной программе с отходами (см. упр. 3.3.2 и 3.3.4).
3.4. Метод ветвей и границ
Метод, известный как метод ветвей и границ, похож на методы с отходами назад тем, что он исследует древовидную модель пространства решений и применим для широкого круга дискретных комбинаторных задач. Алгоритмы с отходами нацелены на то, чтобы найти одну или все конфигурации, моделируемые TV-векторами, которые удовлетворяют определенным свойствам. Алгоритмы ветвей и границ ориентированы в большей степени на оптимизацию. В решаемой задаче определена числовая функция стоимости для каждой из вершин, появляющихся в дереве поиска. Цель — найти конфигурацию, на которой функция стоимости достигает максимального или минимального значения.
Алгоритм ветвей и границ хорошо работает в задаче коммивояжера, рассмотренной в разд. 1.3. В данном разделе изложение будет вестись на примере задачи коммивояжера. Предупреждаем читателя, что алгоритмы ветвей и границ, как правило, бывают довольно сложны и представленный здесь — не исключение. При помощи алгоритмов ветвей и границ удалось решить большой круг разнообразных серьезных практических задач (см. гл. 7); эти алгоритмы редко оказываются простыми.
Напомним, что задача заключается в нахождении в торговом участке коммивояжера тура из N городов с наименьшей стоимостью. Каждый город входит в тур только один раз. В терминах сетей в сети городов надо найти покрывающий цикл наименьшей стоимости. Имеется матрица С, каждый элемент которой сц равен стоимости (обычно в единицах времени, денег или расстояния) прямого проезда из города i в город j. Задача называется симметричной, если сг7-=с,-г для всех i и j, т. е. если стоимость проезда между каждыми двумя городами не зависит от направления. Предположим, что сгг=оо для всех i.
Алгоритмы ветвей и границ для задачи коммивояжера могут быть сформулированы разными способами. Авторы излагаемого алгоритма — Литл, Мерти, Суини и Карел. Это своего рода классика.
Во-первых, рассмотрим ветвление. На рис. 3.4.1, а показана матрица стоимостей для асимметричной (несимметричной) задачи коммивояжера с пятью городами, представленной на рис. 3.4.1, б. Обратите внимание на то, что мы пользуемся направленной сетью, чтобы указать стоимости, так как стоимость проезда из города i прямо в город j не обязательно такая же, как стоимость проезда из города / в город i. Корень нашего поискового дерева будет соответствовать множеству «всех возможных туров», т. е. эта вершина представляет множество всех 4! возможных туров в нашей задаче с пятью городами. В общем случае для любой асимметричной задачи с N городами корень будет представлять полное множество R всех (N—1)! возможных туров. Ветви, выходящие из корня, определяются выбором одного ребра, скажем (i, у). Наша цель состоит в том, чтобы разделить множество
всех туров на два множества: одно, которое, весьма вероятно, содержит оптимальный тур, и другое, которое, вероятно, не содержит. Для этого выбираем ребро (i, j); оно, как мы надеемся, входит в оптимальный тур, и разделяем /? на два множества {i, j} и {i, j}. В мно-жество {i, j} входят туры из R, содержащие ребро (t, /), а в {i, /} — не содержащие (i, /).
Рис. 3.4.1. Задача коммивояжера: (а) матрица стоимостей; (б) сеть из пяти городов.
Предположим, в нашем примере мы производим ветвление на ребре (t, /)= (3,5), имеющем наименьшую стоимость во всей матрице. Корень и первый уровень дерева пространства решений будут тогда такими, как показано на рис. 3.4.2. Заметим, что каждый тур из R
Рис. 3.4.2. Построение дерева поиска по методу ветвей и границ.
содержится только в одном множестве уровня 1. Если бы мы как-то могли сделать вывод, что множество {3, 5} не содержит оптимального тура, то нам нужно было бы исследовать только множество {3, 5}.
Затем разделяем множество {3, } таким же о разом, как и множе-ство R- Следующее по дешевизне ребро в матрице — это ребро (2, 1) со стоимостью c2i=5. Поэтому можно разделить множество {3, 5} на туры, включающие ребро (2, 1), и туры, не включающие этого ребра; это показано на уровне 2 на рис. 3.4.2. Путь от корня к любой вершине дерева выделяет определенные ребра, которые должны или не должны быть включены в множество, представленное вершиной дерева. Например, левая вершина уровня 2 на рис. 3.4.2 представляет множество всех туров, содержащих ребро (3, 5) и не содержащих ребра (2, 1). Вообще, если X — вершина дерева, a (i, /) — ребро ветвления, то обозначим вершины, непосредственно следующие за X, через У м У. Множество У обозначает подмножество туров из X с ребром (i, /), а множество У — подмножество X без (I, j).
Проведенное обсуждение должно дать читателю некоторое представление о том, что подразумевается под ветвлением. Перед тем как приступить к полному описанию алгоритма для задачи коммивояжера, поясним, что подразумевается под вычислением границ.
С каждой вершиной дерева мы связываем нижнюю границу стоимости любого тура из множества, представленного вершиной. Вычисление этих нижних границ — основной фактор, дающий экономию усилий в любом алгоритме типа ветвей и границ. Поэтому особое внимание следует уделить получению как можно более точных границ. Причина этого следующая. Предположим, что мы построили конкретный полный тур со стоимостью т. Если нижняя граница, связанная с множеством туров, представленных вершиной vk, равна МУ^-т, то до конца процесса поиска оптимального тура не нужно рассматривать вершину vk и все следующие за ней (почему?).
Основной шаг при вычислении нижних границ известен как приведение. Оно основано на следующих двух соображениях:
1. В терминах матрицы стоимостей С каждый полный тур содержит только один элемент (ребро и соответствующую стоимость) из каждого столбца и каждой строки. Заметим, что обратное утверждение не всегда верно. Множество, содержащее один и только один "элемент из каждой строки и из каждого столбца С, не обязательно представляет тур. Например, в задаче, изображенной на рис. 3.4.1, множество {(1, 5), (5, 1), (2, 3), (3, 4), (4, 2)} удовлетворяет этому условию, но не образует тура.
2. Если вычесть константу h из каждого элемента какой-то строки или столбца матрицы стоимостей С, то стоимость любого тура при новой матрице С ровно на h меньше стоимости того же тура при матрице С. Поскольку любой тур должен содержать ребро из данной строки или данного столбца, стоимость всех туров уменьшается на h. ото вычитание называется приведением строки (или столбца).
Пусть t — оптимальный тур при матрице стоимостей С. Тогда
стоимостью тура t будет
z{t)= S <Му-
Если С' получается из С приведением строки (или столбца), то I должен остаться оптимальным туром при С и
z(t)=h+z' (t),
где z' (t) — стоимость тура t при С.
1 2 3 4 5
h, = 25
h2 =5
h3 = 1
h4 =S
h5=?
h6 = 0 ti7=0 he = 0 hg = 3 tilo=O
«1 = 25 + 5 + 1+6 + 7 + 3 = 47
Рис. 3.4.3. Приведение матрицы стоимостей, показанной на рис. 3.4.1, а.
03 0 15 3 2
0 Оо 12 22 20
18 14 ©о 2 0
3 44 18 ©О 0
15 1 0 0 ОО
Под приведением всей матрицы стоимостей С понимается следующее. Последовательно проходим строки С и вычитаем значение наименьшего элемента hi каждой строки из каждого элемента этой строки. Потом то же самое делаем для каждого столбца. Если для некоторого столбца или строки /гг=0, то рассматриваемый столбец или строка уже приведены, и тогда переходим к следующему столбцу или строке. Положим
h = S h{.
все строки и столбцы
Полученную в результате матрицу стоимостей назовем приведенной из С. На рис. 3.4.3 показано приведение матрицы стоимостей, изображенной на рис. 3.4.1, а. Значения ht даны в конце каждой строки и столбца (строки и столбцы последовательно перенумерованы).
Общее приведение составляет h=41 единиц. Следовательно, нижняя граница стоимости любого тура из R также равна 47, т. е.
z(t)=h+z’ (t)^h=47,
так как г' (/)^0 для любого тура t при приведенной матрице С. Эта граница указана около корня дерева на рис. 3.4.2.
Рассмотрим нижние границы для вершин уровня 1, т. е. для мно-
жеств {3, 5} и {3, 5}. Будем работать с приведенной матрицей, изображенной на рис. 3.4.3, имея в виду, что значение 47 должно быть прибавлено к стоимости оптимального тура t при С' для того, чтобы получить истинную стоимость t при С.
По определению ребро (3, 5) содержится в каждом туре множества {3, 5}. Этот факт препятствует выбору ребра (5, 3), так как ребра (3, 5) и (5, 3) образуют цикл, а это не допускается ни для какого тура.
сю 0 15 3
0 ©О 12 22
3 44 18 СЮ
15 1 СЮ 0
Рис. 3.4.4. (а) Приведенная матрица стоимостей после вычеркивания строки 3 и столбца 5 и установления с63=со; (б) приведение матрицы стоимостей, изображенной в части (а).
Ребро (5, 3) исключаем из рассмотрения, положив cs3=oo. Строку 3 и столбец 5 также можно исключить из дальнейшего рассмотрения по отношению к множеству {3, 5}, потому что уже есть ребро из 3 в 5. Часть приведенной матрицы стоимостей, показанной на рис. 3.4.3, которая будет хоть сколько-нибудь полезна для дальнейшего поиска на множестве туров {3, 5}, показана на рис. 3.4.4, а. Она может быть приведена к матрице стоимостей, показанной на рис. 3.4.4, б с /г=15. Теперь нижняя граница для любого тура из множества {3, 5} равна 47+15=62; она указана около вершины {3, 5} на рис. 3.4.2.
Нижняя граница для множества {3, 5} получается несколько иным способом. Ребро (3, 5) не может находиться в этом множестве, поэтому полагаем с36=оо в матрице, изображенной на рис. .3.4.3. В любой тур из {3,5} будет входить какое-то ребро из города 3 и какое-то ребро к городу 5. Самое дешевое ребро из города 3, исключая старое значение (3, 5), имеет стоимость 2, а самое дешевое ребро к городу 5 имеет стоимость 0. Следовательно, нижняя граница любого тура в множестве {3,5} равна 47+2+0=49; это указано около вершины {3, 5} на рис. 3.4.2.
На данной стадии нам удалось сократить размер матрицы стоимостей, рассматриваемой в вершине {3, 5}. Кроме того, если мы сможем найти тур из множества {3, 5} со стоимостью, меньшей или рав-н°и 62, тогда не нужно проводить дальше ветвления и вычисления границ в вершине {3, 5}. В этом случае будем говорить, что вершина
{3, 5} в дереве отработана. Тогда следующей целью может быть ветвление из вершины {3, 5} в надежде найти тур со стоимостью в пределах 49^0^62.
В основных чертах блок-схема этого алгоритма ветвей и границ показана на рис. 3.4.5. Вскоре мы дополним эту схему рядом важных
Рис. 3.4.5. Блок-схема алгоритма ветвей и границ.
деталей. Здесь используются следующие обозначения. Буква X обозначает текущую вершину на дереве поиска, a w (X) — соответствующую нижнюю границу. Вершины, следующие непосредственно за X, назовем Y и Y\ они выбираются ветвлением по некоторому ребру (k, I). Символ г0 обозначает стоимость самого дешевого тура, известного на данный момент. В начальный момент z0=oo. Советуем хорошо изучить эту блок-схему.
Теперь раскроем более детально содержание некоторых блоков этой схемы.
Блок 1. Установление начальных значений переменных, или инициализация, не представляет труда; детали оставлены в качестве упражнения.
Блок 2. Первое приведение — это непосредственная реализация описанной ранее процедуры; детали оставляем в качестве упражнения.
Блок 3. Выбор следующего ребра ветвления (k, I) определяет множества Y и Y, непосредственно следующие за текущим X. Ребро {k, I) нужно выбирать так, чтобы попытаться получить большую по величине нижнюю границу на множестве Y={k, /}, что облегчит проведение оценки для множества Y. Обычно предпочтительнее провести оценку для Y, так как размер этого множества и соответствующая ему матрица стоимостей обычно больше, чем у Y (из матрицы для Y вычеркнуты строка k и столбец /). Можно надеяться также, что Y с большей вероятностью содержит оптимальный тур.
Как применить эти идеи к выбору конкретного ребра ветвления (k, I)? В приведенной матрице стоимостей С', связанной с X, каждая строка и столбец имеют хотя бы по одному нулевому элементу (если нет, то С не полностью приведена). Можно предположить, что ребра, соответствующие этим нулевым стоимостям, будут с большей вероятностью входить в оптимальный тур, чем ребра с большими стоимостями. Поэтому мы выберем одно из них. Но какое? Пусть ребро (t, /) имеет cf,=0 в С. Мы хотим, чтобы у K={i, j} была как можно большая нижняя граница. Вспоминая метод вычисления нижней границы для {3, 5} в нашем примере, мы видим, что для Y эта граница задается в виде
w (Y)=ш(Х)4~ (наименьшая стоимость в строке I, не включая СО‘)+ -|- (наименьшая стоимость в столбце /, не включая сг,).
Следовательно, из всех ребер (t, /) с Сц=0 в текущей матрице С мы выбираем то, которое дает наибольшее значение для w(Y). Пусть это будет ребро (k, I).
Поэтому более подробное описание выбора, представленного блоком 3, имеет следующий вид:
Шаг 1. Пусть S — множество ребер (i, /), таких, что Сг;=О в текущей матрице стоимостей С.
Шаг 2. Положим Ё)ц равным наименьшей стоимости в строке i, исключая сц, плюс наименьшая стоимость в столбце /, исключая Сц. Вычисляем для всех (I, /)£$.
Шаг 3. Выбираем следующее ребро ветвления (k, I) из условия D*ki= max Du.
(й /) e-S
Рассмотрим опять задачу с пятью городами, изображенную на рис. 3.4.1. Из приведенной матрицы С видно, что первое значение X, корень /?, имеет ш(Х)=47. Применяя подалгоритм, описанный выше, находим наше первое ребро ветвления следующим образом:
Шаг 1. S={(1, 2), (2, 1), (3, 5), (4, 5), (5, 3), (5, 4)}
Шаг 2. £12=2+1=3
£21=12+3= 15
#3S=2+0=2
#4S—3+0—3 Ds3=0+12=12 #54=0+2=2
Шаг 3. Выбираем ребро (k, l)=(2, 1), так как #21 — это максимальный элемент множества {#^}.
Блок 4. Определяем вершину Y, следующую за X, точно так же, как мы делали раньше.
В рассматриваемом примере X=R и У={2, 1}, т. е. это множество всех туров, не содержащих ребро (2, 1). Вычисляем нижнюю границу да (У) так же, как в блоке 3, т. е.
w(F)=w(X)+#;cZ
и w({2, 1}) = 47+15 = 62.
Блок 5. Вершине Y, следующей за X, соответствует подмножество туров из X, содержащих то ребро (k, I), которое выбрано в блоке 3. В рассматриваемом примере Y={2, 1}. При вычислении да (У) необходима известная осторожность. Подробный подалгоритм имеет следующий вид:
Шаг 1. Из С исключаем строку k и столбец I.
Шаг 2. Все туры множества, представленного вершиной У, содержат сколько-то (быть может, ни одного) из ранее выбранных ребер, помимо ребра (k, I). Ребро (k, /) будет или изолировано от этих других ребер, или будет частью пути, включающего некоторые или все эти ребра. Пусть р и q — начальный и конечный города этого пути. Возможно, что p=k и (или) q=l. Положим сдр=оо. Эта мера предохраняет от выбора ребра (</, р) в качестве последующего для У, а тем самым предохраняет от формирования замкнутого цикла длины меньше N. Такие циклы, конечно, не разрешены при построении тура. Есть ли какие-то случаи, в которых мы не полагаем СЗЛ>=ОО?
Шаг 3. Приводим рассматриваемую матрицу С. Пусть h будет равно сумме констант приведения.
Шаг 4. Вычисляем w(Y) по формуле w(Y)=w(X)4~h.
Возвращаясь к примеру, вычеркиваем строку 2 и столбец 1 из матрицы С, показанной на рис. 3.4.3. Так как ребро (2, 1) — един-
ственное выбранное ребро, полагаем p—l2, q=\ и с12=оо. После этих шагов, соответствующих шагам 1 и 2 описанного выше подалгоритма, текущая матрица показана на рис. 3.4.6, а. После приведения получаем матрицу, изображенную на рис. 3.4.6, б, с /г=3 и w [(2, 1)]= =йу(Х)+Л=47+3=50. Текущее состояние показано на уровнях О и 1 на рис. 3.4.7.
Рис. 3.4.6. (а) Приведенная матрица стоимостей после вычеркивания строки 2 и столбца 1 и установления с12=оо; (б) приведение матрицы стоимостей, изображенной в части (а).
Рис. 3.4.7. Дерево поиска, построенное для задачи, изображенной на рис. 3.4.1.
Блок 6. В конце концов мы должны прийти к множествам, содержащим так мало туров, что мы можем рассмотреть каждый из них и провести оценку для этой вершины без дальнейшего ветвления. Блок 6 проверяет, не пришли ли мы уже к таким множествам. Каждое ребро, про которое мы знаем, что оно содержится во всех турах из Y, сокращает размер С на одну строку и один столбец. Если в исходной задаче было N городов, а текущая матрица С имеет размер 2x2, то выбрано
уже N—2 ребер каждого тура У. Поэтому множество У содержит самое большее два тура (почему?). Вопрос о том, как их распознать, оставим в качестве упражнения. Таким образом, блок 6 проверяет, является ли С матрицей размера 2x2. Заметим, что это, по^существу, дает ответ на вопрос, поставленный в конце шага 2 при обсуждении блока 5.
Блоки 7 и 8. Блок 7 работает, только если С — матрица размеров 2x2. В этом блоке отыскивается самый дешевый тур в У и его вес обозначается через ш(У). В блоке 8 проверяется, лучше ли данный тур, чем текущий лучший из известных туров. Если нет, то новый тур отбрасывается. Если да, то текущим лучшим туром становится новый тур, и мы полагаем г0=г<у(У).
Блок 9. Теперь нужно выбрать следующую вершину X, от которой проводить ветвление. Этот выбор довольно очевиден. Выбираем вершину, из которой в данный момент не выходят ветви и которая имеет наименьшую нижнюю границу. Следовательно, данный блок состоит из следующего подалгоритма:
Шаг 1. Ищем множество S конечных вершин текущего дерева поиска. Шаг 2. Пусть вершина X будет выбрана так, что
u>(X) = mintiy(v). lies
В рассматриваемом примере:
Шаг 1. 5^{{2?Т}, {2, 1}}.
Шаг 2. ш({2, 1})=62,
ш({2, 1})=50.
Поэтому Х={2, 1}.
Блок 10. Наше обсуждение помогает решить, что делать с этим беспокоящим вопросительным знаком, поставленным в блоке 10. Вы, должно быть, заметили, что алгоритм, представленный блок-схемой на рис. 3.4.5, не имеет окончания. Блок 10 показывает, должны ли мы остановиться. Если текущая граница для нашего лучшего тура г0 меньше или равна w(X) — наименьшей из неисследованных нижних границ,— тогда никакая из вершин, следующих за X, не может содержать лучшего тура. Благодаря способу выбора X в блоке 9 лучший тур не может также содержаться ни в какой другой из неоцененных конечных вершин. Теперь все дерево поиска оценено, и мы останавливаемся.
Если w(X)<Z.Zq, поиск должен быть продолжен. В нашем примере z0=oo, поэтому поиск не прекращается.
Блок 11. В этой части алгоритма получается откорректированная матрица стоимостей С для текущей вершины X. Процедура корректировки следующая:
Шаг 1. Равно ли множество X множеству Y, последний раз образо-ванному в блоке 5? Если да, то текущая матрица С — это то, что нам нужно, и мы возвращаемся в блок 3. Именно это обычно случается на уровне 2 дерева поиска.
Шаг 2. Устанавливаем С ч- исходная матрица стоимостей.
Шаг 3. Устанавливаем S {множество всех пар (г, /), которые должны быть ребрами в X}.
Шаг 4. Вычисляем р^сц.
Шаг 5. Для каждой (i, f) £ S вычеркиваем строку I и столбец / в С.
Для каждого пути, проходящего через (i, /), находим начальный и конечный города р и q и полагаем cqp=ea. У каждого ребра (fe, /), запрещенного для туров в X, полагаем с1а—оо. Шаг 6. Приводим матрицу С. Полагаем h равным сумме констант приведения.
Шаг 7. Вычисляем w(X)=g-\-h.
Шаг 5 вносит неудобство, так как он сводится к повторению того, что мы делали раньше. Очевидная альтернатива, осуществление которой потребует большого объема памяти,— запоминать матрицы С' для каждой конечной вершины дерева. Как правило, это непрактично. В рассматриваемом примере мы просто выходим из подалгоритма на шаге 1.
Продолжим пример. Сейчас мы находимся в блоке 3, Х={2, 1}, ш(Х)=50, и дерево содержит только уровни 0 и 1 (рис. 3.4.7). Для определения множеств, следующих за X, нужно ребро (k, I). Подходящая матрица С показана на рис. 3.4.6, б. Используя подалгоритм, описанный в блоке 3, имеем
Шаг 1. S={(1, 5), (3, 5), (4, 5), (5, 2), (5, 3), (5, 4)}
О16=1+0=1
D%=2+0=2
D„=18+0=18
DS2=13+0=13
£>„=13+0=13
Г>5,=0+1 = 1
Шаг 3. £>/*z=£>45=18 (в случае нескольких равных выбираем произвольно). Таким образом, (k, 5).
Теперь устанавливаем F, используя блок 4:
У = {4Г5} и ш({4?5}) = ш({2, 1}) + £>;в = 50 +18 = 68.
Далее рассматриваем вершину У={4, 5}. Во-первых, вычеркиваем из С строку 4 и столбец 5. Так как ребро (4, 5) не пересекается с ребром (2, 1), р=4 и <7=5. Полагаем с54=оо и приводим С. Находим, что й=3 и ш(К)=50+й=53. Приведенная матрица С показана на рис. 3.4.8, а. Заметим, что нижние границы не уменьшаются при прохождении в глубь дерева.
Теперь мы находимся в блоке 6. Является ли текущая матрица С матрицей 2x2? Так как С —матрица 3x3, переходим в блок 9. Подалгоритм блока 9 выполняется следующим образом:
Шаг 1. 5={{2ГТ}, «"б), {4, 5}}.
Шаг 2. ш({2, 1})=62
щ({4, 5})=68
щ({4, 5})=53
Следовательно, Х={4, 5}.
0 СО
оо 0
7 2 3 4 5
оо 0 15 3 2
оо СО 0 10 8
,15 14 ОО 2 0
0 44 18 ©О 0
12 1 0 0 оо
a ё в
Рис. 3.4.8. Дополнительные приведенные матрицы стоимостей для задачи, сформу лированной на рис. 3.4.1.
В блоке 10 z0=oo, поэтому идем дальше. В блоке 11 нам повезло, и мы выходим на шаге 1. Опять переходим в блок 3 с Х={4, 5}, ш(Х) =53, и матрица С представлена на рис. 3.4.8, а.
Еще один раз, и цель может быть достигнута! Подалгоритм блока 3 дает следующее:
Шаг 1. S={(1, 4), (3, 4), (5, 2), (5, 3)}.
Шаг 2. П14=12+0=12
£>84=11+0=11
£>б2=11+0=11
£>бз=12+0=12
Шаг 3. Dki=DМы произвольно выбираем (k, Z)= (1, 4).
Теперь К={1, 4} и •
щ(Г) = ш({4, 5}) + £>м = 53 +12 = 65.
Поскольку У={1, 4}, из С вычеркиваем строку 1 и столбец 4. Ребро (1, 4) вместе с ребрами (2, 1) и (4, 5) образует путь. Поэтому р=2 и <7=5. Полагаем сБа=оо и приводим текущую матрицу С. Находим, что /г=11 и щ(Е)=53+/1=64. На рис. 3.4.8, б показана приведенная матрица С.
Теперь мы находимся в блоке 6 с матрицей С размеров 2x2. Блок вырабатывает тур со следующим порядком городов:
321453
и стоимостью 2=64 (проверьте это). В блоке 8 полагаем z0=64; теперь это текущий лучший тур.
Все ли мы сделали? Нам не надо рассматривать вершины, следующие за вершинами {4, 5} и {1, 4}, так как их нижние границы больше чем 64. Однако в блоке 10 мы видим, что у конечной вершины {2, 1} нижняя граница равна 62<64. Следовательно, возможно, что тур из этого подмножества может быть несколько лучше, чем тот, который мы получили. Таким образом, надо еще кое-что сделать.
Мы находим, что Х={2, 1}, щ(Х)=62, а матрица С, откорректированная с помощью подалгоритма блока 11, имеет вид, как на рис. 3.4.8, в. Затем в блоке 3 выбирается ребро (4, 1) с £>^=12 в качестве следующего ребра ветвления. В блоках 4 и 5 вычисляются щ({4, 1})= =62+12=74 и w({4, 1})=62. Необходима еще одна итерация. Оставим это в качестве упражнения. Существует ли тур со стоимостью 62 или 63?
Хотя кажется, что только что построенный алгоритм работает очень долго на нашем маленьком примере с пятью городами, на самом деле это достаточно мощный инструмент. Тщательно выполненная программа обычно решает задачу коммивояжера с 20—30 городами существенно быстрее чем за одну минуту на серийных машинах CDC 6000 или IBM 360/lxx. Задачи с 40—50 городами часто могут быть решены за вполне доступное время (меньше 10 мин времени работы центрального процессора). Сопоставьте это с безобразными результатами работы алгоритма исчерпывающего поиска ETS (см. разд. 1.3) для задачи с 20 городами, решаемой на суперкомпьютере.
Существуют различные эвристические приемы, которые могут ускорить этот основной алгоритм ветвей и границ (некоторые из них были использованы для получения указанных выше оценок времени). Два таких приема были рассмотрены в разд. 3.2.
Алгоритм GTS2 можно использовать как начальный этап для алгоритма ветвей и границ из данного раздела. Как мы видели при построении этого последнего алгоритма, может понадобиться некоторое время, прежде чем будет найден первый полный тур и г0 станет реалистической оценкой стоимости оптимального тура. Если в начале работы алгоритма известен довольно хороший тур, скажем полученный алгоритмом GTS2, тогда г0 с самого начала устанавливается на достаточно низкий уровень. В этом случае любая вершина на дереве поиска, нижняя граница которой оказывается больше или равной 2о, сразу может считаться исследованной. Таким образом, можно в значительной мере избежать бесполезного поиска при работе точного алгоритма.
Этот алгоритм считался одним из лучших для задачи коммиво
яжера почти до 1970 г. С тех пор появились более быстрые алгоритмы, но они используют методы, не рассматриваемые в этой книге.
Обо всех более или менее эффективных алгоритмах ветвей и границ известно или имеются предположения, что их трудоемкость в худшем случае является экспоненциальной. Анализ ожидаемой трудоемкости очень сложен и часто выходит за рамки наших аналитических возможностей. Все, что известно о большинстве алгоритмов ветвей и границ, описанных в литературе, это лишь некоторые экспериментальные статистические данные.
Упражнения 3.4
3.4.1. Завершите решение примера с пятью городами из этого раздела.
3.4.2. Используя алгоритм ветвей и границ этого раздела, решите следующую задачу коммивояжера с шестью городами:
1 2 3 4 5 6
1 ОО 21 42 31 6 24
2 11 Оо 17 7 35 18
3 25 5 ОО 27 14 9
4 12 9 24 ОО 30 12
5 14 7 21 15 ОО 48
6 39 15 16 5 20 СО
3.4.3. Начальный подалгоритм. Разработайте детальный подалгоритм для шага инициализации (блок 1) блок-схемы, изображенной на рис. 3.4.5.
3.4.4. Подалгоритм начального приведения. Разработайте детальный подалгоритм для шага начального приведения (блок 2) блок-схемы на рис. 3.4.5.
3.4.5. Процесс ветвления для множества Y. Разработайте детальный подалгоритм генерации Y (блок 4) для блок-схемы на рис. 3.4.5.
3.4.6. Подалгоритм исчерпывающего поиска. Разработайте детальный подалгоритм для шагов исчерпывающего исследования (блоки 6, 7 и 8) на рис. 3.4.5.
1.3.4. 7. Полное изложение алгоритма коммивояжера. Дайте полное, детальное изложение всего алгоритма ветвей и границ, построенного в этом разделе. Организуйте алгоритм так, чтобы он был готов для непосредственной реализации в качестве программы для ЭВМ. См. упр. 3.4.3 — 3.4.6.
* 3.4.8. Правильность. Докажите правильность алгоритма, построенного в этом разделе.
* 3.4.9. Симметричный случай. Какие улучшения могут быть внесены в алгоритм этого раздела, если матрица стоимостей симметрична?
Каждая из следующих четырех задач должна решаться группами от двух до пяти студентов.
* L3.4.10. Реализация. Реализуйте алгоритм этого раздела (см. упр. 3.4.7) как машинную программу. Внимательность в процессе разработки и написания программы поможет избежать многих неприятностей на стадии отладки. Особая тщательность требуется для правильной обработки различных матриц стоимостей.
*L3.4.11. Проверка. Примените программу из упр. 3.4.10 для экспериментальной проверки качества алгоритма коммивояжера, изученного в этом разделе. Ограничьтесь случаями 7VC2O городов.
***L3.4.12. Задача о рюкзаке (полное построение). Имеется рюкзак объема V и неограниченный запас каждого из N разных видов предметов. Для 1=1, ... , N один предмет вида i имеет известный объем V/ и известную стоимость т;. В рюкзак можно положить целое число различных предметов. Нужно упаковать рюкзак так, чтобы общая стоимость упакованных предметов была как можно большей, при условии, чтобы их общий объем не превосходил V. Форма предметов в задаче не играет роли. Постройте полностью алгоритм ветвей и границ для задачи о рюкзаке.
***L3.4.13. Составление расписания для параллельных процессоров (полное тстрое~ ние). Три одинаковых центральных процессора могут выполнять М заданий. Каждое задание может быть выполнено на любом процессоре, и, если задание загружено в процессор, оно находится в нем до полного завершения (т. е. задания не могут прерываться или разделяться между двумя или более процессорами). При i=l.7И
задание i требует времени t/ для выполнения. Для любого линейного порядка заданий следующее задание из списка выполняется на первом освободившемся процессоре. Задания могут быть перечислены в любом порядке.
Полностью постройте алгоритм ветвей и границ для поиска оптимального списка, т. е. такого, который дает возможность завершить все задания в кратчайшее время. Рассмотрим в качестве примера четыре задания: с /х=3, t2=3, ts=3 и /4=6. Взятые в порядке (1, 2, 3, 4), все задания полностью завершатся за время 7=9. Для порядка (4, 1, 2, 3) 7=6, и ясно, что это наилучшее возможное расписание.
*L3.4.14. Оценка алгоритма GTS2 (проверка). Это упражнение может быть выполнено, только если у вас есть программы как для алгоритма GTS2, так и для алгоритма ветвей и границ, построенного раньше. Экспериментально проверьте качество алгоритма GTS2 по сравнению с точными решениями, полученными алгоритмом ветвей и границ, для случайно генерируемых задач не более чем с 20 городами. Используйте алгоритм GTS2 в качестве начального этапа для алгоритма ветвей и границ, как описано в этом разделе. Каковы результаты сравнения экспериментальных величин математического ожидания и дисперсии времени работы алгоритмов?
3.5. Рекурсия
В математике и программировании рекурсия — это метод определения или выражения функции, процедуры, языковой конструкции или решения задачи посредством той же функции, процедуры и т. д. Несколько примеров придадут этой идее более конкретный характер.
Факториалы и числа Фибоначчи
Факториальная функция определяется рекурсивно следующим образом:
0! = 1,
N\=Nx (N—1)!, если Af>0,
или в виде фрагмента программы:
FAC(0)=l, (1)
FAC(N)=N%FAC(N—1), если N>0. (2)
Областью определения функции FAC является множество неотрицательных целых чисел.
Уравнение (2) — это пример рекуррентного соотношения. Рекуррентные соотношения выражают значения функции при помощи дру
гих значений, вычисленных для меньших аргументов. Уравнение (1) — нерекурсивно определенное начальное значение функции. Для каждой рекурсивной функции нужно хотя бы одно такое начальное значение, в противном случае ее нельзя вычислить в явном виде.
Аналогично числа Фибоначчи определяются следующей бесконечной последовательностью целых чисел: 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, .... Проверка показывает, что TV-й элемент этой последовательности равен сумме двух непосредственно предшествующих элементов. Таким образом, если FIB (У) обозначает У-е число Фибоначчи, то значение FIB (А) может быть определено из рекуррентного соотношения:
FIB (7V)=FIB (N— 1)+FIB (TV—2).
Так как FIB (А) определено через два разных значения для меньших аргументов, необходимы два начальных значения. Ими служат
FIB(1)=1, FIB(2)=1.
Определенные здесь числа Фибоначчи х) являются рекурсивным решением следующей задачи:
Каждый месяц самка из пары кроликов приносит двух кроликов (самца и самку). Через два месяца новая самка сама приносит пару кроликов. Нужно найти число кроликов в конце года, если в начале года была одна новорожденная пара кроликов и в течение этого года кролики не умирали.
Посмотрим, какую работу надо проделать, чтобы вычислить FAC (N) для произвольного натурального числа N. Для вычисления FAC(TV) мы должны произвести рекурсивное обращение и вычислить FAC(AT—1). Это в свою очередь требует другого рекурсивного обращения для вычисления FAC(/V—2) и т. д. Таким образом, для того чтобы вычислить FAC(TV), нужно произвести N рекурсивных обращений, последнее из которых выполняется для FAC(O)=1. Принято говорить, что глубина рекурсии, требуемой для вычисления FAC(TV), равна N. В машинных программах глубина рекурсии соответствует самой длинной последовательности обращений к процедуре, требуемой для вычисления функции. Поэтому глубина рекурсии — это мера вычислительной сложности рекурсивно определенной функции.
Для вычисления значения FIB (А) функции Фибоначчи нужно вычислить два значения функции [FIB (TV—1) и FIB (А—2)]. Каждое из этих вычислений в свою очередь требует двух вычислений — два для FIB (TV—1) и еще два для FIB (А—2) и т. д. Это подсказывает, что глубина рекурсии, требуемая для вычисления FIB (TV), равна приблизительно 2ЛГ-2. Однако после недолгого размышления мы
х) Эта последовательность названа в честь итальянского математика Фибоначчи, который в 1202 г, сформулировал изложенную здесь задачу.
видим, что такой подход дает сильно завышенную оценку. Ясно, что если известны N—1 значений, FIB(l), FIB (2), . . ., FIB (А—1), то можно вычислить FIB (А). Более того, поскольку сразу были заданы FIB(l) и FIB (2), потребуется только N—3 вычислений для FIB(3), . . ., FIB (АГ—1). Таким образом, N—2 вычислений функции будет достаточно для вычисления FIB (АД
Функция Аккермана
Две рекурсивные функции, рассмотренные до сих пор, были достаточно простыми. Поэтому, чтобы не сложилось неправильное впечатление о том, насколько сложны рекурсивные функции, представим следующую, довольно простую на первый взгляд, дважды рекурсивную функцию, известную как функция Аккермана. Функция дважды рекурсивна, если сама функция и один из ее аргументов определены через самих себя.
f ЛА +1,
А(Л4, ЛГ) = Д(Л4 —1, 1),
(Д[М— 1, А(М/ N — 1)]
если М = 0;
если ЛА = О;
в остальных случаях.
Беглый просмотр рис. 3.5.1 показывает, как трудно вычислить эту функцию даже для таких малых аргументов, как М=4 и N—2. Заметьте, например, что А (4, 1)=Д(3, 13).
Разбиения целого
Разбиение положительного целого числа М — это представление М в виде суммы целых чисел. Классическая счетная задача — определение количества Р(М) разбиений числа М.
Для /VI=6 разбиениями являются
6
5+1
4+2, 4+1+1
3+3, 3+2+1, 3+1+I+1
2+2+2, 2+2+1+1, 2+1+1+1+1
1 + 1+1 + 1+1 + 1.
Интересен способ выражения функции Р (Л4) через другую функцию Q (Л4, N), которая определяется как число разбиений целого М со слагаемыми, не превышающими N. Несложные рекурсивные рассуждения приводят к следующему:
1. 0(Л4, 1)=1. Это значит, что существует только одно разбиение целого числа М, в котором наибольшее слагаемое есть единица, а именно Л1=1+1+. . .+1.
2. Q(l, N)=l. Очевидно, существует только одно разбиение целого числа 1 независимо от величины N наибольшего слагаемого.
3. Q(M, N)~Q(M, M), если M<ZN. Ясно, что никакое разбиение М не может содержать слагаемого N, большего М.
4. Q(Af, 7W)=1+Q(A1, М—1). Существует только одно разбиение М со слагаемым, равным М. Все другие разбиения М имеют наибольшее слагаемое Л^Л4—1.
5. Q(/W, N)=Q(M, N—1)+Q (М—N, N). Это означает, что любое разбиение М с наибольшим слагаемым, меньшим или равным N, или не содержит N в качестве слагаемого — в этом случае данное разбиение также входит в число Q(M, N—1), или содержит N — при этом остальные слагаемые образуют разбиение числа М—N.
Уравнения 1—5 рекурсивно определяют функцию Q(M, N). Они )еделяют Р(М), так как Р М).
Каждый, кто знаком с Фортраном, знает, что в этом языке нельзя производить рекурсивных обращений к подпрограммам. Казалось бы, это должно препятствовать нам в реализации вычисления рекурсивной функции Q(M, N) на Фортране. Однако ниже представлена программа реализации итеративного алгоритма на Фортране, правильно вычисляющая Q(A1, ЛГ).
INTEGER FUNCTION Q(M.N)
INTEGER M, N, VAL(M.N)
IF (M .LT. 1 .OR, N .LT. 1) GO TO 70
DO 60 K = 1,M
DO 50 L = 1,N
IF (K .EQ. 1 .OR. L .EQ. 1) GO TO 40
IF (K-L) 10.20,30
10 VAL(K L) = VAL(K,K)
GO TO 50
20 VAL(K,L) = 1+VAL(K,K-1)
GO TO 50
30 VAL(K,L)=VAL(K,L-1) + VAL(K-L,L)
GO TO 50
40 VAL(K,L) = 1
50 CONTINUE
60 CONTINUE
Q = VAL(M.N) RETURN
70 WRITE (6,1000) M.N
1000 FORMAT (1H0.21H НЕВЕРНЫЕ АРГУМЕНТЫ, 216) RETURN
END
Заметим, что для вычисления Q(M, N) сначала вычисляются и запоминаются в виде массива VAL(/, J) все предыдущие значения Q(M, N) для 1^М и Таким образом, то, что кажется рекурсивными обращениями (например, строка 10), на самом деле есть только обращения к массиву.
Предыдущий пример показывает, что с некоторым усилием можно написать на Фортране программу реализации рекурсивной функции. С другой стороны, сопоставьте это с естественностью реализации той же функции на Алголе:
beglnU М<1 OR Nd then PRINT НЕВЕРНЫЕ АРГУМЕНТЫ е1зеИМ=>1 QRN=1 thenQP:=1
el«0ltM<N t hen QP;—QP(M, M)
e!selfM=N toenQP:=1+QP(M,M-1)
else •• 0P;«ftPlM,N-1).+CP(M-N,NJ
end
Идентификаторы языка
Рекурсия естественным образом встречается во всех областях машинной математики. Например, в Фортране идентификатор (переменная, функция или имя подпрограммы) обычно определен как последовательность, содержащая от одной до шести букв или цифр, первая из которых — буква. В Алголе идентификаторы определены почти так же, но без ограничения на длину. Определение идентифи
катора обычно задается так:
(цифра) : =071/2/3/4/5/6/7/8/9
(буква) : =А]В]С]. . .[X[Y]Z
(идентификатор) : = (буква)
(идентификатор) : = (идентификатор) (цифра)
(идентификатор) : = (идентификатор) (буква)
Обращаем внимание на то, что в последних двух определениях идентификатор выражен сам через себя.
Формулы, аналогичные приведенным выше, используются компиляторами Алгола, чтобы определять, все ли переменные в исходной программе правильно сформированы. Предположим, что функция VAR определяется таким образом, что для любой цепочки символов X, VAR (X)=«YES» тогда и только тогда, когда X — правильный идентификатор; в противном случае VAR(X)=«NO». Функция VAR определяется рекурсивно следующим образом:
( YES, VAR(A)-J VAR’ (Г)’ VAR(A)-4 VAR>
( NO
если X = <буква>; если X = Y <цифра>; если X — Y <буква>; в остальных случаях;
здесь X=Y (цифра) означает, что X — цепочка символов, последний из которых цифра.
Поиск в глубину и в ширину
Во многих сетевых теоретических задачах нужно найти произвольное остовное дерево в сети G (например, для определения, связна ли G) или проверить каждое ребро G хотя бы по разу. Тарьян предложил простой рекурсивный алгоритм для этих двух задач. Алгоритм называется поиском в глубину. Его основная идея может быть применена во многих ситуациях, когда нужно найти какой-то оптимум в результате поиска по большой структуре типа дерева. Проиллюстрируем этот алгоритм (алгоритм DFS) с сетью на рис. 3.5.2, которая представлена списками смежности.
Алгоритм DFS выражен рекурсивно и требует в качестве начальных данных сеть G, произвольную начальную вершину V и начальные значения 1=0 и Т=в.
Algorithm DFS (Поиск в глубину). Найти остовное дерево Т в связной сети G, вершины которой перенумерованы 1, 2, . . ., 7И. Алгоритм является рекурсивным и обращается к себе самому оператором CALL DFS(V), вершина V — новая вершина, которую нужно просмотреть; если VISIT(1F)=/, тогда вершина W была /-й новой просмотренной вершиной: VISIT (W) не определена, если W не просмотрена.
Шаг Т. [Просмотр вершины! Set I /-FT; and VISIT (V) /.
Шаг 2. [Поиск непросмотренной вершины, смежной с V] For всех вершин W, смежных с V, do шаг 3 od; and RETURN.
Шаг 3. [Просмотрена ли вершина IF?] If VISIT (IF) не определена then set T-<-T-F(V, W)x); and CALL DFS (IF) fi.
Предложим интуитивное объяснение работы алгоритма. Переменная V показывает текущую вершину, т. е. вершину, в которой мы сейчас находимся. Алгоритм DFS работает, проходя произвольное ребро
INPUT
2,4
3,1
1,5
3,4
1,4
Б,2
ADJ NEXT
1 о 14
2 0 17
3 0 12
4 0 15
5 о 10
6 4 0
7 2 0
8 1 О
9 3 0
10 5 9
11 1 0
12 4 3
13 3 7
14 4 10
15 1 13
16 2 11
17 5 6
tf 6
Рис. 3.5.2. Представление сети связанными списками: (а) сеть, (б) ребра, (в) связанные списки.
из V, скажем, к вершине W. Если вершина W ранее не была просмотрена, алгоритм рекурсивно обращается к себе самому при помощи оператора CALL DFS (IF). Если же, наоборот, вершина W уже просмотрена, алгоритм испытывает другое ребро из V, всегда пытаясь отыскать непросмотренные вершины для просмотра на следующем шаге. Если непросмотренных вершин, смежных с V, не обнаружено, алгоритм возвращается в вершину, из которой он опустился в V, и проверяет новые ребра отсюда. Если сеть связна, алгоритм DFS «проверит» каждое ребро дважды и найдет остовное дерево.
Теперь проследим шаги алгоритма DFS, работающего на графе рис. 3.5.2, начиная (произвольно) с вершины 4. Первое обращение к алгоритму — DFS(4).
Ребра сети G пройдены в порядке a b с d е f, как показано на рис. 3.5.3, с; окончательное остовное дерево, найденное алгоритмом DFS, приведено на рис. 3.5.3, б.
х) Здесь знак + означает добавление элемента к множеству,— Прим, ред.
DFS(4)
V=4,T=0,1 = 0 1=1
VISIT(4) = 1
W=1
T-T+(4,1) ШАГЗ.
•DFS(1)
V = 1
1 = 2
VISIT(1)=2 W = 4
W=5
T=T+(1,5) DFS(5}
V = 5 1 = 3 VISIT(5) = 3 W = 2
T=T+(5,2) DFS(2)
V=2 1 = 4 VISIT(2)=4 W = 5 W=4
RETURN to DFS(5) W=1
RETURN to DF2(1) W=3
T=T + (1,3)
DFS(3}
V = 3. 1 = 5 VISIT(3).= 5 W=4 W = 1
RETURN to DFS(1) RETURN to DFS(4) .
W=3
W=2
RETURN
Для реализации алгоритма DFS удобно писать программу на таких языках программирования, как Алгол или ПЛ/1, в которых можно производить рекурсивные обращения к процедурам. Если вы знакомы с таким языком, советуем вам это сделать.
Мы представим реализацию алгоритма DFS на Фортране, так как она поможет проиллюстрировать: (1) создание и использование связанного списка представления сети; (2) использование стека и (3) метод, которым может быть итеративно реализован рекурсивный алгоритм.
Для того чтобы понять, как можно использовать' стек для реализации рекурсивных обращений, рассмотрим опять последова
тельность операций, выполняемых алгоритмом DFS для нахождения остовного дерева графа G (рис. 3.5.2), начиная с вершины 4.
Каждый раз, когда мы производим рекурсивное обращение (CALL), например, к DFS(5), прерывается процесс проверки всех вершин, смежных с вершиной У=1, и заменяется значение V (например, У=5).
Рис. 3.5.3. Остовное дерево, найденное алгоритмом DFS.
После возврата (RETURN) из обращения (CALL) к DFS(5) нам надо как-то запомнить, где мы были, а были мы в вершине 1 и проверили только что следующую вершину W=5, смежную с V.
Чтобы запомнить местоположение в тот момент, когда мы производили обращение (CALL) к DFS(5), мы запоминаем текущие значения U и IF в стеке (т. е. F=1 и IF=5). Значения К и IF называются текущей внешней средой алгоритма DFS. Если во время выполнения обращения (CALL) к DFS(5) произведено другое обращение [например, к DFS(2)J, то новая текущая внешняя среда помещается в верхнюю часть стека (именно F=5 и IF=2). При каждом возврате (RETURN) из процедуры, к которой мы обращались, берем самую последнюю внешнюю среду из верхней части стека и с ее помощью восстанавливаем предыдущие значения V и IF.
Рис. 3.5.4 показывает, что содержалось бы в стеке в этом примере. На рис. 3.5.5 показана реализация на Фортране рекурсивного алгоритма DFS. Заметим, что подпрограмма SUBROUTINE DFS хранит в стеке значения переменной V и указателя К на вершину IF вместо самой вершины IF.
Относительно алгоритма DFS нужно сделать несколько дополнительных замечаний. Первое касается его названия: почему он называется поиском в глубину? Этот алгоритм на самом деле является алгоритмом с отходом (см. разд. 3.3), осуществляющим поиск по древовидной структуре таким образом, чтобы как можно быстрее найти «нижнюю» вершину. На рис. 3.5.6 показана древовидная структура, исследованная алгоритмом DFS для случая, изображенного на рис. 3.5.2; обведенные окружностями номера показывают порядок,
в котором обходятся вершины этого дерева (они точно соответствуют последовательности значений W в DFS). Знак х под вершиной означает, что она уже просмотрена. Заметим, что, продвигаясь непрерывно
---1 I г—-----1 I
RETURN RETURN 1 RETURN RETURN
от данной вершины к первой непросмотренной вершине, DFS достигает нижней вершины дерева самым быстрым из возможных способов. Видно, что на рис. 3.5.6 у дерева Т (G) ровно в два раза больше ребер, чем у G, и каждое ребро сети G встречается дважды в T(G).
Доказательство правильности алгоритма DFS может быть основано на следующих замечаниях:
1. Ребро прибавляется к Т только в том случае, если одна из его двух вершин еще не просмотрена. Это означает, что Т не может содержать цикла.
2. Если каждая из М—1 вершин, отличных от начальной вершины, на самом деле проверена, то к Т прибавляется М—1 ребер.
3. Остовное дерево Т в сети G с М вершинами состоит из М—1 ребер, не образующих цикла.
С помощью этих замечаний вы можете попробовать построить доказательство правильности алгоритма DFS.
Завершим обсуждение алгоритма DFS анализом его сложности. Число операций, необходимых при работе алгоритма с сетью G= (У, Е), есть О(|Е|), т. е. линейная функция от числа ребер в сети. Это следует из того факта, что алгоритм проходит каждое ребро G дважды и обработка любого ребра требует не больше 12 шагов. Также заметим, что к DFS производится в точности | V\ обращений.
Методу поиска по дереву в глубину следует противопоставить другой метод, известный как поиск в ширину. При поиске в ширину
с с с с с с с с с с с с с с с с с с с с с с с с с С’
с с с
PROGRAM SPAN (INPUT,OUTPUT,TAPE5=INPUT,TAPE6=OUTPUTI
ЭТА ПРОГРАММА НАХОДИТ ОСТОВНОЕ ДЕРЕВО В НЕВЗВЕШЕННОЙ СЕТИ G. ОНА ИЛЛЮСТРИРУЕТ ПРЕДСТАВЛЕНИЕ СЕТИ СВЯЗАННЫМ СПИСКОМ И, В ПОДПРОГРАММЕ DFS, ИСПОЛЬЗОВАНИЕ СТЕКА КАК СРЕДСТВА РЕАЛИЗАЦИИ РЕКУРСИВНОГО АЛГОРИТМА НА ФОРТРАНЕ.
ПЕРЕМЕННАЯ. ОПИСАНИЕ
ДОЛЮ МАССИВЫ ДЛЯ ЗАПОМИНАНИЯ Р СВЯЗАННЫХ СПИСКОВ Г)ЕХТ(К) ВЕРШИН, СМЕЖНЫХ С ДАННОЙ. ДЛЯ 1 .LE. К .LE.P
ADJ(K) = О, И ЕСЛИ J = NEXT(K), ТОГДА ADJ (JJ-ПЕРВАЯ ВЕРШИНА, СМЕЖНАЯ С К. СЛЕДУЮЩАЯ ВЕРШИНА, СМЕЖНАЯ С К, СОДЕРЖИТСЯ В ADJ (NEXT(J>), .И Т.Д.
TREE!J,11 ’ J-Е РЕБРО, ВЫБРАННОЕ ДЛЯ ОСТОВНОГО ДЕРЕВА. TREE(J,2>
р, Q ЧИСЛО ВЕРШИН И РЕБЕР, СООТВЕТСТВЕННО, В G.
ВЕРШИНЫ Б ПОМЕЧЕНЫ 1, 2, . . . , Р.
U, V РЕБРО В G МЕЖДУ ВЕРШИНАМИ U И V.
WORDS WORDS = Р + 2*0, ЧИСЛО СЛОВ ПАМЯТИ ДЛЯ МАССИВОВ
ADJ И NEXT.
INTEGER Pt Q, Т, U, V, WORDS
INTEGER ADJ(IOOO), NEXT(IOOO), TREE<100,2»
СЧИТЫВАНИЕ ЧИСЛА ВЕРШИН И РЕБЕР Б.
READ’(5,10001 P,Q
1000 FORMAT (14,141
I = P + 1
WORDS = P + 2 ♦ a
c
С ИНИЦИАЛИЗАЦИЯ МАССИВОВ ADJ И NEXT.
DO 10O M = 1, P
ДОЛИ) = 0
NEXHM! = 0
100 CONTINUE
c С СЧИТЫВАНИЕ Q РЕБЕР G И ОРГАНИЗАЦИЯ СВЯЗАННОГО .СПИСКА.
- С
СО 206 N = 1, Q READ (5,1000) U,V NEXT(I) * NEXTIUl ДОЛИ = V NEXT(U) = I 1 = 1 + 1 NEXTdl = NEXT(V) ДОЛИ = U NEXTCVl = I 1 = 1 + 1
- 200 continue
С ВЫЗОВ DFS ДЛЯ НАХОЖДЕНИЯ ОСТОВНОГО ДЕРЕВА О,
С НАЧИНАЯ С V=l. DFS ПОМЕСТИТ РЕБРА ОСТОВНОГО ДЕРЕВА
С В МАССИВ TREE.
С
CALL DFs < ADJ, NEXT, 1, TREE, P, WORDS, T )
С ПЕЧАТЬ СЕТИ G И ОСТОВНОГО ДЕРЕВА G.
Рис. 3.5.5. Реализация алгоритма DFS на Фортране. (Текст в операторе 2000: ^Представление списком сети С»; 2100: «Ребра остовного дерева»; 2300: «Заметим, что сеть не связная»; 1000: «Ошибка в подпрограмме DFS»,)
WRITE (6,2000» (I. ADj(U .NExT( I). I = 1.WORDS)
2000 FORMAT ( 1H113SH THE LIST REPRESENTATION OF NETWORK 6 ,///»
-4 + 23H I ADJ NEXT ,/, ( 1H01ISt 16,I
WRITE (6,2100)
2100 FORMAT ( 1H1,22H SPANNING TREE EDGES > К = T - 1
WRITE (6,2200) (< TREEdidli J=l,2>, I=ltK !
2200 FORMAT ( IHOt 110, 16 )
IF < T .EQ. P » STOP
WRITE (6.23001
2300 FORMAT ( 1НХ.Ч1Н NOTE THAT THE NETWORK IS NOT CONNECTED. )
STOP ENO SUBROUTINE DFS ( ADJ, NEXT* V, TREE, P, WORDS, T I
ПППЛП nnftO nnnnnnnftnon Of) nnnoonftnonnnnnn
ПРИМЕНЕНИЕ РЕКУРСИВНОГО АЛГОРИТМА ТАРЬЯНА ПОИСКА В ГЛУБИНУ. DFS НАХОДИТ ОСТОВНОЕ ДЕРЕВО СВЯЗАННОЙ НЕВЗВЕШЕННОЙ СЕТИ G, ИМЕЮЩЕЙ Р .LE. 10D ВЕРШИН И О. РЕБЕР. G ПРЕДСТАВЛЕНА СВЯЗАННЫМИ СПИСКАМИ, С ИСПОЛЬЗОВАНИЕМ МАССИВОВ AOJ(WORDS) И NEXT (WORDS), ГДЕ WORDS = P+2*Q. DFS ПОМЕЩАЕТ ВЫБРАННЫЕ ДЛЯ ОСТОВНОГО ДЕРЕВА РЕБРА В МАССИВ TREE И НАЧИНАЕТ ПОИСК ОСТОВНОГО ДЕРЕВА В ВЕРШИНЕ V. ЕСЛИ Б НЕ СВЯЗАНА, DFS НАЙДЕТ ОСТОВНОЕ ДЕРЕВО СВЯЗНОЙ КОМПОНЕНТЫ В, СОДЕРЖАЩЕЙ V. DFS МОДЕЛИРУЕТ СТЕК, ЧТОБЫ РЕАЛИЗОВАТЬ РЕКУРСИЮ В АЛГОРИТМЕ.
ПЕРЕМЕННАЯ ОПИСАНИЕ
V В ЛЮБОЙ МОМЕНТ РАССМАТРИВАЕМ ВЕРШИНУ V.
V СЛЕДУЮЩАЯ ВЕРШИНА, СМЕЖНАЯ С V.
VISIT(V)=I ОЗНАЧАЕТ, ЧТО V БЫЛА I-Й ВЕРШИНОЙ, ПРОСМОТРЕННОЙ ВПЕРВЫЕ. VISIT(.V) = O ОЗНАЧАЕТ, ЧТО V ЕЩЕ НЕ ПРОСМОТРЕНА.
STORE СТЕК’ИСПОЛЬЗОВАН ДЛЯ ЗАПОМИНАНИЯ ПРОШЛОЙ ПОСЛЕДОВАТЕЛЬНОСТИ ПРОСМОТРЕННЫХ ВЕРШИН. СТЕК НУЖЕН, ЧТОБЫ ЗАПОМНИТЬ ТЕКУЩУЮ ВЕРШИНУ V И ЗАПОМНИТЬ, НАСКОЛЬКО ПРОДВИНУЛСЯ УКАЗАТЕЛЬ к В СПИСКЕ СМЕЖНОСТИ V. ЕСЛИ Р .LE. 100, ТО В СТЕКЕ НЕ БУДЕТ ХРАНИТЬСЯ БОЛЕЕ 200 ЭЛЕМЕНТОВ.
PTR УКАЗАТЕЛЬ НА ВЕРХ СТЕКА.
T- СЧЕТЧИК ЧИСЛА РЕБЕР В ОСТОВНОМ ДЕРЕВЕ.
к УКАЗАТЕЛЬ, ИСПОЛЬЗУЕМЫЙ ПРИ ПРОХОЖДЕНИИ СВЯЗАННЫХ СПИСКОВ СМЕЖНОСТЕЙ.
INTEGER р, PTR, Т, V, V, WORDS
INTEGER ADJ(WORDS), NEXT(WORDS), STOREI2001, TRE£(100t2> INTEGER VISIT(IOO)
С ИНИЦИАЛИЗАЦИЯ ПЕРЕМЕННЫХ.
С
DO 100 I = 1,100
VISIT(I) = 0
100 CONTINUE PTR = О T = 1
Рис. 3.5.5. Продолжение
с С ПРОСМОТР ВСЕХ ВЕРШИН.
С 00 ЧОО I = 1.Р с С' Vr ЭТО I-Я НОБЛЯ ВЕРШИНА.
С
VISIT(V) = I К = V с С СЛЕДУЮЩАЯ СМЕЖНАЯ С V ВЕРШИНА.
С 200 К s NEXT(K) С С ЕСТЬ ЛИ ЕЩЕ СМЕЖНЫЕ С V ВЕРШИНЫ?
С
IF ( К .ОТ. О > GOTO 300 С С ОСТАЛОСЬ ЛИ ЧТО-НИБУДЬ В СТЕКЕ? -
с
IF ( PTR .ЕО. О > RETURN С С УДАЛЕНИЕ ТРЕХ ВЕРХНИХ ЭЛЕМЕНТОВ
С ИЗ СТЕКА.
С
V = STOREIPTRJ К = STOREIPTR-l» STORE(PTR> = О STORE(PTR-l) = О PTR = PTR - 2 GOTO 200 c С СЛЕДУЮЩАЯ СМЕЖНАЯ С V ВЕРШИНА
С
300 ы = долю
с С ПРОВЕРЕНА ли ВЕРШИНА W?
С
IF ( VISIT(W) .GT. О ) GOTO 200 С С ПРИБАВЛЕНИЕ РЕБРА VX,
С К ОСТОВНСМУ ДЕРЕВУ.
TREE(T.l) = V
TREE(T.2> = W
I = Т ♦ 1
с
С ИМЕЕМ ЛИ МЫ УЖЕ ОСТОВНОЕ
С ДЕРЕВО?
IF ( Т .EQ. Р ) RETURN
С
С ЗАНОСИМ К, V И U В СТЕК
С И ПРОВЕРЯЕМ W.
С
STORE(PTR+1> = К STORE(PTR+2I = у PTR = PTR + а V = W С ООО CONTIWE С
С ЭТОТ ОПЕРАТОР НИКОГДА НЕ ДОЛЖЕН ДОСТИГАТЬСЯ,
с
WRITEU.IOOO»
1000 FORMAT(1H1«25H ERROR IN SUBROUTINE DFS.J ’ RETURN end
Рис. 3.5.5. Продолжение
последовательно просматриваются все вершины дерева на уровне k, затем все вершины на уровне &+1 и т. д. При отыскании остовного дерева в сети G, изображенной на рис. 3.5.2, методом поиска в ширину было бы построено такое дерево, как на рис. 3.5.7.
Теперь для полноты изложения опишем алгоритм отыскания остовного дерева в сети G методом поиска в ширину (алгоритм BFS).
Алгоритм BFS начинает
с
работу с произвольной вершины V и добавляет к списку LIST все смежные с V, еще не просмотренные вершины, отмечая каждую из них «просмотрена» в момент, когда она прибавляется к LIST. На каждой из последовательных итераций алгоритма для следующей вершины IF из LIST проверяется, нет ли непросмотренных смежных с ней вершин, которые можно добавить к LIST. Как только
Рис. 3.5.6. Дерево поиска в глубину, построенное алгоритмом DFS.
Список
4 1
3
2 Б
Рис. 3.5.7. Дерево поиска в ширину, построенное алгоритмом BFS.
od; set LIST(l) ч- U; VISIT (t7) ч- 1;
к LIST добавляется новая вершина, ребро от нее к текущей, уже проверенной вершине добавляется к остовному дереву.
Algorithm BFS (Поиск в ширину). Поиск остовного дерева Т в связной сети G, вершины которой перенумерованы 1, 2, . . ., М. Алгоритм начинает работу в вершине U; VISIT (IF)=1 означает, что вершина IF уже просмотрена; VISIT (IF)=0, если IF не просмотрена.
Шаг 0. [Инициализация] Set /ч- 1; 7ч- 1; for ТСч- 1 to М do set LIST (К) ч-0;
and VISIT (/<) ч-0 and 7ч— 0.
Шаг 1. [Проверка всех вершин] While LIST (J)#=0 do through шаг 3 od; and STOP.
Шаг 2. [Следующая вершина] Set V ч- LIST (J); and J ч- J+ + 1.
Шаг 3. [Поиск всех непросмотренных смежных с V вершин] For всех вершин W, смежных с V, do шаг 4 od. Шаг 4. [Добавление непросмотренной вершины в LIST, а ребра —к Г] If VISIT (Ц7)=0 then set /^/+1; LIST(/)^IV; VISIT (IF) ч-1; and Г^Г+(У, W) fi.
Рис. 3.5.8. Векторное представление остовного дерева.
Теперь покажем простую, нерекурсивную реализацию алгоритма BFS. Выход VECTOR подпрограммы BFS — это рекурсивное представление остовного дерева Т сети G, которое обсуждалось в конце разд. 2.3. На рис. 3.5.8 показано это представление Т. Полная программа нахождения остовного дерева, использующая поиске ширину, представлена на рис. 3.5.9.
Доказательство правильности и анализ сложности алгоритма BFS можно провести точно так же, как и для алгоритма DFS. Оставляем это читателю. Рассмотрите также следующий вопрос: какой алгоритм предпочтительнее, DFS или BFS? Или это можно установить не во всех случаях? Предлагаем вам проверить оба алгоритма, чтобы ответить на эти вопросы.
Рекурсия в сравнении с итерацией
Полное рассмотрение преимуществ и недостатков рекурсивных и итерационных алгоритмов лежит за пределами этой книги. Так же обстоит дело и с рассмотрением связей между рекурсией и итерацией, представляющих глубокий теоретический интерес. Кое-кто утверждал, что любой рекурсивный алгоритм следует преобразовывать в эквивалентный итеративный алгоритм. Другие утверждают, что это не всегда имеет смысл делать.
PROGRAM BFSPAN (INPUT.0UTPUT.TAPE6=0UTPUT.TAP£5:slNPUT> c
С ПРОГРАММА НАХОДИТ OCTOBHOE ДЕРЕВО В НЕВЗВЕШЕННОИ СЕТИ G, С ИСПОЛЬЗУЯ ПОДПРОГРАММУ BFS, В КОТОРОЙ ПРИМЕНЯЕТСЯ
С МЕТОД ПОИСКА В ШИРИНУ.
<с
С ПЕРЕМЕННАЯ ОПИСАНИЕ
С
С ADJ(I) МАССИВЫ ДЛЯ Р СВЯЗАННЫХ СПИСКОВ ВЕРШИН,
С NEXT(II СМЕЖНЫХ С ДАННОЙ.
С Р ВЕРШИНЫ G ПОМЕЧЕНЫ 1,2,..., Р
С
.С М.н СЧИТЫВАЕМОЕ РЕБРО G. ЕСЛИ М<0,-
С БОЛЬШЕ РЕБЕР НЕТ.
С с V НАЧАЛЬНАЯ вершина, ИЗ КОТОРОЙ НАЧИНАЕТСЯ
С ПОИСК В ШИРИНУ.
с
INTEGER АОЛ 1000). NEXTdOOOl INTEGER V, P c С СЧИТЫВАНИЕ ЧИСЛА ВЕРШИН, с
PEAD (5.10001 Р 1000 FORMAT ( 14. 14 I
I = P + 1 c с ИНИЦИАЛИЗАЦИЯ МАССИВОВ ADJ И NEXT, c
DO 50 II = l.P
AOJdl) = 0 NEXT(II) = 0 50 CONTINUE c С СЧИТЫВАНИЕ РЕБЕР G. C
100 READ (5.1000) M.N
IF ( M .LT. 0 ) GO TO 200 NEXT(I) = wEXT(M) AOJ(I) = N ПЕХТ(М) = I 1 = 1 + 1 NEXT(II = NEXKNI ADJ(I> = H NEXT(N) = I 1 = 1 + 1 GO TO 100 c С СЧИТЫВАНИЕ ВЕРШИН V И ВЫЗОВ BFS. С 200 READ (5.10001 V
CALL BPS (V* ADJ» NEXT» P 1 STOP END
SUBROUTINE BFS CV< ADJ» NEXT» P > c
С ПОДПРОГРАММА РЕАЛИЗУЕТ АЛГОРИТМ ПОИСКА В ШИРИНУ
С ДЛЯ НАХОЖДЕНИЯ ОСТОВНОГО ДЕРЕВА В НЕВЗВЕШЕННОЙ СЕТИ. С с *♦* Формальные параметры ***
с v вершина, из которой начинается
С ПОИСК В ШИРИНУ.
Рис. 3.5.9. Реализация алгоритма BFS на Фортране (Текст в операторе 2000: «Вектор остовного дерева».)
ADJ«NEXT
P
МАССИВЫ ДЛЯ ПРЕДСТАВЛЕНИЯ СЕТИ С СВЯЗАННЫМ СПИСКОМ.
ЧИСЛО ВЕРШИН В С.
*** ЛОКАЛЬНЫЕ ПЕРЕМЕННЫЕ***
LAELEII) МАССИВ, ИСПОЛЬЗУЕМЫЙ ТОЛЬКО
ДЛЯ ПЕЧАТИ ОСТОВНОГО ДЕРЕВА.
VECTOR!!) ЕСЛИ VECTOR(I) = J, ТО РЕБРО (l,j)
В ССТОВНОМ ДЕРЕВЕ.
VISITIJIxI ОЗНАЧАЕТ, ЧТО ВЕРШИНА БЫЛА 1-Й, ПРОСМОТРЕННОЙ ВПЕРВЫЕ. VISIT(.V) = O ОЗНАЧАЕТ, ЧТО V ЕЩЕ НЕ ПРОСМОТРЕНА
LISTII) LIST-МАССИВ ВЕРШИН, КОТОРЫЕ НУЖНО ПРОСМОТРЕТЬ ВПЕРВЫЕ.
N ИНДЕКС, ПРОБЕГАЮЩИЙ МАССИВ LIST.
I ИНДЕКС ДЛЯ ДОБАВЛЕНИЯ ВЕРШИН
К МАССИВУ LIST.
PTR ИНДЕКС, ПРОБЕГАЮЩИЙ СВЯЗАННЫЙ
СПИСОК СМЕЖНОСТЕЙ.
INTEGER AOJUCOO). NEXTUOOO) integer vector(ioo). visiTiiool INTEGER LABEL(100 I .
INTEGER LISTIlcO) INTEGER V, P, PTR
ИНИЦИАЛИЗАЦИЯ МАССИВОВ.
DO 10 I = l.P LABEL(I) = I LIST!!) = 0 VISITII) = 0 VECTORII) = 0 10 CONTINUE
LISTIP+1) = 0
1 = 1 N = 1
ВЕРШИНА V ПРОСМОТРЕНА ВПЕРВЫЕ.
LIST(l) = V
VECTORIV) = 0 visitiv) = i
СЛЕДУЮЩАЯ НЕПРОСМОТРЕННАЯ ВЕРШИНА M.
50 М = LISTIN) PTR = М
ПРОВЕРКА СМЕЖНЫХ С М ВЕРШИН.
100 PTR = NEXTIPTR) IF I PTR .EQ. О ) GO ТО 150 J = ADJ(PTR)
ПРОВЕРКА, ПРОСМОТРЕНА ЛИ ВЕРШИНА.
IF I VISITIJ) .NE. о > GO ТО 100
Рис. 3.5.9. Продолжение
с
С ДОБАВЛЕНИЕ ВЕРШИНЫ К СПИСКУ И ОСТОВНОМУ ДЕРЕВУ.
С
1 = 1 + 1
LIST(I) = J
VISIT(J)’= I
VECTOR(J) я И
. БО ТО 10.0
150 N = N + 1
IF ( LIST(N) .ME. О ) СО ТО 50
WRITE (6,2000) (LABEL(К),'К = 1,р)
ЙООО FORfJAT(lHl,30H THE SPANNING TREE VECTOR IS ,/ZldHO,
WRITE (6,2100) (VECTOR(K) .Ksl.P) (c/H*nOi
2100 FORMAT (1HQ, 4013)-
RETURN
ENJ
Рис.3.5.9. Продолжение.
Наша точка зрения состоит просто в том, что рекурсия — это естественный метод представления алгоритмов решения множества математических и вычислительных задач и что это метод, о котором не следует забывать. Как только алгоритм рекурсивно сформулирован, возникает несколько вариантов реализации. Первый и наиболее очевидный — реализовать его на языке программирования, допускающем рекурсию. Второй вариант — реализовать его на нерекурсивном языке, моделируя стек, как мы делали в алгоритме DFS. Третья возможность — обратиться за помощью к литературе по разным «автоматическим» процедурам преобразования рекурсивного алгоритма в итеративный. Наконец, можно пересмотреть задачу с тем, чтобы выяснить, действительно ли рекурсия необходима, т. е. можно построить новый алгоритм.
Упражнения 3.5
3.5.1. Факториалы. Что произойдет, если попытаться вычислить У! на Фортране, пользуясь определением рекурсии, данным в начале этого раздела?
3.5.2. Биномиальные коэффициенты. Напишите рекурсивный алгоритм для вычисления биномиальных коэффициентов;
( п\ п\ _ -
- =—г?-------п Для
\т) т\(п—т)\
Реализуйте ваш алгоритм, если вы знаете язык, допускающий рекурсивные обращения.
*3.5.3. Пусть G(n) обозначает число n-значных последовательностей нулей и единиц, в которых не содержится двух или более единиц подряд. Выразите рекурсивно G(n). Сравните G(n) с числами Фибоначчи.
3.5.4. Поиск в глубину. Используя поиск в глубину, найдите остовное дерево для полной двусвязной сети К31 3 (см. упр. 2.2.12).
3.5.5. Поиск в ширину. Используя поиск в ширину, найдите остовное дерево для полной двусвязной сети Ks, 3. Сравните это дерево с деревом, найденным в упр. 3.5.4.
3.5.6. Разбиения целых чисел. Напишите машинную программу вычисления Р (N) для Л1=1, 2, 3, . , . , 50.
3.5.7. Разбиения целых чисел. Определите количество вычислений, совершаемых FUNCTION Q(M, N) для получения Q(M, N). Нужно ли знать все значения (?(Д, В) для Д<Л4 и B^.N, чтобы вычислить Q(M, N)?
**3.5.8. Разбиения целых чисел. Предположим, мы хотим послать по почте посылку и почтовая плата составляет 84 цента. Предположим далее, что все, что у нас есть, это в большом количестве 4-, 6- и 10-центовые марки. Сколькими разными способами можно отобрать марки для посылки? Пусть S(N) означает число разбиений целого М использующих только числа 4, 6 и 10. Выразите рекурсивно S(N), обобщив рекуррентное соотношение для чисел Фибоначчи.
3.5.9. Идентификаторы Фортрана. Напишите программу, принимающую в качестве ввода произвольную цепочку символов Л' и выдающую YES, если X — правильный идентификатор. Предположите, что X считывается по одному символу.
***3.5.10. Вероятностная рекурсия. Игра имеет следующие правила. Перед вами большое число ящиков с деньгами. Сумма денег в каждом ящике — случайная величина, равномерно распределенная на [0, 1]. Вы выбираете ящик, открываете его и или берете деньги из ящика, или отказываетесь от них. Если вы берете деньги, игра кончается. В противном случае вы можете выбрать другой.ящик. Эта процедура повторяется максимум до пяти ящиков (деньги из пятого ящика должны быть взяты, если он открыт). Каким образом можно попытаться максимизировать ожидаемый выигрыш?
**3.5.11. Пусть требуется провести на плоскости и замкнутых кривых С±, . . . , Сп в соответствии со следующими правилами: (а) никакая кривая не пересекает саму себя; (б) Сх проводится произвольно; (в) для каждого i^2 С;- пересекает каждую из кривых Сь С2, . . ., С(_! ровно в двух различных точках; (г) никакие три кривые не пересекаются в одной точке. Пусть R (и) обозначает число областей на плоскости, определенных построением п замкнутых кривых по указанным выше правилам. Верно ли, что R (1)=2 и /?(2)=4? (Заметим, что всегда есть неограниченная область, содержащая «точку» бесконечности.)
Выведите общее рекуррентное соотношение для R(n) через R(n—1). Вычислите /?(1), R(2), ... , R(25). Если вам не знаком никакой рекурсивный язык, проделайте это, проходя последовательно от /?(1) до /?(25).
3.6. Моделирование
Большая часть алгоритмов, представленных в этой книге, решает относительно простые задачи. Многие из этих задач легко сформулировать и смоделировать. Они содержат не много параметров, и обычно их можно решить аналитически. Более того, получающиеся алгоритмы довольно компактны.
Эти задачи резко отличаются от задач, описывающих большие системы, например, для (1) военных расчетов, (2) космических полетов, (3) принятия административных решений, (4) управления производством, (5) сетей связи или (6) картотек и инвентаризационных описей.
.Задачи, относящиеся к большим системам, значительно труднее моделировать, анализировать и решать. Например, трудно определить все переменные, влияющие на поведение системы, внутренние связи между переменными. Обычно неизвестны распределения вероятностей случайных переменных системы, а присущие функциям системы свойства непрерывности и согласованности нелегко моделировать.
Появление ЭВМ позволило подойти к изучению таких сложных систем при помощи моделирования. Машинное моделирование — это
процесс экспериментирования на ЭВМ над моделью динамической системы. Непосредственная цель этих экспериментов — наблюдение за поведением системы при заданных предположениях, условиях и значениях параметров. Конечной целью может быть: (1) формулирование стратегии управления, (2) определение оптимальных или возможных конфигураций системы, (3) установление реальных производственных планов или (4) решение вопроса об оптимальных экономических стратегиях.
Преимущества машинного моделирования. многочисленны. Они позволяют изучить с желаемой степенью детальности все части системы, объединенные в единое целое, в то время как аналитически можно изучить только отдельные части системы. Всеми переменными можно управлять, и все можно измерять. Машинное моделирование позволяет получить информацию о реальной системе, когда непрактично проводить на ней прямой эксперимент. Имитация позволяет испытать систему до того, как на соответствующую реальную систему затрачены время и деньги.
Имитационные эксперименты можно проводить в разных масштабах времени. Время может быть замедлено, чтобы проверить на микроскопическом уровне свойства, которые трудно проанализировать в реальной системе. Время может быть ускорено, чтобы охватить все на макроскопическом уровне, например, при изучении отдаленных последствий тех или иных допущений. Время также можно остановить, повернуть вспять и проиграть заново, чтобы изучить случаи необычного поведения более детально. В реальных системах часто бывает, что, начав некоторый эксперимент, остановить его нельзя.
Кто-то вполне может задать вопрос: почему мы не прибегаем к моделированию во всех случаях? Существует несколько частичных ответов на этот вопрос. Во-первых, моделирование — это экспериментальный метод. Поэтому всегда возникает серьезный вопрос, как истолковать результаты. Важно пойять, что достоверность выходных данных зависит от того, в какой степени модель и основные допущения отражают характеристики системы. Машинная имитация может стать дорогостоящей, если модель становится чрезмерно детализированной.
Область имитационного моделирования слишком обширна, чтобы всесторонне охватить ее здесь. Для наших целей достаточно будет представить несколько важных соображений, относящихся к построению имитационных моделей; мы также проиллюстрируем их одним-двумя примерами. Это должно помочь читателю подойти к разработке и анализу вычислительного имитационного алгоритма достаточно разумно.
Возможно, самые простые и наиболее распространенные из всех имитационных алгоритмов — это алгоритмы, моделирующие очереди. Они будут отправной точкой нашего обсуждения, так как на них можно проиллюстрировать понятия, присутствующие во многих
машинных моделях. Задачи об очередях допускают также большое число разных предположений и обобщений, что делает их хорошими примерами для дальнейшего изучения.
Основными объектами в простой очереди (линии обслуживания) являются клиенты, прибывающие через случайные интервалы времени, и обслуживающее устройство, которое обслуживает каждого клиента в течение случайного интервала времени. Когда клиенты прибывают, их или сразу обслуживают, или они выстраиваются, образуя очередь, и их обслуживают по принципу: первым пришел — первым обслужен. Рис. 3.6.1 иллюстрирует систему одна очередь/ одно обслуживающее устройство.
Лри'мёшоцие
Оёмдже№ые
ОВаужиВающее дапроВапво
Рис. 3.6.1. Система «одна очередь / одно обслуживающее устройство».
Функционирование такой очереди определяется следующими характерными особенностями и предположениями:
1. Имеется случайная переменная X, которая определяет время прибытия следующего клиента. Существует несколько возможностей для решения вопроса о времени прибытия клиента. Мы будем предполагать, что если клиент К прибывает в момент врегиени t, то клиент /С+1 прибывает в момент /+Т, где Т — случайная переменная, значение которой лежит между 1 и некоторым фиксированным целым числом МАХА, с заданным распределением вероятностей.
2. Имеется случайная переменная S, определяющая, сколько времени длится обслуживание клиента К. Предполагается, что значение величины S лежит между 1 и некоторым другим фиксированным целым числом МАХС с заданным распределением вероятностей. Если обслуживание начато, оно продолжается до полного завершения, т. е. не Допускается прерывание или обслуживание с приоритетом.
3. Существует очередь клиентов, обслуживаемая по принципу: первым пришел — первым обслужен. Как только клиент встает в очередь, он остается в ней, пока не будет обслужен. Сразу после обслуживания он покидает систему.
4. Все действия в системе описываются дискретными «событиями»; отсюда название «моделирование дискретных событий». Событие, грубо говоря, может быть описано как что-то меняющее «состояние» Или конфигурацию системы. Говорят, что событие является первичным или независимым, если оно не вызвано другим событием; в противном
случае оно называется вторичным или условным событием. Независимыми событиями в системе обслуживания являются:
(а) Прибытие клиента.
(б) Завершение обслуживания клиента.
5. В начальном состоянии система пуста. В момент времени t=Q обслуживающее устройство не занято и в очереди никого нет.
6. Потоком действий управляют часы с дискретным, постоянным приращением времени. Эти часы отсчитывают постоянные единицы времени; это могут быть секунды, наносекунды (при рассмотрении имитационных моделей операционных систем ЭВМ) или месяцы, годы (при рассмотрении имитационных моделей народонаселения).
7. Для определения промежутков времени между прибытиями клиентов и продолжительностей их обслуживания применяется датчик случайных чисел.
Чтобы разработать алгоритм для моделирования конкретной системы одна очередь/одно обслуживающее устройство, нужно выяснить ряд вопросов:
1. Каковы распределения вероятностей промежутков времени между прибытиями клиентов и продолжительности обслуживания?
2. Каким датчиком случайных чисел и как пользоваться для получения случайных промежутков времени?
3. Каковы правила в очереди (свойства очереди)? Например, пойдут ли первыми клиенты, имеющие самый высокий приоритет? Будут ли нетерпеливые клиенты покидать очередь из-за того, что она слишком большая или слишком медленно движется? Ограничено ли число клиентов, которые одновременно могут находиться в очереди?
4. Сколько времени следует продолжать процесс имитации? Должны ли часы отсчитывать по единице времени, или они должны переходить к моменту следующего определенного события?
5. Как будут «составлены расписания» для событий, относительно которых установлено (случайно или не случайно), что они должны произойти в определенное время? Иными словами, как мы убедимся, что эти события и все другие, являющиеся их следствием, действительно происходят и происходят вовремя? Что делать в случае «совпадения», т. е. когда два или более событий случаются одновременно?
6. Какие данные нужно собрать во время процесса имитации? Типичные данные, в получении которых могла бы возникнуть заинтересованность, следующие:
(а) Число прибытий в процессе имитации.
(б) Средняя длина очереди.
(в) Среднее время ожидания в очереди.
(г) Максимальная длина очереди.
(д) Эффективность использования обслуживающего устройства, т. е. процент времени, в течение которого обслуживающее устройство было занято.
(е) Среднее, максимальное и минимальное время обслуживания.
(ж) Функция распределения длины очереди, т. е. процентные доли времени, в течение которого длина очереди была t.
(з) Число клиентов, которым не пришлось ждать.
Ответы на вопросы 1—6 зависят от специфики моделируемой системы обслуживания. Но как на них отвечать?
Можно начать с наблюдения за реальной системой обслуживания в течение некоторого времени и собрать данные такого рода, как указано в пункте 6, регистрируя промежутки времени между прибытиями и продолжительность обслуживания. В большинстве систем обслуживания моменты прибытия подвержены большим колебаниям, зависящим от времени дня (явление времени пика). Возникает несколько дополнительных вопросов по поводу этих данных. Например, что можно из них вывести? Достаточно ли велика выборка? Можно ли эти временные интервалы аппроксимировать некоторыми стандартными распределениями? Разумные ответы на эти вопросы требуют понимания теории проверки гипотез, теории выборок и т. п. Заинтересованный читатель может обратиться к литературе, указанной в конце книги.
Фактически во всех вычислительных устройствах имеется системный датчик случайных чисел для равномерного распределения на интервале [0, 1). Это распределение может быть использовано для того, чтобы смоделировать другие распределения случайной переменной, применяя методы, описанные в разд. 6.3.
Большинство систем обслуживания имеют заранее установленный неизменный порядок (правила) очереди. Поэтому для таких систем этот вопрос не входит в задачу разработки имитационного алгоритма. Но в других случаях, таких, как операционные системы ЭВМ, определение оптимальных порядков очереди — важная цель моделирования.
Основное предположение в системах с дискретными событиями заключается в том, что состояние системы изменяется, только когда происходит событие; в противном случае состояние остается неизменным. Таким образом, нет нужды в беспрерывном ходе часов, когда ничего не случается. Наиболее общий подход — произвести все изменения, необходимые вследствие совершившегося события, а затем продвинуть имитируемое время ко времени следующего события. Такой подход к моделированию дискретных событий называется методом планирования событий.
Для иллюстрации этого подхода на рис. 3.6.2 представлена принципиальная блок-схема алгоритма моделирования системы одна очередь/одно обслуживающее устройство. Чтобы получить моделирующую программу, необходима некоторая переработка этой блок-схемы. В частности, на рис. 3.6.2 нет условия для остановки (или возвращения). С этой целью мы вводим три различные целочисленные переменные ARR, СОМР и TERM, обозначающие соответственно
Рис. 3.6.2. Блок-схема моделирования системы «одна очередь/одно обслуживающее устройство».
время следующего прибытия, время завершения обслуживания и время окончания моделирования. Мы также вводим переменную CLOCK для записи текущего времени. Так как мы используем метод планирования событий, полагаем переменную CLOCK равной времени следующего запланированного события: это или время следующего прибытия, или время завершения обслуживания, или время окончания моделирования. Тогда блоки 2, 3 и 4 становятся такими, как показано на рис. 3.6.3.
Далее рассмотрим, что должно быть сделано в блоке 5 на рис. 3.6.2, когда имеет место новое прибытие. Во-первых, мы можем определить время следующего прибытия в соответствии с правилом вида
ARR=CLOCK+RANARR(1, МАХА)
где RANARR(1, МАХА) — функция, которая дает случайное целое число между 1 и некоторой фиксированной константой МАХА с определенным распределением вероятностей.
Следующая работа, которую нужно выполнить, когда прибывает новый клиент,— это или поставить клиента в очередь, или если обслуживающее устройство свободно, то обслужить его. Если очереди нет (длина очереди определяется переменной QUEUE), то можно определить время ухода данного клиента (т. е. время полного обслуживания) из уравнения
COMP=CLOCK+
RANCOM(1, МАХС) Тогда блок 5 становится таким, как на рис. 3.6.4.
Для завершения блока 6 также потребуется определить время завершения следующего обслуживания:
COMP=CLOCK4-RANCOM (1, МАХС)
Рис. 3.6.3. Блок-схема определения следующего события.
Следует, однако, рассмотреть и особую ситуацию, когда очередь
становится пустой. Конечно, в этом случае время завершения следующего обслуживания не имеет смысла. Поэтому мы произвольно полагаем COMP=TERM~r-l, чтобы гарантировать, что завершение не является следующим запланированным событием. Тогда блок 6 становится таким, как показано на рис. 3.6.5.
Что еще осталось сделать? Во-первых, нужно задать начальные значения (инициализовать) всем переменным, таким, как ARR, TERM,
Рис. 3.6.4. Блок-схема для нового прибытия.
QUEUE, QMAX, МАХА, MAXC и COMP. Затем нужно определить подпрограммы для вычисления RANARR и RANCOM. Наконец, нужно представить какой-то вывод — в окружности, обозначенной Т на рис. 3.6.3. Заметим, что эта блок-схема еще не совсем полна. Например, не организован сбор данных — по существу мы регистрировали только QMAX.
Рис. 3.6.5. Блок-схема для завершения обслуживания.
Оставляем вам самим обеспечить вычисление любых нужных вам статистических данных. Обратите также внимание на неявные допущения, сделанные в отношении порядка и размера очереди.
Приведенный выше пример очереди не слишком сложен. Поэтому теперь представим более сложную и тем не менее разрешимую задачу, которая проиллюстрирует взаимозависимость отдельных параметров и поведение всей системы.
Задача о пшенице, мышах и кошках
Жители одной деревни выращивают пшеницу, которая является для них основным продуктом питания. Они собирают 2 миллиона фунтов пшеницы каждый июль и хранят ее в амбаре. Хотя они потребляют только 100 000 фунтов пшеницы в месяц (поэтому урожай дает запас на 20 месяцев), они иногда оказываются без пшеницы, так как мыши в амбаре съедают запасы.
Деревенские жители, находясь на невысокой ступени развития, не пользуются ядами, вместо этого они пытаются уничтожать мышей, заведя в амбаре кошек. Они обнаруживают, что по какой-то причине кошки не решают их проблему, так как периодически они по-прежнему остаются без пшеницы.
Единственный выход для жителей деревни — убирать пшеницу из амбара, когда там остается меньше 1,5 миллиона фунтов. Затем они убивают мышей, затопляя их. Однако этот метод не очень хорош:
работы затрачивается много, а уничтожается только 80% мышей. Во всяком случае, жители решают, что они будут проделывать это самое большее раз в год.
Теперь жители деревни просят нас помочь решить проблему. Сначала введем несколько дополнительных переменных, которые могут существенно влиять на ситуацию. Первая переменная — минимальное число кошек в амбаре. Вторая переменная — число амбаров, используемых для хранения пшеницы. Третья переменная — количество собранной в год пшеницы (очевидно, что жители собирают урожай с наибольшей отдачей, но, может быть, им следует собирать меньше пшеницы!).
Теперь ясно, что нужна математическая модель, имитирующая на ЭВМ систему пшеница — мыши — кошки. Это позволит за короткое время проделать большое число «экспериментов» для того, чтобы сравнить результаты различных стратегий и, возможно, найти среди них оптимальную.
Для построения модели нужно больше фактов и/или допущений. Например:
1. Каждая мышь съедает около 10 фунтов пшеницы в месяц.
2. Каждая мышь живет около 12 месяцев, т. е. каждый месяц от старости умирает приблизительно 1/12 всех мышей.
3. Если в амбаре нет пшеницы, все мыши умрут в течение месяца. К сожалению, в этом случае из полей в амбар переберутся 20 мышей. Следовательно, в амбаре никогда не бывает меньше 20 мышей.
4. Если на каждую мышь приходится больше 100 фунтов пшеницы, число мышей будет удваиваться каждый месяц. (Если 1К>100»Л1, то число рождений = М.) При меньшем количестве пшеницы число рождений есть наименьшее из чисел М и W7100 х).
5. Кошки процветают при изобилии мышей. Если на одну кошку приходится более 50 мышей (т. е. /И>50«С), то каждая кошка съедает 30 мышей в месяц. Когда Л4^50*С, число съедаемых мышей в 30 раз больше наименьшего из чисел С и А'1/50.
6. Когда М<25*С (т. е. на кошку приходится меньше чем по 25 мышей), некоторые кошки умирают от голода. Когда нет мышей, каждый месяц умирает половина кошек; когда Л'1<25-хС, (25*С—М)/50 кошек умирают ежемесячно.
7. Когда мышей много (7И>50*С), каждая кошка-самка (половина от общего числа кошек) приносит шесть котят в течение марта и сентября. Но, когда /И<25*С, кошки настолько истощены, что они совсем не размножаются. Для промежуточных соотношений мыши/ кошки, 25*С^/И^50*С, число новорожденных кошек (в марте и сентябре) изменяется от 0, когда /И=25«С, до 3*С, когда /И=50*С. Число рождений равно 3 (Д4/25—С).
Заметим, что MIN (М, 1F/100) = Г/100, a MIN (С, Л4/5О) = 44/50,— Прим.
Начало
Рис. 3.6.6. Блок-схема для задачи о пшенице, мышах и кошках.
- 8. Каждая кошка живет около 10 лет. Поэтому ежемесячно умирает от старости примерно 1 из каждых 120 кошек. Когда С<120, за месяц с вероятностью С7120 умирает одна кошка. Никогда не допускается, чтобы число кошек было меньше некоторого минимального значения MINCATS.
Теперь, когда мы имеем всю эту информацию, что нам с ней делать? Какое решение мы ищем? Какие сделать допущения?
Предположим, что мы 1) хотим изучить, как влияет минимальное число кошек на количество мышей, 2) не будем уничтожать мышей, 3) будем содержать только один амбар и 4) будем продолжать собирать 2 миллиона фунтов пшеницы каждый июль. Теперь предложим алгоритм, моделирующий систему пшеница — мыши — кошки за период, скажем, 10 лет, варьируя в каждом эксперименте минимальное число кошек. Принципиальная блок-схема такого алгоритма приведена на рис. 3.6.6.
Рассмотрим блок 7 более детально. Здесь мы вычисляем ежемесячное изменение количества пшеницы, а также числа кошек и мышей. Месячное изменение количества пшеницы вычислить легко. Если месяц — июль, то произведены 2 миллиона фунтов. В остальных случаях 100 000 фунтов в месяц съедают жители деревни и 10 фунтов в месяц съедает каждая мышь (рис. 3.6.7а).
Рис. 3.6.7а. Блок-схема для ежемесячного изменения в запасе пшеницы.
Месячное изменение числа мышей вычислить несколько сложнее (см. выше допущения 2, 3, 4 и 5). Из допущения 2 мы знаем, что каждый месяц число погибающих от старости мышей равно MICE/12. Из допущения 5 находим, что если на кошку приходится более 50 мышей, то в месяц съедаются 30«CATS мышей; в противном случае число съеденных мышей — MIN (30-x-CATS, 30*М1СЕ/50). Из допущения 4 следует, что если на мышь приходится более 100 фунтов пшеницы, то число мышей, рожденных за месяц, равно имеющемуся числу мышей; в остальных случаях число рожденных мышей равно наименьшему из имеющегося числа мышей и количества пшеницы,
Рис. 3.6.76. Блок-схема для ежемесячного изменения численности мышей.
''
DCATS = O
DCATS = DCATS-((25*CATS-M1CE)/5O)
DCATS =
DCATS-1
+3*CATS
+3*(MICE/25-CATS)
Рис. 3.6.7b. Блок-схема для ежемесячного изменения численности кошек.
деленного на 100. Наконец, если пшеницы нет, все мыши погибают (рис. 3.6.76). Аналогично можно вычислить ежемесячное изменение в численности кошек, используя допущения 6, 7 и 8 (рис. 3.6.7в).
На рис. 3.6.8 приведены подробная программа и пример выдачи для этой задачи. Переменные DWHEAT, DMICE и DCATS представляют собой изменения за месяц (рост или убыль) соответственно в запасах пшеницы (WHEAT), численности мышей (MICE) и численности кошек (CATS).
Упражнения 3.6
L3.6.1. Задача об амбаре. Модифицируйте алгоритм, построенный в этом разделе для задачи о пшенице, мышах и кошках, принимая во внимание одно или несколько из'следующих условий: а) ежегодное истребление мышей; б) второй амбар; в) меньший годовой сбор урожая; г) влияние случайных колебаний в размере урожая; д) совы и змеи.
L3.6.2. Случайное блуждание. Отравленный жук начинает движение из центра квадрата 10 дюймов х Ю дюймов, подвешенного над баком с кипящим маслом. За каждую секунду жук продвигается на 1 дюйм в произвольном направлении. С помощью имитационного моделирования вычислите Р (N) — вероятность того, что к моменту времени T—N жук упадет в кипящее масло. Также вычислите среднее расстояние, на которое удалится живой жук от центра, через N секунд.
L3.6.3. Очередь. Постройте модель следующей системы одна очередь/два обслуживающих устройства. Временные интервалы обслуживания для устройства 1 имеют равномерное распределение U (0, 3), а для устройства 2 — равномерное распределение U (0, 4). Перед двумя обслуживающими устройствами выстраивается одна очередь, первый клиент из очереди идет к первому освободившемуся устройству, а если они оба
свободны, то к устройству 1. Моменты прибытия клиентов нормально, j,
распределены (будьте здесь внимательны). Время дано в минутах. Промоделируйте работу системы за 1 и за 2 ч. Вычислите среднюю длину очереди и среднее время ожидания клиента. Какой части клиентов совсем не приходится ждать?
L3.6.4. Модифицируйте задачу об очереди из упр. 3.6.3 следующим образом. Клиенты стали нетерпеливыми и не встают в очередь, если в ней уже есть пять или более человек. Какая часть потенциальных клиентов теряется? Каковы средняя длина очереди и время ожидания клиента?
L3.6.5. Вычисление л. Испытайте процедуру вычисления приближенного значения л=3,14159... Следующие соотношения описывают четверть круга единичного радиуса с площадью л/4, лежащую в первом квадранте двумерной декартовой системы координат:
х2+уг<1. х>0, у>0.
Рассмотрим единичный квадрат х^0, у<1. Выберем случайно в квадрате N равномерно распределенных точек. Если п из этих точек лежат в четверти круга, то отношение п/N должно аппроксимировать площадь, т е п!Теперь можно приближенно вычислить л. Вычислите приближения к л для Л'100, 500, 1000, 5000. Кто-то может попытаться это сделать для Л’^бО 000 и больших значений.
*L3.6-6. Жуки. В момент времени 1—0 четыре жука выползают из четырех углов прямоугольника 10x12 дюймов. Пятый жук начинает движение из случайной точки внутри прямоугольника. Каждый жук может двигаться со скоростью 1 дюйм в секунду, и каждый непрерывно ползет к своему ближайшему соседу. Постройте модель такой системы. Опробуйте разные величины шага по времени и постройте диаграмму движения жуков.
PROGRAM BARN<OUTPUT,TAPEG-OUTPUT»
c С ЭКОЛОГИЯ АМБАРА С
c wheat - чиоло Фунтов пшеницы в амбаре
С CATS - ЧИСЛО КОШЕК В АМБАРЕ
С MINCATS- МИНИМАЛЬНОЕ ЧИСЛО КОШЕК
С MICE - ЧИСЛО МЫШЕИ В АМБАРЕ „
С MINMICE- МИНИМАЛЬНОЕ ЧИСЛО МЫШЕИ
С IWHEAT • УВЕЛИЧЕНИЕ ИЛИ УМЕНЬШЕНИЕ ПШЕНИЦЫ ЗА МЕСЯЦ
С ICATS • УВЕЛИЧЕНИЕ ИЛИ УМЕНЬШЕНИЕ ЧИСЛА КОШЕК ЗА МЕСЯЦ с IMICE . УВЕЛИЧЕНИЕ ИЛИ УМЕНЬШЕНИЕ ЧИСЛА МЫШЕИ ЗА МЕСЯЦ С MONTH > 1,2,3.........
С YEAR > 1.2,3,...,10
С
INTEGER WHEAT,CATS,MINCATS,MICE,MINMICE.MONTH.YEAR INTEGER DWHEAT,DCATS,DMICE c С ИЗМЕНЕНИЕ МИНИМАЛЬНОГО ЧИСЛА КОШЕК ,MINCATS,
С ОТ 2 ДО В
00 900 MINCATS = 2,8 С С ИНИЦИАЛИЗАЦИЯ ВСЕХ ПЕРЕМЕННЫХ '
С
WHEAT = О MICE = 20 MINMICE = 20 YEAR = О MONTH = 6 CATS = MINCATS c С ПЕЧАТЬ НАЧАЛЬНОГО ЗАГОЛОВКА
С WRITE(6,1) MINCATS 1 FORMAT)////,15H NEW EXPERIMENT.Z/.9H MINCATS=,I2>
C
С ПОМЕСЯЧНЫЕ ШАГИ И ПЕРЕХОД ОТ ДЕКАБРЯ К ЯНВАРЮ
с ГОД- ЭТО 12 МЕСЯЦЕВ, НАЧИНАЯ С ИЮНЯ
с с
АО MONTH = MONTH + 1
IF < MONTH .GT. 12 ) MONTH = 1
IF < MONTH .NE. 7 ) GOTO 10
YEAR = YEAR + 1 IF ( YEAR .GT. 10 ) GOTO 900 WRITE (6,2) YEAR
2 FORMAT <//.5H YEAR. 13//, 2X. 5HMONTH, 3X. 5HWHEAT. W.ltHHICE.RX.AHCATSJ
С ВЫЧИСЛЕНИЕ ИЗМЕНЕНИЙ WHEAT, CATS, MICE
c
10 IWHEAT = OWHEATIMICE, MONTH) ICATS = DCATSICATsiMICE.MONTH) IMICE = DNICE(WHEAT.CATS.MICE)
C
С ПРИБАВЛЕНИЕ ЕЖЕМЕСЯЧНЫХ ИЗМЕНЕНИЙ К ТЕКУЩИМ УРОВНЯМ
С ПШЕНИЦЫ, МЫШЕЙ И КОШЕК
С
WHEAT = МАХО<WHEAT+IWHEAT,О I
MICE = МАХО(MICE+IMICE,MINMICE)
CATS = MAXOCCATS+ICATS.MINCATS) c
WRITE (6.39) MONTH.WHEAT.MICE.CATS,IWHEAT.IMICE.ICATS
31, FORMATUX I2.3X. 17,3X. 16.3X, Щ, 4X.7HDWHEAT=. T9.aX,6HDNICE=. I6.2X, + 6HDCATS='. IS)
c GOTO 40
c
900 CONTINUE
c
с КОГДА ИСПОЛЬЗОВАНЫ ЗНАЧЕНИЯ MINCATS, СТОП
STOP END*
Рис. 3.6.8. Реализация на Фортране задачи о пшенице, мышах и кошках. (Текст в операторе J: «Новый эксперимент»; 2: «Год, месяц, пшеница, мыши, кошки».)
INTEGER FUNCTION DCATS(CATS.MlCE.MONTH)
INTEGER CATS.MICE,MONTH c
С ВЫЧИСЛЕНИЕ УВЕЛИЧЕНИЯ ИЛИ УМЕНЬШЕНИЯ OCATS.
С КОШКИ УМИРАЮТ ОТ ГОЛОДА И ОТ СТАРОСТИ И ПРИНОСЯТ
С ПОТОМСТВО. СРЕДНЯЯ ПРОДОЛЖИТЕЛЬНОСТЬ ЖИЗНИ-10 ЛЕТ.
с
dcats = о
IF < MICE .LT. 25*CATS > OCATS X DCATS - ((25*CATS-MICE)/50l c
C . СЛУЧАЙНЫЕ числа: КОГДА КОШКИ УМИРАЮТ ОТ СТАРОСТИ.. с
IF ( RANF(O.) AT. FLOAT(CATS)/120. > DCATS=DCATS-MAXO(1.CATS/120)
IF ( MONTH .NE. 3 .AND. MONTH .NE. 9 > GOTO 20
IF < MICE .GT. 50*CATS ) DCATS = 0CATS+3*CATS
IF ( MICE .GE. 25*CatS .AND. MICE .LE. 50+CATS J
+ DCATS = DCATS + 3»(MICEZ2S - CATS) •
20 RETURN END
INTEGER FUNCTION DNICE (WHEAT.CATS.MICE) INTEGER WHEAT.CATS.NICE C С ВЫЧИСЛЕНИЕ УВЕЛИЧЕНИЯ ИЛИ УМЕНЬШЕНИЯ OMICE.
С С МЫШИ УМИРАЮТ ОТ СТАРОСТИ, ИХ УБИВАЮТ КОШКИ, но они
С РАЗМНОЖАЮТСЯ. ВСЕ МЫШИ УМИРАЮТ, ЕСЛИ НЕТ ПШЕНИЦЫ.
С
DMICE = -MICE/12
IF ( NICE .GT. SO*CATS ) DNICf = DnICE-30*CATS
IF ( NICE ,UE. 50*CATS ) DNICF = DMICE-NINO<30*CATS.30*MICE/50)
IF ( WHEAT .GT. 100*nICE ) DNICE = ONICE+HTCE
IF ( WHEAT .LE. 100»HICE ) DMICE = DNICE+NINO(NICE,WHEAT/100>
IF ( WHEAT .EQ. 0 ) DMICE = -NICE Return End
INTEGER FUNCTION DWHEAT (NICE.MONTH) INTEGER MICE.MONTH c
С ВЫЧИСЛЕНИЕ ЕЖЕМЕСЯЧНОГО УВЕЛИЧЕНИЯ ИЛИ УМЕНЬШЕНИЯ
С DWHEAT. В ИЮЛЕ УРОЖАЙ-2 МЛН ФУНТОВ.
С ЛЮДИ ЕДЯТ 100 000 ФУНТОВ ЕЖЕМЕСЯЧНО.
С МЫШИ ЕДЯТ ПО 10 ФУНТОВ КАЖДАЯ.
С
DWHEAT = О
IF < MONTH .EQ. 7 ) DWHEAT г DWHEAT+2000000
DWHEAT = OWHEAT-IOOOOO-IOTMICF RETURN
END
Рис. 3.6,8. Продолжение
новый ЭКСПЕРИМЕНТ
MlNCATS= г
ГОД 1
МЕСЯЦ ПШЕНИЦА МЫШИ кошки
7 1699600 20 2 DWHEATs I8998OO DMlCEs -20 DCATS= *O
8 1799600 27 2 DWHEATs -100200 DMlCEs 7 DCAT.Ss -0
9 1699330 36 2 □wheats -100270 DMicEs 9 DCATSs -G
10 1596970 48 2 DWHEATs -100360 DMICEs 12 DCATSs -0
11 1496490 64 2 DWHEATs -100480 □MlCEs 16 DCATSs “0
ia 1397650 65 2 DWHEaT= -IOO64O DMlCEs 21 DCATSs -1
1 1297000 112 2 □wheats -lOOfiSD DMlCEs 27 DCATSs a
2 1195660 155 2 DWHEATs -101120 □MlCEs 43 DCATSs 0
3 1094330 236 8 OWHEAT= -101550 DMlCEs 63 DCATSS e
4 991950 315 6 DWHEATs -102360 DMlCEs 77 DCATSs □
5 666600 415 8 DWHEATs -103150 DMIcEs 100 DCATS= 0
6 784650 556 8 DWHEATs -104150 DMlCEs 141 DCATSS 0
ГОД 2
МЕСЯЦ ПШЕНИЦА МЫШИ кошки
7 2679090 826 6 dwheats 1894440 □MlCEs 270 DCATSs 0
8 2570630 1344 8 DWhEATs -106260 DMlCEs 516 DCATSs 0
9 2457390 2336 32 DWHEAl= -113440 □MlCEs 992 DCATSs 24
10 2334030 3516 32 DWHEATs -123360 DMlCE= 1182 DCATSs a
11 2196650 5783 31 dwheat= -135180 DMIcEs 2265. DCATSs -1
ia 2041020 10155 31 □wheats -157630 DMICEs 4372 DCATSs 0
1 1639470 16534 31 DWHEATs -201550 DMlCEs 6379 DCATSs 0
Z 1554130 34454 31 ВWHEATS -265340 OMICEs 15920 DCATSs 0
3 1109590 46194 124 OWHEATs -444540 □«Ices 11740 DCATSs 93
ц 547650 49720 123 dwheat= -561940 DMlCEs 3526 DCATS= -1
S 0 47363 122 DWHEAt= -597200 DMICE= -2357 DCATSs •i
6 0 20 121 dwheat= -573630 DMICES’ ’*♦7363 DCATSs -1
год 3
МЕСЯЦ ПШЕНИЦА МЫШИ КОШКИ
7 1699800 20 60 DWHEATs 1899600 DMICEx -20 DCATSs -si
8 1799600 27 31 DWHEATS -100200 OMICEs 7 DCATSs -29
9 1699330 36 16 DWHEATs -100270 DMlCEs 9 DCATSs -15
10 1596970 48 9 DWHEATs -100360 DMICEs 12 DCATSs -7
11 1496490 6** 6 DWHEATs -1C0480 DMlCEs 16 DCATSs -3
12 1397650 65 5 DWHEAT= -100640 DMICEx 21 DCATSs -1
1 1297000 112 5 DWHEATs -100650 DMlCEs 27 DCATSs -0
2 1195680 148 5 DWHEATs -101120 DMlCEs 36 DCATSs -0
3 Ю94400 196 5 ' DWHEATs -101480 DMICE= 46 DCATSs 0
4 992440 259 5 DWHEATs -101960 DMlCEs 63 DCATSs 0
5 869850 347 5 DWHEATs -IO259O □MlCEs 66 DCATSs 0
8 786360 516 5 □WHEATS -103470 DMICE= 169 DCATSs 0
ГОД 4
МЕСЯЦ ПШЕНИЦА МЫШИ КОШКИ
7 2661220 639 5 DWhEATs 1894640 OMICEs 323 OCATS« c
В 2572630 1459 5 DWHEATs -106390 OMICEs 620 OCATS» 0
9 2456240 2647 20 DWHEATs -114590 DMlCEs 1168 DCATSs 15
10 2331770 4474 20 DWHEATs -126470 □MlCEs 1827 DCATSs a
11 2167030 7976 20 DWHEATs -144740 □MlCEs 3502 DCATSS 0
12 2007270 14666 20 DWHEATs -179760 □MlCE= 6712 DCATSs D
1 1760390 27552 20 DWHEATs -2468A0 DMlCEs 12864 DCATSx a
2 1364870 42259 20 DWHEATs -375520 DMlCEs 14707 DCATSs 0
3 662260 51966 во DWHEATs -522590 OMICEs 9727 DCATSs 60
4 242420 53676 79 □WHEATS -619860 □MICE= 1690 DCATSs -1
5 0 49441. 79 DWHEATs -636760 DMICE= -4435 DCATSs 0
6 0 20 76 DWHEATs -594410 DMlCEs- •49441 DCATSs -I
Рис. 3.6.8. Продолжение
ГОД 5
МЕСЯЦ, ПШЕНИЦА МЫШИ кошки
7 1699800 20 39 ОЫнЕАт= 1899800 DMICEs -20 DCATSa -39
6 1799600 27 20 DWHEAT= -100200 DMICEs 7 □CATSs -19
9 1699330 36 11 DWHEAts -100270 DMlCEs 9 DCATSa -9
10 1598970 48 7 DWHEAT= -100360 DMICEs 12 OCATSs -4
11 1498490 64 5 □WHEATS -100460 □MIcEs 18 OCATSs -2
12 1397850 85 4 □WHEATS -ЮО64О DMICEs 21 DcATSs •1
1 1297000 112 4 □WHEATS -ЮО85О □MlCEs 27 OCATSs -0
2 1195880 148 4 DWHEAT= -101120 DMICEs 36 DCATSa 0
3 1094400 196 7 DWHEAT= -1014fi0 □MlCEs 48 □CATSs 3
ч 992490 259 7 DWHEAT= -101960 DMICEs 63 □CATSs 0
5 689650 342 7 □WHEATS *102590 DMICEs 83 □CATSs 0
6 786430 451 7 DWHEATs -103420 DMICEs 109 □CATSs 0
ГОД 6 МЕСЯЦ 7 ПШЕНИЦА 2681920 МЫШИ 655 кошки 7 □WHEATS 1895490 □MlCEs 204 □CATSs 0
в 2575370 1046 7 □WHEATS -106550 DMICEs 391 □CATSs 0
9 2464910 1795 28 DWHEATs -110460 DMICE= 749 DCATSa 21
10 234^960 2601 28 □WHEATS -II795O DMICEs 806 □CATS» 0
11 2220950 4146 28 □WHEATS -126010 □MlCEs 1545 □CATSs 0
12 2079490 7107 2В CWHEATS -141460 DMICEs 2961 dcats® 0
1 190В420 12782 27 □WHEATS -171070 DMICEs 5675 □CATSs -1
2 1660600 23689 27 DWHEATs -227820 DMICEs 10907 □CATSs 0
3 13457Ю 37711 107 □WHEATS -336890 DMICEs 14022 DCATSa 80
ч 866600 44796 106 □WHEATS -477110 DMICEs 7085 □CATSs -1
5 31864-0 46549 105 □WHEATS -547960 DMICEs 1753 □CATSs -1
6 0 4270S Ю4 □wheats -565490 DMICEs -3643 OCATSs -1
Рис. 3.6.8. Окончание
Глава 4. Полный пример
В гл. 1 обсуждались несколько основных этапов, входящих в полное построение алгоритма. Гл. 2 и 3 продемонстрировали некоторые основные средства проектирования и методы, которые можно использовать при построении алгоритма. В этой главе многие из этих идей проиллюстрированы на конкретном примере •— полностью построенном алгоритме отыскания остовного дерева минимального веса в некоторой сети. Этот пример также иллюстрирует многие приемы проверки программ и составления документации.
Размер этой главы показывает, что мы не сможем описать другие алгоритмы настолько же полно. Следовательно, в последующих главах мы выделим лишь наиболее интересные аспекты построения того или иного алгоритма.
4.1. Построение алгоритма для отыскания
остовного дерева минимального веса
Администратор вычислительного центра сталкивается с необходимостью принять решение, надо или нет организовать сеть малых вычислительных машин в W различных территориальных пунктах. Это решение является довольно сложным и зависит от большого количества факторов. Эти факторы включают вычислительные ресурсы, доступные в каждом пункте, соответствующие уровни потребностей, пиковые нагрузки на систему, возможное неэффективное использование основного ресурса в системе и, кроме того, стоимость предлагаемой сети. В эту стоимость входят приобретение оборудования, прокладка линий связи, обслуживание системы и стоимости прогона задания данного. типа в данном пункте. Администратор просит нас определить стоимость такой сети.
Поразмыслив, мы решаем, что нужна сеть минимальной стоимости, в которой каждый пункт может связаться с любым другим. Позвонив представителю телефонной компании, мы можем выяснить, какова стоимость Сц прокладки прямой линии связи (некоммутируемой линии) между двумя пунктами i и j в предполагаемой сети. Представитель телефонной компании информирует нас, что стоимость некоммутируемой линии является функцией географического расстояния между пунктами, необходимой скорости передачи и желаемой информационной емкости линии.
После дальнейшего обсуждения этого вопроса вместе с администратором и представителем телефонной компании нам удается определить
подходящие цены Cj/>0, т. е. мы получаем симметричную матрицу стоимостей, подобную использованной в задаче о коммивояжере в разд. 1.3.
Построение модели
Что представляет собой решение задачи? Мы должны решить, какие именно соединения следует установить, а какие не следует, т. е. для каждой пары i и / следует решить, устанавливать или нет соединение стоимостью Сц.
Следовательно, решение должно представлять собой модифицированную матрицу С, полученную из первоначальной матрицы цен, в которой элементы (/, /) и (/, г) равны оо, если мы не устанавливаем соединения, и сц, если устанавливаем. Кроме того, поскольку предполагается, что каждый пункт может устанавливать связь в сети с любым другим, то в каждой строке (и в каждом столбце) матрицы С должен содержаться по крайней мере один конечный элемент. Но любая ли модифицированная матрица, удовлетворяющая этому условию на строки и столбцы, является решением? Оставив пока этот вопрос открытым, давайте рассмотрим вторую модель для этой же задачи. Рис. 4.1.1 показывает, как можно представить любую симметричную матрицу стоимостей полной сетью с весами. Рис. 4.1.1, а представляет гипотетическую матрицу С для сети связи, состоящей из пяти пунктов, помеченных цифрами 1, 2, 3, 4 и 5. Для удобства стоимости сц для i=/=j предполагаются положительными целыми числами. Заметим, что Сц=Сц, т. е. С — симметричная матрица. Все элементы на главной диагонали сделаны бесконечными, чтобы избежать установления связи некоторого пункта с самим собой. Пять вершин полной сети с весами на рис. 4.1.1, б, помеченные цифрами 1, 2, 3, 4 и 5, соответствуют пяти
1 2 3 4 5
1 ~ 11 9 7 8
2 11 оо 15 14 13
3 9 15 °о 12 14
4 7 14 12 оо 6
5 8 13 14 6 °о
Рис. 4.1.1. (с) матрица стоимостей С; (б) соответствующая взвешенная полная сеть G.
пунктам сети связи. Для любой пары различных вершин vt и Vj ребро, соединяющее их, помечено стоимостью сц.
Возвращаясь к вопросу о том, что же представляет собой решение задачи, рассмотрим модифицированную матрицу С' для матрицы С на рис. 4.1.2, которая удовлетворяет условию, что каждая строка (и каждый столбец) имеет по крайней мере один конечный элемент. Могло
Рис. 4.1.2. (с) С'; (6) G'.
бы это быть решением? Визуальное рассмотрение соответствующей подсети G' и G показывает, что это не может быть решением, так как в G' не существует пути, соединяющего пункты 3, 4 или 5 с пунктами 1 или 2.
На рис. 4.1.2 мы обнаружили, что подсеть G' не является связной. Поэтому образуем связную сеть добавлением (самой дешевой) линии связи между пунктами 1 или 2 и пунктами 3, 4 или 5, т. е. соединяем пункты 1 и 4, стоимость (?i4=7 (см. сеть G" на рис. 4.1.3, а). Могла бы
Рис. 4.1.3. (d) G"; (6) G'".
сеть G" быть решением? Стоимость этой сети является суммой стоимостей всех линий связи, которые она содержит. Посмотрим, что произошло бы, если бы мы удалили соединение между пунктами 3 и 5
(см. сеть G'" на рис. 4.1.3, б). Полученная сеть оказывается более дешевой, но все еще связной, т. е. любой пункт может связаться с любым другим пунктом.
Таким образом, сеть, соответствующая решению задачи, не будет содержать циклов. Если бы решение содержало цикл, тогда можно было бы найти более дешевое решение, удалив самую дорогую связь в цикле. Следовательно, решением задачи является самая дешевая подсеть, которая связна, не содержит циклов и содержит все вершины. Таким образом, согласно теореме 2.2.4, эта црдсеть окажется остов-ным деревом.
Наша первоначальная задача теперь может быть сформулирована математически следующим образом: Дана связная полная сеть G с весами, найти остовное дерево минимальной стоимости (или веса).
Разработка алгоритма
Теперь, когда мы поставили нашу задачу математически, мы должны найти решение. Возможно, естественнее всего было бы испытать грубый алгоритм, т. е. выбрать сперва самое дешевое ребро, затем следующее самое дешевое из оставшихся и т. д. Но, выбирая ребра, мы должны помнить о трех требованиях: (1) окончательная подсеть должна содержать все вершины и должна быть связной; (2) окончательная сеть не должна содержать циклов; (3) окончательная сеть должна обладать минимальным возможным весом. Заглядывая несколько вперед, мы должны также приготовиться доказать, что наша окончательная сеть действительно обладает минимальным весом.
Попытаемся сформулировать эту процедуру в виде алгоритма.
Algorithm А. Отыскание остовного дерева Т минимального веса во взвешенной, связной и полной сети G с М вершинами и N ребрами. Шаг 0. [Инициализация] Set Т сеть, состоящая из М вершин, но без ребер; set Н G.
Шаг 1. [Цикл] While Т не является связной сетью do through шаг 3 od; and STOP.
Шаг 2. [Отыскание ребра с минимальным весом] Пусть (U, V) — ребро с наименьшим весом в Н\ if T-\-(U, V) не имеет циклов then [добавить (U, V) к Т\ set Г <-+-T+GJ, V) fi.
Шаг 3, [Удаление (U, V) из Н] Set Н Н—(U, У)-
Возникает несколько вопросов относительно этого алгоритма:
1. Всегда ли он выходит на STOP?
2. Когда он выходит на STOP, всегда ли Т оказывается остовным деревом для G?
3. Гарантировано ли, что Т — остовное дерево минимального веса?
4. Является ли алгоритм замкнутым (или содержит скрытые или неявные подалгоритмы)?
5. Эффективен ли алгоритм?
Сейчас вы уже могли бы подумать над вопросами 1, 2 и 3; ответ на все три будет «да». Сосредоточимся на вопросах 4 и 5.
На вопрос 4 ответ будет «нет», а на вопрос 5 — «может быть». Шаг 1 требует подалгоритма определения связности сети, а шаг 2 требует подалгоритма для решения вопроса о наличии циклов в сети. Эти два шага могут сделать алгоритм неэффективным, потому что подалгоритмы могли бы потребовать много времени.
Это наводит на мысль, что можно было бы улучшить алгоритм А, если бы удалось найти метод построения остовного дерева, гарантирующий без проведения проверок, что создана связная сеть без циклов.
Следующий алгоритм, принадлежащий Приму, делает как раз то, что мы хотим. Он настолько прост, что трудно поверить в то, что он всегда работает. Его правильность будет доказана в следующем разделе.
Algorithm PRIM. Найти остовное дерево Т минимального веса во взвешенной связной сети G с М вершинами и N ребрами.
Шаг 0. [Инициализация] Помечаем все вершины «невыбранными»; set Т сеть с М вершинами и без ребер; выбираем произвольную вершину и помечаем ее «выбранной».
Шаг 1. [Цикл] While существует невыбранная вершина do шаг 2 od; and STOP.
Шаг 2. [Отыскание ребра с минимальным весом] Пусть (U, V) — ребро с наименьшим весом между произвольной выбранной вершиной U и произвольной невыбранной вершиной V; помечаем V как «выбранную»; and set Т T-\-(U, V).
Блок-схема алгоритма PRIM приведена на рис. 4.1.4.
На рис. 4.1.5, о: показана сеть с рис. 4.1.1, б; рис. 4.1.5, б—е иллюстрируют рост остовного дерева Т минимального веса по мере работы алгоритма PRIM; выбранные вершины указываются черными квадратами, а невыбранные — окружностями. Начальной вершиной на рис. 4.1.5, б является вершина 5.
Заметим, что оба алгоритма построения остовного дерева минимального веса можно было бы применить и к произвольной связной сети G, т. е. сети на входе алгоритма не обязательно ограничивать классом полных сетей. Ребрам, отсутствующим в G, следует приписать бесконечный вес.
Отрабатывание назад часто используется для обнимания разработки алгоритма. Ключевую идею разработки алгоритма PRIM можно было бы найти отрабатыванием назад. Предположим, что мы нашли каким-либо методом остовное дерево Т минимального веса для сети G. Ребра G, не входящие в Т, должны быть как-то устранены из рассмотрения. Введем одно из них обратно в Т, например ребро е. По теореме 2.2.4(e) Т-\-е имеет в точности один цикл, который мы назовем С. Вес ребра е должен быть не меньше веса каждого из остальных ребер из С. Это следует из того, что если ребро f из С обладает весом, боль-
PRIM.
Рис. 4.1.4. Блок-схема
алгоритма
Рис. 4.1.5.
шим, чем у ребра е, то тогда остовным деревом для G было бы Т-\-е—f с весом, меньшим, чем у Т. Последнее противоречило бы предположению о том, что Т является остовным деревом минимального веса для G.
Это подсказывает естественную процедуру отыскания остовного дерева минимального веса, которая последовательно находит циклы в G и разрывает их, удаляя из цикла ребро, обладающее наибольшим весом.
Правильность алгоритма
Алгоритм PRIM является еще одним примером того, что называется «грубым» алгоритмом (см. разд. 3.2). Нужно принимать последовательность решений (в данном случае выбор ребер). Каждый раз, когда мы принимаем одно из этих решений, мы просматриваем всю текущую информацию и делаем по возможности наименее дорогой выбор. Этот выбор производится без учета воздействия, которое он может оказать на последующие выборы.
Правильность алгоритма PRIM основана на различных фундаментальных результатах, касающихся деревьев, в частности на теореме 2.2.4. Прежде чем обсуждать правильность, имеет смысл остановиться на одном общем факте, относящемся к разработке алгоритмов.
Вообще говоря, нетрудно разработать какой-то алгоритм для решения некоторой проблемы. Трудно разработать эффективный алгоритм, и очень трудно разработать наилучший возможный алгоритм (см. разд. 1.3).
Чаще всего различие между эффективным и неэффективным алгоритмами состоит в наличии ясного представления не только о самой задаче, но и о соответствующих математических свойствах структур, используемых для ее моделирования. Поэтому не следует удивляться, что для разработки эффективного алгоритма могут понадобиться несколько ключевых теорем, помогающих выбрать направление разработки.
Наше доказательство правильности алгоритма PRIM состоит из приведенной ниже последовательности теорем.
Теорема 4.1.1. При каждом завершении шага 2 алгоритма PRIM ребра, принадлежащие в данный момент Т, образуют дерево на множестве вершин, выбранных к данному моменту.
Доказательство. Проведем индукцию по числу К выполнений шага 2. Очевидно, при К=\ должны существовать две выбранные вершины и одно ребро в Т между ними.
Теперь предположим, что-после К выполнений шага 2 ребра, в данный момент входящие в Т, образуют дерево (назовем его Тс) на множестве выбранных к данному моменту вершин. Рассмотрим (М+1)-е выполнение шага 2.
Оно обязательно включает добавление одной новой вершины и одного нового ребра к Тс. Так как это новое ребро является единствен-
ним ребром между новой вершиной и Тс, добавление этой вершины и ребра не может создать цикла в Тс и новое Тс по-прежнему связно. Таким образом, Тс остается деревом.
Теорема 4.1.2. При завершении работы алгоритма PRIM. Т является остовным деревом для G.
Доказательство. Это непосредственно следует из теоремы 4.1.1, которая гарантирует нам, что Т — дерево, и из того, что Т содержит все вершины G, т. е. алгоритм прекращает работу только тогда, когда все вершины выбраны.
Теорема 4.1.3. Пусть Т — поддерево сети G, а е — ребро с наименьшим весом, соединяющее вершину, принадлежащую Т, и вершину, не принадлежащую Т. Тогда в G существует остовное дерево Т', содержащее Т и е, такое, что если Т" — любое остовное дерево в G, содержащее Т, то W(T')^W(T").
Доказательство. Пусть Т” — остовное дерево для G, содержащее Т и обладающее-.минимальным весом среди всех остовных деревьев, содержащих Т. Предположим далее, что Т" не содержит е. Рассмотрим сеть Т" (J {е} и единственный цикл С в ней, содержащий е. Теперь цикл С должен содержать ребро f=A=e, соединяющее вершину, принадлежащую Т, с вершиной, не принадлежащей Т. Почему? Согласно нашим предположениям, однако, мы знаем, что w(e)^w(f). Следовательно, дерево, полученное из Т" удалением f и добавлением е:
T"-{f} U {е}=Тг,
является остовным деревом G, содержащим Т и е, и удовлетворяет условию W (Г)< W (Т").
Теорема 4.1.3 дает достаточное обоснование шага 2 алгоритма PRIM; она утверждает, что оснований для выбора нового ребра на шаге 2 достаточно, чтобы гарантировать существование остовного дерева минимального веса, содержащего выбранное ребро. Далее мы будем использовать обозначение ОДМВ для остовного дерева минимального веса.
Теорема 4.1.4. Пусть G=(V, Е) — связная взвешенная сеть, и пусть e=(v, w) — ребро с наименьшим весом, инцидентное вершине v. Тогда существует ОДМВ Т, содержащее е.
Доказательство. Пусть Т — ОДМВ G, не содержащее е. Рассмотрим сеть Т (J {е}. Согласно теореме 2.2.4(e), Т (J {е} содержит в точности один цикл. Этот цикл содержит два ребра, инцидентных вершине о, включая e=(v, w) и другое ребро., скажем f=(u, v). Согласно гипотезе, w(e)^w(f), и поэтому Г— {/} и {е} является ОДМВ для G, содержащим е.
Теорема 4.1.5. Алгоритм PRIM находит ОДМВ Т во взвешенной связной сети G с М вершинами.
Доказательство. Согласно теореме 4.1.2, алгоритм PRIM находит остовное дерево.
Согласно теореме 4.1.4 существует ОДМВ Т1г содержащее первое ребро — назовем его ег— выбранное алгоритмом PRIM.
Согласно теореме 4.1.3, существует остовное дерево Т2, содержащее первое ребро ех и второе ребро е2, выбранное алгоритмом PRIM. Т\ также обладает минимальным весом среди всех остовных деревьев, содержащих т. е. W(Т2) = W(7\), так как 7Х— наше ОДМВ.
Повторяя этот процесс, по теореме 4.1.3, мы убеждаемся в существовании ОДМВ, содержащего первые k ребер, выбранных алгоритмом PRIM, для всех fe=l, 2, . . . , М—1.
Наконец, так как выбранные М—1 ребер сами образуют остовное дерево, из этого следует, что Т есть остовное дерево минимального веса для G.
Реализация алгоритма
Теперь настало время описать программу для машины, отыскивающую ОДМВ, с использованием алгоритма PRIM. Алгоритм будет реализован в виде подпрограммы. Это соглашение вводится для того, чтобы избежать определенных вопросов ввода и вывода, зависящих от местных требований к организации вычислений и вопросов стиля. Используя данное соглашение, мы не подразумеваем этим, что вопросы ввода и вывода тривиальны. Например время ввода/вывода может оказаться существенно больше времени вычислений при отыскании ОДМВ для очень больших сетей.
Первое, что можно было бы спросить: каковы должны быть входные и выходные параметры этой подпрограммы? Начальное предложение алгоритма PRIM частично отвечает на этот вопрос: на входе должна быть взвешенная связная сеть G с М вершинами и N ребрами, а на выходе нужно получить для G остовное дерево Т минимального веса.
Следовательно, мы должны решить, как хранить сеть в памяти. В разд. 2.2 и 2.3 обсуждались некоторые способы представления сети в машине. Пока мы произвольно решим организовать массив размера МхМ (т. е. матрицу стоимостей), где Сц равно весу ребра G между vt и V]. Если же между vt и Vj нет ребра, то используем Сц=\ ООО 000, т. е. некоторое значение, большее веса любого ребра в G. Мы также будем предполагать для удобства, что все веса — положительные целые.
Выходная информация будет состоять из последовательности М—1 упорядоченных троек, элементы которых расположены в трех массивах FROM(7), ТО(7), COST(7). Пара FROM(7), ТО(7) представляет 7-е ребро ОДМВ Т, вес которого равен COST (7).
Решив, как представить входную и выходную информацию для подпрограммы, мы приступаем к реализации каждого шага алгоритма PRIM. Шаги 0 и 1 предполагают наличие массива CHOSEN, в котором CHOSEN(7)=1, если вершина 7 «выбрана», и CHOSEN (7)=0, если вершина I пока еще «не выбрана».
Однако шаг 2 требует двух массивов CHOSEN и UNCHOSEN, чтобы найти минимальный вес ребра между вершиной в CHOSEN и вершиной в UNCHOSEN. Имея это в виду, мы можем представить себе реа-
лизацию шага 2 в виде проверки всех ребер с одной вершиной в
Рис. 4.1.6. Более детальная блок-схема алгоритма PRIM.
CHOSEN, а другой в UNCHOSEN. Как только будет найдено ребро с минимальным весом, невыбранная вершина этого ребра исключается из массива UNCHOSEN и добавляется к массиву CHOSEN. Шаг 2 можно затем повторить с обновленными массивами.
При более пристальном взгляде на этот подход к реализации шага 2 мы обнаруживаем, что будет производиться много лишних проверок ребер и что возникают некоторые трудности при обновлении массивов CHOSEN и UNCHOSEN. Более эффективная реализация шага 2 получается, если хранить только список невыбранных вершин UNCHSN (7), который первоначально содержит NUMUN=A1—1 вершин, и создать два дополнительных массива. Это будут массивы LIGHT, каждый 7-й элемент которого равен наименьшему весу ребра между 7-й невыбранной вершиной и некоторой выбранной вершиной, и VERTEX, содержащий в 7-м элементе выбранную вершину на этом ребре.
При наличии этих массивов шаг 2 можно реализовать следующим образом: (1) ищем ребро с наименьшим весом в массиве LIGHT; (2) исключаем 7С-й элемент из списка UNCHSN (помещаем последнюю невыбранную вер
шину UNCHSN (NUMUN) в
UNCHSN (70); (3) уменьшаем значе-
ние NUMUN, числа невыбранных вер-
шин, на 1; (4) запоминаем или выдаем на печать вновь выбранное ребро LIGHT; (5) используя UNCHSN (К) в качестве вновь выбранной вершины, обновляем значения LIGHT для остающихся невыбранных вершин, сравнивая LIGHT(7) с С(7, UNCHSN (К)).
Приняв решение о реализации самого трудного шага алгоритма PRIM, мы можем теперь завершить реализацию остальных шагов. Шаг О сводится к произвольному выбору вершины М в качестве начальной и к размещению вершин 1, 2, 3, . . . , М—1 в массиве UNCHSN. Шаг 1
реализуется посредством проверки, остались ли еще невыбранные вер-шины, т. е. не равно ли значение NUMUN нулю. Эти соображения сведены в блок-схему на рис. 4.1.6.
В программе на Фортране, показанной на рис. 4.1.7, мы произвольно решили отвести достаточное пространство в памяти для работы с сетью, имеющей 100 вершин. Символы в крайних правых позициях записи программы будут кратко пояснены; числа в левых позициях будут обсуждены в следующем разделе.
Оператор CALL’CHECK, на рис. 4.1.7 вызывает подпрограмму, которая должна проверять, допустимы ли значение М и значения С. Если обнаружено недопустимое значение, подпрограмма CHECK
SUBROUTINE PR1М(С,И,FROM,ТО,COST.WEIGHT) С
0 ЭТА ПОДПРОГРАММА НАХОДИТ ОСТОВНОЕ ДЕРЕВО МИНИМАЛЬ-
с НОГО ВЕСА (ОДМВ) ВО ВЗВЕШЕННОЙ СВЯЗНОЙ СЕТИ G , ИС-
с ПОЛЬЗУЯ АЛГОРИТМ Р.ПРИМА (BELL SYSTEM TECH.J. 36
с (НОЯБРЬ 1957), 1389-1401). ДАННАЯ РЕАЛИЗАЦИЯ ЯВЛЯ-
с ЕТСЯ МОДИФИКАЦИЕЙ ПРОГРАММЫ В.КИВИНА И М.УИТНИ с (СОММ.АСМ (АПРЕЛЬ 1972), АЛГОРИТМ 422).
С
С =.== ФОРМАЛЬНЫЕ ПАРАМЕТРЫ С
С ' С(!,Л ВЕС РЕБРА СОЕДИНЯЮЩЕГО ВЕРШИНЫ I И J , С ГДЕ I.LE.Cl I,Л.LE.999999. ЕСЛИ РЕБРО
С ОТСУТСТВУЕТ , ТО С(1,Л = 1 000 000 .
с ПРОИЗВОЛЬНОМУ БОЛЬШОМУ 4ИСЛУ.
С
с М ВЕРШИНЫ В G ПРОНУМЕРОВАНЫ 1.....М,
с ГДЕ 2.LE.M.LE.100
С
С FROM!Г) 1-Е РЕБРО В ОДМВ СОЕДИНЯЕТ ВЕРШИНУ FROM(I)
с Т0(|>’ С ВЕРШИНОЙ Т0(1) ПРИ ЦЕНЕ COST(l)
С COST(I)
С
с WEIGHT ОБЩИЙ ВЕС ОДМВ
С
с -=« ВНУТРЕННИЕ ПЕРЕМЕННЫЕ С
С EDGES ТЕКУЩЕЕ ЧИСЛО РЕБЕР В ОДМВ
С
с LIGHT(I) НАИМЕНЬШИЙ ВЕС РЕБРА ИЗ VERTEX(I) К
С UNCHSN(T)
С NEXT ОЧЕРЕДНАЯ ВЕРШИНА , ПРИСОЕДИНЯЕМАЯ К ОДМВ
С
с NUMUN ЧИСЛО НЕВЫВРАННЫХ ВЕРШИН
С
с UNCHSN(I) МАССИВ НЕВЫБРАННЫХ ВЕРШИН
С
с VERTEX!I) ВЕРШИНЫ ЧАСТИЧНОГО ОДМВ , БЛИЖАЙШИЕ К ВЕР-
с ШИНЕ UNCBSN(I)
С
Рис. 4.1.7. Подпрограмма PRIM,
INTEGER ED-GES ,L 1G HT110.0), NEXT,NUHUN.UNCHSN(1 DO)
INTEGER VERTEX (100)
INTEGER C(100»100) tMtFROM(100),TO(1005 .COSTdDO) INTEGER WEIGHT “ C ₽ с ПРОВЕРКА ВХОДНЫХ ДАННЫХ НА ДОПУСТИМЫЕ ЗНАЧЕНИЯ = С
Ь CALL CHECK (С .Н) в С = с ПРИСВОЕНИЕ НАЧАЛЬНЫХ ЗНАЧЕНИЙ (ИНИЦИАЛИЗАЦИЯ) = С ‘
1= EDGES = О 1
1 = NEXT « М 1
1= NUMUN = М-1 1
1= WEIGHT = О 1
1= DO 100 I = 1,NUMUN 1
49= UNCHS.Nd) « I М-1
49 = L IGHTl I) = C( l SNEXT1 М-1
49 = VERTEXl I) . NEXT м-1
49 = 106 CONTINUE М-1
- = C
*= С ОБНОВЛЕНИЕ ТАБЛИЦЫ РЕБЕР НАИМЕНЬШЕГО ВЕСА •, СО ЕДИНЯ-
= с ’ ЮЩИХ КАВДУЮ НЕВЫБРАННУЮ ВЕРШИНУ С КАКОЙ-НИБУДЬ ВЫБ-
С РАННОЙ
= С
49 = 200 ВО 300 I = 1.NUMUN М-1
1225= J - UNCHSNUl М(М-1)/2
1225= JK =. C(J,NEXT> ШМ-11/2
1225 = IFiL IGHTl I) .LE. JK) GO TO 300 MIM-D/2,
151 = VERTEXlI) - NEXT В
151 = L IGHTl I) - JK В
1225= -300 CONTINUE MIM-D/2
ж c -
t= С ОТЫСКАНИЕ РЕБРА С НАИМЕНЬШИМ ВЕСОМ , СОЕДИНЯЮЩЕГО
CS С НЕВЫБРАННУЮ ВЕРШИНУ С ВЫБРАННОЙ
» С
Рис. 4.1.7. Продолжение
49» К - 1 H-1 '
' 49 = L -L1GHTI1) H-1
49= DO 400 I -1,NUMUN H-1
-1225= IF(LlGlTr( I) .GE, L) GO TO 400, H(M-1)/2,C
122= L » LIGHT(I)
•122= К = । D <
1225= 400 CONTINUE
1 = С X.
1 “с ВКЛЮЧЕНИЕ РЕБРА В ОДМВ
= с J
49 = EDGES » EDGES + 1 ’ H-1
49= FROM(EDGES) = UNCHSN(K) H-1
49= TO(EDGES) = VeRTEX(K) H-1
49= .'cOST(EOGES) = L Hr1
49= WEIGHT = WEIGHT +L H-1
49- NEXT = UNCHSN(K) H-1
-С
” с ИСКЛЮЧЕНИЕ ВНОВЬ ВЫБРАННОЙ ВЕРШИНЫ ИЗ ОРИСКА НЕВЫБ-
= с РАННЫХ
« с
49= LIGHT(K) - LIGHT!NUMUN) IM*
49 = unCHSN(K) - UNCHSN(NUHUN) H-1
49= VERTEX(K) - VERTEXtNUMUN) IM
\ <= с
« С ОСТАЛИСЬ ЛИ НЕВЫБРАННЫЕ ВЕРШИНЫ
= С •
49= ‘ NUMUN » NUMUN - 1 IM
49= IF(NUMUN .NE. O) GO TO 200 <4-1
1м RETURN •
м END
Рис. 4.1.7. Продолжение
напечатает соответствующее сообщение об ошибке и прекратит выполнение алгоритма. Построение этой простой подпрограммы мы предоставляем читателю.
Анализ алгоритма
Теперь проанализируем сложность алгоритма PRIM. Цель состоит в том, чтобы попытаться определить наибольшее количество операций, которые должен выполнить этот алгоритм, чтобы найти ОДМВ для произвольной связной сети с М вершинами.
Прежде чем проводить детальный анализ реализации на рис. 4.1.7, дадим сначала грубый анализ «по порядку величины».
Шаг 0 алгоритма PRIM требует О (Л1) операций для инициализации списка невыбранных вершин. В нашей реализации это включает О(Л4) операций для инициализации каждого из трех массивов по (Л4—1) элементов плюс постоянное количество (не зависящее от Л4) вспомогательных операций. Так как количество работы здесь прямо пропорционально М, шаг 0 имеет сложность О(Л4).
Шаг 1, итерационный, по существу требует О(Л4) проверок, чтобы установить, есть ли еще невыбранные вершины.
Шаг 2 выполняется точно М—1 раз. Каждое выполнение шага 2 требует поиска в текущем списке LIGHT для отыскания ребра с наименьшим весом от невыбранной вершины к выбранной. Эта работа требует О (NUMUN) операций, где NUMUN — текущее число невыбранных вершин (см. алгоритм МАХ из разд. 1.2). Так как NUMUN^JW—1, эта часть шага 2 ограничена сверху О(М) операциями. После идентификации вновь выбранной вершины I нужно обновить список невыбранных UNCHSN. Для каждой невыбранной вершины К мы должны сравнить значение LIGHT (К) с С (К, /), чтобы увидеть, не дешевле ли теперь связать какую-нибудь из невыбранных вершин с некоторой выбранной, используя вновь выбранную вершину I. Необходим один проход по текущему списку LIGHT; процесс обновления ограничен сверху О(М) операциями. Так как ни один из остальных подшагов шага 2 не требует более, чем О(М) операций, сложность шага 2 ограничена сверху величиной О(М) (напомним, что О(Л4)+О(М)=0(Л4)).
Мы показали, что шаг 2 имеет сложность О(М) и выполняется (М—1) раз. Следовательно, полная работа, производимая на шаге 2, составит (Л4—1)(О(Л4))=О(Л42), т. е. алгоритм PRIM имеет общую сложность О(Л42).
Алгоритм PRIM весьма эффективен, особенно если мы полагаем, что можно проверить О(Л42) ребер *). Таким образом, ни один алгоритм построения ОДМВ не мог бы сколько-нибудь улучшить результат О(Л42), и алгоритм PRIM достигает этой нижней границы.
Наиболее важной целью анализа является получение функциональной зависимости числа операций, выполняемых алгоритмом, от параметров, характеризующих размеры задачи. Разумеется, алгоритм, требующий 2Л42+1 операций на сети с М вершинами, гораздо эффективнее алгоритма, требующего 30Л42+500 операций. Тем не менее оба алгоритма имеют сложность О(Л42), а их время работы, приблизительно пропорциональное числу операций, возрастает с ростом М, по существу, одинаково. Сравните это со случаем двух алгоритмов, один из которых требует 1000Л42+2000Л1+3000 операций, тогда как другой требует 0.5Л4! операций для решения той же задачи. Для значений около М=2 второй алгоритм превосходен, но обычно нас интересуют большие значения М. Каков будет результат сравнения этих алгоритмов при М—10, Л4=20 или 7И=100?
Теперь предпримем более детальный анализ алгоритма PRIM. При таком анализе тщательно рассматривают программную реализацию и подсчитывают число исполнений каждого оператора или по крайней мере стремятся получить ближайшую верхнюю границу для этого числа. Сумма всех этих чисел дает довольно точную оценку числа операций, необходимых данному алгоритму для задачи размера М. Этот тип анализа обычно более трудоемок, чем анализ «по порядку величи? ны», но зато дает более тонкую оценку сложности алгоритма и его частной рассматриваемой реализации.
*) Заметим, что полная сеть с М вершинами имеет М (М— 1) ребер,
На рис. 4.1.7 справа от каждого оператора приведена верхняя гра-ница числа его выполнений. Большую часть этих чисел легко проверить, и читателю следует проделать это. Однако некоторые участки программы требуют специального пояснения.
Мы опускаем детальный анализ сложности оператора CALL CHECK, который исполняется только один раз. Легко вцдеть, что любая реализация этой подпрограммы будет иметь сложность О(Л42), так как необходимо проверить все Л42 элементов матрицы стоимостей.
Цикл DO300 выполняется М—1 раз. Каждое исполнение этого цикла включает итерации по NUMUN, причем значение NUMUN изменяется от М—1, М—2, ... до 1. Таким образом, оператор J= =UNCHSN (/), помещенный после оператора DO300, выполняется М—1 раз при первом выполнении этого цикла DO, М—2 раз при втором и т. д. Следовательно, всего он выполняется
М-1
(Л4-1) + (М-2)+... + 1= Е i=i
раз.
Теперь легко определить кратность выполнения каждого из остальных операторов в подпрограмме PRIM. Объяснения требуют только кратности выполнения, помеченные буквами А, В, С и D. Они, очевидно, удовлетворяют уравнениям
л+в = ^м-1) и с+г = Я(^-1).
Если мы просуммируем все кратности выполнения, то увидим, что количество операторов, выполняемых подпрограммой PRIM, ограничено сверху величиной
4Л42+16Л4—14+B+D.
Так как значенияВиО оба ограничены сверху величиной М (Л4—2)/2, общее число исполняемых операторов ограничено сверху величиной
5Л42+15Л4—14.
Таким образом, общая сложность равна О(Л42). Заметим, что в трудоемкости подпрограммы PRIM относительно мало неопределенности. Иначе говоря, число исполняемых операторов для двух различных сетей с М вершинами различается только в числах В и D.
Хотя мы и считали каждый оператор за одну операцию, на выполнение этих операторов затрачивается различное количество времени. Например, на операцию сравнения затрачивается больше времени, чем на операцию сложения. Такие уточнения анализа требуют детального знания компиляторов и операционных систем.
Упражнения 4.1
4.1.1. ОДМВ-алгоритмы (обобщение). Хотя наша задача о сети связи была сформулирована в терминах полной сети, алгоритмами этого раздела можно воспользоваться для отыскания остовного дерева минимального веса на произвольных связных сетях. Покажите это явно.
4.1.2. Возможны ли ситуации, когда алгоритм А оказался бы лучше алгоритма PRIM?
4.1.3. Преобразование двоичных чисел в десятичные (полное построение). Разработайте полностью алгоритм, преобразующий двоичные числа в десятичные и наоборот. Можно ограничиться преобразованием целых чисел.
4.1.4. Треугольник Паскаля (полное построение). Разработайте полностью алгоритм, строящий первые W строк треугольника Паскаля. Если вам это необходимо, можете найти определение (и краткую историю) этого треугольника в книге [56], стр. 52.
* *4.1.5. Алгоритм А (разработка). Восполните явно все отсутствующие подалгоритмы в алгоритме А.
* **L4.1.6. Агентство безопасности Ас осуществляет патрулирование. Оно имеет п патрульных автомобилей и обслуживает т клиентов. Ас знает, сколько нужно времени для проверки учреждения каждого из клиентов и сколько нужно времени для проезда от каждого из клиентов к любому другому. По очевидным соображениям секретности Ас любит менять схемы патрулирования. Оплата патрульных служащих почасовая.
Постройте полностью алгоритм для этой задачи. Привлеките любую дополнительную информацию, которая, по вашему мнению, необходима.
* 4.1.7. Целочисленное умножение (полное построение). Постройте алгоритм, вычисляющий произведение двух целых чисел, используя только три операции: сложение, удвоение и деление иа 2.
4.1.8. Покажите явно, что среднее время Т(М) прогона подпрограммы PRIM равно О(М2).
* 4.1.9. Алгоритм проверки на цикл (разработка, правильность). Разработайте алгоритм, проверяющий, содержит ли произвольная сеть цикл. Докажите правильность алгоритма.
* *4.1.10. Алгоритм проверки свойств дерева (разработка, правильность). Разработайте алгоритм, определяющий, является ли произвольная сеть деревом. Докажите правильность алгоритма.
* *4.1.11. Алгоритм построения остовного дерева (наискорейший подъем). Всегда ли следующая процедура находит остовное дерево Т минимального веса в сети G?
Algorithm EXCHANGE (ПЕРЕСТАНОВКА). Нужно найти остовное дерево Т минимального веса на взвешенной связной сети G, имеющей М вершин и N ребер.
Шаг 0. [Инициализация] Set Т ч- произвольное остовное дерево для G; and пусть ребрами G, не входящими в Т, будут е±, е2,... ек.
Шаг 1. [Проверка каждого ребра, не входящего в Т] For i ч-1 to k do шаг 2 od; and STOP.
Шаг 2. [Перестановка ребра с максимальным весом] Пусть f — ребро с максимальным весом в единственном цикле в Т-\-ет, set T=T-\-ei—f.
4.2. Проверка программ
Существует три аспекта проверки программы: (1) на правильность, 2) на эффективность реализации и (3) на вычислительную сложность. Вместе взятые, эти проверки направлены на получение экспериментального ответа на вопросы: работает ли алгоритм? Насколько хорошо он работает?
Предполагается, что проверка правильности удостоверяет, что программа делает в точности то, для чего она была предназначена. Это гораздо труднее, чем может показаться с первого взгляда, особенно для больших программ. Важно понять, что математическая безупречность алгоритма не гарантирует правильности перевода его в программу. Аналогично ни отсутствие диагностических сообщений компилятора, ни «разумный вид» результатов прогона не дают достаточной гарантии правильности программы. Это часто иллюстрируют многие примеры машинных программ, которые работают месяцы или годы, прежде чем в них обнаруживаются ошибки.
Проверка эффективности реализации направлена на отыскание способов заставить правильную программу работать быстрее или расходовать меньше памяти. Чтобы улучшить программу, пересматриваются результаты этапа реализации в процессе построения алгоритма.
Проверка вычислительной сложности сводится к экспериментальному анализу сложности алгоритма или к экспериментальному сравнению двух или более алгоритмов, решающих одну и ту же задачу. Кроме того, проверки этого типа применяются для дополнения теоретического анализа алгоритма. Если теоретический анализ слишком трудно провести, необходимо все же накопить некоторый вычислительный опыт работы с этим алгоритмом. Этот опыт можно использовать, например, для предсказания продолжительности работы программы на определенном наборе входных данных. Результаты экспериментального анализа редко оказываются исчерпывающими, и не следует выходить за разумные пределы в их интерпретации.
Проверка правильности
Предположим, что у нас есть программа, которая получает правильные результаты для нескольких простых вариантов входных данных J). Задача состоит в том, чтобы проверить ее так, чтобы ею можно было пользоваться с уверенностью. Далее мы сообщим несколько принципов, которые должны быть представлены в любом плане проверки.
) Многие программисты сказали бы, что такая программа «отлажена», а не «проверена». Некоторые пользуются этими двумя словами вперемежку. Остальные называют «проверкой» процесс отыскания ошибок, а «отладкой» процесс локализации и устранения- их. Мы различаем три типа проверки, а термин «отладка» применяем для проверки правильности.
Меры предосторожности. Легче проверять правильность программы, если более ранние шаги ее построения были тщательно организованы и выполнены. В значительной степени развитие структурного программирования «сверху вниз» было мотивировано такими соображениями.
Планируйте проверку программы в процессе ее разработки. Думайте о том, как можно проверить каждый модуль и какие следует использовать для этого данные, еще в процессе его написания.
Кроме того, планируйте наперед предполагаемые изменения программы в будущем. Задайтесь вопросом: какие изменения вероятнее всего придется сделать? Здоровая забота об универсальности программы поможет избежать дорогостоящих переделок целых сегментов написанной программы.
Локальные проверки. Ряд простых тестов или проверок может быть выполнен вручную:
1. Проверяйте соответствие между оператором алгоритма или блок-схемы и его реализацией в программе. Медленно пройдите по всем операторам программы и попытайтесь представить себе назначение каждого из них и его связь с алгоритмом или блок-схемой.
2. Проделайте локальные проверки описаний всех переменных, изменяя все вхождения переменной, имя которой было изменено, проверьте соответствие размерностей массивов, вставьте операторы отладки или печати. Делайте все изменения сразу же, как только они осознаны, или по крайней мере отмечайте их, иначе их легко забыть.
3. Проверка на недопустимые значения. В каждом операторе, если это возможно, рассмотрите возможность появления недопустимого значения некой переменной и постарайтесь определить, из-за чего это могло бы произойти. Убедитесь, что все переменные инициализируются правильно, например, при каждом вызове подпрограммы или процедуры. Убедитесь, что индексы никогда не могут принимать значения, слишком малые либо слишком большие. Кроме того, проверьте, чтобы недопустимые значения не могли быть внесены извне в подпрограмму или процедуру.
4. Проверка на бесконечные циклы. Попытайтесь определить, существует ли путь, по которому программа могла бы попасть в бесконечный цикл.
Проверка всех частей программы. Руководствуйтесь следующим критерием. Проверяйте до тех пор, пока каждый присутствующий в программе оператор не будет давать правильного результата. В частности, проверьте каждую ветвь и каждое условие ошибки хотя бы раз. Попытайтесь проверить возможно больше различных путей через программу. Заметьте, что программы со структурой дерева имеют гораздо меньше путей, чем программы со сложными структурами циклов.
Тестовые данныеГСерьезные усилия следует направить на получение хороших данных для первых же тестов. Первоначальный набор тестовых данных должен покрывать широкий диапазон частных случаев; должны быть известны правильные ответы. Нужно включать данные, проверяющие все условия ошибок. Можно также пропустить через программу какие-нибудь «бессмысленные» данные, чтобы посмотреть, правильно ли они обрабатываются.
Избегайте прогона данных, по существу требующих, чтобы система снова и снова выполняла одно и то же. Также старайтесь избегать тестовых данных, ответы на которые нельзя проверить. Случайные данные обычно страдают обоими этими недостатками.
Проверяйте программу на данных, лежащих на границах допустимых диапазонов. Если диапазон для входных данных определяется размером задачи, сделайте отдельную попытку проверить очень большие и очень маленькие задачи. Обратите особое внимание на «нулевые случаи», например пустые строки, сети без вершин или ребер, нулевые матрицы и т. д. Если программой будут пользоваться часто, то можете быть уверены, что все возможные крайние случаи рано или поздно проявятся. Проверьте их вовремя.
Проверяйте программу на данных, выходящих за пределы приемлемого диапазона входных данных. Остерегайтесь опасной ситуации, когда программа выдает правдоподобные (но неверные) результаты.
Если доступна другая программа, решающая эту же задачу, используйте ее для контроля проверяемой программы. Хотя это и маловероятно, имейте в виду, что обе программы могут оказаться неправильными.
Следует также затратить некоторые усилия, чтобы проверить программу на реальных данных, если предполагается ее практическое использование. Может оказаться необходимым содействие потенциальных пользователей.
Поиск скрытых ошибок. Испробуйте все, что сможете придумать, чтобы выявить в программе ошибку. Если возможно, попросите кого-нибудь другого сделать это. Непредубежденность и свежий подход могли бы оказаться как раз тем, что нужно для локализации не замеченной вами ошибки.
Время, необходимое для проверки. Проверка требует обычно существенного количества времени, и ее не следует торопить. Зарезервируйте для отладки достаточно времени.
Повторная проверка. Если при проверке обнаружены ошибки, нужно. сделать изменения, чтобы их исправить. Следует позаботиться о том, чтобы не громоздить одно исправление на другое, нужно установить все места в программе, на которые воздействует данная ошибка. Убедитесь, что исправление одной ошибки не порождает новых. Для
этой цели можно было бы сохранить старые тестовые данные и использовать их для повторной проверки программы.
Когда прекратить проверку. На этот вопрос не существует общего ответа. Для любой конкретной программы ответ зависит от ее возможного применения и от уровня уверенности, которого желает достичь программист. Большие программы, предназначенные для важных производственных целей, может оказаться необходимым проверять месяцами. В действительности за ними нужно наблюдать в течение некоторого времени после внедрения в производство. Часто вопрос решается по соображениям времени и денег.
Проверка эффективности реализации
Этот тип проверки применяется при поиске способов ускорить выполнение программы или сократить требуемый объем памяти. Такая проверка оказывается потерей времени для простых программ или для программ, которыми будут пользоваться редко, но в высшей степени полезна для программ, которыми, вероятно, будут пользоваться часто.
Следует проводить различие между эффективностью реализации или кодирования и вычислител ной сложностью. Предположим, что мы разработали алгоритм и теоретический анализ показывает, что он имеет сложность О (п3), где п — некоторое число, характеризующее размер задачи. Предположим далее, что детальный анализ реализации этого алгоритма дает точную верхнюю границу 2п34-5«+17 для числа выполняемых операторов. Чего же мы должны ожидать от проверки эффективности реализации? Важно понять, что упрощение кодировки обычно не изменяет основного поведения порядка 0(п3); это существенное свойство алгоритма и связанных с ним структур данных. Однако более эффективное кодирование может существенно уменьшить количество операций. Например,.некоторая перестановка операторов могла бы понизить точную верхнюю границу до -^-м3 |-5м ]-20. Новая реализация потребует вчетверо меньше времени, чем первоначальная, хотя сложность по-прежнему будет О (и3).
Здесь уместно предостеречь. Предельно эффективное кодирование может нарушить ясность программы и сделать проверку ее правильности гораздо более трудной. Вообще следует избегать изменений, угрожающих ясности, если они не могут быть оправданы существенной экономией времени и/или памяти.
Существует много методов, которыми можно воспользоваться для повышения эффективности программы. Многие из них используют детальные знания о- конкретном компиляторе или операционной системе. Ими мы пренебрежем, а только упомянем несколько наиболее широко применяемых машинно-независимых методов. Затем мы обсудим полезную универсальную процедуру проверки, известную под названием профилирования,
рифметические операции. Арифметические операции сложения и вычитания выполняются быстрее, чем умножение и деление. Возведение в степень — самая медленная операция. Кроме того, целочисленная арифметика обычно быстрее арифметики вещественных чисел. Таким образом, величину X2 быстрее вычислить как Х»Х, чем Х^-х-2.0, а Х\-Х может оказаться быстрее, чем 2.0»Х.
Избыточные вычисления. Если сложное выражение встречается более чем в одном месте, вычисляйте его один раз и присваивайте вычисленное значение переменной. Хорошим примером служит формула для вычисления корней квадратного уравнения. Вместо того чтобы писать
ПООТ1 = (-В + SQRT(B **2-4.6 *А* С))/(2.0 * А)
ROOT2 = (-В - SQRT(B ** 2-4.0 * А * С))/(2.0 * А)
эффективнее воспользоваться записью
DENOM = A+A
DISCRIM.= SQRT(B * В - 4.0 * А * С) ROOT1 = (-B + DISCRIM)/DENOM ROOT2 = (-В -DISCRIMJ/DENOM
(Мы исключили проверку на мнимый корень.) Экономия времени зависит от конкретного компилятора.
Порядок в логических выражениях. Большинство компиляторов прекращает вычисление логических выражений, как только результат получен. Например, в выражении A .OR. В .OR. С вычисление будет прекращено, как только будет найдено значение TRUE. Некоторое время можно сэкономить, разместив А, В и С так, чтобы А вероятнее всего оказалось истинным, В — следующим по величине вероятности, а С — с наименьшей вероятностью.
Исключение циклов. Наибольшие возможности повышения эффективности выполнения заключены в сегментах программы, повторяемых часто. Такие сегменты почти всегда имеют форму циклов.
Одним из методов сокращения затрат времени на циклы является сокращение числа повторений. Это исключает дорогие операции увеличения счетчика цикла и его проверки. Например, рассмотрим следующую программу инициализации:
ПО 10 1 = 1,1000
А(!) = 0.0
10 CONTINUE
DO 20 J = 1.1000
B(J) = 0.0
20 CONHNUE
Здесь содержится 2000 операций увеличения счетчика и проверки. Требующееся для их выполнения время можно сэкономить, если инициализировать начальные значения оператором DATA во время компиляции. Если это сделать невозможно, тогда следует объединить эти два цикла.
Развертывание циклов. Дальнейшее снижение накладных расходов, обусловленных циклами, можно получить, применяя метод, известный как развертывание циклов. В предыдущем примере экономия достигается следующим образом:
DO 10 1=1,1000,2 A(l)=0.0 В(1) = 0.0 А(1 + 1) = 0.0 В(1+1) = 0.0
10 CONTINUE
Чрезмерное развертывание угрожает ясности и делает программу излишне длинной.
Упрощение внутренних циклов. Несомненно, наиболее ценный одиночный прием ускорения заключается в упрощении внутренних циклов. Если ничего больше не делается для проверки эффективности, нужно хотя бы проверить, нельзя ли уменьшить количество вычислений во внутренних циклах.
Например, рассмотрим следующую структуру со вложенными циклами:
DO 30 1 = 1,50
DO 20 J = 1,100
DO 10 K = 1,200
ОПЕРАТОР X
10 CONTINUE
20 CONTINUE
30 CONTINUE
А что, если действие оператора X никак не зависит от I, J или К? Там, где он,находится, он будет выполнен миллион раз. Если его убрать из всей структуры циклов и разместить перед оператором DO 30, он будет выполняться только один раз.
Профили исполнения. Здесь следовало бы заметить, что многие компиляторы обладают встроенными программами оптимизации, которые могут автоматически повышать эффективность программы. Однако мы не хотели бы представить эти компиляторы в качестве единст
венного средства повышения эффективности программы, особенно если можно повысить эффективность изменением логики алгоритма.
Время ценно, и мы не хотели бы его терять, проходя по всем строчкам программы ради экономии нескольких микросекунд времени центрального процессора. Существует ли эксперимент, который помог бы нам найти, какие именно части программы съедают большую часть времени выполнения? Если удастся выделить эти сегменты, то мы сможем сосредоточить на них наши усилия по проверке эффективности.
Один из хороших способов выполнения этого заключается в построении профиля исполнения программы. Работа программы контролируется набором таймеров и счетчиков, и выдается листинг, показывающий, сколько раз выполнялся каждый оператор и сколько единиц времени затрачено на выполнение каждого оператора. Библиотечные программы, вырабатывающие такие профили, становятся обычным средством на вычислительных установках.
Если нет готового пакета программ для построения профиля, не так уж трудно собрать грубые профили. Можно разместить счетчики в программе так, чтобы следить за количеством выполнений операторов или групп операторов. Получить точные оценки времени оказывается гораздо труднее. Многие внутренние часы не удобны для определения времени выполнения отдельных операций. Один из способов получения грубой оценки времени состоит в следующем. Найдите, сколько времени занимает выполнение простейшего возможного оператора присваивания, например А=2.0. Определите это как единицу времени. Затем найдите относительные продолжительности выполнения более сложных операторов; например, выполнение простого оператора присваивания с использованием индексированной переменной (такого, как А(1)=2.0) может занять две единицы времени. При небольшой тренировке и некотором вычислительном опыте можно построить довольно полную таблицу.
Статистические исследования с использованием профилей исполнения обнаружили замечательный факт, что менее чем 5% объема большинства программ поглощают приблизительно 50% времени выполнения. Как и следовало ожидать, внутренние циклы ответственны за большую часть этой концентрации.
Профили исполнения полезны не только для проверки эффективности реализации, но ценны и для остальных двух типов проверки. При проверке правильности эти профили можно использовать для того, чтобы увидеть, какие сегменты программы выполняются, а какие нет. Таким образом, профили могут помочь проверить, все ли части программы протестированы. Профили также полезны для проведения экспериментального детального анализа сложности на основе последовательного просмотра операторов.
Проверка вычислительной сложности
Для большинства алгоритмов трудно проверить вычислительную сложность серьезно и убедительно. Возникают две главные проблемы: (1) выбор входных данных и (2) перевод результатов эксперимента в эмпирические кривые сложности.
Как мы выбираем данные для проверки сложности алгоритма? Стандартный метод состоит в прогоне алгоритма на некоторых случайных данных и в построении графиков зависимости продолжительности прогона от одного или более параметров, характеризующих размеры задачи. Какое количество случайных данных мы должны создать и насколько случайны случайные данные? Количество создаваемых данных обычно определяется терпением программиста и бюджетом машинного времени. Случайность чаще всего определяется посредством равномерного или нормального распределения, так как эти распределения наиболее удобны.
Как быть с переводом выходных данных в эмпирические кривые сложности? Эта проблема, по существу, безнадежна, если входные данные зависят от трех или более параметров. Вычисления становятся очень трудными, и часто для достижения самого грубого заключения нужен невероятно большой объем выходных данных. К счастью, для многих программ размер задачи с достаточной точностью измеряется единственным параметром N, например для некоторых задач о сетях и для сортировки.
Как производится анализ для этих программ? Случайные данные прогоняют для некоторого диапазона N и для каждого значения N вычисляют средние длительности прогона. Последние изображают на графике как функции N и используют какой-нибудь метод для аппроксимации данных кривой заданного вида. Этот подход может оказаться информативным, особенно если он применяется для подтверждения теоретического анализа сложности.
Насколько серьезно следует относиться к выбору аппроксимирующей кривой? Мы не можем дать определенного ответа на этот вопрос, но имеется несколько полезных указаний. (Предупреждение: нетрудно найти контрпример для каждого из следующих правил.)
1. Согласие с аппроксимирующей кривой должно увеличиваться с увеличением размера выборки. Скорость роста должна быть меньше для более сложных алгоритмов. Так, грубо говоря, согласие должно быть лучше для хорошей линейной аппроксимации, чем для хорошей экспоненциальной аппроксимации.
2. Согласие с аппроксимирующей кривой должно убывать с ростом N. Скорость убывания должна быть больше для более сложных алгоритмов.
3. Никогда не доверяйте полиномиальной аппроксимации для алгоритма, который, как вы подозреваете, должен давать экспоненциальную зависимость. Можно получить разумную интерполяцион
ную кривую для экспериментального диапазона значений N, но любое более строгое утверждение будет, вероятно, неоправданным.
4. До экспериментального анализа попытайтесь провести теоретический анализ сложности. Обратный порядок может привести к психологической предубежденности.
5. Будьте бдительны к ошибкам эксперимента и неправильной интерпретации. В частности, не путайте ожидаемую трудоемкость с трудоемкостью в худшем случае. Будьте бдительны к отклонениям, навеянным генераторами случайных чисел.
6. Чрезвычайно легко потерять дробные степени или логарифмические множители при экспериментальном анализе. Алгоритм порядка О(7У5/г), возможно, будет выглядеть, как алгоритм порядка O(TV-) или О(№).
7. Не будьте слишком доверчивы к параметрам «качества аппроксимации», вычисляемым попутно аппроксимирующими алгоритмами (например, библиотечными пакетами «наименьших квадратов»).
8. Не забывайте о возможности ошибки в программе. Все ваши результаты могут оказаться ложными.
Наше обсуждение было скорее негативным, но было бы трудно рассуждать по-другому. Тем не менее проверку сложности следует рассматривать как важную часть разработки любого алгоритма. Грубая информация, заботливо собранная и тщательно оцененная, существенно лучше полного отсутствия информации вообще. Экспериментальное подтверждение теоретического анализа сложности — это ценное добавление к любой программе. Следует серьезно отнестись к расхождению между теорией и экспериментом. Важность вычислительного опыта достаточно очевидна.
Легче ли сравнить два алгоритма, если они решают одну и ту же задачу? Можно ли измерить относительную вычислительную сложность надежнее, чем абсолютную? Ответом на эти вопросы будет ограниченное «да» (в отличие от безусловного «да!»). Разумеется, существуют серьезные проблемы:
1. Важно устранить «мешающие параметры», запутывающие суть дела. Сюда входят различия в машинах, языках и программистах. Искушенный программист может реализовать экспоненциальный алгоритм настолько эффективно, что он может показаться лучше полиномиального алгоритма, реализованного новичком. Прямое сравнение продолжительностей прогонов окажется бессмысленным, если такие различия не устранены или иным способом не учтены в эксперименте.
2. Как выбирать набор задач, на котором будет основано сравнение? Это тот же вопрос, который возникает при обсуждении любого вида проверки. Простейший ответ состоит в том, чтобы произвести объединение всех нетривиальных задач, которые использовались при разработке алгоритмов, и проверить эти два алгоритма раздельно. При этом, вероятно, возникнут отдельные случаи, когда каждый
алгоритм работает очень хорошо (людям, разрабатывающим алгоритмы, обычно удается найти несколько таких случаев), и получится приемлемая смесь случайных задач. К сожалению, плохое документирование часто мешает следовать этому плану.
3, Не следует делать поспешных выводов. Алгоритм, показавший преимущество над другим в двух тестах из трех, еще не обязательно демонстрирует превосходство над первым. Как обычно, требуется обширная проверка прежде, чем можно будет сделать определенный вывод. Остерегайтесь особых классов задач, в которых почти всюду «проигравший» обходит «победителя».
4, Абсолютная продолжительность прогона (с учетом различий в машинах) не является единственной мерой относительного качества. Важны также потребность в памяти, специфические особенности, длина программы, простота. Пользователь может найти более привлекательным алгоритм, решающий задачу за 5 секунд времени центрального процессора, по сравнению с алгоритмом, требующим 1 секунду. Почему? Возможно, из-за того, что на обучение пользованию вторым алгоритмом может потребоваться несколько часов, а на обучение пользованию первым — считанные минуты.
Этот раздел мы завершим обсуждением того, как можно было бы проверить подпрограмму PRIM (разд. 4.1) на правильность, эффективность реализации и вычислительную сложность.
К сожалению, беспристрастно подойти к вопросу о правильности подпрограммы PRIM затруднительно, поскольку в прологе программы сказано, что разновидность ее опубликована в журнале и предполагается правильной. Однако мы еще можем рассмотреть контроль или тестирование ряда аспектов этой подпрограммы.
Во-первых, структурирована ли (разумным образом) эта подпрограмма? Проверка блок-схемы (рис. 4.1.6) показывает, что это так. Во-вторых, соответствует ли блок-схема тексту программы? Можно считать, что комментарии (и блоки операторов между ними) соответствуют блокам на схеме. Здесь мы могли бы предпринять мысленную проверку, чтобы удостовериться, что логика каждого блока операторов согласуется с намеченной в блок-схеме целью. Далее выпишем список всех, переменных подпрограммы, чтобы (1) убедиться, что они объявлены правильно, (2) убедиться, что им присвоены правильные начальные значения, (3) определить диапазон значений каждой переменной, (4) сосчитать число операторов, содержащих каждую из переменных, и (5) определить, какие переменные используются в качестве индексов. Это можно записать, как, например, в прилагаемой ниже таблице.
Следует отметить, что большинство компиляторов автоматически генерируют список переменных в программе вместе с операторами, в которых они встречаются.
Для необъявленных переменных мы можем проверить, нуждаются ли они в объявлении и правильного ли они типа. Для переменных, которым не присвоены начальные значения (FROM, ТО, COST), мы
можем принять решение, нуждаются ли они в этом; в данном случае нет. Проверка диапазона значений каждой переменной может использоваться в качестве вспомогательного средства при проверке соответствия их фактического использования с предполагаемым.
Имя переменной Объявлено Индекс Начальное значение Диапазон Число опе« раторов
EDGES да * да 1—*(М-1) 5
NEXT да * да 1 —> (М—1) 6
NUMUN да * Да (М— 1)—>0 6
М да входн. 2 —> 100 2
WEIGHT да Да 0—>(М—1)*106 2
I нет * цикл DO 1—> NUMUN 13
J нет * да 1 —> NUMUN 2
JK нет да 1 —► 10е 3
К нет * да 1 —> NUMUN 3
L нет да как LIGHT 5
LIGHT (100) да да 1 —> 10е 7
UNCHSN (100) Да да 1 —> NUMUN 5
VERTEX (100) да да 1 —>(М— 1) 4
FROM (100) да нет как UNCHSN 1
TO (100) да нет как VERTEX 1
COST (100) да нет как L 1
C(100, 100) да входн. 1 10е 1
Подсчет числа операторов, в которые входит данная переменная, может оказаться полезным не только при определении диапазона значений, которые она могла бы принимать, но и для выяснения, какие операторы нужно изменить, если изменяется имя переменной. Например, имена переменных I, J, JK, К и L в подпрограмме PRIM почти никак не связаны с их использованием в подпрограмме. Более того, переменная I служит нескольким различным целям. Поэтому произведем изменения, перечисленные во второй таблице.
Переменная
Заменяется на
Число операторов
I 11 в цикле DO 100 4
I 13 в цикле DO 300 5
I 14 в цикле DO 400 4
J VTX 2
JK NEWCST 3
К NEW VTX 3
L LEAST 5
Список переменных, используемых в качестве индексов, вместе с диапазонами их предполагаемых значений полезен при решении вопроса, не выходит ли индекс за предписанные пределы. В данном случае значения всех индексов заключены в пределах от 1 до М— 1 или от 1 до NUMUN и числа М и NUMUN ограничены сверху числом 100 и снизу числом 0. Индекс не может принимать значение 0 благодаря двум последним операторам:
IF (NUMUN .NE. 0) GO TO 200 RETURN
Что касается вопроса о том, не зациклится ли подпрограмма, представляется, что это может произойти, если по какой-нибудь причине NUMUN никогда не обратится в нуль. Из приведенного выше списка видно, что, хотя NUMUN присутствует в шести операторах, ее значение изменяется только в двух:
NUMUN = М—1 (в начале программы)
NUMUN = NUMU-N—1 (около конца программы)
Поскольку величина М объявлена как целая переменная, а подпрограмма CHECK определяет М как целую переменную со значениями между 2 и 100, мы можем быть в достаточной степени уверены, что программа не зациклится, так как значение NUMUN никогда не будет равно 0.
Что касается поиска чего-нибудь, что может привести к ошибке подпрограммы PRIM, можно задаться вопросом: могла бы подпрограмма когда-нибудь выбрать ребро с весом 1 000 000? И если да, то что бы это значило?
Что касается проверки подпрограммы PRIM на конкретных данных, то рассмотрим: (1) сеть, у которой значения С(/, J) или М неправильные; (2) сеть с М=2 и М=100 вершинами; (3) несколько маленьких сетей, для которых можно проверить ОДМВ вручную; (4) сеть со всеми равными значениями C(I, J)-, (5) сеть, в которой C(I, J)<Z <ZC(I, J-Н) для 7=1, . . . , М—1 и 1<J. Чтобы проверить, что все операторы выполнялись, и для проверки эффективности реализации исследуем профиль исполнения подпрограммы PRIM.
Числа слева от операторов в программе на рис. 4.1.7 показывают, сколько раз выполняется каждый из них при вызове подпрограммы PRIM для отыскания ОДМВ в случайно сгенерированной сети с 50 вершинами. Использованная нами программа построения профилей не указывала количества выполнений операторов GOTO 300 и GOTO 400. Однако, зная, что Л+В=1225 и С+£)=1225, мы можем вычислить, что они исполнялись соответственно 1225—151 = 1074 и 1225—122= = 1103 раз.
Этот профиль не только показывает, что каждый оператор был выполнен хотя бы однажды, но и подтверждает наш анализ сложности, проведенный в предыдущем разделе. Например, если Л1=50, то М (М—1)/2 =25(49)=1225. Этот профиль также показывает, что про
грамма проводит основную часть своего времени, выполняя шесть операторов 1225 раз. Следовательно, именно на этих операторах нам следует сосредоточить внимание при попытках улучшить реализацию.
Внимательное изучение циклов DO 300 и DO 400 обнаруживает два места, в которых можно достичь экономии времени выполнения. Во-первых, не обязательно выполнять цикл DO 300 непосредственно после цикла DO 100. Можно было бы непосредственно после 100 CONTINUE вставить оператор GO ТО 350, где 350 — метка оператора, непосредственно следующего за 300 CONTINUE, т. е.
300 CONTINUE
350 К—1
Поскольку такое изменение подпрограммы PRIM устранило бы первое выполнение цикла DO 300—(Л4—1) операторов (ценой добавления одного оператора) — и так как оно не приводит к неоправданному усложнению логики, его стоит сделать. Во-вторых, цикл DO 400 (с необходимыми предосторожностями) можно было бы преобразовать к виду DO 400 1=2, NUMUN. Это позволило бы избавиться от 1 = 1, так же как и от /14—1 сравнений LIGHT (1) с самим собой, от М—1 выполнений оператора GO ТО 400 и от Л4—1 выполнений CONTINUE, т. е. не выполнялось бы 3(Л4—1)+1 операторов. Однако npnNUMUN= = 1 не следует выполнять этот цикл DO. Такого выполнения можно избежать, заменив в конце программы строки
IF (NUMUN .NE. 0) GO TO 200 RETURN
END следующими операторами:
IF (NUMUN .GE. 2) GO TO 200
J = UNCHSN(1) JK=C(J, NEXT) IF (LIGHT(1) ,LE. JK) GO TO 500 VERTEX(1) = NEXT LIGHT(1)=JK
500 EDGES - EDGES+1
FROM(EDGES)=J
TO(EDGES)=VERTEX(1) COST(EDGES) = LIGHT(1) WEIGHT = WEIGHT+ LIGHTfl) RETURN
END
Можно считать, что эти новые операторы в свою очередь позволяют избежать выполнения 16 операторов, с риском, что сложность логики достигнет предела, за которым могла бы возникнуть ошибка
Таким образом, общая экономия в результате этих изменений составит 5(Л4—1)—1+3(Л4—1)+1 +16=8714+8 операторов. По сравнению с верхней границей 5Л42+15/14—14 числа выполнений операторов в подпрограмме PRIM экономия 8/И+8 операторов составит при
близительно 14% для Л4=10, 6% для 44=25, 3% для 44=50 и 1% для 44 = 100.
На рис. 4.2.1 дан пересмотренный вариант подпрограммы PRIM с учетом сделанных замечаний. Кратности выполнения операторов для той же случайной сети, что и на рис. 4.1.7, дают экономию 3% по сравнению с первоначальным вариантом. Однако это улучшение не следует рассматривать слишком серьезно, так как оно не обязательно приводит к такому же проценту уменьшения времени выполнения. Действительная экономия времени при выполнении зависит от конкретного компилятора и степени оптимизации.
SUBROUTINE FR1M(C,M, FROM, ТО .COST, WEIGHT) С
с ЭТА ПОДПРОГРАММА НАХОДИТ ОСТОВНОЕ ДЕРЕВО МИНИМАЛЬ» С НОГО ВЕСА (ОДМВ) ВО ВЗВЕШЕННОЙ СВЯЗНОЙ СЕТИ G , ИС-
с ПОЛЬЗУЯ АЛГОРИТМ Р.ПРИМА (BELL SYSTEM TECH.J. %
с (НОЯБРЬ 1957), 1389-1401). ДАННАЯ РЕАЛИЗАЦИЯ ЯВЛЯ-
с е ЕТСЯ’МОДИФИКАЦИЕЙ ПРОГРАММЫ В.КИВИНА И М.УИТНИ С (СОММ.АСМ (АПРЕЛЬ 1972), АЛГЦ.’ИТМ 422).j С
С ФОРМАЛЬНЫЕ С с C1I.J) с с с с с м с с с FROM(I)
С Т0(1)
с С03Т(1)
с с WEIGHT
ПАРАМЕТРЫ
БЕС РЕБРА , СОЕДИНЯЮЩЕГО ВЕРШИНЫ I И J , ГДЕ 1.LE.C(I,J).LE.999999. ЕСЛИ РЕБРО ОТСУТСТВУЕТ , ТО С( I,J) а 1 000 000 , ПРОИЗВОЛЬНОМУ БОЛЬШОМУ ЧИСЛУ.
ВЕРШИНЫ В G ПРОНУМЕРОВАНЫ 1
ГДЕ 2.LE.M.LE.100
1-е'рЕБРО в ОДМВ СОЕДИНЯЕТ ВЕРШИНУ FROM(I) С ВЕРШИНОЙ Т0{I) ПРИ ЦЕНЕ COST(l)
ОБЩИЙ ВЕС ОДМВ
С
с «.» ВНУТРЕННИЕ ПЕРЕМЕННЫЕ
С
С edges текущее число ребер в ОДМВ
с
с LIGHTfl) НАИМЕНЬШИЙ ВЕС РЕБРА ИЗ VERTEX(I) К
С UNCrSNfl)
С NEXT ОЧЕРЕДНАЯ ВЕРШИНА , ПРИСОЕДИНЯЕМАЯ К ОДМВ
С с NUMUN ЧИСЛО НЕЕНБРАННЫХ ВЕРШИН ,,
С с UNCHSN11) МАССИВ НЕВЫБРАННЫХ ВЕРШИН
С
с VERTEX!и ВЕРШИНЫ ЧАСТИЧНОГО ОДМВ , БЛИЖАЙШИЕ К ВЕР-
С ШИНЕ UNCHSN(I) .
С
Рис. 4.2.1. Подпрограмма PRIM после внесения изменений.
„ INTEGER EDGES.tICHTlIDO.NEXT.NUMUN.UNCfCNdOO)
и INTEGER VERTEXI1OO)
• INTEGER CdOO.lOD) tM,FROMl1DO) ,TO(1CO) »COSTl1QD>
« 1NTEGER WE 1GHT,LEAST,{I.EWCST,NEWVTX, VTX
*=c
' с ПРОВЕРКА ВХОДНЫХ ДАННЫХ НА ДОПУСТИМЫЕ ЗНАЧЕНИЯ
*= С и ПРИСВОЕНИЕ НАЧАЛЬНЫХ ЗНАЧЕНИЙ {ИНИЦИАЛИЗАЦИЯ))
>=С
1“ CALL CHECKlC.M) EDGES а О
1= NEXT • И
1 = NUMUN .«Н-1
1= WEIGHT «О
1» ВО 1DO И в 1.NUMUN
49= UNCHSN! И) » 11
49» LIGHT!И) а С ( 11 .NEXT)
49= VERTEX! 11) и NEXT
49= ЮО CONTINUE
1" GO ТО 350
« с
« С ОБНОВЛЕНИЕ ТАБЛИЦЫ РЕБЕР НАИМЕНЬШЕГО ВЕСА , СОЕДИНИ-
* С ВЩИХ КАМУЙ НЕВЫБРАННУЮ ВЕРШИНУ С КАКОЙ-НИБУДЬ ВЫВ*
* с РАННОЙ
"С
47= 200 ВО 300 13 е1,NUMUN
1175= VTX a UNCHSN! I3)
1175= NEWCST И CIVTX.NEXT)
1175= If[LIGHT1I3) .LE. NEWCST) СО ТО 300
451» VERTEX[13) «NEXT
151 = LIGHT! 13) "NEWCST
1175= 300 CONTINUE'
«С
«С ОТЫСКАНИЕ РЕБРА С НАИМЕНЬШИМ ВЕСОМ * СОЕДИНЖЕП)
*С НЕВЫБРАННУЮ ВЕРШИНУ С ВЫБРАННОЙ «С
48= 350 NEWVTX " 1
48= LEAST » LIGHT(I)
48= JJO ЧОО 14 а г,NUMUN
1176= IFIL1GHT! 14) .гСЕ, LEAST) СО ТО ЧС9
122= LEAST " LIGHT! 14)
122= NEWVTX а |Ч
1170= ЧОО CONTINUE
Рис. 4.2.1. Продолжение
«С ВКЛЮЧЕНИЕ РЕБРА В ОДМВ «С
ЧБ=» EDGES = EDGES + 1
48» NEXT = UNC HSN(NEWVTX)
48=» FROM(EDGES) = NEXT
46= TO (EDGES) = VERTEX(NEWVTX)
48= COST(EDGES) = LEAST
48» WEIGHT » WEIGHT + LEAST
“С ИСКЛЮЧЕНИЕ ВНОВЬ ВЫБРАННОЙ ВЕРШИНЫ ИЗ СПИСКА НЕВ’ЫБ-
=с РАННЫХ
-с
Ча» LIGHT(NEWVTX) = LIGHT(NUMUN)
48= UNCHSN(NEWVTX) = UNCHSN(NUHUN)
48= YERTEX(NEWVTX) = VERTEX(NUMUN)
= c
= C ОСТАЛИСЬ ЛИ НЕВЫБРАННЫЕ ВЕРШИНЫ
= с
48= NUMUN = NUMUN - 1
48»* IF(NUMUN .GE. 2) GO TO 2ОЯ
1= VTX = UNCHSN(t)
1= NEWCST = C(VTX,NEXT)
1= IF [L IGHTd) .LE. NEWCST] GO TO 500
C= VERTEX! 1) = NEXT
C= L IGHTd) » NEWCST
1= 500 EDGES = EDGES + 1
4= FROM(EDGES) = V-TX
1= TO(EDGES) = VERTEXd)
1- COST(EDGES) =L IGHT(1)
1= WEIGHT = WEIGHT + LIGHTd)
RETURN
. «. ENO
Рис. 4.2.1. Продолжение
Чтобы выяснить, какова действительная экономия машинного времени в результате таких изменений, следовало бы несколько раз прогнать обе программы на случайных сетях различного размера.
Прежде чем покончить с обсуждением вопроса о профилях, мы должны отметить, что не следует ожидать от единственного профиля (как в данном случае) точного указания на то, где программа тратит большую часть времени. Для построения точного среднего профиля может потребоваться большое количество профилей. Нам в этом случае повезло, что в основном верхние границы кратностей выполнения операторов оказались точными (только числа В и D нельзя было бы предсказать заранее). Если бы эти верхние границы были неточными, ценность профилей исполнения оказалась бы еще больше.
Наконец, рассмотрим проблему проверки вычислительной сложности подпрограммы PRIM посредством измерения времени ее выполнения. Эта попытка окажется не такой уж сложной, но она подскажет нам некоторые идеи.
Можно зафиксировать время центрального процессора, которое потребовалось программе на данном прогоне. Мы могли бы также опрашивать часы непосредственно перед началом выполнения основной части программы и непосредственно после окончания и печатать разность времен.
Недостатком этого метода является присущая ему неточность, обусловленная неточностью измерения времени. Многие компьютеры способны выполнять тысячи команд за единичное изменение показаний часов. Например, на CDC 6400 время измеряется с точностью три десятичных знака (0.001 с), хотя время выполнения основных команд в некотором операторе может оказаться приблизительно равным Ю-6 с. Существуют также различия в способах изменения показаний часов, и это вносит трудиоизмеримую ошибку.
Во всяком случае, это единственный механизм, который мы будем использовать при проверке подпрограммы PRIM. Сделав много тестовых прогонов на больших сетях, можно устранить часть этой изменчивости с помощью усреднения.
Непосредственно перед инициализацией переменных (перед установкой их начальных значений) в подпрограмме PRIM вставим оператор вида
TIMIN = SECOND (Т)
где SECOND (Т) — локально определенная системная функция с вещественными значениями, использующая фиктивный аргумент Т. Эта функция дает время с точностью до нескольких миллисекунд.
Так как программа завершает свою работу по отысканию ОДМВ оператором RETURN, вставим перед этим оператором еще два:
TIMOUT = SECOND (Т) TIME (I) = TIMOUT—TIMIN
которые опрашивают часы вторично и записывают разность показаний в новый массив Т1МЕ(1).
В качестве источника входных данных для тестовых прогонов воспользуемся локально определенным генератором случайных чисел RANF(O.O), генерирующим случайные полные сети с М вершинами. Это может делать следующий фрагмент программы:
ММ=М-1
DO 10 I- 1.ММ
К=Н-1
DO 10 J = K,M
C(l, J) = C(J, 0=1+ 1NT(R AN F(0.0) * 1000000.0)
10 CONTINUE
Функция RANF(O.O) генерирует случайное вещественное число в пределах от 0.0 до 1.0; функция INT выделяет целую часть вещественного числа RANF (0.0) X 1 000 000.0; мы добавляем 1, чтобы гарантировать отсутствие весов, равных 0, и произвольно решаем, что все веса
лежат между 1 и 1 000 000. Можно задать вопрос: не влияет ли замет-но диапазон весов ребер на длительность прогнозов? По-видимому, не влияет. Это заключение согласуется с доводами из разд. 4.1 и с элементарной теорией вероятности, но убедительнее всего экспериментальное доказательство. Были проведены прогоны с весами от 1 до 100 и с весами от 1 до 10е. Отличие средних длительностей прогонов было только в третьем десятичном знаке (что уже объяснимо системной неточностью).
Теперь проверим анализ сложности из разд. 4.1. Первой целью будет определение среднего времени прогона Для сети с М вершинами.
Сколько следует прогнать случайных сетей с М вершинами, чтобы получить достаточно надежное среднее значение? Подходящий размер выборки будет определен экспериментально (с неявным использованием закона больших чисел) т). Начнем с Л4=50, так как при меньших значениях М прогоны столь коротки, что ошибка в третьем десятичном знаке составляет заметную часть общего времени прогона. Теперь выполним прогоны для переменного числа полных случайных сетей с 50 вершинами. Мы прогоняли от 25 до 200 случайных сетей и зафиксировали среднее около 0.034 с на сеть для всех размеров выборки. Это указывает на то, что среднее значение устанавливается быстро. Исключительно для уверенности и в предположении, что, возможно, большие значения М могли бы потребовать больших размеров выборки, мы обычно вслед за этим пользуемся для проверки выборкой из 100 случайно сгенерированных полных сетей. Если бы прогон стоил заметно дороже, мы не могли бы быть столь предусмотрительными.
Рассмотрим значение М =75. Прежде чем выполнять прогон 100 сетей с 75 вершинами, проверим предсказания разд. 4.1. Если подпрограмма PRIM требует времени, пропорционального Л42, и если сети с 50 вершинами потребовали в среднем времени 0.034 с, то сети с Л!=75 вершинами должны потребовать в среднем около (75/50)2(0.034)= =0.076 с.Испытание 100 сетей с 75 вершинами дает экспериментальное среднее 0.075 с.
При Л!=100 среднее время прогона должно быть приблизительно вчетверо больше, чем при М=50 (почему?). Следовательно, мы ожидаем, что среднее будет приблизительно равно 0.136 с. Экспериментальный прогон 100 сетей дает среднее 0.129 с.
В самом деле, оказывается, что подпрограмма PRIM требует времени, пропорционального М2. Теперь построим функцию, предсказывающую длительность прогона. Пусть Т (М) обозначает среднюю продолжительность прогона при использовании подпрограммы PRIM для сети с М вершинами. Так как Т(М)=0(Л12), можно явно записать Т(М)=АМ2-\-ВМ+С, где А, В, С — константы, которые предстоит определить экспериментально.
*) В данном примере закон больших чисел, по существу, сводится к утверждению о том, что экспериментальное среднее приближается к истинному с увеличением размера выборки.
Требуется, чтобы кривая Т(М) проходила через три экспериментальных точки:
/И=50 Т (М)=0.034 /14=75 Т(М)=0.075 Л! = 100 Т(М)=0.129
Так как каждая из этих точек лежит на кривой Т (/И), должны выполняться следующие три уравнения:
(50)М+(50)В+С=0.034 (75)М+(75)В+С=0.075 (100)8Д+(100)В+С=0.129
Эта система линейных уравнений легко решается относительно коэффициентов А, В, С. Получаем
А = 1.04(10"!) В=3.4(10-4) С=9.0(10-3)
так что
Т(Л4)=((1.04(10-!))Л42+((3.4(10-4))Л4—9.0(10“®)
Теперь рассмотрим /14 = 150. Воспользовавшись этим уравнением, мы могли бы предсказать среднюю продолжительность прогона 7'(150)=0.276 с для сети со 150 вершинами. Мы получили экспериментальное значение 0.284; таким образом, относительная ошибка составляет 8/284=0.028, или около 3%.
Уместно сделать некоторые замечания относительно этой ошибки. Процедура, когда данные в некотором диапазоне аппроксимируют какой-либо кривой, а затем эту кривую используют для предсказания значений за пределами этого диапазона, называется экстраполяцией. Экстраполяция полиномами опасна. Небольшие ошибки в данных могут слегка изменить значения коэффициентов полинома. Эти маленькие ошибки в коэффициентах приводят к гораздо большим ошибкам, как только аргумент полинома выходит за пределы интервала аппроксимации. Экспериментальные значения Т (Л4) подвержены ошибкам в третьем десятичном знаке по причинам, обсуждавшимся раньше. «Слишком маленькая» ошибка в 2.8% легко могла бы подскочить из-за изменений в наблюдаемых последних десятичных знаках. Хорошее элементарное обсуждение экстраполяции и ошибок, которые вносятся в нее, можно найти в книге [43].
Упражнения 4.2
4 .2.1. Счетчики операторов (проверка). Измените подпрограмму PRIM так, чтобы она печатала общее число выполненных операторов при отыскании ОДМВ. Для случайных входных данных найдите средние значёния для операторов с кратностями выполнения А, В, С и D на рис. 4,1.7,
4 .2.2. Счет при игре в кегли (построение алгоритма). Постройте алгоритм подсчета очков при игре в кегли. Используйте стандартные правила относительно ударов, очередности, расположения и т. д. Запрограммируйте и проверьте ваш алгоритм.
* L4.2.3. Простые числа (полное построение, сравнительная, проверка). Полностью постройте алгоритм, выдающий все простые .числа от 2 до некоторого введенного W. Вы могли бы воспользоваться литературой, чтобы найти два таких алгоритма и провести их сравнительные испытания.
* 4.2.4. Относительные величины времени выполнения (анализ). Найдите пр ближен-ные значения относительных величин времени выполнения для различных типов операторов на имеющейся в вашем распоряжении вычислительной машине. Выразите эти величины в единицах, равных времени выполнения оператора присваивания вида А=1.0. Затем, например, вы могли бы обнаружить, что выполнение простого присваивания для индексированной переменной, например А(1)=1.0, требует две такие единицы. Будьте осторожны. Эта задача не так проста, как кажется.
* 14.2.5. Головоломка «8» (реализация и проверка). Реализуйте и проверьте алгоритм отхода назад для головоломки «8», описанной в разд. 3.3.
* 4.2.6. Интерполяция и экстраполяция (проверка программы). Определите и противопоставьте «интерполяцию» и «экстраполяцию». Что из них кажется надежнее? Можете воспользоваться книгой по численному анализу (например, [43]).
* 4.2.7. Приближение по методу наименьших квадратов (проверка программы). Просмотрите книгу по численному анализу и изучите материал об аппроксимации данных кривыми по методу наименьших квадратов. Сравните эту процедуру с использованием интерполирующих и экстраполирующих полиномов (см. упр. 4.2.6).
* L4.2.8. Полиномиальная аппроксимация данных (проверка программы). Закодируйте подпрограмму PRIM и продолжите ее проверку. Является ли полином Т(М) из этого раздела удовлетворительным аппроксимирующим полиномом (см. упр. 4.2.6)? Для имеющейся в вашем распоряжении машины необходимо заново вычислить А, В и С. Почему? Насколько сильно могут отличаться длительности отдельных прогонов от средней длительности? Попробуйте, используя метод наименьших квадратов (см. упр. 4.2.7), получить аппроксимацию квадратичным полиномом. Каков аппроксимирующий полином при методе наименьших квадратов по сравнению с Т(Л1)?
L4.2.9. Алгоритм PRIM (разработка и реализация). Реализуйте алгоритм PRIM, используя связанные списки. Сравните трудоемкость измененной версии программы с трудоемкостью программы на рис. 4.2.1.
L4.2; 10. Многие наблюдали, что большинство программ, по-видимому, затрачивает большую часть времени на выполнение малой части операторов в программе. Соберите несколько старых программ и, применив метод профилей, проверьте справедливость этого наблюдения.
L4.2.11. Проверьте сложность либо программы KNIGHT (разд. 2.1), либо эвристики, описанной в упр. 2.1.2.
4.2.12. Как можно было бы изменить и дополнить обсуждение в этом разделе, если бы расход памяти рассматривался как важнейший фактор?
4.3. Документация и обслуживание
Общее обсуждение
Одним из показателей квалификации программиста является степень понимания им всего процесса программирования. При этом важный и часто упускаемый из виду аспект состоит в передаче другим, npoi раммистам деталей данной программы.
Многие программисты научаются ценить документацию, пройдя трудный путь. Распространены такие ситуации. Первым заданием программиста на новой работе оказывается обновление важной программы, с автором которой связаться уже невозможно. Программа состоит из нескольких тысяч карт, лежащих в ящике в углу комнаты. В программе крайне мало комментариев, отсутствуют блок-схемы и нет никаких других видов документации или. инструкций!
Главная цель документации состоит в том, чтобы помочь читателю или даже самому автору понять программу. Это важно для того, чтобы программой можно было пользоваться, чтобы она могла просуществовать долго. Часто документация помогает сэкономить значительное время и позволяет избежать многих недоразумений. В идеале программа должна быть написана так, чтобы она была как бы само-документируемой, но это редко удается в программах среднего и большого размера. Для всех программ, кроме самых простейших, текст должен быть снабжен как (1) внешней документацией, так и (2) программной документацией.
Внешняя документация
В сущности, внешняя документация представляет собой нечто о программе, не содержащееся в самой программе. Она часто оформляется в виде руководства для пользователей или технического отчета. Можно считать, что часть текста этой книги в действительности представляет собой внешнюю документацию к приведенным программам.
В зависимости от размера и сложности программы внешняя документация может принимать различные, формы. Некоторыми такими, формами являются (1) блок-схемы, (2) инструкции для пользователей, (3) образцы входных и выходных данных, (4) полное описание построения сверху-вниз, (5) словесное описание алгоритма, (6) ссылки на источники информации, (7) справочники по именам переменных и подпрограммам с указанием их ролей в данной программе и (8) обсуждение различных частных особенностей (например, результатов проверки, о-граничений, истории и математического обоснования).
Программная документация
Мы не собираемся предлагать каких-либо жестких правил для программной документации. На самом деле, таких правил не существует. Однако мы покажем несколько основных приемов, которыми пользуются многие хорошие программисты.
Комментарии должны быть правильными и информатив ыми. Хотя это правило и очевидно, его часто нарушают. Рассмотрим следующий фрагмент программы:
С ПРОВЕРКА, ЕСЛИ к БОЛЬШЕ L;
С ТОГДА ПЕРЕЙТИ НА 150
С
IF (К .GE. L) GO ТО 150
Комментарий, предшествующий оператору IF, не является ни правильным, ни информативным. Он просто повторяет оператор и не дает никакой информации относительно цели оператора IF или того, что делает оператор с меткой 150. Комментарий также создает впечатление, что оператор с меткой 150 будет выполняться, даже если К не больше L. К тому же оператор с меткой 150 исполняется при K=L. Такой комментарий хуже, чем бесполезный.
Комментарии, которые просто повторяют операторы программы, не дают ничего, они лишь загромождают программу. Неправильные комментарии опасны; люди склонны им верить без проверки текста программы.
Пишите комментарии одновременно с текстом программы. Эта практика помогает объединить документацию этапов разработки и реализации. Полезные комментарии часто удается извлечь прямо из блок-схем или словесного текста алгоритма. Если они написаны одновременно с текстом программы, они с большей вероятностью аккуратно отразят логические этапы программы, чем в случае, если они написаны позже. Разумеется, неплохо пересмотреть всю документацию после завершения программы.
Следует использовать мнемонические имена для переменных и подпрограмм. Имена переменных и подпрограмм должны намекать на их функцию в алгоритме. Эта практика содействует самодокументации текста программы.
Начинайте каждую программу с пролога. Сообщайте читателю полезную информацию в начале каждой программы. Пролог может содержать:
1. Хороший описательный заголовок, имя автора, дату последнего изменения и т. д.
2. Краткое описание того, что делает программа, и, возможно, того, как она это делает (или по крайней мере соответствующие ссылки).
3. Список используемых подпрограмм с кратким описанием цели каждой из них.
4. Список и описание всех переменных, назначение которых не очевидно с первого взгляда.
5, Информацию о возвратах и умолчаниях при обнаружении ошибок.
6. Информацию о необходимых входных данных и выдаваемых выходных данных.
Для некоторых программ все упомянутое может быть необязательным. Нет нужды предварять программу из 10 операторов комментарием на 100 картах.
Мини-прологами следует снабжать большинство подпрограмм. Особое внимание следует уделять документации связей между подпрограммами.
Не перестарайтесь при документации. Документации может оказаться так много, что трудно будет отыскать самое программу. Это едва ли поможет читателю.
Избегайте плохого или заумного текста программы. Лучшей документацией является ясный текст программы. Плохой или заумный текст плодит ошибки и требует дополнительной документации. Не пытайтесь компенсировать такой текст программы многочисленными комментариями; лучше перепишите программу.
Стремитесь к четкости. Легче читать ясную, правильно расположенную программу, чем продираться через перегруженную программу. Отметим несколько конкретных приемов обеспечения наглядности.
1. Упорядочивайте объявления переменных и массивов в некоторой логической последовательности или в алфавитном порядке. Это облегчает проверку, все ли переменные объявлены и правильны ли их размеры и типы.
2. Упорядочивайте номера операторов. Эти номера должны возрастать для выполняемых операторов сверху-вниз вдоль листинга программы.
3. Выделяйте отступом от начала строки фрагменты программы в соответствии с логическими уровнями; особенно после операторов DO и IF. Относительно некоторых приемов см. разд. 2.1 и приложение А.
4. Выделяйте отступом от начала строки комментарии и отделяйте их от текста программы картами пустых комментариев.
5. Пользуйтесь пробелами для облегчения чтения программы. Например,
IF (ALPHA .LE. 0.5+EPS) GO TO 100
легче читать, чем
IF(ALPHA.LE..5+EPS)GOTO 100
6. Длинные выражения разбивайте на части. Избегайте логических или арифметических выражений, занимающих большую часть карты или требующих карт продолжения.
Вообще следуйте золотому правилу: пишите такую программу, которую вам было бы приятно читать.
Избегайте нестандартных средств версии языка. Если вы предполагаете, что программа должна использоваться другими, и, особенно, если, как вы ожидаете, работать на других машинах, хорошо бы указать все нестандартные средства Фортрана, используемые в программе (см. Стандарт Фортрана ANSI (1966)). Это можно сделать без подмешивания в тело программы дополнительных карт комментария. Соответствующие операторы можно пометить символами в колонках с 73 по 80.
Описывайте правильно все входные и выходные данные. Документация должна давать пользователю всю необходимую информацию для успешного ввода данных. Эту информацию можно включить в программу, если она еще не перегружена документацией. Обширные спецификации входных данных следует помещать в руководстве для пользователя, а в прологе должна быть явная ссылка на такое руководство.
Можно утверждать, что выходная информация является наиболее важным документом любой программы, так как она может оказаться единственным документом, который видят многие пользователи. Разработчик программы должен стараться сделать всю выходную информацию очевидной.
Программист должен заботиться о пользователе. Обычно следует распечатывать входные данные в удобном для чтения виде. Это дает пользователю возможность проверить еще раз входную информацию, а также обеспечивает более полную запись прогона. Разработчик программы должен также помогать ’ пользователю, составляя осмысленные сообщения об ошибках. Следует попытаться предвидеть, какие возможны неприятности, и приготовиться к появлению ошибок, так как они появятся рано или поздно. Особое внимание нужно уделить возможным ошибкам во входных данных и вырожденным случаям (например, циклам DO, которые ничего не делают при данной входной информации), входным массивам и переменным, значения которых слишком малы или слишком велики, и т. д.
Одной из самых скучных и непривлекательных частей этапа реализации и документации является работа по подготовке привлекательных для глаза форматов выходной информации. Однако эту работу следует выполнять тщательно, так как некрасивая или неразборчивая распечатка компрометирует всю программу.
Обслуживание
Многие программисты полагают, что не существует больших программ, свободных от ошибок или полностью протестированных. Так как число возможных путей в программе зависит экспоненциально
от числа операторов IF в тексте программы, редко удается (или редко оказывается целесообразным) проверить все эти пути Поэтому часто приходится слышать об ошибках в довольно больших программах, которые не обнаруживались месяцами или годами, после того, как программа была признана правильной. Исправлять такие программы трудно, если они документированы плохо.
Существует множество других причин, по которым программы нужно обновлять, развивать или как-то модифицировать со временем. Например, может понадобиться изменить значения программных переменных, увеличить объем входных данных, подсчитать и выдать некоторую дополнительную статистическую информацию, вставить более эффективный алгоритм вместо имеющегося или переписать программу полностью либо для новой конфигурации машины или системы, либо на другом языке программирования.
Эта деятельность относится к категории обслуживания программы. Это важная работа, увеличивающая время полезной жизни программы. Ее важность возросла и она стала требовать столько времени, что простота обслуживания программы может оказаться важнее ее эффективности. Программы, предельно изощренные, компактные, эффективные и быстрые, обычно труднее обслуживать. Лучше пожертвовать частью скорости программы ради простоты обслуживания.
Ни в коем случае не проводите обновление или другое изменение единственной колоды или ленты с текстом программы (в любом случае должна существовать по меньшей мере одна копия). Все работы по обслуживанию следует выполнять над копией программы. Копию старой версии следует хранить неприкосновенной в течение значительного периода. Все изменения в ходе работ по обслуживанию следует тщательно фиксировать. Старую документацию следует обновлять; это касается не только описания изменений, но и удаления устаревшей или неправильной документации. Любую внешнюю документацию желательно снабжать приложением, которое должно содержать подробное описание работы по обслуживанию, включая такую информацию, как даты изменений, их причины и т. д.
Подпрограмма PR IM
На рис. 4.2.1 приведена достаточно хорошо документированная реализация алгоритма PRIM, которая является результатом улучшений, рассмотренных в ходе анализа первой реализации на рис. 4.1.7.
Пролог программы мог бы содержать больше информации, но и та, что приведена, в достаточной степени объясняет цель программы, природу входных и выходных данных, определяет все переменные. Комментарии в тексте программы сведены к минимуму, отделены пустыми картами и соответствуют блок-схеме на рис. 4.1.6. Текст разделен на обозримые куски и разбит на страницы в точках естественного соединения логических ветвей. Метки некоторых операторов программы использованы для отображения внутренней логики программы.
Глава 5. Алгоритмы машинной математики
В первых четырех главах мы обсудили большую часть принципов, на которых основывается процесс разработки алгоритма. В данной главе эти принципы будут применены в некоторых областях вычислительной математики.
В разд. 5.1 и 5.2. разработан ряд алгоритмов, относящихся к важной практической области, связанной с вопросами сортировки и поиска информации. В разд. 5.1 обсуждаются и анализируются два из наиболее сложных алгоритма сортировки, QUICKSORT и HEAP-SORT, и доказывается, что никакой алгоритм сортировки с помощью сравнений не может иметь лучшую среднюю трудоемкость, чем O(N In N). В разд. 5.2 обсуждаются два эффективных алгоритма отыскания данной записи в множестве записей, отсортированных по некоторому ключу. Мы также рассматриваем алгоритм оптимального размещения записей в структуре дерева в соответствии с заданными вероятностями появления этих записей. Показано, что при использовании такой структуры дерева среднее число сравнений, необходимых для отыскания произвольной записи, минимально.
В этой главе мы приводим примеры алгоритмов из трех других областей: арифметические выражения, страничная обработка в вычислительных системах с виртуальной памятью и параллелизм.
В разд. 5.3 дано индуктивное определение как арифметических, так и логических выражений. Рассматриваются инфиксные, префиксные и постфиксные формы для описания арифметического выражения как линейной последовательности символов, а также средства представления этих выражений с использованием двоичных деревьев. Предлагаются два алгоритма — один для вычисления арифметического выражения в постфиксной форме, другой для преобразования арифметического выражения из инфиксной в постфиксную форму.
В разд. 5.4 на элементарном уровне обсуждается вопрос о распределении памяти в вычислительной системе с виртуальной памятью. После рассмотрения пяти алгоритмов, обрабатывающих страничйые отказы в такой вычислительной системе, представлена простая модель работы программы. Она используется для проверки относительной эффективности этих алгоритмов.
Завершается глава введением в параллельные алгоритмы (разд. 5.5) — предмет, который находится в начальной стадии развития, но может сыграть важную роль в будущем:.
5.1. Сортировка
Сортировка стала важным предметом вычислительной математики в основном потому/ что она отнимает значительную часть времени работы ЭВМ. Осознание того, что 25% всего времени вычислений расходуется на сортировку данных, придает особое значение эффективным алгоритмам сортировки.
К сожалению, нет алгоритма сортировки, который был бы наилучшим в любом случае. Трудно даже решить, какой алгоритм будет лучшим в данной ситуации, так как эффективность алгоритма сортировки может зависеть от множества факторов, например от того, (1) каково число сортируемых элементов; (2) все ли элементы могут быть помещены в доступную оперативную память; (3) до какой степени элементы уже отсортированы; (4) каковы диапазон и распределение значений сортируемых элементов; (5) записаны ли элементы на диске, магнитной ленте или перфокартах; (6) каковы длина, сложность и требования к памяти алгоритма сортировки; (7) предполагается ли, что элементы будут периодически исключаться или добавляться; (8) можно ли элементы сравнивать параллельно.
Очевидно, что с отсортированными данными работать легче, чем с произвольно расположенными. Когда элементы отсортированы, их проще найти (как в телефонном справочнике), обновить, исключить, включить и слить воедино. На отсортированных данных легче определить, имеются ли пропущенные элементы (как в колоде игральных карт), и удостовериться, что все элементы были проверены. Легче также найти общие элементы двух множеств, если они оба отсортированы. Сортировка применяется при трансляции программ, когда составляются таблицы символов; она также является важным средством для ускорения работы практически любого алгоритма, в котором часто нужно обращаться к определенным элементам.
Обычно сортируемые элементы представляют собой записи данных определенного вида. Каждая запись имеет поле ключа и поле информации. Поле ключа содержит положительное число, обычно целое, и записи упорядочиваются по значению ключа.
В этом разделе мы рассматриваем два из наиболее эффективных алгоритмов сортировки, быстрой сортировки и сортировки пирамидой (QUICKSORT и HEAPSORT), и устанавливаем теоретически неулуч-шаемые границы для всех алгоритмов сортировки с помощью сравнений. В других разделах обсуждаются еще два алгоритма сортировки: сортировка простыми включениями (SIS) (разд. 2.4) и параллельная сортировка (PARSORT) (разд. 5.5).
QUICKSORT: Алгоритм сортировки
со средним временем работы О (N In N)
Основная причина медленной работы алгоритма SIS заключается в том, что все сравнения и обмены между ключами в последовательности alt а2, . . ., aN происходят для пар из соседних элементов. При
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Строка 38 ов 16 06 79 76 57 24 56 02 58 48 04 7о 45 47 Действие-
1 зв 47 уменшете]
2 38 45
з за
70
4 38
б 04
6 08
7 16
38 обмен
за увеличение!
зв
9 79
10 38
38 >
7s обмен
11 38
12 38
13 38
14 02
4В
58
>
обмен
15
16
17
18
19
76 38
38 76
38 56
38 24
24 38
увеличение !.> обмен
уменьшение j
\ >
обмен
20 57 36 увеличение !.>
21 33 67 обмен, уменьшение
22 04 08 16 06 02 24 38 57 56 76 58 48 79 70 45 47
<1
2 3 4 6
6) 7 (8 9 10 11 12 13 14 16 181
Рис. 5.1 Л. Начальные шаги алгоритма QUICKSORT при сортировке последовательности целых чисел.
таком способе требуется относительно большое время, чтобы поставить ключ, находящийся не на месте, в нужную позицию в сортируемой последовательности. Естественно попытаться ускорить этот процесс, сравнивая пары элементов, находящихся далеко друг от друга в последовательности.
К. Хоор изобрел и весьма эффективно применил эту идею (алгоритм QUICKSORT), сократив среднее время работы алгоритма SIS от порядка О(№) до порядка O(N In N). Поясним этот алгоритм следующим примером.
Предположим, что мы хотим отсортировать последовательность чисел из первой строки на рис. 5.1.1. Начнем с предположения, что первый ключ в этой последовательности (38) служит хорошей аппроксимацией ключа, который в конечном счете появится в середине отсортированной последовательности. Используем это значение в качестве ведущего элемента, относительно которого ключи могут меняться местами, и продолжим следующим образом. Устанавливаем два указателя I и J, из которых I начинает отсчет слева (/=1), а j — справа в последовательности (J=N). Сравниваем и а}. Если a^Uj, то устанавливаем /ч-J—1 и проводим следующее сравнение. Продолжаем уменьшать J до тех пор, пока не достигнем а^>а}. Тогда поменяем местами (рис. 5.1.1, строка 5, обмен ключей 38 и 04), устанавливаем /ч-/+1 и продолжаем увеличивать I до тех пор, пока не получим a^aj. После следующего обмена (строка 10, 79<->38) снова уменьшаем J. Чередуя уменьшение J и увеличение I, продолжаем этот процесс с обоих концов последовательности к «середине» до тех пор, пока не получим I=J.
Теперь имеют место два факта. Во-первых, ключ (38), который сначала находился в первой позиции, к этому времени занимает надлежащее место в сортируемой последовательности. Во-вторых, все ключи слева от этого элемента будут меньшими, а все ключи справа — большими.
Ту же процедуру можно применить к левой и правой подпоследовательностям для окончательной сортировки всей последовательности. Последняя строка (с номером 22) рис. 5.1.1 показывает, что когда будет получено I=J, то 1=1. После этого процедура снова применяется к подпоследовательностям (1,6) и (8,16).
Рекурсивный характер алгоритма наводит на мысль, что следует значения индексов крайних элементов большей из двух неотсортированных подпоследовательностей (8,16) поместить на стек и затем перейти к сортировке меньшей подпоследовательности (1,6).
В строке 4 на рис. 5.1.2 число 04 перешло в позицию 2 и сортировке подлежат подпоследовательности (1,1) и (3,6). Так как (1,1) уже отсортирована (число 02), сортируем (3,6), что в свою очередь ведет к строке 6, в которой подлежат сортировке (3,4) и (6,6). В строке 7 подпоследовательность (1,6) отсортирована. Теперь извлекаем (8,16) из стека и начинаем сортировку этой подпоследовательности. В строке 13 находятся подпоследовательности (8,11) и (13,16), которые надо отсортировать. Помещаем (13, 16) на стек, сортируем (8,11) и т. д. В строке 20 последовательность целиком отсортирована.
Прежде чем описать алгоритм QUICKSORT формально, нужно точно показать, как он работает. Мы пользуемся стеком [LEFT (К), RIGHT (К)] для запоминания индексов крайних левого и правого элементов еще не отсортированных подпоследовательностей. Так как короткие подпоследовательности быстрее сортируются при помощи обычного алгоритма, алгоритм QUICKSORT имеет входной параметр Л4, который определяет, насколько короткой должна быть подпосле
довательность, чтобы ее сортировать обычным способом. Для этой цели пользуемся сортировкой простыми включениями (SIS).
Algorithm QUICKSORT. Нужно отсортировать последовательность N ключей А (1), А (2), . . ., A (N), N^2, в порядке возрастания, оставив ее на том же месте. Подпоследовательности, длина которых меньше М, сортируются методом сортировки простыми включениями. Алгоритм использует стек (LEFT (A), RIGHT (А)), который содержит индексы крайних левого и правого элементов подпоследовательностей, подлежащих сортировке. Переменная К — число элементов на стеке.
1 2 3 4 5 6 7 8 9 10
1 (04 08 16 06 02 24) 38 (57 56 76
2 02 04
3 04 08
4 (02 04 16 06 08 24)
Е 08 16
6 (08 06) 16 (241
7 02 04 06 08 16 24 38 (57 56 76
8 47
9 57
10 45
11
12
13 (47 56 45
14 45 47
15
16
17
18
19
20
47 56
(45) 47 (56
45 47 48
45 47 48
11 12 13 14 15 16 Стек
58 48 79 70 45 47) (8,16)
(8,16)
(8,16)
(8,16)
(8,16)
(8,16)
58 48 79 70 45 47) (8,16)
57
76
57
57 58
48 57
48) 57 (79 70 58 76) (13,16)
(13,16)
(13,16)
48) (10,11)113,16)
56 57 (79 70 58 76) (13,16)
76 79
(76 70 58) 79 (13,15)
56 57 58 70 76 79
Рис. 5.1.2. Завершение работы алгоритма QUICKSORT при сортировке последовательности, представленной на рис. 5.1.1.
Шаг 0. [Инициализация стека] Set Кч-1; LEFT(/Q*-1; and RIGHT (КМ-
Шаг 1. [Цикл] While К>0 do through шаг 12 od; and STOP.
Шаг 2. [Выталкивание из стека] Set Zx-LEFT (Л); R-s-RIGHT (Л); and К+-К— 1.
Шаг 3. [Сортировка длинной последовательности] While R—L^M do through шаг 11 od.
Шаг 4. [Инициализация] Set I-ь-Ц J-+-R', and MID^-Л (I).
Шаг 5, [Сравнение MID : A (J)] While МЮ<Л (J) do set J+-J— 1 od.
Шаг 6, [Прохождение завершено?] If then set A (/)-e-MID; and go to шаг 11 fi.
Шаг 7. [Обмен] Set Л(/)ч-Л(7); Л(/)ч-МП); and M-/+1.
Шаг 8. [Сравнение А (I) : MID] While A (/)<MID do set I+-Ч-/+1 od.
Шаг 9. [Прохождение завершено?] If J^l then set and goto шаг 11 fi.
Шаг 10. [Обмен] Set Л(7)ч-Л(/); /ч-J—1; and goto шаг 5.
'Шаг 11. [Магазин] Set Кч-К+l; if R——L then set LEFT(/C)4-/+1; RIGHT (M)4-R; and R<-I—\.
else set LEFT(K)4-L; RIGHT (К)ч-/—1; and £ч-/+1 fi.
Шаг 12. [Начало включения] For /ч-L+l to R do through шаг 15 od.
Шаг 13. [Берется следующий ключ] Set Вч-Л(У); and /ч-J—1.
Шаг 14. [Сравнение В и А (/)] While B<zA (/) AND Г^Ъ do set Л(1+1)ч-Л(1); and I+-I— 1 od.
Шаг 15. [Включение] Set Л(/+1)ч-В.
Перед тем как обсуждать сложность алгоритма QUICKSORT, рассмотрим доказательство его правильности. Этот алгоритм демонстрирует еще один пример, где доказательство можно проводить по индукции. Предположение индукции заключается в том, что QUICKSORT правильно сортирует все последовательности из N—1 элементов. Пусть Л(1), Л (2), . . ., A(N)— произвольная последовательность из N элементов. Если следующие три условия выполнены после первого прохождения через последовательность (шаг 11), то из предположения индукции немедленно вытекает, что QUICKSORT правильно отсортирует подпоследовательности (1, I—1) и (/+1, М).
1. QUICKSORT правильно устанавливает окончательное положение Л (1), скажем I.
2. Все элементы, находящиеся слева от /-й позиции, меньше, чем Л(1).
3. Все элементы, находящиеся справа от /-й позиции, больше, чем Л (1).
Но все три условия следуют из того факта, что QUICKSORT сравнивает каждый элемент последовательности А (2), .... Л (N) с Л (1)
при первом прохождении, производя все необходимые обмены для того, чтобы поставить все элементы, меньшие А (1), слева, а все элементы, большие А (1), справа.
Чтобы оценить эффективность алгоритма, положим Q(N) равным среднему числу шагов, необходимых для сортировки N элементов. Предположим также, что М = 1, т. е. что нельзя добиться ускорения, применяя сортировку простыми включениями на коротких подпоследовательностях.
При первом прохождении QUICKSORT проверяет каждый элемент последовательности и выполняет не больше, чем cN, шагов, где с — некоторая константа. После этого остается отсортировать две подпоследовательности, длины которых равны соответственно I—1 и N—1. Поэтому среднее число шагов, необходимых для сортировки N элементов, зависит от среднего числа шагов, требуемых для сортировки I—1 и N—1 элементов, где I изменяется от 1 до N.
Если мы предположим, что все значения I от 1 до N могут с равными вероятностями оказаться в окончательной позиции для I в отсортированной последовательности, то
N
Q(N)^cN + ±- £ [Q(/-1) + Q(AI-/)].
/ = i
Так как эта сумма, очевидно, равна
Q (0)+Q (W-l)+Q (1)+Q (^-2)+...+Q (N-2)+Q (1)+Q(W-l)+Q(0), мы получаем
N—l
+ Q(/). (1)
/ = 0
Покажем индукцией no N, что Q (7V)=CA7VlnM для 7V:>2, где /С=» ==2с+26 и &=Q(O)=Q(1). (Последнее означает, что QUICKSORT требует постоянного числа шагов b для сортировки 0 или 1 элемента.)
Для N=2 имеем Q(2)<2c+-|(Q(0)+Q(l))=2c+2fo=/<. Поэтому предположим, что Q(/)</<71n/ для 1=2, 3, . . ., N— 1, и перепишем (1) в виде
W-1
Q(^)<c^ + |(Q(0) + Q(1)) + 4- Е
1 = 2 или
W-1
+ (2)
1 =2
Теперь, поскольку функция Лп/ вогнута (рис. 5.1.3), 7V-1 Л'
1 . ^,№1пЛ/ №
I m / I х ш х dx —р-------j-.
1 = 2 х Z 4
Подстановка этого неравенства в (2) дает л/лп^-.ЛА । 46 . 2АГ /№lnW №\
Q(N)^cN+^+KNlnN-^-.
Наконец, поскольку N^2, имеем
cN + ^-<^f^±I^L^cN+bN.
Таким образом,
Q(7V)</OVlnW+0£-— bN^KN In AC
Рис. 5.1.3. Вогнутая функция.
Поэтому средней оценкой трудоемкости алгоритма QUICKSORT является O(N In N). Последнее замечание об этом алгоритме касается значения М, обусловливающего сортировку коротких подпоследовательностей; более детальный анализ сложности QUICKSORT — см. [59] — показывает, что подходящим значением является М =9.
HEAPSORT: Алгоритм сортировки,
имеющий в худшем случае порядок O(N log N)
Существует не много алгоритмов сортировки, которые в худшем случае могут гарантировать не более О (N log N) сравнений. Одним из них является предложенный Вильямсом остроумный алгоритм, использующий специальную структуру дерева, называемую пирамидой. Пирамида состоит из помеченного корневого двоичного дерева заданной высоты h, обладающего следующими тремя свойствами:
1. Каждая конечная вершина имеет высоту h или h—1.
2. Каждая конечная вершина высоты h находится слева от любой конечной вершины высоты h—1.
3. Метка любой вершины больше метки любой следующей за ней вершины.
Из свойства 3 непосредственно вытекает, что метка корня пирамиды является наибольшей меткой дерева. На рис. 5.1.4 изображены
Рис. 5.1.4. Только дерево является пирамидой,
три помеченных корневых двоичных дерева, не являющихся пирамидами, и одно (7\) — пирамида. Заметим, что для дерева 7\ не выполняется свойство i при i=l, 2, 3.
Специальная структура пирамид позволяет компактно размещать их в памяти. В частности, мы можем разместить пирамиду с п вершинами в массиве А, в котором две непосредственно следующие за вершиной из A (i) вершины помещаются в Л (20 и А (2(0-1). Например, пирамиду 70, изображенную на рис. 5.1.4, можно разместить в массиве А из девяти элементов следующим образом:
12 345 6789
Л I 27 9 14 8 5 11' 7 2 3
Заметим, например, что элементы 11 и 7 в Л (6) и Л (7) — это те два элемента, которые следуют за элементом 14 в Л(3). Если 2i>«, тогда за вершиной Л (0 не следуют другие вершины, и она является конечной вершиной пирамиды. Этот порядок расположения элементов пирамиды такой же, как и порядок при методе поиска в ширину по дереву (см. разд. 3.5).
Йепользуя такое представление массива, легко отсортировать вершины пирамиды. Проиллюстрируем это на пирамиде
1. Переставляем Л(1) с Л (п). Таким образом,
27 9 14 8 5 11 7 2 3
преобразуется в
39 14 8 5 11 7 2 27
что эквивалентно замене 7\ деревом Тъ на рис. 5.1.5.
2. Устанавливаем п+-п—1. Это эквивалентно вычеркиванию вершины 27 из Т5 на рис. 5.1.5.
3 9 14 8 5 117 2
27
Ts
3-27 переставлены
3 9 14 8 5 11 7 2
27
перестановка 3-14
14 9 3 8 5 11 72
27
Т7
перестановка 3-11
14 9 11 8 5 3 7 2
27
Т8
Рис. 5.1.5. Первые шаги при сортировке вершин пирамиды Tit представленной на рис. 5.1.4.
3. Преобразуем модифицированное дерево в другую пирамиду. Это достигается повторением перестановки нового корня с большей из двух новых непосредственно следующих за ним вершин до тех пор, пока он не станет больше, чем обе вершины, непосредственно за ним Следующие. В 71, переставлены вершины 3 и 14, а в Т8 в соответствии с этой процедурой переставлены вершины 3 и 11. Поэтому Т8— преобразованная пирамида.
4. Повторяем шаги 1, 2 и 3 до тех пор, пока не получим п=1.
Рис. 5.1.6 иллюстрирует завершение этого процесса сортировки для пирамиды Т4 на рис. 5.1.5.
Поскольку для такой процедуры сортировки на входе требуется пирамида, нам нужен алгоритм для преобразования произвольного масцива целых чисел в пирамиду. Такой алгоритм использует шаг 3 ранее описанного процесса. Это иллюстрируется на массиве целых чисел — рис. 5.1.7, а. Начнем с предположения, что целые числа этого массива расположены в корневом двоичном дереве, как было бы в случае, если в массиве была бы размещена пирамида — рис. 5.1.7, б. Затем проходим справа налево весь массив, проверяя, больше ли A (i), чем A (2i) и X (2г'Ч-1) для i=Ln/2J, . . ., 1 (рис. 5.1.8). Если для какого-то значения i A (i) не больше, чем A (2i) и A (2i+1), то приме-
2 S 11 8 S 3 7
14 27
2 9 7 8 S 3 297853 S278S3
ij 14 27 22 25 23 12 25 23
। 3 8 7 2 5 38725
© 11 14 27 9 1_1 14 27
8 3 7 2 5
9 11 14 27
8 5 7 2 3
9 1_1 14 27
3 2 3 2 2
Б 7 8 П 11 14 27 Б 7 8 9 11 14 27 3 Й 7 9 11 14.27
Рис. 5.1.6. Полная последовательность шагов при сортировке вершин пирамиды Т& представленной на рис. 5.1,5,
няем процедуру шага 3 и переставляем Я (i) с большим из элементов А (21) и Я(2Ж).
На рис. 5.1.8 показано, что массив, изображенный на рис. 5.1.7, а, после 15 шагов преобразуется в пирамиду Т4, показанную на рис. 5.1.4.
Рис. 5.1.7. Создание дерева из вводимой в произвольном порядке последовательности целых чисел.
Ша ’ , Массив А
1 2 3 4 5 e 7 8 9
1 5 3 7 27 ♦ 9 и 14 2 8 A(4J>A{8J,A(9> f
2 I Б 3 7 t 27 3 и 14 2 8 А(3}>Д(6)илиА(7) Перестановка A{3)«A(7)
3 Б 3 14 f 27 S и 7 + 2 8 A(7J конечная вершин»
4 Б 3 i 14 27 s и 7 2 8 A(2J>A(4) A(5) * Перестановка A(2) ~ A{4)
6 5 27 f 14 3 * s и 7 2 8 A{4}>A(9> Перестановка A(4) - A(9)
6 5 T 14 3 9 и 7 2 3 1 A(9) конечная вершина
7 Г Б t 27 14 8 9 и 7 2 3 А(1}>А(21илиА(3) Перестановка A(1J—A[2J
е 27 t Б 14 8 9 и 7 2 3 A|2J>A(4)hbhA{5) Перестановка A(2)**A{5)
е 27 f 9 14 8 5 1 и 7 2 3 AW конечная вершина
10 I27 9 14 8 5 и 7 2 3 стоп
Рис. 5.1.8. Создание пирамиды из последовательности, представленной на рис. 5.1.7.,
Теперь настало время четко сформулировать алгоритм HEAPSORT. Во-первых, сформулируем алгоритм HEAP (ПИРАМИДА), «подпрограмму», используемую алгоритмом HEAPSORT для преобразования линейного массива в пирамиду.
Algorithm HEAP. Поставить элемент A (7) на надлежащее ему место в пирамиде с элементами А (1), А (2),. . ., А (М), М^З и 1^7^Л4 Шаг 1. [Помещаем A(J) в пирамиду] While 27+1ЙМ4 AND(A(7)<
<ZA (27)ORA (J)<ZA (27+1)) do [Перестановка c A (J)] If A (27)>A(27+1) then set TEMP ч- A (7); A (7) A (2J); A (27) ч- TEMP; and J +- 2J else set TEMP A (7); A (J) ч-ч-A (27+1); A (27+1)TEMP; and 7 ч-27+1 fi od. Шаг 2. [Выполняется ли равенство 2J=M?] If 2J=M AND A (7)<
<A (27) then set TEMP ч- A (J); A(J)+-A (2J); and A (2J) *-ч- TEMP fi; and RETURN.
Algorithm HEAPSORT. Отсортировать (на месте) массив целых чисел А(1), А (2), . . ., A (N), N^2, в возрастающем порядке.
Шаг 0. [Инициализация] Set 1 ч- |_ N/2 J ; and М N.
Шаг 1. [Создание пирамиды] Do through шаг 3 while 7^1 od.
Шаг 2. [Помещаем А (7) в пирамиду] CALL HEAP (7, А, /И).
Шаг 3. [Новое значение 7] Set 7 ч- 7—-1.
Шаг 4. [Сортировка] Do through шаг 6 while od; and STOP.
Шаг 5. [Перестановка A (1) A (At)] Set ТЕМРч-А(1);
А (1)ч-A (M); А(7И)ч-ТЕМР; and Мч-М-1.
Шаг 6. [Помещаем A (1) в пирамиду] CALL НЕАР(1, А, М).
Реализации алгоритмов HEAP й HEAPSORT даны на рис. 5.1.9 и 5.1.10. Доказательство правильности алгоритма HEAPSORT довольно длинное и утомительное. Интересующемуся читателю советуем заглянуть в книгу [59].
Анализ сложности подпрограммы HEAPSORT относительно прост. Максимальное количество выполнений оператора указано справе от каждого оператора на рис. 5.1.10. Только две величины заслуживают внимания; они помечены Hi-xN/2 и (N—1)»772, где HI и Н2 обозначают число выполнений операторов в подпрограмме HEAP.
Величины А, В, С и D (рис. 5.1.9) связаны следующими соотношениями:
A+BClog^riogaMI, С+7)=1.
Нужно только объяснить, почему число выполнений оператора 100 ограничено сверху величиной [" log2M"]. В худшем случае имеем начальное значение 7=1 и значениями К являются 2, 4, 8, 16 (т. е. степени 2). Максимальное число выполнений оператора 100 ограничено наименьшим целым k, таким, что 2к+ 1>М, т. е. k= log2(M—1)"].
Поэтому можно заметить, что в худшем случае подпрограмма HEAP выполняет не больше, чем 27V+(lllog2M~]+6)+НМ+3, или 22N f log2M 'J +2377+3, операторов.
SUBROUTINE HEAP <IiA,N>
ПОДПРОГРАММА ПОМЕЩАЕТ. ЭЛЕМЕНТ A(j)
Б ПИРАМИДУ ИЗ ЦЕЛЫХ ЧИСЕЛ А(1), А(2),
A(N).
INTEGER A<N).TEHP
С с (ПОМЕЩАЕМ A(J) В ПИРАМИДУ)
с с с J 5 I 1 100 К ® 2*j L0G N L a K+l LOG N IF (L .LE. N -AND. (A|J) .LT. A(K) .OR. A(J) .LT. A(LJ1> GOTO 200 LOG N t LOG N •! СОТО 500 1 ТОГДА (ОБМЕН C А(Д)).
с с с с с с с S. с с 200 IF <AW A(L1> GOTO 300 LOG N < A GOTO ЧОО В THEN 300 TEMP a A(J} A A(JI a A(KJ A J = К A A(KJ = TEMP A GOTO 100 A ELSE 400 TEMP « A(J) В A(J1 = A(L1 В A (LI = TEMP В J = L В •GOTO 100 В ELSE (IS I*J .EQ. N}
с с с 500 IF <K .EQ. N .AND. A(J| .LT. A(K)) GOTO 600 1* C GOTO 700 D THEN
с ЬОО TEMP e A(J> C A(J) s A(N> C ‘ A(N) в TEMP C 7.00 RETURN 1 END Рис. 5.1.9. Реализация на Фортране алгоритма HEAP,
с SUBROUTINE HPSORT (A,N)
с ПОДПРОГРАММА (HEAPSORT) СОРТИРУЕТ МАССИВ
с ЦЕЛЫХ ЧИСЕЛ А(1), А(2), А(3),'. . . , A(N), С ИСПОЛЬЗОВАНИЕМ
с с с АЛГОРИТМА ДЖ. ВИЛЬЯМСА.(САСМ 7(1964), 347-348) INTEGER AtNl.TEMP
с с (ИНИЦИАЛИЗАЦИЯ I, М)
1 = к/г 1
0=1 1
с И а П 1
с с (ПОСТРОЕНИЕ ПИРАМИДЫ)
ОО 100 К = 1.L 1
CALLHEAP tl.A.H) Hl.N/2
I = I-X NZ2
с loo continue м/г
с с (сортировка)
oq гоо'к =-2,n i
)EMP = All) N-l
A(l)‘ a A(H> N-l
AIM), a TEMP N-l
M = M-l N-l
CALL HEAP (1tA<M) (N-1)*H2
800 -CONTINUE' N-l
Return i end
Рис. 5.1.10. Реализация на Фортране алгоритма HEAPSORT,
Обсудив средние оценки эффективности алгоритмов SIS, QUICKSORT и HEAPSORT, проведем некоторое простое тестирование для проверки нашего анализа. Для каждой из трех разных выборок (А=100, 200, 500) мы образуем 50 различных множеств из AZ случайных целых чисел и затем отсортируем каждое множество, применив все три алгоритма. Зафиксируем среднее число перестановок и сравнений, выполненных для каждого из трех алгоритмов и трех значений N. Тогда экспериментальные кривые, вид которых предсказан теорией, будут поставлены в соответствие данным.
Ключи для тестовых данных были получены с помощью датчика случайных чисел с равномерным распределением в области целочисленных значений от 1 до 100 000. Размер выборки 50 множеств для каждого значения N был экспериментально определен по тому же эмпирическому правилу, которое использовалось для проверки алгоритма PRIM в гл. 4.
Мы интересуемся как числом сравнений, так и числом перестановок, произведенных каждым алгоритмом. Сравнение осуществляется оператором типа: if A (I)<ZA (J) или if B<ZA (J). Перестановка состоит из набора трех операторов присваивания, таких, как
T<-A(I) A(J)<-A(J) A(J)+-T.
Однако в алгоритме SIS перестановка происходит несколько иначе; во-первых, выбирается величина для сравнения В ч- A (Z), что считается одной третью перестановки. Затем выполняется присваивание А (7+1) ч- А (I), также представляющее треть перестановки. Наконец, при помощи оператора типа А (1) ч- В заменяется начальное значение — еще одна треть перестановки.
Средние значения, полученные в этих местах для каждого значения N и каждого алгоритма, сведены в табличку. Мы будем анализировать только число сравнений для алгоритма QUICKSORT; остальные данные обрабатываются аналогично и оставлены для интересующегося читателя.
Результаты проверки сложности алгоритмов SIS, QUICKSORT и HEAPSORT
и Алгоритм QUICKSORT Алгоритм HEAPSORT Алгоритм SIS
Среднее число сравнений в 50 испытаниях.
100 712 2 842 2 595
200 1682 9 736 10 307
500 5102 53113 62 746
Среднее число перестановок в 50 испытаниях
100 148 581 899
200 328 1366 3 503
500 919 4042 21083
Поскольку наш анализ сложности показал, что QUICKSORT имеет среднюю оценку трудоемкости порядка O(N log2 N), было бы разумным попытаться подогнать к данным кривую вида
ZQ(Af)=C1Mog27V+C2^+C3.
Рассмотрим пока только главный член CiN\og2N. Подгоним (несколько произвольно) главный член к данным при N=100 и 500, используем среднее этих двух значений Сг для предсказания среднего числа сравнений для 7V=2OO и затем сравним предсказание с наблюдением (см. упр. 4.2.6 по интерполяции и экстраполяции).
Для Af=100 находим, что Сх 100 log2100=712, или Сх«1,07. Для ДГ=500 имеем, что Сх500 log2500=5102, или Сх»1,14. Это дает среднее значение
5=1.07+1.14==2^=1 105>
на основании чего для Af=200 предсказываем 1.105(200) (log2200)« «Д690 .сравнений; полученное экспериментальное значение равно 1682. Хотя фактическое отсутствие ошибки отчасти случайно, этот простой анализ оказывает значительную поддержку теории.
Нижние границы при сортировке сравнениями
Если оценивать алгоритмы сортировки, которые мы до сих пор рассматривали, то трудоемкость алгоритма SIS в худшем случае имеет порядок О(№) и средняя трудоемкость — тоже порядка О(№). Средняя трудоемкость алгоритма QUICKSORT — порядка O(NlogN), и трудоемкость алгоритма HEAPSORT в худшем случае — порядка 0(NlogN). Естественно поинтересоваться, возможно ли разработать алгоритм сортировки, средняя трудоемкость или трудоемкость в худшем случае которого была бы меньше, чем O(N\ogN). К сожалению, такого алгоритма не существует. Можно доказать, что для любого алгоритма, который работает путем сравнения пар элементов, средняя трудоемкость и трудоемкость в худшем случае имеют порядок по меньшей мере O(NlogN).
Во-первых, заметим, что любой алгоритм для сортировки N элементов сравнениями может быть представлен M-элементным деревом решений, как показано на рис. 5.1.11. Каждая внутренняя вершина дерева решений представляет сравнение (или решение), сделанное алгоритмом в некотором месте во время его выполнения. Ребра, выходящие вниз из вершины, представляют два возможных результата сравнения. Конечные вершины дерева решений представляют отсортированные последовательности, получаемые алгоритмом. Поскольку любая из М! перестановок N произвольных элементов а±, а2, . . aN является возможным результатом работы сортирующего алгоритма, N —• элементное дерево решений каждого алгоритма сортировки сравнениями должно иметь по крайней мере АЛ конечных вершин.
Длина пути от корня к конечной вершине дерева решений представляет число проделанных сравнений, потребовавшихся для получения отсортированной последовательности, представленной конечной вершиной пути. Поэтому длина самого длинного такого пути, которая совпадает с высотой дерева,— это число сравнений, требующихся алгоритму в худшем случае.
В трехэлементном дереве решений, изображенном на рис. 5.1.11, 1 : 2 обозначает сравнение а± с а2; ребро с меткой 12 показывает, что конечные вершины указывают окончательный отсортированный порядок ключей at, а2 и а3. Поскольку высота этого дерева равна трем, то для сортировки трех элементов требуется не больше чем три сравнения.
Теперь мы хотели бы рассмотреть трудоемкость в худшем случае для любого алгоритма сортировки сравнениями. W-элементное дерево решений для каждого такого алгоритма должно иметь по крайней мере АП конечных вершин и будет иметь некоторую высоту h. Каково минимальное значение h, такое, чтобы W-элементное дерево решений высоты h имело W! конечных вершин?
Во-первых, доказываем индукцией по h, что любое дерево высоты h имеет самое большее 2й конечных вершин. Без сомнения, при й=1 это справедливо. Далее полагаем, что каждое дерево решений высоты h—1 имеет самое большее 2h~l конечных вершин. Пусть Т — дерево решений высоты h. Если мы уберем корневую вершину Т, останутся два поддерева Т± и Т2, каждое имеет самое большее высоту h—1. Из предположения индукции следует, что Тг и Т2 имеют самое большее 2Й~Х конечных вершин каждое. Таким образом, поскольку число конечных вершин Т равно числу конечных вершин 7\ и Т2, то Т имеет самое большее 2А-Х+2Й-Х=2Й конечных вершин.
Нижнюю границу для наименьшего значения h, такого что 2Л>АГ! или h^logNl, можно получить следующим образом:
GN 1 \ /Ы\НЦ *
Следовательно,
/i>loglV!> log 4г-
С помощью аппроксимации Стирлинга для Л/'! получена более точная нижняя граница. А именно при достаточно больших N, Л7!== =O(N/e)N.
A>log NI&N loglV—Nioge=N loglV—1.441V.
Таким образом, дерево решений каждого сортирующего сравнениями алгоритма имеет высоту по крайней мере h^N log/V—1.447V; другими словами, каждый такой алгоритм в худшем случае имеет порядок по меньшей мере O(TVlogTV).
Для средней оценки трудоемкости каждого алгоритма сортировки сравнениями также существует нижняя граница O(TVlogTV). Опять воспользуемся моделью TV-элементного дерева решений.
Любой результат относительно средней трудоемкости для сортирующего алгоритма зависит от вероятностного распределения входных данных алгоритма. Анализ, который мы проведем, предполагает функцию равномерного распределения, т. е. каждая перестановка из N элементов с равной вероятностью может появиться в качестве ввода для алгоритма сортировки сравнениями. На практике это предположение может не выполняться, так как на входе сортирующего алгоритма может быть «частично» отсортированное множество.
Если каждая из IV! перестановок с равной вероятностью может получиться при данном алгоритме сортировки сравнениями, то каждая из соответствующих 7V! конечных вершин TV-элементного дерева решений будет достигнута с равной вероятностью. При этом все другие конечные вершины никогда не будут достигнуты. Тогда среднее число сравнений равно средней высоте этих 7V! конечных вершин.
Теорема 5.1.1. При условии равномерного распределения вероятностей каждое N-элементное дерево решений имеет среднюю высоту по меньшей мере log(7V!)^7V logTV.
Доказательство. Пусть Н(Т, k) обозначает сумму высот всех конечных вершин дерева решений Т с k конечными вершинами, и пусть Н (^)=min{Ef(7’, k)} — минимум сумм высот всех деревьев решений с k конечными вершинами. Если мы сможем показать, что Н (k)^k log/г, то для средней высоты любого дерева решений с k конечными вершинами будет выполнено Н (k)]k~^\ogk.
Продолжим рассуждения с помощью индукции по числу конечных вершин k. Очевидно, что при k—\ результат верен. Поэтому
полагаем, что H(k)^k log/г для всех деревьев решений с числом конечных вершин, меньшим k.
Рассмотрим все деревья решений с k конечными вершинами. Каждое такое дерево Т имеет два поддерева 7\ и 7’2, расположенных сразу под корнем и имеющих k± и k2 конечных вершин, где ki, k2<.k и +k2=k. Таким образом,
Н(Т, k)=ki+H(Tb kJ+HiTb k2)+k2
и минимум всех Н(Т, k) равен
H(k) = min (k^ + H (kz)}.
ki+kz—k
По предположению индукции H (k^^ki log/?t и Я (/г2)^/г2 log^2. Таким образом,
H(k')'^k+ min log ki + kz log k2}.
kt + k2=k
Легко показать, что минимум достигается при /Ji=&2—-|-. Следовательно,
Я (k) k-\- /гlog-^- = k log k.
Теперь мы можем сделать вывод, что поскольку каждое Л/-элементное дерево решений Т имеет по крайней мере Я! конечных вершин, то
Я(Я!)>Я! log№
и средняя высота каждого -элементного дерева решений равна по меньшей мере
> log Я! ~ Я log Я.
Следствие из теоремы 5.1.1 вытекает из того факта, что средняя высота каждого Я-элементного дерева решений равна по крайней мере log/VI, а к^Я!«Я logAl—1,441V; таким образом, каждый алгоритм сортировки сравнениями имеет оценку средней трудоемкости по меньшей мере O(N log/V).
Упражнения 5.1
5.1.1. Отсортируйте следующий список, используя QUICKSORT и HEAPSORT: 17 23 114 28 35 72 16 84 90 65
L5.1.2. Сортировка пузырьками (полное построение). Основная идея, заложенная в методе, известном как сортировка пузырьками (bubblesort), состоит в следующем. При каждом прохождении через список первый ключ сравнивается со вторым и меньший ставится на первое место. Второй ключ сравнивается с третьим и меньший ставится на второе место. Эта процедура продолжается до тех пор, пока не будет обработан весь список. Затем совершаются второй, третий и т. д. прохода, пока мы наконец не сделаем проход, при котором не будет произведено ни одной перестановки, Т. у. рее ключи останутся на местах. Теперь список отсортирован.
Полностью постройте алгоритм, основанный на этой идее.
L5 1-3. QUICKSORT (реализация). Составьте блок-схему и программу для алгоритма QUICKSORT.
5.1.4. Докажите, что минимальное значение
min {йг log Й1+ ft2 log ft2} fe1+fe2=fe
достигается при k1=k2=k/2.
5.1.5. QUICKSORT (анализ). Покажите, что трудоемкость алгоритма QUICKSORT в худшем случае—порядка О(№).
5.1.6. Составьте дерево решений, как на рис. 5.1.11, которое показывает, как алгоритм QUICKSORT сортирует ключи в упр. 5.1.1.
L5.1.7. Сортировка методом отыскания наименьшего ключа (полное построение). Полностью постройте алгоритм, сортирующий список путем отыскания наименьшего ключа, второго по величине ключа и т. д. до тех пор, пока список не исчерпается и все числа не установятся в возрастающем порядке.
* L5.1.8. Слияние (полное построение). Пусть А=(а1г а2, ... , а„), В~(Ь1Г Ь&, . . .. Ьт) и С=(с1, с2, . . . , ср) — три конечные последовательности действительных чисел, Допустим, что каждая отдельная последовательность упорядочена по возрастанию. Слейте три последовательности в одну последовательность Ь= {dj, d2, . . ., dn+m+p}, являющуюся списком всех чисел из А, В и С (включая построения), такую, что dr<. ^d2<.. . .^dn+m+p. Разработайте и проанализируйте такой алгоритм. Можете сначала попробовать случай, когда п=т—р.
* 5.1.9. Сортировка слиянием (разработка, анализ). Разработайте и проанализируйте алгоритм сортировки, работающий с использованием метода слияния (см. упр. 5.1.8). Какие благоприятные возможности вы можете найти для параллельной обработки данных?
* 5.1.10. Пересечение множеств (разработка, анализ). Пусть А и В — два множества неотрицательных целых чисел, в каждом из которых по k элементов. Существует довольно очевидный способ построения множества /f)B с использованием О (ft2) операций. Применив сортировку, разработайте и проанализируйте алгоритм, находящий Л ПЛ за О (ft log ft) операций.
* *L5.1.11. Сравнение методов сортировки (проверка). Рассмотрите все знакомые вам методы сортировки, включая те, которые мы не рассматривали в этом разделе. На основе анализа и экспериментов установите, какой из этих методов наиболее эффективен (дайте критерий!) при различных диапазонах значений N. Задача, по существу, заключается в определении, какой метод сортировки является лучшим для «малых» N, лучшим для «средних» N и лучшим для «больших» N. Уделите особое внимание вопросу о том, где кончается диапазон малых значений и начинается диапазон средних значений. Вы можете счесть необходимым рассмотреть более трех диапазонов. Воспользуйтесь генераторами случайных чисел.
5.2. Поиск
Теперь обратимся к исследованию некоторых основных проблем, относящихся к поиску информации на структурах данных. Как и в разд. 5.1, посвященном сортировке, будем предполагать, что вся информация хранится в записях, которые можно идентифицировать значениями ключей, т. е. записи соответствует значение ключа, обозначаемое Кг.
Предположим, что в файле расположены случайным образом N записей в виде линейного массива. Очевидным методом поиска за
данной записи будет последовательный просмотр ключей, как это делалось в алгоритме МАХ в гл. 1. Если найден нужный ключ, поиск оканчивается успешно; в противном случае будут просмотрены все ключи, а поиск окажется безуспешным. Если все возможные порядки расположения ключей равновероятны, то такой алгоритм требует О (К) основных операций как в худшем, так и в среднем случаях (см. упр. 5.2.4). Время поиска можно заметно уменьшить, если предварительно упорядочить файл по ключам. Эта предварительная работа имеет смысл, если файл достаточно велик и к нему обращаются часто.
Далее будем предполагать, что у нас есть N записей, уже упорядоченных по ключам так, что • .<Kn. Пусть дан ключ /<
и нужно найти соответствующую запись в файле (успешный поиск) или установить ее отсутствие в файле (безуспешный поиск).
Предположим, что мы обратились к середине файла и обнаружили там ключ Ki- Сравним К и Kt- Если K=Ki, то нужная запись найдена. Если K<ZKi, то ключ К должен находиться в части файла, предшествующей Kt (если запись с ключом К вообще существует). Аналогично, если Kt<K, то дальнейший поиск следует вести в части файла, следующей за Kt- Если повторять эту процедуру проверки ключа Kt из середины непросмотренной части файла, тогда каждое безуспешное сравнение К с Ki будет исключать из рассмотрения приблизительно половину непросмотренной части.
Блок-схема этой процедуры, известной под названием двоичный поиск, приведена на рис. 5.2.1.
Algorithm BSE ARCH (Binary search — двоичный поиск) поиска записи с ключом К в файле с N^2 записями, ключи которых упорядочены по возрастанию Ki<ZK2- -<ZKk-
Шаг 0. [Инициализация] Set FIRST-*-!; LAST-*-N. (FIRST и LAST — указатели первого и последнего ключей в еще не просмотренной части файла.)
Шаг 1. [Основной цикл] While LAST>FTRST do through шаг 4 od. Шаг 2. [Получение центрального ключа] Set/-*- [_ (FIRST+ +LAST)/2J . (Ki—ключ, расположенный в середине или слева от середины еще не просмотренной части файла.)
Шаг 3. [Проверка на успешное завершение] If K=Kr then PRINT «Успешное окончание, ключ равен А/>; and STOP fi.
Шаг 4. [Сравнение] If K<Kr then set LAST I—1 else
set FIRST-*- /+! fi.
Шаг 5. [Безуспешный поиск] PRINT «безуспешно»; and STOP.
Алгоритм BSEARCH используется для отыскания К=42 на рис. 5.2.2.
Метод двоичного поиска можно также применить для того, чтобы представить упорядоченный файл в виде двоичного дерева. Значение
ключа, найденное при первом выполнении шага 2 (К (8)—53), является корнем дерева. Интервалы ключей слева (1, 7) и справа (9, 16) от этого значения помещаются на стек. Верхний интервал снимается со стека и с помощью шага 2 в нем отыскивается средний элемент (или элемент слева от середины). Этот ключ (7\(4)=33) становится следующим после корня элементом влево, если его значение меньше значения корня, и следующим вправо в противном случае. Подынтервалы этого интервала справа и слева от вновь добавленного ключа 1(1. 3), (5, 7)] помещаются теперь на стек. Эта процедура повторяется До тех пор, пока стек не окажется пустым. На рис. 5.2.3 показано Двоичное дерево, которое было бы построено для 16 упорядоченных ключей с рис. 5.2.2.
Двоичный поиск можно теперь интерпретировать как прохождение этого дерева от корня до искомой записи. Если достигнута конечная вершина, а заданный ключ не найден, искомая запись в данном файле отсутствует. Заметим, что число вершин на единственном
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
7 14 27 33 42 49 51 53 67 70 77 SI S9 94 95 99
tpiRST=1 t[ = 8 LAST = iet
7 14 27 33 42 49
If!RST=H t|=4
51
tl_AST=7
42 49 51 FIRST’st t tl_AST=7
I = 6
42
t FIRST = LAST= I = Б, K=KS, ВОЗВРАТ
Рис. 5.2.2. Использование алгоритма BSEARCH для отыскания записи с ключом 42,
пути от корня к заданному ключу К. равно числу сравнений, выполняемых алгоритмом BSEARCH при попытке отыскания А.
Рис. 5.2.3. Представление файла с рис. 5.2.2 в виде двоичного дерева, построенного с помощью алгоритма BSEARCH,
Представление упорядоченного файла в виде двоичного дерева оказывается полезным при анализе алгоритма BSEARCH. Для удобства предположим, что число N записей в файле таково, что N=2k—1 при некотором положительном целом k. В этом случае двоичное дерево является полным, т. е. у каждой внутренней вершины есть как левый, так и правый преемники, дерево имеет высоту k—1, а число вершин на уровне i равно 2г, при t=0, 1, . . ., k—1.
Вначале рассмотрим наихудший случай работы алгоритма BSEARCH. Очевидно, что число сравнений является первоочередным фактором, определяющим его сложность. Число сравнений, необходимых для отыскания заданного ключа, на единицу превосходит уровень ключа в дереве. В худшем случае мы должны пройти дерево до конечной вершины, т. е. произвести &=loga (ЛЧ~ 1) сравнений. Таким образом, алгоритм BSEARCH в худшем случае имеет сложность 0(log2W).
Вычисление среднего числа сравнений для успешного поиска будет несколько сложнее. Предположим, что все записи встречаются равновероятно. Пусть NCOMP (i) будет уровнем ключа Ki в двоичном дереве, увеличенным на единицу. Тогда NCOMP(t) равно числу сравнений, необходимых для отыскания Kt. Среднее число сравнений равно
- 1 "
C = 3_^2VC°Mp(0.
1=1
Так как мы считаем двоичное дерево полным и N=2k—1, существует
N
2*-1 вершин уровня k—1. Если обозначить через о сумму ^NCOMPR’), i = l
то о является суммой первых N членов ряда
+24-24-3 + 3 + 34-3 4-...
= 1 + 2(2) + 2= (3) + 2^(4) + •.. + 2/-1 (/) + ...+ 2*-1(k).
Выражение для о в замкнутой форме можно получить, используя стандартный вычислительный прием. Если обозначить через Sk сумму k членов геометрической прогрессии, то
sk(.y)=i+y+y2+- +yk-s=^. у¥--1.
Пусть y~2z, тогда
Sk (2г) = 1 + 2г + (2z)2 + . •. + (2г}*-* = .
Далее
4 <2z) -1} z] = 2 (2г) + 2* (Зг2) + ... + 2^ (kz^).
Мы почленно дифференцировали ряд {SA(2z)—1}г. Если вычислить
эту производную при 2=1 и прибавить 1, то мы получим о, т. е. а = 1 +~^[{•$*(2z) — 1} z] при z — 1 (проверьте это).
Используя выражение для частичной суммы геометрической прогрессии в замкнутой форме, получим
а = 14-2й (k— 1);
- а i+2*(^-l)_l+(W+l)[loga(W+l)-l] W+1. п ,
К ~ N ~~ N *•
Таким образом, средняя сложность двоичного поиска равна O(log2TV). Сопоставьте этот результат со средним числом сравнений N]2 для алгоритма последовательного поиска (см. упр. 5.2.4).
До сих пор мы обсуждали только файлы с фиксированным числом записей. Теперь рассмотрим случай переменного размера файла, т. е. файла, в котором записи можно вставлять и удалять.
Сначала разработаем алгоритм обслуживания растущего файла записей, упорядоченных по ключам. Для этого йужно выбрать удобную структуру данных и соответствующий алгоритм, который быстро найдет данную запись в структуре, если она там содержится, или вставит запись на подходящее место, если ее там нет.
Какие структуры данных мы будем использовать? Связанные списки — одна из возможных структур. В разд. 2.3 мы видели, что этот тип структуры данных позволяет эффективно производить вставление и удаление элементов. К сожалению, нелегко выполнять двоичный поиск в связанных списках.
Существует ли другая структура данных, которая позволяла бы сохранить эффективность двоичного поиска и в то же время позволяла бы эффективно вставлять или удалять записи? Далее мы покажем, что двоичное дерево является хорошим решением этой проблемы.
В приведенной ниже таблице указаны 10 городов, упорядоченных по убыванию численности населения (на 1970 г.). Числа в правом столбце показывают алфавитный порядок. Прочтем эти города в алфавитном порядке и запомним их в двоичном дереве в порядке возрастания численности населения.
Энн Арбор первый на входе, и он становится корнем дерева. Шарлоттсвилль следующий, он сравнивается с корневой вершиной. Так как население Шарлоттсвилля меньше населения Энн Арбора, то Шарлоттсвилль становится левым преемником Энн Арбора. Каждый из последующих городов читается и сравнивается с корнем. Если его население меньше, чем у корня, он далее сравнивается с левым преемником корня; если больше, то с правым. Раньше или позже каждый город сравнивается с вершиной, не имеющей правого или левого преемника, и он становится новой конечной вершиной этого дерева. Пронумерованные фиктивные вершины будут использованы для обозначения недостающих преемников для городов, не имеющих
Город Население Номер
New York (Ныо-Йорк) 7 868 000 7
Chicago (Чикаго) 3 367 000 3
Washington (Вашингтон) 757 000 10
Pasadena (Пасадена) 114 000 8
Ann Arbor (Энн Арбор) 100 000 1
Charlottesville (Шарлотсвилль) 39 000 2
Coatzocoalcos (Коацакоалькос) 37 000 4
Goochland (Гучлэнд) 400 6
Sleetmute (Слитмут) 109 9
Dry Lake (Драй Лейк) 10 5
двух преемников. После того как прочитаны первые 9 городов, двоичное дерево приобретает вид, показанный на рис. 5.2.4.
Рассмотрим то, что произойдет далее, когда будет прочитан Вашингтон. Так как население Вашингтона больше, чем Энн Арбора, мы переходим к правому преемнику. Затем мы движемся влево от Чикаго, так как в нем больше народу, чем в Вашингтоне. Наконец, мы движемся вправо от Пасадены, так как она меньше Вашингтона. Далее Вашингтон помещается в позицию, отмеченную цифрой 7, и к нему присоединяются фиктивные левый и правый преемники.
При дальнейшем изложении мы будем предполагать, что различные записи не могут иметь одинаковых значений ключа; например, у разных городов должны быть разные численности населения.
Процедура поиска для этой структуры работает точно так же, как процедура вставления, за исключением того, что процедура поиска успешно завершается, как только мы достигаем вершину со значением ключа, равным ключу поиска. Если достигнута фиктивная вершина, то запись не содержится в дереве, и поиск оказывается безуспешным. Если требуется добавить запись с ключом поиска, ее нужно поместить в дереве вместо достигнутой фиктивной вершины.
Algorithm BTSI (Binary Tree Search and Insertion) — (поиск и вставление в двоичном дереве). Нужно найти заданный ключ А в файле с записями, организованными в виде двоичного дерева Т. Если А отсутствует, то для него создается новая вершина. А(Р) означает ключ в вершине Р; LEFT (Р) и RIGHT (Р) обозначают левого и правого преемников вершины Р. Корневая вершина Т помечена как ROOT; все фиктивные вершины помечены символом Л.
ZZ/аг 0. [Инициализация] Set Р ROOT.
Шаг 1. [Цикл] While А^А(Р) do шаг 2 od.
Шаг 2. [Сравнение и переход] If А<А (Р) then И LEFT (Р)=И=Л then set P<-LEFT(P)
else пусть Q обозначает новую вершину; set
LEFT (Q)^- A; RIGHT (Q)+- A;
LEFT(P)-«-Q; and STOP fi else if RIGHT(P)=#A
i then set P-*~ RIGHT (P)
else пусть Q обозначает новую вершину; set /C(Q)*-A;
LEFT (Q) 4- A; RIGHT (Q) ч- A;
RIGHT (P)4-Q; and STOP fi fi.
Шаг 3. [Успешный поиск] Печать «УСПЕШНОЕ ЗАВЕРШЕНИЕ ПОИСКА»; and STOP.
По-видимому, самое худшее, что может сделать алгоритм BTSI, это вести себя, подобно последовательному поиску. К сожалению, это возможно. Это произойдет, если записи считываются в дерево упорядоченно. В таком случае двоичное дерево вырождается в простой путь, по существу являющийся линейным списком. Нетрудно видеть, что это наихудший случай.
Ann Arbor
Dry Lake
Goochland
Рис. 5.2.4. Двоичное дерево, упорядоченное по численности населения и построенное при чтении первых девяти городов в алфавитном порядке,
А как обстоит дело с ожидаемой трудоемкостью алгоритма BTSI? На этот вопрос нелегко ответить. Если дерево полное или почти полное, то алгоритм подобен двоичному поиску и имеет сложность О (log2M). Оказывается, что, если ключи вставляются в случайном порядке, среднее число сравнений по-прежнему равно 0(log2M). Если считать все двоичные деревья равновероятными, то среднее число сравнений будет O(|//V). Доказательства этих утверждений непросты, и их можно найти в книгах [56, 59].
Проблема удаления вершины из двоичного дерева, представляющего упорядоченный файл, несколько сложнее. Не существует никаких затруднений, если оба преемника данной вершины являются
фиктивными (пустыми) вершинами. Например, чтобы удалить Слитмут из дерева на рис. 5.2.4, достаточно просто заменить этот ключ на А. Чтобы удалить вершину с одним фиктивным преемником — например, Коацакоалькос на рис. 5.2.4,— достаточно просто переместить его левое (или правое) поддерево на место этой вершины.
Проблема связей оказывается гораздо сложнее, если у вершины, которую нужно удалить, имеется два непустых преемника. Обычная процедура состоит в следующем: (1) заменить удаляемую вершину ее правым поддеревом RT; (2) сделать левое поддерево удаленной вершины левым поддеревом самой левой вершины RT.
На рис. 5.2.5 изображено дерево рис. 5.2.4 после удаления Энн Арбора. В упр. 5.2.10 требуется более явная формулиров-
Рис. 5.2.5. Двоичное дерево, полученное из дерева на рис. 5.2.4 удалением Энн Арбора, переносом первого поддерева в корень и присоединением левого поддерева ниже Пасадены.
ка алгоритма удаления.
Рассмотрим следующую общую задачу поиска. Дано конечное множество объектов. Один из этих объектов предварительно «выделен» в некотором смысле. Мы не знаем выделенного объекта, но известно распределение вероятностей, управлявшее этим выбором.
Таким образом, объект i имеет известную вероятность pt выбора и Spi=l, где суммирование производится по всем объектам. Мы должны найти выделенный объект с помощью ряда вопросов типа «да или нет». Разрешается выбрать подмножество объектов и спросить: «принадлежит ли данный объект этому подмножеству?». Некоторый посредник дает правдивый ответ «да» или «нет». Нашей первоочередной задачей будет построение алгоритма, решающего любую задачу поиска в такой форме при минимуме математического ожидания числа вопросов. Заметим, что каждый заданный вопрос делит текущее множество непроверенных объектов на два множества, одно из которых будет проверяться на данном шаге, а другое нет.
Например, пусть D — колода из 55 карт, в которой содержится 1 туз, 2 двойки, 3 тройки, . . ., 9 девяток и 10 десяток. Случайно выбрана карта, и мы должны угадать какая. В рамках общей постановки задачи наше множество состоит из 10 объектов (туз, двойка, тройка, . . ., десятка) с вероятностями Р (туз)=1/55, Р (двойка)=2/55, Р (тройка)=3/55, . . ., P(fe)=fe/55, . . ., Р (десятка)=10/55.
Начнем разработку алгоритма с попытки обобщения двоичного поиска. Предположим, что объекты упорядочены по возрастанию значений pi. Попытаемся разбить множество непроверенных объектов посередине. Если число объектов нечетно, отнесем средний объект к подмножеству с меньшими значениями pt. В данном примере первым вопросом будет, «является ли объект шестеркой или больше?». Этот вопрос и ответ на него делят множество возможных ответов на два множества равной мощности. Предположим, что ответом на вопрос будет «нет». Тогда следующим вопросом будет: «четверка или пятерка?». Дерево решений для этого примера показано на рис. 5.2.6.
Рис. 5.2.6. Дерево решений для отыскания карты, случайно выбранной из колоды, содержащей тузы, двойки.....................десятки.
Как же вычислить математическое ожидание числа заданных вопросов при отыскании правильной карты? Числа на самом правом краю рис. 5.2.6 показывают число вопросов, необходимых для достижения вершины на данном уровне при этом алгоритме. Например, если выбранная карта была пятерка, потребуются три вопроса, чтобы убедиться в этом. Математическое ожидание числа задаваемых вопросов при использовании двоичного поиска вычисляется по формуле
EQBS= 2 Р (выбран объект i) [NQ(i)] = 2ptNQ(i), по всем i
объектам
где NQ(i) — число вопросов, которые будут заданы, если будет выбран объект i. В нашем примере
EQBS=4 (1/55)4-4 (2/55)4-3 (3/55)4-3(4/55)4-3 (5/55)+4 (6/55)+4 (7/55)+ +3 (8/55)+3 (9/55)4-3 (10/55)=181/55=3.291.
Прежде чем смотреть, можно ли разработать лучший алгоритм, отметим несколько общих соображений. Должно быть очевидно, что любое правило принятия решений можно моделировать двоичным деревом решений (см. разд. 5.1). Каждый вопрос разделяет вершину, представляющую непроверенное множество, на два преемника, представляющих разбиение этого множества. Конечные вершины дерева, т. е. вершины без преемников, представляют одиночные объекты первоначального множества. Внутренние вершины, т. е. те, которые имеют по два преемника, представляют множества из двух или более объектов. Математическое ожидание числа вопросов, которые будут заданы, при любом правиле равно
EQ = 2^/f, i
суммирование производится по конечным вершинам, а /, — длина пути от корня до i-й конечной вершины.
Существует довольно очевидный способ улучшить имеющийся алгоритм двоичного поиска для класса рассматриваемых задач. Попытаемся разбить множество на два подмножества с приблизительно равными вероятностями принадлежности выбранного объекта данному подмножеству. В приведенном примере, если воспользоваться этой модификацией, первым вопросом был бы: «восьмерка или больше?». Этот вопрос порождает два множества с Р (восьмерка или больше)= =27/55 и Р (семерка или меньше)=28/55. Двоичное дерево для этого алгоритма показано на рис. 5.2.7; для этого дерева EQ=173/55=3.145 (проверьте).
Очевидным недостатком этой модификации двоичного поиска является то, что мы вынуждены группировать объекты таким способом, который позволяет нам только выбирать интервалы подряд стоящих объектов при линейном упорядочении. Можно ли получить лучший «вероятностной баланс», задавая следующие вопросы:
Имеет ли объект нечетный номер?
Принадлежит ли объект набору 3, 17, 28, 49?
Мы можем воспользоваться этой дополнительной гибкостью, применив весьма простой алгоритм, гарантирующий наилучшее возможное решение этой задачи поиска.
Рис. 5.2.7. Дерево решений для отыскания карты, случайно выбранной из колоды, содержащей тузы, двойки, . . . , десятки, с разбиением множеств на два подмножества с приблизительно равными вероятностями.
Следующая процедура была независимо открыта Хафманом и Циммерманом. Она представляет собой рекурсивный алгоритм, строящий дерево двоичного поиска в обратную сторону, т. е. от конечных вершин к корню. Конечные вершины представляют отдельные объекты и их вероятности, корень представляет множество всех объектов, а внутренние вершины представляют группированные подмножества и их вероятности. Пусть Рт будет задачей поиска с т^2 объектами, где объект i имеет вероятность pt быть выбранным, и pi^p2^. . .^pm. Основная идея алгоритма состоит в том, чтобы объединить два объекта с наименьшими вероятностями в одно множество и далее решать задачу Рт_^ с т—1 объектами и вероятностями р1=р1+р2, р2=рз. ... . . ., p'tn-L=Pm. Практически дерево поиска в явном виде строится в обратном направлении, как показано на рис. 5.2.8, а для нашего примера. После того как дерево на рис. 5.2.8, а обращено и упорядочено по уровням, мы получаем дерево поиска на рис. 5.2.8, б. Простой подсчет дает EQOST=173/55=3.145. Хотя это значение равно
найденному с помощью метода модифицированного двоичного поиска (который является хорошей эвристикой), связанные с этими методами деревья отличаются друг от друга. Явная пошаговая формулировка данного алгоритма оставлена в качестве упражнения (см. упр. 5.2.14).
. Мы завершим этот раздел доказательством того, что рассмотренный алгоритм дает дерево двоичного поиска, минимизирующее EQ= —'Zpili. Предположим, что рг упорядочены, т. е. -^рт-
Алгоритм объединяет pi и р2 в одной вершине и затем решает редуцированную задачу с т—1 объектами. Когда решена редуцированная задача, вершина на рис. 5.2.9, а в дереве, соответствующем решению редуцированной задачи, заменяется на поддерево, показанное на рис. 5.2.9, б. Пусть Тт — дерево, минимизирующее EQ, a v — внутренняя вершина, т. е. максимально удаленная от корня. Если рх и р2 не являются вероятностями, приписанными преемникам вершины v, то можно эти значения поменять местами со значениями вероятностей действительных преемников v, не увеличивая значения EQ. Это новое дерево Т'т минимизирует EQ и содержит поддерево с рис. 5.2.9, б.
Пусть Гт-1 будет дерево Т'т, в котором поддерево с рис. 5.2.9, б заменено вершиной’ с рис. 5.2.9, а. Если мы сможем показать, что Т’т-i оптимально для задачи Pm~i тогда и только тогда, когда Т'т оптимально для Рт, то простая индукция докажет правильность алгоритма. Мы покажем явно, что если Т'т оптимально для Рт, то Т'т-i будет оптимально для Pm-i- Предположим, что Т’т-i не оптимально для Рт-±, а Т’т-i оптимально. Тогда EQ (7^ _г)< <EQ (7^-1). По условию задачи Pm-i дерево T^-i должно иметь конечную вершину такого вида, как на рис. 5.2.9, а. Заменим эту вершину поддеревом с рис. 5.2.9, б и назовем это новое дерево Т'^. Тогда
EQ (7") = EQ(7"-х)+Р1+Р2 < EQ (7«-i) + Pi+р2 = EQ(Т'т), что противоречит утверждению, что оптимально для Рт.
Упражнения 5.2
5.2.1. Постройте блок-схемы алгоритмов BSEARCH и BTSI.
5.2.2. Постройте дерево двоичного поиска для следующего списка ключей:
6 17 21 35 46 51 59 66 78 83
5.2.3. Последовательный поиск (разработка). Разработайте простой алгоритм последовательного поиска (см. второй абзац этого раздела).
5-2.4. Последовательный поиск (анализ). Проанализируйте алгоритм последовательного поиска из упр. 5.2.3. Предположите, что все возможные расположения ключей Равновероятны. Покажите, что для числа операций в наихудшем случае и математического ожидания числа операций справедлива оценка О (N),
5-2.5. Воспользуйтесь алгоритмом BTSI для того, чтобы вставить населенный пункт Scaggsville (население 350) в дерево на рис. 5.2.5.
5-2.6. Проверьте, что o=l-|-(d/dz)[{S/e(2z)—l)z] при 2=1,
Рис. 5.2.8. Оптимальное дерево решений, получаемое последовательным объединением двух множеств с наименьшими вероятностями,
Рис. 5.2.9. Объединение двух наименьших вероятностей Pj и Р^,
L5.2.7. Алгоритм BTSI (реализация, проверка) Реализуйте и проверьте алгоритм BTSI.
L5.2.8. Алгоритм BSEARCH (реализация, проверка). Реализуйте и проверьте алгоритм BSEARCH. Экспериментально убедитесь в том, что его сложность логарифмическая.
**5.2.9. Алгоритм BSEARCH (анализ). Обобщите анализ математического ожидания трудоемкости, приведенный в данном разделе, на случай, когда дерево поиска неполно.
*5.2.10. Дайте явную пошаговую формулировку алгоритма удаления вершин—> см. рис. 5.2.5.
5.2.11. Воспользуйтесь процедурой Хафмэна — Циммермана, чтобы построить оптимальное дерево поиска для задачи с семью объектами и вероятностями выбора: рх=0.05, р2=0.10, р3=0.10, р4=0.15, р5=0.16, р6=0.20, р,=0.24.
*L5.2.12. Вероятностный поиск (полное построение). Постройте следующую модификацию алгоритма двоичного поиска: вместо деления пополам интервала на каждом этапе поиска обращайтесь к случайно выбираемым элементам с равными вероятностями. Сравните трудоемкость этого алгоритма с трудоемкостью алгоритма двоичного поиска.
5.2.13. Случайные запросы с множественными ответами (разработка). Мы выполняем поиск в базе данных всех записей определенного типа. Обсудите некоторые обычные способы такого поиска. Сформулируйте разумную задачу этого типа из реальной жизни и постройте алгоритм ее решения.
**5.2.14. Дайте явную формулировку алгоритма Хафмэна — Циммермана.
*L5.2.15. Задача выбора (полное построение). Постройте алгоритм решения задачи выбора: Для произвольного набора из п входных чисел найти k-e по величине число. Входные числа предварительно не упорядочены. Предположите, что k — фиксированное целое число и что IcAcn.
5.2.16. Длины путей в двоичном дереве с корнем (анализ). Определите длину внешнего пути EPL двоичного дерева с корнем как сумму по всем конечным вершинам длин единственных путей от корня к каждой конечной вершине. Длина внутреннего пути IPL определяется аналогично через сумму по всем внутренним вершинам. Покажите, что если в дереве N внутренних вершин, то EPL=IPL-f-2M.
**L5.2.17. Поиск в лабиринте (разработка, реализация). Пусть М.— матрица 15x15, элементами которой являются буквы «О» (для «открыто») и «3» (для «закрыто»), Каждый элемент выбирается случайно с вероятностями Р(О)=2/3 и Р(3)=1/3. Наша цель состоит в отыскании пути, составленного из горизонтальных и вертикальных отрезков, соединяющих соседние элементы, который проходит от позиции (1, 1) до позиции (15, 15). Запрещено проходить через элементы 3. Все элементы пути должны быть буквами О.
5.3. Арифметические и логические выражения
Тема арифметических и логических выражений проходит через большую часть программирования, так как с ней связаны синтаксис и семантика языков программирования, компиляция, формальные языки, структуры данных, логика, рекурсия и вычислительная сложность. Поскольку эти выражения являются неотъемлемой частью фактически всех вычислительных программ, нужно иметь алгоритмы, распознающие и вычисляющие их как можно быстрее и эффективнее.
Задача чтения произвольной последовательности S=S(1), S(2), . . ., S (TV), состоящей из символов, и принятия решения о том, что
она представляет собой правильное арифметическое или логическое выражение, является нетривиальной. Ее решение затрагивает теорию формальных языков и составляет отдельную часть теории компиляции. Здесь у нас недостаточно места для построения теории, необходимой, чтобы объяснить алгоритмы распознавания выражений. Поэтому мы предположим, что все выражения правильны, и сосредоточим усилия на более легкой задаче вычисления этих выражений.
Существует по крайней мере три различных способа определения арифметических выражений. Учебники программирования для начинающих, как правило, дают их на примерах. Разумная основа этого подхода заключается в том, что можно научиться писать правильные выражения, просмотрев достаточное количество примеров. Это в значительной степени похоже на обучение разговорной речи на каком-нибудь языке. Так как было замечено, что большинство программистов используют в своих программах довольно простые выражения, этот подход в большинстве случаев представляется пригодным.
Более формальный подход заключается в том, чтобы определить синтаксис и семантику арифметических и логических выражений с помощью контекстно-свободных правил преобразования, как это сделано в описании Алгола. Промежуточный подход, сохраняющий некоторую долю математической точности определений Алгола и в значительной степени рассчитанный на интуицию, заключается в определении этих выражений индуктивно или рекурсивно.
Арифметическое выражение, сокращенно (а. в.), индуктивно определяется следующим образом:
1. Любая переменная — это (а. в.>.
2. Любая константа — это (а. в.).
3. Любая ссылка на арифметическую функцию — это (а. в.).
4. Если X — (а. в.>, то (X) — тоже (а. в.).
5. Если X и Y—оба (а. в.), то (а. в.) также будут (Х+У), (X—У), (Х*У), (Х/У), (Х**У).
6. Ни один объект не является арифметическим выражением, если то, что он арифметическое выражение, не следует из конечного числа применений правил 1—5.
Это определение дает набор эффективных правил, пригодных для построения любого арифметического выражения в терминах переменных, констант, ссылок на функции и операций +, —, *, / и **. Заметим, что в этом определении отсутствуют определения «переменной», «константы» и «ссылки на функцию». Мы предполагаем, что читатель знаком с этими терминами.
Рассмотрим выражение
(((А-В)*С)+ (D/(E**F)))
Если это правильное арифметическое выражение, то должна существовать возможность построить его с помощью правил 1—5. Пример такого построения приведен на рис. 5.3.1.
Возможно иное описание этого арифметического выражения с помощью корневого двоичного дерева — рис. 5.3.2. Заметим, что все конечные вершины этого дерева соответствуют переменным или операндам, а все внутренние вершины соответствуют арифметическим операциям. Если задано это двоичное дерево, выражение легко вычисляется при известных значениях переменных. Например, предположим, что переменные имеют следующие значения: Л =4.0, В=1.0, С=5.0, £>=64.0, £=2.0 и F=5.0. Значение арифметического выражения можно вычислить, проходя вверх по дереву от конечных вершин к корню, как показано на рис. 5.3.3.
Интересно заметить, что рис. 5.3.3, а и б наглядно показывают, что некоторые из промежуточных вычислений, необходимых для получения значения всего выражения, можно провести параллельно. Например, вычитание Л — В можно выполнить параллельно с возведением в степень E**F. В литературе можно найти множество работ, посвященных параллельному вычислению арифметических выражений; заинтересованного читателя мы отсылаем к гл. 7 за ссылками по этому вопросу.
Логические выражения можно определить так же, как и арифметические. Для этого нам прежде всего нужно определить выражение отношения. Выражением отношения называется выражение вида (а. в.) (отн.) <а. в.), где (отн.) — одна из следующих шести операций отношения:
<< = ¥=>>
Логическое выражение, сокращенно (л. в.), определяется индуктивно следующим образом:
1. Любая логическая константа есть (л. в.).
2. Любая логическая переменная есть (л. в.).
3. Любое выражение отношения есть (л. в.).
4. Если X — (л. в.), то (X) — тоже (л. в.).
5. Если X и Y — оба (л. в.), то также (л. в.) будут (X AND У), (X OR У) и NOT(X).
6. Ни один объект не является <л. в.), если то, что он (л. в.), не следует из конечного числа применений правил 1—5.
Пример правильного логического выражения
((NOT A) AND В) OR (С AND (D OR £))
Соответствующее дерево приведено на рис. 5.3.4.
Вы могли бы обратить внимание на то, что определения (а. в.) и (л. в.) содержат, видимо, лишние скобки. Можно дать определения, не требующие такого количества скобок, но такие определения неизменно приводят к двусмысленностям. Например, выражения
А+В/С или NOT A AND В
Строка является <а.в.>- согласно правилу , использованием строк
1 А 1
2 В 1
3 (А-В) 5b 1,2
4 С 1
5 ((А-В)*С). 5с 3,4
6 Е 1
7 F 1
6 I5 'h (E**F) 5е 6,7
3 D 1
10 (D/(E**F)) 5d 9,8
11 U(A-B)*C) + (D/(E*' f))) 5а 5,10
Рис. 5.3.1. Построение арифметического выражения.
Рис. 5.3.2. Двоичное дерево для описания арифметического выражения (((A—B)*Q+(D/(E**F))).
Рис. 5.3.3. Вычисление значения
арифметического выражения.
должны вычисляться с использованием правила приоритета, устанавливающего, что деление (/) имеет больший приоритет, чем сложение (+), a NOT имеет больший приоритет, чем AND. С учетом этих приоритетов выражение А\-В/С эквивалентно выражению А+(В/С), a NOT A AND В эквивалентно выражению (NOT A) AND В. Мы ввели в этом разделе скобки во избежание подобных осложнений.
Интересно заметить, что три различных способа прохождения деревьев на рис. 5.3.2 и 5.3.4 приводят к трем различным способам записи соответствующих выражений в виде линейной последовательности символов. Рассмотрим дерево простого арифметического выражения (Д+В), приведенное на рис. 5.3.5. Если мы начнем с корня
или верхней точки (Т) этого дерева и напечатаем +, затем перейдем к левой (L) нижней вершине и напечатаем А, а далее перейдем обратно в корень и спустимся вправо (R) и напечатаем В, мы пройдем дерево в прямом порядке. Последовательность напечатанных символов, +АВ называется префиксной формой арифметического выражения; знак
операции (+) предшествует операндам А И В.
@ TLR Прямой + АВ Префиксная
/ \ LTR Обратный А+В* Инфиксная
@ (§) LRT Концевой АВ+ Постфиксная
Рис. 5.3.5. Три различных прохода по двоичному дереву и соответствующие линейные выражения.
Более привычная форма арифметического выражения (Д+В) называется инфиксной формой; она получается при прохождении дерева в обратном порядке, обозначаемом LTR. Постфиксная форма арифметического выражения — в которой знак операции следует за операндами, например ДВ+, получается при концевом порядке (LRT) прохождения дерева.
Здесь будет поучительно рассмотреть снова дерево на рис. 5.3.2. Для прохождения этого дерева в прямом порядке мы начнем с самой верхней вершины ТОР (помеченной +). Затем пройдем в прямом порядке левое поддерево (с корнем, помеченным *) и далее правое поддерево в прямом порядке (с корнем, помеченным /). Прохождение левого поддерева в прямом порядке начинается с корня (помеченного *), затем следует прямое прохождение левого его поддерева (порож
дающее последовательность —АВ) и далее правого поддерева (последовательность С). Поэтому вся последовательность, порождаемая прохождением левого поддерева вершины ТОР, будет *—АВС. Аналогично прохождение в прямом порядке правого поддерева с корнем, помеченным /, порождает последовательность /D**EF. Таким образом, прохождение всего дерева в прямом порядке порождает последовательность
+ * — ABC /D**EF
—11_____11_______।
Прохождение этого дерева в обратном и концевом порядках порождает последовательности соответственно
А —В *С + D/E »*F
1_. J ।। (инфиксная)
АВ — С* DEF **/ 4-
I ji----------—1‘—। (постфиксная)
L R Т
Заметим, что во всех трех выражениях порядок вхождения переменных совпадает; меняется только порядок знаков операций. Заметим также, что ни одно из этих выражений не имеет скобок, и, таким образом, если не заданы правила приоритета, значение приведенного выше выражения в инфиксной форме нельзя вычислить однозначно. По причинам, которые станут очевидными, определение значения этого выражения ни в префиксной, ни в постфиксной форме не содержит двусмысленностей. Иначе говоря, можно для каждой из форм построить простой алгоритм, однозначно вычисляющий выражение в этой форме. Приведем алгоритм вычисления значения арифметического выражения в постфиксной форме.
Algorithm POSTFIX. Вычислить арифметическое выражение в постфиксной форме; выражение состоит из последовательности S(l) S(2) ... S (A), N^A, где S (/) — либо буква (т. е. операнд, или переменная), либо один из знаков + , —, *, /, *« (т. е. двухместная арифметическая операция); в алгоритме используется стек STORE.
Шаг 0. [Инициализация] Set J ч- 0.
Шаг 1. [Цикл] For /ч- 1 to N do шаг 2 od; and STOP. (Значение выражения будет на верху стека STORE.)
Шаг 2. [Чему равно S (/)?] If S (/) — операнд
then [поместить S(/) на стек] set J ч- J4-1;
and STORE (J) 4-S(Z).
else [оценка подвыражения] set 7T ч— STORE (J);
T2 4- STORE (J—1) [выполнение операции
S(/) над T\ и Т2] set ТЗ ч- Т1-S (/)Т2; set J ч- J—1; and STORE (J) ч- T3fi.
Рис. 5.3.6 иллюстрирует выполнение алгоритма POSTFIX над арифметическим выражением в постфиксной форме: АВ—C*DEF**/+.
Например, в строке /=5 входной символ 5(5)=* вызывает перемножение значений двух самых верхних элементов стека, С и 3.0
(строка 4); эти два элемента затем удаляются со стека, а их произведение 15.0 помещается на верх стека.
Входной символ AB-C*DEF"/ + Содержимое стека Значения переменных В стеке или переменная 1234 операция
1 А А А = 4.0
2 В А В В = 1.0
3 - 3.0 А-В = 3.0
4 с 3.0 С = 5.0
5 1Б.0 3.0*С=15.0
е D 15.0 D D = 64.0
7 Е 15.0 D Е Е = 2.0
В F 15.0 D Е Е Е = 5.0
5 15.0 D 32.0 Е**Е = 32.0
10 / 15.0 2.0 В/32.0 = 2.0
11 17.0 15.0 + 2.0 = 17.0
Рис. 5.3.6. Вычисление арифметического выражения в постфиксной форме с использованием алгоритма POSTFIX.
Доказательство правильности алгоритма POSTFIX можно получить индукцией по длине N постфиксного выражения 5 (1)5 (2). . . 5 (Л/). Такое доказательство зависит от индуктивного определения арифметического выражения и от процесса трансляции арифметического выражения из инфиксной формы в постфиксную (обсуждалось ранее).
Очевидно, что алгоритм POSTFIX работает правильно на постфиксных выражениях длины Л^=1 или 7V=3. (По определению не существует постфиксных выражений длины М=2.) Это можно проверить с помощью ручного вычисления. Поэтому предположим, что алгоритм POSTFIX правильно вычисляет все постфиксные выражения длины
Рассмотрим произвольное постфиксное выражение S (1)5(2). .'. 5 (ЛД|-1) длины N+1 • Пусть k — наименьшее целое, такое, что 5 (В) — операция. Тогда легко видеть, что эта операция должна быть применена к S (k—1) и S (k—2); S (k—1) и S (k—2) — оба являются операндами. Вообще говоря, 5 (/—-1) и 5 (/—2) не обязательно операнды,
если S (7) — операция. Однако из-за того, что 5 (А) — первая операция в последовательности, S (k—1) и S (/г—2) должны быть операндами. На шаге 2 алгоритм POSTFIX удаляет S (k—1) и S(k—2) со стека, вычисляет T=S(k—l)S(k)S(k—2) и помещает Т на стек, как если бы Т был еще одним операндом.
В этот момент конфигурация стека в точности такова, как было бы в случае, если первоначальное постфиксное выражение было более коротким: S(l). . .S(k—3)TS (£4~1). . ,S(N). Но, поскольку значение такого измененного выражения (можно показать, что оно правильное постфиксное выражение) равно значению первоначального выражения и так как по предположению индукции алгоритм POSTFIX правильно работает на всех постфиксных выражениях длины мы заключаем, что алгоритм POSTFIX правильно вычисляет исходное выражение.
Полное доказательство правильности алгоритма POSTFIX должно было бы включать в себя доказательства некоторых из приведенных выше утверждений. Мы опускаем эти доказательства ради краткости.
Легко видеть, что постфиксное выражение можно вычислить за время 0(N) с помощью стека, так как при чтении каждого из N символов 5(1), S(2), . . ., S(N) выполняется не более, чем постоянное число операций. Следует отметить несколько свойств алгоритма POSTFIX:
1. Алгоритм предполагает, что входная последовательность является правильным постфиксным выражением; отсутствуют тесты, гарантирующие правильность входной последовательности.
2. Алгоритм разрабатывался для обработки выражений, в которых операнды не должны состоять из нескольких букв или цифр.
3. Недопустимо появление в выражении констант или обращений к функциям.
4. В выражении не должно быть одноместных операций, например —А или 4-Л—В.
5. Алгоритм никогда не инициализирует стек нулями и не заполняет стек нулями после того, как значения были использованы; наверное, это стоило бы делать из эстетических соображений, но не обязательно.
Можно, однако, изменить алгоритм POSTFIX так, чтобы можно было освободиться от каждого из этих пяти условий; мы оставляем это в качестве упражнения вместе с задачей реализации алгоритма POSTFIX.
Мы уже убедились, насколько легко вычисляется арифметическое выражение, как только оно переведено в постфиксную форму.
Однако в большинстве языков программирования требуется записывать арифметические выражения в инфиксной форме. Следующий алгоритм разработан для перевода выражений из инфиксной формы в постфиксную. Он основан на таком правиле приоритетов:
символ
приоритет
О
1
2
3
Алгоритм работает, читая символы инфиксного выражения слева направо. Все операнды (переменные) поступают на выход по мере чтения; остальные символы помещаются на стек и либо удаляются, либо поступают на выход позже в соответствии с приведенным выше правилом приоритетов.
Algorithm ITP (Инфиксная в Постфиксную). Перевести инфиксное выражение S(l) S(2) . . . S(/V), Л£>1, в постфиксную форму. S(7) — либо буква (т. е. операнд, или переменная), левая или правая скобка, либо знак операции (т. е. один из символов +, —, *, /, или **. Алгоритм использует стек STORE и приоритетную функцию Р, где «е», «(», «)» имеют приоритет О, Р(+)=Р(—)=1, Р(*)=Р(/)=2, Р(»»)=3. Шаг 0. [Инициализация] Set STORE (1)=е; and J«- 1.
Шаг 1. [Цикл] For I ч- 1 to N do through шаг 6 od.
Шаг 2. [Буква] If S (7) буква then PRINT S(7) fi.
Шаг 3. [Левая скобка] If S (/)=«(» then [поместить на стек] set J ч- J+l; STORE (J) ч- S (7) fi.
Шаг 4. [Правая скобка] If S (7)=«)». then [снять co стека] while STORE (/)#=«(» do шаг 5 od; and set J ч- J—1 fi. Шаг 5. [Печать верхнего элемента стека] PRINT STORE (J); and set 7ч-7-1.
Шаг 6. [Оператор] While P(S(7))<P(STORE (J)) do PRINT STORE (J); and set J 4- J—1 od; [поместить на стек] set J ч- J+1; and STORE (J) ч- S (7).
Шаг 7. [Печать остатка стека] While STORE (J)#=e do PRINT STORE (J); and set J 4- J—1 od; and STOP.
На рис. 5.3.7 приведена блок-схема алгоритма ITP, а рис. 5.3.8 иллюстрирует выполнение этого алгоритма на заданном инфиксном арифметическом выражении. Например, в строке 3 знак операция помещается на стек; в строке 4 операнд В поступает на выход; в строке 5 символ «)» вызывает передачу на выход верхнего символа стека (этим символом оказался знак —).
Сложность алгоритма ITP оказывается 0(77). Это следует из таких свойств алгоритма:
1. Один проход производится над 77 символами последовательности.
2. На стек может попасть самое большее N/2 символов (т. е. операций).
3. Все символы, остающиеся на стеке, могут быть выведены по окончании чтения не более, чем за O(N) операций.
4. Для обработки произвольного символа в последовательности требуется не более постоянного числа операций.
Шаг Вход (A-B1*C + D/(E**F) Выход Содержимое стека 1 2345
с
1 ( «(
2 А А е(
3 - «(-
4 в В е(-
S 1 - - €
6 * с*
7 с с е*
8 + *
9 D D е+
10 / е+7
11 ( е+/(
12 Е Е е+/(
13 £+/(**
14 F F £+/(**
15 ** е+/
16 /+
Выводимая последовательность символов: AB-C*DEF**/+-
Рис. 5.3.8. Преобразование выражения из инфиксной формы в постфиксную с помощью алгоритма ITP.
Упражнения 5.3
5.3.1. Рассмотрите следующее арифметическое выражение:
((%! « + (Л'3 * У2)) * * 1) - ((Л + В) 4 С)
(а) Постройте это выражение, используя правила 1—5 для арифметических выражении и представьте эту конструкцию в виде таблицы, аналогичной рис. 5.3,1.
(б) Постройте представление в виде корневого двоичного дерева аналогично рис. 5.3.2.
5.3.2. Вычислите выражение в упр. 5.3.1 для значений Xi—3, У1=4, Хя~4, Y%=6, Л=5, В=7, С=1. Воспользуйтесь рисунком, аналогичным рис. 5.3.3,
5.3.3. Рассмотрите следующее логическое выражение:
(X .OR. У).AND. (( .NOT. (A)) .OR. В) .OR. ( .NOT. (X))
(а) Постройте это выражение, используя правила 1—6 для логических выражений, и представьте эту конструкцию в виде таблицы, аналогичной рис. 5.3.1.
(б) Постройте представление в виде корневого двоичного дерева, аналогичного рис. 5.3.4.
5.3.4. Пройдите корневые двоичные деревья, построенные в упр. 5.3.1 и 5.3.3, в прямом, обратном и концевом порядках.
**5.3.5. Докажите правильность алгоритма ITP.
5.3.6. Примените алгоритм POSTFIX для вычисления выражения в упр. 5.3.1 для значений, заданных в упр. 5.3.2.
5.3.7. Алгоритм POSTFIX (реализация). Запрограммируйте алгоритм POSTFIX, 5.3.8. Примените алгоритм ITP для обработки выражения в упр. 5.3.1.
5.3.9. Напишите в префиксной и постфиксной форме логическое выражение на рис. 5.3.4.
5.3.10. Какое свойство арифметического выражения определяет высоту соответствующего двоичного дерева?
5.3.11. Постройте алгоритм типа POSTFIX для логических выражений.
5.3.12. Постройте алгоритм типа PREFIX для логических выражений.
*5.3.13. Алгоритм POSTFIX (анализ). Оцените верхнюю границу для максимального числа символов, которые должны размещаться в стеке алгоритма POSTFIX. Приведите пример выражения, реализующего наихудший случай.
*5.3.14. Алгоритм ITP (анализ). Повторите упр. 5.3.13 для алгоритма ITP. Каково поведение этого алгоритма в наихудшем случае?
5.4. Страничная организация памяти
Одним из наиболее ценных ресурсов цифровой машины, с точки зрения пользователя, оказывается размер доступной оперативной памяти. Следовательно, важно, чтобы она использовалась как можно более эффективно. В большинстве случаев трудно добиться эффективного использования памяти либо из-за того, что программа не помещается в оперативной памяти, либо из-за того, что большие области памяти заняты редко используемыми сегментами программ.
Строить структуру компьютера так, чтобы каждая программа могла занимать всю память, или невозможно, или неэкономично. Следовательно, структура программ должна быть такова, чтобы различные сегменты могли размещаться в одних и тех же частях памяти в различные моменты времени. Обычно для этого используется метод перекрытия сегментов (оверлейный метод). При этом происходит обмен сегментами программы между оперативной памятью и вспомогательными накопителями (диски, барабаны, ленты). Однако по многим причинам предпочтительно освободить программиста от управления размещением сегментов программы.
Другой подход демонстрирует компьютер с виртуальной памятью (КВП). Программист может писать программу так, как будто бы ему
предоставлена (виртуальная) память неограниченного размера. Когда КВП выполняет программу с виртуальными адресами, он автоматически вносит в память время от времени некоторые сегменты программы, отображая пространство виртуальных адресов на физические адреса оперативной памяти. Когда при исполнении программы встречается ссылка на сегмент программы, не находящийся в памяти, КВП извлечет этот сегмент из вспомогательного хранилища и разместит его в памяти, если имеется достаточно большая область свободной памяти. Если свободной памяти нет, он выводит тот или иной сегмент программы из памяти на вспомогательный накопитель, чтобы освободить пространство для необходимого в данный момент сегмента.
В принципе КВП мог бы замещать каждый раз по одному слову программы, но практически это было бы неэкономно. Поскольку вспомогательные накопители требуют относительно большого времени для доступа к информации, но относительно малого времени на ее передачу, экономнее передавать сразу целый сегмент. Это также оправдывается тем, что раз была ссылка на данное слово, то велика вероятность, что скоро будут ссылки на соседнее слово или соседние слова.
Таким образом, возникает задача: насколько мал или велик должен быть сегмент, извлекаемый за одну операцию замещения. Опыт эксплуатации различных схем замещения показывает, что удобнее замещать сегменты фиксированного размера, называемые страницами. Это позволяет избежать затруднений, связанных с обменом сегментами переменной длины и с принятием решений о размещении их в памяти. Это также позволяет избежать излишне больших сегментов и неэффективного использования памяти.
Число слов в странице обычно выбирается равным степени двух, скажем 2т. Если число слов в программе равно 2" то про-
грамма автоматически делится на 2ft страниц, где k=n—т. Память также делится на-сегменты такой же длины, называемые страничными областями.
Теперь мы опишем последовательность действий при переносе страниц программы в память и из памяти.
1. Программа делится на страницы, некоторые из которых размещаются в памяти. Существенно отметить, что некоторые из этих страниц могут содержать только текст программы, а некоторые могут содержать только данные.
2. Во время исполнения может потребоваться доступ к странице, не находящейся в памяти. Это обнаруживается посредством обращения к таблице страниц, показывающей, находится ли данная страница в памяти.
3. Возникает страничный отказ (прерывание по отсутствию страницы в памяти).
4. Программа КВП, называемая алгоритмом управления страничной памятью, помещает необходимую страницу в память, замещая,
если необходимо, какую-нибудь из страниц, находящихся в памяти; это называется замещением страниц по требованию.
5. Исполнение виртуальной программы прерывается на то время, пока происходит страничный обмен, и выполняется другая виртуальная программа.
6. Как только затребованная страница помещена в память, выполнение первой программы возобновляется.
7. Когда возобновляется исполнение прерванной виртуальной программы, происходит обращение к той же странице; на этот раз страничного отказа не возникает.
В этом разделе мы обсуждаем в несколько идеализированном виде некоторые алгоритмические аспекты управления страничной памятью. Мы продемонстрируем несколько простых алгоритмов управления страничной памятью, интересных с теоретической или практической стороны, и испытаем их, чтобы выяснить, как они влияют на эффективность использования памяти в компьютере.
Главной целью алгоритма управления страничной памятью является минимизация числа страничных отказов, возникающих при исполнении произвольной программы. Второстепенной целью будет такое принятие решения о выборе удаляемой из памяти страницы, чтобы накладные расходы были минимальны. В идеальном случае алгоритм управления страничной памятью удаляет те страницы, к которым дольше всего не будет ссылок, и оставляет страницы, которые будут требоваться чаще всего. К сожалению, информация о последующих обращениях к данной странице обычно отсутствует в момент страничного отказа.
В таких случаях решение о выборе замещаемой страницы может быть либо случайным, либо может основываться на некоторой накопленной информации о предыдущих обращениях к страницам виртуальной программы.
Мы обсудим следующие пять алгоритмов управления страничной памятью:
RANDOM (СЛУЧАЙНЫЙ). Этот алгоритм предполагает, что в любой момент времени обращения ко всем страницам равновероятны. Замещаемая страница выбирается случайно.
FIFO (первым пришел — первым ушел). Этот алгоритм всегда замещает страницу, которая дольше всех находилась в памяти. Его оправдание основано на принципе локальности программы, утверждающем, что число ссылок в программе между двумя последовательными замещениями страниц относительно велико. Иначе говоря, программы проявляют тенденцию к выполнению команд из данного множества страниц в течение некоторого времени, после чего переходят к другому множеству страниц. Следовательно, предполагается, что страница, дольше всех находящаяся в памяти, имеет наименьшую вероятность использования в будущем.
LRU (самое давнее обращение). Этот алгоритм замещает в памяти страницу, к которой самое продолжительное время не было обращений. При этом мы рассчитываем, что раз к этой странице не было обращений в недавнем прошлом, то их не будет и в ближайшем будущем.
LFU (самое редкое использование). Этот алгоритм следит за таблицей частоты обращений для всех страниц программы (как находящихся в памяти, так и вне ее) и замещает в памяти страницу, частота обращений к которой оказывается наименьшей. Оправданием этого алгоритма является то, что страницы программы проявляют тенденцию к делению на две категории: страницы, используемые часто (например, содержащие циклы DO), и страницы, используемые редко (например, содержащие операторы инициализации программы, операторы ввода/вывода или редко требующиеся данные).
BEST (НАИЛУЧШИЙ). Этот алгоритм представляет прежде всего теоретический интерес, так как он предполагает полное знание о всех предстоящих обращениях к страницам и всегда производит наилучший возможный выбор замещаемой страницы, т. е. замещает страницу, обращение к которой произойдет позже, чем к любой другой.
Как мы увидим, алгоритмы СЛУЧАЙНЫЙ и НАИЛУЧШИЙ весьма полезны, так как они являются эталонами, с которыми можно сравнивать трудоемкость любого другого алгоритма управления страничной памятью.
Ради простоты предположим, что входные данные для каждого из этих алгоритмов управления страничной памятью состоят из массива REF(l), . . ., REF(А/) целого типа, целого FRAMES, указывающего число доступных страничных областей и целого PAGES, указывающего число страниц в данной программе. Массив REF(l), . . ., REF (TV), называемый цепочкой обращений, представляет полную последовательность обращений к страницам, генерируемых при исполнении данной виртуальной программы, причем мы предполагаем, что эти страницы пронумерованы числами 1, 2, . . ., PAGES. Хотя на практике возможно, что цепочка обращений будет содержать много подпоследовательностей повторяющихся обращений к одним и тем же страницам, при изучении алгоритмов управления страничной памятью такие повторения номеров страниц мы будем считать несущественными. То есть мы будем предполагать, что REF (7)=A=REF (7+1) для 7=1, . . ., N—1.
Прежде чем рассматривать реализацию алгоритмов управления страничной памятью, рассмотрим пример, иллюстрирующий работу алгоритма BEST (наилучший). Предположим, что даны три страничные области памяти, в которых должна работать программа, состоящая из пяти страниц. Цепочка обращений при исполнении этой программы пусть будет: 12341253452 5.
На рис. 5.4.1 показана последовательность замещений страниц, выполняемых алгоритмом BEST. Хотя и можно сказать, что странич
ные отказы происходят в строках 1, 2 и 3, мы их будем считать «свободными» замещениями. Заметьте, что при страничном отказе на строке 4 мы замещаем страницу 3, так как следующее обращение к ней
Обращение к странице Содержимое страничных областей Новое содержимое. страничных областей
1 2 3 1 2 3
1 1 1 СВОБОДНОЕ ЗАМЕЩЕНИЕ
2 2 1 1 2 СВОБОДНОЕ ЗАМЕЩЕНИЕ
3 3 1 2 1 2 3 СВОБОДНОЕ ЗАМЕЩЕНИЕ
4 4 1 2 3 -> 1 2 4 отказ: 3 ПОЗЖЕ ВСЕХ
Б 1 1 2 4 * 1 2 4
6 2 1 2 4 * 1 2 4
7 Б 1 2 4 Б 2 4 отказ’: 1 позже всех
8 3 5 2 4 •* 5 3 4 отказ: 2 ПОЗЖЕ ВСЕХ
3 4 Б 3 4 Б 3 4
10 5 Б 3 4 -> 5 3 4
11 2 Б 3 4 -* 5 2 4 отказ: з позже всех
12 5 5 2 4 -* 5 2 4
Рис. 5.4.1. Последовательность замещений страниц при использовании алгоритма BEST, т, е, замещается та страница в памяти, следующее обращение к которой произойдет позже всех.
произойдет в момент времени 8, тогда как к страницам 1 и 2 произойдут обращения в моменты 5 и 6 соответственно. Заметьте также, что при равных возможностях (например, в строке 11) мы замещаем страницу с меньшим номером. Советуем читателю построить аналогичную таблицу замещения страниц еще хотя бы для одного алгоритма управления страницами, прежде чем продолжать чтение.
Мы оставляем реализацию алгоритмов RANDOM и BEST в качестве упражнений и сосредоточим внимание на реализации алгоритмов FIFO, LRU и LFU.
Для реализации алгоритма FIFO организуем круговую очередь FRAME (1), FRAME (2), . . ., FRAME (М), где M=FRAMES — число страниц в оперативной памяти. Как только происходит обращение к новой странице, она помещается в первую попавшуюся свободную область до тех пор, пока все области не окажутся заполненными, после чего мы продолжаем загрузку новых страниц в области FRAME (1), FRAME (2) и т. д. Эта реализация показана на рис. 5.4.2.
Для реализации алгоритма LRU создадим таблицу страниц TABLE, в которой TABLE (7)=J, если в данный момент страница / находится в области памяти J. Для упорядочения множества страниц, находящихся в памяти в соответствии с наиболее давним обращением, используется список с двумя связями вперед и назад— BEFORE (/)
SUBROUTINE FIFO (REF.N,FRAMES.PAGES) C С ЭТА ПОДПРОГРАММА ПОДУЧАЕТ НА ВХОД ПОСЛЕДОВАТЕЛЬНОСТЬ С ОБРАЩЕНИЙ К’ СТРАНИЦАМ FEF(1) ,REF(2)..........REF(N).
С ЦЕЛОЕ «FRAMES» УКАЗЫВАЕТ ЧИСЛО ВЫДЕЛЕННЫХ СТРАНИЧНЫХ С ОБЛАСТЕЙ , А ЦЕЛОЕ «PAGES= - УКАЗЫВАЕТ ЧИСЛО РАЗЛИЧ-С ПЫХ СТРАНИЦ. ПОДПРОГРАММА НАХОДИТ ЧИСЛО .СТРАНИЧНЫХ С ОТКАЗОВ . ПОРОЖДАЕМЫХ ДАННОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ ПРИ С ИСПОЛЬЗОВАНИИ АЛГОРИТМА ЗАМЕЩЕНИЯ FIFO (ПЕРВЫМ ПРИ» I С ШЕЛ - ПЕРВЫМ УВЕЛ). ПОДПРОГРАММА ПЕЧАТАЕТ СТРОКУ ОБ-С РАЩЕНИЙ REF(1)..,REF(N), ПОСЛЕДОВАТЕЛЬНОСТЬ FAULT (1) С ...FAULT(N),-niE FAULT(1)«1, ЕСЛИ REFC I) ПОРОЖДАЕТ С СТРАНИЧНЫЙ ОТКАЗ, И FAULT!I)=D В ПРОТИВОПОЛОЖНОМ
С СЛУЧАЕ. ОНА ТАКЖЕ ПЕЧАТАЕТ ОБЩЕЕ ЧИСЛО СТРАНИЧНЫХ
С ОТКАЗОВ И ЧАСТОТУ ОТКАЗОВ ДЛЯ ДАННОГО ЧИСЛА СТРАНИЧ»
С ПЫХ ОБЛАСТЕЙ.
С । С «« ФОРМАЛЬНЫЕ ПАРАМЕТРЫ
с
c REF(H,.,REF(N) СТРОКА ОБРАЩЕНИЙ
с C FRAMES ЧИСЛО СТРАНИЧНЫХ ОБЛАСТЕЙ
с С PAGES ЧИСЛО РАЗЛИЧНЫХ СТРАНИЦ
С с ВНУТРЕННИЕ ПЕРЕМЕННЫЕ
с с FAULFAULT(N1 *1 ЕСЛИ REFt!I ПОРОЖДАЕТ ОТКАЗ
С «0 В ОСТАЛЬНЫХ СЛУЧАЯХ
с с FRAME(I) НОМЕР СТРАНИЦЫ, РАЗМЕЩЕННОЙ В
С Области i
С С TABLE(1} «J ЕСЛИ СТРАНИЦА 1 В ОБЛАСТИ J
С «0 в ОСТАЛЬНЫХ СЛУЧАЯХ
С С TOTAL Общее число страничных отказов
с INTEGER REFfNJ.FRAMES.PAGES
. INTEGER FAULT(IOOO) .FRAME(50) ,P;TABLEdOO) .TOTAL
С
С ИНИЦИАЛИЗАЦИЯ ПЕРЕМЕННЫХ
С
ВО 10 1 = 1.N FAULT!I] = 0
10 CONTINUE P=PAGES+1 ВО 20 I = 1.Р
TABLE!I) « О
20 CONTINUE
ВО 30 I « 1,FRAMES FRAME!I) = P
30 CONTINUE J = 1 TOTAL » 0
Рис. 5.4.2. Реализация алгоритма FIFO.
с
с Пикл ГО СТРОКЕ ОБРАЩЕНИЙ RE Ft 1)...RE FtN) С
DO 100 I » 1,N
C
С НАХОДИТСЯ ЛИ СТРАНИЦА К В ПАМЯТИ
С
К - REF(I)
IF( TABLE(K) .NE. Oj 00 TO 100 C
С УДАЛЕНИЕ СТРАНИЦЫ И5 ОБЛАСТИ FRAME(J) И J?A3-
0 -МЕШЕНИЕ СТРАНИЦЫ К
С
L - FRAME(J) TABLE(L) = О TABLE(K) = I FRAME(J) = К J = J - J/FRAMES* FRAMES + 1 FAULT! I} = 1 TOTAL - TOTAL +1
100 CONTINUE c с ПЕЧАТЬ РЕЗУЛЬТАТОВ С
WRITE (6,900) FRAMES,PACES
900 РОЯМАТ(1НО,ЗеНАЛГОРИТМ УПРАВЛЕНИЯ СТРАНИЧНОЙ ПАМЯТЬЮ, 1 ЮН FIFO ДЛЯ ,13,12Н ОБЛАСТЕЙ И ,I3.8H СТРАНИЦ)
WRITE (6,950)
950 FORMAT(1HO,38HCTPOKA ОБРАЩЕНИЙ И ПОСЛЕДОВАТЕЛЬНОСТЬ
1 7НООТКАЗОВ)
WRITE (6,1000) (REF{ l)ltl=1,N)
WRITE (6,1000) (FAULT!I),1-1,N)
1000 FORMAT!1H0,4013)
c
с ПЕРВЫЕ «FRAMES» ОТКАЗОВ - СВОБОДНЫЕ С
TOTAL » TOTAL - FRAMES’
RATE » FLOAT(TOTAL) / (N - FRAMES)
WRITE (6,1010) TOTAL,RATE
1010 Р0ЯМАТ(1Н0,20НЧИСЛО ОТКАЗОВ РАВНО ’, I3.11H А ЧАСТОТА •
1 6HPABHA ,F6.3) RETURN END
Рис. 5.4.2. Продолжение
и AFTER (7). Переменная FRONT указывает на страницу в памяти, к которой дольше всех не было обращений. Когда происходит страничный отказ, страница, указанная в FRONT, удаляется из списка (и из памяти), а ссылка на страницу, к которой только что произошло обращение, помещается в переменную END списка. Если происходит обращение к странице, находящейся в памяти, ссылка на эту страницу извлекается из списка и помещается в END. Рис. 5.4.3 иллюстрирует эту реализацию алгоритма LRU.
SUBROUTINE LRU (REF.N,FRAMES.PACES) C
С ЭТА ПОДПРОГРАММА ЯВЛЯЕТСЯ РЕАЛИЗАЦИЕЙ АЛГОРИТМА LRU, С ИСПОЛЬЗУЮЩЕГО СПИСОК С ДВОЙНЫМИ ССЫЛКАМИ ДЛЯ УПОРЯ-С ДОЧЕНИЯ СТРАНИЦ В ПАМЯТИ В СООТВЕТСТВИИ С МОМЕНТАМИ
С ПОСЛЕДНИХ ОБРАЩЕНИЙ К НИМ. ПОДПРОГРАММА ПОЛУЧАЕТ НА
С вход СТРОКУ ОБРАЩЕНИЙ, ЧИСЛО РАЗЛИЧНЫХ СТРАНИЦ И С ЧИСЛО СТРАНИЧНЫХ ОБЛАСТЕЙ. ПОДПРОГРАММА ВЫВОДИТ НА
С ПЕЧАТЬ СТРОКУ ОБРАЩЕНИЙ REF(1)...REF(N), ПОСЛЕДОВА-С ТЕЛЬНОСТЬ FAULT(1)...FAULT(N), ГДЕ FAULT! 1)=1, ЕСЛИ С REFC I) ВЫЗЫВАЕТ СТРАНИЧНЫЙ ОТКАЗ , И FAULT{lj=O В с ОСТАЛЬНЫХ СЛУЧАЯХ. ОНА ТАКЖЕ ПЕЧАТАЕТ ОБЩЕЕ ЧИСЛО
с СТРАНИЧНЫХ ОТКАЗОВ И ЧАСТОТУ ОТКАЗОВ для этого чис-
с ЛА ОБЛАСТЕЙ с
С === ФОРМАЛЬНЫЕ ПАРАМЕТРЫ с
с REF(1)...REF(N) СТРОКА ОБРАЩЕНИЙ К СТРАНИЦАМ
С
С FRAMES ЧИСЛО СТРАНИЧНЫХ ОБЛАСТЕЙ
С
С PAGES ЧИСЛО СТРАНИЦ ПРОГРАММЫ
С
С =»= ВНУТРЕННИЕ ПЕРЕМЕННЫЕ С
С BEFORE( П С AFTER( I} С С СВЯЗИ В СПИСКЕ С ДВОЙНЫМИ ССЫЛКАМИ, BEFORE!I) {AFTER!I}) - СТРАНИЦА, ПОСЛЕДНЕЕ ОБРАЩЕНИЕ К КОТОРОЙ БЫЛО НЕПОСРЕДСТВЕННО ДО (ПОСЛЕ) ПОСЛЕД-
С С С' FAULT( I) НЕГО ОБРАЩЕНИЯ К СТРАНИЦЕ 1 «=1 ЕСЛИ REF(I) ВЫЗЫВАЕТ СТРАНИЧНЫЙ
С С С FRONT.END С С с с с С J с с к с С TABLE( I) С с С TOTAL С ОТКАЗ, =0 В ОСТАЛЬНЫХ СЛУЧАЯХ в списке с двойными ссылками front (END) УКАЗЫВАЕТ НА СТРАНИЦУ , К КОТОРОЙ ДОЛЬШЕ ВСЕГО НЕ БЫЛО ОБРАЩЕНИЙ (к которой обратились позже ВСЕХ) ИНДЕКС ОБЛАСТИ УКАЗАТЕЛЬ ТЕКУЩЕЙ СТРАНИЦЫ ЕСЛИ СТРАНИЦА I РАЗМЕШЕНА В ОБЛАСТИ J, =0 В ОСТАЛЬНЫХ СЛУЧАЯХ ЧИСЛО СТРАНИЧНЫХ ОТКАЗОВ; ВЫЗВАННЫХ REFI1)...REF(N)
с
Рис. 5.4.3. Реализация алгоритма LRU
INTEGER REF(N),FRAMES.PAGES
INTEGER AFTERdOO) .BEFOREdOC) ,END.FAULT(1O.OC)
INTEGER FRAME(50),FRO NT,J,K.TABLE(100).TOTAL,T1,T2 C
С ИНИЦИАЛИЗАЦИЯ ПЕРЕМЕННЫХ С
J -1
DO 30 I - 1.PAGES
TABLE!I) « 0
BEFORE! I) » 0
AFTER!I) « 0
30 CONTINUE
C
С заполнение всех страничных областей с
I »1
К - REF(1)
TABLE(К) - 1 FRONT » К END » К.
FAULT(1) • 1.
TOTAL - 1
FRAME(1) » REF(1)
DO 100 J = 2.FRAMES
40 I » I + 1
C
С КОНЧИЛАСЬ ЛИ СТРОКА ОБРАЩЕНИЙ С
IF( I .GT. N ) GO TO 170 C
С ВЫБОРКА 1-ГО ОБРАЩЕНИЯ С
К - REF(1)
С
С НАХОДИТСЯ ЛИ К-Я СТРАНИЦА В ПАМЯТИ С
IFtTABLE(K) .НЕ. 0) GO ТО 50 GO ТО 90
С
С ПОМЕСТИТЬ В КОНЕЦ СПИСКА СТРАНИЧНЫХ ОБЛАСТЕЙ
С
50 FAULT(I) » О
Рис. 5.4.3. Продолжение
С НАХОДИТСЯ ДИ СТРАНИЦА К В КОНЦЕ СПИСКА
с IFC AFTER(K) .EQ. 0 ) GO ТО 40
с с с с НАХОДИТСЯ ЛИ СТРАНИЦА К В НАЧАЛЕ СПИСКА (FRONT) IF(FRONT .EQ. К) GO TO 6Q GO TO 70-
с 60 УДАЛЕНИЕ ИЗ FRONT FRONT » AFTER(K) BEFORE (FRO NT) = 0 GO TO 80
с 70 УДАЛЕНИЕ ИЗ СЕРЕДИНЫ СПИСКА Т1 = BEFORe(K) Т2 - AFTER(K) AFTER (Fl) = T2 BEF0RE(T2) » T1
с с г. 80 РАЗМЕЩЕНИЕ СТРАНИЦЫ К В КОНЦЕ СПИСКА (END) BEFORE (К)- » END AFTER(K) » 0 AFTER (END) » К END а К GO TO 40
С с 90 РАЗМЕЩЕНИЕ СТРАНИЦЫ К В ОБЛАСТИ J И ДОБАВЛЕНИЕ ЕЕ К КОНЦУ СПИСКА TABLE(К) » J FRAME!J) = К AFTER(END) а К BEFORECK) - END END а К FAULT!I) а 1 TOTAL - TOTAL + 1
100 CONTINUE
Рис. 5.4.3. Продолжение
с с ВСЕ ЛИ ОБЛАСТИ ИСПОЛЬЗОВАНЫ С IN = 1+1 ВО 160 I = IN,N К = REF(I) С с НАХОДИТСЯ ЛИ СТРАНИЦА К В ПАМЯТИ С
IF ( TABLE(K) .NE. О ) GO ТО 110 GO ТО 150 С ЗАПИСАТЬ , ЧТО НЕ БЫЛО ОТКАЗА 110 FAULT! I) =0
С с НАХОДИТСЯ ЛИ СТРАНИЦА К В КОНЦЕ СПИСКА (ЕNDJ С
IF( AFTER(K) .EQ. -О ) GO ТО 160 С С НАХОДИТСЯ ЛИ СТРАНИЦА К В НАЧАЛЕ СПИСКА (FRONT)
С
IF ( FRONT .EQ. К ) GO ТО 120 GO ТО 130 С УДАЛЕНИЕ СТРАНИЦЫ К ИЗ НАЧАЛА СПИСКА
120 FRONT = AFTER(K)
BEFORE(FRONT) = О GO ТО 140 с удаление страницы к из середины списка
130 Т1 = BEFORE(K)
Т2 = AFTER (К) BEFORE(Т2) - Т1 AFTER (Т1) ч Т2 С С ДОБАВЛЕНИЕ СТРАНИЦЫ К В КОНЕЦ СПИСКА
С 140 BEFORE (К) = END
AFTER(К) = О AFTER(END) = К END к К GO ТО 160 С с УДАЛЕНИЕ ИЗ ПАМЯТИ СТРАНИЦЫ J, КОТОРАЯ ДОЛЬШЕ
С ВСЕХ НЕ ИСПОЛЬЗОВАЛАСЬ И РАЗМЕЩЕНИЕ СТРАНИЦЫ
С КВ ОБЛАСТИ J
С 150 J = TABLE(FRONT)
TABLE(К) = J TABLE(FRO NT) = О
Рис. 5.4.3. Продолжение
с
С РАЗМЕЩЕНИЕ СТРАНИЦЫ К В КОНЦЕ СПИСКА И УДАЛЕНИЕ
С ИЗ НАЧАЛА СПИСКА СТРАНИЦЫ , КОТОРАЯ ДОЛЬШЕ ВСЕХ
С НЕ ИСПОЛЬЗОВАЛАСЬ
С
FRA-WEf J) = К AFTER! END) = К BEFORE(K) = END END - К Т1 = AFTER(FRONT) BEFORE(T1) = О after(front) « о FRONT = T1 FAULT!I) = 1 TOTAL » TOTAL t 1 160 CONTINUE 170 CONTINUE C С ПЕЧАТЬ РЕЗУЛЬТАТОВ С WRITE (6,900) FRAMES,PAGES 900 Р0РМАТ(1НВ,39НАЛГ0РИТМ УПРАВЛЕНИЯ СТРАНИЧНОЙ ПАМЯТЬЮ 1 9Н LRU ДЛЯ , I3.12H ОБЛАСТЕЙ'И ,13,8Н СТРАНИЦ) WRITE (6,950)
950 FORMAT! 1НО.37НСТРОКА ОБРАЩЕНИЙ И ПОСЛЕДОВАТЕЛЬНОСТЬ, 1 8Н ОТКАЗОВ)
WHITE (6,1000) (REF( I) ,I=1,N) WRITE (6,1000) (FAULT!I),1=1,N) 1000 FORMAT(1HO,4CI3) C С ПЕРВЫЕ =FRAMES= ОТКАЗОВ - СВОБОДНЫЕ С
TOTAL » TOTAL - FRAMES
RATE = FLOATlTOTAL) / (N-FRAMES) WRITE (6,1010) TOTAL,RATE
1010 FDRMAT(1H0,21H ЧИСЛО ОТКАЗОВ РАВНО ,I3,11H А ЧАСТОТА 1 7Н РАВНА ,F6.3) RETURN END
Рис. 5.4.3. Продолжение
Реализация алгоритма LFU аналогична реализации предыдущих двух алгоритмов. Основное отличие состоит в использовании массива FREQ, элемент которого FREQ (Д') равен числу появлений страницы К в цепочке обращений. Когда происходит страничный отказ, мы удаляем из памяти страницу J, обладающую наименьшим значением FREQ(J). Если две или более страниц, находящихся в памяти, обладают одинаковым наименьшим значением частоты, то мы удаляем ту из них, которая находится в памяти дольше. Для этого проверяется массив ENTER, где ENTER (J) равно времени последнего поступления страницы J в память, т. е. если REF(/)=/( вызывает страничный отказ, то мы устанавливаем ENTER (К)=/. Эта реализация приведена на рис. 5.4.4.
Теперь испытаем эти алгоритмы управления страничной памятью. Для каждого алгоритма мы построим цепочку обращений длины N и запишем число страничных отказов (TOTAL) в этой цепочке. Частотой отказов для каждого алгоритма будет отношение (TOTAL — FRAMES)/(N—FRAMES), где FRAMES — число страничных областей в памяти. Причина уменьшения как TOTAL, так и А на величину FRAMES состоит в том, что мы рассматриваем первые FRAMES отказов как «свободные», так как при этих отказах все алгоритмы одинаково заполняют свободные области страницами»
Для выработки плана проверки мы должны принять несколько упрощающих предположений:
1. Программы, генерирующие цепочку обращений, будут иметь 20 страниц. Первые 6 страниц будут заняты текстом программы, а остальные 14 — данными (рис. 5.4.5).
2. Так как частота страничных отказов для любого алгоритма сильно зависит от отношения PAGES к FRAMES, мы будем менять FRAMES от 2 до 18 шагами по 2 единицы. При .каждом значении FRAMES будем использовать для вычисления частоты страничных отказов одну и ту же строку обращений.
3. Самые существенные предположения относятся к механизму генерации цепочки обращений. В идеальном случае она должна быть «представительна» относительно обращений к страницам, которые генерируются «типичной» 20-страничной программой с 14 страницами данных. К сожалению, очень трудно решить, какую программу считать типичной. Поэтому мы сделаем несколько предположений, основываясь на рис. 5.4.5.
Рассмотрим операторы А=В-|-С и GO ТО 400, находящиеся во второй странице; переменные А, В и С запоминаются на страницах данных с номерами 12, 15 и 19 соответственно. При трансляции в код ассемблера эти операторы, по-видимому, породят строку обращений 2—19—2—15—2—12—2—3. Это наводит на мысль, что строки обращений, вероятно, состоят из перемежающихся обращений к страницам программы и к страницам данных, причем изредка встречаются пары последовательных обращений к страницам текста про-
SUBROUTINE LEU (REF.N,FRAMES.PAGES) C С ЭТА ПОДПРОГРАММА ПОЛУЧАЕТ НА ВХОД ПОСЛЕДОВАТЕЛЬНОСТЬ С REF(1)...........REF{N) ОБРАЩЕНИЙ К СТРАНИЦАМ , ЦЕЛОЕ
С =FRAMES= УКАЗЫВАЕТ ЧИСЛО СТРАНИЧНЫХ ОБЛАСТЕЙ, А ЦЕ-С ЛОЕ =PAGES = УКАЗЫВАЕТ ЧИСЛО РАЗЛИЧНЫХ СТРАНИЦ» ПОД-с ПРОГРАММА НАХОДИТ ЧИСЛО СТРАНИЧНЫХ ОТКАЗОВ , ВЫЗВАН-С НЫХ ДАННОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ ПРИ ИСПОЛЬЗОВАНИИ С АЛГОРИТМА ЗАМЕЩЕНИЯ LFU. ПОДПРОГРАММА ПЕЧАТАЕТ С СТРОКУ ОБРАЩЕНИЙ REF(1)..»REF(N), ПОСЛЕДОВА-С ТЕЛЬНОСТЬ FAULT!1)...FAULT(N), ГДЕ FAULT( 0=1, ЕСЛИ С REF(I) ВЫЗЫВАЕТ СТРАНИЧНЫЙ ОТКАЗ , И FAULT!1)=0 В с ОСТАЛЬНЫХ СЛУЧАЯХ. ОНА ТАКЖЕ ПЕЧАТАЕТ ОБЩЕЕ ЧИСЛО С СТРАНИЧНЫХ ОТКАЗОВ, ВЫЗВАННЫХ ДАННОЙ ПОСЛЕДОВАТЕЛЬ-С НОСТЬЮ И ЧАСТОТУ ОТКАЗОВ ДЛЯ ЭТОГО ЧИСЛА СТРАНИЧНЫХ
с ОБЛАСТЕЙ
С С === ФОРМАЛЬНЫЕ ПАРАМЕТРЫ С с REF(1)...REF(N) СТРОКА ОБРАЩЕНИЙ К СТРАНИЦАМ
С С FRAMES ЧИСЛО СТРАНИЧНЫХ ОБЛАСТЕЙ
С С PAGES ЧИСЛО СТРАНИЦ ПРОГРАММЫ
С С === ВНУТРЕННИЕ ПЕРЕМЕННЫЕ
С
с ENTER! I) ЗАПОМИНАЕТ САМОЕ ПОСЛЕДНЕЕ ОБРАЩЕ-
С НИЕ К СТРАНИЦЕ I.
С
С FAULT!I) =1 Если REF!I) ВЫЗЫВАЕТ СТРАНИЧНЫЙ
С ОТКАЗ, =0 В ОСТАЛЬНЫХ СЛУЧАЯХ
С С FRAME! I) =J ЕСЛИ СТРАНИЦА J В ОБЛАСТИ I
С
С FREQ!I) ЧИСЛО ПОЯВЛЕНИЙ СТРАНИЦЫ I В СТРОКЕ
С ОБРАЩЕНИЙ
С
С TABLE!I) ЕСдИ СТРАНИЦА I РАЗМЕЩЕНА В ОБ-
С ЛАСТИ J, =0 ЕСЛИ СТРАНИЦЫ I НЕТ В
С ПАМЯТИ
С С TOTAL ОБЩЕЕ ЧИСЛО СТРАНИЧНЫХ ОТКАЗОВ,
С ВЫЗВАННЫХ REF{1)...REF(N)
С INTEGER REF(N).FRAMES,PAGES INTEGER ENTER(IOO),FAULT(1000),FRAME(50).FREQUOOJ INTEGER TABLE(IOO).TOTAL
Рис. 5.4.4. Реализация алгоритма LFU,
С ИНИЦИАЛИЗАЦИЯ ПЕРЕМЕННЫХ С
J 3 1 TOTAL 3 О DO 10 I « 1,PAGES TABLE!I) 3 О FREQ!I) - О ENTER!f) - 0 10 CONTINUE
C
С ЦИКЛ ПО СТРОКЕ ОБРАЩЕНИЙ
с
DO 100 I 3 1 ,N c
С ПОЛУЧЕНИЕ l-ГО ОБРАЩЕНИЯ И УВЕЛИЧЕНИЕ ЕГО ЧАСТОТЫ С
К 3 REF(1) FREQ(K) = FREQ(K) + 1
С с НАХОДИТСЯ ЛИ К-Я СТРАНИЦА В ПАМЯТИ с
IF(TABLEfK) .NE. Oj GO TO 20 GO TO 30 c с НЕТ СТРАНИЧНОГО ОТКАЗА
С
20 FAULT! I) = 0
GO TO 100
C
С, СТРАНИЧНЫЙ'ОТКАЗ
С 30. FAULT! I) =1
TOTAL 3 TOTAL + 1 c С ВСЕ ЛИ СТРАНИЧНЫЕ ОБЛАСТИ ЗАПОЛНЕНЫ
С
IFIJ .GT. FRAMES) GO TO 40 GO TO 90
С НАЙТИ НАИМЕНЕЕ ЧАСТО ИСПОЛЬЗУЕМУЮ СТРАНИЦУ
с ДЛЯ УДАЛЕНИЯ
40 М 3 1
М1 =. FRAME(1) MIN = FREQ(M1) DO 80 L 3 2, FRAMES L1 = FRAME(L) !F(M IN-FREQO-1) ) 80,70,50 50 MIN = FREQ(LI)
60 H = L-
M1 3 LI
GO TO 80
70 IF(ENTER(M1) - ENTER(LI) ) 80,80,60
80 CONTINUE
Рис. 5.4.4. Продолжение
С УДАЛЕНИЕ наименее часто используемой страницы
с И РАЗМЕЩЕНИЕ страницы, к в памяти
с
Л = FRAME (М) fRAME(M) = И enter!к) = I TABLE!К) « М TABLE!Л) =. О СО ТО 100 с РАЗМЕЩЕНИЕ СТРАНИЦЫ К В ОБЛАСТИ J
90 TABLE!К) « J
FRAME (Л = К ENTER!К) - I J - J ♦ 1 100 CONTINUE
Г.
С ПЕЧАТЬ РЕЗУЛЬТАТОВ С
WRITE (6,900) FRAMES .PAGES
900 РОКМАТ(1НО,39НАЛГОРИТМ УПРАВЛЕНИЯ СТРАНИЧНОЙ ПАМЯТЬЮ 1 9H LEU ДЛЯ ,13,12'Н ОБЛАСТЕЙ И ,13,8Н СТРАНИЦ)
WRITE (6,950)
950 FORMAT! WO,37НСТР0КА ОБРАЩЕНИЙ И ПОСЛЕДОВАТЕЛЬНОСТЬ, 1 8Н ОТКАЗОВ)
WRITE (6,100.0) (REF(I).I-1.NJ
WRITE (.6,1000) {FAULT! I), 1-1 ,NJ
1COO FQRMAT(1HO,4OJ3) C.
с ПЕРВЫЕ =FRAMES = ОТКАЗОВ - СВОБОДНЫЕ С
TOTAL = TOTAL = FRAMES
RATE = FLOAT(TOTAL) I (N-FRAMES)
WRITE (6,1010) TOTAL,RATE
1010 FORMAT(1 HO,21H ЧИСЛО ОТКАЗОВ РАВНО ,13,ЮН А ЧАСТОТА 1 7Н РАВНА ,F6.3)
RETURN ENO
Рис. 5.4.4. Продолжение
граммы. Кроме того, принцип локальности предполагает, что обращения к страницам с текстом программы будут концентрироваться вокруг небольшого количества страниц с текстом программы в течение некоторого периода времени, а затем переходить к другому множеству страниц. Таким образом, мы предполагаем, что:
ннц текста программы и 14 страниц данных.
1. За каждым обращением к странице с текстом программы будет следовать обращение к странице с данными в 98% случаев; в 2% случаев за ними будут следовать обращения к произвольно выбранной новой странице с текстом программы.
2. Страница данных выбирается по принципу «самого последнего обращения». С этой целью для запоминания страниц с данными в порядке самого последнего обращения используется стек. Новые страницы данных выбираются из вершины стека и ниже с соответствующими вероятностями 0.50, 0.25, 0.125, 0.0625, 0.03125 и т. д.
3. Если выбрана некоторая страница данных, за ней в 98% случаев следует обращение к предыдущей странице текста программы. В 2% случаев за ней следует другая произвольно выбранная страница с текстом программы.
4. Строка обращений длины N= 10 000 считается достаточной для того, чтобы произошли обращения ко всем страницам.
Рис. 5.4.6 показывает, какой могла бы быть типичная строка обращений к страницам, основанная на этих предположениях. На рис. 5.4.7 представлены результаты испытания пяти алгоритмов управления страничной памятью. Эти результаты позволяют предполо-
жить, что алгоритм LRU следует предпочесть алгоритмам RANDOM, FIFO и LFU — факт, подтверждаемый практикой.
Упражнения 5.4
5.4.1. Постройте схемы замещения страниц, аналогичные рис. 5.4.1, хотя бы еще для одного алгоритма управления страничной памятью из этого раздела.
СТРОКА ОБРАЩЕНИЙ’ К, СТРАНИЦАМ ДЛЯ ПРОГРАММЫ, ЗАНИМАЮЩЕЙ 20 СТРАНИЦ
СТРАНИЦЫ 1 ... 6 ЗАНЯТЫ' ТЕКСТОМ ПРОГРАММЫ
СТРАНИЦЫ 7. . . 20 ЗАНЯТЫ ДАННЫМИ
1 11 1 11 1 11 1 11 1 11 1 11 6967676 1С
6 11 6 11 6 10 6 10 6 10 6 11 ft 9 6 9 6 7 в 7
67696967676767696Т67 67696767676 11 6 11 696769 6 7 6 7 6 7 6 10 6 7 6 11 6 10 6 10 6 11 6 11
6 11 6 10 6 10 6 10 6 11 6 10 6 10 6 10 6 10 6 11
6 11 6 11 6 7 6 Т 6 7 6 11 6 11 6 10 6 10 6 11
6 10 6 10 6 11 6 7 6 7 6 7 6 7 6 10 6 10 6 10
6 10 6 10 6 10 696969696 10 6В6 10 6 10 6 10 6 10 6 10 666866469 10 9 6 49494 .9 Ч949Ц 7 47974 15 9 15 4 9 4 9 9 ? ч 9 9 10 9 16 9 16 9 10 4 10 9 16
4 10 9 10 4 10 4 16 4 9 9 15 9 7 9 7 4 7 4 15
479797974 15 4797474999 9 94 10 4 10 4 15 4 15 4 15 49494949
4 15 4 7 4 7 4 15 4 15 4 15 4 15 4 15 4 15 4 в
4 10 4 10 4 10 9 в 4 в 4 Ю 4 10 4 10 4 10 4 10
4 10 4 10 4 Ю 4 10 4 16 4 10 4 в 9 15 4 15 4 7
Рис. 5.4.6. Цепочка обращений к страницам для программы с 20 страницами; страницы с 1 по 6 — текст программы, а страницы с 7 по 20 — данные.
5.4.2. Реализуйте алгоритм RANDOM.
5.4.3. Реализуйте алгоритм BEST.
5.4.4. Алгоритмы управления страничной памятью (проверка). Ради простоты и краткости обсуждения мы сделали ряд упрощающих предположений. Оцените критически эти предположения и процедуры проверки, которым мы следовали в этой главе.
L5.4.5. Алгоритмы управления страничной памятью (проверка). Исследуйте процедуры управления страничной памятью (если таковые существуют), применяемые на вашей ЭВМ.
L5.4.6. Алгоритмы управления страничной памятью (проверка). Алгоритмы управления страничной памятью, рассмотренные в данном разделе, проверены недостаточно тщательно. Подкрепите проведенное обсуждение собственными экспериментами.
5.5. Параллелизм
За последние 30 лет развития вычислительной техники были сделаны поистине впечатляющие достижения в областях скорости, размера и сложности компьютеров. Начав с компьютеров, обладавших памятью 8К. слов и с миллисекундным циклом (10_? с), мы пришли
1.00
0.90
Число страниц В памяти
Рис. 5.4.7. Результаты испытания пяти алгоритмов управления страничной памятью.
к таким компьютерам, как ИЛЛИАК IV, обладающий памятью в | 512К 64-битовых слов и циклом 240 нс (нс = 10~® с). В основном повышение производительности больших машин за прошедшие годы было достигнуто за счет прогрессивных компонентов, в особенности за счет микроминиатюризации электронных схем.
Однако при наблюдаемом повсюду ненасытном аппетите в отношении все больших и более быстрых компьютеров мы, по-виднмому, подходим к технологическому тупику, который воспрепятствует значительным достижениям в будущем. Скорости сегодняшних компьютеров фактически ограничены из-за физической длины проводов, которые используются для передачи данных.
Одним из многообещающих путей обхода ограничения скорости из-за времени передачи данных является перестройка вычислительных систем на параллельное выполнение большего числа операций. Эта идея привела к развитию многопроцессорных систем, структурированных процессоров для обработки массивов, неструктурированных машин для обработки линейных массивов, ассоциативных процессоров и конвейерных процессоров. Это все различные виды параллельных машин.
Укажем на нескольких примерах, как можно использовать па-раллелизм для ускорения вычислений:
1. Одновременное выполнение операций ввода/вывода и вычислений в программе.
2. Присвоение нулевого значения всем элементам массива.
3. Арифметическая обработка вектора или массива, например А *-4— BJ-C, где В и С — векторы или матрицы (эта возможность уже реализована в таких языках, как APL).
4. Одновременное отслеживание ветвей и границ в различных узлах древовидной структуры.
5. Выполнение одинаковых последовательностей операций над различными множествами данных.
6. Выполнение различных и независимых операций над одним и тем же множеством данных.
7. Конвейерная обработка, или предвидение, т. е. одновременная обработка различных команд в последовательном списке команд, когда эти команды находятся на различных стадиях выполнения.
8. Выполнение одновременного поиска.
9. Параллельная сортировка.
10. Выполнение одновременных функциональных преобразований, например, при поиске максимума или нуля функции.
Мы не собираемся утверждать, что все вычисления можно «сделать» параллельными. В этой связи, по-видимому, за краткую историю параллельных вычислений выработалось эмпирическое правило, называемое эффектом Амдаля. Грубо говоря, оно гласит, что для достаточной эффективности вычислений на параллельной машине с т процессорами вычисления должны распадаться на т потоков данных, причем нужно, чтобы последовательно выполнялась существенно меньшая, чем 1/т, доля сегментов. Эффект Амдаля основан на отсутствии внутреннего параллелизма в большинстве современных программ. Хотя реальный мир сам по себе «параллелен», наш алгоритмический подход к нему в своей основе последовательный. Отчасти это объясняется более чем тремя столетиями последовательной математики и более чем двумя десятилетиями последовательного программирования на Фортране.
Параллельный алгоритм отыскания остовного дерева
Давайте начнем с некоторых интуитивных представлений, необходимых для разработки и анализа параллельных алгоритмов. Вернемся к алгоритму построения остовного дерева минимального веса из гл. 4. Можно попытаться построить параллельную версию этого алгоритма, рассмотрев, что произошло бы, если бы мы одновременно выбрали по ребру с наименьшим весом, инцидентному каждой вершине во взвешенной сети G,
Из примера на рис. 5.5.1 видно, что если бы мы так сделали, то могли бы выбрать нежелательный цикл из ребер, например для Vi выбрать ef2, для vs выбрать е24, для vi выбрать e4i. Мы могли бы также выбрать е64 для v5, е62 для и е32 для f3. Одновременно выбранные ребра показаны жирными линиями.
Однако если мы выберем для каждой вершины vt то из ребер наименьшего веса, которое инцидентно вершине Vj (j^i) с наименьшим индексом, то мы исключим возможность циклов. Чтобы показать
Рис. 5.5.1. Цикл из ребер, полученный одновременным выбором в каждой вершине любого ребра с наименьшим весом.
это, предположим, что vt, v}, vk, — цикл, выбранный этим способом, т. е. ец выбрано для vit ejk выбрано для Vj, a ek! выбрано для vh. Предположим, что i — наименьший индекс среди i, j, k. Отсюда следует, что вес так как если то ei} было бы вы-
брано для Vj. По тем же причинам wj^wki и wk^wi}. Таким образом, все веса должны быть равны. Если это так, то eiS должно быть выбрано для vit так как i — наименьший индекс. Это противоречит нашему предположению, что ejk выбрано для Vj. Аналогичные рассуждения можно провести для цикла из любого числа ребер.
Рис. 5.5.2. Остовное дерево, полученное одновременным выбором ребер, имеющих наименьший вес и наименьший индекс.
На рис. 5.5.2 показаны ребра, которые были бы выбраны при такой модификации. Отметим, что это правило не только позволяет нам отыскать остовное дерево в G за один «параллельный» шаг, но
7 1 6
Рис. 5.5.3. Сеть, требующая более чем одного параллельного шага для отыскания остовного дерева минимального веса.
это дерево имеет минимальный вес! Сеть G на рис. 5.5.3, однако, показывает, что такой параллельный алгоритм не всегда оказывается настолько быстрым.
Теперь предложим алгоритм, принадлежащий Соллину и являющийся простой модификацией описанной процедуры.
Algorithm SOLLIN. Для отыскания остовного дерева Т минимального веса во взвешенной связной сети G с М. вершинами Vlt Vs, .... Ул. и N ребрами.
Шаг 1. [Выбор ребер с наименьшим весом.] Выбирается одновременно для каждой вершины V в G ребро с наименьшим весом, инцидентное V; if одинаковый наименьший вес имеют два или более ребер, инцидентных V then выбрать
ребро, соединяющее V с вершиной, обладающей наименьшим индексом fi; set К число уже выбранных ребер.
Шаг 2. [Выбраны уже М—1 ребер?] While K<ZM—1 do шаг 3 od; and STOP.
Шаг 3. [Выбор ребер между поддеревьями]. Пусть Tlt Т2, . . ., TL обозначают поддеревья С, образуемые выбранными к данному моменту ребрами; одновременно выберем для каждого поддерева Тt ребро с наименьшим весом между некоторой вершиной в Tt и любым другим поддеревом Tj\ if одинаковым наименьшим весом обладают два или более ребер, скажем (Vp, VQ) и (Рд, Vs), then выбрать ребро по следующему правилу, предполагая P<ZQ и /?•<£:
if P<ZR then выбрать (Vp, V~) fi;
if P<ZP then выбрать V$) fi;
if P=R then if Q<S then выбрать (Vp, VQ) else выбрать (V„, Vs) fi fi;
set К число уже выбранных ребер.
Прежде чем комментировать правильность и сложность алгоритма Соллина, проиллюстрируем его на примере.
Применив шаг 1 алгоритма к сети G на рис. 5.5.3, мы обнаружим четыре поддерева 7\, Т2, 7\ и Тй на рис. 5.5.4. Три ребра (е27, е23 и е36), соединяющие с другим деревом, имеют одинаковый вес (2); из этих ребер мы выберем е27, так как 2 — наименьший индекс. Для выбор производится между е4, и е53; мы выбираем е53, так как 3 — наименьший
индекс. Для TR выбор происходит между е72, е68 и е63; выбираем е7Я. Наконец, для Тг из е82 и £86 выбираем е82. Таким образом, после однократного применения шага 3 мы получаем остовное дерево минимального веса, приведенное на рис. 5.5.5.
Чтобы установить правильность алгоритма SOLLIN, достаточно показать справедливость следующих утверждений:
Однократное применение шага 1 дает лес.
Рис. 5.5.4. Поддеревья сети с рис. 5.5.3, сформированные алгоритмом SOLLIN за один шаг.
Рис. 5.5.5. Остовное дерево минимального веса, найденное алгоритмом SOLLIN за два шага.
Если множество ребер, выбранных до шага 3, образует лес, то это же верно для множества ребер, выбранного после шага 3.
Шаг 3 (и шаг 1) выбирает по крайней мере одно ребро; это гарантирует, что алгоритм SOLLIN завершит работу за конечное число шагов.
Если эти утверждения верны, то можно утверждать, что алгоритм SOLLIN находит остовное дерево Т. Остается только показать, что:
Остовное дерево Т, найденное алгоритмом SOLLIN, имеет минимальный вес.
Доказательства этих четырех предположений можно построить как обобщение доказательств, проведенных для алгоритма PRIM в гл. 4; они предлагаются в качестве упражнений.
Пример н.а рис. 5.5.4 иллюстрирует, что минимальное возможное число ребер, выбранных на шаге 1, равно М/2 и что в этом случае образуется |_Л4/2 J поддеревьев. По тем же причинам очевидно, что если при входе в шаг 3 было сформировано г поддеревьев, то будет выбрано по крайней мере f г/2"] дополнительных ребер при однократном применении шага 3. Кроме того, очевидно, что каждое из этих выбранных ребер уменьшит на 1 число остающихся поддеревьев.
Таким образом, если мы обозначим через n(k) число деревьев, ос-тающихся после (k—1)-кратного применения шага 3 и однократного применения шага I, то
или в общем виде
Если обозначить через К наименьшее целое, для которого то в наихудшем случае К удовлетворяет неравенству 2А'~1</И^2А', т. е. /C^log2M. Следовательно, в наихудшем случае алгоритм SOLLIN выполняет 0(log2Al) шагов.
Такова элементарная часть анализа сложности алгоритма SOLLIN. Сколько операций и сколько времени потребуется на выполнение каждого шага алгоритма? Ответ на этот вопрос зависит от типа ЭВМ и других факторов.
Представим, что у нас имеется М процессоров (компьютеров) Р±, Pit . . ., Рм, каждый из которых назначен одной из вершин Vi, и^, . . ., vM сети G. На любом шаге алгоритма каждый процессор Pt будет, по существу, просматривать i-ю строку матрицы смежности сети G, отыскивая ребро с наименьшим весом и наименьшим индексом, от Vi до какой-нибудь вершины в дереве, отличающемся от дерева, которое содержит Vj. Представим, что с каждой вершиной связана метка TREE(i) поддерева, к которому в данный момент времени принадлежит вершина vt. На рис. 5.5.6 показаны матрица смежности для сети
1 2 3 4 5 6 7 8 Дерево Дерево Дерево
р,-*1 0 оо ОО оо ОО 4 оо 1 1 1 1
Р2-*2 оо 0 1 ©° 4 оо 2 2 2 2 1
р3-*з оо 1 0 ОО 3 2 ОО СЮ 3 2 1
Р«-4 со оо ОО Qi* 1 оо 3 оо 4 4
Ps-5 оо 4 3 1 0 оо оо оо 5 4 ।
Р6-*6 4 оо 2 оо ОО 0 1 2 6 6 1
Р7->7 оо 2 °° 3 ОО 1 0 оо 7 6 1
Ps-*8 1 2 оо оо ОО 2 оо 0 8 1 1
Рис. 5.5.6. Применение параллельных процессоров Ръ Р2, .... Р8 для реализации алгоритма SOLLIN.
рис. 5.5.3 и метки TREE, которые могли бы появляться после шага 1, после шагов 2 и 3 и после второго исполнения шагов 2 и 3.
Следовательно, шаг 1 может исполняться параллельно за время 0(М), но он потребует от каждого из М процессоров 0(М) шагов, т. е. будет выполнено О(М'2) шагов.
На шаге 3 процессор Pt снова просмотрит все ребра, инцидентные вершине vt, для отыскания наименьшего индекса на ребре с мини
мальным весом, идущем к вершине в другом дереве от vt. Для всех процессоров это потребует 0(М) времени и 0(М2) шагов. Кроме того, потребуется второй проход [О (А4)] по всем вершинам для выбора ребра с наименьшим весом в каждом дереве Тj. Окончательный проход [О(Л4)1 по всем вершинам потребуется для обновления вектора TREE и объединения поддеревьев.
Таким образом, алгоритм SOLLIN потребует времени 0(М) на шаг 1 и О (М) на каждое из О (|_ Iog2M J) исполнений шагов 2 и 3, т. е. он потребует 0(М Iog2TW) времени. Однако легко видеть, что он выполнит 0(M2log27W) операций. Сравните это с алгоритмом PRIM, требующим 0(М2) времени и 0(М2) операций.
О языках параллельного программирования
Для реализации параллельного алгоритма, аналогичного алгоритму SOLLIN, нам понадобилась бы вычислительная система с достаточным количеством процессоров, способных выполнять команды параллельно и независимо друг от друга. Нам также понадобился бы язык
6
а
Рис. 5.5.7. Преобразование после-» довательного процесса в параллельный.
программирования, который позволял бы выразить параллелизм в алгоритмах, т. е. такой, чтобы он позволял записывать команды, реализующие слово «одновременно».
Рассмотрим блок-схему на рис.
5.5.7, а. Если блоки программы
Q2 и Q3 могут выполняться одновременно, а блок Q4 может быть выполнен только после выполнения всех команд блоков Qi, Q2 и Qs, то мы могли бы перейти от последовательной схемы на рис. 5.5.7, а к параллельной на рис. 5.5.7, б. На языке программирования это можно было бы выразить так:
{Q1//Q2//Q3}; &
Эта запись показывает, что блоки Qi, Q2 и Q3 независимы и могут выполняться параллельно. Чтобы гарантировать, что мы достигнем желаемого результата, мы могли бы потребовать, чтобы ни одна из переменных, изменяемых в не использовалась в Qj
Действие этого оператора состоит в инициации выполнения каждого блока операторов параллельно. Оператор завершается — и Q4 может выполняться — только после завершения всех операторов во всех блоках
Внутри каждого блока можно использовать большинство обычных типов операторов, как то: присваивания, условные операторы, цик
лы DO, вызовы подпрограмм. Возможно, придется сделать исключение для условных переходов из данного Qj (или снаружи в него), реализовать которые было бы затруднительно.
Подобные операторы реализованы в фортраноподобном языке IVTRAN, который был разработан в Иллинойском университете для ЭВМ Иллиак IV- с высокой степенью параллелизма. Оператор имеет вид
DO k CONC FOR ALL (it, i2, . . in) £ S
где k — метка выполняемого оператора, ограничивающего цикл DO; (it, i2, . . ., in),— последовательность целочисленных индексных переменных; S — конечное множество наборов по п целых чисел, которые служат для определения диапазона допустимых значений индексных переменных. Цель этого оператора состоит в том, чтобы назначить по одному процессору каждому набору из п чисел, например (сч, и2, . . ., vn)£S. Этот процессор далее будет выполнять все операторы, лежащие внутри цикла DO, в предположении it=Vi, i2=v2, . . ., in=vn. Одновременно другие процессоры, соответствующие различным наборам по п чисел, будут выполнять те же операторы внутри цикла DO.
Например, рассмотрим следующий сегмент текста программы, вычисляющий параллельно квадратный корень от каждого элемента массива В (3x5) и помещающий результат в массив А:
DO 10 CONC FOR ALL (I,J)6{1 sls3,1 £js5)..
A(l, J) = SQRT(B(I, J)) 10 CONTINUE
Этот параллельный цикл DO потребует 15 различных процессоров, каждый из которых будет выполнять тело этого цикла DO, что называется, асинхронно, т. е. никакие два процессора не обязаны выполнять одну и ту же команду в точности одновременно.
При параллельной обработке встречаются случаи, когда эффективнее заставить все процессоры работать полностью синхронно. Для Иллиака IV такой режим можно задать с помощью следующего оператора:
DO k SIM FOR ALL (it, i2, . . in)$S
где S — конечное множество наборов целых чисел по п штук. Этот оператор подобен оператору DO k CONC, за исключением того, что команды в цикле DO выполняются синхронно всеми процессорами.
Иногда возникает необходимость выполнить определенные вычисления последовательно. В виде цикла DO это можно выразить так:
DO k SEQ FOR К € {1<А<10}
Мы теперь можем объединить эти операторы в программе умножения двух матриц 10X 10 А и В; это потребует 10х 10=100 процессоров.
DO 200 CONC FOR ALL (I, J)e{1 £ls10,1 sJS10} C(I.J) = 0
'DO 100 SEQ FOR Ke{1sKs10} C(l, J) = C(l, J)+A(I,K) * B(K, J)
100 CONTINUE
200 CONTINUE
Параллельный алгоритм сортировки
Рассмотрим задачу сортировки п целых чисел или ключей. Предположим, что имеется п процессоров Ри Р2, . . Рп. В каждом из них помещен один ключ. Не теряя общности, предположим, что целые числа ilt 1ъ, . . ., in представляют собой первые п натуральных чисел. Рис. 5.5.8 иллюстрирует одну из возможных конфигураций для п=8.
Pi Рг Р3 р< Ps р6 рт рв
6 3 7 2 8 4 1 5
ч z з Ц ’s в <7 ’8
Рис. 5.5.8. Восемь параллельных процессоров для упорядочения целых чисел 1,2,... ,8 при заданном начальном расположении.
Каждому процессору Pt разрешено связываться и обмениваться ключами только с двумя процессорами Pt_t и Pt+t, его непосредственными соседями слева и справа. Например, на рис. 5.5.8 Рв может связываться только с Р& и Р7.
Algorithm PARSORT (параллельная сортировка) для перестановки N ключей 1и /2, . . ., JN в порядке возрастания.
Шаг 0. [Инициализация] Set М ч- 0; and TIME 0.
Шаг 1. [Чередовать, пока дважды не произойдет ни одного обмена местами в строке]
DO through шаг 3 while Ml=£2 od; and STOP.
Шаг 2. [Четный или нечетный] If TIME четно
then одновременно сравнить ключи /2А в процессорах Р2А-с ключами в процессорах P2A._t для всех К=1, 2, . . ., M/2; if Izk^Izk-i then обменять местами ключи в этих двух процессорах fi
else одновременно сравнить ключи 12К в процессорах Р2/( с ключами /аА.+1 в процессорах P2A+i для всех К = 1, 2, . . ., M/2; if /2А-+1< </2А- then обменять ключи в этих двух процессорах fi fi.
Шаг 3. [Были обмены?] If хотя бы один обмен произведен на шаге 2 then set М ч- 0 else set М -*-Л14-1 fi; set TIMETIME+1.
Алгоритм PARSORT чередует сравнение /2Д. с или при исполнении шагов 1 и 2 до тех пор, пока при двух последовательных шагах расположение не останется неизменным.
1ШаП
2 Шаг 2 5Шэг1
W 2 5шаг1 £Шаг2
7Шаг 1
В Шаг 2
ЗШаг1
Окончание
Рис. 5.5.9. Диаграмма сортировки алгоритмом PARSORT.
На рис. 5.5.9 показано, как алгоритм PARSORT сортировал бы ключи с рис. 5.5.8. Такое изображение называется диаграммой сортировки. Заметим, что, хотя алгоритм останавливается после выполнения м-|-1=9 шагов, фактически он завершает сортировку за семь шагов. Далее мы докажем, что сортировка всегда завершается не более, чем за п шагов.
Теорема 5.5.1. Алгоритм PARSORT упорядочивает в порядке возрастания произвольный набор п ключей ilt iz, . . ., in не более, чем за п шагов.
Доказательство. Доказательство проводится индукцией по числу ключей п. Легко убедиться непосредственно, что при п=1, 2, 3 алгоритм работает в соответствии с формулировкой теоремы.
Предположим далее, что алгоритм PARSORT может упорядочить произвольный набор т ключей не более, чем за т шагов. Нам нужно
показать, что он сможет упорядочить произвольный набор ilt iz, . . im+i из т-1-1 ключей не более, чем за /п+1 шагов.
Рассмотрим диаграмму сортировки алгоритмом PARSORT ключей ii, iz, . . ., ira+i. Рассмотрим также путь наибольшего ключа, т. е. рассмотрим путь целых чисел, помеченных как М=т-}-\. Общий вид этого пути показан на рис. 5.5.10.
Рис. 5.5.10. Путь наибольшего ключа М по диаграмме сортировки.
Рис. 5.5.11. Объединение частей А и В диаграммы сортировки.
Такой путь делит диаграмму сортировки на две части А и В. Рассмотрим диаграмму, которая получится после удаления этого пути и
объединения двух частей по точкам а и а', b и Ь', с и с' и т. д. (рис. 5.5.11).
Очевидно, что, за исключением частично заполненной верхней строки на рис. 5.5.11, б, остальная часть рис. 5.5.11, б является диаграммой сортировки для т ключей. По предположению индукции т элементов второй строки этой диаграммы упорядочиваются не более, чем за т шагов. Считая верхнюю строку еще одним шагом, получим, что первоначальные /п+1 ключей упорядочиваются не более, чем за /п+1 шагов.
Заметим, что алгоритм PARSORT требует только постоянного числа операций с для параллельного выполнения шагов 1 и 2. Таким образом, алгоритм упорядочивает ключи в реальном времени, т. е. за 0(п) шагов по времени, производя на каждом шаге п/2 сравнений. Следовательно, он требует всего 0(п2) сравнений.
Компромиссы сложности параллельных вычислений
На примере алгоритма SOLLIN мы видели, что параллельные вычисления позволяют увеличить скорость работы алгоритма с О(Л42) до 0(М iog2M).Mbi убедились, что наилучшие алгоритмы последовательной сортировки требуют 0(М log2M), а алгоритм PARSORT — 0(М). В литературе имеется достаточно свидетельств того, что, грубо говоря, можно получить выигрыш на порядок величины, если реализовать алгоритм в параллельной модификации. Это утверждение содержится в так называемой гипотезе Минского: параллельные машины, выполняющие последовательную программу над п множествами данных, повышают производительность по крайней мере на множитель О (log п).
Хотя гипотезе Минского найдено несколько контрпримеров, в достаточно большом числе случаев она, по-видимому, дает удовлетворительную оценку повышения скорости вычислений.
Такое повышение скорости не дается бесплатно. Платой оказывается добавление п процессоров, увеличение на порядок величины числа выполняемых операций и, возможно, довольно низкий коэффициент использования процессоров. Вообще говоря, по-видимому, трудно занять все процессоры работой на все время.
Упражнения 5.5
5.5.1. Воспользуйтесь (вручную) алгоритмом SOLLIN для отыскания остовного дерева минимального веса в сети на рис. 5.5.12.
5.5.2. Примените алгоритм PARSORT для упорядочения (вручную) последовательности
12 4 8 11 7 5 6 2 9 3 1 10
*5.5.3. Операции над множествами и арифметические операции. Какие операции над множествами и арифметические операции, по вашему мнению, особенно просто реализовать в виде параллельных алгоритмов? Какие, как вам кажется, особенно трудно запараллелить?
Б.5.4. Напишите простую программу, использующую одну или более параллельных языковых конструкций, описанных в этом разделе.
*5.5.5. Покажите, что всегда можно занумеровать вершины произвольной сети так, чтобы алгоритм SOLLIN нашел остовное дерево минимального веса за один параллельный шаг. Имеет ли этот факт какое-нибудь практическое значение?
Рис. 5.5.12. Найдите остовное дерево минимального веса с помощью алгоритма SOLLIN.
**5.5.6. Алгоритм SOLLIN (доказательство). Восстановите опущенные детали доказательства для алгоритма SOLLIN.
5.5.7. Алгоритм PARSORT (анализ). Какие исходные конфигурации заставляют алгоритм PARSORT выполнить наибольшее количество обменов?
**5.5.8. Алгоритм PARSORT (анализ). Предположим, что все размещения равновероятны. Каково среднее число обменов местами, производимых алгоритмом PARSORT?
***5.5.9. Кратчайшие пути (полное построение). Постройте полностью алгоритм отыскания кратчайшего пути между двумя заданными произвольными вершинами в сети, веса ребер в которой означают их длины. Последовательные алгоритмы отыскания кратчайших путей представлены в разд. 6.2.
Глава 6. Математические алгоритмы
На протяжении этой книги мы уже иллюстрировали многие концепции и методы, строя алгоритмические решения математических задач. В трех разделах этой главы содержится несколько дополнительных примеров.
В разд. 6.1 мы рассмотрим две игры и комбинаторную головоломку. Для всех трех задач будут построены самые эффективные стратегии и решения. Эти примеры представляют большое число игр и головоломок, решения которых просты и остроумны.
В разд. 6.2 ставится задача отыскания кратчайшего пути между двумя заданными вершинами в сети. Эта задача имеет много важных приложений в исследовании операций и вычислительной математике. Как мы увидим, алгоритм, построенный в этой главе, оказывается фактически идентичным алгоритму PRIM (гл. 4).
В разд. 6.3 рассмотрены алгоритмы, использующие случайные числа. Первый из этих алгоритмов дает эффективный способ выбора случайного набора М объектов из множества N (M^N) объектов. Остальная часть этого раздела посвящена алгоритмам генерации случайных чисел.
6.1. Игры и комбинаторные головоломки
В этом разделе мы изучим классическую комбинаторную головоломку и две игры, что позволит проиллюстрировать ряд интересных процедур.
В нескольких местах этой книги изучались другие игры, например головоломка «8» и тур коня в разд. 2.1 и 3.3 соответственно. В алгоритмах решения этих задач применялись поисковые и эвристические методы, использующие скорость и вычислительную мощность компьютера. Большинство машинно-ориентированных реализаций игр характеризуется тем же. В данном разделе будут приведены различные примеры. Каждый содержит очень эффективный точный алгоритм, который настолько прост, что его труднее реализовать в виде машинной программы, чем выполнить с помощью карандаша и бумаги.
Магические квадраты
Магическим квадратом порядка N называется такое расположение целых чисел в матрице NxN, что суммы элементов по каждой строке, каждому столбцу и двум главным диагоналям совпадают.
Обычно выбирают целые числа 1, 2, . . №. На рис. 6.1.1, с показан
единственный магический квадрат порядка 3. Мы исследуем алгоритмы построения нечетных и дважды четных (N=4 т, т=1, 2, 3, . . .) магических квадратов. Однократно четный случай (Лг=4т+2, т=1, 2, 3, . . .) будет оставлен в качестве упражнения.
Рис. 6.1.1. Построение магического квадрата порядка 3.
Нечетные магические квадраты (N=2m-|-l, т=0, 1, 2, ...). Следующая процедура будет порождать магический квадрат для нечетного N. Поместим число 1 в центральную позицию верхней строки. Затем перейдем вверх на квадрат и вправо на один квадрат для размещения следующего числа. Это перемещение может вывести нас за пределы массива, но простая схема на рис. 6.1.1, б показывает, куда на самом деле приводит нас такое перемещение при построении магического квадрата порядка 3. Это перемещение «вверх и вправо на один» — основная операция при построении магических квадратов нечетного порядка. Однако при каждом N-м перемещении мы сдвигаемся на позицию вниз при размещении очередного числа (рис. 6.1.1, в). Завершающие перемещения при построении магического квадрата порядка 3 показаны на рис. 6.1.1, а.
Algorithm ODDMS (магический квадрат нечетного порядка) для построения магического квадрата нечетного порядка N.
Шаг 0. [Инициализация] Set /-<- 1; and J ч- ((V+l)/2.
Шаг 1. [Цикл] For COUNT 1 to № do through шаг 3 od; and STOP.
Шаг 2. [Присваивание! Set SQUARE (7, J) COUNT.
Шаг 3. [Отыскание следующей позиции]
1 {(COUNT) MOD (М)=0
then set / 74-1
else if /=1 then set 1 N else set I *- I—1 fi; and if J=N then set J 1 else set J 74-1 fi fi.
Для демонстрации правильности алгоритма ODDMS удобно рассматривать все целые mod(X)1). Для всех целых k от 1 до № определим части Хи У как У— (А—1) mod(N)+l и Х=&—У (заметим, что /г=Х4-4-У). На рис. 6.1.2 показаны части X и У для целых чисел от 1 до 9 в магическом квадрате 3x3.
В последующем обсуждении удобнее представлять себе квадрат
N х N нарисованным на торе. Столбцы 1 и N окажутся соседними как и строки 1 и N.
Так как детальное доказательство для алгоритма ODDMS довольно утомительно, мы выделим только тот факт, что алгоритм размещает целые числа от 1 до № так, что суммы по строкам и по столбцам равны. Утверждение
6.2 0.1 3.3
0.3 3.2 6.1
3.1 6.3 о. г
Рис. 6.1.2. Части (X, Y) целых чисел k— 1, 2, ... . . ., 9, где X=k—Y и У=(/г—l)mod (У)+1
относительно диагональных сумм будет оставлено в качестве упражнения.
Целые числа от 1 до № можно считать расположенными в виде N групп по N последовательных чисел. В каждой группе части X по-
стоянны, а части У изменяются от 1 до N. Целые числа в каждой группе размещены в виде массива Ххй/ таким образом, что в каждой строке
и в каждом столбце содержится в точности один член этой группы. Это
следует из того, что алгоритм размещает все числа в каждой группе по-
следовательно, и из того, что координаты каждого числа отличаются на единицу от координат предыдущего, т. е. если k помещается в позиции (7, 7), то k+1 помещается в (/—1, 74-1). Следовательно, алгоритм размещает числа таким образом, что одни только части X сами образуют магический квадрат.
В каждой группе части У являются числами от 1 до N, размещенными в квадратах последовательно. Рассмотрим расположение всех чисел с частью У, равной 1 (рис.6 .1.2). Если некоторая единица расположена в (7Ъ /J, то следующая часть У=1 находится в (714-2, Ji—1). Это следует из того, что последний член первой группы (У=Х) помещается в (/i+l, Ji—1), а затем алгоритм «спускается» для размещения первого числа из следующей группы. Читателю следует убедиться, что алгоритм помещает У=1 в каждую строку и каждый столбец. Аналогичные доводы можно привести за то, что Y—j, j=l, . . ., N, помещается в каждую строку и в каждый столбец. Следовательно, части У сами по себе образуют магический квадрат.
х) По определению, если a (mod т)=х для целых а и т, то х — целый остаток от деления а на т. Например, 5 (mod 3)=2.
Дважды четные магические квадраты (7V=4m, m=0, I, 2,...). Этот алгоритм несколько сложнее алгоритма ODDMS. Мы начинаем с одного квадранта со стороной 2т, где N~$m для некоторого положительного целого т. Ради удобства выберем левый верхний квадрант. Теперь пометим 4m2 квадратов из этого квадранта произвольным образом, но так, чтобы в каждой строке и каждом столбце оказались помеченными в точности т квадратов. Для т—2 это показано на рис. 6.1.3, а.
1 63 3 61 60 6 58 8
56 10 54 12 13 51 15 49
17 47 46 20 21 43 42 24
40 26 27 37 36 30 31 33
32 34 35 29 28 38 39 25
41 23 22 44 45 19 18 48
16 50 14 52 53 11 55 9
57 7 59 '5 4 62 2 64
в г
Рис. 6.1.3. Построение магического квадрата порядка 8.
Теперь отразим эти пометки относительно вертикальной оси симметрии на правый верхний квадрант, а затем относительно горизонтальной оси симметрии на нижний левый квадрант. После этого отразим эти пометки в правый нижний квадрант относительно диагонали, идущей из нижнего левого угла в правый верхний. В результате получим множество пометок, показанное на рис. 6.1.3, б.
Просмотрим все квадраты слева направо и сверху вниз. Если квадрат не имеет пометки, поместим в него первое еще невыбранное число К из последовательности 1, 2, . . ., № и поместим число (№-*-1)—К
в отражение этого квадрата относительно центра. Если очередной квадрат содержит пометку, поместим число (№Н-1)—К в этот квадрат, а число К в его отражение. Продолжим эту процедуру вплоть до заполнения всего массива. На рис. 6.1.3, в показан пример заполнения квадрата после 14 шагов; на рис. 6.1.3, г приведен полностью заполненный магический квадрат.
Algorithm DEMS (дважды четный магический квадрат) для построения магического квадрата NxN, где N=4m для некоторого положительного целого т. Элементы магического квадрата запоминаются в линейном массиве MATRIX из № элементов.
Шаг 0. [Инициализация] Set HALFN *- 7V/2; MAR К 1; MIDDLE *-*-А/2; UPPER -<-№+1; and HALF-<-№/2-
Шаг 1. [Внешний цикл пометок] For К *- 1 to HALFN do through шаг 4 od. (Этот и следующий циклы задают первоначальную расстановку пометок первой половины массива.)
Шаг 2. [Внутренний цикл пометок] For J *- I to HALFN do шаг 3 od.
Шаг 3. [Расстановка пометок]
Set MATRIX (MIDDLE — 7+1) MARK; MATRIX (MIDDLE+J) *- MARK;
and MARK*- —MARK.
Шаг 4. [Переход к следующей строке] Set MIDDLE *-MIDDLE+M; and MARK*- —MARK.
Шаг 5. [Цикл расстановки чисел] For I ч- 1 to HALF do шаг 6 od; and STOP.
Шаг 6. [Запись чисел] Set L *- 7; if MATRIX (7)<0 then set L *- UPPER—7 fi (L — это будущая координата числа 7); set MATRIX (7.)7; and
MATRIX (UPPER—L) *- UPPER—7. (В массиве размещаются I и его отражение.)
Алгоритм DEMS использует шахматный порядок расстановки пометок в левом верхнем квадранте и число MIDDLE для попадания в середину каждой строки. Пометки ставятся одновременно в обоих верхних квадрантах. Очевидно, что сложность имеет порядок 0(№).
Чтобы убедиться в правильности этого алгоритма, снова воспользуемся частями (X, Y), введенными выше. Рассмотрим любые две строки, равноудаленные от центра, например, строки i—1 и N-—i. Эти две строки показаны на рис. 6.1.4. Все квадраты пронумерованы последовательно, начиная с левого верхнего угла, слева направо и сверху вниз. Иначе говоря, все квадраты пронумерованы так, как будто никаких пометок не существует. Заметим, что каждое число представлено в виде k=X+Y.
Все элементы, первоначально находившиеся в этих двух строках, остаются в них после всех перестановок, вызванных отмеченными квадратами в алгоритме. В (i—1)-й строке 2т частей X со значением X— — (i—1)А обмениваются местами с 2т частями X со значением Х=
= (N—i)N из строки N—i. По симметрии каждая перестановка в паре с другой затрагивают 4 числа. Алгоритм переставляет части Y этих четырех чисел таким образом, что в каждой строке имеется полный набор частей Y — от У=1 до Y=N— после того, как произведены
• • • i
(i-1)N + 1 (i-1)N + 2 • • • (i-1)N+N
(N-0N+1 (N-i)N + 2 • ° • (N-i)N + N
• • •
Рис. ®.1.4. Размещение чисел в двух строках, расположенных эквидистантно относительно центра, при использовании алгоритма DEMS.
все перестановки. Следовательно, после всех перестановок между этими двумя строками части Y каждой строки представляют перестановку целых чисел от 1 до N. Таким образом, сумма чисел в каждой строке после завершения работы алгоритма равна
ROWSUM= 1+ 2 + 3 +...+M + [(i—1) W+ (1V — t)=
_М(М + 1) М(№—N) 7V(№ + 1)
2 + 2 ~ 2
Это как раз та сумма, которая должна быть у магического квадрата (см. упр. 6.1.3).
Аналогичные рассуждения можно провести, чтобы показать, что в момент окончания работы алгоритма суммы по столбцам и главным диагоналям равны также [N (№+1)1/2.
Игра «нимбы»
«Нимбы» — это игра двух лиц, в которой существует изумительно простая стратегия выигрыша для одного из игроков.
Поле для игры представляет прямоугольную область, разделенную на клетки. Каждому игроку предоставлено одно из напр-авлений, вертикальное или горизонтальное, и ходы делаются поочередно. При данном ходе игрок, движущийся по горизонтали, захватывает незанятую клетку. Далее этот игрок занимает эту клетку и все клет
ки в этой же строке, которые могут быть достигнуты без пересечения границы поля или клеток, занятых противником. Если «горизонтальный» игрок ходит первым, как на рис. 6.1.5, то первый ход займет це-
лую строку. Второй игрок занимает клетки в столбцах аналогичным образом. Игра заканчивается, когда одному из игроков не останется клетки для очередного хода, что означает проигрыш. Полный пример игры приведен на рис. 6.1.5. Эта игра относится к классу игр с полной информацией. Это означает, что каждый игрок полностью знает прошлые ходы и возможности своего противника.
Прежде чем строить процедуру игры, попытаемся получить некоторое представление о ней, рассматривая аналогичную, но более простую игру. Правила этой игры те же, но поле в данном случае является квадратом Л'хЛ', а первый игрок, который не сможет сделать ход, будет теперь победителем.
На всех квадратных полях УхУ побеждает второй игрок В. У игрока А первоначально есть У возможных ходов. Каждый ход занимает прямоугольную область (часть строки). Если игрок В никогда не делит поле надвое ни на одном из ходов, то В не вмешивается в монотонное убывание числа возможных ходов игрока А. Так как А ходил первым, он делает последний ход и проигрывает, т. е. после (N—1)-го хода игрока В игрок А должен исчерпать поле. Если поле не квадратной формы, то игрок, движущийся параллельно короткой стороне, выиграет, пользуясь стратегией игрока В.
Теперь вернемся к «нимбам», игре, в которой первый из игроков, не имеющий хода, проигрывает. Все области будут помечены по четности их измерений, причем первым будет измерение, обращенное к А. Так, на рис. 6.1.5 область, остающаяся после первого хода игрока А, является четно-нечетной. Будет показано, что для А можно гарантировать выигрыш на четно-четном, нечетно-нечетном и нечетно-четном полях; для В можно гарантировать выигрыш на четно-нечетном поле. Таким образом, игрок В, движущийся параллельно четному измере
нию, может выигрывать на полях смешанной четности, а А может выигрывать на всех полях одинаковой четности.
Рассмотрим три случая, когда игроку А можно гарантировать выигрыш. Четно-нечетный случай, когда выигрывает В, оставим в качестве упражнения.
Цель игрока А — управлять игрой так, чтобы вынудить В оставлять нечетное число нечетно-нечетных областей после каждого хода. Так как 1 — наименьшее нечетное число, А всегда будет иметь хотя бы одну незанятую клетку, доступную на каждом ходе, т. е. у игрока А всегда будет ход.
В качестве первого хода на четно-четном поле игроку А следует выбрать верхнюю строку. При этом он оставит игроку В нечетно-четное поле. Первый ход игрока В должен оставить игроку А нечетно-нечетное поле. В случае нечетно-четного поля игрок А выбирает вторую строку, оставляя две нечетно-четные области. Первый ход игрока В будет сделан в одной из этих областей, и В должен создать нечетно-нечетную область. Каков был бы первый ход игрока А в нечетно-нечетном случае?
При последующих ходах А должен находить нечетно-нечетную область. Если первый нечетный размер в этой паре есть 1, то А занимает всю область. В остальных случаях игроку А следует занимать вторую строку области.
Чтобы доказать, что эта процедура гарантирует выигрыш для А, мы сначала покажем, что после первого хода все области окажутся нечетно-нечетными или нечетно-четными. Следуя данной стратегии, игрок А будет на каждом ходе или разрушать нечетно-нечетную область, или создавать две новые. Если В ходит в нечетно-нечетной области, то он должен создать одну или две нечетно-четные области или две нечетно-нечетные. Если В делает ход в нечетно-четной области, он должен создать одну нечетно-нечетную область или одну нечетно-нечетную и одну нечетно-четную область. Поэтому может не оказаться четно-четных или четно-нечетных областей, так как такие области были бы уничтожены первым ходом, а новые не были бы созданы впоследствии.
Чтобы доказать, что А выиграет, мы должны показать, что В всегда оставляет нечетное число нечетно-нечетных областей. Мы уже убедились, что любой первоначальный ход А оставляет четное число (возможно, 0) нечетно-нечетных областей. Путем исчерпывающего рассмотрения возможностей игрока В можно доказать, что В должен изменить четность числа нечетно-нечетных областей и что А может опять изменить четность. При своем ходе В встретится с четным числом нечетно-нечетных областей и с произвольным числом нечетно-четных областей. Если В делает следующий ход в нечетно-нечетной области, то он уничтожит область совсем (если нечетный размер 1), превратит ее в нечетно-четную область (если В сделал ход у одной из границ области) или превратит ее в две нечетно-нечетные области (если В сделал ход внутри области). Если В делает ход в нечетно-четнбй области, В
должен создать нечетно-нечетную область (если В сделал ход у одной из границ области) или одну нечетно-нечетную область и одну нечетночетную область (если В сделал ход внутри области). В любом случае В должен изменить четность числа нечетно-нечетных областей. Относительно стратегии игрока А можно заметить, что А всегда может оставить игрока В с четным числом нечетно-нечетных областей.
Формулировка этого алгоритма (в дальнейшем называемого EXNIM) и его машинная реализация оставлены в качестве упражнений. Сложность алгоритма сильно зависит от методов его реализации. Основная проблема, разумеется, состоит в том, чтобы обеспечить процедуру, быстро идентифицирующую нечетно-нечетные области и обновляющую поле.
Тройная дуэль
В последующем примере проанализируем ожидаемую трудоемкость необычайно простой и эффективной стратегии в довольно своеобразной игре. Сэм, Билл и Джон (ниже обозначенные буквами С, Б и Д) договорились сразиться на дуэли втроем по следующим правилам: (1) они тянут жребий, кто стреляет первым, вторым и третьим; (2) далее они располагаются в вершинах равностороннего треугольника; (3) обмениваются выстрелами в порядке вытянутых номеров, пока двое не будут убиты, и (4) очередной стреляющий может стрелять в любого из остальных.
Известно, что С — снайпер и никогда не промахивается на данной дистанции, Б поражает мишень в 80% случаев, а Д — приблизительно в 50% случаев. Какова наилучшая стратегия для каждого из участников и каковы их вероятности выживания, если они следуют оптимальным стратегиям?
Если С стреляет первым, у него нет лучшего выбора, чем убить Б. В самом деле, если он убьет Д, то Б (с вероятностью 0,8) получит право следующего выстрела и должен целиться в С (так как Д уже убит). Ясно, что С предпочтет, чтобы стрелял Д.
Аналогично, если Б стреляет первым, он попытается убить С. Если он этого не сделает, то С наверняка убьет его при первой возможности, ведь С — снайпер.
Перед Д стоит дилемма. Если он стреляет первым, то ему в действительности не выгодно никого убивать. В самом деле, если он сделает это, то оставшийся в живых (а он хороший стрелок) будет стрелять в него в следующую очередь независимо от вытянутого номера. Таким образом, Д решает промахиваться нарочно, пока один из остальных дуэлянтов не будет убит. Тогда наступит очередь Д, и он постарается сделать все, на что он способен. Эта стратегия преобладает на дуэли в том смысле, что, если Д принимает ее, она максимизирует вероятность его выживания. Если кто-нибудь из противников, С или Б, предпочтет отклониться от предварительно выбранной стратегии (не отменяя самой дуэли), вероятность выживания Д соответственно уменьшится.
ТАРТ
(*) С убивает Д
1
с первый
Д убивает С
2 С убивает Б
z
Д убивает Б
2 / -
I 2
1 I 51
Д-промохиОается
1
2
Д промахивается Б промахивается <
4
5
Д
2——• д убивает Б
д
———»Д убивает Б
4
5
Д промахивается 1 2 Б промахивается д 5
Б первый
1\
г д\
s \
~ Б убивает С Д промахивается
С убивает Б Д промахивается
4
-- — * Б убивает Д®
Б убивает Д (Т)
Б Промахибается 1 1 Г 1 г/
1
С убивает Д
Д убивает С
Рис. 6.1.6. Дерево вероятностей для тройной дуэли.
Мы моделируем ход дуэли деревом, которое первоначально имеет только две ветви, так как Д на самом деле не вступает в дело, пока не убит С или Б. В этом случае дерево остается двоичным и довольно маленьким.
Каждая вершина дерева означает событие (например, Д убивает Б), а ребра имеют веса, равные вероятностям событий на их концах (в вершинах, наиболее далеких от корня СТАРТ), при условии, что произошло событие, расположенное в начале ребра (вершина, ближайшая к корню). Дерево дуэли приведено на рис. 6.1.6.
Пунктирная ветвь в верхней правой части рис. 6.1.6 означает бесконечное повторение основной последовательности, в которой Б и Д продолжают стрелять друг в друга (и, возможно, промахиваются до бесконечности).
Теперь мы вычислим различные вероятности выживания. Первым рассмотрим С. Существуют два пути в дереве, означающие победу С, они отмечены символами * и **. Так как эти два пути представляют взаимно исключающие события, то их вероятности аддитивны. Рассмотрим событие *. По определению условной вероятности получим (см. определение в разд. 2.4):
Р (*) = Р (С первый) х Р (С убьет Б I С первый) х Р(Д промах
нется по С I С первый, С убьет Б) х Р (С убьет Д I С первый, С убьет Б, Д промахнется по С)=
= (1/2)(1)(1/2)(1)=1/4
Аналогично
Р(**)= (1/2) (1/5) (1) (1/2) (1)== 1/20
Обратите внимание на то, что структура дерева гарантирует взаимнооднозначное соответствие между конечным событием и единственным путем от корня в конечной вершине. Дерево было построено так, чтобы вычисление различных сложных условных вероятностей сводилось не более, чем к перемножению всех чисел вдоль ребер данного пути. Мы успешно вычисляем составные вероятности по мере «наращивания» дерева. Тогда Рс=Р(С выживет)=1/4+1/20=3/10. Теперь перейдем К Б'. а
РБ = Р (Б выживет) = Р (Б убьет С)хР(Б убьет Д\Б убьет С) = = Р(Б первый)х(Б убьет С|Б первый)х хР(Б убьет Д\Б убьет С) =
= (1/2)(4/5) £ А (2/5) (4/9) = 8/45 П=1
с учетом того, что все исходы, в которых Б побеждает расположены на правой верхней ветви дерева рис. 6.1.6 (все эти события обозначены номерами в кружочках).
Вероятность выживания Д Рд можно получить из условия нормировки Рс А-Рб +Рд =1. Получим Рд =47/90. Таким образом, немного подумав, Д может гарантировать себе наибольшие шансы на выживание в ситуации, которая на первый взгляд казалась для него крайне невыгодной.
Упражнения 6.1
6.1.1. Воспользуйтесь алгоритмом ODDMS, чтобы построить магический квадрат 7X7.
6.1.2. Выпишите в явном виде части X и Y чисел, составляющих магический квадрат, построенный в упр. 6.1.1 (см. рис. 6.1.2).
*6.1.3 ."Магические квадраты. Докажите, что сумма элементов по строке, столбцу и главной диагонали магического квадрата МхМ равна [М(Л/2+1)]/2.
6.1.4. Воспользуйтесь алгоритмом DEMS для построения магического квадрата8х8. Совпадает ли он с квадратом, построенным на рис. 6.1.3?
6.1.5. Покажите явно расположение пометок в алгоритме DEMS.
**6.1.6. Алгоритм ODDMS (правильность). Покажите, что алгоритм располагает [МС(М2-Н)]Л2 °беих^ главных диагоналей так, что сумма по каждой из них равна 6.1.7. Алгоритмы ODDMS и DEMS (сложность). Покажите явно, что эти алгоритм имеют сложность О (№).
*L6.1.8. Латинские квадраты (полное построение). Латинским квадратом называется матрица NyN, элементы которой выбраны из целых чисел от 1 до Af так, что каждое число встречается только один раз в каждой строке и каждом столбце. Заметим, что каждое из N чисел используется N раз. Полностью постройте алгоритм заполнения латинского квадрата.
**L6.1.9. Игра на матрице. Постройте выигрышную стратегию для одного из игроков в следующей игре. Два игрока, «нечетный» и «четный», по очереди ставят единицы и нули в незанятые позиции поля КуК. Каждый из игроков может ставить 1 или О в произвольную свободную позицию, тем самым занимая е е. Заметим, что «нечетный» не обязательно должен пользоваться только единицами, а «четный» — нулями. Игра продолжается до заполнения всех позиций. После этого суммируются числа вдоль каждой строки, иаждого столбца и главных диагоналей. Число ODD нечетных сумм далее сравнивается с числом EVEN четных сумм. Если ODD>EVEN, выигрывает «нечетный»; если EVEN>ODD, выигрывает «четный»; если ODD=EVEN, результат считается ничейным.
**1.6.1.10. Алгоритм SEMS (полное построение). Постройте полностью алгоритм SEMS (однократно четные магические квадраты), для заполнения магических квадратов NXN при М=4т+2, т=1, 2, 3, ... .
6.1.11. Найдите выигрышную стратегию игрока А в игре в «нимбы» для полей 10x10, 9X9, 9X10.
6.1.12. Какова должна быть стратегия игрока В при игре в «нимбы» на четно-нечетной доске?
* *L6.1.13. Алгоритм EXNIM (формулировка, реализация.). Сформулируйте и запрограммируйте алгоритм EXNIM.
* 6.1.14. Алгоритм. EXNIM (сложность). Проанализируйте сложность программы для упр. 6.1.13.
* L6.1.15. Простой чНим» (полное построение). Это хорошо известная игра двух лиц, в которой игроки по очереди берут предметы из наборов. Имеется п наборов предметов. Каждый набор содержит т,- предметов при i=l, 2, . . . , п. Игрок при очередном ходе берет один или несколько предметов из какого-то одного набора. Игра продолжается до тех пор, пока все предметы не будут взяты; игрок, сделавший последний ход, считается победителем.
Постройте полностью алгоритм игры в эту игру. Указание: воспользуйтесь двоичными числами для представления количества предметов в каждом наборе.
* 6.1.16. Классические нимбы (эвристика). В классические «нимбы» играют аналогично описанной нами игре «нимбы» с той разницей, что необязательно занимать все квадраты, в которые можно попасть, не пересекая границы поля или квадрата противника. Не существует также предпочтительных направлений. Например, на первом ходе А не обязан занимать целую строку, а может занять строку любого размера из расположенных подряд квадратов. Общая стратегия выигрыша для этой игры неизвестна. Разработайте некоторые полезные эвристики для игры в классические нимбы. *6.1.17. Фальшивые монеты.. Имеется 12 не различимых по внешнему виду монет. Одна монета фальшивая и отличается от остальных по весу. Даны простые рычажные весы без гирь. Определите, которая монета фальшивая. Попытайтесь изобрести алгоритм, требующий только трех взвешиваний, чтобы идентифицировать фальшивую монету и определить, «тяжелая» она или «легкая».
* *6.1.18. Головоломка «8». Рассмотрите опять пример из разд. 3.3 с головоломкой «8». Разработайте эффективный алгоритм, проверяющий, возможно ли (не обязательно выполняя это) перевести одну заданную конфигурацию в другую. Попытайтесь обобщить ваш алгоритм па головоломку «V». Указание: воспользуйтесь соображениями четности.
L6.1.19. Крестики-нолики, Постройте алгоритм беспроигрышной игры в крестики-нолики.
L6.1.20. Трехмерная игра крестики-нолики. Эта игра похожа на обычные крестики-нолики, но играется в кубе, ребром три или четыре. Игрок выигрывает, заполнив строку, столбец или диагональ. Разработайте алгоритм реализации этой игры и используйте его для проверки нескольких стратегий. Существует ли выигрышная стратегия для куба 3x3x3?
6.1.21. Повторите анализ тройной дуэли для общего случая вероятностей попадания pi, Рг и Рз. гДе
6.1.22. Из обычной колоды взяты карты пик и червей. 13 пиковых карт выложены по порядку от туза до короля. Карты червей перетасованы и выложены вниз лицевой стороной. Их переворачивают по одной. Как только очередная карта перевернута, соответствующая карта пик удаляется из ряда. Игрок выигрывает, если карты червей окажутся в таком порядке, что не возникает «просвета» между любыми из остающихся карт пик. Какова вероятность выигрыша в этой игре?
L6.1.23. Вероятностный вариант крестиков-ноликов. Пронумеруем клетки обычной игры в крестики-нолики 3x3 числами от 1 до 9. Игрок, пытающийся поместить крестик или нолик в клетку i, с вероятностью рг- (0>р,->1) не сможет сделать этого, теряя ход. Центральная клетка всегда имеет большую вероятность потери хода, чем любая из остальных. Запрограммируйте и испытайте алгоритм игры, приняв различные наборы {/?;} и различные стратегии игры.
*6.1.24. Модифицированная рулетка. В игре используется рулеточное колесо с номерами от 1 до N. Игрок, ставящий D долларов ня число k, выигрывает (/г-|-2)£) долларов, если это число выпадает при данной ставке. Возможно ли играть в эту игру, никогда не проигрывая?
*L6.1.25. Ноль за единицу (моделирование). Смоделируйте следующую игру, иногда называемую «ноль за единицу», и экспериментально подберите хорошее правило принятия решений.
Зафиксирована очередность ходов двух игроков. Каждый из игроков, когда наступает его очередь, бросает игральную кость до тех пор, пока не решит прекратить или не выпадет 1. Если выпадает 1, за этот ход игроку приписывается ноль очков; если единица ни разу не выпадет, ему приписывается сумма всех выпавших чисел. Очки, полученные за все ходы, суммируются в конце игры. Выигрывает игрок, получивший наибольшую сумму очков за все N ходов.
6.2. Кратчайшие пути
Пусть нам дана часть карты Дорожной сети, показанная на рис. 6.2.1 (где 32 @ 70 означает 32 мили при разрешенной скорости до 70 миль в час), и нужно найти наилучший маршРУТ от Лексингтона (Lexington) до Дэнвилла (Danville). Такая задача выгл>.?.ит достаточно простой, но небольшое размышление выявляет, что «наилучше» мар_ шрут могут определять многие факторы. Например, к этим факторе... относятся: (1) расстояние в милях; (2) время прохождения маршрута с учетом ограничений скорости; (3) ожидаемая продолжительность поездки с учетом дорожных условий и плотности движения; (4) задержки, вызванные проездом через города или объездом городов; (5) число городов, которые необходимо посетить, например, в целях доставки грузов.
Будем решать задачу поиска наилучшего маршрута в смысле кратчайшего расстояния. Эта задача естественно моделируется с помощью сетей. Задана связная сеть G, в которой каждому ребру приписан положительный целый вес, равный длине ребра. Длина пути в такой сети равна сумме длин ребер, составляющих путь. В терминах сетей задача
31 @70
32 @70
23 @40
Lexington
7@60
Buena Vista
10 @70
Natural Bridge
27 @50
Amherst
Island
15 @60
15 @50
17@40
Lynchburg
32 @60
1@60
22 @40
20 @60
Roanoke
23 @40
21 @50
Altavista
28 @40
12 @60
0@40
Gretna
31 @40
29@40
10 @60
Floyd
26 @60
Chatham
40 @40
20 @40
19 @60
® од
Danville
Martinsville
26 @60
6.2.1. И-^ДИте «лучший» маршрут от Лексингтона до Дэнвилла.
Рис.
Bedford
10 @40
Moneta
39 @50
Rocky Mount
Callands
1@40
8 @40
9 @50
Glasgow
11@50\ B'9
Christiansburg
срг.„пгся к отысканию кратчайшего пути между двумя заданными вершинами.
Задачи о кратчайших путях относятся к самым фундаментальным задачам комбинаторной оптимизации, так как многие такие задачи можно свести к отысканию кратчайшего пути на сети. Существуют различные типы задач о кратчайшем пути: (1) между двумя заданными вершинами; (2) между данной вершиной и всеми остальными вершинами сети; (3) между каждой парой вершин в сети; (4) между двумя заданными вершинами для путей, проходящих через одну или несколько заданных вершин; (5) первый, второй, третий и т. д. кратчайшие пути в сети.
Есть что-то удивительное в том, что среди десятков алгоритмов для
BED BfL BVA GLA LYN NBR ROA
АМН BED BfL ROA GLA LYN NBR
Рис. 6.2.2. Первые несколько шагов алгоритма Дейкстры чайшего пути от LEX до BED.
для отыскания
крат-
отыскания кратчайшего пути один из лучших (принадлежащий Дейк-стре), по существу, совпадает с (грубым) алгоритмом Прима, находящим остовное дерево минимального веса (см. гл. 4). Алгоритм Дейкстры, определяющий кратчайшее расстояние от данной вершины до конечной, легче пояснить на примере. Рассмотрим часть карты с рис. 6.2.1, показанную на рис. 6.2.2, как сеть, в которой мы хотим найти кратчайший путь от LEX до BED. Мы представим сеть матрицей смежности А, в которой:
А (7, 7)= длина ребра между вершинами 7 и J;
A(I, J)=+oo, если между 7 и J нет ребра; А (7, 7)=0 для всех 7=1, 2,. . М.
Алгоритм Дейкстры состоит из повторяемых выполнений следующих шагов:
1. Он начинает с определения непосредственных расстояний (т. е. длиной в одно ребро) от заданной вершины (LEX) до всех остальных вершин (рис. 6.2.2, а).
2. Затем он отбирает наименьшее из них в качестве «постоянного» наименьшего расстояния (выбирая выделенное ребро между LEX и BVA на рис. 6.2.2, б).
3. Далее алгоритм добавляет это наименьшее расстояние (7) к длинам ребер от новой вершины BVA до всех остальных вершин,
4. Он сравнивает эту сумму с предыдущим расстоянием от LEX до остальных вершин и заменяет прежнее расстояние, если новое меньше.
5. Затем новая вершина BVA удаляется из списка вершин, до которых еще не определены кратчайшие расстояния. В данном примере последняя вершина этого списка (ROA) заменяет вновь определенную вершину BVA и список укорачивается на один элемент (см. списки на рис. 6.2.2, а и 6.2.2, б).
Затем весь этот процесс повторяется, присоединяется новое кратчайшее расстояние к списку и т. д,, пока конечная вершина BED не окажется соединенной с LEX путем из выделенных ребер.
На второй итерации расстояние (см. рис. 6.2.2, б) до NBR (10) минимально. Это значение используется для обновления расстояния до ROA (становится 41 вместо оо), а затем NBR удаляется из списка. На третьей итерации (см. рис. 6.2.2. в), расстояние до GLA минимально, что вынуждает нас обновить расстояние до BIL (вместо оо сделать 27). Результирующее множество кратчайших расстояний показано в виде дерева (корневого) кратчайших путей на рис. 6.2.3, где числа в кружочках показывают порядок выбора ребер алгоритмом. Кратчайший путь до данной вершины отыскивается в явном виде прослеживанием пути по этому дереву из корня (LEX) до интересующей нас вершины.
В этом примере вершина BED оказалась последней, достигнутой из LEX, Следовательно, для того чтобы вычислить кратчайшее рас
стояние от LEX до BED, нам пришлось вычислить кратчайшие пути от LEX до всех остальных вершин. Итак, в наихудшем случае задача отыскания кратчайшего расстояния от начальной вершины до конеч-
ной имеет ту же сложность, что и задача отыскания кратчайших путей из начальной вершины во все остальные вершины.
Теперь мы готовы к тому, чтобы сформулировать алгоритм Дейкстры для отыскания кратчайшего пути.
Algorithm DIJKSTRA для определения кратчайшего расстояния DIST (IV) от заданной начальной вершины V0 до конечной вершины W в связной сети G с положительными весами, имеющей М вершин и N ребер и представленной матрицей смежности А.
Шаг 0. [Помечаем все вершины] Помечаем V0 как «определенная»; and помечаем все остальные вершины как «неопределенная».
Шаг 1. [Инициализация переменных] Set DIST (U) ч- A (VO, U) для
Рис. 6.2.3. Дерево кратчайших путей с корнем в LEX.
всех вершин V в G; set
DIST (VO) ч- 0; and set NEXT ч- VO.
Шаг 2. [Цикл] While NEXT=£lV do through, шаг 4 od; and STOP.
Шаг 3. [Обновление кратчайшего расстояния до «неопределенной» вершины] Для каждой «неопределенной» вершины U set DIST (£7) ч-меньшее из DIST (£7) и DIST(NEXT)+A (NEXT, U).
Шаг 4. [Выбор кратчайшего расстояния до «неопределенной» вершины] Пусть U — неопределенная вершина, для которой расстояние DIST (£7) — наименьшее среди всех «неопределенных» вершин; помечаем U «опре-
деленная»; and set NEXT ч- U.
Доказательство правильности алгоритма DIJKSTRA можно провести по индукции.
Теорема 6.2.1. Алгоритм DIJKSTRA находит кратчайшее расстояние от V0 до W.
Доказательство. Мы докажем по индукции, что после и повторений шагов 3 и 4 для каждой вершины V, помеченной алгоритмом как «определенная», DIST (V) равно длине кратчайшего пути от V0 до V. Мы также покажем, что для каждой «неопределенной» вершины U DIST (£7) есть длина кратчайшего пути от V0 до £7, в котором все вершины определенные, кроме £7.
Для и=0 после выполнения шагов 0 и 1 существует только одна определенная вершина, т. е. VO, a DIST(V0)=0, очевидно, есть длина
кратчайшего пути от V0 до нее же. Кроме того, для любой «неопределенной» вершины U расстояние DIST (£7), очевидно, определяется ребром между V0 и U, т. е. путем с двумя вершинами, только одна из которых U «неопределенная».
Предположим, что теорема верна для п повторений, и предположим, что происходит (п+1)-е выполнение шага 3. Требуется показать, что для всех «неопределенных» вершин U величина DIST (U) есть длина кратчайшего пути от V0 до LJ, в котором «определена» каждая вершина, кроме U.
Предположим, что это не так, т. е. что существует «неопределенная» вершина U и путь Р от V0 до U, в котором U — единственная «неопределенная» вершина, а длина Р, скажем т, удовлетворяет неравенству mCDIST (£7). Пусть V —• «определенная» вершина в пути Р, соседняя с £7. Если V^NEXT, то по предположению индукции значение DIST(£7) было «определено» после n-го повторения и m=DIST(£7). Это противоречит нашему предположению, что m<DIST (£7). С другой
SUBROUTINE DIJKST (А,М, VO,W,FROM,ТО,LENGTH,EDGES) С *
С ЭТА ПОДПРОГРАММА ОПРЕДЕЛЯЕТ КРАТЧАЙШЕЕ РАССТОЯНИЕ ОТ С НАЧАЛЬНОЙ ВЕРШИНЫ ф £0 КОНЕЧНОЙ ВЕРШИНЫ W В СВЯЗНОЙ СЕТИ G С НЕОТРИЦАТЕЛЬНЫМИ ВЕСАМИ С ПОМОЩЬЮ АЛГОРИТМА, fi ПРИНАДЛЕЖАЩЕГО ДИЙКСТРЕ (NUMERISCHE MATHEMATIC,V 1. с 269-271). ДАННАЯ РЕАЛИЗАЦИЯ ЯВЛЯЕТСЯ ВАРИАНТОМ ПРОГ-fi РАММЫ, ПРИНАДЛЕЖАЩИМ КИВИНУ И УИТНИ (СОММ.АСМ (АПРЕЛЬ с 1972).АЛГОРИТМ 422). РЕЗУЛЬТАТОМ РАБОТЫ ЭТОЙ ПОДПРОГ-С РАННЫ ЯВЛЯЕТСЯ ДЕРЕВО КРАТЧАЙШИХ ПУТЕЙ С КОРНЕМ W. С
С ==а ФОРМАЛЬНЫЕ ПАРАМЕТРЫ
С с с с с с с с с с с с с. С с с с с с с
А( ),J) ДЛИНА РЕБРА , СОЕДИНЯЮЩЕГО ВЕРШИНЫ I II J , ЕСЛИ РЕБРО ОТСУТСТВУЕТ , ТО.
Х(1 ,J) = 1 000 000 , ПРОИЗВОЛЬНОМУ БОЛЬШОМУ ЧИСЛУ.
VC НАЧАЛЬНАЯ ВЕРШИНА
W КОНЕЧНАЯ ВЕРШИНА
Н ВЕРШИНЫ В G ПРОНУМЕРОВАНЫ 1,...,М,
ГДЕ 2.LE.M.LE.100
FROM(I) СОДЕРЖИТ I-Е РЕБРО В ДЕРЕВЕ КРАТЧАЙШИХ
ТО (I) ПУТЕЙ ОТ ВЕРШИНЫ =FROM( 1) = К ВЕРШИНЕ
LENGTH(I) =Т0(1)= ДЛИНЫ eLENGTHd)=.
EDGES ЧИСЛО РЕБЕР В ДЕРЕВЕ КРАТЧАЙШИХ ПУТЕЙ.
НА ДАННЫЙ МОМЕНТ
Рис. 6.2.4. Реализация алгоритма DIJKSTRA.
С «=э ВНУТРЕННИЕ ПЕРЕМЕННЫЕ С
С DIST(I) КРАТЧАЙШЕЕ РАССТОЯНИЕ ОТ UWET(I);£6
с ЧАСТИЧНОГО ДЕРЕВА КРАТЧАЙШИХ ПУТЕЙ
с 1
с NEXT ОЧЕРЕДНАЯ ВЕРШИНА * ДОБАВЛЯЕМАЯ К ДЕРЕВУ
с КРАТЧАЙШИХ ПУТЕЙ'
с -W
с NUMUN ЧИСЛО НЕОПРЕДЕЛЕННЫХ ВЕРШИН i
с з
с UNDET(I) СПИСОК НЕОПРЕДЕЛЕННЫХ ВЕРШИН
с
с VERTEX(I) ВЕРШИНЫ ЧАСТИЧНОГО ДЕРЕВА КРАТЧАЙШИХ
с ПУТЕЙ, ЛЕЖАЩИЕ НА КРАТЧАЙШЕМ ПУТИ
с ОТ UNDET(I) ДО ТО о
с
INTEGER А(100,100) ,М,VO,W,FROM(100).ТО(100) ,LENGTH(10D)
INTEGER EDGES,DISTdOO).NEXT,NUMUN,UNDET(IDO)
INTEGER VERTEX(IOD)
C *
с Инициализация переменных
EDGES « 0 1 1
NEXT е ТО 1 1
NUMUN « М-1 1 1
ВО 100 I Я 1,М 1 1
UNDET(I) « 1 H M
DlST(1) я A(VO,1) M M
VERTEX(1) в VO M M
100 CONTINUE M M
j UNDET(W) в M 1 1
DIST(VO) «= OIST(M) 1 1
c f"’s. '
GO TO 350 1 1
c
с ОБНОВЛЕНИЕ КРАТЧАЙШЕГО РАССТОЯНИЯ ДО ВСЕХ НЕОПРЕДЕ-
с ЛЕННЬ.'Х ВЕРШИН
С
200 DO 300 I «И,NUMUN 1 М-2
JnUNDET(l) N (М-2)(М-1)/2
JK = L + A(NEXT,J) N (М-2)(М-1)/2
IF(D IST( I) .LE. JK) GO TO 300 N.A (M-2HM-1 )/2,E
VERTEX(I) <» NEXT В F
DIST(I)=JK В F
3fts continue .. (M-2HM-11/2
Рис. 6.2.4. Продолжение
сЗАПОМИНАНИЕ КРАТЧА ШЕГО РАССТОЯНИЯ ДО НЕОПРЕДЕЛЕННОЙ
С ВЕРШИНЫ
С
350 К • 1 L -DISTCI) СО ЧОО 1 -1,NUMUN IF(DISTU) .GE. L) GO TO 400 L « DISTU) К « t 1 1 1 N,C D D M-1 H-1 M-1 (M-1)(M)/2,G H H
, 400 CONTINUE' c N (M-1)(M)/2
с добавление’рёбра к дереву кратчайших путей с
edges « Edges +1 1 M-1
FROM(EDGES) о VERTEXfK) 1 M-1
TO (EDGES) « UNDET(K) 1 M-1
LENGTHiEDGES) «I. 1 M-1
NEXT - UNDET(K) C с достигли ли мы w с 1 M-1
1 • IF(NEXT .EQ. W) RETURN M-T,1
c
С ИСКЛЮЧЕНИЕ ВНОВЬ ОПРЕДЕЛЕННОЙ ВЕРШИНЫ ИЗ СПИСКА-- С НЕОПРЕДЕЛЕННЫХ С
DIST(K) «DIST(NUMUN) T M-2
UNDET(K) « UNDET(NUMUN) i M-2
VERTEX(K) ° VERTEX(NUMUN) C С ОСТАЛИСЬ ЛИ.НЕОПРЕДЕЛЕННЫЕ ВЕРШИНЫ С M-2
NUMUN > NUMUN - 1 M-2
GO TO 200 c END M-2
Рис. 6.2.4. Продолжение
стороны, если V=NEXT, то DIST(17)—DIST(NEXT)H-A (NEXT, V)—m. Это также противоречит нашему предположению, что m<DIST(t/).
Теперь предположим, что вершина V выбрана при (п+ 1)-м выполнении шага 4, т. е. что V оказывается (п-Н)-й «определенной» вершиной. Требуется показать, что DIST (V) — длина кратчайшего пути от V0 до V.
Предположим, что это неверно. Тогда должен существовать путь Р от V0 до V, длина которого меньше, чем DIST (V). Из предыдущего мы знаем, что DIST (V) — длина кратчайшего пути от V0 до V, где V — единственная «неопределенная» вершина. Следовательно, путь Р должен содержать по крайней мере еще одну «неопределенную» вер
шину. Пусть U будет первой «неопределенной» вершиной, встреченной при прохождении Р от V0 до V. Из этого следует, что расстояние от V0 до U короче, чем расстояние От V0 до V; более того, подпуть Р от V0 до U содержит только одну «неопределенную» вершину, а именно U. Следовательно, по предположению индукции DIST (U)<DIST (V), что противоречит тому, что V была выбрана на шаге 4. Таким образом, пути Р не существует, a DIST (V) — длина кратчайшего пути от V0 до V.
Тот факт, что алгоритм Дейкстры определяет кратчайшее расстояние от V0 до W, следует из того, что алгоритм останавливается при NEXT—IF, когда W становится «определенной». Это должно произойти, так как G — конечная и связная сеть, а следовательно, может произойти самое большее М—1 повторений шагов 3 и 4.
Следует отметить, что приведенная реализация алгоритма Дейкстры (рис. 6.2.4), по существу, идентична пооператорной реализации алгоритма Прима (см. гл. 4). В подпрограмме DIJKST мы задаем на входе матрицу смежности А, число вершин М, начальную и конечную вершины V0 и W. Выходная информация подпрограммы состоит из троек чисел — FROM (/), TO(Z) и LENGTH (I), где (FROM(Z), ТО(/)) — ребра дерева кратчайших путей, выбранных алгоритмом при поиске кратчайшего расстояния до вершины IF; LENGTH (/) содержит кратчайшее расстояние от V0 до вершины ТО(/).
Вершины (VERTICES), помеченные алгоритмом DIJKSTRA как «неопределенная», запоминаются в массиве UNDET (подпрограмма DIJKST). Вершины, получившие пометку «определенная», удаляются из массива LJNDET. Два столбца кратностей выполнения операторов, помещенные правее текста операторов, будут далее объяснены при анализе сложности.
Анализ наихудшего случая трудоемкости подпрограммы DIJKST, по существу, совпадает с аналогичным анализом подпрограммы PRIM. Самый правый столбец на рис. 6.2.4 указывает максимально возможную кратность выполнения каждого оператора. Суммируя эти величины и учитывая, что
E + и G + Н^Я^.,
получим верхнюю границу 5/И2-]-8Л4—7 числа выполнений операторов подпрограммы DIJKST. Таким образом, в наихудшем случае подпрограмма имеет сложность О (/И2).
Заметим, что если мы удалим оператор
IF (NEXT .EQ. IF) RETURN и заменим оператор GO ТО 200 на
IF(NUMUN ,GE. 1) GO TO 200 RETURN
то получившаяся подпрограмма будет вычислять кратчайшее рас
стояние от V0 до всех остальных вершин G. Следовательно, и эта задача о кратчайшем пути имеет в наихудшем случае такую же сложность О(Л42).
Теперь оценим нижнюю границу ожидаемой трудоемкости подпрограммы DIJKST. Алгоритм работает итеративно, и каждая итерация добавляет одну вершину к множеству «определенных». Если на n-й итерации добавляется вершина W, алгоритм завершает работу Пусть значение L (и) равно наименьшему числу повторений операторов, выполняемых при п итерациях. Нашей целью будет вычислить L(n) для п=1, 2, . . ., М—1, а затем найти среднее этих чисел в предположении, что вершина W добавляется к списку «определенных» с равной вероятностью на любой итерации. При таком предположении нижняя граница получается меньшей, чем она могла бы оказаться в действительности, так как для большинства приложений, W может, вероятно, оказаться вершиной, довольно далекой от V0.
Нетрудно убедиться, что если мы прекратим выполнение после точно одной итерации, то L(1)=7A4+14, Если потребуются в точности две итерации, минимальное количество выполненных операторов равно
L (2)=[L (1)—11+5+1+5 (М—2)+3+3 (М—2)+7=L (1)+8Л4—1. При вычислении А(1) и А (2) вспомним, что они означают минимальные значения. Следовательно, мы всегда выполняем операторы GO ТО 300 и GO ТО 400 в циклах DO, оканчивающихся соответственно на метках 300 и 400. Кроме того, отметим, вычисляя А (2), что мы не выполняем оператор RETURN в первой итерации — отсюда возникает член А(1)—1.
Вычисления А(3), А (4) и т. д. выполняются аналогично. Действительно, небольшое размышление показывает, что L(n) удовлетворяет следующему рекуррентному соотношению:
L (1)=7Л4+14;
А(п)=А(п—1)+8(Л4—п)+15 для 2^п^Л4—1.
Это рекуррентное соотношение непосредственно следует из детального вычисления А (2) в предыдущем абзаце.
Чтобы получить выражение для А(п) в замкнутой форме, не содержащее L(n—1), проделаем следующие вычисления:
L (n)—L (п—1)=8 (М—п)+15;
L (п—2)=8[Л4— (п—1)1+15;
L (n—2)—L (п—3)=8[Л4— (п—2)1+15;
А(2)—А(1)=8(Л4—2)+15.
Теперь сложим все эти и—1 уравнений и убедимся, что в левой части
почти все члены взаимно уничтожились. Это дает
L(n) —L(l) = 15(п—1)+18 ТЛМ-1)^
1=2
= 15(n—1) + 8 I i/W-ii+l |_i = 2 i = l
= 8пМ — 8М — 4n2+lln — 7.
Таким образом, L(n)=8nM—М—4п2+11п+7.
В предположении, что. последняя вершина W появляется с одинаковой вероятностью на любой итерации, нижняя граница среднего числа выполняемых операторов в подпрограмме DIJKST определяется выражением
М-1
LBD=jnEtw=
п— 1
( М-1 М-1 М~ 1
= 7Й=Л ]8/И 22п-Л4(Л4-1)-4 у п2+ 11 £пЧ-7(/И—1)} =
V п = 1 л = 1 П = 1 )
+ ”M(M-1) + 7(M-1)} =
= 4Л42 —Л4 —J М2+ у М +у М + 7 = -|Л42 М + 7.
Заметим, что нижняя граница ожидаемой трудоемкости алгоритма все же составляет О (/И2). Удивляет ли это вас? Как вы полагаете, что бы мы получили, если бы вычислили верхнюю границу?
Рис. 6-2,5. Найдите кратчайший путь от U до V. (Указание: его длина 12.)
Упражнения 6.2
6.2.1. Закончите выполнение алгоритма Дейкстры на сети с рис. 6.2.1 и найдите кратчайший путь от Лексингтона к Данвиллу.
6.2.2. Найдите кратчайший путь от Лексингтона к Данвиллу в смысле затраченного времени. Вы получите путь, не совпадающий с полученным в упр. 6.2.1.
6.2.3. Найдите кратчайший путь от U до V в сети, показанной на рис. 6.2.5.
6.2.4. Могут ли существовать два различных дерева кратчайших путей в сети?
6.3. Вероятностные алгоритмы
Извлечение выборки
В ряде задач обработки данных и в игровых задачах требуется несмещенная выборка в точности М предметов из множества N предметов. Например, может возникнуть желание смоделировать раздачу карт при игре в покер или взять ограниченную выборку из набора записей.
Один из наивных подходов состоит в том, чтобы выбирать записи с вероятностью MIN. Этот метод удобен тем, что каждый предмет принимается или отвергается в момент его прохождения, и можно делать только один проход вдоль набора предметов. К сожалению, такая процедура не гарантирует, что будет выбрано точно М. предметов.
Чтобы убедиться в этом, определим случайные переменные для i=l, . . ., N:
1, если выбран предмет i;
О, если предмет i не выбран.
Вероятностная мера для каждого Xt равна
Р(Х.= 1) = ^-.
— независимые, одинаково распределенные случайные переменные. Каждая имеет среднее MIN и дисперсию (M/N)-[l—(M/N)]. Случайная переменная
Х-Хх+Х2+. . .+ХЛ-
означает число предметов, извлеченных в некотором испытании. Тогда
Е[Х] = Е[Х1]+..-+£[Х^ = Л/-^=Л4;
var [X] = var [XJ + • • - + var [XA] = N (1 - 4) = M (1 - .
Таким образом, только среднее число выбранных предметов равно М, а большая дисперсия приводит к тому, что действительное число выб-
ранных предметов в некотором испытании может оказаться сущест-венно больше или меньше, чем М.
Другой интуитивный подход при выборе М чисел из N состоит в том, чтобы многократно генерировать случайные целые числа до тех пор, пока не окажется М различных. Эту процедуру можно сформулировать в виде алгоритма следующим образом:
Algorithm TRY AGAIN (Еще одна попытка) для извлечения несмещенной выборки 1^/И^Л/ чисел из множества 1,2, . . ., N. Выбранные числа будут помещены в массив SELECT (1), SELECT (2), . . ., SELECT (М).
Шаг 0. [Инициализация) Set L ч- 0 (переменная L используется для записи текущего числа выбранных объектов); and пометить все целые числа 1, . . ., N как «невыбранные».
Шаг 1. [цикл] Do through шаг 3 while L<M od; and STOP.
Шаг 2. [Генерация случайного целого числа] Генерируется (с равномерным распределением) случайное число К между 1 и N.
Шаг 3. [Было ли выбрано К?] If К помечено «не выбрано» then set L ч- L+l; SELECT (L) ч- К; and пометить К «выбрано» fi.
Хотя алгоритм TRYAGAIN интуитивно привлекателен и прост, он может оказаться очень медленным и неэффективным, потому что может понадобиться сгенерировать большое количество случайных чисел прежде, чем появится следующее невыбранное число. Проанализируем ситуацию.
Пусть pL= (N—L)/N — вероятность генерации невыбранного числа из 1, . . ., N при условии, что уже выбрано L целых чисел. Пусть qL= 1—pL=UN — вероятность генерации одного из L ранее выбранных чисел.
Если XL — случайная переменная, равная количеству целых чисел, сгенерированных прежде, чем появилось невыбранное число, при условии, что уже было выбрано L чисел, то
Р (XL — k) — q^~1pL.
Таким образом, XL имеет геометрическое распределение и
E(XL)=j^kqtlpL = j-.
k=i
(См. упр. 2.4.31.)
Например, если нужно выбрать 97 целых чисел из 100 с помощью алгоритма TRYAGAIN и уже выбрано 96, потребуется сгенерировать в среднем еще 100/(100—96)=25 чисел прежде, чем будет получено одно из оставшихся трех чисел.
Если Т — случайная переменная, равная общему количеству це
лых чисел, сгенерированных при выборе 7И чисел из N, то
7И-1
Е(Т)= 2 Е(Х£);
L = 0
, N , N , , N Л7 1
£(О +/V—i+w—2+ ‘ ‘ (М— 1) N S k~~
k=M-\
= М(^-^Л1_1);
N 1
Z/7V=^2-^- (это N-e гармоническое число).
Й=1
Таким образом, E(T)=O(N log2TV).
Нам желательно иметь алгоритм, гарантирующий извлечение точно М предметов при каждом испытании, но обладающий тем же свойством, что и первая описанная процедура: решение «принять / отвергнуть» достигается за один проход.
Предположим, что мы собираемся рассматривать (&+1)-й предмет и что уже выбрано q предметов. Какое значение вероятности следует приписать принятию этого предмета? Убедимся, что существует способов выбрать М—q предметов из остающихся N—k. Все способы следует рассматривать как равновероятные, и один должен иметь место, если мы в конце концов выберем М предметов. Аналогично, ' N—k—1 ' \М—q— 1
если выбран (А+1)-й предмет, то существует (
брать Nl—q—1 предметов из N—k—1 оставшихся. При всех способах выбора М предметов из N, когда q выбраны из k первых, в точности
) способов вн-
N— k—1\ М—q — 1) (N—k\ \M—q)
M—q N — k
из них выбирают (/г+ 1)-й элемент. Мы утверждаем, что это та вероятность, которую следует приписать выбору (А+1)-го предмета.
Прежде чем принять это утверждение, сформулируем весь алгоритм извлечения выборки.
Algorithm SS (извлечение выборки) для извлечения несмещенной выборки предметов из множества N предметов.
Шаг .О. [Инициализация] Set К-е-0; and Q-ч-О. (К+1 указывает рассматриваемый предмет, a Q обозначает число уже выбранных предметов.)
Шаг 1. [Цикл] Do through шаг 4 while Q<7W od; and STOP.
Шаг 2. [Генерация случайного числа] Генерируется (с равномерным распределением) случайное число Y между 0 и 1.
Шаг 3. [Проверка: взять или отвергнуть] If (М—K)Y<ZM—Q then выбрать предмет К+Г, and set Q-e-Q+l fi.
Шаг 4. [Увеличение К] Set Ач-А+1.
На первый взгляд вовсе не очевидно, что алгоритм SS выбирает в точности М предметов и что выборка будет несмещенной, т. е. что все предметы будут выбираться с равной вероятностью.
Теорема 6.3.1. Алгоритм SS выбирает точно М предметов.
Доказательство. Очевидно, что невозможно выбрать более М предметов, так как алгоритм прекращает работу, как только выбран /И-й предмет.
На шаге 3, если уже выбрано q предметов и остается просмотреть только М—q предметов, то все остающиеся предметы будут выбраны. Таким образом, выбирается по меньшей мере М предметов. Следовательно, выбирается точно М предметов.
Теорема 6.3.2. Алгоритм SS выбирает каждый предмет несмещенным образом.
Рассмотрим (&+1)-й предмет. При любом испытании вероятность принятия этого предмета равна (М—q)/ (N—k), где q — число уже выбранных предметов. Значение q является случайной переменной, зависящей от выборов, сделанных при первых k пробах. Мы хотим показать, что при любых k, М и N среднее значение величины (M—q)/ (N—k) равно в точности MIN. Именно в этом смысле алгоритм SS является несмещенным.
Так как полное доказательство теоремы 6.3.2 слишком сложно, мы просто продемонстрируем его правильность для /г=2.
Так как k=2, рассмотрим предмет 3. Следующая таблица возможных исходов для первых двух предметов не нуждается в пояснениях. Для указанных действий с первыми двумя предметами показаны значения q и вероятности выбора предмета 3.
Предмет 1 Предмет 2 Q Р (выбрать предмет 3)
Принять Принять 2 (М—2)/(N—2)
Принять Отвергнуть 1 (М — 1)/(7V—2)
Отвергнуть Принять 1 (М— 1)/(.У—2)
Отвергнуть Отвергнуть 0 M/(N—2)
Вероятность того, что q=2, равна
Р (q = 2) = P (принять предмет 1) [Р (принять предмет 2] предмет 1 принят)] =
_ М М—1
~ N N— 1 •
Аналогично мы можем вычислить остальную часть вероятностной
меры для q:
D, .. М f. М—1 X , Л MX М 2М(К—М)
P(Q = —raj + -1V-J W(/V-lj ;
Р?Я_ПХ Л М\Л M
W 'J) Nj\ N—l)~ N(N — 1)
Убедитесь, что P (q—2)+P (q=\)-\-P (q=O)~ 1.
Среднее значение P (принять предмет 3) равно
/’сред <k = 3) = Р (q = 2) + Р 0/ = 1) +
+ 77^2 Р 0/ = °) = 4г (проверьте это!).
Очевидно, что в худшем случае алгоритм SS просмотрит все предметы, прежде чем получит полную выборку из М предметов. В лучшем случае будет просмотрено только М предметов. В качестве упражнения попробуйте доказать, что среднее значение k, при котором алгоритм SS прекращает работу, равно
, _М^+1)
ксред Л4+1 ’
Дадим еще один метод выбора М чисел из N.
Algorithm SELECT (выбор) для извлечения несмещенной выборки чисел из набора 1,2,.. ., N. Выбранные числа помещаются в массив SELECT (1),. . SELECT (М).
Шаг 0. [Инициализация] For I <- 1 to N do set ITEM (/) <- 1 od; set LAST N; and set L 1.
Шаг 1. [Повторение M. раз] Do through шаг 4 while od; and STOP.
Шаг 2. [Генерация случайного числа] Генерируется с равномерным распределением случайное число А между 1 и LAST.
Шаг 3. [Выбор следующего числа] Set SELECT (L) ч-ITEM(A); set L^-L+L
Шаг 4. [Уменьшение размера выборки] Set ITEM (А)-е-ITEM(LAST); and LAST ч- LAST— 1.
Рисунок 6.3.1 иллюстрирует применение алгоритма SELECT на примере выбора 5 чисел из 10.
Легко доказать, что алгоритм является несмещенным. Пусть Pi (k) — вероятность выбора t-ro числа на k-й итерации алгоритма SELECT. Тогда вероятность выбора числа i равна
м
pi = S Pi (fi),
£=i
где
... N~ 1 W— 2 N—3
Pi(k)— N X N _ j x N _2
N-(fe-l)xz 1 1
/V—(fe—2)ЛЛ'- (k—1)~ N •
Таким образом,
Заметим, что для выбора М различных чисел из N при использовании алгоритма SELECT должно генерироваться только фиксированное
ITEM ITEM ITEM ITEM ITEM
1 1 1 1 1 1
2 2 2 2 2 2
3 3 3 3 3 3
4 4 4 4 4 9
5 5 5 5 5 5
6 6 10 10 8 8
7 7 7 9 9
В 8 8 8
э 9 3
10 ю
СГЕНЕРИРОВАННОЕ’ СЛУЧАЙНОЕ
ЧИСЛО
6 7 8 4 3
МЕЖДУ
1-10 1-9 18 1-7 16
ВЫБРАННОЕ
ЧИСЛО
!ТЕМ(6) = в ITEM.(7J = 7 1ТЕМ(6) = 10 1ТЕМ(4)=4 |ТЕМ[3) =3
Рис. 6.3.1. Пример работы алгоритма SELECT (выбор).
количество М случайных чисел. В действительности объем необходимой работы равен 0(N+M), т. е. алгоритм SELECT выполняет:
2V+2 операторов присваивания на шаге 1;
47И операторов присваивания на шаге 2;
М обращений к генератору случайных чисел на шаге 3.
Сравните это с алгоритмом SS, выполняющим:
2 оператора присваивания на шаге 0;
O(N) обращений к генератору случайных чисел на шаге 2;
O(N) проверок на шаге 3;
ЗЛ1 операторов присваивания на шаге 3;
0(N) сложений на шаге 4.
Заметим также, что в качестве побочного продукта алгоритм SELECT дает случайную перестановку чисел 1, . . N, что еще увеличивает его полезность.
Генераторы случайных чисел
В разд. 2.4 мы определили дискретные случайные переменные, т. е. случайные переменные, множества значений х) которых конечны или являются бесконечными счетными множествами. Случайные переменные, множества значений которых — бесконечные несчетные множества, называются непрерывными. Хотя большинство элементарных приложений теории вероятности и статистики в вычислительной математике используют только дискретные случайные переменные, существует два важных непрерывных распределения, возникающих столь часто, что они заслуживают специального рассмотрения.
Случайная переменная X является непрерывной, если существует неотрицательная функция fix), определенная на всей вещественной прямой и обладающая тем свойством, что если S — произвольное множество вещественных чисел, то
P(X£S)=\f(x)dx.
s
Функция f(x) называется плотностью распределения вероятности X.
В частности, если S — вся вещественная прямая, то, поскольку X обязательно принимает некое значение,
1 = Р(ХС(—°°> °°))= $ f(x)dx.
— оо
Аналогично, если S — некоторый интервал [а, Ь] на вещественной прямой, то
ь P(a^X^b) = ^f(x)dx.
а
Непрерывным аналогом дискретной переменной с равновероятным распределением является равномерно распределенная переменная. Если X — случайная переменная, принимающая с одинаковой вероятностью любое значение в интервале [0, 1], ее плотность вероятности равна
1, 1;
О, в остальных случаях.
*) Напоминаем, случайная переменная является функцией.
Тогда, например,
3/4
Р(1/4<Х<3/4) = J 1 dx= 3/4—1/4= 1/2;
1/4
1/2
Р(Х = 1/2) = $ ldx= 1/2-1/2 = 0.
1/2
Последний результат особенно важен. Вероятность того, что непрерывная случайная переменная окажется равной некоторому частному значению из своего интервала, всегда равна 0, а не /(X). Невозможно поставить в соответствие конечную вероятность каждому из бесконечного множества значений, так как «сумма» всех этих вероятностей окажется бесконечной (а не единицей). Не забывайте об этом. Равномерное распределение на интервале [ОД]1)—или (ОД); имеет ли это какое-нибудь значение? — по существу является именно тем распределением, которое моделируют программные генераторы случайных чисел. То есть случайное число, генерируемое компьютером, по существу представляет собой выборку из равномерно распределенной переменной.
Математическое ожидание и дисперсия непрерывной случайной переменной определяются аналогично соответствующим величинам для дискретной случайной переменной, за исключением того, что суммы заменяются на интегралы. Таким образом,
оо
Е[Х] = J xf(x)dx;
— оо
со
var[X] = (х—E[X])2f (x)dx.
Для равномерно распределенной переменной U в [ОД] получим
оо 1
В[П]= j* xf(x)dx — Jxdx = -^-|’ =-А-;
— ОО 0
оо ]
var[t/]= J (х—E[X])2f(x)dx= J (х— у)2^х = -^.
— ОО 0
Еще одно важное непрерывное распределение — это нормальное распределение. Плотность вероятности для случайной переменной X, обладающей нормальным распределением с параметрами р и о2,
г) Иногда для обозначения этого распределения мы будем пользоваться символом U (0, 1).
Гзадается формулой
f (X) = —е[-(*-Юг1/2а* —оо < х < оо.
v V 2М
Это знаменитая «колоколообразная кривая теории вероятностей».
График этой функции приведен на рис. 6.3.2. Кривая симметрична
Рис. 6.3.2. Функция плотности нормального распределения.
относительно р», имеет резко заостренный вид при малых значениях о2 и более «сглаженный» при больших. Нормальное распределение с параметрами р, и о2 обозначается как Л/ (р, о2). Распределение N(0,1) называется стандартным нормальным.
Простые, но несколько трудоемкие выкладки показывают, что если X — нормальная случайная переменная с параметрами р и о2, то £[Х]=р и var [Х]=о2.
Неожиданно большое количество случайных переменных обладает нормальным распределением или близким к нормальному. Многие из этих случайных переменных испытывают суммарное влияние со стороны других случайных переменных. Теоретически это следует из ряда важных теорем, известных под совместным названием центральных предельных теорем. Грубо говоря, эти теоремы гласят, что случайная переменная, являющаяся суммой многих других случайных переменных, приближается к нормально распределенной.
Можно показать, что X и s2 являются несмещенными и состоятельными оценками с минимальной дисперсией для р и о2 любой нормально распределенной случайной переменной. В тех случаях, когда предполагается, что случайная переменная отражает суммарное влияние других случайных переменных, нормальное распределение с параметрами X и s2 (основанное на статистических наблюдениях) может оказаться хорошей оценкой для всего неизвестного распределения случайной переменной.
В разд. 2.4 и 4.2 мы уже видели, что важно иметь машинно-генери-руемые «случайные числа» для облегчения тестирования и анализа алгоритмов. Следовательно, важно иметь эффективные алгоритмы для генерации случайных чисел.
Машинные генераторы случайных чисел чаще всего генерируют значения выборки случайной переменной, распределенной равномер
но на интервале от 0 до 1. Остальные распределения случайных пе-ременных можно затем легко моделировать, используя это основное распределение. Итак, алгоритм, генерирующий случайные числа, пытается выбрать число между 0 и 1 так, чтобы вероятность того, что число лежит в некотором частном подынтервале единичного интервала, была равна длине этого частного подынтервала.
Одним из очевидных механических средств достижения этого является колесо с единичной окружностью. Это колесо вращается против конца очень острой иглы, и координата точки окружности против конца иглы служит очередным случайным числом. Почему такое устройство не вводят в состав аппаратуры компьютера? Такие колеса не применяются потому, что случайные числа можно генерировать быстро, дешево, точно и почти так же надежно с помощью некоторых простых алгоритмов.
В действительности эти алгоритмы не генерируют случайных чисел с той неопределенностью, которая присуща вращающемуся колесу. На самом деле они используют простые арифметические операции для детерминированной выработки последовательности чисел, которые только кажутся случайными. Эти числа можно предсказать до того, как они будут сгенерированы. Этот факт, по-видимому, раздражает некоторых, но на самом деле для этого нет оснований. Последовательности псевдослучайных чисел, генерируемых этими алгоритмами, оказываются случайными и удовлетворяют ряду сложных статистических тестов, что в результате «узаконивает» их как удовлетворительные.
Один из ранних генераторов случайных чисел, принадлежащий Джону фон Нейману (1946), известен как метод середины квадрата.
Algorithm MS (середина квадрата) для генерации /(-разрядных псевдослучайных чисел. Должно быть задано /(-разрядное начальное число Хо. Для удобства предполагаем, что /( четно и нужна последовательность Х(1), Х(2).......Х(М) из М случайных чисел (см.
упр. 6.3.20).
Шаг 0. [Инициализация] Set X ч- Хо,
Шаг. 1, [Основной цикл] For J ч- 1 to М do шаг 2 od; and STOP.
Шаг 2, [Генерация нового случайного числа X (J)] Set Y ч-X2; X(J) ч— (средние К. разрядов числа У); and X ч-X (J). (Число Y будет иметь 2Л разрядов, а следую-i щее случайное число X (J) получается, если удалить
по К/2 разрядов с каждого конца Y. Ясно, что десятичная точка помещается перед первым разрядом числа X (J) до поступления его на выход случайного генератора.)
Для /(=4 и Х0=2134 первые 10 псевдослучайных чисел, выработанные алгоритмом MS, будут:
XI = 04 5539 56 Xi =* 0.5539
х?= 30 6805 21 Х2= 0.6805
XI= 46 3080 25 Х3 = 0.3080
Хз2 = 09 4864 00 Х4 = 0.4864
XI = 23 6584 96 Х5 = 0.6584
xi= 43 3490 56 Хе = 0.3490
XI = 12 1801 00 Х7 = 0.1801
х?= 03 2436 01 Х8 = 0.2436
XI = 05 9340 96 Х9 = 0.9340
XI = 87 2356 00 Х40 = 0.2356
Несмотря на видимую случайность чисел, генерируемых алгоритмом MS, ему свойственны недостатки, которые привели к тому, что им избегают пользоваться в серьезных приложениях. Убедитесь, что если в последовательности когда-нибудь появится 0.0000, то все следующие за ним числа будут также 0.0000. Генерация случайных чисел в алгоритме MS может вырождаться различными путями. Для /(=4 и Хо=1357 последовательность оказывается следующей:
Хг=0.8414
Х2=0.7953
Х3=0.2502
Х4=0.2600
Ха=0.7600
Хв=0.7600
Х7=0.7600
Хп—0.7600 для а£>5.
Это вряд ли похоже на случайные числа. Даже при более тщательном выборе К и Хо последовательности, генерируемые этим методом, склонны к быстрому «зацикливанию» и работают неудовлетворительно при проверке по сложным статистическим критериям.
Среди различных детерминированных арифметических процедур, генерирующих случайные числа, шире всего используется класс алгоритмов, называемый линейными конгруэнтными методами. Общий вид таких алгоритмов приведен ниже.
Algorithm LCM (линейный конгруэнтный метод) для генерации последовательности X(l), X (2), . . ., X(М) из М псевдослучайных чисел. Должны быть заданы следующие входные значения:
X (0) = начальное «необработанное» случайное число Х(0)^1;
целое
В = множитель
К = шаг
MOD = модуль
целое
целое
MOD>X(0), В, целое
Шаг 1. [Основной цикл] For J 1 to 7И do through шаг 3 od; and STOP.
Шаг 2. [Генерация нового необработанного случайного числа] Set X(J)+- (B*X(J— 1)+X)(mod MOD)1).
(Число X (J) должно лежать в интервале О^Х (/)< <MOD.)
Шаг 3. [Генерация следующего случайного числа] Set Y (J)
X (J)/MOD. (У (J) будет лежать в интервале 0^ ^У (Т)<1 и будет обладать желаемым распределением.)
Возьмем /<=0, MOD=210, £3=101 и Х(0)=432. Первые числа, выработанные алгоритмом LCM, будут
Хг=624 У1=624/1024=0.610
X 2=560 У2=560/1024==0.546
Х3=240 У3=240/1024=0.234
Х4=688 У4=688/1024=0.673
Х5=880 У5=88О/1О24=О.859
Х6=816 У6=816/1024=0.796
Х7=496 У.=496/1024= 0.484
Х8=944 У‘=944/1024=0.923
Существует глубокая и интересная теория по вопросу «хорошего» выбора X, В, MOD и Х(0), которая выходит за рамки этой книги. Для наших целей достаточно просто утверждения, что существует такой выбор этих параметров, при котором алгоритм LCM будет генерировать числа в интервале [0, 1), представляющиеся непредсказуемыми и удовлетворяющие определенным статистическим критериям. Для всех практических целей эти числа оказываются последовательностью наблюдений равномерно распределенной случайной переменной.
Равномерно распределенные случайные переменные можно, в частности, использовать при моделировании случайных переменных с другими распределениями. Начнем с двух относительно простых примеров.
Пусть X — дискретная случайная переменная со следующим распределением:
Р(Х=1)=0.1
Р(Х=2)=0.2
Р(Х=3)=0.4
Р(Х=4)=0.2
Р(Х=5)=0.1
Как можно получить от компьютера «выборки» из X, такие, что значение Х=1 встретится приблизительно в 10% случаев, значение Х=2 приблизительно в 20% случаев и т. д.
По определению, если a (mod т)=х для целых а и т, то х есть (целый) остаток от деления а на т. Например, 5 (mod 3)=2,
Так как сумма всех вероятностей в распределении равна единице, проще всего разбить интервал [0, 1) на пять подынтервалов и назначить каждое возможное значение X подынтервалу, длина которого равна вероятности того, что X реально принимает это значение. В нашем примере мы могли бы установить следующее соответствие;
Х=1<->[0, 0.1)
Х=2<->[0.1, 0.3)
Х=3«->[0.3, 0.7)
Х=4<->[0.7, 0.9)
Х=5<->[0.9, 1.0)
Для машинного моделирования случайной переменной X генерируют стандартное (равномерно распределенное) случайное число Z. Если Z С [0, 0.1), берем Х=1; если Z£[0.1, 0.3), берем Х=2. После извлечения большого числа выборок наблюдаемое распределение частот X должно быть довольно близко к искомому распределению.
Только что описанная процедура может применяться к произвольной дискретной случайной переменной на конечном интервале; ее также можно применять (приближенно) для многих случайных переменных, интервал значений которых представляет собой бесконечное счетное множество. Этот метод широко используется при разработке алгоритмов моделирования.
Теперь рассмотрим использование генератора равномерно распределенных случайных чисел. Хороший простой алгоритм основывается непосредственно на центральной предельной теореме и на преобразовании, с помощью которого можно превратить распределение Х(р, о2) в N (0, 1) и наоборот.
Следующая теорема является простейшей из центральных предельных теорем, и именно ее часто называют центральной предельной теоремой.
Теорема 6.3.3 (центральная предельная теорема). Пусть Х±, Х2, . . ., Хп — последовательность независимых, одинаково распределенных случайных переменных со средним р и дисперсией оа. Распределение вероятности для случайной ..переменной
2 X, -|- Х2 Т ... Ч~ Х„—пр,
о У п
стремится к N(Q, 1) при п->оо.
Теорема 6.3.4. Если случайная переменная У имеет распределение 7V (р,, о2), то переменная
Z = ^-=^ О
имеет распределение N (0, 1). Обратное также верно.
Доказательство теоремы 6.3.3 требует некоторой квалификации и поэтому опущено; доказательство теоремы 6.3.4 очевидно и оставлено в качестве упражнения.
Algorithm NRN (нормальные случайные числа) для генерации нормально распределенных случайных чисел с использованием генератора равномерно распределенных случайных чисел RANN. Равномерно распределенные случайные числа применяются для выработки случайных чисел с распределением 7V (О, 1) на основе теоремы 6.3.3. Случайные числа с распределением N (0, 1) преобразуются в случайные числа N (р, о2) с использованием теоремы 6.3.4. Необходимо задать на входе в алгоритм значения п, р, о2. Предполагается, что нужна последовательность У(1), У(2), . . ., Y (М) из Л4 случайных чисел.
Шаг 1. [Основной цикл] For J 1 to М do through шаг 3 od; and STOP.
Шаг 2. [Генерация нового случайного числа с распределением N (0, 1)] CALL RANN п раз; на выходе процедуры — последовательность . . ., Хп\ set
7 , п _ Х1 + Х2+---+ХП-(»/2)
( ’ 1/7712
(Так как каждое Xk обладает равномерным распределением со средним 1/2 и дисперсией 1/12, то Z(J) будет обладать распределением N (0, 1) согласно теореме 6.3.3. Практически для большинства применений достаточно п=10.)
Шаг 3. [Генерация нового числа с распределением N (р, о2)] Set Y (J) crZ (J)+p.
Теперь рассмотрим две более совершенные процедуры. Начнем с общей задачи моделирования произвольного непрерывного распределения с использованием равномерного распределения.
Для любой случайной переменной X интегральная функция распределения определяется как
F (а)=Р (Х^.а), —оо<а<оо.
Легко убедиться, что любая интегральная функция распределения обладает следующими свойствами:
1) F(a) — неубывающая функция а;
2) lim F(a)=l;
3) lim Е(а)=0;
4) Р (a<ZX^ib)=F (b)—F(a) для всех a<Zb.
Если X — непрерывная случайная переменная с плотностью f (х), то
а
F(a) = P(X^a) = J f(x)dx
и по основной теореме интегрального исчисления
sr(«MW.
Если Y обладает равномерным распределением на [0, 1), то его интегральная функция распределения равна
при а^О;
( О
G(a) = P(Y <Со) = ^\dy = a при 0 < а 1;
при 1 < а.
Пусть случайная переменная X имеет интегральную функцию распределения F, и пусть случайная переменная равномерно распределена на [0, 1). Предположим, что обратная функция F~l ведет себя достаточно хорошо. Мы хотим показать, что случайная переменная, определяемая формулой Х'=Е~1(У), имеет интегральную функцию распределения F. Тогда, если {уг, у2, . . ., уп} — последовательность равномерно распределенных чисел, то последовательность {xi=F-1(z/i), x2=F-1(y2), . . ., xn=F-1(z/n)} будет иметь распределение F.
Таким образом, мы хотим показать, что
Р (X'sStx)=F(x), если X'==F~1(Y),
a Y обладает равномерным распределением. Это доказывается так:
FM
Р(Х' ^x) = P(F~1(Y)^x) = P(Y^F(x))^ j ldy = F(x).
Мы уже отмечали, что F(x) всегда лежит между 0 и 1; здесь мы также использовали интегральную функцию распределения для Y.
Хотя эта процедура в принципе весьма обща и проста, она применяется не так часто, как можно было бы ожидать. В первую очередь это обусловлено тем, что трудно получить явные аналитические выражения для обратных функций многих распределений. Однако мы рассмотрим один важный случай, когда этот метод работает очень хорошо.
Экспоненциальное распределение (с параметром К) имеет функцию плотности
f (х)=Хе~хх, 0<х<оо;
=0 в остальных случаях.
Интегральная функция распределения для экспоненциально распределенной случайной переменной задается выражением
F(x) = 0
при х^О;
— J "Ке~}-Хdx=(l —е~Кх) при х > 0м о
Это распределение является фундаментальным в теории очередей. Экспоненциально распределенные случайные переменные хорошо подходят для моделирования интервалов между прибытиями.
Если V распределена равномерно, то
Y==F (Х)=1—е~^х.
Обращая F (т. е. решая относительно X), получим
Х = —yln(l—У).
Таким образом, если {yi, у2...уп} — равномерно распределенные
случайные числа, то
|%1 = — ->(!- ^1)> ^2 = — у 1п(1— у2), Хп= — у 1п(1 — уп)}
будут экспоненциально распределенными случайными числами.
Невозможно воспользоваться этой процедурой с обратной функцией для генерации нормально распределенных случайных чисел. Кроме того, алгоритм NRN (нормально распределенные числа) имеет неприятную особенность — он требует п равномерно распределенных случайных чисел для генерации единственного случайного числа с нормальным распределением. Большая важность нормального распределения послужила причиной построения нескольких эффективных алгоритмов генерации случайных чисел с нормальным распределением. Следующий алгоритм демонстрирует один из таких методов.
Algorithm PNRN (полярный метод генерации случайных чисел с нормальным распределением) для генерации двух независимых случайных чисел с распределением N (0, 1) из двух независимых, равномерно распределенных случайных чисел. Распределение N (0, 1) преобразуется в N (у, о2) с использованием теоремы 6.3.4.
Шаг 1. [Генерация двух равномерно распределенных случайных чисел] Генерируются два независимых случайных числа Ut и U2 с распределением U (0, 1); set Vi-«-2171—1; and V2-<-2[/2—1. (Vj и Vz имеют распределение U (—1, +1).)
Шаг 2. [Вычисление и проверка S] Set S V2+ VI; if then go to шаг 1 fi. _________
Шаг 3. [Вычисление Nj и N2] Set Ni+- ViK (—21nS)/S; and N2<-V# (—21nS’)/S; and STOP. (Nt и Nz распределены нормально.)
Алгоритм PNRN имеет важное вычислительное преимущество перед алгоритмом NRN, а именно: он обычно генерирует по одному числу с нормальным распределением на каждое число с равномерным распределением. Компенсируется ли этим дополнительное время, затрачиваемое на вычисление натуральных логарифмов и квадратных корней?
Доказательство правильности алгоритма PNRN существенно опи-рается на интегральное исчисление и аналитическую геометрию; оно оставлено в качестве упражнения.
Упражнения 6.3
6.3.1. Разработайте алгоритм для случайной генерации двух карточек «бинго» (игра наподобие лото) типа показанных на следующем примере:
1—15 16-30 31-45 46—60 61—75
Б ’ И Н Г О
4 17 32 49 73
11 25 42 51 67
12 19 ПУСТО 46 62
8 29 37 54 64
5 30 44 50 74
Проследите, чтобы ни одно число не появлялось дважды в одном столбце.
6.3,2. Алгоритм SS часто используется для извлечения несмещенной выборки М файлов данных из N, где N — большое число. Почему для такого применения важна однопроходность?
6.3.3. Проверьте теорему 6.3.2 для случая k=l.
*L6.3.4. Алгоритм SS (проверка). Проведите обширную проверку алгоритма SS. Попытайтесь получить экспериментальное подтверждение теоремы 6.3.2.
***6.3.5. Алгоритм SS (анализ), Покажите, что среднее значение k в момент остановки алгоритма SS равно
_Л4(/У+1) «сред----Л1+,
6,3.6. Обсудите относительные достоинства и недостатки алгоритмов SS и SELECT.
6.3.7. Равномерно распределенные случайные переменные. Если Y — равномерно распределенная случайная переменная на интервале [а, 0], то какова ее функция плотности? Вычислите Е [К] и var IF],
6,3,8. В этом разделе было описано колесо, которое можно было бы использовать для механической генерации «настоящих» случайных чисел с равномерным распределением. Перечислите некоторые трудности, связанные с таким прибором.
6.3.9. Большинство случайных генераторов сконструировано таким образом, что генерируются одни и те же числа при каждом выполнении программы, если не принято специальных мер, чтобы избежать этого. Как вы думаете, почему принимаются такие меры?
6.3.10. Если X — случайная переменная с распределением N (и, о2), покажите явно, что Е £Х]=р,, a var [Х]=о8.
6.3.11. Вычислите выборочную дисперсию s2 для эксперимента по упорядочению прямой вставкой (в упр. 2.4.25).
*L6.3.12. Алгоритм MS (реализация). Запрограммируйте алгоритм MS, используя любые удобные значения и Хй, Сгенерируйте 10 случайных чисел и вычислите сцен
ки X и s2. Каковы эти величины по сравнению с истинными средним и дисперсией равномерно распределенной случайной переменной? Повторите для 25, 50 и 100 случайных чисел.
6.3.13. Равномерно распределенные случайные переменные, определенные на каждом из следующих замкнутых и открытых интервалов, по существу, эквивалентны: [0, 1], (0, 1], [0, 1), (0, 1). Почему?
6.3.14. Является ли интервал машинного генератора случайных чисел (например, для алгоритма LCM) действительно непрерывным интервалом [0, 1)?
*L6.3.15. Алгоритм NRN (реализация). Запрограммируйте алгоритм NRN, используя свой генератор случайных чисел в качестве процедуры RANN, при значениях п=10 и 20. Выполните с вашей программой некоторые эксперименты, чтобы убедиться, что она дает нормально распределенные случайные числа. Воспользуйтесь для контроля таблицами нормального распределения.
6.3.16. Докажите теорему 6.3.4.
* *L6.3.17. Тест хи-квадрат. Он часто применяется для того, чтобы взять выборку случайной переменной и задаться вопросом: какое распределение скрывается под этой выборкой? В общем виде ответ на этот вопрос должен носить вероятностный характер. Существует много тестов, призванных облегчить получение ответа на подобные вопросы. Известно, что наилучшим является тест хи-квадрат (у2-тест). Изучите этот тест и научитесь им пользоваться. Обсуждение ряда таких статистических тестов можно найти в разд. 3.3 книги Кнута [57].
* 6.3.18. В упр. 2.4 был получен ряд общих результатов относительно средних и дисперсий дискретных случайных переменных. Убедитесь, что эти результаты верны и для непрерывных случайных переменных.
* 6.3.19. Пусть X и Y — две независимые случайные переменные. Пусть {Xj, . . . , Хп} — выборка из п наблюденных значений X, а {Уу, . . . , Yn} — выборка из п наблюденных значений Y. Найдите несмещенную оценку для Е [Z], где Z=XY.
6.3.20. Генераторы, случайных чисел. Ни одни из коммерческих генераторов случайных чисел не содержит шага 1 с циклом DO, присутствующим в алгоритмах MS, LCM и NRN. Какая процедура применяется для генерации последовательности случайных чисел в генераторе, реализованном на вашей машине?
L6.3.21. Экспоненциально распределенные случайные числа. Используйте процедуру, построенную в этом разделе, для генерации нескольких экспоненциально распределенных случайных чисел. Примите Х=1. Сравните теоретическую функцию распределения с распределением частот, полученным экспериментально.
6.3.22. Вычислите среднее и дисперсию через % для экспоненциально распределенной случайной переменной.
***6.3.23. Алгоритм PNRN (доказательство). Докажите правильность алгоритма PNRN. Указание: (а) обратите внимание на то, что (Иь И2) — случайная точка, равномерно распределенная внутри единичного круга (if S<1 на шаге 2); (б) воспользуйтесь полярными координатами S=R2 (квадрат расстояния от начала координат): (в) вычислите вероятность того, что —2 In S<:r2 при 0<г<1.
* L6.3.24. Алгоритм PNRN (проверка). Реализуйте алгоритм PNRN и примените его для генерации случайных чисел с распределением М(0, 1). Сравните теоретическую функцию распределения с экспериментальным распределением частот.
* *L6.3.25. Алгоритм PNRN (проверка, анализ). Проведите сравнительную проверку времени, затрачиваемого на получение нормально распределенных случайных чисел, с помощью алгоритмов PNRN и NRN. Проанализируйте различие с учетом сложности обращений к программам, генерирующим равномерно распределенные-числа и вычисляющим квадратные корни и логарифмы на вашей машине.
* L6.3.26. Тасовка карт (полное построение). Проведите полное построение алгоритма, моделирующего тасовку колоды карт.
Глава 7. Дополнительные замечания и ссылки
Цель этой главы — привлечь внимание к материалу, дополняющему содержание этой книги. Она не должна служить исчерпывающей библиографией. Мы попытались найти хорошие, легко читаемые источники по вопросам, которые заинтересуют читателя.
В этой главе две части. Первая — аннотированная библиография, упорядоченная по главам и разделам. Вторая — алфавитный список (по фамилиям авторов) работ, упомянутых в первой части. Где возможно, мы предпочитали цитировать учебники более или менее элементарного уровня вместо трудных журнальных статей. Для обозначения уровня- работы использовались следующие сокращения:
Е: элементарные,
I: промежуточного уровня,
А: трудные,
VA: очень трудные.
Дополнительным символом М помечены источники, требующие или использующие значительное количество математических выкладок. В качестве калибровки этой шкалы укажем, что данная книга характеризуется как IM.
Глава 1. Полное построение алгоритма
Не существует «официального» определения термина «полное построение алгоритма». Похоже, что большинство специалистов в области вычислительной математики находят приемлемым перечень, данный в конце разд. 1.1.
Хорошим введением в математические машины и формальную теорию вычислений является книга [89]. Более обширным и немного более трудным введением является [72].
Хотя некоторые пуристы признают в качестве описания алгоритма только полную программу в кодах, мы думаем, что полусло-весные пошаговые описания, использованные здесь (см. приложение А), и некоторое прозаическое обсуждение очень полезны (и часто необходимы) для основательного понимания работы алгоритма. Многим людям трудно вникать непосредственно в программу, если даже она хорошо документирована.
Естественно было бы полагать, что идея математической модели является наиболее фундаментальным понятием в прикладной мате
матике. Несмотря на это, мы не смогли найти хорошего элементарного обсуждения этой темы, ориентированного на применение вычислительной техники.
Считается, что первоначальная формулировка задачи коммивояжера принадлежит Мерриллу М. Флуду (Колумбийский университет, 1937 г.). Она возникла в связи с выбором маршрутов для школьных автобусов. К середине 50-х годов в литературе по исследованию операций начали появляться журнальные статьи, посвященные этой задаче, и она широко изучается до сих пор. Хотя для задачи не известны алгоритмы, полиномиальные в худшем случае, существует ряд впечатляющих эвристических и точных (но экспоненциальных в худшем случае) процедур ее решения. Ссылки на некоторые из них даны в разд. 4.4. В [63] описаны некоторые практические приложения задачи коммивояжера.
Хорошее общее обсуждение реализации, отладки и документации дано в [99]. В качестве учебника по «стилю программирования» см. [54].
Несмотря на то что для многих людей полиномиально-экспоненциальный критерий сложности кажется вполне очевидным, до середины 60-х годов он, по-видимому, не находил широкого применения. Первая явная его формулировка, которую мы нашли, содержится в [22]. Обозначения «О-большое» и «о-малое» стали популярными в ряде математических дисциплин. Подробное обсуждение можно найти в гл. 1 книги [56].
Глава 2. Некоторые основные приемы и алгоритмы
2.1. Структурное программирование сверху-вниз и правильность программ
Предмет структурного программирования сверху-вниз нов и противоречив. Среди программистов он, кажется, быстро завоевывает признание, хотя пока далеко не всеобщее. Литература по структурному программированию растет экспоненциально. Для дальнейшего изучения мы бы рекомендовали [70]. Эта достаточно основательная книга содержит краткий исторический обзор предмета. Можно также посмотреть специальные выпуски двух популярных журналов [12], [17].
Более глубокое изложение материала содержится в [16].
2.2. Сети
Словарь терминов, связанных с сетями, все еще точно не определен. Для этих структур не выбрано даже единого общеупотребительного названия. Примерно в одной половине книг их называют сетями, а в другой — графами. Вершины часто называются точками или узлами; ребра часто называются линиями или дугами. Мы пытались
пользоваться некоторой достаточно общеупотребительной терминологией.
Почти энциклопедическое изучение деревьев можно найти у Кнута 156].
Нетрудной, ориентированной на приложения книгой является [20]. Здесь можно найти хорошо изложенные основы применения сетей к теории переключателей и кодирования, анализу электрических схем и исследованию операций. Книга содержит также краткое обсуждение вопросов, связанных с применением теории сетей в химии.
При работе с сетями в теоретическом плане большую помощь может оказать книга [7], которая содержит наиболее полную математическую трактовку графов и сетей на современном уровне изложения этих вопросов. По-видимому, свое фундаментальное значение эта книга не утеряет и в ближайшем будущем.
Алгоритмы обработки сетей очень интенсивно используются в области исследования операций. Литература в этой области обширна, мы укажем лишь на работы [34], [29] и [62].
Алгоритм CONNECT можно найти в [20]; там же рассматриваются другие матричные представления и ряд алгоритмов обработки сетей.
Хорошая эвристика для проблемы изоморфизма описана в [14]. К сожалению, некоторые из высказанных в этой статье теоретических предположений, как было показано позднее, неверны. Впрочем, рассматриваемый в статье основной алгоритм остается одной из наиболее известных общих эвристик.
Проблема изоморфизма была решена для некоторых специальных классов сетей, самым важным из них являются деревья; см. [13].
Для работы с сетями было разработано много специальных языков программирования и пакетов программ. Приводим небольшую подборку литературы по этим вопросам: [3], [10], [44], [55], [68]. Язык CLAMAR [68] замечателен тем, что он был полностью разработан двумя студентами. Использование большинства специальных языков ограничено и локализовано.
2.3. Некоторые структуры данных
Большой и детальный перечень различных структур данных можно найти у Кнута [56]. Среди других широко используемых книг можно назвать [8], [771 и [87].
2.4. Элементарные понятия из теории вероятностей и статистики
Легко читаемым, ориентированным на практическое применение введением в теорию вероятностей является [81]. В гл. 8 этой книги содержится прекрасное введение к теме надежности систем — теме, имеющей серьезное применение в вычислительной науке.
Достаточно элементарную и легко понимаемую трактовку дискретных событий и случайных переменных можно найти в классической работе Феллера [26].
Очень элементарное, ориентированное на программистов (язык Basic) введение в дискретную вероятность содержится в [85].
Анализ ожидаемой трудоемкости алгоритмов, как правило, очень труден; анализ алгоритма SIS в этом разделе является исключением. Анализ ожидаемой трудоемкости алгоритма МАХ (см. разд. 1.2) можно найти в книге [56]. Алгоритм ETS (см. разд. 1.3) всегда выполняет одно и то же число операций для любого множества N городов. Алгоритм PRIM настолько бесхитростен, что едва ли стоит заниматься анализом его ожидаемой трудоемкости. Это видно и по результатам экспериментального анализа средней трудоемкости в разд. 5.2.
Ниже приводится подборка ссылок, относящихся к приложениям, которые описаны в начале разд. 2.4.
По теме «имитационное моделирование» смотрите [28]. Дополнительные ссылки даются для разд. 3.6 и 6.3. По вычислительной статистике мы рекомендуем [30]. Генерация случайных чисел рассмотрена в [57]. По Бейесовской теории принятия решений см. [98] и [18]. Достаточно полное введение в статистические методы можно найти в [73]. Книгой на элементарном уровне является [48]. Более фундаментальная трактовка содержится в [15].
Глава 3. Методы разработки алгоритма
3.1. Методы частных целей, подъема и отрабатывания назад
В области общих методов решения задач работали психологи, математики и специалисты по вычислительной математике. Некоторые из наиболее известных источников — следующие. Психологом написана книга [96], математиком — [78, 79], специалистом по вычислительной математике — [76].
Большинство работ специалистов по вычислительной математике в области методов решения задач можно найти под рубрикой «искусственный интеллект». Исчерпывающими обзорами являются [25] и [71]. Значительная часть этой литературы связана с играми на ЭВМ.
Полное рассмотрение задачи о джипе можно найти в [35].
Ричард Беллман и другие развили метод отрабатывания назад в нечто, лежащее между искусством и наукой, известное как динамическое программирование. Хорошо написанные вводные обзоры можно найти в [45] и [52].
3.2. Эвристики
Каждый год многие студенты «заново открывают» алгоритм GTS2. Гораздо более действенный (и более сложный) эвристический метод
для задачи коммивояжера дан в [64]. Быстрые, простые (но не особенно мощные) эвристические методы для очень больших задач рассмотрены в [94].
Наглядное рассмотрение с большим количеством интересных примеров эвристических алгоритмов для составления расписаний и упаковки можно найти в [41].
Анализ ряда простых, но эффективных эвристических алгоритмов содержится в [50].
3.3. Программирование с отходом
Этот метод «заново открывался» много раз. Например, см. [39]. Хорошее общее описание процедуры отхода можно найти в [60]. В последней статье также содержится полезный полуэкспериментальный анализ средней трудоемкости, применимый к любому алгоритму с отходом.
3.4. Метод ветвей и границ
Алгоритм этого раздела основан на статье [65], которая во многом способствовала популяризации процедуры ветвей и границ.
Более содержательное рассмотрение см. в [38]. Как показывает последняя работа, процедуры ветвей и границ очень полезны для решения задач оптимизации, известных как задачи целочисленного линейного программирования. В этих задачах требуется найти множество целых чисел, которые максимизируют или минимизируют линейную форму при линейных ограничениях. Многие важные задачи, включая задачу коммивояжера, можно сформулировать как задачи целочисленного линейного программирования.
Обзор работ по задаче коммивояжера до 1968 г. можно найти в [6].
Заслуживающими внимания вкладами в литературу по задаче коммивояжера являются работы [5] и [46]. Впечатляют результаты вычислительных экспериментов с этими двумя алгоритмами. Заметим, что в работе [46] используются остовные деревья минимального веса.
Один из наиболее эффективных с точки зрения скорости и качества решения эвристических алгоритмов для задачи коммивояжера можно найти в работе [64].
3.5. Рекурсия
Прекрасное описание рекурсии дано в книге [2].
Рекуррентные соотношения часто возникают в приложениях, и для нахождения решений таких уравнений в замкнутой форме существует много методов. Хорошее вводное изложение этого материала можно найти в [66].
В книге [76] обсуждаются методы поиска в ширину и глубину.
Рекурсивный поиск в глубину недавно был использован как основа для ряда эффективных сетевых алгоритмов. Одной из наиболее ранних и основополагающей является статья [88].
3.6. Моделирование
Большие усилия сделаны для развития хороших методов и языков моделирования. Эти усилия полностью оправданы важностью имитационных моделей для практических задач. В дополнение к книге [28] мы рекомендуем [401. Оба труда содержат главы по специальным языкам моделирования. В книге [28] приведена обширная библиография, к которой следует обратиться каждому, кто серьезно интересуется этой темой.
Глава 4. Полный пример
4.1. Алгоритм построения остовного дерева минимального веса
Алгоритм, приведенный в этом разделе, впервые сформулирован в работе [80]. Существует ряд уловок, которыми можно воспользоваться для ускорения этого основного алгоритма, но после этих изменений он все же остается алгоритмом сложности О(Л42). Мы предпочли пренебречь этими уловками и избежать ненужных усложнений.
Хорошее вводное обсуждение интерполяции, экстраполяции и приближения данных по методу наименьших квадратов можно найти в книгах [43] и [33].
4.2. Проверка программ
По проверке программ хорошая литература отсутствует. Нетрудно понять, почему дело обстоит так. Опубликованные описания процедур проверки обычно отражают подходы и эмпирические правила, используемые отдельными группами в «реальном мире». В некоторой степени материал этого раздела отражает наши собственные идеи и опыт. По-видимому, пройдет еще некоторое время, прежде чем какой-то конкретный набор процедур проверки станет широко принятым.
Легко читаемое, довольно полное описание проверок на правильность можно найти в книге [92]. В [99] также содержатся полезные советы. Некоторые заботятся о строгих доказательствах правильности программы, но пока что это направление исследований остается довольно бесплодным. (См. несколько ссылок в [99].)
Два простых описания проверки эффективности содержатся в исследованиях [58] и [49]. Программы, строящие профили других программ, обычно велики и сложны. Однако сильный студент может разработать и запрограммировать неплохую программу вычисления профилей (см. [27]).
4.3. Документация и обслуживание
Вопросы документирования программ и их обслуживания освещаются в работах [54], [99], [92], а также [42] и [74].
Глава 5. Алгоритмы вычислительной математики
5.1. Сортировка
Вероятно, алгоритмы сортировки являются наиболее широко изученными алгоритмами во всей машинной математике. Большая часть из того, что известно в этой области, исчерпывающе отражена в третьем томе.труда Кнута [59]. Прекрасной обзорной статьей является [69]. Другие книги в порядке возрастания трудности: [77], [75], [1].
5.2. Поиск
Исчерпывающее обсуждение машинного поиска можно найти у Кнута [59]. Более элементарный подход содержится в книге [75].
В обоих этих источниках обсуждается важный метод, называемый хэшированием, которого мы не касались. При хэшировании ключи отыскиваются путем вычисления функции от самого ключа. Значение этой функции задает точное или приблизительное расположение искомой записи.
Задачи вероятностного поиска требуют для своего решения изощренных математических средств — пример, приведенный в данном разделе, представляет собой редкое исключение. Описание более сложных задач можно найти в работе [18]. Ссылки на оригинальные работы Хафмана и Циммермана можно найти у Кнута [56].
5.3. Арифметические и логические выражения
Дальнейшее обсуждение арифметических выражений можно найти в работах [56], [75] и [95].
5.4. Управление страничной памятью
Есть несколько хороших источников информации по алгоритмам управления страничной памятью, в том числе [4], [19], [11].
Мы смогли только слегка коснуться темы алгоритмов, применяемых в математическом обеспечении ЭВМ (разд. 5.3 и 5.4). Компиляторы и операционные системы конструируются с использованием широкого разнообразия таких алгоритмов. К некоторым из ранее цитированных источников можно обратиться за дополнительными примерами. В их число входят все три тома Кнута [56], [57], [59], а также [47], [8], [77], [75], [11] и [95].
5.5. Параллелизм
Описание машины Иллиак IV приведено в работе [84]. Ссылки на несколько интересных статей о параллельных вычислениях можно
найти в книге 191]. Оказывается, М. Солин так и не опубликовал свой параллельный алгоритм нахождения остовного дерева минимального веса. Мы обнаружили краткое обсуждение в книге [24].
Алгоритм PARSORT взят из статьи [53]. Этот алгоритм обсуждается также в [24].
Глава 6. Математические алгоритмы
6.1. Игры и комбинаторные головоломки
Литература по играм обширна и разнообразна, и мы не сможем осветить ее в достаточной мере. Однако мы предоставим список, которого заинтересованному читателю хватит на годы.
Элементарное, полу историческое введение в магические квадраты можно найти в книге Гарднера [36]. В этой' книге цитируется ряд более серьезных источников.
Регулярную колонку Гарднера «Математические игры» в журнале Scientific American не пропускает ни один энтузиаст игр. Он также опубликовал или отредактировал более дюжины книг по математическим играм и головоломкам; например, см. [37].
Игра «нимбы», рассмотренная в этом разделе, была изобретена Джеймсом Байнамом и описана Гарднером в его колонке в феврале 1974 г. Задача о тройной дуэли является классической. Гарднер [36] описывает ее возникновение. Несколько более общую и более серьезную трактовку, чем приведена здесь, можно найти в книге [32].
Существует формальная математическая теория игр, которую мы не рассматривали, поскольку этот предмет заслуживает отдельного курса в большинстве университетов. Следующие книги служат введением на нескольких различных уровнях: [97], [83], [93], [67].
Как и следовало ожидать, много усилий было направлено на анализ серьезных азартных игр. Книги [82] и [23] весьма основательны, хотя и каждая в своем роде.
Энтузиасты компьютерных игр должны обращаться к литературе по искусственному интеллекту, например к книгам [25], [76], а также к книге [86].
В книге [75] также имеется хорошая глава о машинно-ориентированных играх.
6.2. Кратчайшие пути
Проблема отыскания кратчайших путей в сетях изучалась до оскомины. Из рассмотренных в этом тексте проблем особенно основательно изучена сортировка. (Некоторые темы, как, например, поиск, слишком разнообразны, чтобы их можно было рассматривать как одну проблему.) Книга [62] содержит хорошее обсуждение, гораздо более исчерпывающее, чем то, которое мы привели здесь. Алгоритм Дейкстры впервые был сформулирован в работе [21].
6.3. Вероятностные алгоритмы
Центральная предельная теорема (теорема 6.3.3) позволяет нам аппроксимировать ряд дискретных и непрерывных распределений стандартным нормальным распределением N (0, 1). Некоторые примеры можно найти у Росса [81]. Эта аппроксимация часто позволяет значительно упростить вычисления.
В книге Кнута [57] очень детально рассмотрены генераторы случайных чисел. В ней обсуждается выбор параметров алгоритма LCM и дан широкий ассортимент статистических тестов для проверки «случайности» последовательности случайных чисел. Многих читателей книги Кнута может также заинтересовать обсуждение вопроса, что такое случайная последовательность? (Этот материал несколько труден, но по крайней мере вы получите некоторое представление об усилиях, которые необходимо приложить для ответа на этот вопрос.)
Книга Кнута [57], а также работа [47] могут быть использованы при дальнейшем изучении теории и примеров, относящихся к вероятностным алгоритмам. Две отличающихся точки зрения можно найти в статьях Гренандера и Нойтса в сборнике [61].
Статистическая оценка производительности вычислительных систем привлекала до недавнего времени заметное внимание. Интересующиеся читатели могут обратиться к книгам [31], [47]. Для чтения этих книг необходимо иметь некоторое представление об организации вычислительных машин и операционных систем.
Численная оценка сложности вычислений и NP-полные задачи
Существует две важные темы, которых мы не смогли коснуться, так как их включение потребовало бы увеличения объема книги и некоторых сведений из дополнительного курса. Мы удовлетворимся простым их упоминанием и дадим несколько библиографических ссылок.
Предмет численной или аналитической оценки вычислительной сложности относится к проектированию и анализу, численных алгоритмов. Сюда относятся алгоритмы матричных операций, целочисленная арифметика и арифметика многочленов, решение алгебраических и дифференциальных уравнений, быстрые преобразования Фурье и т. д. Интересующийся читатель может обратиться к работам [57], [91], [1] и к статье Трауба в сборнике [61]. Краткий и весьма легкий для чтения обзор содержится в [90].
Было показано, что комбинаторные задачи, относящиеся к широкому классу, включающему задачу о коммивояжере, и общие задачи планирования и упаковки (см. разд. 3.2) — все эквивалентны в том смысле, что либо все они разрешимы, либо ни одна из них не разрешима полиномиальными алгоритмами. Таким образом, если бы удалось показать, что хотя бы для одной из этих задач не может существовать алгоритма решения, имеющего в худшем случае полиномиаль
ную трудоемкость, то таких алгоритмов не должно существовать и для всех остальных задач этого класса. Наоборот, если можно найти хотя бы для одной из таких задач алгоритм, имеющий в худшем случае полиномиальную трудоемкость, то его можно было бы применить при построении полиномиальных алгоритмов для остальных задач. Задачи из этого класса называются N p-полными. Наиболее элементарной работой по этому вопросу, по-видимому, является [51]. Для более серьезного изучения можно порекомендовать [1].
1. Aho, А. V., J. Е. Hopcroft, and J. D. Ullman, The Design and Analysis of Computer r Algorithms, Addison-Wesley, Reading, Mass., 1974(VAM).
2. Barron, D. W., Recursion Techniques in Programming, American Elsevier, New York, 1968(IM). •
. 3. Basili, V. R„ С. K. Mesztenyi, and W. C, Reinboldt, “FGRAAL: Fortran Extended Graph Algorithmic Language,” Tech. Rept. 179, Computer Science' Center, University of Maryland, 1972(1); see also Tech. Rept. 225,1973(1).
4. Belady, L. A., “A Study of Replacement Algorithms for a Virtual Storage Computer,” IBM Syst. L, 5: 78-101 (1966)(l).
5. Bellmore, M., and-J. C. Malone, “Pathology of Traveling Salesman Subtour Elimination Algorithms,” Oper. Res., 19: 278-307 (1971)(AM).
6. —----, and G. L. Nemhauser, "The Traveling Salesman Problem: A Survey,” Oper.
Res., 16: 538-558 (1968)(IM).
7. Berge, C., Graphs and Hypergraphs, North-Holland, Amsterdam, 1973(AM).
8. Berztis“s, A. T., Data Structures; Theory and Practice, Academic, New York, 1971 (IM).
Э. Busacker, R. G., and T. L, Saaty, Finite Graphs and Networks, McGraw-Hill, New York, 1965(IM).
10. Chase, S. M., “GASP—Graph Algorithm Software Package," Q. Tech. Prog. Rept. (Oct.-Dec. 1969), Department of Computer Science, University of Illinois (I).
11. Coffman,’ E. G., and P. J. Denning, Operating Systems Theory, Prentice-Hall, Englewood Cliffs' N.J., 1?73(AM).
12. Comput. Sure., 6: (1974)(E).
13. Corneil, D. G., "Graph Isomorphism," doctoral .thesis, Department of Computer Science, University of Toronto, Canada, 1968(AM); see also Tech. Rept. 18, Department of Computer Science, University of Toronto, 1970.
14. ----, and С. C. Gotlieb, "An Efficient Algorithm for Graph Isomorphism," J. ACM,
17:51-64 (1970)(AM).
15. Cox, D. R., and D. V. Hinkley, Theoretical Statistics, Chapman and Hall, London, 1974(AM).
16. Dahl, О., E. Dijkstra, and C. A.- R. Hoare, Structured Programming, Academic, New York, 1972(1).
17. Datamation, 19: (1973)(E).
18. DeGroot, M. H., Optimal Statistical Decisions, McGraw-Hill, New York, 1970(VAM).
19. Denning, P. J., "Virtual Memory," Comput. Sure., 2: 153-189 (1970)(l).
2Q.Peo, N., Graph Theory with Applications to Engineering and Computer Science, Prentice-Hall,'Englewood Cliffs, N.J., 1974(IM).
,21 . Dijkstra, E. W., "A Note on Two Problems in Connexion with Graphs," Numer. Math., 1: 269-271 (1959)(IM).
22. Edmonds, J., “Paths, Trees, and Flowers," Can. J. Math., 17:449-467 (1965)(AM). • 23. Epstein, R. A., The Theory of Gambling and Statistical Logic, Academic, New York, >. . 1967(AM).
24. Even, S., Algorithmic Combinatorics, Macmillan, New York, 1973(IM).
25. Feigenbaum, E. A., and J. Feldman, Computers and Thought, McGraw-Hill. New York, 1963(1). ' . L,
26. Feller, W., An Introduction to Probability Theory and Its Applications, 2d ed., vol, 1, Wiley, New York, 1957(IM).
27. Ferguson, L„ "PROFILE, A GDC Fortran Profiling Program,”' Tech. Rept. 75-6, Department of Applied Mathematics and Computer Science, University of Virginia; 1975(1).
28. Fishman, G. S., Concepts and Methods in Discrete Event Digital Simulation, Wiley, New York, 1973(IM)., .
29, Frank, H„ and I. T. Frisch,' Communications, Transmission, and Transportation Networks,-Addison-Wesley, Reading, Mass., 1971(AM).
30. Freiberger, W., and U. Grenander, A Short Course in Computational Probability and Statistics, Springer-Verlag, New York; 1971 (VAM).,
31. Freiberger, W. (ed.), Statistical Computer Performance Evaluation, Academic, New York, 1972(A).
32. Freudenthal, H., Probability and Statistics, Elsevier, Amsterdam, 1965(IM). '
33. Frbberg, C.E., Introduction to Numerical Analysis, 2d ed., Addison-Wesley, Reading, Mass., 1969(AM).
34. Fulkerson, D. R., “Flow Networks and Combinatorial Operations Research,” Am. Math, Mon., 73:115-138 (1966)(IM).
35. Gale, D., “The Jeep Once More or Jeeper by the Dozen," Am. Math. Mon., 77: 493-501 (1970)(IM).
36. Gardner, M., The 2nd Scientific American Book of Mathematical Puzzles and Diversions, Simon and Schuster, New York, 1961 (EM).
37. , The Unexpected Hanging and Other Mathematical Diversions, Simon and
Schuster, New York, 1969(EM).
38. Garfinkel, R. S., and G. L. Nemhauser, Integer Programming, Wiley, New York, 1972(AM).
39. Golomb, S.W., and L. D. Baumert, “Backtrack Programming," J. ACM, 12:516-524 (1965)(l).
40. Gordon, G., System Simulation, Prentice-Hall, Englewood Cliffs, N.J., 1969(1). I
41. Graham, R. L., “Bounds on Multiprocessing Anomalies and Related Packing Algorithms,” in Proc. Spring Joint Comput. Conf., 205-217 (1972)(IM).
42. Gunderman, R. E., “A Glimpse into Program Maintenance,” Datamation, 19:99-101 (1973)(E).
43. Hamming, R. W.,.Introduction to Applied Numerical Analysis, McGraw-Hill, New York. 1971 (IM).
44. Hart, R., “HINT: A Graph Processing Language,” Res. Rept., Computer Institute for Social Science Research, Michigan State University, 1969(1).
45. Hastings, N. A. J., Dynamic Programming! Crane, Russak, New York, 1973(IM).
46. Held, M„ and R. M. Karp,-"The Traveling Salesman Problem and Minimum ) Spanning Trees, Part II,” Math. Prog., 1: 6-25 (1971)(AM).
47. Hellerman, H„ and T. F. Conroy Computer System Performance, McGraw-Hill, New York, 1975(AM). ,
48. Huntsberger, D. V., and P. Billingsley, Elements of Statistical Inference, 3d ed., Allyn and Bacon, Boston, Mass., 1973(EM).
49. Ingalls, D. H. H., “FETE: A Fortran Execution Time Estimator,” Tech. Rept. ) STAN-CS-71-204, Stanford University; Stanford, Calif., 1971(E).
50. Johnson, D., "Approximation Algorithms for Combinatorial Problems,” J. Comput; Syst. Set., 9: 256-276 (1974)(AM).
51. Karp, R. M„ “On the Computational Complexity of Combinatorial Problems,” Networks, 5: 45-68 (1975)(AM).
52. Kaufmann, A., Graphs, Dynamic Programming and Finite Games, Academic, New York, 1967(IM)
53. Kautz, W. H., K. N. Levitt, and A. Waksman, "Cellular Interconnection Arrays," IEEE Trans. Comput.. C-17: 443-451 (1968)(IM).
54. Kernighan, B. W., and P. J. Plauger, The Elements of Programming Style, McGraw-Hill, New York, 1970(E).
55. King. C. A., “A Graph-Theoretic Programming Language,” in R. C. Read(ed-), Graph Theory and Computing, Academic, New York, 1972, 63-74(1).
56. Knuth, D. E., Fundamental Algorithms, The Art of Computer Programming, vol. 1, Addison-Wesley, Reading, Mass., 1969a(AM).
57.-------, Seminumerical Algorithms, The Art of Computer Programming, vol. 2,
Addison-Wesley, Reading, Mass., 1969b(AM).
58.-------. “An Empirical Study of Fortran Programs," Software Pract. Esper., 1:
105-133 (1971)(E).
59.-------, Sorting and Searching, The Art of Computer Programming, vol. 3,
Addison-Wesley, Reading, Mass., 1973(AM).
50.-------, “Estimating the Efficiency of Backtrack Programs," Matin Comput., 29:
121-136. (1975)(IM).
61. LaSalle, J. P., The Influence of Computing on Mathematical Research and Education: Proc. Symp. Appl. Math., vol. 20, American Mathematical Society, Providence, R.I., 1974(AM).
62. Lawler, E„ Combinatorial Optimization: Networks and Matroids, Holt, Rinehart and Winston, New York, 1975(AM).
63. Lenstra, J. K., and A. H. G. Kan Rinnooy, "Some Simple Applications of the Traveling Salesman Pioblem,” Publication BW 38/74, Mathematisch Centrum,-Amsterdam, 1974(AM).
64. Lin, S., and B. W. Kernighan, "An Effective Heuristic Algorithm for the Traveling Salesman Problem,” Oper. Res., 21: 498-516 (1973j(l).
65. Little, J. D. С., K.- G. Murty, D. W. Sweeney, and C. Karel, “An Algorithm for the Traveling Salesman Problem,” Oper. Res., 11: 979-989 (1963)(IM).
66. Liu, C. L., Introduction to Combinatorial Mathematics, McGraw-Hill, New York, 1968(1M).
67. Luce, R. D., and H. Raiffa, Games and Decisions, Wiley, New York, 1957(AM).
68. Martin, C., and D. S. Richards, “CLAMAR: A Combinatorial Language,” Tech. Rept. 75-5, Department of Applied Mathematics and Computer Science, University of Virginia, 1975(1).
69. Martin, W. A„ “Sorting,” Comput. Surv.,3; 148-174 (1971)(l).
70. McGowan, C. L., and J. R. Kelly, Top-Down Structured Programming Techniques, Petrocelli/Charter, New York, 1975(E).
71. Meltzer, B., and D. Michie, Machine Intelligence 7, Wiley, New York, 1972(AM).
72. Minsky, M., Computation: Finite and Infinite Machines, Prentice-Hall, Englewood Cliffs, N.J., 1967(IM).
73. Mood, A. M., and F. A. Graybill, Introduction to the Theory of Statistics, kfcGraw-Hill, New York, 1963(IM). -' ’ '
74. Mooney, J. W., “Organized Program Maintenance,” Datamation, 21: 63-64 (1975) (E).
75. Nievergelt, J., J. C. Farrar, and E. M. Reingold, Computer Approaches to Mathematical Problems, Prentice-Hall, Englewood Cliffs, N.J., 1974(IM).
76. Nilsson, N. J., Artificial Intelligence. McGraw-Hill, New York, 1971(IM).
77 Page, E. S., and L. B. Wilson, Information Representation and Manipulation in a Computer, Cambridge, London, 1973(IM).
78. Polya, G„ How to Solve It, Doubleday, Garden City, N.Y., 1957(EM).
79. ------, Mathematical Discovery, vols. 1 and 2, Wiley, New York, 1962(EM).
60. Prim, R. C., “Shortest Connection Networks and Some Generalizations,” Bell Syst.
Tech. J., 36: 1389-1401 (1957)(IM).
81. Ross, S. M.. Introduction to Probability Models, Academic, New. York,.1972(IM).
82. Scarne. J., Scarne's Complete Guide to Gambling, Simon and Schuster, New York, 1961(E).
83. Singleton, R. R., and W. F. Tyndall, Games and Programs: Mathematics for Modeling, Freeman, San Francisco, 1974(IM).
84. Slotnick, D. L., “The Fastest Computer,” Sei. Am., 224: 76-88 (1971)(E).
85. Snell, J. L., Introduction to Probability Theory with Computing, Prentice-Hall, Englewood Cliffs, N.J., 1975(EM).
86. Spencer, D. D., Game Playing with Computers, Spartan, New York, 1968(E).
87. .Stone, H„ Introduction to Computer Organization and Data Structures, McGraw-Hill, New York, 1972(1).
86. Tarjan, R„ “Depth-First Search and Linear Graph Algorithms,” SIAM J. CompUt,!: 146-160 (1972)(IM).
89. Trakhtenbrot, B. A,, Algorithms and Automatic Computing Machines, Heath, Boston, Mass., 1963(IM).
90. Traub. J. F., "Numerical Mathematics and Computer Science,” Comm. ACM, 15: 537-541 (1972)(!M).
91. (ed.), Complexity of Sequential and Parallel Numerical Algorithms, Academic,
New York, 1973(IM to AM).
92, Van Tassel, D., Program Style, Design, Efficiency, Debugging, and Testing, Prentice-Hall, Englewood Cliffs, N.J., 1974(E).
93. Von Neumann, J., and O. Morgenstern, Theory of Games and Economic Behavior, Princeton University Press, Princeton, N.J., 1944(AM).
94. Webb, M. H. J.,1 Some Methods of Producing Approximate Solutions to Traveling ( Salesman Problems with Hundreds or Thousands of Cities," Oper. Res. Q., 22.: J 49-66 (1971)(E).
95. Wegner, P., Programming Languages, Information Structures, and Machine
Organization, McGraw-Hill, New York, 1968(1).
96. Wickelgren, W. A., How to Solve Problems; Elements of a Theory of Problems and Problem Solving, Freeman, San Francisco, 1974(EM).
97. Williams, J. D., The'Compleat Strategyst, McGraw-Hill, New York, 1966(EM).
98. Winkler, R. L., Introduction to Bayesian Inference and Decision, Holt, Rinehart and
... Winston, New York, 1972(IM).
r$9 Yohe, J. M„ “An Overview of Programming Practices,” Comput. Sun., 6:221-245 (1974)(E).
ИМЕЕТСЯ РУССКИЙ ПЕРЕВОД
К СЛЕДУЮЩИМ РАБОТАМ:
1. Ахо А., Хлопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов.— М.: Мир, 1979.
2. Баррон Д. Рекурсивные методы в программировании.— М.: Мир, 1974.
8. Берзтисс А. Структуры данных.— М.: Статистика, 1974.
9. Басакер Р., Саати Т. Конечные графы и сети.— М.: Наука, 1974.
15. КоксД., Хинкли Д. Теоретическая статистика.— М.: Мир, 1978.
16. Дал У., Дейкстра Э., Хоор К- Структурное программирование.— М.: Мир, 1975.
25. Фейгенбаум Э. Вычислительные машины и мышление.— М.: Мир, 1967.
26. Феллер В. Введение в теорию вероятностен и ее приложения.— М.: Мир, 1967.
36. Гарднер М. Математические головоломки и развлечения.— М.: Мир, 1971.
37. Гарднер М. Математические досуги.— М.: Мир, 1972.
56. Кнут Д. Искусство программирования для ЭВМ. Т. 1. Основные алгоритмы.— М.: Мир, 1976.
57. Кнут Д. Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы.— М.: Мир, 1977.
59. Кнут Д. Искусство программирования для ЭВМ. Т. 3. Сортировка и поиск.— М.: Мир, 1978.
67. ЛыосР., РайфаХ. Игры и решения.— М.: ИЛ, 1961.
72. Минский М. Вычисления и автоматы.— М.: Мир, 1971.
75. Нивергельт Ю., Феррар Дж., Рейнголд Э. Машинный подход к решению математических задач.— М.: Мир, 1977.
76. Нильсон Н. Искусственный интеллект. Методы поиска решений.— М.: Мир, 1973.
78. Пойа Дж. Как решать задачу. Пособие для учителей.— М.: Учпедгиз, 1961.
79. Пойа Дж. Математическое открытие. Решение задач: основные понятия, изучение и преподавание.— М.: Наука, 1970.
93. Фон Нейман Дж., Моргенштерн О. Теория игр и экономическое поведение,— М.: Наука, 1970.
Работа [87] — Трахтенброт Б. А. «Алгоритмы и вычислительные автоматы» — была выпущена издательством «Советское радио» в 1974 г.
Приложение А. Соглашения, принятые для описания алгоритмов
В этом приложении содержится объяснение соглашений, которые применялись при изложении алгоритмов в этой книге. Мы говорим «соглашения», а не «правила», потому что они не подразумеваются зафиксированными раз и навсегда; наоборот, подразумевается, что эти соглашения достаточно гибкие для того, чтобы изложить любой алгоритм в виде, удобном для чтения и понимания.
Далее следует пример (из разд. 1.2) формы, в которой были описаны алгоритмы.
Algorithm МАХ. Даны N действительных чисел в одномерном массиве R (1), R(2), . . ., R(M); найти такие М и J, что M=R(J)= max R(K). В случае, когда два или более элементов R имеют
наибольшее значение, выбирается наименьшее значение J.
Шаг 0. [Инициализация] Set 7W-<-R(l); and
Шаг 1. [Д=1?] If М=1 then STOP fi.
Шаг 2. [Проверка каждого числа] For К 2 to N do шаг 3 od; and STOP.
Шаг 3. [Сравнение] If M<R(K) then set M~<—R(K)', and J К. (Теперь M — наибольшее число из про-
веренных, а К — его номер в массиве.)
В оставшейся части этого приложения объясняется этот формат.
Общий формат. Общий формат изложения алгоритма проиллюстрирован ниже.
Algorithm ИМЯ ( ). Описание назначения алгоритма вместе
с описанием соответствующих параметров и переменных ввода и вывода.
Шаг 0. [ ] Операторы.
Шаг 1. [ ] Операторы___________________________
(Комментарии.)
Шаг 2. [ ] Операторы.
Шаг К- [
Шаг R+1. [
] Операторы. (Комментарии.) ] Операторы.
Шаг N. [
] Операторы.
Имя и описание. Начало «Algorithm ИМЯ ( )» выделено
жирным шрифтом. Описание алгоритма читается как абзац с последующими строками, продолжающимися вниз от левого края.
Имя алгоритма пишется только заглавными буквами и должно указывать сущность или автора алгоритма. В некоторых случаях имя может быть аббревиатурой, при этом выделенное курсивом имя может стоять в скобках; например,
Algorithm SIS (Straight Insertion Sort — прямое включение)
Algorithm PARSORT (PARallel Sort—параллельная сортировка)
Сразу за именем алгоритма следует краткое описание его назначения, включая описание требуемого ввода и получаемого вывода. Где необходимо, также дается описание появляющихся в алгоритме переменных, назначение которых не сразу очевидно.
Шаги. Перенумерованные шаги алгоритма — Шаг i — выделены курсивом и начинаются с левого края. Некоторые шаги могут быть дважды (трижды и т. д.) сдвинуты вправо, чтобы подчеркнуть логические уровни, повысить наглядность и т. п. Если для операторов внутри Шага i требуется больше одной строки, последующие строки начинаются ниже и правее номера шага.
Шаги алгоритма указываются обозначениями Шаг i, где i — неотрицательное целое число. Нумерация шагов всегда последовательная и начинается с 0 или 1; Шаг 0 обычно используется для установки в начальное состояние (инициализации) переменных или массивов. Шаг используется для определения смысловой логической единицы в детализированном изложении алгоритма, для которого дальнейшая детализация не кажется необходимой для понимания.
Скобки. Сразу за Шагом i следует краткая фраза, заключенная в скобки [ ], описывающая цель шага. Эти скобки могут быть
опущены в случае, когда цель шага очевидна и не требует объяснения. Скобки служат другой полезной цели, когда они используются для комментариев или замечаний по реализации алгоритма; это помогает прямо показать, где конкретный шаг реализован в кодах.
Пунктуация и комментарии к операторам. За фразой в скобках следует последовательность из одного или более операторов, отделенных точками с запятой (;). Эта последовательность оканчивается точкой. Сразу за последней точкой с запятой и перед последним оператором в последовательности может появиться слово and для удобства чтения. После всех операторов внутри шага могут появиться дополнительные комментарии, заключенные в круглые скобки; они используются для объяснения особенностей алгоритма или различных этапов вычислений.
Соглашения о языке операторов. Предполагается, что все операторы можно читать как предположения или как последовательность команд. Например, вместо того чтобы писать COST *- 0, мы можем писать Set COST <- 0. В этом случае мы говорим, что Set — элемент языка операторов, тогда как COST— переменная, выбранная разработчиком алгоритма. Все слова языка операторов выделяются жирным шрифтом; к ним относятся:
and do else fi for goto if od set then through to while
Если с этих слов начинается предложение, начальные буквы — заглавные, например Set, Do, If.
Чтобы отличить имена переменных и логические операции от слов языка операторов, имена переменных и логические операции пишутся полностью заглавными буквами. Обращаем внимание на разницу между AND и and в следующем примере:
If Z<10 AND /<10 then set /-/+1; and set /W-М fi.
Операторы присваивания. Операторы присваивания записываются с помощью стрелки (ч-). Слово set необязательно; например,
Set 1 1 или
Set /«-1; J+-2; and Кч-3.
Операторы If. Операторы if могут быть двух видов, а именно:
If КJ then set I /+1 fi или
If KJ then set I 1+1
else set J +- J—1 fi.
После then и else могут появляться заключенные в скобки предложения, если они улучшают или понимание, или читаемость, или и то и другое; например,
If KJ then [исключаем вершину] set /<- Z+1 else [сдвигаем указатель] set PTR LEFT (PTR) fi.
Обычно мы рекомендуем ставить fi в конце оператора if, особенно когда его отсутствие может повлечь двусмысленность или неправильность оператора.
Рассмотрим оператор
If I<J then set I /+1
else set J +- J+1; /С 1.
Он может быть интерпретирован одним из двух способов:
If I<J then set I1+1
else set /-«-J-j-l; set ч-1 fi.
или
If I<Z J then set I *- 7+1 else set J J+l fi; set /С 1.
В первом операторе /С полагается равным 1, если только I не меньше J; во втором операторе /С полагается равным 1 независимо от значения I или J.
Операторы цикла. Операторы цикла появляются в разных формах; например,
1. Шаг i. [ ] Do шаг i+1 while /++'[ od.
Шаг i+1. [ 1 If COST(/, J)^MIN
then set MIN COST (I, J)- and I^-I+i fi.
2. Шаг i. [ 1 Do through шаг i+3 while J>0 od.
Шаг i+1. [ ] Операторы.
Шаг i+2. [ ] Операторы.
Шаг i+3. [ 1 Операторы.
Шаг i+4. [ ] Операторы.
Порядок выполнения цикла 2 следующий: выполняются шаги i+1, i+2 и i+З, затем проводится проверка, положительно ли J: J>0; если J^O, то следующим выполняется шаг i+4; если +>0, то выполняются опять шаги i+1, i+2 и i+З и J еще раз сравнивается с нулем и т. д. Предполагается, что где-то в пределах шагов i+1, i+2 или i+З значение J меняется; в противном случае существует возможность бесконечного цикла.
3. Шаг i. [ 1 While PTR>0 do PTR ч-LEFT (PTR) od.
4. Шаг i. [ ] While J>0 do through шаг i+2 od.
Шаг i+1. [ ] Операторы.
Шаг i+2. [ ] Операторы.
Шаг i+3. [ ] Операторы.
Выполнение цикла. while-do отличается от выполнения цикла do-while только- тем, что в одной форме проверка осуществляется перед первым выполнением шага (шагов), предписанного оператором do, а не после. Использование od, как в форме 3, служит для определения конца действия do; его применение идентично применению fi.
5. Шаг i. [ 1 For I -t- 1 to N do шаг i+1 od.
Цель формы 5 — допустить выполнение типичного DO- или FOR-цикла с приращением, равным 1, вместо того, чтобы инициализировать индексную переменную I и увеличивать ее внутри цикла do-while или while-do.
Операторы goto. Хотя принципы структурного программирования исключают потребность в операторах goto, иногда встречаются ситуации, когда goto кажется подходящим и естественным средством. В таких случаях алгоритмы бывают обычно очень короткими, и применение операторов goto не мешает пониманию логики алгоритма. Поэтому мы умеренно используем операторы goto.
Приложение Б. Множества и некоторые основные алгоритмы на множествах
Множества являются наиболее общей из всех математических структур и появляются почти в каждой математической модели. Часто задачи моделируются в терминах множеств, а алгоритмы решения формулируются в терминах основных операций на этих множествах. Реализация любого алгоритма может включать различные способы представления множеств и их обработки.
Это приложение не является «введением в теорию множеств». Скорее оно предполагает знание основ теории'множеств и операций над ними. В какой-то мере мы хотели установить обозначения, используемые в книге, но основная цель приложения — ознакомить читателя с некоторыми вопросами, возникающими при использовании множеств для реализации алгоритмов.
Б.1. Обозначения
1. Множества обозначаются латинскими заглавными буквами, а элементы множеств изображаются строчными буквами; например, f7={r, s, t, и, v, w}.
2. v£U v — элемент множества U.
v(£U v — не является элементом множества U.
V^U V—подмножество U, т. е. каждый элемент V является также элементом U.
VcU V — собственное подмножество U, т. е. существует элемент U, который не является элементом V.
3. V=0 V— пустое множество, т. е. в V нет элементов.
4. | VI Кардинальность V, т. е. для конечных множеств
число элементов в V.
5. U и V Объединение множеств U и V, т. е. множество,
состоящее из всех элементов U и всех элементов V.
U П V Пересечение множеств U и V, т. е. множество, со-
стоящее изч всех элементов, являющихся одновременно элементами и V, и V.
V—U Разность V и U, т. е. множество, состоящее из тех
элементов V, которые не являются элементами U.
V^U, V ' Если V — подмножество U, тогда V обозначает дополнение V в U, т. е. V—U—V.
6. Если v2, . . ип} — Конечное множество действительных
чисел, то
2^г=^+^+---+^ и ПЧ=ад---ч, i=i г=1
означают соответственно сумму и произведение всех элементов V.
7. Г о, -] Наименьшее целое число, большее или равное Vi.
L4-J Наибольшее целое число, меньшее или равное v^.
8. |V|=oo V — бесконечное множество, т. е. оно содержит бесконечное счетное число элементов.
|У|<оо » V — конечное множество.
9. Если i, k — положительные целые числа, то i!=i’x (i—1)Х. . .X Х2Х1 читается «i-факториал» (см. разд. 4.5).
0) читается «число сочетаний из i по /» и означает число способов выбора / разных объектов из i разных объектов.
10. Гармонический ряд — это бесконечный ряд рациональных чисел 1+4+т+4+ -
^=1+|+--+7=£т
4=1
называется N-ti частной суммой гармонического ряда.
Б.2. Применение множеств и операции на множествах
Как узнать, является ли данный элемент и элементом множества V? Глядя на V и проверяя, находится ли и там, не правда ли? Проблема, однако, состоит в следующем: как может ЭВМ «смотреть» на V и проверять наличие и? Это задача представления множества в машине. Здесь будет дан один очень простой ответ. Возможны и другие ответы.
Особенно простое представление возможно, если мы предполагаем, что все рассматриваемые множества являются подмножествами некоторого конечного универсального множества U. Пусть U содержит п различных элементов, помеченных как 1, 2, . . ., и (каждый элемент помечен определенным целым числом). Мы можем представить любое подмножество V множества U цепочкой, или последовательностью, нулей и единиц. Если i-я позиция, или бит, этой цепочки есть 1, тогда элемент под номером i и обозначаемый vt находится в V; если же там 0, то v^V; например, если в U шесть элементов, то
У= (0,0,1,0,1,1)
представляет множество V, состоящее из элементов v3, vb и ve, и 0— (0,0,0,0,0,0)
представляет пустое множество (всегда обозначаемое 0), не содержащее ни одного элемента, в то время как U— (1,1,1,1,1,1). Любая такая последовательность, представляющая множество V, известна как характеристический вектор V (по отношению к U).
Если U содержит п элементов, сколько имеется различных подмножеств U?
Заметим, что если | U\ меньше, чем число битов в слове вашей ЭВМ, то можно представить любое одним словом памяти.
Как тогда мы проверяем справедливость принадлежности v £ V? В представлении характеристическим вектором мы смотрим, какая целочисленная метка была поставлена в соответствие v. Предположим, что это i. Тогда мы проверяем i-й бит в последовательности, представляющей V. Если там стоит 0, то v^V, в противном случае v g V.
Операция объединения множеств легко реализуется с помощью характеристических векторов. Все, что надо сделать, чтобы получить Л и В, это «сложить» характеристический вектор, представляющий А, с вектором, представляющим В. .Мы проделываем это «сложение» покомпонентно при условии, что «сумма» двух единиц есть единица. Такое модифицированное сложение называется операцией двоичного ИЛИ и обозначается символом V- Основные правила этой операции сведены в четыре формулы:
1 vi=i
1 vo=l
OV1 = 1
0V0=0
Для примера пусть |Д|=7; рассмотрим два характеристических вектора
Л= (1,0,1,0,1,1,0)
В= (1,1,0,0,1,0,0)
Тогда
А иВ=(1,1,1,0,1,1,0)
На многих ЭВМ эта реализация операции объединения может быть выполнена одной операцией, если |t/|^ размера основного машинного слова. В противном случае нам может понадобиться |Д| операций.
Мы можем также определить операцию двоичного И А и воспользоваться ею, чтобы сформулировать алгоритм для представления А П В характеристическим вектором'из представлений для А и В.
Аналогично операция .NOT. (не) может быть определена для представления дополнения множества.
Каковы другие операции на множествах, которые никогда не
рассматриваются в математических курсах, но которые следует детально рассматривать для машинной реализации? Задумайтесь над этим вопросом, прежде чем читать дальше.
По поводу операции исключения элемента v из множества V, обозначаемой V—{п}, можно сказать следующее: она требует одного шага, если использовать представление характеристическими векторами.
Далее, существует проблема отыскания элемента v. Какое из нашего текущего набора множеств содержит и (если какое-нибудь содержит)? Это пример задачи поиска. Более общие задачи поиска требуют отыскания всех элементов, обладающих некоторыми свойствами.
Часто бывает, что рассматриваемые элементы множеств все являются действительными или целыми числами и могут быть упорядочены естественным образом, т. е. с использованием отношения между действительными числами «равно» и «больше, чем». Другие множества элементов также могут быть упорядочены некоторым естественным или хорошо определенным способом. Можете ли вы придумать несколько примеров?
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Аккермана функция 147
Алгоритм (algorithm) 14
•—, анализ 27, 193
— генерации случайных чисел (random number generation)
-----------LCM 330
-----------MS 329
-----------NR N 333
-----------PNRN 335
— Дейкстры 312
— для тура коня 43—44
— извлечения несмещенной выборки (unbiased sample selection) 321
-----------SELECT 324
----------- SS 322
-----------TRYAGAIN 321
— исчерпывающий (exhaustive) 20, 25
— отыскания остовного дерева минимального веса 184,. 343
— параллельной сортировки (prallel sort) 292
— поиска в глубину (depth-first search) 150—151
---в ширину (breadth-first search) 158
— полиномиальный 23
—, полное построение (complete development) 13
— построения магических квадратов 298
— , правильность (correctness) 21
— Прима 185
— , разработка (design) 19—20
— , реализация (implementation) 22
— , сложность (complexity) 23
— сортировки (sorting) 96
— с отходами (backtracking) 129
— управления страничной памятью
(paging algorithms) 268, 344
-----------FIFO 269
-----------LFU 279
-----------LRU 269, 273
— эвристический (heuristic) 63, 113
— экспоненциальный 23, 25
— A 184
— BFS 158
— BSEARCH 242
— CONNECT 56
— DELETE 69
— DEMS 301
— DFS 150—151
— ETS 20, 25
— GTS 113
— GTS2 114
— HEAP 234
— HEAPSORT 234
— INSERT 70
— ITP 263
— MAX 15
— ODDMS 298
— PARSORT 292
— POSTFIX 260
— PRIM 185, 210
— QUICKSORT 226
— SIS 96
— . SOLLIN 287
— WELLFORMED 79
Амдаля эффект 285
Анализ сложности (complexity analysis) 193
-- алгоритма
---------BSEARCH 245
---------BTSI 249
---------DFS 154
---------DIJKSTRA 318
---------ETS 25
---------HEAP 234
---------PARSORT 295
---------PRIM 194, 209
---------QUICKSORT 225, 229
--------- SIS 98
---------SOLLIN 289
— трудоемкости алгоритма (performance analysis) 85, 341
Арифметическое выражение 256
Блок-схема (flow-chart) 31
— алгоритма ветвей и границ 136
----для задачи о пшенице, мышах и кошках 172
— ---тура коня 43
----CONNECT 57
----DELETE 71
----INSERT 74
----I TP 264
----PRIM 186, 190
---- SIS 97
------DIJKSTRA 314
------PAR SORT 293
------POSTFIX 261
------QUICKSORT 211
--------SOLLIN 288
--------SS 323
Документация программы (documentation) 28, 217, 344
Дуга (arc) 50
Вектор смежности (adjacency vector) 54
Вероятностная модель (probabilistic model) 85
Вероятность события (probability of an event) 89
Ветвление (branching) 131
Вершина (vertex) 49
— изолированная (isolated) 50
— разделяющая (cut-vertex) 51
Взвешенная сеть (weighted network) 50, 182
Виртуальная память 266
Внешняя документация (external documentation) 217
Выборка (sample) 99, 321
Выражение отношения 257
Высота дерева (height) 59
Вычисление границ (bounding) 133
Ганта схема 118
Генератор случайных чисел (random numbers generator) 326, 346
Глубина рекурсии 146
Гол оволомка «8» 127
Граф (graph) 19
Данные входные и выходные (input, output) 220
Дважды рекурсивная функция 147
Дейкстры алгоритм 312
Дек (deque) 84
Дерево (tree) 45, 57, 82, 340
— корневое (rooted tree) 59
---двоичное (binary) 59
— остовное (spanning tree) 61, 181
— рекурсивное (recursive tree) 82
— решений (decision tree) 237
Диаграмма сортировки 293
Динамическое программирование (dynamic programming) 341
Дискретная случайная переменная 94
Дискретные события (discrete events) 167
Дисперсия (variance) 95
Доказательство правильности алгоритма
(proof of correctness)
--------DFS 154
Задание (job) 118
Задача коммивояжера (traveling salesman problem) 16, 132, 342
— об изоморфизме сетей 63
-----упаковке (packing) 120
--------рюкзака 124
— о велосипедном замке 125
-----джипе 109, 341
-----количестве разбиений целого числа (partitions) 147
— — пшенице, мышах и кошках 170
-----Ханойской башне 112
— статистическая 99
Закон больших чисел 101
Замкнутый маршрут (closed walk) 51
Игра «нимбы» (nimbi) 302, 345
Идентификатор 149
Изоморфизм 61
Имитационные алгоритмы 164
Инвариант сети (network invariant) 62
Интегральная функция распределения
(cumulative distribution function) 333
Инфиксная форма выражений (infix form) 259
Инцидентность 49
Испытание (trial) 88
Итерация 31
Код сети (coding of a network) 63
Комментарий (comment) 28, 218
Компонента сети (component of a network) 51
Контекстно-свободные правила (context-free rules) 256
Корень дерева (root of a tree) 59
Латинские квадраты (latin squares) 308
Лес (forest) 57
Линейное программирование 342
Линейный связанный список (linear linked list) 68
Логическое выражение 257
Магические квадраты (magic squares) 112, 297, 345
Маршрут (walk) 51
Массив (array) 66
Математическое ожидание (expected value) 94
Матрица инцидентности (incidence matrix) 53
— смежности (adjacency matrix) 53
— стоимостей (cost matrix) 19
Метод ветвей и границ (branch and bound) 131, 342
— линейный конгруэнтный 330
— отрабатывания назад (working backward) 108, 341
— планирования событий (event scheduling) 167
— подъема (hill climbing) 107, 114, 341
— поиска в глубину (depth-first search) 150
----в ширину (breadth-first search) 154
— середины квадрата (middle-square method) 106, 341
— сортировки 344
----«быстрый» (quicksort) 226
----«пирамидой» (heapsort) 230
----простыми включениями (straight insertion sort) 97
----«пузырьками» (bubble sort) 240
Минского гипотеза 295
Моделирование (simulation) 163, 341 — очереди (simulation of a queue) 165 Модель (model) 17
— сетевая (network model) 19
Мост (bridge) 51
Мультипроцессорная система 87, 118
Мультиребра (multiedges) 49
Независимые случайные переменные (independent random variables) 104
Неориентированное ребро (undirected edge) 49
Непрерывная случайная переменная (continuous random variable) 326
Несмещенная оценка (unbiased estimator) 100
Нормальное распределение (normal distribution) 327
Обслуживание программы (maintenance) 220, 344
Объединяющая вершина (collecting vertex) 31
Ориентированная сеть (directed network) 50
Остовная подсеть (spanning subnetwork)
Открытый маршрут (open walk) 51
Отладка программы (debugging) 197
Оценка (estimator) 100
— несмещенная (unbiased) 100
— согласующаяся (consistent) 101
Очередь (queue) 80
Параллельные машины (parallel machines) 284, 345
Пирамида (heap) 229
Поиск (search) 344
— двоичный (binary) 242
— кратчайшего пути (shortest path) 309, 345
Полиномиальный алгоритм 23
Полная сеть (complete network) 65
Порядок функции (order of a finction) 24
Постановка задачи (statement of the problem) 16
Постфиксная форма выражений (postfix form) 259
Правильность алгоритма (correctness of an algorithm) 187
Предикатная вершина (predicate vertex) 31
Представление задачи (problem representation) 18
— сети 53
Префиксная форма выражений (prefix form) 259
Приведение (reduction) 133
Приоритет операций (priority) 263
Проверка программы (testing) 26, 197
Программирование сверху-вниз (top-down) 22, 31, 339
— с отходом назад (backtrack programming) 125, 342
— структурное (structured) 9, 31, 339
Программная документация (program documentation) 217
Пролог программы 218
Пространство элементарных событий
(sample space) 87
Профиль исполнения программы (execution profile) 29, 203
Процедура (procedure) 14
— Хаффмана и Циммермана 252
Процессор (processor) 118
Псевдослучайные числа (pseudorandom numbers) 329
Путь (path) 51
Разбиение целого числа (partition) 147
Развертывание циклов (loop unrolling) 202
Разделяющая вершина (cut-vertex) 51
Распределение вероятности (distribution) 93
Реализация (implementation)
— алгоритма Дейкстры 314
---- для тура коня 44
----BFS 160
----BSEARCH 243
----BTSI 248
----DELETE 72
----DFS 155
----FIFO 271 i
----HEAP 235 *
----HEAPSORT 235
----INSERT 75
----LFU 279
----LRU 273
----PRIM 191
— очереди 82
— рекурсии на Фортране 148
----— Алголе 149
Ребро (edge) 49
Рекурсия (recursion) 145, 342
Сеть (network) 16, 47, 340
— взвешенная (weighted network) 50
— двудольная (bipartite) 65
-----полная (complete) 65
— несвязная (disconnected) 51
— связная (connected) 51
Система с дискретными событиями 167
Слияние вершин (fusion) 56
Сложность (complexity) 23
Событие (event) 88, 165
Селлина алгоритм 287
Сортировка (sorting) 96, 223, 344
Список связанный (linked list) 67—68 — смежности (adjacency list) 72 Стандартное отклонение (standard deviation) 95
Статистическая задача 99
Стек (stack) 78
Стековая память (pushdown store) 78
Степень вершины (degree of a vertex) 50
Стоимость тура (cost of a tour) 20
Страница памяти (page) 267
Страничный отказ (missing page fault) 267
Структура данных (data structure) 65 — древовидная (tree structure) 45
— управления программы (control structure) 31, 45
Структурная блок-схема (structured flow-chart) 31
Структурное программирование (structured programming) 9, 31
Тестовые данные (test data) 199
Тройная дуэль 305, 345
Тур (tour) 19
— коня 36
Узел (node) 50
Указатель в списке (связь) (pointer, link) 68
Управление страничной памятью (paging) 268, 344
Функциональная вершина (function vertex) 31
Хаффмана и Циммермана, процедура 252
Центральная предельная теорема 328, 332
Цепочка обращений (reference string) 269
Цикл (cycle) 51
Частотная интерпретация вероятности 89
Числа Фибоначчи 145
ЭВМ Иллиак IV 291, 345
Эвристика 113, 341
Эвристический алгоритм (heuristic al-
gorithm) 63, 113
Экспоненциальное распределение 334
Экспоненциальный алгоритм 23, 25
Экстраполяция 215
Эффективность реализации алгоритма (implementation efficiency) 200
Язык параллельного программирования 290
-------IVTRAN 291
NP-полные задачи 347