/











































































































































































































































































































































































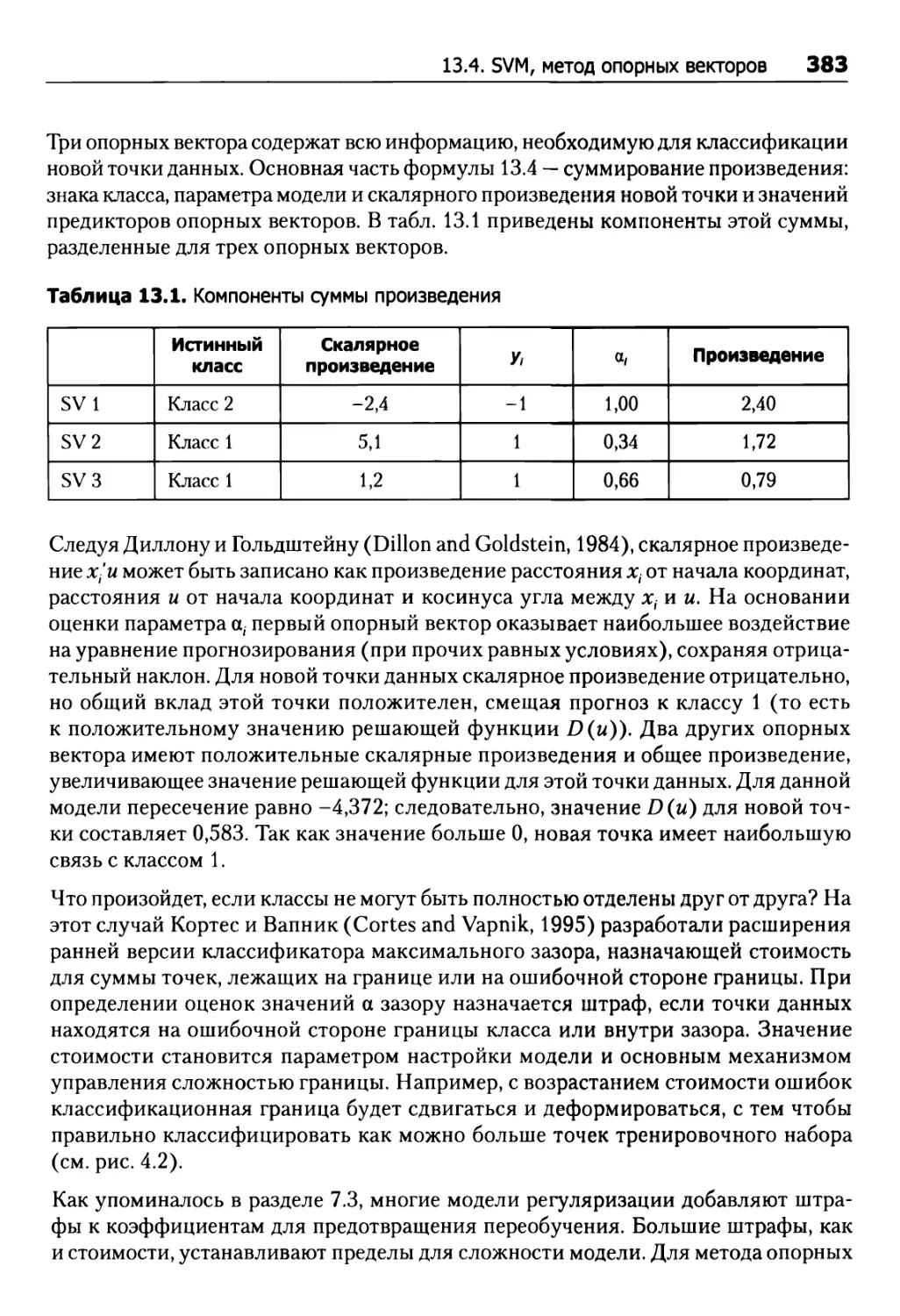

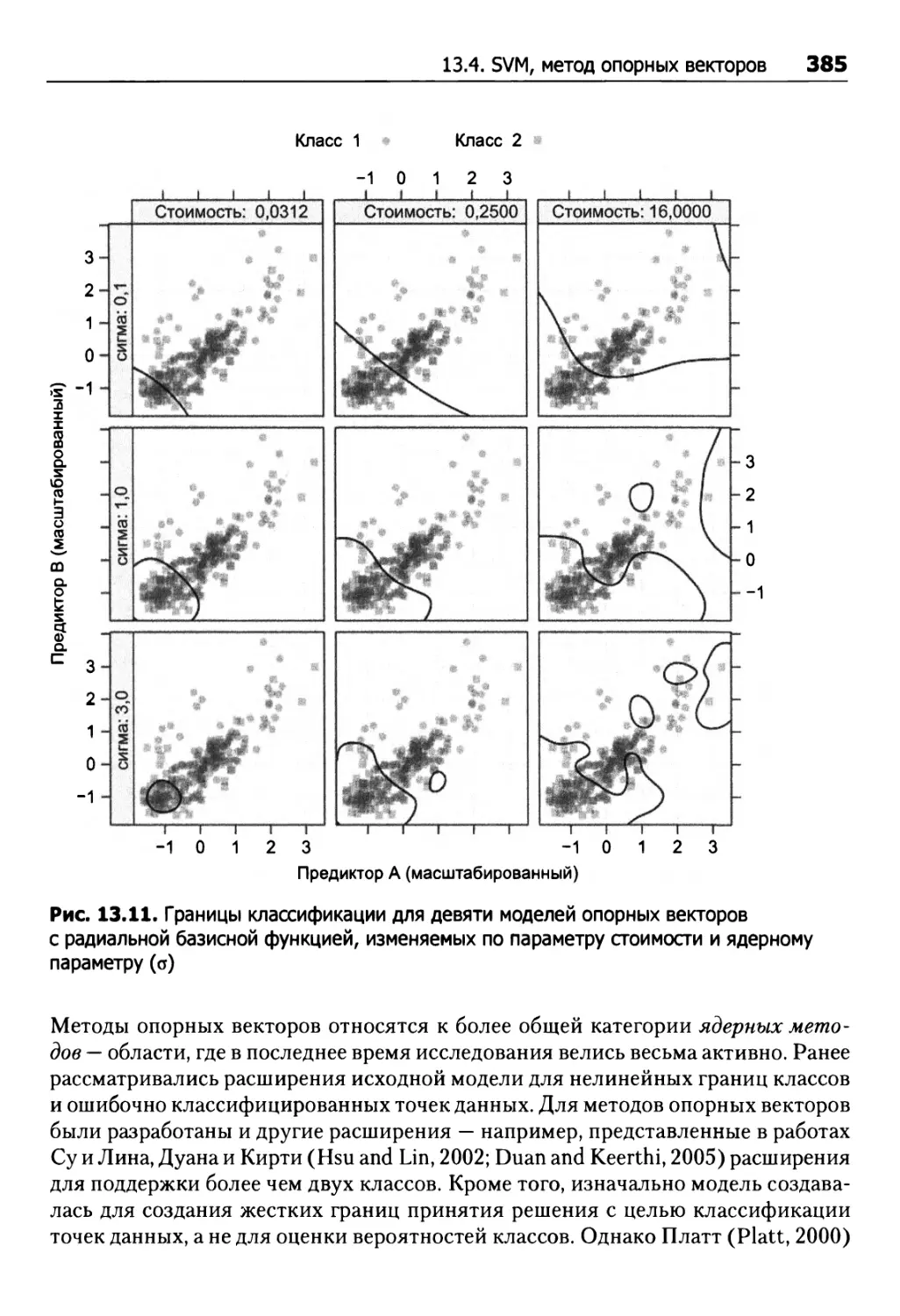






































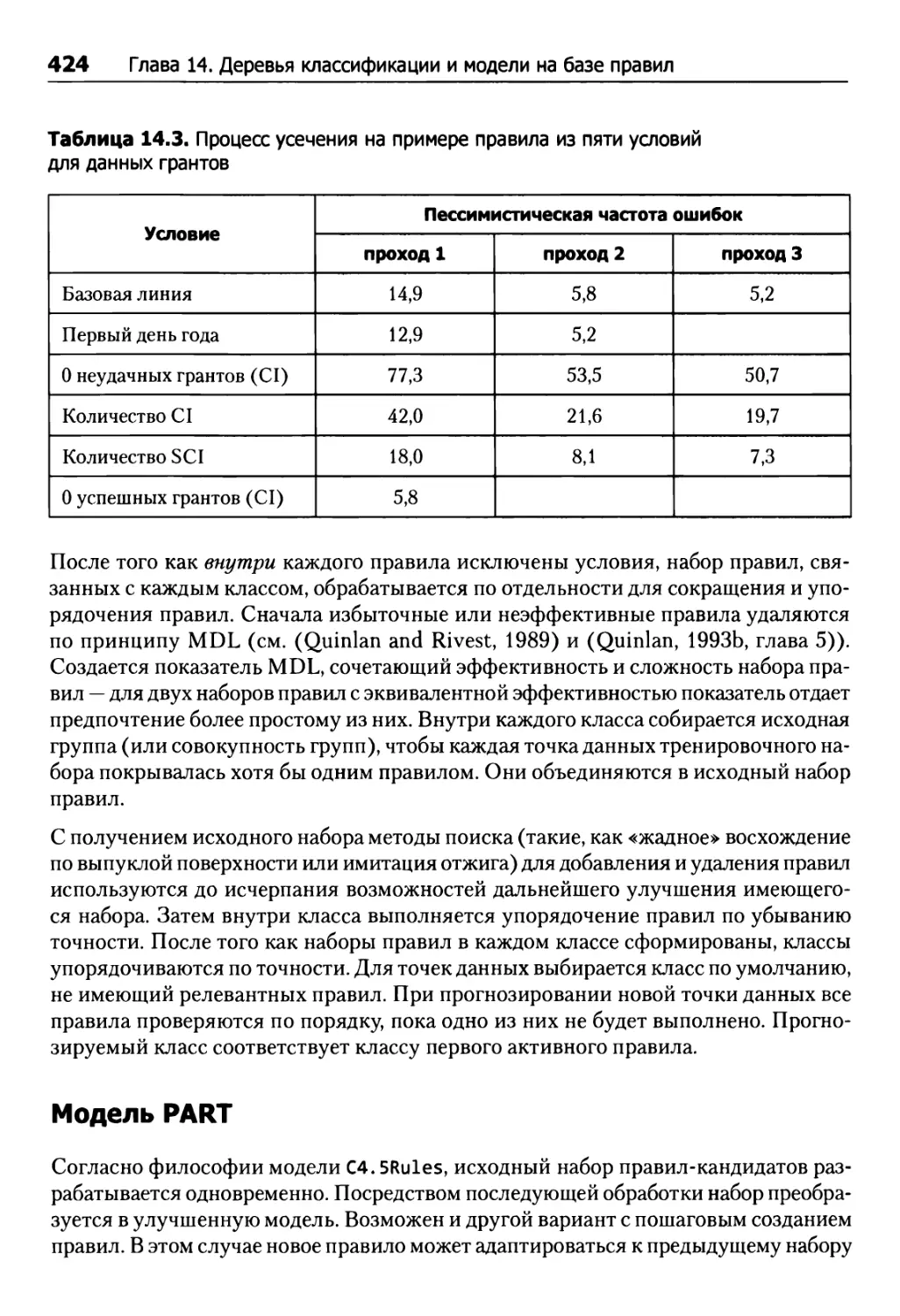


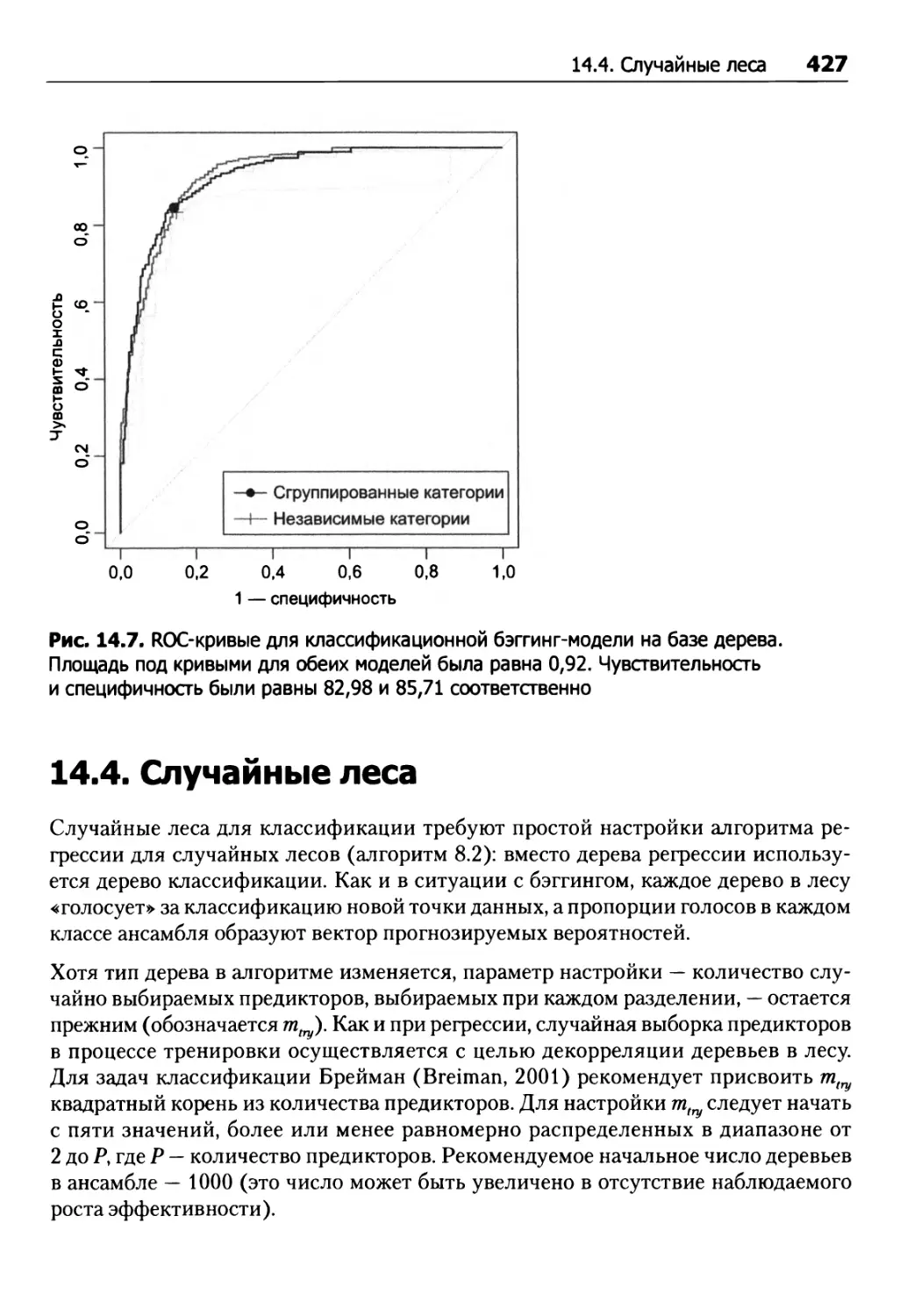













































































































































































































Tags: исследование операций математика программирование базы данных моделирование аналитика
ISBN: 978-5-4461-1039-1
Year: 2019




Text
С&ППТЕР'
Applied
Predictive Modeling
Max Kuhn and Kjell Johnson
Springer
Препиктивное моделирование на практике
Макс Кун и Кьвлл Джонсон
С^ППТЕР’
Санкт-Петербург • Москва * Екатеринбург•Воронеж Нижний Новгород•Ростов-на-Дону
Самара > Минск
2019
ББК 22.183.5
УДК 519.8
К91
Кун Макс, Джонсон Кьелл
К91 Предиктивное моделирование на практике. — СПб.: Питер, 2019. — 640 с.: ил. — (Серия «Для профессионалов»).
ISBN 978-5-4461-1039-1
«Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R.
Эта книга может использоваться как введение в предиктивные модели и руководство по их применению. Читатели, не обладающие математической подготовкой, оценят интуитивно понятные объяснения конкретных методов, а внимание, уделяемое решению актуальных задач с реальными данными, поможет специалистам, желающим повысить свою квалификацию.
Авторы постарались избежать сложных формул, для усвоения основного материала достаточно понимания основных статистических концепций, таких как корреляция и линейный регрессионный анализ, но для изучения углубленных тем понадобится математическая подготовка.
Для работы с книгой нужно иметь базовые знания о языке R. Премия Zecgel Technometrics 2014.
16+ (В соответствии с Федеральным законом от 29 декабря 2010 г. № 436-ФЗ.)
ББК 22.183.5
УДК 519.8
Права на издание получены по соглашению с Springer Science+Business Media, LLC. Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные. Тем не менее, имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственности за возможные ошибки, связанные с использованием книги. Издательство не несет ответственности за доступность материалов, ссылки на которые вы можете найти в этой книге. На момент подготовки книги к изданию все ссылки на интернет- ресурсы были действующими.
ISBN 978-1461468486 англ.
First published in English under the title Applied Predictive Modeling, 1st Edition by Max Kuhn, Kjell Johnson by Springer Science+Business Media, LLC © 2013, Springer Science+Business Media New York
This edition has been translated and published under licence from Springer Science+Business Media, LLC.
Springer Science+Business Media, LLC takes no responsibility and shall not be made liable for the accuracy of the translation.
ISBN 978-5-4461-1039-1
© Перевод на русский язык ООО Издательство «Питер», 2019
© Издание на русском языке, оформление ООО Издательство «Питер», 2019 ©Серия «Для профессионалов», 2019
Краткое содержание
Предисловие 18
Глава 1. Введение 21
ЧАСТЫ
ОБЩИЕ СТРАТЕГИИ
Глава 2. Краткий обзор процесса предиктивного моделирования 42
Глава 3. Предварительная обработка данных 51
Глава 4. Переобучение и настройка модели 87
ЧАСТЬ II РЕГРЕССИОННЫЕ МОДЕЛИ
Глава 5. Измерение эффективности регрессионных моделей 122
Глава 6. Модели с признаками линейной регрессии 128
Глава 7. Нелинейные регрессионные модели 169
Глава 8. Древовидные модели. Модели на базе правил 202
Глава 9. Обзор моделей растворимости 254
Глава 10. Практический пример: сопротивление сжатию бетонных смесей 257
6 Краткое содержание
ЧАСТЬ III
КЛАССИФИКАЦИОННЫЕ МОДЕЛИ
Глава 11. Определение эффективности в классификационных моделях 278
Глава 12. Дискриминантный анализ и другие линейные классификационные
модели 307
Глава 13. Нелинейные классификационные модели 365
Глава 14. Деревья классификации и модели на базе правил 407
Глава 15. Сравнительный анализ моделей для заявок на получение грантов 456
Глава 16. Решение проблемы дисбаланса классов 460
Глава 17. Практикум: планирование заданий 488
ЧАСТЫУ ПРОЧИЕ ВОПРОСЫ ПРЕДИКТИВНОГО МОДЕЛИРОВАНИЯ
Глава 18. Определение важности предикторов 506
Глава 19. Выбор признаков 531
Глава 20. Факторы, влияющие на эффективность модели 567
ПРИЛОЖЕНИЯ
Приложение А. Краткая сводка различных моделей 596
Приложение Б. Введение в R 599
Приложение В. Рекомендуемые веб-сайты 616
Список источников 619
Оглавление
Предисловие 18
От издательства 20
Глава 1. Введение 21
1.1. Прогнозирование и интерпретация 24
1.2. Ключевые ингредиенты предиктивных моделей 25
1.3. Терминология 27
1.4. Примеры наборов данных и типичные сценарии данных 29
Музыкальный жанр 29
Заявки на получение грантов 30
Поражение печени 31
Проницаемость 32
Производство химикатов 32
Мошенничество в финансовых отчетах 33
Сравнения наборов данных 34
1.5. Структура книги 36
1.6. Условные обозначения 38
ЧАСТЬ I
ОБЩИЕ СТРАТЕГИИ
Глава 2. Краткий обзор процесса предиктивного моделирования 42
2.1. Пример прогнозирования экономии топлива 42
2.2. Аспекты, заслуживающие отдельного рассмотрения 48
Разделение данных 48
Данные предикторов 48
Оценка эффективности 49
Оценка нескольких моделей 49
Выбор модели 49
2.3. Итоги 50
Глава 3. Предварительная обработка данных 51
3.1. Практический пример: сегментация клеток в высокопроизводительном
скрининге 53
3.2. Преобразования данных для отдельных предикторов 55
Центрирование и масштабирование 55
Преобразования для устранения смещения 55
3.3. Преобразования данных с несколькими предикторами 58
Преобразования для решения проблемы выбросов 58
Прореживание данных и выделение признаков 60
3.4. Отсутствующие значения 66
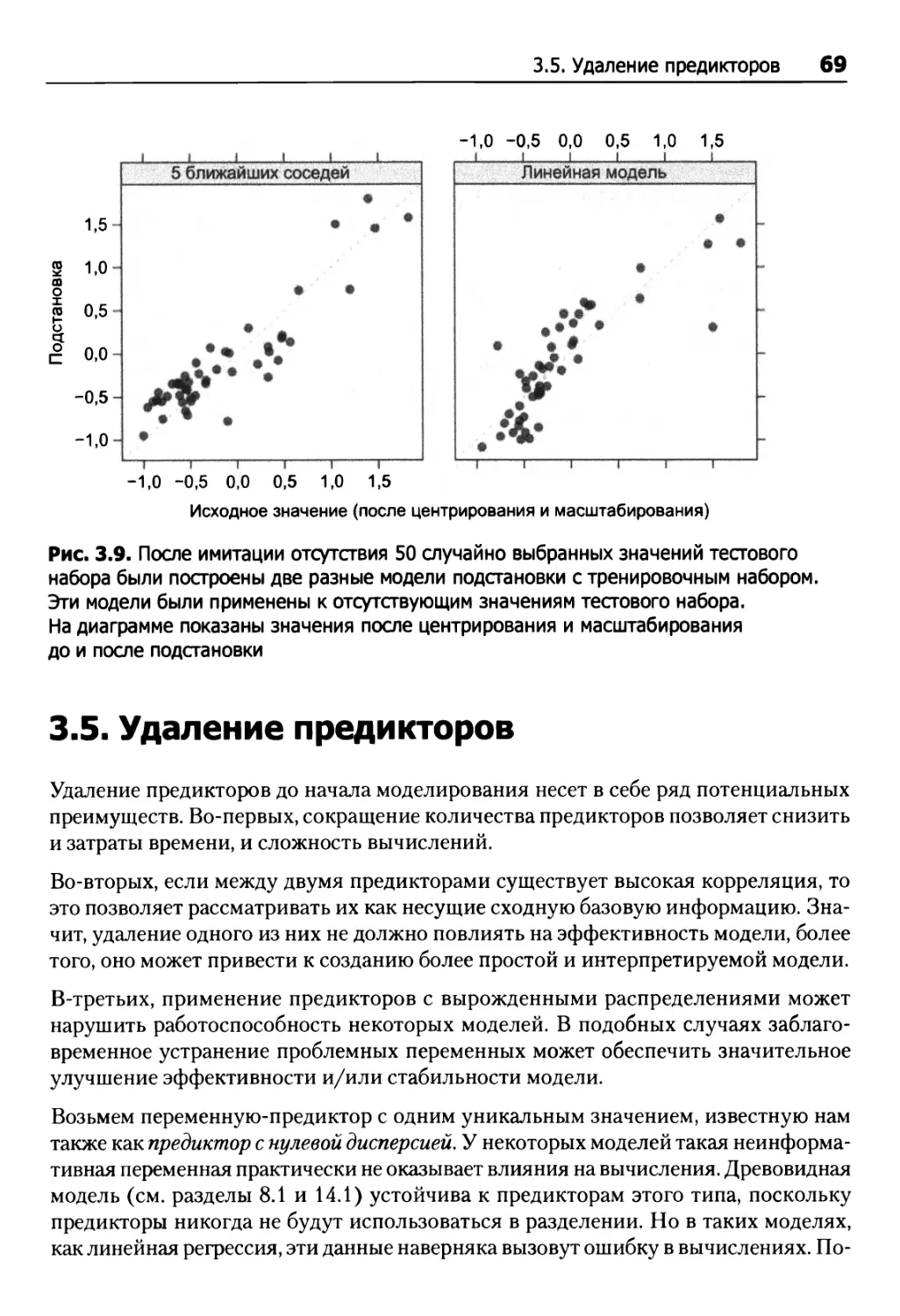
3.5. Удаление предикторов 69
Корреляции между предикторами 71
3.6. Добавление предикторов 73
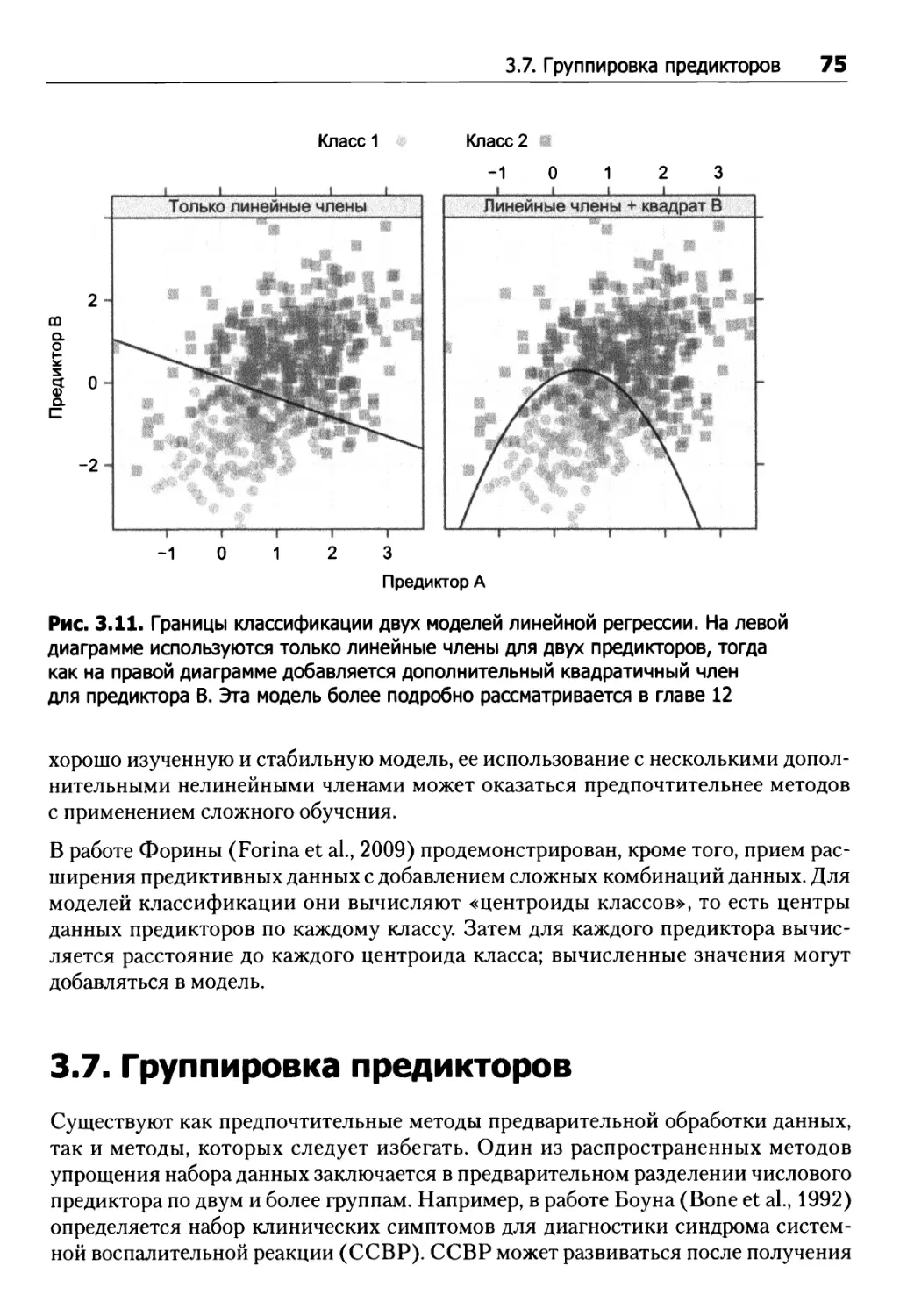
3.7. Группировка предикторов 75
3.8. Вычисления 77
Преобразования 79
Фильтрация 81
Создание фиктивных переменных 83
Упражнения 85
Глава 4- Переобучение и настройка модели 87
4.1. Проблема переобучения 88
4.2. Настройка модели 90
4.3. Разделение данных 93
4.4. Методы повторной выборки 96
К-кратная перекрестная проверка 96
Обобщенная перекрестная проверка 98
Повторное разделение тренировочного/тестового набора 98
Бутстрэп 99
4.5. Практикум: оценка кредитоспособности 101
4.6. Выбор итоговых параметров настройки 101
4.7. Рекомендации по разделению данных 105
4.8. Выбор между моделями 106
4.9. Вычисления 108
Разделение данных 109
Повторная выборка 110
Базовый процесс построения модели в R 111
Определение параметров настройки 112
Сравнение моделей 116
Упражнения 118
ЧАСТЬ II
РЕГРЕССИОННЫЕ МОДЕЛИ
Глава 5. Измерение эффективности регрессионных моделей 122
5.1. Количественные показатели эффективности 122
5.2. Обратное отношение между смещением и дисперсией 124
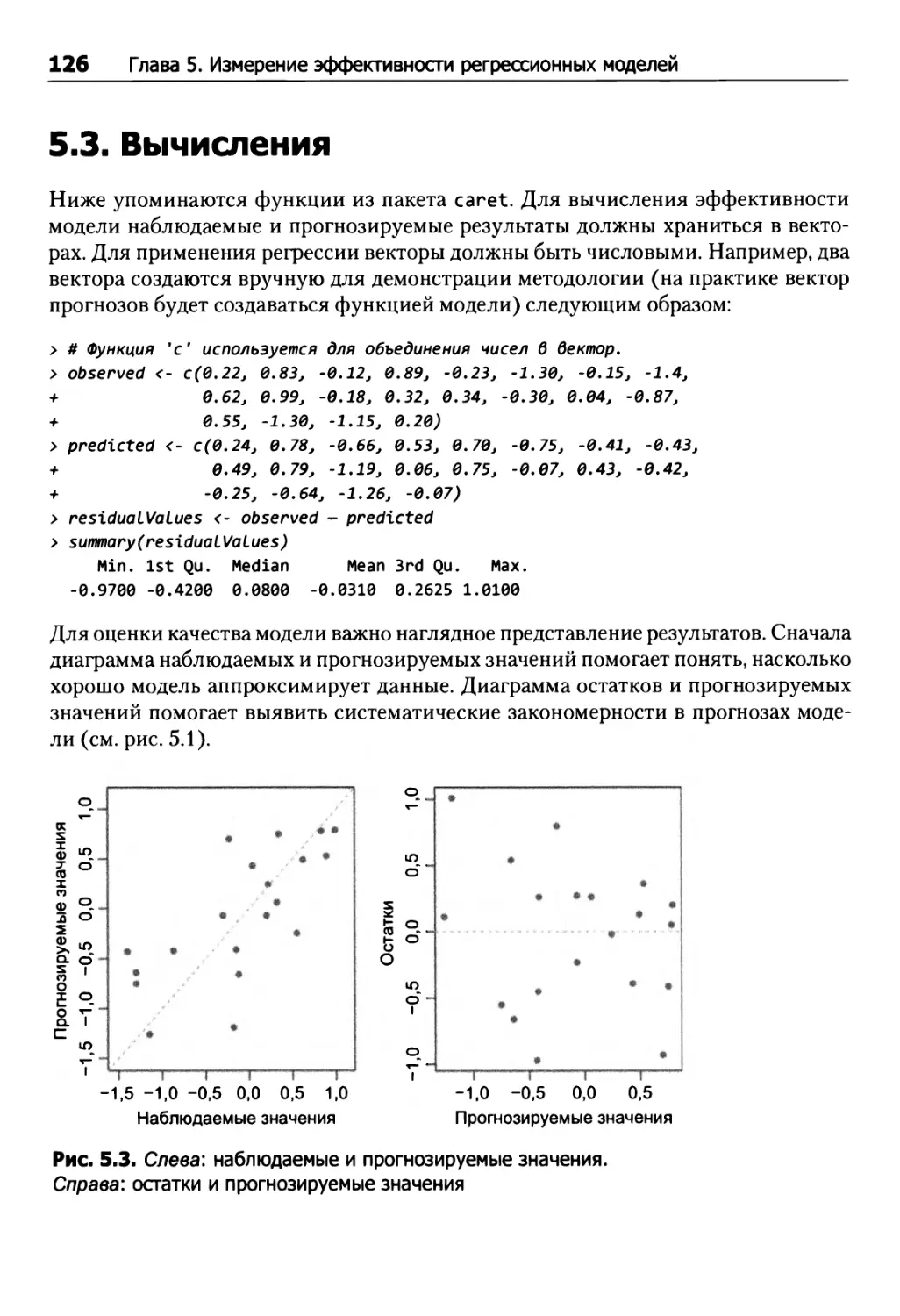
5.3. Вычисления 126
Глава 6. Модели с признаками линейной регрессии 128
6.1. Практикум: моделирование количественного соотношения «структура-
активность» 129
6.2. Линейная регрессия 135
Линейная регрессия для данных растворимости 139
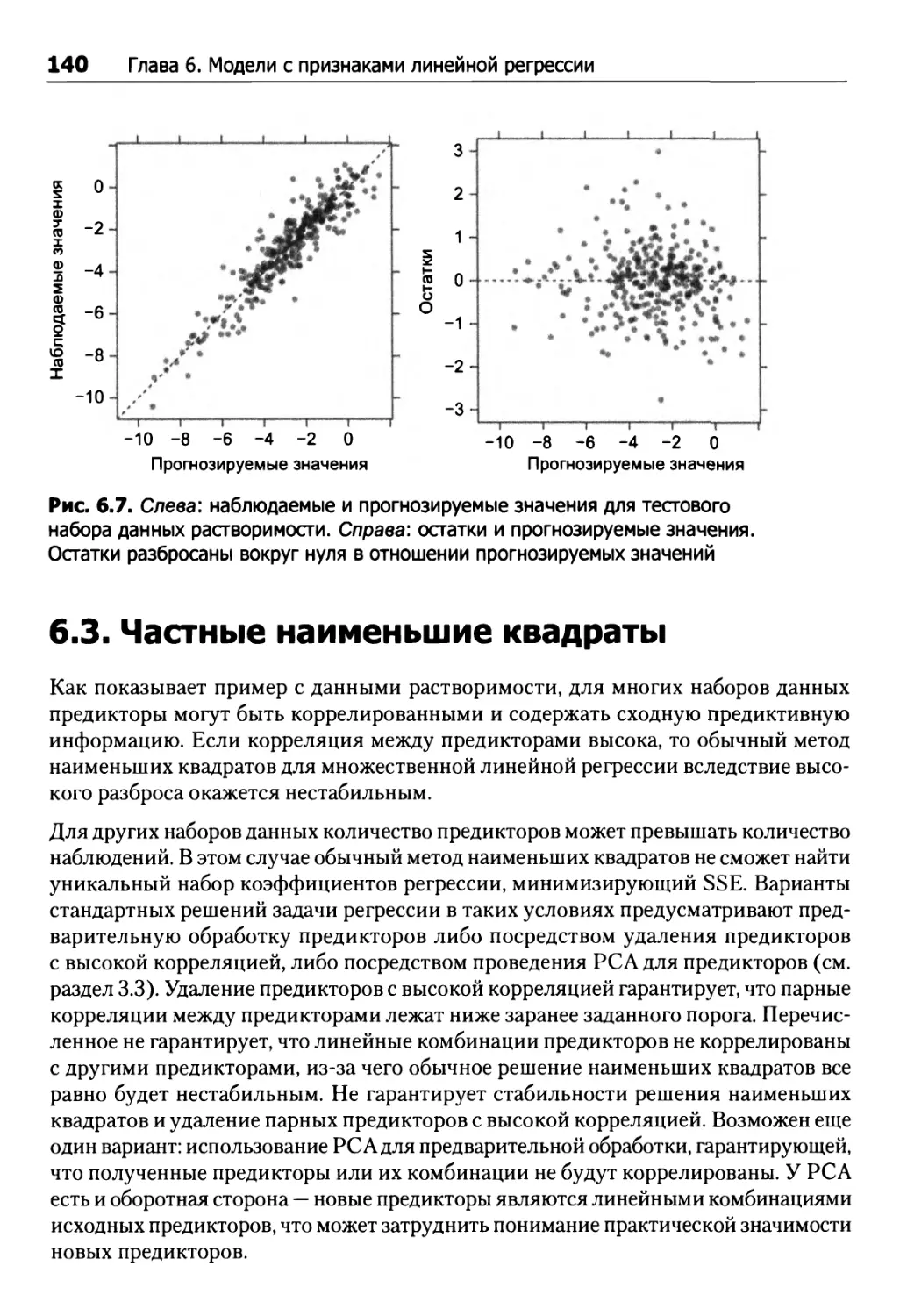
6.3. Частные наименьшие квадраты 140
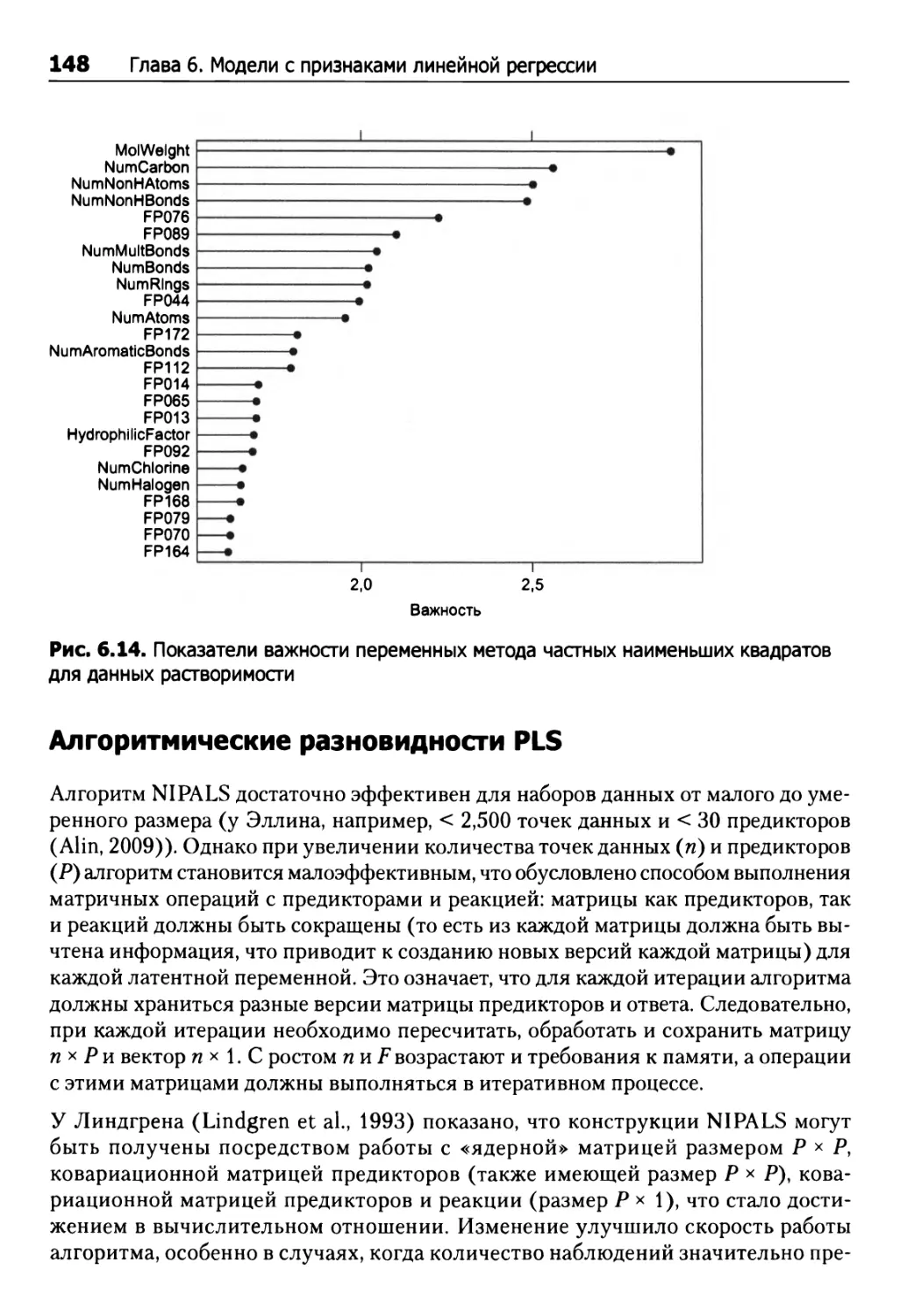
Применение методов PCR и PLSR для прогнозирования данных растворимости 144
Алгоритмические разновидности PLS 148
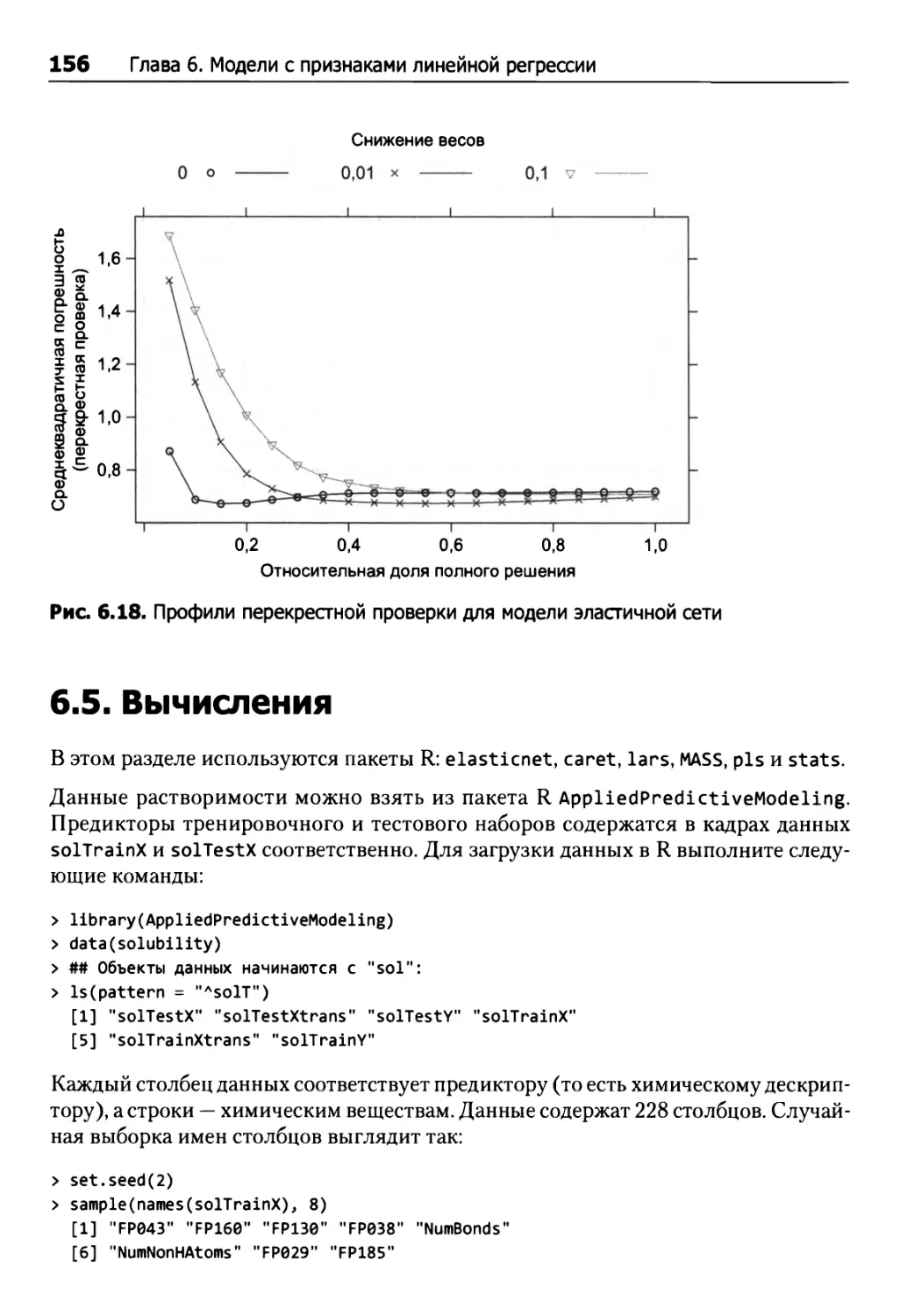
6.4. Штрафные модели 150
6.5. Вычисления 156
Обычная линейная регрессия 157
Частные наименьшие квадраты 162
Штрафные регрессионные модели 163
Упражнения 166
Глава 7. Нелинейные регрессионные модели 169
7.1. Нейросети 169
7.2. Многомерные адаптивные регрессионные сплайны 174
7.3. SVM, или метод опорных векторов 180
7.4. Метод к ближайших соседей 188
7.5. Вычисления 191
Нейросети 191
Многомерные адаптивные регрессионные сплайны 193
SVM, метод опорных векторов 196
Метод KNN 198
Упражнения 198
Глава 8. Древовидные модели. Модели на базе правил 202
8.1. Базовые деревья регрессии 204
8.2. Деревья регрессионных моделей 214
8.3. Модели на базе правил 221
8.4. Бэггинг-деревья 224
8.5. Случайные леса 230
8.6. Усиление 235
8.7. Модель Cubist 241
8.8. Вычисления 246
Простые деревья 246
Деревья моделей 247
Деревья бэггинга 248
Случайные леса 248
Усиленные деревья 249
Модель Cubist 250
Упражнения 250
Глава 9. Обзор моделей растворимости 254
Глава 10. Практический пример: сопротивление сжатию бетонных смесей 257
10.1. Стратегия построения модели 261
10.2. Эффективность моделей 262
10.3. Оптимизация сопротивления сжатию 265
10.4. Вычисления 269
ЧАСТЬ III КЛАССИФИКАЦИОННЫЕ МОДЕЛИ
Глава 11. Определение эффективности в классификационных моделях 278
11.1. Прогнозы классов 278
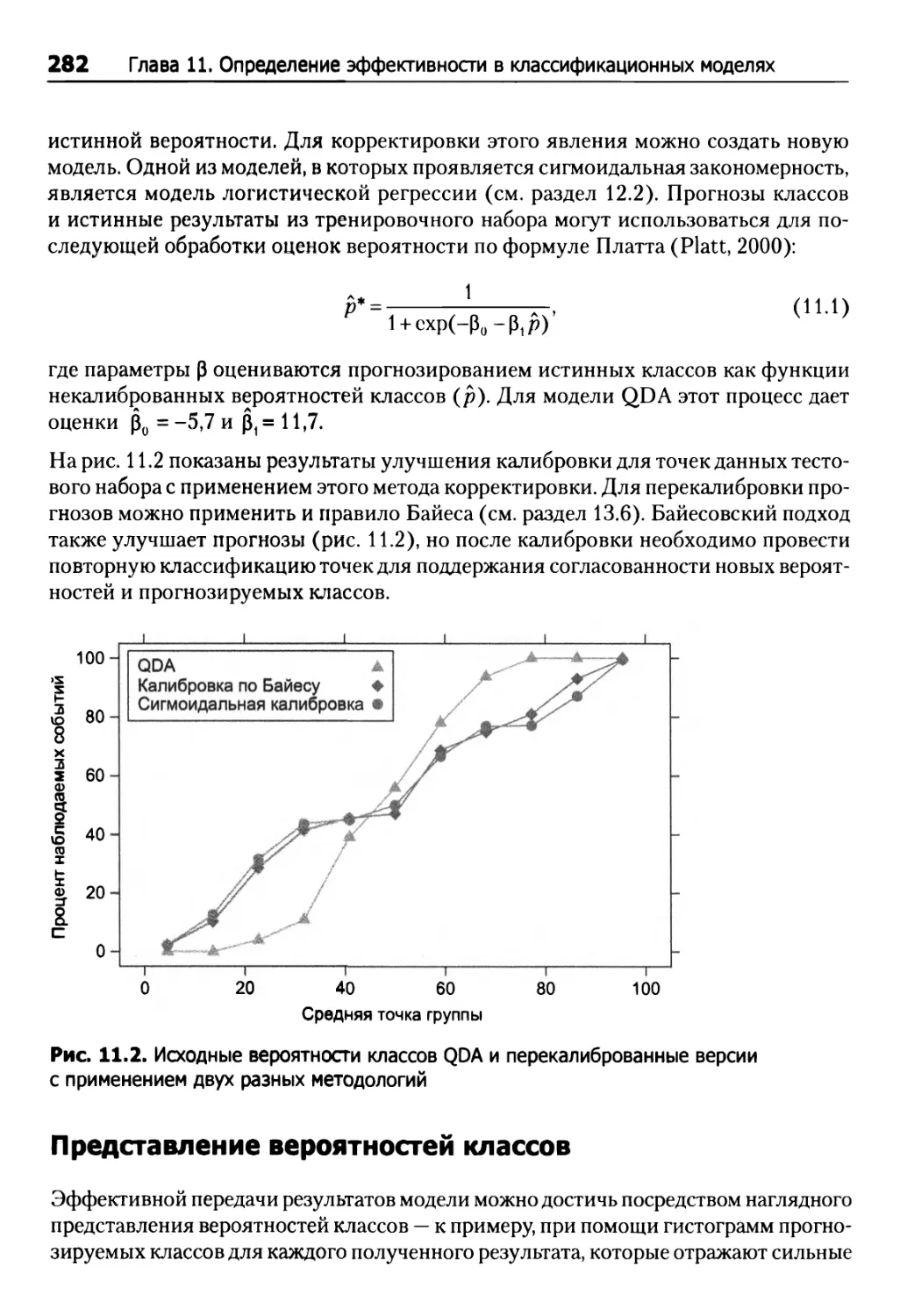
Хорошо откалиброванные вероятности 280
Представление вероятностей классов 282
Неоднозначные зоны 284
11.2. Оценка прогнозируемых классов 286
Задача двух классов 288
Критерии, не основанные на точности 292
11.3. Оценка вероятностей классов 294
ROC-кривые 295
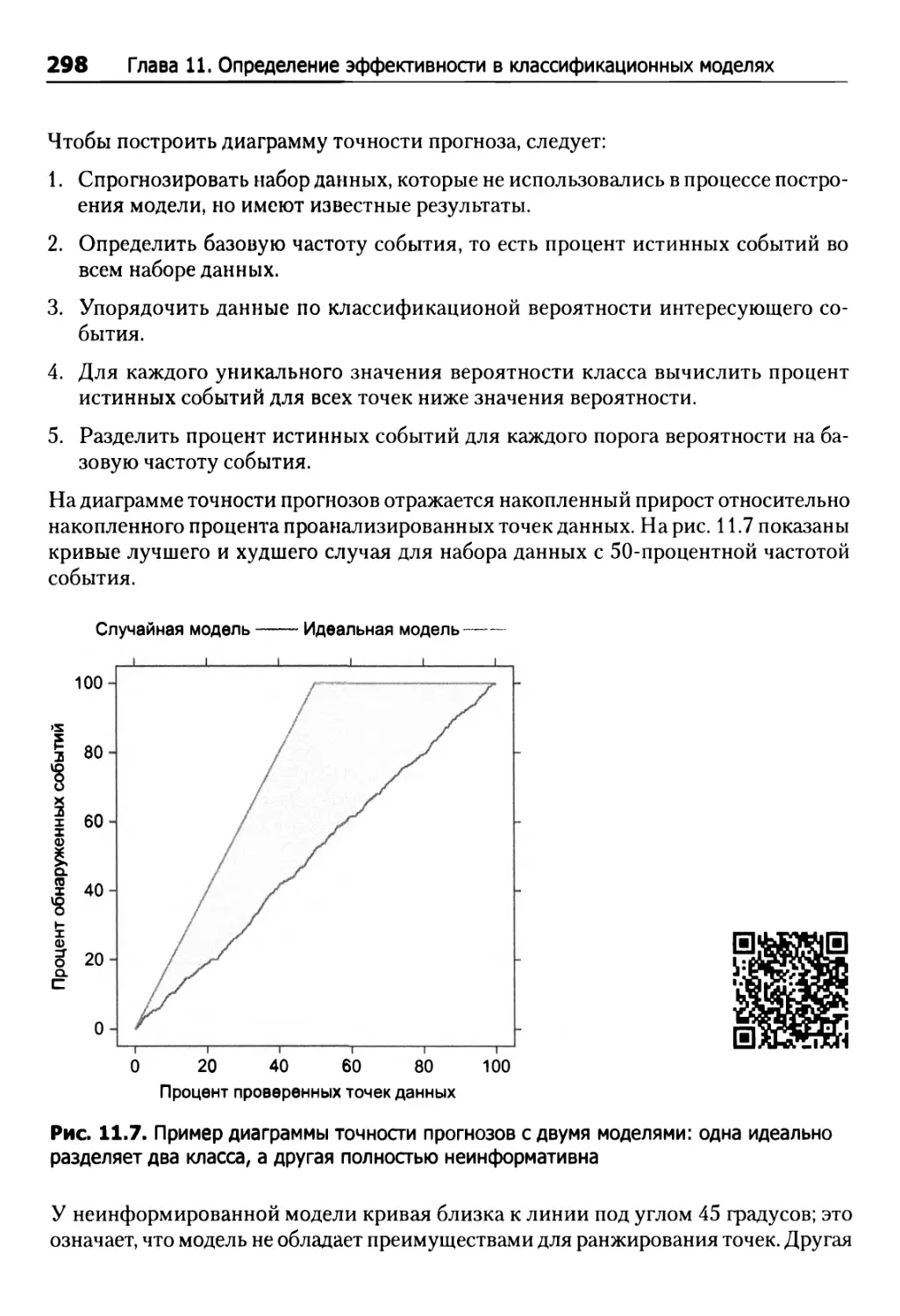
Диаграммы точности прогнозов 297
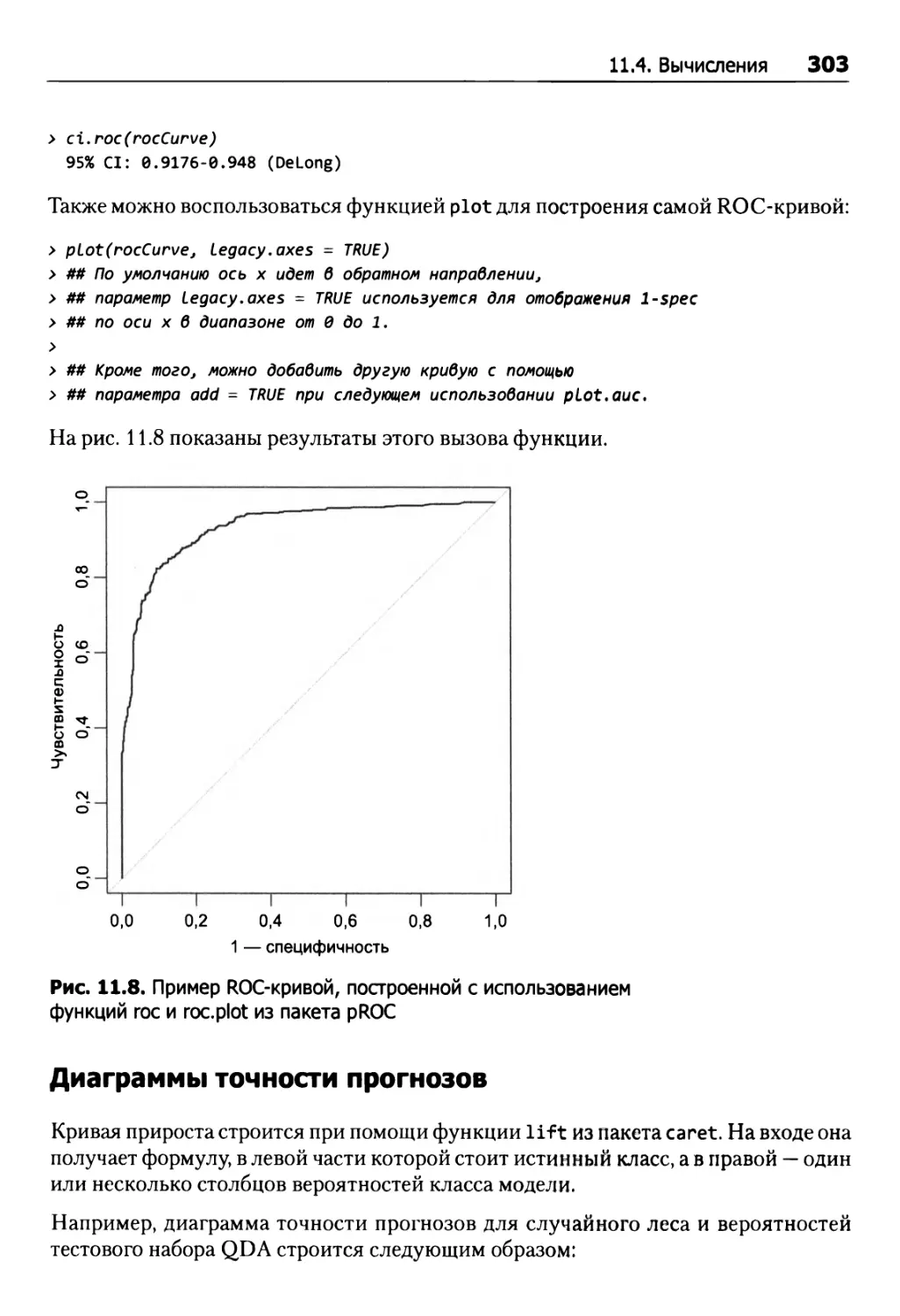
11.4. Вычисления 299
Чувствительность и специфичность 301
Матрица несоответствий 301
ROC-кривые 302
Диаграммы точности прогнозов 303
Калибровка вероятностей 304
Глава 12. Дискриминантный анализ и другие линейные классификационные модели 307
12.1. Практикум: прогнозирование успешных заявок на получение грантов 307
12.2. Логистическая регрессия 315
12.3. Линейный дискриминантный анализ (LDA) 320
12.4. Дискриминантный анализ методом частных наименьших квадратов 331
12.5. Штрафные модели 337
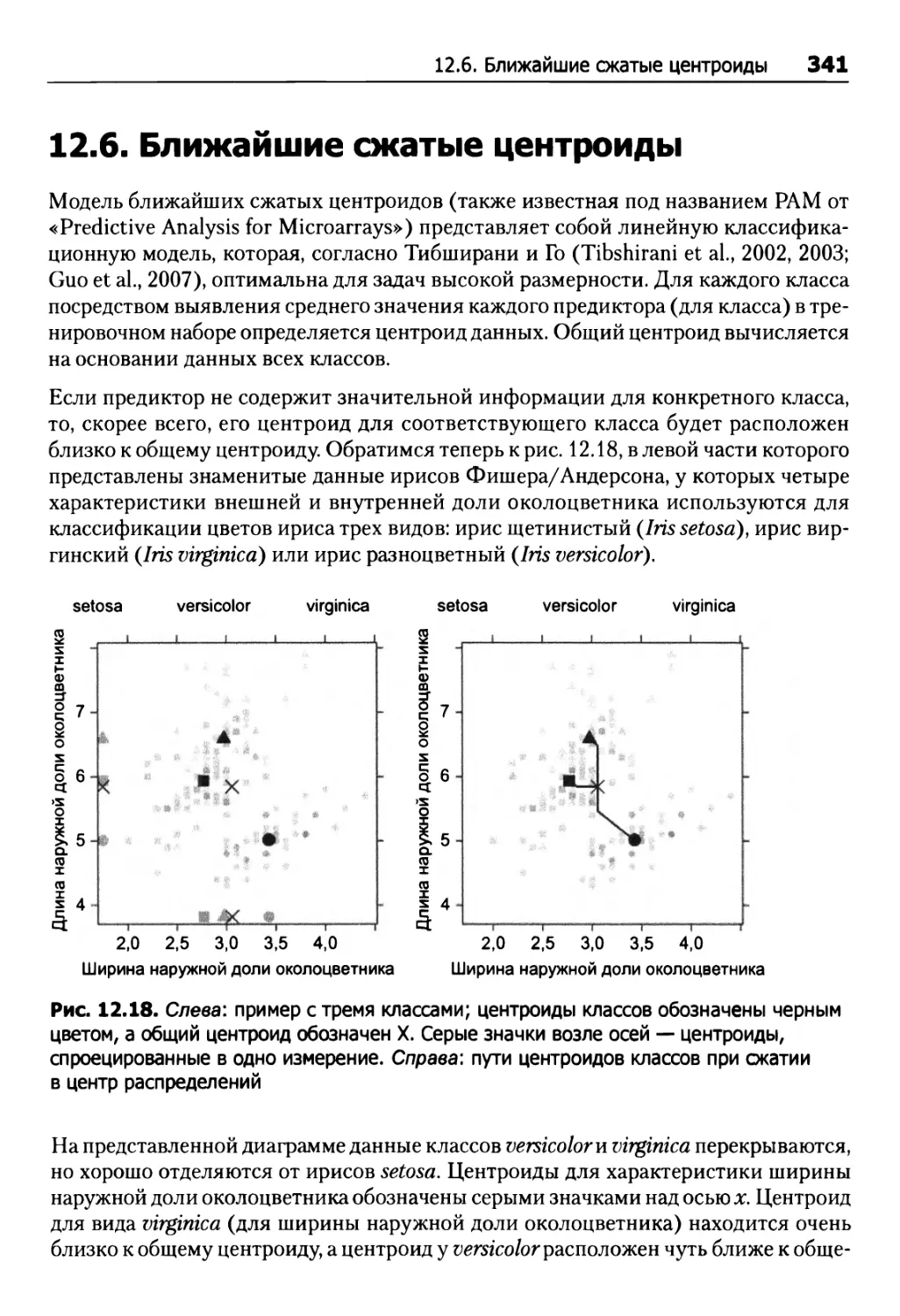
12.6. Ближайшие сжатые центроиды 341
12.7. Вычисления 344
Логистическая регрессия 347
Линейный дискриминантный анализ 353
Дискриминантный анализ методом частных наименьших квадратов 355
Штрафные модели 357
Метод ближайших сжатых центроидов 359
Упражнения 362
Глава 13. Нелинейные классификационные модели 365
13.1. Нелинейный дискриминантный анализ 365
Квадратичный и регуляризированный дискриминантный анализ 365
Смешанный дискриминантный анализ 367
13.2. Нейросети 369
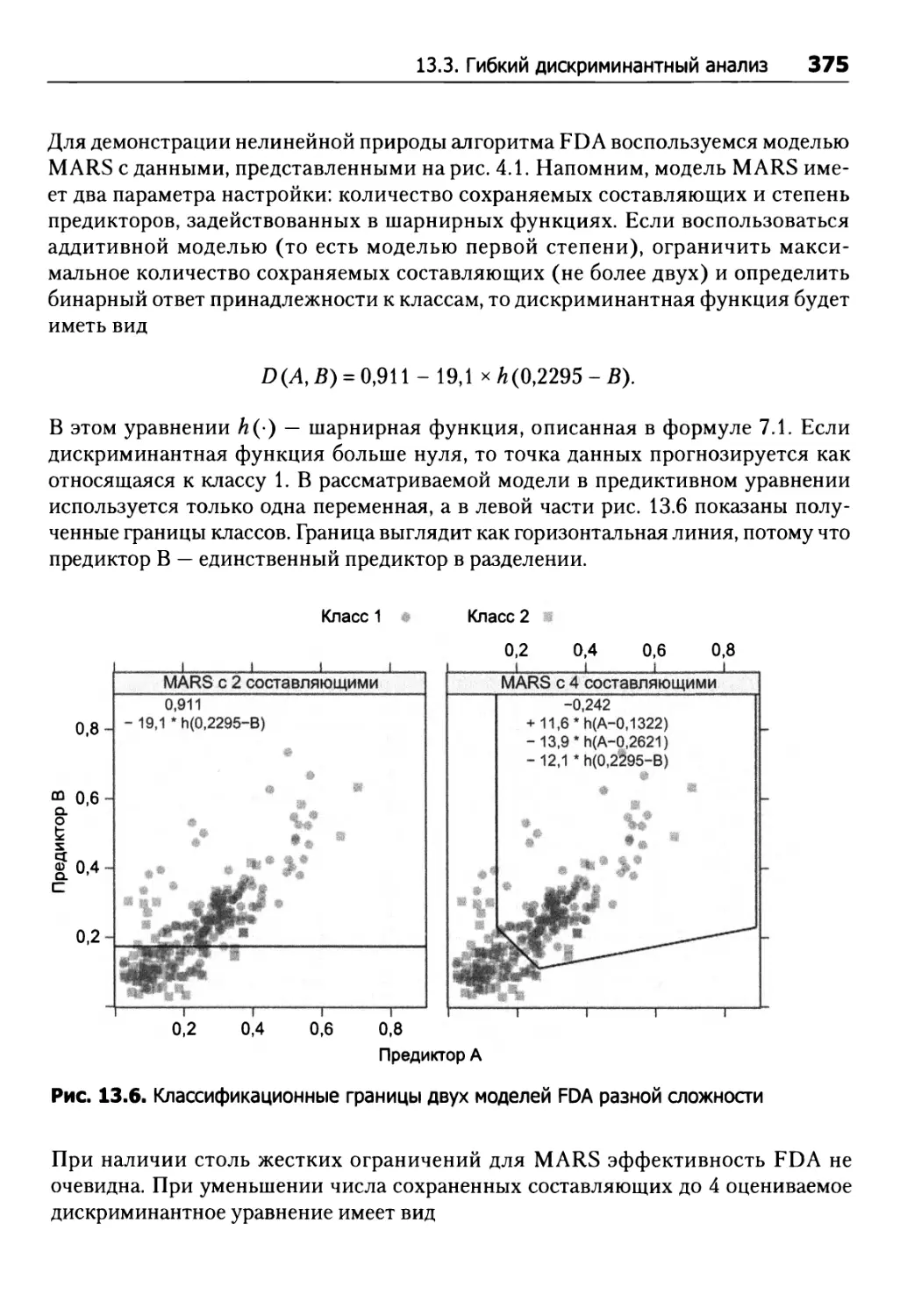
13.3. Гибкий дискриминантный анализ 374
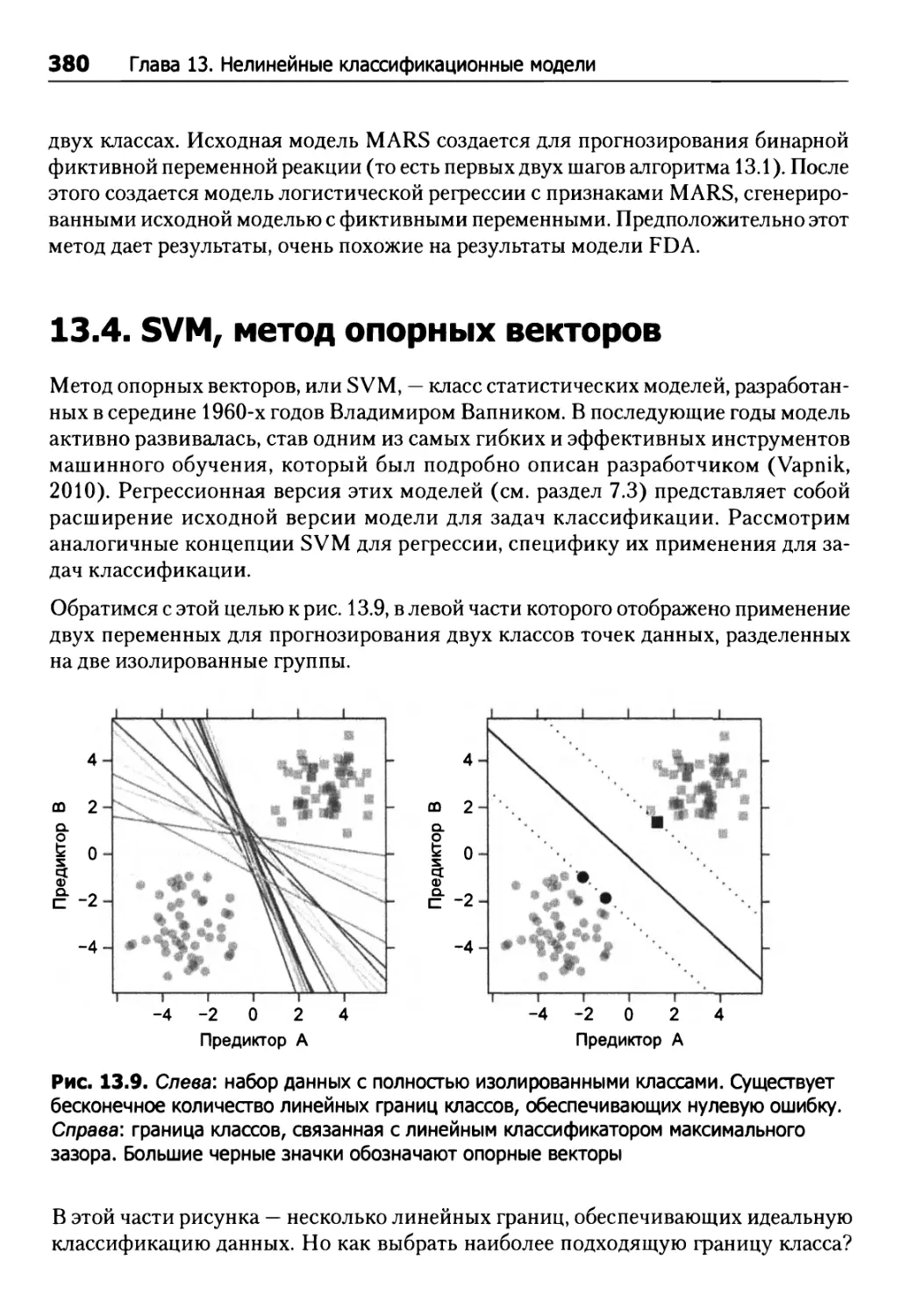
13.4. SVM, метод опорных векторов 380
13.5. Метод KNN 389
13.6. Наивный байесовский классификатор 391
13.7. Вычисления 396
Нелинейный дискриминантный анализ 397
Нейросети 398
FDA 400
Модель SVM 401
Модель KNN (к ближайших соседей) 403
Наивный байесовский классификатор 403
Упражнения 405
Глава 14. Деревья классификации и модели на базе правил 407
14.1. Базовые деревья классификации 408
14.2. Модели на базе правил 423
Модель C4.5Rules 423
Модель PART 424
14.3. Бэггинг деревьев 425
14.4. Случайные леса 427
14.5. Бустинг 429
Алгоритм AdaBoost 429
Стохастический градиентный бустинг 431
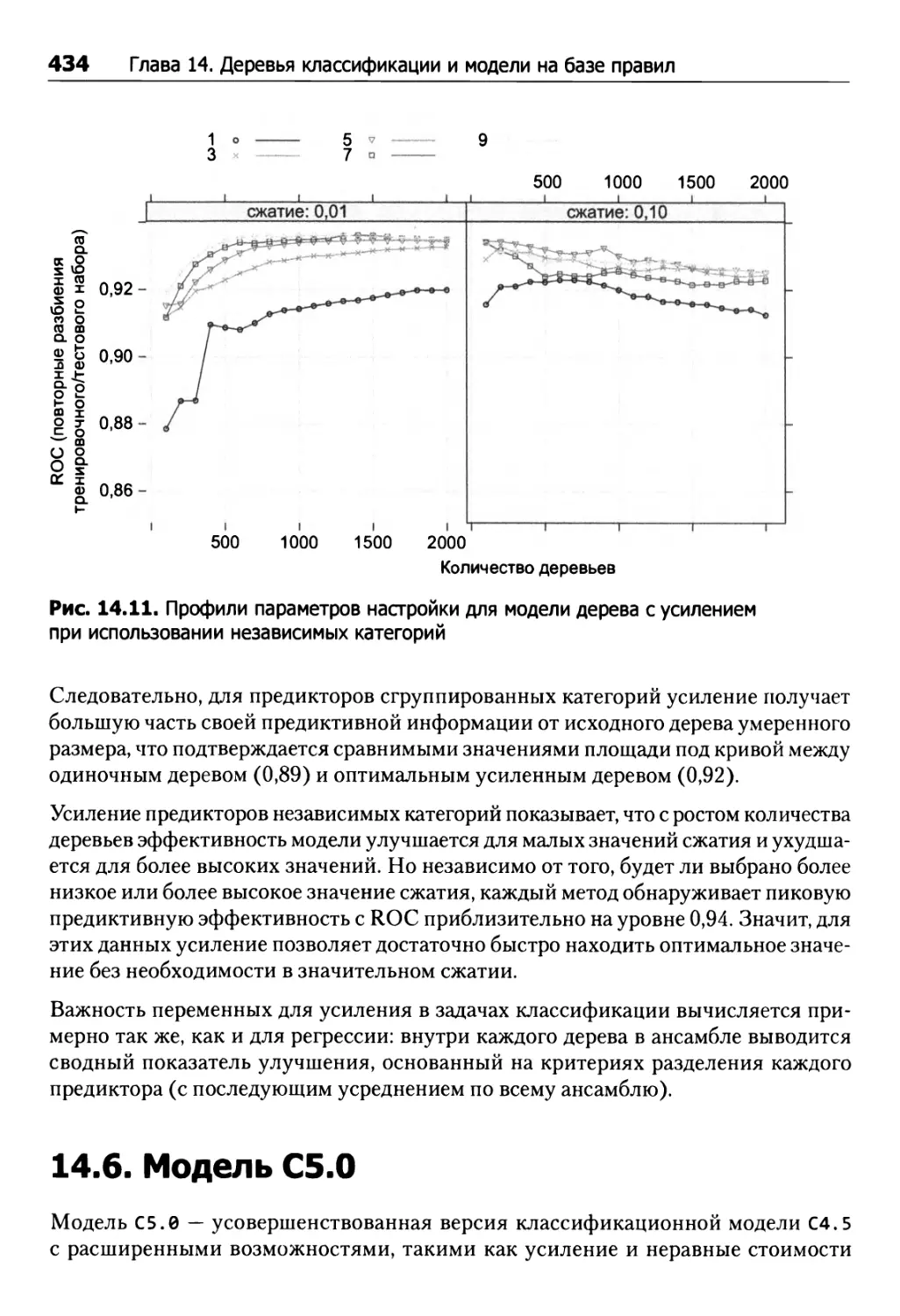
14.6. Модель С5.0 434
Классификационные деревья 435
Правила классификации 436
Усиление 437
Другие аспекты модели 438
Данные грантов 440
14.7. Сравнение двух кодировок категорийных предикторов 442
14.8. Вычисления 443
Классификационные деревья 443
Правила 447
Деревья с бэггингом 449
Случайный лес 450
Деревья с усилением 451
Упражнения 453
Глава 15. Сравнительный анализ моделей для заявок на получение грантов 456
Глава 16. Решение проблемы дисбаланса классов 460
16.1. Практикум: прогнозирование политики страхования 461
16.2. Эффект дисбаланса классов 462
16.3. Настройка модели 465
16.4. Альтернативные пороги отсечения 465
16.5. Корректировка априорных вероятностей 468
16.6. Неравные веса 469
16.7. Методы выборки 469
16.8. Тренировка с учетом стоимости 473
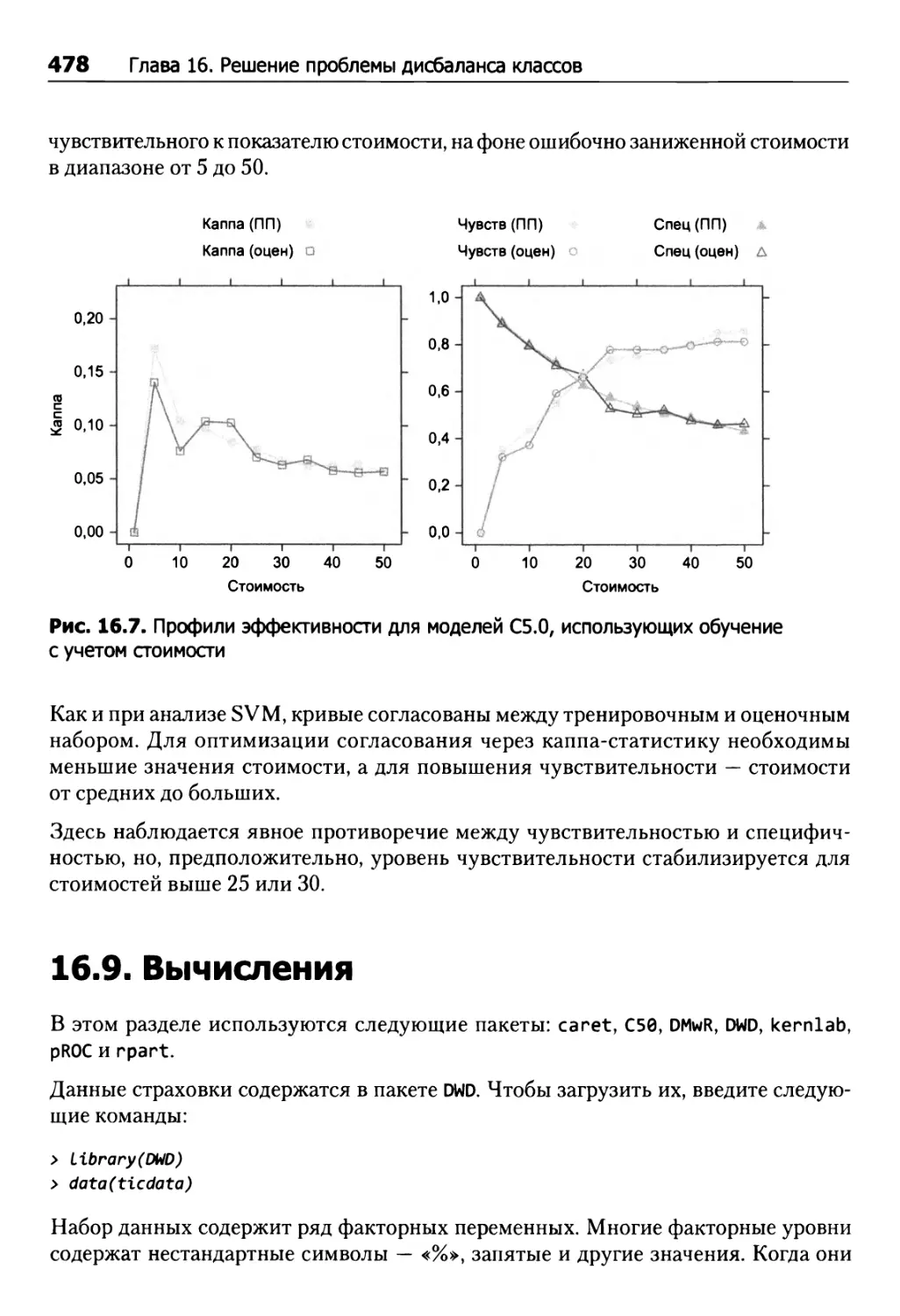
16.9. Вычисления 478
Альтернативные пороги отсечения 482
Методы выборки 482
Тренировка с учетом стоимости 483
Упражнения 486
Глава 17. Практикум: планирование заданий 488
17.1. Разделение данных и стратегия модели 496
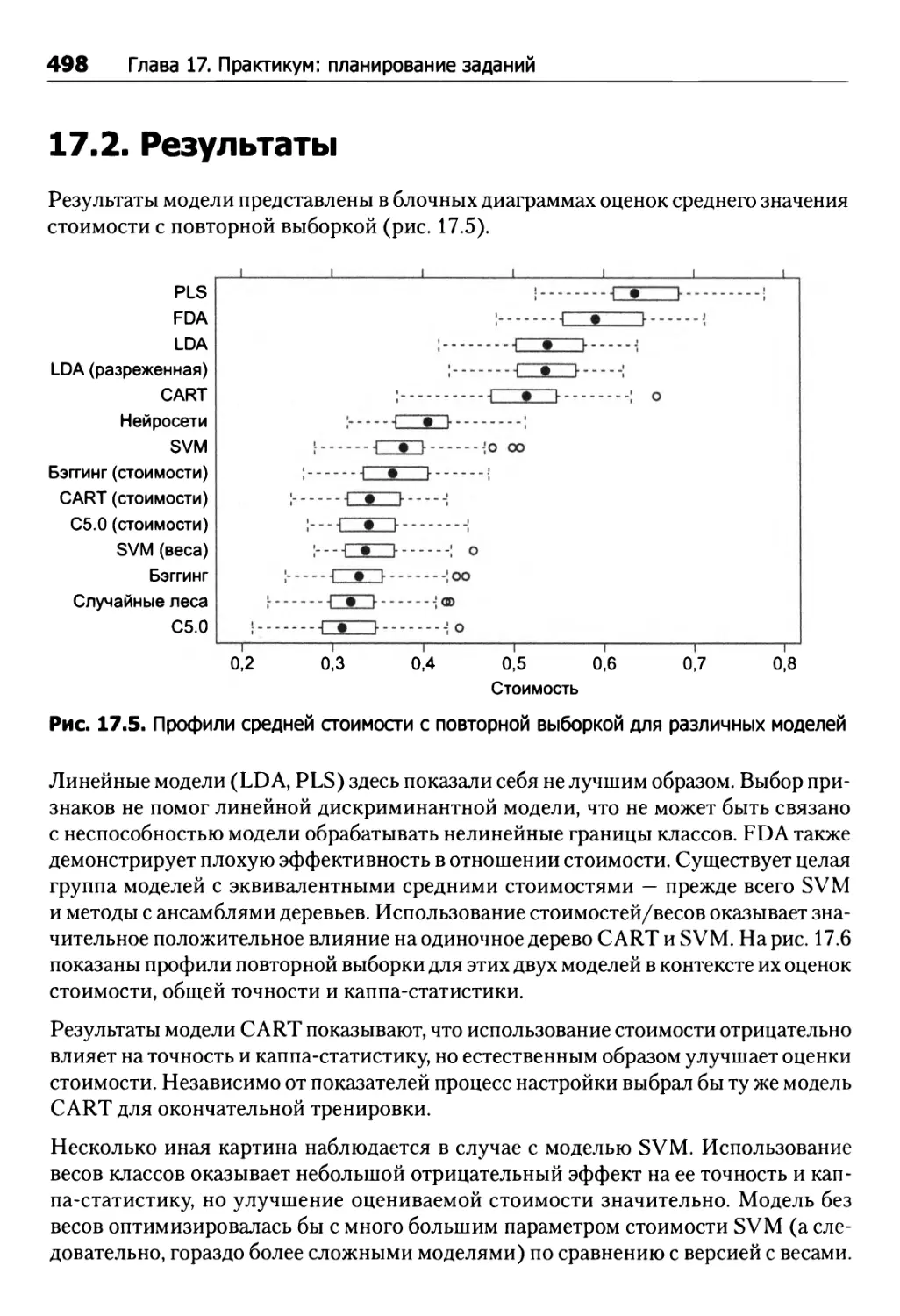
17.2. Результаты 498
17.3. Вычисления 501
ЧАСТЬ IV
ПРОЧИЕ ВОПРОСЫ ПРЕДИКТИВНОГО МОДЕЛИРОВАНИЯ
Глава 18. Определение важности предикторов 506
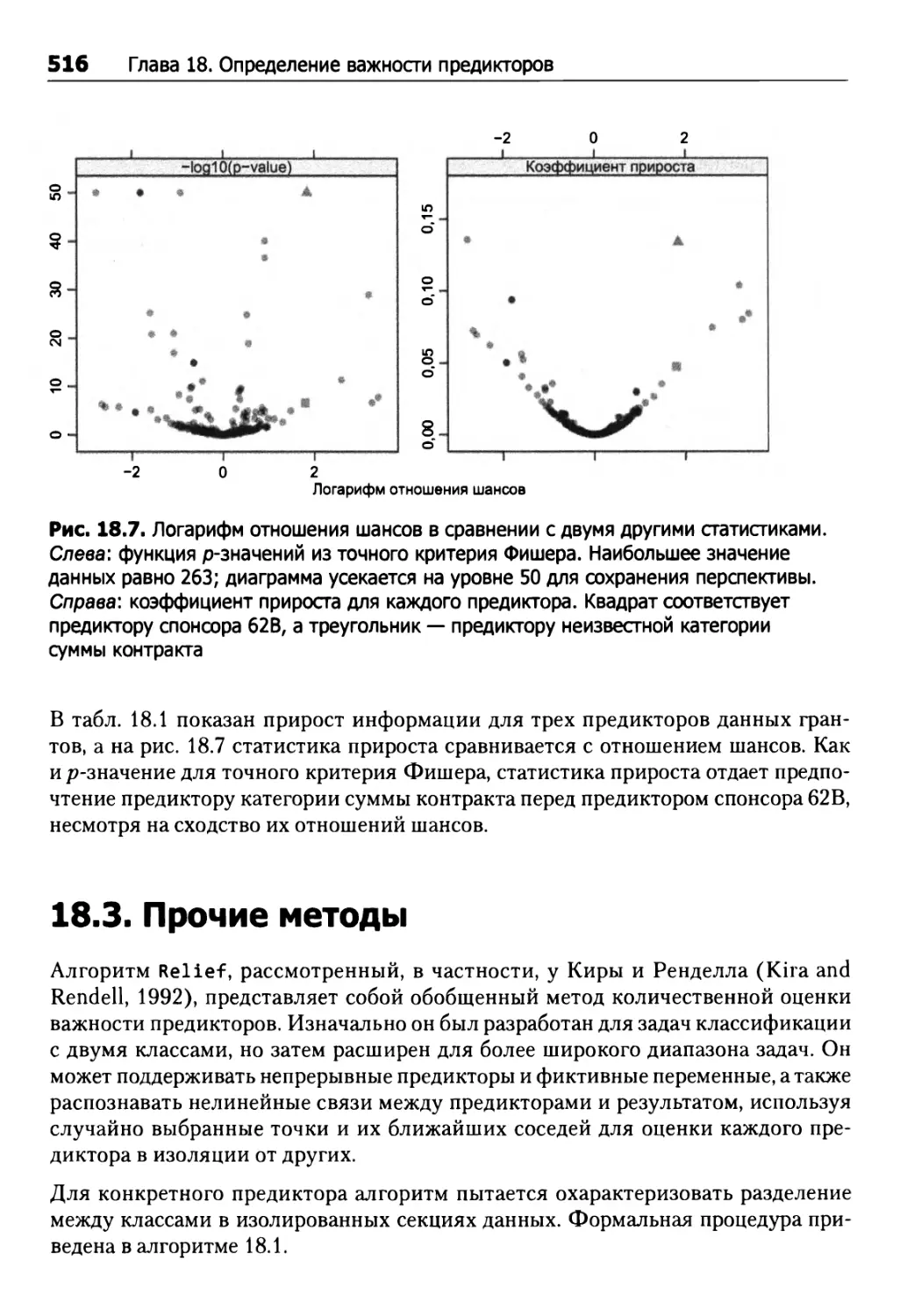
18.1. Числовые результаты 507
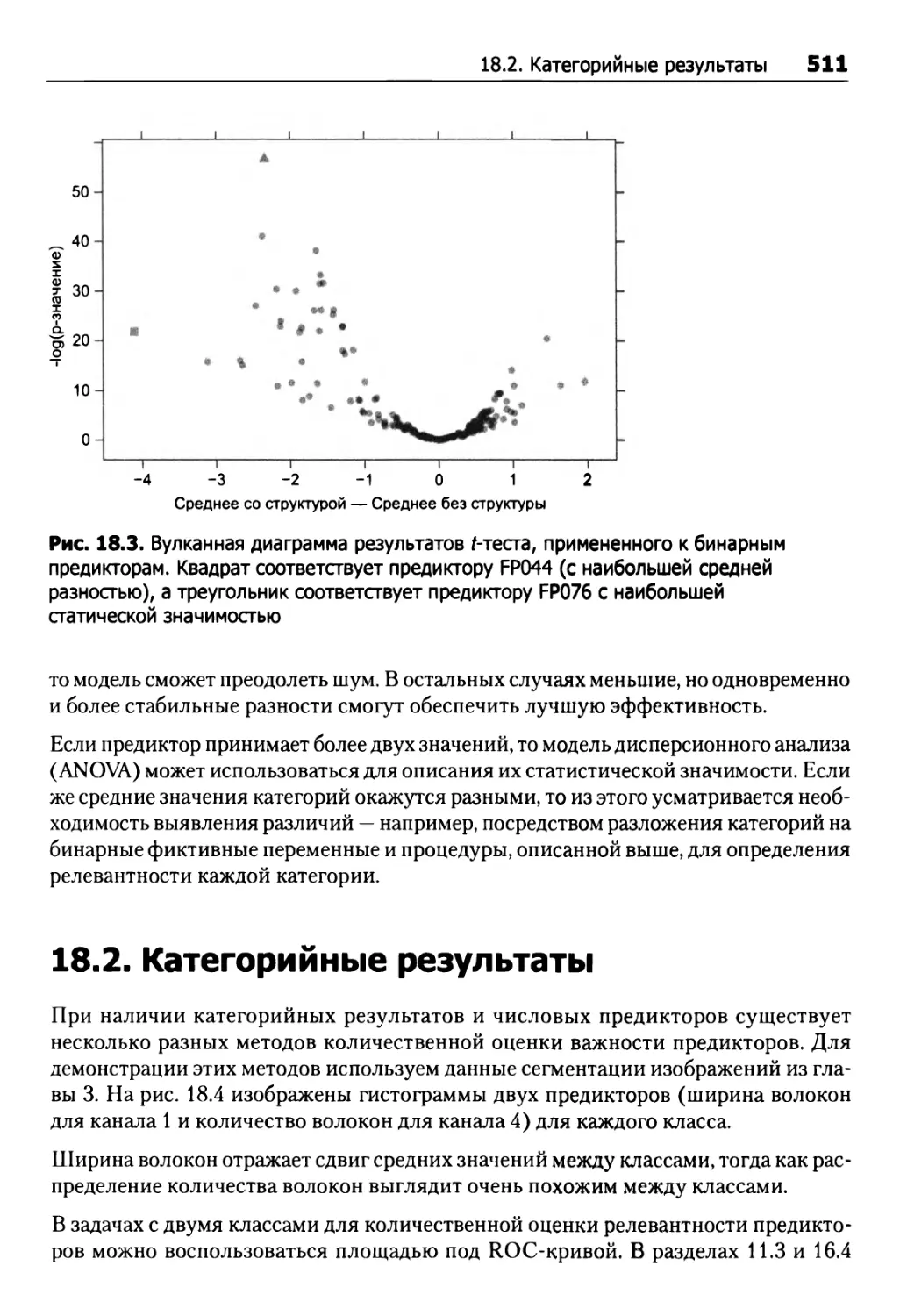
18.2. Категорийные результаты 511
18.3. Прочие методы 516
18.4. Вычисления 522
Числовые результаты 522
Категорийные результаты 525
Показатели важности для разных моделей 528
Упражнения 529
Глава 19. Выбор признаков 531
19.1. Последствия использования неинформативных предикторов 532
19.2. Методы сокращения количества предикторов 534
19.3. Методы-обертки 535
Прямой, обратный и пошаговый выбор 539
Имитация отжига 540
Генетические алгоритмы 541
19.4. Методы-фильтры 544
19.5. Смещение выбора 545
19.6. Практикум: прогнозирование когнитивного расстройства 548
19.7. Вычисления 557
Прямой, обратный и пошаговый выбор 558
Рекурсивное исключение признаков 560
Методы-фильтры 563
Упражнения 565
Глава 20. Факторы, влияющие на эффективность модели 567
20.1. Ошибки III типа 568
20.2. Ошибка измерения результата 571
20.3. Погрешность измерений в предикторах 572
Практикум: прогнозирование нежелательных побочных эффектов 576
20.4. Дискретизация непрерывных результатов 578
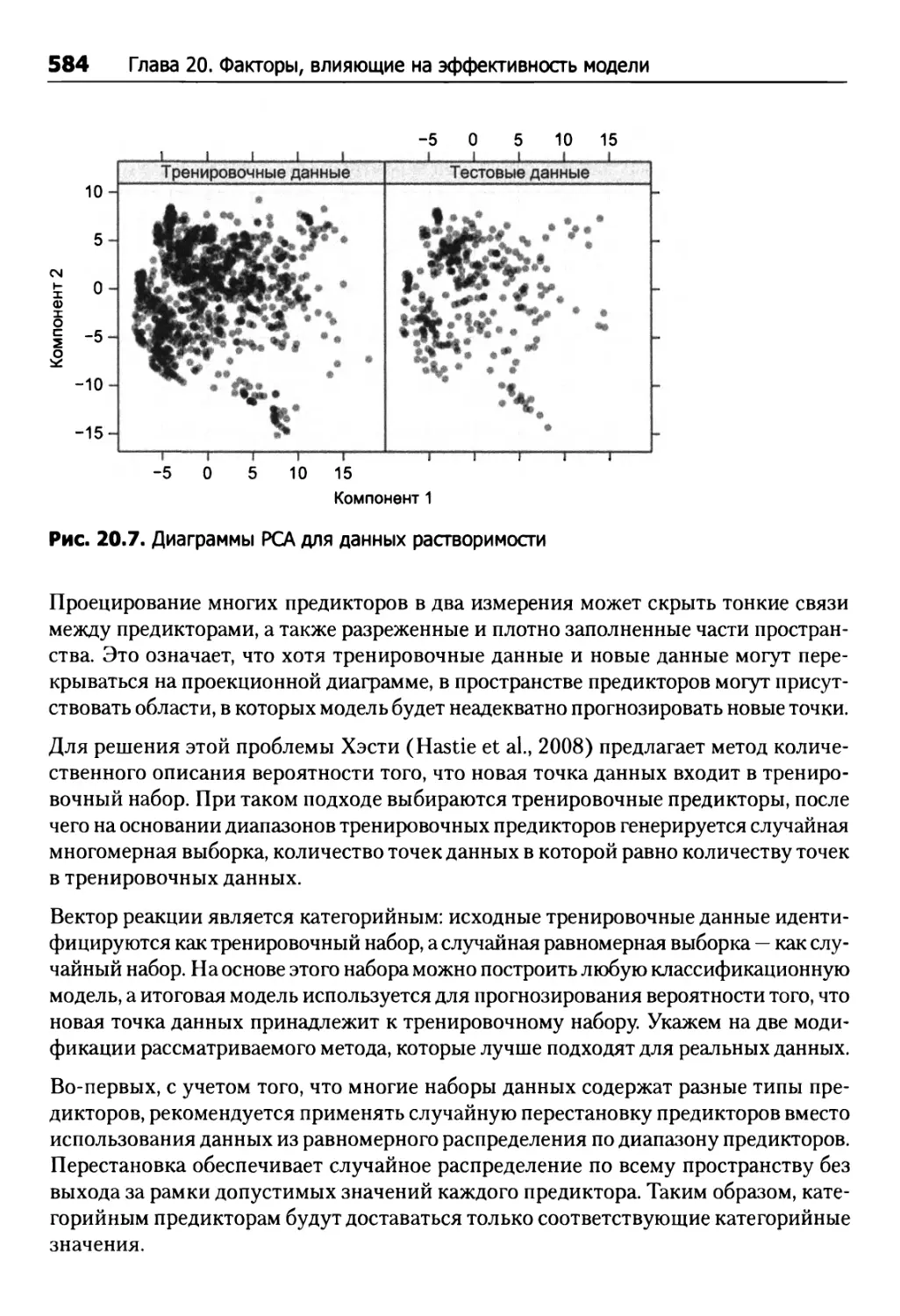
20.5. Когда следует доверять прогнозу вашей модели? 582
20.6. Влияние большой выборки 586
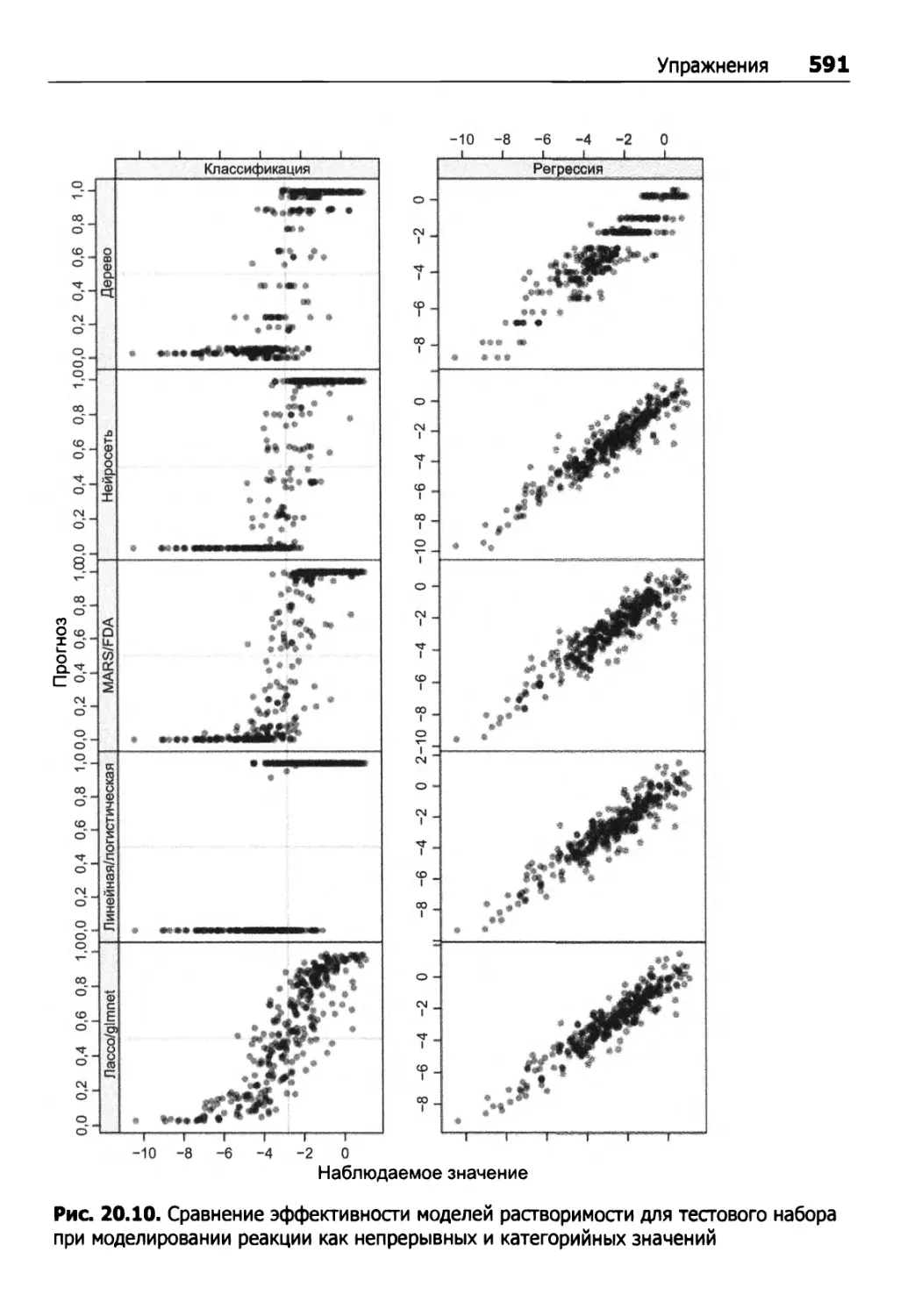
20.7. Вычисления 588
Упражнения 590
ПРИЛОЖЕНИЯ
Приложение А. Краткая сводка различных моделей 596
Приложение Б. Введение в R 599
Б.1. Запуск и вывод справочной информации 599
Б.2. Пакеты 600
Б.З. Создание объектов 602
Б.4. Типы данных и базовые структуры 602
Б.5. Работа с прямоугольными наборами данных 606
Б.6. Объекты и классы 609
Б.7. Функции R 610
Б.8. Три грани = 611
Б.9. Пакет AppliedPredictiveModeling 611
Б.10. Пакет caret 612
Б.11. Пакеты, используемые в книге 615
Приложение В. Рекомендуемые веб-сайты 616
Слисок источников 619
Посвящается нашим семьям:
Миранде и Стефану
Валери, Трумэну и малышу Гидеону
Предисловие
Эта книга посвящена анализу данных, при этом особое внимание в ней уделяется практике предиктивного моделирования (predictive modeling). Термин «предиктивное моделирование» может вызвать ассоциации с такими темами, как машинное обучение, распознавание образов и глубокий анализ данных (data mining.) Действительно, эти ассоциации уместны, а методы, которые обычно связываются с этими терминами, являются неотъемлемой частью процесса предиктивного моделирования. Однако предиктивное моделирование отнюдь не ограничивается инструментами и методами выявления закономерностей в данных. Практика предиктивного моделирования определяет такой процесс разработки модели, который бы позволил нам понять и дать численную оценку предиктивной точности модели для будущих, пока еще отсутствующих данных. Центральное место в книге занимает этот процесс в целом.
Мы стремились к тому, чтобы эта книга послужила руководством для специалиста-практика к процессу предиктивного моделирования, а также источником информации, в котором читатель мог бы узнать о методе и получить представление о многих распространенных современных мощных моделях. В книге рассматриваются некоторые статистические и математические методы, но практически в каждом случае мы старались описывать методы так, чтобы дать читателю представление об их сильных и слабых сторонах, а не об их происхождении и математическом обосновании. Почти везде мы избегаем сложных формул, хотя без нескольких неизбежных исключений не обошлось. Если вас больше интересует теоретический взгляд на предиктивное моделирование, мы рекомендуем книги Хэсти и др. (Hastie et al., 2008) и Бишопа (Bishop, 2006). Для понимания материала читатель должен быть знаком с основными понятиями статистики: дисперсия, корреляция, простая линейная регрессия и базовая проверка гипотез (p-значения и статистика критерия).
Процесс предиктивного моделирования по своей природе практичен. Однако в ходе наших исследований для этой работы мы узнали, что во многих статьях и публикациях читатель не может воспроизвести результаты, потому что данные отсутствуют в свободном доступе или программное обеспечение недоступно либо доступно только на коммерческой основе. У Бакхайта и Донохо (1995) приведена уместная критика этой традиционной «дымовой завесы», свойственной для научной среды:
Предисловие 19
«Статья о вычислительных методах в научном издании — не сами научные знания, а всего лишь реклама научных знаний. Настоящие научные знания — это полная среда разработки и полный набор инструкций, на основе которых были построены графики».
Следовательно, мы стремились по возможности излагать материал на практическом уровне, чтобы читатель мог воспроизводить результаты с разумной точностью, а также естественным образом расширять метод предиктивного моделирования для своих данных. Кроме того, мы используем язык R (Ihaka and Gentleman, 1996; R Development Core Team 2010) — бесплатно распространяемый программный продукт для статистических и математических вычислений — на всех стадиях процесса предиктивного моделирования. Почти все наборы данных из примеров доступны в виде пакетов R. Пакет R AppliedPredictiveModeling содержит многие наборы данных и сценарии R, использованные в книге, для воспроизведения анализа в каждой главе.
Мы выбрали R в качестве вычислительного ядра этого текста по нескольким причинам. Во-первых, R распространяется бесплатно (хотя существуют и коммерческие версии) для нескольких операционных систем. Во-вторых, R публикуется на условиях стандартной общественной лицензии GPL (Free Software Foundation, июнь 2007 года), определяющей возможности повторного распространения программы. В этой структуре любой желающий может свободно анализировать и изменять исходный код. Благодаря модели распространения с открытым кодом уже существуют десятки предиктивных моделей, реализованных в виде бесплатных пакетов. Кроме того, R содержит мощную и обширную поддержку общего процесса предиктивного моделирования. Читатель, не знакомый с R, легко найдет в интернете множество учебников. Вводный курс R и руководство для начинающих приведены в приложении.
Некоторые темы нам не удалось рассмотреть из-за нехватки времени и/или места, и прежде всего обобщенные аддитивные модели, ансамбли разных моделей, сетевые модели, модели временных рядов и еще несколько.
У книги также существует веб-сайт:
http://appliedpredictivemodeling.com/
На нем будет публиковаться обновленная информация.
Эта книга появилась на свет только благодаря поддержке и наставлениям многих людей: Уолтера Г. Картера (Walter Н. Carter), Джима Гарретта (Jim Garrett), Криса Дженнингса (Chris Gennings), Пола Хармса (Paul Harms), Криса Кифера (Chris Keefer), Уильяма Клингера (William Klinger), Дайдзина Ко (Daijin Ко), Рича Мура (Rich Moore), Дэвида Нохаузера (David Neuhouser), Дэвида Поттера (David Potter), Дэвида Пайна (David Рупе), Уильяма Рэйенса (William Rayens), Арнольда Стромберга (Arnold Stromberg) и Томаса Видмара (Thomas Vidmar). Мы также хотим поблагодарить Росса Кинлана (Ross Quinlan) за помощь с Cubist и С5.0 и за
20 Предисловие проверку наших описаний этих двух тем. В издательстве Springer нам хотелось бы поблагодарить Марка Стросса (Mark Strauss) и Ханну Брэкен (Hannah Bracken), а также научных редакторов: Вини Бонато (Vini Bonato), Томаса Миллера (Thomas Miller), Росса Кинлана (Ross Quinlan), Эрика Сигела (Eric Siegel), Стэна Янга (Stan Young). Наконец, мы благодарим за поддержку свои семьи: Миранду Кун (Miranda Kuhn), Стефана Куна (Stefan Kuhn), Бобби Куна (Bobby Kuhn), Роберта Куна (Robert Kuhn), Карен Кун (Karen Kuhn) и Мэри Энн Кун (Mary Ann Kuhn); Уоррена (Warren) и Кей Джонсон (Kay Johnson); Валери (Valerie) и Трумэна Джонсона (Truman Johnson).
Гротон, штат Коннектикут, США, Макс Кун Сейлайн, штат Мичиган, США, Кьелл Джонсон
От издательства
Некоторые иллюстрации для лучшего понимания нужно смотреть в цветном варианте. Мы снабдили их QR-кодами, перейдя по которым вы можете ознакомиться с цветной версией рисунка.
Ваши замечания, предложения, вопросы отправляйте по адресу comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства www.piter.com вы найдете подробную информацию о наших книгах.
Введение
Люди ежедневно сталкиваются с вопросами вроде: «По какому маршруту мне сегодня ехать на работу?», «Не переключиться ли мне на другого оператора сотовой связи?», «Как мне лучше вложить свои деньги?» или «Заболею ли я раком?». Эти вопросы свидетельствуют о нашем желании узнать, что произойдет в будущем, и мы непрестанно стараемся принять наилучшие решения на пути к этому будущему.
Обычно решения принимаются на основании информации. Иногда доступны реальные, объективные данные — например, информация об утренних пробках или метеосводки. В других случаях мы руководствуемся интуицией и опытом: «Мне лучше не ехать по мосту этим утром, потому что с началом снегопада здесь обычно возникают пробки» или «Мне стоит пройти анализ ПСА1, потому что у моего отца был рак простаты». В любом случае мы прогнозируем будущие события на основании уже имеющейся информации и опыта, а на основании этих прогнозов принимаются решения.
По мере того как с появлением интернета и социальных сетей информация стала более доступной, возросло и наше желание пользоваться этой информацией для принятия решений. И хотя человеческий мозг может сознательно и подсознательно накапливать огромные объемы данных, он не способен обработать еще больший объем доступной информации, относящейся к текущей задаче. Чтобы упростить процессы принятия решений, мы пользуемся такими инструментами, как Google, для фильтрации миллиардов веб-страниц и поиска самой релевантной информации для наших запросов, WebMD (для диагностики заболеваний по симптомам) и E*TRADE (для просеивания тысяч акций и нахождения лучших капиталовложений для наших портфелей).
Эти сайты наряду со многими другими используют инструменты, которые на основе текущей информации фильтруют данные в поисках закономерностей, относящих-
1 Простатический специфический антиген. — Примеч. пер.
22 Глава 1. Введение ся к сформулированной задаче, и возвращают ответы. Процесс разработки таких инструментов развивался в нескольких областях — химии, информатике, физике и статистике — и сегодня известен как «машинное обучение», «искусственный интеллект», «распознавание образов», «глубокий анализ данных», «предиктивная аналитика» и «извлечение информации». Хотя каждой области присуще решение свойственных ей задач с разных позиций и с использованием разных инструментов, конечная цель остается неизменной: создание точного прогноза. В этой книге мы объединим все эти термины в широко используемом выражении ^предиктивное моделирование».
Напомним, Гейссер (Geisser, 1993) определяет предиктивное моделирование как «процесс, используемый для создания или выбора модели в попытках наилучшим образом предсказать вероятность исхода». Мы слегка подправим это определение:
Предиктивное моделирование — это процесс разработки математического инструментария или модели, на основании которой генерируется точный прогноз.
В свою очередь, Стив Леви (Steve Levy) писал в журнале Wired о нарастающем присутствии предиктивных моделей (Levy, 2010) следующее: «Примеры [искусственного интеллекта] встречаются повсюду: глобальная машина Google использует искусственный интеллект для интерпретации невразумительных человеческих запросов. Компании — эмитенты кредитных карт — для выявления мошенничества. Netflix — для того, чтобы рекомендовать фильмы подписчикам. А финансовая система использует его для обработки миллиардов торговых операций (с относительно редкими обвалами)». Вот примеры вопросов, для получения ответов на которые нам хотелось бы использовать прогнозирование:
О Сколько экземпляров этой книги разойдется на рынке?
О Перенесет ли этот клиент свой бизнес в другую компанию?
О За сколько я смогу продать свое жилье при текущем состоянии рынка?
О Имеется ли у этого пациента конкретное заболевание?
О Какие фильмы заинтересуют зрителя, если руководствоваться его прошлыми решениями?
О Стоит ли мне продавать эти акции?
О Каких людей стоит свести друг с другом в нашем интернет-сервисе знакомств?
О Является ли это сообщение электронной почты спамом?
О Отреагирует ли пациент на некоторый вид терапии?
Теперь — пример иного рода. Как известно, страховые компании должны прогнозировать риски потенциальных страхователей автомобилей, здоровья и жизни.
Введение 23
Эта информация затем используется для определения того, стоит ли предоставить клиенту страховой полис, а если стоит, то с какой страховой премией.
Правительства, как и страховые компании, тоже стараются прогнозировать риски, но с целью защиты своих граждан. Из последних примеров правительственных предиктивных моделей можно привести биометрические модели выявления потенциальных террористов, модели выявления мошенничества (Westphal, 2008), модели беспорядков и бунтов (Shachtman, 2011). Даже посещение гастронома или бензоколонки (повседневных мест, в которых собирается и анализируется наша информация о покупках, в попытках определения того, кто мы и что нам нужно (Duhigg, 2012)) приводит нас в мир предиктивного моделирования, причем часто мы даже не подозреваем об этом. Как видим, предиктивные модели стали неотъемлемой частью нашего существования.
Хотя предиктивные модели помогают создавать продукты, отвечающие запросам потребителей, более качественные лекарства и делать более выгодные инвестиции, они регулярно порождают и неточные прогнозы, и неправильные ответы. Например, многие из нас не получали порой важные сообщения электронной почты из-за того, что предиктивная модель (фильтр электронной почты) неправильно распознала их как спам. Точно так же, впрочем, медицинские диагностические модели ставят ошибочные диагнозы, а финансовые предиктивные модели (финансовые алгоритмы) ошибочно покупают и продают акции в расчете на прибыли, которые в реальности оборачиваются потерями. Подобная ошибка предиктивной модели дорого обошлась многим инвесторам в 2010 году. Специалисты, следящие за состоянием фондовой биржи, наверняка помнят «молниеносный обвал» 6 мая 2010 года, когда рынок стремительно потерял более 600 пунктов, а затем немедленно отыграл их обратно. Через несколько месяцев исследований Комиссия по срочной биржевой торговле и Государственная комиссия по ценным бумагам и фондовому рынку определили, что причиной обвала стала ошибка алгоритмической модели (U.S. Commodity Futures Trading Commission and U.S. Securities & Exchange Commission. 2010).
По поводу «молниеносного обвала» и других подобных финтов предиктивных моделей Родригес (Rodriguez, 2011), в частности, пишет: «Предиктивное моделирование, как процесс создания или выбора модели в попытках наилучшим образом предсказать вероятность исхода, утратило доверие как инструмент прогнозирования». Он выдвигает гипотезу, согласно которой предиктивные модели регулярно сбоят, поскольку не учитывают такие сложные переменные, как человеческое поведение. В самом деле, наши возможности по прогнозированию или принятию решений ограничиваются нашими текущими и прошлыми знаниями, а также факторами, которые мы не учитываем. Эти реалии становятся ограничивающими факторами для любой предиктивной модели, однако они не должны препятствовать совершенствованию процесса их функционирования и улучшению самих моделей.
24 Глава 1. Введение
Отказы предиктивных моделей объясняются целым рядом типичных причин, которые будут описаны в последующих главах. Вот наиболее распространенные причины.
1. Недостаточная предварительная обработка данных.
2. Недостаточная проверка модели.
3. Неоправданная экстраполяция (например, применение модели к данным в пространстве, неизвестном для модели).
4. Переобучение модели к существующим данным.
Более того, замечено, что специалисты по предиктивному моделированию часто исследуют относительно небольшое количество моделей при поиске предиктивных связей. Чаще всего это объясняется личными предпочтениями, знаниями или опытом разработчика модели в использовании нескольких моделей либо отсутствием необходимого программного обеспечения, которое бы позволило проанализировать более широкий диапазон средств.
В этой книге мы попытались помочь разработчикам предиктивных моделей в построении надежных достоверных моделей. Для этого мы предоставили пошаговое описание процесса построения модели и общие сведения о широком спектре распространенных моделей. В книге также изложены:
О основополагающие принципы построения предиктивных моделей;
О доступные объяснения многих методов предиктивного моделирования, чаще иных применяемых для решения классификационных и регрессионных задач;
О принципы и этапы проверки предиктивной модели;
О компьютерный код для выполнения важнейших операций по построению и проверке предиктивных моделей.
Для демонстрации этих принципов и методов авторами использован широкий спектр реальных примеров из самых разных областей — от финансов до фармацевтики (они будут подробно описаны в разделе 1.4). Однако прежде следует проанализировать фактор, препятствующий применению методов предиктивного моделирования: компромисс между прогнозированием и интерпретацией.
1.1. Прогнозирование и интерпретация
Во всех перечисленных выше примерах обычно присутствуют исторические данные, пригодные для создания математических средств прогнозирования будущих непредвиденных случаев. Более того, конечная цель примеров не сводится лишь к пониманию того, почему что-то произойдет (или не произойдет). Нас прежде всего интересует точное определение вероятности того, что некое событие произойдет
1.2. Ключевые ингредиенты предиктивных моделей 25
или, напротив, не произойдет. Помните, что моделирование этого типа прежде всего направлено на оптимизацию точности прогнозов.
Например, нас не интересует, почему фильтр электронной почты считает, что сообщение является спамом. Важно лишь то, чтобы фильтр безошибочно искоренял спам и пропускал в электронный почтовый ящик только те сообщения, которые представляют для нас интерес.
Другой пример: если я продаю дом, то меня интересует не то, по каким критериям веб-сайт (скажем, zillow.com) сформирует его оценку, — важно лишь то, чтобы эта цена была определена правильно. Заниженная оценка означает снижение ставок и более низкую цену продажи, завышенная — отпугнет потенциальных покупателей. Противоречия между прогнозированием и интерпретацией наглядно проявляются и в области медицины. Представьте процесс, с которым сталкиваются врач и пациент при принятии решений об изменении терапии. Пациент и врач должны учитывать такие факторы, как режим дозирования, потенциальные побочные эффекты, уровень смертности. Но если достаточное количество пациентов прошло альтернативную терапию благополучно, то появляется возможность аккумулировать информацию, относящуюся к их заболеванию, истории лечения и демографии. Кроме того, можно провести лабораторные исследования по анамнезу пациента, некоторым другим данным (например, по выполненным ранее анализам уровня белка).
В результате становится возможным создать модель для прогнозирования реакции на альтернативную терапию. Критически значимым для врача и пациента является вопрос о том, как пациент отреагирует на смену терапии. Подобный прогноз должен быть максимально точным. Создаваемая для этого модель не должна ограничиваться требованием интерпретируемости (даже если кто-то сочтет это неэтичным). Ведь в конце концов, если модель может пройти соответствующую проверку, то неважно, будет это некий «черный ящик» или обычная интерпретируемая модель. Хотя главной задачей предиктивного моделирования должно быть генерирование точных прогнозов, его вторичной задачей может быть интерпретация модели и выработка понимания того, почему она работает. К сожалению, при стремлении к повышению точности модели становятся все более сложными, причем усложняется и их интерпретируемость. Как следствие, разработчикам моделей постоянно приходится отыскивать приемлемый компромисс между сложностью модели и точностью ее прогнозов.
1.2. Ключевые ингредиенты предиктивных моделей
Обиходные примеры, приводившиеся ранее, демонстрировали, что данные — более того, очень большие наборы данных — теперь могут легко генерироваться в попытке ответить на едва ли не любые вопросы исследователей, возникающие в ходе
26 Глава 1. Введение моделирования. Бесплатные или относительно недорогие программы построения моделей — JMP, НЕКА, многочисленные пакеты R, а также мощь современных персональных компьютеров позволяют любому человеку, мало-мальски разбирающемуся в компьютерных технологиях, без особого труда приступить к разработке предиктивных моделей. Но, как справедливо замечает тот же Родригес (Rodriguez, 2011), достоверность построения моделей снижается, особенно с расширением окна доступа к данным и аналитическим инструментам.
Как увидят далее наши читатели, если в наборе данных присутствует предиктивный сигнал, то он в той или иной степени будет обнаружен многими моделями независимо от метода или усилий, затраченных на их разработку. Таким образом, даже наивная модель может быть до известной степени эффективной; как гласит пословица, «раз в год даже палка стреляет».
Но самые лучшие, самые сильные предиктивные модели находятся под фундаментальным влиянием разработчика, обладающего экспертными знаниями, и контекста задачи, «под которую» создается модель. Сначала эти знания должны быть применены для получения релевантных данных, соответствующих целям исследования. Хотя огромные базы данных с информацией могут использоваться в качестве субстрата для построения прогнозов, не относящаяся к делу информация способна снизить предиктивную эффективность значительной части создаваемых моделей. Знания, относящиеся к конкретной теме, помогают отделить потенциально содержательную информацию от посторонней, снизив таким образом помехи и усилив скрытый сигнал.
В данных также могут присутствовать нежелательные искажающие сигналы, которые не могут быть выявлены без экспертных знаний. Ярким примером последнего служит база данных системы отчетов о нежелательных явлениях Управления США по надзору в сфере пищевых продуктов и лекарственных средств, включающая информацию о миллионах заявленных побочных эффектов от применения лекарств. В этом массиве данных присутствуют явные несуразности — например, поиск лекарства для лечения тошноты может показать, что значительная часть пациентов, использовавших это лекарство, болела лейкемией. Некомпетентный анализ может определить лейкемию как потенциальный побочный эффект от применения лекарства. Более вероятное объяснение, впрочем, заключается в том, что пациенты принимали лекарство от тошноты для подавления побочных эффектов терапии рака. Этот факт может быть очевиден интуитивно, но, несомненно, доступность огромного количества данных не защищает пользователей от издержек их использования, подобных описанным выше.
Эйрес (Ayres, 2007) в результате всестороннего изучения взаимодействий между экспертным мнением и эмпирическими моделями, управляемыми данными, делает два важных замечания, подчеркивающих необходимость знания специфики проблемы. Во-первых, пишет Эйрес, «в конечном итоге [предиктивное моделирование] не заменяет интуицию, а скорее дополняет ее».
1.3. Терминология 27
Говоря несколько иначе, ни модели, управляемые данными, ни эксперты, полагающиеся исключительно на интуицию, не обеспечат, действуя порознь, наилучшее решение задачи — необходимо объединение их усилий.
Во-вторых, указывает Эйрес, «традиционные эксперты принимают более качественные решения, когда они получают результаты статистического прогнозирования. Люди, цепляющиеся за авторитет традиционных экспертов, обычно склонны представлять идею объединения двух форм “знаний” при получении экспертом “статистической поддержки”. На самом деле люди обычно делают лучшие прогнозы, располагая для этого результатами статистического прогнозирования».
В некоторых случаях, например при обнаружении спама, можно поручить большую часть анализа компьютерам. Но при более серьезных потенциальных последствиях (например, при прогнозировании реакции пациента на лечение) комбинированный подход часто приводит к лучшим результатам.
Подведем итог: фундаментом эффективной предиктивной модели является интуиция и глубокое знание контекста проблемы. Именно эти факторы критически значимы для принятия решений относительно разработки модели. Процесс начинается с релевантных данных — еще один ключевой ингредиент. Третьим ингредиентом становится вариативный вычислительный инструментарий, включающий средства предварительной обработки и визуализации данных, а также набор средств моделирования для широкого спектра возможных сценариев; некоторые из этих сценариев перечислены в табл. 1.1.
1.3. Терминология
Как упоминалось ранее, «предиктивное моделирование» — всего лишь одно из обозначений процесса выявления связей в данных для прогнозирования некоторого желательного результата. Поскольку рассматриваемая нами область знаний лежит на стыке нескольких научных дисциплин, у многих понятий существуют синонимы.
О Так, термины точка данных (data point), выборка (sample), наблюдение (observation) или экземпляр (instance) обозначают независимую единицу данных, например клиента, пациента или вещество. Термин «выборка» также может обозначать подмножество точек данных — например, «выборка тренировочного набора» (training set sample). При использовании этого термина в дальнейшем нами будет уточняться контекст.
О Тренировочный набор (training set) состоит из данных, используемых для разработки моделей, тогда как термины тестовый набор (test set) или контрольный набор (validation set) используются исключительно для оценки эффективности итогового набора вариантов моделей.
28 Глава 1. Введение
Таблица 1.1. Сравнение некоторых характеристик наборов данных из примеров
Набор данных
производство химикатов
177
Непрерыв¬
ная
X
X
X
X
X
X
проницаемость
165
о
Непрерывная
X
X
X
X
мошенничество в финансовых отчетах
204
о см
Категорийная
X
X
X
X
поражение печени
281
с© |> со
Категорий¬
ная
X
X
X
X
X
X
X
заявки на предоставление грантов
8707
ОТ) хг см
Категорийная
X
X
X
X
X
X
музыкальный жанр
12 495
съ
Категорийная
X
X
X
X
X
Характеристика
Размеры
Точки данных
3 си о н X
5
4
6 е
Характеристики реакции
Категорийная или непрерывная
Сбалансированная / симметричная
Несбалансированная /скошен¬
ная
Независимая
Характеристики предикторов
Непрерывность
Счетность
Категорийность
Коррелированность
Разные шкалы измерений
Отсутствующие значения
Разреженность
1.4. Примеры наборов данных и типичные сценарии данных 29
О Предикторы (predictors), независимые переменные (independent variables), атрибуты (attributes) и дескрипторы (descriptors) — данные, используемые в качестве входных в формуле прогнозирования.
О Термины результат (outcome), зависимая переменная (dependent variable), цель (target), класс (class) млп реакция (response) обозначают итоговое прогнозируемое событие или величину
О Непрерывные (continuous) данные измеряются по естественной числовой шкале. Артериальное давление, стоимость товара, количество спален в доме — все это примеры непрерывных величин. В последнем случае значение не может быть дробным, но оно все равно относится к непрерывным данным.
О Категорийные данные (categorical data), также называемые качественными (nominal), или дискретными (discrete), принимают конкретные значения, не имеющие определенной шкалы. Примеры таких данных — кредитная история («хорошая» или «плохая») или цвет («красный», «синий» и т. д.).
О Термины построение модели (model building), обучение модели (model training) и оценка параметра (parameter estimation) обозначают процесс использования данных для определения значений в уравнениях модели.
1.4. Примеры наборов данных и типичные сценарии данных
В последующих главах для демонстрации методов будет использоваться анализ конкретных ситуаций. Но прежде, по-видимому, стоит кратко исследовать несколько примеров задач предиктивного моделирования и типы данных, используемых для их решения. Основное внимание будет уделяться разнообразию задач и характеристик собираемых данных. Некоторые наборы данных из примеров позаимствованы с конкурсов по машинному обучению, на которых ставятся реальные задачи с поощрением (часто денежным) за нахождение лучшего решения. Такие конкурсы уже давно проводятся в области предиктивного моделирования. Они оказали значительное воздействие на ее развитие.
Музыкальный жанр
Этот набор данных был опубликован в качестве конкурсного на веб-сайте TunedIT (http://tunedit.org/challenge/music-retrieval/genres). Цель конкурса — разработка предиктивной модели для классификации музыки по шести категориям. Набор включал 12 495 музыкальных фрагментов, для которых была определена 191 характеристика. Распределение по категориям не было сбалансированным (рис. 1.1): наименьший сегмент относился к категории «хэви-метал» (7 %), а наибольший — к категории
30 Глава 1. Введение «классика» (28 %). Все предикторы были непрерывными; многие из них обладали высокой корреляцией, охватывая несколько разных шкал измерения. Коллекция данных была создана на основе композиций 60 исполнителей (от 15 до 20 композиций для каждого). Затем 20 фрагментов каждой композиции были параметризованы для создания итогового набора данных. Следовательно, образцы по своей природе не являются независимыми друг от друга.
Рис. 1.1. Частотное распределение жанров в музыкальных данных
Заявки на получение грантов
Этот набор данных также был опубликован для конкурса — на веб-сайте Kaggle (http://www.kaggle.com). Цель конкурса — разработка предиктивной модели вероятности успеха заявки на получение гранта. База данных состояла из 8707 заявок на гранты, поданных в Университет Мельбурна с 2009 по 2010 год (количество предикторов — 249). Результат рассмотрения отражался в статусе заявки («успех» или «отказ»), из которых 46 % были квалифицированы как успешные. На веб-сайте упоминается, что текущий коэффициент успешности подобных заявок на гранты в Австралии составляет менее 25 %. Таким образом, показатели, присутствующие в базе данных, не являются типичными для Австралии. В числе предикторов — идентификатор спонсора, категория гранта, диапазон размеров гранта, область исследований и факультет. Все они являются непрерывными, счетными и категорийными. У этого набора данных есть и другая важная особенность: многие значения (83 %) предикторов отсутствовали. Кроме того, данные не были независимыми, так как одни и те же составители заявок фигурировали в них по несколько раз. Эти данные используются нами далее для демонстрации различных методов класси-
1.4. Примеры наборов данных и типичные сценарии данных 31
фикационного моделирования (см. главы 12-15, в том числе пояснение и сводку в подразделе 12.1).
Поражение печени
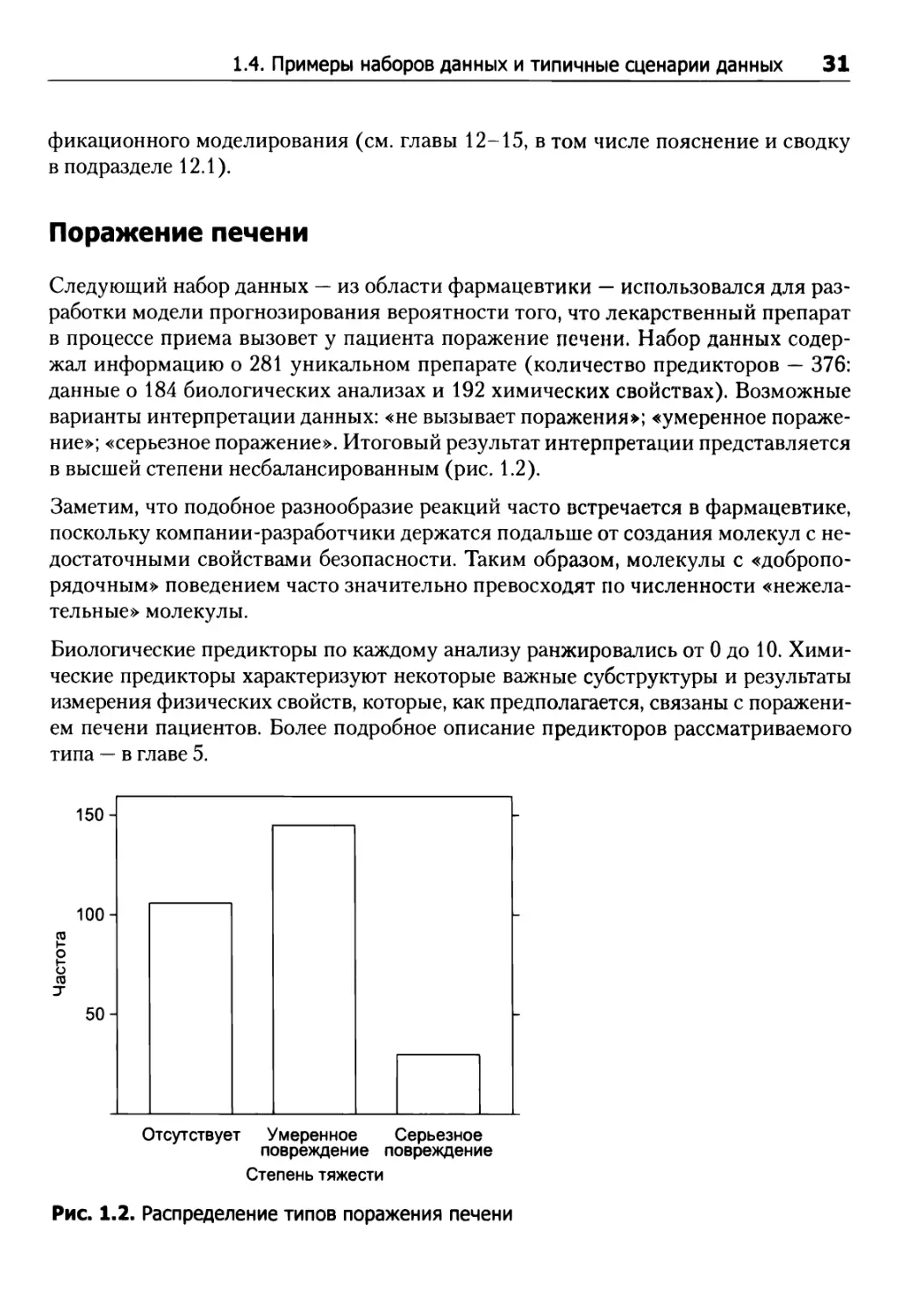
Следующий набор данных — из области фармацевтики — использовался для разработки модели прогнозирования вероятности того, что лекарственный препарат в процессе приема вызовет у пациента поражение печени. Набор данных содержал информацию о 281 уникальном препарате (количество предикторов — 376: данные о 184 биологических анализах и 192 химических свойствах). Возможные варианты интерпретации данных: «не вызывает поражения»; «умеренное поражение»; «серьезное поражение». Итоговый результат интерпретации представляется в высшей степени несбалансированным (рис. 1.2).
Заметим, что подобное разнообразие реакций часто встречается в фармацевтике, поскольку компании-разработчики держатся подальше от создания молекул с недостаточными свойствами безопасности. Таким образом, молекулы с «добропорядочным» поведением часто значительно превосходят по численности «нежелательные» молекулы.
Биологические предикторы по каждому анализу ранжировались от 0 до 10. Химические предикторы характеризуют некоторые важные субструктуры и результаты измерения физических свойств, которые, как предполагается, связаны с поражением печени пациентов. Более подробное описание предикторов рассматриваемого типа — в главе 5.
Рис. 1.2. Распределение типов поражения печени
32 Глава 1. Введение
Проницаемость
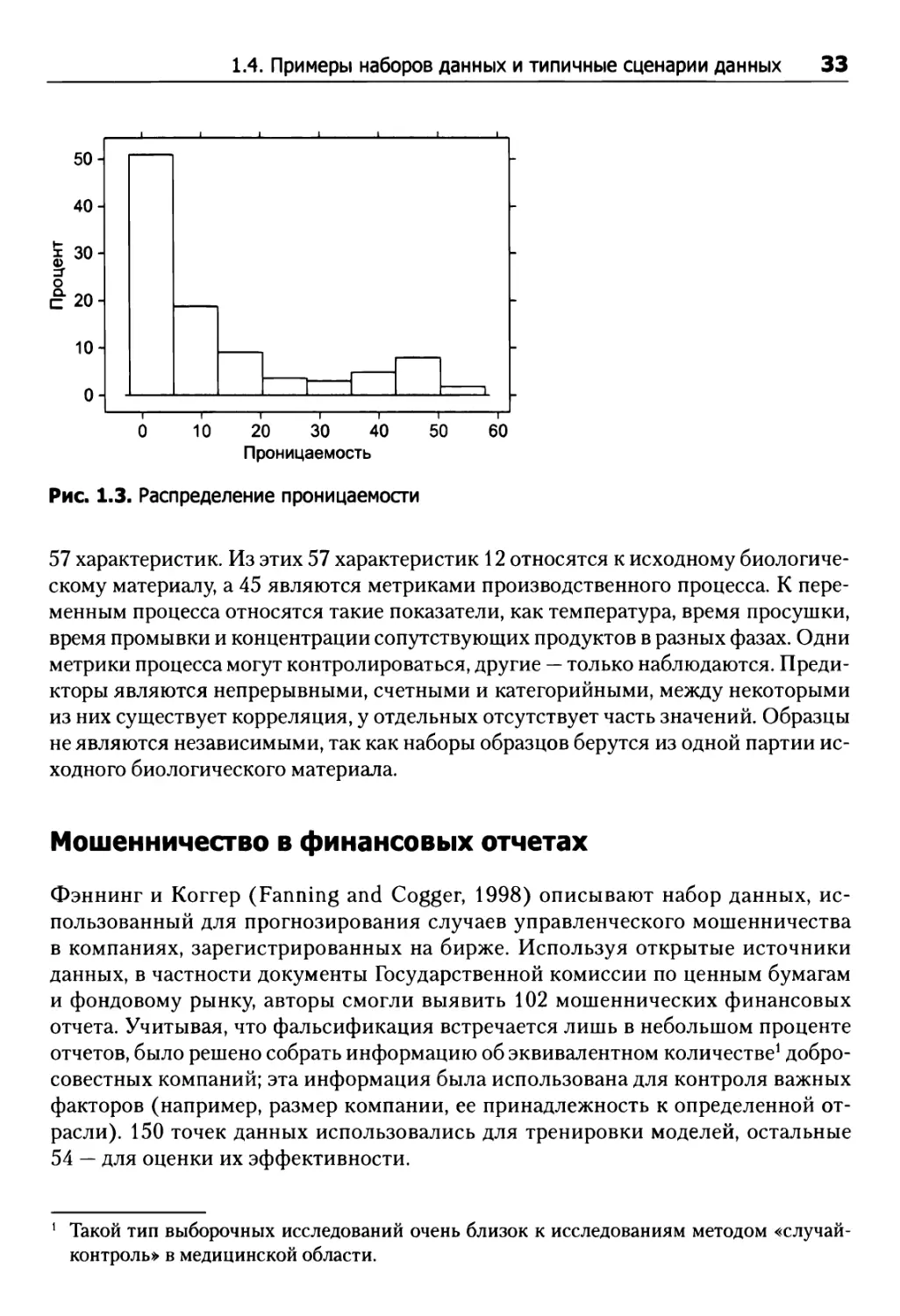
Другой набор фармацевтических данных использовался для разработки модели прогнозирования проницаемости препаратов. Последняя определяет способность молекулы проникать через мембраны. Например, в человеческом теле существуют заметные мембраны между телом и мозгом (так называемый «гемато-энцефалический барьер»), между кишечником и телом во внутренних органах. Эти мембраны помогают телу защищать критически значимые участки от нежелательных или вредных веществ. Чтобы перорально принимаемые препараты эффективно влияли на мозг, они сначала должны пройти через стенки кишечника, а затем преодолеть гемато-энцефалический барьер для попадания в нужный неврологический приемник. Следовательно, способность препарата преодолевать соответствующие биологические мембраны исключительно важно понять уже на ранней стадии поиска нового лекарства. Если препарат эффективно противодействует конкретной болезни в исследовательских экспериментах, но обладает плохой проницаемостью, возможно, его придется модифицировать для улучшения проницаемости (способности препарата достигать нужной цели). Выявление проблем с проницаемостью может помочь химикам в построении более эффективных молекул.
Для оценки проницаемости препаратов были разработаны такие методы количественного анализа, как PAMPA и Сасо-2 (Kansy et al., 1998). Эти методы эффективны для количественной оценки проницаемости вещества, но анализ достаточно дорог и трудоемок. Если вы располагаете данными по достаточному количеству препаратов, прошедших лабораторные испытания, можно разработать предиктивную модель проницаемости, чтобы сократить необходимость в анализе. В рассматриваемом нами проекте были задействованы 165 уникальных препаратов, для каждого из которых определены 1107 молекулярных сигнатур (fingerprints). Молекулярная сигнатура представляет собой двоичную последовательность, отражающую наличие или отсутствие конкретных молекулярных субструктур. Реакции распределены в высшей степени неравномерно (рис. 1.3), предикторы сильно разрежены (их присутствие отмечено в 15,5 % случаев), при сохранении между многими предикторами сильных связей.
Производство химикатов
Следующий набор данных содержит информацию о процессе производства химикатов. Цель исследования — понять связь между процессом и выходом продукта. Уточним, что в рассматриваемом примере для создания итогового лекарственного препарата сырье проходит 27 фаз обработки. Исходный материал генерируется биологическим отделением и обладает разнообразными показателями качества и характеристиками. Целью данного проекта является построение модели для прогнозирования выхода производственного процесса в процентах. Набор данных состоит из 177 образцов биологического материала, для которого определяются
1.4. Примеры наборов данных и типичные сценарии данных 33
Рис. 1.3. Распределение проницаемости
57 характеристик. Из этих 57 характеристик 12 относятся к исходному биологическому материалу, а 45 являются метриками производственного процесса. К переменным процесса относятся такие показатели, как температура, время просушки, время промывки и концентрации сопутствующих продуктов в разных фазах. Одни метрики процесса могут контролироваться, другие — только наблюдаются. Предикторы являются непрерывными, счетными и категорийными, между некоторыми из них существует корреляция, у отдельных отсутствует часть значений. Образцы не являются независимыми, так как наборы образцов берутся из одной партии исходного биологического материала.
Мошенничество в финансовых отчетах
Фэннинг и Коггер (Fanning and Cogger, 1998) описывают набор данных, ис- пользованный для прогнозирования случаев управленческого мошенничества в компаниях, зарегистрированных на бирже. Используя открытые источники данных, в частности документы Государственной комиссии по ценным бумагам и фондовому рынку, авторы смогли выявить 102 мошеннических финансовых отчета. Учитывая, что фальсификация встречается лишь в небольшом проценте отчетов, было решено собрать информацию об эквивалентном количестве1 добросовестных компаний; эта информация была использована для контроля важных факторов (например, размер компании, ее принадлежность к определенной отрасли). 150 точек данных использовались для тренировки моделей, остальные 54 — для оценки их эффективности.
1 Такой тип выборочных исследований очень близок к исследованиям методом «случай- контроль» в медицинской области.
34 Глава 1. Введение
Первоначально использовалось неопределенное количество предикторов, выявленных в результате анализа ключевых областей, таких как коэффициент текучести руководства, судебные разбирательства и структура долга. В итоге количество предикторов сократилось до 20. Примеры — отношение дебиторской задолженности к объему продаж, отношение складских запасов к объему продаж, изменение валовой прибыли по годам и др. Многие предиктивные переменные, содержащие различные отношения, используют общие знаменатели (например, отношение дебиторской задолженности к объему продаж и отношение складских запасов к объему продаж). Хотя фактические точки данных не были опубликованы, скорее всего, между предикторами существуют сильные корреляции.
С точки зрения моделирования этот пример интересен по нескольким причинам.
Во-первых, из-за значительного дисбаланса в классах частоты двух классов в наборах данных сильно отличались от прогнозируемой генеральной совокупности. Распространенная стратегия минимизации последствий подобных дисбалансов — так называемое прореживание (down-sampling) данных.
Во-вторых, количество возможных предикторов было существенно больше количества точек данных. В этом примере выбор предикторов для моделей был нетривиальной задачей из-за небольшого количества подходящих точек данных, в том числе для построения моделей и для оценки их эффективности. В дальнейших главах будет рассмотрена проблема переобучения, при которой тенденции в тренировочных данных не встречаются в других выборках. При большом количестве предикторов и малом количестве точек данных появляется риск того, что релевантный предиктор, обнаруженный в этом наборе данных, не будет воспроизводиться в других наборах.
Сравнения наборов данных
Дальнейшие примеры демонстрируют характеристики, общие для большинства наборов данных. Прежде всего, реакция может быть непрерывной или категорийной, а для категорийных реакций могут быть задействованы две и более категории. Для данных непрерывной реакции распределение реакции может быть симметричным (например, производство химикатов) или асимметричным (например, проницаемость); для данных категорийных реакций распределение может быть сбалансированным (например, заявки на предоставление грантов) или несбалансированным (например, музыкальный жанр, поражение печени).
В главе 4 наши читатели увидят, что понимание распределения реакции критично для одного из первых шагов процесса предиктивного моделирования — разбиения данных на тренировочные и тестовые наборы. Понимание распределения реакции поможет разработчику модели в поиске лучших способов разбиения данных; непонимание характеристик реакции может создать вычислительные сложности для
1.4. Примеры наборов данных и типичные сценарии данных 35
некоторых видов моделей и моделей, обладающих субоптимальной предиктивной способностью.
Наборы данных, описанные в табл. 1.1, также подчеркивают характеристики предикторов, универсальные для большинства наборов данных. Так, значения предикторов могут быть непрерывными, счетными и/или категорийными, в них может отсутствовать часть значений, могут использоваться разные шкалы измерения предикторов, и др. Кроме того, предикторы в наборе данных могут иметь высокую корреляцию — признак того, что набор предикторов содержит избыточную в числовом отношении информацию.
Также предикторы могут быть разреженными', это означает, что большинство точек данных содержит одну и ту же информацию, и только некоторые из них — уникальную информацию. Как и реакции, предикторы могут иметь симметричное или смещенное распределение (для непрерывных предикторов), быть сбалансированными или несбалансированными (для категорийных предикторов). Наконец, предикторы в пределах набора данных могут иметь скрытые связи с реакцией или не иметь их. Разные виды моделей по-разному решают проблемы с подобными характеристиками. Например, метод частных наименьших квадратов естественным образом решает проблемы с корреляцией предикторов, но в числовом отношении он работает стабильнее, если предикторы измеряются по сходным шкалам. С другой стороны, на рекурсивное секционирование различия в шкалах не влияют, при этом структура секционирования становится менее стабильной при наличии корреляции между предикторами. Другой пример: множественная линейная регрессия не справляется с отсутствием информации предикторов, но рекурсивное секционирование может применяться в том случае, если предикторы содержат умеренное количество отсутствующей информации. В любой из этих ситуаций отсутствие необходимой регулировки предикторов до моделирования — предварительной обработки (pre-processing) — создает модели с субоптимальной эффективностью прогнозирования. Оценка характеристик предикторов и их регулировка посредством предварительной обработки рассматриваются в главе 3.
Наконец, каждый из этих наборов данных демонстрирует другую фундаментальную характеристику, которая должна учитываться при построении предиктивной модели: связь между количеством точек данных (я) и количеством предикторов (Р). В случае с набором данных музыкальных жанров количество точек данных (п - 12 496) намного превышает количество предикторов (Р= 191). Все предиктивные модели справляются с этой ситуацией, но время вычислений зависит от модели и, скорее всего, увеличится с ростом количества точек данных и предикторов. И наоборот, в наборе данных проницаемости количество точек данных (п = 165) намного меньше количества предикторов (Р= 1107). Соответственно, такие предиктивные модели, как множественная линейная регрессия или линейный дискриминантный анализ, не могут использоваться напрямую. Тем не
36 Глава 1. Введение менее некоторые модели (например, рекурсивное секционирование и метод k ближайших соседей (KNN)) можно применять напрямую и в описываемых условиях. При рассмотрении каждого метода в последующих главах мы будем указывать, насколько хорошо метод справляется с наборами данных при п < Р. Для тех методов, которые в этой ситуации не работают, будут предложены альтернативные методы моделирования или действия по предварительной обработке, фактически сокращающие размерность пространства предикторов.
Итак, до построения модели необходимо сформировать глубокое понимание предикторов и реакции на любой набор данных. Отсутствие такого понимания может привести к вычислительным сложностям и, как следствие, весьма условной эффективности модели. Кроме того, многие наборы данных потребуют известной предварительной обработки для расширения пространства возможных предиктивных моделей и оптимизации эффективности прогнозирования каждой модели.
1.5. Структура книги
Книга состоит из четырех частей, в которых будет представлен процесс построения и критической оценки предиктивных моделей. Так как многие читатели, скорее всего, захотят реализовать представленные концепции, в конце каждой главы имеется раздел с кодом реализации рассмотренных тем. В тексте будет использоваться язык программирования R (R Development Core Team 2010). Для читателей, не знакомых с языком R, в приложении Б приведен краткий вводный курс.
Цель приложения Б — ознакомить читателей с наиболее существенной информацией по основным программным конструкциям R. Тем не менее для читателей без опыта работы с R информации в приложении может оказаться недостаточно. В качестве дополнительного учебного материала мы можем порекомендовать следующие публикации: Verzani (2002); Venables et al. (2003); Maindonald and Braun (2007); Muenchen (2009); Spector (2008).
В части I объясняются методы закладки надежных фундаментов, на которых строятся модели. Прежде чем пытаться моделировать какие-либо данные, необходимо хорошо понять краеугольные концепции их предварительной обработки (глава 3) и повторной выборки (глава 4).
В главе 3 рассматриваются распространенные методы предварительной обработки: преобразование данных, добавление и/или удаление переменных, статистическая группировка непрерывных переменных. Здесь же подробно объясняется, почему для большинства моделей перед моделированием необходимо произвести предварительную обработку данных.
В главе 4 представлена суть расходования данных, а также методы их расходования для соответствующей настройки модели и оценки ее эффективности. Там же по-
1.5. Структура книги 37
меняется, что для решения любой конкретной задачи специалист-практик всегда должен опробовать разнообразные модели.
Заложив, таким образом, фундамент предиктивного моделирования, мы перейдем к обзору традиционных и современных регрессионных методов (часть II). Эта часть книги начинается с освещения способов оценки эффективности при моделировании непрерывного результата (глава 5).
В главе 6 представлено рабочее и интуитивное понимание регрессионных моделей, формирующих иерархически ниже следующую структуру данных в форме линейной комбинации предикторов. К этому классу моделей относятся линейная регрессия, метод частных наименьших квадратов и L1-регуляризация.
Далее (глава 7) дается объяснение регрессионных моделей, не основанных на простых линейных комбинациях предикторов. К этому классу, напомним, относятся нейросети, многомерные адаптивные регрессионные сплайны (MARS), метод опорных векторов (SVM) и KNN.
Древовидные модели также не ограничиваются линейными комбинациями предикторов. С учетом популярности и широты применения в ансамблевых методах древовидные модели рассматриваются в отдельной главе (глава 8), где представлен обзор регрессионных деревьев, случайных лесов, усиления и Cubist.
Часть II завершается анализом практического примера (глава 10), в котором сравниваются все вышеперечисленные методы применительно к конкретной задаче: моделированию прочности сжатия бетона для получения состава с улучшенными свойствами.
После регрессионных моделей в рамках части III рассматриваются предиктивные классификационные модели. Метрики производительности для задач классификации отличаются от метрик регрессионных задач (глава 11).
В главе 12 представлено рабочее и интуитивное понимание классификационных моделей, основанных на линейных комбинациях предикторов, таких как линейные, квадратичные, регуляризованные модели и дискриминантный анализ частных наименьших квадратов. Здесь же рассматриваются штрафные методы классификации.
В главе 13 исследуются методы классификации, основанные на в высшей степени нелинейных функциях предикторов. К этому классу относятся гибкий дискриминантный анализ, нейросети, SVM, KNN, наивная классификация Байеса и ближайшие центроиды. Древовидные методы классификации рассматриваются в главе 14. В главе 17 представлен практический пример классификации со сравнительным анализом методов.
В части IV рассматриваются другие важные соображения построения модели или оценки ее эффективности. В стремлении к поиску самых релевантных предикторов для имеющейся задачи было предложено множество различных типов методов выбора. Хотя эти методы обладают потенциалом обнаружения информации, со-
38 Глава 1. Введение держательной в практическом смысле, они часто помогают пользователю уяснить помехи в данных, а не их структуру.
В главе 18 продемонстрированы различные методы количественной оценки важности предикторов. В главе 19 представлено введение и руководство по правильному использованию методов выбора признаков. Заметим, что на эффективность модели могут влиять самые разные факторы, вводя, таким образом, в заблуждение практика и заставляя его поверить, что модель имеет плохую предиктивную эффективность (тогда как в действительности эффективность хорошая) или модель имеет хорошую предиктивную эффективность (хотя на деле все обстоит наоборот). Некоторые типичные факторы, влияющие на эффективность модели, — избыточные помехи в наборе предикторов, реакции и предиктивная экстраполяция рассматриваются в главе 20.
1.6. Условные обозначения
Среди прочих целей авторы книги стремились предоставить интуитивно понятные описания многих методов. Там, где это возможно, вместо формул используются слова. Многие модели могут быть выражены в алгоритмическом виде, но для некоторых из них предпочтительнее формулы. Обычно символы х и у с разными шрифтами и в разном регистре представляют предикторы и реакцию модели соответственно. В тексте они выглядят следующим образом:
О п = количество точек данных;
О Р = количество предикторов;
О yi - i-e наблюдаемое значение результата, г = 1 ... п;
О £ = прогнозируемый результат г-й точки данных, i = 1 ... п;
О у = выборочное среднее значение для п наблюдаемых значений результата;
О у = вектор всех п значений результата;
О х- = значение у-го предиктора для г-й точки данных, i = 1,..., п uj = 1 ..., Р;
О Xj = выборочное среднее значение п точек данных для/го предиктора, J = 1,
О х, = коллекция (то есть вектор) Р предикторов для г-й точки данных, г = 1,..., п;
О X = матрица Р предикторов для всех точек данных; матрица содержит п строк и Р столбцов;
О Xх = транспонированная матрица X; эта матрица содержит Р строк и п столбцов.
1,6. Условные обозначения 39
Другие условные обозначения, встречающиеся по ходу изложения в формулах:
О С = количество классов в категорийном результате;
О Се = значение уровня /*-го класса;
О р = вероятность события;
О = вероятность Лго события;
О Рг[.] = вероятность события;
п
О £ = оператор суммирования по индексу i;
i=l
О Z = теоретическая ковариационная матрица;
О £[•] = ожидаемое значение •;
О /(•) = функция .; для функций в тексте также используются обозначения g(-) и/г();
О р = неизвестный или теоретический коэффициент модели;
О Ь = оценочный коэффициент модели, полученный на основании выборки точек данных.
Для освещения отдельных тем и моделей авторами также используются другие обозначения (см. соответствующие пояснения по ходу изложения).
Часть I
ОБЩИЕ СТРАТЕГИИ
Краткий обзор процесса предиктивного моделирования
Прежде чем перейти к глубокому изучению формальных компонентов построения модели, рассмотрим простой пример, иллюстрирующий основы ее построения, точнее, то, что в дальнейшем будет именоваться как «расходование» данных, построение моделей-кандидатов и выбор оптимальной модели.
2.1. Пример прогнозирования экономии топлива
На веб-сайте fueleconomy.gov, принадлежащем Управлению по энергоэффективности и возобновляемым источникам энергии Министерства энергетики США и Агентству охраны окружающей среды США, перечислены различные оценки экономии топлива для легковых и грузовых автомобилей. Для каждого вида транспорта регистрируются различные характеристики, включая объем двигателя и число цилиндров. Параллельно проводятся лабораторные измерения потребления топлива в городе и на автострадах (в милях на галлон (MPG)).
На практике для нахождения наиболее эффективной предиктивной модели ее следовало строить с учетом максимально возможного числа характеристик. Тем не менее в данном примере нас интересуют прежде всего высокоуровневые концепции построения модели, поэтому мы ограничимся одним предиктором — объемом двигателя (пространством в цилиндрах двигателя) и одной реакцией — нескорректированным показателем MPG на автостраде для автомобилей 2010-2011 годов выпуска.
Построение модели начинается с уяснения исходных данных — допустим, посредством их представления в графическом виде. Поскольку в нашем примере используются один предиктор и одна реакция, эти данные могут быть представлены в виде графика (рис. 2.1), отражающего зависимость между объемом двигателя и экономией топлива. На графике слева представлены данные по всем машинам
2.1. Пример прогнозирования экономии топлива 43
2010 года, на графике справа — данные только по новым машинам 2011 года. Очевидно, что с ростом объема двигателя эффективность потребления топлива падает независимо от года выпуска. Зависимость выглядит достаточно линейной, но на концах оси, отражающей изменение объема двигателя, наблюдается некоторая тенденция к искривлению.
2 4 6 8
-0- ф
70
60
50
40
30
20
2 4 6 8
Объем двигателя
Рис. 2.1. Зависимость между объемом двигателя и эффективностью потребления топлива для автомобилей 2010 и 2011 года выпуска
Если бы в модели использовалось несколько предикторов, то пришлось бы продолжить анализ их характеристик, а равно и зависимостей между предикторами. Эти характеристики могут указывать на обязательность выполнения ряда операций по обработке данных, предшествующих построению модели (подробнее см. главу 3).
Получив первое представление о данных, можно приступить к построению и оценке модели. Стандартный подход заключается в том, чтобы использовать случайную выборку данных для построения модели, а остальные данные — для оценки ее эффективности. Предположим, однако, что нам необходимо спрогнозировать MPG для нового семейства автомобилей. Подобные модели могут создаваться на основе данных 2010 года (для 1107 автомобилей), а тестироваться — на основе данных 2011 года (для 245 автомобилей). Условимся, что данные за 2010 год будут именоваться нами «тренировочным набором» модели, а данные за 2011 год — «тестовым» или «контрольным» набором.
Теперь необходимо решить, как именно оценивать эффективность модели. Для регрессионных задач, в которых мы пытаемся предсказать то или иное числовое значение, важным источником информации могут стать погрешности. Остаточная погрешность (residual) вычисляется как разность между наблюдаемым и спрогнозированным значением (то есть г/, - г/?) При прогнозировании числовых значений для оценки моделей обычно применяется среднеквадратичная погрешность. Эта
44 Глава 2. Краткий обзор процесса предиктивного моделирования характеристика (подробнее см. главу 7) показывает, насколько в среднем погрешность отклоняется от нуля.
В процессе оценки модели ее разработчик опробует различные приемы математического определения зависимости между предиктором и результатом. Здесь тренировочный набор используется для оценки различных значений, задействованных в уравнениях модели. Тестовый набор используется только после того, как несколько наиболее подходящих моделей (далее также — моделей-кандидатов) будут приняты разработчиком для окончательного выбора в пользу наиболее подходящей. Отметим, что повторное использование тестового набора в процессе построения модели не позволяет применять его в качестве «арбитра» модели.
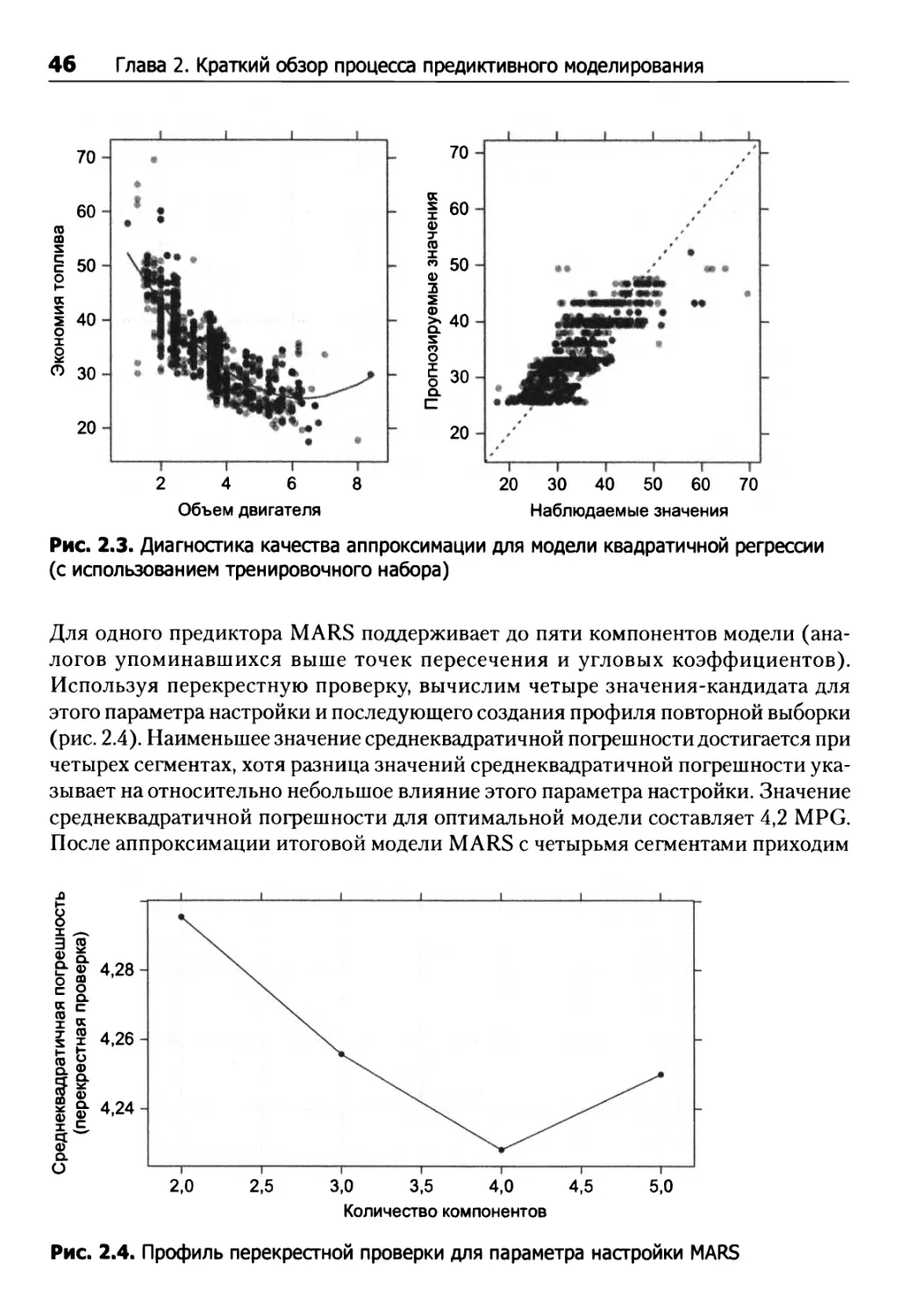
Предположим, нами была создана модель линейной регрессии, в которой прогнозируемая величина MPG определяется простейшим уравнением прямой с угловым коэффициентом. На основании тренировочных данных мы посредством метода наименьших квадратов (подробнее см. раздел 6.2) оцениваем точку пересечения 50,6 и угловой коэффициент -4,5 MPG. На рис. 2.2 показана погрешность модели для данных тренировочного набора1. В левой части отображен тренировочный набор данных с линейной аппроксимацией, определяемой вычисленной точкой пересечения и угловым коэффициентом. В правой части отображены наблюдаемые и спрогнозированные значения MPG. Как видим, модель упускает некоторые закономерности в данных — например, занижение эффективности потребления топлива, если объем двигателя меньше 2 л или, напротив, больше 6 л.
70
к х X ф
7
X со
ф >ч
о.
60
50
40
30
20
ф
3
2
о Е а
с
2 4 6 8
20 30 40 50 60 70
Объем двигателя
Наблюдаемые значения
Рис. 2.2. Диагностика качества аппроксимации для модели линейной регрессии
1 Как говорил наш преподаватель в аспирантуре:« Если вы хотите чувствовать себя уверенно со своими данными, никогда не смотрите на них».
2.1. Пример прогнозирования экономии топлива 45
Подчеркнем: не следует оценивать производительность модели на данных, использованных для построения модели. Выполнив прогнозирование на основе данных тренировочного набора, вы рискуете получить завышенную оценку качества работы модели, особенно если модель обладает высокой адаптируемостью. Альтернативный способ оценки качества модели основан на использовании повторной выборки (resampling) с вариативным использованием данных тренировочного набора для обучения модели (подробнее см. главу 4). В рассматриваемом примере использован прием повторной выборки, именуемый далее десятикратной перекрестной проверкой (10-fold cross-validation); значение среднеквадратичной погрешности составляет 4,6 MPG.
Исходя из рис. 2.2 можно предположить, что задача решается введением некоторой нелинейности в модель несколькими возможными способами — например, посредством искусственного усложнения вычислительного аппарата модели. Так, добавление квадратного члена для объема двигателя позволяет дополнительно оценить параметр углового коэффициента (через квадрат предиктора). В этом случае уравнение модели принимает вид:
Эффективность = 63,2 - 11,9 х объем + 0,94 х объем2.
Такое уравнение называется квадратичной моделью, поскольку включает квадратный член (см. аппроксимацию модели на рис. 2.3). Добавление квадратного члена улучшает качество аппроксимации — значение среднеквадратичной погрешности, вычисленной с использованием перекрестной проверки, составляет 4,2 MPG. Один из недостатков квадратичных моделей — неэффективность в крайних диапазонах предиктора. На рис. 2.3 нечто похожее наблюдается для автомобилей с очень большим объемом двигателя. Результаты подобного прогнозирования могут характеризоваться серьезными погрешностями.
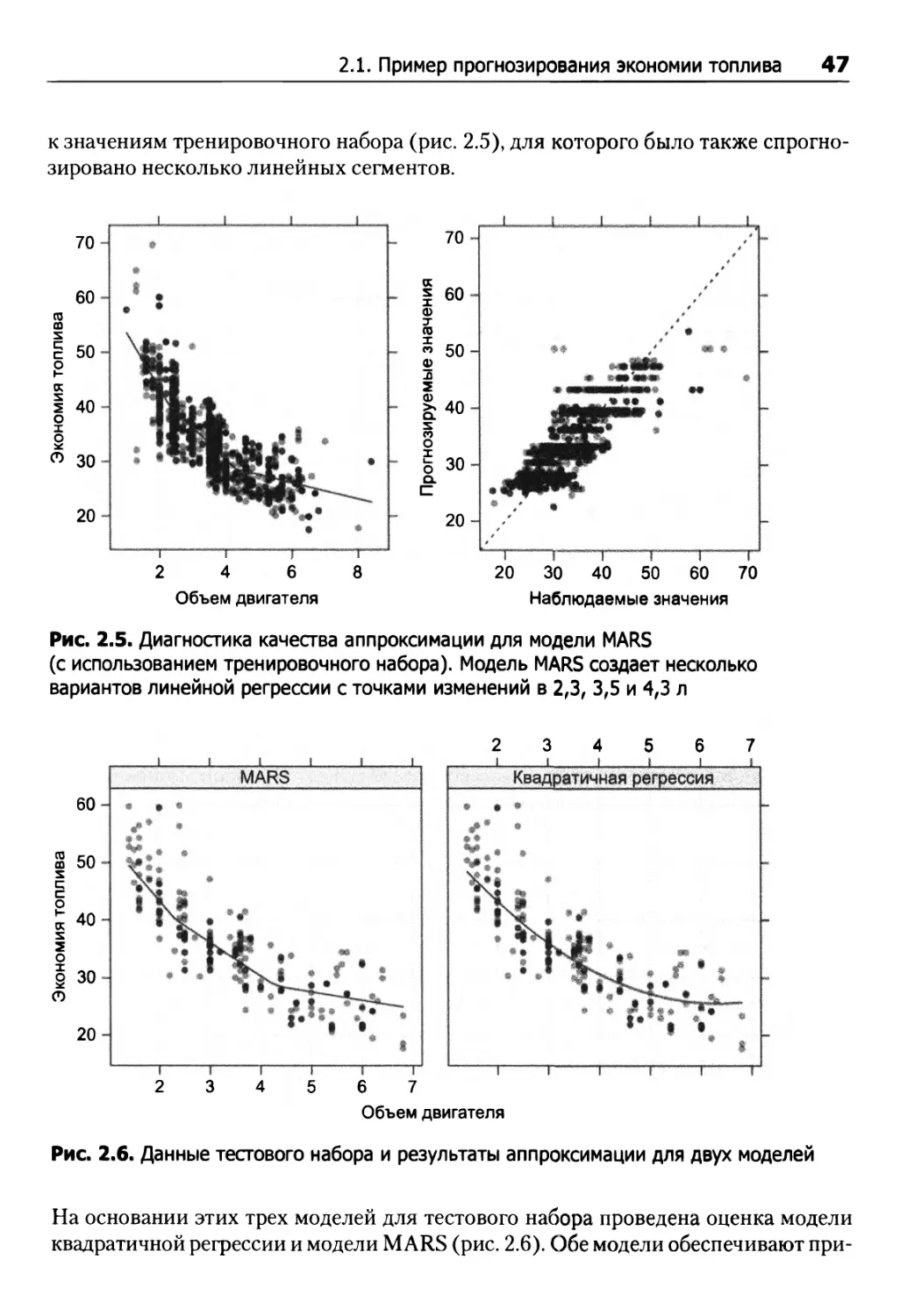
В главах 6-8 рассматривается немало других методов создания сложных зависимостей между предикторами и результатом. Это, например, рассмотренная Фридманом (Friedman, 1991) модель многомерных адаптивных регрессионных сплайнов (MARS). При наличии только одного предиктора MARS может произвести аппроксимацию разных линейных регрессий для разных диапазонов объема двигателя. Для этой модели вычисляется точка пересечения оси и угловой коэффициент, а также количество и размеры нескольких областей для линейных моделей. В отличие от линейных регрессионных моделей, у модели, формируемой рассматриваемым методом, имеется параметр настройки, который не может быть напрямую выведен из данных. Не существует и формулы, по которой можно было бы определить количество сегментов для моделирования данных. Хотя в модели MARS предусмотрены внутренние алгоритмы для определения этой характеристики, можно опробовать разные значения и использовать повторную выборку для определения наиболее подходящего из них. Это позволит провести обучение итоговой модели MARS по всем данным тренировочного набора, после чего использовать ее для прогнозирования.
46 Глава 2. Краткий обзор процесса предиктивного моделирования
70
60 га га х £ 50 О н (X i 40 О х § & 30
20
70
(1)
3
ф >ч
Q.
X о О г о Q.
60
50
40
30
С
2 4 6 8
20 30 40 50 60 70
Объем двигателя
Наблюдаемые значения
Рис. 2.3. Диагностика качества аппроксимации для модели квадратичной регрессии (с использованием тренировочного набора)
Для одного предиктора MARS поддерживает до пяти компонентов модели (аналогов упоминавшихся выше точек пересечения и угловых коэффициентов). Используя перекрестную проверку, вычислим четыре значения-кандидата для этого параметра настройки и последующего создания профиля повторной выборки (рис. 2.4). Наименьшее значение среднеквадратичной погрешности достигается при четырех сегментах, хотя разница значений среднеквадратичной погрешности указывает на относительно небольшое влияние этого параметра настройки. Значение среднеквадратичной погрешности для оптимальной модели составляет 4,2 MPG. После аппроксимации итоговой модели MARS с четырьмя сегментами приходим
2,0
2,5
3,0 3,5 4,0 4,5
Количество компонентов
5,0
Рис. 2.4. Профиль перекрестной проверки для параметра настройки MARS
2.1. Пример прогнозирования экономии топлива 47
к значениям тренировочного набора (рис. 2.5), для которого было также спрогнозировано несколько линейных сегментов.
70
2 4 6 8
Объем двигателя
(X X X ф т го X со
ф
5
ф >4
о.
о о. С
60
50
40
30
20
20 30 40 50 60 70
Наблюдаемые значения
Рис. 2.5. Диагностика качества аппроксимации для модели MARS
(с использованием тренировочного набора). Модель MARS создает несколько вариантов линейной регрессии с точками изменений в 2,3, 3,5 и 4,3 л
2 3 4 5 6 7
60
S 50
х
q
О
о
О 30 О
20
2 3 4 5 6 7
Объем двигателя
Рис. 2.6. Данные тестового набора и результаты аппроксимации для двух моделей
На основании этих трех моделей для тестового набора проведена оценка модели квадратичной регрессии и модели MARS (рис. 2.6). Обе модели обеспечивают при-
48 Глава 2. Краткий обзор процесса предиктивного моделирования близительно одинаковое качество аппроксимации. Значение среднеквадратичной погрешности тестового набора для квадратичной модели составило 4,72 MPG, а для модели MARS — 4,69 MPG. Следовательно, любая из этих моделей пригодна для прогнозирования эффективности новых моделей автомобилей.
2.2. Аспекты, заслуживающие отдельного рассмотрения
У процесса построения модели есть несколько аспектов, о которых стоит рассказать подробнее, особенно для читателей, не имеющих опыта в предиктивном моделировании.
Разделение данных
Способ распределения данных на части, используемые, например, для построения модели и для оценки ее эффективности, является (подробнее см. следующую главу) важным аспектом моделирования. В рассмотренном примере нас прежде всего интересовала возможность прогнозирования экономии топлива новых автомобилей, а эти данные не принадлежат той же совокупности, что и данные, использованные для построения модели. Тем самым мы до определенной степени проверяем, насколько хорошо модель экстраполируется на другую совокупность данных. Если бы нас интересовало прогнозирование по той же совокупности машин (то есть интерполяция), то правильнее было бы воспользоваться случайной выборкой этих данных. Значит, способ определения тренировочного и тестового наборов должен отражать и особенности применения модели.
Сколько именно данных следует выделить под тренировочный и тестовый наборы, зависит от ситуации. Если набор данных мал, то решение о разделении данных следует принимать крайне осмотрительно. Малый набор данных обладает ограниченными возможностями для оценки эффективности. Для получения адекватной оценки в данной ситуации можно прибегнуть к методу повторной выборки, отказавшись от применения тестового набора.
Данные предикторов
В рассмотренном примере центральное место занимал один из предикторов: объем двигателя. Но исходные данные включают также сведения о количестве цилиндров, о типе передачи, о производителе автомобиля. Более серьезная попытка прогнозирования экономии топлива учитывала бы максимально возможное количество предикторов для повышения эффективности. Заметим, при использовании нескольких предикторов представляется возможным уменьшить значения среднеквадратичной
2.2. Аспекты, заслуживающие отдельного рассмотрения 49
погрешности для новых моделей машин. Вам могут помочь и дополнительные исследования данных — с учетом, например, того, что ни одна модель не обеспечивала эффективного прогнозирования экономии топлива для автомобилей с малым объемом двигателя. Соответственно, включение предикторов, ориентированных именно на автомобили с малолитражными двигателями, способно повысить эффективность моделирования (о процессе определения минимально необходимого набора релевантных предикторов подробнее см. главу 19).
Оценка эффективности
Перед использованием тестового набора мы применили два метода определения эффективности модели. Первый из них — количественная оценка статистики (например, среднеквадратичная погрешность) с использованием повторной выборки — позволяет понять, насколько применим каждый метод в отношении новых данных. Другой метод — создание простых визуализаций модели (например, посредством нанесения на график наблюдаемых и спрогнозированных значений) для обнаружения областей данных, в которых модель показывает наилучшие или, напротив, наихудшие результаты. Эта информация особенно важна для улучшения моделей и, наоборот, утрачивает свое значение, если модель оценивается только на основе сводной статистики.
Оценка нескольких моделей
Мы выполнили оценку трех разных моделей. Между тем многие практики моделирования замечены в склонности к использованию только одной модели, облеченной их доверием (быть может, чрезмерным). Однако представленная Уолпертом (Wolpert, 1996) «Теорема о бесплатном сыре» утверждает, что без обладания наиболее важной информацией о проблеме, решить которую предполагается посредством моделирования, невозможно сделать выбор в пользу модели, которая бы априори работала лучше любой другой. Значит, следует опробовать разнообразные методы оценки моделей и лишь затем определить, на какой именно модели следует остановиться. В рассмотренном примере график данных указал на наличие нелинейной зависимости между предиктором и реакцией, что позволяет исключить из дальнейшего рассмотрения линейные модели (при сохранении множества иных вариантов), сделав окончательный выбор в пользу простой квадратичной модели.
Выбор модели
Итак, мы рассмотрели два варианта выбора. В соответствии с первым из них модели сравнивались между собой, что повлекло исключение из числа моделей-кандидатов модели линейной регрессии (как не обеспечивающей требуемой аппроксимации).
50 Глава 2. Краткий обзор процесса предиктивного моделирования
Во втором варианте к моделям определенного типа, например MARS, выбор параметра осуществлен посредством перекрестной проверки. Соответственно, искомый тип модели MARS определялся посредством выбора между несколькими однотипными моделями.
В обоих случаях для получения оценок моделей, упрощающих выбор, применены перекрестная проверка и тестовый набор. Поскольку в рассмотренном примере использовался всего один предиктор, что на практике случается редко, были построены графики аппроксимации, способствовавшие принятию обоснованного решения. Выбранные в итоге варианты моделей, на первый взгляд, обладали одинаковой эффективностью. Но поскольку квадратичные модели могут недостаточно хорошо работать для машин с очень большим объемом двигателя, интуиция подсказывает, что лучше отдать предпочтение модели MARS. К слову, одна из целей этой книги заключается в том, чтобы помочь читателю сформировать интуитивное представление о сильных и слабых сторонах разных моделей, что, в свою очередь, способствует принятию последующих взвешенных решений.
2.3. Итоги
На первый взгляд, построение модели выглядит прямолинейно: выберите метод моделирования, введите данные и сформируйте прогноз. Да, в результате такого подхода будет сгенерирована предиктивная модель, но вряд ли она окажется достаточно надежной и достоверной для прогнозирования по новым выборкам. Чтобы получить искомую модель, необходимо уяснить цель моделирования, требования к данным, используемым в процессе моделирования. Это, в свою очередь, позволит провести предварительную обработку данных, их обоснованное разделение. Только после этого можно приступить к построению, оценке и выбору моделей.
Предварительная обработка данных
Под методами предварительной обработки обычно понимается добавление, удаление или преобразование тренировочных наборов данных. Подготовка данных может сыграть решающую роль в предиктивной эффективности модели. Разные модели обладают разной чувствительностью к типу предикторов; важно и то, как предикторы входят в модель. Преобразования данных для сокращения влияния асимметричности или выбросов могут привести к значительному улучшению эффективности модели. Выделение признаков (подробнее см. раздел 3.3) — один из эмпирических методов создания суррогатных переменных, представляющих сочетание нескольких предикторов. Но и более простые стратегии, например удаление предикторов из-за нехватки информационного контента, тоже могут оказаться эффективными.
Необходимость предварительной обработки данных определяется с учетом типа модели. Так, древовидные модели наименее чувствительны к характеристикам данных предикторов, что, напротив, не характерно для линейной регрессии. В этой главе рассматривается широкий спектр возможных методологий. При последующем описании методов моделирования внимание читателей будет обращено на те из них, что представляются в контексте повествования наиболее подходящими.
В этой же главе обозначены подходы к неконтролируемой обработке данных, когда результирующая переменная не учитывается методом предварительной обработки. Рассмотрены контролируемые методы, например модели частных наименьших квадратов (PLS), по сути, являющиеся контролируемыми версиями метода главных компонент (РСА, Principal Component Analysis). Будут описаны и стратегии удаления предикторов без проведения анализа взаимосвязи переменных с результатом (о методах нахождения подмножеств предикторов, оптимизирующих способность модели к прогнозированию реакции, см. главу 19).
52 Глава 3. Предварительная обработка данных
Способ кодирования предикторов, называемый конструированием признаков (feature engineering), может оказывать значительное влияние на эффективность модели. Например, использование комбинаций предикторов иногда может быть более эффективным, чем их раздельное использование. Часто выбор наиболее эффективной кодировки данных определяется не каким-либо математическим методом, а исходя из понимания разработчиком модели стоящей перед ним задачи.
Обычно применяются несколько различных методов кодирования данных предикторов. Так, в главах 12-15 описан набор данных для прогнозирования успеха заявки на получение академических грантов. В числе данных фигурирует и дата подачи заявки, представляемая:
О как количество дней, отсчитываемых от некоторой начальной даты;
О с выделением месяца, года и дня недели в отдельные предикторы;
О как порядковый номер дня года;
О как признак принадлежности даты к учебному году (в отличие от дней, не относящихся к числу учебных).
«Правильное» конструирование признаков зависит от нескольких факторов.
Во-первых, некоторые кодировки могут быть оптимальными для одних моделей, но абсолютно непригодными для других. Например, древовидные модели разделяют данные на два и более гнезда. Теоретически, если месяц важен, дерево разобьет числовой день года соответствующим образом. Кроме того, в некоторых моделях множественные способы кодирования определенных данных могут оказаться трудноприменимыми. Ряд моделей (см. далее) содержат встроенные средства выбора признаков; это означает, что модель будет включать только те предикторы, которые способствуют максимизации ее точности.
Во-вторых, необходимо учитывать взаимозависимость между предиктором и результатом. Например, если в данных присутствует фактор сезонности, то определение признака дня года по порядковому номеру будет лучшим вариантом. Кроме того, если в некоторых месяцах наблюдаются более высокие показатели успешности, чем в других, кодировка на базе месяца будет предпочтительной.
На вопрос «Какие методы конструирования признаков работают лучше всего?» ответ будет таким же, как и на многие иные вопросы из области статистики: это зависит от ситуации (подробнее о кодировке данных см. раздел 12.1).
Прежде чем приступить к изучению конкретных методов конструирования признаков, рассмотрим следующий пример.
3.1. Практический пример: сегментация клеток 53
3.1. Практический пример: сегментация клеток в высокопроизводительном скрининге
Медики-исследователи часто пытаются понять эффект воздействия препарата или заболевания на размер, форму, состояние развития и количество клеток в живом организме. Для этого под микроскопом исследуются сыворотка или ткань, после чего выбираются нужные для оценки состояния клеток характеристики. Эта работа утомительна и требует экспертных знаний типов и характеристик клеток. Но для указанных целей возможно и применение высокопроизводительного скрининга, упоминаемого, например, у Джулиано (Giuliano et al., 1997), в соответствии с которым исследуемый образец сначала окрашивается веществом, позволяющим выявить соответствующие характеристики клеток. Например, если требуется получить количественную оценку размера или формы ядра клетки, то в образце применяется вещество, взаимодействующее с ДНК клетки. Состояние клетки при этом консервируется. Затем образец исследуется при помощи инструмента (например, конфокального микроскопа), где краситель отражает свет, а датчики определяют степень рассеяния с учетом конкретной длины волны. Для исследования нескольких характеристик клеток допустимо одновременное использование нескольких красителей и нескольких световых частот. Результаты измерений обрабатываются специальной программой для получения числовой оценки искомых характеристик исследуемых клеток.
Впрочем, и подобный способ определения характеристик клеток иногда дает недостоверные результаты. Так, у Хилла (Hill et al., 2007) описан исследовательский проект, в котором высокопроизводительный скрининг применен для измерения нескольких параметров, характеризующих состояние клеток. По ходу исследований выяснилось, что у программы, определявшей форму и местонахождение клеток, возникали проблемы с сегментированием (то есть определением границ) клеток. На изображениях (рис. 3.1) ярко-зеленые границы обозначают ядро клетки, синие — ее периметр. Очевидно, что одни клетки имеют четкую сегментацию, а другие — нет. Клетки с плохой сегментацией кажутся поврежденными, но в действительности это не так. Таким образом, если предметом исследования является определение размера, формы и/или количества клеток, очень важно, чтобы программа обработки изображений правильно сегментировала исследуемые клетки.
Для проведения исследований группа Хилла (Hill et al., 2007) сформировала набор данных из 2019 клеток, из которых 1300 считались плохо сегментированными (PS,
54 Глава 3. Предварительная обработка данных
Poorly Segmented), а 719 — хорошо сегментированными (WS, Well Segmented); еще 1009 клеток были зарезервированы для тренировочного набора1.
Для конкретного типа клеток исследователи применяли разные красители, видимые в разных оптических каналах. Канал 1 был связан с клеточным телом и мог использоваться для определения периметра клетки, ее площади и ряда других показателей. Канал 2 был связан с ядром клетки и использовался для окрашивания ядерной ДНК (синие участки на рис. 3.1). Каналы 3 и 4 были направлены на обнаружение актина и тубулина соответственно. Эти два типа волокон проходят через клеточный каркас и являются частью цитоскелета клетки. Для клеток в составе набора вычислены 116 признаков (например, площадь или количество волокон), которые использовались при прогнозировании качества сегментации клеток2.
d
е
Рис. 3.1. Изображение с сегментацией клеток из исследования Хилла (Hill et al., 2007). Фрагменты [(d) и (е)] обозначают плохо сегментированные клетки, а клетки в фрагментах (с) и (Ь) являются примерами хорошей сегментации
В этой главе будут использоваться выборки тренировочного набора, выделенные авторами для демонстрации методов предварительной обработки данных.
' Конкретные точки данных можно найти на веб-сайте журнала или в пакете R AppliedPredictiveModeling. См. раздел «Вычисления» в конце этой главы.
2 Авторы также включили несколько «статусных» признаков, которые являлись бинарными представлениями других признаков в наборе данных. Мы исключили их из анализа в этой главе.
3.2. Преобразования данных для отдельных предикторов 55
3.2. Преобразования данных для отдельных предикторов
Преобразования переменных-предикторов могут понадобиться по разным причинам. Так, у некоторых методов моделирования существуют требования к наличию у предикторов единой шкалы масштаба. Иногда хорошую модель трудно создать из-за особых характеристик данных (например, выбросов), в связи с чем необходимы рассматриваемые далее преобразования: центрирование, масштабирование и смещение.
Центрирование и масштабирование
Самое тривиальное и распространенное преобразование данных — центрирование переменных-предикторов по оси координат. Чтобы отцентровать предиктор, из всех имеющихся значений вычитается среднее значение. В результате получается нулевое среднее значение предиктора. Аналогичным образом для масштабирования данных каждое значение переменной-предиктора делится на ее среднеквадратичное отклонение. Масштабирование данных модифицирует значения так, чтобы среднеквадратичное отклонение равнялось единице. Рассматриваемые преобразования обычно используются для улучшения числовой стабильности некоторых вычислений. Так, модели наподобие PLS (разделы 6.3 и 12.4) выигрывают от приведения шкалы предикторов к одному масштабу. Недостаток таких преобразований — потеря интерпретируемости индивидуальных значений (поскольку данные уже не измеряются в исходных единицах).
Преобразования для устранения смещения
Другая стандартная причина, влекущая необходимость преобразований, — устранение асимметрии в распределении. Несмещенное распределение приблизительно симметрично. Это означает, что вероятность попадания по обе стороны от математического ожидания распределения приблизительно одинакова. В распределении, смещенном вправо, в его левой части (меньшие значения) оказывается большее количество точек, чем в правой части (большие значения). Например, данные сегментации клеток содержат предиктор, оценивающий среднеквадратичное отклонение пикселов в волокнах актина. В данных, выраженных в натуральных единицах, наблюдается сильное смещение вправо; в области малых значений наблюдается большая концентрация точек данных, тогда как в области больших значений их относительно немного (рис. 3.2).
56 Глава 3. Предварительная обработка данных
Рис. 3.2. Слева: гистограмма среднеквадратичного отклонения интенсивности пикселов в волокнах актина. У этого предиктора наблюдается сильное смещение вправо с концентрацией точек с низкими значениями. Для этой переменной отношение большего значения к меньшему равно 870, а коэффициент асимметрии составляет 2,39. Справа', те же данные после логарифмического преобразования. Коэффициент асимметрии для логарифмических данных равен -0,4
Принято считать, что данным, у которых отношение наибольшего значения к наименьшему превышает 20, присуще значительное смещение. Коэффициент асимметрии может использоваться и как диагностический признак. Если же распределение приблизительно симметрично, то величины смещения будут близки к нулю. По мере нарастания смещения вправо увеличивается и коэффициент асимметрии. При нарастании смещения распределения влево значение становится отрицательным. Формула коэффициента асимметрии выборки выглядит так:
асимметрия =
Х(х(-*)3
(w-l)r3/2 ’
где
(п-1)
гдех — переменная-предиктор, п — количество значений, х — выборочное среднее для предиктора. Для данных волокон актина на рис. 3.2 вычисленный коэффициент асимметрии равен 2,39, а отношение наибольшего значения к наименьшему равно 870. Замена данных логарифмом, квадратным корнем или обратной величиной может помочь устранить асимметрию. Для данных на правой панели (рис. 3.2) показано распределение после логарифмического преобразования. Как видим, и преобразованное распределение не является абсолютно симметричным, но эти данные обладают намного лучшим поведением, чем в натуральных единицах.
3.2. Преобразования данных для отдельных предикторов 57
Для эмпирического определения подходящего преобразования можно воспользоваться и статистическими методами. Бокс и Кокс (Box and Сох, 1964) предлагают семейство преобразований1, индексированных по параметру X:
если X фО
если X — О
Кроме логарифмического преобразования, это семейство может выявлять преобразование возведения в квадрат (X = 2), квадратный корень (X = 0,5), вычисление обратной величины (X = -1) и другие промежуточные преобразования. Используя тренировочные данные, можно оценить значение X. Бокс и Кокс (Box and Сох, 1964) показывают, как при помощи оценивания методом максимального правдоподобия определить параметр преобразования. Эта процедура будет применяться независимо ко всем данным предикторов, содержащих положительные значения.
Рис. 3.3. Слева: гистограмма предиктора периметра клетки. Справа: те же данные после преобразования Бокса—Кокса с вычисленной оценкой X = -1,1
Для данных сегментации 69 предикторов не были преобразованы из-за нулевых или отрицательных значений, а у трех предикторов оценки X лежали в диапазоне
1 Некоторые читатели, знакомые с работой Бокса и Кокса (Box and Сох, 1964), знают, что это преобразование было разработано для данных результата, тогда как у Бокса и Тидуэлла (Box and Tidwell, 1962) описаны аналогичные методы преобразования набора предикторов в линейной модели. Наш опыт показывает, что преобразование Бокса—Кокса более прямолинейно, создает меньше проблем с числовыми данными и не уступает по эффективности преобразованию отдельных переменных-предикторов.
58 Глава 3. Предварительная обработка данных 1 ± 0,02, поэтому преобразование не применялось. У остальных 44 предикторов значения оценивались в диапазоне от -2 до 2. Например, для данных предикторов на рис. 3.2 оценка значения преобразования равна 0,1, что указывает на оптимальность логарифмического преобразования. Для другого предиктора, примененного при оценке периметра клетки, значение X составляло -1,1 (рис. 3.3).
3.3. Преобразования данных с несколькими предикторами
Преобразования для решения проблемы выбросов
Выбросы (outliers) обычно определяются как точки данных, лежащие аномально далеко от основного потока данных. Отметим, что даже при доскональном понимании данных выявление выбросов может оказаться проблематичным. Тем не менее нетипичные значения часто выявляются при рассмотрении графиков. Чтобы квалифицировать одну или несколько точек в качестве выбросов, следует убедиться в том, что оцениваемые значения являются действительными с научной точки зрения (например, кровяное давление положительно), а регистрация данных не сопровождалась ошибками. Никогда не торопитесь с удалением или изменением значений, особенно при малом размере выборки. В малых выборках очевидные выбросы могут быть результатом смещения в распределении, когда объем данных еще недостаточен для того, чтобы заметить это смещение.
Выбросы данных могут свидетельствовать и о том, что из особой части изучаемой совокупности еще только начинают поступать данные. В зависимости от того, как собирались данные, «кластер» действительных точек вне основного потока данных может принадлежать к другой совокупности, чем другие выборки1.
Отметим, что существует несколько предиктивных моделей, устойчивых к выбросам. Древовидные модели классификации создают разделения тренировочных данных, а формула прогнозирования представляет собой набор логических утверждений типа «если предиктор А больше X, то прогнозировать класс У», так что выброс обычно не оказывает значительного влияния на модель. Метод опорных векторов, применяемый для классификации данных, обычно игнорирует часть данных в составе тренировочного набора при создании предиктивного уравнения. Исключенные данные могут лежать как за пределами принятия решения, так и за пределами основного потока данных.
1 В разделе 20.5 рассматривается экстраполяция модели, при которой модель прогнозирует точки данных, находящиеся за пределами основного потока тренировочных данных. Другая важная концепция, область применимости модели, представляет собой совокупность точек данных, которые могут эффективно прогнозироваться моделью.
3.3. Преобразования данных с несколькими предикторами 59
Если известно, что модель чувствительна к выбросам, можно прибегнуть к предлагаемому Сернилсом (Serneels et al., 2006) преобразованию пространственного знака. Эта процедура проецирует значения предиктора на многомерную сферу В результате все данные находятся на одинаковом расстоянии от центра сферы. С математической точки зрения каждое значение делится на среднеквадратичную
норму:
Поскольку знаменатель должен отражать расстояние до центра распределения предиктора, важно отцентрировать и масштабировать данные предиктора до преобразования. Обратите внимание: в отсутствие центрирования или масштабирования эта операция с предикторами преобразует их как группу. Удаление переменных- предикторов после применения преобразования пространственного знака может оказаться проблематичным.
Основной поток данных
Выбросы
-6 -4 -2 0 2 4
-1,0 -0,5 0,0 0,5 1,0
о
о
о о
ю о
I
<э
7
Переменная-предиктор 1
Рис. 3.4. Слева: характерный пример с группой аномальных точек данных. Справа: после преобразования исходных данных выбросы приближаются к основной группировке данных
На рис. 3.4 изображен другой набор данных с двумя коррелированными предикторами, не менее восьми точек которого группируются обособленно от большинства других. Вероятно, эти точки образуют действительную, но нетипичную подобласть данных. Необходимо выяснить, почему эти точки отличаются от других; возможно, отображаемые данные представляют интерес, например, применительно к клиентам,
60 Глава 3. Предварительная обработка данных приносящим особенно высокую прибыль. В правой части (рис. 3.4) изображено преобразование пространственного знака, при котором все точки данных проецируются на равном расстоянии от центра. В северо-западной части распределения по-прежнему остаются выбросы, но они «втягиваются» внутрь. В результате сокращается эффект влияния точек на обучение модели.
Прореживание данных и выделение признаков
Методы прореживания данных — отдельный класс преобразований предикторов. Эти методы сокращают объем данных посредством генерирования меньшего набора предикторов, сохраняющих большую часть информации из исходных переменных. При этом можно использовать меньшее количество переменных, с удовлетворительной точностью отражающих исходные данные. В большинстве методов прореживания данных новые предикторы являются функциями исходных предикторов; таким образом, сохраняется потребность во всех исходных предикторах для создания суррогатных переменных. Подобные методы обычно именуются методами выделения признаков или методами выделения сигнала.
Одним из распространенных методов прореживания является метод главных компонент РСА, упоминаемый, в частности, Эбди и Уильямсом (Abdi and Williams, 2010). Этот метод направлен на нахождение линейных комбинаций предикторов, называемых главными компонентами (PC, Principal Components) и фиксирующих максимально возможную дисперсию. Первая главная компонента определяется как линейная комбинация предикторов, отражающая максимально возможный разброс среди всех возможных линейных комбинаций. Далее выводятся последующие главные компоненты, отражающие максимальный остаточный разброс при сохранении корреляции со всеми предшествующими главными компонентами. j-я главная компонента записывается в следующем виде:
РС; = (ау1 х Предиктор 1) + (aj2 х Предиктор 2) + ••• + (а-р х Предиктор Р),
где Р — количество предикторов. Коэффициенты ajV aJ2,..., ajP называются весами компонентов и помогают понять, какие предикторы наиболее важны для каждой главной компоненты.
Чтобы продемонстрировать практическое применение РСА, обратимся к рис. 3.5. Набор содержит подмножество двух коррелированных предикторов средней интенсивности пикселов канала 1, энтропии значений интенсивности в клетке (метрика формы клетки) и категорийный результат. С учетом высокой корреляции между предикторами (0,93) можно заключить, что значения средней интенсивности пикселов и энтропии значений интенсивности содержат избыточную информацию о клетках, а вместо исходных предикторов может использоваться только один из них или их линейная комбинация. В этом примере можно вывести две главные
3.3. Преобразования данных с несколькими предикторами 61
компоненты (правая часть рис. 3.5); преобразование представляет поворот данных по оси с наибольшей дисперсией. Первая главная компонента отражает 97 % исходного разброса, вторая — 3 %. Следовательно, предпочтительнее использовать для моделирования только первую главную компоненту как учитывающую большую часть информации в данных.
2,8
Исходные данные PS WS
Преобразованные данные
СМ
с го X
го
2,6
2,4
2,2
2,0
го н X ф X о с
2
-2
2
0
1,3 1,4 1,5 1,6
Канал 1 Ширина волокон
-2 0 2
Главная компонента 1
Рис. 3.5. Пример преобразования главных компонент для данных сегментации клеток
Главное преимущество метода РСА — в том, что при прореживании данных образуются некоррелированные компоненты. Как упоминалось в этой главе, для некоторых предиктивных моделей желательно, чтобы предикторы были некоррелированными (или, по крайней мере, имели низкую корреляцию), — это необходимо как для поиска оптимальных решений, так и для улучшения числовой стабильности модели. Предварительная обработка РСА позволяет создать новые предикторы с характеристиками, предпочтительными для моделей исследуемого типа.
Вместе с тем нужно учитывать, что метод РСА работает с дисперсией набора предикторов без учета применяемых шкал измерения или распределений и целей моделирования (то есть переменной реакции). В результате РСА может сгенерировать компоненты, которые обобщают характеристики данных, не являющиеся релевантными ни для структуры данных, ни для конечной цели моделирования. Метод РСА ориентирован на линейные комбинации предикторов, максимизирующие разброс, и, следовательно, прежде всего будет обобщать предикторы с большей дисперсией. Если масштаб шкалы исходных предикторов отличается на порядки (представьте такие предикторы, как уровень дохода (в долларах) и рост (в футах)), то несколько первых компонент сосредоточатся на обобщении предикторов
62 Глава 3. Предварительная обработка данных с большими значениями (например, дохода), тогда как последующие компоненты будут обобщать предикторы с меньшей дисперсией (например, рост). Таким образом, в нескольких начальных компонентах весовые значения будут выше для предикторов с более высоким разбросом. Кроме того, это означает, что метод PC А будет нацелен на идентификацию структуры данных исходя из масштаба шкалы, без должного учета важных связей между данными в контексте решаемой задачи. Далее обратим внимание на то, что для большинства наборов данных предикторы имеют разный масштаб и асимметричные распределения. Во избежание обобщения различий, обусловленных распределением и значениями масштаба предикторов, предпочтительнее сначала преобразовать смещенные предикторы (см. раздел 3.2), а затем (также до применения РСА) провести центрирование и масштабирование предикторов. Последние позволят РСА выявить скрытые зависимости в данных без влияния исходных масштабов шкалы измерения.
Другой недостаток РСА заключается в том, что этот метод не учитывает цель моделирования или переменную реакции при обобщении дисперсии. Поскольку метод РСА не учитывает реакцию, он, по существу, является неконтролируемым (unsupervised). Если прогнозируемая зависимость между предикторами и реакцией не связана с разбросом предикторов, то полученная главная компонента не будет обеспечивать подходящей зависимости с реакцией. В этом случае контролируемый метод, такой как PLS (см. разделы 6.3 и 12.4), позволит получить нужные компоненты с учетом соответствующих реакций.
После того как выбраны подходящие преобразования переменных-предикторов, можно переходить к применению РСА. Для наборов данных с большим количеством переменных-предикторов необходимо решить, сколько именно компонентов будет сохранено. Эвристический способ определения количества компонентов основан на создании графика каменистой осыпи, на котором представлено количество упорядоченных компонентов (ось х) и количество обобщаемого разброса (ось у) (рис. 3.6). Для большинства наборов данных несколько первых главных компонент будут обобщать основную часть разброса, а на графике будет наблюдаться резкое снижение; для остальных компонент оно будет замедляться. В общем случае номер компоненты, непосредственно предшествующей этому замедлению, становится максимальным номером сохраняемой компоненты. На рис. 3.6 замедление начинается с компоненты 5. Согласно приведенному ранее эмпирическому правилу, следует оставить четыре главные компоненты. При автоматизированном построении модели оптимальное количество компонент может определяться посредством перекрестной проверки (см. раздел 4.4).
Визуальный анализ главных компонент является важнейшим этапом оценки качества данных и формирования интуитивного представления о задаче. Для этого можно отобразить несколько первых главных компонент на графике, окрасив их по соответствующим характеристикам (например, по меткам классов). Если РСА удалось отразить достаточный объем информации в данных, то на таком графике
3.3. Преобразования данных с несколькими предикторами 63
О 20 40 60 80 100
Компонента
Рис. 3.6. На графике каменистой осыпи отображается процент общей дисперсии, объясняемый каждой компонентой могут сформироваться кластеры точек данных или выбросы, указывающие на необходимость более глубокого изучения отдельных точек. Для задач классификации на диаграмме РСА может быть отражено потенциальное разделение классов (при наличии последнего). Такой график может выявить исходные ожидания разработчика модели; если степень кластеризации классов невысока, то на графике для значений главных компонент между точками классов будет наблюдаться значительное перекрытие. При нанесении компонент на диаграмму следует учитывать, что по мере того, как компоненты начинают отражать все меньший разброс данных, их масштаб обычно уменьшается. Например, на рис. 3.5 значения компоненты 1 лежат в диапазоне от -3,7 до 3,4, тогда как компонента 2 лежит в диапазоне от -1 до 1,1. Если оси отображаются в разных масштабах, то возникает риск переоценки закономерностей, встречающихся в компонентах с меньшими объемами разброса (о других аналогичных примерах см. Джелади, Мэнли и Лестандер (Geladi, Manley, and Lestander, 2003)).
Метод РСА применялся ко всему набору предикторов данных сегментации. Как показано ранее, некоторые предикторы обладают значительной асимметрией. Учитывая, что смещенные предикторы могут повлиять на работу РСА, 44 переменные были преобразованы по описанной ранее процедуре Бокса—Кокса. После преобразований (до применения анализа РСА) предикторы прошли центрирование и масштабирование.
На рис. 3.6 показан процент общего разброса данных, отражаемого каждой компонентой. Отметим, что значения уменьшаются с добавлением новых компонент. Первые три компоненты отражали 14 %, 12,6 % и 9,4 % общей дисперсии соответственно. Начиная с пятой компоненты, наблюдается выраженное снижение процентных значений, хотя на первые четыре компоненты приходится всего 42,4 % информации набора данных.
64 Глава 3. Предварительная обработка данных
PS WS
Матрица точечной диаграммы
Рис- 3-7- Первые три главные компоненты данных сегментации клеток, окрашенные в соответствии с типом клеток
На рис. 3.7 изображена матрица точечной диаграммы для первых трех главных компонент. Точки окрашены в соответствии с классом (качество сегментации). Так как проценты разброса для первых трех компонент невелики, не следует увлекаться чрезмерной интерпретацией полученного изображения. Из графика видно, что при выводе первой и второй компоненты между классами как будто имеет место некоторое разделение. При этом распределение хорошо сегментированных клеток наблюдается преимущественно внутри распределения неявно идентифицированных клеток. Один из выводов, которые можно сделать в этой связи: типы клеток не удастся легко разделить. Однако это не означает, что другие модели, особенно поддерживающие зависимости с высокой степенью нелинейности, придут к такому же выводу. Хотя в данных присутствуют значения, не вполне соотносящиеся с основным потоком данных, очевидных выбросов нет.
Метод РСА применим и для определения взаимосвязи предикторов с той или иной компонентой. Вспомним, что каждая компонента представляет собой линейную комбинацию предикторов, а коэффициент каждого предиктора называется нагрузкой (loading). Нагрузки, близкие к нулевому значению, означают, что
3.3. Преобразования данных с несколькими предикторами 65
переменная-предиктор не оказывает сколь-нибудь существенного влияния на эту компоненту На рис. 3.8 показаны нагрузки для первых трех компонент в данных сегментации клеток. Каждая точка соответствует переменной-предиктору и окрашивается оптическим каналом, использованным в эксперименте. Для первой главной компоненты нагрузки первого канала (связанного с клеточным телом) принимают исключительно высокие значения. Это означает, что характеристики клеточного тела имеют наибольшее влияние для первой главной компоненты и, как следствие, для значений предикторов. Значения большинства нагрузок для третьего канала (оценка актина и тубулина) близки к нулю для первой компоненты. И наоборот, третья главная компонента в основном связана с третьим каналом, тогда как канал клеточного тела играет в этом случае второстепенную роль. Хотя метрики клеточного тела отвечают за больший разброс в данных, это не означает, что рассматриваемые переменные будут связаны с прогнозированием качества сегментации.
Канал 1 Канал 3
Канал 2 Канал 4
Матрица точечной диаграммы
Рис. 3.8. График нагрузок первых трех главных компонент для данных сегментации клеток, окрашенных в соответствии с оптическим каналом. Канал 1 связан с клеточным телом, канал 2 — с ядром клетки, канал 3 — с актином и канал 4 — с тубулином
66 Глава 3. Предварительная обработка данных
3.4. Отсутствующие значения
Во многих случаях у некоторых предикторов отсутствуют значения для заданной точки. Отсутствующие значения могут быть структурно невозможными — например, количество детей, рожденных мужчиной. В других случаях отсутствующее значение не могло быть определено (или не было определено) в момент построения модели.
Подчеркнем: важно понимать, почему именно отсутствуют те или иные данные, и в частности то, связана ли закономерность отсутствия данных с результатом. Этот феномен можно обозначить как «информативное отсутствие», имея в виду, что закономерность отсутствия данных сама по себе несет полезную информацию. Информативное отсутствие данных может создавать в модели значительное смещение. Во вводной главе приведен пример с реакцией пациента на лекарственный препарат. Допустим, лекарство оказалось в высшей степени малоэффективным или обладало значительными побочными эффектами. Пациент с большой вероятностью пропустит посещения врача или выйдет из исследования. В этом случае существует очевидная зависимость между вероятностью отсутствия значений и способом лечения. Так, информативное отсутствие данных часто может встречаться в пользовательских оценках; люди с большей вероятностью оценивают продукты, когда имеют твердое мнение о предмете оценки (хорошее или плохое). Это ведет к поляризации данных: в середине шкалы оценок значений относительно мало. Так, в конкурсе машинного обучения Netflix Prize требовалось предсказать, какие фильмы понравятся людям, на основании их предыдущих оценок. Фильм «Napoleon Dynamite Effect» привел в замешательство многих участников: ставивший оценку либо был в восторге от него, либо, напротив, крайне разочарован им.
Отсутствующие данные не следует путать с цензурированными данными, то есть данными, точное значение которых отсутствует, но вместе с тем о нем что-то известно. Например, компания, которая выдает напрокат диски по почте, может использовать в своих моделях такой параметр, как продолжительность нахождения диска у клиента. Если клиент еще не вернул фильм, то фактический период проката неизвестен, и в этом случае можно лишь констатировать, что итоговое значение, характеризующее продолжительность проката, не будет меньше текущего. Цензурированные данные также встречаются при использовании лабораторных измерений. Так, некоторые виды анализа не могут выполнять измерения ниже своего порога обнаружения. Соответственно, мы знаем, что интересующее нас значение ниже порогового, но не имеем возможности определить его более точно.
Следует ли относиться к цензурированным данным иначе, чем к отсутствующим? При построении традиционных статистических моделей, целью которых является интерпретация или логические выводы, факт цензурирования обычно учитывается формально, для чего делаются предположения о механизме цензурирования. Для предиктивных моделей такие данные чаще рассматриваются именно как отсут-
3.4. Отсутствующие значения 67
ствующие данные, или же цензурированное значение используется как наблюдаемое. Например, когда значение точки данных ниже порога обнаружения, вместо реального значения может использоваться его фактический предел. В подобной ситуации также часто используется случайное число в диапазоне от нуля до порога обнаружения.
Как правило, отсутствующие значения чаще связаны с переменными-предикторами, чем с данными. По этой причине отсутствующие данные могут быть сконцентрированы в подмножестве предикторов, не распределяясь случайным образом между всеми ими. Порой процент отсутствующих данных оказывается достаточно значимым, что дает основания для исключения предиктора из последующего моделирования.
Иногда отсутствующие значения могут концентрироваться в конкретных выборках. Для больших наборов данных исключение некоторых из них из-за отсутствующих значений допустимо, если предположить, что отсутствие не является информативным. В малых наборах данных исключение отдельных значений может обернуться отрицательными последствиями (см. ниже).
Если отсутствующие данные не удаляются, то возможны два основных подхода к их интерпретации. Во-первых, применение некоторых предиктивных моделей, в особенности древовидных методов, предполагает учет отсутствующих данных (см. главу 8).
Во-вторых, отсутствующие данные могут быть выведены посредством подстановки (imputation). В этом случае информация из предикторов тренировочного набора используется для фактической оценки других предикторов, образуя подмодель внутри основной предиктивной модели.
Подстановка широко освещалась в литературе по статистике в контексте генерирования корректных процедур проверки гипотез при наличии отсутствующих данных. Применительно к предиктивным моделям нас, однако, в первую очередь интересует точность прогнозов, а не правильность заключений. Литературы по применению подстановки для предиктивных моделей не так много. Саар-Цечански и Провост (Saar-Tsechansky and Provost, 2007b) анализируют вопрос отсутствующих значений и то, как конкретные модели справляются с этой проблемой. Джерез (Jerez et al., 2010) рассматривает разнообразные методы подстановки для конкретного набора данных.
Напомним, что подстановка представляет собой еще один уровень моделирования при попытке оценивать значения переменных-предикторов на основании других предикторов. Наиболее релевантный способ достижения этой цели заключается в использовании тренировочного набора для построения модели подстановки для каждого предиктора в наборе данных. До использования тренировочного набора или прогнозирования новых точек данных отсутствующие значения заполняются посредством подстановки. Обратите внимание: дополнительный уровень модели
68 Глава 3. Предварительная обработка данных добавляет неопределенности. Если вы используете повторную выборку для значений параметров настройки или для оценки эффективности, то подстановка должна быть встроена в повторную выборку. Вычислительное время для построения моделей при этом увеличится, но одновременно возрастет и объективность оценки эффективности модели.
Если количество предикторов, на которые влияют отсутствующие значения, невелико, можно прибегнуть к анализу связей между предикторами. Например, визуализация или такие методы, как РСА, могут использоваться для выявления выраженных связей между предикторами. Если переменная с отсутствующими значениями обладает высокой корреляцией с другим предиктором, имеющим незначительное количество отсутствующих значений, то более эффективной зачастую оказывается специализированная модель (см. ниже).
Одним из распространенных методов подстановки является метод KNN. Новая точка данных вычисляется поиском в тренировочном наборе сходных точек данных и усреднением значений ближайших точек для вычисления значения. К примеру, Троянская (Troyanskaya et al., 2001) анализирует этот метод для данных высокой размерности с малым размером выборки. Одно из его преимуществ — в том, что подстановочные данные ограничиваются диапазоном значений тренировочного набора. К недостаткам метода можно отнести то, что для вычисления очередного отсутствующего значения требуется задействовать весь тренировочный набор. Кроме того, количество сходных точек данных является параметром настройки, как и метод определения «близости» двух точек. В упоминаемом исследовании отмечено, что метод ближайших соседей достаточно устойчив как к параметрам настройки, так и к объему отсутствующих данных.
В разделе 3.2 предиктор, оценивающий периметр клетки, использовался для демонстрации асимметрии (см. рис. 3.3). Для этого применена модель с пятью сходными точками данных, использующая значения из тренировочного набора. В последнем отсутствующие значения были случайным образом введены в 50 имеющихся в составе набора значений периметра клетки, а затем сгенерированы с использованием модели.
На рис. 3.9 изображена точечная диаграмма исключенных данных. Слева показаны результаты применения метода на основе модели с пятью сходными точками данных. Модель подстановки удовлетворительно прогнозирует отсутствующие данные — корреляция между реальными и подставленными значениями составляет 0,91. Отметим, что для подстановки периметра клетки применим и более простой метод. Длина клеточного волокна — другой предиктор, связанный с размером клетки, — обладает очень высокой (0,99) корреляцией с данными периметра клетки.
Для прогнозирования отсутствующих значений можно воспользоваться моделью линейной регрессии (см. правую часть рис. 3.9). Для этого метода корреляция между реальными и сгенерированными значениями составляет 0,85.
3.5. Удаление предикторов 69
-1,0 -0,5 0,0 0,5 1,0 1,5
1,5
2
1,0
ш
X
g
0,5
5
о С
0,0
-0,5
-1,0
-1,0 -0,5 0,0 0,5 1,0 1,5
Исходное значение (после центрирования и масштабирования)
Рис. 3.9. После имитации отсутствия 50 случайно выбранных значений тестового набора были построены две разные модели подстановки с тренировочным набором. Эти модели были применены к отсутствующим значениям тестового набора.
На диаграмме показаны значения после центрирования и масштабирования до и после подстановки
3.5. Удаление предикторов
Удаление предикторов до начала моделирования несет в себе ряд потенциальных преимуществ. Во-первых, сокращение количества предикторов позволяет снизить и затраты времени, и сложность вычислений.
Во-вторых, если между двумя предикторами существует высокая корреляция, то это позволяет рассматривать их как несущие сходную базовую информацию. Значит, удаление одного из них не должно повлиять на эффективность модели, более того, оно может привести к созданию более простой и интерпретируемой модели.
В-третьих, применение предикторов с вырожденными распределениями может нарушить работоспособность некоторых моделей. В подобных случаях заблаговременное устранение проблемных переменных может обеспечить значительное улучшение эффективности и/или стабильности модели.
Возьмем переменную-предиктор с одним уникальным значением, известную нам также как предиктор с нулевой дисперсией. У некоторых моделей такая неинформативная переменная практически не оказывает влияния на вычисления. Древовидная модель (см. разделы 8.1 и 14.1) устойчива к предикторам этого типа, поскольку предикторы никогда не будут использоваться в разделении. Но в таких моделях, как линейная регрессия, эти данные наверняка вызовут ошибку в вычислениях. По-
70 Глава 3. Предварительная обработка данных скольку эти данные не содержат существенной информации, ими можно пренебречь. Аналогичным образом некоторые предикторы могут иметь небольшой набор значений, встречающихся крайне редко. Предикторы «с дисперсией, близкой к нулю» могут иметь одно и то же значение для подавляющего большинства точек данных. Возьмем приложение для интеллектуального анализа текстов, в котором набор ключевых слов собирается для большого набора документов. После фильтрации часто используемых игнорируемых слов (таких, как the или of) можно создать переменные-предикторы для выявления ключевых слов, интересующих исследователей. Допустим, ключевое слово встречается в небольшой группе документов, но в других не используется вовсе. В 531 исследованном документе (табл. 3.1) было обнаружено всего четыре редких слова.
Таблица 3.1. Предиктор, описывающий количество документов,
в которых встречается ключевое слово
Количество документов
Ключевых слов: 0
523
Ключевых слов: 2
6
Ключевых слов: 3
1
Ключевых слов: 6
1
В абсолютном большинстве документов (523) ключевое слово отсутствовало; в шести документах было обнаружено по два таких слова, в одном документе — три и еще в одном — шесть. Поскольку 98 % данных имеет нулевое значение, влияние столь малого числа документов на моделирование может быть неоправданно высоким. Кроме того, при проведении повторной выборки (см. раздел 4.4) существует высокая вероятность того, что один из наборов данных повторной выборки будет содержать только документы без ключевого слова, в связи с чем предиктор будет иметь всего одно уникальное значение.
Как пользователь может диагностировать данные такого рода? Во-первых, количество уникальных точек в совокупности данных должно быть относительно мало. Так, в рассмотренном выше примере доля уникальных значений составила всего 0,8 %. Малый процент уникальных значений сам по себе не является причиной для беспокойства, так как многие «фиктивные переменные» (см. раздел 3.6), сгенерированные по категорийным предикторам, подходят под это описание. Проблема возникает при серьезной диспропорции частот уникальных значений. Отношение самой типичной частоты к следующей из них отражает дисбаланс частот. В большинстве документов набора данных (п = 523) ключевое слово отсутствует. Второй по распространенности случай — документы, в которых ключевые слова встречаются дважды (п = 6). Отношение этих частот (523/6 = 87) указывает на явный дисбаланс.
3.5. Удаление предикторов 71
Эмпирические правила для обнаружения предикторов с дисперсией, близкой к нулевой, можно сформулировать следующим образом.
О Доля уникальных значений по размеру выборки низка (допустим, 10 %).
О Отношение частоты самого распространенного значения к частоте второго по распространенности заметно выше (допустим, около 20 %).
При наличии в модели предиктора, соответствующего вышеназванным критериям, представляется правильным скорее отказаться от его использования для целей моделирования.
Корреляции между предикторами
Коллинеарность — термин, применяемый для обозначения ситуации, в которой пара переменных-предикторов обладает значительной взаимной корреляцией. Возможны связи и между большим количеством предикторов (подобное явление принято именовать мультиколлинеарностью).
Например, данные сегментации клеток содержат ряд предикторов, отражающих размер клетки: значения периметра клетки, ее ширины и длины и др. Одновременно существуют и признаки, оценивающие морфологию клетки, — допустим, ее жесткость.
На рис. 3.10 изображена корреляционная матрица тренировочного набора. Каждая парная корреляция вычисляется по тренировочным данным и окрашивается в соответствии с ее величиной. Визуализация симметрична: верхние и нижние диагонали представляют идентичную информацию. Темно-синие цвета обозначают сильную положительную корреляцию, темно-красный цвет — сильные отрицательные корреляции, белый цвет — отсутствие эмпирических связей между предикторами. На схеме переменные-предикторы сгруппированы посредством метода кластеризации по Эверитту (Everitt et al., 2011) с тем, чтобы коллинеарные группы предикторов находились по соседству друг от друга. При рассмотрении вдоль диагонали заметны блоки сильных положительных корреляций, указывающие на существование «кластеров» коллинеарности. Вблизи центра диагонали расположен большой блок предикторов из первого канала, относящихся к размеру клетки (например, ее ширине и длине).
Если набор данных содержит слишком много предикторов для визуального анализа, то для описания масштабности проблемы могут использоваться такие методы, как РСА. Например, если первая главная компонента покрывает большой процент дисперсии, то это означает, что существует по крайней мере одна группа предикторов с однородной информацией. Например, из рис. 3.6 следует, что первые три- четыре компоненты вносят взаимосвязанный вклад в общую дисперсию, то есть между предикторами существуют хотя бы три-четыре значимые связи. Для того
72 Глава 3. Предварительная обработка данных
1
о.в
0.6
0.4
0.2
0
-0.2
-0.4
-0.6
-0.8
-1
Рис. 3.10. Визуализация корреляционной матрицы сегментации клеток. Порядок переменных основан на алгоритме кластеризации
чтобы понять, какие предикторы связываются с каждой компонентой, также применим метод РСА.
В классическом регрессионном анализе существуют средства выявления мультиколлинеарности для линейной регрессии. Поскольку коллинеарные предикторы могут влиять на дисперсию оценок параметров в модели, для выявления последних можно воспользоваться статистикой — тем ее инструментом, который, по Майерсу (Myers, 1994), обозначается как фактор, увеличивающий дисперсию (VIF, Variance Inflation Factor). За пределами линейной регрессии этот метод может быть трудноприменим, поскольку разрабатывался для линейных моделей, количество точек данных в которых должно быть больше количества переменных-предикторов, без возможности выявления предикторов, подлежащих удалению.
3.6. Добавление предикторов 73
Иной, более эвристический подход к решению проблем такого рода сводится к удалению минимального количества предикторов, исходя из того, что все парные корреляции лежат ниже определенного порога. Хотя этот метод позволяет выявлять коллинеарности только в двух измерениях, он может способствовать повышению эффективности некоторых моделей.
Приведем алгоритм реализации метода.
1. Вычислить корреляционную матрицу предикторов.
2. Найти два предиктора, связанных наибольшей абсолютной парной корреляцией (предикторы А и В).
3. Определить среднюю корреляцию между А и другими переменными. Сделать то же для предиктора В.
4. Если предиктор А обладает большей средней корреляцией, удалить его; в противном случае — удалить предиктор В.
5. Повторять действия, описанные в пунктах 2-4, до тех пор, пока остаются абсолютные корреляции, превышающие заданный порог.
Идея заключается в том, чтобы сначала удалялись предикторы, обладающие наибольшим количеством корреляционных связей.
Предположим, требуется модель, особенно чувствительная к корреляциям между предикторами — с порогом, близким 0,75. Для достижения парных корреляций менее 0,75 предстоит удалить минимальное количество предикторов. В частности, для данных сегментации рассматриваемый алгоритм предложит удалить 43 предиктора. Методы выделения признаков (например, метод главных компонент) могут использоваться и для устранения эффекта сильных корреляций между предикторами. Однако эти методы усложняют связи между предикторами и результатом. Кроме того, поскольку методы выделения сигнала обычно являются неконтролируемыми, нет гарантий того, что полученные суррогатные предикторы будут более или менее тесно связаны с результатом.
3.6. Добавление предикторов
Если предиктор является категорийным (например, пол или национальность), он часто раскладывается на набор более конкретных переменных. Например, в данных оценки кредитоспособности (см. раздел 4.5) присутствует предиктор, основанный на количестве денег, хранящихся на сберегательном счете претендента. Эти данные были закодированы в виде нескольких групп, включая группу «неизвестно». В табл. 3.2 приведены значения этого предиктора и количество претендентов, относящихся к каждой группе.
74 Глава 3. Предварительная обработка данных
Таблица 3.2. Категорийный предиктор с пятью группами из данных оценки кредитоспособности. Значения описывают сумму на сберегательном счету (в марках ФРГ (DM))
Значение
n
Фиктивные переменные
< 100
100-500
500-1000
> 1000
Неизвестно
< 100 DM
103
1
0
0
0
0
100-500 DM
603
0
1
0
0
0
500-1000 DM
48
0
0
1
0
0
> 1000 DM
63
0
0
0
1
0
Неизвестно
183
0
0
0
0
1
Для использования данных в моделях категории перекодируются в меньшие фрагменты информации — так называемые фиктивные переменные. Обычно каждой категории соответствует определенная фиктивная переменная — своего рода индикатор «0/1» для этой группы. В табл. 3.2 приведены возможные фиктивные переменные. Отметим, что в рассматриваемом примере достаточно четырех фиктивных переменных, на основе которых возможно определить следующую. Однако решение о включении всех фиктивных переменных может зависеть от выбора модели. Модели, включающие свободный член, например простая линейная регрессия (раздел 6.2), столкнутся с вычислительными проблемами при включении в них всех наличествующих фиктивных переменных, поскольку для каждой точки данных эти переменные будут накапливаться, сообщая модели ту же информацию, что и свободный член. Если же модель нечувствительна к подобным проблемам, то использование полного набора фиктивных переменных поможет усовершенствовать интерпретацию.
Многие модели, описанные в этой книге, автоматически генерируют сложные нелинейные связи между предикторами и результатом. Многие упрощенные модели, наоборот, не позволяют этого сделать, кроме случаев, когда пользователь «в ручном режиме» определяет, какие именно предикторы (и в какой мере) должны быть нелинейными. Например, логистическая регрессия представляет собой хорошо известную модель классификации, по умолчанию генерирующую границы линейной классификации.
На рис. 3.11 представлен характерный пример с двумя предикторами и двумя классами. Слева обозначены границы базовой логистической регрессии при добавлении предикторов обычным (линейным) способом, справа — логистическая модель с базовыми линейными членами и дополнительным членом, содержащим квадрат предиктора В. Поскольку логистическая регрессия представляет собой
3.7. Группировка предикторов 75
Класс 1 Класс 2
-10 12 3
2
□о Q.
С
-2
-10 12 3
Предиктор А
Рис. 3.11. Границы классификации двух моделей линейной регрессии. На левой диаграмме используются только линейные члены для двух предикторов, тогда как на правой диаграмме добавляется дополнительный квадратичный член для предиктора В. Эта модель более подробно рассматривается в главе 12
хорошо изученную и стабильную модель, ее использование с несколькими дополнительными нелинейными членами может оказаться предпочтительнее методов с применением сложного обучения.
В работе Форины (Forina et al., 2009) продемонстрирован, кроме того, прием расширения предиктивных данных с добавлением сложных комбинаций данных. Для моделей классификации они вычисляют «центроиды классов», то есть центры данных предикторов по каждому классу. Затем для каждого предиктора вычисляется расстояние до каждого центроида класса; вычисленные значения могут добавляться в модель.
3.7. Группировка предикторов
Существуют как предпочтительные методы предварительной обработки данных, так и методы, которых следует избегать. Один из распространенных методов упрощения набора данных заключается в предварительном разделении числового предиктора по двум и более группам. Например, в работе Боуна (Bone et al., 1992) определяется набор клинических симптомов для диагностики синдрома системной воспалительной реакции (ССВР). ССВР может развиваться после получения
76 Глава 3. Предварительная обработка данных человеком физической травмы (например, вследствие автомобильной аварии). Упрощенная версия клинических критериев ССВР включает следующие признаки:
О температура — менее 36 °C или выше 38 °C;
О частота сердечных сокращений (ЧСС) — выше 90 ударов в минуту;
О частота дыхания — более 20 раз в минуту;
О уровень лейкоцитов в крови — ниже 4000 на мм3 или выше 12 000 на мм3.
Если у пациента наблюдаются два и более из этих критериев, то, следовательно, у него можно диагностировать ССВР.
Такой подход как будто обладает рядом очевидных преимуществ.
О Его применение позволяет формулировать либо простое правило для принятия решений (как в примере с ССВР), либо предположения, что у модели существует простая интерпретация.
О При этом разработчику модели не обязательно обладать данными, отражающими точную взаимосвязь между предикторами и результатом.
О Представляется достижимым и получение более высокой доли ответов на вопросы анкет (с ограниченной вариативностью ответов) — например, на вопрос о дате последней прививки от столбняка ответов будет меньше, чем на вопрос с указанием диапазона (последние 2 года, последние 4 года и т. д.).
Но группировка непрерывных данных «в ручном режиме» порождает и множество проблем. Во-первых, она может привести к существенной потере эффективности модели. Многие методы моделирования, описанные в этой книге, вполне подходят для выявления сложных связей между предикторами и результатами. Ручная группировка предикторов явно ограничивает этот потенциал.
Во-вторых, при прогнозировании с распределением предикторов по категориям неизбежна потеря точности. Например, при группировке двух предикторов в наборе данных возможны всего четыре комбинации и, как следствие, только простые прогнозы. В-третьих, исследования, выполненные Остином и Брюннером (Austin and Brunner, 2004), показали, что разделение предикторов по категориям может привести к неоправданно высокой доле ложных ожиданий (то есть шумовые предикторы определяются как информативные).
К сожалению, самые мощные предиктивные модели обычно оставляют наименьшие возможности для интерпретации. Кажущееся улучшение интерпретируемости, обеспечиваемое ручным делением на категории, обычно оборачивается значительной потерей эффективности. Для предиктивных моделей потеря эффективности нежелательна. Более того, в некоторых случаях произвольное деление предикторов на категории может оказаться и неэтичным. Например, в области прогнозирования аспектов заболевания (реакции на терапию, массовые обследования) ведутся масштабные исследования. Если для принятия столь важных решений используется
3.8. Вычисления 77
медицинская диагностика, то пациенты желают получить самые точные прогнозы из всех возможных. Но учитывая, что сложные модели проходят необходимую проверку, было бы нелогично использовать модель, построенную для интерпретации, а не для достижения наивысшей эффективности прогнозирования.
Последний аргумент относится к ручному делению предикторов на категории до построения модели. Существуют, впрочем, модели (например, деревья классифи- кации/регрессии и многомерные адаптивные регрессионные сплайны), вычисляющие пороговые точки в процессе построения модели. Различие между этими методологиями и ручной группировкой прежде всего в том, что модели используют для формирования групп все предикторы, нацеленные, например, на достижение максимальной точности. Они одновременно оценивают большое количество переменных и обычно базируются на статистически обоснованных методологиях.
3.8. Вычисления
В этом разделе используются данные из пакета AppliedPredictiveModeling и функции из пакетов caret, corrplot, е1071 и lattice.
Соответствующий код R можно найти:
О во-первых, в каталоге chapters пакета AppliedPredictiveModeling — там хранится код, воспроизводящий конкретные модели, рассмотренные в этой главе. Тем самым читателю предоставляется возможность увидеть, как именно создавались модели;
О во-вторых, многие последующие главы завершаются подробными описаниями того, как подобные вычисления могут в принципе выполняться в R. Например, существуют отдельные функции для методов предварительной обработки данных, продемонстрированных в этой главе. Хотя их подробности приводятся в завершающем разделе, на практике те или иные функции могут и не использоваться напрямую. Например, при использовании функции train операции предварительной обработки задаются в одном аргументе, тогда как отдельные функции не используются вовсе. В этих разделах упоминаются модели, создаваемые в каждой главе, но в основном в контексте обсуждения функций.
Вот почему в разделах «Вычисления» каждой главы объясняются общие принципы выполнения вычислений, а код в каталоге chapters пакета AppliedPredictiveModeling является лучшим для вычислений конкретных моделей этой главы.
Есть (см. приложение Б) несколько полезных функций R, пригодных для поиска существующих функций и классов и потому представляющих очевидный интерес для читателей. Функция apropos ищет заданный критерий во всех загруженных пакетах R. Например, чтобы найти функции для создания матрицы несоответствий в загруженных пакетах, используйте команду:
78 Глава 3. Предварительная обработка данных
> apropos ( "confusion")
[1] "confusionMatrix" "confusionMatrix.train"
Для поиска функции в любом пакете может использоваться функция RSiteSearch. Команда
> RSiteSearchf"confusion", restrict = "functions")
проведет поиск в интернете и откроет результаты в браузере.
Необработанный набор данных сегментации содержится в пакете AppliedPredictiveModeling1. Чтобы загрузить этот набор данных в R, используйте команды:
> Library(АррLiedPredictiveModeLing)
> data(segmentationOriginaL)
В них присутствуют поля, идентифицирующие каждую клетку (Cell), и факторный вектор, указывающий, какие клетки были хорошо сегментированы (Class). Переменная Case позволяет определить, какие именно клетки изначально использовались в тренировочном и тестовом наборах. В этой главе центральное место занимают примеры тренировочного набора, поэтому и данные отфильтрованы для названных клеток:
> segData <- subset(segmentationOriginaL, Case = "Train")
Поля Class и Cell сохраняются в отдельных векторах, а затем удаляются из основного объекта:
> ceLLID <- segData$CeLL
> с Lass <- segDatafCLass
> case <- segData$Case
> # Теперь столбцы удаляются
> segData <- segData[, -(1:3)]
Исходные данные содержали несколько столбцов со «статусными» данными, представляющими собой бинарные версии предикторов. Чтобы исключить их, находим столбцы, имена которых содержат слово «Status», после чего удаляем их:
> statusCoLNum <- grep ("Status", names(segData))
> statusCoLNum
[1]
2
4
9
10
11
12
14
16
20
21
22
26
27
28
30
32
34
[18]
36
38
40
43
44
46
48
51
52
55
56
59
60
63
64
68
69
[35]
70
72
73
74
76
78
80
82
84
86
88
92
93
94
97
98
103
[52]
104
105
106
110
111
112
114
segData <
- segData[,
-statusCoLNum]
1 Версия этих данных, прошедшая предварительную обработку, также находится в пакете caret и используется в последующих главах.
3.8. Вычисления 79
Преобразования
Как отмечалось, некоторые признаки характеризуются значительной асимметрией. Функция skewness в пакете е1071 позволяет вычислить статистику асимметрии для каждого предиктора:
> Library(el071)
> # For one predictor:
> skewness(segData$AngLeChl)
[1] -0.0243
> # Так как все предикторы являются числовыми столбцами, функция appLy
> # может использоваться для вычисления асимметрии между столбцами.
> skewVaLues <- appLy(segData, 2, skewness)
> head(skewVaLues)
AngleChl AreaChl AvglntenChl AvgIntenCh2 AvgIntenCh3 AvgIntenCh4
-0.0243 3.5251 2.9592 0.8482 2.2023 1.9005
Используя значения в качестве основы, назначим приоритеты переменных для визуализации распределения. Для оценки формы распределения воспользуемся базовой функцией R hist или функцией histogram из lattice.
Для определения используемого типа преобразования в пакете MASS есть функция Ьохсох. Хотя эта функция вычисляет оценку X, она не создает преобразованную переменную (или переменные). Функция BoxCoxTrans из caret может найти подходящее преобразование и применить его к новым данным:
> Library(caret)
> ChlAreaTrans <- BoxCoxTrans(segDatafAreaChl)
> ChlAreaTrans
Box-Cox Transformation
1009 data points used to estimate Lambda
Input data summary:
Min. 1st Qu. Median Mean 3rd Qu. Max.
150 194 256 325 376 2190
Largest/Smallest: 14.6
Sample Skewness: 3.53
Estimated Lambda: -0.9
> # Исходные данные
> head(segData$AreaChl)
[1] 819 431 298 256 258 358
> # После преобразования
> predict(ChlAreaTrans, head(segData$AreaChl))
[1] 1.1085 1.1064 1.1045 1.1036 1.1036 1.1055
> (819Л(-.9) - l)/(-.9)
[1] 1.1085
80 Глава 3. Предварительная обработка данных
Другая функция caret — preProcess — применяет преобразование к набору предикторов (см. ниже). Базовая функция R prcomp может использоваться для выполнения РСА. В следующем коде до выполнения РСА к данным было применено центрирование и масштабирование:
> pcaObject <- prcomp(segData,
+ center = TRUE, scaLe. = TRUE)
> # Вычисление накапливаемого процента дисперсии,
># за который отвечает каждая компонента.
> percentVariance <- pcaObject$sdA2/sum(pcaObject$sdA2)*100
> percentVariance[l:3]
[1] 20.9 17.0 11.9
Преобразованные значения сохраняются в pcaObject в виде подобъекта с именем х:
> head(pcaObject$x[, 1:5])
РС1
РС2 РСЗ РС4
РС5
2
5.099
4.551 -0.0335 -2.64
1.278
3
-0.255
1.198 -1.0206 -3.73
0.999
4
1.293
-1.864 -1.2511 -2.41
-1.491
12 -1.465 -1.566 0.4696 -3.39 -0.330
15 -0.876 -1.279 -1.3379 -3.52 0.394
16 -0.862 -0.329 -0.1555 -2.21 1.473
Другой подобъект с именем rotation содержит нагрузки; строки соответствуют переменным-предикторам, столбцы связаны с компонентами:
> head(pcaObject$rotation[, 1:3])
PCI РС2 РСЗ
AngleChl 0.00121 -0.0128 0.00682
AreaChl 0.22917 0.1606 0.08981
AvglntenChl -0.10271 0.1797 0.06770
AvgIntenCh2 -0.15483 0.1638 0.07353
AvgIntenCh3 -0.05804 0.1120 -0.18547
AvgIntenCh4 -0.11734 0.2104 -0.10506
Класс spatialSign из пакета caret содержит функциональность преобразования пространственного знака. Хотя это преобразование не применяется к данным, базовый синтаксис имеет вид spatialSign (segData).
В представленных данных нет отсутствующих значений для подстановки — для выполнения последней в пакете impute имеется функция impute.knn, использующая KNN для оценки отсутствующих данных. Упоминавшаяся ранее функция preProcess применяет методы подстановки на основании KNN или бэггинга деревьев.
Для серий преобразований к нескольким наборам данных возможно применение средств преобразования, центрирования, масштабирования или подстановки значений, средств преобразования пространственного знака и выделения признаков
3.8. Вычисления 81
в составе функции preProcess из пакета caret, вычисляющей все необходимые значения. После вызова функции preProcess метод predict применяет результаты к набору данных. Например, чтобы выполнить преобразование Бокса—Кокса, отцентрировать и масштабировать данные, а затем провести РСА для выделения сигнала, применим синтаксис:
> trans <- preProcess(segData,
+ method = с("ВохСох", "center”, "scaLe", "pea"))
> trans
Call:
preProcess.default(x = segData, method = c("BoxCox", "center”,
"scale”, "pea”))
Created from 1009 samples and 58 variables
Pre-processing: Box-Cox transformation, centered, scaled,
principal component signal extraction
Lambda estimates for Box-Cox transformation:
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
-2.00 -0.50 -0.10 0.05 0.30 2.00 11
PCA needed 19 components to capture 95 percent of the variance
> # Применение преобразований:
> transformed <- predict(trans, segData)
> # Эти значения отличаются от предыдущих компонент РСА,
> # потому что до применения РСА они были преобразованы.
> head(transformed[, 1:5])
PCI РС2 РСЗ РС4 РС5
2
1.568 6.291 -0.333 -3.06 -1.342
3
-0.666 2.046 -1.442 -4.70 -1.742
4
3.750 -0.392 -0.669 -4.02 1.793
12
0.377 -2.190 1.438 -5.33 -0.407
15
1.064 -1.465 -0.990 -5.63 -0.865
16
-0.380 0.217 0.439 -2.07 -1.936
Здесь, как видим, применялись центрирование, масштабирование, подстановка, выделение признаков, а после них — пространственный знак. У многих функций моделирования предусмотрена возможность центрирования и масштабирования перед моделированием. Например, при использовании функции train (рассматриваемой в следующих главах) возможно применение preProcess перед моделированием в итерациях повторной выборки.
Фильтрация
Чтобы отфильтровать предикторы с дисперсией, близкой к нулевой, функция nearZeroVar из пакета caret возвращает номера столбцов любых предикторов, для
82 Глава 3. Предварительная обработка данных которых выполняются условия из раздела 3.5. Для данных сегментации клеток проблемные предикторы отсутствуют:
> nearZeroVar(segData)
integer(0)
> # При удалении предикторов возвращается вектор целых чисел,
> # показывающий, какие столбцы должны быть удалены.
Аналогичным образом для выполнения фильтрации по корреляции между предикторами функция сот вычисляет корреляции между переменными-предикторами:
> correLotions <- cor(segData)
> dim(correLotions)
[1] 58 58
> correLations[l:4, 1:4]
AngleChl AreaChl AvglntenChl AvgIntenCh2
AngleChl 1.00000 -0.00263
-0.0430
-0.0194
AreaChl -0.00263 1.00000
-0.0253
-0.1533
AvglntenChl -0.04301 -0.02530
1.0000
0.5252
AvgIntenCh2 -0.01945 -0.15330
0.5252
1.0000
Для изучения корреляционной структуры данных в пакете corrplot имеется одноименная функция, поддерживающая большое число управляющих параметров и позволяющая переупорядочивать переменные для выявления кластеров предикторов с высокой корреляцией. Для формирования изображения (см. рис. 3.10) использована команда:
> Librory(corrpLot)
> corrpLot(correLations, order = "hcLust")
Размер и цвет точек отражают степень корреляции между двумя переменными- предикторами.
Чтобы выполнить фильтрацию на основании корреляций, функция f indCorrelation применяет алгоритм из раздела 3.5. Для заданного порога парных корреляций функция возвращает номера столбцов для предикторов, рекомендованных к удалению:
> highCorr <- findCorreLation(correLotions, cutoff = ,75)
> Length(highCorr)
[1] 33
> head(highCorr)
[1] 23 40 43 36 7 15
> fiLteredSegData <- segData[, -highCorr]
Пакет subselect также содержит несколько функций аналогичного назначения.
3.8. Вычисления 83
Создание фиктивных переменных
Существуют несколько методов создания фиктивных переменных на базе конкрет- ной модели. В разделе 4.9 рассматриваются различные методы определения передачи предикторов модели. Один из методов — метод формул — допускает большую гибкость при создании функции модели. Применение формул в функциях модели параметризирует предикторы так, что не во всех категориях будут присутствовать фиктивные переменные. Этот подход будет более подробно описан для линейной регрессии.
В некоторых случаях полный набор фиктивных переменных может оказаться полезен. Например, разделение в древовидной модели лучше интерпретируется тогда, когда фиктивные переменные кодируют всю информацию для соответствующего предиктора. Рекомендуем использовать полный набор фиктивных переменных при работе с древовидными моделями.
Чтобы продемонстрировать работу кода, используем подмножество набора данных cars в пакете caret, относящихся ко вторичным продажам 804 машин GM за 2005 год по Kelly Blue Book (Kuiper, 2008). Цель модели — прогнозирование цены автомобилей на основании известных характеристик. При рассмотрении работы кода ограничимся тремя характеристиками: ценой, пробегом и типом автомобиля (например, седан) для подмножества машин:
> head(carSubset)
Type
Price Mileage
214
19981
24323
sedan
299
21757
1853
sedan
460
15047
12305
sedan
728
15327
4318
sedan
162
20628
20770
sedan
718
16714
26328
sedan
> LeveLs(carSubset$Type)
[1] "convertible” "coupe" "hatchback" "sedan" "wagon"
Чтобы смоделировать цену как функцию, отражающую пробег и тип машины, воспользуемся функцией dummyVars для определения кодировок предикторов. Допустим, что моделирование цены в первой модели выполняется как простая аддитивная функция пробега и типа машины:
> simpLeMod <- dummyVars(^MiLeage * Type,
+ data = carSubset,
+ ## Убрать имя переменной
+ ## из имени столбца
+ LeveLsOnLy = TRUE)
> simpLeMod
Dummy Variable Object
84 Глава 3. Предварительная обработка данных
Formula: ^Mileage + Type
2 variables, 1 factors
Factor variable names will be removed
Чтобы продемонстрировать использование фиктивных переменных для тренировочного набора или любых новых точек данных, воспользуемся методом predict в сочетании с объектом dummyVars:
> predict(simpLeMod, head(carSubset))
Mileage convertible
coupe
hatchback
sedan
wagon
214
24323
0
0
0
1
0
299
1853
0
0
0
1
0
460
12305
0
0
0
1
0
728
4318
0
0
0
1
0
162
20770
0
0
0
1
0
718
26328
0
0
0
1
0
Поле type развернуто в пять переменных для пяти уровней. Простая модель предполагает, что эффект пробега остается постоянным для всех типов автомобилей. В более сложной модели учитывается совместный эффект пробега и типа машины (эффект взаимодействия (interaction)). В формуле модели двоеточие между факторами означает, что взаимодействие для них должно быть сгенерировано. Для имеющихся данных в кадр данных добавляются пять предикторов:
> withlnteraction <- dummyVars(~MiLeage + Type + MiLeage:Type,
+ data = carSubset,
+ LeveLsOnLy = TRUE)
> withlnteraction
Dummy Variable Object
Formula: ^Mileage + Type + Mileage:Type 2 variables, 1 factors
Factor variable names will be removed
> predict(withlnteraction, head(carSubset))
Mileage convertible
coupe
hatchback
sedan
wagon Mileage:convertible
214
24323
0
0
0
1
0
0
299
1853
0
0
0
1
0
0
460
12305
0
0
0
1
0
0
728
4318
0
0
0
1
0
0
162
20770
0
0
0
1
0
0
718
26328
0
0
0
1
0
0
Mileage:coupe Mileage:hatchback Mileage:sedan Mileage:wagon
214
0
0
24323
0
299
0
0
1853
0
460
0
0
12305
0
728
0
0
4318
0
162
0
0
20770
0
718
0
0
26328
0
Упражнения 85
Упражнения
3.1. Репозиторий UC Irvine Machine Learning Repository1 содержит набор данных, относящихся к идентификации 214 образцов стекла в соответствии с одной из семи категорий. Для них определены девять предикторов: рефракционный индекс и процентное содержание восьми химических элементов (Na, Mg, Al, Si, К, Ca, Ba и Fe). Доступ к данным выполняется следующим образом:
> Library(mLbench)
> data(GLass)
> str(GLass)
’data.fr
ame*:
214
L obs. of 10 variables:
$
RI :
num
1.52 1.52
1.52 1.52 1.52 ...
$
Na :
num
13.6 13.9
13.5 13.2 13.3 ...
$
Mg :
num
4.49 3.6 3
».55 3.69 3.62 3.61 3.6 3.61 3.58 3.6 ...
$
Al :
num
1.1 1.36 1
..54 1.29 1.24 1.62 1.14 1.05 1.37 1.36 ...
$
Si :
num
71.8 72.7
73 72.6 73.1 ...
$
К :
num
0.06 0.48
0.39 0.57 0.55 0.64 0.58 0.57 0.56 0.57 ..
$
Ca :
num
8.75 7.83
7.78 8.22 8.07 8.07 8.17 8.24 8.3 8.4 ...
$
Ba :
num
0 0 0 0 0
00000...
$
Fe :
num
0 0 0 0 0
0.26 000 0.11 ...
$
Type:
Factor w/ 6 levels "I","2"/’3","5”,..: 1 1 1 1 1 1 1 111
A. Используя средства визуализации, проанализируйте переменные-предикторы, чтобы понять характер их распределения, а также связи между предикторами.
Б. Есть ли в данных выбросы? Наблюдается ли асимметрия в каких-либо предикторах?
B. Существуют ли релевантные преобразования одного или нескольких предикторов, позволяющих улучшить модель классификации?
3.2. В репозитории UC Irvine Machine Learning Repository также хранится информация о соевых бобах. Были собраны данные для прогнозирования заболеваемости 683 видов соевых бобов. 35 предикторов являются преимущественно категорийными и включают информацию об условиях окружающей среды (например, температура и уровень осадков) и состоянии растения (рост плесени, бляшки). Результат состоит из 19 разных классов.
Данные могут быть загружены следующим образом:
> Library(mLbench)
> data(Soybean)
> ## Подробности см. 6 ?Soybean
1 http://archive.ics.ud.edu/ml/index.html.
86 Глава 3. Предварительная обработка данных
A. Исследуйте распределение частот категорийных предикторов. Являются ли какие-либо из распределений вырожденными, как было рассмотрено ранее в этой главе?
Б. Приблизительно 18 % данных отсутствуют. Есть ли предикторы, которые будут отсутствовать с большей вероятностью? Связана ли закономерность отсутствия данных с классами?
B. Разработайте стратегию для решения проблемы отсутствующих данных — либо посредством исключения предикторов, либо посредством подстановки.
3.3, В модели количественного соотношения «структура-активность» (QSAR, Quantitative Structure-Activity Relationship, глава 5) характеристики химического вещества используются для прогнозирования других химических свойств. Пакет caret содержит набор данных QSAR от Менте и Ломбардо (Mente and Lombardo, 2005), в котором экспериментально определена способность 208 веществ к преодолению гемато-энцефалического барьера, для каждого из которых измерены 134 дескриптора.
A. Запустите R и используйте следующие команды для загрузки данных:
> Library(caret)
> data(BLoodBrain)
> # Подробности см, в fBLoodBrain
Результат содержится в векторе logBBB, предикторы — в кадре данных bbbDescr.
Б. Имеют ли какие-либо из предикторов вырожденные распределения?
B. В общем случае существуют ли сильные связи между данными предикторов? Если они существуют, то как сократить корреляции в наборе предикторов? Окажет ли это серьезное воздействие на количество предикторов, доступных для моделирования?
Переобучение и настройка модели
Многие современные модели классификации и регрессионные модели высокоэффективны для моделирования сложных связей. Тем не менее они также очень легко переоценивают невоспроизводимые закономерности. Без методологического подхода к оценке моделей разработчик модели не будет знать о проблеме до прогнозирования следующего набора точек.
Проблема переобучения (over-fitting) рассматривалась в области прогнозирования Кларком (Clark, 2004), медицинских исследований — Саймоном, Стейер- бергом (Simon et al., 2003; Steyerberg, 2010), хемометрики — Гоуэном, Хокинсом, а также Дефернисом и Кимсли (Gowen et al., 2010; Hawkins, 2004; Defernez and Kemsley, 1997), метеорологии — Си и Тангом (Hsieh and Tang, 1998), финансов — Двайером (Dwyer, 2005), брачных исследований — Хейманом и Слипом (Heyman and Slep, 2001) и т. д. Выполненные исследования показали, что переобучение проблематично для любой предиктивной модели независимо от области исследований. В этой главе мы постараемся объяснить и продемонстрировать ключевые принципы, на основе которых могут формироваться достоверно функционирующие предиктивные модели. Здесь же будут описаны стратегии, позволяющие с уверенностью утверждать, что построенная модель будет прогнозировать новые выборки с аналогичной степенью точности для того набора данных, на основе которого она была сформирована. Без этой уверенности любые прогнозы будут бесполезны.
Результат построения модели во многом предопределяется исходными данными. Исходные данные могут быть недостаточными для решения поставленной задачи, обладать низким качеством и/или не иметь непосредственного отношения к моделируемым данным. И хотя существуют способы построения предиктивных моделей для малых наборов данных, которые также будут описаны в этой главе, будем исходить из того, что качество имеющихся в нашем распоряжении данных достаточно высокое, а выборка достаточно представительна для всей выборочной совокупности данных.
88 Глава 4. Переобучение и настройка модели
С учетом сказанного имеющиеся в нашем распоряжении исходные данные следует использовать для поиска наилучшей предиктивной модели. Почти у всех методов предиктивного моделирования имеются параметры настройки, позволяющие видоизменять модель на базе структурирования данных. Следовательно, исходные данные должны использоваться и для нахождения параметров модели, обеспечивающих наибольшую эффективность прогнозирования (этот процесс называется настройкой модели). Традиционно эта задача решалась разделением данных на тренировочный и тестовый наборы. Тренировочный набор используется для построения и настройки модели, тестовый — для оценки ее предиктивной эффективности. Современные методы построения моделей допускают разделение данных на несколько тренировочных и тестовых наборов, поскольку такое разделение часто приводит к отысканию наиболее эффективных параметров настройки и обеспечивает более точное понимание предиктивной эффективности модели.
Рассмотрим концепцию переобучения на наглядном примере. Чтобы избежать переобучения, прибегнем к обобщенному методу построения модели, включающему этапы настройки и оценки модели с конечной целью нахождения воспроизводимой структуры в данных. В этом методе существующие данные разделяются на разные наборы для целей настройки параметров модели и оценки ее эффективности. Выбор варианта разделения данных зависит от характеристик существующих данных, таких как размер и структура. В разделе 4.4 определяются и объясняются наиболее универсальные методы разделения данных, исследуются достоинства и недостатки каждого метода. Глава завершается разделом «Вычисления» с кодом реализации общей стратегии построения модели.
4.1. Проблема переобучения
В настоящее время существует множество методов, анализирующих структуру набора данных настолько хорошо, что при применении модели к данным, на основе которых она построена, модель достоверно прогнозирует буквально каждую точку данных. Кроме общих закономерностей, модель выявляет характеристики искажений, присущих каждой точке данных. Такие модели обеспечивают переобучение, что оборачивается низкой точностью прогнозирования каждой следующей новой точки данных. Для наглядности рассмотрим пример классификации с двумя переменными-предикторами (то есть с двумя независимыми переменными) (рис. 4.1).
Эти данные содержат 208 точек, распределенных между двумя классами: «Класс 1» (111 точек) и «Класс 2» (97 точек). Между классами существует значительное перекрытие, что характерно для большинства прикладных задач моделирования. Одна из целей, достигаемых посредством такого набора, — разработка модели для классификации новых точек данных. В рассматриваемом примере модели или пра-
4.1. Проблема переобучения 89
вила классификации могут быть представлены граничными линиями. На рис. 4.2 изображены примеры граничных линий для двух разных моделей классификации.
Класс 1 Класс 2
0,0
0,0
0,2 0,4
0,6
Предиктор А
Рис. 4.1. Пример классификационных данных, используемых в настоящей главе
Класс 1
Класс 2 *
0,2 0,4 0,6 0,8
0,8
£
ф 0,4 о.
С
0,2
0,2 0,4 0,6 0,8
Предиктор А
Рис. 4.2. Пример тренировочного набора с двумя классами и двумя предикторами. На диаграммах изображены две разные модели классификации и соответствующие граничные линии
90 Глава 4. Переобучение и настройка модели
Эти линии охватывают область, в которой каждая модель прогнозирует данные как относящиеся к классу 2 (квадраты). В левой части («Модель 1») изображена сложная граница, стремящаяся охватить каждую возможную точку данных, из-за чего этот шаблон вряд ли удастся обобщить для новых данных. В правой части изображено альтернативное обучение модели; здесь граница получается достаточно гладкой и не перегружается попытками правильно классифицировать каждую точку данных в тренировочном наборе.
Чтобы оценить, насколько хорошо модель классифицирует данные, можно воспользоваться тренировочным набором. В этом случае оцениваемая частота ошибок для модели в левой части будет заниженной. Оценка пригодности модели для целей повторного прогнозирования по тренировочному набору позволяет установитьмни- мую эффективность модели. В двух измерениях нетрудно наглядно представить, что модель обеспечивает переобучение. Но поиск решения большинства задач моделирования осуществляется в условиях полиразмерности. В подобных ситуациях важно располагать инструментами, позволяющими достоверно установить степень переобучения модели по тренировочным данным.
4.2. Настройка модели
Для многих моделей характерно наличие важных параметров, непосредственное вычисление которых на основе имеющихся исходных данных не представляется возможным. Например, в модели классификации KNN новая точка данных прогнозируется на основании KNN точек данных в тренировочном наборе.
Пример функционирования модели с пятью ближайшими соседями для прогнозирования двух новых точек данных представлен на рис. 4.3 (искомые точки — кружок и закрашенный треугольник). Одна точка данных (•) практически сочетает в себе оба класса; следующие три указывают, что точка должна быть отнесена к первому классу. У второй точки (±) все пять соседей указывают на второй класс.
Возникает вопрос — сколько именно соседей следует использовать? Выбор недостаточного количества может привести к переобучению отдельных точек тренировочного набора, тогда как модель с избыточным количеством соседей может не обеспечить требуемое быстродействие. Рассматриваемые параметры модели принято называть параметрами настройки, имея в виду, что для вычисления наиболее подходящего значения не существует соответствующих формул.
Некоторые модели, рассмотренные в этой главе, имеют, по крайней мере, один параметр настройки. Увеличение количества параметров ведет к усложнению модели, а неудачный выбор значений — к переобучению. В этой связи вновь обратимся к рис. 4.2: метод опорных векторов (см. раздел 13.4) использован для генерирования границ классов в каждой из двух частей. Один из параметров настройки в представленной модели задает штраф за неверную классификацию точек данных в тре-
4.2. Настройка модели 91
Класс 1 Класс 2
0,6
СП
О.
Ф
О. с
0,2
0,0
0,0 0,2 0,4 0,6
Предиктор А
Рис. 4.3. Модель классификации с к ближайшими соседями. Две новые точки, изображенные в виде черного треугольника и черного кружка, спрогнозированы на основании тренировочного набора
нировочном наборе, обычно обозначаемый как «стоимость» (cost). При заданной высокой стоимости модель стремится к тому, чтобы правильно пометить каждую точку (как на левой панели), но при более низких значениях этого показателя качество работы модели ухудшается. Граница класса в левой части сформирована вручную — присваиванием параметру стоимости пикового значения. В правой части стоимость была определена методом перекрестной проверки (см. раздел 4.4). Существуют разные подходы к определению оптимальных параметров. Общий подход, который может быть применен практически для любой модели, заключается в определении набора значений-кандидатов, генерировании надежных оценок полезности модели с разными кандидатами и выборе оптимальных настроек (рис. 4.4). После определения набора возможных значений параметра необходимо получить достоверные оценки эффективности модели. Данные об оценке эффективности на точках из контрольной выборки объединяются в профиль эффективности, используемый для определения итоговых параметров настройки. Затем строится — с использованием выбранных параметров настройки — итоговая модель со всеми тренировочными данными. Если использовать пример с KNN для демонстрации процедуры на рис. 4.4, то в состав значений-кандидатов могут войти все нечетные значения k от 1 до 9 (нечетные значения используются в ситуации с двумя классами для предотвращения «ничьих»).
92 Глава 4. Переобучение и настройка модели
Рис. 4.4. Блок-схема процесса настройки параметров. В качестве набора параметров настройки для к ближайших соседей может использоваться набор нечетных чисел от 1 до 9. Для каждого из этих значений производится многократная повторная выборка для оценки эффективности модели при каждом значении
Следующий шаг — повторная выборка из тренировочных данных и многократная оценка каждого значения параметра настройки. Полученные результаты обрабатываются для нахождения оптимального значения k.
Рассматриваемая процедура использует набор моделей-кандидатов, определяемый параметрами настройки. Другие методы, такие как генетические алгоритмы Митчелла (Mitchell, 1998) или симплексный метод поиска Олесона—Нельсона (Olsson and Nelson, 1975), также могут применяться для поиска оптимальных параметров настройки. Эти процедуры последовательно определяют наиболее подходящие значения параметров настройки и выполняются до тех пор, пока не будут достигнуты их оптимальные значения. Обычно подобные методы оценивают большое
4.3. Разделение данных 93
количество моделей-кандидатов, в том числе с выходом за заранее определенные наборы параметров настройки в тех случаях, когда эффективность модели может быть вычислена. Отметим, что у Коэна (Cohen et al., 2005) описано сравнение функций поиска для настройки модели метода опорных векторов.
Труднее получить достоверные оценки эффективности для моделей-кандидатов. Как уже упоминалось, мнимая частота ошибок может порождать чрезмерно оптимистичные оценки эффективности модели, в связи с чем представляется предпочтительным проверять модель на данных, которые не использовались для тренировки. Однако для получения оптимальной точности показателей эффективности размер тестового набора должен быть достаточно большим.
Альтернативный способ оценки модели для одного тестового набора основан на повторной выборке тренировочного набора. Для этого используется несколько измененных версий тренировочного набора, позволяющих сформировать несколько моделей и объективно оценить их эффективность посредством применения статистических методов. В разделе 4.4 продемонстрированы некоторые методы повторной выборки. Способы выбора итоговых параметров по результатам повторной выборки обсуждаются в разделе 4.6.
4.3. Разделение данных
Теперь, когда мы в общих чертах обрисовали процедуру поиска оптимальных параметров настройки, можно переходить к рассмотрению сути разделения данных.
Перечислим ключевые этапы построения модели:
О предварительная обработка данных предикторов;
О оценка параметров модели;
О выбор предикторов для модели;
О оценка эффективности модели;
О точная настройка правил прогнозирования классов (кривые ошибок и т. д.).
Располагая сведениями о заданном фиксированном объеме данных, разработчик модели должен решить, как наиболее продуктивно использовать для оценки эффективности модели точки данных и произвести мотивированный отбор последних. Для обеспечения объективной оценки эффективности модели целесообразно использовать точки, которые не задействовались для ее построения или регулировки. При наличии достаточно большого объема данных можно заранее зарезервировать набор точек данных для оценки эффективности итоговой модели. Поясним, что под тренировочным набором данных понимается выборка для формирования модели, а под тестовым или контрольным набором данных — выборка для оценки эффективности модели.
94 Глава 4. Переобучение и настройка модели
При недостатке данных от тестового набора целесообразно отказаться, с тем чтобы использовать их только для построения модели. К слову, некоторые исследователи, включая Молинаро, Мартина и Хиршберга, Хокинса (Molinaro, 2005; Martin and Hirschberg, 1996; Hawkins et al., 2003), рассматривают решение о проверке, основанной исключительно на тестовом наборе, как неудачное. В частности, у Хокинса (Hawkins et al., 2003) находим следующий вывод: «Контрольные выборки приемлемого размера [...] уступают перекрестной проверке в отношении надежности для оценки аппроксимации модели, и их применение трудно оправдать».
Методы повторной выборки (например, перекрестная проверка) могут использоваться для оценки эффективности модели на основе тренировочного набора (подробнее см. раздел 4.4). Эти методы могут работать и некорректно, как в примере у Эмброуза и Маклахлана (Ambroise and McLachlan, 2002); тем не менее эти методы позволяют оценить эффективность модели объективнее, нежели методы, основанные на использовании единичного тестового набора, поскольку предполагают использование альтернативных вариантов данных. При принятии решения в пользу метода с использованием тестового набора можно воспользоваться различными методами разделения данных. Например, если модель предназначена для прогнозирования результата лечения, то ее можно создать на основе данных некоторых пациентов (например, с одинаковой клинической базой или стадией заболевания), а протестировать — уже на другой выборке.
В химическом моделировании, сопровождающем поиск новых лекарств, постоянно исследуется новое «химическое пространство». Нас, по понятным причинам, больше интересует точность прогнозов в актуальном химическом пространстве, чем в пространстве, которое анализировалось несколько лет назад. То же самое можно сказать и о фильтрации спама: для модели важнее информация о новых методах рассылки спама, чем об уже известных.
Однако в большинстве случаев желательно, чтобы тренировочный и тестовый наборы данных были настолько однородными, насколько это возможно. Для создания таких наборов могут использоваться методы случайной выборки. Элементарный способ разделения данных на тренировочный и тестовый наборы основан на простой случайной выборке. Атрибуты данных при этом не контролируются. Если один класс имеет непропорционально низкую частоту по сравнению с другими, то сохраняется вероятность того, что распределение результатов между тренировочным и тестовым наборами будет существенно различаться.
Чтобы учитывать результат при разделении данных, расслоенная случайная выборка применяется в подгруппах (например, в классах). При этом существует высокая вероятность того, что распределения результатов будут совпадать. Если результат является числом, то можно воспользоваться аналогичной стратегией: числовые значения делятся на сходные группы (например, низкие, средние и высокие), а их рандомизация выполняется в соответствующих группах.
4.3. Разделение данных 95
Разделение данных может производиться и на основании значений предикторов. В частности, Уиллетт (Willett, 1999) и Кларк (Clark, 1997) предлагают выполнять разделение на основании максимального расхождения. Распределение между двумя выборками может осуществляться разными способами. Проще всего использовать разницу между значениями предикторов двух выборок. Незначительная разница указывает на близость взаимного расположения точек, и наоборот. Чтобы использовать расхождение как механизм разделения данных, предположим, что тестовый набор инициализируется одной точкой данных. Вычислим расхождения между исходной точкой и нераспределенными точками. Затем нераспределенная точка с наибольшим расхождением добавляется в тестовый набор. Для включения новых точек данных в тестовый набор необходим метод определения расхождения между группами точек (то есть двумя точками из тестового набора и нераспределенными точками).
Другой способ основан на использовании среднего или минимального расхождения. Например, чтобы измерить расхождение между двумя точками в тестовом наборе и одной нераспределенной точкой, можно вычислить два расхождения и затем усреднить их. Для добавления в тестовый набор выбирается точка с максимальным средним расхождением относительно существующего набора. Этот процесс выполняется до тех пор, пока не будет достигнут заданный размер тестового набора (рис. 4.5).
Класс 1 Класс 2 Класс 1 Класс 2
со CL £ S EI Ф О.
с
0,6
00
Q. О
0,6
0,4
£
5
о
0,4
С
0,2
0,2
0,0
0,0
0,0
0,2
0,4 0,6
Предиктор А
0,0
0,2
0,4 0,6
Предиктор А
Рис. 4.5. Пример формирования тестового набора методом максимального расхождения. После выбора исходной точки данных в класс добавляются еще 14 точек
Выбор посредством вычисления расхождения проводился отдельно в каждом классе. Сначала в каждом классе было выбрано по одной точке для запуска процесса (на диаграмме эти точки обозначены символами ■ и •.). Далее вычислено расхождение
96 Глава 4. Переобучение и настройка модели исходной точки с нераспределенными точками внутри класса, а точка с наибольшим расхождением добавлена в тестовый набор. Для первого класса точка с наибольшим расхождением находится в юго-западном углу исходного примера. Затем расхождения были обобщены по принципу минимума (вместо усреднения). На этот раз для первого класса выбранная точка находилась в северо-восточном углу пространства предикторов. По ходу формирования сначала добавлялись периферийные точки. Затем происходило постепенное продвижение к центру.
Отметим, подытоживая параграф, что у Мартина (Martin et al., 2012) сравниваются различные методы разбиения данных, включая случайную выборку, выборку методом расхождения и другие методы.
4.4. Методы повторной выборки
В общем случае методы повторной выборки для оценки эффективности модели работают так: подмножество точек данных используется для обучения модели, остальные точки — для оценки ее эффективности. Процесс повторяется несколько раз, его результаты накапливаются и обобщаются. Различия в методах обычно обусловлены способом выбора этих множеств. Основные варианты повторной выборки будут рассмотрены в следующих разделах.
К-кратная перекрестная проверка
При выполнении А-кратной перекрестной проверки точки данных случайным образом разбиваются на k множеств приблизительно одинакового размера. Обучение модели производится по всем точкам, кроме первого подмножества. Зарезервированные точки данных прогнозируются по полученной модели, а результат используется для оценки значений эффективности. Первое подмножество возвращается в тренировочный набор, после чего процедура повторяется с резервированием второго подмножества, и т. д. В конце производится обобщение k полученных оценок эффективности (обычно с использованием математического ожидания и среднеквадратичной погрешности). На основе полученной информации анализируется зависимость между параметрами настройки и эффективностью модели. Процесс перекрестной проверки для k = 3 представлен на рис. 4.6.
В модифицированной версии этого метода по Кохави (Kohavi, 1995) k подмножеств выбираются так, чтобы они были сбалансированы в отношении результата. Расслоенная случайная выборка (см. раздел 4.3) осуществляет балансировку с учетом результата.
Другая разновидность — перекрестная проверка с исключением (LOOCV, Leave-One- Out Cross-Validation) — представляет собой особый случай, в котором значение k равно количеству точек данных. Поскольку каждый раз резервируется только одна
4.4. Методы повторной выборки 97
Исходные данные
Построение модели
Прогнозирование
Группа перекрестной проверки 1
Группа перекрестной проверки 2
Группа перекрестной проверки 3
Рис. 4.6. Процедура трехкратной перекрестной проверки. Двенадцать точек данных тренировочного набора изображены в виде геометрических фигур и распределены потрем группам. Группы последовательно исключаются из рассмотрения в процессе обучения модели. Для каждого набора исключенных точек вычисляется метрика эффективности — например, частота ошибок или R2. Среднее значение этих трех метрик определяет межвыборочную оценку эффективности модели. На практике количество точек в исключенной части может меняться, но размеры этих подмножеств остаются приблизительно равными точка данных, итоговая эффективность вычисляется на основании k отдельных прогнозов. Повторная ^-кратная перекрестная проверка повторяет процедуру, представленную на рис. 4.6, несколько раз. Например, если десятикратная перекрестная проверка повторяется пять раз, то эффективность модели будет оцениваться на основании 50 разных наборов.
Значение k обычно выбирается равным 5 или 10, но это не является формальным правилом. С увеличением k разность в размере между тренировочным набором и подмножествами повторной выборки сокращается. В свою очередь, с уменьшением разности сокращается погрешность рассматриваемого метода (разность между оцениваемыми и истинными значениями эффективности), то есть для k = 10 смещение будет меньше, чем для k = 5).
Другим важным аспектом методов повторной выборки является неопределенность (дисперсия или искажение данных). Несмещенный метод может выявить теоретическую эффективность модели, но с учетом влияния на результат дисперсии. Это означает, что при следующем выполнении повторной выборки будет получено иное значение (хотя, повторив процедуру достаточное количество раз, можно получить более или менее объективную оценку эффективности). К-кратная перекрестная проверка обычно обладает высокой дисперсией по сравнению с другими методами, что снижает ее привлекательность в контексте целей исследования. При использовании больших тренировочных наборов потенциальные проблемы с дисперсией становятся пренебрежимо малыми.
Большие значения k заметно повышают вычислительную нагрузку. Показательный пример — перекрестная проверка с исключением, при выполнении которой количество адаптаций равно количеству точек данных, а каждая адаптация ис-
98 Глава 4. Переобучение и настройка модели пользует подмножество, размер которого почти не отличается от размера тренировочного набора. Молинаро (Molinaro, 2005) обнаружил, что перекрестная проверка с исключением и десятикратная перекрестная проверка дают сходные результаты; следовательно, значение k = 10 оказывается более привлекательным в контексте вычислительной эффективности. Кроме того, с малыми значениями k (допустим, 2 или 3) процедура имеет высокое смещение, но обладает чрезвычайно высокой вычислительной эффективностью. С другой стороны, смещение, обусловленное малыми значениями k, приблизительно равно смещению, полученному в результате выборки с возвратом (см. ниже), но обладает гораздо большей дисперсией.
Исследования того же Молинаро, а также Кима (Molinaro, 2005; Kim, 2009) подтвердили возможность выполнения повторной ^-кратной перекрестной проверки для реального повышения точности оценки при минимальных значениях дисперсии.
Обобщенная перекрестная проверка
Для моделей линейной регрессии существует формула аппроксимации частоты ошибок для перекрестной проверки с исключением. Статистика обобщенной перекрестной проверки (GCV, Generalized Cross-Validation), согласно Голубу (Golub et al., 1979), не требует итеративного переобучения модели по разным подмножествам данных. Формула для г-го обучающего набора выглядит так: GCV= —
п
Vi ~Vi Y
где yt — i-й результат в тренировочном наборе, у{ — прогноз этого результата моделью, a df — число степеней свободы модели. Показатель степеней свободы учитывает, сколько параметров оценивает модель, а следовательно, и сложность моделей линейной регрессии. На основании уравнения две модели с одинаковыми суммами среднеквадратичной ошибки (числитель) будут иметь разные значения GCV, если модели различаются по сложности.
Повторное разделение тренировочного/тестового набора
Повторное разделение тренировочного/тестового набора также называется «пере- крестной проверкой с исключением групп» и «перекрестной проверкой методом Монте-Карло». Этот метод позволяет создать несколько вариантов разделения данных на моделирующий и предиктивный набор (рис. 4.7).
Часть данных, попадающая в каждый набор, и количество их повторений задаются специалистом. Как упоминалось, дисперсия методов повторной выборки умень-
4.4. Методы повторной выборки 99
Исходные данные
Построение модели
Прогнозирование
Группа перекрестной проверки 1
Группа перекрестной проверки 2
Группа перекрестной проверки 3
Рис. 4.7. Процедура В повторных разбиений тренировочного/тестового набора. Двенадцать точек данных тренировочного набора изображены в виде геометрических фигур и распределены по В подмножествам, образующим 2/3 исходного тренировочного набора. Одно из отличий этой процедуры от k-кратной перекрестной проверки заключается в том, что точки данных могут содержаться в нескольких зарезервированных подмножествах. Кроме того, количество повторений обычно больше k-кратной перекрестной проверки шается по мере того, как объем данных в подмножестве приближается к объему моделирующего набора. Вполне удовлетворительным является показатель в диапазоне от 75 до 80 %. Более высокие показатели достижимы при большом количестве повторений.
Увеличение количества подмножеств способствует сокращению дисперсии оценок эффективности. Например, для получения общей оценки эффективности модели 25 повторений будет достаточно, если представляется приемлемой некоторая нестабильность итоговых значений. Для более или менее гарантированного получения стабильных оценок эффективности рекомендуется большее количество повторений — от 50 до 200. Это же значение является функцией для пропорции точек данных, случайным образом выделяемых в предиктивный набор: чем выше процент, тем больше повторений понадобится для сокращения дисперсии в оценках эффективности.
Бутстрэп
Выборка с возвратом, или бутстрэп (bootstrap), — случайная выборка данных, при которой точка данных, выбранная для подмножества, «возвращается» в исходный набор и остается доступной для выбора в будущем, как это показано, например, у Эфрона и Тибширани (Efron and Tibshirani, 1986). Бутстрэп имеет такой же размер, как и исходный набор данных. В результате некоторые точки данных будут встречаться в выборке с возвратом несколько раз, тогда как другие выбираться вообще не будут. Точки, которые не были выбраны, обычно называются не вошедшими в набор (out-of-bag). Для заданной итерации повторного бутстрэпа модель строится
100 Глава 4. Переобучение и настройка модели на основе выбранных точек данных и используется для прогнозирования точек, не вошедших в набор (рис. 4.8).
Исходные данные
Построение модели
Прогнозирован ие
Группа перекрестной проверки 1
Группа перекрестной проверки 2
Группа перекрестной проверки 3
Рис. 4.8. Процедура повторной выборки с возвратом. Двенадцать точек данных тренировочного набора изображены в виде геометрических фигур и распределены по В подмножествам. Размер каждого подмножества равен размеру оригинала, и одна точка данных может встречаться многократно. Точки, не выбранные в процессе выборки, используются для оценки эффективности модели
В общем случае частота ошибок выборки обладает несколько меньшей неопределенностью, чем ^-кратная перекрестная проверка по Эфрону (Efron, 1983). В среднем 63,2 % точек данных представлены как минимум однократно, так что дисперсия этого метода сходна с дисперсией ^-кратной перекрестной проверки при k ~ 2. Если размер тренировочного набора мал, то дисперсия может существенно возрасти, и наоборот.
Для устранения дисперсии был разработан ряд модификаций простой процедуры выборки с возвратом. Метод 632 (Efron, 1983) решает проблему дисперсии посредством оценки эффективности, являющейся комбинацией простой оценки выборки с возвратом и оценки повторного прогнозирования тренировочного набора (то есть кажущейся частоты ошибок). Например, если классификация модели характеризовалась частотой ошибок, то метод 632 использует следующую формулу:
(0,632 х простая оценка выборки с возвратом) +
+ (0,368 х кажущаяся частота ошибок).
Измененная процедура выборки с возвратом сокращает дисперсию при сохранении рисков нестабильности для малых размеров выборки. Она может привести и к завышенным результатам, если модели присуще переобучение данных, потому что мнимая частота ошибок при этом будет близка к нулю. Заметим, что позднее у Эфрона и Тибширани (Efron and Tibshirani, 1997) рассмотрен и другой метод корректировки оценки выборки с возвратом — так называемый метод 632+.
4.6. Выбор итоговых параметров настройки 101
4.5. Практикум: оценка кредитоспособности
Одно из очевидных применений предиктивных моделей — оценка кредитоспособности, когда на основе определенных данных модель прогнозирует вероятность возврата кредита заемщиком. Этот прогноз может использоваться для оценки риска банка-заимодавца.
Используемый в Германии набор данных — популярный инструмент для проверки алгоритмов машинного обучения. Он содержит 1000 точек данных, которым присвоены метки «хороший кредит» и «плохой кредит». В наборе данных 70 % кредитов были оценены как «хорошие». Требование о базовой оценке точности модели в 70 % (достигаемой простым прогнозированием всех точек данных как «хороших») обсуждается в разделе 11.2.
С учетом изложенного собирались данные, относящиеся к кредитной истории потенциального заемщика, о наличии у него работы, о состоянии его счета и т. д. Некоторые предикторы были числовыми — например, сумма кредита. Однако большинство предикторов были категорийными по своей природе — например, цель кредита, пол или семейное положение. Категорийные предикторы были преобразованы в «фиктивные переменные», относящиеся к одной категории. Например, информация о проживании была разбита на категории «арендованное жилье», «жилье в собственности» или «служебное жилье». Этот предиктор был преобразован в три ответа «да/нет» для каждой категории. Например, один предиктор будет иметь значение 1, если заемщик снимает жилье, и 0 — в противном случае (о фиктивных переменных см. раздел 3.6). Всего для моделирования кредитного статуса заемщика применен 41 предиктор.
Эти данные приводятся для демонстрации настройки моделей с применением повторной выборки (см. рис. 4.4) на основе расслоенной случайной выборки 800 клиентов, которая использовалась для тренировки моделей. Остальные точки данных использовались как тестовый набор для проверки эффективности итоговой модели. Результаты обработки тестового набора будут рассмотрены более подробно в разделе 11.2.
4.6. Выбор итоговых параметров настройки
После оценки эффективности модели по наборам параметров настройки можно перейти к выбору итоговых настроек, следуя одному из общепринятых подходов. Простейший вариант — выбор настроек, связанных с наиболее высокими значениями оценки эффективности модели. Так, в примере с оценкой кредитоспособности
102 Глава 4. Переобучение и настройка модели нелинейная модель опорных векторов1 оценена на значениях стоимости в диапазоне от 2 2 до 27. Для каждой модели оценка выполнена на основе пяти повторений десятикратной перекрестной проверки. На рис. 4.9 и в табл. 4.1 представлен профиль точности для разных значений-кандидатов параметра стоимости.
Кажущаяся С перекрестной проверкой
1,00
0,95 5 0,90 о
о
X
о 0,85
| 0,80 О
0,75
0,70
2Л-2 2А0 2А2 2Л4 2*6
Стоимость
Рис. 4.9. Профиль эффективности метода опорных векторов с радиальной базисной функцией в примере оценки кредитоспособности для разных значений параметра стоимости. Вертикальные линии обозначают ± две стандартные погрешности
Для каждой модели перекрестная проверка сгенерировала 50 разных оценок точности; заполненные точки на рис. 4.9 представляют средние значения этих оценок. Вертикальные «скобки» отражают среднее значение плюс-минус две стандартные погрешности. Профиль отражает возрастание точности до достижения значения стоимости, равной 1. Модели со значениями стоимости от 1 до 16 относительно постоянны, после чего точность снижается (вероятно, из-за переобучения). Оптимальное значение параметра стоимости равно 8, с соответствующей степенью точности 75 %. Мнимая частота точности, определяемая повторным прогнозированием для данных тренировочного набора, указывает на постепенное улучшение модели с ростом значения стоимости, хотя в более сложных моделях наблюдается переобучение тренировочного набора.
1 Эта модель использует ядро радиальных базисных функций (раздел 13.4). Хотя здесь эта тема не рассматривается, мы использовали аналитический подход, рассмотренный ниже, для определения параметра ядра, и скорректировали это значение для всех методов повторной выборки.
4.6. Выбор итоговых параметров настройки 103
Таблица 4.1. Результаты многократной перекрестной проверки для модели опорных векторов
Точность (%)
Стоимость
Мат. ожидание
Стандартная погрешность
Допуск (%)
0,25
70,0
0,0
-6,67
0,50
71,3
0,2
-4,90
1,00
74,0
0,5
-1,33
2,00
74,5
0,7
-0,63
4,00
74,1
0,7
-1,20
8,00
75,0
0,7
0,00
16,00
74,9
0,8
-0,13
32,00
72,5
0,7
-3,40
64,00
72,0
0,8
-4,07
128,00
72,0
0,8
-4,07
Метод «одной стандартной погрешности» выбирает простейшую модель с точностью не менее 74,3 (75-0,7) %, что соответствует значению стоимости 2. Информация о лучшем решении выделена полужирным шрифтом.
В общем случае желательно отдавать предпочтение простым моделям перед сложными. Выбор параметров настройки на основании оптимальных значений может привести к чрезмерному усложнению модели. Стоит исследовать и другие схемы выбора менее сложных моделей. Они могут привести к более простым моделям с приемлемой эффективностью (относительно числовых оптимальных настроек). Метод «одной стандартной погрешности» для выбора более простых моделей находит оптимальное значение и его соответствующую стандартную погрешность, после чего ищет простейшую модель, эффективность которой лежит в пределах одной стандартной погрешности от наилучшего значения. Эта процедура, следуя Брейману (Breiman et al., 1984), происходит от классификационных и регрессионных деревьев (см. разделы 8.1 и 14.1).
На рис. 4.10 стандартная погрешность значений точности при значении стоимости 8 составляет около 0,7 %. Рассматриваемый метод позволяет определить простейшие параметры настройки с точностью не менее 74,3 (75 - 0,7) %, используя два заданных значения стоимости.
Возможен и выбор модели в пределах заданного допуска от числового лучшего значения. Снижение показателя эффективности может быть представлено как
104 Глава 4. Переобучение и настройка модели (X - 0)/0, где X — значение эффективности, а О — числовое оптимальное значение. Например, на рис. 4.9 лучшее значение точности в пределах профиля достигало 75 %. Если четырехпроцентное снижение точности приемлемо как цена упрощения модели, то, соответственно, приемлемы значения точности в 71,2 % и выше. Для профиля, представленного на рис. 4.9, этот метод приведет к выбору значения стоимости 1.
2Л-2 2л0 2Л2 2Л4 2Л6
0,80
0,75
0,70
>Х о
Q. О Ю
-Q СО
>х о X
0.80
о. о н CD О С
0,75
о л ь о
0,70
X
7 О 1-
0,80-
0,75-
0,70-
2л-2 2л0 2Л2 2Л4 2Л6
Стоимость
Рис. 4.10. Профиль эффективности нелинейной машины опорных векторов для разных значений параметра стоимости в примере оценки кредитоспособности с использованием разных процедур повторной выборки. Вертикальные линии обозначают ± две стандартные погрешности
4.7. Рекомендации по разделению данных 105
Те же данные были обработаны и посредством других методов повторной выборки: повторная десятикратная перекрестная проверка, перекрестная проверка с исключением, выборка с возвратом (с поправкой 632 и без) и повторное разделение тре- нировочного/тестового набора (с 20-процентным резервированием). Последние два метода использовали для оценки эффективности 50 повторных выборок (рис. 4.10). На диаграмме отражена стандартная закономерность, присущая методам перекрестной проверки: пик точности достигается при значениях стоимости от 4 до 16, оставаясь в пределах интервала сравнительно постоянным. Эффективность быстро растет со значением стоимости, а после достижения пика — плавно снижается вследствие переобучения. Методы перекрестной проверки оценивают точность в диапазоне от 74,5 до 76,6 %. Простая выборка с возвратом оценивает точность на уровне 74,2 %, тогда как «метод 632» — на уровне 82,3 %. Следует учитывать, что интервал стандартной погрешности простой десятикратной перекрестной проверки — больше, чем у других методов, поскольку стандартная погрешность является функцией количества используемых повторных выборок (100 против 50, используемых выборкой с возвратом или с повторным разделением).
Время вычислений существенно различалось. Десятикратная перекрестная проверка выполнена за 0,82 минуты. Многократная перекрестная проверка, выборка с возвратом и повторное разбиение тренировочного/тестового набора работают с одинаковым количеством моделей и, в среднем, занимают в пять раз больше времени (до 4 минут). Перекрестная проверка с исключением, у которой количество моделей равно количеству точек данных в тренировочном наборе, длилась 70 минут, что указывает на предпочтительность применения этого варианта только при очень небольшом размере набора данных.
4.7. Рекомендации по разделению данных
Как упоминалось, против использования единственного независимого тестового набора существует ряд серьезных возражений, а именно:
О тестовый набор обеспечивает однократную оценку модели, а его возможности по описанию дисперсии в результатах ограниченны;
О пропорционально большие тестовые наборы делят данные способом, увеличивающим смещение в оценках эффективности;
О при малых размерах выборки модели может понадобиться каждая возможная точка данных для адекватного определения значений модели;
О дисперсия тестового набора может быть достаточно большой до момента, когда разные тестовые наборы могут создавать совершенно разные результаты;
О методы повторной выборки могут давать внятные прогнозы того, как модель поведет себя на будущих выборках.
106 Глава 4. Переобучение и настройка модели
Ни один метод повторной выборки не является однозначно лучшим. Соответственно, при выборе метода следует учитывать несколько факторов. При небольших размерах выборки рекомендуется применять повторную десятикратную перекрестную проверку. В этом случае смещение и дисперсия приемлемы, а вычислительные затраты относительно невелики при заданном размере выборки.
Для выбора между моделями предпочтительнее использовать одну из процедур выборки с возвратом, потому что они характеризуются очень низкой дисперсией. Для больших наборов различия между методами повторной выборки становятся менее выраженными, а на первый план выходит фактор вычислительной эффективности. Здесь приемлемую дисперсию, низкое смещение и относительно малое время вычисления возможно обеспечить посредством простой десятикратной перекрестной проверки.
Варма и Саймон (Varma and Simon, 2006), Булестье и Стробл (Boulesteix and Strobl, 2009) замечают, что при оценке эффективности модели в ходе настройки параметров может наблюдаться потенциальное смещение. Предположим, итоговая модель выбирается в соответствии с параметром настройки, связанным с наименьшим процентом ошибок. Возникает возможность завышенной оценки процента ошибок как случайной величины, выбираемой из потенциально большого набора параметров настройки. В исследованиях центральное место занимали ситуации с малым количеством точек данных и большим количеством предикторов, в которых обозначенная проблема усугубляется. Впрочем, для относительно больших тренировочных наборов это смещение несущественно. Оценки эффективности, полученные методом повторной выборки на базе тестового набора, рассматриваются далее (с учетом незначительности влияния на результаты оптимизационного смещения).
4.8. Выбор между моделями
После того как для каждой модели определены параметры настройки, предстоит сделать выбор между несколькими моделями. Этот выбор в основном зависит от характеристик данных и вопросов, на которые нужно ответить по ходу выбора. Тем не менее предсказать, какая модель лучше всего подходит для заданной цели, непросто. Возможна следующая схема окончательного выбора типа модели.
1. Начните с нескольких моделей, обладающих наименьшей интерпретируемостью и наибольшей гибкостью, например усиленных деревьев решений или опорных векторов. Эти модели с высокой вероятностью приведут к эмпирически оптимальным (то есть наиболее точным) результатам.
2. Исследуйте более простые модели, обладающие наибольшей прозрачностью, например многомерные адаптивные регрессионные сплайны (MARS), частные наименьшие квадраты, обобщенные аддитивные модели и наивные байесовские модели.
4.8. Выбор между моделями 107
3. Рассмотрите возможность использования простейшей модели, обеспечивающей эффективность, достаточно близкую к эффективности более сложных методов.
Посредством представленной схемы разработчик может обнаружить «потолок эффективности» для набора данных до выбора в пользу конкретной модели. Не исключено, что сразу несколько моделей окажутся равными по эффективности и для окончательного выбора потребуется оценить их индивидуальные преимущества: вычислительную сложность, простоту прогнозирования, интерпретируемость. Например, нелинейный метод опорных векторов или модель случайного леса могут обладать более высокой точностью, но сложность и громоздкость уравнения прогнозирования могут помешать внедрению формулы прогнозирования в реально функционирующую систему. При сопоставимых показателях точности целесообразно отдать предпочтение модели, функционирующей на основе формулы, внедрение которой требует меньших временных затрат.
Рассмотрим классификационную модель оценки кредитоспособности на базе метода опорных векторов с использованием повторной выборки (см. раздел 4.6). При использовании повторной десятикратной перекрестной проверки точность модели оценена в 75 %, тогда как у большинства остальных методов повторной выборки точность составляла от 66 до 82 %.
Логистическая регрессия (см. раздел 12.2) — более простой метод оценки граничных линий, чем нелинейная модель метода опорных векторов. У нее нет параметров настройки, а формула прогнозирования проста и легко реализуема во многих программных продуктах. При использовании той же схемы перекрестной проверки оцениваемая точность модели составляла 74,9 %, тогда как у большинства остальных методов повторной выборки точность составляла от 66 до 82 %. Уточним, что для оценки каждой модели использовались одни и те же повторные выборки (всего — 50). На рис. 4.11 представлена диаграмма, отображающая распределение оценок точности при повторной выборке.
Очевидно, что использование более простой модели для этих данных не приводит к потере эффективности.
В работах Хоторна (Hothorn et al., 2005) и Эгстера (Eugster et al., 2008) описаны статистические методы сравнения методологий на основании результатов повторной выборки. Поскольку точность измерялась с использованием наборов данных с идентичными повторными выборками, то при определении статистической значимости различий можно было воспользоваться статистическими методами для парных сравнений. Парная ^-проверка может использоваться для оценки гипотезы о том, что модели обладают эквивалентными точностями (или средними значениями) или что средняя разность точности для наборов данных повторной выборки равна нулю. Для этих двух моделей средняя разность точности модели составила 0,1 %, при этом логистическая регрессия позволила получить лучшие результаты. 95-процентным доверительным интервалом для этой разности был интервал от -1,2 до 1 %. Следовательно, нет оснований утверждать, что одна из сопоставляемых
108 Глава 4. Переобучение и настройка модели
Модель опорных векторов
(SVM)
Модель логистической регрессии
0,65 0,70 0,75 0,80 0,85
Точность
Рис. 4.11. Сравнение оценок точности перекрестной проверки от модели опорных векторов и модели логистической регрессии для данных оценки кредитоспособности (раздел 4.5)
моделей обладает значительно лучшей точностью. Значения точности повторной выборки (рис. 4.11) лежат в диапазоне от 61,3 до 85 %, и с учетом разброса в результатах повышением точности на 0,1 % можно пренебречь.
Заметим, что если речь идет о модели, характеризующейся несколькими показателями, то существует вероятность того, что сравнения между моделями приведут к разным выводам. Например, если модель создается для прогнозирования двух классов, то для определения эффективности моделей могут использоваться чувствительность и специфичность (см. главу 11). Если набор данных включает больше событий, чем несобытий, то чувствительность может быть определена с большей точностью, чем специфичность. При повышении точности повышается и вероятность того, что модели удастся различить именно в контексте их чувствительности, а не их специфичности.
4.9. Вычисления
Для демонстрации методов моделирования используется язык R. Напомним вновь, что краткий обзор R и базовые принципы его использования приведены в приложении Б.
Читателям, не имеющим опыта работы с R, стоит прежде всего ознакомиться с указанными материалами, а затем уже продолжить чтение этой книги. В этом разделе упоминаются функции из пакетов AppliedPredictiveModeling, caret, Design, е1071, ipred и MASS. Синтаксис продемонстрирован на простом примере с двумя классами (см. рис. 4.2 и 4.3) и данными из практикума по оценке кредитоспособности.
4.9. Вычисления 109
Разделение данных
Данные с двумя классами (см. рис. 4.1) содержатся в пакете AppliedPredictiveModeling и загружаются командами:
> Library(AppLiedPredictiveModeLing)
> data(twoCLassData)
Предикторы данных примера хранятся в кадре данных predictors. Для предикторов предусмотрено два столбца, 208 точек данных представлены строками. Классы результатов содержатся в факторном векторе classes.
> str(predictors)
’data.frame’: 208 obs. of 2 variables:
$ PredictorA: num 0.158 0.655 0.706 0.199 0.395 ...
$ PredictorB: num 0.1609 0.4918 0.6333 0.0881 0.4152 ...
> str(cLasses)
Factor w/ 2 levels ’’Classi", ”Class2": 2222222222 ...
Базовая функция R sample может создавать простые случайные разделения данных. Чтобы создать расслоенное случайное разделение данных (с учетом классов), можно воспользоваться функцией createDataPartition из пакета caret. При вызове функции задается процент данных, выделяемых в тренировочный набор.
> # Инициализация генератора случайных чисел для воспроизведения результатов
> set.seed(l)
> # По умолчанию числа возвращаются в виде списка. С параметром
> # List - FALSE генерируется матрица номеров строк.
> # Эти данные выделяются в тренировочный набор.
> trainingRows <- createDataPartition(сLasses,
+ р = .80,
+ List= FALSE)
> head(trainingRows)
Resamplel
[1,] 99
[2,] 100
[3,] 101
[4,] 102
[5,] 103
[6,] 104
> # Выделить подмножества данных в объекты для тренировки.
> trainPredictors <- predictors[trainingRows, ]
> trainCLasses <- cLasses[trainingRows]
> # Сделать то же самое для тестового набора с отрицательными числами.
> testPredictors <- predictors[-trainingRows, ]
> testCLasses <- cLasses[-trainingRows]
> str(trainPredictors)
110 Глава 4. Переобучение и настройка модели
’data.frame': 167 obs. of 2 variables:
$ PredictorA: num 0.226 0.262 0.52 0.577 0.426 ...
$ PredictorB: num 0.291 0.225 0.547 0.553 0.321 ...
> str(testPredictors)
'data.frame': 41 obs. of 2 variables:
$ PredictorA: num 0.0658 0.1056 0.2909 0.4129 0.0472 ...
$ PredictorB: num 0.1786 0.0801 0.3021 0.2869 0.0414 ...
Для генерирования тестового набора с использованием принципа максимального расхождения для последовательной выборки данных можно воспользоваться функцией maxdissim из пакета caret.
Повторная выборка
Пакет caret содержит различные функции для разделения данных. Например, для повторного разделения тренировочного/тестового набора можно еще раз воспользоваться функцией createDataPartition с дополнительным аргументом times для генерирования множественных вариантов разделения.
> set.seed(l)
> # Для примера будет сгенерирована информация, необходимая для трех
> # версий тренировочного набора, полученных при повторной выборке.
> repeatedSpLits <- createDataPartitionftrainCLasses, p = .80, times = 3)
> str(repeatedSpLits)
List of 3
$ Resamplel: int [1:135] 12345679 11 12 ...
$ Resample2: int [1:135] 4 6 7 8 9 10 11 12 13 14 ...
$ Resample3: int [1:135] 2 3 4 6 7 8 9 10 11 12 ...
В пакете caret имеются, кроме того, функции createResamples (для выборки с возвратом), createFolds (для ^-кратной перекрестной проверки) и createMultiFolds (для повторной перекрестной проверки). Чтобы создать индикаторы для десятикратной перекрестной проверки, выполните следующее:
> set.seed(l)
> cvSpLits <- createFoLds(trainCLasses, k = 10,
+
returnTrain = TRUE)
> str(cvSpLits)
List of 10
$ Fold01: int [1:151] 1 2 345678911...
$ Fold02: int [1:150] 1 2 3456891012..
$ Fold03: int [1:150] 1 2 34678101113.
$ Fold04: int [1:151] 1 2 345678910...
$ Fold05: int [1:150] 1 2 3457891011..
$ Fold06: int [1:150] 2 4 56789101112.
4.9. Вычисления 111
$ Fold07: int [1:150] 1 2 345678910..
$ Fold08: int [1:151] 1 2 345678910.. $ Fold09: int [1:150] 1 3 45679101112 $ Foldl0: int [1:150] 1 2 3567891011.
> # Получение первого набора номеров строк из списка.
> foLdl <- cvSpLits[[l]]
Чтобы получить первые 90% данных (первая свертка):
> cvPredictorsl <- trainPredictors[foLdl,]
> cvCLassesl <- trainCLasses[fotdl]
> nrow(trainPredictors)
[1] 167
> nrow(cvPredictorsl)
[1] 151
На практике функции, рассмотренные в следующем разделе, могут использоваться для автоматического создания наборов данных с повторной выборкой, для обучения модели и для оценки ее эффективности.
Базовый процесс построения модели в R
Итак, получены тренировочный и тестовый наборы данных, что позволяет применить модель классификации с пятью ближайшими соседями (рис. 4.3) к тренировочным данным и использовать ее для прогнозирования тестового набора. R предлагает несколько функций для построения таких моделей: функция knn из пакета MASS, функция ipredknn из пакета ipred, функция кппЗ из пакета caret. Функция кппЗ может генерировать прогнозы классов, а также пропорции соседей в каждом классе.
В R существуют две основные схемы задания моделей: интерфейс формул и «матричный» интерфейс. В первом случае предикторы перечисляются явно. Базовая формула R состоит из двух частей: в левой части указывается результат, а ее правая часть описывает, как используются предикторы. Обе части разделяются символом тильды (~). Например, следующая формула прогнозирует окончательную цену дома по трем количественным характеристикам:
> modelFunction(price ~ numBedrooms + numBaths + acres,
+ data = housingData)
Формула y~. означает, что в качестве предиктора должны использоваться все столбцы набора данных (за исключением у). В интерфейсе формул предусмотрено много удобных обозначений. Например, такие преобразования, как log(acres), могут задаваться во встроенном формате. К сожалению, информация в составе формул хранится в R недостаточно эффективно. Использование этого интерфейса с наборами данных, содержащими большое количество предикторов, может
112 Глава 4. Переобучение и настройка модели привести к излишнему замедлению вычислений. Матричный интерфейс задает предикторы для модели в формате матрицы или кадра данных (все предикторы в объекте используются в модели). Результат обычно передается модели в виде векторного объекта. Например:
> modelFunction(x = housePredictors, у = price)
Отметим, что не все функции R поддерживают оба интерфейса.
Оценить модель 5 ближайших соседей для кппЗ можно следующим образом:
> trainPredictors <- as.matrix(trainPredictors)
> knnFit <- knn3(x = trainPredictors, у = trainclasses, к = 5)
> knnFit
5-nearest neighbor classification model
Call:
knn3.matrix(x = trainPredictors, у = trainclasses, к = 5)
Training set class distribution:
Classi Class2
89 78
Теперь объект кппЗ готов к прогнозированию. Для добавления новых точек данных в классы используем метод predict с объектом модели. Стандартная схема выглядит так:
> testPredictions <- predict(knnFit, newdata = testPredictors,
+ type = "class”)
> head(testPredictions)
[1] Class2 Class2 Classi Classi Class2 Class2
Levels: Classi Class2
> str(testPredictions)
Factor w/ 2 levels "Classi","Class2": 2211222222 ...
Значение аргумента type меняется в зависимости от моделирующей функции.
Определение параметров настройки
Для выбора параметров настройки с использованием повторной выборки прово- дится вариативная оценка значений-кандидатов (с использованием нескольких выборок). Для анализа связи между эффективностью и значениями параметров обычно строится профиль: в R имеется несколько подходящих функций и пакетов. Пакет е1071 содержит функцию tune, позволяющую оценить четыре типа моделей по набору параметров. Функция errorest из пакета ipred может выполнять повторную выборку в отдельных моделях. Функция train в пакете caret содержит
4.9. Вычисления 113
подмодели для 144 моделей, поддерживает разные методы повторной выборки, значения эффективности и алгоритмы для выбора лучшей модели из профиля. Функция позволяет выполнять параллельную обработку моделей с повторной выборкой (на нескольких компьютерах или процессорах).
Остановимся подробнее на функции train.
В разделе 4.6 продемонстрирована настройка параметров для машины опорных векторов с использованием данных оценки кредитоспособности. Значение параметра стоимости оценивается с применением повторной выборки. Как показано в дальнейших главах, модель SVM характеризуется типом ядерной функции, используемой моделью. Например, линейная ядерная функция задает линейную связь между предикторами и результатом. Для данных оценки кредитоспособности в качестве ядерной функции использовалась радиальная базисная функция (RBF, Radial Basis Function). С этой ядерной функцией связывается дополнительный параметр настройки о, влияющий на гладкость принятия решений. Обычно при использовании повторной выборки оцениваются несколько комбинаций обоих параметров настройки. Тем не менее в работе Капуто (Caputo et al., 2002) описана аналитическая формула, которая может использоваться для получения разумных оценок а. Функция train из пакета caret использует этот метод для оценки ядерного параметра, оставляя для настройки только одно значение стоимости.
Чтобы настроить модель SVM с использованием тренировочного набора данных оценки кредитоспособности, можно воспользоваться функцией train. Предикторы тренировочного набора и результаты содержатся в кадре данных R с именем GermanCreditT rain.
> library(caret)
> data(GermanCredit)
Каталог chapters пакета AppliedPredictiveModeling содержит код создания тренировочного и тестового наборов. Эти наборы содержатся в кадрах данных GermanCreditTrain и GermanCreditTest соответственно. Для моделирования результата будут использоваться все предикторы. Для этого воспользуемся интерфейсом с формулой Class ~. Классы хранятся в столбце кадра данных с именем class. Простейший вызов функции будет выглядеть так:
> set.seed(1056)
> svmFit <- train(Class ~
> data = GermanCreditTrain,
> # Аргумент "method" обозначает тип модели.
> # Для получения списка доступных моделей см. ?train.
> method = "svmRadial")
Требуется адаптировать вычисления, переопределяя некоторые значения по умолчанию. Выполним предварительную обработку данных предикторов — центриро-
114 Глава 4. Переобучение и настройка модели
вание и масштабирование их значений. Для этого можно использовать аргумент preProc:
> set.seed(1056)
> svmFit <- train(Class ~
> data = GermanCreditTrain,
> method = "svmRadial",
> preProc = c("center", "scale”))
Для этой функции пользователь может задать и точные значения стоимости. Кроме того, функция содержит алгоритмы для определения оптимальных значений многих моделей. Посредством параметра tuneLength = 10 анализируются значения стоимости 2 2, 2 2... 27:
> set.seed(1056)
> svmFit <- train(Class ~
> data = GermanCreditTrain,
> method = "svmRadial",
> preProc = c("center", "scale"),
> tuneLength = 10)
По умолчанию для вычисления метрик эффективности используется базовая выборка с возвратом. Повторная десятикратная перекрестная проверка может быть задана функцией traincontrol. В этом случае итоговый синтаксис выглядит так:
sures. Repeated 10-fold cross-validation can be specified with the traincontrol function. The final syntax is then
> set.seed(1056)
> svmFit <- train(Class ~
> data = GermanCreditTrain,
> method = "svmRadial",
> preProc = c("center", "scale"),
> tuneLength = 10,
> trControl = trainControl(method = "repeatedcv",
>
>
> svmFit
repeats = 5, classProbs = TRUE))
800 samples
41 predictors
2 classes: 'Bad', 'Good'
Pre-processing: centered, scaled
Resampling: Cross-Validation (10-fold, repeated 5 times)
Summary of sample sizes: 720, 720, 720, 720, 720, 720, ...
4.9. Вычисления 115
Resampling results across tuning parameters:
с
0.25
Accuracy Карра
Accuracy SD Kappa SD
0.7
0
0
0
0.5
0.724
0.141
0.0218
0.0752
1
0.75
0.326
0.0385
0.106
2
0.75
0.363
0.0404
0.0984
4
0.754
0.39
0.0359
0.0857
8
0.738
0.361
0.0404
0.0887
16
0.738
0.361
0.0458
0.1
32
0.732
0.35
0.043
0.0928
64
0.732
0.352
0.0453
0.0961
128
0.731
0.349
0.0451
0.0936
Tuning
parameter
'sigma* was held
constant <
at a value of 0.0202 Accuracy was used to select the optimal model using the largest value. The final values used for the model wereC=4and sigma = 0.0202.
В исходном анализе использовалось другое значение инициализации генератора случайных чисел и набор значений стоимости, поэтому результаты отчасти не совпадают с приведенными в разделе 4.6. Итоговая модель, использовавшая метод «выбора лучшего варианта», соответствовала всем 800 точкам данных тренировочного набора со значением о, равным 0,0202, и значением стоимости, равным 4. Для построения наглядного представления профиля эффективности можно воспользоваться методом plot.
2a_2
2A0
2Л2 2Л4
Стоимость
2Л6
Рис. 4.12. Наглядное представление профиля средней эффективности модели классификации SVM, построенное методом plot для класса train
116 Глава 4. Переобучение и настройка модели
На рис. 4.12 показан пример визуализации, созданной для синтаксиса:
> # A Line pLot of the average performance
> pLot(svmFit, scaLes = List(x = List(Log =2)))
Для прогнозирования новых точек данных с моделью вызывается метод predict:
> predictedCLasses <- predict(svmFit, GermanCreditTest)
> str(predictedCLasses)
Factor w/ 2 levels "Bad"/’Good”: 1122122211...
> # Use the "type" option to get cLass probabiLities
> predictedProbs <- predict(svmFit, newdata = GermanCreditTest,
+ type = "prob")
> head(predictedProbs)
Bad Good
1 0.5351870 0.4648130
2 0.5084049 0.4915951
3 0.3377344 0.6622656
4 0.1092243 0.8907757
5 0.6024404 0.3975596
6 0.1339467 0.8660533
Есть и другие пакеты R, позволяющие оценить эффективность посредством повторной выборки. Функция validate из пакета Design и функция errorest из пакета ipred позволяют оценить эффективность модели с одним набором кандидатов для параметров настройки. Функция tune из пакета е1071 позволяет определять значения параметров с использованием повторной выборки.
Сравнение моделей
В разделе 4.6 модель SVM сравнивалась с моделью логистической регрессии. Хотя базовая логистическая регрессия не имеет параметров настройки, для характеристики эффективности модели допустимо воспользоваться повторной выборкой. Здесь вновь используется функция train, но с аргументом ”glm" (сокращение от «generalized linear model», то есть «обобщенная линейная модель»). При этом сохранена спецификация повторной выборки. Учитывая, что генератор случайных чисел инициализируется до моделирования, повторные выборки в точности совпадают с теми, которые используются в модели SVM.
> set.seed(1056)
> LogisticReg <- train(CLass ~
+ data - GermanCreditTrain,
+ method = "gLm",
+ trControL = trainControL(method = "repeatedcv",
+ repeats =5))
4.9. Вычисления 117
> LogisticReg
800 samples
41 predictors
2 classes: ’Bad’, ’Good’
No pre-processing
Resampling: Cross-Validation (10-fold, repeated 5 times)
Summary of sample sizes: 720, 720, 720, 720, 720, 720, ...
Resampling results
Accuracy Kappa Accuracy SD Kappa SD
0.749 0.365 0.0516 0.122
Для сравнения моделей на основании статистик перекрестной выборки воспользуемся функцией resamples с моделями, использующими общее множество наборов данных с повторной выборкой. Поскольку генератор случайных чисел был инициализирован до отработки модели SVM и логической модели, для каждого набора данных представлены парные значения точности. Сначала на базе моделей создается объект resamples:
> resamp <- re samp Les(List(SVM = svmFit, Logistic = LogisticReg))
> summary(resamp)
Call:
summary.resamples(object = resamp)
Models: SVM, Logistic
Number of resamples: 50
Accuracy
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
SVM 0.6500 0.7375 0.7500 0.754 0.7625 0.85 0
Logistic 0.6125 0.7250 0.7562 0.749 0.7844 0.85 0
Kappa
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
SVM 0.18920 0.3519 0.3902 0.3897 0.4252 0.5946 0
Logistic 0.07534 0.2831 0.3750 0.3648 0.4504 0.6250 0
Как видим, показатели распределения эффективности сходны. Столбец NA представляет возможные сбои моделей (обычно из-за вычислительных проблем) с повторной выборкой. Класс resamples содержит несколько методов визуализации парных значений (список типов диаграмм см. ?xyplot. resamples). Для оценки возможных различий между моделями используется метод dif f:
> modeLDifferences <- diff(resamp)
> summary(modeLDifferences)
Call:
summary.diff.resamples(object = modelDifferences)
118 Глава 4. Переобучение и настройка модели
p-value adjustment: bonferroni
Upper diagonal: estimates of the difference
Lower diagonal: p-value for H0: difference = 0
Accuracy
SVM Logistic
SVM 0.005
Logistic 0.5921
Kappa
SVM Logistic
SVM 0.02498
Logistic 0.2687
P-значения для сравнений модели велики (0,592 для точности и 0,269 для каппа- статистики). Вывод — модели не проявляют различий в эффективности.
Упражнения
4.1. Обратитесь к набору данных музыкальных жанров (раздел 1.4), где предикторы должны использоваться для классификации фрагментов по жанрам.
А. Какие методы разделения данных вы бы использовали? Объясните свой выбор.
Б. Используя инструменты, описанные в этой главе, приведите код реализации своего решения.
4.2. Рассмотрите набор данных проницаемости (раздел 1.4), где предикторы должны использоваться для моделирования проницаемости химических веществ.
А. Какие методы разделения данных вы бы использовали? Объясните свой выбор.
Б. Используя инструменты, описанные в этой главе, приведите код реализации своего решения.
4.3. Метод частных наименьших квадратов (раздел 6.3) использовался для моделирования результативности химического производства (раздел 1.4). Данные находятся в пакете AppliedPredictiveModeling, для их загрузки можно воспользоваться командами:
> Library(АррLiedPredictiveModeLing)
> data(ChemicaLManufacturingProcess)
Цель анализа — нахождение количества компонентов PLS, обеспечивающих оптимальное значение R2 (раздел 5.1). Модели PLS с количеством компонентов от 1 до 10 были оценены с пятью повторениями посредством десятикратной перекрестной проверки (табл. 4.2).
Упражнения 119
Таблица 4.2. Результаты оценки модели PLS
Повторная выборка R2
Компонента
Мат. ожидание
Стандартная погрешность
1
0,444
0,0272
2
0,500
0,0298
3
0,533
0,0302
4
0,545
0,0308
5
0,542
0,0322
6
0,537
0,0327
7
0,534
0,0333
8
0,534
0,0330
9
0,520
0,0326
10
0,507
0,0324
A. Какое количество компонентов PLS обеспечивает самую простую модель при использовании метода одной стандартной погрешности?
Б. Вычислите значение допуска для этого примера. Каким будет оптимальное количество компонентов PLS при потерях в R2 не более 10 %?
B. Были опробованы несколько других моделей (см. часть II) различной сложности (см. рис. 4.13). Какую модель(-и) вы бы выбрали для оптимизации R2 и почему?
Г. При выборе оптимальной модели(-ей) должно, кроме прочего, учитываться время прогнозирования и сложность модели (раздел 4.8). Какую модель(-и) вы бы выбрали с учетом времени прогнозирования каждой модели, ее сложности и оценок R2 и почему?
4.4. В работе Бродняка—Вонины (Brodnjak—Vonina et al., 2005) представлена методология определения типа масла в пробах для лабораторий продовольственных исследований с применением газового хроматографа (инструмента, выделяющего отдельные химические составляющие в образце) для измерения уровней семи жирных кислот в маслах. Результаты измерений используются для прогнозирования типа масла в пробах продуктов питания. Для создания модели использовались 96 образцов1 семи типов масел.
Вы найдете эти данные в пакете caret командой data (oil). Типы масел содержатся в факторной переменной с именем oilType: тыквенное (А), подсолнечное (В),
По утверждению авторов, в их распоряжении было 95 образцов известных масел. Однако мы насчитали 96 образцов в их таблице 1 (с. 33-35 оригинальной статьи).
120 Глава 4. Переобучение и настройка модели арахисовое (С), оливковое (D), соевое (Е), рапсовое (F) и кукурузное (G.) В R это выглядит так:
> data(oiL)
> str(oiLType)
Factor w/ 7 levels "A", "В", ”CV'D",..: 1111111111 ...
> tabLe(oiLType)
oilType
А В C D E F G
37 26 3 7 11 10 2
A. Используйте функцию sample из базового R для создания полностью случайной выборки проб 60 масел. Насколько близко частоты случайной выборки соответствуют частотам исходных выборок? Повторите эту процедуру несколько раз, чтобы понять разброс в процессе выборки.
Б. Используйте функцию createDataPartition из пакета caret для создания расслоенной случайной выборки. Как она выглядит на фоне полностью случайной выборки?
B. Какие варианты определения эффективности модели доступны при столь малом размере выборки? Следует ли использовать тестовый набор?
Г. Для понимания неопределенности тестового набора можно воспользоваться доверительным интервалом. Чтобы получить доверительный интервал для общей точности, воспользуйтесь функцией R binom.test. Для вычисления интервала требуется ввести количество точек данных и число правильно классифицированных точек. Например, зарезервирован тестовый набор из 20 проб масла, а 76 проб использованы для тренировки модели. Для этого размера тестового набора и модели, имеющей точность 80 % (16 правильных классификаций из 20), доверительный интервал будет вычисляться следующим образом:
> binom^testfiej 20)
Exact binomial test
data: 16 and 20
number of successes = 16, number of trials = 20, p-value = 0.01182 alternative hypothesis: true probability of success is not equal to 0.5 95 percent confidence interval:
0.563386 0.942666
sample estimates: probability of success
0.8
В данном случае ширина 95 %-го доверительного интервала составляет 37,9 %. Поэкспериментируйте с разными размерами выборки и степенями точности, чтобы понять суть компромиссов между неопределенностью результатов, эффективностью модели и размером тестового набора.
Часть II
РЕГРЕССИОННЫЕ МОДЕЛИ
Измерение эффективности регрессионных моделей
Оценка эффективности моделей, прогнозирующих числовой результат, обычно определяется с использованием определенных значений точности. Существует множество способов измерения точности, у каждого из которых есть свои нюансы. Для лучшего понимания плюсов и минусов конкретной модели не следует полагаться только на один показатель, характеризующий ее эффективность. Так, важная роль в определении пригодности модели для решения той или иной задачи отводится графикам. Соответствующие методы и будут рассмотрены в этой главе.
5.1. Количественные показатели эффективности
Если результат представляет собой число, то для оценки предиктивных возможностей модели вполне применим такой показатель, как среднеквадратичная погрешность (RMSE, Root Mean Squared Error), представляющая функцию остатков модели (разностей между наблюдаемыми значениями и предсказаниями модели). Для вычисления значения MSE (Mean Squared Error) остатки возводятся в квадрат, после чего суммируются и делятся на количество выборок. Чтобы получить среднеквадратичную погрешность, из MSE извлекается квадратный корень. Полученное значение обычно интерпретируется либо как среднее удаление остатков от нуля, либо как средняя разница между фактическими и прогнозируемыми значениями.
Другой часто применяемый показатель — коэффициент детерминации, обычно записываемый в виде Л2. Это значение может интерпретироваться как часть информации данных, объясняемая моделью. Так, значение 7?2, равное 0,75, указывает, что модель может объяснить три четверти дисперсии результатов. Существует ряд формул для вычисления этого показателя, например, из числа предложенных Квэлсетом (KvMseth, 1985), хотя простейшая версия находит коэффициент корре-
5.1. Количественные показатели эффективности 123
ляции между наблюдаемыми и прогнозируемыми значениями (который обычно обозначается R) и возводит его в квадрат.
Хотя эта статистика легко интерпретируется, следует помнить, что R2 является показателем корреляции, а не точности. На рис. 5.1 представлен пример, в котором метрика R2 между наблюдаемыми и прогнозируемыми значениями достаточно высока (51 %), но модель склонна завышать прогнозы для низких значений и занижать их для высоких. Этот феномен типичен для некоторых древовидных регрессионных моделей (см. главу 8). В зависимости от контекста это систематическое смещение в прогнозах может быть приемлемым, если в остальном модель работает удовлетворительно.
-10 -5 0
Наблюдаемое значение
Рис. 5.1. Диаграмма наблюдаемых и прогнозируемых результатов, где значение R2 является умеренным (51 %), но прогнозы не обладают однородной точностью. Пунктирная контрольная линия показывает, где наблюдаемые и прогнозируемые значения были бы равны
Важно понимать, что R2 зависит от разброса результатов. Следует также помнить, что знаменатель вычисляется с использованием дисперсии результата. Например, результат тестового набора имеет дисперсию 4,2. Если среднеквадратичная погрешность предиктивной модели равна единице, то значение R2 составит приблизительно 76 %. Если имеется другой тестовый набор с точно такой же среднеквадратичной погрешностью, но с менее разнообразными результатами, то оценка ухудшится: например, при значении дисперсии тестового набора, равном трем, R2 составит 67 %.
124 Глава 5. Измерение эффективности регрессионных моделей
С практической точки зрения такая зависимость от дисперсии заметно влияет на то, как следует рассматривать модель. Например, формируется модель для прогнозирования стоимости продажи домов с использованием таких предикторов, как характеристики дома (площадь, количество спален, количество туалетов), а также его размера и местонахождения. Если диапазон цен в тестовом наборе был широким (скажем, от 60 000 до $2 000 000), то и дисперсия цены продажи будет значительной. Так, для модели с 7?2, равным 90 %, среднеквадратичная погрешность составит десятки тысяч долларов, что неприемлемо для людей, продающих дома по цене, близкой к нижней границе стоимостного диапазона.
В некоторых случаях модель создается для ранжирования новых точек данных. Так, фармацевтам сначала приходится анализировать большое количество веществ (см. один из примеров раздела 1.4), после чего продолжать исследования только тех, что, согласно прогнозам, считаются наиболее биологически активными. Здесь основное внимание уделяется способности модели к ранжированию, а не ее предиктивной точности. В такой ситуации определение ранговой корреляции между наблюдаемыми и прогнозируемыми значениями может быть более подходящим оценочным показателем. Ранговая корреляция использует ранги наблюдаемых результатов (вместо их фактических значений) и оценивает, насколько они близки к рангам прогнозов модели. Для вычисления этого значения получаются ранги наблюдаемых и прогнозируемых результатов, между которыми вычисляется коэффициент корреляции. Этот показатель известен как ранговая корреляция Спирмена (Spearman’s rank correlation).
5.2. Обратное отношение между смещением и дисперсией
Значение MSE можно разложить на несколько составляющих. Формально значение MSE модели равно
где г/. — результат, а г/. — прогноз результата этой точки данных. Если предположить, что точки данных статистически независимы, а остатки имеют теоретическое среднее значение 0 и постоянную дисперсию о2, то
E[MSE] = ст2 + (Смещение модели)2 + Дисперсия модели,
(5.1)
где Е — ожидаемое значение.
Первая часть (о2) обычно называется «неснижаемым шумом» и не может быть устранена посредством моделирования. Второе слагаемое равно квадрату смещения
5.2. Обратное отношение между смещением и дисперсией 125
модели. Оно показывает, насколько близко функциональная форма модели может отражать фактическую зависимость между предикторами и результатом. Последнее слагаемое равно дисперсии модели. На рис. 5.2 изображены особые случаи моделей с высоким смещением или высокой дисперсией.
1,5
1,0
н 0,5 ш
5
5. о-0
со ф
-0,5
-1,0
-1,5
4 6 8 10
Предиктор
Рис. 5.2. Два варианта аппроксимации синусоиды. Горизонтальная линия прогнозирует данные по простому среднему значению первой и второй половины данных. Кривая вычисляется методом трехточечного скользящего среднего
Данные представляют смоделированную синусоиду. Аппроксимация модели, отмеченная горизонтальной чертой, делит данные пополам и прогнозирует каждую половину простым средним значением. Модель обладает низкой дисперсией, поскольку не подвержена существенным изменениям при генерировании другого набора точек данных тем же способом. Тем не менее она неэффективна для моделирования данных из-за своей упрощенности, и, как следствие, обладает высоким смещением. Кривая представляет трехточечное скользящее среднее. Если она обладает достаточной гибкостью для моделирования синусоиды (то есть низкого смещения), то даже незначительные колебания данных приведут к значительному изменению обучения модели. По этой причине модель обладает высокой дисперсией.
Как правило, более сложные модели могут иметь очень высокую дисперсию, что приводит к переобучению. С другой стороны, простые модели склонны не к переобучению, а к недообучению, не обеспечивая достаточной гибкости для моделирования. Предикторы с высокой корреляцией также могут приводить к проблемам коллинеарности, что чревато усилением дисперсии модели. Далее будут рассматриваться модели, которые могут повышать смещение для значительного сокращения дисперсии с целью преодоления проблемы коллинеарности, или разрешения так называемой дилеммы дисперсии. Это называется дилеммой смещения-дисперсии (variance-bias trade-off).
126 Глава 5. Измерение эффективности регрессионных моделей
5.3. Вычисления
Ниже упоминаются функции из пакета caret. Для вычисления эффективности модели наблюдаемые и прогнозируемые результаты должны храниться в векторах. Для применения регрессии векторы должны быть числовыми. Например, два вектора создаются вручную для демонстрации методологии (на практике вектор прогнозов будет создаваться функцией модели) следующим образом:
> # Функция ’с' используется для объединения чисел в вектор.
> observed <- с(0.22, 0.83, -0.12, 0.89, -0.23, -1.30, -0.15, -1.4,
+ 0.62, 0.99, -0.18, 0.32, 0.34, -0.30, 0.04, -0.87,
+ 0.55, -1.30, -1.15, 0.20)
> predicted <- с(0.24, 0.78, -0.66, 0.53, 0.70, -0.75, -0.41, -0.43,
+ 0.49, 0.79, -1.19, 0.06, 0.75, -0.07, 0.43, -0.42,
+ -0.25, -0.64, -1.26, -0.07)
> residuaLVaiues <- observed - predicted
> summary(residuaLVaiues)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.9700 -0.4200 0.0800 -0.0310 0.2625 1.0100
Для оценки качества модели важно наглядное представление результатов. Сначала диаграмма наблюдаемых и прогнозируемых значений помогает понять, насколько хорошо модель аппроксимирует данные. Диаграмма остатков и прогнозируемых значений помогает выявить систематические закономерности в прогнозах модели (см. рис. 5.1).
о
о
ю о’'
£ (О
о V Q. I с
ю о ■
о
-1,5 -1,0 -0,5 0,0 0,5 1,0
Наблюдаемые значения
-1,0 -0,5 0,0 0,5
Прогнозируемые значения
Рис. 5.3. Слева: наблюдаемые и прогнозируемые значения. Справа: остатки и прогнозируемые значения
5.3. Вычисления 127
Для построения диаграмм (рис. 5.3) использовались команды:
> # Наблюдаемые и прогнозируемые значения.
> # Желательно отображать значения на общей шкале масштаба.
> axisRange <- extendrange(c(observed, predicted))
> plot(observed, predicted,
+ ylim = axisRange,
+ xlim = axisRange)
> # Добавляем ориентировочную линию под углом 45 градусов.
> abline(0, 1, col = ’’darkgrey", lty = 2)
> # Прогнозируемые значения и остатки.
> plot(predicted, residualvalues, ylab = "residual")
> abline(h = 0, col = "darkgrey", lty = 2)
Пакет caret содержит функции для вычисления среднеквадратичной погрешности и значения R2:
> R2(predicted, observed)
[1] 0.5170123
> RMSE( predicted, observed)
[1] 0.5234883
Существуют разные формулы для R2; соответствующий обзор приведен у Квалсета (KvSlseth, 1985). По умолчанию функция R2 использует квадрат коэффициента корреляции. В базовый пакет R входит функция для вычисления корреляции, включая ранговую корреляцию Спирмена.
> # Простая корреляция
> cor(predicted, observed)
[1] 0.7190357
> # Ранговая корреляция
> cor(predicted, observed, method = "spearman")
[1] 0.7554552
Модели с признаками линейной регрессии
В этой главе рассматриваются некоторые модели, обладающие признаками линейной регрессии, то есть модели, которые могут быть выражены в следующем общем виде:
Vi = b0 + + Ьра + - + bPxiP + ер
(6.1)
где г/, представляет числовую реакцию на z-ю точку данных, bQ — оценку пересечения с осью, Ь} — оценку коэффициента дляу-го предиктора, х~ — значениеу-го предиктора для z-й точки, е. — случайную ошибку. Подобные модели линейны по своим параметрам. Кроме обычной линейной регрессии, к моделям этого же типа относятся модели частных наименьших квадратов (PLS) и так называемые штрафные модели: гребневая регрессия, лассо и эластичная сеть.
Каждая из этих моделей стремится найти оценки параметров, минимизирующие сумму квадратов погрешностей или функцию суммы квадратов погрешностей. Ранее, в разделе 5.2, показано, что значение MSE может быть разделено на составляющие: неустранимое искажение, смещение и дисперсию модели. Методы, представленные в этой главе, позволяют отыскивать оценки параметров, лежащие в диапазоне обратного отношения между смещением и дисперсией. На одном полюсе этого диапазона находится обычная линейная регрессия, выявляющая оценки параметров с минимальным смещением, а на противоположном — гребневая регрессия, лассо и эластичная сеть, выявляющие оценки с минимальной дисперсией (о влиянии обратного отношения на предиктивную способность моделей см. далее). Отличительная черта моделей, имеющих вид (6.1), — высокая интерпретируемость. Например, если оцененный коэффициент предиктора равен 2,5, то увеличение значения этого предиктора на 1 в среднем повысит реакцию на 2,5. Кроме того, оценки коэффициентов способствуют дальнейшей интерпретации связей между предикторами.
Другая отличительная черта — в том, что эти модели позволяют вычислять стандартные погрешности их коэффициентов (при условии некоторых допущений относительно распределения остатков модели). Стандартные погрешности могут
6.1. Практикум 129
использоваться для оценок статистической значимости каждого предиктора в составе модели. Это логическое представление может обеспечить лучшее понимание модели — при условии распределения ее остатков в пределах допустимого.
Линейно-регрессивные модели характеризуются высокой интерпретируемостью, но их применение оправданно, когда связь между предикторами и реакцией лежит в гиперплоскости. Например, если данные имеют только один предиктор, то использование модели уместно при условии, что между предиктором и реакцией усматривается прямая зависимость. При большем количестве предикторов связь должна проходить достаточно близко к гиперплоскости. Если же связь между предикторами и реакцией нелинейна (например, квадратичная, кубическая и т. д.), то модели линейной регрессии могут быть дополнены новыми предикторами, являющимися функциями исходных предикторов.
Стратегии применения дополнительных исходных предикторов подробнее рассматриваются ниже. Так или иначе, линейно-регрессивные модели не способны адекватно отразить нелинейные связи между предикторами и реакциями. Для этого более пригодны методы, описанные в главах 7 и 8.
6.1. Практикум: моделирование количественного соотношения «структура—активность»
Химические вещества, в том числе лекарства, могут обозначаться химическими формулами. Например, на рис. 6.1 изображена молекула аспирина, содержащая девять атомов углерода, восемь атомов водорода и четыре атома кислорода.
Рис. 6.1. Изображение молекулы аспирина, состоящей из атомов углерода (черные шарики), водорода (белые шарики) и кислорода (серые шарики). Химическая формула этой модели имеет вид o=C(OclccccclC(=0)0)C; из нее могут быть выведены молекулярные дескрипторы, например молекулярная масса 180,2 г/моль
130 Глава 6. Модели с признаками линейной регрессии
Конфигурация позволяет определить некоторые количественные значения — молекулярную массу, электрический заряд или площадь поверхности. Подобные значения именуются химическими дескрипторами, причем из химической формулы может быть выведено значительное число дескрипторов. Одни из них тривиальны (например, число атомов углерода), другие понятны только посвященным (например, сумма коэффициентов последнего собственного вектора из матрицы Бариша (Barysz), взвешенной по объему Ван-дер-Ваальса). Некоторые характеристики молекул невозможно определить аналитически по их химической структуре. Например, один из признаков вещества, имеющий неоспоримую ценность для практической медицины, — способность к подавлению выработки конкретного белка (то, что принято называть биологической активностью вещества). Связь между химической структурой и активностью может быть достаточно сложной и, как правило, выявляется эмпирически, посредством экспериментов. Один из способов основан на создании экспериментальных биологических проб, например белка. В биологическую пробу вводится набор химических веществ, после чего измеряется их активность (ее рост или снижение). На основании информации об активности генерируются данные, используемые далее как тренировочный набор для предиктивного моделирования активности веществ, которые, возможно, еще даже не существуют. Этот процесс называется моделированием количественного соотношения «структура—активность», или (ЛОДЯ-моделированием (Quantitative Structure—Activity Relationship). Отметим, что у Лича и Гилле (Leach and Gillet, 2003) дано обстоятельное введение в QSAR-моделирование и молекулярные дескрипторы.
Активность — важное качество, но для определения у вещества «сходства с лекарством», следуя Липински (Lipinski et al., 1997), необходимо оценить и другие его характеристики, включая такие физические качества, как растворимость или липофильность (то есть «сродство к жирам»), токсичность и т. д. Растворимость вещества чрезвычайно важна, если предполагается, что создаваемый препарат должен вводиться орально или посредством инъекций. Рассмотрим некоторые методы регрессионного моделирования, прогнозируя растворимость на основании структур химических веществ.
В работах Тетко (Tetko et al., 2001) и Хуусконена (Huuskonen, 2000) анализируется набор веществ с соответствующими экспериментальными значениями растворимости на основании сложных наборов дескрипторов. Для этого использовались модели линейной регрессии и нейросетей для оценки связей между химической структурой и растворимостью. В рассматриваемом примере используются 1267 веществ и набор дескрипторов, относящихся к одной из трех категорий:
О 208 бинарных признаков, обозначающих наличие или отсутствие конкретной химической субструктуры;
О 16 счетных дескрипторов (например, отражающих количество химических связей или атомов брома);
6.1. Практикум 131
О 4 непрерывных дескриптора (например, молекулярная масса или площадь поверхности).
Дескрипторы преимущественно не коррелированы, однако многие пары демонстрируют сильную положительную корреляцию: так, у 47 пар корреляция превышает 0,90. В некоторых случаях наличие корреляций между дескрипторами ожидаемо. Например, в данных растворимости площадь поверхности вещества вычисляется для областей, связанных с атомами азота или кислорода. Один дескриптор измеряет площадь поверхности, связанную с двумя конкретными элементами, другой использует, помимо названных элементов, еще два. С учетом полученных результатов следует ожидать, что два предиктора площади поверхности будут коррелированы, при этом для 87 % веществ дескрипторы идентичны. Небольшое различие между предикторами площади поверхности может содержать важную информацию для прогнозирования, но разработчик должен понимать, что избыточность в модели может иметь и отрицательные последствия. Еще одно важное качество предикторов растворимости — значительное смещение вправо у счетных дескрипторов, что также может повлиять на некоторые модели (см. главу 3).
Результаты измерялись по шкале log10 в диапазоне от -11,6 до 1,6 со средним логарифмическим значением растворимости -2,7. На рис. 6.2 показана связь между значениями растворимости, полученными экспериментальным путем, и двумя
типами дескрипторов из примера.
а
б
0
0
О) о
л
Б
2 -5
X
5
1 ’5
2
Б
S Б
£
£
-10
200
400 600
-10
Молекулярная масса
структура отсутствует
структура присутствует
Рис 6.2. Связь между растворимостью и двумя дескрипторами. Слева: с ростом молекулярной массы молекулы растворимость обычно снижается. Связь обычно имеет приближенно логарифмически-линейную природу, за исключением нескольких компонент с низкой растворимостью и большим весом и растворимостью в диапазоне от 0 до -5. Справа: для конкретного дескриптора бинарного признака при отсутствии в молекулах интересующей субструктуры наблюдается чуть более высокая растворимость
132 Глава 6. Модели с признаками линейной регрессии
Данные разделены методом случайной выборки на тренировочный набор (п = 951) и тестовый набор (п = 316). Тренировочный набор использован для настройки и оценки моделей, а также для определения исходных оценок эффективности с применением повторной десятикратной перекрестной проверки, тестовый набор — для окончательного описания моделей.
Для лучшего понимания характеристик данных тренировочный набор целесообразно исследовать до начала моделирования. Вспомним, что 208 предикторов обладают бинарными признаками. Поскольку эти переменные принимают только два значения, их предварительная обработка ничего существенного не даст.
Далее можно оценить подверженность непрерывных предикторов смещению. Среднее значение смещения — 1,6 (с минимумом 0,7 и максимумом 3,8), что указывает на склонность предикторов к смещению вправо. Для корректировки смещения ко всем предикторам применено преобразование Бокса—Кокса (то есть параметр преобразования по оценке не был близок к какому-либо из непрерывных предикторов). Но если мы используем преобразованные предикторы, то какова вероятность того, что связь между предикторами и результатом линейна? На рис. 6.3 показаны графики разброса предикторов относительно результата с линией регрессии из гибкой и сглаженной модели (по Кливленду — модель LOESS1 (Cleveland, 1979)).
Сглаженные линии регрессии указывают на наличие линейных связей между предикторами и результатом (например, молекулярной массой) и нелинейными связями (например, количеством точек начала или хлоринами). С учетом этого обстоятельства следует рассмотреть возможность дополнения набора предикторов квадратичными слагаемыми для некоторых переменных.
Существуют ли значимые корреляции между предикторами? В поисках ответа применим анализ главных компонент (РСА) к полному набору преобразованных предикторов, определив процент дисперсии, объясненный каждой компонентой. На рис. 6.4 представлен график, который называется графиком каменистой осыпи, отображающий покомпонентный профиль дисперсии.
Обратим внимание на то, что ни один компонент не объясняет более 13 % дисперсии. Профиль показывает, что структура данных содержится в гораздо меньшем количестве измерений исходного пространства, что обычно связано с большим числом коллинеарностей между предикторами. На рис. 6.5 показана структура корреляций между преобразованными непрерывными предикторами с отображением множества сильных положительных корреляций (обозначены большими темно-синими кругами).
Как упоминалось, это может затруднить формирование некоторых моделей (например, линейной регрессии), в связи с чем и требуется предварительная обработка.
1 LOESS — метод локальных полиномиальных регрессий (от англ. Local regressions). — При- меч. ред.
6.1. Практикум 133
Рис. 6.3. Диаграммы разброса преобразованных непрерывных предикторов в наборе данных растворимости. Красная линия обозначает сглаживающую функцию диаграммы
134 Глава 6. Модели с признаками линейной регрессии
Накапливаемый процент дисперсии
ю
5
0
0
50 100 150 200
Компоненты
Рис. 6.4. График каменистой осыпи для анализа РСА предикторов растворимости
0,8
0,6
0,4
0,2
о -0,2
-0,4
-0,6
-0,8 -1
Рис. 6.5. Корреляции между преобразованными непрерывными предикторами
растворимости
6.2. Линейная регрессия 135
6.2. Линейная регрессия
Целью линейной регрессии по методу наименьших квадратов является нахождение плоскости, минимизирующей сумму квадратов погрешностей (SSE) между наблюдаемой и прогнозируемой реакцией:
55Я = £(г/!.-р;)2,
1=1
где г/, — результат, а у. — прогноз результата для этой точки данных. Математически оптимальная плоскость описывается формулой
(Х'ХУХ'у, (6.2)
где X — матрица предикторов, а г/ — вектор реакции. Формула (6.2) встречается в работах по статистике под обозначением р; это — вектор, содержащий оценки параметров коэффициентов для каждого предиктора. Выражение (6.2) легко вычисляется, а его коэффициенты можно интерпретировать напрямую. Весьма вероятно, что оценки параметров, минимизирующие SSE, являются оценками с наименьшим смещением всех возможных оценок параметров по Грейбиллу (Graybill, 1976). Следовательно, эти оценки минимизируют составляющие смещения в обратном отношении между смещением и дисперсией.
Интерпретируемость коэффициентов превращает эту модель в весьма привлекательный инструмент моделирования. Но характеристики, обеспечивающие ее интерпретируемость, одновременно повышают уязвимость модели для неустранимых дефектов. Обратите внимание: в формулу (6.2) встроена составляющая (X7 X) 1, пропорциональная ковариационной матрице предикторов. Уникальная матрица, обратная исходной, существует, если, во-первых, ни один предиктор не может быть определен комбинацией других предикторов и, во-вторых, количество точек данных превышает количество предикторов. Если данные не удовлетворяют хотя бы одному из этих критериев, то уникальный набор коэффициентов регрессии не существует. Тем не менее для данных, нарушающих первое из вышеназванных условий, можно получить уникальный набор спрогнозированных значений — посредством замены (X7 X) 1 условной обратной матрицей (Graybill, 1976) либо удалением коллинеарных предикторов. По умолчанию, если при аппроксимации линейной модели в R между предикторами существует коллинеарность, то, согласно Фарауэю, «...R аппроксимирует наибольшую идентифицируемую модель, удаляя переменные в порядке, обратном порядку их следования в формуле модели» (Faraway, 2005). Следовательно, линейная регрессия применима для прогнозирования и в тех случаях, когда данным присуща коллинеарность. Но поскольку коэффициенты регрессии для определения этих прогнозов не уникальны, их осмысленная интерпретация едва ли возможна.
136 Глава 6. Модели с признаками линейной регрессии
Если второе из вышеназванных условий выполняется для набора данных, то можно попытаться построить регрессионную модель. Применение методов предварительной обработки (см. раздел 3.3) целесообразно для удаления попарно коррелированных предикторов, что приведет к сокращению их общего количества. Однако на этом этапе предварительной обработки коллинеарность неустранима полностью, поскольку один или несколько предикторов могут быть функциями двух (и более) других предикторов. Для диагностирования мультиколлинеарности в контексте линейной регрессии можно применить предложенный Майерсом фактор, увеличивающий дисперсию (Myers, 1994). Вычисления, выполняемые для каждого предиктора, представляют функцию корреляции между выбранным и всеми остальными предикторами.
Если и после предварительной обработки данных количество предикторов превышает количество наблюдений, то для сокращения размерности пространства предикторов выполняется предварительная обработка РСА (см. раздел 3.3) и сокращение размерности одновременно с регрессией средствами PLS или применяются методы, снижающие оценки параметров (гребневая регрессия, лассо или эластичная сеть).
Другой недостаток множественной линейной регрессии — линейность решения по всем параметрам. Это означает, что полученное решение локализуется в пределах уплощенного, однородного участка гиперплоскости. Если бы данные имели криволинейную или нелинейную структуру, то регрессия бы не смогла выявить эти характеристики. Чтобы понять, является ли связь между предикторами и реакцией нелинейной, применим анализ базовых диагностических диаграмм (см. рис. 5.3). Криволинейность на графике прогнозов и остатков — главный признак того, что исследуемая связь нелинейна. Квадратичные, кубические зависимости или взаимодействия между предикторами могут быть отражены в регрессии посредством добавления квадратичных либо кубических составляющих или взаимодействий между исходными предикторами. Но чем больше количество исходных предикторов, тем менее оправданно учитывать все или некоторые из этих составляющих. В результате может оказаться, что матрица данных содержит больше предикторов, чем наблюдений, из-за чего матрицу не удастся инвертировать.
Если между предиктором и реакцией существуют легко выявляемые нелинейные связи, то в матрицу дескрипторов могут быть добавлены соответствующие дополнительные предикторы. Если же идентифицировать эти связи невозможно или связи между предикторами и реакцией отличаются неординарно высокой нелинейностью, то отыскание требуемой структуры возможно посредством более сложных методов — например, из числа описанных в главе 7.
Третья существенная проблема множественной линейной регрессии — в том, что она склонна уделять слишком много внимания наблюдениям, выпадающим из общей тенденции, характерной для большинства данных. Напомним, что линей-
6.2. Линейная регрессия 137
ная регрессия стремится найти оценки параметров, минимизирующие SSE; таким образом, наблюдения, лежащие далеко от основного потока данных, будут иметь экспоненциально большие остатки. Чтобы минимизировать SSE, линейная регрессия скорректирует оценки параметров так, чтобы они лучше соответствовали этим аномальным наблюдениям. Наблюдения, вызывающие значимые изменения оценок параметров, называются влиятельными. Для преодоления вышеописанных проблем разработана теория устойчивой регрессии. Один из стандартных методов заключается в использовании вместо SSE альтернативного значения, менее чувствительного к большим выбросам, — например, через поиск оценок параметров, минимизирующих сумму абсолютных погрешностей (рис. 6.6).
о
-4 -2 0 2 4
Остатки
Рис. 6.6. Связь между остатками модели и ее вкладом в целевую функцию для нескольких методов. Для метода Губера был использован порог 2
Функция Губера использует квадраты остатков, когда они малы, а простую разность между наблюдаемыми и прогнозируемыми значениями — если остатки превышают заданный порог. Такой метод может эффективно минимизировать влияние наблюдений, заметно отклоняющихся от общей тенденции в данных.
138 Глава 6. Модели с признаками линейной регрессии
У множественной линейной регрессии нет параметров настройки. Впрочем, это не препятствует применению формальных методов проверки модели, особенно при использовании этой модели для прогнозирования. Так, методы тренировки и проверки, описанные в главе 4, могут быть пригодны для понимания предиктивной способности модели применительно к данным, с которыми она еще не взаимодействовала.
Вышеизложенное следует учесть при использовании методов повторной выборки (таких, как выборка с возвратом или перекрестная проверка). Например, для набора данных из 100 точек данных и 75 предикторов найти уникальный набор коэффициентов регрессии посредством повторной выборки, использующей 2/3 данных для тренировки, не удастся, потому что количество предикторов в тренировочном наборе будет превышать количество точек данных. Следовательно, при применении множественной линейной регрессии необходимо учитывать особенности ее работы как с исходным набором данных, так и с подмножествами данных, созданными в ходе тренировки и оценки модели.
Для демонстрации проблемы коррелированных предикторов была выполнена аппроксимация линейных моделей с комбинациями дескрипторов, имеющих отношение к количеству неводородных атомов и количеству неводородных связей. В тренировочном наборе эти предикторы обладают высокой корреляцией (0,994). На рис. 6.3 показана их связь с результатом — практически полная идентичность. Сначала выполнена аппроксимация двух разных регрессионных моделей с отдельными составляющими, а затем — третьей модели с обеими составляющими. Перед моделированием было выполнено центрирование и масштабирование предикторов. В табл. 6.1 приведены коэффициенты регрессии, а в круглых скобках — их стандартные погрешности.
Таблица 6.1. Коэффициенты регрессии двух предикторов с высокой корреляцией для четырех моделей
Модель
NumNonHAtoms
NumNonHBonds
Только NumNonH Atoms
-1,2 (0,1)
Только NumNonH Bonds
-1,2 (0,1)
Оба
-0,3 (0,5)
-0,9 (0,5)
Все предикторы
8,2 (1,4)
-9,1 (1,6)
Для отдельных моделей коэффициенты регрессии практически идентичны, как изображенные стандартные погрешности. Тем не менее при аппроксимации модели с обеими составляющими результаты оказались разными; наклон, обусловленный количеством неводородных атомов, значительно уменьшается. Значения погреш-
6.2. Линейная регрессия 139
ности, в зависимости от модели, могут различаться в пять раз, что подтверждает нестабильность линейной регрессии, обусловленную связями между предикторами и оказывающую влияние на прогнозы модели. В табл. 6.1 также приведены коэффициенты, учитывающие включение в модель всех дескрипторов. Обилие коллинеарных предикторов (см. рис. 6.5) приводит к усилению эффекта коллинеарности, из-за чего их значения сильно искажаются, а погрешность в 14-16 раз превышает стандартные погрешности отдельных моделей.
На практике проблему высокой корреляции предикторов можно решить исключением одного из предикторов-«нарушителей». Но при большем количестве предикторов, усилении их взаимовлияния задача усложняется, из-за чего удаление предикторов может оказаться невозможным. В этой связи имеет смысл обратиться к моделям, нивелирующим влияние коллинеарности.
Линейная регрессия для данных растворимости
Вспомним, что в разделе 6.1 при разделении данных растворимости на тренировочный и тестовый наборы для устранения смещения к непрерывным предикторам применено преобразование Бокса—Кокса. Следующий шаг процесса построения модели для линейной регрессии — выявление предикторов, обладающих высокой взаимной корреляцией, с последующим удалением части из них (во избежание превышения заданных уровней абсолютной взаимной корреляции).
В рассматриваемом ранее примере (см. раздел 3.3) решено удалить 38 предикторов, у которых взаимные корреляции превышают 0,9, с последующим обучением линейной модели по тренировочным данным1. В линейной модели применена повторная выборка с использованием десятикратной перекрестной проверки; оценка среднеквадратичной погрешности (RMSE) составила 0,71, а соответствующее значение R1 — 0,88.
Затем предикторы были удалены и из тестовых данных, после чего модель проверена по тестовому набору. Значение R1 между наблюдаемыми и прогнозируемыми значениями составило 0,87 (базовые диаграммы регрессии см. на рис. 6.7). В прогнозе не выявлено смещение; распределение между прогнозируемыми значениями и остатками подобно случайному разбросу со значением, близким к нулю.
1 На практике для достижения значительного влияния на коллинеарность, возможно, придется использовать более низкий порог. В имеющихся данных это также приведет к удалению важных переменных. Также следует проанализировать, как составляющие входят в модель. Например, могут присутствовать взаимодействия между предикторами, которые играют важную роль, а также нелинейные преобразования предикторов, способные улучшить модель. Эти операции более подробно рассматриваются в главе 19.
140 Глава 6. Модели с признаками линейной регрессии
3
2
1
-ю -8 -6 -4 -2 о
Прогнозируемые значения
О
-1
-2
-3
-10 -8 -6 -4 -2 0
Прогнозируемые значения
Рис. 6.7. Слева: наблюдаемые и прогнозируемые значения для тестового набора данных растворимости. Справа: остатки и прогнозируемые значения. Остатки разбросаны вокруг нуля в отношении прогнозируемых значений
6.3. Частные наименьшие квадраты
Как показывает пример с данными растворимости, для многих наборов данных предикторы могут быть коррелированными и содержать сходную предиктивную информацию. Если корреляция между предикторами высока, то обычный метод наименьших квадратов для множественной линейной регрессии вследствие высокого разброса окажется нестабильным.
Для других наборов данных количество предикторов может превышать количество наблюдений. В этом случае обычный метод наименьших квадратов не сможет найти уникальный набор коэффициентов регрессии, минимизирующий SSE. Варианты стандартных решений задачи регрессии в таких условиях предусматривают предварительную обработку предикторов либо посредством удаления предикторов с высокой корреляцией, либо посредством проведения РСА для предикторов (см. раздел 3.3). Удаление предикторов с высокой корреляцией гарантирует, что парные корреляции между предикторами лежат ниже заранее заданного порога. Перечисленное не гарантирует, что линейные комбинации предикторов не коррелированы с другими предикторами, из-за чего обычное решение наименьших квадратов все равно будет нестабильным. Не гарантирует стабильности решения наименьших квадратов и удаление парных предикторов с высокой корреляцией. Возможен еще один вариант: использование РСА для предварительной обработки, гарантирующей, что полученные предикторы или их комбинации не будут коррелированы. У РСА есть и оборотная сторона — новые предикторы являются линейными комбинациями исходных предикторов, что может затруднить понимание практической значимости новых предикторов.
6.3. Частные наименьшие квадраты 141
Предварительная обработка предикторов средствами РСА до применения регрессии у Мэсси называется регрессией главных компонент (PCR) (Massy, 1965); этот метод широко применялся в контексте проблем с изначально высокой корреляцией предикторов или задач, в которых количество предикторов превышало количество наблюдений. Хотя этот двухшаговый метод регрессии (сокращение размерности с последующей регрессией) успешно использовался для разработки предиктивных моделей в подобных условиях, он может привести и к неудаче. При сокращении размерности средствами РСА не обязательно создаются новые предикторы, объясняющие ответ. Рассмотрим данные с двумя предикторами и одной реакцией (рис. 6.8).
0,2
сч 0
X >
0,0
-1
-0.2
-2 -0,4
-1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 -2 -1 0 1 2
Х1 РСА1
Рис. 6.8. Пример регрессии главных компонент для простого набора данных с двумя предикторами и одной реакцией. Слева: диаграмма разброса двух предикторов показывает направление первой главной компоненты. Справа: первое направление РСА не содержит предиктивной информации для реакции
Два предиктора коррелированы, а РСА обобщает эту связь, используя направление максимальной дисперсии. Однако, судя по правой части изображения, первое направление РСА не содержит существенной предиктивной информации.
Как показывает этот пример, при выборе компонентов РСА не учитывает аспекты ответа, а лишь следует в направлении дисперсии, присутствующей в пространстве предикторов. Если эта дисперсия связана с дисперсией реакции, то PCR, скорее всего, сможет идентифицировать предиктивные связи. Если нет, то, вероятно, у PCR возникнут сложности с выявлением предиктивных связей там, где они могут существовать. Поскольку эта проблема изначально присуща PCR, мы рекомендуем применять PLS в тех случаях, когда между предикторами существует корреляция и требуется получить решение наподобие линейной регрессии.
142 Глава 6. Модели с признаками линейной регрессии
Метод PLS происходит от нелинейного итеративного метода частных наименьших квадратов (NIPALS) Уолда (Wold, 1966, 1982), приводящего к линейному виду модели, нелинейные по своим параметрам. В работе Уолда (Wold et al., 1983) метод NIPALS адаптирован для условий регрессии с коррелированными предикторами и получил название «метода частных наименьших квадратов», или PLS (Partial Least Squares). Алгоритм NIPALS итеративным методом выявляет скрытые связи между предикторами, имеющими высокую корреляцию с ответом. Для одномерной реакции каждая итерация алгоритма оценивает связь между предикторами (X) и реакцией (у), обобщая ее в числовом виде вектора весов (да), именуемым также направлением. Далее данные предикторов ортогонально проецируются на направление для генерирования рейтингов (0, используемых для генерирования нагрузок (р), оценивающих корреляцию вектора рейтингов с исходными предикторами. После каждой итерации предикторы и реакции «сокращаются» вычитанием текущей оценки предиктора и структуры реакции соответственно. Новый сокращенный предиктор и усеченная информация реакции используются для генерирования следующего набора весов, рейтингов и нагрузок. Эти величины последовательно сохраняются в матрицах W, Т и Р соответственно, а затем используются для прогнозирования новых точек данных и вычисления важности предикторов. Схема связей PLS между предикторами и реакцией — на рис. 6.9; обсуждение алгоритма приведено у Гелади и Ковальски (Geladi and Kowalski, 1986).
Рис. 6.9. Структура модели PLS. PLS находит компоненты, одновременно обобщающие дисперсию предикторов при сохранении оптимальной корреляции с результатом
6.3. Частные наименьшие квадраты 143
Чтобы лучше понять функцию алгоритма, Стоун и Брукс (Stone and Brooks, 1990) связали ее с хорошо известными статистическими концепциями ковариации и регрессии. В частности, Стоун и Брукс доказали, что метод PLS, как и РСА, находит линейные комбинации предикторов. Эти линейные комбинации обычно называются компонентами, или латентными переменными. Если линейные комбинации РСА выбираются для максимального обобщения вариативности пространства предикторов, то линейные комбинации предикторов в PLS выбираются для максимального обобщения ковариации с реакцией. Это означает, что метод PLS находит компоненты, максимально обобщающие дисперсию предикторов, одновременно требуя максимальной корреляции этих компонент с реакцией. Таким образом, PLS достигает компромисса между целями сокращения размерности пространства предикторов и предиктивной связи с реакцией. Другими словами, PLS может рассматриваться как контролируемая процедура сокращения размерности, тогда как PCR является процедурой неконтролируемой.
Чтобы лучше понять суть метода PLS и его взаимосвязь с PCR, еще раз обратимся к данным, представленным на рис. 6.8. Теперь нас интересует первая компонента PLS, сопоставляемая на левой диаграмме разброса (рис. 6.10) с первым направлением РСА.
-2
0,4
0,2
0,0
"0,2
-0,4
-1,5 -1,0 -0,5 0,0 0,5 1,0 1,5 -0,4 -0,2 0,0 0,2 0,4
Х1 PLS1
Рис. 6.10. Пример регрессии методом частных наименьших квадратов для простого набора данных с двумя предикторами и одной реакцией. Слева: первое направление PLS практически ортогонально первому направлению РСА. Справа'. в отличие от РСА, направление PLS содержит высокий уровень предиктивной информации для результата
В данном случае оба направления практически ортогональны, то есть оптимальное направление сокращения размерности не связано с максимальной дисперсией в пространстве предикторов. Вместо этого PLS идентифицирует оптимальное со-
144 Глава 6. Модели с признаками линейной регрессии кращение размерности пространства предикторов в контексте регрессии с реакцией. Этот пример призван подчеркнуть столь важный недостаток PCR. На практике PCR строит модели, сравнимые по предиктивной способности с PLS. Количество компонент, сохраненных при перекрестной проверке с использованием PCR, всегда одинаково.
До применения PLS с предикторами следует выполнить центрирование и масштабирование, особенно если предикторы измеряются по осям с разным масштабом. PLS ищет направления с максимальной дисперсией, одновременно учитывая корреляцию с результатом. Даже с учетом ограничения последней он будет более ориентирован на предикторы с большой дисперсией. Следовательно, предикторы должны пройти соответствующую предварительную обработку до применения PLS.
После этого можно приступать к моделированию ответа. У PLS есть только один параметр настройки: количество сохраняемых компонент. Для определения их оптимального количества могут использоваться методы повторной выборки (см. раздел 4.4).
Применение методов PCR и PLSR для прогнозирования данных растворимости
Чтобы продемонстрировать процесс построения модели с использованием PLS, вернемся к данным растворимости (см. раздел 6.1). Многие из 228 предикторов (см. рис. 6.4) обладают высокой корреляцией, а общая информация из пространства предикторов содержится в меньшем количестве измерений. Эти условия вполне подходят для применения PLS.
Перекрестная проверка служит для определения оптимального числа сохраняемых компонент PLS, минимизирующих среднеквадратичную погрешность. Одновременно применен метод PCR с использованием тех же наборов перекрестной проверки, что позволяет сравнить его эффективность с PLS. На рис. 6.11 показаны результаты: PLS находит минимальную среднеквадратичную погрешность (0,682) с 10 компонентами, a PCR находит минимальную среднеквадратичную погрешность (0,731) с 35 компонентами.
Таким образом, управляемое сокращение размерности находит минимальную среднеквадратичную погрешность с существенно меньшим числом компонент, чем неуправляемое сокращение. Использование правила одной стандартной погрешности (см. раздел 4.6) позволяет сократить количество необходимых компонент PLS до 8.
На рис. 6.12 сравниваются связи каждой из первых двух компонент PCR и компонент PLS с реакцией.
6.3. Частные наименьшие квадраты 145
л 2.0
§
и
о
10 20 30
Количество компонент
Рис- 6.11. Среднеквадратичная погрешность с перекрестной проверкой для PLS и PCR. Минимум достигается при 10 компонентах PLS и 35 компонентах PCR
Поскольку среднеквадратичная погрешность для каждой из первых двух компонент PLS ниже, чем у первых двух компонент PCR, неудивительно, что между компонентами существует корреляция, а реакция для PLS выше, чему у PCR.
Результат прогнозирования тестового набора с использованием оптимальных моделей PCR и PLS представлен на рис. 6.13.
Оба метода обладают хорошей предиктивной способностью, а остатки случайным образом распределены вокруг нуля. Несмотря на близость предиктивных способностей, метод PLS находит более простую модель с существенно меньшим числом компонент, чем у PCR. Коэффициенты регрессии PLS для данных растворимости представлены в табл. 6.2; их величины сходны со значениями модели линейной регрессии, включающей только эти два предиктора.
Латентные переменные из PLS строятся с использованием линейных комбинаций исходных предикторов, что усложняет оценку вклада каждого предиктора в модель. В работе Уолда (Wold et al., 1993) представлен эвристический подход к оценке важности переменных при использовании алгоритма NIPALS, а сами вычисления обозначены определением важности переменных в проекции (VIP). В наиболее простом случае связь между предикторами и реакцией может быть адекватно обобщена однокомпонентной моделью PLS. В этом случае важность j-го предиктора пропорциональна значению нормализованного вектора весов w, соответствующего у-му предиктору. Если связь между предикторами и реакцией требует более одной компоненты, то вычисление важности переменной усложняется. В этом случае
146 Глава 6. Модели с признаками линейной регрессии числитель важности у-го предиктора представляет собой взвешенную сумму нормализованных весов, соответствующиху-му предикторуу-й нормализованный вес £-го компонента wkj масштабируется по величине дисперсии реакции, объясняемой k-й компонентой. Знаменателем важности переменной является общая величина дисперсии результата, объясняемой всеми k компонентами. Следовательно, чем больше нормализованный вес и величина дисперсии реакции, объясняемой компонентой, тем большую важность имеет предиктор в модели PLS.
Показатели важности переменных частных наименьших квадратов для данных растворимости представлены на рис. 6.14.
-10 0 10
0
-5
£ -10 о о
S
S CL
§
о со CL
о
-5
-10
-10 0 10
Количество компонент
Рис. 6.12. Сравнение связей между первыми двумя компонентами PCR и PLS с реакцией растворимости. Поскольку сокращение размерности, обеспечиваемое PLS, контролируется реакцией, этот метод быстрее продвигается к нижележащей связи между предикторами и реакцией
6.3. Частные наименьшие квадраты 147
к О
х
X
П
3 -4
2
2
1
н
[В О
о
О
-1
-2
X
-10
-10 -8 -6 -4 -2 О
Прогнозируемые значения
-10 -8 -6 -4 -2 О
Прогнозируемые значения
-10 -8 -6 -4 -2 0
Прогнозируемые значения
3
2
1
н
g О
о
О
-1
-2
-3
-10 -8 -6 -4 -2 0
Прогнозируемые значения
Рис. 6.13. Слева: наблюдаемые и прогнозируемые значения для тестового набора данных растворимости для методов PCR {сверху) и PLS {внизу). Справа: остатки и прогнозируемые значения для PCR и PLS. Остатки случайным образом разбросаны вокруг нуля относительно прогнозируемых значений. Оба метода обладают сходной предиктивной способностью, но PLS использует гораздо меньшее количество компонент
Чем больше значение VIР, тем более важную роль играет предиктор в установлении связи структуры скрытых предикторов с реакцией, при этом сумма квадратов значений VIP равна общему количеству предикторов. Условимся, что значения VIP, превышающие единицу, содержат предиктивную информацию для реакции. Уолд (Wold, 1995) также полагает, что предикторы с малыми коэффициентами регрессии PLS и малыми значениями VIP в силу их небольшой значимости допустимо исключить из модели.
148 Глава б. Модели с признаками линейной регрессии
MolWelght NumCarbon NumNonHAtoms NumNonHBonds FP076 FP089 NumMultBonds NumBonds NumRIngs FP044 NumAtoms FP172 NumAromaticBonds FP112 FP014 FP065 FP013 HydrophilicFactor FP092 NumChlorine NumHalogen FP168 FP079 FP070 FP164
2,0 2,5
Важность
Рис. 6.14. Показатели важности переменных метода частных наименьших квадратов для данных растворимости
Алгоритмические разновидности PLS
Алгоритм NIPALS достаточно эффективен для наборов данных от малого до умеренного размера (у Эллина, например, < 2,500 точек данных и < 30 предикторов (Alin, 2009)). Однако при увеличении количества точек данных (п) и предикторов (Р) алгоритм становится малоэффективным, что обусловлено способом выполнения матричных операций с предикторами и реакцией: матрицы как предикторов, так и реакций должны быть сокращены (то есть из каждой матрицы должна быть вычтена информация, что приводит к созданию новых версий каждой матрицы) для каждой латентной переменной. Это означает, что для каждой итерации алгоритма должны храниться разные версии матрицы предикторов и ответа. Следовательно, при каждой итерации необходимо пересчитать, обработать и сохранить матрицу п х Р и вектор п х 1. С ростом п и F возрастают и требования к памяти, а операции с этими матрицами должны выполняться в итеративном процессе.
У Линдгрена (Lindgren et al., 1993) показано, что конструкции NIPALS могут быть получены посредством работы с «ядерной» матрицей размером Р* Р, ковариационной матрицей предикторов (также имеющей размер Р х Р), ковариационной матрицей предикторов и реакции (размер Р х 1), что стало достижением в вычислительном отношении. Изменение улучшило скорость работы алгоритма, особенно в случаях, когда количество наблюдений значительно пре-
6.3. Частные наименьшие квадраты 149
вышает количество предикторов. Примерно в то же время, когда был разработан «ядерный» метод, де Йонг (de Jong, 1993) усовершенствовал алгоритм NIPALS, для чего задача рассматривалась как поиск в пространстве предикторов латентных ортогональных переменных, максимизирующих ковариацию с реакцией. Так появился алгоритм, ориентированный на сокращение матрицы ковариации между предикторами и реакцией (в отличие от сокращения обеих матриц предикторов и реакции). Де Йонг (de Jong, 1993) назвал новый метод SIMPLS, как представляющий модификацию алгоритма PLS. Поскольку метод SIMPLS сокращает матрицу ковариации, на каждой итерации требуется сохранять только сокращенную матрицу ковариации размером Р * 1, и это значительное усовершенствование по сравнению с NIPALS. Хотя метод SIMPLS решает проблему оптимизации иным способом, для единичной реакции латентные переменные SIMPLS идентичны латентным переменным NIPALS (о возможностях моделирования многовариантной реакции см. ниже).
Вычислительные модификации алгоритма NIPALS посредством корректировки ядерного метода предложены и другими исследователями (de Jong and Тег Braak, 1994; Dayal and MacGregor, 1997). В последней работе представлены две эффективные (особенно при п » Р) модификации, по аналогии с SIMPLS требующие только сокращения матрицы ковариации между предикторами и реакцией на каждом шаге итеративного процесса. В первой модификации внутренних механизмов алгоритма в вычислениях использовалась полная исходная матрица предикторов, во второй — полная матрица ковариации предикторов.
Эйлин приводит подробное сравнение вычислительной эффективности NIPALS с эффективностью других алгоритмических модификаций, используя переменное количество точек данных (500-10 000), предикторов (10-30), реакций (1-15) и количество выводимых латентных переменных (3-10). При этом второй ядерный алгоритм Дайала и Макгрегора оказался эффективнее с вычислительной точки зрения, обеспечивая лучшую производительность при п > 2500 и Р > 30. В исключительных случаях, когда второй алгоритм все же не обеспечивал лучшей вычислительной эффективности, ее обеспечивал первый алгоритм.
Другие подходы к реализации PLS обладают очевидными вычислительными преимуществами перед исходным алгоритмом. Тем не менее с ростом количества предикторов их эффективность снижается. Для ситуаций с Р > п в работе Раннара (RMnnar et al., 1994) на основании матрицы предикторов и реакции строилось ядро размером п х п с последующим анализом PLS, в котором, помимо ядра, задействованы внешние векторные произведения предикторов и внешние произведения реакций (размером п х и). Отметим, что этот алгоритм обладает большей вычислительной эффективностью, если количество предикторов превышает количество точек данных.
Компоненты PLS (см. рис. 6.9) обобщают данные посредством линейных субструктур (гиперплоскостей) исходного пространства предикторов, связанных
150 Глава 6. Модели с признаками линейной регрессии с реакцией. Но для многих задач структура в пространстве предикторов, обладающая оптимальной связью с реакцией, может оказаться как криволинейной, так и нелинейной. Предпринимались попытки преодолеть этот недостаток PLS для выявления связей пространства предикторов с соответствующим откликом. Лучшие варианты представлены Берглундом и Уолдом (Berglund and Wold, 1997) и группой Берглунда (Berglund et al., 2001). Согласно выводам Берглунда и Уолда (Berglund and Wold, 1997), наряду с исходными предикторами могут применяться квадратичные и даже кубические предикторы. Затем к дополненному набору данных применяется PLS, при этом в добавлении перекрестных произведений нет необходимости, что ведет к существенному снижению числа новых предикторов. Позднее у Берглунда (Berglund et al., 2001) был использован описанный ранее Михаилидисом и де Лиувом метод GIFI (Michailidis and de Leeuw, 1998), согласно которому для каждого предиктора, предположительно имеющего нелинейную связь с реакцией, выполняется разделение данных на две группы и более. Точки отсечения выбираются пользователем и базируются на имеющейся информации или на характеристиках данных. Исходные предикторы, распределенные по группам, исключаются из набора данных, включающего распределенные версии предикторов. Затем к новому набору предикторов применяется метод PLS.
Оба метода успешно находили нелинейные связи между предикторами и реакцией. Однако построение наборов данных для ввода в PLS может потребовать значительных усилий, особенно при большом количестве предикторов. Как показано ниже, другие методы предиктивного моделирования позволяют выявлять нелинейность структур между предикторами и реакцией без необходимости изменения пространства предикторов. Следовательно, если между предикторами и реакцией существует более сложная связь, то целесообразно применить один из этих методов, отказавшись от попыток повысить эффективность PLS усовершенствованиями, подобными описанным выше.
6.4. Штрафные модели
В общем случае коэффициенты, созданные обычной регрессией наименьших квадратов, не смещены. Относящаяся к классу несмещенных линейных методов штрафная модель обладает наименьшей дисперсией. Однако если учесть, что значение MSE является комбинацией дисперсии и смещения (см. раздел 5.2), представляется весьма вероятным нахождение модели с меньшим значением MSE, если допустить некоторое смещение оценок параметров. Ограниченность смещения может более значительно снизить дисперсию и, следовательно, уменьшить значение MSE, чем при использовании коэффициентов регрессии, полученных методом обычных наименьших квадратов. Одно из следствий значительных корреляций между дисперсиями предикторов — существенное возрастание дисперсии. Преодоление коллинеарности посредством смещенных моделей может привести
6.4. Штрафные модели 151
к созданию регрессионных моделей с конкурентоспособными значениями общего показателя MSE.
Один из методов создания смещенных регрессионных моделей заключается в добавлении штрафа к сумме квадратичных погрешностей. Вспомним, что исходная регрессия методом наименьших квадратов находит оценки параметров, минимизирующие сумму квадратичных погрешностей (SSE):
= £(//,.-р,.)2.
i=l
При чрезмерном обучении модели или при возникновении проблем с коллинеарностью (см. табл. 6.1) оценки параметров линейной регрессии могут оказаться завышенными. Следовательно, нужно иметь возможность контролировать величину этих оценок для сокращения SSE. Управление оценками параметров (регуляризация) может осуществляться прибавлением штрафа к SSE при завышенных оценках. Гребневая регрессия по Хёрлу (Hoerl, 1970) добавляет штраф к сумме параметров квадратичной регрессии:
^=Z(.^-.V,)2+xfp2.
i=1 j=\
L2 означает, что к оценкам параметров применяется штраф второго порядка (то есть квадрат). Эффект штрафа заключается в том, что оценкам параметров разрешается принимать большие значения только при пропорциональном сокращении SSE. Фактически этот метод сжимает оценки к нулю, если штраф X становится большим (отсюда второе название рассматриваемого метода — метод сжатия).
Включение в модель штрафа допускает компромисс между дисперсией и смещением модели. Жертвуя некоторым смещением, представляется возможным сократить дисперсию, с тем чтобы общее значение MSE стало меньше, чем у несмещенных моделей.
Например, на рис. 6.15 показаны графики коэффициентов регрессии для данных растворимости при разных значениях X.
Каждая линия соответствует определенному параметру модели; перед проведением анализа предикторы прошли центрирование и масштабирование. При отсутствии штрафов многие параметры имеют приемлемые значения (как, например, выделенный оранжевым цветом предиктор количества множественных связей). Однако некоторые оценки параметров выглядят явно завышенными — например, количество неводородных атомов (зеленая линия) и количество неводородных связей (фиолетовая линия, см. табл. 6.1). Подобные значения типичны для ситуаций, характеризующихся наличием коллинеарности. С увеличением штрафа оценки параметров смещаются к нулю с разной скоростью. К тому моменту, когда штраф принимает значение X = 0,002, эти два предиктора заметно улучшаются, хотя другие значения коэффициента все еще представляются завышенными.
152 Глава 6. Модели с признаками линейной регрессии
0,000 0,002 0,004 0,006 0,008 0,010
Штраф
Рис. 6.15. Графики коэффициентов гребневой регрессии
Значение штрафа оптимизировано с использованием перекрестной проверки. На рис. 6.16 показано, как среднеквадратичная погрешность изменяется с X.
0,720
-D
h °’715
О g 0,710
(О к
| ™ 0,705
3 g 0,700
“ о-
© ®
0,695
ф
Q
0,690
0,00 0,02 0,04 0,06 0,08
Штраф
0,10
Рис. 6.16. Профили перекрестной проверки для модели гребневой регрессии
6.4. Штрафные модели 153
При отсутствии штрафа значение погрешности возрастает, при увеличении — уменьшается с 0,72 до 0,69. При превышении штрафом значения 0,036 смещение становится слишком большим, а в модели начинает проявляться недостаточность обучения, что приводит к возрастанию MSE.
Хотя гребневая регрессия направляет оценки параметров к нулю, модель не сокращает значения до абсолютного минимума при любых значениях штрафа. И хотя некоторые оценки параметров становятся пренебрежимо малыми, модель не осуществляет выбора признаков.
Популярной альтернативой гребневой регрессии является модель наименьшего абсолютного сжатия и оператора выбора, или модель «лассо» (lasso, сокращение от «least absolute shrinkage and selection operator» по Тибширани) (Tibshirani, 1996). Эта модель использует аналогичный штраф для гребневой регрессии:
*'=1 у=1
Изменение может показаться незначительным, но практические его следствия примечательны. При сохраняющемся стремлении коэффициентов регрессии к нулю введение штрафов для абсолютных значений обнуляет некоторые параметры при определенных значениях X. В результате формируются модели, которые одновременно применяют регуляризацию и для улучшения прогноза, и для выбора признаков. О сравнении двух типов штрафов в работе Фридмана (2010) читаем следующее:
«Известно, что гребневая регрессия сжимает коэффициенты коррелированных предикторов по направлению друг к другу, что позволяет им пользоваться взаимным потенциалом. В случае к идентичных предикторов они получают идентичные коэффициенты с l/k-й той величины, которая была бы назначена любому предиктору, если бы он уравнивался отдельно. <...>
С другой стороны, метод лассо отчасти безразличен к чрезмерно коррелированным предикторам; он склонен выбрать один и проигнорировать остальные».
На рис. 6.17 изображены графики коэффициентов лассо для разных значений штрафа.
По оси х откладывается относительная доля полного решения (то есть обычного метода наименьших квадратов без штрафа). Меньшие значения по оси х показывают, что используется большой штраф. При большом значении штрафа многим коэффициентам регрессии присваивается нулевое значение. С сокращением штрафа появляется много ненулевых коэффициентов. При анализе количества не водородных связей (фиолетовая линия) коэффициент изначально равен нулю, затем немного увеличивается, после чего снова стремится к нулю. Для значения
154 Глава 6. Модели с признаками линейной регрессии
10
>х
3 X X S а §
о.
2 и
-10
о
0,0 0,2 0,4 0,6 0,8 1,0
Относительная доля полного решения
Рис. 6.17. График коэффициентов модели лассо для данных растворимости. По оси х измеряется относительная доля решения методом полных квадратов. С возрастанием этой относительной доли штраф лассо (к) уменьшается около 0,4 этот предиктор вводится обратно в модель с ненулевым коэффициентом, который постоянно возрастает (скорее всего, из-за коллинеарности). В табл. 6.2 приведены коэффициенты регрессии для обычных наименьших квадратов, PLS, гребневой регрессии и модели лассо.
Штраф гребневой регрессии, использованной в этой таблице, равен 0,036, штраф лассо — 0,15. Модель гребневой регрессии значительно сжимает коэффициенты предикторов неводородных атомов и неводородных связей по направлению к нулю по сравнению с моделью обычных наименьших квадратов, тогда как модель лассо сжимает предиктор неводородных атомов до его устранения из модели. Модель лассо обладает наименьшей погрешностью перекрестной проверки 0,67 — немного лучше, чем у модели PLS (0,68) и гребневой регрессии (0,69).
Модель лассо была распространена и на иные методы, включая линейный дискриминантный анализ (Clemmensen et al., 2011; Witten and Tibshirani, 2011) и PLS (Chun and Kele§, 2010) и РСА (Jolliffe et al., 2003; Zou et al., 2004). Отметим также работу Эфрона (Efron et al., 2004), описывающую регрессию наименьшего угла (LARS, Least Angle Regression), которая представляет широкую инфраструктуру,
6.4. Штрафные модели 155
Таблица 6.2. Коэффициенты регрессии двух предикторов с высокой корреляцией для PLS, гребневой регрессии, эластичной сети и других моделей
Модель
NumNonHAtoms
NumNonHBonds
Только NumNonHAtoms
-1,2 (0,1)
Только NumNonH Bonds
-1,2 (0,1)
Обе
-0,3 (0,5)
-0,9 (0,5)
Все предикторы
8,2 (1,4)
-9,1 (1,6)
PLS, все предикторы
-0,4
-0,8
Гребневая регрессия, все предикторы
-0,3
-0,3
Лассо/эластичная сеть
0,0
-0,8
охватывающую модель лассо и другие похожие модели. Модель LARS может использоваться для обучения моделей лассо, и прежде всего в задачах высокой размерности. В работах Фридмана (Friedman et al., 2010) и Хестерберга (Hesterberg et al., 2008) приводится обзор соответствующих методов. Обобщением модели лассо является, по мнению Зу и Хэсти, эластичная сеть (Zou and Hastie, 2005). Эта модель объединяет два типа штрафов:
sse^
i=1 J=1 M
Штраф гребневой регрессии, используемый в табл. 6.2, равен 0,036, штраф модели лассо — 0,15. Модель PLS использует 10 компонентов.
Преимущество этой модели — в способности обеспечить эффективную регуляризацию через штраф гребневой регрессии с качеством выбора признаков штрафа модели лассо. Зу и Хэсти (Zou and Hastie, 2005) полагают, что эта модель будет более эффективно справляться с группами высококоррелированных предикторов. Оба штрафа требуют настройки для достижения оптимальной эффективности. Модель была настроена для данных растворимости с использованием повторной выборки. На рис. 6.18 показаны профили эффективности для трех значений гребневого штрафа и 20 значений штрафа лассо.
У нулевой модели лассо (с Xt= 0) наблюдается исходное падение погрешности с последующим ее увеличением до отметки 0,2 и выше. Две модели с ненулевыми значениями штрафа гребневой регрессии имеют минимальные ошибки. В итоге оптимальная эффективность обеспечена моделью лассо с относительной долей 0,15, что соответствует 130 предикторам из возможных 228.
156 Глава 6. Модели с признаками линейной регрессии
Снижение весов
0,2 0,4 0,6 0,8 1,0
Относительная доля полного решения
Рис. 6.18. Профили перекрестной проверки для модели эластичной сети
6.5. Вычисления
В этом разделе используются пакеты R: elasticnet, caret, lars, MASS, pls и stats. Данные растворимости можно взять из пакета R AppliedPredictiveModeling. Предикторы тренировочного и тестового наборов содержатся в кадрах данных solTrainX и solTestX соответственно. Для загрузки данных в R выполните следующие команды:
> library(AppliedPredictiveModeling)
> data(solubility)
> ## Объекты данных начинаются с "sol":
> Is(pattern = "AsolT")
[1] "solTestX" "solTestXtrans" "solTestY" "solTrainX"
[5] "solTrainXtrans" "solTrainY"
Каждый столбец данных соответствует предиктору (то есть химическому дескриптору), а строки — химическим веществам. Данные содержат 228 столбцов. Случайная выборка имен столбцов выглядит так:
> set.seed(2)
> sample(names(solTrainX), 8)
[1] "FP043" "FP160" "FP130" "FP038" "NumBonds"
[6] "NumNonHAtoms" "FP029" "FP185"
6.5. Вычисления 157
Столбцы «FP» соответствуют бинарным предикторам 0/1, которые отражают наличие или отсутствие конкретной химической структуры. Альтернативные версии этих данных, преобразованные по Боксу—Коксу, содержатся в кадрах данных solTrainXtrans и solTestXtrans. Эти модифицированные версии использованы при анализе в этой и предыдущей главах. Значения растворимости для каждого вещества содержатся в числовых векторах solTrainY и solTestY.
Обычная линейная регрессия
Основная функция для создания моделей линейной регрессии с использованием простого метода наименьших квадратов — 1т — дает формулу и кадр данных. Следовательно, предикторы тренировочного набора и результаты должны находиться в одном кадре данных. Для этого можно создать новый кадр данных:
> trainingData <- solTrainXtrans
> ## Добавление реакции для данных растворимости
> trainingData$Solubility <- solTrainY
Для аппроксимации линейной модели со всеми предикторами, входящими в модель как простые независимые линейные составляющие, воспользуемся сокращенной записью Solubility ~:
> LmFitALLPredictors <- Lm(SoLubiLity ~ data = trainingData)
Составляющая пересечения автоматически добавляется в модель. Метод summary выводит сводную статистику модели, оценки параметров, их стандартные погрешности и p-значения для проверки того, что каждый коэффициент отличен от нуля:
> summary(LmFitALLPredictors)
Call:
lm(formula = Solubility ~ data = trainingData)
Residuals:
Min IQ Median 3Q Max
-1.75620 -0.28304 0.01165 0.30030 1.54887
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
2.431e+00
2.162e+00
1.124
0.261303
FP001
3.594e-01
3.185e-01
1.128
0.259635
FP002
1.456e-01
2.637e-01
0.552
0.580960
FP003
-3.969e-02
1.314e-01
-0.302
0.762617
FP004
-3.049e-01
1.371e-01
-2.223
0.026520 *
FP005
2.837e+00
9.598e-01
2.956
0.003223 **
158 Глава 6. Модели с признаками линейной регрессии
FP006
-6.886e-02
2.041e-01
-0.337
0.735917
FP007
4.044e-02
1.152e-01
0.351
0.725643
FP008
1.121e-01
1.636e-01
0.685
0.493331
FP009
-8.242e-01
8.395e-01
-0.982
0.326536
MolWeight
-1.232e+00
2.296e-01
-5.365
1.09e-07
**♦
NumAtoms
-1.478e+01
3.473e+00
-4.257
2.35e-05
***
NumNonHAtoms
1.795e+01
3.166e+00
5.670
2.07e-08
**♦
NumBonds
9.843e+00
2.681e+00
3.671
0.000260
**♦
NumNonHBonds
-1.030e+01
1.793e+00
-5.746
1.35e-08
NumMultBonds
2.107e-01
1.754e-01
1.201
0.229990
NumRotBonds
-5.213e-01
1.334e-01
-3.908
0.000102
***
NumDblBonds
-7.492e-01
3.163e-01
-2.369
0.018111
*
NumAromaticBonds -
- 2.364e+00
6.232e-01
-3.794
0.000161
***
NumHydrogen
8.347e-01
1.880e-01
4.439
1.04e-05
***
NumCarbon
1.730e-02
3.763e-01
0.046
0.963335
NumNitrogen
6.125e+00
3.045e+00
2.011
0.044645
*
NumOxygen
2.389e+00
4.523e-01
5.283
1.69e-07
NumSulfer
-8.508e+00
3.619e+00
-2.351
0.018994
*
NumChlorine
-7.449e+00
1.989e+00
-3.744
0.000195
NumHalogen
1.408e+00
2.109e+00
0.668
0.504615
NumRings
1.276e+00
6.716e-01
1.901
0.057731
.
HydrophilicFactor
1.099e-02
1.137e-01
0.097
0.922998
SurfaceAreal
8.825e-02
6.058e-02
1.457
0.145643
SurfaceArea2
9.555e-02
5.615e-02
1.702
0.089208
•
Signif. codes: 0 '
***' 0.001
'*♦’ 0.01 ’
♦’ 0.05
0.1 ’
’ 1
Residual standard error: 0.5524 on 722 degrees of freedom
Multiple R-squared: 0.9446, Adjusted R-squared: 0.9271
F-statistic: 54.03 on 228 and 722 DF, p-value: < 2.2e-16
Модель содержит 229 предикторов, из-за чего полный вывод получается очень длинным, поэтому результаты были сокращены. Линейные модели в R более подробно рассматриваются у Фарауэя (2005).
Простые оценки среднеквадратичной погрешности и R2 равны 0,55 и 0,945 соответственно. Скорее всего, эти оценки являются завышенными, поскольку получены повторным прогнозированием данных тренировочного набора.
Для вычисления значений растворимости модели для новых точек данных используется метод predict:
> LmPredl <- predict(LmFitALLPredictorSj soLTestXtrans)
> head(LmPredl)
20 21 23 25 28 31
0.99370933 0.06834627 -0.69877632 0.84796356 -0.16578324 1.40815083
6.5. Вычисления 159
Наблюдаемые и прогнозируемые значения можно объединить в кадр данных, а затем воспользоваться функцией defaultsummary из пакета caret для оценки эффективности тестового набора:
> LmVaLuesl <- data.frame(obs = soLTestY, pred = LmPredl)
> defauLtSummary(LmVaLuesl)
RMSE Rsquared
0.7455802 0.8722236
На основании тестового набора можно сделать вывод, что сводные данные, произведенные функцией summary для 1т, были завышенными.
Для получения более устойчивой регрессионной модели можно воспользоваться функцией rim (Robust Line Model) из пакета MASS, которая по умолчанию применяет метод Хубера. По аналогии с функцией 1т функция rim вызывается следующим образом:
> rLmFitALLPredictors <- rLm(SoLubiLity ~ ., data = trainingData)
Функция train генерирует оценку эффективности с повторной выборкой. Поскольку размер тренировочного набора достаточно велик, десятикратная перекрестная проверка должна обеспечить приемлемую оценку эффективности модели. Функция traincontrol задает тип повторной выборки:
> Ctrl <- trainControL(method = "cv", number = 10)
Функция train получает формулу модели (о способах задания моделей см. раздел 4.9) или использует матричный интерфейс:
> set.seed(100)
> LmFitl <- train(x = soLTrainXtrans, у - soLTrainY,
+ method = "Lm", trControL = ctrL)
Генератор случайных чисел инициализируется перед моделированием, чтобы результаты можно было воспроизвести. Результаты выглядят так:
> LmFitl
951 samples
228 predictors
No pre-processing
Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 856, 857, 855, 856, 856, 855, ...
Resampling results
RMSE Rsquared RMSE SD Rsquared SD
0.721 0.877 0.07 0.0247
160 Глава 6. Модели с признаками линейной регрессии
Для моделей, построенных для объяснения, важно проверять, например, распределение остатков. Для предиктивных моделей некоторые рассмотренные диагностические методы могут пролить свет на те области, в которых модель посредственно справляется с прогнозированием. Например, можно построить сравнительную диаграмму остатков и прогнозируемых значений для модели. Если диаграмма выглядит как случайное облако точек, то весьма вероятно, что в модели учтены главные составляющие или значительные выбросы.
Важно и сравнение прогнозируемых значений с наблюдаемыми для оценки того, насколько прогнозы близки к фактическим значениям. Для этого используются два метода (применены данные из тренировочного набора):
> xypLot(soLTrainY ~ predict (LmFitl),,
+ ## Отображение точек (type = ’р') и фоновой сетки (’д')
+ type = с("р", "д"),
+ xLab = "Predicted", yLab = "Observed")
> xypLot(resid(LmFitl) ~ predict(LmFitl),
+ type = c("p", "g"),
+ xLab = "Predicted", yLab = "ResiduaLs")
Результаты показаны на рис. 6.19.
Функция resid генерирует остатки модели для тренировочного набора; функция predict без дополнительного аргумента данных возвращает спрогнозированные значения для тренировочного набора. На диагностических графиках модели не
1
5
го
6
О
О
-10 -5 О
Прогнозируемые значения
-10 -5 0
Прогнозируемые значения
Рис. 6.19. Диагностические диаграммы для линейной модели с использованием тренировочного набора. Слева: наблюдаемые и прогнозируемые значения. На этой диаграмме можно обнаружить выбросы или те области, в которых модель не откалибрована. Справа: остатки и прогнозируемые значения. Если модель была хорошо выбрана, на диаграмме должно отображаться случайное облако точек без явных выбросов и закономерностей (например, «воронки»)
6.5. Вычисления 161
отмечено явных тревожных признаков. Для построения уменьшенной модели без предикторов с предельно высокими корреляциями подходят методы из раздела 3.3, позволяющие сократить количество предикторов, с тем чтобы в модели не оставалось абсолютных парных корреляций выше 0,9:
> corThresh <- .9
> tooHigh <- findCorreLation(cor(soLTrainXtrans), corThresh)
> corrPred <- names(soLTrainXtrans)[tooHigh]
> trainXfiLtered <- soLTrainXtrans[, -tooHigh]
> testXfiLtered <- soLTestXtrans[, -tooHigh]
> set,seed(100)
> LmFiLtered <- trainftestXfiLtered, soLTrainY, method = "Lm",
+ trControL = ctrL)
> LmFiLtered
951 samples
228 predictors
No pre-processing
Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 856, 857, 855, 856, 856, 855, ...
Resampling results
RMSE Rsquared RMSE SD Rsquared SD
0.721 0.877 0.07 0.0247
Устойчивая линейная регрессия также может выполняться функцией train (в сочетании с функцией rim). Подчеркнем, что функция rim не допускает использования вырожденной матрицы ковариации (в отличие от функции 1т). Во избежание вырожденности предикторов выполним их предварительную РСА-обработку. Посредством отфильтрованного набора предикторов определим следующую эффективность модели устойчивой регрессии:
> set.seed(100)
> rLmPCA <- train(soLTrainXtrans, soLTrainY,
+ method = "rLm",
* preProcess = "pea",
+ trControL = ctrL)
> rLmPCA
951 samples
228 predictors
Pre-processing: principal component signal extraction, scaled, centered Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 856, 857, 855, 856, 856, 855, ...
Resampling results
RMSE Rsquared RMSE SD Rsquared SD
0.782 0.854 0.0372 0.0169
162 Глава 6. Модели с признаками линейной регрессии
Частные наименьшие квадраты
Пакет pls, по Мевику и Беренсу (Mevik and Wehrens, 2007), содержит функции для PLS и PCR. Доступен как SIMPLS, первый алгоритм Дайала и Макгрегора, так и алгоритм, разработанный Раннаром (Rannar et al., 1994). По умолчанию пакет pls использует первый ядерный алгоритм Дайала и Макгрегора, тогда как другие алгоритмы могут задаваться аргументом method со значениями "oscorespls", "simpls" или "widekernelpls”. Функция plsr, как и функция 1т, требует передачи формулы модели:
> pisFit <- pLsr(SoLubiLity ~ data = trainingData)
Количество компонент фиксируется аргументом ncomp (при присвоении последнему значения по умолчанию будет вычислено максимальное количество компонент). Прогнозы для новых точек данных могут вычисляться функцией predict (при задании конкретных значений количества компонент или для нескольких их значений одновременно). Пример:
> predict(pLsFit, soLTestXtrans[l:5, ], ncomp - 1:2)
, , 1 comps
Solubility
20 -1.789335
21 -1.427551
23 -2.268798
25 -2.269782
28 -1.867960
, j 2 comps
Solubility
20 0.2520469
21 0.3555028
23 -1.8795338
25 -0.6848584
28 -1.5531552
Функция plsr поддерживает параметры для ^-кратной перекрестной проверки или перекрестной проверки с исключением (аргумент validation) или алгоритма PLS — например, SIMPLS (аргумент method).
Существуют вспомогательные функции для извлечения компонент PLS (в функции loadings), рейтингов PLS (scores) и других величин. Функция plot позволяет визуально оценить различные аспекты модели. Функция train также может использоваться со значениями method="pls", такими как "oscorespls", "simpls" или "widekernelpls". Пример:
6.5. Вычисления 163
> set.seed(100)
> pLsTune <- train(soLTrainXtrans, soLTrainY,
+ method = "pLs",
+ ## The defauLt tuning grid evaLuates
+ ## components 1... tuneLength
* tuneLength = 20,
+ trControL = ctrL,
+ preProc = c( "center", "scaLe"))
Этот код воспроизводит модель PLS (см. рис. 6.11).
Штрафные регрессионные модели
Модели гребневой регрессии могут создаваться функцией lm. ridge (пакет MASS) или функцией enet (пакет elasticnet). При вызове функции enet аргумент lambda определяет штраф гребневой регрессии:
> ridgeModeL <- enetfx = as.matrix(soLTrainXtrans), у = soLTrainY,
* Lambda = 0.001)
Вспомним, что в модели эластичной сети назначаются штрафы как для гребневой регрессии, так и для лассо, а объект R ridgeModel фиксирует только значение гребневого штрафа. Штраф лассо может эффективно вычисляться для многих значений. Функция predict для объектов enet генерирует прогнозы для одного или нескольких значений штрафа лассо при помощи аргументов s и mode. Для гребневой регрессии необходим только один штраф лассо, равный нулю, а значит, нужно полное решение, для получения которого методом гребневой регрессии определим s=l с mode = "fraction". Последний параметр указывает, каким образом определяется величина штрафа; в данном случае значение 1 соответствует относительной доле 1, то есть полному решению:
> ridgePred <- predict(ridgeModeL, пемх = as.matrix(soLTestXtrans),
+ s = 1, mode = "fraction",
+ type = "fit")
> head(ridgePred$fit)
20 21 23 25 28 31
0.96795590 0.06918538 -0.54365077 0.96072014 -0.03594693 1.59284535
Для настройки штрафа можно воспользоваться вызовом train иначе:
> ## Определение набора значений-кандидатов.
> ridgeGrid <- data.frame(.Lambda = seq(0, .1, Length = 15))
> set.seed(100)
> ridgeRegFit <- train(soLTrainXtrans, soLTrainY,
164 Глава б. Модели с признаками линейной регрессии
+ +
+
■#>
method = "ridge",
## Обучение модели no разным значениям штрафа tuneOrid = ridgeOrid, trControL - Ctrl,
## Приведение предикторов к единой шкале preProc = с("center", "scale"))
> ridgeRegFit 951 samples 228 predictors
Pre-processing: centered, scaled Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 856, 857, 855, 856, 856, 855, ...
Resampling results across tuning parameters:
lambda
RMSE
Rsquared
RMSE SD
Rsquared
0
0.721
0.877
0.0699
0.0245
0.00714
0.705
0.882
0.045
0.0199
0.0143
0.696
0.885
0.0405
0.0187
0.0214
0.693
0.886
0.0378
0.018
0.0286
0.691
0.887
0.0359
0.0175
0.0357
0.69
0.887
0.0346
0.0171
0.0429
0.691
0.888
0.0336
0.0168
0.05
0.692
0.888
0.0329
0.0166
0.0571
0.693
0.887
0.0323
0.0164
0.0643
0.695
0.887
0.032
0.0162
0.0714
0.698
0.887
0.0319
0.016
0.0786
0.7
0.887
0.0318
0.0159
0.0857
0.703
0.886
0.0318
0.0158
0.0929
0.706
0.886
0.032
0.0157
0.1
0.709
0.885
0.0321
0.0156
RMSE was used to select the optimal model using the smallest value. The final value used for the model was lambda = 0.0357.
Модель лассо может оцениваться при помощи нескольких функций со сходным синтаксисом. Пакет lars содержит одноименную функцию lars, в пакете elasticnet присутствует функция enet, а в пакете glmnet — одноименная функция glmnet. Пример использования функции enet:
> enetModel <- enet(x = as.matrix(solTrainXtrans), у = solTrainY,
+ lambda = 0.01, normalize = TRUE)
Данные предикторов должны храниться в объекте матрицы, поэтому кадр данных solTrainXtrans должен быть преобразован для функции enet. До моделирования необходимо выполнить центрирование и масштабирование предикторов (в том
6.5. Вычисления 165
числе автоматически — посредством аргумента normalize). Параметр lambda управляет штрафом гребневой регрессии. При присвоении ему нулевого значения параметр выполняет обучение модели лассо. Штраф лассо не обязательно задавать до момента прогнозирования:
> enetPred <- predict(enetModeL, newx = as .matrix(soLTestXtrans),
+ s = .1, mode = "fraction",
+ type = "fit")
> ## Возвращается список из нескольких элементов:
> names(enetPred)
[1] "s" ’’fraction” "mode" "fit"
> ## Предиктивные значения для компоненты 'fit':
> head(enetPredffit)
20 21 23 25 28 31
-0.60186178 -0.42226814 -1.20465564 -1.23652963 -1.25023517 -0.05587631
Чтобы определить, какие предикторы используются в модели, метод predict используется с аргументом type = "coefficients”:
> enetCoef<- predict(enetModeL, newx = as.matrix(soLTestXtrans), + s = .1, mode = "fraction",
+ type = "coefficients")
> taiL(enetCoeffcoefficients)
NumChlorine
0.00000000
SurfaceAreal
NumHalogen
0.00000000
SurfaceArea2
NumRings HydrophilicFactor
0.00000000 0.12678967
0.09035596
0.00000000
Использование сразу нескольких значений s в функции predict позволяет сгенерировать одновременно прогнозы для двух и более моделей.
Для обучения модели лассо или ее альтернативной версии могут использоваться пакеты biglars (для больших наборов данных), FLLat (для объединенной модели лассо), grplasso (для групповой модели лассо), penalized, relaxo (для ослабленной модели лассо) и др. Для настройки модели эластичной сети с использованием train следует задать аргумент method="enet ”.
В следующем примере модель настраивается для специализированного набора штрафов:
> enetGrid <- expand,grid(.Lambda = c(0, 0.01, .1),
+ .fraction = seq(.05, 1, Length = 20))
> set.seed(100)
> enetTune <- train(soLTrainXtrans, soLTrainY,
+ method = "enet",
+ tuneGrid = enetGrid,
+ trControL = ctrL,
+ preProc = c("center", "scaLe"))
166 Глава 6. Модели с признаками линейной регрессии
Диаграмма, представленная на рис. 6.18, может быть создана на основе этого объекта посредством plot(enetTune).
Упражнения
6.1. Технология инфракрасной (IR) спектроскопии используется для определения химического состава вещества. Согласно теории инфракрасной спектроскопии, уникальные молекулярные структуры поглощают инфракрасные частоты по-разному. На практике спектрометр излучает на образец материала пучок инфракрасных частот, а устройство измеряет поглощательную способность образца для каждой отдельной частоты. На основании измерений строится профиль спектра, который затем используется для определения химического состава образца материала. Прибор Tecator Infratec Food and Feed Analyzer использовался для анализа 215 образцов мяса по 100 частотам (рис. 6.20).
5,0
4,5
Рис. 6.20. Десять спектров данных Tecator. Цвета кривых отражают величины поглощения: желтый — низкое поглощение, красный — высокое поглощение
Кроме инфракрасного профиля, для каждого образца определялось процентное содержимое воды, жира и белка. Если удастся установить предиктивную связь между инфракрасным спектром и содержанием жира, то специалисты по продуктам питания смогут прогнозировать содержание жира в образце на основании данных инфракрасной спектроскопии, не прибегая к инструментам аналитической химии.
Упражнения 167
Такой подход обещает известную экономию, поскольку аналитическая химия является более дорогостоящим и длительным процессом.
Запустите R и введите следующие команды для загрузки данных:
> Library(caret)
> data(tecator)
> # Для получения дополнительной информации см. ?tecator
Матрица absorp содержит 100 значений для 215 образцов, а матрица endpoints — данные о содержании воды, жира и белков (столбцы 1-3 соответственно).
A. В этом примере предикторами являются результаты измерений для конкретных частот, следующих в систематическом порядке (850-1,050 нм), что обусловливает высокую степень корреляции предикторов. Данные располагаются в пространстве, размерность которого меньше общего количества предикторов (100). Используйте РСА для определения фактической размерности этих данных. Чему равна фактическая размерность?
Б. Разделите данные на тренировочный и тестовый набор, проведите предварительную обработку данных и постройте модели каждого вида, описанные в этой главе. Какими будут оптимальные значения параметров настройки для моделей, которым присущи эти параметры?
B. Какая модель обладает наилучшей предиктивной способностью? Можно ли сказать, что какая-либо модель значительно лучше или хуже других?
Г. Объясните, какую модель вы предпочтете для прогнозирования содержания жира в образце.
6.2. Разработка модели для прогнозирования проницаемости (см. раздел 1.4) позволит фармацевтическим компаниям сэкономить значительные средства, одновременно ускоряя идентификацию молекул, обладающих достаточной проницаемостью для использования в качестве лекарства.
Запустите R и введите следующие команды для загрузки данных:
> Library(АррLiedPredictiveModeLing)
> data(permeabiLity)
Матрица fingerprints содержит 1107 бинарных молекулярных предикторов для 165 веществ, матрица permeability — данные реакции, то есть проницаемости.
А. Бинарные предикторы обозначают присутствие или отсутствие субструктур молекулы; часто они оказываются разреженными, то есть каждая субструктура присутствует в относительно малом количестве молекул. Отфильтруйте предикторы с низкими частотами при помощи функции nearZeroVar из пакета caret. Сколько предикторов остается для моделирования?
168 Глава 6. Модели с признаками линейной регрессии
Б. Разделите данные на тренировочный и тестовый набор, проведите предварительную обработку данных и настройте модель PLS. Какое количество латентных переменных будет оптимальным, чему равна соответствующая оценка R2 при повторной выборке?
В. Спрогнозируйте реакцию для тестового набора. Чему равна оценка R2 для тестового набора?
Г. Попробуйте построить другие модели, описанные в этой главе. Обладает ли какая-либо модель лучшей предиктивной эффективностью?
Д. Порекомендуете ли вы какую-либо из своих моделей для замены лабораторного эксперимента по измерению проницаемости?
6.3. Процесс производства химикатов для фармацевтического продукта рассматривался в разделе 1.4. В этой задаче требуется понять связь между биологическими метриками сырья (предикторами) и реакцией (выходом продукта). Биологические предикторы невозможно изменить, но они могут использоваться для оценки качества сырья перед обработкой. С другой стороны, предикторы производственного процесса могут быть изменены в процессе производства. Улучшение выхода продукта на 1 % увеличивает прибыль приблизительно на 100 000 долларов США на пакет.
Запустите R и введите следующие команды для загрузки данных:
> Library(AppLiedPredictiveModeLing)
> data(chemicaLManufacturingProcess)
Матрица processPredictors содержит 57 предикторов (12 из них описывают входной биологический материал, остальные 45 — предикторы процесса) для 176 производственных серий, yield содержит выход (в процентах) для каждой серии.
A. Небольшой процент ячеек в наборе предикторов содержит отсутствующие значения. Используйте функцию подстановки для заполнения отсутствующих значений (см. в этой связи раздел 3.8).
Б. Разделите данные на тренировочный и тестовый наборы, проведите предварительную обработку данных и настройте выбранную вами модель из этой главы посредством PLS. Каким будет оптимальное значение эффективности?
B. Спрогнозируйте реакцию для тестового набора. Чему равно значение эффективности? Сравните ее с показателем эффективности тренировочного набора с повторной выборкой.
Г. Какие предикторы наиболее важны для оцениваемой модели? Какие предикторы доминируют в списке: биологические или предикторы процесса?
Д. Исследуйте связи между каждым важнейшим предиктором и реакцией. Как эта информация может применяться для улучшения выхода продукта в будущих отработках производственного процесса?
Нелинейные регрессионные модели
В главе 6 рассматривались регрессионные модели, являющиеся линейными по своей природе. Многие из них могут адаптироваться для нелинейных тенденций в данных посредством ручного добавления составляющих модели (например, квадратичных), что требует знаний о сути нелинейности данных.
Заметим, что существует множество нелинейных регрессионных моделей, применение которых, впрочем, возможно и без учета конкретной формы нелинейности. В этой главе рассматриваются некоторые из таких моделей: нейросети, многомерные адаптивные регрессионные сплайны (MARS), метод опорных векторов (SVM) и метод k ближайших соседей (KNN). Древовидные модели, рассматриваемые в главе 8, также нелинейны.
7.1. Нейросети
Нейросети, согласно заключениям Бишопа, Рипли и Титтерингтона (Bishop, 1995; Ripley, 1996; Titterington, 2010), представляют собой мощные методы нелинейной регрессии, в основу которых положены теории мозговой активности. Как и в случае с частными наименьшими квадратами, результат моделируется промежуточным набором ненаблюдаемых или скрытых переменных, представляющих собой линейные комбинации исходных предикторов, но, в отличие от моделей PLS, не оценивающихся в иерархическом контексте (рис. 7.1).
Как упоминалось, каждая скрытая переменная является линейной комбинацией, обычно преобразуемой нелинейной функцией g( •), например логистической (сигмоидальной):
р
ht(*) = g(|3w + £ х,Р jk), где
170 Глава 7. Нелинейные регрессионные модели
Рис. 7.1. Диаграмма нейросети с одним скрытым уровнем. Скрытые переменные являются линейными комбинациями предикторов, которые были преобразованы сигмоидальной функцией. Результат моделируется линейной комбинацией скрытых переменных
Yo +Yihi(x) + ^h2(x) +Vi3(x)
Коэффициенты р аналогичны коэффициентам регрессии; коэффициент описывает воздействие j-ro предиктора на k-ю скрытую переменную. Модель нейросети обычно включает несколько скрытых переменных для моделирования результата. Следует учесть, что, в отличие от линейных комбинаций в PLS, не существует ограничений, которые бы помогали определять эти линейные комбинации. В этой
7.1. Нейросети 171
связи маловероятно, чтобы коэффициенты каждой переменной представляли некий осмысленный фрагмент информации.
После определения количества скрытых переменных каждая из них должна быть связана с результатом, например, следующим образом:
/(x) = Yo + ZyA-
Для нейросетей такого типа и Р предикторов оцениваются всего Н(Р + 1) + Н + 1, причем эта величина быстро возрастает с ростом Р. Вспомним в этой связи, что данные растворимости содержали 228 предикторов. Модель нейросети с тремя скрытыми переменными будет оценивать 691 параметр, тогда как у модели с пятью скрытыми переменными их число составит 1151. Если интерпретировать эту модель как нелинейную регрессионную, то при этом параметры обычно оптимизируются для минимизации суммы квадратов остатков. Обычно параметры инициализируются случайными значениями, после чего для решения уравнений используются специализированные алгоритмы. Представленный у Румелхарта (Rumelhart et al., 1986) алгоритм обратного распространения — высокоэффективная методология, работающая с производными для нахождения оптимальных параметров. Тем не менее решение уравнения не гарантирует, что полученный набор параметров будет однозначно лучше любого другого набора.
Кроме того, нейросети склонны к чрезмерному обучению связей между предикторами и реакцией из-за большого количества коэффициентов регрессии. Для решения этой проблемы существует несколько методов.
Во-первых, это описанный у Уанга и Венкатеша (Wang and Venkatesh, 1984) метод ранней остановки, основанный на заблаговременном прекращении работы итеративных алгоритмов по отысканию решения регрессионных уравнений. Процедура оптимизации прерывается, как только значение оценки параметров или частоты ошибок выходит за пределы допустимой стабильности. У этой процедуры есть очевидные минусы. Во-первых, как объективно оценить погрешность модели? Кажущаяся частота ошибок может оказаться завышенной (см. раздел 4.1). Определенные затруднения могут быть обусловлены и последующим разделением тренировочного набора. Кроме того, поскольку значениям измеренной частоты ошибок тоже присуща некоторая неопределенность, как убедиться в том, что она на самом деле возрастает?
Другой подход к преодолению чрезмерного обучения основан на снижении весов — штрафном методе регуляризации модели, сходном с гребневой регрессией (см. главу 6). Для больших коэффициентов регрессии добавляется штраф, с тем чтобы любое большое значение оказывало значительное влияние на погрешности модели. Формально это должно привести к минимизации альтернативной версии суммы квадратов погрешностей:
172 Глава 7. Нелинейные регрессионные модели
i=l *=1 >0 k=0
для заданного значения X.
С ростом значения регуляризации аппроксимированная модель становится более плавной и с меньшей вероятностью вызовет чрезмерное обучение тренировочного набора. Этот параметр, наряду с количеством скрытых переменных, является параметром настройки модели. Допустимые значения X лежат в диапазоне от 0 до 1. Поскольку коэффициенты регрессии суммируются, они должны измеряться по одной и той же шкале; следовательно, перед моделированием предикторы должны пройти центрирование и масштабирование.
Описываемая структура модели соответствует простейшей архитектуре нейросети: одноуровневой сети прямого распространения. Существует и много других разновидностей, включая модели с несколькими уровнями скрытых переменных (то есть уровень скрытых переменных, моделирующий другие скрытые переменные). В других вариантах архитектуры модели также присутствуют циклы, проходящие в обоих направлениях между уровнями. Для дальнейшей оптимизации моделей допускается удаление отдельных связей между объектами, в том числе посредством методов Байеса. Так, байесовская инфраструктура, описанная у Нила (Neal, 1996), автоматически интегрирует регуляризацию и выбор признаков. Этот метод считается высокоэффективным, хотя его реализация требует обстоятельного учета вычислительных аспектов оптимизируемой модели. Очень близка к нейросетям модель самоорганизующихся карт Кохонена (Kohonen, 1995), используемая и как неконтролируемый исследовательский метод, и как контролируемый метод для выполнения прогнозирования по Мельссену (Meissen et al., 2006).
С учетом проблем, связанных с оценкой большого количества параметров, аппроксимированная модель позволяет найти оценки параметров, являющиеся локально оптимальными. Заметим, что разные локально оптимальные решения могут приводить к формированию моделей, которые, сильно отличаясь друг от друга по формальным признакам, обладают при этом почти эквивалентной эффективностью. Подобная нестабильность модели иногда может затруднять ее применение. Альтернатива — создание нескольких моделей с разными начальными значениями и последующее усреднение результатов моделей для получения более стабильного прогноза, о чем упоминают, в частности, Перрон и Купер, Рипли, Тьюмер и Гош (Perrone and Cooper, 1993; Ripley, 1995; Turner and Ghosh, 1996).
Усреднение моделей часто приводит к значительному положительному эффекту для нейросетей. Вместе с тем на такие модели не исключено отрицательное влияние высокой корреляции между предикторными переменными, использующими градиенты для оптимизации параметров модели.
7.1. Нейросети 173
Существуют два способа решения этой проблемы. Первый основан на предварительной фильтрации и удалении предикторов, связанных с высокими корреляциями, второй — на предшествующем моделированию выделении признаков для устранения корреляций (например, посредством анализа главных компонент). Оба способа требуют оптимизации меньшего количества составляющих модели, а это означает ускорение вычислений.
Для данных растворимости (см. ранее) использовались нейросети с усреднением моделей. Были вычислены три разных значения снижения весов (X = 0,00, 0,01, 0,10) наряду с одним скрытым уровнем с размерами от 1 до 13 скрытых переменных. Итоговые прогнозы представляли результаты усреднения пяти разных нейросетей, созданных с разными исходными значениями параметров. Профили среднеквадратичной погрешности с перекрестной проверкой для этих моделей представлены на рис. 7.2.
Снижение весов
2 4 6 8 10 12
Количество скрытых переменных
Рис. 7.2. Профили среднеквадратичной погрешности для модели нейросети. Оптимальная модель использует X = ОД и 11 скрытых переменных
Нарастание снижения весов очевидным образом улучшает эффективность модели. Увеличение числа скрытых переменных сокращает ошибку модели. Оптимальная модель использовала 11 скрытых переменных с 2531 коэффициентом, и ее эффективность достаточно стабильна для высокой степени регуляризации (то есть X = 0,1), что позволяет ожидать того же и от моделей с меньшим числом переменных и коэффициентов.
174 Глава 7. Нелинейные регрессионные модели
7.2. Многомерные адаптивные регрессионные сплайны
Как и нейросети и частные наименьшие квадраты, модель MARS, согласно Фридману (Friedman, 1991), использует суррогатные признаки вместо исходных предикторов. Но если PLS и нейросети базируются на линейных комбинациях предикторов, то MARS создает две контрастные версии предиктора для ввода в модель. Кроме того, суррогатные признаки MARS обычно являются функцией только одного или двух предикторов.
С учетом специфики MARS предикторы разделяются на две группы, в каждой из которых моделируются линейные связи между предиктором и результатом: в заданной точке разделения для предиктора двумя новыми признаками становятся «шарнирные» функции оригинала (рис. 7.3).
У одной функции нулевые значения следуют после точки разделения, у другой — до нее. Новые признаки добавляются в базовую модель линейной регрессии для оценки угла наклона и точки пересечения оси. Фактически эта схема создает фрагментарную линейную модель, в которой каждый новый признак моделирует изолированную часть исходных данных.
Для выбора точки разделения предварительно оценивается каждая точка данных этого предиктора. Для этого строится соответствующая модель линейной регрессии с потенциальными признаками и вычисляется соответствующая погрешность модели. После этого для модели используется комбинация предиктора/точки разделения, при которой достигается наименьшая погрешность. Способ преобразования предикторов допускает вычисление большого количества линейных регрессий. В некоторых реализациях MARS, включая приведенную здесь, кроме того, оценивается применимость простых линейных составляющих для каждого предиктора (то есть без шарнирной функции).
После создания исходной модели с первыми двумя признаками модель проводит другой исчерпывающий поиск для нахождения следующего набора признаков, которые для заданного исходного набора обеспечивают наилучшую аппроксимацию модели. Процесс продолжается до тех пор, пока не будет достигнута точка остановки (которая может задаваться пользователем).
При исходном поиске признаков в данных растворимости наименьшая частота ошибок достигалась с точкой разделения 5,9 для молекулярной массы. Полученные искусственные предикторы показаны на двух верхних областях рис. 7.3. У одного предиктора все значения, не достигающие точки разделения, обнуляются, а значения, превышающие точку разделения, остаются без изменений. Второй предиктор является зеркальным отражением первого. Вместо исходных данных два новых предиктора используются для прогнозирования результата в модели линейной регрессии.
7.2. Многомерные адаптивные регрессионные сплайны 175
2,0
1,5 1,0
сл
< 0,5
8 0,0
X
со
X
Q.
С
m 2,0
О
I
1,5
1,0
0,5
0,0
4,0 4,5 5,0 5,5 6,0 6,5
Молекулярная масса (преобразованная)
4,0
4,5 5,0
5,5 6,0
6,5
Молекулярная масса (преобразованная)
Рис. 7.3. Пример признаков, используемых MARS для данных растворимости. После нахождения точки разделения 5,9 для молекулярной массы были созданы два новых признака, которые использовались в модели линейной регрессии. Две верхние области показывают связь между исходным предиктором и двумя полученными признаками. На нижней области показано прогнозируемое соотношение при использовании двух признаков в модели линейной регрессии. Красная линия обозначает вклад «левосторонней» шарнирной функции, тогда как синяя линия связана с другим признаком
На нижней области рис. 7.3 показан результат линейной регрессии с двумя новыми признаками и фрагментарным характером связи. «Левосторонний» признак связывается с отрицательным наклоном, когда молекулярная масса меньше 5,9, тогда
176 Глава 7. Нелинейные регрессионные модели
как «правосторонний» признак оценивает положительный наклон для больших значений предиктора. Для новых признаков шарнирная функция может записываться в виде
h(x) =
х х>0
О х<0
(7-1)
Пара шарнирных функций обычно записывается в виде h(x - a)nh(a - х). Первая отлична от нуля при х> а, тогда как вторая отлична от нуля при х<а. Для модели MARS (см. рис. 7.3) фактическое уравнение модели имеет вид
-5+2,1 х А(МолМасса - 5,94516) + 3 х 6(5,94516 - МолМасса).
Первое слагаемое в этой формуле (-5) определяет точку пересечения, второе слагаемое связано с правосторонним признаком на рис. 7.3, а третье — с левосторонним признаком. В табл. 7.1 представлены несколько первых этапов фазы генерирования признака (до усечения).
Таблица 7.1. Результаты нескольких итераций алгоритма MARS до усечения
Предиктор
Тип
Точка разделения
Среднеквадратичная погрешность
Коэффициент
Intercept
4,193
-9,33
MolWeight
Правосторонний
5,95
2,351
-3,23
MolWeight
Левосторонний
5,95
1,148
0,66
Surface Areal
Правосторонний
1,96
0,935
0,19
Surface Areal
Левосторонний
1,96
0,861
-0,66
NumNonHAtoms
Правосторонний
3,00
0,803
-7,51
NumNonHAtoms
Левосторонний
3,00
0,761
8,53
FP137
Линейный
0,727
1,24
NumOxygen
Правосторонний
1,39
0,701
2,22
NumOxygen
Левосторонний
1,39
0,683
-0,43
NumNonH Bonds
Правосторонний
2,58
0,670
2,21
NumNonH Bonds
Левосторонний
2,58
0,662
-3,29
Примечание. Для оценки среднеквадратичной погрешности использовалась статистика GCV.
7.2. Многомерные адаптивные регрессионные сплайны 177
Признаки вводились в модель линейной регрессии сверху вниз. Здесь бинарный дескриптор вводится в модель как простой линейный член (разделение бинарной переменной лишено смысла). В столбце обобщенной перекрестной проверки (GCV) выводится оценка среднеквадратичной погрешности для модели, содержащей слагаемые текущей строки и всех предшествующих ей строк. До усечения в модели содержится каждая пара шарнирных функций, несмотря на незначительность сокращения оцениваемой среднеквадратичной погрешности.
После того как создан полный набор признаков, алгоритм последовательно удаляет отдельные признаки, не представляющие значения для уравнения модели. Эта процедура «усечения» оценивает каждую предикторную переменную и то, в какой степени частота ошибок снижена в результате ее включения в модель. Обратное движение по пути добавления признаков в данном случае не предусмотрено, при этом некоторые признаки, изначально рассматривавшиеся как важные, могут быть удалены, тогда как признаки, квалифицированные в качестве важных позднее, могут быть сохранены. Для определения вклада каждого признака в модель используется статистика GCV. Это ускоряет вычисления для моделей линейной регрессии, производящих значение погрешности, аппроксимирующее перекрестную проверку с исключением по Голубу (Golub et al., 1979). Для определения важности каждого признака модели GCV создает лучшие оценки, чем кажущаяся частота ошибок. Количество удаляемых составляющих может задаваться вручную или же рассматриваться как параметр настройки и определяться посредством тех или иных форм повторной выборки.
Этот процесс описывает аддитивную модель MARS, где каждый суррогатный признак включает один предиктор. Тем не менее MARS может строить модели, в которых признаки включают сразу несколько предикторов. Для модели MARS второй степени алгоритм выполняет тот же поиск одной составляющей, улучшающей модель, и после создания исходной пары признаков инициирует поиск для создания новых точек разделения в сочетании с каждым из исходных признаков. Предположим, что имеется пара шарнирных функций А и В. Процедура поиска пытается найти шарнирные функции С и D, которые при умножении на А приводят к улучшению модели; последняя будет включать составляющие для А, А * В и А х С. Та же процедура выполняется для признака В. Алгоритм не добавляет дополнительные составляющие, не способствующие улучшению модели. Кроме того, процедура усечения может удалить дополнительные составляющие. В поведении моделей MARS с двумя и более составляющими время от времени наблюдалась нестабильность, если прогнозы для нескольких точек данных оказывались крайне неточными (то есть отличались от истинного значения на порядок). Для аддитивных моделей MARS эта проблема не наблюдалась.
Таким образом, с моделью MARS связаны два параметра настройки — степень признаков, добавляемых в модель, и количество оставленных составляющих. Последний параметр может автоматически определяться с использованием стандартной процедуры усечения, заданной пользователем или определяемой с применением
178 Глава 7. Нелинейные регрессионные модели внешних методов повторной выборки. Напомним, в анализе данных растворимости применялась десятикратная перекрестная проверка для описания эффективности моделей первой и второй степени и 37 вариантов количества составляющих модели (от 2 до 38, см. профиль производительности на рис. 7.4).
Степень
10 20 30
Количество составляющих
Рис. 7.4. Профили среднеквадратичной погрешности для модели MARS. Процедура перекрестной проверки выбрала модель второй степени с 38 составляющими, хотя различия между моделями первой и второй степени невелики. С учетом этой эквивалентности в качестве итоговой была выбрана более простая модель первой степени
Процедура перекрестной проверки выбрала модель второй степени с 38 составляющими. Поскольку профили моделей первой и второй степени практически идентичны, в качестве финальной модели была выбрана более простая модель первой степени. Эта модель использовала 38 составляющих, являясь функцией лишь 30 предикторов (из 228 возможных).
Перекрестная проверка оценивает среднеквадратичную погрешность равной 0,7 логарифмической единицы, a R2 — равной 0,887. Процедура MARS во внутренней реализации использует GCV для оценки эффективности модели, согласно которой среднеквадратичная погрешность оценивалась в 0,4 логарифмической единицы, a R2 — 0,908. Среднеквадратичная погрешность с тестовым набором из 316 точек оценивалась равной 0,7, a R1 — равным 0,879. Оценки GCV представляются более предпочтительными, чем оценки, полученные процедурой перекрестной проверки или с использованием тестового набора. Однако внутренняя оценка GCV, применяемая MARS, характеризует отдельную модель,
7.2. Многомерные адаптивные регрессионные сплайны 179
тогда как внешняя процедура перекрестной проверки подвержена дисперсии всего процесса построения модели, включая выбор признаков. Так как оценка GCV не отражает неопределенность выбора признаков, она, по мнению Эмброуса и Маклахлана (Ambroise and McLachlan, 2002), подвержена смещению выборки (подробнее см. главу 19).
Итак, модель MARS обладает рядом преимуществ. Во-первых, модель автоматически проводит выбор признаков; уравнение модели независимо от предикторных переменных, не задействованных в итоговых признаках модели, что не стоит недооценивать. С учетом большого количества предикторов, встречающихся во многих предметных областях, MARS потенциально сокращает набор предикторов с использованием того же алгоритма, который строит модель. При этом процедура выбора признаков напрямую связана с функциональной эффективностью.
Вторым преимуществом является интерпретируемость. Каждый шарнирный признак отвечает за моделирование конкретного участка в пространстве предикторов с использованием фрагментарной линейной модели. Применительно к аддитивной модели MARS вклад каждого предиктора может рассматриваться обособленно от других, в том числе и для ясного понимания взаимосвязи предиктора с результатом. Для неаддитивных моделей интерпретационный потенциал модели сохраняется.
Рассмотрим признак второго уровня с двумя предикторами. Поскольку каждая шарнирная функция разбита на два участка, три из четырех возможных участков равны нулю и, следовательно, не влияют на модель. Это позволяет дополнительно изолировать эффект двух факторов, упрощая интерпретацию (по аналогии с аддитивной моделью).
Наконец, в-третьих, модель MARS практически не требует фильтрации предикторов, предварительной обработки данных и их преобразования. Например, предиктор с нулевой дисперсией не будет выбран для разделения как не несущий существенной предиктивной информации. Коррелированные предикторы не оказывают заметного влияния на эффективность модели, но могут усложнить ее интерпретацию. Предположим, тренировочный набор содержит два идеально коррелированных предиктора. Поскольку MARS может многократно выбрать предиктор в ходе итераций, выбор того, какой именно предиктор будет использован в признаке, будет носить случайный характер. В этом случае интерпретация модели затрудняется двумя избыточными блоками информации, присутствующими в двух разных частях модели под разными именами.
Другой прием, помогающий понять суть влияния предикторов на модель, — количественная оценка их важности. Для MARS один из возможных методов такой оценки заключается в отслеживании сокращения среднеквадратичной погрешности (измеренной с использованием статистики GCV), наблюдаемого при добавлении конкретного признака в модель. Это сокращение приписывается одному (или нескольким) исходному предиктору, связанному с признаком. Улучшения модели
180 Глава 7. Нелинейные регрессионные модели могут обобщаться для каждого предиктора, отражая их относительное влияние на модель. Как видно из табл. 7.1, значение среднеквадратичной погрешности падает с 4,19 до 1,15 (разница значений составляет 3,04) после добавления в модель двух признаков молекулярных масс. Последующее добавление составляющих для первого предиктора площади поверхности привело к сокращению ошибки на 0,29. Следовательно, предиктор молекулярной массы для модели важнее, чем первый предиктор площади поверхности. Этот процесс повторяется для каждого предиктора, использованного в модели. Предикторы, которые не используются ни в одном признаке, имеют нулевую важность. Для модели растворимости предикторы MolWeight, NumNonHAtoms и SurfaceArea2 оказывают наибольшее влияние на модель MARS (подробнее см. раздел 7.5).
На рис. 7.5 продемонстрирована интерпретируемость аддитивной модели MARS с непрерывными предикторами.
На каждой панели линия представляет профиль прогнозирования для одной из переменных при сохранении остальными переменными средних постоянных значений. Аддитивная природа модели позволяет рассматривать каждый предиктор изолированно от остальных; изменение значений предикторных переменных не меняет форму профиля, а только точку оси у, с которой начинается профиль.
7.3. SVM, или метод опорных векторов
SVM — самостоятельный класс мощных и гибких методов моделирования. Теория, лежащая в основе SVM, изначально разрабатывалась в контексте моделей классификации (о некоторых других аспектах применения SVM см. главу 13). Для рассмотрения примера регрессии обратимся к работам Смолы (Smola, 1996) и Друкера и др. (Drucker et al., 1997). Этот метод предлагается применять в контексте устойчивой регрессии для минимизации эффекта выбросов в уравнениях регрессии. Поскольку регрессия опорных векторов проявляется в нескольких разновидностях, сосредоточимся далее на одной из них — г — нечувствительной регрессии.
Линейная регрессия стремится находить оценки параметров, минимизирующие сумму квадратов погрешностей (SSE) (см. раздел 6.2). Один из недостатков минимизации SSE — в том, что на оценки параметров может существенно повлиять всего одно наблюдение, лежащее за пределами основной области данных. Для поиска лучших оценок параметров можно воспользоваться альтернативным показателем минимизации, обладающей меньшей чувствительностью (например, функцией Хубера) и использующей квадраты остатков, когда они незначительны, и абсолютные значения — для достаточно больших остатков (см. рис. 6.6). Для регрессии SVM использует функцию Хубера с одним важным отличием. С заданным пользователем пороговым значением е точки данных с остатками,
7.3. SVM, или метод опорных векторов 181
Предсказанный результат
Рис. 7.5. Прогнозируемая связь между результатом и непрерывными предикторами с использованием модели MARS (для всех остальных предикторов используются средние значения). Аддитивная природа модели позволяет рассматривать каждый предиктор по отдельности. Итоговые прогнозируемые значения вычисляются суммированием всех отдельных профилей. Области упорядочены сверху вниз в соответствии со своей важностью для модели
182 Глава 7. Нелинейные регрессионные модели лежащими в пределах порога, не влияют на подгонку регрессии, тогда как влияние точек данных с абсолютной разностью, превышающей порог, носит выраженный линейный характер.
У такого подхода есть несколько следствий. Во-первых, поскольку квадраты остатков не используются, большие выбросы оказывают на уравнение регрессии ограниченное воздействие. Во-вторых, точки данных, хорошо аппроксимирующиеся моделью (то есть для которых остатки малы), не влияют на регрессионное уравнение, то есть если порогу задано относительно большое значение, то выбросы являются единственными точками, определяющими линию регрессии. Это выглядит несколько противоестественно: линия определяется плохо спрогнозированными точками. Тем не менее высокая эффективность этого метода для определения модели нашла свое подтверждение. Для оценки параметров модели SVM использует функцию потерь е (рис. 7.6) с добавлением к ней штрафа.
-4 -2 0 2 4
ю
см
о
см
ю
о
X-
LO
5°
§
СО
со
СМ
о
-4 -2 0 2 4
Остатки
Рис. 7.6. Связь между остатком модели и его вкладом в линию регрессии для нескольких методов. Для метода Хубера использовался порог 2, тогда как для модели SVM используется значение г = 1. Обратите внимание: на диаграммах используются разные масштабы по оси у, чтобы упростить чтение информации иллюстраций
7.3. SVM, или метод опорных векторов 183
Коэффициенты регрессии SVM минимизируются
i=\ >1
где £е( ) — е-нечувствительная функция.
Параметр стоимость определяет штраф стоимости, заданный пользователем, для больших остатков1. Напомним, что простая модель линейной регрессии прогнозирует новые точки данных с использованием линейных комбинаций данных и параметров. Для новой точки данных и уравнение прогнозирования имеет вид
У ~ Ро + Mi + ••• + Рр^р ~
= Ро +XP/Z/r
>1
Предиктивная функция линейной модели SVM выглядит похоже. Оценки параметров могут записываться как функции набора неизвестных параметров (а,) и точек данных тренировочного набора:
У ~ Ро “*■ Pi^i + ••• + PpZ//> —
= ₽о+£₽Л =
7=1
n VV (7.2)
=₽о+ХЕа,*л =
;=1 М
= Ро+£>,-
Краткий комментарий к формуле. Во-первых, количество параметров а равно количеству точек данных. С точки зрения классического регрессионного моделирования эта модель считалась бы излишне параметризованной; предпочтительнее оценивать количество параметров, не превышающее количества точек данных. Регуляризация модели достигается посредством применения штрафа.
Во-вторых, отдельные точки данных тренировочного набора (то есть х^) необходимы для новых прогнозов. При большом размере тренировочного набора уравнения становятся менее компактными (по сравнению с прочими методами). С другой стороны, для части точек данных тренировочного набора параметры а, будут равны нулю, то есть они не влияют на уравнение прогнозирования. Точки данных, связанные
Штраф здесь определяется не так, как он определялся для гребневой регрессии или снижения весов в нейросетях, — в данном случае он связывается с остатками, а не с параметрами.
184 Глава 7. Нелинейные регрессионные модели
О
(U I- -D
>4
Ф
CL
ю I
-2 -1 О
Предиктор
2
СМ
S т-
I-
та
<§ о.
т
I
-5 0 5 Ю
Прогнозируемая стоимость
ю i
2 4 6 8 10
Предиктор
Рис. 7.7. Демонстрация устойчивости моделей SVM. Наверху: небольшой смоделированный набор данных с одним аномальным выбросом, используемым для демонстрации различий между обычной линией регрессии (серая) и линейной моделью SVM (черная). В середине: остатки SVM и прогнозируемые значения (масштаб верхней части оси у был сокращен для того, чтобы диаграмма лучше читалась). На диаграмме обозначены опорные векторы (кружочки) и другие точки данных (крестики). Горизонтальные линии обозначают ±е = 0,01. Внизу: имитированная синусоида с несколькими выбросами. Серая линия представляет обычную линию регрессии (точка пересечения и составляющая для sin(x)), а черная линия — модель SVM с радиальной базисной функцией
7.3. SVM, или метод опорных векторов 185
с параметром а,, равным нулю, являются точками данных тренировочного набора, лежащими в пределах ±£ от линии регрессии (то есть в пределах «воронки» или «трубы» вокруг линии регрессии). Как следствие, для прогнозирования необходимо только подмножество точек данных тренировочного набора с а = 0. Поскольку линия регрессии определяется с использованием точек данных тренировочного набора, эти подмножества называются опорными векторами как «поддерживающие» линию регрессии и обеспечивающие таким образом устойчивость модели (рис. 7.7).
Здесь имитируется простая линейная модель с наклоном 4 и точкой пересечения оси 1 с добавлением одного аномального выброса. Сверху изображена аппроксимация модели для линейной регрессии (сплошная линия) и регрессии модели опорных векторов (пунктирная линия) с в = 0,01. Линия линейной регрессии «подтягивается» к выбросу, что приводит к оценкам наклона и точки пересечения 3,5 и 1,2 соответственно. Аппроксимация методом опорных векторов, линия SVM, намного ближе к истинной линии регрессии с наклоном 3,9 и точкой пересечения 0,9. В средней части снова показана модель SVM, но на этот раз опорные векторы обозначены заполненными кружками, а остальные точки — крестиками. Горизонтальные серые линии обозначают 0 ± £. Из 100 точек данных 70 принадлежали опорным векторам.
Отметим, что в последней форме уравнения 7.2 новые точки данных входят в предиктивную функцию как сумма перекрестных произведений с новыми значениями точек данных. В понятиях матричной алгебры это соответствует скалярному произведению (то есть х'и), что позволяет представить уравнение регрессии в более общем виде:
/(и) = МЕаЛ(*,,и),
1=1
где К( ) называется ядерной функцией. Если предикторы входят в модель линейно, то ядерная функция сводится к простой сумме перекрестных произведений:
р
u') = Y.xyuj=x'iu-
7=1
Другие типы ядерных функций могут использоваться для обобщения регрессионной модели и охватывают нелинейные функции предикторов:
полиномиальная = (ф(х'г/) + 1)<7Ле™™
радиальная базисная функция = ерх (-о || х - и ||2) гиперболический тангенс = tanh (ф(х'г/) + 1),
где ф и а — параметры масштабирования. Поскольку эти функции предикторов ведут к нелинейным моделям, представленное обобщение часто называют «ядерным трюком» (kernel trick).
186 Глава 7. Нелинейные регрессионные модели
Для демонстрации способности модели адаптироваться к нелинейным связям представим данные (с добавлением выбросов) в форме синусоиды в нижней части рис. 7.7. Сплошной линией изображена модель линейной регрессии с пересечением оси и составляющей для sin(x). И в этом случае, как видим, линия регрессии «подтягивается» к точкам выбросов. Модель SVM с радиальной базисной функцией изображена пунктирной линией (без указания функциональной формы sin), более соответствующей общей структуре данных. Решение об использовании ядерной функции принимается исходя из решаемой задачи. Так, для решения определенных задач наиболее эффективна радиальная базисная функция. Однако для выраженной линейной регрессии предпочтительнее использование линейной ядерной функции ит. д.
Следует учитывать, что некоторые ядерные функции имеют дополнительные параметры. Например, для полиномиальной ядерной функции должна быть задана степень, а у радиальной базисной функции — параметр (о), управляющий масштабом. Последние, в совокупности со стоимостью, образуют параметры настройки модели. Для радиальной базисной функции также существует метод ускорения вычислений оценки параметра ядерной функции. У Капуто (Caputo et al., 2002) предлагается оценивать параметр по комбинации точек тренировочного набора для вычисления распределения | |х - х211 с последующим использованием а в диапазоне от 10 до 90 %. Вместо настройки этого параметра по таблице значений-кандидатов можно использовать среднюю точку пороговых значений.
Параметр стоимости — главный инструмент настройки сложности модели. При высокой стоимости модель становится очень гибкой, потому что эффект ошибок усиливается. При малой стоимости модель «деревенеет» и становится менее подверженной эффекту переобучения (при одновременном нарастании риска недостаточного обучения). Модель может настраиваться и по размеру воронки, например е, но с учетом взаимосвязи между е и параметром стоимости (последний предоставляет больше гибкости настройке модели, что указывает на желательность корректировки его значения для е и настройки других параметров ядерной функции).
Поскольку предикторы входят в модель в виде суммы перекрестных произведений, следует учитывать и влияние различий в масштабах предикторов и до построения модели SVM выполнить центрирование и масштабирование предикторов. В примере с данными растворимости сначала использована радиальная базисная функция. Ядерный параметр был аналитически оценен равным о = 0,0039. Модель настраивалась для 14 значений стоимости от 0,25 до 2048 по шкале log2 (рис. 7.8). При малых значениях стоимости модель склонна к недообучению, но с ростом погрешности при достижении стоимости 210 наблюдается переобучение. Для оценки полиномиальной модели выполнена настройка по стоимости, степени полиномиальной модели и масштабному фактору. В общем случае квадратичные модели характеризуются меньшей частотой ошибок, чем линейные модели, а модели с большими масштабными факторами — и более высокой эффективно-
7.3. SVM, или метод опорных векторов 187
стью. Оптимальной признана квадратичная модель с масштабным фактором 0,01 и стоимостью 2 (рис. 7.9).
0,80
0,75
0,70
0,65
0,60
2Л0
2А5 Стоимость
Рис. 7.8. Профили перекрестной проверки для модели SVM с радиальной базисной функцией, примененной к данным растворимости. Ядерный параметр был оценен аналитическим методом, равным о = 0,0039
Степень полиномиальной модели
2А-2 2а0 2а2 2а4 2а-2 2а0 2а2 2а4
Стоимость
Рис. 7.9. Результаты перекрестной проверки для полиномиальной модели SVC и данных растворимости. Итоговая аппроксимация осуществлялась с использованием квадратичной модели с масштабным фактором 0,01 и значением стоимости 2
188 Глава 7. Нелинейные регрессионные модели
Для сравнения: оптимальная радиальная базисная и полиномиальная модель SVM используют примерно одинаковое количество опорных векторов (623 и 627 соответственно из 951 тренировочной точки данных). Настройка ядерного параметра радиальной базисной функции проще настройки полиномиальной модели (с тремя параметрами настройки). В области моделей SVM и других ядерных методов велись активные исследования, породившие много альтернативных методологий. Так, описываемый Типпингом метод релевантных векторов (Tipping, 2001) представляет собой байесовский аналог модели SVM. В данном случае параметры а, описанные выше, имеют ассоциированные априорные распределения, учитываемые при выборе релевантных векторов. Если апостериорное распределение концентрируется преимущественно вблизи нулевой отметки, то точка данных в предиктивном уравнении не используется. В общем случае количество релевантных векторов в этой модели меньше количества опорных векторов в модели SVM.
7.4. Метод к ближайших соседей
Метод k ближайших соседей (далее — KNN) прогнозирует новую точку данных по К ближайшим точкам данных из тренировочного набора (по аналогии с рис. 4.3). В отличие от других методов, рассматриваемых в этой главе, метод KNN не может быть наглядно представлен моделью — допустим, сходной с выраженной формулой 7.2. Его построение базируется исключительно на отдельных точках из тренировочных данных. Чтобы спрогнозировать новую точку данных для регрессии, метод KNN определяет требуемое число ближайших соседей этой точки в пространстве предикторов. Прогнозируемой реакцией новой точки становится среднее значение реакций k соседей, а вместо среднего значения для прогнозирования могут использоваться другие сводные статистики, например медиана.
Применение базового метода KNN зависит от того, как пользователь определяет расстояние между точками. Последнее может выполняться, например, с использованием евклидова расстояния (то есть расстояния по прямой):
1
( Р >2
Т/Х«ГХ^ > \ 7=1 7
где ха и хь — две точки данных. Расстояние Минковского, согласно Лиу (Liu, 2007), является обобщением евклидова расстояния:
(' ¥
где q > 0.
7.4. Метод к ближайших соседей 189
Как видим, при q = 2 расстояние Минковского идентично евклидову расстоянию. При q = 1 расстояние Минковского эквивалентно расстоянию городских кварталов, или манхэттенскому расстоянию, — значению, широко используемому с бинарными предикторами. Другие значения, например расстояния Танимото, Хемминга и косинусоидальное расстояние, применяются для конкретных типов предикторов в контексте решаемых задач моделирования. Например, расстояние Танимото регулярно используется в задачах вычислительной химии, в которых молекулы описываются, как, например, у Маккарена (McCarren et al., 2011), бинарными признаками.
Поскольку метод KNN преимущественно зависит от расстояния между точками, необходимо учитывать масштаб, используемый для исчисления соответствующего расстояния. Данные с предикторами, которые сильно отличаются в масштабах, генерируют расстояния, смещенные в направлении предикторов, обладающих наибольшими масштабами. Иначе говоря, предикторы с большими масштабами внесут наибольший вклад в расстояние между точками. Чтобы избежать потенциального смещения и обеспечить равный вклад всех предикторов в вычисление расстояния, требуется предварительное центрирование и масштабирование всех предикторов.
Использование расстояний между точками может создать проблемы и при отсутствии одного или нескольких значений предикторов для точки данных, поскольку в этом случае вычислить расстояние между точками не удастся. Одно из возможных решений — исключение некоторых точек или предикторов из анализа, что, к слову, нежелательно (хотя при разреженных точках или предикторах это единственно возможное решение). Если предиктор содержит достаточный объем информации для разных точек, то возможно альтернативное решение — подстановка отсутствующих данных с использованием среднего значения предиктора или посредством метода KNN, использующего только предикторы с полной информацией (см. раздел 3.4).
После предварительной обработки данных и выбора показателя расстояния требуется определить оптимальное количество соседей. Как и параметры настройки в других моделях, значение k может быть определено посредством повторной выборки. Для данных растворимости оценены 20 значений k от 1 до 20. Профиль среднеквадратичной погрешности (рис. 7.10) быстро убывает при первых четырех значениях k, затем остается приблизительно на одном уровне до k - 8, после чего с ростом k наблюдается устойчивое нарастание среднеквадратичной погрешности.
Такой профиль эффективности типичен для KNN, поскольку при малых значениях k обычно наблюдается переобучение, а при больших, напротив, недостаточное обучение данных. Среднеквадратичная погрешность изменяется в диапазоне от 1,041 до 1,23 для значений-кандидатов при минимуме для k = 4; значение R2 с перекрестной проверкой при оптимальном k составляет 0,747.
190 Глава 7. Нелинейные регрессионные модели
1,20
1,15
1,10
1,05
5 10 15
Количество соседей
20
Рис. 7.10. Профиль среднеквадратичной погрешности с перекрестной проверкой для модели KNN, примененной к данным растворимости. Оптимальное количество соседей равно 4
Элементарная версия KNN может создавать неплохие прогнозы, особенно когда реакция зависит от локальной структуры предикторов. Тем не менее у этой версии есть и серьезные недостатки: продолжительность вычислений и разрыв связи между локальной структурой и предиктивной способностью KNN.
Прежде всего, для прогнозирования точки данных необходимо вычислить расстояния между этой точкой и остальными точками. Таким образом, время вычислений растет с ростом п, потому что тренировочные данные загружаются в память, после чего должны быть вычислены расстояния от новой точки до всех тренировочных точек. Но исходные данные можно заменить представлением данных, описывающим расположение исходных данных. Одним из конкретных примеров такого представления, согласно Бентли (Bentley, 1975), является k-мерное дерево, или k-d дерево. K-d дерево осуществляет ортогональное разделение пространства предикторов с использованием древовидной иерархии, но по правилам, отличным от описанных в главе 8. После того как дерево «вырастает», через структуру добавляется новая точка данных. Расстояния вычисляются только для тренировочных наблюдений в дереве, близких к новой точке данных. Такой метод обеспечивает значительные вычислительные улучшения, особенно если число тренировочных точек данных намного больше количества предикторов.
Метод KNN может обладать низкой предиктивной эффективностью, если локальная структура предикторов не связана с реакцией — например, вследствие нерелевантности или искажения предикторов, что влечет удаление сходных точек данных друг от друга в пространстве предикторов. Следовательно, удаление нерелевантных
7.5. Вычисления 191
и искаженных предикторов является ключевым этапом предварительной обработки для KNN.
Другой подход к повышению предиктивной способности KNN основан на взвешивании вклада соседей в прогнозирование новой точки на основании их расстояний до новой точки. В этом варианте тренировочные точки данных, более близкие к новой точке, вносят больший вклад в прогнозируемый ответ, тогда как у дальних точек этот вклад, наоборот, уменьшается.
7.5. Вычисления
В этом разделе будут использоваться функции из пакетов R caret, earth, kernlab и nnet.
В R имеется немало пакетов и функций для создания нейросетей. К их числу относятся и пакеты nnet, neural и RSNNS. Основное внимание уделяется пакету nnet, поддерживающему базовые модели нейросетей с одним уровнем скрытых переменных, снижение весов, и характеризующемуся сравнительно простым синтаксисом. RSNNS поддерживает широкий спектр нейросетей. Отметим, что у Бергмейра и Бенитеса (Bergmeir and Benitez, 2012) есть краткое описание различных пакетов нейросетей в R. Там же приводится учебное руководство по RSNNS.
Нейросети
Для апрроксимации регрессионной модели функция nnet может получать как формулу модели, так и матричный интерфейс. Для регрессии линейная связь между скрытыми переменными и прогнозом используется с параметром linout = TRUE. Простейший вызов функции нейросети будет иметь вид:
> nnetFit <- nnet(predictors, outcome,
+ size - 5,
+ decay = 0.01,
+ Linout = TRUE,
+ ## Сокращенный вывод
+ trace = FALSE,
+ ## Расширение количества итераций для нахождения
+ ## оценок параметров..
+ maxit = 500,
+ ## и количества параметров, используемых моделью
+ MaxNWts = 5 * (ncoL(predictors) + 1) + 5 + 1)
Этот вызов создает одну модель с пятью скрытыми переменными. Предполагается, что данные в предикторах были стандартизированы по одной шкале.
192 Глава 7. Нелинейные регрессионные модели
Для усреднения моделей используется функция avNNet из пакета caret, имеющая тот же синтаксис:
> nnetAvg <- avNNet(predictors, outcome,
+
+
+
+
+
+
+
+
+ + +
size = 5,
decay = 0.01,
## Количество усредняемых моделей
repeats = 5,
Linout = TRUE,
## Сокращенный вывод
trace = FALSE,
## Расширение количества итераций
## для нахождения оценок параметров..
maxit = 500,
## и количества параметров, используемых моделью
MaxNWts = 5 * (ncoL(predictors) + 1) + 5 + 1)
Новые точки данных обрабатываются командой
> predict(nnetFit, newData)
> ## или
> predict(nnetAvg, newData)
Чтобы воспроизвести представленный ранее метод выбора количества скрытых переменных и величины снижения весов посредством повторной выборки, применим функцию train с параметром method = "nnet" или method = "avNNet", сначала удалив предикторы (с тем, чтобы максимальная абсолютная парная корреляция между предикторами не превышала 0,75):
> ## findCorreLation получает матрицу корреляции и определяет
> ## номера столбцов, которые должны быть удалены для поддержания
> ## всех парных корреляций ниже заданного порога
> tooHigh <- findCorreLation(cor(soLTrainXtrans), cutoff = .75)
> trainXnnet <- soLTrainXtrans[, -tooHigh]
> testXnnet <- soLTestXtrans[, -tooHigh]
> ## Создание набора моделей-кандидатов для оценки:
> nnetGrid <- expand.grid(.decay = c(0, 0.01, .1),
+ .size = c(l:10),
+ ## Другой вариант - использование бзггинга
+ ## (см. следующую главу) вместо случайной
+ ## инициализации генератора.
+ .bag = FALSE)
> set.seed(100)
> nnetTune <- train(soLTrainXtrans, soLTrainY,
+ method = "avNNet",
+ tuneGrid = nnetGrid,
+ trControL = ctrL,
+ ## Автоматическая стандартизация данных
7.5. Вычисления 193
## перед моделированием и прогнозированием preProc = c("center", "scale"),
Linout = TRUE,
trace = FALSE,
MaxNWts = 10* (ncoL(trainXnnet) + 1) + 10 + 1, maxit = 500)
Многомерные адаптивные регрессионные сплайны
Модели MARS содержатся в нескольких пакетах, но самая обширная реализация находится в пакете earth. Модель MARS, использующая номинальную фазу прямого прохода и усечения, может вызываться следующим образом:
> marsFit <- earth(soLTrainXtrans, soLTrainY)
> marsFit
Selected 38 of 47 terms, and 30 of 228 predictors
Importance: NumNonHAtoms, MolWeight, SurfaceArea2, SurfaceAreal, FP142, ...
Number of terms at each degree of interaction: 1 37 (additive model)
GCV 0.3877448 RSS 312.877 GRSq 0.907529 RSq 0.9213739
Поскольку эта модель во внутренней реализации использует метод GCV для выбора модели, ее устройство несколько отличается от модели, описанной ранее в этой главе. Метод summary генерирует более обширный вывод:
> summary(marsFit)
Call: earth(x=solTrainXtrans, y=solTrainY)
coefficients
(Intercept)
FP002
FP003
FP059
FP065
FP075
FP083
FP085
FP099
FP111
FP135
FP142
FP154
FP172
FP176
FP188
FP202
FP204
FP207
-3.223749
0.517848
-0.228759
-0.582140
-0.273844
0.285520
-0.629746
-0.235622
0.325018
-0.403920
0.394901
0.407264
-0.620757 -0.514016
0.308482
0.425123
0.302688
-0.311739
0.457080
194 Глава 7. Нелинейные регрессионные модели
h(MolWeight-5.77508) h(5.94516-MolWeight)
h(NumNonHAtoms-2.99573) h(2.99573-NumNonHAtoms) h(2.57858-NumNonHBonds) h(NumMultBonds-1.85275) h(NumRotBonds-2.19722) h(2.19722-NumRotBonds)
h(NumAromaticBonds-2.48491)
h(NumNitrogen-0.584815) h(0.584815-NumNitrogen) h(NumOxygen-1.38629)
h(1.38629-NumOxygen) h(NumChlorine-0.46875) h(HydrophilicFactor- -0.816625) h(-0.816625-HydrophilicFactor)
-1.801853
0.813322
-3.247622
2.520305
-0.564690
-0.370480
-2.753687
0.123978
-1.453716
8.239716
-1.542868
3.304643
-0.620413
-50.431489
h(SurfaceAreal-1.9554) h(SurfaceArea2-4.66178) h(4.66178-SurfaceArea2)
0.237565
-0.370998
0.149166
-0.169960
-0.157970
Selected 38 of 47 terms, and 30 of 228 predictors
Importance: NumNonHAtoms, MolWeight, SurfaceArea2, SurfaceAreal, FP142, ...
Number of terms at each degree of interaction: 1 37 (additive model)
GCV 0.3877448 RSS 312.877 GRSq 0.907529 RSq 0.9213739
В этом выводе Л() — шарнирная функция. В приведенных результатах составляющая h (MolWeight-5.77508) равна нулю при значении молекулярной массы меньше 5,77508 (как в верхней части рис. 7.3). Отраженная шарнирная функция имеет вид h(5.77508 -MolWeight).
Функция plotmo из пакета earth может использоваться для построения диаграмм, сходных с изображенными на рис. 7.5. Для настройки модели с использованием внешней повторной выборки можно воспользоваться train. В следующем коде воспроизведены результаты, отображенные на рис. 7.4:
> # Определение моделей-кандидатов для тестирования
> marsGrid <- expand.grid(.degree = 1:2, .nprune = 2:38)
> # Инициализация генератора для воспроизведения результатов
> set.seed(100)
> marsTuned <- train(soLTrainXtrans, soLTrainY,
+ method = "earth",
+ # Явное объявление моделей-кандидатов для тестирования
+ tuneGrid = marsGrid,
+ trControL = trainControL(method = "cv"))
> marsTuned
951 samples
228 predictors
7.5. Вычисления 195
No pre-processing
Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 856, 857, 855, 856, 856, 855, ...
Resampling results across tuning parameters:
degree
nprune
RMSE
Rsquared
RMSE SD
Rsquared SD
1
2
1.54
0.438
0.128
0.0802
1
3
1.12
0.7
0.0968
0.0647
1
4
1.06
0.73
0.0849
0.0594
1
5
1.02
0.75
0.102
0.0551
1
6
0.984
0.768
0.0733
0.042
1
7
0.919
0.796
0.0657
0.0432
1
8
0.862
0.821
0.0418
0.0237
2
33
0.701
0.883
0.068
0.0307
2
34
0.702
0.883
0.0699
0.0307
2
35
0.696
0.885
0.0746
0.0315
2
36
0.687
0.887
0.0604
0.0281
2
37
0.696
0.885
0.0689
0.0291
2
38
0.686
0.887
0.0626
0.029
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were degree = 1 and nprune = 38.
> head(predict(marsTuned, soLTestXtrans))
[1] 0.3677522 -0.1503220 -0.5051844 0.5398116 -0.4792718 0.7377222
Для оценки важности каждого предиктора в модели MARS используются две функции: evimp из пакета earth и varlmp из пакета caret (при этом вторая вызывает первую):
> varlmp(marsTuned)
earth variable importance
only 20 most important variables shown (out of 228)
Overall
MolWeight
100.00
NumNonHAtoms
89.96
SurfaceArea2
89.51
SurfaceAreal
57.34
FP142
44.31
FP002
39.23
NumMultBond
s 39.23
FP204
37.10
FP172
34.96
196 Глава 7. Нелинейные регрессионные модели
NumOxygen NumNitrogen FP083 NumNonHBonds
FP059
FP135
FP154
FP207
FP202
30.70
29.12
28.21
26.58
24.76
23.51
21.20
19.05
17.92
16.94
16.02
NumRotBonds
FP085
Эти результаты масштабируются в интервале от 0 до 100, отличаясь от приведенных в табл. 7.1 (представленная в табл. 7.1 модель не прошла полный процесс роста и усечения). Отметим, что переменные, следующие за несколькими первыми из них, менее значимы для модели.
SVM, метод опорных векторов
Реализации моделей SVM содержатся в нескольких пакетах R. У Чанга и Лина (Chang and Lin, 2011) функция svm из пакета е1071 использует интерфейс к библиотеке LIBSVM для регрессии. Более полная реализация моделей SVM для регрессии по Карацоглу (Karatzoglou et al., 2004) содержится в пакете kernlab, включающем и функцию ksvm для регрессионных моделей и большого количества ядерных функций. По умолчанию используется радиальная базисная функция. Если значения стоимости и ядерных параметров известны, то аппроксимация модели может быть выполнена следующим образом:
> svmFit <- ksvm(x = soLTrainXtrans, у = soLTrainY,
+ kerneL = "rbfdot", kpar = "automatic",
+ C = 1, epsiLon = 0.1)
Для оценки о применен автоматизированный анализ. Так как у является числовым вектором, функция заведомо аппроксимирует регрессионную модель (вместо классификационной модели). Можно использовать и другие ядерные функции, включая полиномиальные (kernel = "polydot") и линейные (kernel = "vanilladot").
Если значения неизвестны, то их можно оценить посредством повторной выборки. В train значения "svmRadial", "svmLinear" или "svmPoly" параметра method выбирают разные ядерные функции:
> svmRTuned <- train(soLTrainXtrans, soLTrainY,
* method = "svmRadiaL",
+ preProc = c("center", "scaLe"),
+ tuneLength = 14,
+ trControL = trainControL(method = "cv"))
7.5. Вычисления 197
Аргумент tuneLength использует по умолчанию 14 значений стоимости 2 2, 2 \ 211. Оценка о по умолчанию выполняется посредством автоматического анализа.
> svmRTuned
951 samples
228 predictors
Pre-processing: centered, scaled
Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 855, 858, 856, 855, 855, 856, ...
Resampling results across tuning parameters:
c
RMSE
Rsquared
RMSE SD
Rsquared SD
0.25
0.793
0.87
0.105
0.0396
0.5
0.708
0.889
0.0936
0.0345
1
0.664
0.898
0.0834
0.0306
2
0.642
0.903
0.0725
0.0277
4
0.629
0.906
0.067
0.0253
8
0.621
0.908
0.0634
0.0238
16
0.617
0.909
0.0602
0.0232
32
0.613
0.91
0.06
0.0234
64
0.611
0.911
0.0586
0.0231
128
0.609
0.911
0.0561
0.0223
256
0.609
0.911
0.056
0.0224
512
0.61
0.911
0.0563
0.0226
1020
0.613
0.91
0.0563
0.023
2050
0.618
0.909
0.0541
0.023
Tuning parameter 'sigma' was held constant at a value of 0.00387 RMSE was used to select the optimal model using the smallest value.
The final values used for the model were C = 256 and sigma = 0.00387.
Подобъект f inalModel содержит модель, созданную функцией ksvm:
> svmRTuned$finaLModeL
Support Vector Machine object of class "ksvm"
SV type: eps-svr (regression)
parameter : epsilon =0.1 cost C = 256
Gaussian Radial Basis kernel function.
Hyperparameter : sigma = 0.00387037424967707
Number of Support Vectors : 625
Objective Function Value : -1020.558 Training error : 0.009163
198 Глава 7. Нелинейные регрессионные модели
В качестве опорных векторов модель использует 625 точек данных тренировочного набора (то есть 66 % тренировочного набора).
Пакет kernlab содержит реализацию модели RVM для регрессии в функции rvm. Ее синтаксис очень похож на представленный в примере для ksvm.
Метод KNN
Функция knnreg из пакета caret аппроксимирует регрессионную модель KNN; функция train настраивает модель по К:
> # Сначала удаляются разреженные и несбалансированные предикторы.
> knnDescr <- solTrainXtrans[, -nearZeroVar(solTrainXtrans)]
> set.seed(100)
> knnTune <- train(knnDescr,
+ solTrainY,
+ method = "knn",
+ # Центрирование и масштабирование будет выполняться
+ # для новых прогнозов
+ preProc = c("center", "scale"),
ч- tuneGrid = data.frame(.k = 1:20),
+ trControl = trainControl(method = "cv"))
При прогнозировании новых точек с использованием этого объекта новые точки данных автоматически проходят центрирование и масштабирование с использованием значений, определяемых тренировочным набором.
Упражнения
7.1. Смоделируйте один предиктор и нелинейную связь (по аналогии с синусоидой на рис. 7.7). Проанализируйте связь между стоимостью, г и ядерными параметрами для модели SVM:
> set.seed(100)
> х <- runif(100, min = 2, max = 10)
> у <- sin(x) + rnorm(Length(x)) ♦ .25
> sinData <- data.frame(x = x, у = у)
> pLot(x, у)
> ## Создание таблицы из х значений для использования при прогнозировании
> dataGrid <- data.frame(x = seq(2, 10, Length = 100))
А. Проведите аппроксимацию разных моделей с использованием радиальной базовой функции, разных значений стоимости (параметр 0 и е. Выведите график полученной кривой. Пример:
Упражнения 199
> library(kernlab)
> rbfSVM <- ksvm(x = x,y=y, data = sinData,
+ kernel ="rbfdot", kpar = "automatic",
+ C = 1, epsilon = 0.1)
> modelprediction <- predict(rbfSVM, newdata = dataGrid)
> ## Матрица с одним столбцом. Мы можем вывести прогнозы модели,
> ## добавляя точки на предыдущую диаграмму
> points(x = dataGrid$x, у = modelPrediction[,1],
+ type = "1", col = "blue")
> ## Проверка других параметров
Б. Параметр о можно регулировать при помощи аргумента краг — например, краг = list (sigma = 1). Опробуйте разные значения а, чтобы понять, как этот параметр влияет на обучение модели. Как стоимость, ей о влияют на модель?
7.2. Фридман (Friedman, 1991) предложил ряд эталонных наборов данных, создаваемых посредством имитационных вычислений. В одном из этих наборов для создания данных используется следующее нелинейное уравнение:
у = 10sin(nx1x2) + 20(х3 - 0,5)2 + 10х4 + 5х5 + У(0, о2),
где значения х представляют собой случайные переменные, равномерно распределенные в интервале [0,1] (также в имитации создаются пять других неинформативных переменных). Пакет mlbench содержит функцию с именем mlbench. f riedmanl, которая генерирует эти данные:
> Library(mLbench)
> set.seed(200)
> trainingData <- mLbench.friedmanl(200, sd - 1)
> ## Данные 'x' преобразуются из матрицы в кадр данных.
> ## В частности, это делается для того, чтобы столбцам
> ## были назначены имена.
> trainingData$x <- data.frame(trainingData$x)
> ## Для анализа данных используется визуальное представление
> featurePLot(trainingData$x, trainingData$y)
> ## или другие методы.
>
> ## Создается список с вектором ’у’ и матрицей предикторов
> ## 'х'. Также имитируется большой тестовый набор
> ## для оценки истинной частоты ошибок с хорошей точностью:
> testData <- mLbench.friedmanl(5000, sd = 1)
> testData$x <- data.frame(testDota$x)
>
Настройте несколько моделей для этих данных. Пример:
> Library(caret)
> knnModeL <- train(x = trainingData$x,
200 Глава 7. Нелинейные регрессионные модели
+
у = trainingData$y,
+
method = "knn",
+
preProc = c("center", "scaLe"),
+
tuneLength = 10)
> knnModeL
200 samples
10 predictors
Pre-processing: centered, scaled Resampling: Bootstrap (25 reps)
Summary of sample sizes: 200, 200, 200, 200, 200, 200, ...
Resampling results across tuning parameters:
k
RMSE
Rsquared
RMSE SD
Rsquared SD
5
3.51
0.496
0.238
0.0641
7
3.36
0.536
0.24
0.0617
9
3.3
0.559
0.251
0.0546
11
3.24
0.586
0.252
0.0501
13
3.2
0.61
0.234
0.0465
15
3.19
0.623
0.264
0.0496
17
3.19
0.63
0.286
0.0528
19
3.18
0.643
0.274
0.048
21
3.2
0.646
0.269
0.0464
23
3.2
0.652
0.267
0.0465
RMSE was used to select the optimal model using the smallest value. The final value used for the model was к = 19.
> knnPred <- predict(knnModeL, newdata = testDatafx)
> ## Функция 'postResampLe' может использоваться для получения
> ## значений эффективности тестового набора
> postResampLe(pred = knnPred, obs = testDatafy)
RMSE Rsquared
3.2286834 0.6871735
Какие модели обеспечивают наилучшую эффективность? Выбирает ли модель MARS информативные предикторы (с именами Х1-Х5)?
7.3. Постройте модели SVM, нейросети, MARS и KNN для данных Tecator, описанных в этой главе. Поскольку нейросети особенно чувствительны к предикторам с высокой корреляцией, улучшит ли модель предварительная РСА-обработка?
7.4. Вернитесь к задаче проницаемости, описанной в упражнении 6.2. Проведите тренировку нескольких нелинейных регрессионных моделей, оцените эффективность повторной выборки и тестового набора.
Упражнения 201
A. Какая модель нелинейной регрессии обеспечивает оптимальную эффективность повторной выборки и тестового набора?
Б. Превосходит ли по эффективности какая-либо из нелинейных моделей оптимальную линейную модель, разработанную в упражнении 6.2? Если превосходит, то как это характеризует связи между предикторами и реакцией?
B. Порекомендуете ли вы какую-либо из своих моделей для замены лабораторного эксперимента по измерению проницаемости?
7.5. В упражнении 6.3 описаны данные производственного процесса химикатов. Используйте те же этапы подстановки данных, разделения данных и предварительной обработки, как и прежде, и проведите тренировку нескольких моделей нелинейной регрессии.
A. Какие модели нелинейной регрессии обеспечивают оптимальную эффективность повторной выборки и тестового набора?
Б. Какие предикторы наиболее важны для оптимальной модели нелинейной регрессии? Доминируют ли в списке биологические предикторы или предикторы процесса? Что можно сказать о сравнении десяти самых важных предикторов с десятью верхними предикторами из оптимальной линейной модели?
B. Исследуйте связи между важнейшими предикторами и реакцией для предикторов, уникальными для оптимальной модели нелинейной регрессии. Дают ли эти диаграммы какую-либо информацию о биологических предикторах или предикторах процесса, а также об их связи с выходом продукта?
Древовидные модели. Модели на базе правил
Древовидные модели состоят из одной или нескольких вложенных команд if-then для предикторов, разделяющих данные, и в дальнейшем прогнозируют результаты для каждого из образованных разделов. Например, простейшее дерево может быть определено в виде:
if Predictor А >= 1.7 then
| if Predictor В >= 202.1 then Outcome =1.3
| else Outcome =5.6
else Outcome =2.5
Здесь двумерное пространство предикторов разделяется на три области, для каждой из которых результат прогнозируется одним числом (1,3,2,5 или 5,6, см. также рис. 8.1).
Для древовидных моделей применимы два метода разделения данных на три терминальных (концевых) узла, или листа дерева.
Согласно первому из них, для получения прогноза новой точки данных движение по командам if-then, определяемым деревом, исходя из значений предикторов точки, продолжается до терминального узла, в котором формула модели использована для генерирования прогноза. Второй метод предусматривает определение терминального узла посредством более сложной функции предикторов (подробнее о деревьях регрессии см. разделы 8.1 и 8.2).
Обратите внимание: команды if-then, генерируемые деревом, определяют для каждой точки данных уникальный маршрут к одному терминальному узлу. Правило представляет собой набор условий if-then (возможно, созданных деревом), объединенных в независимое условие. В приведенном выше примере задействованы три правила:
if Predictor А >= 1.7 and Predictor В >= 202.1 then Outcome =1.3
if Predictor A >= 1.7 and Predictor В < 202.1 then Outcome =5.6
if Predictor A < 1.7 then Outcome =2.5
Древовидные модели. Модели на базе правил 203
250
150
200
100
0,5 1,0 1,5 2,0 2,5
Предиктор А
Рис. 8.1. Пример прогнозирования значений в областях, определяемых древовидной моделью
Правила могут упрощаться или уточняться так, чтобы точки данных соответствовали одновременно нескольким правилам. Такой подход обладает некоторыми преимуществами перед простыми древовидными моделями (о моделях на базе правил см. разделы 8.3 и 8.7).
Древовидные модели и модели на базе правил стали популярными инструментами моделирования по ряду причин. Эти модели генерируют набор условий, которые легко интерпретируются и легко реализуются. Вследствие логики своего построения они способны эффективно обрабатывать многие типы предикторов (разреженные, смещенные, непрерывные, категорийные и т. д.) без необходимости предварительной обработки. Кроме того, эти модели не требуют от пользователя задавать форму связи предикторов с реакцией (в отличие от модели линейной регрессии). И наконец, эти модели могут эффективно справляться с отсутствующими данными и неявно проводить выбор признаков.
Тем не менее у моделей, основанных на одиночных деревьях или правилах, имеются и специфические недостатки. Первый из них — нестабильность модели, проявляющийся в том, что небольшие изменения в данных могут радикально изменять структуру данных или правил, а следовательно, и их интерпретацию.
Второй недостаток — не вполне оптимальная предиктивная эффективность рассматриваемых моделей, обусловленная тем, что они определяют прямоугольные модели, содержащие более однородные значения результата. Если же связь между
204 Глава 8. Древовидные модели. Модели на базе правил предикторами и реакцией не может быть адекватно определена прямоугольными подпространствами предикторов, то древовидные модели или модели на базе правил будут обладать большей погрешностью прогнозирования, чем другие типы моделей.
Для преодоления этих проблем исследователи разработали ансамблевые методы, объединяющие несколько деревьев (или моделей на базе правил) в одну модель. Ансамбли (подробнее см. разделы 8.4-8.7) обычно обладают намного лучшей предиктивной эффективностью, чем одиночные деревья (последнее в целом применимо и к древовидным моделям).
8.1. Базовые деревья регрессии
Базовые деревья регрессии разбивают данные на меньшие группы, более однородные в отношении прогноза. Для достижения однородности результата деревья регрессии определяют:
О предиктор, по которому производится разделение, и его значение;
О глубину или сложность дерева;
О уравнение прогнозирования в терминальных узлах.
В этом разделе мы сосредоточимся на рассмотрении методов, основанных на моделях, содержащих в терминальных узлах простые константы.
Существуют различные методы построения деревьев регрессии. Один из самых старых и популярных вариантов — описанная у Бреймана (Breiman et al., 1984) методология деревьев классификации и регрессии (CART, Classification And Regression Tree). Для регрессии модель начинается со всего набора данных S и проверяет все значения каждого предиктора, чтобы найти предиктор и значение разделения, при котором данные делятся на две группы (5t и 52) с минимальной общей суммой квадратов погрешностей (SSE):
SSE=Е й )2 + Е (-^- у 2 )2 - (8.1)
i 6 5, ieS2
где ух и у2 — средние значения результатов тренировочного набора в группах Sx и S2 соответственно. Затем в каждой из групп Sx и S2 отыскиваются предиктор и значение разделения, наиболее заметно снижающие SSE. Из-за рекурсивной природы разделения деревьев регрессии этот метод также называется рекурсивным разделением.
Вернемся к примеру с данными растворимости. На рис. 8.2 показан график SSE для континуума разделений количества атомов углерода (по преобразованной шкале).
8.1. Базовые деревья регрессии 205
О о о
о о о со
1 2 3 4 5 6
Количество атомов углерода (преобразованное)
Рис. 8.2. Вверху: диаграмма разброса значений растворимости (ось у) и количества атомов углерода (по преобразованной шкале). Внизу: профиль SSE для всех возможных разбиений данного предиктора. В данном случае для разбиения используются средние точки между двумя разными точками данных
В дереве регрессии оптимальная точка разделения для этой переменной равна 3,78. Сокращение SSE, обусловленное разделением, сравнимо с оптимальными значениями для всех остальных предикторов. Разделение, связанное с минимумом абсолютной погрешности, используется для формирования подмножеств 51 и 52. После рассмотрения всех вариантов эта переменная выбрана как наилучшая (рис. 8.3).
При остановке процесса все точки со значениями предиктора, меньшими 3,87, прогнозировались бы на уровне -1,84 (среднее значение результатов растворимости для этих точек данных), а для точек выше порога разделения — на уровне -4,49:
if the number of carbon atoms >= 3.78 then Solubility = -4.49
else Solubility = -1.84
На практике процесс продолжается в множествах и S2 до тех пор, пока количество точек данных в разделении не снизится до некоторого порога, например до 20 точек
206 Глава 8. Древовидные модели. Модели на базе правил данных. На этом завершается этап формирования дерева. На рис. 8.4 показан второй набор разделений для данных примера.
Рис. 8.3. Наверху: исходные разбиения данных растворимости, внизу: после первого разбиения две группы снова разбиваются на четыре области
8.1. Базовые деревья регрессии 207
Рис. 8.4. Итоговая модель CART для данных растворимости. Блочные диаграммы в терминальных узлах демонстрируют распределение значений растворимости тренировочного набора. Итоговый прогноз базируется на среднем значении точек данных в блочных диаграммах
208 Глава 8. Древовидные модели. Модели на базе правил
Если предиктор является непрерывным, то процесс поиска оптимальной точки разделения достаточно тривиален, поскольку данные могут быть упорядочены естественным образом. Бинарные предикторы также легко прогнозируются вследствие существования только одной возможной точки разделения. Если же предиктор имеет более двух категорий, то возможно несколько приемлемых вариантов поиска оптимальной точки разделения (подробнее об этом см. раздел 14.1).
Сформированное дерево может оказаться очень большим, что, как правило, ведет к переобучению тренировочного набора. Затем дерево усекается до потенциально меньшей глубины. У Бреймана (Breiman et al., 1984) для этого используется процесс настройки «стоимость—сложность», позволяющий определить требуемый размер дерева с наименьшей частотой ошибок посредством назначения последней частоте штрафа по размеру дерева:
SSEf = SSE + ср х (#терминальных узлов),
где ср — параметр сложности.
Для конкретного значения параметра сложности находится усеченное дерево с наименьшей штрафной частотой ошибок. У Бреймана (Breiman et al., 1984) приведена теория и алгоритмы поиска лучшего дерева для конкретного значения ср. Меньшие штрафы, по аналогии с рассмотренными ранее методами регуляризации, обычно ведут к формированию более сложных моделей, в данном случае — к большим деревьям. При больших значениях параметра сложности можно получить дерево с одним разделением («пень») и даже дерево без разделений. Последнее означает, что ни один предиктор не дает адекватного объяснения наблюдаемому объему разброса результатов при заданном значении параметра сложности.
Чтобы найти лучшее усеченное дерево, следует провести оценку данных по последовательности значений ср. Этот процесс генерирует одно значение SSE для каждого выбранного значения ср. Но сгенерированные значения SSE изменятся при другой выборке наблюдений. Чтобы понять вариативность SSE для каждого значения ср, Брейман (Breiman et al., 1984) рекомендует метод перекрестной проверки (по аналогии с методом, рассмотренным в главе 4). Кроме того, предлагается использовать правило одной стандартной погрешности как критерий оптимизации для выявления простейшего дерева, то есть найти наименьшее дерево, лежащее в пределах одной стандартной погрешности от дерева с наименьшей абсолютной погрешностью (см. раздел 4.6). Метод, представленный Хэсти (Hastie et al., 2008), выбирает размер дерева, связанный с минимальным значением погрешности.
При использовании правила одной стандартной погрешности дерево регрессии, построенное на данных растворимости, характеризуется наличием 11 терминальных узлов (ср = 0,01) при значении оценки среднеквадратичной погрешности с перекрестной проверкой 1,05.
8.1. Базовые деревья регрессии 209
Вновь обратимся к рис. 8.4. Во всех разделениях, сохраненных в представленной модели, задействованы непрерывные или счетные предикторы, а некоторые пути по дереву используют одни и те же предикторы неоднократно.
На первый взгляд это дерево представляется вполне интерпретируемым. Например, можно заключить, что если вещество содержит относительно большое количество атомов углерода, характеризуется очень низкой площадью поверхности и большим количеством неводородных атомов, то оно обладает и самой низкой растворимостью. Однако в данных существует много перекрывающихся разделов. Например, узлы 12 и 16 имеют приблизительно одинаковое распределение значений растворимости, хотя в одном случае наблюдается малая площадь поверхности, а в другом, наоборот, большая.
Модель может настраиваться и посредством выбора значения параметра сложности, связанного с наименьшим возможным значением среднеквадратичной погрешности. Профиль перекрестной проверки показан на рис. 8.5.
10Л-2,5 10л-2,0 10л-1,5 10л-1,0 10л-0,5
Параметр сложности
Рис. 8.5. Профиль среднеквадратичной погрешности с перекрестной проверкой для дерева регрессии
В этом случае процесс настройки выбирает большее дерево со значением с, равным 0,003, и 25 терминальными узлами. Оцениваемая среднеквадратичная погрешность модели составила 0,97. Эта модель более точно аппроксимирует данные, хотя по глубине заметно превосходит дерево, представленное на рис. 8.4, в связи с чем и интерпретировать ее будет намного сложнее.
Эта конкретная методология дерева также справляется с отсутствующими данными (посредством их игнорирования). Для каждого разделения оцениваются различные
210 Глава 8. Древовидные модели. Модели на базе правил альтернативы (именуемые суррогатными разделениями). Суррогатное разделение дает результаты, близкие к результатам исходного разделения, фактически используемого в дереве. Если суррогатное разделение хорошо аппроксимирует исходное разделение, то оно может использоваться тогда, когда данные предикторов, связанные с исходным разделением, недоступны. На практике для каждого конкретного разделения в дереве могут сохраняться несколько суррогатных разделений.
После формирования дерева следует оценить относительную важность предикторов для результата. Один из способов вычисления агрегатных значений важности, упоминаемых Брейманом (Breiman et al., 1984), заключается в отслеживании общего сокращения в критерии оптимизации для каждого предиктора. Если критерием оптимизации является SSE, то сокращение SSE для тренировочного набора агрегируется для всех предикторов. При этом предикторы, расположенные выше, или те, что встречаются в дереве неоднократно, будут важнее предикторов, расположенных ниже или не встречающихся вообще. На рис. 8.6 показаны значения важности для 16 предикторов в более сложной итоговой модели растворимости.
Важность
Рис. 8.6. Показатели важности переменных для 16 предикторов, используемых в модели дерева регрессии для растворимости
Преимущество древовидных моделей и в том, что при небольшом дереве модель получается простой и легко интерпретируемой. Кроме того, деревья этого типа могут вычисляться достаточно быстро (несмотря на многократный исчерпывающий поиск). Древовидные модели проводят выбор признаков автоматически; если пре-
8.1. Базовые деревья регрессии 211
диктор не используется в разделении, то уравнение прогнозирования независимо от соответствующих данных.
Это преимущество нивелируется при наличии предикторов с высокой корреляцией. Если два предиктора избыточно коррелированы, то выбор того, какой из них следует использовать в разделении, во многом случаен. Например, два предиктора площади поверхности обладают исключительно высокой корреляцией (0,96), и каждый используется в дереве, показанном на рис. 8.4. Возможно, малое различие между этими предикторами оказывает сильное влияние на выбор между ними, однако более вероятно, что он будет предопределяться мелкими, случайными различиями в переменных. Это может привести к выбору большего числа предикторов, чем необходимо. Кроме того, на значения важности переменных влияет корреляция. Если данные растворимости содержат только один из предикторов площади поверхности, то именно этот предиктор с большой вероятностью и будет дважды использоваться в дереве, что приведет к росту его важности. С другой стороны, включение в данные обоих предикторов площади поверхности приведет к тому, что их важность останется на умеренном уровне.
Деревья хорошо интерпретируются и вычисляются, но у них есть недостатки, о которых следует упомянуть особо. Во-первых, одиночные деревья регрессии могут иметь субоптимальную предиктивную эффективность по сравнению с другими средствами моделирования. Отчасти это обусловлено их сравнительной простотой: древовидные модели разделяют данные на прямоугольные области пространства предикторов. Но если связь между предикторами и их результатом не может быть адекватно описана такими прямоугольниками, то предиктивная эффективность дерева не будет оптимальной. Кроме того, количество возможных прогнозируемых результатов дерева является конечным и предопределяется количеством терминальных узлов. Так, для данных растворимости оптимальное дерево содержит 11 терминальных узлов и, следовательно, может породить только 11 возможных прогнозируемых значений.
Такое ограничение вряд ли позволит отразить все нюансы данных. Например, на рис. 8.4 узел 21 соответствует прогнозу с наивысшей растворимостью, однако данные тренировочного набора, приходящиеся на этот путь по дереву, изменяются в масштабе нескольких логарифмических единиц данных. Если новые точки данных согласуются с тренировочными данными, то многие из новых точек данных, приходящихся на этот путь, не будут прогнозироваться с требуемой точностью. У двух моделей деревьев регрессии, рассмотренных ранее, значения среднеквадратичной погрешности были существенно выше среднеквадратичной погрешности модели простой линейной регрессии (см. главу 6).
Дополнительный недостаток — в том, что отдельные деревья нередко оказываются нестабильными, о чем, в частности, упоминают Брейман и Хэсти (Breiman 1996b, Hastie et al., 2008, Chap. 8). Даже при малом изменении данных может быть получен совершенно иной набор разделений, что указывает на значительность дисперсии модели. Однако рассматриваемые ниже ансамблевые методы используют эту осо-
212 Глава 8. Древовидные модели. Модели на базе правил бенность для создания моделей, обычно обладающих эффективностью, близкой к максимальной.
Наконец, эти деревья подвержены смещению выбора: предикторам, принимающим больше разных значений, отдается предпочтение перед предикторами с большей гранулярностью, о чем пишут Кэролин, Лу и Ши (Carolin et al., 2007; Loh and Shih, 1997; Loh, 2010). Двое последних (Loh and Shih, 1997) замечают также, что «...опасность возникает в тех случаях, когда набор данных содержит смесь информативных и шумовых переменных и шумовые переменные имеют намного больше разделений, чем информативные. Тогда возникает высокая вероятность того, что шумовые переменные будут выбраны для разделения верхних узлов дерева. После усечения будет построено дерево с нарушенной структурой, или же дерево вообще не будет построено».
Кроме того, с ростом количества отсутствующих значений еще более увеличивается смещение выбора предикторов (Carolin et al., 2007).
Показатели важности переменных для дерева регрессии данных растворимости (см. рис. 8.6) подтверждают склонность модели к большей зависимости от непрерывных (то есть менее гранулярных) предикторов, чем от бинарных показателей, что может объясняться или смещением выбора, или содержимым переменных.
Существуют и несмещенные методы деревьев регрессии. Например, Лу (Loh, 2002) предлагает обобщенный несмещенный алгоритм с обнаружением взаимодействий и оценкой (GUIDE), который решает проблему за счет обособления процессов выбора переменной и значения разделения. Алгоритм ранжирует предикторы с использованием статистической проверки гипотез, после чего находит подходящее значение разделения, связанное с самым важным фактором.
Другое возможное решение, предложенное Хоторном (Hothorn et al., 2006), — деревья условного вывода (conditional inference trees). Они описывают унифицированную основу для построения несмещенных моделей на базе деревьев для регрессии, классификации и других сценариев. В этой модели проверки статистических гипотез используются для проведения исчерпывающего поиска по предикторам и возможным точкам разделения. Для потенциального разделения статистическая проверка используется при оценке разности между средними значениями двух групп, созданными в результате разделения (с вычислением р-значения).
Применение статистики p-значения обладает рядом преимуществ. Во-первых, появляется возможность сравнения предикторов с разными шкалами, поскольку p-значения лежат на одной шкале. Во-вторых, к необработанным p-значениям могут применяться, как это показано у Уэстфолла и Янга (Westfall and Young, 1993), корректировки множественных сравнений для сокращения смещения. Оно возникает из-за большого числа кандидатов для разделения, посредством уменьшения количества ложноположительных результатов проверки, обусловленных избыточным количеством проверок статистических гипотез. Процедуры множественных
8.1. Базовые деревья регрессии 213
сравнений назначают предикторам возрастающие штрафы с ростом количества разделений (и связанных с ними ^-значений), что ведет к сокращению смещения для данных с высокой гранулярностью. Порог статистической значимости позволяет выяснить, нужно ли создавать дополнительные разделения (у Хоторна (Hothorn et al., 2006) используется 1-p-значение).
По умолчанию этот алгоритм не использует усечения; с дальнейшим разделением наборов данных уменьшение количества точек данных сокращает влияние проверок гипотез. Это приводит к более высоким p-значениям, более низкой вероятности нового разделения и переобучения. Однако проверки статистических гипотез не связаны напрямую с предиктивной эффективностью, из-за чего сложность дерева рекомендуется выбирать на основе эффективности (с использованием повторной выборки или других методов).
С порогом значимости 0,05 (что соответствует 5 % ложноположительных значений) дерево условного вывода для данных растворимости содержит 32 терминальных узла. Это дерево намного больше базового дерева регрессии (см. рис. 8.4). Кроме того, интерпретирован статистический порог как параметр настройки с оценкой 16 значений от 0,75 до 0,99 (см. профиль перекрестной проверки на рис. 8.7).
-D
Ь о
0,75 0,80 0,85 0,90 0,95 1,00
Порог = 1 - р-значение
Рис. 8.7. Профиль среднеквадратичной погрешности для регрессионных деревьев условного вывода
Дерево, связанное с наименьшей ошибкой, содержит 36 терминальных узлов (с порогом 0,853). Настройка порога позволила улучшить оцениваемую среднеквадратичную погрешность до значения 0,92 (по сравнению со среднеквадратичной погрешностью 0,94, связанной с порогом значимости 0,05).
214 Глава 8. Древовидные модели. Модели на базе правил
8.2. Деревья регрессионных моделей
Один из минусов простых деревьев регрессии — в том, что каждый терминальный узел использует для прогнозирования среднего значения результаты тренировочного набора соответствующего узла. Как следствие, эти модели не всегда хорошо справляются с прогнозированием точек, истинные результаты которых были аномально низки или высоки. Ранее, на рис. 5.1, представлен пример диаграммы наблюдаемых и прогнозируемых результатов для набора данных. Изображенная на рисунке модель в каждом из крайних случаев склонна к занижению прогнозов, построенных с использованием ансамблевого метода деревьев регрессии, именуемого случайными лесами (подробнее см. далее). Этот метод также использует среднее значение тренировочных данных в терминальных узлах и подвержен той же проблеме (пусть и в меньшей степени, чем с одиночным деревом).
Один из способов решения проблемы — использование другой оценочной функции в терминальных узлах. Обратимся в этой связи к методу деревьев моделей, описанному у Кинлана (Quinlan, 1992), или методу А/5, сходному с методом деревьев регрессии, за исключением следующих аспектов:
О используется другой критерий разделения;
О терминальные узлы прогнозируют результат с использованием линейной модели, а не посредством простого усреднения;
О прогноз для точки данных часто является комбинацией прогнозов разных моделей, находящихся на одном пути по дереву.
Основная реализация этого метода является «рациональной реконструкцией» модели М5, описанной у Ванга и Уиттена (Wang and Witten, 1997) и включенной в программный пакет Weka. Существуют и другие варианты реализации моделей с более сложной и разветвленной структурой, упоминаемые Лу (Loh, 2002) и Зей- лейсом (Zeileis et al., 2008).
Как и для простых деревьев регрессии, исходное разделение — результат исчерпывающего поиска по предикторам и точкам данных тренировочного набора, но, в отличие от этих моделей, здесь используется ожидаемое сокращение частоты ошибок узла. Пусть S — весь набор данных, а ..., Sp — Р подмножеств данных после разделения. Критерий разделения имеет вид
уменьшение = SD(S) - V—х SD(Si), (8.2)
п
где SD — стандартное отклонение, a ni — количество точек данных в разделе I. Представленное выражение позволяет определить, будет ли общая дисперсия в разделениях, взвешенных по размеру выборки, ниже, чем у заранее разделенных данных. Эта схема напоминает методологию классификационных деревьев, рас-
8.2. Деревья регрессионных моделей 215
смотренную у Кинлана (Quinlan, 1993b), в соответствии с которой выбирается разделение, связанное с наибольшим сокращением частоты ошибок, и создается линейная модель в разделах, использующих переменную разделения в модели. Для последующих итераций разделения процесс повторяется: сначала определяется исходное разделение, затем создается линейная модель с использованием текущей переменной разделения и переменных, ей предшествующих. Погрешность, связанная с каждой линейной моделью, используется вместо SD(S) в формуле 8.2 для определения ожидаемого сокращения частоты ошибок для следующего разделения. Процесс формирования дерева продолжается по ветвям до тех пор, пока частота ошибок не перестанет улучшаться, или до исчерпания точек. После того как дерево будет полностью сформировано, в каждом его узле будет содержаться линейная модель.
Рис. 8.8. Пример дерева регрессионных моделей
На рис. 8.8 показан пример дерева с четырьмя разделениями и восемью субмоделями линейной регрессии. Например, модель 5 будет создана с использованием всех предикторов из разделений 1-3 и точками данных тренировочного набора, удовлетворяющими условиям \а, 2Ь и ЗЬ.
После формирования полного набора линейных моделей каждая из них проходит процедуру упрощения посредством удаления некоторых составляющих. Для заданной модели вычисляется скорректированная частота ошибок. Сначала вычисляются
216 Глава 8. Древовидные модели. Модели на базе правил
абсолютные разности между наблюдаемыми и прогнозируемыми данными, после чего результат умножается на составляющую, которая вводит штраф для моделей с большим количеством параметров: где п — количество точек данных тренировочного набора, которые использовались для построения модели, ар — число параметров. Каждая составляющая модели последовательно исключается, затем вычисляется скорректированная частота ошибок. Составляющие удаляются из модели до тех пор, пока скорректированная частота ошибок не начнет расти. В некоторых случаях линейную модель можно упростить так, чтобы она содержала только точку пересечения. Эта процедура применяется независимо к каждой линейной модели.
Деревья моделей также включают разновидность сглаживания для снижения возможности переобучения. Этот метод основан на методологии «рекурсивного сжатия» Хэсти и Прегибона (Hastie and Pregibon, 1990). При прогнозировании новая точка данных проходит вниз по соответствующему пути дерева, после чего линейные модели на этом пути объединяются с движением снизу вверх. Воспользовавшись примером, представленным на рис. 8.8, предположим, что новая точка данных проходит вниз по пути, связанному с моделью 5.
Дерево генерирует прогноз для этой точки с использованием модели 5, а также линейной модели в родительском узле (в данном случае — модель 3). Два прогноза объединяются по формуле: У(Р) =
где y(k) — прогноз от дочернего узла (модель 5), n(k) — количество точек данных тренировочного набора в дочернем узле, у^ — прогноз от родительского узла, а с — константа со значением, равным по умолчанию 15. После вычисления этого комбинированного прогноза он аналогичным образом объединяется со следующей моделью в дереве (модель 1), и т. д. В нашем примере новая точка данных, соответствующая условиям 1а, 2Ь и ЗЬ, будет использовать комбинацию трех линейных моделей. Обратите внимание: уравнение сглаживания представляет собой относительно простую линейную комбинацию моделей.
Такой тип сглаживания может оказать серьезное положительное влияние на дерево моделей, когда линейные модели между узлами сильно различаются. Линейные модели могут строить противоречивые прогнозы по нескольким причинам. Во-первых, количество точек данных в тренировочных наборах, доступных в узле, будет убывать с добавлением новых разделений. Это может привести к тому, что
8.2. Деревья регрессионных моделей 217
узлы, моделирующие сильно различающиеся области тренировочного набора, производят и столь же сильно различающиеся линейные модели, что особенно справедливо для малых тренировочных наборов. Во-вторых, линейные модели, полученные в результате процесса разделения, могут страдать от значительной коллинеарности. Допустим, два предиктора в тренировочном наборе чрезвычайно высоко коррелированы друг с другом. В этом случае алгоритм может выбирать между двумя предикторами случайным образом. Если оба предиктора в конечном итоге используются в разделениях и станут кандидатами для линейных моделей, то линейная модель будет содержать две составляющие для одного и того же фрагмента информации, что может привести к существенной нестабильности в коэффициентах модели. Сглаживание с использованием нескольких моделей может привести к сокращению влияния любых нестабильных линейных моделей. После того как дерево будет полностью сформировано, оно усекается — для этого выполняется поиск и удаление «нежизнеспособных» деревьев. Скорректированная частота ошибок вычисляется, начиная с терминальных узлов (с учетом удаляемого дерева и без него). Дерево исключается из модели, если очевидно, что его сохранение в модели не ведет к снижению скорректированной частоты ошибок. Этот процесс продолжается до исчерпания возможности удаления деревьев из модели.
Деревья моделей строились на данных растворимости при условиях наличия/от- сутствия усечения и наличия/отсутствия сглаживания. На рис. 8.9 показан график профилей перекрестной проверки для этих данных.
Сглаживание
£ 0,90
0,90
о о X
ф
J 0,75
0,75
Да
Нет
Усечение
Рис- 8-9- Профили среднеквадратичной погрешности с перекрестной проверкой для дерева моделей
218 Глава 8. Древовидные модели. Модели на базе правил
В неусеченном дереве существуют 159 путей, которые могут привести к переобучению тренировочных данных. В неусеченном дереве сокращение числа ошибок достигается сглаживанием модели. Для данных, представленных в примере, эффект усечения модели тоже был весьма существенным: количество путей по дереву сократилось со 159 до 18. Для усеченных деревьев сглаживание обеспечивает небольшой прирост эффективности. Оптимальная модель использует и усечение, и сглаживание.
Представленное на рис. 8.10 дерево моделей показывает, что во многих разделениях задействованы одни и те же предикторы, например количество атомов углерода. Кроме того, предпочтение отдается преимущественно непрерывным предикторам перед бинарными1, причем разделение и на базе SSE, и на базе сокращения частоты ошибок дает практически идентичные результаты. Подробности линейных моделей показаны на рис. 8.11 (коэффициенты модели нормализованы по одной шкале). Здесь в большинстве моделей используется множество предикторов, включая бинарные. Тем не менее коэффициенты бинарных предикторов малы по сравнению с непрерывными. Модель может использоваться и для демонстрации проблем с коллинеарностью. Так, линейная модель 5 (в левой нижней части дерева) связывается со следующими условиями:
NumCarbon <= 3.777 &
MolWeight <= 4.83 & SurfaceAreal > 0.978 & NumCarbon <= 2.508 & NumRotBonds <= 0.347 & SurfaceArea2 > 10.065
После сокращения и сглаживания в соответствующей линейной модели остаются 57 коэффициентов, включая оба предиктора площади поверхности. В тренировочном наборе эти предикторы обладают высокой корреляцией (0,96), что позволяет ожидать и значительной коллинеарности. Два масштабированных коэффициента этих предикторов почти всегда противоположны: 0,9 для SurfaceAreal и -0,8 для SurfaceArea2. Идентичность предикторов порождает противоречие: повышение площади поверхности и увеличивает, и уменьшает растворимость — так, у многих моделей на рис. 8.11 эти две переменные имеют противоположные знаки. Несмотря на это, эффективность модели вполне конкурентоспособна; сглаживание модели приводит к минимизации проблем коллинеарности. Удаление коррелированных предикторов позволяет получить менее противоречивую и более интерпретируемую модель. Тем не менее применение этой стратегии сопровождается объективным снижением эффективности.
1 Также обратите внимание на то, что в первых трех разбиениях задействованы те же предикторы, что и в дереве регрессии на рис. 8.4 (а два из трех значений разбиения были идентичны).
8.2. Деревья регрессионных моделей 219
Рис. 8.10. Итоговое дерево моделей для данных растворимости. Числа в нижней части каждого терминального узла представляют количество точек данных и процент покрытия узла
220 Глава 8. Древовидные модели. Модели на базе правил
Модель
Рис. 8.11. Коэффициенты линейных моделей для дерева моделей на рис. 8.10. Коэффициенты были нормализованы по одной шкале. Белые прямоугольники означают, что предиктор не был задействован в линейной модели
8.3. Модели на базе правил 221
8.3. Модели на базе правил
Правило (rule) определяется как отдельный путь по дереву. Рассмотрим дерево моделей из последующего раздела и путь к линейной модели 15 в правой нижней части рис. 8.10:
NumCarbon > З.ТП &
SurfaceArea2 > 0.978 &
SurfaceAreal > 8.404 &
FP009 <= 0.5 &
FP075 <= 0.5 &
NumRotBonds > 1.498 &
NumRotBonds > 1.701
Дерево моделей на рис. 8.10 содержит 18 правил. Новая точка данных может перемещаться вниз по дереву только по одному из путей, определенных этими правилами. Количество точек данных, на которые распространяется правило, называется покрытием этого правила.
В дополнение к алгоритмам усечения, описанным в последнем разделе, сложность дерева моделей может быть дополнительно сокращена либо удалением целых правил, либо удалением некоторых условий, определяющих правило. Отметим, что в предыдущем правиле количество углеродных связей, способных к вращению (NumRotBonds), используется дважды. Это произошло потому, что другой путь по дереву определил, что считается важным моделирование подмножества данных, для которого количество связей, способных к вращению, лежит в диапазоне от 1,498 до 1,701. С другой стороны, рассматривая это правило обособленно, нельзя не признать его излишне сложным из-за избыточности, что указывает на желательность исключения из правила ряда условий второстепенной значимости.
Кинлан (Quinlan, 1993b) описывает методологии упрощения правил, генерируемых деревьями классификации. Похожие методы могут быть применены к деревьям моделей для создания упрощенных наборов правил по сравнению с исходным деревом моделей (этот подход описан ниже в разделе 8.7 в контексте моделей Cubist).
Другой подход к созданию правил на базе деревьев моделей, описанный у Холмса (Holmes et al., 1993), основан на стратегии под названием «разделяй и властвуй», предполагающей вывод правила не из одного, а из нескольких деревьев моделей. Сначала создается исходное дерево моделей (предпочтительнее — на основе не- сглаженных деревьев). Из этой модели сохраняется только правило с наибольшим покрытием. Точки данных, покрываемые этим правилом, исключаются из тренировочного набора, после чего создается другое дерево моделей с оставшимися данными. Из него сохраняется только правило с максимальным покрытием, и т. д.
222 Глава 8. Древовидные модели. Модели на базе правил
Процесс повторяется до тех пор, пока данные всех тренировочных наборов не будут покрываться хотя бы одним правилом. Чтобы спрогнозировать новую точку, сначала определяется, каким правилам она будет соответствовать, после чего применяется линейная модель, связанная с наибольшим покрытием.
Для данных растворимости была проведена оценка модели на базе правил. По аналогии с процессом настройки дерева моделей четыре модели были аппроксимированы со всеми возможными комбинациями усечения и сглаживания. Те же наборы данных повторной выборки были использованы и при анализе дерева моделей (рис. 8.12).
Сглаживание
Да
Нет
Да
Нет
Усечение
Рис. 8.12. Профили среднеквадратичной погрешности с перекрестной проверкой для моделей деревьев до и после преобразования в правила
Правая диаграмма выглядит так же, как на рис. 8.9. На левой диаграмме показаны результаты преобразования деревьев моделей в правила. Для этих данных при использовании сглаживания и усечения дерево моделей и версия на базе правил имеют эквивалентные частоты ошибок. Как и в случае с деревьями моделей, усечение оказывает значительное влияние на модель, а сглаживание — на неусеченные модели.
Для дерева моделей с наилучшей аппроксимацией значение среднеквадратичной погрешности с перекрестной проверкой равняется 0,737. Лучшая модель на базе правил обеспечивала значение среднеквадратичной погрешности, равное 0,741.
Эти данные как будто указывают на то, что более подходящим для прогнозирования представляется дерево моделей. Тем не менее в демонстрационных целях
8.3. Модели на базе правил 223
Номер правила
Рис. 8.13. Коэффициенты линейной модели для версии М5 на базе правил. Коэффициенты были нормализованы, чтобы они располагались на одной шкале с рис. 8.11. Белые прямоугольники означают, что предиктор не был задействован в уравнении линейной регрессии для этого правила
224 Глава 8. Древовидные модели. Модели на базе правил модель на базе правил проанализирована более подробно. Всего для моделирования использовано девять правил (с последним из них не связаны какие-либо условия):
Rule 1: NumCarbon <= 3.777 & MolWeight >4.83
Rule 2: NumCarbon > 2.999
Rule 3: SurfaceAreal > 0.978 & NumCarbon > 2.508 & NumRotBonds > 0.896
Rule 4: SurfaceAreal > 0.978 & MolWeight <= 4.612 & FP063 <= 0.5
Rule 5: SurfaceAreal > 0.978 & MolWeight <= 4.612
Rule 6: SurfaceAreal <= 4.159 & NumHydrogen <= 3.414
Rule 7: SurfaceAreal > 2.241 & FP046 <= 0.5 & NumBonds >2.74
Rule 8: NumHydrogen <= 3.414
Правило, соответствующее модели 10 (см. рис. 8.10), обладает наибольшим покрытием по условиям NumCarbon > 3.77 и MolWeight > 4.83 и сохранено как первое правило в новой модели. Следующее дерево моделей создано с использованием оставшихся точек данных. Здесь правило с наибольшим покрытием имело условие, сходное с предыдущим правилом: NumCarbon > 2.99. В данном случае точка данных с NumCarbon >2.99 покрывается по меньшей мере двумя правилами. Те же предикторы используются и в других правилах: SurfaceAreal (пять раз), MolWeight (три раза) и NumCarbon (также три раза).
На рис. 8.13 показаны коэффициенты линейных моделей для каждого правила (по аналогии с рис. 8.11 для полного дерева моделей). Представленные модели получаются более разреженными, а количество составляющих в них убывает по мере создания новых правил, что вполне логично, поскольку для построения глубоких деревьев остается меньше точек данных.
8.4. Бэггинг-деревья
В 1990-е годы зародились ансамблевые методы (то есть методы, объединяющие прогнозы нескольких моделей). Бэггинг (bagging — сокращение от Bootstrap AGGregation), изначально предложенный Брейманом (Breiman, 1996а), стал одним из первых ансамблевых методов. Бэггинг представляет собой обобщенный подход, использующий бутстрэп (см. раздел 4.4) в сочетании с любой моделью регрессии (или классификации, см. раздел 14.3) для формирования ансамбля. Этот метод имеет относительно простую структуру и состоит из этапов, перечисленных в алгоритме 8.1.
Каждая модель в ансамбле затем используется при генерировании прогноза для новой точки данных, а т прогнозов усредняются для получения прогноза бэггинг- модели.
Бэггинг-модели обладают рядом преимуществ перед другими моделями. Во-первых, бэггинг фактически сокращает дисперсию прогноза посредством агрегирования
8.4. Бэггинг-деревья 225
Алгоритм 8.1. Бэггинг
1 for i-1 to т do
2 Сгенерировать выборку с возвратом для исходных данных
3 Провести тренировку модели неусеченного дерева для этой выборки
4 end
(см. раздел 5.2 и обсуждение обратного отношения между смещением и дисперсией). Для моделей, производящих нестабильные прогнозы (таких, как деревья регрессии), агрегирование по многим версиям тренировочных данных сокращает дисперсию прогноза, одновременно повышая стабильность прогноза. Обратимся в этой связи к рис. 8.14.
Здесь сгенерированы шесть точек данных с применением выборки с возвратом. Для каждой точки строится дерево максимальной глубины. Эти деревья имеют различную структуру (сравните позиции bnd, имеющие разные структуры на правой и левой стороне каждого дерева). Таким образом, прогнозы для точек будут изменяться от дерева к дереву. Если прогнозы усредняются между всеми одиночными деревьями, то средний прогноз будет иметь дисперсию ниже дисперсии отдельных прогнозов. Если сгенерировать разные последовательности точек данных с применением выборки с возвратом, построив модель для каждой точки и усреднив прогнозы между моделями, то для выборки с большой вероятностью будет получено значение, очень близкое к предыдущей бэггинг-модели. Эта характеристика также улучшает предиктивную эффективность бэггинг-модели по сравнению с моделью без бэггинга. Если целью моделирования является поиск наилучшего прогноза, то бэггинг обладает очевидным преимуществом.
С другой стороны, для стабильных моделей с низкой дисперсией, таких как линейная регрессия и MARS, бэггинг не предоставляет значительных улучшений в предиктивной эффективности. Взгляните на рис. 8.15, где бэггинг применяется к деревьям, линейным моделям и моделям MARS для данных растворимости, а также к данным исследования составов бетона (см. главу 10).
Для каждого набора данных строится график зависимости эффективности тестового набора, основанной на среднеквадратичной погрешности, с учетом количества итераций бэггинга. Для данных растворимости снижение среднеквадратичной погрешности между итерациями аналогично для деревьев, линейной регрессии и MARS, что не является типичным результатом: либо прогнозы моделей линейной регрессии и MARS обладают некоторой внутренней нестабильностью, которая может быть улучшена использованием бэггинг-ансамбля, либо деревья менее эффективны для моделирования данных. Результаты бэггинга для данных бетона более типичны — линейная регрессия и MARS в наименьшей мере выигрывают от применения ансамбля, тогда как прогнозы для деревьев регрессии заметно улучшаются.
226 Глава 8. Древовидные модели. Модели на базе правил
Рис. 8.14. Примеры деревьев максимальной глубины с бэггингом для данных растворимости. Следует учитывать, что деревья различаются по структуре, а следовательно, прогнозы будут различаться от дерева к дереву. Дисперсия прогноза для ансамбля деревьев будет меньше дисперсии прогнозов от отдельных деревьев, (а) Выборка 1. (б) Выборка 2. (в) Выборка 3. (г) Выборка 4. (д) Выборка 5. (е) Выборка 6
Чтобы дополнительно продемонстрировать способность бэггинга к сокращению дисперсии прогноза модели, обратимся к имитации синусоидальной волны на рис. 5.2 с моделированием 20 синусоид и последующим вычислением для каждого набора данных деревьев регрессии и модели MARS. Горизонатльные линии обозначают истинный тренд, а множественные черные линии — прогнозы для каждой модели. У модели CART истинную синусоиду окружает больший шум, чем у модели MARS,
8.4. Бэггинг-деревья 227
о г-‘
10 20
30 40
50
О
Количество итераций бэггинга
Рис. 8.15. Профили среднеквадратичной погрешности тестовых наборов для бэггинг- деревьев, линейных моделей и моделей MARS для данных растворимости (верхний график) и данных состава бетона (нижний график; см. главу 10) по количеству точек данных выборки с возвратом. Для данных растворимости бэггинг обеспечивает приблизительно одинаковую степень улучшения среднеквадратичной погрешности для всех трех методов, что нетипично. Более типичная закономерность улучшения от бэггинга наблюдается для данных состава бетона. В этом случае для деревьев достигается наибольший выигрыш у которой вариации проявляются только в точках изменения. В данном случае наблюдается высокая дисперсия дерева регрессии, обусловленная ее нестабильностью. В нижней части отображены результаты 20 деревьев регрессии с бэггингом и моделей MARS (каждая — с 50 итерациями модели). Разброс вокруг истинной кривой сильно сокращается для деревьев регрессии, тогда как для MARS наблюдается снижение разброса только на криволинейных частях графика. При использовании смоделированного тестового набора среднее сокращение среднеквадратичной погрешности при бэггинге для дерева составило 8,6 %, а у более стабильной модели MARS — всего 2 % (рис. 8.16).
Другое преимущество моделей с бэггингом — в их способности к собственной внутренней оценке предиктивной эффективности, хорошо сочетающейся с оценками перекрестной проверки или оценками тестового набора. При построении выборки с возвратом для каждой модели в ансамбле некоторые точки данных опускаются.
228 Глава 8. Древовидные модели. Модели на базе правил
2 4 6 8 10
1.0
0,5
0,0
1,0
0.5
0,0
-0,5
-1,0
2 4 6 8 10
Предиктор
Рис. 8.16. Эффект от применения бэггинга для деревьев регрессии и моделей MARS
Такие точки называются исключенными (out-of-bag) и могут использоваться для оценки предиктивной эффективности конкретной модели, поскольку не использовались для ее построения. Таким образом, каждая модель в ансамбле генерирует показатель предиктивной эффективности благодаря исключенным точкам. Среднее значение метрик эффективности исключенных точек может использоваться для оценки предиктивной эффективности всего ансамбля, причем это значение обычно хорошо коррелирует с оценкой предиктивной эффективности, полученной либо посредством перекрестной проверки, либо по тестовому набору. Эта оценка погрешности обычно называется оценкой по исключенным точкам.
В простейшем варианте пользователь принимает для бэггинга только решение о количестве точек выборки с возвратом для агрегирования т. Часто с возрастанием количества итераций наблюдается экспоненциальное уменьшение предиктивной эффективности, наибольшее улучшение которой достигается при малом количестве деревьев (т < 10). На рис. 8.17 показана предиктивная эффективность (среднеквадратичная погрешность) для разного количества точек данных выборки с возвратом для деревьев CART.
Предиктивная эффективность улучшается до 10 деревьев, после чего почти сходит на нет. На практике некоторые усовершенствования могут быть достигнуты при использовании бэггинг-ансамблей размером до пятидесяти. Если после 50 итераций бэггинга эффективность все еще не достигла приемлемого уровня, следует опробовать более мощные предиктивные ансамблевые методы, такие как случайные леса и усиление (см. далее).
8.4. Бэггинг-деревья 229
Л ь о X В ф В о
1,05
1,00
0,95
0,90
0
20 40 60 80 100
Количество итераций бэггинга
Рис. 8.17. Профиль эффективности с перекрестной проверкой для бэггинга CART- деревьев с данными растворимости по количеству точек данных выборки с возвратом. Вертикальные линии обозначают ± одну стандартную погрешность. Улучшение предиктивной эффективности достигается в основном агрегированием 10 повторений выборки с возвратом
Для данных растворимости деревья CART без бэггинга дают оптимальную среднеквадратичную погрешность при перекрестной проверке, равную 0,97, со стандартной погрешностью 0,021. После бэггинга среднеквадратичная погрешность падает до 0,9 со стандартной погрешностью 0,019. К деревьям условного вывода (таким, как деревья CART) тоже может применяться бэггинг. Так, деревья условного вывода без бэггинга имеют оптимальную среднеквадратичную погрешность и стандартную погрешность 0,93 и 0,034 соответственно. Деревья условного вывода с бэггингом уменьшают оптимальную среднеквадратичную погрешность до 0,8 при стандартной погрешности 0,018. Для обоих типов моделей бэггинг повышает эффективность и сокращает дисперсию оценки, при этом у деревьев условного вывода с бэггингом как будто имеется небольшое преимущество перед деревьями CART в предиктивной эффективности, оцениваемой по среднеквадратичной погрешности. Значения Л2 тестового набора находятся в прямой зависимости от эффективности среднеквадратичной погрешности с перекрестной проверкой; деревья условного вывода слегка превосходят (0,87) деревья CART (0,85). Хотя бэггинг обычно улучшает предиктивную эффективность для нестабильных моделей, у него есть и недостатки.
Во-первых, с увеличением количества точек данных бутстрэпа возрастает и время вычислений, и требования к памяти. Этот недостаток может быть в значительной мере преодолен посредством параллельных вычислений. Вспомним, что каждая точка выборки с возвратом и соответствующая модель не зависят от других точек
230 Глава 8. Древовидные модели. Модели на базе правил и моделей. Это означает, что каждая модель может быть сначала построена отдельно (с последующим сведением всех моделей воедино).
Другой недостаток этого метода — в том, что модель с бэггингом намного менее интерпретируема, чем модель без бэггинга. Удобные правила, применяемые в одиночных деревьях регрессии (наподобие показанных на рис. 8.4), для моделей с бэггингом получить не удастся. Однако значения важности переменных могут быть получены объединением значений важности отдельных моделей в рамках ансамбля (о важности переменных см. далее).
8.5. Случайные леса
Как показано на примере данных растворимости, деревья с бэггингом (или любым другим методом с высокой дисперсией и низким смещением) улучшают предиктивную эффективность по сравнению с отдельным деревом за счет сокращения дисперсии прогноза. Генерирование выборок с возвратом включает в процесс построения дерева случайный компонент, что влечет за собой распределение деревьев, а также распределение прогнозируемых значений для каждой точки данных. Однако деревья при бэггинге не полностью независимы друг от друга, поскольку при каждом разделении исходного дерева учитываются все исходные предикторы. Можно представить, что если начать с достаточно большого количества исходных точек данных и связи между предикторами и реакцией, которая может адекватно моделироваться деревом, то деревья из разных точек данных выборок с возвратом могут иметь сходные структуры (особенно в верхней части деревьев) из-за связи, лежащей в их основе. Эта характеристика, называемая корреляцией деревьев, мешает бэггингу оптимально сократить дисперсию прогнозируемых значений (см. рис. 8.14).
Несмотря на применение выборки с возвратом, каждое дерево начинает разделение по числу атомов углерода с масштабированным значением около 3,5. Разделения второго уровня чуть более разнообразны, но ограничены предикторами площади поверхности и молекулярной массы. Хотя все деревья в конечном счете уникальны (нет двух полностью совпадающих деревьев), все они начинают формироваться с похожей структуры и, соответственно, структурно связаны друг с другом. Следовательно, сокращение дисперсии, обеспечиваемое бэггингом, может быть улучшено (математическое объяснение феномена корреляции деревьев см. у Хэсти (Hastie et al., 2008)), а следующим логичным шагом улучшения эффективности бэггинга становится сокращение корреляции между деревьями.
С точки зрения статистики сокращение корреляции между предикторами может быть реализовано добавлением случайности в процесс построения дерева. После того как Брейман представил метод бэггинга, несколько авторов видоизменили алгоритм добавлением случайности в процесс обучения. Так как деревья были
8.5. Случайные леса 231
популярной областью для применения бэггинга, Диттерих (Dietterich, 2000) разработал концепцию случайного выбора разделения, согласно которой деревья строятся с использованием случайного подмножества верхних k предикторов при каждом разделении. Другой метод, описанный Хо, Эмитом и Геманом (Но, 1998; Amit and Geman, 1997), основан на построении целых деревьев на базе случайных подмножеств дескрипторов.
Брейман (Breiman, 2000) также пытался добавить в ответ искажения, чтобы внести возмущение в структуру дерева. После тщательного анализа обобщений исходного алгоритма бэггинга Брейман (Breiman, 2001) построил унифицированный алгоритм случайных лесов. Возможная реализация обобщенного алгоритма случайных лесов для модели на базе дерева приведена в алгоритме 8.2.
Алгоритм 8.2. Базовые случайные леса
1 Выбрать количество моделей для построения т
2 for г-1 tom do
3
4
5
6
7
8
9
Сгенерировать выборку с возвратом из исходных данных Провести тренировку модели на этой выборке for каждое разбиение do
Случайно выбрать k (<Р) исходных предикторов
Выбрать лучший предиктор среди k предикторов и провести разбиение данных
end
Использовать типичный критерий остановки моделей деревьев для определения завершенности дерева (но не проводить усечение)
10 end
Каждая модель в ансамбле используется при генерировании прогноза для новой точки данных; эти т прогнозов усредняются для получения прогноза по лесу. Так как алгоритм случайным образом выбирает предикторы при каждом разделении, корреляция деревьев будет сокращаться. Например, начальные разделения для первых шести деревьев случайного леса для данных растворимости — NumNonHBonds, NumCarbon, NumNonHAtoms, NumCarbon, NumCarbon и NumCarbon — отличаются от деревьев, показанных на рис. 8.14.
Параметром настройки случайных лесов служит количество предикторов к, случайно выбираемых при каждом разделении, которое обозначается как mtry. В контексте регрессии Брейман (Breiman, 2001) рекомендует присваивать т[гу каждому третьему предиктору. В контексте настройки параметра mtry (учитывая, что случайные леса обладают высокой вычислительной трудоемкостью) рекомендуется начать с пяти значений k, относительно равномерно распределенных
232 Глава 8. Древовидные модели. Модели на базе правил в диапазоне от двух до Р. Следует задать и количество деревьев в лесу. Брейман (Breiman, 2001) доказал, что случайные леса защищены от переобучения; следовательно, построение большого количества деревьев для леса не окажет отрицательного влияния на модель. Вместе с тем чем больше лес, тем более значительны вычисления в процессе тренировки и построения модели.
Рекомендуемый минимум — 1000 деревьев. Если при этом профили эффективности с перекрестной проверкой продолжают улучшаться, то добавляются новые деревья — до тех пор, пока рост эффективность не затормозится.
Согласно Брейману, линейная комбинация многих независимых обучаемых моделей сокращает дисперсию общего ансамбля относительно любой отдельной обучаемой модели в ансамбле. Модель случайного леса обеспечивает сокращение дисперсии за счет выбора сильных, сложных обучаемых моделей с низким смещением. Полученный ансамбль множества независимых сильных обучаемых моделей обеспечивает улучшение частоты ошибок. Поскольку каждая такая модель выбирается независимо от остальных, случайные леса устойчивы перед зашумленными реакциями (подробнее см. раздел 20.2, где, кроме того, рассматривается подверженность различных моделей влиянию искажений). В то же время независимость обучаемых моделей может привести к недообучению, если реакция не зашумлена (см. рис. 5.1).
По сравнению с бэггингом случайные леса более эффективны в отношении вычислений, поскольку процессу построения дерева достаточно оценить небольшую долю исходных предикторов при каждом разделении (хотя случайные леса обычно требуют большего количества деревьев). Объединение этого атрибута с возможностью параллельной обработки построения дерева обеспечивает случайным лесам более высокую эффективность по сравнению с усилением (см. раздел 8.6).
В качестве базовой обучаемой модели в случайных лесах, помимо бэггинга, могут использоваться деревья CART или деревья условного вывода. Обе разновидности использованы в сочетании с десятикратной перекрестной проверкой и проверкой по исключениям для тренировки моделей на данных растворимости. Параметр mtry оценивался при 10 значениях (в интервале от 10 до 228). Профили среднеквадратичной погрешности для этих комбинаций представлены на рис. 8.18.
В отличие от бэггинга, деревья CART обладают лучшей эффективностью, чем деревья условного вывода, при всех значениях параметра настройки. В каждом из профилей наблюдается горизонтальный участок между mtry = 58 и mtry =155. Модель случайного леса на базе CART была оптимальной в числовом отношении при mtry =131 независимо от метода оценки среднеквадратичной погрешности. На практике параметр настройки случайного леса не оказывает заметного влияния на эффективность. Определенное различие в среднеквадратичной погрешности наблюдается только при использовании наименьшего значения (в данном случае — 10). Как правило, подобные значения не связаны с оптимальной эффективностью. Тем не менее известны примеры, в которых малое значение параметра настройки обеспечивало наилучшие результаты. Для быстрой и адекватной оценки
8.5. Случайные леса 233
CART (CV) CART (OOB)
Условный вывод (CV) Условный вывод (ООВ)
0,9
-D
5 о X
3 а> Q.
О С
0,8
0,7
0 50 100 150 200
Количество случайно выбираемых предикторов
Рис. 8.18. Профиль среднеквадратичной погрешности с перекрестной проверкой для методов CART и деревьев условного вывода при построении случайных лесов эффективности модели случайного леса вполне применимо принимаемое по умолчанию значение параметра настройки для регрессии (mtTy = Р/3). Максимальная эффективность достигается посредством настройки этого значения.
Модели случайных лесов, построенные на базе деревьев CART (рис. 8.18), демонстрируют чрезвычайно близкие результаты среднеквадратичной погрешности с оценкой ошибки по исключениям и перекрестной проверкой (при сравнении между параметрами настройки). Неясно, насколько обобщается закономерность, наблюдаемая в этих данных, в том числе, например, при малом размере выборки. Использование частоты ошибок по исключениям ведет к значительному сокращению времени вычислений для настройки моделей случайных лесов. Для лесов, созданных с использованием деревьев условного вывода, ошибка по исключениям была намного более оптимистичной, чем среднеквадратичная погрешность с перекрестной проверкой (при недостаточной обоснованности этой закономерности). Ансамблевая природа случайных лесов не позволяет понять природу связи между предикторами и реакцией. Поскольку в этом методе типичной базовой обучаемой моделью является дерево, можно дать количественную оценку влияния предикторов в ансамбле. Брейман (Breiman, 2000) предложил выполнять случайную перестановку значений каждого предиктора при выборке с исключением одного предиктора для каждого дерева. Различия в предиктивной эффективности между выборкой без перестановки и с перестановкой для каждого предиктора сохраняются и агрегируются по всему лесу. Другой подход основан на измерении улучшений чистоты узлов исходя из значений эффективности для каждого предиктора в каж-
234 Глава 8. Древовидные модели. Модели на базе правил дом вхождении этого предиктора в лес, с последующим обобщением полученных значений по всему лесу для определения общей важности предиктора.
Хотя представленная стратегия определения относительного влияния предиктора заметно отличается от метода, описанного в разделе 8 для отдельных деревьев регрессии, ей присущи те же недостатки, связанные со смещением. У Стробла (Strobl et al., 2007) показано, кроме того, что на показатели важности могут значительно влиять и корреляции между предикторами. Например, неинформативные предикторы, имеющие высокие корреляции с информативными предикторами, характеризуются аномально высокими значениями важности, причем в некоторых случаях их важность была выше или равнялась важности некоторых ключевых переменных. В той же работе подтверждено и серьезное влияние на значения важности параметра настройки т(гу.
Корреляции между предикторами размывают и важность ключевых предикторов. Допустим, критически значимый предиктор имеет важность X. Если другой предиктор не менее значим, но почти идеально коррелируется с первым, то важность этих двух предикторов будет равна приблизительно Х/2. Если модель содержит три таких предиктора, то значения уменьшаются до Х/3, и т. д., что может иметь глубокие последствия для некоторых задач. Например, данные профилирования РНК часто измеряют один ген во многих местах, из-за чего внутригенные переменные часто связаны очень высокими корреляциями. Если этот ген важен для прогнозирования некоторого результата, то включение всех переменных в модель случайного леса ведет к тому, что ген будет выглядеть менее важным, чем в действительности. У Стробла (Strobl et al., 2007) описывается альтернативный метод вычисления важности в моделях случайных лесов, учитывающий корреляции между предикторами, что ведет к сокращению эффекта межпредикторной избыточности, не влияя на эффект размывания.
На рис. 8.19 представлены значения важности 25 верхних предикторов данных растворимости для случайного леса. В этой модели MolWeight, NumCarbon, SurfaceArea2 и SurfaceAreal характеризуются наибольшими показателями важности, постепенно убывающими с бинарными признаками. Значения важности для предикторов 116 и 75 находятся в начале списка важности бинарных предикторов, это может означать, что структуры, представленные этими предикторами, влияют на растворимость вещества.
Сравнение результатов важности для случайного леса с одиночным деревом CART (см. рис. 8.6) показывает, что два из четырех верхних предикторов не изменились (Surf асеАгеа2 и NumCarbon). То же касается и четырнадцати из верхних шестнадцати предикторов. Однако упорядочение их по важности существенно изменилось. Например, NumNonHBonds является верхним предиктором для дерева CART, но для случайных лесов оказывается только на 14-м месте; случайные леса определяют MolWeight как верхний предиктор, тогда как в дереве CART он оказывается на 5-м месте. Эти различия подтверждают, что одиночные деревья расставляют приоритеты предикторов не так, как случайные леса.
8.6. Усиление 235
MolWeight
NumCarbon
SurfaceArea2
SurfaceAreal
HydrophilicFactor
NumHydrogen
NumRotBonds
NumAtoms
NumMultBonds
FP116
NumNonH Atoms
NumBonds
NumNonHBonds
NumHalogen
FP075
NumOxygen
Num Nitrogen
FP092
FP065
FP009
FP148
FP101
NumChlorine
FP040
FP011
10 20 30 40
Важность
Рис. 8.19. Рейтинги важности для 25 верхних предикторов, использованных в модели случайного леса деревьев CART для растворимости
8.6. Усиление
Модели усиления (boosting) изначально были разработаны для задач классификации, а позднее расширены для регрессии (читателям, не знакомым с концепцией усиления, рекомендуется перейти к разделу 14.5, после чего вернуться в текущий раздел). Здесь же необходимо кратко осветить историю методологии усиления, начиная с алгоритма AdaBoost и заканчивая машиной стохастического градиентного усиления Фридмана, рассматриваемой ныне в среде специалистов-практиков в качестве основного алгоритма усиления.
В начале 1990-х годов появились алгоритмы усиления Шапира и Фройнда (Schapire, 1990; Freund, 1995; Schapire, 1999), находившиеся под влиянием теории обучения, описанной Вэлиантом и Кернсом (Valiant 1984; Kearns and Valiant, 1989), в которой определенное количество слабых классификаторов (классификаторов, способность которых к прогнозированию была лишь ненамного выше
236 Глава 8. Древовидные модели. Модели на базе правил случайной) объединялось (или усиливалось) для создания ансамблевого классификатора с заметно лучшей обобщенной частотой ошибок классификации. Исследователи продолжали поиск эффективной реализации теории усиления, пока совместными усилиями Фройнда и Шапира не был выработан (см. алгоритм 14.2) алгоритм AdaBoost (Schapire, 1999), позволяющий реализовать концепцию усиления слабой обучаемой модели, предложенную Кернсом и Вэлиантом (Kearns and Valiant, 1989).
Усиление, особенно в форме алгоритма AdaBoost, показало себя мощным предиктивным инструментом, который обычно превосходил любую отдельную модель по эффективности. Это привлекло к нему внимание сообщества моделирования. Применение метода усиления стало массовым в области исследования генов, о чем упоминают Дюдо и Бен-Дор (Dudoit et al., 2002; Ben-Dor et al., 2000), хемометрике, классификации музыкальных жанров (о двух последних см. работы Вармузы и Бергстры (Varmuza et al., 2003; Bergstra et al., 2006) и др.
Успешный дебют AdaBoost дал исследователям, в частности группе Фридмана (Friedman et al., 2000), основание для увязывания этого алгоритма со статистическими концепциями функций потерь, аддитивного моделирования и логистической регрессии. В результате усиление стало интерпретироваться как прямая поэтапная аддитивная модель, минимизирующая экспоненциальные потери, что привело к новому взгляду на усиление, который позволил сформулировать ряд алгоритмических обобщений для задач классификации (см. в этой связи раздел 14.5) и одновременно расширить сферу применения этого метода на задачи регрессии.
Статистическая основа усиления позволила создать алгоритм, пригодный для разных видов задач (Friedman, 2001). Фридман назвал этот метод «машиной градиентного бустинга», действие которой основано как на классификации, так и на регрессии. Согласно базовым принципам градиентного усиления, для заданной функции потерь (то есть квадратичной погрешности для регрессии) и слабой обучаемой модели (например, деревьев регрессии) алгоритм стремится найти аддитивную модель, минимизирующую функцию потерь. Алгоритм обычно инициализируется «наилучшим предположением» реакции (например, средним значением реакции в регрессии). После вычисления градиента модель аппроксимирует остатки для минимизации функции потерь. Текущая модель добавляется в предыдущую, после чего процедура продолжается посредством итераций, количество которых задано пользователем.
Как отмечалось, методам моделирования с параметрами настройки присущи весьма различные предиктивные способности. Для бустинга, или усиления, требуется слабо обучаемая модель, которую можно создать искусственно — путем изменения параметров настройки. Отметим, что деревья служат отличной базовой обучаемой моделью для усиления по нескольким причинам. Во-первых, они обладают достаточной гибкостью для того, чтобы быть преобразованными в слабую обучаемую модель простым ограничением их глубины. Во-вторых, раздельные деревья можно
8.6. Усиление 237
легко объединить по аналогии с тем, как отдельные предикторы могут объединяться в регрессионной модели для генерирования прогноза. В-третьих, деревья могут генерироваться очень быстро. Таким образом, результаты отдельных деревьев могут объединяться напрямую, что делает их изначально подходящими для процесса аддитивного моделирования.
При использовании дерева регрессии в качестве базовой обучаемой модели простое градиентное усиление для регрессии имеет два параметра настройки: глубину дерева и количество итераций. Глубина дерева в контексте сказанного известна также под названием глубины взаимодействия, поскольку каждое последующее разделение может рассматриваться как составляющая, характеризующая взаимодействие более высокого уровня со всеми остальными предикторами разделений. Если в качестве функции потерь используется квадратичная погрешность, то простой метод усиления, использующий эти параметры, сводится к алгоритму 8.3.
Алгоритм 8.3. Простое градиентное усиление для регрессии
1 Выбрать глубину дерева D и количество итераций К
2 Вычислить среднюю реакцию у с чертой и использовать ее
как исходное прогнозируемое значение для каждой точки данных
3 for&=7toKdo
4
5
6
7
Вычислить остаток — разность между наблюдаемым и текущим прогнозируемым значением — для каждой точки данных Аппроксимировать дерево регрессии глубины D с использованием остатков как реакции
Спрогнозировать каждую точку данных с использованием дерева регрессии с предыдущего шага
Обновить прогнозируемое значение каждой точки данных, добавляя прогнозируемое значение предыдущей итерации к прогнозируемому значению, сгенерированному на предыдущем шаге
8 end
Версия усиления, представленная в алгоритме 8.3, отчасти напоминает случайные леса: окончательный прогноз базируется на ансамбле моделей, а деревья используются в качестве базовой обучаемой модели. Тем не менее способы построения ансамблей в каждом из этих методов существенно отличаются.
В случайных лесах все деревья создаются независимо, при этом каждое дерево создается с максимальной глубиной, внося равный вклад в итоговую модель. При усилении деревья зависят от предшествующих деревьев, имеют минимальную глубину и вносят разный вклад в итоговую модель. Несмотря на различия, слу-
238 Глава 8. Древовидные модели. Модели на базе правил чайные леса и усиление обеспечивают сравнимую предиктивную эффективность. Время вычислений для усиления, как правило, больше, чем для случайных лесов, поскольку для последних вполне применима параллельная обработка (при условии, что деревья создаются независимо).
Фридман установил, что машина градиентного усиления может быть подвержена переобучению, так как задействованной обучаемой модели — даже при неявно выраженной способности к обучению — поручается задача оптимальной подгонки градиента, и, следовательно, усиление будет выбирать оптимальную обучаемую модель на каждой стадии алгоритма. Несмотря на использование слабых обучаемых моделей, усиление все еще применяет максималистскую («жадную») стратегию выбора оптимальной обучаемой модели на каждой стадии. Эта стратегия позволяет генерировать оптимальное решение для текущей стадии, но у нее есть и недостатки: она не находит оптимальную универсальную модель и, кроме того, склонна к переобучению тренировочных данных.
Проблемы решаются ограничением процесса обучения за счет применения регуляризации (или сжатия — shrinkage) способом, продемонстрированным в разделе 6.4. В алгоритме 8.3 регуляризация может быть внедрена в последнюю строку цикла. Вместо того чтобы добавлять прогнозируемое значение точки данных к прогнозируемому значению предыдущей итерации, к последнему добавляется только часть текущего прогнозируемого значения. Эта часть обычно называется скоростью обучения и параметризуется символом X. Этот параметр может принимать значения в диапазоне от 0 до 1 и служит дополнительным параметром настройки для модели. Риджуэй (Ridgeway, 2007) высказывается в пользу низкоскоростного обучения (< 0,01), замечая, впрочем, что значение этого параметра обратно пропорционально времени вычислений, необходимых для поиска оптимальной модели, потому что это требует большего количества итераций. Рост числа итераций также означает, что для хранения модели требуется и больше памяти.
Опубликовав описание машины градиентного бустинга, Фридман проанализировал некоторые свойства метода бэггинга, разработанного Брейманом. Он обратился к природе случайной выборки, присущей бэггингу, которая открывает возможность сокращения дисперсии прогнозирования, дополнил алгоритм схемой случайной выборки и назвал новую процедуру стохастическим градиентным бустингом. Для этого он добавил в цикл новый шаг: «Случайно выбрать часть тренировочных данных». Соответственно, остатки и модели оставшихся шагов текущей итерации базируются только на частичной выборке данных.
Используемая часть тренировочных данных, называемая долей бэггинга, становится новым параметром настройки модели. Эта несложная модификация улучшает точность прогнозирования метода усиления при одновременном сокращении вычислительных ресурсов. Фридман предлагает использовать долю бэггинга около 0,5 (это значение может настраиваться, как и любой другой параметр).
8.6. Усиление 239
На рис. 8.20 представлены результаты среднеквадратичной погрешности с перекрестной проверкой для усиленных деревьев по таким параметрам настройки, как глубина дерева (1-7), количество деревьев (100-1000) и коэффициент сжатия (0,01 или 0,1); доля бэггинга на иллюстрации — на уровне 0,5.
200 400 600 800 1000
о
0,6
200 400 600 800 1000
Количество деревьев
Рис. 8.20. Профили среднеквадратичной погрешности с перекрестной проверкой для модели усиленного дерева
Как видим, большие значения коэффициента сжатия (правая диаграмма) влияют на уменьшение среднеквадратичной погрешности для всех вариантов глубины дерева и количества деревьев. Отметим, что среднеквадратичная погрешность снижается с увеличением глубины дерева при коэффициенте сжатия 0,01. Та же закономерность наблюдается и для среднеквадратичной погрешности при коэффициенте сжатия 0,1 и количестве деревьев, меньшем 300.
С правилом одной стандартной погрешности оптимальное усиленное дерево имеет глубину 3 с 400 деревьями и коэффициентом сжатия 0,1, при этом обеспечивается среднеквадратичная погрешность с перекрестной проверкой 0,616.
Важность переменной для усиления является функцией сокращения квадратичной погрешности. Так, улучшение квадратичной погрешности, обусловленное каждым предиктором, суммируется внутри каждого дерева в ансамбле (то есть каждый предиктор получает значение улучшения для каждого дерева). Затем значения улучшения всех предикторов усредняются по всему ансамблю для получения общего показателя важности, упоминаемого Фридманом и Риджуэем
240 Глава 8. Древовидные модели. Модели на базе правил (Friedman, 2002; Ridgeway, 2007). Верхние 25 предикторов модели представлены на рис. 8.21.
NumCarbon
MolWeight
SurfaceAreal
SurfaceArea2
HydrophilicFactor
NumAromaticBonds
NumNonHAtoms
FP172
NumMultBonds
NumHydrogen NumHalogen NumChlorine
NumNonHBonds
NumRotBonds
NumAtoms
FP075 NumOxygen
FP072
NumBonds
FP084
FP059
FP043
FP015
FP135
FP028
0 500 1000 1500 2000 2500
Важность
Рис. 8.21. Рейтинги важности для 25 верхних предикторов, использованных в модели стохастического градиентного усиления для данных растворимости
Предикторы NumCarbon и MolWeight в этом примере выделяются как важнейшие, а за ними следуют SurfaceAreal и Surf асеАгеа2. Значения важности перестают убывать после семи предикторов. Оба метода выявляют те же верхние четыре предиктора, хотя и в порядке, отличном от порядка случайных лесов. Профиль важности для бустинга имеет намного более крутой угол наклона, чем в случае со случайными лесами. Отчасти это обусловлено тем, что деревья из усиления зависят друг от друга и, следовательно, имеют коррелированные структуры по мере продвижения метода по градиенту.
Как следствие, многие предикторы будут выбираться между деревьями, что увеличит их вклад в показатель важности. Различия между величинами и порядком важности переменных в случайных лесах и бустинге следует рассматривать как
8.7. Модель Cubist 241
две разные перспективы данных, используя каждое представление для того, чтобы лучше понять общие связи между предикторами и реакцией.
8.7. Модель Cubist
Cubist — модель на базе правил, представляющая сплав нескольких методологий, описанных, например, Кинланом (Quinlan, 1987,1992,1993а). Ранее модель Cubist распространялась только на коммерческой основе, но в 2011 году исходный код был опубликован на условиях лицензии открытого кода. Тогда же стали общедоступными все подробности текущей версии модели.
За основу взята версия модели с открытым кодом1. Обозначим некоторые различия между Cubist и ранее описанными методами построения деревьев моделей и их разновидностей на базе правил:
О Использование других методов сглаживания линейных моделей, создания правил и усечения.
О Необязательная процедура, сходная с бустингом, — так называемые комитеты (committees).
О Возможность корректировки прогнозов, сгенерированных правилами модели, с использованием ближних точек из данных тренировочного набора.
Процесс построения дерева моделей почти идентичен процессу, описанному в разделе 8.2, хотя процесс сглаживания между линейными моделями сложнее процесса, описанного у Кинлана (Quinlan, 1992). В Cubist модели также объединяются с использованием линейной комбинации двух моделей:
где y{k} — прогноз текущей модели, а у^ — прогноз родительской модели, расположенной выше в дереве.
Cubist вычисляет пропорции по другой формуле. Пусть e{k} — набор остатков дочерней модели (то есть у - г/(^, а — аналогичные значения для родительской модели). Процедура сглаживания сначала определяет ковариацию между двумя наборами остатков (она обозначается Covfe^ - e(jJ). Полученный результат является общим показателем линейной связи между двумя наборами остатков. Если ковариация высока, то остатки в общем случае имеют одинаковый знак и относительную величину, тогда как значение около нуля означает отсутствие (линейной) связи между
1 Мы многим обязаны Крису Киферу (Chris Keefer), подробно изучавшему исходный код Cubist.
242 Глава 8. Древовидные модели. Модели на базе правил погрешностями двух моделей. Cubist также вычисляет дисперсию между остатками, например Var[e(/?) - e(jt)]. Затем Cubist использует коэффициент сглаживания
= Var[e(p)]-Cov[ew,e(p)]
Var[e(p)-e(J
Первая часть числителя пропорциональна среднеквадратичной погрешности родительской модели. Если дисперсия погрешностей родительской модели больше ковариации, то процедура сглаживания назначает модели-«потомку» больший вес, чем модели-«родителю». И наоборот, если дисперсия родительской модели низка, то новой модели назначается больший вес.
В итоге модель с наименьшей среднеквадратичной погрешностью обладает более высоким весом в сглаженной модели. Если же модели обладают одинаковой среднеквадратичной погрешностью, то им назначаются равные веса в процедуре сглаживания (независимо от ковариации).
В отличие от ранее рассмотренной методологии «разделяй и властвуй» итоговое дерево моделей используется для построения исходного набора правил. Cubist собирает последовательность линейных моделей в каждом узле в одно сглаженное представление моделей, чтобы с каждым правилом была связана одна линейная модель. Скорректированная частота ошибок (формула 8.3) — критерий для правил усечения и/или объединения. Начиная с разбиений возле терминальных узлов, каждое условие правил проверяется с использованием скорректированной частоты ошибок для тренировочного набора. Если удаление условия в правиле не приводит к возрастанию частоты ошибок, то условие удаляется. Это может привести к удалению целых правил из общей модели. После того как условия правил будут завершены, новая точка данных прогнозируется с использованием среднего линейных моделей соответствующих правил (вместо правила с наибольшим покрытием).
Комитеты моделей создаются генерированием последовательности моделей на базе правил. Как и при усилении, на каждую модель влияет результат предыдущей модели. Усиление использует для каждой точки данных новые веса, основанные на предыдущих аппроксимациях, а затем аппроксимирует новую модель с использованием этих весов. Комитеты работают по-другому. Результат тренировочного набора корректируется на основании аппроксимации предыдущей модели, после чего строится новый набор правил с использованием этой «псевдореакции». Так, т-я модель комитета использует скорректированную реакцию:
У*{т)
По сути, если для точки данных генерируется заниженный прогноз, то значение выборки увеличивается в надежде на то, что на следующей итерации модель вы-
8.7. Модель Cubist 243
даст больший прогноз. Аналогичным образом точки с завышенным прогнозом корректируются так, чтобы следующая модель снизила свой прогноз. После того как будет создан полный набор комитета моделей, новые выборки прогнозируются с использованием каждой модели, а окончательный прогноз на базе правил формируется как простое среднее значение прогнозов отдельных моделей (вспомните, что усиление использует веса для вычисления среднего).
После того как модель на базе правил будет завершена (с использованием одной модели или комитета), Cubist получает возможность скорректировать прогноз модели по точкам из тренировочного набора (Quinlan, 1993а). При прогнозировании новой точки данных в тренировочном наборе определяются k наиболее похожих соседей. Предположим, что модель выдает для новой точки прогноз у; в этом случае окончательный прогноз вычисляется по формуле
1 к
* г=1
где tc — наблюдаемый результат для соседа в тренировочном наборе, te — прогноз модели для этого соседа и - вес, вычисленный с использованием расстояния соседей по тестовому набору до новой точки. С ростом расхождений между прогнозами новой точки данных и ее ближайшего соседа корректировка увеличивается. Чтобы запустить процесс, необходимо задать ряд показателей. Прежде всего понадобится значение расстояния для определения соседей. В реализации Cubist для определения ближайших соседей используются расстояния городских кварталов, или манхэттенские расстояния, причем соседи включаются только в том случае, если они расположены вплотную к прогнозируемой точке. Для фильтрации соседей в качестве порога используется среднее взаимное расстояние точек данных в тренировочном наборе. Если расстояние от потенциального соседа до точки прогнозирования больше среднего, то этот сосед исключается. Веса также используют расстояние до соседей. Начальные веса вычисляются по формуле
1
где D[ — расстояние от соседа до прогнозируемой точки. Эти веса нормализуются так, чтобы их сумма была равна 1. Назначение весов приводит к усилению роли соседей, близких к прогнозируемой точке (подробнее см. у Кинлана (Quinlan, 1993а) и в исходном коде Cubist по адресу www.RuleQuest.com).
Для настройки модели проведена оценка разного количества комитетов и соседей. Профили перекрестной проверки изображены на рис. 8.22.
Тенденция к значительному сокращению погрешности наблюдается, вне зависимости от числа используемых соседей, с ростом количества комитетов в интервале от 1 до 50. Применение тренировочного набора для корректировки прогнозов модели
244 Глава 8. Древовидные модели. Модели на базе правил
0,70
0,65
0,60
о
20 40 60 80 100
Количество комитетов
Рис. 8.22. Профили среднеквадратичной погрешности с перекрестной проверкой для количества комитетов и соседей, используемых в Cubist позволяет сделать вывод о том, что чистая модель на базе правил эффективнее корректировки с одним соседом, но погрешность сокращается при использовании более девяти соседей. Так, модель с наименьшей погрешностью (0,57 логарифмической единицы) связана со 100 комитетами и корректировкой по девяти соседям, хотя можно было использовать и меньшее количество комитетов без ущебра для эффективности. В итоговой модели Cubist среднее количество правил на комитет составляло 5,1, но значения лежали в диапазоне от 1 до 15.
Можно сравнить модель Cubist с одним комитетом без корректировки по соседям с предыдущей моделью на базе правил. У модели М5 на базе правил оцениваемая погрешность с перекрестной проверкой равна 0,74, тогда как у соответствующей модели Cubist она равна 0,71. С учетом дисперсии результатов эта разность обладала некоторой статистической значимостью (р-значение = 0,0485), что указывает на несущественность методологических различий между двумя методами построения моделей на базе правил.
Не существует надежного метода оценки важности предикторов и для моделей Cubist. Каждая линейная модель содержит соответствующий наклон для каждого предиктора, но, как показано ранее, эти значения могут быть огромными при существенной коллинеарности в данных. Показатели, базирующиеся исключительно на этих значениях, проигнорируют то, какие предикторы были использованы в разделениях. Однако разработчик модели может подсчитать, сколько раз предикторная переменная использовалась в линейной модели или в разделении,
8.7. Модель Cubist 245
использовав эти данные для получения общего представления о влиянии каждого предиктора на модель. С другой стороны, такой подход игнорирует корректировку на базе соседей, иногда используемую моделью Cubist. Разработчик модели может выбрать, как назначить веса количеств разбиений и линейных моделей в общих вычислениях. Для данных растворимости значения важности предикторов были вычислены для модели со 100 комитетами, а прогноз корректировался по девяти ближайшим соседям. На рис. 8.23 по оси х измеряется общее использование предиктора (то есть количество раз его использования в разбиении или линейной модели).
NumCarbon MolWeight NumHydrogen SurfaceArea2 NumOxygen SurfaceAreal NumBonds Num Atoms NumNonHBonds NumNonHAtoms NumMultBonds HydrophilicFactor NumRotBonds NumRings NumNitrogen NumDbIBonds NumChlorine NumAromaticBonds NumHalogen FP065 FP202 FP085 FP074
FP064 FP094
Рис. 8.23. Рейтинги важности для 25 верхних предикторов, использованных в модели Cubist для данных растворимости
Как видим, непрерывные предикторы влияют на модель сильнее, чем бинарные дескрипторы. В отличие от усиленного дерева моделей, значение этих данных постепенно снижается, при этом не представляется возможным выделить набор предикторов, доминирующих в аппроксимации модели.
246 Глава 8. Древовидные модели. Модели на базе правил
8.8. Вычисления
В этом разделе используются пакеты R caret, Cubist, gbm, ipred, party, partykit, randomForest, rpart, RWeka.
Простые деревья
В R широко применяются две реализации одиночных деревьев регрессии: rpart и party. Пакет rpart выполняет разделение на основании методологии CART с использованием функции rpart, тогда как party — на основании инфраструктуры условного вывода с использованием функции с tree. Обе функции, rpart и ctree, используют интерфейс формул:
> Library(rpart)
> rpartTree <- rpart(у ~ ., data = trainData)
> # или
> ctreeTree <- ctreefy ~ data = trainData)
Функция rpart имеет несколько управляющих параметров, к которым можно обратиться через аргумент rpart.control. Два параметра, часто используемых при тренировке и доступных через функцию train, — параметр сложности (ср) и максимальная глубина узла (maxdepth). Чтобы настроить дерево CART по параметру сложности, следует задать параметру method функции train значение method = "rpart". Для настройки максимальной глубины параметру method присваивается значение method="rpart2":
> set.seed(100)
> rpartTune <- train(soLTrainXtrans, soLTrainY,
+ method = "rpart2",
+ tuneLength = 10,
+ trControL = trainControL(method - "cv”))
Пакет party также имеет несколько управляющих параметров, к которым можно обратиться через аргумент ctree_control. При тренировке особенно часто используются два параметра: mincriterion и maxdepth, mincriterion определяет статистический критерий, используемый для продолжения разделения; maxdepth определяет максимальную глубину дерева. Чтобы настроить дерево условного вывода по mincriterion, следует задать параметру method функции train значение method = "ctree". Для настройки максимальной глубины параметру method присваивается значение method="ctree2".
Метод plot в пакете party позволяет построить диаграммы деревьев, показанные на рис. 8.4, следующей командой:
> рLot(treeobject)
8.8. Вычисления 247
Чтобы построить такие диаграммы для деревьев г part, можно воспользоваться пакетом partykit и сначала преобразовать объект rpart в объект party, а затем воспользоваться функцией plot:
> Library(partykit)
> rpartTree2 <- as,party(rpartTree)
> pLot(rpartTree2)
Деревья моделей
Главную реализацию деревьев модели можно найти на сайте программного продукта Weka, но модель также можно использовать в R при помощи пакета RWeka. Существуют два интерфейса: М5Р аппроксимирует дерево моделей, a MSRules использует версию на базе правил. В обоих случаях функции работают с методами формул:
> Library(RWeka)
> m5tree <- М5Р(у - ,, data = trainData)
> # или для правил:
> mSruLes <- M5RuLes(y - ,, data = trainData)
В нашем примере минимальное количество точек тренировочного набора данных, необходимое для создания дополнительных разделений, увеличено по сравнению с используемыми по умолчанию 4-10. Для этого можно воспользоваться аргументом control:
> m5tree <- М5Р(у - ,, data = trainData,
+ controL = Weka_controL(M = 10))
Аргумент control также поддерживает параметры для управления сглаживанием и усечения. Если используется полное дерево модели, то визуализация, сходная с рис. 8.10, может создаваться функцией plot для вывода М5Р.
Для настройки этих моделей функция train в пакете caret имеет два параметра: method = "М5” оценивает деревья моделей и версии модели на базе правил, а также обеспечивает использование сглаживания и усечения. На рис. 8.12 показаны результаты оценки этих моделей из кода:
> set.seed(100)
> mSTune <- train(solTrainXtrans, solTrainY,
+ method = "M5",
+ trControl = trainControl(method = "cv”)>
+ ## Параметр M5() to задает минимальное
+ ## количество точек данных, необходимых для дальнейшего
+ ## разбиения данных, равным 10.
+ control = Weka_control(M = 10))
за которым следует вызов plot(mSTune). train с параметром method = "MSRules” оценивает только версию модели на базе правил.
248 Глава 8. Древовидные модели. Модели на базе правил
Деревья бэггинга
Пакет ipred содержит две функции для деревьев бэггинга: bagging использует интерфейс формул, a ipredbagg — матричный интерфейс:
> library(ipred)
> baggedTree <- ipredbagg(soLTrainY, solTrainXtrans)
>##или
> baggedTree <- baggingfy - ., data = trainData)
При использовании функции rpart подробная информация о типе дерева может быть задана посредством передачи rpart.control в аргументе control функций bagging и ipredbagg. По умолчанию создается наибольшее возможное дерево.
Функции для бэггинга содержатся и в ряде других пакетов. Упоминавшийся выше пакет RWeka содержит функцию Bagging, а пакет caret содержит общую инфраструктуру бэггинга bag для многих типов моделей, включая деревья. Бэггинг также может применяться к деревьям условного вывода; для этой цели используется функция cforest из пакета party с аргументом mtry, равным количеству предикторов:
> Library(party)
> ## Параметр mtry должен содержать количество предикторов
> ## (количество столбцов минус 1 для результата)
> bagCtrl <- cforest_control(mtry = ncol(trainData) - 1)
> baggedTree <- cforest(у ~ ., data - trainData, controls - bagCtrl)
Случайные леса
Основная реализация случайных лесов находится в пакете randomForest:
> library(randomForest)
> гfMode I <- randomForest(soLTrainXtrans, soLTrainY)
> ## или
> rfModel <- randomForest(у ~ ,, data - trainData)
Два главных аргумента: mtry для количества предикторов, случайным образом выбираемых в качестве кандидатов для каждого разбиения, и ntrees для количества точек выборки с возвратом. По умолчанию значение mtry для регрессии равно количеству предикторов, разделенному на 3. Количество деревьев должно быть достаточно большим для получения стабильных воспроизводимых результатов. Хотя значение по умолчанию равно 500, следует использовать по крайней мере 1000 точек (а возможно, и больше — в зависимости от количества предикторов и значений mtry). Другой важный параметр — importance (важность); по умолчанию рейтинги важности переменных не вычисляются, так как это занимает много времени; параметр importance = TRUE сгенерирует эти значения:
8.8. Вычисления 249
> Library(randomForest)
> rfModeL <- randomForest(soLTrainXtrans, soLTrainY,
importance = TRUE,
+ ntrees = 1000)
Для лесов, построенных с использованием деревьев условного вывода, доступна функция cforest в пакете party с теми же параметрами, но аргумент controls (обратите внимание на множественное число) позволяет пользователю выбрать тип алгоритма разбиения (например, смещенный или несмещенный). Ни одна из этих функций не может использоваться с отсутствующими данными.
Функция train содержит возможность настройки каждой из этих моделей, для чего при вызове передается аргумент method = "rf ” или method = ’’cforest”. Оптимизация параметра mtry может привести к небольшому приросту эффективности. Кроме того, train может использовать стандартные методы повторной выборки для оценки эффективности (в отличие от оценки с исключением).
Для моделей randomForest с обращением к рейтингам важности переменных может использоваться функция этого же пакета importance. Для объектов cforest в пакете party имеется аналогичная функция varimp.
В каждом пакете обычно имеется собственная функция для вычисления рейтингов важности, сходная по ситуации с вероятностями классов из табл. В.1 в составе приложения В. Пакет caret содержит унифицированную функцию varimp, представляющую собой оболочку для функций важности переменных следующих объектов моделей деревьев: rpart, classbagg, randomForest, cforest, gbm и cubist.
Усиленные деревья
Для усиления деревьев регрессии посредством машины стохастического градиентного усиления чаще всего используется пакет gbm. Как и в случае с интерфейсом случайных лесов, модели могут строиться двумя разными способами:
> Library(gbm)
> gbmModeL <- gbm,fit(soLTrainXtrans, soLTrainY, distribution - "gaussian")
> ##или
> gbmModeL <- gbmfy ~ ,, data - trainData, distribution = "gaussian")
Аргумент distribution определяет тип функции потерь, которая будет оптимизироваться в процессе усиления. Для непрерывной реакции distribution должно быть присвоено значение "gaussian". Количество деревьев (n.trees), глубина деревьев (interaction. depth), сжатие (shrinkage) и доля наблюдений для включения в выборку (bag.fraction) могут напрямую задаваться при вызове gbm.
Функция train может использоваться для настройки по этим параметрам. Например, для настройки по глубине взаимодействия, количеству деревьев и сжатию сначала определяется таблица настройки. Затем проводится тренировка:
250 Глава 8. Древовидные модели. Модели на базе правил
> + +
>
>
+
+
+
+
+
gbmGrid <- expand.grid(.interaction,depth = seq(l, 7, by = 2),
.n.trees = seq(100, 1000, by = 50), .shrinkage = c(0.01, 0.1))
set.seed(100) gbmTune <- train(soLTrainXtrans, soLTrainY,
method = "gbm",
tuneGrid = gbmGrid,
## Функция gbm() выдает достаточно обширные
## результаты, поэтому передается параметр verbose ## для предотвращения длинного вывода на экран, verbose = FALSE)
Модель Cubist
Как упоминалось, реализация этой модели, созданная RuleQuest, распространяется по лицензии с открытым кодом. Пакет R Cubist также создан с использованием открытого кода. Функция не имеет метода формул, потому что код Cubist должен управлять созданием и использованием фиктивных переменных. Для создания простой модели на базе правил с одним комитетом без корректировки на базе экземпляров можно воспользоваться следующим простым кодом:
> Library(Cubist)
> cubistMod <- cubist(soLTrainXtrans, soLTrainY)
Для новых точек данных используем метод predict:
> predict(cubistMod, soLTestXtrans)
Выбор коррекций на базе экземпляров не обязательно должен осуществляться до прогнозирования. Функция predict содержит аргумент neighbors, который может получать одно целое значение (от 0 до 9) для настройки прогнозов на базе правил из тренировочного набора.
После тренировки модели функция summary генерирует точные правила, которые были использованы при тренировке, а также окончательную сглаженную линейную модель для каждого правила. Кроме того, как и в случае с другими моделями, функция train в пакете caret может настраивать модель по значениям committees и neighbors посредством повторной выборки:
> cubistTuned <- trainfsoLTrainXtrans, soLTrainY, method = "cubist")
Упражнения
8.1. Воссоздайте имитированные данные из упражнения 7.2:
> Library(mLbench)
> set.seed(200)
Упражнения 251
> simuLated <- mLbench,friedmanl(200, sd = 1)
> simuLated <- cbind(simuLated$x, simuLatedfy)
> simuLated <- as.data,frame(simuLated)
> coLnames(simuLated)[ncoL(simuLated)J <- "y"
A. Аппроксимируйте модель случайного леса по всем предикторам, а затем оцените рейтинги важности переменных:
> Library(randomForest)
> Library(caret)
> mode LI <- randomForest(y ~ ,, data = simuLated,
+ importance = TRUE,
+ ntree = 1000)
> rflmpl <- varlmpfmodeLl, scaLe = FALSE)
Будет ли модель случайного леса значимо использовать неинформативные предикторы (V6-V10)?
Б. Добавьте случайный предиктор, высококоррелированный с одним из информативных предикторов. Например:
> simuLated$dupLicatel <~ simuLatedfVl + rnorm(200) * .1
> cor(simuLated$dupLicatel, simuLated$Vl)
Аппроксимируйте другую модель случайного леса по этим данным. Изменился ли рейтинг важности для изменения VI? Что произойдет, если добавить еще один предиктор, обладающий высокой корреляцией с VI?
B. Используйте функцию cforest в пакете party для аппроксимации модели случайного леса с использованием деревьев случайного вывода. Функция varimp из пакета party может вычислять важность предикторов. Аргумент conditional этой функции переключается между традиционным значением важности и модифицированной версией, описанной у Стробла (Strobl et al., 2007). Проявляются ли в них те же закономерности, что и в традиционной модели случайного леса?
Г. Повторите этот процесс с разными моделями деревьев, такими как усиленные деревья и Cubist. Проявляется ли в результатах та же закономерность?
8.2. Используйте имитацию для демонстрации смещения дерева с разными вариантами гранулярности.
8.3. В стохастическом градиентном усилении доля бэггинга и скорость обучения руководят построением деревьев, управляемым градиентом. Хотя оптимальные значения этих параметров должны получаться посредством процесса настройки, следует понимать, как величины этих параметров влияют на величину важности переменных. На рис. 8.24 представлены графики важности переменных для усиления с использованием двух крайних значений доли бэггинга (0,1 и 0,9) и скорости обучения (0,1 и 0,9) для данных растворимости.
252 Глава 8. Древовидные модели. Модели на базе правил
MolWeight HydrophilicFactor NumAromaticBonds NumCarbon SurfaceAreal NumMultBonds NumAtoms NumHalogen FP172 SurfaceArea2 NumNonHAtoms NumHydrogen NumBonds NumRotBonds NumNonHBonds FP075
NumRings FP015 FP072 FP074 FP107 FP070 FP065 FP044
FP104
0 200 400 600
Важность
NumCarbon
MolWeight SurfaceArea2 SurfaceAreal HydrophilicFactor NumNonHAtoms NumBonds NumHydrogen FP059 FP135 FP092 FP198 FP077 NumMultBonds NumRotBonds NumAtoms NumOxygen NumHalogen NumNonHBonds FP176 NumChlorine
FP137 FP205 FP141 NumAromaticBonds
Рис. 8.24. Сравнение величин важности переменных для различных значений доли бэггинга и параметров сжатия. Обоим параметрам настройки на левой диаграмме присвоено значение ОД. На правой диаграмме обоим параметрам присвоено значение 0,9
На левой диаграмме обоим параметрам присвоено значение 0,1, а на правой — значение 0,9:
A. Почему на правой модели выделяется важность нескольких первых предикторов, тогда как на левой диаграмме важность распределяется между большим количеством предикторов?
Б. Какая модель будет лучше прогнозировать другие точки данных?
B. Как возрастающая глубина взаимодействий влияет на наклон графика важности предикторов для каждой модели на рис. 8.24?
8.4. Используйте один предиктор в данных растворимости (например, молекулярную массу или количество атомов углерода) и выполните аппроксимацию нескольких моделей:
A. Простое дерево регрессии.
Б. Модель случайного леса.
B. Разные модели Cubist с одним правилом или несколькими комитетами с корректировкой на базе соседей и без нее.
Упражнения 253
Постройте диаграмму с данными предиктора и результатами растворимости для тестового набора. Наложите на нее прогнозы модели для тестового набора. Чем отличаются модели? Оказывает ли изменение параметра(-ов) настройки значительное влияние на обучение модели?
8.5. Аппроксимируйте разные модели на базе деревьев и правил для данных Tecator, описанных в упражнении 6.1. Как они сравниваются с линейными моделями? Влияют ли корреляции между предикторами на ваши модели? Если влияют, то как бы вы преобразовали или перекодировали данные предикторов для устранения этой проблемы?
8.6. Вернитесь к проблеме проницаемости, описанной в упражнениях 6.2 и 7.4. Проведите тренировку нескольких моделей на базе деревьев и оцените эффективность повторной выборки и тестового набора:
A. Какая модель на базе деревьев обеспечивает оптимальную эффективность повторной выборки и тестового набора?
Б. Превосходят ли какие-либо из этих моделей модели регрессии с ковариацией или без нее, разработанные ранее для этих данных? Какие критерии вы использовали для сравнения эффективности моделей?
B. Какую из моделей, разработанных до настоящего момента, вы бы порекомендовали для замены лабораторного эксперимента по проницаемости (и есть ли такая модель)?
8.7. Обратитесь к упражнениям 6.3 и 7.5, в которых описан процесс производства химикатов. Используйте те же операции подстановки данных, разделения данных и предварительной обработки, что и прежде, и проведите тренировку нескольких моделей на базе деревьев:
A. Какая модель на базе деревьев обеспечивает оптимальную эффективность повторной выборки и тестового набора?
Б. Какие предикторы наиболее важны для оптимальной модели регрессии на базе деревьев? Доминируют ли в списке биологические предикторы или предикторы процесса? Что можно сказать о сравнении десяти самых важных предикторов с десятью верхними предикторами из оптимальной линейной и нелинейной модели?
B. Постройте диаграмму оптимального одиночного дерева с распределением выхода продукта в терминальных узлах. Содержит ли это представление данных какую-либо информацию о биологических предикторах или предикторах процесса, а также об их связи с выходом продукта?
Обзор моделей растворимости
В нескольких последних главах для аппроксимации набора данных растворимости использовались различные модели. Какие выводы можно сделать из сравнительного анализа этих моделей? Какой вариант следует выбрать для итоговой модели? На рис. 9.1 и 9.2 изображены диаграммы разброса показателей эффективности, вычисленных с использованием перекрестной проверки и данных тестового набора.
Достаточно высокая корреляция между результатами, полученными на основе повторной выборки, и результатами тестового набора (0,9 для среднеквадратичной погрешности, 0,88 для R2) присуща всем моделям, за исключением моделей с низкой эффективностью. Большинство моделей обеспечивают приблизительно
Перекрестная проверка
Тестовый набор
Cubist Boosted Tree SVMp SVMr Random Forest Elastic Net Neural Net
MARS
Ridge
PLS
Linear Reg.
M5 Bagged Cond. Tree Cond. Random Forest Bagged Tree Tree
Cond. Tree
KNN
0,75 0,80 0,85 0,90
R2
Рис. 9.1. Диаграмма значений R2 моделей растворимости, оцениваемых по 10-кратной перекрестной проверке и тестовому набору
Обзор моделей растворимости 255
Перекрестная проверка Тестовый набор
KNN
Cond. Tree
Tree
Bagged Tree
Cond. Random Forest
Bagged Cond. Tree
M5
Linear Reg.
PLS
Ridge
MARS
Neural Net
Elastic Net
Random Forest
SVMr
SVMp
Boosted Tree
Cubist
0,6 0,7 0,8 0,9 1,0 1,1
RMSE
Рис. 9.2. Диаграмма среднеквадратичной погрешности моделей растворимости, оцениваемых по 10-кратной перекрестной проверке и тестовому набору одинаковый порядок ранжирования. Модель KNN показала наихудшие результаты, за ней следовали два метода на базе одиночных деревьев. Применение бэггинга для таких деревьев помогло, но не привело к кардинальным улучшениям. Довольно посредственные результаты показали и условные модели случайных лесов.
Предпочтительнее выглядит группа моделей, в которую входили деревья моделей, линейная регрессия, штрафные линейные модели, модели MARS и нейросети. Эти модели оказались более простыми, но не настолько, чтобы их можно было считать интерпретируемыми (из-за количества предикторов, задействованных в линейных моделях, а также сложности деревьев моделей и MARS). Реализация перечисленных моделей, как правило, не вызывает затруднений, что существенно для, например, фармацевтических компаний, выполняющих анализ миллионов потенциальных лекарственных средств.
В группу высокоэффективных моделей вошли модели опорных векторов (SVM), усиленные деревья, случайные леса и Cubist. Каждая из них представляет собой «черный ящик» с исключительно сложным предиктивным уравнением. По своей эффективности перечисленные модели значительно опережают остальные, так что, вероятно, поиск эффективных в вычислительном отношении реализаций, которые могут использоваться для прогнозирования большого количества новых точек, имеет практическую ценность.
Существуют ли реальные различия между этими моделями? По результатам повторной выборки построен набор доверительных интервалов, характеризующих различия в среднеквадратичной погрешности моделей с использованием методов, представленных в разделе 4.8 (рис. 9.3).
256 Глава 9. Обзор моделей растворимости
rf-SVMr
rf - gbm
rf - cubist
gbm - SVMr
gbm - cubist
cubist - SVMr
-0,05 0,00 0,05 0,10
Различия в среднеквадратичной погрешности
Доверительный уровень 0,992
(с учетом множественности сравнений)
Рис. 9.3. Доверительные интервалы для различий среднеквадратичной погрешности в высокоэффективных моделях
Статистически значимых различий очень мало. Кроме того, большинство оцениваемых средних различий менее 0,05 логарифмической единицы, что несущественно с научной точки зрения. С учетом этого обстоятельства выбор любой из этих моделей приемлем.
Практический пример: сопротивление сжатию бетонных смесей
До настоящего момента мы занимались экспериментальными наборами данных, не содержащими заранее заданных значений предикторов. Например, данные QSAR включали коллекцию разнообразных составляющих, для которых не были заданы точные значения химических свойств (например, молекулярной массы), а химические вещества, подходящие для использования в модели, выбирались из соответствующей совокупности.
Спланированные эксперименты реализуются посредством, в том числе, планирования точных значений предикторов (в контексте изложенного называемых также факторами) с использованием определенной стратегической методологии. Создаются конфигурации значений предикторов с хорошими математическими и экспериментальными свойствами. Одним из таких свойств является баланс. Например, сбалансированным называется план, в котором ни одному экспериментальному фактору (например, предикторам) не уделяется больше внимания, чем остальным. Обычно это означает, что каждый предиктор имеет одинаковое количество возможных уровней, а частоты уровней эквивалентны для каждого фактора. Свойства, используемые для выбора лучшего спланированного эксперимента, определяются стадией эксперимента.
В работе Бокса (Box et al., 1978) изложена концепция последовательного экспериментирования, согласно которой большое количество возможных экспериментальных факторов анализируется с низкой частотой (методом «заброса крупной сети») для определения активных или важных факторов, связанных с результатом. После того как важность предикторов получит количественную оценку, проводятся целенаправленные эксперименты с подмножеством важных факторов. В последующих экспериментах дополнительно проясняется природа связи между важными факторами. Последний шаг в последовательности экспериментов — тонкая настройка небольшого количества важных факторов. Эксперименты с поверхностью реакции, описываемые Майерсом и Монтгомери (Myers and Montgomery, 2009), используют меньшее множество значений предикторов. Их основной целью является оптими-
258 Глава 10. Практический пример: сопротивление сжатию бетонных смесей зация параметров эксперимента на основании нелинейной модели предикторов эксперимента.
У спланированных экспериментов и предиктивных моделей есть ряд отличий.1
О Так, последовательность аналитических исследований предпочтительнее одного большого набора данных, охватывающего все возможные предикторы (то есть экспериментальные факторы) с многочисленными значениями для каждого из них. Итеративная парадигма планирования, проектирования и последующего анализа эксперимента по внешним проявлениям отличается от большинства проблем предиктивного моделирования.
О До завершающих стадий последовательного экспериментирования основной упор делается на понимание того, какие предикторы влияют на результат и в чем именно проявляется это влияние. По завершении экспериментов вся последующая деятельность сосредоточена исключительно на прогнозировании.
Бетон, как известно, используется практически во всех строениях и в дорожных покрытиях. Одно из главных свойств, характеризующих затвердевший бетон (кроме стоимости), — сопротивление сжатию. В состав многих видов бетона входит ряд сухих ингредиентов, смешиваемых с водой; образовавшаяся смесь должна высохнуть и затвердеть. С учетом распространенности и критической роли бетона в инфраструктуре становятся понятны и важность его состава, и необходимость его всесторонних исследований. В этой главе рассматриваются модели, упрощающие поиск потенциальных составов, обеспечивающих максимальное сопротивление сжатию.
У Йе (Yeh, 2006) описан стандартный тип соответствующего экспериментального плана, называемый в ряде источников (Cornell, 2002; Myers and Montgomery, 2009) подбором состава. Границы верхнего и нижнего лимита пропорций каждого ингредиента используются для создания нескольких составов, методично заполняющих пространство в этих границах. Для подбора конкретного состава существует соответствующая модель линейной регрессии, обычно используемая для моделирования связи между ингредиентами и результатом. Подобные модели могут включать эффекты взаимодействий и составляющие более высокого порядка для ингредиентов. У Йе (Yeh, 2006) используются следующие ингредиенты, измеряемые в килограммах на метр кубический (кг/м3):
1 В некоторых случаях специализированные типы спланированных экспериментов используются с предиктивными моделями. В области хемометрики было показано, что план типа «ортогональный массив», сопровождаемый алгоритмом последовательного устранения комбинаций уровней, улучшает модели QSAR (Mandal et al., 2006, 2007). Кроме того, в области активного обучения последовательно добавлялись точки данных на базе тренировочного набора с использованием результатов предиктивной модели (Cohn et al., 1994; Saar-Tsechansky and Provost, 2007a).
Практический пример: сопротивление сжатию бетонных смесей 259
О цемент;
О зольная пыль — мелкие частицы, возникающие при горении угля;
О доменный шлак;
О вода;
О суперпластификатор — добавка, сокращающая агрегацию частиц;
О крупный заполнитель;
О мелкий заполнитель.
Дополнительный фактор, относящийся к сопротивлению сжатия, но не связанный с составом смеси, — возраст смеси, определяемый на момент тестирования. Возраст смеси обычно рассматривается как фактор процесса.
Для экспериментов, сочетающих переменные состава и процесса, существуют конкретные экспериментальные планы и линейные модели (подробнее см., например, у Корнелла (Cornell, 2002)), но Йе (Yeh, 1998) подходит к моделированию экспериментов по составу бетона иначе. Отдельные эксперименты из 17 источников (с общими факторами эксперимента) были объединены в один «метаэксперимент». Затем Йе применил нейронные сети для создания предиктивных моделей во всем пространстве составов, учитывая при этом и возраст смеси. Общедоступная версия набора данных включает 1030 точек данных. В табл. 10.1 приведена сводка данных предикторов (в объемах) и результатов.
На рис. 10.1 представлены диаграммы разброса каждого предиктора относительно сопротивления сжатию.
Возраст смеси (Age) демонстрирует сильную нелинейную связь с предиктором, тогда как количество цемента (Cement) обладает линейной связью. У некоторых ингредиентов наблюдается большая частота одного значения — например, нуль для суперпластификатора и зольной пыли. В таких случаях сопротивление сжатию значительно изменяется для соответствующих значений предикторов. Следовательно, некоторые методы разделения, такие как деревья или MARS, смогут преобразовать эти составы в модели и более эффективно спрогнозировать сопротивление сжатию. Например, 53 состава не содержат ни суперпластификатора, ни зольной пыли, но включают ровно 228 кг/м3 воды. Это — самостоятельная подгруппа составов, для которой стоило бы создать особую модель. Модели на базе деревьев или правил способны смоделировать такие подгруппы, классические регрессионные модели — нет.
Доступные нам данные не позволяют установить, какие формулы были взяты из того или иного источника. Вместе с тем в них присутствует 19 разных составов с повторяющимися точками данных, большинство из которых имеет 2-3 дублирующих условия. При моделировании этих данных повторяющиеся результаты не будут обрабатываться так, как если бы они были независимыми наблюдениями.
260 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
Таблица 10.1. Данные состава бетона
9 Переменных 1030 Наблюдений
10.1. Стратегия построения модели 261
Признак
Рис. 10.1. Диаграммы разброса предикторов состава бетона относительно сопротивления сжатию
Например, наличие повторяющихся составов как в тренировочном, так и в тестовом наборе может привести к завышенным оценкам работоспособности модели, в связи с чем допустимо усреднение результатов в пределах каждого уникального состава. Соответственно, и количество составов, доступных для моделирования, сократится с 1030 до 992.
10.1. Стратегия построения модели
Модели нейросетей, упоминаемые Йе (Yeh, 1998), использовали одноуровневые сети с восемью скрытыми переменными. Для разделения данных применялись несколько разных стратегий. Четыре модели аппроксимированы с разными тренировочными наборами таким образом, чтобы каждый раз исключить все данные, заимствованные из одного источника. В результате значения R1 тестового набора лежали в интервале от 0,814 до 0,895. Также использовалась случайная выборка 25 % данных для контрольных наборов. Процедура повторялась четырежды для получения значений R2 тестового набора в интервале от 0,908 до 0,922.
262 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
Хотя аналитика Йе (Yeh, 1998) не позволяет сравнивать сопоставимые объекты, в рассматриваемом примере представляется допустимым использовать аналогичный подход к разделению данных. Случайная контрольная выборка (п = 247, то есть 25 % от 992) образует тестовый набор, а пять повторений десятикратной перекрестной выборки применены для настройки различных моделей.
В нашем примере будут создаваться и оцениваться серии моделей. После выбора итоговой модели последняя будет использоваться для прогнозирования составов с оптимальным сопротивлением сжатию в рамках практических ограничений.
Как предикторы должны использоваться для моделирования результата? Йе (Yeh, 1998), обсуждая традиционные методы (такие, как использование водоцементного соотношения), оценивает имеющиеся в распоряжении экспериментальные данные как не соответствующие классическим стратегиям. В рассматриваемом примере предикторы будут подаваться в модели в виде пропорций от общего объема. Это порождает встроенную зависимость от значений предикторов, согласно которой любой предиктор может быть автоматически определен по значениям семи остальных. Несмотря на это, парные корреляции невелики, и, следовательно, методы, спроектированные с расчетом на решение проблемы коллинеарности (например, PLS или гребневая регрессия), едва ли будут обладать эффективностью, превосходящей эффективность других моделей (подробное описание процесса настройки моделей см. в разделе «Вычисления»). Были, в частности, протестированы:
О Линейная регрессия, частные наименьшие квадраты и эластичная сеть. Каждая модель использовала расширенный набор предикторов, включавший двухфакторные взаимодействия (например, возраст х вода) и квадратичные составляющие.
О Модели SVM с радиальной базисной функцией.
О Модели нейросетей.
О Модели MARS.
О Деревья регрессии (CART и деревья условного вывода), деревья моделей (с правилами и без), модели Cubist (с комитетами и без, с корректировкой по соседям и без).
О Деревья регрессии с бэггингом и усилением, модели случайных лесов.
10.2. Эффективность моделей
Для каждой модели использовались одни и те же комбинации перекрестной проверки. На рис. 10.2 изображены диаграммы результатов повторной выборки между моделями (в параллельных координатах).
10.2. Эффективность моделей 263
Дерево усл. вывода Линейная регрессия
CART PLS
Эластичная сеть Дерево с бэггингом
MARS SVM
Случайный лес Cubist
Дерево с усилением Нейросеть
Нейросеть Дерево с усилением Cubist Случайный лес SVM MARS Дерево с бэггингом Эластичная сеть Дерево усл. вывода PLS Линейная регрессия CART
0,65 0,7 0,75 0,8 0,85 0,9 0,95
R2
Рис. 10.2. Диаграммы среднеквадратичной погрешности с перекрестной проверкой и R2 в параллельных координатах. Каждая линия представляет результаты общего контрольного набора перекрестной проверки
Каждая линия соответствует общей контрольной выборке перекрестной проверки. Самыми эффективными оказались ансамбли деревьев (случайные леса и усиление), ансамбли правил (Cubist) и нейросети. Линейные модели и простые деревья показали себя не лучшим образом. Деревья с бэггингом, SVM и MARS показали промежуточные результаты. Усредненная статистика R2 для разных моделей лежала в диапазоне от 0,76 до 0,92. Верхние три модели (по ранжированию в результате повторной выборки) были применены к тестовому набору. Значения среднеква-
264 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
дратичной погрешности этих моделей приблизительно соответствуют рангам перекрестной проверки: 3,9 (дерево с усилением), 4,2 (нейросети) и 4,5 (Cubist).
Наблюдения ® Наблюдения О\ Наблюдения
80
60
40
20
20 40 60 80
Прогнозы
15
10
80
60
40
20
0
0 20 40 60
Прогнозы
15
10
5
1-
0
О
О
”5
”10
80
-15
0
20 40 60 80
Прогнозы
20 40 60 80
Прогнозы
80
60
40
20
15
10
20 40 60 80
Прогнозы
20 40 60 80
Прогнозы
Рис. 10.3. Диагностические диаграммы результатов тестовых наборов для трех моделей: а) нейросеть, б) усиленные деревья, в) Cubist
10.3. Оптимизация сопротивления сжатию 265
На рис. 10.3 изображены диаграммы необработанных данных, прогнозов и остатков для трех моделей. Диаграммы каждой модели сходны: в частности, каждая из них демонстрирует хорошее соответствие между наблюдаемыми и прогнозируемыми значениями с небольшим «рассеянием» на верхнем уровне сопротивления сжатию. Большинство остатков лежит в пределах ±2,8 МПа, причем наибольшие погрешности лишь слегка превышают 15 МПа. На основании диаграмм среди моделей невозможно выделить явных лидеров или отстающих.
Модель нейросети использовала 27 скрытых переменных со значением снижения весов 0,1. Профиль эффективности модели (здесь не приводится, но может быть воспроизведен с использованием синтаксиса из раздела «Вычисления») показывает, что снижение весов оказывает крайне незначительное влияние на эффективность модели. Итоговая модель Cubist использовала 100 комитетов и корректировала прогнозы по трем ближайшим соседям. По аналогии с профилями Cubist, приведенными для данных вычислительной химии (см. рис. 8.22), эффективность ухудшается при слишком низком или слишком высоком количестве соседей. Для дерева с усилением предпочтительны высокая скорость обучения и глубокие деревья.
10.3. Оптимизация сопротивления
сжатию
Нейросеть и модели Cubist использовались для определения возможных составов с улучшенным сопротивлением сжатию, в частности, посредством числового поиска для нахождения формул с высоким сопротивлением сжатию (по прогнозам модели). После выявления потенциального набора составов проводятся дополнительные проверки улучшения сопротивления. Для наглядности возрасту присвоено фиксированное значение, равное 28 дням (тренировочный набор содержал большое количество точек данных с этим значением), а ингредиенты составов оптимизировались.
Существует множество числовых оптимизированных процедур для поиска в семимерном пространстве. Многие из них основаны на определении градиента (то есть первой производной) предиктивного уравнения. Некоторые модели включают плавные уравнения прогнозирования (например, нейросети и SVM). Функции с многочисленными разрывами (например, модели на базе деревьев и правил, многомерные адаптивные регрессионные сплайны и т. п.) непригодны для градиентных методов поиска.
Альтернативное решение — использование оптимизаторов, или так называемых прямых методов, без производных для нахождения конфигураций с оптимальным сопротивлением сжатию и оценивающих предиктивное уравнение интенсивнее, чем оптимизаторы на базе производных. Например:
266 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
О симплексный метод Нельдера—Мида (Nelder and Mead, 1965), упоминаемый также Оллсоном и Нельсоном (Olsson and Nelson, 1975);
О метод имитации отжига, предложенный Богачевским (Bohachevsky et al., 1986). Симплексный поиск обеспечивает в целом лучшие результаты1, за исключением субоптимальных зон пространства поиска, в пределах которых не исключается генерирование «плохих» составов. Для решения этой проблемы поиск повторяется с другой стартовой точкой, после чего выбираются наиболее перспективные результаты поиска. Для этого из тренировочного набора были выбраны пятнадцать 28-дневных составов. Первая из пятнадцати точек была выбрана случайно, а остальные выбирались при помощи процедуры выборки с максимальным расхождением, описанной в разделе 4.3. До начала поиска были установлены ограничения для предотвращения поиска в частях пространства формул, квалифицированных как непрактичные или невозможные. Например, допустимое содержание воды в смеси — от 5,1 до 11,2 %. Соответственно, процедура поиска настроена так, чтобы выявить составы, содержащие не менее 5 % воды.
В тренировочном наборе — 416 формул, которые тестировались 28 дней. Показатель сопротивления сжатию трех лучших составов — 81,75,79,99 и 78,8 соответственно. В табл. 10.2 представлены три лучших спрогнозированных состава для плавной и неплавной модели (нейросети и Cubist соответственно). Как видим, модели смогли найти составы, характеризующиеся наиболее высоким сопротивлением сжатию. Составы Cubist по прогнозу имеют сходное сопротивление сжатию. Формулы различаются по составляющим цемента, шлака, зольной пыли и пластификатора. Составы нейросетей находились в близлежащей зоне пространства составов, их прогнозируемые значения ниже, чем у прогнозов моделей Cubist, но, одновременно, — выше, чем у лучших наблюдаемых составов.
В каждом из шести случаев составы имели очень низкие пропорции воды. Метод анализа главных компонент использован для представления состава тренировочного набора (в семимерном пространстве) с использованием двух компонент. На рис. 10.4 изображена диаграмма РСА для 28-дневных данных.
На диаграмму нанесены значения главных компонент для 15 составов, используемых в качестве начальных точек для процедуры поиска (они обозначены символами *), и еще 401 точка данных в тренировочном наборе (изображаются небольшими серыми точками). Также показаны три лучших прогноза двух моделей. Многие прогнозируемые составы лежат у границ пространства составов, и скорее всего, им присуща известная неточность, обусловленная экстраполяцией. С учетом этого обстоятельства крайне важно организовать проверку новых формул — как теоретическую, так и экспериментальную.
1 Читатель также может опробовать метод имитации отжига с использованием кода, приведенного в конце главы.
10.3. Оптимизация сопротивления сжатию 267
Таблица 10.2. Три верхних оптимальных состава, спрогнозированных по двум моделям с возрастом, зафиксированным со значением 28. В тренировочном наборе самые сильные составы имели сопротивления сжатию 81,75, 79,99 и 78,8
Модель
Цемент
Шлак
Пыль
Пласт.
Круп, зап.
Мелк. зап.
Вода
Прогноз
Cubist
Новый состав 1
12,7
14,9
6,8
0,5
34,0
25,7
5,4
89,1
Новый состав 2
21,7
3,4
5,7
0,3
33,7
29,9
5,3
88,4
Новый состав 3
14,6
13,7
0,4
2,0
35,8
27,5
6,0
88,2
Нейросеть
Новый состав 4
34,4
7,9
0,2
0,3
31,1
21,1
5,1
88,7
Новый состав 5
21,2
11,6
0,1
1,1
32,4
27,8
5,8
85,7
Новый состав 6
40,8
4,9
6,7
0,7
20,3
20,5
6,1
83,9
Итоговый набор
Cubist
Начальные значения
Нейросеть
-4 -2 0
РС1
2
Рис. 10.4. Диаграмма РСА данных тренировочного набора с возрастом составов
28 дней. Алгоритм поиска был выполнен 28 раз для 15 разных тренировочных наборов (обозначены * на диаграмме). Также представлены три верхних оптимальных состава, спрогнозированных двумя моделями
268 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
Могут использоваться и более сложные методы поиска оптимальных составов — например, учитывающих стоимость состава, и т. п. Такая многомерная, или поли- параметрическая, оптимизация может быть проведена несколькими способами. Одно из простых решений, представленных группой Косты, Деррингером и Суичем (Derringer and Suich, 1980; Costa et al., 2011), — функции желательности. Здесь важные характеристики состава (например, сопротивление сжатию и стоимость) отображаются на общую шкалу желательности с интервалом от 0 до 1, где 1 — максимальная желательность, а 0 — полная нежелательность. Например, стоимость выше определенного порога может оказаться неприемлемой. Соответственно, составы, обладающие стоимостью, равной этому значению или превышающей его, квалифицируются как нежелательные. С уменьшением стоимости связь между стоимостью и желательностью может выражаться линейной зависимостью. На рис. 10.5 приведены два примера функции желательности для сопротивления сжатию и стоимости.
0,8
0,6
0,4
0,2
1,0
£
* 0,2
0,0
л н о о X
0,0
0 5 10 15 20 25 30
0 20 40 60 80 100
Стоимость
Сопротивление сжатию
Рис-10.5. Примеры отдельных функций желательности для стоимости и сопротивления сжатию. Среднее геометрическое этих показателей может оптимизироваться для поиска прочных и недорогих составов
Формулы со стоимостью выше 20 и сопротивлением сжатию меньше 70 считаются полностью неприемлемыми. После того как пользователь создаст функции желательности для каждой оптимизируемой характеристики, вычисляется общая желательность (обычно с использованием среднего геометрического). Поскольку при вычислении среднего геометрического значения умножаются, если хотя бы одна функция желательности имеет нулевой рейтинг, все остальные характеристики будут считаться нерелевантными (так как и общее значение тоже будет равно нулю). Общая желательность будет оптимизироваться процедурой поиска для нахождения решения, учитывающего все характеристики (см. соответствующие примеры у Уэйджера (Wager et al., 2010) и Крус—Монтеагудо (Cruz—Monteagudo et al., 2011)).
10.4. Вычисления 269
10.4. Вычисления
В этом разделе используются функции из пакетов caret, desirability, Hmisc и plyr. Данные, характеризующие состав бетона, находятся в репозитории UCI Machine Learning. Пакет AppliedPredictiveModeling содержит исходные данные (в долях) и альтернативную версию с пропорциями:
> Library(AppLiedPredictiveModeLing)
> data(concrete)
> str(concrete)
'data.frame': 1030 obs. of 9 variables:
$ Cement
$ BlastFurnaceSlag
$ FlyAsh
$ Water
$ Superplasticizer
$ CoarseAggregate
$ FineAggregate
$ Age
num 540 540 332 332 199 ...
num 0 0 142 142 132 ...
num 0000000000 ...
num 162 162 228 228 192 228 228 228 228 228
num 2.5 2.5 0 0 0 0 0 0 0 0 ...
num 1040 1055 932 932 978 ...
num 676 676 594 594 826 ...
: int 28 28 270 365 360 90 365 28 28 28 ...
$ CompressiveStrength: num 80 61.9 40.3 41 44.3 ...
> str(mixtures)
'data.frame': 1030 obs. of 9 variables: $ Cement
$ BlastFurnaceSlag $ FlyAsh
$ Water
$ Superplasticizer $ CoarseAggregate
$ FineAggregate
$ Age
: num 0.2231 0.2217 0.1492 0.1492 0.0853 ...
: num 0 0 0.0639 0.0639 0.0569 ...
: num 0000000000 ...
: num 0.0669 0.0665 0.1023 0.1023 0.0825 ...
: num 0.00103 0.00103 000 ...
: num 0.43 0.433 0.418 0.418 0.42 ...
: num 0.279 0.278 0.266 0.266 0.355 ...
: int 28 28 270 365 360 90 365 28 28 28 ...
$ CompressiveStrength:
num 80 61.9 40.3 41 44.3 ...
Таблица 10.1 создана с использованием функции describe из пакета Hmisc, а рис. 10.1 — с использованием функции featurePlot из пакета caret:
> featurePLotfx = concrete[, -9],
+ у - concrete$CompressiveStrength,
* ## Добавить расстояние между панелями
+ between = List(x = 1,у=1),
+ ## Добавить фоновую сетку (’д') и сглаживание ('smooth')
+ type = с("д", "р", "smooth"))
Код усреднения составов и разделения данных на тренировочный и тестовый наборы выглядит так:
> averaged <- ddpLy(mixtures,
+ .(Cement, BLastFurnaceSLag, FLyAsh, Hater,
270 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
+
+
> set,seed(975)
> forTraining < +
SuperpLasticizer, CoarseAggregate, FineAggregate, Age),
function(x) c(CompressiveStrength = mean(x$CompressiveStrength)))
createDataPartition(averaged$CompressiveStrength,
P = 3/4)[[l]]
> trainingSet <- averaged[ forTraining, ] > testSet <- averaged[-forTraining,]
Для аппроксимации линейных моделей с расширенным набором предикторов (например, с взаимодействиями) создана специальная формула модели. Точка в приведенной ниже формуле — сокращенное обозначение всех предикторов, а (. )Л2 расширяется в модель со всеми линейными составляющими и всеми двухфакторными взаимодействиями. Квадратичные составляющие создаются вручную и инкапсулируются внутри функции 1(). Эта функция сообщает R, что вычисление квадратов предикторов должно выполняться арифметически (а не по символам). Формула сначала создается как строка командой paste, после чего преобразуется в нормальную формулу R.
> modFormuLa <- paste("CompressiveStrength ~ + I(CementA2) + ",
+ "I(BLastFurnaceSLagA2) + I(FLyAshA2) + I(WaterA2) + ",
+ " I(SuperpLasticizerA2) + I(CoarseAggregateA2) + ",
+ "I(FineAggregateA2) + I(AgeA2)")
> modFormuLa <- as,formuLa(modFormuLa)
Каждая модель использует повторяющуюся десятикратную перекрестную проверку, задаваемую функцией traincontrol:
> controLObject <- trainControL(method = "repeatedcv",
+ repeats = 5,
+ number =10)
Для создания точно повторяющихся комбинаций генератор случайных чисел сбрасывается в конкретное состояние перед выполнением train. Например, аппроксимация модели линейной регрессии выполняется следующим образом:
> set,seed(669)
> LinearReg <- trainfmodFormuLa,
+ data = trainingSet,
+ method = "Lm",
+ trControL = controLObject)
> LinearReg
745 samples
44 predictors
No pre-processing
10.4. Вычисления 271
Resampling: Cross-Validation (10-fold, repeated 5 times)
Summary of sample sizes: 671, 671, 672, 670, 669, 669, ...
Resampling results
RMSE Rsquared RMSE SD Rsquared SD
7.85 0.771 0.647 0.0398
Из выходных данных видно, что использовались 44 предиктора, это указывает на использование расширенной формулы модели.
Две другие линейные модели строились следующим образом:
> set.seed(669)
> pLsModeL <- trainfmodForm, data = trainingSet,
+ method = "pLs",
+ preProc = c("center", "scaLe"),
+ tuneLength = 15,
+ trControL = controLObject)
> enetGrid <- expand.grid(.Lambda = c(0, .001, .01, .1),
+ .fraction = seq(0.05, 1, Length = 20))
> set.seed(669)
> enetModeL <- train(modForm, data = trainingset,
+ method = "enet",
+ preProc = c("center", "scaLe"),
+ tuneGrid - enetGrid,
+ trControL = controLObject)
Модели MARS, нейросетей и SVM создавались следующим образом:
> set.seed(669)
> earthModeL <- train(CompressiveStrength ~ ., data = trainingSet,
+ method = "earth",
+
+
> set.seed(669)
tuneGrid = expand.grid(.degree = 1, .nprune = 2:25), trControL = controLObject)
> svmRModeL <- train(CompressiveStrength - ., data = trainingSet, + method = "svmRadiaL",
+ tuneLength = 15,
+ preProc = c("center", "scaLe"),
+ trControL = controLObject)
> nnetGrid <- expand.grid(.decay = c(0.001, .01, .1),
+ .size = seq(l, 27, by = 2),
+ .bag = FALSE)
> set.seed(669)
> nnetModeL <- train(CompressiveStrength ~ .,
HI Глава 10. Практический пример: сопротивление сжатию бетонных смесей
+
data = trainingSet,
method = "avNNet",
+
tuneGrid = nnetGrid,
+
preProc = c("center", "sea
+
Linout = TRUE,
+
trace = FALSE,
+
maxit = 1000,
trControL = controLObject)
Деревья моделей и регрессии создавались аналогичным образом:
>
> +
+ +
+
>
>
+
+
+
+
>
>
+
+ +
set.seed(669) rpartModeL <- train(CompressiveStrength ~ ., data = trainingSet, method = "rpart", tuneLength = 30, trControL = controLObject)
set.seed(669)
ctreeModeL <- train(CompressiveStrength ~ data = trainingset, method = "ctree", tuneLength =10, trControL = controLObject)
•»
set.seed(669) mtModeL <- train(CompressiveStrength ~ ., data = trainingSet, method = "MS", trControL = controLObject)
Следующий код создает остальные объекты моделей:
>
>
+
+
+
>
>
set.seed(669) treebagModeL <-
train(CompressiveStrength ~ ., data = trainingSet, method = "treebag", trControL = controLObject)
•
set.seed(669)
rfModeL <- train(CompressiveStrength ~
+
data = trainingSet,
+
method = "rf",
+
tuneLength =10,
+
ntrees = 1000,
+
importance = TRUE,
+
trControL = controLObject)
> gbmGrid <-
expand.grid(.interaction.depth =
+
.n.trees = seq(100, :
.shrinkage = c(0.01,
-- seq(l, 7, by = 2), 1000, by = 50),
ел))
10.4. Вычисления 273
> set.seed(669)
> gbmModeL <- train(CompressiveStrength - .,
+ data = trainingSet,
+ method = "gbm",
+ tune6rid = gbmGrid,
+ verbose = FALSE,
+ trControL = controLObject)
> cubistGrid <- expand.grid(.committees = c(l, 5, 10, 50, 75, 100),
+ .neighbors - c(0, 1, 3, 5, 7, 9))
> set.seed(669)
> cbModeL <- train(CompressiveStrength - .,
+ data = trainingSet,
+ method = "cubist",
+ tuneGrid - cubistGrid,
+ trControL = controLObject)
Результаты повторной выборки для этих моделей собраны в один объект при помощи функции resamples из пакета carets. Этот объект затем может использоваться для визуализаций или формальных сравнений между моделями:
> aLLResampLes <- resampLes(List("Linear Reg" = LmModeL,
+
+
+
+
+
+
*
*
"PLS" = pLsModeL,
"ELastic Net" = enetModeL, MARS = earthModeL,
SVM = svmRModeL,
"NeuraL Networks" = nnetModeL, CART = rpartModeL,
"Cond Inf Tree" = ctreeModeL, "Bagged Tree" = treebagModeL, "Boosted Tree" = gbmModeL, "Random Forest" = rfModeL, Cubist = cbModeL))
Диаграмма на рис. 10.2 создана на базе этого объекта следующим образом:
> ## Графическое представление значений среднеквадратичной погрешности
> paraLLeLPLot(aLLResampLes)
> ## С использованием метрики R-квадрат:
> paraLLeLpLot(aLLResampLes, metric = "Rsquared")
Также возможно создать другие наглядные представления результатов повторной выборки (см. ?xyplot. resamples). Прогнозы для тестового набора строились посредством функции predict:
> nnetPredictions <- predict(nnetModeL, testData)
> gbmPredictions <- predict(gbmModeL, testData)
> cbPredictions <- predict(cbModeL, testData)
274 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
Для прогнозирования оптимальных составов сначала используем 28-дневные данные генерирования набора случайных начальных точек из тренировочного набора. Поскольку расстояния между формулами будут использоваться как метрика непохожести, данные проходят предварительную обработку, чтобы все предикторы имели одинаковые средние значения и дисперсию. После этого один случайный состав выбирается для инициализации процесса выборки с максимальным расхождением:
> age28Data <- subset(trainingData, Age = 28)
> ## Удалить столбцы возраста и сопротивления сжатию,
> ## затем выполнить центрирование и масштабирование столбцов.
> ppi <- preProcess(age28Data[, -(8:9)], с( "center", "scaLe"))
> scaLedTrain <- predict(ppl, age28Data[, 1:7])
> set.seed(91)
> startMixture <- sampLe(l:nrow(age28Data), 1)
> starters <- scaLedTrain[startMixture, 1:7]
Затем метод выборки с максимальным расхождением из раздела 4.3 выбирает еще 14 составов; таким образом строится разнообразный набор начальных точек для исходного алгоритма:
> pooL <- scaLedTrain
> index <- maxDissim(starters, pooL, 14)
> startPoints <- c(startMixture, index)
> starters <- age28Data[startPoints,1:7]
Поскольку все семь долей составляющих в сумме должны давать единицу, процедуры поиска проводят поиск без учета одного ингредиента (воды), а пропорция воды будет определяться суммой пропорций шести других ингредиентов. Без этого шага процедуры поиска будут выбирать потенциальные составы с суммой долей ингредиентов, не равной единице.
> ## Удаление воды
> startingVaLues <- starters[, -4]
Для достижения максимального сопротивления сжатию функция R optim ищет в пространстве составов оптимальные формулы. Для преобразования потенциального состава в прогноз потребуется специальная функция R. Эта функция находит конфигурации, минимизирующие значение функции, поэтому она будет возвращать значение, обратное значению сопротивления сжатию. Приведенная ниже функция проверяет, что, во-первых, пропорции лежат в интервале от 0 до 1 и, во-вторых, пропорция воды не падает ниже 5 %. Если эти условия нарушаются, то функция возвращает большое положительное число, которое будет обходиться процедурой поиска (так как функция optim предназначена для минимизации).
> ## Входные данные функции составляют вектор из шести пропорций состава
> ## (аргумент 'х') и модель, используемая для прогнозирования ('mod')
10.4. Вычисления 275
> modeLPrediction <- function(x, mod)
+ {
+
+ + + + +
+
+
+ + + + + +
+
+
+
+
+
+
+
## Убедиться в том, что пропорции ингредиентов ## лежат в правильном диапазоне if(x[l] < 0 I х[1] > 1) return(10A38)
if(x[2] < 0 I х[2] > 1) return(10Л38)
if(x[3] < 0 I x[3] > 1) return(10A38)
if(x[4] < 0 I x[4] > 1) return(10A38)
if(x[5] < 0 I x[5] > 1) return(10A38)
if(x[6] < 0 I x[6] > 1) return(10A38) ## Определить пропорцию воды
x <- c(x, 1 - sum(x)) ## Проверить диапазон для воды
if(x[7] < 0.05) return(10A38)
## Преобразовать вектор в кадр данных, присвоить имена
## и зафиксировать возраст 28 дней
tmp <- as.data.frame(t(x)) names(tmp) <- c('Cement','BLastFurnaceSLag','FLyAsh',
'SuperpLasticizer', 'CoarseAggregate',
' FineAggregate', 'Hater')
tmp$Age <-28
## Получить прогноз модели, возвести в квадрат для возвращения
## к исходным единицам, затем вернуть величину, обратную результату. -predict(mod, tmp)
}
Затем тот же процесс используется для модели нейросети:
> nnetResuLts <- startingVaLues
> nnetResuLts$Water <- NA
> nnetResuLts$Prediction <- NA
> forfi in 1:nrow(nnetResuLts))
+ {
+ results <- optim(unList(nnetResuLts[i, 1:6,]),
+ modeLPrediction,
+ method = "NeLder-Mead",
+ controL=List(maxit=5000),
+ mod = nnetModeL)
+ nnetResuLts$Prediction[i] <- -resuLts$vaLue
+ nnetResuLts[i,l:6] <- resuLtsfpar
* }
> nnetResuLts$Nater <- 1 - appLy(nnetResuits[,l:6], 1, sum)
> nnetResuLts <- nnetResuLts[order(-nnetResuLtsfPrediction),][1:3,]
> nnetResuLtsfModeL <- "NNet"
276 Глава 10. Практический пример: сопротивление сжатию бетонных смесей
Для создания рис. 10.4 проведен РСА-анализ 28-дневных составов с последующим проецированием шести спрогнозированных составов. Компоненты объединяются и выводятся на диаграмме:
> ## Проведение анализа РСА для данных с возрастом 28,дней
> рр2 <- preProcess(age28Data[, 1:7], "pea")
> ## Получить компоненты для этих составов,
> peal <- predict(pp2, age28Data[, 1:7])
> pcal$Data <- "Training Set"
> ## Пометить точки данных, использованные для начала поиска
> pcal$Data[startPoints] <- "Starting VaLues"
> ## Проецирование новых составов (не забудьте переупорядочить
> ## столбцы в соответствии с порядком объекта age28Data).
> рсаЗ <- predict(pp2, cbResuLts[, names(age28Data[, 1:7])])
> pca3$Data <- "Cubist"
> pca4 <- predict(pp2, nnetResuLts[, names(age28Data[, 1:7])])
> pca4$Data <- "NeuraL Network"
> ## Объединить данные, определить диапазоны осей и построить график
> pcaData <- rbind(pcal, рсаЗ, рса4)
> pcaData$Data <- factor(pcaDatafData,
+ LeveLs = c("Training Set","Starting VaLues",
+ "Cubist","NeuraL Network"))
> Lim <- extendrange(pcaData[, 1:2])
> xypLot(PC2 - PCI, data = pcaData, groups = Data,
+ auto,key = List(coLumns = 2),
+ xLim = Lim, yLim = Lim,
+ type = c("g", "p"))
Для вычисления функций желательности можно воспользоваться пакетом desirability. Функции dMin и dMax могут использоваться для создания определений кривых функций желательности (для минимизации и максимизации соответственно).
Часть III
КЛАССИФИКАЦИОННЫЕ МОДЕЛИ
1 Определение эффективности в классификационных моделях
Предыдущая часть книги была посвящена построению и оценке моделей для непрерывной реакции. Теперь обратимся к построению и оценке моделей для категорийных ответов. Хотя многие методы регрессионного моделирования могут использоваться и для классификации, оценки эффективности модели будут сильно отличаться, поскольку такие показатели, как среднеквадратичная погрешность и R2, неуместны в контексте классификации, в связи с чем сначала предлагается рассмотреть показатели, применимые для оценки эффективности классификационных моделей. После этого перейдем к освещению различных аспектов прогнозов классификационных моделей и стратегий оценки классификационных моделей с использованием статистики и визуализаций.
11.1. Прогнозы классов
Классификационные модели обычно генерируют прогнозы двух типов. Как и регрессионные модели, они выдают прогнозы с непрерывными значениями, обычно выражающиеся в форме вероятности (то есть прогнозируемые значения принадлежности к классу для любой отдельной точки данных лежат в интервале от 0 до 1, а их сумма равна 1). Кроме того, классификационные модели генерируют прогнозируемый класс, выступающий в форме дискретной категории. На практике для принятия решения довольно часто требуется прогноз принадлежности к конкретной категории — например, автоматическая фильтрация спама требует определенного решения для каждого сообщения.
Хотя классификационные модели строят прогнозы обоих типов, часто задача ориентируется на дискретный, а не на непрерывный прогноз. Тем не менее оценки вероятности принадлежности к каждому классу могут быть чрезвычайно полезными для оценки уверенности модели относительно прогнозируемой классификации. Возвращаясь к примеру со спам-фильтром, отметим, что сообщение
11.1. Прогнозы классов 279
с прогнозируемой вероятностью принадлежности к категории «спам» 0,51 будет классифицировано точно так же, как и сообщение с прогнозируемой вероятностью 0,99. При том, что оба сообщения будут обработаны фильтром с одинаковыми результатами, с большей уверенностью можно полагать, что второе сообщение действительно было спамом. Другой пример: представим процесс построения модели для классификации молекул в отношении их безопасности для жизни по трем следующим классам — нетоксичные, слабо токсичные, сильно токсичные (см. в этой связи работу Пирсма (Piersma et al., 2004)). Молекула с прогнозируемыми вероятностями в категориях токсичности 0,34, 0,33 и 0,33 будет классифицирована так же, как и молекула с вероятностями 0,98, 0,01 и 0,01. Однако во втором случае можно быть намного более уверенными в нетоксичности второй молекулы по сравнению с первой.
В некоторых случаях желательный результат представляет собой прогнозируемые вероятности принадлежности к классам, которые подаются на вход других вычислений. Предположим, что некая страховая компания хочет обнаруживать и преследовать мошеннические требования. На основе накопленной статистики требований строится классификационная модель для прогнозирования вероятности мошеннических заявок. Эта вероятность объединяется с затратами на расследование и потенциальными убытками для определения того, соответствует ли проведение расследования финансовым интересам страховой компании.
В другом примере, представленном в работе Гупты (Gupta et al., 2006), использование вероятностей классификации на входе последующей модели, условно обозначаемой как пожизненная ценность клиента (CLV, Customer Lifetime Value), определяется как суммарная прибыль, связанная с клиентом, за определенный период времени. Для оценки CLV необходим набор величин, среди которых сумма, выплаченная клиентом за определенный период времени, затраты на обслуживание клиента и вероятность того, что клиент сделает покупку за расчетный период. Как упоминалось, большинство классификационных моделей генерирует спрогнозированные вероятности принадлежности к классам (или просто вероятности классов). Однако при использовании для классификации некоторых моделей, таких как нейросети и частные наименьшие квадраты, прогнозируемые значения не обязательно лежат в интервале от 0 до 1 и, кроме того, не обязательно дают в сумме 1. Например, модель классификации методом частных наименьших квадратов (более подробно описанная в разделе 12.4) создает для каждого класса фиктивные переменные 0/1 и одновременно моделирует эти значения как функцию предикторов. При прогнозировании точек данных модель не гарантирует, что прогнозы будут лежать в диапазоне от 0 до 1. Для таких классификационных моделей должно использоваться преобразование, которое приводит прогнозы к таким «вероятностным» значениям, чтобы они могли интерпретироваться и использоваться для классификации. Один из подобных методов — преобразование softmax по Бридлу (Bridle, 1990), которое определяется следующим образом:
280 Глава 11. Определение эффективности в классификационных моделях где у{ — числовой прогноз модели для Л го класса, а р* — преобразованное значение в диапазоне от 0 до 1. Предположим, результат имеет три класса, а модель PLS прогнозирует значения у{ = 0,25, у2= 0,76 и z/3 = -0,1. Softmax-функция преобразует эти значения в Д*=0,30, р\ = 0,49 и р3 =0,21. Стоит пояснить, что это преобразование не создает никаких утверждений относительно вероятностей, лишь гарантируя, что прогнозы будут обладать теми же математическими качествами, что и вероятности.
Хорошо откалиброванные вероятности
Что бы ни делала классификационная модель — выявляла спам в сообщениях электронной почты, определяла статус токсичности молекул, служила входными данными для страховых мошенничеств или расчетов пожизненной ценности клиента, — весьма желательно, чтобы оцениваемые вероятности классов отражали истинную вероятность, лежащую в основе прогноза. Другими словами, прогнозируемая вероятность класса (или значение, представляющее вероятность) должна быть хорошо откалибрована. Чтобы вероятности могли считаться хорошо откалиброванными, они должны отражать истинную вероятность события, которое представляет интерес. Возвращаясь к иллюстрации со спам-фильтром, отметим, что если модель прогнозирует вероятность (или значение, представляющее вероятность) того, что некоторое сообщение электронной почты является спамом, равную 20 %, то это значение следует считать хорошо откалиброванным, если сообщения аналогичного типа действительно будут относиться к этому классу в одной из пяти точек данных.
Для оценки качества вероятностей классов можно воспользоваться калибровочным графиком. Для заданного набора данных этот график отображает некоторый показатель наблюдаемой вероятности события по сравнению с прогнозируемой вероятностью класса. Один из способов основан на создании коллекции точек данных с известными результатами (желательно тестового набора) при использовании классификационной модели. Далее данные разбиваются на группы на основании их вероятностей классов. Например, может быть определен следующий набор групп: [0 %, 10 %], (10 %, 20 %],..., (90 %, 100 %]. Для каждой группы определяется наблюдаемая частота события. Предположим, 50 точек данных попали в группу с вероятностью класса менее 10 %, где произошло одно событие. Среднее значение вероятности класса для этой группы — 5 %, тогда как наблюдаемая частота события составит 2 %. На калибровочном графике по оси х будут отображаться средние точки, а по оси у — наблюдаемая частота события. Если точки идут вдоль линии с наклоном 45, значит, модель производит хорошо откалиброванные вероятности.
11.1. Прогнозы классов 281
Для наглядности был смоделирован набор данных с известными истинными вероятностями событий. Для двух классов (классы 1 и 2) и двух предикторов (А и В) истинная вероятность (р) события генерируется уравнением:
log^y^—^) = -1 - 2Л - .2Л2 +2В2.
На рис. 11.1 показан смоделированный тестовый набор с контурной линией для вероятности события р - 0,50. Для тренировочного набора были аппроксимированы две модели: модель квадратичного дискриминантного анализа (QDA, см. раздел 13.1) и модель случайного леса (см. раздел 14.4). Тестовый набор из п = 1000 точек данных использовался для оценки модели и создания калибровочного графика, показанного на рис. 11.1. Обе классификационные модели имеют сходную точность для тестового набора (около 87,1 % для каждой модели). На калибровочном графике видно, что вероятности классов QDA показывают не лучшие результаты по сравнению с моделью случайного леса. Например, в группе с вероятностями в диапазоне от 20 до 30 % доля наблюдаемых событий для QDA равна 4,6 %, то есть намного ниже, чем процент модели случайного леса (35,4 %).
Вероятности классов могут калиброваться для более точного воспроизведения правдоподобия событий (или, по крайней мере, правдоподобия, наблюдаемого в фактических данных).
qda
4
rf
ей
о. о
Ct
о.
0
-2
-4
-2-10123
Предиктор А
£
3 ю о о
X
3
S ф !
ю ф X н X ф а с
100
80
60
40
20
60 80 100
20 40
Средняя точка группы
£
ф
С
2
0
0
Рис. 11.1. Слева: смоделированный набор данных с двумя классами и двумя предикторами. Сплошная черная линия обозначает контур 50 % вероятности. Справа: калибровочный график вероятностей тестового набора для моделей случайного леса и квадратичного дискриминантного анализа
Например, на рис. 11.1 представлена сигмоидальная кривая, при которой модель QDA недооценивает вероятность события при достаточно низкой или высокой
282 Глава И. Определение эффективности в классификационных моделях истинной вероятности. Для корректировки этого явления можно создать новую модель. Одной из моделей, в которых проявляется сигмоидальная закономерность, является модель логистической регрессии (см. раздел 12.2). Прогнозы классов и истинные результаты из тренировочного набора могут использоваться для последующей обработки оценок вероятности по формуле Платта (Platt, 2000):
1 + cxpHVP^)’
где параметры Р оцениваются прогнозированием истинных классов как функции некалиброванных вероятностей классов (р). Для модели QDA этот процесс дает оценки р0 = -5,7 и pt = 11,7.
На рис. 11.2 показаны результаты улучшения калибровки для точек данных тестового набора с применением этого метода корректировки. Для перекалибровки прогнозов можно применить и правило Байеса (см. раздел 13.6). Байесовский подход также улучшает прогнозы (рис. 11.2), но после калибровки необходимо провести повторную классификацию точек для поддержания согласованности новых вероятностей и прогнозируемых классов.
100
>s
80
8
X
s 60 ф !
5 40 га z
| 20 а с
0
0
20 40 60
80 100
Средняя точка группы
Рис. 11.2. Исходные вероятности классов QDA и перекалиброванные версии с применением двух разных методологий
Представление вероятностей классов
Эффективной передачи результатов модели можно достичь посредством наглядного представления вероятностей классов — к примеру, при помощи гистограмм прогнозируемых классов для каждого полученного результата, которые отражают сильные
11.1. Прогнозы классов 283
и слабые стороны модели. Так, в главе 4 рассмотрен пример с оценкой кредитоспособности с применением двух классификационных моделей: модели опорных векторов (SVM) и модели логистической регрессии. Поскольку эффективность моделей оказалась сопоставима, предпочтение было отдано модели логистической регрессии (вследствие ее сравнительной простоты). Обратимся теперь к рис. 11.3, в верхней части которого представлены гистограммы вероятностей тестового набора для модели логистической регрессии (на диаграммах указан истинный статус кредитоспособности).
0.0 0,2 0.4 0,6 0.8 1.0
40 о 30 со
| 20
о
10
0
0,0 0.2 0,4 0,6 0,8 1.0
Вероятность плохой кредитоспособности
100
>х
X
I 80
8
н
1 60
о
о.
с
’1 40
S
ф
СО
С[
2 20
io
со
I
0
0 20 40 60 80 100
Средняя точка группы
Рис. 11.3. Наверху: гистограммы для набора вероятностей, связанных с плохой кредитоспособностью. Две области разбивают клиентов по их истинному классу. Внизу: калибровочный график для этих вероятностей
284 Глава И. Определение эффективности в классификационных моделях
Вероятность плохой кредитоспособности для клиентов с хорошей кредитоспособностью характеризуется асимметричным распределением, в котором вероятности для большинства клиентов достаточно малы. С другой стороны, вероятности для клиентов с плохой кредитоспособностью характеризуются равномерным распределением, отражающим неспособность модели различать плохую кредитоспособность.
Здесь же представлен калибровочный график для этих данных. Точность вероятности плохой кредитоспособности убывает с ее возрастанием до точки, в которой ни одна точка данных с плохой кредитоспособностью не была предсказана с вероятностью выше 82,7 %, что типично для моделей с плохой калибровкой и плохой эффективностью.
С тремя и более классами для оценки уверенности в прогнозах можно воспользоваться тепловой картой вероятностей классов. На рис. 11.4 показаны результаты тестового набора для восьми классов (A-I) и 48 точек данных.
Истинные классы выводятся по строкам (с идентификаторами точек данных), а столбцы представляют вероятности классов. В некоторых случаях (например, для точки 20) с прогнозируемым классом связан четкий сигнал (вероятность класса С равна 78,5 %), тогда как в других случаях ситуация неоднозначна. Возьмем точку 7. Четыре наибольшие вероятности (и связанные с ними классы) — 19,6 % (В), 19,3% (С), 17,7% (А) и 15 % (Е). Хотя модель помещает самую высокую отдельную вероятность для этой точки в правильный класс, нет уверенности в том, что это произойдет с классами С, А или Е.
Неоднозначные зоны
Для улучшения эффективности классификации определяются неоднозначные, или неопределенные, зоны, в которых класс не прогнозируется формально при недостаточно высокой уверенности. В задаче с двумя классами, практически сбалансированной в реакции, неоднозначная зона может определяться в форме 0,50 ± z. При значении z = 0,10 точки с вероятностями прогнозирования в диапазоне от 0,40 до 0,60 называются «неоднозначными» (equivocal). В этом случае эффективность модели будет вычисляться с исключением точек данных в неопределенной зоне.
Для лучшего понимания доли неспрогнозированных результатов полоса неоднозначности также должна прилагаться к оценке эффективности. Для наборов данных более чем с двумя классами (С > 2) могут применяться аналогичные пороги с наибольшей вероятностью класса более (1/C) + z, обеспечивающие получение определенного прогноза. При установлении для данных на рис. 11.4 (1/C) + z равным 30 % пять точек данных будут интерпретированы как неоднозначные.
11.1. Прогнозы классов 285
A (SampleOl) A (Sample02) A (Sample03) A (Sample04) В (Sample05) В (Sample06) В (Sample07) В (Sample08) В (Sample09) В (Sample 10) В (Sample11) С (Sample12) С (Sample13) С (Sample14) С (Sample 15) С (Sample16) С (Sample17) С (Sample18) С (Sample19) С (Sample20) С (Sample21) С (Sample22) С (Sample23) С (Sample24) С (Sample25) С (Sample26) Е (Sample27) Е (Sample28) Е (Sample29) Е (Sample30) Е (Sample31) Е (Sample32) Е (Sample33) Е (Sample34) Е (Sample35) Е (Sample36) Е (Sample37) Е (Sample38) F (Sample39) F (Sample40) F (Sample41) F (Sample42) G (Sample43) G (Sampte44) H (Sample45) H (Sample46)
I (Sample47) I (Sample48)
А В С E F G H
Вероятность класса
Рис 11.4. Тепловая карта тестового набора с восемью классами. Истинные классы указаны в метках строк, тогда как столбцы определяют вероятности для каждой категории (с метками A-I)
286 Глава 11. Определение эффективности в классификационных моделях
11.2. Оценка прогнозируемых классов
В стандартном способе описания эффективности классификационной модели используется матрица несоответствий — простая перекрестная таблица наблюдаемых и прогнозируемых классов для данных. В табл. 11.1 показан пример для двух классов.
Таблица 11.1. Матрица несоответствий для задачи с двумя классами («событие» и «несобытие»). В ячейках таблицы указано количество истинно положительных значений (ТР), ложноположительных значений (FP), истинно отрицательных значений (TN) и ложноотрицательных значений (FN)
Прогноз
Наблюдение
событие
несобытие
Событие
ТР
FP
Несобытие
FN
та
Диагональные ячейки соответствуют случаям правильного прогнозирования классов, тогда как ячейки вне главных диагоналей содержат количество ошибок для каждого возможного случая.
Простейшим показателем является общая степень точности (или частота ошибок), отражающая согласованность между наблюдаемыми и прогнозируемыми классами и имеющая наиболее прямолинейную интерпретацию. Тем не менее у этого показателя есть ряд недостатков. Во-первых, общее количество верных прогнозов не учитывает типы совершаемых ошибок. При фильтрации спама потери от ошибочного удаления важного сообщения, вероятно, будут выше, чем от случайного прохождения спама через фильтр. В ситуациях, в которых потери различны, точность может не отражать некоторые важные характеристики модели. Подробное обсуждение этой темы можно найти у Провоста (Provost et al., 1998, см. также далее).
Во-вторых, следует учитывать естественные частоты каждого класса. Например, в США беременные женщины сдают анализы крови на альфа-фетопротеин для выявления таких генетических отклонений, как синдром Дауна. Предположим, частота этого отклонения1 у эмбриона составляет приблизительно 1:800, или около 1/10 %. Предиктивная модель может достигнуть практически идеальной точности, прогнозируя у всех проб отсутствие синдрома Дауна.
Какой показатель точности следует использовать для определения того, насколько удовлетворительно функционирует модель? Неинформированная точность — сте-
1 В медицинской терминологии эта частота называется распространенностью (или заболеваемостью), тогда как в байесовской статистике будет использоваться термин «априорное распределение».
11.2. Оценка прогнозируемых классов 287
пень точности, которая может быть достигнута без модели. Существуют разные способы определения этого показателя. Для набора данных с С классами простейшее определение, основанное на чистой случайности, равно 1 /С. Тем не менее оно не учитывает относительные частоты классов в тренировочном наборе. В примере с синдромом Дауна при выборке 1000 случайных проб из совокупности ожидаемое количество положительных результатов будет малым (возможно, 1 или 2). Модель, которая просто прогнозирует все пробы на синдром Дауна как отрицательные, легко превзойдет неинформированную точность, основанную на случайном предположении (50 %). Альтернативное определение неинформированной точности основано на выявлении доли самого большого класса тренировочного набора. Модели с точностью, превышающей эту, могут считаться разумными. Эффекты значительного дисбаланса классов и некоторые возможные меры по их преодолению рассматриваются в главе 16.
Вместо того чтобы вычислять общую точность и сравнивать ее с неинформированной, можно воспользоваться некоторыми другими показателями, учитывающими распределение классов для точек из тренировочного набора. Каппа-статистика (или каппа Коэна (Cohen, I960)) изначально создавалась для оценки согласованности мнений двух экспертов, оценивающих одни и те же объекты. Каппа-статистика учитывает точность, которая будет генерироваться вследствие простой случайности. Эта статистика имеет следующую форму:
О-Е
каппа = ,
]-Е
где О — наблюдаемая точность, а Е — ожидаемая точность, базирующаяся на суммах матрицы несоответствия. Статистика может принимать значения в интервале от -1 до 1; значение 0 означает отсутствие согласования между наблюдаемыми и прогнозируемыми классами, тогда как значение 1 означает точное совпадение прогноза модели с наблюдаемыми классами. Отрицательные значения указывают на то, что прогноз находится в противоположном направлении от истины, но большие отрицательные значения крайне редко встречаются при работе с предиктивными моделями1.
При эквивалентных распределениях классов общая точность и каппа-статистика пропорциональны. В зависимости от контекста значения каппа от 0,30 до 0,50 обозначают разумное согласование. Допустим, точность модели высока (90 %), но и ожидаемая точность при этом тоже высока (85 %); каппа-статистика будет демонстрировать умеренное согласование (каппа =1/3 между наблюдаемыми и прогнозируемыми классами.
1 Это объясняется тем, что предиктивные модели стремятся найти согласованную связь с истинными значениями. Большое отрицательное значение каппа-статистики будет означать, что между предикторами и реакцией существует связь, а предиктивная модель будет стараться искать связь в правильном направлении.
288 Глава 11. Определение эффективности в классификационных моделях
Каппа-статистика также может быть расширена для оценки согласований в задачах с более чем двумя классами. При естественном порядке классов (например, «низкий», «средний» и «высокий») альтернативная форма статистики — так называемая взвешенная каппа-статистика — может использоваться для введения более существенных штрафов для ошибок, сильнее отклоняющихся от истинного результата. Например, «низкая» точка, ошибочно спрогнозированная как «высокая», сократит каппа-статистику сильнее, чем «низкая» точка, ошибочно спрогнозированная как «средняя» (см. также работу Агрести (Agresti, 2002)).
Задача двух классов
Возьмем случай с двумя классами. В табл. 11.1 приведена матрица несоответствий для обобщенных классов «событие» и «несобытие». Верхняя строка таблицы соответствует точкам данных, прогнозируемым как события. Некоторые прогнозы верны (истинно положительные, или ТР), другие классифицируются ошибочно (ложноположительные, или FP). Во второй строке содержатся спрогнозированные отрицательные результаты с истинно отрицательными (TN) и ложноотрицательными (FN) значениями.
Для двух классов существует дополнительная статистика, которая может быть актуальной, когда один класс интерпретируется как событие, представляющее интерес (например, синдром Дауна из предыдущего примера). Чувствительностью (sensitivity) модели называется частота правильного прогнозирования интересующего события для всех точек с этим событием, или
кол-во выборок, где есть событие и где оно было предсказано чувствительность = - - £
кол-во выборок, где есть событие
Чувствительность иногда интерпретируется как частота истинно положительных значений, потому что она измеряет точность в совокупности событий. И наоборот, специфичность (specificity) определяется как частота прогнозирования точек с не- событиями как несобытий, или
. кол-во выборок, где нет события и где это было предсказано
специфичность = £
кол-во выборок, где нет события
Частота ложноположительных значений определяется как 1 -- специфичность. Если предположить, что модель имеет фиксированный уровень точности, то обычно между чувствительностью и специфичностью существует определенный баланс. Очевидно, что повышение чувствительности модели с большой вероятностью приведет к потере специфичности, так как большее количество точек прогнозируется как события. Потенциальный компромисс между чувствительностью и специфичностью может быть уместен, если с разными типами ошибок связаны разные штра-
11.2. Оценка прогнозируемых классов 289
фы. При фильтрации спама центральное место обычно занимает специфичность; многие пользователи согласны изредка получать спам при условии, что сообщения от членов семей и коллег не будут удаляться. Кривая операционных характеристик приемника, или ROC-кривая (Receiver Operating Characteristic), — один из инструментов оценки компромиссов такого рода — рассматривается в следующем разделе. В главе 4 был представлен пример с оценкой кредитоспособности. Были созданы две классификационные модели для прогнозирования кредитоспособности клиента: модель SVM и модель логистической регрессии. Так как эффективности двух моделей были приблизительно эквивалентными, предпочтение было отдано модели логистической регрессии из-за ее простоты.
В табл. 11.2 приведена матрица несоответствий, связанная с моделью логистической регрессии, для ранее выбранного тестового набора из 200 клиентов.
Таблица 11.2- Матрица несоответствий для тренировки модели логистической регрессии с данными оценки кредитоспособности из раздела 4.5
Прогноз
Наблюдения
хорошая
плохая
Хорошая
24
10
Плохая
36
130
Общая точность составила 77 %, что немного лучше неинформированной точности (70 %). Для тестового набора каппа-статистика составила 0,375, что указывает на умеренное согласование. Если бы в качестве события была выбрана плохая кредитоспособность, то чувствительность этой модели составила бы 40 %, а специфичность — 92,9 %. Очевидно, у этой модели возникли проблемы с прогнозированием в случаях с неудовлетворительно кредитоспособными клиентами, что может быть обусловлено дисбалансом классов и отсутствием сильного предиктора для плохой кредитоспособности.
Зачастую для оценки частоты ложноположительных значений и ложноотрицательных значений предпочтительнее использовать только один сравнительно простой показатель, равныйJ-индексу Юдена (Youden, 1950):
J = чувствительность + специфичность -1.
Этот показатель измеряет пропорции правильно спрогнозированных точек для обеих групп (события и несобытия). В некоторых контекстах он может стать подходящим методом обобщения величины ошибок обоих типов. Самый распространенный метод объединения чувствительности и специфичности в одно значение использует ROC-кривую (см. ниже).
У чувствительности и специфичности есть один аспект, о котором часто забывают при обсуждении: эти показатели являются условными. Чувствительность
290 Глава И. Определение эффективности в классификационных моделях определяется степенью точности только для совокупности событий (а специфичность — для несобытий). Используя чувствительность и специфичность, акушер может делать утверждения вроде «в предположении о том, что эмбрион не имеет синдрома Дауна, точность анализа равна 95 %». Тем не менее для пациента такие утверждения могут оказаться бесполезными, потому что для новых точек известен только прогноз. Человека, использующего прогноз модели, обычно интересуют безусловные запросы типа «Какова вероятность того, что у эмбриона имеется наследственное заболевание?». Это зависит как от чувствительности и специфичности диагностического теста, так и от частоты события в совокупности. Очевидно, что если событие встречается редко, то этот факт должен быть отражен в ответе. С учетом частоты события аналогом чувствительности становится положительное прогностическое значение (positive predicted value, PPV), а аналогом специфичности — отрицательное прогностическое значение (negative predicted value, NPV). Эти значения представляют безусловные оценки данных1. PPV отвечает на вопрос: «Какова вероятность того, что точка данных является событием?»
рру _ чувствительность х превалирование
(чувствительность х превалирование) +
+ ((1 - специфичность)х(1 - превалирование))
^ру _ специфичность х (1 - превалирование)
(превалирование х (1 - чувствительность)) + (специфичность) + +((1 - специфичность х (1 - превалирование))
Очевидно, что показатели прогнозирования являются нетривиальными комбинациями эффективности и частоты событий. В верхней части рис. 11.5 представлено влияние превалирования на показатели прогнозирования, когда модель обладает специфичностью в 95 % при чувствительности, равной 90 и 99 %. Большие значения NPV могут достигаться при низком превалировании. Тем не менее с ростом частоты событий NPV могут стать очень малыми. Для PPV справедливо обратное. Диаграмма также показывает, что значительные различия в чувствительности (90 и 99 %) не оказывают особого влияния на значения PPV. В нижней части рис. 11.5 PPV представлен как функция чувствительности и специфичности при сбалансированной частоте событий (50 %).
В этом случае положительное прогностическое значение составит
PPV =
чувствительность
чувствительность (1 - специфичность)
ТР
TP+FP
1 В контексте байесовской статистики чувствительность и специфичность называются условными вероятностями, распространенность — априорной вероятностью, а прогностические положительные/отрицательные значения — апостериорными вероятностями.
11.2. Оценка прогнозируемых классов 291
PPV (Чувствительность = 90 %)
PPV (Чувствительность = 99 %) NPV (Специфичность = 95%)
1,0
0,8
0,6
0,4
0,2
0,0
1,0
0,2 0,4 0,6 0,8
Превалирование
Метрика прогнозирования позитивов
1,0
1,0
0,9
0,9
&
о X
0,8
0,8
7
5
t
Д
0,7
0,7
ф
О
0,6
0,6
0,6 0,7 0,8
0,9
1,0
0,5
Чувствительность
Рис. 11.5. Наверху: влияние превалирования на положительные и отрицательные прогностические значения. PPV вычислен при специфичности 95 % и двух значениях чувствительности. NPV вычислен при чувствительности 90 % и специфичности 95 %. Внизу: для фиксированного превалирования 50 % значения PPV представлены как функция чувствительности и специфичности
Эти формулы также показывают, что значение чувствительности имеет меньший эффект, чем специфичность. Например, при высокой специфичности (скажем, > 90 %) больший PPV может достигаться в широком диапазоне чувствительности. Показатели прогнозирования не так часто используются для описания моделей. Это объясняется несколькими причинами, большинство из которых относится
292 Глава И. Определение эффективности в классификационных моделях к превалированию. Во-первых, превалирование трудно оценить в численном виде. Экспертов, готовых предложить обоснованную оценку этой величины, сегодня можно пересчитать по пальцам. Кроме того, превалирование изменяется динамически. Например, частота спама возрастает с изобретением новых схем, но позднее падает до стандартных уровней. Для медицинских диагнозов превалирование заболеваний (заболеваемость) может сильно изменяться в зависимости от географических факторов (города/сельская местность). Например, в многоцентровом клиническом исследовании диагностического теста Neisseria gomorrhoeae (Becton Dickinson and Company, 1991) превалирование в исследуемой категории пациентов изменялось в диапазоне от 0 до 42,9 % между девятью клиническими базами.
Критерии, не основанные на точности
Для многих коммерческих применений предиктивных моделей точность не является главной целью модели. Модель может предназначаться и, например, для: О прогнозирования инвестиционных возможностей с максимальной прибылью; О улучшения качества обслуживания клиентов за счет сегментации рынка;
О снижения складских расходов за счет повышения качества прогнозов спроса на продукт;
О сокращения расходов, связанных с мошенническими операциями.
Точность важна, но она характеризует лишь то, насколько хорошо модель прогнозирует данные. Если модель строится для конкретной цели, то следует рассмотреть и другие, более прямолинейные показатели эффективности, позволяющие дать количественную оценку последствий правильных и неправильных прогнозов. Например, при обнаружении попыток мошенничества модель может использоваться для количественного представления вероятности того, что операция является мошеннической. Допустим, мошенничество в данном случае является событием, представляющим интерес. С любыми прогнозами попыток мошенничества (истинными или нет) связаны затраты на более подробное рассмотрение дела. Для истинно положительных значений также имеется выгода от обнаружения незаконных операций, имеющая числовое выражение. Аналогичным образом ложноотрицательные значения приводят к потерям прибыли.
Возьмем пример прямого маркетинга из работы Лароса (Larose, 2006, глава 7). Компания, занимающаяся пошивом одежды, собирается провести рекламную акцию, сообщения о которой будут рассылаться по почте. Используя существующие данные о покупательских привычках клиента, компания хочет заранее определить, кто из клиентов откликнется на предложение (два класса: «ответившие» и «не ответившие»). В табл. 11.3 представлена сводка возможных исходов: слева идут типы решений, справа — прибыль или потери для каждого решения.
11.2. Оценка прогнозируемых классов 293
Таблица 11.3. Матрица несоответствий и прибыли/затраты для примера с почтовой рассылкой (Larose, 2006)
Прогноз
Наблюдение
Наблюдение
ответ
нет ответа
ответ
нет ответа
Ответ
ТР
FP
$26,40
-$2,00
Нет ответа
FN
TN
-$28,40
-
Например, если модель точно спрогнозирует ответившего, то средняя прибыль на клиента, ответившего на предложение, оценивается в $28,40. Отправка предложения связана с небольшими затратами ($2,00), поэтому чистая прибыль при правильном решении составит $26,40. Если модель ошибочно спрогнозирует, что клиент ответит на предложение (ложноположительное значение), потери ограничиваются затратами на рассылку (те же $2,00).
Если модель точно спрогнозирует отсутствие ответа, ни потерь, ни прибыли не будет — клиент все равно не сделает покупку, а предложение не будет отправлено1. С другой стороны, ошибочное прогнозирование отсутствия ответа со стороны клиента, который ответил бы на предложение, означает потерю потенциальных $28,40, квалифицируемую как потери от ложноотрицательного значения. Таким образом, общая прибыль для конкретной модели составит:
прибыль = $26,40ТР - $2,00FP - $28,40FN. (11.2)
Однако следует принять во внимание превалирование классов. Частота ответов на предложения при прямом маркетинге часто очень низка, о чем упоминают, в частности, Линг и Ли (Ling and Li, 1998), поэтому ожидаемая прибыль для заданной кампании маркетинга может определяться затратами на ложноотрицательные значения — это значение с большой вероятностью окажется больше двух других, представленных в выражении (11.2).
В табл. 11.4 приведены гипотетические матрицы несоответствий для 20 000 клиентов с 10-процентной долей ответов. Таблица слева содержит результат прогнозируемой модели с чувствительностью 75 % и специфичностью 94,4 %. Общая прибыль составит $23 400, или $ 1,17 на клиента. Допустим, другая модель имеет такую же чувствительность при 100-процентной специфичности. В этом случае общая прибыль возрастет до $25 400, что отражает незначительный прирост на фоне значительного возрастания эффективности модели (в основном объясняемый низкой стоимостью рассылки). В правой части табл. 11.4 приведены результаты при массовой рассылке по всем клиентам. Такой метод обладает идеальной чувствительностью и худшей специ-
1 Это зависит от некоторых предположений, истинность которых не гарантирована. В разделе 20.1 этот аспект рассматривается более подробно.
294 Глава 11. Определение эффективности в классификационных моделях фичностью из всех возможных. В этом случае из-за низких затрат прибыль составит $16 800, или $0,84 на клиента. Эту эффективность можно считать базовой, которую должна превосходить любая другая предиктивная модель. Модели также могут описываться приростом прибыли, определяемым как прибыль модели, превосходящая прибыль от массовой рассылки.
Таблица 11.4. Слева: гипотетическая матрица несоответствий для модели с чувствительностью 75 % и специфичностью 94,4 %. Справа: матрица несоответствий при массовой рассылке всем клиентам
Прогноз
Наблюдение
Наблюдение
ответ
нет ответа
ответ
нет ответа
Ответ
1500
1000
2000
18 000
Нет ответа
500
17 000
0
0
Общее описание включения неравных затрат в показатели эффективности (с двумя классами) приведено у Драммонда и Холта (Drummond and Holte, 2000), которые определяют функцию PCF (Probability Cost Function) следующим образом:
PCF = РхС(+|-)
РхС(-|+) + (1-Р)хС(+|-)’
где Р — (априорная) вероятность события, С(-|+) — потери, связанные с ошибочным прогнозированием события (+) как несобытия, а С(+|-) — потери от ошибочного прогнозирования несобытия. PCF определяет часть общих затрат, связанных с ложноположительным значением. Авторы рекомендуют использовать для описания модели (применительно к конкретному набору затрат) функцию нормализованных ожидаемых затрат NEC (Normalized Expected Cost):
NEC = PCFx(l-TP) + (l-PCF)xFP.
По сути, NEC принимает в расчет превалирование события, эффективность модели и затраты, масштабируя общие затраты так, чтобы они находились в диапазоне от 0 до 1. Отметим, что этот метод присваивает затраты только двум типам ошибок и может оказаться неподходящим для задач, в которых задействованы другие затраты или прибыли (например, затраты на прямой маркетинг, приведенные в табл. 11.3).
11.3. Оценка вероятностей классов
Вероятности классов способны предоставить больше информации о прогнозах моделей, чем простые значения классов. В этом разделе рассматриваются некоторые способы использования вероятностей для сравнения моделей.
11.3. Оценка вероятностей классов 295
ROC-кривые
Упоминаемые в ряде работ (Altman and Bland, 1994; Brown and Davis, 2006; Fawcett, 2006), ROC-кривые разрабатывались как общий метод, определяющий для заданной коллекции непрерывных точек данных некоторый порог. Превышение этого порога указывает на определенное событие (подробнее об этом см. главу 19). Теперь — несколько слов о том, как ROC-кривые могут использоваться при определении альтернативных порогов отсечения для вероятностей классов.
Для тестового набора модели кредитоспособности, упоминавшейся ранее, чувствительность для модели логистической регрессии сравнительно низка (40 %), тогда как специфичность — довольно значительна (92,9 %). Эти значения вычислялись на основе классов, определенных с принятым по умолчанию 50-процентным порогом вероятности. Можно ли улучшить чувствительность, понизив порог1 для отражения большего количества истинно положительных значений? Снижение порога для классификации плохой кредитоспособности до 30 % приводит к модели с улучшенной чувствительностью (60 %), но с ухудшенной специфичностью (79,3 %). По рис. 11.3 видно, что уменьшение порога позволяет охватывать большее количество клиентов с плохой кредитоспособностью, отчасти вторгаясь и в область клиентов с хорошей кредитоспособностью.
ROC-кривая создается оценкой вероятностей классов для модели по континууму порогов. Для каждого потенциального порога строится совместный график доли истинно положительных значений (то есть чувствительности) и доли ложноположительных значений (1 - специфичность). На рис. 11.6 показаны результаты этого процесса для кредитных данных.
Жирная черная точка отмечает порог по умолчанию, равный 50 %, а зеленый квадрат соответствует характеристикам эффективности для порога в 30 %. Числа в круглых скобках на этой диаграмме — (специфичность, чувствительность). Обратите внимание на крутизну кривой от точки (0, 0) до порога 50 %: она означает, что чувствительность растет быстрее, чем снижается специфичность. Когда чувствительность превышает 70 %, снижение специфичности начинает опережать темпы роста чувствительности.
Эта диаграмма является удобным инструментом для выбора порога, максимизирующего баланс между чувствительностью и специфичностью. Однако изменение порога приводит только к тому, что в выборке окажется больше положительных или, напротив, отрицательных результатов (в зависимости от обстоятельств). В матрице несоответствий это не может привести к одновременному вытеснению точек из
1 В этом анализе мы использовали тестовый набор для анализа эффектов альтернативного порога. Как правило, новый порог должен выводиться на основе отдельного набора данных, отличного от того, который использовался для тренировки модели или оценки эффективности.
296 Глава И. Определение эффективности в классификационных моделях
О
со о~
е «>
8 °
X л с
х Ч.
2 о
>»
Сч|
О
О О
0,0 0,2 0,4 0,6 0,8 1,0
1 — Специфичность
Рис. 11.6. ROC-кривая модели логистической регрессии для модели кредитных данных. Точкой обозначено значение, соответствующее порогу 50 %, тогда как квадрат соответствует порогу отсечения 30 % (то есть вероятности, превышающие 0,30, считаются событиями)
обеих ячеек вне главной диагонали. Почти всегда уменьшается чувствительность или специфичность при увеличении на 1.
Показателям специфичности и чувствительности на протяжение почти всего графика присуща понижательная тенденция, за исключением участка вблизи области 1 (северо-восточный угол графика). ROC-кривая также может использоваться для количественной оценки модели. Идеальная модель, которая полностью разделяет два класса, будет обладать 100-процентной чувствительностью и специфичностью. Графически ROC-кривая будет представлять собой одну ступень между (0, 0) и (0,1), оставаясь постоянной от (0,1) до (1,1). Площадь под ROC-кривой для такой модели будет равна 1. Полностью неэффективная модель характеризуется сближением ROC-кривой с диагональной линией 45, при этом площадь под ROC-кривой составит около 0,50. Для визуального сравнения разных моделей их ROC-кривые должны быть наложены на одну диаграмму. Сравнение ROC-кривых может быть полезно для оценки двух и более моделей с разными наборами предикторов (для одной модели), разных параметров настройки (то есть в рамках сравнения одной модели) или совершенно разных классификаторов (то есть между моделями).
Оптимальная модель должна быть сдвинута к левому верхнему углу диаграммы. Наиболее эффективной окажется модель с наибольшей площадью под ROC-
11.3. Оценка вероятностей классов 297
кривой. Для данных кредитоспособности у логистической модели оцениваемая площадь под ROC-кривой будет равна 0,78, при этом 95-процентный доверительный интервал (0,7, 0,85) определяется с помощью бутстрэповского метода доверительных интервалов по Халлу (Hall et al., 2004). В области методов формального сравнения нескольких ROC-кривых велись серьезные исследования (см. в этой связи также работы Хэнли и Макнейла, де Лонга, Венкатрамана и Пепе (Hanley and McNeil, 1982), (DeLong et al., 1988), (Venkatraman, 2000) и (Pepe et al., 2009)).
Одно из преимуществ использования ROC-кривых для описания моделей — в том, что кривая, являющаяся функцией чувствительности и специфичности, устойчива к расхождениям в пропорциях классов, о чем упоминают, к примеру, Провост и Фа- усетт (Provost et al., 1998; Fawcett, 2006). Недостаток использования площади под кривой для оценки моделей — сокрытие информации. Например, при сравнении моделей ни одна отдельная RO С-кривая не может считаться однозначно лучше другой (то есть кривые пересекаются). Обобщение этих кривых приводит к потере информации, особенно если вас интересует одна конкретная область кривой. Например, одна модель может иметь крутой наклон ROC-кривой в левой части, но одновременно и меньшую площадь под кривой, чем у другой модели. Если вас интересует прежде всего нижняя часть ROC-кривой, то площадь не позволит выявить лучшую модель. Частичная площадь под ROC-кривой — альтернативное решение, концентрирующееся на отдельных частях кривой, представленное у Макклиша (McClish, 1989).
ROC-кривая определяется только для задач с двумя классами, но она была расширена для трех и более классов. Отметим, что в ряде работ (Hand and Till, 2001), (Lachiche and Flach, 2003) и (Li and Fine, 2008) используются разные методы, расширяющие определение ROC-кривой для большего числа классов.
Диаграммы точности прогнозов
Диаграммы точности прогнозов (lift charts) (Ling and Li, 1998) — инструмент визуализации данных для оценки способности модели к обнаружению событий в наборе данных с двумя классами. Предположим, что группа точек с М событиями обрабатывается с использованием вероятностей классов событий. При упорядочении по вероятностям классов можно рассчитывать на то, что события будут ранжированы выше, чем несобытия. Диаграммы точности прогнозов работают именно так: они ранжируют точки данных по оценкам и определяют накапливаемую частоту события по мере оценки все большего количества точек, В оптимальном случае М точек, находящихся на самых высоких позициях, будут содержать все М событий. Если модель не информирована, то верхние X % данных будут содержать в среднем X событий. Приростом (lift) называется количество точек, обнаруживаемых моделью сверх полностью случайной выборки точек данных.
298 Глава 11. Определение эффективности в классификационных моделях
Чтобы построить диаграмму точности прогноза, следует:
1. Спрогнозировать набор данных, которые не использовались в процессе построения модели, но имеют известные результаты.
2. Определить базовую частоту события, то есть процент истинных событий во всем наборе данных.
3. Упорядочить данные по классификационой вероятности интересующего события.
4. Для каждого уникального значения вероятности класса вычислить процент истинных событий для всех точек ниже значения вероятности.
5. Разделить процент истинных событий для каждого порога вероятности на базовую частоту события.
На диаграмме точности прогнозов отражается накопленный прирост относительно накопленного процента проанализированных точек данных. На рис. 11.7 показаны кривые лучшего и худшего случая для набора данных с 50-процентной частотой события.
Случайная модель - Идеальная модель
100
с:
0
0 20 40 60 80 100
Процент проверенных точек данных
Рис. 11.7. Пример диаграммы точности прогнозов с двумя моделями: одна идеально разделяет два класса, а другая полностью неинформативна
У неинформированной модели кривая близка к линии под углом 45 градусов; это означает, что модель не обладает преимуществами для ранжирования точек. Другая
11.4. Вычисления 299
кривая соответствует модели, способной идеально разделять два класса. В 50-процентной точке по оси х все события были успешно опознаны моделью.
Как и ROC-кривые, кривые прироста разных моделей могут сравниваться для нахождения самой подходящей модели, а площадь под кривой — использоваться как количественная оценка эффективности. По аналогии с ROC-кривыми некоторые части кривой прироста представляют больший интерес, чем другие. Например, часть кривой, связанная с точками данных, находящимися на верхних позициях, должна иметь улучшенную частоту истинно положительных значений и с большой вероятностью станет самой важной частью кривой.
Рассмотрим пример с прямым маркетингом. На основании этой кривой можно определить квазипорог для модели. Пусть частота ответа равна 10 %, а большая часть ответивших находится в верхних 7 % прогнозов модели. Отправка предложений этому подмножеству фактически устанавливает новый порог для ответов клиентов, поскольку для точек ниже порога ответные действия выполняться не будут.
Напомним, в этом примере предиктивная модель должна генерировать прибыль, превышающую базовую прибыль при рассылке предложений всем клиентам. С помощью диаграммы точности прогнозов можно вычислить ожидаемую прибыль для каждой точки кривой, чтобы определить, достаточно ли прироста для превышения базовой прибыли.
11.4. Вычисления
В этом разделе будут использоваться пакеты R AppliedPredictiveModeling, caret, klaR, MASS, pROC и randomForest.
Для наглядности в этом разделе будет использоваться смоделированный набор данных, показанный на рис. 11.1. Чтобы получить эти данные, используем функцию quadBoundaryFunc из пакета AppliedPredictiveModeling для генерирования предикторов и результатов:
> Library(АррLiedPredictiveMode Ling)
> set,seed(975)
> simuLatedTrain <- quadBoundaryFunc(500)
> simuLatedTest <- quadBoundaryFunc(1000)
> head(simuLatedTrain)
XI X2 prob class
1 2.4685709 2.28742015 0.9647251 Classi
2 -0.1889407 -1.63949455 0.9913938 Classi
3 -1.9101460 -2.89194964 1.0000000 Classi
4 0.3481279 0.06707434 0.1529697 Classi
5 0.1401153 0.86900555 0.5563062 Classi
6 0.7717148 -0.91504835 0.2713248 Class2
300 Глава И. Определение эффективности в классификационных моделях
Далее по этим данным аппроксимируются модели случайных лесов и квадратичного дискриминанта:
> Library(randomForest)
> rfModeL <- randomForest(class ~ XI + X2,
+ data = simuLatedTrain,
+ ntree = 2000)
> Library(MASS) ## for the qda() function
> qdaModeL <- qda(cLass ~ XI + X2, data = simuLatedTrain)
Вывод функции predict для объектов qda включает как прогнозируемые классы (в позиции class), так и связанные с ними вероятности в матрице с именем posterior. Для моделей QDA прогнозы создаются для тренировочного и тестового наборов. Позднее в этом разделе вероятности тренировочного набора будут использованы в дополнительной модели для калибровки вероятностей классов. Затем калибровка будет применена к вероятностям тестового набора:
> qdaTrainPred <- predict(qdaModeL, simuLatedTrain)
> names(qdaTrainPred)
[1] "class” "posterior"
> head(qdaTrainPredfcLass)
[1] Classi Classi Classi Class2 Classi Class2
Levels: Classi Class2
> head(qdaTrainPred$posterior)
Classi Class2
1 0.7313136 0.268686374
2 0.8083861 0.191613899
3 0.998S019 0.001498068
4 0.3549247 0.645075330
5 0.5264952 0.473504846
6 0.3604055 0.639594534
> qdaTestPred <- predict(qdaModeL, simuLatedTest)
> simuLatedTrainfQDAprob <- qdaTrainPred$posterior[,"CLassl"]
> simuLatedTest$QDAprob <- qdaTestPred$posterior[, "CLassl"]
Модель случайного леса требует двух вызовов функции predict для получения прогнозируемых классов и вероятностей классов:
> rfTestPred <- predict(rfModeL, simuLatedTest, type = "prob")
> head(rfTestPred)
Classi Class2
1 0.4300 0.5700
2 0.5185 0.4815
3 0.9970 0.0030
4 0.9395 0.0605
5 0.0205 0.9795
6 0.2840 0.7160
> simuLatedTest$RFprob <- rfTestPred[,"CLassl"]
> simuLatedTest$RFcLass <- predict(rfModeL, simuLatedTest)
11.4. Вычисления 301
Чувствительность и специфичность
Пакет caret содержит функции для вычисления чувствительности и специфичности. Эти функции требуют, чтобы пользователь обозначил роль каждого из классов:
> # Класс 1 будет использоваться как интересующее событие
> sensitivity(data = simuLatedTestfRFcLass,
+ reference = simuLatedTest$cLassJ
+ positive = "CLassl")
[1] 0.8278867
> specificity(data = simuLatedTest$RFcLassJ
+ reference = simuLatedTest$cLass,
+ negative = "CLass2")
[1] 0.8946396
Предиктивные значения также могут вычисляться либо по превалированию, обнаруженному в наборе данных (46 %), либо с использованием априорной оценки:
> posPredVaLue(data = simuLatedTest$RFcLass,
+ reference = simuLatedTest$cLass,
+ positive = "CLassl")
[1] 0.8695652
> negPredVaLue(data = simuLatedTest$RFcLassJ
+ reference = simuLatedTest$cLass,
+ positive = "CLass2")
[1] 0.8596803
> # Превалирование изменяется вручную
> posPredVaLue(data = simuLatedTest$RFcLass,
+ reference = simuLatedTestfcLass,
+ positive = "CLassl"j
+ prevaLence = .9)
[1] 0.9860567
Матрица несоответствий
Для создания матрицы несоответствий в R существует несколько функций. Функция conf usionMatrix из пакета caret строит таблицу и связанные с ней статистики:
> confusionMatrixfdata = simuLatedTest$RFcLass,
+ reference = simuLatedTestfcLass,
+ positive = "CLassl")
Confusion Matrix and Statistics
Reference
Prediction Classi Class2
Classi 380 57
Class2 79 484
302 Глава И. Определение эффективности в классификационных моделях
Accuracy : 0.864
95% CI : (0.8412, 0.8846)
No Information Rate : 0.541
Р-Value [Acc > NIR] : < 2e-16
Kappa : 0.7252
Mcnemar's Test P-Value : 0.07174
Sensitivity : 0.8279
Specificity : 0.8946
Pos Pred Value : 0.8696
Neg Pred Value : 0.8597
Prevalence : 0.4590
Detection Rate : 0.3800
Detection Prevalence : 0.4370
’Positive' Class : Classi
У функции имеется и параметр для ручного задания превалирования. Если количество классов больше двух, то чувствительность, специфичность и аналогичные статистики вычисляются по принципу «один против всех» (то есть первый класс против объединения второго и третьего классов).
ROC-кривые
Пакет pROC (Robin et al., 2011) строит ROC-кривые и вычисляет различные статистики1. Сначала создается объект R с необходимой информацией при помощи функции гос из пакета pROC. Затем полученный объект используется для генерирования ROC-кривой или вычисления площади под кривой. Пример:
> Library(pROC)
> rocCurve <- roc(response = simutatedTestfcLass,
+ predictor = simuLatedTest$RFprob,
+ ## Функция предполагает, что интересующее событие
+ ## представлено вторым классом, поэтому метки
+ ## меняются местами.
+ Levels = rev(LeveLs(simuLatedTest$cLass)))
По этому объекту можно получить статистику (например, площадь под ROC- кривой и ее доверительный интервал):
> аис(rocCurve)
Area under the curve: 0.9328
1 В R также существует ряд других пакетов для вычисления ROC-кривых, включая ROCR, caTools, PresenceAbsence и т. д.
11.4. Вычисления 303
> ci.roc(rocCurve)
95% CI: 0.9176-0.948 (DeLong)
Также можно воспользоваться функцией plot для построения самой ROC-кривой:
> pLotfrocCurve, Legacy.axes = TRUE)
> ## По умолчанию ось х идет в обратном направлении,
> ## параметр Legacy.axes = TRUE используется для отображения 1-spec
> ## по оси х в диапазоне от 0 до 1.
>
> ## Кроме того, можно добавить другую кривую с помощью
> ## параметра add = TRUE при следующем использовании pLot.auc.
На рис. 11.8 показаны результаты этого вызова функции.
оо о"
см о
о_ о"
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 11.8. Пример ROC-кривой, построенной с использованием функций гос и roc.plot из пакета pROC
Диаграммы точности прогнозов
Кривая прироста строится при помощи функции lift из пакета caret. На входе она получает формулу, в левой части которой стоит истинный класс, а в правой — один или несколько столбцов вероятностей класса модели.
Например, диаграмма точности прогнозов для случайного леса и вероятностей тестового набора QDA строится следующим образом:
304 Глава 11. Определение эффективности в классификационных моделях
> Labs <- c(RFprob = "Random Forest",
+ QDAprob = "Quadratic Discriminant AnaLysis")
> LiftCurve <- Lift(cLass - RFprob + QDAprob, data = simuLatedTest,
+ LabeLs = Labs)
> LiftCurve
Call:
lift.formula(x = class ~ RFprob + QDAprob, data = simulatedTest, labels
= labs)
Models: Random Forest, Quadratic Discriminant Analysis
Event: Classi (45.9%)
Чтобы построить графики двух кривых прироста, воспользуемся функцией xyplot (рис. 11.9):
> ## Добавить параметры для вывода условных обозначений наверху
> xyplot(liftCurve,
+ auto.key = list(columns = 2,
+ lines = TRUE,
+ points = FALSE))
Калибровка вероятностей
Калибровочные графики в том виде, в каком они описаны выше, доступны в функ- ции calibration. plot из пакета PresenceAbsence и в функции calibration из пакета caret (см. ниже). Синтаксис функции calibration сходен с синтаксисом функции lift:
> caLCurve <- caLibration(cLass RFprob + QDAprob, data = simuLatedTest)
> caLCurve
Call:
calibration.formula(x = class - RFprob + QDAprob, data = simulatedTest)
Models: RFprob, QDAprob
Event: Classi
Cuts: 11
> xypLotfcaLCurve, auto, key = List(coLumns = 2))
Этот график также показан на рис. 11.9. Совершенно иной подход к калибровочным графикам, которые моделируют наблюдаемый процент событий как функцию вероятностей классов, представлен функцией calibrate.plot из пакета gbm.
Чтобы перекалибровать вероятности QDA, создается модель последующей обработки, моделирующая истинный результат как функцию вероятности класса. Для аппроксимации сигмоидальной функции используется модель логистической регрессии (подробнее см. раздел 12.2) на основе функции glm из базового R. Функция предоставляет интерфейс к обширному набору методов, называемых обобщенными
11.4. Вычисления 305
100
80
60
40
20
0
О 20 40 60 80 100
Процент протестированных точек данных
100
к
3 80
I 60
а
с
>s
1 40
ф
(U
! 20
X
0
О 20 40 60 80 100
Средняя точка группы
Рис. 11.9. Примеры кривой прироста и калибровочной кривой для случайного леса и моделей QDA линейными моделями (Dobson, 2002), к числу которых относится и логистическая регрессия.
Для аппроксимации модели функции требуется аргумент family, задающий тип моделируемых данных результата. Так как результат представляет собой дискретные категории, выбирается биномиальное распределение:
306 Глава 11. Определение эффективности в классификационных моделях
> ## Функция gLm() моделирует вероятность второго уровня фактора,
> ## поэтому функция reteveL() используется для временной перестановки
> ## уровней факторов.
> sigmoidaLCaL <- gLm(reLeveL(cLass, ref = "CLass2") ~ QDAprob,
+ data = simuLatedTrain,
+ famiLy = binomiaL)
> coef(summary(sigmoidaLCaL))
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.701055 0.5005652 -11.38924 4.731132e-30
QDAprob 11.717292 1.0705197 10.94542 6.989017e-28
Скорректированные вероятности создаются применением к исходной модели формулы 11.1 с оценками наклона и точки пересечения оси. В R можно воспользоваться функцией predict:
> sigmoidProbs <- predict(sigmoidaLCaL,
+ newdata = simuLatedTest[,"QDAprob", drop = FALSE],
+ type = "response")
> simuLatedTest$QDAsigmoid <- sigmoidProbs
Байесовский подход к калибровке основан на использовании вероятностей классов тренировочного набора для оценки вероятностей Рг[Х] и Pr[X| Y = CJ (см. формулу 13.5). В R для выполнения вычислений можно воспользоваться функцией наивной байесовской модели NaiveBayes из пакета klaR:
> BayesCaL <- NaiveBayes(сLass - QDAprob, data - simuLatedTrain,
■f usekerneL = TRUE)
> ## Как и в случае с qda(), функция predict для этой модели создает
> ## как классы, так и вероятности.
> BayesProbs <- predict(BayesCaL,
+ newdata = simuLatedTest[, "QDAprob", drop = FALSE])
> simuLatedTest$QDABayes <- BayesProbs$posterior[, "CLassl"]
> ## Значения вероятностей до и после калибровки.
> head(simuLatedTest[, с(5:6, 8, 9)])
QDAprob RFprob QDAsigmoid QDABayes
1 0.3830767 0.4300 0.22927068 0.2515696
2 0.5440393 0.5185 0.66231139 0.6383383
3 0.9846107 0.9970 0.99708776 0.9995061
4 0.5463540 0.9395 0.66835048 0.6430232
5 0.2426705 0.0205 0.05428903 0.0566883
6 0.4823296 0.2840 0.48763794 0.5109129
Параметр usekernel = TRUE позволяет гибкой функции моделировать распределение вероятностей для вероятностей классов. Для оценки этих новых вероятностей используется следующий вызов plot:
> caLCurve2 <- caLibration(cLass ~ QDAprob + QDABayes + QDAsigmoid,
+ data = simuLatedTest)
> xypLot(caLCurve2)
Дискриминантный анализ и другие линейные классификационные модели
В общем случае дискриминантные методы стремятся разбить точки данных на группы в зависимости от характеристик предикторов, используя разные пути к достижению такой классификации, как математический путь (например, линейный дискриминантный анализ (LDA)), алгоритмический путь (например, метод k ближайших соседей) и т. д. В этой главе рассматриваются классические методы: LDA, дискриминантный анализ методом частных наименьших квадратов (PLSDA), логическая регрессия и т. д. Основное внимание при этом уделено разделению точек данных на группы исходя из характеристик дисперсии предикторов.
12.1. Практикум: прогнозирование успешных заявок на получение грантов
Данные для очередного практикума использовались при проведении конкурса Kaggle (2011 год), спонсированного Университетом Мельбурна. Напомним, в этом конкурсе требовалось спрогнозировать успех или неудачу заявки на получение гранта. Вследствие тенденции к сокращению бюджетного финансирования грантов оценка заявок по вероятности их успеха могла сыграть важную роль для оценки потенциального финансирования для университета. Одновременно университет хотел выяснить, какие факторы важны для прогнозирования успеха. Как отмечалось, при выборе оптимальной модели часто приходится идти на компромисс между моделями, разработанными для понимания, и моделями, разработанными для прогнозирования. Этот принцип, как увидят читатели, в полной мере применим и к классификационным моделям.
По условиям конкурса для построения модели были доступны данные 8708 грантов за период с 2005 по 2008 год, а тестовый набор содержал заявки за 2009-2010 годы. Победителю удалось добиться того, что область под ROC-кривой для тестового набора достигла показателя 0,968. Обладатели первого и второго места обсуждают
308 Глава 12. Дискриминантный анализ и другие линейные классификационные модели свои подходы к данным и моделированию в блоге Kaggle1. Набор данных доступен на сайте Kaggle2, но результаты заявок содержатся только в тренировочном наборе. Исходный набор данных содержал множество предикторов, в том числе:
О Роль каждого участника, упомянутого в тексте заявки. Возможные значения — старший аналитик («С1» в данных), полномочный исследователь (DR), ведущий куратор (PS), внешний советник (ЕА), внешний старший аналитик (SCI), студент-исследователь (SR), почетный посетитель (HV), неизвестно (UNK). Общее количество участников, упомянутых в тексте гранта, лежит в интервале от 1 до 14.
О Среди характеристик участников, упоминаемых в тексте заявки, — дата рождения, родной язык, ученая степень, национальность, количество предыдущих успешных (и неуспешных) заявок на получение грантов, кафедра, статус на факультете, должностное положение, уровень занятости в университете и количество публикаций в журналах четырех разных категорий.
О Один или несколько кодов австралийской классификации RFCD (Research Fields, Courses and Disciplines). Грант может классифицироваться на подгруппы (прикладная экономика, микробиология, библиотековедение и т. д.). Всего в данных используются 738 разных значений кодов RFCD. Если в заявке указано более одного кода, то сохраняются относительные частоты этих кодов. Коды RFCD по списку Австралийского бюро статистики3 лежат в диапазоне от 210 000 до 449 999. Многочисленные заявки с бессмысленными кодами (к примеру, 0 или 999 999) выделены в отдельную категорию.
О Один или несколько кодов из классификации SEO (Socio-Economic Objective). Эта классификация описывает целевое назначение гранта (например, область строительных работ или здравоохранения). Если в заявке указано более одного кода, то сохраняются относительные частоты этих кодов. Как и в случае с кодами RFCD, в данных присутствуют некоторые значения, не соответствующие кодам, перечисленным австралийским правительством, и сгруппированные в отдельную категорию «неизвестное».
О Дата подачи заявки.
О Денежная ценность гранта (с разбивкой на 17 групп).
О Код категории гранта, описывающий тип спонсора, а также содержащий код конкретного спонсора.
Одним из первых шагов процесса построения модели становится преобразование (или кодирование) структуры исходных данных в форму, наиболее информативную
1 http://blog.kaggle.com/.
2 http://www.kaggle.eom/c/unimelb.
3 Коды RFCD доступны по адресу http://tinyurl.com/25zvts, а коды SEO — по адресу http:// tlnyurl.com/8435ae4.
12.1. Практикум: прогнозирование успешных заявок на получение грантов 309
для модели (то есть конструирование признаков). Процесс кодирования чрезвычайно важен, и он должен проводиться с учетом будущего анализа, чтобы из исходных данных можно было выделить подходящие предикторы. Если предикторы не будут должным образом отформатированы, это может помешать разработке эффективных предиктивных моделей.
Исходная форма данных не в полной мере соответствует цели моделирования. Например, многие поля проходят разбивку для отдельных участников гранта. В каждой заявке присутствуют 15 столбцов данных, характеризующих каждого участника. Поскольку в каждую заявку могут быть включены до 14 лиц, большое количество столбцов остаются пустыми.
Первый вопрос: как следует кодировать эти данные? Например, поскольку с грантом часто связано несколько участников, как эта информация должна представляться в данных? Если заявка содержит несколько кодов RFCD и связанных с ними процентных значений, то как эти данные должны передаваться моделям? Наконец, очевидно, что особенности присущи и кодировке данных с отсутствующими значениями.
С учетом изложенного сначала была создана группа предикторов, описывающих количество участников с разбивкой по должностям (например, старший аналитик). Затем — счетные переменные, относящиеся к конкретным должностям, для родного языка, национальности, ученой степени, года рождения, кафедры и истории получения грантов. Например, одна переменная содержит количество старших аналитиков из Австралии, другая — общее количество успешных грантов для всех полномочных исследователей, упоминаемых в заявке, и т. п. Данные о трудовом стаже, об общем количестве публикаций в журналах четырех категорий были обобщены по всем должностям.
Кроме того, были созданы индикаторные переменные для кодов спонсоров и категории гранта. Для кодов RFCD и SEO использовалось количество ненулевых процентов для каждого гранта. Наконец, были сгенерированы индикаторы для месяца и дня недели подачи заявки. В целом по этой схеме кодирования было создано 1784 предиктора, подавляющее большинство которых имело дискретную природу (то есть переменные 0/1 или счетные переменные) с многочисленными нулевыми значениями.
Поскольку многие предикторы были категорийными по своей природе, отсутствующие значения кодировались как «неизвестные». Например, в 912 заявках отсутствовали коды категорий, в связи с чем был создан бинарный предиктор для представления информации об отсутствующей категории гранта.
Как упоминалось в главе 3, в некоторых предиктивных моделях ограничено использование определенных типов предикторов. Например, в этих данных значительное количество предикторов было связано взаимными абсолютными корреляциями, которые превышали 0,99. По этой причине к набору предикторов был применен
310 Глава 12. Дискриминантный анализ и другие линейные классификационные модели корреляционный фильтр, устраняющий из данных избыточные предикторы, что привело к исключению 56 предикторов. Бинарная природа многих предикторов также приводила к многочисленным случаям крайней разреженности и несбалансированности данных. Для кодов RFCD 95 % предикторов имело менее 50 ненулевых индикаторов. Высокая степень дисбаланса классов свидетельствует о том, что многие предикторы Moiyr классифицироваться как предикторы с почти нулевой дисперсией, потенциально грозящей вычислительными затруднениями во многих моделях.
Поскольку эта проблема актуальна не для всех моделей, то, в зависимости от модели, используются два разных набора предикторов. «Полный набор» предикторов включает все переменные независимо от их распределения (1070 предикторов). Для моделей, чувствительных к разреженным и несбалансированным предикторам, был разработан «сокращенный набор» из 252 предикторов. В последующих главах и разделах будет указано, какой набор предикторов использовался для каждой модели1.
Напомним, что процесс удаления предикторов без оценки их связи с результатом называется неуправляемым выбором признаков. Отметим также, что в этой главе описаны лишь некоторые модели, использующие управляемый выбор признаков, а более развернутое пояснение выбора признаков читатели найдут, обратившись к главе 19.
Поверхностный одномерный анализ закодированных данных позволяет выявить ряд примечательных связей с результатом. Так, два непрерывных предиктора — количество предыдущих успешных и неуспешных заявок на гранты от старшего аналитика — обнаруживали сильную связь с успешностью заявок (рис. 12.1).
Представленные гистограммы наводят на мысль о том, что предыдущие успех или неудача смещают соответствующее распределение к текущим успеху или неудаче. На основании этой информации можно ожидать, что предикторы сохранят свою значимость почти для любой классификационной модели. Три категорийных предиктора («сумма контракта категории А»; «спонсор неизвестен»; «январь») имели наиболее выраженные одномерные связи с успехом заявки на грант — не слишком сильные, но тем не менее открывающие ряд полезных закономерностей.
Обратимся в этой связи к данным, наводящим на мысль о том, что заявки с большой суммой, неизвестным спонсором или поданные в январе имеют более высокие шансы на успех (табл. 12.1). В свете представленных данных неуспешные заявки с большей вероятностью имеют малую сумму, известного спонсора или подаются в другие месяцы, кроме января.
1 Впрочем, в главе 14 будут описаны некоторые методы на базе деревьев, которые более эффективны в том случае, если категорийные предикторы не преобразуются в фиктивные переменные. В таких случаях использовался полный набор предикторов.
12.1. Практикум: прогнозирование успешных заявок на получение грантов 311
Успехи
Неудачи!
ф
Р 40
о
ф
У
S
I 30
о
ф
3 ю
О 20
о
(Z
о
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Рис. 12.1. Два верхних непрерывных предиктора, связанных с успешностью заявок на получение грантов, на основании данных до 2008 года. Предыдущие успехи получения грантов старшим аналитиком и предыдущие неудачи в высшей степени сильно связаны с успехом или неудачей получения будущих грантов. Ось х усечена до 15 грантов, чтобы длинные хвосты распределения не скрывали различия
Таблица 12.1. Статистики трех категорийных предикторов с наивысшей одномерной зависимостью с успехом заявки на получение гранта
Успех заявки
да
нет
N
процент
шансы
отношение шансов
Сумма контракта
А
1501
818
2319
64,7
1835
2,84
Другие категории
2302
3569
5871
39,2
0,645
Спонсор
Неизвестен
732
158
890
82,2
4,633
6,38
Известен
3071
4229
7300
42,1
0,726
Месяц
Январь
480
45
525
91,4
10,667
13,93
Другие месяцы
3323
4342
7665
43,4
0,765
В таблице приведены частоты успехов для каждой группы, а также шансы (odds) — отношение вероятности успеха заявки к вероятности неудачи. Отношение шансов является одним из стандартных методов количественной оценки предиктивной
312 Глава 12. Дискриминантный анализ и другие линейные классификационные модели способности бинарного предиктора. Например, при подаче заявки в январе отношение шансов намного выше (10,7), чем в другие месяцы (0,8).
Соотношение шансов для этого предиктора предполагает, что заявки, поданные в январе, в 13,9 раза успешнее заявок, поданных в другие месяцы. При высоких соотношениях шансов можно ожидать, что эти предикторы окажут влияние на разработку большинства классификационных моделей.
Наконец, необходимо выбрать оптимальный способ разделения данных. При этом нужно учесть, что процент успешных заявок менялся по годам: 45 % (2005), 51,7 % (2006), 47,2 % (2007) и 36,6 % (2008). Хотя в 2008 году отмечено наименьшее относительное число успешных заявок, это не следует рассматривать в качестве признака понижающей тенденции. Схема разделения данных должна учитывать прикладные аспекты модели и, в частности, то, как она будет использоваться и по какому критерию следует оценивать ее пригодность для поставленной цели. Целью потенциальной модели является создание предиктивной модели для количественной оценки вероятности успеха новых грантов. Это объясняет, почему в конкурсе для целей тестирования использовались самые свежие данные.
Если бы процент успеха заявок оставался относительно стабильным на протяжении нескольких лет, то разумная стратегия разделения данных выглядела бы достаточно прямолинейно: используя данные с 2005 по 2008 год, зарезервировать часть из них для тестового набора и применить повторную выборку к остальным точкам данных для настройки различных вариантов моделей. Тем не менее случайная тестовая выборка за весь период с большой вероятностью приведет к существенному снижению релевантности тестового набора; по сути, мы будем строить модели, ориентированные на старую среду подачи заявок.
Альтернативная стратегия заключается в создании моделей на данных до 2008 года с их последующей настройкой в зависимости от того, насколько хорошо они аппроксимируют данные 2008 года, служащие тестовым набором, который более релевантен по времени исходному тестовому набору данных с 2009 по 2010 год. Более существенно, впрочем, то, что подобная стратегия может привести к значительному переобучению этого конкретного набора данных за 2008 год, не позволяя выполнить их качественное обобщение на последующие годы. Например, среди моделей регрессии существует ряд классификационных моделей, автоматически выполняющих выбор признаков при построении модели. Одна из возможных методологических ошибок, присущих отдельному тестовому набору в процессе многократной оценки, заключается в выборе предикторов, пригодных только для работы с заявками за 2008 год. Выяснить, так ли это на самом деле, возможно только после оценки другого набора данных о недавних заявках на гранты.
Что же дает сравнительный анализ этих двух подходов? На рис. 12.2 показаны результаты для классификационной модели опорных векторов (эта модель, весьма сходная с регрессионной моделью опорных векторов из раздела 7.3, подробно рас-
12.1. Практикум: прогнозирование успешных заявок на получение грантов 313
сматривается в разделе 13.4). При использовании радиальной — базисной ядерной функции, о которой говорилось ранее, параметрами настройки становятся ядерный параметр а и значение стоимости С, используемое для контроля переобучения.
0,88
0,86
8 О'84
ОС
0,82
0,80
2Л-2 2л0 2Л2 2Л4 2*6 2Л8
С
Рис. 12.2. Две модели успешности заявок на получение грантов, основанные на данных до 2008 года, но с разными наборами данных, использованными для настройки модели
Уточним, что здесь представлены оба подхода к обучению модели и, соответственно, два профиля параметров настройки для SVM. Оценены некоторые значения ядерного параметра радиальной базисной функции, а также некоторые значения функции стоимости.
О Первая модель строится на базе 8189 грантов, включающих все данные, полученные до 2008 года, и 25 % данных за 2008 год (п = 290). Для выбора регуляризации и ядерного параметра используется десятикратная перекрестная проверка. Профиль эффективности для параметра стоимости, использующий оптимальное значение ядерного параметра, обозначен линией с кружочками. Набор грантов за 2008 год (п = 1785) резервируется для проверки выбора последнего параметра настройки.
О Вторая модель строится только на данных, полученных до 2008 года. Значение параметра настройки выбирается для максимизации площади под ROC- кривой для грантов 2008 года. Дополнительные точки данных для проверки выбора параметров при этом не резервируются (линия с крестиками).
Линия с кружочками указывает на то, что со значением параметра стоимости, равным 32, площадь под ROC-кривой составит 0,88. Линия с крестиками демонстрирует результаты оценки данных только за 2008 год (то есть без повторной
314 Глава 12. Дискриминантный анализ и другие линейные классификационные модели выборки). Процесс настройки предполагает, что для достижения оптимальной модели с площадью под ROC-кривой 0,89 требуется меньшее значение стоимости (в данном случае — 4). Из этого можно заключить следующее.
С учетом объема данных для оценки модели тот факт, что кривые предполагают разные значения параметров настройки, создает проблемы. Кроме того, при оценке модели с перекрестной проверкой на данных 2008 года площадь под ROC-кривой становится существенно ниже (0,83), чем следует из результатов перекрестной проверки.
Было выбрано компромиссное решение — строить модели на данных до 2008 года и настраивать их на случайной выборке из 2075 грантов за 2008 год (в тексте этот набор будет называться контрольным набором 2008 года). После того как оптимальные параметры будут определены, строится итоговая модель с этими параметрами и всем тренировочным набором (то есть данными до 2008 года и дополнительными 2075 грантами). Сокращенный контрольный набор из 518 грантов за 2008 год позволит убедиться в том, что повторная оценка данных за 2008 год в ходе настройки модели не приводит к значительным методологическим ошибкам. Этот набор, называемый далее тестовым набором, не будет оцениваться до того, как будет выявлен набор моделей-кандидатов (см. в этой связи главу 15, где результаты тестового набора будут сравниваться с результатами, сгенерированными в ходе настройки модели). Эти стратегии и представлены в табл. 12.2.
Таблица 12.2. Стратегия разделения данных заявок на получение грантов, используемая в этой и последующих главах
Настройка модели
Итоговая модель
тренировка
контроль
тренировка
контроль
До 2008 года (п = 6633)
X
X
2008 год (и =1557)
X
X
2008 (и = 518)
X
Таким образом, единообразного подхода к решению этой проблемы для данных, изменяющихся во времени, не существует и для достижения цели моделирования требуется не только ее ясное понимание, но и тщательное планирование процессов тренировки и тестирования моделей. Отметим, что данные о грантах характеризуются умеренной актуальностью и содержат достаточно информации для выделения небольшого контрольного набора без значительного влияния на процесс настройки. Но у такого подхода имеются и недостатки.
1. Во-первых, он основан на предположении о том, что параметры модели, выведенные в процессе настройки, будут подходить для итоговой модели, использующей данные до 2008 года, а также 2075 заявок за 2008 год.
12.2. Логистическая регрессия 315
2. Во-вторых, поскольку итоговая модель использует часть заявок за 2008 год, эффективность тестового набора с некоторой вероятностью будет выше результатов, сгенерированных в процессе настройки (где, напомним, параметры модели вырабатывались без учета заявок 2008 года).
12.2. Логистическая регрессия
Линейная регрессия (раздел 6.2) формирует модель, линейную в отношении параметров, формируемых посредством минимизации суммы квадратов остатков. При этом модель, минимизирующая сумму квадратов остатков, производит и максимально правдоподобные оценки параметров, если исходить из нормального (то есть Гауссова) распределения остатков модели.
Оценка параметров методом максимального правдоподобия применима, если речь идет о предположительном характере распределения вероятности данных. Функция правдоподобия базируется на теоретическом распределении вероятности и наблюдаемых данных, представляя собой вероятностное утверждение относительно конкретного набора значений параметров. При выявлении двух наборов значений параметров набор с большим правдоподобием будет считаться более соответствующим наблюдаемым данным.
Распределение вероятности чаще всего используется с двумя классами при биномиальном распределении1. Такое распределение имеет единственный параметр/? — вероятность события или конкретного класса. Допустим, для данных грантов р определяет вероятность успешной заявки. До 2008 года насчитывается 6633 заявки, из которых 3233 были успешными. В этом случае биномиальная функция правдоподобия будет иметь вид
t(P,'(3233)?al,<1 ’ <121)
где показатели степеней р и 1 - р отражают частоты классов в наблюдаемых данных. Первая часть формулы — «и выборов г» — учитывает все возможные способы выбора 3233 успехов и 3400 неудач в данных.
Метод оценки максимального правдоподобия находит значение р, обеспечивающее наибольшее значение f (р). В этой ситуации пропорция выборки 3233/6633 = = 0,487 является максимально правдоподобной оценкой.
Но частота успеха зависит от нескольких факторов, что побуждает к построению модели, использующей эти факторы для получения более проработанной оценки
1 Данные с тремя и более классами обычно моделируются с использованием полиномиального распределения. Подробности см.: Agresti, 2002.
316 Глава 12. Дискриминантный анализ и другие линейные классификационные модели вероятности. В данном случае желательно изменить параметризацию модели так, чтобы значение р было функцией этих факторов. Как и модель линейной регрессии, модель логистической регрессии содержит, помимо параметров угла наклона для каждой составляющей модели, и дополнительную составляющую (точку пересечения). Поскольку вероятность события должна лежать в интервале от 0 до 1, невозможно гарантировать, что модель наклона и точки пересечения будет ограничивать значения именно этим интервалом.
Как упоминалось, если р является вероятностью события, то шансы события составляют р/(1 - р). Логическая регрессия моделирует логарифмические шансы события в виде линейной функции:
(12.2)
Здесь Р — количество предикторов. Правая часть уравнения обычно называется линейным предиктором. Поскольку логарифм шансов может лежать в диапазоне от -оо до оо, не придется беспокоиться о диапазоне значений, которые могут генерироваться линейным предиктором. Переместив некоторые составляющие, мы возвращаемся к функции вероятности события:
1 р- •
l + exp[-(₽o +₽txi +- + Мр)1 (12.3)
Это — сигмоидальная функция составляющих модели, ограничивающая оценки вероятности интервалом от 0 до 1. Кроме того, модель производит линейные границы классов, кроме случая, когда использованные в модели предикторы являются нелинейными версиями данных (например, возведенное в квадрат значение предиктора используется в качестве одной из х составляющих модели).
Выявив характер связи модели с параметром биномиального распределения, представляется возможным найти кандидатов для значений параметров (0) и, с учетом наблюдаемых данных, вычислить значение функции правдоподобия. После того как будут найдены значения 0, обеспечивающие максимальное правдоподобие данных, эти значения могут использоваться для прогнозирования результатов по точкам данных.
Логистическая регрессия и обычная линейная регрессия принадлежат к более широкому классу методов, называемых обобщенными линейными моделями (GLM, Generalized Linear Models); эта категория охватывает много вариантов распределения вероятностей. Вводный курс в эти модели представлен в работе Добсона (Dobson, 2002). Модели линейны в том смысле, что некоторые функции результата моделируются с использованием линейных предикторов — например, логарифмических шансов в формуле 12.2. Часто они производят нелинейные уравнения
12.2. Логистическая регрессия 317
(как уравнение р в формуле 12.3). Но несмотря на нелинейность формулы р, эта формула производит линейные классификационные границы.
Например, можно выполнить обучение модели простой логистической регрессии по данным грантов с одним предиктором — скажем, днем года. На рис. 12.3 показана наблюдаемая вероятность успешной заявки при группировке данных по 5-дневным интервалам.
О 100 200 300
гс 1,0
о I
3 0,6
ф
о о
f 0,2
к
0 100 200 300
День
Рис. 12.3. Наблюдаемая вероятность успешной заявки при группировке данных по 5-дневным интервалам. Подходящая модель не использовала разделенную на интервалы версию предиктора; логарифм отношения шансов был смоделирован как функция дня года (например, 1, 2,..., 365)
На этой диаграмме наблюдается более высокая частота успехов, связанная с началом и концом года. Более того, для данных до 2008 года из 343 заявок, поданных в первый день года, отмечено нулевое количество отказов. В середине года частота принятия заявок несколько убывает, но в конце года снова растет. Модель простой логистической регрессии пытается оценить наклон, соответствующий дню, а также составляющую точки пересечения оси. По тренировочным данным процедура обучения модели (см. левую часть рис. 12.3) ищет по разным значениям двух параметров комбинацию, которая при наблюдаемых тренировочных данных максимизирует правдоподобие биномиального распределения. В конечном итоге оценка пересечения равна 0,919, а оценка параметра наклона равна -0,0042. Это означает, что логарифмические шансы ежедневно снижались на 0,0042. Эта закономерность не обеспечивает адекватного представления тенденции в завершающей части года.
Можно построить другую модель, в которой третий параметр соответствует квадратичной составляющей дня. Для этой модели оценка пересечения становится равной
318 Глава 12. Дискриминантный анализ и другие линейные классификационные модели 1,88, наклон линейной составляющей дня — равным -0,019, а наклон квадратичной составляющей — равным -0,000038.
В правой части рис. 12.3 наблюдается явное усовершенствование модели, не совсем адекватно отражающее повышение доли успешных заявок в конце года. В пользу необходимости дополнительной составляющей говорит и то, что площадь под ROC-кривой линейной модели была равна 0,56, но она улучшается до 0,66 при использовании дополнительной составляющей модели.
Чтобы построить эффективную модель логистической регрессии, необходимо проанализировать связь частоты успеха с каждым из непрерывных предикторов и на основании этого результата параметризовать составляющие модели с учетом нелинейных эффектов. В одном из эффективных методов, рассмотренных у Харрелла (Harrell, 2001), ограниченные кубические сплайны используются для создания гибких адаптивных версий предикторов, которые могут отражать многие типы нелинейных зависимостей. В разделе «Вычисления» (см. ниже) эта методология рассматривается более подробно.
Другой метод основан на использовании обобщенной аддитивной модели (Hastie and Tibshirani, 1990; Hastie et al., 2008), также использующей гибкие методы регрессии (например, сплайны) для адаптивного моделирования логарифмических шансов. За дополнительной информацией об этих методах читателям следует обратиться к библиографическим источникам.
Для данных заявок на получение грантов полный набор предикторов был использован в модели логистической регрессии. Другие непрерывные предикторы были проверены на нелинейность. Однако многие предикторы содержат несколько точек данных на одном или нескольких полюсах распределения, как для двух предикторов на рис. 12.1. Это усложняет предварительное определение точной функциональной формы предикторов. При использовании этого набора предикторов модель логистической регрессии смогла достичь площади под ROC- кривой, равной 0,78, при чувствительности 77 % и специфичности 76,1 % для контрольного набора 2008 года.
Многие категорийные предикторы имеют разреженные и несбалансированные распределения. По этой причине можно ожидать, что модель, использующая полный набор предикторов, будет менее эффективной, чем с набором после удаления предикторов с почти нулевой дисперсией. Для сокращенного набора из 253 переменных площадь под ROC-кривой равна 0,87, чувствительность — 80,4 %, а специфичность — 82,2 % (рис. 12.4).
Матрица несоответствий показана в табл. 12.3. Существенного улучшения модели удалось добиться посредством удаления предикторов.
Для логистической регрессии можно провести формальные проверки статистических гипотез для оценки статической значимости коэффициентов наклона по каждому предиктору. Обычно для таких моделей применяется Z-cmamucmuKa
12.2. Логистическая регрессия 319
Добсона (Dobson, 2002), по сути, являющаяся показателем соотношения «сиг- нал/шум»: оцениваемый наклон делится на соответствующую стандартную погрешность.
о
оо о
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — Специфичность
Рис. 12.4. ROC-кривая для тестового набора данных грантов с использованием модели логистической регрессии. Площадь под кривой равна 0,87
Таблица 12.3. Матрица несоответствий контрольного набора 2008 года для модели логистической регрессии
Наблюдаемый класс
успех
неудача
Успех
439
236
Неудача
131
751
При использовании этой статистики предикторы могут ранжироваться для понимания того, какие составляющие оказывают наибольшее воздействие на модель. Для этих данных пятью важнейшими предикторами стали: количество неуспешных заявок от старших аналитиков, количество успешных заявок от старших аналитиков, категория суммы контракта F, категория суммы контракта Е, числовой день года (квадратичный). Эта модель обладает общей точностью 76,4 %, чувствительностью 77 % и специфичностью 76,1 %.
320 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Модель логистической регрессии чрезвычайно популярна из-за своей простоты и способности к построению заключений относительно составляющих модели. Например, исследователь может захотеть получить формальную оценку того, связан ли календарный день года статистически значимой связью с вероятностью предоставления гранта. Отметим, что отличным источником информации о разработке статистических моделей, предназначенных для формулировки логически обоснованных утверждений относительно параметров модели, является работа Харрелла (Harrell, 2001).
Эта модель также может быть эффективной, если прогнозирование является единственной целью, но как было показано выше, для нее пользователь должен определить представления данных предикторов, обеспечивающих наилучшую эффективность. Существуют, впрочем, и другие классификационные модели, которые эмпирически выводят эти отношения в процессе тренировки модели (см. далее). Если модель предполагается использовать только для прогнозирования, то эти методы могут оказаться предпочтительными.
12.3. Линейный дискриминантный анализ (LDA)
Корни метода LDA уходят к работам Фишера (Fisher, 1936) и Уэлча (Welch, 1939). Эти исследователи по-разному смотрели на проблему получения оптимальных правил классификации, придя в итоге к одному и тому же правилу в области классификации с двумя группами. В этом разделе представлено краткое описание обоих методов и характеристика ряда математических конструкций, необходимых для связывания их с другими методами, рассматриваемыми позднее.
Для задачи классификации Уэлч (Welch, 1939) идет по пути минимизации общей вероятности ошибочной классификации, которая зависит от вероятностей классов и многомерных распределений предикторов. Чтобы понять суть подхода Уэлча, необходимо базовое понимание правила Байеса1:
Рг[У = С,|Х
Prft^CJPrtXly^C,]
ЕмРг[^=с;]Рг[х|г=с,]’
Здесь Рг[У= С,] называется априорной вероятностью принадлежности к классу Cz. На практике эти значения либо известны, либо определяются пропорциями численности точек в каждом классе, либо неизвестны в том случае, если все априорные значения считаются равными. Рг[Х | У = CJ — условная вероятность наблюдения предикторов X при условии, что данные относятся к классу С{. Предполагается,
1 Правило Байеса более подробно рассматривается в разделе 13.6.
12.3. Линейный дискриминантный анализ (LDA) 321
что данные генерируются из распределения вероятностей (например, многомерного нормального распределения), определяющего математическую форму этой величины. Результат уравнения Рг[У = CjX] обычно называется апостериорной вероятностью того, что точка данных X принадлежит к классу С, (подробнее см. в разделе 13.6).
Для задачи классификации с двумя группами правило, минимизирующее общую вероятность ошибочной классификации, выглядит так: X относится к группе 1, если Рг[ Y=С} |Х] > Рг[У= С2 |Х], и к группе 2, если выполняется обратное неравенство. С формулой 12.4 это правило напрямую преобразуется к следующему виду: X относится к группе 1, если
Рг[У = С, ]Рг[Х | У = С, 1 > Рг[У = С2]Рг[Х | У = С2 ]. (12.5)
Это правило распространяется и на случай с более чем двумя группами. В этой ситуации Xотносится к группе С,, если Рг[ У = Ct] Рг[Х | У = обладает наибольшим значением между всеми классами С.
Класс 2
Класс 1
4 6 8
Предиктор
Рис. 12.5. Один предиктор используется для классификации точек данных на две группы. Кривые над каждой группой обозначают функцию плотности вероятности для нормального распределения, определяемую средними значениями и дисперсиями для каждого класса
На рис. 12.5 ситуация продемонстрирована на примере одного предиктора и двух классов (отдельные точки данных были слегка смещены для сокращения перекрытия). Кривые над каждой группой точек данных представляют функцию плотности вероятности нормального распределения для каждого из классов (то есть Рг[Х| У = CJ и Рг[Х| У = С2]). Учитывая наличие единственного предиктора, для классификации новой точки следует найти ее значение на оси х, а затем опреде-
322 Глава 12. Дискриминантный анализ и другие линейные классификационные модели лить значение каждой функции плотности вероятности для каждого класса (в дополнение к общей вероятности Рг[Х], определяемой соединением обеих групп). Предположим, у новой точки данных значение предиктора равно 4. Вероятность класса 2 практически нулевая, это означает, что точка будет спрогнозирована как принадлежащая к классу 1.
Поскольку в примере используется только один предиктор, это приводит к неверному представлению о сложности практического применения правила Байеса. Для классификации количество предикторов почти всегда больше единицы, причем может быть и чрезвычайно большим. Как в подобных ситуациях вычислять такие величины, как Pr[X| Y = CJ во многих измерениях1? Какие многомерные распределения вероятности могут использоваться для этой цели?
Один особый, часто встречающийся на практике случай — считать, что распределение предикторов является многомерно нормальным. Такое распределение имеет два параметра: многомерный вектор средних pz и ковариационную матрицу Кроме того, если предположить, что средние значения всех групп уникальны (то есть значения для всех групп различны), а матрицы ковариации идентичны между группами, то можно решить уравнение 12.5 или более общую задачу нескольких классов для нахождения линейной дискриминантной функции /-й группы:
ХТ 1Ц, -О^г1 ц, +log(Pr[y = СД). (12.6)
На практике теоретические средние р, оцениваются по средним значениям классов (х(). Теоретическая ковариационная матрица L аналогичным образом оценивается по наблюдаемой ковариационной матрице данных 5, а X заменяется наблюдаемой точкой данных и. В примере, представленном на рис. 12.5, математического ожидания выборки и дисперсии данных было достаточно для получения распределений вероятностей, обозначенных кривыми. Для двух классов математические ожидания и дисперсии по каждому из них будут вычисляться вместе с ковариацией выборки между двумя предикторами (для заполнения ковариационной матрицы выборки). Следует заметить, что формула 12.6 является линейной функцией по X и определяет границы, разделяющие классы. Отсюда и название: линейный дискриминантный анализ. Рассмотрение ковариационных матриц как не идентичных между группами требует применения квадратичного дискриминантного анализа (см. раздел 13.1).
Фишер сформулировал задачу классификации по-другому, стремясь найти такую линейную комбинацию предикторов, чтобы дисперсия между группами максимизировалась относительно дисперсии внутри групп, то есть обеспечивающую максимальное разделение между центрами данных и в то же время минимизирующую дисперсию в каждой группе данных (рис. 12.6).
1 Мы вернемся к этой ситуации при изучении наивных байесовских классификаторов в следующей главе.
12.3. Линейный дискриминантный анализ (LDA) 323
Класс 2
Класс 1
4 6 8
Предиктор
Рис. 12.6. Данные, показанные на рис. 12.5. Здесь представлены дисперсии между классами и внутри классов. Диапазоны внутри классов основаны на математическом ожидании ± два стандартных отклонения
Здесь синие полосы обозначают средние значения классов. При наличии единственного предиктора дисперсия между группами является квадратом разности этих средних значений. Дисперсия внутри групп будет оцениваться по дисперсии, объединяющей дисперсии предиктора внутри каждой группы (красные линии на диаграмме). Отношение этих двух величин, по сути, является отношением «сиг- нал/шум». Метод Фишера определяет линейные комбинации предикторов для максимизации отношения «сигнал/шум». По аналогии с методом Уэлча ситуация усложняется при добавлении новых предикторов. Дисперсии между группами и внутри групп требуют сложных вычислений, в которых задействована ковариационная структура предикторов и т. д.
С математической точки зрения пусть В представляет ковариационную матрицу между группами, a W — ковариационную матрицу внутри групп. Тогда задача Фишера может быть сформулирована как нахождение значения Ь, при котором значение
Ь'ВЬ b'Wb
(12.7)
будет максимальным.
Решением задачи оптимизации будет собственный вектор, соответствующий наибольшему собственному значению W 1В. Этот вектор является линейным дискриминантом, а последующие дискриминанты находятся посредством той же оптимизации с ограничением, требующим, чтобы новые направления не были коррелированы с предыдущими дискриминантами.
324 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Теперь рассмотрим конфигурацию с двумя группами. Решение уравнения 12.7 для двух групп дает дискриминантную функцию 5 1 -х2), где 5 1 — обращенная ко¬
вариационная матрица данных, которая умножается на разность между векторами средних значений предикторов для каждой группы (то есть х, содержит средние значения каждого предиктора, вычисленные по данным класса 1). На практике новая точка данных и проецируется на дискриминантную функцию как и 'S 1 (jq - х2). Новая точка данных классифицируется в группу 1, если она ближе к среднему значению группы 1, чем к среднему значению группы 2, в проекции:
| b\u - xt) | -1 b'(u - х2) | < 0.
На рис. 12.7 представлен набор данных с двумя классами и двумя предикторами, А и В.
10
0
-5 0 5 10
Предиктор А
Рис. 12.7. Простой пример двух четко разделенных групп точек
Линия А = В разделяет два набора точек на разные группы, не являясь, впрочем, дискриминантной функцией, скорее, дискриминантная функция ортогональна линии, разделяющей их в пространстве (рис. 12.8).
12.3. Линейный дискриминантный анализ (LDA) 325
ю
-5 0 5 10 -3 -2 -1 0 1 2 3
Предиктор А Дискриминантный показатель
Рис. 12.8. Приблизительная линия А = В — вектор, визуально разделяющий две группы. Оценка принадлежности к классам определяется проецированием точки на дискриминантный вектор (стрелка) и последующим вычислением расстояния от среднего значения до каждой группы. Затем точка данных классифицируется в ту группу, которая находится ближе к среднему. Блочные диаграммы описывают распределение точек данных для каждого класса после применения LDA, демонстрируя максимизацию межгрупповой/внутригрупповой дисперсии
С двумя предикторами дискриминантная функция для неизвестной точки и имеет вид
Здесь xiA является выборочным средним значением для предиктора А, вычисленного с использованием данных только из класса 1, ах2А — выборочным средним значением для предиктора А, вычисленного для класса 2 (для предиктора В используется аналогичная запись). Кроме того, s24 — выборочная дисперсия для предиктора А (вычисленная по данным обоих классов), s2B — выборочная дисперсия для предиктора В и sAB — выборочная ковариация между двумя предикторами.
Обратите внимание: для этой функции в уравнении используются все дисперсии предикторов и ковариация между ними. Если количество предикторов велико, то предиктивное уравнение требует оценки очень большого количества параметров.
326 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Для Р= 2 и двух классов в уравнении задействованы четыре средних значения и три параметра дисперсии. В общем случае модель требует СР + Р(Р + 1)/2 параметра с Р предикторами и С классами. По сравнению с логистической регрессией аналогичная модель требует оценки только трех параметров.
Различия между моделями становятся более значительными с ростом количества предикторов. Однако положительный эффект дополнительных параметров в моделях LDA заключается в том, что межпредикторные корреляции явно обрабатываются моделью. Это создает некоторые преимущества для LD А перед логистической регрессией при значительных корреляциях, хотя обе модели перестают работать при крайне высоких уровнях мультиколлинеарности.
Формулировка задачи Фишером интуитивно понятна, имеет простое математическое решение и, в отличие от подхода Уэлча, не требует никаких предположений относительно распределения данных. Математическая оптимизация ограничивает максимальное количество создаваемых дискриминантных функций меньшим из значений количества предикторов или количеством групп, уменьшенным на единицу. Например, при 10 предикторах и трех группах можно извлечь максимум два линейных дискриминантных вектора. По аналогии с РСА собственные значения в этой задаче представляют величину дисперсии, объясняемую каждым компонентом W 1В. Таким образом, LDA принадлежит к числу таких методов с латентными переменными, как РСА и PLS (частные наименьшие квадраты). На практике количество дискриминантных векторов является параметром настройки, оцениваемым обычным методом перекрестной проверки или повторной выборкой с соответствующими критериями эффективности.
Внимательное изучение линейной дискриминантной функции ведет к двум результатам, сходным с теми, которые наблюдались для множественной линейной регрессии (раздел 6.2). Во-первых, решение LDA зависит от инвертирования ковариационной матрицы, а уникальное решение существует только в том случае, если матрица инвертируема. Как и в случае с регрессией, это означает, что данные должны содержать больше точек, чем предикторов, а последние должны быть независимыми (о том, как проверить инвертируемость матрицы, см. в разделе «Вычисления»). Если предикторов больше, чем точек данных, или предикторы обладают в высшей степени сильной корреляцией, то, как и при регрессии, обычно сначала применяется метод РСА для сокращения размерности и генерирования некоррелированных комбинаций предикторов. Отметим, что при сокращении отсутствует информация о структуре классов данных. Для включения структуры классов в сокращение размерности рекомендуем применять PLSDA или методы регуляризации (см. также далее).
Во-вторых, линейная дискриминантная функция представляет собой P-мерный вектор, значения которого напрямую связаны с исходными предикторами. Величины этих значений дают представление о вкладе каждого предиктора в классификацию точек данных, позволяя также интерпретировать используемую систему.
12.3. Линейный дискриминантный анализ (LDA) 327
Как следует из сказанного, практики должны особенно серьезно отнестись к предварительной обработке данных перед использованием LD А: рекомендуется выполнить центрирование и масштабирование, удалить предикторы с почти нулевой дисперсией. Если ковариационная матрица по-прежнему неинвертируема, то рекомендуется применить PLS или воспользоваться регуляризацией (то же, если количество предикторов превышает количество точек данных, см. далее). Кроме того, требуется знать соотношение точек данных и предикторов при использовании процедур перекрестной проверки для методов, зависящих от инвертирования ковариационной матрицы. Например, если количество точек на 5 % больше количества предикторов в тренировочном наборе, то при выборе десятикратной перекрестной проверки ковариационная матрица не будет инвертируемой для любой свертки, так как во всех них количество точек данных окажется меньше количества предикторов.
Возвращаясь к примеру с данными грантов, отметим, что метод LD А чувствителен к предикторам с почти нулевой дисперсией и коллинеарным предикторам, из-за чего набор предикторов сокращен до 253 (включая квадратичную составляющую дня как в логистической регрессии). При использовании этого подмножества предикторов площадь под ROC-кривой для контрольного набора 2008 года равна 0,89.
Таблица 12.4. Матрица несоответствий контрольного набора 2008 года для модели LDA
Наблюдаемый класс
успех
неудача
Успех
458
175
Неудача
112
812
В табл. 12.4 приведена матрица несоответствий для этих данных, а на рис. 12.9 показана соответствующая ROC-кривая. Светло-серая линия на графике также обозначает ROC-кривую для предыдущей модели логистической регрессии.
Как упоминалось, анализ коэффициентов линейной дискриминантной функции позволяет понять относительную важность предикторов. Важнейшими пятью предикторами на основании абсолютной величины коэффициента дискриминантной функции следует считать: числовой день года (квадрат) (2,2), числовой день года (-1,9), количество безуспешных заявок от старших аналитиков (-0,62), количество успешных заявок от старших аналитиков (0,58) и сумму контракта категории А (0,56). Отметим, что перечень содержит несколько предикторов, которые идентифицируются одномерным методом как связанные с успехом заявки. Здесь количество предыдущих неудачных заявок от старшего аналитика обратно пропорционально количеству предыдущих успешных заявок от старшего аналитика и самой крупной категорией суммы контракта. Модель обладает общей точностью 81,6 %, чувстви-
328 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
тельностью 80,4 % и специфичностью 82,3 %. Данные контрольного набора 2008 года можно спроецировать на линейный дискриминантный вектор и проанализировать распределение дискриминантных оценок (рис. 12.10).
00 о
со о”
-О
5 о X -О
CN о о о"
0,0 0,2 0,4 0,6 0,8 1J)
1 — Специфичность
Рис. 12.9. ROC-кривая для контрольного набора 2008 года с использованием LDA.
Площадь под кривой равна 0,89. Светло-серая линия — ROC-кривая предыдущей модели логистической регрессии
Неудача
Успех
-5 0 5
Дискриминантное значение
Рис. 12.10. Блочная диаграмма дискриминантных оценок для контрольного набора 2008 года
12.3. Линейный дискриминантный анализ (LDA) 329
Хотя между распределениями удачных и неудачных заявок существует перекрытие, LDA обеспечивает неплохую эффективность классификации, особенно если учесть, что LDA обобщает все нижележащие связи в одном измерении (см. табл. 12.4). Если точек данных больше, чем предикторов, то ковариационная матрица инвертируется, а данные нормально разделяются по линейной гиперплоскости; LDA строит удовлетворительную (в предиктивном отношении) модель, которая также дает некоторое представление о связях между предикторами и реакцией.
Однако следует понимать, что существует сценарий набора данных, удовлетворяющий этим базовым требованиям, но характеризующийся завышенными оценками вероятности классов. Требуется осторожность и при рассмотрении прогнозируемых вероятностей классов LD А, когда количество точек данных начинает приближаться к количеству предикторов.
Предположим, для 500 точек сгенерированы наборы данных, содержащие 10,100, 200 и 450 предикторов из случайной нормальной выборки. Реакция для точек данных сгенерирована случайно, с включением 250 точек в каждую категорию. Следовательно, предикторы и реакция для каждого набора данных не связаны друг с другом. Теперь построим модели LDA для каждого из наборов данных и проанализируем их эффективность.
Как и следовало ожидать, точность классификации тестового набора для каждого набора данных составляет приблизительно 50 %. Поскольку данные полностью случайны, можно ожидать, что прогнозируемые вероятности классов для тестового набора также будут равны приблизительно 0,5. Это справедливо в случае, если количество предикторов мало относительно количества точек. Но с ростом количества предикторов вероятности прогнозируемых классов приближаются к 0 и 1 (рис. 12.11).
На первый взгляд эти результаты кажутся противоестественными: эффективность тестовых наборов говорит о том, что эффективность модели близка к 50 % (что соответствует вероятности «орел-решка»), однако она в высшей степени уверенно классифицирует точки по категориям.
Но противоречивые на первый взгляд выводы обусловлены математической конструкцией LDA. Вспомним в этой связи, что LDA находит оптимальный дискриминирующий вектор.
При равенстве количества точек количеству предикторов (или измерений) можно найти как минимум один вектор, идеально разделяющий точки. Так, в случае с двумя точками и двумя измерениями для несовпадающих точек всегда можно найти один вектор (фактически — бесконечное множество векторов), идеально разделяющий две точки. Три точки (две в одном классе, одна в другом) в двух измерениях также могут быть идеально разделены, если не находятся на одной линии, а одиночная точка не находится между двумя точками из другого класса.
330 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
0,0 0,2 0,4 0,6 0,8 1,0
60
50
40
60
50
40
30
20
10
О
0,0 0,2 0,4 0,6 0,8 1,0
Вероятности тестового набора для класса #1
Рис. 12.11. Гистограммы вероятностей классов тестового набора смоделированного примера с двумя классами, в котором все предикторы неинформативны.
Когда количество предикторов приближается к количеству точек данных (500 в тренировочном наборе), вероятности классов начинают сходиться к двум крайним случаям (однако общая точность остается около 50 %)
Разумеется, этот сценарий может привести к оценкам вероятности классов, которые плохо откалиброваны (см. раздел 11.3). Из-за этой проблемы, присущей LDA, а также других функциональных требований мы рекомендуем применять LDA с наборами данных, у которых количество точек данных по меньшей мере в 5-10 раз больше количества предикторов. С результатами LDA, у которых названное отношение ниже пяти, следует обращаться особенно внимательно.
Наконец, по аналогии с логистической регрессией, любые предикторы, использованные в модели LDA, могут быть преобразованы и включены в модель по аналогии с тем, что мы наблюдали с квадратичным днем года на рис. 12.3.
12.4. Дискриминантный анализ методом частных наименьших квадратов 331
Создание перекрестных составляющих позволяет LDA находить нелинейные дискриминантные границы. Тем не менее преобразования взаимодействий между предикторами должны включаться только тогда, когда есть веские причины полагать, что эти дополнительные предикторы дают содержательную предиктивную информацию. Включение дополнительных неинформативных предикторов ухудшает предиктивную способность LDA и может привести к тому, что ковариационная матрица станет неинвертируемой. Если же между предикторами и результатом классификации предполагается нелинейная структура, но остается неясной роль предикторов, рекомендуется прибегнуть к методам, представленным в этой главе.
12.4. Дискриминантный анализ методом частных наименьших квадратов
Как уже неоднократно упоминалось, измеряемые предикторы в любой конкретной задаче могут быть сильно коррелированы или же превышать количество собранных точек данных. Если хотя бы одно из этих условий выполняется, то не удастся напрямую применить обычный подход LDA для нахождения оптимальной дискриминантной функции.
Как и в случае с регрессией, можно попытаться провести предварительную обработку данных с удалением высококоррелированных предикторов. Если в данных существуют более сложные корреляционные структуры или количество предикторов все еще превышает количество точек данных (или отношение количества точек данных к количеству предикторов слишком мало), то метод РСА может использоваться для сокращения размерности пространства предикторов.
Однако РСА не может идентифицировать комбинации предикторов, оптимально разбивающие точки данных на группы (см. раздел 6.3). Так, целью LD А у Фишера являлось нахождение подпространства, максимизирующего межгрупповую/ внутригрупповую дисперсию. Учитывая, что метод РСА игнорирует информацию о классификации реакций, едва ли удастся найти оптимальное подпространство для классификации. Вместо применения пошагового метода (РСА-затем-LDA) к излишне детерминированной задаче рекомендуется использовать метод PLS для дискриминационного анализа.
PLS применяется в задачах классификации с середины 1980-х годов, о чем упоминают, например, Бернтссон и Уолд (Berntsson and Wold, 1986). Как говорилось при описании регрессии, исходный алгоритм NIPALS разработан и уточнен в хемометрическом сообществе, которое затем исследовало и расширило применение PLS в контексте классификации, назвав этот метод «дискриминантным анализом PDS» (или PLSDA). Например, Данн и Уолд (Dunn and Wold, 1990) продемонстрировали применение метода PLSDA на примере распознавания хемометрических законо-
332 Глава 12. Дискриминантный анализ и другие линейные классификационные модели мерностей, показав, что он обеспечивает лучшее разделение точек на группы, чем традиционный метод «РСА-затем-LDA».
Чтобы понять, почему PLS естественным образом расширяется на задачу классификации, кратко вернемся к PLS для регрессии. Вспомним, что PLS находит латентные переменные, которые одновременно сокращают размерность и максимизируют корреляцию со значением непрерывной реакции (см. рис. 6.9).
В задаче классификации с двумя группами можно использовать значения классов точек (представленные 0 и 1) как реакцию модели. С учетом того, что мы знаем о применении PLS для регрессии, можно ожидать, что латентные переменные будут выбраны для сокращения размерности при оптимизации корреляции с вектором категорийных реакций. Конечно, оптимизация корреляции не является естественной целью; если вы занимаетесь классификацией, лучше стремиться к минимизации ошибки классификации или к другой цели, связанной с классификацией. Несмотря на это, метод PLSD А должен работать лучше, так как информация групп учитывается при попытке сокращения размерности пространства предикторов.
Хотя критерий корреляции используется PLS для сокращения размерности в отношении реакции, его присутствие более чем оправданно. Прежде чем переходить к обоснованию, необходимо обсудить практический аспект: кодирование реакции. Для задачи с двумя группами классы кодируются в набор фиктивных переменных 0/1. С классами С результатом будет набор из С фиктивных переменных, в котором каждая точка данных содержит 1 в столбце, представляющем соответствующий класс1.
В результате реакция в данных представляется матрицей фиктивных переменных. По этой причине задача не может быть решена методом регрессии PLS, показанным на рис. 6.9, и приходится переключаться на парадигму многомерной реакции.
Применение PLS в задаче классификации с многомерной реакцией характеризуется сильными математическими связями как с каноническим корреляционным анализом, так и с LDA (подробнее см. у Баркера и Рэйенса (Barker and Rayens, 2003)). Предполагая приведенную выше структуру для результата, Баркер и Рэйенс (Barker and Rayens, 2003) демонстрируют, что направления PLS в этом контексте были собственными векторами слегка искаженной ковариационной матрицы между группами (то есть В из LDA2).
1 С математической точки зрения если известны С - 1 фиктивных переменных, то значение последней фиктивной переменной выводится напрямую. Следовательно, также возможно использовать только С - 1 фиктивных переменных.
2 Искажение ковариационной структуры объясняется ограничениями оптимальности для матрицы реакций. Баркер и Рэйенс (Barker and Rayens, 2003) поняли, что ограничение оптимальности реакции в этой ситуации не имеет смысла, удалили ограничение, а затем заново решили задачу. Без ограничения пространства реакций именно решение PLS использует межгрупповую ковариационную матрицу.
12.4. Дискриминантный анализ методом частных наименьших квадратов 333
Таким образом, PLS пытается найти оптимальное разделение групп, руководствуясь межгрупповой информацией. С другой стороны, РСА стремится сократить размерность с использованием полной дисперсии, определяемой общей матрицей ковариантности предикторов. Этот анализ дает четкое обоснование для выбора PLS вместо РСА в тех случаях, когда при попытках классификации требуется сокращение размерности (табл. 12.5).
Таблица 12.5. Матрица несоответствий контрольного набора 2008 года для модели PLS
Наблюдаемый класс
успех
неудача
Успех
490
220
Неудача
80
767
Эта модель обладает общей точностью 80,7 %, чувствительностью 86 % и специфичностью 77,7 %. Для построения матрицы использован сокращенный набор предикторов.
Однако Лю и Рэйенс (Liu and Rayens, 2007) указывают, что если сокращение размерности не обязательно, а целью является классификация, то метод LDA всегда обеспечивает более низкую частоту ошибок классификации, чем PLS, сохраняя за собой важную роль в инструментарии классификации.
Как и при применении PLS для регрессии, имеется только один параметр настройки: количество сохраняемых латентных переменных. При выполнении LD А для данных грантов использовался сокращенный набор предикторов, описанный нас. 310 (в нем устранены предикторы с почти нулевой дисперсией и предикторы, порождавшие чрезвычайно высокую коллинеарность), с добавлением дополнительной квадратичной составляющей для дня года. Однако PLS может построить модель и при таких условиях. Включение предикторов, содержащих минимум предиктивной информации, влияет на эффективность PLS. Применение PLS для полного набора предикторов создает шестикомпонентную оптимальную модель с площадью под ROC-кривой 0,87 (рис. 12.12), чувствительностью 83,7 % и специфичностью 77 %. ROC-результаты чуть хуже модели LD А, что можно объяснить добавлением предикторов. На самом деле включение предикторов, содержащих минимум информации о реакции, снижает эффективность модели PLS (подробнее см. раздел 19.1). Если PLS работает хуже LD А с большим набором предикторов, то логично проанализировать эффективность PLS с использованием сокращенного набора предикторов (используемого и LDA1).
1 Напомним, что набор предикторов отбирается не на основе их связи с результатом. Неконтролируемый выбор не должен создавать смещения выборки — эта проблема описана в разделе 19.5.
334 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Полный набор
Сокращенный набор
0,88
0,86
0,84
0,82
2
4 6 8
Количество компонент
Рис. 12.12. Зависимость ROC-значений от компонент для метода PLS с данными грантов, использующими два набора предикторов. ROC-кривая имеет максимальную площадь при шести компонентах с использованием всех предикторов. С сокращенным набором предикторов ROC-кривая имеет максимальную площадь с четырьмя компонентами
Согласно Лю и Рэйенсу (Liu and Rayens, 2007), метод LDA должен превосходить PLS в контексте минимизации ошибок классификации. Для преодоления этой проблемы оптимизируем ROC. Будет ли LDA превосходить PLS и при использовании этого критерия? Оптимальное количество компонент PLS с сокращенным набором предикторов равно четырем, с площадью под ROC-кривой 0,89 (рис. 12.12) и матрицей несоответствий, представленной в табл. 12.5. Меньший набор предикторов улучшает ROC-кривую, использует меньше компонент и получает значение, эквивалентное эффективности модели LDА.
Метод PLSDA кодирует реакцию в виде набора фиктивных 0/1. Поскольку PLS является линейной моделью, прогнозы модели PLSDA не ограничены диапазоном от 0 до 1. Итоговым становится класс, «выбираемый» на основе наиболее вероятного прогноза модели. Для ранжировки других классов потребуется продолжить обработку прогнозных данных, например, методом softmax (см. раздел 11.1), вероятности классов которого, впрочем, удалены от значений 0 или 1. Альтернативный подход основан на использовании правила Байеса для преобразования вывода исходной модели в вероятности классов (рис. 12.13).
В этом случае создаются более осмысленные вероятности классов. Одно из преимуществ правила Баейса — возможность задания априорной вероятности. Это
12.4. Дискриминантный анализ методом частных наименьших квадратов 335
о
оо о"
со о"
м- о
CN О
О o'
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 12.13. ROC-кривая для контрольного набора 2008 года с использованием модели PLS (черная кривая). Площадь под кривой = 0,89. Для сравнения на график нанесена ROC-кривая для LDA и логистической регрессии. Все три метода имеют приблизительно сходную эффективность важно, если данные включают один или несколько редких классов. В такой ситуации тренировочный набор может быть искусственно сбалансирован, а спецификация априорной вероятности позволяет сгенерировать более точные вероятности.
На рис. 12.14 показаны вероятности классов для грантов 2008 года1. Хотя между классами существует перекрытие, распределения имеют соответствующий сдвиг (вероятности обычно бывают выше для действительно успешных заявок и ниже для неуспешных).
Как и в случае с регрессией, можно определить важность предикторов PLS (рис. 12.15).
Для имеющихся данных неизвестная категория суммы контракта имеет относительно высокую важность по сравнению с другими предикторами. Как и в случае с LDA, успех или неудача старшего аналитика находятся на первых позициях списка важности. Далее следуют сумма контракта, количество других категорий грантов и месяцы январь или август. Воскресенье также попадает в начало списка.
1 Напомним, что модели строятся на данных до 2008 года, а затем настраиваются на основании контрольного набора за 2008 год. Эти прогнозы взяты из модели PLSDA с четырьмя компонентами, созданной только с использованием данных до 2008 года.
336 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Если же между предикторами и реакцией существуют нелинейные связи, то для нахождения этих связей посредством PLS можно воспользоваться методами, описанными в разделе 6.3.
8
Неудача
со
5
>з
3
Успех
0,0 0,2 0,4 0,6 0,8 1,0
Вероятность успеха
Рис. 12.14. Блочная диаграмма для вероятностей классов PLSDA контрольного набора 2008 года, вычисленных с использованием правила Байеса
ContractValueBandUnk
SponsorUnk
Jan
Unsuccess.CI
ContractValueBandA
Day
Aug
Sun
Success.CI
Day2
ContractValueBandE
GrantCatlOA
GrantCat30B
ContractValueBandD
ContractValueBandF
ContractValueBandG
Sponsor24D
Sponsor21A
Sponsor2B NumSR
0,01 0,02 0,03 0,04 0,05
Важность
Рис. 12.15. Показатели важности переменных, вычисленные методом частных наименьших квадратов, для данных заявок на гранты
12.5. Штрафные модели 337
12.5. Штрафные модели
По аналогии с методами регуляризации, описанными в разделе 6.4, многие модели классификации применяют штрафы (или регуляризацию) для улучшения обучения данных — как, например, модель лассо (о штрафах для нелинейных моделей (SVM и нейросети) см. далее).
Например, можно включить штрафную составляющую для модели логистической регрессии (по аналогии с гребневой регрессией). Вспомним, что логистическая регрессия находит значения параметров, максимизирующие биноминальную функцию правдоподобия L(p) (формула 12.1). Простой способ регуляризации этой модели заключается в добавлении квадратичной штрафной функции к логарифмической метрике правдоподобия и нахождении оценок параметров, которые максимизируют
log£(p)-xf^.
У Эйлерса (Eilers et al., 2001), Парка и Хэсти (Park and Hastie, 2008) эта модель обсуждается в контексте данных с большим количеством предикторов и малой выборкой тренировочного набора. В таких ситуациях штрафная составляющая может стабилизировать коэффициенты модели логистической регрессии1. Как и при гребневой регрессии, добавление штрафа также может служить контрмерой против высокой корреляции предикторов. В другом методе регуляризации моделей линейной регрессии добавляется штраф, основанный на абсолютных значениях коэффициентов регрессии (по аналогии с моделью лассо из раздела 6.4). Представленная у Фридмана (Friedman et al., 2010) модель glmnet использует штраф по образцу модели лассо в биномиальной (или полиномиальной) функции правдоподобия. Как и у лассо, это приводит к появлению коэффициентов регрессии с абсолютными значениями 0, одновременно обеспечивающих регуляризацию и выбор признаков. Модели glmnet используют штрафы гребневой регрессии и лассо одновременно, как эластичная сеть, но по-разному структурируют эти штрафы:
log£(p)-X
(1_а)|£р*+а£|р;.
2 >1 /=1
1 Другой метод добавления этого штрафа с применением нейросетей рассматривается в следующей главе. В этом случае нейросеть со снижением весов и одной скрытой переменной образует штрафную модель логистической регрессии. Тем не менее нейросети не обязательно используют биномиальное правдоподобие при определении оценок параметров (см. раздел 13.2).
338 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Здесь значение а определяет «пропорции смешивания» для переключения между чистым штрафом модели лассо (при а = 1) и чистым штрафом в стиле гребневой регрессии (а = 0). Другой параметр настройки, X, управляет общей величиной штрафа. Для данных грантов модель glmnet настроена на семи значениях параметра а и 40 значениях общей величины штрафа с использованием полного набора предикторов. На рис. 12.16 изображена тепловая карта площади под ROC-кривой для этих моделей.
Для данных более пригодны модели с преобладанием гребневого штрафа, а не штрафа лассо, хотя многие сочетания имеют сравнимую эффективность. Нижняя строка тепловой карты показывает, что решение с простым гребневым штрафом работает плохо независимо от величины штрафа. В конечном итоге оптимальные в числовом отношении значения — пропорция смешивания 0,1 и величина регуляризации 0,19. В результате в окончательной модели glmnet используются всего 44 предиктора из 1070, вследствие чего площадь под ROC-кривой возрастает до 0,91. Предыдущая модель логистической регрессии с сокращенным набором предикторов обеспечивала площадь под кривой 0,87; таким образом, методичное удаление неинформативных предикторов повысило эффективность модели (о других подходах к контролируемому выбору признаков см. главу 19).
Штрафные стратегии могут применяться и к моделям LDA. Например, у Клеммен- сена (Clemmensen et al., 2011) этот метод применяется к моделям LD А с использованием инфраструктуры гибкого дискриминантного анализа (FDA) (см. разделы 13.1 и 13.3). В этой модели используется стратегия эластичной сети; штрафы приводят к исключению предикторов, а штрафы L2 сжимают коэффициенты дискриминантных функций в направлении нуля. Другие подходы к введению штрафов в моделях LDA описаны у Уиттена и Тибширани (Witten and Tibshirani, 2009, Witten and Tibshirani, 2011) co ссылками на более ранние работы. Тот же штраф лассо был применен Чангом и Келесом (Chung and Keles, 2010) к дискриминантным моделям PLS для исключения некоторых нагрузок PLS.
Штрафная модель LDA, представленная в работе Клемменсена (Clemmensen et al., 2011), применена к данным грантов. Программное обеспечение этой модели позволяет задать количество сохраненных предикторов как параметр настройки (вместо значения штрафа £t). Модель была настроена по этому параметру, а также по значению штрафа L2. На рис. 12.17 показаны результаты одного значения штрафа гребневой регрессии (разные значения этого штрафа приводили к очень незначительным различиям в эффективности).
Когда количество предикторов близко к максимуму, эффективность находится на умеренном уровне. С ростом штрафа и исключением предикторов эффективность улучшается, оставаясь относительно постоянной до исключения важных факторов, после чего резко падает. В результате процесса настройки шесть предикторов были использованы в модели, сравнимой по эффективности с другими моделями (площадь под кривой равна 0,9).
12.5. Штрафные модели 339
Площадь под ROC-кривой
0,90
0,88
0,86
0,84
0,82
Величина регуляризации
с>
со о
сч о
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 12.16. Наверху: тепловая карта площади под ROC-кривой для двух параметров настройки gkmnet. Оптимальные числовые значения — пропорция смешивания ОД и величина регуляризации 0,19. Внизу: ROC-кривая для контрольных данных 2008 года с использованием модели glmnet (площадь под ROC-кривой = 0,91)
340 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
0,90
2 со Q *5 О
р о т
о э
<
о о
0,88
0,86
от
0,84
0,82
10Л0,0 10л0,5 10л1,0 10л1,5 10л2,0 10А2,5
Количество предикторов
10лЗ,0
<э
о о
0,0
0,2
0,4 0,6 0,8
1,|
1 — специфичность
Рис. 12.17. Наверху: профиль параметров настройки для разреженной модели LDA. Внизу: ROC-кривая для модели (площадь под кривой = 0,901)
12.6. Ближайшие сжатые центроиды 341
12.6. Ближайшие сжатые центроиды
Модель ближайших сжатых центроидов (также известная под названием РАМ от «Predictive Analysis for Microarrays») представляет собой линейную классификационную модель, которая, согласно Тибширани и Го (Tibshirani et al., 2002, 2003; Guo et al., 2007), оптимальна для задач высокой размерности. Для каждого класса посредством выявления среднего значения каждого предиктора (для класса) в тренировочном наборе определяется центроид данных. Общий центроид вычисляется на основании данных всех классов.
Если предиктор не содержит значительной информации для конкретного класса, то, скорее всего, его центроид для соответствующего класса будет расположен близко к общему центроиду. Обратимся теперь к рис. 12.18, в левой части которого представлены знаменитые данные ирисов Фишера/Андерсона, у которых четыре характеристики внешней и внутренней доли околоцветника используются для классификации цветов ириса трех видов: ирис щетинистый (Iris setosa), ирис виргинский (Iris virginica) или ирис разноцветный (Iris versicolor).
setosa
versicolor
virginica
setosa
versicolor
virginica
2 X X
Ф m zr о
§ * о
X
о C[
>x о
Is
Q. (0 X
Ф
г
2,5 3,0 3,5 4,0
2,0
Ширина наружной доли околоцветника
Q.
T «J
X
X
5
2,0
Ширина наружной доли околоцветника
2,5 3,0 3,5
4,0
7
7
6
6
5
4
Рис. 12.18. Слева: пример стремя классами; центроиды классов обозначены черным цветом, а общий центроид обозначен X. Серые значки возле осей — центроиды, спроецированные в одно измерение. Справа: пути центроидов классов при сжатии в центр распределений
На представленной диаграмме данные классов versicolor и virginica перекрываются, но хорошо отделяются от ирисов setosa. Центроиды для характеристики ширины наружной доли околоцветника обозначены серыми значками над осью х. Центроид для вида virginica (для ширины наружной доли околоцветника) находится очень близко к общему центроиду, а центроид у versicolor расположен чуть ближе к обще-
342 Глава 12. Дискриминантный анализ и другие линейные классификационные модели му центроиду, чем у цветов setosa. Значит, предиктор ширины наружной доли околоцветника оказывается наиболее информативным для того, чтобы отличать вид setosa от двух других. Для длины наружной доли околоцветника (показана рядом с осью у) центроид versicolor очень близок к центру данных, а центроиды двух других видов находятся на концах оси.
Один из подходов к классификации неизвестных точек данных заключается в поиске ближайшего центроида класса в полномерном пространстве и выборе этого класса для прогнозирования (то есть модель «ближайшего центроида»). Как выясняется, этот подход приводит к линейным границам классов.
Подход, выбранный Тибширани (Tibshirani et al., 2002), основан на сжатии центроидов классов для приближения их к общему центроиду. При этом центроиды, изначально располагающиеся ближе к общему центроиду, перемещаются к нужной точке раньше других. Например, в размерности ширины наружной доли околоцветника центроид virginica достигнет центра раньше двух других.
В этой модели, как только центроид класса соприкасается с общим центроидом, он перестает влиять на классификацию точек этого класса. И снова для ширины наружной доли околоцветника при достижении центроидом virginica общего центра эта характеристика может использоваться только для классификации цветов versicolor или setosa.
При достаточной степени сжатия может оказаться, что все классы будут стянуты к центру Когда предиктор достигает центроида, он не оказывает влияния на модель. Соответственно, модель ближайшего сжатого центроида также проводит выбор признаков в ходе процесса тренировки модели. Метод ближайших сжатых центроидов имеет один параметр настройки: степень сжатия. В правой части рис. 12.18 показаны траектории центроидов для разных значений степени сжатия. Отметим, что каждый предиктор двигается по диагонали по направлению к центру, пока один из центроидов классов не достигнет центра. В этот момент классы двигаются к центру в одном измерении. Для модели рекомендуется выполнить центрирование и масштабирование предикторов.
Эта модель оптимальна для задач с большим количеством предикторов, так как она автоматически выполняет выбор признаков, управляемый параметром настройки сжатия. Метод ближайших сжатых центроидов был изначально разработан для данных профилирования РНК, где количество предикторов велико, а количество точек данных, напротив, мало.
Многие наборы данных профилирования РНК содержат менее одной-двух сотен точек данных. В этих сценариях «низкое п при высоком Р» данные, скорее всего, не смогут поддержать модель с высокой нелинейностью, и линейные границы классификации будут хорошим вариантом. Кроме того, априорные вероятности классов вместе с расстояниями между центроидами классов и общим центроидом могут использоваться для построения вероятностей классов. Показатели важности
12.6. Ближайшие сжатые центроиды 343
переменных вычисляются по разности между центроидами классов и общим центроидом (большие абсолютные значения подразумевают большую важность в модели). Для данных грантов обработан полный набор из 1070 предикторов. Модель настроена на 30 значениях параметра степени сжатия, в диапазоне от 0 (минимум сжатия и выбора признаков) до 25 (рис. 12.19).
0,8
0,7
0,6
0,5
5 10 15
Порог сжатия
20 25
со о'
СО о*
л о X л
CXI о‘
0,0 0,2 0,4 0,6
0,8 1,0
0
о о
1 — специфичность
Рис. 12.19. Наверху: профиль параметра настройки для модели ближайших сжатых центроидов. Внизу: ROC-кривая для модели (площадь под кривой = 0,873)
344 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
С большими величинами сжатия предикторы практически не сохраняются, а площадь под ROC-кривой очень мала. При снижении порога приблизительно до 17 добавляются 5 предикторов: количество неуспешных заявок от старших аналитиков, неизвестный спонсор, сумма контракта категории А, неизвестная категория суммы контракта, подача заявки в январе.
Добавление предикторов оказывает заметное влияние на обучение модели. В высшей точке кривой (степень сжатия 2,59) начинают удаляться важные переменные, а с ростом сжатия проявляется недостаточное обучение. Достижение пикового значения при пороге 8,6 обусловлено удалением двух предикторов: кода спонсора 2В и суммы контракта категории Е
Следующее значение сжатия удаляет еще три предиктора (сумма контракта категории D, сумма контракта категории Е и сумма контракта категории G), но это приводит к существенному падению площади под ROC-кривой.
Вероятно, подобный скачок эффективности обусловлен тем фактом, что для оценки эффективности используется только один контрольный набор. Истинная связь между эффективностью и степенью сжатия с большой вероятностью будет более гладкой, чем показано на этом графике.
Лучший показатель площади под ROC-кривой (см. рис. 12.19) — 0,87 при 36 предикторах. С контрольными данными 2008 года чувствительность равна 83,7 %, а специфичность — 77 %.
12.7. Вычисления
В этом разделе упоминаются следующие пакеты R: AppliedPredictiveModeling, caret, glmnet, MASS, pamr, pls, pROC, rms, sparseLDA и subselect.
Данные заявок на получение грантов доступны на веб-сайте Kaggle1. Пакет R AppliedPredictiveModeling содержит сценарии, которые могут использоваться для воспроизведения объектов и анализа, приведенного в этом разделе.
После применения метода разделения данных, описанного в части I, с данными грантов связаны два кадра данных: training содержит данные до 2008 года и контрольный набор 2008 года, используемый для настройки модели, а кадр данных testing содержит только данные грантов 2008 года (используется в последующих главах). Вектор с именем рге2008 содержит индексы строк 6633 заявок тренировочного набора до 2008 года (сводка стратегии разделения данных приведена в табл. 12.2).
Предикторы этого набора в основном являются бинарными. Например, коды RFCD, коды SEO, спонсоры и категории суммы контракта содержатся в отдельных
1 http://www.kaggle.eom/c/unimelb
12.7. Вычисления 345
бинарных значениях с идентификационными префиксами (например, RFCD или ContractValueBand1). Если значение неизвестно, то для этой ситуации создается специальная фиктивная переменная — например, SponsorUnk. Бинарные фиктивные переменные также существуют для месяца подачи и дня недели.
Также существуют счетные и непрерывные предикторы, такие как частоты каждой роли, связанной с грантом. Например, NumCI и NumEA представляют количество старших аналитиков и внешних советников в гранте соответственно. Количество лиц с неопределенными ролями отражается в предикторе numUnk. В данных также присутствуют счетные предикторы — например, количество людей, родившихся в заданный период времени (например, CI.1925 для старших аналитиков, родившихся между 1925 и 1930 годом), количество родившихся в конкретном регионе (например, HV.Australia) и учетная степень (например, ECI.PhD). Количество предшествующих успешных и неуспешных заявок указывается в предикторах Unsuccess.PS или Success.CI. Информация о публикациях представляется двумя способами. Доступны как суммы по каждой роли (например, B.CI или Astar.CI), так и сводные значения по отдельным участникам (Ast а г Tot al) или всем типам журналов (allPub).
Календарный день года хранится в числовой переменной.
Наконец, результат класса хранится в столбце Class с уровнями successful и unsuccessful.
Как показано в разделе книги, посвященном регрессии, разные модели имеют разные ограничения по типам данных. Так, были созданы две общие группировки предикторов: набор предикторов с полным набором бинарных фиктивных переменных и счетными данными и сокращенный набор, из которого были отфильтрованы предикторы с почти нулевой дисперсией и сильно коррелированные предикторы. Например, столбцы AstarTotal, ATotal, BTotal и CTotal в сумме дают столбец allPub. В сокращенном наборе данных столбец all Pub был удален. Аналогичным образом из сокращенного набора также должна быть удалена одна фиктивная переменная для месяца и одна для дня недели. Два столбца с наименьшими частотами, Маг и Sun, были исключены из сокращенного набора.
Для задания групп были созданы два символьных вектора — f ullSet и reducedSet:
> Length(fuLLSet)
[1] 1070
> head(fuLLSet)
[1] "NumCI" "NumDR" "NumEA” "NumECI" ’’NumHV” ”NumPS"
1 В одной из последующих глав рассматриваются модели, которые могут представлять категорийные предикторы разными способами. Например, деревья могут использовать фиктивные переменные при разделениях, но часто создают разделения на основании одной или нескольких группировок категорий. В этой главе подробно рассматриваются факторные версии этих предикторов.
346 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
> Length(reducedSet)
[1] 252
> head(reducedSet)
[1] "NumCI" "NumDR" "NumECI" "NumPS" "NumSR" "NumSCI"
Как выявить проблемы чрезмерной коллинеарности (например, линейные комбинации)? Функция trim.matrix из пакета subselect получает квадратную симметричную матрицу (например, ковариационную матрицу) и использует алгоритм для устранения линейных комбинаций. Например, с сокращенным набором таких проблем не будет:
> reducedCovMat <- cov(training[, reducedSet])
> Library(subseiect)
> trimmingResuits <- trim,matrix(reducedCovMat)
> names(trimmingResuits)
[1] "trimmedmat" "numbers.discarded" "names.discarded"
[4] "size"
> ## Проверить, были ли исключены какие-либо предикторы:
> trimmingResuLtsfnames,discarded character(e)
Но при применении той же функции к полному набору обнаруживаются несколько таких предикторов:
> fuLLCovMat <- cov(training[, fuLLSet])
> fuLLSetResuits <- trim,matrix(fuLLCovMat)
> ## Функция принимает разные решения относительно
> ## исключаемого дня,
> fuLLSetResuLts$names,discarded
[1] "NumDR" "PS.1955" "CI.Deptl798" "PS.Dept3268" "PS.Facultyl"
[6] "DurationUnk" "ATotal" "Nov" "Sun"
Другая функция из пакета caret — f indLinearCombos — использует похожую методологию, но не требует квадратной матрицы.
При разработке моделей функция train используется для настройки параметров на основании ROC-кривой. Для получения искомых результатов понадобится управляющая функция. Для этой цели используется функция traincontrol из пакета caret. Сначала для вычисления площади под ROC-кривой необходимо сгенерировать вероятности классов. По умолчанию train генерирует только прогнозы классов. Если вам нужны вероятности, передайте параметр classProbs. Кроме того, по умолчанию для оценки модели используется общая точность и каппа-статистика. Пакет caret содержит встроенную функцию twoClassSummary, которая вычисляет площадь под ROC-кривой, чувствительность и специфичность. Для решения этих задач используется следующий синтаксис:
> ctri <- trainControi(summaryFunction = twoCLassSummary,
+ ciassProbs = TRUE)
12.7. Вычисления 347
Но существует и схема разделения данных, которая строила модель на основании данных до 2008 года, а затем использовала контрольные данные 2008 года (в тренировочном наборе) для настройки модели. Для этого функция train должна точно знать, какие точки данных следует использовать при оценке параметров. Аргумент index функции traincontrol выявляет эти точки. Для любого метода повторной выборки можно точно задать набор контрольных точек. Например, с десятикратной перекрестной проверкой при помощи этого параметра можно исключить конкретные точки для каждой из 10 сверток. В этом случае index определяет строки, соответствующие данным до 2008 года. В точном синтаксисе эти номера строк должны быть упакованы в списке (в том случае, если контрольных точек несколько).
Вспомним, что вектор рге2008 содержит позиции грантов, поданных до 2008 года. Вызов traincontrol выглядит так:
Ctrl <- trainControl(method = "LGOCV",
summaryFunction = twoClassSummary, classProbs = TRUE, index = list(TrainSet = pre2008))
После того как параметры настройки будут выбраны с использованием оценок эффективности за 2008 год, итоговая модель строится со всеми заявками из тренировочного набора, включая заявки 2008 года.
Наконец, для демонстрации необходимо сохранить прогнозы заявок 2008 года, основанные на модели до 2008 года (то есть до того, как итоговая модель будет заново аппроксимирована со всеми тренировочными данными). Для этой цели используется аргумент savePredictions:
Ctrl <- trainControl(method = "LGOCV",
summaryFunction = twoClassSummary, classProbs = TRUE, index = list(TrainSet = pre2008), savePredictions = TRUE)
Поскольку многие модели, описанные в тексте, используют случайные числа, генератор случайных чисел инициализируется до выполнения каждой модели — это позволит воспроизвести вычисления. Для этой главы было выбрано случайное значение инициализации 476.
Логистическая регрессия
Функция glm из базового пакета R обычно используется для обучения моделей логи- стической регрессии. По своему синтаксису она аналогична предыдущим функциям моделирования, использующим интерфейс формул. Например, обучение модели в левой части рис. 12.3 для данных до 2008 года выполняется следующим образом:
348 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
> LeveLs(training$CLass)
[1] "successful" "unsuccessful"
> modeLFit <- gtm(CLass ~ Day,
+ ## Выбрать строки для данных до 2008 года:
+ data = training[рге2008,],
+ ## 'famity' относится к распределению данных.
+ ## Значение 'binomiaL ' используется для логистической регрессии.
+ famity = binomiaL)
> modeLFit
Call: glm(formula = Class ~ Day, family = binomial, data = training[pre2008,
1)
Coefficients:
(Intercept) Day
-0.91934 0.00424
Degrees of Freedom: 6632 Total (i.e. Null); 6631 Residual
Null Deviance: 9190
Residual Deviance: 8920 AIC: 8920
Функция glm интерпретирует уровень второго фактора как событие, представляющее интерес. Поскольку для дня года угол наклона положителен, он обозначает возрастание частоты неуспешных заявок. Чтобы получить вероятность успешной заявки, следует вычесть значение из 1:
>
+
+
+
+
>
successProb <- 1 - predict(modeLFit,
## Прогнозировать на несколько дней newdata = data.frame(Day - с (10, 150, 300, 350)),
## gtm не прогнозирует класс, но может
## выдать вероятность события
type = "response")
successProb
1 2
3 4
0.70619 0.57043 0.41287 0.36262
В целях добавления нелинейного члена для дня года дополним предыдущую формулу следующим образом:
> daySquaredModeL <- gLm(CLass ~ Day + I(DayA2),
+ data = training[pre2008, ],
+ famity = binomiaL)
> daySquaredModeL
Call: glm(formula = Class ~ Day + I(DayA2), family = binomial,
data = training[pre2008,
])
Coefficients:
12.7. Вычисления 349
(Intercept) Day I(DayA2)
-1.881341 0.018622 -0.000038
Degrees of Freedom: 6632 Total (i.e. Null); 6630 Residual Null Deviance: 9190
Residual Deviance: 8720 AIC: 8730
Функция glm поддерживает только интерфейс формул, так что создание моделей с большим количеством предикторов требует большего объема работы. Альтернативное решение показано ниже. Другая функция R для логистической модели, по ассоциации с пакетом, упоминаемым Харрелом (Harrell, 2001), называется rms (Regression Modeling Strategies). Функция lrm очень похожа на glm и включает вспомогательные функции. Например, ограниченный кубический сплайн (restricted cubic spline) представляет собой инструмент для обучения гибких нелинейных функций предиктора. Пример для дня года:
> Library(rms)
> rcsFit <- Lrm(CLass ~ rcs(Day), data = training[pre2008,])
> rcsFit
Logistic Regression Model
lrm(formula = Class ~ rcs(Day), data = training[pre2008, ])
Model Likelihood Discrimination
Rank Discrim.
Ratio Test
Indexes
Indexes
Obs
6633 LR chi2
461.53 R2
0.090
C 0.614
successful 3233 d.f.
4
g
0.538
Dxy 0.229
unsuccessful 3400 Pr(> chi2)
<0.0001
gr
1.713
gamma 0.242
max |deriv| 2e-06
gP
0.122
tau-a 0.114
Brier
0.234
Coef S.E.
Wald Z
Pr(>|Z|)
Intercept
-1.6833 0.1110
-15.16
<0.0001
Day
0.0124 0.0013
9.24
<0.0001
Day'
-0.0072 0.0023
-3.17
0.0015
Day''
0.0193 0.0367
0.52
0.6001
Day''’
-0.0888 0.1026
-0.87
0.3866
Функция lrm, как и glm, моделирует вероятность уровня второго фактора. В нижней таблице выходных данных приведены p-значения для разных нелинейных компонентов ограниченного кубического сплайна. Так какр-значения для первых трех нелинейных компонентов малы, это означает, что должна использоваться нелинейная связь между классом и днем. Пакет содержит еще одну функцию Predict, быстро создающую профиль прогнозирования для одной или нескольких переменных. Например, код
> dayProfiLe <- Predict(rcsFit,
+ ## Задает диапазон переменной
+ Day - 0:365,
350 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
+ ## Переключить прогноз для получения модели
* ## для успешных грантов
+ fun = function(x) -х)
> pLot(dayProfiLe, у Lab = "Log Odds")
строит график, представленный на рис. 12.20. Аргумент fun изменяет знак прогноза, чтобы на графике отражалась вероятность успешного гранта. Из диаграммы очевидно, что квадратичная составляющая для дня года должна аппроксимировать тренды, представленные сплайном.
Пакет г ms содержит много актуальных функций, включая методы повторной выборки для проверки модели и функций визуализации модели (подробнее см. у Харрелла (Harrell, 2001)).
Рис. 12.20. Ограниченный кубический сплайн для дня года, сгенерированный пакетом rms. Серые полосы обозначают границу доверительного интервала
В случае большого набора предикторов метод формул для определения моделей может быть громоздким. Как и в предыдущих главах, функция train может эффективно использоваться для обучения и проверки моделей. Для логистической регрессии train предоставляет интерфейс к функции glm, который обходит формулу модели, напрямую генерирует прогнозы классов и вычисляет площадь под ROC- кривой и другие метрики. До обучения модели набор данных и группы предикторов дополняются квадратом переменной дня:
> training$Day2 <- training$DayA2
> fuLLSet <- с(fuLLSet, "Day2")
> reducedSet <- c(reducedSet, "Day2")
Для данных грантов код, осуществляющий обучение модели с полным набором предикторов, выглядит так:
12.7. Вычисления 351
> Library(caret)
> set.seed(476)
> LrFuLL <- train(training[,fuLLSet],
+ у = training$CLass,
+ method = "gLm",
+ metric = "ROC",
+ trControL = ctrL)
> LrFuLL
8190 samples
1071 predictors
2 classes: 'successful', 'unsuccessful'
No pre-processing
Resampling: Repeated Train/Test Splits (1 reps, 0.75%)
Summary of sample sizes: 6633
Resampling results
ROC Sens Spec
0.78 0.77 0.76
Обратите внимание: в начале вывода указано, что используются 8190 грантов, но в разделе сводки размера выборки указано значение 6633 точки данных. Второе число отражает размер одного набора точек до 2008 года (см. табл. 12.2). Раздел результатов повторной выборки в действительности содержит оценку эффективности контрольного набора 2008 года. А вот как создается модель с меньшим набором предикторов:
> set.seed(476)
> LrReduced <- train(training[,reducedSet],
+ у = training$CLass,
+ method = "gLm",
+ metric = "ROC",
+ trControL = ctrL)
> LrReduced
8190 samples
253 predictors
2 classes: 'successful', 'unsuccessful'
No pre-processing
Resampling: Repeated Train/Test Splits (1 reps, 0.75%)
Summary of sample sizes: 6633
Resampling results
ROC Sens Spec
0.87 0.8 0.82
352 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Как и при анализе LDA, удаление предикторов с почти нулевой дисперсией положительно воздействует на обучение модели. Прогнозы контрольного набора (с грантами 2008 года) содержатся в подобъекте pred:
> head(LrReduced$pred)
pred
obs
successful
unsuccessful
rowindex
.parameter
6634
successful
successful
0.99878
0.0012238
6634
none
6635
successful
successful
0.85151
0.1484924
6635
none
6636
successful
successful
0.92019
0.0798068
6636
none
6637
successful
successful
0.96694
0.0330572
6637
none
6639
successful
successful
0.98928
0.0107160
6638
none
6642
successful
successful
0.57563
0.4243729
6639
none
Resample
6634 TrainSet
6635 TrainSet
6636 TrainSet
6637 TrainSet
6639 TrainSet
6642 TrainSet
Обратите внимание на столбец .parameter. Когда функция train сохраняет прогнозы, она делает это для каждого параметра настройки. Этот столбец в выводе показывает, какая модель сгенерировала прогнозы. Эта версия логистической регрессии не имеет параметров настройки, так что в столбце . parameter отображается единственное значение "попе'’. По этим данным может быть вычислена матрица несоответствий:
> confusionMatrix(data = LrReduced$pred$pred, + reference = LrReduced$pred$obs)
Confusion Matrix and Statistics
Prediction successful unsuccessful
Reference
successful
458
112
Accuracy :
95% CI :
No Information Rate : Р-Value [Acc > NIR] :
Kappa : Mcnemar's Test P-Value :
unsuccessful
176
811
0.815
(0.795, 0.834)
0.634
< 2e-16
0.611
0.000205
Sensitivity : 0.804
Specificity : 0.822
Pos Pred Value : 0.722
Neg Pred Value : 0.879
12.7. Вычисления 353
Prevalence : 0.366
Detection Rate : 0.294
Detection Prevalence : 0.407
’Positive' Class : successful
Эти результаты совпадают co значениями, приведенными выше для IrReduced. Также можно вычислить и вывести ROC-кривую с использованием пакета pROC:
> reducedRoc <- roc(response = LrReduced$pred$obs,
+ predictor = LrReduced$pred$successfuL,
+ LeveLs = rev(LeveLs(LrReduced$pred$obs)))
> pLot(reducedRoc, Legacy.axes - TRUE)
> auc(reducedRoc)
Area under the curve: 0.872
Линейный дискриминантный анализ
Популярная функция для создания моделей LDA — Ida в пакете MASS. Входные данные для этой функции могут быть либо формулой, либо фреймом данных, либо матрицей предикторов и переменной группировки в качестве фактора, который содержит информацию о вхождении в класс. Мы можем обучить модель LDA следующим образом:
> Library(MASS)
> ## First, center and scaLe the data
> grantPreProcess <- preProcess(training[pre2008, reducedSet])
> grantPreProcess
Call:
preProcess.default(x = training[pre2008, reducedSet])
Created from 6,633 samples and 253 variables
Pre-processing: centered, scaled
> scaLedPre2008 <- predict(grantPreProcess,
+ newdata = training[pre2008, reducedSet])
> scaLed2008HoLdOut <- predict(grantPreProcess,
+ newdata = training[-pre2008, reducedSet])
> LdaModeL <- Lda(x = scaLedPre2008,
+ grouping = training$CLass[pre2008])
Поскольку данные включают два класса, может быть получен только один дискриминантный вектор. Этот дискриминантный вектор содержится в объекте ldaModel$scaling; первые шесть элементов этой матрицы:
> head(LdaModeL$scaLing)
LD1
NumCI 0.1301673
354 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
NumDR 0.0017275
NumECI 0.1219478
NumPS 0.0042669
NumSR -0.0642209
NumSCI -0.0655663
Эта информация помогает интерпретировать предикторы и связи между предикторами, а если данные прошли центрирование и масштабирование, — еще и значения относительной важности. Дискриминантный вектор задействован в прогнозировании точек данных, а пакет MASS упрощает этот процесс, предоставляя функцию predict. Для тестового набора данных грантов для создания прогнозов используется следующий синтаксис:
> LdaHoLdOutPredictions <- predict(LdaModeL, scaLed2008HoidOut)
В этом объекте содержится прогнозируемый класс, апостериорная вероятность и значение линейного дискриминанта, по которым пользователь может создать (1) матрицу несоответствий наблюдаемых и прогнозируемых значений, (2) распределение апостериорных вероятностей и/или (3) распределение значений линейных дискриминантов. Прямым следствием ситуации с двумя классами является отсутствие тренировки по количеству дискриминантных векторов, сохраняемых для прогнозирования. При работе с данными, содержащими более двух классов, оптимальное количество линейных дискриминантных векторов может определяться обычным процессом проверки. С функцией Ida количество линейных дискриминантов, сохраняемых для прогнозирования, может задаваться параметром dimen функции predict. К счастью, функция train из пакета caret автоматизирует этот процесс оптимизации:
> set.seed(476)
> IdaFitl <- train(x = training^ reducedSet],
+ у = training$Class,
+ method = "Ida",
+ preProc = c("center","scale"),
+ metric = "ROC",
+ ## Defined above
+ trControl = Ctrl)
> IdaFitl
8190 samples
253 predictors
2 classes: 'successful', 'unsuccessful'
Pre-processing: centered, scaled
Resampling: Repeated Train/Test Splits (1 reps, 0.75%)
Summary of sample sizes: 6633
12.7. Вычисления 355
Resampling results
ROC Sens Spec
0.89 0.8 0.82
Никакая формальная настройка не выполняется, потому что в модели всего два класса, а следовательно, только один дискриминантный вектор. Спрогнозированные классы и вероятности генерируются для тестового набора стандартным способом:
> IdaTestClasses <- predict(ldaFitl,
+ newdata = testing[,reducedSet])
> IdaTestProbs <- predict(ldaFitl,
+ newdata = testing^ reducedSet],
+ type = "prob")
Когда проблема включает более двух классов и вы хотите провести оптимизацию по количеству дискриминантных векторов, вы все равно можете использовать функцию train с параметром method =”lda2” и параметром tuneLength, которому присваивается максимальное количество анализируемых измерений.
Дискриминантный анализ методом частных наименьших квадратов
Анализ PLSDA может выполняться функцией plsr из пакета pls с использованием категорийной матрицы, определяющей категории реакции (за описанием алгоритмических разновидностей PLS, которые напрямую расширяются для задач классификации, обращайтесь к разделу 6.3).
Пакет caret содержит функцию (plsda) для создания модели PLS с фиктивными переменными для данных и последующей обработки исходных прогнозов модели для получения вероятностей классов. Синтаксис очень похож на код регрессионной модели PLS из раздела 6.3. Главное отличие — использование факторной переменной для результата. Например, обучение модели с сокращенным набором предикторов выполняется следующим образом:
> plsdaModel <- plsda(x = training[pre2008,reducedSet],
+ у = training[pre2008, "Class"],
+ ## Для PLS данные должны измеряться по единой шкале.
+ ## Параметр 'scale' выполняет предварительную
+ №№ обработку.
+ scale = TRUE.,
+ ## Для вычисления вероятностей используется
+ ## метод Байеса.
+ probMethod = "Bayes",
+ ## Задать количество компонент для моделирования.
356 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
+ ncomp = 4)
> ## Прогнозирование контрольного набора 2008 года
> plsPred <- predict(plsdaModel,
+ newdata = training[-pre2008, reducedSet])
> head(plsPred)
[1] successful successful successful successful successful successful
Levels: successful unsuccessful
> plsProbs <- predict(plsdaModel,
+ newdata = training[-pre2008, reducedSet],
+ type = "prob")
> head(plsProbs)
[1] 0.98842 0.88724 0.83455 0.88144 0.94848 0.53991
Объект plsdaModel наследует все те же функции, которыми должен был бы обладать объект, полученный напрямую от функции plsr. Это позволяет использовать другие функции из пакета pls, такие как loadings или scoreplot.
Функция train также может использоваться с PLS в задачах классификации. Следующий фрагмент оценивает первые десять компонент PLS в отношении площади под ROC-кривой, а также автоматически выполняет центрирование и масштабирование предикторов до обучения модели и прогнозирования точек данных:
> set.seed(476)
> plsFit2 <- train(x = training^ reducedSet],
+ у = training$Class,
+ method = "pls",
+ tuneGrid = expand.grid(.ncomp = 1:10),
+ preProc = c("center","scale"),
+ metric = "ROC",
+ trControl = Ctrl)
Базовый вызов predict выполняет прогнозирование новых точек, а с параметром type = "prob" он возвращает вероятности классов. Вычисление важности переменных, продемонстрированное на рис. 12.15, может осуществляться следующим кодом:
> plsImpGrant <- varImp(plsFit2, scale = FALSE)
> plsImpGrant
pls variable importance
only 20 most important variables shown (out of 253)
Overall
ContractValueBandUnk
0.0662
SponsorUnk
0.0383
Jan
0.0338
Unsuccess.CI
0.0329
ContractValueBandA
0.0316
Day
0.0266
Aug
0.0257
12.7. Вычисления 357
Success.CI
GrantCatlOA
Day2
GrantCat30B
ContractValueBandE ContractValueBandD ContractValueBandF ContractValueBandG Sponsor24D Sponsor21A Sponsor2B
NumSR
Jul
0.0219
0.0211
0.0209
0.0202
0.0199
0.0193
0.0188
0.0184
0.0172
0.0169
0.0147
0.0144
0.0124
> plot(plsImpGrant, top = 20, scales = list(y = list(cex = .95)))
Штрафные модели
Основным пакетом для штрафной логистической регрессии является glmnet (хотя в следующей главе рассказано, как осуществлять обучение аналогичных моделей с использованием нейросетей). Функция glmnet очень похожа на функцию enet, описанную ранее в разделе 6.5. Главные аргументы соответствуют данным: х — матица предикторов, а у — фактор классов (для логистической регрессии). Кроме того, аргумент family связан с распределением реакции. Для двух классов параметр family="binomial” соответствует логистической регрессии, а при трех и более классах следует использовать параметр family="multinomial".
Функция автоматически выбирает последовательность значений для величины регуляризации, хотя пользователь может выбрать собственные значения при помощи параметра lambda. Вспомните, что тип регуляризации определяется параметром пропорции смешивания а. У функции glmnet по умолчанию используется параметр alpha = 1, соответствующий полному штрафу модели лассо.
Функция predict для glmnet прогнозирует разные типы значений, включая прогнозируемый класс, предикторы которого используются в модели, и/или оценки параметров регрессии. Пример:
> library(glmnet)
> glmnetModel <- glmnet(x = as.matrix(training[,fullSet]),
+ у = training$Class,
+ family = "binomial")
> ## Вычисление прогнозов для трех разных уровней регуляризации.
> ## Обратите внимание: результаты - не факторы.
> predict(glmnetModel,
+ newx = as.matrix(training[l:5,fullSet]),
+ s = c(0.05, 0.1, 0.2),
358 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
+ type = "class")
12 3
1 "successful" "successful" "unsuccessful"
2 "successful" "successful" "unsuccessful"
3 "successful" "successful" "unsuccessful"
4 "successful" "successful" "unsuccessful"
5 "successful" "successful" "unsuccessful"
> ## Какие предикторы использовались в модели?
> predict(glmnetModel,
+ newx = as.matrix(training[l:5,fullSet]),
+ s = c(0.05, 0.1, 0.2),
+ type = "nonzero")
$ Г
[1] 71 72 973 1027 1040 1045 1055
$2'
[1] 1027 1040
$3'
[1] 1040
Попутно отметим, что в пакет glmnet входит функция с именем аис. Если пакет pROC загружается до glmnet, появляется сообщение о том, что в пакете pROC замещается объект аис. Если вызвать функцию в этот момент, R не будет знать, какую функцию использовать. У проблемы есть два потенциальных решения.
О Так, если один из пакетов перестает быть необходимым, его можно отсоединить вызовом detach(package:pROC).
О Нужную функцию можно вызвать с указанием пространства имен. Например, обозначения pROC::: аис и glmnet::: аис будут ссылаться на конкретные функции.
Другое потенциальное проявление этой проблемы будет описано ниже.
Настройка этой модели с использованием площади под ROC-кривой может осуществляться при помощи train. Для данных грантов это выглядит так:
> ## Specify the tuning values:
> glmnGrid <- expand.grid(.alpha = c(0, .1, .2, .4, .6, .8, 1),
+ .lambda = seq(.01, .2, length = 40))
> set.seed(476)
> glmnTuned <- train(training[,fullSet],
+ у = training$Class,
+ method = "glmnet",
+ tuneGrid = glmnGrid,
+ preProc = c("center", "scale"),
+ metric = "ROC",
+ trControl = Ctrl)
12.7. Вычисления 359
Тепловая карта в верхней части рис. 12.16 построена вызовом plot(glmnTuned, plotType = "level"). Штрафные функции LDA находятся в пакетах sparseLDA и PenalizedLDA. Главная функция пакета sparseLDA называется sda1. Эта функция получает аргумент с именем lambda. Штраф модели лассо может быть выражен двумя возможными способами при помощи аргумента stop. Положительное значение выражает величину штрафа лассо (например, stop=0.01), а отрицательное значение выражает количество сохраняемых предикторов (например, stop = -6 для шести предикторов). Пример:
> library(sparseLDA)
> sparseLdaModel <- sda(x = as.matrix(training[,fullSet]),
+ у = training$Class,
+ lambda = 0.01,
+ stop = -6)
Аргумент method =" sparseLDA" может использоваться с функцией train. В этом случае train настраивает модель по lambda и по количеству сохраненных предикторов.
Метод ближайших сжатых центроидов
Исходная реализация этой модели в R находится в пакете pamr (аббревиатура от «Predictive Analysis of Microarrays in R»). Другой пакет, rda, содержит расширения модели, описанные у Го и др. (Guo et al., 2007).
Синтаксис функций из пакета pamr выглядит несколько нестандартно. Функция тренировки модели pamr.train получает входные данные в виде одного объекта списка с компонентами х и у. Обычно для наборов данных строки представляют точки данных, а столбцы — предикторы. Функция pamr .train требует, чтобы предикторы тренировочного набора кодировались в обратном формате: строки соответствуют предикторам, а столбцы — точкам данных2. Для грантов входные данные будут иметь следующий формат:
> ## Размерности меняются местами при помощи функции t(),
> ## выполняющей транспонирование данных.
> ## При этом кадр данных training также неявно
> ## преобразуется в матрицу.
> inputData <- list(x = t(training[, fullSet]), у = training$Class)
1 Здесь может возникнуть еще одна проблема с дублированием имен. Ее причиной может стать функция sda из пакета sda (сокращение от Shrinkage Discriminant Analysis). Если оба пакета загружены, конструкции sparseLDA::: sda и sda::: sda помогут решить проблему.
2 В данных-микромассивах количество предикторов обычно намного выше количества строк. По этой причине и из-за ограниченности количества столбцов в популярных программных продуктах электронных таблиц была применена обратная схема.
360 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
Базовый синтаксис создания модели:
> library(pamr)
> nscModel <- pamr.train(data = inputData)
По умолчанию функция выбирает 30 подходящих значений степени сжатия для оценки. Параметры позволяют задать конкретные значения для степени сжатия, априорные вероятности и другие аспекты модели. Функция pamr. predict генерирует прогнозы для новых точек данных, а также определяет, какие конкретные предикторы использовались моделью для заданной величины сжатия. Например, если вы хотите задать степень сжатия 5, это можно сделать так:
> exampleData <- t(training[l:5, fullSet])
> pamr.predict(nscModel, newx = exampleData, threshold = 5)
[1] successful unsuccessful successful unsuccessful successful
Levels: successful unsuccessful
> ## Какие предикторы использовались при этом пороге? Функция
> ## predict выводит номера столбцов для сохраненных предикторов.
> threshl7Vars <- pamr.predict(nscModel, newx = exampleData,
+ threshold = 17, type = "nonzero")
> fullSet[threshl7Vars]
[1] "Unsuccess.CI" "SponsorUnk" "ContractValueBandA"
[4] "ContractValueBandUnk" "Jan"
Пакет также содержит функции k кратной перекрестной проверки для выбора подходящей величины сжатия, но ограничивается одним типом повторной проверки и настраивает модель по общей четности.
Синтаксис функции train:
> ## Здесь выбирается конкретный диапазон параметров настройки:
> nscGrid <- data.frame(.threshold = 0:25)
> set.seed(476)
> nscTuned <- train(x = training[,fullSet],
+ у = training$Class,
+ method = "pam",
+ preProc = c("center", "scale"),
+ tuneGrid = nscGrid,
+ metric = "ROC",
+ trControl = Ctrl)
Этот подход открывает больше возможностей для настройки модели (например, по площади под ROC-кривой), а также предоставляет более последовательный синтаксис. Функция predict для train не требует, чтобы пользователь вручную вводил величину сжатия (автоматически используется оптимальное значение, определенное функцией).
12.7. Вычисления 361
Функция predictors выводит предикторы, указанные в уравнении прогнозирования (при оптимальном пороге, определенном train). В настроенной модели были выбраны 36 предикторов:
> predictors(nscTuned)
[1] ’’NumSR"
[4] "CI.Facultyl3"
[7] "DurationGT15"
[10] ’’allPub’’
[13] ’’Sponsor2B"
[16] "Sponsor62B"
[19] "SponsorUnk"
[22] "ContractValueBandD"
[25] "ContractValueBandG"
[28] "GrantCat30B"
[31] "Jan"
[34] "Sun"
"Success.CI" "CI.Faculty25" "Astar.CI" "Sponsor21A" "Sponsor34B" "Sponsor6B" "ContractValueBandA" "ContractValueBandE" "ContractValueBandllnk" "Aug"
"Jul" "Day"
"Unsuccess.CI" "CI.Faculty58" "AstarTotal" "Sponsor24D" "Sponsor4D" "Sponsor89A" "ContractValueBandC" "ContractValueBandF "GrantCatlOA" "Dec"
"Fri" "Day2"
Функция varlmp возвращает показатели важности переменных, основанные на расстоянии между центроидом класса и общим центроидом:
> varImp(nscTuned, scale = FALSE)
pam variable importance
only 20 most important variables shown (out of 1071)
Importance
ContractValueBandUnk
-0.2260
SponsorUnk
0.1061
Jan
0.0979
ContractValueBandA
0.0948
Unsuccess.CI
-0.0787
Day
-0.0691
Aug
-0.0669
Sun
0.0660
GrantCatlOA
-0.0501
Success.CI
0.0413
Day2
-0.0397
ContractValueBandE
0.0380
GrantCat30B
-0.0379
ContractValueBandD
0.0344
Sponsor21A
0.0340
ContractValueBandF
0.0333
ContractValueBandG
0.0329
Sponsor24D
-0.0299
Sponsor2B
-0.0233
NumSR
0.0224
362 Глава 12. Дискриминантный анализ и другие линейные классификационные модели
В этих данных знак минус обозначает направление влияния предиктора. Например, когда категория суммы контракта неизвестна, успешен только малый процент заявок (19,4 % в отличие от базового процента успеха (46,4 %)). Отрицательное значение для этого предиктора означает падение частоты события. И наоборот, когда неизвестен спонсор, частота успеха высока (82,2 %; см. табл. 12.1). Расстояние для этого предиктора положительно, что указывает на возрастание частоты события.
Упражнения
12.1. Набор данных поражения печени описан в главе 1. Он содержит 281 уникальное вещество, каждое из которых было классифицировано как «не вызывает поражения», «умеренное поражение» или «серьезное поражение» (см. рис. 1.2). Эти вещества были проанализированы в ходе 184 биологических экспериментов, в ходе которых оценивалось воздействие каждого вещества на конкретный биологически релевантный приемник в теле. Чем больше значение каждого из этих предикторов, тем выше активность вещества. Кроме биологических экспериментов, для этих веществ были определены 192 бинарных предиктора, каждый из которых представлял некоторую субструктуру (атом или комбинацию атомов в веществе) и содержал либо количество таких субструктур, либо индикатор присутствия/ отсутствия конкретной субструктуры. Этот набор данных предназначался для построения предиктивной модели повреждения печени с целью прогнозирования вероятности повреждения печени для других веществ. Запустите R и введите следующие команды для загрузки данных:
> library(caret)
> data(AppliedPredictiveModeling)
> # Для получения дополнительной информации см. ?hepatic
Матрицы Ыо и chem содержат биологические данные и химические бинарные признаки для 281 вещества, а вектор injury содержит классификацию уровня поражения печени для каждого вещества.
A. Опишите, как бы вы создали тренировочный и тестовый наборы с учетом дисбаланса классификации состояний поражения печени.
Б. Какую статистику классификации вы бы выбрали для выполнения оптимизации в этом упражнении и почему?
B. Разбейте данные на тренировочный и тестовый наборы. Проведите предварительную обработку данных и постройте модели, описанные в этой главе, для биологических предикторов и отдельно — для химических бинарных предикторов. Какая модель обладает лучшей предиктивной способностью для химических предикторов, какова ее оптимальная эффективность? Если руководствоваться
Упражнения 363
этими результатами, какой набор предикторов содержит максимум информации о токсичности?
Г. Определите пять самых важных предикторов для оптимальных моделей биологических и химических бинарных предикторов.
Д. Теперь объедините биологические и химические бинарные предикторы в один набор. Проведите повторную тренировку предиктивных моделей, построенных в части (В). Какая модель обеспечивает наилучшую предиктивную эффективность? Превосходит ли эта модель по эффективности какую-либо из лучших моделей части (В)? Как выглядит пятерка самых важных предикторов для оптимальной модели? Сравните ее с составом оптимальных предикторов для каждого отдельного набора.
Е. Какую модель (любая из моделей с отдельными биологическими предикторами, отдельными химическими бинарными предикторами или с объединенным набором предикторов) вы бы порекомендовали использовать для прогнозирования токсичности вещества для печени? Объясните свой выбор.
12.2. В упражнении 4.4 описан набор данных из 96 образцов, каждый из которых относится к одному из семи типов масел (тыквенное, подсолнечное, арахисовое, оливковое, соевое, рапсовое и кукурузное). С каждым образцом была проведена газовая хроматография, и был определен процент каждого типа 7 жирных кислот. Эти данные должны использоваться для построения модели, прогнозирующей тип масла на основании процентного содержания жирных кислот в образце.
A. Как и данные поражения печени, эти данные подвержены исключительному дисбалансу. С учетом этого дисбаланса следует ли разбить данные на тренировочный и тестовый наборы?
Б. Какую статистику классификации вы бы выбрали для выполнения оптимизации в этом упражнении и почему?
B. Какая из моделей, представленных в этой главе, лучше всего работает с этими данными? Какой тип масла наиболее точно прогнозируется моделями? Наименее точно?
12.3. На веб-сайте1 программного пакета MLC++ содержится несколько наборов данных машинного обучения. Набор данных churn был разработан для прогнозирования ухода клиентов в телекоммуникационной отрасли на основании информации их учетных записей. В файлах данных указано, что данные «созданы искусственно, но сходны со встречающимися в реальном мире». Данные состоят из 19 предикторов, относящихся к учетной записи клиента: количество обращений в службу поддержки, код зоны, количество минут и т. д. Результатом считается
1 http://www.sgi.com/tech/mlc.
364 Глава 12. Дискриминантный анализ и другие линейные классификационные модели решение клиента уйти или остаться. Данные содержатся в пакете С50 и могут быть загружены следующими командами:
> library(C50)
> data(churn)
> ## Загружены два объекта: churnTrain and churnTest
> str(churnTrain)
> table(churnTrain$Class)
A. Проанализируйте данные, создав визуальное представление связи между предикторами и результатом. Существуют ли важные признаки самих данных предикторов — например, корреляции между предикторами или вырожденные распределения? Могут ли функции нескольких предикторов использоваться для более эффективного моделирования данных?
Б. Проведите обучение базовых моделей на тренировочном наборе и настройте их с использованием повторной выборки. Какие критерии следует использовать для оценки эффективности моделей?
B. Используйте диаграммы точности прогнозов для сравнения моделей. Если вы хотите идентифицировать 80 % уходящих клиентов, то сколько клиентов других категорий будут идентифицированы моделью?
13
Нелинейные классификационные модели
В главе 12 описаны модели, линейные по своей природе, — структура модели производит линейные границы классов, если нелинейные функции предикторов не были заданы вручную. В этой главе речь пойдет о нелинейных моделях (за исключением использующих деревья или правила для моделирования данных, которые будут обсуждаться в главе 14).
За некоторыми исключениями (такими, как модели FDA, см. раздел 13.3) эффективность методов, описанных в этой главе, может страдать при большом количестве неинформативных предикторов во входных данных.
Соответственно, объединение таких моделей с инструментами выбора признаков (см. главу 19) способно существенно повысить их эффективность. Уточним, что в рамках этой главы анализ моделей проводится без контролируемого удаления неинформативных предикторов, поэтому эффективность с большой вероятностью будет ниже той, которую бы обеспечил более комплексный подход.
13.1. Нелинейный дискриминантный анализ
Начнем с анализа возможностей изменения линейных дискриминантных методов, описанных в главе 12, для работы с данными, которые лучше разделяются нелинейными структурами. К числу таких методов относятся квадратичный дискриминантный анализ (QDA), регуляризированный дискриминантный анализ (RDА) и смешанный дискриминантный анализ (MDA).
Квадратичный и регуляризированный дискриминантный анализ
Линейный дискриминантный анализ может быть сформулирован так, чтобы модель, прошедшая тренировку, минимизировала общую вероятность ошибочной
366 Глава 13. Нелинейные классификационные модели классификации. Вследствие предположения о том, что предикторы в каждом классе имеют общую структуру ковариации, границы классов выражены линейными функциями предикторов.
В квадратичных дискриминантных моделях это предположение ослаблено, чтобы модель могла использовать структуру ковариации, специфическую для конкретного класса. Главное следствие такого изменения — в том, что границы принятия решений становятся квадратичными кривыми в пространстве предикторов. Растущая сложность дискриминантной функции может улучшить эффективность модели для многих задач. Однако у этого обобщения есть и другое следствие: ужесточение требований к данным. Так как здесь применяются ковариационные матрицы уровня классов, должны существовать и обратные матрицы. Это означает, что количество предикторов должно быть меньше количества случаев внутри каждого класса. Также предикторы внутри каждого класса не должны иметь патологических уровней коллинеарности. Кроме того, если большинство предикторов в данных являются индикаторами отдельных категорий, QDA сможет моделировать их только как линейные функции, тем самым ограничивая эффективность модели.
В контексте чисто математической оптимизации методы LD А и QD А минимизируют общую вероятность ошибочной классификации в предположении, что данные действительно могут разделяться гиперплоскостями или квадратичными поверхностями. На практике может оказаться, что данные лучше разделяются структурами, лежащими где-то между линейными и квадратичными границами классов. Метод RD А, предложенный Фридманом (Friedman, 1989), — один из вариантов связывания разделяющих поверхностей, используемых LD А и QDA. Фридман предлагает следующую ковариационную матрицу:
Sf(X) = X£r +(1-ад (13.1)
где L, — ковариационная матрица/-го класса, a S — объединенная ковариационная матрица для всех классов. Легко видеть, что параметр настройки X позволяет методу «сгибать» ковариационную матрицу между LDА (с X = 0) и QDA (с X = 1). Если модель настраивается по X, то подход, управляемый данными, может использоваться для выбора между линейными и квадратичными границами, а также границами, лежащими между ними.
RDA применяет еще одно обобщение данных: объединенной ковариационной матрице разрешается переходить от наблюдаемого значения к значению, представленному тождественной матрицей, в котором предполагается независимость предикторов:
Цу) = у2 + (1-у)ст21,
(13.2)
13.1. Нелинейный дискриминантный анализ 367
где а2 — стандартная дисперсия всех предикторов, а I — единичная матрица (то есть матрица, у которой диагональные элементы равны 1, а все остальные элементы равны 0), что заставляет модель считать все предикторы независимыми. В главе 4 рассмотрен пример с двумя классами и двумя предикторами, между которыми существует высокая корреляция, указывающая на то, что подходящими с наибольшей вероятностью окажутся значения у около 1. Однако при большей размерности становится все сложнее визуально распознавать такие закономерности, так что настройка модели RD А по X и у позволяет данным тренировочного набора выбрать наиболее подходящие предположения для модели. За исключением случая, когда значение у равно 1, а значение X равно 0, необходимо применять более жесткие стандарты данных QDA.
Смешанный дискриминантный анализ
Метод MDA, разработанный Хэсти и Тибширани (Hastie и Tibshirani, 1996), является расширением LDА. Метод LDA предполагает такое распределение данных предикторов, чтобы средние значения классов различались (но ковариационная структура не зависит от классов). Метод MDA позволяет представлять каждый класс несколькими многомерными нормальными распределениями, которые могут иметь разное математическое ожидание, но, как и в случае с LDA, предполагается, что их ковариационные структуры одинаковы.
На рис. 13.1 каждый класс представляется тремя нормальными распределениями с разными математическими ожиданиями и одинаковыми дисперсиями. Фактически это — подклассы данных.
Класс 2
Класс 1
4 6 8
Предиктор
Рис. 13.1. Для одного предиктора три разных подкласса определяются в каждом классе с использованием смешанного дискриминантного анализа
368 Глава 13. Нелинейные классификационные модели
Разработчик модели указывает, сколько разных распределений будет использоваться, а модель MDA определяет их оптимальное положение в пространстве предикторов. Как происходит объединение распределений для вычисления прогноза класса? В контексте правила Байеса (формула 12.4) MDA изменяет Pr[X| Y = CJ. Распределения, специфичные для классов, объединяются в одно многомерное нормальное распределение посредством создания «смеси» уровней классов. Допустим, Dlk(x) — дискриминантная функция для £-го подкласса в Лм классе; общая дискриминантная функция для /-го класса будет пропорциональна
k=\
где Lt — количество распределений, используемых для /-го класса, а — пропорции смешивания, оцениваемые во время тренировки.
Эта общая дискриминантная функция может производить вероятности классов и прогнозы. Для этой модели количество распределений на класс является параметром настройки модели (они не обязаны быть равными для всех классов).
Хэсти и Тибширани (Hastie and Tibshirani, 1996) описывают алгоритмы определения начальных значений средних арифметических уровня классов, необходимых для каждого распределения, вместе с функциями числовой оптимизации для решения нетривиальных уравнений. Кроме того, по аналогии с LDA, у Клеммен- сена (Clemmensen et al., 2011) описываются штрафы MDA, сходные с моделями гребневой регрессии и лассо, интегрирующими выбор признаков в модель MDA. Следующая модель MDA (рис. 13.2) настроена по количеству подклассов на группу с возможными значениями в диапазоне от 1 до 8.
0,88
0,86
0,84
0,82
2 4 6 8
Количество субклассов на класс
Рис. 13.2. Профиль параметра настройки модели MDA для данных грантов.
Оптимальное количество подклассов равно 1, что эквивалентно анализу LDA
13.2. Нейросети 369
Площади под ROC-кривой оптимизированы с использованием одного подкласса на группу, что эквивалентно LDА. В этих данных более сложные дискриминантные границы могут отрицательно сказаться на эффективности MDA из-за большого количества бинарных предикторов.
13.2. Нейросети
Как было показано для других методов классификации, таких как дискриминантный анализ методом частных наименьших квадратов, С классов можно закодировать в С бинарных столбцов фиктивных переменных, которые затем используются как результаты модели. Хотя в предшествующем обсуждении нейросетей для регрессии использовалась одна реакция, модель может легко обеспечить множественные реакции как для регрессии, так и для классификации. Для классификации на базе нейросетей рассматривается именно такой подход.
На рис. 13.3 изображена архитектура модели для классификации.
Вместо одного результата (как для регрессии на рис. 7.1) на нижнем уровне расположены несколько узлов для разных классов. В отличие от применения нейросетей, для регрессии к комбинации скрытых переменных применяется дополнительное нелинейное преобразование. Каждый класс прогнозируется линейной комбинацией скрытых переменных, преобразованных к интервалу от 0 до 1 (обычно с использованием сигмоидальной функции). Хотя прогнозы лежат в интервале от 0 до 1 (благодаря дополнительной сигмоидальной функции), они не могут считаться аналогами вероятностей, поскольку их сумма не равна 1. Преобразование softmax, описанное в разделе 11.1, применяется для того, чтобы результаты модели нейросети соответствовали этому дополнительному ограничению:
где/Xх) ~ прогноз модели для Л го класса и г-й точки данных.
Что должна оптимизировать нейросеть для нахождения оценок параметров? Критерий для регрессии — сумма квадратов погрешностей, но в данном случае этот критерий придется изменить для множественных результатов модели, накапливая погрешности по точкам данных и классам: где уи — индикатор 0/1 для класса Л Для классификации это может стать эффективным методом определения значений параметров. Класс с самым большим прогнозируемым значением будет использован для классификации точки данных.
370 Глава 13. Нелинейные классификационные модели
Рис. 13.3. Диаграмма классификационной нейросети с одним скрытым уровнем. Скрытые переменные представляют собой линейные комбинации предикторов, преобразованные сигмоидальной функцией. Вывод также моделируется сигмоидальной функцией
Возможен и другой вариант: искать оценки параметров, максимизирующие правдоподобие распределения Бернулли, что соответствует биномиальной функции правдоподобия (формула 12.1) с размером выборки п = 1:
13.2. Нейросети 371
ZZVnA(*)- (13.3)
Эта функция также известна под названием энтропии или перекрестной энтропии, и используется в некоторых моделях на базе деревьев (см. главу 14). Правдоподобие имеет большую теоретическую достоверность, чем решение с квадратичной погрешностью, хотя исследования Клайна и Берарди (Kline and Berardi, 2005) показали, что различия в эффективности обычно пренебрежимо малы. Однако Бишоп (Bishop, 1995) предполагает, что малые вероятности будут оцениваться функцией энтропии точнее вероятностей, сгенерированных функцией квадратичной погрешности.
У классификационных нейросетей, как и у их регрессионных аналогов, существует значительный потенциальный риск переобучения. При оптимизации суммы квадратов погрешностей или энтропии снижение весов смягчает размер оценок параметров. Таким образом можно получить намного более гладкие классификационные границы. Кроме того, как объяснялось ранее, усреднение моделей способствует сокращению переобучения. В этом случае оценки вероятности классов (Z/(x)) будут усреднены между сетями, а средние значения — использоваться для классификации точек данных.
На рис. 13.4 показаны примеры обучения моделей с разными степенями снижения весов и усреднения моделей.
Все модели инициализированы одним и тем же значением генератора случайных чисел, использовали три скрытых параметра и были оптимизированы для суммы квадратов погрешностей. В первой строке моделей без снижения весов проявляется значительное переобучение, и в этих случаях усреднение моделей оказывает минимальное влияние. Малое значение снижения во второй строке демонстрирует некоторое улучшение (как и усреднение моделей), но модель все еще излишне адаптируется к тренировочным данным при использовании одной сети. Наивысшее значение снижения весов показало наилучшие результаты практически без ущерба для усреднения моделей. Вероятно, для таких данных одна модель со снижением весов будет наилучшим вариантом (как характеризующаяся наименьшей вычислительной нагрузкой).
Многие иные аспекты моделей классификации нейросетей присущи и регрессии. Рост количества предикторов или скрытых переменных ведет к значительному числу параметров в модели, для оценки которых могут использоваться те же числовые процедуры (такие, как обратное распространение). Отметим, что на эффективность модели оказывают значительное влияние коллинеарность и неинформативные предикторы. Данные грантов аппроксимированы для нескольких типов нейросетей. Сначала односетевые модели (то есть без усреднения) были аппроксимированы с применением энтропии для оценки коэффициентов модели. Модели настраивались по количеству переменных на скрытом уровне (от 1 до 10), а также по величине снижения весов (X = 0, 0,1, 1, 2). Лучшая модель использовала восемь скрытых переменных с X =2, а площадь под ROC-кривой составляла 0,884. Профили пара-
372 Глава 13. Нелинейные классификационные модели
Класс 1
Класс 2
-10 12 3
3
2
1
0
-1
-10 12 3 -10 12 3
Предиктор А (с масштабированием)
Рис. 13.4. Границы классификации для нейросетей с различными уровнями сглаживания и регуляризации. Со снижением весов и ростом количества моделей границы становятся более плавными метров настройки демонстрируют значительный разброс без видимой взаимосвязи с параметрами настройки.
Для подавления этого разброса процесс настройки был повторен: обучение прошли 10 моделей, а ее результаты были усреднены. Лучшая модель имела шесть скрытых переменных с к = 2, а площадь под ROC-кривой вновь составила 0,884.
Для повышения эффективности модели были рассмотрены различные варианты преобразования данных. Преобразование пространственного знака оказало серьезное положительное воздействие на эффективность нейросетей. При объединении
13.2. Нейросети 373
с односетевой моделью площадь под кривой увеличилась до 0,903. С усреднением модели площадь под ROC-кривой достигла 0,911.
На рис. 13.5 представлены профили параметра настройки для разных моделей.
Снижение весов
2 4 6 8 10
0,90
0,85
m о
5 сч
0,80
о 1
о 1
* § 0,75
0,90
0,85
0,80
0,75
Количество скрытых переменных
00 о
со o'
o'
CM о"
о
о’
0,0 0.2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 13.5. Наверху: модели успешности заявок на гранты настраивались при четырех разных условиях: с преобразованием предикторов и без него и с усреднением моделей и без него. Внизу: ROC-кривая для контрольного набора 2008 года при использовании усреднения с преобразованием пространственного знака (площадь под кривой = 0,911)
374 Глава 13. Нелинейные классификационные модели
Без преобразования данных усреднение моделей повышает эффективность модели по всем параметрам настройки. Оно также сглаживает различия между моделями; кривые профилей располагаются гораздо ближе друг к другу.
Применение преобразования пространственного знака с односетевой моделью обеспечивает улучшение по сравнению с моделью без преобразования. Тем не менее эффективность оптимизируется при использовании как усреднения, так и преобразования пространственного знака.
13.3. Гибкий дискриминантный анализ
В главе 12 описано применение классического линейного дискриминантного анализа для минимизации общей вероятности ошибочной классификации. Но та же модель может быть выведена и иным способом. Так, у Хэсти (Hastie et al., 1994) набор из моделей линейной регрессии аппроксимируется по бинарным индикаторам С классов, при этом коэффициенты регрессии моделей могут подвергаться последующей обработке для получения дискриминантных коэффициентов (алгоритм 13.1). Это позволяет шире взглянуть на линейный дискриминантный анализ.
Алгоритм 13.1. Алгоритм гибкого дискриминантного анализа для обобщения модели FDA (Hastie et al., 1994):
1 Создать новую матрицу реакции, содержащую столбцы бинарных фиктивных переменных для всех С классов.
2 Создать многомерную регрессионную модель любым методом, который генерирует углы наклона и точки пересечения для предикторов или функций предикторов (линейная регрессия, MARS и т. д.).
3 Провести последующую обработку параметров модели посредством метода оптимального оценивания.
4 Использовать скорректированные коэффициенты регрессии как дискриминантные значения.
Во-первых, многие модели из числа упоминаемых в главах 6 и 7 (лассо, гребневая регрессия, MARS) могут быть расширены для создания дискриминантных переменных. Так, модель MARS может быть использована для создания набора шарнирных функций, ведущих к созданию дискриминантных функций, являющихся нелинейными комбинациями исходных предикторов. Модель лассо может создавать дискриминантные функции с выбором признаков. Эта концепция получила название гибкого дискриминантного анализа, или FDA (Flexible Discriminant Analysis).
13.3. Гибкий дискриминантный анализ 375
Для демонстрации нелинейной природы алгоритма FDА воспользуемся моделью MARS с данными, представленными на рис. 4.1. Напомним, модель MARS имеет два параметра настройки: количество сохраняемых составляющих и степень предикторов, задействованных в шарнирных функциях. Если воспользоваться аддитивной моделью (то есть моделью первой степени), ограничить максимальное количество сохраняемых составляющих (не более двух) и определить бинарный ответ принадлежности к классам, то дискриминантная функция будет иметь вид
Е>(А, В) = 0,911 - 19,1 */г (0,2295 - В).
В этом уравнении /г( ) — шарнирная функция, описанная в формуле 7.1. Если дискриминантная функция больше нуля, то точка данных прогнозируется как относящаяся к классу 1. В рассматриваемой модели в предиктивном уравнении используется только одна переменная, а в левой части рис. 13.6 показаны полученные границы классов. Граница выглядит как горизонтальная линия, потому что предиктор В — единственный предиктор в разделении.
Класс 1 Класс 2
0,2 0,4 0,6 0,8
0,8
со 0,6
О.
О
£
I 0,4
С
0,2
0,2 0,4 0,6 0,8
Предиктор А
Рис. 13.6. Классификационные границы двух моделей FDA разной сложности
При наличии столь жестких ограничений для MARS эффективность FDA не очевидна. При уменьшении числа сохраненных составляющих до 4 оцениваемое дискриминантное уравнение имеет вид
376 Глава 13. Нелинейные классификационные модели
£>(А, В) = -0,242
+11,6 *Л(А-0,1322)
- 13,9 *h(A- 0,2621)
- 12,1 х//(0,2295 - В).
Эта модель FDA использует оба предиктора и границы классов, показанные в правой части рис. 13.6. Шарнирная функция MARS h обнуляет значения с одной стороны от точки перелома. Таким образом, шарнирные функции изолируют некоторые области данных. Например, если А < 0,1322 и В > 0,2295, то шарнирные функции не влияют на прогнозирование, а отрицательные точки пересечения в модели означают, что все точки этой области соответствуют классу 2. Однако если А > 0,2621 и В < 0,2295, то прогноз является функцией всех трех шарнирных функций. Фактически признаки MARS изолируют многомерные области пространства предикторов и прогнозируют общий класс внутри этих областей.
Модель FDА была настроена и тренирована на модели заявок на получение грантов. Была проведена оценка шарнирных функций MARS первой степени с количеством сохраненных составляющих в диапазоне от 2 до 25. Эффективность повышается при количестве составляющих от 2 до 15 (рис. 13.7).
Оптимальное значение — 19, хотя очевидно, что этому параметру присуща определенная гибкость. Для этой модели площадь под ROC-кривой (для данных 2008 года) оценивалась равной 0,924, с чувствительностью 82,5 % и специфичностью 86,4 %. И хотя модель FDA содержит 19 составляющих, использовались 14 уникальных предикторов (из возможных 1070). Кроме того, 9 составляющих модели — это простые линейные функции бинарных категорийных предикторов. Дискриминантное уравнение модели выглядит так:
D(x)=0,85
- 0,53 х h(l - количество старших аналитиков)
+0,11 х Ь(количество успешных заявок от старших аналитиков - 1)
- 1,1 х h(l - количество успешных заявок от старших аналитиков)
- 0,23 х ^количество неуспешных заявок от старших аналитиков - 1) +1,4 х h(l - количество неуспешных заявок от старших аналитиков) +0,18 х ^количество неуспешных заявок от старших аналитиков - 4)
- 0,035 х h(8 - количество статей группы А от всех аналитиков)
- 0,79 х код спонсора 24D
- 1 х код спонсора 59С
- 0,98 х код спонсора 62В
- 1,4 х код спонсора 6В
+1,2 х неизвестный спонсор
- 0,34 х сумма контракта категории В
- 1,5 х неизвестная категория суммы контракта
- 0,34 х код категории гранта 30В
13.3. Гибкий дискриминантный анализ 377
+0,3 х подача заявки в субботу +0,022 х h(54 - числовой день года) +0,076 х И(числовой день года - 338)
Площадь под ROC-кривой (контрольные данные 2008)
0,92
0,90
0,88
0,86
0,84
0,82
5 10 15 20
Количество составляющих
о
25
со о"
со о"
4t о
CXI о“ о
о'
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 13.7. Наверху: профиль параметра настройки для модели FDA.
Внизу: ROC-кривая FDA (площадь под кривой = 0,924) представлена относительно кривой предыдущей модели нейросети (серая линия)
378 Глава 13. Нелинейные классификационные модели
Формула позволяет уяснить влияние предикторов. Например, когда количество старших аналитиков возрастает с 0 до 1, вероятность успешного получения гранта растет.
Наличие более чем одного старшего аналитика не влияет на модель, поскольку противоположная шарнирная функция исключена. Кроме того, вероятность успеха возрастает с количеством успешных заявок от старших аналитиков и уменьшается с количеством поданных ими неуспешных заявок; этот результат аналогичен тому, что наблюдалось в предыдущих моделях. Для дня года вероятность успешного гранта убывает с течением времени и не оказывает влияния на модель вплоть до завершающей части года, когда вероятность успеха возрастает.
Дискриминантная функция, приведенная выше, может быть дополнительно преобразована для получения оценок вероятностей классов. Тренды вероятностей для непрерывных предикторов наглядно представлены на рис. 13.8.
1,0
0,8
0,6
0,4
0,2
5
I 0,0
g 0 50 100 150 0 100 200 300
|1,0
ф
00 0,8
0,6
0,4
0,2
0,0
0 5 10 0 5 10 15 20 0 10 20 30 40
Рис. 13.8. Профили вероятностей для каждого из непрерывных предикторов, использованных в аддитивной модели FDA
Вспомним, что из-за использования дополнительной модели профиль вероятностей каждой переменной может рассматриваться независимо от других. В данном случае
13.3. Гибкий дискриминантный анализ 379
показатели количества старших аналитиков и количества публикаций в журналах категории А влияют на прогноз только до определенной точки, поскольку алгоритм усечения устраняет одну из аналитических пар каждого предиктора. Профиль дня года имеет две составляющие, остающиеся от двух разных аналитических пар. В результате этот предиктор влияет на модель только на ранних и поздних периодах года. В главе 12 приведены веские доказательства нелинейной связи предиктора с результатом, аппроксимированным добавлением квадратичной функции предиктора. FD А пытается аппроксимировать ту же связь. Один предиктор — количество неуспешных грантов от старших аналитиков — имеет несколько составляющих в модели; этот факт отражен в более плавном профиле вероятностей. Из бинарных составляющих предиктора суммы контракта категории В неизвестна категория суммы контракта; код категории гранта ЗОВ, коды спонсора 24D, 59С, 62В и 6В оказывают положительное влияние на вероятность успеха, тогда как составляющие подачи заявки в субботу и неизвестного спонсора были связаны со снижением вероятности успеха.
Бэггинг модели заставляет FDA генерировать более плавные связи между предикторами и результатом. Модели MARS обладают умеренной нестабильностью, поскольку используют исчерпывающий поиск данных, а разделения базируются на конкретных точках данных тренировочного набора1. Бэггинг модели FDA приведет к добавлению дополнительных разделений для важных предикторов и, как следствие, — к лучшему обучению. Тем не менее опыт показывает, что бэггинг моделей MARS и FDA оказывает минимальное влияние на эффективность модели, а повышение количества составляющих затрудняет интерпретацию дискриминантного уравнения (по аналогии с трендом на рис. 8.16).
Поскольку многие предикторы модели FDA измеряются по разным шкалам, по дискриминантной функции трудно определить, какие именно переменные оказывают наибольшее влияние на результат. Можно воспользоваться методом оценки важности переменных, описанным в разделе 7.2. Перечислим пять важнейших предикторов:
О неизвестная категория суммы контракта;
О количество неуспешных заявок от старших аналитиков;
О количество успешных заявок от старших аналитиков;
О неизвестный спонсор;
О числовой день года.
В качестве альтернативы использованию MARS в методологии FDA Милборроу (Milborrow, 2012) описывает двухфазное решение с логистической регрессией при
1 При этом модели MARS и FDA обладают большей стабильностью, чем древовидные модели, потому что они используют линейную регрессию для оценки параметров модели.
380 Глава 13. Нелинейные классификационные модели двух классах. Исходная модель MARS создается для прогнозирования бинарной фиктивной переменной реакции (то есть первых двух шагов алгоритма 13.1). После этого создается модель логистической регрессии с признаками MARS, сгенерированными исходной моделью с фиктивными переменными. Предположительно этот метод дает результаты, очень похожие на результаты модели FDA.
13.4. SVM, метод опорных векторов
Метод опорных векторов, или SVM, — класс статистических моделей, разработанных в середине 1960-х годов Владимиром Вапником. В последующие годы модель активно развивалась, став одним из самых гибких и эффективных инструментов машинного обучения, который был подробно описан разработчиком (Vapnik, 2010). Регрессионная версия этих моделей (см. раздел 7.3) представляет собой расширение исходной версии модели для задач классификации. Рассмотрим аналогичные концепции SVM для регрессии, специфику их применения для задач классификации.
Обратимся с этой целью к рис. 13.9, в левой части которого отображено применение двух переменных для прогнозирования двух классов точек данных, разделенных на две изолированные группы.
4
4
оо 2
сп 2
0
-2
0
-2
-4 -2 0 2 4
Предиктор А
-4 -2 0 2 4
Предиктор А
Рис. 13.9. Слева: набор данных с полностью изолированными классами. Существует бесконечное количество линейных границ классов, обеспечивающих нулевую ошибку. Справа: граница классов, связанная с линейным классификатором максимального зазора. Большие черные значки обозначают опорные векторы
В этой части рисунка — несколько линейных границ, обеспечивающих идеальную классификацию данных. Но как выбрать наиболее подходящую границу класса?
13.4, SVM, метод опорных векторов 381
Многие показатели эффективности (такие, как точность) для этого непригодны, так как все кривые будут считаться эквивалентными. Как же найти более подходящий показатель для оценки эффективности модели?
Вапник определил в качестве альтернативного показатель, названный зазором (margin). Условно говоря, зазор соответствует расстоянию между классификационной границей и ближайшей точкой тренировочного набора. Так, в правой части рис. 13.9 одна из возможных границ выделена сплошной линией. Пунктирные линии по обе стороны границы проходят на максимальном расстоянии от линии до ближайшей точки данных тренировочного набора (с равным удалением от граничной линии). В данном примере три точки данных находятся на равном удалении от классификационной границы (они выделены черными значками). Зазор, определяемый этими точками данных, можно оценить количественно и использовать полученный результат для оценки потенциальных моделей. В контексте терминологии, принятой для SVM, угол наклона и точка пересечения границы, максимизирующие буфер между границей и данными, называется классификатором максимального зазора.
Рассмотрим несколько примеров математических конструкций SVM, позволяющих лучше понять внутренние механизмы этого метода. Предположим, имеется задача с двумя классами; точки данных класса 1 кодируются значением 1, а точки данных класса 2 — значением -1. Условимся, что векторы xt- содержат данные предикторов для точки данных тренировочного набора. Классификатор максимального зазора создает порог решения D(x), классифицирующий точки данных так, что в случае D (х) > 0 точка данных прогнозируется с классом 1, а в противном случае — с классом 2.
Для неизвестной точки данных и решающее уравнение может быть записано как линейная дискриминантная функция, параметризуемая по углу наклона и точке пересечения:
0(«) = Ро+Р’«
=Ро+ЁРл-
Это уравнение можно преобразовать так, чтобы классификатор максимального зазора выражался точками данных в выборке:
^(«) = Ро+£ра =
'Г (13.4)
=р0+£л«х«-
1=1
с а, > 0 (по аналогии с формулой 7.2).
382 Глава 13. Нелинейные классификационные модели
В случае с полным разделением параметры а равны 0 для всех точек данных, не лежащих на линии зазора. И наоборот, ненулевые значения а соответствуют точкам, лежащим на границе зазора (см. черные значки на рис. 13.9). По этой причине уравнение является функцией только подмножества точек тренировочного набора, которые называются опорными векторами. При этом функция прогнозирования является функцией только тех точек тренировочного набора, которые лежат ближе всего к границе и прогнозируются с наименьшей определенностью1.
Поскольку уравнение прогнозирования строится исключительно на основе этих точек данных, классификатор максимального зазора обычно называется методом опорных векторов.
Формула 13.4 позволяет понять, как метод опорных векторов классифицирует новые точки. На рис. 13.10 прогнозируемая моделью новая точка изображена серым кружком, а расстояния между опорными векторами и новыми точками обозначены пунктирными линиями.
4
2
со
Q.
-2
-4
-4 -2 0 2 4
Предиктор А
Рис. 13.10. Прогнозирование новой точки данных с использованием метода опорных векторов. Итоговое значение решающего уравнения О(ц) = 0,583. Пунктирные линии обозначают расстояние от новой точки данных до опорных векторов
1 Вспомните похожую ситуацию с регрессионными моделями опорных векторов, в которых предиктивная функция определялась точками данных с наибольшими остатками.
13.4. SVM, метод опорных векторов 383
Три опорных вектора содержат всю информацию, необходимую для классификации новой точки данных. Основная часть формулы 13.4 — суммирование произведения: знака класса, параметра модели и скалярного произведения новой точки и значений предикторов опорных векторов. В табл. 13.1 приведены компоненты этой суммы, разделенные для трех опорных векторов.
Таблица 13.1. Компоненты суммы произведения
Истинный класс
Скалярное произведение
У/
а/
Произведение
SV1
Класс 2
-2,4
-1
1,00
2,40
SV2
Класс 1
5,1
1
0,34
1,72
SV3
Класс 1
1,2
1
0,66
0,79
Следуя Диллону и Гольдштейну (Dillon and Goldstein, 1984), скалярное произведение х-и может быть записано как произведение расстояния х, от начала координат, расстояния и от начала координат и косинуса угла между х,- и и. На основании оценки параметра а, первый опорный вектор оказывает наибольшее воздействие на уравнение прогнозирования (при прочих равных условиях), сохраняя отрицательный наклон. Для новой точки данных скалярное произведение отрицательно, но общий вклад этой точки положителен, смещая прогноз к классу 1 (то есть к положительному значению решающей функции D(u)). Два других опорных вектора имеют положительные скалярные произведения и общее произведение, увеличивающее значение решающей функции для этой точки данных. Для данной модели пересечение равно -4,372; следовательно, значение D(u) для новой точки составляет 0,583. Так как значение больше 0, новая точка имеет наибольшую связь с классом 1.
Что произойдет, если классы не могут быть полностью отделены друг от друга? На этот случай Кортес и Вапник (Cortes and Vapnik, 1995) разработали расширения ранней версии классификатора максимального зазора, назначающей стоимость для суммы точек, лежащих на границе или на ошибочной стороне границы. При определении оценок значений а зазору назначается штраф, если точки данных находятся на ошибочной стороне границы класса или внутри зазора. Значение стоимости становится параметром настройки модели и основным механизмом управления сложностью границы. Например, с возрастанием стоимости ошибок классификационная граница будет сдвигаться и деформироваться, с тем чтобы правильно классифицировать как можно больше точек тренировочного набора (см. рис. 4.2).
Как упоминалось в разделе 7.3, многие модели регуляризации добавляют штрафы к коэффициентам для предотвращения переобучения. Большие штрафы, как и стоимости, устанавливают пределы для сложности модели. Для метода опорных
384 Глава 13. Нелинейные классификационные модели векторов значения стоимости штрафуют количество ошибок; как следствие, большие значения стоимости порождают более высокую сложность модели, вместо того чтобы ограничивать ее.
До сих пор для таких моделей рассматривались линейные границы классификации. Вновь обратим внимание на скалярное произведение х'и в формуле 13.4. Поскольку предикторы поступают в уравнение в линейном виде, граница решения будет линейной. В работе Босера (Boser et al., 1992) линейная природа модели расширяется на нелинейные границы классификации посредством замены простого линейного перекрестного произведения ядерной функцией:
0(«) = ₽о+£^аХ" =
1=1
= ₽о+1л,аЛ(хР «).
j=l
где К(-, ) — ядерная функция двух векторов. Для линейного случая ядерная функция является тем же внутренним произведением х'и. Но, как и в регрессионных моделях SVM, здесь могут применяться и другие нелинейные преобразования, в том числе:
полиномиальная = (масштаб (х'и) 4- 1)степень радиальная базисная функция = ехр(-о || х - и ||2) гиперболический тангенс = tanh (масштаб (х'и) + 1).
Из-за вычисления скалярного произведения перед обучением необходимо провести центрирование и масштабирование данных предикторов, с тем чтобы атрибуты с большими значениями не доминировали в вычислениях. Использование ядерной функции позволяет модели SVM создавать исключительно гибкие границы решений. Выбранные параметры ядерной функции и значение стоимости определяют сложность и должны быть настроены так, чтобы модель не выполняла переобучение тренировочных данных. На рис. 13.11 показаны примеры границ классификации, созданных несколькими моделями с разными комбинациями стоимости и параметров настройки.
При малых значениях стоимости модели явно склонны к недообучению. И наоборот, когда стоимость относительно высока (допустим, 16), модель может выполнять переобучение данных, особенно если и параметр ядра имеет высокое значение. Применение повторной выборки для нахождения оценок этих параметров обычно обеспечивает разумный баланс между недообучением и переобучением. Ранее, напомним, метод опорных векторов с радиальной базисной функцией использовался как пример настройки модели (см. раздел 4.6).
13.4. SVM, метод опорных векторов 385
Класс 1
Класс 2
-10 12 3
3
2
1
О
1
1
-1
2
1
О
-1
-10 12 3 -10 12 3
Предиктор А (масштабированный)
Рис. 13.11. Границы классификации для девяти моделей опорных векторов с радиальной базисной функцией, изменяемых по параметру стоимости и ядерному параметру (о)
Методы опорных векторов относятся к более общей категории ядерных методов — области, где в последнее время исследования велись весьма активно. Ранее рассматривались расширения исходной модели для нелинейных границ классов и ошибочно классифицированных точек данных. Для методов опорных векторов были разработаны и другие расширения — например, представленные в работах Су и Лина, Дуана и Кирти (Hsu and Lin, 2002; Duan and Keerthi, 2005) расширения для поддержки более чем двух классов. Кроме того, изначально модель создавалась для создания жестких границ принятия решения с целью классификации точек данных, а не для оценки вероятностей классов. Однако Платт (Platt, 2000)
386 Глава 13. Нелинейные классификационные модели описывает методы последующей обработки результатов модели SVM именно для оценки вероятностей классов. Существуют и альтернативные версии модели SVM, такие как модели SVM наименьших квадратов (Suykens and Vandewalle, 1999), модели векторов релевантности (Tipping, 2001) и модели векторов импорта (Zhu and Hastie, 2005).
Разработаны и специализированные варианты ядра. Например, при анализе QSAR (см. раздел 6.1) в качестве предикторов использовались химические дескрипторы. На рис. 6.1 изображена химическая формула аспирина. Вместо того чтобы выводить дескрипторы из молекулярной формулы, можно преобразовать формулу в граф или сеть. Специализированный класс ядерных функций — так называемые ядерные функции графов — может, по утверждению Маэ и Верта (Mahe et al., 2005; Mahe and Vert, 2009), напрямую связать содержимое химической формулы с моделью без вывода дескрипторных переменных. Существуют и некоторые другие ядерные функции, которые могут применяться в задачах глубокого анализа текстов. Так, метод «набора слов» (bag-of-words) обобщает содержимое блока текста, вычисляя частоты вхождения отдельных слов. Счетчики интерпретируются как предикторные переменные в классификационных моделях. Однако подобный подход не свободен от некоторых проблем. Во-первых, возможны внушительные дополнительные затраты времени и ресурсов на вычисление предикторных переменных. Во-вторых, этот подход не учитывает последовательность слов в составе текста. Например, тексты «Miranda ate the bear» («Миранда съела медведя») и «the bear ate Miranda» («медведь съел Миранду») в модели набора слов получат одинаковые оценки, обладая совершенно разным смыслом. Строковые ядерные функции (Lodhi et al., 2002; Cancedda et al., 2003) могут использовать весь текст документа напрямую и с большей вероятностью выявляют важные связи, чем методология набора слов.
Для данных грантов есть несколько способов применения SVM. Мы провели оценку как ядерных радиальных базисных функций, так и полиномиальных ядерных функций (в линейной или квадратичной конфигурации). Кроме того, были оценены как полные, так и сокращенные наборы предикторов (об отрицательном влиянии неинформативных предикторов, присутствующих в модели, на ее эффективность см. главу 19).
Для ядерной радиальной базисной функции был оценен аналитический подход определения параметра радиальной базисной функции. Для полного набора предикторов оценка составила о = 0,000559, для сокращенного набора — о = 0,00226. Однако эффективность этих моделей оставляла желать лучшего, поэтому параметр был проанализирован по значениям ниже аналитических оценок (рис. 13.12).
Меньший набор предикторов демонстрирует лучшие результаты, чем более полный набор: оптимальная площадь под ROC-кривой — 0,895, чувствительность — 84 %,
13.4. SVM, метод опорных векторов 387
специфичность — 80,4 %. Кроме того, для сокращенного набора меньшие значения а обеспечивали лучший результат, хотя значения ниже 0,001167 не улучшали обучения модели.
сигма = 0,00023857 о сигма = 0,00116699 х
2А-4 2л-2 2а0 2л2 2а4
So 0,90
о о см Ф 0,88
S 0,86 ф -О g 0,84 8.
§ 0,82
О
§ 0,80
0,78
2л_4 2л-2 2А0 2А2 2А4
Стоимость
Рис. 13.12. Профиль параметров настройки для модели SVM с радиальной базисной функцией для данных грантов
В случае полиномиальных моделей определение подходящих значений для коэффициента масштабирования ядерной функции осуществлялось методом проб и ошибок. Неподходящие значения приводили к числовым сложностям для моделей, а подходящие — зависели от степени полинома и параметра стоимости. На рис. 13.13 показаны результаты для контрольного набора.
Модели, построенные с сокращенным набором предикторов, стабильно показывали лучшие результаты, чем модели с полным набором. Кроме того, оптимальная эффективность линейной и квадратичной модели была примерно одинаковой. Это наводит на мысль, что модели в основном используют линейные отношения в данных. С учетом того, что многие предикторы являются бинарными, это логично. У таких моделей лучшая площадь под ROC-кривой равна 0,898. В целом модели SVM не обладали сопоставимой эффективностью по сравнению с иными моделями, созданными до настоящего момента. Многие линейные модели, представленные в главе 12, обладали сходной (или лучшей) эффективностью (при наибольшей эффективности модели FDA). Однако накопленный опыт показывает, что модели SVM вполне конкурентоспособны для большинства задач.
388 Глава 13. Нелинейные классификационные модели
scale = 0,005 о scale = 0,010 х
2Л-6 2А-5 2А-4 2А-3 2А-2
0,90
0,89
0,88
0,87
0,86
0,85
0,84
0,90
0,89
0,88
0,87
0,86
0,85
0,84
2л-б 2л-5 2а-4 2а-3
2л-2
Стоимость
со о
СО о"
CN о
о о“
0,0
0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 13.13. Наверху: профили эффективности для квадратичной модели SVM. Внизу: ROC-кривая для оптимальной модели (площадь под кривой: 0,895)
13.5. Метод KNN 389
13.5. Метод KNN
Метод KNN рассматривался применительно к классификации при обсуждении настройки модели и проблемы переобучения (раздел 4.2), а также в контексте регрессии (раздел 7.4). Настало время для того, чтобы охарактеризовать уникальные особенности применения этого метода и для целей классификации. Ранее обсуждались методы классификации с линейными и нелинейными границами, обеспечивавшими оптимальное разделение данных. Затем эти границы используются для прогнозирования новых точек данных.
KNN идет по другому пути: классификация точки данных определяется географическим соседством точки данных. По аналогии с контекстом регрессии, KNN для классификации прогнозирует новую точку с использованием k ближайших точек тренировочного набора. «Близость» взаимного расположения определяется показателем расстояния — например, евклидова или расстояния Минковского (раздел 7.4), а выбор показателей (их значений) зависит от характеристик предикторов. В данном случае важно помнить, что исходные масштабы измерения предикторов влияют на вычисления расстояний. Следовательно, если предикторы измеряются по сильно различающимся осям, то значение расстояния между точками данных будет смещаться к предикторам с большим масштабом. Чтобы все предикторы могли вносить равный вклад в вычисляемое расстояние, до применения KNN рекомендуется провести центрирование и масштабирование всех предикторов.
Как и в контексте регрессии, для определения классификации новой точки k ближайших точек тренировочного набора определяются на основании показателя расстояния. Оценки вероятностей классов для новой точки данных вычисляются как пропорции количества соседей в тренировочном наборе для каждого класса. Прогнозируемым классом новой точки становится класс с наивысшей оценкой вероятности; если два и более класса имеют одинаковую наивысшую оценку, то решение принимается случайным образом или проверкой по k + 1 ближайшим соседям.
Любой метод с параметрами настройки может страдать от переобучения. Метод KNN особенно подвержен этой проблеме (см. рис. 4.2). Если соседей слишком мало, то возникает эффект переобучения, а если их слишком много, то формируются границы, которые могут не отражать необходимых разделительных структур в данных. Следовательно, для определения оптимального значения k необходимо пойти по обычному пути перекрестной проверки или повторной выборки. Для данных грантов число соседей, оцениваемых для настройки, лежало в диапазоне от 1 до 451. На рис. 13.14 изображен профиль настройки площади под ROC-кривой для контрольных данных 2008 года.
390 Глава 13. Нелинейные классификационные модели
0,80
0,75
0,70
I 0,65
8
(Г
0
100
200 Количество о
300 оседей
400
о
оо о
со о
2) ь о
I с:
ф
со
о m >» □"
’’Г о
ем о
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 13.14. Наверху: профиль параметров настройки для модели KNN.
Внизу: ROC-кривая для данных тестового набора. Площадь под кривой равна 0,81
При изменении числа соседей в интервале от 1 до 5 наблюдается явный скачок предиктивной эффективности, после чего продолжается стабильный прирост эффективности в диапазоне настройки. Исходный скачок предиктивной эффективности указывает, что локальная информация местонахождения в высшей степени
13.6. Наивный байесовский классификатор 391
информативна для классификации. На основании устойчивого и постепенного роста предиктивной эффективности можно сделать вывод о том, что значение количества ближайших соседей для категоризации точек данных достаточно велико. Эта закономерность несколько необычна для KNN, так как с ростом количества соседей начинают проявляться недообучение и соответствующее снижение предиктивной эффективности (см. рис. 7.10).
В большинстве наборов данных использование такого количества соседей при прогнозировании маловероятно. Этот пример помогает выявить проблему числовой нестабильности KNN: с ростом количества соседей возрастает и вероятность «ничейных» результатов. Для этого примера количество соседей, превышающее 451, приводит к слишком большому количеству «ничьих». Оптимальная площадь под ROC-кривой, равная 0,81, наблюдалась при k = 451.
Нижняя диаграмма на рис. 13.14 сравнивает ROC-профиль KNN с профилями SVM и FDA. Для этих данных предиктивная способность KNN уступает другим настроенным нелинейным моделям. И хотя информация о местонахождении важна с точки зрения прогнозирования, она уступает по полезности моделям, ищущим глобальные оптимальные границы разделения.
13.6. Наивный байесовский классификатор
Правило Байеса ранее обсуждалось в контексте линейного дискриминантного анализа. Теперь обсуждение будет расширено и сосредоточено на конкретной классификационной модели, которая, как и предыдущие модели LD A, QD А и RD А, определяется в контексте способа создания многомерных плотностей вероятностей.
Правило Байеса отвечает на вопрос: «Какова вероятность того, что на основании наблюдаемых предикторов результат относится к классу С/?» Пусть Y— переменная класса, аХ — набор предикторных переменных. Попытаемся оценить Рг[У= CZ|X], то есть установить, «какова вероятность того, что при заданном X результат принадлежит Лу классу». Правило Байеса предоставляет средства для получения ответа:
Рг[У = CJXJ =р4Г1ргИ|у^.]
1 ' J Рг[Х]
Вероятности Pr[Y = С,|Х] обычно называются апостериорными вероятностями классов. Основные компоненты:
О Рг[ У] — априорная вероятность результата. Вопрос формулируется так: на основании того, что мы знаем о задаче, какие вероятности классов следует ожидать? Например, при прогнозировании ухода клиентов существенно обладание информацией об общей текучести клиентской базы. Для проблем, связанных
392 Глава 13. Нелинейные классификационные модели
с заболеваниями, такой априорной информацией стали бы данные заболеваемости (см. раздел 11.2).
О Рг[Х] — вероятность значений предикторов. Например, если прогнозируется новая точка данных, то насколько вероятен именно этот расклад по сравнению с тренировочными данными? Формально эта вероятность вычисляется с использованием многомерного распределения вероятностей. На практике обычно делаются важные предположения для сокращения сложности вычислений.
О Pr[X | Y = CJ — условная вероятность. Какова вероятность наблюдаемых значений предикторов для данных, связанных с классом Q? По аналогии с Рг[Х] без ограничивающих предположений могут потребоваться сложные вычисления.
Наивный байесовский классификатор упрощает вероятности значений предикторов, исходя из того, что все предикторы независимы друг от друга. Это предположение небезосновательно, но вместе с тем в контексте рассмотренных примеров трудно признать это предположение реалистичным. С другой стороны, предположение о независимости значительно сокращает сложность вычислений.
Например, для вычисления условной вероятности Pr[X| Y = используется про¬
изведение плотностей вероятностей для каждого отдельного предиктора:
Pr[X|y = CJ = nPr[X.|y = CJ.
Безусловная вероятность Рг[Х] дает похожую формулу в предположении о независимости. При оценке отдельных вероятностей для непрерывных предикторов должно быть сделано предположение о нормальном распределении (с математическим ожиданием и дисперсией из тренировочного набора).
Другие методы, такие как приводимые Хардлом (Hardie et al., 2004) непараметрические ядерные оценки плотности, могут более гибко оценить вероятности плотности. Для категорийных предикторов распределение вероятности может быть определено с наблюдаемыми частотами данных тренировочного набора. Например, на рис. 13.15 показан уже знакомый пример с двумя классами.
Слева представлены тренировочные данные. Очевидно, что оба предиктора вряд ли независимы (их корреляция составляет 0,78). Предположим, что нужно вычислить прогноз для новой точки данных (обозначенной черным треугольником).
Для вычисления общей условной вероятности Рг[Х| У = CJ каждый предиктор рассматривается по отдельности. Для предиктора А две условные плотности обозначены в правой части рис. 13.15 вертикальной черной линией, представляющей значение новой точки для этого предиктора. Для данных тренировочного набора при использовании только этого предиктора первый класс кажется намного более вероятным.
13.6. Наивный байесовский классификатор 393
Класс 1 Класс 2
Класс 1
Класс 2
1,0
0,8 л & § 0,6 I- о
С 0,4
0,2
0,0
0,0
0,2 0,4 0,6
Предиктор А
0,0
0,0 0,2 0,4 0,6 0,8 1,0
Предиктор А
Рис. 13.15. Слева: диаграмма данных двух классов при прогнозировании новой точки данных (черный треугольник). Справа: диаграмма условных плотностей предиктора А, созданная с использованием непараметрической оценки плотности. Значение предиктора А для новой точки данных обозначено вертикальной черной линией
Чтобы получить вероятность класса Pr[X| Y = CJ для класса 1, определяются две условные вероятности для предикторов А и В, которые затем перемножаются, чтобы вычислить общую условную вероятность для класса.
Для Рг[Х] будет применяться аналогичная процедура, не считая того, что вероятности предикторов А и В будут определяться по всему тренировочному набору (то есть по обоим классам). Наблюдаемая на рис. 13.15 корреляция между предикторами достаточно сильна, это говорит о том, что новая точка данных чрезвычайно маловероятна. Однако с предположением о независимости эта вероятность, скорее всего, будет переоценена.
Априорная вероятность позволяет разработчику модели сместить финальную вероятность к одному или нескольким классам. Например, при моделировании редкого события обычно применяется избирательная выборка данных, с тем чтобы добиться более сбалансированного распределения классов в тренировочном наборе. Однако разработчик модели может назначить событию низкую априорную вероятность. Если же априорная вероятность не задана явно, то обычно для ее оценки используются наблюдаемые пропорции из тренировочного набора.
Зачем вообще рассматривать эту модель при столь жестких и нереалистичных предположениях? Во-первых, наивный байесовский классификатор быстро вычисляется даже для больших тренировочных наборов. Например, если все предикторы являются категорийными, то достаточно простых таблиц с распределениями частот тренировочного набора. Во-вторых, при столь обоснованных предположениях модель показывает неплохие результаты во многих случаях.
394 Глава 13. Нелинейные классификационные модели
Правило Байеса, по сути, является вероятностным утверждением. Создаются вероятности классов, и прогнозируемым классом становится тот, который связан с наибольшей вероятностью класса. Суть модели — в определении условных и безусловных вероятностей, связанных с предикторами. Для непрерывных предикторов можно выбрать простые предположения о характере распределения — например, нормальное распределение. Непараметрические плотности могут давать более гибкие оценки вероятностей (рис. 13.16).
0,008
0,006
ё
J 0,004
О
с
0,002
0,000
0 100 200 300
Числовой день года
Рис. 13.16. Два подхода к оценке функции плотности Рг[Х] для дня года. Синяя линия базируется на нормальном распределении, а красная линия сгенерирована с использованием непараметрической оценки плотности
Для данных заявок на получение грантов предиктор числового дня года имеет несколько временных кадров с чрезмерным количеством поданных заявок. На иллюстрации черная кривая нормального распределения слишком обширна и поэтому не отражает нюансы данных. Красная кривая является непараметрической оценкой, как будто воспроизводящей тренды в данных с более высокой точностью. Для категорийных предикторов частотное распределение предиктора в тренировочном наборе используется для оценки Pr[X] и Pr[X | Y= CJ. В табл. 13.2 показаны наблюдаемые частоты для дня недели, в который были поданы заявки.
Столбцы с процентами от общего количества содержат оценки Pr[X | Y = CJ для каждого класса. При прогнозировании новой точки оценка вероятностей получается простым поиском по таблице.
Очевидная проблема, особенно для малых размеров выборки, встречается в том случае, когда одна или несколько частот равны нулю. Если у предиктора в тренировочном наборе отсутствуют точки данных для конкретного класса, условная вероятность будет нулевой, а поскольку вероятности перемножаются, то один предиктор обнулит апостериорную вероятность.
13.6. Наивный байесовский классификатор 395
Таблица 13-2. Частоты и условные вероятности Pr[X | Y = CI] для дня недели
День
Количество
Процент от общего количества
успех
неудача
успех
неудача
Понедельник
749
803
9,15
9,80
Вторник
597
658
7,29
8,03
Среда
588
752
7,18
9,18
Четверг
416
358
5,08
4,37
Пятница
606
952
7,40
11,62
Суббота
619
861
7,56
10,51
Воскресенье
228
3
2,78
0,04
Один из методов решения этой проблемы, рассмотренный в работах Ниблетта, За- дрозны и Элкана, Провоста и Домингоса (Niblett, 1987; Zadrozny and Elkan, 2001; Provost and Domingos, 2003), основан на применении корректировки Лапласа, или сглаживания Лапласа, когда к числителю добавляется один и тот же поправочный коэффициент, обычно в интервале от 1 до 2. В знаменателе частоты увеличиваются на поправочный коэффициент, умноженный на количество значений предиктора. Например, для заявок, поданных в воскресенье, частоты крайне низки. Для их корректировки коэффициент 1 изменяет наблюдаемые частоты на 229 и 4, но знаменатель при этом увеличивается на 7.
С учетом большого размера выборки для тренировочного набора эта корректировка оказывает незначительное воздействие (оцениваемая частота успеха для воскресенья увеличивается с 2,78 до 2,79 %). Однако все три неуспешные заявки в таблице были поданы после 2008 года. Тренировка на данных, относящихся к периоду до 2008 года, сгенерирует нулевые вероятности. В этом случае корректировка значением 1 увеличит вероятность успеха до 0,02 %, тогда как коэффициент 2 увеличит значение до 0,03 %. Для меньших размеров тренировочных наборов коррекция может оказать значительный положительный эффект при отсутствии ячеек в таблице. Для данных грантов многие предикторы были счетными. Хотя их значения представляют собой числа, это дискретные значения, которые могут интерпретироваться и как категории.
Во многих случаях наблюдаемое распределение частот компактно. Например, в тренировочном наборе количество старших аналитиков из раздела 2678 принимает четыре значения от 0 до 3 с распределением, сильно смещенным вправо. Если рассматривать предиктор с подобной гранулярностью так, словно он был сгенерирован симметричным нормальным распределением, оценки вероятности окажутся неудовлетворительными. Для этого был вычислен сокращенный набор
396 Глава 13. Нелинейные классификационные модели предикторов: все предикторы менее чем с 15 возможными значениями интерпретировались как дискретные, а их вероятности вычислялись с использованием их частотного распределения (как, например, для дня недели из табл. 13.2). Всего, таким образом, вычислено 14 предикторов более чем с 15 уникальными значениями, включая количество успешных грантов от старших аналитиков, количество статей в журналах категории А* от старших аналитиков и числовой день года.
Эти предикторы моделировались с использованием либо нормального распределения, либо непараметрической плотности (тип плотности интерпретировался как параметр настройки), с использованием корректировки Лапласа с коэффициентом 2. При использовании нормального распределения для непрерывных предикторов были получены следующие оценки: площадь под кривой — 0,78, чувствительность — 58,8 %, специфичность — 79,6 %. При использовании непараметрической оценки плотностей вероятности площадь под ROC-кривой улучшается до 0,81, с соответствующим возрастанием показателей чувствительности (64,4 %) и специфичности (82,4 %). К сожалению, эффективность этой модели находится на одном уровне с моделями KNN и существенно хуже результатов других моделей.
При рассмотрении в разделе 11.1 применения правила Байеса для калибровки оценок вероятностей классов истинные классы использовались как Y, а вероятности классов для тренировочного набора использовались как «предиктор», причем вероятности Рг[Х|У= С(] определялись по прогнозам моделей для тренировочного набора. При прогнозировании новых точек вероятности классов, генерируемые соответствующей моделью, проходят последующую обработку с использованием правила Байеса для улучшения калибровки. Вероятности классов, созданные нормальным применением правила Байеса, обычно недостаточно хорошо откалиброваны.
С ростом количества предикторов (относительно размера выборки) апостериорные вероятности становятся более экстремальными (по аналогии с наблюдениями, связанными с линейным дискриминантным анализом на рис. 12.11). Вспомним в этой связи, что модель QDA базируется на правиле Байеса (с использованием многомерного нормального распределения для предикторов), а представленные на рис. 11.1 результаты QDA указывают на плохую калибровку с двумя предиктор- ными переменными (которая, впрочем, улучшается при повторной калибровке с повторным применением правила Байеса).
13.7. Вычисления
В этой главе используются следующие пакеты R: caret, earth, kernlab, klaR, MASS, mda, nnet и rrcov. В этом разделе также используются созданные в главе 12 объекты R, содержащие данные (например, кадр данных training).
13.7. Вычисления 397
Нелинейный дискриминантный анализ
Существует ряд пакетов для выполнения разновидностей нелинейного дискриминантного анализа, описанных в этой главе. Метод QD А реализуется функцией qda из пакета MASS, а также устойчивой к выбросам версией в функции QdaCov из пакета rrcov. Метод RDA доступен в функции rda из пакета klaR, а поддержка MDA находится в пакете mda. Все эти модели используют очень похожий синтаксис, а для демонстрации мы применим модель MDA к данным грантов.
Функция mda использует интерфейс формул. Параметром настройки является количество подклассов на класс, причем эти значения могут быть разными для всех классов. Например, обучение модели MDA к данным грантов с тремя подсовокупностями на класс выполняется следующим образом:
> Library(mda)
> mdaModeL <- mda(CLass - .,
+ ## Reduce the data to the re Levant predictors and the
+ ## cLass variabLe to use the formuLa shortcut above
+ data = training[pre2008, c ("CLass", reducedSet)],
+ subcLasses = 3)
> mdaModeL
Call:
mda(formula = Class ~ data = training[pre2008, c("Class", reducedSet)], subclasses = 3)
Dimension: 5
Percent Between-Group Variance Explained:
vl v2 v3 v4 v5
72.50 92.57 96.10 98.66 100.00
Degrees of Freedom (per dimension): 253
Training Misclassification Error: 0.18709 ( N = 6633 )
Deviance: 6429.499
> predict(mdaModeL,
+ newdata = head(training[-pre2008, reducedSet]))
[1] successful successful successful successful successful successful
Levels: successful unsuccessful
Далее построим каждую из представленных нелинейных дискриминантных моделей, оптимальные параметры настройки которых могут быть найдены при помощи пакета caret. Здесь будет использован параметр trControl, описанный в разделе 12.7:
398 Глава 13. Нелинейные классификационные модели
> set,seed(476)
> mdaFit <- train(training[,reducedSet], trainingfCLass,
+ method = "mda",
+ metric = "ROC",
+ tuneGrid = expand,grid(,subcLasses = 1:8),
+ trControL = ctrL)
Сходный синтаксис может использоваться для RDA (method = "rda") и QDA (для устойчивой к выбросам версии из пакета rrcov используются значения "rda" или "QdaCov").
Штрафная версия MDA также доступна в функции smda из пакета sparseLDA (подробнее см. у Клеменсена (Clemmensen et al., 2011)).
Нейросети
Существует много пакетов R для нейросетей, включая nnet, RSNNS, qrnn и neuralnet. Два основных информационных ресурса, посвященных использованию нейросетей в R — (Venables and Ripley, 2002) и (Bergmeir and Benitez, 2012, раздел 7).
Ограничимся пакетом nnet. Синтаксис очень похож на синтаксис регрессионных моделей с несколькими исключениями. Аргументу linout должно быть присвоено значение FALSE, так как большинство моделей классификации использует сигмоидальное преобразование для связывания скрытых переменных с результатами. Суммы квадратов погрешностей или энтропия оценивают параметры модели, алогические аргументы softmax и entropy переключаются между ними.
Пакет поддерживает как интерфейс формул, так и интерфейс передачи матриц или кадров данных для предикторов и результата. Во втором случае результат не может быть факторной переменной, он должен быть преобразован в набор из С бинарных индикаторов. Пакет содержит функцию class.ind, которая может быть полезна для выполнения преобразования:
> head(с Lass,ind(trainingfCLass))
successful unsuccessful
[1J
[2,]
[3J
[4,]
[5J
[6 J
1
1
1
1
0
1
0
0
0
0
1
0
Использование интерфейса формул для обучения простой модели:
> set,seed(800)
> nnetMod <- nnet(CLass ~ NumCI + CI,1960,
* data = training[pre2008, J.
13.7. Вычисления 399
+ size = 3, decay = .1)
# weights: 13
initial value 4802.892391
iter 10 value 4595.629073
iter 20 value 4584.893054
iter 30 value 4582.614616
iter 40 value 4581.010289
iter 50 value 4580.866146
iter 60 value 4580.781092 iter 70 value 4580.756342 final value 4580.756133 converged
> nnetMod
a 2-3-1 network with 13 weights
inputs: NumCI CI.1960
output(s): Class
options were - entropy fitting decay=0.1
> predict(nnetMod, newdata = head(testing))
LU
6641 0.5178744
6647 0.5178744
6649 0.5138892
6650 0.5837029
6655 0.4899851
6659 0.5701479
> predict(nnetMod,, newdata = head(testing), type = "class")
[1] "unsuccessful" "unsuccessful" "unsuccessful" "unsuccessful"
[5] "successful" "unsuccessful"
Если моделируется три и более класса, то базовый вызов predict создает столбцы для всех классов.
Как и прежде, train предоставляет для этой функции обертку для настройки модели по величине снижения весов и количеству скрытых параметров. Используется тот же код модели (method = "nnet”) и поддерживаются оба интерфейса модели, хотя train разрешает использовать факторные векторы для классов (с внутренним использованием class.ind для кодирования фиктивных переменных). Кроме того, как и при регрессии, можно применить усреднение модели при помощи автономной функции avNNet или функции train (с параметром method = "avNNet").
Итоговая модель данных грантов имеет следующий синтаксис:
> nnetGrid <- expand,grid(.size = 1:10,
+ .decay = c(0, .1, 1, 2))
> maxSize <- max(nnetGrid$.size)
> numWts <- 1*(maxSize * (Length(reducedSet) + 1) + maxSize + 1)
> set.seed(476)
> nnetFit <- train(x = training],reducedSet],
400 Глава 13. Нелинейные классификационные модели
+ у = training$CLass,
+ method = "nnet",
+ metric = "ROC",
+ preProc = c("center", "scaLe", "spatiaLSign"),
+ tuneGrid = nnetGrid,
+ trace = FALSE,
+ maxit = 2000,
+ MaxNWts = numWts,
+ ## За описанием ctrL обращайтесь к главе 12
+ trControL = ctrL)
FDA
Пакет mda содержит функцию (f da) для построения модели. Модель поддерживает интерфейс формул и может получать параметр (method), который задает точный метод оценки параметров регрессии. Для использования FDA с MARS существуют два подхода. Параметр method = mars использует реализацию MARS из пакета mda. Однако пакет earth, ранее описанный в разделе 7.5, осуществляет обучение модели MARS с расширенным набором параметров. Загрузите пакет earth и укажите method = earth. Например, простая модель FDA для данных заявок на получение грантов может быть создана следующим образом:
> Library(mda)
> Library(earth)
> fdaModeL <- fda(CLass - Day + NumCI, data = training[pre2008,],
+ method = earth)
Аргументы функции earth (например, nprune) могут задаваться при вызове fda и передаваться earth. Модель MARS содержится в подобъекте с именем fit:
> summary(fdaModeL$fit)
Call: earth(x=x, y=Theta, weights=weights)
coefficients
(Intercept) 1.41053449 h(Day-91) -0.01348332
h(Day-202) h(Day-228) h(228-Day) h(Day-282) h(Day-319) h(Day-328) h(Day-332) h(Day-336) h(l-NumCI)
0.03259400
-0.02660477
-0.00997109
-0.00831905
0.17945773
-0.51574151
0.50725158 -0.20323060 0.11782107
Selected 11 of 12 terms, and 2 of 2 predictors
13.7. Вычисления 401
Importance: Day, NumCI
Number of terms at each degree of interaction: 1 10 (additive model)
GCV 0.8660403 RSS 5708.129 GRSq 0.1342208 RSq 0.1394347
Учтите, что коэффициенты модели, приведенные здесь, не проходили последующую обработку Итоговые коэффициенты модели можно узнать вызовом coef (fdaModel). Прогнозирование выполняется так:
> predict(fdaModeLJ head(training[-pre2008J]))
[1] successful successful successful successful successful successful Levels: successful unsuccessful
Функция train может использоваться с параметром method = "fda" для настройки этой модели по количеству сохраненных составляющих. Кроме того, функция varlmp из этого пакета определяет важность предикторов так же, как для моделей MARS (см. раздел 7.2).
Модель SVM
Как обсуждалось в главе, посвященной регрессии, реализация SVM и других ядерных методов существует в нескольких пакетах R, включая е1071, kernlab, klaR и svmPath. Самая полная реализация содержится в пакете kernlab.
Синтаксис моделей классификации SVM очень похож на синтаксис регрессии. Хотя параметр epsilon актуален только для регрессии, другие параметры будут полезны для классификации.
Логический аргумент prob.model заставляет ksvm оценить дополнительный набор параметров для сигмоидальной функции, чтобы преобразовать решающие значения SVM в вероятности классов по методу Платта (Platt, 2000). Если этому параметру не присвоено значение TRUE, то вероятности классов не прогнозируются.
Аргумент class .weights назначает всем классам асимметричные стоимости (Osuna et al., 1997). Это может быть особенно важно, когда один или несколько конкретных типов ошибок оказываются вреднее других или когда существует жесткий дисбаланс классов, который смещает модель к мажоритарному классу (см. главу 16). В таких ситуациях используется синтаксис именованного вектора весов или стоимостей. Например, если вы захотите ввести в модель грантов смещение для обнаружения неуспешных заявок, синтаксис будет выглядеть так:
class.weights = c(successful = 1, unsuccessful = 5)
В результате ошибки ложноотрицательных заключений обходятся в 5 раз дороже, чем ошибки ложноположительных. Учтите, что реализация весов классов в ksvm влияет на прогнозируемый класс, но на модель вероятностей классов веса не влияют (в этой реализации). Данная возможность используется в главе 17.
402 Глава 13. Нелинейные классификационные модели
Следующий код выполняет обучение радиальной базисной функции к сокращенному набору предикторов данных грантов:
> set»seed(202)
> sigmaRangeReduced <- sigest(as.matrix(training[,reducedSet]))
> svmRGridReduced <- expand,grid(.sigma = sigmaRangeReducedfl J,
+ ,C = 2A(seq(-4, 4)))
> set.seed(476)
> svmRModeL <- train(training[,reducedSet], trainingfCLass,
+ method = "svmRadiaL",
+ metric = "ROC",
+ preProc = c("center"j "scaLe"),
+ tuneGrid = svmRGridReduced,
+ fit = FALSE,
+ trControL = ctrL)
> svmRModeL
8190 samples
252 predictors
2 classes: ’successful’, 'unsuccessful'
Pre-processing: centered, scaled
Resampling: Repeated Train/Test Splits (1 reps, 0.75%)
Summary of sample sizes: 6633
Resampling results across tuning parameters:
с
ROC
Sens
Spec
0.0625
0.866
0.775
0.787
0.125
0.88
0.842
0.776
0.25
0.89
0.867
0.772
0.5
0.894
0.851
0.784
1
0.895
0.84
0.804
2
NaN
0.814
0.814
4
0.887
0.814
0.812
8
0.885
0.804
0.814
16
0.882
0.805
0.818
Tuning parameter 'sigma' was held constant at a value of 0.00117 ROC was used to select the optimal model using the largest value. The final values used for the model wereC=land sigma = 0.00117.
Когда результат является фактором, функция автоматически использует prob, model = TRUE.
Другие ядерные функции могут определяться при помощи аргументов kernel и краг. Прогнозирование новых точек данных происходит по той же схеме, что и с другими функциями:
13.7. Вычисления 403
> Library(kern Lab)
> predict(svmRModeL, newdata - head(training[-pre2008, reducedSet]))
[1] successful successful successful successful successful successful Levels: successful unsuccessful
> predict(svmRModeL, newdata = head(training[-pre2008, reducedSet]), + type = "prob")
successful unsuccessful
1 0.9522587
2 0.8510325
3 0.8488238
0.04774130
0.14896755
0.15117620
4 0.9453771
0.05462293
5 0.9537204
0.04627964
6 0.5009338
0.49906620
Модель KNN (к ближайших соседей)
Синтаксис обучения классификационной модели KNN очень похож на синтаксис обучения регрессионной модели. В этом случае модель генерируется пакетом caret с параметром method = "knn". Для получения верхней части рис. 13.14 использовался следующий синтаксис:
> set.seed(476)
> knnFit <- train(training[,reducedSet], trainingfCLass,
+ method = "knn",
+ metric = "ROC",
+ preProc = c("center", "scaLe"),
+ tuneGrid = data.framef.k = c(4*(0:5)+l,
+ 20^(1:5)4-1,
4- 50* (2:9)4-1)),
4- trControL = ctrL)
Следующий фрагмент кода прогнозирует данные тестового набора и соответствующую ROC-кривую:
> knnFitfpred <- merge(knnFitfpred, knnFit$bestTune)
> knnRoc <- roc(response = knnFit$pred$obs,
4- predictor = knnFit$pred$successfuL,
4- LeveLs = rev(LeveLs(knnFit$pred$obs)))
> pLot(knnRoc, Legacy.axes = TRUE)
Наивный байесовский классификатор
Две основные функции для обучения наивного байесовского классификатора в R — naiveBayes из пакета е1071 и NaiveBayes из пакета klaR. Обе функции предоставляют корректировки Лапласа, но у версии из пакета klaR предусмотрен параметр для использования более гибких оценок условной плотности.
404 Глава 13. Нелинейные классификационные модели
Обе функции поддерживают для определения модели как интерфейс формул, так и матричный интерфейс. Однако попытка передать этим моделям бинарные фиктивные переменные (вместо факторных) создаст проблемы, потому что отдельные категории будут интерпретироваться как числовые данные, и модель будет оценивать функцию плотности вероятности (то есть Рг[Х]) из непрерывного распределения (например, распределения Гаусса).
Чтобы реализовать описанную выше стратегию с преобразованием многих предикторов в факторные переменные, мы создадим альтернативные версии тренировочного и тестового набора:
> ## Некоторые предикторы уже хранятся как факторы
> factors <- с ("Sponsor Code", "ContractVaLueBand", "Month", "Weekday")
> ## Получить другие предикторы из сокращенного набора
> nbPredictors <- factorPredictors[factorPredictors %in% reducedSet]
> nbPredictors <- c(nbPredictors, factors)
> ## Отобрать только то, что необходимо
> nbTraining <- trainings с("CLass", nbPredictors)]
> nbTesting <- testing[, c("CLass", nbPredictors)]
> ## Перебрать предикторы и преобразовать некоторые в факторы,
> for(i in nbPredictors)
+ {
+ varLeveLs <- sort(unique(training[,i]))
+ if(Length(varLeveLs) <= 15)
+ {
+ nbTraining[, i] <- factor(nbTraining[,i],
+ LeveLs = paste(varLeveLs))
+ nbTesting[, i] <- factor(nbTesting[,i],
+ LeveLs = paste(varLeveLs))
+ }
+ }
Теперь можно воспользоваться интерфейсом формул функции NaiveBayes для создания модели:
> Library(kLaR)
> nBayesFit <- NaiveBayes(CLass ~ .,
+ data = nbTraining[pre2008,],
+ ## Следует ли использовать
+ ## непараметрическую оценку?
+ usekerneL = TRUE,
+ ## Значение корректировки Лапласа
+ fL=2)
> predict(nBayesFit, newdata = head(nbTesting))
$class
6641 6647 6649 6650 6655 6659
successful successful successful successful successful successful
Упражнения 405
Levels: successful unsuccessful
Sposterior successful unsuccessful 6641 0.9937862 6.213817e-03
6647 0.8143309 1.856691e-01
6649 0.9999078 9.222923e-05
6650
0.9992232
7.768286e-04
6655
0.9967181
3.281949e-03
6659
0.9922326
7.767364e-03
Иногда появляется предупреждение: «Численная вероятность 0 для всех классов с наблюдением 1». Функция predict этой модели поддерживает аргумент threshold, который заменяет нулевые значения малым числом, отличным от 0 (по умолчанию 0,001).
Функция train рассматривает метод оценки плотности (то есть usekernel) и коррекцию Лапласа как параметры оценки. По умолчанию функция оценивает вероятности с нормальным распределением и непараметрическим методом (и с отсутствием корректировки Лапласа).
Упражнения
13.1. Используйте данные поражения печени из предыдущей серии упражнений (упражнение 12.1). Вспомним, что матрицы bio и с hem содержат биологические и химические бинарные предикторы для 281 вещества, тогда как вектор injury содержит классификацию поражения печени для каждого вещества.
A. Используйте те же тренировочные и тестовые наборы, а также операции последующей обработки, как при предыдущей работе с этими данными. Используя ту же классификационную статистику, что и прежде, постройте модели, описанные в этой главе, для биологических предикторов и отдельно для химических бинарных предикторов. Какая модель обладает наилучшей предиктивной способностью для биологических предикторов, какова оптимальная эффективность?
Б. Какая модель обладает наилучшей предиктивной способностью для химических предикторов, какова оптимальная эффективность? Способствует ли нелинейная структура этих моделей улучшению эффективности классификации?
B. Как выглядят пять самых важных предикторов оптимальных моделей для биологических и химических предикторов?
Г. Теперь объедините биологические и химические бинарные предикторы в один набор. Проведите повторную тренировку набора предиктивных моделей, построенных в пункте А. Какая модель обеспечивает наилучшую предиктивную эффективность? Превосходит ли она по эффективности какую-либо из лучших
406 Глава 13. Нелинейные классификационные модели
моделей из пункта А? Как выглядят пять самых важных предикторов для оптимальной модели? Сравните их с оптимальными предикторами из каждого набора предикторов. Как они связаны с предикторами из линейных моделей?
Д. Какую модель (модель только с биологическими предикторами, модель только с химическими предикторами, объединенная модель) вы бы порекомендовали для прогнозирования токсичности веществ для печени? Объясните свой выбор.
13.2. Используйте данные жирных кислот из предыдущей серии упражнений (упражнение 12.2).
А. Используйте тот же способ разделения данных и операции последующей обработки, что и в главе 12. Используя ту же классификационную статистику, что и прежде, постройте модели, описанные в этой главе для тех данных. Какая модель обладает лучшей предиктивной способностью? Как выглядит эффективность этой оптимальной модели на фоне эффективности лучшей линейной модели? Как на основании этого сравнения сделать вывод о нелинейных разделительных границах?
Б. Какой тип масла наиболее точно прогнозируется оптимальной моделью? Наименее точно?
Деревья классификации и модели на базе правил
Деревья классификации относятся к семейству моделей на базе деревьев и, по аналогии с деревьями регрессии, состоят из вложенных команд if-then. Для уже знакомой нашим читателям задачи с двумя классами простое дерево классификации может выглядеть так:
if Predictor В >= 0.197 then
| if Predictor A >= 0.13 then Class = 1
| else Class = 2
else Class = 2
В данном случае двумерное пространство предикторов делится на три области (или терминальных узла), в каждой из которых результат относится к категории «Класс 1» или «Класс 2». На рис. 14.1 изображено дерево в пространстве предикторов.
Как и в случае с регрессией, вложенные команды if-then могут быть свернуты в правила следующего вида:
if Predictor А >= 0.13 and
Predictor В >= 0.197 then Class = 1
if Predictor A
>= 0.13 and
Predictor В < 0.197 then Class = 2
if Predictor A
< 0.13 then
Class = 2
Очевидно, структура деревьев и правил аналогична структуре, которая была представлена в задаче регрессии. Достоинства и недостатки деревьев в задаче классификации тоже отчасти похожи: высокая интерпретируемость, возможность обработки многих типов предикторов и отсутствующих данных. С другой стороны, модель нестабильна и может не обеспечивать оптимальную эффективность прогнозирования. Процесс нахождения оптимальных разделений и правил несколько отличается из-за изменения критерия оптимизации (см. далее). Случайные леса, усиление и другие ансамблевые методологии, использующие деревья классификации или правила, также расширяются для этой задачи (подробнее см. разделы 14.3-14.6).
408 Глава 14. Деревья классификации и модели на базе правил
Класс 1 Класс 2
0,2 0,4 0,6
Предиктор А
Рис. 14.1. Пример прогнозирования классов в областях, определяемых моделью на базе дерева
14.1. Базовые деревья классификации
Как и в случае с деревьями регрессии, деревья классификации предназначены для разделения данных на меньшие, более однородные группы. «Однородность» в данном случае означает, что узлы разделения более чисты (то есть каждый узел содержит большую пропорцию одного класса). Более простой способ определения чистоты в классификации основан на максимизации точности или эквивалентной минимизации ошибок классификации. Однако точность как показатель чистоты несколько запутывает ситуацию, поскольку она ориентирована прежде всего на поиск разделения данных, которое сводит к минимуму ошибки классификации, а не на поиск разделения, размещающего точки преимущественно в одном классе.
Два альтернативных показателя — предложенный группой Бреймана (Breiman et al., 1984) коэффициент Джини и перекрестная энтропия, которая также называется отклонением (определяется позднее в этом разделе), — смещают акцент с точности на чистоту. В задаче с двумя классами коэффициент Джини для заданного узла вычисляется по формуле
(14.1) где/?! ир2 — вероятности класса 1 и класса 2 соответственно.
14.1. Базовые деревья классификации 409
В задаче с двумя классами/^ + р2 = 1, следовательно, формулу 14.1 можно записать в эквивалентном виде 2pj)2. Очевидно, коэффициент Джини достигает минимума, когда вероятность любого из классов стремится к нулю; это означает, что узел является чистым по отношению к одному из двух классов. И наоборот, коэффициент Джини достигает максимума при рх = р21 в этом случае узел обладает наименьшей чистотой.
При работе с непрерывным предиктором и категорийной реакцией процесс поиска оптимальной точки разделения напоминает процесс, продемонстрированный в разделе 8.1. Сначала точки данных сортируются на основании значений предикторов. Точками разделения становятся средние точки между уникальными значениями предикторов. Если реакция бинарна, то этот процесс генерирует таблицу сопряженности 2 х 2 в каждой точке разделения (табл. 14.1).
Таблица 14.1. Пример таблицы сопряженности
Класс 1
Класс 2
> разделения
Иц
и12
< разделения
и21
П22
П+2
п2+
п
Коэффициент Джини до разделения равен
Gini (перед разделением)=2
Коэффициент Джини можно вычислить и после разделения в каждом из новых уз¬
лов со значениями выражения
( >
( А
2
«12.1
и 2
W21
l«+i;
\«+2 )
для значений больших,
меньших или равных точке разделения соответственно. Эти значения объединяются с использованием пропорций точек данных в каждой части разделения как весов;
выражения
представляют веса для значений больших, меньших или
равных точке разделения соответственно. После некоторого упрощения коэффициент Джини для оценки разделения принимает вид
Gini (после разделения)=2
/ \
П12
410 Глава 14. Деревья классификации и модели на базе правил
Теперь рассмотрим пример, представленный на рис. 14.1, основываясь на данных табл. 14.2.
Таблица 14.2. Таблица сопряженности для разделения предиктора В
Класс 1
Класс 2
В >0,197
91
30
121
В <0,197
20
67
87
Коэффициент Джини для точки данных в разделении В > 0,197 равен 0,373, а для точек с В < 0,197 — 0,354. Чтобы определить, насколько хорошо работает это разделение в целом, значения необходимо объединить посредством назначения каждому значению чистоты весового коэффициента, определяемого пропорцией точек в узле относительно общего количества точек в родительском узле. В данном случае вес для разделения В > 0,197 равен 0,582, а для В < 0,197 — 0,418. Общий коэффициент Джини для этого разделения равен (0,582)(0,373) + (0,418)(0,354) = 0,365.
Здесь оценивается всего одна возможная точка разделения; с другой стороны, алгоритмы разделения оценивают практически все точки разделения1 и выбирают значение, минимизирующее критерий чистоты. Процесс продолжается в каждом вновь созданном разделе, увеличивая глубину дерева до тех пор, пока не будет достигнут критерий остановки (например, минимальное количество точек данных в узле или максимальная глубина дерева).
Деревья, построенные по критерию максимальной глубины, известны своей склонностью к переобучению тренировочных данных. Более общее дерево, представляющее собой усеченную версию исходного дерева, может определяться настройкой стоимости/сложности, в которой к критерию чистоты применяется штраф, равный общему количеству терминальных узлов в дереве. Коэффициент стоимости/ сложности называется параметром сложности и может применяться в процессе настройки для оценки оптимального значения (см. раздел 8.1).
После усечения дерево может использоваться для прогнозирования. В классификации каждый терминальный узел создает вектор вероятностей классов на основании тренировочного набора, который затем используется как прогноз для новой точки данных. Если у новой точки данных значение предиктора В равно 0,10, то прогнозируемый вектор вероятностей классов равен (0,23, 0,77) для класса 1 и класса 2 соответственно.
По аналогии с деревьями регрессии, деревья классификации могут решать проблему отсутствующих данных. При построении дерева для создания разделения
1 За пояснением технических нюансов алгоритмов разделения обращайтесь к (Breiman, 1996с).
14.1. Базовые деревья классификации 411
рассматриваются только точки данных с полной информацией. При прогнозировании вместо разделений, для которых отсутствуют данные, могут использоваться суррогатные разделения. Аналогичным образом важность переменных может вычисляться для деревьев классификации, для чего оценивается общее улучшение критерия оптимизации каждого предиктора (параллельное объяснение для регрессии см. в разделе 8.1).
Для непрерывных предикторов процесс разделения с целью определения оптимальной точки разделения выглядит тривиально. Для категорийных предикторов процесс может пойти по нескольким равноценным путям, один из которых отличается от традиционного статистического моделирования. Например, возьмем модель логистической регрессии, оценивающую углы наклона и точки пересечения, связанные с предикторами. Для категорийных предикторов создается набор бинарных фиктивных переменных (см. раздел 3.6), разлагающий категории на независимые блоки информации. Каждая из фиктивных переменных включается в модель автономно.
Модели на базе деревьев также могут осуществлять группировку категорийных предикторов. Оценка чистоты для каждого из них выполняется элементарно, поскольку каждый предиктор имеет лишь одну точку разделения.
Для моделей на базе деревьев процедура разделения может характеризоваться более динамическим разделением данных — например, в группах из двух и более категорий с каждой из сторон разделения. Для этого алгоритм должен интерпретировать категорийные предикторы как упорядоченный набор битов. Следовательно, при обучении моделей на базе деревьев и правил необходимо решить два вопроса, касающихся интерпретации данных категорийных предикторов:
1. Каждый категорийный предиктор должен подаваться в модель таким образом, чтобы модель решила, как группировать или разбивать значения (далее этот способ представления предиктора именуется использованием сгруппированных категорий).
2. Категорийные предикторы сначала раскладываются на бинарные фиктивные переменные. Таким образом, полученные фиктивные переменные рассматриваются независимо, что форсирует применение бинарных разделений для категорий. Фактически разделение по бинарным фиктивным переменным до моделирования приводит к разделению категорий по принципу «один против всех» (далее этот подход именуется использованием независимых категорий).
Выбор наиболее подходящего подхода зависит от данных и модели. Если подмножество категорий оказывает значительное предиктивное воздействие на результат, то первый способ, вероятно, предпочтительнее. Но как показано далее, его применение может значительно повлиять на сложность модели и, как следствие, на ее эффективность. Для объективного сравнения далее рассмотрены примеры создания моделей с применением обоих способов (см. также рис. 14.14).
412 Глава 14. Деревья классификации и модели на базе правил
Процесс разделения для категорийного предиктора рассмотрим на примере модели CART. Первое разделение для этих данных производится по категории суммы контракта с 17 возможными классами; категории I, J, Р и Unknown включаются в один раздел, остальные — в другой. С комбинаторной точки зрения с ростом количества возможных категорий число возможных упорядочений категорий растет в факториальной зависимости. Следовательно, алгоритмический метод должен идти по рациональному, хотя и «жадному» пути, с упорядочением категорий перед определением оптимального разделения.
Один из способов предполагает упорядочение категорий на основании пропорций точек данных в выбранной категории. В верхней части рис. 14.2 отображены вероятности успеха заявок в каждой категории суммы контракта с упорядочением по возрастанию успешности.
сэ
00
о"
(О
о’
о"
(XI
о"
о
о"
>ч
ю
СМ
о"
тг
см
o'
со
СМ
о'
я
о
см
о*
о
(XI о“
PJUnkl MOBHCADGEFQKL
Категория суммы контракта
Рис. 14.2. Наверху: диаграмма разброса упорядоченной вероятности успеха (ось у) для всех категорий суммы контракта. Внизу: профиль коэффициента Джини для всех упорядоченных разделений. Коэффициенты Джини для точек разделения между категориями Unknown, I, М, О и В практически эквивалентны, а минимум наблюдается между категориями I и М
14.1. Базовые деревья классификации 413
Для вычисления коэффициента Джини точками разделения становятся границы между упорядоченными классами, при этом категория слева помещается в одну группу, а все категории справа — в другую группу Результаты последовательных разделений представлены на нижней диаграмме.
Очевидно, что добавление точек данных из категории Unknown к точкам данных из категорий Р и J значительно сокращает коэффициент Джини. Минимальное значение достигается в точке разделения между категориями I и М. Таким образом, алгоритм решает поместить точки данных из категорий I, J, Р и Unknown в один раздел, а все остальные точки данных — в другой. При использовании только этого разделения модель классифицирует новую точку данных как неуспешную, если у нее категория суммы контракта равна I, J, Р или Unknown, и как успешную — в противном случае.
Продолжение построения дерева с применением предикторов как сгруппированных категорий и усечением по сложности приведет к результату, изображенному на рис. 14.3.
Поскольку предикторы закодированы, дереву трудно интерпретировать их в отсутствие полного понимания данных. Чтобы получить информацию о релевантности предикторов для ответа, можно использовать структуру дерева.
Переменные сгруппированных категорий, такие как код спонсора, день недели и месяц, релевантны для успеха финансирования гранта. У модели сгруппированных категорий площадь под ROC-кривой составляет 0,91 при использовании 16 терминальных узлов.
Была построена и модель CART с использованием независимых категорийных предикторов. Поскольку этот метод создает большее число предикторов, можно предположить, что усеченное дерево будет содержать и больше терминальных узлов. Однако вопреки ожиданиям, итоговое усеченное дерево также содержит 16 узлов при показателе площади под кривой 0,912 (рис. 14.4).
На рис. 14.5 его эффективность сравнивается с предикторами сгруппированных категорий. Отметим, что для деревьев классификации, использующих CART, при применении предикторов сгруппированных категорий и независимых категорий практических различий нет.
Сравнение рис. 14.3 и рис. 14.4 позволяет выявить несколько примечательных сходств и различий между тем, как модель дерева работает со сгруппированными категориями и с независимыми предикторами. Для первых четырех верхних уровней деревьев характерны совпадения: в каждом выбирается категория суммы контракта, код спонсора, количество неуспешных и успешных грантов от старших аналитиков. Хотя информация, выявляемая деревьями, обладает равной важностью, дерево независимых категорий интерпретируется намного проще, чем дерево сгруппированных категорий. Например, хотя в качестве первого разделения в каждом дереве выбирается предиктор категории значения контракта, дерево независимых
414 Глава 14. Деревья классификации и модели на базе правил
Рис. 14.3. Итоговая модель CAR.T для данных грантов с использованием предикторов сгруппированных категорий
14.1. Базовые деревья классификации 415
Рис 14.4. Итоговая модель CART для данных грантов с использованием предикторов независимых категорий
416 Глава 14. Деревья классификации и модели на базе правил
о
со о
Л (О
и
X л
§
х Ч CD О
5
CD
>ч
ZT
сч
О
о
о“'
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 14.5. ROC-кривые модели CART для контрольных данных. При использовании сгруппированных категорий площадь под кривой была равна 0,89. С независимыми категориями площадь под кривой также была равна 0,89
категорий указывает, что значение Unknown наиболее критично для создания последующих узлов, обладающих большей чистотой. Без построения графика чистоты упорядоченных категорий важность категории Unknown маскируется группировкой категорий I, J, Р и Unknown для дерева сгруппированных категорий. Аналогичные сравнения можно провести с предикторами месяца и дня недели: дерево независимых категорий сообщает больше информации о важности конкретных месяцев и дней недели. Итак, в случае деревьев создание предикторов независимых категорий может предоставить важные сведения о связях между предикторами и реакцией, неочевидные при интерпретации предикторов как сгруппированных категорий. Другой подход к классификационным деревьям основан на применении модели С4.5, описанной, к примеру, в работе Кинлана (Quinlan, 1993b). Применяемые ею критерии разделения базируются на теории информации в изложении Уоллеса, Кавера и Томаса (Wallace, 2005; Cover and Thomas, 2006). Предположим, необходимо передать некоторую информацию — распределение вероятностей классов в терминальном узле дерева — в серии сообщений. Если распределению вероятностей присуща выраженная разбалансированность, то точка данных наверняка относится к мажоритарному классу, что оставляет меньше неопределенности при предположениях. Однако при равенстве вероятностей классов в узле в отношении истинного класса точки данных сохраняется высокая неопределенность. При передаче содержимого распределения
14.1. Базовые деревья классификации 417
вероятностей в серии сообщений на фоне высокой неопределенности в каждом сообщении потребуется передать в среднем больше информации.
Согласно теории передачи информации (см. у Шеннона (Shannon, 1948) и др.), величина, именуемая информационной статистикой, представляет среднее количество битов, необходимых для передачи в сообщении. Допустим, используются С = 2 класса, вероятность первого из которых равна р. Формальное определение информационной статистики имеет вид:
info = - [plog2 р + (1 - p)log2 (1 - р)].
Прир - 0 обычно 0 log2(0) - 0.
Для данных двух классов (см. рис. 14.1) классы практически равны. Если р — пропорция точек данных в классе 1, тор = 0,53. Отсюда следует, что среднее количество битов информации для предположения истинного класса (то есть информации) будет равно 0,997. Теперь рассмотрим дисбалансированную ситуацию, в которой к классу 1 относится меньшая часть точек (р = 0,10). В этом случае информация составит только 0,46 бита, поскольку из-за дисбаланса классов проще случайно угадать истинный класс1. Этот показатель упоминался ранее дважды: как целевая функция для нейросетей (формула 13.3) и в контексте логистической регрессии (формула 12.1 с одной точкой данных).
Как соотносится изложенное с определением разделений? При использовании общего синтаксиса таблиц сопряженности общее информационное содержимое данных до разделения вычисляется по формуле:
info (до разделения) в -
^xlog2hJ
_fe±.xlog2|^M
п \ п )
п \ п )
Как и прежде, при п1+ = 0 или п2+ = 0 составляющие в квадратных скобках принято задавать равными 0.
Улучшение информационного критерия за счет создания разделений в классификационном дереве можно измерить. Прирост информации2 (или просто прирост) составит
прирост (разделение) = info (до разделения) - info (после разделения).
1 Также можно рассматривать происходящее в контексте энтропии (метрики неопределенности). Когда классы сбалансированы 50/50, оба варианта равновероятны: ситуация максимально неопределенная. Но если 10 точек данных принадлежат классу 1, неопределенность уменьшается: намного более вероятно, что случайная точка данных будет принадлежать классу 1.
2 Или «статистика взаимной информации». Эта статистика также подробно рассматривается в главе 18.
418 Глава 14. Деревья классификации и модели на базе правил
Разделения с большим приростом информации привлекательнее разделений с меньшим приростом.
Для бинарного разделения, представленного ранее, информация после разделения равна сумме значений информации по каждому из полученных разделов. Например, информация для данных со значениями, превышающими значение разделения, равна
info (до разделения) = -
—xlog2f—1
—xlog2f—'l
_и+1
Формула для данных на другой стороне разделения выглядит аналогично. Общая информация после разделения представляет собой взвешенное среднее этих значений, где веса связаны с количеством точек данных в листьях разделения
info (после разделения) = -^-info (болыпе)+—— infо (меньше). п п
Возвращаясь к данным двух классов, рассмотрим разделение предиктора В по значению 0,197. Информация при В > 0,197 равна 0,808, а на другой стороне разделения значение составляет 0,778 при взвешивании по пропорциям точек данных на каждой стороне разделения; общая информация равна 0,795, а прирост составляет 0,997-0,795 = 0,201.
При выборе другого, полностью неинформативного разделения информация после разделения останется такой же, как и до разделения, то есть прирост равен нулю. Для непрерывных предикторов дерево может строиться посредством поиска предиктора и разделения, максимизирующих прирост информации1. Для таких данных этот прирост будет наибольшим при разделении предиктора В по значению 0,197 (см. рис. 14.1). Отметим, это разделение оказывается лучшим для критерия Джини, используемого моделью CART.
Недостаток стратегии состоит в следующем. Поскольку предикторы могут иметь разное количество возможных значений, критерий прироста информации смещается в направлении от предикторов с большим количеством возможных результатов (то есть предпочтение отдается категорийным предикторам с несколькими разными значениями перед непрерывными предикторами). Это явление напоминает рассмотренное ранее смещение для деревьев регрессии (раздел 8.1). Подобное смещение связано со способностью алгоритма выполнять разделение категорийных предикторов множеством разных способов (в отличие от бинарного разделения для непре-
1 По умолчанию модель С4.5 использует простое бинарное разделение непрерывных предикторов. Тем не менее Кинлан (Quinlan, 1993b) также описывает метод, называемый нежестким выбором порога (soft thresholding), в котором значения рядом с точкой разделения интерпретируются иначе. Для краткости этот метод здесь не рассматривается.
14.1. Базовые деревья классификации 419
рывных предикторов). Многосторонние разделения с большей вероятностью будут иметь большой прирост. Для корректировки смещения используется коэффициент прироста: прирост делится на величину объема информации в самом разделении. Отметим, что у Кинлана, наряду с дополнительными примерами (Quinlan, 1993b), можно найти и описание усовершенствования этой процедуры для непрерывных предикторов (Quinlan, 1996b) с использованием принципа минимальной длины дескриптора (MDL).
При оценке разделений категорийных предикторов одна из стратегий заключается в представлении предиктора с использованием многосторонних разделений, так что для каждой категории существует отдельное разделение. Если предиктор имеет слишком много возможных значений, это может привести к излишне сложным деревьям. Например, предиктор кода спонсора в данных грантов имеет 298 уникальных значений. Если этот предиктор будет считаться важным, то будет создано исходное 298-стороннее разделение данных (до усечения). После усечения некоторые из этих разделений будут с большой вероятностью объединены и упрощены.
У Кинлана (Quinlan, 1993b, глава 7) описан модифицированный метод создания многосторонних разделений, позволяющих группировать две и более категории. До рассмотрения категорийного предиктора в качестве переменной разделения модель сначала вычисляет коэффициент прироста при представлении предиктора: О в виде многостороннего разделения, в котором количество разделений равно количеству уникальных значений (способ, используемый по умолчанию, когда каждая категория соответствует отдельному разделению);
О в виде многосторонних разделений для всех возможных комбинаций, в которых две категории группируются вместе, а остальные — разделяются по отдельности.
На основании результатов представлений предикторов применяется «жадный» алгоритм для поиска лучших категорий для объединения. Соответственно, у категорийного предиктора существует много возможных представлений. После построения итоговых группировок для этой конфигурации вычисляется коэффициент прироста, сопоставляемый с другими предикторами при поиске лучшей переменной разделения. Процесс повторяется каждый раз, когда модель проводит поиск новой переменной разделения, что требует высоких затрат вычислительных ресурсов, но может оказать минимальное влияние на дерево, если категорийные предикторы имеют лишь несколько начальных уровней. К сожалению, этот вариант недоступен в текущей реализации модели С4.5 (в программном пакете Weka под именем J48). Влияние этого варианта на данные рассматривается при описании модели С5.0 (модернизированного варианта модели С4.5 (последняя далее упоминается как J48)).
При построении деревьев с тренировочными наборами содержащем отсутствующие значения предикторов, модель С4.5 вносит ряд корректировок в процесс тренировки.
420 Глава 14. Деревья классификации и модели на базе правил
О Так, при вычислении прироста информации вычисляется информационная статистика с использованием присутствующих данных, которые затем масштабируются по доле присутствующих данных в разделении.
О Напомним, модель С4.5 решает проблему смещения выбора корректированием статистики прироста по значению информации предиктора. Когда предиктор содержит отсутствующие значения, количество ветвей увеличивается на 1; отсутствующие данные интерпретируются как «дополнительная» категория или значение предиктора.
О Наконец, когда для полученных разделений определяется распределение классов, отсутствующие значения предикторов вносят частичный вклад в каждый класс. Частичный вклад точек данных базируется на распределении классов присутствующих значений. Предположим, 11 точек данных участвуют в разбивке, при этом одно значение отсутствует. Если три точки относятся к классу 1, а остальные к классу 2, то отсутствующее значение будет вносить 0,30 вклада в класс 1, и 0,70 вклада в класс 2 (по разные стороны от разделения).
Из-за частичных вкладов распределения частот классов в каждом узле могут содержать дробные значения. Кроме того, количество ошибок в терминальном узле тоже может быть дробным.
Как и CART, модель С4.5 строит большое дерево, которое с большой вероятностью приведет к переобучению данных, а затем усекает дерево посредством простого исключения поддерева (стратегия I) либо подъема поддерева с заменой узла, расположенного выше (стратегия II).
Хотя CART использует усечение по стоимости/сложности, пессимистичное усечение позволяет оценить, стоит ли упрощать дерево. Рассмотрим случай, когда поддерево является кандидатом для удаления. Пессимистичное усечение оценивает количество ошибок с поддеревом и без него. Однако хорошо известно, что кажущаяся частота ошибок завышена. Чтобы преодолеть эту особенность, пессимистичное усечение вычисляет верхнюю доверительную границу количества ошибок (соответствует пессимистичной оценке количества ошибок). Значение вычисляется с поддеревом и без него. Если оцениваемое количество ошибок без поддерева ниже, чем в дереве, в котором это поддерево присутствует, то поддерево исключается из модели.
При определении оценки частоты ошибок для заданного интервала моделью С4.5 по умолчанию используется доверительный уровень в интервале 0,25 (называемый коэффициентом доверия). Он может считаться параметром настройки модели, так как повышение коэффициента доверия ведет к большему размеру деревьев. Следует подчеркнуть, что этот подход строится на непрочном статистическом фундаменте. Кинлан (Quinlan, 1993b) признает этот факт, отмечая, что подход «искажает статистические понятия выборки и уровней доверия, так что к его обоснованию следует относиться немного скептически».
14.1. Базовые деревья классификации 421
Тем не менее этот метод может быть очень эффективным и менее затратным, чем определение размера дерева посредством перекрестной проверки.
После того как дерево построено и усечено, новые точки классифицируются продвижением сверху вниз по соответствующему пути, пока не будет достигнут терминальный узел. Здесь мажоритарный класс данных тренировочного набора, приходящихся на терминальный узел, используется для прогнозирования новой точки данных. Значение достоверности (confidence value), по аналогии с вероятностями классов, может вычисляться на основе частот класса, связанных с терминальными узлами. Кинлан (Quinlan, 1993b) описывает, как вычислить коэффициенты доверия посредством алгоритма, сходного с описанным выше для пессимистичного усечения.
При прогнозировании точки данных с одним или несколькими отсутствующими значениями снова применяется частичная обработка точки данных. Когда встречается разделение для переменной, отсутствующей в данных, определяется каждый возможный путь вниз по дереву.
Обычно прогнозируемый класс будет основан на классе с наибольшей частотой от одного терминального узла. Поскольку отсутствующее значение теоретически может наблюдаться в нескольких терминальных узлах, каждый класс получает взвешенный балл для определения итогового прогнозируемого класса. Веса классов для всех релевантных терминальных узлов агрегируются, а для прогнозирования точки данных используется класс, ассоциированный с наибольшим общим весом. В этом случае каждый терминальный узел, имеющий возможные связи с точкой данных, вносит свой вклад в общий прогноз.
Для данных заявок на получение грантов были созданы деревья J48. Коэффициент доверия может рассматриваться как параметр настройки, учитывая, что значение по умолчанию (0,25) работает корректно. Две модели аппроксимированы с использованием двух разных подходов представления категорийных предикторов. С учетом изложенного интерпретация категорий как связного набора должна привести к построению существенно большего дерева, чем при использовании независимых категорий.
Действительно, для рассматриваемого набора данных группировка категорий привела к усеченному дереву с 2918 терминальными узлами. Результат объясняется большим количеством разделений по коду спонсора; предиктор участвует в 2384 разделениях из 2918 (82 %). При использовании независимых категорий дерево было намного меньше (821 терминальный узел). Площадь под ROC-кривой для большой модели равна 0,835, тогда как при использовании независимых категорий она равна 0,842. На рис. 14.6 показаны две ROC-кривые и точки на каждой кривой, соответствующие используемому по умолчанию 50-процентному порогу отсечения вероятности.
Из диаграммы видно, что показатели специфичности примерно одинаковы для каждого подхода (81,7 % для большей модели против 83,8 %), но в чувствительности моделей существуют серьезные различия; более сложная модель имела
422 Глава 14. Деревья классификации и модели на базе правил
О
со о
<0 О
о
см о"
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 14.6. ROC-кривые J48 для контрольных данных с использованием двух разных способов обработки категорийных предикторов. Значки (кружок и крестик) представляют 50-процентный порог отсечения вероятности. Площади под кривыми были равны 0,835 для сгруппированных категорий и 0,842 при использовании независимых категорий. Серая линия соответствует предыдущей модели CART чувствительность 83,9 %, тогда как модель независимых категорий характеризовалась относительно низкой способностью к прогнозированию успешных заявок (с чувствительностью 76,8 %). Результаты базировались на номинальном 50-про- центном пороге отсечения для успеха. Между кривыми существует значительное перекрытие, а альтернативные пороги отсечения приводят к практически идентичным результатам (см. раздел 16.4).
Хотя классификационные деревья С4.5 и CART пользуются наибольшей популярностью, существуют и многочисленные варианты модели на базе деревьев. Например, деревья условного вывода (Hothorn et al., 2006, см. также ранее) предотвращают смещение выборки при разделении. В ряде методов, упоминаемых в работах Фрэнка, Лу, Чана, Зайлайса (Frank et al., 1998; Loh, 2002; Chan and Loh, 2004; Zeileis et al., 2008), в терминальных узлах присутствуют более сложные модели — такие как М5 и Cubist.
Применимы и другие типы разделений. Например, в работе Бреймана (Breiman et al., 1984) представлена идея разделения по линейной комбинации предикторов. Эти наклонные деревья могут принести пользу, когда у классов существует линейное
14.2. Модели на базе правил 423
разделение (с обучением которого, напомним, у традиционных разделений возникают проблемы). Ансамблевые модели с наклонными деревьями рассматриваются у Мензе (Menze et al., 2011).
14.2. Модели на базе правил
Как упоминалось, модели на базе правил состоят из одного или нескольких независимых условных утверждений. В отличие от деревьев, точка данных может прогнозироваться по набору правил. Рассмотрим способы создания правил классификации.
Модель C4.5Rules
Существует несколько подходов и алгоритмов для создания моделей на базе правил по классификационным деревьям. Некоторые их первоначальные варианты описаны Кинланом (Quinlan, 1987) и (Quinlan, 1993b). Модель, названная С4. SRules, строится на базе методологии С4.5 (см. ранее) посредством создания неусеченного дерева, после чего каждый путь по дереву трансформируется в самостоятельное правило, оцениваемого автономно, с тем чтобы понять, возможно ли его обобщение с исключением составляющих в условном утверждении. Процесс усечения аналогичен использующемуся для усечения деревьев в модели С4.5.
Для правила сначала вычисляется базовая пессимистическая частота ошибок. Затем выполняется последовательное исключение условий. После удаления условия пессимистическая частота ошибок вычисляется заново. Если любая из частот ошибок окажется ниже базовой, то условие, ассоциируемое с наименьшей частотой ошибок, исключается.
Процесс повторяется до тех пор, пока все условия не будут лежать выше базовой линии или до удаления всех условий (в последнем случае правило полностью удаляется из модели). Процесс усечения на примере правила из пяти условий для данных грантов представлен в табл. 14.3.
На первом проходе удаление условия, связанного с нулевым количеством успешных грантов от старшего аналитика, оказало наименьшее воздействие на частоту ошибок, поэтому это условие удаляется из правила. При выполнении трех последующих проходов усечения частоты ошибок оставались ниже базовой линии. Следует заметить, что пессимистические частоты ошибок убывают при каждой итерации. Наибольшей важностью для правила обладает условие, в соответствии с которым от старшего аналитика не получено ни одной неудачной заявки на грант (при удалении условия частота ошибок достигает наибольшего значения).
424 Глава 14. Деревья классификации и модели на базе правил
Таблица 14,3. Процесс усечения на примере правила из пяти условий для данных грантов
Условие
Пессимистическая частота ошибок
проход 1
проход 2
проход 3
Базовая линия
14,9
5,8
5,2
Первый день года
12,9
5,2
0 неудачных грантов (CI)
77,3
53,5
50,7
Количество CI
42,0
21,6
19,7
Количество SCI
18,0
8,1
7,3
0 успешных грантов (CI)
5,8
После того как внутри каждого правила исключены условия, набор правил, связанных с каждым классом, обрабатывается по отдельности для сокращения и упорядочения правил. Сначала избыточные или неэффективные правила удаляются по принципу MDL (см. (Quinlan and Rivest, 1989) и (Quinlan, 1993b, глава 5)). Создается показатель MDL, сочетающий эффективность и сложность набора правил — для двух наборов правил с эквивалентной эффективностью показатель отдает предпочтение более простому из них. Внутри каждого класса собирается исходная группа (или совокупность групп), чтобы каждая точка данных тренировочного набора покрывалась хотя бы одним правилом. Они объединяются в исходный набор правил.
С получением исходного набора методы поиска (такие, как «жадное» восхождение по выпуклой поверхности или имитация отжига) для добавления и удаления правил используются до исчерпания возможностей дальнейшего улучшения имеющегося набора. Затем внутри класса выполняется упорядочение правил по убыванию точности. После того как наборы правил в каждом классе сформированы, классы упорядочиваются по точности. Для точек данных выбирается класс по умолчанию, не имеющий релевантных правил. При прогнозировании новой точки данных все правила проверяются по порядку, пока одно из них не будет выполнено. Прогнозируемый класс соответствует классу первого активного правила.
Модель PART
Согласно философии модели С4.5Rules, исходный набор правил-кандидатов разрабатывается одновременно. Посредством последующей обработки набор преобразуется в улучшенную модель. Возможен и другой вариант с пошаговым созданием правил. В этом случае новое правило может адаптироваться к предыдущему набору
14.3. Бэггинг деревьев 425
правил и более эффективно отражать важные тренды в данных. Фрэнк и Уиттен (Frank and Witten, 1998) описывают другую модель на базе правил — модель PART (алгоритм 14.1).
Алгоритм 14.1. Алгоритм PART для построения моделей на базе правил (Frank and Witten, 1998)
1 repeat
2
3
4
5
Создать усеченное классификационное дерево Определить путь по дереву с наибольшим покрытием Добавить этот путь в виде правила в набор правил Удалить точки данных тренировочного набора, покрываемые этим правилом
6 until правило покрывает все точки тренировочного набора
Здесь усеченное дерево С4.5 создается по данным, а путь по дереву, покрывающий большинство точек данных, сохраняется как правило. Точки данных, покрываемые правилом, отбрасываются из набора данных, а процесс повторяется, пока все точки данных не будут покрываться хотя бы одним правилом. Хотя модель использует деревья для создания правил, каждое правило создается по отдельности и обладает большей потенциальной свободой для адаптации к данным.
Модель PART для данных грантов отдавала некоторое предпочтение модели сгруппированных категорий. Для этой модели результаты не показывают значительных улучшений по сравнению с предыдущими моделями: оценка чувствительности составляла 77,9 %, специфичность — 80,2 %, а площадь под ROC-кривой (не показана) — 0,809. Модель содержала 360 правил, из которых 181 классифицировало заявки как успешные, а 179 — как неудачные. Пятью самыми продуктивными предикторами были код спонсора (332 правила), категория суммы контракта (30 правил), количество неудачных грантов от старших аналитиков (27 правил), количество успешных грантов от старших аналитиков (26 правил) и количество старших аналитиков (23 правила).
14.3. Бэггинг деревьев
Бэггинг для классификации — это простая модификация бэггинга для регрессии (см. раздел 8.4), в соответствии с которой дерево из алгоритма 8.1 заменяется неусеченным классификационным деревом для моделирования С классов. Как и в условиях регрессии, каждая модель в ансамбле используется для прогнозирования класса новой точки данных.
426 Глава 14. Деревья классификации и модели на базе правил
Поскольку все модели обладают равным весом в ансамбле, каждая модель может рассматриваться как голосование за класс, к которому модель относит новые точки данных. Общее количество голосов по каждому классу затем делится на общее количество моделей в ансамбле (М) для получения вектора прогнозируемых вероятностей по каждой точке данных. Новая точка классифицируется в ту группу, которая обладает наибольшим количеством голосов, а следовательно, и наивысшей вероятностью (табл. 14.4).
Таблица 14.4. Матрица несоответствий контрольного набора 2008 года для модели случайного леса
Наблюдаемый класс
успех
неудача
Успех
491
144
Неудача
79
843
Общая точность этой модели равна 85,7 %, чувствительность — 86,1 %, а специфичность — 85,4 %.
Для данных грантов были построены бэггинг-модели, использующие обе стратегии для категорийных предикторов. Учитывая, что эффективность бэггинга обычно перестает расти после примерно 50 деревьев, это значение (50 деревьев) принято для каждой из рассматриваемых моделей.
На рис. 14.7 представлена эффективность бэггинг-ансамблей с использованием независимых или сгруппированных категорий.
Обе ROC-кривые получаются более плавными, чем кривые, построенные с деревьями классификации или 348, что указывает на способность бэггинга к сокращению дисперсии за счет использования ансамбля. Кроме того, у обеих бэггинг-моделей площадь под кривой лучше, чем у любой из предыдущих моделей (0,92 в обоих случаях). Похоже, для этих данных нет очевидных различий в эффективности бэггинга при использовании независимых или сгруппированных категорий: ROC-кривые, значения чувствительности и специфичности практически идентичны. Эффективность контрольного набора, представленного на рис. 14.7, явно лучше результатов модели 348 (см. рис. 14.6). По аналогии с задачами регрессии показатели важности переменных могут вычисляться агрегированием значений важности переменных из отдельных деревьев в ансамбле. Сравнить важность переменных верхних 16 предикторов для бэггинг-моделей как с независимыми, так и со сгруппированными категориями читатели могут, обратившись к рис. 14.15 в ходе выполнения упражнения 14.1 (см. ниже).
14.4. Случайные леса 427
О
со о
со
-О
о о X -О
тг о
см о
о_ о"
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 14.7. ROC-кривые для классификационной бэггинг-модели на базе дерева.
Площадь под кривыми для обеих моделей была равна 0,92. Чувствительность и специфичность были равны 82,98 и 85,71 соответственно
14.4. Случайные леса
Случайные леса для классификации требуют простой настройки алгоритма регрессии для случайных лесов (алгоритм 8.2): вместо дерева регрессии используется дерево классификации. Как и в ситуации с бэггингом, каждое дерево в лесу «голосует» за классификацию новой точки данных, а пропорции голосов в каждом классе ансамбля образуют вектор прогнозируемых вероятностей.
Хотя тип дерева в алгоритме изменяется, параметр настройки — количество случайно выбираемых предикторов, выбираемых при каждом разделении, — остается прежним (обозначается mtry). Как и при регрессии, случайная выборка предикторов в процессе тренировки осуществляется с целью декорреляции деревьев в лесу. Для задач классификации Брейман (Breiman, 2001) рекомендует присвоить mtTy квадратный корень из количества предикторов. Для настройки mtry следует начать с пяти значений, более или менее равномерно распределенных в диапазоне от 2 до Р, где Р — количество предикторов. Рекомендуемое начальное число деревьев в ансамбле — 1000 (это число может быть увеличено в отсутствие наблюдаемого роста эффективности).
428 Глава 14. Деревья классификации и модели на базе правил
Обычно случайные леса для классификации обладают примерно теми же свойствами, что и обсуждавшийся выше их аналог для регрессии. Перечислим их:
О Модель относительно малочувствительна к значениям mtry.
О Как и с большинством деревьев, требования к предварительной обработке данных минимальны.
О Возможность непосредственного вычисления метрик эффективности, включая точность, чувствительность, специфичность, и матриц несоответствия.
В качестве отличия отметим возможность избирательного назначения весов классам (подробнее см. главу 16).
Были построены модели случайных лесов как с независимыми, так и со сгруппированными категориями. Параметр настройки т(гу оценивался со значениями от 5 до 1000. Для независимых категорий оптимальное значение mtry равно 100, для сгруппированных категорий — 250. Результаты представлены на рис. 14.8.
со о“
со о"
о
С\1 о
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 14.8. ROC-кривые для модели случайных лесов. Площадь под кривой для независимых категорий равна 0,92, а для модели сгруппированных категорий — 0,9
Как видим, независимые категории имеют чуть более высокую площадь под кривой (0,92) по сравнению со сгруппированной категорией (0,9). Модель бинарных предикторов также обладала лучшей чувствительностью (86,1 против 84,7 %) при чуть худшей специфичности (85,4 и 87,2 %).
14.5. Бустинг 429
Для одиночных деревьев важность переменных может определяться агрегированием улучшений в критерии оптимизации для каждого предиктора. Для случайных лесов критерий улучшения (по умолчанию обычно коэффициент Джини) агрегируется по ансамблю для генерирования общей метрики важности переменных. Влияние предикторов на ансамбль может вычисляться и представленным у Бреймана (Breiman, 2000) методом перестановок, как обсуждалось в разделе 8.5. Значения важности переменных, основанные на совокупном улучшении, были вычислены для данных грантов с двумя типами предикторов (важнейшие из них представлены на рис. 14.15).
Деревья условного вывода также могут использоваться в качестве базовой обучаемой модели для случайных лесов. Однако имеющиеся реализации методологии характеризуются высокой вычислительной нагрузкой для задач, по сложности сопоставимых с рассмотренной нами на примере задачи с грантами (сравнение эффективности случайных лесов с деревьями CAR и деревьями условного вывода рассматривается в упражнении 14.3).
14.5. Бустинг
Бустинг был разработан для задач классификации (Valiant, 1984; Kearns and Valiant, 1989): множество слабых классификаторов (например, классификатор, результаты которого лишь немногим лучше случайных) объединялись в сильный классификатор. Из существующего многообразия алгоритмов усиления обратим внимание на наиболее значимые.
Алгоритм Ada Boost
В начале 1990-х годов появилось несколько алгоритмов усиления, представленных, например, в работах Шапира и Фройнда (Schapire, 1990; Freund, 1995), которыми несколько позднее (Freund and Schapire, 1996) была описана и первая реализация теории усиления посредством алгоритма AdaBoost (алгоритм 14.2).
В обобщенном виде AdaBoost функционирует следующим образом.
Сначала алгоритм генерирует последовательность слабых классификаторов, находя при каждой итерации наилучший классификатор на основании текущих весов точек данных.
Точки данных, неверно классифицированные на &-й итерации, получают больший вес на (k + 1 )-й итерации, а правильно классифицированным точкам данных на следующей итерации присваивается уменьшенный вес. Это означает, что точкам, классификация которых затруднена, будут назначаться возрастающие веса до тех пор, пока алгоритм не найдет модель, которая правильно классифицирует эти точки.
430 Глава 14. Деревья классификации и модели на базе правил
Алгоритм 14.2. Алгоритм AdaBoost для задачи с двумя классами
1 Поставить в соответствие одному классу значение +1, а другому — значение -1.
2 Назначить всем точкам данных одинаковые начальные веса (1 /п).
3 for k= 1 to К do
4
5
6
Выполнить обучение слабого классификатора с использованием взвешенных точек данных и вычислить погрешность ошибочной классификации k-й модели (errk).
Вычислить &-й вес стадии по формуле In ((1 - errk) /errk).
Обновить веса точек данных, увеличивая веса неправильно спрогнозированных точек и уменьшая их для правильно спрогнозированных точек.
7 end
8 Вычислить прогноз усиленного классификатора для каждой точки, умножая k-й вес стадии на k-й прогноз модели и суммируя эти величины по k. Если сумма положительна, то точка данных классифицируется как относящаяся к классу +1, в противном случае — к классу -1.
Следовательно, каждая итерация алгоритма должна изучить новый аспект данных, сосредоточиваясь на областях, содержащих трудно классифицируемые точки. При каждой итерации вычисляется вес стадии на основании частоты ошибок данной итерации.
Природа веса стадии (см. алгоритм 14.2) подразумевает, что у более точных моделей будут более высокие положительные, а у менее точных — более низкие отрицательные значения1. Затем общая последовательность взвешенных классификаторов объединяется в ансамбль, который имеет серьезный потенциал к тому, чтобы классифицировать лучше любых отдельных классификаторов.
Усиление может применяться к любому методу классификации, но классификационные деревья стали популярным методом классификации, потому что их можно преобразовать в слабые обучаемые модели посредством ограничения глубины дерева для создания деревьев с небольшим количеством разделений. У Бреймана (Breiman, 1998) приводится объяснение того, почему классификационные деревья особенно хорошо подходят для усиления. Поскольку классификационные деревья относятся к методам с низким смещением/высокой дисперсией, ансамбль деревьев помогает снизить дисперсию; полученный результат обладает низким смещением и низкой дисперсией.
Так как используется слабый классификатор, веса стадий часто близки к нулю.
14.5. Бустинг 431
Работая в контексте алгоритма AdaBoost, Джонсон и Рэйенс (Johnson and Rayens, 2007) показали, что методы с низкой дисперсией невозможно значительно улучшить посредством усиления. Таким образом, для методов усиления, таких как LDA или KNN, не будет наблюдаться улучшение, аналогичное тому, что имеет место для нейросети (Freund and Schapire, 1996) или наивной модели Байеса (Bauer and Kohavi, 1999).
Стохастический градиентный бустинг
Напомним, что статистические обоснования алгоритма AdaBoost содержатся в работе Фридмана и др. (Friedman et al., 2000). Применительно к задаче классификации AdaBoost может интерпретироваться как прямая поэтапная аддитивная модель, минимизирующая экспоненциальную функцию потерь. Это представление привело к появлению таких алгоритмических обобщений, как Real AdaBoost, Gentle AdaBoost и LogitBoost. В дальнейшем эти обобщения были помещены в общую инфраструктуру, называемую градиентным методом усиления (см. в этой связи раздел 8.2). По аналогии с задачей регрессии, когда деревья используются в качестве базовой обучаемой модели, базовое градиентное усиление имеет два параметра настройки: глубину дерева (или глубину взаимодействий) и количество итераций. Одна из формулировок стохастической градиентной модели усиления моделирует вероятность события по аналогии с тем, что было продемонстрировано для логической регрессии:
. 1
Р* 1 + ехр[-/(х)] ’
где/(х) — прогноз модели в диапазоне [-оо,оо]. Например, исходной оценкой модели может быть логарифм отношения шансов: /.(()) = log А , где р — доля одного класса в точках из тренировочного набора. &
Алгоритм стохастического градиентного усиления для двух классов с использованием распределения Бернулли приведен в алгоритме 14.3.
Пользователь может осуществить более точную настройку алгоритма, выбирая функцию потерь и соответствующий градиент (Hastie et al., 2008). Сжатие может быть реализовано на последнем шаге алгоритма 14.3. Более того, этот алгоритм может быть включен в инфраструктуру стохастического градиентного усиления посредством схемы случайной выборки до первого шага внутреннего цикла for (см. раздел 8.6).
Для данных грантов была построена таблица параметров настройки, в которой глубина взаимодействия изменяет значения от 1 до 9, количество деревьев — от 100 до 2000, а сжатие — от 0,01 до 0,1. Эта же таблица применена и при построении модели усиления: категорийные переменные рассматривались как независимые категории
432 Глава 14. Деревья классификации и модели на базе правил
Алгоритм 14.3. Простое градиентное усиление для классификации (с двумя классами)
1 Инициализировать все прогнозы логарифмом отношения шансов: Г=1оётЬ.
2 for итерация j = 1,..., М do
3
4
5
6
7
Вычислить остаток (градиент) zt = у. - pt
Получить случайную выборку тренировочных данных
Провести тренировку модели на случайном подмножестве, используя остатки как результаты
Вычислить оценки остатков Пирсона для терминальных узлов:
г‘
Обновить текущую модель по формуле / = / +У-(У)
8 end
и отдельно как сгруппированные категории. Для модели независимых категорий оптимальная площадь под ROC-кривой равна 0,94, при глубине взаимодействия 9, количестве деревьев 1300 и сжатии 0,01. Для модели сгруппированных категорий оптимальная площадь под ROC-кривой равна 0,92 при глубине взаимодействия 7, количестве деревьев 100 и сжатии 0,01 (рис. 14.9).
В этом случае по критерию ROC модель независимых категорий работает лучше, чем модель сгруппированных категорий. Однако количество деревьев в двух моделях существенно различалось, что вполне логично, поскольку набор бинарных предикторов больше набора сгруппированных категорий.
Изучение профилей параметров настройки для предикторов независимых категорий и сгруппированных категорий на рис. 14.10и 14.11 выявляет некоторые примечательные контрасты.
Так, усиление предикторов независимых категорий обычно обладает лучшей предиктивной эффективностью для разных параметров настройки относительно усиления предикторов сгруппированных категорий. Это объясняется тем, что только одно значение для многих важных предикторов сгруппированных категорий содержит содержательную предиктивную информацию. Следовательно, деревья, использующие предикторы независимых категорий, с большей вероятностью позволят выявить информацию, управляющую процессом усиления.
Среди предикторов сгруппированных категорий увеличение параметра сжатия почти однозначно ухудшает предиктивную эффективность для разных глубин дерева.
14.5. Бустинг 433
О
00 о
<0 о
-0
& о X .0
о
СМ о
о о
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 14.9. ROC-кривые для модели дерева с усилением. Площадь под кривой для независимых категорий равна 0,936, а для модели сгруппированных категорий — 0,916
1 з
5 9
7
500 1000 1500 2000
0,92
0,90
0,88
0,86
500
1000 1500 2000
Количество деревьев
Рис. 14.10. Профиль параметров настройки для модели дерева с усилением при использовании сгруппированных категорий
434 Глава 14. Деревья классификации и модели на базе правил
5
7
1 з
9
500 1000 1500 2000
со о.
к S
ю
I
си
ф
X
S ю
2
СО
о
СО
ф
Q.
о
Ф
Ь
-D
ф
X О.
-t: о
о
1-
о
ф о с
X
5
ф
о
о
О
о. s
X ф о.
0,92
0,90
0,88
0,86
500
1000
1500 2000
Количество деревьев
Рис. 14.11. Профили параметров настройки для модели дерева с усилением при использовании независимых категорий
Следовательно, для предикторов сгруппированных категорий усиление получает большую часть своей предиктивной информации от исходного дерева умеренного размера, что подтверждается сравнимыми значениями площади под кривой между одиночным деревом (0,89) и оптимальным усиленным деревом (0,92).
Усиление предикторов независимых категорий показывает, что с ростом количества деревьев эффективность модели улучшается для малых значений сжатия и ухудшается для более высоких значений. Но независимо от того, будет ли выбрано более низкое или более высокое значение сжатия, каждый метод обнаруживает пиковую предиктивную эффективность с ROC приблизительно на уровне 0,94. Значит, для этих данных усиление позволяет достаточно быстро находить оптимальное значение без необходимости в значительном сжатии.
Важность переменных для усиления в задачах классификации вычисляется примерно так же, как и для регрессии: внутри каждого дерева в ансамбле выводится сводный показатель улучшения, основанный на критериях разделения каждого предиктора (с последующим усреднением по всему ансамблю).
14.6. Модель С5.0
Модель С5.0 — усовершенствованная версия классификационной модели С4.5 с расширенными возможностями, такими как усиление и неравные стоимости
14.6. Модель С5.0 435
разных типов ошибок. В отличие от С4.5 или Cubist, эти улучшения слабо документированы. Представленное здесь описание модели основано преимущественно на анализе исходного кода программы, опубликованного в 2011 году.
Модель обладает множеством функций и параметров, но основное внимание предлагается сосредоточить на:
О создании отдельного классификационного дерева;
О создании соответствующей модели на базе правил;
О процедуре усиления С 5.0;
О особенностях алгоритма (важность переменных и т. д.).
Классификационные деревья
Деревья С5.0 обладают некоторыми базовыми улучшениями, которые с большой вероятностью приведут к генерированию меньших деревьев. Например, алгоритм будет объединять не встречающиеся условия для разделений с несколькими категориями, выполняя завершающую глобальную процедуру усечения, которая пытается исключать поддеревья методом «стоимость-сложность». Поддеревья удаляются до тех пор, пока частота ошибок не превысит одну стандартную погрешность от частоты базовой линии (то есть без усечения). Эти дополнительные процедуры обычно создают более простые деревья, чем предыдущий алгоритм.
Номинальное дерево С5.0 обучалось на данных грантов с категорийными предикторами, интерпретируемыми как связное множество. Дерево содержит 86 терминальных узлов и обеспечивает площадь под ROC-кривой 0,685. Здесь пятью самыми продуктивными предикторами в дереве были следующие: категория суммы контракта (6 разделений), числовой день года (6 разделений), код спонсора (5 разделений), код категории (4 разделения) и день недели (4 разделения). Аналогичное дерево J48 содержит значительно больше терминальных узлов (2918), что отчасти объяснялось способом разделений категорийных переменных с множеством возможных значений (таких, как код спонсора). Дерево С5.0 обходит эту проблему при помощи эвристического алгоритма, описанного в разделе 14.1, пытающегося консолидировать категории в две и более меньшие группы. Если отключить этот параметр в С5.0, то дерево заметно увеличивается (213 терминальных узлов) из-за категорийных предикторов, при этом площадь под ROC-кривой для большего дерева (0,685) остается практически такой же, как у меньшего дерева.
Ни одна модель С5.0 не приближается к размеру описанного ранее дерева 348. Для J48 и С5.0 (без группировки) категорийные предикторы с множеством значений используются с большим количеством разделений, образуя в каждом из них более двух ветвей, если параметр группировки не используется.
436 Глава 14. Деревья классификации и модели на базе правил
Правила классификации
Процесс, используемый для создания правил, аналогичен С4.5: исходное дерево строится, преобразуется в правила, после чего отдельные правила упрощаются посредством усечения и ко всему набору применяется глобальная процедура для потенциального сокращения количества составляющих правил. Процесс усечения условий в правилах и упрощения набора правил в целом соответствует С4.5, но С5.0 правила не упорядочивает. Вместо этого при прогнозировании новых точек С5.0 использует все активные правила, каждое из которых «голосует» за наиболее вероятный класс. Правила каждого класса взвешиваются по уровням достоверности, после чего используется класс, связанный с наивысшим количеством голосов. При этом прогнозируется уровень достоверности, связанный с наиболее конкретным активным правилом. Напомним, что С4.5 сортирует правила, используя для прогнозирования первое активное правило.
Данные грантов проанализированы посредством этого алгоритма. Модель на базе правил состоит из 22 правил с оцениваемой площадью под ROC-кривой 0,675. Сложность этой модели намного ниже, чем у CART. При упорядочении по уровню достоверности правил три верхние позиции в списке правил, используемых для прогнозирования успешного гранта, выглядят следующим образом:
1. (Первый день года).
2. (Количество старших аналитиков > 0) и (количество ведущих кураторов < 0) и (количество студентов-исследователей < 0) и (количество неудачных грантов от старших аналитиков < 0) и (код SEO / 730106) и (числовой день года < 209).
3. (Количество внешних старших аналитиков < 0) и (количество старших аналитиков, родившихся около 1975 года < 0) и (количество успешных грантов от старших аналитиков < 0) и (числовой день года > 109) и (неизвестный код категории) и (день недели = вторник, пятница, понедельник, среда, четверг).
Далее перечислим три наиболее существенных правила для неудачных грантов:
1. (Количество неудачных грантов от старших аналитиков > 0) и (числовой день года > 327) и (код спонсора = 2В, 4D, 24D, 60D, 90В, 32D, 176D, 7С, 173А, 269А) и (категория суммы контракта = Unk, J) и (код категории = 10А, ЗОВ, 30D, ЗОС).
2. (Количество старших аналитиков < 1) и (количество неудачных грантов от старших аналитиков > 0) и (количество статей в журналах категории В у старших аналитиков > 3) и (код спонсора = 4D) и (категория суммы контракта в В, Unk, J) и (месяц = ноябрь, декабрь, февраль, март, май, июнь).
3. (Количество старших аналитиков > 0) и (количество старших аналитиков, родившихся около 1945 года < 0) и (количество успешных грантов от старших аналитиков <0) и (числовой день года > 209) и (код спонсора = 21 A, 60D, 172D, 53А, 103С, 150В, 175С, 93А, 207С, 294В).
14.6. Модель С5.0 437
Всего создано 11 правил для прогнозирования успешных грантов и столько же — для неудачных результатов. Предикторами, задействованными в большинстве правил, были количество неуспешных грантов от старших аналитиков (11 правил), категория суммы контракта (9 правил), код категории (8 правил), числовой день года (8 правил) и месяц (5 правил).
Модель С5.0 позволяет также создавать диапазоны практичности. Здесь практичность (utility) измеряется как возрастание частоты ошибок при удалении правила из набора. Правила упорядочиваются итеративным алгоритмом: модель удаляет правило с наименьшей практичностью, заново вычисляя показатель практичности для других правил. Последовательность, в которой удаляются правила, определяет их важность. Например, первое удаляемое правило обладает наименьшей практичностью, а последнее — наибольшей.
Диапазоны (bands) представляют собой группы правил приблизительно одинакового размера, основанные на порядке практичности (от наибольшего к наименьшему). При добавлении групп правил в модель может строиться профиль накапливаемой частоты ошибок.
Усиление
Процедура усиления в модели С5.0 сходна с алгоритмом AdaBoost: обучение моделей осуществляется последовательно, а каждая итерация регулирует веса на основании точности прогнозирования точки данных. Тем не менее существуют и некоторые различия, заслуживающие внимания. Во-первых, модель С5.0 старается создавать деревья, размер которых примерно равен размеру первого дерева; для этого модель требует, чтобы деревья имели приблизительно то же количество терминальных узлов, что и исходное дерево. В предшествующих методах усиления сложность дерева рассматривалась как параметр настройки.
Во-вторых, модель С5.0 объединяет прогнозы составляющих деревьев не так, как AdaBoost. Каждая усиленная модель вычисляет уровни достоверности для каждого класса так, как описано выше, вычисляя простое среднее этих значений. Выбирается класс с наибольшим уровнем доверия. Веса стадий в процессе тренировки модели не вычисляются.
В-третьих, модель С5.0 проводит две разновидности «анализа целесообразности» в процессе тренировки. Модель автоматически прекращает усиление, если она становится очень эффективной (то есть сумма весов для ошибочно классифицированных точек данных меньше 0,10) или, напротив, крайне неэффективной (например, средний вес неправильно классифицированных точек превышает 50 %). Кроме того, после половины обязательных итераций усиления каждая точка оценивается на предмет возможности правильного прогнозирования. При невозможности правильного прогнозирования случай исключается из последующих вычислений.
438 Глава 14. Деревья классификации и модели на базе правил
Наконец, модель С5.0 использует другую схему назначения весов в процессе тренировки, для рассмотрения которой введем несколько обозначений:
N= размер тренировочного набора;
N_ = количество неверно классифицированных точек данных;
wk = вес точки данных для k-й итерации усиления;
= сумма весов правильно классифицированных точек данных;
5. = сумма весов неверно классифицированных точек данных.
Алгоритм начинает работу с определения средней точки между суммой весов для неверно классифицированных точек данных и половиной общей суммы весов:
средняя точка = —
’ 1(5 +5.)-5 =1(5.+5).
По вычисленному значению производится корректировка правильно классифи-
цированных точек:
5. - средняя точка = «>4-1 х 5
Ошибочно классифицированные точки данных обновляются:
^=^-1
средняя точка
N_
Эта схема обеспечивает большой положительный прирост весов при неверном прогнозировании точки данных. Если же точка данных спрогнозирована верно, мультипликативность формулы заставляет веса снижаться все медленнее по мере того, как точка данных продолжает правильно прогнозироваться. На рис. 14.12 показан пример изменения весов для одной точки данных в нескольких итерациях усиления. Отметим также, что Кинлан (Quinlan, 1996а) описывает несколько экспериментов с применением усиления и бэггинга к моделям на базе деревьев, включая ряд случаев, когда усиление С4.5 привело к снижению эффективности модели.
Другие аспекты модели
Модель С5.0 измеряет важность предикторов, определяя процент точек тренировочного набора, приходящихся на все терминальные узлы после разделения. Например, предиктору первого разделения автоматически присваивается стопроцентная важность, поскольку это разделение влияет на все точки данных. Другие предикторы также могут использоваться в разделениях достаточно часто, но если
14.6. Модель С5.0 439
Правильно классифицированные • Ошибочно классифицированные •
6
5
X
? 4
Z си С[ § 3
о
»-
О о
Ф
СО
1
О
О 50 100 150 200
Итерация усиления
Рис. 14.12. Пример схемы назначения весов точкам данных в С5.0 при использовании усиления
терминальные узлы покрывают лишь малую часть точек тренировочного набора, то показатели важности могут быть близки к нулю. Та же стратегия применяется к моделям на базе правил и версиям модели с усилением.
В модели C5.0 имеется возможность удаления предикторов: исходный алгоритм обнаруживает, какие именно предикторы связаны с результатом, и итоговая модель создается только с использованием значимых для результата предикторов. Для этого тренировочный набор случайным образом делится надвое, после чего строится дерево для оценки предикторов — так называемое дерево отсеивания (winnowing tree). Важность каждого предиктора для модели характеризуется двумя моментами:
1. Предикторы считаются неважными, если они не присутствуют ни в одном разделении в дереве отсеивания.
2. Половина точек тренировочного набора, не включенная для создания дерева отсеивания, используется для оценки частоты ошибок дерева. Частота ошибок последовательно оценивается без учета одного из предикторов и сравнивается с частотой ошибок, когда используются все предикторы. Если частота ошибок улучшается без предиктора, то он считается несущественным и временно исключается.
После формирования условного списка неинформативных предикторов модель С5.0 строит дерево заново. Если частота ошибок ухудшилась, то процесс отсеивания приостанавливается и предикторы в период приостановки отсева не исключаются.
440 Глава 14. Деревья классификации и модели на базе правил
После выявления важных предикторов (если их удалось выявить) условный процесс тренировки модели С5.0 используется с полным тренировочным набором, но только с теми предикторами, которые пережили процесс отсеивания.
Например, С5.0 разбивает данные грантов на приблизительно равные части, строя дерево на основе одной половины данных и используя вторую половину для оценки частоты ошибок на уровне приблизительно 14,6 %. После исключения предиктора, связанного с количеством студентов-исследователей, частота ошибок слегка уменьшилась до 14,2 %, в связи с чем предиктор был исключен из дальнейшего рассмотрения.
И наоборот, при исключении категории суммы контракта частота ошибок поднялась до 24,8 %. Соответственно, этот предиктор сохранен для последующих моделей С5.0.
Данные грантов
Для данных грантов были оценены несколько разновидностей модели С5.0:
О Модели на базе одиночных деревьев и правил.
О Деревья и правила с усилением (до 100 итераций).
О Все предикторы и отсеянное множество.
О Два ранее описанных метода для обработки категорийных предикторов.
Для последнего множества условий модели различий почти не отмечено. На рис. 14.13 показаны ROC-кривые для двух методов кодирования категорийных предикторов.
Как видим, кривые практически идентичны. В верхней части рис. 14.13 показан профиль настройки для моделей С5.0 со сгруппированными категориями. Применение алгоритма отсеивания привело к небольшому снижению эффективности, но, скорее всего, в пределах допустимого. Усиление имело очевидный положительный эффект для этих моделей, но после приблизительно 50 итераций последующие улучшения стали минимальными. Хотя простые правила работали не так хорошо, как одиночные деревья, усиление продемонстрировало наибольшее воздействие для моделей на базе правил, которые в итоге имели лучшую эффективность. Оптимальная площадь под ROC-кривой для рассматриваемой модели составила 0,942 (лучший показатель среди моделей).
Подавляющее большинство предикторов использовалось редко (99 % предикторов использовались менее чем в 0,71 % правил). В десятку самых часто используемых предикторов вошли: категория суммы контракта (9,2 %), количество неудачных грантов от старших аналитиков (8,3 %), количество успешных грантов от старших аналитиков (7,1 %), числовой день года (6,3 %), код категории (6 %), месяц (3,5 %),
14.6. Модель С5.0 441
Тип модели
правила о
дерево х
0 20 40 60 80 100
0,94
0,92
0,90
0,88
см о" о
о"
0,0 0,2
0,4 0,6 0,8
1 — специфичность
1,0
Рис. 14.13. Наверху: профиль параметров настройки для модели CS5.0
с использованием сгруппированных кодировок. Внизу: ROC-кривые для моделей CS5.0 с усилением. Версии модели со сгруппированными и независимыми предикторами почти идентичны: площадь под ROC-кривой равна 0,942
442 Глава 14. Деревья классификации и модели на базе правил день недели (3,1 %), код спонсора (2,8 %), количество внешних старших аналитиков (1,1 %) и количество статей в журналах категории С от старших аналитиков (0,9 %). Напомним, предикторы могут ранжироваться по значениям важности, вычисляемым как накапливаемый процент точек, покрываемых предиктором. При усилении этот показатель менее информативен, потому что при первом разделении предиктор имеет 100-процентную важность. В данной модели, в которой использовалось значительное число итераций усиления, у 40 % показатель важности был равен абсолютному. Модель использовала только 357 предикторов (24 %).
14.7. Сравнение двух кодировок категорийных предикторов
Рассмотренные в рамках этой главы модели использовали два метода кодирования категорийных предикторов. Так, на рис. 14.14 показаны результаты контрольного набора для каждой модели и метода.
В общем случае особых различий в площади под ROC-кривой для двух кодировок не наблюдалось. Для J48 с отдельными бинарными фиктивными переменными
Сгруппированные категории о Независимые категории х
0,80 0,85 0,90 0,95
CART
J48
PART
Дерево с бэггингом
Случайный лес
Дерево с усилением
С5.0
0,80 0,85 0,90 0,95 0,80 0,85 0,90 0,95
Рис. 14.14. Влияние разных методов представления категорийных предикторов в моделях на базе деревьев и правил. «Сгруппированные» предикторы означают, что категории предиктора рассматриваются как связный набор, а «независимые» — что категории были преобразованы в независимые фиктивные переменные до моделирования
14.8. Вычисления 443
наблюдалась потеря чувствительности, тогда как у стохастического градиентного усиления и PART использование групповых переменных привело к потере специфичности. В некоторых случаях кодирование влияло на сложность модели. Для усиленных деревьев выбор кодировки приводил к заметному изменению профиля настройки (см. рис. 14.10 и 14.11). Эти результаты трудно экстраполировать на другие модели и наборы данных, поэтому, возможно, в фазе тренировки модели стоит опробовать обе кодировки.
14.8. Вычисления
В этом разделе используются функции из следующих пакетов: С50, caret, gbm, ipred, partykit, pROC, randomForest и RWeka. В этом разделе также используются объекты R, созданные в разделе 12.7, которые содержат данные заявок на получение грантов (например, кадр данных training).
Кроме наборов фиктивных переменных, описанных в разделе 12.7, несколько категорийных предикторов кодируются в виде факторов R: SponsorCode, ContractValueBand, CategoryCode и Weekday. В процессе обучения моделей с независимыми категориями для этих предикторов используется символьный вектор f ullSet. Когда категорийные предикторы используются как единый набор, альтернативный список предикторов хранится в векторе factorPredictors, содержащем факторные версии соответствующих данных. Кроме того, символьная строка f actorForm содержит формулу R, созданную с использованием всех предикторов из factorPredictors (эта строка довольно длинная). Значительная доля синтаксиса, представленного в этом разделе, напоминает другие аналогичные разделы — особенно предыдущий, связанный с деревьями регрессии. Здесь мы сосредоточимся на нюансах функций отдельных моделей и интерпретации их вывода. Также приводится код для воспроизведения анализа в этой главе.
Классификационные деревья
Существует целый ряд пакетов R для построения отдельных деревьев классификации. Основным среди них является пакет rpart. Как упоминалось при обсуждении регрессии, функция поддерживает только интерфейс формул для определения формы модели.
Данные грантов используют множество предикторов, и как упоминалось ранее, для моделирования классов сгруппированных категорий была создана формула R. Следующий синтаксис выполняет обучение модели CART по этим предикторам с нашей стратегией разделения данных:
> Library(rpart)
> cartModeL <- rpart(factorForm, data = training[pre2008,])
444 Глава 14. Деревья классификации и модели на базе правил
Этот фрагмент автоматически строит и усекает дерево с использованием внутренней процедуры перекрестной проверки. Один из важных аргументов классификации parms позволяет объявить некоторые модификации процесса тренировки модели — например априорные вероятности результата и тип разделения (коэффициент Джини или информационная статистика). Эти значения должны размещаться в списке1 (за подробностями обращайтесь к ?rpart). Кроме того, аргумент control может настраивать процедуру обучения в отношениях числовых методов (например, глубины дерева).
Выходные данные модели несколько отличаются от выходных данных деревьев регрессии. Для демонстрации мы сгенерируем уменьшенную модель с двумя предикторами:
> rpart(СLass ~ NumCI + Weekday, data = training[pre2008,])
n = 6633
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 6633 3200 unsuccessful (0.49 0.51)
2) Weekday=Sun 223 0 successful (1.00 0.00) *
3) Weekday=Fri,Mon,Sat,Thurs,Tues,Wed 6410 3000 unsuccessful (0.47 0.53)
6) Weekday=Mon,Thurs,Tues 2342 1000 successful (0.57 0.43) *
7) Weekday=Fri,Sat,Wed 4068 1700 unsuccessful (0.41 0.59) *
В этом выводе указывается переменная/значение разделения вместе с количеством точек данных, выделенных в ветвь (223 для второго узла в приведенных результатах). Также выводится мажоритарный класс (successful для узла 2) и прогнозируемые вероятности классов для точек данных с завершением в этом узле.
Синтаксис прогнозирования почти не отличается от других моделей в R. Функция predict по умолчанию генерирует вероятности для каждого класса. Конструкция predict (object, type = "class”) генерирует факторный вектор для класса-победителя. Реализация С4.5 в R находится в функции 348 пакета RWeka. Функция также получает формулу модели:
> Library(RWeka)
> J48(CLass ~ NumCI + Weekday, data - training[pre2008,])
348 pruned tree
Weekday = Fri: unsuccessful (1422.0/542.0)
Weekday = Mon: successful (1089.0/455.0)
Weekday = Sat
1 Пример аргументов этого типа встречается в разделе 16.9, где выполняется обучение rpart с использованием различных стоимостей для разных типов ошибок.
14.8. Вычисления 445
| NumCI <= 1: unsuccessful (1037.0/395.0)
| NumCI > 1
| | NumCI <= 3: unsuccessful (378.0/185.0)
| | NumCI > 3: successful (61.0/26.0)
Weekday = Sun: successful (223.0)
Weekday = Thurs
| NumCI <= 0: unsuccessful (47.0/21.0)
| NumCI > 0: successful (520.0/220.0)
Weekday = Tues
| NumCI <= 2
| | NumCI <= 0: unsuccessful (45.0/21.0)
| | NumCI > 0: successful (585.0/251.0)
| NumCI > 2: unsuccessful (56.0/22.0)
Weekday = Wed: unsuccessful (1170.0/521.0)
Number of Leaves : 12
Size of the tree : 18
Вспомните, что эта реализация С4.5 не пытается группировать категории перед усечением. Функция прогнозирования автоматически генерирует список победивших классов, а вероятности классов можно получить вызовом predict (object, type = "prob").
При визуализации деревьев CART или 348 функция plot из пакета partykit может строить подробные диаграммы. Объекты должны быть преобразованы к соответствующему классу вызовом функции as. party, за которым следует вызов plot.
Одиночное дерево С5.0 может быть построено с использованием пакета С50:
> Library(С50)
> C5tree <- C5.0(CLass ~ NumCI + Weekday, data = training[рге2008,])
> C5tree
Call:
C5.0.formula(formula = Class ~ NumCI + Weekday, data
= training[pre2008, ])
Classification Tree
Number of samples: 6633
Number of predictors: 2
Tree size: 2
Non-standard options: attempt to group attributes
> summary(C5tree)
Call:
C5.0.formula(formula = Class - NumCI + Weekday, data
= training[pre2008, ])
446 Глава 14. Деревья классификации и модели на базе правил
С5.0 [Release 2.07 GPL Edition] Thu Dec 6 13:53:14 2012
Class specified by attribute outcome’
Read 6633 cases (3 attributes) from undefined.data
Decision tree:
Weekday in Tues,Mon,Thurs,Sun: successful (2565/1010) Weekday in Fri,Wed,Sat: unsuccessful (4068/1678)
Evaluation on training data (6633 cases):
Decision Tree
Size Errors
2 2688(40.5%) «
(a) (b)
1555 1678
1010 2390
Attribute usage:
100.00% Weekday
Time: 0.0 secs
<-classified as
(a) : class successful
(b) : class unsuccessful
Учтите, что, в отличие от 348, эта функция может отделять значения дней недели из групп значений. Функция управления этой модели (C5.0Control) отключает эту возможность (subset = FALSE). Также доступны другие параметры, такие как отсеивание и показатель достоверности для разделения. В отличие от 348, функция прогнозирования по умолчанию производит классы, а с type = "prob" она производит вероятности.
Существуют обертки для этих моделей, использующие функцию train из пакета caret. Например, для обучения модели со сгруппированными категориями для CART используется следующий код:
> set.seed(476)
> rpartGrouped <- trainfx = training[,factorPredictors],
* у = trainingfCLass,
+ method = "rpart",
+ tuneLength = 30,
+ metric = "ROC",
+ trControL - ctrL)
14.8. Вычисления 447
Напомним, что объект Ctrl указывает, какие данные входят в контрольный набор и какие метрики эффективности следует вычислить (например, чувствительность, специфичность и площадь под ROC-кривой). Коды моделей для деревьев 148 и С5.0 равны 148 и С5.0Тгее соответственно. Основные различия между train и исходной функцией модели — унифицированный интерфейс к моделям и возможность настройки моделей с альтернативными метриками, такими как площадь под ROC-кривой.
Учтите, что rpart, С5.0 и 148 используют интерфейс формул не так, как большинство других функций. Обычно метод формул автоматически раскладывает все категорийные предикторы в набор бинарных фиктивных переменных. Эти функции учитывают категорийный характер данных и интерпретируют эти предикторы как сгруппированные наборы категорий (если только данные не были уже преобразованы в фиктивные переменные).
Функция train следует более распространенной в R схеме с созданием фиктивных переменных до моделирования. Это главная причина, по которой приведенный выше фрагмент не использует метод формул при вызове train.
Правила
Пакет RWeka содержит несколько моделей на базе правил. Функция PART создает модели на основании исследований Фрэнка и Уиттена (Frank and Witten, 1998). По синтаксису он аналогичен 148:
> PART(CLass ~ NumCI + Weekday, data = training[pre2008,])
PART decision list
Weekday = Fri: unsuccessful (1422.0/542.0)
Weekday = Sat AND
NumCI <= 1: unsuccessful (1037.0/395.0)
Weekday = Mon: successful (1089.0/455.0)
Weekday = Thurs AND
NumCI > 0: successful (520.0/220.0)
Weekday = Wed: unsuccessful (1170.0/521.0)
Weekday = Tues AND
NumCI <= 2 AND
NumCI > 0: successful (585.0/251.0)
Weekday = Sat AND
448 Глава 14. Деревья классификации и модели на базе правил
NumCI <= 3: unsuccessful (378.0/185.0)
Weekday = Sun: successful (223.0)
Weekday = Tues: unsuccessful (101.0/43.0)
Weekday = Sat: successful (61.0/26.0)
: unsuccessful (47.0/21.0)
Number of Rules : 11
Другие функции RWeka для правил можно найти на справочной странице ?Weka_ classifier_rules.
Правила С5.0 создаются при помощи функции С5.0, которая используется так же, как для деревьев, но с параметром rules = TRUE:
> CSruLes <- C5.0(CLass ~ NumCI + Weekday, data = training[pre2008,],
+ ruies = TRUE)
> C5rutes
Call:
C5.0.formula(formula = Class ~ NumCI + Weekday, data
= training[pre2008, ], rules = TRUE)
Rule-Based Model
Number of samples: 6633
Number of predictors: 2
Number of Rules: 2
Non-standard options: attempt to group attributes
> summary(C5ruLes)
Call:
C5.0.formula(formula = Class ~ NumCI + Weekday, data
= training[pre2008, ], rules = TRUE)
C5.0 [Release 2.07 GPL Edition] Thu Dec 6 13:53:14 2012
Class specified by attribute 'outcome’
Read 6633 cases (3 attributes) from undefined.data
Rules:
Rule 1: (2565/1010, lift 1.2)
14.8. Вычисления 449
Weekday in Tues, Mon, Thurs, Sun
-> class successful [0.606]
Rule 2: (4068/1678, lift 1.1)
Weekday in Fri, Wed, Sat
-> class unsuccessful [0.587] Default class: unsuccessful
Evaluation on training data (6633 cases): Rules
No Errors
2 2688(40.5%) «
(a)
(b)
<-classified as
1555
1010
1678
2390
(a) : class successful
(b) : class unsuccessful
Attribute
usage:
100.00% Weekday
Time: 0.0 secs
Прогнозирование использует тот же синтаксис, что и прежде. Показатели важности переменных для деревьев С5.0 и правил вычисляются функцией C5imp или функцией varlmp из пакета caret.
При работе с функцией train доступны коды моделей С5.©Rules и PART.
Другие пакеты для работы с одиночными деревьями — party (деревья условного вывода), tree (деревья CART), oblique.tree (наклонные деревья), partDSA (для модели Молинаро и др. (Molinaro et al., 2010)) и evtree (деревья, разработанные с использованием генетического алгоритма).
Другой класс методов разделения, который здесь не рассматривается, называется логической регрессией (Ruczinski et al., 2003); он реализован в нескольких пакетах, включая LogicReg.
Деревья с бэггингом
Основной пакет для работы с деревьями с бэггингом — ipred. Функция bagging создает бэггинг-версии деревьев rpart с использованием метода формул (другая функция ipredbagg использует другой метод). Синтаксис выглядит знакомо:
> bagging(CLass ~ Weekday + NumCI, data = training[pre2008j])
450 Глава 14. Деревья классификации и модели на базе правил
Аргумент nbagg управляет количеством деревьев в ансамбле (25 по умолчанию). По умолчанию стандартный метод predict определяет класс-победитель, а параметр type ="prob” производит вероятности.
Другая функция из пакета caret, которая называется bag, создает более общие модели (то есть другие модели, кроме деревьев).
Случайный лес
Версия исходной программы случайных лесов, портированная для R, содержится в пакете randomForest. Его базовый синтаксис идентичен синтаксису дерева регрессии, показанному на с. 248. Значение по умолчанию mtry~ отличается от используемого при регрессии. Один из параметров, cutoff, предназначен только для классификации; он управляет порогом(-ами) отсечения при голосовании для определения класса-победителя в ансамбле деревьев. Этот параметр также доступен при использовании функции predict для случайных лесов.
Модель поддерживает синтаксис формул и матричный синтаксис. В обоих случаях любой категорийный предиктор, закодированный в факторных переменных R, интерпретируется как группа. Синтаксис predict по умолчанию генерирует класс- победитель, но аргумент type позволяет прогнозировать и другие величины, например вероятности классов (type = "prob") или фактические счетчики голосования (type = "votes").
Базовый пример для данных грантов с выходными данными:
> Library(randomForest)
> randomForest(CLass - NumCI + Weekday, data = training[pre2008J])
Call:
randomForest(formula = Class ~ NumCI + Weekday, data = training[pre2008, ]) Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
00B estimate of error rate: 40.06%
Confusion matrix:
successful unsuccessful class.error
successful 1455 1778 0.5499536
unsuccessful 879 2521 0.2585294
Так как включены только два предиктора, при каждом разделении случайно выбирается только один предиктор.
Функция выводит out-of-bag оценку ошибок, а также аналогичную матрицу несоответствий. Out-of-bag оценки чувствительности и частота ложноположительных заключений (то есть 1 — специфичность) приведены в столбце class.error.
14.8. Вычисления 451
Код модели для настройки модели случайных лесов функцией train равен ”rf”. Также для работы со случайными лесами используются функции cforest (из пакета party), obliqueRF (леса с наклонными деревьями из пакета obliqueRF), rFerns (для модели случайного папоротника (Ozuysal et al., 2010) из пакета rFerns) и RRF (регуляризированные модели случайных лесов из пакета RRF).
Деревья с усилением
Основной пакет для работы с усиленными деревьями в R, gbm, реализует стохастическое градиентное усиление. Основным различием между усилением в области регрессии и классификационных деревьев становится выбор распределения данных. Функция gbm поддерживает только задачи с двумя классами, и для них следует использовать параметр distribution = "bernoulli".
Другой вариант distribution = "adaboost" воспроизводит функцию потерь, используемую этой методологией.
Одно из затруднений, связанных с применением gbm для классификации, заключается в том, что функция ожидает, что результат кодируется в форме 0/1. Пример простой модели для данных грантов может выглядеть так:
> Library(gbm)
> forGBM <- training
> forGBM$CLass <- ifeLse(forGBM$CLass = "successfuL", 1, 0)
> gbmModeL <- gbm(CLass ~ NumCI + Weekday,
+ data = forGBM[pre2008,],
+ distribution = "bernouLLi",
+ interaction.depth = 9,
+ n.trees = 1400,
+ shrinkage = 0.01,
+ #4 По умолчанию функция выдает
## большой объем выходных данных.
+ verbose = FALSE)
Функция прогнозирования для этой модели не прогнозирует класс-победитель. Вызов predict(gbmModel, type = "response”) вычислит вероятность класса, закодированного как 1 (в нашем примере успешная заявка на получение гранта кодировалась в форме 1). Этот результат может быть преобразован в факторную переменную с классом-победителем:
> gbmPred <- predict(gbmModeL,
+ newdata - head(training[-pre2008,]),
+ type = "response",
+ 44 Количество деревьев должно быть
+ 44 задано явно.
452 Глава 14. Деревья классификации и модели на базе правил
* л.trees = 1400)
> gbmPred
[1] 0.5697346 0.5688882 0.5688882 0.5688882 0.5697346 0.5688882
> gbmCLass <- ifeLse(gbmPred > .5, "successfuL", "unsuccessful-")
> gbmCLass <- factorfgbmCLass, LeveLs = LeveLs(training$CLass))
> gbmCLass
[1] successful successful successful successful successful successful
Levels: successful unsuccessful
Обучение этой модели функцией train существенно упрощает процесс. Например, факторная переменная может использоваться как формат результата (train автоматически выполняет преобразование). При прогнозировании класса-победителя генерируется фактор. Если требуются вероятности классов, укажите параметр predict (object, type = "prob") (предиктивная функция train автоматически использует количество деревьев, которое было сочтено оптимальным в процессе настройки модели).
Исходный алгоритм AdaBoost доступен в пакете ada. Еще одна функция для усиления деревьев — blackboost из пакета mboost. Этот пакет также содержит функции для усиления моделей других типов (например, логистической регрессии), как и пакет bst.
Для тренировки усиленных версий С5.0 используется аргумент trials (со значениями от 1 до 100).
> Library(C50)
> C5Boost <- C5.0(CLass ~ NumCI + Weekday, data ~ training[pre2008,],
+ triaLs = 10)
> C5Boost
Call:
C5.0.formula(formula = Class ~ NumCI + Weekday, data
= training[pre2008, ], trials = 10)
Classification Tree
Number of samples: 6633
Number of predictors: 2
Number of boosting iterations: 10 requested; 6 used due to early stopping
Average tree size: 2.5
Non-standard options: attempt to group attributes
По умолчанию алгоритм содержит внутренние проверки, которые оценивают эффективность усиления и прекращают тренировку модели в том случае, если она стала неэффективной (обратите внимание на сообщение о том, что изначально было запрошено 10 итераций, но из-за преждевременной остановки использовано только 6). Эту возможность можно отключить при помощи С5.©Control (earlyStopping = FALSE).
Упражнения 453
Эти модели могут настраиваться функцией train, для чего параметру method присваиваются значения gbm, ada или С5.0.
Упражнения
14.1. Важность переменных для бэггинга, случайных лесов и усиления была вычислена как для независимых категорий, так и для факторных предикторов модели. Шестнадцать важнейших предикторов для каждого метода и набора предикторов представлены на рис. 14.15.
А. Для каждого метода моделирования какие факторы являются общими между моделями независимых категорий и факторов?
Б. Сравните эти результаты с наиболее продуктивными предикторами из результатов модели PART, рассмотренных в разделе 14.2.
14.2. Для данных ухода клиентов, описанных в упражнении 12.3:
A. Выполните обучение нескольких базовых деревьев по данным тренировочного набора. Как следует представить код зоны — в виде независимых фиктивных переменных или сгруппированного набора значений?
Б. Улучшает ли бэггинг эффективность деревьев? А усиление?
B. Примените к данным модели на базе правил. Что можно сказать об их эффективности? Насколько разумно выглядят правила?
Г. Используйте диаграммы точности прогнозирования для сравнения моделей на базе деревьев или правил с лучшими методами из предыдущих глав.
14.3. В упражнении 12.1 подробно описан набор данных поражения печени. Основной научной целью было построение модели для прогнозирования степени поражения печени. Напомним, что модель случайных лесов может использоваться с деревьями CART или деревьями условного вывода. Запустите R и введите следующие команды для загрузки данных:
> Library(АррLiedPrediсtгveModeLing)
> data(hepatic)
А. Проведите обучение модели случайных лесов с использованием как деревьев CART, так и деревьев условного вывода, по химическим предикторам. Используйте в качестве метрики каппа-статистику:
> Library(caret)
> set.seed(714)
> indx <- createFoLdsfinjury, returnTrain = TRUE)
> ctrL <- trainControL(method - "cv", index = indx)
454 Глава 14. Деревья классификации и модели на базе правил
Риа 14.15. Сравнение важности переменных для ансамблевых методов бэггинга, случайных лесов и усиления для предикторов независимых и сгруппированных категорий
Упражнения 455
> mtryVaLues <- с(5, 10, 25, 50, 75, 100)
> rfCART <- train(chem, injury,
+ method = "rf",
+ metric = "Kappa",
+ ntree = 1000,
+ tuneGrid = data.frame(.mtry - mtryVaLues))
> rfcForest <- train(chem, injury,
* method = "cforest",
+ metric = "Kappa",
+ tuneGrid = data.frame(.mtry = mtryVaLues))
Какая модель обладает лучшей эффективностью, какие параметры настройки ей соответствуют?
Б. Используйте следующий синтаксис для определения времени вычисления для каждой модели:
> rfCART$times$everything
> rfcForest$times$everything
Какая модель просчитывается быстрее? Какую модель вы предпочтете с учетом отношения между эффективностью и временем выполнения?
В. Используйте следующий синтаксис для определения важности переменных для старших 10 предикторов каждой модели:
> varlmp(rfCART)
> varlmp(rfcForest)
Существуют ли заметные различия в важности переменных между верхними 10 предикторами каждой модели? Приведите возможные обоснования таких различий.
Сравнительный анализ моделей для заявок на получение грантов
В трех предыдущих главах рассматривались различные стратегии и методы прогнозирования успеха заявок на финансирование грантов. Представляется оправданным сравнить несколько разных моделей для каждого набора данных, поскольку трудно заранее сколько-нибудь достоверно определить, какая именно модель покажет наилучшие результаты.
Вспомним в этой связи, что в процессе разделения данных гранты до 2008 года использовались для настройки модели, а после определения итоговых параметров весь тренировочный набор (который содержал часть грантов 2008 года) использовался для обучения модели. Тестовый набор из 518 точек, еще не использованный при анализе, состоял исключительно из грантов 2008 года. Ожидаемая эффективность тестового набора, скорее всего, окажется лучше результатов, сгенерированных в процессе настройки, потому что итоговые параметры модели базировались лишь на части информации за 2008 год (см. в этой связи раздел 12.1). На рис. 15.1 показана площадь под ROC-кривой для итоговых моделей с двумя наборами данных, рассмотренных в трех предыдущих главах.
Связь между оценками достаточно высока (0,96), хотя контрольный набор настройки более пессимистичен по сравнению с тестовым (последний на 0,029 единицы больше, что объясняется формированием прогноза на основе информации 2008 года), что позволяет надеяться на более релевантные результаты прогнозирования на основе актуальных данных о грантах. Подчеркнем, что при всех различиях между эффективностью контрольного и тестового набора показатели эффективности модели почти не зависят от процесса разделения данных (табл. 15.1).
На рис. 15.2 показана площадь под ROC-кривыми для каждой модели, оцениваемая по грантам тестового набора. Полосы представляют 95-процентные доверительные интервалы, полученные, согласно Робину (Robin et al., 2011), с помощью бутстрэпа.
Сравнительный анализ моделей для заявок на получение грантов 457
0,95
0,90
0,85
0,85 0,90 0,95
Тестовый набор 2008 года
Рис. 15.1. Сравнение площади под ROC-кривой для контрольных данных 2008 года и площади, полученной при оценке тестового набора. Каждая точка представляет модель, оцениваемую в главах 12-14
Оценки неопределенности, во-первых, упрощают понимание преимуществ и недостатков каждой модели. Доверительный интервал отражает численную оценку дисперсии модели и специфику данных. Например, усеченные тестовые наборы, шум или неправильная маркировка в реакции (как это представлено далее на рис. 20.2) могут приводить к расширению интервалов. Таким образом, доверительные интервалы помогают оценить вес доступной аналитической информации при сравнении моделей. Во-вторых, доверительные интервалы облегчают компромиссы между моделями. Так, значительное взаимное перекрытие доверительных интервалов указывает на их статистическую эквивалентность, что может рассматриваться в качестве обоснования при выборе в пользу менее сложной или, напротив, более интерпретируемой модели.
Напомним также, что относительная эффективность моделей для этих данных не может экстраполироваться на другие ситуации (раздел 14.7), в связи с чем модель с низкими оценками для этих данных может, к примеру, оказаться эффективнее других моделей, использующих иные наборы данных.
458 Глава 15. Сравнительный анализ моделей для заявок на получение грантов
Таблица 15.1. Ранжированная эффективность моделей на примере контрольных данных 2008 года (тренировочный набор) и тестового набора 2008 года
Модель
Контрольный набор
Тестовый набор
С5.0
1
1
Дерево с усилением
2
4
Дерево с бэггингом
4
3
Случайный лес
5
2
FDA
3
6
Нейросети
6
5
Разреженная модель FDA
8
7
glmnet
7
79
SVM (полиномиальная)
9
8
CART
12
10
LDA
10
12
MDA
И
И
Логистическая регрессия
14
14
Ближайшие сжатые центроиды
13
15
PLS
15
13
J48
16
16
PART
17
17
Наивный байесовский классификатор
18
18
KNN
19
19
Какие предикторы наиболее значимы1? Во многих моделях на результат прогнозирования повлияли многолетние данные об успехах и неудачах старших аналитиков (в соответствии с принципом «успех влечет за собой новый успех»). В то же время имеются основания полагать, что многие из этих данных неполны, однако неизвестные значения категории суммы контракта и кода спонсора используются многими моделями. Остается также не до конца проясненной выраженная связь
1 Как упоминалось ранее, более формальные статистические методы намного лучше справляются с генерированием логически обоснованных заключений относительно важности предикторов, чем метрики важности переменных.
Сравнительный анализ моделей для заявок на получение грантов 459
«сезонного эффекта», в соответствии с которым заявки, поданные в конце декабря и начале января (см. табл. 12.1, рис. 12.3 и 13.8), с большей вероятностью приводили к успеху. Напротив, гранты с кодом категории ЗОВ ассоциировались со снижением вероятности успеха. Учет этой тенденции позволяет повысить шансы на успешное рассмотрение заявок.
С5.0
Случайный лес
Дерево с бэггингом
Дерево с усилением
Нейросети
FDA
Разреженная модель LDA
Модель SVM (полиномиальная)
glmnet
CART
MDA LDA PLS Логистическая регрессия Ближайшие сжатые центроиды
J48
PART
Наивная модель Байеса
KNN
0,80 0,85 0,90 0,95
Площадь под ROC-кривой для тестового набора
Рис. 15.2. Диаграмма площади под ROC-кривой тестового набора и их 95-процентные доверительные интервалы
Решение проблемы дисбаланса классов
При моделировании дискретных классов их относительные частоты могут оказывать значительное влияние на эффективность модели. Дисбаланс возникает, если один или несколько классов встречаются в тренировочных данных очень редко по сравнению с другими классами. Присутствие дисбаланса следует учитывать при определении особенностей моделирования. Вот несколько ситуаций, в которых часто возникает дисбаланс классов:
О Интернет-реклама', реклама отображается на веб-страницах, соответствующим образом воздействуя на пользователя. Процент переходов (click through rate) — это количество щелчков по рекламным текстам или изображениям, разделенное на общее количество показов, обычно характеризуемое довольно низким показателем. Так, в работе Ричардсона (Richardson et al., 2007) показатель состоявшихся переходов — ниже 2,4 %.
О Фармацевтические исследования', высокопроизводительный скрининг — это методология экспериментирования, при которой быстро оценивается биологическая активность десятков тысяч молекул. Обычно лишь малый процент молекул проявляет высокую активность; следовательно, концентрация веществ, представляющих интерес, низка.
О Страховые претензии', у Арти (Artis et al., 2002) анализируются страховые требования о возмещении ущерба вследствие автомобильных аварий (в Испании за период с 1993 по 1996 год). В результате мошенническими считаются до 22 % претензий.
В этой главе обсуждается влияние дисбаланса классов на показатели эффективности, методологии последующей обработки прогнозов моделей и предиктивное моделирование, позволяющее устранить проблему в ходе тренировки. Начнем с еще одного примера, характеризующего разные подходы к решению проблемы дисбаланса классов.
16.1. Практикум: прогнозирование политики страхования 461
16.1. Практикум: прогнозирование политики страхования
Для демонстрации методов преодоления дисбаланса классов используется набор данных, сгенерированный исследовательской сетью CoIL (Computational Intelligence and Learning). Конкурс 2000 CoIL Challenge предлагал спрогнозировать, стоит ли клиенту приобретать комбинированную страховку для фургонов или жилых трейлеров (caravan insurance)1. Соответствующий комплексный анализ представлен в работе ван дер Путтена и ван Сомерена (Van Der Putten and Van Someren, 2004), мы же сосредоточим внимание именно на эффекте дисбаланса классов.
Как следует из представленных данных, только 6 % клиентов приобрели соответствующую страховку.
Предикторы набора данных состояли из следующих категорий:
О Обозначение подтипа клиента — например, «традиционные семьи» или «зажиточные молодые семьи». Здесь встречаются 39 уникальных значений, хотя многие подтипы охватывают менее 5 % клиентов.
О Демографические факторы: религия, образование, социальный класс, доход и еще 38 показателей. Значения предикторов определялись по данным, «привязанным» к почтовому индексу клиента (zip code), так что у клиентов с одинаковыми почтовыми индексами эти атрибуты будут иметь одинаковые значения2.
О Информация о ранее оформленных страховых продуктах — например, количество различных страховых полисов.
Всего применено 85 предикторов. Многие категорийные предикторы имели десять и более уровней, а счетные предикторы обычно были разреженными (то есть количество ненулевых значений было относительно малым).
При сравнении различных методологий применена расслоенная случайная выборка (где слои определялись переменной реакцией) для создания трех разных наборов данных:
О Тренировочный набор клиентов (п = 6877), используемый для оценки параметров модели, настройки моделей и т. д.
1 Мы благодарны Питеру ван дер Путтену (Peter van der Putten) за разрешение использовать эти данные.
2 Назначение всем клиентам с одним почтовым индексом одинаковых значений предикторов подразумевает, что в предикторах присутствует невидимый шум. Последствия шума в наборе предикторов обсуждаются в разделе 20.3.
462 Глава 16. Решение проблемы дисбаланса классов
О Усеченный оценочный набор клиентов (п = 983), используемый для разработки методов последующей обработки (например, альтернативных порогов отсечения вероятностей).
О Тестовый набор клиентов (п - 1962), используемый исключительно для итоговых оценок моделей.
Доля клиентов с комбинированной страховкой для фургонов или жилых прицепов приблизительно одинакова для всех трех наборов данных (6, 5,9 и 6 % соответственно).
16.2. Эффект дисбаланса классов
Для моделирования данных использовались три предиктивных модели: случайный лес, модель гибкого дискриминантного анализа FDA (с шарнирными функциями MARS) и модель логистической регрессии. Для настройки моделей использовался метод десятикратной перекрестной проверки; каждая контрольная выборка содержала примерно 687 клиентов. Для выбора оптимальной модели оптимизировалась площадь под ROC-кривой1. Модель случайного леса включает 1500 деревьев и настраивалась по пяти значениям параметра т(гу (раздел 8.5); итоговая модель имела оптимальное значение т[гу, равное 126. Модель FDA использовала признаки первой степени и настраивалась по 25 значениям количества сохраняемых составляющих.
Процесс повторной выборки определил, что наиболее подходящей является модель с 13 составляющими. Логистическая регрессия использовала простую аддитивную модель (то есть без взаимодействий и нелинейных составляющих) с сокращенным набором предикторов (для повышения стабильности работы модели многие предикторы с почти нулевой дисперсией были удалены).
Оценены следующие показатели эффективности:
О общая точность;
О каппа-статистика;
О площадь под ROC-кривой;
О чувствительность;
О специфичность (в качестве «события, представляющего интерес», обозначено приобретение страхового полиса).
1 Здесь приведена краткая сводка результатов процесса настройки. Более полная информация о процессе содержится в каталоге Chapters пакета AppliedPredictiveModeling и в разделе «Вычисления» этой главы.
16.2. Эффект дисбаланса классов 463
Все модели прогнозировали точки из оценочного набора данных со сходными результатами (табл. 16.1). В каждой модели все закономерности, полезные для прогнозирования результата, уходили на второй план, «укрываясь» за большим процентом клиентов без комбинированной страховки.
Таблица 16.1. Результаты для трех предиктивных моделей с использованием оценочного набора
Модель
Точность
Каппа
Чувствительность
Специфичность
Площадь под ROC-кривой
Случайный лес
93,5
0,091
6,78
99,0
0,757
FDA (MARS)
93,8
0,024
1,69
99,7
0,754
Логистическая регрессия
93,9
0,027
1,69
99,8
0,727
В сущности, ни одна из моделей не спрогнозировала наличие страховки более чем у 13 клиентов из оценочного набора, несмотря на то что в оценочном наборе страховка была у 59 клиентов. Таким образом, модели добиваются хорошей специфичности (так как почти у всех клиентов прогнозируются отсутствие страховки) при плохой чувствительности. Дисбаланс заметно влияет и на прогнозируемые вероятности классов. Так, в модели случайного леса вероятность наличия страховки для 82 % клиентов прогнозируется на уровне 10 % и менее. Прогнозируемое распределение вероятностей с сильным смещением влево наблюдается и в двух других моделях. На рис. 16.1 изображены диаграммы точности прогнозов и ROC-кривые для оценочного набора.
Диаграммы точности прогнозирования сходны и могут использоваться для определения того, сколько человек нужно опросить для отражения конкретного процента тех, кто может приобрести страховой полис. Например, чтобы получить информацию о 60 % обладателей полиса с использованием модели случайного леса, необходимо протестировать около 30 % выборки. ROC-кривые демонстрируют существенное перекрытие, и в этом смысле модели между собой не различаются.
На рисунке (рис. 16.1) существует сильное сходство между приростом и ROC- кривыми. Если классы более сбалансированы, то диаграммы точности прогнозов и ROC-кривые не настолько похожи. Сходство обусловлено дисбалансом классов, что следует рассматривать в качестве исключения, а не правила. При большей сбалансированности классов кривые вряд ли будут проявлять сходные закономерности. Например, максимальная площадь под кривой прироста ограничивается частотой события в данных (серая фоновая область на диаграмме точности прогнозов), тогда как у ROC-кривой такого ограничения не наблюдается. Другие стратегии преодоления дисбаланса классов рассмотрены ниже. Так, в следующем
464 Глава 16. Решение проблемы дисбаланса классов
00 о
§
со о
о
CXI o'
о
о~‘
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
100
’1 80
з ю
8 к 60
5
от 40
20
0
0 20 40 60 80 100
Процент протестированных клиентов
Рис. 16.1. Наверху: ROC-кривые оценочного набора для каждой из трех базовых моделей. Внизу: соответствующие диаграммы точности прогнозов разделе обсуждаются возможности использования настройки модели для повышения чувствительности миноритарного класса. В разделе 16.4 показано, как на основании данных вычислить альтернативные пороги отсечения вероятностей, чтобы снизить частоту ошибок для миноритарного класса, что равносильно по-
16.4. Альтернативные пороги отсечения 465
следующей обработке прогнозов модели для переопределения прогнозов классов. Также будут рассмотрены модификации весов и априорных вероятностей, аспекты изменения тренировочных данных для преодоления дисбаланса классов до тренировки модели. В разделе 16.6 рассмотрены вопросы изменения процесса тренировки для некоторых моделей, с тем чтобы вывести на первый план точность модели для менее частых классов.
16.3. Настройка модели
Простейший подход к преодолению отрицательных эффектов дисбалансов классов основан на настройке модели для максимизации точности миноритарных классов. Для максимизации чувствительности прогнозирования страховки при настройке модели можно в известной мере пожертвовать чувствительностью процесса тренировки, с тем чтобы повысить выявляемость данных в составе тренировочного набора, не несущих информации о наличии страховки. Модель случайного леса, настроенная для этих данных, не демонстрировала осмысленной тенденции в чувствительности по параметру настройки.
В модели FDA такая тенденция проявляется: с ростом количества составляющих модели чувствительность возрастает от нулевой для очень простых моделей до 5,4 % при сохранении 16 составляющих. Это незначительное улучшение чувствительности не приводит к снижению специфичности. Если учесть, что повышение чувствительности недостаточно велико, такой подход к решению задачи неэффективен для этого конкретного набора данных (см. также раздел 16.8).
16.4. Альтернативные пороги отсечения
Если существуют только две возможные категории результата, то повышения точности прогнозирования точек данных миноритарного класса можно добиться посредством определения альтернативных порогов отсечения для прогнозируемых вероятностей, которые фактически изменяют определение прогнозируемого события. Простейший подход основан на использовании ROC-кривой, вычисляющей чувствительность и специфичность по континууму порогов отсечения, что позволяет определить подходящий баланс между чувствительностью и специфичностью. На рис. 16.2 изображена ROC-кривая для модели случайного леса, основанной на оценочном наборе.
На кривой обозначено несколько порогов отсечения; очевидно, что уменьшение порога отсечения для вероятности реакции повышает чувствительность (за счет специфичности). Возможны ситуации, в которых компромисс «чувствительность/ специфичность» может быть достигнут без значительного ущерба для точности мажоритарного класса (в контексте решаемой задачи).
466 Глава 16. Решение проблемы дисбаланса классов
О
со о
J) (О
X -О
>ч
ZT
СМ о" о о“
0,0 0,2 0,4 0,6 0,8 1,0
1 — специфичность
Рис. 16.2. ROC-кривая случайного леса для прогнозирования классов, использующих оценочный набор. Число слева представляет порог отсечения вероятности, а числа в скобках — специфичность и чувствительность соответственно. Используются несколько возможных порогов отсечения вероятности, включая порог, геометрически ближайший к идеальной модели (0,064)
Существует несколько методов для определения нового порога отсечения. Во- первых, если существует конкретное целевое значение, которое должно выполняться для чувствительности или специфичности, то можно попытаться найти эту точку на ROC-кривой и таким образом определить соответствующий порог отсечения. Во-вторых, можно попытаться найти на ROC-кривой точку, ближайшую (то есть находящуюся на кратчайшем расстоянии) к идеальной модели (со стопроцентной чувствительностью и стопроцентной специфичностью), то есть к левому верхнему углу диаграммы. На рис. 16.2 ближайшее к идеальной модели значение порога отсечения — 0,064.
Иной подход к определению порога отсечения использует J-индекс Юдена (см. раздел 11.2), учитывающий доли правильно предсказанных точек как для групп событий, так и для несобытий. Этот индекс может вычисляться для каждого порога отсечения, использованного для создания ROC-кривой.
Порог отсечения, связанный с наибольшим значением индекса Юдена, может демонстрировать повышение эффективности относительно значения, равного по умолчанию 50 %. Для ROC-кривой случайного леса порог отсечения, максимизирующий индекс Юдена (0,021), близок к точке, ближайшей к оптимальной модели.
16.4. Альтернативные пороги отсечения 467
При использовании оценочного набора предиктивная чувствительность для нового порога отсечения 0,064 равна 64,4 % — это существенно лучше по сравнению со значением, сгенерированным с порогом отсечения по умолчанию. В результате оценка специфичности уменьшается с 99 до 75,9 %. Приемлемость полученного результата определяется в контексте задачи, решаемой моделью.
В нашем анализе альтернативный порог отсечения модели не был выведен на основании тренировочного или тестового набора. Очень важно (особенно для малых размеров выборки) использовать независимый набор данных для вывода порога отсечения. Если используются прогнозы тренировочного набора, то, скорее всего, в вероятностях класса существует большое оптимистическое смещение, ведущее к неточным оценкам чувствительности и специфичности. Отметим, что тестовый набор перестает быть несмещенным источником для оценки эффективности модели. Например, Эвальд (Ewald, 2006) обнаружил посредством моделирования, что апостериорный вывод порогов отсечения может преувеличивать эффективность тестового набора.
Таблица 16.2 содержит матрицы несоответствий, выведенные из тестового набора, для порогов отсечения (по умолчанию и альтернативного).
Таблица 16.2. Матрицы несоответствий для тестового набора для случайных лесов с использованием порога отсечения по умолчанию и альтернативного порога отсечения
Порог отсечения 0,50
Порог отсечения 0,064
страховка
нет страховки
страховка
нет страховки
Страховка
И
19
71
441
Нет страховки
105
1827
45
1405
Прогнозы с 50-процентным порогом отсечения повторяют значения эффективности, полученные посредством перекрестной проверки (чувствительность — 9,5 %, специфичность — 99 %). Для нового порога отсечения получена чувствительность тестового набора 61,2 %, тогда как специфичность была равна 76,1 %. Оцениваемая разница в чувствительности между двумя наборами данных (64,4 и 61,2 %), скорее всего, обусловлена высокой неопределенностью показателя (что само по себе является результатом низкой частоты событий). Эти два значения могут быть эквивалентными с учетом экспериментального шума. Повторимся: этот порог был получен в условиях, максимально приближенных к оптимальной модели.
Стоит заметить, что основа модели, ее параметры не изменились. Изменение порога отсечения для повышения чувствительности не влияет на общую предиктивную эффективность модели. Главный смысл альтернативного порога отсечения — принятие компромиссных решений между конкретными типами
468 Глава 16. Решение проблемы дисбаланса классов ошибок. Например, в матрице несоответствий альтернативные пороги отсечения могут только перемещать точки данных вверх и вниз по строкам матрицы (в отличие от перемещения из недиагональных ячеек на диагонали). Другими словами, использование альтернативного порога не создает дополнительного разделения между классами.
Рисунок 16.2 и табл. 16.2 показывают, почему для многих задач классификации сравнение моделей на основе значений чувствительности и специфичности по умолчанию может искажать картину происходящего. Анализ ROC-кривой может приводить к улучшению этих показателей при нахождении более эффективного порога отсечения. Однако дисбаланс классов может усугубить ситуацию. Соответственно, показатели эффективности, не зависящие от порогов отсечения вероятности (например, площади под ROC-кривой) скорее будут свидетельствовать о наличии более выраженных отличий между моделями. Тем не менее некоторые предиктивные модели позволяют получить только дискретные прогнозы классов.
16.5. Корректировка априорных вероятностей
Ряд моделей, в том числе наивная модель Байеса и классификаторы с дискриминантным анализом, используют априорные вероятности. В общем случае эти модели формируют значения априорных вероятностей на основе тренировочных данных. Вайсс и Провост (Weiss and Provost, 2001а) предполагают, что априорные вероятности, отражающие естественный дисбаланс классов, будут ощутимо смещать прогнозы к мажоритарному классу. Решению проблемы дисбаланса классов может способствовать использование более сбалансированных априорных значений или сбалансированного тренировочного набора. Для данных страховки априорные вероятности составляют 6 и 94 % для наличия и отсутствия страховки соответственно. Прогнозируемая вероятность наличия страховки сильно смещена влево для всех трех моделей.
Корректировка априорных вероятностей может сдвинуть распределение вероятностей от малых значений. Например, новые априорные вероятности — 60 % для наличия страховки, 40 % для ее отсутствия в модели FDA — значительно повышают вероятность наличия страховки. С порогом отсечения по умолчанию прогнозы новой модели имеют чувствительность 71,2 % и специфичность 66,9 % для тестового набора.
Однако новые вероятности классов не изменяют ранжирование клиентов в тестовом наборе, и модель имеет такую же площадь под ROC-кривой, что и предыдущая модель FDA. Как видим, эта стратегия не изменяет модель, но допускает компромиссы между чувствительностью и специфичностью.
16.7. Методы выборки 469
16.6. Неравные веса
Во многих предиктивных моделях для классификации предусмотрена возможность использования весов, позволяющая придать любой отдельной точке данных большую значимость в фазе тренировки модели. Например, рассматривавшиеся ранее методы усиления применительно к деревьям классификации и регрессии способны создать последовательность моделей, каждая из которых применяет разные веса на каждой итерации.
Один из подходов к перебалансировке тренировочного набора основан на увеличении весов точек данных в миноритарных классах (Ting, 2002). Во многих моделях это может интерпретироваться как наличие идентичных точек данных с одинаковыми значениями предикторов. Например, логистическая регрессия может использовать веса подобным образом. Процедура решения проблемы с дисбалансом классов связана с методами выборки, рассматриваемыми в следующем разделе.
16.7. Методы выборки
При наличии априорной информации о дисбалансе классов один из простых методов сокращения его влияния на тренировку модели основан на выборе точек данных тренировочного набора, имеющих приблизительно одинаковые частоты ошибок в ходе начального сбора данных (например, см. Artis et al., 2002). По сути, вместо того чтобы решать проблему дисбаланса на уровне модели, можно попытаться сбалансировать частоты классов.
Этот подход устраняет фундаментальную проблему дисбаланса, преследующую тренировку модели. Тем не менее если выборка из тренировочного набора сбалансирована, то выборка из тестового набора должна отражать естественное состояние дел и дисбаланс для вычисления честных оценок будущей эффективности.
Если априорная выборка невозможна, то существуют апостериорные методы, помогающие компенсировать эффект дисбаланса во время тренировки модели. Два главных апостериорных метода — понижающая выборка и повышающая выборка. Повышающая выборка (up-sampling) — любой метод, моделирующий или подставляющий дополнительные точки данных для улучшения баланса между классами. Понижающая выборка — любой метод, сокращающий количество точек данных для улучшения баланса между классами.
Лин и Ли (Ling and Li, 1998) описывают один из методов повышающей выборки, при котором точки данных из миноритарных классов выбираются с заменой до тех пор, пока каждый класс не достигнет приблизительно одинакового числа. Для данных страховки тренировочный набор содержал 6466 клиентов без страховки и 411 застрахованных клиентов. Если сохранить исходные данные миноритарного класса, то добавление 6055 случайных точек данных (с заменой) доведет миноритарный
470 Глава 16. Решение проблемы дисбаланса классов класс до равной численности с мажоритарным. При этом некоторые точки данных миноритарного класса могут появляться в тренировочном наборе с достаточно высокой частотой, а каждая точка мажоритарного класса представлена в данных однократно. Этот метод очень похож на метод весов, описанный в предыдущем разделе. Понижающая выборка выбирает точки данных из мажоритарного класса, с тем чтобы последний имел приблизительно такой же размер, что и миноритарный класс. Существует несколько способов понижающей выборки.
Основной подход заключается в случайной выборке из мажоритарных классов, чтобы все классы имели приблизительно одинаковые размеры. Другой подход заключается во взятии выборки с возвратом по всем точкам, чтобы классы были сбалансированы в наборе выборки с возвратом. Преимущество такого подхода заключается в том, что выборка с возвратом может выполняться многократно для получения оценки дисперсии.
Одна из реализаций случайных лесов может выполнять встроенную понижающую выборку, управляя процессом формирования выборки с возвратом при помощи стратификационной переменной. Если класс используется в качестве стратификационной переменной, то будет создана выборка, размер которой приблизительно одинаков для всех классов. Эти версии тренировочного набора с внутренней понижающей выборкой затем используются для построения деревьев в ансамбле.
Метод SMOTE (Synthetic Minority Over-sampling TEchnique), описанный у Чавлы (Chawla et al., 2002), представляет собой процедуру выборки данных, использующую как повышающую, так и понижающую выборку в зависимости от класса, на основе трех параметров: величина повышающей выборки, величина понижающей выборки и количество соседей, которые используются для подстановки новых точек. Чтобы выполнить повышающую выборку для миноритарного класса, SMOTE синтезирует новые точки данных. Для этого точка данных случайным образом выбирается из миноритарного класса и определяются ее k ближайших соседей (KNN).
В работе Чавлы (Chawla et al., 2002) для анализа используются пять соседей, но это число может варьироваться. Новая синтетическая точка данных представляет собой случайную комбинацию предикторов случайно выбранной точки данных и ее соседей. Хотя алгоритм SMOTE добавляет новые точки данных в миноритарный класс посредством повышающей выборки, он также может выполнять случайную понижающую выборку из мажоритарного класса для балансировки тренировочного набора.
На рис. 16.3 представлен пример методов выборки с использованием смоделированного набора данных.
Исходные данные содержат 168 точек данных из первого класса и 32 из второго (отношение 5,2:1). Версия с понижающей выборкой сократила общий размер выборки до 64 точек, равномерно распределенных между классами. Данные повышающей выборки содержат 336 точек с 168 событиями. SMOTE-версия данных имеет
16.7. Методы выборки 471
Класс 1
-2-10 1 2
Класс 2
-2-10 1 2
СП
2
Q.
О
1
£
5
0
Q.
С
-1
-2
-2-1012 -2-1012
Предиктор А
Рис. 16.3. Слева направо: исходный смоделированный набор данных и реализации версии с пониженной выборкой, с повышенной выборкой и выборкой SMOTE, при которой выполняется выборка и/или подстановка
меньший дисбаланс (с отношением 1,3:1), возникающий из-за наличия 128 точек из класса 1 и 96 точек из класса 2. В основном новые синтетические точки данных очень похожи на другие точки из набора данных; пространство, охватывающее миноритарный класс, заполняется, вместо того чтобы расширяться.
Следует отметить, что при использовании модифицированных версий тренировочного набора оценки эффективности модели могут оказаться смещенными. Например, если к данным была применена повышающая выборка, то в результате процедуры повторной выборки одни и те же точки с некоторой вероятностью появятся как в выборке, использованной для построения модели, так и в контрольном наборе, что приведет к оптимистическим результатам. Несмотря на это, методы повторной выборки могут быть эффективными для настройки моделей.
В области эффективности процедур выборки для преодоления асимметричных распределений классов серьезные исследования проводились Вайссом и Провостом (Weiss and Provost, 2001b), группой Батисты (Batista et al., 2004), группой ван Хулсе (Van Hulse et al., 2007), Бюресом и Ван дер Поэлем (Burez and van den Poel, 2009), а также группой Джетракула (Jeatrakul et al., 2010). Эти и некоторые другие публикации показывают, что во многих случаях выборка может преодолеть проблемы, возникающие из-за дисбаланса, но среди применяемых методов сложно выбрать наиболее эффективный. Кроме того, многие методы моделирования по-разному реагируют на выборку, что только усложняет создание рекомендаций по выбору конкретной процедуры. Эти методы выборки были применены к модели случайного леса для данных страховки с использованием такого же процесса настройки, как у исходной модели. ROC-кривая и кривая точности прогнозов для оценочного набора для трех моделей случайных лесов показаны на рис. 16.4.
472 Глава 16. Решение проблемы дисбаланса классов
00 о
CD о'
o’
CXI О
О о"
0,0
0,2
0,4 0,6 0,8
1 - специфичность
1,0
100
80
Процент найденных событий
60
40
0 20 40 60 80 100
Процент оцененных клиентов
Рис. 16.4. Вверху: тестовый набор кривых ROC для трех моделей случайных лесов. Внизу: соответствующие участки lift
Числовые сводки моделей приведены в табл. 16.3.
В табл. 16.3 площадь под ROC-кривой вычисляется для оценочного и тестового наборов. При использовании оценочного набора новые пороги отсечения для каждой
16.8. Тренировка с учетом стоимости 473
модели получены выбором точки ROC-кривой, ближайшей к оптимальной модели. Значения чувствительности и специфичности в таблице получены в результате применения этих порогов к тестовому набору
Таблица 16.3. Сводка результатов для моделей случайных лесов с разными механизмами выборки
Метод
Оценка
Тест
ROC
ROC
чувствительность
специфичность
Исходный
0,757
0,738
64,4
75,9
Понижающая выборка
0,794
0,730
81,4
70,3
Понижающая выборка (внутренняя)
0,792
0,764
78,0
68,3
Повышающая выборка
0,755
0,739
71,2
68,1
SMOTE
0,767
0,747
78,0
67,7
Результаты показывают, что процедура повышающей выборки не обеспечивает реального улучшения площади под кривой. SMOTE демонстрирует улучшение для оценочного набора, но увеличение площади под ROC-кривой не наблюдается для большего набора данных. Простая понижающая выборка данных также имела ограниченное влияние на эффективность модели. Однако понижающая выборка внутри модели случайного леса дала эффективные площади под ROC-кривой для обоих наборов данных — возможно, вследствие использования независимых реализаций мажоритарного класса в каждом дереве. В целом эти результаты неоднозначны. Хотя улучшения были достаточно скромными, методы выборки обеспечивали лучшие компромиссы между чувствительностью и специфичностью (в отличие от изменения порогов отсечения или априорных вероятностей).
16.8. Тренировка с учетом стоимости
Вместо оптимизации типичных метрик эффективности (таких, как точность или чистота) некоторые модели могут оптимизировать стоимость или функцию потерь, которая применяет разные веса к конкретным типам ошибок. Например, может быть уместно полагать, что ошибочная классификация истинных событий (ложноотрицательные значения) обходится в X раз дороже, чем ошибочная классификация несобытий (ложноположительные значения).
Включение конкретных стоимостей в процессе тренировки модели может вызвать смещение модели к более редким классам. В отличие от использования
474 Глава 16. Решение проблемы дисбаланса классов альтернативных порогов отсечения, неравные стоимости могут влиять на параметры модели и, следовательно, теоретически способны по-настоящему улучшить классификатор.
У моделей SVM (модели опорных векторов) показатели стоимости могут связываться с конкретными классами (в отличие от конкретных типов ошибок). Вспомним, что эти модели управляют сложностью при помощи функции стоимости, увеличивающей штраф, если точки находятся с неверной стороны текущей границы классов. При дисбалансе классов неравные стоимости классов могут, согласно Веропоулусу (Veropoulos et al., 1999), скорректировать параметры для повышения снижения чувствительности модели к конкретным классам. Здесь налицо различие с подходом, согласно которому разные типы ошибок могут иметь разные дифференциальные стоимости. Для SVM всему классу можно назначить повышенную важность. Таким образом, можно засвидетельствовать сходство рассмотренных подходов применительно к каждому из двух классов.
Одно из последствий такого подхода заключается в том, что для модели не могут генерироваться вероятности классов — по крайней мере, в текущей реализации. Это не позволяет вычислить ROC-кривую, из-за чего придется использовать другой показатель эффективности. Для оценки влияния взвешенных классов будет использоваться каппа-статистика, чувствительность и специфичность.
Вернемся к результатам сравнения эффективности моделей SVM. При настройке модель SVM без весов требовала достаточно большого значения параметра стоимости SVM (256) для оптимизации каппа-статистики. В результате применения модели без весов к тестовому набору каппа-статистика была равна 0,121, с чувствительностью 15,5 % и специфичностью 95,7 %. Эффекты весов в диапазоне от 6 до 25 были оценены для тренировочного набора (с использованием повторной выборки) и оценочного набора. В выбранном диапазоне весов эффективность модели, основанная на каппа-статистике, чувствительности и специфичности, была очень похожей для двух наборов данных (рис. 16.5).
Меньшие веса оптимизируют каппа-статистику, веса от умеренных до высоких — чувствительность. По диаграмме разработчик модели может выбрать подходящие рабочие характеристики модели для текущей задачи (см. раздел 16.3).
Кроме того, многие модели деревьев классификации могут включать дифференциальные стоимости, в том числе CART и деревья С5.0. Потенциальная стоимость прогнозирования учитывает факторы, перечисленные в работе Джонсона и Уихерна (Johnson and Wichern, 2001):
О стоимость конкретной ошибки;
О вероятность совершения этой ошибки;
О априорная вероятность классов.
16.8. Тренировка с учетом стоимости 475
Каппа (ПП)
Каппа (оцен) о
Чувст (ПП)
Чувст (ПП)
Спец (оцен)
Спец (оцен) д
0,20
0,15
(0
с
S 0,10
0,05
0,00
10 15 20 25
Вес
1,0
0,8
0,6
0,4
0,2
0,0
10 15 20 25
Вес
Рис. 16.5. Результаты настройки для модели опорных векторов с весами классов, определенными с использованием перекрестной проверки и оценочного набора
Чтобы продемонстрировать, как учитываются стоимости, вернемся к концепциям и обозначениям из раздела 13.6. Пусть л, — априорная вероятность принадлежности точки данных к классу г, а Рф | г] — вероятность ошибочного прогнозирования класса i как класса/ Для задачи с двумя классами общая вероятность ошибочной классификации точки данных равна
Рг[2|1]Я, +Рг[1|2]л2.
На практике значения Рф | г] обычно неизвестны и вместо них используются оценки вероятностей г-го класса, /?•.
Для двух классов приведенная формула может быть преобразована в правило классификации точки данных к классу 1, если
£l>5_.
Pi Ъ
Это правило предполагает, что стоимости ошибочной классификации точки данных класса 1 к классу 2 или точки класса 2 к классу 1 равны. Уравнение легко расширяется для сценария с разными значениями стоимости.
Пусть C(j\i) — стоимость ошибочной классификации точки класса i к классу/ Тогда ожидаемая общая стоимость ошибочной классификации равна
Ожидаемая стоимость = С(211)Рг[211]я1 +С(112)Рг[112]л2.
476 Глава 16. Решение проблемы дисбаланса классов
Пересмотренная граница принятия решений для классификации точки данных к классу 1 равна
А ; ( Q112)У х?
Pi 1с(2|1)ДлД
Для равных априорных вероятностей первый класс прогнозируется, когда отношение вероятностей больше отношения стоимостей. Если/?! = 0,75 ир2 = 0,25, то класс 2 будет прогнозироваться для значений стоимости ошибочного прогнозирования класса выше 3,0. После того как задана стоимость ошибок всех типов, деревья CART могут интегрировать их в процесс тренировки. У Бреймана (Breiman et al., 1984) рассматривается использование обобщенного критерия Джини:
Gini* = С(112)р, (1 - Р1) + С(211)р2 (1 - р2)
= [С(1|2) + С(2|1)]Р1Р2,
где pt и р2 — наблюдаемые вероятности классов, полученные в результате разделения.
В этом случае две стоимости объединяются при использовании коэффициента Джини для определения разделений. Если классов больше двух, то возникает та же проблема. Соответственно, использование стоимостей с матрицей Джини сим- метризирует стоимости, то есть стоимости C(i \j) и C(j | i) усредняются при определении общих стоимостей разделения. У Бреймана (Breiman et al., 1984) также отмечено, что в некоторых случаях использование неравных стоимостей оказывается эквивалентно использованию модифицированных априорных вероятностей. В ряде примеров деревья, чувствительные к устойчивости, обычно оказываются меньше деревьев, построенных номинальной процедурой, поскольку в фазе роста дерево выбирает «жадные» разделения для получения точных прогнозов потенциально дорогостоящих ошибок, но не прикладывает таких усилий для достижения точности при остальных ошибках с меньшей стоимостью.
Для деревьев (и правил) прогнозируемые вероятности классов (или уровня достоверности) могут не соответствовать прогнозам дискретных классов при использовании неравных стоимостей. Итоговый прогноз класса для точки данных является функцией вероятности класса и структуры стоимостей.
Как отмечалось, вероятности классов в терминальных узлах могут ощутимо отдавать предпочтение одному классу, но при этом иметь большую ожидаемую стоимость. Из-за этого между уровнями достоверности и прогнозируемыми классами существует расхождение. Следовательно, простые вероятности классов (или уровни достоверности) не должны применяться в таких обстоятельствах.
Чтобы продемонстрировать тренировку модели с учетом стоимости, выполним обучение одиночных деревьев CART к данным с равными стоимостями, а также
16.8. Тренировка с учетом стоимости 477
с широким диапазоном значений стоимости (от 2,5 до 30) по аналогии с предыдущими моделями SVM с весами. На рис. 16.6 представлены результаты для тренировочного и оценочного наборов.
Каппа (ПП)
Чувст (ПП)
Спец (ПП)
Каппа (оцен)
Чувст(оцен)
Спец (оцен)
0,20
0,15
с
I 0,10
0,05
0,00
0 5 10 15 20 25 30
1,0
0,8
0,6
0,4
0,2
0,0
0 5 10 15 20 25 30
Стоимость
Стоимость
Рис. 16.6. Настройка результатов для моделей классификационных деревьев с учетом стоимости, определяемых с использованием перекрестной проверки и оценочного набора
Представленные на диаграммах тренды зашумлены (из-за нестабильности деревьев CART), в особенности для чувствительности, которая имеет наименьший размер выборки. Оценка чувствительности с повторной выборкой более пессимистична, чем у оценочного набора. Результаты показывают, что чувствительность и специфичность модели становятся соразмерными высоким значениям стоимости.
Модель С5.0 не использует критерий Джини для разделения. Со стоимостями используется приведенная ранее формула, предполагающая равенство априорных вероятностей.1
Ожидаемая стоимость = С(21 l)pt + С(112)р2.
Для прогнозирования новых точек используется класс, связанный с наименьшей ожидаемой стоимостью.
Для модели С5.0 настройка выполнялась по типу (деревья или правила) и количеству итераций усиления. На рис. 16.7 представлены закономерности для обучения,
1 Альтернативное представление этого критерия заключается в том, что априорные вероятности включаются в соответствующее значение стоимости.
478 Глава 16. Решение проблемы дисбаланса классов
чувствительного к показателю стоимости, на фоне ошибочно заниженной стоимости в диапазоне от 5 до 50.
Каппа (ПП)
Чувств (ПП)
Спец (ПП)
Каппа (оцен)
Чувств (оцен)
Спец (оцен)
0,20
0,15 с
* 0,10
0,05
0,00
1.0
0,8
0,6
0,4
0,2
0,0
0 10 20 30 40 50
Стоимость
0
10
20 30 40
50
Стоимость
Рис. 16.7. Профили эффективности для моделей С5.0, использующих обучение с учетом стоимости
Как и при анализе SVM, кривые согласованы между тренировочным и оценочным набором. Для оптимизации согласования через каппа-статистику необходимы меньшие значения стоимости, а для повышения чувствительности — стоимости от средних до больших.
Здесь наблюдается явное противоречие между чувствительностью и специфичностью, но, предположительно, уровень чувствительности стабилизируется для стоимостей выше 25 или 30.
16.9. Вычисления
В этом разделе используются следующие пакеты: caret, С50, DMwR, DWD, kernlab, pROC и rpart.
Данные страховки содержатся в пакете DWD. Чтобы загрузить их, введите следующие команды:
> Library(DHD)
> data(tiedata)
Набор данных содержит ряд факторных переменных. Многие факторные уровни содержат нестандартные символы — «%», запятые и другие значения. Когда они
16.9. Вычисления 479
преобразуются в столбцы фиктивных переменных, значения будут нарушать правила выбора имен новых переменных. Чтобы обойти эту проблему, перекодируем имена для их упрощения:
> recodeLeveLs <- function(x)
* {
+ х <- as.numeric(х)
-I- ## Добавить нули к текстовой версии:
+ х <- gsub(" ", "0",format(as.numeric(x)))
+ factor (х)
+ }
> ## Определить, какие столбцы являются регулярными факторами
> ## или упорядоченными факторами
> isOrdered <- unListf LappLy(ticdata, is.ordered))
> isFactor <- unList(LappLy(tiedata, is.factor))
> convertCoLs <- names(isOrdered)[isOrdered I isFactor]
> for(i in convertCoLs) ticdata[,i] <- recodeLeveLs(ticdata[,i])
> ## Сделать уровень 'insurance' первым факторным уровнем
> ticdatafCARAVAN <- factor(as.character(ticdata$CARAVAN),
+ LeveLs = rev(LeveLs(ticdata$CARAVAN)))
Тренировочный и тестовый наборы были созданы с использованием расслоенной случайной выборки:
> Library(caret)
> ## Сначала отделить тренировочный набор
> set.seed(156)
> spLitl <- createDataPartition(ticdata$CARAVAN, р = .7)[[1]]
> other <- ticdata[-spLitl,]
> training <- ticdata[ spLitl,]
> ## Теперь создать оценочный и тестовый набор
> set.seed(934)
> spLit2 <- createDataPartition(other$CARAVAN, р = 1/3)[[1]]
> evaLuation <- other[ spLit2,]
> testing <- other[-spLit2,]
> ## Определить имена предикторов
> predictors <- names(training)[names(training) != "CARAVAN"]
Фиктивные переменные используются для нескольких моделей, которые обучаются в этом разделе.
У функции randomForest установлено ограничение — факторные предикторы не могут иметь более 32 уровней. Предиктор типа клиента имеет 39 уровней, поэтому для этой и других моделей, использующих функцию model. matrix, создается набор фиктивных переменных:
> ## Первый столбец содержит точку пересечения, которая исключается:
> traininglnd <- data.frame(modeL.matrix(CARAVAN - .,
480 Глава 16. Решение проблемы дисбаланса классов
+ data = training))[,-1]
> evaluationlnd <- data.frame(mode I.matrix(CARAVAN - .,
+ data = evaluation))[,-1]
> testinglnd <- data.frame(modeI.matrix(CARAVAN ~ .,
+ data = testing))[, -1]
> ## Добавить результат в набор данных
> traininglndfCARAVAN <- trainingfCARAVAN
> evaluationlndfCARAVAN <- evaluation$CARAVAN
> testingIndfCARAVAN <- testing$CARAVAN
> ## Определить набор предикторов без сильно разреженных
> ## и дисбалансных распределений:
> isNZV <- nearZeroVar(traininglnd)
> noNZVSet <- names(traininglnd)[-isNZV]
Для получения разных метрик эффективности создаются две функции-обертки:
> ## Точность, каппа, площадь под ROC-кривой,
> ## чувствительность и специфичность:
> fiveStats <- functionf...) с(twoClassSummary(...),
+ defauItSummary(...))
> ## Все, кроме площади под ROC-кривой:
> fourStats <- function (data, lev = levels(data$obs), model = NUll)
+ {
+
+ accKapp <- postResample(data[, "pred"], data[, "obs"])
+ out <- c(accKapp,
+ sensitivity(data[, "pred"], data[, "obs"], lev[l]),
+ specificity(data[, "pred"], data[, "obs"], lev[2]))
+ names(out)[3:4] <- c("Sens", "Spec")
+ out
+ }
Две управляющие функции написаны для ситуаций, в которых возможно или невозможно создание вероятностей классов:
> Ctrl <- traincontrol(method = "cv",
+ classProbs = TRUE,
+ summaryFunction = fiveStats,
+ verboselter = TRUE)
> ctrlNoProb <- Ctrl
> ctrlNoProbfsummaryFunction <- fourStats
> ctrlNoProbfclassProbs <- FALSE
Обучение трех базовых моделей осуществлялось со следующим синтаксисом:
> set.seed(1410)
> rfFit <- train(CARAVAN ~ ., data = traininglnd,
+ method = "rf",
16.9. Вычисления 481
* trControL = ctrL,
+ ntгее = 1500,
+ tuneLength = 5,
+ metric = "ROC")
> set.seed(1410)
> LrFit <- train(CARAVAN ~ .,
+ data - traininglnd[, noNZVSet],
+ method = "gLm",
+ trControL = ctrL,
+ metric = "ROC")
> set.seed(1401)
> fdaFit <- train(CARAVAN ~ ., data = training,
+ method = "fda",
+ tuneGrid = data.frame(.degree = 1, .nprune = 1:25),
-I- metric = "ROC",
+ trControL = ctrL)
>
Кадр данных используется для размещения прогнозов разных моделей:
> evaLResuLts <- data.frame(СARAVAN = evaLuationfCARAVAN)
> evaLResuLtsfRF <- predict(rfFit,
+ newdata = evaLuationlnd,
+ type = "prob ") [, 1 ]
> evaLResuLts$FDA <- predict(fdaFit,
+ newdata = evaLuation[, predictors],
+ type = "prob")[,l]
> evaLResuLts$LogReg <- predict(LrFit,
♦ newdata = vaLuationInd[, noNZVSet],
+ type = "prob")[,l]
На основании этих объектов создаются ROC-кривые и кривые lift. Пример:
> Library(pROC)
> rfROC <- roc(evaLResuLts$CARAVAN, evaLResuLts$RF,
+ LeveLs = rev(LeveLs(evaLResuLts$CARAVAN)))
> ## Создать метки для моделей:
> Labs <- c(RF = "Random Forest", LogReg = "Logistic Regression",
+ FDA = "FDA (MARS)")
> Liftl <- Lift (CARAVAN ~ RF + LogReg + FDA, data = evaLResuLts,
+ LabeLs = Labs)
> rfROC
Call:
roc.default(response = evalResults$CARAVAN, predictor = evalResults$RF, levels = rev(levels(evalResults$CARAVAN)))
Data: evalResults$RF in 924 controls (evalResults$CARAVAN noinsurance) <
482 Глава 16. Решение проблемы дисбаланса классов
59 cases (evalResults$CARAVAN insurance).
Area under the curve: 0.7569
> Liftl
Call:
lift.formula(x = CARAVAN ~ RF + LogReg + FDA, data = evalResults,
labels = labs)
Models: Random Forest, Logistic Regression, FDA (MARS)
Event: insurance (6%)
Построение кривых:
> pLot(rfROC, Legacy.axes = TRUE)
> xypLot(Liftl,
+ yLab = "%Events Found", xLab = "^Customers EvaLuated",
+ Lwd = 2, type = "L")
Альтернативные пороги отсечения
После того как ROC-кривая будет создана, можно воспользоваться различными функциями пакета pROC для анализа порогов отсечения. Функция coords возвращает точки на ROC-кривой, а также строит новые пороги отсечения. Ее главный аргумент х определяет, что должна вернуть функция. Со значением х = "all" функция вернет координаты на кривой и связанные с ними пороги отсечения. Со значением "best" будет сгенерирован новый порог отсечения. Использование х = "best" в сочетании с best.method ("youden" или "closest.topleft") может предоставить полезную информацию:
> rfThresh <- coords(rfROC, х = "best", best.method = "cLosest.topLeft")
> rfThresh
threshold specificity sensitivity
0.06433333 0.75865801 0.64406780
С этими данными можно вычислить новые прогнозируемые классы:
> newVaLue <- factor(ifeLse(evaLResuLts$RF > rfThresh,
+ "insurance", "noinsurance"),
+ LeveLs = LeveLs(evaLResuLts$CARAVAN))
Методы выборки
Пакет caret содержит две функции, downSample и upSample, которые корректируют частоты классов. Каждая функция получает аргументы для предикторов (х) и класса результата (у). Обе функции возвращают кадр данных с выборочной версией тренировочного набора:
16.9. Вычисления 483
> set.seed(1103)
> upSampLedTrain <- upSampLefx = training[,predictors],
+ у = trainingSCARAVANj
+ ## Оставить то же имя переменной класса:
+ у name = "CARAVAN")
> dim(training)
[1] 6877 86
> dim(upSampLedTrain)
[1] 12932 86
> tabLe(upSampLedTrain$CARAVAN)
insurance noinsurance
6466 6466
Функция понижающей выборки имеет тот же синтаксис.
Функция поддержки SMOTE находится в пакете DMwR. Она получает на входе формулу модели с параметрами (такими, как величина повышения или понижения либо количество соседей). Базовый синтаксис выглядит так:
> Library(DMwR)
> set.seed(1103)
> smote Train <- SMOTE(CARAVAN ~ ., data = training)
> dim(smoteTrain)
[1] 2877 86
> tabLe(smoteTrain$CARAVAN)
insurance noinsurance
1233 1644
Эти наборы данных могут использоваться в качестве входных данных для приведенного выше кода моделирования.
Тренировка с учетом стоимости
Модели SVM с весами, назначаемыми классам, могут создаваться при помощи пакета kernlab. Синтаксис функции ksvm аналогичен синтаксису из предыдущих описаний, но функция использует аргумент class.weights. Функция train тоже имеет похожий синтаксис:
> Library(kernLab)
> ## Тренировка будет осуществляться по большому диапазону стоимости,
> ## поэтому мы заранее вычислим параметр sigma
> ## и построим специальную таблицу настройки:
> set.seed(1157)
> sigma <- sigest(CARAVAN ~ ., data = traininglnd[, noNZVSet], frac = .75)
> names(sigma) <- NULL
> svmGrid <- data.frame(.sigma = sigma[2],
484 Глава 16. Решение проблемы дисбаланса классов
+ .С = 2Aseq(-6, 1, Length = 15))
> ## Вероятности классов не могут быть сгенерированы с весами классов,
> ## поэтому используем управляющий объект 'ctrlNoProb', чтобы
> ## избежать оценки ROC-кривой.
> set.seed(1401)
> SVMwts <- train (CARAVAN ~ .,
* data = traininglnd[, noNZVSet],
+ method = "svmRadial",
* tuneGrid = svmGrid,
+ preProc = c("center”, "scale"),
+ class.weights = cfinsurance = 18, noinsurance = 1),
+ metric = "Sens",
+ trControl = ctrlNoProb)
> SVMwtS
6877 samples
203 predictors
2 classes: 'insurance', 'noinsurance'
Pre-processing: centered, scaled
Resampling: Cross-Validation (10-fold)
Summary of sample sizes: 6189, 6190, 6190, 6189, 6189, 6189, ...
Resampling results across tuning parameters:
с
Accuracy
Карра
Sens
Spec
0.0156
0.557
0.0682
0.742
0.545
0.0221
0.614
0.0806
0.691
0.609
0.0312
0.637
0.0864
0.669
0.635
0.0442
0.644
0.0883
0.662
0.643
0.0625
0.658
0.0939
0.657
0.658
0.0884
0.672
0.0958
0.633
0.674
0.125
0.684
0.101
0.625
0.688
0.177
0.7
0.106
0.611
0.705
0.25
0.711
0.108
0.591
0.719
0.354
0.724
0.111
0.572
0.734
0.5
0.737
0.112
0.543
0.75
0.707
0.75
0.109
0.506
0.765
1
0.765
0.104
0.46
0.785
1.41
0.776
0.097
0.416
0.799
2
0.791
0.102
0.394
0.817
Tuning parameter 'sigma' was held constant at a value of 0.00245 Sens was used to select the optimal model using the largest value.
The final values used for the model were C = 0.0156 and sigma = 0.00245.
Столбцы стандартного отклонения не показаны для экономии места. Прогнозирование использует такой же синтаксис, как у моделей без весов.
16.9. Вычисления 485
Для моделей CART с учетом стоимости пакет rpart используется с аргументом parms, который содержит список параметров обучения. Один из этих параметров — loss — может получать матрицу стоимостей:
> costMatrix <- matrix(c(0, 1, 20, 0), ncoL = 2)
> rownames(costMatrix) <- LeveLs(training$CARAVAN)
> coLnames(costMatrix) <- LeveLs(training$CARAVAN)
> costMatrix
insurance noinsurance
insurance 0 20
noinsurance 1 0
Здесь ложноотрицательному значению присваивается стоимость в 20 раз выше, чем у ложноположительного значения. Обучение модели происходит так:
> Library(rpart)
> set,seed(1401)
> cartCosts <- trainfx = training[, predictors],
+ у = trainingfCARAVAN,
+ method = "rpart",
+ trControL = ctrLNoProb,
+ metric = "Kappa",
+ tuneLength = 10,
+ parms = List(Loss = costMatrix))
По аналогии с моделью SVM синтаксис генерирования прогнозов классов выглядит так же, как у номинальной модели. Однако любые вероятности классов, сгенерированные на базе этой модели, могут не соответствовать прогнозируемым классам (которые являются функцией стоимости и вероятностей).
В модели С5.0 поддерживается аналогичный синтаксис rpart с передачей матрицы стоимости, хотя эта функция использует матрицу, транспонированную относительно той, которая используется rpart:
> cSMatrix <- matrix(c(0, 20, 1, 0), ncoL = 2)
> rownames(cSMatrix) <- LeveLs(training$ CARAVAN)
> coLnames(cSMatrix) <- LeveLs(training$CARAVAN)
> cSMatrix
insurance noinsurance
insurance 0 1
noinsurance 20 0
> Library(C50)
> set,seed(1401)
> C5Cost <- trainfx = trainings predictors],
+ у = train ing$CARAVAN,
+ method = "C5,0",
+ metric = "Kappa",
+ cost = cSMatrix,
+ trControL = ctrLNoProb)
486 Глава 16. Решение проблемы дисбаланса классов
При использовании стоимостей функция predict для этой модели генерирует только дискретные классы (то есть без вероятностей).
Упражнения
16.1. Набор данных «adult» из репозитория UCI Machine Learning Repository был получен в результате обработки данных переписи населения1. В этих данных целью было прогнозирование уровня дохода физических лиц — высокого (что в 1994 году означало «выше $50 000») или низкого. В число предикторов входит образование, тип занятости (никогда не работал, муниципальная работа и т. д.), доходы от прироста и убытки капитала, рабочая неделя в часах, страна рождения и т. д.2 После фильтрации данных с неизвестным классом результата осталось 48 842 записи. Большинство данных было связано с низким доходом (75,9 %).
Данные содержатся в пакете аги les, а нужная версия загружается командой data(AdultUCI).
A. Загрузите данные и проанализируйте предикторы на предмет их распределений и потенциальных корреляций.
Б. Определите подходящее разделение данных.
B. Постройте несколько классификационных моделей для этих данных. Проявляется ли в результатах предпочтение класса с низким уровнем дохода?
Г. Существует ли хорошее компромиссное решение между чувствительностью и специфичностью?
Д. Используйте методы выборки для улучшения обучения модели.
Е. Способствуют ли модели с учетом стоимости улучшению эффективности?
16.2. Данные прямого маркетинга (Larose, 2006, chap. 7), обсуждавшиеся в главе И, доступны на сайте авторов3. Цель анализа — прогнозирование того, кто из клиентов откликнется на объявление о рекламной акции, рассылаемое по почте.
Из 65 220 клиентов в наборе данных 16,6 % откликнулись на предложение. Предикторы в наборе данных включают:
1 Эти данные впервые упоминаются в (Kohavi, 1996). Описание коллекции данных и сводку результатов предыдущих моделей можно найти в репозитории UCI Machine Learning Repository (http://archive.ics.ud.edu/ml/machine-leaming-databases/adult/adult.names).
2 Другой атрибут, «fnlwgt», содержит информацию только о процессе сбора данных и не должен использоваться в качестве предиктора.
3 http://www.dataminingconsultant.com/data.
Упражнения 487
О покупательские пристрастия — совокупные и разбитые по месяцам и часто посещаемым магазинам;
О типы приобретаемых продуктов;
О время между посещениями;
О исторические данные о частоте отклика на рекламные предложения;
О заранее определенные данные о кластерном распределении клиентов.
Лароуз (Larose, 2006) рассматривает дисбаланс классов для этой задачи и демонстрирует некоторые приемы эффективного достижения результатов.
A. Загрузите данные в R, проведите исследовательский анализ и определите лучший метод кодирования предикторов.
Б. Определите подходящее разделение данных и постройте несколько классификационных моделей для этих данных.
B. Постройте диаграммы точности прогнозов, чтобы понять возможную стратегию для определения того, со сколькими клиентами нужно связаться для достижения оцениваемых 60 % откликов.
Г. Используйте методы выборки с несколькими моделями. Обладают ли эти модели лучшими диаграммами точности прогнозов? Можно ли использовать их для того, чтобы связаться с меньшим количеством клиентов для достижения 60 % отклика (среди клиентов, получивших рекламное предложение)?
Практикум: планирование заданий
Высокопроизводительные вычислительные среды (НРС, High-Performance Computing) используются во многих технологических и исследовательских компаниях для организации крупномасштабных вычислений. Среда НРС обычно состоит из многочисленных «вычислительных узлов», объединенных в вычислительную сеть. Такие среды могут иметь разную структуру — например, сети из множества компьютеров с малым количеством процессоров или, наоборот, сети из небольшого количества компьютеров с многими процессорами. Объем памяти на каждом компьютере зачастую определяется соотношением доступных средств и природы выполняемых вычислений.
Выполнение задания в среде НРС инициируется пользователем. Поскольку множество программ выполняется одновременно, среда должна управлять заданиями так, чтобы обеспечить более эффективное получение результатов, что сопряжено с определенными сложностями.
Так, в некоторых ситуациях объем работы по существующим заданиям превышает возможности вычислительной среды. В таких случаях системе приходится откладывать запуск некоторых заданий до освобождения необходимых ресурсов. Частота подачи заданий может изменяться, но при этом следует избегать перераспределения вычислительных ресурсов в пользу одних за счет других.
Проекты с более высоким приоритетом могут требовать более привилегированного доступа к аппаратным ресурсам. Например, задания фармацевтической компании, необходимые для подачи регистрационной заявки в сжатые сроки, могут обладать более высоким приоритетом, чем задания, связанные с научными исследованиями. Обычно для решения этой задачи применяется планировщик заданий — программа, назначающая приоритеты заданиям, управляющая вычислительными ресурсами и инициирующая выполнение полученных заданий для достижения максимальной эффективности. Планировщик заданий может сформировать систему очередей на основании таких факторов, как требования к ресурсам для
Практикум: планирование заданий 489
заданий (например, количество необходимых процессоров, требования к памяти и т. д.), приоритеты проектов и текущая нагрузка в среде. Перед распределением вычислительных ресурсов планировщик заданий также может учитывать историю отправки заданий конкретными пользователями. На рис. 17.1 изображена схема такой системы.
Рис. 17.1. Гипотетический пример планирования заданий в высокопроизводительной вычислительной среде
В верхней части схемы представлены три гипотетических задания, отправленных одновременно. Первые два задания содержат по одному блоку вычислений, но имеют разные требования. Например, первое задание может быть научным вычислением, которое распределяет нагрузку между несколькими процессорами одной физической машины. Второе задание может быть коротким запросом к базе данных, который был введен ученым в интерактивном сеансе на сайте. Это задание должно быть обработано быстро с минимумом дополнительных затрат ресурсов. Третье задание представляет связный набор вычислений, которые запускаются одновременно, но выполняются независимо с использованием одной программы (например, с целью моделирования). Массив заданий запускает 50 независимых вычислений, которые могут работать на разных машинах, но при этом требуют операций отслеживания и управления как единое целое. И снова целью плани-
490 Глава 17. Практикум: планирование заданий ровщика заданий является распределение заданий в системе, обеспечивающее максимальную эффективность.
Эффективность планировщика заданий в значительной мере зависит от объема и качества информации о заданиях, доступной на момент отправки. Это позволяет планировщику заданий размещать задания на подходящих машинах в подходящее время.
Для многократно повторяемых вычислений существует простое решение: сохранить информацию о существующих заданиях, а затем спрогнозировать потребность в ресурсах для новых заданий. Например, полезно спрогнозировать время выполнения или максимальные требования задания к памяти в момент отправки.
Такие прогнозы должны быть быстрыми и точными. Тем не менее в требованиях к точности следует учитывать тот факт, что ошибки прогнозирования вряд ли будут оказывать идентичное влияние на эффективность среды.
Например, если прогнозируемые требования к памяти были серьезно недооценены, ресурсы физической машины могут быть перегружены, что значительно повлияет на все задания на этой машине. Стоимость ошибок этого типа должна быть высокой, чтобы планировщик заданий избегал подобных проблем.
С другой стороны, переоценка затрат памяти может привести к аномально низкой загруженности аппаратных ресурсов, но не окажет критического влияния на существующие задания в системе. Такой ошибке тоже должна быть назначена стоимость, но, скорее всего, не такая высокая, как для ошибок первого типа.
В рассматриваемом примере фармацевтическая компания Pfizer выполняет большое количество заданий в корпоративной среде НРС. Один класс заданий (для получения характеристик веществ) выполняется регулярно, причем некоторые задания создают значительную вычислительную нагрузку. За период времени собрана информация об использовании ресурсов заданиями этого типа. Кроме того, существуют дополнительные характеристики заданий, которые могут собираться в момент запуска задания:
О Протокол', для вычисления результатов по каждому веществу могут использоваться разные аналитические методы, называемые протоколами. Протоколы кодируются буквами от А до 0; чаще всего использовался протокол J (22,8 % всех заданий), тогда как протокол К встречался очень редко (0,1 %).
О Количество веществ', количество веществ, обрабатываемых заданием. Этот показатель изменяется в очень широком диапазоне.
О Количество входных полей', каждая задача может обрабатывать различные входные поля в данных в зависимости от того, что нужно проанализировать ученому. Этот предиктор смещен вправо.
О Количество итераций', каждый протокол может выполняться заранее заданное количество раз. По умолчанию используется 20 итераций — это значение чаще всего встречается в этих данных.
Практикум: планирование заданий 491
О Количество незавершенных заданий: количество незавершенных заданий (то есть рабочая нагрузка в среде) на момент регистрации запуска. При прочих равных условиях количество незавершенных заданий не должно напрямую влиять на время выполнения заданий, но может отражать объем ресурсов, используемых на текущий момент. Большинство заданий запускалось при наличии доступных ресурсов, и отсутствующих заданий не было. Тем не менее небольшая часть запросов выдавалась при высокой нагрузке на оборудование (в системе уже были тысячи незавершенных заданий).
О Время суток: время суток (восточное стандартное время) на момент запуска задания (от 0 до 24 часов). Распределение является мультимодальным, что отражает нахождение пользователей в трех разных часовых поясах на двух континентах.
О День недели: день недели на момент запуска задания.
Для каждого задания было зарегистрировано время его выполнения. Время, проведенное в ходе ожидания или в приостановленном состоянии, в этих значениях не учитывалось. Хотя результат непрерывен по своей природе, для этой информации планировщику заданий понадобится количественное представление. Задания должны классифицироваться как очень быстрые (1 минута и менее) — VF, быстрые (1-5 минут) — F, средние (5-30 минут) — М или долгие (более 30 минут) — L. Большинство заданий относится либо к категории очень быстрых (51,1 %), либо быстрых (31,1 %); только 11,9 % заданий было классифицировано как средние, 6 % — как долгие.
Целью эксперимента было прогнозирование классов заданий по информации, представленной в табл. 17.1.
Очевидно, что типы ошибок различаются, а классификации очень долгих заданий, как и очень коротких, должен назначаться повышенный штраф. Кроме того, поскольку уравнение прогнозирования должно быть реализовано в программе и быстро вычисляться, предпочтение отдается моделям с более простыми формулами прогнозирования.
За последние годы оборудование для сред НРС несколько изменилось. Как следствие, при запуске одного задания на двух разных модификациях оборудования могут быть получены разные значения времени выполнения.
Это приводит к «раздуванию» внутреннего разброса времени выполнения и потенциальным ошибкам пометки наблюдаемых классов. Хотя простого аналитического решения этой проблемы не существует, любую модель классификации времени выполнения следует пересматривать с течением времени (предполагая, что новое оборудование сокращает время выполнения).
Прежде чем браться за построение модели, важно исследовать данные. До моделирования можно ожидать, что основными определяющими факторами времени
492 Глава 17. Практикум: планирование заданий выполнения будут количество веществ, количество задач и используемый протокол. Для первого знакомства с данными на рис. 17.2 представлена мозаичная диаграмма, отражающая связь между протоколами и классами времени выполнения.
Таблица 17.1. Предикторы для данных планировщика заданий
7 переменных 4331 наблюдений
Практикум: планирование заданий 493
А С D Е F G Н
К L М N О
>
Рис. 17.2. Мозаичная диаграмма частот классов для каждого протокола. Ширина блоков определяется количеством заданий, наблюдаемых в наборе данных
Ширина блоков представляет количество запусков заданий для протокола (то есть протокол 3 запускался чаще, а протокол К — реже остальных). Из диаграммы видно, что долгое выполнение наблюдается лишь для некоторых протоколов. Другие протоколы (например, D) обычно выполняются очень быстро. С учетом этих связей можно предположить, что информация о протоколе потенциально важна для модели.
На рис. 17.3 представлена еще одна визуализация данных с использованием наложения. Здесь данные упорядочиваются по классу, а затем разбиваются на 100 сегментов.
В каждом сегменте определяется среднее значение числовых предикторов и частотное распределение категорийных предикторов. Результаты для каждого предиктора приводятся в столбцах, что позволяет лучше понять, как каждый предиктор связан с результатом. Из диаграммы следует, что:
О Задания, связанные с большим количеством веществ, обычно имеют среднее или большое время выполнения.
О Многие задания средней длины были отправлены при очень высоком количестве незавершенных заданий. Тем не менее эта тенденция не воспроизводится для очень долгих заданий. Поэтому будет важно проверить это наблюдение проспективно и убедиться в том, что это не было аномалией этого конкретного набора данных.
О При большом количестве итераций задания обычно выполняются долго.
Один из недостатков визуализации — в том, что она скрывает связи между предикторами. Диаграммы корреляции и матрицы диаграмм разброса — эффективные
494 Глава 17. Практикум: планирование заданий
Рис. 17.3. Наложение данных
Практикум: планирование заданий 495
средства для поиска таких типов связей. На рис. 17.4 изображены диаграммы разброса зависимости количества веществ против количества входных полей для разных протоколов.
На диаграммах задания окрашены в соответствии с классом. В некоторых случаях (например, для протоколов 0041, С, D, H, I и К) данные о количестве веществ и полей предположительно содержат информацию, позволяющую различать классы.
Тем не менее эти связи присущи конкретным классам; закономерности для протоколов I и К отличаются. Другой интересный аспект этого анализа заключается
VF
F М L
ф □о
Входные поля
Рис. 17.4. Диаграмма разброса количества веществ против количества входных полей для разных протоколов. Точки окрашены в разные цвета по классу времени выполнения
496 Глава 17. Практикум: планирование заданий в том, что закономерность корреляции между количеством веществ и количеством входных полей тоже зависит от конкретного протокола.
Например, у одних протоколов (например, J или 0) эти два предиктора имеют крайне незначительную корреляцию, а у других (например, D, Е и H) наблюдается сильная корреляция. Эти закономерности могут быть важными и, скорее всего, будут обнаружены при анализе фактических точек данных разработчиком модели.
17.1. Разделение данных и стратегия модели
Данные содержат 4331 точку данных; 80 % будут использоваться для тренировки алгоритмов, а остальные будут использоваться для оценки итоговых моделей-кандидатов. Данные разбивались с использованием расслоенной случайной выборки для сохранения распределения классов результата. Настройка моделей осуществлялась пятью повторениями десятикратной перекрестной проверки.
Вместо того чтобы создавать модели, максимизирующие общую точность или каппа-статистику, нестандартная функция стоимости используется для назначения повышенных весов ошибкам, в которых долгие и средние задания ошибочно классифицировались как быстрые или очень быстрые. Стоимости, связанные с каждым типом ошибки, влияют на общий показатель эффективности (табл. 17.2).
Таблица 17.2. Структура стоимостей, используемая для оптимизации модели
Наблюдаемый класс
VF
F
м
L
VF
0
1
5
10
F
1
0
5
5
М
1
1
0
1
L
1
1
1
0
К стоимостям применяются веса, чтобы долгие задания не ставились в очередь (или распределялись на оборудование), предназначенную для небольших, быстрых заданий. Заданиям средней продолжительности назначаются штрафы при ошибочной классификации их как более эффективных.
Лучший из возможных способов тренировки модели основан на использовании функции стоимости для оценки параметров модели (см. раздел 16.8). Некоторые модели на базе деревьев предоставляют такую возможность, но у большинства рассмотренных моделей она отсутствует.
17.1. Разделение данных и стратегия модели 497
Серии моделей проходили обучение по тренировочному набору. Комбинация параметров настройки, связанных с наименьшим средним значением стоимости, выбиралась для итоговой модели и использовалась со всем тренировочным набором. Были проанализированы следующие модели:
О Линейный дискриминантный анализ: эта модель была создана с использованием стандартного набора уравнений, а также со штрафной версией, которая проводит выбор признаков в процессе тренировки модели. Исследованы размеры подмножеств предикторов от 2 до 112 в сочетании с некоторыми значениями гребневого штрафа: 0, 0,01, 0,1,1 и 10.
О Дискриминантный анализ методом частных наименьших квадратов: обучение модели PLS осуществлялось для количества компонентов в интервале от 1 до 91.
О Нейросети: при обучении моделей использовалось количество скрытых переменных в интервале от 1 до 19, а также 5 значений снижения весов: 0, 0,001, 0,01, 0,1 и 0,5.
О Гибкий дискриминантный анализ: использовались шарнирные функции MARS первой степени, количество сохраненных составляющих изменялось от 2 до 23.
О Метод опорных векторов (SVM): выполнено обучение двух разных моделей с радиальной базисной функцией. Одна модель использовала равные веса, в другой средним заданиям назначались пятикратные веса, а долгим — десятикратные. В каждом случае аналитические вычисления для оценки ядерной функции RBF использовались в сочетании со значениями стоимости в интервале от 2 2 до 212 по логарифмической шкале.
О Одиночные деревья CART: аналогичным образом обучение моделей CART осуществлялось с равными стоимостями на класс и со стоимостями из табл. 17.2. В каждом случае модель настраивалась по 20 значениям параметра сложности.
О Деревья CART с бэггингом: модели использовали 50 деревьев CART с бэггингом (со структурой стоимости и без).
О Случайные леса: модель использовала лес из 2000 деревьев и настраивалась по 6 значениям параметра настройки.
О С5.0: эта модель оценена с моделями на базе деревьев и правил, с отсеиванием и без, с одиночными моделями и с использованием до 100 итераций усиления. Альтернативная версия этой модели обучалась с помощью структуры стоимости, приведенной в табл. 17.2.
В этой ситуации предпочтительнее модели, способствующие быстрым прогнозам. Если формулы прогнозирования для этой модели могут быть легко закодированы в программном коде (например, простое дерево или нейросеть) или могут быть выполнены из простого интерфейса командной строки (например, С5.0), то этой модели отдается предпочтение.
498 Глава 17. Практикум: планирование заданий
17.2. Результаты
Результаты модели представлены в блочных диаграммах оценок среднего значения стоимости с повторной выборкой (рис. 17.5).
PLS
FDA
LDA
LDA (разреженная)
CART
Нейросети SVM Бэггинг (стоимости) CART (стоимости) С5.0 (стоимости) SVM (веса) Бэггинг
Случайные леса
С5.0
0,2 0,3 0,4 0,5 0,6 0,7 0,8
Стоимость
Рис. 17.5. Профили средней стоимости с повторной выборкой для различных моделей
Линейные модели (LDA, PLS) здесь показали себя не лучшим образом. Выбор признаков не помог линейной дискриминантной модели, что не может быть связано с неспособностью модели обрабатывать нелинейные границы классов. FDA также демонстрирует плохую эффективность в отношении стоимости. Существует целая группа моделей с эквивалентными средними стоимостями — прежде всего SVM и методы с ансамблями деревьев. Использование стоимостей/весов оказывает значительное положительное влияние на одиночное дерево CART и SVM. На рис. 17.6 показаны профили повторной выборки для этих двух моделей в контексте их оценок стоимости, общей точности и каппа-статистики.
Результаты модели CART показывают, что использование стоимости отрицательно влияет на точность и каппа-статистику, но естественным образом улучшает оценки стоимости. Независимо от показателей процесс настройки выбрал бы ту же модель CART для окончательной тренировки.
Несколько иная картина наблюдается в случае с моделью SVM. Использование весов классов оказывает небольшой отрицательный эффект на ее точность и каппа-статистику, но улучшение оцениваемой стоимости значительно. Модель без весов оптимизировалась бы с много большим параметром стоимости SVM (а следовательно, гораздо более сложными моделями) по сравнению с версией с весами.
17.2. Результаты 499
Равные веса Неравные веса
10А-2,5 10А-1,5 10А-0,5
1,0
0,8
0,6
0,4
0,2
0,0
10А-2,5 10А-1,5
10А-0,5
10л-2,5
10Л-1,5 10А-0.5
Параметр сложности
Равные веса
Неравные веса
2А0 2А5 2А10
0,8
0,7
0,6
0,5
0,4
2А0 2А5 2А10
2А0 2А5 2л10
Стоимость
Рис. 17.6. Эффект внедрения структуры стоимости в процесс тренировки CART (наверху) и веса для опорных векторов (внизу)
Отметим, что модель C5.0 без стоимостей показала очень хорошие результаты, а добавление структуры стоимости в процесс построения дерева увеличило оценку стоимости модели. Применение бэггинга к деревьям CART без стоимости оказало на
500 Глава 17. Практикум: планирование заданий модель незначительное отрицательное воздействие. Для этих данных хорошие результаты показали деревья, модели опорных векторов и нейросети. Но существуют ли значительные различия между моделями-лидерами? Один из способов анализа результатов основан на рассмотрении матрицы несоответствий, сгенерированной между повторными выборками. Напомним, при повторной выборке использовалось 50 контрольных наборов, содержавших в среднем около 347 заданий. Для каждого из контрольных наборов вычислена матрица несоответствий, а затем методом усреднения частот ячеек вычислена средняя матрица несоответствий (табл. 17.3).
Таблица 17.3. Матрицы несоответствий с повторной выборкой для модели случайного леса и модели CART с учетом стоимости
CART с учетом стоимости
Случайные леса
VF
F
М
L
VF
F
М
L
VF
157,0
24,6
2,0
0,2
164,7
18,0
1,3
0,2
F
10,3
43,2
3,1
0,2
11,9
83,7
11,5
1,8
М
9,6
38,3
34,5
5,8
0,2
5,5
27,4
1,8
L
0,0
1,7
1,6
14,6
0,0
0,6
0,9
17,0
Для случайных лесов среднее количество долгих заданий, которые были ошибочно классифицированы как очень быстрые, равно 0,2, тогда как то же значение для дерева классификации равно 0,24. Дерево CART демонстрирует очень плохую точность для быстрых заданий по сравнению с моделью случайных лесов. Тем не менее для заданий средней длины справедливо обратное; случайные леса ошибочно классифицировали 72,56 % таких заданий (в среднем) по сравнению с 65,52 % для одиночных деревьев. Для долгих заданий одно дерево обладало более высокой частотой ошибок, чем ансамбль. Стоимость тестового набора для случайного леса составляла 0,316, тогда как для одиночных классификационных деревьев средняя стоимость равна 0,37. В табл. 17.4 приведены матрицы несоответствий для двух моделей.
Таблица 17.4. Матрицы несоответствий тестового набора для модели случайного леса и модели CART с учетом стоимости
CART с учетом стоимости
Случайные леса
VF
F
М
L
VF
F
М
L
VF
383
61
5
1
414
45
3
0
F
32
106
7
2
28
206
27
5
М
26
99
87
15
0
18
71
6
L
1
3
3
33
0
0
1
40
17.3. Вычисления 501
Тенденции тестового набора очень похожи на оценки с повторной выборкой. Одно дерево показывает лучшие результаты с быстрыми и долгими заданиями, тогда как у случайных лесов возникают проблемы с прогнозированием заданий средней длины. В итоге общие различия между двумя моделями невелики. Столбцы соответствуют истинным классам заданий.
17.3. Вычисления
Данные содержатся в пакете AppliedPredictiveModeling. После загрузки данных были созданы тренировочный и тестовый наборы:
> Library(AppLiedPredictiveModeLing)
> data(scheduLingData)
> set.seed(1104)
> inTrain <- createDataPartition(scheduLingData$CLass,
+ p = ,8,
+ List = FALSE)
> scheduLingDatafNumPending <- scheduLingData$NumPending + 1
> trainData <- scheduLingData[ inTrain,]
> testData <- scheduLingData[-inTrain, ]
Так как стоимости, определенные в табл. 17.2, использовались для формирования мнения о моделях, были написаны функции для оценки этого значения по набору наблюдаемых и прогнозируемых классов:
> cost <- function(pred, obs)
+
{
+
isNA <- is.na(pred)
+
if(!aLL(isNA))
{
+
pred <- pred[ HsNA]
+
obs <- obs[!isNA]
+
cost <- ifeLse(pred = obs, 0,1)
+
if(any(pred = "VF" & obs == "L"))
cost[pred = "L" & obs = "VF"] <- 10
if (any (pred == "F" & obs = ”L"))
+
cost[pred == "F" & obs = "£"J <- 5
+
if (any (pred = "F" & obs = "M"))
cost[pred == "F" & obs = "M"] <- 5
+
if(any(pred == "VF" & obs == "M"))
cost[pred = "VF" & obs == "M"] <- 5
+
out <- mean(cost)
+
} eLse out <- NA
+
out
}
502 Глава 17. Практикум: планирование заданий
> costsummary <- function (data. Lev = NULL, modeL = NULL)
+ {
+ if (is.character(datafobs)) data$obs <- factor(data$obs,
LeveLs = Lev)
+ c(postResampLe(data[, "pred"], data[, "obs"]),
+ Cost = cost(data[, "pred"], data[, "obs"]))
+ }
Последняя функция используется в объекте управления будущих вычислений:
> ctrL <- trainControL(method = "repeatedcv", repeats = 5,
+ summaryFunction = costsummary)
Для моделей деревьев с учетом стоимости также было создано матричное представление стоимости:
> costMatrix <- ifeLse(diag(4) = 1, 0, 1)
> costMatrix[1,4] <- 10
> costMatrix[1,3] <- 5
> costMatrix[2,4] <- 5
> costMatrix[2,3] <- 5
> rownames(costMatrix) <- LeveLs(trainDatafCLass)
> coLnames(costMatrix) <- LeveLs(trainData$CLass)
> costMatrix
Методы на базе деревьев не использовали независимые категории, но другие модели требовали, чтобы категорийные предикторы (например, протокол) были разложены на фиктивные переменные. Была создана формула модели, которая выполняла логарифмическое преобразование некоторых предикторов (с учетом смещения, продемонстрированного в табл. 17.1):
> modForm <- as.formuLa(CLass ~ ProtocoL + Logl0(Compounds) +
+ Logl0(InputFieLds)+ Logl0(Iterations) +
+ Logl0(NumPending) * Hour * Day)
Подробное описание обучения модели по данным можно найти в каталоге Chapter пакета AppliedPredictiveModeling; при этом используется синтаксис, похожий на синтаксис из предыдущих глав. Однако вызовы функций моделей с учетом стоимости и весами выглядели так:
> ## Модель CART с учетом стоимости
> set.seed(857)
> rpFitCost <- train(х = trainData[, predictors],
+ у = trainData$CLass,
+ method = "rpart",
+ metric = "Cost",
+ maximize = FALSE,
+ tuneLength = 20,
17.3. Вычисления 503
+ ## В матрице стоимости rpart истинные классы
+ ## находятся в строках,, поэтому матрицу стоимостей
+ ## необходимо транспонировать,
+ parms =List(Loss = t(costMatrix)),
+ trControL = ctrL)
> ## C5.0 с учетом стоимости
> set.seed(857)
> c50Cost <- trainfx = trainData[, predictors].
+
у = trainData$CLass,
+
method = "C5.0",
+
metric = "Cost",
+
maximize = FALSE,
+
+
costs = costMatrix,
tuneGrid = expand.grid(.triaLs = c(l, (1:10) *10),
+
.modeL = "tree",
+
.winnow = C(TRUE, FALSE)),
+
trControL = ctrL)
> ## Бэггинг-деревья с учетом стоимости
> rpCost <- functionfx, y)
{
+
+
+
+
+
+
+
+
+
+
costMatrix <- costMatrix[4, costMatrix[3, costMatrix[4, costMatrix[3,
ifeLse(diag(4) = 1, 0, 1)
1] <- 10
1] <- 5
2] <- 5
2] <- 5
Library(rpart)
tmp <- x
tmp$y <- у
rpart(y~.,
data = tmp, controL = rpart.controL(cp = 0), parms = List(Loss = costMatrix)) }
> rpPredict <- function(object, x) predict(object, x)
> rpAgg <- function (x, type = "cLass")
+ + + + + + + +
+
+
+
{
pooLed <- x[[l]] * NA
n <- nrow(pooLed)
cLasses <- coLnames(pooLed)
for (i in l:ncoL(pooLed))
{
tmp <- LappLy(x, function(y, coL) y[, coL], coL = i) tmp <- do.caLL(”rbind", tmp)
pooLed[, i] <- appLy(tmp, 2, median)
)
pooLed <- appLy(pooLed, 1, function(x) x/sum(x)) if (n != nrow(pooLed)) pooLed <- t(pooLed)
504 Глава 17. Практикум: планирование заданий
+ out <- factor(cLasses[appLy(pooLed, 1, which.max)],
+ LeveLs = cLasses)
+ out +}
> set.seed(857) > rpCostBag <- train(trainData[, predictors],
+
+
+
+
+
+
+
+
trainData$CLass,
"bag”,
В = 50,
bagControL = bagControL(fit = rpCost, predict = rpPredict, aggregate = rpAgg,
downSampLe = FALSE), trControL - ctrL)
>
> ## SVM с весами > set.seed(857) > svmRFitCost <- train(modForm, data = trainData,
+
+
+
method - "svmRadiaL", metric = "Cost", maximize = FALSE,
+ preProc = c( "center", "scaLe"),
+ cLass.weights = c(VF = 1, F = 1,
+ M = 5, L = 10),
+ tuneLength = 15,
+ trControL = ctrL)
Версии матриц несоответствия с применением повторной выборки были вычислены применением функции conf usionMatrix к объектам, произведенным функцией train:
> confusionMatrix(rpFitCost, norm = "none")
Cross-Validated (10-fold, repeated 5 times) Confusion Matrix
(entries are un-normalized counts)
Reference
Prediction
VF
F
M
L
VF
157.0
24.6
2.0
0.2
F
10.3
43.2
3.1
0.2
M
9.6
38.3
34.5
5.8
L
0.0
1.7
1.6
14.6
Аргумент norm определяет, как должны быть нормализованы непосредственные данные, полученные в результате каждой повторной выборки. Со значением "попе" в ячейках таблицы содержатся средние значения. Со значением norm = "overall" данные ячеек сначала делятся на общее количество точек данных в таблице, после чего эти проценты усредняются.
Часть IV
ПРОЧИЕ ВОПРОСЫ ПРЕДИКТИВНОГО МОДЕЛИРОВАНИЯ
Определение важности предикторов
Часто бывает нужно получить количественную оценку силы связей между предикторами и результатом. С увеличением количества атрибутов исследовательский анализ всех предикторов может стать неприемлемым. Если сосредоточиться на предикторах, имеющих сильные связи с результатом, это может стать эффективной стратегией назначения приоритетов. Подобное ранжирование предикторов может быть очень полезным при обработке больших объемов данных.
Одна из главных причин для измерения силы или релевантности предикторов — фильтрация предикторов, которые должны стать входными данными модели. Такой контролируемый выбор признаков может управляться существующими данными. Результаты процесса фильтрации вместе с компетенцией в предметной области могут стать важнейшим шагом в создании эффективной предиктивной модели. Как будет показано в следующей главе, многие алгоритмы выбора признаков основаны на количественном показателе релевантности для фильтрации.
Для многих предиктивных моделей характерно наличие встроенных (или внутренних) показателей важности предикторов (см. ранее). Например, MARS и многие другие модели на базе деревьев отслеживают повышение эффективности при добавлении очередного предиктора в модель. Другие модели, например линейная регрессия и логистическая регрессия, могут использовать количественные оценки на основании коэффициентов модели или статистических показателей (например, t-статистики). Методологии, описываемые в этой главе, не привязаны к конкретным типам моделей, являясь, по сути, универсальными. Если созданная модель эффективна, то показатели, полученные для этой модели, скорее всего, будут более надежными, чем методологии, описанные в этой главе, потому что они напрямую связаны с моделью.
Уточним, что под важностью переменных здесь понимается общая количественная оценка связи между предиктором и результатом. Большинство рассмотренных методологий не позволяет разработчику модели получить информацию о природе этой связи. Но это возможно для моделей с точными параметрическими форма-
18.1. Числовые результаты 507
ми — например, линейной или логистической регрессии, многомерных адаптивных регрессионных сплайнов и некоторых других. Например, в разделе 8.5 рассматриваются показатели важности переменных для случайного леса. По сути, показатели релевантности предикторов вычисляются посредством последовательных перестановок предикторов и оценки изменения эффективности модели при исключении воздействия предиктора. Существенное снижение эффективности модели свидетельствует о том, что предиктор важен. Но, обладая известными возможностями, этот метод не позволяет получить детальную информацию о зависимости между эффективностью модели и применяемыми в ней предикторами, давая, впрочем, возможность для изучения конкретных предикторов при помощи визуализаций и других подобных средств.
Отметим, что многие показатели важности переменных относятся ко вполне определенному типу данных, что нашло свое отражение в содержании главы. Так, в разделе 18.1 рассматриваются (в том числе на примерах из предшествующих глав) методы для числовых результатов, в разделе 18.2 — для категорийных результатов, а в разделе 18.3 — более общие подходы к решению поставленной задачи.
18.1. Числовые результаты
Влияние числовых предикторов на работу модели можно установить посредством классического способа, основанного на статистике корреляции точки данных. Эта количественная характеристика отражает линейные связи; для случаев квазилинейной или криволинейной связи более эффективным может оказаться коэффициент корреляции Спирмена (раздел 5.1). Эти показатели следует рассматривать как приближенные оценки связей; для более сложных отношений они могут оказаться неэффективными.
Например, данные QSAR, использованные в главах, посвященных регрессии, содержали ряд числовых предикторов. На рис. 18.1 изображены диаграммы разброса двух предикторов и результата.
Отношение между растворимостью и количеством атомов углерода относительно линейно и тривиально. Оценка простой корреляции равна -0,61, ранговой корреляции 0,67.
Для предиктора площади поверхности ситуация усложняется. Так, существует группа веществ с низкой площадью поверхности и относительно низкой растворимостью. Остальные вещества обладают более высокой растворимостью, последовательно возрастающей до точки, после которой дальнейший прирост показателя растворимости минимален. Эта потенциально важная информация, однако, не будет отражаться статистикой корреляции. Для соответствующего предиктора оценка простой корреляции равна 0,27, ранговой корреляции — 0,14. Эти значения относительно малы, что сказывается и на ранжировке предиктора (17-е место из 20).
508 Глава 18. Определение важности предикторов
о
-fl
§
-10
1 2 3 4 5 6 0 5 10 15 20
Рис. 18.1. Диаграммы разброса для двух числовых предикторов
(на преобразованных осях) для данных растворимости. Линиями обозначены сглаженные варианты обучения модели
Альтернативное решение — использование более гибких методов, способных моделировать общие нелинейные отношения. Один из таких методов — модель регрессии с локальными весами (более известная под названием LOESS), описанная у Кливленда и Девлина (Cleveland and Devlin, 1988) — основан на серии полиномиальных регрессий, моделирующих данные в малых окрестностях (по аналогии с вычислением скользящего среднего). Этот метод достаточно эффективен для создания плавных регрессионных трендов, отличающихся исключительно высокой адаптивностью. Обратим внимание на линии (рис. 18.1), соответствующие плавному LOESS-обучению. По обучению модели на основании остатков можно вычислить статистику псевдо-/?2. Для данных растворимости, отображаемых на рис. 18.1, LOESS-статистика псевдо-/?2 для площади поверхности равна 0,22, что обеспечивает сравнительно более высокое ранжирование (7-е место из 20), чем с показателями корреляции.
На рис. 18.2 представлены отношения между показателями важности всех непрерывных предикторов.
Третий показатель, MIC (Maximal Information Coefficient), рассматривается в разделе 18.3. Ранговая корреляция и LOESS-метрика псевдо-/?2 дают приблизительно одинаковые результаты, за исключением двух предикторов площади поверхности. Оба метода отражают три разные группы предикторов, определяемые их рангами: О набор из четырех предикторов с высокой важностью (два значительных перекрытия на диаграмме);
О набор из четырех предикторов с умеренной важностью;
О набор с крайне низкой важностью.
18.1. Числовые результаты 509
Рис. 18.2. Метрики важности на матричной диаграмме разброса для 20 непрерывных предикторов в данных растворимости.
Два предиктора площади поверхности обозначены квадратами
Единственное расхождение между методами — в том, что два предиктора площади поверхности с LOESS показывают более высокие результаты, чем с другими методами. Эти предикторы выделены на диаграмме квадратами.
Поскольку каждый предиктор оценивается без учета остальных, это может привести к искажениям в интерпретации их значимости. Во-первых, если два предиктора сильно коррелированы с реакцией и друг с другом, то одномерное решение идентифицирует оба предиктора как важные, что в дальнейшем может отрицательно повлиять на некоторые модели. Одно из решений, направленных на нейтрализацию подобной проблемы, — предварительная обработка (например, исключение сильно коррелированных предикторов).
Во-вторых, одномерное решение не позволяет идентифицировать группы предикторов, которые в сочетании друг с другом сильно связаны с реакцией. Например, каждый из предикторов в отдельности может не иметь сильной корреляции с реакцией, но такая корреляция наблюдается у комбинации предикторов.
510 Глава 18. Определение важности предикторов
Одномерные корреляции не смогут отразить подобные предиктивные отношения. В таких случаях целесообразно провести дальнейшее исследование предикторов, вместо того чтобы использовать ранжирование как единственный источник понимания существующих трендов. Для определения того, какие именно отношения следует анализировать, обычно требуются более обстоятельные сведения о данных, их более глубокое осмысление.
Для категорийных предикторов требуются другие методологии. Вспомним в этой связи, что в данных растворимости встречаются 208 бинарных предикторов — индикаторных переменных, представляющих конкретные структуры атомов в веществе. Самый прямолинейный метод для определения релевантности каждого бинарного предиктора основан на оценке различий между средними результатами по каждой категории. Для предиктора FP175 различия между средним значением растворимости с этой структурой и без нее составляет -0,002. С учетом того, что растворимость изменяется в интервале от -11,6 до 1,6, это изменение с большой вероятностью следует рассматривать как пренебрежимо малое. Для предиктора FP044 разность составит 4,1 логарифмической единицы, что не добавляет относящейся к делу информации. Также необходимо учитывать дисперсию данных.
Наиболее подходящим представляется метод сравнения средних значений двух групп — стандартная ^-статистика, представляющая собой соотношение «сигнал/ шум» (разность средних значений делится на функцию дисперсии в группах и предполагает нормальное распределение данных). Этот метод позволяет получить р-значение, характеризуемое нулевым ожиданием отсутствия различий между группами. Допустимо и применение некоторых других методов, в частности, основанных на оценке критериев суммы рангов Уилкоксона и т. п.
Для каждого из 208 бинарных предикторов был применен £-тест (без абсолютизации важности p-значений). На рис. 18.3 изображена так называемая вулканная диаграмма (одна из разновидностей диаграммы рассеяния) с преобразованной версией p-значения на оси у и разностью средних значений растворимости на оси х.
Более высокие значения по оси у свидетельствуют о сильной статистической значимости (то есть низком p-значении). Большинство разностей средних значений — отрицательно, что указывает на то, что растворимость склонна к повышению без структуры. Предиктор FP044 имеет наибольшую разность (обозначен квадратом), не являющуюся, впрочем, статистически значимой. Наибольшей статистической значимостью обладает предиктор FP076 (синий треугольник) при разности средних -2,3 логарифмической единицы. Как упоминалось ранее, ^-статистика фактически представляет отношение «сигнал/шум». Хотя предиктор FP044 обладает наиболее высокой сигнальной составляющей, он характеризуется и заметным разбросом, снижающим его значимость. Это обстоятельство отражено в 95-процентных доверительных интервалах для разности средних значений: (3,6,4,7) для FP044 и (2,1, 2,6) для FP076 соответственно. Какой же предиктор важнее? Ответ на этот вопрос зависит от контекста и конкретного набора данных. Если сигнал достаточно высок,
18.2. Категорийные результаты 511
50
_ 40
а>
s
z
I зо
Z
ср
| 20
10
0
-4 -3-2-10 1 2
Среднее со структурой — Среднее без структуры
Рис-18.3. Вулканная диаграмма результатов f-теста, примененного к бинарным предикторам. Квадрат соответствует предиктору FP044 (с наибольшей средней разностью), а треугольник соответствует предиктору FP076 с наибольшей статической значимостью
то модель сможет преодолеть шум. В остальных случаях меньшие, но одновременно и более стабильные разности смогут обеспечить лучшую эффективность.
Если предиктор принимает более двух значений, то модель дисперсионного анализа (ANOVA) может использоваться для описания их статистической значимости. Если же средние значения категорий окажутся разными, то из этого усматривается необходимость выявления различий — например, посредством разложения категорий на бинарные фиктивные переменные и процедуры, описанной выше, для определения релевантности каждой категории.
18.2. Категорийные результаты
При наличии категорийных результатов и числовых предикторов существует несколько разных методов количественной оценки важности предикторов. Для демонстрации этих методов используем данные сегментации изображений из главы 3. На рис. 18.4 изображены гистограммы двух предикторов (ширина волокон для канала 1 и количество волокон для канала 4) для каждого класса.
Ширина волокон отражает сдвиг средних значений между классами, тогда как распределение количества волокон выглядит очень похожим между классами.
В задачах с двумя классами для количественной оценки релевантности предикторов можно воспользоваться площадью под ROC-кривой. В разделах 11.3 и 16.4
512 Глава 18. Определение важности предикторов
О 10 20 30 40
50
40
30
20
10
50
40
30
20
10
О
0
О 10 20 30 40
Рис. 18.4. Гистограммы двух предикторов в данных сегментации клеток, разделенные по классам использована ROC-кривая с прогнозируемыми вероятностями классов в качестве входных данных (здесь — данных предикторов). Если предиктор способен обеспечить идеальное разделение классов, то порог отсечения, обеспечивающий чувствительность и специфичность, равен 1, при этом площадь под кривой также равна 1. Как и прежде, у абсолютно нерелевантного предиктора площадь под кривой равна приблизительно 0,5. На рис. 18.5 изображена площадь под кривой для предикторов ширины волокон и количества волокон.
Площадь под ROC-кривой для данных ширины волокон равна 0,836, тогда как значение для количества волокон равно 0,538. Как видим, здесь повторяются тренды, представленные на рис. 18.4, где ширина волокон демонстрировала большую степень разделения между классами. При наличии нескольких классов можно воспользоваться расширениями ROC-кривых, описанными у Хэнли и Макнила (Hanley and McNeil, 1982), Делонга (DeLong et al., 1988), Венкатрамана (Venkatraman, 2000) и Пепе (Pepe et al., 2009). Возможно и создание набора ROC-кривых «один против всех», в котором объединяются все классы, кроме одного. В этом случае для каждого класса площадь под кривой вычисляется отдельно, а общая релевантность оценивается с использованием средней или максимальной площади под кривой между классами.
Другой, более простой способ сводится к проверке различий между средними значениями предикторов в каждом классе. Он напоминает метод, описанный в предыдущем разделе, но в этом контексте предиктор рассматривается как результат. Вулканные диаграммы в данном случае неприменимы, потому что разности могут измеряться по разным шкалам. Тем не менее ^-статистики позволяют сравнить предикторы с разными шкалами. Для ширины волокна значение ^-статистики
18.2. Категорийные результаты 513
о
о
1,0 0,8 0,6 0,4 0,2 0,0
Специфичность
Рис. 18.5. ROC-кривые для двух предикторов в данных сегментации клеток равно -19, что показывает наличие четкого сигнала над шумом. Для количества волокон значение сигнала равно трем.
Для данных сегментации 58 непрерывных предикторов оценены каждым из методов (вместе с показателем важности переменной для случайного леса) и двумя методами, описанными в разделе 18.3 (MIC and Relief). Отметим, что эти методы приблизительно эквивалентны (рис. 18.6).
Площадь под ROC-кривой демонстрирует плотную криволинейную связь с показателем случайного леса и сильную линейную связь с ^-статистикой, ^-статистика и модель случайного леса на первый взгляд ранжируют одни и те же предикторы как менее важные, но в показателях предикторов, квалифицированных как самые важные, существуют различия. Трем предикторам оба метода обычно назначают очень высокий ранг: средней интенсивности (канал 2), ширине волокон (канал 1) и общей интенсивности (канал 2).
Для категорийных предикторов существует несколько подходящих показателей. Так, для бинарных предикторов и двух классов одним из эффективных методов измерения релевантности является отношение шансов (OR). Напомним, что шансами (odds) вероятности называется величина р/(1 - р). Вероятность события может быть вычислена для двух уровней предиктора. Если обозначить ихрх и р2, то отношение шансов, следуя Агрести, Блэнду и Альтману (Bland and Altman, 2000; Agresti, 2002), вычисляется по формуле
Р2О-Р1)
514 Глава 18. Определение важности предикторов
Канал 1 Канал 3
Канал 2 Канал 4
Матричная диаграмма разброса
Рис. 18.6. Матричная диаграмма разброса для нескольких разных метрик ранжирования предикторов с набором данных сегментации изображений
Для наглядности вновь обратимся к данным заявок на получение грантов. В этих данных существовало 226 бинарных предикторов, причем каждая ячейка таблицы 2 х 2 содержала не менее 25 точек. В табл. 18.1 представлена перекрестная табуляция трех предикторов в данных грантов.
В случае категории суммы контракта вероятность успеха определялась показателями рх = 0,661 ир2= 0,237 для, соответственно, известной или неизвестной категории. Отношение шансов равно 6,3; это означает, что при известной категории шансы на успех возрастают шестикратно. Как и в случае с разностью средних значений, отношение шансов отражает сигнал, а не шум. Формулы для вычисления довери-
18.2. Категорийные результаты 515
Таблица 18.1. Статистика трех бинарных категорийных предикторов в данных грантов
Успех гранта
Про- цент
OR
р-значение
Коэффициент прироста
да
нет
Спонсор
62В
7
44
14
Другие
3226
3356
49
6,0
2,бе 07
0,04726
Категория суммы контракта (CVB)
Неизвестна
644
2075
24
Известна
2589
1325
66
6,3
1,7е 263
0,13408
Код RFCD
240302
13
15
46
Другой код
3220
3385
49
1,1
8,5е 01
0,00017
тельного интервала для отношения шансов известны, но более распространенное решение заключается в проверке статистической гипотезы о паритете соотношения шансов. Точный критерий Фишера ( Agresti, 2002) может использоваться для оценки гипотезы с двумя категориями и двумя значениями предиктора, а для обобщения результата — итоговое p-значение. Для этого предикторар-значение практически не отличалось от нуля; это означает, что уровни категории суммы контракта связаны с успехом заявки. В табл. 18.1 представлен еще один предиктор «Спонсор» 62В, с похожим отношением шансов (OR = 6), но количество грантов с этим спонсором очень низко. Здесь p-значение также оказалось незначительным, но ранжировалось гораздо ниже с использованием статистической значимости.
В левой части рис. 18.7 представлены вулканная диаграмма отношения шансов и соответствующее p-значение для 226 бинарных предикторов грантов.
При наличии более двух классов (предикторов) с двумя и более уровнями можно воспользоваться другими методами. Точный критерий Фишера по-прежнему может использоваться для оценки связи между предиктором и классами. Коэффициент прироста, используемый для модели С4.5, может быть применен для количественной оценки связи между двумя переменными (по принципу «чем больше — тем лучше»). Напомним, что коэффициент прироста вносит корректировку для количества уровней предиктора, позволяющую устранить смещение против атрибутов с малым количеством уровней. С учетом этого обстоятельства коэффициент прироста может применяться ко всем категорийным предикторам независимо от их характеристик.
516 Глава 18. Определение важности предикторов
§
3
-2 0 2
ю
о
о
о'
о
о
8 о'
-2 0 2
Логарифм отношения шансов
Рис. 18.7. Логарифм отношения шансов в сравнении с двумя другими статистиками.
Слева: функция p-значений из точного критерия Фишера. Наибольшее значение данных равно 263; диаграмма усекается на уровне 50 для сохранения перспективы.
Справа: коэффициент прироста для каждого предиктора. Квадрат соответствует предиктору спонсора 62В, а треугольник — предиктору неизвестной категории суммы контракта
В табл. 18.1 показан прирост информации для трех предикторов данных грантов, а на рис. 18.7 статистика прироста сравнивается с отношением шансов. Как и p-значение для точного критерия Фишера, статистика прироста отдает предпочтение предиктору категории суммы контракта перед предиктором спонсора 62В, несмотря на сходство их отношений шансов.
18.3. Прочие методы
Алгоритм Relief, рассмотренный, в частности, у Киры и Ренделла (Kira and Rendell, 1992), представляет собой обобщенный метод количественной оценки важности предикторов. Изначально он был разработан для задач классификации с двумя классами, но затем расширен для более широкого диапазона задач. Он может поддерживать непрерывные предикторы и фиктивные переменные, а также распознавать нелинейные связи между предикторами и результатом, используя случайно выбранные точки и их ближайших соседей для оценки каждого предиктора в изоляции от других.
Для конкретного предиктора алгоритм пытается охарактеризовать разделение между классами в изолированных секциях данных. Формальная процедура приведена в алгоритме 18.1.
18.3. Прочие методы 517
Алгоритм 18.1. Исходный алгоритм Relief для ранжирования предикторных переменных в классификационных моделях с двумя классами.
1 Инициализировать показатели предикторов S} нулями.
2 for i = 1,т случайно выбранных точек тренировочного набора (/?•) do
3
4
5
6
7
Найти ближайший промах и попадание в тренировочном наборе, forу = 1,р предикторных переменных do
Скорректировать показатель каждого предиктора на основании близости Rj к ближайшему промаху и попаданию:
= Sj - diff^ Hity/m + cliffy Missy/т
end 8 end
Для случайно выбранной точки тренировочного набора алгоритм находит ближайшие точки из обоих классов (называемые «попаданиями» и «промахами» — hits and misses). Для каждого предиктора вычисляется разность значений между случайной точкой данных и попаданиями/промахами. Для непрерывных предикторов Кира и Ренделл (Kira and Rendell, 1992) предлагают использовать расстояние между двумя точками, разделенное на общий диапазон значений предиктора:
diff(x, у) = (х- у)/С,
где С — константа для предиктора, масштабирующая разность в диапазоне от О до 1. Для бинарных данных (то есть 0/1) можно воспользоваться простым индикатором эквивалентности (при сохранении диапазона значений в пределах от 0 до 1):
diff(x, у) = |х - у |.
Общий показатель (5.) представляет собой накопленную форму этих различий; показатель уменьшается, если попадание сильно удалено от случайно выбранного значения, но увеличивается, если далеко находится промах. Идея заключается в том, что у предиктора, который демонстрирует разделение между классами, попадания должны находиться вблизи, а промахи — далеко. С учетом этого обстоятельства большие показатели указывают на важность предикторов. Например, на рис. 18.8 представлен набор данных для нескольких предикторов.
В верхней части показан предиктор, полностью разделяющий классы. Допустим, процедура выборки выбирает предпоследнюю точку из левой части (предиктор А = -1,1). Ближайшее попадание находится с одной из сторон этой точки данных с разностью приблизительно 0,2. Ближайший промах находится далеко (А = 0,5) с соответствующей разностью -1,61. Если предположить, что эта точка
518 Глава 18. Определение важности предикторов
Класс 1 Класс 2
Рис-18.8. Три набора данных, демонстрирующих алгоритм Relief.
Наверху для предиктора А видно полное разделение с показателем ReliefF, равным 0,19. Внизу изображен полностью неинформативный предиктор с соответствующим показателем ReliefF, равным 0
является первой случайно выбранной точкой тренировочного набора, то показатель составит
S4 = 0 - 0,22 +-1,612= 2,55.
Это значение будет разделено на т, и будут сгенерированы новые значения. В контрпримере предиктор В на рис. 18.8 полностью неинформативен. Каждое попадание и каждый промах являются соседними для любой случайно выбранной точки, поэтому разности всегда будут компенсировать друг друга, а показатель этого предиктора будет равен SB= 0.
Данная процедура была дополнительно усовершенствована Кононенко (Kononenko, 1994). Модифицированный алгоритм, получивший название ReliefF, использует более одного ближайшего соседа, измененную метрику разности и поддерживает более двух классов и отсутствующие значения предикторов. Робник-Сиконья и Кононенко (Robnik-Sikonja and Kononenko, 1997) адаптировали алгоритм для регрессии (то есть числовых результатов).
На рис. 18.9 (в нижней его части) показан гипотетический набор данных с двумя классами и двумя коррелированными предикторами (обозначенными С и D).
Граница классов создана посредством простого уравнения модели логистической регрессии с двумя сильными основными эффектами и умеренным эффектом взаимодействия:
18.3. Прочие методы 519
log^j = -4С - W + 2CD.
Данные на рис. 18.9 смоделированы с этой границей класса. Модель логистической регрессии смогла достичь точности перекрестной проверки 90,6 %. Исходя из истинного уравнения модели, оба предиктора следует оценивать как важные. Поскольку в уравнении модели существует эффект взаимодействия, можно ожидать, что алгоритм Relief F будет демонстрировать более высокий сигнал, чем другие методы, рассматривающие предикторы по одному. Для этих данных алгоритм Relief F использовался ст = 50 случайными точками и k = 10 ближайшими соседями.
-3-2-10 1 2
Предиктор С
0,0 0,1 0,2 0,3
30
_ 25
со
о 20
5 15
о 10
0)
5
0
0,0 0,1 0,2 0,3
Relief Score
Рис. 18.9. Наверху: два предиктора с выраженной границей классов. В этом примере показатели ReliefF для предикторов С и D были равны 0,17 и 0,25 соответственно. Внизу: перестановочное распределение показателей при отсутствии связей между предикторами и классами. Пунктирные линии обозначают наблюдаемые показатели ReliefF
520 Глава 18. Определение важности предикторов
До выполнения алгоритма к двум предикторам было выполнено центрирование и масштабирование. Показатели предикторов С и D составили 0,17 и 0,25 соответственно. Площади под ROC-кривыми для предикторов С и D были умеренными, со значениями 0,65 и 0,69 соответственно.
Какой порог отсечения должен использоваться для этих показателей? Кира и Рен- делл (Kira and Rendell, 1992) предполагают, что порог «может быть много меньше 1/у1ат», где а — желательная частота ложноположительных значений (то есть процент случаев, в которых нерелевантный предиктор был сочтен важным). При использовании этого эталона с 5-процентной частотой ложноположительных значений значения выше 0,63 могут считаться важными. Есть альтернатива — использование проверенного статистического метода, называемого критерием перестановки (Good, 2000), для оценки показателей. Здесь метки истинных классов случайным образом переставляются, а показатели ReliefF многократно вычисляются заново. Это должно дать некоторое представление о распределении показателей, когда предиктор нерелевантен. Далее наблюдаемый показатель можно проверить по этому распределению для описания того, насколько оно экстремально относительно предположения о нерелевантности предиктора. При использовании 500 случайных перестановок данных распределения показателей для предикторов С и D напоминали нормально распределенные данные (см. рис. 18.9). Для предиктора С значения показателя лежали в интервале от -0,05 до 0,11, для предиктора D — от -0,05 до 0,11. В этом контексте два наблюдаемых значения для данных на рис. 18.9 характерны для очень важных предикторов.
По симметричным, нормально распределенным формам случайных перестановок можно определить, что показатели для предикторов С и D находятся в 4,5 и 11,6 стандартного отклонения от того, чего следовало бы ожидать по вероятности. Если принять во внимание, насколько экстремальны показатели, то следует сделать вывод, что оба предиктора являются важными факторами для разделения классов.
Для данных сегментации клеток на рис. 18.6 представлены показатели ReliefF для всех предикторов. Эти значения умеренно коррелированы с другими показателями, демонстрируя большую изменчивость в связях. Например, площадь под ROC-кривой проявляет меньше шума в связях с другими метриками. Это может объясняться метриками, оценивающими другие аспекты данных, или произвольной выборкой, используемой ReliefF.
Решеф (Reshef et al., 2011) описывает новый показатель для количественного описания связи между двумя переменными — MIC. Предлагаемый им метод разбивает двумерную область, определяемую предиктором и результатом, на наборы двумерных сеток. Например, на рис. 18.10 показана диаграмма разброса данных растворимости: для предиктора количества атомов углерода создаются четыре случайные сетки 4^3.
В каждой сетке рассчитывается количество точек данных, которое используется для вычисления статистики взаимной информации (Brillinger, 2004), связанной
18.3. Прочие методы 521
2 3 4 5 6
о
-5
* -10
о о
S
s
о. о о га О_
0
-5
-10
1 2 3 4 5 6
Количество атомов углерода
Рис. 18.10. Примеры создания критерия MIC (Maximal Information Criterion). На каждой диаграмме показана случайная конфигурация сеток 4x3 для одного из предикторов растворимости с соответствующей статистикой взаимной информации
с критерием информации, описанным в главе 14 для деревьев принятия решений C4.5 и С 5.0. Вычисляются несколько разных конфигураций с одинаковым размером сетки, после чего определяется наибольшее значение взаимной информации. Процесс повторятся для различных вариантов размеров сетки (например, 2 * 2,10 * 3). Сводка значений взаимной информации по всем группам нормализуется; самое большое значение по всем конфигурациям используется для оценки устойчивости связи между предиктором и результатом.
По мнению ряда авторов, этот метод пригоден для выявления самых разных типов связей, включая синусоиды, эллипсоиды и другие сильно нелинейные закономерности. Масштаб показателя аналогичен масштабу простой статистики корреляции; нулевое значение означает отсутствие связи, тогда как значение 1 характеризует исключительно сильную связь. Один из потенциальных недостатков подобных обобщенных методов — в том, что в некоторых ситуациях она может уступать другим методам. Например, если истинная связь между предиктором и результатом
522 Глава 18. Определение важности предикторов линейна, то статистика простой корреляции может оказаться более эффективной (как изначально предназначенная для линейных трендов).
Статистика MIC для непрерывных предикторов растворимости представлена на рис. 18.1. Как видим, значения MIC обладают сильной связью с другими показателями. Для данных сегментации клеток (см. рис. 18.6) статистика MIC сильно коррелирована с абсолютной Z^-статистикой, площадью под ROC-кривой и показателем случайного леса. С Relief F наблюдается более умеренный уровень корреляции.
18.4. Вычисления
В этом разделе используются функции из следующего пакета R: AppliedPredictiveModeling, caret,CORElearn, minerva, pROC и randomForest.
Также здесь используются данные сегментации ячеек из главы 3, находящиеся в пакете caret. Данные растворимости из глав 6-9 также находятся в пакете AppliedPredictiveModeling. Наконец, здесь также используются данные заявок на получение грантов из глав 12-15 (о том, как выполняется чтение и обработка этих данных, см. раздел 12.7).
Числовые результаты
Для оценки корреляции между предикторами и результатом используется функция сог. Пример:
> Library(АррLiedPredictiveModeLing)
> data(soLubiLity)
> corfsoLTrainXtransfNumCarbon^ soLTrainY)
[1] -0.6067917
Чтобы получить результаты для всех числовых предикторов, можно воспользоваться функцией apply для выполнения тех же вычислений по нескольким столбцам:
> ## Определить, имена каких столбцов содержат строку "FP",
> ## и исключить их для получения числовых предикторов,
> fpCois<- grepL("FP”, names(soLTrainXtrans))
> ## ExcLude these to get the numeric predictor names
> numericPreds <- names(soLTrainXtrans)[IfpCoLs]
> corrVaLues <- appLy(soLTrainXtrans[, numericPreds]>
+ MARGIN = 2,
+ FUN - function(x, y) cor(x, y),
+ у = soLTrainY)
18.4. Вычисления 523
> head(corrVaLues)
MolWeight NumAtoms NumNonHAtoms NumBonds NumNonHBonds
-0,6585284 -0.4358113 -0.5836236 -0.4590395 -0.5851968
NumMuItBonds
-0.4804159
Для получения ранговой корреляции у функции согг имеется параметр method = ’’spearman".
Чтобы применить сглаживание LOESS, можно воспользоваться функцией loess из библиотеки stats. Для определения модели можно воспользоваться интерфейсом формул:
> smoother <- Loess(soLTrainY ~ soLTrainXtrans$NumCarbon)
> smoother
Call:
loess(formula = solTrainY ~ solTrainXtrans$NumCarbon)
Number of Observations: 951
Equivalent Number of Parameters: 5.3
Residual Standard Error: 1.548
Функция xyplot удобна для графического представления обучения LOESS:
> xypLotfsoLTrainY ~ soLTrainXtransfNumCarbon,
* type = c("p", "smooth"),
+ xLab = "# Carbons"j
+ у Lab = "SoLubiLity")
Функция f ilterVarlmp из пакета caret с параметром nonpara = TRUE (для непараметрической регрессии) создает модель LOESS для каждого предиктора и вычисляет качественную оценку связи с результатом:
> LoessResuLts <- fiLterVarlmpfx = soLTrainXtrans[, numericPreds],,
+ у = soLTrainY,
-I- nonpara = TRUE)
> head(LoessResuLts)
Overall
MolWeight 0.4443931
NumAtoms 0.1899315
NumNonHAtoms 0.3406166
NumBonds 0.2107173
NumNonHBonds 0.3424552
NumMultBonds 0.2307995
Пакет minerva может использоваться для вычисления статистик MIC между предикторами и результатами. Функция mine вычисляет несколько величин, включая значение MIC:
524 Глава 18. Определение важности предикторов
> Library(minerva)
> micVaLues <- mine(soLTrainXtrans[, numericPreds], soLTrainY)
> ## SeveraL statistics are caLcuLated
> names(micVaLues)
[1] "MIC" "MAS" "MEV" "MCN" "MICR2"
> head(micVaLues$MIC)
Y
MolWeight 0.4679277
NumAtoms 0.2896815
NumNonHAtoms 0.3947092
NumBonds 0.3268683
NumNonHBonds 0.3919627
NumMultBonds 0.2792600
Для категорийных предикторов простая функция t. test вычисляет разность средних значений ир-значение. Для одного предиктора:
> t.test(soLTrainY - soLTrainXtrans$FP044)
Welch Two Sample t-test
data: solTrainY by solTrainXtrans$FP044
t = 15.1984, df = 61.891, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
3.569300 4.650437
sample estimates:
mean in group 0 mean in group 1
-2.472237 -6.582105
Этот метод можно распространить на все предикторы. Для этого используйте apply по аналогии с тем, как было показано выше для корреляций.
> getTstats <- function(x, у)
+ {
+ tTest <- t.test(y~x)
+ out <- c(tStat = tTestfstatistic, p = tTest$p.vaLue)
+ out
* }
> tVaLs <- appLy(soLTrainXtrans[j fpCoLs],
+ MARGIN = 2,
+ FUN = getTstats>
+ у - soLTrainY)
> ## switch the dimensions
> tVaLs <- t(tVaLs)
> head(tVaLs)
tStat.t p
FP001 -4.022040 6.287404e-05
FP002 10.286727 1.351580e-23
18.4. Вычисления 525
FP003 -2.036442 4.198619е-02
FP004 -4.948958 9.551772е-07
FP005 10.282475 1.576549е-23
FP006 -7.875838 9.287835е-15
Категорийные результаты
Функция filterVarlmp также вычисляет площадь под ROC-кривой в том случае, когда переменная результата является факторной переменной R:
> Library(caret)
> data(segmentationData)
> ceLLData <- subset(segmentationData, Case == "Train")
> ceLLData$Case <- ceLLData$CeLL <- NULL
> ## Класс находится в первом столбце
> head(names(ceLLData))
[1] "Class" "AngleChl" "AreaChl" "AvglntenChl"
[5] "AvgIntenCh2" "AvgIntenCh3"
> rocVaLues <- fiLterVarlmpfx = ceLLData[,-1],
+ у = ceLLData$CLass)
> ## Для каждого класса создается столбец
> head(rocVaLues)
PS ws
AngleChl 0.5025967 0.5025967
AreaChl 0.5709170 0.5709170
AvglntenChl 0.7662375 0.7662375
AvgIntenCh2 0.7866146 0.7866146
AvgIntenCh3 0.5214098 0.5214098
AvgIntenCh4 0.6473814 0.6473814
По сути, это простая обертка для функций гос и аис в пакете pROC. С тремя и более классами filterVarlmp вычислит ROC-кривые для каждого класса (вместо того, чтобы вычислить их для каждого класса в сравнении с другими, а затем вернуть наибольшую площадь под кривой).
Статистики Relief вычисляются при помощи пакета CORElearn. Функция attrEval вычисляет несколько версий Relief (с параметром estimator):
> Library(CORELearn)
> reLiefVaLues <- attrEvaL(CLass - data = ceLLData,
+ ## Доступны многие другие методы Re Lief.
+ ## См. tattrEvaL
+ estimator = "ReLiefFequaLK",
+ ## Количество протестированных экземпляров:
+ Re LiefIterations = 50)
> head(reLiefVaLues)
AngleChl AreaChl AvglntenChl AvgIntenCh2 AvgIntenCh3 AvgIntenCh4
0.01631332 0.02004060 0.09402596 0.17200400 0.09268398 0.02672168
526 Глава 18. Определение важности предикторов
Функция также может использоваться для вычисления коэффициента прироста, коэффициента Джини и других показателей. Для анализа наблюдаемых значений статистики Relief F с применением метода перестановок в пакет AppliedPredictiveModeling включена функция permuteRelief:
> perm <- permuteReLief(x = ceLLData[,-1],
-I- у = ceLLData$CLass,
+ nperm = 500,
+ estimator = "ReLiefFequaLK",
+ Re LiefIterations = 50)
Показатели перестановок Relief F содержатся в подобъекте с именем permutations:
> head(perm$permutations)
Predictor
1 AngleChl
2 AngleChl
3 AngleChl
4 AngleChl
5 AngleChl
6 AngleChl
value -0.009364024 0.011170669 -0.020425694 -0.037133238 0.005334315 0.010394028
Перестановочные распределения для показателей Relief F могут оказаться полезными для анализа. Гистограммы наподобие тех, что показаны на рис. 18.9, могут создаваться синтаксисом следующего вида:
> histogram(~ vaLue/Predictor,
+ data = permfpermutations)
Кроме того, стандартизированные версии показателей хранятся в подобъекте с именем standardized и представляют количество стандартных отклонений наблюдаемых значений Relief F (без перестановок) от центра перестановочного распределения:
> head(permfstandardized)
AngleChl AreaChl AvglntenChl AvgIntenCh2 AvgIntenCh3 AvgIntenCh4
-1.232653 3.257958 3.765691 8.300906 4.054288 1.603847
Статистика MIC может вычисляться так же, как и прежде, но с кодированием классов в бинарных фиктивных переменных:
> micVaLues <- mine(x = ceLLData[,-l],
+ у = ifeLse(ceLLData$CLass = "PS", 1, 0))
>
> head(micVaiues$MIC)
Y
AngleChl 0.1310570
18.4. Вычисления 527
AreaChl 0.1080839
AvglntenChl 0.2920461
AvgIntenCh2 0.3294846
AvgIntenCh3 0.1354438
AvgIntenCh4 0.1665450
Чтобы вычислить отношение шансов и статистический критерий взаимосвязи, можно воспользоваться функцией fisher.test из библиотеки stats. Например, вычисление этих статистик для объектов грантов, созданных в разделе 12.7, происходит так:
> Sp62BTabLe <- tabLe (training [pre2008_, "Sponsor62B"],
+ training[pre2008, "CLass"])
> Sp62BTabLe
successful unsuccessful
0 3226 3356
1 7 44
> fisher, test(Sp62BTabLe)
Fisher's Exact Test for Count Data
data: Sp62BTable
p-value = 2.644e-07
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
2.694138 15.917729
sample estimates:
odds ratio
6.040826
Если предиктор содержит более двух классов, вычислить одиночное отношение шансов не удастся, но использовать p-значение для этой взаимосвязи все равно
возможно:
> ciTabte <- tabLe(training[pre2008_, "CI, 1950"].
+ training[pre2008, "CLass"])
> ciTabLe
successful unsuccessful
0 2704 2899
1 476 455
2 45 39
3 7 7
4 10
> fisher,test(ciTabLe)
Fisher's Exact Test for Count Data data: ciTable p-value = 0.3143 alternative hypothesis: two.sided
528 Глава 18. Определение важности предикторов
В некоторых случаях точный критерий Фишера может быть неприемлемым с точки зрения вычислительных затрат. В таких случаях можно вычислить критерий х2 для этой взаимосвязи:
> DayTabLe <- tabLe(training[pre2008, "Weekday"], + training[pre2008, "CLass"])
DayTabLe
successful
unsuccessful
Fri
542
880
Mon
634
455
Sat
615
861
Sun
223
0
Thurs
321
246
Tues
377
309
Wed
521
649
> chisq.test(DayTabLe)
Pearson's Chi-squared test data: DayTable
X-squared = 400.4766, df = 6, p-value < 2.2e-16
Показатели важности для разных моделей
Как упоминалось в предыдущих главах, многие модели содержат встроенные средства для измерения совокупного воздействия предикторов на модель. Пакет caret содержит общий класс для вычисления или получения этих значений. На момент написания книги существовали методы для 27 классов R, включая: С5.0, JRip, PART, RRF, RandomForest, bagEarth, classbagg, cubist, dsa, earth, fda, gam, gbm, glm, glmnet, lm, multinom, mvr, nnet, pamrtrained, plsda, randomForest, regbagg, rfe, rpart, sbf и train.
Для демонстрации было произведено обучение модели случайного леса к данным сегментации клеток:
> Library(randomForest)
> set.seed(791)
> rflmp <- randomForest(CLass ~ ., data = segTrain,
+ ntree = 2000,
+ importance = TRUE)
Пакет randomForest содержит функцию importance, которая возвращает соответствующую метрику. Функция varimp выполняет стандартизацию между моделями:
> head(varimp(rflmp))
PS WS
AngleChl -1.002852 -1.002852
AreaChl 8.769884 8.769884
Упражнения 529
AvglntenChl 21.460666 21.460666
AvgIntenCh2 22.377451 22.377451
AvgIntenCh3 7.690371 7.690371
AvgIntenCh4 9.108741 9.108741
Обратите внимание на то, что одни модели возвращают отдельный показатель для каждого класса, а другие этого не делают.
При использовании функции train функция varlmp выполняет соответствующий код в зависимости от значения аргумента method. Если модель не имеет встроенной функции для измерения важности, train применяет более общий подход, описанный выше.
Упражнения
18.1. Для данных ухода клиентов, описанных в упражнении 12.3:
A. Вычислите корреляции между предикторами. Существуют ли сильные связи между этими переменными? Соответствуют ли полученные результаты тем, которые можно было бы ожидать с этими атрибутами?
Б. Оцените важность категорийных предикторов (код зоны, план голосовой почты и т. д.) по отдельности, с использованием тренировочного набора.
B. Также оцените показатели важности непрерывных предикторов по отдельности.
Г. Воспользуйтесь ReliefF для совместной оценки важности предикторов. Наблюдаются ли различия в полученном ранжировании? Почему?
18.2. Для данных типов масел из упражнения 4.4 оцените показатели важности переменных. Влияет ли большое количество классов на процесс количественной оценки важности?
18.3. Данные UCI Abalone (http://archive.ics.uci.edu/ml/datasets/Abalone) состоят из данных 4177 моллюсков-абалонов. Данные содержат метрики типа (мужская особь, женская особь, незрелая особь), максимальный размер раковины, диаметр, высоту и несколько вариантов веса (целый, без раковины, внутренности и раковина). Результат определяет число колец. Возраст абалона равен количеству колец, увеличенному на 1,5. Данные содержатся в пакете AppliedPredictiveModeling:
> Library(AppLiedPredictiveModeLing)
> data(abaLone)
> str(abaLone)
'data.frame': 4177 obs. of 9 variables:
$ Type : Factor w/ 3 levels "F”/’I","M": 331322 1131...
$ LongestShell : num 0.455 0.35 0.53 0.44 0.33 0.425 0.53 0.545 ...
$ Diameter : num 0.365 0.265 0.42 0.365 0.255 0.3 0.415 0.425 ...
530 Глава 18. Определение важности предикторов
$ Height : num
$ Wholeweight : num
$ ShuckedWeight: num
$ VisceraWeight: num
$ Shellweight : num
$ Rings : int
> head(abaLone)
0.095 0.09 0.135 0.125 0.08 0.095 0.15 0.125 ...
0.514 0.226 0.677 0.516 0.205 ...
0.2245 0.0995 0.2565 0.2155 0.0895 ...
0.101 0.0485 0.1415 0.114 0.0395 ...
0.15 0.07 0.21 0.155 0.055 0.12 0.33 0.26 ...
15 7 9 10 7 8 20 16 9 19...
1
Type LongestShell Diameter Height WholeWeight ShuckedWeight
M
0.455
0.365
0.095
0.5140
0.2245
2
M
0.350
0.265
0.090
0.2255
0.0995
3
F
0.530
0.420
0.135
0.6770
0.2565
4
M
0.440
0.365
0.125
0.5160
0.2155
5
I
0.330
0.255
0.080
0.2050
0.0895
6
I
0.425
0.300
0.095
0.3515
0.1410
VisceraWeight Shellweight Rings
1
0.1010
0.150
15
2
0.0485
0.070
7
3
0.1415
0.210
9
4
0.1140
0.155
10
5
0.0395
0.055
7
6
0.0775
0.120
8
A. Постройте диаграмму для оценки функциональных связей между предикторами и результатом.
Б. При помощи диаграмм разброса и графиков корреляции определите, как предикторы связаны друг с другом.
B. Оцените показатели важности переменных для всех предикторов. Разработайте метод определения сокращенного набора предикторов без избыточности.
Г. Примените анализ РСА к непрерывным предикторам и определите, сколько различных блоков информации содержится в данных. Принесет ли пользу выделение признаков при обработке этих данных?
Выбор признаков
Ответ на вопрос о том, какие именно предикторы должны быть включены в модель, обретает особую важность для случаев с многомерными данными. Вот несколько характерных примеров:
О Коммерческие компании все успешнее справляются с хранением и чтением больших объемов информации о своих заказчиках и продуктах. Часто они применяют глубинный анализ больших данных для обнаружения критически значимых связей (Lo, 2002).
О В фармацевтических исследованиях химики могут вычислять тысячи предикторов, используя методологию QSAR (Quantitative Structure-Activity Relationship), упоминавшуюся при описании регрессии, для числового описания различных аспектов молекул. Например, один популярный программный продукт вычисляет 17 разновидностей площади поверхности вещества. Эти предикторы могут быть как категорийными, так и непрерывными, а их количество может достигать десятков тысяч.
О В биологии в ходе анализа образца биологического материала (например, крови) может определяться гигантский массив биологических предикторов. Микромассивы профилирования выражений РНК могут оценивать тысячи последовательностей РНК одновременно. Кроме того, микромассивы ДНК и технологии расшифровки генетической последовательности могут подробно описывать генетическое строение образца с получением множества числовых предикторов. Стремительное развитие этих технологий позволяет теперь получать доступ к еще большим объемам информации.
С практической точки зрения модель с меньшим количеством предикторов может быть более интерпретируемой и менее дорогостоящей, особенно если измерение предикторов требует затрат времени и материальных ресурсов. Со статистической точки зрения часто бывает удобнее оценивать меньшее количество параметров. Кроме того, как мы вскоре увидим, неинформативные предикторы могут отрицательно влиять на работу некоторых моделей.
532 Глава 19. Выбор признаков
Отдельные модели при этом обладают естественной устойчивостью к неинформативным предикторам. Например, модели на базе деревьев и правил, MARS и модель лассо включают внутренний механизм выбора признаков. Если предиктор не используется при построении дерева, то уравнение прогнозирования становится функционально независимым от этого предиктора.
При выборе признаков необходимо различать контролируемые и неконтролируемые методы. Если результат игнорируется в ходе исключения предикторов, то метод является неконтролируемым. Речь идет, к примеру, об исключении предикторов, сильно коррелированных с другими предикторами или имеющих очень разреженные и несбалансированные распределения (так называемые предикторы с почти нулевой дисперсией, см. главу 3). В каждом подобном случае результат независим от фильтрующих вычислений.
Для контролируемых методов предикторы специально выбираются с целью повышения точности или нахождения набора предикторов для сокращения сложности модели. Здесь для количественной оценки важности предикторов обычно используется результат (глава 18).
Каждому типу выбора признаков присущи свои особенности. Обратимся в этой связи к более подробному рассмотрению необходимости выбора признаков, типичных методов выбора и наиболее типичных проблем, сопровождающих эти процессы.
19.1. Последствия использования неинформативных предикторов
Выбор признаков направлен прежде всего на исключение неинформативных или избыточных предикторов из модели. Важность выбора признаков зависит от используемой модели.
Многие модели, особенно основанные на углах наклона и точках пересечения регрессии, оценивают параметры для каждой составляющей модели. Присутствие неинформативных переменных может добавить неопределенности в прогнозы и сократить общую эффективность модели.
Данные растворимости QSAR, проанализированные в главах 6-9 и 20, будут использоваться и для демонстрации влияния неинформативных предикторов на разные модели. Будем исходить из того, что эти данные, как правило, содержат неинформативные предикторы. Проведем первичную и повторную настройки нескольких моделей с добавлением новых нерелевантных предикторов. Для этого модифицируем исходные данные предикторов случайной перестановкой строк (независимо для каждого столбца), что должно исключить связи между новыми предикторами и значениями растворимости. Эта процедура сохраняет природу отдельных предикторов (то есть бинарных с одинаковым распределением частот),
19.1. Последствия использования неинформативных предикторов 533
но имеет побочный эффект, проявляющийся в исключении межпредикторных корреляций.
Для формирования количественной оценки влияния дополнительных предикторов созданы модели с 228 исходными предикторами. В дальнейшем модели дополнялись неинформативными предикторами (в количестве от 10 до 500). Затем модели прошли настройку и были приведены к окончательному виду. Вычислены значения среднеквадратичной погрешности для тестового набора (рис. 19.1). Подобным образом оценены модели линейной регрессии, частных наименьших квадратов, одиночных деревьев регрессии, многомерных адаптивных регрессионных сплайнов, случайных лесов, нейросетей и опорных векторов с радиальной базисной функцией.
Как и ожидалось, на деревья регрессии и модели MARS эта процедура не повлияла из-за встроенного выбора признаков. Случайные леса продемонстрировали небольшое снижение эффективности.
0 100 200 300 400 500
U Линейная регрессия
Дерево регрессии
10 MARS
’ Случайные леса
0 q Частные наименьшие
’ квадраты
n q Опорные вектора
Лассо Нейросети
0 100 200 300 400 500
Количество дополнительных неинформативных предикторов
Рис. 19.1. Профили среднеквадратичной погрешности моделей растворимости при добавлении неинформативных предикторов
534 Глава 19. Выбор признаков
Однако случайный выбор предикторов для разделения может привести к включению в модель и некоторых несущественных предикторов, не оказывающих, впрочем, серьезного влияния на модель в целом. В наибольшей степени эта проблема присуща моделям с параметрической структурой (линейная регрессия, частные наименьшие квадраты и нейросети). Наиболее заметные проблемы возникли у нейросетей — возможно, из-за избыточного количества параметров, добавленных в модель. Например, сеть с пятью скрытыми параметрами начинает с оценки 961 параметра регрессии. Добавление 500 нерелевантных предикторов увеличивает количество параметров до 3461. Поскольку тренировочный набор уже содержит 951 точку данных, будет слишком трудно решить поставленную задачу без переобучения. Метод опорных векторов также видит существенное возрастание среднеквадратичной погрешности, что соответствует комментариям Хэсти (Hastie et al., 2008, глава 12).
С учетом риска отрицательного влияния возникает необходимость в нахождении наименьшего подмножества предикторов. Основная цель — сократить их количество и связанную с этим сложность модели с максимизацией ее эффективности.
19.2. Методы сокращения количества предикторов
Большинство методов сокращения количества предикторов, за исключением относящихся к моделям со встроенным выбором признаков, можно причислить, согласно Джону (John et al., 1994), к одной из двух основных категорий:
О Методы-обертки оценивают несколько моделей посредством добавления и/или удаления предикторов для нахождения оптимальной комбинации, максимизирующей эффективность модели. В сущности, методы-обертки представляют собой алгоритмы поиска, рассматривающие предикторы как входные данные, используя эффективность модели как оптимизируемый результат.
О Методы-фильтры оценивают релевантность предикторов вне предиктивных моделей и, соответственно, моделируют только те предикторы, которые удовлетворяют вполне конкретному критерию. Например, для задач классификации можно проверить каждый предиктор по отдельности, чтобы понять, существует ли ощутимая связь между ним и наблюдаемыми классами. В классификационную модель будут включены только предикторы с важными связями. Обзор методов-фильтров приведен в работе Сэйеса (Saeys et al., 2007).
Оба представленных метода имеют свои достоинства и недостатки. Методы-фильтры обычно более эффективны с вычислительной точки зрения, чем методы-обертки, но критерий выбора не связан напрямую с эффективностью модели. Кроме того, многие методы-фильтры оценивают каждый предиктор по отдельности и, следовательно, в результате могут быть выбраны избыточные (то есть сильно кор-
19.3. Методы-обертки 535
релированные) предикторы, тогда как важные взаимодействия между переменными не получат должной количественной оценки. Недостаток метода-обертки — в том, что оцениваться будут многие модели (которые также могут требовать настройки параметров), что приводит к возрастанию времени вычислений. Стоит отметить и возросший риск переобучения при использовании оберток.
Рассмотрим эти методы подробнее на соответствующих примерах.
19.3. Методы-обертки
Как упоминалось, методы-обертки проводят поиск предикторов для определения того, какие из них при использовании в модели обеспечивают наилучший результат. В качестве примера рассмотрим классический прямой выбор для линейной регрессии (алгоритм 19.1).
Алгоритм 19.1. Классический прямой выбор для моделей линейной регрессии
1 Создать исходную модель, содержащую только составляющую для точки пересечения.
2 repeat
3
4
5
6
7
8
9
10
11
for каждый предиктор, не входящий в текущую модель do
Создать возможную модель, добавив предиктор в текущую модель Использовать проверку гипотезы для оценки статистической значимости новой составляющей модели
end if наименьшее р -значение меньше порога включения then
Обновить текущую модель и включить составляющую, которая соответствует наиболее статически значимому предиктору
else
| Остановиться end
12 until за пределами модели не осталось статистически значимых предикторов
Предикторы оцениваются (по одному) в текущей модели линейной регрессии. Для проверки статистической значимости каждого из вновь добавленных предикторов (с некоторым заранее определенным порогом) можно воспользоваться проверкой статистической гипотезы. Если хотя бы у одного предиктора ^-значение лежит ниже порога, то предиктор, связанный с наименьшим значением, добавляется в модель, после чего процесс повторяется. Алгоритм останавливается, когда ни одно из
536 Глава 19. Выбор признаков p-значений оставшихся предикторов не является статистически значимым. В этой схеме линейная регрессия — базовая обучаемая модель, а прямой поиск — процедура поиска. Целевой функцией является оптимизируемая величина, которой в данном случае становится статистическая значимость, представленная р-значением.
У этого подхода есть несколько проблем:
1. Процедура прямого поиска является жадной, то есть она не пытается переоценивать прошлые решения.
2. Использование повторных проверок гипотез блокирует многие из статистических свойств, поскольку одни и те же данные оцениваются многократно (рис. 19.2).
3. Максимизация статистической значимости не всегда эквивалентна максимизации более релевантных характеристик на базе точности.
Для первой проблемы более сложные процедуры поиска могут оказаться и наиболее эффективными (см. также ниже). Вторая проблема широко изучалась в научных исследованиях Дерксена и Кеселмана, Олдена и Джексона, Харрелла, Уиттингема (Derksen and Keselman, 1992; Olden and Jackson, 2000; Harrell, 2001; Whittingham et al., 20061). Так, Харрелл (Harrell, 2001) обобщает использование p-значений в ходе автоматизированного выбора модели, указывая, что «...если бы эта процедура предлагалась всего лишь как статистический метод, то, скорее всего, она была бы отвергнута, потому что она нарушает все каноны статистической оценки и проверки гипотез».
Для разрешения второй и третьей проблем можно воспользоваться показателем предиктивной эффективности — например, среднеквадратичной погрешностью, точностью классификации или площадью под ROC-кривой.
Допустим, среднеквадратичная погрешность служит целевой функцией вместо статистической значимости. Алгоритм останется неизменным, но добавит в модель предикторы, приводящие к наименьшей среднеквадратичной погрешности модели. Процесс будет продолжаться до достижения некоторого заранее установленного количества предикторов или до использования полной модели. Отслеживание значений среднеквадратичной погрешности позволяет определить точку, с которой ошибка начинает возрастать. При этом выбран размер подмножества, связанный с наименьшей среднеквадратичной погрешностью. Как и следовало ожидать, главная проблема — получение хороших оценок частоты ошибок, не подверженных проблеме переобучения, обусловленной моделью или процессом выбора признаков (см. раздел 19.5).
1 В большинстве исследований этой проблемы изучался пошаговый выбор модели — разновидность прямого выбора. Тем не менее результаты применимы к любой процедуре поиска, которая использует проверку гипотезы подобным образом.
19.3. Методы-обертки 537
Рис. 19.2. Опасности повторной оценки одних данных
(Randall Munroe, http://xkcd.com/882, изменено для экономии места)
538 Глава 19. Выбор признаков
Существует и несколько других критериев, назначающих штрафы эффективности на основании количества предикторов в модели. Например, при выборе между двумя моделями с одинаковой среднеквадратичной погрешностью предпочтение отдается более простой модели с меньшим количеством предикторов. Для линейной регрессии обычно используется статистика информационного критерия Акаике (AIC) — штрафная версия суммы квадратов ошибки:
AIC = nlog^(^-^.)2J-h2JP>
где Р — количество составляющих в модели. При всех прочих равных условиях предпочтение отдается простоте перед сложностью. Аналогичные статистики AIC доступны и для других моделей, например логистической регрессии. Поиск в пространстве предикторов модели с наименьшим значением AIC может способствовать предотвращению переобучения1.
Другой метод — выбор признаков на основе корреляции (Hall and Smith, 1997) — пытается найти лучшее подмножество предикторов, имеющее сильную корреляцию с результатом, но слабые корреляции между предикторами. Одна из возможных метрик имеет вид
с_ PRy
JP+P(P-i)Rx ’
где Rv — метрика корреляции между предиктором-кандидатом и результатом, a Rx — средняя корреляция между текущим предиктором и Р предикторами, уже включенными в подмножество. На каждой стадии поиска показатель может ранжировать предикторы в зависимости от функции эффективности и избыточности.
Для моделей, построенных для прогнозирования, а не для объяснения, следует обратить внимание на два важных обстоятельства:
О Многие критические замечания в адрес методов-оберток, перечисленных выше2, концентрируются на применении статистической проверки гипотез.
О Как и во многих других случаях, представленных в тексте, методологии, основанные на сомнительной статистической основе, все равно могут приводить
1 Следует заметить, что статистика AIC предназначена для заранее запланированных сравнений между моделями (в отличие от сравнения многих моделей в ходе автоматического поиска).
2 Впрочем, Дерксен и Кесельман (Derksen and Keselman, 1992), а также Хендерсон и Вел- леман (Henderson and Velleman, 1981) приводят аргументы против автоматизированного выбора признаков в целом.
19.3. Методы-обертки 539
к очень точным моделям. Главная защита в таких ситуациях — тщательный, методичный процесс проверки с независимыми данными.
Методы поиска, используемые совместно с методами-обертками, рассматриваются далее.
Прямой, обратный и пошаговый выбор
Классический прямой выбор, напомним, описан в алгоритме 19.1. Пошаговый выбор представляет собой популярную модификацию, в которой после добавления каждой переменной — кандидата в модель — каждая составляющая заново оценивается на возможность удаления из модели. В некоторых случаях пороги p-значения для добавления и удаления предикторов могут заметно отличаться (Derksen and Keselman, 1992). Хотя это обстоятельство делает процедуру поиска менее жадной, оно усугубляет проблему повторной проверки гипотез. При обратном выборе исходная модель содержит все Р предикторов, которые затем итеративно исключаются для выявления предикторов, не имеющих значительного вклада в модель. Эти процедуры можно усовершенствовать с применением критериев, не основанных на логическом выводе (например, статистике AIC), для добавления или удаления предикторов из модели. В работе Гуйона (Guyon et al., 2002) описан алгоритм обратного выбора (называемый рекурсивным исключением признаков, или RFE), который избегает повторного обучения слишком большого количества моделей на каждом шаге поиска. После создания полной модели вычисляется показатель важности переменной, которая ранжирует предикторы по убыванию важности. Метод вычисления важности может базироваться на модели (например, критерий важности случайного леса); также возможно применение более общего метода, не зависящего от полной модели. На каждой стадии поиска происходит итеративное исключение наименее важных предикторов перед перестраиванием модели. Как и прежде, после создания новой модели для нее оценивается целевая функция. Процесс продолжается в некоторой заранее определенной последовательности; размер подмножества, соответствующий лучшему значению целевой функции, используется для итоговой модели.
Этот процесс более подробно отражен в алгоритме 19.2 (см. также раздел 19.6).
Алгоритм рекурсивного исключения признаков легко рассматривать как «черный ящик», но следует учитывать и некоторые особенности. Например, если результат содержит более двух классов, то некоторые классы могут быть сильнее отделены от остального тренировочного набора. Соответственно, для таких классов проще добиться меньших частот ошибок, чем для других. В процессе ранжирования предикторы, связанные с «простыми» классами, могут занять позиции для более высоких рангов. В результате модель пренебрегает «трудными» классами и сохраняет высокую частоту ошибок. В этом случае показатели важности, относящиеся к конкретным классам, могут способствовать выбору более уравновешенного набора для балансировки частот ошибок между классами.
540 Глава 19. Выбор признаков
Алгоритм 19-2. Обратный выбор с использованием алгоритма рекурсивного исключения признаков (Guyon et al., 2002)
1 Выполнить настройку/тренировку модели на тренировочном наборе с использованием всех Р предикторов
2 Вычислить эффективность модели
3 Вычислить важность или ранги переменных
4 for каждый размер подмножества Sif i- 1..., S do
5
6
7
8
9
Оставить Si самых важных переменных
[Не обязательно] Провести предварительную обработку данных Выполнить настройку/тренировку модели на тренировочном наборе с Si предикторами
Вычислить эффективность модели
[Не обязательно] Пересчитать ранги для каждого предиктора
10 end
11 Вычислить профиль эффективности по Si
12 Определить подходящее количество предикторов (то есть Si для наилучшей эффективности)
13 Выполнить обучение итоговой модели на основании оптимального Si
Имитация отжига
Рассмотрим далее некоторые способы поиска оптимального набора признаков. Имитация отжига, согласно Богачевскому (Bohachevsky et al., 1986), напоминает процесс охлаждения металла. Этот процесс подробно описан в алгоритме 19.3.
Исходное подмножество предикторов выбирается и используется для оценки эффективности модели (обозначается £t). Текущее подмножество предикторов, несколько отличающееся от исходного, применено для создания другой модели с оценкой частоты ошибок Е2. Если новая модель оказывается лучше предыдущей (то есть Е2< Е}), то новый набор признаков принимается. Если новая модель оказывается хуже исходной, то примененный набор признаков может быть принят на основании некоторой вероятности/?", где i — итерация процесса. Эта вероятность задается с уменьшением по времени, чтобы при больших значениях i принятие субоптимальной конфигурации становилось крайне маловероятным. Процесс продолжается для некоторого заранее заданного количества итераций, после чего используется лучшее подмножество переменных по всем итерациям, что позволяет избежать локального оптимума. Принимая «плохие» решения, алгоритм может продолжить поиск в других участках модели, становясь, таким образом, менее жадным.
19.3. Методы-обертки 541
Алгоритм 19.3- Имитация отжига для выбора признаков. Е — показатель эффективности, у которого малые значения являются лучшими, а Т — значение температуры, изменяющееся между итерациями.
1 Сгенерировать исходное случайное подмножество предикторов
2 Для итераций i = 1 t do
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Создать случайную перестановку текущего лучшего набора предикторов [Необязательно] Выполнить предварительную обработку данных Выполнить настройку/тренировку модели с использованием этого набора
Вычислить эффективность модели (Д)
<Ebesr then
Принять текущий набор предикторов как лучший
Присвоить Де5, = Д
else
Вычислить вероятность приема текущего набора предикторов
р“ =exp[(Ehesf-Ei)/T]
Сгенерировать случайное число U в интервале [0,1] if р- <U then
Принять текущий набор предикторов как лучший Присвоить £^ = Д
else
Сохранить текущий лучший набор редикторов end
end 20 end
21 Определить набор предикторов, связанный с наименьшим Д по всем итерациям
22 Завершить построение модели с набором предикторов
Генетические алгоритмы
«Дальним родственником» имитации отжига являются генетические алгоритмы (GA), рассматриваемые, в частности, в работах Холланда и Гольдберга (Holland, 1975; Goldberg, 1989). Этот инструмент оптимизации основан на эволюционных принципах популяционной биологии; его эффективность доказана для поиска оп-
542 Глава 19. Выбор признаков тимальных решений сложных многомерных функций. Так, генетические алгоритмы конструировались для имитации эволюционного процесса: текущая популяция решений начинает «размножаться», создавая «потомков, конкурирующих за выживание». «Выжившие» получают возможность создать следующее поколение. Достижение горизонтального уровня прироста эффективности (Holland, 1992) позволяет выбрать оптимальное решение.
Задача выбора признаков является сложной оптимизационной задачей по поиску комбинации признаков, обеспечивающей оптимальный прогноз ответа. Чтобы применить генетические алгоритмы в этом направлении, необходимо привести задачу выбора признаков в рамки механизмов GA. Эти механизмы работают с хромосомами, состоящими из генов и оценивающимися на основании своей приспособленности. Чтобы создать следующее поколение потомков, две хромосомы размножаются в процессе скрещивания и мутации (рис. 19.3).
Родители Размножение Дети
Позиция Кроссовер Мутация
кроссовера
Рис. 19.3. Схема репродуктивной фазы генетического алгоритма
Эффективность генетических алгоритмов для выбора признаков в области хемометрии, анализа изображений, финансов подтверждается Лавинье (Lavine et al., 2002), Бану и Лином (Bhanu and Lin, 2003), Мином и Хуангом (Min et al., 2006; Huang et al., 2012).
В контексте выбора признаков хромосома представляется двоичным вектором, длина которого равна количеству предикторов в наборе данных. Каждый двоичный элемент хромосомы (ген) представляет наличие или отсутствие предиктора в данных. Приспособленность хромосомы определяется моделью с использованием предикторов, обозначенных двоичным вектором. Таким образом, генетические алгоритмы должны решить задачу нахождения оптимальных решений из 2" возможных комбинаций наборов предикторов.
19.3. Методы-обертки 543
Для начала процесса поиска генетические алгоритмы часто инициализируются случайным выбором хромосом из популяции всех возможных хромосом. Вычисляется приспособленность каждой хромосомы, определяющая вероятность выбора данной хромосомы для процесса размножения. Две хромосомы из текущей популяции выбираются на основании критерия приспособленности и получают возможность размножаться. В фазе размножения две родительские хромосомы разделяются в случайной позиции (также называемой локусом); начало одной хромосомы объединяется с концом другой хромосомы, и наоборот. После скрещивания отдельные элементы новых хромосом могут быть случайно выбраны для мутации: текущее двоичное значение заменяется другим значением (алгоритм 19.4).
Алгоритм 19.4. Генетический алгоритм выбора признаков
1 Определить критерий остановки, количество потомков для каждого поколения (GenSize) и вероятность мутации (рт).
2 Сгенерировать случайный исходный набор из т двоичных хромосом, каждая из которых имеет длину р.
3 repeat
4
5
6
7
8
9
10
11
for каждая хромосома do
Выполнить настройку/тренировку модели и вычислить приспособленность каждой хромосомы
end
hr размножение & = 1,..., GenSize/2 do
Выбрать две хромосомы на основании критерия приспособленности Кроссовер: случайным образом выбрать локус и поменять местами гены каждой хромосомы после локуса
Мутация: случайным образом изменить двоичные значения каждого гена в каждой новой дочерней хромосоме с вероятностью рт
end
12 until выполняется критерий остановки
Фаза скрещивания направляет последующие поколения к оптимумам в подпространствах сходных генетических материалов. Другими словами, подпространство поиска сужается до пространства, определяемого хромосомами с наибольшей приспособленностью. Это означает, что алгоритм может быть захвачен локальным оптимумом. В контексте выбора признаков это может привести к формированию оптимальной модели при сохранении вероятности существования и более оптимальных подмножеств признаков. Фаза мутации позволяет алгоритму оторваться от локальных оптимумов посредством случайной перестановки генетического материала. Обычно вероятность мутации остается малой (скажем, рт< 0,05).
544 Глава 19. Выбор признаков
Тем не менее если разработчика модели беспокоят возможные локальные минимумы, вероятность мутации можно поднять, что приведет к замедлению поиска оптимального решения.
19.4. Методы-фильтры
Как упоминалось, методы-фильтры оценивают предикторы до тренировки модели. На основании этой оценки подмножество предикторов подается на вход модели. Так как обработка предикторов изолируется от модели, многие показатели важности переменных, рассмотренные в главе 18, могут пригодиться для фильтрации переменных. Многие из этих методов одномерны, то есть оценивают каждый предиктор обособленно от других. Наличие коррелированных предикторов делает невозможным выбор важных, но избыточных предикторов. В результате выбирается слишком много предикторов, что порождает проблемы коллинеарности. Гуйон и Елисеев (Guyon and Elissee, 2003) рассматривают некоторые аспекты избыточности предикторов в ходе фильтрации.
Отметим, что в ходе проверки наличия статистически значимых связей предикторов с результатом (например, посредством £-теста) могут возникнуть проблемы множественности сравнений (см. (Westfall and Young, 1993) и рис. 19.2). Например, если доверительный уровень а = 0,05 используется в качестве порога р-значения для значимости, то у каждой отдельной проверки теоретическая частота ложноположительных значений равна 5 %. При проведении большого количества одновременных статистических проверок общая вероятность ложноположительного значения возрастает экспоненциально.
Специальные процедуры корректировки p-значения могут управлять частотой ложноположительных значений. Одной из таких процедур является поправка Бонфер- рони (Bland and Altman, 1995). Если порог отсечения p-значения а используется для определения статистической значимости каждой из М проверок, то использование порога а/М повышает строгость и помогает контролировать вероятность ложноположительных результатов. С другой стороны, эта процедура может быть очень консервативной, ограничивая количество истинно положительных результатов. Другие подходы к проблеме множественности сравнений можно найти у Уэстфолла и Янга (Westfall and Young, 1993). Кроме того, Адесмаки и Стриммер (Ahdesmaki and Strimmer, 2010) предлагают модифицированный £-тест, учитывающий большое количество проводимых тестов, а также корреляции между предикторами.
Хотя методы-фильтры обычно просты и быстры, процедуре присуща некоторая субъективность. Большинство методов не имеет очевидной точки отсечения, позволяющей определить, какие именно предикторы наиболее важны для попадания в модель. В случае проверки статистических гипотез все равно потребуется выбрать доверительный уровень, применяемый к результатам. На практике для нахожде-
19.5. Смещение выбора 545
ния подходящего значения уровня достоверности а оценки придется производить многократно, пока не будет достигнута приемлемая эффективность.
19.5. Смещение выбора
В контексте очевидных различий эффективности методов фильтрации и процедур поиска приемлемого набора предикторов особого внимания заслуживает вопрос о вычислении эффективности модели. Так, переобучение предикторов к тренировочным данным без соответствующей проверки последних может остаться незамеченным. Например, у Гуйона (Guyon et al., 2002) продемонстрировано рекурсивное исключение признаков с классификационными моделями опорных векторов для хорошо известного микромассива с данными о раке прямой кишки. В этих данных измерения 2000 уникальных последовательностей РНК использовались в качестве предикторов статуса заболевания (рак или нормальное состояние) в группе из 62 пациентов. Тестовые наборы для проверки результатов не использовались. Для контроля эффективности к каждой модели применена перекрестная проверка с исключением (строка 8 в алгоритме 19.2). Последующий анализ показал, что модель SVM может обеспечивать точность свыше 95 % с использованием только четырех предикторов и абсолютную точность с моделями, использующими от 8 до 256 предикторов.
Частоты ошибок с исключением были основаны на модели SVM после выбора признаков. Можно представить, что при повторении выбора признаков со слегка отличающимся набором данных результаты могут измениться. Как выясняется, в некоторых случаях неопределенность, внесенная выбором признаков, может значительно превышать неопределенность модели (после того, как соответствующие признаки были выбраны). Так, Амбруаз и Маклахлан (Ambroise and McLachlan, 2002) провели ту же процедуру рекурсивного исключения признаков с тем же набором данных, но со случайной перестановкой меток классов (чтобы преобразовать все предикторы в неинформативные). Они показали, что стратегия перекрестной проверки с исключением, использованная Гуйоном (Guyon et al., 2002), обеспечивает нулевые ошибки даже в том случае, если предикторы полностью неинформативны. Логическая ошибка в следующем. Модель создана на базе тренировочного набора; оценка и ранжирование предикторов производились с использованием этих данных. Если повторное обучение модели осуществляется только с этими важными предикторами, то эффективность для того же набора данных почти наверняка улучшится. Кроме того, отношение Р к п является экстремальным (2000:62), это заметно повышает вероятность того, что совершенно нерелевантный предиктор будет случайно объявлен важным.
Методологическая ошибка возникла из-за того, что выбор признаков не рассматривался как часть процесса построения модели. Его следовало бы включить в процедуру повторной выборки, чтобы дисперсия выбора признаков была отражена
546 Глава 19. Выбор признаков в результатах. Процедура перекрестной проверки с исключением в строке 8 алгоритма 19.2 не учитывает действия за пределами оцениваемого ею процесса тренировки модели. Например, если процесс выбора признаков приходит к истинной модели после оценки большого количества моделей-кандидатов, то оценки эффективности должны отражать процесс, который привел к этому результату.
Для правильной организации процесса выбора признаков необходим «внешний» цикл повторной выборки, охватывающий весь процесс. Алгоритм 19.5 демонстрирует такую схему повторной выборки для рекурсивного исключения признаков.
Алгоритм 19.5- Рекурсивное исключение признаков с правильной повторной выборкой
1 for каждая итерация повторной выборки do
2
3
4
5
6
7
8
9
10
11
12
Разбить данные на тренировочный и тестовый/контрольный набор с применением повторной выборки
Выполнить настройку/тренировку модели на тренировочном наборе с использованием всех Р предикторов
Вычислить эффективность модели
Вычислить важность или ранги переменных
for каждый размер подмножества Sif i = 1 ..., 5 do
Оставить 5. самых важных переменных
[Необязательно] Провести предварительную обработку данных
Выполнить настройку/тренировку модели на тренировочном наборе с Sj предикторами
Вычислить эффективность модели с использованием зарезервированных данных
[Необязательно] Пересчитать ранги для каждого предиктора
end
13 end
14 Вычислить профиль эффективности по 5( с использованием зарезервированных точек данных
15 Определить подходящее количество предикторов
16 Определить итоговые ранги всех предикторов
17 Выполнить обучение итоговой модели на основании оптимального S- с использованием исходного тренировочного набора
В строке 1 применяется повторная выборка, внутри которой происходит весь процесс выбора признаков. Например, если десятикратная перекрестная выборка вы-
19.5. Смещение выбора 547
полняется в исходном цикле, то 90 % данных будут использоваться для проведения выбора признаков, а зарезервированные 10 % будут использоваться для оценки эффективности (например, строка 10) для каждого подмножества предикторов. Весь процесс выбора признаков будет проведен дополнительно еще девять раз с разными наборами резервируемых точек данных. В итоге эти десять резервных наборов и определяют оптимальное количество предикторов в итоговой модели (строка 14). С учетом этого результата весь тренировочный набор используется для ранжирования предикторов и тренировки итоговой модели (строки 16 и 17 соответственно). Дополнительный «внутренний» уровень повторной выборки может понадобиться для оптимизации параметров настройки модели (строки 3 и 9).
Амбруаз и Маклахлан (Ambroise and McLachlan, 2002) также показали, что при правильном использовании выборки с возвратом, десятикратной перекрестной проверки или многократной повторной выборки с тестовым набором результаты модели правильно определялись как находящиеся вблизи неинформативного уровня.
Метод повторной выборки может оказать значительное отрицательное влияние на вычислительную эффективность процесса выбора признаков. С другой стороны, этот процесс радикально снижает и вероятность переобучения предикторов, особенно с малыми тренировочными наборами.
Таким образом, допустить ошибку при проверке результатов процедур выбора признаков несложно. Например, в работе Кастальди (Castaldi et al., 2011) с обзором статей, использующих приемы классификации с биологическими данными (например, микромассивы РНК и протеины), обнаружено, что в 64 % случаев анализ неправильно проверяет процесс выбора признаков, причем в этих случаях наблюдалась значительная разница между оценками эффективности с использованием повторной выборки и оценками, вычисленными на базе независимого тестового набора (результаты тестового набора более пессимистичны).
Риск переобучения не ограничивается рекурсивным выбором признаков или обертками вообще; он сохраняется и при использовании других процедур поиска или фильтров для сокращения числа предикторов. Назовем ситуации, повышающие риск смещения выбора:
О набор данных мал;
О количество предикторов велико (так как растет вероятность ложного объявления неинформативного предиктора как важного);
О мощь предиктивной модели (например, модели «черного ящика»), которая более склонна к переобучению данных;
О независимый тестовый набор недоступен.
Если набор данных достаточно велик, рекомендуется использовать отдельные наборы данных для выбора признаков, настройки моделей и проверки итоговой модели (и набора признаков). Для малых тренировочных наборов очень важно
548 Глава 19. Выбор признаков правильно применять повторную выборку. Если объем данных не слишком мал, то также рекомендуется зарезервировать маленький тестовый набор, чтобы лишний раз убедиться в отсутствии серьезных ошибок.
19.6. Практикум: прогнозирование когнитивного расстройства
Болезнь Альцгеймера (AD) — нарушение когнитивных функций, характеризующееся потерей памяти и постепенной утратой функций организма ниже уровня, типичного для данного возраста. Это — самая распространенная причина деменции, наблюдаемой у пожилых людей. С биологической точки зрения болезнь Альцгеймера связана с накоплением в мозге амилоидных-0 (А0) бляшек и нейрофибрил- лярных клубков в форме тау-протеина.
Диагностика болезни Альцгеймера основана на клинических признаках, проявление которых означает, что течение болезни стало серьезным и труднообратимым. Ранняя диагностика болезни Альцгеймера может привести к значительному улучшению состояния пациента. Отсюда и интерес к выявлению биомаркеров — количественных признаков, не требующих клинического анализа1. Подробное обсуждение биомаркеров в контексте болезни Альцгеймера приведено в работах де Леона и Кланка (de Leon and Klunk, 2006) и Хэмпела (Hampel et al., 2010).
Методы диагностической визуализации помогают спрогнозировать начало заболевания. Вместе с тем сохраняется и интерес к низкозатратным биомаркерам, которые могут быть получены из плазмы или спинномозговой жидкости. В настоящее время существует несколько общепринятых биомаркеров, не связанных с визуальной диагностикой: уровни протеинов в конкретных формах Ар- и тау-про- теинов и Е-генотип аполипопротеина (точнее, три его основные разновидности: Е2, ЕЗ и Е4). Поясним, что Е4 — это аллель, по мнению Кима и Бу (Kim et al., 2009; Bu, 2009), чаще всего ассоциируемая с болезнью Альцгеймера. Предиктивная точность может быть улучшена добавлением в список и некоторых других биомаркеров.
В работе группы Крейга-Шапиро (Craig-Schapiro et al., 2011) описано клиническое исследование 333 пациентов, среди которых были как лица, страдавшие умеренным (но четко выраженным) когнитивным расстройством, так и вполне здоровые люди. У всех участников были взяты образцы спинномозговой жидкости. В ходе
1 Существуют разные типы биомаркеров. Например, считается, что уровень холестерина в крови указывает на функциональность сердечно-сосудистой системы. Отслеживание таких признаков позволяет оценить текущее состояние здоровья пациента, а также характеризует эффект лечения. В последнем случае данные холестерина рассматриваются как суррогатные конечные точки для действительно важных атрибутов (например, заболеваемости и смертности).
19.6. Практикум: прогнозирование когнитивного расстройства 549
исследования требовалось определить, возможно ли отличить участников на ранних стадиях заболевания от здоровых людей. С этой целью для каждого участника были собраны различные данные, в том числе:
О демографические характеристики (возраст, пол и т. д.);
О Е-генотип аполипопротеина;
О протеиновые показатели для Ар, тау и фосфорилированной версии тау-про- теина (р-тау);
О протеиновые показатели для 124 исследовательских биомаркеров;
О клинические показатели деменции.
Собранные данные были преобразованы к двум классам: больные и здоровые. Цель анализа — создание классификационных моделей, использующих демографические и аналитические данные для прогнозирования того, кто из пациентов находится на ранней стадии заболевания.
С учетом относительно малого размера выборки можно предположить, что лучшей стратегией разделения данных является включение в тренировочный набор всех участников для увеличения объема информации, используемой для оценки параметров и выбора предикторов. Заметим, что возможность смещения выбора в известной мере предопределяется отношением количества предикторов к количеству точек данных в составе анализируемых данных. По этой причине небольшое подмножество участников будет выделено в тестовый набор для проверки того, что в исследовании не были допущены серьезные методологические ошибки. Тестовый набор содержал данные о 18 больных и 48 здоровых участниках. Показатели эффективности, вычисленные на основании данных, характеризуются высокой неопределенностью, но вместе с тем они достаточны для выявления переобучения из-за выбора признаков.
Для 267 участников из тренировочного набора пять повторений десятикратной перекрестной проверки используются для оценки процедур выбора признаков (например, «внешней» процедуры повторной выборки). Если модели обладают дополнительными параметрами настройки, то используется десятикратная перекрестная проверка. В ходе выбора признаков и настройки модели оптимизировалась площадь под ROC-кривой (для прогнозируемых вероятностей классов). На рис. 19.4 изображена корреляционная матрица предикторов (размером 124 х 124). Как видим, здесь присутствует много сильных межпредикторных корреляций, обозначенных темно-красной и синей областями. Средняя парная корреляция равна 0,27. Минимальная и максимальная корреляции равны -0,93 и 0,99 соответственно. Корреляции содержатся в большой группе предикторов (обозначенной большим красным прямоугольником на диагонали), что может отрицательно повлиять на моделирование и процесс выбора признаков. Анализ, приведенный ниже, использует все предикторы для моделирования данных. Применение неконтролируемого
550 Глава 19. Выбор признаков
Рис. 19.4. Межпредикторные корреляции для данных болезни Альцгеймера. Каждая строка и каждый столбец представляют один предиктор. Строки и столбцы были отсортированы средствами кластеризации фильтра для сокращения набора признаков до анализа может способствовать улучшению результатов (см. далее упражнение 19.1). Почти все предикторы в данных являются непрерывными. Тем не менее к Е-генотипу аполипопротеина это не относится. Для трех его генетических разновидностей (Е2, ЕЗ и Е4) существуют шесть возможных значений с наследованием одной копии гена от каждого родителя (табл. 19.1).
Таблица 19.1. Частоты тренировочного набора для двух кодировок данных генотипа
Е2/Е2
Е2/ЕЗ
Е2/Е4
ЕЗ/ЕЗ
ЕЗ/Е4
Е4/Е4
Е2
ЕЗ
Е4
Больные
0
6
1
27
32
7
7
65
40
Контроль
2
24
6
107
51
4
32
182
61
При разбивке на родительские генные комбинации некоторые варианты характеризуются чрезвычайно малыми частотами (например, Е2/Е2). У отдельных предиктивных моделей в этой связи могут возникнуть проблемы с оценкой некоторых параметров, особенно если частоты сокращаются во время повторной выборки. В альтернативном способе кодировки данных создаются три бинарных индикатора для каждой аллели (Е2, ЕЗ и Е4, см. три правых столбца табл. 19.1). Поскольку
19.6. Практикум: прогнозирование когнитивного расстройства 551
эти частоты менее разрежены, подобная кодировка используется для всех предиктивных моделей этой главы. Для демонстрации выбора признаков рекурсивное исключение признаков применено для нескольких моделей и 66 размеров подмножества (от 1 до 131). Модели, требующие настройки параметров, настраивались при каждой итерации исключения признаков. Оценивались следующие модели:
О Случайные леса: при каждой итерации использовалось значение по умолчанию mtTy = 'Ip, лес состоял из 1000 деревьев.
О Линейный дискриминантный анализ: использовался стандартный подход (то есть без штрафов или внутреннего выбора признаков).
О Нерегуляризированная логистическая регрессия: рассматривалась модель только с основными эффектами.
О К ближайших соседей: модель настраивалась по нечетному количеству соседей от 5 до 43.
О Наивная модель Байеса: для непрерывных предикторов использовались непараметрические ядерные оценки.
О Опорные векторы: использовалась радиальная базисная функция и аналитическая оценка а со значениями стоимости в интервале от 2 2 до 29.
Показатели важности переменных случайного леса (основанные на исходной модели) определили ранжирование предикторов для этой модели, тогда как логистическая регрессия использовала абсолютное значение Z-статистики для каждого параметра модели. Другие модели ранжировали предикторы по области под ROC-кривой для каждого отдельного предиктора. На рис. 19.5 показаны профили повторной выборки процесса выбора признаков для каждой модели.
Случайный лес демонстрирует очень незначительные изменения до того, как из модели были исключены важные предикторы. Это отчасти ожидаемо — хотя случайные леса осуществляют минимальную встроенную фильтрацию предикторов, неинформативные предикторы оказывают на прогнозы модели минимальное воздействие. Оптимальное количество предикторов по оценке для модели равно семи.
Модель LDА показала значительное улучшение и достигла пика при 35 предикторах, при этом площадь под ROC-кривой по оценке была чуть лучше, чем у модели случайного леса. Логистическая регрессия демонстрировала очень незначительные изменения в эффективности до приблизительно 50 предикторов, когда после некоторого снижения эффективность значительно улучшилась. Лучший размер подмножества для этой модели — 13. Однако после удаления важных предикторов наблюдалось значительное снижение эффективности модели.
Наивный байесовский классификатор показывал незначительное улучшение после удаления предикторов, достигнув максимальной эффективности для 17 предикторов. В отличие от других, у модели не наблюдалось резкого снижения эффективности
552 Глава 19. Выбор признаков
0,9
0,8
0,7
50 юо
0,9
0.8
0,7
0,6
0,8-
0,7-
0,6 -
0 50
100
Количество предикторов
Рис. 19.5. Профили повторной выборки процедуры рекурсивного исключения признаков для нескольких моделей при относительно малом количестве предикторов. В то же время и модель опорных векторов, и модель KNN по мере удаления предикторов существенно утрачивали эффективность. Что касается модели опорных векторов, то ее низкая эффективность может быть не связана со смещением выбора. Более внимательное изучение результатов SVM позволяет сделать вывод о том, что модели данного типа обладали высокой специфичностью и низкой чувствительностью (см. также результаты в разделе «Вычисления»). Другими словами, плохие результаты с большой вероятностью объясняются дисбалансом классов в данных.
В столбце «Дов. инт.» представлены 95-процентные доверительные интервалы. Столбец «p-значение» соответствует статистическому тесту, проверяющему, было ли значение ROC для сокращенной модели больше значения кривой, связанной со всеми предикторами. В табл. 19.2 приведена сводка результатов повторной выборки для каждой модели.
19.6. Практикум: прогнозирование когнитивного расстройства 553
Таблица 19.2. Результаты перекрестной проверки для рекурсивного выбора признаков
Полный набор
Сокращенный набор
р-зна- чение
ROC
Дов. ИНТ.
Размер
ROC
Дов. ИНТ.
LDA
0,844
(0,82-0,87)
35
0,916
(0,90-0,94)
0
Случайные леса
0,891
(0,87-0,91)
7
0,898
(0,88-0,92)
0,1255
SVM
0,889
(0,87-0,91)
127
0,891
(0,87-0,91)
0,0192
Логистическая регрессия
0,785
(0,76-0,81)
13
0,857
(0,83-0,88)
0
Наивный байесовский классификатор
0,798
(0,77-0,83)
17
0,832
(0,81-0,86)
0,0002
k ближайших соседей
0,849
(0,83-0,87)
125
0,796
(0,77-0,82)
1,0000
Приведена площадь под ROC-кривой для полной модели (то есть всех предикторов) по сравнению с моделями, полученными в результате рекурсивного исключения признаков. В табл. 19.2 также приведены 95-процентные доверительные интервалы, вычисленные по 50 оценкам повторной выборки, полученным в результате многократной перекрестной проверки. Из всех проанализированных моделей наилучшая оценка эффективности наблюдалась у LDA. Тем не менее на основании доверительных интервалов это значение сравнимо с эффективностью других моделей (по крайней мере, в пределах экспериментальной ошибки, отраженной в интервалах), включая модель случайного леса (после выбора признаков) и модель опорных векторов (до или после выбора признаков). Столбец p-значений связан со статистической проверкой, где нулевая гипотеза утверждает, что сокращенный набор предикторов имеет более высокое ROC-значение, чем полный набор. Это значение было вычислено с использованием процесса парной повторной выборки (раздел 4.8). Хотя модели опорных векторов и k ближайших соседей не были существенно усовершенствованы, они доказывают, что другие модели улучшены рекурсивным исключением признаков.
Продемонстрировал ли тестовый набор те же тренды, что и результаты повторной выборки? На рис. 19.6 показаны оценки площади под ROC-кривой для сокращенных моделей.
Ось у соответствует значениям ROC с повторной выборкой (и доверительным интервалам, см. табл. 19.2). По оси х отложены сходные значения разных моделей, вычисленных по ROC-кривым с использованием прогнозов по тестовому набору из 66 участников. В результатах тестового набора наблюдалась существенно большая
554 Глава 19. Выбор признаков
KNN
LDA
Логистическая регрессия
Наивная модель Байеса Случайный лес SVM
1,00
5 о.
0,95
£
а
о 0,90
X
§
&
2. 0,85 ф с
3 I-
§
о.
0,80
0,75
0,75 0,80 0,85 0,90 0,95 1,00
Результаты тестового набора
Рис. 19.6. Оценки площади под ROC-кривой для сокращенной модели с использованием тестового набора и повторяющейся перекрестной проверки. Горизонтальные и вертикальные полосы представляют 95-процентные доверительные интервалы для каждого метода неопределенность; доверительные интервалы тестового набора обычно более чем в 3 раза шире соответствующих интервалов от повторной выборки. Существует умеренная корреляция между ROC-значениями, вычисленными с использованием тестового набора и повторной выборки. Результаты тестового набора более оптимистичны, чем результаты повторной выборки для наивного байесовского классификатора, моделей логистической регрессии и k ближайших соседей. Модель опорных векторов ранжирована перекрестной выборкой выше, чем тестовым набором. Несмотря на эти расхождения, результаты тестового набора в целом подкрепляют результаты из табл. 19.2; процесс выбора признаков демонстрирует преимущества нескольких моделей и не приводит к серьезному смещению выбора. Две ведущие модели (LDA и случайные леса) весьма различны. Как следует из рис. 19.5, ни один из профилей этих моделей не содержал единственный пик. По этой причине оптимальный размер подмножества неочевиден. Отметим, что для результата, оптимального в числовом отношении, модель случайного леса использовала
19.6. Практикум: прогнозирование когнитивного расстройства 555
семь предикторов, а модель LDA — 35 предикторов. Все предикторы случайного леса были включены в модель LDA, но 28 из предикторов LDA не входят в модель случайного леса.
На рис. 19.7 показаны оценки важности переменных для обеих моделей (вспомним в этой связи, что площадь под ROC-кривой использовалась для LDA).
Только LDA
Обе модели
0,80
0,75
0,70
0,65
0,60
6 8 10 12 14 16
Важность переменных модели случайного леса
Рис. 19.7. Сравнение двух методов для определения важности переменных. Значения случайного леса соответствуют моделям с 7 предикторами, тогда как ROC- значения основаны на верхних 35 предикторах (то есть лучшем подмножестве для LDA). Значения усредняются по 50 повторным выборкам. Значения «только LDA» соответствуют предикторам, которые входят в итоговую модель LDA, но не в модель случайного леса. Перпендикулярные отрезки (не ось у!) относятся к предикторам LDA, которые не были выбраны ни в одной из 50 моделей случайного леса с повторной выборкой
Здесь значения важности вычислялись усреднением значений, обнаруженных в ходе процесса повторной выборки для итогового размера множества. Например, на графике имеются точки для предикторов, содержащихся только в модели LDА. Эти предикторы имеют значения случайного леса, поскольку выбраны по крайней мере в одной из 50 повторных выборок с подмножеством из семи предикторов. Диаграмма по оси у представляет площадь под ROC-кривой для предикторов, не вы-
556 Глава 19. Выбор признаков бранных ни в одной из моделей случайных лесов. Обе модели в значительной мере согласуются друг с другом; ранговая корреляция между основными предикторами составляет 0,44. Несогласующиеся предикторы обычно имеют низкие показатели важности у обеих моделей. Обе модели содержали два предиктора (концентрации Ари тау-протеина), оказывающие значительное влияние на модели. Третий по важности предиктор для обеих моделей — модифицированная концентрация тау- протеина. После этого показатели важности начинают расходиться с моделью LD А/ ROC, использующей ММР10, и случайным лесом, использующим VEGF.
Этот факт подчеркивает, что выбор признаков плохо подходит для определения наиболее значимых переменных в данных (в отличие от предикторов, оказывающих наибольшее влияние на модель). Разные модели оценивают предикторы по-разному. Для получения информации о том, какие предикторы обладают индивидуальными связями с результатом, предпочтительнее использовать классические статистические методы. Например, группой Крейга-Шапиро (Craig-Schapiro et al., 2011) для оценки возможных ассоциаций также использовался анализ ковариации и другие логические модели. Эти методы разрабатывались для получения вероятностных утверждений о потенциальных биомаркерах — более качественных, чем у любого метода, основанного на важности переменных. Наконец, биологические аспекты анализа теоретически превосходят любые эмпирические оценки. Хотя анализ и направлен на поиск новых биомаркеров, определенная степень научной правомерности все же необходима, как и последующие эксперименты для дальнейшей проверки результатов, обнаруженных в имеющихся данных.
Проанализировано и использование фильтров при линейном дискриминантном анализе. Для непрерывных предикторов простой £-тест использован при генерировании p-значения для разности средних значений предиктора между двумя классами. Для категорийных предикторов (например, пола или Е-генотипа аполипопротеина) точный критерий Фишера был использован для вычисления p-значения, оценивающего связь между предиктором и классом. После вычисления ^-значений были применены два способа фильтрации:
О Сохранить предикторы с необработанными p-значениями меньше 0,05 (то есть принять 5-процентную частоту ложноположительных значений для каждого отдельного сравнения).
О Применить поправку Бонферрони, чтобы предикторы сохранялись в случае, если ихр-значения меньше 0,000379 или 0,05/132.
В первом случае сохранены 47 предикторов из 132. К процессу также применена повторная выборка с использованием той же многократной перекрестной проверки, что и для анализа оберток. По 50 повторным выборкам фильтр в среднем выбирал 46,06 предиктора (при вариативности значений в диапазоне от 38 до 57). Выполнено обучение модели LDA по подмножеству предикторов. Полученная площадь под ROC-кривой для тестового набора с этой моделью равна 0,918. При применении повторной выборки к операциям фильтрации и моделирования получена похожая
19.7. Вычисления 557
площадь под кривой (0,917). Отфильтрованный набор переменных состоял из элементов с относительно низкими парными корреляциями. Исключение — предикторы тау-протеина и/2-тау-протеина (корреляция равна 0,91). При повторении процесса без предиктора р-тау-протеина площадь под ROC-кривой практически не изменилась.
Когда фильтр p-значения применяется для сокращения количества ложноположительных результатов, задействовано только 17 предикторов (в среднем при перекрестной проверке выбиралось 13,46). Здесь воздействие на модель не столь очевидно. Площадь под ROC-кривой для тестового набора немного улучшилась (0,926), но оценка повторной выборки существенно хуже — площадь под кривой равна 0,856. При заданном размере выборки в тестовом наборе наблюдался значительный разброс; 95-процентный доверительный интервал для площади под кривой равен (0,841,1). Процесс перекрестной проверки, в среднем резервировавший только 27 пациентов, повторен 50 раз. В этой связи оценки повторной выборки представляются более достоверными.
19.7. Вычисления
В этом разделе рассматриваются данные и/или функции из следующих пакетов: AppliedPredictiveModeling, caret, klaR, leaps, MASS, pROC, rms и stats.
Данные содержатся в пакете AppliedPredictiveModeling. Объекты данных состоят из кадра данных предикторов с именем predictors и факторного вектора значений классов с именем diagnosis (с уровнями impaired и control). Следующий код использовался для подготовки данных к анализу:
> Library(AppLiedPredictiveModeLing)
> data(ALzheimerDisease)
> ## Ручное создание новых фиктивных переменных
> predictors$E2 <- predictors$E3 <- predictors$E4 <- 0
> predictors$E2[grepL("2", predictors$Genotype)] <- 1
> predictors$E3[grepL("3", predictors$Genotype)] <- 1
> predictors$E4[grepL("4", predictorsfGenotype)] <- 1
>
> ## Разбиение данных с использованием расслоенной выборки
> set.seed(730)
> spLit <- createDataPartition(diagnosis, p = .8, List = FALSE)
> ## Объединение в один кадр данных
> adData <- predictors
> adData$CLass <- diagnosis
> training <- adData[ spLit, ]
> testing <- adData[-spLit, ]
> ## Сохранение вектора имен предикторных переменных
> predVars <- names(adData)[/(names(adData) %in% c( "CLass", "Genotype"))]
558 Глава 19. Выбор признаков
> ## Вычисление площади под ROC-кривой, чувствительности, специфичности,
> ## точности и каппа -статистики
>
> fiveStats <- functionf...) c(twoCLassSummary(...),
+ defauLtSummary(...))
> ## Создание наборов данных повторной выборки для всех моделей
> set.seed(104)
> index <- createMuLtiFoLds(training$CLass, times =5)
> ## Создание вектора размеров подмножеств для оценки
> varSeq <- seq(l, Length(predVars)-l, by = 2)
Код, воспроизводящий вычисления из этой главы, весьма обширен; вы найдете его в пакете AppliedPredictiveModeling. В этом разделе показано, как в R может проводиться выбор признаков для подмножества анализов.
Прямой, обратный и пошаговый выбор
Для этого класса оберток в R существуют следующие функции:
О Функция step из пакета stats может использоваться для поиска подходящих подмножеств для моделей линейной регрессии и обобщенных линейных моделей (функции 1т и glm соответственно). Аргумент direction управляет методом поиска («both», «backward» или «forward»). Более общая функция stepAIC из пакета MASS может поддерживать большее количество типов моделей. В любом случае, в качестве целевой функции используется статистика AIC (или ее разновидности ).
О Функция f astbw из пакета rms проводит аналогичный поиск, но поддерживает возможность (хотя и не рекомендованную) использования p-значений в качестве целевой функции.
О Функция regsubsets из пакета leaps поддерживает аналогичную функциональность.
О Пакет klaR содержит функцию stepclass, которая ищет в пространстве предикторов модели, максимизирующие степень точности с перекрестной проверкой. Функция имеет встроенные методы для нескольких моделей (таких, как Ida), но может обобщаться в более широком виде.
Функция train из пакета caret имеет обертки для leaps, stepAIC и stepclass, так что весь процесс выбора признаков может включать повторную выборку, а риск смещения выбора сокращается.
Например, чтобы использовать stepAIC с логистической регрессией, функция получает исходную модель на входе. Для демонстрации будет использована небольшая модель:
19.7. Вычисления 559
> initial <- glm(Class ~ tau + VEGF + E4 + IL_3, data = training,
+ family = binomial)
> library(MASS)
> stepAIC(initial, direction = "both")
Start: AIC=189.46
Class - tau + VEGF + E4 + IL_3
Df
Deviance
AIC
- IL_3
1
179.69
187.69
- Е4
1
179.72
187.72
<none>
179.46
189.46
- VEGF
1
242.77
250.77
- tau
1
288.61
296.61
Step: AIC=187.69
Class ~ tau + VEGF + E4
Df
Deviance
AIC
- E4
1
179.84
185.84
<none>
179.69
187.69
+ IL_3
1
179.46
189.46
- VEGF
1
248.30
254.30
- tau
1
290.05
296.05
Step: -
AIC=
=185.84
Class
- tau + VEGF
Df
Deviance
AIC
<none>
179.84
185.84
+ E4
1
179.69
187.69
+ IL_3
1
179.72
187.72
- VEGF
1
255.07
259.07
- tau
1
300.69
304.69
Call: glm(formula = Class ~ tau + VEGF, family = binomial, data = training)
Coefficients:
(Intercept)
tau
VEGF
9.8075
-4.2779
0.9761
Degrees of Freedom: 266 Total (i.e. Null); 264 Residual
Null Deviance: 313.3
Residual Deviance: 179.8 AIC: 185.8
Функция возвращает объект glm с итоговым набором предикторов. Другие функции, перечисленные выше, используют аналогичные стратегии.
560 Глава 19. Выбор признаков
Рекурсивное исключение признаков
Пакеты caret и varSelRF содержат функции для рекурсивного исключения признаков. Если функция varSelRF из пакета varSelRF специализирована для случайных лесов, функция rf е из пакета caret предоставляет обобщенную основу для любой предиктивной модели. В этом случае существуют заранее определенные функции для случайных лесов, линейного дискриминантного анализа, деревьев с бэггингом, наивных байесовских классификаторов, обобщенных линейных моделей, моделей линейной регрессии и логистической регрессии. Функции случайного леса объединены в список с именем rf Funes:
> Library(caret)
> ## Встроенные функции случайных лесов находятся в списке гfFunes.
> str(rfFuncs)
List of 6
$ summary :function (data, lev = NULL, model = NULL)
$ fit :function (x, y, first, last, ...)
$ pred :function (object, x)
$ rank :function (object, x, y)
$ selectsize:function (x, metric, maximize)
$ selectVar :function (y, size)
Каждая из этих функций определяет шаг в алгоритме 19.2:
О Функция summary определяет, как будут оцениваться предикторы (строка 10 в алгоритме 19.2).
О Функция fit позволяет пользователю задать модель и провести настройку параметров (строки 19.2, 6 и 12).
О Функция pred генерирует прогнозы для новых точек данных.
О Функция rank обобщает метрики важности переменных (строка 2).
О Функция selectSize выбирает размер подмножества предикторов (строка И).
О Функция selectVar выбирает переменные, которые будут использоваться в итоговой модели.
Эти параметры можно изменить. Например, для вычисления расширенного набора метрик эффективности, представленных выше, используются следующие команды:
> newRF <- гfFunes
> newRFfsummary <- fiveStats
Синтаксис выполнения процедуры рекурсивного исключения признаков для случайных лесов выглядит так:
> ## Управляющая функция аналогична trainControLf):
> ctrL <- rfeControLfmethod = "repeatedev",
19.7. Вычисления 561
+ repeats = 5,
+ verbose = TRUE,
+ functions = newRF,
+ index = index)
> set.seed(721)
> rfRFE <- rfe(x - training[, predVars],
+ у = training$CLass,
+ sizes = varSeq,
+ metric = "ЯОС",
+ rfeControL = ctrL,
+ ## Передача параметров для randomForest()
+ ntгее = 1000)
> rfRFE
Recursive feature selection
Outer resampling method: Cross-Validation (10-fold, repeated 5 times)
Resampling performance over subset size:
Variables ROC Sens Spec
1 0.8051 0.5375 0.8806
3 0.8661 0.6407 0.9167
5 0.8854 0.6736 0.9365
7 0.8980 0.6571 0.9414
9 0.8978 0.6850 0.9506
11 0.8886 0.6750 0.9609
13 0.8895 0.6604 0.9609
15 0.8950 0.6586 0.9629
17 0.8867 0.6554 0.9621
19 0.8900 0.6418 0.9642
129 0.8923 0.4439 0.9826
131 0.8918 0.4439 0.9836
132 0.8895 0.4439 0.9815
Accuracy Kappa Selected
0.7869 0.4316
0.8415 0.5801
0.8645 0.6386
0.8637 0.6300 *
0.8779 0.6679
0.8825 0.6756
0.8786 0.6636
0.8794 0.6628
0.8780 0.6576
0.8758 0.6514
0.8351 0.4947
0.8360 0.4976
0.8345 0.4963
The top 5 variables (out of 7): Ab_42, tau, p_tau, VEGF, FAS
(Вывод сокращен; столбцы для стандартных отклонений удалены в целях сокращения места.)
Процесс прогнозирования новых точек данных несложен:
> predict(rfRFE, head(testing))
pred Impaired Control
2 Control 0.291 0.709
6 Impaired 0.695 0.305
562 Глава 19. Выбор признаков
15
Control
0.189
0.811
16
Impaired
0.794
0.206
33
Control
0.302
0.698
38
Impaired
0.930
0.070
Встроенные функции прогнозируют классы и вероятности для классификации.
Также имеются встроенные функции для выполнения рекурсивного выбора признаков для моделей, требующих перенастройки на каждой итерации. Например, обучение SVM осуществляется следующим образом:
>
> > + + + +
>
> -#■
+ + + + + + + +
+
>
svmFuncs <- caretFunes svmFuncs$summary <- fivestats ctrL <- rfeControL(method = "repeatedev", repeats = 5, verbose = TRUE, functions = svmFuncs, index = index) set.seed(721)
svmRFE <- rfe(x = training[, predVars],
у - training$CLass, sizes = varSeq, metric = "ROC", rfeControL = ctrL, ## Параметры для train() method = "svmRadiaL", tuneLength = 12, preProc = c( "center", "scaLe"), ## Далее внутренний процесс повторной выборки trControL = trainControL(method = "cv", verboselter = FALSE, cLassProbs = TRUE))
svmRFE
Recursive feature selection
Outer resampling method: Cross-Validation
(10-fold, repeated 5 times)
Resampling performance over subset size:
Variables ROC
Sens Spec Accuracy
Kappa Selected
1 0.6043 0.000000 0.9959
0.7237 -0.005400
3 0.6071 0.005714 0.9858
5 0.5737 0.000000 0.9979
7 0.5912 0.005357 0.9969
9 0.5899 0.000000 0.9979
11 0.6104 0.000000 0.9959
13 0.5858 0.000000 0.9979
0.7178 -0.010508
0.7252 -0.002718
0.7259 0.002849
0.7252 -0.002799
0.7237 -0.005625
0.7252 -0.002829
19.7. Вычисления 563
121 0.8172 0.513571 0.9241
123 0.8210 0.514286 0.9199
125 0.8844 0.608571 0.9559
127 0.8914 0.671786 0.9548
129 0.8877 0.647500 0.9445
131 0.8891 0.644643 0.9487
132 0.8879 0.647143 0.9455
0.8116 0.473426
0.8087 0.469536
0.8610 0.613538
0.8775 0.666157 *
0.8632 0.629154
0.8655 0.631925
0.8639 0.630313
The top 5 variables (out of 127): Ab_42, tau, p_tau, MMP10, MIF
Как мы видим, плохая эффективность связана с дисбалансом классов; модель смещена по направлению к высокой специфичности, потому что многие предикторы являются управляющими. На веб-странице1 caret приведена более подробная информация и примеры, относящиеся к rf е.
Методы-фил ьтры
Пакет caret содержит функцию sbf (от «Selection By Filter»), которая может использоваться для анализа предикторов моделей и оценки эффективности с применением повторной выборки. Вы можете написать любую функцию для анализа предикторов. Например, чтобы вычислить для каждого предиктора ^-значение с учетом типа данных, можно поступить так:
> pScore <- function(х, у)
+ {
+ питХ <- Length(unique(x))
+ iffnumX > 2)
+ {
+ ## With many vaiues in x, compute a t-test
+ out <- t.testfx - y)$p.vaLue
+ } eLse {
+ ## Для бинарных предикторов проверяется
♦ ## отношение шансов = 1 с использованием
+ ## точного критерия Фишера
+ out <- fisher .test(factor(х), y)$p.vatue
+ }
+ out
+ }
> ## Применение показателей ко всем столбцам предикторов
> scores <- appLy(X = training[, predVars],
+ MARGIN = 2,
* FUN = pScore,
+ у = training$Ciass)
1 http://caret.r-forge.r-project.org/.
564 Глава 19. Выбор признаков
> taiL(scores)
p_tau Ab_42 male E4 ЕЗ
1.699064e-07 8.952405e-13 1.535628e-02 6.396309e-04 1.978571e-01
E2
1.774673e-01
Также функцию можно использовать для коррекции p-значения, такой как поправка Бонферрони:
> pCorrection <- function (score, х, у)
+ {
+ ## Параметры х и у необходимы для пакета caret,
+ ## но здесь они не используются
+ score <- p.adjust(score, "bonferroni")
+ ## Вернуть логический вектор для принятия решений
+ ## о том, какие предикторы следует оставить после фильтра
+ keepers <- (score <= 0.05)
+ keepers
+ }
> taiL(pCorrection(scores))
p_tau Ab_42 male E4 ЕЗ E2
TRUE TRUE FALSE FALSE FALSE FALSE
Как и прежде, caret содержит ряд встроенных функций для методов-фильтров: линейная регрессия, случайные леса, деревья с бэггингом, линейный дискриминантный анализ и наивная модель Байеса (дополнительную информацию см. в ?rfSBF). Например, IdaSBF содержит следующие функции:
> str(LdaSBF)
List of 5
$ summary:function (data, lev = NULL, model = NULL)
$ fit :function (x, у, ...)
$ pred :function (object, x)
$ score ifunction (x, y)
$ filter :function (score, x, y)
Эти функции похожи на те, которые показаны для rf е. Функция score вычисляет некоторую количественную метрику важности (например, p-значения, сгенерированные предыдущей функцией pScore). Функция filter получает эти значения (и необработанные данные тренировочного набора) и определяет, какие предикторы проходят фильтр.
Для данных биомаркеров обучение отфильтрованной модели LD А было выполнено так:
> LdaHithPvaLues <- LdaSBF
> LdaWithPvaLues$score <- pScore
> LdaWithPvaLues$summary <- fiveStats
Упражнения 565
> LdaWithPvaLues$fiLter <- pCorrection
> sbfCtrL <- sbfControL(method = "repeatedcv",
+ repeats = 5,
+ verbose = TRUE,
+ functions = LdaWithPvaLueSj
+ index = index)
> LdaFiLter <- sbf(training[, predVars],
+ training$CLassJ
+ toL = l.Qe-12,
+ sbfControL - sbfCtrL)
> LdaFiLter
Selection By Filter
Outer resampling method: Cross-Validation (10-fold, repeated 5 times)
Resampling performance:
ROC Sens Spec Accuracy Kappa ROCSD SensSD SpecSD AccuracySD
0.9168 0.7439 0.9136 0.867 0.6588 0.06458 0.1778 0.05973 0.0567
KappaSD
0.1512
Using the training set, 47 variables were selected:
Alpha_l_Antitrypsin, Apolipoprotein_D, B_Lymphocyte_Chemoattractant_BL, Complement_3, Cortisol...
During resampling, the top 5 selected variables (out of a possible 66): Ab_42 (100%), Cortisol (100%), Creatine_Kinase_MB (100%),
Cystatin_C (100%), E4 (100%)
On average, 46.1 variables were selected (min = 38, max = 57)
И снова на веб-сайте пакета caret содержится дополнительная информация о функции rfе и sbf, в том числе и о возможностях, которые здесь не упоминаются.
Упражнения
19.1. Для данных биомаркеров определите, влияют ли межпредикторные корреляции, показанные на рис. 19.4, на процесс выбора признаков, и с этой целью:
A. Создайте исходный фильтр, который исключает предикторы для минимизации величины мультиколлинеарности в данных перед моделированием.
Б. Проведите повторное обучение моделей с рекурсивным выбором признаков.
B. Изменились ли профили рекурсивного исключения признаков, показанные на рис. 19.4? На какие модели с наибольшей вероятностью повлияет мультиколлинеарность?
566 Глава 19. Выбор признаков
19.2. Используйте тот же процесс повторной выборки для оценки штрафной модели LDA. Что можно сказать о сравнении этих моделей? Наблюдается ли одна и та же закономерность выбора переменных в обеих моделях?
19.3. Примените разные комбинации фильтров и предиктивных моделей к данным биомаркеров. Сохраняют ли разные фильтры одни и те же предикторы? Будут ли модели по-разному реагировать на один набор предикторов?
19.4. Вспомните упражнение 7.2, в котором аналитические инструменты Фридмана (Friedman, 1991) использовали нелинейную функцию предикторов:
у = 10 sin (лх^) + 20(х3 - 0,5)2 + 10х4 + 5х5 + е,
где предикторы с хх по х5 имеют равномерное распределение, а погрешность е имеет нормальное распределение с нулевым математическим ожиданием и стандартным отклонением, которое может быть задано разработчиком модели:
A. Смоделируйте тренировочный и тестовый наборы с п = 500 точками данных в каждом наборе. Выведите графическое представление зависимости результата от предикторов в тренировочном наборе, используя диаграммы разброса, графики корреляции, табличные диаграммы и другие средства визуализации.
Б. Используйте прямой, обратный и пошаговый алгоритмы выбора признаков. Выбрали ли финальные модели полный набор предикторов? Почему? Если перекрестная проверка использовалась с этими инструментами поиска, была ли эффективность близка к эффективности тестового набора?
B. Используйте рекурсивный выбор признаков с несколькими разными моделями. Насколько эффективно работают модели? Были ли выбраны информативные предикторы?
Г. Примените методы фильтрации к данным. Используйте фильтры, которые оценивают каждый предиктор отдельно, а другие — одновременно (например, алгоритм Relief F). Были ли выбраны два взаимодействующих предиктора (х, и х2)? Был ли один из них более предпочтительным, чем другой?
Д. Уменьшите размер выборки тренировочного набора и добавьте большое количество неинформативных предикторов. Как эти процедуры поиска поведут себя в более экстремальных обстоятельствах?
19.5. Для данных сегментации клеток:
А. Используйте методы-фильтры и методы-обертки для определения оптимального набора предикторов.
Б. Для линейного дискриминантного анализа и логистической регрессии используйте альтернативные версии этих моделей со встроенным выбором признаков (например, glmnet и разреженную модель LDA). Сравните эти модели по эффективности, количеству необходимых предикторов и времени тренировки.
Факторы, влияющие на эффективность модели
В предыдущих главах упоминались технические недостатки предиктивных моделей, такие как переобучение и дисбаланс классов. Но достижение требуемой эффективности модели может зависеть и от аспектов задачи, не связанных напрямую с самой моделью. Например, могут существовать ограничения для области, которая может поддерживаться данными, или скрытые препятствия, связанные с целью моделирования.
Еще одна проблема связана с отношением к моделированию, особенно в тех областях, в которых эти методы рассматриваются как новаторские или революционные (см. в этой связи работу Эйреса (Ayres, 2007). Другой важный аспект моделирования, который также не затрагивается нами, — конструирование признаков, то есть методы для кодирования одного или нескольких предикторов модели.
Ниже, впрочем, рассматривается несколько иных важных аспектов создания и сопровождения предиктивных моделей. Так, в первом разделе этой главы рассматриваются так называемые ошибки типа III: разработка модели, которая «отвечает не на тот вопрос». Соответствующий пример показывает, что из-за проблем выборки с тренировочным набором модель выдает прогнозы, отвечающие не на тот вопрос, который интересует создателей модели.
Шум (или погрешности) в разной степени влияет на предиктивную эффективность модели. В большинстве наборов данных шум присутствует в трех основных формах:
О Систематический шум, сопровождающий измерение множества предикторов. Происхождение такого шума связано с системой измерения. Любой избыточный шум в предикторах с большой вероятностью будет распространяться непосредственно через уравнение прогнозирования модели, что приведет к ее неудовлетворительной эффективности.
О Шум, обусловленный включением неинформативных предикторов (например, не связанных с реакцией). Отметим, что некоторые модели способны отфильт-
568 Глава 20. Факторы, влияющие на эффективность модели
ровывать нерелевантную информацию, при этом их предиктивная эффективность остается относительно неизменной.
О Шум, проникающий в процесс моделирования через переменную реакции. Как и в случае с предикторами, некоторые результаты могут измеряться под воздействием систематического нежелательного шума. Возникающие при этом ошибки устанавливают для эффективности модели верхнюю границу, которую невозможно преодолеть предварительной обработкой, сложностью модели или настройкой. Например, если измеренный категорийный результат неправильно помечается в тренировочных данных в 10 % случаев, то маловероятно, чтобы любая модель могла обеспечить степень точности более 90 %. Игнорирование этого обстоятельства может привести к неоправданным затратам времени на бесплодную борьбу с шумом.
Вышеперечисленные аспекты моделирования рассматриваются в разделах 20.2- 20.3. В разделе 20.4 рассмотрен эффект дискретизации результатов в предиктивном моделировании, в разделе 20.5 — последствия экстраполяции модели. Глава завершается обзором влияния больших данных на эффективность модели.
20.1. Ошибки III типа
Одна из самых распространенных ошибок при моделировании — разработка модели, которая «отвечает не на тот вопрос» (ошибка III типа (Kimball, 1957)). Происхождение этой ошибки связано с неспособностью разработчика правильно обозначить задачу, для решения которой создается модель: вместо сосредоточения на выработке общей стратегии решения задачи приоритет отдается технической тактике потенциальных решений.
Например, в бизнес-приложениях целью почти всегда является извлечение максимальной прибыли. Когда наблюдаемый результат является категорийным (покупка/ отказ от покупки, уход/сохранение клиента), очень важно связать эффективность модели и прогнозы классов с ожидаемой прибылью. Менее очевидна проблематичность стратегии при моделировании отклика в области маркетинга. Вспомним в этой связи пример с прямым маркетингом (глава И), где группа клиентов магазинов одежды получала предложения по участию в рекламной акции. Для каждого клиента регистрировалась потребительская реакция (то есть была или нет совершена покупка).
Истинная цель магазина — получение максимальной прибыли, но кампания, рассматриваемая в примере, проводилась без учета всех доступных данных о клиентах. Соответственно, в модели учитывались данные только о потребительской реакции тех клиентов, к которым магазин обращался с предложением.
На основе этих данных делалось предположение о том, что все клиенты повторяют поведение, совпадающее с реакцией клиентов, получивших рекламное предложе-
20.1. Ошибки III типа 569
ние1. Таким образом, модель, построенная на основе этих данных, ограничивается прогнозированием вероятности покупки только в том случае, если клиент получил предложение. Это условное утверждение противоречит цели повышения общей прибыли. Фактически предложение участия клиентам, которые всегда отвечают на подобные предложения, ведет к снижению прибыли.
Например, существует подгруппа клиентов, которые сделают покупку независимо от рекламной акции. Скорее всего, такие клиенты попадут в наблюдаемые данные, и модель не сможет отличить их реакцию от реакции клиентов, получивших рекламное предложение. Но целью построения модели является повышение прибыли, для чего рекламные предложения должны адресоваться только тем клиентам, которые не сделают покупку, не получив соответствующих предложений. Сигел (Siegel, 2011) описывает четыре возможных случая.
Без обращения
реакция
без реакции
Обращение
Реакция
А
В
Без реакции
С
D
В ячейках таблицы содержится следующая информация:
О А: клиенты, которые реагируют (то есть сделают покупку) в любом случае.
О В: клиенты, которые среагируют только из-за обращения.
О С: клиенты, которые плохо относятся к рекламным акциям и реагируют только в том случае, если к ним не обращались.
О D: клиенты, которые в любом случае не среагируют.
Для получения максимальной прибыли требуется модель, точно прогнозирующая, какие клиенты принадлежат к категории В, поскольку именно эти клиенты могут принести новую прибыль. Перечислим далее потенциальные отрицательные последствия модели простой реакции:
О Частота реакции часто завышается, поскольку в нее включаются и клиенты, которые реагируют в любом случае. Общая оцениваемая прибыль не будет чистой, поскольку в нее встроена базовая прибыль. Например, кривая прироста, генерируемая на основе модели реакции, может показать, что при обращении к 30 % клиентов можно достичь 70 % частоты реакции. Существует большая
1 В области маркетинга Ржепаковский и Ярошевич (Rzepakowski and Jaroszewicz, 2012) определили следующие классы маркетинговых моделей: «В моделях склонности используется историческая информация о покупке (или другие метрики успеха — например, посещения), тогда как в моделях отклика пилотная кампания распространяется на всех клиентов».
570 Глава 20. Факторы, влияющие на эффективность модели
вероятность того, что клиенты, которые реагируют всегда, будут учтены этой моделью и, таким образом, войдут в 30-процентную долю.
О Рассылка рекламных предложений клиентам в ячейках С и D повышает затраты. Для структуры затрат, описанной у Лароуза (Larose, 2006, Chap. 7), затраты на рекламную акцию были относительно небольшими, однако в некоторых ситуациях они могут быть значительно выше. Кроме того, спонтанная рассылка предложений может отрицательно сказаться на отношении клиента к компании. При использовании моделей реакции для удержания клиентов существует определенная вероятность того, что обращение приведет к уходу клиента, если он получит более выгодное предложение от другой компании.
Подчеркнем, что эти проблемы могут проявиться только после того, как рекламная акция будет запущена.
Методы, которые пытаются проанализировать последствия реакции клиента, называются моделями прогнозирования воздействия (Siegel, 2011; Radcliffe and Surry, 2011; Rzepakowski and Jaroszewicz, 2012), моделями истинного прироста (Lo, 2002), моделями чистого прироста, моделями инкрементного прироста или моделями фактической реакции. Ло (Lo, 2002) предполагает, что контрольная группа клиентов, которым не направлялись предложения, может использоваться для разработки отдельной модели реакции, которая бы отличала клиентов в ячейках А и С от клиентов в ячейках BiaD (хотя категории В и D не могут различаться моделью). В сочетании с традиционной моделью реакции, создаваемой на основании информации о клиентах, которым было направлено рекламное предложение, вторая возможная стратегия может заключаться в поиске клиентов с большими значениями
Рг[реакция \ обращение] - Рг[реакция \без обращения].
Вычитание вероятности реакции клиентов без обращения позволяет более точно идентифицировать группы клиентов. Недостаток такого метода — его косвенность. Кроме того, не исключается, что прогнозы модели окажутся тесно связанными, поскольку они моделируют очень похожие события. В подобных случаях могут найтись немногочисленные клиенты, для которых две вероятности не похожи. Рэдклифф и Сарри (Radcliffe and Surry, 2011) описывают модели на базе деревьев, у которых фактический прирост моделируется напрямую по данным контрольной группы клиентов, которым не направлялись обращения.
Другой метод основан на применении более сложных методов выборки для создания тренировочного набора. Для приведенной выше таблицы невозможно направить и не направить рекламное предложение одному и тому же клиенту.
С другой стороны, в медицинских исследованиях эта проблема часто возникает при сравнительной оценке нового варианта лечения с существующей терапией. Здесь в клинических испытаниях иногда используется парная выборка', находятся два почти идентичных пациента, которые затем посредством рандомизации преоб-
20.2. Ошибка измерения результата 571
разуются в терапевтические группы. Идея заключается в том, что единственным различающимся фактором является способ лечения, и реакция пациента может быть оценена с большей точностью, чем без парной выборки. Таким образом, основной точкой данных в анализе становится пара.
Эта стратегия может быть применена и в нашей ситуации. Допустим, для исходной выборки клиентов можно подобрать другую, включающую клиентов с теми же атрибутами (такими, как демографические факторы и уровень дохода). В каждой паре рекламное предложение назначается случайным образом одному из двух клиентов. Теперь для каждой пары можно создать табл. 20.1. Если результаты агрегируются по всем парам, то можно создать классификационную модель для четырех разных исходов (от А до D) и проанализировать клиентов по вероятности их принадлежности к классу В — основной группе, представляющей интерес. Этот метод моделирует группу, представляющую интерес, непосредственно в одной модели.
20.2. Ошибка измерения результата
Какая минимальная частота ошибок может быть обеспечена моделью? Вспомним в этой связи модель линейной регрессии, представленную в формуле 6.1:
yi = b(l + ЬХХЛ + Ь#й + - + bPxip + еР
Предполагается, что остатки ei имеют некоторую дисперсию, которая обозначается о2. Если мы знаем истинную структуру модели (то есть точные предикторы и их связь с результатом), то а2 будет представлять наименьшую возможно достижимую погрешность, или неустранимую погрешность. Но истинная структура модели, как правило, неизвестна, поэтому вышеуказанное значение обычно расширяется и включает погрешность модели (то есть погрешность модели, связанную с недооб- учением). Процесс моделирования направлен на устранение погрешности модели. Однако в о2 также вносит свой вклад другой компонент, который не может быть исключен в процессе моделирования. Если результат содержит значительный шум измерений, то величина неустранимой погрешности возрастает. У среднеквадратичной погрешности и R2 появляются, соответственно, нижняя и верхняя границы, обусловленные этой погрешностью. Таким образом, составляющая погрешности не только включает дисперсию реакции, не объясняемую моделью, но и накапливает системную ошибку измерений. Чем более ясное представление о системе измерений, присущих ей ограничениях, а также об отношениях между предикторами и реакцией, тем точнее прогнозируются ограничения эффективности модели.
Как упоминалось во введении к этой главе, аналогичная проблема существует и в классификации. Чтобы продемонстрировать влияние величины погрешности в реакции на эффективность модели, вернемся к данным растворимости QSAR (главы 6-9). Реакцией для этих данных служат логарифмы метрики растворимости
572 Глава 20. Факторы, влияющие на эффективность модели (см. рис. 6.2), тогда как предикторы могут быть непрерывными или бинарными (раздел 6.1). У лучшей модели линейной регрессии для этих данных среднеквадратичная погрешность равна 0,7; она включает системную погрешность измерений, погрешность обучения и ошибки, обусловленные релевантными предикторами, которые не были включены в модель. В рассматриваемом примере это значение будет использоваться в качестве базового уровня погрешности, а ошибка реакции будет пропорционально возрастать. Для этого в логарифмическое значение растворимости каждого вещества добавляется шум, имеющий нормальное распределение с нулевым математическим ожиданием и стандартным отклонением, равным среднеквадратичной погрешности модели линейной регрессии, умноженной на коэффициент от 0 до 3. Для каждого уровня дополнительного шума выполнена тренировка и настройка следующих моделей: линейная регрессия, частные наименьшие квадраты, одиночные деревья регрессии, многомерные адаптивные регрессионные сплайны, случайные леса, нейросети и модели опорных векторов с радиальной базисной функцией. Эффективность каждой из этих моделей оценена на основании среднеквадратичной погрешности и К2 тестового набора (рис. 20.1 и 20.2). Очевидно, что эффективность ухудшается независимо от типа модели (линейные модели, нелинейные модели, деревья), но пропорционально степени дополнительной погрешности, сопровождающей реакцию.
Из этого простого примера следуют два важных вывода.
Во-первых, подобный тип шума не может быть спрогнозирован и с его влиянием остается лишь примириться. Следовательно, чем больше разработчик знает о системе измерений, тем лучше он будет понимать ожидания относительно эффективности модели.
Во-вторых, с увеличением шума модели практически сравниваются в своей предиктивной эффективности. Это означает, что преимущества некоторых более сложных моделей (например, ансамблей) проявляются только в том случае, если системная погрешность измерений относительно низка. Сложная внутренняя структура, которую может обнаружить модель (такая, как ансамбль), теряет четкость с увеличением шума. Значит, при высоком шуме системы измерений с таким же успехом можно обойтись простой, эффективной в вычислительном отношении моделью.
20.3. Погрешность измерений в предикторах
Судя по некоторым наборам данных, многие предикторы вычисляются. Например, данные растворимости содержат предикторы, обозначавшие наличие или отсутствие конкретной химической структуры. Предикторы могут определяться в результате наблюдений или некоторого внешнего процесса и т. д. Еще раз сошлемся на рассмотренные ранее примеры:
О Данные сегментации клеток измеряли разные аспекты клеток (например, площадь ядра).
20.3. Погрешность измерений в предикторах 573
0,0 0,5 1,0 1,5 2,0 2,5 3,0
2 g Линейная регрессия Дерево регрессии MARS
2,0 Случайные леса
Частные наименьшие
1 5 квадраты
Опорные векторы Лассо
1 «0 Нейросети
0,0 0,5 1,0 1,5 2,0 2,5 3,0
Фактор дополнительной среднеквадратичной погрешности
Рис. 20.1. Профили среднеквадратичной погрешности тестового набора для моделей растворимости при увеличении системного шума измерений
О Данные заявок на получение грантов собирали информацию об успешных и неуспешных заявках.
Традиционные статистические модели обычно предполагают, что предикторы измеряются с определенной погрешностью, но на практике возможны и иные ситуации. Воздействие случайности на предикторы может быть очень значительным и зависеть от нескольких факторов: степени случайности, важности предикторов, типа модели и т. д. В некоторых случаях, когда исходные данные, входящие в тренировочный набор, генерируются в контролируемых условиях, случайность может быть скрыта. Представим, что данные генерируются человеком, вручную измеряющим объект (скажем, при назначении рейтинга). Восприятие объекта разными людьми может отличаться, что приведет к появлению шума, зависящего от эксперта. Смещение, обусловленное индивидуальными различиями экспертов в восприятии объекта, наверняка создаст проблемы.
574 Глава 20. Факторы, влияющие на эффективность модели
0,0 0,5 1,0 1,5 2,0 2,5 3,0
0,8
Линейная регрессия Дерево регрессии MARS
Случайные леса 0'6 Частные наименьшие квадраты
Опорные вектора 0 4 Лассо
’ Нейросети
0,0 0,5 1,0 1,5 2,0 2,5 3,0
Фактор дополнительной среднеквадратичной погрешности
Рис. 20.2. Профили R2 тестового набора для моделей растворимости при увеличении шума системы измерений
Другой пример: возьмем данные состава бетона, упоминавшиеся ранее. Несмотря на то что точные пропорции и количества каждого ингредиента известны заранее, при создании смеси в них всегда присутствуют некоторые отклонения. Если процесс создания бетона достаточно сложен, то реальная величина может отклоняться от формулы (при этом фактические различия не только не наблюдаются, но и не измеряются).
Для демонстрации воздействия случайного шума предикторов на модель смоделирована простая синусоидальная волна со случайной погрешностью. На рис. 20.3 исходные данные изображены на диаграмме пометкой «SD = 0».
По оси х представлены равномерно распределенные значения от 2 до 10. Результат сгенерирован добавлением к данным умеренного, нормально распределенного шума.
20.3. Погрешность измерений в предикторах 575
2 4 6 8 10
1 о -1
-2
н (U н
1
0
-1
-2
2 4 6 8 10
Измеренные значения предикторов
Рис. 20.3. Смоделированная синусоида и две модели с разными уровнями шума, добавленными к значениям предикторов
На каждой диаграмме истинная связь между предиктором и реакцией обозначена сплошной черной линией. Для обучения данных использовались две разные модели регрессии. В левом столбце диаграмм содержатся обычные модели линейной регрессии, где истинная модель (то есть sin(x)) обучается на данных.
Правый столбец диаграмм соответствует подгонке дерева регрессии CART. Кривые обучения этих моделей обозначены сплошными красными линиями.
576 Глава 20. Факторы, влияющие на эффективность модели
В строках на рис. 20.3 содержатся те же данные без шума (верхняя строка и с инкрементным добавлением случайной погрешности в значения предикторов). Точнее, к истинным значениям прибавляются случайные нормальные значения с разными стандартными отклонениями. Малые кривые в виде колокола на диаграммах показывают распределение вероятностей точек данных с математическим ожиданием, равным шести, и соответствующим среднеквадратичным отклонением. Значения по оси у одинаковы для всех диаграмм.
Линейная регрессия способна эффективно моделировать истинную связь без дополнительного шума. С добавлением шума к предикторам модель линейной регрессии начинает ухудшаться в верхних и нижних точках кривой. Эффект становится явно выраженным при среднеквадратичном отклонении 0,75. Тем не менее иллюстрация довольно оптимистична, поскольку предполагает, что разработчик модели уже знает истинную связь между х и у и выбрал модель с учетом этого знания.
Без дополнительного шума дерево регрессии вполне приемлемо аппроксимирует закономерность в диапазоне наблюдаемых данных. Результаты дерева регрессии более проблематичны, поскольку алгоритму приходится определять закономерность в данных эмпирически. Кроме того, эта конкретная модель нестабильна (то есть имеет низкое смещение при высокой дисперсии). В этом случае разность между прогнозируемой и истинной связью начинает выражаться более четко с меньшими величинами случайной погрешности.
Ошибки измерения в предикторах могут создать серьезные проблемы при построении моделей, особенно в отношении воспроизводимости результатов будущих наборов данных (эффект, аналогичный эффекту переобучения). В этом случае последующие результаты могут оказаться неудовлетворительными, потому что используемые данные предикторов отличаются от значений, используемых в тренировочном наборе.
Практикум: прогнозирование нежелательных побочных эффектов
В фармацевтических компаниях имеются отделы по снижению риска лекарственных препаратов. Задача этих подразделений — определить, имеет ли лекарственный препарат вредные побочные эффекты, не токсичен ли он для человека и т. д. Один из способов выявления подобных проблем основан на создании клеточных анализов, по которым можно сделать вывод о потенциальной опасности препарата. В связи с этими лабораторными результатами выявляется набор веществ с известными проблемами, а также набор «чистых» веществ, не имеющих известных проблем. Создаются биологические пробы, используемые в качестве входных данных для предиктивных моделей. По аналогии с предыдущим примером, в котором растворимость вещества прогнозировалась по его химической структуре, эти модели
20.3. Погрешность измерений в предикторах 577
используют реакцию клеточных линий на вещества для прогнозирования потенциальных проблем безопасности.
В предыдущем примере рассмотрено построение предиктивной модели для конкретной токсичности. Для этого создан набор приблизительно из 10 проб, которые измеряли величину транскрипции РНК (также называемую генным выражением) в конкретном типе клеток. Было проанализировано около 250 препаратов (токсичных или безвредных); полученные результаты использовались для тренировки набора моделей. Показатели чувствительности и специфичности составили около 80 %.
Тем не менее при тестировании новой группы препаратов (вместе с несколькими контрольными препаратами из исходного тренировочного набора) результаты были не лучше, чем при случайном гадании. После анализа процесса построения модели с поиском методологических ошибок было исследовано качество анализов и проведен эксперимент с измерением показателей 46 препаратов в трех разных партиях (дни следовали не подряд).
В каждой партии один и тот же препарат повторялся в нескольких экземплярах. Визуализация отдельных точек данных для одного из анализов показана на рис. 20.4, где препараты упорядочены по среднему значению.
2А2
Партия1 Партия 2
Партия 3
2А1
2А0
2А-1
2А-2
Препарат
Рис. 20.4. Результаты эксперимента, используемого для описания источников нежелательного шума в серии биологических проб
На полученных данных в ряде случаев отразились особенности, обусловленные принадлежностью препарата к определенной партии. Значения предикторов,
578 Глава 20. Факторы, влияющие на эффективность модели
относящихся к одной и той же партии, также могут значительно изменяться — иногда в пределах двух логарифмических единиц. Например, препарат 35 охватывает весь диапазон данных предикторов.
Статистические методы, называемые моделями компонентов дисперсии (или методами воспроизводимости и повторяемости (Montgomery and Runger, 1993)), дают количественную оценку источника шума в данных. В экспериментальных условиях дисперсия уровня препаратов в данных может объяснять до 100 % шума (что означает отсутствие шума между партиями или внутри партий).
При использовании анализа компонентов дисперсии на препараты приходилось 38 % шума в данных. На долю дисперсии уровня пакетов приходилось 13 % дисперсии, а дисперсия внутри партии составляла 49 %. Очевидно, что ситуация далека от оптимальной, поскольку большинство дисперсии в данных приходилось на нежелательный шум1. Учитывая весьма различный уровень токсичности исследуемых препаратов, вряд ли результаты измерений помогли бы отличить высокотоксичные препараты от безвредных. К аналогичным результатам приводили и последующие пробы. Отметим, что анализы выбраны на основании данных других экспериментов, представлявших убедительное биологическое обоснование для использования их в этом контексте. Следовательно, в предикторах содержался сигнал, который затем терялся в шуме системы измерений.
20.4. Дискретизация непрерывных результатов
Работать с категорийными результатами удобно, даже если исходный результат измеряется по непрерывной шкале2. Это может быть обусловлено, например, тем, что реальное распределение результата является бимодальным. На рис. 20.5 представлены две гистограммы числовых результатов от разных наборов данных.
На верхней гистограмме представлены данные растворимости, уже упоминавшиеся в этой главе, на нижней — распределение измерений для другого набора данных. Если распределение данных растворимости является симметричным, то нижнее распределение — явно бимодально: большинство данных сосредоточено на концах шкалы результатов, тогда как в середине результатов относительно немного. Категорировать данные верхнего распределения нелегко, потому что в них отсутствует естественное категорийное деление. С другой стороны, классификация данных
1 Обратите внимание: в данном случае шум в предикторах был систематическим и случайным. Иначе говоря, источник дисперсии можно было связать с конкретной причиной.
2 Примером могут послужить данные планирования заданий, где время выполнения заданий делилось на 4 группы. В этом случае система очередей не может использовать оценки длины задания, но может использовать классифицированные версии этого результата.
20.4. Дискретизация непрерывных результатов 579
Рис. 20.5. Сравнение распределений между двумя наборами данных. Наверху: данные растворимости для веществ, рассматривавшиеся ранее в этой главе. Пунктирная вертикальная линия — среднее логарифмическое значение растворимости, которое будет использоваться для классификации данных. Внизу: значения результата для другого набора данных. Это распределение очевидно является бимодальным, и классификация данных на две категории будет более естественной
на нижней диаграмме носит более естественный характер. Стремление иметь дело с реакцией, оцениваемой по категорийной шкале, может быть обусловлено и практическими соображениями. Так, для данных, рассмотренных ранее, растворимость может быть лишь одной из многих характеристик, которые оцениваются учеными для продвижения в процессе поиска новых лекарств.
Для упрощения задачи многомерной оптимизации может оказаться предпочтительнее информация о том, достаточна ли прогнозируемая растворимость вещества или
580 Глава 20. Факторы, влияющие на эффективность модели
нет (вместо конкретного значения логарифма растворимости вещества). В этом случае выбор оптимального набора веществ упрощается до контрольного списка условий; предпочтение отдается веществам, обладающим большей частью свойств, представляющих интерес. Хотя этот процесс может упростить идентификацию наиболее перспективных веществ для дальнейших исследований, более тонкие различия между веществами утрачиваются из-за потери информации.
Когда реакция является бимодальной (или многомодальной), классификация реакции выглядит естественно. Тем не менее если реакция имеет непрерывное распределение, как с данными растворимости, то классификация реакции до моделирования приведет к потере информации, что ослабляет и общую полезность модели.
Для наглядности продолжим работать с данными растворимости, классифицируя реакцию как лежащую выше или ниже среднего значения (-2,72 логарифмической единицы) и настраивая каждую модель классификации с парой необходимых изменений. Линейная регрессия заменена логистической регрессией, модель MARS — моделью FDA, а вместо LASSO используется glmnet (во всех заменах используется параллельный метод классификации). После тренировки каждой модели прогнозируется вероятность каждого вещества в тестовом наборе, а также значение каппа-статистики для тестового набора. Для каждого вещества в тестовом наборе также имеется прогнозируемый непрерывный ответ, который можно совместить с прогнозируемой вероятностью того, что это вещество окажется растворимым. После этого диаграммы разброса непрерывного прогноза можно сравнить с прогнозом вероятности по разным веществам.
На рис. 20.6 представлены результаты тестового набора для регрессионного и классификационного подхода к моделям PLS, SVM и случайные леса (результаты других моделей выглядят аналогично и представлены в упражнении 20.1, см. далее).
Для каждой из моделей регрессии наблюдаемые и прогнозируемые значения log(pacTBopnMOCTb) следуют линии согласования с прогнозируемыми значениями, находящимися приблизительно в четырех единицах log(pacTBopnMocTb) от фактических значений в диапазоне реакции. Если взглянуть на центр распределения, то заметно, что прогнозируемое значение log(pacTBopHMocTb) -4 берет начало от диапазона наблюдаемых значений от -6 до -2 логарифмических единиц между разными моделями.
С другой стороны, прогнозируемая вероятность 0,5 для моделей классификации берет начало от диапазона фактических значений от -6 до 0 для PLS и от -4 до 0 для SVM и случайных лесов. Диапазоны прогнозов в предельных случаях моделей классификации еще шире. Например, прогнозируемая вероятность около 0 для SVM соответствует фактическим значениям log(pacTBopHMocTb) в диапазоне от -10 до -2, а прогнозируемые вероятности около 1 соответствуют фактическим значениям от -3,5 до 2 (аналогично для случайных лесов). Работа с данными
20.4. Дискретизация непрерывных результатов 581
в исходном масштабе повышает точность прогнозов по диапазону реакций для всех моделей.
-10 -8 -6 -4 -2 0
о Е о Q. С
Наблюдение
Рис. 20.6. Сравнение эффективности моделей растворимости для тестового набора при моделировании реакции в форме непрерывных и категорийных значений
Вторая распространенная причина для разделения непрерывной реакции на категории проистекает из ожиданий более высокой погрешности непрерывной реакции, из-за чего представляется возможным правильно классифицировать только значения реакции на концах распределения. В подобной ситуации данные могут быть разбиты на следующие категории:
О на концах распределения данные обобщенно классифицируются как «положительные» или «отрицательные»;
О данные в середине диапазона классифицируются как неизвестные или неопределенные. Эта категория может быть включена в модель (или, наоборот, исключена из процесса настройки модели), чтобы модели было проще различать две крайние категории.
582 Глава 20. Факторы, влияющие на эффективность модели
20.5. Когда следует доверять прогнозу вашей модели?
Процесс предиктивного моделирования предполагает, что используемый механизм, сгенерировавший текущие данные для предикторов и реакции, продолжит генерировать данные. В качестве простого механизма генерирования данных можно рассмотреть компанию по производству продуктов питания. Компании-производители стараются производить один и тот же продукт в неизменном виде, чтобы потребители получали те же вкусовые впечатления. По этой причине компании сохраняют неизменным рецепт, ингредиенты и процесс приготовления. При моделировании влажности шоколадного печенья, произведенного на хлебозаводе, можно ожидать, что предикторы, измеренные на новой партии печенья, с большой вероятностью будут лежать в том же диапазоне, что и предикторы из тренировочного набора (собранные когда-то в прошлом). Это означает, что новые данные будут обладать сходными характеристиками и будут занимать примерно те же части пространства предикторов, что и данные, на которых строилась модель.
В рассмотренных ранее примерах, как правило, создавались тестовые наборы, аналогичные по свойствам в пространстве предикторов тренировочному набору. Принципы, лежащие в основе этого процесса, описаны в разделе 4.3. Если новые данные создаются тем же механизмом — генератором данных, можно быть уверенным в том, что модель выдаст разумные прогнозы для новых данных. Если новые данные не будут генерироваться тем же механизмом или если тренировочный набор слишком мал или разрежен для нормального покрытия части пространства, обычно покрываемой механизмом генерирования данных, то прогнозы модели могут оказаться недостоверными. Экстраполяцией обычно называется использование модели для прогнозирования точек данных, выходящих за пределы диапазона тренировочных данных (Armitage and Berry, 1994). Однако для данных высокой размерности важно понимать, что в диапазоне предикторов могут присутствовать области, для которых тренировочные данные не существуют. Следовательно, необходимо расширить понятие экстраполяции так, чтобы оно включало эти незаполненные области пространства предикторов. Экстраполированные прогнозы — как выходящие за границы диапазона предикторов, так и находящиеся в пустых областях пространства — могут оказаться недостоверными и привести к принятию неудачных решений.
Зачастую сложно понять, выдает модель экстраполированный прогноз или нет. Первой «линией защиты» разработчика должно стать глубокое понимание механизма, использованного для генерирования как тренировочного набора, так и нового набора точек данных, для которых будет генерироваться прогноз. Вернемся к процессу производства шоколадного печенья. Допустим, производитель изменил рецепт, ингредиенты и процесс выпечки. Ранее разработанная модель прогнозирования
20.5. Когда следует доверять прогнозу вашей модели? 583
влажности может выдать для текущего процесса неточные прогнозы, поскольку предикторы для новых данных с большой вероятностью окажутся в другой части пространства (не в той, в которой находятся тренировочные данные). Если разработчик располагает информацией об имеющихся данных, то он может применить соответствующие меры для использования модели и интерпретации полученных прогнозов.
Впрочем, достаточно часто разработчик не знает, используется ли для новых данных тот же механизм генерирования, что и для тренировочных. Наборы данных с малым количеством предикторов намного проще понять, а связи между предикторами в тренировочном наборе и новом наборе точек данных можно проанализировать при помощи простых диаграмм разброса и сравнения распределений каждого предиктора. Но с увеличением размерности пространства анализ диаграмм разброса и распределений становится крайне неэффективным и может привести к неправильному пониманию пространства предикторов между тренировочными и новыми данными. В таких обстоятельствах применяются инструменты, помогающие лучше понять сходство новых данных с тренировочными данными.
Областью применимости модели называется участок пространства предикторов, в котором, как отмечается в работе Нетцевой (Netzeva et al., 2005), «модель выдает прогнозы с заданной надежностью». Существуют разные версии определения, но в простейшем варианте область определяется в контексте сходства с данными тренировочного набора. Если новые прогнозируемые данные достаточно близки к тренировочному набору, то делается предположение о том, что эти точки в среднем будут обладать надежностью, которая характеризуется оценками эффективности модели (например, степенью точности, вычисленной на основании тестового набора).
Для грубого сравнения пространства, покрываемого предикторами из тренировочного набора и нового набора, можно воспользоваться стандартными средствами сокращения размерности — например, методом главных компонент (раздел 3.3) или многомерным масштабированием (Davison, 1983). Если тренировочный набор и новые данные генерируются одним и тем же механизмом, проекция этих данных будет перекрываться на диаграмме разброса. Но если тренировочные и новые данные занимают разные участки диаграммы, то эти данные не могут быть сгенерированы тем же механизмом, и прогнозы для новых данных следует использовать с осторожностью. На рис. 20.7 изображены проекции тренировочного и тестового набора для данных растворимости на первые две главные компоненты тренировочных данных.
По-видимому, тренировочные и тестовые данные занимают одно и то же пространство, определяемое этими компонентами. Это вполне ожидаемый результат, поскольку тренировочный и тестовый наборы получены случайным разделением исходного набора данных (анализ сходства между тренировочным и тестовым набором продолжен в разделе 20.7 и упражнении 20.3).
584 Глава 20. Факторы, влияющие на эффективность модели
-5 0 5 10 15
10
5
CXI
£ 0
ф
-10
-15-
-5 0 5 10 15
Компонент 1
Рис. 20.7. Диаграммы РСА для данных растворимости
Проецирование многих предикторов в два измерения может скрыть тонкие связи между предикторами, а также разреженные и плотно заполненные части пространства. Это означает, что хотя тренировочные данные и новые данные могут перекрываться на проекционной диаграмме, в пространстве предикторов могут присутствовать области, в которых модель будет неадекватно прогнозировать новые точки. Для решения этой проблемы Хэсти (Hastie et al., 2008) предлагает метод количественного описания вероятности того, что новая точка данных входит в тренировочный набор. При таком подходе выбираются тренировочные предикторы, после чего на основании диапазонов тренировочных предикторов генерируется случайная многомерная выборка, количество точек данных в которой равно количеству точек в тренировочных данных.
Вектор реакции является категорийным: исходные тренировочные данные идентифицируются как тренировочный набор, а случайная равномерная выборка — как случайный набор. На основе этого набора можно построить любую классификационную модель, а итоговая модель используется для прогнозирования вероятности того, что новая точка данных принадлежит к тренировочному набору. Укажем на две модификации рассматриваемого метода, которые лучше подходят для реальных данных. Во-первых, с учетом того, что многие наборы данных содержат разные типы предикторов, рекомендуется применять случайную перестановку предикторов вместо использования данных из равномерного распределения по диапазону предикторов. Перестановка обеспечивает случайное распределение по всему пространству без выхода за рамки допустимых значений каждого предиктора. Таким образом, категорийным предикторам будут доставаться только соответствующие категорийные значения.
20.5. Когда следует доверять прогнозу вашей модели? 585
Во-вторых, если у данных велико количество предикторов и размерность, рекомендуется строить категорийную модель на подмножестве исходных предикторов. Представляется целесообразным выбрать 20 верхних важных предикторов из исходной модели тренировочных данных, что значительно сократит время построения модели, позволяющей оценить, является ли сформированный прогноз экстраполированным. Основные этапы этого процесса представлены в алгоритме 20.1.
Алгоритм 20.1. Алгоритм определения сходства с тренировочным набором
1 Вычислить важность переменных для исходной модели и выделить
20 верхних предикторов.
2 Сгенерировать случайную перестановку этих предикторов.
3 Выполнить построчную конкатенацию верхних предикторов исходного тренировочного набора и версии этих предикторов со случайной перестановкой.
4 Создать вектор классификации, который идентифицирует строки исходного тренировочного набора и строки тренировочного набора с перестановкой.
5 Выполнить тренировку модели классификации на вновь созданных данных.
6 Использовать модель классификации для прогнозирования вероятности того, что новые данные принадлежат классу тренировочного набора.
Тренировочный набор Случайные данные
0,6
0,4
0,2
0,0
0,0 0,2 0,4 0,6
Предиктор А
Рис. 20.8. В данные на рис. 4.1 добавляются случайные равномерные данные для покрытия пространственного диапазона двух предикторов
586 Глава 20. Факторы, влияющие на эффективность модели
Для наглядности вернемся к двумерному примеру (см. рис. 4.1). Здесь, минуя этап выбора переменных, мы переходим сразу к следующему этапу, дополняя исходные данные случайно переставленными значениями исходных предикторов (см. рис. 20.8) и выстраивая дерево классификации с бэггингом.
После этого сгенерировано 50 случайных точек данных, последовательно отодвинутых от исходных данных и обработанных деревом классификации с бэггингом для прогнозирования вероятности того, что точки данных взяты из тренировочных данных. Расположение новых точек данных, а также вероятность принадлежности точек к тренировочному набору показаны на рис. 20.9. Очевидно, что при удалении точек от исходных тренировочных данных вероятность принадлежности к тренировочному набору снижается.
20.6. Влияние большой выборки
До настоящего момента эффективность модели рассматривалась с точки зрения предикторов и реакции. Посмотрим, как влияет на эффективность модели количество точек данных. Предполагается, что чем больше точек данных мы имеем, тем лучшую модель можно построить. Разумеется, это предположение зависит от нашей способности получить столько точек данных, сколько потребуется. Простой способ получения данных приведен у Эйреса (Ayres, 2007), описавшего процесс, который был применен им для выбора названия его книги «Super Crunchers».
Чтобы лучше понять мнение читателей относительно выбора названий, Эйресом использовалось несколько вариантов целенаправленной рекламы Google Ads с разными возможными названиями книги. Вскоре он собрал четверть миллиона точек данных, которые определяли, на какой рекламе чаще всего щелкали пользователи. Поскольку реклама отображалась случайным образом, этот широкомасштабный эксперимент предоставлял веские доказательства того, какое название книги больше нравилось читателям. Этот простой и умный подход к пониманию выборочной совокупности дает положительный пример того, как можно эффективно использовать большое количество точек данных. Однако шум в предикторах или реакции может свести к минимуму все преимущества, полученные из-за увеличения количества точек данных. Более того, увеличение количества точек может иметь и менее положительные последствия.
Во-первых, многие предиктивные модели сталкиваются со значительной вычислительной нагрузкой с ростом количества точек данных (и предикторов). Например, одиночные деревья классификации выполняют множество поисков с полным перебором по точкам данных и предикторам для нахождения оптимальных разбиений данных. С ростом размерности данных также возрастает время вычислений. Вычислительная нагрузка для ансамблей деревьев становится еще выше, часто требуя более дорогого оборудования и/или специальных реализаций моделей, которые делают вычисления реальными. Во-вторых, снижается эффективность добавления
20.6. Влияние большой выборки 587
Предиктор В Предиктор В Предиктор В
0,6
0,4
0,2
Предиктор А
0,6
0,4
0,2
0,5 1,0
Предиктор А
0,6
0,4
0,2
0,0 0,5 1,0
Предиктор А
Сходство с тренировочным набором
0.0 0,2 0,4 0,6 0,8 1,0
Сходство с тренировочным набором
100
80
60
40
20
о
0.0 0,2 0,4 0,6 0,8 1,0
Сходство с тренировочным набором
Рис. 20.9. Пример проверки экстраполяции модели. В левом столбце изображены три сценария с тестовыми наборами (наверху — тестовые данные расположены вблизи от тренировочных данных, внизу — тестовые данные удалены от тренировочных данных), В правом столбце представлена вероятность того, что точки данных тестового набора принадлежат к числу исходных тренировочных данных
588 Глава 20. Факторы, влияющие на эффективность модели
все тех же данных из той же выборки. Поскольку модели стабилизируются при достаточно большом количестве точек данных, получение новых точек данных с меньшей вероятностью повлияет на последующее обучение модели.
Например, технология веб-поиска изначально использовала для ранжирования результатов содержимое веб-сайта. Если пользователь проводил поиск по критерию «предиктивное моделирование», то алгоритм поиска работал с веб-сайтами в своей базе данных и использовал их для прогнозирования того, какие страницы будут релевантными. Для конкретного поиска релевантными могут оказаться сайты, относящиеся к темам «машинное обучение», «распознавание образов», «глубокий анализ данных» и т. д.; следовательно, алгоритм должен это учитывать. Для подобных алгоритмов добавление новых веб-сайтов в коллекцию вряд ли существенно улучшит результаты поиска, но добавление других данных может привести к улучшениям. Поисковые порталы (такие, как Google) могут отслеживать процесс взаимодействия пользователя с получением более непосредственной и более качественной информации для поиска.
Например, если большая часть пользователей, проводивших поиск по критерию «предиктивное моделирование», переходила на сайт А, то это повышало вероятность того, что сайт является релевантным. В этом примере добавление других данных более эффективно, чем добавление новых реализаций тех же атрибутов данных. В отдельных ситуациях добавление точек данных может заметно улучшить качество прогнозов, но следует помнить, что количество данных не всегда означает их качество. Итак, большое количество точек данных может приносить пользу, особенно если точки данных содержат информацию из всего пространства предикторов (шум в предикторах и реакции можно минимизировать), а также если добавляется новый контент. В то же время увеличение количества точек данных повышает вычислительную нагрузку.
20.7. Вычисления
Технические подробности тренировки моделей, описанных в этой главе, приводились в предшествующих главах. Одна из новых тем, которые рассматриваются здесь, касается реализации алгоритма 20.1. Для демонстрации будет использован пакет R caret.
Чтобы продемонстрировать реализацию алгоритма определения сходства, сначала загрузите данные растворимости и определите управляющую структуру для тренировки. Мы воспользуемся структурой, которая уже использовалась в книге для этих данных:
> Library(АррLiedPredictiveModeLing)
> data(soLubiLity)
> set.seed(100)
20.7. Вычисления 589
> indx <- createFoLds(soLTrainY, returnTrain = TRUE)
> ctrL <- trainControL(method = "cv", index = indx)
Теперь настройте нужную модель и вычислите важность переменных, поскольку эффективность алгоритма определения сходства можно повысить за счет работы с наиболее важными предикторами. Здесь мы настроим модель случайных лесов и создадим подмножество тренировочных и тестовых данных, используя верхние 20 предикторов (шаг 1) для включения в алгоритм:
> set.seed(100)
> mtryVaLs <- fLoor(seq(10, ncoL(soLTrainXtrans), Length = 10))
> mtryGrid <- data.frame(.mtry - mtryVaLs)
> rfTune <- train(x = soLTrainXtrans, у = soLTrainY,
+ method = "rf
+ tuneGrid = mtryGrid,
+ ntree = 1000,
+ importance = TRUE,
+ trControL = ctrL)
> Importanceorder <- order(rfTune$finaLModeL$importance[,l],
+ decreasing = TRUE)
> top20 <- rownames(rfTune$finaLModeL$importance[Importanceorder,])[1:20]
> soLTrainXimp <- subset(soLTrainX, seLect = top20)
> soLTestXimp <- subset(soLTestX, seLect = top20)
Затем в подмножестве предикторов создается перестановка для создания случайного набора. Есть много способов перестановки данных в R; в простом и прямолинейном способе используется сочетание функций apply и sample. Исходное подмножество данных и набор с перестановкой объединяются, и создается новая классификационная переменная, определяющая принадлежность каждой строки. Таким образом определяются строки 2-4 алгоритма, которые могут быть реализованы следующим образом:
> permutesoLTrainXimp <- appLy(soLTrainXimp, 2, function(х) sampLe(x))
> soLSimX <- rbind(soLTrainXimp, permutesoLTrainXimp)
> groupVaLs <- c("Training", "Random")
> groupY <- factor(rep(groupVaLs, each = nrow(soLTrainX)))
Наконец, модель настраивается по вновь созданным классификационным данным и используется для прогнозирования вероятности принадлежности к тренировочному набору.
> rfSoLCLass <- train(х = soLSimX, у = groupY,
+ method = "rf",
+ tuneLength = 5,
+ ntree = 1000,
+ controL = trainControLfmethod = "LGOCV"))
> soLTestGroupProbs <- predict(rfSoLCLass, soLTestXimp, type = "prob")
590 Глава 20. Факторы, влияющие на эффективность модели
Упражнения
20.1. На рис. 20.10 приведено сравнение нескольких моделей, у которых реакция моделируется как непрерывное или категорийное значение. Ось х представляет наблюдаемую растворимость из тестового набора, а ось у — прогнозируемую растворимость или прогнозируемую вероятность растворимости.
A. На основании рис. 20.10 какая непрерывная модель лучше всего (и хуже всего) работает для тестового набора? Какая категорийная модель работает лучше (или хуже)?
Б. Проанализируйте результаты моделей нейросетей. Если прогнозируемая вероятность для вещества близка к нулю, каким будет диапазон фактических значений растворимости для тестового набора? Если прогнозируемое значение растворимости (от непрерывной модели) близко к -10, каким будет диапазон значений растворимости? Какая модель (категорийная или непрерывная) дает более точные результаты на этом конце шкалы?
B. Можно ли сказать, что какая-то из категорийных моделей лучше соответствующей регрессионной модели? Объясните.
20.2. Как упоминалось в разделе 20.4, классификация непрерывного результата может отрицательно повлиять на эффективность модели, особенно когда распределение не имеет ярко выраженных группировок. Тем не менее в некоторых ситуациях группировка непрерывных данных может иметь рациональное обоснование. Если в подобных ситуациях данные имеют распределение, близкое к распределению данных растворимости (см. рис. 20.5), то одно из возможных решений разработчика модели заключается в построении реакции, разбивающей данные на три группы, для которых на концах шкалы существует высокая достоверность. Например, данные растворимости веществ могут разбиваться на группы «Нерастворимое», «Растворимое» и «Неопределенное», где последняя группа состоит из данных, расположенных вокруг среднего значения реакции.
Загрузите данные растворимости и создайте два тренировочных набора. Для первого набора выполните разбиение данных по среднему значению реакции. Для второго набора вещество относится к неопределенной группе, если оно лежит в границах одного среднеквадратичного отклонения от среднего значения реакции. Это может быть сделано так:
> Library(АррLiedPredictiveModeLing)
> data(soLubiLity)
> trainData <- soLTrainXtrans
> Lowcut <- mean(soLTrainY) - sd(soLTrainY)
> highcut <- mean(soLTrainY) + sd(soLTrainY)
> breakpoints <- c(min(soLTrainY), Lowcut, highcut, max(soLTrainY))
> groupNames <- c("InsoLubLe”, "MidRange", "SoLubLe")
> soLTrainY3bin <- cutfsoLTrainY,
Упражнения 591
Прогноз
Наблюдаемое значение
Рис. 20.10. Сравнение эффективности моделей растворимости для тестового набора при моделировании реакции как непрерывных и категорийных значений
592 Глава 20. Факторы, влияющие на эффективность модели
+ breaks = breakpoints, ♦ incLude. Lowest = TRUE, + LabeLs = groupNames)
> soLTestY3bin <- cutfsoLTestY, + breaks = breakpoints, + incLude.Lowest = TRUE, + LabeLs = groupNames)
А. Выполните обучение линейной модели, нелинейной модели и модели на базе дерева по данным с тремя группами. Например, для генерирования модели рекурсивного разбиения может использоваться следующий код:
> set.seed(100)
> indx3bin <- createFoLds(soLTrainY3bin, returnTrain = TRUE)
> ctrL3bin <- trainControL(method = "cv",
+ index = indx3bin,
+ cLassProbs = TRUE,
+ savePredictions = TRUE)
> Rpart3bin <- trainfx = trainXfiLtered, у = soLTrainY3bin,
+ method = "rpart",
+ metric = "Kappa",
+ tuneLength = 30,
-I- trControL = ctrL3bin)
>
Б. Спрогнозируйте эффективность тестового набора с использованием метрики эффективности на ваш выбор для каждой из моделей в (А). Какая модель лучше подходит для данных, разбитых на три группы?
В. Исключите данные "MidRange" из тренировочного набора, заново постройте каждую модель и проведите прогнозирование для тестового набора. Это может быть сделано посредством рекурсивного разбиения:
> trainXfiLtered2bin <- trainXfiLtered[soLTrainY3bin != "MidRange",]
> soLTrainY2bin <- soLTrainY3bin[soLTrainY3bin != "MidRange"]
> testXfiLtered2bin <- testXfiLtered[soLTestY3bin 1= "MidRange",]
> soLTestY2bin <- soLTestY3bin[soLTestY3bin != "MidRange"]
> set.seed(100)
> indx2bin <- createFoLds(soLTrainY2bin, returnTrain = TRUE)
> ctrL2bin <- trainControL(method = "cv",
index = indx2bin,
+ cLassProbs = TRUE,
+ savePredictions = TRUE)
> Rpart2bin <- trainfx = trainXfiLtered2bin, у = soLTrainY2bin,
method = "rpart",
+ metric = "Kappa",
+ tuneLength = 30,
Упражнения 593
+ trControt = ctrL2bin)
> Rpart2binPred <- predict(Rpart2binJ newdata = testXfittered)
> Rpart2binCM <- confusionMatrix(Rpart2binPredJ soLTestY3bin)
Г. Сравните чувствительность и специфичность для нерастворимого и растворимого класса для методов группировки в (Б) и (В) внутри каждой модели и между моделями.
0,0 0,2 0,4 0,6 0,8 1,0
m
8
| 1,0
I 0,8
н
X
1 0,6
о
х 0,4
л
Б
g 0,2
fe
I 0,0
СП
0,0 0,2 0,4 0,6 0,8 1,0
Вероятность из модели двух классов
Рис. 20.11. Прогнозируемые вероятности для моделей с двумя и тремя классами для тестового набора из модели рекурсивного разбиения. Вероятности были слегка скорректированы для отображения относительного количества точек данных
Д. На рис. 20.11 сравниваются прогнозируемые вероятности классов из моделей с двумя и тремя группами для растворимых и нерастворимых веществ из тестового набора. Если судить по вероятностям классов, обладает ли модель с двумя или тремя классами явными преимуществами прогнозирования для растворимых и/или нерастворимых веществ? Сравните прогнозируемые вероятности классов в растворимой и нерастворимой группе с другими моделями, которые были разработаны вами.
20.3. В разделе 20.7 представлены подробности вычислений алгоритма 20.1, примененные к данным растворимости. Выполните этот код и выведите диаграмму распределения вероятности принадлежности данных тестового набора к тренировочному набору. Для каких точек данных тестового набора вхождение в распределение тренировочного набора маловероятно?
20.4. В упражнении 4.4 описан набор данных, в котором растительные масла анализировались на содержание семи типов жирных кислот. Загрузите данные и создайте тренировочный и тестовый наборы:
594 Глава 20. Факторы, влияющие на эффективность модели
> data(oiL)
> set.seed(314)
> sampLeRows <- sampte.int(nrow(fattyAcids), size = 0.5*nrow(fattyAcids))
> fattyAcidsTrain <- fattyAcids[sampteRows,]
> fattyAcidsTest <- fattyAcids[-sampLeRows, ]
А. Выполните алгоритм 20.1 для тренировочного набора. Для каких точек данных тестового набора вхождение в распределение тренировочного набора маловероятно? Почему?
Б. На рис. 20.12 представлены проекции данных тестового набора на первые три компоненты РСА, определяемые тренировочным набором. Цвет и форма точек определяются вероятностью их принадлежности к тренировочному набору. Какую информацию можно получить из этой диаграммы о местонахождении точек данных, которые с малой вероятностью принадлежат к тренировочному набору?
Рис. 20.12. Проекции данных тестового набора на первые три компоненты РСА, определяемые тренировочным набором
В. Что можно сделать для повышения вероятности того, что тренировочный и тестовый наборы входят в одну область пространства предикторов?
Приложения
А Краткая сводка различных моделей
В табл. АЛ приведена краткая сводка различных характеристик моделей, рассмотренных в книге. Эти свойства типичны, но не следует полагать, что они всегда истинны для любых задач. Например, модели линейного дискриминантного анализа не выполняют выбор признаков. Однако существуют специализированные версии модели, использующие регуляризацию для устранения предикторов. Кроме того, интерпретируемость модели субъективна. Одиночное дерево понятно, если оно не будет слишком большим, а разбиения не включают большое количество категорий.
Как утверждалось в главе 2, ни одна модель не может быть признана однозначно лучше других. Применимость метода зависит от типа анализируемых данных, потребностей разработчика модели и контекста применения модели.
Таблица А.1. Сводка моделей и некоторых их характеристик
Краткая сводка различных моделей 597
Время вычислений
S
S
S
X
X
о
S
S
S
о
X
X
X
S
Стойкость к шумам предиктора
X
X
X
X
X
X
о
о
S
S
S
S
S
X
Количество параметров настройки
О
-
-
1-2
CN
1-3
1-2
-
-
1-2
о
о
со
CN
<О
Автоматический выбор признаков
X
о
X
S
X
X
S
X
S
S
S
о
S
О
X
Интерпретируемость
S
S
S
X
X
О
X
О
О
X
X
X
X
S
Предварительная обработка
CS, NZV, Согг
оо О
CS,NZV,
CS,NZV
CS, NZV, Согг
ио О
CS,NZV
t
О
:> N Ъ у? О
Допускает п < р
X
S
X
S
S
S
S
S
S
S
S
S
S
X
Модель
Линейная регрессия
Частичные наименьшие ква¬
драты
Хребтовая регрессия
Эластичная сеть
Нейронные сети
Метод опорных векторов
MARS/FDA
метод ^-ближайших соседей
Одиночные деревья
Model trees/rulesf
Деревья с бэггингом
Случайный лес
Усиленные деревья
Cubist
Логистическая регрессия*
598 Приложение А. Краткая сводка различных моделей
Время вычислений
S
S
о
X
Стойкость к шумам предиктора
X
X
о
S
Количество параметров настройки
0-2
-
1 о
0-3
Автоматический выбор признаков
о
S
X
S
Интерпретируемость
о
о
X
о
Предварительная обработка
NZV
NZV
NZV
Допускает п < р
X
S
S
S
Модель
2
§
Ближайшие усеченные
центроиды*
Наивный байесовский классификатор
С5.0*
Введение в R
Язык R (Ihaka and Gentleman 1996; R Development Core Team 2010) представляет собой платформу для математических и статистических вычислений. Он распространяется бесплатно (хотя существуют и коммерческие версии), и любой желающий может проанализировать или изменить его исходный код. R распространяется на условиях открытого лицензионного соглашения General Public License (Free Software Foundation, июнь 2007 года), которое описывает возможности распространения программы.
Исходный код программы, а также откомпилированные версии, готовые к использованию, доступны на веб-сайте CRAN (Comprehensive R Archive Network): http:// cran.r-project.org/.
Данное приложение содержит краткую сводку основных концепций и синтаксиса R. Более подробное изложение основ языка можно найти у Спектора (Spector, 2008) и Джентльмена (Gentleman, 2008). Жизненный цикл разработки продукта подробно описан в документации R Development Core Team (2008).
Б.1. Запуск и вывод справочной информации
На сайте CRAN доступны откомпилированные версии R для Microsoft Windows, Apple OS X и нескольких версий Linux. Для Windows и OS X программа поставляется с графическим интерфейсом пользователя (GUI). При установке откомпилированных версий R для этих двух операционных систем на компьютере появляется значок для запуска R. Чтобы запустить интерактивный сеанс, запустите программу при помощи этого значка. Также можно запустить R из командной строки командой R.
600 Приложение Б. Введение в R
После того как программа будет запущена, функция q (сокращение от quit) завершает сеанс.
> # Символы после знаков являются комментариями и не используются,
> # Эта команда используется для завершения сеанса:
> д()
При выходе пользователю будут предложены варианты сохранения текущей работы. Язык учитывает регистр символов: символ Q не может использоваться для завершения сеанса.
Чтобы получить справку по конкретной теме (например, функции), поставьте вопросительный знак перед функций и нажмите Enter:
> # Получение справки по функции Sweave
> ?Sweave
Команда открывает справочную страницу Sweave. Одна из распространенных проблем с R — поиск нужной функции. Чтобы провести поиск по всем локальным функциям R на вашем компьютере, введите команду apropos с ключевым словом:
> apropos ("prop")
[1] "apropos” "getProperties"
[3] "pairwise.prop.test" "power.prop.test"
[5] "prop.table" "prop.test"
[7] "prop.trend.test" "reconcilePropertiesAndPrototype"
Функция RSiteSearch проводит сетевой поиск ключевого слова по всем функциям, руководствам, документации, конференциям R-Help и другим источникам. Например, если вы хотите найти информацию о разных способах построения ROC- кривых, команда
> RSiteSearch("гос")
откроет браузер и выведет результаты. Атрибут restrict этой функции позволяет расширить поиск (дополнительную информацию см. ?RSiteSearch).
Б.2. Пакеты
Базовая система R включает основные средства языка (исполняемая программа, фундаментальная основа для программирования). Большая часть реального кода R содержится в отдельных модулях, называемых пакетами (packages). При установке R также устанавливается небольшой набор базовых пакетов (полный список приведен в документации R Development Core Team (2008)). Тем не менее существует большое количество пакетов за пределами этого набора. На сайте CRAN содержится более 4150 пакетов, доступных для загрузки, тогда как проект Bioconductor
Б.2. Пакеты 601
(Gentleman et al., 2004), система вычислительной биологии на базе R, включает более 600 пакетов R.
Для загрузки пакетов используется функция library:
> # Загрузка пакета для работы со случайными лесами
> Library(randomForest)
> # Вывод списка текущих загруженных пакетов и другой информации
> sessioninfo()
R version 2.15.2 (2012-10-26)
Platform: x86_64-apple-darwin9.8.0/x86_64 (64-bit)
locale:
[1] c
attached base packages:
[1] splines tools stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] randomForest_4.6-7 Bioclnstaller_1.8.3 caret_5.15-045
[4] foreach_1.4.0 cluster_1.14.3 reshape_0.8.4
[7] plyr_1.7.1 lattice_0.20-10 Hmisc_3.10-1
[10] survival_2.36-14 weaver_1.24.0 codetools_0.2-8
[13] digest_0.6.0
loaded via a namespace (and not attached):
[1] grid_2.15.2 iterators_1.0.6
Функция install. packages используется для установки дополнительных модулей. Например, следующая команда устанавливает пакет rpart для деревьев регрессии и классификации, рассмотренных в разделах 8.1 и 14.1:
> instaLL.packages("rpart")
Также на сайте CRAN размещены «группы задач», объединяющие сходные пакеты. Например, группа задач «Машинное обучение» устанавливает набор пакетов предиктивного моделирования:
> # Сначала устанавливается пакет групп задач
> instaLL.packages("ctv")
> # Загрузить библиотеку перед первым использованием
> Library(ctv)
> instaLL.views("MachineLearning")
Некоторые пакеты зависят от других пакетов (или их конкретных версий). Функции install.packages и install.views определяют дополнительные требования к пакетам и устанавливают необходимые зависимости.
602 Приложение Б. Введение в R
Б.З. Создание объектов
Все, что создается в R, является объектом. Значения объектов присваиваются с использованием синтаксиса <-.
Пример:
> pages <- 97
> town <- "Richmond"
> ## Знак равенства тоже работает (см. раздел Б. 8)
Чтобы просмотреть значение объекта, просто введите его имя и нажмите Enter. Также можно явно запросить у R вывести значение объекта:
> pages
[1] 97
> print(town)
[1] "Richmond"
Еще одна полезная функция, которая помогает понять содержимое объекта, — str (сокращение от «structure»). Например, в R включен объект с сокращенными названиями месяцев:
> month.abb
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov"
[12] "Dec"
> str(month.abb)
chr [1:12] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" ...
Из выходных данных видно, что month.abb — символьный объект, содержащий 12 элементов. Также можно определить структуру объектов, которые не содержат данных, — например, упоминавшейся выше функции print:
> str(print)
function (х, ...)
> str(sessioninfo) function (package = NULL)
Эта функция может пригодиться для получения имен аргументов функций. Функции будут более подробно рассмотрены ниже.
Б.4. Типы данных и базовые структуры
В R существует целый набор базовых типов данных. Для нас представляют интерес числовые, символьные, факторные и логические типы. Логические данные могут
Б.4. Типы данных и базовые структуры 603
принимать значение TRUE или FALSE. Например, эти значения можно использовать для сравнения или присвоить объектам:
> if(3 > 2) print("greater") eLse printf'Less")
[1] "greater”
> isGreater <- 3 > 2
> isGreater
[1] TRUE
> is.LogicaLfisGreater)
[1] TRUE
Числовые данные включают целые числа и числа с двойной точностью. Присваивание одного числового значения объекту R выполняется так:
>х<-3.6
> is.numeric(х)
[1] TRUE
> is.integer(х)
[1] FALSE
> is.doubLe(x)
[1] TRUE
> typeof(x)
[1] "double”
Чтобы создать символьную строку, заключите текст в кавычки:
> у <- "your ad here"
> typeof(y)
[1] "character”
> z <- "you can aLso 'quote' text too"
>z
[1] "you can also ’quote’ text too"
В R длина символьных строк не ограничивается.
Есть несколько полезных функций, работающих со строками. Функция char подсчитывает количество символов:
> nchar(y)
[1] 12
> nchar(z)
[1] 29
Функция grep определяет, присутствует ли заданная подстрока в символьной строке:
> grep ("ad", у)
[1] 1
604 Приложение Б. Введение в R
> grep ( "ту", у)
integer(0)
> # If the string is present, return the whole value
> grep ("too", z, value = TRUE)
[1] "you can also 'quote' text too"
До настоящего момента все рассматривавшиеся объекты R содержали одно значение или элемент. Основная структура данных для хранения нескольких значений с одним типом данных — вектор. Для создания векторов чаще всего используется функция с (сокращение от «combine»). Пример создания вектора для числовых данных:
> weights <- с(90, 150, 111, 123)
> is.vector(weights)
[1] TRUE
> typeof(weights)
[1] "double"
> Length(weights)
[1] 4
> weights + .25
[1] 90.25 150.25 111.25 123.25
Последняя команда демонстрирует операции с векторами. В отличие от последовательного перебора элементов вектора, векторные операции используют более компактный и эффективный синтаксис.
Многие функции работают с векторами:
> mean(weights)
[1] 118.5
> colors <- с ("green", "red", "blue", "red", "white")
> grep("red", colors)
[1] 2 4
> nchar(colors)
[1] 5 3 4 3 5
Также для хранения символьных данных в векторе можно воспользоваться факторами. Фактор сначала определяет в данных все уникальные значения, называемые факторными уровнями. Затем символьные данные сохраняются как целые числа, соответствующие факторным уровням:
> colors2 <- as.factor(colors)
> colors2
[1] green red blue red white
Levels: blue green red white
> Levels(colors2)
[1] "blue" "green" "red" "white"
Б.4. Типы данных и базовые структуры 605
> as.numeric(coLors2)
[1] 2 3 1 3 4
Хранение данных в факторах имеет ряд преимуществ. Во-первых, для хранения значений требуется меньше памяти, потому что длинные символьные строки сохраняются только в одном экземпляре, а их вхождения сохраняются в виде векторов. Во-вторых, факторный вектор «запоминает» все возможные значения. Допустим, мы создаем сегмент (подмножество) факторного вектора, удаляя первое значение:
> coLors2[-l]
[1] red blue red white
Levels: blue green red white
Хотя элемент co значением "green" был удален, в факторе сохраняются исходные уровни. Факторы являются основным средством хранения дискретных переменных в R и используются многими классификационными моделями для определения данных результата.
При работе с сегментами векторов поддерживаются различные варианты использования квадратных скобок:
> weights
[1] 90 150 111 123
> # Положительные целые числа обозначают элементы,
> # которые должны остаться
> weights[c(l, 4)]
[1] 90 123
> # Отрицательные целые числа обозначают исключаемые элементы
> weights[-с(1, 4)]
[1] 150 111
> # Вектор логических значений тоже может использоваться,
># но количество логических значений должно соответствовать
> # количеству элементов
> weights[с(TRUE, TRUE, FALSE, TRUE)]
[1] 90 150 123
В векторах должны храниться данные одного типа. Также можно воспользоваться списком — разновидностью вектора, в элементах которого могут храниться объекты любого типа:
> both <- List(coLors = coLors2, weight = weights)
> is.vector(both)
[1] TRUE
> is.List(both)
[1] TRUE
> Length(both)
[1] 2
606 Приложение Б. Введение в R
> names(both)
[1] "colors” "weight”
Списки можно фильтровать так же, как и векторы. Однако в этом случае двойные квадратные скобки возвращают только элемент, а одиночные квадратные скобки возвращают другой список:
> both[[l]]
[1] green red blue red white
Levels: blue green red white
> is.List(both[[l]])
[1] FALSE
> both[l]
$colors
[1] green red blue red white
Levels: blue green red white
> is.List(both[l])
[1] TRUE
> # Me can aLso subset using the name of the List
> both[["coLors"]]
[1] green red blue red white
Levels: blue green red white
Отсутствующие значения в R кодируются в форме значений NA:
> probabiLities <- с (.05, .67, NA, .32, .90)
> is.па(probabiLities)
[1] FALSE FALSE TRUE FALSE FALSE
> # NA не считается символьной строкой
> probabiLities == "NA"
[1] FALSE FALSE NA FALSE FALSE
> # Многие функции распространяют отсутствующие значения в результат...
> mean(probabiLities)
[1] NA
> # ... если только при вызове не указано обратное.
> mean(probabiLities, па.rm = TRUE)
[1] 0.485
Б.5. Работа с прямоугольными наборами данных
Термином «прямоугольные наборы данных» обычно обозначаются ситуации, в которых точки данных соответствуют строкам набора данных, а столбцы — переменным (в некоторых областях используется обратная схема). В области прямоугольных данных используются две основные структуры: матрицы и кадры данных. Эти
Б.5. Работа с прямоугольными наборами данных 607
два типа объектов различаются прежде всего типом данных, которые могут в них храниться. Матрицы могут содержать данные только одного типа (символьные или числовые), тогда как кадры данных должны содержать столбцы с одним типом данных. Матрицы более эффективны с точки зрения вычислений, но их возможности очевидно ограниченны.
Мы можем создать матрицу, используя матричную функцию. Здесь мы создаем числовой вектор целых чисел от одного до двенадцати и используем три строки и четыре столбца:
> mat <- matrix(l:12, nrow - 3)
> mat
[,1]
L
»2] |
:,3] [,4]
[1.]
1
4 7
10
[2>]
2
5 8
11
[3,]
3
6 9
12
Строкам и столбцам можно присвоить имена:
> rownames (mat) <- с ("row Iй, "row 2", "row 3")
> coLnames(mat) <- с("соИ", "coL2"J "C0L3", "coL4")
mat
coll
CO12
col3
CO14
row
1
1
4
7
10
row
2
2
5
8
11
row
3
3
6
9
12
> rownames(mat)
[1] "row 1" "row 2" "row 3"
Для матриц можно создавать сегменты по аналогии с тем, как это делается для векторов, но диапазоны могут определяться отдельно для строк и столбцов:
> mat[I, 2:3]
со12 со13
47
> mat ["row 1", "coL3"]
[1] 7
> mat[l,]
coll col2 col3 col4
14710
Создавая сегменты матриц, следует помнить о возможности потери размерности; если в результате сегментации будет создана отдельная строка или столбец, то результатом будет вектор:
> is.matrix(mat[l,])
[1] FALSE
> is.vector(mat[1,])
[1] TRUE
608 Приложение Б. Введение в R
Для предотвращения потери размерности можно передать матрице параметр drop при создании сегмента:
> mat[lJ]
coll со12 со13 со14
14710
> mat[1,drop = FALSE]
coll col2 col3 col4
row 1 1 4 7 10
> is .matrix (mat [1, drop = FALSE])
[1] TRUE
> is, ve ctor (mat [1^ drop = FALSE])
[1] FALSE
Фреймы данных могут быть созданы с помощью функции data. frame:
> df <- data,frame(coLors = coLors2,
time = 1:5)
colors
time
1
green
1
2
red
2
3
blue
3
4
red
4
5
white
5
> dim(df)
[1] 5 2
> coLnames(df)
[1] "colors" "time"
> rownames(df)
[1] ”1” ”2" "3" "4” "5"
Кроме методов сегментации, продемонстрированных выше для матриц, также можно воспользоваться оператором $ для получения одиночных столбцов, а функция subset может возвращать более сложные сегменты строк:
> df$coLors
[1] green red blue red white
Levels: blue green red white
> subset(dfj coLors %in% c("red", "green") & time <= 2)
colors time
1 green 1
2 red 2
Полезная функция complete.cases проверяет, имеются ли в строке матрицы или кадра данных отсутствующие значения; эта функция возвращает TRUE, если отсутствующих значений нет:
Б.6. Объекты и классы 609
> df2 <- df
> # Add missing vaLues to the data frame
> df2[l, 1] <- NA
> df2[5, 2] <~ NA
> df2
colors time
1 <NA> 1
2 red 2
3 blue 3
4 red 4
5 white NA
> compLete,cases(df2)
[1] FALSE TRUE TRUE TRUE FALSE
Б.6. Объекты и классы
С каждым объектом связывается как минимум один тип или класс. Класс объекта указывает, что представляет собой объект (символьную строку, линейную модель, URL-адрес сайта и т. д.). Класс определяет структуру объекта (то есть способ его хранения) и возможные операции, связанные с этим типом объектов (они называются методами класса). Например, если вы создали некий объект модели, возможно, вы захотите выполнить с ним стандартные операции:
О вывести подробную информацию о модели;
О построить графическое представление модели;
О прогнозировать новые точки данных.
В этом случае операции вывода, построения графика и прогнозирования могут стать возможными методами для этого конкретного типа модели (это определяется ее классом). Такая парадигма называется объектно-ориентированным программированием.
Вы можете легко получить информацию о классе созданных объектов:
> pages
[1] 97
> cLass(pages)
[1] "numeric"
> town
[1] "Richmond"
> cLass(town)
[1] "character"
Когда пользователь приказывает R выполнить некоторую операцию (например, сгенерировать прогнозы по объекту модели), класс находит конкретный код для
610 Приложение Б. Введение в R
уравнения прогнозирования. Этот процесс называется диспетчеризацией методов. В R поддерживаются две основные концепции объектно-ориентированного программирования: классы S3 и классы S4, Подход S3 проще S4, поэтому он используется во многих пакетах. Методы S4 мощнее методов S3, но они слишком сложны, чтобы их можно было нормально изложить в этом кратком обзоре. Чемберс (Chambers, 2008) описывает эти концепции более подробно.
В синтаксисе методов S3 класс отделяется от метода точкой. Например, функция summary. Im используется для вычисления сводных значений объекта с классом 1т (этот класс предназначен для обучения линейных моделей — например, линейный регрессионный анализ). Предположим, пользователь создал объект с именем myModel при помощи функции 1т. Команда
modeLSummary <- summary(myModet)
вычисляет стандартную описательную статистику для модели. R видит, что myModel относится к классу 1т, и выполняет код функции summary. Im.
Для этой книги важно понимать концепцию объектов, классов и методов. Тем не менее эти концепции будут использоваться на высоком уровне; приведенный в книге код редко углубляется в технические подробности. Например, функция predict часто используется в книге, но пользователю не обязательно знать, какой конкретный метод при этом выполняется.
Б.7. Функции R
В R модульные фрагменты кода могут оформляться в виде функций. В этом приложении уже использовались функции, как, например, функция library для загрузки пакетов. Функции получают аргументы — позиционные элементы, используемые для передачи объектов функциям. В R аргументам присваиваются имена (в отличие от других языков — например, matlab). Например, функция чтения данных в формате с разделением запятыми (CSV) в объект R получает следующие аргументы:
> str(read.csv)
function (file> header = TRUE, sep = quote = ", dec =
fill = TRUE, comment.char = ..)
Здесь file — символьная строка, определяющая файл в формате CSV, a header сообщает, содержит ли первая строка данных имена переменных. Аргумент file не имеет значения по умолчанию, и если имя файла не задано, функция выдает ошибку. Поскольку аргументам назначены имена, эти функции могут вызываться разными способами:
Б.9. Пакет AppliedPredictiveModeling 611
> read.csv("data.csv")
> read.csv(header = FALSE, fiLe = "data.csv")
Обратите внимание: список аргументов функции read.csv завершается тремя точками. Это означает, что в вызов функции read.csv могут добавляться другие аргументы, которые передаются конкретной функции в коде read. csv. В этом случае в коде используется другая, более общая функция read. table. Функция read. table получает аргумент па.strings, отсутствующий у read.csv. Этот аргумент сообщает R, какие символьные значения обозначают отсутствующее значение в файле. Команда
> read.csv("data.csv", na.strings = "?")
передает аргумент na. strings = " ?" из функции read. csv функции read .table. Учтите, что для сквозной передачи аргумент должен быть именованным. Многоточие широко используется в разделах «Вычисления» каждой главы.
Б.8. Три грани =
До сих пор символ = использовался в нескольких разных контекстах:
1. Создание объектов (например, х=3).
2. Проверка эквивалентности: х=4.
3. Определение значений аргументов функций: read. csv(header = FALSE).
Это разнообразие может сбить с толку начинающих программистов. Например, в команде
> new = subsetfoLd, subset = vaLue — "bLue", drop = FALSE)
символ = используется четыре раза во всех трех контекстах. Один из способов предотвращения путаницы — использование конструкции < - в качестве оператора присваивания.
Б.9. Пакет AppliedPredictiveModeling
Этот пакет — своего рода приложение к книге — включает многие наборы данных, недоступные в других пакетах R. Он также включает код R, используемый в главах книги. Пакет доступен на сайте CRAN.
Функция train в пакете caret использует стандартный синтаксис:
predict (object, type = ’’prob”)
612 Приложение Б. Введение в R
Б.10. Пакет caret
Пакет caret (сокращение от «Classification And Regression Training») был создан для упрощения процесса построения и оценки предиктивных моделей. При помощи этого пакета разработчик может быстро оценить много разных типов моделей, чтобы найти наиболее подходящий инструмент для своих данных.
Большой, разнообразный набор пакетов моделирования — одна из сильных сторон R. Тем не менее, поскольку эти пакеты создаются в разное время разными людьми, существует минимальный набор соглашений, общих для каждой модели. Например, в табл. Б.1 показан синтаксис вычисления вероятностей классов для нескольких разных типов моделей классификации. Запоминать все варианты синтаксиса сложно, и это отбивает у пользователей желание оценивать разные модели. Один из способов упрощения этой задачи — унификация интерфейса для функций построения и прогнозирования модели. Пакет caret предоставляет такой интерфейс для широкого спектра моделей (свыше 140). Пакет также предоставляет разнообразные параметры для предварительной обработки данных и средства настройки параметров на базе повторной выборки (см. главы 3 и 4).
Таблица Б.1. Сводка команд для получения вероятностей классов в разных пакетах
Класс объекта
Пакет
Синтаксис функции predict
Ida
MASS
predict(object) (параметры не нужны)
glm
stats
predict(object, type = "response")
gbm
gbm
predict(object, type = "response", n.trees)
mda
mda
predict(object, type = "posterior")
rpart
rpart
predict(object, type = "prob")
Weka_ classifier
RWeka
predict(object, type = "probability")
LogitBoost
caTools
predict(object, type = "raw", niter)
В этой книге повторная выборка применяется как основной механизм оптимизации предиктивных моделей с параметрами настройки. Альтернативные версии тренировочного набора используются для тренировки модели и прогнозирования контрольного набора. Процесс повторяется много раз для получения оценок эффективности, обобщаемых для новых наборов данных. Каждый набор данных с повторной выборкой не зависит от остальных, поэтому не существует формального требования о том, что модели должны обрабатываться последовательно. При наличии компьютера с несколькими процессорами или ядрами вычисления могут распределяться между ними для повышения вычислительной эффективности. Для
Б.10. Пакет caret 613
этого пакет caret использует одну из инфраструктур параллельной обработки R. Пакет f oreach позволяет организовать последовательное или параллельное вычисление кода R с использованием разных технологий, например пакетов multi core или Rmpi (сводка и краткие описания возможных вариантов приведены в работе Шмидбергера и др. (Schmidberger et al., 2009)). Некоторые пакеты R используют foreach для реализации этих методов, например doMC (для multicore) или doMPI (для Rmpi).
Для настройки предиктивной модели с использованием нескольких рабочих потоков синтаксис функций пакета caret (train, rfе, sbf и т. д.) не изменяется. Отдельная функция «регистрирует» метод параллельной обработки и задает количество используемых рабочих потоков. Например, чтобы использовать пакет multicore (недоступный в системе Windows) с пятью ядрами на одной машине, следует загрузить и зарегистрировать пакет:
> library(doMC)
> registerDoMC(cores =5)
> ## Все последующие модели будут выполняться параллельно
> model <- train(y ~ ,, data = training, method = "rf")
Синтаксис других пакетов, связанных с foreach, почти не отличается. Учтите, что с ростом количества рабочих потоков также возрастают затраты памяти. Например, для использования пяти рабочих потоков в памяти будут храниться шесть версий данных. Если данные велики или вычислительная модель создает большую вычислительную нагрузку, а объем требуемой памяти превышает объем физической памяти, быстродействие может пострадать.
Способствует ли параллелизация ускорению обучения? Данные планирования заданий (глава 17) были смоделированы многократно с разным количеством рабочих потоков для разных моделей. Использовался случайный лес с 2000 деревьев, который настраивался с 10 разными значениями mtry. Также при каждом обучении модели вычислялась важность переменных. Также использовались линейный дискриминантный анализ и модель опорных векторов с радиальной базисной функцией с учетом стоимости (настраивавшейся по 15 значениям стоимости). Все модели настраивались с 5 повторениями 10-кратной перекрестной проверки. Результаты показаны на рис. Б.1. Ось у соответствует общему времени выполнения (включая настройку модели и обучение итоговой модели) относительно количества рабочих потоков. Очевидно, для случайного леса настройка заняла больше всего времени, а модели LDA обладали очень высокой вычислительной эффективностью. Общее время (в минутах) сокращалось с возрастанием количества рабочих потоков, но стабилизировалось приблизительно на 7 рабочих потоках. Данные для этой диаграммы генерировались с рандомизацией, поэтому смещения в порядке выполнения быть не должно. На правой нижней диаграмме представлен коэффициент ускорения — время последовательного выполнения, разделенное на время параллельного выполнения. Например, коэффициент ускорения 3 означает, что параллельная
614 Приложение Б. Введение в R
версия выполнялась втрое быстрее последовательной. В лучшем случае паралле- лизация обеспечивает линейное ускорение; иначе говоря, с М рабочими потоками время параллельного выполнения составит 1 /М. Для таких моделей ускорение происходит близко к линейной зависимости, пока не будут использованы 4 или 5 рабочих потоков. После этого эффективность практически не улучшается. Так как метод LD А уже является эффективным в вычислительном отношении, ускорение перестает расти быстрее, чем у других моделей. Хотя ускорение не было линейным, сокращение времени выполнения было достаточно заметным — почти 10-часовое обучение модели сократилось до 90 минут.
SVM V LDA
5
ю см
о см
ю
со о
СМ о'
о о со
о о тГ
о о со
см
со
СО
см
о о
ю
о о
о о
о
ю
5 10 15
Рабочие потоки
Рис. Б.1. Три модели работают с разным количеством рабочих потоков. Ось у — время выполнения в минутах
Учтите, что некоторые модели, особенно использующие пакет RWeka, не могут выполняться в параллельном режиме из-за структуры кода. Для повышения вычислительной эффективности train можно применить дополнительный трюк: использовать субмодель; одно обучение модели может выдать прогнозы для нескольких параметров настройки. Например, в большинстве реализаций моделей с ускорением модель, тренированная на В итерациях усиления, может создавать прогнозы для моделей с числом итераций меньше В. Для данных грантов было выполнено обучение модели gbm, которая проверяла 200 разных комбинаций
Б. 11. Пакеты, используемые в книге 615
трех параметров настройки (см. рис. 14.10). В действительности функция train создавала объекты только для 40 моделей и выводила другие прогнозы на основании этих объектов.
Более подробную информацию о пакете caret можно найти в (Kuhn, 2008) или в четырех расширенных руководствах на веб-сайте пакета (Kuhn, 2010).
Б.11. Пакеты, используемые в книге
Превосходная функция Sweave (Leisch, 2002а, b) в R позволяет интегрировать код анализа данных с содержимым этого текста. Функция выполняет код R и заменяет этот код элементами, сгенерированными кодом, например текстом, иллюстрациями и таблицами. Все программы и данные, используемые здесь, находятся в открытом доступе на момент написания книги. Многие из использованных наборов данных содержатся в пакетах R AppliedPredictiveModeling и caret. Для данных, которые нельзя было включить, в пакет AppliedPredictiveModeling включается код R для воссоздания наборов данных, встречающихся в тексте. Полный список пакетов и функций R, относящихся к воспроизводимым исследованиям, представлен на сайте CRAN: http://cran.r-project.org/web/views/ ReprodudbleResearch.html.
В книге используется R версии 2.15.2 (2012-10-26) в сочетании со следующими версиями пакетов: AppliedPredictiveModeling (1.01), arules (1.0-12), С50 (0.1.0-013), caret (5.15-045), coin (1.0-21), CORElearn (0.9.40), corrplot (0.70), ctv (0.7-4), Cubist (0.0.12), desirability (1.05), DMwR (0.2.3), doBy (4.5-5), doMC (1.2.5), DWD (0.10), el071 (1.6-1), earth (3.2-3), elasticnet (1.1), ellipse (0.3-7), gbm (1.6-3.2), glmnet (1.8-2), Hmisc (3.10-1), ipred (0.9-1), kernlab (0.9-15), klaR (0.6-7), lars (1.1), latticeExtra (0.6-24), lattice (0.20-10), MASS (7.3-22), mda (0.4-2), minerva (1.2), mlbench (2.1-1), nnet (7.3-5), pamr (1.54), partykit (0.1-4), party (1.0-3), pls (2.3-0), plyr (1.7.1), pROC (1.5.4), proxy (0.4-9), QSARdata (1.02), randomForest (4.6-7), RColorBrewer (1.0-5), reshape2 (1.2.1), reshape (0.8.4), rms (3.6-0), rpart (4.0-3), RWeka (0.4-12), sparseLDA (0.1-6), subselect (0.12-2), svmpath (0.952) и tabplot (0.12). Некоторые из этих пакетов не связаны напрямую с предиктивным моделированием, но они использовались для компиляции, форматирования контента или визуализации.
LF Рекомендуемые веб-сайты
Программное обеспечение
http://www.r-project.org
Основной сайт R со ссылками на объявления, руководства, книги, конференции и другую информацию.
http: //era n. r-project.org
CRAN (Comprehensive R Archive Network) — основной репозиторий R и многочисленных пакетов расширения.
http://cran.r-project.org/web/views/MachineLearning.html
Список многих пакетов предиктивного моделирования в R.
http://caret.r-forge.r-project.org
Основной сайт пакета caret.
http://www.rulequest.com
RuleQuest публикует коммерческие и свободно распространяемые версии Cubist ИС5.0.
http://rattle.togaware.com
Rattle (Williams, 2011) — графический интерфейс пользователя для предиктивных моделей R.
Рекомендуемые веб-сайты 617
http://www.cs.waikato.ac.nz/ml/weka/
Weka — подборка Java-программ для глубокого анализа данных.
http://orange.biolab.si
Orange — кросс-платформенный графический интерфейс с открытым кодом для многих инструментов машинного обучения. Этот интерфейс представляет собой «конвейер»: пользователи объединяют компоненты в цепочки для создания рабочего потока.
http://www.knime.org
KNIME (Konstanz Information Miner) — удобная и полнофункциональная платформа с открытым кодом для интеграции, обработки, анализа и исследования данных.
http://www.spss.com/software/modeler
IBM SPSS Modeler (ранее Clemintine) — визуальная платформа для построения моделей.
http://www.sas.com/technologies/analytics/datamining/miner
Программа SAS для глубокого анализа данных.
Списки других программных продуктов можно найти по адресу http://www.kdnuggets. com/software/suites.html.
Конкурсы
http://www.kaggle.com
http://tunedit.org
Наборы данных
http://archive.ics.ud.edu/ml
Калифорнийский университет (Ирвайн) — известный научный центр, занимающийся классификацией и регрессией наборов данных.
http://www.kdnuggets.com/datasets
Ассоциация по вычислительной технике (АСМ, Association For Computing Machinery) создала специальную группу KDD (Knowledge Discovery in Data). Группа KDD проводит ежегодные конкурсы по машинному обучению.
618 Приложение В. Рекомендуемые веб-сайты http://fueleconomy.gov
На сайте Управления по энергоэффективности и возобновляемым источникам энергии Министерства энергетики США и Агентства охраны окружающей среды США перечислены различные оценки экономии топлива для легковых и грузовых автомобилей.
http://www.cheminformatics.org
Сайт содержит многочисленные примеры наборов данных из области вычислительной химии.
http://www.ncbi.nlm.nih.gov/geo
Сайт NCBI GEO представляет собой «общедоступный репозиторий для архивации и свободного распространения микромассивов, секвенирований следующего поколения и других форм высокопроизводительных функциональных геномных данных, предоставленных научным сообществом».
Список источников
Abdi Н., Williams L. (2010). «Principal Component Analysis». Wiley Interdisciplinary Reviews: Computational Statistics, 2(4), 433-459.
Agresti A. (2002). Categorical Data Analysis. Wiley-Interscience.
Ahdesmaki M., Strimmer K. (2010). «Feature Selection in Omics Prediction Problems Using CAT. Scores and False Nondiscovery Rate Control». The Annals of Applied Statistics, 4(1), 503-519.
Alin A. (2009). «Comparison of PLS. Algorithms when Number of Objects is Much Larger than Number of Variables». Statistical Papers, 50,711 -720.
Altman D., Bland J. (1994). «Diagnostic Tests 3: Receiver Operating Characteristic Plots». British MedicalJournal, 309(6948), 188.
Ambroise C., McLachlan G. (2002). «Selection Bias in Gene Extraction on the Basis of Microarray Gene-Expression Data». Proceedings of the National Academy of Sciences, 99(10), 6562-6566.
Amit Y., Geman D. (1997). «Shape Quantization and Recognition with Randomized Trees». Neural Computation, 9,1545-1588.
Armitage P., Berry G. (1994). Statistical Methods in Medical Research. Blackwell Scientific Publications, Oxford, 3rd edition.
Artis M., Ayuso M., Guillen M. (2002). «Detection of Automobile Insurance Fraud with Discrete Choice Models and Misclassified Claims». The Journal of Risk and Insurance, 69(3), 325-340.
Austin P, Brunner L. (2004). «Inflation of the Type I. Error Rate When a Continuous Confounding Variable Is Categorized in Logistic Regression Analyses». Statistics in Medicine, 23(7), 1159-1178.
Ayres I. (2007). Super Crunchers: Why Thinking-By-Numbers Is The New Way To Be Smart. Bantam.
Barker M., Rayens W. (2003). «Partial Least Squares for Discrimination».Journal of Chemometrics, 17(3), 166-173.
Batista G., Prati R., Monard M. (2004).«A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data». ACM. SIGKDD. Explorations Newsletter, 6(1), 20-29.
Bauer E., Kohavi R. (1999). «An Empirical Comparison of Voting Classification Algorithms: Bagging, Boosting, and Variants». Machine Learning, 36,105-142.
620 Список источников
Becton Dickinson and Company (1991). ProbeTec ET. Chlamydia trachomatis and Neisseria gonorrhoeae Amplified DNA. Assays (Package Insert).
Ben-Dor A., Bruhn L, Friedman N., Nachman I., Schummer M., Yakhini Z. (2000). «Tissue Classification with Gene Expression Profiles». Journal of Computational Biology, 7(3), 559-583.
Bentley J. (1975).»Multidimensional Binary Search Trees Used for Associative Searching». Communications of the ACM., 18(9), 509-517.
Berglund A., KettanehN., Uppg^rd L.,Wold S., DR. NB., Cameron (2001). «The GIFI. Approach to Non-Linear PLS. Modeling». Journal of Chemometrics, 15, 321-336.
Berglund A., Wold S. (1997). «INLR., Implicit Non-Linear Latent Variable Regression».Journal of Chemometrics, 11,141-156.
Bergmeir C., Benitez JM. (2012). «Neural Networks in R. Using the Stuttgart Neural Network Simulator: RSNNS». Journal of Statistical Software, 46(7), 1-26.
BergstraJ., Casagrande N., Erhan D., Eck D., K£gl B. (2006). «Aggregate Features and AdaBoost for Music Classification». Machine Learning, 65,473-484.
Berntsson P., Wold S. (1986). «Comparison Between X-ray Crystallographic Data and Physiochemical Parameters with Respect to Their Information About the Calcium Channel Antagonist Activity of 4-Phenyl-1,4-Dihydropyridines». Quantitative Structure-Activity Relationships, 5,45-50.
Bhanu B., Lin Y. (2003). «Genetic Algorithm Based Feature Selection for Target Detection in SAR. Images». Image and Vision Computing, 21, 591-608.
Bishop C. (1995). Neural Networks for Pattern Recognition. Oxford University Press, Oxford.
Bishop C. (2006). Pattern Recognition and Machine Learning. Springer.
Bland J., Altman D. (1995). «Statistics Notes: Multiple Significance Tests: The Bonferroni Method». British MedicalJournal, 310 (6973), 170-170.
Bland J., Altman D. (2000). «The Odds Ratio». British MedicalJournal, 320(7247), 1468.
Bohachevsky I., Johnson M., Stein M. (1986). «Generalized Simulated Annealing for Function Optimization». Technometrics, 28(3), 209-217.
Bone R., Balk R., Cerra F., Dellinger R., Fein A., Knaus W., Schein R., Sibbald W. (1992). «Definitions for Sepsis and Organ Failure and Guidelines for the Use of Innovative Therapies in Sepsis». Chest, 101(6), 1644-1655.
Boser B., Guyon I., Vapnik V. (1992). «А Training Algorithm for Optimal Margin Classifiers». In «Proceedings of the Fifth Annual Workshop on Computational Learning Theory», pp. 144-152.
Boulesteix A., Strobl C. (2009). «Optimal Classifier Selection and Negative Bias in Error Rate Estimation: An Empirical Study on High-Dimensional Prediction». ВМС. Medical Research Methodology, 9(1), 85.
Box G., Cox D. (1964). «An Analysis of Transformationsof the Royal Statistical Society. Series B. (Methodological), pp. 211-252.
Список источников 621
Box G., Hunter W., Hunter J. (1978). Statistics for Experimenters. Wiley, New York.
Box G., Tidwell P. (1962). «Transformation of the Independent Variables». Technometrics, 4(4), 531-550.
Breiman L. (1996a). «Bagging Predictors». Machine Learning, 24(2), 123-140.
Breiman L. (1996b). «Heuristics of Instability and Stabilization in Model Selection». The Annals of Statistics, 24(6), 2350-2383.
Breiman L. (1996c). «Technical Note: Some Properties of Splitting Criteria». Machine Learning, 24(1), 41-47.
Breiman L. (1998). «Arcing Classifiers». The Annals of Statistics, 26,123-140.
Breiman L. (2000). «Randomizing Outputs to Increase Prediction Accuracy». Mach. Learn., 40, 229-242. ISSN. 0885-6125.
Breiman L. (2001). «Random Forests». Machine Learning, 45, 5-32.
Breiman L., Friedman J., Olshen R., Stone C. (1984). Classification and Regression Trees. Chapman and Hall, New York.
Bridle J. (1990). «Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition». In «Neurocomputing: Algorithms, Architectures and Applications», pp. 227-236. Springer-Verlag.
Brillinger D. (2004). «Some Data Analyses Using Mutual Informat ion».Brazilian Journal of Probability and Statistics, 18(6), 163-183.
Brodnjak-Vonina D., Kodba Z., Novi M. (2005). «Multivariate Data Analysis in Classification of Vegetable Oils Characterized by the Content of Fatty Acids». Chemometrics and Intelligent Laboratory Systems, 75(1), 31-43.
Brown C., Davis H. (2006). «Receiver Operating Characteristics Curves and Related Decision Measures: A. Tutorial». Chemometrics and Intelligent Laboratory Systems, 80(1), 24-38.
Bu G. (2009). «Apolipoprotein E. and Its Receptors in Alzheimer’s Disease: Pathways, Pathogenesis and Therapy». Nature Reviews Neuroscience, 10(5), 333-344.
Buckheit J., Donoho DL. (1995). «WaveLab and Reproducible Research». In A. Antoniadis, G. Oppenheim (eds.), «Wavelets in Statistics», pp. 55-82. Springer-Verlag, New York.
Burez J., Van den Poel D. (2009). «Handling Class Imbalance In Customer Churn Prediction». Expert Systems with Applications, 36(3), 4626-4636.
CanceddaN., Gaussier E., Goutte C., Renders J. (2003). «Word-Sequence Kernels». The Journal of Machine Learning Research, 3, 1059-1082.
Caputo B., Sim K., Furesjo F., Smola A. (2002). «Appearance-Based Object Recognition Using SVMs: Which Kernel Should I. Use?» In «Proceedings of NIPS. Workshop on Statistical Methods for Computational Experiments in Visual Processing and Computer Vision».
Strobl C., Carolin C., Boulesteix A-L., Augustin T. (2007). «Unbiased Split Selection for Classification Trees Based on the Gini Index». Computational Statistics & Data Analysis, 52(1), 483-501.
622 Список источников
Castaldi Р., Dahabreh I., Ioannidis J. (2011). «An Empirical Assessment of Validation Practices for Molecular Classifiers». Briefings in Bioinformatics, 12(3), 189-202.
Chambers J. (2008). Software for Data Analysis: Programming with R. Springer.
Chan K., Loh W. (2004). «LOTUS: An Algorithm for Building Accurate and Comprehensible Logistic Regression Trees». Journal of Computational and Graphical Statistics, 13(4), 826-852.
Chang CC., Lin CJ. (2011). «LIBSVM: A. Library for Support Vector Machines». ACM. Transactions on Intelligent Systems and Technology, 2,27:1-27:27.
Chawla N., Bowyer K., Hall L., Kegelmeyer W. (2002). «SMOTE: Synthetic Minority Over- Sampling Technique». Journal of Artificial Intelligence Research, 16(1), 321-357.
Chun H., Kele S. (2010). «Sparse Partial Least Squares Regression for Simultaneous Dimension Reduction and Variable Selection». Journal of the Royal Statistical Society: Series B. (Statistical Methodology), 72(1), 3-25.
Chung D., Kele S. (2010). «Sparse Partial Least Squares Classification for High Dimensional Data». Statistical Applications in Genetics and Molecular Biology, 9(1), 17.
Clark R. (1997). «OptiSim: An Extended Dissimilarity Selection Method for Finding Diverse Representative Subsets». Journal of Chemical Information and Computer Sciences, 37(6), 1181— 1188.
Clark T. (2004). «Can Out-of-Sample Forecast Comparisons Help Prevent Overfitting?»Journal of Forecasting, 23(2), 115-139.
Clemmensen L., Hastie T, Witten D., Ersboll B. (2011). «Sparse Discriminant Analysis». Technometrics, 53(4), 406-413.
Cleveland W. (1979). «Robust Locally Weighted Regression and Smoothing Scatterplots».Journal of the American Statistical Association, 74(368), 829-836.
Cleveland W., Devlin S. (1988).» Locally Weighted Regression: An Approach to Regression Analysis by Local Fitting».Jowraz/ of the American Statistical Association, pp. 596-610.
Cohen G., Hilario M., Pellegrini C., Geissbuhler A. (2005). «SVM. Modeling via a Hybrid Genetic Strategy. A. Health Care Application». In R. Engelbrecht, AGC. Lovis (eds.), «Connecting Medical Informatics and Bio-Informatics», pp. 193-198. IOS. Press.
Cohen J. (1960). «А Coefficient of Agreement for Nominal Data». Educational and Psychological Measurement, 20,37-46.
Cohn D., Atlas L, Ladner R. (1994). «Improving Generalization with Active Learning». Machine Learning, 15(2), 201-221.
Cornell J. (2002). Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data. Wiley, New York, NY.
Cortes C., Vapnik V. (1995). «Support-Vector Networks». Machine Learning, 20(3), 273-297.
Costa N., Lourenco J., Pereira Z. (2011). «Desirability Function Approach: A. Review and Performance Evaluation in Adverse Conditions». Chemometrics and Intelligent Lab Systems, 107(2), 234-244.
Список источников 623
Cover ТМ., Thomas JA. (2006). Elements of Inf ormation Theory. Wiley-Interscience.
Craig-Schapiro R., Kuhn M., Xiong C., Pickering E., Liu J., Misko TP., Perrin R., Bales K., Soares H., Fagan A., Holtzman D. (2011). «Multiplexed Immunoassay Panel Identifies Novel CSF. Biomarkers for Alzheimer’s Disease Diagnosis and Prognosis». PLoS. ONE., 6(4), el8850.
Cruz-Monteagudo M., Borges F., Cordeiro MND. (2011). «Jointly Handling Potency and Toxicity of Antimicrobial Peptidomimetics by Simple Rules from Desirability Theory and Chemoinformatics». Journal of Chemical Information and Modeling, 51(12), 3060-3077.
Davison M. (1983). Multidimensional Scaling. John Wiley and Sons, Inc.
Dayal B., MacGregor J. (1997). «Improved PLS. Algorithms». Journal of Chemometrics, 11, 73-85.
de Jong S. (1993). «SIMPLS: An Alternative Approach to Partial Least Squares Regression». Chemometrics and Intelligent Laboratory Systems, 18, 251-263.
de Jong S., Ter Braak C. (1994). «Short Communication: Comments on the PLS. Kernel Algorithm». Journal of Chemometrics, 8, 169-174.
de Leon M., Klunk W. (2006). «Biomarkers for the Early Diagnosis of Alzheimer’s Disease». The Lancet Neurology, 5(3), 198-199.
Defemez M., Kemsley E. (1997). «The Use and Misuse of Chemometrics for Treating Classification Problems». TrAC. Trends in Analytical Chemistry, 16(4), 216-221.
DeLong E., DeLong D., Clarke-Pearson D. (1988). «Comparing the Areas Under T\vo Or More Correlated Receiver Operating Characteristic Curves: A. Nonparametric Approach». Biometrics, 44(3), 837-45.
Derksen S., Keselman H. (1992). «Backward, Forward and Stepwise Automated Subset Selection Algorithms: Frequency of Obtaining Authentic and Noise Variables». BritishJournal of Mathematical and Statistical Psychology, 45(2), 265-282.
Derringer G., Suich R. (1980).»Simultaneous Optimization of Several Response Variables»..Journal of Quality Technology, 12(4), 214-219.
Dietterich T (2000). «An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization». Machine Learning, 40,139-158.
Dillon W., Goldstein M. (1984). Multivariate Analysis: Methods and Applications. Wiley, New York.
Dobson A. (2002). An Introduction to Generalized Linear Models. Chapman & Hall/CRC.
Drucker H., Burges C., Kaufman L, Smola A., Vapnik V. (1997). «Support Vector Regression Machines». Advances in Neural Information Processing Systems, pp. 155-161.
Drummond C., Holte R. (2000). «Explicitly Representing Expected Cost: An Alternative to ROC. Representation». In «Proceedings of the Sixth ACM. SIGKDD. International Conference on Knowledge Discovery and Data Mining», pp. 198-207.
Duan K., Keerthi S. (2005). «Which is the Best Multiclass SVM. Method? An Empirical Study». Multiple Classifier Systems, pp. 278-285.
624 Список источников
Dudoit S., Fridlyand J., Speed T. (2002). «Comparison of Discrimination Methods for the Classification of Tumors Using Gene Expression Data». Journal of the American Statistical Association, 97(457), 77-87.
Duhigg C. (2012). «How Companies Learn Your Secrets». The New York Times. URL. http://www. nytimes.com/2012/02/19/magazine/shopping-habits.html.
Dunn W., Wold S. (1990). «Pattern Recognition Techniques in Drug Design». In C. Hansch, P. Sammes, J. Taylor (eds.), «Comprehensive Medicinal Chemistry», pp. 691-714. Pergamon Press, Oxford.
Dwyer D. (2005). «Examples of Overfitting Encountered When Building Private Firm Default Prediction Models». Technical report, Moody’s KMV.
Efron B. (1983). «Estimating the Error Rate of a Prediction Rule: Improvement on Cross- Validation ». Journal of the American Statistical Association, pp. 316-331.
Efron B., Hastie T, Johnstone I., Tibshirani R. (2004). «Least Angle Regression». The Annals of Statistics, 32(2), 407-499.
Efron B., Tibshirani R. (1986). «Bootstrap Methods for Standard Errors, Confidence Intervals, and Other Measures of Statistical Accuracy». Statistical Science, pp. 54-75.
Efron B., Tibshirani R. (1997). «Improvements on Cross-Validation: The 632+ Bootstrap Method». Journal of the American Statistical Association, 92(438), 548-560.
Eilers P, Boer J., van Ommen G., van Houwelingen H. (2001). «Classification of Microarray Data with Penalized Logistic Regression». In «Proceedings of SPIE», volume 4266, p. 187.
Eugster M., Hothom T, Leisch F. (2008). «Exploratory and Inferential Analysis of Benchmark Experiments». Ludwigs-Maximilians-Universitat Miinchen, Department of Statistics, Tech. Rep, 30.
Everitt B., Landau S., Leese M., Stahl D. (2011). Cluster Analysis. Wiley.
Ewald B. (2006). «Post Hoc Choice of Cut Points Introduced Bias to Diagnostic Research». Journal of clinical epidemiology, 59(8), 798-801.
Fanning K., Cogger K. (1998). «Neural Network Detection of Management Fraud Using Published Financial Data». InternationalJournal of Intelligent Systems in Accounting, Finance & Management, 7(1), 21-41.
Faraway J. (2005). Linear Models with R. Chapman & Hall/CRC., Boca Raton.
Fawcett T (2006). «An Introduction to ROC. Analysis». Pattern Recognition Letters, 27(8), 861-874.
Fisher R. (1936). «The Use of Multiple Measurements in Taxonomic Problems». Annals of Eugenics, 7(2), 179-188.
Forma M., Casale M., Oliveri P, Lanteri S. (2009). «CAIMAN, brothers: A. Family of Powerful Classification and Class Modeling Techniques». Chemometrics and Intelligent Laboratory Systems, 96(2), 239-245.
Frank E., Wang Y., Inglis S., Holmes G. (1998). «Using Model Trees for Classification». Machine Learning.
Список источников 625
Frank Е., Witten I. (1998). «Generating Accurate Rule Sets Without Global Optimization». Proceedings of the Fifteenth International Conference on Machine Learning, pp. 144-151.
Free Software Foundation (June 2007). GNU General Public License,
Freund Y. (1995). «Boosting a Weak Learning Algorithm by Majority». Information and Computation, 121, 256-285.
Freund Y., Schapire R. (1996). «Experiments with a New Boosting Algorithm». Machine Learning: Proceedings of the Thirteenth International Conference, pp. 148-156.
Friedman J. (1989). «Regularized Discriminant Analysis». Journal of the American Statistical Association, 84(405), 165-175.
Friedman J. (1991). «Multivariate Adaptive Regression Splines». The Annals of Statistics, 19(1), 1-141.
Friedman J. (2001). «Greedy Function Approximation: A. Gradient Boosting Machine». Annals of Statistics, 29(5), 1189-1232.
Friedman J. (2002). «Stochastic Gradient Boosting». Computational Statistics and Data Analysis, 38(4), 367-378.
Friedman J., Hastie T., Tibshirani R. (2000). «Additive Logistic Regression: A. Statistical View of Boosting». Annals of Statistics, 38, 337-374.
Friedman J., Hastie T., Tibshirani R. (2010). «Regularization Paths for Generalized Linear Models via Coordinate Descent». Journal of Statistical Software, 33(1), 1-22.
Geisser S. (1993). Predictive Inference: An Introduction. Chapman and Hall.
Geladi P., Kowalski B. (1986). «Partial Least-Squares Regression: A. Tutorial». Analutica Chimica Acta, 185,1-17.
Geladi P, Manley M., Lestander T. (2003). «Scatter Plotting in Multivariate Data Analysis». Journal of Chemometrics, 17(8-9), 503-511.
Gentleman R. (2008). R. Programming for Bioinformatics. CRC. Press.
Gentleman R., Carey V, Bates D., Bolstad B., Dettling M., Dudoit S., Ellis B., Gautier L, Ge Y., Gentry J., Homik K., Hothom T, Huber M., Iacus S., Irizarry R., Leisch E, Li C., Maehler M., Rossini A., Sawitzki G., Smith C., Smyth G., Tierney L, Yang JY., Zhang J. (2004). «Bioconductor: Open Software Development for Computational Biology and Bioinformatics». Genome Biology, 5( 10), R80.
Giuliano K., DeBiasio R., Dunlay R., Gough A., Volosky J., Zock J., Pavlakis G., Taylor D. (1997). «High-Content Screening: A. New Approach to Easing Key Bottlenecks in the Drug Discovery Process». Journal of Biomolecular Screening, 2(4), 249-259.
Goldberg D. (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Addison- Wesley, Boston.
Golub G., Heath M., Wahba G. (1979). «Generalized Cross-Validation as a Method for Choosing a Good Ridge Parameter». Technometrics, 21(2), 215-223.
Good P. (2000). Permutation Tests: A. Practical Guide to Resampling Methods for Testing Hypotheses. Springer.
626 Список источников
Gowen A., Downey G., Esquerre C., O’Donnell С. (2010). «Preventing Over-Fitting in PLS. Calibration Models of Near-Infrared (NIR) Spectroscopy Data Using Regression Coefficients». Journal of Chemometrics, 25, 375-381.
Graybill F. (1976). Theory and Application of the Linear Model. Wadsworth & Brooks, Pacific Grove, CA.
Guo Y., Hastie T., Tibshirani R. (2007). «Regularized Linear Discriminant Analysis and its Application in Microarrays». Biostatistics, 8(1), 86-100.
Gupta S., Hanssens D., Hardie B., Kahn W., Kumar V., Lin N., Ravishanker N., Sriram S. (2006). «Modeling Customer Lifetime Value». Journal of Service Research, 9(2), 139-155.
Guyon I., Elisseeff A. (2003). «An Introduction to Variable and Feature Selection». The Journal of Machine Learning Research, 3,1157-1182.
Guyon I., Weston J., Barnhill S., Vapnik V. (2002). «Gene Selection for Cancer Classification Using Support Vector Machines». Machine Learning, 46(1), 389-422.
Hall M., Smith L. (1997). «Feature Subset Selection: A. Correlation Based Filter Approach». International Conference on Neural Information Processing and Intelligent Information Systems, pp. 855-858.
Hall P, Hyndman R., Fan Y. (2004). «Nonparametric Confidence Intervals for Receiver Operating Characteristic Curves». Biometrika, 91, 743-750.
Hampel H., Frank R., Broich K., Teipel S., Katz R., Hardy J., Herholz K., Bokde A., Jessen E, Hoessler Y. (2010). «Biomarkers for Alzheimer’s Disease: Academic, Industry and Regulatory Perspectives». Nature Reviews Drug Discovery, 9(7), 560-574.
Hand D., Till R. (2001). «A Simple Generalisation of the Area Under the ROC. Curve for Multiple Class Classification Problems».Machine Learning, 45(2), 171-186.
Hanley J., McNeil B. (1982). «The Meaning and Use of the Area under a Receiver Operating (ROC) Curvel Characteristic». Radiology, 143(1), 29-36.
Hardie W., Werwatz A., Muller M., Sperlich S., Hardie W., Werwatz A., Muller M., Sperlich S. (2004). «Nonparametric Density Estimation». In «Nonparametric and Semiparametric Models», pp. 39-83. Springer Berlin Heidelberg.
Harrell F. (2001). Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis. Springer, New York.
Hastie T., Pregibon D. (1990). «Shrinking Trees». Technical report, AT&T. Bell Laboratories Technical Report.
Hastie T, Tibshirani R. (1990). Generalized Additive Models. Chapman & Hall/CRC.
Hastie T, Tibshirani R. (1996). «Discriminant Analysis by Gaussian Mixtures». Journal of the Royal Statistical Society. Series B., pp. 155-176.
Hastie T, Tibshirani R., Buja A. (1994). «Flexible Discriminant Analysis by Optimal Scoring». Journal of the American Statistical Association, 89(428), 1255-1270.
Hastie T, Tibshirani R., Friedman J. (2008). The Elements of Statistical Learning: Data Mining, Inference and Prediction. Springer, 2 edition.
Список источников 627
Hawkins D. (2004). «The Problem of Overfitting».Jouraa/ of Chemical Inf ormation and Computer Sciences, 44(1), 1-12.
Hawkins D., Basak S., Mills D. (2003). «Assessing Model Fit by Cross-Validation». Journal of Chemical Information and Computer Sciences, 43(2), 579-586.
Henderson H., Velleman P. (1981). «Building Multiple Regression Models Interactively». Biometrics, pp. 391-411.
Hesterberg T., Choi N., Meier L, Fraley C. (2008). «Least Angle and £1 Penalized Regression: A. Review». Statistics Surveys, 2, 61-93.
Heyman R., Slep A. (2001). «The Hazards of Predicting Divorce Without Cross-validation». Journal of Marriage and the Family, 63(2), 473.
Hill A., LaPan P., Li Y., Haney S. (2007). «Impact of Image Segmentation on High-Content Screening Data Quality for SK-BR-3 Cells». ВМС. Bioinformatics, 8(1), 340.
Ho T. (1998). «The Random Subspace Method for Constructing Decision Forests». IEEE. Transactions on Pattern Analysis and Machine Intelligence, 13, 340-354.
Hoerl A. (1970). «Ridge Regression: Biased Estimation for Nonorthogonal Problems». Technometrics, 12(1), 55-67.
Holland J. (1975). Adaptation in Natural and Artificial Systems. University of Michigan Press, Ann Arbor, MI.
Holland J. (1992). Adaptation in Natural and Artificial Systems. MIT. Press, Cambridge, MA.
Holmes G., Hall M., Frank E. (1993). «Generating Rule Sets from Model Trees». In «Australian Joint Conference on Artificial Intelligence».
Hothorn T, Hornik K., Zeileis A. (2006). «Unbiased Recursive Partitioning: A. Conditional Inference Frame work». Journal of Computational and Graphical Statistics, 15(3), 651-674.
Hothorn T, Leisch E, Zeileis A., Hornik K. (2005). «The Design and Analysis of Benchmark Experiments».Joi/ma/ of Computational and Graphical Statistics, 14(3), 675-699.
HsiehW., Tang B. (1998). «Applying Neural Network Models to Prediction and Data Analysis in Meteorology and Oceanography». Bulletin of the American Meteorological Society, 79(9), 1855-1870.
Hsu C., Lin C. (2002). «А Comparison of Methods for Multiclass Support Vector Machines». IEEE. Transactions on Neural Networks, 13(2), 415-425.
Huang C., Chang B., Cheng D., Chang C. (2012). «Feature Selection and Parameter Optimization of a Fuzzy-Based Stock Selection Model Using Genetic Algorithms». International Journal of Fuzzy Systems, 14(1), 65-75.
Huuskonen J. (2000). «Estimation of Aqueous Solubility for a Diverse Set of Organic Compounds Based on Molecular Topology». Journal of Chemical Information and Computer Sciences, 40(3), Т13-ТП.
Ihaka R., Gentleman R. (1996). «R: A. Language for Data Analysis and Graphics». Journal of Computational and Graphical Statistics, 5(3), 299-314.
628 Список источников
Jeatrakul Р., Wong К., Fung С. (2010). «Classification of Imbalanced Data By Combining the Complementary Neural Network and SMOTE. Algorithm». Neural Information Processing. Models and Applications, pp. 152-159.
Jerez J., Molina I., Garcia-Laencina P., Alba R., Ribelles N., Martin M., Franco L. (2010). «Missing Data Imputation Using Statistical and Machine Learning Methods in a Real Breast Cancer Problem». Artificial Intelligence in Medicine, 50,105-115.
John G., Kohavi R., Pfleger K. (1994). «Irrelevant Features and the Subset Selection Problem». Proceedings of the Eleventh International Conference on Machine Learning, 129,121-129.
Johnson K., Rayens W. (2007). «Modern Classification Methods for Drug Discovery». In A. Dmitrienko, C. Chuang-Stein, R. D’Agostino (eds.), «Pharmaceutical Statistics Using SAS: A. Practical Guide», pp. 7-43. Cary, NC: SAS. Institute Inc.
Johnson R., Wichern D. (2001). Applied Multivariate Statistical Analysis. Prentice Hall.
Jolliffe I., Trendafilov N., Uddin M. (2003). «А Modified Principal Component Technique Based on the \asso». Journal of Computational and Graphical Statistics, 12(3), 531-547.
Kansy M., Senner E, Gubemator K. (1998). «Physiochemical High Throughput Screening: Parallel Artificial Membrane Permeation Assay in the Description of Passive Absorption Processes». Journal of Medicinal Chemistry, 41,1007-1010.
Karatzoglou A., Smola A., Hornik K., Zeileis A. (2004). «Kernlab - An S4 Package for Kernel Methods in R». Journal of Statistical Software, 11(9), 1-20.
Kearns M., Valiant L. (1989). «Cryptographic Limitations on Learning Boolean Formulae and Finite Automata». In «Proceedings of the Twenty-First Annual ACM. Symposium on Theory of Computing».
Kim J., Basak J., Holtzman D. (2009). «The Role of Apolipoprotein E. in Alzheimer’s Disease». Neuron, 63(3),'287-303.
Kim JH. (2009). «Estimating Classification Error Rate: Repeated Cross-Validation, Repeated Hold-Out and Bootstrap». Computational Statistics &Data Analysis, 53(11), 3735-3745.
Kimball A. (1957). «Errors of the Third Kind in Statistical Consulting» .Journal of the American Statistical Association, 52,133-142.
Kira K., Rendell L. (1992). «The Feature Selection Problem: Traditional Methods and a New Algorithm». Proceedings of the National Conference on Artificial Intelligence, pp. 129-129.
Kline DM., Berardi VL. (2005). «Revisiting Squared-Error and Cross-Entropy Functions for Training Neural Network Classifiers». Neural Computing and Applications, 14(4), 310-318.
Kohavi R. (1995). «А Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection». InternationalJoint Conference on Artificial Intelligence, 14,1137-1145.
Kohavi R. (1996). «Scaling Up the Accuracy of Naive-Bayes Classifiers: A. Decision-Tree Hybrid». In «Proceedings of the second international conference on knowledge discovery and data mining», volume 7.
Kohonen T. (1995). Self-Organizing Maps. Springer.
Список источников 629
Kononenko I. (1994). «Estimating Attributes: Analysis and Extensions of Relief». In F. Bergadano, L. De Raedt (eds.), «Machine Learning: ECML-94», volume 784, pp. 171-182. Springer Berlin / Heidelberg.
Kuhn M. (2008). «Building Predictive Models in R. Using the caret Package».Jo umal of Statistical Software, 28(5).
Kuhn M. (2010). «The caret Package Homepage». URL. http://caret.r-forge.r-project.org/.
Kuiper S. (2008). «Introduction to Multiple Regression: How Much Is Your Car Worth?»Journal of Statistics Education, 16(3).
Kv^lseth T. (1985). «Cautionary Note About R2». American Statistician, 39(4), 279-285.
Lachiche N., Flach P. (2003). «Improving Accuracy and Cost of Two-Class and Multi-Class Probabilistic Classifiers using ROC. Curves». In «Proceedings of the Twentieth International Conference on Machine Learning», volume 20, pp. 416-424.
Larose D. (2006). Data Mining Methods and Models. Wiley.
Lavine B., Davidson C., Moores A. (2002). «Innovative Genetic Algorithms for Chemoinformatics». Chemometrics and Intelligent Laboratory Systems, 60( 1),161-171.
Leach A., Gillet V. (2003). An Introduction to Chemoinformatics. Springer.
Leisch F. (2002a). «Sweave: Dynamic Generation of Statistical Reports Using Literate Data Analysis». In W. Hardie, B. Ronz (eds.), «Compstat 2002 — Proceedings in Computational Statistics», pp. 575-580. Physica Verlag, Heidelberg.
Leisch F. (2002b). «Sweave, Part I: Mixing R. and LATEX». R. News, 2(3), 28-31.
Levy S. (2010). «The AI. Revolution is On». Wired.
Li J., Fine JP. (2008). «ROC. Analysis with Multiple Classes and Multiple Tests: Methodology and Its Application in Microarray Studies». Biostatistics, 9(3), 566-576.
Lindgren E, Geladi P, Wold S. (1993). «The Kernel Algorithm for PLS». Journal of Chemometrics, 7,45-59.
Ling C., Li C. (1998). «Data Mining for Direct Marketing: Problems and solutions». In «Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining», pp. 73-79.
Lipinski C., Lombardo E, Dominy B., Feeney P. (1997). «Experimental and Computational Approaches To Estimate Solubility and Permeability In Drug Discovery and Development Settings». Advanced Drug Delivery Reviews, 23, 3-25.
Liu B. (2007). Web Data Mining. Springer Berlin / Heidelberg.
Liu Y., Rayens W. (2007). «PLS. and Dimension Reduction for Classification». Computational Statistics, pp. 189-208.
Lo V. (2002). «The True Lift Model: A. Novel Data Mining Approach To Response Modeling in Database Marketing». ACM. SIGKDD. Explorations Newsletter, 4(2), 78-86.
Lodhi H., Saunders C., Shawe-Taylor J., Cristianini N., Watkins C. (2002). «Text Classification Using String Kernels». The Journal of Machine Learning Research, 2,419-444.
630 Список источников
Loh WY. (2002). «Regression Trees With Unbiased Variable Selection and Interaction Detection». Statistica Sinica, 12, 361-386.
Loh WY. (2010). «Tree-Structured Classifiers». Wiley Interdisciplinary Reviews: Computational Statistics, 2, 364-369.
Loh WY., Shih YS. (1997). «Split Selection Methods for Classification Trees». Statistica Sinica, 7, 815-840.
Mahe P., UedaN., Akutsu T, Perret J., Vert J. (2005). «Graph Kernels for Molecular Structure- Activity Relationship Analysis with Support Vector Machines» Journal of Chemical Information and Modeling, 45(4), 939-951.
Mahe P., Vert J. (2009). «Graph Kernels Based on Tree Patterns for Molecules». Machine Learning, 75(1), 3-35.
Maindonald J., Braun J. (2007). Data Analysis and Graphics Using R. Cambridge University Press, 2nd edition.
Mandal A., Johnson K., Wu C., Bornemeier D. (2007). «Identifying Promising Compounds in Drug Discovery: Genetic Algorithms and Some New Statistical Techniques» Journal of Chemical Information and Modeling, 47(3), 981-988.
Mandal A., Wu C., Johnson K. (2006). «SELC: Sequential Elimination of Level Combinations by Means of Modified Genetic Algorithms». Technometrics, 48(2), 273-283.
Martin J., Hirschberg D. (1996). «Small Sample Statistics for Classification Error Rates I: Error Rate Measurements». Department of Informatics and Computer Science Technical Report.
Martin T, Harten P, Young D., Muratov E., Golbraikh A., Zhu H., Tropsha A. (2012). «Does Rational Selection of Training and Test Sets Improve the Outcome of QSAR. Modeling?» Journal of Chemical Information and Modeling, 52(10), 2570-2578.
Massy W. (1965). «Principal Components Regression in Exploratory Statistical Research».Journal of the American Statistical Association, 60, 234-246.
McCarren P, Springer C., Whitehead L. (2011). «An Investigation into Pharmaceutically Relevant Mutagenicity Data and the Influence on Ames Predictive Potent\л\» Journal of Cheminformatics, 3(51).
McClish D. (1989). «Analyzing a Portion of the ROC. Curve». Medical Decision Making, 9, 190-195.
Meissen W., Wehrens R., Buydens L. (2006). «Supervised Kohonen Networks for Classification Problems».Chemometrics and Intelligent Laboratory Systems, 83(2), 99-113.
Mente S., Lombardo F. (2005). «А Recursive-Partitioning Model for Blood-Brain Barrier Permeation». Journal of Computer-Aided Molecular Design, 19(7), 465-481.
Menze B., Keim B., Splitthoff D., Koethe U., Hamprecht F. (2011). «On Oblique Random Forests». Machine Learning and Knowledge Discovery in Databases, pp. 453-469.
Mevik B., Wehrens R. (2007). «The pls Package: Principal Component and Partial Least Squares Regression in R» Journal of Statistical Software, 18(2), 1-24.
Список источников 631
Michailidis G., de Leeuw J. (1998). «The Gifi System Of Descriptive Multivariate Analysis». Statistical Science, 13, 307-336.
Milborrow S. (2012). Notes On the earth Package. URL. http://cran.r-project.org/package=earth.
Min S., Lee J., Han I. (2006). «Hybrid Genetic Algorithms and Support Vector Machines for Bankruptcy Prediction». Expert Systems with Applications, 31(3), 652-660.
Mitchell M. (1998). An Introduction to Genetic Algorithms. MIT. Press.
Molinaro A. (2005). «Prediction Error Estimation: A. Comparison of Resampling Methods». Bioinformatics, 21(15), 3301-3307.
Molinaro A., Lostritto K., Van Der Laan M. (2010). «partDSA: Deletion/ Substitution/Addition Algorithm for Partitioning the Covariate Space in Prediction». Bioinformatics, 26(10), 1357-1363.
Montgomery D., Runger G. (1993). «Gauge Capability and Designed Experiments. Part I: Basic Methods». Quality Engineering, 6(1), 115-135.
Muenchen R. (2009). R. for SAS. and SPSS. Users. Springer.
Myers R. (1994). Classical and Modem Regression with Applications. PWSKENT. Publishing Company, Boston, MA., second edition.
Myers R., Montgomery D. (2009). Response Surface Methodology: Process and Product Optimization Using Designed Experiments. Wiley, New York, NY.
Neal R. (1996). Bayesian Learning for Neural Networks. Springer-Verlag.
Nelder J., Mead R. (1965). «А Simplex Method for Function Minimization». The Computer Journal, 7(4), 308-313.
Netzeva T, Worth A., Aldenberg T, Benigni R., Cronin M., Gramatica P, Jaworska J., Kahn S., Klopman G., Marchant C. (2005). «Current Status of Methods for Defining the Applicability Domain of (Quantitative) Structure-Activity Relationships». In «The Report and Recommendations of European Centre for the Validation of Alternative Methods Workshop 52», volume 33, pp. 1-19.
Niblett T. (1987). «Constructing Decision Trees in Noisy Domains». In I. Bratko, N. Lavrad (eds.), «Progress in Machine Learning: Proceedings of EWSL-87», pp. 67-78. Sigma Press, Bled, Yugoslavia.
Olden J., Jackson D. (2000). «Torturing Data for the Sake of Generality: How Valid Are Our Regression Models?» Ecoscience, 7(4), 501-510.
Olsson D., Nelson L. (1975). «The Nelder-Mead Simplex Procedure for Function Minimization». Technometrics, 17(1), 45-51.
Osuna E., Freund R., Girosi F. (1997). «Support Vector Machines: Training and Applications». Technical report, MIT. Artificial Intelligence Laboratory.
Ozuysal M., Calonder M., Lepetit V, Fua P. (2010). «Fast Keypoint Recognition Using Random Ferns». IEEE. Transactions on Pattern Analysis and Machine Intelligence, 32(3), 448-461.
Park M., Hastie T. (2008). «Penalized Logistic Regression for Detecting Gene Interactions». Biostatistics, 9(1), 30.
632 Список источников
Pepe MS., Longton G., Janes H. (2009). «Estimation and Comparison of Receiver Operating Characteristic Curves». StataJournal, 9(1), 1-16.
Perrone M., Cooper L. (1993). «When Networks Disagree: Ensemble Methods for Hybrid Neural Networks». In RJ. Mammone (ed.), «Artificial Neural Networks for Speech and Vision», pp. 126-142. Chapman & Hall, London.
Piersma A., Genschow E., Verhoef A., Spanjersberg M., Brown N., Brady M., Burns A., Clemann N., Seiler A., Spielmann H. (2004). «Validation of the Postimplantation RatWhole-embryo Culture Test in the International ECVAM. Validation Study on Three In Vitro Embryotoxicity Tests». Alternatives to Laboratory Animals, 32, 275-307.
Platt J. (2000). «Probabilistic Outputs for Support Vector Machines and Comparison to Regularized Likelihood Methods». In B. Bartlett, B. Schdlkopf, D. Schuurmans, A. Smola (eds.), «Advances in Kernel Methods Support Vector Learning», pp. 61-74. Cambridge, MA: MIT. Press.
Provost E, Domingos P. (2003). «Tree Induction for Probability-Based Ranking». Machine Learning, 52(3), 199-215.
Provost E, Fawcett T, Kohavi R. (1998). «The Case Against Accuracy Estimation for Comparing Induction Algorithms». Proceedings of the Fifteenth International Conference on Machine Learning, pp. 445-453.
Quinlan R. (1987). «Simplifying Decision Trees». InternationalJournal of Man-Machine Studies, 27(3), 221-234.
Quinlan R. (1992). «Learning with Continuous Classes». Proceedings of the 5th Australian Joint Conference On Artificial Intelligence, pp. 343-348.
Quinlan R. (1993a). «Combining Instance-Based and Model-Based Learning». Proceedings of the Tenth International Conference on Machine Learning, pp. 236-243.
Quinlan R. (1993b). C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers.
Quinlan R. (1996a). «Bagging, Boosting, and С4.5». In «Proceedings of the Thirteenth National Conference on Artificial Intelligence».
Quinlan R. (1996b). «Improved use of continuous attributes in С4.5». Journal of Artificial Intelligence Research, 4, 77-90.
Quinlan R., Rivest R. (1989). «Inferring Decision Trees Using the Minimum Description Length Principle». Information and computation, 80(3), 227-248.
Radcliffe N., Surry P. (2011). «Real-World Uplift ModellingWith Significance-Based Uplift Trees». Technical report, Stochastic Solutions.
Rannar S., Lindgren E, Geladi P, Wold S. (1994). «А PLS. Kernel Algorithm for Data Sets with Many Variables and Fewer Objects. Part 1: Theory and Algorithm». Journal of Chemometrics, 8, 111-125.
R. Development Core Team (2008). R: Regulatory Compliance and Validation Issues A. Guidance Document for the Use of R. in Regulated Clinical Trial Environments. R. Foundation for Statistical Computing, Vienna, Austria.
Список источников 633
R. Development Core Team (2010). R: A. Language and Environment for Statistical Computing.
R. Foundation for Statistical Computing, Vienna, Austria.
Reshef D., ReshefY., Finucane H., Grossman S., McVean G., Tumbaugh P., Lander E., Mitzenmacher M., Sabeti P. (2011). «Detecting Novel Associations in Large Data Sets». Science, 334(6062), 1518-1524.
Richardson M., Dominowska E., Ragno R. (2007). «Predicting Clicks: Estimating the Click- Through Rate for New Ads». In «Proceedings of the 16th International Conference on the World Wide Web», pp. 521-530.
Ridgeway G. (2007). «Generalized Boosted Models: A Guide to the gbm Package». URL. http:// cran.r-project.org/web/packages/gbm/vignettes/gbm.pdf.
Ripley B. (1995). «Statistical Ideas for Selecting Network Architectures». Neural Networks: Artificial Intelligence and Industrial Applications, pp. 183-190.
Ripley B. (1996). Pattern Recognition and Neural Networks. Cambridge University Press.
Robin X., Turck N., Hainard A., Tiberti N., Lisacek E, Sanchez JC., Muller M. (2011). «pROC: an open-source package for R. and S+ to analyze and compare ROC. curves». ВМС. Bioinformatics, 12(1), 77.
Robnik-Sikonja M., Kononenko I. (1997). «An Adaptation of Relief for Attribute Estimation in Regression». Proceedings of the Fourteenth International Conference on Machine Learning, pp. 296-304.
Rodriguez M. (2011). «The Failure of Predictive Modeling and WhyWe Follow the Herd». Technical report, Concepcion, Martinez & Bellido.
Ruczinski I., Kooperberg C., Leblanc M. (2003). «Logic Regression». Journal of Computational and Graphical Statistics, 12(3), 475-511.
Rumelhart D., Hinton G., Williams R. (1986). «Learning Internal Representations by Error Propagation». In «Parallel Distributed Processing: Explorations in the Microstructure of Cognition», The MIT. Press.
Rzepakowski P., Jaroszewicz S. (2012). «Uplift Modeling in Direct Marketing». Journal of Telecommunications and Information Technology, 2,43-50.
Saar-Tsechansky M., Provost F. (2007a). «Decision-Centric Active Learning of Binary-Outcome Models». Information Systems Research, 18(1), 4-22.
Saar-Tsechansky M., Provost F. (2007b). «Handling Missing Values When Applying Classification Models». Journal of Machine Learning Research, 8,1625-1657.
Saeys Y., Inza I., Larranaga P. (2007).«A Review of Feature Selection Techniques in Bioinformatics». Bioinformatics, 23(19), 2507-2517.
Schapire R. (1990). «The Strength of Weak Learnability». Machine Learning, 45,197-227.
Schapire YFR. (1999). «Adaptive Game Playing Using Multiplicative Weights». Games and Economic Behavior, 29,79-103.
634 Список источников
Schmidberger М., Morgan М., Eddelbuettel D., Yu H., Tierney L, Mansmann U (2009). «State- of-the-Art in Parallel Computing with R». Journal of Statistical Software, 31(1).
Serneels S., Nolf ED., Espen PV. (2006). «Spatial Sign Pre-processing: A. Simple Way to Impart Moderate Robustness to Multivariate Estimators». Journal of Chemical Information and Modeling, 46(3), 1402-1409.
Shachtman N. (2011). «Pentagon’s Prediction Software Didn’t Spot Egypt Unrest». Wired.
Shannon C. (1948). «А Mathematical Theory of Communication». The Bell System Technical Journal, 27(3), 379-423.
Siegel E. (2011). «Uplift Modeling: Predictive Analytics Can’t Optimize Marketing Decisions Without It». Technical report, Prediction Impact Inc.
Simon R., Radmacher M., Dobbin K., McShane L. (2003). «Pitfalls in the Use of DNA. Microarray Data for Diagnostic and Prognostic Classification». Journal of the National Cancer Institute, 95(1), 14-18.
Smola A. (1996). «Regression Estimation with Support Vector Learning Machines». Master's thesis, Technische Universit at Munchen.
Spector P. (2008). Data Manipulation with R. Springer.
Steyerberg E. (2010). Clinical Prediction Models: A. Practical Approach to Development, Validation, and Updating. Springer, 1st ed. softcover of orig. ed. 2009 edition.
Stone M., Brooks R. (1990). «Continuum Regression: Cross-validated Sequentially Constructed Prediction Embracing Ordinary Least Squares, Partial Least Squares, and Principal Component Regression». Journal of the Royal Statistical Society, Series B., 52,237-269.
Strobl C., Boulesteix A., Zeileis A., Hothorn T. (2007). «Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution». ВМС. Bioinformatics, 8(1), 25.
Suykens J., Vandewalle J. (1999). «Least Squares Support Vector Machine Classifiers». Neural processing letters, 9(3), 293-300.
Tetko I., Tanchuk V, Kasheva T, Villa A. (2001). «Estimation of Aqueous Solubility of Chemical Compounds Using E-State Indices». Journal of Chemical Information and Computer Sciences, 41(6), 1488-1493.
Tibshirani R. (1996). «Regression Shrinkage and Selection via the lasso». Journal of the Royal Statistical Society Series B. (Methodological), 58(1), 267-288.
Tibshirani R., Hastie T, Narasimhan B., Chu G. (2002). «Diagnosis of Multiple Cancer Types by Shrunken Centroids of Gene Expression». Proceedings of the National Academy of Sciences, 99(10), 6567-6572.
Tibshirani R., Hastie T, Narasimhan B., Chu G. (2003). «Class Prediction by Nearest Shrunken Centroids, with Applications to DNA. Microarrays». Statistical Science, 18(1), 104-117.
Ting K. (2002). «An Instance-Weighting Method to Induce Cost-Sensitive Trees». IEEE. Transactions on Knowledge and Data Engineering, 14(3), 659-665.
Список источников 635
Tipping М. (2001). «Sparse Bayesian Learning and the Relevance Vector Machine». Journal of Machine Learning Research, 1, 211-244.
Titterington M. (2010). «Neural Networks». Wiley Interdisciplinary Reviews: Computational Statistics, 2( 1), 1 -8.
Troyanskaya O., Cantor M., Sherlock G., Brown P., Hastie T, Tibshirani R., Botstein D., Altman R. (2001). «Missing Value Estimation Methods for DNA. Microarrays». Bioinformatics, 17(6), 520-525.
Turner K., Ghosh J. (1996). «Analysis of Decision Boundaries in Linearly Combined Neural Classifiers». Pattern Recognition, 29(2), 341-348.
US. Commodity Futures Trading Commission and US. Securities & Exchange Commission (2010). Findings Regarding the Market Events of May 6,2010.
Valiant L. (1984). «А Theory of the Learnable». Communications of the ACM., 27,1134-1142.
Van Der Putten P, Van Someren M. (2004).«A Bias-Variance Analysis of a Real World Learning Problem: The CoIL. Challenge 2000». Machine Learning, 57(1), 177-195.
Van Hulse J., Khoshgoftaar T, Napolitano A. (2007). «Experimental Perspectives On Learning From Imbalanced Data». In «Proceedings of the 24th International Conference On Machine learning», pp. 935-942.
Vapnik V. (2010). The Nature of Statistical Learning Theory. Springer.
Varma S., Simon R. (2006). «Bias in Error Estimation When Using Cross-Validation for Model Selection». ВМС. Bioinformatics, 7(1), 91.
Varmuza К., He P., Fang K. (2003). «Boosting Applied to Classification of Mass Spectral Data». Journal of Data Science, 1, 391-404.
Venables W., Ripley B. (2002). Modem Applied Statistics with S. Springer.
Venables W., Smith D., the R. Development Core Team (2003). An Introduction to R. R. Foundation for Statistical Computing, Vienna, Austria, version 1.6. 2 edition. ISBN. 3-901167-55-2, URL. http://www.R-project.org.
Venkatraman E. (2000). «А Permutation Test to Compare Receiver Operating Characteristic Curves». Biometrics, 56(4), 1134-1138.
Veropoulos K., Campbell C., Cristianini N. (1999). «Controlling the Sensitivity of Support Vector Machines». Proceedings of the InternationalJoint Conference on Artificial Intelligence, 1999,55-60.
Verzani J. (2002). «simpleR. - Using R for Introductory Statistics». URL. http:// www.math.csi. cuny.edu/Statistics/R/simpleR.
Wager TT, Hou X., Verhoest PR., Villalobos A. (2010). «Moving Beyond Rules: The Development of a Central Nervous System Multiparameter Optimization (CNS. MPO) Approach To Enable Alignment of Druglike Properties». ACS. Chemical Neuroscience, 1(6), 435-449.
Wallace C. (2005). Statistical and Inductive Inference by Minimum Message Length. Springer- Verlag.
636 Список источников
Wang С., Venkatesh S. (1984). «Optimal Stopping and Effective Machine Complexity in Learning». Advances in NIPS., pp. 303-310.
Wang Y., Witten I. (1997). «Inducing Model Trees for Continuous Classes». Proceedings of the Ninth European Conference on Machine Learning, pp. 128-137.
Weiss G., Provost F. (2001a). «The Effect of Class Distribution on Classifier Learning: An Empirical Study». Department of Computer Science, Rutgers University.
Weiss G., Provost F. (2001b). «The Effect of Class Distribution On Classifier Learning: An Empirical Study». Technical Report ML-TR-44, Department of Computer Science, Rutgers University.
Welch B. (1939). «Note on Discriminant Functions». Biometrika, 31,218-220.
Westfall P, Young S. (1993). Resampling-Based Multiple Testing: Examples and Methods far P-Value Adjustment. Wiley.
Westphal C. (2008). Data Mining for Intelligence, Fraud & Criminal Detection: Advanced Analytics & Information Sharing Technologies. CRC. Press.
Whittingham M., Stephens P, Bradbury R., Freckleton R. (2006). «Why Do We Still Use Stepwise Modelling in Ecology and Behaviour?» Journal of Animal Ecology, 75(5), 1182-1189.
Willett P. (1999). «Dissimilarity-Based Algorithms for Selecting Structurally Diverse Sets of Compounds». Journal of Computational Biology, 6(3), 447-457.
Williams G. (2011). Data Mining with Rattle and R: The Art of Excavating Data for Knowledge Discovery. Springer.
Witten D., Tibshirani R. (2009). «Covariance-Regularized Regression and Classification For High Dimensional Problems». Journal of the Royal Statistical Society. Series В. (Statistical Methodology), 71(3), 615-636.
Witten D., Tibshirani R. (2011). «Penalized Classification Using Fisher’s Linear Discriminant». Journal of the Royal Statistical Society. Series B. (Statistical Methodology), 73(5), 753-772.
Wold H. (1966). «Estimation of Principal Components and Related Models by Iterative Least Squares». In P. Krishnaiah (ed.), «Multivariate Analyses», pp. 391-420. Academic Press, New York.
Wold H. (1982). «Soft Modeling: The Basic Design and Some Extensions». In K. Joreskog, H. Wold (eds.), «Systems Under Indirect Observation: Causality, Structure, Prediction», pt. 2, pp. 1-54. North-Holland, Amsterdam.
Wold S. (1995). «PLS. for Multivariate Linear Modeling». In H. van de Waterbeemd (ed.), «Chemometric Methods in Molecular Design», pp. 195-218. VCH., Weinheim.
Wold S., Johansson M., Cocchi M. (1993). «PLS-Partial Least-Squares Projections to Latent Structures». In H. Kubinyi (ed.), «3D. QSAR. in Drug Design», volume 1, pp. 523-550. Kluwer Academic Publishers, The Netherlands.
Wold S., Martens H., Wold H. (1983). «The Multivariate Calibration Problem in Chemistry Solved by the PLS. Method». In «Proceedings from the Conference on Matrix Pencils», Springer-Verlag, Heidelberg.
Список источников 637
Wolpert D. (1996). «The Lack of a priori Distinctions Between Learning Algorithms». Neural Computation, 8(7), 1341-1390.
Yeh I. (1998). «Modeling of Strength of High-Performance Concrete Using Artificial Neural Networks». Cement and Concrete research, 28(12), 1797-1808.
Yeh I. (2006). «Analysis of Strength of Concrete Using Design of Experiments and Neural Net works». Journal of Materials in Civil Engineering, 18,597-604.
Youden W. (1950). «Index for Rating Diagnostic Tests». Cancer, 3(1), 32-35.
Zadrozny B., Elkan C. (2001). «Obtaining Calibrated Probability Estimates from Decision Trees and Naive Bayesian Classifiers». In «Proceedings of the 18th International Conference on Machine Learning», pp. 609-616. Morgan Kaufmann.
Zeileis A., Hothorn T, Hornik K. (2008). «Model-Based Recursive Partitioning». Journal of Computational and Graphical Statistics, 17(2), 492-514.
Zhu J., Hastie T. (2005). «Kernel Logistic Regression and the Import Vector Machine». Journal of Computational and Graphical Statistics, 14(1), 185-205.
Zou H., Hastie T. (2005). «Regularization and Variable Selection via the Elastic Net».Journal of the Royal Statistical Society, Series B., 67(2), 301-320.
Zou H., Hastie T., Tibshirani R. (2004). «Sparse Principal Component Analysis». Joumal of Computational and Graphical Statistics, 15, 2006.
Макс Кун, Кьелл Джонсон
Предиктивное моделирование на практике
Перевел с английского Е. Матвеев
Заведующая редакцией
Ведущий редактор
Научный редактор Литературный редактор Художественный редактор Корректоры
Ю. Сергиенко
К. Тульцева
А. Логунов
М. Рогожин
В. Мостипан
С. Беляева, Н. Викторова
Изготовлено в России. Изготовитель ООО «Прогресс книга» Место нахождения и фактический адрес 194044, Россия, г. Санкт-Петербург, Б. Сампсониевский пр., д. 29А, пом. 52. Тел +78127037373
Дата изготовления: 07.2019. Наименование: книжная продукция. Срок годности, не ограничен. Налоговая льгота — общероссийский классификатор продукции ОК 034-2014, 58.11.12 — Книги печатные профессиональные, технические и научные.
Импортер в Беларусь. ООО «ПИТЕР М», 220020, РБ, г. Минск, ул Тимирязева, д. 121/3, к. 214, тел./факс: 208 80 01 Подписано в печать 26.06 19. Формат 70x100/16. Бумага офсетная Усл. п. л. 51,600 Тираж 1000 Заказ 5329.
Отпечатано в АО «Первая Образцовая типография» Филиал «Чеховский Печатный Двор» 142300, Московская область, г. Чехов, ул. Полиграфистов, д. 1 Сайт: www.chpd.ru, E-mail: sales@chpd.ni, тел. 8(499)270-73-59