














































































































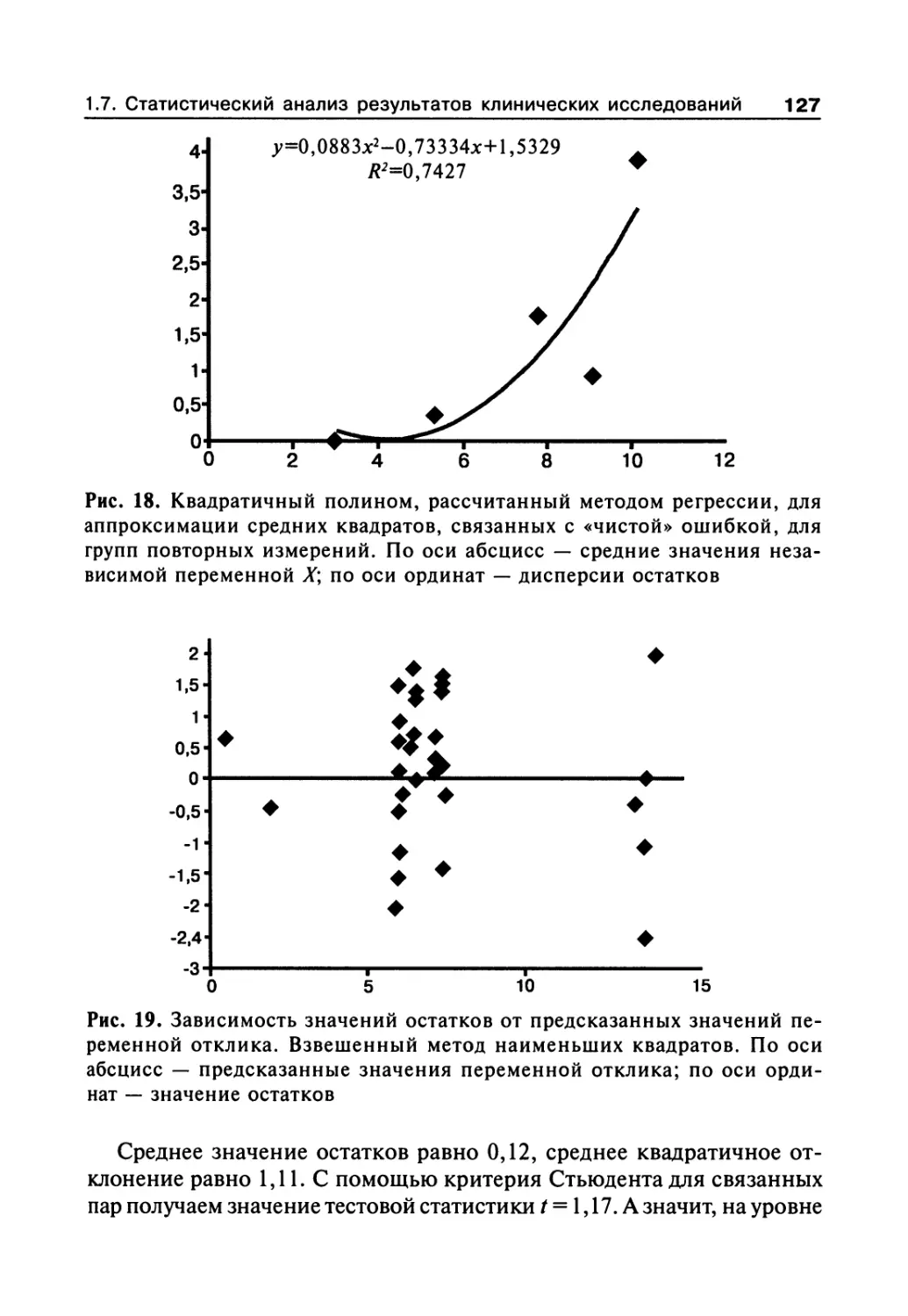
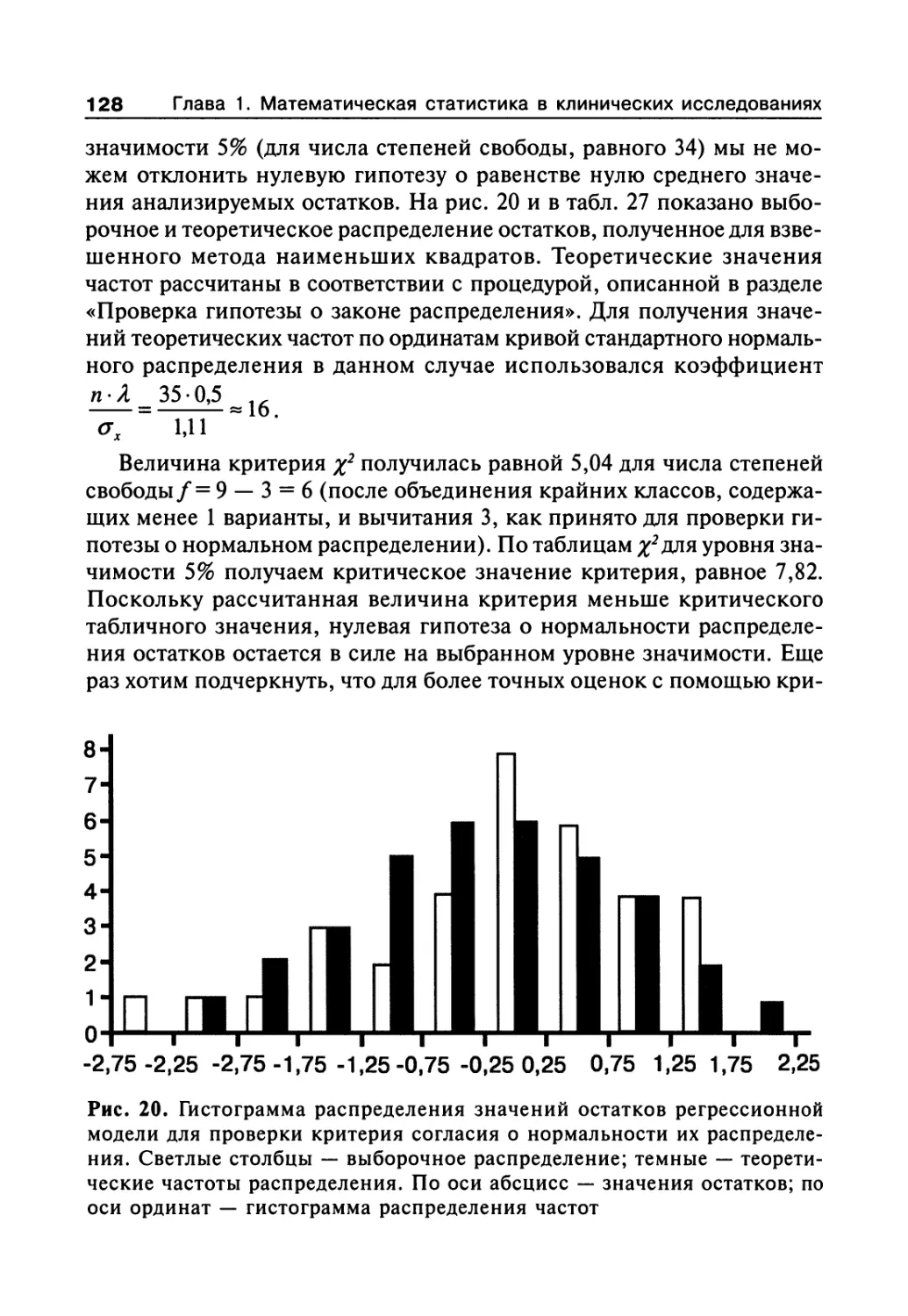
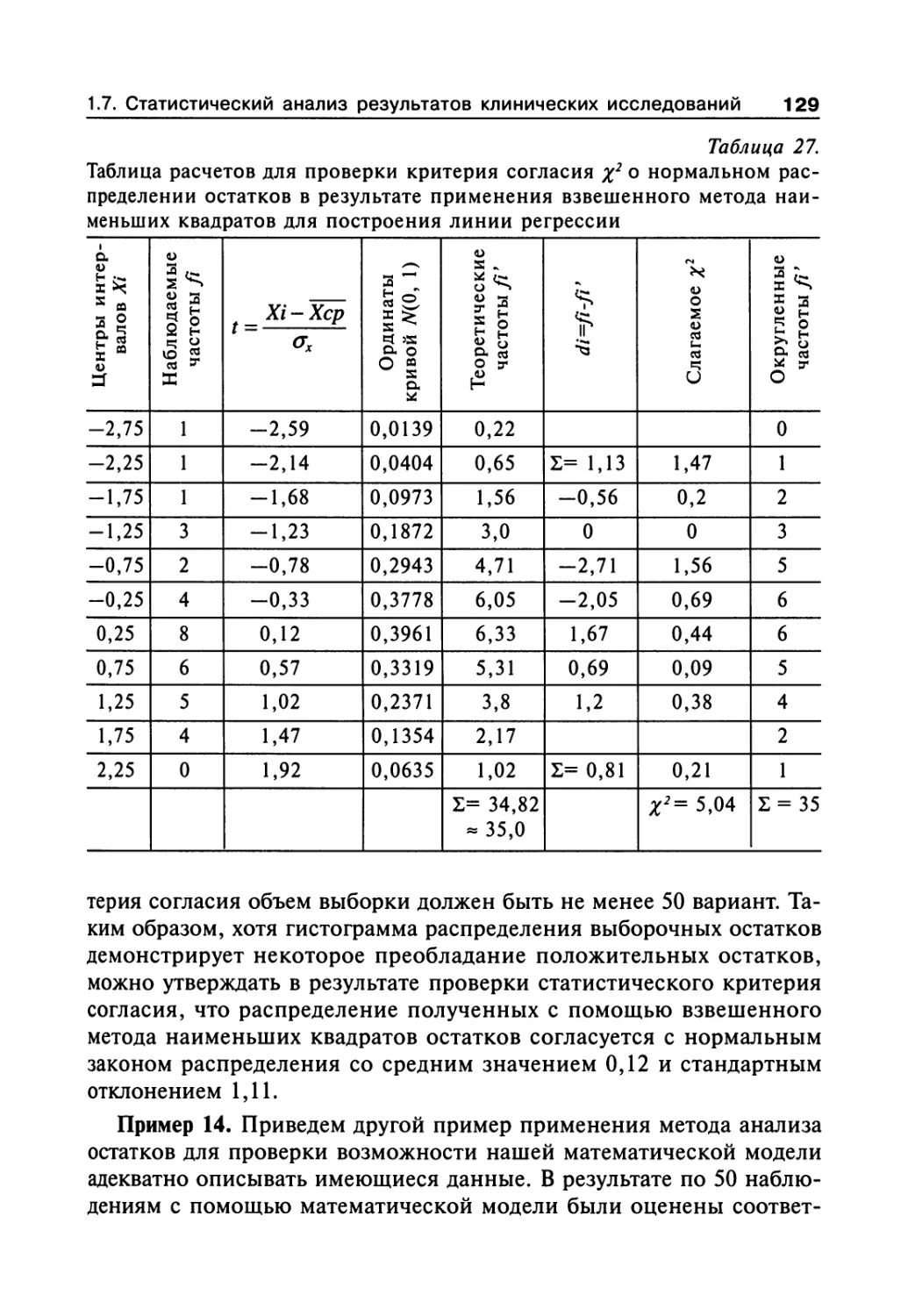
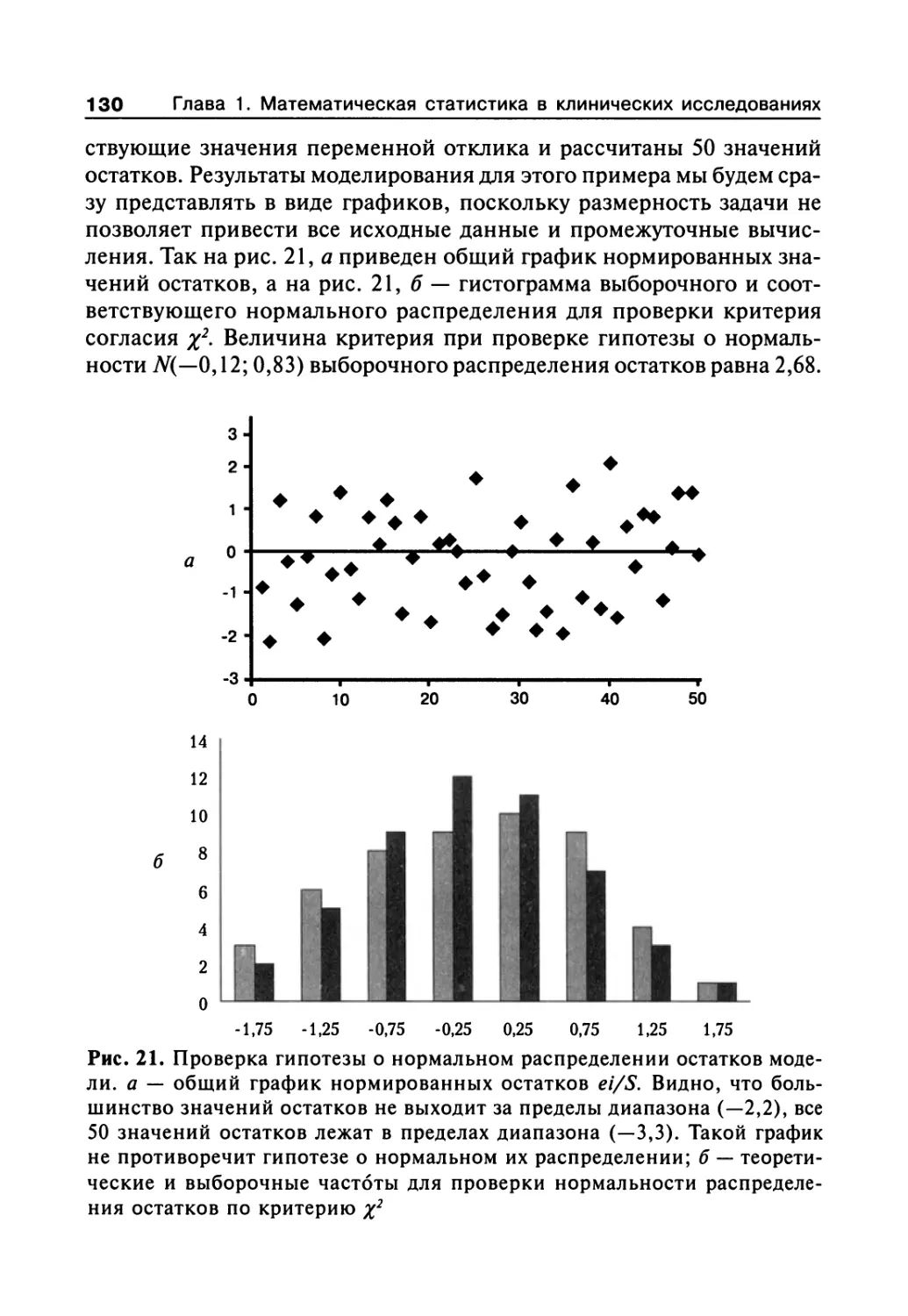





























































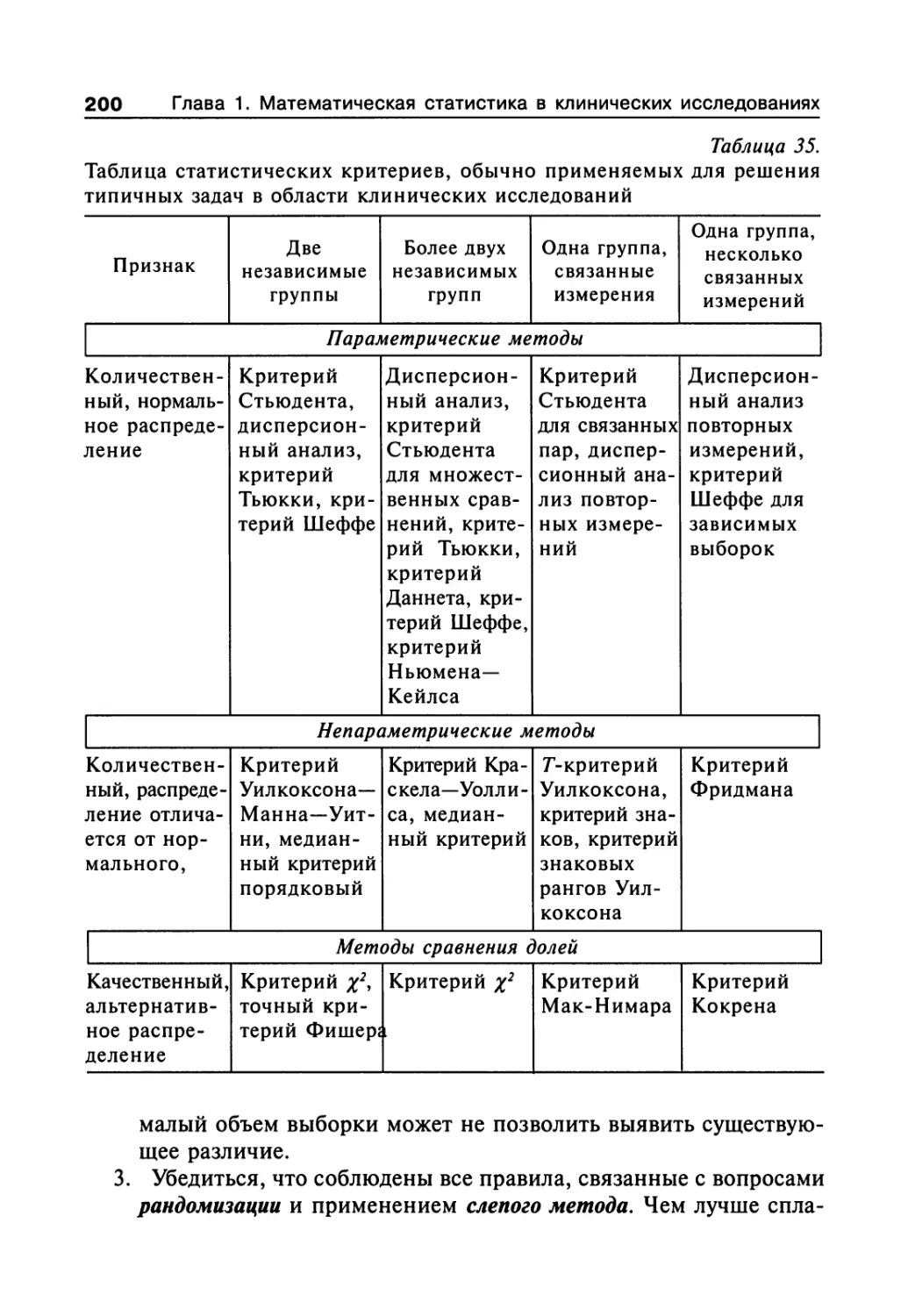





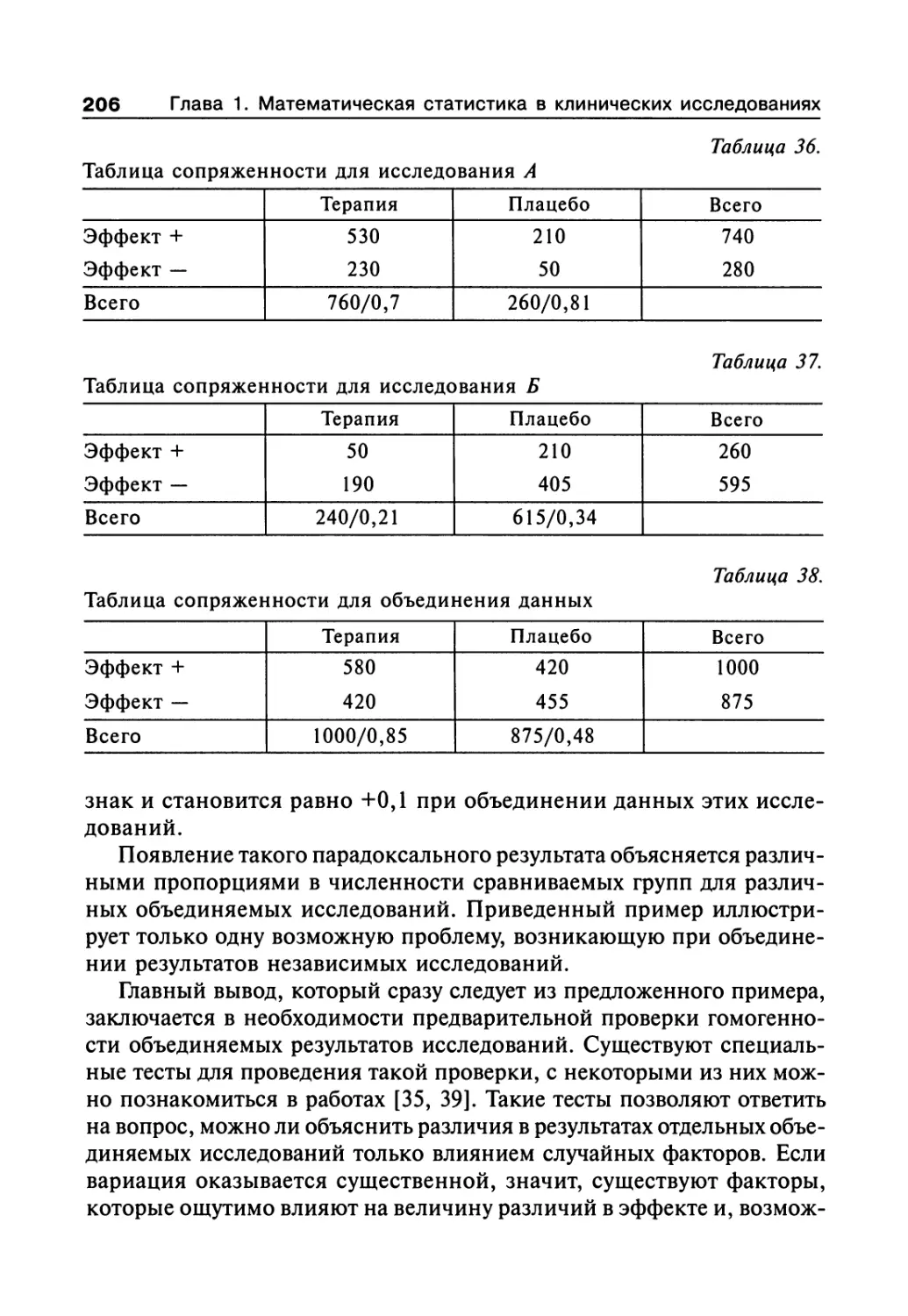









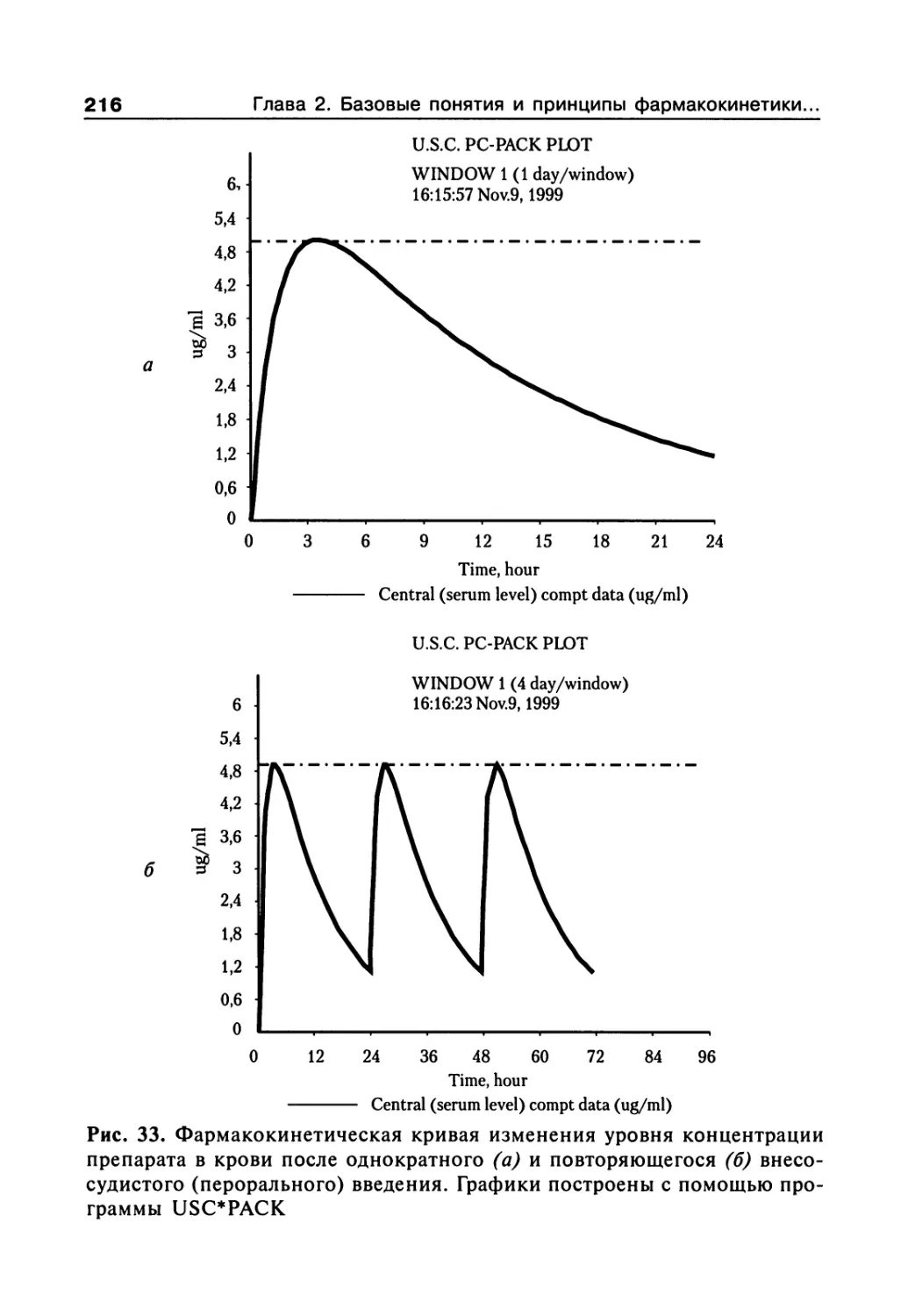


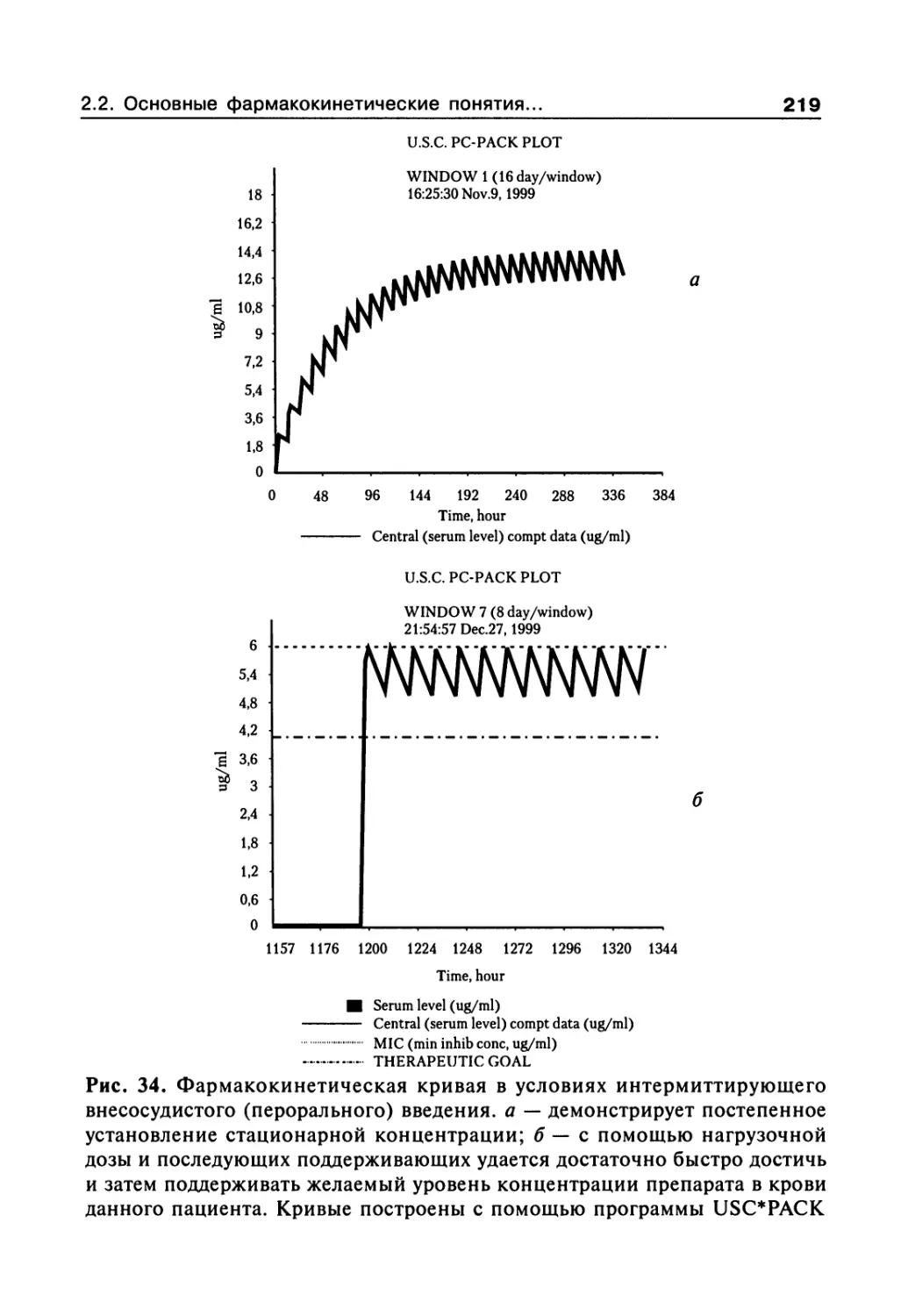


























































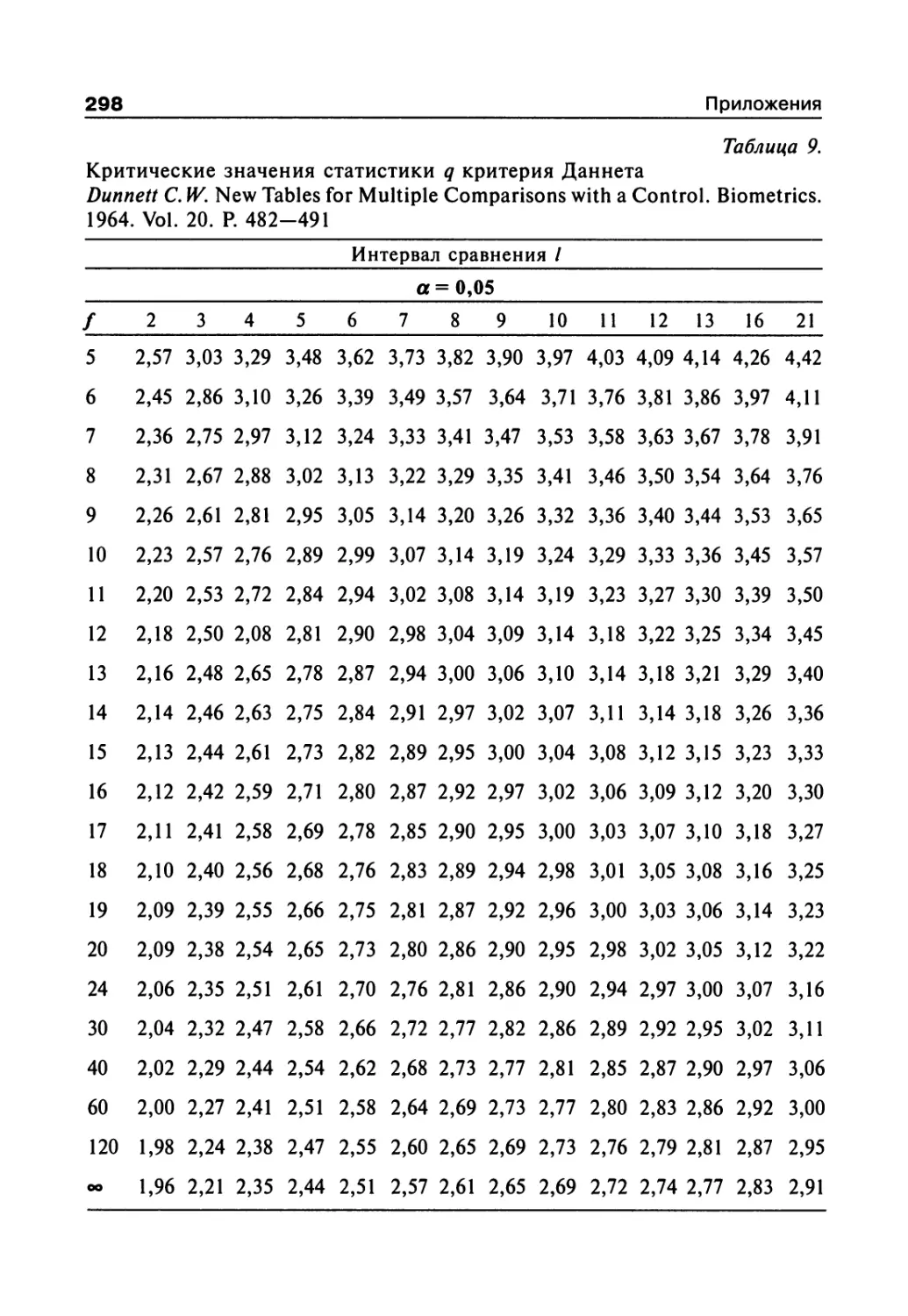

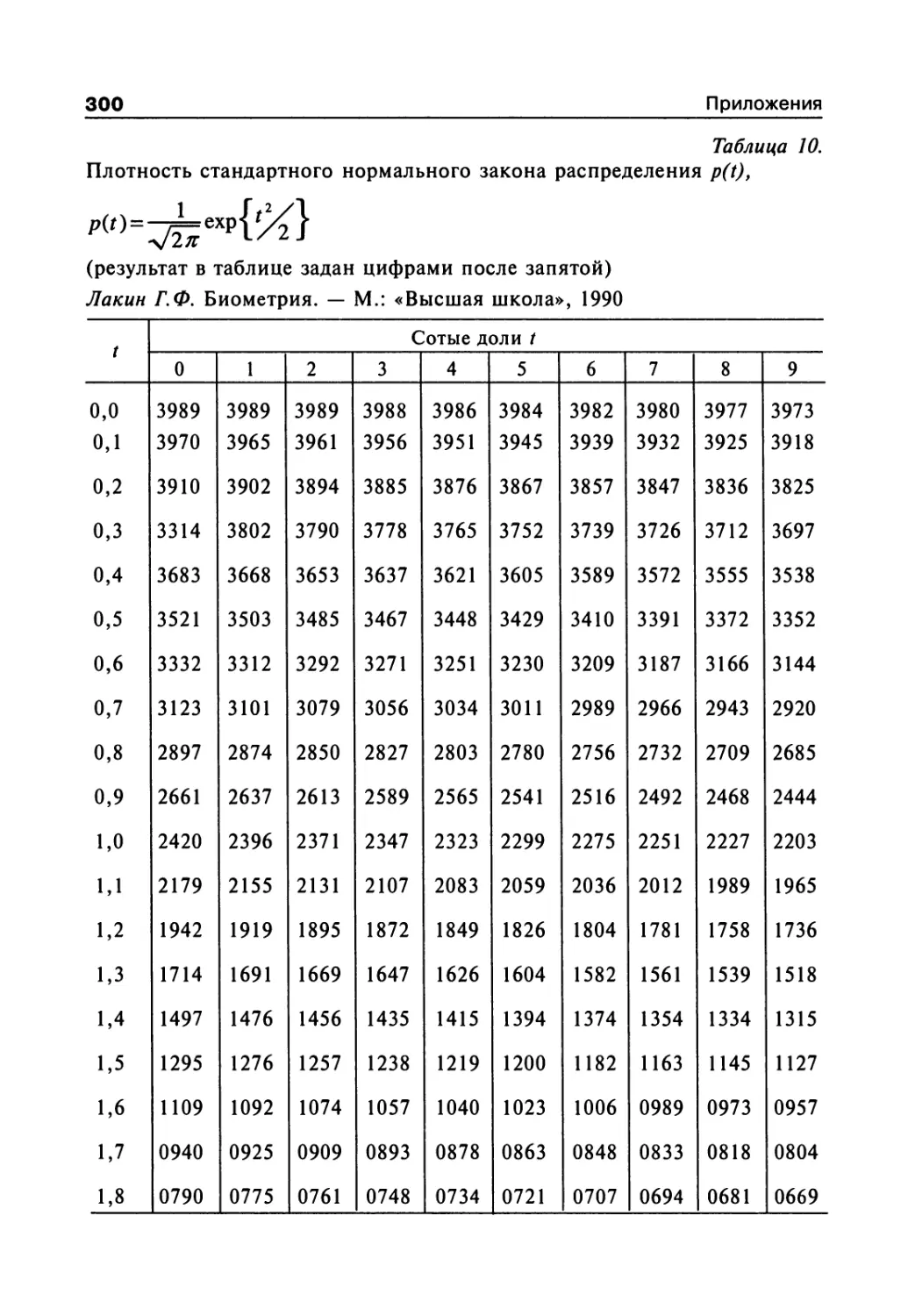
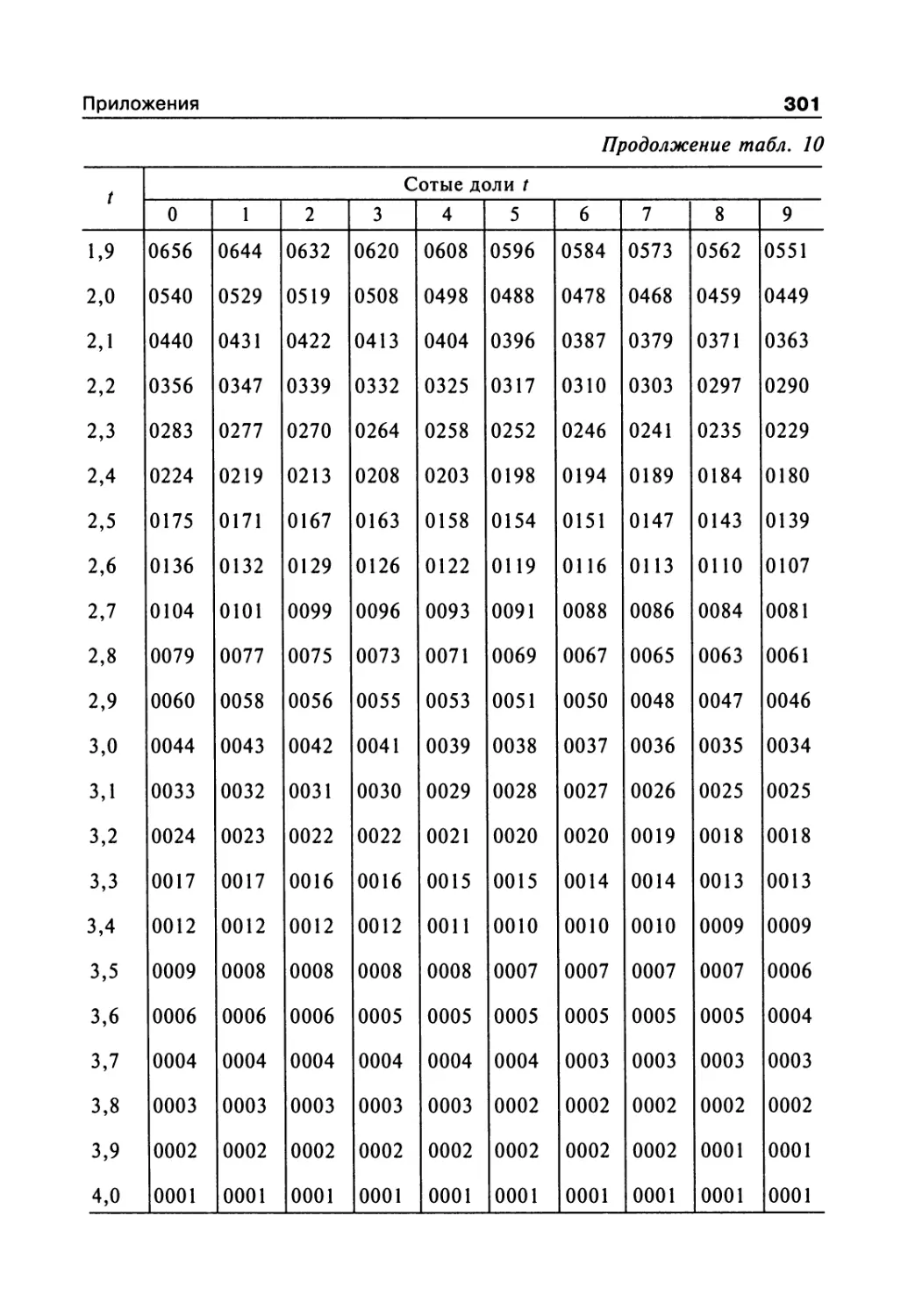




Author: Сергиенко В.И. Бондарева И.Б.
Tags: семиология симптоматология признаки и симптомы заболеваний исследование диагностика пропедевтика теория вероятностей и математическая статистика общая диагностика медицина математика
ISBN: 5-9704-0197-8
Year: 2006




В.И. Сергиенко, И.Б. Бондарева
МАТЕМАТИЧЕСКАЯ
СТАТИСТИКА
В КЛИНИЧЕСКИХ
ИССЛЕДОВАНИЯХ
Практическое руководство
Москва
Издательская группа «ГЭОТАР-Медиа»
2006
УДК 616-07:519.22
ББК 53.4
С32
В.И. Сергиенко, И.Б. Бондарева
С32 Математическая статистика в клинических исследованиях. -
2-е изд., перераб. и доп. — М. : ГЭОТАР-Медиа, 2006. - 304 с.
ISBN 5-9704-0197-8
В книге приведены основные определения и статистические процедуры,
обычно применяемые при планировании и анализе данных клинических ис-
следований. Показаны возможности и ограничения этих методов, основные
ошибки, возникающие при их некорректном применении. С точки зрения
математики и статистики рассмотрены различные этапы проведения клини-
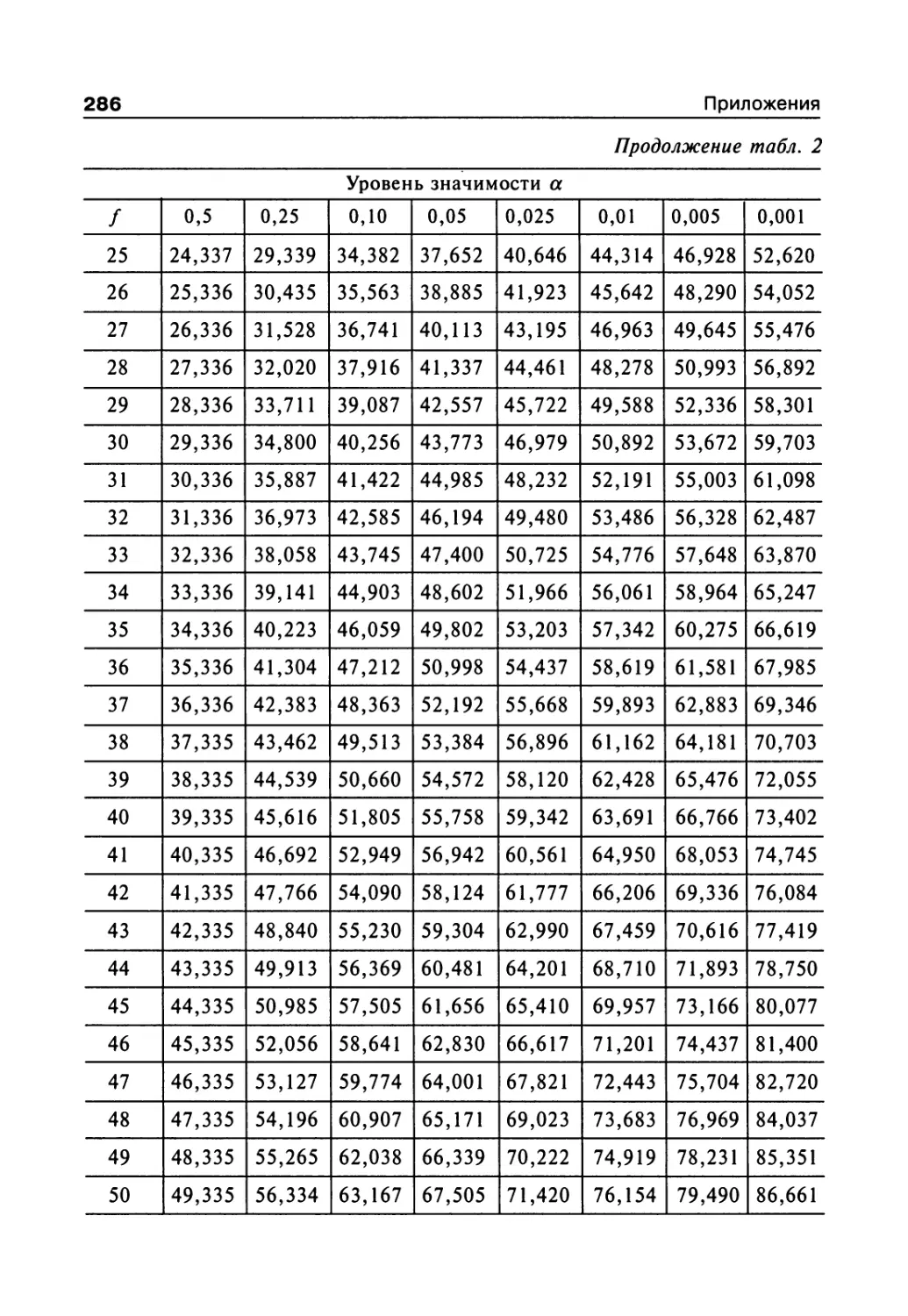
ческих исследований. Приведенные основные понятия и математические мо-
дели фармакокинетики и фармакодинамики важны для понимания особен-
ностей клинических исследований.
Книга может быть полезна для участников клинических исследований, а
также специалистов, применяющих методы прикладной статистики в меди-
цине и биологии.
УДК 616-07:519.22
ББК 53.4
Права на данное издание принадлежат издательской группе «ГЭОТАР-Медиа».
Воспроизведение и распространение в каком бы то ни было виде части или це-
лого издания не могут быть осуществлены без письменного разрешения изда-
тельской группы.
© Сергиенко В.И., Бондарева И.Б., 2006
ISBN 5-9704- 0197-8 © Издательская группа «ГЭОТАР-Медиа», 2006
Оглавление
Предисловие 5
ГЛАВА 1. Математическая статистика в клинических исследованиях 7
1.1. Введение 7
1.2. Краткая историческая справка 9
1.3. Основные определения математической статистики,
встречающиеся в области клинических исследований 13
1.4. Основные методы рандомизации 17
1.5. Основные типы планов 20
1.6. Величины, характеризующие эффект 25
1.7. Статистический анализ результатов
клинических исследований 30
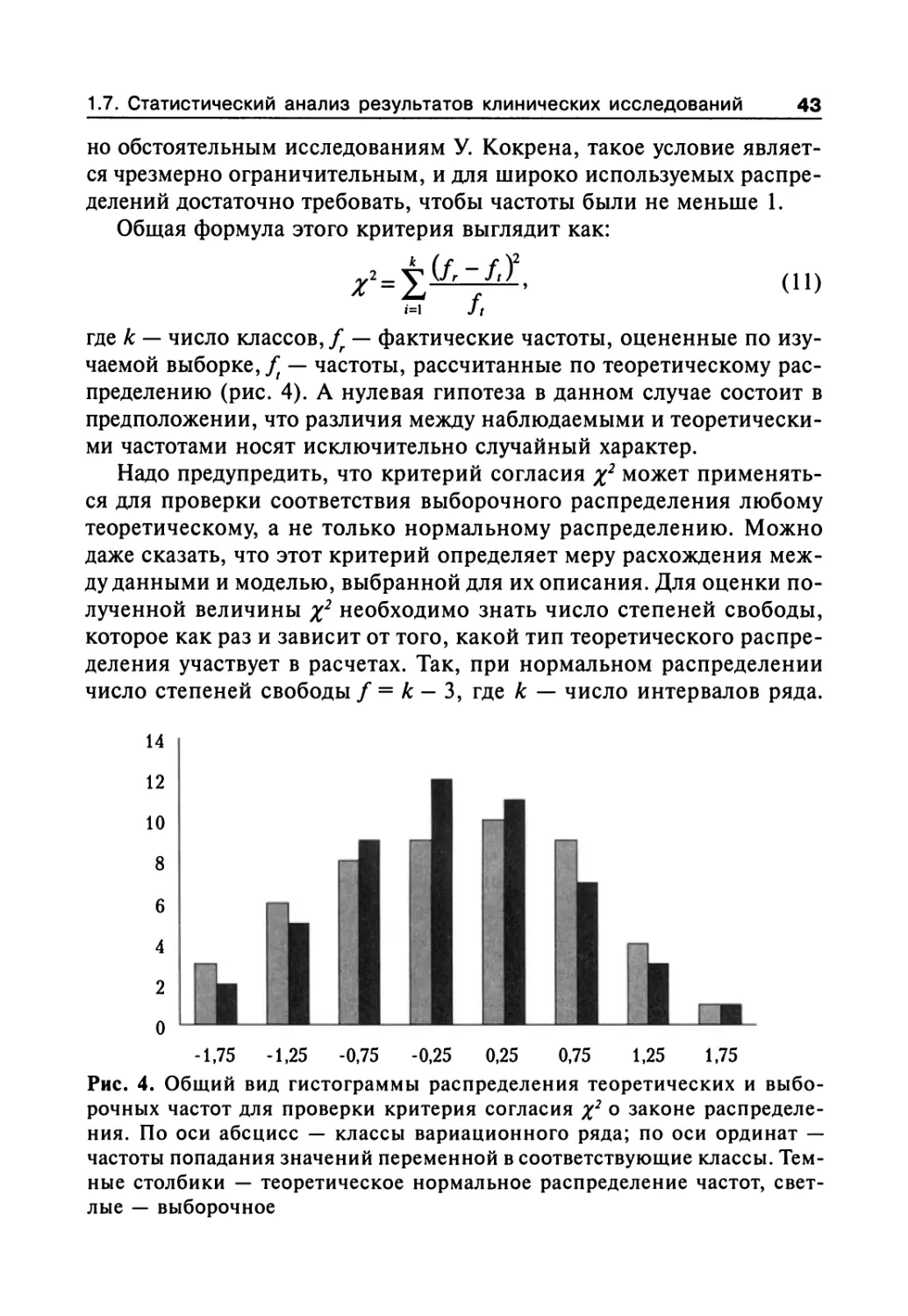
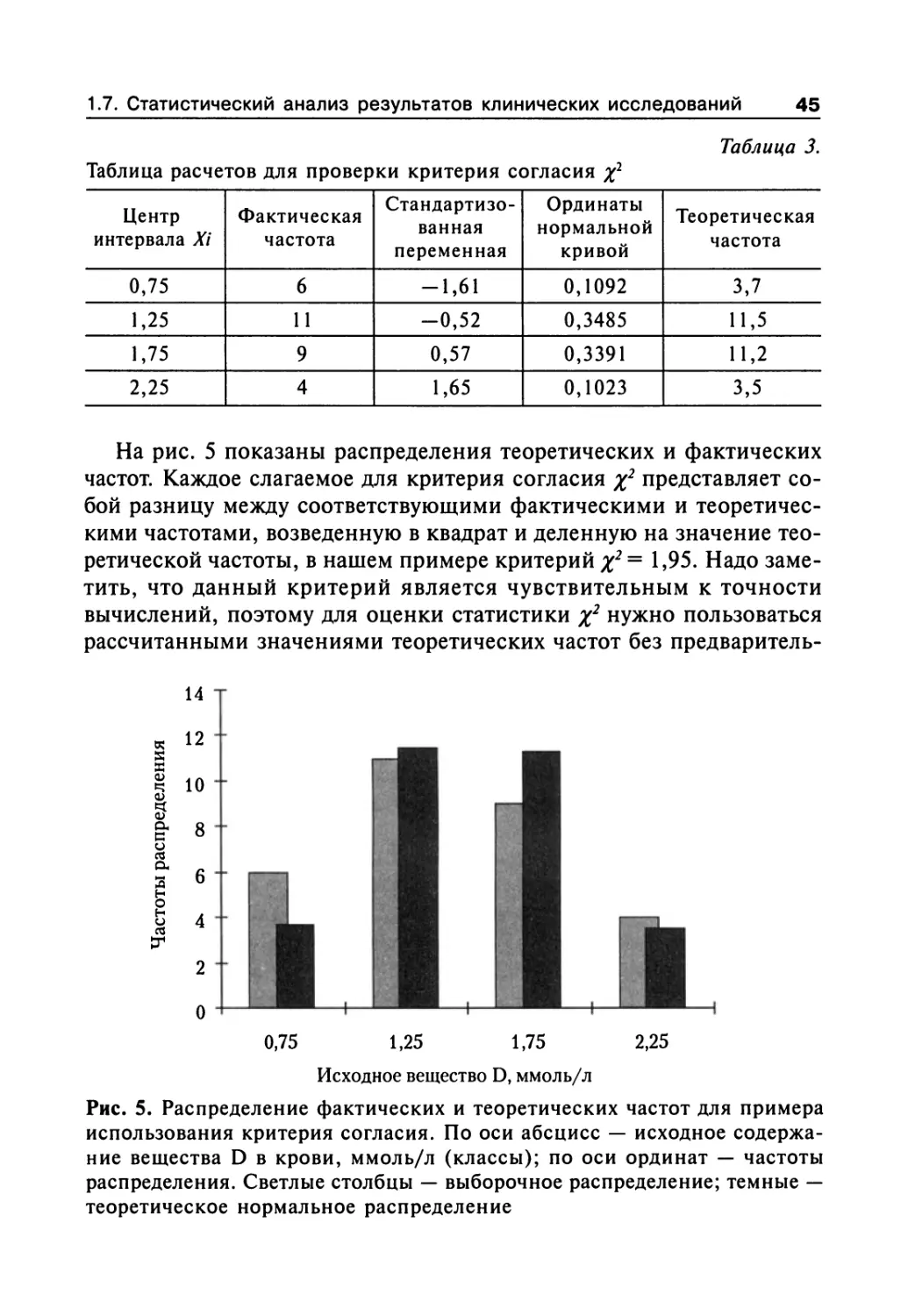
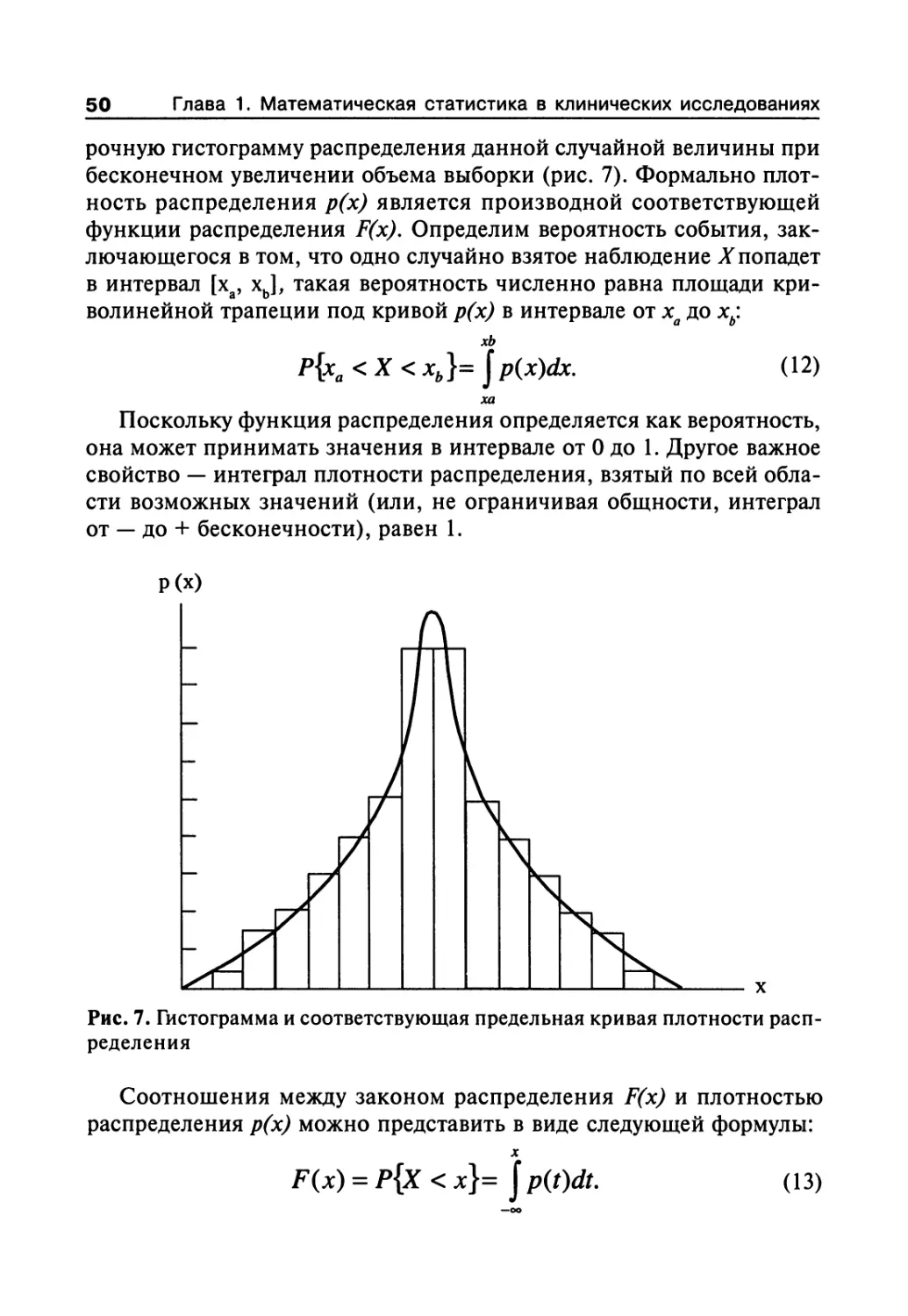
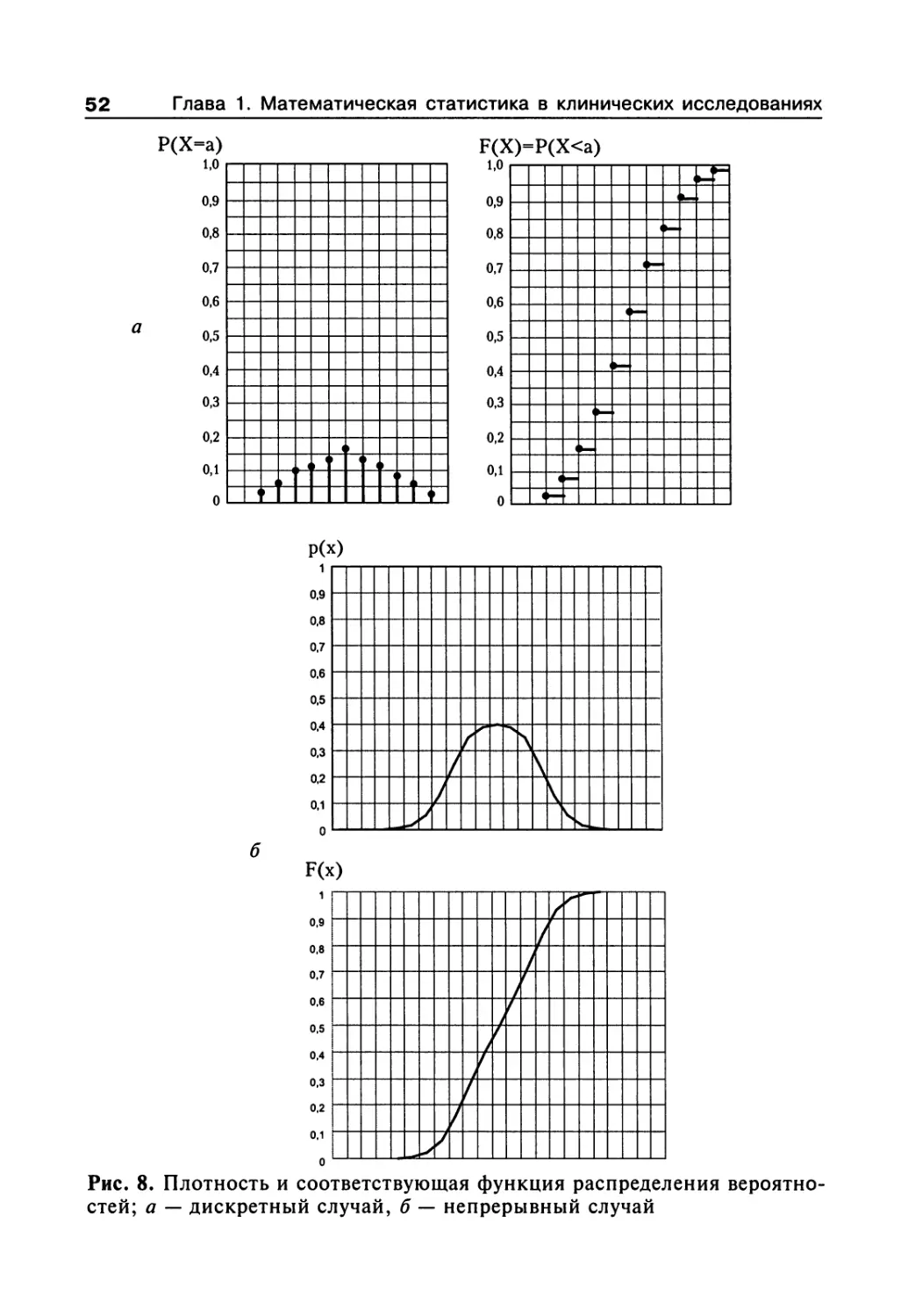
1.7.1. Нормальное распределение показателей и основные
статистические характеристики совокупности 31
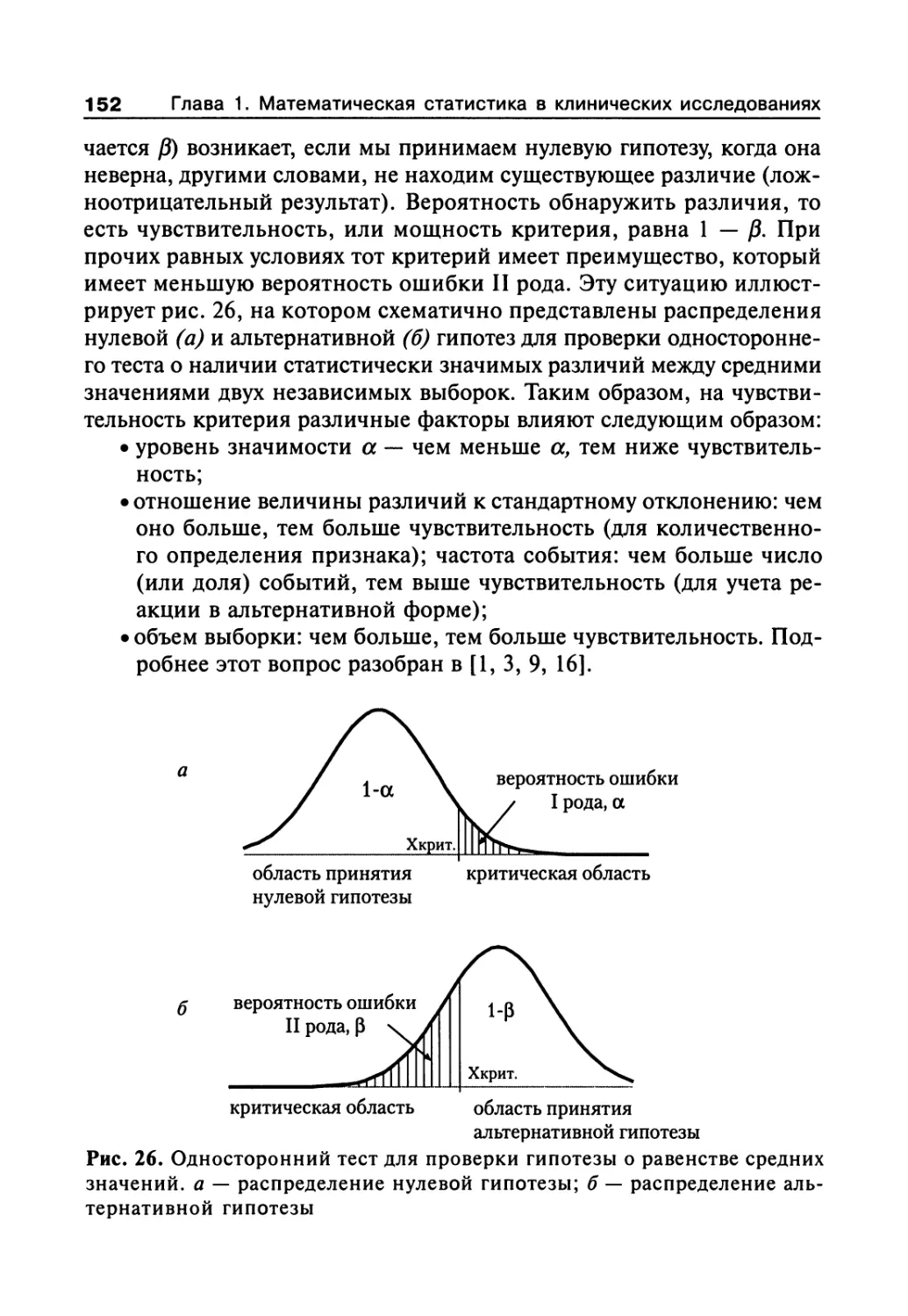
1.7.2. Статистические гипотезы и их проверка 37
1.7.3. Проверка гипотезы о законах распределения 40
1.7.4. Первичная обработка результатов 46
1.7.5. Закон распределения случайных величин 49
1.7.6. Параметрические критерии для проверки гипотезы
о различии (или сходстве) между средними значениями 57
1.7.7. Непараметрические критерии для проверки гипотезы
о различии (или сходстве) между средними значениями 62
1.7.8. Сравнение средних значений нескольких выборок
(множественные сравнения) 65
1.7.9. Оценка эффекта при альтернативной
форме учета реакций 72
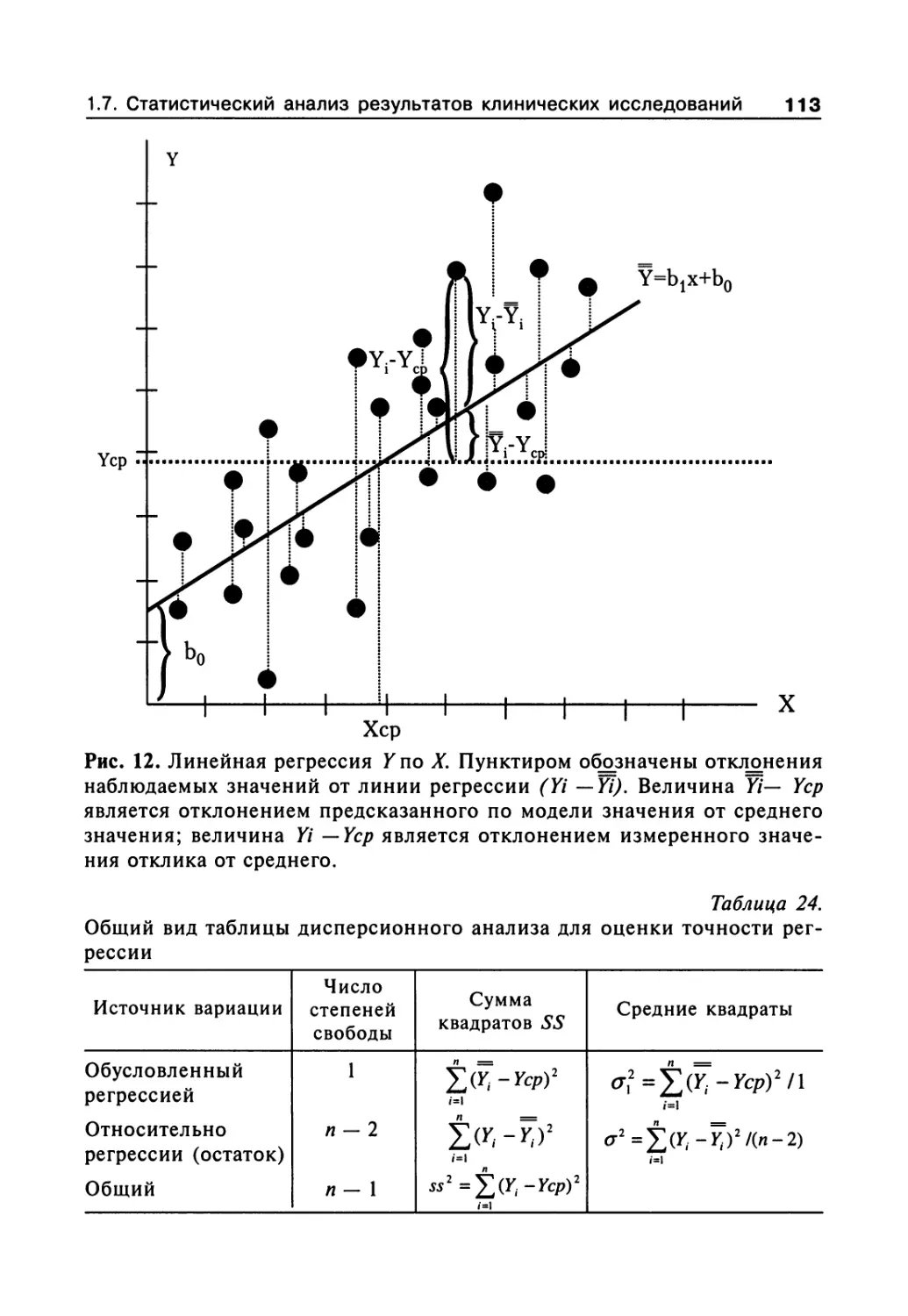
1.7.10. Элементы дисперсионного анализа 88
1.7.11. Построение доверительного интервала
для значений измеряемого признака 100
1.7.12. Установление по двум или более сопряженным
рядам чисел наличия связи (корреляции)
между признаками 101
1.7.13. Регрессионный анализ 108
4 Оглавление
1.7.14. Кривая выживаемости 142
1.7.15. Статистическое сравнение с помощью
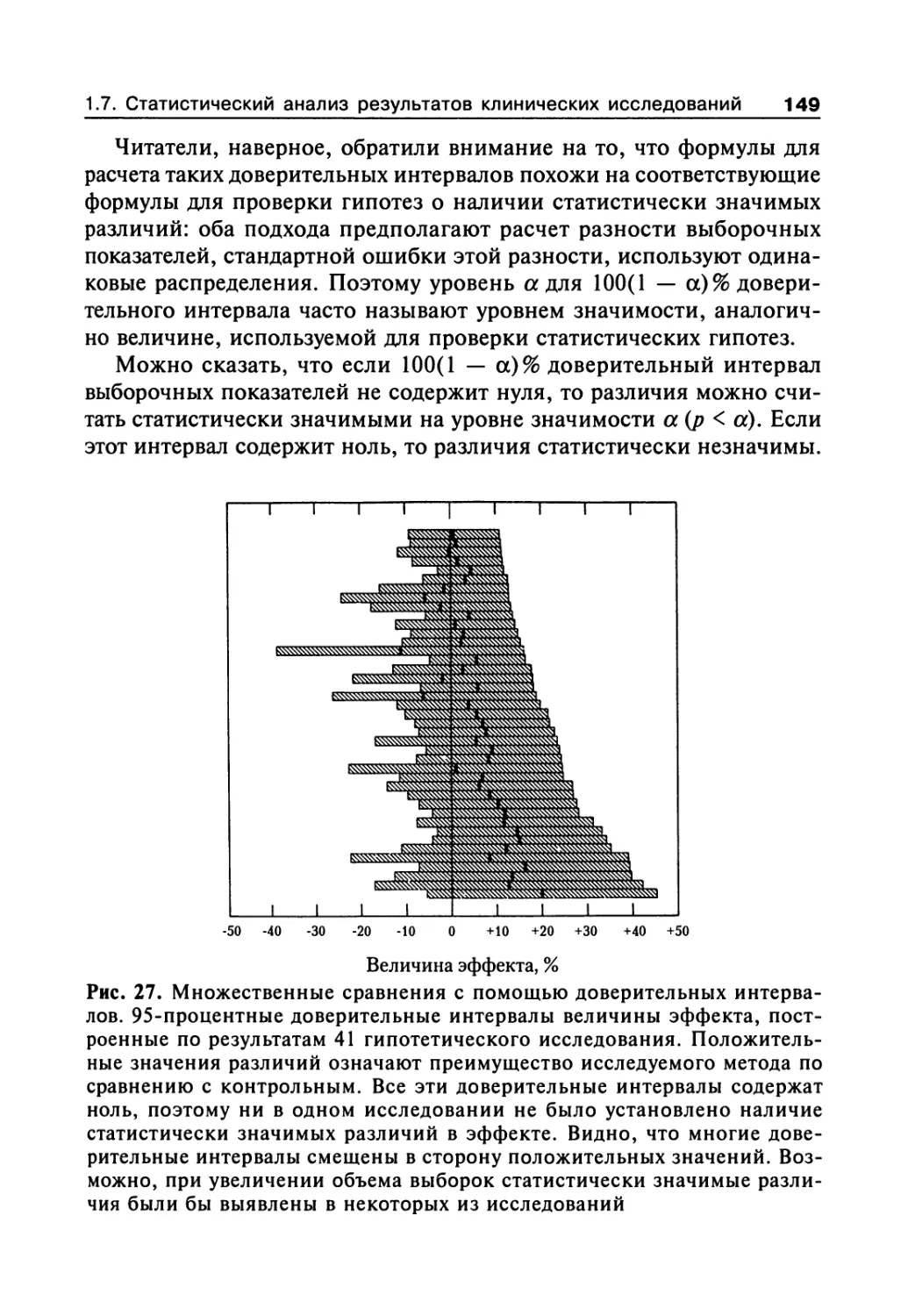
метода доверительных интервалов 148
1.7.16. Некоторые вопросы планирования
клинических исследований 150
1.7.16.1. Планирование клинических
исследований: цели и статистические
гипотезы 161
1.7.16.2. Показатели эффекта 172
1.7.16.3. Вмешивающиеся факторы
и взаимовлияющие факторы 178
1.7.16.4. Случайная и систематическая ошибка 183
1.7.16.5. Групповой последовательный дизайн
и промежуточный анализ данных 189
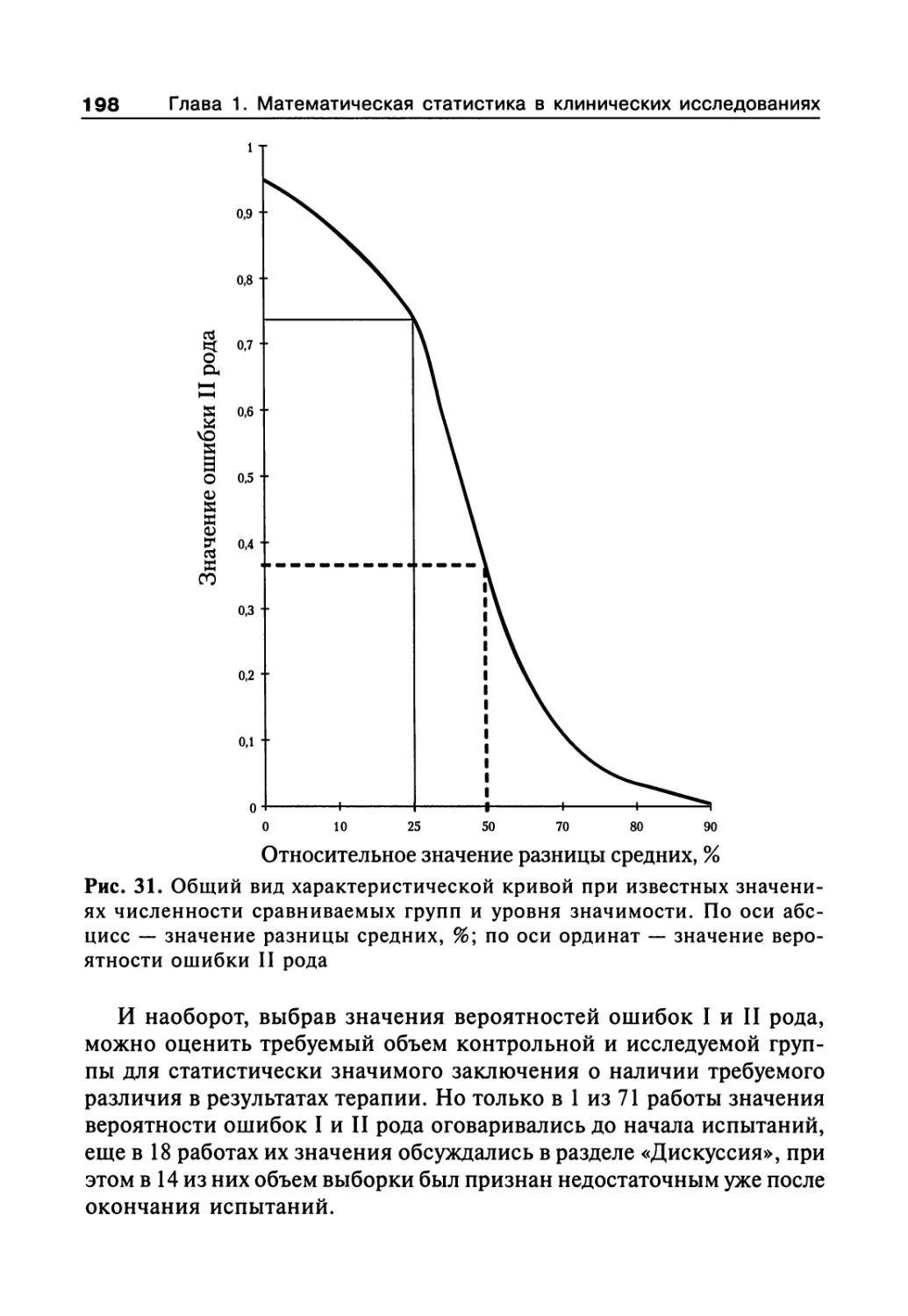
1.8. Заключение. Некоторые практические рекомендации 196
Литература 208
ГЛАВА 2. Базовые понятия и принципы фармакокинетики
и фармакодинамики. Приложение к анализу данных
клинических исследований 211
2.1. Введение 211
2.2. Основные фармакокинетические понятия.
Модельный подход 212
2.3. Некомпартментный подход к анализу
фармакокинетических данных 232
2.4. Анализ зависимостей доза—эффект 234
2.5. Статистические процедуры, применяемые
для анализа биоэквивалентности 241
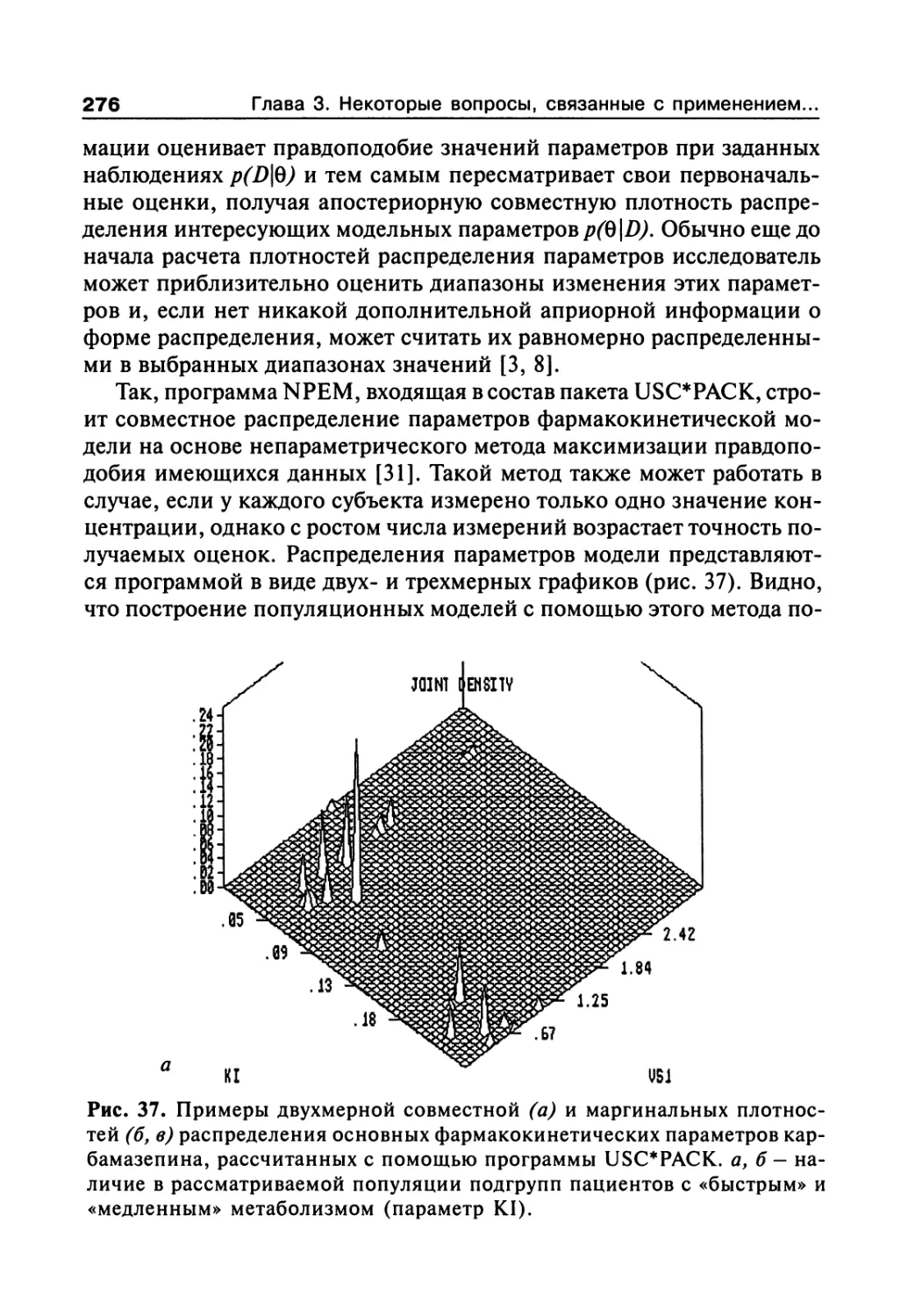
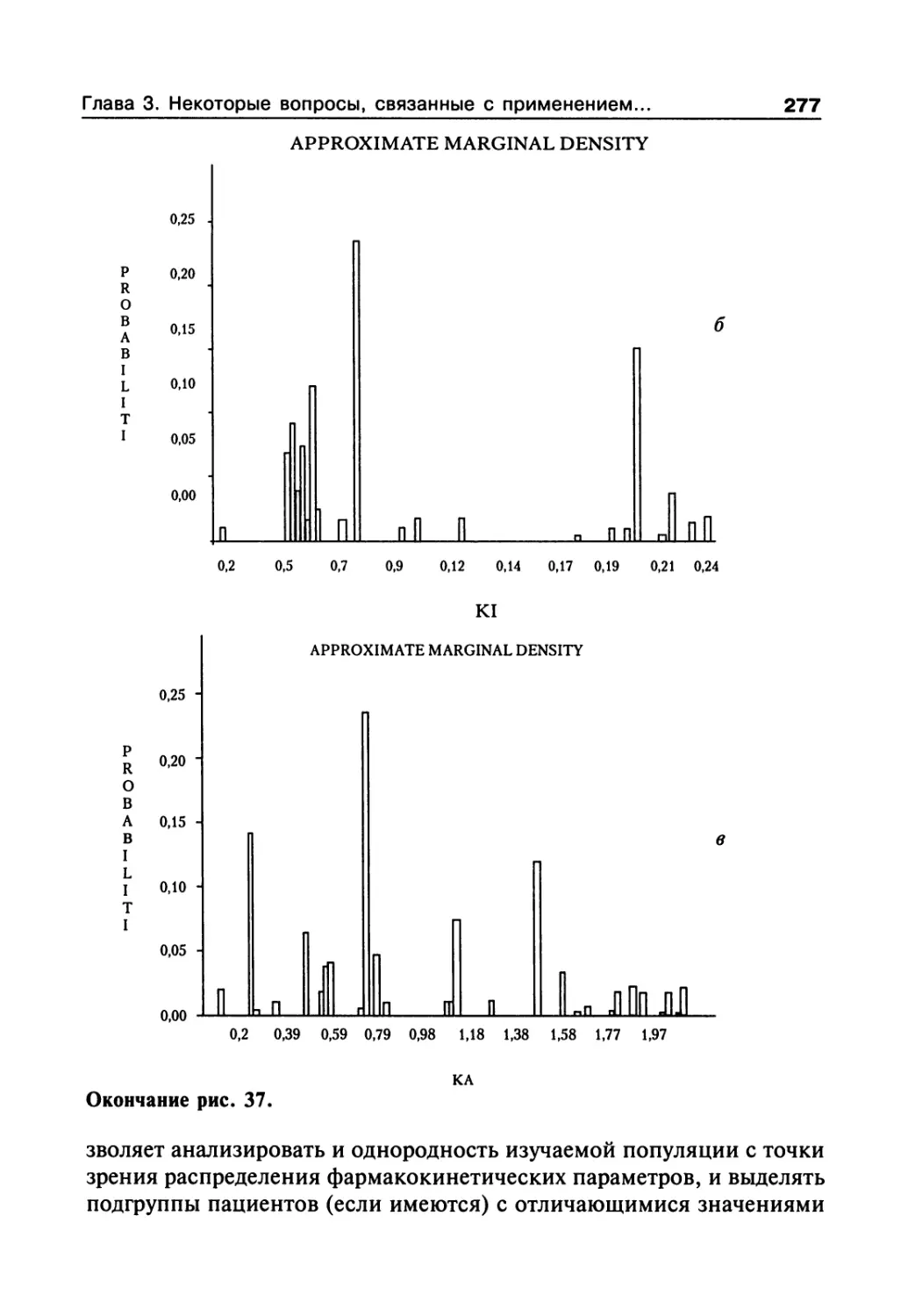
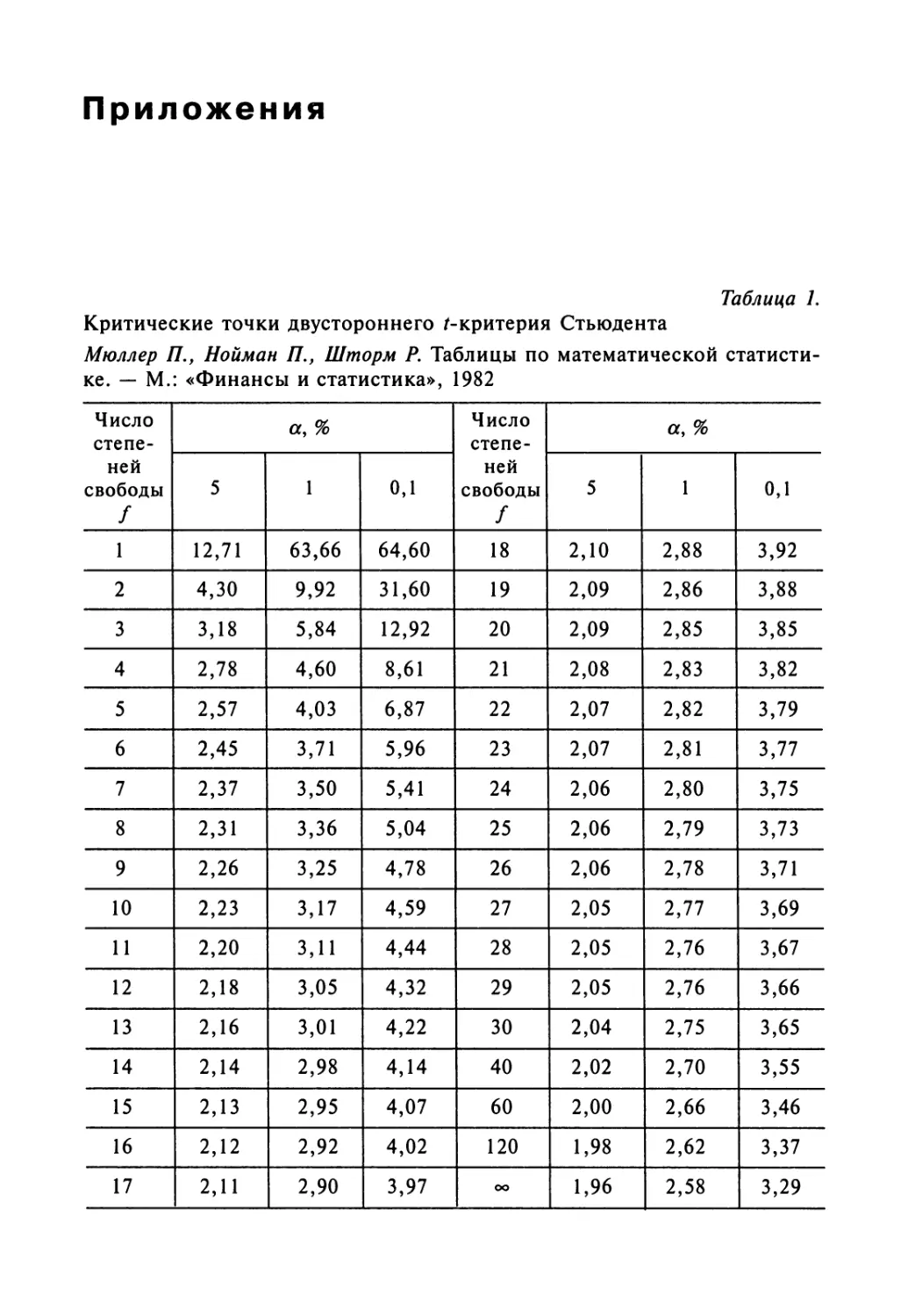
2.6. Популяционный дизайн и модели 256
Литература 259
ГЛАВА 3. Некоторые вопросы, связанные с применением
байесовского подхода к анализу клинических данных 263
Литература 279
Заключение 282
Приложения 284
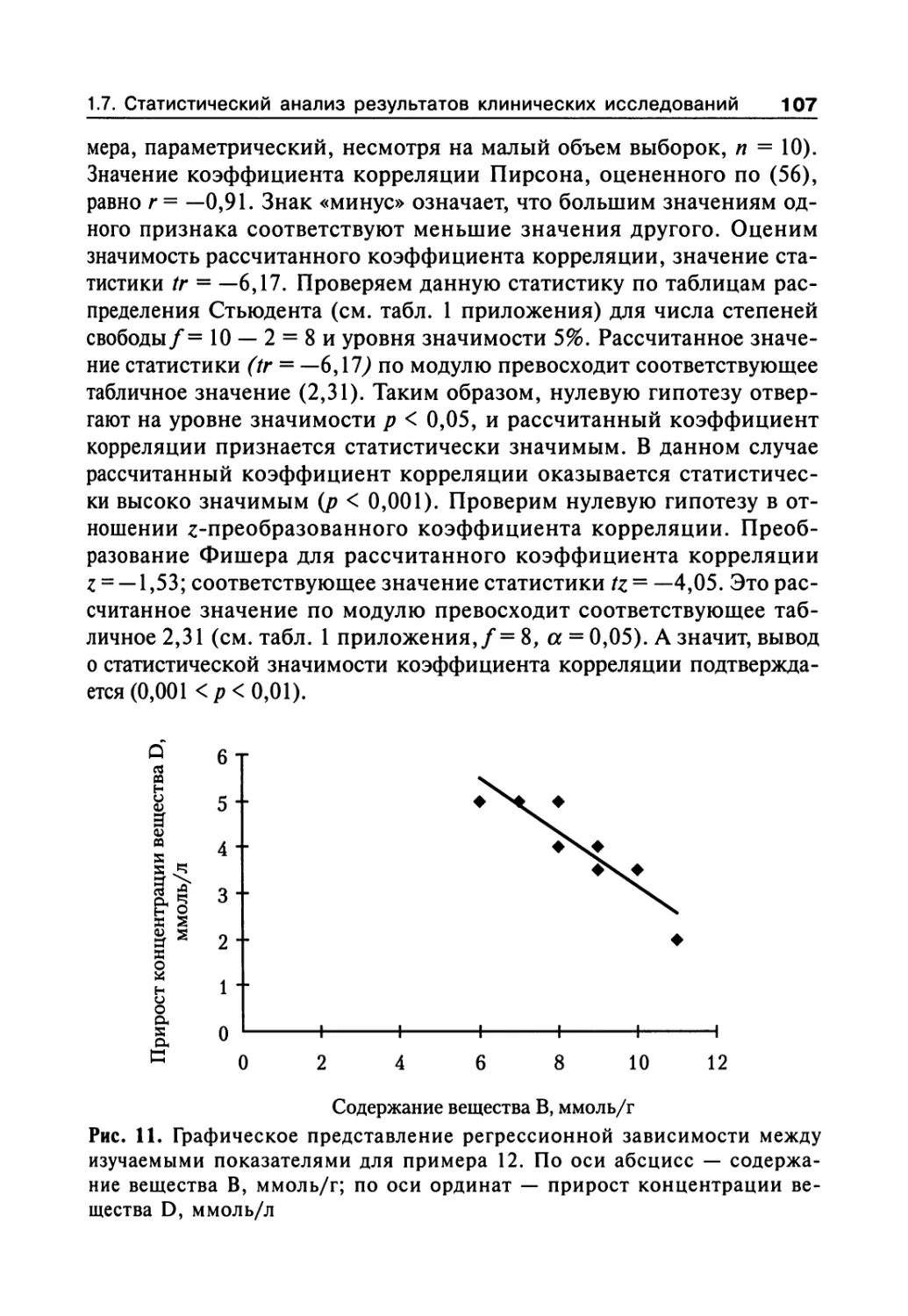
Предисловие
Хорошо известно, что проведение клинических исследований на-
прямую связано со всесторонним анализом полученных данных. По-
этому изучение прикладной статистики является неотъемлемой час-
тью обучения персонала, принимающего участие не только в статис-
тическом анализе результатов, но и в процессе сбора клинических
данных. Этические и экономические соображения диктуют необхо-
димость внимательного отношения к планированию клинических
исследований. Кроме того, владение методиками обработки инфор-
мации позволяет персоналу более эффективно организовать проце-
дуру сбора исходных данных.
В последние годы широкое распространение персональных ком-
пьютеров и различных программных средств для статистического
анализа данных в различных прикладных областях, включая меди-
цинские приложения, тем не менее не снимает необходимости вла-
дения хотя бы основами математической статистики. От пользовате-
ля требуются: умение грамотно выбирать подходящие статистичес-
кие процедуры, знание их возможностей и ограничений, корректная
и осмысленная интерпретация результатов. Произвольное примене-
ние статистических тестов может привести к ложным выводам об
эффективности изучаемых методов лечения. К сожалению, в после-
днее время мало издается специальной и популярной литературы,
посвященной вопросам медико-биологической статистики и особен-
но вопросам статистического анализа в клинических исследовани-
ях. И персонал, принимающий участие в проведении клинических
исследований, все больше ощущает потребность в подобной инфор-
мации и обучении.
Настоящее пособие рассчитано на медицинских работников, уча-
ствующих в клинических исследованиях, кроме того, оно может быть
полезно для научных сотрудников, студентов и аспирантов, планиру-
ющих и проводящих исследования в медицинских и биологических
приложениях. При написании данного пособия авторы использова-
ли и максимально адаптировали для читателя, не имеющего специ-
альной математической подготовки, различные литературные источ-
ники, предназначенные для специалистов в области математической
6
Предисловие
статистики, а также собственный опыт обработки результатов кли-
нических исследований. В книге приведены основные определения
и описания статистических процедур, применяемых в области кли-
нических исследований: первичная обработка данных, тестирование
статистических гипотез, проблема множественных сравнений, эле-
менты корреляционного, дисперсионного и регрессионного анали-
за, вопросы планирования эксперимента и т. п. Примеры и рисунки
помогают в понимании представляемого материала. Статистические
таблицы, часто используемые для практической работы, приведены
в приложении. В книге с точки зрения математической статистики
освещены практически все этапы клинических исследований: от ста-
дии планирования и создания протокола до проведения анализа ре-
зультатов и формирования заключения. Даже если читателю и не при-
дется самому проводить статистический анализ результатов и само-
му пользоваться теоретическими положениями и практическими
рекомендациями, содержащимися в этой книге, знакомство с дан-
ным пособием позволит по-новому взглянуть на результаты, пред-
ставляемые в научной медицинской литературе.
Приведенные основные положения фармакокинетики и фармако-
динамики, а также некоторые подходы к анализу результатов фарма-
кокинетических исследований и исследований биоэквивалентности
также являются полезными для врачей-практиков. Доходчиво объяс-
няются в книге и различия между традиционным классическим под-
ходом в математической статистике и становящимся все более попу-
лярным в настоящее время байесовским подходом к анализу данных.
Академик РАМН,
член президиума Фармакологического
комитета Минздрава России
В. И. ПЕТРОВ
Глава 1
МАТЕМАТИЧЕСКАЯ СТАТИСТИКА
В КЛИНИЧЕСКИХ ИССЛЕДОВАНИЯХ
1.1. ВВЕДЕНИЕ
Нет такого аспекта в сложном процессе создания лекарственных
препаратов, в котором не применялись бы методы математической
статистики: от процедуры отбора химических соединений для получе-
ния заданного спектра биологической активности на первом этапе до
прогнозирования продажи уже зарегистрированного препарата. В на-
стоящее время участие специалиста-статистика в планировании и ана-
лизе результатов клинических исследований является обычной и ши-
роко распространенной практикой. Причем возрастает роль статисти-
ка в обсуждении проекта в целом. Применительно к проведению
клинических исследований математическая статистика может помочь
в формулировании цели, разработке дизайна, выборе методов рандо-
мизации, определении необходимого числа пациентов для получения
статистически значимого заключения, непосредственно в проведении
анализа полученных результатов, формировании заключения.
Применение статистических методов не является формальной про-
цедурой, это — творческая деятельность. И, как любая творческая дея-
тельность, планирование исследований и интерпретация полученных
результатов требуют глубоких знаний в области математики. Велика
и ответственность — часто именно статистическое оценивание резуль-
татов клинических исследований определяет решение в пользу дан-
ного метода лечения. На практике статистический анализ или фор-
мально выполняют сами медики, или уже после сбора данных их ана-
лиз поручается математикам, не имеющим отношения к медицинским
приложениям. Кроме того, нередко недостаточное внимание уделя-
ется планированию исследований, в результате уже после окончания
этапа сбора информации при попытке применить статистические те-
сты может оказаться, что собранных данных не хватает для формиро-
вания статистически значимого вывода о преимуществах одного срав-
ниваемого метода лечения над другим. И тут даже самые сложные
математические методы анализа полученных результатов не спасут
ситуацию, если они были получены в ходе неграмотно спланирован-
ного исследования.
8 Глава 1. Математическая статистика в клинических исследованиях
В данной работе мы попытаемся дать основные представления о
процедурах и методах математической статистики, применяемых в
области клинических исследований, понимание сути которых в той
или иной степени необходимо практически всем активным участни-
кам процесса. Даже если при проведении исследований сами медики
и не будут заниматься статистической обработкой, они должны уметь
грамотно объяснить привлекаемым со стороны математикам цели и
суть проводимого исследования, помочь в интерпретации получае-
мых результатов, то есть перевести решаемую задачу с медицинского
языка на математический. Мы надеемся, что знакомство с этим по-
собием будет способствовать сближению позиций медиков и матема-
тиков, принимающих участие в клинических исследованиях.
Описанию статистических методов посвящено большое количе-
ство различных учебников, ту или иную формулу для расчета извест-
ных статистических характеристик можно найти в справочниках [3,
6—9, 12—23, 26]. Нашей целью является не простое перечисление
методов и схем расчетов из области математической статистики, ко-
торые принято использовать в медико-биологических приложениях,
а анализ применимости этих подходов к статистической обработке
результатов клинических исследований. Другими словами, мы попы-
тались проиллюстрировать преимущества и недостатки известных
статистических методов, показать «хорош» или «плох» данный под-
ход в наиболее часто встречающихся практических ситуациях, скон-
центрировав внимание на практических вопросах и часто возникаю-
щих ошибках. Поскольку в рамках одного пособия невозможно оди-
наково подробно осветить все темы и разобрать все возникающие
статистические задачи, в каждом разделе мы привели ссылки на ра-
боты, в которых нужные методы, процедуры и примеры их использо-
вания разобраны более детально. При этом в некоторых случаях мы
приводили ссылки на авторов упоминаемого метода или подхода, а в
некоторых приведены ссылки на работы, в которых, по нашему мне-
нию, данные вопросы рассмотрены достаточно подробно и доступ-
но. Выбор тем и подмножества статистических критериев диктуется
особенностями статистического анализа результатов клинических
исследований. Кроме того, в рамках каждой рассматриваемой темы
мы не стремились привести весь известный набор математических
формул, поскольку в настоящее время для проведения статистичес-
кого анализа все шире используются пакеты прикладных программ,
включающие обычно весь спектр статистических процедур и мето-
дов анализа данных. Однако мы надеемся, что приведенные в этой
1.2. Краткая историческая справка
9
работе теоретические и практические сведения помогут исследовате-
лю правильно сформулировать конкретную задачу анализа данных на
языке математики и выбрать соответствующие статистические про-
цедуры для ее решения, а также правильно интерпретировать полу-
ченные результаты.
1.2. КРАТКАЯ ИСТОРИЧЕСКАЯ СПРАВКА
Теория вероятностей и математическая статистика возникли в се-
редине XVII века в результате развития общества и товарно-денежных
отношений. Свою роль в этом процессе сыграли и азартные игры —
они послужили простыми моделями для выявления закономернос-
тей в появлении случайных событий. Кроме того, развитие матема-
тической статистики было обусловлено необходимостью обрабаты-
вать скопившиеся к тому времени данные в области управления го-
сударством: демографии, здравоохранении, торговле и других
отраслях хозяйственной деятельности. Можно привести довольно
длинный список имен великих ученых, внесших свой вклад в разви-
тие математической статистики: П. Ферма (1601—1665) и Б. Паскаль
(1623-1662), Я. Бернулли (1654-1705) и П. Лаплас (1749-1827),
К. Гаусс (1777-1855) и С. Пуассон (1781-1840), Т. Байес (1701-1761)
и др. Эти имена должны быть уже известны читателям по названиям
часто применяемых статистических процедур, тестов и распределе-
ний. Первым, кто удачно объединил методы антропологии и соци-
альной статистики с достижениями в области теории вероятностей и
математической статистики, был бельгийский статистик Л. Кетле
(1796—1874). Из его работ следовало, что задача статистики заключа-
ется не в одном лишь сборе и классификации данных, а в их анализе
с целью открытия закономерностей. Л. Кетле одним из первых пока-
зал, что случайности, наблюдаемые в живой природе, вследствие их
повторяемости обнаруживают определенную тенденцию, которую
можно описать языком математики. Л. Кетле заложил и основы био-
метрии. Создание же математического аппарата этой науки принад-
лежит английской школе статистиков XIX века, во главе которой сто-
яли Ф. ГальтониК. Пирсон. Разработанные Ф. Гальтоном (1822—1911)
и К. Пирсоном (1857—1936) биометрические методы вошли в золо-
той фонд математической статистики. Пирсон ввел в биометрию та-
кие понятия, как «среднее квадратичное отклонение» и «вариация»,
ему принадлежит разработка метода моментов, критерия согласия %2,
10 Глава 1. Математическая статистика в клинических исследованиях
он ввел термин «нормальное распределение», который сейчас обще-
принят во многих странах. (Известно еще много вариантов названия
этого распределения, например «лапласовское распределение», «га-
уссовское распределение», «распределение Гаусса-Лапласа», «рас-
пределение Лапласа-Гаусса». В качестве аппроксимации к биноми-
альному распределению оно рассматривалось Муавром еще в 1733
г., однако Муавр не изучал его свойств.) К. Пирсон усовершенство-
вал предложенные Гальтоном методы корреляции и регрессии. Тер-
мин «регрессия» был введен Ф. Гальтоном в 1886 г. Гальтон обнару-
жил, что в среднем сыновья высоких отцов имеют не такой боль-
шой рост, а сыновья отцов с небольшим ростом выше своих отцов.
Это было интерпретировано им как «регрессия к посредственности».
Ошибки в рассуждениях Гальтона были разъяснены позднее, напри-
мер Браунли [2].
Однако биологи не сразу оценили преимущества, которые давало
использование математической статистики в естествознании. Поло-
жение несколько изменилось в лучшую сторону, когда была обосно-
вана теория малых выборок. Думаем, что читателям будет интересно
узнать, что пионером в этой области был ученик Пирсона В. Госсет,
который опубликовал в журнале «Биометрика» свою статью под псев-
донимом Стьюдент (отсюда — «критерий Стьюдента»). Считается [11],
что ценность работы Стьюдента заключалась не в значительных чис-
ловых изменениях при расчете тестовой статистики. Многие ученые
задолго до Стьюдента использовали отношение, которое теперь но-
сит его имя, но без учета объема выборок (числа степеней свободы),
и соотносили полученный результат с таблицами стандартного нор-
мального распределения (аналог критерия Стьюдента для бесконеч-
ного числа степеней свободы), пользуясь при этом разными предос-
тережениями при интерпретации результатов. Ценность работы Стью-
дента состоит в осознании того, что надо принимать во внимание
«капризы» малых выборок, причем не только в той задаче, с которой
начинал Стьюдент, но и во всех подобных. Кроме того, он разработал
таблицы, которые можно использовать для определения доверитель-
ных интервалов и проверки критериев значимости даже на основе
очень малых выборок, что делает возможным решение многих стати-
стических задач в области клинических исследований. Дальнейшее
развитие теория малых выборок получила в трудах Р. Фишера (1890—
1962), основное место в его работе занимали вопросы планирования
эксперимента. Фишер ввел в биометрию целый ряд новых терминов
и понятий, рассмотрел фундаментальные принципы статистических
1.2. Краткая историческая справка
11
выводов, показал, что планирование экспериментов и обработка их
результатов — две неразрывно связанные задачи статистики.
Нельзя не отметить тот огромный вклад, который внесли в разви-
тие теории вероятностей и математической статистики ученые на-
шей страны: А.Я. Хинчин (1894-1959), А.И. Хотимский (1892-1939),
Б.С.Ястремский (1877-1962), В.И. Романовский (1879-1954), А.А. Ля-
пунов (1911—1973), А.Н. Колмогоров и его школа и многие другие.
В современной статистической науке существует деление на две
основные школы: наиболее многочисленная классическая школа —
последователи Фишера и его учеников, а также субъективистская, или
байесовская, школа. И хотя на уровне прикладной статистики резуль-
таты, получаемые в рамках этих различных научных школ, достаточ-
но хорошо согласуются, по широкому кругу теоретических и фило-
софских вопросов эти два направления часто расходятся, предлагая
различные подходы к решению задач, в том числе в области биомет-
рии. Коротко основное различие в подходах можно было бы охарак-
теризовать следующим образом: сторонники классического подхода
единственно возможной считают частотную интерпретацию вероят-
ности (поэтому такой подход называют еще «frequentist school»), суть
их подхода в том, что они начинают решение задачи с выбора модели
и проверяют, может ли данная модель «объяснить» полученные (или
еще более «экстремальные») данные. Отличие байесовского подхода
состоит в том, что до того, как будут получены данные, статистик рас-
сматривает степень своего доверия к различным возможным моде-
лям и представляет их в виде вероятностей (априорные вероятности).
Как только данные получены, теорема Байеса позволяет рассчитать
новое множество вероятностей, которые представляют пересмотрен-
ные степени доверия к возможным моделям на основе полученных
данных (апостериорные вероятности). Оценка априорных вероятно-
стей является субъективной, поэтому данный подход и носит назва-
ние «субъективистский».
В настоящее время основные статистические процедуры и тесты в
области клинических исследований основаны на классических под-
ходах, хотя при необходимости допускается применение байесовских
процедур. Байесовский подход становится все более популярным в
области фармакокинетики. Подробнее основные положения байесов-
ского подхода рассмотрены нами в соответствующем разделе.
Можно сказать, что клинические исследования имеют еще более
продолжительную историю, чем математическая статистика. Клини-
ческие исследования в том смысле, который мы привыкли вклады-
12 Глава 1. Математическая статистика в клинических исследованиях
вать в это понятие, в основном получили развитие после Второй ми-
ровой войны, хотя известны и гораздо более ранние примеры. Счита-
ется, что уже в трудах средневекового ученого, врача и философа Ибн
Сины (Авиценны) (980—1037), чьи трактаты в области теоретичес-
кой и клинической медицины были необычайно популярны в тече-
ние многих веков и являлись обязательным руководством, содержа-
лись упоминания о технологии проведения «клинических исследова-
ний». А в книге выдающегося армянского врача и естествоиспытателя
Амирдовлата Амасиаци (умер в 1496 г.) «Ненужное для неучей» (пе-
ревод с армянского языка и комментарий канд. мед. наук С.А. Варда-
нян; серия «Научное наследие». — М.: «Наука», 1990), которая явля-
ется обобщением длительного исторического пути развития армянс-
кой медицины и естественных наук в XV веке, содержатся 7 основных
условий, которых автор рекомендует придерживаться при проведе-
нии испытаний лекарств. Мы решили привести эти условия (в сокра-
щении), поскольку они перекликаются с принципами, лежащими в
основе современных клинических исследований.
«И говорят, что природа лекарств познается опытным путем. Пер-
вое условие заключается в том, что применяют испытанное лекарство
в чистом виде, без посторонних примесей. Второе условие заключа-
ется в том, что, когда испытывают одно лекарство, надо давать его
человеку с умеренной натурой, так чтобы видно было его действие на
природу (понятие «умеренная натура», согласно средневековой тео-
рии, на современном медицинском языке означало бы «группу нор-
мы». — Прим. авт.). Третье условие состоит в том, что одно лекарство
следует испытывать при одной болезни, а не при двух и более забо-
леваниях. Ибо оно полезно при одном заболевании, а на другое не
действует, и тогда человек не может понять, куда же делось его полез-
ное действие. Четвертое условие заключается в том, что, когда лекар-
ство оказывается полезным при нескольких болезнях, то следует про-
верить, является ли это действие чем-то, присущим только ему, или
же оно зависит от других посторонних обстоятельств. Пятое условие
состоит в том, чтобы сила лекарства соответствовала бы силе болез-
ни. Шестое условие состоит в том, чтобы учитывать время года, ибо
имеется такое время, когда лекарство действует, и такое, когда оно не
действует или оказывает слабое действие. Седьмое условие состоит в
том, чтобы при введении этих лекарств действие их было бы посто-
янным, ибо если оно то действует, а то не оказывает действия — знай,
что это зависит не от лекарства, а от посторонних причин». Можно
сказать, что автор этих правил понимал необходимость правильной
1.3. Основные определения математической статистики...
13
постановки и соблюдения условий эксперимента, а также важность
грамотной интерпретации полученных в исследовании результатов.
Сегодня уже невозможно представить себе клинические исследо-
вания без статистической обработки полученных результатов. Впер-
вые же рандомизированные клинические исследования в современ-
ном понимании были проведены в Англии, а одним из основных ис-
полнителей был известный статистик Остин Б. Хилл (1897—1991).
В настоящее время статистическая наука продолжает развиваться.
Так, в 90-е гг. XX века была проделана огромная методологическая
работа, имеющая непосредственное отношение к статистическому
анализу клинических исследований. Интересные работы ученых-ста-
тистиков в этой области касались вопросов метаанализа, перекрест-
ного дизайна, исследований биоэквивалентности, анализа выживае-
мости, последовательного дизайна, повторяющихся измерений и т.
п. С некоторыми интересными выводами и результатами мы позна-
комим читателей в соответствующих разделах и дадим ссылки на ра-
боты, в которых они рассмотрены более подробно.
1.3. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ
МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ, ВСТРЕЧАЮЩИЕСЯ
В ОБЛАСТИ КЛИНИЧЕСКИХ ИССЛЕДОВАНИЙ
Прежде чем перейти к математической интерпретации задач, воз-
никающих в области клинических исследований, приведем некото-
рые общие определения, встречающиеся в области планирования и
анализа результатов клинических исследований.
Достаточно трудно дать исчерпывающее определение статисти-
ки как дисциплины. Наиболее удачным, с нашей точки зрения, мож-
но считать следующее определение: «наука, изучающая методы сбора
и интерпретации числовых данных». Таким образом, главная цель
статистики — получение осмысленных заключений из несогласован-
ных (подверженных разбросу) данных [16]. Так как индивидуумам
присуща врожденная изменчивость признаков (например, рост, мас-
са тела и т. п.) и, кроме того, биологические признаки могут случай-
ным образом меняться во времени, природа клинических данных,
характеризующихся разбросом или вариацией, диктует необходимость
их статистического оценивания. Еще одна причина, по которой при-
менение статистических методов к данным клинических исследова-
ний становится необходимым, — случайные ошибки измерения кли-
14 Глава 1. Математическая статистика в клинических исследованиях
нических показателей. На языке математики величина любого варь-
ирующего признака является переменной случайной величиной, а ее
конкретные значения принято называть вариантами.
Важной задачей при проведении статистического анализа клини-
ческих данных является определение одного или нескольких призна-
ков, которые в данном клиническом исследовании будут адекватно
оценивать сравниваемый эффект. Вообще словом «эффект» незави-
симо от его медицинского смысла мы будем называть любые прояв-
ления действия изучаемого препарата (или метода лечения), которые
выбраны исследователем для демонстрации его эффективности, бе-
зопасности и т. д. Показатели определенного таким образом эффекта
обладают межиндивидуальной вариабельностью.
Статистику еще часто определяют как науку принятия разумных
решений перед лицом неопределенности [2]. При этом двум катего-
риям задач статистики уделяют особое внимание: статистическое оце-
нивание и проверка статистических гипотез. Первая задача делится
на точечное и интервальное оценивание параметров распределения.
Вообще статистические задачи появляются тогда, когда необходимо
дать наилучшие, в некотором смысле, ответы по ограниченному чис-
лу наблюдений. Если бы число наблюдений не было ограниченным,
можно было бы точно определить параметры распределений и срав-
нить их, при этом никакой статистической задачи не было бы. Если в
ходе исследований мы могли бы изучить все объекты интересующей
нас совокупности (например, всех больных с определенным заболе-
ванием), то можно было сказать, что мы имеем дело со сплошным
изучением генеральной совокупности. На самом деле обследовать все
объекты совокупности удается редко, обычно приходится изучать
лишь выборку, надеясь, что эта выборка достаточно хорошо отражает
свойства изучаемой совокупности. При этом также возникают важ-
ные статистические задачи: случайный отбор вариант из генеральной
совокупности и представительность выборки, а также определение
необходимого объема выборки для формирования статистически зна-
чимого заключения по результатам проведенных исследований.
Все статистические методы исходят из предположения, что дан-
ные извлечены из совокупности случайно. А это значит, что вероят-
ность оказаться выбранным для всех членов совокупности должна
быть одинакова. Случайным должно быть и отнесение пациента к той
или иной сравниваемой группе, то есть каждый пациент должен иметь
равный шанс попасть в любую группу в исследовании. Предназна-
ченные для решения этой статистической задачи методы называются
1.3. Основные определения математической статистики... 15
методами рандомизации. Наиболее известные методы рандомизации:
простая рандомизация, блочная рандомизация, послойная рандомизация,
адаптивная рандомизация, или рандомизация по принципу несиммет-
ричной монеты, «игра на лидера» и др. Рандомизация не только урав-
нивает вероятность получения пациентом различных сравниваемых
воздействий, но и позволяет формировать группы, сходные с точки
зрения прогностических факторов. Таким образом, рандомизация
обеспечивает подбор больных так, чтобы контрольная группа ни в чем
не отличалась от экспериментальной, кроме изучаемого метода лече-
ния. Но и этого оказывается недостаточно. Тесно связана с пробле-
мой рандомизации и так называемая проблема слепоты исследова-
ния. Для того чтобы ни врач, ни исследователь, ни пациент не могли
каким-либо образом влиять на получаемые результаты, используется
такое понятие, как слепота исследования. Например, если позволя-
ют клинические особенности данного исследования, часто применя-
ется так называемый двойной слепой метод, когда ни врач, ни паци-
ент не знают, какой из методов лечения был применен.
Важным вопросом является и вопрос представительности (ширеп-
резентативности) выборки по отношению ко всей популяции, из ко-
торой она отбиралась. Обычно, если выборка извлечена из совокуп-
ности случайным образом и имеет достаточно большой объем, сред-
ние характеристики пациентов в выборке практически такие же, как
в соответствующей популяции. На практике большинство групп па-
циентов, включенных в различные клинические исследования, пред-
ставляют собой смещенные выборки. Это связано с особенностями
включения пациентов в исследование: часто пациенты включаются
потому, что находятся на лечении в центре, проводящем исследова-
ние, или потому, что, с точки зрения исследователя, представляют со-
бой интересный клинический случай. В принципе такое отсутствие
репрезентативности не приводит к каким-то неправильным выводам.
Однако исследователь должен четко понимать, на какую популяцию
реально могут быть распространены результаты, полученные в таком
исследовании [38].
Следующая важная математическая задача — определение необхо-
димого объема выборки. Под «необходимым» понимают минимально
возможное число пациентов, включенных в исследование, которое
при выбранном дизайне позволяет установить наличие статистичес-
ки значимых различий между сравниваемыми методами. К сожале-
нию, о важности решения этой задачи вспоминают, как правило, когда
исследования уже закончены и начинается процесс статистической
16 Глава 1. Математическая статистика в клинических исследованиях
обработки полученных результатов. Эта проблема очень важна, и она
будет рассмотрена нами подробно в разделе, посвященном планиро-
ванию клинических исследований.
Цель клинических исследований — выявление методов, позволя-
ющих улучшить существующие результаты лечения, диагностику, пре-
дупреждение заболеваний. Если новый метод позволяет получить
высокий процент излечения больных, страдающих ранее неизлечи-
мым заболеванием, доказать его эффективность можно путем оцен-
ки результатов лишь в одной группе, без сопоставления с контролем.
Такие исследования называются неконтролируемыми. Контролируемые
клинические исследования — это исследования, в которых сопоставля-
емые группы получают различные виды лечения. Обычно контроли-
руемые исследования являются проспективными, то есть данные по-
лучают после начала исследования. В отличие от проспективных ис-
следований известны случаи, когда в качестве контроля может
использоваться ретроспективно собранная информация: данные ли-
тературы или результаты других исследований.
При планировании исследования очень важно сформулировать его
цель. Если целью проводимого исследования является установление
различий (или преимущества) методов лечения, математически дан-
ный вопрос решается обычно с помощью проверки статистического
критерия (или теста). Применяемые для этого процедуры связаны с
формулированием статистических гипотез. Иногда для решения этой
задачи применяют и метод доверительных интервалов.
Статистическая гипотеза — это утверждение, ошибочного отри-
цания которого хотелось бы избежать. Обычно в области клиничес-
ких исследований принято формулировать так называемую нулевую
гипотезу (Н0) таким образом, чтобы это утверждение желательно было
бы отвергнуть (например, нет различия в эффекте у сравниваемых
методов). Нельзя забывать, что нулевой гипотезе соответствует аль-
тернативная гипотеза (НА) — это вывод, к которому хотелось бы
прийти в результате исследования (например, эффекты сравниваемых
методов различны). С процедурами проверки гипотез тесно связаны
понятия ошибки I и IIрода. Так, ошибка Iрода — возможность оши-
бочно отклонить нулевую гипотезу, то есть найти различия там, где
их нет (ложноположительный результат). Приемлемая для данного
эксперимента вероятность ошибки I рода называется уровнем значи-
мости а. Ошибка IIрода возникает тогда, когда мы принимаем нуле-
вую гипотезу, а она не верна, другими словами, не находим существу-
ющее различие (ложноотрицательный результат). Вероятность ошиб-
1.4. Основные методы рандомизации
17
ки II рода обозначается буквой р. Вероятность обнаружить имеющи-
еся различия, то есть чувствительность, или мощность критерия, рав-
на 1 - р. При прочих равных условиях тот критерий имеет преимуще-
ство, у которого вероятность ошибки II рода меньше (соответствен-
но, чувствительность больше).
Кроме того, для оценки справедливости Н0 важен показатель, ко-
торый обычно обозначается буквой/? и называетсяр-значение. Он оце-
нивает вероятность того, что значение критерия окажется не меньше
критического значения при условии справедливости нулевой гипоте-
зы (то есть при отсутствии различий между сравниваемыми группами).
При планировании клинических исследований в зависимости от
конкретных условий и целей может быть выбран различный порядок
их проведения, или дизайн. Говоря о дизайне исследования, обычно
подразумевают его основные компоненты: установление порядка про-
ведения исследования или плана, указание выбранных методов ран-
домизации и степени слепоты, оценка необходимого числа включае-
мых пациентов. Наиболее часто встречающиеся варианты планов
исследования: перекрестный план, план латинских квадратов, мульти-
перекрестный план, план параллельных групп, блочные планы, план «игра
на лидера», последовательный план.
Необходимые определения и сведения о различных элементах ди-
зайна содержатся в описаниях Good Clinical Practice. Приведенные
выше понятия планирования клинического исследования будут рас-
смотрены нами с точки зрения математики и статистики.
1.4. ОСНОВНЫЕ МЕТОДЫ РАНДОМИЗАЦИИ
Одним из основных положений дизайна клинического исследова-
ния является рандомизация, то есть процесс случайного распределе-
ния вариантов опыта между объектами [4]. Распределение вариантов
лечения в случайном порядке не может быть достигнуто путем бес-
порядочного отбора. Если в процессе отбора участвует человек, ни-
какая схема отбора не может считаться по-настоящему случайной.
Известно из практики, что если у участников исследования появля-
ется возможность влиять на результаты исследования, эта возмож-
ность обязательно будет использована. Задача рандомизации как раз
и состоит в том, чтобы обеспечить такой подбор больных, при кото-
ром контрольная группа отличалась бы от экспериментальной толь-
ко методом лечения.
18 Глава 1. Математическая статистика в клинических исследованиях
Слово «случайность» в его обычном разговорном смысле применя-
ется ко всякому методу выбора, не имеющему определенной цели. Од-
нако выбор, производимый человеком, не является случайным в стро-
гом смысле, поскольку на практике он не выбирает одинаково часто те
события, которые имеется основание считать равновероятными [7].
Есть только один способ получить процедуру истинно случайного
отбора — воспользоваться каким-либо не зависящим от человека ме-
тодом, например использовать датчик (или таблицу) случайных чи-
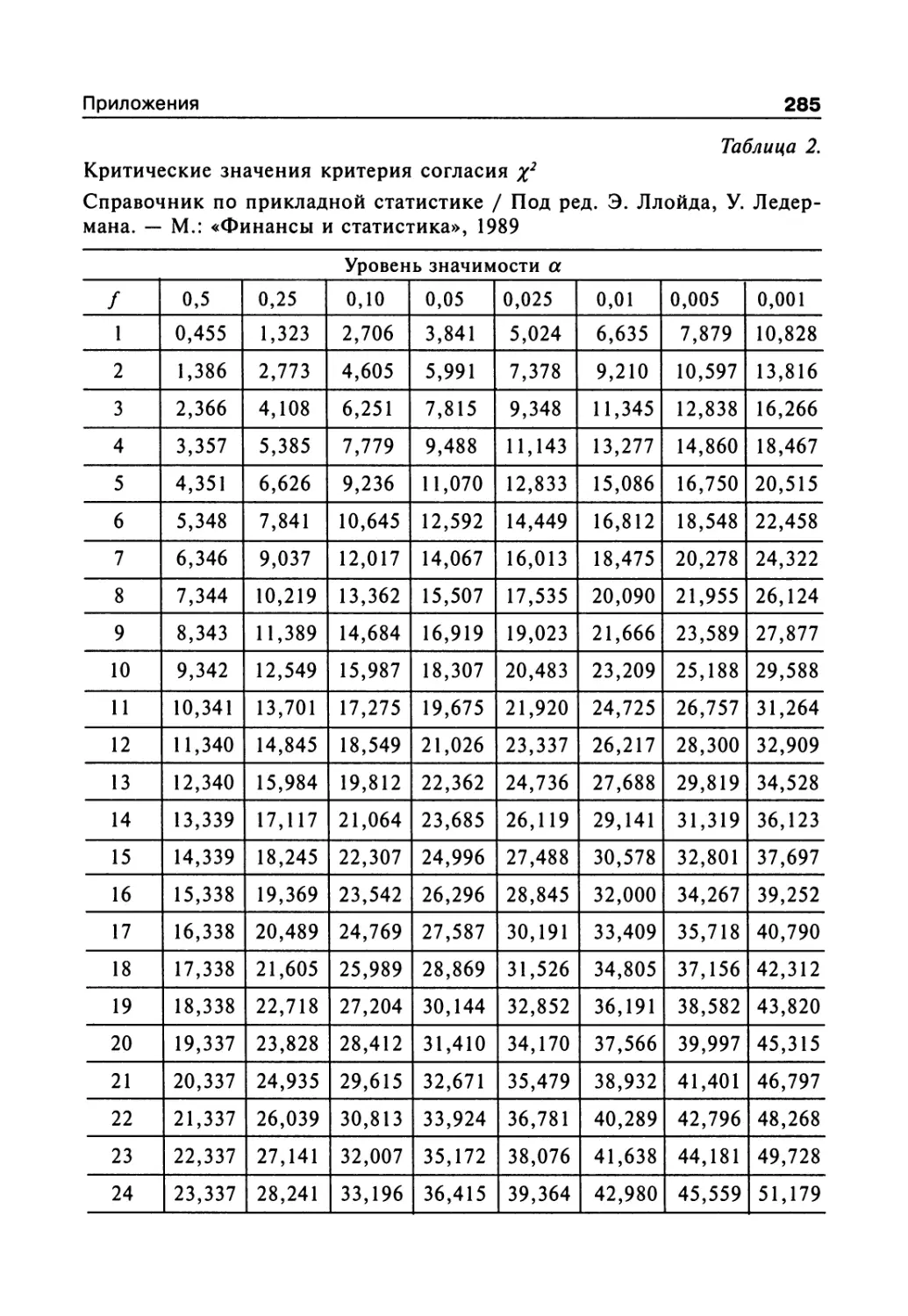
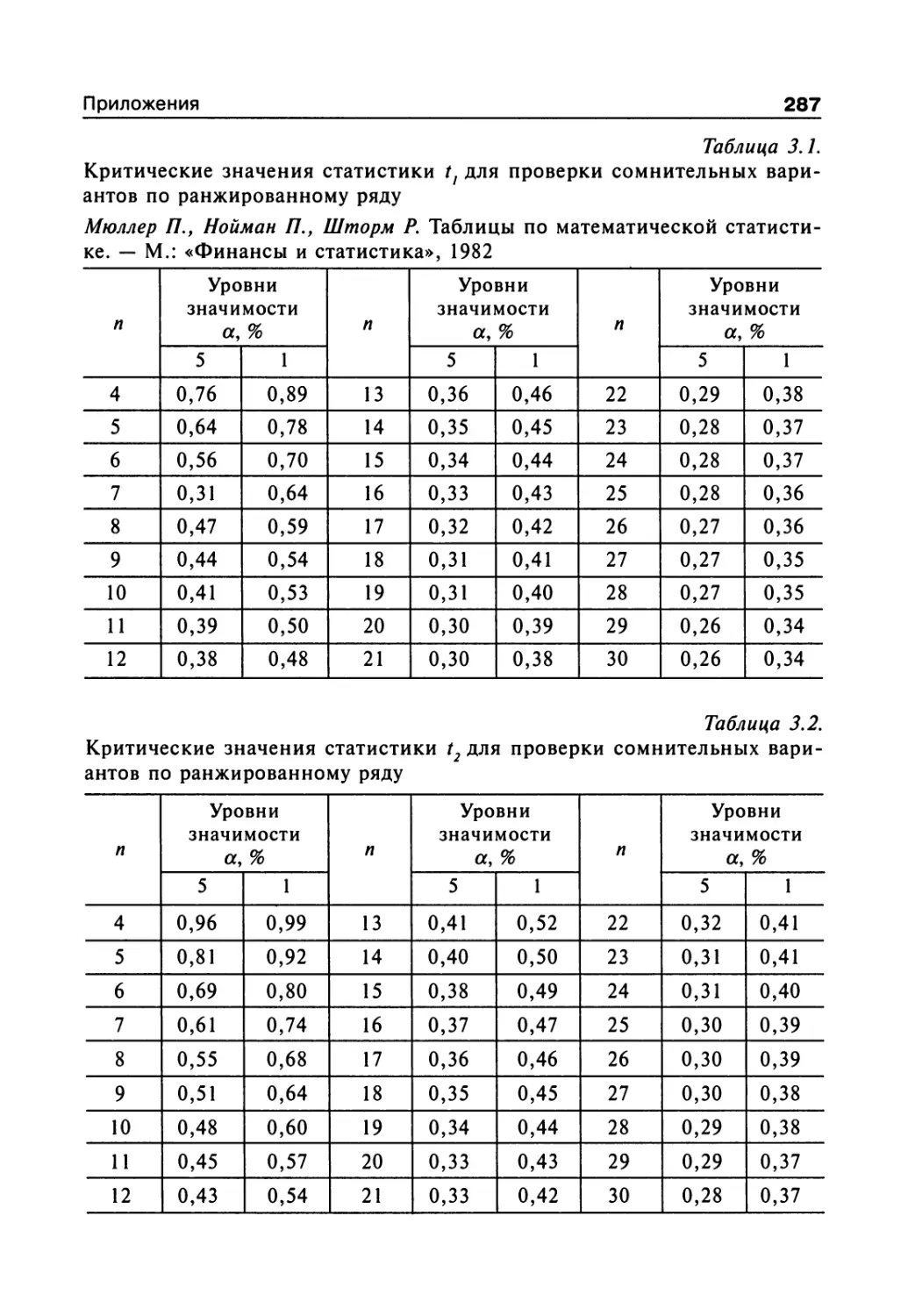
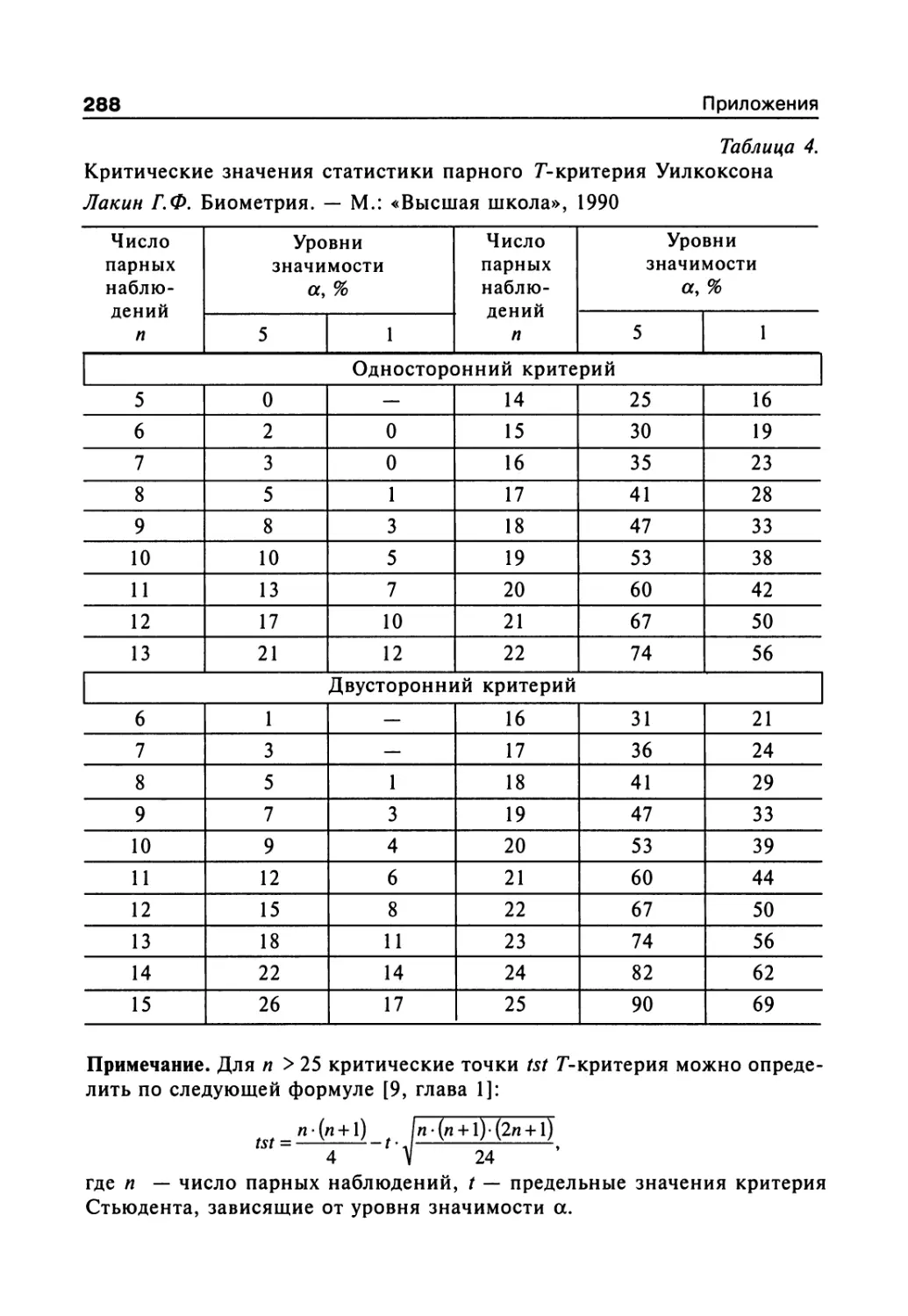
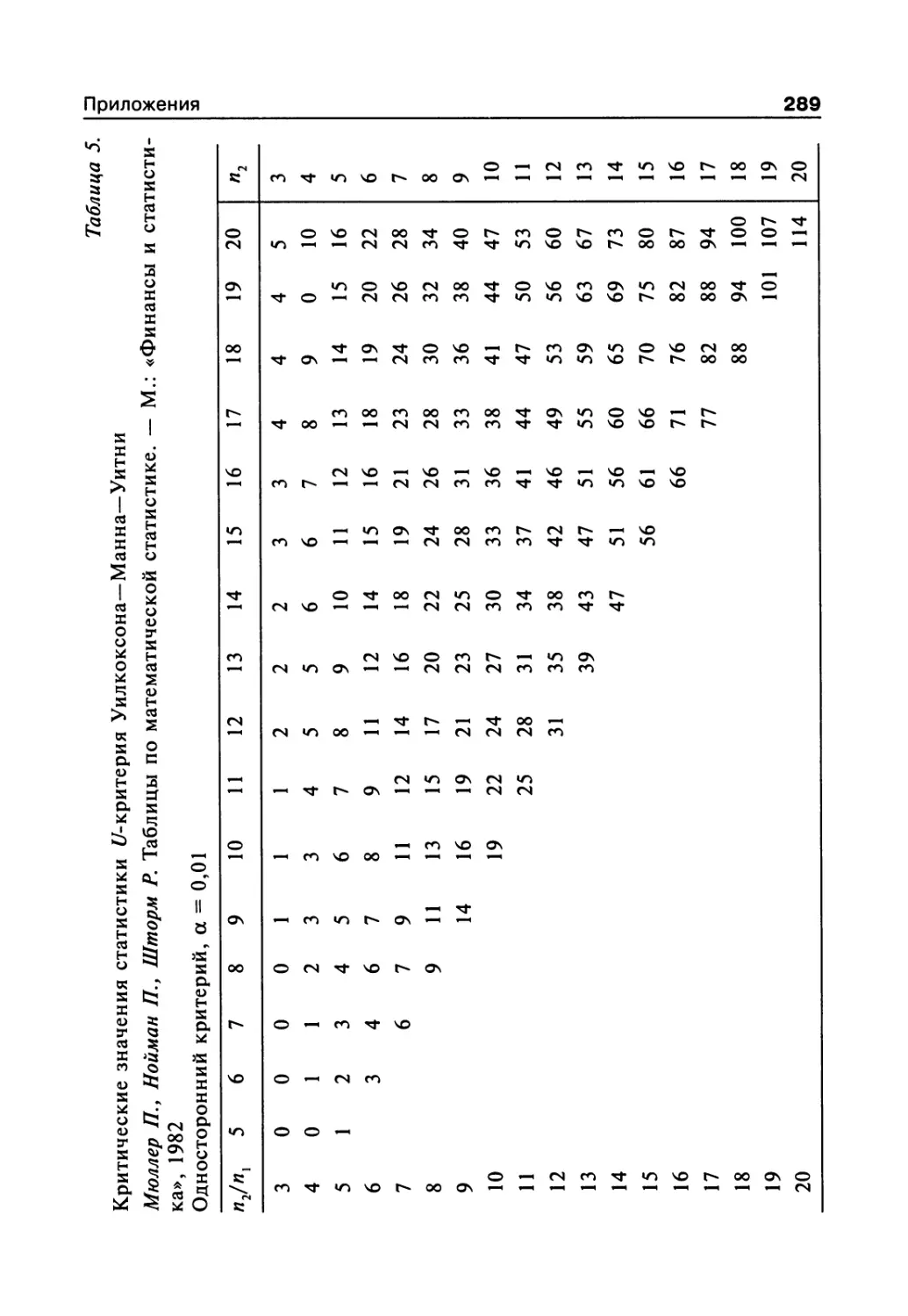
сел (приложение, табл. 11).
Так, простая рандомизация основана на прямом применении та-
кой таблицы. Числа в таблице случайных чисел сгруппированы та-
ким образом, чтобы вероятность для каждого из однозначных чисел
оказаться в любом месте таблицы была одинакова (равномерное рас-
пределение). Крайний левый столбец таблицы представляет собой
номера строк, верхняя строчка — номера сгруппированных по 5 стол-
бцов. Произвольно выбираются начальная точка (пересечение стро-
ки с каким-то номером и столбца (или столбцов) в зависимости от
того, сколько знаков должно быть в извлекаемых случайных числах)
и направление движения. Количество пациентов, которых необходи-
мо рассортировать по группам, определяет, какие числа будут отбирать-
ся: при п < 10 — только однозначные числа; при п = 10—99 — двузнач-
ные и т. д. Например, для распределения 99 пациентов в три группы
выбираем исходную точку на пересечении произвольной строки и двух
соседних столбцов, а также направление движения. Выбираем двузнач-
ные числа. Встретив числа 1—33, разместим очередного пациента в
первую группу, числа 34—66 — во вторую группу, 67—99 — в третью
группу. Для распределения на две группы можно действовать следую-
щим образом: встретив четные номера, отправлять очередного паци-
ента в первую группу, а нечетные — во вторую. Однако такой метод
может привести к формированию различных по численности групп.
От этого недостатка свободен метод последовательных номеров.
Каждому пациенту присваивают номер, являющийся случайным чис-
лом из таблицы случайных чисел. Затем эти номера ранжируются в
порядке возрастания, и в соответствии с выбранным правилом рас-
пределяют методы лечения. Например, для распределения на две груп-
пы: четные номера в ранжированном ряду — первая группа, нечет-
ные — вторая. Однако число пациентов в группах уравновешивается
только к концу процедуры рандомизации.
Метод адаптивной рандомизации поддерживает равное число па-
циентов в группах в течение всей процедуры рандомизации. В общем
1.4. Основные методы рандомизации
19
виде такая процедура предполагает следующее: в начале лечения па-
циенты распределяются равновероятно, затем, перед тем как опреде-
лить, к какой группе отнести очередного пациента, оценивается чис-
ленность уже созданных на данный момент групп. Если численность
групп одинакова, лечение распределяют равновероятно, если числен-
ность одной из групп превосходит другую, вероятность попасть в эту
группу снижается.
Хорошо сохраняет равную численность групп в течение всего про-
цесса рандомизации и метод блочной рандомизации. Больных, кото-
рых предполагается включить в исследование, условно разделяют на
равные блоки. В пределах блока методы лечения распределяются так,
чтобы разными методами лечилось одинаковое число пациентов, но
последовательность назначения лечения была бы различной. Затем
блоки случайно распределяют, например пользуясь таблицей случай-
ных чисел.
Для повышения эффективности рандомизации и улучшения од-
нородности групп применяется метод стратификационной рандоми-
зации. При этом по основным прогностическим признакам форми-
руются однородные группы (страты). Для каждого конкретного ис-
следования выбираются прогностические факторы, связанные как с
заболеванием, так и с особенностями пациентов. После поступления
сведений об очередном больном и определения его стратификацион-
ной группы по выбранной схеме распределяются методы лечения.
Схемы распределения лечения в пределах группы могут быть анало-
гичны предложенным ранее, например, можно использовать перемен-
ную последовательность двух вариантов лечения и назначать их па-
циентам, поступающим в случайной последовательности.
Следующие два метода рандомизации основаны на процедурах,
заимствованных из теории игр. Чтобы лучше понять их смысл, пред-
ставьте себе, что вы оказались в казино и перед вами — разные игро-
вые автоматы. Время игры ограничено. Какую стратегию вам выбрать
для получения максимального выигрыша? Итак, рассматриваем три ва-
рианта стратегии: а) двигаясь от автомата к автомату, играть с каждым
из них по одному жетону, пока какой-либо автомат не заплатит вам
выигрыш, после этого продолжать играть на этом автомате все оставше-
еся время независимо от последующих результатов; б) играть на каждом
автомате несколько раз независимо от результата, чтобы определить
«частоту» выигрыша для каждого из них, а затем продолжать играть с
«лучшим»; в) переходить к следующему автомату только после пораже-
ния на предыдущем, продолжать играть на одном и том же автомате,
20 Глава 1. Математическая статистика в клинических исследованиях
пока вам удается выигрывать у него. Понятно, что, выбрав первую стра-
тегию, вы рискуете все оставшееся время играть на автомате, выиг-
рать на котором вам удалось однажды и, возможно, лишь случайно.
В области клинических исследований метод рандомизации, осно-
ванный на третьей стратегии, носит название «игра на лидера».
Метод «игра на лидера» — первый пациент получает методы лече-
ния равновероятно, затем, в случае успеха терапии, следующий па-
циент также получает это лечение, а в случае неудачи — другое. Па-
циенты, уже получившие лечение, его продолжают. Этот дизайн счи-
тается не очень удачным, поскольку такая процедура практически не
имеет «памяти», даже после серии успехов достаточно одной неудачи
для изменения выбора терапии.
Метод «однорукий бандит» — процедура адаптивного размещения,
постоянно корректируется по мере появления новой информации о
сравниваемых терапиях с целью повышения вероятности размеще-
ния пациента в группы, получающие более успешную терапию. Ос-
новная идея имеет отношение скорее ко второй игровой стратегии:
на данном этапе не всегда нужно размещать очередного пациента в
группу, которая в данный момент считается наиболее успешной. Воз-
можно, что наших знаний еще недостаточно, чтобы точно оценить,
какой метод лучше, поэтому на данном этапе необходимо продолжить
сбор информации. При этом выявляются группы с наибольшей веро-
ятностью успеха. В случае двух последних процедур рандомизации
большинство пациентов получают лучший метод лечения. Однако
может возникнуть существенная разница в численности групп, что
затруднит в дальнейшем статистический анализ. Кроме того, для та-
ких стратегий необходимо иметь точное определение успеха для изу-
чаемых методов лечения.
Более подробно с различными процедурами рандомизации можно
познакомиться в [4, 7, 32, 38].
1.5. ОСНОВНЫЕ ТИПЫ ПЛАНОВ
Коротко познакомим читателей с некоторыми наиболее часто
встречающимися планами исследований.
Перекрестный план (cross-over design) схематично можно предста-
вить себе таким образом: есть два лекарственных препарата — А и В,
в результате все пациенты получают и лекарство А, и лекарство В. Для
этого пациентов каким-то образом делят на группы: одна группа по-
1.5. Основные типы планов
21
лучает терапию АВ, другая — ВА. Между назначением двух различ-
ных препаратов существует так называемый временной промежуток
(wash-out period) выведения лекарства из организма для исключения
взаимовлияния изучаемых препаратов.
Такой дизайн часто применяется в фармакокинетических и фар-
макодинамических приложениях, при выборе оптимальных доз пре-
парата, оценке биоэквивалентности и т. д. Поскольку в данном слу-
чае не учитывается межгрупповая вариабельность, данный дизайн при
некоторых условиях требует меньшего числа включаемых пациентов.
Другим преимуществом этого подхода является возможность учиты-
вать предпочтения пациентов. Однако данный метод не свободен от
недостатков. Эффекты различных лечений могут перекрываться и сме-
шиваться, кроме того, план, включающий период выведения лекарства
из организма, может оказаться безответственным с точки зрения эти-
ки. В случае выбывания пациента после завершения первого этапа не-
возможно использовать его данные на этапе статистического анализа.
План латинских квадратов — группы пациентов подбираются так,
чтобы число пациентов в группе совпадало с количеством испытыва-
емых препаратов. Пациенты получают каждое лекарство по 1 разу в
различной последовательности. Можно увеличить число пациентов
в группе пропорционально количеству испытываемых препаратов.
При этом, например, в случае трех препаратов можно позволить 4-му
пациенту выбирать любую последовательность приема, 5-му — одну
из двух оставшихся и т. д. В случае сравнения М лекарственных пре-
паратов потребуется М, 2 М, 3 М, ... и т. д. пациентов. В табл. 1 при-
веден план латинских квадратов 4x4.
Так же, как при перекрестном плане, в данном случае существует
возможность учитывать мнение пациентов, и для проведения иссле-
дования не требуется большого количества пациентов. Аналогично
перекрестному плану в числе недостатков можно назвать возможное
наличие эффекта продолжающегося действия и существование рис-
ка возможного исключения целого блока пациентов. Кроме того, со-
Таблица 1.
План латинских квадратов 4x4
А
В
С
D
В
С
D
А
С
D
А
В
D
А
В
С
22 Глава 1. Математическая статистика в клинических исследованиях
бранные в соответствии с таким планом данные нуждаются в слож-
ном статистическом анализе, например с использованием методов
дисперсионного анализа.
Мультиперекрестный план схематично можно изобразить следу-
ющим образом: изучаемый препарат — А, плацебо — П. Каждый па-
циент получает последовательность АПАПАПАП или ПАПАПАПА.
Промежутки времени получения А и П одинаковы, а в конце каждо-
го фиксируются показатели состояния пациента. Целью такого ис-
следования является установление того, что препарат А дает боль-
ший эффект, чем П. Для этого рассматриваются смежные периоды
терапии и вычисляется, например, обобщенный показатель, равный
общему числу периодов А, по окончании которых состояние паци-
ента было лучше, чем после окончания соответствующего периода
П. В случае данной схемы в зависимости от целей исследования пла-
цебо может быть заменено изучаемым препаратом в другой дозиров-
ке или тем же препаратом, изготовленным другой фармацевтичес-
кой компанией.
Условием для применения такого плана являются короткий период
выведения препарата и достаточно быстрое восстановление симпто-
мов болезни после прекращения лекарственной терапии. В случае вы-
полнения всех условий применимости такая модель достаточно хоро-
ша для правильного учета реакций пациентов на изучаемый препарат.
Можно ввести для такой модели понятие «индекс эффективнос-
ти». Допустим, в исследовании предусмотрено п периодов, число раз-
ниц между показателями до и после очередного периода (обозначим
их Yi) равно, соответственно, п — 1. Тогда индекс эффективности мож-
но определить как:
Положительное значение данного показателя говорит об эффекте
лечения, близость к нулю — об отсутствии такого эффекта, отрица-
тельное — об отрицательном эффекте.
План параллельных групп — наиболее распространенный вариант,
порядка 95% клинических исследований проводится в соответствии
с планом такого типа. Общее число пациентов при этом зависит в том
числе от количества групп и может оказаться достаточно большим с
учетом межиндивидуальных различий. С помощью указанных выше
способов рандомизации пациентов случайным образом распределя-
ют в группы. Строгое сравнение эффективности различных методов
1.5. Основные типы планов
23
лечения возможно лишь при соблюдении условий однородности со-
поставляемых групп больных по всем признакам.
Некоторая модификация этого метода — многогрупповая модель
применяется, например, при изучении влияния различных доз пре-
парата. Кроме того, известна так называемая неоднородная модель, в
этом случае на первом этапе все пациенты получают изучаемое лече-
ние, а затем пациенты, продемонстрировавшие наличие реакции на
проводимую терапию, с помощью методов рандомизации распреде-
ляются по группам для проведения дальнейшего исследования.
План «игра на лидера» — допустим, сравниваются 2 варианта тера-
пии, каждый пациент получает одну и ту же терапию (разные паци-
енты начинают с разных терапий) в течение стольких временных ин-
тервалов, пока в конце одного из них не будет обнаружен «неуспех».
После этого у данного пациента происходит смена терапии.
Последовательный план применяется для исследования новых
сильнодействующих препаратов, кроме того, в случае применения
плана параллельных групп такой подход можно использовать, если
результат сравнения становится очевидным еще до конца исследова-
ния. Этот статистический метод применяется для сравнения двух пре-
паратов или препарата с плацебо. В качестве необходимого условия
выдвигается достаточно быстрое проявление эффекта лечения, по-
этому обычно используется в случае лечения острых заболеваний. При
этом количество пациентов не определяется заранее (открытый ди-
зайн), а процесс исследования останавливается после получения ин-
формации об эффекте во время очередной инспекции результатов,
если обнаружено ярко выраженное преимущество одного из методов.
Известна также модификация данного метода, когда максимальный
размер групп ограничивается на этапе планирования (закрытый ди-
зайн). Существуют различные правила остановки (или «останова» —
технический термин) такой процедуры исследования [38]. Наиболее
известным является граничный подход (boundary approach): заранее
очерчивается область продолжения исследования (в зависимости от
цели исследования) на графике зависимости кумулятивного разли-
чия величин эффекта к моменту данной инспекции Z/ от другой ста-
тистической информационной переменной К(в качестве Кможет ис-
пользоваться и число включенных пациентов), в терминах которой
измеряется вариабельность Z/ при условии справедливости нулевой
гипотезы об отсутствии эффекта терапии. Верхняя и нижняя грани-
цы области продолжения исследования вычисляются таким образом,
чтобы при их пересечении исследование можно было остановить, еде-
24 Глава 1. Математическая статистика в клинических исследованиях
лав однозначное заключение о преимуществе одной из терапий [38].
Классический подход к последовательному дизайну, предложенный
автором [25, 27], предполагает проведение попарных сравнений па-
циентов в группах. Однако очень мало клинических исследований
действительно проводилось по такой схеме, поскольку случайно выб-
ранные пары могут существенно отличаться по многим прогности-
ческим факторам [32]. Для устранения этого ограничения был пред-
ложен так называемый групповой последовательный дизайн, который
предусматривает деление всего множества пациентов на подгруппы,
число которых равно числу предполагаемых инспекций результатов.
В каждой подгруппе половина пациентов получает одну терапию,
половина — другую терапию, статистический анализ производится
каждый раз, как только заканчивается сбор информации для очеред-
ной подгруппы. И каждый раз данные для уже проанализированных
подгрупп пересчитываются. Уровень значимости при такой процеду-
ре выбирается с учетом множественных сравнений. В остальном этот
подход не отличается от классического. С описанием других проце-
дур последовательного дизайна можно познакомиться, например, в
работах [25, 27, 32].
Поскольку в отличие от плана параллельных групп в данном слу-
чае количество пациентов не определяется заранее, не может возник-
нуть ситуация, когда собранных данных не хватает для формирова-
ния статистически значимого заключения о различии в эффекте.
Мультицентровые исследования — это исследования, проводи-
мые по единой методике и программе одновременно в нескольких
лечебных учреждениях, что позволяет сократить сроки сбора необхо-
димого объема информации. Число пациентов при этом возрастает
непропорционально, поскольку необходимо учесть межцентровую
вариацию интересующих параметров. Существует мнение, что муль-
тицентровые клинические исследования могут оказаться неэффектив-
ными, если в каждом центре в процесс исследования включено разное
число пациентов [32]. Статистический анализ данных мультицентро-
вых исследований требует особого внимания, с некоторыми статис-
тическими процедурами можно познакомиться в работах [32, 38].
Многие ученые сходятся во мнении, что, несмотря на единый про-
токол, лежащий в основе мультицентровых исследований, условия
проведения исследования в каждом центре могут приводить к такой
существенной межцентровой вариации данных, что полученные ре-
зультаты можно рассматривать как частный случай метаанализа [26,
31, 32, 36, 38].
1.6. Величины, характеризующие эффект
25
Метаанализ и объединение данных (pooling) — процесс обобщения
результатов различных исследований на одну тему с применением спе-
циальных процедур синтеза данных. К такому объединению обычно
прибегают в случае, если объемов отдельных исследований оказыва-
ется недостаточно для формирования статистически значимого зак-
лючения. При этом существуют 2 подхода к анализу данных: 1) объе-
динение данных отдельных исследований и проведение анализа для
всей совокупности, как если бы они были получены в одном иссле-
довании; 2) проведение анализа полученных данных для каждого ис-
следования в отдельности и последующее объединение не данных, а
статистических результатов. Такое объединение результатов не может
проводиться путем вычисления обычных средних значений. При про-
ведении метаанализа используют процедуры «взвешивания» данных
различных источников в соответствии с числом включенных паци-
ентов, процедуры анализа и т. д. Наиболее простой способ для пони-
мания такого объединения результатов — графический. На один и тот
же график наносят доверительные интервалы для интересующего по-
казателя эффекта, вычисленные в различных исследованиях. Преиму-
ществом объединения данных является возможность получения ста-
тистически достоверного заключения вследствие увеличения общего
объема выборки. Однако известны и противники такого подхода. По
их мнению, процедуры отбора пациентов, методы проведения иссле-
дований и оценки эффекта могут настолько варьироваться, что объе-
динение результатов теряет всякий практический смысл [32, 38]. По-
этому данные для проведения метаанализа должны специальным об-
разом подбираться.
1.6. ВЕЛИЧИНЫ, ХАРАКТЕРИЗУЮЩИЕ ЭФФЕКТ
При проведении клинических исследований обычно преследуют-
ся 2 основные цели: во-первых, оценить действие предлагаемого пре-
парата (или лечения) на пациентов (или здоровых добровольцев),
включенных в данное исследование, а во-вторых, более общая цель
— на основе полученных результатов предвидеть будущий возмож-
ный клинический результат при внедрении изучаемого препарата
(или метода лечения) в широкую практику. Другими словами, ос-
новной формальной целью клинических исследований является
оценка эффекта (в широком смысле слова) у изучаемой группы лиц
для того, чтобы можно было сказать, какой лечебный эффект воз-
26 Глава 1. Математическая статистика в клинических исследованиях
можен или скорее всего возможен с точки зрения теории вероятнос-
ти в будущем. Можно сказать, что решить первую задачу на практике
достаточно сложно, в то время как вторую — экстремально сложно,
если вообще возможно [38].
Для того чтобы грамотно планировать клиническое исследова-
ние, необходимо с самого первого этапа сформулировать его цель и
попытаться понять, какие именно показатели можно использовать
для демонстрации и сравнения эффекта данного метода. Обычно
один из таких показателей считается основным, а остальные — до-
полнительными. Сразу хотим предупредить, что с точки зрения ма-
тематики и статистики не существует принципиального различия
между эффектами, которые медики относят к прямому или побоч-
ному действию. В дальнейшем мы не будем останавливаться на ме-
дицинских определениях показателей эффекта. Однако нам кажет-
ся целесообразным определить понятие «эффект или эффект в ре-
зультате изучаемой терапии» в контексте клинических исследований
и математической статистики. В общем виде это определение мо-
жет звучать так: эффектом любого лечения у конкретного пациен-
та называется разница между тем, что произошло с данным паци-
ентом в результате проведения данного лечения, и тем, что могло
бы с ним произойти в случае отказа от лечения данным методом.
Конечно, возникают некоторые практические трудности при таком
подходе к определению эффекта. Так, например, одна из них связа-
на с тем, что это определение эффекта дано в терминах выбора. Вто-
рая связана с тем, что, наблюдая за произошедшим в результате про-
ведения данного лечения, мы не можем наблюдать, что могло бы про-
изойти. И, наконец, третья — мы не можем оценить, что было бы
именно с этим пациентом, если бы его лечили другим методом. Такое
сравнение возможно лишь на основе изучения параллельных групп
или на основе исторического контроля, при этом не только сравни-
ваемые методы лечения, но и сами пациенты могут различаться, и
не всегда все различия возможно учесть. Несмотря на эти тонкости,
из принятия такого определения сразу следует ряд важных практи-
ческих выводов.
Самым важным выводом является то, что эффект определяется
не просто как разница между показателями пациента до и после про-
ведения терапии, хотя во многих случаях эффект можно оценивать
именно так. Такой метод сравнения называется сравнение с исход-
ным состоянием (baseline comparison). He во всех случаях примене-
ние этого подхода приводит к желаемым результатам. Проиллюст-
1.6. Величины, характеризующие эффект
27
рируем справедливость этого утверждения на примерах. Так, допус-
тим, что мы имеем дело с неизлечимым заболеванием, предполага-
ющим прогрессивное ухудшение состояния пациента. Испытание
нового препарата показало, что, например, через 5 лет его примене-
ния разница между исходными и результирующими показателями
пациентов равна нулю, то есть ухудшения состояния не произошло,
что само по себе говорит о наличии клинического эффекта. Однако
при таком выборе способа оценки эффекта лечения формально мы
получим полное отсутствие всякого эффекта от лечения данным
препаратом.
Еще один интересный пример, касающийся оценки эффекта, при-
веден в [38]. Представьте себе, что в клинических исследованиях ле-
карственного препарата участвуют 10 человек: 5 получают изучаемый
препарат, а 5 — плацебо. В результате проведения данной терапии
предполагается увеличение значения какого-то клинического пока-
зателя X, это изменение и будет оценивать эффект. Допустим, в ре-
зультате испытаний получены следующие значения изменений пока-
зателя X: —0,2; —0,1; 0,0; 0,2; 0,5 для группы, получающей активное
лечение, и —0,5; —0,4; —0,3; —0,1; 0,2 в случае плацебо. Видно, что
даже не у всех пациентов в первой группе достигнут эффект с точки
зрения критерия данного исследования. Однако можно заметить, что
вычитание 0,3 из всех значений показателя в первой группе дает со-
ответствующее значение показателя во второй (данные подобраны так
специально, для наглядности). Таким образом, на основе предложен-
ного нами общего определения эффекта можно заключить, что каж-
дый пациент первой группы в результате проведения лечения полу-
чает дополнительное улучшение рассматриваемого параметра на 0,3
единицы по сравнению с отсутствием данной терапии (плацебо). Это
еще одна иллюстрация того, насколько важно неформально отно-
ситься к выбору параметров для оценки эффекта и анализу получен-
ных результатов.
Другой, не менее показательный пример связан с использовани-
ем метода регрессии для демонстрации наличия эффекта от прово-
димой терапии. Предположим, проводится гипотетическое неконт-
ролируемое исследование выдуманного препарата, скажем, для нор-
мализации систолического давления. Пусть исходная выборка
пациентов состоит из пациентов как с повышенным, так и понижен-
ным давлением. Мы измеряем систолическое давление каждому па-
циенту 2 раза: до и после проведения терапии; после окончания ис-
следования для всех пациентов рассчитываем среднее давление до и
28 Глава 1. Математическая статистика в клинических исследованиях
среднее давление после. К нашему удивлению, разница между этими
величинами практически равна нулю, поскольку измерения «до» по-
вышенного и пониженного давления дали в среднем нормальное, а
«после» — давление нормализовалось в результате терапии. Значит,
если бы мы таким образом оценивали эффект терапии, он оказался
бы нулевым. Среднее арифметическое попарных разностей также
равнялось бы нулю. Использовать в данном случае корреляционный
анализ также бесполезно. Теперь попробуем обозначить на регрес-
сионной плоскости измерения наших пациентов в координатах «дав-
ление до — давление после» и проведем прямую из начала коорди-
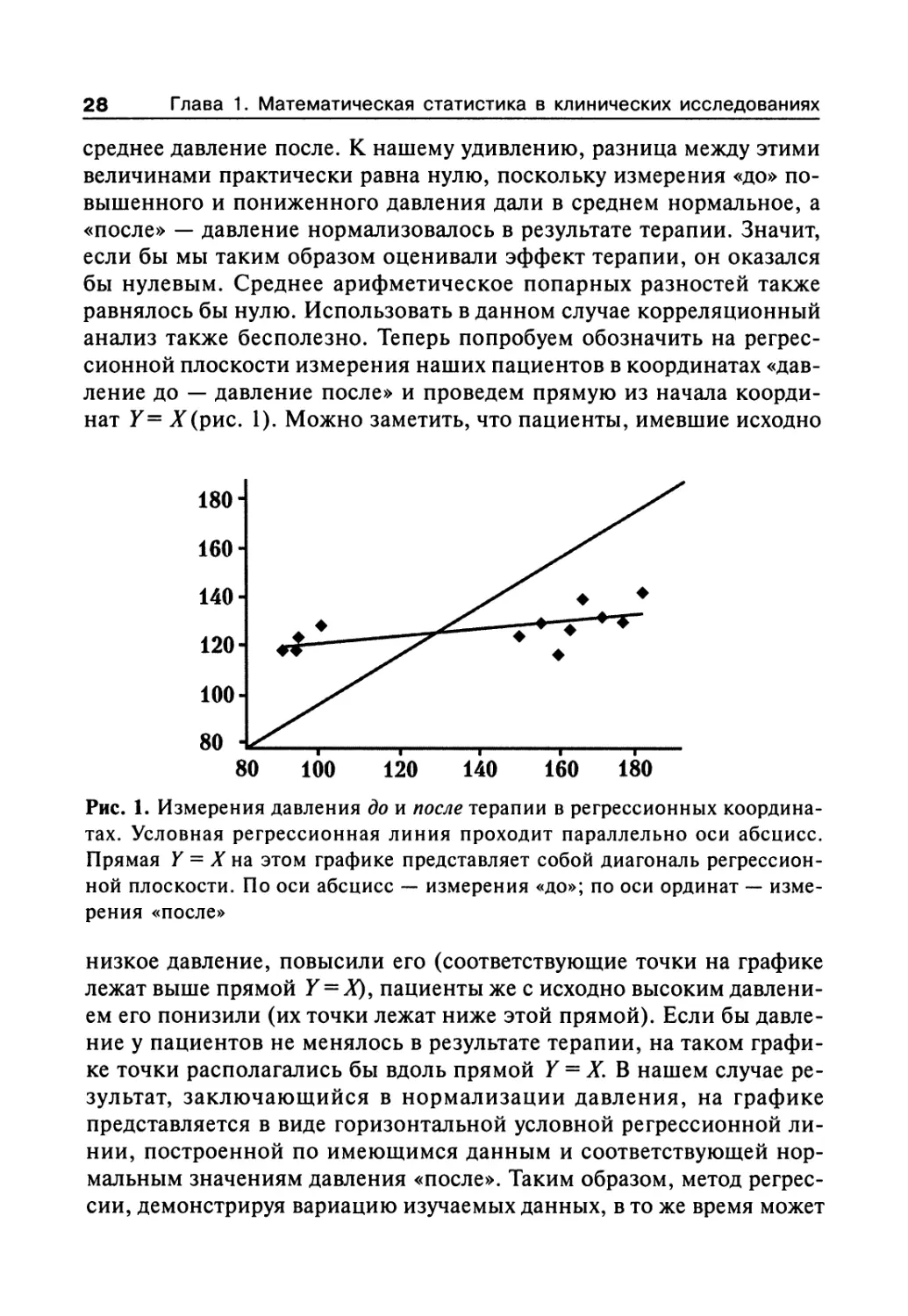
нат Y= ^(рис. 1). Можно заметить, что пациенты, имевшие исходно
180-
160-
140-
120-
100-
80 -
80 100 120 140 160 180
Рис. 1. Измерения давления до и после терапии в регрессионных координа-
тах. Условная регрессионная линия проходит параллельно оси абсцисс.
Прямая Y = X на этом графике представляет собой диагональ регрессион-
ной плоскости. По оси абсцисс — измерения «до»; по оси ординат — изме-
рения «после»
низкое давление, повысили его (соответствующие точки на графике
лежат выше прямой Y = X), пациенты же с исходно высоким давлени-
ем его понизили (их точки лежат ниже этой прямой). Если бы давле-
ние у пациентов не менялось в результате терапии, на таком графи-
ке точки располагались бы вдоль прямой Y = X. В нашем случае ре-
зультат, заключающийся в нормализации давления, на графике
представляется в виде горизонтальной условной регрессионной ли-
нии, построенной по имеющимся данным и соответствующей нор-
мальным значениям давления «после». Таким образом, метод регрес-
сии, демонстрируя вариацию изучаемых данных, в то же время может
1.7. Статистический анализ результатов клинических исследований 29
дать наглядное представление о наличии эффекта терапии в подоб-
ных ситуациях. Однако, рассматривая подробнее регрессионный ана-
лиз в соответствующем разделе, мы объясним, почему не рекоменду-
ется в случае, когда непонятно, какую переменную считать зависи-
мой, а какую — независимой (случай сравнения результатов
измерения двумя приближенными методами или случай повторных
измерений), рассчитывать линию регрессии между такими перемен-
ными. Здесь, строго говоря, расположение результатов измерений
на регрессионной плоскости используется только для демонстрации
имеющегося эффекта.
Еще одна интересная задача возникает при необходимости срав-
нения результатов двух непрямых методов измерения или проверки
согласованности повторных измерений, выполненных одним и тем
же методом. Поскольку в данном случае невозможно принять какой-
то метод измерения за эталонный, обычно для каждой связанной пары
измерений определяют ее разность. Систематическое расхождение
результатов оценивается с помощью средней разности, как обычно,
дисперсия разности (или соответствующее среднее квадратичное от-
клонение) — степень разброса результатов. Понятно, что, если из-
мерения действительно согласованы и систематические расхожде-
ния отсутствуют, средняя разность будет несущественно отличаться
от нуля (с учетом рассчитанной оценки дисперсии). Стандартное от-
клонение разности также не должно быть слишком велико по срав-
нению с самими значениями. Кроме того, не должно быть выражен-
ной зависимости парных разностей измерений от величины измеря-
емого признака. Коэффициент корреляции между измерениями,
выполненными различными способами, должен быть близок к 1. Это
практически единственный подход к анализу данных такого типа, ко-
торый принимает во внимание сразу 3 статистические характеристи-
ки: среднее значение, вариацию и корреляцию. Еще раз хотим подчер-
кнуть, что коэффициент корреляции между измерениями, даже если
он принимает значения достаточно большие (по модулю близкие к
1), не может использоваться в качестве единственного показателя для
анализа данных такого типа. Регрессионный анализ в такой ситуа-
ции также неприменим, поскольку неизвестно, какую переменную
считать зависимой, а какую — независимой. Однако в регрессион-
ных координатах результаты измерений должны располагаться вдоль
прямой Y = X.
Более подробно вопросы оценки эффекта при проведении клини-
ческих исследований рассмотрены в [32, 38].
30 Глава 1. Математическая статистика в клинических исследованиях
1.7. СТАТИСТИЧЕСКИЙ АНАЛИЗ
РЕЗУЛЬТАТОВ КЛИНИЧЕСКИХ ИССЛЕДОВАНИЙ
Статистический анализ данных, полученных в ходе клинических ис-
следований, необходим, поскольку известно, что индивидуальная ре-
акция пациентов (или здоровых добровольцев) может варьировать в до-
статочно широких пределах. Наряду с естественным варьированием на
величине признаков сказываются и ошибки измерений, и погрешнос-
ти в проведении исследований. В силу этого параметры, количествен-
но оценивающие изучаемый эффект, являются случайными величина-
ми и должны быть описаны соответствующими статистическими ха-
рактеристиками. На языке математики отдельные числовые значения
варьирующего параметра принято называть вариантами. Все изучае-
мые показатели эффекта варьируются, но не все они поддаются непос-
редственному измерению. Так возникает деление на количественные
показатели (допускающие непосредственное измерение величины эф-
фекта) и качественные (не поддающиеся непосредственному измере-
нию, например, характеристики пациента: диагноз, пол, врожденные
аномалии и т. п.). Качественные данные, которые могут быть отнесе-
ны только к двум противоположным категориям да—нет, называются
дихотомическими (dichotomous data), с их помощью учитывают показа-
тели эффекта в альтернативной форме (например, определение коли-
чества или доли пациентов из числа испытуемых, у которых наблюдал-
ся определенный эффект, — responders). Качественные переменные
могут иметь число градаций больше двух, их обычно называют много-
значными качественными переменными. Количественные данные мо-
гут быть непрерывными и дискретными. Непрерывные данные могут
принимать любое значение на непрерывной шкале, например масса
тела, температура, уровень глюкозы в крови и т. д. Дискретные данные
могут принимать лишь определенные значения из диапазона измере-
ния, обычно целые, например число рецидивов за период, количество
перенесенных операций и т. п. Выделяют еще один вид данных — по-
рядковые данные. Можно сказать, что они занимают промежуточное
положение между количественными и качественными типами данных.
Их можно упорядочить как количественные данные, но над ними
нельзя производить арифметические действия, как и над качествен-
ными данными. Примером таких данных может служить любой воп-
росник, предполагающий, например, оценку состояния пациента в тер-
минах «очень хорошо», «хорошо», «плохо», «очень плохо». Надо пре-
дупредить, что во многих случаях такое деление данных весьма условно.
1.7. Статистический анализ результатов клинических исследований 31
1.7.1. Нормальное распределение
показателей и основные статистические
характеристики совокупности
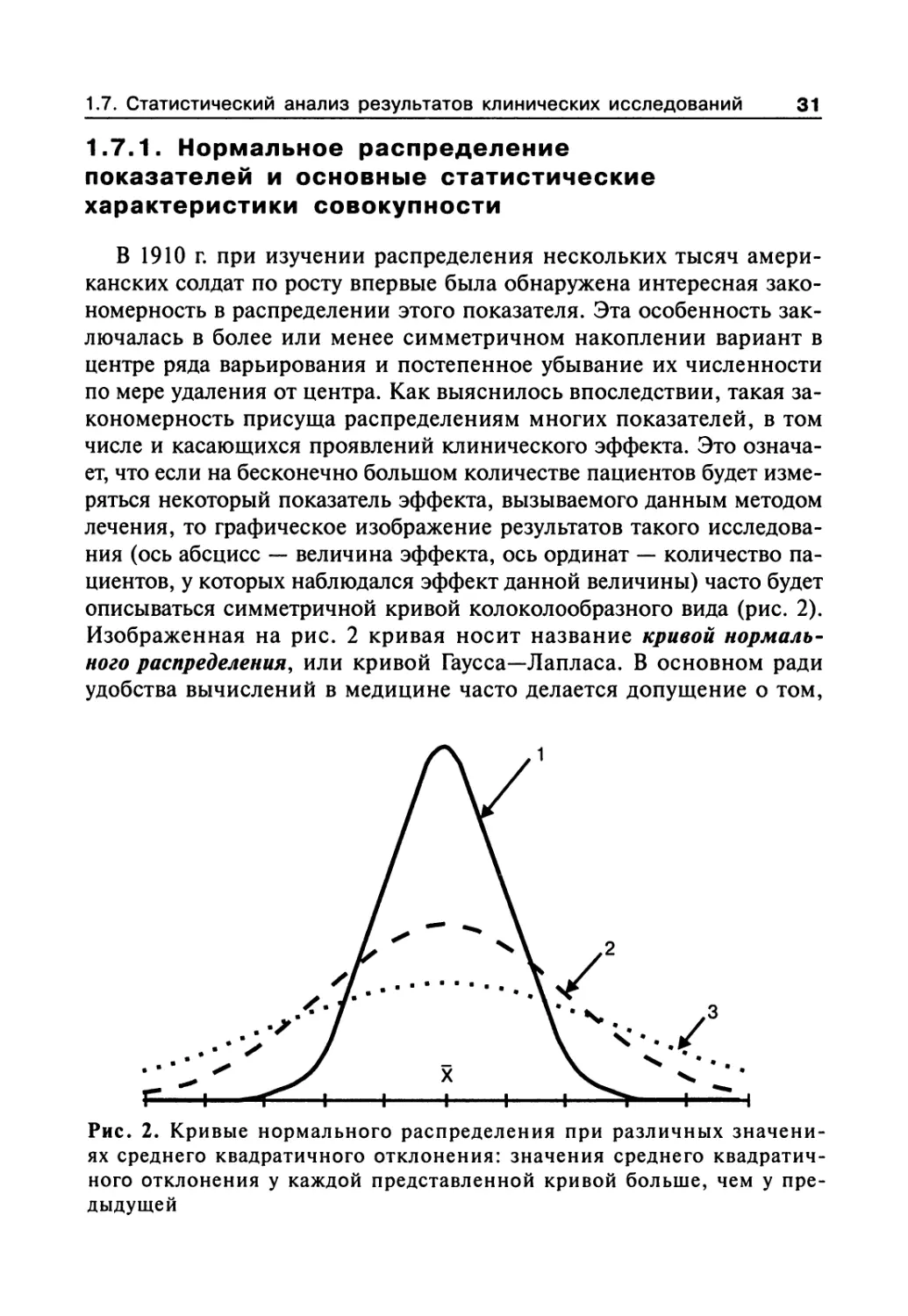
В 1910 г. при изучении распределения нескольких тысяч амери-
канских солдат по росту впервые была обнаружена интересная зако-
номерность в распределении этого показателя. Эта особенность зак-
лючалась в более или менее симметричном накоплении вариант в
центре ряда варьирования и постепенное убывание их численности
по мере удаления от центра. Как выяснилось впоследствии, такая за-
кономерность присуща распределениям многих показателей, в том
числе и касающихся проявлений клинического эффекта. Это означа-
ет, что если на бесконечно большом количестве пациентов будет изме-
ряться некоторый показатель эффекта, вызываемого данным методом
лечения, то графическое изображение результатов такого исследова-
ния (ось абсцисс — величина эффекта, ось ординат — количество па-
циентов, у которых наблюдался эффект данной величины) часто будет
описываться симметричной кривой колоколообразного вида (рис. 2).
Изображенная на рис. 2 кривая носит название кривой нормаль-
ного распределения, или кривой Гаусса—Лапласа. В основном ради
удобства вычислений в медицине часто делается допущение о том,
Р 1 *Г I 1 1 1 1 ^> 1 *** I
Рис. 2. Кривые нормального распределения при различных значени-
ях среднего квадратичного отклонения: значения среднего квадратич-
ного отклонения у каждой представленной кривой больше, чем у пре-
дыдущей
32 Глава 1. Математическая статистика в клинических исследованиях
что тот или иной клинический показатель распределен по нормаль-
ному закону. Однако надо обратить внимание читателей на то, что
сходство реальных распределений различных медицинских показа-
телей с кривой нормального закона не является доказанным раз и
навсегда, поскольку оно обычно лишь приближенное. Окончатель-
ное заключение о конкретном законе распределения данной сово-
купности делается лишь на основании проверки специальных ста-
тистических тестов.
Кривая нормального распределения однозначно характеризуется
двумя величинами: М — математическим ожиданием (или арифме-
тическим средним) и а — средним квадратичным (или стандартным)
отклонением. Значения этих величин определяют положение кривой
в системе координат и ее форму. Так, максимум достигается в точке,
соответствующей среднему значению М\ среднее квадратичное откло-
нение определяет форму кривой: при большой вариабельности дан-
ных, то есть большом значении а, кривая будет более пологой, при
малой — крутой. Таким образом, количественный показатель эффек-
та, распределенный по нормальному закону N(M, а), может быть оха-
рактеризован средним значением М и средним квадратичным откло-
нением а (или дисперсией с2).
Последнее утверждение справедливо в предположении об исполь-
зовании в исследовании достаточно большого количества пациентов
или, говоря математическим языком, при сплошном изучении гене-
ральной совокупности. Однако в реальных условиях численность ис-
пытуемых ограничена и представляет выборку из генеральной сово-
купности, а значит, точные значения М и а неизвестны. Количество
объектов в выборке (число пациентов в исследовании) называется
объемом выборки и обозначается п. При анализе данных клинических
исследований обычно приходится иметь дело с выборками ограни-
ченного объема. Известно, что правильно отобранная часть генераль-
ной совокупности довольно хорошо отображает структуру этой сово-
купности, но полного совпадения выборочных показателей с харак-
теристиками генеральной совокупности, как правило, не бывает.
Выборочные характеристики являются лишь приближенными оцен-
ками генеральных параметров. Это — случайные величины, их оцен-
ки могут быть точечными и интервальными.
Выборочное среднее X и выборочное среднее квадратичное (или
стандартное) отклонение Sx, являющиеся точечными оценками со-
ответствующих параметров М и о генеральной совокупности, вычис-
ляются по следующим формулам:
1.7. Статистический анализ результатов клинических исследований 33
x=J[^i, (2)
V п-\
где xi — /-значение оцениваемого признака, п — объем выборки, X —
знак суммирования по всем элементам выборки (/ =1, ..., п).
Dx = Sx2 — выборочная дисперсия признака. (4)
Величину отклонения выборочного показателя (статистики) от его
генерального параметра называют статистической ошибкой. Для из-
мерения этой ошибки некоторой статистики служат дисперсия или
квадратичная (стандартная) ошибка статистики (нельзя путать соот-
ветственно с выборочными дисперсией и средним квадратичным от-
клонением изучаемой случайной переменной). Так, стандартная
ошибка среднего арифметического ох может быть найдена по формуле:
Sx
crx = -f=- (5)
Л/И
На практике достаточно часто приходится сравнивать изменчи-
вость признаков, выраженных разными единицами. В этих случаях
используют относительные показатели вариации, например коэффи-
циент вариации CV. Этот показатель представляет собой среднее квад-
ратичное отклонение, выраженное в процентах от величины средне-
го арифметического:
CV=100%-=. (6)
л.
Этот показатель также является выборочным, и его ошибка может
быть оценена по формуле:
*СУ = СУ^5 + 0>™1СУ2. (7)
Обычно варьирование признака считается средним, если величи-
на коэффициента вариации находится в пределах от 10 до 25%.
По известным точечным выборочным характеристикам можно по-
строить интервальную оценку, или доверительный интервал, в котором
с той или иной вероятностью находится значение генерального пара-
метра. Вероятности, признанные достаточными для уверенного суж-
дения о генеральных параметрах на основании известных выбороч-
34 Глава 1. Математическая статистика в клинических исследованиях
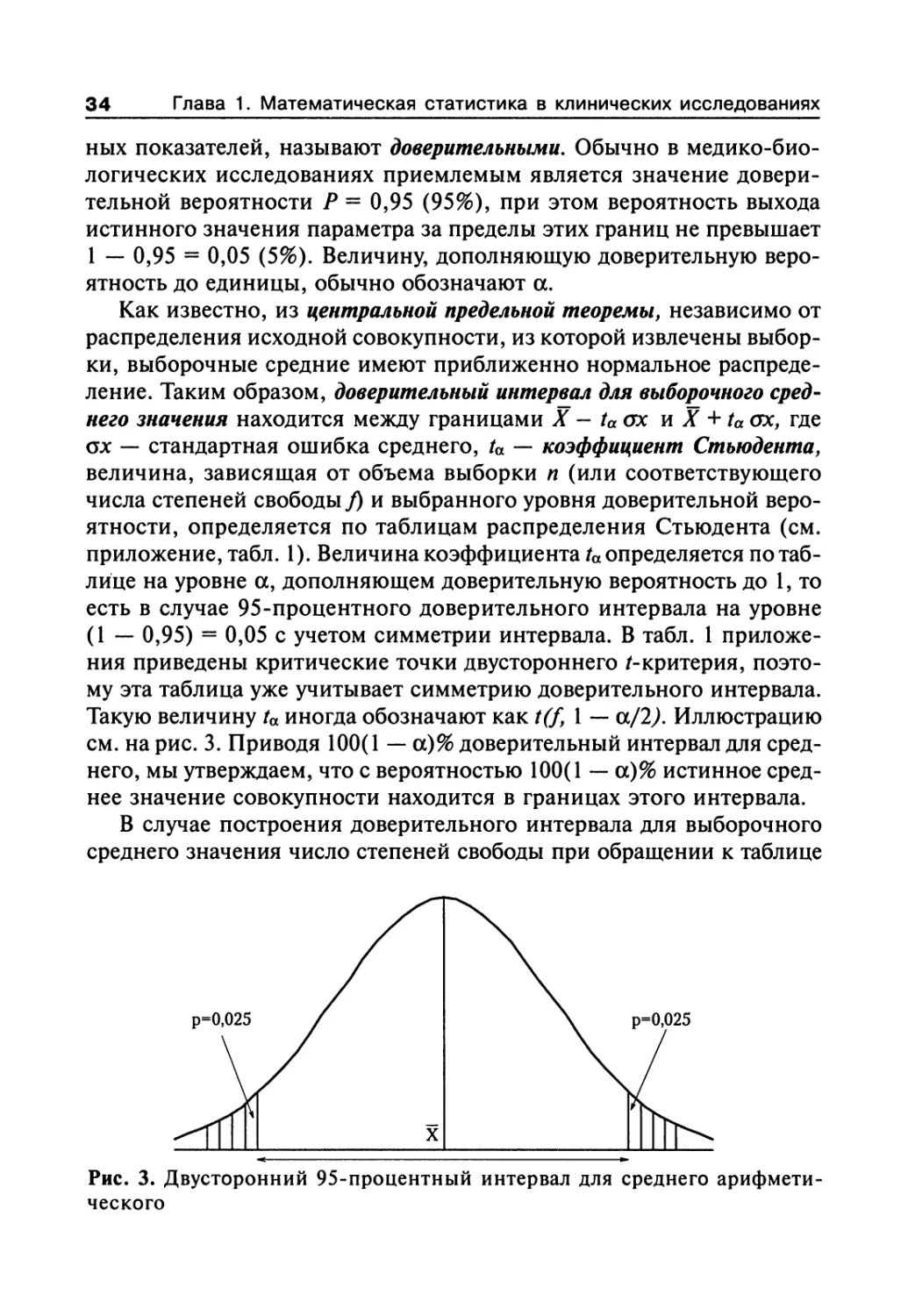
ных показателей, называют доверительными. Обычно в медико-био-
логических исследованиях приемлемым является значение довери-
тельной вероятности Р = 0,95 (95%), при этом вероятность выхода
истинного значения параметра за пределы этих границ не превышает
1 — 0,95 = 0,05 (5%). Величину, дополняющую доверительную веро-
ятность до единицы, обычно обозначают а.
Как известно, из центральной предельной теоремы, независимо от
распределения исходной совокупности, из которой извлечены выбор-
ки, выборочные средние имеют приближенно нормальное распреде-
ление. Таким образом, доверительный интервал для выборочного сред-
него значения находится между границами X — ta ох и X + ta ох, где
ох — стандартная ошибка среднего, ta — коэффициент Стьюдента,
величина, зависящая от объема выборки п (или соответствующего
числа степеней свободы./) и выбранного уровня доверительной веро-
ятности, определяется по таблицам распределения Стьюдента (см.
приложение, табл. 1). Величина коэффициента /а определяется по таб-
лице на уровне а, дополняющем доверительную вероятность до 1, то
есть в случае 95-процентного доверительного интервала на уровне
(1 — 0,95) = 0,05 с учетом симметрии интервала. В табл. 1 приложе-
ния приведены критические точки двустороннего /-критерия, поэто-
му эта таблица уже учитывает симметрию доверительного интервала.
Такую величину /а иногда обозначают как t(ft 1 — ос/2,). Иллюстрацию
см. на рис. 3. Приводя 100(1 — а)% доверительный интервал для сред-
него, мы утверждаем, что с вероятностью 100(1 — ос)% истинное сред-
нее значение совокупности находится в границах этого интервала.
В случае построения доверительного интервала для выборочного
среднего значения число степеней свободы при обращении к таблице
р=0,025
1 Х
р=0,025
Рис. 3. Двусторонний 95-процентный интервал для среднего арифмети-
ческого
1.7. Статистический анализ результатов клинических исследований 35
Стьюдента вычисляется как/= п — 1. Надо обратить внимание, что в
некоторых руководствах по биометрии предлагается при построении
доверительного интервала для генерального среднего в качестве зна-
чений коэффициента ta брать критические значения стандартного
нормального распределения Za (см. приложение, табл. 7) или, други-
ми словами, предельные значения распределения Стьюдента (см. при-
ложение, табл. 1, для числа степеней свободы, равного бесконечнос-
ти). Тогда наиболее часто используемым доверительным вероятностям
соответствуют следующие табличные значения коэффициента: для зна-
чения />, = 0,95 z = 1,96; для Р2 = 0,99 z = 2,58; для Р3 = 0,999 z = 3,29.
Однако такой метод применим только в том случае, если дисперсия
изучаемой совокупности известна заранее. В случае неизвестной и
оцененной по выборке дисперсии и при малом объеме выборки для
построения доверительного интервала нужно пользоваться коэффи-
циентом Стьюдента с учетом числа степеней свободы.
При достаточно большом объеме выборки (п > 30,) получается, что
истинное среднее значение при уровне вероятности Р = 0,95 нахо-
дится в пределах Л" ±2 ах.
Пример 1. Практическое применение предлагаемых теоретических
положений мы проиллюстрируем на примерах. Мы не будем приво-
дить результаты реальных клинических исследований, а для просто-
ты восприятия возьмем вымышленные примеры, чтобы у читателя
была возможность провести необходимые преобразования самостоя-
тельно, с помощью обычного калькулятора.
Так, допустим, в ходе исследований изучали влияние препарата А
на содержание вещества В (в ммоль/г) в ткани С и концентрацию ве-
щества D в крови (в ммоль/л) у пациентов, разделенных по какому-
то признаку Е на 3 группы равного объема (п = 10,). Мы выбрали та-
кой пример не случайно, в дальнейшем он будет использоваться для
расчетов корреляции и применения различных статистических тестов
при сравнении групп. Результаты такого выдуманного исследования
приведены в табл. 2. Хотим предупредить читателей, что выборки объе-
ма 10 рассматриваются нами для простоты представления данных и
вычислений, на практике такого объема выборок обычно оказыва-
ется недостаточно для формирования статистического заключения.
В качестве примера для расчета рассмотрим данные 1-го столбца
табл. 2. Выборочное среднее вычисляется по формуле:
Х =
10
= 13,1.
36 Глава 1. Математическая статистика в клинических исследованиях
Выборочная дисперсия данного показателя равна Dx = 3,2; сред-
нее квадратичное отклонение Sx = 4Dx = ^/ЗД = 1,79.
1 7Q
Су = iiiZ..iOO% = 13,7%; ошибка коэффициента вариации аСК=3,12;
13,1 179
Ошибка выборочного среднего ах = -h= = 0,57.
Таблица 2.
Результаты гипотетического клинического исследования
Содержание вещества В,
ммоль/г
группа 1
12
13
14
15
14
13
13
10
11
16
группа 2
8
8
9
10
7
7
9
9
И
6
группа 3
8
9
9
11
12
12
13
13
12
И
Вещество D, ммоль/л
исходное содержание
в крови
группа 1
0,7
1,4
1,8
1,5
1,1
1,6
1,7
1,3
1,4
2,2
группа 2
0,8
0,9
2,5
1,2
1,3
1,5
1,6
2,1
2,0
1,0
группа 3
0,8
0,9
2,3
2,0
1,4
1,6
1,3
1,7
1,5
1,6
прирост
концентрации
группа 2
4
5
4
3,5
5
5
3,5
4
2
5
группа 3
4
3
3,5
2
1
1,5
1
1,5
2
2
Коэффициент Стьюдента / в данном случае для числа степеней
свободы/= 10 — 1 = 9 и уровня доверительной вероятности 95% ра-
вен 2,26 (см. приложение, табл. 1), 95-процентный доверительный
интервал для среднего заключен между границами 13,1 ± 2,26 • 0,57.
Таким образом, левая граница интервала равна 11,81, а правая— 14,39.
Обычно при анализе результатов контролируемых клинических ис-
следований средние значения вычисляются для сопоставления их с
показателями группы контроля, на основе такого сравнения делают-
ся определенные выводы, ради которых и проводятся исследования.
Если исследователь просто сопоставляет средние значения, рассчи-
танные по малым выборкам, без учета их случайной природы, возни-
кает реальная опасность ошибочных заключений. Необходимо иметь
в виду, что разность средних арифметических двух выборок, каждая
из которых имеет свою ошибку, также является случайной величиной
1.7. Статистический анализ результатов клинических исследований 37
со своей стандартной ошибкой. Сопоставление выборочных средних
арифметических, рассчитанных на основе ограниченного количества
наблюдений, позволяет оценить лишь доверительные границы, в пре-
делах которых при данном уровне значимости находится разность
истинных средних значений. Такие сопоставления методами матема-
тической статистики требуют проверки гипотезы о равенстве средних
значений выборок.
1.7.2. Статистические гипотезы и их проверка
О преимуществе той или иной из сравниваемых групп судят обыч-
но по разности между средними значениями, долями или другими
выборочными показателями — величинами случайными и являю-
щимися статистическими оценками соответствующих генеральных
показателей. Вопрос о достоверности различий решается обычно на
основе проверки по выборочным характеристикам той или иной ста-
тистической гипотезы.
В области клинических исследований широкое применение полу-
чила так называемая нулевая гипотеза Н0. Смысл ее сводится к пред-
положению, что разница между генеральными параметрами сравни-
ваемых групп равна нулю и различия, наблюдаемые между выбороч-
ными характеристиками, носят исключительно случайный характер.
Так, например, если одна выборка извлечена из нормально распреде-
ленной генеральной совокупности с параметрами М\ и ol, а другая —
из совокупности с параметрами Л/2 и а2, то нулевая гипотеза состоит
в том, что Л/1 = Л/2, то есть Л/1 — Л/2 = 0. Противоположная нулевой
альтернативная гипотеза состоит в том, что средние считаются либо
просто неравными Л/1 — Ml *0 (двусторонний тест), либо исследо-
ватель ориентирован в направлении преимущества одного метода над
другим, а возможность преимущества другого исключается, напри-
мер Л/1 > Л/2 (односторонний тест). При таком подходе не ставится
задача количественной оценки имеющихся различий, достаточно
лишь проверить, принадлежат ли обе группы с определенной вероят-
ностью к различным генеральным совокупностям. Надо заметить, что
при решении других статистических задач нулевая гипотеза будет
иметь другую формулировку.
Проверяется статистическая гипотеза с помощью величин или,
другими словами, статистик, функции распределения которых из-
вестны и табулированы (например, /-распределение Стьюдента, рас-
пределение х2 и ДР-)- Эти величины в каждом конкретном случае
38 Глава 1. Математическая статистика в клинических исследованиях
позволяют проверить, подтверждают/опровергают ли выборочные по-
казатели выдвинутую гипотезу. Процедура проверки гипотезы связа-
на с объемом выборки (или соответствующим числом степеней свобо-
ды f) и уровнем значимости а. Уровень значимости, или вероятность
ошибки I рода, допускаемой при оценке принятой гипотезы, может
различаться (5; 1; 0,1%), но в медико-биологических приложениях,
если специально не оговорено другое значение, он обычно принима-
ется равным 5%. Если результаты значимы на уровне 1—5%, обычно
говорят о наличии статистической значимости, на уровне меньше 1% —
о высокой статистической значимости.
С уровнем значимости связана величина, называемая степенью
недоверия к нулевой гипотезе. Она представляет собой величину, до-
полняющую уровень значимости до единицы (\ — а). Близкий к нулю
уровень значимости, а значит, близкая к единице степень недоверия
интерпретируются как сильный довод против нулевой гипотезы. Близ-
кий к единице уровень значимости показывает, что степень недове-
рия близка к нулю, то есть доводы против Н0 слабы, что указывает на
согласие имеющихся данных с нулевой гипотезой.
Важным является также вопрос о справедливости нулевой гипоте-
зы. Для оценки справедливости Н0 рассчитывается р-значение. Можно
сказать, что оно оценивает вероятность при многократном повторе-
нии исследования получения такого же или еще более экстремально-
го значения критерия при условии справедливости нулевой гипоте-
зы, то есть при отсутствии различий между сравниваемыми группа-
ми. Если в результате проверки нулевой гипотезы она была отвергнута
на уровне значимости а, то для отражения наличия статистически
значимых различий результат сравнения может быть записан в виде
р < ос. Это означает, что при справедливости нулевой гипотезы ошиб-
ка сравнения возможна не более чем в а • 100% случаев, а значит, ма-
ловероятна. Однако часто используемая запись вида/? < 0,05 означает
лишь то, что уровень значимости результатов — не более чем 5%. Го-
раздо больше информации о степени значимости будет заключаться,
например, в записи двойного неравенства 0,01 < р < 0,05.
Р-значение может задаваться не только неравенством. Его значе-
ние можно рассчитать точно, и эта процедура является в некотором
смысле обратной обычной процедуре проверки гипотезы. Для этого
рассчитывается величина тестовой статистики, а затем, например по
относящимся к данному критерию таблицам (или в результате под-
становки значения статистики критерия в ее функцию распределе-
ния), определяется уровень вероятности, соответствующий оценен-
1.7. Статистический анализ результатов клинических исследований 39
ному значению тестовой статистики. При такой процедуре, прини-
мая решение отвергнуть (принять) гипотезу Н0, мы указываем точное
значение уровня, равное /^-значению, на котором происходит откло-
нение (принятие) нулевой гипотезы. Указание точного /^-значения
является более информативным, чем оформление результатов про-
верки гипотезы в виде неравенства типа р < а.
Как мы сказали, чаще всего в области клинических исследований
проверяются гипотезы о статистической значимости различий, од-
нако нужно иметь в виду, что в статистике существуют и иные вари-
анты, например гипотезы о согласии (или форме) распределений,
гипотезы о значимости корреляции, гипотезы о величине парамет-
ров распределения и т. п. Независимо от конкретной формулировки
гипотезы можно дать краткое описание типичных этапов процедуры
проверки статистических гипотез. Следующие действия лежат в ос-
нове всех статистических проверок:
• выбрать уровень значимости а;
• сформулировать нулевую гипотезу (обычно как заключение, ко-
торое хотелось бы отвергнуть) Н0 и обязательно соответствую-
щую ей альтернативную гипотезу НА;
• выбрать тестовую статистику или, другими словами, подходящий
критерий для проверки сформулированной гипотезы;
• вычислить значение тестовой статистики по имеющимся данным;
• определить с помощью распределения тестовой статистики или
обычно по имеющимся таблицам ее распределения критическую
область, вероятность попадания в которую при справедливости
нулевой гипотезы равна а;
• сделать вывод, сравнив рассчитанное значение статистики с выб-
ранным критическим значением, — если полученное значение
статистики лежит в критической области, то следует отклонить
нулевую гипотезу и принять альтернативную; в противном слу-
чае принимается нулевая гипотеза.
При этом важна правильная интерпретация полученных результа-
тов проверки гипотезы. То, что значение критерия получилось незна-
чимым, не является строгим доказательством справедливости нуле-
вой гипотезы. Это означает лишь, что имеющиеся данные ей не про-
тиворечат. Нельзя забывать, что, проверяя статистическую гипотезу,
мы имеем дело лишь с ограниченной выборкой из генеральной со-
вокупности. Поэтому все выводы, делаемые при проверке статис-
тических гипотез, носят вероятностный характер. Вот почему уров-
ни вероятности ошибок I и II рода имеют такое большое значение
40 Глава 1. Математическая статистика в клинических исследованиях
для этой процедуры. Вопросы выбора уровня ошибок I и II рода, оп-
ределения чувствительности критерия, необходимого числа паци-
ентов для получения статистически значимого заключения будут
рассмотрены нами в разделе «Некоторые вопросы планирования ис-
следования».
Для проверки гипотез в биометрии возможны 2 вида критериев:
параметрические (построенные на основании параметров данной со-
вокупности) и непараметрические (построенные непосредственно по
вариантам данной совокупности и их частотам). Первые служат для
проверки гипотез о параметрах совокупности, распределенных по
известному закону (обычно в биометрии по нормальному закону),
вторые — для проверки гипотез независимо от формы распределе-
ния совокупностей. Так, при нормальном распределении признака па-
раметрические критерии обладают большей мощностью, чем непа-
раметрические, поэтому, если известно, что сравниваемые выборки
извлечены из нормально распределенных совокупностей, предпоч-
тение следует отдавать параметрическим критериям. В случае значи-
мых отличий распределения признака от нормального закона, при
малых объемах выборки, а также для анализа порядковых данных ре-
комендуется применять непараметрические критерии. Если варьиру-
ющие признаки выражаются не числами, а условными знаками, при-
менение непараметрических критериев оказывается единственно воз-
можным. Проверить, извлечена ли рассматриваемая выборка из
нормально распределенной совокупности, в свою очередь, можно с
помощью специальных статистических тестов. Коротко познакомим
с некоторыми из них.
1.7.3. Проверка гипотезы о законах распределения
Гипотезу о законе распределения проверяют разными способами,
например с помощью коэффициентов асимметрии и эксцесса. Для
вычисления этих показателей используется понятие момента гене-
ральной совокупности, множество таких моментов связано со слу-
чайной переменной и ее распределением вероятностей. Различают
моменты относительно начала отсчета и центральные моменты
относительно среднего значения. Моментом первого порядка от-
носительно начала отсчета является математическое ожидание,
или среднее значение случайной величины, центральным моментом
второго порядка является дисперсия (один из вариантов расчета
дисперсии предполагает деление на п, а не на п - 1). Выборочное
1.7. Статистический анализ результатов клинических исследований 41
1 п
значение момента порядка к рассчитывается по формуле: т\ = — ^Г jcf»
а выборочный центральный момент fc-порядка рассчитывается по
формуле: j »
m* = ^2/*,-*) для/: =1,2,...
i=i
Кроме того, известны формулы, связывающие моменты выборки от-
носительно среднего и относительно начала отсчета:
т2-т\-Х ;
тз=тз"3 -т\-Х + 2-Х ;
m4=m4-4m'3X +6-/п'2-Х2-3-Х4 ит.д. (8)
На практике моменты выше четвертого порядка используются редко.
Для симметричных распределений (нормальное распределение яв-
ляется симметричным) все центральные моменты нечетного порядка
равны нулю, они положительны, если распределение асимметрично
и имеет длинный «хвост» справа от среднего значения, и, соответ-
ственно, отрицательны, если распределение имеет такой «хвост» сле-
ва. Мерой асимметрии распределения является коэффициент асим-
метрии, который вычисляется по формуле:
Ajc = w/3/. (9)
Для симметричных распределений такой показатель будет близок
к 0, при правосторонней скошенности показатель будет иметь поло-
жительный знак, а при скошенности влево — отрицательный.
Кроме того, полезным может оказаться и другой показатель, рас-
считываемый на основе моментов и называемый коэффициентом
эксцесса:
Яс = ^-3. (10)
щ
Для нормального распределения эксцесс равен 0. О кривых плот-
ности, для которых показатель эксцесса равен 0, говорят, что они
имеют нормальный эксцесс. Если коэффициент больше нуля, гово-
рят о положительном эксцессе, если меньше нуля — об отрицатель-
ном. Считалось, что знак коэффициента свидетельствует о форме
кривой распределения (положительный знак — более острая верши-
на, отрицательный — более пологая форма по сравнению с нормаль-
ным распределением). Однако это утверждение выполняется не все-
42 Глава 1. Математическая статистика в клинических исследованиях
гда [7], тем не менее эта характеристика распределения достаточно
полезна в практических приложениях. Далее мы приведем формулу
распределения Шарлье, в которой используются коэффициенты асим-
метрии и эксцесса для конструирования формы кривых, аппрокси-
мирующих «искаженное» нормальное распределение.
При нормальном распределении показатели асимметрии и эксцес-
са должны быть близки к нулю. Однако на практике точное равен-
ство нулю почти не встречается, так как эти показатели оценены по
выборке; они также являются случайными величинами, имеющими
ошибки. Поэтому для проверки нормальности распределения реко-
мендуется использовать соответствующие таблицы, в которых указа-
ны критические точки для этих коэффициентов при различных уров-
нях значимости и объемах выборки п [9]. Если рассчитанные значе-
ния для асимметрии и эксцесса превосходят эти критические точки,
гипотеза о нормальности распределения отвергается. Методы провер-
ки нормального характера распределения по асимметрии, эксцессу и
средним отклонениям рассматриваются также в [1].
На практике для проверки нормальности распределения чаще всего
используется критерий х2- Рассмотрим схему проверки данного кри-
терия. Для проведения расчетов по этому критерию нужно уметь стро-
ить выборочное распределение случайной величины. Для этого по-
лученные в ходе исследования результаты нужно представить в виде
вариационного ряда, или ряда распределения. Вариационный ряд пред-
ставляет собой двойной ряд чисел, показывающий для каждого зна-
чения признака (варианты), сколько раз оно (она) встречается в дан-
ной совокупности (частота варианты). Это определение в большей мере
относится к так называемому безынтервальному вариационному ряду.
Однако, если общую вариацию признака (в пределах от минималь-
ной до максимальной варианты) разбить на промежутки (классы) и
подсчитать частоту попадания вариант данной совокупности в эти
интервалы, получится интервальный вариационный ряд. Графически
вариационные ряды могут быть представлены в виде полигонов рас-
пределения для безынтервальных рядов и гистограмм распределения
частот для интервальных рядов.
Данный критерий согласия эффективен при условии наличия не
менее 50 элементов в выборке. В учебниках часто говорится, что для
успешного применения критерия %2 наименьшая частота в интерва-
лах вариационного ряда должна быть равна 5. Если же в каком-ни-
будь интервале вариационного ряда содержится менее 5 частот, то этот
класс рекомендуют объединять с соседним классом. Однако, соглас-
1.7. Статистический анализ результатов клинических исследований 43
но обстоятельным исследованиям У. Кокрена, такое условие являет-
ся чрезмерно ограничительным, и для широко используемых распре-
делений достаточно требовать, чтобы частоты были не меньше 1.
Общая формула этого критерия выглядит как:
i=l Jt
где к — число классов,/^ — фактические частоты, оцененные по изу-
чаемой выборке,^ — частоты, рассчитанные по теоретическому рас-
пределению (рис. 4). А нулевая гипотеза в данном случае состоит в
предположении, что различия между наблюдаемыми и теоретически-
ми частотами носят исключительно случайный характер.
Надо предупредить, что критерий согласия %2 может применять-
ся для проверки соответствия выборочного распределения любому
теоретическому, а не только нормальному распределению. Можно
даже сказать, что этот критерий определяет меру расхождения меж-
ду данными и моделью, выбранной для их описания. Для оценки по-
лученной величины х2 необходимо знать число степеней свободы,
которое как раз и зависит от того, какой тип теоретического распре-
деления участвует в расчетах. Так, при нормальном распределении
число степеней свободы / = к — 3, где к — число интервалов ряда.
14
12
10
8
6
4
2
0
-1,75 -1,25 -0,75 -0,25 0,25 0,75 1,25 1,75
Рис. 4. Общий вид гистограммы распределения теоретических и выбо-
рочных частот для проверки критерия согласия х2 ° законе распределе-
ния. По оси абсцисс — классы вариационного ряда; по оси ординат —
частоты попадания значений переменной в соответствующие классы. Тем-
ные столбики — теоретическое нормальное распределение частот, свет-
лые — выборочное
44 Глава 1. Математическая статистика в клинических исследованиях
Вычисленное значение %2 не должно превышать табличное (см. при-
ложение, табл. 2) при данных значениях/и а, тогда мы имеем право
сделать вывод о несущественном различии теоретического и эмпи-
рического распределений. При полном совпадении эмпирических
частот с вычисленными значение статистики %2 было бы равно 0.
Процедура расчета критерия %2 в случае проверки гипотезы о нор-
мальном распределении совокупности рассмотрена нами в следую-
щем примере. Более подробно с различными тестами для проверки
гипотез о законе распределения можно ознакомиться, например, в
[7,9,13,14,19].
Пример 2. Проиллюстрируем применение критерия согласия £2 для
проверки нормального закона распределения. Для этого будем ис-
пользовать данные столбцов 4—6 табл. 2 (исходное содержание ве-
щества D в крови). Данные этих трех столбцов могут быть объедине-
ны в одну обобщенную выборку, поскольку в нашем примере счита-
ем, что до начала терапии все пациенты составляли однородную
популяцию. Таким образом, мы получаем выборку объемом п = 30 и
хотим проверить, является ли она выборкой из генеральной совокуп-
ности, распределенной по нормальному закону. Среднее значение
нашей выборки равно 1,49, а среднее квадратичное отклонение — 0,46.
Ранжируя обобщенную выборку в порядке возрастания, видим, что
значения изучаемого показателя варьируют от 0,7 до 2,5. Построим
интервальный вариационный ряд: диапазон значений данного пока-
зателя (0,5; 2,5) разобьем на интервалы длиной 0,5 (получим 4 интер-
вала) и определим частоту попадания вариант нашей выборки в соот-
ветствующие интервалы (см. табл. 3, столбцы 1—2). Поскольку табу-
лировано (см. приложение, табл. 10) распределение нормальной
случайной величины с нулевым математическим ожиданием и еди-
ничной дисперсией (стандартная нормальная переменная), проводим
стандартизацию нашей переменной Xi (вычитаем среднее значение
из величин Xi, делим результат на среднее квадратичное отклонение),
полученное значение заносим в 3-й столбец табл. 3. По табл. 10 для
значений стандартизованной переменной определяем соответствую-
щие ординаты кривой нормального распределения (столбец 4). Тео-
ретические частоты нормального распределения (столбец 5) получа-
ем, умножая ординаты нормальной кривой из столбца 4 на произве-
дение объема выборки (30) и ширины интервала (0,5), а затем поделив
результат на среднее квадратичное отклонение (0,46). Надо заметить,
что это достаточно удобный, но не единственный способ расчета те-
оретических частот нормального распределения.
1.7. Статистический анализ результатов клинических исследований 45
Таблица 3.
Таблица расчетов для проверки критерия согласия х2
Центр
интервала XI
0,75
1,25
1,75
2,25
Фактическая
частота
6
11
9
4
Стандартизо-
ванная
переменная
-1,61
-0,52
0,57
1,65
Ординаты
нормальной
кривой
0,1092
0,3485
0,3391
0,1023
Теоретическая
частота
3,7
11,5
11,2
3,5
На рис. 5 показаны распределения теоретических и фактических
частот. Каждое слагаемое для критерия согласия %2 представляет со-
бой разницу между соответствующими фактическими и теоретичес-
кими частотами, возведенную в квадрат и деленную на значение тео-
ретической частоты, в нашем примере критерий %2 = 1,95. Надо заме-
тить, что данный критерий является чувствительным к точности
вычислений, поэтому для оценки статистики %2 нужно пользоваться
рассчитанными значениями теоретических частот без предваритель-
14
12
10
8
6
4
2
0
0,75 1,25 1,75 2,25
Исходное вещество D, ммоль/л
Рис. 5. Распределение фактических и теоретических частот для примера
использования критерия согласия. По оси абсцисс — исходное содержа-
ние вещества D в крови, ммоль/л (классы); по оси ординат — частоты
распределения. Светлые столбцы — выборочное распределение; темные —
теоретическое нормальное распределение
5
Он
с
о
Л
сх
3
н
о
н
о
л
46 Глава 1. Математическая статистика в клинических исследованиях
ного округления. В данном случае выборочное и теоретическое рас-
пределения различаются несущественно, так как рассчитанная вели-
чина статистики %2 не превышает табличного значения 3,84 (см. при-
ложение, табл. 2), взятое для числа степеней свободы /= 4-3=1
и уровня значимости а = 5%. Таким образом, существуют достаточные
основания для утверждения, что наша выборка извлечена из совокуп-
ности, распределенной по нормальному закону. Считается, что для про-
верки распределения по критерию %2 выборка должна содержать менее
50 элементов. В данном случае мы использовали выборку меньшего
объема только для простоты и уменьшения необходимых вычислений.
1.7.4. Первичная обработка результатов
Построение рядов распределения — один из возможных способов
описания полученных данных. А среднее арифметическое и диспер-
сия — одни из основных характеристик варьирующих объектов. Од-
нако надо иметь в виду, что эти характеристики не являются универ-
сальными; для статистического описания данных в качестве обобща-
ющих характеристик совокупности полезными (особенно если
совокупность не распределена по нормальному закону) могут оказать-
ся и так называемые структурные показатели. На практике часто ис-
пользуют такие структурные показатели, как медиана, мода, кванти-
ли (квартили, децили, перцентили), минимальное значение, максималь-
ное точение, размах вариации и другие (рис. 6). Подробнее об этом
можно прочитать в [1, 9, 14, 19, 20].
Размах
Мода Медиана Среднее
Рис. 6. Основные структурные показатели распределения
Значение
переменной
1.7. Статистический анализ результатов клинических исследований 47
Так, медиана определяется как средняя, относительно которой ряд
распределения делится на 2 равные части: в обе стороны от медианы
располагается одинаковое число вариант. Для ранжированного ряда с
нечетным числом членов центральная варианта и будет его медианой.
При четном числе членов ряда медиана определяется по полусумме двух
соседних вариант, расположенных в центре ранжированного ряда.
Еще одна структурная характеристика — мода. Так называется ве-
личина, наиболее часто встречающаяся в данной совокупности. В слу-
чае нормального распределения значения средней арифметической,
медианы и моды совпадают.
Квантили — конкретная варианта совокупности, отсекающая в
пределах вариационного ряда определенную часть (указывается в про-
центах) его членов. На практике используются обычно перцентили
Р3, Р10, Р25, Р50, Р75, Р90 и Р97. Причем Р25 и Р75 соответствуют первому
и третьему квартилям, между которыми содержится 50% элементов
выборки, а Р50 равен медиане. Формулы для расчета моды и кванти-
лей для интервальных вариационных рядов содержатся, например,
в [9, 19, 20].
Размах вариации равен разности между максимальным и мини-
мальным вариантами совокупности.
Расположение некоторых характеристик гипотетического распре-
деления показано на рис. 6.
При первичной обработке данных часто возникает ситуация —
отдельные варианты полученной в исследовании выборки по своим
значениям сильно отличаются от остальных ее членов. Возможно,
это произошло из-за погрешностей измерений или погрешностей в
организации самого исследования, тогда эта сомнительная вариан-
та должна быть исключена. Однако делать это только по желанию
исследователя недопустимо, поскольку возможно, что эта варианта
на самом деле принадлежит изучаемой совокупности. Вопрос о та-
ком исключении может быть решен только на основе проверки спе-
циальных статистических критериев [1,9, 13, 19]. Одним из наиболее
простых непараметрических критериев является проверка разно-
стей между сомнительными и соседними членами ранжированно-
го ряда для переменной Х[9, 13]. Для этого вычисляются статистики
Х>у ~ Х% Х„ ~ Х„ 1
h = Y 2 ' или f2=-* з±.
лп-\ л\ Хп ~ Х2
Первая для проверки наименьших хх, вторая — для наибольших хп со-
мнительных вариант ранжированного ряда. Гипотезу о принадлежно-
48 Глава 1. Математическая статистика в клинических исследованиях
сти сомнительной варианты изучаемой совокупности отвергают, если
соответствующее рассчитанное значение статистики превзойдет таб-
личное (см. приложение, табл. 3.1 и 3.2) для выбранного уровня зна-
чимости и объема выборки п.
Пример 3. Для оценки перцентилей рассмотрим выборку из при-
мера 1, ранжируем ее в порядке возрастания, получаем ряд: 10 11 12
13 13 13 14 14 15 16.
Медианой выборки (Р50) будет среднее значение 5-й и 6-й вариан-
ты, то есть она равна 13, мода также равна 13 (это значение встреча-
лось чаще других), Р25 оценим как 12, соответственно, Р75 можно оце-
нить как 14. В данном случае мы можем только оценить значения
квартилей, поскольку точно обеспечить разбиение порядковых ста-
тистик на 4 подмножества равного размера с помощью квартилей
(Р25, Р50, Р75) можно лишь в том случае, если объем выборки имеет вид
п = 4к + 3 (к — любое целое число). В этом случае квартилям соответ-
ствуют следующие варианты ранжированного ряда:
р _ у . р = у . р _. у
1 25 'Ч+Р 50 ^2к+2' х 75 ^Зк+З*
Максимальная варианта нашей выборки равна 16, а минималь-
ная — 10, размах равен 6. Статистические результаты опыта можно
записать в форме X ± Sx (Tmax + Xmm). Так, в нашем примере эта
запись будет_выглядеть как 13,1 ± 1,79 (10 ч-16). Иногда применяется
запись вида X± Sx (X — t • ex + X +1 • ox), то есть в скобках указывают
границы 95-процентного доверительного интервала для среднего ариф-
метического. В нашем случае получаем запись 13,1 ± 1,79(11,81 +14,39).
В тексте должно быть указано, какой именно вид записи результатов
используется в данном случае.
Допустим, что в данном примере в результате неконтролируемых
нарушений в ходе исследования вместо какого-то из значений (напри-
мер, последнего) было получено значение 6. Эта варианта является
сомнительной — ее значение существенно меньше остальных, про-
верим возможность ее исключения. Ранжированный вариационный
ряд в данном случае будет выглядеть как 6 10 И 12 13 13 13 14 14 15.
Рассчитаем для сомнительной варианты статистику tx\
и = = 0,5.
1 14-6
Критическое значение для статистики /, (уровень значимости ра-
вен 5% и п = 10) равно 0,41 (см. приложение, табл. 3.1), а значит, рас-
считанное значение критерия превосходит табличное. Нулевая гипо-
1.7. Статистический анализ результатов клинических исследований 49
теза о принадлежности сомнительной варианты рассматриваемой
выборке может быть отвергнута на выбранном уровне значимости, и
сомнительная варианта отбрасывается.
1.7.5. Закон распределения случайных величин
Выше, не давая точного определения, мы уже говорили о законе
распределения случайных величин, описывая часто встречающееся в
медицинских приложениях нормальное распределение. Однако хо-
телось бы еще раз подчеркнуть, что это отнюдь не единственный из-
вестный тип распределения. Кроме того, говоря о построении выбо-
рочной гистограммы распределения и проверке нормальности рас-
пределения с помощью критерия согласия, мы также затрагивали тему
построения выборочной плотности распределения случайной вели-
чины. Дадим теперь формальное определение.
Функция F(x), связывающая значения х. переменной случайной ве-
личины А" с их вероятностями р., называется законом распределения
(или функцией распределения) этой случайной величины. Таким обра-
зом, закон распределения, или, как его еще называют, интегральная
функция распределения, описывает распределение вероятностей слу-
чайной переменной X. Закон распределения можно задать в виде таб-
лицы, построить в виде графика или описать соответствующей фор-
мулой. Значение функции F(x) в точке х равно вероятности Р (Х< х)
того, что рассматриваемая случайная величина X принимает значе-
ния меньшие и равные данного значения х. Такая функция очень удоб-
на для наглядного и краткого представления распределения вероят-
ностей случайных переменных независимо от их характера. Интег-
ральная функция распределения соответствует экспериментальной
кривой накопления частот. Например, пусть некоторая случайная
величина X может принимать значения только на участке числовой
оси от х, до х2. Тогда вероятность того, что случайная величина при-
нимает значения меньше х1 или больше х2, равна нулю. Вероятность
того, что случайная величина принимает значения меньше или рав-
ные xv равна единице. А для всех значений х, принадлежащих отрез-
ку [х{, х2], функция F(x) представляет собой неубывающую функцию,
изменяющую свои значения от нуля до единицы.
С понятием закона распределения случайной величины неразрыв-
но связано понятие плотности распределения. Так, плотность распре-
деления непрерывной случайной величины можно представить себе
как предельную кривую р(х), которая будет аппроксимировать выбо-
50 Глава 1. Математическая статистика в клинических исследованиях
рочную гистограмму распределения данной случайной величины при
бесконечном увеличении объема выборки (рис. 7). Формально плот-
ность распределения р(х) является производной соответствующей
функции распределения F(x). Определим вероятность события, зак-
лючающегося в том, что одно случайно взятое наблюдение Л"попадет
в интервал [ха, хь], такая вероятность численно равна площади кри-
волинейной трапеции под кривой р(х) в интервале от ха до хь:
хЬ
Р{ха < X < xb}= jp(x)dx. (12)
ха
Поскольку функция распределения определяется как вероятность,
она может принимать значения в интервале от 0 до 1. Другое важное
свойство — интеграл плотности распределения, взятый по всей обла-
сти возможных значений (или, не ограничивая общности, интеграл
от — до + бесконечности), равен 1.
Р(х)
Рис. 7. Гистограмма и соответствующая предельная кривая плотности расп-
ределения
Соотношения между законом распределения F(x) и плотностью
распределения р(х) можно представить в виде следующей формулы:
X
F(x) = P{X<x}= jp(t)dt.
(13)
1.7. Статистический анализ результатов клинических исследований 51
С другой стороны, зная функцию F(x), можно определить вероят-
ность того, что случайная величина Л" принимает значения на любом
интересующем участке диапазона возможных значений. Так можно
оценить вероятность того, что случайная величина принимает значе-
ния в интервале [ха, xj:
P{xa<X<xb}=F(xb)-F(xa). (14)
Таким образом, по заданной плотности распределения можно од-
нозначно вычислить значение функции распределения для любого
действительного значения Хи наоборот. На рис. 8 показан общий вид
функции и плотности распределения случайной величины в дискрет-
ном и непрерывном случаях.
Так, в случае нормального закона распределения случайной вели-
чины с математическим ожиданием ^ и средним квадратичным от-
клонением о (обычно такая случайная величина обозначается Щ^,<5))
плотность распределения представляется следующей формулой:
р(х,^а)= . -exp\-{X~Y L для всех Н<оо. (15)
Из формулы видно, что закон нормального распределения пред-
ставляет собой зависимость между вероятностью и нормированным
отклонением t = (х — fy/a. Эта формула и иллюстрирует известное
утверждение, что нормальное распределение однозначно задается
средним значением и дисперсией. Нормальная кривая с параметрами
£ = 0 и о = 1 называется стандартизованной, или стандартной, плот-
ность ее распределения (стандартное нормальное распределение (N(0,1))
задается формулой:
Любую нормальную кривую можно привести к стандартному виду
вычитанием среднего значения из вариант Xi и делением полученной
разности на среднее квадратичное отклонение. Подобное преобразо-
вание пришлось проделывать при проверке нормальности распреде-
ления по критерию х2' Такое преобразование позволяет перейти к
стандартизованному распределению, ординаты которого табулирова-
ны (см. приложение, табл. 10). Стандартизованная плотность распре-
деления симметрична относительно 0, в точке X = 0 достигает макси-
мального значения. Вправо и влево от 0 случайная величина может
принимать любые значения, вероятность таких отклонений и описы-
52 Глава 1. Математическая статистика в клинических исследованиях
Р(Х-а)
1,0
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
IHtltUl
1 f I I I I I I I • L
♦ I I I I I I I I I 4
F(X)=P(X<a)
1,0
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
P(X)
1
0,9
0,8
0,7
0,6
0,5
0.4
0.3
0.2
0.1
0
F(x)
Щ
1 К N
им
IIIIILMIIIIIIIIRIIIIII
1
u,y
0.8
0./
O.b
O.b
0.4
0.3
0,2
0.1
Рис. 8. Плотность и соответствующая функция распределения вероятно-
стей; а — дискретный случай, б — непрерывный случай
1.7. Статистический анализ результатов клинических исследований 53
вается функцией стандартного нормального распределения, для удоб-
ства эта функция также табулирована во всех справочниках по мате-
матической статистике.
Как мы уже говорили, нормальное распределение играет очень
важную роль в статистике, однако оно не является единственным из-
вестным распределением. Так, при проверке статистических гипотез
часто используются еще 3 типа распределений, связанных с нормаль-
ным: распределение Фишера, или .F-распределение; распределение #2;
распределение Стьюдента, или /-распределение. Эти распределения
также табулированы, и соответствующие таблицы приведены в при-
ложении.
В табл. 4 мы приводим краткие сведения о некоторых других за-
конах распределения дискретных и непрерывных случайных вели-
чин, которые также могут встретиться в реальных приложениях.
Таблица 4.
Сведения о некоторых известных распределениях
Плотность распределения
1
Дискретная случайная ве-
личина — биномиальное рас-
пределение.
Формула Бернулли:
РЛт) = — *—рт(\-рГт>
т\{п-т)\
т = 0, ..., я.
Предельный случай биноми-
ального распределения —
формула Пуассона:
т
рп(т) = —гехР{-я}>Д s п' Р
/и = 0, 1, 2, ...
Комментарии
2
Схема Бернулли: случайное событие А в п
независимых испытаниях встретилось т раз,
р - вероятность появления события А в каж-
дом испытании. Формула Бернулли позво-
ляет оценить вероятность того, что среди п
взятых наугад элементов окажется т ожида-
емых. Данное распределение характеризует-
ся двумя параметрами: средним числом
ожидаемого результата \i-np (математичес-
кое ожидание) и дисперсией частоты собы-
тия А в п независимых испытаниях:
<т = Vя-Р-О-/*)
Случайная величина распределена по зако-
ну Пуассона, если она принимает счетное
множество возможных значений 0, 1, 2,... с
вероятностями Рп(т). Когда в схеме Бернул-
ли вероятность появления события А (вели-
чина р = сотые или тысячные доли едини-
цы), то есть доля успехов, очень мала, рас-
пределение частот таких редких событий в
п испытаниях становится несимметричным
54 Глава 1. Математическая статистика в клинических исследованиях
Продолжение табл. 4
1 1
Непрерывное распределе-
ние — равномерное распре-
деление на отрезке [0, 1]:
fl,0<jc<l;
*x) = t<U«[<U]
(рис. 9, а)
Непрерывное распределе-
ние — экспоненциальное
(показательное):
{Яе\р(-Ях),х>0
(рис. 9, б)
Непрерывное распределе-
ние — распределение Макс-
велла:
Величина / =х/а (рис. 9, в)
2
и обычно описывается формулой Пуассона.
Распределение характеризуется одним пара-
метром — средней величиной, равной а,
среднее квадратичное отклонение в данном
случае также равно а. Для такого распреде-
ления характерна высокая вариация. С ро-
стом значений а распределение стремится
к нормальному закону. Распределение Пу-
ассона является приемлемой моделью для
описания случайного числа появления оп-
ределенных событий в фиксированном про-
межутке времени
Можно распространить на случай отрезка
[а, Ь], тогда вероятность принимать значе-
ние в любой точке отрезка равна \/(Ь — а).
Математическое ожидание распределения
равно (Ь + а)/2, дисперсия равна (Ь — а)2/\2
X — параметр экспоненциального распреде-
ления. Математическое ожидание равно 1 /X,
дисперсия — \/Х2
Описывает асимметричные распределения.
В этой формуле параметр а равен среднему
арифметическому, умноженному на вели-
чину 0,6267. Характерным признаком рас-
пределения Максвелла является равенство
среднего квадратичного отклонения вели-
чине 0,674-д. Кривая распределения по
формуле напоминает нормальное распре-
деление, но начинается от нуля, круче под-
нимается со стороны малых значений слу-
чайной величины и затем, достигнув мак-
симума, более полого спускается в сторону
больших значений. Такое распределение
возникает, например, при построении рас-
1.7. Статистический анализ результатов клинических исследований 55
Окончание табл. 4
1
Непрерывное распределе-
ние — распределение Шарлье:
р(х)=р(х)-{Ах-р'"(х)}/6+
+{Ех-р""(х)}/24,
где р(х) — плотность нор-
мального распределения,
р'(х) обозначает производ-
ную соответствующего по-
рядка плотности нормаль-
ного распределения р(х),
Ах — асимметрия, Ех — эк-
сцесс (рис. 9, г)
Непрерывное распределе-
ние — гамма-распределение:
р(х) = ха~] exJ-~i//ma),jc>a
символ Т(а) обозначает гам-
ма-функцию, ее определение
по Эйлеру задается соотно-
шением:
Г(*)= Jexpf-O-f'-'A,
0
основные свойства гамма-
функции Г(х)\
Г(1) = 1, Г(х+ 1) = хГ(х)
(рис. 9, д)
2
пределения особей и популяции по их рас-
стояниям до оптимального фенотипа, кото-
рые обратно пропорциональны их феноти-
пической ценности
Описывает асимметричное распределение с
выраженным эксцессом, возникающее при
нарушении формы кривой, характерной для
нормального распределения. Такая кривая
распределения является асимметричной, ее
колоколообразная вершина — становится
или пикообразной, или трапециевидной. С
помощью распределения такого вида «кон-
струируется» нарушение нормальной формы
распределения
Двухпараметрическое распределение: a —
параметр формы; Р — параметр масштаба.
Математическое ожидание равно ар, дис-
персия задается соотношением: сф2, мода
равна (а—1)Р при а> 1. Является непрерыв-
ным аналогом отрицательного биномиаль-
ного распределения. При a = 1 гамма-рас-
пределение совпадает с показательным, при
a = п, р = 1//1-Ц гамма-распределение назы-
вается эрланговским распределением с па-
раметрами (п, \i) и описывает распределение
длительности интервала времени до появле-
ния п событий процесса Пуассона с пара-
метром |i
Кривые этих плотностей распределения приведены на рис. 9. Для каж-
дого типа распределения с помощью критерия %2 может быть прове-
рена гипотеза о том, что ваша выборка распределена именно по это-
му закону. Подробнее о законах распределения и проверке гипотез о
соответствии выборочных распределений теоретическим можно уз-
нать, например, в [1, 2, 7, 9, 13, 14, 19, 20].
56 Глава 1. Математическая статистика в клинических исследованиях
о(а-1)Р д о (а-1)р
Рис. 9. Различные виды распределений: а — плотность равномерного рас-
пределения на отрезке [а, Ь]; б — плотность показательного распределе-
ния; в — общий вид распределения Максвелла; г — общий вид распреде-
ления Шарлье: левосторонняя асимметрия, выраженный эксцесс; д —
плотность гамма-распределения при различных значениях параметров
1.7. Статистический анализ результатов клинических исследований 57
1.7.6. Параметрические критерии
для проверки гипотезы о различии
(или сходстве) между средними значениями
Итак, если ваши выборки имеют нормальное распределение, для
проверки статистических гипотез на их основе можно пользоваться
параметрическими критериями. Наиболее распространенным пара-
метрическим методом оценки различий между сравниваемыми сред-
ними значениями независимых выборок является критерий Стьюден-
та, или t-критерий. Нулевая гипотеза заключается в равенстве гене-
ральных средних Ml и Ml (Ml — Ml) = 0 совокупностей, из которых
извлечены выборки, или, другими словами, проверяется нулевая ги-
потеза о принадлежности двух сравниваемых выборок одной и той
же генеральной совокупности. Проверяемый /-критерий выражается
в виде отношения разности соответствующих выборочных средних к
ошибке такой разности, то есть:
,|=Х1-Х2 или |,|= **-*2 , (17)
11 cd " Va*l2+a*22
где cd — стандартная ошибка разности выборочных средних значе-
ний, cxl, cxl — стандартные ошибки средних значений сравнивае-
мых выборок. Надо обратить внимание, что дисперсия разности (так
же, как и дисперсия суммы) двух средних значений равна сумме дис-
персий этих средних значений.
Для проверки критерия знак разности средних значений не играет
роли, поэтому в формуле для расчета тестовой статистики берется
модуль разности. Однако знак разности важен для интерпретации
результатов сравнения и заключения о преимуществе одного из срав-
ниваемых методов. В дальнейшем при сравнении параметров в фор-
мулах для тестовых статистик мы будем опускать знак модуля.
Гипотезу о равенстве математических ожиданий отвергают, если
фактически полученная величина /-критерия превзойдет или окажется
равной табличному значению (распределение Стьюдента, приложе-
ние, табл. 1) для принятого уровня значимости и числа степеней сво-
боды/. При этом делается заключение о наличии статистически зна-
чимых различий между средними значениями на соответствующем
уровне значимости.
Формулы для расчета тестовой статистики t и числа степеней сво-
боды/несколько различаются в зависимости от равенства или нера-
венства дисперсий сравниваемых совокупностей. Этот вопрос требу-
58 Глава 1. Математическая статистика в клинических исследованиях
ет внимательного рассмотрения, особенно для выборок малого объе-
ма (п < 20).
В случае равенства дисперсий или выборок достаточно большого
объема ошибка разности средних cd определяется по следующим фор-
мулам:
Для неравночисленных выборок при п\ Ф п2:
ad = Х^'-Х1)2+Х^'-Х2)2 Ы + п2Л (18)
\ nl + n2-2 У п\п2 J
Для равночисленных выборок при п\ = п2 формула несколько уп-
рощается:
|X(x/-xi)2+x^'-^)2 (19)
\ (л-1)л
Число степеней свободы для случая равных дисперсий равно
f=n\ +п2 — 2.
Если хотя бы одна из сравниваемых выборок мала, то сначала сле-
дует проверить гипотезу о равенстве дисперсий выборок. В зависи-
мости от ответа на этот вопрос последующее сравнение средних ариф-
метических производят двумя различными способами.
Для проверки гипотезы о равенстве генеральных дисперсий пользу-
ются критерием Фишера. При этом вычисляют показатель Фишера,
равный отношению большей выборочной дисперсии к меньшей:
5jc12
5jc22
Показатель Фишера всегда F> 1, а при равенстве дисперсий F = l.
Чем значительнее неравенство, тем больше будет значение показате-
ля, и наоборот. Функция F табулирована [7, 9, 13, 19, 20] (см. при-
ложение, табл. 8) и зависит от чисел степеней свободы/1 = п\ — I,
/2 = п2 — 1. Если вычисленное значение F превысит соответствую-
щее табличное значение и гипотеза о равенстве дисперсий будет от-
вергнута, то это означает, что выборки взяты из совокупностей с раз-
ными дисперсиями.
Итак, в случае несущественно различающихся или равных диспер-
сий средние арифметические сравниваются по формулам (17—19).
А при различных по величине дисперсиях выборок разница сред-
них арифметических оценивается по формуле (22) с числом степе-
ней свободы:
F = —r Sxl2>Sx2\ (20)
1.7. Статистический анализ результатов клинических исследований 59
,'Sxl2 Sx22
(nl - 1)(п2 -1) ——+-
/ = ; тг ;—тт 21>
, Sxl2
(n2-l)
♦w-ч^-
п\
(число степеней свободы округляется до целого числа),
I, X1-X2
к =
Sxl2 Sxl2
+ -
(22)
nl nl
Пример 4. Допустим, что в ходе исследования были получены зна-
чения определенного параметра, характеризующего эффект изучае-
мого воздействия, для двух групп пациентов. Используя данные при-
мера 1 (см. табл. 2, 2-й и 3-й столбцы), покажем, как можно сравнить
две независимые выборки, взятые из нормально распределенных со-
вокупностей, для получения ответа на вопрос о существовании ста-
тистически достоверных различий между их средними значениями.
Поскольку значения генеральных параметров неизвестны, определим
выборочные средние и дисперсии для обеих выборок. В нашем слу-
чае nl = 10; п2 = 10; Ji= 8,4; А2= И; Dxl = 2,28; Dx2 = 3,1. Прежде
всего проверим по критерию Фишера гипотезу о равенстве диспер-
сий обеих выборок, F-отношение равно 3,1/2,28 = 1,36. По таблицам
находим критическую точку для отношения Фишера в случае уровня
значимости 5% и числа степеней свободы/1 =/2 = 9, ее значение рав-
но 3,18. Наше рассчитанное /'-отношение не превышает табличного,
то есть на 5-процентном уровне значимости нулевая гипотеза о ра-
венстве дисперсий остается в силе.
Это означает, что расчет критерия Стьюдента будем проводить по
формулам (17) и (19) (случай равенства дисперсий и равночисленных
выборок). Для двустороннего критерия Стьюдента определим модуль
разности между выборочными средними, он равен 2,6. Найдем ошибку
разности средних:
л [Б^Ш JX28T3J
У п V Ю
Тогда значение /-критерия Стьюдента равно / = 2,6/0,73 = 3,56.
Для уровня значимости 5% и числа степеней свободы /= 10+10—2=18
по табл. 1 приложения находим критическое значение, равное 2,1.
Так как вычисленное значение критерия превосходит соответству-
60 Глава 1. Математическая статистика в клинических исследованиях
ющее табличное, нулевая гипотеза отвергается на уровне значимости
5%. Разница между средними в двух сравниваемых группах оказалась
статистически достоверной и на уровне значимости 1% (0,001 </К0,01),
при этом среднее значение во второй группе превосходит среднее
в первой.
Для сравнения двух зависимых выборок или выборок с попарно свя-
занными вариантами проверяют гипотезу о равенстве нулю среднего
значения их попарных разностей. Такая задача возникает, когда име-
ются данные об изменении интересующего признака у каждого па-
циента. Например, если группа пациентов получала изучаемый ме-
тод лечения и у каждого пациента измерялось значение признака до
и после лечения. В данном случае предстоит проверить нулевую ги-
потезу о равенстве нулю изменений этого признака в результате по-
лучения терапии. В этом случае оценкой разности между генераль-
ными средними будет средняя разность, определяемая из суммы по-
парных разностей, то есть:
d=^— = Xl-X2. (23)
п
Оценкой генеральной дисперсии разности средних будет выбороч-
ная дисперсия:
Я'-^*-0*. (24)
л-1
где di = Xli — X2i — попарные разности связанных вариант, п —
число парных наблюдений.
Ошибку средней разности определяют по формуле:
Е(^ (25)
1) л(л-1)
Если члены генеральной совокупности распределяются нормаль-
но, то разности между ними будут также распределяться нормально.
Поэтому для проверки нулевой гипотезы о равенстве нулю среднего
изменения значений показателя рассчитывается тестовое отношение:
t = d/cd, (26)
которое проверяется по таблицам распределения Стьюдента (см. при-
ложение, табл. 1) для выбранного уровня значимости и числа степе-
ней свободы/= п — 1, в случае двустороннего теста без учета знака.
Нулевая гипотеза отвергается для данного уровня значимости, если
вычисленное значение превзойдет соответствующее табличное.
1.7. Статистический анализ результатов клинических исследований 61
Пример 5. Для примера сравнения выборок с попарно связанны-
ми вариантами рассмотрим результаты изменения содержания веще-
ства D в крови из примера 1. Для группы 2 пациентов будем решать
так называемую статистическую задачу «до и после», анализируя стол-
бцы 5 и 7 табл. 2. Таким образом, получаем 2 связанные выборки кон-
центрации вещества D в крови у пациентов группы 2: исходно и пос-
ле терапии (табл. 5).
£<й 41
Средняя разность равна: d = = — = 4,1;
п 10
Ошибка разности: od = sd/r- = °'/Г77; = 0,31.
Критерий / = d/ad = 4,1/0,31 = 13,4. Для уровня значимости 1% и
числа степеней свободы/= 10—1 = 9 критическое значение равно 3,25
(см. приложение, табл. 1). Так как вычисленное значение критерия
превышает соответствующее табличное, нулевую гипотезу отвергают,
и разница между сравниваемыми выборками признается в высокой
степени статистически достоверной (р < 0,01).
Правильное применение /-критерия предполагает нормальное рас-
пределение совокупностей, из которых извлечены сравниваемые вы-
борки. Если это условие не выполняется, то более эффективными
будут непараметрические критерии.
Таблица 5.
Вычисление попарных разностей для проверки критерия Стьюдента в
случае зависимых выборок (связанных пар)
Группа 2 — «ДО»
0,8
0,9
2,5
1,2
1,3
1,5
1,6
2,1
2,0
1,0
Группа 2 - «ПОСЛЕ»
4,8
5,9
6,5
4,7
6,3
6,5
5,1
6,1
4,0
6,0
Попарные разности
di=X\i-X2i
4,0
5,0
4,0
3,5
5,0
5,0
3,5
4,0
2,0
5,0
62 Глава 1. Математическая статистика в клинических исследованиях
1.7.7. Непараметрические критерии
для проверки гипотезы о различии
(или сходстве) между средними значениями
Для сравнения средних значений может применяться и целый ряд
непараметрических критериев, среди которых важное место занима-
ют так называемые ранговые критерии. Применение этих критериев
основано на ранжировании членов сравниваемых групп. При этом
сравниваются не сами члены ранжированного ряда, а их порядковые
номера или ранги. Познакомиться с основными непараметрически-
ми критериями можно, например, в книгах [3, 6, 9, 13, 14, 18, 19]. Там
же даны и основные таблицы для проверки этих критериев. При ре-
шении конкретной задачи очень важно правильно выбрать критерий.
Решение этих вопросов для медико-биологических приложений дос-
таточно подробно рассмотрено в [3, 9, 18, 19].
Приведем IJ-критерий Уилкоксона (Манна—Уитни) для проверки
гипотезы о принадлежности сравниваемых независимых выборок к
одной и той же генеральной совокупности. Гипотезу проверяют, рас-
положив в обобщенный ряд значения сравниваемых выборок в воз-
растающем порядке. Всем значениям полученного обобщенного ряда
присваиваются ранги от 1 до N = п\ + п2. Для каждой выборки нахо-
дятся суммы рангов R и рассчитываются статистики:
Ui = Ri для / = 1 и 2 — номер выборки. (27)
Если нулевая гипотеза верна и выборки извлечены из одной и той
же генеральной совокупности, мы не должны ожидать преобладания
наблюдений из одной выборки на одном из концов объединенного
вариационного ряда, их значения должны быть достаточно равномер-
но рассеяны по всему обобщенному ряду. Таким образом, слишком
большие или слишком маленькие значения статистики R должны за-
ставить нас усомниться в справедливости нулевой гипотезы.
В качестве тестовой статистики выбирают минимальную величи-
ну U и сравнивают ее с табличным значением для принятого уровня
значимости. Гипотеза принимается, и различия считаются недосто-
верными, если рассчитанное значение больше соответствующего таб-
личного (см. приложение, табл. 5).
Обычно в таблицах приводятся критические значения данного
критерия для объема выборок 20 или 40. В случае выборок большего
объема для проверки данного критерия применяется нормальная ап-
1.7. Статистический анализ результатов клинических исследований 63
проксимация. Тогда критические значения для критерия U можно
рассчитать по формуле:
UnMa = ^nl-n2-za-^nhn2-(nl + n2 + l) (28)
где za — критические значения стандартного нормального распреде-
ления (см. приложение, табл. 7).
Пример 6. Проверим гипотезу о принадлежности сравниваемых не-
зависимых выборок к одной и той же генеральной совокупности с по-
мощью непараметрического (/-критерия Уилкоксона. Сравним ре-
зультаты, полученные в примере 4 для 2-го и 3-го столбцов табл. 2 по
критерию Стьюдента, с результатами непараметрического сравнения.
Для расчета [/-критерия Уилкоксона расположим варианты сравни-
ваемых выборок в порядке возрастания в один обобщенный ряд и
присвоим вариантам обобщенного ряда ранги от 1 до я 1 + п2. Первая
строка представляет собой варианты первой выборки, вторая — вто-
рой выборки, третья — соответствующие ранги в обобщенном ряду:
67788 999 10 11
8 9 9 11 11 12 12 12 13 13
1 2,5 2,5 5 5 5 9 9 9 9 9 12 14 14 14 17 17 17 19,5 19,5.
Надо обратить внимание, что, если имеются одинаковые вариан-
ты, им присваивается средний ранг, однако значение последнего ранга
должно быть равно п\ + я2 (в нашем случае — 20). Это правило ис-
пользуют для проверки правильности ранжирования.
Отдельно для каждой выборки рассчитываем суммы рангов их ва-
риант R\ и R2. В нашем случае:
R\ = 1 + 2,5 + 2,5 + 5 + 5 + 9 + 9 + 9 + 12 + 14 = 69;
R2 =5 + 9 + 9+ 14+ 14+ 17+17+17+ 19,5 + 19,5 = 141.
Для проверки правильности вычислений можно воспользоваться
другим правилом: Rl + R2 = 0,5 • («1 + п2) • (nl + п2 + 1). В нашем
случае Rl + R2 = 69 + 141 = 0,5 • 20 • 21 = 210.
Статистика t/1 = 69 — 10 11/2 = 14, U2 = 141 — 10 - 11/2 = 86. Для
проверки одностороннего критерия выбираем минимальную статис-
тику U\ = 14 и сравниваем ее с табличным значением (см. приложе-
ние, табл. 5) для п\ = п2 = 10 и уровня значимости 1%, равным 19. Так
как вычисленное значение критерия меньше табличного, нулевая ги-
потеза отвергается на выбранном уровне значимости, и различия между
64 Глава 1. Математическая статистика в клинических исследованиях
выборками признаются статистически значимыми. Таким образом,
вывод о существовании различий, сделанный с помощью параметри-
ческого критерия Стьюдента, подтверждается с помощью данного
непараметрического метода.
В случае попарно связанных выборок применяется Т-критерий
Уилкоксона. При этом ранжируют попарные разности — положитель-
ные и отрицательные (кроме нулевых) в один ряд так, чтобы наимень-
шая абсолютная разница (без учета знака) получила первый ранг, оди-
наковым величинам присваивают один ранг. Отдельно вычисляют
сумму рангов положительных (Т+) и отрицательных разностей (Т-),
меньшую из двух таких сумм без учета знака считают тестовой стати-
стикой данного критерия. Нулевую гипотезу принимают на данном
уровне значимости, если вычисленная статистика превзойдет таблич-
ное значение (см. приложение, табл. 4) (число парных наблюдений
уменьшают на число исключенных нулевых разностей). Таким обра-
зом, можно сказать, что если нулевая гипотеза верна, статистики Г+
и Т— примерно равны, сравнительно малые или большие значения
Г-статистик заставят нас отклонить нулевую гипотезу об отсутствии
различий.
Пример 7. Допустим, в результате проведения исследования был
вычислен ряд попарных разностей между показателем эффекта в двух
попарно связанных группах («1 = п2 = 10) (например, так называемая
задача «до и после»):
0,2 -0,4 0,7 -0,9 1,3 1,5 -0,1 0,8 -1,0 1,1.
Ранжируем попарные разности в один ряд, независимо от знака
разности, получаем следующий ранжированный ряд:
-0,1 0,2 -0,4 0,7 0,8 -0,9 -1,0 1,1 1,3 1,5
12345 6 789 10.
Рассчитаем отдельно сумму рангов положительных (Т+) и отри-
цательных (Т-) разностей, в нашем случае:
Т+ = 2 + 4 + 5 + 8 + 9+ 10 = 38;
Т- = 1 + 3 + 6 + 7 = 17.
Для проверки двустороннего Г-критерия используем меньшую ста-
тистику Г— = 17 и сравним ее с табличным значением (см. приложе-
ние, табл. 4) для числа попарных разностей п = 10 и уровня значимо-
сти 5%. Такое табличное критическое значение равно 9. Рассчитанное
минимальное значение Г-статистики превосходит соответствующее
табличное значение, а значит, нулевая гипотеза остается в силе.
1.7. Статистический анализ результатов клинических исследований 65
В случае анализа результатов клинических исследований непара-
метрические критерии бывают полезны не только для анализа коли-
чественных данных, а также при качественной или альтернативной
(дихотомической) форме представления данных. Этот вопрос будет
рассмотрен нами подробнее в соответствующем разделе.
1.7.8. Сравнение средних значений
нескольких выборок (множественные сравнения)
Приведенный выше критерий Стьюдента может быть использован
для проверки гипотезы о различии средних только для двух групп.
Если план исследования предполагает сравнение большего числа
групп, совершенно недопустимо просто сравнивать их попарно. Для
корректного решения этой задачи можно воспользоваться, например,
дисперсионным анализом [3, 7, 9, 14, 19], он будет рассмотрен нами в
соответствующем разделе. Однако дисперсионный анализ позволяет
проверить лишь гипотезу о равенстве всех сравниваемых средних. Но,
если гипотеза не подтверждается, нельзя узнать, какая именно груп-
па отличалась от других. Это позволяют сделать методы множествен-
ного сравнения, которые, в свою очередь, также бывают параметри-
ческие и непараметрические. Эти методы дают возможность провес-
ти множественные сравнения так, чтобы вероятность хотя бы одного
неверного заключенная оставалась на первоначально выбранном
уровне значимости а, например, а = 5%.
Среди параметрических критериев наиболее известны критерий
Стьюдента для множественных сравнений, критерий Ньюмена—Кей-
лса [3, 19], критерий Тьюкки [3], критерий Шеффе [14], критерий
Даннета [3, 30], а среди непараметрических — критерий Краскела—
Уоллиса [14, 18, 19], медианный критерий [14, 18, 19]. Надо сказать,
что основные параметрические критерии для множественного срав-
нения независимых групп могут после некоторых модификаций при-
меняться для установления различий и в повторных измерениях, если
дисперсионный анализ установил наличие таких различий [3, 14].
Рассмотрим некоторые критерии. Еще раз обращаем внимание, что
к применению этих критериев надо прибегать в случае, если диспер-
сионный анализ показал наличие значимых различий между средни-
ми значениями выборок.
Буквой т обозначим число сравниваемых групп.
Критерий Стьюдента для множественных сравнений основан на
использовании неравенства Бонферрони [3, 19, 38]: если к раз приме-
66 Глава 1. Математическая статистика в клинических исследованиях
нить критерий с уровнем значимости а, то вероятность хотя бы в од-
ном случае найти различие там, где его нет, не превышает произведе-
ния к на а. Из неравенства Бонферрони следует, что если мы хотим
обеспечить вероятность ошибки ос,' то в каждом из сравнений мы дол-
жны принять уровень значимости а'/к — это и есть поправка Бон-
феррони (к — число сравнений). Понятно, что такое уменьшение в
несколько раз уровня значимости делает тест достаточно «жестким»,
с ростом числа сравнений установить различия становится достаточ-
но трудно. Чтобы несколько смягчить данный тест, пользуются обоб-
щенной оценкой внутригрупповой дисперсии, число степеней сво-
боды при этом возрастает, что, в свою очередь, приводит к уменьше-
нию критического значения для проверки теста. Обобщенную оценку
внутригрупповой дисперсии в случае групп разного объема можно
вычислять по формуле:
s2 = (Я, -lK +(Я2 -1>2 +- + К -1)^ ? (29)
gr nx+n2+... + nm-m
где п. — численность соответствующей /-группы, величины s, в фор-
муле обозначают средние квадратичные отклонения в сравниваемых
группах. Для групп одинакового объема данная формула несколько
упрощается и обобщенная оценка внутригрупповой дисперсии вы-
числяется как среднее значение дисперсий, рассчитанных для всех
сравниваемых групп в отдельности. Величина тестовой статистики
при сравнении /- и у-групп рассчитывается по обычной формуле с
учетом обобщенной оценки дисперсии:
- *-* - ™Г* (30)
и опять в случае групп равного объема п формула упрощается:
Число степеней свободы для критерия Стьюдента при таком под-
ходе равно/= т(п— 1), где п — объем групп, а для групп разного объе-
ма число степеней свободы будет равно суммарной численности всех
групп #минус количество групп т (что в случае т > 2 превышает обыч-
ное число степеней свободы для критерия Стьюдента, равное суммар-
ной численности двух непосредственно сравниваемых групп минус 2).
1.7. Статистический анализ результатов клинических исследований 67
Этот метод хорошо работает, если число сравнений невелико,
обычно не больше 8. При большом числе сравнений критерий Нью-
мена—Кейлса и критерий Тьюкки дают более точную оценку вероят-
ности ос'[3, 19].
Иногда задача заключается в том, чтобы сравнить несколько групп
с единственной — контрольной. Конечно, можно использовать лю-
бой из указанных выше методов: попарно сравнить все группы, а по-
том выбрать только те сравнения, в которых участвовала контрольная
группа. Однако из-за большого числа лишних сравнений критичес-
кое значение окажется неоправданно высоким. Для решения этой
задачи статистики существуют специальные методы, например еще
одна модификация критерия Стьюдента с поправкой Бонферрони и
критерий Даннета.
В случае использования поправки Бонферрони необходимо учесть
реальное число сравнений для этой задачи, оно равно числу групп
т — 1, и соответственно рассчитать уровень значимости а = а/(/и — 1).
Критерий Даннета более чувствительный, чем предыдущий, осо-
бенно при большом числе групп. Критерий Даннета является моди-
фикацией критерия Ньюмена—Кейлса, и тестовая статистика в этом
случае вычисляется как [30]:
Хк - Хс (32)
где s2 — оценка внутригрупповой дисперсии, и Хк и Хс — сравниваемые
средние значения, пкипс — численность групп контроля и сравнения.
Для проверки критерия Даннета средние значения для всех групп
упорядочиваются по абсолютной величине их отличия от контрольной
группы, сравнения начинают с группы, наиболее отличающейся от
контроля. При обращении к таблице для проверки критерия исполь-
зуется еще один параметр /, представляющий собой число сравнивае-
мых групп вместе с контрольной. Вычисленное значение q сравнива-
ется с табличным (см. приложение, табл. 9) значением; если оно пре-
восходит табличное или равно ему, делается вывод о наличии
статистически значимого различия. Число степеней свободы для этого
критерия также равно f=m(n — 1) = N — т, где N — суммарная чис-
ленность всех групп, т — число сравниваемых групп. Если различия
с очередной группой не найдены, сравнения прекращаются.
Непараметрический критерий Краскела—Уоллиса для сравнения
средних значений нескольких независимых выборок основан на по-
68 Глава 1. Математическая статистика в клинических исследованиях
строении объединенного вариационного ряда из вариант рассматри-
ваемых выборок и присвоении рангов всем вариантам в объединен-
ном ряду объемом N. Далее вычисляются статистики Ri для каждой
рассматриваемой выборки отдельно, равные суммам рангов в обоб-
щенном ряду вариант, входящих в данную /-ю выборку. При этом для
каждого наблюдения в конкретной выборке мы можем указать сред-
ний ранг, равный Ri/ni, для всех / от 1 до /я. Если выполняется нуле-
вая гипотеза и все совокупности имеют одно и то же распределение,
то можно ожидать, что все средние ранги примерно равны. А именно
они примерно равны общему среднему рангу R:
Л = <1 + 2+~+А% = 1(АГ+1). (33)
В качестве статистики критерия используется мера, которая чув-
ствительна к отклонению выборочного Ri/ni от теоретического зна-
чения R:
K = yRjL_N(N + iy
^ ni 4
Сумма берется по всем т выборкам.
Проверить статистику Краскела—Уоллиса можно по специаль-
ным таблицам [9, 13, 19]. Однако если почти все ni > 5, то удобна ап-
12К
проксимация, которая основана на том, что статистика имеет
N(N + 1)
распределение %2 с т — 1 степенью свободы при условии справедли-
вости нулевой гипотезы. Таким образом, рассчитав значение статис-
тики К, его сравнивают с критическим значением распределения х2
(см. приложение, табл. 2), умноженным на коэффициент: * —± 1.
12
Если вычисленное значение К превосходит скорректированное кри-
тическое, нулевая гипотеза отвергается на выбранном уровне значи-
мости а%, и различия считаются статистически значимыми.
Для попарного сравнения групп или попарного сравнения групп с
одной контрольной известны непараметрические аналоги парамет-
рических критериев Ньюмена—Кейлса и Даннета [3].
Непараметрический критерий Фридмана [3, 18] применяется для
анализа повторных измерений, связанных с одним и тем же индиви-
дуумом. Для применения этого критерия столбцы таблицы данных от-
ражают различные значения переменной эффекта, а строки соответ-
ствуют повторным измерениям одного и того же субъекта. С помо-
щью критерия Фридмана мы проверяем нулевую гипотезу о том, что
1.7. Статистический анализ результатов клинических исследований 69
различные методы лечения дают практически одинаковые результа-
ты. Процедура состоит в упорядочивании (ранжировании) значений
в каждой строке (при этом ранги в каждой строке принимают значе-
ния от 1 до /я), суммировании полученных рангов по каждому столб-
цу и вычислении тестовой статистики х2г'
т
12l(X*;)2
Х> "' _,,, Зв(« + 1) (35)
пт(т +1)
где п — число пациентов (число строк), т — число сравниваемых ме-
тодов лечения (число столбцов), Y*Ri — сумма рангов для /-терапии
(по столбцу).
Рассчитанная статистика %) имеет такое же распределение, как и
£2при (т — 1) степенях свободы. Если рассчитанное значение пре-
взойдет соответствующее табличное (см. приложение, табл. 2) для
выбранного уровня значимости и соответствующего числа степеней
свободы, то нулевая гипотеза отклоняется. В качестве проверки рас-
четов можно использовать правило: общая сумма рангов должна
равняться
■=•*.♦.>
Этот критерий может применяться и в случае, когда вместо отдель-
ных пациентов сравниваются однородные группы (рандомизирован-
ный блочный план исследования). В этом случае п — число однород-
ных групп.
Пример 8. Применение критериев множественного сравнения
проиллюстрируем на примере результатов вымышленного исследо-
вания из примера 1, относящихся к содержанию вещества А в ткани
В у пациентов групп 1, 2 и 3 (табл. 2, столбцы 1—3). Группу 1 будем
считать контрольной и сравним полученные в этой группе резуль-
таты с результатами в группах 2 и 3 с помощью критерия Даннета.
Прежде всего вычислим для этих групп средние значения и диспер-
сии: Х1= 13,1; Х2= 8,4; JB= 11,0; Dx\ = 3,2; Dx2 = 2,28; Dx3 = 3,1.
Рассчитаем величины отклонений средних значений групп 2 и 3 от
среднего значения контрольной группы 1; эти отклонения равны со-
ответственно 4,7 и 2,1. Таким образом, сначала будем определять
значения критерия Даннета для сравнения контрольной группы с
группой 2, а затем, если статистически значимое различие будет ус-
тановлено, — с группой 3. Поскольку объем групп в данном случае
70 Глава 1. Математическая статистика в клинических исследованиях
одинаков, обобщенная оценка величины внутригрупповой диспер-
сии sgr2 может быть определена как среднее арифметическое дис-
персий сравниваемых групп. Тогда ^/оценивается как 2,86. Кри-
терии Даннета для сравнения контрольной группы с группой 2 и 3
соответственно равны:
,= .т-*А =6.2,;
V uo ioJ
,- ."■■-"■° =2.78;
Ы±+±
\ Uo юJ
Число степеней свободы в данном случае равно 30 — 3 = 27, / = 3,
уровень значимости выберем равным 5%, тогда по табл. 9 приложе-
ния критическое значение равно 2,33. Вычисленные значения крите-
рия превзошли критическое табличное, значит, различия между кон-
трольной и двумя другими группами можно признать статистически
значимыми на выбранном уровне значимости.
Критерий Стъюдента с поправкой Бонферрони. По-прежнему срав-
ниваем группы 2 и 3 с контрольной 1. Для этих двух сравнений рас-
считываем по формулам (30—31) значения критерия Стьюдента. По-
лучаем значения t2 = 6,21 для сравнения с группой 2 и t3 = 2,78 для
группы 3. В данном случае уровень значимости выбираем из расчета
0,05/2 = 0,025, число степеней свободы равно/= 3(10—1) = 27. Со-
ответствующее значение в таблице распределения Стьюдента при-
близительно равно 2,5. Рассчитанные нами значения /-критерия
превзошли выбранное критическое значение, а значит, нулевая ги-
потеза отвергается в обоих случаях, и различия признаются статис-
тически значимыми на уровне значимости (для всего критерия) 5%.
В данном случае мы не делаем заключения о различии групп 2 и 3
между собой.
Для сравнения этих трех независимых групп применим непарамет-
рический подход, для чего проанализируем эти же данные с помо-
щью критерия Краскела—Уоллиса. Как и для критерия Уилкоксона—
Манна—Уитни, мы будем использовать ранги вариант в объединенной
совокупности. Как и раньше, одинаковым вариантам присваиваем
средний ранг, так чтобы последнее значение ранга было равно объе-
му объединенного ряда.
1.7. Статистический анализ результатов клинических исследований 71
Как и раньше, сумма всех рангов должна быть равна 0,5 • TV- (7V+ 1),
где N — объем обобщенного ряда. В нашем случае сумма рангов дол-
жна быть равна 465. Рассчитываем статистику Краскела—Уоллиса:
(233,5)2 (71)2 (160,5)2 30(30+1)2
К=
10 10 10
Тестовая статистика:
4
12
-=5452,2+504,1+2576,0-7207,5 = 1324Д
-£=17,1
30(30+1)
Критическое значение критерия %2 для двух степеней свободы и уров-
ня значимости 5% (см. приложение, табл. 2) равно 5,99. Поскольку вы-
численное значение критерия превзошло соответствующее табличное
на уровне значимости 5%, нулевая гипотеза отвергается, а различия
между всеми тремя группами признаются статистически значимыми.
Для иллюстрации применения критерия Фридмана представим
себе, что в результате клинического исследования (8 пациентов для
оценки действия 4 методов лечения) была получена табл. 6 результа-
тов (через черту приведены ранги наблюдений).
Таблица 6.
Таблица данных для расчетов по критерию Фридмана
Пациент
1
2
3
4
5
6
7
8
Терапия 1
80/1
60/1
56/1
51/1
53/1
37/1
45/2
33/1
Щ = 9
Терапия 2
95/4
75/4
63/2
56/2
55/2
46/2
40/1
39/3
Щ = 20
Терапия 3
85/2
68/3
71/4
68/3
63/3
48/3
49/3
35/2
Щ = 23
Терапия 4
88/3
77/2
68/3
72/4
77/4
56/4
51/4
44/4
Щ = 28
72 Глава 1. Математическая статистика в клинических исследованиях
Выберем уровень значимости а =0,01, число степеней свободы
(т — 1) в нашем гипотетическом примере равно 3, п = 8. Общая сум-
ма рангов равна 9 + 20 + 23 + 28 = 80.
Значение п\
T(»+i)
= 80.
Проверочное условие выполняется, значит, суммы рангов вычис-
лены правильно. Тестовая статистика в нашем примере равна:
, 12(81 + 400+529 + 784)
*'- HI -*«•>-'«*
Критическое значение распределения %2 для выбранного уровня
значимости и трех степеней свободы равно 11,34. Поскольку рассчи-
танное значение превзошло табличное, мы отклоняем нулевую гипо-
тезу и принимаем альтернативную — сравниваемые методы лечения
приводят к различным значениям показателей эффекта.
1.7.9. Оценка эффекта
при альтернативной форме учета реакций
Всестороннее изучение картины действия исследуемого лекар-
ственного препарата требует выделения сопоставимых параметров.
Эта задача решается, например, если из всей массы наблюдений ис-
пользовать для статистического анализа только наблюдения за исхо-
дами, например, получен эффект от проводимой терапии — да или
нет; выявлены побочные эффекты — да или нет; отмечено появление
определенных симптомов — да или нет и т. д. Все эти примеры иллю-
стрируют способ учета реакции в альтернативной форме, то есть ре-
акции, которая или наступает, или нет. Альтернативное распределе-
ние — это распределение элементов совокупности на 2 части (2 аль-
тернативы) по какому-либо признаку, чаще по качественному. Эти
признаки не связаны между собой никакими арифметическими со-
отношениями. Единственный способ описания качественных призна-
ков состоит в том, чтобы подсчитать число объектов, имеющих одно
и то же значение, или долю от общего числа объектов, приходящую-
ся на то или иное значение.
В случае альтернативной классификации невозможно ввести та-
кие количественные параметры, как математическое ожидание, дис-
персия и др. Тем не менее можно указать определенный численный
параметр, имеющий вполне точный и объективный смысл: доля ва-
риант одного из двух типов. Так, доля р может быть оценена как:
1.7. Статистический анализ результатов клинических исследований 73
p=-J*-=?L, Об)
п\ + п2 п
где п\, п2 — численности альтернатив, п—п\ + п2 — численность всей
совокупности. Кроме того, доля может быть выражена в процентах:
р = ^—100% = ^™%. (37)
nl + n2 n
В отношении доли вариант в альтернативном распределении воз-
никают те же статистические задачи, что и для параметров, представ-
ленных в количественной форме:
• оценка доли р в генеральной совокупности по выборочным
данным, нахождение доверительного интервала для р\
• выявление различия между генеральными долями р\ и р2 двух
совокупностей по выборочным данным, то есть сравнение двух
выборочных долей вариант.
Формулы (36—-37) позволяют рассчитать выборочную оценку ге-
неральной доли р. Поскольку в исследовании участвует ограниченное
число пациентов, возникает вопрос об определении доверительного
интервала для доли р. Строго эта задача решается с использованием
биномиального распределения [3, 7, 13, 19, 20, 22]. Соответствующие
расчеты очень громоздки, поэтому составлены таблицы [13] и номог-
раммы [19], в которых можно сразу найти 95- и 99-процентные дове-
рительные границы для выборочной доли. Ввиду большого объема
этих таблиц они обычно приводятся лишь в специальных справочни-
ках. Поэтому на практике часто пользуются различными приближен-
ными методами. Как правило, применяется нормальное приближе-
ние, то есть замена биномиального распределения нормальным. Из
центральной предельной теоремы следует, что при достаточно боль-
шом объеме выборки выборочная оценка доли приближенно подчи-
няется нормальному закону распределения, имеющему генеральное
среднее и стандартное отклонение, равное стандартной ошибке доли ср.
При таком подходе доверительные границы для генеральной доли
определяются как/? ± zaop, где ср — стандартная ошибка доли зада-
ется соотношением:
ор~^^- (38)
a za — определяется по значению доверительной вероятности по
табл. 7 приложения (обычно в случае клинических исследований
а = 5% и соответствующее значение z = 1,96).
74 Глава 1. Математическая статистика в клинических исследованиях
При малых объемах выборок нормальное приближение дает слиш-
ком неточные результаты. Условием применимости аппроксимации
с помощью нормального распределения в данном случае является вы-
полнение соотношения пр < 5. В случае невыполнения этого усло-
вия для исправления положения Р. Фишер предложил пользоваться
угловой трансформацией или, проще говоря, вспомогательной вели-
чиной ф, связанной с долей р равенством:
(p = 23icsin^p, (39)
Эта величина имеет распределение, близкое к нормальному. По-
рядок действий предполагается следующий: для получения довери-
тельных границ для доли вариант сначала нужно найти значение ф и
вычислить интервал <p±zy /-. Затем по формуле р = sin2 % пересчи-
тать полученные для ф значения границ, вернувшись снова к значе-
ниям р. Конечно, переход от р к ф и обратно с применением таблицы
тригонометрических функций достаточно неудобен. Поэтому была со-
ставлена специальная таблица, которая непосредственно связывает
значения р и ф (см. приложение, табл. 6).
Еще одна задача возникает при анализе выборочных долей и тре-
бует внимания. При значениях/?, близких к 0 или 1 (при нулевом или
100-процентном эффекте), в случае малого объема выборки условия
центральной предельной теоремы нарушаются, при этом нужно не-
сколько изменить процедуру построения доверительных интервалов.
Статистические оценки
нулевого и 10О-процентного эффекта
Очевидно, что, если любой признак наблюдался в 100% случаев у
группы, состоящий из 10 вариант, такой результат может объясняться
случайным совпадением и не воспроизводиться в дальнейшем при про-
должении исследования. Тот же признак, наблюдаемый в 100% случа-
ев у группы, состоящей из 1000 вариант, имеет, вероятно, большую до-
стоверность. Поэтому даже в случае появления в результате исследо-
вания 0 или 100% долей эти результаты должны быть скорректированы.
Для статистической обработки нулевого (или 100-процентного
эффекта) можно пользоваться следующим подходом: рассматривать
возможный скорректированный процент эффекта при дальнейшем
увеличении числа подобных наблюдений и его стандартную ошибку:
р = ^±1.Ю0; (40)
и + 2
1.7. Статистический анализ результатов клинических исследований 75
ар = ШЕК9 (41)
V п + Ъ
где а — полученный в исследовании обобщенный показатель (0%),
р — скорректированное значение этого показателя (%).
Доверительный интервал для скорректированного значения доли за-
дается соотношением: а ± tap, где /определяется по табл. 1 приложения
для выбранного уровня доверительной вероятности и объема выборки.
Пример 9. Допустим, в другом придуманном нами исследовании
пациенты получали в опытной группе препарат А, а в контрольной —
препарат Б. Эти препараты должны были вызывать (или не вызывать)
у пациентов определенную реакцию. Контрольная группа включала
36 пациентов, а опытная — 25. Если положительная реакция прояви-
лась, такой исход будем обозначать как ДА; соответственно, альтер-
нативный — НЕТ. Результаты содержатся в табл. 7.
Таблица 7.
Таблица сопряженности 2x2 для примера 9
Исходы
Опытная группа (по)
Контрольная группа (пк)
Всего
ДА
9
28
37
НЕТ
16
8
24
Всего
25
36
61
Доля пациентов с положительными исходами, например, в опыт-
ной группе, равна р = 9/25 = 0,36; или 36%. Ошибка выборочной
доли в данном случае равна ср = 0,096; или 9,6%. Соответствующий
95-процентный доверительный интервал для выборочной доли заклю-
чается между 0,17 и 0,55 или, другими словами, между 17 и 55%. Рас-
считаем доверительный интервал для выборочной доли с учетом уг-
ловой трансформации. По табл. 6 находим для доли 0,36 значение
Ф = 1,287. Границы 95-процентного доверительного интервала зада-
ются соотношением <р± /JZ , в нашем случае получаем диапазон от
0,9 до 1,68 (значение za = 1,96 определяем по табл. 7 приложения для
уровня доверительной вероятности 95% и соответствующем а= 5%).
Теперь по табл. 6 приложения по рассчитанным граничным значени-
ям ф определяем значения р, соответствующие границам доверитель-
ного интервала, получаем диапазон от 0,19 до 0,55. И, хотя этот ин-
тервал тоже достаточно широк, он имеет практическое значение.
76 Глава 1. Математическая статистика в клинических исследованиях
Проиллюстрируем ситуацию с возникновением в исследовании так
называемого нулевого эффекта. Допустим, что в предыдущей табли-
це в опытной группе ни у одного пациента не было положительной
реакции (0%).
Тогда:
и 25 + 2 и V 25 + 3
95-процентный доверительный интервал для этой выборочной
доли заключен между значениями 0% — 0 + 2,06-3,57% (так как доля
не может иметь отрицательное значение), или можно записать, что с
вероятностью 95% доля пациентов в опытной группе, демонстриро-
вавших положительную реакцию, заключена в интервале 0 —7,35%.
Таким образом, несмотря на нулевой эффект в исследовании на 25
пациентах, с вероятностью более 95% можно утверждать, что при про-
должении исследования доля пациентов с положительными исхода-
ми будет заключена в пределах от 0 до 7,35% случаев. При этом с
вероятностью более 95% можно сказать, что при продолжении ис-
следования доля противоположных исходов будет не менее чем у
92,65% пациентов.
Оценка разности между долями
Поскольку выборочная доля аналогична выборочному среднему,
задача оценки разности между долями решается аналогично задаче
оценки разности между средними значениями. При этом также мож-
но использовать различные параметрические и непараметрические
методы сравнения долей.
Рассмотрим аналог критерия Стьюдента. Рассчитываемая тесто-
вая статистика Z представляет собой отношение разности выбороч-
ных долей к стандартной ошибке разности выборочных долей:
z=pl-p25 (42)
odp
где/?1, р2 — сравниваемые выборочные доли, с dp — стандартная ошиб-
ка разности выборочных долей. Величина Zимеет приближенно нор-
мальное распределение.
Нулевая гипотеза в данном случае состоит в том, что р\ =р2. И ее
отвергают, если рассчитанная статистика ZnpeB3oifaeT или будет равна
табличному значению, выбранному в соответствии с заданным уров-
нем значимости а (см. табл. 7 приложения).
1.7. Статистический анализ результатов клинических исследований 77
Ошибка разности между долями, взятыми из приблизительно рав-
новеликих выборок (объем выборок отличается менее чем на 25%),
вычисляется по формуле:
«ф-jgl'+g2* =^-Pl) + p2(^2) (43)
В случае когда сравнивают доли из неравновеликих выборок, для
повышения чувствительности теста ошибку разности долей опреде-
ляют по формуле:
-f-K"^- <44)
где р определяют как средневзвешенную из р\ ир2 долей:
р\п\ + р2п2 /А4-Л
Р = ; ~—• \ч:*)
и п\ + п2
Если доли выражают в процентах от л, то в приведенных формулах
вместо значения 1 — р нужно брать 100 — р.
Описанный выше критерий проверки равенства долей в двух вы-
борках применим при не слишком больших и не слишком малых
значениях р (25% < р <75%). Особенно это важно учитывать в слу-
чае малых выборок. Свободным от подобного рода ограничений и
более универсальным оказывается способ проверки равенства до-
лей, основанный на ср-преобразовании Фишера. Для компенсации
ошибок вводится специальная поправка Йейтса, называемая также
поправкой на непрерывность, равная _L_ . Эту поправку вычитают
2п
из большей и прибавляют к меньшей доле. Исправленные доли вы-
ражают в процентах и трансформируют с помощью табл. 6 прило-
жения. С учетом этой поправки величина критерия определяется
формулой [9]:
{ = (<р1-<р2)№^, (46)
Г Y \nl + n2
Ф — угловая трансформация частоты, задаваемая формулой (39), cpl и
ф2 — трансформированные величины исправленных долей.
Условием для неприятия нулевой гипотезы служит превышение
рассчитанным значением статистики / соответствующего таблично-
го значения (см. табл. 1 приложения) для выбранного уровня значи-
мости и числа степеней свободы/ = п\ + п2 — 2.
78 Глава 1. Математическая статистика в клинических исследованиях
Таблицы сопряженности: критерий %2
Для оценки значимости расхождения частот какого-либо явления
в двух группах может быть использован статистический метод, кото-
рый носит название критерия х2- Этот критерий может быть приме-
нен, например, при сравнении групп, получивших различные срав-
ниваемые по своей активности препараты; групп, получивших раз-
личные дозы изучаемого препарата или одну и ту же дозу различными
путями введения, и т. д. Для описания результатов такого исследова-
ния удобно применять таблицу сопряженности, в которой для каж-
дой из групп указывается число пациентов с каждой из градаций при-
знака. Таким образом, для двух рассматриваемых групп и для двух
возможных исходов получается таблица размерности 2x2 (см. табл. 7).
Допустим, в результате проведения исследования было определе-
но, например, что процент летальных исходов при лечении изучае-
мым методом ниже (или выше), чем в контрольной; но является ли
это различие значимым? Для ответа на этот вопрос вычисляется ве-
личина статистики %2, которая является показателем максимально
возможных при данном уровне значимости отклонений частот.
Как обычно, для анализа таблицы сопряженности выдвигается
нулевая гипотеза: отсутствует влияние изучаемого препарата на ре-
зультаты в данном исследовании. Исходя из нулевой гипотезы, мож-
но подсчитать, какова была бы смертность (или любой другой аль-
тернативно распределенный признак) в каждой из групп, если бы
интересующие исходы по частоте равномерно распределились в обе-
их группах. Результаты исследования в двух группах объединяются, и
определяется процент «хороших» и «плохих» исходов по суммарным
результатам в двух группах. При этом рассчитываются таблицы ожи-
даний, то есть результаты, которых можно было бы ожидать в обеих
группах, при справедливости нулевой гипотезы и равномерности рас-
пределения частот различных исходов в обеих группах. На основа-
нии сопоставления таблиц сопряженности и таблиц ожидания состав-
ляется таблица отклонений наблюдавшихся частот рп от ожидаемых
ро. Для расчета величины %2 из абсолютной величины каждого откло-
нения вычитают 0,5 (поправка Йейтса), полученную разность возво-
дят в квадрат и результат делят на соответствующее ожидание. По-
правка применяется только для таблиц сопряженности 2x2. Статис-
тика х2 представляет собой сумму полученных величин:
1.7. Статистический анализ результатов клинических исследований 79
Вычисленное значение х2 сопоставляют с табличными значения-
ми (см. табл. 2 приложения) для разных уровней вероятности. Для
таблиц сопряженности 2x2 (число степеней свободы равно 1) крити-
ческие значения для #2 равны 3,84 (для а = 0,05) и 6,63 (для а = 0,01).
Нулевая гипотеза отвергается, если вычисленное значение превосхо-
дит табличное при данном уровне значимости.
Следует подчеркнуть, что в таком виде этот критерий может быть
использован только при сопоставлении данных, представленных в
альтернативной форме. Кроме того, правомерность его применения
ограничивается в соответствии с условием Кокрена. Рекомендация Кок-
рена для таблиц 2x2 состоит в следующем: если сумма 4 частот мень-
ше 20, следует использовать точный критерий Фишера. Если сумма
между 20 и 40 и наименьшая ожидаемая частота меньше 5, то следу-
ет использовать точный критерий Фишера. Если сумма равна 40 и
более, то можно применять критерий %2 с поправкой на непрерыв-
ность [19].
Критерий х2 может применяться и к таблице сопряженности про-
извольной размерности в случае, если все ожидаемые числа не мень-
ше 1 и доля клеток с ожидаемыми числами меньше 5 не превышает
20%. При этом данный критерий является аналогом критериев для
множественного сравнения групп. Кроме того, критерий х2 приме-
няется и для сравнения качественных переменных с числом града-
ций больше двух. В формуле для вычисления тестовой статистики
сумма берется по всем возможным градациям качественной перемен-
ной. Поправка на непрерывность в случае размерности больше чем
2x2 не требуется, а число степеней свободы для проверки критерия
равно произведению числа градаций минус один на число групп ми-
нус один. Подробнее об этом написано в [14, 18, 19, 22].
Точный критерий Фишера
Когда число наблюдений невелико и в таблицах ожиданий встре-
чаются клетки со значениями меньше 5, критерий ^неприменим. В
этом случае используют другой непараметрический критерий — точ-
ный критерий Фишера, Он основан на переборе всех возможных ва-
риантов заполнения таблицы сопряженности при данной численно-
сти групп, поэтому чем она меньше, тем проще его применять. Кри-
терий Фишера позволяет получать точные значения вероятности
событий, столь же или еще менее вероятных, чем те, которые наблю-
дались в действительности. Подробнее с этим методом можно позна-
комиться, например, в книгах [2, 3, 18, 19].
80 Глава 1. Математическая статистика в клинических исследованиях
/ill п\2
п2\ п22
пЛ п.2
Нулевая гипотеза состоит в том, что между воздействием препара-
та и исходом нет никакой связи, а значит, показатели опытной и кон-
трольных групп совпадают. Тогда вероятность /^получить некоторую
таблицу 2x2 вида:
\п\.
\п2. _ п1ЛпЛ\п2Ап.2\
Р- равна Pf = — (48)
\N л11!я12!я21!л22!М
где п 1. и п2. — суммы по строкам (число пациентов в опытной и кон-
трольной группах), пЛ и я.2 — суммы по столбцам (число пациентов
с первым и вторым исходом в обеих группах), N — общее число на-
блюдений. Знак! обозначает факториал (л! = 1-2 •... (п — 1) п; О! = 1).
Построив все остальные варианты заполнения таблицы, возможные
при данных суммах по строкам и столбцам, по этой же формуле рас-
считывают их вероятность. Вероятности, которые не превосходят ве-
роятность исходной таблицы (включая саму эту вероятность), сумми-
руют. Надо заметить, что числитель данной формулы и величина М
зависят только от величин сумм по строкам и столбцам, которые оста-
ются постоянными при изменении варианта заполнения таблицы,
поэтому их значения можно не пересчитывать каждый раз. Другой спо-
соб уменьшить объем вычислений — выписать в числителе и знамена-
теле вместо факториалов соответствующие им произведения натураль-
ных чисел, а затем произвести очевидные сокращения сомножителей.
Таким образом, алгоритм точного критерия Фишера может быть
сформулирован следующим образом:
• по полученной в исследовании таблице сопряженности вычис-
лить вероятность получения этой таблицы;
• рассмотреть все остальные возможные варианты заполнения таб-
лицы при неизменных суммах по строкам и столбцам (для этого
в одной из клеток надо поставить все числа от нуля до макси-
мально возможного, пересчитывая числа в остальных клетках так,
чтобы суммы по строкам и столбцам сохранялись);
• вычислить вероятность для всех полученных таблиц;
• просуммировать вероятность получения исходной таблицы и все
вероятности, которые ее не превышают.
Суммарное значение Pf соответствует /^-значению, обсуждавшему-
ся в разделе о проверке гипотез. А значит, данная нулевая гипотеза от-
вергается на заданном уровне значимости «при значении Pf<a. Необ-
ходимо обратить внимание на то, что предложенный в некоторых кни-
гах по биометрии вариант данного критерия, учитывающий лишь
1.7. Статистический анализ результатов клинических исследований 81
вероятность получения исходной таблицы, дает заниженное значение
Pf. А это, в свою очередь, приводит к тому, что делается вывод о нали-
чии значимых различий в то время, когда их на самом деле нет. Кроме
того, надо предупредить, что в различных учебниках и справочниках
предложены различные модификации данного критерия [3, 18, 19, 22].
Для примера рассмотрим таблицу сопряженности 2x2 (табл. 8).
Таблица 8.
Таблица сопряженности 2x2 для примера расчета по точному критерию
Фишера
Исходы
Опытная группа (по)
Контрольная группа (пк)
В с е го
ДА
1
5
6
НЕТ
6
8
14
Всего
7
13
20
Так как некоторые значения в клетках таблицы меньше 5, пользо-
ваться критерием %2 невозможно. Для точного критерия Фишера су-
ществуют односторонний и двусторонний варианты. Рассмотрим од-
носторонний вариант критерия. Рассчитаем вероятность при тех же
значениях сумм по строкам и столбцам получить такой же набор чи-
сел в клетках, что и в исходной таблице:
7!13!6!14!
J 20!1!6!5!8!
Возьмем наименьшее из чисел в клетках, это единица на пересе-
чении первой строки и первого столбца. Уменьшим это значение на
1, числа в остальных клетках изменим так, чтобы суммы по строкам и
столбцам сохранялись. Получим табл. 9.
Таблица 9.
Промежуточная таблица для расчетов по точному критерию Фишера
Исходы
Опытная группа (по)
Контрольная группа (пк)
Всего
ДА
0
6
6
НЕТ
7
7
14
Всего
7
13
20
Для этой таблицы вероятность заполнения равна:
7!13!6!14!
/>/"20!0!7!6!7!"°'<Ж'
82 Глава 1. Математическая статистика в клинических исследованиях
Наименьшее из чисел в таблице равно нулю, продолжать процесс
уменьшения невозможно. Таким образом, односторонний вариант
критерия дает значение вероятности Pf= 0,23 + 0,044 = 0,274. Мы по-
лучили точное значение вероятности событий, столь же или менее ве-
роятных, чем те, которые в действительности наблюдались. Рассчи-
танное значение вероятности достаточно высокое (по сравнению с
а = 0,05), данные следует считать согласующимися с нулевой гипоте-
зой, согласно которой распределение двух совокупностей одинаково.
Чтобы воспользоваться двусторонним вариантом критерия, нуж-
но было бы перебрать все остальные варианты заполнения таблицы
при сохранении неизменными сумм по строкам и столбцам. В нашем
случае, например, надо было бы увеличивать элемент на пересече-
нии первой строки и первого столбца, пересчитывая все остальные
клетки таблицы, пока какой-либо другой элемент таблицы не обра-
тится в 0. При этом появляются еще 5 вариантов (кроме двух пока-
занных выше) заполнения таблицы, из которых только три дают ве-
роятность заполнения соответствующей таблицы меньше вероятнос-
ти заполнения исходной таблицы. Суммарная вероятность в данном
случае Pf= 0,35. Таким образом, сделанный с помощью односторон-
него критерия статистический вывод подтверждается.
Пример 10. Сравним результаты в опытной и контрольной группе
из примера 9 (см. табл. 7). Данные примера 9 представлены в альтерна-
тивной форме, и мы можем рассчитать соответствующие значения до-
лей. Попробуем использовать критерий Стьюдента для проверки раз-
ности между выборочными долями 0,36 и 0,78 опытной и контрольных
групп (неравновеликие группы из табл. 7). Определим средневзвешен-
ную долю р = (9 + 28)/(25 + 36) = 0,61. Ошибка выборочной доли
равна ср = 0,13. Значение критерия / = (0,36—0,78)/0,13 = —3,23. По
таблицам критерия Стьюдента (см. приложение, табл. 1) для числа
степеней свободы/= 61 — 2 = 59 и уровня значимости 1% определяем
критическое значение, равное 2,66. Нулевая гипотеза о равенстве до-
лей отвергается, так как рассчитанная нами статистика по модулю пре-
восходит критическое табличное значение. Различия признаются в вы-
сокой степени статистически значимыми (0,001 <р < 0,01).
Применим угловую трансформацию. По табл. 6 приложения для
значений долей 0,36 и 0,78 (без поправки Йейтса) определим соот-
ветствующие значения ф f<pl = 1,287; ср2 = 2,165,). Разность между зна-
чениями ф1 — ф2 равна —0,878; значение критерия / в этом случае
будет —3,37. Оно также по модулю превышает соответствующее таб-
1.7. Статистический анализ результатов клинических исследований 83
личное значение для 5-процентного уровня значимости, а значит, ну-
левая гипотеза может быть отвергнута.
Проверим полученные выводы с помощью критерия %2 для таблиц
сопряженности. Всего в опытной и контрольной группе (см. табл. 7,
объем двух групп N = 61) положительная реакция наблюдалась у
37 пациентов, или у 61%. Если бы препараты действовали одинаково,
частота появления положительной реакции в обеих группах была бы
одинакова. Рассчитав, сколько составляет 61% от 25 и 36 пациентов в
разных группах, определим ожидаемые доли при справедливости ну-
левой гипотезы. Ожидаемая таблица сопряженности будет иметь сле-
дующий вид (табл. 10).
Таблица 10.
Ожидаемая таблица сопряженности для примера 10
Исходы
Опытная группа (по)
Контрольная группа (пк)
Всего
ДА
15,25
21,96
37,21
НЕТ
9,75
14,04
23,79
Всего
25
36
61
Для каждой из четырех клеток найдем разницы между наблюдае-
мыми и ожидаемыми значениями (разницу между соответствующи-
ми значениями в табл. 7 и 10). Рассчитаем величину статистики
X2- 9,14 (с учетом поправки). Табличное значение критерия (см. при-
ложение, табл. 2), соответствующее одной степени свободы и уровню
значимости 1% , равно 6,63. Рассчитанное нами значение тестовой
статистики превзошло критическое табличное, поэтому с вероятнос-
тью более 99% мы отклоняем нулевую гипотезу об отсутствии разли-
чий между препаратами. Различия признаются статистически досто-
верными. Статистические выводы согласуются с полученными ранее
с помощью критерия Стьюдента.
Задача ДО—ПОСЛЕ в случае
альтернативного распределения признака
Аналогом параметрического критерия Стьюдента для попарных
разностей или непараметрического Г-критерия Уилкоксона является
критерий Мак-Нимара, применяющийся для анализа связанных из-
мерений в случае измерения реакции с помощью дихотомической
переменной. По результатам такого исследования составляется ре-
зультирующая таблица 2x2 в таком виде (табл. 11):
84 Глава 1. Математическая статистика в клинических исследованиях
Таблица 11.
Общий вид таблицы 2x2 для критерия Мак-Нимара
ДО/ПОСЛЕ
1
0
Всего
0
А
С
А + С
1
В
D
В + D
Всего
А + В
С + D
N
В клетках А и D представлены изменения от ДО к ПОСЛЕ, причем
в клетке А изменения благоприятных результатов на неблагоприятные,
а в клетке D — наоборот. Нулевая гипотеза состоит в том, что в гене-
ральной совокупности доля тех, кто изменяет благоприятную реакцию
на неблагоприятную в результате воздействия, равна доле тех, кто из-
меняет реакцию в обратном порядке. Объем выборки N определяется
как сумма частот в диагональных клетках А и D. Для проверки гипоте-
зы в случае N > 50 рассчитаем статистику %2 по упрощенной формуле
[18] (для данного критерия число степеней свободы всегда равно 1):
z>JA-*-V\ (49)
л A + D
где \А — D\ — абсолютное значение разности значений соответствую-
щих клеток, единица вычитается в качестве поправки на непрерыв-
ность. Данный критерий проверяется по табл. 2 приложения для выб-
ранного уровня значимости. Если рассчитанное значение статисти-
ки превосходит соответствующее табличное, нулевая гипотеза
отвергается. Так, в результате исследования была получена табл. 12.
Таблица 12.
Таблица данных для примера расчетов по критерию Мак-Нимара
ДО/ПОСЛЕ
1
0
Всего
0
26
38
64
1
30
32
62
Всего
56
70
126
Пусть в качестве уровня значимости выбран 1%, N= 26 + 32 = 58 > 50.
Тестовая статистика в данном случае:
(126-321-1)'
Л 26+32
1.7. Статистический анализ результатов клинических исследований 85
Соответствующее критическое значение в табл. 2 приложения рав-
но 6,63. Поскольку рассчитанное значение критерия меньше крити-
ческого табличного, мы не можем отвергнуть нулевую гипотезу об
отсутствии различий между показателями ДО и ПОСЛЕ на выбран-
ном уровне значимости.
Если значение N для данного критерия < 50, критерий проверя-
ется как двусторонний с помощью таблиц биномиального распре-
деления [18].
Множественные сравнения повторных измерений
в случае альтернативного распределения признака
Критерий Кокрена является аналогом непараметрического крите-
рия Фридмана для случая альтернативного учета реакции. Как и в
случае критерия Фридмана, сравнивается влияние различных воздей-
ствий на одну группу пациентов (мультиперекрестный план — повтор-
ные измерения) или однородные группы (рандомизированный блоч-
ный план). Исходной для проверки критерия является таблица ре-
зультатов исследования в следующем виде: по столбцам — значения
эффекта от соответствующей терапии, в данном случае в виде 0 и 1,
по строкам — повторные измерения значения эффекта для одного
индивидуума (или однородной группы) (всего п объектов). Нулевая
гипотеза состоит в том, что в генеральной совокупности доли всех
изучаемых воздействий одинаковы. Для проверки критерия рассчи-
тывается тестовая статистика:
("*-DI
Q =
т£(£хк)2-(£хТ)2
«Z<I**>-I<I*2>
(50)
где m — число изучаемых воздействий;
(1ХТ)2 = (IX, + 1Х2 + ... + IXJ2
где^ Хк = ^Г Xik — сумма значений по А:-му столбцу.
*=1 1(1Х)2 = (IX) 2+ (IX) 2 + ... + (IXf
I(IXj) — сумма итоговых значений по строкам;
1(1Х2) — сумма квадратов итоговых значений по строкам.
Полученное значение статистики Q проверяется по таблицам %2
для выбранного уровня значимости и числа степеней свободы, рав-
ного m — 1. Если рассчитанное значение превосходит табличное, ну-
левая гипотеза отклоняется на выбранном уровне значимости а.
86 Глава 1. Математическая статистика в клинических исследованиях
Рассчитаем для примера критерий Кокрена для гипотетической
таблицы результатов исследования 4 различных воздействий на 15
пациентах (табл. 13).
Таблица 13.
Таблица результатов гипотетического исследования для примера расче-
тов по критерию Кокрена
Пациент
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
^
Терапия 1
0
0
0
0
1
0
1
1
0
0
1
1
0
1
1
7
Терапия 2
0
1
1
0
0
1
1
0
1
0
1
1
0
0
1
8
Терапия 3
0
0
0
0
1
0
0
0
1
0
0
1
0
0
1
4
Терапия 4
0
0
0
11
***
0
2
2
0
3
2
3
2
2
1
3
3
1
2
4
WXR) =
1 30
***
0
4
4
0
9
4
9
4
4
1
9
9
1
4
16
WXR2) =
78
Подставляем рассчитанные суммы в итоговую формулу для тесто-
вой статистики:
3[4-(49+ 64+ 16+ 121)-9001^300
40-30-78 " 42 " '
Поскольку рассчитанное значение статистики меньше таблич-
ного (см. приложение, табл. 2, уровень значимости равен 1%, число
степеней свободы равно 3), отклонить нулевую гипотезу не удается.
1.7. Статистический анализ результатов клинических исследований 87
Критерий для объединения результатов,
представленных в виде нескольких таблиц
сопряженности 2x2 (Mantel—Haenszel test)
Данный критерий применяется в случае, если дизайн исследова-
ния предусматривал процедуру стратификации, а также при объеди-
нении результатов независимых исследований с помощью метаана-
лиза. Допустим, исследователь с помощью процедуры рандомизации
по какому-либо исходному признаку выделил несколько страт (под-
групп) пациентов (например, различные центры в мультицентровом
исследовании), и в ходе исследования были получены результаты в
виде таблиц сопряженности отдельно для каждой подгруппы. Теперь
задача исследователя состоит в том, чтобы дать обобщенное заклю-
чение без учета стратификации.
Таблица 14.
Общий вид таблицы сопряженности 2x2 представляет результаты иссле-
дованиям в /-подгруппе
Тестовая группа
Контрольная группа
Всего
Да (1 или + )
а,
с.
а. + с.
Нет (0 или —)
*,
d.
bl + di
Всего
«, + */
с, + d,
N,
Тогда величина (а. + c.)/N. дает долю пациентов обеих сравнивае-
мых групп /-страты, продемонстрировавших положительную реакцию
на воздействия. Для сравнения эффекта в двух группах внутри /-стра-
ты нужно сравнить доли пациентов с положительной реакцией, то есть
а/(а. + с) и с. /(с. + d.) соответственно для двух сравниваемых групп.
Это сравнение параллельных групп обычно делается с помощью стан-
дартного теста #2 для таблиц сопряженности 2x2. Если исследователь
хочет объединить результаты всех страт (к — число объединяемых таб-
лиц сопряженности) и сравнить воздействия сразу для всех пациен-
тов, нужно рассчитать обобщенную статистику МН [32]:
|Sfo -(*, + с,)(а,+*,)/*,]}
МН = - {— }- (51)
S (в, + с, Щ + d, Xfl, + b, Xc, +d,)/ Nf (N,-1)
Предложенная статистика учитывает различия между наблюдае-
мым и ожидаемым числом пациентов с положительной реакцией,
88 Глава 1. Математическая статистика в клинических исследованиях
имеет распределение #2с 1 степенью свободы. Если рассчитанное зна-
чение статистики превосходит критическое табличное (см. приложе-
ние, табл. 2), нулевая гипотеза об отсутствии различий в эффекте от-
клоняется на выбранном уровне значимости. 5-процентному уровню
значимости в табл. 2 приложения соответствует критическое значе-
ние 3,84; 1-процентному — значение 6,63.
1.7.10. Элементы дисперсионного анализа
Дисперсионный анализ был разработан английским математиком
Р. Фишером. Само название метода говорит о том, что в центре вни-
мания находится дисперсия, то есть мера изменчивости признаков.
Иногда дисперсионный анализ называют еще анализом вариаций. Под
вариацией в данном случае понимают сумму квадратов отклонений
относительно выбранного среднего значения. Основные обобщающие
возможности дисперсионного анализа состоят в том, что, исходя из
имеющихся данных, он «обеспечивает прямую оценку внутренней
неопределенности». Базовая идея дисперсионного анализа заключа-
ется в разложении общей дисперсии изучаемых признаков на состав-
ляющие в соответствии с возможными источниками вариации, вы-
числении /^-отношений в качестве тестовой статистики и проверки
значимости нулевой гипотезы об отсутствии существенного влияния
данного фактора на общий разброс данных. На получаемых с помо-
щью дисперсионного анализа оценках вариаций построено большое
количество различных статистических критериев, он применяется в
различных разделах математической статистики. Покажем, как дис-
персионный анализ может успешно применяться для проверки гипо-
тезы о равенстве средних значений для независимых выборок и вы-
борок с попарно связанными вариантами. Кроме того, в соответству-
ющем разделе методы дисперсионного анализа будут использоваться
нами для оценки значимости выборочной линии регрессии.
Ранее мы обсуждали проблему оценки значимости различий меж-
ду средними значениями двух (или нескольких) выборок. При этом
соответствующая параметрическая вероятностная модель предпола-
гала, что обе выборки извлечены из нормальной совокупности с об-
щей дисперсией, но, возможно, с различными математическими ожи-
даниями, и проверялось, согласуются ли данные с нулевой гипотезой
о фактическом равенстве этих математических ожиданий. На прак-
тике эти выборки могли быть измерениями каких-либо сопостави-
мых величин, полученных в результате различных воздействий (ле-
1.7. Статистический анализ результатов клинических исследований 89
чений). А расхождение между математическими ожиданиями, если
оно имеется, приписывалось именно различию этих воздействий.
Дисперсионный анализ является параметрическим методом и
предполагает, что выборки извлечены из совокупности, распределен-
ной по нормальному закону. В общем виде метод дисперсионного
анализа основан на расчете как полной вариации или дисперсии при-
знаков, так и отдельных ее элементов, обусловленных различными
причинами. Статистические сравнения этих различных дисперсий
позволяют сделать вывод о том, какие именно факторы вносят наи-
больший вклад в наблюдаемый разброс данных. Для сравнения групп
мы будем рассматривать однофакторную модель дисперсионного ана-
лиза. Нужно обратить внимание на то, что дисперсионный анализ
позволяет ответить на вопрос, равны ли все сравниваемые математи-
ческие ожидания. В случае если равны лишь несколько из общего
числа сравниваемых средних значений, в результате применения дис-
персионного анализа такое равенство установлено не будет.
Чтобы оценить величину различий средних значений нескольких не-
зависимых выборок, нужно попытаться сравнить разброс самих выбо-
рочных средних с разбросом значений признака вокруг соответству-
ющего группового среднего внутри групп. Чем больше разброс сред-
них и меньше разброс значений внутри групп, тем меньше вероятность
того, что данные группы представляют собой случайные выборки из
одной и той же генеральной совокупности. Обозначим буквой Z ва-
рианты обобщенной выборки, состоящей из значений Хи У сравни-
ваемого признака в двух группах сравнения объемом п\ и п2 соответ-
ственно. Тогда объем выборки Zбудет п\ + «2. Рассчитаем величину
главного среднего объединенной выборки:
(52)
Дисперсионный анализ основан на справедливости алгебраичес-
кого тождества: полная сумма квадратов, измеряющая изменчивость
совокупности данных в целом, равна сумме общей изменчивости внут-
ри выборок (внутривыборочная сумма квадратов) и различия между
выборками (межвыборочная сумма квадратов). Если исследуемые вы-
борки на самом деле не различаются, то появившееся межвыбороч-
ное различие вызвано лишь случайными флуктуациями. Не вдаваясь
в математические выкладки, доказывающие справедливость данного
статистического метода, приведем таблицу дисперсионного анализа,
90 Глава 1. Математическая статистика в клинических исследованиях
которая обычно используется для анализа различий между двумя не-
зависимыми выборками [19] (табл. 15).
Таблица 15.
Общий вид таблицы дисперсионного анализа для анализа различий меж-
ду двумя независимыми выборками
Источник изменчивости
Различия между выбор-
ками — величина b
Различия внутри выбо-
рок — величина w
Полная изменчивость
Сумма квадратов
E(*<--x)2+LM)2
Яя-zf
Число степеней свободы
1
п\ + п2-2
п\ + п2- 1
Для проверки нулевой гипотезы о равенстве средних значений двух
групп с помощью дисперсионного анализа нужно рассчитать величи-
ну дисперсионного отношения Fc учетом числа степеней свободы
F = b/\w/, Л „г • Большие значения этой величины (значимо пре-
l/m + Ai2-2J
вышающие единицу) указывают на существование значимых разли-
чий между группами. Для более точной проверки пользуются крите-
рием Фишера для отношения дисперсий (аналогично сравнению
дисперсий в случае критерия Стьюдента). При этом нужно сравнить
рассчитанное значение F(\, п\ + п2 — 2) с табличным (см. приложе-
ние, табл. 8) для числа степеней свободы /1 = 1и/2=я1 + я2 — 2,
а также выбранного уровня значимости а.
Данный метод может быть распространен на случай сравнения т
выборок. Таблица дисперсионного анализа в данном случае будет иметь
вид [19] (табл. 16).
Таблица 16.
Общий вид таблицы дисперсионного анализа для анализа различий меж-
ду несколькими (т) независимыми выборками
Источник изменчивости
Различия между выбор-
ками — величина Ь
Различия внутри выбо-
рок — величина w
Полная изменчивость
Сумма квадратов
S
S Г
S Г
Число степеней свободы
т- 1
N -т
N- 1
Хп — значения сравниваемого признака в объединенном ряду; Xs —
среднее значение признака в группе s объемом ns; X— главное среднее
1.7. Статистический анализ результатов клинических исследований 91
обобщенной выборки; в данном случае N— объем обобщенной выбор-
ки, равен сумме объемов т выборок. Как и в предыдущем случае, для
проверки критерия вычисляется .F-статистика F = *■ ^т ~ 'д ,(N__ , л,
затем она сравнивается с табличным значением F(m — 1, N — т) (см.
приложение, табл. 8) на выбранном уровне значимости а. Если рас-
считанное значение превосходит табличное, нулевая гипотеза отвер-
гается на выбранном уровне значимости. Надо заметить, что оценка
внутригрупповой дисперсии w/(N — m), предоставляемая дисперси-
онным анализом, как раз и используется в качестве обобщенной оцен-
ки дисперсии или соответствующего среднего квадратичного откло-
нения s при проведении множественных сравнений с помощью па-
раметрических критериев.
Еще одно соотношение кажется нам полезным с практической точ-
ки зрения. Оказывается, можно доказать [19], что при справедливос-
ти нулевой гипотезы о равенстве средних значений в двух группах,
поскольку квадратный корень из случайной величины Д1, п\ + п2 — 2)
подчиняется распределению Стьюдента с п\ + п2 — 2 степенями сво-
боды, дисперсионный анализ дает тот же уровень значимости, что и
соответствующий критерий Стьюдента. А значит, взяв квадратный
корень из рассчитанного в дисперсионном анализе .F-отношения
(только в случае сравнения двух групп), можно сравнить полученное
значение с табличным по табл. 1 приложения.
Дисперсионный анализ может применяться также и для анализа
связанных или повторных измерений, то есть в случае, если одни и те
же пациенты получали несколько сравниваемых методов лечения или
сравнивается эффект от проводимого лечения в одной группе в кон-
це нескольких последовательных периодов времени. С помощью дис-
персионного анализа можно проверить, вызвали ли все эти различ-
ные методы лечения статистически достоверные различия в эффекте
у данных пациентов [3, 14].
Представим результаты исследования в виде таблицы: по строкам —
информация о различных пациентах (всего п пациентов), а по столб-
цам — значения изучаемого показателя X у конкретного пациента в
результате различных вариантов терапии (всего т различных измере-
ний). Тогда в матричном представлении: Xij — значение показателя эф-
фекта у /-пациента в результате у-терапии. Вычислим средние значения:
2*,Xij у — индивидуальное среднее значение для /-пациента по
X, = j у всем вариантам терапии;
92 Глава 1. Математическая статистика в клинических исследованиях
_ zv
ту = / / — среднее значение по всем пациентам дляу-терапии;
X = £ ]Г Х(/ /т • и — главное среднее.
J » /
Основной принцип, так же, как и раньше, состоит в том, что об-
щая вариация показателей вокруг главного среднего значения пред-
ставляет собой сумму внутрииндивидуальной вариации значений по-
казателя вокруг индивидуального среднего и межиндивидуальной
вариации индивидуальных средних вокруг главного среднего значе-
ния. В свою очередь, внутрииндивидуальная вариация может быть
представлена р виде суммы вариации, обусловленной проводимым
лечением, и остаточной вариации. Тогда таблица дисперсионного
анализа будет представлена в таком виде (табл. 17).
Таблица 17.
Общий вид таблицы дисперсионного анализа для анализа повторных из-
мерений
Источник изменчивости
Межиндивидуальная
вариация
Внутрииндивидуальная
вариация
Вариация, обуслов-
ленная лечением
Остаточная вариация
Общая вариация
Сумма квадратов
Sl = n£(xi-xJ
52=ZZ(^-^)2
S3 = riZ[¥j-xJ
S4 = S2- S3
Число степеней свободы
п- 1
п(т- 1)
т- 1
(п-\Нт-\)
тп — 1
Для проверки нулевой гипотезы используется статистика
F = {S3/(m — \)}/{S4/(n — l)(m — 1)} — отношение дисперсии, обус-
ловленной лечением, к остаточной дисперсии. Статистика проверя-
ется по табл. 8 приложения для F(m — 1,(я — 1)(/и — 1)) и выбранно-
го уровня значимости.
Подробнее с методами дисперсионного анализа можно познако-
миться в [2, 3, 14, 19].
Пример 11. Проиллюстрируем возможности дисперсионного ана-
лиза для множественного сравнения независимых групп на примере
данных из табл. 2 (1—3-й столбцы). Выше эти же данные использова-
1.7. Статистический анализ результатов клинических исследований 93
лись для множественных сравнений с помощью критерия Стьюдента
и критерия Даннета (см. пример 8). Средние значения для трех срав-
ниваемых групп соответственно равны 13,1; 8,4; 11,0. Численность
всех групп одинакова и равна 10. Главное среднее Х= 10,8. Рассчита-
ем таблицу дисперсионного анализа для этой задачи (табл. 18).
Таблица 18.
Таблица дисперсионного анализа для данных примера 8
Источник
изменчивости
Различия
между выборками
Различия
внутри выборок
Полная
изменчивость
Сумма квадратов
£ = 10(5,3 + 5,76 + 0,04)= 111
w = 28,8+ 20,52+ 27,9 = 77,22
188,3
Число степеней
свободы
3- 1
30-3
30- 1
Для оценки дисперсионного отношения F найдем отношение ве-
личины Ъ к соответствующему числу степеней свободы (111/2 = 55,5)
и отношение величины w к своему числу степеней свободы (77,22/27=2,9).
Тогда F = 55,5/2,9 = 19,4. Вероятность получить такое или большее
значение /'мала. А значит, с вероятностью более 99% (см. табл. 8 при-
ложения) для F(2,27) можно утверждать, что все 3 сравниваемые груп-
пы достоверно различаются. Эти выводы полностью согласуются с
полученными ранее в примере 8.
Для проведения расчетов с помощью методов дисперсионного ана-
лиза таблица данных должна быть заполнена полностью. Однако не
секрет, что в данных клинических исследованиях могут встретиться
пропуски. Для решения проблем, возникающих из-за пропущенных
значений (одного-двух), можно применять методы, изложенные в
[12,14]. Вообще методы статистической обработки пропущенных на-
блюдений рассмотрены в [1, 10]. При этом нужно иметь в виду, что
отсутствие значения какого-либо признака для корректного приме-
нения этих процедур может быть вызвано только причинами техни-
ческого характера, а не состоянием самого изучаемого объекта вслед-
ствие проводимого исследования. Например, в случае гибели живот-
ного из-за отравления изучаемым препаратом в ходе проведения
доклинических испытаний отсутствующие данные не подлежат вос-
становлению.
94 Глава 1. Математическая статистика в клинических исследованиях
Дисперсионный анализ результатов исследования,
построенного по перекрестному плану типа АВ/ВА
Перекрестный дизайн позволяет сравнивать эффекты различных
терапий у одной и той же группы пациентов во время различных пе-
риодов наблюдения, и в этом смысле он может анализироваться в рам-
ках попарных сравнений. Мы не будем останавливаться на медицин-
ских аспектах дизайна такого типа и его достоинствах и недостатках
с клинической точки зрения. Мы приведем лишь одну из статисти-
ческих моделей данных и связанные с ней статистические приемы их
анализа. Рассмотрим простейшую схему перекрестного дизайна АВ/ВА,
при котором каждый включенный в исследование пациент получает
2 сравниваемые терапии X и Y в различные периоды времени (назо-
вем их периодами наблюдения), разделенные между собой достаточ-
ным времениь/м промежутком для исключения влияния предыдущей
терапии. Субъекты исследования размещаются случайным образом в
двух группах: А и В. Испытуемые группы А (объем группы равен п\)
получают сначала терапию X, затем терапию Y. Испытуемые группы
В (объем группы равен л2), наоборот, сначала получают терапию У, а
затем — X. Именно это обстоятельство несколько усложняет проце-
дуру расчетов. Число пациентов в группах может быть одинаковым
(сбалансированное исследование) или различным. Анализ данных,
как обычно, зависит от типа переменной, выбранной в качестве пе-
ременной эффекта, но общие принципы сохраняются. Поэтому мы
рассмотрим случай количественного выражения переменной эффек-
та, а остальные случаи рассмотрены, например, в [34].
Рассматриваемая статистическая модель данных предполагает, что
переменная эффекта содержит информацию не только об эффекте от
получаемой терапии, но и о случайном изменении этого показателя
во времени [34]. Такие временные изменения имеют межиндивиду-
альную вариабельность, но в некоторых случаях возможно наличие
устойчивого изменения, и тогда можно говорить о временном тренде
данного показателя (например, в случае, если болезнь прогрессирует).
Для того чтобы в рамках статистического анализа «отделить» изучае-
мый терапевтический эффект от вклада изменения данного показате-
ля в течение времени, делается несколько специальных предположе-
ний. Первое допущение, общее для многих процедур статистическо-
го анализа, предполагает аддитивность вкладов различных эффектов.
Второе допущение является специфическим для такого вида дизайна
и предполагает, что эффект от терапии, полученной второй, не зави-
сит от эффекта первой терапии.
1.7. Статистический анализ результатов клинических исследований 95
Пусть значение переменной эффекта в отсутствие терапии будет
обозначаться е\ для первого периода и е2 для второго. Величины, на
которые получение соответствующей терапии изменяет переменную
эффекта, обозначим как Тх и Ту. Тогда соотношения для переменной
эффекта можно записать в виде табл. 19.
Таблица 19.
Общий вид соотношений для переменной эффекта в случае выбранной
модели данных и перекрестного дизайна ЛВ/ВЛ
Период терапии 1
Период терапии 2
Субъекты группы Л
у\ = Тх + е\
у2 = Ту + е2
Субъекты группы В
у\ = Ту + е\
у2 = Тх + е2
Считается, что значения у\, у2, el, е2 являются специфическими
для каждого пациента, а значения Тх и Ту остаются постоянными.
Для группы А разница в эффекте между терапиями X— У оценивается
различиями у\ — у2, в то время как для группы В — различиями
у2 — у\. Тогда можно ввести величины dA =у\ —у2 = Тх—Ту+(е\ — е2)
и dB = у2 — у\ = 7jc — Ту — (el — е2). Значения el — e2 оценивают
временной тренд показателя, такие средние изменения обозначим 8.
В результате получим следующие статистические оценки:
Величина -\dA + dB) оценивает разницу Тх— Ту, то есть относите-
льную эффективность сравниваемых терапий.
Величина —\dA-dB) оценивает 8, то есть временной тренд показа-
теля между различными периодами наблюдения.
Стандартная ошибка для обеих оценок может быть выражена фор-
мулой:
-л/<т2/и1 + <72/и2' (53)
2
где а — среднее квадратичное отклонение различий в группах А и В.
Тогда статистическая значимость различий в эффекте сравнивае-
мых терапий и статистическая значимость влияния периода наблю-
дений могут быть проверены с помощью гипотез о равенстве нулю
Тх — Ту или 8 соответственно. Статистические гипотезы тестируются
с помощью отношения соответствующей оценки к ее стандартной
ошибке; как обычно, полученное отношение сравнивается с крити-
96 Глава 1. Математическая статистика в клинических исследованиях
ческими точками стандартного нормального распределения на выб-
ранном уровне значимости.
В данных тестах предполагается, что для групп А и В величина сред-
него квадратичного отклонения а имеет одинаковую оценку. Однако
для выборок малого объема различия в этих оценках могут оказаться
существенными. Для исправления ситуации можно получить обоб-
щенную оценку s величины о по известной формуле:
2 (nl-l)'sdA2+(n2-l)-sdB2 ,„ ч
s = , pja;
п1 + и2-2
где sdA2 и sdB2 — стандартные отклонения различий в соответствую-
щих группах.
Тогда стандартная ошибка оценок вычисляется на основе усред-
ненного значения s по формуле:
1 п 5 (54)
-V*2 /nl + s2 1п2
2
В этом случае тестовое отношение сравнивается с табличным для
распределения Стьюдента с числом степеней свободы п\ + п2 — 2 и
для выбранного уровня значимости. Таким образом, этот тест боль-
ше подходит для выборок малого объема.
Приведем пример, демонстрирующий порядок вычислений. Для
упрощения предположим, что по исходным данным уже вычислены
индивидуальные значения соответствующих различий dA и dB для всех
включенных пациентов и средние результаты отражены в табл. 20, 21.
Таблица 20.
Средние результаты гипотетического исследования, выполненного по
перекрестному плану АВ/ВА, группа А
Число испытуемых, п\
Среднее значение
Среднее квадратичное отклонение
Период 1
17
7,86
3,84
Период 2
17
5,72
4,25
Различия
1-2
17
2,14
3,47
Различия в эффекте двух сравниваемых терапий можно оценить
такой
1 /tt.47^2 / ШУ>2 / 1 и„.
оценки равна:
как -\dA + dB)= 1/2(2,14 + 0,89) = 1,52. Стандартная ошибка
«1^47)% + ft(0Y2 -V0JU0J5 =0,604.
1.7. Статистический анализ результатов клинических исследований 97
Таблица 21.
Средние результаты гипотетического исследования, выполненного по
перекрестному плану АВ/ВА, группа В
Число испытуемых, л2
Среднее значение
Среднее квадратичное отклонение
Период 1
12
7,51
3,2
Период 2
12
8,4
2,81
Различия
1-2
12
0,89
3,0
Полученную оценку можно было бы уточнить с помощью обоб-
щенной формулы:
2 16 12,04 + 11,9 192,64 + 99 Лппо
s = = = Ш,7о .
17 + 12-2 27
Тогда уточненное значение стандартной ошибки оценки равно:
1^8/+Ю,78/= 1Д63Т09=0(62.
Гипотезу о значимости различий между терапиями проверяем с
помощью отношения 1,52/0,6 = 2,53, различия оказываются значи-
мыми для 0,01 < р < 0,05. 95-процентный доверительный интервал для
величины различий в эффекте задается выражением: 1,52 ± 1,96- 0,6,
то есть интервал лежит между границами 0,34 и 2,7. Проверка ги-
потезы с учетом объема выборки приводит к тестовому отношению
1,52/0,62 = 2,45, которое также указывает на статистическую значи-
мость различий (число степеней свободы равно 27) 0,01 < р < 0,05.
95-процентный доверительный интервал с учетом числа степеней сво-
боды становится немного шире: 1,52 ± 2,050,62 и расположен между
границами 0,25 и 2,79.
Аналогично можно оценить и наличие временного тренда, то есть
наличие влияния периода времени наблюдений на величину эффек-
та. Оценка 8 равна 0,63, стандартная ошибка этой оценки по-пре-
жнему равна 0,62. Тестовая статистика вычисляется как отношение
0,63/0,62 = 1,02, то есть влияние периода времени на результирую-
щий эффект статистически незначимо.
Представленная статистическая модель данных предполагала от-
сутствие влияния последовательности получения сравниваемых те-
рапий на результирующий эффект от лечения. Говоря математичес-
ким языком, это означает, что величины эффекта Тх и Ту от получе-
98 Глава 1. Математическая статистика в клинических исследования>
ния терапии одинаковы для двух периодов наблюдения, и взаимовли-
яние между терапиями (Т) и периодами (П) отсутствует. Однако в реаль-
ных исследованиях это предположение может нарушаться. Одной из
возможных причин может оказаться слишком короткий временной
интервал между периодами наблюдения. Другой возможной причиной
такого взаимовлияния может быть зависимость величины эффекта
терапии от состояния пациента перед началом терапии. При прове-
дении статистического анализа достаточно трудно распознать конк-
ретные причины такого взаимовлияния, но есть достаточно простые
статистические тесты для проверки наличия зависимости величины
эффекта терапии от последовательности ее получения. Для этого мож-
но, например, по критерию Стьюдента сравнить отношение разно-
сти средних значений эффекта в группах А и В к ее стандартной ошибке:
t=p5-^)/0Wjjl + -L}f (55)
где cm — стандартное отклонение величины эффекта в каждой груп-
пе. Для оценки данной величины справедливы все правила, приве-
денные выше для оценки величины а. Число степеней свободы для
проверки вычисленного отношения по критерию Стьюдента равно
п\ + п2 — 2. При необходимости параметрический критерий Стьюдента
для проверки гипотез в данном исследовании может быть заменен на со-
ответствующий непараметрический критерий (например, Уилкоксона).
Похожая статистическая модель данных может использоваться для
обработки результатов исследований такого типа с помощью мето-
дов дисперсионного анализа. Мы приведем одну из схем анализа ва-
риации для перекрестного плана типа АВ/ВА [34]. Знакомство с этим
подходом может быть полезно для понимания статистических про-
цедур оценки биоэквивалентности двух препаратов. Обычно иссле-
дования биоэквивалентности проводятся в соответствии с планом
подобного типа. Подробнее вариационный анализ для перекрестно-
го дизайна рассмотрен в работах [33, 34].
Итак, как и в общем случае дисперсионного анализа, анализ вари-
аций в случае перекрестного дизайна основан на вычислении так на-
зываемого общего среднего (т), среднего в группах А и В (тА и тВ) и
соответствующих им вариаций (К, smA2w smB2соответственно). Пусть
sA2 и sB2 обозначают вариации различий в соответствующих группах.
По-прежнему полная вариация параметра эффекта делится на межин-
дивидуальную и интраиндивидуальную вариации. В свою очередь, эти
1.7. Статистический анализ результатов клинических исследований 99
две части вариации также подразделяются в соответствии с конкрет-
ными источниками различий. При этом может быть получена следу-
ющая таблица дисперсионного анализа (табл. 22), позволяющая с
помощью критерия Фишера для соответствующих отношений дис-
персии проверить гипотезы о различиях в эффекте сравниваемых те-
рапий, наличии временного тренда и наличии влияния последователь-
ности получения терапии.
Тесты для сравнения эффектов терапий и проверка наличия вре-
менного тренда основаны на анализе интраиндивидуальной части
Таблица 22.
Общий вид таблицы дисперсионного анализа для перекрестного плана
А В/В А
Источник
вариации
Число
степеней
свободы
Сумма квадратов отклонений
Средний
квадрат
Между пациентами (межиндивидуальная)
Взаимовлияние
ТхП — терапии
и последователь-
ности ее получе-
ния
Остаточная
1
ajI +«2-2
С =
2-nl-n2'(mA-mB)2
n\ + n2
Е = 2 • {(и1 -1) • smA2 + (л2 -1) • smB2}
2sm2
Интраиндивидуальная
Прямой эффект
терапии Т
Влияние периода
Я, связанное
с терапией Т
или
Эффект терапии
Г, связанный
с периодом Я
Прямое влияние
периода Я
Остаточная
Общая
п\ +п2-2
2(л1 + гй) -
- 1
G' =
Н =
G =
Я'=
(nl-dA + n2dB)2
2-(л1 + л2)
nl-n2-(dA-dB)2
2-(п\ + п2)
п\-п2-(атА + атВ)2
2-(п\ + п2)
(nldA-n2 ~dB)2
2-(л1 + л2)
J=-'{(nl-l)-sA2+(n2-l)-sB2}
Н
s2/2
100 Глава 1. Математическая статистика в клинических исследованиях
/"»
вариации. Дисперсионное отношение -j-r (F(l,nl+n2-2)) соответ-
s /
/2
ствует приведенному выше критерию Стьюдента для проверки гипо-
тезы о различии в эффекте двух сравниваемых терапий. Аналогично
дисперсионное отношение -г-т (F(l,nl+n2-2)) соответствует крите-
ША
рию Стьюдента для проверки гипотезы о наличии временного трен-
да. Для сбалансированного дизайна при п\ — п2 соответствующие ве-
личины G = G' и Н = Н'. Для проверки гипотезы о взаимовлиянии
сравниваемых терапий можно на основе анализа межиндивидуальной
С
вариации проверить дисперсионное отношение г- (F( 1 ,п 1+п2-2)).
2sm
Если такое влияние обнаружено, последующий статистический ана-
лиз данных может основываться только на первом периоде наблюде-
ния. При этом такой усеченный вариант перекрестного дизайна пол-
ностью соответствует дизайну параллельных групп. Однако уменьше-
ние объема выборки при этом может не позволить установить наличие
различий между терапиями.
Таким образом, независимо от конкретной статистической моде-
ли данных для анализа результатов исследований, проведенных в со-
ответствии с перекрестным дизайном, такой анализ позволяет отве-
тить на вопрос о статистической значимости различий эффектов срав-
ниваемых терапий с учетом межиндивидуальной вариабельности,
возможного влияния конкретной последовательности получения те-
рапий и возможного наличия временного тренда самого показателя,
выбранного для оценки эффекта.
1.7.11. Построение доверительного интервала
для значений измеряемого признака
Рассмотренные выше процедуры позволяли строить доверитель-
ные интервалы для различных параметров распределения, например
для средних значений или долей. Сами значения изучаемых клини-
ческих показателей также являются реализациями соответствующих
случайных величин, и иногда может возникнуть потребность по име-
ющимся данным оценить доверительный интервал для самих значе-
ний измеряемого признака. Например, наиболее известная задача:
оценить диапазон, в который попадают 95% всех значений совокуп-
ности. Если речь идет о нормальном распределении и объем выборки
1.7. Статистический анализ результатов клинических исследований 101
достаточно большой, этот диапазон задается выборочным средним ±
2 стандартных отклонения. Правило же трех сигм (выборочное сред-
нее ± 3 стандартных отклонения) задает интервал, в который попада-
ют практически все значения совокупности. В случае малых выборок
для решения этой задачи надо брать более широкий диапазон, грани-
цы которого задаются выражением X± KaSx, где X — выборочное
среднее, Sx — выборочное стандартное (или среднее квадратичное)
отклонение, Ка — коэффициент, зависящий от доли членов совокуп-
ности, которые должны попасть в интервал, от выбранной вероятно-
сти, что они туда действительно попадут 1 — а, и от объема выборки п.
Таблицу для значений коэффициента Ка можно найти, например,
в [13], а графики для Ка представлены в [3]. Так, для вычисления
95-процентного доверительного интервала (а = 0,05), в который дол-
жно попадать 90% членов совокупности, по выборке объемом 10—20
значение Ка равно 2,3—2,8. А 95-процентный интервал по выборке
того же объема, в который должны попадать 99% членов совокупнос-
ти, определяется значениями Ахх, равными 3,7—4,4. Если несколько
увеличить объем выборки п = 20—30, то для 95-процентного довери-
тельного интервала (а = 0,05), в который должно попадать 90% чле-
нов совокупности, Ка равно 2,14—2,3. А 95-процентный интервал по
выборке того же объема, в который должны попадать 99% членов со-
вокупности, определяется значениями Ахх, равными 3,4—3,7. Видно,
что с ростом объема выборки значения коэффициентов убывают и в
пределе (при бесконечно больших значениях п) стремятся к крити-
ческим значениям для стандартного нормального распределения.
При расчете доверительных интервалов для значений признака нуж-
но обратить внимание, что в расчетную формулу входит именно выбо-
рочная дисперсия, а не стандартная ошибка средней арифметической.
Ошибочная подстановка в формулу стандартной ошибки средней при-
водит к построению другого интервала, а именно интервала, в кото-
рый с вероятностью 95% попадет генеральное среднее совокупности.
1.7.12. Установление по двум
или более сопряженным рядам чисел
наличия связи (корреляции) между признаками
Одним из важных разделов статистики является корреляционный
анализ. Понятие корреляции отражает главным образом степень выра-
женности связи между вариационными рядами. Наглядно эта связь
может быть отражена графически. На координатной плоскости по оси
102 Глава 1. Математическая статистика в клинических исследованиях
абсцисс откладывают значения одного вариационного ряда, а по оси
ординат — другого. Совокупность таких точек на координатной плос-
кости (их число равно числу наблюдений) создает общую картину кор-
реляции и обычно позволяет построить некоторую усредненную кри-
вую (чаще прямую) взаимозависимости параметров, составляющих оба
вариационных ряда (регрессионный анализ). На практике исследо-
вателя часто может интересовать не сама зависимость одной перемен-
ной от другой, а именно характеристика тесноты связи между этими
переменными, которую можно было бы выразить одним числом. Эта
характеристика называется коэффициентом корреляции. В случае кор-
реляционного анализа 2 рассматриваемых вариационных ряда для нас
равноправны в причинном смысле. Силу или выраженность линейной
связи между двумя случайными величинами XI и Х2, имеющими нор-
мальное распределение, обычно оценивают коэффициентом корреля-
ции Пирсона, рассчитываемым по следующей формуле:
]Г(Х1/-Х1ИХ2/-Х2)
г= , /=1 (56)
W{Xli-Xl)2.£(x2i-X2f
V i=i i=i
где XIi и Xli — соответствующие значения параметра в /-наблюдении,
Х\, XI — средние значения рядов, состоящих из п наблюдений. Вы-
численный коэффициент корреляции является выборочной оценкой
генерального коэффициента корреляции совокупности, а значит, как
и любая случайная величина, имеет ошибку or. Отношение выбороч-
ного коэффициента корреляции к своей ошибке является критерием
для проверки нулевой гипотезы о равенстве нулю генерального ко-
эффициента корреляции совокупности (или, соответственно, о неза-
висимости случайных величин XI и XI):
"-'■№■ <57>
Число степеней свободы для проверки критерия равно / = п — 2,
гипотезу проверяют по таблицам распределения Стьюдента (см. при-
ложение, табл. 1) в соответствии с выбранным уровнем значимости.
Если вычисленное значение превзойдет или окажется равным соот-
ветствующему табличному, нулевую гипотезу отвергают.
Приведенная формула для вычисления коэффициента корреляции
является параметрической, то есть предполагает, что анализируемые
переменные распределены по нормальному закону. Поэтому перед ее
1.7. Статистический анализ результатов клинических исследований 103
использованием необходимо проверить гипотезу о нормальности обо-
их распределений.
Существуют и другие формулы для вычисления коэффициента
корреляции, а также эти формулы могут уточняться по отношению к
большим и малым выборкам [9, 12, 14, 19]. Так, было установлено,
что при выборках малых объемов (п < 30) расчет коэффициента по
этим формулам дает заниженные оценки соответствующего генераль-
ного параметра. Для корректировки можно применять, например, z-
преобразование Фишера:
z=l/ln±±L. (58)
Переменная z принимает свои значения в интервале от + до — бес-
конечности, распределение этой величины приближенно нормальное.
Тогда критерием достоверности является показатель:
tz = Z-Jn^3. (59)
По таблице распределения Стьюдента (см. приложение, табл. 1)
для выбранного а и числа степеней свободы/= п — 2 проверяют ну-
левую гипотезу о том, что в генеральной совокупности этот параметр
равен 0. Гипотезу отвергают на выбранном уровне значимости, если
tz превзойдет соответствующее табличное значение.
Однако независимо от способа вычисления коэффициент корре-
ляции обладает определенными свойствами. Величина коэффициен-
та корреляции всегда заключена в пределах — 1 < г < 1. Если г < 0, то
это означает, что с увеличением в вариационном ряду наблюдаемых
величин XI соответствующие им значения XI второго вариационного
ряда в среднем уменьшаются. Если г > 0, то с увеличением значений
одного показателя другой показатель также в среднем возрастает. Если
г = 0, то это означает, что показатели XI и XI абсолютно независимы.
При г = 1 между показателями существует прямо пропорциональная
функциональная зависимость (в медико-биологических исследовани-
ях крайне редкий случай). Чем больше абсолютная величина коэф-
фициента корреляции, тем при данном объеме выборки больше до-
верительная вероятность того, что характер связи действительно со-
ответствует полученному коэффициенту корреляции. На рис. 10
показаны некоторые типичные варианты зависимостей и соответству-
ющие им значения коэффициентов корреляции.
В медико-биологических приложениях часто встречаются случаи,
когда характеристики взаимосвязанных структур представляются по-
104 Глава 1. Математическая статистика в клинических исследованиях
• •
•
• •
• •<
••••
•
• ••
* •
• • •
•••
s: •
•• •
• •
X
гху=0
/ч-ч
Гху=0
X
X
в Гху-1
X
« •«
# • •• •
ййй!
3*V
X
rxy=+0,5
• • •
• •••
• •
• •
ч»
• •:
X
гху=-0,30
X
гху=+1
Рис. 10. Схематичное изображение различных вариантов зависимостей
между переменными Л" и У и соответствующие значения коэффициента
корреляции Пирсона
рядковыми переменными. При этом приходится оперировать так на-
зываемыми ранговыми коэффициентами корреляции [3, 6, 9, 12, 14,
19]. Кроме того, такой непараметрический подход применяется в слу-
чае малых выборок и если изучаемые выборки не распределены по
1.7. Статистический анализ результатов клинических исследований 105
нормальному закону. Так, например, коэффициент корреляции рангов,
предложенный К. Спирменом, вычисляется по формуле:
rs = l ^ , (60)
п(и2-1)
где di — разность между рангами сопряженных признаков, п — число
парных членов ряда. При полной связи ранги признаков совпадут и
разность между ними будет равна 0, соответственно, коэффициент
корреляции будет равен 1. Если же признаки варьируются независи-
мо, коэффициент корреляции получится равным 0.
Аналогично коэффициент корреляции рангов является оценкой
соответствующего генерального параметра, его значимость оценива-
ется с помощью статистики:
trs = ^=(l--^-), (61)
где zan m связаны соотношениями с уровнем значимости: для а = 5%
Z - 1,96 и т = 0,16; для а = 1% z = 2,58 и т = 0,69. Нулевую гипотезу
отвергают, если полученное значение rs превзойдет или окажется рав-
ным рассчитанному критическому значению trs.
Обычно, говоря «коэффициент корреляции», подразумевают ко-
эффициент корреляции Пирсона. При этом важно понимать, что та-
кой коэффициент корреляции удовлетворительно характеризует лишь
связи, не слишком отклоняющиеся от прямолинейных (линейная зависи-
мость). А значит, если коэффициент корреляции несущественно от-
личается от нуля, то это не означает отсутствие связи вообще, это го-
ворит только об отсутствии линейной связи между исследуемыми пе-
ременными. Первоначально оценить, к какому типу относится данная
связь — прямолинейному или криволинейному, можно, построив эм-
пирическую линию регрессии. Более точно допустимая степень откло-
нения связи от прямолинейной определяется при помощи критериев
криволинейности. Если изучаемая связь является криволинейной (см.
рис. 10, б), силу такой связи можно оценивать с помощью методов,
изложенных в справочниках или книгах [5, 9, 14, 19].
Мы хотим обратить внимание читателей на принципиальные
ошибки, которые достаточно часто возникают при оценке корреля-
ционных зависимостей. Одна из наиболее распространенных оши-
бок — отсутствие проверки статистической значимости рассчитан-
ного коэффициента корреляции. Обычной практикой является рас-
106 Глава 1. Математическая статистика в клинических исследованиях
чет выборочного коэффициента корреляции (часто по выборкам до-
статочно малого объема) и в качестве оценки значимости последую-
щее сравнение рассчитанного значения с 0,3. Этот способ некоррек-
тен, поскольку статистическая значимость выборочного коэффици-
ента корреляции существенно зависит от объема выборок, по которым
он рассчитывается. Часто имеющихся объемов выборок недостаточ-
но для получения статистически значимого выборочного коэффици-
ента корреляции. Надо иметь в виду, что, например, в случае п = 15
даже значение выборочного коэффициента корреляции г = 0,5 ока-
жется статистически незначимым на уровне а = 5%, в то время как
при п = 50 меньшее значение коэффициента корреляции г = 0,3 ока-
зывается статистически значимым на том же уровне а.
Если соответствующий критерий показал отсутствие значимости
оцененного коэффициента корреляции, можно для полученного зна-
чения г оценить объем выборки п, достаточный для получения стати-
стически значимого выборочного коэффициента корреляции (то есть
для опровержения нулевой гипотезы об отсутствии корреляции, если
корреляция действительно существует):
z2
л = ^ + 3, (62)
z
где величина za задается по принятому уровню значимости (предель-
ной точки распределения Стьюдента, см. приложение, табл. 1), a z —
преобразование рассчитанного коэффициента корреляции г (фор-
мула 58).
Однако при обнаружении статистически достоверной корреляции
между явлениями часто возникает другая ошибка — желание связать
их непосредственной причинной связью. Неверная логическая цепоч-
ка выводов при этом приводит к ошибочному заключению: раз явле-
ния А и В находятся в тесной корреляционной связи и явление В воз-
никает во времени позднее А, следовательно, А является причиной В.
Однако явления А и В могут быть не только не связаны друг с другом
причинно-следственной связью, но и не иметь единой первопричины.
Пример 12. Изучали зависимость между содержанием вещества В
в ткани С и приростом концентрации вещества D в крови у пациен-
тов, получавших препарат А (пример 1, табл. 2, 2-й и 7-й столбцы).
Прежде всего построили линию регрессии для изучаемых параметров
и убедились, что данная зависимость хорошо аппроксимируется пря-
мой, то есть связь является линейной (рис. И). Для оценки тесноты
такой линейной связи рассчитаем коэффициент корреляции (для при-
1.7. Статистический анализ результатов клинических исследований 107
мера, параметрический, несмотря на малый объем выборок, п = 10).
Значение коэффициента корреляции Пирсона, оцененного по (56),
равно г = —0,91. Знак «минус» означает, что большим значениям од-
ного признака соответствуют меньшие значения другого. Оценим
значимость рассчитанного коэффициента корреляции, значение ста-
тистики tr = —6,17. Проверяем данную статистику по таблицам рас-
пределения Стьюдента (см. табл. 1 приложения) для числа степеней
свободы/= 10 — 2 = 8 и уровня значимости 5%. Рассчитанное значе-
ние статистики (tr = —6,17,) по модулю превосходит соответствующее
табличное значение (2,31). Таким образом, нулевую гипотезу отвер-
гают на уровне значимости р < 0,05, и рассчитанный коэффициент
корреляции признается статистически значимым. В данном случае
рассчитанный коэффициент корреляции оказывается статистичес-
ки высоко значимым (р < 0,001). Проверим нулевую гипотезу в от-
ношении ^-преобразованного коэффициента корреляции. Преоб-
разование Фишера для рассчитанного коэффициента корреляции
z = —1,53; соответствующее значение статистики tz = — 4,05. Это рас-
считанное значение по модулю превосходит соответствующее таб-
личное 2,31 (см. табл. 1 приложения,/= 8, а = 0,05). А значит, вывод
о статистической значимости коэффициента корреляции подтвержда-
ется (0,001 < р< 0,01).
1
и
S 2
о
н
о
о
Он
5
С
6т
5 +
4 t
3 +
2 +
1 +
0
8
10
12
Содержание вещества В, ммоль/г
Рис. 11. Графическое представление регрессионной зависимости между
изучаемыми показателями для примера 12. По оси абсцисс — содержа-
ние вещества В, ммоль/г; по оси ординат — прирост концентрации ве-
щества D, ммоль/л
108 Глава 1. Математическая статистика в клинических исследованиях
Оценим для нашего примера коэффициент корреляции рангов
(табл. 23). Если бы отдельные варианты ряда не повторялись, их ран-
гами были бы натуральные числа от 1 в порядке возрастания. Но оди-
наковым значениям вариант присваиваются ранги, равные средним
арифметическим их рангов. Величина di представляет собой попар-
ные разности рангов изучаемых выборок. В качестве правила для про-
верки правильности ранжирования используют равенство 0 суммы di.
Таблица 23.
Таблица для расчета рангового коэффициента корреляции Спирмена (по
данным табл. 2 из примера 1)
Показатель
XX
8
8
9
10
7
7
9
9
11
6
Показатель
4
5
4
3,5
5
5
3,5
4
2
5
Ранг Rxx
4,5
4,5
7
9
2,5
2,5
7
7
10
1
Ранг Rn
5
8,5
5
2,5
8,5
8,5
2,5
5
1
8,5
di = Rx- Rn
-0,5
-4,0
2,0
6,5
-6,0
-6,0
4,5
2,0
9
-7,5
di2
0,25
16,0
4,0
42,25
36,0
36,0
20,25
4,0
81,0
56,25
Сумма di2 равна 296, по (60) для л = 10 получаем ранговый коэф-
фициент корреляции rs = —0,82. Критическая точка, рассчитанная
по формуле (61) для уровня значимости 5% (za= 1,96; т = 0,16), равна
0,64. Так как значение рангового коэффициента корреляции по моду-
лю превосходит соответствующее критическое значение, с вероятнос-
тью более 95% можно утверждать, что между сравниваемыми показа-
телями существует значимая отрицательная корреляционная связь.
1.7.13. Регрессионный анализ
При проведении современных клинических исследований обыч-
но нет недостатка в информации, каждому пациенту соответствует
целое множество различных клинических показателей и данных. В
этих числах могут быть завуалированы некоторые соотношения или
1.7. Статистический анализ результатов клинических исследований 109
же эти соотношения могут непосредственно следовать из данных.
Методы регрессионного анализа помогают выявлять основные чер-
ты таких соотношений. Для многих задач с изменяющимися количе-
ственными переменными представляет интерес исследование влия-
ния (действительного или подозреваемого) некоторых переменных на
остальные. Обычно существующая функциональная связь слишком
сложна для описания, задача регрессионного анализа при этом со-
стоит в подборе упрощенной аппроксимации этой связи с помощью
математической модели. Регрессионный анализ имеет в своем рас-
поряжении специальные процедуры проверки, является ли выбран-
ная математическая модель адекватной для описания имеющихся дан-
ных. При исследовании такой приближенной математической моде-
ли можно больше узнать об изучаемой истинной зависимости. Даже
если по физическому смыслу между переменными не существует ре-
альной связи, отражение ее с помощью математического уравнения
может быть полезно, например для уменьшения пространства исход-
ных признаков. Таким образом, можно сказать, что регрессия часто
используется при попытках установить причинную связь. Еще одно
возможное использование регрессии — количественное измерение
эффекта с помощью коэффициента регрессии. Однако чаще всего
регрессионный анализ используется для прогноза, то есть для пред-
сказания значений ряда зависимых переменных по известным значе-
ниям других переменных. Коротко суть основной задачи регресси-
онного исчисления можно сформулировать следующим образом: как
по величине переменной X можно судить о величине переменной К
Простейшим примером процедуры регрессионного анализа явля-
ется часто возникающая практическая задача — подбор прямой по
парам наблюдений (XI, Yl), (Xlt Y2),..., (Хп, Yn). На этом примере ли-
нейной однофакторной модели регрессии мы продемонстрируем ос-
новные этапы регрессионного анализа. Если задача включает большее
число переменных-предикторов (или регрессоров), то она называется
многофакторной и решается обычно с помощью матричного подхода
[5, 19]. В случае регрессионного анализа, когда говорят о том, что мо-
дель линейна или нелинейна, обычно подразумевают линейность по
параметрам, а не по переменным-регрессорам. Величина наивысшей
степени регрессора в модели называется порядком модели.
Мы не будем приводить определения и расчетные формулы для
матричного многофакторного анализа, поскольку он предполагает
более глубокие знания в области математики. Кроме того, обычно для
решения подобных задач используют готовые компьютерные про-
110 Глава 1. Математическая статистика в клинических исследованиях
граммы. Для случая многофакторных моделей порядка выше первого
мы дадим лишь некоторые практические рекомендации по выбору
модели оптимальной структуры для описания имеющихся данных.
Прямолинейная связь между двумя переменными
Итак, связь между зависимой случайной величиной Y и величи-
ной Ху которая является переменной (но не случайной переменной),
выражается уравнением регрессии К относительно X. Мы не случай-
но оговорили, что переменная-предиктор X не подвержена случай-
ной вариации, тогда как переменная отклика У подвержена. В прак-
тическом смысле такое предположение редко выполняется, однако
если это не так, то требуются более сложные математические методы
построения зависимостей, даже в случае однофакторной модели. По-
этому всегда полезно по возможности организовать эксперимент так,
чтобы разброс истинного значения предикторной переменной (или
диапазон ее изменения) существенно превышал разброс случайных
ошибок, содержащихся, вероятно, в этой переменной. Тогда ошибка-
ми, содержащимися в предикторной переменной, можно будет пренеб-
речь и пользоваться обычными методами регрессионного анализа.
Наиболее простой вариант линии регрессии переменной У от пе-
ременной X имеет вид:
У= ]80+Д* + е. (63)
Это уравнение представляет собой линейную по регрессору X од-
нофакторную математическую модель, е — случайная ошибка моде-
ли. Обычно с помощью метода наименьших квадратов или метода
максимального правдоподобия [19], на основе имеющихся данных
идентифицируются коэффициенты полинома bQ, bv являющиеся вы-
борочными оценками соответствующих параметров модели /50 и j3r
Тогда в качестве предсказывающего можно использовать уравнение:
7= Ь0 + ЬХХУ две черты над символом У означают предсказанное зна-
чение У для данного Л'при определенных значениях регрессионных
параметров.
Метод наименьших квадратов предполагает идентификацию не-
известных параметров модели в соответствии с минимизацией функ-
ционала качества приближения. Слагаемые такого функционала пред-
ставляют собой квадрат отклонений реальных значений переменной
отклика У от соответствующих модельных значений [2, 5, 11, 14]:
^ = Zvv^2=2w,.(^-^0-^X,.)2^min> (64)
1=1 1=1
1.7. Статистический анализ результатов клинических исследований 111
где все w. = 1 для обычного метода наименьших квадратов и могут
быть любыми неотрицательными числами в качестве весов для взве-
шенного метода наименьших квадратов. Процедура взвешивания,
которая будет рассмотрена нами позднее, позволяет по-разному оце-
нивать вклад каждого наблюдения в общую картину данных.
Не вдаваясь в вычислительные тонкости, скажем только, что ме-
тод наименьших квадратов дает оценки b0, bx коэффициентов поли-
нома р0, рг Обычно получение таких оценок проводят с помощью со-
ответствующей компьютерной программы. В наиболее простом слу-
чае линейной однофакторной модели оценки коэффициентов могут
быть рассчитаны по следующим формулам:
Ъ = J=! ^ & w— , (65)
£^-<1"Л)2/£",
*о=- ^ • (66)
Для обычного метода наименьших квадратов все w. = 1, и форму-
лы несколько упрощаются:
ъ\ = —
1*д-
IVlr*
In ^Xi-XcpW-Ycp)
(67)
2>,2-<1*,)2/* 1(*,-вд2
b0=Ycp-brXcp, (68)
где Xcp, Yep — средние арифметические значения наблюдений Хи Y
соответственно.
Для графического изображения задачи используется прямоуголь-
ная система координат, любой паре значений (Xi, Yi) соответствует точка
в регрессионной области. Через скопление точек на регрессионном
графике нужно провести прямую, так чтобы, исходя из значений X,
можно было бы максимально точно оценить значения У (см. рис. 12).
Еще раз хотим предупредить читателей, что в дальнейшем для про-
стоты изложения мы будем анализировать случай однофакторной
линейной регрессии, однако основные принципы являются справед-
ливыми и в отношении других, более сложных моделей.
112 Глава 1. Математическая статистика в клинических исследованиях
Точность оценки регрессии
Изучим вопрос о том, какая точность может быть приписана на-
шей оценке линии регрессии. Точность аппроксимации данных рег-
рессионной моделью оценивается с помощью анализа остатков, то
есть разностей между наблюдаемыми и предсказанными по модели
значениями. Для этого представим остаток е. = Yi — Yi в виде разно-
сти двух величин: 1) отклонение наблюдаемого значения отклика Yi
от среднего отклика Yep; 2) отклонение предсказанного значения от-
клика Yi от того же самого среднего значения Yep. Если рассмотреть
все п наблюдений, то можно выразить сумму квадратов отклонений
наблюдений Yi от среднего в виде двух основных слагаемых: суммы
квадратов отклонений наблюдаемых значений Yi относительно рег-
рессии и суммы квадратов отклонений регрессионных значений от-
носительно среднего. Второй член в правой части характеризует
вариацию, связанную с регрессией, и объясняет разброс за счет иссле-
дуемого фактора. Первое слагаемое в этой сумме является «необъяс-
нимой» вариацией, отклонения отражают влияние случайных факто-
ров, и эта вариация обычно называется остаточной (рис. 12). При-
годность линии регрессии зависит от соотношения этих слагаемых.
Тогда, воспользовавшись методами дисперсионного анализа, строим
таблицу дисперсионного анализа [2, 5, 11, 14] (табл. 24).
При проведении регрессионного анализа с помощью различных
статистических программ часто можно встретиться с величиной Л2, ее
обычно называют коэффициентом детерминации. Эта величина изме-
ряет долю общего разброса относительно среднего (ss2), объясняемую
регрессией I X у1 - YcP) I. Таблица дисперсионного анализа может по-
мочь вычислить искомую величину R2:
Y^-Ycp)2
Rl=>f • (69)
£(Г,-К5Р)2
1=1
Величину Л2 часто выражают в процентах, умножая на 100. Факти-
чески R — это корреляция между наблюдаемыми значениями Yn пред-
сказанными значениями Y. Коэффициент R2 может достигать значе-
ния 1 (или 100%), когда все значения А"различны. Если среди данных
существуют повторяющиеся наблюдения, то величина R2 никогда не
достигает 1, как бы хороша ни была модель. Таким образом, величина
1.7. Статистический анализ результатов клинических исследований 113
YH^x+Dq
Yep Ц
\ Ь-Ч 1 1 1 1 г
Хер
X
Рис. 12. Линейная регрессия Y по X. Пунктиром обозначены отклонения
наблюдаемых значений от линии регрессии (Yi —Ti). Величина Yi— Yep
является отклонением предсказанного по модели значения от среднего
значения; величина Yi —Yep является отклонением измеренного значе-
ния отклика от среднего.
Таблица 24.
Общий вид таблицы дисперсионного анализа для оценки точности рег-
рессии
Источник вариации
Число
степеней
свободы
Сумма
квадратов SS
Средние квадраты
Обусловленный
регрессией
Относительно
регрессии (остаток)
Общий
1
л-2
п- 1
£(Y,-Ycp)2
1=1
M2=£(l",-Kj>)2
a? =%(.¥,-Yep)2/l
<72=Ztf-^)2A«-2)
114 Глава 1. Математическая статистика в клинических исследованиях
R2 оценивает процент вариации данных вокруг среднего значения,
который может быть объяснен с помощью выбранного уравнения рег-
рессии.
Коэффициенты регрессионного уравнения являются случайными
величинами и по имеющимся данным мы находим лишь их выбороч-
ные оценки. С помощью таблицы дисперсионного анализа можно
оценить дисперсию коэффициентов j50 и Д регрессионной модели [2,
5, 11, 14]. Так, оценка дисперсии Д> равна:
D[b0] = (a2 .fdX?)/(nfd(Xi-Xcp)2). (70)
Оценка дисперсии fy равна:
Ф.] = <г2/£(*/-*Ф)2. (71)
Оценка величины остаточного стандартного отклонения а содер-
жится в таблице дисперсионного анализа (см. табл. 24). Корень квад-
ратный из дисперсии D[b0] и D[b,] задает соответствующие стандарт-
ные ошибки оценок регрессионных коэффициентов.
С помощью дисперсионного анализа можно, кроме того, прове-
рить гипотезу о равенстве нулю коэффициента Д в уравнении регрес-
сии. Для проверки справедливости нулевой гипотезы #0: Д = 0 нужно
IT2 /
по таблице дисперсионного анализа вычислить /'-отношение F = у 2
и проверить по табл. 8 приложения для выбранного уровня значимо-
сти и F(l, (n —2)). Если рассчитанное значение F превосходит таб-
личное, нулевая гипотеза отвергается на выбранном уровне а. Таким
образом проверяется значимость выбранного уравнения регрессии.
Проверить значимость рассчитанного коэффициента Д можно и с
помощью /-критерия Стьюдента. Для этого формулируется нулевая
гипотеза HQ: р, = 0 против альтернативы НА: Д Ф 0. Как обычно, рас-
считываем статистику критерия как отношение оценки коэффици-
ента Д к оценке его стандартной ошибки:
t-
^•{z^-^)2}'
(72)
а
и сравниваем полученную величину с табличным значением для выб-
ранного уровня значимости (с учетом двустороннего теста) и числом
степеней свободы п — 2. Если рассчитанное значение превосходит
табличное (см. приложение, табл. 1), нулевая гипотеза отвергается на
выбранном уровне значимости.
1.7. Статистический анализ результатов клинических исследований 115
Аналогично можно проверить и значимость оценки свободного
члена р0 в уравнении регрессии. Даже если априори известно, что дан-
ная линия регрессии должна проходить через начало координат, луч-
ше исходить из того, что модель содержит ненулевой свободный член.
Получив выборочную оценку для коэффициента р0, нужно проверить
гипотезу о его значимости (другими словами, проходит ли данное
уравнение регрессии через начало координат). Для этого рассчиты-
вается /-статистика критерия Стьюдента в виде:
t =
L*,2
п^(Х,-Хср)г
/=1
Уг
(73)
Для значений коэффициентов регрессии р0и pj по их выборочным
оценкам Ь0 и 6, могут быть рассчитаны доверительные интервалы по
формуле bL ± t(n — 2, 1 — 0,5 • a)-^D\bLJ, где t(n — 2, 1 — 0,5 • а) —
коэффициент Стьюдента, определяемый по табл. 1 приложения;
(п — 2) — число степеней свободы, индекс L может принимать значе-
ния 0 и 1 для обозначения коэффициентов уравнения регрессии, таб-
личное значение t выбирается с учетом двустороннего доверительно-
го интервала, а обычно равно 5%. Кроме того, возможно построение
совместной доверительной области для параметров Р0 и Pj [5, 19].
Доверительные интервалы уравнения регрессии
Выражения для дисперсий коэффициентов Р0 и pj используются
для построения доверительных интервалов уравнения регрессии. Для
любого фиксированного значения х имеет место равенство, дающее
оценку дисперсии соответствующего Y:
D\Y\=G'
1
- +
п
(х-ХсрУ
£(X,.-Xc/>)2
(74)
При любом значении переменной X соответствующие значения
переменной отклика У распределены нормально со средним значе-
нием Y. Поэтому по заданному значению х можно построить 95-про-
центный доверительный интервал для «истинного» среднего значе-
ния уравнения регрессии Y: Y ±t- д/^И > гДе величина коэффициента
116 Глава 1. Математическая статистика в клинических исследованиях
Стьюдента t определяется для 95-процентной доверительной вероят-
ности и числа степеней свободы, равного (п — 2) (см. табл. 1 прило-
жения). Нужно еще раз подчеркнуть, что таким образом мы задаем
доверительные границы для линии регрессии, и построение такой
доверительной области производится в связи с тем, что уравнение
регрессии строится по выборке значений. Доверительные границы
представляют собой кривые—гиперболы, лежащие по обе стороны от
линии регрессии. Наименьшую ширину область имеет вблизи значе-
ний X, равных Хер, и расширяется при удалении от среднего значе-
ния. По мере удаления от «центра» значений Хи, тем более за преде-
лами нашего наблюдения, точность предсказания ухудшается, соот-
ветственно и доверительная область становится шире (рис. 13). С
заданной вероятностью, обычно 95%, можно утверждать, что «истин-
ная» линия регрессии находится в границах полученной доверитель-
ной области. Неудивительно, что некоторые наблюдаемые значения
Yi лежат вне построенного доверительного интервала (см. рис. 13).
Дело в том, что мы строили доверительную область для линии рег-
X
Рис. 13. Линия регрессии и соответствующая 95-процентная доверитель-
ная область для данной линии регрессии
1.7. Статистический анализ результатов клинических исследований 117
рессии, а не для значений переменной отклика, которая получилась
бы шире построенной нами доверительной области.
Однако исследователя может интересовать задача построения до-
верительной области не для уравнения регрессии, а для значений зави-
симой переменной К Такая доверительная область также может быть
построена. Ее границы задаются соотношением Т± t- ->JD\Y], а оценка
D [У]вычисляется по следующей формуле для любого значения пе-
ременной X:
d[y] = ct2
1 + 1 +
п
(х-Хер)2
£(Х,.-Хф)2
(75)
Таким образом определяется доверительная область, в которую
попадает определенный процент (например, 95% при соответствую-
щем выборе коэффициента Стьюдента) всех значений переменной
отклика. Данный интервал называется также интервалом прогноза.
Поскольку он задает доверительные пределы, между которыми с за-
данной вероятностью будет находиться новое наблюдение Y, отвеча-
ющее заданному значению переменной Х[2, 3,5, 9, 19].
Надо обратить особое внимание читателей на связь корреляции и
регрессии, поскольку часто эти понятия путают. Корреляционный ко-
эффициент Пирсона rXY учитывает меру линейной зависимости между
двумя переменными Хи Y В то время как оценка коэффициента рег-
рессии Ьх измеряет величину изменения переменной Y, которую мож-
но предсказать, если изменение Jf равно единице. При этом справед-
ливо соотношение:
bt =
£(г,-кр)2
£(Х,.-ХФ)2
X
ГУу
— У
(76)
где СуИ ах — выборочные оценки средних квадратичных отклонений
для выборок У и А" соответственно.
В корреляционном анализе X и Y — случайные переменные, рас-
пределенные по нормальному закону, и они симметричны в том смыс-
ле, что rXY= rYX. В случае же регрессионного анализа мы различаем не-
зависимую переменную X, которая по предположению свободна от
случайных ошибок, и зависимую переменную У, условное распреде-
ление которой при заданном А" является нормальным.
118 Глава 1. Математическая статистика в клинических исследованиях
В более общих задачах коэффициенты регрессии тоже связаны с
выборочным коэффициентом корреляции, но более сложным обра-
зом [5, 19].
Исследование остатков
Построенная линия регрессии — это расчетная линия, основан-
ная на некоторой модели и предположениях. Корректность выбран-
ной модели проверяют с помощью исследования остатков е. = Yi — Yi,
i = 1,2, ..., п (Y— наблюдаемая величина, Y— величина, прогнозиру-
емая в соответствии с моделью). Остатки содержат всю информацию
относительно того, почему построенная модель недостаточно пра-
вильно объясняет наблюдаемый разброс значений зависимой пере-
менной К Вообще выводы, содержащиеся в данном параграфе, при-
ложимы к любой ситуации, связанной с подбором математической
модели самого общего вида — как линейной, так и нелинейной. Та-
кие задачи могут возникать и в случае применения регрессионного
анализа, и в случае построения любой математической модели, опи-
сывающей результаты измерений, то есть при возникновении при-
годной для анализа меры необъясненной вариации в форме остатков.
Если предложенная модель правильная, остатки будут наблюдаемы-
ми проявлениями случайных ошибок. При построении математичес-
кой модели обычно делаются предположения относительно ошибок.
Обычно предполагается, что такие ошибки независимы, нормально
распределенные с нулевым математическим ожиданием и постоян-
ной дисперсией о2 (рис. 14). Таким образом, основная идея анализа
остатков как раз и состоит в проверке этих предположений на основе
реальных данных. Анализ остатков часто проводится графическим
способом, который позволяет сравнительно просто выявить наруше-
ния сделанных предположений. Основными видами графиков, кото-
рые строятся с целью анализа остатков, являются: а) общий график
остатков; б) зависимость остатков от времени, если известна после-
довательность полученияизмерений; в) зависимость остатков от пред-
сказываемых значений У; г) зависимость остатков от предикторных
переменных X.
а) Общий график остатков
Такой график может быть вычерчен в виде гистограммы вариаци-
онного ряда для диапазона изменений полученных остатков или по
оси абсцисс — номер очередного остатка, а по оси ординат — значе-
ние соответствующего остатка. Среднее остатков должно быть равно
нулю, и это утверждение может быть проверено по критерию Стью-
1.7. Статистический анализ результатов клинических исследований 119
«Истинная*
регрессионная
прямая
Y=Po+PiX
N(P0+PiX,g2)
x. -.- ' \
i x. ' ^
[ \ i \
т^у ! ^
Ж ^^. Л N
/\ ^^. l\ ^
/ \ ^^. V ч
\ ^**ЬчГ j ч
Наблюдаемые ■ i ^^^
значения • \f ^*^^
^ ! f
X
Xj X2 Xn
Рис. 14. Каждое наблюдение отклика Yi имеет нормальное распределе-
ние относительно вертикали со средним, получаемым из регрессионной
модели. Стандартные отклонения всех нормально распределенных остат-
ков предполагаются одинаковыми и равными с
дента. Остатки должны более или менее симметрично располагаться
по обе стороны от нулевого значения. Преимущество остатков со зна-
ком «минус» говорит о том, что наша модель «переоценивает» значе-
ние переменной У, преимущество остатков со знаком «плюс» — о си-
стематической недооценке соответствующих значений. Является ли
распределение полученных остатков нормальным, проверяется по
критерию х2 так> как это было описано раньше, в разделе «Проверка
гипотезы о законе распределения». Если модель правильная, то оценкой
дисперсии остатков может служить величина: $2 = — , где /? — общее
п~р
число параметров регрессионной модели. Среди остатков могут при-
сутствовать единичные «выбросы», то есть остатки, которые по абсо-
лютной величине значительно превосходят остальные и отличаются
от среднего по остаткам более чем на 3 стандартных отклонения. Та-
кие выбросы должны быть проанализированы с помощью специаль-
ных критериев для проверки резко выделяющихся наблюдений, про-
извольное же их отбрасывание недопустимо [5]. Преобладание таких
остатков свидетельствует о нарушении предположения о нормальном
законе их распределения. Величины eyi , при условии правильности
выбранной модели, должны иметь распределение 7V(0, 1), поэтому в
120 Глава 1. Математическая статистика в клинических исследованиях
качестве общего графика бывает удобно анализировать график для
величин еу . При этом можно ожидать, что примерно 95% таких
величин будут в пределах (—2, 2). Если число (п — р) мало, то при
установлении 95% пределов можно пользоваться распределением
Стьюдента.
б) График временной последовательности
Многие клинические показатели у одного и того же индивидуума
могут существенно меняться с течением времени, а кроме того, могут
быть подвержены, например, каким-то сезонным колебаниям. Такие
изменения во времени должны учитываться и математическими мо-
делями, если изучается временная тенденция и промежуток модели-
рования достаточен для анализа таких изменений.
Если известна временная последовательность сбора данных и ясно,
что фактор времени может вносить изменения в получаемые данные,
строится график временнбй последовательности остатков модели.
Если вычерченные в известной временнбй последовательности остат-
ки располагаются в пределах горизонтальной полосы, можно утвер-
ждать, что зависимость остатков от времени получения измерений не
выявлена. Однако если график принимает вид, похожий на один из
вариантов, изображенных на рис. 15, то можно утверждать, что эф-
фект времени существует и не учтен в модели:
1) дисперсия остатков не постоянна, а растет во времени. Возмож-
но, поможет применение взвешенного метода наименьших
квадратов;
2) линейная зависимость значений остатков от времени. В модель
должен быть включен линейный член, учитывающий зависи-
мость от времени;
3) зависимость от времени существует и, скорее всего, квадратич-
ная. В модель должны быть включены линейный и квадратич-
ный члены для учета зависимости от времени.
При изучения временных изменений значений параметра или, дру-
гими словами, рядов динамики для выделения тренда и сезонных ко-
лебаний применяется математический аппарат анализа временных
рядов [5, 12, 19].
в) График зависимости остатков от Y
В случае адекватности выбранной модели этот график должен про-
демонстрировать полное отсутствие всякой зависимости между по-
лучаемыми значениями остатков модели и предсказанными с помо-
щью этой модели значениями переменной отклика.
1.7. Статистический анализ результатов клинических исследований 121
I
2
3
Рис. 15. Примеры неудовлетворительных графиков остатков (см. текст)
Желательно, чтобы такой график был похож на горизонтальную
полосу или бесформенное облако. Появление графиков, похожих на
любой из графиков рис. 15, говорит об определенной ненормальнос-
ти выбранной модели:
1) дисперсия непостоянна. Нужно пробовать взвешенный метод
наименьших квадратов или какое-нибудь преобразование наблю-
дений Y, стабилизирующее дисперсию;
2) модель неадекватна, поскольку отрицательные значения остатков
соответствуют низким значениям У, а положительные — высоким.
Возможно, ошибочно в модели пропущен свободный член р0;
3) модель неадекватна. Может помочь предварительное преобра-
зование значений Y или нужно вводить в модель дополнитель-
ные квадратичные члены.
г) График зависимости остатков от предикторных переменных X
Эти графики должны иметь ту же форму, что и графики зависимо-
сти остатков от значений Г. Так же, как и раньше, графики должны
демонстрировать отсутствие зависимости. Так же, как и раньше, гра-
фики, похожие на представленные на рис. 15, говорят о наличии ано-
малий. Рекомендации в случае 1) остаются прежними; в случае 2) не-
обходимо ввести в модель линейную зависимость от X; в случае
3) нужно ввести в модель дополнительные квадратичные члены зави-
симости от X или провести предварительное преобразование К
122 Глава 1. Математическая статистика в клинических исследованиях
Если модель многофакторная и включает несколько переменных
Л7, можно строить двухмерные и трехмерные графики. Если размер-
ность задачи большая, строить графики зависимости остатков от пе-
ременных Xi можно для различных подмножеств предикторных пе-
ременных.
Преобразования, стабилизирующие дисперсию
Довольно часто можно найти такое преобразование случайной ве-
личины Y, что соответствующая преобразованная случайная величи-
на будет иметь постоянную дисперсию. Такое преобразование назы-
вается преобразованием, стабилизирующим дисперсию. Если при
проведении линейного регрессионного анализа выясняется, что рас-
сеяние значений отклика Y на графике данных изменяется система-
тически с изменением независимой переменной X, то дисперсию мож-
но стабилизировать путем простой процедуры взвешивания. Напри-
мер, если выборочное стандартное отклонение Y(X), то есть
отклонение значений У, соответствующих значению X, возрастает про-
порционально значению X, то переход от Y(X) к взвешенным данным
Z(X) = Y(X)/X будет стабилизировать дисперсию [19].
Если известно, например, что стандартное отклонение отклика Y(X)
пропорционально математическому ожиданию Т(Х) с коэффициентом
пропорциональности К, то преобразование In Y будет стабилизировать
дисперсию, причем среднее квадратичное отклонение а[1пУ(Л0] = К.
В этом случае полезно бывает рассматривать регрессию In У на Х[2].
Взвешенный метод наименьших квадратов
Иногда случается так, что часть наблюдений, используемых в рег-
рессионном анализе, менее надежна, чем остальная. Обычно это оз-
начает, что не все дисперсии наблюдений равны. В этом случае помочь
стабилизировать дисперсию может взвешенный метод наименьших
квадратов. Основная идея метода состоит в преобразовании наблю-
дений У в новые переменные Z, обладающие тем же свойством, и если
к ним применить обычный метод наименьших квадратов и получить
уравнение регрессии, то полученные при этом остатки будут обла-
дать нужными свойствами (математическое ожидание равно нулю, и
дисперсия практически одинакова для всех измерений). Затем полу-
ченные оценки можно снова выразить через обычные переменные.
Наиболее простой случай приложения взвешенного метода наи-
меньших квадратов имеет место, когда наблюдения независимы, но
некоторые дисперсии о.2 различны. Тогда задача состоит в определе-
1.7. Статистический анализ результатов клинических исследований 123
нии весов w. (7 = 1, 2, ..., п), равных w. =1/ о.2. При такой процедуре
могут возникнуть практические трудности с определением величин
о.2. Одним из возможных путей может быть следующий. По имею-
щимся данным строится обычная линия регрессии, задаваемая урав-
нением Y= b0 + b{X. Имеющиеся пары наблюдений (Xi, Yi) упорядо-
чиваются, и среди них выделяются повторные или приблизительно
повторные (группируются наблюдаемые значения У, соответствующие
одним и тем же или близким значениям X). Для полученных группи-
ровок повторных наблюдений оцениваем средние значения Xj и со-
ответствующие величины дисперсий остатков (разницы между наблю-
даемыми и модельными значениями У для данной группы наблюде-
ний) ае2 (J — номер соответствующей группы наблюдений). По
полученным парам среднее значение X — дисперсия остатков для
выделенных групп строим линию регрессии се2 на X. Полученное урав-
нение регрессии се2(Х) используем для оценки величин а,.2 с помо-
щью подстановки Xi для всех значений / = 1, 2,..., п. Искомые значения
весов получаются с помощью обратного преобразования w. =1/ а.2.
Соответствующие наблюдаемые и предсказанные^значения откликов
после такого^преобразования равны yjwi Yt и д/w"^ . А остатки имеют
вид yfw^iy. -У-] • Оцененные веса используются для проведения про-
цедуры взвешенного метода наименьших квадратов и получения но-
вой регрессионной зависимости Y(X). Для случая однофакторной ли-
нейной модели формулы для вычисления коэффициентов регрессии
с помощью взвешенного метода наименьших квадратов были приве-
дены выше (формулы 65—66).
Подробнее с вопросами анализа остатков можно познакомиться в
книгах [5, 11, 14].
Пример 13. Продемонстрируем применение основных процедур
регрессионного анализа на примере данных, взятых из книги [5].
В первых двух столбцах (не считая столбца номеров) табл. 25 при-
ведены 35 пар (Xi, Yi)y в третьем столбце таблицы содержатся вели-
чины остатков для регрессионной прямой, построенной по имею-
щимся данным с помощью обычного метода наименьших квадратов.
Обычный метод наименьших квадратов по наблюдаемым значени-
ям переменных позволил идентифицировать регрессионную пря-
мую (рис. 16):
7= -0,579+ 1,1354 X
На рис. 17 представлен график остатков в зависимости от прогно-
зируемых откликов. Видно, что общий вид такого графика — расши-
124 Глава 1. Математическая статистика в клинических исследованиях
Таблица 25,
Таблица расчетов уравнения регрессии с помощью взвешенного метода
наименьших квадратов
N
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
**
М5
1,9
3,0
3,0
3,0
3,0
3,0
5,34
5,38
5,4
5,4
5,45
7,7
7,8
7,81
7,85
7,87
7,91
7,94
9,03
9,07
9,И
9,14
9,16
9,37
10,17
10,18
10,22
10,22
10,22
10,18
10,5
10,23
10,03
10,23
^
0,99
0,98
2,6
2,67
2,66
2,78
2,8
5,92
5,35
4,33
4,89
5,21
7,68
9,81
6,52
9,71
9,82
9,81
8,5
9,47
11,15
12,14
11,5
10,65
10,64
9,78
12,39
11,03
8,0
11,9
8,68
7,25
13,46
10,19
9,93
ei |
0,26
-0,6
-0,23
-0,16
-0,17
-0,047
-0,027
0,44
-0,18
-1,22
-0,62
-0,4
-0,48
1,53
-1,77
1,38
1,46
1,41
0,06
-0,2
1,73
2,38
1,7
0,83
0,58
-1,18
1,41
0,005
-3,02
0,88
-2,3
-4,1
2,42
-0,62
-1,11
**2
0,81
0,46
0,1274
0,1274
0,1274
0,1274
0,1274
0,134
0,143
0,147
0,147
0,159
1,12
1,185
1,19
1,22
1,23
1,26
1,28
2,11
2,15
2,18
2,21
2,22
2,41
3,21
3,22
3,26
3,26
3,26
3,22
3,57
3,27
3,06
3,27
wi 1
1,24
2,18
7,85
7,85
7,85
7,85
7,85
7,44
7,0
6,79
6,79
6,31
0,89
0,84
0,84
0,82
0,81
0,8
0,78
0,47
0,47
0,46
0,45
0,45
0,41
0,31
0,31
0,31
0,31
0,31
0,31
0,28
0,31
0,33
0,31
№> 1
0,48
1,91
7,15
7,15
7,15
7,15
7,15
14,28
13,96
13,82
13,82
13,46
7,5
7,4
7,39
7,35
7,34
7,3
7,27
6,52
'6,5
6,47
6,46
6,45
6,34
6,02
6,01
6,0
6,0
6,0
6,01
5,9
6,0
6,07
6,0
^-у)
0,62
-0,46
0,14
0,33
0,3
0,64
0,7
1,87
0,18
-2,54
-1,08
-0,38
-0,25
1,61
-1,42
1,45
1,52
1,45
0,25
0,0024
1,32
1,75
1,28
0,69
0,5
-0,56
0,89
0,11
-1,57
0,59
-1,17
-2,07
1,45
-0,24
-0,51
1.7. Статистический анализ результатов клинических исследований 125
14i
12-
101
8
6-1
4-1
2-1
y=l,1354jc—0,579
Д2=0,8401 ♦
i
10
0 2 4 6 8 10 12
Рис. 16. Регрессионная прямая, построенная обычным методом наимень-
ших квадратов по данным табл. 25. По оси абсцисс — значение независи-
мой переменной Х\ по оси ординат — значения переменной отклика Y
Зт
2 |
1 t
О
-1
-2 +
-3 +
-4-f
♦ ♦
♦ ♦
♦♦♦
♦
10 ♦
#
♦
♦
15
Рис. 17. График остатков в зависимости от предсказанных значений от-
клика представляет собой расширяющуюся полосу. По оси абсцисс —
предсказанные значения переменной отклика; по оси ординат — значе-
ния остатков
ряющаяся полоса. Это означает, что дисперсии непостоянны и, зна-
чит, нарушается одно из основных условий обычного метода наимень-
ших квадратов. Для стабилизации дисперсии попробуем использовать
взвешенный метод наименьших квадратов. Искомые веса для взве-
шенного метода наименьших квадратов должны быть обратно про-
порциональны соответствующим оценкам дисперсии остатков. Таким
126 Глава 1. Математическая статистика в клинических исследованиях
образом, необходимо оценить величину дисперсии остатков для каж-
дой пары наблюдений. С этой целью для каждой группы повторных
или почти повторных измерений (всего в нашем примере было 5 та-
ких групп) вычислим средние значения независимой переменной Хер
и соответствующие им средние квадраты, связанные с «чистой» ошиб-
кой (о 2) (табл. 26).
Таблица 26.
Средние квадраты, связанные с «чистой» ошибкой, для групп повторных
измерений
N=j
1
2
3
4
5
Хер
3,0
5,4
7,8
9,1
10,2
^
0,0072
0,344
1,74
0,868
3,896
Данные табл. 26 использовались для нахождения формулы зави-
симости ое2(Х) в виде квадратичного полинома (рис. 18):
ое2 = 1,5329 - 0,7334 • X + 0,0883 • X2.
Подставляя в полученную зависимость имеющиеся значения пере-
менной X, получаем оценки величин оJ для всех /= 1, 2,..., 35 (столбец
4, см. табл. 25). Оценки весов w. получаем, взяв обратные значения от
полученных величин о2 (столбец 5, см. табл. 25). Использование этих
весов во взвешенном методе наименьших квадратов приводит к следу-
ющему регрессионному уравнению (коэффициенты уравнения рассчи-
таны по формулам для взвешенного метода наименьших квадратов):
Y = -0,8891 +1,1468- X.
Теперь предсказанные значения откликов задаются выражением
V W/ Y; (столбец 6, см. табл. 25), а остатки — формулой у[щу( - Yt) (стол-
бец 7, см. табл. 25). Построив график зависимости взвешенных ос-
татков от предсказанных значений откликов, видим, что вертикаль-
ные размахи остатков примерно одинаковые на двух основных уров-
нях преобразованных откликов (рис. 19). Таким образом, применение
взвешенного метода наименьших квадратов позволило стабилизиро-
вать дисперсию откликов.
1.7. Статистический анализ результатов клинических исследований 127
>>=0,0883jt2-0,73334;c+l,5329
Д2=0,7427
Рис. 18. Квадратичный полином, рассчитанный методом регрессии, для
аппроксимации средних квадратов, связанных с «чистой» ошибкой, для
групп повторных измерений. По оси абсцисс — средние значения неза-
висимой переменной Х\ по оси ординат — дисперсии остатков
2\
1,5-
1-
0,5-
П т
и ■
•0,5-
-1-
■1,5'
-2-
-2,4-
-3-
♦
♦
♦♦*
г *
: ♦
♦
■ i
♦
ж
V
♦
♦
♦
10
15
Рис. 19. Зависимость значений остатков от предсказанных значений пе-
ременной отклика. Взвешенный метод наименьших квадратов. По оси
абсцисс — предсказанные значения переменной отклика; по оси орди-
нат — значение остатков
Среднее значение остатков равно 0,12, среднее квадратичное от-
клонение равно 1,11. С помощью критерия Стьюдента для связанных
пар получаем значение тестовой статистики / = 1,17. А значит, на уровне
128 Глава 1. Математическая статистика в клинических исследованиях
значимости 5% (для числа степеней свободы, равного 34) мы не мо-
жем отклонить нулевую гипотезу о равенстве нулю среднего значе-
ния анализируемых остатков. На рис. 20 и в табл. 27 показано выбо-
рочное и теоретическое распределение остатков, полученное для взве-
шенного метода наименьших квадратов. Теоретические значения
частот рассчитаны в соответствии с процедурой, описанной в разделе
«Проверка гипотезы о законе распределения». Для получения значе-
ний теоретических частот по ординатам кривой стандартного нормаль-
ного распределения в данном случае использовался коэффициент
пЛ 35-0,5 л.
Величина критерия %2 получилась равной 5,04 для числа степеней
свободы/= 9 — 3 = 6 (после объединения крайних классов, содержа-
щих менее 1 варианты, и вычитания 3, как принято для проверки ги-
потезы о нормальном распределении). По таблицам #2для уровня зна-
чимости 5% получаем критическое значение критерия, равное 7,82.
Поскольку рассчитанная величина критерия меньше критического
табличного значения, нулевая гипотеза о нормальности распределе-
ния остатков остается в силе на выбранном уровне значимости. Еще
раз хотим подчеркнуть, что для более точных оценок с помощью кри-
-2,75-2,25-2,75-1,75-1,25-0,75-0,25 0,25 0,75 1,25 1,75 2,25
Рис. 20. Гистограмма распределения значений остатков регрессионной
модели для проверки критерия согласия о нормальности их распределе-
ния. Светлые столбцы — выборочное распределение; темные — теорети-
ческие частоты распределения. По оси абсцисс — значения остатков; по
оси ординат — гистограмма распределения частот
1.7. Статистический анализ результатов клинических исследований 129
Таблица 27.
Таблица расчетов для проверки критерия согласия %2 о нормальном рас-
пределении остатков в результате применения взвешенного метода наи-
меньших квадратов для построения линии регрессии
Центры интер-
валов Xi
-2,75
-2,25
-1,75
-1,25
-0,75
-0,25
0,25
0,75
1,25
1,75
2,25
Наблюдаемые
частоты fi
1
1
1
3
2
4
8
6
5
4
0
Xi-Xcp
°х
-2,59
-2,14
-1,68
-1,23
-0,78
-0,33
0,12
0,57
1,02
1,47
1,92
Ординаты
кривой N(0, 1)
0,0139
0,0404
0,0973
0,1872
0,2943
0,3778
0,3961
0,3319
0,2371
0,1354
0,0635
Теоретические
частоты fi *
0,22
0,65
1,56
3,0
4,71
6,05
6,33
5,31
3,8
2,17
1,02
1= 34,82
«35,0
^
?
Ч
1= 1,13
-0,56
0
-2,71
-2,05
1,67
0,69
1,2
1= 0,81
Слагаемое х2
1,47
0,2
0
1,56
0,69
0,44
0,09
0,38
0,21
Х2= 5,04
Округленные
частоты/?'
0
1
2
3
5
6
6
5
4
2
1
1 = 35
терия согласия объем выборки должен быть не менее 50 вариант. Та-
ким образом, хотя гистограмма распределения выборочных остатков
демонстрирует некоторое преобладание положительных остатков,
можно утверждать в результате проверки статистического критерия
согласия, что распределение полученных с помощью взвешенного
метода наименьших квадратов остатков согласуется с нормальным
законом распределения со средним значением 0,12 и стандартным
отклонением 1,11.
Пример 14. Приведем другой пример применения метода анализа
остатков для проверки возможности нашей математической модели
адекватно описывать имеющиеся данные. В результате по 50 наблю-
дениям с помощью математической модели были оценены соответ-
130 Глава 1. Математическая статистика в клинических исследованиях
ствующие значения переменной отклика и рассчитаны 50 значений
остатков. Результаты моделирования для этого примера мы будем сра-
зу представлять в виде графиков, поскольку размерность задачи не
позволяет привести все исходные данные и промежуточные вычис-
ления. Так на рис. 21, а приведен общий график нормированных зна-
чений остатков, а на рис. 21, б — гистограмма выборочного и соот-
ветствующего нормального распределения для проверки критерия
согласия х2- Величина критерия при проверке гипотезы о нормаль-
ности N(—0,12; 0,83) выборочного распределения остатков равна 2,68.
I ♦
Т^
♦♦♦
♦ А ♦
1 ♦ t—
-1
-2
J*
♦ ♦
♦ ♦
—i—
10
i
30
20
40
50
14
12
10
0
-1,75 -1,25 -0,75 -0,25 0,25 0,75 1,25 1,75
Рис. 21. Проверка гипотезы о нормальном распределении остатков моде-
ли, а — общий график нормированных остатков ei/S. Видно, что боль-
шинство значений остатков не выходит за пределы диапазона (—2,2), все
50 значений остатков лежат в пределах диапазона (—3,3). Такой график
не противоречит гипотезе о нормальном их распределении; б — теорети-
ческие и выборочные частоты для проверки нормальности распределе-
ния остатков по критерию х2
1.7. Статистический анализ результатов клинических исследований 131
Проверив по табл. 2 приложения на уровне значимости 5% (соответ-
ствующее критическое значение для трех степеней свободы равно
7,82), приходим к выводу, что наше распределение остатков имеет
приближенно нормальное распределение. Среднее значение остат-
ков —0,12 незначимо отличается от нулевого значения (р = 0,32,) (пар-
ный критерий Стьюдента, число степеней свободы равно 49). Рис. 22
♦ ♦♦♦♦♦ ♦
♦♦ ♦ .♦ \ й
♦ 4 ~ 6 \ 8 10 12
*♦ ♦♦ ♦* **
♦ ♦♦ *
Предсказанные значения отклика
Рис. 22. Зависимость остатков от предсказанных значений переменной
отклика, график напоминает «бесформенное облако». По оси абсцисс —
предсказанные значения отклика; по оси ординат - значения остатков
демонстрирует полное отсутствие зависимости значений остатков от
значений переменной отклика (бесформенное облако). Таким обра-
зом, можно сделать вывод, что выбранная нами математическая мо-
дель не противоречит имеющимся данным.
Некоторые практические рекомендации
по выбору наилучшей структуры модели
Ранее мы говорили в основном о линейной однофакторной моде-
ли регрессионного анализа, но предупреждали читателей, что это не
единственная, а наиболее простая и распространенная модель, на
примере которой легче всего продемонстрировать основные проце-
дуры регрессионного анализа.
Приступая к описанию данных, исследователь, как правило, не
имеет четкого представления о структуре математической модели.
Если из имеющейся информации о сущности рассматриваемого яв-
ления следует, что зависимая переменная /является непрерывной
и
о
н
о
о
я
X
0)
a
X
го
1,5
0,5
-0,5
-1,5 1
132 Глава 1. Математическая статистика в клинических исследованиях
функцией независимых факторов, обычно применяется полиномиаль-
ная модель. Однако неизвестно, какой степени полином будет доста-
точен для описания имеющихся данных. Если применяется полино-
миальная т-факторная модель первого порядка, можно говорить о
линейной многофакторной регрессии. Если рассматривается т-фак-
торная регрессионная модель и степень полинома предполагается не
выше второй (уравнение, включающее линейные и квадратичные чле-
ны, называется параболой второго порядка), то общий вид такой мо-
дели будет следующий:
tn tn~\ tn tn
Yu = fi0 +1 Р,ХШ +Х XД,ВД, + ХPHXl +eu. (77)
Это пример более сложной модели, чем линейная модель первого
порядка с одним или несколькими регрессорами. Можно записать
более общий тип регрессионной модели, линейной по регрессионным
параметрам и специально введенным фиктивным переменным Z:
Г=р0 + р^ + р2^ + ...+p,Z +е, (78)
где новые фиктивные переменные Zj (j = l,...,p) - известные функ-
ции от исходных независимых регрессоров X. (i = l,...,k), которые
могут иметь любую форму и, в свою очередь, быть как линейными,
так и нелинейными по переменным X. Модель, представленная в та-
ком виде, является линейной, и для ее анализа могут применяться
общие матричные методы регрессионного анализа [4], в компьютер-
ных программах для проведения регрессионного анализа также пре-
дусмотрены подобные преобразования. Из уравнения видно, что при
р = к и Zj =Xj мы получаем обычную линейную А:-факторную регрес-
сионную модель. Если, например, р = 2, Z, = X, Z2 = X2, р2 = Рп, по-
лучаем модель второго порядка (параболу) с одним регрессором:
Y = р0 + pj X+ $иХ* + е. В случае полной А>факторной модели второго
орядка соответствующее значение р = -(к2+3к) . Аналогично стро-
ятся модели третьего и более высоких порядков. Допускается, что пе-
ременные Z могут представлять собой и более сложные функции пе-
ременных X, чем взятие целых степеней, например, l/X, 1/X2 — об-
ратное преобразование или преобразование типа квадратного корня
и т. д. Таким образом, практически любая нелинейная по независи-
мым переменным X, но линейная по параметрам р функция может
быть приведена к обобщенному виду линейной регрессионной зави-
симости. При идентификации параметров такой модели может полу-
1.7. Статистический анализ результатов клинических исследований 133
читься, что некоторые коэффициенты р окажутся незначимыми, тог-
да соответствующие члены в уравнении регрессии можно отбросить.
Такая модель будет более экономичной, считается, что она имеет оп-
тимальную структуру.
Вообще определение наилучшей структуры регрессионной моде-
ли имеет существенное значение. Во-первых, уменьшение числа рег-
рессоров увеличивает число степеней свободы остаточной дисперсии
(таблица дисперсионного анализа) и делает связанные с ней провер-
ки гипотез более надежными. Во-вторых, уменьшение числа регрес-
соров может помочь в выявлении сущности изучаемого явления. В-
третьих, желательно исключить из модели линейно зависимые рег-
рессоры. Надо отметить, что понятие наилучшей структуры модели
довольно условно и зависит от особенностей конкретного исследо-
вания. Поэтому мы коротко охарактеризуем основные вопросы, свя-
занные с процедурой поиска наилучшей структуры регрессионной
модели:
• самый простой путь решения задачи в случае однофакторной мо-
дели состоит в нанесении наблюдаемых значений на график в
прямоугольной системе координат. В некоторых случаях даже
простой визуальный анализ может помочь в выборе подходяще-
го уравнения регрессии;
• в случае многофакторной модели может возникнуть ситуация,
при которой данные о различных факторах А7, которые желатель-
но было бы включить в модель, имеют различные физические
размерности. Для уменьшения этого эффекта регрессоры и от-
клики центрируют (вычитают математическое ожидание из зна-
чений вариант) и нормируют (обычно делят на среднее квадра-
тичное отклонение);
• с помощью частных коэффициентов корреляции определяют, ка-
кой регрессор оказывает наибольшее влияние на отклик. А для
принятия решения о том, существенно ли это влияние, проверя-
ют гипотезы о равенстве нулю некоторых коэффициентов рег-
рессии с помощью частного /'-критерия. Понятия «частный ко-
эффициент корреляции» и «частный /^-критерий» возникают в
случае многофакторных моделей, и по математическому смыслу
они аналогичны обычному коэффициенту корреляции и обыч-
ному .F-критерию, рассмотренным нами для однофакторного
случая. Идея этих понятий для многофакторной модели основа-
на на так называемом принципе дополнительной суммы квадра-
тов. Поскольку расчет этих величин производится с помощью
134 Глава 1. Математическая статистика в клинических исследованиях
матричного исчисления, мы приводим лишь общий смысл этих
понятий. Расчет частного /'-критерия обычно включается в со-
став статистических компьютерных программ, там часто этот
критерий называется «критерий /'для исключения», похожий
последовательный /^критерий может иметь название «критерий
/'для включения». Итак, принцип «дополнительной суммы квад-
ратов» предполагает возможность оценки дополнительной доли
дисперсии, порожденной регрессией, которая связана с вклю-
чением в модель рассматриваемых членов. Затем средний квад-
рат, который получается из этой дополнительной суммы, сопос-
тавляется с общей оценкой вариации относительно регрессии о2
(см. таблицу дисперсионного анализа). Если средний квадрат
значимо превышает оценку о2, то такие члены следует включать
в модель (проверка на основе F-критерия). Подобную проверку
с помощью таблицы дисперсионного анализа мы уже проводи-
ли, оценивая значимость коэффициента pj для линейной одно-
факторной модели. Таким образом, дополнительная сумма квад-
ратов измеряет вклад каждого коэффициента Ь. в сумму квадра-
тов, обусловленную регрессией, при условии что все члены, не
содержащие Д., уже включены в модель. Другими словами, она
дает меру для оценки важности параметра, как если бы он был
включен в модель последним. Соответствующий средний квад-
рат (дополнительная сумма квадратов всегда имеет одну степень
свободы) сравнивается с оценкой о2 с помощью частного F-кри-
терия. Если дополнительный член, который мы рассматриваем,
есть /ЗД, то, проверяя гипотезу о значимости коэффициента Д,
мы на самом деле проверяем гипотезу о включении в модель пе-
ременной Хг Влияние переменной ^на величину отклика может
быть большим, если регрессионное уравнение включает только эту
переменную. Однако если эта переменная входит в модель после
остальных переменных, она может слабо влиять на отклик из-за
наличия сильной корреляции с другими, уже включенными пере-
менными. Если переменные добавляются к регрессионному урав-
нению последовательно, одна за другой, то говорят о последова-
тельном ./-критерии. Многие методы выбора оптимальной регрес-
сионной модели основаны на расчете частного F-критерия [2, 5];
• известно, что в случае, если одна из степеней свободы при про-
верке /'-критерия равна 1, справедливо следующее равенство для
F- и /-распределений: F(\,f,\-a) = \t(f,l-—)\, при любых значе-
1.7. Статистический анализ результатов клинических исследований 135
ниях a nf(f— число степеней свободы). А это значит, что част-
ный F-критерий с числами степеней свободы 1 и/для проверки
гипотезы Н0: р. = О против альтернативы НА: (3*0 даст те же
результаты, что и проверка той же гипотезы с помощью крите-
рия / Стьюдента (с учетом уровня значимости обоих критериев).
Это положение уже рассматривалось нами при проверке значи-
мости коэффициента наклона /?р для линейной однофакторной
регрессии с помощью этих двух критериев. Тестовая статистика
для критерия Стьюдента в случае многофакторной модели рас-
Ь /
считывается по формуле t= у < . Критерий проверяется по
табл. 1 приложения с учетом выбранного уровня значимости а.
В многофакторном случае предполагается матричная форма за-
писи уравнения регрессии, поэтому и дисперсия D[b] представ-
ляется в матричной форме. Тогда, если записать уравнение рег-
рессии в виде 7= ХЬУ то дисперсия коэффициента Ъ. равна диаго-
нальному элементу матрицы (Х'Х)~1с2 и базируется на/степенях
свободы для а2 (если не учитывать повторные измерения, число
степеней свободы/определяется обычно как число наблюдений
п минус число параметров /3, включенных в модель) [5];
• для выбора наиболее приемлемой модели регрессии можно из-
брать следующий путь: вычислить коэффициенты всех возмож-
ных моделей и сравнить их с помощью параметра R2 и анализа
остатков. Такой способ выбора структуры модели называется
методом полного перебора. Однако это весьма трудоемкая проце-
дура, и она редко применяется на практике. Для каждого регрес-
сора возможны 2 варианта: быть или не быть в результирующей
модели, например, для модели с к коэффициентами при усло-
вии обязательного наличия свободного члена число возможных
комбинаций (различных моделей) становится равным 2*-/;
• для ускорения поиска приемлемой регрессионной модели разра-
ботаны специальные процедуры: метод включения и метод ис-
ключения, а также шаговая регрессия. Так, в методе включения
начинают с модели, содержащей только свободный член. Затем
постепенно, один за другим, добавляют остальные регрессоры, а
порядок включения определяется по частным коэффициентам
корреляции регрессоров с откликом. После введения нового рег-
рессора вычисляется коэффициент детерминации R2 и частный
/'-критерий для этого регрессора. Процедура останавливается,
когда величина очередного частного F-критерия станет меньше
136 Глава 1. Математическая статистика в клинических исследованиях
соответствующего выбранного табличного значения распределе-
ния Фишера. При этом считается, что добавление новых членов
в модель существенно не уменьшит вариации отклика. Метод
исключения действует в обратном порядке, начиная с модели с
полной возможной структурой. Сначала по имеющимся данным
оцениваются коэффициенты модели с полной структурой и вы-
числяются значения частных F-критериев при условии, что имен-
но этот регрессор будет исключен из модели. Находят минималь-
ное значение такого частного .F-критерия и сравнивают его с
выбранным при определенном уровне значимости табличным F-
значением. Если наше минимальное значение Fменьше выбран-
ного табличного, соответствующий регрессор исключают из мо-
дели и продолжают процесс. В противном случае процесс оста-
навливается. Шаговая регрессия является промежуточным
вариантом этих двух подходов. Задаются двумя значениями F-
распределения: для включения регрессоров и для исключения.
Метод начинает работать с включения одного регрессора в соот-
ветствии с ранее описанным правилом. На каждом шаге прове-
ряют, нет ли среди включенных членов теперь уже ненужных.
Такая ситуация может возникнуть из-за коррелированности ото-
бранного регрессора с другими регрессорами, включенными в
модель к этому шагу алгоритма. Процедура исключения также
аналогична описанной ранее. Процесс останавливается, если на
очередном шаге не удается реализовать ни процедуры включе-
ния, ни процедуры исключения регрессора. Бывает, что для прак-
тических целей выбирается уровень значимости для исключения
больше, чем для включения, чтобы сохранить в модели больше
включенных членов;
• считается, что в комбинации с методом анализа остатков шаго-
вая регрессия дает наилучшие результаты при выборе оптималь-
ной структуры модели. В настоящее время это самый распрост-
раненный метод поиска оптимальной структуры модели;
• если модель выбранного порядка неадекватна, вряд ли имеет
смысл механически добавлять в модель члены более высоких по-
рядков. Часто бывает эффективно применить преобразования не-
зависимых переменных Х9 отличные от взятия целых степеней.
Возможно, поможет преобразование переменной отклика или
одновременное применение преобразований к переменным X и
У. Помимо упомянутых выше обратных преобразований и пре-
образований типа квадратного корня полезными могут оказать-
1.7. Статистический анализ результатов клинических исследований 137
ся преобразования типа взятия логарифмов. Так, если пары то-
чек Xi — In Yi в системе прямоугольных координат лежат на од-
ной прямой, скорее всего, оптимальная линия регрессии выра-
жается уравнением показательного типа Y=a- Мили экспонен-
циального типа Y = a- exp {ЬХ\. Если пары точек IgXi — IgYi лежат
на одной прямой в системе прямоугольных координат, это явля-
ется отличительной особенностью регрессионного уравнения сте-
пенного типа Y = а • Л6. Кроме того, в биологических и медицинс-
ких приложениях интерес может представлять логистическая рег-
рессионная зависимость, описываемая уравнением типа:
где Y — учитываемый признак, С — начальная величина этого при-
знака, N— его предельное значение, t — время, необходимое для изме-
нения значения признака от С до N, а и b — параметры регрессионного
уравнения. Эта зависимость графически может быть представлена в виде
так называемой S-образной кривой. С помощью логарифмического
преобразования эта зависимость приобретает вид lg 1 = а + Ъг.
Любые преобразования отклика влияют на распределение ошибок.
После преобразования ошибки преобразованного отклика должны
иметь нормальное распределение с нулевым математическим ожида-
нием и одинаковой дисперсией. Поэтому важно провести анализ ос-
татков модели, которая была в результате выбрана в качестве опти-
мальной, чтобы проверить, не нарушается ли предположение о рас-
пределении остатков.
Итак, решая вопрос, какую же регрессионную модель выбрать,
необходимо принимать во внимание следующие основные принципы:
1. Возможно, существует теоретическое обоснование математичес-
кой формы регрессионной модели.
2. Регрессионное уравнение должно обеспечить наилучшее прибли-
жение к реальным данным.
3. Регрессионное уравнение должно быть как можно более простым.
Хотя регрессия — один из наиболее мощных инструментов анали-
за данных, пользуясь методами регрессионного анализа, необходимо
помнить и об ограничениях, и об особенностях данного метода [2,
5,11,14,19].
Приведем еще несколько примеров практических задач, решаемых
на основе регрессионного анализа.
138 Глава 1. Математическая статистика в клинических исследованиях
Сравнение двух регрессионных линий
Часто в практических приложениях требуется сравнить несколько
линий регрессии, рассчитанных для нескольких независимых выбо-
рок. Решение этой задачи в общем виде для случая fc-выборок приве-
дено в работе [2]. Мы покажем, как это делается для двух регрессион-
ных линий. Допустим, по двум наборам наблюдений объемом п{ и п2
мы получили оценки для линий регрессии:
У, = ax + bx • X и Y2 = a2 + b2 • X, (79)
на основании которых следует сделать вывод: отвечают ли они одной
и той же линии регрессии или разным. Если бы рассчитанные линии
регрессии совпадали, то оценки дисперсии, обусловленной регрес-
сией, а2, и о22 для двух имеющихся выборок оценивали бы один и тот
же параметр о2, а их отношение подчинялось бы /^-распределению.
Таким образом, если с помощью /'-критерия отвергается нулевая ги-
потеза о равенстве дисперсий а2, = а22 = а2, то остается сделать вывод,
что регрессионные линии различны. Но, если нулевая гипотеза оста-
ется в силе, можно подсчитать объединенную оценку дисперсии:
а2 = (п,-2)ст2+(п2-2)ст22 (80)
И, +7!2 -4
После этого можно проверить гипотезу о равенстве коэффициен-
тов наклона Ь. И опять, если нулевая гипотеза о равенстве отвергает-
ся, можно сделать вывод, что уравнения регрессии различны. В про-
тивном случае сравнение коэффициентов сдвига а позволяет сделать
вывод, являются ли сравниваемые прямые параллельными (нулевая
гипотеза о равенстве свободных членов отвергнута) или совпадающими
(нулевая гипотеза остается в силе). Если нулевая гипотеза о равен-
стве коэффициентов наклона прямых имеет место, то разность Ьх — Ь2
будет распределена нормально с нулевым математическим ожидани-
ем и дисперсией, оцениваемой по формуле:
D[bx-b2] = D[bx] + D{b2] = - ^ + -2 ^ (81)
Z(*W-*cp,)2 £<*2,-*с2)2
/=1 1=1
Таким образом, для проверки нулевой гипотезы рассчитывается
тестовая статистика ^-критерия Стьюдента:
' = - ^ -у* (82)
о £(*,,-ХС„)Ч + £(Х21.-ХС„2)Ч
1.7. Статистический анализ результатов клинических исследований 139
число степеней свободы для проверки критерия по табл. 1 приложе-
ния равно (пх + п2 — 4). Критерий проверяется, как обычно, с учетом
выбранного уровня значимости. Если нулевая гипотеза о равенстве
6, = Ь2 остается в силе, следует найти обобщенную оценку для углово-
го коэффициента b [2].
Теперь можно перейти к проверке гипотезы о равенстве свобод-
ных членов регрессионных прямых. Нулевая гипотеза о равенстве
проверяется с помощью критерия Стьюдента и расчета тестовой ста-
тистики:
r fli"fl2 gi-g2
jD[ax-a2] ^D[ax] + D[a2}'
выражения для оценки дисперсий свободных членов регрессионной
модели были приведены нами ранее. Число степеней свободы для
проверки данного критерия по табл. 1 приложения равно (п{+ п2 — 3),
критерий проверяется, как обычно, с учетом уровня значимости.
Кроме того, известны специальные процедуры сравнения линий
регрессии в целом, и они приведены в [2, 3].
Обратная регрессия
Еще одной достаточно распространенной практической задачей
является определение значения независимой переменной Х0, соот-
ветствующего определенному значению переменной отклика Y0, с по-
мощью регрессии, построенной предварительно по набору данных
(Л7, Yi), i = 1,2, ..., п. В данном случае, как и раньше, мы рассмотрим
решение этой задачи для линейной однофакторной регрессии перво-
го порядка, подразумевая, что ее решение может быть распростране-
но на многофакторный случай более высокого порядка.
Эту задачу называют задачей обратной регрессии. Такая задача на
практике может возникнуть, например, при выполнении калибровки
измерительной аппаратуры. Допустим, приготовив ряд растворов из-
вестной концентрации, ее измерили с помощью прибора (иногда изме-
рение на каждой концентрации повторяют несколько раз) и получили
соответствующие значения измерений Yi. Затем по имеющимся резуль-
татам измерений известных концентраций Xi строят калибровочную
линию Y(X) с помощью регрессионных методов (прямая задача). При
дальнейших измерениях концентраций, значения которых заранее не-
известны, с помощью этого же прибора получаем какие-то значения
измерений. Возникает обратная задача: определить по полученному
измерению Y0 соответствующее ему значение концентрации Х0.
140 Глава 1. Математическая статистика в клинических исследованиях
Хотим предупредить читателей, что обычно регрессия^Y на А" не
идентична регрессии Хна У. По регрессионному уравнению Y=b0+b]-X
нельзя просто выразить X через Y. Это утверждение легко проверить,
вычертив в одних и тех же прямоугольных осях обе линии регрессии.
Легко заметить, что они образуют между собой угол. Линии регрес-
сии совпадут, и угол станет равен нулю только в случае совершенно
однозначной линейной связи между переменными Хи Y.
Известно несколько способов решения задачи обратной регрес-
сии. Один из таких способов предполагает идентификацию исходной
линии регрессии Y(X) по результатам исследования и построение
100(1 — а)% доверительных интервалов для истинного среднего зна-
чения Y при данном X (формулы для вычисления границ таких ин-
тервалов были приведены ранее). Далее на уровне У0 проводим гори-
зонтальную линию параллельно оси X. Там, где эта линия пересечет
линии границ доверительных интервалов, опускаем перпендику-
ляры на ось X, определяя тем самым верхнюю и нижнюю границы
100(1 — а)% интервала для искомой величины Х0. Перпендикуляр,
опущенный на ось X из точки пересечения двух прямых, дает иско-
мую оценку величины ^(рис. 23).
Верхняя граница 100 (1-а) %
доверительного интервала для
«истинного» значения Y при данном X
Горизонтальная прямая
Y=Y0
Регрессионная прямая
Y^X+bo
X
XL Х0 Xv
Рис. 23. Обратная регрессия: получение 100(1 — а)% доверительного ин-
тервала для значения Х0 для данного значения Y0. XL и Хц — полученные
границы этого интервала
1.7. Статистический анализ результатов клинических исследований 141
Данная процедура может быть записана в аналитической форме, в
результате чего значения нижней и верхней границы 100(1 — а) %
интервала для искомой величины Х0 могут быть выражены в виде рас-
четных формул [5]:
х , (X0-Xcp).g±(t(T/bl).{(Xo-Xcp)2/sJ+(l-g)/nY2 (83)
где S^ = ^(Х. - Хер)2, t — коэффициент Стьюдента (см. приложение,
табл. 1), число степеней свободы/для величины остаточной дисперсии
а2 обычно равно п — 2 (см. табл. 24), g = t2 a2 lip2 -Szz). Оценку ве-
личины Х0 получаем из обратного уравнения регрессии: Х0 = (YQ — b0)/br
Однако надо обратить внимание читателей, что в случае, если пря-
мое уравнение регрессии Y(X) определено недостаточно хорошо, ре-
шение задачи обратной регрессии может получиться несколько стран-
ным. Например, значения нижней и верхней границы 100(1 — а)%
интервала для искомой величины Х0 могут оказаться по одну сторону
от оценки самого значения Х0. Подробнее решение этой задачи и воз-
никающие при этом проблемы рассмотрены в работе [5].
Показатели точности математической модели
Нам кажется целесообразным привести еще 2 формулы, которые
довольно полезны в практических приложениях, так как позволяют
оценить предсказывающие свойства выбранной математической мо-
дели. Кроме того, если у вас есть несколько моделей для описания од-
них и тех же данных и все они, с точки зрения предложенного выше
анализа остатков, признаются адекватными, с помощью следующих по-
казателей ошибки приближения эти модели можно сравнивать между
собой. Первый показатель оценивает среднюю относительную ошибку
(средний относительный остаток) модели:
ME^LyliZX^ (84)
п £f_Yt
где п — общее число наблюдений, К— значения, предсказанные по
математической модели, У. — соответствующие наблюдаемые значе-
ния. Второй показатель оценивает среднее значение модуля относи-
тельной ошибки и вычисляется по формуле:
MAE = --f}Yi~Y'^ (85)
142 Глава 1. Математическая статистика в клинических исследованиях
Таким образом, второй показатель не учитывает знака отклонения
остатка от нулевого значения.
Кроме того, по обычным формулам вычисляется среднее квадра-
тичное отклонение соответственно для обычных относительных ос-
татков и для значений их модулей. Умножив полученные средние по-
казатели ошибки (ME и МАЕ) и их средние квадратичные отклоне-
ния на 100%, можем записать результаты анализа точности
приближения в виде: среднее значение показателя ошибки модели (в
процентах) ± среднее квадратичное отклонение показателя ошибки
(в процентах). Та модель лучше приближает имеющиеся данные, у ко-
торой показатели ошибки меньше.
1.7.14. Кривая выживаемости
Статистические методы анализа более отдаленных результатов воз-
действия используют понятие выживаемости и представление дан-
ных в виде таблиц и кривых выживаемости [3, 4].
Выживаемость S(t) — это вероятность прожить интервал времени
более / с момента начала наблюдения. А кривая выживаемости, при-
меняемая для описания выживаемости, отражает вероятность пере-
жить любой из моментов времени / после некоторого начального со-
бытия. Надо сказать, что подход и математический аппарат, которые
относятся к анализу выживаемости, могут успешно применяться для
анализа и других показателей эффекта, представляющих собой про-
межуток времени до возникновения интересующего события, напри-
мер до появления опухолей или метастазов, до выздоровления или
окончания периода госпитализации, до завершения терапии и т. п.
Но для простоты изложения в дальнейшем мы будем говорить только
в терминах выживаемости и продолжительности жизни. Типичная
кривая выживаемости представлена на рис. 24. В начальный момент
выживаемость равна 1 (все субъекты живы и находятся под наблюде-
нием), затем кривая постепенно понижается (происходят интересу-
ющие события) и приближается к 0. Время, до которого доживает
половина совокупности, называется медианой выживаемости.
Как и в случае выборочного среднего, в данной задаче существует
понятие кривой выживаемости для совокупности и ее выборочной
оценки по результатам исследования. Если бы не возможное выбы-
вание в процессе исследований, выборочная оценка выживаемости
S(t) определялась бы как отношение числа переживших момент / к
объему выборки п.
1.7. Статистический анализ результатов клинических исследований 143
■М
5Г И
В 0,8 I X
§ 0,6 I \
« X
й 0,4 + N.
N.
Ю 0,2 j ^^^^^^^
о-^
Время, t
Рис. 24. Типичная кривая выживаемости. По оси абсцисс — время, /; по
оси ординат — выживаемость, S(t)
Для учета выбывания при построении таблиц выживаемости ис-
пользуется, например, моментальный метод. В общем виде матема-
тическое выражение для него задается следующей формулой:
so=П о-<%/)- (86)
где dti — число умерших в момент f/, nti — число наблюдавшихся к
моменту //. Символ произведения означает, что нужно перемножать
значения (\ — dt/nt) для всех моментов времени, когда произошла хотя
бы одна смерть, за период от 0 до /.
Такой подход позволяет даже в случае выбывания пациента из ис-
следования использовать для статистического анализа собранную
ранее информацию о данном пациенте.
Полученные результаты расчетов представляются в виде таблицы,
строки которой соответствуют моментам времени, в которые проис-
ходила хотя бы одна смерть, а также в виде графика. Точки на графи-
ке также соответствуют моментам, когда умер хотя бы один из на-
блюдавшихся. Эти точки соединяются ступенчатой линией, этот гра-
фик и будет выборочной оценкой кривой выживаемости. Кроме того,
построенную кривую можно охарактеризовать и обобщенным пока-
зателем, например медианой. Для этого надо найти точку, в которой
кривая выживаемости впервые опускается ниже 0,5. Если в исследо-
вании число умерших было меньше половины, найти медиану невоз-
можно. При этом обобщенным показателем может быть любой дру-
гой перцентиль (меньше 50%). По таблицам выживаемости более точ-
но, чем при использовании общепринятого расчета среднего
значения, может быть определен и показатель, называемый средней
продолжительностью жизни.
144 Глава 1. Математическая статистика в клинических исследованиях
Допустим, что в исследовании нового препарата на 10 пациентах
были получены следующие результаты: 8 пациентов умерли через 3, 5,
7 (2 пациента), 8, И, 12 (2 пациента) месяцев после начала исследова-
ния. Кроме того, в связи с невозможностью дальнейшего наблюдения
2 пациента выбыли из исследования через 6 и 9 месяцев (в таблице эти
события обозначим знаком —). Построим таблицу выживаемости по
полученным в ходе такого мнимого исследования результатам (табл. 28).
Таблица 28.
Таблица выживаемости, рассчитанная поданным гипотетического иссле-
дования
Момент
времени, /
3
5
6-
7
8
9-
11
12
Наблюдались к
моменту t, nt
10
9
7
5
3
2
Умерли к
моменту /, dt
1
1
2
1
1
2
Доля пережив-
ших момент /,
1 - dt/nt
0,9
0,889
0,71
0,8
0,67
0
Выживае-
мость, S(t)
0,9
0,8
0,57
0,46
0,31
0
Полученные моментальным методом результаты из табл. 28 при-
ведены на рис. 25. Для данной кривой выживаемости медиану визу-
ально оценим как 8 месяцев, так как в этой точке кривая впервые
опустилась ниже отметки 0,5.
Если кривую выживаемости построить в логарифмической систе-
ме координат (t — \rvS(t)), то наклон кривой в каждой конкретной вре-
менной точке будет показывать уровень летальности среди выживших
в данный период времени.
Как всегда при исследовании выборки, выборочная кривая выжи-
ваемости представляет собой оценку кривой выживаемости для со-
вокупности. При этом для каждой точки на кривой можно, например
по формуле Гринвуда [3], определить оценку точности приближения
или стандартную ошибку выживаемости:
1.7. Статистический анализ результатов клинических исследований 145
% 1 «^
Й 0,8 f 1
о
а 0,2 +
PQ
0 -I 1 1 1 1 1 1 1
0 3 5 7 8 11 12
Время, мес
Рис. 25. Кривая выживаемости для примера, ход вычислений показан в
табл. 28. Кривая представляет собой ступенчатую линию, каждая ступень
соответствует моменту смерти хотя бы одного из наблюдавшихся паци-
ентов. Горизонтальная линия проведена для оценки медианы. По оси аб-
сцисс — время /, мес; по оси ординат — выживаемость, S(t)
где сумма берется по всем моментам времени из таблицы выживае-
мости от 0 до / включительно.
Доверительные интервалы для выживаемости в момент / можно
строить аналогично построению такого интервала для выборочной
доли. Такой доверительный интервал для каждого момента / задается
соотношением S(t) ± za • cs(t), где za — двустороннее критическое зна-
чение для стандартного нормального распределения (в случае 95-про-
центного интервала za = 1,96, для других значений см. табл. 7 прило-
жения). Более точный метод построения доверительного интервала
для выживаемости представлен в [3]. В клинических исследованиях
(особенно в онкологии, [4]) часто возникает необходимость сравни-
вать показатель выживаемости в различных группах.
Если, скажем, в сопоставленных группах число выживших за пери-
од наблюдения одинаково, но при этом в одной из них большая часть
пациентов умирают в более ранние сроки по сравнению со второй,
эти различия будут наглядно продемонстрированы при построении кри-
вых выживаемости и скрыты при оценке эффекта с помощью долей.
Сравнение кривых выживаемости
Существуют методы множественного сравнения кривых выжива-
емости, но эти методы требуют большого количества вычислений, они
подробно рассмотрены в [3, 4, 37]. Мы покажем, как это можно еде-
146 Глава 1. Математическая статистика в клинических исследованиях
лать в случае сравнения двух групп. Нулевая гипотеза в данном слу-
чае состоит в том, что выживаемость в группах одинакова. Статисти-
ческие методы для решения данной задачи также делятся на парамет-
рические и непараметрические. Среди непараметрических методов для
сравнения кривых выживаемости, построенных моментальным мето-
дом, наиболее известны логранговый критерий и критерий Гехана, они
применимы, если число наблюдений в каждой группе не менее 10.
Логранговый критерий предполагает, что функции выживаемости свя-
заны соотношением S2(t) = [Sx(t)Yn в случае соблюдения этого предпо-
ложения данный критерий предпочтительнее. Проверить соблюдение
данного условия можно, нарисовав графики этих двух функций в осях /,
ln[—In S(t)\, если они параллельны, условие выполняется [3]. Пересече-
ние говорит о нарушении данного условия. Величина ^ называется от-
ношением смертности. Если Ч* равно 1, кривые совпадают, если мень-
ше 1, пациенты во второй выборке умирают позже, чем в 1, и наоборот.
Для проверки этого критерия для каждого момента времени в таб-
лице выживаемости рассчитываем ожидаемое число умерших по обе-
им таблицам совместно (аналогично анализу таблиц сопряженнос-
ти). При этом определяем возможный процент смертности по двум
группам вместе при условии справедливости нулевой гипотезы. Да-
лее рассчитываем ожидаемое число умерших в каждой группе при ус-
ловии отсутствия различий между группами. Критерий проверяется
по степени близости реальных значений в таблицах выживаемости к
ожидаемым, оцененным при условии соблюдения нулевой гипотезы.
Ожидаемое число умерших в первой группе в каждый момент вре-
мени /, когда произошла хотя бы одна смерть хотя бы в одной группе
(вычисления проводятся для одной из групп, и не имеет значения —
для какой):
Esx = «,/• dtot/ntot, (88)
где nxt — число наблюдавшихся пациентов в этой группе к этому мо-
менту, dtot — общее число смертей в этот момент в обеих группах,
ntot — общее число наблюдавшихся к этому моменту.
Сумма разностей наблюдаемого и ожидаемого числа умерших бе-
рется по всем моментам времени, когда хотя бы одна смерть наступа-
ла в какой-либо группе, в результате получается статистика UL Эта
статистика приближенно подчиняется нормальному закону распре-
деления со стандартным отклонением:
|у nxt • n2t • dtot • (ntot - dtot) (89)
\^ ntot2-(ntot-I)
1.7. Статистический анализ результатов клинических исследований 147
Статистика z для проверки критерия получается при делении значе-
ния UI на его стандартную ошибку. Эта статистика распределена при-
ближенно по нормальному закону. Как обычно, рассчитанное значение
сравнивается с критическим значением для стандартного нормального
распределения (см. табл. 7 приложения с учетом уровня значимости).
Если рассчитанное значение больше табличного, нулевая гипотеза об
отсутствии различий отклоняется на выбранном уровне значимости.
В данном случае также приходится делать поправку, связанную с
нормальной аппроксимацией, поправка Йейтса позволяет скоррек-
тировать статистику:
М-05 (90)
oUl
Критерий Гехана представляет собой обобщенный критерий Уил-
коксона [3, 4]. Коротко идея метода состоит в анализе продолжитель-
ности жизни, при этом каждый пациент из наибольшей по численно-
сти группы сравнивается с каждым из другой группы. Результату срав-
нения присваивают +1, если пациент из первой группы наверняка
прожил дольше, в противном случае ставится — 1; 0 — если сделать
такое заключение наверняка невозможно. Последняя ситуация мо-
жет возникнуть, если оба выбыли, если один выбыл до того, как дру-
гой умер, и если продолжительность жизни одинакова.
Результаты сравнения для каждого пациента суммируются, обо-
значим эту сумму v. Степень отличия величины v от 0 в ту или иную
сторону является мерой оценки достоверности различий между эф-
фектом в сравниваемых группах.
Сумма всех v дает величину wg, стандартная ошибка которой вы-
числяется по формуле:
o»8J ЩП^2 — (91)
\{пх+п2){пх+п2-\)
Как и в случае прошлого критерия, статистика z для проверки дан-
ного теста вычисляется как отношение величины wg к ее стандартной
ошибке cwg. Полученное значение сравнивается с критическим зна-
чением стандартного нормального распределения (см. табл. 7 прило-
жения). Аналогично в данном случае применяется и поправка Йейтса.
Мы дали лишь упрощенное представление об основных подходах
к оценке эффекта с помощью кривых выживаемости. Более детально
с другими методами построения таких кривых, их статистического
анализа и сравнения можно познакомиться, например, в [3, 4, 28, 37].
148 Глава 1. Математическая статистика в клинических исследованиях
1.7.15. Статистическое сравнение
с помощью метода доверительных интервалов
В разных параграфах данной работы мы подчеркивали, что для
ответа на вопросы, поставленные перед клиническим исследовани-
ем, с помощью различных критериев приходится проверять нулевую
гипотезу об отсутствии эффекта, сравнивая при этом выборочные
средние, доли, кривые выживаемости, линии регрессии и т. п. Кроме
того, мы неоднократно обращали внимание читателя на то, что срав-
ниваемые средние, доли, кривые выживаемости, линии регрессии и
т. п. являются лишь выборочными оценками соответствующих пара-
метров генеральной совокупности по имеющимся данным. Для каж-
дого такого выборочного показателя, помимо его точечной оценки
мы давали формулы для построения интервальных оценок, или дове-
рительных интервалов. Доверительные интервалы дают информацию,
аналогичную статистической значимости и могут быть использова-
ны для оценки статистической значимости различий.
Приведем формулу для доверительного интервала разности срав-
ниваемых истинных средних значений Ml и Л/2 (в случае нормально-
го распределения совокупностей):
(Х1-Х2)-га-о/<М1-М2<(Х1"Х2) + ^-а/, (100)
где XI, XI — выборочные средние значения; ad — стандартная ошиб-
ка разности выборочных средних; /о — коэффициент Стьюдента, оп-
ределяется с учетом симметрии интервала и числа степеней свободы.
Уровень а, как и раньше, определяется дополнением выбранной до-
верительной вероятности до единицы. Число степеней свободы и фор-
мулы для расчета стандартной ошибки разности выборочных сред-
них приведены в разделе, посвященном критерию Стьюдента для
сравнения средних значений двух независимых выборок.
Подобным образом может быть построен доверительный интер-
вал и для разности долей. Пусть р]ир2 — значения генеральных долей
сравниваемых совокупностей, а рх и р2— соответствующие выбороч-
ные значения долей. Тогда доверительный интервал для разности ис-
тинных значений долей может быть записан как:
(Pi -P2)-Za-(Xlp<pl-p2<(px-p2) + za-<xlp, (101)
где с dp — стандартная ошибка разности выборочных долей, коэффи-
циент z определяется по табл. 7 приложения с учетом доверительной
вероятности и соответствующего значения а.
1.7. Статистический анализ результатов клинических исследований 149
Читатели, наверное, обратили внимание на то, что формулы для
расчета таких доверительных интервалов похожи на соответствующие
формулы для проверки гипотез о наличии статистически значимых
различий: оба подхода предполагают расчет разности выборочных
показателей, стандартной ошибки этой разности, используют одина-
ковые распределения. Поэтому уровень а для 100(1 — а)% довери-
тельного интервала часто называют уровнем значимости, аналогич-
но величине, используемой для проверки статистических гипотез.
Можно сказать, что если 100(1 — а)% доверительный интервал
выборочных показателей не содержит нуля, то различия можно счи-
тать статистически значимыми на уровне значимости а(р < а). Если
этот интервал содержит ноль, то различия статистически незначимы.
+20 +30 +40 +50
Величина эффекта, %
Рис. 27. Множественные сравнения с помощью доверительных интерва-
лов. 95-процентные доверительные интервалы величины эффекта, пост-
роенные по результатам 41 гипотетического исследования. Положитель-
ные значения различий означают преимущество исследуемого метода по
сравнению с контрольным. Все эти доверительные интервалы содержат
ноль, поэтому ни в одном исследовании не было установлено наличие
статистически значимых различий в эффекте. Видно, что многие дове-
рительные интервалы смещены в сторону положительных значений. Воз-
можно, при увеличении объема выборок статистически значимые разли-
чия были бы выявлены в некоторых из исследований
150 Глава 1. Математическая статистика в клинических исследованиях
Доверительные интервалы имеют и ряд преимуществ по сравне-
нию с записью результата тестирования соответствующей статисти-
ческой гипотезы в виде (р <а). Во-первых, доверительный интервал
позволяет увидеть диапазон правдоподобных значений. Поэтому, про-
веряя гипотезу о статистической значимости различий, желательно
приводить еще и границы соответствующего доверительного интер-
вала, дающие возможность судить о величине эффекта. Величина
эффекта, в свою очередь, позволяет оценить выявленный статисти-
чески значимый эффект с точки зрения его клинической значимости.
Во-вторых, доверительные интервалы содержат и информацию о ста-
тистической мощности. Если размах доверительного интервала велик,
а величина, соответствующая отсутствию эффекта, лежит близко к од-
ной из границ интервала, скорее всего, для установления статистичес-
ки значимого различия следует увеличить мощность исследования.
Таким образом, можно сказать, что метод доверительных интер-
валов является достаточно информативным способом представления
результатов клинических исследований. С помощью метода довери-
тельных интервалов можно сравнивать показатели для нескольких
групп, кроме того, этот метод успешно применяется и при проведе-
нии метаанализа (рис. 27).
1.7.16. Некоторые вопросы
планирования клинических исследований
Вопросы экономики и этики требуют внимательного отношения
к планированию клинических исследований. Теперь, когда приведе-
ны основные понятия математической статистики и разобраны мно-
жество статистических критериев для анализа получаемых результатов,
мы решили еще раз вернуться к вопросу планирования клинических
исследований. Этот вопрос достаточно сложен в математическом пла-
не, особенно в случаях, когда при статистической обработке прове-
денных исследований необходимо проверять несколько статистичес-
ких гипотез [3, 29, 32, 35, 38] или при невозможности использования
для сравнения показателей эффекта равночисленных групп [4, 29].
Поэтому в рамках этой работы мы познакомим читателя лишь с общи-
ми подходами и приведем несколько наиболее простых приближенных
формул для оценки необходимой численности сравниваемых групп.
Особенностью планирования клинических исследований являет-
ся то, что исследователь никогда не имеет в своем распоряжении всей
популяции (генеральной совокупности) для проведения исследова-
1.7. Статистический анализ результатов клинических исследований 151
ния и обычно имеет дело лишь с выборкой из этой совокупности. При
этом особую важность приобретают задачи планирования, например
определение объема выборки, которого оказалось бы достаточно для
формирования статистически значимого заключения о различиях
(или об отсутствии таких различий) в эффекте по результатам прове-
денного клинического исследования. На практике часто на этапе пла-
нирования исследования эта задача не решается строго, а планируе-
мый объем назначается на основе прошлого опыта проведения сход-
ных исследований. При этом в ходе статистического анализа может
оказаться, что полученных данных или недостаточно для статисти-
чески достоверного ответа на вопросы, ради которых и проводилось
исследование, или их структура не соответствует цели исследования.
Исследователям надо иметь в виду, что неэтичными являются иссле-
дования как имеющие чрезмерно большую численность включенных
пациентов, так и исследования слишком малого объема.
Чтобы ответить на вопросы, поставленные перед клиническим
исследованием, с помощью различных критериев приходится прове-
рять нулевую гипотезу об отсутствии различий в эффекте, сравнивая
при этом выборочные средние, доли, кривые выживаемости и т. п.
Вывод об отсутствии таких различий тесно связан с понятием чув-
ствительности критерия. Чувствительностью критерия называется
его способность обнаружить различия. Чтобы оценить чувствитель-
ность критерия, нужно задать величину различий, которые он дол-
жен выявлять. Если в результате проверки гипотезы о существовании
различий был сделан вывод об их отсутствии, необходимо проверить,
была ли чувствительность критерия достаточной для обнаружения та-
ких различий. Чувствительность зависит не только от величины раз-
личий, но и от разброса данных и объема выборки. При этом наиболее
важным параметром является объем выборки: чем он больше, тем мень-
шие различия окажутся статистически значимыми. Таким образом,
появляется возможность заранее оценивать численность выборок, не-
обходимых для выявления эффекта. Надо заметить, что вопросы чув-
ствительности важны и при использовании методов корреляционно-
го, дисперсионного анализа и других методов статистики [3, 19].
С понятием чувствительности критерия связаны понятия ошибок I
и Ирода, определения которых были приведены выше. Так, ошибка I
рода — возможность ошибочно отклонить нулевую гипотезу, то есть
найти различия там, где их нет (ложноположительный результат). При-
емлемая для данного исследования вероятность ошибки I рода назы-
вается уровнем значимости а. Ошибка II рода (ее вероятность обозна-
152 Глава 1. Математическая статистика в клинических исследованиях
чается /3) возникает, если мы принимаем нулевую гипотезу, когда она
неверна, другими словами, не находим существующее различие (лож-
ноотрицательный результат). Вероятность обнаружить различия, то
есть чувствительность, или мощность критерия, равна 1 — /5. При
прочих равных условиях тот критерий имеет преимущество, который
имеет меньшую вероятность ошибки II рода. Эту ситуацию иллюст-
рирует рис. 26, на котором схематично представлены распределения
нулевой (а) и альтернативной (б) гипотез для проверки односторонне-
го теста о наличии статистически значимых различий между средними
значениями двух независимых выборок. Таким образом, на чувстви-
тельность критерия различные факторы влияют следующим образом:
• уровень значимости а — чем меньше а, тем ниже чувствитель-
ность;
• отношение величины различий к стандартному отклонению: чем
оно больше, тем больше чувствительность (для количественно-
го определения признака); частота события: чем больше число
(или доля) событий, тем выше чувствительность (для учета ре-
акции в альтернативной форме);
• объем выборки: чем больше, тем больше чувствительность. Под-
робнее этот вопрос разобран в [1, 3, 9, 16].
вероятность ошибки
I рода, а
область принятия критическая область
нулевой гипотезы
вероятность ошибки
II рода, р
критическая область
область принятия
альтернативной гипотезы
Рис. 26. Односторонний тест для проверки гипотезы о равенстве средних
значений, а — распределение нулевой гипотезы; б — распределение аль-
тернативной гипотезы
1.7. Статистический анализ результатов клинических исследований 153
Надо заметить, что в большинстве случаев параметрические кри-
терии являются более мощными, чем их непараметрические аналоги,
и если соблюдаются все предпосылки использования параметричес-
кого критерия, замена его соответствующим непараметрическим мо-
жет привести к увеличению ошибки II рода. Подробнее об этом мож-
но узнать в [18].
Кроме того, надо обратить внимание, что для различных статис-
тических критериев и методов анализа чувствительность вычисляет-
ся по разным формулам. Эти же формулы можно использовать для
решения обратной задачи: при выбранных значениях вероятность
ошибок I и II рода (заданной чувствительности) и желаемой величи-
не различий между эффектами оценить требуемый объем выборок для
получения статистически достоверных результатов сравнения. Суще-
ствуют графики, номограммы [3, 28 29, 31, 37] и таблицы [4], связы-
вающие чувствительность с величиной различий для наиболее часто
встречающихся значений а и различных объемов выборок. Известны
формулы расчета и соответствующие таблицы требуемых объемов
выборок для различных планов клинических исследований. Мы при-
ведем лишь некоторые для наиболее часто используемых критериев.
Нужно иметь в виду, что формулы для расчета необходимого объе-
ма выборок являются приближенными и применимы при объемах
выборок больше 20. Можно сказать, что они дают только прибли-
женную оценку объема. Приближенный характер таких вычислений
обусловлен несколькими факторами: приближенными априорны-
ми оценками величин, входящих в состав расчетных формул; при-
ближенными оценками различий в эффекте, которые были выбра-
ны до начала исследования; и, наконец, приближенным характе-
ром самих математических моделей, лежащих в основе таких
расчетов. Кроме того, надо иметь в виду, что оцененное таким обра-
зом необходимое количество пациентов должно быть увеличено
(обычно на 10-20%) с учетом возможного выбывания в процессе ис-
следования. Оценка численности групп, выполненная до начала ис-
следования на этапе планирования, может затем пересчитываться
исследователем по мере получения результатов (например, на этапе
промежуточного анализа).
Таким образом, прежде чем оценивать требуемый объем групп для
данного исследования, необходимо:
• понять, переменные какого типа (количественные; качествен-
ные; переменные, представляющие собой промежуток времени
до наступления интересующего события и учитывающиеся с по-
154 Глава 1. Математическая статистика в клинических исследованиях
мощью кривых выживаемости) будут измерять эффект в данном
исследовании;
• выбрать, исходя из специфики данного исследования, подходя-
щий план;
• оценить величину различий между эффектами, приемлемую для
данного исследования с клинической точки зрения (клиничес-
ки значимое различие);
• выбрать подходящий статистический тест для последующего ана-
лиза интересующих различий, это определит выбор конкретных
формул для расчета;
• определить, односторонний или двусторонний тест будет умес-
тен в данном случае и в соответствии с этим установить подхо-
дящие уровни ошибок I и II рода;
• оценить по данным литературы, пилотному исследованию или
результатам сходных исследований величины показателей, вхо-
дящих в выбранные для расчета формулы;
• увеличить рассчитанные по формулам значения объема с учетом
возможного исключения в процессе исследования.
Приведенные нами формулы предназначены для оценки числа
пациентов, необходимого для установления различий в эффекте при
сравнении двух групп в контролируемых клинических исследованиях.
Если критериями эффекта в контролируемых клинических иссле-
дованиях служат количественные признаки, выражаемые статистичес-
кими средними величинами, то формула расчета минимального объе-
ма групп для сравнения показателя в двух независимых группах с уче-
том вероятности ошибок I и II рода имеет вид (равновеликие группы):
n = (Za+Zfi)2 , (92)
где Sxo2 и Sxk2 — дисперсии показателей сравниваемых опытной и конт-
рольной групп, А — требуемая величина различий между средними зна-
чениями сравниваемых групп, Za и Zp — критические значения нор-
мального распределения, соответствующие установленным уровням
ошибок а и /J, определяются по таблицам (см. табл. 7 приложения).
В случае если вместо Sxo2 и Sxk2 — дисперсий показателей сравнива-
емых опытной и контрольной групп используется их обобщенная оцен-
ка Sx2, соответствующая формула может быть преобразована к виду:
n = (Ze+Z,)'^. (93)
1.7. Статистический анализ результатов клинических исследований 155
Из приведенных формул видно, что для оценки необходимого
объема выборки важно скорее соотношение дисперсии и требуемой
величины различий, чем их численные значения. Это обстоятельство
имеет важное практическое значение при планировании исследова-
ния, когда конкретные точные значения дисперсий и А могут быть
еще неизвестны. Обычно для таких приближенных предварительных
оценок объема выборки используют соотношения A/Sx, равные 1; 0,9;
0,8; 0,7 и т. д.
Нами была разработана компьютерная программа для оценки не-
обходимого числа пациентов при проведении исследований в со-
ответствии с различными вариантами дизайна. Пользователь вы-
бирает вариант дизайна и задает значения статистических парамет-
ров, необходимые для проведения таких расчетов: вероятности
ошибки I и II рода, предполагаемые величины дисперсий и желае-
мые значения клинически значимых различий между средними зна-
чениями показателей эффекта. В следующих двух таблицах мы при-
ведем некоторые результаты таких расчетов для плана параллельных
равновеликих групп и различных значений статистических парамет-
ров в случае сравнения количественных признаков (для двусторон-
него и одностороннего теста). Сравнив результаты в различных стро-
ках и столбцах приведенных таблиц, можно получить представле-
ние, в какой степени используемые в расчетах статистические
параметры влияют на значение необходимого объема выборки. Рас-
четы проводились в предположении о равенстве дисперсий в обеих
группах. В табл. 29, 30 приведены значения минимального объема
для одной группы без учета возможного выбывания в процессе ис-
следования.
Таблица 29.
Необходимый объем группы. Количественные признаки, параллельный
план, двусторонний тест
а=5%,р = 5%
a=5%J=\0%
а=5%,р = 20%
a=\%,fi = 5%
яг=1%,/?=10%
1 а=\%,0 = 2О%
A/Sx=l
25
21
16
35
29
23
A/Sx = 0,9
32
25
19
43
36
28
A/Sx = 0,8
40
32
25
55
46
36
A/Sx = 0,7
53
42
32
72
60
47
A/5jc = 0,6
72
58
44
98
82
64
156 Глава 1. Математическая статистика в клинических исследованиях
Таблица 30.
Необходимый объем группы. Количественные признаки, параллельный
план, односторонний тест
\а=5%,0 = 5%
\а=5%,0= 10%
\а=5%,р = 20%
\а= \%,р = 5%
\а= \%,р= 10%
\а= \%,р = 20%
A/Sx = 1
22
17
12
31
26
20
A/Sx = 0,9
27
21
16
38.
32
24
A/Sx = 0,8
34
26
19
49
40
31
A/Sx = 0,7
44
34
25
64
53
40
A/Sx = 0,6
60
47
34
87
72
55
При альтернативной форме описания эффекта с помощью час-
тот (или долей) ро и рк необходимое число наблюдений при рав-
ных по численности опытной и контрольной групп определяется
по формуле:
.2 ро(\00- ро) + рк(100- рк)
n = (Za+ZfiY
(94)
где А — величина разности между частотами ро — рк. Такой метод дает
достаточно точные результаты при 25% < р < 75%. При других значе-
ниях частот для корректировки возникающих искажений, как гово-
рилось выше, вводится поправка ср = 2• arcsin д//? (см. табл. 6 прило-
жения). Объем выборки вычисляется при этом как:
„-2(Z«+Z'f. (95,
Финансовые, этические или другие соображения могут требовать
формирования различных по численности опытной и контрольной
групп. Если известна фиксированная численность одной (например,
контрольной группы пк), можно оценить требуемую численность дру-
гой группы (по) для получения статистически значимого заключения
о различиях в эффекте между ними.
В случае количественного представления признаков эта формула
приведена, например, в [4]:
(Za+Z,)2Sxo2
по = -
^_{Za+Z^)2Sxk2
(96)
пк
1.7. Статистический анализ результатов клинических исследований 157
Для альтернативного представления признаков:
по =
(Za+Zfi) (OJ)
(9o-q>*)2-(Z»+ZP)/
Данные формулы предполагают использование одностороннего
теста (показатель одной группы лучше показателя другой, исклю-
чая возможность превосходства последнего). В случае необходимо-
сти «улавливания» различий в эффекте в ту или иную сторону при-
меняется двусторонний тест. Приведенные формулы для расчета
при этом не меняются, но значение уровня значимости а заменяет-
ся на ос/2.
Так, например, для 5-процентного уровня значимости а и 95-про-
центной мощности двустороннего теста (соответствующее значение
Р= 5%) число пациентов для достоверного установления различий в
эффекте А/с = 0,8 для каждой из двух групп одинаковой численности
равно п = 2(1,96 + 1,645)2 • (1/0,8)2 « 41. Видно, чем больше величина
отношения различия к среднему квадратичному отклонению (или,
проще говоря, к разбросу данных) А/а, тем меньше требуется чис-
ленность групп для получения статистически значимого заключения.
Кроме того, чем ниже выбран уровень ошибок I и II рода, тем боль-
шей должна быть соответствующая выборка.
Аналогично решается данная задача для случая представления по-
казателей эффекта в альтернативной форме. Так, критическое число
пациентов, соответствующее уровню значимости а = 5%, уровню /3= 5%
и одностороннему варианту теста, при 60% доле положительных ис-
ходов в одной из групп для установления 20-процентного различия
А.л. <л*лс ,„cV 0,6-0,4 + 0,8-0,2 1ЛП
в эффекте, равно п = (1,645 +1,645 Г = « 109 в каждой
0,22
из двух одинаковых по численности групп.
Допустим, теперь необходимо определить количество пациентов
для исследования, в котором в качестве переменной эффекта будет
использоваться изменение значения интересующего параметра до и
после начала терапии. Математически эта задача похожа на предыду-
щую задачу сравнения двух независимых групп. Только в данном слу-
чае для статистически достоверного заключения понадобится мень-
ше пациентов, поскольку вариация разности между наблюдениями
значительно меньше, чем вариация одиночных наблюдений. Это
объясняется наличием корреляции (часто более 0,5) между последо-
вательными измерениями [29, 32].
158 Глава 1. Математическая статистика в клинических исследованиях
Известны специальные формулы определения необходимой числен-
ности групп и в случае, когда в качестве переменной для оценки эф-
фекта используется скорость изменения какого-либо интересующего
показателя [32]. Так, представим, что выбранная для сравнения непре-
рывная количественная переменная эффекта измеряется в начале, на
промежуточных этапах и в конце исследования. Рассмотрим случай
только двух таких измерений: до и после исследования. Тогда одним из
возможных подходов к решению задачи является предположение о
линейном характере изучаемых изменений во зремени (один из источ-
ников погрешностей вычислений). При таком предположении скорость
изменения является постоянной и может быть описана одним пара-
метром — коэффициентом наклона прямой, аппроксимирующей изме-
нения показателя во времени. Математическая модель таких изменений
будет записываться в виде: х — а + bt + error, где Ъ — наклон прямой,
оценивающий скорость изменений, t — время, error представляет от-
клонение измеренных значений от модельной линии регрессии. Эта
ошибка может объясняться погрешностями измерений, биологичес-
кой вариабельностью, нелинейностью процесса изменения показате-
ля и т. д. Обычно считается, что эта ошибка равномерно распределена
вокруг нуля и имеет дисперсию <52(error)\ предполагается также, что эта
дисперсия приблизительно одинакова для всех пациентов. Параметры
прямой а и by и c2(error) идентифицируются по результатам измерений
показателя с помощью метода наименьших квадратов для каждого па-
циента. До начала исследования оценка величины a2(error) делается
на основе данных литературы или предыдущих аналогичных работ.
Чтобы оценить эффективность, исследователь должен сравнить
средний наклон прямой в одной группе со средним наклоном, полу-
ченным в другой группе. Межиндивидуальную вариабельность накло-
нов обозначим как оь2. Если D — общее время наблюдения и А'— чис-
ло равномерно распределенных во времени измерений изучаемого
показателя, дисперсия о.2 может быть выражена как:
-2 ^-2
12{К-1)а2 (error)
(т:=ст;+< ч . /, % . ^ > С»)
d2k{k+\)
где а52 — компонента в вариации наклона прямой, не зависящая от оши-
бок измерений и наличия нелинейности в данных. Тогда требуемый объ-
ем групп для установления различий А в средних скоростях изменений
изучаемого показателя в двух группах может быть оценен по формуле [32]:
2(za+Z/?):
п = -
Д2
12(АГ-1)сг2 (error)
D2K(K + l)
(99)
1.7. Статистический анализ результатов клинических исследований 159
Видно, что, варьируя значения £> и К, можно с учетом специфики
данного исследования попытаться снизить влияние ошибок o2(error),
связанных с применяемой математической моделью и измерениями,
и выбрать оптимальные параметры дизайна.
Расчет необходимого числа пациентов для исследований, резуль-
таты которых обрабатываются с помощью методов анализа выживае-
мости, предложены, например, в работах [3, 32]. Мы дадим только
один самый простой вариант используемых для этого формул. Допу-
стим, нам необходимо сравнить кривые выживаемости, построенные
по результатам клинического исследования в двух группах. Наиболее
общим подходом является аппроксимация кривых выживаемости экс-
поненциальной функцией 5(0 = e~h. Каждая такая кривая может быть
однозначно охарактеризована параметром А, — коэффициентом смер-
тности. Коэффициент смертности X может рассматриваться как ве-
личина, характеризующая скорость процесса и обратная среднему вре-
мени выживания. Нулевая гипотеза в данном случае формулируется как
Нр Хк — Я0. Тогда требуемый размер каждой группы для проверки
i[z +z )2
гипотезы оценивается по формуле:/! = -г—j ir-.
Предположим для сравниваемых препаратов Хк = 0,3 и Х0 = 0,2,
тогда \/Х0 = 1,5. Для двустороннего теста и а = 0,05, /3 = 0,1 получим
необходимый объем выборки для каждой группы, равный п = 128.
Однако недостатком такого подхода является предположение о том,
что до конца временного интервала исследования у всех пациентов,
включенных в исследование, обязательно наступает изучаемый ис-
ход. Некоторая модификация данной формулы позволяет уйти от это-
го предположения, подробнее об этом см. в [32].
Формулы расчета объема выборки могут быть преобразованы для
оценки мощности соответствующего теста 1 — Д В этом случае неиз-
вестной считается величина Zp, а значение а, число испытуемых п в
группе, величина различий и другие параметры, входящие в соответ-
ствующую расчетную формулу, считаются известными. Расчетная фор-
мула выбирается, как и ранее, исходя из применяемого статистического
теста. По оцененному значению Zp с помощью табл. 7 приложения полу-
чаем интересующее значение /J и вычисляем мощность теста как 1 — Д
Оценить требуемый объем выборок или чувствительность метода
можно и в случае применения дисперсионного анализа. Чувствитель-
ность дисперсионного анализа определяется практически теми же фак-
торами, что и чувствительность критерия Стьюдента для сравнения
160 Глава 1. Математическая статистика в клинических исследованиях
двух параллельных групп [3, 33, 34]. Для этого вычисляется параметр
А Гп~
нецентральности, равный /7 = —,— , где о — стандартное отклоне-
с \2т
ние совокупности, т — число групп, п — численность каждой из них,
А — величина различий (используется минимальная величина разли-
чий между любыми двумя группами). По соответствующим графикам
[3, 34] находят чувствительность дисперсионного анализа как функ-
цию параметра нецентральности при выбранном уровне значимости,
определенном межгрупповом числе степеней свободы (равно числу
групп т минус 1) и определенном внутригрупповом числе степеней
свободы (равно т • (п — 1)).
Может быть определена чувствительность и при работе с таблица-
ми сопряженности в случае использования в качестве показателя эф-
фекта переменной в альтернативной форме. Формулы и таблицы для
решения этой задачи даны в [3, 18].
Разные вопросы планирования клинических исследований рас-
смотрены более детально, например, в [3, 4, 24, 28, 29, 32, 35, 38].
Однако на практике при использовании этих достаточно простых
расчетных формул могут возникнуть проблемы. Дело в том, что для
некоторых исследований заранее может быть неизвестна величина дис-
персии (или среднего квадратичного отклонения) признака. Обычно
эта проблема решается с помощью использования вместо этой величи-
ны ее аналога, известного из проведенных ранее похожих исследований,
или используются данные литературы. Кроме того, уже на этапе плани-
рования расчеты могут показать, что необходимый объем контрольной
и тестируемой групп для констатации требуемых различий при желае-
мых уровнях ошибок I и II рода превышает реально возможный для про-
ведения таких исследований. Однако объем групп можно попробовать
снизить, варьируя желаемые значения вероятностей ошибок I и II рода
или величины различий между группами. Если и это не приводит к
желаемому результату, надо отдавать себе отчет в ограниченных воз-
можностях такого исследования. Это также является сигналом к более
внимательному отношению к результатам «негативных» клинических
исследований с малым объемом выборок. Возможно, именно недостат-
ки в планировании могли привести к тому, что изучавшиеся методы
лечения, имеющие клинически важный эффект, были забракованы.
Проблема усложняется, если в ходе планируемого исследования
должны быть получены ответы на несколько вопросов о различных
параметрах эффективности, что, соответственно, потребует провер-
1.7. Статистический анализ результатов клинических исследований 161
ки нескольких статистических критериев, эта проблема подробно ос-
вещена, например, в [3, 32, 38].
В заключение можно сказать, что хотя на практике вычисление тре-
буемого объема выборок является скорее оправданием уже выбранной
численности групп (на основе экономических, практических или эти-
ческих соображений), такие расчеты обязательно должны быть прове-
дены на стадии планирования исследования. Результаты же «негатив-
ных» исследований (не выявивших искомые различия) не могут счи-
таться достоверными без вычисления оценки чувствительности или
мощности критериев, применявшихся для проверки статистически зна-
чимых различий. Детальный анализ ошибок планирования испытаний,
которые привели, в свою очередь, к сомнительным выводам в результа-
те статистической обработки данных, проведен авторами [35], и их
выводы, безусловно, имеют теоретическую и практическую ценность.
1.7.16.1. Планирование клинических
исследований: цели и статистические гипотезы
Целью любой научной активности является получение новых зна-
ний. Достоверность любых научных результатов зависит от способа
сбора данных, или наблюдений, т.е. от дизайна исследования, а так-
же от способа анализа полученных данных. Сам по себе правильно
проведенный статистический анализ недостаточен для достижения
научной достоверности, поскольку качество любой информации, по-
лучаемой в результате анализа данных, зависит от качества самих дан-
ных. Поэтому, желая собрать в ходе клинического исследования дей-
ствительно полезную информацию, необходимо принимать во вни-
мание все его аспекты: дизайн, порядок проведения и последующий
анализ полученных данных. Клинические исследования проводятся
для демонстрации и сравнения с контролем прямого и побочного дей-
ствия одной или нескольких новых терапий или вмешательств. Не
ограничивая общности, мы говорим, в основном, о терапевтических
клинических исследованиях, в которых новая терапия — лекарствен-
ный препарат сравнивается с контролем.
Процесс создания нового лекарства долгий и дорогостоящий.
Обычно он включает поиск вещества с заданными свойствами, раз-
работку лекарственных форм, выбор оптимальных путей введения,
лабораторные и доклинические исследования, несколько фаз клини-
ческих исследований и регистрацию лекарственного препарата. Кли-
нические исследования играют огромную роль в этом процессе. Они
162 Глава 1. Математическая статистика в клинических исследованиях
основываются на теории планирования эксперимента, но имеют ряд
специфических особенностей, отличающих их от экспериментов в
других дисциплинах. А проведение клинических исследований на
пациентах (или здоровых добровольцах) создает целый комплекс эти-
ческих проблем, с которыми не приходится сталкиваться исследова-
телям в других областях науки и практики.
В отличие от идеального научного эксперимента, клинические
исследования предполагают участие «экспериментальных единиц»
(пациентов или добровольцев), чьи индивидуальные характеристики
значительно варьируются. В отличие, например, от лабораторных
экспериментов, которые можно тщательно контролировать и мони-
торировать и которые ставятся в специально оборудованных лабора-
ториях, клинические исследования распространяются на самые раз-
ные составляющие клинической практики и проводятся в кабинетах
врачей, в стенах клиник и больниц. Некоторые исследования включа-
ют пациентов, проходящих лечение амбулаторно. Многие клиничес-
кие исследования являются мультицентровыми, а значит, их проведе-
ние зависит от большого числа медицинских сотрудников разных ме-
дицинских учреждений. Огромный объем информации собирается и
вводится в компьютеризированные базы данных. Качество получаемых
результатов зависит от совместных усилий врачей, медицинских сес-
тер, специалистов в области хранения и защиты информации, матема-
тиков-статистиков. Основным документом, регламентирующим эти
совместные усилия, является протокол исследования — документ, опи-
сывающий цель(и), процедуры, официальную политику и научные сто-
роны проводимого клинического исследования. Важность протокола
не может быть переоценена: участники исследования, допускающие
отклонения от протокола, могут внести систематическую ошибку, что
в свою очередь, может привести к неправильным выводам. Разные
вопросы, которые должны найти отражение в протоколе исследова-
ния, рассматриваются нами в этой книге.
Для регистрации лекарственного препарата в США необходимо,
чтобы по меньшей мере два так называемых «адекватных и хорошо-
контролируемых» клинических исследования предоставили «веские»
доказательства его эффективности и безопасности. Для того чтобы
разобраться в смысле этой фразы с точки зрения статистики, нужно
ответить на следующие специфические вопросы: 1) что такое «адек-
ватное и хорошо-контролируемое» клиническое исследование; 2) ка-
кие доказательства можно считать «вескими»; 3) почему требуется не
менее двух исследований; 4) может ли оказаться достаточно одного
1.7. Статистический анализ результатов клинических исследований 163
исследования, включающего большое число пациентов; 5) какое число
пациентов необходимо для проведения подобных исследований. По-
пробуем ответить на эти вопросы.
Принятые основные характеристики так называемого адекватного
и хорошо-контролируемого клинического исследования можно пред-
ставить в виде таблицы 31 (Chow S-Ch., Shao J., Wang H. Sample Size Cal-
culations in Clinical Research // Marcel Dekker, Inc. - New York—Basel, 2003).
Таблица 31.
Основные обобщенные характеристики адекватного и хорошо-контроли-
руемого клинического исследования
Критерий
Цель исследования
Методы анализа
Дизайн
Выбор субъектов
для исследования
Включение пациентов
в исследование
Участники
исследования
Показатели ответа на
проводимую терапию
Оценка эффекта
Характеристика
Ясно сформулированное предложение
Краткое изложение предложенных и/или акту-
альных методов анализа
Валидное сравнение с контролем, позволяющее
количественно выразить и сопоставить изучае-
мый в исследовании эффект
Адекватная постановка диагноза или выявление
клинического состояния, соответствующих оп-
ределению изучаемой в исследовании популяции
пациентов
Минимизация систематической ошибки, связан-
ной с формированием несопоставимых групп
пациентов
Минимизация систематической ошибки, связан-
ной с проведением исследования в определен-
ном медицинском центре, определенной груп-
пой исследователей
Ясно определены, и их оценки (измерения) дос-
таточно точны и надежны
Требование подходящих статистических методов
анализа данных
Таким образом, можно сказать, что цели адекватного и хорошо-
контролируемого» клинического исследования должны быть четко
сформулированы в протоколе - так, чтобы их можно было легко пре-
образовать в статистические гипотезы. В соответствии с гипотезами
выбираются и описываются в протоколе подходящие методы статис-
тического анализа. Удачно выбранный дизайн исследования должен
164 Глава 1. Математическая статистика в клинических исследованиях
позволить количественно оценить эффект и предоставить возмож-
ность валидного сравнения его с контролем. Еще одним из ключевых
положений является выбор и включение в исследование достаточного
числа субъектов с изучаемым заболеванием или клиническим состоя-
нием. При этом субъекты должны быть размещены в сравниваемые
группы таким образом, чтобы систематическая ошибка, связанная с
исходными различиями демографических характеристик (возраст, пол,
раса, рост, масса тела и т.п.) и/или прогностических факторов (исто-
рия болезни, тяжесть заболевания и т.п.), была минимальна. Первич-
ный показатель в адекватном и хорошо-контролируемом клиническом
исследовании должен быть ясно определен, а метод оценки показате-
ля должен предоставлять ее с определенной степенью точности и на-
дежности. Подходящие статистические методы, соответствующие ди-
зайну и целям исследования, должны быть привлечены для анализа
полученных данных. Под вескими доказательствами принято пони-
мать результаты (отчеты) адекватного и хорошо-контролируемого кли-
нического исследования, проводимого специалистами высокой ква-
лификации, имеющими опыт работы в этой области медицины.
Проанализируем причину требования по меньшей мере двух кли-
нических исследований. На практике благоразумно планировать бо-
лее одного клинического исследования на фазе III из-за любой ком-
бинации следующих причин: 1) отсутствие фармакологических обо-
снований; 2) новый фармакологический принцип; 3) результаты
исследований, проведенных на фазах I и II, ограничены или неубе-
дительны; 4) наличие данных о так называемых негативных исследо-
ваниях в этой области; 5) необходимость продемонстрировать эффек-
тивность и/или безопасность у различных подпопуляций пациентов;
6) наличие любых дополнительных вопросов для изучения на фазе III.
Требование проведения по меньшей мере двух клинических исследо-
ваний объясняется необходимостью проверки не только воспроизво-
димости результатов, но также и их обобщаемости. Под воспроизво-
димостью при этом понимают сходство результатов в зависимости от
места проведения исследования (в разных центрах внутри одного ре-
гиона или в разных регионах), а под обобщаемостью — возможность
распространения полученных результатов на другие сходные популя-
ции пациентов в одном и том же регионе или в разных регионах. Пос-
леднее позволяет выявить влияние, например, расовых различий на
эффективность и/или безопасность изучаемого препарата.
Хотя в настоящее время золотым стандартом является демонстра-
ция эффективности и/или безопасности по меньшей мере в двух кли-
1.7. Статистический анализ результатов клинических исследований 165
нических исследования, при определенных условиях результаты един-
ственного клинического исследования могут быть приняты разреши-
тельными органами США. Это в основном относится к препаратам,
разрабатываемым для лечения редких патологий или эффективных
при лечении очень ограниченной группы пациентов (так называемый
«препарат-сирота»), единственное исследование может рассматри-
ваться также в случае очень длительной терапии или заболеваний,
представляющих угрозу для жизни. Как видно из табл. 32, относи-
тельно сильные статистические результаты, полученные в одном кли-
ническом исследовании (скажем, /^-значение менее 0,001), могут
иметь практически 90%-ную воспроизводимость в последующих сход-
ных клинических исследованиях.
При планировании клинических исследований важным является
вопрос оценки необходимого числа пациентов для достижения задан-
ной мощности статистического теста, выбранного для сравнения ре-
зультатов с контролем, при заданном уровне статистической значи-
мости. В ходе выполнения некоторых клинических исследований
может потребоваться проведение промежуточного анализа (как .зап-
ланированного, так и незапланированного). Промежуточный анализ
результатов приводит к проблеме множественных сравнений, что тре-
бует корректировки оценки необходимого числа пациентов для под-
держания вероятности ошибки I рода на заданном в исследовании
уровне значимости (обычно в клинических исследованиях принят 5%-
ный уровень значимости). Кроме того, пересчет необходимого числа
пациентов может проводиться в ходе промежуточного анализа на ос-
нове дополнительно полученной информации о значениях первич-
Таблица 32.
Вероятность воспроизводимости, оцененная по результатам одного про-
веденного клинического исследования
Значение / - статистики
1,96
2,05
2,17
2,33
2,58
2,81
3,3
Соответствующее
р - значение
0,050
0,040
0,030
0,020
0,010
0,005
0,001
Вероятность воспроиз-
водимости результатов
0,500
0,536
0,583
0,644
0,732
0,802
0,901
166 Глава 1. Математическая статистика в клинических исследованиях
ного показателя эффекта. Если в ходе начального этапа исследова-
ния или пилотного исследования статистические характеристики пер-
вичного показателя эффекта оказались отличными от предполагае-
мых до начала исследования, оценка необходимого числа пациен-
тов может измениться как в сторону увеличения, так и в сторону
уменьшения. Все эти вопросы рассмотрены в соответствующих раз-
делах книги.
При планировании клинического исследования важно четко сфор-
мулировать цель(и) исследования (одну или несколько из следующих
четырех): 1) продемонстрировать/подтвердить эффективность, 2) изу-
чить профиль безопасности, 3) предоставить адекватную базу для
оценки соотношения риск/польза, 4) установить соотношение доза-
эффект. В большинстве клинических исследований первичная пере-
менная выбирается для демонстрации эффективности или безопас-
ности терапии. Например, планируется оценить эффективность и
безопасность терапии по сравнению с плацебо. При этом, возможно,
нужно будет продемонстрировать, что активная терапия имеет пре-
имущество по эффективности и незначимо отличается от плацебо по
безопасности. Но для многих клинических ситуаций плацебо-конт-
ролируемые исследования неэтичны, тогда стандартная терапия мо-
жет играть роль активного контроля. В этом случае часто бывает дос-
таточно показать, что изучаемая терапия не хуже стандарта. Таким
образом, можно сформулировать классификацию исследований по
типам сравнения. Различаются типы исследований, в которых нужно
показать, что 1) тестируемое лекарство также эффективно/безопас-
но, как контроль, 2) имеет преимущество по эффективности/безопас-
ности по сравнению с контролем или 3) по меньшей мере так же эф-
фективно/безопасно (не хуже), как и стандартная терапия. Поскольку
большинство исследований проводится для изучения эффективнос-
ти и безопасности лекарственных препаратов, предлагается, чтобы
следующие цели (см. табл. 33) были определены до выбора подходя-
щего дизайна исследования. Например, если исследование планиру-
ется для сравнения новой альтернативной терапии с достаточно ток-
сичным стандартным лечением, стратегия E/S может показать, что
тестовый препарат близок по эффективности, но менее токсичен (пре-
имущество по безопасности).
На практике статистические гипотезы обычно формулируются на
основе цели(ей) исследования. Они представляют собой постулаты,
предположения или утверждения, относящиеся к популяции паци-
ентов, для которой предназначается изучаемый лекарственный пре-
1.7. Статистический анализ результатов клинических исследований 167
Таблица 33.
Комбинации различных целей клинических исследований безопасности
и эффективности.
Безопасность
Эффективность
Эквивалентность
(equivalence)
«Не хуже» контро-
ля (non-inferiority)
Преимущество
(superiority)
Эквива-
лентность
(equivalence)
Е/Е
N/E
S/E
«Не хуже»
контроля
(non-inferi-
ority)
E/N
N/N
S/N
Преиму-
щество
(superiority)
E/S
N/S
S/S
парат. Например, статистическая гипотеза может представлять собой
утверждение, что имеется прямой эффект от применения изучаемого
препарата. Для тестирования статистической гипотезы обычно берет-
ся случайная выборка пациентов из изучаемой популяции, опреде-
ляемой критериями включения/исключения, у которой оценивают-
ся значения выбранных показателей эффективности и/или безопас-
ности. Статистические тесты позволяют принять или отвергнуть
выдвинутую гипотезу (на заданном уровне значимости) по имеющим-
ся выборочным данным. В клинических исследованиях принято на-
зывать нулевой гипотезой утверждение, доказательства которого хо-
телось бы избежать.
В прошлом данные контролируемых клинических исследований
сравнивались в основном с помощью тестирования стандартной ну-
левой гипотезы об отсутствии различий в эффекте между терапиями
против альтернативы о наличии различий:
Н0:МТ=МС (а)
HA:juT*Mc>
где /лти/лс— средние значения ответов на тестируемую и контрольную
терапии соответственно.
Тестируя такие гипотезы, исследователь отвечает на вопрос, явля-
ется ли различие между терапиями статистически значимым (являет-
ся ли ассоциированное с нулевой гипотезой ^-значение меньше ус-
тановленного уровня 0,05). Отвергнув нулевую гипотезу, исследова-
168 Глава 1. Математическая статистика в клинических исследованиях
тель делает заключение о статистически значимом преимуществе од-
ной терапии над другой. Если отвергнуть нулевую гипотезу не удается,
делается заключение об отсутствии статистически значимых различий
между терапиями (одинаковая эффективность/безопасность). При та-
ком подходе сама величина различий между терапиями игнорируется,
а клиническая значимость различий подменяется статистической зна-
чимостью. Поскольку наличие или отсутствие статистической значи-
мости различий зависит от числа включенных в исследование пациен-
тов, даже незначительные с клинической точки зрения различия могут
оказаться значимыми со статистической точки зрения при включе-
нии относительно большого числа пациентов, и наоборот. Кроме того,
проверка гипотезы об отсутствии различий не принимает во внимание
тип сравнения, характерный для данного исследования.
Большим шагом вперед в статистическом анализе данных кли-
нических исследований было требование учета величины клиничес-
ки значимых различий между сравниваемыми терапиями. При этом
несколько изменились и формулировки тестируемых гипотез. Но
независимо от того, используется ли при статистическом анализе
формальное тестирование гипотез или терапии сравниваются с по-
мощью расчета доверительных интервалов, сравнения в исследова-
ниях всех типов основаны на величине клинически значимых раз-
личий А. Например, в рандомизированном клиническом исследо-
вании сравнения нового антигипертензивного препарата с плацебо
среднее различие между тестируемым препаратом и контролем в сни-
жении диастолического давления на А=5 мм рт.ст. может рассмат-
риваться как клинически значимое. В случае демонстрации преиму-
щества одного антигипертензивного препарата над другим клини-
чески значимым может считаться среднее снижение диастолического
давления на 5 мм рт.ст. и более.
С учетом клинически значимых различий для проверки равенства/
неравенства двух терапий нулевая и альтернативные гипотезы фор-
мулируются как:
Я0: цт- iic = А (б)
tfA:jUr- /лс*А
Если в исследовании планируется продемонстрировать преимуще-
ство тестируемой терапии над контрольной на заданную величину А,
нулевая гипотеза представляет собой утверждение, что изучаемая те-
рапия не лучше контроля на величину А, а соответствующая альтер-
нативная гипотеза отражает цель исследования — тестируемая тера-
пия лучше контрольной на клинически значимую величину А:
1.7. Статистический анализ результатов клинических исследований 169
"о: д,- Цс < А
Нк:цт-»С>А W
Если тестируемый препарат дешевле активного контроля или реже
вызывает побочные эффекты, часто бывает достаточно продемонст:
рировать, что по эффективности он не хуже контроля. Альтернатив-
ная гипотеза может быть сформулирована так - тестируемая терапия
не хуже стандартной на клинически значимую величину А, а нулевая
гипотеза - тестируемая терапия хуже стандартной на величину А:
Н0:цт- цс<-А
НА:цт-^с>-А
Когда заранее неизвестно, как ведет себя изучаемый препарат по
сравнению с контролем, в исследовании проверяется эквивалентность
эффективности/безопасности сравниваемых терапий. Альтернатив-
ная гипотеза представляет собой утверждение «две терапии не отли-
чаются друг от друга на величину клинически значимого различия А».
Это может быть записано математически как:
Яо:К~ МС|<А (д)
HA:\ftT- мс|>А
Подобные гипотезы используются в исследованиях биоэквивален-
тности лекарственных препаратов. Подробнее об этом говорится в
соответствующем разделе книги.
Тестировать сформулированные выше гипотезы, соответствующие
типам исследований, можно с помощью стандартного статистичес-
кого подхода, заключающегося в расчете так называемого/?-значения.
Проверка гипотез (а, б) проводится с помощью двусторонних тестов,
поскольку предполагается, что преимущество может быть как в одну,
так и в другую сторону. Гипотезы типа (в, г) тестируются чаще всего
на одностороннем уровне значимости. Последнее связано с предпо-
ложением, что тестируемый препарат не может быть хуже контроля.
На практике тем не менее встречаются препараты (особенно препа-
раты, влияющие на центральную нервную систему), эффект от при-
менения которых может оказаться хуже плацебо-эффекта. Это слу-
жит аргументом против использования односторонних тестов. Дру-
гой аргумент против использования односторонних тестов связан с
понятием «label invariant» — результат сравнения не зависит от того,
как были рандомизированы пациенты в исследовании. Основная идея
состоит в том, что если между сравниваемыми терапиями действи-
170 Глава 1. Математическая статистика в клинических исследованиях
тельно имеется обнаруженное в исследовании различие, простая сме-
на ярлыков на препарате или, другими словами, назначение тестируе-
мого препарата пациентам из группы контроля и наоборот, приведет
только к изменению знака наблюдаемых различий между терапиями.
Проверку сформулированных выше гипотез можно проводить так-
же методом доверительных интервалов. Хотя оба эти метода взаимо-
связаны, применение метода доверительных интервалов часто быва-
ет более удобным и информативным. Как тот, так и другой метод под-
робно рассматривается нами в главе 1. Интерпретация результатов
расчета доверительных интервалов (обычно 90 или 95%-ных) и ста-
тистический вывод зависят от следующих ситуаций.
•Двусторонний доверительный интервал для различий между сред-
ними значениями изучаемой и контрольной терапии \iT — цс ле-
жит правее значения А, применительно к гипотезам (в) это озна-
чает, что нулевая гипотеза может быть отвергнута, а изучаемая
терапия имеет преимущество по сравнению с контролем.
• Доверительный интервал 1) содержит значение А, но не содер-
жит ноль, или 2) содержит и ноль, и значение А - можно сказать,
что в обоих случаях доверительный интервал содержит значения,
представляющие клинически незначимые различия, а значит,
нельзя заключить, что тестируемая терапия имеет преимущество
по сравнению с контролем. Однако мы можем сделать заключе-
ние, что изучаемая терапия не хуже контрольной (поскольку
нижняя граница доверительного интервала расположена правее
значения -А). Между случаями 1) и 2) есть различие: результат
сравнения (гипотеза (а)) признается статистически значимым в слу-
чае 1), но не в случае 2). Может возникнуть и зеркальная ситуация
принципиально не изменяющая суть статистического вывода.
• Доверительный интервал полностью содержится в интервале
[-А,А], можно заключить, что две сравниваемые терапии эк-
вивалентны. Если доверительный интервал не содержит 0, мож-
но говорить о статистической значимости сравнения для гипо-
тезы (а).
•Доверительный интервал полностью лежит левее -А, значит, пред-
лагаемая терапия хуже контрольной.
• Доверительный интервал шире интервала [-А,А], невозможно
сделать однозначное заключение.
Вернемся к примеру с антигипертензивным препаратом и приня-
тым в исследовании значением А=5 мм рт.ст. Понятно, что если дове-
рительный интервал для различий между тестируемым и контрольным
1.7. Статистический анализ результатов клинических исследований 171
препаратами в снижении диастолического давления лежит между 10
и 16 мм рт.ст., тестируемый препарат имеет статистически значимое
преимущество по сравнению с контролем. Этот вывод не изменится,
даже если в качестве значения А было бы выбрано значение 6 или 7.
Если доверительный интервал лежит в пределах от 1 до 3 мм рт.ст.,
две терапии, без сомнения, не отличаются друг от друга по эффек-
тивности. Если целью исследования было продемонстрировать, что
тестируемый препарат не хуже контроля, а доверительный интервал
заключен между 1 и 6 мм рт.ст., мы можем сделать желаемое заключе-
ние, поскольку нижняя граница интервала (1 мм рт.ст.) лежит правее
границы -Д=-5 мм рт.ст. (независимо от выбора в качестве величины
А 5, 6 или 8 мм рт.ст.). Однако могут возникать и не такие очевидные
ситуации, тогда статистический вывод будет определяться выбран-
ной величиной А. Например, если доверительный интервал лежит
между 4 и 10 мм рт.ст. выбор величины 4 мм рт.ст. в качестве А приве-
дет к заключению о наличие статистически значимого преимущества
эффективности тестового препарата, а при выборе А=5 мм рт.ст. зак-
лючение будет неочевидным.
Поскольку статистический вывод зависит от выбранной величины
клинически значимого различия, понятно, что выбор А в каждом кон-
кретном исследовании является важной задачей. Обычно граничное
значение А в исследованиях «не хуже» не должно браться большим, чем
минимальное значение эффекта, прогнозируемое для активной терапии
по сравнению с плацебо в условиях, сходных с планируемым иссле-
дованием, а выбор меньшего значения может быть обоснован клини-
ческими соображениями. Обычно такое граничное значение устанав-
ливается на основе результатов прошлых плацебо-контролируемых
исследований с дизайном, сопоставимым с планируемым для нового
исследования. Для некоторых исследований и некоторых дихотоми-
ческих показателей эффекта регуляторными органами США установ-
лены значения границ А в исследованиях типа «не хуже», например для
показателей выздоровления при лекарственной терапии некоторых
инфекций, в том числе при использовании противогрибковых пре-
паратов (Chow S-Ch., Shao J., Wang H. Sample Size Calculations in Cli-
nical Research// Marcel Dekker, Inc. - New York—Basel, 2003) (см. табл. 34).
Например, если доля выздоравливающих при использовании лекар-
ственного препарата лежит в пределах 80—90%, предлагается в каче-
стве границы А в исследованиях «не хуже» принимать значение 15%.
Объяснение выбора границ в исследованиях биоэквивалентности
представлено нами в соответствующем разделе.
172 Глава 1. Математическая статистика в клинических исследованиях
Таблица 34.
Границы А для дихотомических показателей ответа в исследованиях типа
«не хуже контроля»
А, %
20
15
10
5
Доля ответивших на активную терапию, %
50-80
80-90
90-95
>95
В клинических исследованиях выбор величины А может зависеть
от абсолютного изменения первичного показателя эффекта, его от-
носительного изменения или самой величины эффекта. На практи-
ке в качестве значения А обычно выбирается стандартизованная ве-
личина эффекта (величина эффекта, нормированная на стандарт-
ное отклонение) в пределах 0,25—0,5, если нет никакой другой
априорной информации относительно поведения препарата у изу-
чаемой популяции пациентов. Эта рекомендация основана на том
факте, что клинически значимая стандартизованная величина эф-
фекта, наблюдаемая в большинстве клинических исследований, ле-
жит в пределах 0,25-0,5.
1.7.16.2. Показатели эффекта
Заболевание может иметь много симптомов, а проводимое лече-
ние — много эффектов: желаемых и побочных. Одно и то же заболе-
вание может по-разному протекать у разных людей, так же как тера-
пия может быть в разной степени эффективна и безопасна у разных
пациентов. В ходе клинических исследований мы имеем возможность
наблюдать течение болезни и действие терапии лишь у ограниченной
группы лиц из общей популяции заболевших. Полученный в клини-
ческом исследовании опыт и заключения мы хотели бы распростра-
нить и использовать для лечения пациентов в будущем. Измерение
наилучшим образом того, что возможно в ограниченном исследова-
нии, того, что определенная терапия может в отношении включен-
ной в исследование группы пациентов, не означает измерения того,
как хорошо изучаемая терапия действительно «работает». Кроме того,
определенные стандартные статистические процедуры требуют про-
ведения измерений в определенной форме. Все это объясняет, поче-
му выбор показателя эффекта в клиническом исследовании не явля-
1.7. Статистический анализ результатов клинических исследований 173
ется таким уж простым вопросом и почему в решении этого вопроса
принимают участие не только врачи, но и статистики.
Цель(и) исследования или соответствующие статистические гипо-
тезы определяют изучаемую популяцию пациентов, период наблюде-
ния и, что особенно важно для статистика, показатели, которые мо-
гут рассматриваться в качестве переменных, демонстрирующих эф-
фект. Выбор клинических показателей зависит от области медицины,
к которой относится клиническое исследование, и от показаний к
применению изучаемой терапии. Например, в области заболеваний
коронарных артерий наиболее важными показателями является смер-
тность и снижение частоты летального исхода под действием лекар-
ственных препаратов. В исследованиях антигипертензивных препара-
тов в качестве переменных эффекта обычно выбираются изменения
систолического и диастолического давления по сравнению с исходным,
смертность и инвалидизация из-за сердечно-сосудистых заболеваний;
специальные когнитивные шкалы применяются для оценки показате-
лей в исследованиях, связанных с болезнью Альцгеймера и Паркинсо-
на; частота переломов может быть показателем эффекта в исследова-
ниях препаратов для остеопороза; кривые выживаемости обычно ис-
пользуются для оценки эффекта в области онкологии.
Можно сказать, что относительно короткие исследования фикси-
рованной длительности обычно фокусируются на прямой оценке эф-
фекта терапии в терминах различий средних значений, долей, или
пропорций, например между группой пациентов, получающих новое
лечение, против группы стандартной терапии. В исследованиях с
большой продолжительностью наблюдений эффект часто оценивается
в терминах периода времени до наступления интересующего собы-
тия (метод анализа выживаемости), например, до выздоровления,
летального исхода, рецидива или какого-то показателя прогрессиро-
вания заболевания.
Выбор определенных переменных эффекта обычно определяется
клиническими аспектами планируемого исследования. Однако если
в данном исследовании показатель эффекта может быть измерен раз-
личными методами, выбор должен быть оговорен в протоколе. На-
пример, показатель смертности может быть оценен долей выживших
к определенному моменту времени или кривой выживаемости для
рассматриваемого периода времени. Или если исследователя инте-
ресует наступление какого-то события, то в качестве показателя эф-
фекта можно рассматривать время до его первого наступления, ди-
хотомическую переменную — долю событий в группе или скорость
174 Глава 1. Математическая статистика в клинических исследованиях
появления этого события и т.п. Кроме того, если в исследовании в
качестве показателя эффекта применяется дихотомическая перемен-
ная «успех-неуспех», в протоколе необходимо четко оговорить кри-
терий успеха/неуспеха в данном конкретном случае.
Очень соблазнительно, но опасно спланировать клиническое ис-
следование для получения информации только о биологической ак-
тивности терапии, например оценивая эффект как уменьшение раз-
мера опухоли в онкологических исследованиях или снижение уровня
CD4 в результате терапии СПИДа. Такую информацию можно полу-
чить относительно просто и быстро. Но биологическая активность яв-
ляется лишь суррогатной переменной для интересующего показателя
эффекта, гораздо важнее попытаться оценить в исследовании действи-
тельный клинический эффект. Он может быть продемонстрирован с
помощью таких показателей, как продолжительность жизни (время
выживания), качество жизни и т.п. Для оценки изменений этих пока-
зателей может потребоваться больше времени, но достоверное кли-
ническое исследование должно выявлять реальный клинический эф-
фект от получения пациентами изучаемого воздействия.
Т. Fleming и D. DeMets (1996) (Fleming TR., DeMets DL. Surrogate
end points in clinical trials: are we being misled? // Annals of Internal
Medicine 125: 605-613, 1996) представили четыре следующие модели,
обобщающие ситуации, в которых суррогатная переменная не может
использоваться для оценки клинического эффекта.
Модель 1. Заболевание влияет как на суррогатный, так и на дей-
ствительный показатель клинического эффекта, но независимо. На-
пример, курение может быть причиной как пожелтевших пальцев ку-
рильщика, так и рака легких, приводящего к смерти. Изучаемое ме-
дицинское воздействие может приводить к восстановлению цвета
кожи на пальцах пациента (суррогатная переменная), но не влияет на
показатель смертности из-за курения (переменная клинической эф-
фективности).
Модель 2. Заболевание влияет на действительный показатель кли-
нического эффекта посредством суррогатной переменной, а изучае-
мое медицинское воздействие «обходит» суррогатную переменную.
Например, препарат может каким-то образом приводить к улучше-
нию показателя выживаемости (клиническая эффективность), но не
влияет при этом на уровень CD4 (суррогатная переменная) у боль-
ных СПИДом.
Модель 3. Заболевание влияет на действительный показатель кли-
нического эффекта посредством суррогатной переменной, а изучае-
1.7. Статистический анализ результатов клинических исследований 175
мое медицинское воздействие, направленное на суррогатный пока-
затель, вызывает побочные эффекты по отношению к действитель-
ному клиническому эффекту. Например, флекаинид помогает при
аритмии, но при его применении показатель смертности возрастает
практически в три раза по сравнению с приемом плацебо (Echt DS.,
Liebson PR., Mitchell LB., Peters RW., et al. Mortality and morbidity in
patients receiving encainide, flecainide, or placebo // New England Journal
of Medicine 324: 781-788, 1991).
Модель 4. Заболевание влияет на действительный показатель кли-
нического эффекта посредством суррогатной переменной, а изучае-
мое медицинское воздействие, направленное на действительный по-
казатель, не имеет эффекта в отношении суррогатного. Например, g-
интерферон по сравнению с плацебо практически на 70% улучшает
показатели клинической эффективности при лечении детей с хрони-
ческим гранулематозным заболеванием, хотя эффект препарата и не
связан с уничтожением бактерий (International Chronic Granulomatous
Disease Cooperative Study Group. A controlled trial of interferon gamma
to prevent infection in chronic granulomatous disease // New England
Journal of Medicine 324: 509-516, 1991).
Основная идея, лежащая в основе использования суррогатных
переменных, — более быстрое и дешевое получение впечатления об
изучаемом эффекте. Т. Fleming и D. DeMets сформулировали два кри-
терия, относящихся к возможности использования в клиническом ис-
следовании суррогатной переменной. Во-первых, она должна корре-
лировать с действительным показателем клинического эффекта. А во-
вторых, она должна адекватно отражать величину влияния изучаемой
терапии на клинический эффект. Второй критерий часто бывает труд-
но определить. Для ответа на этот вопрос нужно достаточно глубоко
понимать процессы, лежащие в основе изучаемого заболевания, и
механизмы действия изучаемого медицинского вмешательства. В
любом случае при использовании суррогатной переменной ключевым
вопросом должен быть следующий: действительно ли получение зна-
чений суррогатной переменной дает необходимые знания об изучае-
мой терапии, позволяющие прогнозировать значения действительно-
го показателя эффекта? Если ответ на ключевой вопрос будет отри-
цательным, значит, изучаемая терапия приводит к эффекту, который
не может быть выявлен с помощью суррогатной переменной.
Высокое артериальное давление может быть причиной многих ме-
дицинских проблем. Если мы измеряет артериальное давление, что
достаточно просто на практике, а не сами проблемы, к которым оно,
176 Глава 1. Математическая статистика в клинических исследованиях
возможно, приводит, то тем самым используем суррогатный показа-
тель эффекта. Преимущество такого подхода очевидно. Мы с полным
основанием можем считать, что получили индикатор эффективности,
оценивать который можно с гораздо меньшими трудностями, чем дей-
ствительный показатель эффекта. Недостаток - возможность обманы-
ваться в отношении действительного эффекта. Рассмотрим, например,
случай с остеопорозом, действительный показатель эффекта при лече-
нии которого состоит в снижении частоты переломов костей, а сурро-
гатный показатель может быть оценен измерением минеральной
плотности костной ткани. Снижение минеральной плотности костей
приводит к их хрупкости и повышению риска переломов. Если, следо-
вательно, терапия повышает плотность, но в качестве побочного дей-
ствия негативно влияет на конструкцию костей, это может привести к
отрицательному эффекту в отношении частоты переломов. А значит,
адекватность использования суррогатной переменной в исследовани-
ях остеопороза зависит от изучаемой терапии. Например, и замести-
тельная гормональная терапия, и бисфосфонаты снижают потерю ми-
нералов в костях, но механизмы действия этих терапий различны, в
результате одна может влиять на частоту переломов положительно, а
другая — отрицательно. Поэтому в исследованиях бисфосфонатов для
лечения остеопороза требуется использовать действительный пока-
затель эффективности - частоту переломов, а в исследованиях заме-
стительной гормональной терапии достаточно результатов денсито-
метрии в качестве суррогатной переменной эффективности.
В некоторых исследованиях невозможно выбрать один показатель
в соответствии с целью(ями) исследования. Т. Capizzi и J. Zhang (1996)
(Capizzi Т. and Zhang J. Testing the hypothesis that matters for multiple
primary endpoints // Drug Information Journal 30: 349—956, 1996) пред-
ложили классификацию показателей эффекта и их деление на пер-
вичные, вторичные и описательные. Показатель(и) эффекта, удовлет-
воряющий следующим критериям, может рассматриваться в качестве
первичного: 1) имеет большое биологическое и/или клиническое зна-
чение; 2) отражает цель(и) исследования; 3) незначимо коррелирует
с другими показателями; 4) может иметь достаточную мощность для
проверки статистической гипотезы, сформулированной в соответ-
ствии с целью(ями) исследования; 5) их может быть выбрано как мож-
но меньше, лучше 1 и не более 4.
Иногда исследователю может потребоваться несколько показате-
лей эффекта, среди которых невозможно выбрать наиболее важный.
Наличие и последующее сравнение нескольких одинаковых по зна-
1.7. Статистический анализ результатов клинических исследований 177
чимости показателей эффекта приводят к возникновению проблемы
множественных сравнений. Чтобы избежать этой проблемы, если воз-
можно, пытаются разработать обобщенный показатель эффекта и тем
самым прийти к одному статистическому сравнению вместо несколь-
ких. Примером такого обобщенного показателя может быть любая
шкала, применяемая в психиатрии. Если показатель такого типа вы-
бирается в качестве основного в данном исследовании, в протоколе
необходимо привести ссылки на работы, в которых доказывается его
валидность, надежность и чувствительность. Другим примером мо-
жет служить, изменение определенного показателя с течением вре-
мени, например снижение вирусной нагрузки или снижение боли под
действием терапии. Сопоставление терапевтических групп может про-
водиться в нескольких выбранных временных точках (распределен-
ных во временном интервале наблюдения после приема препарата),
что неизбежно приведет к проблеме множественных сравнений. Дру-
гой подход заключается в расчете обобщенного показателя, напри-
мер представляющего собой площадь по кривой зависимости изме-
ренной вирусной нагрузки или оценки интенсивности боли от вре-
мени. При таком подходе мы приходим к единственному
статистическому сравнению обобщенного показателя эффекта. Иног-
да избежать проблемы множественных сравнений не удается. О воз-
можных ее решениях мы говорили в соответствующем разделе книги,
подробнее этот вопрос освещается, например, в следующих работах
(Hsu J.С. Multiple Comparisons. Theory and Methods // Chapman & Hall,
Boca Raton - London - New York - Washington, D.C., 1996; Chow SC,
Liu JP. Design and Analysis of Clinical Trials // John Wiley and Sons, New
York, NY, 1998).
Расчет необходимого числа включаемых в исследование пациен-
тов проводится на основе одной первичной переменной.
Итак, на этапе планирования клинического исследования статис-
тик должен помочь исследователям сформулировать цель(и) таким
образом, чтобы она(они) однозначно определяла(и) статистичес-
кую(ие) гипотезу(ы); первичную и вторичные переменные эффекта,
что в свою очередь позволило бы оценить необходимое число паци-
ентов и спланировать первичный статистический анализ. Кроме того,
на этапе планирования часто возникают следующие вопросы:
1. Достаточно ли для демонстрации эффекта пациентам (добро-
вольцам) получить одну дозу изучаемого препарата (single-dose
study) или для оценки эффекта необходимо достижение стацио-
нарного распределения препарата (steady-state study)?
178 Глава 1. Математическая статистика в клинических исследованиях
2. Для адекватной демонстрации эффекта сравнение лучше прово-
дить с плацебо, активным контролем или по отношению к ис-
ходным значениям показателя эффекта (baseline comparison)?
3. Достаточно ли сравнивать средние значения показателей или
необходимо учитывать индивидуальные значения показателей
эффекта?
4. Сколько временных точек оценки эффекта необходимо для на-
дежной демонстрации интересующего эффекта?
5. Достаточно ли у каждого субъекта в каждой временной точке
однократно измерять показатель эффекта или для повышения
точности оценки необходимы повторные измерения?
В решение этих вопросов также важную роль играет математик-
статистик.
1.7.16.3. Вмешивающиеся факторы
и взаимовлияние факторов
Так называемые вмешивающиеся факторы (confounding) являют-
ся важной проблемой в клинических исследованиях. Можно опре-
делить их как эффекты, вносимые различными факторами, которые
не могут быть разграничены при определенном дизайне исследова-
ния. Когда такие факторы присутствуют в каком-либо исследова-
нии, изучаемый эффект терапии не может быть оценен адекватно,
поскольку он затушевывается эффектами от других факторов. В кли-
нических исследованиях существует много источников вариации,
которые могут влиять на значения первичной переменной эффекта.
Если некоторые из этих источников вариации не идентифициро-
ваны и не контролируются нужным образом, их эффекты могут сме-
шиваться с эффектом, изучаемым в исследовании. Так, в класси-
ческом исследовании факторов, влияющих на рождение детей с
синдромом Дауна, первоначально в качестве основного фактора рас-
сматривался порядковый номер рождения ребенка в семье (рис. 28, а).
Было замечено, что вероятность синдрома Дауна намного выше у
ребенка, рожденного вторым, третьим, четвертым и пятым. Однако
была обнаружена и зависимость частоты синдрома Дауна от возрас-
та матери (рис. 28, б). На вопрос, какой же из факторов является
основным, а какой —вмешивающимся, удалось ответить с помощью
стратификационной процедуры. На рис. 28, в видно, что внутри каж-
дой возрастной подгруппы вероятность появления ребенка с синд-
ромом Дауна практически не зависит от порядкового номера его
1.7. Статистический анализ результатов клинических исследований 179
180
160
140
120
100
80
60
40
20
О
1000 л
900 \
800-1
700
600-1
500
400
300
200
100-1
0
<20
20-24 25-29 30-34 35-39 40+
*.
^
'*
1
'*0
Ъ
Рис. 28. Случаи синдрома Дауна (по вертикальной оси - число случаев
на 100 000 рожденных) в зависимости: а) от порядкового номера рожде-
ния ребенка в семье (по горизонтальной оси); б) от возраста матери (по
горизонтальной оси); в) от порядкового номера рождения ребенка в се-
мье (по горизонтальной оси) и возраста матери (по правой оси в гори-
зонтальной плоскости) — стратификация.
180 Глава 1. Математическая статистика в клинических исследованиях
рождения, но эта вероятность значительно возрастает с ростом воз-
раста матери.
Другая часто возникающая в клинических исследованиях пробле-
ма связана с взаимовлиянием различных факторов (interaction). При
изучении наличия такого взаимовлияния пытаются оценить, равен
ли совместный эффект действия различных факторов сумме эффек-
тов от каждого из этих факторов. Если взаимовлияние существует,
изучаемый эффект от терапии должен быть выделен и оценен отдель-
но от остальных влияющих факторов. Например, при проведении
мультицентровых клинических исследований может оказаться, что
значения показателя эффекта зависят от центра, в котором лечились
и наблюдались пациенты. С помощью специальных статистических
тестов можно проверить однородность результатов, получаемых из
разных участвующих в исследовании центов (treatment-by-center
interaction). Природа такого взаимовлияния может быть как количе-
ственная, так и качественная. Количественное взаимовлияние меж-
ду терапией и центром приводит к тому, что направление различий в
эффекте между сравниваемыми группами одинаковое во всех цент-
рах, но амплитуда этих различий меняется от центра к центру. А каче-
ственное означает, что значимые преимущества в эффекте между срав-
ниваемыми группами в разных центрах могут оказаться как в одну,
так и в другую сторону.
В клинических исследованиях учесть наличие вмешивающихся
факторов и взаимовлияний различных факторов можно с помощью
стратификации, например, по отношению к некоторым прогности-
ческим факторам или ковариатам. Вмешивающиеся и влияющие фак-
торы могут привести к ошибочным заключениям, если они не будут
адекватно учтены в ходе анализа данных. Стратификация может по-
мочь в решении этой проблемы. Стратификация может применять-
ся как на стадии рандомизации (стратификационная рандомизация),
так и в процессе статистического анализа (независимо от использо-
вания в исследовании стратификационной рандомизации). При
стратификационной рандомизации пациенты группируются в соот-
ветствии со значениями ковариат (например, демографические ха-
рактеристики, тяжесть или длительность заболевания и т.п.) до ран-
домизации, а затем рандомизируются в соответствующую страту.
Внутри каждой такой страты предусмотрена собственная последо-
вательность рандомизационных кодов. При их расчете для поддер-
жания сбалансированности размещения пациентов в группы срав-
нения обычно используется блочная рандомизация. Например, если
1.7. Статистический анализ результатов клинических исследований 181
стратификационная рандомизация проводится по полу пациента и
5 участвующим в исследовании центрам, в рандомизации выделяет-
ся 10 страт: медицинский центр с 5 градациями и пол пациента с 2.
В этом случае 10 случайных последовательностей рандомизацион-
ных номеров должны быть сгенерированы, а затем использоваться
для каждого пола в каждом медицинском центре. Например, при
включении в третьем центре пациента мужского пола ему будет при-
своен очередной рандомизационный код из соответствующей после-
довательности «центр № 3 — мужчины».
Стратификация может также использоваться на стадии статисти-
ческой обработки данных, при этом пациенты группируются в соот-
ветствии со значениями стратификационных переменных. На первом
этапе анализа терапии А и Б будут сравниваться внутри каждой стра-
ты, это так называемый анализ подгрупп (subgroup analysis). На вто-
ром этапе могут быть применены различные статистические методы,
объединяющие результаты различных страт, или подгрупп, для срав-
нения результатов по всем стратами. В приведенном выше примере в
анализе данных будут участвовать 10 страт. Пусть эффект терапии
оценивается дихотомической переменной: 1 — есть ответ на тера-
пию, 0 — нет ответа. Внутри каждой страты « центр — пол » для пред-
ставления результатов могут применяться таблицы 2X2, по которым
рассчитываются отношения шансов. Для оценки агрегированных ре-
зультатов по всем стратам может использоваться Mantel-Haenszel
тест (см. соответствующий раздел). Такой подход позволяет оценить
скорректированное (на эффект стратификационных факторов) зна-
чение общего отношения шансов как линейную комбинацию отно-
шений шансов в каждой страте, а также провести стратификацион-
ный тест на наличие взаимосвязи (an aggregate stratified-adjusted test).
Альтернативный подход заключается в объединении данных по всем
стратам в единой таблице 2X2 (pooled or combined analysis) и расчете
одного общего значения отношения шансов, не скорректированно-
го на эффект стратификационных факторов. Нужно иметь в виду,
что как первый, так и второй подход могут применяться независимо
от наличия или отсутствия стратификационной рандомизации в ис-
следовании.
Стратификация улучшает точность оценок и дает дополнительные
преимущества в исследованиях, включающих относительно неболь-
шое число субъектов. Стратификационная рандомизация имеет тен-
денцию к увеличению эффективности оценок и мощности тестов в
относительно небольших исследованиях п<100, но ее преимущества
182 Глава 1. Математическая статистика в клинических исследованиях
пренебрежительно малы при использовании в больших исследовани-
ях. При нестратификационной рандомизации вероятность несбалан-
сированности групп по отношению к демографическим характерис-
тикам и ковариатам снижается с ростом объема выборок. Считается,
что в большей степени стратификационный анализ, а не стратифи-
кационная рандомизация может скорректировать систематическую
ошибку, связанную с несбалансированностью ковариат. Поэтому ре-
комендуется проводить стратификационную рандомизацию только по
отношению к факторам, которые абсолютно необходимы в соответ-
ствии со смыслом исследования.
Во многих мультицентровых клинических исследованиях раз-
личия между исследовательскими центрами являются основной
причиной разнородности результатов. Поскольку в ходе исследова-
ния центр(ы) может закрыться, было бы желательно, чтобы такое
прекращение участия в сборе данных не отражалось на рандомиза-
ционном плане. Для этого обычно рекомендуется в мультицентро-
вых клинических исследованиях проводить стратификационную
рандомизацию по меньшей мере по отношению к исследователь-
ским центрам.
Другим способом борьбы с потенциальными вмешивающимися и
влияющими факторами является метод сопоставления пар (matching).
Для поддержания баланса между сравниваемыми группами в отно-
шении важных переменных (ковариат и/или прогностических фак-
торов), например возраста, пола, расы, подбираются сопоставимые
клинические случаи. В качестве недостатков метода можно назвать
его достаточно сложную практическую реализацию, особенно в слу-
чае наличия многих потенциальных факторов (требуется стратифи-
кация), необходимость использования достаточно сложных статис-
тических методов анализа данных, и, главное, невозможность найти
действительно идентичные случаи.
Зависимости показателей эффекта от значений известных кова-
риат могут быть установлены в ходе статистического анализа данных
с помощью математического аппарата многофакторных регрессион-
ных моделей, обсуждавшегося нами в соответствующем разделе кни-
ги. Наличие среди анализируемых данных количественных, дискрет-
ных и качественных переменных требует применения специальных
математические приемов. Если показатель эффекта выражается ка-
чественной переменной с альтернативным распределением, исполь-
зуется логистическая регрессионная модель.
1.7. Статистический анализ результатов клинических исследований 183
1.7.16.4. Случайная и систематическая ошибка
Фундаментальный принцип, лежащий в основе сравнительных
клинических исследований, состоит в том, что любые наблюдаемые
различия в эффекте между тестовой и контрольной группой могут
появиться из-за действительных различий между сравниваемыми те-
рапиями, а также из-за систематической и/или случайной ошибки.
Основные типы ошибок, возникающих в клинических исследованиях,
можно условно представить в виде результатов стрельб (рис. 29). Сис-
тематически смещенный результат (biased) приводит к низкой досто-
верности данных, например, из-за ошибки, связанной с выборкой, с
влиянием вмешивающихся факторов и т.п. Результат при этом от-
личается от истинного значения параметра и не зависит от числа на-
блюдаемых в исследовании субъектов (см. рис. 30). Случайная ошибка
означает низкую воспроизводимость данных, например, из-за неста-
Рис. 29. Случайная (левая мишень) и систематическая (правая мишень)
ошибка.
Ошибка
А
I Случ. ошибка (chance)
| Систем, ошибка (bias)^^
Объем изучаемой группы
Рис. 30. Ошибки в клинических исследованиях. Зависимость от объема
выборки.
184 Глава 1. Математическая статистика в клинических исследованиях
бильности прибора, участия разных наблюдателей, малого числа вклю-
ченных в исследование субъектов и т.п. В серии измерений истинное
значение параметра не искажается, а случайная ошибка снижается с
ростом численности групп (sample size) (рис. 30). Случайная ошибка
может быть количественно оценена с помощью доверительного ин-
тервала.
Целью любого клинического исследования является исключающее
систематическую ошибку сравнение результатов между терапевтичес-
кими группами, поэтому рандомизация пациентов является важным
элементом таких исследований. Рандомизация не только обеспечи-
вает случайность распределения пациентов по группам, но и позво-
ляет формировать группы, сходные с точки зрения демографических
характеристик и/или прогностических факторов. Конечно, никакая
рандомизация не в состоянии сформировать абсолютно одинаковые
группы. Однако применение формальной процедуры рандомизации
делает возможным, в случае необходимости, на основе теории веро-
ятности принять во внимание этот источник вариации и неопреде-
ленности. Следующий пример можно рассматривать как популярное
объяснение сути рандомизации. Если вы летите на самолете на высо-
те 10000 м над уровнем моря, и пилот объявляет, что отказали 3 мото-
ра, вы немедленно перестаете думать, что самолет — в среднем самый
безопасный вид транспорта. Если же вы представляете страховую ком-
панию, при проведении соответствующих расчетов вам достаточно
бывает рассматривать малую вероятности летных катастроф в сред-
нем. Это означает, что для неизвестных факторов среднее распреде-
ление является приемлемым, наличие известных и важных прогнос-
тических факторов требует для их учета предпринять что-то лучшее,
чем просто рассматривать ситуацию «в среднем». Возможно, что и
после рандомизации с учетом известных факторов группы останутся
несбалансированными в отношении неизвестных заранее ковариат,
что будет приводить к так называемой случайной систематической
ошибке. Однако можно сказать, что хотя рандомизация и не гаранти-
рует сбалансированность сравниваемых групп по отношению к неиз-
вестным ковариатам, различные процедуры рандомизации в той или
иной степени имеют тенденцию снижать вероятность появления слу-
чайной несбалансированности и уменьшать наносимый ею вред
(Rosenberger WF, Lachin JM. Randomization in Clinical Trials. Theory
and Practice // Wiley-Interscience, New York, 2002).
Часто в ходе статистического анализа данных для описания баланса
проведенной рандомизации в отношении известных ковариат их по-
1.7. Статистический анализ результатов клинических исследований 185
лученные значения используют для изучения связи с показателями
эффекта (например, для получения зависимости эффективности те-
рапии от пола пациента), такие функции называют «взаимовлияние
терапия —ковариата». Нужно иметь в виду, что рандомизация не устра-
нит наличие такого взаимовлияния, если оно действительно является
характеристикой изучаемого феномена, а не просто случайностью.
Например, плацебо-контролируемое исследование метформина про-
демонстрировало 31%-ное снижение риска развития диабета II типа у
лиц с нарушением толерантности к глюкозе (р < 0,001). Для более точ-
ного описания эффекта терапии пациенты были разделены на подгруп-
пы в соответствии с исходным значением индекса массы тела (BMI) в
кг/см2. Улиц с BMI < 30 кг/см2 прием метформина привел к снижению
риска лишь на 3%, в то время как в подгруппе 30 < BMI < 35 кг/см2 риск
снизился на 16%, а в подгруппе BMI > 35 кг/см2 на 53%. Разнород-
ность эффекта терапии среди подгрупп была статистически значимой
(р < 0,05). Следовательно, сбалансированность сравниваемых групп
по исходному значению BMI не приводит к правильному заключе-
нию, о том, что препарат является эффективным только в определен-
ной подгруппе пациентов и не эффективен в другой. Если важность
такого анализа подгрупп известна заранее, он предусматривается на
этапе планирования для обеспечения необходимой мощности теста.
Но на практике обычно необходимость анализа подгрупп заранее не-
известна, а у исследований не хватает мощности для выявления ста-
тистически значимых взаимовлияний терапия — ковариаты.
Как было показано в работе (Lachin JM. Statistical Considerations
in the Intent-to-treat Principle // Controlled Clinical Trials 21: 167—189,
2000), рандомизация является необходимым, но недостаточным ус-
ловием отсутствия систематической ошибки. Необходимо также, (1)
чтобы у всех субъектов показатели эффекта оценивались сходным
образом и без систематического смещения и (2) чтобы пропущенные
данные у рандомизированных субъектов не приводили к системати-
ческим различиям между сравниваемыми группами. Положение (1)
отражает важность стандартизации и «слепоты», а положение (2) —
важность философии статистического анализа. Стандартизация осо-
бенно важна в многоцентровых исследованиях, поскольку каждый
включенный в исследование пациент должен находиться в равных
условиях независимо от центра, в котором он получает медицинс-
кое обслуживание. Все участвующие в исследовании медицинские
исследовательские группы должны работать в сходной манере по
сходному алгоритму и на основе одинаковых критериев. Иногда в
186 Глава 1. Математическая статистика в клинических исследованиях
многоцентровых исследованиях даже используются централизованные
лаборатории. Все, что происходит с пациентом после рандомизации,
так или иначе может влиять на изучаемые клинические показатели.
Поэтому, насколько возможно, в протоколе должны быть стандарти-
зованы все аспекты назначаемого лечения, получаемых пациентом
процедур и используемых медицинских ресурсов, регистрации клини-
ческих событий (например, отражающих прогрессирование заболева-
ния, нежелательные явления и т.п.). Это важно не только с клиничес-
кой, но и со статистической точки зрения. «Слепоте» исследования
также уделяется большое внимание. Систематическая ошибка мо-
жет появиться и если схема рандимизации становится предсказуе-
мой для исследователей. Надо предупредить, что в случае блочной
рандимизации фиксированная длина блока не обеспечивает двой-
ной слепоты» исследования, для исключения систематической ошиб-
ки по возможности нужно использовать переменную (случайную)
длину блока.
Что касается философии статистического анализа данных клини-
ческих исследований, есть два основных направления, особенно на-
глядно проявляющиеся в области исследований лекарственных пре-
паратов. С одной стороны, фармаколог хотел бы получить информа-
цию о фармакологической эффективности режима дозирования. В
свете этого анализ эффективности выполняется с участием пациен-
тов, у которых были хорошая переносимость изучаемой терапии и
приемлемый комплайнс. Основная стратегия предполагает, что из
полученных в исследовании данных обо всех включенных пациентах
для статистического анализа показателей эффективности выбирает-
ся подмножество пациентов, удовлетворяющее указанным критери-
ям. С другой стороны, врач и сотрудник регуляторных органов хоте-
ли бы иметь данные о клинической эффективности в целом, то есть о
результатах лечения всех пациентов, которым изучаемый препарат
был назначен, независимо от появившихся в результате терапии по-
бочных эффектов или от реально полученного пациентами режима
дозирования. Хотя комплайнс является важным фактором эффектив-
ности, задача заключается в оценке эффективности терапии в попу-
ляции обычных пациентов с различной степенью комплайнса. Такая
подгруппа пациентов называется популяцией, наблюдавшейся в по-
рядке «намерения лечения» (the intent-to-treat population, ITT), по-
скольку значения переменных эффекта сравниваются независимо от
степени переносимости и комплайнса между группами пациентов,
которые исходно получали разную терапию.
1.7. Статистический анализ результатов клинических исследований 187
За исключением фармакодинамических исследований, основан-
ных на однократном дозировании препарата, и клинических иссле-
дований, предполагающих госпитализацию пациентов, практически
во всех исследованиях некоторые пациенты могут принимать препа-
рат или получать лечение со значительными отклонениями от прото-
кола. Это отсутствие комплайнса может принимать разные формы.
Пациент может прервать участие в исследовании, перестать прини-
мать препарат или время от времени забывать его принимать, прини-
мать препарат не в назначенной дозе и не в назначенное время. Воз-
можность отклонений от протокола в ходе исследования является
причиной выделения популяции, наблюдавшейся в порядке «наме-
рения лечения», и так называемой популяции «по протоколу». Пос-
ледняя исключает из анализа данных пациентов, в ходе лечения ко-
торых допускались значительные нарушения протокола, и пациен-
тов, не закончивших все предусмотренные протоколом процедуры.
Обычно спонсор предпочитает проводить статистический анализ
данных пациентов из популяции «по протоколу». Основным аргу-
ментом для использования этой популяции пациентов в анализе яв-
ляется следующий: терапия, которую пациент не получил или полу-
чил не в полном объеме, не может привести к желаемому результату,
а включение в статистический анализ эффективности пациентов с
плохим комплайнсом приводит к занижению реальной эффективно-
сти изучаемой терапии.
В работе (Lachin JM. Statistical Considerations in the Intent-to-treat
Principle // Controlled Clinical Trials 21: 167-189, 2000) автор на про-
стом примере продемонстрировал, как систематическая ошибка мо-
жет быть внесена в анализ эффективности. Допустим, исследование
изначально включает 100 пациентов, рандомизированных в две груп-
пы равной численности, но к концу исследования окончательные дан-
ные об эффективности терапии имеются только у 60 пациентов. Это
приводит к систематической ошибке, поскольку наличие или отсут-
ствие конечного наблюдения у пациента не является чисто случай-
ным. Например, пациенты в группе плацебо могли преждевременно
прервать прием препарата, почувствовав недостаточную его эффек-
тивность. С другой стороны, пациент в группе изучаемой терапии
может прекратить терапию раньше времени или самостоятельно сни-
зить принимаемую дозу, почувствовав себя значительно лучше уже
вначале курса лечения. В этих случаях отсутствие данных об эффекте
в конце терапии объясняется противоположными с точки зрения эф-
фективности причинами. Анализ оставшегося подмножества паци-
188 Глава 1. Математическая статистика в клинических исследованиях
ентов не сможет учесть важную информацию об эффективности изу-
чаемой терапии, содержащуюся в опыте выбывших пациентов. По-
пытаться избежать такой систематической ошибки можно с помощью
анализа популяции, наблюдавшейся в порядке «намерения лечения».
При этом целью исследователей является разработка такого дизайна,
который позволяет провести оценку эффективности терапии для каж-
дого включенного в исследование пациента независимо от степени
его активного участия в исследовании, комплайнса и побочных эф-
фектов (исключением могут быть только смерть пациента, клиничес-
кие противопоказания для процедур, оценивающих в данном иссле-
довании эффективность, и добровольный отказ пациента от дальней-
шего участия в исследовании). Причины выбывания пациента из
исследования должны документироваться и анализироваться.
Таким образом, можно сказать, что выбывание пациентов из ис-
следования обычно не приводит к систематической ошибке, если
причины отказа от участия не зависят от реакции на терапию, не яв-
ляются следствием появившихся нежелательных явлений, связанных
с приемом препарата. При расчете необходимого числа пациентов
полученная оценка обычно увеличивается на 10% с учетом такого слу-
чайного выбывания. А выбор для статистического анализа эффектив-
ности подмножества из числа рандомизированных пациентов зави-
сит от реальной возможности и дизайна исследования. Философия
использования популяции «намерения лечения» хорошо работает в
исследованиях серьезных заболеваний, в которых выживаемость яв-
ляется показателем эффективности терапии. В такой ситуации обыч-
но есть возможность наблюдать исходы терапии у большинства па-
циентов. Практические трудности возникают в исследованиях хро-
нических заболеваний, например астмы или гипертонии, когда
необходимы регулярные измерения клинических показателей у па-
циентов, а отказ пациента от дальнейшего участия приводит к невоз-
можности продолжения наблюдений. Практические трудности воз-
никают и при использовании в анализе эффективности популяции
«по протоколу». В основном они связаны с определением реальной
степени комплайнса каждого пациента. Раньше комплайнс устанав-
ливался на основе беседы с пациентом (родственниками или меди-
цинским персоналом), а также по числу возвращаемых пациентом
пустых упаковок и неиспользованных таблеток. В настоящее время
терапевтический лекарственный мониторинг помогает выявлять нео-
жиданно низкие концентрации препарата в крови пациента. После-
дним достижением можно считать электронный мониторинг, осно-
1.7. Статистический анализ результатов клинических исследований 189
ванный на внедрении микросхем в контейнер с препаратом, которые
активизируются при его открывании и фиксируют точное время. Ко-
нечно, мониторинг времени открывания контейнера не гарантирует
последующий прием препарата и комплайнс, а лишь несколько умень-
шает неопределенность в отношении правильности режима дозиро-
вания. Наличие всех этих проблем приводит к тому, что в некоторых
исследованиях анализ переменных эффективности производится с
участием как популяции »по протоколу», так и популяции, наблю-
давшейся в порядке «намерения лечения».
1.7.16.5. Групповой последовательный дизайн
и промежуточный анализ данных
В любом эксперименте, в котором информация собирается и на-
капливается в течение некоторого периода наблюдения, желательно
иметь возможность время от времени проводить ревизию получен-
ных к этому моменту данных, чтобы при некоторых условиях можно
было остановить процесс исследования раньше намеченного срока
или как-то модифицировать его дизайн. Основные причины прове-
дения такого промежуточного анализа можно условно разделить на
три категории: этические, административные и экономические.
В ходе клинических исследований по этическим соображениям
желательно иметь возможность убедиться, что включенные в иссле-
дование пациенты не получают опасное и/или неэффективное лече-
ние. Желательно иметь возможность как можно быстрее получить
доказательства, что исследование «негативное» (например, не выяв-
ляется клинически значимое различие между эффективностью актив-
ной терапии и плацебо), по этическим причинам лучше прервать
исследование, как только такая тенденция стала очевидна, чтобы ре-
сурсы могли быть направлены на изучение более перспективной те-
рапии. Этические соображения требуют проведения промежуточно-
го анализа и при появлении новой информации о препарате или за-
болевании из внешних источников.
Административные причины включают необходимость проверки
строгого соблюдения в ходе исследования утвержденного протокола,
соответствия характеристик включаемых в исследование пациентов
выбранным критериям включения/исключения. Промежуточный ана-
лиз позволяет выявить проблемы на ранних стадиях проведения ис-
следования, до того, как будут затрачены впустую огромные средства.
Другая административная причина проведения промежуточного ана-
190 Глава 1. Математическая статистика в клинических исследованиях
лиза связана с проверкой допущений, сделанных на стадии плани-
рования исследования при расчете необходимого числа включенных
пациентов. Если в качестве первичного показателя эффекта в иссле-
довании выбрана количественная переменная, расчет необходимого
числа пациентов обычно производится в предположении ее нормаль-
ного распределения с определенным значением дисперсии. Для ди-
хотомической первичной переменной эффекта для подобного расче-
та необходимо предположить, например, определенную величину
доли пациентов, ответивших на терапию. Оценки предполагаемых
значений обычно берутся из литературы или из прошлого опыта на
основе результатов проведенных раннее сходных клинических иссле-
дований. На практике в ходе выполнения данного исследования эти
априорные предположения могут нарушаться. Обнаружить такие от-
клонения можно, проведя промежуточный анализ имеющихся дан-
ных. Эта информация может быть использована для корректировки
необходимого числа пациентов. Обычно увеличение объема выборок
по сравнению с их априорными оценками и включение в исследова-
ние дополнительных пациентов потребуется, если, как показали пер-
вые этапы исследования, исходно дисперсия первичной переменной
была недооценена, и наоборот.
Статистические методы последовательного анализа были разрабо-
таны для получения экономических преимуществ. Для «позитивно-
го» клинического исследования возможность ранней остановки оз-
начает возможность более быстрого появления нового зарегистриро-
ванного препарата на рынке. Выявление «негативного» исследования
на ранних стадиях позволяет избежать неоправданных расходов. Пос-
ледовательный анализ является экономически выгодным по сравне-
нию с традиционным подходом (в котором необходимое число паци-
ентов оценивается и фиксируется на этапе планирования), посколь-
ку он минимизирует необходимое число включаемых в исследование
пациентов, а значит, дает возможность сберечь время и деньги.
Конечно, непрерывный мониторинг исследования был бы жела-
телен, но обычно невозможен практически. Практические преимуще-
ства последовательного мониторинга связаны с разработкой методов,
дающих возможность периодических инспекций данных. Такая схема
называется многоэтапной, или групповой последовательной. После-
довательный подход имеет многовековую историю. Можно считать,
что одним из первых его применил Ной, который день за днем (пос-
ледовательно) выпускал голубя из Ковчега для поиска суши (цель ис-
следования). В XVII — XVIII веках работы Бернулли, Лапласа и др. в
1.7. Статистический анализ результатов клинических исследований 191
области азартных игр можно также рассматривать в качестве предве-
стников появления последовательного подхода к анализу данных.
Формальное приложение последовательных процедур началось по-
зднее, в двадцатые годы XX века в области статистического контроля
качества продукции мануфактур. Armitage (1954, 1958, 1975) и Bross
(1952, 1958) считаются пионерами в использовании последователь-
ных методов в области медицины, а именно для сравнительных кли-
нических исследований. Первоначально предложенные ими планы
были полностью последовательными (данные анализируются после
получения каждого нового наблюдения) и не получили широкое
распространение из-за их непрактичности. Shaw (1966) предложил
применять последовательный групповой метод для клинического ис-
следования (он использовал термин «блочный последовательный ана-
лиз»). Более широко групповые последовательные методы начали
применяться в области клинических исследований сравнительно не-
давно, в семидесятые годы XX века. Считается, что основной вклад в
разработку этих методов внес Рососк (1977). Он разработал четкое ру-
ководство по внедрению групповых последовательных эксперимен-
тальных дизайнов, не изменяющих заданный в исследовании уровень
значимости и поддерживающий желаемую мощность статистическо-
го сравнения (Рососк S.J. Group sequential methods in the design and
analysis of clinical trials //Biometrika 64:191-199,1977). В статье O'Brien
и Fleming (1979) (O'Brien P.C., Fleming T.R. A multiple testing procedure
for clinical trials // Biometrics 35: 549-556, 1979), появившейся чуть
позднее работы Рососк, авторы предложили другой класс групповых
последовательных тестов, имеющих определенные практические пре-
имущества. Эти тесты имеют консервативные границы остановки на
ранних стадиях анализа, когда получено еще слишком мало инфор-
мации, а на поздних приводят к решению, сходному с принимаемым
в случае фиксированного числа включенных в исследование пациен-
тов при стандартном подходе и отсутствии промежуточного анализа.
В результате этот метод обычно не требует значительного увеличения
объема выборок по сравнению с первоначально запланированным.
Более поздние работы Slud и Wei (1982), Lan и DeMets (1983) также
имеют большое значение, поскольку авторы показали, что групповые
последовательные методы применимы в случае неравных и даже не-
предсказуемых размеров сравниваемых групп. Эта проблема характер-
на для клинических исследований, но не возникает, например, в про-
мышленных приложениях. В восьмидесятые годы XX века групповые
последовательные методы получили дальнейшее методологическое
192 Глава 1. Математическая статистика в клинических исследованиях
развитие и широкое практическое внедрение в связи с ростом числа
мультицентровых клинических исследований с длительным периодом
наблюдения. Такие исследования требовали проведения промежуточ-
ного анализа для контроля за безопасностью и эффективностью.
Последующее развитие этих методов можно проиллюстрировать с
помощью простейшего примера сравнения двух терапий. Групповые
последовательные методы мониторируют статистическое различие
между значениями первичной переменной эффекта в двух сравнива-
емых группах в серии временных точек в ходе клинического исследо-
вания. Если абсолютное значение тестовой статистики превышает
некоторое определенное критическое значение, исследование оста-
навливается, нулевая гипотеза об отсутствии различий между тера-
пиями отвергается, что означает «позитивный» результат исследо-
вания. Критические значения формируют границу для последова-
тельности тестовых статистик, нулевая гипотеза отвергается при
пересечении этой границы. Если значения статистики остаются внут-
ри заданных границ вплоть до запланированной остановки, или за-
вершения исследования, нулевая гипотеза принимается («негатив-
ный» результат). Как справедливо отмечали Armitage, McPhetson и
Rowe (1969), многократные сравнения и обычно применяемый фик-
сированный объем выборки приводят к возрастанию вероятности
ошибки I рода и превышению номинального уровня, скажем, а=0,05
(проблема множественных сравнений). В работах Рососк (1977),
O'Brien и Fleming (1979), Fleming, Harrington и O'Brien (1984) были
предложены методы корректировки критических значений для под-
держания полной вероятности ложноположительной ошибки на за-
данном уровне, дополнительные расчеты необходимого числа паци-
ентов для группового последовательного дизайна обеспечивают же-
лаемый уровень мощности сравнения. Подобным образом может
решаться и задача проверки нулевой гипотезы об отсутствии разли-
чий против односторонней альтернативы (демонстрация преимуще-
ства и исследования «не хуже» контроля). Более подробно групповые
последовательные методы рассмотрены в (Jennison С, Turnbull B.W.
Group Sequential Methods with Applications to Clinical Trials // Charman
& Hall/CRC, 2000).
Математически задачу групповых последовательных методов мож-
но в общем виде сформулировать следующим образом. Предполага-
ется, что число К промежуточных анализов аккумулируемых данных,
выполняемых через равные промежутки времени, специфицировано
в протоколе исследования. Пусть N — общее число пациентов, кото-
1.7. Статистический анализ результатов клинических исследований 193
рое предполагается включить в исследование с делением на две срав-
ниваемые группы равной численности. Длительность исследования
можно разделить на К одинаковых интервалов, в ходе каждой стадии
аккумулируются данные о n=N/K субъектах. В конце каждого интер-
вала выполняется промежуточный анализ с расчетом Z-статистики
(обозначим Z. для i-анализа, i=l,2,...,K) по собранным к этому мо-
менту данным. Два решения могут быть приняты на основе результа-
тов каждого промежуточного анализа. Во-первых, исследование мо-
жет быть продолжено, если:
|z|<*,.,i==l,...,K-l,
где z. - некоторые критические значения, называемые групповыми
последовательными границами.
Мы не можем отвергнуть нулевую гипотезу, если \z\ < z. для всех
i=l,...K.
Мы можем прервать клиническое исследование, если удается от-
вергнуть нулевую гипотезу в ходе любого из К промежуточных ана-
лизов (\Z.\ > Z;, i=l,...K). Например, в конце первого интервала в про-
межуточном анализе используются данные п пациентов. Если отверг-
нуть нулевую гипотезу не удается, мы продолжаем исследование до
второго запланированного промежуточного анализа. Если нулевая ги-
потеза отвергается на этом этапе, исследование можно остановить. Бы-
вает, что нулевую гипотезу не удается отвергнуть и в ходе финального
анализа. Тогда исследование завершается, а мы делаем заключение, что
данные исследования не предоставляют достаточно доказательств про-
тив валидности нулевой гипотезы. Если нулевая гипотеза отвергается,
мы заключаем, что статистически значимое различие между сравнива-
емыми терапиями обнаружено. В отличие от традиционной процедуры,
предусматривающей однократный расчет необходимого (фиксирован-
ного) числа пациентов на этапе планирования и однократный заклю-
чительный анализ данных, групповой последовательный дизайн пред-
полагает проведение К статистических анализов данных после окон-
чания каждой последовательной стадии исследования. Множественные
сравнения приводят к возрастанию вероятности ошибки I рода. Раз-
личные групповые последовательные методы были разработаны для
поддержания заранее заданного в исследовании уровня значимости.
Рососк (1977) адаптировал идею последовательного метода и пред-
ложил использовать постоянное скорректированное значение уров-
ня значимости для относительно небольшого числа последовательно
194 Глава 1. Математическая статистика в клинических исследованиях
выполняемых К статистических сравнений аккумулируемых на каж-
дом этапе исследования данных. Включаемые в исследование паци-
енты делятся на К групп, включающих одинаковое число п субъектов
в каждую из сравниваемых групп (специальные методы рандомиза-
ции позволяют проводить стратификацию в соответствии с прогнос-
тическими факторами). Специальное правило расчета граничных зна-
чений z., зависящих от заданного числа промежуточных анализов К и
общего уровня значимости, позволяет избежать проблемы множе-
ственных сравнений. Так, например, в случае К=5 и общего двусто-
роннего уровня значимости а=0,05 так называемый номинальный уро-
вень значимости для каждого из К сравнений накопленных к соответ-
ствующему моменту времени данных будет равен «'=0,0158. В случае
теста O'Brien и Fleming (1979) номинальный уровень значимости, не-
обходимый для проверки нулевой гипотезы на каждой стадии, посте-
пенно растет, то есть нулевую гипотезу труднее отвергнуть на ранних
стадиях исследования и становится легче по мере приближения к зап-
ланированному завершению исследования. Например, в случае К=5 и
общего двустороннего уровня значимости а=0,05 номинальные уров-
ни значимости в последовательных сравнениях будут а^О,000005,
а2'=0,0013, а3'=0>0084, а4'=0,0225, а5'=0,0413. Отличительным свой-
ством теста O'Brien и Fleming является его независимость от вариации
объемов выборок на первых стадиях исследования, поскольку в пер-
вых промежуточных анализах сравнения проводятся при очень низких
значениях уровня значимости, таким образом, на начальном этапе
число пациентов, включаемых в исследование на каждой стадии, мо-
жет несколько меняться. Более подробно эти методы, а также груп-
повые последовательные методы, допускающие неравные доли вклю-
чаемых на каждой стадии пациентов и неравные объемы групп, опи-
саны, например, в (Jennison С, Turnbull B.W. Group Sequential Methods
with Applications to Clinical Trials // Charman & Hall/CRC, 2000).
Пересчет необходимого числа включенных в исследование паци-
ентов по данным промежуточного анализа может проводиться как со
снятием «слепоты» (вскрытием рандомизационных кодов), так и без
него. На практике было бы желательно избежать процедуры снятия
«слепоты» до завершения исследования. Авторы (Shih W.J. Sample size
re-estimation for triple blind clinical trials // Drug Information Journal
27:761—764,1993; ShihW.J., Zhao P.L. Design for sample size re-estimation
with interim data for double-blind clinical trials with binary outcomes //
Statistics in Medicine 16: 1913—1923, 1997) предложили некоторые про-
цедуры пересчета объема выборок без снятия «слепоты» в случае ди-
1.7. Статистический анализ результатов клинических исследований 195
хотомической первичной переменной по данным промежуточного
анализа в двойном слепом клиническом исследовании. Идея заклю-
чалась в том, чтобы объем выборок пересчитывался на основе значе-
ний первичной переменной по объединенным данным сравниваемых
групп. Другие авторы, например Herson и Wittes (1993) (Herson J.,
Wittes J. The use of interim analysis in sample size adjustment // Drug
Information Journal, 27: 753—760, 1993), предложили схемы, в которых
внешний анализ данных предполагал доступ к значениям перемен-
ных и кодам исследования, на основе которых проводился пересчет
объема выборок, но вся исходная информация не передавалась иссле-
дователям и пациентам. Поскольку ранняя остановка исследования в
этом случае не предполагалась (вне зависимости от полученных резуль-
татов статистического сравнения), такой анализ данных можно рас-
сматривать как административную инспекцию. Действительно, поми-
мо корректировки необходимого числа включенных в исследование
пациентов, мониторы могли убедиться в соблюдении протокола ис-
следования, проверить комплайнс, показатели безопасности и т.п.
Часто объем выборок пересчитывается со снятием «слепоты» ис-
следования и с соответствующей корректировкой уровня значимос-
ти для последовательных сравнений. Такие процедуры предусматри-
ваются на стадии планирования, отражаются в протоколе и прово-
дятся статистиком, не зависимым от команды исследователей.
Одной из основных проблем в процедурах последовательного ана-
лиза является правило ранней остановки исследования. Существует
большое количество причин для мониторирования исследования и
большое количество причин, по которым исследование может быть
остановлено (или, наоборот, продолжено), например побочные эф-
фекты, финансовые вопросы, качество жизни пациентов, появление
новой многообещающей терапии, неизвестной до начала исследова-
ния. Нужно иметь в виду, что решение остановить клиническое ис-
следование довольно сложное и субъективное, в большей степени
«политическое», чем медицинское или статистическое.
1.8. ЗАКЛЮЧЕНИЕ.
НЕКОТОРЫЕ ПРАКТИЧЕСКИЕ РЕКОМЕНДАЦИИ
В заключение хотелось бы еще раз обратить внимание читателей
на некоторые важные практические вопросы, касающиеся планиро-
вания и анализа результатов клинических исследований.
196 Глава 1. Математическая статистика в клинических исследованиях
Прежде всего перечислим пункты протокола и отчета о клини-
ческих исследованиях, которые имеют непосредственное отношение
к теме данной работы. Без информации, содержащейся в данных пун-
ктах, невозможно грамотно провести исследование и тем более пред-
ставить необходимый статистический анализ результатов.
Клинические исследования не могут быть адекватно интерпрети-
рованы без информации о методах, которые были использованы при
разработке дизайна испытаний и статистической обработке получен-
ных данных. Так, группа математиков из Департамента биостатисти-
ки Harvard University (School of Public Health) [35] проанализировала
67 описаний клинических испытаний, опубликованных в журналах
New England Journal of Medicine, Lancet, British Medical Journal и
Journal of the American Medical Association в течение года. При этом
были предварительно определены 11 важнейших положений дизайна
и статанализа (например, критерии включения пациентов в иссле-
дование и порядок информированности о проводимом лечении, ме-
тоды рандомизации, информация о побочных эффектах, правила ис-
ключения и информация о выбывших пациентах, расчет базовой
статистики, название используемых статистических процедур, кри-
териев, тестов и компьютерных программ, так называемая мощность
исследования — размеры групп, требуемая величина различий между
группами, значения вероятностей ошибок I и II рода и т. д.), кото-
рые, по мнению специалистов, обязательно должны присутствовать
в описании проведенных испытаний. Результаты обзора показали, что
56% работ с точки зрения освещения перечисленных 11 положений
были оформлены совершенно корректно, еще 10% содержали нечет-
кое описание этих 11 пунктов, а оставшиеся 34% работ включали в
себя лишь отдельные положения этого списка. При этом более де-
тальный анализ выявил, что практически 80% работ содержали ин-
формацию о статистическом анализе и применяемых статистических
методах, процедурах случайного распределения пациентов, но толь-
ко 19% исследований описывали используемые методы рандомиза-
ции. Информация об исключенных пациентах содержалась в 79% ра-
бот, о наличии побочных эффектов — в 64%, но критерии включения
упоминались только в 37%. Хотя сведения об информированности
пациентов о проводимой терапии были даны в 55% работ, об инфор-
мированности пациентов о проведенном лечении по окончании те-
рапии говорилось лишь в 30%. Статистическая мощность критериев,
используемых для сравнения эффекта от проводимого лечения, об-
суждалась вообще только в 12% статей.
1.7. Статистический анализ результатов клинических исследований 197
Показательны также результаты, полученные этой группой статис-
тиков в отношении планирования клинических испытаний, важности
выбора значений уровней ошибок I и II рода и размеров выборки при
разработке дизайна и интерпретации результатов рандомизированных
контролируемых испытаний. Так, было проанализировано и «пересчи-
тано» в общей сложности 71 испытание, результаты которого первона-
чально оценили как отрицательные, то есть это были испытания, после
проведения которых статистический анализ показал, что различия между
процентом пациентов с положительными результатами терапии в тес-
тируемой и контрольных группах незначимы на уровне значимости 5%.
При пересчете результатов математики изменили значение веро-
ятности ошибки I рода, увеличив ее до 10%, однако и это не привело
к признанию результатов положительными ни для одного из рассмат-
риваемых испытаний. Теперь делалась попытка оценить, действитель-
но ли изучавшаяся в испытании выборка содержала достаточное ко-
личество пациентов для формирования с высокой вероятностью (бо-
лее 90%) заключения о преимуществах (25- или 50-процентное
увеличение положительных исходов) рассматриваемого метода лече-
ния по сравнению с контрольным. Вычислив для каждого испытания
значение вероятности ошибки II рода (вероятность ошибочно отвер-
гнуть существующее различие), статистики пришли к заключению,
что в 67 рассматриваемых негативных испытаниях содержался более
чем 10-процентный риск отвергнуть правильное заключение об име-
ющемся 25-процентном преимуществе; из них 50 испытаний могли
отвергнуть правильное заключение о 50-процентном преимуществе.
Это объясняется тем, что многие из проанализированных клиничес-
ких испытаний, в результате которых был сделан вывод «нет разли-
чий по сравнению с контролем», используют неадекватно маленький
размер выборки испытуемых.
Как мы уже говорили, значения объема выборки, вероятностей оши-
бок I и II рода, мощности критерия связаны между собой математи-
ческими соотношениями. Это хорошо иллюстрирует характеристичес-
кая кривая (зависимость вероятности ошибки II рода от желаемой ве-
личины расхождений между средними значениями сравниваемых
групп), которая может быть построена для заданных значений а и чис-
ленности групп (рис. 31). Часто величина расхождений между средни-
ми значениями сравниваемых групп выбирается 25—50%, значение же
вероятности ошибки II рода должно быть как можно меньше, для ме-
дицинских приложений обычно это значение выбирается порядка 10—
20%, тогда мощность критерия будет более 80—90%.
198 Глава 1. Математическая статистика в клинических исследованиях
g
Он
К
VO
К
Э
о
о>
S
X
V
К
СО
1 -
0,9 •
0,8 •
0,7 ■
0,6 ■
0,5 ■
0,4 ■
0,3
0,2 ■
0,1 "
о-
I 1
1 1 1 ^^"^1
0 10 25 50 70 80 90
Относительное значение разницы средних, %
Рис. 31. Общий вид характеристической кривой при известных значени-
ях численности сравниваемых групп и уровня значимости. По оси абс-
цисс — значение разницы средних, %; по оси ординат — значение веро-
ятности ошибки II рода
И наоборот, выбрав значения вероятностей ошибок I и II рода,
можно оценить требуемый объем контрольной и исследуемой груп-
пы для статистически значимого заключения о наличии требуемого
различия в результатах терапии. Но только в 1 из 71 работы значения
вероятности ошибок I и II рода оговаривались до начала испытаний,
еще в 18 работах их значения обсуждались в разделе «Дискуссия», при
этом в 14 из них объем выборки был признан недостаточным уже после
окончания испытаний.
1.7. Статистический анализ результатов клинических исследований 199
Независимо от конкретных клинических особенностей, для отве-
та на вопросы, поставленные перед клиническим исследованием, с
помощью различных критериев приходится проверять нулевую гипо-
тезу об отсутствии эффекта или различиях в эффекте, сравнивая при
этом выборочные средние, доли, кривые выживаемости и т. п. Табл. 35
может помочь ориентироваться во множестве статистических кри-
териев (параметрических и непараметрических), обычно применяе-
мых для анализа результатов клинических исследований. Чтобы пра-
вильно выбрать статистический метод, необходимо учитывать преж-
де всего характер интересующего нас признака (количественный,
порядковый или качественный) и тип распределения (нормальное или
какое-либо другое). Для сравнения качественных переменных с чис-
лом градаций больше двух применяются статистические методы срав-
нения распределений, например критерий х2 или таблицы сопряжен-
ности соответствующей размерности. Кроме того, необходимо разли-
чать ситуации, связанные со сравнением двух или более групп (при этом
применяются различные критерии), а также сравниваются ли незави-
симые группы или одна группа пациентов получает сравниваемые воз-
действия. 1—2 статистических метода из каждой клетки табл. 35, наи-
более приспособленные для решения соответствующей задачи, мы
рассмотрели в главе «Статистический анализ результатов клиничес-
ких исследований». В результате применения любого из этих крите-
риев наличие статистически значимых различий будет или не будет
установлено.
Итак, для успешного применения статистических методов при ана-
лизе результатов клинических исследований нужно принимать во
внимание 4 основных правила [3, 32, 38]:
1. Обнаружив, что нулевая гипотеза об отсутствии эффекта не мо-
жет быть отвергнута, необходимо выяснить почему. Для этого
нужно оценить чувствительность критерия, то есть мог ли во-
обще данный критерий выявить имеющееся различие. Если чув-
ствительность мала, причиной может быть малый объем выбор-
ки, если чувствительность достаточна, то эффект (различие), ско-
рее всего, действительно отсутствует.
2. Обнаружив статистически значимый эффект, необходимо вы-
числить его величину и доверительные интервалы, по которым
можно судить о его клинической значимости. Необходимо по-
мнить, что высокую статистическую значимость могут иметь и
незначительные различия в лечебном эффекте, если в исследо-
вание включено достаточно большое число пациентов. И наоборот,
200 Глава 1. Математическая статистика в клинических исследованиях
Таблица 35.
Таблица статистических критериев, обычно применяемых для решения
типичных задач в области клинических исследований
Признак
Две
независимые
группы
Более двух
независимых
групп
Одна группа,
связанные
измерения
Параметрические методы
Количествен-
ный, нормаль-
ное распреде-
ление
Критерий
Стьюдента,
дисперсион-
ный анализ,
критерии
Тьюкки, кри-
терий Шеффе
Дисперсион-
ный анализ,
критерий
Стьюдента
для множест-
венных срав-
нений, крите-
рий Тьюкки,
критерий
Даннета, кри-
терий Шеффе,
критерий
Ньюмена—
Кейлса
Критерий
Стьюдента
для связанных
пар, диспер-
сионный ана-
лиз повтор-
ных измере-
ний
Непараметрические методы
Количествен-
ный, распреде-
ление отлича-
ется от нор-
мального,
Критерий
Уилкоксона—
Манна—Уит-
ни, медиан-
ный критерий
порядковый
Критерий Кра-
скела—Уолли-
са, медиан-
ный критерий
Г-критерий
Уилкоксона,
критерий зна-
ков, критерий
знаковых
рангов Уил-
коксона
| Методы сравнения долей
Качественный,
альтернатив-
ное распре-
деление
Критерий х2>
точный кри-
терий Фишерг
Критерий х2
Критерий
Мак-Нимара
Одна группа,
несколько
связанных
измерений
Дисперсион-
ный анализ
повторных
измерений,
критерии
Шеффе для
зависимых
выборок
Критерий
Фридмана
Критерий
Кокрена
малый объем выборки может не позволить выявить существую-
щее различие.
3. Убедиться, что соблюдены все правила, связанные с вопросами
рандомизации и применением слепого метода. Чем лучше спла-
1.7. Статистический анализ результатов клинических исследований 201
нировано и проведено исследование, тем менее вероятно, что его
результат смещен в пользу исследуемого метода.
4. Убедиться, что учтены все возможные скрытые множественные
сравнения при проведении анализа данных или возможных их
группировках. Проверить, соответствует ли результирующее зна-
чение вероятности ошибки I рода принятому для данного иссле-
дования уровню.
О последнем пункте хотелось бы сказать еще раз дополнительно.
Исследователь часто не учитывает эту множественность при анализе
и в результате, сам того не понимая, многократно занижает вероят-
ность ошибочно выявить мнимый эффект (ошибка I рода). Дело в том,
что при применении множественных сравнений нужно пользоваться
либо специальными статистическими методами, например диспер-
сионным анализом, либо применять обычный критерий Стьюдента,
но с поправкой Бонферрони (или любые другие методы множественно-
го сравнения, указанные в соответствующем разделе). Эта поправка
означает, что если к раз применить критерий с уровнем значимости
а, то вероятность хотя бы в одном случае найти различие там, где его
нет, не превышает произведения к на а, то есть если мы хотим обес-
печить в исследовании вероятность ошибки, например, 5%, то в каж-
дом сравнении мы должны принять уровень значимости 5%, делен-
ный на к сравнений. Мы уже говорили об этом раньше. Более точно
оценить вероятность ошибки хотя бы в 1 из £ сравнений, выполнен-
ных на уровне значимости а, можно по формуле: р = 1 — (1 — а)к.
При статистическом анализе данных клинических исследований,
которые представляют собой описание огромного числа разнообраз-
ных признаков, очень распространены различные группировки с це-
лью выяснения наиболее информативных показателей. Если для срав-
ниваемых групп не удается выявить статистически значимые разли-
чия в эффекте, то при значительном числе возможных группировок
не составит труда выделить подгруппы, в которых изучаемый метод
лечения можно будет назвать эффективным. Понятно, к чему может
привести игнорирование учета множественных сравнений и замены
его простым попарным сравнением подгрупп, проведенным много-
кратно без корректировки уровня значимости [3, 32, 38]. Допустим, в
контролируемых исследованиях сравнивались 2 группы. Пусть попав-
шие в экспериментальную группу больные принимали некий препа-
рат А, эффективность которого предстояло доказать. По таким при-
знакам, как пол, возраст, некоторые симптомы заболевания, между
группами не было обнаружено статистически значимых различий. По
202 Глава 1. Математическая статистика в клинических исследованиях
самому важному параметру эффекта в данном исследовании разли-
чие также было статистически незначимым. Тогда исследователи по-
пытались разделить больных на М подгрупп, например по возрасту,
полу, наличию тех или иных симптомов. Усилия обычно вознаграж-
даются, и различия в эффекте у леченных и не леченных препаратом
А оказались статистически значимы для одной из подгрупп пациен-
тов. Можно было бы сказать, что эффективность препарата А для этой
подгруппы доказана на уровне значимости 5%. Но при этом было вы-
полнено, например, 12 сравнений, и вероятность ошибиться хотя бы в
одном из них теперь возрастает до 60% (более точно вероятность ошиб-
ки хотя бы в 1 из 12 сравнений при уровне а = 5% для каждого сравне-
ния может быть оценена как 0,46 (46%)), а не 5%, как было заявлено в
исследовании. А в этих же условиях в среднем 1 из 20 сравнений пока-
жет отсутствующий статистически значимый результат. Этот схема-
тичный пример иллюстрирует важность учета множественных срав-
нений при проведении группировок данных. Таким образом, при
большом числе сравнений (вследствие чистой случайности) неко-
торые из них, скорее всего, приведут к установлению статистически
значимых различий, то есть чем больше сравнений делается, тем
выше вероятность выявить наличие несуществующих взаимосвязей.
Проблема множественных сравнений возникает и при проведении
промежуточного анализа данных, а также в случае, когда цель дан-
ного исследования предполагает получение ответов сразу на не-
сколько вопросов.
Существуют самые разные подходы к решению проблемы множе-
ственных сравнений. Некоторые предлагают еще на этапе планиро-
вания оценивать численность групп с учетом поправки Бонферрони
для уровня значимости, другие справедливо возражают, что такое мно-
гократное снижение уровня значимости приводит к бесконечно боль-
шим по численности группам. Авторы [32], например, предлагают
на этапе планирования оценивать размер выборки исходя из основ-
ной цели исследования, а при анализе данных в случае необходимо-
сти дополнительных сравнений обратить особое внимание на их ста-
тистическую значимость. Разное мнение существует и в отношении
деления на подгруппы. Однако все ученые сходятся во мнении, что,
поскольку эта процедура также увеличивает уровень значимости, к
ней нужно относиться с большим вниманием. Желательно, чтобы
деление на подгруппы было заранее зафиксировано в протоколе, это
снизит риск произвольного деления на стадии анализа с целью полу-
чить достоверное различие хотя бы в некоторых подгруппах. Кроме
1.7. Статистический анализ результатов клинических исследований 203
того, деление на подгруппы по какому-либо признаку должно произ-
водиться во всех группах сравнения. Неприемлемым считается срав-
нение результатов, полученных, например, в определенной подгруп-
пе исследуемой группы, с результатами для контрольной группы в
целом [32, 38].
Так называемая проблема множественных сравнений возникает и
при проведении промежуточного статистического анализа на различ-
ных этапах исследования. Если нулевая гипотеза тестируется всякий
раз при промежуточном анализе результатов, вероятность ошибки
I рода возрастает. А значит, при планировании промежуточного ана-
лиза необходимо внести соответствующие поправки в выбираемый
уровень значимости для поддержания мощности теста. Внимательно
нужно относиться и к результатам промежуточного статистического
анализа, особенно если на их основе может быть принято решение о
досрочном прекращении исследования. Известны реальные случаи,
когда даже статистически значимое различие, выявленное на ранних
стадиях исследования, может не подтвердиться при продолжении это-
го исследования [32].
На основании результатов промежуточного анализа может быть
принято решение и о необходимости внесения изменений в дизайн
исследования. Допустим, при планировании исследования в расче-
тах участвовала предполагаемая величина эффекта в контрольной
группе — 40-процентная скорость смертности в течение 2-летнего
периода. Предполагалось также, что изучаемая терапия должна иметь
25-процентное улучшение этого показателя в тестируемой группе. Для
двустороннего теста 5% уровня значимости и 90% мощности теста
была оценена общая численность групп сравнения. Однако на этапе
промежуточного анализа было получено другое значение эффекта в
контрольной группе, например 30%. Как видно из формул для расче-
та необходимого объема выборки, когда исходы выражаются в аль-
тернативной форме, статистическая мощность критерия зависит от
частоты событий. Если не внести изменения в первоначальный ди-
зайн, то для установления статистически значимого различия тести-
руемая группа должна демонстрировать 25-процентное снижение по-
казателя по сравнению со значением 30%, то есть метод должен ока-
заться еще более эффективным. При сохранении первоначальной
численности групп мощность теста снижается до 75%. Если эта вели-
чина не является приемлемой для исследователя, общая численность
групп должна быть увеличена для поддержания мощности теста на
первоначальном уровне 90%. Другим возможным решением может
204 Глава 1. Математическая статистика в клинических исследованиях
быть увеличение продолжительности исследования или комбинация
этих двух вариантов решения [32]. К статистическим методам, ис-
пользуемым на стадиях промежуточного анализа, относятся клас-
сический и групповой последовательный анализ, эти процедуры
аналогичны применяемым для последовательного плана исследова-
ния [28, 32, 38].
Важным с точки зрения статистики является и вопрос исключения
пациентов из исследования. Если такое исключение происходит уже
после процедуры рандомизации, оно может влиять на однородность
групп даже в том случае, если в каждой группе будет исключено оди-
наковое количество пациентов. По вопросу исключения пациентов
также не существует единого мнения, и также известно несколько
общих вариантов стратегий, каждая из которых имеет свои достоин-
ства и недостатки [32, 37]. Мы не будем рассматривать детали этого
вопроса, поскольку они связаны обычно со спецификой конкретных
исследований. Скажем только, что независимо от причины такого
исключения оно приводит к сокращению пригодной для статисти-
ческого анализа информации. В результате может оказаться невоз-
можным проведение статистически значимого сравнения. Поэтому
мы бы посоветовали внимательно относиться к сбору данных для каж-
дого включенного пациента, чтобы, по крайней мере, снизить про-
цент исключения уже на стадии проведения анализа из-за неполного
набора собранных данных.
Как мы уже отмечали, относительно небольшой объем сравнивае-
мых групп при проведении клинических исследований может приве-
сти к недостаточной статистической мощности или, другими слова-
ми, невозможности получить статистически значимое заключение о
наличии различий в эффекте. Такие исследования могут при опреде-
ленных условиях рассматриваться как потенциальная составная часть
последующего объединения данных для получения результатов с по-
мощью метаанализа. Примитивный вариант объединения данных
проводится обычно всеми учеными, например, при подготовке обзо-
ра литературы по изучаемой теме. Правда, формулируя фразу «ана-
лиз литературы показал, что значения интересующего параметра ле-
жат в пределах...», исследователь, как правило, не задумывается, что,
усредняя или объединяя значения границ диапазона изменения «ин-
тересующего параметра», опубликованные в различных литературных
источниках, он тем самым производит метаанализ. Привычные фра-
зы «различные исследования демонстрировали...» или «значения по-
казателей, полученные многими исследователями, подтверждают...»
1.7. Статистический анализ результатов клинических исследований 205
— также результаты объединения данных. Говоря о том, что это при-
митивный вариант объединения данных, мы имеем в виду использу-
емые при формулировании этих утверждений методы анализа резуль-
татов. Для проведения метаанализа разработаны специальные стати-
стические процедуры, которые позволяют получать статистические
оценки обобщенных результатов. Проведение метаанализа является
довольно сложной статистической процедурой, и для обоснованного
объединения результатов независимых исследований может потребо-
ваться знание многих статистических методов. Обычно среди стати-
стических методов, применяемых для объединения результатов, вы-
деляют 2 основные группы: методы, объединяющие результаты про-
верок статистических критериев отдельных исследований, и методы,
объединяющие полученные в независимых исследованиях оценки
интересующих параметров. Статистические тесты позволяют ответить
на вопрос, является ли изучаемая терапия (или метод лечения) доста-
точно эффективной (или безопасной), в то время как статистические
оценки предоставляют информацию о популяционных значениях
интересующих нас клинических параметров, а доверительные интер-
валы таких оценок показывают, насколько можно доверять получен-
ным значениям.
Если для проведения метаанализа объединяются конечные ре-
зультаты независимых исследований, а не их исходные данные, воз-
можно появление различных неожиданных трудностей при интер-
претации результатов. Например, существует риск возникновения
так называемого парадокса Симпсона [35]. Суть данной проблемы
состоит в том, что при проведении метаанализа заключение, полу-
чаемое для объединения, может противоречить заключениям, полу-
ченным для отдельных исследований, входящих в данное объедине-
ние. В работе [35] был предложен интересный пример, демонстри-
рующий появление парадокса Симпсона в ходе метаанализа. В
предложенном примере объединяли результаты двух гипотетичес-
ких контролируемых исследований (терапия — плацебо). Результа-
ты каждого исследования были представлены в виде таблиц 2x2, ин-
тересующий эффект учитывался с помощью дихотомической пере-
менной выживаемости (табл. 36-—38). В последней строке таблиц
через черту указаны доли выживших пациентов в сравниваемых груп-
пах. Видно, что разность таких долей для сравниваемых методов рав-
на —0,11 в исследовании А, —0,13 в исследовании 2>, что подразуме-
вает негативный эффект от проводимой терапии, подтвержденный
в двух независимых исследованиях. Но значение разности меняет
206 Глава 1. Математическая статистика в клинических исследованиях
Таблица 36.
Таблица сопряженности для исследования А
Эффект +
Эффект —
Всего
Терапия
530
230
760/0,7
Плацебо
210
50
260/0,81
Всего
740
280
Таблица 37.
Таблица сопряженности для исследования Б
Эффект +
Эффект —
Всего
Терапия
50
190
240/0,21
Плацебо
210
405
615/0,34
Всего
260
595
Таблица 38.
Таблица сопряженности для объединения данных
Эффект +
Эффект —
Всего
Терапия
580
420
1000/0,85
Плацебо
420
455
875/0,48
Всего
1000
875
знак и становится равно +0,1 при объединении данных этих иссле-
дований.
Появление такого парадоксального результата объясняется различ-
ными пропорциями в численности сравниваемых групп для различ-
ных объединяемых исследований. Приведенный пример иллюстри-
рует только одну возможную проблему, возникающую при объедине-
нии результатов независимых исследований.
Главный вывод, который сразу следует из предложенного примера,
заключается в необходимости предварительной проверки гомогенно-
сти объединяемых результатов исследований. Существуют специаль-
ные тесты для проведения такой проверки, с некоторыми из них мож-
но познакомиться в работах [35, 39]. Такие тесты позволяют ответить
на вопрос, можно ли объяснить различия в результатах отдельных объе-
диняемых исследований только влиянием случайных факторов. Если
вариация оказывается существенной, значит, существуют факторы,
которые ощутимо влияют на величину различий в эффекте и, возмож-
1.7. Статистический анализ результатов клинических исследований 207
но, даже на направление такого различия в объединяемых исследова-
ниях. Кроме того, при проведении метаанализа важна и субъективная
оценка гетерогенности объединяемых исследований, проводимая ис-
следователем и направленная на сравнение отдельных исследований с
точки зрения характеристик включенных пациентов, режимов терапии,
дизайна исследований, процедур оценки переменных эффекта и т. д.
Поскольку известно, что дизайн является одним из наиболее суще-
ственных факторов варьирования результатов различных исследований,
при проведении метаанализа обычно или объединяют результаты с
похожим дизайном, или проводят стратификацию, объединяя работы
со сходным дизайном в страты и демонстрируя результаты объединения
для выделенных страт в отдельности. Процедура стратификации поз-
воляет уменьшить влияние гетерогенности на получаемые результаты.
Известны различные статистические процедуры, применяемые для
метаанализа. Коротко представим некоторые из них. Так, наиболее
простой критерий знаков в качестве исходной информации использу-
ет только направление различий между сравниваемыми терапиями
(например, что лучше — терапия или плацебо) без учета величины
статистических различий. Он позволяет получить направление раз-
личий для объединения результатов, но его чувствительность, или
способность выявить правильное различие, является достаточно низ-
кой. Этот тест применяется, если об объединяемых исследованиях нет
полной статистической информации. Процедуры объединения ре-
зультатов исследований, эффект которых представляется дихотоми-
ческой переменной, обычно с помощью операции «взвешивания»
учитывают различия в пропорциях численности сравниваемых групп
в отдельных исследованиях. Один из таких тестов, наиболее часто
применяемый для объединения результатов, учитывающих реакцию
в альтернативной форме, был подробно рассмотрен нами в разделе
«Учет реакций в альтернативной форме».
Известны также методы метаанализа, основанные только на рас-
чете ^-значения для объединения результатов. Так, метод Фишера по-
зволяет оценить /^-значения для объединения результатов с помощью
тестовой статистики — 2S log /?., где р. — /^-значения для /-исследова-
ния. Данная статистика имеет распределение #2, число степеней сво-
боды равно удвоенному числу объединяемых исследований. Значе-
ние —log p всегда положительно и тем больше, чем меньше само
/^-значение. Такую статистику легко вычислить, но условием приме-
нения критерия является одинаковая формулировка нулевой и аль-
тернативной гипотез во всех объединяемых исследованиях. Другой
208 Глава 1. Математическая статистика в клинических исследованиях
метод оценки /^-значения состоит в вычислении тестовой статисти-
ки, имеющей нормальное распределение и представляющей собой
сумму стандартных нормальных отклонений, ассоциирующихся с от-
дельными /^-значениями, деленную на квадратный корень из числа
объединяемых исследований.
Возможна ситуация, когда различные клинические исследования
проводились для ответа на один и тот же вопрос, но в качестве пере-
менной эффекта использовали различные показатели. Для объеди-
нения результатов таких исследований предлагается провести норма-
лизацию переменных эффекта, позволяющую уйти от конкретных
единиц измерения таких переменных. Для этой цели средние значе-
ния показателей эффекта делят на их средние квадратичные откло-
нения, при этом при определенных условиях появляется возможность
сравнивать и обобщать различные показатели [39].
Кроме того, известны методы получения объединенных оценок
параметров эффекта по их оценкам в отдельных исследованиях, на-
пример метод максимального правдоподобия, метод взвешенного ус-
реднения отдельных результатов [7,19]. Процедура взвешивания объе-
диняемых исследований производится в соответствии с содержащейся
в них информацией и может осуществляться по самым разным пока-
зателям: по объему выборки, точности оценок (вариации результа-
тов) и т. д. Более подробно с различными процедурами метаанализа
можно познакомиться в работах [31, 32, 36—39].
Итак, мы попытались показать, что применение статистических
методов к анализу результатов клинических исследований не сводится
к знанию нескольких статистических критериев и умению отыскать
для их проверки требуемое табличное значение. Это творческий про-
цесс. Кроме того, не все вопросы, касающиеся планирования и ана-
лиза результатов клинических исследований, в настоящее время име-
ют однозначное решение. И единственный общий совет мы могли бы
позволить себе дать людям, которые по роду своей деятельности стал-
киваются со статистическим анализом данных клинических исследо-
ваний, — продумать предстоящий процесс анализа результатов еще
до начала сбора данных в ходе самого исследования.
Литература к 1 главе
1. Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Основы моделирования и
первичная обработка данных. — М.: Финансы и статистика, 1983.
2. Браунли К.А. Статистическая теория и методология в науке и технике.
- М.: Наука, 1977.
1.7. Статистический анализ результатов клинических исследований 209
3. Гланц С. Медико-биологическая статистика. — М.: Практика, 1999.
4. Двойрин В.В., Клименков А.А. Методика контролируемых клинических
испытаний. — М.: Медицина, 1985.
5. Дрейпер Я., Смит Г. Прикладной регрессионный анализ. — М.: Фи-
нансы и статистика, 1986.
6. Зайцев Т.Н. Методика биометрических расчетов. — М.: Наука, 1973.
7. Кендалл Л/., Стъюарт А. Теория распределений. — М.: Наука, 1966.
8. Кокс Д., Снелл Э. Прикладная статистика. Принципы и примеры. —
М.: Мир, 1984.
9. Лакин Г.Ф. Биометрия. — М.: Высш. шк., 1990.
10. Литл Р.Дж., Рубин Д.Б. Статистический анализ данных с пропуска-
ми. — М.: Финансы и статистика, 1991.
11. Мостеллер Ф., Тьюкки Дж. Анализ данных и регрессия. — М.: Финан-
сы и статистика, 1982.
12. Мэйндоналд Дж. Вычислительные алгоритмы в прикладной статисти-
ке. — М.: Финансы и статистика, 1988.
13. Мюллер П., Пойман П., Шторм Р. Таблицы по математической стати-
стике. — М.: Финансы и статистика, 1982.
14. Лоллард Дж. Справочник по вычислительным методам статистики.
— М.: Финансы и статистика, 1982.
15. Поляков И.В., Соколова И.С. Практическое пособие по медицинской
статистике. — J1.: Медицина, 1975.
16. Рафалес-Ламарка Э.Э., Николаев В.Г. Некоторые методы планирова-
ния и математического анализа биологических экспериментов. — Киев: Наук,
думка, 1971.
17. Рокицкий П.Ф. Биологическая статистика. — Минск, 1973.
18. Рунион Р. Справочник по непараметрической статистике. — М.: Фи-
нансы и статистика, 1982.
19. Справочник по прикладной статистике / Под ред. Э. Ллойда, У. Ле-
дермана. — М.: Финансы и статистика, 1989.
20. Справочник по теории вероятностей и математической статистике /
Под ред. B.C. Королюка и др. — М.: Наука, 1985.
21. Теннант-Смит Дж. Бейсик для статистиков. — М.: Мир, 1988.
22. Урбах В.Ю. Статистический анализ в биологических и медицинских
исследованиях. — М., 1976.
23. Черныш В.И., Напалков А.В. Математический аппарат биологической
кибернетики. — М., 1976.
24. Altman D.G. Statistics and ethics in medical research. III. How large a
sample? // Br. Med. J. - 1980. - Vol. 281, N 15. - P. 1336-1338.
25. Armitage P. Sequential Medical Trials. — 2nd ed. — N.Y.: John Wiley and
Sons, 1975.
26. Armitage P. Statistical Methods in Medical Research. — N.Y.: John Wiley
and Sons, 1977.
210 Глава 1. Математическая статистика в клинических исследованиях
27. Armitage P. The analysis of data from clinical trials // Statistician. — 1980.
-Vol. 28.-P. 171-183.
28. Armitage P., Gehan E.A. Statistical methods for the identification and use
of prognostic factors // Int. J. Cancer. — 1974. — Vol. 13. — P. 16-36.
29. Desu M.M.y Rhaghavarao D. Sample Size Methodology. — Boston:
Academic Press, 1990.
30. Dunnett C. W. New tables for multiple comparisons with a control //
Biometrics. - 1964. - Vol. 20. - P. 482-491.
31. Fleiss J. The statistical basis of meta-analysis // Stat. Methods Med. Res.
— 1993. - Vol. 2. - P. 121-145.
32. Friedman L.M., Furberg CD., DeMets D.L. Fundamentals of Clinical Trials.
— 2nd ed. — Littleton: PSG Publishing Company, 1985.
33. Grizzle J.E. The two-period change-over design and its use in clinical trials
// Biometrics. - 1965. - Vol. 21. - P. 467-480.
34. Hills M., Armitage P. The two-period cross-over clinical trial // Br. J. Clin.
Pharmacol. - 1979. - Vol. 8. - P. 7-20.
35. Medical Uses of Statistics / Eds. J.С Bailar, F. Mosteller. — Waltham:
NEJM Books, 1986.
36. Petitti D. Meta-Analysis, Decision Analysis and Cost-Effectiveness Analysis.
— Oxford: Oxford University Press, 1994.
37. Peto R., Pike M.C., Armitage P. et al. Design and analysis of randomized
clinical trials requiring prolonged observation of each patient // Br. J. Cancer. —
1976. - Vol. 34. - P. 585-612.
38. Senn S. Statistical Issues in Drug Development. — N.Y.: John Wiley and
Sons, 1997.
39. Snedecor G. W., Cochran W.G. Statistical Methods. — 7th ed. — Ames: Iowa
State University Press, 1980.
Глава 2
БАЗОВЫЕ ПОНЯТИЯ И ПРИНЦИПЫ
ФАРМАКОКИНЕТИКИ И ФАРМАКОДИНАМИКИ.
ПРИЛОЖЕНИЕ К АНАЛИЗУ ДАННЫХ
КЛИНИЧЕСКИХ ИССЛЕДОВАНИЙ
2.1. ВВЕДЕНИЕ
Работа в области планирования и статистической обработки ре-
зультатов клинических исследований требует от специалистов знаний
также в области фармакокинетики и фармакодинамики. Чтобы раз-
рабатываемый лекарственный препарат был эффективен и безопасен,
помимо оптимальной химической структуры для него должна быть
выбрана и оптимальная схема дозирования. Статистическая наука и
математическое моделирование внесли свой вклад в разработку ме-
тодов проведения и анализа клинических исследований, непосред-
ственно связанных с изучением фармакокинетики и фармакодина-
мики, например определение основных фармакокинетических пара-
метров изучаемого лекарственного препарата, оценка биодоступности
и биоэквивалентности, определение оптимальных терапевтических
доз, изучение взаимовлияния препаратов и т. п. Однако знания хотя
бы на элементарном уровне в этой специфической области могут ока-
заться полезны исследователям даже при планировании исследова-
ний, напрямую не связанных с изучением фармакокинетики, напри-
мер для разработки перекрестного дизайна исследования, когда не-
обходимо учитывать период выведения препарата, или при решении
вопроса о проведении исследования на основе однократного или по-
вторяющегося дозирования. Знания о фармакокинетике препарата
могут оказаться полезными также при выборе оптимального момен-
та времени измерения значений показателей эффекта. Для читателей,
которые захотят детально ознакомиться с теорией фармакокинетики
и фармакодинамики, мы можем рекомендовать следующие книги и
статьи [3, 7, 8, 18, 29, 35, 37, 39, 42]. Мы же приведем лишь основные
определения и положения, которые, с нашей точки зрения, могут ока-
заться полезными для понимания некоторых специальных матема-
тических методов, используемых в этой области для анализа данных.
Все эти вопросы мы будем рассматривать с позиций математики, ста-
тистики и обработки данных.
212
Глава 2. Базовые понятия и принципы фармакокинетики...
2.2. ОСНОВНЫЕ ФАРМАКОКИНЕТИЧЕСКИЕ
ПОНЯТИЯ. МОДЕЛЬНЫЙ ПОДХОД
Фармакокинетические исследования в основном проводятся в
I фазе исследований на здоровых добровольцах, хотя различные ва-
рианты таких исследований могут проводиться и во II и III фазах. В
общем виде основная идея фармакокинетических исследований зак-
лючается в том, что терапевтический эффект и побочные эффекты
являются функцией концентрации изучаемого препарата в местах его
действия в организме человека. Однако лекарственные препараты
редко вводятся непосредственно в место действия, а значит, чтобы
давать эффект, они должны «достичь» этого места действия, «двига-
ясь» от места введения. Обычно такое движение фракции дозы пре-
парата от места непосредственного введения к месту действия про-
исходит в крови. Во многих случаях можно предположить, что после
достаточно короткого промежутка времени устанавливается равно-
весие концентраций препарата в месте действия и крови. Поскольку
часто бывает достаточно сложно или вообще невозможно определить
концентрацию препарата в месте действия, обычно изучаются уров-
ни препарата в крови или плазме. Так, в результате проведения раз-
личных исследований для многих лекарственных препаратов были
установлены определенные средние диапазоны значений концентра-
ции препарата в крови, соответствующие оптимальному терапевти-
ческому эффекту. Этот диапазон терапевтических концентраций так-
же носит название «терапевтические пределы концентрации», или
«терапевтические рамки». Терапевтические пределы концентрации
могут быть определены с учетом их вероятностной природы как «ди-
апазон концентраций препарата в крови, в пределах которого суще-
ствует достаточно высокая вероятность получения положительного
терапевтического эффекта и достаточно низкая вероятность появле-
ния побочных эффектов» [13].
Подробное описание всех деталей процесса распределения препа-
рата во внутренней среде организма представляет собой исключитель-
но сложную задачу. Модель, детально описывающая этот процесс,
включала бы огромное количество различных параметров, которые
все равно было бы невозможно идентифицировать по нескольким
измерениям концентрации препарата в крови. Поэтому такая модель
оказалась бы бесполезна с практической точки зрения. Фармакоки-
нетика ограничивается формальным описанием процессов переноса ве-
щества, приводящих к количественным изменениям концентрации пре-
2.2. Основные фармакокинетические понятия...
213
парата в организме. Поэтому в рамках фармакокинетики появляется
возможность строить достаточно простые математические модели
кинетики изучаемого препарата, включающие лишь несколько основ-
ных идентифицируемых параметров. Такой упрощенный подход к
моделированию, без учета молекулярных механизмов, приводит к
уровню формализации, допускающему использование хорошо разра-
ботанного аппарата математического моделирования и теории опти-
мизации. Для описания кинетических процессов используются ди-
намические модели — системы дифференциальных уравнений. При
построении фармакокинетической модели принимается во внимание
принцип простоты, справедливый для биологической кинетики [2] и
означающий, что модель процесса должна содержать минимальное
число уравнений. Вместе с тем число уравнений должно быть доста-
точным для описания главной функции процесса.
В фармакокинетике при модельном подходе к анализу данных при-
нято выделять в качестве единиц системы камеры (или компартмен-
ты), и само моделирование носит название камерное (или компарт-
ментноё). Камера не имеет никаких пространственных ограничений
в анатомическом смысле и не обязательно должна совпадать с опре-
деленным органом. Фармакокинетическая камера при этом — это
часть организма, в которой равномерно распределен препарат. Таким
образом, для целей фармакокинетического моделирования выделя-
ется такое число камер, которое необходимо в данном случае для адек-
ватного модельного описания имеющихся опытных данных.
Минимальным числом камер является единица, соответственно,
получающаяся при этом модель — однокамерная. Поскольку весь
организм при этом представлен единственной камерой, предпола-
гается фармакокинетическая однородность всех тканей, в которые
способен проникнуть препарат. Это не означает, что препарат рав-
номерно распределен во всех органах и тканях организма, это озна-
чает только, что в рассматриваемый период времени соотношения
между уровнями препарата в тест-ткани и других тканях организма
остаются постоянными. В соответствии с законами линейной кине-
тики скорость изменения количества препарата в единственной ка-
мере однокамерной модели пропорциональна его количеству в ка-
мере, то есть в рамках линейной кинетики предполагается, что сра-
зу после введения препарата непосредственно в тест-камеру его
концентрация в этой единственной камере модели становится рав-
новесной и убывает по моноэкспоненциальному закону без види-
мой фазы распределения.
214 Глава 2. Базовые понятия и принципы фармакокинетики...
Чтобы перейти от количества препарата в камере к его концентра-
ции, вводится коэффициент пропорциональности, который носит
название кажущийся объем распределения препарата (не эквивалентен
физиологическому объему тканей камеры). Величина Vd в рамках од-
нокамерной модели и в предположении внутривенного болюсного
введения препарата равна такому условному объему жидкости, в ко-
тором нужно растворить всю попавшую в организм дозу препарата,
чтобы получилась концентрация, равная начальной концентрации
(С0) в крови. Обычно объем распределения измеряется в литрах или
нормируется на массу тела — л/кг. Для многих препаратов после од-
нократного внутривенного болюсного введения дозы D уменьшение
их концентрации в единственной камере модели может быть описа-
но уравнением:
C(t) = ^-txp(-kelt). (102)
Линейный характер процесса или, другими словами, процесс ки-
нетики первого порядка, предполагает, что скорость процесса про-
порциональна количеству или концентрации препарата в системе. В
предположении о линейном характере процесса выведения в рамках
однокамерной модели элиминация препарата описывается моноэкс-
поненциальной зависимостью и характеризуется константой скорос-
ти элиминации kel (обратное время, например 1/ч). Такая константа
элиминации обобщенно характеризует процесс выведения препарата
(биотрансформация или метаболизм и экскреция) и в общем виде
представляет собой сумму скоростей выведения почечным и непочеч-
ным путем.
В рамках линейной модели может использоваться и другой пока-
затель, характеризующий процесс выведения препарата, — период по-
луэлиминации (полувыведения), который связан с константой скорос-
ти элиминации: Т]/2 = \п2/ке1=0,693/кеГ Количественную оценку эли-
минируемого препарата дает клиренс препарата (О) — объем крови
(в общем виде тест-ткани), очищаемый от препарата за единицу вре-
мени (мл/мин или л/ч). Для препаратов, которые быстро распреде-
ляются и чье поведение может быть описано в рамках линейной мо-
дели, клиренс может быть выражен как произведение кажущегося
объема распределения (VJ центральной камеры и константы скорос-
ти элиминации (kj.
Существуют 2 основных варианта структуры однокамерной моде-
ли для описания различных способов введения препарата: 1) поступ-
2.2. Основные фармакокинетические понятия...
215
ление всего препарата непосредственно в тест-камеру (внутривенное
введение: болюсное или постоянная инфузия); 2) постепенное поступ-
ление препарата в тест-камеру из некоторого депо (учитывает про-
цесс абсорбции при внесосудистом введении).
Схемы таких моделей представлены на рис. 32.
D,F
Kabs I
у
Vd
Kel
J б
Рис. 32. Схема однокамерной модели в случае внутривенного (а) и вне-
сосудистого (б) способа введения препарата
При поступлении препарата в кровь из депо его концентрация по-
степенно нарастает, достигая своего максимального значения Стахв мо-
мент времени Ттах, и затем начинает убывать. При непосредственном
поступлении препарата в тест-камеру Стах соответствует начальному мо-
менту времени. Общий вид кривых изменения концентрации препарата
в крови с течением времени после однократного и интермиттирующе-
го (повторяющегося) внесосудистого введения представлен на рис. 33.
Обычно предполагается линейный процесс абсорбции, хотя вооб-
ще абсорбция может быть и постоянной (процесс нулевого порядка),
и нелинейной. В случае линейного процесса абсорбции его скорость
характеризуется константой скорости абсорбции kabs, которая изме-
ряется в единицах обратное время, например в 1/ч. Для линейного
процесса данную константу можно выразить через период полувсасы-
вания Tl/2abs — время, за которое всасывается половина дозы препа-
рата, с помощью формулы kabs = 1п2/Ty2abs.
Надо иметь в виду, что практически сразу после того, как в резуль-
тате всасывания фракция препарата попала в кровь, процессы абсор-
бции и выведения препарата протекают параллельно. Обычно в рам-
ках модельного подхода оценку параметров абсорбции и элиминации
получают с помощью идентификации параметров соответствующей
216
Глава 2. Базовые понятия и принципы фармакокинетики...
U.S.C. PC-PACK PLOT
WINDOW l (1 day/window)
16:15:57 Nov.9,1999
3 6 9 12 15 18 21 24
Time, hour
Central (serum level) compt data (ug/ml)
U.S.C. PC-PACK PLOT
WINDOW 1 (4 day/window)
16:16:23 Nov.9,1999
36 48 60
Time, hour
Central (serum level) compt data (ug/ml)
Рис. 33. Фармакокинетическая кривая изменения уровня концентрации
препарата в крови после однократного (а) и повторяющегося (б) внесо-
судистого (перорального) введения. Графики построены с помощью про-
граммы USC*PACK
2.2. Основные фармакокинетические понятия...
217
фармакокинетической модели по измерениям концентрации препа-
рата в тест-ткани. Иногда делается попытка оценить значения пара-
метров абсорбции или выведения, условно разделив во времени фар-
макокинетический профиль на интервалы только абсорбции или толь-
ко элиминации, считая, что в данном временном интервале влиянием
другого параллельно протекающего процесса можно пренебречь. Та-
кой подход корректен не во всех случаях, нужно быть уверенным, что
на данном временном этапе другой процесс действительно не вносит
существенного вклада в результирующие значения уровня препарата
в тест-ткани.
При внесосудистом способе введения может оказаться, что не весь
препарат, а лишь какая-то его часть проникает в кровь. Биодоступ-
ность (F) характеризует ту часть дозы препарата, которая достигает
кровотока. При расчетах биодоступности того или иного препарата
сравнивают площади под кривой концентрация—время (AUC) после
введения эквивалентных доз.
= AUCtest (ЮЗ)
AUC standard
Биодоступность может оцениваться как относительная и абсолют-
ная. Если в качестве стандарта используют данные о внутривенном
введении этого препарата, а в качестве тестовых — фармакокинети-
ческие данные о внесосудистом введении этого же препарата в той
же дозе, речь идет об определении абсолютной биодоступности. В ка-
честве стандарта и теста могут использоваться сходные препараты или
один и тот же препарат в разных лекарственных формах для внесосу-
дистого введения, тогда речь идет об оценке относительной биодос-
тупности (относительно стандарта).
В рамках однокамерной линейной модели при внутривенном вве-
дении препарата площадь под фармакокинетической кривой может
быть выражена через известные фармакокинетические параметры:
AUC = CJkel. Следующее уравнение позволяет связать основные
фармакокинетические параметры линейной кинетики при любом
пути введения препарата: площадь под кривой концентрация—вре-
мя пропорциональна дозе препарата, обратно пропорциональна об-
щему клиренсу препарата, а значит, связана с величиной объема рас-
пределения соотношением: AUC = D • F/(kel* VJ.
В предположении о линейности процессов абсорбции и элимина-
ции (процессы кинетики первого порядка) зависимость концентра-
218
Глава 2. Базовые понятия и принципы фармакокинетики...
ции от времени после однократного приема препарата описывается
следующим кинетическим уравнением:
С(0 = v\^-ъ ЛехрС-М-ехрН^О], (104>
где D — полученная доза препарата, F — биодоступность препарата.
Таким образом, при определенных значениях биодоступности F по-
лучаемой дозы D форма фармакокинетической кривой определяется
соотношением основных параметров кинетики Vd, Kabs и КеГ
Если препарат вводится в постоянной дозе через фиксированные
промежутки времени (интервал дозирования), меньшие, чем время
элиминации препарата, то его концентрация в крови возрастает сту-
пенчатым образом, а затем наступает период, когда в каждом интервале
между приемом очередных доз препарата количество всасывающегося
препарата равно количеству элиминируемого. Это состояние называ-
ется стационарным (steady state), а концентрация, достигнутая при этом,
называется стационарной и обозначается Css. (рис. 34, а). При одной и
той же скорости абсорбции чем длиннее период полувыведения пре-
парата по отношению к интервалу дозирования, тем медленнее дости-
гается стационарный уровень. Это значит, что чем больше Т1/2 выведе-
ния препарата, тем больше времени потребуется для достижения ста-
ционарного уровня концентраций. Для практических расчетов можно
принять, что состояние равновесия достигается по прошествии 4—5
периодов полувыведения препарата. Для выбора оптимального интер-
вала дозирования препарата важна информация о ширине терапевти-
ческого коридора (другими словами, о допустимой амплитуде колеба-
ний концентрации препарата в крови) и времени полувыведения. Ва-
рьируя значения интервала дозирования, стараются «удержать» уровень
концентрации в крови пациента в пределах желаемого диапазона.
Если препарат вводится внутривенно с постоянной скоростью ин-
фузии R, уровень устанавливающейся стационарной концентрации
равен: СМ=Д
При повторяющемся (интермиттирующем) введении одинаковых
доз препарата D через одинаковые промежутки времени т зависимость
концентрации от времени (в интервале дозирования) в стационарном
состоянии описывается уравнением:
* d ' \kabs Kel )
exp(-*„Q e\p(-kabst)
(105)
1 - exp(*e/ T) 1 - exp(-kahs t) _
где т — интервал дозирования, D — получаемые дозы препарата, F —
биодоступность препарата. Таким образом, стационарная концентрация
2.2. Основные фармакокинетические понятия...
219
U.S.C. PC-PACK PLOT
48
WINDOW l (16 day/window)
16:25:30 Nov.9,1999
96 144 192 240 288 336 384
Time, hour
- Central (serum level) compt data (ug/ml)
U.S.C. PC-PACK PLOT
WINDOW 7 (8 day/window)
21:54:57 Dec.27,1999
тшшш
1157 1176 1200 1224 1248 1272 1296
Time, hour
1320 1344
Serum level (ug/ml)
Central (serum level) compt data (ug/ml)
MIC (min inhib cone, ug/ml)
THERAPEUTIC GOAL
Рис. 34. Фармакокинетическая кривая в условиях интермиттирующего
внесосудистого (перорального) введения, а — демонстрирует постепенное
установление стационарной концентрации; б — с помощью нагрузочной
дозы и последующих поддерживающих удается достаточно быстро достичь
и затем поддерживать желаемый уровень концентрации препарата в крови
данного пациента. Кривые построены с помощью программы USC*PACK
220 Глава 2. Базовые понятия и принципы фармакокинетики...
меняется от своего минимального до максимального значения в каж-
дом интервале дозирования. Если величина этих колебаний не очень
значительна, можно провести некоторое упрощение этого соотноше-
ния и ввести понятие так называемой средней стационарной концен-
трации. Тогда при повторяющемся введении одинаковых поддержи-
вающих доз препарата D через одинаковые промежутки времени т в
рамках линейной кинетики средняя стационарная концентрация вы-
ражается через основные фармакокинетические параметры следую-
щим образом:
С^ = — ■ (106)
_ ss Cl-т
или в более общем виде: Css= (F • средняя скорость дозирования препа-
рата)/О.
Если требуется создать в крови определенную концентрацию немед-
ленно, а затем поддерживать ее на этом уровне, то сначала дается нагру-
зочная доза, а затем соответствующие поддерживающие (рис. 34, б).
Все эти и другие формулы зависимости уровня препарата в крови
от введенной дозы используются при расчетах оптимального режима
дозирования лекарственных препаратов [3, 18, 29].
Некоторое усложнение модели кинетики с увеличением числа ка-
мер модели до двух (и, возможно, более) может быть произведено в
случае, если математический анализ данных показывает неадекват-
ность описания их моделью с более простой структурой или необхо-
димость такого усложнения диктуется известными свойствами дан-
ного препарата. При этом предполагается быстрое распределение
препарата в одной камере, а затем относительно медленный обмен с
другой (или несколькими) камерой. Любая линейная многокамерная
модель строится на основе системы дифференциальных уравнений
баланса. Эти модели, так же, как и однокамерная модель, могут опи-
сывать различные варианты введения препарата (входы модели). Так,
двухкамерная модель состоит из центральной и периферической ка-
мер, которые отличаются степенью доступности для проникновения
препарата и между которыми предполагается обратимый обмен пре-
паратом. Применяемая обычно схема модели представлена на рис. 35.
При использовании такой модели появляются еще 2 дополнительных
параметра: константы скоростей обмена между камерами К с и Кс.
Уравнение для изменения концентрации во времени теперь может
быть составлено не только для центральной, но и для периферичес-
кой камер. Соответственно, зная значения фармакокинетических
параметров двухкамерной модели, можно построить фармакокине-
2.2. Основные фармакокинетические понятия...
221
1
D,F I
Kabs \
Kel
Крс
J Kcp
2
Рис. 35. Общая схема двухкамерной (7 — центральная и 2 — периферичес-
кая камера) модели для внесосудистого (перорального) введения препарата
тические кривые зависимости концентрации препарата от времени
для обеих камер (рис. 36).
Рассмотренные нами модели и формулы предполагали, что про-
цессы абсорбции, выведения, обмена между камерами являются ли-
нейными и описываются кинетикой первого порядка. Известны не-
которые общие признаки, которые позволяют определить, является
ли фармакокинетическая модель линейной [3, 18, 39, 42]. Коротко
можно сформулировать основные принципы линейной фармакоки-
нетики так:
• фармакокинетические параметры не зависят от введенной дозы
препарата;
• при внутрисосудистом введении существует пропорциональность
между экстраполированными в момент / = 0 уровнями препара-
та и соответствующими дозами;
• количество препарата в камерах линейно зависит от дозы;
• площадь под кривой изменения концентрации препарата во вре-
мени для тест-камеры линейно зависит от дозы при любом спо-
собе введения препарата.
Последний принцип означает, что с возрастанием дозы площадь
под фармакокинетической кривой концентрация—время будет про-
порционально увеличиваться (dose-proportionality). Если данное ус-
ловие выполняется, это облегчает задачу прогнозирования уровня
концентрации препарата в крови при изменении режима дозирования.
Обычно для проверки этого условия проводятся исследования с муль-
типерекрестным планом, в которых каждый из включенных здоровых
222
Глава 2. Базовые понятия и принципы фармакокинетики...
U.S.C. PC-PACK PLOT
WINDOW l (4 day/window)
176:06:24 Nov.9,1999
36 48 60
Time, hour
Serum level (ug/ml)
Central (serum level) compt data (ug/ml)
Periph compt data (ugAg)
96
Рис. 36. Фармакокинетические кривые для двухкамерной модели. На осях
ординат: слева — шкала измерений для центральной камеры, справа —
для периферической. 7 — изменение концентрации препарата в централь-
ной камере; 2 — в периферической камере. Кривые построены с помо-
щью программы USC*PACK
добровольцев получает каждую из изучаемых доз препарата (мини-
мальное число таких доз равно 2). Последующий анализ обычно осно-
ван на регрессионных соотношениях. Так, если пропорциональность
между площадью под кривой AUC и соответствующей дозой D суще-
ствует, регрессионная линия в координатах A UC—D должна проходить
через начало координат. Ясно, что нулевая доза должна создавать ну-
левую концентрацию и, соответственно, нулевое значение AUC. По-
этому, проведя через имеющиеся точки в координатах AUC—D регрес-
сионную прямую, нужно проверить гипотезу о равенстве нулю свобод-
ного члена (этот вопрос был разобран в разделе «Регрессионный
анализ»). Другой подход предполагает построение регрессионной мо-
дели, проходящей через начало координат и состоящей из линейного
и квадратичного члена зависимости от дозы Y = а • D + b • D2, и после-
2.2. Основные фармакокинетические понятия...
223
дующую проверку статистической гипотезы о равенстве нулю коэф-
фициента й. Еще один вариант регрессионной модели для проверки
такой пропорциональности был предложен в работе [14]. При этом под-
ходе предлагался следующий вариант зависимости площади под кри-
вой, полученной у /-субъекта после получения у-дозы (Dj) препарата:
AUCu=a-(DjY'eu, (107)
где е — случайная ошибка модели, обычно предполагается, что logfe)
имеет нормальное распределение. Если пропорциональность имеет
место, коэффициент /3 должен быть равен единице. Для проверки это-
го условия применяют логарифмическое преобразование данных, при-
водящее к линейной регрессии:
log(A(/Q) = log(tf) + ft • log(Dy) + log(^) • (108)
С помощью регрессионного анализа проверяется статистическая
гипотеза о значении коэффициента /J. Что касается планирования
исследований для проверки такой гипотезы, считается, что если про-
порциональная зависимость от дозы выявляется для двух экстремаль-
ных доз, близких к верхней и нижней границам терапевтического
коридора, то, скорее всего, это соотношение будет сохраняться и для
всех остальных доз внутри терапевтического коридора [42]. Поэтому
теоретически для проверки выполнения условия пропорциональнос-
ти достаточно двух доз, близких к верхней и нижней границам тера-
певтического коридора. Однако на практике измерения, проводимые
на низких дозах препарата, имеют большую погрешность, что, в свою
очередь, приводит к большим вариациям значений \og(AUC). Поэто-
му реально для корректности модели требуются измерения по мень-
шей мере для трех различных доз [42].
В случае невыполнения хотя бы одного из перечисленных усло-
вий применимости линейной модели фармакокинетические данные
необходимо описывать нелинейной фармакокинетической моделью.
Существуют различные типы нелинейной кинетики, например кине-
тика, зависящая от дозы (dose-dependent kinetics), или кинетика, за-
висящая от времени (time-dependent kinetics). Так, если клиренс пре-
парата возрастает с увеличением дозы, это значит, что описание про-
цесса выведения такого препарата в рамках линейной кинетики
невозможно. Часто такой зависящий от введенной дозы (или, говоря
точнее, от созданной концентрации) процесс метаболизма лекар-
ственного препарата удается описать уравнением Михаэлиса-Ментен
(например, для фенитоина, салицилата, пропафенона, никардипина)
224
Глава 2. Базовые понятия и принципы фармакокинетики...
[18]. Тогда скорость процесса биотрансформации или ферментатив-
ного процесса описывается следующим уравнением:
У = Утах-С(Од (109)
Km + C(t)
где C(t) — концентрация препарата в тест-камере, Vmax, Km — пара-
метры кинетики Михаэлиса-Ментен: Vmax — максимальная скорость
образования метаболита, Km — концентрация препарата, при кото-
рой скорость метаболизма достигает половины максимального зна-
чения Vmax.
При малых концентрациях препарата по сравнению с Km (С < 0,1 Km),
то есть если процесс метаболитического превращения препарата да-
лек от насыщения, кинетика выведения становится аналогичной ли-
нейной однокамерной модели со скоростью выведения Vmax/Km. При
высоких концентрациях препарата в крови, то есть если метаболизм
препарата носит насыщенный характер, процесс описывается кине-
тикой нулевого порядка:
dC/dt = -Vmax. (ПО)
Таким образом, если выведение препарата описывается в рамках
кинетики Михаэлиса—Ментен, относительная скорость выведения
препарата меньше для высоких концентраций препарата в крови по
сравнению со значениями скоростей выведения на более низких уров-
нях концентрации. Другими словами, время, необходимое для сниже-
ния высоких уровней концентраций в крови на 50%, будет больше, чем
для снижения низких уровней концентрации на то же количество про-
центов. Это означает, что в рамках такой модели процесс элиминации
препарата не может быть однозначно охарактеризован одной констан-
той скорости выведения или соответствующим параметром Т1/г
Для нелинейной кинетики Михаэлиса—Ментен формула для сред-
ней стационарной концентрации при введении препарата со скорос-
тью R может быть записана как:
Gss= RKm ■ (HI)
У max-Л
Тогда в случае, если R < 0,1 Vmax, средняя стационарная концент-
рация пропорциональна R и обратно пропорциональна клиренсу (ли-
нейная кинетика). Когда R находится в интервале от 0,1 Vmaxjxo Vmax,
увеличение стационарной концентрации происходит на величину,
которая больше соответствующего увеличения скорости введения R
(пропорциональность нарушается); и при стремлении значения R к
2.2. Основные фармакокинетические понятия...
225
максимальной скорости выведения Vmax уровень стационарной кон-
центрации растет асимптотически. Если значения R равны или пре-
вышают Vmax, стационарная концентрация вообще не устанавлива-
ется [29].
Рассмотрим нелинейную кинетику фенитоина. Среднее значение
константы Km для фенитоина оценивается различными исследовате-
лями в диапазоне 1—15 мг/л, что сравнимо со значениями терапевти-
ческих концентраций этого препарата (3—20 мг/л). Таким образом,
нелинейность процесса выведения фенитоина необходимо учитывать
уже в пределах терапевтического коридора концентраций [7, 29]. Зна-
чения параметра Vmax для фенитоина ранжируются в диапазоне от
1,5 до 15 мг/кг в сутки (со средними значениями, равными 8 мг/кг в
сутки), то есть в среднем печень нормального, среднего пациента (мас-
са тела равна 70 кг) не может метаболизировать больше чем 560 мг
фенитоина в течение 24 ч. Однако надо иметь в виду, что из-за высо-
кой межиндивидуальной вариабельности параметров Михаэлиса—
Ментен эта предельная величина также существенно различается у
разных пациентов. Если пациент получает препарат в суточной дозе,
величина которой близка к его индивидуальной способности мета-
болизировать данный препарат, происходит увеличение уровня кон-
центрации в крови, которое, в свою очередь, ведет к дальнейшему
снижению относительной скорости выведения. Нелинейность кине-
тики проявляется в том, что постепенно даже незначительное превы-
шение индивидуальной допустимой дозы достаточно быстро приво-
дит к возникновению побочных эффектов, связанных с быстрым уве-
личением концентрации препарата в крови.
Другим вариантом нелинейной кинетики является так называемая
кинетика, зависящая от времени. При этом известны 2 варианта та-
кой зависимости: индуцируемая физиологическим (chronopharmaco-
kinetics) и химическим путем [18, 29]. Первый тип зависимости от
времени фармакокинетических параметров связан с наличием вре-
менных циклов или ритмов изменений этих параметров, характерных
для некоторых лекарственных препаратов (например, фенацетина,
N-ацетил-п-аминофенола, антипирина, индометацина, теофиллина
и др.). Автоиндукция или гетероиндукция являются примерами дру-
гого варианта зависимости фармакокинетических параметров от вре-
мени. Так, известно, что в результате автоиндукции скорость метабо-
лизма при постоянной терапии карбамазепином увеличивается при-
близительно в 2—3 раза по сравнению со скоростью метаболизма
при получении дозы карбамазепина однократно [7, 18]. Это, в свою
226 Глава 2. Базовые понятия и принципы фармакокинетики...
очередь, приводит к существенному снижению концентрации препа-
рата в крови пациентов при его постоянном получении и к невозмож-
ности прогнозировать значения этих уровней в постиндукционном
периоде по результатам терапевтического лекарственного мониторин-
га в первые дни терапии. Изменение скорости метаболизма от пре-
диндукционного значения до соответствующего постиндукционного
в течение периода автоиндукции может быть достаточно хорошо опи-
сано экспоненциальной функцией [18, 29]. Гетероиндукция часто
проявляется при политерапии, например при политерапии различ-
ными антиконвульсантами, и также выражается в изменении скоро-
стей метаболизма одних препаратов в присутствии других [18, 29].
Вообще различают 2 типа взаимодействия лекарственных препа-
ратов — фармакодинамическое, при котором эффект от действия од-
ного препарата изменяет качественно или количественно эффект от
другого препарата, не изменяя концентрацию второго препарата в
тест-камере. При фармакокинетическом взаимодействии (примером
является гетероиндукция) один препарат изменяет фармакокинети-
ческие параметры другого, и при этом изменяется концентрация вто-
рого препарата в крови. В настоящее время известно достаточно при-
меров, когда при применении лекарственных препаратов происходит
подобное взаимодействие. Взаимовлияние лекарственных препара-
тов является предметом специального изучения.
Итак, изменение уровня препарата в крови с течением времени
зависит от таких основных процессов, как абсорбция, распределение
и элиминация, а задача фармакокинетических исследований — изу-
чение и описание этих процессов.
Известно, что связывание препарата белками крови может влиять
на эти процессы, а в некоторых случаях — и на результаты терапии.
Поскольку обычно несвязанная фракция препарата легче проходит
через клеточные мембраны, именно несвязанный, скорее, чем общий,
уровень препарата в крови может лучше коррелировать с терапевти-
ческим и побочными эффектами. Однако последнее положение в каж-
дом конкретном случае нуждается в специальном изучении. Для мно-
гих лекарственных препаратов связывание может влиять на характе-
ристики процессов выведения и распределения препарата. Считается,
что влияние степени связывания на время полувыведения препарата
зависит от кажущегося объема распределения препарата [15]. Для
препаратов с относительно маленькими значениями кажущегося
объема распределения (Vd < 0,25 л/кг,) время полувыведения чувстви-
тельно к изменениям степени связывания, уменьшение степени свя-
2.2. Основные фармакокинетические понятия...
227
зывания приводит к снижению их времени полувыведения. Время
полувыведения для препаратов с Vd > 0,5 л/кг практически не зависит
от степени связывания белками плазмы.
Следующие фармакокинетические соотношения демонстрируют
влияние показателей связывания на основные фармакокинетические
процессы (выведение и распределение). Кроме того, эти соотноше-
ния помогают описать возможные изменения фармакокинетических
параметров, связанные с наличием у пациента заболеваний печени
или почек, приводящих к нарушениям процесса связывания. Так, хотя
кажущийся объем распределения препарата не имеет физиологичес-
кого смысла, он может быть выражен в терминах объема плазмы (VJ
и внесосудистого пространства (плюс объем эритроцитов) (V) [29]:
Vd = Vp + Vt&, (112)
ft
где^ — представляет фракцию несвязанного препарата в плазме,^ —
несвязанная фракция в тканях. Это выражение означает, что объем
распределения является функцией способности препарата связывать-
ся белками плазмы и в тканях. Таким образом, это соотношение объяс-
няет изменения в распределении препарата при различных патоло-
гических состояниях (гипоальбуминемия или уремия), влияющих на
степень связывания. Так, рост/ (соответствующий снижению степе-
ни связывания белками плазмы) должен приводить к увеличению ка-
жущегося объема распределения препарата, если связывание в тка-
нях (f) остается неизменным. Подобные изменения часто наблюда-
ются, примером может быть распределение фенитоина при уремии.
В некоторых случаях нарушаться могут сразу оба процесса связыва-
ния, что происходит, например, при приеме дигоксина при уремии.
Обычно в случае дигоксина рост величины ft оказывается более зна-
чительным по сравнению с ростом фракции f9 что также приводит к
уменьшению кажущегося объема распределения этого препарата [29].
Другой важный фармакокинетический параметр — общий систем-
ный клиренс — также связан со степенью связывания препарата белка-
ми крови. Общий клиренс, или объем крови, очищающийся от лекар-
ственного препарата за единицу времени (С1), может быть представ-
лен в виде суммы печеночного клиренса (CIJ и почечного выведения
неметаболизированного препарата (Cl^.
Рассмотрим процесс печеночного метаболизма с точки зрения
фармакокинетического моделирования. Выражение для печеночно-
го клиренса основывается на следующих анатомических и физиоло-
228
Глава 2. Базовые понятия и принципы фармакокинетики...
гических фактах: препарат доставляется к печени по портальной вене
и печеночной артерии, а «покидает» орган по печеночной вене. Пред-
положим, что выведение препарата происходит только посредством
печеночного метаболизма. Печень при этом можно представить как
«хорошо смешивающий» орган, тогда можно считать, что концент-
рация свободного препарата в печени равна его концентрации в ве-
нозной крови печени. Из плазмы посредством диффузии препарат
достигает внутриклеточных метаболитических ферментов. При этих
упрощающих допущениях 3 основных параметра вносят свой вклад в
процесс выведения препарата печеночным путем: 1) Q — печеноч-
ный кровоток, который отражает транспорт, или доставку, препарата
к органу; 2) степень связывания, представленная в формуле коэф-
фициентом / — фракция несвязанного препарата в плазме, которая
характеризует доступ препарата к метаболитическим ферментам; 3)
так называемая способность ферментов печени метаболизировать
препарат, доставленный кровотоком, не зависящая от кровотока и от
степени связывания, — С/'. Выражение для печеночного клиренса
(CIJ, представляющего собой кажущийся объем крови, очищающий-
ся от лекарственного препарата с помощью печеночного метаболиз-
ма в единицу времени, может быть представлено в виде:
С/„=-=-^ т. (ИЗ)
и Q + fp-Cl'
Величины Q, С1Н, С/'имеют размерность потока или объема в еди-
ницу времени. Если процесс метаболизма описывается уравнением
Михаэлиса—Ментен, то при концентрациях препарата намного мень-
ших, чем параметр Km:
c/l=Vjnax (114)
Km
Предельное значение печеночного клиренса равно объему крови,
достигающей органа в единицу времени, то есть печеночному крово-
току. Поэтому печеночный клиренс препарата обычно сравнивают с
величиной кровотока с помощью специального параметра. Степень
экстракции препарата оценивается специально введенным коэффи-
циентом, который называется отношением печеночной экстракции
(EJ [29]. Этот коэффициент равен отношению печеночного клирен-
са к печеночному кровотоку. Минимальное значение Ен равно нулю
для препаратов, которые не являются объектами печеночного мета-
болизма, а максимальное значение равно 1, когда печеночный кли-
ренс равен кровотоку печени. Так, если величина/- СГнамного мень-
2.2. Основные фармакокинетические понятия...
229
ше значения Q, все члены, зависящие от печеночного кровотока, со-
кращаются, и печеночный клиренс равен/-С/'. В этом случае пече-
ночный клиренс не зависит от параметров печеночного кровотока, а
определяется величиной свободной фракции препарата в крови.
Исследования показывают, что для некоторых препаратов мета-
болитические процессы в печени могут ускоряться при нарушениях
функции почек [7, 18, 29, 39]. Этот механизм еще не изучен детально.
Однако известно, что препараты с низкой печеночной экстракцией и
высокой степенью связывания с белками плазмы (к такой группе пре-
паратов относятся, например, многие антиконвульсанты) чувстви-
тельны к изменениям связывания и могут иметь более высокие ско-
рости метаболизма при заболеваниях почек из-за снижения степени
связывания. При этом растущая свободная фракция увеличивает кли-
ренс и объем распределения препарата.
Почечную составляющую общего клиренса также можно детали-
зировать с точки зрения участвующих физиологических процессов.
Почечный клиренс (CIJ можно представить как соотношение:
ClR=(ClRF+ClRS)-(l-FR), (Ц5)
где ClRF — клиренс посредством клубочковой фильтрации, С/Л5— кли-
ренс путем почечной секреции, FR — фракция препарата, вернувша-
яся в кровоток в результате реабсорбции. Составляющая клиренса ClRF
является функцией степени связывания (fj препарата в крови и ско-
рости клубочковой фильтрации (GFR):
ClRF=fpGFR, (116)
где GFR оценивается обычно измерением клиренса креатинина.
Другая составляющая клиренса ClRS может быть выражена через
почечный кровоток (RBF) и клиренс путем секреции свободной фрак-
ции препарата (С1)\
a RBF'fr'cl' . (и?)
RS RBF + fpCl,
Таким образом, видно, что почечный клиренс может определять-
ся почечным кровотоком (blood flow rate-limited), когда RBF«fpCln
и зависеть от степени связывания (capacity-limited binding) при
RBF»fp-Clt[lS, 29].
Все приведенные выше параметры фармакокинетики и методы
расчета относились в основном к так называемому модельному спо-
собу анализа фармакокинетических данных. С точки зрения матема-
тического моделирования такой подход состоит: 1) в выборе подхо-
230 Глава 2. Базовые понятия и принципы фармакокинетики...
дящей модели для описания кинетики изучаемого препарата в орга-
низме; 2) в последующем решении одного из двух возможных вари-
антов математических задач моделирования: прямой или обратной.
Как мы говорили, модель кинетики препарата в организме обычно
представляет собой систему дифференциальных уравнений кинети-
ки с неизвестными коэффициентами (чаще выбираются модели с
постоянными коэффициентами).
Прямая задача состоит в генерации с помощью численных мето-
дов кривых изменения во времени концентрации препарата в выб-
ранных камерах модели, а коэффициенты модели и схема приема пре-
парата в данном случае предполагаются известными. Обратная зада-
ча заключается в идентификации неизвестных параметров выбранной
модели по измеренным уровням препарата в тест-ткани при извест-
ной схеме дозирования препарата. Последняя задача позволяет полу-
чить индивидуальные значения фармакокинетических параметров, и
решается она с помощью различных математических методов теории
оптимизации. Так, на рис. 37, а приведены нормализованные кривые
зависимости количества препарата от времени, рассчитанные про-
граммой для случая применения однокамерной модели с всасывани-
ем для известных значений скорости абсорбции, скорости элимина-
ции и объема распределения при пероральном введении однократ-
ной дозы препарата «среднему» пациенту. Три кривые, приведенные
на рис. 37, а — всасывание препарата из места введения, концентра-
ция препарата в тест-камере, накопление препарата в дополнитель-
ной камере, введенной в модель для представления о процессе выве-
дения, — иллюстрируют решение прямой задачи. Рис. 37, б относит-
ся к решению обратной задачи. Здесь квадратами обозначены
измерения уровня препарата (фенитоина) в тест-камере, а непрерыв-
ная линия построена с помощью нелинейной модели Михаэлиса—
Ментен таким образом, чтобы наилучшим образом описывать имею-
щиеся данные о концентрации препарата (для известного режима до-
зирования). При этом были идентифицированы индивидуальные
параметры фармакокинетики данного препарата у этого пациента.
Приведенные на рис. 37 кривые были построены с помощью PC про-
грамм ISIMUL и IDPAR, разработанных И.Б. Бондаревой для мате-
матического моделирования в фармакокинетических приложениях.
Подробнее применяемые при идентификации параметров модели
методы и функционалы качества приближения реальных данных и
модельных кривых рассмотрены нами в разделе, посвященном при-
менению байесовского подхода в статистике.
2.2. Основные фармакокинетические понятия...
231
MODEL CURVES
а
EXPERIMENTAL AND MODEL CURVES
100
б
Рис. 37. Модельный подход к анализу фармакокинетических данных, а —
генерация модельных кривых — решение прямой задачи моделирования;
б — решение обратной задачи моделирования. По нескольким измерени-
ям уровней препарата в крови (обозначены черными квадратами) были
идентифицированы индивидуальные фармакокинетические параметры и
построена модельная фармакокинетическая кривая
232
Глава 2. Базовые понятия и принципы фармакокинетики...
2.3. НЕКОМПАРТМЕНТНЫЙ ПОДХОД
К АНАЛИЗУ ФАРМАКОКИНЕТИЧЕСКИХ ДАННЫХ
Наряду с компартментным существует и некомпартментный метод
анализа фармакокинетических данных, несколько основных соотно-
шений которого мы приведем. Некомпартментный подход часто оши-
бочно называют «немодельным», на самом деле в его основе тоже ле-
жит модель - предполагается, что изучаемая субстанция вводится пря-
мо в и элиминирует прямо из центрального измеряемого пула(ов). На
практике такие условия могут часто выполняться лишь приближенно,
использование некомпартментного подхода приводит к той или иной
степени ошибки в оценке ФК параметров в зависимости от степени
отклонения от данного допущения. Два других общих предположения
также ограничивают практическое применение некомпартментного
подхода: система (организм, в который вводится препарат) линейна
(принцип суперпозиции) и стационарна, или не зависит от времени
(ФК параметры не зависят от момента введения препарата в систему).
Некомпартментный метод анализа фармакокинетических данных
основан на теории статистических моментов. Основной анализируе-
мой информацией, как и раньше, является фармакокинетический
профиль, или, другими словами, график зависимости концентрации
препарата в тест-ткани C(t) от времени, который рассматривается как
аналог статистической плотности вероятности. Нулевым статистичес-
ким моментом такой кривой будет ее интеграл от начального момента
времени до бесконечности, что соответствует площади под фармако-
кинетической кривой (AUC). Этот параметр используется не только для
оценки биоэквивалентности, но и, например, для вычисления клирен-
са, который равен отношению внутривенно введенной дозы к AUC.
Первым моментом фармакокинетического профиля будет отноше-
ние площади под кривой (от нулевого момента времени до бесконеч-
ности) зависимости C(t)-t к AUC. Этот момент измеряет так называе-
мое среднее резидентное время (MRT). Параметр МЛ Г оценивает,
сколько времени в среднем препарат проводит в организме, и являет-
ся, в свою очередь, функцией скорости выведения препарата и его
объема распределения. При внутривенном введении и быстром рас-
пределении препарата параметр MRT говорит нам, какое время тре-
буется для выведения 63,2% введенной дозы [18]. Л/ЛГявляется так-
же функцией способа введения препарата. МЛ Г при любом способе
введения данного препарата, отличного от внутривенного болюсно-
го введения, будет всегда больше, чем при его внутривенном болюс-
2.2. Основные фармакокинетические понятия...
233
ном введении. Этот принцип часто используют при некомпартмент-
ной оценке параметров процесса абсорбции. Обычно среднее время
абсорбции (МАТ) равно разности МЛ Г при изучаемом способе введе-
ния и MRT при внутривенном введении данного препарата.
Вторым моментом фармакокинетической кривой является отно-
шение площади под кривой (от нулевого момента времени до беско-
нечности) зависимости C(t) • (t — MRT)2 к нулевому статистическому
моменту AUC. Этот параметр обычно обозначается VRT, он может
служить оценкой дисперсии параметра MRT
Для вычисления площадей под соответствующими кривыми в об-
ласти проведенных измерений применяется численное интегрирова-
ние, обычно методом трапеций. Для оценки так называемых хвостов
интеграла, или, другими словами, значения площади под кривой от
момента времени Т последнего измерения до бесконечности приме-
няется экстраполяция кривой C(t) с помощью моноэкспоненциаль-
ной функции а • exp(-bt). Параметры аи b этой функции находят, на-
пример, методом наименьших квадратов по последним измеренным
точкам концентрации препарата в крови. Однако надо заметить, что
точность такой экстраполяции зависит от числа и конкретного рас-
положения этих точек. Поэтому необходимо хотя бы визуально убе-
диться, что выбранные для подобной экстраполяции точки (не мень-
ше 4—5) могут быть достаточно хорошо описаны убывающей экспо-
нентой. Необходимые для экстраполяции приближенные формулы
можно записать таким образом [51]:
т
50 = Гс(0А + 7вхр(-ЬГ); (118)
о *
Sl= J/C(OA + (^2 + a%)exp(-W); (119)
т °
52= jt2C(t)dt + l2</b3 +2аТ/ьг +аТУь)ы?(-ЬТ), (120)
о
Тогда:
\tC{t)dt
AUC=\c(t)dt = S0; MRT=° /ш = %0'
\c{t)dt
о
\(t - MRT)2 C(t)dt
VRT=°
(121-123)
\c(t)dt
=%-(%))2
234 Глава 2. Базовые понятия и принципы фармакокинетики...
Некомпартментный способ анализа данных также позволяет при
некоторых условиях оценить клиренс, стационарную концентрацию
и объем распределения. Но, поскольку анализ данных в рамках тако-
го подхода основан на численном интегрировании фармакокинети-
ческих кривых, понятно, что в этом случае такие кривые должны
иметь достаточно много измерений. Некомпартментный метод ши-
роко применяется, например, при решении вопроса о биоэквивален-
тности [18, 33,37,42,46].
2.4. АНАЛИЗ ЗАВИСИМОСТЕЙ ДОЗА-ЭФФЕКТ
Итак, фармакокинетика как наука занимается описанием и количе-
ственной интерпретацией изменений во времени уровня лекарственно-
го препарата и его метаболитов в организме. Однако надо иметь в виду,
что при проведении таких исследований основным вопросом является
не само по себе изучение концентрации препарата. Описание связи оп-
ределенного режима дозирования препарата с его уровнями в тест-тка-
ни (обычно крови) является важным шагом к описанию зависимости
«фармакологического ответа» при получении определенной дозы пре-
парата. Решение задачи совершенствования режима лечения требует не
только выяснения характера распределения препарата, но и установле-
ния зависимости эффекта от концентрации. Такие модели строятся в
рамках фармакодинамических исследований, которые в отличие от фар-
макокинетических обычно проводятся не на здоровых добровольцах, а
на пациентах. Сложным при проведении таких исследований остается
вопрос выбора параметров: биохимических или физиологических, ко-
торые могут адекватно оценивать эффект терапии. Такие исследования
позволяют оценить границы среднего терапевтического коридора для
данного препарата, а также временные рамки проявления эффекта. Спе-
циальные варианты дизайна клинических исследований для определе-
ния минимальной эффективной и максимальной переносимой доз под-
робно обсуждаются в соответствующей главе монографии [42].
Соотношения между получаемой дозой и эффектом очень важны для
клинической практики. Если у данного пациента получаемый режим
дозирования не приводит к желаемому эффекту или имеются клиничес-
кие проявления побочного эффекта, возможно, ему требуется соответ-
ствующая корректировка дозирования. Полученное для изучаемого пре-
парата среднее соотношение доза—эффект обычно имеет достаточно
большую межиндивидуальную вариабельность: во-первых, различные
2.2. Основные фармакокинетические понятия...
235
пациенты могут быть в большей или меньшей степени чувствительны
или толерантны к данному препарату (фармакодинамическая вариа-
бельность), во-вторых, одни и те же дозы препарата могут приводить у
различных пациентов к различным уровням концентрации препарата
в крови из-за межиндивидуальных различий в параметрах основных
фармакокинетических процессов (фармакокинетическая вариабель-
ность). Так возникает задача индивидуализации режима дозирования.
Для множества лекарственных препаратов зависимость эффекта
от получаемой дозы удается описать S-образной функцией, при этом
на малых дозах наблюдается низкий уровень эффекта, постепенно при
увеличении получаемых доз эффект растет, достигая на больших до-
зах насыщения или плато. Обычно такая зависимость хорошо опи-
сывается моделью Хилла [24], или так называемой моделью Етах
(максимально возможный уровень эффекта). Эта модель имеет 3 па-
раметра: максимально возможный уровень эффекта (Етах), концен-
трация, на которой достигается 50% максимального эффекта (ЕС50),
параметр формы (у), который для многих препаратов принимается
равным 1. Зависимость эффекта от концентрации (С) в рамках такой
модели задается уравнением:
ЕтахС*- (124)
На рис. 38 приведены кривые зависимости эффекта от концентра-
ции препарата в крови для различных значений параметра формы у.
Обычно такую зависимость анализируют, приведя к линейному виду
в координатах 1гц - In С или приведя к логистической функ-
V Е max- EJ
ции в координатах Е/Е max - In С
В разделе, касающемся выбора переменных для оценки эффекта
лечения, мы приводили примеры неудачного выбора таких перемен-
ных и схем расчета. Нами были приведены примеры, которые иллю-
стрировали необходимость учета при оценке эффекта лечения суще-
ствующих изменений показателей во времени. Фармакодинамичес-
кая модель для учета таких изменений у /-пациента может быть
получена из модели Хилла [42]:
^)=*+щ^Г)+е^ (125)
где \it — временной тренд показателя, который предполагается
идентичным для всех пациентов, е — ошибка модели. В случае конт-
236 Глава 2. Базовые понятия и принципы фармакокинетики...
ит 1 1 1 1 г
0 12 3 4 5
Рис. 38. Зависимость эффекта от концентрации препарата в крови для
различных значений параметра формы у. 1 — значение параметра формы
у = 0,5; 2 — у = 1; 3 — у = 2; 4 — у= 5. По оси абсцисс — отношение
C(t)/EC50; по оси ординат — эффект Е
ролируемых исследований с применением плацебо аналогичное урав-
нение может быть записано для среднего эффекта в группе и для сред-
него временного тренда. Тогда для пациентов, получающих плацебо,
второе слагаемое в данной модели будет равно 0, так как уровень кон-
центрации изучаемого препарата в любой момент времени равен 0. А
первое слагаемое модели будет корректировать разницу в эффекте
между пациентом (или группой пациентов), получающим препарат,
и пациентом (или группой), получающим плацебо.
В некоторых исследованиях эффект может описываться не непре-
рывной, а дихотомической переменной (переменной в альтернатив-
ной форме). В этом случае применять модель Етах непосредственно
становится невозможно. При этом для описания зависимости доза-
эффект применяются различные преобразования или шкалы, напри-
мер, логит- или пробит-преобразования [3, 4, 42]. Такой тип перемен-
ной эффекта характерен часто для доклинических исследований или
для клинических исследований в онкологии.
Для изучения влияния различных доз препарата в доклинических
испытаниях, как правило, опыт ставят так, чтобы дозы принимали
определенные значения из изучаемого диапазона. Такие значения
дозы являются аргументом функции доза—эффект. Значения такой
функции, или «ответы», имеют альтернативное распределение — на-
личие или отсутствие эффекта (гибель, судороги, изменение положе-
ния, появление определенных симптомов и т. д.). Доля р тест-объек-
тов, дающих положительный ответ, рассматривается как оценка ве-
2.2. Основные фармакокинетические понятия...
237
роятности реагирования при данной дозе. Эта доля может изучаться
методами, описанными выше: построение доверительного интервала
для доли, выяснение значимости различий долей для сравниваемых
групп и т. д. Однако исследователя может интересовать связь между
вероятностью реагирования/? и интенсивностью воздействия (доза D).
Обычно доля р возрастает с увеличением D, принимая значения от О
до 1. Данная зависимость называется кривой эффекта, или кривой
доза—эффект, и изображается несимметричной S-образной кривой
(рис. 39, а). Эта кривая может быть построена и в логарифмических
координатах lg(/)) — р (рис. 39, б).
Анализ кривой доза—эффект заключается в оценке с ее помощью
обобщенных численных характеристик, отражающих наиболее суще-
ственные стороны изучаемого явления. Одной из таких характерис-
тик может быть доза, вызывающая эффект у 50% тест-объектов. Ее
называют 50-процентной эффективной дозой — ЭД50. Для некоторых
лекарственных препаратов может употребляться показатель 50-про-
центная летальная доза (ЛД50). Показателем широты фармакологичес-
кого действия является индекс, равный отношению ЛД50 к ЭД50, под-
1'
0,8«
0,6'
0,4'
0,2'
о
Доза, D
1
0,8-
0,6-
0,4-
0,2-
0-
/ = lg(D)
Рис. 39. а — кривая доза—эффект; б — логарифмическая кривая доза-
эффект
238
Глава 2. Базовые понятия и принципы фармакокинетики...
робнее об этом в [1]. Существует достаточно много методов оценки
ЭД50 (метод Рида и Менча, метод Кербера, метод Беренса, формула
Г.Н. Першина, графические методы пробит-анализа и др.), каждый
из которых имеет свои преимущества и недостатки. Детальное изло-
жение этих методов содержится в [1, 5]. Надо обратить внимание, что
независимо от выбранного метода расчета, величина ЭД50 и другие
обобщенные характеристики оцениваются по выборочным данным,
поэтому, как обычно, для них необходимо строить доверительные
интервалы. Метод Рида и Менча — один из наиболее простых и часто
применяемых методов определения ЭД50, однако условием его при-
менения является изучение равноотстоящих доз в серии опытов и
одинаковой численности тест-объектов для каждой дозы. Метод Кер-
бера, например, свободен от этих недостатков, но имеет свои ограни-
чения. Точность этого метода снижается из-за ошибок при вычисле-
нии площадей методом трапеций и неточного экспериментального
определения значения дозы, при которой приближенно достигается
100-процентный положительный результат.
От указанных ограничений и недостатков можно избавиться, если
допустить, что кривая доза—эффект генеральной совокупности пос-
ле логарифмического преобразования координат приближенно опи-
сывается нормальным законом распределения. Это предположение и
лежит в основе так называемого пробит-метода. Тогда доли р поло-
жительных ответов можно приравнять к накопленным частотам z нор-
мального распределения, которые задаются соотношением:
(126)
где Ф — функция распределения стандартной нормальной перемен-
ной, Ми с — параметры нормального распределения.
В дальнейшем при описании данного метода будем обозначать бук-
вой / величину lg(Z>) и для простоты называть ее дозой, тогда /50 —
доза, при которой половина тест-объектов дают положительный от-
вет. Эта величина и позволяет в дальнейшем оценить искомое значе-
ние ЭД50. Заменяя в этой формуле z на р, х на /, М на /50, получаем:
, = ф(^°) С27)
Нам нужно получить зависимость доли р от дозы /, для этого будем
строить график, откладывая по оси ординат вместо значений р значения:
y' = V(p), (128)
■■■<")
2.2. Основные фармакокинетические понятия...
239
где Ч* — функция, обратная функции распределения Ф, то есть
р = Ф(у'), ее значения определяются по специальным таблицам. Та-
ким образом: , ,_Л
у , /-/50 1 , /50 посп
а а с
то есть получаем уравнение прямой линии. Значит, если откладывать
по оси абсцисс значения /, а по оси ординат — значения у' = х¥ (р), то
точки будут представлять прямую линию с углом наклона 1/(5. При зна-
чениях р < 0,5 соответствующие значения у' будут меньше нуля. Для
исправления этой ситуации производится корректировка значений у':
у=Ч(р)+5. (130)
Получаемые значения у называют пробитами. Обратим внимание,
что значения пробитов для р — 0 и р = 1 нельзя найти по такой форму-
ле. На практике часто применяют замену/? =0 на/? = 1/5п., ар = 1 на
р = 1-1/5пг
Поскольку в доклинических испытаниях численность тест-объек-
тов в группах невелика, удобно пользоваться специальной таблицей,
в которой пробит для данного опыта находится непосредственно по
общему числу тест-объектов в опыте и числу положительных отве-
тов, и уйти от использования таблиц для функции распределения
стандартной нормальной переменной [5].
Значение /50 задается абсциссой точки, ордината которой равна 5
(соответствует/? = 0,5). Приближенно эту точку можно найти графи-
чески, проведя через нанесенные на график экспериментальные точ-
ки наилучшим образом описывающую их прямую. Качество аппрок-
симации экспериментальных точек с помощью прямой проверяется
по критерию х2- Известны более сложные методы определения зна-
чения /50, они очень подробно разобраны, например в [1].
Известны также различные методы оценки стандартной ошибки
/50, так, достаточно точной считается формула:
<г/50 = ^. (131)
где п' — число тест-объектов, для которых значения пробитов нахо-
дятся в пределах от 3,5 до 6,5. Величина о задается следующим выра-
жением и оценивается по построенному графику:
<т = У2{1(у = 6)-1(у = 4)), (132)
где запись вида 1(у = а) означает дозу, которой соответствует значе-
ние пробита, равное а.
240
Глава 2. Базовые понятия и принципы фармакокинетики...
Среди упрощенных методов, позволяющих осуществлять графи-
ческий пробит-анализ при необходимости даже на обычной милли-
метровой бумаге без использования логарифмически-пробитной сет-
ки, широкое распространение получил метод Литчфилда и Уилкоксо-
на. Этот метод и его модификация 3. Ротом детально изложены в [1],
там же даны необходимые для расчетов номограммы и разобраны при-
емы вычислений. Данный метод отличается не только простотой вы-
числения, он хорош еще и тем, что позволяет вычислять величины не
только ЭД50, но и ЭДлюбой частоты наступления эффекта [1]. Кроме
того, интересны методы сравнительной оценки фармакологической
активности двух соединений, результаты которых были обработаны
по методу Литчфилда и Уилкоксона. Эти методы также представлены
в [1] наряду с методами расчета среднего эффективного времени, тре-
буемого для наступления определенного фармакологического эффек-
та. В той же работе проанализированы особенности обработки дан-
ных с помощью обычной миллиметровой сетки, что обычно не при-
водит к снижению точности метода.
Таким образом, в предположении о нормальном распределении
ЩМ, с) вероятность того, что случайно отобранное из совокупности
животное будет демонстрировать положительный ответ, зависит от /
= lg(£):
я(1) = Ф(а+ /?•/), где а=-М/с и р=1/с. (133)
Гипотеза об адекватности описания данных такой моделью прове-
ряется по критерию х2' В случае если модель не противоречит дан-
ным, значения а и р могут быть достаточно точно оценены по экспе-
риментальным данным, например методом максимального правдо-
подобия [5]. Тогда уровень дозы, при котором положительный эффект
достигается у 50% животных, находится из уравнения:
0,5 = Ф(а + р • /50) или а + Р • /50 = ф-'(0,5) = 0, (134)
откуда /50 = —а/р. Это логарифм дозы, фактическая доза равна
эд50 = ю/5°-
Можно было предположить и другие функции распределения в
качестве я(1). Так, вполне подходящим было бы логистическое рас-
пределение вида:
*(/) = - А 1r1rv (135)
1 + ехр{-(яг+ >#•/))
величина ос+ Р • /, определяемая значением функции п(1), называется
в этом случае логитом л(1).
2.2. Основные фармакокинетические понятия...
241
Если в эксперименте число опытов не так велико, чтобы можно
было обосновать выбор конкретной функции распределения, часто
пользуются нормальным распределением, которое табулировано и
обычно позволяет получить достаточно хорошие результаты.
Исследователя, как правило, интересуют не только величина ЭД50,
но и значения доз, необходимые для получения заданного значения
отклика, например ЭД]0 или ЭД2У Мы уже говорили, что метод Литч-
филда и Уилкоксона позволяет получать такие оценки. В предполо-
жении о нормальном распределении оценки параметров а и /3 веро-
ятностной модели к(1) = Ф(а + /3 • /) определяют конкретную форму
данного выборочного распределения, что, в свою очередь, позволяет
оценить дозу, необходимую для получения любого заданного откли-
ка. Последнюю задачу можно решить и более точно — на основе, прав-
да, более сложной процедуры, следующей из теоремы Филлера [16].
Методы расчета параметров кривой доза—эффект на основе ста-
тистической модели, свободной от гипотезы о нормальном законе
распределения, рассмотрены в [3], там же рассматривается и вопрос
перехода от зависимости доза—эффект к зависимости концентра-
ция—эффект.
Иногда удается интегрировать полученные фармакокинетические
и фармакодинамические модели: полученная доза определяет уровень
концентрации препарата, который, в свою очередь, приводит к опре-
деленному эффекту. Поэтому теоретически можно изучать эффект,
полученный при определенных дозах, без учета концентраций. Од-
нако на практике осуществить это бывает достаточно сложно [42]. При
проведении подобных исследований важной является также оценка
отношения пик—спад (максимальная концентрация — минимальная
концентрация препарата в крови перед очередным введением) обыч-
но в стационарном состоянии при повторяющемся введении и извес-
тном режиме дозирования. Такие колебания концентрации в течение
интервала дозирования также могут оказывать влияние на интенсив-
ность и продолжительность фармакологического эффекта [25].
2.5. СТАТИСТИЧЕСКИЕ ПРОЦЕДУРЫ, ПРИМЕНЯЕМЫЕ
ДЛЯ АНАЛИЗА БИОЭКВИВАЛЕНТНОСТИ
В последние годы повысился интерес к проблеме статистического
анализа результатов исследования биоэквивалентности. И в литера-
туре все чаще стали появляться статьи, авторы которых анализируют
преимущества и недостатки статистических методов решения этого
242
Глава 2. Базовые понятия и принципы фармакокинетики...
вопроса [11, 17, 21, 30—36, 38, 40, 43, 46—48]. До настоящего времени
по многим вопросам, касающимся статистического анализа исследо-
ваний биоэквивалентности, среди ученых-статистиков не существу-
ет единого мнения. Поэтому мы приведем не столько правила прове-
дения такого анализа, сколько расскажем об имеющихся вариантах
его проведения.
Обычно клинические исследования, целью которых является ус-
тановление биоэквивалентности (с точки зрения фармакокинетики),
проводятся в соответствии с двойным слепым АВ/ВА перекрестным
дизайном. В качестве стандарта для сравнения обычно берется изве-
стный зарегистрированный препарат, а в качестве тестового — изуча-
емый препарат со сходными свойствами. Базовая методология при
таких исследованиях основывается на том, что если при сравнении
фармакокинетических кривых (зависимость концентрации препара-
та в крови от времени) для данных препаратов, обычно оригинала и
генерического препарата, будет установлена идентичность препара-
тов в плане фармакологического эффекта, то это означает их тера-
певтическую эквивалентность.
Стандартная процедура представляет собой измерение концентра-
ции сравниваемых препаратов в крови (иногда еще и в моче) после
получения однократной дозы или при повторяющемся дозировании для
каждого субъекта, включенного в исследование. Периоды измерения
концентрации для различных препаратов у одного и того же субъекта
разделяются достаточно продолжительным временнь/м интервалом (5—
6 периодов полувыведения изучаемого препарата), необходимым для
исключения взаимовлияния препаратов. Измерения концентраций при
однократном приеме препарата производятся в течение по меньшей
мере 3—4 периодов полувыведения препарата или прекращаются пос-
ле снижения концентрации ниже пределов регистрации.
На примере таких исследований мы попробуем продемонстриро-
вать применение различных методов анализа фармакокинетических
данных и статистических процедур. Биоэквивалентность является
достаточно емким и многогранным понятием. Два препарата, пред-
назначенные для внесосудистого введения, считаются биоэквивален-
тными, если они обеспечивают одинаковую биодоступность лекар-
ственного вещества при введении в одинаковых дозах при одинако-
вых условиях. Это означает, что с помощью фармакокинетического
исследования необходимо оценить относительную биодоступность
изучаемого препарата. Относительная биодоступность характеризу-
ется степенью всасывания (относительным количеством препарата,
2.2. Основные фармакокинетические понятия...
243
достигающим системного кровотока) и скоростью этого процесса вса-
сывания. Однако, несмотря на кажущуюся простоту определения био-
эквивалентности, много ученых бьются над задачей найти достаточ-
но точный способ практической оценки скорости абсорбции лекар-
ственного препарата.
Если число измерений и период наблюдения достаточно большие,
биоэквивалентность проверяется с помощью некомпартментного
метода. Основными параметрами сравнения могут быть средние зна-
чения (или медианы) следующих определенных ранее фармакокине-
тических показателей: AUC, Cmax, Tmax^fRT, VRTn их отношений,
например Cmax/AUC и (Cmax — Cmin)/Css.
Основным показателем биоэквивалентности считается так называ-
емое отношение биоэквивалентности — отношение площадей под фар-
макокинетическими кривыми для тестового препарата и стандарта. Это
отношение является оценкой относительной степени всасывания.
До начала 80-х гг. наиболее распространенным статистическим тес-
том для проверки биоэквивалентности был дисперсионный анализ
(ANOVA) [33, 46]. В рамках этого метода выдвигалась стандартная ну-
левая гипотеза (HJ об отсутствии различий между сравниваемыми пре-
паратами (или, другими словами, между выбранными показателями
сравнения препаратов). Смысл этой процедуры в основном аналоги-
чен представленной в разделе «Дисперсионный анализ» для перекрес-
тного дизайна. Обычно статистическая модель данных в предположе-
нии аддитивности вкладов различных составляющих предполагает, что
изучаемый эффект может быть представлен в виде:
то есть Х..к — индивидуальное наблюдение переменной эффекта у
у-субъекта после получения /-препарата в ^-последовательности
(к = 1, 2;у = 1,...,я/2; / = 1 и 2) представляет собой сумму:
• общего среднего ц;
• параметра од, отражающего неслучайную специфическую для
данного у-субъекта реакцию;
• параметра т., отражающего эффект от приема именно /-препа-
рата;
• параметра лп характеризующего вклад, связанный с /-периодом
измерений (1 = 1, 2)\
• гук — случайной ошибки модели. Предполагается, что ошибка
eijk имеет нормальное распределение с нулевым математическим
ожиданием и дисперсией De.
244
Глава 2. Базовые понятия и принципы фармакокинетики...
В рамках такой аддитивной модели среднее значение параметра
эффекта для /-препарата может быть выражено как Xi= ц + т. +ё|,
ошибка Щ имеет нормальное распределение с нулевым средним и дис-
персией, равной De/.
Как было показано ранее, с помощью .Г-теста на определенном
уровне значимости с учетом числа степеней свободы может быть про-
верена гипотеза о несущественном вкладе различий между препара-
тами в общую вариацию данных. Однако такой подход имеет ряд не-
достатков. Один из них связан с ключевым предположением, на ко-
тором основан данный подход. Подход может применяться только в
предположении о полном отсутствии взаимовлияния рассматривае-
мых препаратов в интервалах времени проведения соответствующих
измерений. В случае если период времени между приемом различных
препаратов оказался недостаточным для полного исключения такого
эффекта, данное предположение нарушается, и результаты оказыва-
ются неверными. Если отказаться от этого предположения, необхо-
димые математические модификации модели оказываются слишком
сложными [33]. Другая проблема обусловлена обсуждавшимся ранее
вопросом связи числа испытуемых, устанавливаемой величиной раз-
личия и мощности теста. Как мы уже говорили, при достаточно боль-
шом объеме выборки можно статистически доказать наличие даже
очень незначительных с клинической точки зрения различий. С дру-
гой стороны, наоборот, слишком маленький объем выборки может
не позволить установить даже существенные различия. Попыткой
регулировать последнее ограничение можно считать разработку так
называемого 80/20 правила [22, 33, 42, 46]. Оно означает, что иссле-
дование биоэквивалентности должно быть спланировано и проведе-
но так, чтобы мощность статистического теста для выявления 20-про-
центного статистически значимого различия между препаратами была
не меньше 80%.
В случае сравнения двух препаратов .F-тест для анализа вариаций
эквивалентен проверке традиционной нулевой гипотезы об отсут-
ствии различий между средними значениями параметров биоэквива-
лентности /ит и jiR (XT и XR — их выборочные оценки, полученные на
основе имеющихся данных) с помощью двустороннего критерия
Стьюдента (обычно на уровне значимости 5%). 1С~ -1С
Значение тестовой статистики в этом случае равно: t = —т R ,
(ТЫ 2 In
где п — число субъектов, включенных в исследование, а — среднее
квадратичное отклонение, оцененное с помощью анализа вариации
2.2. Основные фармакокинетические понятия...
245
для перекрестного дизайна (обычно значение о связано со средним
квадратом «ошибки», или остаточной внутрииндивидуальной вариа-
цией). Вычисленное значение статистики сравнивается с табличным
для двустороннего критерия на выбранном уровне значимости. Од-
нако данный тест, как и дисперсионный анализ, устанавливает лишь
наличие или отсутствие различий. Как и в случае дисперсионного
анализа, поскольку результаты тестирования также тесно связаны с
конкретными значениями объема выборки, величины среднего квад-
ратичного отклонения и выбранного уровня значимости, для этого
теста также предполагалось выполнение правила 80/20. Однако даже
в таком случае, как продемонстрировано в работе [40] в результате
детального математического анализа и сравнения с другими статис-
тическими тестами, данный тест является неэффективным. И не толь-
ко потому, что он допускает значение вероятности ошибки II рода на
уровне 20%. Более важной причиной является необходимость пред-
варительного расчета объема выборки для обеспечения требуемой
мощности теста. Как мы уже сказали ранее, такие расчеты связаны с
предварительной оценкой значения среднего квадратичного откло-
нения. Однако, как показывает практика, эти оценки могут оказать-
ся неточными, например, значение среднего квадратичного откло-
нения может оказаться намного меньше запланированного. Тогда дан-
ный тест при выбранном заранее объеме испытуемых почти наверняка
отвергнет нулевую гипотезу. Независимо от мощности этот тест, по
своей сути, является средством для проверки гипотезы о точном со-
впадении средних значений (и соответствующих препаратов), он не
позволяет адекватно проверять гипотезу о «приблизительной экви-
валентности». Поэтому в настоящее время такой подход практически
не применяется для анализа биоэквивалентности.
Авторы [22] пришли к выводу, что для целей исследований биоэк-
вивалентности более корректной формальной формулировкой эк-
вивалентности, с точки зрения статистики, является не традиционная
форма нулевой гипотезы, а соответствующая ей альтернативная. Та-
ким образом, при проверке биоэквивалентности формулировка нуле-
вой гипотезы (HJ обычно состоит в том, что сравниваемые препараты
не эквивалентны, а соответствующая ей альтернативная гипотеза (HJ
— что препараты эквивалентны. Такое изменение формулировок по-
зволяет связать известные в статистике ошибки I и II рода при тести-
ровании статистических гипотез с существующими ошибками или,
другими словами, рисками, возникающими в области анализа биоэк-
вивалентности. При проведении подобного анализа возникает 2 типа
246 Глава 2. Базовые понятия и принципы фармакокинетики...
ошибок или рисков, которые нужно принимать во внимание и, по
мере возможности, стараться снизить. Первая ошибка (соответствует
а — вероятности ошибки I рода) — так называемый риск потребите-
ля, который заключается в том, что в результате тестирования суще-
ствует вероятность признания неэквивалентных препаратов биоэк-
вивалентными. Второй тип ошибки — так называемый риск произво-
дителя, который заключается в наличии ненулевой вероятности не
признать в результате тестирования биоэквивалентные препараты та-
ковыми. Обычно организации, регламентирующие исследования био-
эквивалентности, стараются снизить риск потребителя и предостав-
ляют возможность фармацевтической компании решать, какая вели-
чина риска производителя является для нее приемлемой. Влиять на
величину риска производителя можно с помощью выбора подходя-
щего числа испытуемых (объема выборки). Вопросы определения
необходимого числа испытуемых для проведения исследований био-
эквивалентности с помощью различных статистических тестов рас-
смотрены в работах [9, 10, 12, 23, 34], там же даны таблицы и номог-
раммы, связывающие такие параметры тестов, как мощность, допус-
тимые величины различий, разброс данных, уровни значимости и
соответствующие объемы выборок.
Анализ вариаций и критерий Стьюдента являются параметричес-
кими методами и предполагают нормальное распределение данных.
Если распределение данных отличается от нормального, можно по-
пробовать применить преобразование, приводящее к нормальному
распределению. В данном случае обычно преобразование типа «взя-
тие натурального логарифма» рассматривается в качестве наилучше-
го кандидата. Это объясняется тем, что многие биологические при-
знаки имеют лог-нормальное распределение и, что самое главное,
результаты, полученные после такого преобразования, могут быть
интерпретированы как геометрические средние [4, 33]. Многие био-
логические признаки не могут принимать отрицательные значения,
что также может свидетельствовать в пользу их лог-нормального рас-
пределения по сравнению с нормальным. Но для проведения фор-
мальной проверки соответствия распределения определенного пока-
зателя нормальному закону в случае исследования биоэквивалентно-
сти обычно не хватает данных (при п = 12, 18). Различные тонкости,
связанные с проведением анализа в случае использования преобра-
зованных или исходных значений параметров, а также критерии вы-
бора преобразований подробно разобраны в работах [22, 30, 33]. Чаще
всего, если не возникает явного противоречия с данными, анализ
2.2. Основные фармакокинетические понятия...
247
проводят в предположении о лог-нормальном распределении пара-
метра AUC (иногда и Стах) и нормальном распределении остальных
сравниваемых параметров (иногда кроме Ттах, который анализиру-
ется непараметрическими методами). Если предполагается лог-нор-
мальное распределение соответствующего параметра, сравнение его
средних значений с помощью дисперсионного анализа проводится на
основе мультипликативной модели для ^трансформированных дан-
ных. Приведем общий вид такой модели для проверки биоэквивален-
тности препаратов:
Xijk = M-*i-S;k-Kr€ijk (137)
где Х..к — индивидуальное наблюдение переменной эффекта уу-субъек-
та после получения /-препарата в ^-последовательности (к — 1, 2;у =
1,...,л/2; / = 1 и 2) представляет собой произведение:
• общего среднего ц;
• параметра sjk, отражающего случайный эффект, специфический
для данного у-субъекта при получении терапии в Л-последова-
тельности;
• параметра т., отражающего прямой эффект от приема именно /-
препарата;
• параметра пр характеризующего влияние /-периода измерений
О = 1,2;;
• е к — случайной ошибки модели.
Теперь In sjk будет иметь нормальное распределение с нулевым ма-
тематическим ожиданием и Ds, a In e имеет нормальное распределе-
ние с нулевым математическим ожиданием и De.
Взятие логарифма от обеих частей модели приводит к соотноше-
нию для преобразованных данных:
Kt = In^ = lnM + lnT( + In^ + In*, + InV (138)
Не вдаваясь в математические подробности, приведем сразу ко-
нечный результат, имеющий прикладное значение [31]: разность сред-
них значений Y2 — У\ трансформированных переменных (при лога-
рифмическом преобразовании данных) для сравниваемых препара-
тов является несмещенной оценкой логарифма отношений средних
значений исходных переменных XI — XI, который, в свою очередь,
оценивает логарифм отношения соответствующих прямых эффектов
от сравниваемых препаратов т, и т2.
y2_-yi = ln^^- = lnV. (139)
248
Глава 2. Базовые понятия и принципы фармакокинетики...
Тогда легко выводится соотношение, связывающее коэффициент
вариации для исходных значений X.jk (CVx) с остаточной вариацией
для преобразованных У , предоставляемой, например, дисперсион-
ным анализом после логарифмического преобразования данных:
Ds + De = D(Y.jk) = ln{1 + (CVx)2). (140)
Если значение (CVx)2 мало, 1п{1 + (CVx)2} « (CVx)2. А значит, стан-
дартное отклонение трансформированных данных приблизительно
равно коэффициенту вариации исходных данных.
Последние соотношения часто применяются при расчете таблиц
необходимого числа испытуемых для получения статистически дос-
товерных выводов при исследовании биоэквивалентности [9, 10, 23].
В настоящее время широко применяемый подход при проверке био-
эквивалентности состоит в статистическом сравнении двух средних
значений показателей, выбранных для демонстрации биоэквивалент-
ности (например, AUC, Стах), с помощью интервального критерия.
Если 2 таких средних значения оказываются «достаточно близкими»
(не обязательно равными), препараты считаются биоэквивалентными
[22, 40, 42, 46]. Пусть /иТи^я — генеральные средние показатели биоэк-
вивалентности для тестового и стандартного препаратов. Гипотеза о
биоэквивалентности может быть сформулирована в терминах отноше-
ния сравниваемых параметров или в терминах их абсолютных разли-
чий. Для параметров AUCn Cmax обычно принято сравнение отноше-
ний (мультипликативная модель). Если Ql и Q2 — нижняя и верхняя
принятые допустимые границы биоэквивалентности, может быть за-
писана нулевая гипотеза об отсутствии эквивалентности:
Ho-Mt/<Qi или Мт/, >&•
/ Mr /Mr
А соответствующая альтернативная гипотеза о наличии биоэкви-
валентности формулируется как:
HA:QX<^/ <Q2fi<Ql<KQ2.
/ Mr
В случае проведения логарифмического преобразования форму-
лировка гипотез также трансформируется:
где 8. = ln(Q.), при / = 1, 2, в этом случае цт — /nR — разность средних
значений преобразованных показателей биоэквивалентности, соот-
ветствующая логарифмической трансформации. Такой же вид гипо-
тезы соответствует тестированию абсолютных различий.
2.2. Основные фармакокинетические понятия...
249
Для отношений биоэквивалентности были выбраны допустимые
пределы. В течение достаточно продолжительного времени считалось,
что такими пределами в случае отношений параметров должны быть
значения 0,8—1,2. Эти пределы, однако, не являются инвариантны-
ми к обратному преобразованию, поскольку величина, обратная 0,8,
равна 1,25. А это значит, что, несмотря на кажущуюся симметрию этих
пределов, вывод об эквивалентности двух препаратов зависит от того,
какой препарат считается тестовым, а какой — стандартным. Кроме
того, часто анализируются не сами AUC, а их натуральные логариф-
мы In AUC. Тогда значениям пределов 0,8—1,2 будут соответствовать
также несимметричные пределы —0,223 и 0,183. Поэтому в настоя-
щее время значения несимметричных пределов 0,8—1,25 для отно-
шений показателей считаются более адекватными [9, 10, 33, 42]. Если
рассматривается абсолютная арифметическая разница между средни-
ми, соответствующими допустимыми пределами различий считают-
ся 20% от среднего значения показателя стандартного препарата /j,r.
Процедура тестирования интервальных гипотез типа НА или Н'А
производится с помощью их декомпозиции и проверки двух соответ-
ствующих односторонних тестов для выбранных пределов эквивален-
тности 8, и 82:
H'0l \/iT-/iR<Sl H\x :nT-^iR>Sx
и
Вывод об эквивалентности в результате тестирования гипотез мо-
жет быть сделан, если на одном и том же уровне значимости удается
отвергнуть обе нулевые гипотезы #'01 и H\v а значит, и общую интер-
вальную гипотезу #0. Каждая составляющая данной гипотезы прове-
ряется по стандартной процедуре тестирования простой односторон-
ней гипотезы на одном и том же выбранном уровне значимости а.
Например, в случае нормального распределения показателя по кри-
терию Стьюдента рассчитываются тестовые статистики вида с уче-
том дизайна исследования:
t =(xT-xR)-sl и t _s2-(xT-xR) ^14i)
сгл/2/л 2 a 4l In
Рассчитанные значения статистик сравниваются с табличным для
одностороннего теста и уровня значимости, обычно равного 5%.
В исследованиях биоэквивалентности процедура проверки двух
таких односторонних гипотез приводит к установлению биоэквива-
250
Глава 2. Базовые понятия и принципы фармакокинетики...
лентности в том случае, если 100(1 — 2 • а)% доверительный интервал
для \iT — jiR полностью располагается внутри выбранного интервала
эквивалентности [22, 33, 40, 42, 46]. Поэтому в настоящее время для
проверки биоэквивалентности обычно вычисляются 90-процентные
доверительные интервалы и проверяется, находятся ли они внутри
выбранных пределов эквивалентности. Это соответствует проверке
двух односторонних тестов на уровне значимости 5%. Однако в на-
стоящее время обсуждается вопрос, какой доверительный интервал
— 90 или 95% — является более предпочтительным для такого рода
исследований. Это связано с тем, что обычно для констатации досто-
верных отличий тестируемого препарата от плацебо в контролируе-
мых испытаниях уровень значимости для двустороннего теста уста-
навливается 5%. Однако при этом риск потребителя равен скорее
2,5%, чем 5%, поскольку, если препарат «хуже» плацебо, он вообще
не регистрируется. Таким образом, это является аргументом в пользу
вычисления 95-процентных доверительных интервалов, снижающих
риск потребителя (зарегистрировать неэквивалентные препараты как
эквивалентные) до 2,5% в исследованиях такого рода [42].
В настоящее время обычно принято к индивидуальным вычислен-
ным показателям А НС., применять логарифмическое преобразование
и весь последующий анализ проводить для этих трансформирован-
ных величин. Вычисленные границы 90-процентного доверительно-
го интервала для выборочной средней разности InAUC подвергают-
ся преобразованию, обратному взятию натурального логарифма
(exp{lnAUQ), полученные значения сравниваются с пределами экви-
валентности (0,8; 1,25). Избежать обратного преобразования можно,
сравнив полученные значения для границ доверительного интервала
с пределами эквивалентности по логарифмической шкале (—0,223;
0,223) [30, 33, 42]. Такой подход оказался предпочтительным по срав-
нению с применявшимся ранее способом вычисления доверительно-
го интервала для отношения средних значений AUC, основанным на
теореме Филлера [16]. Иногда логарифмическое преобразование при-
меняется и для переменной Спгах. В общем случае для отношений
Спгах устанавливаются те же допустимые пределы эквивалентности,
что и для переменной AUC.
Значения пределов биоэквивалентности обсуждаются и в настоя-
щее время. Так, для отношений Сяшл: были предложены границы (0,7;
1,43) [10, 33]. Аргументом в пользу такого расширения допустимых
пределов для отношений Спгах было замечание, что такой экстремаль-
ный параметр, как Спгах, основанный на единственном измерении,
2.2. Основные фармакокинетические понятия...
251
имеет большую вариацию, чем интегральный показатель AUC. Есть
предложение также установить для препаратов с узким терапевтичес-
ким коридором более жесткие допустимые границы, скажем (0,9; 1,11)
для AUC и (0,8; 1,25) для Стах [10]. В любом случае выбор допусти-
мых пределов биоэквивалентности должен быть основан не только
на статистических, но и на клинических данных и соображениях, ана-
логично выбору «клинически значимого различия». При этом авторы
[33] не исключают, что для некоторых антибиотиков такие границы
могут быть даже односторонние, например (0,8; <*>).
Рассмотренные до сих пор статистические методы проверки био-
эквивалентности были параметрическими, то есть предполагали нор-
мальное или лог-нормальное распределение сравниваемых парамет-
ров. Для решения этой задачи применяются и непараметрические
методы. Так, поскольку такая переменная, как Ттах, по своей приро-
де не может иметь нормальное или лог-нормальное распределение,
рекомендуется применять непараметрические методы анализа. Одна-
ко для небольшого объема выборок, часто используемых в таких ис-
следованиях (12, 18 испытуемых), традиционные непараметрические
методы являются недостаточно эффективными [33, 42]. Обзор непа-
раметрических методов, применяемых в таких исследованиях, при-
веден в работах [33, 46].
Остановимся подробнее на одном из таких свободных от предпо-
ложений о распределении методов, используемых при проверке био-
эквивалентности. Он представляет собой некоторое обобщение те-
ста знаковых рангов Уилкоксона [43]. Как было сказано выше, для
проверки биоэквивалентности строятся доверительные интервалы
для отношений биоэквивалентности AUC(test)/ AUC(standard) в
предположении конкретной формы их распределения. Метод Уил-
коксона позволяет построить такие интервалы без учета формы рас-
пределения и, кроме того, позволяет построить распределение ве-
роятностей для таких значений отношений биоэквивалентности.
Для данной процедуры предполагается, что в результате исследо-
вания, выполненного в соответствии с перекрестным планом, было
получено п индивидуальных значений отношений биоэквивалент-
ности г. = AUC.(test)/ AUC.(standard) (i = 1, 2, ...,n). Для всех полу-
ченных значений г. вычисляются значения геометрических средних
£«/ = ^rt • ri (для всех значений / меньше или равных j = 1, 2, ...,п)9 все-
го п(п + 1)/2 значений g... Полученные значения геометрических сред-
них ранжируются от меньшего к большему. Не вдаваясь в математи-
ческие подробности (они детально изложены в работе [45]), можно
252 Глава 2. Базовые понятия и принципы фармакокинетики...
сказать, что для наиболее распространенного случая п = 12 искомые
границы 95-процентного доверительного интервала задаются 14-м
(нижняя граница) и 65-м (верхняя граница) значениями ранжирован-
ных геометрических средних. Поскольку при наличии биоэквивален-
тности индивидуальные отношения AUCдолжны распределяться вок-
руг 1, а доверительные интервалы для среднего отношения не долж-
ны выходить за пределы (0,8; 1,25), построенная гистограмма
распределения индивидуальных геометрических средних дает нагляд-
ное представление о соответствии имеющихся данных гипотезе о био-
эквивалентности. Строго гипотезу о равенстве единице медианного
элемента распределения геометрических средних проверяют с помо-
щью критерия знаковых рангов Уилкоксона. Для этого вычисляются
отдельно суммы рангов геометрических средних в ранжированном ряду,
больших и меньших единичного значения. Меньшую из двух таких
сумм сравнивают с соответствующим табличным значением [4, 45].
Медиана распределения в случае п = 12 вычисляется как среднее зна-
чение 39-го и 40-го элементов. Кроме того, визуальный анализ такого
распределения может позволить выявить мультимодальность распре-
деления для некоторых лекарственных препаратов. Такое возможно в
случае, если среди испытуемых выделяются субъекты, например, с
высокой и низкой скоростью метаболизма сравниваемых препаратов.
Еще одним вопросом, часто обсуждающимся в литературе, явля-
ется роль таких показателей, как Стах, Cmax/AUC и Ттах при уста-
новлении биоэквивалентности [11, 36, 38]. Приведем некоторые вы-
воды. Известно, что хорошим индикатором абсолютной биодоступно-
сти является сравнение величин AUC при болюсном внутривенном
введении и внесосудистом введении одной и той же дозы препарата, а
относительной биодоступности — отношения величин AUC для срав-
ниваемых препаратов. Однако одного параметра относительной био-
доступности недостаточно для установления биоэквивалентности.
Понятно, что 2 препарата могут иметь одинаковые значения AUC (а
значит, одинаковую степень всасывания), но различающиеся формы
фармакокинетического профиля, что, в свою очередь, приводит к раз-
личиям в терапевтическом эффекте [42]. Это возможно, если один
препарат имеет высокий уровень Стах и «острую» форму профиля,
быстро стремящуюся к нулевому значению. Другой сравниваемый
препарат при этом может иметь более пологий профиль и меньшее
значение Стах. Таким образом, это является аргументом (хотя и не
бесспорным) в пользу учета отношений Стах при тестировании
биоэквивалентности.
2.2. Основные фармакокинетические понятия...
253
Еще более спорным вопросом является выбор параметра для адек-
ватной оценки скорости всасывания. И эта задача также до сих пор
не решена однозначно. Так, справедливость использования для этой
цели значений Стах и Ттах является предметом непрекращающихся
споров. Достаточно сказать, что конкретные значения этих парамет-
ров зависят от моментов времени измерений концентрации. Авторы
работы [38] на основе математического анализа доказали, что статис-
тическая эквивалентность параметров AUC и Стах является необхо-
димым, но недостаточным условием для признания биоэквивалент-
ности двух препаратов, то есть если 2 препарата имеют эквивалент-
ные значения параметров AUCn Стах, они тем не менее могут не быть
биоэквивалентны.
Существует мнение, что отношение параметров Cmax/AUC лучше,
чем параметр Стах, позволяет оценить, а значит, и сравнить скорости
абсорбции при проверке биоэквивалентности. Однако автор статьи [35]
привел контрпример, который демонстрирует, что равные значения
отношений Cmax/AUC для 2 препаратов могут быть получены и при
неэквивалентных скоростях абсорбции. Дело в том, что преимущества
сравнения Cmax/AUC были доказаны в предположении линейных про-
цессов абсорбции и элиминации препарата. Ясно, что для множества
препаратов такие условия нарушаются. Кроме того, возможна и другая
ситуация — когда процесс абсорбции является линейным, но описы-
вается не одной камерой, часто называемой «депо», а, скажем, после-
довательностью нескольких камер (напоминающих звенья цепочки).
Так, контрпример был построен на сравнении двух гипотетических пре-
паратов, имеющих 100-процентную биодоступность и одинаковую ско-
рость выведения, равную 1. Продукт А абсорбируется из депо в соответ-
ствии с линейным процессом с постоянной скоростью 10, в то время
как линейная абсорбция продукта Б моделируется с помощью после-
довательности четырех соединенных камер, однонаправленная ско-
рость обмена между которыми равна 19,2. В результате расчетов полу-
чены одинаковые отношения Cmax/AUC для обоих продуктов, однако
никто не сможет сказать, что процессы их абсорбции эквивалентны.
В качестве компромисса последние правила проведения исследо-
ваний биоэквивалентности в США (Guidance for Industry. Bioavaila-
bility and Bioequivalence Studies for Orally Administered Drug Products
— General Considerations // U.S. Department of Health and Human
Services FDA, Center for Drug Evaluation and Research (CDER), March
2003) рекомендуют использовать вместо прямых непрямые показате-
лей скорости всасывания, так называемые параметры(меры) систем-
254 Глава 2. Базовые понятия и принципы фармакокинетики...
ного присутствия препарата в организме (measures of systemic exposure).
Показатели Стах и AUCпредложено продолжать использовать как меру
биоэквивалентности продуктов, но теперь в большей степени для
оценки присутствия препарата, чем его скорости и степени всасыва-
ния. Такие показатели присутствия препарата в организме определе-
ны относительно начальной и пиковой частей фармакокинетической
кривой изменения концентрации препарата в крови, сыворотке или
плазме, а также относительно полного ФК профиля. Так, для прини-
маемых внутрь препаратов с быстрым высвобождением биоэквива-
лентность может быть продемонстрирована с помощью сравнения со-
ответствующих пикового {Стах) и общего показателей присутствия
препарата (AUQ. Показатель, относящийся к начальной части кривой
С — / (например, частичная AUCот нуля до медианного поляционного
значения Ттах стандартного препарата), может оказаться информатив-
ным в клинических исследованиях эффективности/безопасности и/или
в ФК/ФД исследованиях, проводимых для изучения характеристик
процесса всасывания и попадания препарата в системный кровоток
(например, для изучения скорости появления желаемого эффекта при
приеме анальгетиков или для выявления возникновения чрезмерного ги-
потензивного эффекта после приема антигипертензивного препарата).
Тем не менее, несмотря на все споры и контраргументы, обычно
сравнение параметров предусматривается правилами проведения ис-
следований биоэквивалентности. Такие статистические сравнения
проводятся по традиционным схемам, подробно обсуждавшимся нами
в главе «Статистический анализ данных», с учетом особенностей ди-
зайна. Поскольку вопрос о нормальности распределения основных
параметров при проверке биоэквивалентности решается в каждом от-
дельном случае, в отчете должна предоставляться не только информа-
ция о параметрической статистике (среднее и среднее квадратичное
отклонение), но и непараметрические структурные показатели (меди-
ана, мода, квантили, минимальное и максимальное значение и т. п.).
Упоминавшиеся нами до сих пор статистические методы провер-
ки биоэквивалентности имели дело с данными, полученными неком-
партментным способом. Сравниваемые параметры определялись
(Стах, Ттах) или вычислялись (AUC, MRT, VRT) непосредственно по
зарегистрированной фармакокинетической кривой. Модельный спо-
соб также применяется в данных приложениях. Общий принцип его
заключается в том, что измеренные значения концентрации препа-
рата в крови используются для идентификации параметров фармако-
кинетической модели, выбранной для описания поведения данных
2.2. Основные фармакокинетические понятия...
255
препаратов в организме. Затем средние значения параметров модели
для двух препаратов (например, Kabs, Kel, Vd в случае линейной одно-
камерной модели) используются для расчетов и последующего срав-
нения параметров биоэквивалентности. Наиболее важным при таком
подходе является вопрос об адекватности описания поведения пре-
парата в организме выбранной для этого фармакокинетической мо-
делью. В случае отсутствия согласия выбранной модели с имеющи-
мися данными о поведении данного препарата при любой точности
статистических методов проверки гипотез о биоэквивалентности по-
лученные выводы окажутся неверными. Идентификация парамет-
ров модели по имеющимся данным производится обычно с помощью
компьютерных программ. Имеющиеся в настоящее время компью-
терные программы для популяционного моделирования в фармако-
кинетике также могут успешно применяться для получения средних
значений сравниваемых фармакокинетических параметров. Так, в
работе [19] продемонстрирована возможность использования програм-
мы NONMEM [6] для анализа данных биодоступности препаратов и
построения доверительных интервалов модельных параметров фар-
макокинетики (объем распределения, скорость абсорбции и скорость
элиминации). Этот подход хорош еще и тем, что он позволяет стро-
ить распределения фармакокинетических параметров и оценивать
интраиндивидуальную вариабельность таких параметров.
Вообще традиционный подход к оценке биоэквивалентности пред-
полагает сравнение средних значений параметров, не изучая в явном
виде интраиндивидуальную вариабельность реакций на сравниваемые
препараты. Такой «усредненный» подход [47, 48] является частным
случаем так называемой популяционной биоэквивалентности. Попу-
ляционная биоэквивалентность подразумевает получение и сравне-
ние не только средних оценок параметров, выбранных для установ-
ления наличия или отсутствия биоэквивалентности, а построение и
сравнение полного распределения таких параметров у изучаемой по-
пуляции пациентов. В этой области существует еще много вопросов,
подробнее этот подход рассмотрен в [22]. Популяционный подход
является важным шагом к изучению индивидуальной биоэквивален-
тности, поскольку предполагает оценку вариабельности параметров.
Однако такой подход не позволяет прогнозировать реакцию пациен-
та на замену одного сравниваемого препарата другим в ходе терапии,
что бывает очень важно в случае препаратов с узким терапевтичес-
ким коридором. Такой анализ возможен в рамках изучения индиви-
дуальной биоэквивалентности [22, 48].
256 Глава 2. Базовые понятия и принципы фармакокинетики...
По определению, предложенному авторами [22], индивидуальная
биоэквивалентность предполагает, что выбранные параметры биоэк-
вивалентности будут достаточно близкими для большинства субъек-
тов рассматриваемой популяции. Это определение содержит 2 поня-
тия, нуждающиеся в уточнении: как определить, что 2 интраиндиви-
дуальных параметра имеют близкие значения, и каков должен быть
минимальный процент пациентов с близкими значениями парамет-
ров в популяции. Существует мнение, что для изучения индивиду-
альной биоэквивалентности для полного исключения взаимовлияния
препаратов более корректным будет исследование, основанное на
перекрестном плане с четырьмя периодами измерений. Каждый ис-
пытуемый должен получить каждый препарат дважды в разной пос-
ледовательности. Другая проблема состоит в том, что пока не выра-
ботано правило, регламентирующее допустимую интраиндивидуаль-
ную вариабельность. С точки зрения математики, трудно разделить
истинные различия между препаратами и интраиндивидуальную ва-
риабельность. Ведь если интраиндивидуальная вариабельность дос-
таточно большая, скорее всего, в ходе исследования препараты будут
признаны небиоэквивалентными. Тогда какой же уровень различий
признать недопустимыми проявлениями интраиндивидуальной вари-
абельности в рамках признания препаратов биоэквивалентными в
среднем? Была сделана попытка для оценки индивидуальной биоэк-
вивалентности применять правило 75/75. В соответствии с этим пра-
вилом у 75% субъектов популяции индивидуальные отношения био-
эквивалентности (отношения AUQ должны быть в пределах от 75%
до 125%. Для тестирования индивидуальной биоэквивалентности раз-
работаны различные алгоритмы, однако все эти вопросы до конца не
изучены, и их текущее состояние обсуждается в работах [22, 42, 48].
2.6. ПОПУЛЯЦИОННЫЙ ДИЗАЙН И МОДЕЛИ
Обычно фармакокинетические исследования лекарственных пре-
паратов включают относительно небольшие группы здоровых добро-
вольцев или, в некоторых случаях, пациентов. В ходе такого исследо-
вания у каждого субъекта измеряются уровни препарата в крови в со-
ответствии с дизайном таким образом, чтобы измеренной информации
было достаточно для построения фармакокинетического профиля и
проведения математического анализа результатов в соответствии с це-
лями исследования. С точки зрения статистики и математики можно
2.2. Основные фармакокинетические понятия...
257
сказать, что эти данные достаточно высокого качества, поскольку они
позволяют проводить достаточно сложный математический анализ и
применять методы математического моделирования. К сожалению,
очень часто фармакокинетические параметры препарата могут разли-
чаться у здоровых добровольцев и пациентов. Кроме того, такие ис-
следования, проводимые у достаточно ограниченного числа лиц, не
могут адекватно оценивать межиндивидуальную вариабельность фар-
макокинетических параметров изучаемого препарата.
В свою очередь, лаборатории, проводящие терапевтический лекар-
ственный мониторинг (ТЛМ), накапливают огромный материал,
представляющий собой соотношение режима дозирования и соответ-
ствующих концентраций изучаемого препарата у огромного количе-
ства пациентов. Ценность этих данных состоит в том, что они гораз-
до лучше отражают реальные характеристики изучаемой популяции
и межиндивидуальную вариабельность реакций различных пациен-
тов на получаемые разные схемы дозирования препарата. Однако ре-
зультаты ТЛМ редко используются в качестве исходных данных для
проведения серьезного статистического анализа, поскольку наличие
ограниченного числа измерений концентрации у каждого конкрет-
ного пациента создает значительные математические трудности. В
последние годы в литературе все чаще стали появляться работы, ав-
торы которых использовали данные ТЛМ для оценки фармакокине-
тических параметров различных препаратов и их сочетаний при по-
литерапии [20, 44, 52—54]. Такой анализ проводился на основе под-
хода, называемого популяционным моделированием, с помощью
специального программного обеспечения.
Известны различные методы популяционного моделирования и их
модификации, позволяющие рассчитывать популяционные модели:
традиционный метод (данные различных субъектов объединяются в
один пул и рассматриваются как данные одного среднего субъекта;
недостаток: невозможно оценить межиндивидуальные различия);
стандартный двухэтапный метод (данных достаточно для определе-
ния индивидуальных параметров каждого субъекта — первый этап,
на втором этапе оцениваются средние и дисперсии идентифициро-
ванных параметров для популяции); глобальный двухэтапный пара-
метрический метод (аналогичен предыдущему, но учитывает корре-
ляцию между параметрами); NONMEM — нелинейная модель смешан-
ных эффектов (один из наиболее распространенных в настоящее
время методов, использует байесовский подход, предполагает нор-
мальное распределение кинетических параметров популяции, учиты-
258 Глава 2. Базовые понятия и принципы фармакокинетики...
вает корреляцию и ковариацию между параметрами, позволяет обра-
батывать данные, содержащие даже одно измерение концентрации
препарата у пациента, программное обеспечение NONMEM [6]); не-
параметрический метод максимального правдоподобия — NPML (сво-
боден от предположений о нормальном распределении параметров,
строит дискретную совместную плотность распределения параметров,
позволяет выделять подпопуляции пациентов, такие как, например,
отличающиеся быстрым и медленным метаболизмом препарата); ме-
тод NPEM — непараметрический метод максимизации вероятности
(использует байесовский подход, итеративно строит непрерывную со-
вместную плотность распределения фармакокинетических парамет-
ров, наилучшим образом описывающую результаты измерений, не
предполагает конкретную форму распределения кинетических пара-
метров, позволяет выделять подпопуляции, также может работать с
данными, содержащими по одному измерению концентрации препа-
рата у пациента, программное обеспечение USC*PACK, R. Jelliffe, A.
Schumitzky и соавт. [26, 27, 41]) и др. Основным недостатком тради-
ционного метода, объединяющего все данные в один общий пул так,
как будто они получены у одного субъекта, является невозможность
оценить межиндивидуальную вариабельность. Стандартный двухэтап-
ный метод требует для идентификации N параметров выбранной мо-
дели не менее N измерений уровня препарата для каждого пациента
популяции, поэтому неприменим в случае обработки данных ТЛМ.
Вообще популяционная фармакокинетическая модель содержит
статистические характеристики фармакокинетических параметров
модели, выбранной для описания поведения данного препарата у дан-
ной группы пациентов. Популяционная модель должна достаточно точ-
но описывать не только средние значения параметров, но и их межин-
дивидуальную вариабельность. Формально задача сводится к иденти-
фикации неизвестных параметров фармакостатистической модели по
реально измеренным концентрациям препарата в крови данного па-
циента (для всех пациентов, представляющих в исследовании изучае-
мую популяцию) и построению распределения таких параметров. Эта
задача в случае ТЛМ усложняется в связи со спецификой данных —
терапевтический лекарственный мониторинг редко предполагает на-
личие более 1—3 замеров уровня препарата у каждого пациента. Тра-
диционные методы не позволяют идентифицировать параметры даже
самой простой фармакокинетической модели по таким данным. Про-
граммы NONMEM и USC*PACK для популяционного моделирования
предоставляют возможность работать с данным ТЛМ. Подробнее об
2.2. Основные фармакокинетические понятия...
259
этом будет рассказано в разделе, посвященном рассмотрению байесов-
ского подхода в статистике. Таким образом, можно сказать, что попу-
ляционные модели становятся самостоятельным видом фармакокине-
тических исследований. Они не только применяются для определения
фармакокинетических параметров лекарственных препаратов на основе
модельного подхода и успешно используются в клинической практике
для индивидуализации дозирования, но также помогают в изучении
фармакокинетического взаимовлияния препаратов в случае примене-
ния комбинированной терапии [52, 54].
Литература к 2 главе
1. Беленький М.Л. Элементы количественной оценки фармакологичес-
кого эффекта. — Л.: Гос. изд-во мед. лит., 1963.
2. Романовский Ю.М., Степанова Н.В., Чернавский Д.С. Математическое
моделирование в биофизике. — М.: Наука, 1975.
3. Соловьев В.Н., Фирсов А.А., Филов В.А. Фармакокинетика: Руководство.
— М.: Медицина, 1980.
4. Справочник по прикладной статистике / Под ред. Э. Ллойда, У. Ледер-
мана. — М.: Финансы и статистика, 1989.
5. Урбах В.Ю. Статистический анализ в биологических и медицинских ис-
следованиях. — М., 1976.
6. Beal S., Sheiner L. NONMEM User's Guide. Pt. 1. Technical Report of the
Division of Clinical Pharmacology. — San Francisco: University of California, 1980.
7. Bourgeois B.F.D. Pharmacokinetics and pharmacodynamics in clinical
practice // Treatment of Epilepsy: Principles and Practice / Ed. E. Wyllie. —
Baltimore: Williams and Wilkins, 1997.
8. Boxenbaum H.G., Riegelman S., Elashoff R.M. Statistical examinations in
pharmacokinetics // J. Pharmacokinet. Biopharm. — 1974. — Vol. 2, N 2. — P.
123-148.
9. Diletti E., Hauschke D., Steinijans K.W. Sample size determination for
bioequivalence assessment by means of confidence intervals // Int. J. Clin.
Pharmacol. Then Toxicol. — 1991. — Vol. 29, N 1. — P. 1-8.
10. Diletti E., Hauschke D., Steinijans V. W. Sample size determination: extended
tables for the multiplicative model and bioequivalence ranges of 0.9 to 1.11 and 0.7
to 1.43 // Ibid. - 1992. - Vol. 30, N 8. - P. 287-290.
11. Endrenyi L.y Fritsch S., Yan W. Cmax/AUC is a clearer measure than Cmax
for absorption rates in investigations of bioequivalence // Ibid. — 1991. — Vol. 29,
N 10. - P. 394-399.
12. Esinhart J.D., Chinchilli V.M. Sample size considerations for assessing
individual bioeauivalence based on the method of tolerance intervals // Ibid. —
1994. - Vol. 32, N 1. - P. 26-32.
260 Глава 2. Базовые понятия и принципы фармакокинетики...
13. Evans W.E., Schentag J.J., Jusko W.J.L. (eds). Applied Pharmacokinetics.
Principles of Therapeutic Drug Monitoring. — 2nd ed. — Spokane: Applied
Therapeutics, 1986.
14. EzzetF., Spiegelhalter D.J. Pharmacokinetic Dose Proportionality: Practical
Issues on Design, Sample Size and Analysis: Presented at the 2nd International
Meeting on Statistical Methods in Biopharmacy. — Paris, 1993.
15. Faed E.M. Protein binding of drug in plasma, interstitial fluids and tissues:
effect on pharmacokinetics // Eur. J. Clin. Pharmacol. — 1981. — Vol. 21. — P.
77-81.
16. Fieller E.C. A fundamental formula in the statistics of biological assay and
some application // Q. J. Pharmacol. - 1944. — Vol. 17. - P. 117-123.
17. Fluehler H., Hirtz J-, Moser H.A. An aid to decision — making in
bioequivalence assessment // J. Pharmacokinet. Biopharm. — 1981. — Vol. 9, N 2.
- P. 235-243.
18. Gibaldi M. Biopharmaceutics and Clinical Pharmacokinetics. — 4th ed. —
Philadelphia; Lond.: Lea and Febiger, 1991.
19. Graves D.A., Chang I. Application of NONMEM to routine bioavailability
data // J. Pharmacokinet. Biopharm. - 1990. - Vol. 18, N 2. - P. 145-159.
20. Graves N.M., Brundage R.C., Wen Y. et al Population pharmacokinetics of
carbamazepine in adults with epilepsy // Pharmacotherapy. — 1998. — Vol. 18, N
2. - P. 273-281.
21. Grieve A.P. Evaluation of bioequivalence studies // Eur. J. Clin. Pharmacol.
- 1991. - Vol. 40. - P. 201-203.
22. Hauck W. W., Anderson S. Types of bioequivalence and related statistical
considerations // Int. J. Clin. Pharmacol. Then Toxicol. — 1992. — Vol. 30, N 5. —
P. 181-187.
23. Hauschke D., Steinijans V. W., Diletti E. etal. Presentation of the intrasubject
coefficient of variation for sample size planning in bioequivalence studies // Ibid.
- 1994. - Vol. 32, N 7. - P. 376-378.
24. Hill A. V. The possible effects of the aggregation of the molecules of
haemoglobin on its dissociation curves // Proc. Physiol. Soc. — 1910. — Vol. 40. —
P. 4-7.
25. Holford N.H.G., Sheiner L.B. Understanding the dose-effect relationship:
clinical application of PK/PD models // Clin. Pharmacol. — 1981. — Vol. 6. — P.
429-453.
26. Jelliffe R.W. et al. User's Manual for Version 10.7 of the USC*PACK
Collection of PC Programs, 1995.
27. Jelliffe R.W., Schumitzky A.y Bayard D. et al. Adaptive Control of Drug
Dosage Regimens: An Overview of Basic Concepts, Relevant Issues and Some
Clinical Applications: Technical Report 94-1. University of Southern California
School of Medicine, Laboratory of Applied Pharmacokinetics, 1994.
28. Jelliffe R.W., Schumitzky A., Van Guilder M. etal. Individualising drug dosage
regimens: roles of population, pharmacokinetics and dynamic models, Bayesian fitting
and adaptive control // Ther. Drug Monk. — 1993. — Vol. 15. — P. 380-393.
2.2. Основные фармакокинетические понятия...
261
29. Levy R.H., Thummel K.E. Basic principles of drug absorption, distribution
and elimination // Treatment of Epilepsy: Principles and Practice / Ed. E. Wyllie.
— Baltimore: Williams and Wilkins, 1997.
30. Liu J. P., Weng C.S. Estimation of direct formulation effect under log normal
distribution in bioavailability/bioequivalence studies // Stat. Med. — 1992. — Vol.
11.-P. 881-896.
31. Mandallaz D., Май J. Comparison of different methods for decision making
in bioequivalence assessment // Biometrics. — 1981. — Vol. 37. — P. 213—222.
32. Marzo A. Open questions in bioequivalence // Pharmacol. Res. — 1995. —
Vol. 32, N 4. - P. 237-240.
33. Pabst G.y Jaeger H. Review of methods and criteria for the evaluation of
bioequivalence studies // Eur. J. Clin. Pharmacol. — 1990. — Vol. 38. — P. 5-10.
34. Phillips K.F. Power of the two one-sided tests procedure in bioequivalence /
/ J. Pharmacokinet. Biopharm. - 1990. - Vol. 18, N 2. - P. 137-144.
35. Rescigno A. Pharmacokinetics, science or fiction? // Pharmacol. Res. —
1996. - Vol. 33, N 4-5. - P. 227-233.
36. Rescigno A. Rate of absorption // Ibid. — 1997. — Vol. 35, N 1. — P. 5-6.
37. Rescigno A. Fundamental concepts in pharmacokinetics // Ibid. — N 5. —
P. 363-390.
38. Rescigno A., Powers J.D. AUC and Cmax are not sufficient to prove
bioequivalence // Ibid. - 1998. - Vol. 37, N 2. - P. 93-95.
39. Rowland M., Tozer ?.N. Clinical Pharmacokinetics: Concepts and
Applications. — 3rd ed. — Baltimore: Williams and Wilkins, 1995.
40. Schuirmann D.J. A comparison of the two one-sided tests procedure and
power approach for assessing the equivalence of average bioavailability // J.
Pharmacokinet. Biopharm. - 1987. - Vol. 15, N 6. - P. 657-680.
41. Schumitzky A. Nonparametric EM algorithms for estimating prior
distributions // Appl. Math. Comput. — 1991. — Vol. 45. — P. 143-157.
42. Senn S. Statistical Issues in Drug Development. — N.Y. John Wiley and
Sons, 1997.
43. Sheiner L.B. Bioequivalence revisited // Stat. Med. — 1992. — Vol. 11. —
P. 1777-1788.
44. SteimerJ.L., Vozeh S., Racine A. etal. The population approach: rationale,
methods and applications in clinical pharmacology and drag development //
Pharmacokinetics of Drugs / Eds Welling, J. Balant. — N.Y.: Springer Verlag,
1994.
45. Steinijans V.W., Diletti E. Generalization of distribution-free confidence
intervals for bioavailability ratios // Eur. J. Clin. Pharmacol. — 1985. — Vol. 28. —
P. 85-88.
46. Steinijans V. W.t Hauschke D. Update on statistical analysis of bioequivalence
studies // Int. J. Clin. Pharmacol. Then Toxicol. — 1990. — Vol. 28, N 3. —
P. 105-110.
47. Steinijans V.W., Hauschke D. International harmonization of regulatory
requirements // Clin. Res. Regul. Aff. — 1993. — Vol. 10. — P. 203-220.
262
Глава 2. Базовые понятия и принципы фармакокинетики...
48. Steinijans V.W., Hauschke D., Schall R. International harmonization of
regulatory requirements for average bioequivalence and current issue in individual
bioequivalence // Drug Inform. J. - 1995. - Vol. 29. - P. 1055-1062.
49. Westlake W.J. Symmetrical confidence intervals for bioequivalence trials /
/ Biometrics. - 1976. - Vol. 32. - P. 741-744.
50. Westlake W.J. Response to bioequivalence testing: a need to rethink // Ibid.
- 1981. - Vol. 37. - P. 591-993.
51. Yamaoka K., Nakagawa Т., Una T. Statistical moments in pharmacokinetics
// J. Pharmacokinet. Biopharm. - 1978. - Vol. 6, N 6. - P. 547-558.
52. Yukawa E., Honda Т., Ohdo S. et al. Detection of carbamazepine-induced
changes in valproic acid relative clearance in man by simple pharmacokinetic
screening // J. Pharm. Pharmacol. - 1997. - Vol. 49. - P. 751-756.
53. Yukawa E., To #., Ohdo S. et al. Population-based investigation of valproic
acid relative clearance using nonlinear mixed effects modeling: influence of drug-
drug interaction and patient characteristics // J. Clin. Pharmacol. — 1997. — Vol.
37.-P. 1160-1167.
54. Yukawa E., To #., Ohdo S. et al. Detection of a drug-drag interaction on
population-based phenobarbitone clearance using nonlinear mixed-effects modeling
// Eur. J. Clin. Pharmacol. - 1998. - Vol. 54. - P. 69-74.
Глава 3
НЕКОТОРЫЕ ВОПРОСЫ, СВЯЗАННЫЕ
С ПРИМЕНЕНИЕМ БАЙЕСОВСКОГО ПОДХОДА
К АНАЛИЗУ КЛИНИЧЕСКИХ ДАННЫХ
В последние годы при описании статистических методов для об-
работки результатов исследований все чаще встречается упоминание
о байесовском подходе к анализу клинических данных. Возрастаю-
щий интерес к этому методу в последнее время частично объясняется
развитием такого направления, как доказательная медицина, в рам-
ках которого фокусируется внимание на использовании данных кли-
нических исследований для демонстрации эффективности того или
иного метода лечения [5, 16, 18, 19, 26]. Поэтому мы решили в самых
общих чертах рассказать об основных принципах байесовского под-
хода и о наиболее успешных процедурах анализа клинических дан-
ных в рамках этого подхода. И хотя в последние годы такой подход
становится все более популярным, например для анализа фармако-
кинетических данных, по-прежнему среди ученых-статистиков нет
единого мнения по поводу определения, классификации, достоинств
и недостатков такого подхода. Наиболее понятным нам кажется сле-
дующее определение: байесовскими методами являются методы, раз-
работанные в результате попыток сформулировать и решить статис-
тические проблемы на основе теоремы Байеса [3].
Прежде чем сформулировать теорему Байеса, нужно остановиться
на некоторых определениях теории вероятностей. Одним из наибо-
лее важных понятий в теории вероятностей является понятие экспе-
римента. Эксперимент, с точки зрения теории вероятностей, состоит
в том, что производится испытание при соблюдении некоторого ком-
плекса условий. Теоретическое изучение случайных экспериментов,
в результате которых возможно наступление взаимоисключающих
событий, и составляет предмет теории вероятностей. К таким случай-
ным, или вероятностным, экспериментам можно отнести, например,
розыгрыш лотереи, задачу о проверке качества партии изделий, слу-
чайную траекторию движения броуновской частицы и т. п. В резуль-
тате проведения такого эксперимента может произойти (или не
произойти) интересующее событие А. Эксперимент в теории вероят-
ностей считается заданным, если определены его условия и указаны
события, наступление или ненаступление которых следует наблюдать.
264 Глава 3. Некоторые вопросы, связанные с применением...
Событие Е называется элементарным, если для всякого события А
случайного эксперимента оно влечет либо А, либо противополож-
ное событие «не А» — событие А не произошло (взаимоисключаю-
щие исходы). В теории вероятностей рассматриваются лишь конеч-
ные случайные эксперименты, для которых определена полная груп-
па элементарных событий, и каждое событие А в таком эксперименте
является суммой элементарных событий, влекущих это событие А.
Случайный эксперимент в теории вероятностей не отождествляется,
например, с естественно-научным экспериментом, он понимается в
самом широком смысле. Так, в качестве примера случайного экспе-
римента можно рассматривать и эксперимент, в котором измеряется
некоторая дискретная величина £ (переменная £ принимает только
целые значения), скажем, на отрезке числовой прямой [а, Ь]. Множе-
ство элементарных событий в таком эксперименте естественно отож-
дествить с множеством целых чисел, принадлежащих отрезку [а, Ь] и
в качестве элементарного события рассматривать событие вида \ = х,
где х — целые числа, а <х<Ь.
Одной из существенных особенностей вероятностных эксперимен-
тов является возможность повторять их сколько угодно раз (неограни-
ченное количество). Осуществление эксперимента означает выбор од-
ного из возможных элементарных событий или исходов, а повторение
этого эксперимента п раз приводит к последовательности из п возмож-
ных элементарных исходов, наблюдавшихся в эксперименте. Обозна-
чим т число появлений события А в п экспериментах, тогда величина
т/п называется частотой появления события А в п экспериментах. Счи-
тается, что при увеличении числа экспериментов п частоты событий
колеблются около некоторых чисел, не зависящих от числа экспери-
ментов. Эти числа и называются вероятностями. При таком подходе
вероятность определяется как предел частоты (при бесконечном по-
вторении эксперимента), и это определение вероятности иногда назы-
вают статистическим. Для иллюстрации данного определения часто
приводят пример с бросанием симметричной монеты. Так, при каж-
дом бросании или, другими словами, в результате эксперимента в дан-
ном случае возможны 2 элементарных исхода: выпадение «орла» или
«решетки». При достаточно большом числе повторений эксперимента
частоты появления того или иного исхода будут стремиться к 1/2. Од-
нако каждый может убедиться, что в серии из 10—15 бросаний число
появлений различных исходов вряд ли будет одинаковым.
По определению, значение вероятности заключено между 0 и 1.
Если вероятность какого-либо события оценивается числом, близким
Глава 3. Некоторые вопросы, связанные с применением...
265
к 0, говорят о практически невозможном событии. Если вероятность
события оценивается числом, близким к 1, такое событие считается
практически достоверным.
При классическом подходе к теории вероятностей в случае любо-
го конечного эксперимента вероятность события А определяется ве-
роятностями элементарных исходов. Для многих конечных экспери-
ментов, если нет другой информации, можно априори установить, что
все элементарные события имеют равную вероятность, то есть при
наличии п элементарных исходов, вероятность каждого из них равна
1/п. Если появление события А зависит от т благоприятствующих
появлению события А исходов, то, согласно классическому опреде-
лению, вероятность появления события А выражается отношением
числа благоприятствующих исходов т к общему числу возможных
исходов п:
П
Для иллюстрации этого определения, которое называется класси-
ческим, обычно используются известные примеры из теории вероят-
ностей или теории игр, например так называемые комбинаторные
задачи. Одна из таких задач состоит в определении вероятности из-
влечь наугад белый шар из урны, содержащей пх белых и п2 черных
шаров. Итак, событие А в данном случае состоит в том, что из урны
наугад извлечен белый шар. Число возможных исходов при такой по-
становке задачи равно числу шаров в урне п = пх + nv число благо-
приятствующих исходов равно числу белых шаров в урне, то есть пг
Тогда вероятность наугад извлечь белый шар равна Р(А) = пх/п.
Говоря об априорной оценке вероятности исходов, мы тем самым
коснулись еще одного важного определения теории вероятностей.
Вероятность, которую принимают до эксперимента, называют апри-
орной вероятностью. Апостериорными вероятностями называют зна-
чения вероятностей, пересмотренные в результате эксперимента (или
анализа данных). Конечно, надо иметь в виду относительность тако-
го определения, поскольку сегодняшние представления являются
апостериорными по отношению к вчерашним и априорными по от-
ношению к завтрашним.
Байесовский подход предполагает, что до того, как будут получе-
ны реальные данные, исследователь для всех потенциально возмож-
ных для изучаемой задачи вероятностных моделей (или полной груп-
пы событий) оценивает их априорные вероятности. Как только дан-
ные собраны, применение теоремы Байеса позволяет пересмотреть
266
Глава 3. Некоторые вопросы, связанные с применением...
априорные суждения и пересчитать апостериорные вероятности для
возможных моделей на основе поступления новой информации. При
таком подходе выборку не считают единственным источником ин-
формации для статистических выводов и стремятся, если возможно,
использовать ту информацию, которая была до проведения исследо-
вания, другими словами, всю априорную информацию.
Попробуем, не вдаваясь в математические подробности, сформу-
лировать в общем виде теорему Байеса (в приложении к анализу ре-
зультатов исследования). Предположим, что выбран конечный спи-
сок взаимоисключающих вероятностных моделей {Л/1, М2, ..., Мк}
для описания конкретной изучаемой задачи. Всем этим моделям до
проведения исследования приписаны значения априорных веро-
ятностей {Р(М\), Р(М2),..., Р(Мк)}, так что все эти вероятности в
сумме дают 1. Обозначим реальные данные, полученные в резуль-
тате исследования, D. Тогда условная вероятность получения та-
ких данных в результате проведения этого исследования при усло-
вии каждой из выбранных альтернативных моделей может быть
обозначена как {P(D\M\)f P(D\M2),..., P(D\Mk)}. Эти величины на-
зывают правдоподобиями выбранных моделей Mi при полученных
данных D. Рассматривая множество правдоподобий, статистик тем
самым пересматривает свои априорные оценки вероятности в свете
новой информации, содержащейся в полученных данных. В мате-
матическом же выражении с помощью теоремы Байеса он как раз и
пересчитывает апостериорное множество вероятностей {Р(М1\ D),
P(M2\D),..., P(Mk\D)}, то есть множество апостериорных вероятностей
выбранных взаимоисключающих моделей при условии получения
данных D [3, 4, 8]. В общем виде теорема Байеса, представленная
впервые более 200 лет назад [7], может быть сформулирована сле-
дующим образом: апостериорная вероятность равна априорной, ум-
ноженной на правдоподобие, оцениваемое по полученным реаль-
ным данным.
В дискретном виде теорема Байеса может быть записана так:
. P(D\Mi)P(Mi)
P(Mi\D) = —J—-—-—L j = 1,2,... д
Рф)
v ' (143-144)
рф) = У£Рф\МОР(МЦ
Таким образом, теорема Байеса позволяет связать апостериорные
вероятности выбранных моделей с их априорными вероятностями
Глава 3. Некоторые вопросы, связанные с применением... 267
и правдоподобиями, рассчитанными на основе полученных в иссле-
довании данных. Правдоподобия подчеркивают тесную связь байе-
совского подхода с известной теорией максимального правдоподо-
бия [3, 7, 14].
В формулировке теоремы Байеса встречается упоминание о спис-
ке вероятностных моделей, выбранных для описания данной зада-
чи. Под моделью при этом понимают упрощенное представление су-
щественных характеристик изучаемого объекта или ситуации. Не-
смотря на кажущуюся сложность, в практическом смысле данное
определение подразумевает необходимость разработки упрощенной
формулировки задачи для последующего решения ее с помощью ста-
тистических методов. Так, можно продемонстрировать построение
вероятностной модели на простом примере с подбрасыванием мо-
нет. Допустим, при проведении этого эксперимента нас интересует
число выпадений «решетки». Для формулировки модели принима-
ются следующие упрощающие предположения: возможно только 2
исхода эксперимента — выпадение «орла» или «решетки»; ситуации,
когда монета становится на ребро, исключаются из рассмотрения.
Кроме того, предполагается, что при многократном повторении эк-
сперимента при одних и тех же условиях относительные частоты двух
возможных исходов будут стабилизироваться около некоторых ха-
рактерных чисел. При формулировке модели используется также
понятие независимости. В данной задаче трудно предположить на-
личие какого-либо случайного фактора, одновременно влияющего
на исходы эксперимента и делающего эти исходы зависимыми друг
от друга. Поэтому в данной задаче предполагается независимость
событий.
Теперь проиллюстрируем возможность применения теоремы Бай-
еса на примере из теории вероятностей. Допустим в этой задаче име-
ется п урн, содержащих белые и черные шары. Пусть вероятность на-
угад извлечь белый шар из Л-урны равна рк. Выбирается наугад одна
из урн, и из нее извлекается шар. Какова вероятность того, что мы
выбрали £-урну, если шар оказался белым? Будем считать, что в дан-
ной задаче взаимоисключающее множество моделей (размерность
множества равна п) состоит из событий — Мк — выбрали &-урну. Тог-
да, поскольку нет никакой дополнительной информации, априорные
вероятности для всех таких событий считаем одинаковыми и равны-
ми \/п. Если в результате эксперимента была выбрана именно £-урна
и событие, представляющее в нашем случае результаты эксперимен-
та Д состоит в том, что шар белый, по теореме Байеса можно оце-
268
Глава 3. Некоторые вопросы, связанные с применением...
нить апостериорную вероятность fc-модели (выбор &-урны) при усло-
вии полученных данных (шар белый):
P{Mk\D)= Рк'{П =^~- (145)
Уп'И Pi Z Pi
1 = 1 1 = 1
Байесовский подход применяется при выборе стратегий в теории
принятия решений [6, 8]. Проиллюстрировать возможность байесов-
ских стратегий в этой области можно на примере известной задачи о
мистере Нельсоне, приехавшем в Северный Фиггинс и пытающемся
одеться по погоде [6], которая имеет некоторый практический смысл.
Так, мистер Нельсон пытается выбрать один из трех вариантов одеж-
ды в соответствии с ожидаемыми изменениями погоды (стратегии
поведения). Однако абсолютно точной информацией о состоянии
погоды Нельсон не располагает, поэтому он может лишь оценивать
ожидаемые потери при выборе любой из стратегий и выбирать наи-
более выгодную стратегию поведения, минимизирующую байесовс-
кий риск. Оценки стратегии зависят от того, какую информацию
Нельсон будет использовать в качестве априорной. Так, один из ва-
риантов — основывать свой выбор только на показаниях барометра.
Кроме того, можно также использовать априорную информацию, что
в Северном Фиггинсе дождь идет в среднем каждые два дня из трех.
Можно воспользоваться и данными о вчерашней погоде, если извес-
тно, например, что в данной местности после 70 дождливых дней из
100 следующий день также будет дождливым, в то время как после
ясного дня дождливый наступает только в 20 случаях из 100. Тогда,
если вчера был дождливый день, мистер Нельсон может применить
байесовскую стратегию, соответствующую априорным вероятностям
0,3 для солнечного дня и 0,7 — для дождливого. Если вчера был сол-
нечный день, мы должны исходить из вероятностей 0,8 и 0,2. Все эти
рассуждения приводят к заполнению таблицы вероятности действий
и ожидаемых потерь для возможных стратегий поведения. Понятно,
что в неявном виде мы фактически каждый день решаем похожую
практическую задачу, не отдавая себе отчет в том, что применяем бай-
есовские стратегии.
Байесовский подход позволяет формулировать и решать типичные
статистические задачи, такие как точечное и интервальное оценива-
ние неизвестного параметра на основе полученных данных, проверка
значимости и др. С решением этих задач с помощью классического
подхода мы познакомились в соответствующей главе. Так, если зада-
Глава 3. Некоторые вопросы, связанные с применением...
269
на модель, включающая неизвестный параметр 0, и заданы данные
А то на основе байесовского подхода можно рассчитать апостериор-
ную плотность P(Q\D), соответствующую любой конкретной специ-
фикации априорной плотности для параметра 0. В рамках байесовс-
кого подхода также определены такие структурные статистические
параметры распределения, как мода, медиана, среднее. Процедура
проверки значимости, или проверки нулевой гипотезы о наличии ста-
тистически значимого отличия значения параметра 0 от заданной ве-
личины Од на уровне значимости 100а% с точки зрения байесовского
подхода состоит в следующем: вычисляется интервал наивысшей ап-
риорной плотности уровня 100(1 — а) для параметра 0 и, если значе-
ние Од лежит вне полученного интервала, нулевая гипотеза отвергает-
ся. Подробно эти вопросы рассмотрены, например, в [3, 6, 8].
Статистики байесовского направления, занимающиеся анализом
данных в биомедицинских приложениях, критикуют широко распро-
страненный классический метод проверки значимости различий и
формирования статистического заключения на основании лишь оцен-
ки/^-значения [8, 18, 19, 32]. Основные аргументы при этом сводятся
к следующему. Во-первых, статистики байесовской школы, пытаясь
сопоставить результаты статистических сравнений с помощью клас-
сического и байесовского подхода, интерпретируют /^-значение как
вероятность справедливости нулевой гипотезы. При этом делается вы-
вод, что в рамках классического подхода не существует прямой оценки
вероятности «несправедливости» нулевой гипотезы. Надо заметить, что
было ошибкой определять ^-значение как вероятность справедливос-
ти нулевой гипотезы, оцененную по полученным результатам иссле-
дования. В рамках классического подхода (по определению /ьзначе-
ния) обозначение наличия статистически значимого различия с по-
мощью записи р < 0,05 означает, что если бы нулевая гипотеза об
отсутствии различий была бы справедлива, то вероятность получить
наблюдаемые или еще более экстремальные различия была бы меньше
5%. Во-вторых, по мнению статистиков байесовского направления,
/^-значение не должно быть единственным и формальным критерием
для признания статистической значимости различий, поскольку изме-
нение объема выборки и мощности теста могут существенно влиять на
статистические выводы. В качестве компромиссного подхода для оцен-
ки значимости различий рассматривается метод доверительных ин-
тервалов, предоставляющий больше статистической информации, чем
единственное/^-значение [18, 19]. Статистики байесовской школы
предлагают при сравнении эффектов с помощью тестирования ста-
270
Глава 3. Некоторые вопросы, связанные с применением...
тистических гипотез основывать выводы не только на полученных в
данном исследовании результатах, а на всей имеющейся к данному
моменту информации, относящейся к рассматриваемой проблеме.
Байесовский подход к тестированию гипотез предполагает исполь-
зование так называемого байесовского фактора В, который в простей-
шем случае также называется отношением правдоподобия [3, 6, 8, 19]:
в_Щ"о) (146)
P(D\HA)
Можно сказать, что этот фактор измеряет «вероятность справед-
ливости обеих гипотез» на основе полученных данных, другими сло-
вами, он позволяет сравнить, насколько хорошо нулевая и альтерна-
тивная ей гипотезы согласуются с полученными данными. Тогда на
основе теоремы Байеса, выраженной в терминах «шансов», можно
записать следующее уравнение для нулевой гипотезы:
Априорные шансы Н0 х байесовский фактор =
= апостериорные шансы Н0.
Шансы (odds) содержат информацию, сходную с оценкой вероят-
ности, но выражают ее в другой форме. Шансы представляют отно-
шение вероятности того, что событие произойдет, к вероятности того,
что оно не произойдет. В нашем случае шансы нулевой гипотезы рав-
ны отношению вероятностей ее справедливости и вероятности спра-
ведливости противоположной ей альтернативной гипотезы. Таким
образом, апостериорные шансы нулевой гипотезы рассчитываются на
основе субъективной оценки ее априорных шансов и на основе ин-
формации, содержащейся в полученных данных, с помощью байесов-
ского фактора.
Вычисление байесовского фактора упрощается в предположении
о нормальном распределении. Правдоподобие гипотезы в случае на-
блюдаемого значения эффекта X пропорционально вероятности по-
явления этого значения Хпри справедливости данной гипотезы. Ве-
роятность появления значения Хв результате исследования при нор-
мальном распределении со средним значением \i и стандартным
отклонением о, задается формулой плотности вероятности:
Поскольку показатель экспоненты отрицательный, последнее вы-
ражение для вероятности достигает максимума при нулевом значе-
Глава 3. Некоторые вопросы, связанные с применением... 271
нии показателя экспоненты, то есть при равенстве наблюдаемого
эффекта А" среднему значению /*. Отношения правдоподобия для ну-
левой гипотезы \i = 0 против наиболее вероятной (соответствующей
реальным данным) гипотезы \i =Xзадает минимальное значение бай-
есовского фактора:
1 [-(*-0)21
D . Р(х\м = 0,<т) <7л/2^еХР1 2<т2 J
В mm = = р -f =
Р(х\м = хуа) 1 Г-(*-*)2]
aV2^eXPl 2(T2 J
где Z представляет число стандартных отклонений от нулевого эф-
фекта. Эту формулу используют для нахождения соотношения между
/^-значением при применении классического подхода к тестированию
гипотез и байесовским фактором. Допустим, результат сравнения
представляет собой 1,96 стандартного отклонения нулевого значения
разницы средних (соответствует/? = 0,05), тогда минимальный байе-
совский фактор при Z= 1,96 равен 0,15. А значит, справедливость ну-
левой гипотезы об отсутствии различий на 15% поддерживается по-
лученными данными по сравнению с гипотезой, наилучшим образом
соответствующей наблюдаемым данным, что, по мнению статисти-
ков данного направления, не такое сильное утверждение против спра-
ведливости нулевой гипотезы, как/? = 0,05 [18, 19]. Подробнее эти
вопросы рассмотрены в работах [6, 8, 18, 19].
Недостатком байесовского подхода, который является одной из
основных причин непрекращающихся споров в течение практически
70 лет среди статистиков классической и байесовской школы, счита-
ется возможный субъективизм в оценке априорных вероятностей. Чем
больше информации имеется к моменту проведения исследования об
изучаемой ситуации, тем «объективнее» и согласованнее будут апри-
орные оценки. Если информации недостаточно, априорные оценки
будут в большей степени зависеть от индивидуального суждения и
предпочтения. Кроме того, не для всех задач можно сформулировать
и оценить полное множество возможных моделей или полное мно-
жество гипотез. А в рамках байесовского подхода невозможно прий-
ти к статистическому заключению о справедливости гипотезы без
рассмотрения всех возможных альтернатив. Другим недостатком та-
кого подхода является необходимость применения достаточно слож-
ных вычислительных процедур, однако эта проблема постепенно ре-
шается в последние годы с помощью разработки все более совершен-
ного программного обеспечения для реализации статистических
-и
= expfz%},(148)
272 Глава 3. Некоторые вопросы, связанные с применением...
методов в рамках данного подхода. Все эти обстоятельства приводят
к тому, что байесовский подход не применяется в настоящее время
для решения всего спектра статистических задач в области анализа
результатов клинических исследований [16, 32], хотя в этой области
разработаны различные байесовские процедуры статистического ана-
лиза данных [9, 10, 12, 13, 15, 20, 34]. Можно сказать, что в случае
выборок большого объема статистические результаты классического
и байесовского подхода практически совпадают. Однако в случае вы-
борок малого объема, или если данных, полученных в исследовании,
недостаточно для применения классических методов статистики или
теории оптимизации, байесовский подход может предоставить опре-
деленные дополнительные возможности [3, 8, 13]. Так, в области кли-
нических исследований байесовский подход может успешно приме-
няться в случае последовательного плана исследования для форми-
рования правила остановки такой процедуры [8]; известна
байесовская процедура для проверки биоэквивалентности, хотя она
достаточно редко применяется на практике [28]. В клинической эпи-
демиологии байесовский подход применяется для оценки прогнос-
тической ценности теста. Математическая формула, связывающая
чувствительность, специфичность теста и распространенность забо-
левания (априорная вероятность выявления болезни до того, как ста-
нут известны результаты теста) с предсказательной ценностью поло-
жительного и отрицательного ответов, выводится непосредственно из
теоремы Байеса для условной вероятности [5, 26].
В последние годы в области фармакокинетических исследований
байесовский подход получил широкое распространение в рамках по-
пуляционного моделирования [13, 21—25, 27, 29—31, 33, 35, 36]. По-
пуляционное фармакокинетическое моделирование позволяет обоб-
щить клиническое и фармакокинетическое поведение лекарственно-
го препарата в организме и сохранить его в форме популяционной
модели с тем, чтобы в дальнейшем можно было сопоставлять фарма-
кокинетическое поведение препарата с клиническими эффектами или
с соответствующей фармакодинамической моделью. Мы уже говори-
ли, чем популяционный подход к изучению фармакокинетики отли-
чается от обычных фармакокинетических исследований. Последние
обычно проводятся на небольшом количестве испытуемых, чаще здо-
ровых добровольцах. Это небольшая и достаточно гомогенная группа
субъектов, поэтому такие исследования не отражают весь спектр воз-
можных вариаций индивидуальных фармакокинетических парамет-
ров изучаемого препарата. Однако с точки зрения анализа данных
Глава 3. Некоторые вопросы, связанные с применением...
273
такие исследования имеют преимущество, поскольку измерений уров-
ня концентрации препарата в тест-камере у каждого субъекта хватает
для получения достаточно точных оценок фармакокинетических па-
раметров. Популяционный подход к изучению фармакокинетики
обычно предполагает анализ данных терапевтического лекарственного
мониторинга, собранных у большого количества пациентов в реаль-
ных клинических условиях. В рамках такого подхода появляется воз-
можность изучения влияния на фармакокинетику таких демографи-
ческих и физиологических факторов, как пол, возраст, раса, курение,
состояние почечной и печеночной функций и т. д. Надо сказать, что
такое деление исследований достаточно условно, поскольку обычные
фармакокинетические исследования можно считать частным случа-
ем популяционных исследований и анализировать собранные в рам-
ках этих исследований данные с помощью методов популяционного
моделирования.
Как мы уже упоминали, существуют различные методы оценки
популяционных параметров для выбранной фармакокинетической
модели поведения лекарственного препарата. Однако с точки зрения
математики все эти методы предполагают измерение уровня препа-
рата в тест-камере у субъектов рассматриваемой популяции и иден-
тификацию параметров кинетической модели по полученной в резуль-
тате таких измерений информации. Последняя задача не является
специфической для данной области, методы решения задачи иденти-
фикации неизвестных параметров математической модели по имею-
щейся информации о значениях модельных переменных разработа-
ны в рамках теории оптимизации [1, 2]. Когда для изучения какого-
либо сложного явления разрабатывается математическая модель, к
оптимизации прибегают для того, чтобы определить такую структуру
и такие параметры модели, которые обеспечивали бы наилучшее со-
гласование с реальными данными. Постановка любой задачи опти-
мизации начинается с определения набора независимых переменных
и предварительной оценки диапазона их возможных значений. Эти
оценки включаются в задачу в форме ограничений. Еще одна обяза-
тельная компонента такой задачи — мера «качества», которая назы-
вается целевой функцией и зависит от неизвестных параметров мо-
дели (или переменных). Решением оптимизационной задачи являет-
ся приемлемый набор значений параметров, которому отвечает
оптимальное значение целевой функции при имеющихся ограниче-
ниях. В нашем случае в качестве целевой функции обычно выбирает-
ся мера приближения измеренных значений концентрации препара-
274
Глава 3. Некоторые вопросы, связанные с применением...
та к соответствующим модельным значениям концентрации, рассчи-
танная на основе взвешенного метода наименьших квадратов. Тогда
функционал качества приближения может быть записан в виде:
^ A (Cobs-Сmod(0))2
F = Y- )-^L- ->min, (149)
tT Var(Cobs) V '
где n — общее число всех измерений концентрации, Cobs — реально
измеренное значение концентрации, Cmod(Q) — соответствующее
значение концентрации, полученное на основе модели с параметра-
ми 6, Var(Cobs) — дисперсия наблюдаемой концентрации, в данном
случае используется в качестве веса.
Последняя формула означает, что мы хотели бы так подобрать зна-
чения фармакокинетических параметров модели 0, чтобы получае-
мые при этом модельные значения концентрации наилучшим обра-
зом «приближали» реально измеренные значения, другими слова-
ми, чтобы сумма квадратов отклонений реальных и модельных
значений концентрации была минимальной. Для решения данной
задачи разработаны различные оптимизационные процедуры [1, 2],
которые позволяют по имеющимся данным оценить оптимальный
набор фармакокинетических параметров модели. Однако данные
методы имеют ограничения, связанные с вопросами идентифици-
руемости, то есть с необходимостью наличия достаточного количе-
ства измерений для получения удовлетворительной оценки неизве-
стных параметров. Считается, что для решения подобной задачи
измерений должно быть не меньше числа идентифицируемых пара-
метров, а для повышения точности оценок число измерений жела-
тельно увеличить. Получается, что такой подход не применим, на-
пример в случае терапевтического лекарственного мониторинга,
когда у пациента измеряется не более 1—2 уровней концентрации
препарата в крови, а модель простейшей структуры содержит не ме-
нее 3 параметров.
Помочь в решении этой проблемы может применение байесовс-
кого подхода. Так, широко применяемый метод байесовского адап-
тивного управления [22, 23] состоит в привлечении, помимо обычно
используемой информации об измерениях концентрации у данного
субъекта, априорной информации об оценках средних значений по-
пуляционных параметров модели. Тогда байесовский функционал
качества приближения, впервые введенный в данные приложения
авторами [33], может быть записан в виде суммы двух компонент, одна
из которых по-прежнему задает «близость» к реальным измерениям,
Глава 3. Некоторые вопросы, связанные с применением...
275
а другая предлагает осуществлять поиск оптимальных значений мо-
дельных параметров вблизи их популяционных значений:
г = ^ (Cobs - С mod (в))2 { ^ (врор - в mod)2 ) min (15Q)
if Var(Cobs) fa Уаг(врор)
где к — число модельных параметров, Qpop — популяционные сред-
ние значения параметров модели, Qmod — оценки соответствующих
значений идентифицируемых параметров модели, Var(Q) — диспер-
сии популяционных параметров. Дополнение функционала качества
приближения новым членом на основе байесовского подхода приво-
дит к тому, что неизвестные параметры фармакокинетической моде-
ли удается идентифицировать даже по одному измерению концент-
рации у субъекта. Такой функционал качества приближения часто
используется в параметрических итерационных алгоритмах расчета
распределений значений фармакокинетических параметров популя-
ции. В этом случае на каждом шаге итераций значением Qpop счита-
ется его приближенная оценка, полученная на предыдущем шаге по
значениям Qmod, а начальное значение Qpop задается исследователем
на основе данных литературы или предварительных исследований.
Постепенно процесс поиска сходится к оптимальным значениям па-
раметров Qpop*, наилучшим образом соответствующим имеющимся
данным. Кроме того, байесовский функционал качества приближе-
ния обычно применяется также в процедурах идентификации инди-
видуальных фармакокинетических параметров пациента Qmod* при
решении задачи индивидуализации лекарственной терапии, когда
значения популяционных параметров Qpop уже определены [11, 21 23].
Байесовский подход к популяционному моделированию может
использоваться и в другой форме в алгоритмах построения совмест-
ной плотности распределения фармакокинетических параметров.
Например, такой подход реализован в методах оценки плотности рас-
пределения параметров популяционной модели, представленных в
работах [13, 24, 25, 27, 29—30, 36] и реализованных в программном
обеспечении. Независимо от конкретных математических деталей
алгоритмов, основная идея такого подхода основывается на модифи-
кации теоремы Байеса для непрерывного случая, когда множество всех
возможных моделей соответствует бесконечному множеству значений
модельных параметров. В этом случае, как и раньше, должна быть
задана априорная плотность распределения параметров модели p(Q).
После получения результатов измерений концентрации, или, други-
ми словами, данных D, исследователь на основе полученной инфор-
276 Глава 3. Некоторые вопросы, связанные с применением...
мации оценивает правдоподобие значений параметров при заданных
наблюдениях p(D\Q) и тем самым пересматривает свои первоначаль-
ные оценки, получая апостериорную совместную плотность распре-
деления интересующих модельных параметров p(Q\D). Обычно еще до
начала расчета плотностей распределения параметров исследователь
может приблизительно оценить диапазоны изменения этих парамет-
ров и, если нет никакой дополнительной априорной информации о
форме распределения, может считать их равномерно распределенны-
ми в выбранных диапазонах значений [3, 8].
Так, программа NPEM, входящая в состав пакета USC*PACK, стро-
ит совместное распределение параметров фармакокинетической мо-
дели на основе непараметрического метода максимизации правдопо-
добия имеющихся данных [31]. Такой метод также может работать в
случае, если у каждого субъекта измерено только одно значение кон-
центрации, однако с ростом числа измерений возрастает точность по-
лучаемых оценок. Распределения параметров модели представляют-
ся программой в виде двух- и трехмерных графиков (рис. 37). Видно,
что построение популяционных моделей с помощью этого метода по-
Рис. 37. Примеры двухмерной совместной (а) и маргинальных плотнос-
тей (б, в) распределения основных фармакокинетических параметров кар-
бамазепина, рассчитанных с помощью программы USC*PACK. а, б — на-
личие в рассматриваемой популяции подгрупп пациентов с «быстрым» и
«медленным» метаболизмом (параметр KI).
Глава 3. Некоторые вопросы, связанные с применением...
277
APPROXIMATE MARGINAL DENSITY
0,25
р
R
О
В
А
В
L
Т
I
0,20
0,15
0,10
0,05
0,00
Л_
0,25 Н
R 0,20
О
В
А 0,15 -\
В
I
L
I 0,10
Т
I
0,05
0,00
ь
JU
JLQI
0,2 0,5 0,7 0,9 0,12 0,14 0,17 0,19 0,21 0,24
KI
APPROXIMATE MARGINAL DENSITY
I П
П Ё
X
-п лПплЛ
0,2 0,39 0,59 0,79 0,98 1,18 1,38 1,58 1,77 1,97
КА
Окончание рис. 37.
зволяет анализировать и однородность изучаемой популяции с точки
зрения распределения фармакокинетических параметров, и выделять
подгруппы пациентов (если имеются) с отличающимися значениями
278 Глава 3. Некоторые вопросы, связанные с применением...
параметров. Так, например, в изучаемой популяции могут присутство-
вать подгруппы субъектов с быстрым и медленным метаболизмом
данного лекарственного препарата. Так, в случае нашей популяции
взрослых пациентов, постоянно получающих карбамазепин для ле-
чения эпилепсии, можно выделить подгруппы пациентов с быстрым
и медленным метаболизмом карбамазепина (рис. 37, в). Кроме того,
программа рассчитывает такие традиционные статистические харак-
теристики распределения, как среднее значение, дисперсия, вариа-
ция, парные корреляции, медиана, мода, коэффициенты асимметрии
и эксцесса, квантили и т. д. Рассчитанные статистические характери-
стики популяционных параметров модели могут использоваться в
дальнейшем для решения вопроса о биоэквивалентности препаратов,
оценки взаимовлияния лекарств, индивидуализации дозирования
препарата.
Понимание конкретных вычислительных алгоритмов для реали-
зации байесовского подхода к анализу данных потребовало бы от чи-
тателей дополнительной математической подготовки. При желании
с ними можно познакомиться в специальной литературе, поэтому мы
затронули лишь основные положения такого подхода. Мы показали,
что наряду с известным классическим статистическим подходом к
анализу данных в статистике существует еще и байесовский подход.
Основные расхождения между этими направлениями касаются интер-
претации самого понятия вероятности: статистики байесовской шко-
лы рассматривают вероятность как «степень доверия», статистики
классической школы единственно возможным считают частотную
интерпретацию вероятности. Если мы считаем, что вероятность есть
мера наших сомнений, то тогда естественно полагать априорные ве-
роятности одинаковыми, когда относительно них нам ничего не из-
вестно, поскольку все предположения одинаково сомнительны. Час-
тотная теория при применении теоремы Байеса требует, чтобы собы-
тия, отвечающие различным вероятностным моделям, были
равновероятны в генеральной совокупности. Таким образом, приме-
нение байесовского подхода к анализу данных требует выражения всех
видов априорных суждений в виде вероятностей независимо от су-
ществования частотной интерпретации этих вероятностей [3]. Дру-
гие различия касаются отношения к источникам информации и под-
хода к интерпретации результатов. Однако, хотя философски и кон-
цептуально байесовский подход сильно отличается от стандартного,
на практике результаты, полученные с помощью этих подходов, дос-
таточно часто хорошо согласуются. Можно сказать, что это во мно-
Глава 3. Некоторые вопросы, связанные с применением...
279
гом определяется количеством информации, содержащимся в реаль-
ных данных. Так, если априорные представления определены недо-
статочно четко по сравнению с информацией, содержащейся в дан-
ных, результаты обоих подходов окажутся сходными, и субъективные
априорные оценки не будут вносить существенный вклад. Наоборот,
если полученных данных недостаточно, априорная информация на-
чинает играть важную роль и влиять на получаемые результаты [3, 8].
В настоящее время имеется так много разногласий по этим вопро-
сам, что ни одну из точек зрения нельзя считать общепринятой. При
этом в обычной жизни нам постоянно приходится интуитивно оце-
нивать степень верности гипотез на основе имеющихся данных.
Литература к 3 главе
1. Васильев Ф.П. Численные методы решения экстремальных задач. —
М.: Наука, 1988.
2. Гилл Ф., Мюррей У., Райт М. Практическая оптимизация. — М.: Мир,
1985.
3. Справочник по прикладной статистике / Под ред. Э. Ллойда, У. Ле-
дермана. — М.: Финансы и статистика, 1989.
4. Справочник по теории вероятностей и математической статистике /
Под ред. B.C. Королюка и др. — М.: Наука, 1985.
5. Флетчер Р., Флетчер С, Вагнер Э. Клиническая эпидемиология. Ос-
новы доказательной медицины. — М.: Медиа сфера, 1998.
6. Чернов Г., Мозес Л. Элементарная теория статистических решений //
Советское радио. — М., 1962.
7. Bayes Т. An essay toward solving a problem in the doctrine of chances //
Philos. Trans. R. Soc. - 1783. - Vol. 53. - P. 370-418.
8. Berger J.O. Statistical Decision Theory and Bayesian Analysis: Springer
Series in Statistics. — 2nd ed. — N.Y.: Springer-Verlag, 1985.
9. Berry D.A. Interim analyses in clinical trials: classical vs. Bayesian approaches
// Stat. Med. - 1985. - Vol. 4. - P. 521-526.
10. Berry D.A. Decision analysis and Bayesian methods in clinical trials //
Cancer Treat. Res. - 1995. - Vol. 75. - P. 125-154.
11. Burton M.E., Brother D.C., Chen PS. et al. A Bayesian feedback method for
aminoglycoside dosing // Clin. Pharmacol. Then — 1985. — Vol. 37. — P. 349—357.
12. Carlin C, Louis T. Bayes and empirical Bayes methods for data analysis. —
Lond.: Charman and Hall, 1996.
13. Davidian M., Giltinan D.M. Nonlinear Models for Repeated Measurement
Data. — Lond.: Charman and Hall, 1995.
14. Edwards A.W.F. The history of likelihood // Int. Stat. Rev. - 1974. - Vol.
42. - P. 9-15.
280
Глава 3. Некоторые вопросы, связанные с применением...
15. Etzioni R.D., Kadane J.В. Bayesian statistical methods in public health and
medicine //Ann. Rev. Public Health. - 1995. - Vol. 16. - P. 23-41.
16. Evidence based medicine working group. Evidence based medicine: a new
approach to teaching the practice of medicine // JAMA. — 1992. — Vol. 268. — P.
2420-2425.
17. Fisher L.D. Comments on Bayesian and frequentist analysis and
interpretation of clinical trials // Control. Clin. Trials. — 1996. — Vol. 17. — P.
423-434.
18. Goodman S.N. Toward evidence-based medical statistics. 1. The p-value
fallacy//Ann. Intern. Med. - 1999. - Vol. 130, N 12. - P. 995-1004.
19. Goodman S.N. Toward evidence-based medical statistics. 2. The Bayes factor
//Ibid.-P. 1005-1013.
20. Hughes M.D. Reporting Bayesian analyses of clinical trials // Stat. Med. —
1993. - Vol. 12. - P. 1651-1664.
21. Hurst A., Yoshinaga M., Mitani G. et al. Application of Bayesian method to
monitor and adjust vancomycin dosage regimens // Antimicrob. Agents Chemother.
- 1990. - Vol. 34. - P. 165-171.
22. Jelliffe R.W., Schumitzky A., Bayard D. et al. Adaptive Control of Drag
Dosage Regimens: An Overview of Basic Concepts, Relevant Issues, and Some
Clinical Applications: Technical Report 94-1. University of Southern California
School of Medicine, Laboratory of Applied Pharmacokinetics, 1994.
23. Jelliffe R. W., Schumitzky A., Van Guilder M. etal. Individualising drug dosage
regimens: roles of population pharmacokinetics and dynamic models, Bayesian fitting
and adaptive control // Ther. Drug Monit. — 1993. — Vol. 15. — P. 380-393.
24. Katz D., D'Argenio D.Z. Discrete approximation of multivariate densities
with application to Bayesian estimation // Comput. Stat. Data Anal. — 1984. —
Vol. 2. - P. 27-36.
25. Katz D., Azen S.P., Schumitzky A. Bayesian approach to analysis of nonlinear
models: implementation and evaluation // Biometrics. — 1981. — Vol. 37. — P.
137-142.
26. Knapp R.G., Miller M.C. Clinical Epidemiology and Biostatistics: The
National Medical Series for Independent Study. — Baltimore. Williams and Wilkins,
1998.
27. Mallei A., Mentre F., SteimerJ.L. etal. Nonparametric maximum likelihood
estimation for population pharmacokinetics with application to cyclosporine // J.
Pharmacokinet. Biopharm. — 1988. — Vol. 16. — P. 311-327.
28. Mandallaz D.t Май J. Comparison of different methods for decision making
in bioequivalence assessment // Biometrics. — 1981. — Vol. 37. — P. 213—222.
29. Merle Y, Mentre F. Stochastic optimization algorithms of a Bayesian design
criterion for Bayesian parameter estimation of nonlinear regression models:
application in pharmacokinetics // Math. Biosci. — 1997. — Vol. 144. — P. 45-70.
30. Rosner G.L.y Muller P. Bayesian population pharmacokinetic and
pharmacodynamic analyses using mixture models // J. Pharmacokinet. Biopharm.
- 1997. - Vol. 25, N 2. - P. 209-233.
Глава 3. Некоторые вопросы, связанные с применением...
281
31. Schumitzky Л. Nonparametric EM algorithms for estimating prior
distributions // Appl. Math. Comput. — 1991. — Vol. 45. — P. 143-157.
32. Senn S. Statistical Issues in Drug Development. — N.Y.: John Wiley and
Sons, 1997.
33. Sheiner L.B., Beat S.L., Rosenberg В., Marathe V.V. Forecasting individual
pharmacokinetics // Clin. Pharmacol. Ther. — 1979. — Vol. 26. — P. 294-305.
34. Spiegelhalter D., Freedman L.y Palmar M. Bayesian approaches to
randomized trials // J. R. Stat. Soc. A. - 1994. - Vol. 157. - P. 357-387.
35. Taright N., Mentre F., Mallet A., Jouvent R. Nonparametric estimation of
population characteristics of the kinetics of lithium from observational and
experimental data: individualization of chronic dosing regimen using a new Bayesian
approach // Ther. Drug Monk. — 1994. — Vol. 16. — P. 258-269.
36. Wakefield J., Walker S. Bayesian nonparametric population models:
formulation and comparison with likelihood approaches // J. Pharmacokinet.
Biopharm. - 1997. - Vol. 25, N 2. - P. 235-253.
Заключение
В книге рассмотрены методы планирования и статистического
анализа результатов клинических исследований. Авторы не просто
привели набор обычно применяемых формул, но и целостно пред-
ставили роль математики в подготовке и проведении таких исследо-
ваний. Для успешного решения математических задач, возникающих
в клинической практике, специалист должен ориентироваться в ма-
тематическом моделировании, методах прикладной статистики, а так-
же в имеющемся программном обеспечении. В этой книге были час-
тично рассмотрены две первые проблемы и сознательно не акценти-
ровалось внимание читателей на конкретных пакетах компьютерных
программ для проведения статистических расчетов. Бурное развитие
вычислительной техники приводит к совершенствованию имеющих-
ся и появлению новых прикладных программ для статистического
анализа данных. Многие математические модели и методы анализа
данных постепенно переходят из теоретических в разряд рутинно при-
меняемых. Поэтому авторы старались использовать базовые опреде-
ления и методы, понимание которых позволит разобраться в меню
имеющихся компьютерных программ, выбрать подходящие процеду-
ры и грамотно их использовать. Скажем только, что официально при-
знанным для анализа данных клинических исследований является
пакет статистических прикладных программ SAS.
Главная цель, которую ставили перед собой авторы, — системати-
ческое изложение участия математической статистики на различных
этапах клинических исследований: от разработки дизайна до форми-
рования заключения о результатах. В книге сознательно не приведе-
ны официальные правила или требования, хотя они сформулирова-
ны специально для статистического анализа применительно к кли-
ническим исследованиям. Так, например, в 1998 г. Международный
конгресс по гармонизации GCP сформулировал и опубликовал «Ста-
тистические принципы для клинических исследований» (ICH Guide-
lines // Good Clin. Pract. J. 1998. Vol. 5. № 4. P. 27-37), которые со-
держат основные методологические требования к применяемым ста-
тистическим методам и подходам. Все основные положения этих
Заключение
283
требований в той или иной форме были рассмотрены авторами в этой
книге. Они касаются вопросов правильного выбора переменных для
оценки эффекта в каждом конкретном случае, методов рандомиза-
ции групп и слепоты исследования, конкретных конфигураций ди-
зайна, типов сравнений (для демонстрации преимущества или экви-
валентности) и тестов для их проведения. Также имеются разделы,
посвященные вопросам проведения фармакокинетических, фармако-
динамических и популяционных исследований. Многократно встре-
чаются в этих требованиях предупреждения о необходимости учета
множественных сравнений. Большое внимание уделяется вопросам
определения необходимого объема выборки и оценки мощности при-
меняемых статистических методов. Подчеркивается, что все приме-
няемые в конкретном случае статистические методы для таких оце-
нок должны быть обязательно указаны в протоколе исследования
вместе с оценками. Читателям книги все эти проблемы должны пока-
заться знакомыми.
Авторы старались избежать излишней математизации текста — для
его понимания не требуются специальные математические знания.
Надеемся, что читателями этой книги станут самые разные специа-
листы, работающие в области медико-биологических исследований.
А для тех читателей, которые пожелают узнать о рассмотренных воп-
росах больше, предложен список специальной литературы по каждо-
му разделу.
Приложения
Таблица 1.
Критические точки двустороннего /-критерия Стьюдента
Мюллер П., Нойман Я., Шторм Р. Таблицы по математической статисти-
ке. — М.: «Финансы и статистика», 1982
Число
степе-
ней
свободы
/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
а, %
5
12,71
4,30
3,18
2,78
2,57
2,45
2,37
2,31
2,26
2,23
2,20
2,18
2,16
2,14
2,13
2,12
2,11
1
63,66
9,92
5,84
4,60
4,03
3,71
3,50
3,36
3,25
3,17
3,11
3,05
3,01
2,98
2,95
2,92
2,90
0,1
64,60
31,60
12,92
8,61
6,87
5,96
5,41
5,04
4,78
4,59
4,44
4,32
4,22
4,14
4,07
4,02
3,97
Число
степе-
ней
свободы
/
18
19
20
21
22
23
24
25
26
27
28
29
30
40
60
120
оо
а, %
5
2,10
2,09
2,09
2,08
2,07
2,07
2,06
2,06
2,06
2,05
2,05
2,05
2,04
2,02
2,00
1,98
1,96
1
2,88
2,86
2,85
2,83
2,82
2,81
2,80
2,79
2,78
2,77
2,76
2,76
2,75
2,70
2,66
2,62
2,58
0,1
3,92
3,88
3,85
3,82
3,79
3,77
3,75
3,73
3,71
3,69
3,67
3,66
3,65
3,55
3,46
3,37
3,29
Приложения
285
Таблица 2.
Критические значения критерия согласия х2
Справочник по прикладной статистике / Под ред. Э. Ллойда, У. Ледер-
мана. — М.: «Финансы и статистика», 1989
Уровень значимости а
/ 1
1 1
2 |
з 1
4 |
5 1
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
0,5 1
0,455
1,386 |
2,366
3,357
4,351
5,348
6,346
7,344
8,343
9,342
10,341
11,340
12,340
13,339
14,339
15,338
16,338
17,338
18,338
19,337
20,337
21,337
22,337
23,337
0,25 1
1,323
2,773 |
4,108 |
5,385
6,626
7,841
9,037
10,219
11,389
12,549
13,701
14,845
15,984
17,117
18,245
19,369
20,489
21,605
22,718
23,828
24,935
26,039
27,141
28,241
0,10 1
2,706
4,605 |
6,251 |
7,779 |
9,236
10,645
12,017
13,362
14,684
15,987
17,275
18,549
19,812
21,064
22,307
23,542
24,769
25,989
27,204
28,412
29,615
30,813
32,007
33,196
0,05 1
3,841
5,991
7,815
9,488
11,070
12,592
14,067
15,507
16,919
18,307
19,675
21,026
22,362
23,685
24,996
26,296
27,587
28,869
30,144
31,410
32,671
33,924
35,172
36,415
0,025 1
5,024
7,378 |
9,348
11,143
12,833
14,449
16,013
17,535
19,023
20,483
21,920
23,337
24,736
26,119
27,488
28,845
30,191
31,526
32,852
34,170
35,479
36,781
38,076
39,364
0,01
6,635
9,210
11,345
13,277
15,086
16,812
18,475
20,090
21,666
23,209
24,725
26,217
27,688
29,141
30,578
32,000
33,409
34,805
36,191
37,566
38,932
40,289
41,638
42,980
0,005
7,879
10,597
12,838
14,860
16,750
18,548
20,278
21,955
23,589
25,188
26,757
28,300
29,819
31,319
32,801
34,267
35,718
37,156
38,582
39,997
41,401
42,796
44,181
45,559
i .
0,001
10,828
13,816
16,266
18,467
20,515
22,458
24,322
26,124
27,877
29,588
31,264
32,909
34,528
36,123
37,697
39,252
40,790
42,312
43,820
45,315
46,797
48,268
49,728
51,179
286
Приложения
Продолжение табл. 2
Уровень значимости а
f
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
0,5
24,337
25,336
26,336
27,336
28,336
29,336
30,336
31,336
32,336
33,336
34,336
35,336
36,336
37,335
38,335
39,335
40,335
41,335
42,335
43,335
44,335
45,335
46,335
47,335
48,335
49,335
0,25
29,339
30,435
31,528
32,020
33,711
34,800
35,887
36,973
38,058
39,141
40,223
41,304
42,383
43,462
44,539
45,616
46,692
47,766
48,840
49,913
50,985
52,056
53,127
54,196
55,265
56,334
0,10
34,382
35,563
36,741
37,916
39,087
40,256
41,422
42,585
43,745
44,903
46,059
47,212
48,363
49,513
50,660
51,805
52,949
54,090
55,230
56,369
57,505
58,641
59,774
60,907
62,038
63,167
0,05
37,652
38,885
40,113
41,337
42,557
43,773
44,985
46,194
47,400
48,602
49,802
50,998
52,192
53,384
54,572
55,758
56,942
58,124
59,304
60,481
61,656
62,830
64,001
65,171
66,339
67,505
0,025
40,646
41,923
43,195
44,461
45,722
46,979
48,232
49,480
50,725
51,966
53,203
54,437
55,668
56,896
58,120
59,342
60,561
61,777
62,990
64,201
65,410
66,617
67,821
69,023
70,222
71,420
0,01
44,314
45,642
46,963
48,278
49,588
50,892
52,191
53,486
54,776
56,061
57,342
58,619
59,893
61,162
62,428
63,691
64,950
66,206
67,459
68,710
69,957
71,201
72,443
73,683
74,919
76,154
0,005
46,928
48,290
49,645
50,993
52,336
53,672
55,003
56,328
57,648
58,964
60,275
61,581
62,883
64,181
65,476
66,766
68,053
69,336
70,616
71,893
73,166
74,437
75,704
76,969
78,231
79,490
0,001
52,620
54,052
55,476
56,892
58,301
59,703
61,098
62,487
63,870
65,247
66,619
67,985
69,346
70,703
72,055
73,402
74,745
76,084
77,419
78,750
80,077
81,400
82,720
84,037
85,351
86,661
Приложения
287
Таблица 3.1.
Критические значения статистики /; для проверки сомнительных вари-
антов по ранжированному ряду
Мюллер П., Нойман П., Шторм Р. Таблицы по математической статисти-
ке. — М.: «Финансы и статистика», 1982
п
4
5
6
7
8
9
10
11
12
Уровни
значимости
а, %
5
0,76
0,64
0,56
0,31
0,47
0,44
0,41
0,39
0,38
1
0,89
0,78
0,70
0,64
0,59
0,54
0,53
0,50
0,48
п
13
14
15
16
17
18
19
20
21
Уровни
значимости
а, %
5
0,36
0,35
0,34
0,33
0,32
0,31
0,31
0,30
0,30
1
0,46
0,45
0,44
0,43
0,42
0,41
0,40
0,39
0,38
п
22
23
24
25
26
27
28
29
30
Уровни
значимости
а, %
5
0,29
0,28
0,28
0,28
0,27
0,27
0,27
0,26
0,26
1
0,38
0,37
0,37
0,36
0,36
0,35
0,35
0,34
0,34
Таблица 3.2.
Критические значения статистики t2 для проверки сомнительных вари-
антов по ранжированному ряду
п
4
5
6
7
8
9
10
11
12
Уровни
значимости
«, %
5
0,96
0,81
0,69
0,61
0,55
0,51
0,48
0,45
0,43
1
0,99
0,92
0,80
0,74
0,68
0,64
0,60
0,57
0,54
п
13
14
15
16
17
18
19
20
21
Уровни
значимости
а, %
5
0,41
0,40
0,38
0,37
0,36
0,35
0,34
0,33
0,33
1
0,52
0,50
0,49
0,47
0,46
0,45
0,44
0,43
0,42
п
22
23
24
25
26
27
28
29
30
Уровни
значимости
а, %
5
0,32
0,31
0,31
0,30
0,30
0,30
0,29
0,29
0,28
1
0,41
0,41
0,40
0,39
0,39
0,38
0,38
0,37
0,37
288
Приложения
Таблица 4.
Критические значения статистики парного Г-критерия Уилкоксона
Лакин Г.Ф. Биометрия. — М.: «Высшая школа», 1990
Число
парных
наблю-
дений
п
Уровни
значимости
а, %
5
1
Число
парных
наблю-
дений
п
Уровни
значимости
а, %
5
1
Односторонний критерий
5
6
7
8
9
10
И
12
13
0
2
3
5
8
10
13
17
21
—
0
0
1
3
5
7
10
12
14
15
16
17
18
19
20
21
22
25
30
35
41
47
53
60
67
74
16
19
23
28
33
38
42
50
56
Двусторонний критерий
6
7
8
9
10
11
12
13
14
15
1
3
5
7
9
12
15
18
22
26
—
—
1
3
4
6
8
И
14
17
16
17
18
19
20
21
22
23
24
25
31
36
41
47
53
60
67
74
82
90
21
24
29
33
39
44
50
56
62
69
Примечание. Для п > 25 критические точки tst Г-критерия можно опреде-
лить по следующей формуле [9, глава 1]:
п± + Ъ Мя + 1)-(2я + 1)
4 V 24
где п — число парных наблюдений, / — предельные значения критерия
Стьюдента, зависящие от уровня значимости а.
Приложения
289
о"
S
а
н
S
а
«
s
о
о
н
о
о
X
О
кГ
о
CN
On
00
г-
ЧО
%п
<*•
СП
CN
ц
о
os
00
i^
Ко
•о
sf
1 sT
Г) rf <Л
о чо
»Г> ^ ^н
^ о —«
Tf ON ~
СП
Tf 00 -н
CN
СП Г- —«
СП ЧО -^
о
CN ЧО ^н
fS «Л 0\
(N >Л ОО
— Tt I**
*-н СП ЧО
»н Г) 1П
О М Tf
О -н СП
О н (S
О О ~н
m ^- <л
чо
CN
О
CN
ON
ОО
чо
ю
^
CN
-
ON
ОО
г^
чо
тГ
СП
чо
г-*
ОО
CN
ЧО
CN
т*
CN
СП
CN
CN
ON
ОО
ЧО
■*■
CN
-
ON
t^
чо
t^
ОО
СП
CN
СП
о
СП
ОО
CN
чо
CN
CN
(N
CN
О
CN
r^
«л
СП
=
ON
00
ON
О
00
СП
чо
СП
СП
СП
СП
ОО
CN
CN
СП
CN
CN
ON
ЧО
Tj-
ON
О
т*
^-
ОО
СП
чо
СП
СП
СП
О
СП
CN
CN
CN
CN
ON
О
_
СП
ir>
о
T*
Tt
СП
Tl-
СП
СП
ОО
CN
<N
^H
CNcnTj->n40t*^000NO
О t^ tJ-
©t^CHOt^Tt©©^
ЧОЧОГ^ОООООЛ'-н^н^н
4OcnON»nCN00Tt©
ЮЧОЧОГ^ООООО\1-н
СП ON U"> © ЧО CN OO
m «л чо t^ r^ oo oo
0\ Ю О чО ^ ^
^- m чо чо r- r-
^O н \o н \0
^- »n ю чо чо
CN Г^ ^ ЧО
Tf rf 1Л »Л
00 СП t—
П Tt Tf
Ю ON
СП СП
СП
CNcnTJ-U^4Ot^00ON©
290
Приложения
с*
б:
сч
on
оо
г-
Ч©
»Л>
^
СО
CN
=
о
ON
00
Г*-
чо
in
^
сп
^~
с:
О ^ <N СП Tf »П ЧО
о
ЧО
(N ЧО О
rf rfr »Л>
•^- 00 <N ЧО
ГО СП Tf Tf
СП -ч Tf 1^ —«
<N со го го г*
^ ^ t^ О го чо
fN fN fN ГО ГО ГО
ЧО On ^ тг чо ON ^
—« ^ fN fN CN fN ГО
—<f040000fN«nr^
pH^H^^(N(Nf4(N
^-н СО «П Г** 00 О fN
О fN fO in ЧО 00
О *-* fN ГО
O — ^fNrOTf«OVOr^r^OOON
OOO^^fNfNrOTtrJ-«ri»0
OOOOOOO^^^fNfN
О «—• fN fO Tt >Л VO
f-
О
ЧО
О
ЧО
«о
ON
ON
CO
ГО
ON
fN
4*
fN
ON
in
О
ЧО
fN
Г^
00
in
о
ON
ГО
in
r-
**
fN
<*-
CO
CO
ЧО
fN
fN
ЧО
-
ЧО
fN
oo
ON
CO
ON
00
00
uo
ON
ЧО
CO
ЧО
in
in
in
ON
CO
CO
00
fN
fN
fN
r-
fN
r^
CO
ON
О
fN
in
О
ON
ON
fN
ON
ЧО
00
ON
CO
ЧО
о
чо
in
oo
fN
ЧО
CO
О
CO
fN
OO
CO
OO
CO
О
fN
fN
fN
in
О
00
ON
ON
OO
00
r^
-4-
ЧО
00
in
in
41-
-4-
oo
CO
fN
CO
in
fN
ON
^*
00
ГО
fN
fN
fN
00
-
o
ON
ON
OO
fN
OO
in
oo
ЧО
4©
in
о
-4-
ГО
fN
fN
ТГ
ON
^
fN
fN
ГО
fN
in
fN
r^
ON
О
fN
О
ON
00
ON
fN
ЧО
in
о
in
CO
ЧО
CO
ON
fN
fN
fN
in
ON
Tl-
CO
fN
^1* «n
fN fN
~ 00
CO CO
CO ON
fN fN
in ~
~ fN
Г*- CO
О ~
ON О
ON —i
*-* чо
ON ON
CO 00
00 OO
ЧО ON
OO *-<
ЧО Г-
О CO
ЧО чо
fN in
in in
in r^
t- ON
CO CO
О CN
CO CO
CO Tf
fN fN
ЧО Г-
О О
^ «n
Tf in
fN fN
Приложения
291
Таблица 6.
Таблица угловой трансформации <р = 2arcsinJp
Двойрин В.В., Клименков А.А. Методика контролируемых клинических
испытаний. — М.: «Медицина», 1985
р
0
1
2
3
4
5
6
7
8
9
0
0,000
0,644
0,927
1,159
1,369
1,571
1,772
1,982
2,214
2,494
1
0,200
0,676
0,952
1,182
1,390
1,591
1,793
2,004
2,240
2,532
i
2
0,284
0,707
0,976
1,203
1,410
1,611
1,813
2,026
2,265
2,568
3
0,348
0,738
1,000
1,224
1,430
1,631
1,834
2,049
2,292
2,606
4
0,403
0,767
1,024
1,245
1,451
1,651
1,855
2,071
2,319
2,647
5
0,451
0,795
1,047
1,266
1,471
1,671
1,875
2,094
2,346
2,691
6
0,495
0,823
1,070
1,287
1,491
1,691
1,897
2,118
2,375
2,739
7
0,536
0,850
1,093
1,308
1,511
1,711
1,918
2,141
2,404
2,793
8
0,547
0,876
1,115
1,328
1,531
1,731
1,939
2,165
2,434
2,858
9
0,609
0,902
1,137
1,349
1,551
1,752
1,961
2,190
2,465
2,941
Таблица 7.
Критические значения Z стандартного нормального распределения
Уровень
значимо-
сти а
Односто-
ронний
тест
Двусто-
ронний
тест
0,005
2,567
2,807
0,01
2,326
2,576
0,012
2,257
2,513
0,02
2,054
2,326
0,025
1,960
2,242
0,05
1,645
1,960
0,1
1,282
1,645
0,2
0,842
1,282
292
Приложения
Таблица 8.
Значение /'-критерия Фишера при уровнях значимости а =5% (верхняя
строка) и а = 1% (нижняя строка)
Лакин Г.Ф. Биометрия. — М.: «Высшая школа», 1990
К
~\
2
3
4
5
6
7
8
9
10
И
12
13
14
15
1 |
~7б1
4052
18,51
98,50
10,13
34,12
7,71
21,20
6,61
16,26
5,99
13,75
5,59
12,25
5,32
11,26
5,12
10,56
4,96
10,04
4,84
9,65
4,75
9,33
4,67
9,07
4,60
8,86
4,54
8,68
к, — степень свободы для большей дисперсии
2 |
~200
4999
19,00
99,00
9,55
30,82
6,94
18,00
5,79
13,27
5,14
10,92
4,74
9,55
4,46
8,65
4,26
8,02
4,10
7,56
3,98
7,21
3,80
6,93
3,80
6,70
3,74
6,51
3,68
6,36
з 1
~2~L6
5403
19,16
99,17
9,28
29,16
6,59
16,89
5,41
12,06
4,76
9,78
4,35
8,47
4,07
7,59
3,86
6,99
3,71
6,55
3,59
6,22
3,49
5,95
3,41
5,74
3,34
556
3,29
5,42
4 |
~225
5625
19,25
99,25
9,12
28,71
6,39
15,98
5,19
11,39
4,53
9,15
4,12
7,85
3,84
7,01
3,63
6,42
3,48
5,99
3,36
5,67
3,26
5,41
3,18
5,21
3,11
5,04
3,06
4,89
5 |
~230
5764
19,30
99,30
9,01
28,42
6,26
15,52
5,05
10,97
4,39
8,75
3,97
7,46
3,69
6,63
3,48
6,06
3,33
5,64
3,20
5,32
3,11
5,06
3,02
4,86
2,96
4,69
2,90
4,56
6 1
"234
5859
19,33
99,33
8,94
27,91
6,16
15,21
4,95
10,67
4,28
8,47
3,87
7,19
3,58
6,37
3,37
5,80
3,22
5,39
3,09
5,07
3,00
4,82
2,92
4,62
2,85
4,46
2,79
14,32
7 |
~237
5928
19,35
99,36
8,89
27,67
6,04
14,98
4,88
10,46
4,21
8,26
3,79
6,99
3,50
6,18
3,29
5,61
3,14
5,20
3,01
4,89
2,91
4,64
2,83
4,44
2,76
4,28
2,71
4,14
8
239
5982
19,37
99,37
8,85
27,49
6,00
14,80
4,82
10,29
4,15
8,10
3,73
6,84
3,44
6,03
3,23
5,47
3,07
5,06
2,95
4,74
2,85
4,50
2,77
4,30
2,70
4,14
2,64
4,00
Приложения
293
Продолжение табл. 8
к'
~7б
17
18
19
20
21
22
23
24
25
26
27
28
29
30
32
1 |
~М9
8,53
4,45
8,40
4,41
8,29
4,38
8,18
4,35
8,10
4,32
8,02
4,30
7,95
4,28
7,88
4,26
7,82
4,24
7,77
4,22
7,72
4,21
7,68
4,20
7,64
4,18
j 7,60
4,17
7,56
4,15
7,50
кj — степень с
2
1^63
6,23
3,59
6,11
3,55
6,01
3,52
5,93
3,49
5,85
3,47
5,78
3,44
5,72
3,42
5,66
3,40
5,61
3,39
5,57
3,37
5,53
3,35
5,49
3,34
5,45
3,33
5,42
3,32
5,39
3,29
5,34
3
3,24
5,29
3,20
5,18
3,16
5,09
3,13
5,01
3,10
4,94
3,07
4,87
3,05
4,82
3,03
4,76
3,01
4,72
2,99
4,68
2,98
4,64
2,96
4,60
2,95
4,57
2,93
4,54
2,92
4,51
2,90
4,46
вободы для большей дисперсии
4 |
"ш
4,77
2,96
4,67
2,93
4,58
2,90
4,50
2,87
4,43
2,84
4,37
2,82
4,31
2,80
4,26
2,78
4,22
2,76
4,18
2,74
4,14
2,73
4,11
2,71
4,07
2,70
4,04
2,69
4,02
2,67
3,97
5 |
~2^85
4,44
2,81
4,34
2,77
4,25
2,74
4,17
2,71
4,10
2,68
4,04
2,66
3,99
2,64
3,94
2,62
3,90
2,60
3,85
2,59
3,82
2,57
3,78
2,56
3,75
2,55
3,73
2,53
3,70
2,51
3,65
6 1
7/74
4,20
2,70
3,93
2,66
4,01
2,63
3,94
2,60
3,87
2,57
3,81
2,55
3,76
2,53
3,71
2,51
3,67
2,49
3,63
2,47
3,59
2,46
3,56
2,45
3,53
2,43
3,50
2,42
3,47
2,40
3,43
7 |
~2№
4,03
2,61
3,79
2,58
3,84
2,54
3,77
2,51
3,70
2,49
3,64
2,46
3,59
2,44
3,54
2,42
3,50
2,40
3,46
2,39
3,42
2,37
3,39
2,36
3,36
2,35
3,33
2,33
3,30
2,31
3,25
8
2,59
3,89
2,55
3,68
2,51
3,71
2,48
3,61
2,45
3,56
2,42
3,51
2,40
3,45
2,37
3,41
2,36
3,36
2,34
3,32
2,32
3,29
2,31
3,26
2,29
3,23
2,28
3,20
2,27
3,17
2,24
3,13
Приложения
Продолжение табл. 8
к*
34
36
38
40
42
44
46
48
50
60
70
80
100
150
200
оо
1
~4ЛЗ
7,44
4,И
7,40
4,10
7,35
4,08
7,31
4,07
7,28
4,06
7,25
4,05
7,22
4,04
7,20
4,03
7,17
4,00
7,08
3,98
7,01
3,96
6,96
3,94
6,90
3,90
6,81
3,89
6,76
3,64
6,63
к{ — степень с
2
3,28
5,29
3,26
5,25
3,24
5,21
3,23
5,18
3,22
5,15
3,21
5,12
3,20
5,10
3,19
5,08
3,18
5,06
3,15
4,98
3,13
4,92
3,11
4,88
3,09
4,82
3,06
4,75
3,04
4,71
3,00
4,61
3
2,88
4,42
2,87
4,38
2,85
4,34
2,84
4,31
2,83
4,29
2,82
4,26
2,81
4,24
2,80
4,22
2,79
4,20
2,76
4,13
2,74
4,08
2,72
4,04
2,70
3,98
2,66
3,92
1 2,65
3,88
2,60
3,78
вободы для большей дисперсии
4
2,65
3,93
2,63
3,89
2,62
3,86
2,61
3,85
2,59
3,80
2,58
3,78
2,57
3,76
2,57
3,74
2,56
3,72
2,53
3,63
2,50
3,60
2,49
3,56
2,46
3,51
2,43
3,45
2,42
3,41
2,37
3,32
5
~М9
3,61
2,48
3,57
2,46
3,54
2,45
3,51
2,44
3,49
2,43
3,47
2,42
3,44
2,41
3,43
2,40
3,41
2,37
3,34
2,35
3,29
2,33
3,26
2,31
3,21
2,27
3,14
2,26
3,11
2,21
3,02
6
2,38
3,39
2,36
3,35
2,35
3,32
2,34
3,29
2,32
3,27
2,31
3,24
2,30
3,22
2,30
3,20
2,29
3,19
2,25
3,12
2,23
3,07
2,21
3,04
2,19
2,99
2,16
2,92
2,14
2,89
2,10
2,80
7
2,29
3,22
2,28
3,18
2,26
3,15
2,25
3,12
2,24
3,10
2,23
3,08
2,22
3,06
2,21
3,04
2,20
3,02
2,17
2,95
2,14
2,91
2,13
2,87
2,10
2,82
2,07
2,76
2,06
2,73
2,01
2,64
8
2,23
3,09
2,21
3,05
2,19
3,02
2,18
2,99
2,17
2,97
2,16
2,95
2,15
2,93
2,14
2,91
2,13
2,89
2,10
2,82
2,07
2,78
2,06
2,74
2,03
2,69
2,00
2,63
1,98
2,60
1,94
2,51
Приложе!
(НИЯ
295
Продолжение табл. 8
#,
к2 1
"1
2
3
4
5
6
7
8
9
10
И
12
13
14
15
16
9
241
6022
19,38
99,39
8,81
27,35
5,94
14,66
4,77
10,16
4,10
17,98
3,68
6,72
3,39
5,91
3,18
5,35
3,02
4,94
2,90
4,63
2,80
4,39
2,71
4,19
2,65
4,03
2,59
3,89
2,54
3,78
1
к, — степень свободы для большей дисперсии
10
"242
6056
19,40
99,40
8,79
27,23
5,94
14,55
4,74
10,05
4,06
7,87
3,64
6,62
3,35
5,81
3,14
5,26
2,98
4,85
2,85
4,54
2,75
4,30
2,67
4,10
2,60
3 94
2,54
3,80
2,49
[3,69
12
~244
6106
19,41
99,42
8,74
27,05
5,91
14,37
4,68
9,89
4,00
7,72
3,57
6,47
3,28
5,67
3,07
5,11
2,91
4,71
2,79
4,40
2,69
4,16
2,60
3,96
1 2,53
3,80
2,48
3,67
2,42
3,55
15
~24б
6157
19,43
99,43
8,70
26,87
5,86
14,20
4,62
9,72
3,94
7,56
3,51
6,31
3,22
5,52
3,01
4,96
2,85
4,56
2,72
4,25
2,62
4,01
2,53
3,82
2,46
3 66
2,40
3,52
2,35
[3,41
20
~248
6209
19,45
99,45
8,66
26,69
5,80
14,02
4,56
9,55
3,87
7,40
3,44
6,16
3,15
5,36
2,94
4,81
2,77
4,41
2,65
4,10
2,54
3,86
2,46
3,66
2,39
3,51
2,33
3,37
2,28
3,26
30
250
6261
19,46
99,47
8,62
26,50
5,75
13,84
4,50
9,38
3,81
7,23
3,38
5,99
3,08
5,20
2,86
4,65
2,70
4,25
2,57
3,94
2,47
3,70
2,38
3,51
2,31
3,35
2,25
3,21
2,19
3,10
оо
254
6366
19,50
99,50
8,53
26,13
5,63
13,46
4,36
9,02
3,67
6,88
3,23
5,65
2,93
4,86
2,71
4,31
2,54
3,91
2,40
3,60
2,30
3,36
2,21
3,16
2,13
3,00
2,07
2,87
2,01
2,75
296
Приложения
Продолжение табл. 8
к2 \
17
18
19
20
21
22
23
24
25
26
27
28
29
30
32
34
9
2,49
3,68
2,42
3,60
2,42
3,52
2,39
3,46
2,37
3,40
2,34
3,35
2,32
3,30
2,30
3,26
2,28
3,22
2,27
3,18
2,25
3,15
2,24
3,12
2,22
3,09
2,21
3,00
2,19
3,02
2,17
2,98
кj — степень свободы для большей дисперсии
10
2,45
3,59
2,38
3,51
2,38
3,43
2,35
3,37
2,32
3,31
2,30
3,26
2,27
3,21
2,25
3,17
2,24
3,13
2,22
3,09
2,20
3,06
2,19
3,03
2,18
3,00
2,16
2,17
2,14
2,93
2,12
2,89
12
2,38
3,46
2,31
3,37
2,31
3,30
2,28
3,23
2,25
3,17
2,23
3,12
2,20
3,07
2,18
3,03
2,16
2,99
2,15
2,96
2,13
2,93
2,12
2,90
2,10
2,87
2,09
2,84
2,07
2,80
2,05
2,76
15
2,31
3,31
2,23
3,23
2,23
3,15
2,20
3,09
2,18
3,03
2,15
2,98
2,13
2,93
2,11
2,89
2,09
2,85
2,07
2,81
2,06
2,78
2,04
2,75
2,05
2,77
2,04
2,74
2,01
2,70
1,99
2,66
20 |
2,23
3,16
2,16
3,08
2,16
3,00
2,12
2,94
2,10
2,88
2,07
2,83
2,05
2,78
2,03
2,74
2,01
2,70
1,99
2,66
1,97
2,63
1,96
2,60
1,94
2,57
1,93
2,55
1,91
2,50
1,89
1 2,46
30 |
2,15
3,00
2,07
2,92
2,07
2,84
2,04
2,78
2,01
2,72
1,98
2,67
1,96
2,62
1,94
2,58
1,92
2,54
1,90
2,50
1,88
2,47
1,87
2,44
1,83
2,41
1,84
2,38
1,82
2,34
1,80
2,30
оо
1,96
2,65
1,88
2,57
1,88
2,49
1,84
2,42
1,81
2,36
1,78
2,31
1,76
2,26
1,73
2,21
1,71
2,17
1,69
2,13
1,67
2,10
1,65
2,06
1,64
2,03
1,62
2,01
1,39
1,96
1,57
1,91
Приложения 297
Продолжение табл. 8
к2 \
36
38
40
42
44
46
48
50
60
70
80
100
150
200
оо
9
2,15
2,95
2,14
2,95
2,12
2,89
2,11
2,86
2,10
2,84
2,09
2,82
2,08
2,80
2,07
2,79
2,04
2,72
2,02
2,67
2,00
2,64
1,97
2,59
1,94
2,53
1,93
2,50
1,88
2,41
к{ — степень свободы для большей дисперсии
10
Тп
2,86
2,09
2,82
2,08
2,80
2,06
2,78
2,05
2,75
2,04
2,73
2,03
2,72
2,03
2,70
1,99
2,63
1,97
2,59
1,95
2,55
1,93
2,50
1,89
2,44
1,88
2,41
1,83
2,32
12
2,03
2,72
2,02
2,69
2,00
2,66
1,99
2,64
1,98
2,62
1,97
2,60
1,96
2,58
1,95
2,56
1,92
2,50
1,89
2,45
1,88
2,42
1,85
2,37
1,82
2,31
1,80
2,27
1,76
2,18
15
1,98
2,62
1,96
2,59
1,95
2,56
1,93
2,54
1,92
2,52
1,91
2,50
1,90
2,48
1,89
2,46
1,86
2,39
1,84
2,35
1,82
2,31
1,79
2,26
1,76
2,20
1,74
2,17
1,69
2,08
20
1,87
2,43
1,85
2,40
1,84
2,37
1,83
2,34
1,81
2,32
1,80
2,30
1,79
2,28
1,78
2,26
1,75
2,20
1,72
2,15
1,70
2,12
1,68
2,06
1,64
2,00
1,62
1,97
1,57
1,88
30
1,78
2,26
1,76
2,23
1,74
2,20
1,73
2,18
1,72
2,15
1,71
2,13
1,70
2,12
1,69
2,10
1,65
2,03
1,62
1,98
1,60
1,94
1,57
1,89
1,53
1,83
1,52
1,79
1,46
1,70
оо
1,55
1,87
1,53
1,84
1,51
1,80
1,49
1,78
1,48
1,75
1,46
1,73
1,45
1,70
1,44
1,68
1,39
1,60
1,35
1,53
1,32
1,49
1,28
1,43
1,22
1,33
1,19
1,28
1,00
1,00
298
Приложения
Таблица 9.
Критические значения статистики q критерия Даннета
Dunnett С. W. New Tables for Multiple Comparisons with a Control. Biometrics.
1964. Vol. 20. P. 482-491
Интервал сравнения /
a =0,05
8 9 10 11 12 13 16 21
5 2,57 3,03 3,29 3,48 3,62 3,73 3,82 3,90 3,97 4,03 4,09 4,14 4,26 4,42
6 2,45 2,86 3,10 3,26 3,39 3,49 3,57 3,64 3,71 3,76 3,81 3,86 3,97 4,11
7 2,36 2,75 2,97 3,12 3,24 3,33 3,41 3,47 3,53 3,58 3,63 3,67 3,78 3,91
8 2,31 2,67 2,88 3,02 3,13 3,22 3,29 3,35 3,41 3,46 3,50 3,54 3,64 3,76
9 2,26 2,61 2,81 2,95 3,05 3,14 3,20 3,26 3,32 3,36 3,40 3,44 3,53 3,65
10 2,23 2,57 2,76 2,89 2,99 3,07 3,14 3,19 3,24 3,29 3,33 3,36 3,45 3,57
11 2,20 2,53 2,72 2,84 2,94 3,02 3,08 3,14 3,19 3,23 3,27 3,30 3,39 3,50
12 2,18 2,50 2,08 2,81 2,90 2,98 3,04 3,09 3,14 3,18 3,22 3,25 3,34 3,45
13 2,16 2,48 2,65 2,78 2,87 2,94 3,00 3,06 3,10 3,14 3,18 3,21 3,29 3,40
14 2,14 2,46 2,63 2,75 2,84 2,91 2,97 3,02 3,07 3,11 3,14 3,18 3,26 3,36
15 2,13 2,44 2,61 2,73 2,82 2,89 2,95 3,00 3,04 3,08 3,12 3,15 3,23 3,33
16 2,12 2,42 2,59 2,71 2,80 2,87 2,92 2,97 3,02 3,06 3,09 3,12 3,20 3,30
17 2,11 2,41 2,58 2,69 2,78 2,85 2,90 2,95 3,00 3,03 3,07 3,10 3,18 3,27
18 2,10 2,40 2,56 2,68 2,76 2,83 2,89 2,94 2,98 3,01 3,05 3,08 3,16 3,25
19 2,09 2,39 2,55 2,66 2,75 2,81 2,87 2,92 2,96 3,00 3,03 3,06 3,14 3,23
20 2,09 2,38 2,54 2,65 2,73 2,80 2,86 2,90 2,95 2,98 3,02 3,05 3,12 3,22
24 2,06 2,35 2,51 2,61 2,70 2,76 2,81 2,86 2,90 2,94 2,97 3,00 3,07 3,16
30 2,04 2,32 2,47 2,58 2,66 2,72 2,77 2,82 2,86 2,89 2,92 2,95 3,02 3,11
40 2,02 2,29 2,44 2,54 2,62 2,68 2,73 2,77 2,81 2,85 2,87 2,90 2,97 3,06
60 2,00 2,27 2,41 2,51 2,58 2,64 2,69 2,73 2,77 2,80 2,83 2,86 2,92 3,00
120 1,98 2,24 2,38 2,47 2,55 2,60 2,65 2,69 2,73 2,76 2,79 2,81 2,87 2,95
оо 1,96 2,21 2,35 2,44 2,51 2,57 2,61 2,65 2,69 2,72 2,74 2,77 2,83 2,91
Приложения
299
f 2
3
4
5
Интервал сравнения /
а =0,01
6 7 8 9 10
Продолжение табл. 9
11 12 13 16 21
5 4,03 4,63 4,98 5,22 5,41 5,56 5,69 5,80 5,89 5,98 6,05 6,12 6,30 6,52
6 3,71 4,21 4,51 4,71 4,87 5,00 5,10 5,20 5,28 5,35 5,41 5,47 5,62 5,81
7 3,50 3,95 4,21 4,39 4,53 4,64 4,74 4,82 4,89 4,95 5,01 5,06 5,19 5,36
8 3,36 3,77 4,00 4,17 4,29 4,40 4,48 4,56 4,62 4,68 4,73 4,78 4,90 5,05
9 3,25 3,63 3,85 4,01 4,12 4,22 4,30 4,37 4,43 4,48 4,53 4,57 4,68 4,82
10 3,17 3,53 3,74 3,88 3,99 4,08 4,16 4,22 4,28 4,33 4,37 4,42 4,52 4,65
И 3,11 3,45 3,65 3,79 3,89 3,98 4,05 4,11 4,16 4,21 4,25 4,29 4,30 4,52
12 3,05 3,39 3,58 3,71 3,81 3,89 3,96 4,02 4,07 4,12 4,16 4,19 4,29 4,41
13 3,01 3,33 3,52 3,65 3,74 3,82 3,89 3,94 3,99 4,04 4,08 4,11 4,20 4,32
14 2,98 3,29 3,47 3,59 3,69 3,76 3,83 3,88 3,93 3,97 4,01 4,05 4,13 4,24
15 2,95 3,25 3,43 3,55 3,64 3,71 3,78 3,83 3,88 3,92 3,95 3,99 4,07 4,18
16 2,92 3,22 3,39 3,51 3,60 3,67 3,73 3,78 3,83 3,87 3,91 3,94 4,02 4,13
17 2,90 3,19 3,36 3,47 3,56 3,63 3,69 3,74 3,79 3,83 3,86 3,90 3,98 4,08
18 2,88 3,17 3,33 3,44 3,53 3,60 3,66 3,71 3,75 3,79 3,83 3,86 3,94 4,04
19 2,86 3,15 3,31 3,42 3,50 3,57 3,63 3,68 3,72 3,76 3,79 3,83 3,90 4,00
20 2,85 3,13 3,29 3,40 3,48 3,55 3,60 3,65 3,69 3,73 3,77 3,80 3,87 3,97
24 2,80 3,07 3,22 3,32 3,40 3,47 3,52 3,57 3,61 3,64 3,68 3,70 3,78 3,87
30 2,75 3,01 3,15 3,25 3,33 3,39 3,44 3,49 3,52 3,56 3,59 3,62 3,69 3,78
40 2,70 2,95 3,09 3,19 3,26 3,32 3,37 3,41 3,44 3,48 3,51 3,53 3,60 3,68
60 2,66 2,90 3,03 3,12 3,19 3,25 3,29 3,33 3,37 3,40 3,42 3,45 3,51 3,59
120 2,62 2,85 2,97 3,06 3,12 3,18 3,22 3,26 3,29 3,32 3,35 3,37 3,43 3,51
оо 2,58 2,79 2,92 3,00 3,06 3,11 3,15 3,19 3,22 3,25 3,27 3,29 3,35 2,42
300
Приложения
Таблица 10.
Плотность стандартного нормального закона распределения p(t),
(результат в таблице задан цифрами после запятой)
Лакин Г.Ф. Биометрия. — М.: «Высшая школа», 1990
t
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
1,2
1,3
1,4
1,5
1,6
1,7
1,8
0
3989
3970
3910
3314
3683
3521
3332
3123
2897
2661
2420
2179
1942
1714
1497
1295
1109
0940
0790
1
3989
3965
3902
3802
3668
3503
3312
3101
2874
2637
2396
2155
1919
1691
1476
1276
1092
0925
0775
2
3989
3961
3894
3790
3653
3485
3292
3079
2850
2613
2371
2131
1895
1669
1456
1257
1074
0909
0761
Сотые доли /
3
3988
3956
3885
3778
3637
3467
3271
3056
2827
2589
2347
2107
1872
1647
1435
1238
1057
0893
0748
4 1
3986
3951
3876
3765
3621
3448
3251
3034
2803
2565
2323
2083
1849
1626
1415
1219
1040
0878
0734
5
3984
3945
3867
3752
3605
3429
3230
ЗОН
2780
2541
2299
2059
1826
1604
1394
1200
1023
0863
0721
6
3982
3939
3857
3739
3589
3410
3209
2989
2756
2516
2275
2036
1804
1582
1374
1182
1006
0848
0707
7 1
3980
3932
3847
3726
3572
3391
3187
2966
2732
2492
2251
2012
1781
1561
1354
1163
0989
0833
0694
8 1
3977
3925
3836
3712
3555
3372
3166
2943
2709
2468
2227
1989
1758
1539
1334
1145
0973
0818
0681
9
3973
3918
3825
3697
3538
3352
3144
2920
2685
2444
2203
1965
1736
1518
1315
1127
0957
0804
0669
Приложения
301
Продолжение табл. 10
f
1,9
2,0
2,1
2,2
2,3
2,4
2,5
2,6
2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
4,0
0 1
0656
0540
0440
0356
0283
0224
0175
0136
0104
0079
0060
0044
0033
0024
0017
0012
0009
0006
0004
0003
0002
0001
1
0644 1
0529
0431
0347
0277
0219
0171
0132
0101
0077
0058
0043
0032
0023
0017
0012
0008
0006
0004
0003
0002
0001
2 1
0632 1
0519
0422
0339
0270
0213
0167
0129
0099
0075
0056
0042
0031
0022
0016
0012
0008
0006
0004
0003
0002
0001
Сотые доли /
3 1
0620 1
0508
0413
0332
0264
0208
0163
0126
0096
0073
0055
0041
0030
0022
0016
0012
0008
0005
0004
0003
0002
0001
4
0608
0498
0404
0325
0258
0203
0158
0122
0093
0071
0053
0039
0029
0021
0015
ООП
0008
0005
0004
0003
0002
0001
5 1
0596 1
0488
0396
0317
0252
0198
0154
0119
0091
0069
0051
0038
0028
0020
0015
0010
0007
0005
0004
0002
0002
0001
6
0584 1
0478
0387
0310
0246
0194
0151
0116
0088
0067
0050
0037
0027
0020
0014
0010
0007
0005
0003
0002
0002
0001
л 1
0573 1
0468
0379
0303
0241
0189
0147
0113
0086
0065
0048
0036
0026
0019
0014
0010
0007
0005
0003
0002
0002
0001
8
0562 1
0459
0371
0297
0235
0184
0143
ОНО
0084
0063
0047
0035
0025
0018
0013
0009
0007
0005
0003
0002
0001
0001
9
0551
0449
0363
0290
0229
0180
0139
0107
0081
0061
0046
0034
0025
0018
0013
0009
0006
0004
0003
0002
0001
0001
302
Приложения
Таблица случайных чисел
1368
5953
7226
8883
7022
4576
8715
4011
1400
6370
4522
7195
0054
5166
1245
8529
8973
9307
2923
6372
6922
9682
3371
6712
3071
9621
5936
9466
3454
5281
1853
1416
0408
3694
1884
5748
6234
0810
5433
3793
7842
3445
2959
4276
2808
1807
8336
1530
9402
8782
9159
2541
9553
6773
1168
7884
7028
2224
4482
0820
8084
6426
2937
0381
7415
7203
4366
5904
9467
1238
4900
6453
5104
9588
7157
2066
4011
7671
8207
4099
2451
4616
7626
3608
4854
3932
7148
2020
9686
7819
1844
9242
4951
9868
8098
5306
0545
3076
7019
5941
1208
0408
8599
5576
8069
3488
3470
0643
1238
9156
7678
9945
2299
6670
1783
8619
2151
3695
2257
5509
0411
6127
5506
9248
8830
4022 9734 7852 9096 0051
9682 8892 3577 0326 5306
6705 2175 9904 3743 1902
1872 8292 2366 8603 4288
2559 7534 2281 7351 2064
4399
6074
7735
3219
9610
3751
8827
7483
2800
1880
9783
7562
9056
6184
7423
5399
9782
0569
7891
3384
5175
3597
5398
8976
4624
Таблица 11.
2664 9822 6599 6911 5112
3593 3679 1378 5936 2651
2119 5337 5953 6355 6889
6386 7487 0190 0867 1298
8721 8353 9952 8006 9045
1286 4842 7719 5795 3953
9938 5703 0196 3465 0034
1149 8834 6429 8691 0143
8221 5129 6105 5314 8385
6509 7123 4070 6759 6113
3549
0358
4198
5129
0506
7404
0244
4529
1925
4617
1628
2741
3101
9192
8563
7387
0050
5393
6809
0611
8894
1209
0036
6123
6653
0051
3247
0846
2103
7848
4215
0922
7197
3382
4099
8634
5967
4143
4223
2252
7056
8517
3032
4357
9613
0296
8562
0056
9397
2900
6761
0519
3937
1125
7673
9969
5887
7179
7244
6705
2331
8447
5845
6455
8109
9331
4376
8432
1072
2000
9483
8593
4547
4019
6290
6952
6550
3986
3404
8740
6948
4883
3239
1781
2386
7247
3017
2095
7947
6880
1317
0788
0612
5611
0327
0400
7461
2006
8389
9286
7041
1327
1019
8785
6629
5643
1177
1783
8037
2830
3230
5709
6127
2474
9912
7833
5443
7972
6822
6145
2272
5645
7681
9508
2395
Приложения
303
Продолжение табл. 11
4778
3887
2977
1312
3890
0793
2139
9153
2234
8837
6605
8390
8053
9837
2557
8818
1619
0248
2919
7179
8818
4552
2880
4778
7686
6380
8175
3046
9378
6395
9229
4164
2793
8220
7799
2992
3444
9053
6639
1771
4599
3525
9102
3237
9496
6300
2542
3351
7285
9190
6300
6462
8220
0862
3374
3333
1646
4515
7016
1884
4239
4042
4922
5902
3275
4239
2524
8680
9509
2894
0713
4019
2944
7593
0612
9595
7799
8878
7882
7840
9595
3372
4284
2141
7314
8401
8390
9763
5958
8102
4234
9084
5703
1403
1872
4384
1848
5044
0208
8956
7146
4344
3003
0068
4402
0611
0278
7421
5354
6232
2264
4172
8931
1450
0440
8940
8973
3408
3114
5498
7687
8422
2054
9913
5195
9279
9667
0861
1222
3766
2629
4489
1199
0456
0422
2800
4330
4391
7109
3148
2128
8277
1517
5281
6047
2006
3423
2791
6840
3335
Практическое руководство
Сергиенко Валерий Иванович,
Бондарева Ирина Борисовна
МАТЕМАТИЧЕСКАЯ СТАТИСТИКА
В КЛИНИЧЕСКИХ ИССЛЕДОВАНИЯХ
2-е издание, переработанное и дополненное
Подписано в печать 02.05.06. Формат 60x90 '/16. Бумага офсетная.
Печать офсетная. Печ. л. 19. Тираж 4000 экз. Заказ № 760.
Издательская группа «ГЭОТАР-Медиа».
119828, Москва, ул. Малая Пироговская, 1а,
тел./факс: (495) 101-39-07,
e-mail: info@geotar.ru, http://www.geotar.ru
Отпечатано в ОАО «Типография "Новости"».
105005, Москва, ул. Ф. Энгельса, 46.
ISBN 5-9704-0197-8
9"7в597СГЧ0197