/




















































































































































































































































































































Text
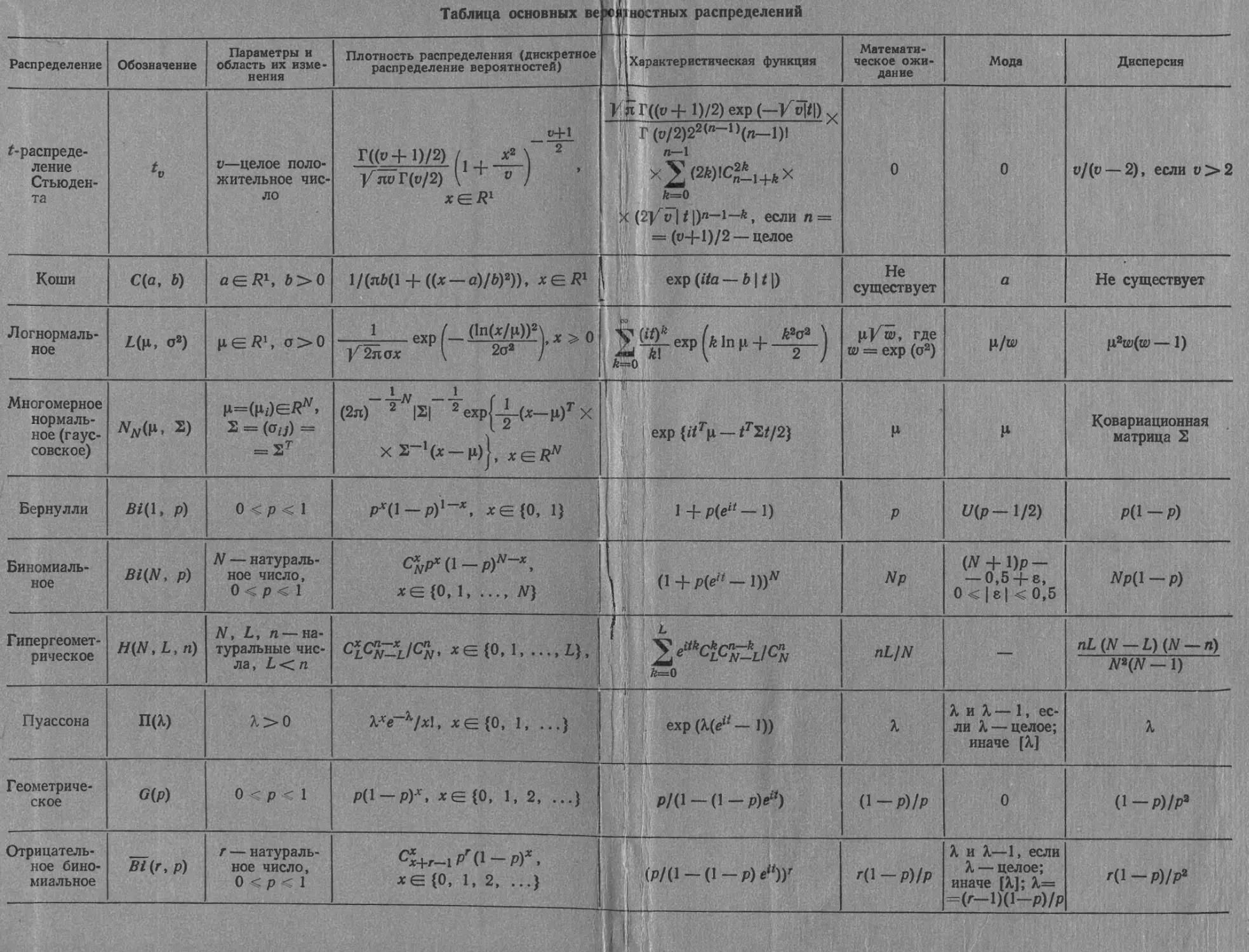
Распределение
Обозначение
Параметры и
область их изме-
нения
Таблица основных версярностных распределений
Плотность распределения (дискретное
распределение вероятностей)
' Характеристическая функция
Математи-
ческое ожи-
дание
Мода
Дисперсия
И’ЙГ((0+1)/2)ехр(-/»|«|)
/-распреде-
ление
Стьюден-
та
v—целое поло-
жительное чис-
ло
Г((и+ 1)/2)
У jw Г(о/2)
v
л
k=0
О
о
о/(и — 2), если о>2
Коши
С(а, Ь)
О
1/(лд(1 4-((х —а)/6)2)), хеR1
Логнормаль-
ное
£(р, о8)
о
—=------ехр
У 2 л ох
I
-Ж
Т~~
Р'Г •
wUi -
IS>
о
у v 1t |)я— 1—«, если п —
— СН~1)/2 — целое
Не
существует
а
Не существует
kW '
2 J
pVw, где
w = ехр (о2)
p?w(w — 1)
Многомерное
нормаль-
ное (гаус-
совское)
S)
Бернулли
£i(l, р)
Биномиаль-
ное
Bi(Nt Р)
Гипергеомет-
рическое
H(N, L, п)
Пуассона
П(Х)
(х —u)
N}
— -^-N
(2л) 2
N — натураль-
ное число,
0<р< 1
2 ехр
l-j-p(^-l)
С7(р— 1/2)
Р
о.
Np
0,5
nL/N
I
ехр(Х(еп—1))
7
CnP* (I - РУ
Ковариационная
матрица 2
р(1 — р)
#р(1 р)
N, L, п — на-
туральные чис-
nL(N — L) (N — n)
N*(N — 1)
Геометриче-
ское
Отрицатель-
ное бино-
миальное
G(P)
Bi (г, р)
г — натураль-
ное число,
0 < о < 1
р/(1-(1-р)^)
(р/(1 - (1 - р) е“)У
Ж . 11
I/ ।
(1 — Р)/Р
г(1 — Р)/Р
X и X — 1, ес-
ли X — целое;
иначе [X]
0
(I-PVP2
X и X—1, если
X — целое;
иначе [X]; Х=
-(г-1)(1-р)/р
Г(1—р)/р2
Ю С ХАРИН
МДСТЕПАНОВА
ПРАКТИКУМ
НА
ПО МАТЕМАТИЧЕСКОЙ
7 СТАТИСТИКЕ
Допущено Министерством высшего и
среднего :специального*• образования
БССР в качестве учебного пособия для
студентов математических специально-
стей университетов
Минск
Издательство «Университетское»
1987
ББК 22.172я73
X 20
УДК 519.22-37(075.8)
Рецензенты:
кафедра прикладной статистики Киевского государственного
университета (зав. кафедрой доктор физико-математических
наук, профессор В. В. Анисимов); кандидат физико-математи-
ческих наук Ю.-И. И. Круопис
Харин Ю. С., Степанова М. Д.
X 20 Практикум на ЭВМ по математической статисти-
ке: Для мат. спец, ун-тов.— Мн.: изд-во «Универси-
тетское», 1987.— 304 с.: ил.
Книга является пособием для выполнения вычислительного практи-
кума по курсу теории вероятностей и математической статистики и
спецкурсам по математической статистике.
Предназначена для студентов математических специальностей уни-
верситетов. Будет полезна студентам физических и инженерно-техни-
ческих специальностей университетов и высших технических учебных
заведений, а также специалистам, желающим познакомиться со стати-
стическими методами и приобрести навыки практического применения
алгоритмического и программного обеспечения теории вероятностей и
математической статистики при решении прикладных задач.
170206000—032
ХМ317(03)—87 24—87
ББК 22.172я73
Юрий Семенович Харин
Маргарита Дмитриевна Степанова
ПРАКТИКУМ НА ЭВМ
ПО МАТЕМАТИЧЕСКОЙ СТАТИСТИКЕ
Заведующий редакцией Б. С. Мельников
Редактор М. Г. Хают и н а
Художник И. А. Д е м к о в с к и й
Художественный редактор С. В. Баленок
Технический редактор А. Я. Максимова
Корректор Л. В. Лебедева
ИБ № 1123
Сдано в набор 30.05.86. Подписано в печать 17.04.87. АТ 07096. Формат
84X108V32. Бумага типографская № 1. Гарнитура литературная. Высокая пе-
чать. Усл. печ. л. 15,96. Усл. кр.-отт. 16,46. Уч.-изд. л. 16,3. Тираж 6040 экз.
Заказ 1015. Цена 85 к. Издательство «Университетское» Госкомиздата БССР.
220048. Минск, проспект Машерова, 11. Ордена Трудового Красного Знамени
типография издательства ЦК КПБ. 220041. Минск, Ленинский проспект, 79.
© Издательство «Университетское», 1987
ОГЛАВЛЕНИЕ
Предисловие.............................................. 7
Основные обозначения и сокращения......................11
ЧАСТЬ 1
МОДЕЛИРОВАНИЕ НА ЭВМ СЛУЧАЙНЫХ ЭЛЕМЕНТОВ
И СТОХАСТИЧЕСКИХ СИСТЕМ
Глава 1. Принципы статистического моделирования на ЭВМ 13
§ 1.1. Предмет статистического моделирования .... 13
§ 1.2. Принципы моделирования. Базовая случайная вели-
чина ..................................................16
§ 1.3. Датчики базовой случайной величины.............20
§ 1.4. Оценка точности моделирования случайных величин 22
§ 1.5. Специальные тесты проверки точности моделирования
базовой случайной величины ........................... 25
Глава 2. Моделирование случайных событий и величин . . 31
§ 2.1. Моделирование на ЭВМ стандартной равномерно рас-
пределенной случайной величины мультипликативным кон-
груэнтным методом......................................31
§ 2.2. Моделирование базовой случайной величины при по-
мощи линейных смешанных формул.........................35
§ 2.3. Моделирование базовой случайной величины при по*
мощи нелинейных формул.................................37
§ 2.4. Моделирование базовой случайной величины мето-
дом Макларена — Марсальи...............................39
§ 2.5. Моделирование базовой случайной величины мето-
дом, основанным на свойстве воспроизводимости равномер-
ного закона............................................41
§ 2.6. Моделирование полной группы случайных событий 44
§ 2.7. Моделирование зависимых случайных событий . . 46
§ 2.8. Моделирование дискретной случайной величины при
помощи случайных событий...............................48
§ 2.9. Моделирование случайной ' величины, распределенной
по биномиальному закону................................50
§ 2.10. Моделирование случайной величины, распределенной
по закону Пуассона................................... 53
3
§ 2.11. Моделирование случайной величины, распределенной
по геометрическому закону..............................54
§ 2.12. Моделирование непрерывной случайной величины
методом обратной функции...............................56
§ 2.13. Моделирование случайной величины с заданной гис-
тограммой .............................................57
§ 2.14. Моделирование случайной величины с заданным по-
лигоном частот.........................................59
§ 2.15. Моделирование непрерывной случайной величины
стандартным методом исключения.........................61
§ 2.16. Моделирование непрерывной случайной величины
методом исключения со ступенчатой мажорирующей функ-
цией ..................................................65
§ 2.17. Моделирование непрерывной случайной величины
методом суперпозиции...................................66
§ 2.18. Моделирование гауссовской случайной величины ме-
тодами обратной функции и суммирования.................68
§ 2.19. Моделирование гауссовской случайной величины
методами функционального преобразования, исключения и
суперпозиции ......................................... 70
§ 2.20. Моделирование случайной величины с экспоненци-
альным распределением..................................73
§ 2.21. Моделирование случайной величины с бета-распре-
делением ..............................................76
§ 2.22. Моделирование случайной величины с гамма-рас-
пределением ...........................................79
§ 2.23. Моделирование случайных величин с ^-распределе-
нием и распределениями Стьюдента, Фишера .... 82
Глава 3. Моделирование случайных векторов, последова-
тельностей, процессов и полей..............................85
§ 3.1. О принципах и точности моделирования случайных
векторов................................................85
§ 3.2. О принципах и точности моделирования случайных
последовательностей, процессов и полей..................90
§ 3.3. Моделирование случайного вектора методом услов-
ных распределений..................................... 96
§ 3.4. Метод исключения для моделирования случайного
вектора.................................................99
§ 3.5. Моделирование случайного вектора, равномерно рас-
пределенного внутри заданного эллипсоида...............102
§ 3.6. Моделирование гауссовского случайного вектора . . 105
§ 3.7. Моделирование случайного вектора с полиномиаль-
ным распределением ................................... 108
§ 3.8. Моделирование случайного вектора с распределением
Дирихле.................................................НО
§ 3 9. Моделирование случайного вектора с многомерным
/-распределением.......................................112
§ 3.10. Моделирование двумерного случайного вектора с
полярным распределением................................114
§ 3.11. Моделирование случайного вектора с распределе-
нием Релея — Райса.....................................116
§ 3.12. Моделирование случайного вектора, равномерно рас-
пределенного в симплексе...............................118
4
§ 3.13. Моделирование случайного вектора, равномерно рас-
пределенного на сфере..................................120
§ 3.14. Моделирование случайной матрицы с распределе-
нием Уишарта...........................................123
§ 3.15. Моделирование цепей Маркова с дискретным вре-
менем .................................................124
§ 3.16. Моделирование гауссовского стационарного случай-
ного процесса методом скользящего суммирования . . . 127
§ 3.17. Моделирование гауссовского случайного процесса с
помощью модели авторегрессии и скользящего среднего . 131
§ 3.18. Моделирование процессов случайного блуждания . 133
§ 3.19. Метод спектральных разложений для моделирова-
ния случайных полей .................................. 135
§ 3.20. Моделирование случайных множеств...............137
Глава 4. Моделирование стохастических систем . . . 140
§ 4.1. Моделирование процессов функционирования комп-
лексного автопредприятия...............................140
§ 4.2. Статистическое моделирование экономики . . . 144
§ 4.3. Моделирование линейной стохастической системы уп-
равления ..............................................147
§ 4.4. Исследование производительности и надежности мно-
гопоточной технологической системы.....................150
ЧАСТЬ 2
СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА ДАННЫХ
Глава 5. Статистическое оценивание вероятностных распре-
делений и сжатие данных..................................156
§ 5.1. Оценивание вероятностных распределений и числовых
характеристик скалярных случайных величин . . . . 156
§ 5.2. Непараметрическое оценивание многомерных плотно-
стей распределения .................................. 161
§ 5.3. Сжатие данных методом главных компонент . . . 165 •
§ 5.4. Метод факторного анализа.......................170
§ 5.5. Оценка собственной размерности распределения . . 175
Глава 6. Методы проверки гипотез в многомерном статисти-
ческом анализе...........................................179
§ 6.1. Проверка гипотезы о значении математического ожи-
дания ................................................179
§ 6.2. Проверка гипотез о линейной зависимости векторов
математических ожидании...............................183
§ 6.3. Проверка гипотезы о совпадении математических
ожидании в q выборках.................................187
§ 6.4. Проверка гипотезы о совпадении компонент вектора
математического ожидания (проблема симметрии) . . . 190
§ 6.5. Проверка гипотез о независимости множеств случай-
ных величин...........................................192
§ 6.6. Проверка гипотезы согласия.....................197
5
§ 6.7. Проверка гипотезы об эквивалентности нескольких
нормальных совокупностей (проблема однородности) . . 199
§ 6.8. Проверка гипотезы о равенстве нескольких ковариа-
ционных матриц.........................................202
§ 6.9. Методы дискриминантного анализа.................204
§ 6.10. Кластерный анализ..............................208
Глава 7. Методы статистического исследования зависимо-
стей .....................................................210
§ 7.1. Оценивание параметров многомерной линейной ре-
грессии ...............................................210
§ 7.2. Проверка гипотезы о коэффициентах регрессии . . 213
§ 7.3. Однофакторный дисперсионный анализ . . . . 216
§ 7.4. Двухфакторный дисперсионный анализ . . . . 221
Глава 8. Статистический анализ временных рядов . . . 225
§ 8.1. Статистическое оценивание характеристик временно-
го ряда.............................................. 225
§ 8.2. Временные ряды с полиномиальным трендом . . 233
§ 8.3. Гармонический анализ периодических трендов . . 237
§ 8.4. Статистическое оценивание зависимости двух времен-
ных рядов..............................................241
§ 8.5. Статистические выводы о процессах авторегрессии и
авторегрессии с остатками в виде скользящего среднего . 246
Глава 9. Программное обеспечение практикума .... 252
§ 9.1. Описание системы STUDENT........................253
§ 9.2. Основные характеристики программных средств по
математической статистике..............................255
§ 9.3. Языки программирования и управления и системное
наполнение........................................... 268
§ 9.4. Технологическая последовательность выполнения
практикума в системе STUDENT...........................273
§ 9.5. Архив статистических данных системы STUDENT . 281
Приложение 1. Стандартные фортран-программы моделирова-
ния равномерной и гауссовских случайных величин .... 290
Приложение 2. Команды системы PRIMUS......................294
Приложение 3. Описание переменных набора
STUDENT. FILE. SCREEN.....................................296
Приложение 4. Описание переменных набора
STUDENT. FILE. CVNORM1....................................299
Приложение 5. Описание переменных набора
STUDENT. FILE. SET1.......................................300
Основная литература.......................................302
Дополнительная литература ............................... 303
ПРЕДИСЛОВИЕ
Современное интенсивное проникновение математиче-
ских методов в различные отрасли науки, техники, произ-
водства характеризуется двумя существенными особен-
ностями: необходимостью учета случайных элементов
и необходимостью применения ЭВМ при построении,
исследовании и использовании математических моделей
для реальных объектов, систем и явлений. Поскольку вы-
пускник вуза должен уметь плодотворно внедрять мате-
матические методы, то практикум на ЭВМ по математи-
ческой статистике является чрезвычайно актуальной
дисциплиной в математическом образовании студента.
Этот факт отмечался в решении ряда крупных форумов
по теории вероятностей и математической статистике
[31, 62].
Сформулируем основные причины, обосновывающие
применение ЭВМ в курсе теории вероятностей и матема-
тической статистики. ЭВМ:
— дает возможность наглядно иллюстрировать основ-
ные теоретические концепции;
— предоставляет студенту возможность проверить на
практике свои вероятностно-статистические представле-
ния, освобождает от рутинных вычислений;
— позволяет работать с большими объемами данных;
— может использоваться как обучающая машина.
Настоящий вычислительный практикум предназначен
для обучения студентов методам моделирования на ЭВМ
разнообразных случайных элементов (событий, скаляр-
ных величин, векторов, процессов и полей, множеств)
и стохастических систем, встречающихся при решении
реальных прикладных задач; методам статистического
анализа данных, применяемым на практике, при исследо-
вании функционирования реальных систем (физических,
7
технических, экономических и др.) или в ходе численных
экспериментов на ЭВМ; для ознакомления студентов
с современным программным обеспечением теории ве-
роятностей и математической статистики.
Учебное пособие состоит из двух частей. В первой
части излагаются задания, предназначенные для изуче-
ния общих методов моделирования случайных элементов
на ЭВМ, методов исследования адекватности моделей,
а также специальных методов моделирования случайных
элементов с наиболее распространенными в приложениях
вероятностными распределениями. Рассматриваются ме-
тоды моделирования типовых стохастических систем,
применяемые в теории массового обслуживания, теории
надежности, в экономике и теории управления стохасти-
ческими системами.
Вторая часть посвящена статистическим методам
анализа данных. Задания этой части практикума распре-
делены по четырем группам в соответствии с четырьмя
основными проблемами статистического анализа данных:
1) статистическое оценивание вероятностных распреде-
лений и сжатие данных; 2) проверка гипотез в многомер-
ном статистическом анализе; 3) статистическое исследо-
вание зависимостей; 4) анализ временных рядов. Во вто-
рой части описаны также архив статистических данных
и программные средства, используемые при выполнении
заданий практикума. Архив статистических данных со-
здан из двух источников: 1) псевдослучайные выборки,
сформированные с помощью программных датчиков на
ЭВМ; 2) реальные данные, полученные в ходе физиче-
ских экспериментов, медицинских и социологических
обследований и использованные сотрудниками Белорус-
ского госуниверситета им. В. И. Ленина при выполнении
научно-исследовательских работ.
Практикум поставлен на базе пакета научных про-
грамм библиотеки Института математики АН БССР
(ПНП-БИМ) [46, 51] и пакета прикладных программ ста-
тистической обработки медицинской информации (ППП
СОМИ) [52], разработанного в Вычислительном центре
Белорусского госуниверситета, являющихся наиболее
распространенными средствами в программном обеспе-
чении ЕС ЭВМ по теории вероятностей и математиче-
ской статистике. Следует отметить, что задания сформу-
лированы таким образом, что позволяют применить для
их выполнения и другие пакеты и библиотеки программ,
8
например пакет прикладных программ прикладного ста-
тистического анализа ЦЭМИ АН СССР [47].
Практикум проводится в дисплейных классах
ЕС ЭВМ, которыми оснащены многие вузы страны, и мо-
жет быть адаптирован к конкретным требованиям и воз-
можностям любого вуза.
По каждой теме сформулировано типовое задание,
методика его выполнения, план численных эксперимен-
тов и указания. Различие индивидуальных заданий до-
стигается модификацией преподавателем исходных чис-
ловых данных, указанных в первоначальном перечне
экспериментов.
Оценка выполненного студентом задания практикума
выставляется преподавателем на основе индивидуального
отчета, представляемого студентом. Отчет должен содер-
жать следующие компоненты: постановку задачи; крат-
кое описание методов решения и их свойств; алгоритмы,
реализующие выбранные методы; блок-схему программы
(если используется самостоятельно разработанная сту-
дентом программа); перечень проведенных на ЭВМ чис-
ленных экспериментов; распечатки программ и числен-
ных результатов; анализ результатов и выводы; список
использованной литературы. Реализуемые на ЭВМ алго-
ритмы надлежит оформлять в виде стандартных подпро-
грамм и документировать в соответствии с требованиями
ГОСТ ЕСПД. Основные достоинства при оформлении
отчета: логичность, краткость и аккуратность.
Настоящий практикум разработан на кафедре теории
вероятностей и математической статистики Белорусского
госуниверситета им. В. И. Ленина и используется в учеб-
ном процессе для студентов, обучающихся по специаль-
ности «Прикладная математика», специализирующихся
в применении средств вычислительной техники для реше-
ния задач теории вероятностей и математической стати-
стики и математическом обеспечении АСУ.
В учебном плане на практикум отводятся 5—9-й се-
местры. Сопутствующими дисциплинами являются:
общий курс теории вероятностей и математической ста-
тистики (4—6-й семестры), спецкурсы по математической
статистике (6—9-й семестры) и спецсеминар по много-
мерному статистическому анализу (7—9-й семестры).
В 1977 г. была поставлена первая часть практикума, свя-
занная со статистическим моделированием на ЭВМ,
а в 1981 г.— вторая часть, связанная со статистическим
9
анализом данных. Программные средства, обеспечиваю-
щие выполнение практикума на ЭВМ, объединены в си-
стему STUDENT и могут быть переданы заинтересован-
ным учебным заведениям на магнитных носителях.
Главы 1—4 и § 5.1, 5.2, 5.4, 5.5, 6.1—6.5, 6.9, 6.10, 7.2,
8.1, 8.5, 9.1 написаны Ю. С. Хариным; глава 8 и § 4.4,
5.3, 5.4, 6.2—6.8, 7.1, 7.3, 7.4, 9.1—9.3 — М. Д. Степановой.
Авторы глубоко признательны рецензентам — доктору
физико-математических наук, профессору В. В. Аниси-
мову и кандидату физико-математических наук, доценту
Ю.-Й. Й. Круопису, а также доктору физико-математи-
ческих наук, профессору Г. А. Медведеву и кандидату
физико-математических наук, доценту Е. В. Чепурину за
замечания и предложения, способствовавшие улучшению
практикума; Е. В. Птичкиной за материал § 9.1 и
В. И. Лобачу, участвовавшему в написании § 4.3. Авторы
благодарят сотрудников кафедры теории вероятностей
и математической статистики Белорусского госуниверси-
тета за обсуждение и советы, сотрудников отдела при-
кладной статистики Вычислительного центра за реали-
зацию системы STUDENT для проведения практикума
на ЭВМ и руководство БелНИИ кардиологии за предо-
ставленные статистические данные массовых профилак-
тических обследований населения г. Минска.
Авторы будут признательны всем, кто в той или иной
форме поделится своими соображениями по улучшению
статистического практикума. Замечания можно направ-
лять по адресу: 220048, Минск-48, проспект Машеро-
ва, 11, Издательство «Университетское».
Ю. С. Харин, М. Д. Степанова
ОСНОВНЫЕ ОБОЗНАЧЕНИЯ И СОКРАЩЕНИЯ
|А|= det(A)—определитель матрицы А
Ат—транспонированная матрица А
cov{£, т]}= М{(£ — Л1{^}) (т] — А1{т]})}—ковариация случайных
величин т]
D{}—символ дисперсии
. f 1, х (Е А,
IА (х) = { — индикаторная функция множества
А
диспер-
вероят-
In — единичная (W X N)-матрица
М{-}—символ математического ожидания
N (Н> °2) = ^1 (р, о2) — одномерный нормальный закон с
сией о2 и математическим ожиданием р
Nn (р, S) — У-мерный нормальный закон распределения
ностей с ковариационной матрицей S и математическим ожиданием р
nN (х I И > 2) > х €= » — плотность распределения для ТУдг (р, S)
о (z) — величина такая, что limо (z)/z = О
z->0
Р{}—символ вероятности
RN— /V-мерное евклидово пространство
tr (71)—след матрицы А
1, z>0,
— единичная функция Хэвисайда
О, z О,
— ^мерное распределение Уишарта с ковариационной
матрицей X и числом степеней свободы р
Iх ]/ 4- . .. x2n — длина (евклидова норма) вектора
</(*) =
[г] — целая часть числа z
Oij = < . . — символ Кронекера
I i /,
Г (z) — гамма-функция
Ф(г) —функция распределения N(0, 1)
Хр — случайная величина с ^-распределением с р степенями
свободы
%р; хг — случайная величина с нецентральным Х2-распределением
с р степенями свободы и параметром нецентральности т2>0
А В — событие А имеет место тогда и только тогда, когда
имеет место В
(х) mod — вычет числа х по модулю М
И — конец доказательства
АР — авторегрессия
АРСС — авторегрессия с остатками в виде скользящего среднего
АЦПУ — алфавитно-цифровое печатающее устройство
БСВ — базовая случайная величина
МНК-оценка — оценка метода наименьших квадратов
ППП — пакет прикладных программ
РНД — рабочий набор данных
СПСС — случайный процесс скользящего среднего
ЯУЗ — язык управления заданиями
ЯУП — язык управления программами
=f(ar...,ar^
МОДЕЛИРОВАНИЕ НА ЭВМ СЛУЧАЙНЫХ
ЭЛЕМЕНТОВ И СТОХАСТИЧЕСКИХ
СИСТЕМ
Глава 1
ПРИНЦИПЫ СТАТИСТИЧЕСКОГО МОДЕЛИРОВАНИЯ
НА ЭВМ
В этой главе сформулированы предмет статистического моделирова-
ния и принципы имитации на ЭВМ. случайных элементов. Изла-
гаются методы оценки точности моделирования. Описаны специаль-
ные тесты проверки точности программных датчиков случайных
величин.
§ 1.1. Предмет статистического моделирования
Моделирование — один из наиболее распространен-
ных способов изучения встречающихся на практике
объектов, систем и явлений. Различают физическое и ма-
тематическое моделирование. При физическом моделиро-
вании модель воспроизводит изучаемую систему с сохра-
нением ее физической природы. Классическим примером
физического моделирования является продувка масштаб-
ных моделей летательных аппаратов в аэродинамических
трубах. Между изучаемой системой и ее моделью должны
быть сохранены некоторые соотношения подобия, выте-
13
кающие из закономерностей физической природы. Это
ограничивает область применения физического модели-
рования.
Более широкие возможности предоставляет матема-
тическое моделирование — способ исследования объек-
тов, систем и явлений путем изучения процессов, имею-
щих различное физическое содержание, но описываемых
одинаковыми математическими отношениями. Например,
механические колебания пружинного маятника описы-
ваются обыкновенным дифференциальным уравнением
второго порядка
= (1-1)
где т — масса маятника; t — текущий момент времени;
| — отклонение центра масс маятника от положения рав-
новесия; Ф — коэффициент жесткости пружины. Колеба-
ния в электрическом контуре описываются уравнением
z-J^L+4-^w=0’
(1-2)
где L — индуктивность, q — заряд конденсатора, С —
емкость контура. Уравнения (1.1), (1.2) однотипны
и определяют общую математическую модель колебаний:
d2z (/) . 9 ~
-~dt. - + «ф (0 = 0.
При изучении любой системы методом математиче-
ского моделирования необходимо построить ее математи-
ческую модель, т. е. при помощи математических соотно-
шений описать функционирование системы. Как правило,
реальная система находится под воздействием случайных
факторов или сам механизм функционирования содержит
элементы случайности. Такая система называется стоха-
стической, а для ее математического описания исполь-
зуется аппарат теории вероятностей и математической
статистики. Математическая модель, содержащая слу-
чайные элементы (события, величины, векторы, процес-
сы, поля, множества), называется вероятностной мо-
делью.
Существуют различные пути исследования вероят-
ностной модели: 1) аналитическое исследование; 2) ана-
литическое исследование с применением численных ме-
тодов, предоставляемых вычислительной математикой
(для реализации численных методов используется вычис-
лительная техника); 3) аппаратурное моделирование,
когда функционирование вероятностной модели воспро-
изводится на аналоговых вычислительных машинах;
4) статистическое моделирование, когда функционирова-
ние вероятностной модели воспроизводится на ЭВМ.
В связи с интенсивным развитием электронно-вычисли-
тельной техники метод статистического моделирования
(или, как его еще называют, метод вероятностного моде-
лирования на ЭВМ) за последние 15 лет получил широ-
кое распространение и при исследовании сложных сто-
хастических систем часто является основным методом.
Характерной особенностью и неотъемлемой частью ста-
- тистического моделирования является имитация (моде-
лирование) на ЭВМ случайных элементов (событий,
величин, векторов, процессов, полей и множеств).
Свою историю статистическое моделирование начи-
нает от метода Монте-Карло, предложенного фон Ней-
маном и Уламом в 1949 г. для решения детерминирован-
ных задач с помощью случайных величин, имитируемых
на ЭВМ. Например, рассмотрим задачу вычисления опре-
деленного интеграла (у, X > 0):
СО
I = j X-1 dx. •
V
Введем «фиктивную» вероятностную модель: пусть g —
экспоненциальная случайная величина с плотностью
pl (х) = Хе~Хж, х 0, а функция
g W = I
0, если x<Zv,
х-1, если x^v.
Тогда по определению математического ожидания
/ = М{£(Ш-
Пусть Xi, х2, ..., хп — случайная выборка объема п из
распределения pi(x). Тогда задачу вычисления I можно
рассматривать как задачу математической статистики:
оценить математическое ожидание случайной величины
g(£) по выборке {xj. Состоятельной оценкой для /, оче-
видно, является статистика
Таким образом, для вычисления I методом статистиче-
ского моделирования в данном примере требуется осу-
ществить моделирование выборки {хг} на ЭВМ и вычис-
ление оценки (1.3). Перечисление областей применения
статистического моделирования и достигнутых результа-
тов имеется в [11,37].
§ 1.2. Принципы моделирования.
Базовая случайная величина
Моделирование на ЭВМ случайных элементов подчи-
няется двум основным принципам: 1) сходство между
случайным элементом-оригиналом и его моделью на ЭВА!
состоит в совпадении (близости) вероятностных законов
распределения или числовых характеристик; 2) всякий
случайный элемент Е определяется («конструируется»)
как некоторая борелевская функция от простейших, так
называемых базовых случайных величин (БСВ).
Простейшим для моделирования на ЭВМ случайным
экспериментом является эксперимент, заключающийся в
бросании точки наудачу в промежуток [0, 1). Матема-
тической моделью этого эксперимента является вероят-
ностное пространство (Q, Fo, р), где Q = [0, ^ — прост-
ранство элементарных событий (элементарное событие
со GE й заключается в том, что координата брошенной точ-
ки равна со); Fo — сигма-алгебра, порожденная интервала-
ми из Й; р (Д) — вероятностная мера, определенная для
подмножеств Л е70 и совпадающая с мерой Лебега, так
что
р ([0, %)) = х, х^ [0, 1].
Определим на (й, Fo, р) случайную величину
а = а (со) = со.
(1-4)
(1-5)
Она порождает вероятностное пространство (7?, F, ра),
где F— числовая прямая, F—борелевская сигма-алгеб-
ра, ра (Д) = р (а-1 (Д)) — индуцированная вероятностная
мера. Согласно (1.4), (1.5) а имеет равномерное распре-
деление на [0, 1), поскольку ее функция распределения
Fa W = р {a <. х]
Го,
если
если 1,
если %>-1.
(1-6)
16
Базовой случайной величиной условимся называть
непрерывную случайную величину а, равномерно распре-
деленную на промежутке [0, 1). Плотность распределе-
ния БСВ
f 1, если О х < 1,
P«W= L если ifitm П (1'7)
U , СVvlxl Л [ (J , 1 | •
Начальные моменты БСВ:
vk = М{а/г} = 1/(/г+ 1), k = 1, 2,
а центральные моменты (/ — 1, 2, ...):
. 1 _(_1 \k +1
ц* = М{(а —v,)*) = - ,( Лц- -
I rv | 1 I X/
(0, если k = 21 — 1,
((2/г (& + I))-1, если k = 21. (1’8)
Зададим некоторое натуральное число г и рассмотрим
теперь составной случайный эксперимент, заключаю-
щийся в повторении г 1 раз независимо друг от друга
описанного выше простейшего эксперимента. Составной
эксперимент описывается вероятностным пространством
(Qr, Fo, Р), где Йг = Й X ...X Q — r-членное декартово
произведение промежутков [0, 1); Fq— наименьшая
сигма-алгебра, содержащая декартово произведение
Fo X ... X Fo; Р(Л)— вероятностная мера, определяе-
мая соотношением
Г
Р(Л) = Пи(А),
f=i
где А = А]_ х ... X Ar с FrQ.
Вероятностное пространство (Qr, Fj, Р) условимся назы-
вать базовым. На нем определены г независимых базо-
вых случайных величин ..., аг:
di = щ (со) = соь i = 1, г; со = (юр ... , сог) е Qr.
Совместная плотность их распределения вероятностей
Pat..a (xv . . Xr) = f если е [°’ О» 1 = Ь (1.9)
(О в противном случае.
Согласно второму принципу моделирования всякий
случайный элемент Е представляется на базовом вероят-
ностном пространстве (Qz, F^, Р) для некоторого пату-
I
17
рального г в виде борелевской функции /(•) от г незави-
симых базовых случайных величин:
3 = f («I, . . . , dr) .
Таким образом, задача моделирования произвольного
случайного элемента Е разбивается на две подзадачи:
1) моделирование па ЭВМ. независимых базовых случай-
ных величин «1, а2, ...; 2) нахождение функции f (-) та-
кой, чтобы Е обладал бы требуемым вероятностным за-
коном распределения и числовыми характеристиками.
Поэтому моделирующий алгоритм состоит из двух бло-
ков: блока моделирования БСВ и блока функциональ-
ного преобразования /(•).
Коэффициентом использования базовых случайных
величин назовем величину, обратную числу г базовых
случайных величин, используемых для моделирования
одной реализации случайного элемента Е:
х = 1/г, 0 х'
Величина х является мерой вычислительных затрат на
моделирование Е. Чем меньше х, тем больше затраты на
моделирование Е. Обычно функция /(•) определяется не
единственным образом, поэтому целесообразно выбирать
функцию f (•), для которой х принимает наибольшее зна-
чение.
На ЭВМ вместо непрерывных приходится иметь дело
с дискретными случайными величинами. Предположим,
речь идет об ЭВМ, в которой представление целых чисел
осуществляется k битами (двоичными разрядами). Тогда
С ={0, 1, ..., 2k — 1}— множество 2k неотрицательных
целых чисел, представимых в ЭВМ. Определим дискрет-
ную случайную величину |3 на (Q,Fo, ц):
₽ = ₽(<») =
если 0 < со < 2~k,
если 2~k < со < 2~/г+1,
(1.10)
еслир;—[2~k со <С 1.
Ее распределение вероятностей согласно (1.4), (1.8) рав-
номерно на С:
(2~k, если i GE С,
p(p=i) = L 1.11
г 1 10, если i С.
18
Из (1.10), (1.11) следует, что случайная величина
a'= p/2fe (1.12)
является дискретной с распределением вероятностей
(2-
, если 1),
если — [0, 1).
0,
Согласно (1.5), (1.10), (1.12)
| ос'—и если >-оо,
то последовательность дис-
кретных случайных величин
а' сходится равномерно к
БСВ а. Таким образом, слу-
чайная величина ос' является
аппроксимацией для БСВ
аА); а' называется в связи с
этим квазиравномерной слу-
чайной величиной. Ее функ-
ция распределения Еа'(х)
изображена на рис. 1.1 и ап-
проксимирует Fa(x) с точ-
ностью 8=2~А В табл. 1.1
приведены соотношения ме-
жду математическими ожиданиями и дисперсиями вели-
чин а, а'. При достаточно больших значениях k (напри-
мер, для ЕС ЭВМ Л=31, 8=0,5-IO9) величины а и а'
отождествляют.
Таблица 1.1
М {а')/М {а} = 1 — 2~k
k 2 3 5 10 15
1Z D } У D{a} 1,290 1,140 1,030 1,001 1,000
*) Напомним, что аппроксимация непрерывных случайных вели-
чин дискретными широко используется в курсе теории вероятностей
при построении интеграла Лебега от случайных величин [20].
19
§ 1.3. Датчики базовой случайной величины
Датчик БСВ — это устройство, позволяющее по за-
просу получать реализацию а или несколько независи-
мых реализаций ai, ..., аг базовой случайной величи-
ны а. Реализации ..., аг иногда называют случайны-
ми числами. Существует три типа датчиков: табличный,
физический, программный.
Табличный датчик, БСВ — это таблица случайных
чисел, представляющая собой экспериментально полу-
ченную выборку реализаций равномерно распределенной
на промежутке [0, 1) случайной величины. Например,
в [27] приведены 12 500 цифр от 0 до 9, которые можно
рассматривать как реализации взаимно независимых и
одинаково распределенных случайных величин, прини-
мающих значения 0, 1, 2, ..., 9 с одной и той же вероят-
ностью, равной 0,1. Применение табличных датчиков при
статистическом моделировании ограничено в силу двух
недостатков: нехватки табличных случайных чисел (час-
то для моделирования требуется порядка миллиона слу-
чайных чисел); большого расхода оперативной памяти
ЭВМ для хранения таблицы.
Физический датчик БСВ — это специальное радио-
электронное устройство, являющееся приставкой к ЭВМ.
Он состоит из источника флуктуационного шума (напри-
мер, «флуктуационно шумящей» радиолампы), значение
которого в произвольный момент времени является слу-
чайной величиной 1] > 0 с плотностью (у), и нелиней-
ного преобразователя
где {ц}д = т] — А[т|/А] — дробная часть числа т] относи-
тельно заданного А>0 ([г] — целая часть числа z).
Исследуем вероятностные свойства а. По правилам
преобразования случайных величин из (1.13) следует,
что плотность распределения а
Ра (х) =
2 +/)д) если о
/=о
0, если хе£ [0, 1).
(1-14)
20
Будем предполагать, что р^у) непрерывно дифференци-
руема и
Рп(0)<о°, рп(оо)<оо. (1-15)
*
Применим в (1.14) формулу Тейлора с остаточным чле-
ном Лагранжа:
Ра (X) =
ОО ОО
S (/А) 2 ((0* + /) А)»
1=0 1=0
если хЕ [0, 1),
(116)
0, если хе£[О, 1),
где 0 < 6 < 1. При А - .- 0
ОО оо
2 АРч (/Д) -* \ Рп (У) dy = 1,
1=0 о
оо оо
2ДРп ((0Х + /) Д) ' •' f (#) Л/ = А1 (°°) — Рч (0),
1=0 о
поэтому из (1.15), (1.16) следует, что
( 1, если хЕ [0, 1),
Ра(я)->|ф, если J).
Таким образом, выбирая А достаточно малой величиной,
удается получить БСВ а.
Недостатки физического датчика БСВ: невозмож-
ность повторения некоторой ранее полученной реализа-
ции а (поскольку ц{а = а} = 0); схемная нестабильность,
приводящая к необходимости контроля работы датчика
при очередном его использовании. По этим причинам на
ЕС ЭВМ. физические датчики БСВ используются весьма
редко.
Указанными недостатками не обладает программный
датчик БСВ. Он может быть получен из физического дат-
чика БСВ введением обратной связи. Будем рассматри-
вать функционирование датчика во времени и обозначим
тр случайную величину, подвергаемую преобразованию
(1.13) в момент времени t; at — выходная величина дат-
чика в момент t. Источник флуктуационного шума в фи-
зическом датчике заменяется обратной связью
T)i = ф(ш-1, а/-2, ..., а<-р),
(М7)
21
использующей р ранее полученных выходных значений
датчика. В (1.17) /=1, 2, а ао, сс-ь •. •, ai-p фикси-
руются заранее: щ = ан, i = 1 — р, 0, и называются
исходными (стартовыми) случайными числами.
Согласно (1.13), (1.17)
_ __ {ф(а/_р
а'-----— _ --------------------- =
= Ф(а/_ь ..., а/_р). (1-18)
Рекуррентная формула (1.18) определяет последователь-
ность псевдослучайных чисел ai-p, аг-Р, ..., ао, at, ...
..., at, ... . Термин «псевдослучайные» используется
по следующим причинам: 1) по происхождению эти чис-
ла — не случайные; они получаются по известному детер-
минированному закону (1.18); 2) при специальном вы-
боре функции ф(-) по вероятностным характеристикам
эти числа похожи на реализации независимых БСВ.
Отметим, что понятие случайности последовательности
можно связать со сложностью моделирующего алгорит-
ма и, в частности, со сложностью функции ф(*) в
(1.18) [40].
§ 1.4. Оценка точности моделирования
случайных величин
Пусть некий алгоритм осуществляет моделирование
случайной величины £ на ЭВМ. В результате /г-кратного
обращения к этому алгоритму моделируется случайная
выборка X ={xi, ..., хп}. Необходимо при помощи X
проверить гипотезу Но о том, что функция распределения
случайной величины | F%(x)= Fo(x), где Fo(x)— некото-
рая фиксированная функция распределения. Конкури-
рующая гипотеза Нс F%(x) Ф Fo(x). Гипотеза Но назы-
вается гипотезой согласия. Для проверки Но известно
несколько статистических критериев, называемых крите-
риями согласия. Кратко опишем основные из них.
1. %2-Критерий Пирсона. В X находим x_=min {xj,
х+ — max{%i} и осуществляем разбиение числовой пря-
i
мой на k > 1 ячеек:
(— оо, х- + h), [х_ -|- h, х- + 2/i), ...,
[х+ — 2h, х+ — h), (х+ — h, + оо),
22
1
где h = (х+ — x-)lk. Рекомендуется [1] k выбирать таким
образом, чтобы min npi 5.
i=i, k
Вычислим теоретическую вероятность попадания £
в i-ю ячейку, если верна Но:
Fo (х_ 4- h), если i = 1,
Fo (х_ + ih) — Fo (r__ + (i— 1) h),
если 1 <C i < k,
J — Fo (%+ — /г), если i — k,
(1.19)
число nt выборочных значений из X, попавших
k k
п, = п.
в i-ю
ячейку. Заметим, что
Вычислим %2-статистику:
Решающее правило:
принимается
гипотеза
npi
(1.20)
Но, если %2
если %2
(1-21)
X
где порог А выбирается так, чтобы вероятность ошибки
первого рода равнялась заданному уровню значимости
ео 1:
Р{Х2^ A|tf0} = е0. (1.22)
Оказывается, что при верной Но и п-+оо случайная ве-
личина х2 имеет не зависящее от Fo(-) х2_РаспРеДеление
с k — 1 степенями свободы; функция этого распределения
Хе 2 dz, у ^0. (1.23)
Порог А тогда можно определить из приближенного ра-
венства (1.22):
1 , (Д) — ео>
откуда
Д = Г-2* (1-е„), (1.24)
1
23
где F % (•) —функция, обратная по отношению к (1.23),
xk— 1
протабулированная в [27, 41]. Точность приближения в
(1-24) достаточно высока, если i= 1, k.
Отметим, что если F$(*) фиксирована с точностью
до т параметров: Е0(х; 6), 0 = (0i, ..., 0m), истинные
значения которых неизвестны, то в (1.19) подставляется
оценка 0, минимизирующая функцию х2 = %2(0); при
этом число степеней свободы в (1.24) уменьшается на т.
Если £ — непрерывная случайная величина с плотностью
то вычисления по ^-критерию целесообразно иллю-
А
стрировать гистограммой. Гистограмма fg(x)—это оцен-
ка плотности f^x) по выборке X:
k W =
' 0, если —оо < х <С X— + /г,
nz/(n/i), если X- + + (Z + l)/i,
i = 1, k — 2,
10, если x <Z oo.
Для построения гистограммы на ЭВМ удобно использо-
вать подпрограмму GIST, имеющуюся в математическом
обеспечении ЕС ЭВМ [46].
2. Критерий Смирнова — Крамера — Мизеса. Обозна-
чим упорядоченный в порядке возрастания 'ряд выбороч-
ных значений из Х\
Х(У) %(2) =5- ... ^5 Х(п), п 3.
Тогда эмпирическая функция распределения
f0, если
F3 (%) = ' z7n» если
1, если
Вычислим статистику:
ОО
f (Fs (х) - (x))MF0 (х) =
(1.25)
Решающее правило:
[ 77О, если nW2 <Z Д,
принимается гипотеза { „
[Нц если nW2 Д,
24
где порог А находится из условия, аналогичного (1.22).
При верной Hq распределение nW2 не зависит от Fo(-).
В табл. 1.2 приведены значения порога А в зависимости
от уровня значимости е0-
Таблица 1.2
ео 0,001 0,01 0,05 0,1
А 1,168 0,743 0,461 0,347
3. Критерий Колмогорова. Определим расстояние
Колмогорова между эмпирической и теоретической функ-
циями распределения:
D = max | F3 (х) — Fo (х)
X
(1.26)
Решающее правило:
принимается гипотеза
HQ, если /пП<А,
Hlf если ]/п£);>А.
Если верна Яо и О 1 (практически п 20), то неза-
висимо от Ео(-) случайная величина ]/ nD имеет распре-
деление Колмогорова:
ОО
—2r2z2
?>0.
Это позволяет аналогично (1.22) определить А. Значе-
ния А содержатся в табл. 1.3.
Таблица 1.3
е0 0,01 0,05 0,1 0,2
А 1,63 1,36 1,22 1,07
§ 1.5. Специальные тесты проверки точности
моделирования базовой случайной величины
Особую роль в статистическом моделировании играют
БСВ, поэтому точность моделирования для датчика БСВ
должна быть особенно тщательно проверена. Пусть
25
имеется датчик БСВ а; в результате «-кратного обраще-
ния к нему получена выборка A = {ai, ..., ап}. Необхо-
димо проверить гипотезу Но', выборочные значения
..., ап являются реализациями независимых случай-
ных величин сел, .. ., ап, равномерно распределенных на
промежутке [0, 1); Hi — конкурирующая гипотеза. Для
проверки этих гипотез используются различные стати-
стические тесты. Рассмотрим основные из них.
1. Тест «апериодичности» (для программных датчи-
ков БСВ). Последовательность псевдослучайных чисел
^1> Q'Zy • • • , • • • ,
полученная при помощи программного датчика БСВ
(1.18), называется периодической с периодом Т 1,
если, начиная с i = i°, выполняются равенства для
/ 1,2,....
При неудачном выборе р, ф(-) в (1.18) период Т может
оказаться сколь угодно малым. Если Т < п, то нару-
шается условие независимости выборочных значений в А
и использовать выборку А при статистическом моделиро-
вании нельзя. Тест «апериодичности» — это программа
для ЭВМ, путем перебора проверяющая условия (1.27)
и определяющая i° и Т. Алгоритм перебора описан в [16].
2. Тест «совпадение моментов». Согласно (1.7), (1.8)
БСВ а имеет математическое ожидание р, = 0,5 и диспер-
сию D = 1/12. Тест «совпадение моментов» — программа
для ЭВМ, проверяющая по выборке А выполнение этих
равенств. Несмещенными и состоятельными оценками
моментов являются выборочные среднее и дисперсия:
п
m —
2 ___
п
Определим
значений:
случайные
отклонения оценок от.истинных
2
12
Если Но верна, а п^>1 (практически п^-20), то в силу
центральной предельной теоремы
?2~м(о, <5^1 )2Х
26
О,0056 0,0028 0,0083
п ~ и2 п3
(1.28)
При вычислении дисперсии £2 использована формула
~ ( п — 1 J Н4 — Р2 2 (И4 — 2^2) , Р4 — 3^2
D —-— s2 =-------------------5— ---------
\ п ) п п2 п3
Решающее правило, основанное на статистике £х:
принимается
Но, если ]/12п | £х | < Д,
если ]/12n I £х I > Д,
• •
(1.29)
где порог Д соответствует уровню значимости е0 и опре-
деляется с учетом (1.28):
Р{|/12я|^|>Л}^2(1-Ф(Д)) = е0.
Из этого уравнения определяем
80
(1.30)
где Ф-1(-)— обратная функция распределения стандарт-
ного нормального закона (табл. 1.4).
Таблица 1.4
8о
Д
0,01 0,05 0,1
2,58 1,96 1,65
0,2
Решающее правило, использующее статистику
п — 1
п
принимается
|£а|
/0,0056п~1 +0,0028п~2 —
Z — 0,0083/г'3
Н1 в противном случае.
(1.31)
Порог Д определяется формулой (1.30) и табл. 1.4.
3. Тест «ковариация». Ковариационной функцией слу-
чайной последовательности ..., ап называется функ-
ция целочисленной переменной / <={0, 1, ..., п — 1}:
R (/) = М {(о^—M{ai}) (a1+i—М {a1+J})} =
= M{aiai+j}— M{ai}M{ai+j}.
27
Если верна Но, то «1 и ai+j независимы для любого / 1,
поэтому
(1/12, если / — О,
R(j) = L ' (1.32)
10, если / > 1. v
Тест «ковариация» позволяет проверить свойство
(1.32) случайной последовательности, моделируемой
исследуемым датчиком БСВ, и заключается в сле-
дующем.
По выборке А оцениваем R(j):
n—j
R (/) nil „ i hi , j = 0, 1, ••., ty
1 i=i
где 1 < t < n. Заметим, что R (0) = s2. Воспользуемся ре-
шающим правилом:
принимается
12/л—1 ’
Н1У если нарушается хотя бы одно неравенство.
Формула (1.33) использует Cj = {]A2, если / = 0, и 1,
если / 1}, а также порог А, определяемый (1.30)
и табл. 1.4. Решающее правило (1.33) при п — 1000,
t = 6, со = 0,01 наглядно иллюстрируется рис. 1.2, где
изображены численные результаты, полученные при
исследовании стандартного программного датчика БСВ
RANDU, имеющегося в математическом обеспечении
ЕС ЭВМ. Здесь R±(j) = R(j)±. Cj&/( 12 ]/ п — 1)— верх-
няя и нижняя доверительные границы для R(j), соответ-
ствующие доверительной вероятности 0 = 1 —- 80 = 0,99.
Из рис. 1.2 видно, что ломаные R±(j) образуют трубку
с осью /?(/) и график истинной ковариационной функции
(1.32) /?(/) (штриховая линия) для /^0 лежит в этой
трубке.
4. Тесты «согласия». Проверку гипотезы Но о том, что
Еа(-) совпадает с функцией распределения равномер-
ного закона, легко осуществить при помощи тестов, опи-
санных в § 1.4.
При использовании %2-критерия Пирсона удобно по-
ложить X- = 0, х+ — 1 и использовать в качестве ячеек
промежутки равной длины h — 1/k:
28
[О, Л), [h, 2/i), [(£- l)/i, 1).
При этом в силу (1.6) теоретические вероятности pi=l/k
одинаковы. Вычисление статистики %2 удобно иллюстри-
ровать при помощи гистограммы. На рис. 1.3 изображена
гистограмма fa(x), вычисленная по 1000 случайным чис-
лам (£ = 20), выработанным подпрограммой RANDU
-0,02 -----------------------1
0 2 0
Рис. 1.3
Рис. 1.2
(см. Приложение 1), и плотность (штриховая линия)
равномерного распределения. Их различие характери-
зуется статистикой %2, которая в данном примере при-
няла значение %2 = 14,12. При е0 = 0,01 согласно (1.24)
порог А — 30,14. Следовательно, надлежит принять гипо-
тезу согласия и считать, что RANDU имитирует равно-
мерное распределение удовлетворительно.
Для применения критериев Смирнова и Колмогорова
достаточно подставить в (1.25) и (1.26) вместо Ао(-)
функцию (1.6). Эти критерии целесообразно иллюстриро-
вать графиками Аэ(-), Fo(-)-
5. Тест «равномерность многомерного распределе-
ния». Зададим натуральное 1 N < п и построим
т = [/г/TV] векторов: 7
29
(«1, «2, • • • , CLn), («Я+1, , (12n), • • •
• • • , (Щт—1)N-H, • • • , ^tun) ,
где си, «2, ..., ап — независимые БСВ. По построению
эти векторы независимы и одинаково равномерно распре-
делены в единичном гиперкубе S cz RN с центром в точ-
ке с = (0,5; 0,5; ...; 0,5) е RN. Разобьем этот гиперкуб
на k ячеек:
где го = 0 < Г1
Гк-1
0,5 — произвольные ве-
щественные числа. Теоретические вероятности попадания
конца случайного вектора (a(i-i^+i, ..., ctnv) в ячейки
равны объемам этих ячеек:
Л/Г (Л//2)
— r^i), i = 1, k— 1;
2ji^2 д/-
✓ Л Г /П\ k-
Л/Г (Л//2)
i = k.
(1.34)
Pt =
По выборке А строятся т векторов {..., xiJV)}
и вычисляются частоты {rrij} попадания концов этих век-
торов в ячейки = т)' Далее аналогично § 1.4 вы-
/=1
числяется статистика
k
X2 = S (rn} — mpjYKmpj)
/=1
и гипотеза Но о равномерности Л/-мерного распределения
случайного вектора (a(i-i)N+i, ..., а^) принимается, если
%2 < Л, где порог А определяется (1.24). При k = 2 этот
тест описан в [16, с. 95]. Заметим, что не следует брать N
слишком большим: при N-> оо согласно (1.34) для лю-
бого i = 1, k— 1 pi ^/2/(7Vr(A//2)2JV-1)-> 0 (напри-
мер, для N = 10 pi 0,0025, i = 1, k— 1). Выбирая
в качестве ячеек более сложные области, можно полу-
чить новые тесты равномерности, например покер-тест
[16, с. 94].
Кроме перечисленных тестов датчика БСВ, существует тест «се-
рий» [11, 15], тест «максимумов и минимумов» [15]. (Для некоторых
30
из них в [15] приведены программы.) Важным инструментом иссле-
дования точности датчиков является еще и спектральный анализ
(см. гл. 8 и статью Журбенко И. Г., Кожевникова И. А., Клиндухо-
ва О. В. Определение критической длины последовательности псев-
дослучайных чисел // Вероятностно-статистические методы исследова-
ния. М.: Изд-во МГУ, 1983. С. 18—39).
Глава 2
МОДЕЛИРОВАНИЕ СЛУЧАЙНЫХ СОБЫТИИ
И ВЕЛИЧИН
В данной главе рассматриваются методы и алгоритмы моделирова-
ния стандартной равномерно распределенной (базовой) случайной
величины, случайных событий, а также непрерывных и дискретных
случайных величин с наиболее распространенными в приложениях
вероятностными распределениями. Приводятся оценки точности
и быстродействия моделирующих алгоритмов.
*
§ 2.1. Моделирование на ЭВМ стандартной равномерно
распределенной случайной величины
мультипликативным конгруэнтным методом
Задание. Реализовать на ЭВМ и исследовать по точ-
ности мультипликативный конгруэнтный метод модели-
рования БСВ. Параметры линейной мультипликативной
формулы выбрать так, чтобы длина интервала аперио-
дичности была наибольшей. Исследовать влияние «стар-
тового» значения датчика БСВ.
Методика выполнения задания. Согласно мультипли-
кативному конгруэнтному методу (методу вычетов)
псевдослучайная последовательность вычисляется по
рекуррентным формулам
nz = nt*/M, a* ='(ptz*_i)'modМ, г=1, 2, ...» (2.1)
где р, М, а0 — параметры программного датчика: р — мно-
житель, М — модуль, а$ — стартовое значение. В (2.1) опе-
рация у = (г) mod М означает:
у = z — M[z/M],
поэтому целые неотрицательные числа nJ, nJ, ... ее {0, 1,
..., М— 1}. Отсюда следует: 1) последовательность п*, а
значит, и nz всегда «зацикливается», т. е., начиная с не-
31
которого номера i iQ, образуется цикл, который повто-
ряется бесконечное число раз; 2) период последователь-
ности Т < М — 1 (если а] = 0, то ai+j — 0 для любого
Определим значения параметров р, М, ао таким обра-
зом, чтобы величина Т была максимальной. Поскольку
Т М — 1, то целесообразно модуль М выбирать макси-
мально возможным. В связи с этим наиболее распростра-
нены три варианта выбора М.
Вариант 1: M = 2q, где q — число двоичных раз-
рядов (битов), используемых для задания целой констан-
ты в ЭВМ. Например, в ЕС ЭВМ М = 231 = 2147483648.
В этой ситуации максимально возможное значение пе-
риода Tmax = 2«-2 = Л4/4. Оно достигается, если: 1) tz0
нечетное число, 1
М— 1; 2) (p)rnod 8 = (3)mod8
или (р) mod 8 = (5) mod 8. Второе из условий выполня-
ется, например, при р = 52*+1, р = 0, 1, 2, ..., или р =
= 2т+3, ш=3, 4, 5, ... . Остающийся «произвол» в
выборе р надлежит использовать для повышения точ-
ности моделирования БСВ. Например, установлено, что
при р = 2т + 3 выполнение описанного в § 1.5 теста «ко-
вариация» облегчается для значений m q/2. Про-
граммные датчики БСВ с М = 2q отличаются простотой
реализации (см., например, в Приложении 1 подпрограм-
му RANDU, входящую в пакет научных подпрограмм
ПНП-БИМ) и поэтому нашли особо широкое примене-
ние. В табл. 2.1 указаны параметры наиболее распро-
страненных датчиков БСВ.
Таблица 2.1
Место использования датчика
Пакет ПНП-БИМ, применяемый в ЕС ЭВМ [53] 2:п 21с + 3
Системы автоматического программирования
СИМУЛА, GPSS
Библиотека АЛГОЛ-процедур [23]
Вариант 2: М= ПК Оптимальный выбор пара-
метров в этой ситуации осуществляется при помощи сле-
дующего утверждения.
32
Теорема [15]. Если М = 107, <7 > 5 и а*0 не кратно
двум или пяти, то максимально возможное значение пе-
риода Тщах = 5 • 10г/-2 и достигается тогда и только
тогда, когда (Р) mod 200 принимает одно из следующих
32 «магических» значений: 3, 11, 13, 19, 21, 27, 29, 37, 53,
59, 61, 67, 69, 77, 83, 91, 109, 117, 123, 131, 133, 139, 141,
147, 163, 171, 173, 179, 181, 187, 189, 197.
Вариант 3: М — простое число. Максимально
возможное значение периода Tmax = М — 1 достигается,
если р не кратно М и
(p(M-i)/Pj _ 1) mod М Ф (0) mod Л4,
где ...» р& — простые числа, входящие в каноническое
разложение числа М. — 1: М — 1 = р™1 * * * • ... • pTs * * * * \ ПЪ* • • •
..., ms — целые положительные числа.
Например, если М = 25 — 1 = 31, то, поскольку
М — 1 = 2 • 3 • 5, р должно удовлетворять неравенствам
(3 3Ui; pis _ 1 31^2; рю _ 1 зиз; ре — 1 #= 31/?4
при любых целых неотрицательных ki, k2, ks, Эти нера-
венства удовлетворяются, в частности, при р = 3.
Таблица 2.2
Номер
множите-
ля
1
2
3
4
5
6
7
8
9
10
11
12
13
14
16807
630360016
1078318381
1203248318
397204094
2027812808
1323257245
764261123
23254
25487
42966
50974
71827
112817
Место использования датчика с параметрами
Р. м
Пакеты LLRANDOM, IMSL [64]
Язык программирования SIMSCRIPT
[63]
[63]
[63]
[63]
[63]
[63]
Настоящий практикум
» »
» »
» »
» »
» »
2 Зак. 1015
33
Для увеличения Ттах целесообразно в этой ситуации
выбирать в качестве М наибольшее простое число, не
превосходящее наибольшего целого числа 2^ — 1, пред-
ставимого в ЭВМ. Отметим, что число M=2q—1 явля-
ется простым при q = 2, 3, 5, 13, 17, 19, 31, 61, ... . Для
ЕС ЭВМ удобно использовать q = 31, М = 231 —1 —
= 2147483647, 0 е{55326, 61617, 123726, 143436, 214223,
334347} *). В табл. 2.2 представлены значения множите-
ля 0, рекомендуемые при таком выборе Л4. При этом
Гтах = М—1 « 2,14-109, что в 4 раза больше, чем
период для подпрограммы RANDU (см. Приложение 1).
Отметим еще, что в [63] множители с номерами 1, 2, .. ., 8 иссле-
довались с помощью тестов из § 1.5, а также с помощью теста неза-
висимости, основанного на периодограммных статистиках; предпочте-
ние отдано множителю 0 = 397204094. В [63] отмечаются преиму-
щества такого датчика по сравнению с RANDU. В частности, спек-
тральный анализ последовательности, генерируемой RANDU, обна-
руживает периодические колебания с периодом, близким к т = 4.
Первоначальный перечень экспериментов
1. М. =з 64; 0=5; nJ—11. Реализовать на ЭВМ програм-
мный датчик с этими значениями параметров; напечатать
таблицу из 100 псевдослучайных чисел А — {п0, ...
..., п99}; по выборке А построить гистограмму и оценить
период.
2. М = 231; р = «о = 2"г 4- 3; m = 4, 8, 12, 16, 20, 24, 28
(при m = 16 получается известный датчик RANDU).
Сравнить эти семь датчиков по точности моделирования,
используя тесты из § 1.5. Найти оптимальное пг*.
3. М = 109; nJ = 65539; 0 = 203. При помощи тестов
из § 1.5 исследовать точность этого программного дат-
чика БСВ.
4. Л4=231—1, 0 выбрать из табл. 2.2. При помощи те-
стов из § 1.5 исследовать точность этого программного
датчика БСВ для различных значений по.
Указания
1. Изучить программный датчик RANDU (см. При-
ложение 1) и способ реализации в нем вычисления вы-
чета по модулю М.
Значения 0 приведены в восьмеричной записи.
34
2. При реализации датчиков на ЭВМ следует избе-
гать введения операций с удвоенной точностью, так как
при этом существенно снижается быстродействие.
3. При выполнении эксперимента 4 для вычисления
вычета по модулю М целесообразно использовать оче-
видное тождество: для любых натуральных L, z таких,
что z — у + kL, k — [z/L], у — (z)mod L, имеет место
тождество
(г) mod (L — 1) == k -|- \у — (L — 1)
k
причем эта формула записана так, чтобы избежать про-
граммных прерываний на ЭВМ по переполнению.
Положив L = М + 1 = 231, z = p£Zf_i, формулу (2.2)
используем в (2.1). При этом у вычисляется, как и в
RANDU, а
k = [0 (ц;_!/(Л- 1)) (1 - 1/L)] = [₽at-i (МДМ + 1))].
Для устранения ошибки округления при у = 0 следует
положить k равным ближайшему целому числу для ве-
щественного числа |Заг-_1М/(М +1).
4. Сравнить датчики по затратам машинного времени
на получение одного псевдослучайного числа.
5. Для доказательства встречающихся в работе
утверждений используется аппарат теории чисел.
§
2.2. Моделирование базовой случайной величины
при помощи линейных смешанных формул
Задание. Реализовать на ЭВМ и исследовать по точ-
ности программные датчики БСВ, использующие линей-
ную смешанную формулу. Параметры датчика выбрать
из условия максимума периода псевдослучайной после-
довательности.
Методика выполнения задания. Псевдослучайная по-
следовательность вычисляется рекуррентно по так назы-
ваемой линейной смешанной формуле, обобщающей
(2.1):
*
а, = а' = + • . + ₽,а'-г + с) mod М,
i = 1, 2......
2*
35
Параметры датчика: г—порядок; fllr+i, а*-г^ •••» Я-1>
а*о — стартовые значения; р Рг— множители; с —
приращение; М — модуль.
Вариант 1 (смешанный конгруэнтный метод),
когда г = 1, с #= 0:
ai — a*i!а* = (pa*_i + с) modAl, i = 1, 2, ... . (2.3)
Согласно (2.3) а* е {0, 1, ..., М— 1}, поэтому: 1) после-
довательность а* (и Oj) всегда «зацикливается»; 2) период
Т М. Справедлива
Теорема [15}. Максимально возможная величина пе-
риода псевдослучайной последовательности ц; равна
Лпах = М и достигается тогда и только тогда, когда:
1) с и М — взаимно просты; 2) р — 1 кратно р для лю-
бого простого р, являющегося делителем М; 3) р — 1
кратно четырем, если М кратно четырем.
Если период Т = Tmax = М, то каждое число от 0 до
Л4 — 1 встречается за один цикл 1 раз. Поэтому из (2.3)
следует, что в этой ситуации а о не влияет на величину
периода и выбирается произвольно. В частности, при
М = 21 надлежит использовать р = 2^ + 1 > <7^2, нечет-
ное с и произвольное а0.
В [16] приводится рассчитанная аналитически по выборке объе-
ма п = М оценка ковариационной функции R(j), введенная в § 1.5.
Вариант 2 (датчик Ван Вейнгардена), когда 1,
с = 0, Р; #= 0, / = 1, г:
аь = а*/М, а* = (2 ₽X-/Jm°d 1' = 2> • • • •
i=i
Период этого датчика Т Мг — 1 увеличивается при
увеличении М и г. Аналитические результаты по опти-
мальному выбору параметров (2.4) в литературе отсут-
ствуют. Экспериментальные результаты показывают, что
достаточно высокая точность моделирования БСВ дости-
гается при весьма произвольном выборе множителей {Pj}.
Например, М = 236, Pt = р2 = 13; М = 23«, pi = 13, р2 = 27;
Л1 = 28, г= 10, pj=l, /=1, Ю. Во всех этих примерах
Tmax > 0,5 • 106.
36
Первоначальный перечень экспериментов
1. M = 231; р = 2?+1; q <={1, 2, 3, 4, 5}; с = 13;
г = 1. Реализовать на ЭВМ программный датчик с этими
значениями параметров. Сравнить датчики при различ-
ных q по точности моделирования, используя тесты из
§ 1.5. Найти оптимальное q*. Для оптимального q* напе-
чатать таблицу из 100 псевдослучайных чисел.
2. Л4 = 256; г = 2; |3i = р2 = 1; с = 0. При помощи
тестов из § 1.5 исследовать точность этого программного
датчика БСВ. Как влияют стартовые значения датчика?
3. Л4 = 256; г => 10; Р, = 1, j — г; с — 0. При помо-
щи тестов из § 1.5 исследовать точность этого програм-
много датчика БСВ. Как влияет г?
Указания
1. При реализации датчиков на ЭВМ следует избе-
гать введения операций с удвоенной точностью, так как
при этом существенно снижается быстродействие.
2. Для каждого датчика оценить машинное время,
расходуемое на получение одного псевдослучайного
числа.
§ 2.3. Моделирование базовой случайной величины
при помощи нелинейных формул
Задание. Реализовать на ЭВМ и исследовать по точ-
ности моделирования программные датчики БСВ, исполь-
зующие нелинейные методы. Параметры датчика выбрать
из условия максимума периода псевдослучайной после-
довательности.
Методика выполнения задания.
1. Метод «середины квадрата» — исторически первый
метод моделирования БСВ, предложенный Джоном фон
Нейманом в 1946 г. Псевдослучайная последовательность
вычисляется рекуррентно:
aL = 2~2ka', а* = (((a*_i)2) mod23* —
— ((a*-i)2) mod 2*)/2\ (2.5)
где х=1, 2, ...; kt Oq — параметры датчика. Стартовое
значение «J ¥= 1 выбирается среди натуральных чисел, не
37
превосходящих 22А'—1 так, чтобы ((nJ)2) тоб2/г =#0. Из
(2.5) видно, что а\—число, образованное средними 2k
битами 46-разрядного двоичного числа (az_i)2. Отсюда и
название метода. Модификацией (2.5) является метод «се-
редины произведения »:
a*i = ((«/—i aZ-2) mod 23* — (n*_i^*_2) mod 2*)/2\
i = 1, 2, . .. . (2.6)
Соотношения (2.5), (2.6) легко программируются на
ЭВМ при помощи специальных операций машинного
языка.
2. Квадратичный метод Ковэю:
at = а*/2^, n* = (tz*_i (ц*_1 + 1)) mod 2 А
1 = 1, 2, ... , (2.7)
где (#о) mod 4 = 2. Длина периода псевдослучайной после-
довательности при этом равна Т — 2^~2. Целесообразно
выбирать q равным числу двоичных разрядов, используе-
мых для записи целого числа в ЭВМ (для ЕС q = 31).
Вычисления по mod 2ч в (2.7) при этом следует выпол-
нять, как в подпрограмме RANDU.
3. Квадратичный конгруэнтный метод является обоб-
щением линейного метода [см. § 2.2 и выражение (2.7)]:
aL = а*/Л4, а* = (у (nj_i )2 -|- P«t*_i -|- с) mod М,
Z= 1, 2, ... . (2.8)
Параметры nJ, Л4, р, у, с датчика (2.8), обеспечивающие
максимальный период последовательности, определяются
теоремой.
Теорема [15]. Псевдослучайная последовательность
(2.8) имеет наибольший период Ттах = Л4, достигаемый
тогда и только тогда, когда выполнены условия: 1) с и
М. — взаимно простые числа; 2) у, р — 1 кратны р, где
р — любой нечетный простой делитель для М; 3) у —
четное, причем (у) mod 4 = (р — l)mod4, если М кратно
четырем, и (у)mod 2 = (р — l)mod 2, если М кратно двум;
4) если М кратно девяти, то или (у) mod 9 = 0, или
(P)mod9 = 1 и (cy)mod9 = 6.
Особую практическую ценность представляет случай
М = 2ч.
Следствие. Если q 2, то наибольший период
7'max=2<? для псевдослучайной последовательности (2.8)
38
достигается тогда и только тогда, когда с нечетно, у чет-
но, ар — нечетное число, удовлетворяющее соотношению
(R)mod 4 = (у + l)mod 4.
с г
Первоначальный перечень экспериментов
1. При k = 7, <7.о=113, а_\ = 13 реализовать на ЭВМ
программные датчики (2.5) и (2.6). Сравнить их по точ-
ности при помощи тестов из § 1.5. Напечатать таблицы
из 100 случайных чисел. Как влияют ц0» i?
2. При q = 31 реализовать датчик (2.7). При помощи
тестов из § 1.5 исследовать его точность.
3. Реализовать и исследовать по точности про-
граммный датчик (2.8) при М = 231, у = 14, р = 3, с = 13.
Указания
1. Результаты эксперимента 3 сравнить с результа-
тами эксперимента 1 из § 2.2.
2. Во избежание программных прерываний при вы-
числениях в (2.8) использовать свойство
а] = ((у («*_ iC*—i) mod Л4) mod М +
+ (ря*_i) mod М + с) mod М.
3. Сравнить датчики по затратам машинного времени
на получение одного псевдослучайного числа.
§ 2.4. Моделирование базовой случайной величины
методом Макларена — Марсальи
Задание. Реализовать па ЭВМ и исследовать по точ-
ности моделирования программные датчики БСВ, по-
строенные методом Макларена — Марсальи.
Методика выполнения задания. Для повышения точ-
ности моделирования БСВ Макларен и Марсалья пред-
ложили комбинировать два простейших датчика БСВ,
точность моделирования у которых недостаточно высока.
Пусть bi, Ci, i = 0, 1, 2, ..., — псевдослучайные после-
довательности, порождаемые независимо работающими
простейшими программными датчиками Д1 и Д2 соответ-
ственно; V={V(0), ..., V(К — 1)}— вспомогательная
39
таблица К целых чисел. Вначале V-таблица заполняется
первыми К членами последовательности Ьр.
V (/) = bj, / = 0, Л'-1.
Через ai будем обозначать комбинированную псевдослу-
чайную последовательность; член ai является результа-
том последовательности операций
s =[сг/С], аг = V(s), V(s) = bi+K, i = 0, 1,2,... .
Отсюда видно, что Д2 осуществляет случайный выбор из
V-таблнцы, а также ее случайное заполнение числами,
порождаемыми Дь Этот метод позволяет ослабить зави-
симость между членами и получать «невероятно»
большие периоды, если периоды 7\, Т2 последователь-
ностей {Ьг}, {Сг} взаимно простые.
Первоначальный перечень экспериментов
1. Реализовать и исследовать по точности Д1, Д2
и датчик Макларена — Марсальи при К = 64, используя
Дх: bi = b*/256, bi = (17^_i + 19) mod 256,
Z = 1, 2, ...; bo = 0;
д2:С. = c*/128, с* - (33c*-i 4-113) mod 128,
1 —- 1, 2, ... , cq — 1 •
Оценить период T для аг и сравнить его с 74, Т2 (описа-
ние датчиков Д1, Д2 дано в § 2.2). Сравнить точность мо-
делирования этих трех датчиков.
2. Реализовать и исследовать по точности датчик
Макларена — Марсальи при К = 73, используя в качест-
ве Дь Д2 подпрограмму RANDU (см. Приложение 1)
с различными стартовыми значениями: для Д1 Ьо =
= 65539, а для Д2 с*0 = 3141569. Оформить этот датчик
в виде подпрограммы.
Указание
Для каждого датчика оценить затраты машинного
времени на получение одного псевдослучайного числа.
40
§ 2.5. Моделирование базовой случайной величины
методом, основанным на свойстве воспроизводимости
равномерного закона
Задание. Реализовать на ЭВМ и исследовать по точ-
ности моделирования программные датчики БСВ, исполь-
зующие свойство воспроизводимости равномерного зако-
на и предназначенные для микро-ЭВМ. с невысокой раз-
рядностью слова.
Методика выполнения задания. Пусть |i, £2, ...—
независимые случайные величины со значениями на про-
межутке [0, 1), N — натуральное число; определены слу-
чайные величины
W — Si + • • • 4~
(2.9)
t,N = m°d 1 = [Ла] •
(2.Ю)
Формула (2.10)—дробная часть тру. Сформулируем ре-
зультат, выражающий свойство воспроизводимости рав-
номерного закона.
Теорема 1. Если ..., имеют равномерное рас-
пределение, то и случайная величина имеет стандарт-
ное равномерное распределение.
Доказательство. По правилам функциональ-
ного преобразования (2.10) случайных величин выразим
плотность распределения (?) случайной величины
£jve[0, 1) через плотность р^(у) распределения слу-
чайной величины тру е [0, N):
N—1
= 2/Чу (*+*)> 0<?<l. (2.11)
1=0
Согласно теореме 2.8.2 [8]
N
PnN(y)= (N-_w
V ' k=0
k). (2.12)
Подставляя теперь
мирования i на / =
по /, k, получаем
(2.12) в (2.11), заменяя индекс сум-
i — k и меняя порядок суммирования
Pin (?)
41
Суммируя по k, находим
PlN (z) =
N~ 1
и*
что и требовалось доказать.
Доказанное свойство позволяет строить весьма эффек-
тивные датчики на микро-ЭВМ с невысокой разряд-
ностью слова. Пусть имеется два простейших датчика
БСВ Д1, Д2; {Bu, Biz, ...}, {Ь, Ь, ...{—независимые
случайные последовательности, моделируемые этими дат-
чиками; рег(х)—плотность распределения случайной
величины хе[0, 1), i = 1, 2; /= 1, 2, ... . Пусть
плотность распределения р%.. (•) отличается от плот-
ности стандартного равномерного распределения
ре (%) = До, и (х) + еД W »
(2.13)
где ЛДх)— ограниченная функция такая, что
hi (х) > — 1/е2; hi (х) = 0 при х^ [0, 1);
1
(4
hi (х) dx = 0;
о
(2-14)
<= [0, 1], и характеризует точность датчика Дг-: чем е?-
меньше, тем точность выше.
Теорема 2. Пусть аналогично (2.9), (2.10)
W = Ви + Ui, Bi = (ili)mod 1. (2.15)
Если s (0, 1) независимы и имеют плотность
(2.13), то имеет плотность распределения
hi (х) (/г2 (г — х) +
+/12 (^ + 1—х)) dx, zGE[0, 1).
(2.1G)
азательство.
Согласно (2.15)
д
Plj (2) = Рч7. (*) + Рч,- (г + 1) J
J J J
+ еЛ (х)) (До, 1) (У — х) 4- е?Д2 (// — х)) dx.
42
Поэтому при ZCEE [0, 1)
1
о
Ч- /[о, 1) (г 4* 1 — %) 4~ (^2 (г — %) 4~ ^2 (z 4“ 1 х))) dx.
Подынтегральное выражение упрощается, поскольку
Ло,1)(2! — х) 4- 710,1) (г 4- 1 — х) =2 1. Тогда с учетом (2.14)
получаем (2.16).
Из сравнения (2.13), (2.16) заключаем, что случайная
последовательность £/ имеет распределение, более близ-
кое к стандартному равномерному, чем гр/, -щ/.
А..
г и
(z) = /[0,1)(г) + О(ег),
Pt,(z) = h<>. i> (г) + О (eie2).
Формула (2.15) и используется при моделировании для
получения /-го псевдослучайного числа. Аналогичным
образом, увеличивая число исходных датчиков Д1, Д2, ...,
можно достичь требуемой точности моделирования.
В заключение отметим еще, что для увеличения отрез-
ка апериодичности последовательности {£/} следует
использовать датчики Д1, Д2, периоды у которых Ti, —
взаимно простые числа.
П ервоначальный перечень экспериментов
1. Построить датчик для 16-разрядной микро-ЭВМ,
использующий в качестве Дь Д2 простейшие мультипли-
кативные датчики, модули у которых — простые числа
(см. § 2.1, вариант 3): '
Й/ - (171 , у_i) mod 30269, Й//30269,
Й/ =(172^,/-i) mod 30307, = Й//30307, /-1,2,...;
|1о = 13, Йо = 117. Периоды для этих датчиков 7\^Т2~
« 3 • 104 и взаимно просты. С помощью тестов из § 1.5
исследовать точность моделирования БСВ алгоритмом
(2.15). Оценить быстродействие датчика.
2. Рассмотреть случай трех исходных датчиков:
Дь Д2 определены выше, а Д3:
Й/ = (170Й./-1) mod 30323, - Й//30323, j = 1, 2, ...;
43
£зо — 511. Теоретически и экспериментально на ЭВМ оце-
нить точность датчика = (£ij + £2; + ^3j)mod 1, извест-
ного в литературе [65] как алгоритм AS 183.
Указание
При вычислении вычетов но модулям 30269, 30307,
30323 удобно воспользоваться приемами, предложенными
в [65].
§ 2.6. Моделирование полной группы случайных
событий
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования полной группы N случай-
ных событий, вероятности которых заданы: р4, ..., pN.
Методика выполнения задания. Исходим из того, что
имеется датчик БСВ а, заданной на базовом вероятност-
ном пространстве (Q, Fo, Р) (см. § 1.2). Система подмно-
жеств Fi, ..., Fn е Fo называется полной группой слу-
JV
чайных событий на (Q, Fo, Р), если: a) U Fi = Q;
____1=1
б) Fi П Fj = 0, i j; в) Р (Fi) >0, i = 1, N. Вероят-
ности {P(F<)} удовлетворяют условию нормировки
АГ
Определим подмножества {Fi} при помощи БСВ а
так, чтобы выполнялись условия а)—в) и, кроме того,
вероятности Р(Л) равнялись pi, i = 1, N. Для этого по-
ложим
Ft = {со : Si-i < а (со) <
i
So = о, Si = 2 Pjf 1 =
/=1
(2.17)
Действительно, из (2.17) имеем согласно (1.7)
P(Ff)
Ра (х) dx = Si — Si-1 = Pi,
44
Таким образом, модели-
рующий алгоритм заключа-
ется в последовательности
шагов.
Шаг 1. Обращение к
датчику БСВ и получение
псевдослучайного числа а.
Шаг 2. Сравнение а с
величинами {5J и определе-
ние номера k, для которого
S k—1 a <Z. S)i.
Ш а г 3. Принятие реше-
ния о том, что наступило со-
бытие Fk-
Заметим, что коэффици-
ент использования БСВ х=
= 1. Меняя в датчике БСВ
♦
стартовое число «о и повто-
ряя алгоритм п раз, получа-
ем модель схемы п независи-
мых испытаний, в-каждом из
которых наступает одно из
событий Fi, ..., fN. На рис.
2.1 изображена блок-схема
моделирующего алгоритма.
Первоначальный
перечень экспериментов
1. Моделирование жре-
бия с N равновероятными
исходами: pi=\IN (П=2 —
бросание монеты, /V=6 —
бросание игральной кости).
2. Af=5; Pi=0,l; р2=
= 0,25; р3=0,15; р4=0,3;
?5=0,2.
3. N = 12; pi = 0,08; р2 = 0,03; р3 = 0,20; р4 = 0,07;
р5 = 0,11; р6 — 0,06; pi = 0,05; р& == 0,02; р9 = 0,16; рю =
= 0,09; рп = 0,06; р12 = 0,07.
Напечатать таблицы результатов 100-кратного повто-
рения независимых испытаний (п = 100).
45
Указания
1. Если pt = 1/N, то шаг 2 алгоритма упрощается:
k =|W|+ 1.
2. Исследование точности проводится по результатам
n-кратного повторения моделирующего алгоритма: «1, ...
..., nN, где tii — число испытаний, при которых насту-
N
пило ЕД S — п) • Точность моделирования характери-
1=1
зуется точечными оценками вероятностей {Р(Л)}:
А
Р(Ег)= tiiln и интервальными оценками: с вероят-
ностью р Р(Л)е[рг_, рг+], где границы pi± опреде-
А
ляются по таблицам [27] в зависимости от р, п, P(Fi).
Если для всех i = 1, N заданные вероятности Рг
e[p$_, рг+], то точность моделирования следует признать
удовлетворительной. Далее необходимо проверить гипо-
тезу Но о том, что для моделирующего алгоритма Р (Fi) =
= Pi, i — 1, N. Альтернатива заключается в нарушении
хотя бы одного из этих равенств. Определим вспомога-
тельную случайную величину
N
с функцией распределения F%(x), а через Fo(x) обозна-
чим функцию распределения дискретной случайной вели-
чины со значениями {1, ..., N} и вероятностями этих
значений {pi, ..., Pn}. Тогда очевидно, что гипотеза Но
эквивалентна гипотезе F%(x)=Fo(x), задача проверки
которой рассмотрена в § 1.4. Следует воспользоваться
Х2-критерием из § 1.4, определяемым формулами (1.20),
(1.21) при k = N.
§ 2.7. Моделирование зависимых случайных событий
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования случайных событий А, А,
зависящих от случайных событий Fl} ..., Fjv, составляю-
щих полную группу событий, для которых заданы услов-
ные и безусловцые вероятности.
46
Методика выполнения задания. Исходим из того, что
имеется датчик БСВ а, позволяющий моделировать две
независимые БСВ aj = aj(co), / = 1, 2, определенные на
базовом вероятностном пространстве (Q2, Fo, Р) (см.
§ 1.2), и полная группа случайных событий {Fc i = 1,7V}cz
cz Fo, вероятности которых заданы: P(Fi) = pi. Событие
A EE Fo есть событие, для которого заданы условные
вероятности Р(А|Fi) = i == ], N\ A^Fl—противопо-
ложное по отношению к А событие, P(a|Fi) = 1—qt.
Вероятности {pi}, {qi} полностью описывают события
A, A, {Fi); любые другие вероятности выражаются через
{pj, {Qi} при помощи формул сложения, умножения ве-
роятностей, полной вероятности и Байеса. Например,
N
безусловная вероятность Р(А) = PiPi. Определим со-
i=i
бытия {Fi} аналогично (2.17):
Fi — {(О — (®1> . Cl, Е~ С , [_1 ~ Qj ({•*}) ^г) >
i
So = О, 5г = 2 Р), i = О'-
/=1
Определим событие AeeF?:
А= и ЛПЛ= и {®GQ2: Sf_, <a1(<o)<Si>
I— 1 1= 1
0<а2 ((о)<ед);
А определяется как дополнение кА.
Таким образом, моделирующий алгоритм заключается
в последовательности шагов.
Шаг 1. Обращение к датчику БСВ и получение
псевдослучайного числа at.
Ш а г 2. Сравнение at с величинами {S?} и определе-
ние номера k, для которого at <Z Sk и, следова-
тельно, наступило Fk. :
Шаг 3. Изменениеустартового числа датчика (o,q : —
= 01) и получение второго псевдослучайного числа а2.
Шаг 4. Сравнение с qk (если а2 <Z qh, то насту-
пило А, иначе А). Заметим, что коэффициент использо-
вания БСВ х = 0,5.
Последовательно меняя стартовое число Оо датчика и
повторяя алгоритм п раз, подобно § 2.6, получаем мо-
дель схемы п независимых испытаний.
47
Первоначальный перечень экспериментов
1. N = 3; pi = 0,2; р2 = 0,5; р3 = 0,3; qi = 0,3; q2 =
= 0,4; q3 = 0,5.
2. М = 6; pt = 0,11; р2 = 0,27; р3 = 0,17; р4 = 0,07;
р5 = 0,25; р6 = 0,13; pi = 0,9; q2 = 0,2; q3 = 0,8; <?4 = 0,3;
q5 = 0,7; q6 = 0,4.
Напечатать таблицы результатов 100-кратного повто-
рения испытаний (п — 100).
Указание
Аналогично § 2.6 исследовать точность моделирова-
ния (получить точечные и интервальные оценки для
Р(А|Л), P(Fi),i= MV).
§ 2.8. Моделирование дискретной случайной величины
при помощи случайных событий
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования дискретной случайной
величины | со множеством N возможных значений
< с2 < ... < cN, принимаемых с заданными вероят-
ностями pi, ..., Pn, N оо.
Методика выполнения задания. Определим на базо-
вом вероятностном пространстве (Q, Fq, Р) события
Fi = {o):oeQ, 1(w) = q}, * = 1, N • (2.18)
Это полная группа случайных событий. Согласно (2.18)
справедливо и обратное выражение £ = £(со) через {Л}:
если со е Fi,
если we f2’
(2.19)
Сдг, если со ее Fn-
Таким образом, моделирование дискретной случайной
величины £ сведено к задаче моделирования полной груп-
пы случайных событий {FJ. Решение этой задачи рас-
смотрено в § 2.6. Описанный в § 2.6 моделирующий алго-
ритм достаточно [согласно (2.19)] дополнить единствен-
ным шагом.
48
Ш а г 4. Принятие решения о том, что реализацией |
является х = Ck-
Заметим, что коэффициент использования датчика БСВ
х = 1. Последовательно меняя стартовое число «о в датчи-
ке БСВ и повторяя алгоритм n-кратно, получаем п реа-
лизаций случайной величины моделирующих резуль-
таты наблюдения над | в п независимых экспериментах
(случайную выборку объема п).
Первоначальный перечень экспериментов
N = 2; Ct = 0; с2 = 1 (случайная величина Вернул*
ли); pi = 0,4; р2 = 0,6; п = 100. ____
2. N — 10; Ct = i; pt =0,1; i= 1,10; n = 200.
3. N = 26; Ct = i; pt = 1/26; i = 1,26; n = 600.
Указания
1. Исследование точности моделирования провести
согласно § 1.4, полагая F0(x) заданной функцией распре-
деления:
0, если х
рг, если сг
2’
Fo (Х) - Pi + если с2
1, если х>с^.
2. При пользовании %2-критерием ячейки удобно вы-
брать так: k = N, {ci}, {с2}, ..., {Cv}.
3. Кроме проверки гипотезы согласия F% (х) == Fo (х),
надлежит по выборке X={xi, ..., хп} вычислить точеч-
ные и интервальные оценки для вероятностей Р{£ = сг},
i = 1, N. Точечными оценками являются частоты
а интервальные находятся с помощью таблиц [27, 48].
4. Модифицировать моделирующий алгоритм для
N = оо согласно [16].
49
§ 2.9. Моделирование случайной величины,
распределенной по биномиальному закону
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования случайной величины %,
распределенной по биномиальному закону:
CnPx (1 — P)N~X, если х Е {0, 1, ..., М},
О в противном случае,
(2.20)
где р е(0, 1) и натуральное число N >» 1—заданные
параметры распределения.
Методика выполнения задания. Исследуем два основ-
ных метода моделирования. Первый метод есть частный
случай метода из § 2.8 и заключается в моделировании
полной группы N + 1 случайных событий {£ = 0},
{£= 1}, ...,{£ = Л/}. Перед применением этого метода
упорядочим события в порядке убывания их вероят-
ностей. Этот прием уменьшает среднее время п, затра-
чиваемое ЭВМ на получение одно?! реализации |. Коэф-
фициент использования БСВ xt=l.
При N 1 первый метод применять затруднительно
из-за понижения точности вычислений в (2.20) и доста-
точно большой величины ть Этих недостатков лишен вто-
рой метод, основанный на следующем результате.
Теорема 1. Если аг (со), ...» аv (со) — независимые БСВ,
определенные на (Q;v, Fo, Р), то случайная величина
N
Щ (®))
(2.21)
имеет распределение (2.20).
Следовательно, для получения реализации х случай-
ной величины £ достаточно получить из датчика БСВ
N псевдослучайных чисел A={ai, ..., On}', вычислить
число k элементов из А, меньших р, и принять х = k.
Нахождение числа k можно существенно упростить.
Пусть вначале N = 2п — 1 и найдена выборочная медиа-
на а (это элемент из А, для которого [7V/2] элементов
из А меньше а, а [Л772] остальных элементов из А боль-
ше а). Если а р, то очевидно, что k = [7У/2] + 1 + k',
где k' — число элементов из А, попавших в интервал
(а, р); очевидно, что k' — реализация биномиальной слу-
50
чайной величины с параметрами р* — (р— d)/(l— а),
АГ* = [Л/72]. Если же а > р, то k можно рассматривать
как реализацию биномиальной случайной величины с па-
раметрами р* = p/а, N* = [N/2].
Таким образом, используя медиану а, можно умень-
шить вдвое параметр N. Далее процесс вычисления k
51
повторяется аналогично, пока М!: не станет достаточно
малой величиной, например А*<15. При малом N*
k вычисляется прямым перебором элементов из А.
Ситуацию с N — 2п легко свести к ситуации с N =
= 2п—1. Действительно, представим согласно (2.21)
S = I W = U {Р — «2п (<»))
2л—1
а/ (со)).
Случайная величина U (р — ос2п (со)) является бернуллиев-
2п— 1
ской и моделируется, как в § 2.8, а U (р— щ (со)),
t=i
— как в выше описанной ситуации.
Теорема 2 [14). Медиана а есть реализация случайной
величины, имеющей бета-распределение с плотностью
Теорема 3. Если ц— стандартная нормально распре-
деленная случайная величина с функцией распределения
Ф(//), то при п~^оо случайная величина
tn = 0,5
1/ “ М--------П-----)
' з \ \/(4/г—1)/3/
имеет бета-распределение (2.22).
Таким образом, для п 1 удобно медиану а получать
моделированием, используя для моделирования т) под-
программу GAUSS (см. Приложение 1). На рис. 2.2 изо-
бражена блок-схема моделирующего алгоритма. Для
ЭВМ IBM-360/65 затраты машинного времени т2 =
= (0,8 log2(M/4)) 10-3 с {N > 1).
Первоначальный перечень экспериментов
1. N = 26, р = 0,4.
2. N = 32, р = 0,6.
3. N = 128, р = 0,8.
Указания
1. Сравнить Ti, т2.
2. Оценить среднее значение х2 и сравнить с xi.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4. См. также указа-
ния 2 и 3 из § 2.8.
52
§ 2.10. Моделирование случайной величины,
распределенной по закону Пуассона
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования случайной величины £,
распределенной по закону Пуассона:
Хе~к/х\у если л'Е{0, 1, 2
в противном случае,
(2.23)
где 0— заданный параметр распределения.
Методика выполнения задания. Исследуем два основ-
ных метода моделирования. Первый метод есть частный
случай метода из § 2.8 и заключается в моделировании
полной счетной системы случайных событий: {£ = 0},
{£ = 1}, ..., {£ = %}, ... . Коэффициент использования
БСВ Xi = 1, а среднее время, затрачиваемое ЭВМ на по-
лучение одной реализации £, обозначим п.
При X 1 понижается точность вычислений в (2.23)
и существенно увеличивается ть Последнее происходит
из-за увеличения дисперсии распределения (2.23) и, как
результат, увеличения числа событий {£ = х}, вероят-
ностью которых пренебречь нельзя. (Напомним, что
М{Й= D®=z.) Этих недостатков лишен второй метод.
Лемма. Если ai, аг, .— независимые БСВ,
то = «1 • ... • (Хд’ имеет плотность
fN(z) = (-\nz)N-i/(N - 1)1, 0^г< 1. (2.24)
Доказательство (метод математической индук-
ции). Лемма верна при М=1, так как fi(z)==l, 0^г<1.
Для £дг+1 = cin+i&v по формуле полной вероятности для
плотностей согласно (2.24)
1
f A'+l ( ) J Р&ДЦ-11
0
1
= f (U(z’~ z)/z')fN(z')dz' = (— lnz)"/M
b
Теорема. Случайная величина определенная соот-
ношением
АЧ-1
g = minpV: П o*<r\ N = 0, 1, ..(2.25)
k=l
распределена по закону Пуассона (2.23).
53
Доказательство. По формуле полной вероят-
ности согласно (1.6), (2.24), (2.25) получаем (2.23):
Р {£ = х} = Р ({^ > е~к} П {^x+i < е-4) =
= М {Р ({^ > П {ах+1 < е~к} | CJ} =
Формула (2.25) и определяет моделирующий алго-
ритм второго метода. Для этого метода характерно слу-
чайное число используемых БСВ: г = £4-1. Средний
коэффициент использования БСВ
х2 — М
lke~K _ 1 — е~к
k\ ~ %
ОО
Заметим, что при X—> 0 1, а при оо х2-> 0.
Первоначальный перечень экспериментов
I ' »
1. Л = 2. 2. Л. = 5. 3. X = 10. 4. Л = 40.
.* <ь •
Указания
1. Оценить средние затраты машинного времени п, т2
и сравнить их в зависимости от X.
2. Построить график хг = хг(%) и сравнить с xi.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
4. Вычислить точечные и интервальные оценки для
параметра X по выборке, имитированной реализованными
алгоритмами, и сравнить с заданными значениями X.
См. также указания 2 и 3 из § 2.8.
§2.11 . Моделирование случайной величины,
распределенной по геометрическому закону
Задание. Реализовать на ЭВМ. и исследовать по точ-
ности алгоритм моделирования случайной величины £,
распределенной по геометрическому закону:
" - « .
54
р {£ = *} =
р (1 — р)х, если хе {0, 1,2, ...},
О в противном случае,
(2.26)
где р е (0, 1)—заданный параметр распределения.
Методика выполнения задания. Распределение (2.26)
часто встречается в приложениях: | описывает число
безуспешных попыток, предшествующих первой успеш-
ной попытке в схеме независимых испытаний, при усло-
вии, что вероятность успеха в отдельном испытании
равна р.
Исследуем два основных метода моделирования £.
Первый метод есть частный случай метода из § 2.8 и за-
ключается в моделировании полной счетной системы
случайных событий: {£ = 0}, {£ = 1}, ..., {£ = %}, ... .
Коэффициент использования БСВ х4 = 1, а среднее вре-
мя, затрачиваемое ЭВМ на получение одной реализа-
ции £, обозначим п.
Второй метод основан на следующей теореме.
Теорема. Если а — БСВ, то случайная величина
|=[1па/1п(1-р)], (2.27)
где [г] — целая часть z, имеет распределение (2.26).
Доказательство. Согласно (2.27), (1.6) полу-
чаем (2.26):
P{g=.v}=P{xsgln tx/ln(I— p)<x+l} =
= Р{(1 - p)»+l С a <(1 — p)*} =
= (1 — p)x —(1 —p)*+‘ = p(l — p)*.
Формула (2.27) и определяет моделирующий алго-
ритм второго метода. Заметим, что коэффициент исполь-
зования БСВ для этого алгоритма хг = xi = 1, а среднее
время обозначим Т2-
Первоначальный перечень экспериментов
1. р = 0,1. 2. р = 0,2. 3. р = 0,3. 4. р = 0,4. 5. р = 0,5.
Указания
1. Оценить Ti, Т2 и сравнить их в зависимости от р.
2. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
3. Вычислить точечные и интервальные оценки для
параметра р по выборке {xi, ..., хп}, имитированной
55
реализованными алгоритмами, и сравнить с заданными
значениями р. Оценкой максимального правдоподобия
для р является статистика
л п
Р = 1/(1 + х), X = 2 Xi!n'
i=\
См. также указания 2 и 3 из § 2.8.
§ 2.12. Моделирование непрерывной случайной
величины методом обратной функции
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод обратной функции при моделировании не-
прерывной случайной величины | с фиксированной плот-
ностью распределения /о(х).
Методика выполнения задания. Определим функцию
распределения для %
X
Fa(x) = J f„(y)dy, (2.28)
— оо
которую будем предполагать строго монотонно возрастаю-
щей. Через Fq (у) обозначим обратную функцию; она
находится при решении уравнения
Fq (х) = у (2.29)
относительно х: х = Fo (у).
Теорема. Если а — БСВ, определенная на (Q,F0, Р),
то случайная величина
5 = Гё' (а)
(2.30)
имеет функцию распределения F%(x)= F0(x).
Доказательство. Поскольку при строго моно-
тонном преобразовании знак неравенства сохраняется,
то из (1.6), (2.29) и (2.30) получаем
Fi(x) = Р{5<*} = Р{^' (а)<х} =
= P{a<f0(x)} = f„(x).
Формула (2.30) и определяет моделирующий алго-
ритм. Коэффициент использования БСВ х = 1. Недостат-
ком описанного метода являются аналитические труд-
ности при вычислениях (2.28), (2.29). Отметим, что в
•56
«чистом виде» метод обратной функции редко исполь-
зуется на практике, так как для многих распределений
(например, нормального) даже Fo(x) (не говоря уже
о Fo'1 (у)) не выражается через элементарные функции,
а табулирование Fo(y) существенно усложняет модели-
рование. На практике метод обратной функции допол-
няют аппроксимацией Fo(y) или сочетают с другими ме-
тодами.
П ервоначальный перечень экспериментов
1. Экспоненциальное распределение:
fo(x) = х О, X = 2.
2. Распределение Вейбулла, описывающее срок служ-
бы элементов электронной аппаратуры:
f0 (х) = bUb-' e-^b, х > О, % = 2, Ь-3.
3. Распределение Парето:
fo W = ухо/хх+1> х х0, х0 = 100, у = 3.
Указания
1. Очевидно, что случайная величина 1 — а тоже имеет
равномерное распределение (1.6), поэтому если Fo (у)
содержит член 1 — у, то с целью сокращения времени
вычислений можно заменить в (2.30) 1—а на а. Напри-
мер, для распределения Парето
Fo' (г/) = х0/(1-г/)'/т,
поэтому | = Хо/а1/^.
2. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации £.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§2.13. Моделирование случайной величины
с заданной гистограммой
Задание. В приложениях часто возникает задача мо-
делирования непрерывной случайной величины | в усло-
виях априорной неопределенности: плотность распредс-
57
ления неизвестна. В такой ситуации проводится серия
наблюдений (экспериментов) над %, по результатам ко-
торых аналогично § 1.4 вычисляется гистограмма —
оценка неизвестной плотности. Общий вид гистограммы
с К ячейками
(2.31)
где Zi)—i-я ячейка, щ— значение гистограммы в
i-Й ячейке. Необходимо реализовать на ЭВМ и исследо-
вать по точности алгоритм моделирования случайной
величины %, плотность распределения которой полагается
совпадающей с гистограммой fo(x).
Методика выполнения задания. Применим метод
обратной функции, описанный в § 2.12. Обозначим
1
Pi = Р{£е [27-1, Zi)}, b0 = 0, bj = ^Рь j = 1, Д. (2.32)
i=l
Из (2.31) и условия нормировки следует, что
Pt = Ct (zi — Zt-i), i = 1, К, bK = 1.
(2.33)
Согласно (2.28), (2.31)—(2.33) вычислим функцию рас-
пределения
{О, если
6/-i + Cj (х — г7-_1), если z/_i < х < Zj, / = 1, /<»
1, если х zK,
причем А'Е [Zj-i, Zj) Fo (х) ее [bj-i, bj). Тогда по теоре-
ме из § 2.12 получаем моделирующий алгоритм
— Zj—1 + ^j—i)/cj,
если bj-i а < bj, 1
К.
(2.34)
Коэффициент использования БСВ х = 1. Иногда гисто-
грамма строится так, что Pi = bi — b i—i = const = l//(.
При этом вычисления по (2.34) упрощаются, так как
для / имеется явное выражение / =[Да]+ 1-
П ервоначальный перечень экспериментов
1. К = 6; z0 = 0; Zi = ih; h = 1; ct = 0,1; c2 = Q = 0,2;
Сз = 0,4; c5 = c6 = 0,05.
2. К = 10; Zo = 0; {zi} pi} заданы в табл. 2.3.
58
Таблица 2.3
i 1 2 3 4 5 6 , 7 8 9 10
Zi 0,1 0,3 0,4 0,5 0,6 0,7 0,9 1,1 1,4 2,0
Pi 0,03 0,18 0,15 0,20 0,15 0,08 0,07 0,06 0,05 0,03
Указания
1. Оценить среднее время т, затрачиваемое ЭВМ на
получение одной реализации £.
2. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§ 2.14. Моделирование случайной величины
с заданным полигоном частот
Задание. Пусть, как и в § 2.13, оценивается плотность
распределения вероятностей случайной величины
Общий вид гистограммы дается выражением (2.31),
а график изображен на
рис. 2.3. Гистограмма — раз-
рывная кусочно-постоянная
функция. Истинная плот-
ность распределения £ обыч-
но является непрерывной.
Поэтому в качестве оценки
плотности используют не ги-
стограмму, а непрерывную
кусочно-линейную функцию
ф(г), получающуюся путем
сглаживания гистограммы.
Построение ф(г) поясняется
рис. 2.3: середины верхних сторон соседних прямоуголь-
ников, образованных гистограммой, соединяются отрез-
ками прямых; получающаяся ломаная и дает график
ф(г). Обозначим площадь под этой ломаной
ОО
(2.35)
59
Функция
fo(z) = ty(z)/S
(2.36)
называется полигоном частот и используется в качестве
искомой оценки плотности. Необходимо реализовать на
ЭВМ и исследовать по точности алгоритм моделирования
случайной величины £, плотность распределения которой
полагается совпадающей с полигоном частот (2.36).
Методика выполнения задания. Применим метод
обратной функции, описанный в § 2.12. Предположим,
гистограмма имеет К ячеек {[г7-ь Zi): i— 1, /(} и Ci есть
значение гистограммы в i-Й ячейке [Zi-i, z-i). Полигон
частот имеет К + 1 ячейку {|Х-—i, zt-): i = 1, К-}- 1};
границы ячеек равны:
го = г0
г0)/2, zK+i = zK + (zK — гк_1 )/2,
г7—1)/2, /- 1, К.
Аналитическое выражение функции ф(г):
(2.37)
где полагается с0 = Су<+1 — 0. Согласно (2.35), (2.37)
к | -1
Заметим, что если Zj — Zj-\ = const = h, то zt —Z[-\ = h
и S = 1, fQ(z) =i|)(z).
При помощи (2.28), (2.36) — (2.38) вычислим функ-
цию распределения
(2.39)
где
z't-i )/2, / = 1, К + 1-
60
Из (2.39) следует, что Fn (4-i) = и xefy-i,
*=> Fo (х) е [bj-i, bj). С учетом (2.39) уравнение (2.29)
для нахождения х — Fo-1 (у) получается квадратным. Ре-
шая его, получаем моделирующий алгоритм (2.30) в виде
I = Z/-i (z'j — г/-1)/(с7' — с--!) + sign (с- — c/_i) X
если bj—\ а <С bj.
Коэффициент использования БСВ z = 1.
Первоначальный перечень экспериментов — тот же,
что и в § 2.13.
Указания — те же, что в § 2.13.
моделировании непрерыв-
Рис. 2.4
§ 2.15. Моделирование непрерывной случайной
величины стандартным методом исключения
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод исключения
ной случайной величины £
с фиксированной плот-
ностью распределения
/о (X).
Методика выполнения
задания. Метод исключе-
ния (метод режекции, ме-
тод Дж. Неймана) осно-
ван на трех следующих
теоремах.
Теорема 1. Если (£,
т)) — двумерный случай-
ный вектор, равномерно
распределенный в области
Fo— {(х, у): Q^y^fo(x)} (заштрихована на рис. 2.4):
Р5,ч(х, У) = У), (2-40)
то компонента £ этого вектора имеет плотность распре-
деления /о(х').
Доказательство. Из (2.40) найдем функцию
распределения случайной величины
61
Fl (x) = P{l<x} =
Р1.ц(х', y)dy =
— ЭО 0 —oo
fl (x) = A (x) = f0 (%).
Тогда
Определим мажорирующую функцию у = g(x):
/о(х)> О
(2.41)
и область G={(x, у): O^y^g (x)}zjF0 (см. рис. 2.4).
Теорема 2. Если (gi, тц), (g2, “Пг), ••• — независимые
случайные векторы, равномерно распределенные в G, то
случайный вектор (g, т]):
£ = Л = Ль где k = min {TV: (g#, л^) e Fo}, (2.42)
распределен равномерно в Fo.
Доказательство. Имеем для любого k 1
Д' ' (*, У) = Ig {х, (G), (2.43)
где mes(G)—площадь фигуры G. Поэтому из (2.42),
(2.43) следует, что условная плотность
P&n)lk(x, y\k) = с = const, если (x, r/)e Fo. (2.44)
Пользуясь условием нормировки для этой плотности и
учитывая, что mes(Fo)= 1 по построению, получаем из
(2.44) с = 1 и
Р<6.т)> । к(х, у | k) = JF, (х, у). (2.45)
Поскольку (2.45) не зависит от k, то найденная плотность
и является Ръ,т\(х, у).
Векторы (gi, т]!), •••> (£л-ь Лл-i), не попавшие в F^
называются исключенными, а процедура нахождения (g^,
Л*)— исключением. Отсюда и название метода.
Теорема 3. Пусть случайная величина g' имеет плот-
ность g (x)/mes (G), а случайная величина ц' при усло-
вии g' = х имеет плотность распределения
Д' IB' (У I х) = /[o,g(x)] (y)!g (х).
Тогда случайный вектор (gz, rf) распределен равномер-
но в G.
62
Д о
ностей
казательство.
По формуле умножения плот-
У) = Pl' М (У\х) = z/)/mes(G).
Моделирующий алгоритм заключается в последова-
тельности шагов.
Шаг 0. Подбираем мажорирующую функцию g(x)
Шаг 1. При помощи теоремы 3 каким-либо методом
моделируем случайный вектор (£', т]')е G; реализацию
(V, лЭ обозначим (х, у) (общие методы моделирования
случайных векторов рассмотрены в гл. 3).
Ш а г 2. Если у 5> fo(%), то (х, у) исключаем и вновь
повторяем шаг 1; если же у fo (х), то значение х при-
нимается в качестве реализации
Повторяя алгоритм ц-кратно, получаем п реализа-
ций моделирующих результаты наблюдения над £
в п экспериментах.
Вычислим средний коэффициент использования БСВ
в ситуации, когда для получения реализации (х, у) слу-
чайного вектора (£', т]') используется фиксированное
число / БСВ (обычно I = 2). Имеем
х = М{1/(/г)},
где г — число использованных в (2.42) векторов (|/, гр)
г = /г. Очевидно, k — 1 имеет геометрическое распределе-
ние (2.26) с параметром
р = Р{(|', т)')е Fo} = l/mes(G).
Поэтому
со
mes (G)
mes (G)
In (mes (G))
(2.46)
Согласно (2.46) для увеличения x необходимо уменьшать
incs(G)^ 1. Это достигается выбором мажорирующей
функции g(x). Заметим, что мажорирующая функция
g(x) должна быть одновременно и простой, чтобы моде-
лирование (£', цх) осуществлялось элементарными ме-
тодами.
63
Представляет интерес способ оптимизации метода исключения,
описанный в [11, с. 28].
Отметим характерный недостаток метода исключения.
Моделирующий алгоритм описывается формулой S, =
= ф(«ь а2, •••), где сц, «2, ••• — независимые БСВ;
ф(-)— функция счетного множества аргументов. Послед-
ний факт предъявляет жесткие требования к псевдослу-
чайным числам.
Если fo(x) задана на бесконечном интервале или не
ограничена, принципиально возможно построить мажо-
рирующую функцию непосредственно. Однако более
удобно подобрать преобразование т] = фн(£) так, чтобы
случайная величина ц имела ограниченную плотность на
конечном интервале; т) моделируют методом исключения,
тогда | = фГ1 (л) •
Первоначальный перечень экспериментов
1. Бета-распределение: /о(х) =Г(/п-|-р)хг>_1(1—х)’п-1/
/(Г(щ)Г(р)); О С х С 1; т, р > 0 — параметры.
1а. р = 2, m = 3. 16. р — 5, пг = 6. 1в. р = 10, tn — 10.
2. Распределение: f0 (х) = 2/(л У1 — х2), 0 х < 1.
Указания
1. В эксперименте 1 использовать прямоугольную
мажорирующую функцию
g(x)= fo(Xo)IlQ,i]
(х)
где хо = argmax /о(х).
2. В эксперименте 2 перейти к rj = I 1 — £ с плот-
ностью распределения (у)=4/(л, ]/2 — //2), 0<г/<1;
т] моделировать методом исключения с прямоугольной
и линейной мажорирующей функциями; £ получать
обратным преобразованием % = 1 — т)2.
3. Оценить х и среднее время т, затрачиваемое на по-
лучение одной реализации для каждого из модели-
рующих алгоритмов.
4. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
64
§ 2.16. Моделирование непрерывной случайной
величины методом исключения со ступенчатой
мажорирующей
ункцией
• Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод исключения со ступенчатой мажорирующей,
функцией при моделировании случайной величины £
с ограниченной плотностью распределения fo(x), сосредо-
точенной на конечном отрезке [Ь, с].
Методика выполнения задания. Применим метод из
§ 2.15, используя ступенчатую мажорирующую функцию
к
где z0 = b; zK = с, а К, b < Zi < z2 < . •. < ^к-i < с —
параметры. Область G = {(х, у): G^y^g(x), b
х с} в (2.43) является многоугольником с пло-
щадью (z; = argmax/о(x), Zi-i^x<Zi)
к
mes (G) = 2 /о (z,) (z£ — z^i). (2.47)
i=l
Для моделирования £' с плотностью g(x)/mes(G)
воспользуемся результатом § 2.13. Согласно (2.31) —
(2.34)
%' = ?j-\ + («! — bj-xjlCj, если bj-i ^ajCbj, j = 1, К,
где cxi — БСВ; Cj=/o(zj)/mes (G);
/
bQ =0, bj = 2 Pi’ Pi = fo (Zi) (Zi ~ )/meS (G)‘
t=l
Случайную величину т/ моделируем в зависимости от х'-
значения, принятого случайной величиной
Т)' = g(x')d2,
где аг— БСВ, не зависящая от сц.
Коэффициент использования БСВ х вычисляется по
формулам (2.46), (2.47) при I — 2. Параметры К, Zi, ...
..., ^к-1 мажорирующей функции надлежит выбирать из
условия максимума х. За счет увеличения К и уменьше-
ния «ширины ступенек» Aj = zj — можно х сколь
угодно приблизить к Хтах = 0,5. Рассмотренный метод
можно распространить и на неограниченные плотности,
3 Зак. 1Q15
заданные на бесконечных интервалах, если воспользо-
ваться вспомогательным преобразованием т) = ф1 (£), как
в § 2.15.
Первоначальный перечень экспериментов — экспери-
менты 1а—в из § 2.15.
Указания
1. Положить /< = 2, 4, 6, 8. Параметры {zj выбрать
из условия максимума х.
2. Оценить х и среднее время т, затрачиваемое на
получение одной реализации для каждого из модели-
рующих алгоритмов.
3. Исследовать зависимости х и т от К.
4. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§ 2.17. Моделирование непрерывной случайной
величины методом суперпозиции
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод суперпозиции (метод композиции) при мо-
делировании непрерывной случайной величины | с фик-
сированной плотностью распределения fo(x).
Методика выполнения задания. Метод суперпозиции
основан на формуле полной вероятности для плотностей.
Пусть £ и v — случайные величины, заданные на одном
и том же вероятностном пространстве; Fv(z)—функция
распределения v; p%|V(x|z)—условная плотность распре-
деления | при условии v = z. Тогда безусловная плот-
ность распределения £
оо
/„€*) = ,f ^|v(x|z)dFv(z). (2.48)
— оо
В частности, если v — дискретная случайная величина со
множеством значений {с±, с^, ..., Сдг} и вероятностями
{P{V = Ci} = pit i = 1, TV, N < oo}, pi\v(x\ct) = fi (x),
to (2.48) принимает вид
66
Моделирующий алгоритм заключается в следующем:
0) определяем вспомогательную случайную величину v
так, чтобы имело место (2.48) или (2.49); 1) модели-
руем v; пусть z — реализация v; 3) моделируем £ при
условии v=z; получаем х — реализацию
Для уменьшения среднего времени т, затрачиваемого
ЭВМ на получение одной реализации х, случайную вели-
чину v надлежит опреде-
лять так, чтобы v и при
фиксированном v доста-
точно быстро моделирова-
лись. Наибольший прак-
тический эффект дает
именно непрерывно-дис-
кретный вариант (2.49).
Графически (2.49) озна-
чает (рис. 2.5), что фи-
гура единичной площади
{(х, у): O^y^fo(x),
^x<Zc} разбивается на М Рис. 2.5
непересекающихся частей
{gi} с площадями pi. Основной принцип разбиения
(2.49) заключается в том, что части gt, имеющие наи-
большую площадь (наибольшую вероятность pi), долж-
ны соответствовать наиболее просто и быстро имити-
руемым плотностям fi(x). Например, на рис. 2.5 выбрано
N—6, причем плотности {fi(x), 1=1,5} —либо треуголь-
ные, либо ступенчатые. Те и другие легко моделируются
(см. § 2.13, 2.14). Остаточную плотность
5 5
Л (х) = (х) — 2 Plfl (х)}/Ре, Ре = 1 — 2 Р‘
i= 1 i= 1
можно имитировать методом исключения (см. § 2.15).
Интересен способ оптимизации рассмотренного мето-
да [16], позволяющий оптимальным образом осуществить
разбиение (2.49).
Первоначальный перечень экспериментов
СО
Очевидно, здесь N = со, pt — М~1е~к/(1 — 1)1, fi (х) =
з*
67
= £vl-I/[o, i] (x). В данном примере v —1 имеет распреде-
ление Пуассона с параметром % (см. § 2.10), а | при
v = z легко моделируется методом обратной функции
(см. § 2.12) или при помощи порядковых статистик
[11, с. 24]; Х=1,3, 5.
2. Бета-распределение: f0(x) = 12х(1 — х)2/го ц(х);
N - 2, 4, 6, 8. : •
Указания
1. Оценить средний коэффициент % использования
БСВ и среднее время т, затрачиваемое на получение
одной реализации для каждого из моделирующих алго-
ритмов.
2. В эксперименте 2 исследовать зависимость и, т
от М.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§ 2.18. Моделирование гауссовской случайной
величины методами обратной функции и суммирования
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы обратной функции и суммирования при
моделировании гауссовской случайной величины | с плот-
ностью распределения
fo W = «1 Ш р, D) =
= ехр(— (х — р.)2/(2О))/У2лО, xEl?; (2.50)
математическое ожидание ц е У?1, дисперсия D 2> 0 —
параметры распределения (2.50).
Методика выполнения задания. Введем в рассмотре-
ние стандартную гауссовскую случайную величину
с плотностью Hi (х 10, 1). Легко убедиться, что
g = p + (2.51)
имеет распределение (2.50). Используя соотношение
(2.51) для моделирования £, обратимся к задаче модели-
рования Исследуем три метода моделирования £*.
Первый метод есть частный случай метода обратной
функции (см. § 2.12):
$8
где
i
Ф (z) = f п-l (x 10,1) dx
—-oo
есть функция распределения стандартного нормального
закона, а Ф-1(«)—обратная ей функция. При записи
(2.52) учтено известное свойство Ф (•): Ф (—z) = 1 —Ф (z).
Выражение Ф-1(г) через элементарные функции
ствует, поэтому используется аппроксимация
2,30753 4-0,270616 ,
1 4- 0,992296 + 0,048102 ~~
с ошибкой |Ф-1(г) — Ti (г) | < 3*10-3 при г <0,9
отсут-
(2.53)
ф-1 (z)^4\(z)
или
ф-l^w/x л. 2,515517+ 0,8028536 +0,0132862
tU(2) Т 2 (Z) — У + 432788е+0 , j 892б962+0,00130863
(2.54)
с ошибкой | Ф-1 (г) — 4r2(z) |<4,5-10~4 при z<0,9. В
(2.53), (2.54) 6 = ]/ —21nz, 0,5<z< 1.
Второй метод (метод суммирования) основан на цен-
тральной предельной теореме. Если си, си, ... — незави-
симые БСВ, то при А—>- оо случайная величина
(2.55)
распределена асимптотически нормально, так что функ-
ция распределения
Fl. (г) ->Ф (г), zeR1-
Формула (2.55) при некотором конечном N и определяет
моделирующий алгоритм. Случайная величина £*, опре-
деляемая (2.55), аппроксимирует стандартную гауссов-
скую случайную величину. Ошибка аппроксимации
Ajv = max | (z) — Ф (z)
тем меньше, чем больше N. Формула (2.55) реализована
в стандартной подпрограмме GAUSS (см. Приложе-
ние 1) при N = 12.
Третий метод является модификацией второго. Оче-
видно, что при помощи специального функционального
преобразования из произвольной случайной величины,
в частности £*, можно получить гауссовскую. Однако это
преобразование через элементарные функции не выра-
69
жается. Тем не менее среди элементарных функциональ-
ных преобразований найдены такие, которые существен-
но уменьшают Ак. В [9] рекомендовано функциональное
преобразование
13 4407V2 "jh
Заметим, что для первого метода xi — 1, а для вто-
рого и третьего хг = хз = 1/N.
Первоначальный перечень экспериментов
1. и = 0; D = 1; N = 3, 6, 12.
2. и = 1; D = 0,1; А = 6, 12.
Указания
1. Для каждого из моделирующих алгоритмов (в том
числе и GAUSS) оценить среднее время т, затрачиваемое
на получение одной реализации.
2. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
3. Сравнить моделирующие алгоритмы по точно-
сти, х, т.
§ 2.19. Моделирование гауссовской случайной
величины методами
функционального преобразования.
исключения и суперпозиции
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы функционального преобразования, исклю-
чения и суперпозиции при моделировании гауссовской
случайной величины % с плотностью распределения
(2.50).
Методика выполнения задания. Учитывая (2.51), рас-
смотрим задачу моделирования стандартной гауссовской
величины £*. Исследуем два метода моделирования £*.
Первый метод основан на следующей теореме.
Теорема. Если оц, аг — независимые БСВ, то случай-
ные величины
Y — 2 In 04 cos (2ла2),
L+2 = V— 2 In cq sin (2ла2)
(2.56)
являются независимыми стандартными гауссовскими.
70
Доказательство. Обратное по отношению к
(2.56) преобразование
ах = ехр(—(Й1 +Йг)/2), а2 = (2л)~1 arctg (^2/5*i)- (2.57)
Якобиан этого преобразования
J = — (2л)-1 ехр (— + &)/2). (2.58)
По правилам преобразования случайных величин из
(1.9), (2.57), (2.58) и (2.50) получаем плотность распре-
деления (£*ъ £*2):
РЬ.Л.. (хк хг) = Р«,.аг (ехр (— (Х1 + х|)/2),
(2л)-1 arctg (а"2А'1)) J | = (л\ | 0,1) (х210,1).
Формула (2.56) и определяет моделирующий алго-
ритм. Коэффициент использования БСВ х = 1.
Второй метод использует комбинацию метода супер-
позиции с методом исключения. Представим в виде
= vt], (2.59)
где v, т) — независимые случайные величины; v — бернул-
лиевая случайная величина, P{v = — 1}= P{v = 1} =
= 0,5; т] —непрерывная случайная величина с плотностью
Рп ('/)='/“ у>0. (2.60)
Г J L
Моделирование v легко осуществляется методом из
§ 2.8. Для моделирования т] применим метод суперпози-
ции из § 2.17:
Рч(Р) = Ptft(y)+РгЬ(у), (2.61)
где
Р2 = 1 - Pi, Р1= V~ f e-y’/^dy « 0,6827, (2.62)
F Л
О
Л (Р) = ~]/-^е-‘',/2Ло,1](р),
/2(Р)=^-]/^^!/2Л1.«)(р).
(2.63)
Середина распределения (fi(f/)) моделируется методом
исключения из § 2.15 с прямоугольной мажорирующей
функцией
§1(Р)=-^-До,!](//). (2.64)
71
«Хвост» распределения (f2(^)) тоже моделируется мето-
дом исключения, причем предварительно используется
вспомогательное преобразование чр = ехр ((1—т]2)/2).
Плотность для ф
Р. ~ V(I
21nz)-1/2, 0<z< 1. (2.65)
При моделировании ф используем метод исключения с
прямоугольной мажорирующей функцией
й(г) =Л- ]/-|-е-1/2/[011](г). (2.66)
Л7 2 r *> v
Случайная величина т) получается обратным преобразова-
нием:
<1 = у 1 — 2 In ф.
(2.67)
Формулы (2.59) — (2.67) определяют следующий мо-
делирующий алгоритм.
Шаг 1. Из датчика БСВ получаем псевдослучайное
число «1. Если «1<0,5, то реализация 5 случайной вели-
чины v равна 5— — 1, иначе s=l.
Шаг 2. Получаем а2. Если а2 < рь то вычисляем
а' = a2/Pi и переходим к шагу 3 (имитация fi (//)), в про-
тивном случае — к шагу 4 (имитация f2 (//)).
Ш а г 3. Получаем а3. Если а3<ехр (—(а')2/2), то
реализация у случайной величины ц равна: у = а'. В про-
тивном случае получаем ц4 и проверку неравенства по-
вторяем, полагая а'\ = а4 и т. д., пока при некоем аи не
выполнится неравенство. Переходим к шагу 6.
Ш а г 4. Вычисляем а" = (а2 — pi) 1(1 — pi).
Ш а г 5. Получаем а^\. Если < (1 — 2 In а")~1/2,
то реализация у случайной величины ц равна: у =*
— У1 — 21па". В противном случае получаем tzzj+2 и про-
верку неравенства повторяем при а": = ak+2 и т. д., пока
неравенство не выполнится.
Шаг 6. Вычисляем реализацию х случайной вели-
чины £*: х = sy.
Отметим, что величины а', а" позволяют использовать
одно и то же псевдослучайное число на различных ша-
гах алгоритма и, следовательно, уменьшают время моде-
лирования и увеличивают
72
Первоначальный перечень экспериментов
1. и = О, D = 1. 2. р, = 1, D = О, 1.
Указания
1. Для каждого из моделирующих алгоритмов оценить
среднее время т, затрачиваемое на получение одной реа-
лизации.
2. Оценить средний коэффициент хг для второго
метода.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
4. Сравнить алгоритмы по точности, х, т.
5. Для уменьшения т целесообразно предварительно
получить в ЭВМ таблицу значений функций sin, cos, In,
используемых в (2.56), (2.67).
§ 2.20. Моделирование случайной величины
с экспоненциальным распределением
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы обратной функции, функционального пре-
образования и суперпозиции при моделировании случай-
ной величины £ с экспоненциальным распределением
fo(x) = ke~Kx, х 0,
(2.68)
где % > 0— параметр распределения.
Методика выполнения задания. Введем в рассмотре-
ние стандартную экспоненциальную случайную величи-
ну с плотностью
pl*(x) = е~х, х 0, (2.69)
получающейся из (2.68) при % = 1. Легко проверить, что
случайная величина
В = (2.70)
имеет распределение (2.68). Используя (2.70) при моде-
лировании £, обратимся к задаче моделирования £*.
Исследуем три метода моделирования £*.
Первый метод есть частный случай метода обратной
функции (см. § 2.12)
= — In а. (2.71)
Коэффициент использования БСВ xi — 1.
73
Второй метод (метод функционального преобразова-
ния) основан на следующей теореме.
Теорема 1. Пусть ах, а2> •••> aw, «лч-ь • ••> «2/v-i—
независимые БСВ, 1; «ь ..., CQy-i —величины а^+-,
.«277—1, расставленные в пс рядке возрастания; а0 = О,
Ct// = 1 - Тогда случайные величины
Uft = (a*-i — aft) In (ax... (Хдг), k =J1, N, (2.72)
независимы и распределены по закону (2.69).
Доказательство. Обозначим
Лй = «й —a/e-i, k -^1, TV—1;т]л7^—1п(ах... адг). (2.73)
Случайная величина тру согласно (2.69), (2.71) и (2.73)
есть сумма N независимых стандартных экспоненциаль-
ных случайных величин:
Поэтому ее характеристическая функция
а плотность распределения
2 л
„и-1 e~yN
- -N-y1nT - > ^>о. (2.74)
Закон распределения (2.74) называется гамма-распреде-
лением. Известно [19], что вектор (тщ ..., rpy-i) распре-
делен равномерно:
Аъ..... 1ру—1 (Z/i* • • • > Ум—\) = (N — 1 )•,*
(2.75)
Из (2.72), (2.73) следует, что Tji, ..., — независимы и
тцт]дг, если /з {1, ...
Лг-1
(2.76)
74
Обратное (2.76) преобразование обозначим ф(«):
б**/2^ если /ге{1,
/=1
у
если k = N.
/=1
N—1},
(2.77)
Якобиан преобразования (2.77)
Тогда по правилам преобразования случайных величин
из (2.74)—(2.77) получаем
— J Рк]1...Чдг—1
pN-l) Px]N (Ум) | у=ф(х) =
-e~XN.
Формула (2.72) и определяет моделирующий алго-
ритм. Коэффициент использования БСВ X2 = A7(2W—1).
Третий метод является частным случаем метода су-
перпозиции (см. § 2.17) и основан на следующей тео-
реме.
Теорема 2. Если щ, аг, ... — независимые БСВ,
v и 0 — не зависящие от ai, аг, ... целочисленные поло-
жительные случайные величины с распределениями
-(ЛГ-1)
то случайная величина
g* = v — max{ai, аг, ..., ае} (2.79)
имеет плотность (2.69).
Доказательство. Обозначим £ = max{ai, ...
. .., ao}. По формуле полной вероятности для плотностей
представим в виде (2.49):
ОО
Pl. (*) = 2 р ь = 0 = Ц
I, /= 1
V = I, о = /). (2.80)
По правилам преобразования случайных величин из
(2.78) и (2.79) находим
75
pv->(x[v = z, e = /) = pt(i — x|e
= j(i — x)i-4[x,x+i)(i),
где учтено еще, что 0г^£<1. Очевидно, /[Х1Х+1)(/) = 1,
если i = х, и 0 в противном случае. Поэтому из (2.78) —
(2.80) получаем
Рь (*) = е~х-
Формула (2.79) и определяет моделирующий алго-
ритм. Моделирование v и 0 легко осуществляется мето-
дом из § 2.8. Средний коэффициент использования БСВ
ОО
хз= 2р{9 = /)/(2 + /)-
/=1
Первоначальный перечень экспериментов
1. % = 1; М = 2, 3, 4, 5. 2. 7 = 3, М - 3.
Указания
< 1. Для каждого из моделирующих алгоритмов оце-
нить среднее время т, затрачиваемое на получение одной
реализации.
2. Оценить хз-
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
4. Сравнить алгоритмы по точности, х, т.
5. Для второго метода выбрать оптимальное М* из
условия минимума т2.
6. Для уменьшения ti целесообразно предварительно
получить в ЭВМ таблицу значений функции In, исполь-
зуемой в (2.71).
§ 2.21. Моделирование случайной величины
с бета-распределением
Г
f
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы функционального преобразования и Понка
при моделировании случайной величины £, имеющей
бета-распределение с плотностью
X / . \ + (1— Х)Ц-1 , , ч /ОО1\
/о(м 'V» Н) г (у) Г (р) Ло, 1] (х)» (2-81)
где v, ц > 0 — параметры.
7Q
Методика выполнения задания. Исследуем два наибо-
лее распространенных метода моделирования £.
Первый метод . (метод функционального преобразо-
вания) «работает» лишь для целочисленных значений
параметров т, ц:
fo (х; v, |i) == |iCv+i-iXv-1 (1 — х)ц-1/[о, 1] W- (2.82)
Он основан на теореме 1.
Теорема 1. Если си, «2, • • •, «v+n-i — независимые БСВ
и «(1) < 0(2) < ... < O(v+U-1) — те же величины, упорядо-
ченные в порядке возрастания, то
Ъ = «(v) (2.83)
имеет распределение (2.82) (a(V) принято называть v-й
порядковой статистикой).
Доказательство. По формуле полной вероят-
ности найдем функцию распределения щху.
Fa(v) (^) = Р {°ГО =
= Р {не менее v величин среди ах, ..., aV4-n-i меньше х} —
величин среди ах, ...» av+u-i меньше
V-J-Ц—1
= 2 Cv+u-i*'(l -лГ'1*-1--.
i=v
Вводя j = i — VE{O, 1, и—1}, используя формулу
бинома Ньютона и формулу
m
2 (—1 =(—1 )mc_i,
fc=O
получаем
a«(v1« = 2 2 cvU-i (- =
/=0 1=0
И—1
= 2 (- l)’*-1-'Cu-iXv+H~1~7(v + и- 1 -/).
1=0
С другой стороны, вычислим функцию распределения,
соответствующую плотности (2.82):
X
Fo (х; v, р) = J fo (t‘, v, р) dt = Fa(v) (х).
о
77
Формула (2.83) и определяет моделирующий алго-
ритм. Коэффициент использования БСВ xi= 1/(т+ц—1)•
Второй метод, предложенный австрийским математи-
ком Йонком, используется при любых р, v > 0 и основан
на теореме 2.
Теорема 2. Если ai, аз, ... — независимые БСВ и k —
целочисленная случайная величина:
k = min {N: W > 1, a^-i + «2/v < 1}, (2.84)
то случайная величина
g = «2*-1/(«2*-1 + а^) (2.85)
имеет плотность распределения (2.81).
Доказательство. Определим случайное событие
BN -= {<о: (со) + <4# (®) < 1}, (2.86)
величину g = «2«-1 + аги и невырожденное преобразова-
ние
11 — y\,vKy\,v I- //Вч // — v’/v_L
У1 -M /I'M -^2 /> У 2 — %2 •
Обратное преобразование
x1 = (y1y2)v, *2 = с/2 (1 — <Л)1‘
имеет якобиан
J =^yvrl (1 - y1)u-'i^+v^',
поэтому
Pl,l(lJi> У2) = рууГ1 (1 — Z/i)u_1*/2+v_1,
&<тт{1/^, 1/(1—О- (2.87)
Запишем (2.84), (2.85) с учетом (2.86):
t _ „I/v ,/1/V | „1/Ц\
S — «27V—1/(«2/7—1 -f- а2дг ),
если наступило В^.
По формуле умножения плотностей
1
( ры dy*
Pi (У1) = PiiBN (Л) = -j-p--------------. (2.88
J [ pi, i dUldyt
b b ~
Подставляя (2.87) в (2.88), получаем
Pl (У1) = fo (Z/i; v, p).
78
Формулы (2.84), (2.85) и определяют моделирующий
алгоритм. Еще один метод моделирования | приведен
в [11, с. 33].
Первоначальный перечень экспериментов
1. v = 2, ц = 3.
2. v = 2,13, ц = 3,69.
Указания
1. Для каждого моделирующего алгоритма оценить
среднее время, затрачиваемое на получение одной реали-
зации.
2. Оценить Х2.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§ 2.22. Моделирование случайной величины
с гамма-распределением
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования случайной величины
имеющей гамма-распределение с плотностью
где v > 0— параметр распределения.
Методика выполнения задания. Исследуем три основ-
ных метода моделирования |.
Первый метод «работает» при целом v > 1 и исполь-
зует свойство безграничной делимости закона (2.89).
Действительно, характеристическая функция
ОО
<рЕ (/; v) = J /0 (х) e^dx = (1 — it)-'1 (2.90)
—-оо
обладает свойством, определяющим безграничную дели-
мость :
m-----—
V (/;
V) = (1 — (/;
ч/т), т = 2, 3, ... .
79
Теорема. Если t]i, т]2, . . . , t]v — независимые стандарт-
ные экспоненциально распределенные случайные вели-
чины, то
V
5-2 Л; (2.91)
/=1
имеет плотность (2.89).
Доказательство. Из (2.69), (2.89) и (2.90)
следует, что имеет гамма-распределение с параметром
Vj = 1, / = 1, v. Поскольку (2.89)— безгранично делимый
закон, то характеристическая функция
По теореме единственности из (2.90), (2.92) следует, что
£ имеет распределение (2.89).
Моделирование щ, ..., легко осуществляется мето-
дами из § 2.20. В частности, согласно (2.71)
W ~ — In aj, / = 1, v, . (2.93)
где ai, ..., av — независимые БСВ. Объединяя (2.91)
и (2.93), получаем формулу
| = -1п(ПаД
/=1
Т’
определяющую моделирующий алгоритм. Коэффициент
использования БСВ xi = 1/v.
Второй метод «работает», когда v = N + 0,5; N =
= 0, 1, ... . Учитывая (2.90), (2.92), представим харак-
теристическую функцию £ в виде
<Н(Л- N + 0,5) = (<Р5 (/; 1))"(1-й)-'/2 =
2V
(Пфч, (0)<Рп.(0
(2.94)
где т)о —_случайная величина с плотностью Рп0(г) =
= е~Ч( V % Г (0,5)), 2^0. Ее легко получить функцио-
нальным преобразованием стандартной гауссовской ве-
личины £, не зависящей от тр, ..., гру:
Ло = £7?.
(2.95)
80
Из (2.93), (2.94) и (2.95) получаем формулу
N
= - 1П (п + £а/2
9
(2.96)
определяющую моделирующий алгоритм. Моделирова-
ние £ осуществляется методами из § 2.18, 2.19. Напри-
мер, согласно (2.56)
£2/2 = —(in адг+1)со52(2ладг+2).
Коэффициент использования БСВ %2 = 1/(М + 2).
Третий метод есть частный случай метода исключения
(см. § 2.15) и «работает» для любого у. Обозначим
и воспользуемся представлением, аналогичным (2.94),
(2.96) :
[V]
= —1п(Па/) + ^,
/=1
< V ф # м • • •
причем совпадает с (2.89), если параметр прини-
мает значение v*. Для моделирования £* применим ме-
тод исключения с мажорирующей функцией g(x):
[ xv*—1, если 0<^х<С1,
Pl, = | е-х еслих>1
Метод исключения из § 2.15 применяется стандартным
образом. Отметим только: 1) величину 5* с плотностью
g(x)/mesG удобно моделировать методом обратной
функции:
(1 4-v^cxEvl+1/e)1/v*, если 0<a[v]+i<l/(l-|-v^/^),
— In ((1 — CX[V]_|_i) (v7l + e~x)) в противном случае;
2) величина щ при условии £* = х моделируется так:
П' -=g(*) a[v]t_2.
Первоначальный перечень экспериментов
81
Указания
1. Для каждого моделирующего алгоритма оценить
среднее время, затрачиваемое на получение одной реа-
лизации.
2. Оценить хз.
3. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
§ 2.23. Моделирование случайных величин
с /^-распределением и распределениями
Стыодента, Фишера
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования случайной величины
с ^-распределением с т степенями свободы:
m/2—1—х/2
= *>0; (2-97)
случайной величины т)т с t-распределением Стьюдента
с m степенями свободы:
h (W, т) =
| шпГ (tn/2) (1 y2/m)(,n+l
(2.98)
случайной величины t,im с распределением Фишера
(I, m — числа степеней свободы):
/3 (*; т) = “
Г
О,(2.99)
где /, пг — натуральные числа — параметры распреде-
лений.
Методика выполнения задания. Прежде всего отме-
тим, что распределения (2.97) — (2.99) широко исполь-
зуются в многомерном статистическом анализе (см.
часть 2).
Теорема 1. Если уь у2, .Тт—независимые стан-
дартные гауссовские случайные величины, то случайная
величина
82
т
U = 2y/ (2-ЮО)
/=1
имеет плотность (2.97).
Доказательство. По правилам преобразования
случайных величин получаем плотность распределе-
2.
ния у/: ____
р 2 (х) = Д(х; 1), / = 1, т,
которой соответствует характеристическая функция
ОО
Ф 2 (t) = f р 2 (х) eitxdx — (1—2it)~l/2, j = 1, tn. (2.101)
A v/
По свойству характеристической функции из (2.101) на-
ходим
2^~т/2- (2Л02)
г i
По теореме единственности р^ (х) = Д (х; tn).
Формула (2.100) и определяет моделирующий алго-
ритм для %т. Моделирование уь ..., ут осуществляется
методами из § 2.18, 2.19, в частности, при помощи под-
программы GAUSS (см. Приложение 1).
Теорема 2. Если у — стандартная гауссовская слу-
чайная величина и — не зависящая от у случайная
величина с распределением (2.97), то
Пт = УIV 1mlт (2.103)
имеет плотность (2.98).
Доказательство. Определим невырожденное пре-
образование
Обратное преобразование
Xi = У1¥У2/т> х2 = у2
имеет якобиан J — y^/tn.
Из (2.103), (2.104) следует
(2.104)
ОО
Ру\ЛУ1)= f"1 (^/1/г/2/т10,1)fr(y2, tn)VyJmdy2. (2.105)
т
о
83
Подставляя (2.50) и (2.97) в (2.105) и делая в интегра-
ле замену переменных у3 = у2 получаем (2.98):
Р^т^1^ j л/пГ (/п/2) (1z/j/jn)^^’1^2 X
S • • л г ‘
•• со т-{-1
х J */з 2 е~Уз<1Уз = f2 (f/i; tri).
Формула (2.103) определяет моделирующий алгоритм
ДЛЯ Т]тп•
Теорема 3. Если Нт — независимые случайные ве-
личины с ^-распределениями (2.97), то случайная ве-
личина
^m = (^//)/(Wm) (2.106)
имеет плотность (2.99).
Доказательство. Определим невырожденное
преобразование i
Zi = mz/i/(/^2), z2 = у2.
Обратное преобразование
y2=z2 (2.107)
имеет якобиан J — г21т~1. Тогда из (2.106), (2.107) сле-
дует
* »
оо
Ри, tn (Z1) = J fl Р) fl z2lnt~{dz2. (2.108)
о
Подставляя (2.97) в (2.108) и заменяя г3 =
= г2(1 + lm~lZi)/2} получаем (2.99):
о
Моделирующий алгоритм для определяется
(2.106).
Заметим, что существуют и другие алгоритмы моде-
лирования %т, Х]т,
*> См., например: Kinder man A. J., Monahan J. F. Computer
methods for sampling from Students /-distribution // Mathematics of
computation. 1977. V. 31. N 140. P. 5—15.
84
Первоначальный перечень экспериментов
1. пг = 3, I = 5. 2. m = 6, I = 3. 3. in = 6, I = 12.
Указания
1. Для каждого моделирующего алгоритма оценить
коэффициент использования БСВ и среднее время, затра-
чиваемое на получение одной реализации.
2. Исследование точности моделирования провести
согласно методике, описанной в § 1.4.
/
I
Глава 3
МОДЕЛИРОВАНИЕ СЛУЧАЙНЫХ ВЕКТОРОВ,
ПОСЛЕДОВАТЕЛЬНОСТЕЙ, ПРОЦЕССОВ И ПОЛЕЙ
Эта глава содержит изложение основных принципов, методов и алго-
ритмов моделирования на ЭВМ случайных векторов, матриц, про-
цессов, полей и множеств с наиболее распространенными в прило-
жениях вероятностными распределениями. Сформулированы способы
оценки точности моделирования.
§ 3.1. О принципах и точности моделирования
случайных векторов
Пусть моделированию подлежит случайный Af-вектор
/о / w \
Г= : =£*(“)= =
\&(«>)/
определенный на некотором вероятностном пространстве
(Q*, F*, Р*). Случайный вектор индуцирует вероят-
ностное пространство (RN, BN, Р|*)> где BN— борелев-
ская сигма-алгебра в RN, а Р|* (В), В ^BN,— распреде-
ление вероятностей £*, взаимно однозначно связанное
с Х-мсрной функцией распределения £*:
(х) = Р* {£i < Хц ..., < х^} =
= Pfc* (1— °°» *i) X [— °°, *2) X • • • X [— xN)),
x=(xt)^RN.
85
Напомним, что если — дискретный случайный вектор
со множеством М значений {ci, ..., см}, G RN, то рас-
пределение вероятностей /Ч*(*) однозначно определяется
величинами
Pv (С1) = Р* {£* = q), ..., (сЛ1) = Р* {Г = см}-
Если же — абсолютно непрерывный случайный вектор,
то Р^*(-)> (•) взаимно однозначно определяются
TV-мерной плотностью распределения
Pl* W = -
(*)
дхх ... dxN
Зададим некоторое натуральное число г и согласно
§ 1.2 построим вероятностное пространство (Qr, Fo, Р),
где Qr = [0, 1) X ... Х[0, 1)— r-мерный единичный гипер-
куб; Fo — наименьшая сигма-алгебра, порожденная
интервалами из Qr; Р(Л)—вероятностная мера, опреде-
ленная для множеств А е Fr0 и совпадающая с мерой
Лебега в Rr:
Р(Л) = шез(Л), 4gFJ.
На этом пространстве определены г независимых базо-
вых случайных величин щ, . .., аг:
щ щ (со) i = 1, г; со = (со^ ... , (ог) ЕЕ Qr.
Каждая из них распределена по стандартному равномер-
ному закону с плотностью (1.7), а их совместная плот-
ность определяется (1.9).
Согласно второму принципу моделирования (см.
§ 1.2) модель g случайного вектора представляется на
вероятностном пространстве (Qr, Fo, Р) для некоторого
г<оов виде Fo — измеримой векторной функции /(•)==
= (fi(•),..., fN(•)) от г независимых БСВ:
«г), i — 1, N.
или покомпонентно
(«) = fi(ai, .
Построенный таким образом случайный TV-вектор £ инду-
цирует вероятностное пространство (RN, BN, Pg) где
86
Pg (В), В е Bv,— распределение вероятностей взаимно
однозначно связанное с М-мерной функцией распреде-
ления:
• , %>N *< %n} =
= ([— оо, м) X • • • X [— xN)), х = (хг) е RN-
Согласно первому принципу моделирования число г
и преобразующая функция /(•) должны выбираться та-
ким образом, чтобы совпали (или были бы близки) рас-
пределения вероятностей £ и £*: Pg(B)=P^ (В), или,
что то же самое, функции распределения
(3.1)
Для дискретных случайных векторов (3.1) эквивалентно
условию
Pg(Ci) = ₽£* (Сг), = b
а для абсолютно непрерывных — условию совпадения
плотностей
Pt(x) = р Цх).
Иногда вместо (3.1) требуется совпадение определенных
числовых характеристик £, £*.
Таким образом, задача моделирования случайного
вектора разбивается на две подзадачи: 1) моделиро-
вание на ЭВМ независимых БСВ сц, аг, .. •; 2) нахожде-
ние числа г и функций fi(-), ..., /Х(-) таких, чтобы |
обладал бы требуемым вероятностным законом распре-
деления (или числовыми характеристиками). Модели-
рующий алгоритм поэтому состоит из двух блоков: блока
моделирования БСВ и блока функционального преобра-
зования j (•).
Сформулируем теперь методы исследования точности
моделирования случайных векторов (обобщающие мето-
ды из § 1.4).
Пусть некий алгоритм осуществляет моделирование
случайного М-вектора £*=(£/*); результат моделирова-
ния— случайный вектор ^==(^j)^RN. При и-кратном
обращении к этому алгоритму получена выборка объе-
ма /г:
где Xi = (xij) е RN — i-c выборочное значение. Необхо-
димо при помощи X проверить гипотезу согласия Но
о том, что функция распределения
87
Fi(y)^ Pi-(у),
у = (yj)^RN,
где Fi*(y)—фиксированная функция распределения.
Конкурирующая гипотеза Яц Ft (у) ^F^* (у). Опишем
статистические критерии согласия для проверки Но.
%5-Критерий Пирсона. Зададимся целым k> 1 и осу-
ществим измеримое разбиение пространства на k
ячеек Vi, ..., Vk:
FN = U Vh Vt A 0, i^j. (3.2)
Вычислим теоретическую вероятность попадания £ в i-ю
ячейку Vi, если верна Но:
Pi=\dFi.(.y) (3.3)
и число tii выборочных значений из X, попавших в
п
Заметим, что
Вычислим %2-статистику по формуле (1.20). Решающее
правило, для которого асимптотическая вероятность
ошибки (при /г-> оо) совпадает с заданным уровнем зна-
чимости 0 < Ео 1, как и в одномерном случае, опреде-
ляется соотношениями (1.21), (1.24). Число ячеек k и
разбиение (3.2) следует выбирать так, чтобы npi 20,
i = 1, k, и интегралы в (3.3) достаточно просто вычис-
лялись.
со2-Критерий. Используя Я-мерпую функцию распре-
деления Fi* {у), определим маргинальную функцию рас-
пределения случайной величины-^*: F * (у) и следующие
условные функции распределения:
(Fw I Ун • • • > Ук—1)-
88
Преобразуем выборку:
А =Ф- А — {-Vj, • • • , Л'л}» Xi — t j — 1» N,
Х.^ — F * (-Vfl), ^2 ~ «* t* (^2 I %il)’ • • •
\%iN | %Ц>
%i, N— 1)-
В силу свойств функций распределения преобразованная
выборка содержится внутри TV-мерного единичного ги-
перкуба. Можно доказать, что если верна гипотеза Но,
т. е. если А — случайная выборка из распределения
/*£*(•), то А' — случайная выборка из TV-мерного равно-
мерного распределения на единичном гиперкубе. Функ-
ция распределения выборочного значения Xi
По выборке А' определим эмпирическую функцию рас-
пределения:
п N
Определим статистику омега-квадрат:
Юп =
n J ... J (X (у) — F' . dyN.
о 6
Решающее правило:
принимается гипотеза
0, если соп
р если Wn А.
Порог А определяется по заданному уровню значимости
Ео из уравнения
1 формула (3.4) приводится к виду, более
При п
удобному для вычислений:
п N
0)/г
п
89
Здесь —число выборочных значений Xk € А', для
каждого из которых выполняется система неравенств
Xkl > Xfa2 • • • , XkN {1» 2, . . . , /?}.
Значения порогов Д при различных 80 приведены в
табл. 3.1 (N = 2) и табл. 3.2 (W = 3). Они найдены из
(3.5) при помощи асимптотического распределения ста-
тистики СОп (и -> оо).
Таблица 3.1
ео 0,001 0,01 0,05 0,1 0,2
А 1,150 0,725 0,442 0,328 0,220
Таблица 3.2
8о 0,001 0,01 0,05 0,1 0,2
А 0,256 0,179 0,126 0,104 0,081
Проверка совпадения маргинальных распределений.
Если справедлива Но, то должны быть справедливы сле-
дующие N гипотез о функциях распределения компонент
£i, • • •,
Hoi-
Л* (^j)’ / 1» N-
Si
Проверку каждой из этих гипотез можно осуществить
при помощи скалярных критериев согласия из § 1.4.
§ 3.2. О принципах и точности моделирования
случайных последовательностей, процессов и полей
Пусть моделированию подлежит случайная функция
/)? определенная на вероятностном простран-
стве (Q*, F*, Р*) для значений аргумента t е D Rm\
значение %*^RN. Если D={tit t2, ...} —дискретное мно-
жество, то (со, t) называется случайной последо-
вательностью .... Если tn = 1, то = £*(о), /)—
90
случайный процесс; если т 1, то |* = |*(о>, 0— СЛУ~
чайное поле (скалярное или векторное в зависимости
от N). При моделировании на цифровых вычислительных
машинах обычно используется случайная последователь-
ность отсчетов ^*, , ..., где (со, /,) — зна-
чение случайной функции в точке {^, /2» • • •» tn} —
дискретное, упорядоченное множество точек. Задача моде-
лирования отсчетов {£*.} есть, по существу, задача моде-
лирования случайного яМ-вектора
*
2’
рассмотренная в § 3.1.
Как и в § 3.1, для некоторого натурального г по-
строим вероятностное пространство (Qr, Fq, Р) и опре-
делим на нем г независимых базовых случайных величин
оц, ...» «г, распределенных по стандартному равномер-
ному закону. Тогда отсчеты {£/} моделируются с по-
мощью функционального преобразования {aj}:
— fi (СХ1> • • • , ССр), i — 1» ci.
Здесь г = r(n), Fro—измеримые функции {fi(-)} подби-
раются так, чтобы достичь совпадения или близости
функций распределения
S = (^Х» » Ьп)
и Е* или их определенных числовых характеристик.
Таким образом, для моделирования Е* применимы
все методы моделирования случайных векторов, однако
учет специальных свойств случайных функций (незави-
симость приращений, марковость, однородность, эргодич-
ность и др.) позволяет построить более простые и эффек-
тивные моделирующие алгоритмы.
Остановимся теперь на вопросах точности моделиро-
вания случайных функций. Отметим прежде всего, что
исследование точности моделирования ...» мож-
но провести, пользуясь методикой исследования точности
моделирования случайных векторов из § 3.1. Однако при
nN 1 эта методика требует значительных вычисли-
тельных затрат.
В связи с этим особо выделим ситуацию, когда
£*(•)—стационарный (в узком смысле) эргодический
91
Случайный процесс. Во избежание громоздких выраже-
ний будем полагать, что N = 1 (т. е. £*(•)—скалярный
случайный процесс), а сетка дискретного времени — рав-
номерная с шагом А:
ti = iA, i = 0, 1, 2, ... . (3.7)
Пусть некий алгоритм осуществляет моделирова-
ние £*(•); результат моделирования — случайный про-
цесс g(-), заданный отсчетами go, |д, ^2А, .... Обозначим
X = (хо, xi, х2, ..., хП') (п' может не совпадать с п)—
реализацию последовательности go, |д, ..., gn'A. На осно-
вании X надлежит осуществить статистические выводы
о совпадении вероятностных характеристик g*(«) и g(-).
Сравнение математического ожидания и дисперсии.
В силу стационарности
M{g*(co, /)} = р*, D{g* (со,/)} = о*2,
M{g(co, t)}= р, D{g(co,/)} = о2
не зависят от t. В силу эргодичности строго состоятель-
ными оценками р и и2 являются временные средние
Л л' и'
|А = 2 + 1), о2 = 2 (*1~ (3.8)
1=о 1=о
А А
р — несмещенная, а о2 — асимптотически несмещенная
оценки. Дисперсии этих оценок равны:
п'
D ОО = {2 2 (1 - г7(«' + 1))7?Е(«Д)-ЯЕ (0)}/(«' + 1),
1=0
Rl (/Д)-2^
(0)).
где /?в(т) = M{(g(co, t)— р) (g (со, t + т)— р)}— ковариа-
ционная функция для g(-). Формула дисперсии получена
для гауссовского случайного процесса g (•). Отметим,
что при А->0, п' -> оо, п'Д~> Т (3.9) удобно представить
в интегральном виде:
D {р} = 2Т-1 f (1 — тТ-1) (т) dr,
6
(3.10)
92
D {a2} = 4T-1
t
fo
(1 - TiT-l)(4)
V
0
(3.10)
Если в (3.9), (3.10) Ri(-) заменить на /?£*(•), то полу-
чим свойства оценок (3.8), когда X — реализация £*(•).
Точность моделирования характеризуется • уклонениями
оценок (3.8) от истинных (заданных) значений:
= н — ц*,
^2 = О2 — О*2.
В условиях асимптотической нормальности р, о2 [18] (при
оо) аналогично тестам (1.29), (1.31) строятся тесты
проверки гипотез: а) Но’, и = ц*, Н: р, ф рЛ; б) Но'.
a2 — , ц. a2 ф a*2. отметим> что условия асимптоти-
ческой нормальности весьма слабые. Например, для
асимптотической нормальности У Т £4 достаточно, чтобы
спектральная плотность Sg(X) процесса £(<о, t) была бы
непрерывной, ограниченной и Sg(O)+= 0.
Оценивание одномерных функций распределения.
В силу стационарности одномерные функции распреде-
ления Fi*(y), F%(y) от времени t не зависят. По свойству
эргодичности справедлива строго состоятельная, несме-
щенная оценка функции распределения по наблюдаемой
реализации X:
h (у)=2 л-
i=0
„)(хг)/(п'-4-1), yeR1.
Точность моделирования характеризуется уклонением
F% (у) — Fi* (у).
Аналогичным образом строятся оценки произвольных
конечномерных функций распределения.
Сравнение ковариационных функций. В предположе-
нии, что ц = р* известно, строго состоятельной и несме-
щенной оценкой ковариационной функции по реализа-
ции X является статистика
л п'~1
Rl (т) = 2 — И*) (*ж — И*)/(п' + 1 — 0»
i=0
т =/А, 1 = 0, 1, 2, ..., и' —1.
93
Для гауссовского процесса £(•) дисперсия этой
оценки
D {Ri (г)} =
X (Ri (ZA) Ri ((Z + Z) Л) + Ri (ZA) Ri( (i - Z) A) +
+ 2Ri ((i + Z) A) Ri ((i - I) A)) - Ri (ZA) - Ri (0) Ri (ZA)).
(3.H)
Аналогично (3.10) приходим к интегральным выраже-
ниям
7_х
0(^(4} = -7^- f (1-^т)(-2-^) X
о '
X (Ri (т + Т1) + Ri (т — т,)) + Ri (т + t^Ri (т —
(3.12)
Если в (3.11), (3.12) подставить /?£*(♦), то получим
дисперсию оценки ЛДт) в ситуации, когда X — реализа-
ция £*(•). При этом в предположении асимптотической
Л
нормальности [3] (Т-> оо) 7?Дт) для т <С Т с заданной
Л
вероятностью 1 — 80 /?Дт) попадает в промежуток:
Л
г-(т)^ г+(т),
где границы
Г± (т) = Ri- (т) ± (т)},
1 2
1 a g е0 = Ф-1 (1---т?-) и определяется таблицей из [27].
i-y к 2 /
Попадание графика (т) в «трубку» с «осью» (т) и
границами г± (т) означает достаточную точность модели-
рования.
Сравнение спектральных плотностей. Обозначим
S^* (л), 5ДХ), л е 7?1, спектральные плотности случай-
ных процессов £*(•) и £(•). Положим для простоты
А = 1 в (3.7).
94
Построим состоятельную оценку спектральной плот-
ности Ss (%) по реализации X. Периодограммой наблюде-
ний х0, ..., хП' называется статистика
/(X) = (2л (п' + I))'1
Хе/?1.
Определим весовую функцию
ОО
Wn' (а) = 2 ^((«+2л/)/ВП')/^п', ае/?1, (3.13)
J =------------оо
где ядро ay(P), р е У?1,— действительная четная абсолют-
но интегрируемая функция ограниченной вариации, при-
чем f w (P)dp = 1. Масштабный сомножитель ВП' такой,
что Bnf > О, ВП'->0, п'ВП'—>- оо при п'-> оо. При весьма
слабых ограничениях [3] оценка
п' \ / \
✓ А \ ИЧ / f « \ 1 ТТЛ/ I П 2jTS | ж i JTS |
Sg (X) — 2 л {п ~Г 1)— 2 Wn'-j-i X — — , . . 11 [ , j ~ j
\ ft* 1 X / \ I v I X /
5=1
(3.14)
является асимптотически несмещенной, нормальной и со-
стоятельной в среднеквадратическом. Границы (1—ео) X
X 100%-ного доверительного интервала для InS^(X)
s_(X) In Sg(X) sC s+(X), X 5-^0(mod 2л), (3.15)
равны *)
s±(X) = InS^(X) ±
/ oo
g- ^'0,4343 ]/ 2л J ^(₽)d₽/((n' + DBn-+i).
1 2 — °°
Попадание графика 1п5^*(Х) в «трубку»
рит о достаточной точности моделирования.
(3.15) гово-
Конкретизация ядер w(-) в (3.13) и оценок (3.14) имеется
л
в [3, 18, 20, 25]. Для вычисления оценки St (%) удобно использовать
алгоритм быстрого преобразования Фурье, реализованный в матема-
тическом обеспечении ЕС ЭВМ [46], а также программы из [50].
*) См.: Бриллинджер Д. Временные ряды: Обработка данных и
теория. М.: Мир, 1980, 536 с.
95
§ 3.3. Моделирование случайного вектора методом
условных распределений
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод условных распределений при моделировании
непрерывного случайного М-вектора £*= с фик-
сированной плотностью распределения
h«(i/)
t* •••> ZA/v)-
6i.....
Методика выполнения задания. По свойству согласо-
ванности многомерной плотности последовательно опре-
делим следующие маргинальные плотности распределе-
ния (k = N — 1, N — 2, ..., 1):
ОО
»
ft* ?*(//1» •••> У к) == \ ft* £* (^/1> •••» Ук-\- \ )dyk-^l • (3.16)
6г•••’ *k J S1.....SJH-1
— оо г
Построим теперь следующие условные плотности распре-
деления:
£=1,М —1. (3.17)
Теорема. Пусть —случайная величина с плотностью
Д* (^/1)» £2 (при условии — уг) имеет плотность Д*)£*
(*/21#1)> —; In (ПРИ условии = ...» ^-1=^-1) име-
ет плотность L* t* (yN |У1, •••, Ун-i)- Тогда слу-
5ДГ lsi 1
чайный вектор £=(|i, ...» имеет плотность распреде-
ления f^y)^f^(y).
Доказательство. По формуле умножения плот-
ностей
A(^/)=h....iN(yi’ •••> Ук) =
N—1
= ЬАУ) П/k, JSi. ute+i l^i, •••» Ук)- (3.18)
к-1 к
Л=1
Но по условию теоремы
96
/Wnll....1^1»-» 0л)
ft* 1Ё* £*(^+1^1» •••» I/ft)’
44-1'4..
Поэтому из (3.18) заключаем: f^(y)=f^(y).
Таким образом, моделирование случайного //-вектора
сводится к последовательному моделированию N случай-
ных величин. Для моделирования последних применимы
методы, изложенные в гл. 2, в частности, метод обратных
функций. Определим функции распределения •
У1 ______
R*(i/i) = f k=\,N—1,
4 4
I Ун •••> Ун) —
•’ 4г
^*(^ I Ун •••» Ук)
k
и обратные к ним
F~»(«), {F~i * *(•)}•
61v 1 U+ii*i........”
Следствие. Если ax, ...» oijv — независимые БСВ, то
случайный вектор £ = (£/) с компонентами
— F * (ai)>
ч
ч
52 = Fr.'lf.(a2|Si), (3-19)
«2 161
*
£/vlBp •
имеет плотность распределения fz*(y).
Доказательство опирается на предыдущую
теорему и теорему из § 2.12.
Моделирующий алгоритм определяется формулой
(3.19). Коэффициент использования БСВ % = 1/N.
Моделирование случайных М-векторов описанным ме-
тодом имеет существенный недостаток: вычисления
(3.16), (3.17), (3.19) часто оказываются очень громозд-
кими. Особенно это относится к случаям, когда плотности
(3.16), (3.17) нельзя выразить аналитически. Поэтому
изложенный метод моделирования обычно используется
лишь при малых размерностях N.
4 Зак. 1015
97
Первоначальный перечень экспериментов
1. N — 2, плотность распределения
У2) = У^~У1Уг0<#1<2, г/2>0.
2. TV-мерное нормальное распределение:
ту i
Н*(У) = пм(у\р, 2) = (2л) 121 2 X
X ехр { — (у — рУЕ-1 (у — р)/2},
где верхний индекс Т — знак транспонирования, ц =
= (pi)eAX— вектор математического ожидания, а 2 =
= (oij)—ковариационная матрица. Численные значения
параметров:
Указания
1. В экспериментах 2а, 26 воспользоваться свойством
нормального закона: маргинальные и условные плот-
ности являются нормальными. Поэтому
<ти); (3.20)
Ь1
А * |£* ?*(//&+ 1 Н 1> ••• > Ук) — П1(У/г-]-1 к^/г+1» )> (1 • 1 )
b/c+llsl’ s/e
Р7<Н-1 ' h
— Oai+i, ан-i — ^й2(/е)2/г;
V , __
^(/?) —
Иц . . .
(J21 . . . O2/i
Ghl • • • °kk
‘-‘k (^^4- 1» 1 *** ^4-1.
k = 1, N— 1.
При моделировании случайных величин с плотностями
(3.20), (3.21) использовать подпрограмму GAUSS (см.
Приложение 1).
2. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации £.
3. В экспериментах 1, 2а получить выборку объема
п — 50 и изобразить графически. На графике для экспе-
римента 2а построить линии постоянного уровня плот-
ности /&*(#).
4. Оценить по выборке заданного объема вектор ма-
тематического ожидания и ковариационную матрицу
и сравнить с теоретическими значениями.
5. Исследование точности моделирования провести
согласно методике, описанной в § 3.1.
§ 3.4. Метод исключения для моделирования
случайного вектора
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод исключения при моделировании непрерывно-
го случайного вектора = (^t-)GE/?'; с фиксированной
плотностью распределения f^*(z/).
Методика выполнения задания. Многомерный вариант
метода исключения базируется на трех следующих тео-
ремах.
Теорема 1. Если % RN— случайный вектор
и г] — случайная величина такие, что составной случай-
ный (М + 1)-вектор (£, т]) распределен равномерно
в области Fo = {(г/, г):
y^RN, zeeR1, 0 < г < ft*(y)} cz RN+l,
то компонента £ этого вектора имеет плотность распреде-
ления f^y)
Определим мажорирующую функцию z = g(y)‘.
о < < g(y)
4*
99
и область
G = {(У,г) -У R” z е= 7?, О < z g (у)} с= /?*+*. (3.22)
Очевидно, что Fo cz G.
Теорема 2. Если (£W, tjW), (|<2>, т/2>), ... — независи-
мые случайные векторы, равномерно распределенные в G,
то случайный вектор
(£, л) • £ = £(Ч Л =
где
k = min{m:
(£<w>, ^(m))^},
распределен равномерно в Fo.
Векторы (£W, tjW), •••> не попавшие
в Fo, называются исключенными, а процедура нахожде-
ния (^ft), — исключением. Отсюда и название метода.
Теорема 3. Пусть случайный вектор £(m> е RN имеет
плотность g(r/)/mes((j), а случайная величина т)<т) при
условии — у имеет плотность распределения
Лп('«)|£('и)(21 У) = Ло. &{уУ\(г)!ё(У)'
Тогда случайный вектор т)<т))е 7^+* распределен
равномерно в G.
Доказательство этих теорем проводится ана-
логично скалярному случаю (см. § 2.15).
Моделирующий алгоритм заключается в следующем.
Шаг 0. Из условия (3.22) подбираем мажорирую-
щую функцию g(y)', полагаем т — 1.
Шаг 1. Каким-либо методом моделируем случайный
•вектор е RN с плотностью g(y)/mes(G).
Ш а г 2. При помощи теоремы 3 моделируем случай-
ный вектор т/т))е G; реализацию (|<w), т](ш)) обо-
значим (у, z).
Шаг 3. Если zZ>fz*(y), то {у, z) исключаем и
вновь повторяем шаги 1, 2, 3 при т: = т -j- 1; если же
z f £*(*/)> то значение у принимается в качестве реали-
зации £.
Повторяя алгоритм n-кратно, получаем п реализа-
ций I, моделирующих результаты наблюдения над
в п экспериментах.
Средний коэффициент использования БСВ вычис-
ляется по формуле (2.46):
In (mes (G))
(mes (G) — 1)/ ’
(3.23)
100
»
где / — число реализаций БСВ, используемых для моде-
лирования одной реализации т/™)) (обычно I =
= N
Согласно (3.23) для увеличения % необходимо умень-
шать mes(G)^ 1, подбирая мажорирующую функцию
£(•). Заметим, что мажорирующая функция g(-) долж-
на быть одновременно и простой, чтобы моделирование
(^т\ т)<т)) осуществлялось элементарными методами.
Первоначальный перечень экспериментов
1. N = 2, плотность распределения
2. Распределение Дирихле:
... X yaNN ’(1 — ‘х
N
(П^(^-))^(1«г>0;
/=1
М=3, «( = 2, «2 = 3, «з=4, «4 = 5.
Указания
1. В эксперименте 1 использовать прямоугольную
мажорирующую функцию
^(//1» Уч) 4л, ।) Ц.—1> +1 —1.+11(^/2) •
Показать, что коэффициент использования БСВ х~ 0,263.
2. В эксперименте 2 использовать прямоугольную ма-
жорирующую функцию
w •
ё{У11 •••» Уы} — •••» у к) х
7=1
X 1/(1— Уг~ Ук),
где
Ы//?> ...» Ук)= max/v yN).
101
3. Оценить х и среднее время т, затрачиваемое па
получение одной реализации для каждого из моделирую-
щих алгоритмов.
4. Исследование точности моделирования провести
по методике, описанной в § 3.1.
§ 3.5. Моделирование случайного вектора,
равномерно распределенного внутри заданного
эллипсоида
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования случайного вектора =
= (£/) GE RN, равномерно распределенного внутри M-мер-
ного эллипсоида:
2 = Ь 9 = (3.24)
7=1 1
где {еД, {dj} — параметры эллипсоида (в каноническом
виде), цу>0, / = 1, N.
Методика выполнения задания. Введем в рассмотрение
случайный вектор л* = (Л/) £= равномерно распреде-
ленный внутри единичной гиперсферы:
zTz = 1, z = (z^RN. (3.25)
Теорема 1. Случайный вектор g связан-
ный с т)* линейным преобразованием
^7 Л/ Н
(3.26)
распределен равномерно внутри эллипсоида (3.24).
Доказательство. Так как якобиан линейного
преобразования (3.26)—константа, то по правилам
функциональных преобразований случайных величин за-
ключаем: при линейных невырожденных преобразова-
ниях равномерный закон распределения сохраняется.
Изменяется лишь область его определения: преобразова-
ние (3.26) переводит внутренность сферы (3.25) во внут-
ренность заданного эллипсоида (3.24). В
Используя соотношение (3.26) при моделировании £*,
обратимся к задаче моделирования т]*. Исследуем два
метода моделирования вектора т]*.
Первый способ использует метод исключения (точнее,
его упрощенный вариант), описанный в § 3.4. Обозначим
102
Fo — единичный гипершар, ограниченный сферой (3.25),
и G — гиперкуб, описывающий Fq:
G = {z = е RN, — 1 < Zj , / = 1, N}; Fo c.'G.
Теорема 2 из § 3.4 допускает переформулировку.
Теорема 2. Если ... — независимые случайные
Дивекторы, равномерно распределенные в G, то
где
k = min{m: е Fo}, (3.27)
распределен равномерно в Fo-
Случайный вектор = (£/fe)) легко моделируется:
= j=l?N, (3.28)
где ai, ..., oov — независимые БСВ.
Таким образом, моделирующий алгоритм при исполь-
зовании метода исключения определяется соотношениями
(3.26) — (3.28). Коэффициент использования БСВ
х = AH(mes (f0)/mes (G)) = (3-29)
В табл. 3.3 приведены значения % в зависимости от N.
Таблица 3.3
N 2 3 4 5 6 10
% 0,393 0,173 0,078 0,032 0,013 0,0003
Второй метод основан на переходе к сферическим ко-
ординатам. Проиллюстрируем его для N = 2.
Теорема 3. Пусть р, ср—полярные координаты слу-
чайного вектора т] — (тщ гр):
Т)1 = Р COS ср, Тр = Р sin ф.
(3.30)
Если случайные величины р, ф независимы и имеют плот-
ности
Рр(г)= 2г/10, !](/•),
р.р(Ф) = (2л)-*/10,2л1(Ф),
(3.31)
то случайный вектор т] равномерно распределен в единич-
ном круге с центром в (0, 0).
103
г sin Ф
г cos Ф
Якобиан преобразования
(3.32)
Обратное преобразование по отношению к (3.30):
P = K'nf+nf, Ф = arctg (т/Пз)- (3-33)
Поэтому по правилам функционального преобразования
случайных величин из (3.30) — (3.33) имеем
Рп(У1, У2) = Р?(У 1Л
^2 ) P<p(arctg z/i/z/a) | JI-1 -=
= Ло. и (z/i + yl)!^-
Случайные величины р, ср моделируются методом
обратной функции (см. § 2.12):
р = у alf ф = 2ла2, (3.34)
где «1, «2 — независимые БСВ. Объединяя (3.30) и (3.34),
получаем окончательно
T]i = |/«i cos (2ла2), т)2 =У «1 sin (2ла2). (3.35)
Таким образом, моделирующий алгоритм (для вто-
рого метода при N = 2) определяется формулами (3.26),
(3.35). Коэффициент использования БСВ х = 1/N и при
N 1 существенно больше по сравнению с (3.29).
Первоначальный перечень экспериментов
N = 2: а) а = с2 = 0, а^ = а2 = 1; б) Су = с2 = 1,
tzi = 4; а2 = 0,25.
2. N = 6, Cj = 1, aj = /, j — 1, N.
Указания
1. Эксперименты la, 16 выполнить двумя методами
и результаты сравнить по точности и быстродействию.
2. В эксперименте 1 выдать па печать таблицу из
100 случайных векторов; изобразить их на графике; изо-
бразить заданный эллипс (3.24).
3. Оценить по выборке заданного объема вектор ма-
тематического ожидания £ и сравнить его с с = .
4. В эксперименте 1а исследовать точность моделиро-
вания £*. При использовании %2-критерия (см. § 3.1) в ка-
104
честве ячеек 1Л, ..., Vk целесообразно выбрать концен-
трические круги с центром в (0, 0).
5. Обобщить второй способ моделирования для про-
извольного N, используя преобразование к сферическим
координатам:
t]i = р cos (pi;
т|2 — р sin cpi cos <р2;
т]з = р sin q)i sin ф2‘,
(3.36)
t]jv—i = Р sin Ф1 si*1 фг • •.. • sin qw~2 cos qzjv-r,
тру = р sin ф1 sin фг • ... • sin <рл--2 sin (рту—i;
N—2
J = pw-i Q sin^’-1 cpj.
f=i
§ 3.6. Моделирование гауссовского случайного
вектора
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования гауссовского случайного N-
вектора £* = (£*) с заданным математическим ожиданием
p = (Pi) и ковариационной матрицей 2 = (о^-); / — Ь М,
2 | =/=р.
Методика выполнения задания. Обозначим т]* = (т]-)€Е
— стандартный гауссовский случайный вектор,
т. е. случайный вектор, распределенный по нормальному
закону (0, Лу). Методы моделирования базируются на
следующем результате [2].
Теорема. Пусть С = (сц)—действительная (N X N)-
матрица, являющаяся решением матричного уравнения
ССТ = 2.
(3.37)
Тогда случайный вектор являющийся линейным преоб-
разованием т)*:
I = Ст)* + щ (3.38)
имеет нормальное распределение 2Va-(p, 2).
Моделирование т|* легко осуществляется. Действи-
тельно, т]*, т)дг некоррелированы, а следовательно,
и независимы; распределение тц — одномерное стандарт-
ное нормальное (2Vi(0, 1)). Поэтому моделирование т|*
105
можно произвести в результате ^/-кратного обращения
к подпрограмме GAUSS (см. Приложение 1).
Различные методы моделирования £*, известные в ли-
тературе, отличаются лишь способом построения мат-
рицы С.
Первый Метод использует матрицу собственных век-
торов для 2. Пусть A = diag(M) —диагональная матри-
ца, по диагонали которой стоят собственные значения
Zi, Хг, .. ., Xjv > 0 матрицы S; W = (wti w2 j... j wN) —
— —матрица соответствующих собственных век-
торов-столбцов Wi, ..., wN. Матрицы A, W являются ре-
шением системы матричных уравнений:
= WWT = IN.
(3.39)
Определим Л1/2 — diag(]/ Аг-) и покажем, что матрица
1
С = ГЛ 2 (3.40)
удовлетворяет уравнению (3.37). Действительно, из
(3.39), (3.40) имеем
ССТ = WAWT = YWWT = S.
Второй метод использует неединственность решения
(3.37) и требует, чтобы С была нижней треугольной мат-
рицей: Cij—Q, если />/. Ненулевые элементы Сц опре-
деляются рекуррентно. Действительно, в силу (3.38)
L = Gi^i + 11ь (3.37) дает соотношение Gi=tfn. Сле-
довательно, оп . Теперь из (3.38)
^2 “ GPll + ^22^2 “Ь Иг»
а из (3.37) имеем
2 । 2
G1 ~Г С22 = С»22»
С21ХТ1 == ^12*
Отсюда
и т. д. Справедлива общая рекуррентная формула
(3-41)
106
Здесь
и вычисления по рекуррентной формуле (3.41) осущест-
вляются в следующем порядке: Сц, С22, Си, с32, с33,
С41, • • < 1 CNN-
Таким образом, моделирующие алгоритмы опреде-
ляются формулами (3.38), (3.40) для первого метода и
(3.38), (3.41)—для второго. Коэффициент использова-
ния БСВ х = 1/N.
Первоначальный перечень экспериментов
1. Эксперимент 2 из § 3.3.
13,1 4,2 9,0 2,7
4,2 4,8 4,1 2,0
9,0 4,1 Ю,8 3,6
2,7 2,0 3,6 1,9
Указания
1. Матрицу С вычислять лишь при первом обраще-
нии к моделирующему алгоритму. Использовать подпро-
граммы из [23, 46, 53, 56].
2. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации £.
3. В эксперименте 1 для N = 2 получить выборку
объема п = 50 и изобразить графически. Изобразить
здесь же линии постоянного уровня плотности распре-
деления.
4. Выполнить указания 4, 5 из § 3.3.
5. По результатам эксперимента 1 сравнить модели-
рующие алгоритмы из данной лабораторной работы
с моделирующим алгоритмом из § 3.3.
6. Изучить моделирующий алгоритм, реализованный
стандартной подпрограммой MVN для моделирования
гауссовского случайного вектора (описание дано в При-
ложении 1).
107
§ 3.7. Моделирование случайного вектора
с полиномиальным распределением
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования дискретного случайного N-
вектора = (£t*) с полиномиальным распределением веро-
ятностей:
- * э
^*{£1 — Z/1» •••> Zn = Ум} =
= ’ (ЗЛ2)
i=l
где ..., /?}, i= 1,W; п, {pt}
N
параметры, п
Методика выполнения задания. Прежде всего отме-
тим, что если N — 2, то (3.42) превращается в бино-
миальный закон распределения, моделирование которого
рассмотрено в § 2.9.
Первый метод, пригодный для моделирования произ-
вольных дискретных случайных векторов, является оче-
видным обобщением метода из § 2.8. Согласно этому ме-
тоду моделирование дискретного случайного вектора сво-
дится к моделированию случайных событий: {£* — q},
где
N
К — число различных возможных значений случайного
вектора £*. Коэффициент использования БСВ для этого
метода равен наибольшему возможному значению: х=1.
Недостатки проявляются при п >> 1, N 1, когда вели-
ко К: а) усложняется моделирующий алгоритм; б) по-
нижается точность моделирования из-за дискретности
псевдослучайных чисел (см. § 1.2).
Второй метод основан на следующих двух легко дока-
зуемых теоремах.
108
Теорема 1. Пусть ар ап — независимые БСВ. Тог-
да случайные //-векторы = (т]/0), компоненты которых
являются бернуллиевскими случайными величинами:
а . ______________________________________________
Tl/t) — 1[Р1+...+Р. ,>Р1+...+Р. ,+Pf) (а0 1, ^), (3.43)
J—1 J—i J
независимы и одинаково распределены:
Р{т)(1° = zlt ..., = zN} = р\1-... -pzN,
N
Теорема 2. Случайный вектор
(3.44)
имеет полиномиальное распределение (3.42).
Таким образом, моделирующий алгоритм второго ме-
тода определяется формулами (3.42), (3.43). Коэффи-
циент использования БСВ х = 1/ц.
Первоначальный перечень экспериментов
1. N = 3; р! = 0,2; р2 = 0,5; р3 = 0,3; п = 3.
2. N = 26; pj = 1/26; / =TjV; п= 100.
Указания
1. По выборке заданного объема оценить математи-
ческое ожидание и ковариационную матрицу для | и
сравнить с теоретическими значениями:
М{Г} = прь М{(Г - М{Г})(-)Ч =
= (nPi(8ij— pj)), i, j = 1, N.
2. Исследование точности моделирования провести
для эксперимента 1 по критерию %2 (см. § 3.1). При этом
ячейки удобно выбрать так: k = X; Vi = {cj, ..., Vr =
= {ck}•
3. Для каждого моделирующего алгоритма оценить
время т, затрачиваемое ЭВМ на получение одной реали-
зации £.
4. Сравнить первый и второй моделирующие алгорит-
мы в эксперименте 1 по точности и быстродействию.
109
§ 3.8. Моделирование случайного вектора
с распределением Дирихле
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод моделирования случайного вектора £* —(£i*)^=
E~-Rn с плотностью распределения Дирихле:
N
1 и (У .) \
W >
- У1 — ... -yN); (3.45)
%i, .. ., 7dv+i > 0 — заданные параметры распределения.
Методика выполнения задания. Распределение (3.45)
иногда называют многомерным бета-распределением.
В самом деле, при N = 1 получаем бета-распределение,
моделирование которого изучалось ранее (см. § 2.21).
Распределение Дирихле часто встречается в теории по-
рядковых статистик. Отметим некоторые свойства рас-
пределения Дирихле:
М{(£*
(3.46)
(3.47)
Докажем теорему, на которой основан моделирующий
алгоритм.
Теорема. Пусть гц, . .., рдг+i — независимые случай-
ные величины, причем тр имеет гамма-распределение
с параметром Кр
е-г1и(гМГ(%1), i=l,N+l. (3.48)
Тогда случайный вектор g = и случайная вели-
чина |0:
(3.49)
110
независимы, причем ; имеет распределение Дирихле
(3.45).
Доказательство. Согласно (3.49) £о, £ порож-
дены преобразованием
Обратное преобразование:
_________________________ w
Zi = yiy0, i=\, N; zN+i=y0(l —
i=l
Его якобиан J = уq. Поэтому по правилам функциональ-
ного преобразования случайных величин найдем совмест-
ную плотность £0, £i,
Pio. 11. —. •••» Ун) —
N N
= (ПРчХОо))/7^. . (Z/o (1 — У.Уг))Уо-
1=1 1=1
(3.50)
Подставляя (3.48) в (3.50) и осуществляя эквивалентные
преобразования, получаем
• •• > Уn) ~ Ръ(Уо) Р%>1 £^(^/i> •••» Ун)^ (3.51)
где pi0(yQ) = Уо 1е Уо и(Уо)/Г (Хо)— плотность гамма-рас-
пределения с параметром Хо, a p^,...,i (ylt ...» Уи) совпа-
дает с (3.45); (3.51) означает также независимость <|0 и
Формула (3.49) и определяет моделирующий алго-
ритм. Моделирование случайных величин тц, ..., тру-и
осуществляется методами из § 2.22. Так как {Xi} могут
быть произвольными положительными числами, то целе-
сообразно применять третий метод из § 2.22.
Первоначальный перечень экспериментов
1. N = 3, Xi — 2, 7.2 — 3, Хз = 4, Х4 — 5.
2. N = 6, Xi = i + 1/i, i = 1, 2, ..., 7.
Указания
1. Оценить х и среднее время т, затрачиваемое ЭВМ
на получение одной реализации
111
2. По выборке заданного объема оценить вектор ма-
тематического ожидания, ковариационную матрицу и
сравнить с теоретическими значениями (3.46), (3.47).
3. Исследование точности моделирования провести
согласно методике, описанной в § 3.1.
4. Используя результаты эксперимента 1, сравнить
по точности и быстродействию моделирующий алгоритм
данной работы с моделирующим алгоритмом из § 3.4.
§ 3.9. Моделирование случайного вектора
с многомерным /-распределением
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод моделирования случайного вектора £* = (£*) с
N-мерным t-распределением с т степенями свободы:
fl-W =
/ tn-{-N \ — 4*
Г-----о-- |2| 2 7 1 ----2~
\ 2 /________(| I (у—Р)Г2 Чу~Р)\
Г(т/2) (тл)^2 \ “Г tn у
(3.52)
У = (yi)<=RN,
где вектор р, = (цг) е RN и положительно определенная
(Af X-/V) "Матрица 2 = (Oij) являются заданными пара-
метрами распределения.
Методика выполнения задания. Напомним, что моде-
лирование одномерного /-распределения (N = 1) было
рассмотрено в § 2.23.
Теорема. Пусть случайный вектор т) = (щ)е/^ рас-
пределен по нормальному закону (0, 2), а случайная
величина £ 0 имеет х2-распределение с т степенями
свободы и не зависит от ту Тогда случайный вектор
£=(&): ________________________________
Ь = TUlVVm + Рг, (3.53)
имеет /-распределение с плотностью (3.52).
Доказательство. В условиях теоремы найдем
совместное распределение ту £:
N _J_
/Ч 2) = (2я) 2 И 2 ехР (— УТ2~'У/2)
т т
X ^2 2 lz 2 ехр(—z/2).
(3.54)
112
Выражение (3.53) определяет преобразование (т|, £)
а, О-
Обратное преобразование (£, £)=>(т|, £):
П* = (& — i=^ N>
имеет якобиан J = (z!m)N^. Поэтому по правилам функ-
ционального преобразования случайных величии из
(3.54) получаем совместную плотность (|, £):
(3.55)
т
__1_ rn+N N
с' = |Е| 2 (2 2 (лт) 2 Г(т/2))~>.
Плотность g найдем, интегрируя (3.55) по г:
ОО
Рб(х) = JPs. t(*> z)dz = Д.(%).
О
Формула (3.53) и определяет моделирующий алго-
ритм для g*. Моделирование ц, £ рассматривалось ранее:
т) — в § 3.6, а g — в § 2.23.
Первоначальный перечень экспериментов
2. N — 4, т = 10, р, 2 — те же, что и в эксперимен-
те 2 из § 3.6.
Указания
1. Для моделирования гауссовского случайного век-
тора -г) использовать стандартную подпрограмму MVN,
приведенную в Приложении 1.
2. Оценить коэффициент использования БСВ и и вре-
мя т, затрачиваемое ЭВМ на получение одной реализа-
ции g.
3. По выборке заданного объема оценить вектор ма-
тематического ожидания, ковариационную матрицу и
сравнить их с теоретическими значениями
М® = р, М{(|-М{£})(.)Г} = —
/ /1 £
4. Исследование точности моделирования провести
согласно методике, описанной в § 3.1.
113
§ 3.10. Моделирование двумерного случайного вектора
с полярным распределением
Задание,
ности метод
ра Г (&L
нием
Реализовать на ЭВМ и исследовать по точ-
моделирования двумерного случайного векто-
£2) с так называемым полярным распределе-
Ыр> ф)
X (7(р)7[о, 2л](ф),
(3.56)
где pi, Ц2 е D>0 — параметры распределения. Это
распределение часто встречается в задачах статистиче-
ской радиотехники.
Методика выполнения задания. Для моделирования
можно применить метод исключения, но наиболее про-
сто моделирование осуществляется при помощи следую-
щей теоремы.
Теорема. Пусть тр, т)2 — независимые гауссовские слу-
чайные величины: тр~М1(цг-, Z)). Тогда случайный век-
тор % = (^i, £2), образующийся при переходе к полярным
координатам вектора т] = (т]1, ’П2) ’
л22.
g2 = arctg(r|1/t|2),
(3.57)
где арктангенс понимается в смысле главного значения,
имеет плотность распределения (3.56).
Доказательство. По условию теоремы плот-
ность Т)
Рп„ пЛУ1> Уг) = (2nD)-'exp {-—''1)J + (Уг—
Обратное по отношению к (3.57) преобразование
yi = р cos ф, уг = р sin ф
имеет якобиан J = р. Поэтому по правилам функцио-
нального преобразования случайных величин получаем
(3.56)
РЬ.'ь(Р- ф) = I JI Al,. n,(p cos <р, р sin ф) ='Д.(р, ср). И
Таким образом, моделирующий алгоритм заключается
в моделировании гауссовских случайных величин т}1, гр
и их функциональном преобразовании (3.57).
114
Первоначальный перечень экспериментов
1. D = 1; = 0,05; рг = 0,1.
2. D = 10; m = 0,1; ц2 = 0,2.
3. D = 2; р.1 = 1; = 2.
Указания
1. Для моделирования гауссовских случайных вели-
чин т]1, т)2 использовать стандартную подпрограмму
GAUSS (см. Приложение 1).
2. Оценить коэффициент использования БСВ х и вре-
мя т, затрачиваемое ЭВМ на получение одной реализа-
ции
3. По выборке заданного объема оценить математи-
ческие ожидания, дисперсии £i, £2 и сравнить их с при-
ближенно вычисленными теоретическими значениями
-1-D/(2V))1
D{^}^P(1-Z)/(2X2)))
если +р.2;
M {У = 0,
если %2 D,
если %2 D.
4. Проверку совпадения маргинальных распределе-
ний %* и £ провести в эксперименте 1 согласно методике,
описанной в § 3.1. Приближенные выражения маргиналь-
ных плотностей для 72 <С D имеют вид
л / 12Л2 \ / П2 4- X2 \
р|4р) ~ + ~4£)2 у ехР 2D )’
ре;(<р) + TTWcos (<р ~ ф<)) +
0 Ф 2л, фо — arctg(pi2/|ii).
5. Обобщить теорем}7 на случай 7С-мерпого распреде-
ления (вместо (3.57) используются сферические коорди-
наты (3.36)).
115
§ 3.11. Моделирование случайного вектора
с распределением Релея — Райса
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования случайного вектора =
— Е= RV с многомерным распределением Релея—Райса:
Уи) =
2
t ( ( 1 ,
^еХр|-(-^-4
(3.58)
где f/i, 0; /о(-)—функция Бесселя нулевого
порядка; q > 0, {аг > 0}— параметры распределения.
Эта задача нередко возникает в статистической радио-
технике в связи с моделированием многомерных распре-
делений амплитуд при наличии корреляционных связей
между векторами напряжений.
Методика выполнения задания. Первый способ моде-
лирования основан на методе условных распределе-
ний, описанном в § 3.3. Введем в рассмотрение случай-
ную величину £, распределенную по закону Релея с па-
раметром q-.
pM=lq-^xp{-P/(2q^}U(i).
(3.59)
Определим еще N независимых случайных величин, каж-
дая из которых подчиняется закону Райса (обобщенному
закону Релея) с параметром 0:
Аь (А 10) = У[10 (afiyt) ехр —
4- \
ХГ/(а), М. (3.60)
Их совместная плотность распределения
..ч», (У1> •••> Уы 10) — ДАь(А 10)* (3.61)
i=l
Используя (3.58)—(3.61) и формулу умножения плотнос-
тей, представим fi*(y) в виде
ОО
(Ук • Уы) = (jh. •••> МО dt =
О
116
оо
~ Jps. пь .... //1» •••» Уы)&. (3.62)
о
Выражение (3.62) означает, что — маргинальное рас-
пределение по отношению к распределению £, тц, ..., тру.
Моделирование £, тц, ..., тру основано на следующей тео-
реме.
Теорема 1. Пусть рх, р2— независимые гауссовские
случайные величины: Pj~A\(Ovi, D). Тогда модуль р =
— ]/ р^ + р^ случайного вектора (Pi> Р2) имеет распреде-
ление Райса:
Рч(г) = 4“ ехр (- - °3) U(z), (3.63)
где а = |/ + v;*.
Доказательство. Воспользуемся теоремой из
§ 3.10 при рг = Огр и найдем рл(г) как маргинальную
плотность:
2 л;
6
Применяя табличный интеграл
1 2jtp(f>0 / aOzcosw \ , т( аОг \
“2л” j ехР( —д-----1dtl = !«(-д' )
—Фо
получим (3.63).
Следствие 1. Если vi=V2=0, D—q\ то ц имеет
распределение Релея (3.59).
Следствие 2. Если D = 1, то т) имеет распреде-
ление Райса (3.60).
Таким образом, моделирующий алгоритм заключается
в следующем.
Шаг 1. Моделируем £ с распределением (3.59):
£ = V РТ+7ПГ- ₽; ~ М(0, <72),
pi, р2 независимы. Предположим, £ = t — реализация £.
Шаг 2. Моделируем N независимых случайных ве-
личин тр, ..., тру с распределением (3.60), (3.61):
Лг — Р21+1 Р214-2 ’
Ру TVj(/Vj, 1), \/~ V2. pi 4“ V2t4-2 =
i = Ov, / = 3, 2N + 2.
Обозначим реализации тц = yi, ..., тру = yN.
117
Ш а г 3. Полученные значения принимаются в качест-
ве реализации £*: = уь i = 1, N-
Повторяя n-кратно описанный алгоритм (с независи-
мыми pi, (Зг, • • •, р2к+2, .. получаем выборку из распре-
деления (3.58).
Второй способ моделирования основан на теореме.
Теорема 2 [9]. Пусть pi, (З2, . .., ~ 2Vi(0, 1)— неза-
висимые стандартные гауссовские случайные величины;
£1, ^2 ~2Vi(0, q2) независимы и не зависят от {р;}. Тогда
случайный вектор £ = (^)e RN\
^ = /(p2i_,
й/£1)2 + (₽2i + с^)2, 1=1,^ (3.64)
имеет распределение вероятностей (3.58).
Формула (3.64) и определяет моделирующий алго-
ритм £*.
Первоначальный перечень экспериментов
1. N = 2; q = 2; ai = 0,5; а2 — 1.
2. N = 5; q = 2; щ = а5 = 2; а2 = а± = 1; а3 = 0,5.
Указания
1. Для моделирования гауссовских случайных вели-
чин {Р;} использовать подпрограмму GAUSS (см. При-
ложение 1).
2. Оценить коэффициент использования БСВ х и вре-
мя т, затрачиваемое ЭВМ на получение одной реализа-
ции £.
3. Оценить по выборке заданного объема вторые на-
чальные моменты для |i, ..., и сравнить их с теорети-
ческими значениями. Последние удобно вычислить,
используя (3.64).
4. Сравнить моделирующие алгоритмы по точности
и быстродействию.
§ 3.12. Моделирование случайного вектора,
равномерно распределенного в симплексе
Задание. Реализовать на ЭВМ и исследовать по точ-
ности методы моделирования случайного вектора =
= (£i> равномерно распределенного в симплексе
118
N
V = {у = (Уи -> yN):yi>0, (3.65)
i=i
Методика выполнения задания. Согласно (3.65) плот-
ность распределения
Н*(У) = (mes (V))~4v(y) =
N
= (mes (H)"1 (П^(//0) W — У1 — ••• — Ук)-
i=i
Поскольку mes (V) = —to
H) = M (П^(Л)) CZ(1 —1/1 — — 1/jv). (3.66)
1=1
Исследуем два способа моделирования £*. Первый
способ основан на методе исключения, описанном в § 3.4.
Теорема 2 из § 3.4 допускает переформулировку.
Теорема 1. Если £<*), ... — независимые случайные
TV-векторы, равномерно распределенные в единичном
гиперкубе, то случайный вектор
£ = £(&)} где k — min{m: s V},
(3.67)
распределен равномерно в V.
Случайный вектор ^(/г) = (^/г))ЕЕ/?дг легко моделируется:
у(^) ~ : 1 л7 /о cq\
где си, , on — независимые БСВ. Моделирующий алго-
ритм, таким образом, определяется соотношениями
(3.67), (3.68). Коэффициент использования БСВ
Х1 = 7V-imcs(V)= 1/(N • TV!). (3.69)
Второй метод основан на частном случае теоремы из
§ 3.8. Сравнивая (3.45) и (3.66), убеждаемся, что распре-
деление (3.66)— частный случай распределения Дирихле
При = %2 = • • • == ^Лг+1 = 1.
Теорема 2. Пусть тщ Ллчл—независимые случай-
ные величины, причем т]г имеет стандартное экспоненци-
альное распределение p^lzt) = e~Zi U(z). Тогда случайный
вектор £ = (£j) ЕЕ RN и случайная величина £0, определяе-
мые
дч-i ____ лч-1
Ь = т/, z=i, TV; £о= 2^’ (3,7°)
/=1 /=1
независимы, причем % имеет распределение (3.66).
119
Согласно § 2.20 Tji, ..., т]лг4-1 легко моделируются:
1паъ
i = 1,#+ 1,
(3.71)
где ui, ..., «N+i — независимые БСВ. Таким образом,
второй моделирующий алгоритм определяется формула-
ми (3.70), (3.71). Коэффициент использования БСВ
х2 = 1/(Л7 + 1).
(3.72)
Из (3.69), (3.72) видно, что xi «С хи при N 1.
Первоначальный перечень экспериментов
1. N = 2. 2.N = 3.3.# = 6.
Указания
1. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации | каждым из моделирующих алго-
ритмов.
2. Исследование точности моделирования провести
согласно методике, описанной в § 3.1. При использова-
нии %2-критерия в качестве ячеек целесообразно исполь-
зовать множества
лг _____
VI = {у = j)-Уj 0» —j I = 1 >
/=1
где с0 = 0, Ci, ..., Cft >> 0, которые выбираются так,
чтобы
mes(Vi) = ... = mes(VT) = mes(V)/& =
3. В эксперименте 1 получить выборку объема п = 20
и изобразить ее графически.
4. Моделирующие алгоритмы сравнить по точности
и быстродействию.
§ 3.13. Моделирование случайного вектора,
равномерно распределенного на сфере
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод моделирования случайного вектора =
= (£*)е. равномерно распределенного на сфере еди-
ничного радиуса
120
N
Методика выполнения задания. Обозначим |ГХ| пло-
щадь поверхности сферы (например, | Г±| = 2л, |Гг| =4л).
Так как с вероятностью 1 компоненты функционально
связаны: V )2 = 1, то распределение — сингуляр-
ное и плотность принадлежит классу обобщенных
функций
Д.('/) = с«з(1-2й2)- (3-73)
1=1
где б(-)—дельта-функция Дирака, a cN — нормировоч-
ная константа, связанная с |1\|.
Моделирующий алгоритм основан на теореме.
Теорема. Пусть щ, ..., тру — независимые стандарт-
ные гауссовские случайные величины. Тогда случайный
вектор £ '= (^):
It = у 2 л'? ’ 1 = ’-АГ.
имеет равномерное на сфере распределение (3.73).
Доказательство. Введем вспомогательную слу-
чайную величину
/=1
Тогда имеем взаимно однозначное функциональное преобра-
зование {щ, ..., Tpv+i}^{£i’ •••»
£г = ty/VЛлч-ь = тру+1. (3.74)
Обратное по отношению к (3.74) преобразование
— УгV , i \ , N; £д4-1 = Ук-у\ (3.75)
имеет якобиан J = Ум'+i. Так как {гц} функционально свя-
заны, то по теореме умножения плотностей их совмест-
ная плотность
Рль .... Чд,, . (21» •••’ hl) — Рлп .... Zn) X
JV-j-1 /V
X Ah,, .141..........Пл,(гЛЧ-1| Zl» •••» zn) =
121
= (2л)-^/2 ехр (—zaa+i/2)6 г^+1
(3.76)
По правилам функционального преобразования случайных
величин из (3.75), (3.76) находим плотность £ah-i:
JV ___________
Pit....I.... (Po •••, Pn+i) = Pn+\ (2л) 2 X
iv-j- 1
yN+\ N
Хе 2 <5['l 2^). (3.77)
i==l
Плотность распределения % найдем интегрированием (3.77)
по f/jv+i:
ОО
PliUit •» Pn) — \pit.........lN J (Pn •••» Pn+i) dyN+], =
о
NT(N/2)
N/2
Л
N
Это совпадает с (3.73).
Первоначальный перечень экспериментов
1. М = 2. 2. 7V = 3. 3. 7V = 6.
Указания
1. Моделирование гауссовских случайных величии
осуществлять подпрограммой GAUSS.
2. В эксперименте 1 получить выборку объема п = 20
и изобразить графически.
3. По выборке заданного объема оцепить вектор ма-
тематического ожидания £ и сравнить его с теоретиче-
ским значением.
4. Исследование точности моделирования провести
в экспериментах 1, 2 по методике, описанной в § 3.1,
используя %2-критсрий.
5. Оценить коэффициент использования БСВ х и вре-
мя т, затрачиваемое ЭВМ для получения одной реализа-
ции £.
122
§ 3.14. Моделирование случайной матрицы
с распределением Уишарта
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод моделирования симметричной положительно
определенной случайной матрицы Е* = (£t/)> i, j = 1, М,
имеющей плотность распределения Уишарта с m степе-
нями свободы H7j!v(S, пг):
m m—N—1
где У = (yij)—симметричная положительно определен-
ная матрица. Параметры: натуральное число m N + 1
и S = (oij)—симметричная положительно определенная
матрица.
Методика выполнения задания. Отметим прежде все-
го, что запись (3.78) носит формальный характер. Дейст-
вительно, с вероятностью 1 , i У= /, поэтому Е*
имеет сингулярное распределение. Последнее, как извест-
но, плотности не имеет. Поэтому (3.78) на самом деле—>
это совместная плотность распределения следующих
Л7(Л7-[- 1)/2 элементов матрицы: Л*2, •••, £iao £22, йз,
• ••, Йль £зз> •••, Inn- В [18] распределение Уишарта
называется многомерным аналогом ^-распределения.
Метод моделирования Е* основан на следующей тео-
реме.
Теорема. Пусть т)(Д ..., тД") — независимые гауссов-
ские У-векторы с нулевыми математическими ожидания-
ми и невырожденной ковариационной матрицей S
(m N + !)• Тогда случайная матрица
m
(3.79)
имеет распределение (3.78).
Формула (3.79) и определяет моделирующий алго-
ритм.
123
Первоначальный перечень экспериментов
1. N = 2, m = 4, S = h.
2. N = 2, m — 4, du = (У12 — (J21 = 1, O22 = 4.
3. N = 4, m = 10, S — та же, что и в эксперименте 2
из § 3.6.
Указания
1. Моделирование т/1), ..., осуществлять при по-
мощи подпрограммы MVN, приведенной в Приложе-
нии 1.
2. Оценить коэффициент использования БСВ х и вре-
мя т, затрачиваемое ЭВМ на получение одной реализа-
ции Е.
3. По выборке заданного объема оценить математи-
ческое ожидание Е и сравнить с теоретическим значе-
нием М{Е} = m2.
4. Исследовать распределение выборочной обобщен-
ной дисперсии | Е |. Оценить по выборке математическое
ожидание и дисперсию случайной величины |Е| и срав-
нить их с теоретическими значениями [2].
§ 3.15. Моделирование цепей Маркова с дискретным
временем
Задание. Реализовать на ЭВМ и исследовать по точ-
ности метод условных распределений для моделиро-
вания:
а) однородной цепи Маркова £*, /е {0, 1, 2, ...}, с N
состояниями
{0, 1, М-1}
и начальным распределением вероятностей состояний
р= о
TQ >0, i = 0, М
1=0
(3.80)
матрицей вероятностей одношаговых переходов
~ Р {^Н-1 = / ~ 0 = Pip
1 = 0, JV-1;
/=0
(3.81)
124
б) неоднородной цепи Маркова тр* с м состояниями,
начальным распределением и матрицей вероятностей одно-
шаговых переходов
Р{т]о = /} = л
= Р{тр-Н =
так называемый тренд, определяющий
а <•) — символ
где f(t)
родность последовательности гр*
по модулю N:
неодно-
вычета
и
N
N.
Методика выполнения задания. В силу марковости
и теоремы умножения вероятностей /г-мерное распределе-
ние вероятностей имеет вид
х Пр&’ = х, | £?_, = х<_„ 5о‘= (3.83)
i=l
I —1 — —1’ •••> = о} =
4* 4*
= Р{^ = xj = xt^}. (3.84)
Формулы (3.80), (3.81), (3.83), (3.84) и теорема из § 3.3
определяют моделирующий алгоритм. Он состоит из двух
этапов.
Вычислим предварительно вспомогательный М-вектор
Q~ (Qo> • • • > Qn—1) — (ло, ЛоЧ-Л1, . . . , Ло-Ьл!-}-. • .“Вл^у—2, 1)
и (МхА^)-матрицу
1 ______________________________
Q = O/ij)’ Qi] = Pik> Qi, N— 1 — 1 > j — 0, N — 1.
k—0
Этап 1. Моделирование начального состояния Й:
£о = А если gt_i < < q-L(?_i А 0).
Предположим, х0—реализация £0, полученная на этапе 1.
Этап 2. Моделирование переходов =>й =>••••
Bi = /, если дХ0' t-_i <а2 < qXo> ((qXot _j 0). (3.85)
125
Иначе говоря, — дискретная случайная величина с рас-
пределением, задаваемым строкой номер %о матрицы Р.
Пусть Xi — получившаяся реализация ь Далее с по-
мощью БСВ ,«3 аналогично (3.85) моделируется (с рас-
пределением, даваемым строкой номер Х[ матрицы Р).
И так далее, этап 2 повторяется, пока не будет получено
заданное число п отсчетов xq, Xi, ..., xn-i цепи Маркова
(3.80), (3.81). Коэффициент использования БСВ х=1/п.
Моделирование щ основано на следующей теореме.
Теорема. Случайная последовательность
л;^<Д/) + ^>, / = 0, 1, 2,..., (3.86)
является неоднородной цепью Маркова (3.82).
Формула (3.86) н определяет алгоритм моделирования
тр при помощи
Первоначальный перечень экспериментов
1. N = 2; п = 200; л0 = 0,321;
/0,4
\о,з
т = t.
2. N = 3; п = 300; зт0 = 0,5; jix = 0,3;
Р
Указания
1. Для моделирования БСВ щ, а2, . • • использовать
RANDU.
2. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации х0, Xt, .. ., xn-i- _____
3. В эксперименте 2 реализации {^, тр : t — 0, 49}
изобразить графически.
4. Оценить по {%о, ..., xn-i} матрицу Р, применив
метод максимального правдоподобия:
Р = (Pij)’ Ра = + 'Vil -I- ^2)>
t~0
126
5. Оценить по {хо, . • •, хп-1} вектор стационарных ве-
роятностей л* = (л;) (Ргл* = л*) при помощи метода
максимального правдоподобия:
Сравнить
Р и Р, л*
/=о
и л*.
/ = 0,2V— 1-
§ 3.16. Моделирование гауссовского стационарного
случайного процесса методом скользящего
суммирования
Задание. Реализовать'па ЭВМ и исследовать по точ-
ности метод скользящего суммирования для моделиро-
вания на отрезке времени [О, Т] отсчетов гауссовского
случайного процесса & с шагом А, имеющего математи-
ческое ожидание ц*, корреляционную функцию 7?(т
и спектральную плотность S(X).
Методика выполнения задания. Пусть v]t(t R1) —
случайный процесс с нулевым математическим ожида-
нием, N — некоторое натуральное число, a ..., cN —
действительные числа. Случайный процесс
N
ь = и* + 2 С'Л-*4
/г=1
(3.87)
называется случайным процессом скользящего среднего
(СПСС) порядка N. Предположим далее, что тц — гаус-
совский случайный процесс со спектральной плотностью
S4(X) = X.1W, Ч = 4Ь (3.88)
Из (3.88)
са 1]/
следует, что ковариационная функция процес-
sin %от
причем согласно (3.88)
ОЫ= 1, Яп(±Л)= ^(±2А)- ... = О (3.89)
и справедливо следующее утверждение.
127
Теорема. Для СПСС в условиях (3.89) моменты
определяются соотношениями
M{U = o, D{U = 2cL
N—tn
R^(mh) = ychCk+mU(N — tn),
k=i
Найдем N, коэффициенты {qJ так, чтобы
[—%o, Xo].
(3.90)
(Уменьшением А можно увеличивать промежуток [—Ло, М
совпадения Sg(Z) и S(%) и, следовательно, повышать
точность моделирования.)
Для этого воспользуемся известным в корреляцион-
ной теории случайных процессов фактом. Если на вход
линейного фильтра с импульсной переходной функцией
h(t) и коэффициентом передачи H(jK) поступает процесс
т)(0, то выходной процесс
(3.91)
является гауссовским, имеет математическое ожида-
ние р* и спектральную плотность
А|//(А) IЧ-Ло.зд(М • (3.92)
Из (3.92) следует, что для выполнения требования (3.90)
достаточно использовать линейный фильтр с коэффи-
циентом передачи:
Ж/Ч = ^(Х);
(3.93)
соответствующая импульсная переходная функция
+ оо
] //(АИ'А =
— оо
rv0 .-------
.) V TS« W cos
b
(3.94)
Приведем теперь (3.91) к виду (3.87). Пусть t — rnA —
произвольный момент времени (т = 0, +1, ±2, ...).
128
В силу (3.88), (3.93) применим к тр, Л(/) теорему Котель-
никова:
оо
W = 2 /l 5МгТ-Лд)й) ’
I—— 50
ср. кв. + sin Хо(т _ _ /)Д)
Т]/_т -= П(пг—/)Д Хо(т — (т — /) А) •
1=—оо
Используя эти представления в (3.91), получаем
В предположении, что /i(iA) убывает с ростом номе-
ра |t|, ограничимся N = 2р -J- 1 главными членами этого
ряда (где р — некоторое натуральное число):
ltn\ = и* + д 2 'Пс/п-од»
которое в силу стационарности тр можно записать в виде
(3.87):
w _________
НтД — И* ОгП(пг-—k) Д, Ш = О, /2 1, П —
А=1
. (3.95)
Здесь с учетом (3.94)
ch = bfr-p-u , bi = А/г(/А) =
i _________
j* j/ A-^(XqW) cos (Ina) du,
b
1 = 0, p.
(3.96)
Зададимся теперь числом 0 < e < 1 и выберем р
(и, следовательно, порядок N = 2р + 1) так, чтобы отно-
сительное отклонение дисперсии D{^} от требуемого
значения D{^*}= R(0) нс превосходило уровень е. Пола-
гая в теореме т = 0, находим согласно (3.96)
D &} = Ь20 + 2^; ь1.
Z=1
Тогда получаем соотношение для р:
р* = min {р : | 1 - (6? + 2У 6f)/7?(O) | < е}. (3.97)
Z=1
б Зак. 1015
129
Отметим, что после того, как 7V* = 2р* 4- 1 выбрано,
целесообразно добиться совпадения дисперсий (D{^} =
=Я(0)) с помощью нормировки коэффициентов {c/J:
/'~N*
c'k = с„1 2е'2 ’ k = 11 Л'*- (3.98)
1=1
Итак, моделирующий алгоритм включает три этапа:
1) по формулам (3.96) — (3.98) вычисляются N* и коэф-
фициенты {Ck} \ 2) последовательным обращением к дат-
чику стандартного нормального закона ЛГДО, 1) генери-
руется последовательность независимых случайных вели-
чин: Tl-NA+A, . • • , Т]0, Т]А> • • • > Л(п-2)Д (эту ПОСЛеДОВЗ-
тельность называют дискретным белым шумом); 3) с по-
мощью скользящего суммирования (3.95) вычисляются
отсчеты моделирующего процесса: g0, £д, • • •, £(п-1)д.
Первоначальный перечень экспериментов
1. р* = 0; Т = 5; А = 0,01; 8 = 0,05;
^(т) = 1 +'<о2^ ’ S (Х) = ехр I!/“*>’ “* = 20л-
2. р* = 1, = ехр(—со*|т|), S(X) = 2co*/(Z2 + со*),
со*, Т, А, е — те же, что и в эксперименте 1. В каждом
эксперименте получить по три реализации процесса.
Указания
1. Для моделирования т|г использовать подпрограмму
GAUSS (см. Приложение 1).
2. Оценить время т, затрачиваемое ЭВМ на получе-
ние одной реализации х0, Xi, х2, ..., xn-i (для £0, £д, •. •
• • • > £(п-1)д) •
3. Изобразить графически 50 первых отсчетов каждой
реализации.
4. Исследование точности моделирования провести по
методике, описанной в § 3.2.
5. Сравнить полученные результаты с результатами
моделирования по методу, изложенному в статье
В. С. Донченко *).
> Донченко В. С. Моделирование ^-процессов //Докл. АН УССР.
1982. Т. 12. С. 63—65.
130
§ 3.17. Моделирование гауссовского случайного
процесса с помощью модели авторегрессии
и скользящего среднего
Задание. Реализовать на ЭВМ. и исследовать ио точ-
ности метод, использующий модель авторегрессии (АР)
и скользящего среднего (АРСС) для моделирования на
промежутке [О, Т] с шагом дискретизации.А случайного
процесса имеющего нулевое математическое ожида-
ние, корреляционную функцию 7?(т) и дробно-рациональ-
ную спектральную плотность S(Z).
Методика выполнения задания. Пусть t — triA(m = О,
±1, ±2, ...)—дискретное время; тц — дискретный бе-
лый шум, т. е. последовательность независимых гауссов-
ских случайных величин, распределенных по стандарт-
ному закону М(0, 1). Случайный процесс определяе-
мый линейным рекуррентным уравнением
q р
й) А t)A,
Го Г1
называется процессом АРСС порядка (р, q).
Из теории временных рядов [3] известно, что в ука-
занных условиях £тд является гауссовской последова-
тельностью с нулевым математическим ожиданием и
спектральной плотностью
z — e~i д,
(3.99)
| A(z) |2 _ Л(г)
| B(z) |2 B(z)
В (г-1) ’
Подберем параметры р, q, {a}i}, {bi} так, чтобы Sg(г)
совпадала бы со спектральной плотностью 5^* (z) моде-
лируемой последовательности £тд. Вычислим S^*(z) по
заданной корреляционной функции R (mA):
—оо
S5.(z) = У /?(mA)zra = f(z) + F(l/z) —7?(0), (3.100)
ДП=-—со
где
ОО
F(z) = У R(rn\)zm (3.101)
m=0
5*
131
есть 2-преобразование [30] последовательности {/?(0),
7?(Д), ...}. По условию <S (X)— дробно-рациональная
функция, поэтому корреляционная функция представима
в виде конечной суммы:
Л’(тД) = ’^Ar.sin'eK‘"‘, +/Х‘2), Л‘2)>0, (3.102)
Г, S
где Аг>8— некоторые коэффициенты, не зависящие от т.
Используя это выражение в (3.101) с учетом свойств
^-преобразования, получаем
F(2) = 2^/,.s(2), (3.103)
Г, S
(1 —ге^)-1, если г — 0;
1 — ze^) Qr_i (ге^), если г 1,
где Qr(2)—определенный многочлен степени г:
Qo(z) = 1, Qt (2) = 1 4- 2, Q2(2) = 1 4- 42 + 22,
Q3(z) = 1 + II2+ 11224-23,
Q4(2) = 1 + 262 + 6622 4- 2623 4- 24.
Подставляя (3.103) в (3.100), элементарными преобразо-
ваниями приводим Sg* (2) к виду (3.99) и из условия
^*(2) = Sg(z) определяем р, q, {ak}, {bi}.
Например, если 7?(т) = е~со*1т1, со* > 0, то по форму*
лам (3.102), (3.103), (3.100), (3.99) получаем
Я(т\) = е~т^, ^ = —7*, у* = со*А, Ло1=1;
f(г) = -------1----=-----------L-P2_____, о = е-V.;
1 ZP 1—z ’р (1—гр) (1—z Jp)
Л(г) = 1 — z2, B(z) = 1 — гр.
Следовательно, q = 0, р = 1, а0 ]/ 1 — р2, = — р и
моделирование осуществляем с помощью процесса
АРСС порядка (1, 0) (чистого авторегрессионного про-
^тД — #0T]mA 1)Д, = 0, 1, 2, . . . .
Первоначальный перечень экспериментов
1. R (т) = 2 схр (—со* |т |); со* = 20л; Т = 5; А = 0,01.
2. 7?(т) = 5ехр(—(o*|t|)cos(coot); со0 = 40л; со*, Г, А —
тс же, что и в эксперименте 1.
132
Указания
1—4 — те же, что и в § 3.16.
5. Познакомиться с табл. 2.2 [30].
6. Согласно [3] для любой непрерывной S(X) (не обя-
зательно дробно-рациональной) существует процесс авто-
регрессии со спектральной плотностью, как угодно
близко приближающей S(Z). Рассмотреть возможно-
сти построения такого процесса на примере S(X) =
= охр (—(Z/«*)2) •
§ 3.18. Моделирование процессов случайного
блуждания
Задание. Реализовать на ЭВМ и исследовать по точ-
ности алгоритм моделирования процесса случайного
блуждания на числовой прямой.
Методика выполнения задания. Процесс случайного
блуждания относится к классу процессов с независимыми
приращениями [38] и часто встречается в прикладных
задачах экономики, статистической физики, техники.
Определим процесс е R1^ е [0, оо)) случайного блуж-
дания «частицы» (в качестве которой может быть при-
нята, например, броуновская частица, некий стохастиче-
ский объект или система, подверженные случайным
воздействиям внешней среды) с дискретным временем
t = mA, т = 0, 1, ..., и дискретным фазовым простран-
ством состояний: х = /б, 1 = 0, ±1, ±2, ...}.
Здесь А>0и б > 0 — шаги дискретизации времени
и фазового пространства соответственно. Пусть в мо-
мент t частица находится в состоянии х е X: = х.
Тогда в следующий момент t + А она переходит в состоя-
ние х+б с вероятностью р±, а с вероятностью 1—р+—р~
остается в том же самом состоянии х (р± > 0, 0 <С р+ 4~
4- р_ 1). Начальное состояние = 0.
Для моделирования определим последовательность
независимых дискретных случайных величин т]о, тц, . . . :
тце{—б, 0, б}, Р{т]7 = ±6} =р+, Р{щ = 0} = 1— р+—р~.
Моделирование {тр} легко осуществляется методом из
§ 2.8. Тогда процесс порождается процессом тр с по-
мощью очевидного соотношения
£/+д = It
+ тр, t = 0, А, 2А, ... .
133
Важное теоретическое и прикладное значение имеет
асимптотическое поведение при А -> 0. При этом, что-
бы избежать вырождения этого процесса, параметры
6, р+, р- должны удовлетворять асимптотическим соот-
ношениям
6 = Ь/Д + о()/Д), р± = -1- + -А_/д + 0(|/д),
где b > 0, а е R1 — некоторые константы. Совершая пре-
дельный переход при А—>-0, получаем в результате диф-
фузионный случайный процесс с коэффициентом перено-
са а и коэффициентом диффузии Ь, а при а = 0, b = 1 —
стандартный винеровский процесс wt.
Первоначальный перечень экспериментов
1. 6 = А = 1, р+ = р- = 0,5. Моделирование провести
на промежутке [0, Т], Т= 1000.
2. р+ = р_ = 0,5; 6=|/Д; Т= 100; Д=1; 0,1; 0.01.
3. 6 = V Д’; р± = 0,5 ± 0,25/Д; Т = 100; Д = 1; 0, 1;
0,01.
Указания
1. В каждом эксперименте получить по К реализаций
хг-(/), 1=1, К, t е [0, 71], процесса случайного блужда-
ния (/(=10). Одну из реализаций изобразить графиче-
ски. Здесь же изобразить «трубку» с границами f±(t) =
= at ± в которую при каждом I диффузиоп-
1 2
ный процесс с параметрами (а, Ь) попадает с вероят-
ностью 1 — 8. Здесь g е = Ф-1(1 — е/2).
1~Т
2. В эксперименте 2 оценить по выборке ко-
вариационную функцию и сравнить ее с теоретической.
3. В эксперименте 3 по выборке {*$(0} согласно ме-
тодике, описанной в § 3.2, проверить гипотезу согласия:
Нт имеет распределение Ni (аТ, Ь2Т). Как решение зави-
сит от А?
134
§ 3.19. Метод спектральных разложений
для моделирования случайных полей
Задание. Реализовать на ЭВМ и исследовать по точ-
ности и быстродействию метод спектральных разложе-
ний для моделирования однородных гауссовских случай-
ных полей с заданными вероятностными характеристи-
ками.
Методика выполнения задания. Случайные поля нахо-
дят растущее практическое применение в радиолокацион-
ной технике, оптике, радиофизике, акустике, геофизике.
Пусть моделированию подлежит случайное поле £* =
= £*(х), т. е. случайная функция N действительных пе-
ременных х = (Xi) е Р s F, i = 1, М; D называется
областью определения поля; е R*-. Поле называется
гауссовским, если все его конечномерные распределе-
ния— гауссовские. Гауссовское поле полностью опреде-
ляется лишь двумя вероятностными характеристиками:
средним значением
а(х)= М{Г(х)}, хёО,
и корреляционной функцией
у) = М {(£*(%) — а(х))(£*(у) — а(у))}, х, y(=D.
Для однородного поля
а(х) = а = const, у) А. — УУ>
определена еще и спектральная плотность
SV(A) = j tfv(T)cos(Vr)dT, (3.104)
rn
Как и для случайных процессов, /?£*(•)’ •$£*(•) связаны
парой преобразования Фурье.
Сформулируем метод спектральных разложений.
Пусть D— ограниченный параллелепипед:
d = [о, Xij х ... х [о, ад.
Обозначим s=(si)^RN, si — n/Xr, {А/<, Вь\ k =
= 0, 1,2,...}— независимые в совокупности гауссовские
случайные величины, причем Ak, Bk одинаково распреде-
лены по закону 2V ДО, oi). Определим случайное поле:
ОО
5(х) = а+
k=Q
cos (ksTx) -f- Bh sin (ksTx)), x^D. (3.105)
135
Из (3.105) и свойств {Л/г, В/J следует, что £(%)—гаус-
совское однородное поле со средним а и корреляционной
функцией
/?^(т) = ^<7/г cos (/es7?). (3.106)
/г=0
Подберем {о/г} так, чтобы обеспечить равенство /?|(’) =
= ^*(«):
ol = ~ ^.(т)cos (/;s''T) dx, /г = О, 1 (3.107)
1 1 ’ D
где p(Z>) = Ху ... >Xn— мера Лебега множества D. Ес-
ли за пределами области D корреляцией /?£*(•) в (3.107)
можно пренебречь, то с учетом (3.104) формулы (3.107)
можно дополнительно упростить.
При моделировании ряд (3.105) приходится обрывать
на /ц-м члене. Тогда с помощью (3.106) число т следует
находить из условия в-близости дисперсий А^(-) и /?&*(•):
т
т* = min {т: 11 — V oi/7?^(0) | < в}.
k—0
Первоначальный перечень экспериментов
N = 2> %! = 20, Х2 = 30, а = 0, /?^(т) =
где ai, а2 — числа, характеризующие степень простран-
ственной корреляции в направлениях ть т2-
1. ai = 10, 02 = 5. 2. ai = 1, а2 = 2.
Указания
1. Для моделирования {Л/г, В]{} использовать подпро-
грамму GAUSS (см. Приложение 1).
2. Отсчеты поля £(х) вычислить на сетке: Xi = 0, 2,
4, ..., 20; х2 = 0, 2, 4, ..., 20.
3. Изобразить реализацию поля графически на ЭВМ,
печатая в узле (jci, х2) сетки знак «+», если £(%i, х2) > 0,
и знак «—» в противном случае.
4. Оцепить машинное время, затрачиваемое па гене-
рацию одной реализации поля.
136
5. Для увеличения быстродействия алгоритма следует
записать в памяти ЭВМ таблицу значений косинуса
и использовать ее в (3.105).
§ 3.20. Моделирование случайных множеств
Задание. Реализовать на ЭВМ метод моделирования
случайных множеств с независимыми элементами и оце-
нить вероятностные характеристики случайных мно-
жеств.
Методика выполнения задания. Теория случайных
множеств — перспективное и быстро развивающееся на-
правление теории вероятностей. Эта теория начинает
интенсивно использоваться при решении прикладных за-
дач, возникающих при изучении объектов сложной при-
роды в таких областях, как металлография, биология,
медицина.
Случайное множество Е = Е((п)еХ, определенное
на вероятностном пространстве (Q, F, Р), возникает как
обобщение понятия случайной величины для таких си-
туаций, в которых фазовое пространство X является
пространством множеств. Пусть У cz R2 есть некоторое
компактное множество в R2 и определено его разбиение
на конечное число k подмножеств У<*>, . ..,
i
k
Примем в качестве X множество всех подмножеств из У.
Тогда случайным множеством Е = Е(со) называется
обобщенная случайная величина в измеримом простран-
стве (Л, 2У).
Случайное множество Е=Е((о) называется люсианом*\
если события cz E(w)}, г=1,&, независимы в сово-
купности. Обозначим
Pi = P({w: у«)с S(со)}) (3.108)
вероятность случайного события, состоящего во включе-
нии подмножества У(0 в множество Е, i=l, k.
*) См.: Орлов А. И. Случайные множества с независимыми эле-
ментами (люсианы) и их применение // Алгоритмическое и програм-
мное обеспечение прикладного статистического анализа. М.: Наука,
1980. С. 287—308.
137
Тогда распределение вероятностей люсиана имеет вид
Р3(Х)
Р ({со: S(<o) == X}) =
(3.109)
и полностью определяется вектором вероятностей
Р = (pi, Р2, ...,рь).
Из (3.108), (3.109) следует, что моделирование
S = В (со) на ЭВМ состоит из двух этапов.
Этап 1. Моделируем схему независимых испыта-
ний: в i-м испытании событие Аг (успех) наступает с ве-
роятностью рг и событие Ai (неуспех)—с вероятностью
1 — Pi, i = 1, k. Обозначим 1 h <. 12 < ... < h k
упорядоченный набор номеров тех испытаний, в которых
имел место успех (наступили события А^, ...» Ai).
Этап 2. Вычисляем реализацию X случайного мно-
жества В:
Моделирование каждого из испытаний (на этапе 1)
осуществляем аналогично § 2.6. При этом коэффициент
использования БСВ х = 1/k.
Определим в X расстояние
d(A, В) = Ia(YW)- /в(У<°)|, А, В<=Х.
1=1
Средним множеством М=М{В} случайного множества
В = В (со) называется решение М е X экстремальной
задачи:
D (Л4) — min П(В),
вех
(3.110)
где 2>(В) = M{c/(S(co), В)}—математическое ожидание
случайной величины d = d(B (со), В). Пусть теперь
Х[, Х2, ..., Хп — последовательность п независимых слу-
чайных множеств с одним и тем же распределением
(3.109) (иначе говоря — случайная выборка). Эмпири-
138
ческам средним множеством М называется решение
М следующей экстремальной задачи:
£>1(Л4) = minD^B),
в<=х
(3.111)
DAB)
При n->oo М сходится к М: с вероятностью 1 Я По=
= n0(w) такое, что при п > п0 решения задач (3.110),
(3.111) совпадают. Поэтому М можно использовать в ка-
честве статистической оценки М.
Первоначальный перечень экспериментов
У = [0,1] X [0,1]- - единичный квадрат на плоскости;
k = 100; разбиение У на {У<й} получить делением каждой
из сторон квадрата У на 10 равных частей; п = 20. Рас-
смотреть два типа распределения (3.109): равномерное
распределение, когда
pi = Р2 = .. • = Pwo = 0,5;
и центрально-симметричное распределение, когда
10,8, если cz С,
[0,2, если У(/)с=С,
i = 1, k,
где С — круг с центром (0,5; 0,5) и радиусом 0,4.
Указания
1. Для моделирования {Ль Ар i= 1,А} использовать
подпрограмму RANDU (см. Приложение 1).
2. Каждую из реализаций люсиана изобразить гра-
фически на АЦПУ (или на графопостроителе).
3. Предложить вычислительную процедуру для реше-
ния задач (3.110), (3.111).
4. Решить задачи (3.110), (3.111) перебором при до-
полнительном ограничении: В — круг с центром (0,5; 0,5)
и радиусом г е{0,05; 0,10; 0,15, ..., 0,50}.
139
Глава 4
МОДЕЛИРОВАНИЕ СТОХАСТИЧЕСКИХ СИСТЕМ
Па примерах четырех типов стохастических систем (комплексного
автопредприятия, государственной экономики, линейной системы
управления, многопоточной технологической системы) показано при-
менение статистического моделирования для анализа и оптимизации
качества функционирования таких систем.
4.1. Моделирование процессов
ункционирования
комплексного автопредприятия
Задание. Реализовать на ЭВМ вероятностную модель
комплексного автотранспортного предприятия с закреп-
ленным за ним парком автомобилей и специализирован-
ными частями зон технического обслуживания и теку-
щего ремонта автомобилей. Методом статистического
моделирования оценить эффективность заданного режи-
ма функционирования автопредприятня.
Методика выполнения задания. Описываемая ниже
вероятностная модель возникла при исследовании *> авто-
предприятия, обслуживающего процесс добычи полезных
ископаемых открытым способом, и излагается в терми-
нах теории массового обслуживания.
Автопредприятие имеет N однотипных автомобилей
и п > 1 зон. Зона № 1 — рабочая. Если автомобиль на-
ходится в этой зоне, значит, он работоспособен и занят
перевозками грузов. Остальные п — 1 зон с номерами
2, ..., п — специализированные ремонтные, причем зона
помер i предназначена для ремонтно-восстановительных
работ Z-го типа. Зона номер i, i = 1, п, состоит из Li
идентичных и независимо работающих каналов. Будем
говорить, что на отрезке времени [О, Т] задан режим
функционирования автопредприятия, если задано мно-
жество
Jn(0:/e[0, Л},
где /;(/)е{0, 1, ..., Li}— число каналов f-й зоны, функ-
ционирующих в момент времени t. В каждый момент вре-
См.: Харин 10. С., Меленец 10. В. Оптимизация режима функ-
ционирования замкнутой системы массового обслуживания па ЭВМ //
Оптимизация динамических систем. Минск: Изд-во БГУ, 1976.
С. 131—137.
140
мени канал может обслуживать (т. е. обеспечивать ра-
ботой, если i = 1, или ремонтировать, если i > 1) только
один автомобиль. Время обслуживания в произвольном
канале i-й зоны является случайной величиной с плот-
ностью экспоненциального распределения
Pi СО = Ч-о1 ехр ( — т/тго),
т О,
(4-1)
где Tio = 0 — заданное среднее время обслужи-
вания, если обслуживание начато в момент времени t.
После обслуживания автомобиль покидает зону и мгно-
венно переходит в другую зону. Переходы между зонами
описываются цепью Маркова с заданной матрицей
Р =(p<7), где pij = pij(l)—вероятность перехода обслу-
женного автомобиля из i-й зоны в j-ю зону, i, j = 1, п,
в момент /. Если в момент прихода автомобиля в /-ю зону
в ней среди /.,•(/) каналов имеются свободные, то авто-
мобиль становится на обслуживание в свободный канал
с наименьшим номером. Если же все /;(/) каналов заня-
ты, то автомобиль становится в очередь последним.
Извлечение из очереди осуществляется по принципу пер-
вым пришел — первым обслужен.
Функционирование автопредприятия носит цикличе-
ский характер с периодом То (например, То = 24 ч соот-
ветствует суточным циклическим изменениям); это озна-
чает, что функции pij(t), Tio(O’ МО периодичны с перио-
дом То- Работа организована посменно в г 1 смен
длительностью То/r, причем Z7(i) с течением времени мо-
гут изменяться лишь в моменты «пересмен».
Известны величины потерь в единицу времени в i-й
зоне: ai 0 — потери на содержание выключенного ка-
пала; bi 0 — разность потерь на содержание включен-
ного канала и аг, Ci е R^Ci 0, с2, ..., сп 0)— поте-
ри от пребывания автомобиля в i-й зоне. Эффективность
функционирования характеризуется средними за проме-
жуток функционирования [0, Т], Т = kTo, потерями:
W = М{&у}, w
1 т п
Y~\^SaiLi^~biliW (4.2)
b i=i
где Xi (/) — случайное 'число автомобилей,
п
момент I в i-й зоне (t)=N •
i=l
находящихся в
141
Задание начального состоянияХ(0),/-0
Ila рис. 4.1 изображена блок-схема простейшего алго-
ритма моделирования случайного процесса X(t) = .
В этой блок-схеме: начальное распределение автомо-
билей по зонам Х(0) задается произвольно; /г =
— ([r//To])mod г + 1 — номер смены, в которую попадает
момент времени /; %г- = min{xi(/), k(t)}—интенсивность
выходящего пауссоновского
потока обслуженных авто-
мобилей из f-й зоны в мо-
мент t; Л = Xi + ... + %п —
интенсивность суммарного
выходящего потока из всех
зон в момент /; т — случай-
ная величина длительности
между двумя соседними мо-
ментами завершения обслу-
живания автомобилей, рас-
пределенная по экспоненци-
альному закону
---- ------- - - --1, — . _ ,
Определение номера смены к
Вычисление {At}, Л
---! --- ------ - - ---------------
Моделирование случайной Величины^
р(т) = Ле~Лт, т 0; (4.3)
Моделирование случайной величины 7
с распределением {р^р^}
Изменение состояний
'Л — условная вероят-
ность того, что обслуженный
автомобиль вышел из f-й зо-
ны; i — случайный номер зо-
ны, из которой вышел обслу-
женный автомобиль; / —
случайный номер зоны, в
которую автомобиль направ-
ляется после обслуживания
в i-й зоне.
эдели имитируем случайную
выборку объема К реализаций процесса X(t) и для каж-
дой из них вычислим значение критерия (4.2). Обозначим
Wi значение критерия w, полученное для /-Й реализации,
I = 1, К. Тогда статистика
С помощью описанной
г = 2 ^,/к
1=1
(4-4)
является несмещенной, строго состоятельной, асимптоти-
чески нормальной оценкой для W.
142
Первоначальный перечень экспериментов
То = 24 ч; г = 3; Т — 168 ч (недельный промежуток
времени); N = 100; п = 3; К — 10;
/0,05 0,80 0,15\
Р = 10,90 0 0,10 |;
\0,15 0,85 0 /
остальные численные данные представлены в табл.
4.1, 4.2.
Таблица 4.1
Характеристика
обслуживания
Номер смены
^2
^3
Тю. ч
Т20» Ч
Тзо > Ч
100 100 100
4 4 2
3 2 1
4 4 3
0,5 0,5 j
3 3 6
Примечание. Символ Z/—число каналов обслу-
живания i-й зоны, Т/о — среднее время обслуживания в
г-й зоне.
Таблица 4.2
Виды потерь Номер зоны
1 2 3
at 0 1 50
bi 0,1 9 300
ct 0 30 900
Указания
1. Моделирование случайных величин с распределе-
ниями (4.1), (4.3) осуществить методами из § 2.20.
2. При интегрировании в (4.2) учесть, что {*/(/),
— кусочно-постоянные функции.
3. Оценить быстродействие алгоритма моделиро-
вания.
143
4. Ознакомиться с работой *), в которой методами
теории массового обслуживания получены аналитические
оценки для W. Сравнить эти оценки со статистической
оценкой (4.4).
5. Используя асимптотическую нормальность W, по-
строить интервальную оценку для W.
6. Рассмотреть возможности нахождения оптималь-
ного режима Л*, минимизирующего W.
§ 4.2. Статистическое моделирование экономики
Задание. Реализовать на ЭВМ макромодель эконо-
мики, разработанную Клейном на примере функциониро-
вания экономики США в 1921—1941 гг. [49]. Исследовать
влияние правительственной финансовой политики на на-
циональный доход.
Методика выполнения задания. Пусть te{0, 1,..., 7} —
дискретное время (с интервалом дискретизации, равным,
например, одному году). Состояние экономики в мо-
мент t будем характеризовать девятью переменными
(измеренными, например, в миллиардах долларов):
С/ — уровень личного потребления за промежуток
времени от t — 1 до t (/-й промежуток);
Wu — фонд заработной платы в частном секторе за
f-й отрезок времени;
Pt — суммарные прибыли на t-м отрезке времени;
It — суммарные инвестиции (вклады капитала за ру-
бежом) на t-м отрезке времени;
Kt — суммарный основной капитал в момент /;
Yt — национальный доход на t-м отрезке времени;
Wzt — правительственный фонд заработной платы за
Лй отрезок времени;
Gt — правительственные заказы на t-м отрезке вре-
мени;
Xt — налог на деловую активность на t-м отрезке
времени.
Переменные W2t, Gt, Xt являются управляемыми,
а остальные переменные называются эндогенными (внут-
ренними), неуправляемыми. Функционирование эконо-
*) Медведев Г. А. Об оптимизации замкнутой системы массового
обслуживания//Изв. АН СССР. Техн, кибернетика. 1978. № 6.
С. 199—203.
144
мики описывается системой шести линейных рекуррент-
ных уравнений:
^7 — “Ь ^2 "Ь ^2/) 4~ #3 t 4~ й4 Р1—1 4
(4.5)
Здесь = (Ли) R3 — случайный вектор возмущений,
имеющий трехмерное нормальное распределение 2V3(0, 2)
с нулевым математическим ожиданием и ковариацион-
ной матрицей 2 = (oij); {at, bi, d}— коэффициенты урав-
нений. Случайные векторы £2, ... независимы и оди-
наково распределены. Отметим, что существует более
подробная Брукингская эконометрическая модель *\ в
которой число уравнений равно 230, а общее число пере-
менных 104.
Обозначим Zt = (Ct, It, Wu, Yt, Pt, Kt) составной век-
тор эндогенных переменных и (6X6) -матрицу
1 0 —0,79 0 —0,13 0
0 1 0 0 0,013 0
0 0 1 —0,40 0 0
— 1—10 1 0 0
0 0 1—1 1 0
0 —1 0 0 0 1
Тогда, подставляя в (4.5) оценки коэффициентов
{ai, bi, из [49], получим матричное соотношение
AZt = Bt,
(4-6)
где вектор Bt определяется покомпонентно:
*) Duesenberry J. S., Fromm G., Klein L. R. The Brookings model:
some further results. Chicago: University of Chicago Press, 1969.
210 p.
145
(16,44 + 0,79 Wa + 0,16 Pt^ +g„
28,18 + 0,76 —0.19X/-1 +
15,08 + 0,40 (X, — Га) + 0,18 (У<_(
— 2, i—i) + 0,15/ +
Gt-Xt
Kt-x
причем является линейной функцией от Zt-i управляе-
мых переменных и от Разрешая (4.6) относительно Zt,
получаем рекуррентное уравнение динамики экономики
Zt = A-'Bt, t= 1,2,
которое и используется для моделирования. Начальные
значения: Ро, Ко, W2,о.
Сформулируем четыре варианта финансовой политики
правительства:
П1) управляемые переменные не изменяются, т. е.
П2) налог ежегодно снижается на 5 %, т. е.
W2t = Gt = Gt-i, Xt = 0,95Xw;
Пз) правительственные заказы ежегодно увеличи-
ваются на 5 %, т. е.
W2t = W2,t-if Gt = l,05Gz_b Xt = Xt-c
П4) правительственный фонд зарплаты увеличива-
ется ежегодно на 5 %, т. е.
W2t = l,05№M_i, Gt = Gt-i, Xt = Xt-i.
В качестве показателя эффективности примем сред-
ний за Т лет национальный доход
Л = М{Х}, % = 2у//7’-
/=1
Первоначальный перечень экспериментов
7=20 лет; Ро=20; Ко=200; Г20=30;
/25 0 0 \
2= 0 9 0 .
\0 0 16/
146
Указания
1. Для моделирования использовать подпрограмму
MVN (см. Приложение 1).
2. Для каждого варианта политики получить по К =
= 10 реализаций Ztk\ k = 1, К, процесса Zz(Ze[l, Т]).
Для каждой реализации Zt вычислить средний (за Т
лет) национальный доход:
т
W'o = 2 Y(it}/T.
1=1
к
Построить точечную 11 интервальную
/г=1
оценку для Л. Какая из политик П1, Пг, П3, П4 лучше?
3. Для каждого варианта политики lij, / = 1, 2, 3, 4,
оценить зависимость от времени среднего национального
дохода цДП;)= М{К}:
к
Изобразить полученные зависимости графически.
§ 4.3. Моделирование линейной стохастической
системы управления
Задание. Реализовать на ЭВМ линейную стохастиче-
скую систему управления и методом статистического мо-
делирования провести ее анализ.
Методика выполнения задания. Одной из основных
задач теории автоматического управления является за-
дача анализа поведения объекта управления при задан-
ной структуре управляющего воздействия и каналов
измерений и управления. Системы автоматического управ-
ления характеризуются управляемыми координатами 0^,
наблюдаемыми координатами и управляющими воз-
действиями u(t). Связь между этими переменными мож-
но описать следующими уравнениями [43]:
dBt = (F(l)Gt + G(t)ut)dt -]-b(t)dWt, (4.7)
d^ = 7/(/)0zJZ + /?
(4.8)
t e [0, T], Wi и Wu — независимые винеровские процес-
147
сы, |0 = 0, Оо имеет гауссовское распределение 2V1 (О, 1).
При рассмотрении вопросов, связанных с анализом
поведения систем автоматического управления, предпола-
гается, что управление w(Z) в правой части уравнения
(4.7) является известной функцией времени t. Управле-
ние выбирается из условия
т
I (ц) = М ( (0z — mty dt] -> min,
о «(•)
(4.9)
где mi — оценка значений ненаблюдаемого случайного
процесса 0/ в момент времени t по наблюдениям за стати-
стически связанным с ним случайным процессом
Известно, что искомую оценку дает фильтр Калмана —
Быоси [43]:
din, = (/• (/) mt + G (t) и (/)) dt + -gjLy H (/) Y (/) -
— H(t)mtdt), (4-10)
V = 2 F (t) у (I) + 6s (/)-’ (H (О у (0)3 (4.11)
с начальными условиями /и0 и у0.
Теорема Бернштейна. Пусть th = tk-i + Д//,
^4 (^/^» tk) ^tfa f cit ) ^tk,
9 1/
dA
где А и — непрерывные ограниченные функции,
t, at)} = 0, M{/2(r/, t, щ)} = В(у, t); функции f,
df d2f _ , .
А- также непрерывны и ограничены. Пусть р0(у)—
начальная плотность вероятностей у при t = 0, причем
Pq (у) имеет непрерывные производные первых двух поряд-
ков. Пусть Р(у, t) и р(у, t) обозначают закон распреде-
ления и плотность распределения вероятностей (Р (у, t) =
у
it
Р (У, t)dy) для предельного значения у, когда пн-
— оо
тервалы между дискретными значениями //- стремятся
к нулю. Тогда р(у, /) определяется уравнением
др (у, I)
dt
t)p(g, on-
us
Из теоремы Бернштейна' следует, что решение урав-
нений (4.7), (4.8), (4.10), (4.11) можно представить как
предел при Д^-^О решений разностных уравнений:
Д0< = (F(t) Qt+G (/) u(t) )dt+b (t)bWf,
Д^ = + В(/)ДГП;
Дт/ = (F (t)mt 4- G(t)ut)dt -|-
(Д^-//(/)т,Д/);
= Z(=[0, F],— последовательность вза-
имно независимых случайных величин, распределенных по
закону М (0, Д/); Д^, Д^— независимые последова-
тельности нормально распределенных случайных величин
TVi (0, Ы).
Если уравнение (4.11) не решается в аналитической
форме, то необходимо рассмотреть разностную аппрокси-
мацию его:
У (t -I- Л/) = У (О + Д/ (4F (0 Y (/) 4- 62 - 4- Y2 (0)-
Первоначальный перечень экспериментов
Провести моделирование системы управления при
следующих значениях параметров.
1. F(/)=-0,8; 6(Z) = 1; G(/) = l; //(/)=2; B(Z)=-1;
u(t) = 1,5; mQ = 1; у0 = 1.
2. F(Z)=—0,8; 6(/) = 1; G(/) = l; //(0=2; £(/)=-!;
niQ = 1; уо = 1; = — s(/)m(/), где s(Z) находится из
уравнения — s=— 1,6s-]-1—s2; s(F) =0.
Указания
1. Для моделирования случайных последовательнос-
тей 0/, Zg{0, Д/, 2Д/, . . .}, воспользоваться подпро-
граммой GAUSS.
2. Построить графики полученных реализаций 0/ и
3. Получить точечные и интервальные оценки для 0/,
осуществляя многократное моделирование системы управ-
ления.
4. Оценить критерий качества, используя при вычис-
лении выражения {•} в (4.9) формулу
N—\
/(и)^ /va7~ — irtk^y.
149
§ 4.4. Исследование производительности и надежности
многопоточной технологической системы
Задание. Реализовать на ЭВМ процесс функциониро-
вания многопоточной технологической системы, состоящей
из г различных групп по nit i= 1, г, параллельно рабо-
тающих однотипных единиц оборудования и накопителей
емкостью m-i между ними, содержащих в начальный мо-
мент по ai заготовок (рис. 4.2). Методом статистического
моделирования оценить производительность и надеж-
ность системы за время /, найти число переполнений на-
копителей.
Рис. 4.2
Методика выполнения задания. При обработке заготовка
проходит через г участков многопоточной системы. Дли-
тельность цикла обработки одной заготовки /-й единицей
оборудования f-й группы равна В процессе функцио-
нирования системы возникают простои из-за отказов
оборудования и отсутствия заделов, прерывающие обра-
ботку. После появления неисправности происходит вос-
становление оборудования и обработка заготовки про-
должается. Последовательность отказов и восстановле-
ний характеризуется законами распределения Fi(/H)
времени наработки на отказ и Фг(/В) времени восстанов-
ления г-й единицы оборудования. Предполагается, что
в начальный момент все агрегаты и группы исправны.
Известны моменты поступления заготовок к первой груп-
пе; вероятность отказа накопителей мала; отсутствуют
простои оборудования по организационным причинам;
наработки па отказ независимы и одинаково распреде-
лены для каждой группы; длительности восстановления
независимы между собой и не зависят от соответствую-
150
щих наработок и одинаково распределены для каждой
группы.
Функционирование системы при моделировании пред-
ставляется в виде последовательной работы звеньев
(предшествующий накопитель — группа оборудования —
последующий накопитель) на отрезке времени (0, /).
Результаты, полученные при моделировании i-ro зве-
на, являются исходными данными при моделировании
(i + 1)-го звена.
Рассмотрим i-e звено, полагая, что в начальный мо-
мент все оборудование в группе исправно и известны
моменты поступления заготовок в (i— 1)-й накопитель:
— и аа. ,4-1
i—l
где —начальный задел в (г—1)-м накопителе; ty-i-h
+ /t_i = mi-1 —емкость (i— 1)-го накопителя; — мо-
менты поступления заготовок к первой группе.
Необходимо найти моменты dj поступления заготовок
в i-й накопитель.
Определяем момент выпуска первой заготовки первым
агрегатом i-й группы:
f(i) = s(i) _|_ JU-1)
'и °п ui »
где —время нахождения заготовки на первом агрегате
(О .
Величина — 1 означает количество отказов, которое
произошло при обработке первой заготовки, и определяет-
ся неравенством
Значения . и 4. моделируются в соответствии с зако-
Z J
нами распределения Ft (iH) и Ф4- (iB). Определяем оста-
ток времени наработки
151
необходимый для моделирования момента выпуска вто-
рой заготовки тем же агрегатом.
Проверяем условие Если оно не выполняется, то
в дальнейшем эта единица оборудования исключается из
рассмотрения.
Аналогично моделируется момент выпуска первой
детали вторым агрегатом i-й группы. Находим
fin = su) 1 яа-1).
/19 J19 Т w9 >
Проверяется условие Вычислив /фр, /(р), ...
... , , 6(‘р, 6^, ... , 6jj), находим значение момента вы-
пуска первой заготовки:
=<₽/. = min Ж -
где Д — номер агрегата, выпустившего первую заготов-
ку*).
Затем проверяется условие переполнения (г—1)-го на-
копителя. Значение <р/ж сравнивается с рядом и на-
ходится номер первой величины из этого ряда, превос-
ходящей Вычисляем разность у{1’) = —(m£-_i + 1) —
— tii. Если у(р) >> 0, то фиксируется факт переполнения и
вычеркиваются моменты dj1’-с номерами /, равными
(i1—1), (i’i — 2), ... , (Zj — У?)), и нижний индекс вели-
*) Если имеется несколько одинаковых то ]\ берется рав-
ным наименьшему /.
152
чип начиная с номера / = получает значение,
уменьшенное на величину у(А Далее определяется мо-
мент выпуска второй заготовки /\-м агрегатом z-й
группы, выпустившим ранее других первую заготовку:
= 4/1 + шах[ф/р 4л + max[daki, cfcVb
L L L
где
Если условие f2jt<Zt не выполняется, то в дальнейшем
агрегат с номером Д не рассматривается.
Среди множества, элементами которого являются
и для / =# Д, минимальное значение
представляет собой момент выпуска второй заготовки t-й
группой, а /2 — номер агрегата, выпустившего эту заго-
товку.
Затем в ряду находим первое из чисел с
ром г2, превосходящее d%\ 2:
L
номе-
11 вычисляем значение = i2—-|- 1) — /Д Если
У^>>0, то в ряду dp—1) вычеркиваем моменты с номерами
(г2—1), (Z2—2),..., (й—у<°), а для моментов Jj1'-!), начиная
с номера / = i2, уменьшаем значение нижнего индекса на
величину у^.
Аналогично определяется момент выпуска третьей за-
готовки /2-м агрегатом f-й группы f^) и т. д.
153
В результате моделирования f-ro звена получаем фак-
тическое значение числа заготовок, выпущенных (i—1)-м
звеном за время t, число т)г—i переполнений (i — 1)-го на-
копителя, исходные моменты для моделирования ра-
боты (/ + 1)-й группы.
Оценка надежности и производительности системы
за время t осуществляется на основании результатов
многократного моделирования. По полученным реализа-
циям процесса функционирования находится фактиче-
ское количество продукции, выпущенной каждой группой
оборудования. Основной показатель надежности — коэф-
фициент готовности моделируемой системы
Л'г (0 = С<н/С^х,
где С<г) — среднее число деталей, выпущенных
(г-й группой),
с'г) = 4-2 Qr);
1=1
системой
Ct-r) — число деталей, выпущенных r-й группой в одной
реализации при моделировании; N — число реализаций мо-
делирования;
пг
= 12 (1/а<6>).
/г=1
Таблица 4.3
г = 3, X;, 1 /мин И/ > 1 / МИН «i mi <Ц l/А/. 1/мип
t = 480 мин, 4О) = о, лг=1оо « 1 2 3 0,1064 0,3571 0,4167 0,4545 0,4762 0,4762 1 1 1 4 42 42 10 10 0,0165 0,0424 0,0597
г = 2, t = 120 мин, 4°>=о, W = 100 1 2 0,20 0,10 0,10 0,08 3 2 20 0,8 1,0
*) i — номер группы.
154
Указания
1. Моделирование случайных величин с функциями
распределения Ft (tn) — 1 — и Ф/ (/„) = 1 —
осуществить методами из § 2.18—2.20.
2. При наличии значительного числа переполнений
накопителей установить новое значение емкостей тг-,
обеспечивающее увеличение производительности систе-
мы. Первоначальный перечень экспериментов определя-
ется табл. 4.3.
3. Построить блок-схему моделируемой системы и
описать ее на языке GPSS*)—общецелевой системы мо-
делирования. Использовать следующие основные блоки:
— генерирование транзактов;
— вхождение в накопитель;
— вхождение в очередь на прибор;
— занятие прибора;
— освобождение прибора;
— моделирование интервалов времени безотказной
работы и времени восстановления;
— моделирование отказа в виде требования, зани-
мающего устройство;
— моделирование перехода устройства в рабочий ре-
жим;
— формирование таблицы частот времени.
*) Шрайбер Т. Дж. Моделирование па GPSS. М.: Машинострое-
ние, 1980. 592 с.
ЧАСТЬ
СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА
ДАННЫХ
Глава 5
СТАТИСТИЧЕСКОЕ ОЦЕНИВАНИЕ
ВЕРОЯТНОСТНЫХ РАСПРЕДЕЛЕНИЙ
И СЖАТИЕ ДАННЫХ
В данной главе изучаются методы и алгоритмы оценивания по наб-
людаемой случайной выборке функции распределения, дискретного
распределения вероятностей, плотности распределения (в том числе
оценки Розенблатта — Парзсна и ближайших соседей), а также чис-
ловых характеристик положения и масштаба. Рассматриваются так-
же задачи сжатия данных с помощью метода главных компонент
и факторного анализа.
§ 5.1. Оценивание вероятностных распределений
и числовых характеристик скалярных
случайных величин
Задание. Наблюдение есть случайный р-вектор £, =
= t=l, р, определенный на вероятностном
пространстве (Q, F, Р) с функцией распределения F^ (х);
t-я компонента этого вектора является скалярной слу-
чайной величиной с маргинальной функцией распределе-
ния Для каждой i-и компоненты возможна одна
156
из двух ситуаций* h О л,(-)-- непрерывная функция
распределения; D) F%. (•) — дискретная функция распре-
деления. В ситуации С существует маргинальная плот-
ность распределения случайной величины
Pi, U'i) =
l'
Xi e
(5.1)
В ситуации D случайная величина принимает значения
из дискретного множества At — {«л, • •• , CLikM
а^ <Z ai2 < • • • aik есть ki возможных значений Диск-
ретное распределение вероятностей
Р {& = ац}
(5.2)
определим набором вероятностей {pij}, удовлетворяю-
щих условию нормировки
k.
I
Наблюдается случайная выборка объема /г:
(zi\...\zn), zt = (zh^Rp, 1=1, p,
из распределения вероятностей с неизвестной функцией
распределения Fg(-). Для каждой i-й компоненты (i=
= 1, р) оценить плотность (5.1) (в ситуации С) или рас-
пределение вероятностей (5.2) (в ситуации D), функцию
распределения Ft (хд), а также следующие их числовые
характеристики.
Характеристики положения:
математическое ожидание (среднее) щ = М{£?:};
мода mi = arg max р^. (х), тд = arg max Р {£д = а^};
х 1 {аа}
медиана Мр. (Mi) = 0,5;
наибольшее аг+ и наименьшее аг-_ значения Р{яг-
= 1, Р — —}— 8 $г-|- б} 1, 8 ^-> 0.
Модель сингулярных распределении и смесей дискретных
и непрерывных распределений здесь нс рассматривается.
157
Характеристики рассеяния:
дисперсия D{£j;
среднеквадратическое (стандартное) отклонение 04 —
коэффициент вариации (если рг- Ф 0) Хг = Пг/р*;
размах ai = а,г+ — а^',
интерквартильный размах yi = Y1-4. — yt_; Fi.(yi\-) —
= 0,75; (yt_) = 0,25;
интервал концентрации распределения (pz— Зо,, рг 4-
Ч- 3cF/);
коэффициент асимметрии р1г = М {(^ — Рг)3}/сг?;
коэффициент эксцесса (островершинности) р2г — М{(£г—
— Нг)4}/°-— 3.
Методика выполнения задания. В ситуации С для
оценивания плотности р% (х^) применим гистограмму. Для
этого разобьем промежуток [at_, at-_|_) на L ячеек точка-
ми деления {biQi ... , biL}:
biQ —, Ьц_ ^4-]-,
Обозначим
L— 1
|-) ~ U [^ij> ^i, /-f-1)’
/=0
n
число выборочных значений среди {zu, ..., zni}, попав-
ших в промежуток [bi,j-it Ьц). Тогда гистограммой явля-
ется статистика
L
~ , ч v_________________УН ______
[Pl,- (Xi) ~ tl (bij — bit 7_!)
г ('^0» XiFFzRX (3«3)
4, / — 1
Точность этой оценки существенно зависит от L и выбора
точек разбиения {Ьц}.
Обозначим вариационный ряд
являющийся результатом упорядочения выборочных зна-
чений {za, ...» zni} по возрастанию. Тогда эмпирическая
функция распределения есть
158
о
п
если
если
Xi е У?1,
если
2(п)г
Эта оценка является строго состоятельной, несмещенной,
и случайная величина
]/n (Fit (*) - a,. (xi))/yFt^xt) - Fi. (х,))
при п -> оо распределена асимптотически нормально по
закону (О, 1). Этот факт может использоваться для
построения интервальной оценки для А (•)• Другая ин-
тервальная оценка [14] для F% (•) получается с исполь-
зованием критерия Колмогорова из § 1.4: с вероятностью
1 — 8
Xi е R1,
min (xf) +
I 1 У п
где А = А (е) определяется по табл. 1.3.
Статистические оценки характеристик положения:
п
mi = argmax р>. (х,);
Mi:FiAMi) = 0,5;
If
^i-|- O-l—
Отметим, что p, — строго состоятельная, несмещенная
оценка, имеющая вариацию V {pj == о?//г.
Статистические оценки характеристик рассеяния:
°i = <£ ~ Hi)7(«— 1); Of =
Z=1
^i ~ Oj/p;, Щ ~ Z(n)i
Y<+: ht (Y>+) = 0,75; y(_: (у,_) = 0,25;
159
Оценка интервала концентрации: (р,/— Зоь Рг + Зо^).
Выборочная дисперсия о? является состоятельной, несмещен-
ной оценкой.
Отметим еще, что если & имеет гауссовское распреде-
ление, то для pj, о2, справедливы интервальные оценки
(с доверительной вероятностью 1—в):
где /(«, п — 1)— квантиль уровня а для /-распределения
Стыодента с п—1 степенями свободы; /С(а, п—1) —
квантиль уровня а для ^-распределения с п — 1 степе-
нями свободы (/(•); /((•) протабулированы в [27, 48]).
В ситуации D наряду с гистограммой и эмпирической
функцией распределения для оценивания вероятностного
распределения (5.2) удобно использовать (если известно
множество Лг) оценки элементарных вероятностей {рц}'-
п
Эти оценки являются несмещенными, строго состоятель-
ными, асимптотически нормальными и эффективными с
вариациями V {pij} = pfJ (1—pij)]n- В [48] приведены
доверительные границы для pij при доверительной вероят-
ности 0,95; 0,99.
Числовые характеристики в ситуации D оцениваются
аналогично, как и в ситуации С.
160
Первоначальный перечень экспериментов
1. Модельные данные: р — 2, п = 100, |— гауссов-
ский вектор с распределением Л2(0, /2) (см- § 3.6).
2. Модельные данные: р = 1, п = 100, |— случайная
величина с распределением Пуассона (см. § 2.10) с пара-
метром % — 3.
3. Реальные данные кардиологических обследований
населения (см. § 9.5): £= (£i, 21 — вектор показателей
антропометрии обследуемых лиц, у которых индекс
Пинье не превосходит порогового значения а = — 23;
£1 — вес человека, а — его рост.
Указания
1. Выборка Z для эксперимента 1 записана в наборе
№ 1 (см. § 9.5).
2. Выборка Z для эксперимента 2 записана в наборе
№ 7 (см. § 9.5) .
3. Выборку Z для эксперимента 3 сформировать из
данных кардиологических обследований, записанных
в наборе № 2 (см. § 9.5). Использовать следующие пере-
менные: индекс Пинье Х(45), вес тела £1 = Х(22), рост
£2 = Х(23). Задать коды пропущенных значений для
Х(22) и X (23) равными нулю.
4. Для вычисления оценок распределений и числовых
характеристик использовать программы BMDP2D и
BMDP5D [52]. Для вычисления квантилей в (5.4) можно
использовать таблицы [48] или подпрограммы из [46].
§ 5.2. Непараметрическое оценивание многомерных
плотностей распределения
Задание. Пусть наблюдением [является случайный р-
вектор £ = (|i) е Rp с неизвестной дваждьР’дифференци-
руемой плотностью распределения f(y)t у = (yi), i= 1, р.
Наблюдается случайная выборка X = (лу!... \хп) объема п
из этого распределения. По выборке X оценить f(-),
используя метод Розенблатта — Парзсна и метод бли-
жайших соседей. Исследовать статистические свойства
оценок.
Методика выполнения задания. Пусть у е Rp — про-
извольная точка, в которой необходимо оценить плот-
6 Зак. 1015
161
ность f(y). Непараметрической оценкой Розенблатта —
Парзена для f(y) называется статистика
Функция р переменных 7<(z) = zp) называется
ядром-, числа hi, ..., hp принято называть коэффициен-
тами сглаживания. Отметим основные свойства оценки
(5.5).
Если при п оо
J К (2) dz = 1, | I < 00, lim I Zj К (г) | — О,
UP "
р
hj = hj (n) -> О, и П hj (n) -> 00,
/=1
(5-6)
то оценка (5.5)—состоятельная и асимптотически несме-
щенная. Если f (у) #= 0, то случайная величина (у) —
—распределена асимптотически нормаль-
но по закону АТ (О, 1). В условиях (5.6) справедливы
асимптотические разложения для моментов уклонения ri =
= fm (y) — f(y)-
р
р
Rp
р
Условия (5.6) не единственным образом определяют
ядро и коэффициенты сглаживания. Этот произвол в вы-
боре К(-), {hj} целесообразно использовать для повы-
шения точности оценивания. Точность оценивания тем
выше, чем меньше относительная интегральная средне-
квадратическая ошибка оценивания:
/ = /(/<(•), Л,. ... , Л„) = J М{(Л.1
Поэтому возникает задача нахождения ядра и коэффи-
циентов сглаживания, минимизирующих /.
й 62
Теорема *).
в виде
Пусть р-мерпое ядро I\(z)
представимо
ПрИЧСМ
оо
нсвозрастающая функция от [zj|;
г;) = Kj
no
оо, т
— СЮ
Тогда минимальное значение / достигается для
( з
если
если |г7-
/5,
/5;
h'j (п) = с* n-vtp-H),
Если при этом все коэффициенты
ны, то
сглаживания {hj} рав-
ОО
р
1/(р+4)
Отмстим, что воспользоваться формулой (5.9) на
практике затруднительно, поскольку с! зависит от f(-),
которая и подлежит оценке. Одним из вариантов вы-
бора {ct} на практике является следующий:
п
*
п
/г1 5
Г
где 5 = (Sij)—выборочная ковариационная матрица.
Опишем теперь метод k-ближайших соседей оценива-
ния плотности, или сокращенно k-NN-метоц (от англ.
*) Епанечников В. А. Непараметрическая оценка многомерной
плотности вероятностей//Теория вероятностей и се применения. 1969.
Т. 14. Вып. 1. С. 156—160.
6*
163
k Nearest Neighbor), предложенный Ловтсгарденом.
Зададимся некоторым натуральным k Z> 1 и, кроме
евклидова расстояния в Rp, будем использовать еще мет-
рику р = р(х, у), х, у е Rp. Выборочное значение Xjt е
е Rp такое, что
р(#> xh) = min р(у, xi),
1 <l<n
называется ближайшим соседом точки у. Если решение /1
определяется этим уравнением не однозначно, то выби-
рается наименьшее из решений /1. Второй ближайший
сосед — выборочное значение Xj2:
Р(*Л xh) = minp(r/, х^
и т. д. Наконец, k-м. ближайший сосед — х; :
Jk
Р(^*а) = min р(у, Xi).
..., ik_l}
Расстояние до k-го соседа обозначим
и определим множество
его мера Лебега V = V(у, X). В частности, если р(-) —
евклидова метрика, то Ву — гипершар с центром в точ-
ке у радиуса г, объем которого
V = 2л"/2г'7(рГ(р/2)).
Статистика
fndy) = (k- l)/(nV(y, X)) (5.10)
называется А-АМАоценкой плотности распределения /(•)
по выборке X объема п в точке у е Rp.
Если число ближайших соседей k = k(n) зависит от и
так, что при оо
^ (/?)-> оо, k(n)/n-+0,
то оценка (5.10) является асимптотически несмещенной
и состоятельной. Асимптотические разложения типа (5.7)
получил И. Мак *).
*) Mack У. Multivariate ^-nearest neighbor density estimation //
J. of Multivariate Analysis. 1979. N 9. P. 1—15.
164
Первоначальный перечень экспериментов
1. Модельные данные: р = 1; f(y) = /г±(г/|О, 1); и =
= 5, 10, 20, 50, 100, 500; k = [jUT].
2. Модельные данные: р = 2; f (у) — п2 (у | р, ^); р —
/1\ / 1 0,5\
= 1 ; S = п п о ; п = 10, 100; k = [Уп].
1 / Л /
3. Реальные данные химического анализа состава
крови (см. § 9.5): р = 5, п — 50, k = 5.
Указания
1. В экспериментах 1—3 использовать евклидову мет-
рику р(р) = уту.
2. В эксперименте 1 изобразить графически плот-
ность f(y), выборку X, оценки fni(y), fn2(y)-
3. Многократно генерируя выборку X и вычисляя
оценку (5.5), в эксперименте 1 оценить смещение и ди-
сперсию fni(y) в точке у = 0 и сравнить с теоретическими
значениями (5.7). Исследовать возможность пренебре-
жения остаточными членами в разложениях (5.7).
4. Эксперименты 1, 2 провести с ядром (5.8) и гаус-
совским ядром К(2) = njv(2|0, In)- Сравнить точность
этих двух вариантов оценок.
5. Сравнить оценку Розенблатта — Парзена и k-NN-
оценку по точности и быстродействию.
6. Анализируя (5.5) при р = 1 и (5.3), установить
связь гистограммы и оценки Розенблатта — Парзена.
7. Исходные данные для экспериментов 1, 2 модели-
ровать с помощью подпрограмм GAUSS и MVN (см.
Приложение 1).
8. Исходные данные для эксперимента 3 записаны
в наборе № 8: использовать переменные Х(1)—возраст,
Х(2)—рост, Х(7)—альбумин, Х(8)—кальций, Х(9) —
мочевина (см. табл. 9.5).
§ 5.3. Сжатие данных методом главных компонент
Задание. Пусть X = (Хь ..., Хр)— р-мерная нормаль-
но распределенная случайная величина с вектором мате-
матического ожидания р = (pi, р2, .. ., рр) и матрицей
165
ковариации Sy. Рассмотрим ортогональное преобразова-
ние У = АГХ; при этом линейная комбинация
У; = Л •'X, 1= 1Тр, (5.11)
где Ai — i-й нормированный собственный вектор Sy, на-
зывается i-й главной компонентой случайного векто-
ра X [2]. На основании (5.11) найти оценки максималь-
ного правдоподобия главных компонент и их дисперсий
по случайной выборке. Определить долю общей диспер-
сии, объясняемой каждой компонентой. Построить тест
и проверить гипотезы равенства дисперсий главных ком-
понент и возможности представления исходных компо-
нент q <Z р главными компонентами.
Методика выполнения задания. Формула (5.11) за-
дает такое полное ортогональное преобразование, при
котором каждая р-мерная исходная случайная величина
представляется в новом пространстве Rp также р-мерной
случайной величиной. Геометрически это эквивалентно
повороту координатных осей X параллельно осям эллип-
соида рассеяния: f(x) = const, где f(x)—плотность нор-
мального распределения случайного вектора X.
Так как ковариационная матрица У равна Sy =
= ATZxA, а А — матрица собственных векторов Sy, то
Sy диагональна:
где Хг — t-e собственное значение Sy, и дисперсия i-й
главной компоненты Уг- равна ХДМ >• 0).
Следовательно, преобразование (5.11) обеспечивает
инвариантность суммы дисперсий:
tr Sx = tr (Лг Ух Л) = Л[2х л, +... + л; Sx л„.
* г-7 *
Дисперсия первых q компонент в Y равна
ЛТХхЛх + ...+Л;ХхЛ,<1г2х. (5.12)
Максимальное значение (5.12) составляет М + .. • +
а общая дисперсия М + ... + Очевидно, первые q
главных компонент «объясняют» (М + ... + %р)-1 X
(М + ... + %q) 100 % общей дисперсии. В связи с тем,
что главные компоненты представляют собой характери-
стики эллипсоида рассеяния, необходимо стандартизиро-
вать исходные наблюдения X, если они измерены в раз-
ных единицах.
166
Задача оценивания в анализе главных компонент
сводится к нахождению оценок собственных значений
и собственных векторов матрицы ковариаций или корре-
ляций для X. Оценками максимального правдоподобия
для Xi,
уравнения
., Хр и Ai,..., Ар являются корни М
х/„1 = о
(5.13)
и собственные векторы А
нениям
.. , Ар, удовлетворяющие урав-
(5.15)
где 2х — оценка максимального правдоподобия для мат-
рицы
Этот результат справедлив, когда матрица имеет
р различных собственных значений. Если не все крат-
ности корней (5.12) равны единице, оценки максималь-
ного правдоподобия нельзя определить по (5.12) — (5.15).
Для наиболее часто изучаемого случая, когда существует
только один корень кратности р, оценка максималь-
ного правдоподобия для Xi равна [2]:
где хи — j-e наблюдение i-й переменной; Xi — среднее
значение i-й переменной; п — общее число наблюдений.
Гипотезы, выдвигаемые в анализе главных компонент,
относятся к оценке возможности замены исходных на-
блюдений X меньшим числом их линейных комбинаций
или проверке необходимости перехода к главным компо-
нентам.
Рассмотрим задачу проверки гипотезы о равенстве
дисперсий главных компонент вектора X:
Но: 2ц = 7-2 —
(5.16)
против альтернативы Hi о том, что не все собственные
значения равны,
167
Выражение (5.16) означает, что эллипсоид рассеяния
является сферой, т. е. преобразование (5.11) нецелесооб-
разно.
Статистика отношения правдоподобия для проверки
Но, Hi равна:
Введем статистику W = — 2 In L. Известно, что при
п-^-оо и верной гипотезе Но асимптотическое распреде-
ление статистики
Ц7 = —(,t—1) ln|X I—pin tr(2^ ) (5.18)
р /
совпадает с ^-распределением с s = -\-р (р ф- 1) — 1 сте-
пенями свободы (если 2% имеет распределение Уишарта).
Используя свойства собственных значений, выражение
(5.18) можно представить как
р _ р
W = — (п — 1) (2 In — р In У
i= 1 i~ 1
Тест для проверки Но, Н± имеет вид:
принимается
Но, если U/<;A(a),
Hv если №>Д(а).
(5.19)
Порог в (5.19) определяется по заданному уровню
значимости а как квантиль уровня 1 — а ^-распреде-
ления:
' 7 Xs
Если главные компоненты
ной матрицы корреляций Rx>
правдоподобия
вычисляются из выбороч-
то статистика отношения
м—1
Если первые q компонент «объясняют» большую часть
общей дисперсии, то можно проверить гипотезу о несу-
щественности различий k — р — q последних компонент:
Но'- = Xq+2 = ... = Zp (5.20)
168
против Не. не все k последних собственных значений рав-
ны. Если Но справедлива, то использование k последних
компонент нецелесообразно.
Отношение правдоподобия для проверки (5.20
Для п —> оо распределение статистики
р
/ р л У U \
о = —21nL = — (п—1)1 V InXj — (р — g)ln t'=(?+1
аппроксимируется при Но ^-распределением с т =
=~2~ — g) (р — g + 1) — 1 степенями свободы.
Тест для проверки (5.20) имеет вид:
О’
принимается
если v <Z Д (а),
если vА (а).
(5.21)
Порог в (5.21) находят по заданному уровню значи-
мости а как квантиль ^-распределения:
А (а) = F 2 (1
Первоначальный перечень экспериментов
1. Биологические данные Фишера (см. § 9.5): р = 4,
п = 50. Построить тест уровня значимости а = 0,05 для
проверки гипотезы (5.20) при q = 2.
2. Реальные данные химического анализа состава
крови: р = 6, п — ПО (см. § 9.5). Построить тест уровня
значимости а=0,05 для проверки гипотезы [5.16].
Указания
1. Исходные данные для эксперимента 1 записаны
в наборе № 9 (см. табл. 9.5). Для вычислений сформиро-
вать выборку при Х(5) = 2.
2. Данные для эксперимента 2 записаны в наборе
№ 3; положить Xi = X (2); Х2 = X (3); Х3 = Х(4); Х4 =
= Х(7); Х5 = Х(8); Х6 = Х(9).
3. Вычисления произвести с помощью программ
BMDP4M или BMDP4R [52] и MINV [46].
169
§ 5.4. Метод факторного анализа
Задание. Пусть N случайных /71-мерных наблюдений
представлены в виде (т X N) -матрицы Z = (г^). Соглас-
но модели факторного анализа элемент Zij представля-
ется в виде линейной комбинации случайных величин-
факторов:
^ij @ik kj Н di Uijf j, — 1, /72, j — 1, N, (5.22)
k=l
где fkj — значение k-ro общего (первичного, латентного)
фактора для /-го наблюдения; г — число общих факто-
ров (г < m); Uij — значение характерного фактора для
i-й компоненты /-го наблюдения; a-ih — нагрузка Л-го
общего фактора для /-й компоненты наблюдения (фак-
торная нагрузка); di — нагрузка характерного фактора
для i-й компоненты наблюдения. В (5.22) случайные ве-
личины {/X: k = 1, г, j = 1, N} и {щр. i = 1, m, j = 1, N}
независимы в совокупности и одинаково распределены
по закону АО (О, 1). Во избежание неоднозначности мо-
дели (5.2) будем предполагать:
г < r+ (m), r+ (т) = [т + 0,5
Уг2т ф- 0,25].
Протабулируем критические (наибольшие возмож-
ные) значения числа факторов г+(т) для различных т:
т о 4 а о / о
r+(m) 1 1 2 3 3 4
10 11 12 13
6 6 7 8
14 15
9 10
16 17 18 19 20
10 11 12 13 14
Требуется оценить: 1) (т X г)-матрицу факторных на-
грузок A= (aik); 2) m-вектор d = (d|, ... , d*); 3) (г X АО-
матрицу факторных значений F = (fkj). Пользуясь произ-
волом в выборе системы координат в пространстве общих
факторов,
[13, 59}.
получить простую факторную структуру
Методика выполнения задания. Примем 'следующие
обозначения: D = diag{d1, ... , dm}~(тХт)-матрица; U =
/ р \
= (utj) — \т X АО-матрица; Н = Ну-) — (г -ф т) X Af-мат-
рица; Р = (A\D)—тХ(тА-г) — матрица. Запишем
(5.22) в матричной форме
Z = PH.
170
Согласно (5.22) наблюдения из Z распределены по за-
кону N т (О, S) , где
2 = (Qi.) = ААт + D2 = В +D2, В - ААТ = (Ьц). (5.23)
Диагональный элемент матрицы В
Ьц — 2 °4k
k=\
О» Ьц — &ii
принято называть i-й (i=l, т) общностью. Ее вероят-
ностный смысл следует из (5.23):
D {ztj} = bad*.
(5.24)
Следовательно, общность Ьц представляет собой ту со-
ставляющую дисперсии i-й компоненты случайного наб-
людения, которая объясняется г общими факторами
в (5.22). Согласно (5.24) ti? характеризует остаточную
дисперсию, не объяснимую г общими факторами, и назы-
вается специфичностью. Вкладом k-vo фактора в суммар-
ную дисперсию называется величина
Идея сжатия данных методом факторного анализа
заключается в переходе от (m\N)-матрицы Z к (rXZV)-
матрице факторных значений F.
Опишем кратко четыре основных метода факторного
анализа: метод главных факторов, метод максимального
правдоподобия, итерационный метод главных факторов
и метод Кайзера [36, 59].
Обозначим выборочную ковариационную матрицу
наблюдений
= (о и) = ZZr/N
(учтено, что согласно (5.22) M{z<j}=0); выборочную кор-
реляционную матрицу
R — rij — &ij
V ^ii^3j\ i, j = 1, rn.
В факторном анализе различают две ситуации.
1. Компоненты Zu, ..., Zim по своей физической природе
являются величинами различной размерности и поэтому
предварительно нормируются (стандартизируются):
171
При этом в качестве исходной статистики для фактор-
ного анализа используется выборочная корреляционная
матрица 7? (которая совпадает с выборочной ковариа-
ционной матрицей, вычисленной по выборке Z0). 2. Ком-
поненты ггч, ..., Zim одинаковой размерности, и в ка-
честве исходной статистики для факторного анализа
используется S. Сущность методов факторного анализа
в обеих ситуациях одинакова. Изложение будем вести
для первой ситуации. (Заметим, что на практике обычно
приходится иметь дело именно с первой ситуацией, по-
скольку исследователи оказывают особое предпочтение
предварительной нормировке наблюдений.)
Обозначим Zfe /г-е собственное значение матрицы
7? (Zi 'Кч 72- 0), a Wji — (w/?j, ...,
собственный вектор 7?, соответствующий Хл, k = 1, tn.
Согласно методу главных факторов в качестве г общих
факторов используются г главных компонент (см. § 5.3):
^4 ’ &ik 1k — 1, Т,
Г
Метод максимального правдоподобия при оценивании
A, {d?: 1—1, т} приводит к системе нелинейных уравне-
ний, для решения которой используется итерационный
процесс.
Шаг 1. Зададим начальное приближение d(0) =
= (^(0)> — С(0))-
Шаг. 2. Вычислим D2(Z) = diag{d2<Z), ..., d^}.
Шаг. 3. Вычислим А^ = (aty)— подматрицу г доми-
нирующих собственных
— Р2^).
Шаг 4. Вычислим
= (б/2(Н1), ... ,d2('+D):
векторов матрицы (D2(O)-1(2-
новое приближение d(/+l) =
4<'+,) = г = Ь т-
Й=1
172
J
J
Этот итерационный процесс продолжается (/ = 0, 1, ...)
до тех пор, пока при t — Т уклонения dW и d(T+r) не ока-
жутся заданной малости или не будет выполнено задан-
ное число итераций. Тогда полагаем
А = А«\ d = dm.
В качестве начального значения di, i = 1, m,. рекомен-
дуется использовать
Н?(0) = 1—/?2
где Ri — выборочный множественный коэффициент кор-
реляции i-й компоненты наблюдаемого вектора с осталь-
ными m — 1 компонентами.
Итерационный метод главных факторов состоит в по-
следовательном выполнении следующих операторов.
Шаг 1. Определим вспомогательную матрицу 7?(0),
получающуюся из R заменой гц на R%, i= 1, m.
Шаг 2. Вычислим г доминирующих собственных зна-
чений {Ц0)} матрицы 7?(0) и соответствующие им собст-
венные векторы ..., w 0).
Шаг 3. Вычислим оценки
aih = rf)K40)» = Ь = 1,
Г
Шаг. 4. Определим новую вспомогательную матрицу
7?(0), получающуюся из R заменой г и на Ьц, i— 1, tn, и
вновь повторим шаги 2 — 4.
Этот итерационный процесс выполняется заданное
число итераций либо до тех пор, пока максимальное при-
ращение оценок общности на двух соседних итерациях
не окажется меньше наперед заданного порога.
Метод Кайзера отличается от итерационного метода
главных факторов лишь другим способом построения 7?(0).
Следующим этапом после оценки факторных нагрузок
является так называемый этап вращения факторов. Суть
его состоит в следующем. Как видно из модели (5.22),
при ортогональном преобразовании (вращении) факто-
ров Л, ..., fr:
173
г
получаем случайные величины f[t ..., f'r, которые могут
быть приняты за новые факторы. При этом новые фак-
торные нагрузки являются линейными комбинациями
старых:
Г
gkj Uijt i = 1, in, k = 1, Г,
а общности bn, ...» brr остаются неизменными. Матрицу
вращения G выбирают таким образом, чтобы после вра-
щения матрица А' — (а ) имела бы простую структуру
[4]: большинство элементов a'.k не слишком сильно отли-
чаются от нуля и лишь некоторые из них имеют относи-
тельно большие значения; каждая из т исходных ком-
понент вектора наблюдений представляется минималь-
ным числом факторов. При этом задача интерпретации
факторов значительно облегчается. Действительно, со-
гласно (5.22) коэффициент корреляции с fkj равен
atk, i — 1, т, k = 1, г. Критерий простой структуры:
г г т
т т
где у ^0— параметр, определяющий различные типы
ортогонального вращения. В частности, наиболее часто
используемый тип вращения — варимакс — получается
при у = 1 в (5.25). В этом случае задача (5.25) прини-
мает эквивалентный вид
г т т
2 2 й/г)2-> шах, а1{ = — ^а.к. (5.26)
k=i о t.=1
Из (5.26) видно, что варимакс максимизирует разброс
квадратов нагрузок для каждого фактора, что приводит
к увеличению больших и уменьшению малых факторных
нагрузок. Описание других типов вращений имеется
в [36, 59].
174
Рассмотрим теперь вопрос оценивания матрицы
j7 = (f/ij) факторных значений. Будем строить линейную
оценку для fkj:
т
fkj Qkizu^ k = г, j = 1, N. (5.27)
/=1
Согласно (5.22), (5.27)
cov {fhj, 2^} = akh
m (5.2o)
cov{ffe/, Ztj} = ^дк10ц.
i=i
Тогда, приравнивая правые части соотношений (5.28),
получаем
откуда
А.
Если в (5.27) вместо {z^} используются {zz°.}, то
Q = Я"1 А.
Первоначальный перечень экспериментов
t. Реальные данные по результатам измерения мор-
фологических параметров человека (см. § 9.5): т = 8;
N = 305; г = 3, 4; у = 1.
2. Реальные данные по результатам анкетирования
курильщиков (см. § 9.5): т = 8; N = 110; г = 3, 4; у = 1.
Указания
1. Исходные данные для экспериментов 1, 2 записаны
в наборах № 12 и № 10 (см. табл. 9.5).
2. Для проведения вычислений использовать про-
грамму BMDP4M из [52].
§ 5.5. Оценка собственной размерности
распределения
Задание. Пусть наблюдением является случайный р-
вектор % — (Ej) ЕЕ Rp• Наблюдается случайная выборка
X = (%i}... ;хп) объема п>р из распределения, соответ-
175
ствующего £. Из физической модели изучаемого явления
есть основания предполагать, что зависимость между
компонентами £i, ..., может быть настолько велика,
что выборка X концентрируется около некоторой /^мер-
ной гиперповерхности S в Rp [1]:
S = {хе R": ft (х) = ... = (х) = 0},
где f (•) = (fi (•)) »= 1. Р — 1°, — некоторая достаточно
гладкая и неизвестная функция (RpRp-1"). Число /°е
^{1, .... р} называется собственной размерностью рас-
пределения |. Если /° <Z р, то исходное пространство
наблюдения Rp избыточно и следует найти отображе-
ние X из Rp в R10. Это может быть сделано с помощью
методов многомерного шкалирования и нелинейного ме-
тода главных компонент.
Задача состоит в построении статистической оценки /°
по выборке X и исследовании свойств этой оценки.
Методика выполнения задания. Метод оценивания *)
использует тот факт, что рассматриваемая задача про-
верки гипотез о значении /° инвариантна по отношению
к группе невырожденных преобразований: Rp Rp.
Отыскивается максимальный инвариант этой группы пре-
образований и строится байесовское решающее правило,
основанное на найденной статистике. Для отыскания
условных распределений максимального инварианта
смысл понятия «концентрации £ около 3» уточняется сле-
дующим образом. Обозначим: произвольную не-
изолированную точку поверхности 3; и—^—х0;
| и | = У и2 + ... + и2' U = и/\ и I;
1 ДУ
s(%o) —/-мерную гиперплоскость, касательную к 3 в точ-
ке Xq. Условимся говорить о «концентрации £ около 3»,
если с заданной достаточно большой вероятностью |3
абсолютная величина угла отклонения случайного век-
тора U от S(xo) не превосходит заданной достаточно
малой величины 0Oiе[0, л/2].
Опишем алгоритм оценивания /°.
Шаг 1. Вычисляем вспомогательные постоянные:
ni0 = 1 4- (Insinв01-/1пР), i=l, p— 1;
*> См.: Харин Ю. С. Инвариантное оценивание собственной раз-
мерности наблюдений // Математическая статистика и ее применения.
Томск: Изд-во ТГУ. 1974. Вып. 60. Ч. 2. С. 31—45.
176
о
(5.29)
1) - D/2;
— (2^ (2^fo
Шаг 2. Для каждого t, i — 1, и, строим окрестность
Q(t) точки Xt так, чтобы в нее попало только р ближай-
ших точек среди п— 1 точек: {х/. j = 1, п, Uj =
= Xj — х^ Перенумеруем эти р точек в порядке возраста-
ния 04/): /— 1> р} и вычислим нормированные век-
торы:
М;)) = «</)/1 «</)|: / = 1. р}-
Шаг 3. Для каждого i, i = 1, п, вычислим величины
zh = ]/detG«>, G<‘> = j, l=T, &+1; k=T, ~p—i.
Шаг. 4. Вычислим статистику г = (rlt rn):
Jr, если zx>Ax, ...» zr_i>Ar_i, zr<^Ar,
Гг ~ \p, если zx>Ax, ..., Zp_i > Ap-i; i = 1, n.
Шаг 5. Вычислим целевую функцию
L(r; 1)=^ In P(rt; I); Р (г; Г) = F (г; I) — F(r—\; Г);
1=1
для значений
Р(г. Т\ = 2 / Г (;/2) Г Г (У2) - ••• -Г((г-1)/2)
r V ’ И / — г г (г/2) ) Г ((/—г)/2) • ... - Г ((/—1)/2) 24
X (Аг)'-Г;
если же г=/ 4~ ? > (0 < ? XJ Р — /)> то
f (/ + ?; /) =
V-
( aq+1, i а/, q—i
t=0
Д, если q = р — 1,
если q р—I
177
где коэффициенты {ak, р. О < i < k — 1, 1 < k < р — 1} оп-
ределяются по рекуррентным формулам: а1г 0 = 1, ak+i, i=
^k, i ( 1 Пц q—k/ftl, q—i) 1, i = 0, k 1, , k == 1 —
ft—1
i-
i=0
Шаг 6. В качестве оценки для собственной размер-
ности I принимается статистика
Первоначальный перечень экспериментов
1. Модельные данные: р = 3; /° == 2; п — 200; S —
= {х g R2\ xi + 2x2 + Зхз = 0}— плоскость в Р2.
2. Реальные данные кардиологических обследований
(см. § 9.5): р = 5; /° = 4; п — 200; gi — Х(1)—возраст;
^2 = Х(2)— индекс биомассы; £3 = Х(3)— систолическое
артериальное давление; ^4=Х(4)—диастолическое арте-
риальное давление; £5 = Х(5)—частота сердечных со-
кращений.
Указания
1. Выборка для эксперимента 1 записана в наборе
№ 14, для эксперимента 2 — в наборе № 15 (см. § 9.5).
2. При вычислениях в (5.29) использовать значения
р = 0,95; 0о,1 = ... — 0о,р-i = 0о = л/6.
3. В эксперименте 1 выборку X объема п = 200 раз-
ю
бить на 10 независимых подвыборок X — U X, одинако-
i=i
вого объема N — 20. Для каждой Z-й подвыборки оценить
/: I (Xi), /=1, 10. С помощью этих статистических дан-
ных построить точечную и интервальную оценки для ве-
роятности ошибки PQ — Р {/ /°}. Исследовать влияние
0О на Ро.
178
Глава 6
МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ В МНОГОМЕРНОМ
СТАТИСТИЧЕСКОМ АНАЛИЗЕ
Эта глава посвящена построению и анализу мощности тестов для
проверки гипотез, возникающих в одновыборочных и многовыбороч-
ных задачах статистического анализа многомерных данных. Изла-
гаются основные методы дискриминантного анализа и кластерного
анализа.
§ 6.1. Проверка гипотезы
о значении математического ожидания
Задание. Наблюдается случайная выборка xL, х2, ...
... , xn^Rp объема п из р-мерного нормального распре-
деления Np (р, 2) с неизвестными вектором математиче-
ского ожидания р = (рг) G Rp и ковариационной (р X р)-
матрицей 2 = (ог;) >0; ха = (х“), i = 1, р,—вектор-стол-
бец сс-го наблюдения (а = 1, п). Задано некоторое фик-
сированное значение р° — (р?) ЕЕ вектора математиче-
ского ожидания. Определены нулевая гипотеза Но и аль-
тернатива Hi.
Hq: р = р°; Нс р =£ р°.
Для проверки гипотез /70, Hi построить тест отноше-
ния правдоподобия, имеющий заданный уровень значи-
мости 8. Рассмотреть две ситуации: 1) S известна;
2) S неизвестна. Сравнить мощности тестов в этих си-
туациях.
Методика выполнения задания.
1. 2 известна. Определим функцию правдоподобия
и статистику отношения правдоподобия
. L(P°, S)
1 max L (р, S)
р-
п
где х = 4 2 хП
а— 1
выборочное среднее. Вычислим
(6.1)
ста-
= ехр
тистику
179
W = n(x— p”)7'(x— p,0). (6.2)
Тест отношения правдоподобия с учетом (6.1), (6.2)
примет вид:
(Яо, если Г<Г0(е),
принимается , ч (6.3)
(Hlf если (б). v 7
Порог \F0(e) в (6.3) найдем, исходя из ограничения на
уровень значимости:
1 -Лу(Г0(б); //о)= 8,
(6.4)
где Fw (z; Но) — функция распределения IF-статистики
(6.2), если верна //0. В силу того, что х ~ 2Vp (р,, п~1 ^),
= Кр-.х2' статистика (6.2) имеет нецентральное ^-распре-
деление с р степенями свободы и параметром нецент-
ральности т2 = п (р, — р.0)7 У}-1 (р, — р,0). В частности, при
р, = р,0 (верна HQ) статистика W имеет центральное х2_
распределение с функцией распределения Fw (г; /70) =
= fZp(z)- Тогда из (6.4) получаем:
»'о(е) = /7-21(1-е) (6.5)
Хр
есть квантиль уровня 1—е для распределения %2.
р
Мощность теста (6.3), (6.5) равна:
ОО
₽! = 1 - Fw (tr0 (е); = f f 2 (г) dz,
W„(e) z₽: Т-':
где / 2 (г)
Хр: х2
[2]
плотность нецентрального %2-распределения
Хр; х2
ОО
(6.6)
Плотность (6.6), оказывается, достаточно хорошо аппрок-
симируется плотностью распределения случайной величи-
ны Рх2, где р — коэффициент пропорциональности. Выбе-
'180
рем р, г из условия совпадения моментов первого и вто-
рого порядка величин у2 т2 и р%^:
Д = и Ж}; D{X*; j = D{₽X2}.
В результате получим
О 1 I Т2 . т4
₽ = I + I 4- т2 ’ r ~ Р р-|-2т2 *
неизвестна. Статистика отношения правдоподо-
max L (р°, 2)
s_______________
max L (ц, 2)
р-. s
где
Т2 = п (х — р°)г 5-1 (х — р°)
(6-7)
есть так называемая Т2-статистика Хотеллинга, S
несмещенная оценка ковариационной матрицы:
п
Тест отношения правдоподобия в этом случае принимает
вид:
о»
если
И Р у» 2
принимается
если
и называется критерием Стьюдента. Порог Д (е) онре-
делим из условия
(6.9)
Р)
где F(n-p) (г; Но) — функция распределения статистики
Р(п— 1)
у ~Р' п ~ > если верна Но- Известно [2], что (и
1)) имеет (при верной Но) центральное F-
р степенями свободы и
X Т2/(р (п
распределение Фишера с р и п
функцией распределения
181
Тогда по (6.9) порог равен квантили уровня 1—в этого
распределения:
р; п—р; О
(6.10)
Значения квантилей (6.5), (6.10) протабулированы в [27, 48].
Мощность теста Стьюдента (6.7), (6.8), (6.10) опре-
деляется соотношениями
СО
/э
Ра ~ 1 — 7(«—р) Г2 (Д (&),’ Т/i) = J fp; п—р; %2 (z) dz,
Р(П— 1) Д(Е)
где/р; x2(z)—плотность нецентрального F-распределения
с р и п—р степенями свободы и параметром нецентраль-
ности т2 [2]:
т2
Первоначальный перечень экспериментов
1. Модельные данные: р=2; п=10, 20, 100; £ —гаус-
совский вектор с распределением /У2 (0, 12); е = 0,01-
Проверку гипотез при каждом п осуществить для двух
вариантов задания Но, Н^. = (0, 0); р,0 = (1, 1).
2. Реальные данные кардиологических обследований:
£= (£i, ^2, £з)—вектор показателей систолического арте-
риального давления (£i), диастолического артериального
давления (£2) и холестерина (£з) в возрастной группе
от 40 до 44 лет; р = 3; pt0 = (130, 90, 210); е = 0,05.
Указания
1. Исходные данные для эксперимента 1 записаны
в наборе № 1, для эксперимента 2 —в наборе № 2 (см.
табл. 9.4).
2. Для эксперимента 2 использовать: переменные
gi = Х(3), ^2 = Х(4), £3 = Х(6), Х(44) (см. Приложе-
182
ние 3). Переменной Х(6) задать минимальное, макси-
мальное и пропущенное значения равными соответствен-
но 150, 400 и 0.
3. Вычисления выполнить программой BMDP3D [52].
4. Пороги тестов (6.5), (6.10) определить с помощью
статистических таблиц [48].
5. Оценить мощности тестов.
6. Исследовать, насколько необходимо увеличить
объем выборки, чтобы при неизвестной ковариационной
матрице S выносить решения с той же мощностью, что
и при известной матрице S.
§ 6.2. Проверка гипотез о линейной зависимости
векторов математических ожиданий
Задание. В Rp наблюдается q 2 независимых случай-
ных выборок Х(1), Х(2), ...» Х(<?) cz = {х[£), ...
... , x(t)} — случайная выборка объема nt из распределе-
ni ____
ния Np (рЯ, 2(0)’ i = 1’ Р, — р-вектор-стол-
бец а-го наблюдения из i-й выборки (а = 1, п^); п —
q
= 2 — суммарный объем выборки. Параметры {рЯ,
i~=l _____
i= 1, q} неизвестны. Фиксированы q действительных
чисел at,..., aq^R1 и р-вектор р,= (р;)е^р. Определе-
ны нулевая гипотеза Но (векторы рЯ, ..., линейно
зависимы) и альтернатива Н:
q q
н(0 = н; h-. 2 ai н(1) m-
i= 1 i= 1
В частности, при 7 = 2, a\ = 1, a2 = — 1, p = 0 гипоте-
за Но эквивалентна гипотезе о совпадении математиче-
ских ожиданий: р<‘) = р/2) (см. § 6.3).
Для проверки гипотез Но, Н необходимо построить
тест, основанный на Т2-статистике (см. § 6.1) и имею-
щий заданный уровень значимости е. Рассмотреть две си-
туации: 1) ковариационные матрицы одинаковы: 2(1) =
= ... = 2(<7) = 2» 2) ковариационные матрицы {2(i): * —
= 1, q} различны.
183
Методика выполнения задания. 1. £6) = 2, i = 1, q~
Определим следующие статистики. Выборочное среднее
для выборки Х&:
=
общую выборочную ковариационную матрицу:
q ni
Т2-статистику:
Тест, основанный на Т^-статистике, имеет вид:
принимается •
Но,
Порог Д(е) определяется так, чтобы размер теста (6.12),
(6.13) был равен заданному уровню значимости е.
Известно [2], что статистика (п—p-q-\-l)T2/((n—q)p)
при верной Но имеет центральное F-распределение Фи-
шера с р и п — р — 7+1 степенями свободы. Поэтому
есть квантиль уровня 1 — 8 указанного распределения
[27], [48].
Мощность теста (6.12), (6.13) определится величи-
ной интеграла
ОФ
где fp- Т2 (•)—плотность нецентрального F-распре-
деления Фишера с р и п— р — 7+1 степенями свободы
и параметром нецентральности
at
184
Плотность этого распределения представима в виде функ-
ционального ряда (6.11).
2. Ковариационные матрицы i = 1, q} различны.
Рассматриваемая задача известна в литературе как мно-
гомерная проблема Беренса — Фишера. Мы рассмотрим
метод решения этой задачи с помощью Т2-статистики.
Предположим (не теряя общности), что п1 = min nt—
i
наименьший из объемов выборок. Определим пЛ вспомо-
гательных р-векторных статистик (а — 1—, nJ:
статистику выборочного среднего на {ра}:
П1 q
у = 2 ^«/^1 = 2ai x{i}
а=1 t'=l
и выборочную ковариационную матрицу
П1
у)7(«1-1)-
Тогда
7-2 = щ (у — ц) TS-‘ (у — ц)
является удобной статистикой для проверки Но, Н: если
Но верпа, то («1 — p)T2/[p(ni—1)1 имеет центральное
F-распределение Фишера с р и щ— 1 степенями свобо-
ды. Тест, основанный на Т2-статистике, примет вид, ана-
логичный (6.8):
Но,
принимается
если
если
бч - р) Т*
Рбч~ О
(пх - р) т*
р(«1 — 1)
(6-14)
где порог А (е) является квантилью уровня 1—8 F-рас-
пределения Фишера с р и пх — 1 степенями свободы:
р; Hi—1; О
185
Первоначальный перечень экспериментов
1. Модельные данные: р — 2, q = 3, п± — 25,
/ 1 \ / 3 X
п3 = 40, е = 0,05; н(1) = о ’ Н(2) = L ’ Н(3)
\ / \ т: /
0 \
о /
Рассмотреть случай равных ковариационных матриц
У (1) = У(2) = V(3) = у = /2
и случай неравных матриц
S42) _
Проверку гипотез осуществить для двух вариантов зада-
ния Яо, Н\
ai = «2 = 1, аз = — 2; аА = 2, а2 = 1, аз = 3.
2. Рассмотреть следующую задачу статистического
анализа реальных данных кардиологического обследова-
ния населения (р = 3; q = 2; 8 = 0,1; цг=(0, 0, 0); «1=1;
«2 = — 1,2). Проверить гипотезу о том, что для контин-
гента, обследованного по поводу ишемической болезни
сердца (см. § 9.5), в группе, определяемой левой
10 %-ной отрезной точкой распределения индекса Пинье
(индекс Пиньер—23), такие антропометрические по-
казатели, как поперечный диаметр грудной клетки, пе-
реднезадний диаметр грудной клетки, окружность груди
при спокойном дыхании, в 1,2 раза больше, чем в группе,
определяемой правой 10 %-ной отрезной точкой распре-
деления индекса Пинье (индекс Пинье 5).
Указания
1. Исходные данные для эксперимента 1 получить
с помощью линейного преобразования данных, записан-
ных в наборе № 1 или с помощью подпрограммы MVN
(см. Приложение 1); для эксперимента 2 — в наборе № 2
(см. табл. 9.4).
2. В эксперименте 2 использовать переменные Xi =
= Х(28), х2 = Х(27), хз = Х(31), Х(45) (см. Приложе-
ние 3). Установить коды пропущенных значений для пе-
186
ременных Х(27), Х(28), Х(31) равными нулю. Распеча-
тать выборочные ковариационные матрицы.
3. Пороги тестов определять с помощью статистиче-
ских таблиц.
4. Оценить мощности тестов (6.13), (6.14).
5. Для вычисления статистики Т2- использовать про-
грамму BMDP3D [52].
§ 6.3. Проверка гипотезы о совпадении математических
ожиданий в q выборках
Задание. В Rp наблюдаются q 2 независимых слу-
чайных выборок Х(1), Х(2), Х(<7); Х^ = (х™ I... j х^)—
случайная выборка объема гц из распределения Np
2); х{а = (х$), / = 1, р, —р-вектор-столбец а-го наблю-
q
дения из i-й выборки (а = 1, nt)\ п = 2^п,1—суммарный
i=l_____________________________________
объем выборки. Параметры {pAz), * = 1, #} неизвестны.
Определена гипотеза о совпадении векторов математи-
ческих ожидании
Но: рФ = и(2) = ... =
(6.15)
и альтернатива Н, заключающаяся в нарушении хотя бы
одного равенства в (6.15).
Требуется построить и исследовать по мощности тест
для проверки гипотез Но, Н, имеющий заданный уровень
значимости е.
Методика выполнения задания. Воспользуемся кри-
терием отношения правдоподобия. Функция правдопо-
добия
W>....... S) = (2л)~ | V |~ “х
X ехр
(!())? S-1 (Д1-^'1)}-
Статистика отношения правдоподобия
max L (р, ..., р, S)
____________ р*> ______________
max L (р^\ ... »р^, 2)
187
где
x(t)) (х£}
х^у/п
— усредненная по q выборкам выборочная ковариацион-
ная матрица;
—выборочное среднее для /-й выборки;
общая выборочная ковариационная матрица;
общее выборочное среднее.
Определим статистику
Известно [2], что если верна //0, то U имеет стандартное
^р;д-1;п-д-распределение. Явный вид плотности этого
распределения получен лишь в частных случаях. Однако
удается получить асимптотическое разложение для функ-
ции распределения случайной величины V, являющейся
монотонной функцией от U:
у = —(п_q—— q) /2) In U;
Fv (г; Ho) = P {V < г; Ho} = F 2 (г) -|-
7p(q— 1)
+ Y(f2 (г)-Г2 (г)) + О(п~4), (6.16)
1)4-4 1)
R = P (q - 1) (P2 + (q - 1 )2 - 5)/(48 (n-q~l-(p-q)/2Y)
m+l (x) = О (x~^m+^) означает, что | xm+! Rm+i (x) | or-;
раничен при x -> оо. Тест для проверки /70, Н тогда при-
мет вид:
[/70, если V «< А (е),
принимается j __ _z . (6.17)
[Н, если V > А (е). 4 7
188
Порог в (6.17) определяется по заданному уровню
значимости в:
Fy(A(e);
Но) =
(6.18)
Уравнение (6.18) может быть разрешено относительно
А(е) численными методами с использованием аппрокси-
мации (6.16). В частности, с точностью до О(п~2) из
(6.16), (6.18) получаем
А (е) — F~1 (1—е) —
2
*Р(<7—1)
квантиль уровня 1 — е, ^-распределения с p(q— 1) сте-
пенями свободы; это значение можно использовать в ка-
честве нулевого приближения для получения более точ-
ного решения уравнения (6.18).
Первоначальный перечень экспериментов
1. Модельные данные: р = 2; <7 = 4; п{ = п2 = Пз =
2. Модельные данные: р = 2; q — 3; пг — 25, п2 = 35
п3 = 40; 8=0,1; У0) = У(2) = у(3)/; „а» = ( Ч
р/2) =
3. Рассмотреть следующую задачу статистического
анализа реальных данных кардиологического обследова-
ния населения: р = 4; q = 3; 8 — 0,1. Сравнить три груп-
пы пациентов с систолической артериальной гипертонией
(в первой группе уровень систолического артериального
давления (САД) 140 САД 159, во второй 160
САД 189, в третьей САД 190 мм рт. ст.) по сле-
дующим показателям: частота сердечных сокращений
сидя, жизненная емкость легких, индекс Пинье, скорость
распространения пульсовой волны по сосудам эластиче-
ского типа. Проверить гипотезу Но о совпадении сред-
них значений этих показателей.
Указания
1. Данные для эксперимента 1 записаны в наборе
№ 1 (см. табл. 9.4).
2. Для получения случайных величин с заданными
189
параметрами в эксперименте 2 использовать линейное
преобразование данных из набора № 1 (см. табл. 9.4).
3. Данные для эксперимента 3 записаны в наборе
№ 2 (см. табл. 9.4). Использовать в анализе переменные
Xi = Х(5), Ха — Х(35), = Х(45), Х\ — Х(47). Выборки
сформировать в соответствии со значениями переменной
САД = X (3). Задать коды пропущенных значений для
указанных переменных равными нулю.
4. Для проверки гипотезы Яо использовать значение
статистики (7, вычисляемое в программе BMDP7M [52}
при значении принудительного уровня включения
ПУР = 1.
5. Пороги теста определить с помощью статистиче-
ских таблиц.
6. Оценить мощность теста.
§ 6.4. Проверка гипотезы о совпадении компонент
вектора математического ожидания
(проблема симметрии)
Задание. В Rp наблюдается случайная выборка х1, ...
... , хп объема п из распределения Np([i, 2); ха = (х?),
j = 1, р, — р-вектор а-го наблюдения. Вектор математи-
ческого ожидания ц = (pj) и ковариационная матрица X
неизвестны. Определены гипотеза симметрии
Но: pi = Ц2 = ... = Цр
(6.19)
и альтернатива Н, заключающаяся в нарушении хотя бы
одного из равенств в (6.19).
Построить и исследовать по мощности тест уровня
значимости £ для проверки гипотез Но, Н.
Методика выполнения задания. Построим тест, осно-
ванный на Р-статистике (см. § 6.1).
Определим произвольно (р— 1) х р-матрицу С = (сг-;),
1=1, р—1; /= 1, р, удовлетворяющую двум условиям:
a) rank С = р—1; б) сумма элементов каждой строки
равна нулю:
Cjj 0, i — 1, р 1.
/=1
С помощью С осуществим линейное преобразование
наблюдений (Rp -» Rp~1): tja = Сха, а = 1, п.
190
По теореме о линейном преобразовании гауссовско-
го вектора {уа} есть случайная выборка объема п из
Np-i(y, Е), где v=Cp, Е=С2СГ. По построению С ги-
потеза (6.19) эквивалентна гипотезе Н'о: v = 0. Для про-
верки Н'о применим Т2-критерий Стьюдента:
о>
принимается
если 7 1 \ 7
(р— 1) (П—1)
(6.20)
если 7----тт~7-тт
(р—1) (п— 1)
где
Если верна гипотеза Но, то статистика (п — р + 1)Т2/
/((р—1) (n—1)) имеет центральное F-распределение
Фишера ср — 1 и п — р+1 степенями свободы. Поэто-
му для обеспечения уровня значимости 8 порог в (6.20)
должен быть выбран аналогично (6.10):
Д (е) = р-1 (1— е).
4 3 * * * 7 р—п—р+1; 7
Мощность построенного теста исследуется аналогично
Первоначальный перечень экспериментов
1. Модельные данные: р = 4; р,т = (0, 1, 2, 3); S =
— Л; а — 10, 20, 50; е — 0,01.
2. Модельные данные: р =2; п — 10, 50, 100; в =
/ 1 0,5\
= o.oi; ^ = (1.1); Z = (0>5 2 •
3. Рассмотреть следующую задачу статистического
анализа реальных данных кардиологического обследова-
ния населения: р = 2, в = 0,1; 0,01. Проверить гипоте-
зу Но о равенстве толщины жировой складки трицепса
и толщины жировой складки под лопаткой у лиц с избы-
точной массой тела.
191
Указания
1. Выборки для экспериментов 1, 2 получить с по-
мощью линейного преобразования данных из набора № 1
(см. табл. 9.4).
2. Данные для эксперимента 3 записаны в наборе
№ 2 (см. табл. 9.4). Использовать переменные Xi = Х(32)
и х2 = X (33). Признак избыточной массы тела Х(20) = 2.
Для Х(32) и Х(33) установить код пропущенных значе-
ний равным нулю.
3. Вычисления выполнить с помощью программы
BMDP3D [52}.
4. Оценить мощность построенного теста в экспери-
менте 1.
§ 6.5. Проверка гипотез о независимости множеств
случайных величин
Задание. Пусть х1, ..., хп — случайная выборка объе-
ма п из распределения Nр(р ,2) с известными р, У, и
q^2, ..., р >1—натуральные числа такие, что рх-|-
+ ... + рр. Определено разбиение наблюдений ха =
= (х®) и параметров р, У, на блоки:
Pi I H(i)
р2 Р(2)
и = . .........
Pq И(<7)
Определена гипотеза независимости случайных подвекто-
ров jv^d, ..., x^q) /^):y= (liag{y,J и альтернатива Н = Нь.
Для заданного уровня значимости е требуется построить
тест для проверки гипотез Но, Н.
192
Методика выполнения задания. Использование кри-
терия отношения правдоподобия. Определим функцию
правдоподобия
ь(н. S) = (2л)“₽"12ГТ" “Pi-vi (л“ —ц)гХ
k а=1
Х2-!(х“-н)1
и статистику отношения правдоподобия
max L(p, diag {S«}) "
л Iх» {2tt}_______________ fI / \
max L (p, S) I ? | ’
2 I П | Ац | j
4=1 '
где
Pl ••• Pq
Введем статистику
V = X = gMI - = (6.22)
П I Au | П | Ru I
i=l i=l
где R — (fij) — (p X р)-матрпца выборочных коэффициентов
корреляции,
Гij —
a R = (Rij)—блочное представление матрицы R, анало-
гичное блочному представлению матрицы А. В силу мо-
нотонной зависимости V и К тест для проверки гипотез
Но, Н примет вид:
\Н^ если V>V0(e),
принимается v<Vo(e).
(6.23)
7 Зак. 1015
193
Для определения порога в (6.23) по заданному уров-
ню значимости е воспользуемся асимптотическим разло-
жением (при истинной гипотезе Но) для функции распре-
деления случайной величины W = — т In V, монотонно
связанной с V [2]:
Fr (&у) = Р {—mln V < w} = F 2 (^) 4
+ (Ш)-Л2(®))+О(т-3),
m Xf+ 4 Xf
где F2 (w) — функция распределения случайной величи-
ны
q
Особо выделим случай q = р, pi = 1: проверка неза-
висимости компонент вектора наблюдений. В этом случае
вычисления (6.22), (6.24) упрощаются:
У = |Я|; т = п--2р + П ; f=-p(p~i) ;
Y = ~Р-'288 ° (2р8-2р-13).
Использование канонических корреляций (случай q=2).
Для двух подвекторов X(d и Х(2) размерности р± и р2
(pi^p2, |л=0) независимость можно установить с по-
мощью канонических корреляций рс [2]:
рс = Цг212Р,
где т) и Р — нормированные векторы, выбираемые таки-
ми, чтобы дисперсии произвольных линейных комбина-
ций U = т|гХ(1) и V = ртХ(2) были равными единице:
1 = М{^} = М{^х(1)х[1)Т|}= Пт2пт)>
I = М{Р}= м{р^(2)х[2)р} = рт222р.
Если векторы Х(1) и Х(2) независимы, то матрица 212,
а следовательно, и рс равны нулю. Таким образом про-
194
верка гипотезы независимости двух векторов с помощью
канонических корреляций сводится к проверке значи-
мости pi канонических коэффициентов корреляции рс-
Известно, что выборочные канонические корреляции гс
равны квадратным корням из собственных значений
0 матрицы
21’
где
п
Распределение квадратов канонических корреляций
достаточно сложно, но Бартлетт показал, что для п 1
и верной Но статистика
pi
Ч=П(1-е;), (6.26)
1=1
где
имеет ^-распределение с f—pip2 степенями свободы.
Если вычисленное по формулам (6.25), (6.26) значение %2
окажется равным или больше критического значения
д1(8)=^~1(1 — 8), соответствующего заданному уров-
ню значимости в, т. е. %2 Ai(e), то первый канониче-
ский коэффициент корреляции существенно отличается
от нуля.
Для проверки существенности оставшихся pi — 1
коэффициентов рассматривается статистика
%2 = —(я — 2 — ф (Р1 + р2+1Й1П к.
степенями свободы, где
pi
Аналогично проверяются и последующие коэффициенты.
7*
195
Первоначальный перечень экспериментов
1. Модельные данные: р — 4; п = 10, 20, 50; е = 0,01;
цт=(0, 1,2,3); S = П.
В экспериментах 2, 3 рассмотреть следующие реаль-
ные задачи кардиологического обследования населения.
2. Для группы лиц, не страдающих ишемической бо-
лезнью сердца и артериальной гипертонией, проверить
независимость следующих показателей сосудистого то-
нуса и антропометрии: систолического артериального
давления, диастолического артериального давления, ча-
стоты сердечных сокращений сидя, жизненной емкости
легких, скорости распространения пульсовой волны по
сосудам эластического типа.
3. Для указанного контингента лиц исследовать не-
зависимость двух множеств признаков, в первое из кото-
рых входят систолическое артериальное давление, диа-
столическое артериальное давление, скорость распро-
странения пульсовой волны по сосудам эластического
типа, во второе — частота сердечных сокращений сидя,
жизненная емкость легких, индекс Пинье, возраст.
Указания
1. Выборки для эксперимента 1 записаны в наборе
№ 16 (см. табл. 9.5). Использовать переменные Х(1),
Х(2),Х(3),Х(4).
2. Данные для экспериментов 2, 3 записаны в наборе
№ 2 (см. табл. 9.4). Использовать переменные %i=X(3),
кг = Х(4),х3 = Х(5),%4 = Х(35),х5 = Х(44),хб = Х(45),
х7 = Х(47), Х(51), Х(52) (см. Приложение 3). Задать
коды пропущенных значений для Х(5), Х(35), Х(47) рав-
ными нулю.
3. Вычисления для экспериментов 1, 2 выполнить
с помощью программы BMDPMH, для эксперимента 3 —
программы BMDP6M [52].
4. Модельные данные в эксперименте 1 получены
подпрограммой MVN. Какие выводы из эксперимента
можно сделать о ее точности?
196
§ 6.6. Проверка гипотезы согласия
Задание. Пусть матрица Y = (у1, ..., уп)—случай-
ная выборка объема п из распределения NP(v, гр) с не-
известными вектором математического ожидания v и ко-
вариационной матрицей гр. Выдвигается гипотеза Но
о том, что выборка получена из распределения Np(y0, хро),
т. е.
Но: v = vo, хр = хро, (6.27)
где vo и хро—заданные вектор и матрица. Обозначим
Н альтернативу, заключающуюся в нарушении хотя бы
одного из равенств в (6.27). Требуется построить тест
для проверки гипотез Но, Н с заданным уровнем значи-
мости 8.
Методика выполнения задания. Гипотеза Но представ-
ляет собой комбинацию двух гипотез: равенства вектора
математических ожиданий v заданному вектору vo при
условии, что матрица ковариаций хр известна:
Hi. v = vo при хр = хро,
и равенства ковариационной матрицы хр заданной мат-
рице хр0:
Hz: хр = хро.
Если перейти к новым случайным величинам
= С(уа — v0), а=1, п,
где С — ортогональная матрица такая, что Cip0Cr = 1Р,
то ха будет иметь распределение
ЛГр(ц, S), pi = C(v-vo), S = СхрСЕ
Тогда гипотеза Но эквивалентна
н'й- и = о, 2 = 1Р.
Отношение правдоподобия X для проверки гипотезы
H'Q будет равно произведению отношений правдоподобия
для гипотез Нг и Н2 [2] и выразится как
197
р
где trА = ^ац‘, А, х определены (6.21).
i=i
Распределение статистики V = —2 1пХ при п-+оо
сходится к %2-распределению с/ = р(р4~1)/2 + р степе-
нями свободы, если верна гипотеза //' [2]. Поэтому тест
для проверки гипотез Но, Н примет вид (6.17); порог
Д(е) этого теста определим равенством
х/
При этом асимптотический размер теста совпадает с за-
данным уровнем значимости е.
В заключение отметим, что если нет априорной инфор-
мации о том, что выборка Y получена из нормального
распределения (т. е. при альтернативе Н выборочные
значения могут иметь негауссовское распределение), то
следует использовать критерии согласия, описанные
в § 1.4, 3.1.
Первоначальный перечень экспериментов
1. Модельные данные: р = 4; п = 10, 20, 50, 100;
в = 0,01; v = vo = (0, 1, 2, 3); ф = ф0 = /4.
2. Модельные данные: р = 2; п = 100; 8 = 0,01;
v=v0=(2,l; 3,1);
/2,05 0,24\
= 1|!о = (о,24 1,75/
3. Реальные данные Фишера по ирисам (см. § 9.5):
р = 4; е = 0,05; п = 150; vo = (6, 3, 4, 1);
(0,2 0,1 0,1 0,03\
0,1 0,1 0,06 0,02 |
0,1 0,06 0,1 0,04 I
0,03 0,02 0,04 0,02/
Указания
1. Данные для эксперимента 1 имеются в наборе
№ 16 (см. табл. 9.5).
2. Данные для эксперимента 2 получить линейным
преобразованием данных из набора № 1 (см. Приложе-
ние 3).
198
3. Данные для эксперимента 3 записаны в наборе
№ 9 (см. табл. 9.5).
4. Вычисления выполнить с помощью программы
BMDP8D [52] и подпрограмм из ПНП-БИМ [46].
§ 6.7. Проверка гипотезы об эквивалентности
нескольких нормальных совокупностей
(проблема однородности)
Задание. Пусть в Rp наблюдаются q 2 независимых
случайных выборок Х(1), ...» Х(<7); Х(1-) = ... , —
случайная выборка объема nt из распределения
Si). Объединенная выборка X —Х^ U ... U Х^> состоит
из п = th + ... + nq р-векторов. Определена гипотеза Но
об однородности выборки X, т. е. о совпадении распреде-
лений для всех q подвыборок:
и(1) = ... = и(9), Si = ... = S7. (6.28)
Альтернатива Н состоит в нарушении (6.28).
Требуется построить тест с уровнем значимости е
(и применить его к решению прикладных задач) для про-
верки Но, Н по наблюдаемой выборке X.
Методика выполнения задания. Гипотеза (6.28) пред-
ставляет собой комбинацию двух гипотез: /Л— равенст-
ва ковариационных матриц и Н2—равенства векторов
математических ожиданий при выполнении Hi. Поэтому
отношение правдоподобия для проверки гипотезы Но
будет равно произведению отношений правдоподобий
для проверки гипотез Hi и Н2 [2]:
X = Zq • Ко
х &
п
(6.29)
где
ni
(6.30)
есть матрица сумм взаимных произведений отклонений
ni
для i-й выборки Х(0; х^ = 2 lnt— вектор средних
/=1
значений для i-й выборки Х(1);
199
q ni
q
= Л + 2 (x^— x) — x)T-
1=1
q _ q
A = £ Ai; x = x^/n.
i=i t=i
При проверке гипотезы (6.28) от отношения
добия (6.29) переходят к статистике
правдопо-
иИЯ го?0??11 известнь1 лишь моменты и тип распределе-
я [2]. При построении решающего правила удобнее
пользоваться асимптотическим разложением функции
распределения V. Пусть Ю ц
W = Vm^ ртПтГ^Р\
Для функции распределения величины —2р In W
справедливо следующее представление с помощью у2-оас-
пределения: z р
где
Р {--2р in W < г} = Р {Х2 < г} + Й2 (Р < г} _
— Р{Х,2<г}) +О(пг~з) = + O(m-3), (6.31)
f = -^(q— 1) р (р -f- 3),
200
- 12 (,? m21) (- 2<?2 + lq 4- 3pq - 2рг - 6p - 4)
I / L
Тогда тест для проверки гипотез /f0, Н примет вид:
если —2 р In W <Z А (в),
принимается {гт Л А / ч (6.32)
1 [Н, если — 2plnlF> А (е), v 7
А(е) ='ф~1(1—е),
где ф(-) определяется формулой (6.31). Асимптотиче-
ский (при оо) размер этого теста равен 8.
Первоначальный перечень экспериментов
1. Модельные данные: р = 4; q = 3; пг = 25; п2 = 35;
п3 = 40; 8 = 0,05; X — выборка объема п = 100 из рас-
пределения -ZV4(p, 2)» 2 — Л’ ^=(0, 1> 2, 3).
2. Модельные данные: р = 2; q = 3; nt = 25; пг = 35;
п3 = 40; е = 0,05; = (1, 2); рЖ = (3, 4); рЖ =
= (2, 3);Х1 = Х2 = Х3-/2.
3. Применить тест (6.32) к решению следующей
реальной задачи химического анализа состава крови (см.
§ 9.5). Проверить гипотезу об идентичности показателей
химического состава крови (р = 4) в двух группах
(q — 2) обследованных: принимавшей лекарство и конт-
рольной (е = 0,03).
Указания
1. Данные для эксперимента 1 записаны в наборе
№ 16 (см. табл. 9.5).
2. Выборки для эксперимента 2 получить с помощью
линейного преобразования данных из набора № 1.
3. Данные для эксперимента 3 записаны в наборе
№ 8. Использовать переменные Х(6)—Х(9). Выборки
Хб), Х<2) формируются в соответствии со значениями пе-
ременной X (5).
4. Вычисления выполнить с помощью программы
BMDPMH [52}.
201
§ 6.8. Проверка гипотезы о равенстве нескольких
ковариационных матриц
Задание. Пусть X cz Rp — случайная выборка объе-
ма п, состоящая из q подвыборок и определенная в § 6.7.
Сформулируем гипотезу о равенстве ковариационных
матриц для распределений этих подвыборок
Яо: Si = ... = (6.33)
Альтернатива Н заключается в нарушении хотя бы
одного равенства в (6.33).
Требуется построить и исследовать тест с уровнем
значимости е для проверки Но, Н.
Методика выполнения задания. Воспользуемся крите-
рием отношения правдоподобия. Статистика отношения
правдоподобия
max L (рх, ..., р7, S, ... , S)
z______________________________
max L(nlt ..., рд, ...»
(6.34)
функция правдоподобия.
Подставив в (6.34) оценки максимального правдоподобия
ДЛЯ {рь 2j}, получим
q
ii .
n
рп
7 РП;
где (р X р)-матрица Ai определяется
«
q
формулой (6.30), а
Критическая область задается неравенством % Хо(е),
где порог Хо(в) выбирается так, чтобы обеспечить задан-
ный уровень значимости. Точное распределение % при
истинной гипотезе Но имеет сложный вид. Чтобы во-
спользоваться асимптотическими результатами, опреде-
лим IF-статистику:
202
mt = nt
1, m =
q
2itni = n — q.
t=\
Если верна Но, то для функции распределения случайной
величины —2р In W справедливо асимптотическое раз-
ложение с помощью ^-распределения:
Р {-2р In W < z} = ф (z) + О (м-3), (6.35)
Ф (z) = Р {tf < г} + <о2 (Р {xz* 1 2 3+4 < г} — Р {/2 < z}),
где f = (q— 1)р(р — 1)/2 — число степеней свободы %2-
распределения;
Q J_________1_\ 2р2 + Зр — 1 .
mi т J 6(р+ 1) («у—1) ’
1=1
/ / q \
р (р+1) ( (р-1)(р+2) (У-Ь---L- )-б(?-1)(1-Р2)
I ™2 J
48р2
(6.36)
Тест, асимптотический размер которого (при п->-оо) ра-
вен 8, определяется формулами (6.32), (6.35), (6.36).
П ервоначальный перечень экспериментов
1. Модельные данные те же, что и в эксперименте 1
из § 6.7.
2. Модельные данные те же, что и в эксперименте 2
из § 6.7.
3. Применить построенный тест к решению следую-
щей реальной задачи кардиологического обследования
населения. Проверить гипотезу о равенстве матриц кова-
риаций показателей антропометрии и сосудистого тонуса:
индекса Пинье, скорости распространения пульсовой
волны по сосудам эластического типа, частоты сердечных
сокращений сидя и жизненной емкости легких для q = 3
групп, определяемых уровнем САД: здоровые (САД <
<С 140 мм рт. ст.), лица с пограничной гипертонией
(140^ САД <С 160), лица с систолической артериаль-
ной гипертонией (САД 160 мм рт. ст.).
Указания
1. Выборки для экспериментов 1, 2 формируются так
же, как в § 6.7.
203
2. Данные для эксперимента 3 записаны в наборе
№ 2 (см. табл. 9.4). Использовать переменные Х(3),
X 5), Х(47), Х(35), Х(45) (см. Приложение 3). Выборки
Х^\ Х<-2\ X® сформировать в зависимости от значений пе-
ременной Х(3).
3. Вычисления выполнить с помощью программы
BMDPMH [52].
§ 6.9. Методы дискриминантного анализа
Задание. В пространстве Rp возникают подлежащие
классификации случайные наблюдения из 2 клас-
сов: Qi, . .., QL. Наблюдение из класса Qi — случайный
р-вектор Xi с гауссовской плотностью fi(x) —пр(х \ щ-, Si);
Рг =(Нй); Si =(oij/t), i = 1, L; j, k = 1, p. Априорные
вероятности классов Qi, ..., Qb равны соответственно
Л1, ..., Ль (лг > О, Я1 + ... -J- nL — 1). Задана матрица
потерь классификации W = (wu), где wu— величина по-
терь при отнесении в класс Q/ наблюдения, принадлежа-
щего на самом деле к классу Qi, i, I = 1, L. В качестве
меры точности классификации принимается вероятность
ошибочной классификации г. Если параметры {лг-, цг-, Si:
i — 1, L} неизвестны, то предоставляется классифициро-
ванная обучающая выборка А суммарного объема
/г = состоящая из L независимых подвыборок:
Xtj cz Rp, j — 1 > ц?},
есть случайная подвыборка объема /г;- из класса Qi.
Необходимо построить и исследовать по точности ре-
шающее правило для классификации случайного наблю-
дения X е Rp (нс зависящего от А) с минимальной ве-
роятностью ошибки.
Методика выполнения задания. Рассмотрим вначале
ситуацию, когда параметры {лг-, цг-, Si} известны.
Установлено, что минимальную вероятность ошибки
обеспечивает байесовское решающее правило:
d
d0(x) = arg max (jtz ft (x)), x e Rp,
IG{1, ...» L)
(6.37)
204
где d^{l, ..., L}— номер класса, к которому будет
отнесено наблюдение х. Учитывая, что fi(-)—гауссов-
ские плотности, из (6.37) получаем
d = d0 (x)=arg min
(ln|S;| +
+ (^-Hi)7'Sr1 (x
pf) — 21n Jij).
(6.38)
Решающее правило (6.38) имеет в общем случае квадра-
тичную дискриминантную функцию. В случае равных
ковариационных матриц
Si = =
дискриминантная функция становится линейной:
cl=с1.(х)=arg шах
iGE 1, ...,
pTS“W2). (6.39)
ч
Особенно простой вид правило (6.39) принимает в слу-
чае двух классов (L = 2):
d = d0(x) = Щ/(х)) + 1, (6.40)
где дискриминантная функция /(х) линейна:
I (х) = bTx р, b = S-1 (ц2 — pi),
₽ = (К 2-1 Pl - К X-1 Us)/2 + In •
Вероятность ошибки для решающего правила (6.40)
/•„ = <6-41)
где ________________________
А = ]/(|Л2 — Pi)7 5J-i (jx2 — nJ
есть так называемое межклассовое расстояние Махала-
нобиса. Чем больше А, тем сильнее различаются классы.
В случае равновероятных классов (6.41) принимает вид
г0 = Ф(—Д/2).
(6.42)
i, Xi} неизвестны,
состоятельные и несмещенные
строго
В ситуации, когда параметры {лг-, р
используются их
оценки:
п.
I
14 .
п ’
205
л
р>-
(6.43)
Правило классификации d = d(x, Д) в этой ситуации
определяется формулами (6.37) —(6.40), в которых
вместо истинных значений параметров используются
оценки (6.43). Доказано [58], что вероятность ошибочного
решения для такого подстановочного правила удов-
летворяет асимптотическому разложению (при /г0 =
= min fii -> оо):
i
' = /'о + 2-^ + 0(п-з/2), (6.44)
1=1
где коэффициенты р;>0 и зависят от L, р, {лг-, S,}.
Из (6.44) видно, что построенное таким образом решаю-
щее правило d = d(x, А) состоятельно: г—>го, если
/го -> оо.
В заключение укажем способы статистического оце-
нивания вероятности ошибки г. Пусть А' = (J Д' — клас-
1-1 1
сифицированная случайная выборка объема п' из
Qi, ..., Qjl, где п' — Ai — {хц. j = 1, /?£}— случай-
ная выборка объема гц из Иг. Несмещенной оценкой г
для решающего правила d = do(x) является частота
ошибочных решений на выборке Д':
(6.45)
Процедуру вычислений (6.45) принято называть экза-
меном решающего правила do(-), а выборку А' — экза-
менационной. Еще один способ оценивания г состоит
в оценивании по выборке А' параметров, входящих
в (6.41), (6.42). В ситуации, когда зтг, цг, 2/) неизвест-
ны, вероятность ошибочного решения для правила
d—d(x, А) оценивается по выборке А с помощью так
называемой процедуры скользящего экзамена. Она со-
стоит в следующем. Из выборки А удаляется реализа-
ция хц (/ = 1, Щ, i = 1, L) и по полученной выборке До-
строится решающее правило d = d(x, Aij); затем хц
206
используется для экзамена этого правила. Состоятельной
оценкой для вероятности ошибки г решающего прави-
ла d(-) является статистика
r(rf) = 1
(6.45) легко построить и интер-
Отметим, что в случае
вальную оценку г(Д>).
Первоначальный перечень экспериментов
1. Модельные данные: р = 2; L = 3; jti = 0,25; Л2 =
= 0,35; лз = 0,40; п\. = 25; п^ — 35; Пз = 40; Si = S2 =
= S3 = /2; рГ = (1, 2); pj=(3, 4), р( = (2, 3). Рассмот-
реть ситуации с известными и неизвестными {лг, цг-, SJ.
2. Данные те же, что и в эксперименте 1, только
0,6\
1 /*
3. Рассмотреть следующую реальную задачу построе-
ния решающего правила для классификации обследуе-
мых пациентов на два класса (L = 2, Л1 = 0,3; Л2 = 0,7):
лица с систолической артериальной гипертонией и лица
без систолической артериальной гипертонии. Вектор на-
блюдений состоит из р = 7 признаков: вес, рост, индекс
Пинье, истинная жизненная емкость легких, скорость
распространения пульсовой волны по сосудам эластиче-
ского типа, скорость распространения пульсовой волны
по бедренной артерии, возраст.
Указания
1. В экспериментах 1, 2 изобразить графически:
а) эллипсоиды рассеяния условных распределений
{f2(-)}; б) дискриминантные кривые классификаторов
d = d0(x), d = d(x, А); в) ошибочно классифицируемые
наблюдения из обучающей выборки А.
2. Выборки для экспериментов 1, 2 построить с по-
мощью соответствующих линейных преобразований дан-
ных из набора № 16 (см. табл. 9.5).
3. Данные для эксперимента 3 записаны в наборе
№ 2 (см. табл. 9.4). Использовать компоненты Х(22),
207
Х(23), Х(35), Х(44), Х(45), Х(47), Х(57). Выборки обра-
зовать в зависимости от значения компоненты Х(54)—
признака наличия систолической артериальной гиперто-
нии. Задать коды пропущенных значений для компонент
Х(22), Х(23), Х(35), Х(47), Х(57) равными нулю.
4. Вычисления для эксперимента 3 выполнить с по-
мощью программы BM.DP7M [52], используя процедуру
скользящего экзамена.
5. В экспериментах 1, 2 вычисление квадратичной
дискриминантной функции произвести с помощью под-
программы SDF [46], линейную дискриминантную функ-
цию определить программой BMDP7M [52] (ПУР = 1).
§6.10. Кластерный анализ
Задание. В пространстве Rp возникают подлежащие
классификации случайные наблюдения из L классов
Qi, ..., Ql. Априорные вероятности классов л1} ...
..., ль(лг>0, ni + • • • + 1) неизвестны. Наблюдение
из класса Qi есть случайный р-вектор Xi с неизвестной
плотностью распределения fi(x). Для каждого i — 1, р
определим в Rp множество
Wi (6i) = {х: х е= Rp, itifi (х) > 6j, (6.46)
где 6i > 0 выберем так, что вероятность попадания Xi
в Wi(6i) достаточно велика:
Р {Xi е IFi (6г)} 1-е, (6.47)
где е >> 0 — заданное достаточно малое положитель-
ное число. Будем предполагать, что распределения
{/*(•)} удовлетворяют гипотезе компактности: множества
{1^г (6г)}' выпуклы и слабо пересекаются, так что при
i #= j выполняются неравенства
H(№i(6i) n^(6j))<min(p(Fi(6i)), р(ГД6;))), (6.48)
где р,(«)— мера Лебега в Rp,
Наблюдается неклассифицированная случайная вы-
борка А объема п:
А — {XiZXt^RP, i~ 1, n},
где Xi — наблюдение из некоторого класса Qc/., di е
е{1,..., L}. Номера классов ..., dn, из которых заре-
гистрированы наблюдения Xi, ..., хп, неизвестны. Задача
заключается в том, чтобы: 1) классифицировать выбор-
208
ку А с наименьшей вероятностью ошибки, т. с. оценить
номера d[, dn (с точностью до переобозначения);
2) построить решающее правило для классификации
вновь поступающих наблюдений.
Методика выполнения задания. Применим один из
простейших методов, основанный на гипотезе компакт-
ности. Так как гипотеза компактности выполняется, то
точки из Wi близки к математическому ожиданию ц;
(центру класса Qi) и далеки от точек из множеств
IFj, / Поэтому используется решающее правило:
d = dlx,*A) =arg min lx— р* I, x^Rp, (6.49)
~ fe{l........L) 1
где центры {p*} зависят от А и определяются при помо-
щи следующей итерационной процедуры.
Обозначим Nl = {1....... I}; t — номер итерации
(/ — 0, 1, 2, ...); pj — оценка р! на £-й итерации;
I If
Л Л* ₽А,
= (di, ... ,j.dy— вектор решений на Лй итерации, где
л,
di е Nl — решение о номере класса для наблюдения
Хг е, Rp на /-й итерации.
При t = 0 задаем вектор априорных решений JD0.
л
На f-й итерации пусть был вычислен вектор D1. Итера-
ция номер t + 1 заключается в следующем. Вычисляем
оценки центров:
п
P;+1 = 2 1 = Ь
i=l ’ i
После этого уточняем вектор решений:
= arg min | xt — p/+11, i = 1, n.
i^NL
A A A A
Если Dt+i то процедуру завершаем; D-D* прини-
маем в качестве наилучшей классификации выборки А;
в решающее правило (6.49) подставляем {ц!=р,(+1: i=
If If
Первоначальный перечень экспериментов
1. Модельные данные те же, что в эксперименте 1
из § 6.9.
209
2. Рассмотреть следующую реальную задачу кардио-
логических обследований (см. § 9.5). Провести кластер-
анализ (разбиение на L — 2 класса) наблюдений за
систолическим артериальным давлением и индексом био-
массы с целью выявления группы с повышенным факто-
ром риска ишемической болезни сердца.
Указания
1. В эксперименте 1 с помощью (6.46) — (6.48) про-
верить выполнение гипотезы компактности. Чему рав-
но 8?
2. В эксперименте 1 изобразить графически: мно-
жества {для найденного значения е; дискриминант-
ные кривые оптимального (байесовского) классифика-
тора и построенного классификатора (6.49); траектории
движения центров {цД при изменении t; ошибочно клас-
сифицированные наблюдения из А.
3. Оценить вероятность ошибочной классификации
в эксперименте 1 и сравнить с байесовской вероятностью
ошибки г0, определенной в § 6.9.
4. Данные (и = 200) для эксперимента 2 записаны
в наборе № 15 (см. табл. 9.5): Х(2)—индекс биомассы,
Х(3)—САД.
Глава 7
МЕТОДЫ СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ
ЗАВИСИМОСТЕЙ
В этой главе рассматривается модель многомерной линейной регрес-
сии. Излагаются методы оценивания параметров регрессии и про-
’ верки гипотез о значениях этих параметров, а также методы одно-
факторного и двухфакторного дисперсионного анализа.
§7.1. Оценивание параметров многомерной
линейной регрессии
Задание. Пусть матрица
У11 У12 ••• У1п
У 41 У 22 У4п
Ур1 У р2 ••• Урп
210
представляет случайную выборку, состоящую из п век-
торных наблюдений, где Р;=(Ро), i = 1, р,— р-вектор-
столбец /-го наблюдения, / = 1, и, распределенного по
закону NP (Bxj, S) с параметрами Bxj (вектор математи-
ческого ожидания) и S (ковариационная матрица); В —
(р X q) -матрица коэффициентов регрессии.
Матрица независимых переменных
X = (%!
ранга q, где Xj = (x/j)—^-мерный вектор-столбец, k =
= 1, q, j = 1, /2, полагается известной.
Построить и исследовать точность оценок максималь-
ного правдоподобия В и S неизвестных матриц В =
= (piu), 2 = (cfij), i, j = 1, p; и = 1, q. Найти параметры
распределения матрицы оценок В.
Методика выполнения задания. Оценки максималь-
ного правдоподобия: В — для матрицы коэффициентов
многомерной регрессии и 5 — для матрицы ковариаций,
полученные из условия максимума функции правдопо-
добия
1 1
— —-пр — п
Ь(В‘\ 5]*) = (2л) 2 |V*~Ч2 X
(относительно S* и В*), имеют следующий вид [2]:
В = (ХТХ)~' XTY,
(7.1)
(7.2)
или в эквивалентной форме:
Матрица имеет распределение Уишарта IFP(S, п—q)
с параметрами S и и — q. Несмещенной и состоятельной
оценкой для 2 является матрица
211
S = /zS/ (n — q).
N
Матрица В является несмещенной оценкой для В, она не
л
зависит от 2 и имеет нормальное распределение с мате-
матическим ожиданием В; взаимная ковариационная
л
матрица для t-го и /-го векторов-строк из В равна а^-А-1.
Отметим в заключение, что минимальная среднеквадра-
тичная ошибка прогноза по xj достигается для
Л Л
Уз = / = 1, п.
Первоначальный перечень экспериментов
1. Модельные данные: р = 2; q = 2; п = 20, 100;
{ха}—независимые случайные векторы, равномерно рас-
пределенные в единичном квадрате;
2. Рассмотреть следующую реальную задачу (см.
§ 9.5) статистического прогнозирования показателей хи-
мического состава крови по косвенным измерениям. Тре-
буется разработать процедуру прогнозирования четырех
показателей химического состава крови (р = 4): —
холестерин, у%—альбумин, уз— кальций, г/4—мочевина
по трем (q = 3) простым косвенным показателям па-
циента: Xi — возраст, Хг — рост, Хз — вес.
Указания
1. Исходные данные для эксперимента 1 записаны
в наборе № 17, для эксперимента 2 — в наборе № 8 (см.
табл. 9.5).
2. Для эксперимента 2 вычислить и напечатать оцен-
ку матрицы ковариаций коэффициентов регрессии, вы-
л
борочпую матрицу ковариаций, остатки RES = У — ВХ,
матрицу В.
3. Вычисления выполнить программой BMDP6R [52].
212
§ 7.2. Проверка гипотезы о коэффициентах регрессии
Задание. Пусть определена регрессионная модель
и сохранены обозначения из § 7.1. Матрица коэффициен-
тов регрессии В разбита на два блока:
в = = (в^в^,
(7.3)
Bi — (р X 7i)-матрица; В2— (р X 72)-матрица, 1 72
7 — 1, qi -J- 72 = 7. Пусть В* — некоторая фиксиро-
ванная (р X 71)-матрица. Определена гипотеза
//о: Bi = В\
(7.4)
и альтернатива Hi, заключающаяся в нарушении хотя
бы одного из p7i равенств в (7.4).
Построить и исследовать по точности тесты для про-
верки гипотез Но, Hi.
Методика выполнения задания. Осуществим разбие-
ние /-го вектора независимых переменных на два блока
соответственно разбиению (7.3):
Применим вначале для проверки Но, Hi критерий
отношения правдоподобия. Статистика отношения прав-
доподобия
Здесь 2
ковариационной
оценка максимального правдоподобия
матрицы:
п
п
О
оценка максимального правдоподобия
(7.1), a — выборочная ковариационная матрица
/ 1 \ ————
наблюдений {7/ = tjj — В\х} : / — 1, п}:
для
213
Обозначим
п
^11.:. ^12
^21 ; А 22
All.2 = Ац
A12A-'A?2.
Тогда пУ,ш допускает представление:
ft Vw = п + (Bi<2 — Bi) Ai i.2 (Вш — Bi)'r. (7.7)
Используя (7.6), (7.7) в (7.5), получаем
Если верна гипотеза Но, то справедливо асимптотиче-
ское разложение (/г->оо) для функции распределения
случайной величины —mlnUp, Q1, k-
F-minu ,;(z) = f2 (z)+J-(f2 (z)_f2 (i)) +
{/l' k T-pqi m Xp<7i+4 t-pqi
+ ++ bx (F 2 (г) - F 2 (г)) -
zP<7i+8 V-pqi
-y22(F2 (z)-F2 (z})} + О (7.8)
^P<7i+4 K-pqt
где коэффициенты разложения:
Y2 = РЧ1 (p2 + q\ — 5)/48,
v2
Y4 = -T- + (3p4 + 3?1 + \0ptf -50(p2 + qt) + 159),
. m = n — q2 — 4-(p + <?i+ 1).
Тест с уровнем значимости e для проверки Ho,
имеет вид:
(tf0, если — m\nUp, qltk< Ai(e),
принимается <
если — т In UP, qi> (s),
а порог Дг (e) есть квантиль уровня 1 — 8 для распреде-
ления (7.8):
Д,(е) - А(1-е). (7.9)
Определение квантили (7.9) следует осуществлять с по-
мощью асимптотического разложения (7.8), ограничиваясь
214
в нем необходимым числом членов. Так, с точностью до
Особо выделим следующий частный случай: р — 1,
B=(pi, рд)—g-вектор коэффициентов регрессии.
Для некоторого фиксированного i, ie{l, ..., q}, рас-
смотрим задачу проверки гипотез
Рг — 0; Нц". Pi 0.
Обозначим bi = pi оценку максимального правдоподобия
для Pi, определяемую согласно (7.1), а
п
<7)~’
несмещенную оценку дисперсии р^. Тогда размер 8 дости-
гается для теста, основанного на статистике Стьюдента ti —
принимается
где А (е) = F~l 1-----1 — квантиль уровня 1 — 8 для
n—q \ /
/-распределения Стьюдента с п — q степенями свободы.
Проверка гипотезы //0: рт — р2 = ... = Р7 = 0 против
альтернативы //[, состоящей в том, что хотя бы одно из
указанных равенств не выполняется, производится с по-
мощью статистики
(ВЛВт-лУ>)/(?-1) 1 у
Г — ——л » * — п ^Уь
л2/(п— q) i=l
S определяется выражением (7.2).
При справедливости Н'о статистика F имеет /^-рас-
пределение Фишера с (q— 1) и (п — q) степенями сво-
боды. Тест размера 8 имеет вид:
принимается
Но, если F <С Д (е),
Н\, если F Д (е),
где Д (б) = F~\ —е) — квантиль уровня 1—8 F-
распределения Фишера с q — 1 и п—q степенями свободы.
215
Первоначальный перечень экспериментов
1. Исходные данные те же, что в эксперименте
§7.1, причем
= 0,05.
2. Данные анализа химического состава крови (см.
§ 9.5): р = 1; q = 5; z/i — холестерин; xi — возраст; х2 —
вес; хз — альбумин; х4 — кальций; х5 — мочевина; е —
= 0,10. Проверить гипотезу независимости z/i от Xi, х2,
•^3, «^4, -^5*
Указания
1. Исходные данные записаны в наборе № 3 с меткой
CHEMISTRY и содержимым ДАНН (см. табл. 9.4).
2. Для вычислений в эксперименте 1 использовать
программу BMDP6R [52] и подпрограммы из [46], в экспе-
рименте 2 — программу BMDP1R [52].
3. Порог теста (7.9) определить с помощью таблиц.
§ 7.3. Однофакторный дисперсионный анализ
Задание. Пусть имеется g 2 групп независимых
наблюдений, образованных различными значениями
признака классификации; i-я группа представляет собой
случайную выборку объема ni наблюдений из распреде-
ления Nt(pf, a2), i = 1, g. Значение /-го наблюдения,
относящегося к i-й группе, можно представить в виде
Угз - — Цг 4~ i 1, g, j — 1, Цг-,
(7.Ю)
где {eij}—ошибки наблюдений — независимые в сово-
купности нормально распределенные случайные вели-
чины (ЛГДО, о2)), или в эквивалентной форме:
где
216
CCi = pi—р— f-й главный эффект i-ro уровня признака
g
классификации; а/ — 0.
i=i п
Проверить гипотезу о равенстве средних значений
групп; получить оценки для р, {а*}, о2; построить дове-
рительные интервалы для {p,J, {р;— р;}.
Методика выполнения задания. Выражение (7.11)
носит название модели однофакторного дисперсионного
анализа с фиксированными эффектами-, (7.10) представ-
ляет собой частный случай общей линейной модели ре-
грессии У=Хр-}-е (см. §7.1):
где 1п и On — n-столбцы, состоящие полностью из еди-
ниц и нулей соответственно. Поэтому оценки для р, {а,}
могут быть получены методом наименьших квадратов:
АЛА
(li — Pi — MJ
при этом iji называется средним i-й группы, а у — общим
средним (для всех групп).
217
Проверка гипотезы однородности наблюдений:
//о: pi — р2= • • • =Pg,
или в эквивалентной форме:
Но: си = «2 = • • • = otg = О,
осуществляется путем сравнения двух выборочных дис-
персий: внутригрупповой 52нгр и межгрупповой £2 гр;
(ytj
yt)2/(n
R
SM.rp = 2 nl (У‘ 1)-
t=l
Так как (g — 1)S2 гр/о2 и (/г — g)<S2H rp/o2 независимы
и имеют ^-распределения с (g—1) и (n—g) степенями
свободы соответственно, то для проверки гипотезы Но
используется статистика F = гр/^вн гр» имеющая при
верной Но F-распределение Фишера с (g — 1) и (п — g)
степенями свободы. Гипотеза Но отвергается с выбран-
ным уровнем значимости 8, если вычисленное значение
статистики F превосходит значение квантили уровня
1 — 8 для F-распределения Фишера eg — 1 и п — g сте-
пенями свободы [61]':
Если все группы имеют равные математические ожида-
ния, т. е. Но верна, то £ г и S являются несмещен-
ными оценками дисперсии о2. Если же гипотеза Но не
верна, то
R
M{S>,rp} = °2+2 (Нг-Н)2«г/и-1).
1=1
a S по-прежнему будет несмещенной оценкой о2.
Результаты однофакторного дисперсионного анализа
принято сводить в таблицу вида 7.1, которая илллюстри-
рует разложение полной суммы квадратов с помощью
теоремы Кокрсна [2].
Отвергая в однофакторном дисперсионном анализе
гипотезу Но, мы делаем заключение о существенности
218
Таблица 7.1
Источник рас- сеивания Сумма квадратов Степе- ни сво- боды Средний квадрат S2 М {з2}
Различия « г т -5 — 54’-. 1:4 •-* =-Н.!1 и е и- 11 § 1 5 '—' 05 СГ) . со СО 1 со £—1 55м<гр о2 4~
между груп- пами Различия внутри групп п—g g — 1 &$ВИ.ГР П — g _। Ир2 (=1 g-1 о2
Полная сум- ssn = 22 yl — п—1 SSn о2 -|~
ма квадратов i п—1 v Мш—и)2 ,^1 «-1
различий между рц, ..., pg. Однако проверка с помощью
F-критерия не позволяет сделать вывод, какие же сред-
ние явились причиной неоднородности. Для решения этой
задачи можно использовать процедуры множественного
сравнения: S-метод Шеффе [61], Т-метод Тьюки [4] и мно-
жественный /-метод [24].
Рассмотрим линейную комбинацию средних h =
g
— 2 Иг (так называемый контраст),
i=i '
g
которой удовлетворяют условию ~ 0.
z=i
коэффициенты
Во всех трех
перечисленных выше методах для проверки гипотезы
(7.12)
против
219
нужно построить (1—8) • 100%-ный доверительный ин-
тервал для h: (/i_, /ц_),
g
(7.13)
где s—некоторая статистика, зависящая от 8.
Гипотеза Н() (7.12) отвергается с уровнем значимости
8, если доверительный интервал (7.13) не содержит точ-
ку нуль. При этом
для S-метода, где п_а (1 — 8) — квантиль уровня
(1 — 8) F-распределения Фишера с g—1 и п— g степе-
нями свободы;
для Г-метода, где m—ni = ti2= ... =пё, — квантиль
уровня (1 — е) распределения стьюдентизированного раз-
маха с g и п—g степенями свободы [24];
0
21г
для /-метода, где t
квантиль уровня 1
---для /-распределения Стьюдента с (п—g) степенями
свободы [24], k— число заранее установленных контра-
стов. •
Границы 100(1—8) %-ного доверительного интервала
для любого группового среднего равны
вн.гр
границы 100(1—8) %-ного доверительного интервала для
сравнения двух средних рг — равны
>ч
tli
вн.гр
220
77ервоначальный перечень экспериментов
1. Данные химического анализа состава крови (см.
§ 9.5): п—188, £=2, признак классификации Х(5) имеет
значения 1 и 2, у = 1g (X (6)). Задать контрасты, k = 2;
е = 0,1.
2. Данные кардиологических обследований (см. § 9.5):
g = 4, признак классификации Х(44)— возраст — задаст
следующие группы: Х(44)^44 (1-я группа); 45
Х(44)^ 49 (2-я группа); 50 Х(44)^ 54 (3-я груп-
па ); Х(44) 55 (4-я группа). Проверить гипотезу о ра-
венстве средних значений уровня холестерина Х(6) и диа-
столического артериального давления Х(4) по четырем
возрастным группам; & = 0,1.
Указания
1. Исходные данные для экспериментов 1, 2 записаны
в наборах № 3, 2 (см. табл. 9.4).
2. Для случайной величины Х(5) (холестерин) в
эксперименте 2 задать минимальное, максимальное и про-
пущенное значения равными соответственно: 150, 400, 0.
3. Вычисления выполнить с помощью программы
BMDP1V [52].
§ 7.4. Двухфакторный дисперсионный анализ
Задание. Рассмотрим случайный эксперимент, в ко-
тором на результаты наблюдений воздействуют одновре-
менно два фактора А и В, причем первый имеет г уров-
ней дискретности, а второй — с уровней. Обозначим
ijijk, k = 1, п, наблюдение, принадлежащее комбинации
r-го уровня фактора А и /-го уровня фактора B(i = 1, г;
/ = 1, с). Предположим, что наблюдения в группе (/, /)
составляют случайную выборку из распределения
# 1 (Ртд о2):
Уць = jiij + eijh> k = 1, n, i = 1, r, / = 1, c, (7.14)
где ецк — независимые в совокупности нормально рас-
пределенные величины TV i(0, о2) и оба фактора А и В
соответствуют модели (7.11).
В условиях модели (7.14) необходимо получить оцен-
ки параметров {ц^}, о2 и проверить гипотезы о равенстве
221
средних значений по уровням факторов А и В и об отсут-
ствии взаимодействия уровней факторов А и В.
Методика выполнения задания. Выражения (7.14)
определяют модель двухфакторного дисперсионного ана-
лиза с фиксированными эффектами и одинаковым чис-
лом наблюдений п в группах [14] и имеют эквивалентную
форму
УijU = Р 4~ -р Pj 4“ (сф) ij 4“ Cijk>
k = TJi, i = iy, j = 177 (7.15)
r c
где p — общее среднее, p = pij/(rc); щ — i-й глав-
4=1 /=1
С
пый эффект фактора А, щ = pij/c — р; Pj — /-й глав-
j=i
ный эффект фактора В, Pj = рц/т — р; (аР)7—эф-
1=1
фект взаимодействия i-ro уровня фактора А и /-го уровня
фактора В, (ap)7j = p*j 4~ Р — ( Мо7г + 2 Уи/С)-
i=i /=1
В силу соотношений
2 аг = О, Pj = О,
4= 1 /= 1
Г С
2 (“₽)<> = 2 (“₽)*; = °
4= 1 /= 1
оценки параметров модели (7.15) по методу наименьших
квадратов принимают вид
где
ytjhi У1]
г п
Суммы квадратов, используемые для проверки гипо-
тез и оценки рассеивания в двухфакторном дисперсион-
222
Таблица 7.2
Источник
рассеивания
Сумма квадратов
Степени
свободы
Фактор А
Фактор В
Взаимодей-
ствие АВ
А, В, АВ
Ошибки
Средний
квадрат S2
9 I 2
О2 -f- С/Ю^
о2 4~
°2 + П°АВ
Полная сум-
ма квадра-
тов
i j k
ном анализе с равным числом наблюдений в группах,
можно представить в виде табл. 7.2. Здесь
Г с
О2 = —-------рД----р— 5 5 (аР)?-
ЛВ (г — 1) (с —1) ' 1 /1/
Проверяемые гипотезы формулируются следующим
образом: отсутствие взаимодействия факторов А и В
(pij = ц + at + P.j):
НАВ. (оф) ij 0, i 1, г, j = 1, с,
отсутствие различий в эффектах уровней фактора А:
НА‘ ос г 0, i 1, г,
отсутствие различий в эффектах уровней фактора В:
223
HB: fo = 0, j = 1, с.
Статистики критерия для проверки гипотез НАВ, НА
и Нв против общих альтернатив имеют соответствен-
но вид:
Рлв = S^/S^ FA'= S’/Sf, FB = sysi (7.16)
Гипотезы HAB, НА, Нв отклоняются с уровнем зна-
чимости 8, если значения статистик (7.16) превысят зна-
чение квантили уровня (1 — 8) F-распределения Фишера
с соответствующими степенями свободы j\ и f2:
FAB^FfJh(l—e), fr = (с-- 1) (г— 1), f2 = rc(n — 1);
П ервоначальный перечень экспериментов
Рассмотреть следующую реальную задачу кардиоло-
гических обследований (см. § 9.5). У служащих, принад-
лежащих к различным социальным группам, измерялось
систолическое и диастолическое артериальное давление
для двух моментов обследования. Будем считать соци-
альное положение фактором А с г — 2 уровнями (Л1 — 2,
А2 — 5), момент (год) обследования — фактором В
с с=2 уровнями Bi, В2. Провести дисперсионный ана-
лиз наблюдений за систолическим и диастолическим
давлением. Задать уровень значимости е = 0,05.
Указания
1. Данные записаны в наборе № 6 (см. табл. 9.4).
Замеры систолического давления представлены в матри-
це исходных данных переменными X (4) (В = Bi) и Х(12)
(В=Вг); замеры диастолического давления-—перемен-
ными Х(5) (В = В[) и X(13) (В = В^)\ социальное по-
ложение — переменной X(9).
2. Для вычислений использовать программу BMDP2V
[52], задав в качестве группирующей переменной соци-
альное положение.
224
Глава 8
СТАТИСТИЧЕСКИЙ АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
Данная глава посвящена методам статистического оценивания харак-
теристик стационарных временных рядов, методам выделения поли-
номиального и гармонического тренда, а также способам построения
статистических выводов о процессах авторегрессии и авторегрессии
с остатками в виде скользящего среднего.
§ 8.1. Статистическое оценивание характеристик
временного ряда
Задание. Наблюдается реализация yt, t = 1, 2, ..., Г,
временного ряда длительностью Т. Методом скользящего
среднего выделить тренд и случайную составляющую
временного ряда. Для случайной составляющей оценить
математическое ожидание, ковариационную функцию
и спектральную плотность.
Методика выполнения задания. Последовательность
случайных наблюдений tji, у2, ..., Ут, полученных в фик-
сированные моменты времени 1, 2, ..., Т, называется вре-
менным рядом. Его простейшей вероятностной моделью
является модель
Pt = f(t)+ut, (8.1)
где f(t)—детерминированная (систематическая) состав-
ляющая, называемая трендом-, щ — случайная состав-
ляющая — последовательность некоррелированных слу-
чайных величин с нулевым математическим ожиданием
ц = M{wJ = 0, постоянной дисперсией о2 = м{«ц и ко-
вариационной функцией o(/i)= M.{utut+h} = o28h,o.
Задача выделения тренда состоит в статистическом
оценивании функциональной зависимости /(•). Оценку/(•)
обычно строят в заданном параметрическом семействе
функций. В качестве таких функций используют, напри-
мер, полиномы (см. § 8.2) или линейные комбинации три-
гонометрических функций (см. § 8.3). На практике часто
параметрический вид тренда не может быть указан,
однако известно, что на малом промежутке времени он
достаточно хорошо может быть аппроксимирован полино-
мом невысокой степени [3, 14}. В таких ситуациях для
оценки f (/), t + 1, ..., Т — m}, и рекомендуется
использовать метод скользящего среднего.
8 Зак. 1015
225
Суть этого метода состоит в следующем. Пусть t —
произвольный момент времени; ш, р — натуральные чис-
ла: т Т, р <Z 2т. Будем предполагать, что на отрезке
времени (7 — т, t + т] с центром в точке t тренд f (t 4- s)
представим в виде полинома степени р с коэффициента-
ми «о = tZo(O> ai = dp = ap(t), вообще говоря,
зависящими от t:
f (t + s) = do(0 + at (0s + ..
s e [— m, + m}.
+ aP(t)s?,
(8.2)
Коэффициенты этого полинома оценим по .. •
..., yt+m} методом наименьших квадратов:
т
2 (yt+s — («o + ais + ••• + лр$р))2-> min. (8.3)
Обозначим {di(t)} решение задачи (8.3). Из (8.2) видно,
что при s = 0 f(t)= a0(t). Поэтому в качестве оценки
тренда в момент t примем статистику
f (0 = «о(0-
Оказывается [14], что
(8.4)
л
а0 (0 =
s= —tn
s= —tn
Коэффициенты для оценки тренда
т Нормированный коэффи- циент S
0 1 2 3
3 231 c±s 131 75 —30 5
4 429 c±s 179 135 30 —55
5 429с, „ 143 120 60 —10
6 2431 с. с i s 677 600 390 ПО
7 46 189с,_ ~Т о 11 063 10 125 7500 3755
8 4199с, „ 1 о 883 825 660 415
9 7429с, „ 1393 1320 1110 750
10 260 015с, _ 44 003 42 120 36 660 28 190
Примечание. Пустые клетки соответствуют нулевым коэффи
226
c_s — cs, t ее {tn 4-1, T — m}, (8.5)
где коэффициенты {cs} зависят лишь от т, р. При р — 2
(или р = 3) эти коэффициенты вычисляются по формуле
3 (3m2 4- 3m — 1 — 5s2) n . 1
Со — 7 л 1 \ /л i 1 \ /л i о\ > > •••> I И .
s (2m— 1) (2m-J-1) (2m3)
При p — 4 (или p = 5) коэффициенты {cs} представлены
в табл. 8.1.
л
После того, как оценка тренда /(•) получена, выде-
лим случайную составляющую
• А
ut = — t 4- 1, ..., Т — т}.
В силу (8.1), (8.4), (8.5) и* является новым временным
рядом, для которого некоррелированность отсчетов уже
нарушена. В качестве модели tz* примем стационарную
случайную последовательность с математическим ожида-
нием p,.i; = М {ц*}, ковариационной функцией о;И (/i) ~
~М{и*иц-ц} и спектральной плотностью
ОО
g* W = -” 2 а* Wcos л < А, < л.
л=о
Таблица 8.1
методом скользящего среднего
S
4 5 6 7 8 9 10
15 —45 —135 —165 135 405 17 655 18 —198 —2937 —177 18 6378 НО —2860 —260 —290 —3940 2145 —195 —420 —11 220 * 195 —225 —13 005 340 —6460 11628
циентам.
8*
227
Выборочными оценками для р*, a;i. (h) являются ста-
тистики
Л - 1 v? *
Р* — у Mf > (8.6)
f=l
t=\
если р* неизвестно. (8.8)
Наряду с (8.7), (8.8) часто используется нормированная
выборочная ковариационная функция, называемая кор-
релограммой:
r(h) = СЛ/С0, h = 0, ± 1, ... .
♦* ь
Коррелограмму удобно использовать при интерпретации
временных рядов. Для периодического ряда и* функция
гь периодична с тем же самым периодом. Для временных
рядов с независимыми членами r(/i)|<^ 1, если Л 1.
Оценки (8.6), (8.7) несмещенные. Оценка (8.8) асим-
птотически (при Т-> оо, |Л|<; оо) несмещенная. Асим-
птотические распределения этих статистик исследованы
в [31.
Определим статистики:
т
А (X) = -у- (w* — и) cos
t=i
Статистика /?2(\), i — 1, 2, ..., рассматривае-
мая в зависимости от г, называется выборочной спектро-
граммой.
Выборочная спектральная плотность [3]
228
и характеризует непрерывный спектр в отличие от линей-
чатого спектра {/?2(Хг)}, рассматриваемого лишь на ча-
стотах {М}. Асимптотические свойства оценки I(%) и ее
распределение рассмотрены в [3, 13]. Показано, что
сходится при 7->оо к спектральной плотности
g*(X), однако оценка (8.9) не является состоятельной,
так как дисперсия /(Z) не стремится при этом к нулю:
limM|Zr(X) — g* (%)
Г—>оо
Поэтому для оценивания спектральной плотности g*(Z)
в точке % = v используют оценки вида
Л
Вт(?)=
wr cos vr • Cr =
rflg wr — (T—|r|>*/T— весовые множители, зависящие
от Т; Сг — оценка ковариационной функции, определяе-
мая формулой (8.8); сг выражаются с помощью выбо-
рочной спектральной плотности:
J I (%) cos Xr —
Оценку
gT (v) можно записать как взвешенное сред-
Функции
V) =
и
-(Т-1)
wr cos Xr cos vr,
WT (Ь I v)
229
называемые спектральными окнами, удовлетворяют еле*
дующим условиям: ^(Х) — четная функция X, которая
с возрастанием Т концентрируется в начале координат,
л
J* Wt (Х| v)dK = 1,
—л
M|gy(X) —g* (X) |2-> О при Тоо, — л<Х<л.
Наиболее важный класс оценок gr (X) определяется
коэффициентами
w*r = (k(r/kT), r = 0, +1, ±kT,
(0, r = ±(^+1), ±(T-1),
где k? -> оо, kr/T -> 0, если Т -> оо. При
этом k (х) — непрерывная четная функция, k (0) = 1,
ОО
I k (х) I < 1 и J k2 (х) dx < оо. Часто вместо a>4(X|0) рас-
— оо
сматривают
00 оо
/С (X10) = J k (х) e~iKxdx = J k (х) cos hxdx.
Процедура вычисления оценок gr (v) часто называется
сглаживанием спектра, а оценки g? (v) — сглаженными.
Наибольшее распространение получили следующие оценки
спектральных плотностей [20, 35, 60].
1. Усеченная оценка:
л
2 cosvr.cr;
r~kT
k (x) =
(4- (2iT+
2л sin (X/2)
* S1'n
(X | 0) = —
7<(X|0) =
sin X
230
2. Оценка Бартлетта:
*,1|ЛЧ sin2(Zj7X/2) .
2nkr sin2 (X/2) ’
3. Общие оценки Блэкмена—Тьюки:
или
Л Л. I л \ л. л. / Л \
gr(v) = agr^v— + (I — 2а) gT (v) + agT\у + ~k' )•
N.
где gr (v) — усеченная выборочная спектральная плот-
ность. Спектральное окно, соответствующее рассматри-
ваемой оценке, выражается через спектральные окна усе-
ченных выборочных спектральных плотностей.
Особо рассматриваются два частных случая оценки
Блэкмена—Тьюки. При а = (окно Хеннинга)
cos лх)
О
и4(Х|0) =-J
231
При а — 0,23 (окно Хемминга) оценка спектральной плот-
ности имеет вид
Перечень экспериментов
1. Модельные данные: {yt} — последовательность неза-
висимых случайных величин со стандартным нормальным
распределением (0, 1), Т — 2048.
2. Реальные данные медицинских обследований пуль-
са и дыхания пациентов (см. § 9.5), Т = 128.
232
Э
Указания
1. Для эксперимента 1 данные получить с помощью
подпрограммы GAUSS (см. Приложение 1), выборку
разбить на отрезки длиной т = 16, на каждом отрезке
усреднить значения ряда и оценить спектральную плот-
ность и ковариационную функцию после осреднения *).
Сглаживание ряда и выделение тренда не производить.
Формирование исходного ряда, усреднение и запись зна-
чении нового ряда в раздел библиотеки
STUDENT.RESULT(TBjjggnn)
(см. § 9.3) выполнить с помощью программы
BMDP1S [52].
2. Данные для эксперимента 2 записаны в наборе
№ 11 (см. табл. 9.5). Реализация ряда представляет зна-
чения первой переменной.
3. Для оценки тренда, характеристик исходного вре-
менного ряда yt и случайной составляющей щ использо-
вать программу BMDP1T [52]. Выделение тренда f (•)
произвести методом скользящего среднего с помощью под-
программы SMO из ПНП-БИМ [46]. Порядок сглажива-
ния т установить по пикам значений выборочной кова-
л
риационной функции; полученные компоненты рядов f(t)
и н* записать в раздел библиотеки
STUDENT.RESULT(TBj jggnn) ;
проверить согласие щ с нормальным распределением с
помощью программы BMDP5D или BMDPDI [52].
§ 8.2. Временные ряды с полиномиальным трендом
Задание. По реализации временного ряда yt, t —
= 1, ..., Т, оценить коэффициенты аппроксимирующего
тренд полинома степени q\ проверить гипотезы о значи-
мости коэффициентов полинома и о порядке полиноми-
ального тренда.
*> См.: Журбенко И. Г., Кожевникова И. А., Клиндухова О. В.
Определение критической длины последовательности псевдослучай-
ных чисел // Вероятностно-статистические методы исследования. М.:
Изд-во МГУ, 1983. С. 18—39.
233
Методика выполнения задания. Пусть yt = f (t) +
где ut — последовательность некоррелированных случай-
ных величин с математическим ожиданием М {щ} = 0 и
дисперсией М{ut} =' о2. Представим тренд f (/) в виде по-
линома степени q:
f (0 = «о + М + • • • +
(8.10)
Тогда, принимая во внимание свойства f (/) и щ, выраже-
ние (8.10) можно рассматривать как полиномиальную
регрессию порядка q:
я
м {yt ю = f (о = «о + 2 а^к-
k=l
(8.Н)
Обозначим {<P/e/ (Z): k= 1, Т — 1} систему Т— 1 орто-
гональных многочленов:
Представим тренд f (/) в виде
разложения по {ykT (t)}'
q
f(O = Yo +
Л=1
(8-12)
где уо, Ть . • •, У<] подлежат оцениванию.
МНК-оценками коэффициентов уь в (8.12), получен-
ными на основании наблюдений временного ряда
У1, • • •, Ут, являются
2 y^kT
Yfe = Ь • • •> Q-
2 (0
Л=1
234
Оценка среднего квадратического отклонения yk вычис-
ляется по формуле
где
ЛАЛ Л
yt = Yo + Yi<Pi т (О + • • + Y,4>«r (О-
Несмещенная оценка дисперсии о2 равна:
где
У = Yo.=
Член
/ Т ч 2
W 2 (0 = --------— = 77 * = 17?-
'=' 2 & «
/=1
-• * я
г А
характеризует уменьшение выборочной дисперсии 52
в результате введения в уравнение регрессии полинома
k-м. степени.
л
Если щ—гауссовская последовательность, то {yft! k
= 0, </} независимы и нормально распределены; для про-
верки гипотезы (для любого k = 1, q) Hok- Ya- = О про-
тив альтернативы H\k'- Y*^^ можно использовать ста-
тистику , имеющую /-распределение с Т — k— 1
степенями свободы (при Hok)- ...
235
Hlh, если |/ft|>Aft(e).
Тест уровня значимости е для проверки Hok, Hlk
имеет вид:
[//оь, если \th |< (в),
принимается
Здесь Аа (е) — квантиль уровня ------|~) /-распределения
Стьюдента с Т — k — 1 степенями свободы.
Проверка гипотезы Hok эквивалентна проверке Ноь'.
л
ak = 0. Оценки коэффициентов aft в (8.11) определяются
л
через {yj:
где {ct (k, Т)} — коэффициенты разложения <рлг (/) по сте-
пеням получаемые при решении системы k уравнений:
т т
с„ (k, Т)^ + С1 (k, Т) 2^'+‘ + • • • +
/=1 /=1
I- Ck— 1
Оценки среднего квадратического отклонения S- и ко-
ft
Л Л Л _____
вариаций cov (afe, az) коэффициентов {aft, k = 0, q} вычис-
ляются по формулам
sa = (cov(aft> <i,..))1/2,
A
COV (aA,
2 ______
vz, k, I = 0, q.
- Степень полиномиального тренда может быть оцене-
на, исходя из следующих предположений. Если ut —
гауссовская последовательность, то величины Tq/cf2 при
yq — о имеют ^-распределение с одной степенью свободы
й статистика Fq = TqIS2 будет иметь ^-распределение
Фишера с одной и Т — q — 1 степенями свободы. Стати-
стика Fq используется для проверки гипотезы о том, что
полином (о котором известно, что его степень не боль-
ше q) на самом деле имеет степень меньшую, чем q [54]:
Но: yq = 0 против Нс yq 0. Гипотеза HQ отклоняется
236
с уровнем значимости 8, если Fq >> Д(е), где Д(е)—
квантиль уровня 1—8 F -распределения Фишера с одной
и Т — q — 1 степенями свободы.
Перечень экспериментов
Реальные данные медицинских обследований (см.
§ 9.5): Xi(/), Х2(/) —временные ряды наблюдений пока-
зателей «Пульс» и «Дыхание».
1. Т = 100, q 5. 2. Т = 50, q 5.
Указания
1. Исходные данные записаны в наборе № 1 (см.
табл. 9.5).
2. Для вычисления оценок коэффициентов полиномов
использовать программу BMDP5R [52].
3. Сравнить качество аппроксимации временного ряда
в зависимости от значения Т.
4. Статистический анализ временных рядов Xi(f)
и х2(/) провести отдельно.
§ 8.3. Гармонический анализ периодических трендов
Задание. Для реализации временного ряда t/t, t =
= 1, ..., Т, имеющего периодический тренд, оценить
коэффициенты представления Фурье; проверить гипотезы
об отсутствии слагаемого с наименьшим заданным пе-
риодом и об отсутствии периодичности.
Методика выполнения задания. Пусть в условиях модели
(8.1) yt = f(t) -рut, t=\, ...» T, f(t) — периодическая
функция с известными периодами, нацело делящими Т.
Значения периодов определяются как Т/kj, j = 1, qy где
( Т__1 ]
{kv ...» kq} — подмножество целых чисел 11, ...» —%—)’
если Т четное. Тог-
если Т нечетное, и
2
да f (t) можно записать в виде линейной комбинации три-
гонометрических функций:
f(t) = а0 4- 2 (а (М cos...у'"' ^ + ₽ (fy) sin у—/
/=1х
237
если Т нечетное, или
f (0 = «о + 2 (а (^)cos ~* +
/=1 v
+ ₽ (£,) sin t) +<x т (-1)',
7 2
если T четное.
Через a(fy) и 0 (kj) определяются еще два параметра:
р (kj) = ]/а2 (kj + ₽2 (Агу),
0 (kj) = arctg -Ш-.
МНК-оценками а0, а т , {a(fy), 0 (kj): j = 1, q} являют-
2
ся статистики
a (kj) = a(kj) ~ Vtcos 23^~ i = 1» • • •>
(8.13)
₽ (kj) = b (kj) = а 2л sin 1, !=\....................д;
Для а2 = М {uf}, {р (kj),
квадратов имеют вид
0 (kj)} оценки наименьших
Q
(«а (Л) + (*;))
_________ 7=1________________
Т-(27 + 1)
для Т нечетного и
т q
2 Л2 -Т(уг+а\) - 21 У <a2 + b2 (ki)}
„2 _ -2 _ Jzl__________2 i=l_________________
Г —(27 + 2)
238
для Т четного,
р (k,) = R (k/) = V a2 (kj) + b2 (kj),
e (kj) = arctg 4^5-. / = Г7-
Оценки (8.13) являются несмещенными, дисперсии их
а2 2а2
соответственно равны - — для а0, а т и —-т- для a{Rj)
и b(kj)> j=l, q. Если ut— гауссовский процесс, то ука-
занные оценки независимы и распределены нормально.
Статистика s2 является несмещенной оценкой о2. Если
щ — гауссовский случайный процесс, то отношение
(Т — 2q — i*)s2/o2 имеет ^-распределение с Т — 2q — i*
степенями свободы (i* •= 1, если Т нечетное; i* = 2,
если Т четное; выражение для s2 выбирается также в за-
висимости от четности 71).
В предположении нормальности {yt} можно проверить
гипотезу об отсутствии слагаемого с наименьшим задан-
ным периодом:
Но: a(kj) — p(^j) = О
или эквивалентную гипотезу
Но: р№)= 0.
Альтернатива Н^ p(kj)=£ 0.
При справедливости Но статистика
Т a* (kj) + b* (kj) __ Т R2 (kj)
z 2 а2 2 а2
имеет ^-распределение с двумя степенями свободы.
В общем случае z имеет нецентральное ^-распределение
с параметром нецентральности Тр2(^)/(2о2) [3]. Для про-
верки Но можно воспользоваться также статистикой
TR2 (k})
2о2
/ (2s2/a2) = 7’7?2(^)/(4s2),
имеющей F-распределение Фишера с двумя и Т — р сте-
пенями свободы (р = 2q + i*). В общем случае £ имеет
нецентральное F-распределение Фишера с параметром не-
центральности Гр2 (kj)/(2o2) [3].
Решающее правило для проверки HQ записывается
следующим образом:
f/70, если z<A(e),
принимается (8.14)
[ /71, “СЛИ Z 1л
239
где A (е)— квантиль уровня (1 — в) центрального F-рас-
пределения Фишера с двумя и Т — р степенями свободы.
Для проверки гипотезы об отсутствии в f (/) периоди-
ческих изменений с периодом т (Т = r/i, т четное):
Hq: a (kh) = р (kh) = 0, k=\, ---1,
используется статистика
г =--------------(Ттпр-------------- • (8-15)
Статистика г' при справедливости /70 имеет F-распределе-
ние с т—1 и Т — т степенями свободы [3]. В общем
случае, когда f (t) периодична с периодом т, статистика
г' имеет нецентральное /^-распределение Фишера с пара-
метром нецентральности
L У (a* (kit) + ₽* (И))2 + Та2т
k=i_______________________________________Т
о4
(8.16)
Решающее правило в этом случае записывается анало-
гично (8.14). Если повторяющиеся значения временного
ряда для каждого из h периодов представить в виде
У1 У2
Ух
Ух-\-\ Ух-\-2 У2х
У(П— 1)т-4-1 У(И— 1)т4-2 Уих>
то нулевая гипотеза
Но- Ц1) = /(2) = ... = /(т)
может быть проверена методами однофакторного диспер-
сионного анализа (см. § 7.3). Для этого вычисляется ста-
тистика
t+xj
240
где
имеющая F-распределение Фишера с (т—1) и т (h—1)
степенями свободы при справедливости нулевой гипотезы
и нецентральное /’’-распределение Фишера с параметром
нецентральности
X
<=1 o8--------, 7 = SfW/T, (8.18)
7=1
если верна альтернатива.
Решающее правило для проверки гипотезы Но форму-
лируется так же, как и для гипотезы Но, вследствие сов-
падения статистик (8.17) и (8.15) и параметров нецент-
ральности (8.16) и (8.18) [3].
Перечень экспериментов
1. Модельные данные: Т = 32, т = 16, h = 2; прове-
рить гипотезу Но для T/kj — 4, 8.
2. Для тех же данных проверить гипотезу Но методом
дисперсионного анализа.
Указания
1. Исходные данные записаны в наборе № 20 (см. табл.
9.5).
2. Для вычисления оценок коэффициентов разложения
Фурье использовать подпрограмму FORIT из ПНП-БИМ [46].
3. Проверку гипотезы Но выполнить с помощью прог-
раммы BMDP1V [52].
§ 8.4. Статистическое оценивание зависимости
двух временных рядов
Задание. Для реализации временного ряда X(Z), t =
= 1, ..., Т, с двумя компонентами вычислить значения
выборочных взаимной ковариационной функции, взаим-
241
ного спектра, когерентности и передаточной функции.
Построить доверительный интервал для когерентности
и передаточной функции, установить распределение
оценки фазы. Оценить зависимость рядов во временной
области с помощью уравнения регрессии.
Методика выполнения задания. Пусть значения наб-
людений представляют r-мерный временной ряд
Х(/) =
где все ХД/), j = 1, ..., г, действительны, t принимает
значения 0, ± 1, ± 2, ... . Векторный ряд Х(/),
t — 1, 2, ..., имеющий г компонент, называется стацио-
нарным в широком смысле (или стационарным второго
порядка), если математическое ожидание не зависит от
времени:
ma(t) = М{Ха(/)} = пга
и взаимная ковариационная функция (кросс-ковариа-
ционная функция)*)
COV{Xft(Z + р),
Xb(t)}= СаЬ(р)
для t, р = 0, 1, ... и a, b = 1, г.
Определим преобразование Фурье для функции
Cab ( * ) •
СО
11=—оо
в предположении^сходимости ряда
ОО
U=—оо
При а = b fa^) называется спектральной плотностью
ряда Xa(t) на частоте X, а при а =£ b fab (к)— взаимной
спектральной плотностью (кросс-спектром) рядов Ха(/)
и Хь(/) на частоте %. Действительная и мнимая части
fab(X) называются соответственно коспектром и квадра-
турным спектром. Функция сраь(к) — arg fab (М-ф аза
... - I. . —"Л
*) Термины, приведенные в скобках, используются в переводной
литературе по анализу временных рядов.
242
спектра, a \fab(k) |— амплитуда спектра. Взаимная спек-
тральная плотность позволяет оценить связь между со-
ставляющей спектра с частотой X ряда Xa(t) и состав-
ляющей с частотой % ряда Хъ (t), а также сдвиг этих со-
ставляющих по фазе.
В качестве меры взаимной зависимости рядов Xa(t)
и Xb(t) вводится величина
п (ТЛ I fab (М I2 1 ,— pl
называемая когерентностью ряда Xa{t) с рядом Хъ(1)
частоты X. Когерентность является аналогом коэффи-
циента корреляции и описывает максимальную степень
связанности, достижимую за счет сдвига по фазе одного
из двух рядов, а (ро& (X) определяет величину такого фазо-
вого сдвига. Для сопоставления рядов используется пе-
редаточная функция от ряда Xa(t) к ряду Xb(t):
^ab ( )
( fab&)
- fa Од
О,
fa (Ч ¥= О,
fa (Ч = 0.
называемая иногда комплексным коэффициентом ре-
грессии.
Если имеется выборка последовательных значений
двумерного ряда Х(^), t = 1, ..., Г, то задача оценки
взаимной спектральной плотности сводится к вычисле-
нию следующих характеристик.
Выборочная взаимная ковариационная функция
т-р
С{& = "Urr 5 (< + Ч. Р = 0, 1...т;
' t=l
Т—р
Cab”' = Т-D S Ха (t + Р) ХЬ (0> Р = 1...................
1 /у
где tn — наибольший желаемый лаг (максимальное зна-
чение лага равно Т— 1), является несмещенной оценкой
Саь(р), имеющей асимптотически нормальное распре-
деление [60].
Несглаженная оценка взаимной спектральной плот-
ности
Иь = № +
будет асимптотически несмещенной для всех частот, не
равных 0 (mod 2л). Здесь обозначены коспектр
к® =
т
" 2 (Й? + С^>) cos-^
р=0
и квадратурный спектр
(&’ =
т
Л ^&p{^ab ^ab )Sin ——
h = 0, 1, ..
т;
Д/—интервал между последовательными отсчетами вре-
менного ряда; К = hnl(m\t)\
1 Л
-Х-, р = 0 или т,
8р = \
(1, О <С р <Z. т.
Выборочная функция когерентности
Л,- »
№ =
11WI*
Л,,. Л .
x(/i) f(h)
la lb
(MS)2 + (Q&)2
la lb
представляет собой оценку максимального правдоподобия.
При Rab =0, 0, + л ее плотность распределения
имеет следующий вид [60]: 2(т—1)х(1—х2)т~2, поэто-
му величина (т— 1) 7?й? (1 — имеет Г-распределе-
ние Фишера с двумя и 2 (т — 1) степенями свободы. Для
(0)
А- = 0, + л {Rab}i/2 асимптотически распределена как вы-
численный по т—1 парам наблюдений выборочный коэф-
фициент корреляции между двумя гауссовскими величи-
нами с коэффициентом корреляции {/\Р?}1/2; {RaT^}^2 имеет
аналогичное распределение с заменой {/?а?}1/2 на {/?!/& л/)р/2
и (т— 1) на т.
Оценкой максимального правдоподобия передаточной
функции является
(Л)
^ab
Р$/М ’-^0, я,
K'ttlK'P, X = 0, я.
244
Известно выражение 100(1—а) %-ной доверитель-
ной области для действительной и мнимой частей иаЬ(к>)
в виде неравенства [60]
{Re«oi> (X) - Re«’^}2 + {1т«йг, W —
<' (W~'fa (1 - Ra^tv (1 - “)> v = m - 2, • Л = 0;
,v = m— 1, % = л,
где F2,2m-2(1—«)—квантиль уровня (1 — a) Е-распре-
деления с указанными степенями свободы, /v(l — а)
имеет аналогичный смысл для /-распределения Стью-
дента.
Если для получения состоятельных оценок спектраль-
ной плотности осуществляется сглаживание (см. § 8.1),
то асимптотическая теория дает следующие распределе-
ния рассмотренных выше оценок.
Оценка фазы ф$ = arctg (Kab/Qab) имеет равномерное
распределение в (—л, л] в случае Ral}= 0, где Kab\\ Qab —
независимые гауссовские величины.
Для функции когерентности при Rab1 = 0, fa > 0» fb > 0»
%=^0,±л величина vR^ распределена как %2 с двумя
V
степенями свободы. При % = 0, + л величина -у Rab рас-
пределена как %2 с одной степенью свободы.
В случае R{ab}=£0, fa>Q> fb>®> А,^0,±л величина
—1— Л । /п |/9 А
V2 (Rab — Rab )/(1 — Rab) нормальна с нулевым средним
и единичной дисперсией, поэтому доверительный интервал
уровня 1—а для Rab имеет вид
А . А ’
n1/2 1 Rab 7 Р Р^{? I- 1 Zi
1\аЪ 1/2 *\ab Г <^1/2
где 21-а — квантиль уровня 1 — а стандартного нормаль-
ного распределения. В формулах для асимптотических
распределений число степеней свободы v определяется
как
2Т
v = kT\k2 (х) dx
где kT, k(x) определены в § 8.1.
245
Первоначальный перечень экспериментов
1. Модельные данные: {Xi(t), X2(t)} имеют двумер-
ное нормальное распределениеN2(p, 2); цт = (0, 0);
2 = /2; г = 2; Т = 200; пг = 100; Xt = 1.
2. Реальные данные медицинских обследований насе-
ления (см. § 9.5): г = 2, Xi(t)—временной ряд наблю-
дений за пульсом, X2(t)—временной ряд наблюдений за
объемом дыхания; Xt = 0,6; Т = 128; m = 64.
Указания
1. Исходные данные для эксперимента 1 записаны
в наборе № 1 (см. табл. 9.4), для эксперимента 2 — в на-
боре № 11 (см. табл. 9.5).
2. Для вычисления статистических характеристик
двумерного временного ряда использовать программу
BMDP1T [52]. Оценку связи рядов во временной области
для эксперимента 2 произвести с помощью программы
BMDP6D [52], выбор закона распределения выполнить
программой BMDPDI [52].
§ 8.5. Статистические выводы о процессах
авторегрессии и авторегрессии
с остатками в виде скользящего среднего
Задание. По реализации случайного временного ряда
длиной Т найти оценки параметров моделей авторегрес-
сии (АР) и авторегрессии с остатками в виде скользя-
щего среднего (АРСС). Проверить условие стационар-
ности моделей, сравнить оценки параметров АР, полу-
ченных методом наименьших квадратов и по уравнениям
Юла — Уокера. Оценить порядок процессов АР и АРСС.
Методика выполнения задания. Процесс авторегрес-
сии порядка р определяется стохастическим разностным
уравнением порядка р:
yt + +
+ $pyt-p = ut, t = p+ 1, ...,
или
(8.19)
246
Здесь up+l, ир+2, .. • представляют собой последователь-
ность независимых и одинаково распределенных случай-
ных величин с математическим ожиданием №{ut}= 0.
Параметры р= (01, ..., |3Р) должны удовлетворять опре-
деленным условиям, чтобы процесс (8.19) был стацио-
нарным. Для этого необходимо, чтобы корни %i, ..., хр
характеристического уравнения
р
г=0
(8.20)
лежали внутри единичного круга:
(8.21)
Обозначим Ofe=M{r/^+4 ковариационную последо-
вательность (& = 0, ± 1, ±2, ...), а рк = Gk/oo = p-k
корреляционную последовательность. Известно, что рк
удовлетворяет системе р уравнений Юла — Уокера:
р
2 ₽,р*-г + ph = 0, k = ТГр- (8.22)
/=1
Метод Юла — Уокера для оценивания р, а2 можно
рассматривать как модификацию метода моментов, и со-
стоит он в следующем. Определим состоятельные оценки
корреляций:
Т—к т
Ра ~ = UtytA-k] "S = 0» 1 *
/=i
Анализ смещения и вариации этих оценок представляет
сложную задачу. В качестве примера приведем выражения
смещения и дисперсии оценки рЛ для марковского времен-
ного ряда (р = 1, ру = (р)у, р = —Pi):
Т — k
.если k>
0{п.} = 4-(
247
Подставляя {г/.} вместо {р^} в (8.22) и решая получен-
ную систему относительно р, получаем оценку Юла —
Уокера (в матричном виде):
где
Укажем явный вид оценки (8.23) для простейших
частных случаев.
Марковский ряд (р = 1): р1 = —
Процесс Юла (р = 2):
Аналогично (8.22) можно получить соотношение
р
Подставляя сюда р, {о;}, получаем оценку дисперсии
т
Оценка ковариационной матрицы для р имеет вид
V{₽} = o2P71.
Теперь построим оценки для р, о2 по методу наимень-
ших квадратов (совпадающие с оценками максимального
правдоподобия, если tit — гауссовская последователь-
ность). Обозначим
248
Тогда модель (8.19) примет регрессионный вид
yt — — Р7 Уt-i +
№{yt\Yt-i} = — РгТ*-1, t = р + 1, р + 2, ... .
При этом yt следует рассматривать как скалярную зави-
симую переменную, Yt-i — как р-вектор независимых пе-
ременных (факторов). Получим МНК-оценки (см. § 7.1):
Используя свойство асимптотической нормальности р
при Т -> оо [50], можно проверить гипотезу о порядке р
процесса АР:
Но (порядок АР меньше р): = 0
против альтернативы Hi (порядок АР есть р): рр =£= 0.
Гипотеза Но отвергается с уровнем значимости е, если
IPpl/Sg >S, е
pl> 1—2~’
2 Л
где S ъ — несмещенная оценка дисперсии для Рр (вычис-
ляемая так же, как в § 7.1); g е —квантиль уровня
1 2~
1 8
I----к- стандартного нормального распределения.
Процесс АРСС yt порядка (р, q) определяется стохас-
тическим разностным уравнением
где ро = «о = 1; Vt — последовательность независимых
случайных величин с нулевым математическим ожида-
нием М{и/}= 0 и дисперсией D{vJ=o2. Параметрами
модели являются рь .. ., щ, ..., ад; о2.
Уравнение (8.24) будет определять стационарный
процесс при условии (8.21).
Если обе части (8.24) умножить на ijt-k и перейти
к математическим ожиданиям, то в результате получим
разностное уравнение для последовательности ковариа-
ций {ok: k = 0, ± 1, ...}:
249
07г = PiOTt-i + 02O7t-2
4- ... 4" PpO’/t—p, k
q 4- 1,
(8.25)
или, поделив обе части (8.25) на оо, аналогичное уравне-
ние для корреляций {рл}:
р/i = Рф/г-1 4~ 02р/г-2 4"
+ Ррр/г—Р, Я 4“ (8.26)
Из (8.25) и (8.26) следует, что в качестве параметров
процесса можно рассматривать 0Ь ..., о0; рь ..., рд.
Если Vt — гауссовская последовательность, то совмест-
ное предельное распределение статистик ]/ Т (п — pi), ...
...,]/ Т (гп — рп), где г/г — выборочная корреляция, при
Т -> оо оказывается [3] многомерным нормальным с ну-
левыми средними и ковариациями
ОО
( Рг+йРг+Л 4- Рг—gPr+Л
J йРг/ г4 g ^Pg-P^Pr-j./t 4~ 2р^-Р/гРг )•»
Оценку параметров |3i, ..., pi, ..., рб/ модели
АРСС (8.24) получают путем максимизации функции,
аппроксимирующей функцию правдоподобия первых
п выборочных корреляций [3]. Процедура оценивания,
использующая указанное выше предельное распределе-
ние, состоит в следующем [3]. Введем величины
Xj — fj, j \, ..., q,
р
xi = ^fisri-s, / = 7 4-1» • ••» 7 4-p;
s=0
p
s, /=o
где r0’ = 1 и г_/ — rj, / = 1, 2, ... . Совместное _предельное
распределение —Pi)» • • • > VT (xq — PQ); КTxq+i , ...;
VTxn будет нормальным с нулевыми средними и ковариация-
ми /, / = 1, .. ., п. Обозначим р = (Pi» - • •» РД7»’ А1 =
== ('^1» • • • > Xq}^f (^<74'1, • • • > XQ~\'P>} » 1»
..., хп)г. Соответственно разобьем ковариационную мат-
рицу Ф = (ф/;) на блоки:
250
АЛ ЛАЛ Л
Тогда оценки р = (рр ...» р^) и р = (pi, ..., рр) являют-
ся решениями следующих уравнений, полученных на осно-
ве аппроксимации функции правдоподобия от X:
р = Х(>)-Ф13Ф7з’Х<»,
где r/_s(zY(3)) — остаток r7_s от его регрессии на Х^ \
Найденные оценки состоятельны и асимптотически нор-
т
ЛА 1 — О
мальны [3]. Оценки р, р и Со = -у- X — У) можно
Л=1
Л ЛА
использовать для вычисления оценок о^, ...» а7 и о2 па-
раметров ах, ..., а7, о2. С этой целью образуется ряд
s—О
Л -----
Если ps = Р5, s =-- 0, р, то согласно (8.24) wt есть про-
цесс скользящего среднего:
q
wt =
;=о
Используя этот факт и анализируя wt как процесс сколь-
Л ЛА
зящего среднего, численные значения ах, ...» а^, а2 по-
лучают при помощи итерационных процедур из соотношений
о о — (1 ~Ь • • • + ^q) и2,
O’/г = (^fe ~Е —р • • • ”Е q—i k 1
в которых ковариации {по, о*л} процесса скользящего сред-
него заменяются их оценками:
где Ck — оценка ковариации процесса АР,
___________________________________ л
elk ~ Ck+г И- Ck—i, k == 0, Q, po = 1.
251
Перечень экспериментов
1. Модельные данные: провести статистический ана-
лиз временного ряда, описываемого авторегрессионной
моделью при Т = 100; р = 2; |3i = — 0,25; р2 = 0,0625;
гг2 —
, если щ — гауссовская последовательность.
2. Реальные данные по наблюдению за числами сол-
нечной активности (см. § 9.5): провести статистический
анализ временного ряда, используя модель АРСС (Т=
= 100, р = 3, q = 1).
Указания
1. Исходные данные для экспериментов 1, 2 записаны
в наборах № 18, 19 (см. табл. 9.5).
2. Вычисления в эксперименте 1 провести с помощью
программы BMDP1R [52] и подпрограммы IDMR [46],
сформировав из исходного временного ряда три ряда
с лагом (задержкой) т = 1, 2, 3 соответственно.
3. Для выполнения эксперимента 2 использовать про-
грамму BMDP1T и подпрограммы IDSM, IDMR, POSM,
INCR, PSMA [46].
4. Построить график выборочной корреляционной
функции а для процессов АР и АРСС.
5. Если установлено, что условие стационарности
(8.21) исследуемой модели не выполняется, следует брать
конечную разность Vd от исходного ряда ^dyt = Wt,
где V — разностный оператор: Vyt = yt — yt-ь до тех
пор, пока не будет обеспечена стационарность ряда wt.
6. Значение максимальной задержки корреляционной
функции в подпрограммах IDSM, IDMR задать рав-
ным 20.
Глава 9
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ПРАКТИКУМА
Эта глава содержит описание программного обеспечения, необходи-
мого для выполнения заданий практикума в дисплейном классе.
Дана характеристика программных средств по математической ста-
тистике, их функциональных и языковых возможностей. Описана
организация работы в дисплейном классе с использованием системы
STUDENT и ДСКД PRIMUS.
252
В качестве программных средств, обеспечивающих
практикум на ЭВМ, используются пакет научных подпро-
грамм на фортране [51], пакет прикладных программ ста-
тистической обработки информации СОМИ [52], диалого-
вая система коллективного доступа (ДСКД) PRIMUS,
функционирующие под управлением операционной си-
стемы ОС ЕС. Выбор перечисленных программных
средств обусловлен характером и целями выполняемых
работ.
В первой части практикума, посвященной моделиро-
ванию на ЭВМ, студент должен программно реализовать
ряд алгоритмов имитации случайных элементов, оценить
вероятностные характеристики по полученным выборкам
и эффективность применяемых методов. Для этого при
создании собственных программ целесообразно использо-
вать подпрограммы из ПНП-БИМ.
Во второй части практикума основное внимание уде-
ляется практике статистического анализа данных с по-
мощью ЭВМ и методам интерпретации результатов.
Поэтому студенту предлагаются готовые к выполнению
программы пакета СОМИ, наборы с исходными дан-
ными и сервисные средства, объединенные в систему
STUDENT. С помощью этой системы студент, работая
за терминалом, должен получить решение задач. В неко-
торых заданиях рекомендуется также использовать под-
программы из ПНП-БИМ (например, вычисление опре-
делителя матрицы, преобразования Фурье для времен-
ного ряда и т. д.), так как применение для этих целей
ППП СОМИ было бы трудоемким.
§ 9.1. Описание системы STUDENT
Для проведения практикума по статистическим мето-
дам анализа данных разработана система STUDENT,
предназначенная для формирования заданий ОС ЕС
и пакета СОМИ с экрана дисплея. Система STUDENT
рассчитана на взаимодействие со студентами, получив-
шими начальные навыки программирования. Ее приме-
нение освобождает от написания и отладки программ
при практическом решении статистических задач, позво-
ляет изучить возможности статистических процедур, реа-
лизованных в ППП СОМИ и ПНП-БИМ, языковые сред-
ства ППП СОМИ и ОС ЕС, прививает навыки работы
с наборами данных в ОС ЕС и ДСКД PRIMUS.
Пользователю системы STUDENT обеспечиваются
следующие возможности:
— диалоговое формирование заданий для ППП
СОМИ и ОС ЕС;
— корректировка текстов заданий и программ;
— выполнение программ в пакетном режиме;
— просмотр результатов на экране дисплея;
— синтаксический анализ текстов программ;
— сохранение текстов программ, сформированных
заданий и результатов вычислений;
— доступ к учебной и справочной информации;
— работа со статистическим архивом данных;
— расширение набора задач и архива данных.
Система функционирует под управлением ОС ЕС
издания 6.1 и более поздних изданий на ЭВМ следующей
конфигурации:
— оперативная память 512 Кбайт;
— устройство ввода;
— алфавитно-цифровое печатающее устройство;
— накопитель на магнитных дисках ЕС5061;
— алфавитно-цифровые дисплеи ЕС7920.
Подготовка заданий к выполнению и корректировка
информации требует 144 Кбайт основной памяти, выпол-
нение заданий с помощью ППП СОМИ — не менее
170 Кбайт.
Компонентами системы STUDENT являются:
— программные средства: ПНП-БИМ и ППП СОМИ,
обеспечивающие решение задач и управление данными,
ДСКД PRIMUS, осуществляющая связь пользователя
с ЭВМ и манипуляции с наборами данных;
— информационные средства: архив статистических
данных, обучающая информация (тексты работ, макеты
заданий на ЯУП ППП СОМИ и на ЯУЗ ОС ЕС, резуль-
таты выполнения работ), справочная информация (описа-
ние операторов ЯУП, описание данных, описание команд
ДСКД PRIMUS);
— методические средства (инструкции, учебные при-
меры) ;
— средства пользователя (тексты заданий и про-
грамм, исходные данные).
Структура системы STUDENT определяется функцио-
нальным программным наполнением, реализующим
основные методы по курсу статистического анализа; язы-
ковыми средствами, которые обеспечивают общение
254
пользователя с системой; системным наполнением, свя-
зывающим языковые средства с функциональным напол-
нением.
§ 9.2. Основные характеристики программных средств
по математической статистике
В состав системы STUDENT включены программы,
реализующие следующие методы статистического анали-
за данных:
— оценивание вероятностных распределений и число-
вых характеристик скалярных случайных величин;
— графическое представление данных в виде графи-
ков, гистограмм, диаграмм разброса, древовидных схем
и т. п.;
— проверку гипотез об однородности статистик, вы-
борок, распределений;
— оценку канонических корреляций и главных ком-
понент;
— факторный и дискриминантный анализ;
— оценивание параметров линейной регрессии, про-
верку гипотез о коэффициентах регрессии;
— однофакторный и двухфакторный дисперсионный
анализ;
— статистическое оценивание характеристик одно-
мерных и двумерных временных рядов;
— статистические выводы о процессах АР и АРСС.
Программным статистическим ядром системы являют-
ся ППП СОМИ и программы из ПНП-БИМ.
ПНП-БИМ представляет собой совокупность 1800 под-
программ на языке фортран, оформленных структурно
в виде библиотеки загрузочных модулей. Раздел по мате-
матической статистике содержит около 200 программных
модулей, каждый из которых предназначен для выпол-
нения определенной статистической процедуры, например
вычисления числовых характеристик случайной величи-
ны, оценки параметров экспоненциального распределе-
ния и т. п. Пользуясь ПНП-БИМ, пользователь может
составить собственную фортран-программу, которая бу-
дет организовывать ввод исходных данных, обращение
к необходимым подпрограммам ПНП-БИМ и вывод ре-
зультатов.
255
Описание подпрограмм пакета по статистическому
анализу и методические материалы по их применению
содержатся в вып. 2, 10, 16, 24, 29 (Математическое обес-
печение ЕС ЭВМ/Ин-т математики АН БССР, 1973—
1981), 35, 45 (Программное обеспечение ЭВМ / Ин-т ма-
тематики АН БССР, 1982—1983).
При решении задач практикума рекомендуется ис-
пользовать следующие подпрограммы из ПНП-БИМ:
RANDU — вычисление равномерно распределенного
случайного числа (вып. 2);
GAUSS — вычисление нормально распределенного
случайного числа (вып. 2);
NDTR—функция нормального распределения (вып. 2);
CDTR — функция ^-распределения (вып. 2);
NDTRI — вычисление квантили нормального распре-
деления (вып. 2);
SDF — квадратичная дискриминантная функция
(вып. 24);
SMO — взвешивание исходных данных (вып. 2);
FFRRE — быстрое преобразование Фурье действи-
тельных временных рядов (для ряда длины 2т) (вып. 16);
FORIT — вычисление коэффициентов Фурье периоди-
ческой функции, заданной таблицей значений (вып. 4);
RHARM — одномерный действительный анализ Фурье
(вып. 4);
IDSM — идентификация стохастической модели
(вып. 10);
IDMR — идентификация модели для заданного по-
рядка разности (вып. 10);
POSM — предварительное оценивание стохастической
модели (вып. 10);
PSMA — проверка стабильности модели АР (вып 24);
INCR — вычисление интервала корреляции (вып. 24);
CDMG — вычисление определителя методом Гаусса
(вып. 12);
MINV — обращение матрицы (вып. 1);
ТАВ1 — вычисление частот (вып. 2);
GIST — печать гистограмм (вып. 10).
Для трансляции, редактирования и выполнения про-
граммы, содержащей обращение к подпрограммам из
ПНП-БИМ, необходимо составить следующее задание
ОС ЕС:
256
//TBjjggnn Л0В(,8РТВ),‘<студент>‘
// EXEC FORTGCLG
//FORT.SYSIN DD *
<текст программы на фортране>
//LKED.SYSLIB DD UNIT=5061,VOL=SER= <имя тома>
// DSN = SYS1.SSPLIB,DISP = OLD
// DD DSN=SYS1.FORTLIB,DISP=SHR
//GO. SYS IN DD '*
<исходные данные>
Пакет прикладных программ СОМИ состоит из 28 го-
товых к выполнению программ и 90 подпрограмм на язы-
ке фортран IV. Каждая из программ пакета ориентиро-
вана на решение некоторого класса задач из определен-
ного раздела статистического анализа.
Все программы пакета СОМИ делятся на следующие
серии: D — описание данных; DI — оценка параметров
и выбор закона распределения; F — таблицы сопряжен-
ности; R — регрессионный анализ; V — дисперсионный
анализ; М — многомерный анализ; S — специальные про-
граммы; Т — анализ временных рядов.
Структурно ППП СОМИ организован в виде четырех
библиотек на магнитном диске: библиотеки загрузочных
модулей программ, библиотеки частично загрузочных мо-
дулей подпрограмм пакета, библиотеки управляющих
предложений редактору связей для каждой из программ
пакета и библиотеки контрольных примеров. Необходи-
мая для решения задачи информация передается про-
граммам пакета с помощью ЯУП, который служит для
идентификации задачи, описания исходных данных (фор-
мат, размер, источник), описания преобразований пере-
менных, назначения процедур статистического анализа,
определения режима вывода (числовые результаты, таб-
лицы, гистограммы, диаграммы, графики).
Элементами ЯУП являются операторы, состоящие из
имени операции (например, ВВОД, ЗАДАЧА, РЕГРЕС-
СИЯ, ПЕЧАТЬ и т. д.) (табл. 9.1) и параметров при-
сваивания или параметров-команд.
Операторы записываются на русском языке, разде-
ляются друг от друга символом /. Параметры заканчи-
ваются точкой. На бланке кодирования операторы ЯУП
размещаются произвольным образом, так как они не
ориентированы на запись в фиксированных позициях.
9 Зак. 1015
257
Таблица 9.1
Операторы ЯУП, общие для всех программ пакета СОМИ
за исключением P4D
Оператор, параметр
/ЗАДАЧА
ЗАГЛавие=‘с‘.
/ВВОД
ПЕРЕМенные=
ФОРМат=‘с‘.
РЕАЛИЗации=^
УСТРойство = ф.
НАЧАЛО.
КОД=с.
СОДЕРЖимое=с.
Стандартное
значение
{пробелы}
{нет/п}
{нет/п}
{5(карты)/п}
{НАЧАЛО/п}
{нет}
{ДАНН}
Определение, ограничение
Описание задачи. Обязателен
Заглавие задачи; не более
160 буквенно-цифровых сим-
волов
Описание входных данных.
Обязателен для первой за-
дачи
Число вводимых переменных.
Обязателен, если данные не
вводятся из файла хранения
Формат вводимых данных; до
800 буквенно-цифровых сим-
волов. Должен быть задан,
если данные не вводятся из
файла хранения и число вво-
димых переменных отлично
от нуля
Число вводимых реализаций.
При отсутствии этого пара-
метра для первой задачи
данные читаются до конца
файла; для подзадач исполь-
зуется значение РЕ АЛ ИЗ а-
ции из предыдущей задачи
Номер логического устройства
ввода данных; не должен
равняться 1, 2, 6
Запрос на возвращение к на-
чалу набора для чтения
исходных данных. Имеет
смысл только для магнитных
носителей
Код BMDP-файла; до восьми
буквенно-цифровых симво-
лов. Обязателен, если данные
вводятся из файла хранения
Содержимое BMDP-файла (дан-
ные, ковариационная или
корреляционная матрица); до
восьми буквенно-цифровых
символов
258
Продолжение табл. 9.1
Оператор, параметр
Стандартное
значение
Определение, ограничение
МЕТКА=‘с‘.
/ПЕРЕМенные
ДОБавляемые=
{пробел}
{нуль/п}
Метка BMDP-файла; до 40 бук-
венно-цифровых символов
Описание переменных. Необя-
зателен
Число переменных, добавлен-
ных при преобразованиях
ИМена=С1, с?,....
ИСПользуемые=
= V1, v2, ... .
МЕТКА=‘с‘.
ПРОПущенные=
МАКСимум=
МИНимум =
ДОПРеобразова-
ний, ПОСЛЕПРе-
образований.
/ПРЕОБРАЗова-
ния
{X (1) ,Х (2) .../п}
{все перемен-
ные}
{нет/п}
{нет/п}
{нет/п}
{нет/п}
{ДОПР/п}
Имена переменных; каждое
имя до восьми буквенно-циф-
ровых символов
Имена или индексы перемен-
ных, используемых в анализе
Имена или индексы одной или
двух переменных, используе-
мых в качестве метки реали-
зации. Указанные перемен-
ные длиною не более четырех
символов, считываются по
формату А. МЕТКА = 0,0.
означает отсутствие перемен-
ной типа метки
Коды пропущенных значений
для каждой переменной
Максимально допустимые зна-
чения переменных
Минимально допустимые зна-
чения переменных
Проверка значений переменных
на допустимые границы до
или после преобразований
Описание преобразований. Не-
обязателен
9*
259
Продолжение табл. 9.1
Оператор, параметр
Стандартное
значение
Определение, ограничение
Имя переменной
или X (индекс) =
—простое выра-
жение.
ИСП= 4“ или про-
стое выражение.
/ФАЙЛ
УСТРойство=
НОВЫЙ.
КОД=с.
МЕТКА=‘с‘.
/кон
/ФИНИШ
{нет}
{1}
{нет}
{нет}
{нет/п}
{не новый}
{нет}
{пробелы}
Примечания.
Если ИСП = 1, реализации ис-
пользуются в анализе
Список номеров реализаций,
спускаемых при анализе
(устанавливается ИСП = 0)
Список номеров удаляемых
реализаций (устанавливается
ИСП = - 1)
Описание файла хранения. Не-
обязателен
Номер логического устройства,
на котором находится файл
хранения. Обязателен, если
осуществляется запись в файл
хранения; не должен равнять-
ся 1, 2, 5, 6
Обязателен, если записывается
первый BMDP-файл в файл
хранения
Код BMDP-файла; до восьми
буквенно-цифровых симво-
лов. Обязателен
Метка BMDP-файла; до 40 бук-
венно-цифровых символов
Конец управляющей информа-
ции для задачи. Обязателен
Конец всех задач
Здесь и в табл. 9.2 символ
— число; *с‘ —
заглавие, метка или формат; v — имя переменной или ее нижний
индекс; с — имя длиной до восьми символов, иногда необходимо за-
ключать в апострофы (‘); п — означает, что любые назначения со-
храняются такими же, как в предыдущей задаче или подзадаче.
260
Все возможные формы записи параметров присваи-
вания представляются следующим образом:
одно число;
,... . одно
2
V.
или более чисел;
одно имя переменной или ее
нижний индекс;
Имя
параметра
Vi, v2, ... .
с.
сР с2, ... .
одно или более имен или ин-
дексов переменных;
одно имя длиною до восьми
символов;
одно или более имен, каждое
до восьми символов;
формат, заглавие или метка,
которые необходимо заклю-
чать в апострофы.
Каждое имя, стоящее справа от знака равенства в
параметре присваивания, имеет максимальную длину —
восемь символов. Имена, метки, заглавия должны быть
заключены в апострофы, если они не начинаются с ла-
тинской или русской буквы; если содержат символ, не
являющийся латинской или русской буквой или числом
(например, пробел, скобки, запятая и т. д.).
Параметр в виде команды задает программное вы-
полнение (или отмену выполнения) конкретной опера-
ции. Например,
НАЧАЛО. — входной файл должен быть уста-
новлен в начало;
НЕ КОРРЕЛЯЦИЯ.— матрица корреляции не должна
распечатываться.
Подробное описание возможностей ЯУП содержится
в [52].
Исходные данные в ППП СОМИ могут вводиться
в форматизованном и неформатизованном виде. При
261
вводе по формату используется исходная информация
следующего вида.
1. Матрица данных, столбцами которой являются
множества значений компонент (признаков, переменных)
исследуемых наблюдений, а строками — векторы (реа-
лизации) наблюдений.
Переменные (столбцы)
Xi Х2 ... Хр
1 Хи Х12 ... Х1р
Реализации 2 j X2i Х22 ... Х2р
(строки) I ..................
fi j Xjii Xn2.... Хпр.
Данные перфорируются на картах по реализациям.
Значения переменных (компонент) одной реализации
перфорируются последовательно на одной или более
картах. Каждая реализация начинается с новой карты
и имеет один формат для всех реализаций. Чтение реа-
лизаций с различными форматами производится с по-
мощью написанных пользователем подпрограмм форт-
рана. Каждая переменная внутри реализации занимает
одну или более последовательных колонок карты.
2. Корреляционные и ковариационные матрицы пред-
ставляются либо полностью, либо сокращенно — в виде
их нижних треугольников. Данные перфорируются на
картах по строкам. Каждая строка матрицы начинается
с новой карты и может располагаться на одной или бо-
лее последовательных картах.
3. Таблицы частот, матрицы расстояний, факторные
нагрузки, коэффициенты значений факторов представля-
ются на перфокартах аналогично матрице данных.
При неформатизованном чтении каждая запись —
строка матрицы (исходных данных или ковариаций).
Все программы пакета производят редактирование
исходных данных и отбор реализаций. Кроме того, дан-
ные можно модифицировать и создавать новые перемен-
ные. Эти операции выполняются оператором ПРЕОБРА-
ЗОВАНИЯ или операторами фортрана, включаемыми в
подпрограмму TRANSF [52].
Данные и результаты вычислений (например, матри-
ца корреляций, повернутые факторные нагрузки и т. п.)
могут быть переданы из одной программы в другую с по-
мощью специального последовательного набора, назы-
262
ваемого BMDP-файлом. Запись и чтение информации
из BMDP-файла происходит в неформатизованном виде.
Для создания BMDP-файла используется оператор
ФАЙЛ.
Идентификаторами BMDP-файла являются КОД,
СОДЕРЖИМОЕ и МЕТКА (табл. 9.2). BMDP-файлы
хранятся в последовательном наборе данных (файле хра-
Таблица 9.2
Операторы ЯУП, относящиеся к BMDP-файлу
Оператор, параметр
Стандартное
значение
Определение, ограничение
/ФАЙЛ
КОД=с.
МЕТКА=‘с‘.
УСТРойство^
НОВЫЙ.
/ВВОД
СОДЕРЖимое=с.
КОД=с.
МЕТКА=‘с‘.
УСТРойство=
{нет}
{пробел}
{нет}
{не новый}
{ДАНН}
{нет}
{пробел}
<
{нет/п}
Необходим для создания
BMDP-файла
Код, идентифицирующий
BMDP-файл. Обязателен
Метка BMDP-файла; до 40 сим-
волов
Номер логического устройства,
на котором записывается
BMDP-файл; не должен рав-
няться 1, 2, 5, 6 и номеру
устройства, с которого считы-
ваются исходные данные
НОВЫЙ, если это первый
BMDP-файл в файле хране-
ния
Обязателен при вводе данных
из BMDP-файла
Данные или матрица в BMDP-
файле
Код для идентификации BMDP-
файла. Обязателен
Метка BMDP-файла
* 5
Номер логического устройства,
с которого читается BMDP-
файл, не должен равняться
1, 2, 5, 6
Примечание. Значения СОДЕРЖимое, КОД и МЕТКА,
задаваемые в операторе ВВОД, идентичны значениям тех же Пара-
метров при создании BMDP-файла (оператор ФАЙЛ).
263
нения) на магнитном носителе. В один файл хранения
можно записать несколько BMDP-файлов. При чтении
или записи BMDP-файла необходимо определять в ЯУП
номер логического устройства УСТРОЙСТВО, который
должен совпадать с номером используемого набора дан-
ных в картах управления заданиями ОС ЕС.
Порядок ввода карт для чтения или записи BMDP-
файла в существующий файл хранения с именем
STUDENT.FILE.NAME
должен быть следующим:
//TBjjggnn
//
//FTyyFOOl
И
//SYS IN
JOB (,SPTB) ,‘<студент>‘
EXEC BIMED,PROG = BMDPXX,
ЬОАО = <имя библиотеки>
DD DSN=STUDENT.FILE.NAME,
DISP=OLD,UNIT=5061,VOL=SER=DISCO
DD*
^Операторы ЯУП
Данные на картах
//
Порядок ввода карт для чтения или создания BMDP-
файла, если преобразования выполнены на фортране:
//TBjjggnn JOB (,SPTB) ,‘<студент>‘
// EXEC BIMEDT,PROG=BMDPXX,
// LOAD = <hmh библиотеки>,
П SUBR=i<hmh библиотеки>,
// OPEN=<hmh библиотеки>
//TRANSF DD *
[Операторы фортрана на картах (преобразования)
//GO.FTyyFOOl DD DSN=STUDENT.FILE.NAME,
// DISP=OLD,UNIT=5061,VOL=SER=DISCO
//GO.SYSIN DD *
^Операторы ЯУП
[Данные на картах
*
// '
Здесь XX — имя программы пакета СОМИ; уу — но-
мер логического устройства, на котором размещен файл
хранения; <студент> — фамилия и инициалы студента.
Пакет прикладных программ СОМИ может эксплуа-
тироваться на ЭВМ серии ЕС, конфигурация которых
обеспечивает следующие характеристики:
— оперативная память не менее 256 Кбайт;
— дисковые устройства ЕС5061—2;
— лентопротяжное устройство— 1;
— устройство печати — 1;
264
— ввод перфокарточный — 1;
— операционная система ОС ЕС издания 6.1 и более
поздних изданий;
— транслятор фортран IV.
Выполнение программ ППП СОМИ в ОС ЕС осу-
ществляется с помощью процедуры BIMED [52]:
//
//SYS IN
EXEC BIMED,PROG = <имя программы^»,
ЬОАО = <имя библиотеки, содержащей загрузочные
модули программ>
DD < описание набора данных, содержащего
операторы ЯУП>
Если необходимо подключить подпрограммы TRANSF,
CON, FUN, SUBRDI с текстом пользователя, предназна-
ченным для обработки компилятором фортрана, исполь-
зуется процедура BIMEDT [52]:
// EXEC BIMEDT,PROG=<hmh программы>,
// LOAD = <hmh библиотеки, содержащей загрузочные
//
//
и
TRANSF
FUN
модули программ>,
SUBR=<hmh библиотеки, содержащей частично загру-
зочные модули подпрограмм^
ОРЕИ=<имя библиотеки, содержащей управляющие
предложения редактору связей>
DD <описание набора данных, содержащего текст
программ>
CON
SUBRDU
//GO.SYSIN DD
<описание набора данных, содержащего опе-
раторы ЯУП>
Пример подготовки задания на выполнение програм-
мы P1D, если данные вводятся с перфокарт:
//TBjjggnn ЛОВ(,5РТВ),‘<студент>‘
// EXEC BIMED,PROG=BMDP1D,
// ЕОАО = <имя библиотеки>
//SYSIN DD *
/ЗАДАЧА ЗАГЛАВИЕ =‘ПРИМЕР Г.
/ВВОД ПЕРЕМЕННЫХ= 10.
РЕАЛИЗАЦИЯМИ.
ФОРМАТ=‘(ЮЕ4.2)‘.
/КОН
/ФИНИШ
/*
//
При вводе-выводе данных или результатов на диск или
магнитную ленту в колоде перфокарт должны присут-
ствовать соответствующие системные управляющие кар-
265
ты DD, осуществляющие связь программы с конкретным
набором данных на магнитном носителе.
Пример задания на выполнение программы P1R,
использующей данные из BMDP-файла с кодом СТАТ
в файле хранения с именем
STUDENT.FILE.OPS
на логическом устройстве номер 8 (FT08F001) и записы-
вающей матрицу ковариаций в BMDP-файл с кодом
RESULT в существующем файле хранения с именем
STUDENT.FILE.RESULT
на логическом устройстве с номером 3 (FT03F001):
//TBjjggnn
//FT03F001
//FT08F001
JOB (,SPTB) ,‘<студент>‘
EXEC BIMED,PROG=BMDP1R,
LOAD = <hmh библиотеки>
DD DSN=STUDENT.FILE.RESULT,
DISP=OLD,UNIT=5061,VOL=SER= <имя тома>
DD DSN = STUDENT.FILE.OPS,
DISP=OLD,UNIT=5061,VOL=SER=<hmh тома>
//SYS IN DD *
/ЗАДАЧА
/ВВОД
/ФАЙЛ
/РЕГРЕССИЯ
ЗАГЛАВИЕ =‘ПРИМЕР 2‘.
УСТРОЙСТВО=8.
КОД=СТАТ.
КОД=РЕ5ииГ.УСТР=3.
СОДЕРЖИМОЕ=КОВА.
ЗАГЛАВИЕ=‘ТЕСТ*.
ЗАВИСИМАЯ=2.
/кон
/ФИНИШ
//
Если преобразования данных выполняются операторами
фортрана, то вызов программ пакета осуществляется
процедурой BIMEDT.
• Пусть для вычислений из исходных данных, записан-
ных в файле хранения
STUDENT.FILE.OPS
с кодом СТАТ, необходимо отобрать реализации с номе-
рами от 100 до 199 включительно и определить перемен-
ную (компоненту) Х5 как Х5 = 0,2 + 2 1g Хз. Тогда зада-
ние на вызов программы P2D и выполнение преобразова-
ний будет иметь вид
//TBjjggnn
//
JOB (,SPTB) ,‘<студент>‘
EXEC BIMEDT,PROG = BMDP2D,
LOAD = <hmh библиотеки>,
SUBR=<hmh библиотеки>,
OPEN=<iimh библиотеки>
//TRANSF DD *
USE=O
IF(KASE.GE.100.AND.KASE.LT.200)USE=l
X(5) =0.2+2.0*ALOG10(X(3))
/*
//GO.FT08F001 DD DSN=STUDENT.FILE.OPS,
// DISP=OLD,UNIT=5061,VOL=SER= <имя тома>
//GO.SYSIN ‘ DD*
/ЗАДАЧА ЗАГЛАВИЕ-‘ПРИМЕР 3‘.
/ВВОД УСТРОЙСТВО=8.
КОД=СТАТ.
/КОН
/ФИНИШ
//
Иногда требуется изменить часть программы в связи
с тем, что количество информации, которое должно хра-
ниться в памяти, превышает 15 000 слов, отводимых для
любой из программ пакета. В этом случае доступная
область памяти увеличивается с помощью процедуры
BIMEDT.
Пример задания на выполнение программы Р4М с
расширением памяти до 16 000 слов и форматизованным
вводом данных из последовательного набора
STUDENT.DS. SERIAL:
//TBjjggnn ЛОВ(,8РТВ),‘<студент>‘
// EXEC BIMEDT,PROG=BMDP4M,
// REGION = <новый объем памяти>,
// LOAD—Кимя библиотеки>,
// 8иВК=<имя библиотеки>,
// ОРЕИ=<имя библиотеки>
//TRANSF DD *
RETURN
END
SUBROUTINE IBSIZE
COMMON /MEMORY/ N,L,IB (16000)
N= 16000
/*
//GO.FT08F001 DD DSN=STUDENT.DS.SERIAL,
// DISP = OLD,UNIT=5061,VOL=SER=<hmh тома>
//GO.SYSIN DD *
/ЗАДАЧА ЗАГЛАВИЕ = ‘ПРИМЕР 4‘.
/ВВОД УСТРОЙСТВО=8.
OOPMAT=‘(50F6.4)‘.
РЕАЛИЗАЦИЙ=2000.
ПЕРЕМЕННЫХ=50.
/КОН
/ФИНИШ
/*
//
267
При выполнении заданий могут возникнуть ошибки,
связанные с неправильным положением карт в колоде
или с неверной записью операторов ЯУЗ ОС ЕС и ЯУП.
Ошибки в операторах ЯУЗ определяются и исправ-
ляются в соответствии с сообщениями ОС ЕС [10, 34].
Диагностика ошибок ЯУП выполняется программами
ППП СОМИ, локализующими неверный оператор. В этом
случае необходимо проверить соблюдение правил записи
и правильности применения операторов ЯУП.
§ 9.3. Языки программирования и управления
и системное наполнение
Базовым языком программирования системы STU-
DENT является фортран IV. На фортране написаны про-
граммы ППП СОМИ, модули ПНП-БИМ, средства фор-
трана используются в ППП СОМИ для выполнения пре-
образований исходных данных, передаваемых програм-
мам, и для расширения памяти, отводимой под массивы.
Управление вычислительным процессом осуществля-
ется средствами ЯУП, реализующего предписания поль-
зователя по описанию исходных данных, назначению
процедур статистического анализа, организации вывода
результатов, и средствами ЯУЗ ОС ЕС.
При выполнении практикума используются следую-
щие возможности ЯУЗ.
Начало задания оформляется оператором JOB в виде
//TBjjggnn JOB [учетная информация] [, имя программиста],
// MSGLEVEL= (2,0),
где jj — номер задания практикума; gg — номер груп-
пы; пп — порядковый номер студента в группе.
Выполнение программ ППП СОМИ в ОС ЕС осу-
ществляется с помощью процедур BIMED и BIMEDT.
Пример подготовки задания на выполнение програм-
мы BMDP1D, если исходные данные записаны в наборе
STUDENT.FILE.SCREEN
на устройстве с номером 3, а операторы ЯУП пакета
СОМИ — в наборе
STUDENT.EXECPCL:
//TBjjggnn JOB [учетная информация],‘IVANOV4,
// MSGLEVEL =(2,0)
// EXEC BIMED,PROG=BMDP1D,V=DISCO,
268
//
//FT03F001
//
//SYS IN
//
//
//
LOAD = ‘STUDENT.LOAD'
DD DSN=STUDENT.FILE.SCREEN,DISP=OLD,
UNIT=5061,VOL=SER=DISCO
DD DSN=STUDENT.EXECPCL(TBjjggnn),
DISP=OLD,UNIT=5061,VOL=SER=DISCO,
LABEL= (,„IN)
Если необходимы преобразования данных, выполняе-
мые операторами фортрана, то вызов программы пакета
осуществляется процедурой BIMEDT.
Пример подготовки задания на выполнение програм-
мы BMDP1D с теми же исходными данными при усло-
вии, что текст программы, реализующей преобразования,
записан в наборе
//TBjjggnn
//
//
//
//
//
//TRANSF
//
//GO.FT03F001
//
//GO.SYSIN
//
//
STUDENT.PCL (EXAMPLE 1):
JOB [учетная информация],‘IVANOV',
MSGLEVEL =(2,0)
EXEC BIMEDT,PROG=BMDP1D,V=DISCO,
LOAD = ‘STUDENT.LOAD',
SUBR=‘STUDENT.SUBR‘,
OPEN=‘STUDENT.OPEN'
DD DSN = STUDENT.PCL (EXAMPLE 1) ,DISP=OLD,
UNIT=5061,VOL = SER = DISCO
DD DSN = STUDENT.FILE.SCREEN,DISP = OLD,
UNIT=5061,VOL=SER=DISCO
DD DSN=STUDENT.EXECPCL(TBjjggnn),
DISP=OLD,UNIT=5061,VOL=SER=DISCO,
LABEL=(,„IN)
Системное наполнение должно обеспечить хранение
текстовой информации, данных и результатов, получен-
ных за сеанс работы в дисплейном классе, корректировку
информации в наборах данных, управление выполнением
задания, представление результатов на экране дисплея
и в виде твердой копии.
Для хранения программных и информационных ком-
понент в системе STUDENT созданы следующие наборы
данных, размещаемые на магнитном диске с серийным
номером VOL=SER=DISCO.
Наборы, содержащие справочную информацию
STUDENT.DSN — библиотечный набор, содержащий
сведения о матрицах исходных данных (выборках) и
программах. Разделы: FILE — описание наборов дан-
269
ных, PROG — описание ' функциональных возможностей
ППП СОМИ.
STUDENT.TEXT — библиотечный набор с текстами
заданий практикума. Разделами являются номера работ
ТЕМА61, ТЕМА62 и т. д.
STUDENT.DOCUMENT — библиотечный набор, со-
держащий документацию системы.-
STUDENT.TEACHER — библиотечный набор, содер-
жащий сведения о составе группы, степени выполнения
заданий практикума и т. д. Разделы: GROUP — сведе-
ния о группе, EXAMINE — тексты проверочных вопросов.
STUDENT.HELP — библиотечный набор, содержа-
щий сведения о ЯУП ППП СОМИ. Разделы: COMMON—
операторы ЯУП, общие для всех программ пакета
СОМИ; P1D — операторы языка управления программой
P1D; P2D— операторы языка управления программой
P2D и т. д.
Наборы, содержащие обучающую информацию
STUDENT.JCL — библиотечный набор с макетами
заданий на языке управления заданиями ОС ЕС. В раз-
делах библиотеки записаны операторы ЯУЗ ОС ЕС в за-
висимости от вида наборов, предназначенных для чте-
ния данных, вывода результатов и данных, использова-
ния операторов преобразования исходных данных. Имена
разделов представлены в табл. 9.3.
Таблица 9.3
Имя раздела
библиотеки
Чтение данных
Вывод
данных
Вывод
результатов
Преобразова-
ния на фор-
тране
FS_FS_PT
FS_PT
Т FS РТ
DS РТ
Из файла хра-
нения (FS)
Из файла хра-
нения (FS)
Из файла хра-
нения (FS)
Из библиотечно-
го набора
В файл хра-
нения (FS)
Без вывода
Без вывода
Без вывода
На печать
(РТ)
На печать
(РТ)
На печать
(РТ)
На печать
(РТ)
Нет
Нет
Есть Т)
Нет
270
STUDENT.PCL — библиотечный набор с макетами
заданий на ЯУП для ППП СОМИ. Разделы: P1D —
макет задания для программы P1D; P2D— макет
задания для программы P2D и т. д. EXAMPLE 1,
EXAMPLE2, ... — тексты программ на фортране, осу-
ществляющих преобразования исходных данных.
STUDENT.MAKET — библиотечный набор с макета-
ми заданий для первоначального распределения памяти
и расширения наборов, а также для трансляции, редак-
тирования и выполнения программ практикума по стати-
стическому моделированию. Разделы: STSET — макет
задания на первоначальное распределение памяти для
наборов
STUDENT.TBGG.SYMB, STUDENT.TBGG.DATA,
STUDENT.TBGG.OUTFILE;
GG — номер группы, модифицируемая часть составного
имени.
FCLGO — макет задания на выполнение процедуры
FCLGO (трансляция, редактирование и выполнение
фортран-программы в системе STUDENT).
SPACE — макет задания на расширение памяти для
библиотечного набора.
SELECT — макет задания на копирование модулей
из ПНП-БИМ в библиотеку STUDENT.PNPBIM.
JOBLGO — макет задания на трансляцию, редакти-
рование и выполнение фортран-программы в системе
STUDENT.
Наборы данных для хранения сформированных
заданий, исходных данных и результатов
выполнения программ
STUDENT.EXECPCL — библиотечный набор с тек-
стами готовых для выполнения заданий на ЯУП ППП
СОМИ. Разделы имеют имена, совпадающие с именем
задания для ОС ЕС.
STUDENT.EXEC — библиотечный набор заданий на
ЯУЗ, готовых для выполнения программ ППП СОМИ.
Имя раздела совпадает с именем задания ОС ЕС.
STUDENT.TBGG.SYMB — библиотечный набор с тек-
стами программ на фортране для практикума по стати-
стическому моделированию. Имена разделов совпадают
с именами заданий ОС ЕС; GG — номер группы, моди-
фицируемая часть составного имени.
271
STUDENT.TBGG.JCLLIB — библиотечный набор со
сформированными заданиями на трансляцию, редактиро-
вание и выполнение программ на фортране. Имена раз-
делов совпадают с именами задании ОС ЕС.
STUDENT.TBGG.DAT А—библиотечный набор с ис-
ходными данными для статистического моделирования.
Имена разделов совпадают с именами заданий ОС ЕС.
STUDENT.TBGG.OUTFILE — библиотечный набор
для хранения результатов статистического моделирова-
ния. Имена разделов совпадают с именами заданий
ОС ЕС.
STUDENT.RESULT — библиотечный набор с резуль-
татами выполнения программ, требующими просмотра на
экране дисплея. Имена раздела совпадают с именем за-
дания ОС ЕС.
STUDENT.TEST — контрольные тексты операторов
ЯУП для выполнения задач. Имена разделов: TEMAijk,
где ij — номер параграфа, к которому относится задача,
к — номер задания в первоначальном перечне экспери-
ментов. Например, ТЕМА681 — имя раздела с операто-
рами ЯУП для эксперимента 1 из § 6.8.
STUDENT.DATA — библиотечный набор с матрицами
исходных данных.
STUDENT.FILE.<hmh файла>— файл хранения, со-
держащий исходные данные. Подробное описание этих
наборов приведено в § 9.5.
STUDENT.FILE.RESULT — файл хранения с резуль-
татами выполнения программ, предназначенными для
передачи в другие программы пакета. Описание файла
хранения содержится в § 9.2.
Наборы с программными средствами
STUDENT.LOAD — библиотека готовых к выполне-
нию программ ППП СОМИ.
STUDENT.SUBR — библиотека частично загрузочных
модулей подпрограмм ППП СОМИ.
STUDENT.OPEN — библиотека управляющих пред-
ложений редактору связей.
STUDENT.PNPBIM — библиотека модулей пакета
ПНП-БИМ, необходимых для выполнения задании прак-
тикума.
STUDENT.PROCLIB — библиотека процедур для
практикума по статистическому моделированию. Разде-
272
лы: FCLGO — процедура трансляции, редактирования и
выполнения фортран-программы в системе STUDENT,
SPACE — процедура расширения памяти для библио-
течного набора, RDRTB — вызов процедур из библиотеки
пользователя.
§ 9.4. Технологическая последовательность
выполнения практикума в системе STUDENT
Практикум проводится в дисплейном классе. Сеанс
работы за терминалом, предназначенный для решения
задач одной темы, состоит из следующих этапов:
1) ознакомление с заданием;
2) получение информации об исходных данных;
3) формирование заданий на ЯУП и ЯУЗ;
4) запись откорректированных заданий в биб-
лиотеку;
5) постановка заданий в очередь на выполнение;
6) выполнение заданий;
7) просмотр результатов на экране дисплея;
8) анализ результатов студентом; обсуждение резуль-
татов с преподавателем;
9) исправление ошибок;
10) вывод результатов на печать.
Этапы 1—5, 7, 9, 10 обеспечиваются средствами
ДСКД PRIMUS, этап 6 — пакетом СОМИ или програм-
мой пользователя.
Инструкции по использованию системы PRIMUS
и описание ее команд подробно изложены в документа-
ции системы и могут быть получены в процессе работы
на экране дисплея.
Опишем организацию подготовки и выполнения зада-
ний практикума в системе STUDENT с помощью ДСКД
PRIMUS. Работа за терминалом состоит в передаче
необходимой последовательности команд PRIMUS и от-
ветов на запросы.
Для получения доступа к системе PRIMUS необхо-
димо нажать на клавишу ввода (ВВ) и дождаться сооб-
щения системы:
РАБОТАЕТ МОНИТОР PRIMUS,
СООБЩИТЕ ВАШЕ ИМЯ.
Далее следует указать имя пользователя (таким именем
является шифр, совпадающий с именем задания ОС ЕС
10 Зак. 1015
273
и для студентов кафедры теории вероятностей и матема-
тической статистики имеющий вид TBjjggnn, где jj —
номер задания практикума, gg — номер группы, пп — по-
рядковый номер студента в списке группы) и нажать
клавишу ВВ. В ответ система сообщает:
МОЖНО РАБОТАТЬ, ПОСЫЛАЙТЕ КОМАНДУ.
<
Для ввода команды нужно набрать код команды
и необходимые операнды, нажать клавишу ВВ. После
выполнения команды на экране дисплея появляется сооб-
щение системы:
ПОСЫЛАЙТЕ КОМАНДУ.
Получив это сообщение, можно ввести новую команду
или закончить работу. При аварийном завершении
команды выдается сообщение:
ABEND, КОД ЗАВЕРШЕНИЯ = XXX,
где XXX — код завершения задачи, принятый в ОС ЕС.
Для продолжения работы в дайной ситуации надо после
нажатия клавиши ВВ и получения ответного сообщения:
ПОСЫЛАЙТЕ КОМАНДУ,
ввести очередную команду.
Для окончания сеанса работы необходимо дождаться
завершения последней команды и передать системе END.
В ответ на экране дисплея должен появиться текст:
РАБОТА ЗАКОНЧЕНА.
Список основных команд ДСКД PRIMUS приведен в
Приложении 2. В начале работы за терминалом следует
передать команду
DVOL^<hmh тома>.
V
Для системы STUDENT операндом <имя тома> явля-
ется имя DISCO и команда имеет вид DVOLu— DISCO.
Все последующие команды, работающие с личными на-
борами данных, будут использовать указанный том.
В связи с тем, что в первой и второй частях практи-
кума по математической статистике используются про-
граммные средства разной структуры и разные наборы
данных, дальнейшая последовательность работы в дис-
плейном классе будет описана раздельно.
Выполнение заданий с помощью ППП СОМИ. После
274
получения доступа к системе STUDENT и фиксации име-
ни тома прямого доступа DISCO студент должен ознако-
миться с необходимой для выполнения задания справоч-
ной и обучающей информацией. Для этого по команде
LOOK на экран дисплея можно получить содержимое
следующих наборов:
1) текст задания с номером jj:
LOOK—STUDENT.TEXT(TEMAjj);
2) сведения о наборах с исходными данными (имена
переменных, число переменных и реализаций, форматы
записей, вид организации набора: библиотечный набор
или файл хранения, параметр DSN оператора DD опре-
деления набора данных, код, содержимое и метка для
файлов хранения):
LOOK—STUDENT.DSN (FILE);
3) сведения о функциональных возможностях про-
грамм ППП СОМИ:
LOOK—STUDENT.DSN (PROG);
4) макеты задания на ЯУП с именем Pkm ППП
СОМИ:
LOOK—STUDENT.PCL (Pkm),
например, для программы Р7М:
LOOK—STUDENT.PCL (Р7М)
или тексты подпрограмм, осуществляющих преобразова-
ния исходных данных:
LOOK—STUDENT.PCL (EXAMPLEi);
5) макеты заданий на ЯУЗ ОС ЕС:
LOOK-STUDENT. JCL (DS.PT);
LOOK—STUDENT. JCL (FS_FS_PT);
LOOK- STUDENT.JCL(FS-PT);
LOOK—STUDENT.JCL(T_FS_PT);
6) сведения о командах системы PRIMUS:
HELP;
7) сведения об общих операторах ЯУП ППП СОМИ:
LOOK-STUDENT.HELP (COMMON);
ю*
275
8) сведения об операторах ЯУП с именем Ркт
ППП СОМИ:
LOOK—STUDENT.HELP (Ркт),
например, для программы P6R:
LOOK—STUDENT.HELP (P6R);
9) операторы ЯУП для выполнения контрольного
примера по теме TEMAijk:
LOOK—STUDENT.TEST (TEMAijk).
Формирование задания на ЯУП происходит в три
этапа. Сначала макет задания для программы с именем
Pkm копируется из набора
STUDENT.PCL(Pkm)
в рабочий набор данных (РИД) командой
COPY-STUDENT.PCL (Pkm).
Затем макет должен быть отредактирован в соответствии
с условиями решаемой задачи с помощью команды
CORR, используя подкоманды R, D, I, G. Выполнение
команды CORR завершается по команде Е. Просмотр
откорректированного текста осуществляется подкоман-
дой G, и при обнаружении ошибки текст можно откор-
ректировать без вызова команды CORR.
После редактирования макет задания записывается
в раздел библиотеки
• STUDENT.EXECPCL (TBjjggnn)
командой
SAVE STUDENT.EXECPCL(TBjjggnn).
Аналогичная последовательность команд необходима
для формирования задания ЯУЗ ОС ЕС:
COPYSTUDENT.JCL(hmh раздела),
где имя раздела определяется по табл. 9.3,
CORR
SAVE STUDENT.EXEC (TBjjggnn).
276
Затем задание передаётся на выполнение в пакетном
режиме командой ЕХЕС или START:
EXEC^STUDENT.EXEC (TBj jggnn).
После выполнения команды EXEC на экран выдается
сообщение:
ЗАДАНИЕ ПОСТАВЛЕНО В ОЧЕРЕДЬ
НА ВЫПОЛНЕНИЕ. КОМАНДА ВЫПОЛНЕНА.
Если результаты выполнения программы хранятся
в наборе данных на диске, то их можно вывести на экран
дисплея командой
LOOK—STUDENT.RESULT (TBjjggnn)
или на АЦПУ командой
PRNT^STUDENT.RESULT (TBjjggnn).
Сформированные тексты в библиотеках
STUDENT.EXECPCL и STUDENT.EXEC
сохраняются в системе STUDENT и могут быть удалены
только после успешного выполнения заданий практи-
кума.
Выполнение в системе STUDENT заданий спецпрак-
тикума, требующих трансляции и редактирования про-
грамм пользователя. Для выполнения заданий спецпрак-
тикума по статистическому моделированию, предусмат-
ривающих составление студентами программ с использо-
ванием стандартных модулей из библиотеки ПНП-БИМ,
в системе STUDENT организованы библиотечные наборы
для хранения исходных текстов программ
STUDENT.TBGG.SYMB,
исходных данных
STUDENT.TBGG.DATA
и выходных результатов
STUDENT.TBGG.OUTFILE.
Студенту с идентификатором TBjjggnn выделяется для
работы раздел с соответствующим именем. Необходимые
277
стандартные подпрограммы из ПНП-БИМ скопированы
в библиотеку
STUDENT.PNPBIM.
Выполнение заданий практикума ведется в установ-
ленной последовательности.
Тексты программ и исходные данные готовятся на
перфокартах и передаются преподавателю для записи
в библиотеки
STUDENT.TBGG.SYMB и STUDENT.TBGG.DATA,
скомплектованные следующим образом. Первая перфо-
карта содержит управляющую информацию для создания
раздела с именем TBjj ggnn в библиотеке исходных мо-
дулей
STUDENT.TBGG.SYMB:
,/~~~ADD^NAME = <имя раздела>, LIST=ALL
затем следует текст программы на фортране.
Аналогично оформляются перфокарты с исходными
данными:
./u-^^ADD^NAME = <имя раздела>,Б1БТ=ALL
<исходные данные>.
Распечатка записанного текста передается для контроля
студентам.
После помещения программы и исходных данных
в соответствующие библиотеки в дисплейном классе осу-
ществляется корректировка текста, выполнение задания
и просмотр результатов. Эти операции выполняются
средствами ДСКД PRIMUS и ОС ЕС.
С помощью команды LOOK просматривается раздел
библиотеки с текстом и данными:
LOOK~STUDENT.TBGG.SYMB (TBjjggnn) ,SHR
LOOK_ STUDENT.TBGG.DATA (TBjjggnn) ,SHR
затем производится копирование программы в рабочий
набор данных и се синтаксический анализ с помощью
команды SYNT:
COPY STUDENT.TBGG.SYMB (TBjjggnn)
SYNT FORT.
278
При обнаружении ошибок выполняются необходимые
корректировки в рабочем наборе следующими коман-
дами:
COPY STUDENT.TBGG.SYMB(TBjjggnn)
CORR
(R'
- I >
и откорректированный модуль сохраняется в библиотеке
с тем же именем раздела:
SAVE STUDENT.TBGG.SYMB(TBjjggnn).
Аналогичная последовательность действий необходима
для корректировки исходных данных из раздела библио-
теки
STUDENT.TBGG.D АТА (TBjjggnn).
Если исходный модуль ошибок не содержит, для тран-
сляции, редактирования и выполнения необходимо во-
спользоваться процедурой FCLGO. Макет задания на
вызов этой процедуры, помещенный в раздел FCLGO
библиотеки
STUDENT.MAKET,
следует откорректировать в соответствии с конкретными
значениями параметров. Последовательность команд
PRIMUS будет иметь вид:
COPY STUDENT.MAKET (FCLGO)
CORR
R
//TBjjggnn JOB (NNN,KK,YYYYYY) ,‘Ф.И.0‘,MSGLEVEL ==(1,1)
// EXEC bCLGO,NAME=TBjjggnn,GG= <номер группы>
E
Подчеркнутые параметры подлежат корректировке:
TBjjggnn — идентификатор студента, NNN — номер за-
дачи, КК=ТВ — код кафедры, YYYYYY—номер зачет-
ной книжки.
Подготовленное задание передается во входную оче-
редь командой ЕХЕС из рабочего набора данных.
Если на вычислительном центре, обеспечивающем
279
практикум на ЭВМ, отсутствует возможность помещения
процедуры FCLGO в системную библиотеку
SYS1.PROCLIB,
то трансляция, редактирование и выполнение программы
производятся с помощью задания ОС ЕС, помещенного
в разделе JOBLGO библиотеки
STUDENT.MAKET.
Это задание необходимо откорректировать, установив
фактические значения параметров GG, NAME и имени
задания в операторе JOB, сохранить в библиотеке
STUDENT.TBGG.JCLLIB
и передать оттуда на выполнение:
COPY STUDENT.MAKET (JOBLGO)
CORR
R
E
SAVE STUDENT.TBGG.JCLLIB (TBjjggnn)
EXEC STUDENT.TBGG.JCLLIB(TBjjggnn).
Контроль за состоянием задания производится коман-
дами DJOB, D А и D N.
После выполнения задания результаты просматри-
ваются на экране с помощью команды SOUT TBjjggnn
и подкоманды L в формате L — просмотр системных
сообщений; L 1 — просмотр сообщений транслятора;
L 2 — просмотр сообщений редактора; L 3 — просмотр
результатов выполнения. Если задание завершено успеш-
но, то после запроса системы PRIMUS можно все выход-
ные данные перевести в класс А для распечатки на
АЦПУ, набрав на клавиатуре букву Н, либо поместить
их в библиотеку результатов:
SAVE STUDENT.TBGG.OUTFILE(TBjjggnn).
Вывод на печать результатов выполнения задания
можно осуществить также подкомандой Н команды
SOUT в следующей форме: Н 3,R.
Если в результате выполнения программы обнаруже-
ны ошибки, то необходимо внести изменения в исходный
модуль программы с помощью команд LOOK или CORR
и сохранить откорректированный текст в разделе библио-
теки с прежним именем
SAVE STUDENT.TBGG.SYMB(TBjjggnn),
как было показано выше, и передать его на трансляцию,
редактирование и выполнение.
280
§ 9.5. Архив статистических данных системы STUDENT
Для выполнения заданий практикума в системе
STUDENT сформирован архив статистических данных,
в который записаны выборки, полученные методом ста-
тистического моделирования на ЭВМ, и реальные дан-
ные: данные массовых кардиологических обследований
и данные из литературных источников, позволяющие по-
лучить хорошо интерпретируемые результаты. На мо-
дельных данных исследуются свойства различных стати-
стических методов, а на реальных данных демонстри-
руются возможности решения конкретных прикладных
задач.
Архив представляет собой совокупность последова-
тельных наборов (файлов хранения) и одного библио-
течного набора. Все наборы имеют однотипные имена:
STUDENT.FILE.<hmh файла>—для файлов хранения,
STUDENT.DATA — библиотечный набор.
Данные из набора STUDENT.DATA читаются по форма-
ту, доступ к конкретной порции информации осуществля-
ется путем задания имени раздела библиотечного набора.
Для этого в картах управления заданиями ОС ЕС дол-
жен присутствовать оператор следующего вида:
//FTyyFOOl DD DSN=STUDENT.DATA (имя раздела),
// DISP=OLD,UNIT=5061,VOL=SER=DISCO,LABEL= (,„IN),
а в ЯУП ППП СОМИ необходимо определить оператор
ВВОД:
/ввод
УСТРОЙСТВО=уу.
ФОРМАТ=‘(спецификация формата)'.
ПЕРЕМЕННЫХ^ =Ц=.
РЕАЛИЗАЦИЙ=
При неформатизованном чтении данных из файла хране-
ния в операторе ВВОД ЯУП пакета СОМИ следует за-
дать идентификаторы конкретного BMDP-файла: КОД,
СОДЕРЖИМОЕ и МЕТКА.
Ниже приводится описание наборов архива системы
STUDENT. Подробная информация об идентификаторах
281
и содержимом архива помещена в табл. 9.4 и 9.5, кото-
рыми необходимо руководствоваться при выполнении за-
даний, так как номер набора в «Указании» к каждой ра-
боте соответствует номеру набора в табл. 9.4 и 9.5.
Файлы хранения
1. STUDENT.FILE.NORMI—-содержит 10 независи-
мых случайных выборок (каждая объемом 200) из стан-
дартного нормального распределения 2Vi(0, 1). Выборки
имитированы с помощью подпрограммы-функции RANDG
из ППП СОМИ, реализующей алгоритм Бокса — Мюл-
лера (см. § 2.19) с исходными случайными числами
1794831, 49819327, 152319, 17635887, 7682489, 1882033,
641129, 545393, 36717885, 1989781.
2. STUDENT.FILE.SCREEN — результаты массовых
кардиологических обследований минской популяции по
поводу ишемической болезни сердца: 57 переменных,
1000 наблюдений.
3. STUDENT.FILE.CVNORM2 — данные химического
состава крови *>: девять переменных, из которых пер-
вая — метка реализации, 188 реализаций; матрицы кор-
реляций и ковариаций размерностью 8X8 для тех же
данных.
4. STUDENT.FILE.TEMP — анкета курильщика: от-
веты на вопросы, закодированные числами от 1 до 5 (бо-
лее высокие значения соответствуют более сильному же-
ланию курить); 12 переменных, 110 реализаций; выбо-
рочная матрица корреляций для 12 переменных этой
анкеты; повернутые и неповернутые факторные нагрузки
для выборочной матрицы корреляций; значения трех
факторов в 110 реализациях; корреляции факторов; мат-
рица коэффициентов значений факторов (размерность
Зх 12).
5. STUDENT.FILE.CVNORM1—данные Фишера но
ирисам *)); пять исходных и две канонические перемен-
ные, 150 реализаций; выборочная ковариационная мат-
рица, вычисленная по случайной выборке объемом 200
из2Ую(0, Ло), записанной в наборе
STUDENT.FILE.NORM1.
*) См.: Dixon IF. G. BMDP Biomedical Computer Programs. Los
Angeles: Univ, of Calif. Press, 1977. 624 p.
*» Ibid.
282
Таблица 9.4
Характеристики файлов хранения системы STUDENT
Имя файла хранения
КОД
BMDP-файла
МЕТКА
BMDP-файла
СОДЕРЖИМОЕ BMDP-файла
1 STUDENT.FILE.NORM1 STUDENT
2 STUDENT.FILE.SCREEN FACTOR
STUDENT.FILE.CVNORM2 STUDENT
STUDENT
STUDENT
CHEMISTRY
CHEMISTRY
CHEMISTRY
ДАНН
ДАНН
ДАНН
КОВА
КОРР
Нормально распределенные псевдослу-
чайные числа ^1(0, 1): 10 переменных;
200 реализаций
Данные кардиологических обследований
минской популяции: 57 переменных;
1000 реализаций (см. Приложение 3)
Данные химического состава крови: де-
вять переменных с именами ИДЕН,
ВОЗРАСТ, РОСТ, ВЕС, ЛЕКАРСТВО,
ХОЛЕСТЕРИН, АЛЬБУМИН, КАЛЬ-
ЦИИ, МОЧЕВИНА; метка реализа-
ции— ИДЕН; 188 реализаций
Выборочная матрица ковариаций для
переменных ВОЗРАСТ, РОСТ, ВЕС, ЛЕ-
КАРСТВО, ХОЛЕСТЕРИН, АЛЬБУ-
МИН, КАЛЬЦИЙ, МОЧЕВИНА из
BMDP-файла с кодом STUDENT и со-
держимым ДАНН
Выборочная матрица корреляций для
переменных ВОЗРАСТ, ВЕС, ЛЕКАР-
СТВО, ХОЛЕСТЕРИН, АЛЬБУМИН,
КАЛЬЦИИ, МОЧЕВИНА из BMDP-
файла с кодом STUDENT и содержи-
мым ДАНН
Продолжение табл. 9.4
STUDENT.FILE.TEMP
КУРЕНИЕ
КУРЕНИЕ
КУРЕНИЕ
КУРЕНИЕ
КУРЕНИЕ
КУРЕНИЕ
STUDENT.FILE.CVN0RM1 STUDENT
КАНОН
6 STUDENT.FILE.SET1
СТАТИСТ
ДАНН Анкета курильщика: 12 исходных пере-
менных и значения трех факторов;
110 реализаций (имена переменных см.
в табл. 9.5)
КОВА Выборочная матрица ковариаций 12 пе-
ременных анкеты курильщика
ННАГ Неповернутые факторные нагрузки для
12 переменных анкеты курильщика, три
реализации (см. § 5.4)
ПНАГ Повернутые факторные нагрузки для
12 переменных анкеты курильщика, три
реализации (см. § 5.4)
ФКОР Матрица корреляций факторов; размер-
ность 3X3; имена факторов: ФАКТОР 1,
ФАКТОР2, ФАКТОРЗ
ФВКЛД Матрица коэффициентов переменных для
вычисления значений факторов; размер-
ность 3X12
ДАНН Данные Фишера по ирисам: пять исход-
ных переменных и две канонические пе-
ременные, полученные по результатам
дискриминантного анализа; 150 реализа-
ций (имена переменных см. в Приложе-
нии 4)
ДАНН Результаты эпидемиологического иссле-
дования сердца: 17 переменных, из кото-
рых первая — метка реализации; 200 реа-
лизаций (имена переменных см. в При-
ложении 5)
Таблица 9.5
Характеристика разделов библиотечного набора STUDENT. DAT А
Номер
набора
Раздел библиотечного набора
Содержимое
Формат
10
to
оо
СП
STUDENT.DAT A (PUASSON)
STUDENT.D АТА (ANALYS)
STUDENT.DATA(IRIS)
STUDENT.D АТА (SMOKE)
STUDENT.DАТА (TIME)
200 реализаций трех переменных, имею-
щих распределение Пуассона
Данные химического состава крови: де-
вять переменных с именами ИДЕН,
ВОЗРАСТ, РОСТ, ВЕС, ЛЕКАРСТВО,
ХОЛЕСТЕРИН, АЛЬБУМИН, КАЛЬ-
ЦИЙ, МОЧЕВИНА; первая перемен-
ная—метка реализации; 188 реализа-
ций. МИНИМУМ = (3)2 * 1,(6)150, 2*1,
0.2. МАКСИМУМ = (6)400
Данные Фишера по ирисам: пять пере-
менных; 150 реализаций (имена пере-
менных см. в Приложении 4)
Анкета курильщика: 12 переменных;
110 реализаций. Имена переменных:
КОНЦЕНТРАЦИЯ, РАЗДРАЖИТЕЛЬ-
НОСТЬ, КУРЕНИЕ 1, СОНЛИВОСТЬ,
КУРЕНИЕ2, НАПРЯЖЕННОСТЬ, КУ-
РЕНИЕЗ, ТРЕВОГА, ЧУВСТВИТЕЛЬ-
НОСТЬ, УСТАЛОСТЬ, содержание,
КУРЕНИЕ4
Измерение пульса и дыхания: две пере-
менные; 128 реализаций
3F15.8
А4, 5F4.0, 3F4.1
4F3.1, F3.0
12F2.0
2F6.2
Продолжение табл. 9.5
12 STUDENT.DATA(CORRF)
13
15
STUDENT.DATA (LOAD)
STUDENT.DATA(RAND55)
STUDENT.D ATA (CARDIO)
STUDENT.D ATA (RAND65)
Выборочная матрица корреляций в ниж-
ней треугольной форме; размерность
8x8. Имена переменных: РОСТ, РАЗ-
МАХ, ДЛ. ПРЕДПЛ, ДЛ. НОГИ, ВЕС,
ОКР. БЕДР, ОДР. ГРУД, ШИР. ГРУД
Матрица факторных нагрузок для двух
факторов: восемь переменных; размер-
ность 2x8
200 реализаций трех переменных: g2—
случайные величины, имеющие стандарт-
ное равномерное распределение, £3 =
= —•(^1+2Ь)/3+'П> гДе Л — случайная ве-
личина, равномерно распределенная в
[—0.01, 0.01] и не зависящая от £i, 52
200 реализаций пяти переменных: Х(1) —
возраст, Х(2)—индекс биомассы, Х(3) —
систолическое артериальное давление,
Х(4)—диастолическое артериальное дав-
ление, Х(5)—частота сердечных сокра-
щений
200 реализаций случайного вектора с
распределением ^(ц, S); р.т=(2, 3, 3,
4, 0, 1, 2, 3);
/ 2ц = 0 \ / 1 °-6 0 \
...ЛЬ. ... ; 5П= 0>6 j о
V U • 5 7 \ 0 о 4 /
8F4.3
8F4.3
3F9.6
F4.1, F5.2, 3F4.0
8F10.6
Продолжение табл. 9.5
Номер
набора
17
19
20
Раздел библиотечного набора
STUDENT.DAT A (RAND71)
STUDENT.D АТА (AUTO)
STUDENT.DATA (ARIMA)
STUDENT.DATA (TREND)
Содержимое
100 наблюдений четырех переменных:
х = (gi, £2)—вектор, равномерно распре-
деленный в единичном квадрате; у =
= (£3, S4) = Вх + т], где Т] ~ Л<2(0, S)
и не зависит от х;
Модельные данные процесса АР (р = 2):
реализации трех временных рядов по
200 наблюдений; = — 0,25; =
=0,0625; р{2)=—0,7; $>2)=0,49; р<3) =
= — 0,9; ₽(3) =0,81;
Числа солнечной активности: временной
ряд 176 наблюдений
Реализация временного ряда с периоди-
ческим трендом (7 = 16); 64 наблюде-
ния (модельные данные)
Формат
4F9.6
3F7.4
F5.1
F4.1
6. STUDENT.FILE.SET1—данные эпидемиологиче-
ского исследования сердца [4]: 17 переменных, из которых
первая — метка реализации; 200 реализаций.
STUDENT.DATA — библиотечный набор
со следующими разделами:
7. STUDENT.DATA (PUASSON)—три независимые
случайные выборки из распределения Пуассона (2.23)
с параметрами А = 3, 5, 8. Выборки имитированы с по-
мощью алгоритма § 2.10.
8. STUDENT.DATA(ANALYS)—данные химического
состава крови: девять переменных, 188 реализаций, пер-
вая переменная — метка реализации. Те же данные за-
писаны в файл хранения
STUDENT.FILE.CVNORM2.
9. STUDENT.DATA(IRIS)—данные Фишера по ири-
сам: пять переменных, 150 реализаций. Те же данные за-
писаны в файл хранения
STUDENT.FILE.CVNORM1.
10. STUDENT.DATA(SMOKE)—анкета курильщика:
12 переменных, ПО реализаций. Те же данные записаны
в файл хранения
STUDENT.FILE.TEMP.
11. STUDENT.DATA (TIME)—показатели, характе-
ризующие пульс и объем дыхания; 128 реализаций.
12. STUDENT.DATA (CORRF)—выборочная матрица
корреляций между восемью морфологическими парамет-
рами (рост, размах рук, длина предплечья, длина ноги,
вес, окружность бедер, окружность груди, ширина гру-
ди), вычисленная по выборке 305 наблюдений [59].
13. STUDENT.DATA (LOAD)—матрица факторных
нагрузок для восьми морфологических параметров (раз-
мерность 2X8).
14. STUDENT.DATA (RAND55)—200 реализаций трех
случайных величин: £2 имеют стандартное равномер-
ное распределение, £з=—(£i+2£2)/3+t], где -г] —рав-
номерно распределена в [—0,01; 0,01]; Ь, получены
с помощью функции RNDU из ППП СОМИ, реализую-
щей алгоритм из § 2.1 с исходными случайными числами
19060433, 46153, 17091941.
288
15. STUDENT.DATA (CARDIO)—результаты массо-
вых кардиологических обследований населения: пять пе-
ременных, 200 наблюдений.
16. STUDENT.DATA (RAND65) — 200 реализаций слу-
чайного вектора с многомерным нормальным распреде-
лением 2V8(p, S).
17. STUDENT.DАТА (RAND71) —100 реализаций двух
двумерных векторов для изучения многомерной ре-
грессии.
18. STUDENT.DATA(AUTO)—реализации трех вре-
менных рядов по 200 наблюдений [3, 25], представляющих
модель процесса АР вида
yt == + fayt-z = ut, (9.1)
где pi = — у, Рг = у2. Корни характеристического урав-
нения для (9.1) равны ye±i2n/6. Случайные отклонения щ
представляют независимые случайные величины с рас-
пределением 2Vi(0, о2), о2 = (1—у6)/(1 4- у2). Каждая
реализация временного ряда начинается со значений
У-i = u-t и уо = Uo -J- yy~i. Приведенные реализации по-
лучены для трех значений параметра у = 0,25; 0,7; 0,9.
19. STUDENT.RAND (ARIMA)—реализация времен-
ного ряда чисел солнечной активности [3]; 176 наблю-
дений.
20. STUDENT.DATA (TREND)—временной ряд с
циклическим трендом; 64 наблюдения; модельные данные.
Приложение 1
СТАНДАРТНЫЕ ФОРТРАН-ПРОГРАММЫ
МОДЕЛИРОВАНИЯ РАВНОМЕРНОЙ И ГАУССОВСКИХ
СЛУЧАЙНЫХ ВЕЛИЧИН
Подпрограмма RANDU [53]
Предназначена для вычисления псевдослучайного
числа, имитирующего реализацию случайной величины
со стандартным равномерным распределением, и псевдо-
случайного числа, имитирующего реализацию целочис-
ленной случайной величины, равномерно распределенной
между 0 и 231. При каждом обращении входным является
целое псевдослучайное число и образуются новое целое
псевдослучайное число и вещественное число, имитирую-
щее реализацию случайной величины, равномерно рас-
пределенной в [0, 1].
Обращение: CALL RANDU(IX,IY,YFL).
Описание параметров
IX—исходное псевдослучайное (стартовое) число,
являющееся нечетным целым с числом цифр девять или
меньшим (обычно полагают IX = 65539); входной пара-
метр. При очередном обращении параметру IX должно
быть присвоено значение IY, вычисленное подпрограм-
мой при предыдущем обращении.
IY — целое псевдослучайное число (между 0 и 231),
требуемое при последующих обращениях к подпрограм-
ме; выходной параметр.
YFL — псевдослучайное число на промежутке [0, 1),
представленное в форме с плавающей точкой и имити-
рующее реализацию равномерно распределенной в [0, 1]
случайной величины; выходной параметр.
Текст подпрограммы:
А
SUBROUTINE RANDU(IX,IY,YFL)
IY=IX*65539
IF(JY)5,6,6 ,
•
290
5 IY= IY+2147483647+1
6 YFL=IY
YFL=YFL*.4656613E-9
RETURN
END
Подпрограмма-функция URAND *)
Предназначена для вычисления псевдослучайного
числа, имитирующего реализацию случайной величины
со стандартным равномерным распределением, и может
быть использована на ЭВМ с различной длиной слова.
FUNCTION URAND (IY)
Описание параметров
IY — исходное псевдослучайное число, имеющее про-
извольное целое значение. Вызывающая программа не
должна менять значение IY между последовательными
вызовами URAND.
Значения функции URAND являются числами из
интервала (0, 1).
Текст подпрограммы-функции:
FUNCTION URAND(IY)
DOUBLE PRECISION HALFM,DATAN,DSQRT
DATA M2/0/JTWO/2/
IF(M2.NE.O)GO TO 20
С ЕСЛИ ЭТО ПЕРВЫЙ ВХОД, ТО ВЫЧИСЛИТЬ ДЛИНУ
С ЦЕЛОЧИСЛЕННОГО МАШИННОГО СЛОВА
М=1
10 М2=М
M=ITWO*M2
IF(M.GT.M2)GO ТО 10
HALFM=M2
С ВЫЧИСЛИТЬ МНОЖИТЕЛЬ И ПРИРАЩЕНИЕ
С ЛИНЕЙНОГО КОНГРУЭНТНОГО МЕТОДА
IA=8*IDINT(HALFM*DATAN(l.D0)/8.D0)+5
IC = 2*1 DINT (IIALFM* (0.5D0- DSQRT (3.D0) /6.D0)) +1
М1С=(М2—1С)+М2
С S —МАСШТАБИРУЮЩИЙ МНОЖИТЕЛЬ ДЛЯ
С ПРЕОБРАЗОВАНИЯ В ЧИСЛО С ПЛАВАЮЩЕЙ ТОЧКОЙ
S = 0.5/HALFM
С ВЫЧИСЛИТЬ СЛЕДУЮЩЕЕ СЛУЧАЙНОЕ ЧИСЛО
20 IY=IY*IA
*) См.: Форсайт Дж., Малькольм М., Моулер К. Машинные ме-
тоды математических вычислений. М.: Мир, 1980. 280 с.
291
С СЛЕДУЮЩИЙ ОПЕРАТОР —ДЛЯ МАШИН, КОТОРЫЕ
С НЕ ДОПУСКАЮТ ПЕРЕПОЛНЕНИЯ ЦЕЛЫХ ЧИСЕЛ
С ПРИ СЛОЖЕНИИ
IF(IY.GT.MIC)IY= (IY—М2)—М2
IY=IY+IC
С СЛЕДУЮЩИЙ ОПЕРАТОР —ДЛЯ МАШИН, У КОТОРЫХ
С ДЛИНА СЛОВА ДЛЯ СЛОЖЕНИЯ БОЛЬШЕ, ЧЕМ ДЛЯ
С УМНОЖЕНИЯ
IF(IY/2.GT.M2)IY= (IY-M2)-M2
С СЛЕДУЮЩИЙ ОПЕРАТОР —ДЛЯ МАШИН, У КОТОРЫХ
С ПЕРЕПОЛНЕНИЕ ЦЕЛОГО ЧИСЛА ВЛИЯЕТ
С НА ЗНАКОВЫЙ РАЗРЯД
IF (IY.LT.0) IY= (IY+M2) +М2
URAND = FLOAT (I Y)*S
RETURN
END
Подпрограмма GAUSS [53]
Предназначена для вычисления псевдослучайного
числа, имитирующего реализацию гауссовской случайной
величины с заданными математическим ожиданием и
средним квадратическим отклонением. Использует
RANDU.
Обращение: CALL GAUSS(IX,S,AM,V)
Описание параметров
IX — имеет тот же смысл, что и в подпрограмме
RANDU; входной параметр.
S — заданное среднее квадратическое (стандартное)
отклонение моделируемой случайной величины; входной
параметр.
AM — заданное математическое ожидание; входной
параметр.
V — псевдослучайное число, имитирующее реализа-
цию случайной величины с распределением 2Vi(AM, S2);
выходной параметр.
Текст подпрограммы:
SUBROUTINE GAUSS (IX,S,AM,V)
А=0.0
DO 50 1 = 1,12
CALL RANDU (IX,IY,Y)
IX=IY
50 A=A+Y
V= (A-6.0)*S+AM
RETURN
END
292
l
Подпрограмма MVN [49]
Предназначена для имитации реализации V-мерного
нормально распределенного случайного вектора с задан-
ными математическим ожиданием и ковариационной
матрицей. Использует подпрограммы GAUSS, RANDU.
Обращение: CALL MVN (IX,V,EX,N,X,K5,D,Z,
SUM2).
Описание параметров
IX—имеет тот же смысл, что и в подпрограмме
RANDU; входной параметр.
V — задаваемая ковариационная (NXN)-матрица.
ЕХ — задаваемый V-мерный вектор математического
ожидания.
N — задаваемая размерность случайного вектора.
X—реализация имитируемого случайного вектора;
массив размерностью N; выходной параметр.
К5 — при первом обращении к MVN (с заданной мат-
рицей V) должен быть равен единице, а при последую-
щих обращениях (с той же самой матрицей V) должен
быть больше единицы; входной параметр.
D, Z, SUM2 — рабочие массивы.
Текст подпрограммы:
SUBROUTINE MVN (IX,V,EX,N,X,KS,D,Z,SUM2)
DIMENSION V(N,N),EX(N) ,X(N),D (N,N) ,Z(N),SUM2(N)
IF (Кб—4) 4,4,29
DO 7 J1 = 1,N
X (JI) =0.0
DO 7 J2=1,N
7
9
D(Jl,J2)=0.0
DO 9 1 = 1,N
D(I,1)=V(I,1)/V(1,1)**.5
DO 28-I=2,N
SUM=0.0
K1 = I—1
DO 14 K=1,K1
14 SUM=SUM-f-D(I,K)*D(I,K)
CK=V(I,I)-SUM
IF(CK) 17, 17, 18
17 STOP
18 D(I,I)=SQRT(CK)
IF(I-N) 20, 28, 28
20 K1 = I
DO 27 J=2, KI
SUMI = 0.0 Г
K2=J—1
DO 25 K=l, K2
293
25 SUM1 = SUM1+D(I+1,K)*D(J,K)
D(I+1,J) = (V(I+1,J)-SUM1)/D(J,J)
27 CONTINUE
28 CONTINUE
29 DO 31 1 = 1,N
SUM2(I)=0.0
31 CALL GAUSS(IX,1.0,0.0,Z(I))
DO 34 1=1,N
DO 34 J=1,N
34 SUM2(I) = SUM2(I)+D(I,J)*Z(J)
DO 36 1=1,N
36 X(I)=SUM2(I)+EX(I)
RETURN
END •
В связи с тем, что в последовательности, вырабатывае-
мой подпрограммой RANDU, наблюдается корреляция
между тремя подряд идущими целыми числами, рекомен-
дуется в подпрограммах GAUSS и M.VN для получения
равномерно распределенных случайных чисел использо-
вать вместо RANDU подпрограмму-функцию URAND.
Приложение 2
КОМАНДЫ СИСТЕМЫ PRIMUS
I. Работа с рабочим набором данных
INPT — ввод информации с экрана дисплея в РНД.
COPY — копирование информации в РНД из личного
набора данных.
CORR — корректировка информации в РНД.
Если необходимо откорректировать записи текста без
изменения их количества, в верхнем левом углу наби-
рается подкоманда R, курсор подводится к позиции, со-
держимое которой должно быть заменено, и в нее вно-
сится нужный символ. После внесения всех изменений
в вызванный на экран фрагмент курсор ставится в пер-
вую позицию строки, следующей за последней исправ-
ленной-строкой, и нажимается клавиша ВВ. Далее под-
командой G на экран вызывается очередной фрагмент,
подлежащий корректировке, и т. д.
Если необходимо удалить несколько строк из текста,
используется подкоманда D в виде
D — удалить первую строку фрагмента.
D^a — удалить а первых строк фрагмента.
D_ (курсор) - -удалить указанную курсором строку.
Du-а (курсор) —удалить а строк, начиная с отмечен-
ной курсором. . . . „ .
294
Вставка записей во фрагмент текста производится
подкомандой I:
I — вставить новые записи за первой записью фраг-
мента.
I а — вставить [новые записи за строкой фрагмента,
имеющей указанный относительный номер.
I —. (курсор) — вставить новые записи за записью, от-
меченной курсором.
I — вставить за первой записью фрагмента записи,
удаленные последней командой D.
I —(курсор) — вставить за записью, отмеченной’кур-
сором, записи, удаленные последней командой D.
I — а* — вставить за^ записью фрагмента с относитель-
ным номером а записи, удаленные последней командой D.
SAVE — запись информации из РИД в личный набор
данных.
SYNT — синтаксический анализ всего текста програм-
мы, находящейся в рабочем наборе данных.
II. Работа с личными наборами данных
DVOL — фиксация имени тома прямого доступа.
LOOK — просмотр и корректировка на месте последо-
вательного набора данных или раздела библиотеки.
CONT — просмотр оглавления библиотеки.
PRNT — печать па АЦПУ информации из личного
или рабочего набора данных.
III. Работа с заданием
ЕХЕС — передача задания на выполнение в пакетном
режиме.
DJOB — получение информации о состоянии задания.
А — получение списка активных заданий.
VTOC — просмотр оглавления тома прямого доступа.
SOUT — просмотр задания, выполненного в пакетном
режиме.
IV. Управление сеансом
END — завершение работы пользователя с системой.
KILL—принудительное завершение выполнения
команды.
V. Получение информации
HELP
системы.
справка о функциональных возможностях
295
Приложение 3
ОПИСАНИЕ ПЕРЕМЕННЫХ НАБОРА
STUDENT.FILE.SCREEN
Переменная
Имя в
BMDP-файле
Комментарий
Номер обследуемого
Систолическое артериальное
давление (среднее), мм
рт. ст.
Диастолическое артериаль-
ное давление (среднее),
мм рт. ст.
Частота пульса (ЧСС сидя),
Холестерин, мг %
Курите ли Вы в настоящее
время?
Количество сигарет (папи-
рос), выкуриваемых за
день
Частота употребления алко-
голя
Количество употребляемого
алкоголя
Хождение, ч/день
Ношение тяжестей, ч/день
Ходьба летом, ч/нед.
Ходьба зимой, ч/нед.
Наличие инфаркта миокарда
CAD_CP
DAD_CP
ЧСС СИДЯ
ХОЛЕСТ
КУРЕНИЕ
ШТУК СИГ
ЧАСТ. АЛК.
АЛКОГОЛЬ
ХОЖДЕНИЕ
ТЯЖЕСТИ
ХОДЬБА. Л
ХОДЬБА. 3
ИНФАРКТ
1,2
3
4
5
6
7
8
9
10
11
12
13
14
15
Метка реали-
зации
1 — нет, 2 —
иногда, 3 — да
1 — несколько
раз в году; 2 —
один раз в ме-
сяц; 3 — один
раз в неделю;
4 — несколько
раз в неделю,
но не ежеднев-
но; 5 — еже-
дневно
1 — отсутству-
ет; 2 — имеется
296
Продолжение приложения 3
Переменная
Имя в
BMDP-файле
Комментарий
Наличие стенокардии
Предшествующее лечение
артериальной гипертонии
Наличие гиперхолестерине-
мии
Курение
Наличие избыточного веса
Физическая активность
1 — отсутству-
ет; 2 — имеется
1 — нет; 2 — да
1 — нет; 2 — да
1 — не курит;
2 — курит
1 — отсутству-
ет; 2 — имеется
1 — достаточ-
ная; 2 — недо-
статочная
Вес тела, кг
Рост стоя, см
Рост сидя, см
Боковая длина туловища, см
Ширина плеч, см
Переднезадний диаметр
грудной клетки, см
Поперечный диаметр груд-
ной клетки, см
Высота грудной клетки, см
Длина верхней конечности,
см
Окружность груди при спо-
койном дыхании, см
Трицепс (кожная складка
справа), мм
Лопатка (кожная складка
справа), мм
Сила правой кисти, кг
Истинная жизненная ем-
кость легких (ЖЕЛист),
мл
СТЕНОКРД
ЛЕЧ. ДАВЛ
ГИПЕРХОЛ
КУРЕНИЕ
ИЗБ. ВЕС
ГИПОДИН
ВЕС ТЕЛА
РОСТ СТ
РОСТ СИД
Б. ДЛ. ТУЛ
ШИР. ПЛЕЧ
П-3. ДИАМ
ПОП. ДИАМ
В. ГР. кл
ДЛ. руки
ОКР. ГР
ТРИЦЕПС
ЛОПАТКА
СИЛА П. К
ЖЕЛ
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
297
Продолжение приложения 3
Переменная
Имя в
BMDP-файле
Комментарии
Длина стопы, см
Ширина тазового пояса, см
Частота сердечных сокраще-
ний лежа (ЧСС лежа),
У д/мин
Длина туловища, см
Должная жизненная емкость
легких (ЖЕ Л дол жн), мл
Окружность плеча, см
Признак наличия погранич-
ной артериальной гипер-
тонии
Эффективное лечение но по-
воду артериальной гипер-
тонии
Возраст, лет
Индекс Пинье
Индекс биомассы, кг/м2
Скорость распространения
пульсовой волны по сосу-
дам эластического типа
(Сэ), см/мс
Скорость распространения
пульсовой волны по сосу-
дам мышечного типа
(См), см/мс
э
ЖЕЛдолжп/ЖЕЛ
ИСТ
Наличие ишемической
лезни сердца
Наличие артериальной
пертонии
бо-
ги-
СТОПА
ШИР. ТАЗ
ЧСС ЛЕЖА
ДЛ. ТУ Л
ДЖЕЛ
ОКР. пл
ПОГР. АГ
ЭФФ. Л. АГ
ВОЗРАСТ
ИН. ПИНЬЕ
БИО-МАСС
СРПВЭ
СРПВМ
СМ/СЭ
ДЖЕЛ/ЖЕЛ
ИБС
АГ
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
1 — отсутству-
ет; 2 — имеется
1 — не эффек-
тивное лечение;
2 — эффектив-
ное лечение
Рост — вес —
окружность
груди при спо-
койном дыха-
нии
Вес/рост2
1 — отсутству-
ет; 2 — имеется
1 — отсутству-
ет; 2 — имеется
298
Продолжение приложения 3
Переменная
I
Имя в £ иЯ. с •&
BMDP-файле [омер енной MDP- Комментарий
Ж ЕЮ
Наличие диастолической
артериальной гипертонии
Наличие систолической
артериальной гипертонии
Наличие систоло-диастоли-
ческой гипертонии
Возраст в градациях
Скорость распространения
пульсовой волны по бед-
ренной артерии, см/с
ДИАСТ.АГ
СИСТ. АГ
С-Д. АГ
ВОЗР. ГР
С. БЕДР
53
54
55
56
57
1 — отсутству-
ет; 2 — имеется
1 — отсутству-
ет; 2 — имеется
1 — отсутству-
ет; 2 — имеется
1—40—44 года
2—45—49 лет
3—50—54 года
4—55—59 лет
Примечание. Данные получены в лаборатории социальной
и профилактической кардиологии БелПИИ кардиологии.
Приложение 4
ОПИСАНИЕ ПЕРЕМЕННЫХ НАБОРА
STUDENT.FILE.CVNORM1
Переменная
Имя в
BMDP-файле
Комментарий
Длина чашелистика
Ширина чашелистика
Длина лепестка
Ширина лепестка
Вид ириса
ЧАШЕЛ. Д
ЧАШЕЛ. Ш
ЛЕПЕСТ. Д
ЛЕПЕСТ. Ш
ИРИС
1
2
3
4
5
1 — махровый;
2 — многоцвет-
ный; 3 — чис-
тый
299
Продолжение приложения 4
Переменная Имя в BMDP-файле Номер пере- менной в BMDP-файле Комментарий
Первая каноническая пере- менная по результатам дискриминантного анализа CNVR1 6
Вторая каноническая пере- менная по результатам дискриминантного анализа CNVR2 7
Приложение 5
ОПИСАНИЕ ПЕРЕМЕННЫХ НАБОРА
STUDENT.FILE.SET1
Переменная
Имя в
BMDP-файле
Комментарий
Номер истории болезни
Возраст в 1950 г.
Доктор, проводивший обсле-
дование в 1950 г.
Систолическое артериаль-
ное давление в 1950 г.,
мм рт. ст.
Диастолическое артериаль-
ное давление в 1950 г.,
мм рт. ст.
Рост, дюйм
Вес в 1950 г., фунт
Холестерин в 1950 г., мг %
Социальное положение
Клиническое состояние (на-
личие болезней сердца)
НОМЕР
ВОЗРАСТ1
ДОКТОР50
*
САД50
ДАД50
РОСТ50
ВЕС50
ХОЛЕСТ50
СОЦ. ПОЛ
ДИАГНОЗ
1
2
3
4
5
6
7
8
9
10
Метка реализа-
ции
Код от 1 до 4
1 — высокое; 2,
3, 4, 5 — низкое
Градации от 0
до 8
300
Продолжение приложения 5
Переменная
Имя в
BMDP-файле
Комментарий
Доктор, проводивший обсле-
дование в 1962 г.
Систолическое артериальное
давление в 1962 г., мм
рт. ст.
Диастолическое артериаль-
ное давление в 1962 г.,
мм рт. ст.
Холестерин в 1962 г., мг %
Вес в 1962 г., фунт
Форма ишемической болез-
ни сердца
Год смерти
ДОКТОР62
САД62
ДАД62
ХОЛЕСТ62
ВЕС62
ИБС
Код от 1 до 5
12
13
14
15
16
ДАТА
17
О — неизвестно;
1—3 — инфаркт
миокарда; 4—
7 — стенокар-
дия; 8, 9 — дру-
гое
О — жив
ОСНОВНАЯ ЛИТЕРАТУРА
1. Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная
статистика: Основы моделирования и первичная обработка данных.
М.: Финансы и статистика, 1983. 471 с.
2. Андерсон Т. Введение в многомерный статистический анализ.
М.: Гос. изд-во физ.-мат. лит., 1963. 500 с.
3. Андерсон Т. Статистический анализ временных рядов. М.:
Мир, 1976. 765 с.
4. Афифи А., Эйзен С. Статистический анализ. Подход с исполь-
зованием ЭВМ. М.: Мир, 1982. 488 с.
5. Боровков А. А. Курс теории вероятностей. М.: Наука, 1976.
288 с.
6. Боровков А. А. Математическая статистика: Оценка парамет-
ров. Проверка гипотез. М.: Наука, 1984. 472 с.
7. Бусленко Н. П. Моделирование сложных систем. М.: Паука,
1978. 399 с.
8. Гихман И. И., Скороход А. В., Ядренко М. И. Теория вероят-
ностей и математическая статистика. Киев: Вища шк„ 1979. 408 с.
9. Голенко Д. И. Моделирование и статистический анализ псев-
дослучайных чисел па ЭВМ. М.: Наука, 1965. 227 с.
10. Данилочкин В. П., Одинцов Б. В., Пеледов \Г. В. Операцион-
ная система ОС ЕС. М.: Статистика, 1980. 288 с.
11. Ермаков С. М., Михайлов Г. А. Курс статистического модели-
рования. М.: Наука, 1976. 320 с.
12. Ивченко Г. И., Медведев Ю. И. Математическая статистика.
М.: Высш, шк., 1984. 248 с.
13. Кендалл М., Стьюарт А. Многомерный статистический анализ
и временные ряды. М.: Наука, 1976. 736 с.
14. Кендалл М., Стьюарт А. Статистические выводы и связи. М.:
Наука, 1973. 900 с.
15. Кнут Д. Искусство программирования для ЭВМ: В 2 т. М.:
Мир, 1977. Т. 2: Получислеиные алгоритмы. 728 с.
16. Полляк 10. Г. Вероятностное моделирование на ЭВМ. М.:
Сов. радио, 1971. 400 с.
17. Розанов 10. А. Теория вероятностей, случайные процессы и
математическая статистика. М.: Наука, 1985. 320 с.
18. Справочник по теории вероятностей и математической стати-
стике/В. С. Королюк, Н. И. Портенко, А. В. Скороход, А. Ф. Тур-
бин. М.: Наука, 1985. 640 с.
19. Феллер В. Введение в теорию вероятностей и ее применения:
В 2 т. М.; Мир, 1984. Т. 2. 752 с.
20. Ширяев А. II. Вероятность. М.: Наука, 1980. 575 с.
302
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
21. Беляев Ю. Д., Чепурин Е. В. Основы математической ста-
тистики: В 3 ч. М.: Изд-во МГУ. 1982—1983. Ч. 1—3.
22. Бендат Дою., Пирсол А. Измерение и анализ случайных про-
цессов. М.: Мир, 1974. 464 с.
23. Библиотека алгоритмов. М.: Сов. радио, 1975—1981.
Вын. 1—4.
24. Бикел П., Доксам Д. Математическая статистика. М.: Финан-
сы и статистика, 1983. Вын. 2. 254 с.
25. Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз
и управление. М.: Мир, 1974. Вып. 1, 2.
26. Болч Б., Хуань Д. Дою. Многомерные статистические методы
для экономики. М.: Статистика, 1979. 320 с.
27. Большее Л. И., Смирнов Н. В. Таблицы математической
статистики. М.: Наука, 1983. 416 с.
28. Боровков А. А. Математическая статистика: Дополн. главы.
М.: Наука, 1984. 143 с.
29. Бусленко Н. П. Математическое моделирование производ-
ственных процессов на цифровых вычислительных машинах. М.: Нау-
ка, 1964. 362 с.
30. Быков В. В. Цифровое моделирование в статистической ра-
диотехнике. М.: Сов. радио, 1971. 326 с.
31. Гренандер У., Фрайбергер В. Краткий курс вычислительной
вероятности и статистики. М.: Наука, 1978. 192 с.
32. Грендоюер Д., Хатанака М. Спектральный анализ временных
рядов в экономике. М.: Статистика, 1972. 312 с.
33. Гроот М. де. Оптимальные статистические решения. М.: Мир,
1974. 491 с.
34. Средства отладки программ в ОС ЕС ЭВМ/В. И. Ерофеев,
Ю. П. Меркушов, В. И. Псршиков и др. М.: Статистика, 1979. 248 с.
35. Журбенко И. Г. Спектральный анализ временных рядов. М.:
Нзд-во МГУ, 1982. 168 с.
36. Иберла Д. Факторный анализ. М.: Статистика, 1978. 396 с.
37. Длейнен Дою. Статистические методы в имитационном моде-
лировании. М.: Статистика, 1978. Вып. 1, 2.
38. Доваленко И. И., Кузнецов Н. Ю., Шуренков В. М. Случай-
ные процессы. Киев: Наукова думка, 1983. 366 с.
39. Докс Д., Хинкли Д. Теоретическая статистика. М.: Мир,
1978. 558 с.
40. Колмогоров А. Н. Сложность алгоритмов и объективное
определение случайности//Успехи мат. наук. 1974. Т. 29. № 4.
41. Дорн Г., Дорн Т. Справочник по математике. М.: Наука,
1973. 832 с.
42. Драмер Г. Математические методы статистики. М.: Мир,
1975. 648 с.
43. Липцер Р. Ш., Ширяев А. Н. Статистика случайных процес-
сов. М.: Наука, 1974. 696 с.
44. Лоули Д., Максвелл А. Факторный анализ как статистиче-
ский метод. М.: Мир, 1967. 144 с.
45. Матвеев В. Ф., Ушаков В. Г. Системы массового обслужива-
ния: Учеб, пособие для вузов. М.: Изд-во МГУ, 1984. 239 с.
46. Математическое обеспечение ЕС ЭВМ. Минск. 1973. Вып. 2,
4; 1976. Вып. 10, 12; 1978. Вып. 16; 1980. Вып. 24, 25; 1981. Вып. 29.
303
47. Материалы по МО ЭВМ. Пакет программ по прикладному
статистическому анализу. М.: Изд-во ЦЭМИ АН СССР, 1983. 188 с.
48. Мюллер П., Нойман П., Шторм Р. Таблицы по математиче-
ской статистике. М.: Финансы и статистика, 1982. 272 с.
49. Нейлор Т. Машинные имитационные эксперименты е моделя-
ми экономических систем. М.: Мир, 1975. 500 с.
50. Отнес Р., Эноксон Л. Прикладной анализ временных рядов.
Основные методы. М.: Мир, 1982. 428 с.
51. Программное обеспечение ЭВМ. Минск. 1982. Вып. 35; 1984.
Вып. 45.
52. Программное обеспечение ЭВМ. Минск. 1983. Вып. 44: В 2 ч.;
1986. Вып. 66.
53. Сборник, научных программ на Фортране. Вып. 1. Статисти-
ка. М.: Статистика, 1974. 316 с.
54. Себер Дж. Линейный регрессионный анализ. М.: Мир, 1982.
394 с.
55. Трифонов Н. П., Пасхин Е. Н. Практикум работы на ЭВМ.
М.: Наука, 1982. 288 с.
56. Уилкинсон, Райнш. Справочник алгоритмов па языке АЛГОЛ.
Линейная алгебра. М.: Машиностроение, 1976. 392 с.
57. Уилкс С. С. Математическая статистика. М.: Наука, 1967.
632 с.
58. Харин 10. С. Исследование риска статистических классифика-
торов, использующих оценки минимального контраста//Теория ве-
роятностей и ее применения. 1983. Т. 28. Вып. 3.
59. Харман Т. Современный факторный анализ. М.: Статистика,
1972. 488 с.
60. Хеннан Э. Многомерные временные ряды. М.: Мир, 1974.
576 с.
61. Шеффе Г. Дисперсионный анализ. М.: Наука, 1980. 512 с.
62. Computer simulation in University teaching. New York: Acad.
Press, 1981. 253 p.
63. Fishman G. S., Moore L. R. In search of correlation in multi-
plicative congruental generators with modulus 231—1. «Computer
Science and Statistics: Proc, of 13th Symp. on the Interface». New
York: Springer Verlag, 1982. P. 155—157.
64. International Mathematical and Statistical Libraries // IMSL
Library. Huston, Texas, 1977.
65. Wichmann B. A., Hill I. D. An efficient and portable pseudo-
random number generator//Appl. statistics. 1982. Vol. 31. N 2.
P. 188—190.