/








































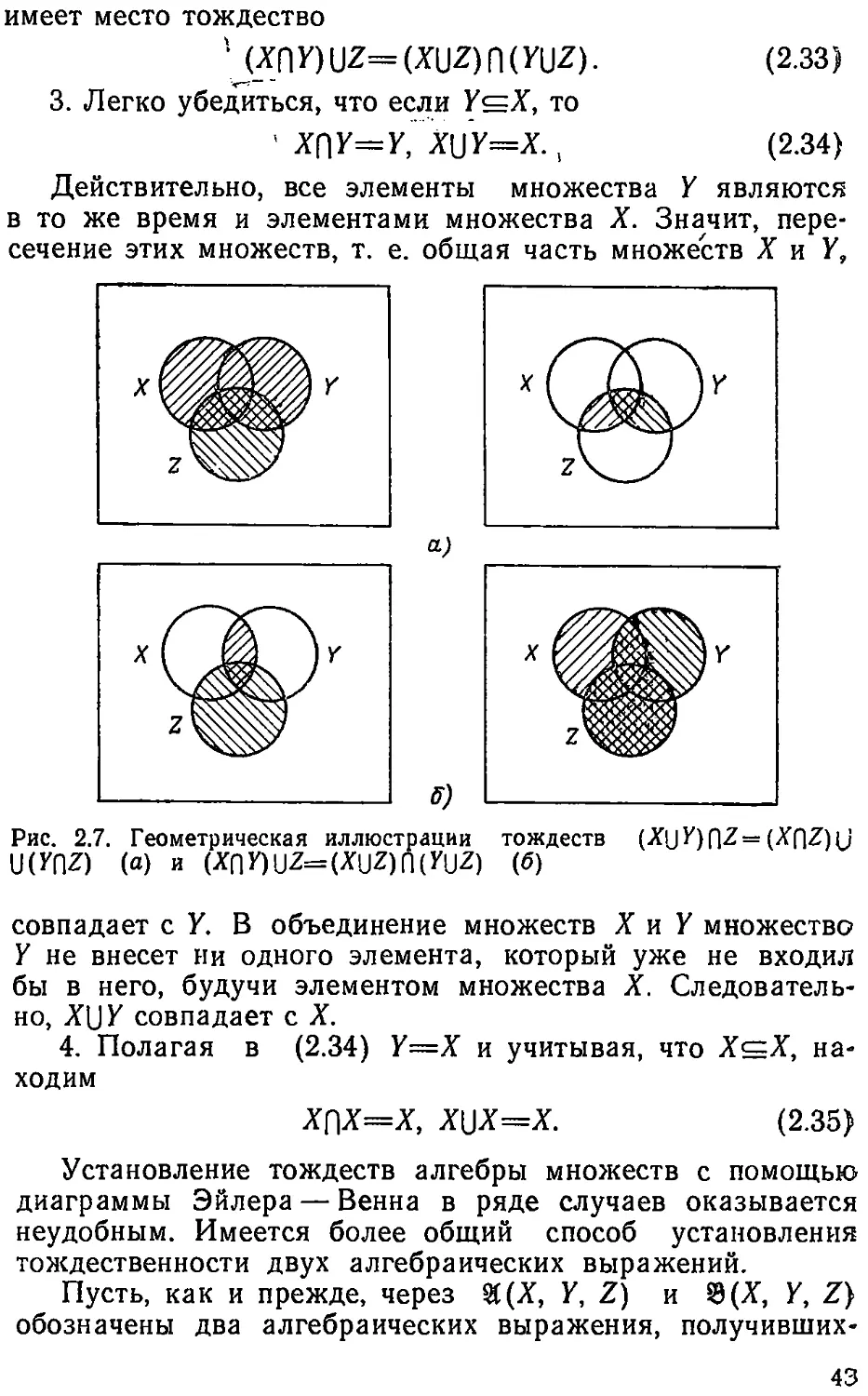





























































































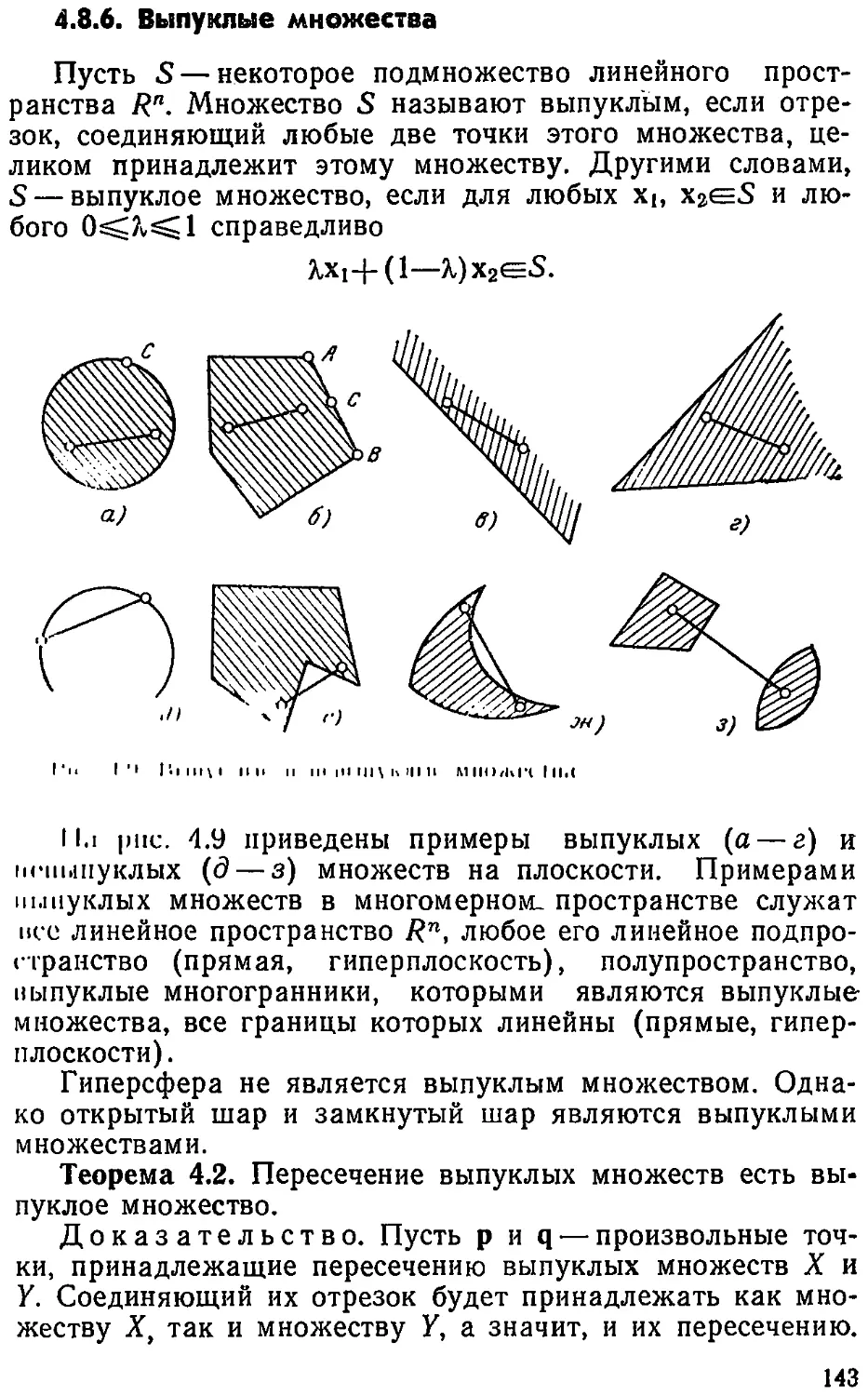

















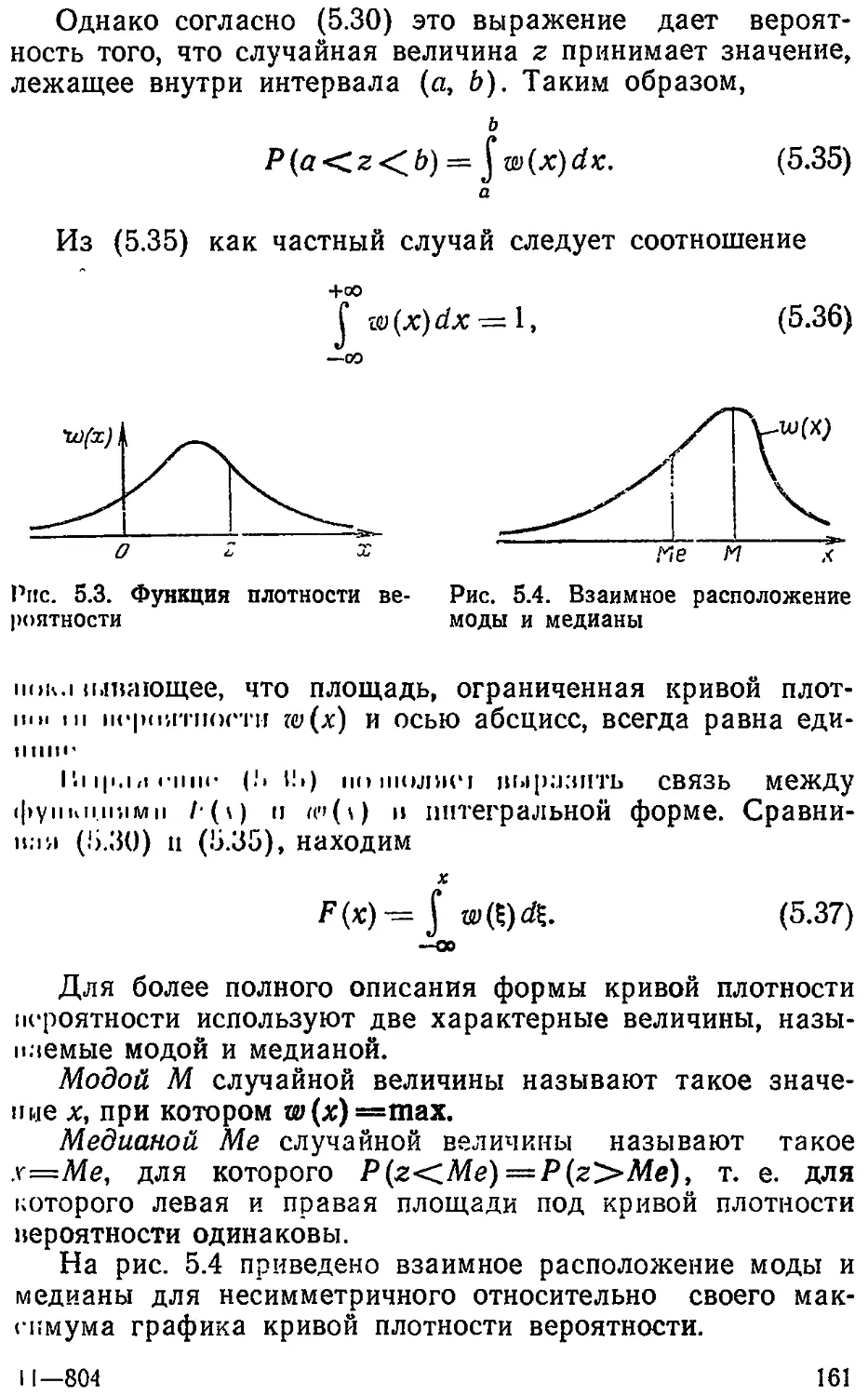








































































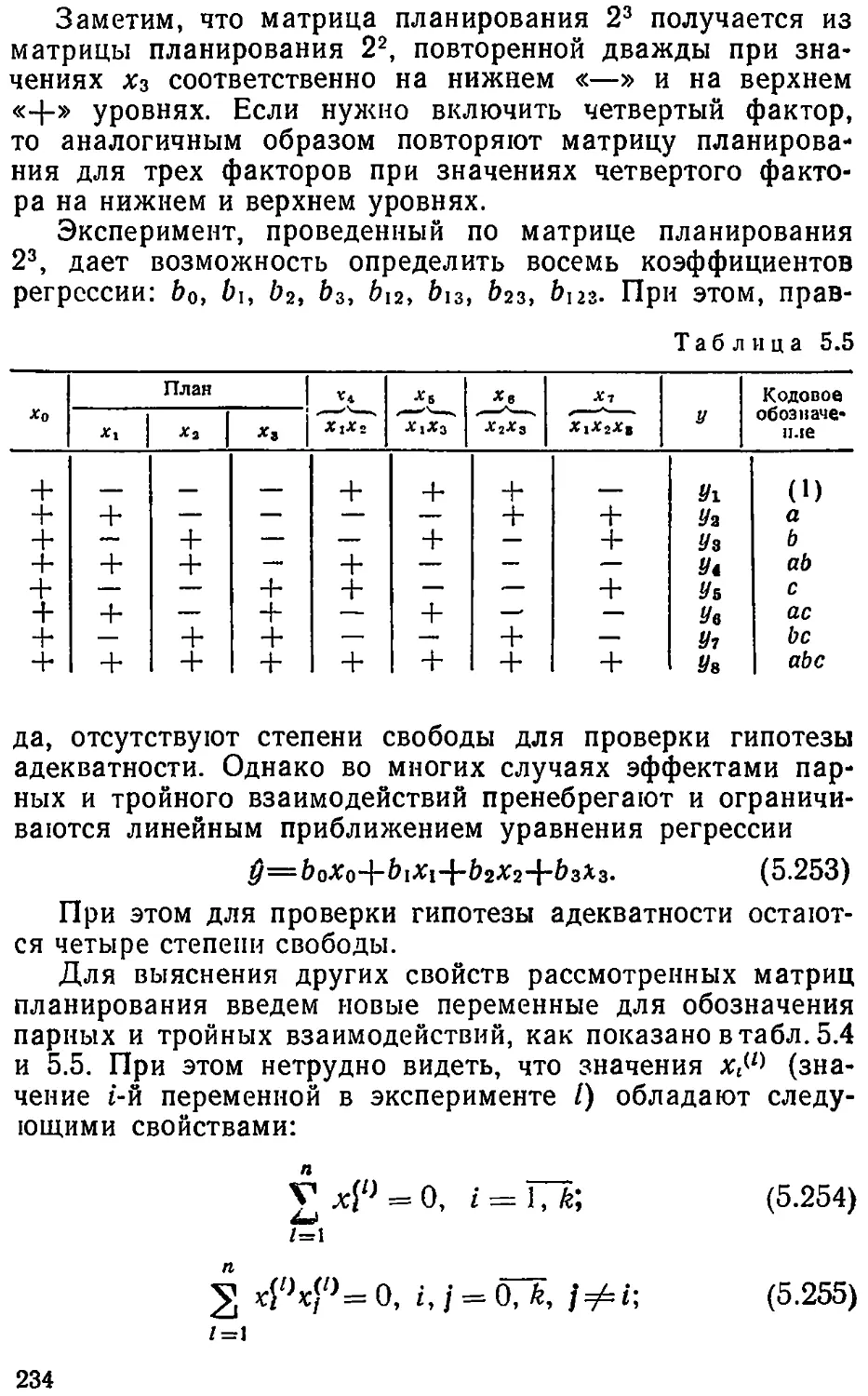










































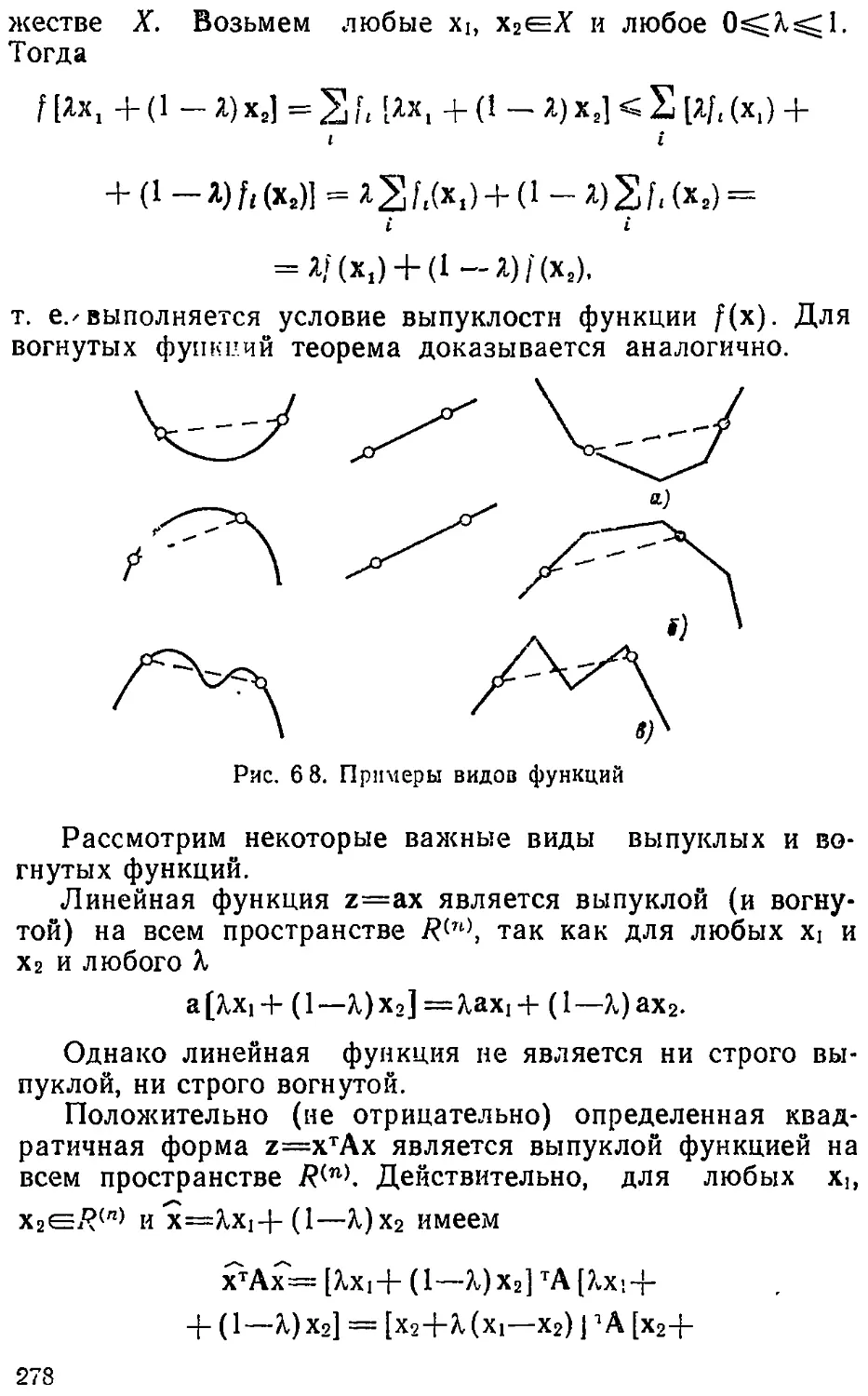





































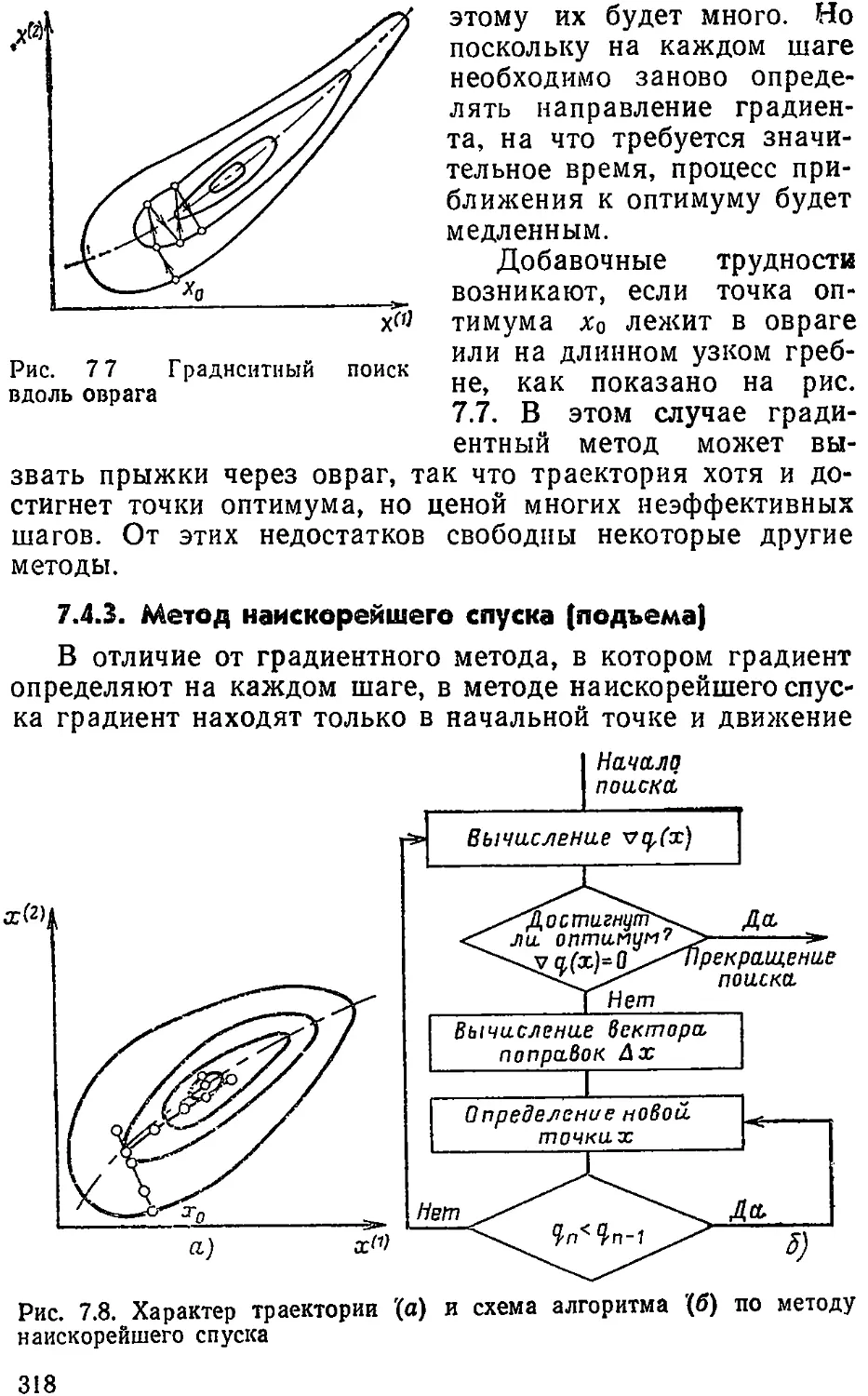

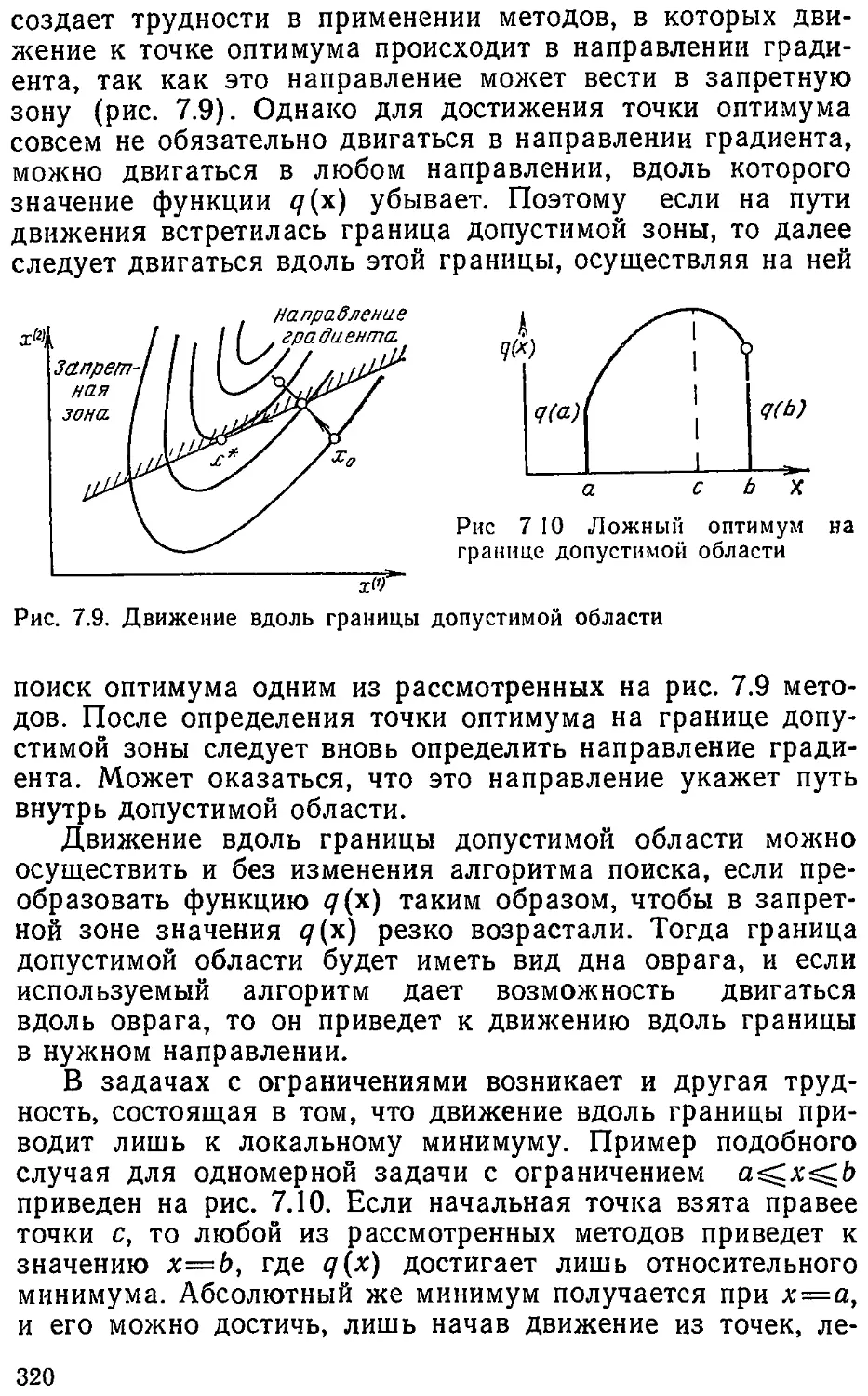
















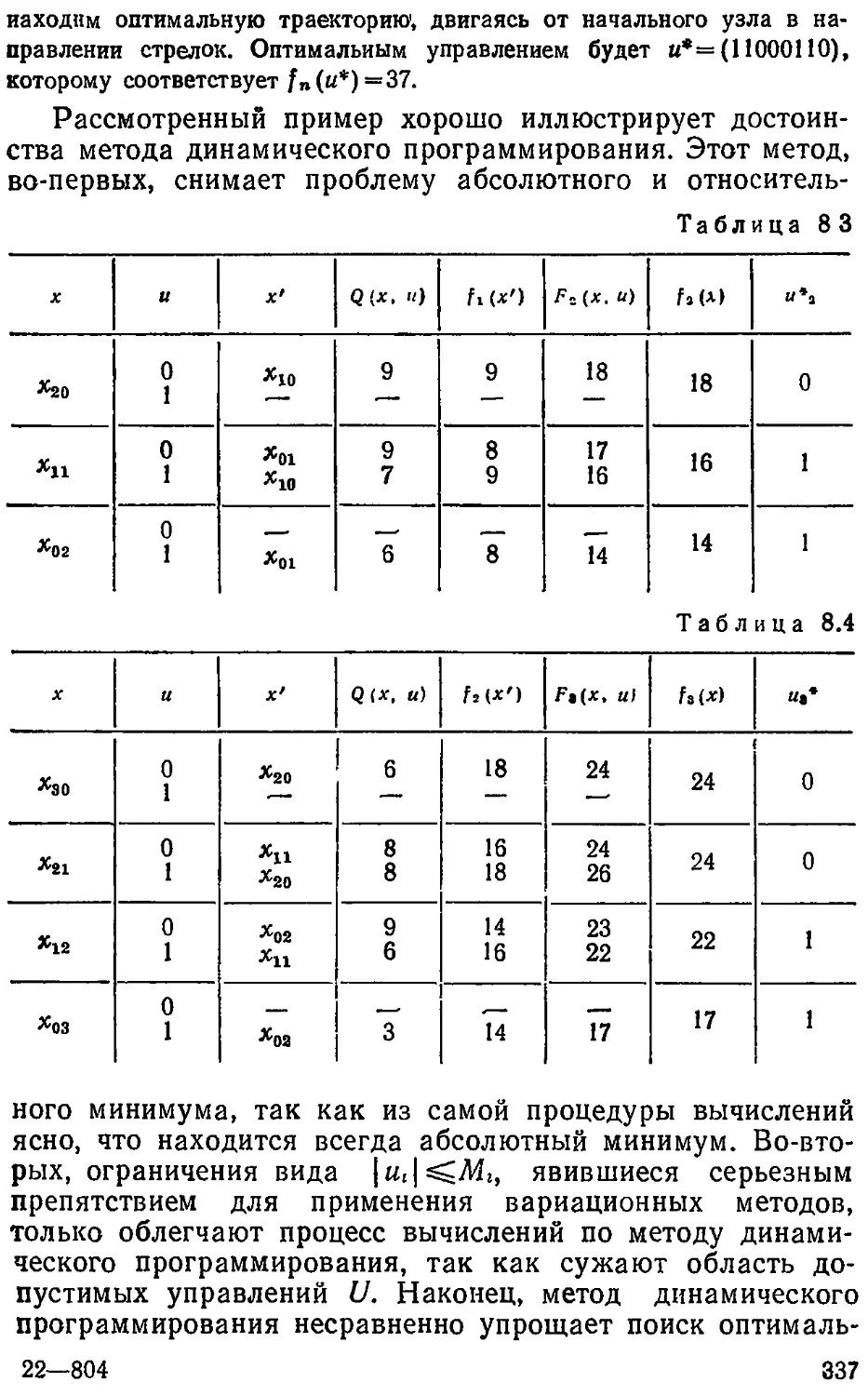




















































































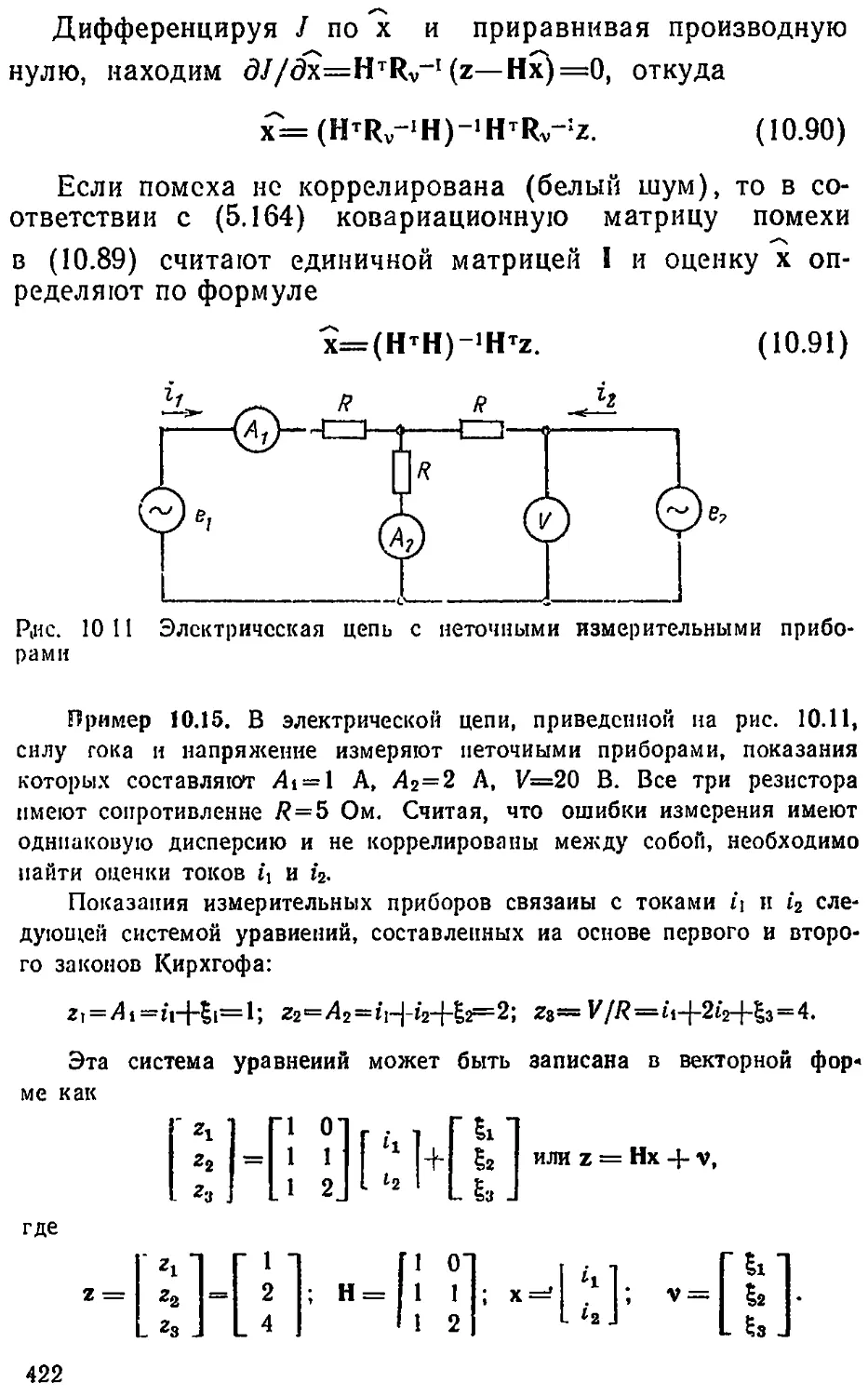




































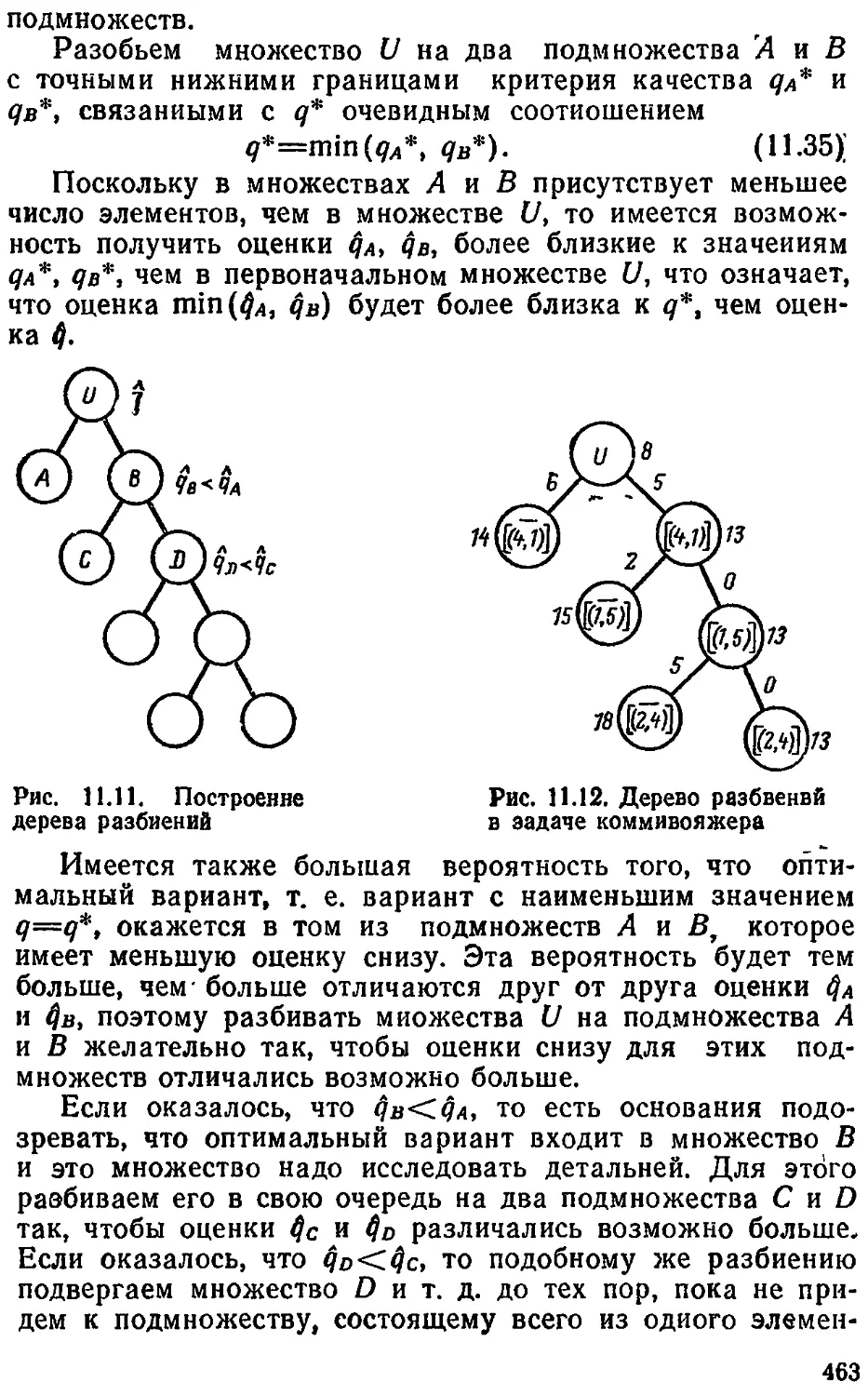



































Text
Ю. М. Коршунов
МАТЕМАТИЧЕСКИЕ
ОСНОВЫ
КИБЕРНЕТИКИ
ИЗДАНИЕ ТРЕТЬЕ,
ПЕРЕРАБОТАННОЕ И ДОПОЛНЕННОЕ
Допущено Министерством высшего и среднего
специального образования СССР в качестве
учебного пособия для студентов, вузов,
обучающихся по специальности
«Автоматика и телемеханика»
Е
99 Москва Энергоатомиздат 1987
ББК 32.81
К 70
УДК 681.5.01 :51
Рецензент доктор технических наук,профессор Л. Т. Кузин
Кортунов Ю. М.
К70 Математические основы кибернетики: Учеб, по-
собие для вузов. — 3-е изд., перераб. и доп. — М.:
Энергоатомиздат, 1987. — 496 с.: ил.
Изложены основы математического аппарата, используемого
при исследовании и описании кибернетических моделей и методов
оптимизации сложных систем По сравнению с изданием 1980 г.
в книгу добавлены новые разделы по векторным производным, много-
мерному нормальному распределению и гауссовским марковским слу-
чайным процессам, матричным моделям систем, фильтрации сигна-
Для студентов, обучающихся по специальности «Автоматика и
телемеханика».
„ 1502000000-033
К 051(01)-87 ,06'87
ББК 32 81
© «Энергия», 1980
© Энергоатомиздат, 1987 с изменениями
ПРЕДИСЛОВИЕ
Вопросы кибернетики как науки об общих закономер-
ностях процессов управления в системах различной физи-
ческой природы [1—6] занимают в последние годы все
больше и больше места в дисциплинах, связанных с изуче-
нием управляемых систем. Чрезвычайно актуальными эти
вопросы являются для специальности «Автоматика и теле-
механика», в которой изучению различных аспектов авто-
матического управления посвящен целый ряд дисциплин
учебного плана.
В таких дисциплинах, как «Основы кибернетики», «Ме-
тоды оптимизации», «Оптимальные и адаптивные системы»,
«Управление сложными системами», широко применяют
методы оптимизации основанные на использовании линей-
ного, нелинейного и динамического программирования,
теории игр, теории статистических решений, методы пла-
нирования эксперимента, методы теории расписаний и
массового обслуживания. В основе всех этих методов ле-
жат общие математические понятия теорий множеств и
отношений, графов, многомерных пространств и линейных
преобразований, теории вероятностей и математической
статистики. Общность математических основ для многочис-
ленных методов оптимизации позволяет изложить их весь-
ма компактно и с единых позиций, что в значительной
степени облегчает изучение перечисленных дисциплин и
установление связи между ними.
В третье издание книги (второе вышло в 1980 г.) вне-
сены некоторые изменения: переработана глава, посвящен-
ная теории вероятностей и методам математической ста-
тистики; рассмотрены многомерные распределения вероят-
ностей, случайные процессы, модели линейных динамиче-
ских систем; введены разделы, знакомящие с теориями
оценивания, фильтрации и основными понятиями киберне-
тики; увеличено число примеров, иллюстрирующих теоре-
тический материал.
Книга начинается с вводной главы (гл. 1), знакомящей
читателя с основными понятиями кибернетики, включая
понятие сложных систем.
Методы управления сложными системами изучаются во
многих дисциплинах учебного плана специальности «Авто-
матика и телемеханика». Для их понимания требуется об-
ширный математический аппарат, включающий в себя ос-
новные разделы традиционного курса высшей математики:
дифференциальное и интегральное исчисление, дифферен-
циальные уравнения, ряды, теорию функций комплексного
переменного, операционное исчисление, спектральный ана-
лиз. Эти разделы считаются известными читателю и в
книге не рассматриваются. Однако традиционных матема-
тических разделов, в основе которых лежит непрерывное
и детерминированное, совершенно недостаточно для пони-
мания и изучения кибернетических систем, ведущую роль
в которых играет дискретное и случайное.
Роль дискретного чрезвычайно велика при описании и
изучении сложных систем. Сложные системы состоят из
разнообразных разнородных элементов, поэтому обладают
ярко выраженной дискретной (прерывной) структурой,
описание которой требует специальных математических
методов. Такими являются теория множеств, теория гра-
фов и линейная алгебра, излагаемые в гл. 2—4.
Другой особенностью сложных систем является веро-
ятностный характер их структуры и неопределенность
внешних условий, в которых такие системы существуют и
работают. Для отражения этих особенностей сложных си-
стем в их моделях в гл. 5 излагаются математический ап-
парат теории вероятностей и математической статистики,
методы экспериментального определения параметров мо-
делей, основанные на регрессионном анализе и планирова-
нии эксперимента.
Как следует из рассмотрения общей структуры управ-
ляемой системы, построение модели есть лишь подгото-
вительный этап к процессу управления, общее описание
которого и классификация решаемых задач дается в гл. 6.
Здесь же приведены примеры использования уже рассмот-
ренного математического аппарата для построения некото-
рых видов моделей и необходимые понятия теории опти-
мизации, являющиеся фундаментом решения многообраз-
ных задач управления, рассматриваемых в последующих
главах.
В гл. 7 рассмотрено линейное и нелинейное програм-
мировавие, относящееся к области математики, разраба-
тывающей теорию и численные методы решения задач на-
хождения экстремума функций многих переменных при
наличии ограничений, связывающих эти переменные. Если
функции и ограничения являются линейными, то задача
решается методами линейного программирования. В про-
тивном случае задача относится к нелинейному програм-
мированию. К задачам линейного и нелинейного програм-
мирования относится широкий круг вопросов планирования
экономических и технологических процессов, в котором ва-
жен поиск наилучшего решения.
В посвященной динамическому программированию гл. 8
рассматриваются методы нахождения последовательности
оптимальных управлений в задачах, которые по своей при-
роде являются многошаговыми или приводятся к таковым.
В гл. 9 и 10 приведены методы принятия наилучших
решений в условиях, когда лицо, принимающее решение,
не может полностью контролировать ситуацию и управлять
ею. Такое положение может сложиться в случае воздей-
ствия на ситуацию активного противника, имеющего про-
тивоположные интересы (теория игр), пли в случае недо-
статочных знаний внешних условий, вызывающих неопре-
деленности в описании ситуации (теория статистических
решений). К этим задачам относятся задачи оценивания
параметров сигналов и систем в условиях невозможности
проведения точных измерений, а также задачи фильтрации
сигналов в условиях помех.
В гл. 11 рассмотрена группа задач, называемых зада-
чами теории расписаний и массового обслуживания, с ко-
торыми приходится сталкиваться при решении вопросов
календарного планирования и оперативного управления
как в промышленности, так и при обслуживании насе-
ления.
Все задачи доведены до алгоритмов, позволяющих про-
водить вычисления на ЭВМ. Однако для лучшего поясне-
ния вычислительной стороны рассмотренных методов ил-
люстрирующие примеры взяты настолько простыми, что все
вычисления можно проделать с карандашом и бумагой в
руках.
Излагаемые в книге положения расположены в поряд-
ке нарастающей сложности и постепенности введения но-
вых понятий, так что материал предыдущих глав является
основой для изложения последующих. Предполагается, что
читатель будет знакомиться с материалом книги последо-
5
вательно. Однако отдельные главы можно изучать и неза-
висимо от других. В случае возникновения затруднений
в связи с используемыми обозначениями и терминами сле-
дует обратиться к указателю обозначений или к предмет-
ному указателю.
Учебное пособие для студентов вузов по специальности
«Автоматика и телемеханика» может быть полезно студен-
там других специальностей, имеющих соответствующие
дисциплины в учебных планах.
Автор благодарен рецензенту доктору техн, наук, проф.
Л. Т. Кузину за ценные замечания, пособствующие улуч-
шению содержания книги.
Выражаю признательность всем, приславшим отзывы и
пожелания после выхода в свет первого и второго издания
учебного пособия. Все замечания по данному изданию сле-
дует посылать по адресу: 113114, Москва, М-114, Шлюзо-
иая паб., 10.
Автор
УКАЗАТЕЛЬ ОБОЗНАЧЕНИЙ
{...} — множество
е — принадлежность множеству
непринадлежность множеству
= — символ включения
cz — символ строгого включения
U — объединение множеств
П — пересечение множеств
\ — разность множеств
X — прямое произведение множеств
X — дополнение множества X
Xs —степень множества
0 — пустое множество
/ — универсальное множество
R — множество вещественных чисел
ЭД — система множеств
sup М — верхняя граница множества М
inf М — нижняя граница множества М
Пр, М — проекция множества на ось i
(Oi,..., ап) — упорядоченное множество (кортеж, вектор)
Л—пустой кортеж
V — квантор общности
— эквивалентность по определению
—>- — следствие, отображение
f о g — композиция функций f и g по связке о
= — символ отношения эквивалентности
— символ отношения порядка
< — символ отношения строгого порядка
— символ отношения доминирования
d(x, у) — расстояние между элементами множества
||х|| — норма величины х
Еп — евклидово n-мерное пространство
С (01 6) — пространство непрерывных функций
х, у —векторы
А, В — матрицы
хт, Ат—транспонированный вектор и матрица
det A — определитель матрицы A
Z — пространство исходов эксперимента
z— исход эксперимента, случайная величина
z—центрированная случайная величина
i=l, п — перечисление i= 1,..., п
p(z), zeZ— распределение вероятностей по пространству
P(S), Ps — вероятность события
p(z|S)—условное распределение вероятностей
р(у, г) —совместное распределение вероятностей
z, £(z), vz, f(z) —среднее значение
о, (Уг — среднеквадратнческое отклонение
о2, о2г — дисперсии
w(z) — плотность вероятности
f(z) — функция распределения вероятностей
R(v, и) —равномерное распределение
N(v, о2) — нормальное распределение
ш(г, п, р) — биномиальное распределение
ш(г, а) —распределение Пуассона
С ” —число сочетаний из п по т
и— управление
& — состояние природы
х — состояние системы
Т(х, и)—преобразование состояния системы
q(x, и), Q(x, и) — целевая функция
Z(w), In (и)— критерий качества управления
£, т] — смешанные стратегии
Л) — функция потерь
А — пространство решений
а — решение, действие
а* — байесовское действие
— потери при байесовском действий
d(z) — решающая функция
р^, d) — функция риска
р*(£) - байесовский риск
ent х —целая часть числа х
Глава 1
ВВЕДЕНИЕ
1.1. ПРЕДМЕТ КИБЕРНЕТИКИ
Кибернетика как наука появилась в первые годы после
второй мировой войны и развивалась столь стремительно,
что к настоящему времени завоевала прочные позиции во
многих областях науки и техники. Своими успехами кибер-
нетика обязана открытию ряда аналогий между функцио-
нированием технических устройств, жизнедеятельностью
организмов и развитием коллективов живых существ. Эти
аналогии, вытекающие из общих рассуждений методологи-
ческого характера, кибернетика подкрепила созданием ма-
тематических методов, позволивших с количественной точ-
ки зрения описывать процессы в системах самой разнооб-
разной физической природы. Принципы кибернетики нахо-
дят широкое применение в автоматике и телемеханике,
теории связи, в экономике и социологии, в биологии и ме-
дицине [1—6].
Само слово «кибернетика» греческого происхождения.
Древние греки обозначали этим словом искусство управ-
ления кораблем. В XVIII в. слово «кибернетика» встреча-
ется у выдающегося французского физика и математика
А. М. Ампера, который этим термином определил науку об
управлении государством. В современном понимании под
кибернетикой понимают науку об управлении в самом ши-
роком- смысле этого слова. Современный смысл термина
«кибернетика» связан с именем крупного американского
математика Н. Винера, книга которого «Кибернетика или
управление и связь в животном и машине», вышедшая в
свет в 1948 г., положила начало формированию этой новой
научной дисциплины.
Возникновение кибернетики как науки об управлении
неразрывно связано с общим техническим прогрессом, ха-
рактеризующим развитие производительных сил в совре-
менную эпоху.
До появления кибернетики основные направления раз-
вития техники характеризовались, во-первых, созданием
устройств, служащих для получения и преобразования
энергии (например, паровые машины, турбины, генераторы
электрической энергии, электрические и другие виды дви-
гателей и т. п.), и, во-вторых, созданием устройств, слу-
жащих для воздействия на окружающую природу. Основ-
ное внимание в таких устройствах обращается на энерге-
тические соотношения, и важнейшим показателем их ра-
боты является коэффициент полезного действия. Сравни-
тельная простота технических устройств не ставила
проблему управления ими на особое место. Человек одно-
временно работал и управлял объектом своей работы. Не-
обходимую для управления информацию он получал не-
посредственно от своих органов чувств, наблюдая за ре-
зультатами работы.
Однако прогресс техники в середине XX в. привел к
созданию столь сложных технических систем, задачи уп-
равления которыми стали превышать физиологические
возможности человека. В конце второй мировой войны
такой задачей явилась задача создания автоматической
системы управления зенитным огнем, которая при скоро-
стях самолетов, сравнимых со скоростью зенитного снаря-
да, могла бы без участия человека следить за курсом са-
молетов, осуществлять расчет их траекторий и наводку
орудий. В подобных системах на первое место выдвига-
ются задачи получения информации об окружающей обста-
новке, обработки этой информации с целью извлечения из
нее пригодных для управления данных и использования
этой информации для осуществления целенаправленных
действий, т. е. задачи создания устройств, служащих для
связи и управления. Необходимость решения этих задач
привела к быстрому прогрессу в области теории связи, вы-
числительной техники и автоматики, что положило начало
развитию тех идей, которые позднее явились фундаментом
кибернетики.
Устройства связи и управления существенно отлича-
Ю1С.я от упоминавшихся выше технических устройств в том
отношении, что энергетические соотношения в них не иг-
рают существенной роли и основное внимание обращается
на способность их передавать и перерабатывать без иска-
жения боиыпне количества информации. Так, в линии ра-
диосвязи лишь ничтожная доля энергии, излучаемой ан-
тенной радиопередатчика, достигает приемника и КПД по-
лучается чрезвычайно низким. Однако линия радиосвязи
считается хорошей, если сообщения по ней передаются с
10
Таким образом,углавные. процессы в устройствах связи и
управления — это процессы передачи, и переработки ин-
формации, а не процессы, связанные с преобразованием и
использованием энергии.
Несущественность энергетических соотношений в зада-
чах связй'и управления позволяет отвлечься от физических
особенностей носителей информации и от физической при-
воды систем, в которых эта информация используется.
Поэтому кибернетика представляет
собой общую теорию связи и управле-
ния, применимую к любой системе не-
зависимо от ее физической природы.
Понятие системы, наряду с поня-
тием управления, точный смысл кото-
рого будет выяснен позднее, является
фундаментальным понятием киберне- мп
тикиУ Любая реально существующая ' бер<иетической,еР КИСи-
система состоит из конкретных, объ- стемы
ектов,'] в качестве .которых могут вы-
ступать технические устройства,
люди, управляющие этими устройствами, материальные
ресурсы и т. Щ_Эти объекты связаны между собой и с ок-
ружающим миром определенными связями,представля-
ющими собой силы, потоки энергии, вещества’ и информа-
ции. Однако кибернетика отвлекается от физического со-
держания свойств объектов и связей и рассматривает
реальную систему как абстрактное множество элементов,
наделенных общими свойствами и находящихся друг с
другом в некоторых отношениях, определяемых характе-
ром существующих связей. Такое представление позволяет
отказаться от привычного разделения систем на механи-
ческие, электрические, химические, биологические и т. п. и
ввести понятие абстрактной кибернетической системы как
совокупности взаимосвязанных и воздействующих друг на
друга элементов. На рис. 1.1 приведен пример кибернети-
ческой системы, содержащей четыре элемента и шесть
взаимных связей.
Рассмотрение системы как совокупности элементов дает
возможность привлечь для ее математического описания
аппарат теории множеств, с изложения которого и начи-
нается настоящая книга. При этом во многих случаях свя-
зи между элементами удобно описываются и анализиру-
ются методами теории графов, а для анализа взаимодей-
ствия элементов широко используются методы линейной
алгебры.
Встречающиеся на практике системы в зависимости от
их структуры и характера связей делятся на детерминиро-
ванные и вероятностные. Детерминированной называют
систему, законы движения которой точно известны и буду-
щее поведение которой можно предвидеть. Для вероятно-
стной системы нельзя сделать точного предсказания ее бу-
дущего' поведёния.'"'Примердм детерминированной системы
может служить часовой механизм. Однако системы стати-
стического контроля продукции, системы прибытия кораб-
лей в морские порты или запас товаров на складе, имею-
щем большое число поставщиков и потребителей, являются
вероятностными системами.
Задачи, которые решает кибернетика, приводят в боль-
шинстве случаев к необходимости рассмотрения достаточ-
но сложных вероятностных систем, которые состоят из
большого числа элементов и имеют разнообразные и раз-
ветвленные внутренние связи. Именно к таким системам
относится большинство производственных систем, экономи-
ческие, социальные и биологические. Для математического
описания таких систем наряду с теорией множеств и ма-
тематической логикой широко применяются аппарат теории
вероятностей и методы математической статистики.
Пока мы коснулись лишь математических методов, ис-
пользуемых для описания кибернетических систем. Однако
целью кибернетики является управление системами. Для
суждения о путях решения этой задачи необходимо четко
представить себе смысл термина «управление».
В широком смысле слова под управлением понимают
организационную деятельность," осуществляющую функции
руководства чужой работой, направленной на достижение
определенных целей. Процесс управления состоит в приня-
тии решений о наиболее целесообразных действиях в той
или иной сложившейся ситуации. Человек, осуществляю-
щий управление, принимает решения, оценивая окружаю-
щую обстановку с помощью информации, получаемой от
своих органов чувств, измерительных приборов, других
лиц. Во многих случаях этой информации оказывается не-
достаточно для однозначной оценки обстановки. Тогда че-
ловек использует свой опыт, свои знания, память, интуи-
цию. Замечательным свойством человека является способ-
ность принимать решения в условиях значительной
неопределенности в отношении окружающей обстановки.
12
Однако в условиях современных крупных промышлен-
ных предприятий знаний и интуиции даже у опытного ру-
ководителя оказывается недостаточно, чтобы осуществлять
эффективное управление. В результате возникают такие
недостатки в работе крупных предприятий, как штурмов-
щина, трудности с регулярным обеспечением сырьем и
материалами без чрезмерного увеличения запасов, серьез-
ные транспортные проблемы и т. п.
Кибернетика ставит задачей облегчение человеку про-
цесса принятия ответственных решений, возлагая на авто-
матические устройства сбор и обработку больших коли-
честв информации относительно состояния производствен-
ного процесса, анализ сложившихся ситуаций и выработку
рекомендаций относительно целесообразных действий. Ав-
томатические устройства, осуществляющие совокупность
таких операций, называются автоматизированными систе-
мами управления (АСУ). В основу работы таких систем
положены электронные цифровые вычислительные машины
(ЭВМ).
Роль ЭВМ в кибернетике настолько важна, что на этом
вопросе следует остановиться подробней. Первоначально
ЭВМ использовались для проведения традиционных рас-
четов, которые раньше занимали много часов, а теперь ста-
ли требовать секунд. Но стало очевидным, что огромное
увеличение скорости вычислений содержит в себе качест-
венно новые явления. Если раньше проектировщик или эко-
номист из всего множества возможных вариантов решения
какой-либо задачи мог проанализировать лишь некоторые,
которые ему по каким-то причинам казались достойными
внимания, то теперь открылась возможность сравнивать
все возможные варианты и выбирать наилучший из них.
Так появились идеи оптимизации, которые в дальнейшем
привели к развитию ряда новых разделов математики.
Далее оказалось, что ЭВМ, установленная на промыш-
ленном предприятии, легко может справиться с обработ-
кой больших количеств информации о ходе производствен-
ного процесса и может стать незаменимым помощником
человека при управлении производством.
Однако для того, чтобы ЭВМ можно было применять
для целей управления, должны быть разработаны матема-
тические методы, позволяющие анализировать имеющиеся
виды информации, отсеивать ненужную информацию и вы-
делять наиболее существенную часть ее, использовать эту
информацию для оценки сложившейся ситуации и выраба-
13
тывать рекомендации, обеспечивающие наиболее эффек-
тивное выполнение целей управления. Необходимость ре-
шения подобных задач -привела к появлению таких разде-
лов математики, как теория информации, теория игр,
теория статистических решений, теория массового обслу-
живания, линейное и динамическое программирования и
др. Часть этих новых математических методов будет рас-
смотрена в настоящей книге. Другие методы рассматрива-
ются в ряде специальных курсов.
1.2. ПЕРЕДАЧА И КОДИРОВАНИЕ ИНФОРМАЦИИ
Связи между элементами какой-либо системы могут
служить различным целям. По ним могут передаваться
энергия, вещество, усилия и т. п. Однако в кибернетиче-
ских системах нас интересует в первую очередь информа-
ционное содержание связей, т. е. возможность использо-
вания связей для передачи сведений о различных состоя-
ниях элементов системы.
Любое сведение о каком-либо событии, происходящем
внутри системы или вне ее, в технике называют сообще-
нием. Информационные связи, служащие для передачи
сообщений, называют каналами связи. Физические носите-
ли информации в каналах связи называют сигналами. На
рис. 1.2 приведена структура канала связи.
Слово «сигнал» происходит от латинского слова sig-
num, т. е. знак, и означает условные электрические, зву-
ковые, зрительные или иной природы знаки, служащие для
передачи сообщений. Вид сигналов является, как правило,
результатом соглашения между лицом, передающим ин-
формацию, и лицом, принимающим ее, и не имеет непо-
средственного отношения к содержанию передаваемой
информации. Поэтому сигналы могут легко преобразовы-
ваться из одного вида в другой, не изменяя содержания
информации, а также могут храниться (например, в фор-
ме буквенной записи) для использования содержащейся
в них информации в будущем.
В качестве примера рассмотрим вид сигналов, исполь-
зуемых при передаче телеграммы. Первоначальное сооб-
щение, отпечатанное на телеграфном бланке, преобразовы-
вается в форму кода Морзе, состоящего из точек и тире,
которые передаются по линии связи в виде длинных и ко-
ротких импульсов тока. На приемной стороне по принятым
импульсам восстанавливается первоначальный текст сооб-
14
щения. Как видим, сообщение здесь существует в виде
сигналов различной формы: буквенного текста, точек и ти-
ре кода Морзе, импульсов тока в линии связи и т. п. Пре-
образование сигнала из одной формы в другую называют
кодированием.
Способ осуществления связи может быть представлен
следующим образом. Прежде всего должен существовать
набор символов — букв, слов, точек, тире и т. п., имеющих
смысл, известный как для отправителя, так и для получа-
Передаваемое ПЙере даваемый
— «г.------ । сигнал
Пере-1
датчик I
сообщение |
1 Источник Ij
информации р|
Линия
связи
Принимаемый Принимаемое
сигнал | сообщение
Прием- U Получатель
ник I || информации |
Рис 1.2. Структура канала связи
теля сообщения. Набор этих символов называют алфави-
том. Сами символы устанавливаются по соглашению сто-
рон.
В основе теории связи лежит положение о том, что
составляющие алфавит символы не могут быть бесконеч-
но разнообразны. Поэтому для передачи всевозможных
сообщений используется ограниченное число различных
символов. Так, всевозможные буквенные сообщения состав-
ляются на русском языке с помощью алфавита из 33 букв.
В процессе передачи отправитель выбирает из имеюще-
гося алфавита один символ за другим, преобразует их
в соответствующие сигналы и передает по каналу связи.
В канале связи сигналы подвергаются действию помех,
что вызывает их искажение. Таким образом, сигналы на
приемной стороне будут отличаться от сигналов, посылае-
мых в канал связи.
Процесс приема состоит в том, что получатель, получив
какой-либо сигнал, должен отождествить его с одним из
имеющихся символов алфавита, т. е. должен исключить все
символы, кроме одного. Эта задача может представлять
значительные трудности, если в канале связи сигналы
подвергаются большим искажениям. Методы преодоления
этих трудностей составляют существо теории связи.
В технических системах связи используются различно-
го вида алфавиты. Однако по ряду причин весьма широ-
15
кое применение находит двоичный алфавит, состоящий из
двух символов, условно обозначаемых 0 и 1. В двоичном
алфавите любое сообщение будет представлять собой по-
следовательность нулей и единиц, например 100110100.
Легко подсчитать, что общее число сообщений, состоя-
щих из пг букв двоичного алфавита, будет равно 2т.
В частности, любая буква русского алфавита может быть
представлена шестью знаками двоичного алфавита, напри-
мер, а —000001, б —000010, в — 000011 и т. д. Так как
шесть двоичных знаков дают 26=64 различных комбина-
ций символов, то с их помощью можно представить не
только все буквы алфавита, но и знаки препинания. Сле-
довательно, с помощью двоичного алфавита может быть
представлено и передано по каналу связи любое буквен-
ное сообщение.
Двоичный алфавит может использоваться и для пере-
дачи числовых данных, однако при этом необходима неко-
торая специальная система счисления.
В распространенной десятичной системе счисления раз-
личные числа записываются с помощью десяти цифр (0,
1,...,9), расположенных в определенном порядке и имею-
щих значения, зависящие от местоположения каждой циф-
ры. Так, запись 395 означает число, определяемое соотно-
шением
3-102+9-104-5-Ю°.
Здесь число 10 называется основанием системы счисле-
ния.
Любое число М может быть аналогичным образом за-
писано в системе счисления с любым другим основанием R
(целое число) с помощью различных цифр, число которых
равно основанию системы счисления. При этом запись
... dididido, где dt — цифры числа N (0^dt<R), опреде-
ляет величину
N^...d3R3+d2R2+dlR'+d0R°. (1.1)
Так, в восьмеричной системе счисления, находящей при-
менение в некоторых видах ЭВМ, число 395 будет иметь
представление
6-82 + 1-81 + 3-8°,
т. е. запишется в виде числа 613.
При использовании двоичного алфавита запись числа
должна производиться только с помощью цифр 0 и 1. При-
годной для такой записи является двоичная система счис-
16
ления, основанием которой служит число 2. Любое число
от 0 до 15 может быть представлено в двоичной системе
счисления с помощью четырехразрядного числа:
з=о-23+о-22+1-2'+1-2°, т. е. ооп;
5=o-23+i-22+o-2|+i-2°, т. е. oioi;
9=1 •23+ 0-22+0-21 + 1 -2°, т. е. 1001.
Естественно, что нули в высших разрядах этих чисел
писать необязательно, т. е. числа 3 и 5 можно записывать
в виде 11 и 101. Число 395, представляемое через основа-
ние 2:
395=28+27+23+2‘+2°,
будет в двоичной системе счисления записано девятираз-
рядным числом 110001011.
Запись больших чисел в двоичной системе счисления
имеет то неудобство, что требует большого числа разря-
дов, что затрудняет чтение чисел и быструю оценку их
величины. Поэтому часто применяют смешанные системы
счисления, например десятично-двоичную, в которой само
число записывается в десятичной системе счисления,
а цифры отдельных его разрядов — в двоичной системе
счисления с использованием четырех двоичных разрядов
на десятичную цифру. Так, число 395 в десятично-двоичной
системе счисления имеет вид:
ООН 1001 0101
" "V '~5~
Однако двоично-десятичная форма записи чисел требу-
ет большего числа двоичных разрядов, чем двоичная, т. е.
является менее экономной. Поэтому широкое применение
нашла двоично-восьмеричная система счисления. Рассмот-
ренное десятичное число 395 в восьмеричной системе счис-
ления представится как 613 (см. задачу 1.3). Если цифры
этого числа записать в двоичной системе счисления, ис-
пользуя три двоичных разряда на цифру, то получаем за-
пись числа 395 в двоичной системе счисления:
17
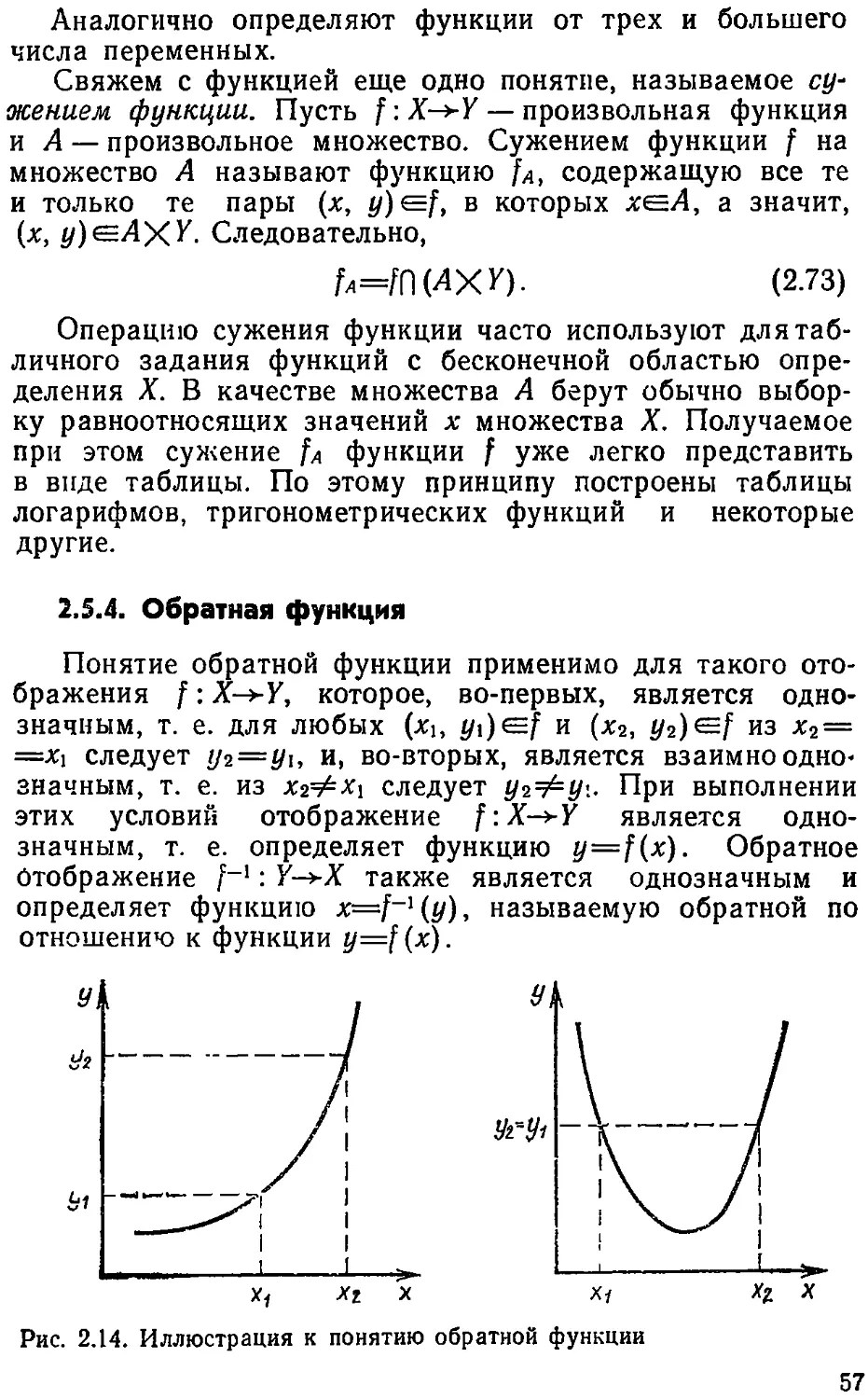
1.3. ПОНЯТИЕ ОБ УПРАВЛЯЕМОЙ СИСТЕМЕ
Приведенное выше определение понятия управления
допускает весьма широкое толкование. Управлять можно
лошадью, автомобилем, самолетом, токарным станком, це-
хом, отделом, промышленным предприятием, отраслью
промышленности, государством Управлять можно не толь-
ко различными машинами и механизмами, но и процесса-
ми. А эти процессы обеспечивают люди. Следовательно,
нужно управлять людьми, их производственной или какой-
Управление
| Канал А
ОУ
Состояние ОУ
Канал В
I Алгоритм
| управления
Модель ОУ
Цель управления
и критерий
УУ (g-
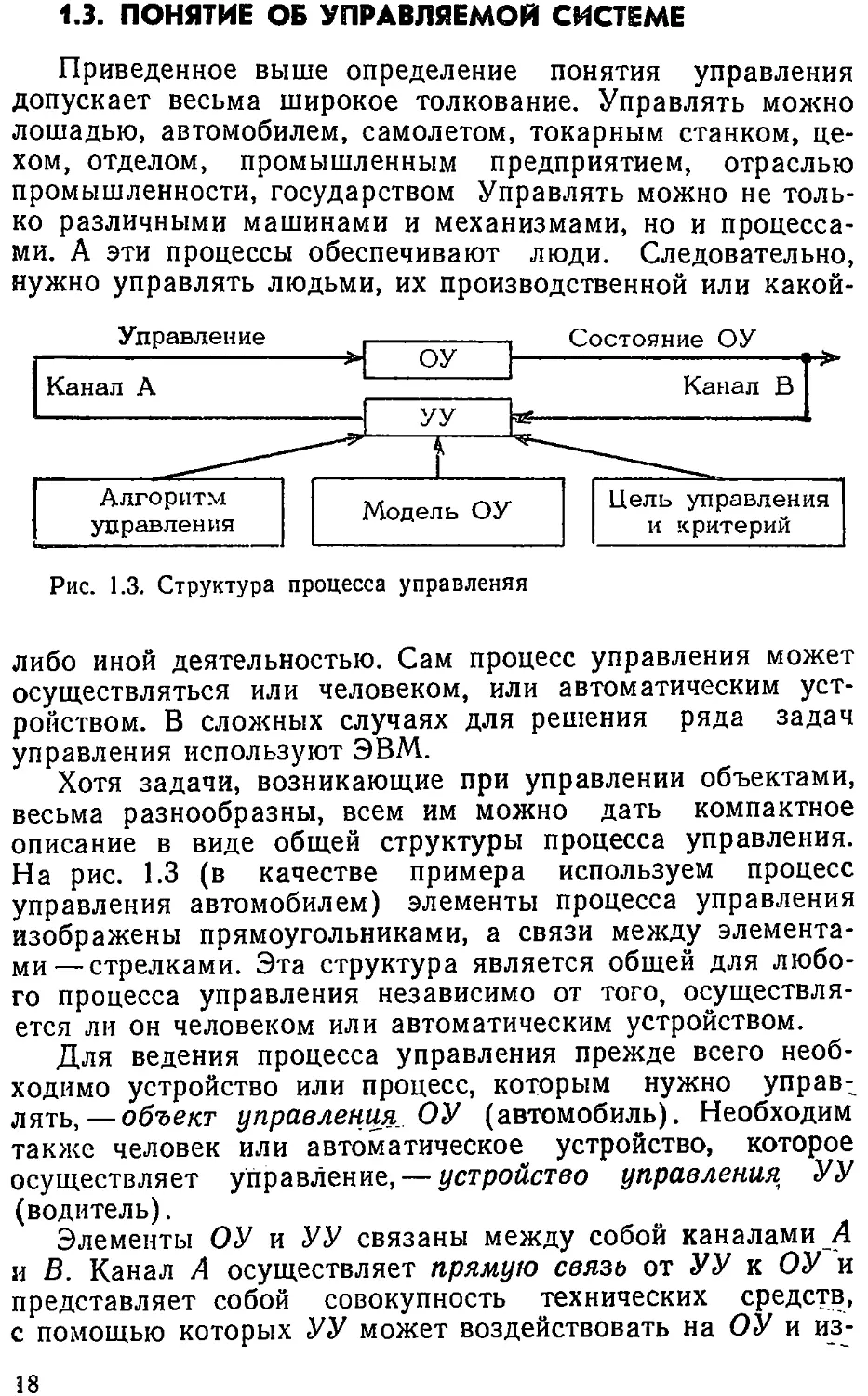
Рис. 1.3. Структура процесса управления
либо иной деятельностью. Сам процесс управления может
осуществляться или человеком, или автоматическим уст-
ройством. В сложных случаях для решения ряда задач
управления используют ЭВМ.
Хотя задачи, возникающие при управлении объектами,
весьма разнообразны, всем им можно дать компактное
описание в виде общей структуры процесса управления.
На рис. 1.3 (в качестве примера используем процесс
управления автомобилем) элементы процесса управления
изображены прямоугольниками, а связи между элемента-
ми-стрелками. Эта структура является общей для любо-
го процесса управления независимо от того, осуществля-
ется ли он человеком или автоматическим устройством.
Для ведения процесса управления прежде всего необ-
ходимо устройство или процесс, которым нужно управ-
лять, — объект управления ОУ (автомобиль). Необходим
также человек или автоматическое устройство, которое
осуществляет управление, — устройство управления УУ
(водитель).
Элементы ОУ и УУ связаны между собой каналами А
и В. Канал А осуществляет прямую связь от УУ к ОУ и
представляет собой совокупность технических средств,
с помощью которых УУ может воздействовать на ОУ и из-
18
менять характер его движения (руль, тормоза, рычаг пе-
реключения скоростей и т. п.). От технического совершен-
ства этих средств зависит простота, гибкость и надежность
управления.
По каналу В осуществляется обратная связь (органы
чувств человека—зрение, слух, а также показания уста-
новленных на панели приборов), которая служит для пе-
редачи УУ информации о состоянии ОУ. От полноты и
достоверности информации, передаваемой по этому кана-
лу, в значительной степени зависит качество управления.
В некоторых случаях управление может осуществляться и
без обратной связи. Однако такие системы управления
бывают весьма негибкими и малоэффективными.
Цель управления определяет состояние объекта или
характер его движения, которые должны быть достигнуты
в процессе управления. Для суждения о степени достиже-
ния цели служит критерий который иногда _ называют
критерием управления.
Слово «алгоритм» означает точное предписание о вы-
полнении в^некотором порядке некоторых действий или
операций, приводящих к желаемому результату. Алгоритм
управления (свод правил дорожного движения)—это
предписание о том, как должны, быть использованы техни-
ческие средства прямого канала в.зависимости от цели и
от сложившейся ситуации, информация о которой поступа-
ет по каналу обратной связи.
Под моделью ОУ понимают совокупность свойств ОУ,
знанием которых располагает УУ. Чем полнее эти знания,
тем лучше может осуществляться процесс управления. Од-
нако весьма часто эти знания недостаточны. В этом случае
недостающие свойства приходится выяснять непосредст-
венно в процессе управления (адаптивное управление) или
действовать методом проб и ошибок.
В задачах управления под моделью понимают матема-
тическое описание'свойств ОУ, называемое математической
моделью и выражаемое обычно в виде систем алгебраиче-
ских или дифференциальных уравнений. Решая эти урав-
нения, можно установить, как будет вести себя ОУ при тех
или иных воздействиях на его входе, и, следовательно,
выбрать наилучший способ управления.
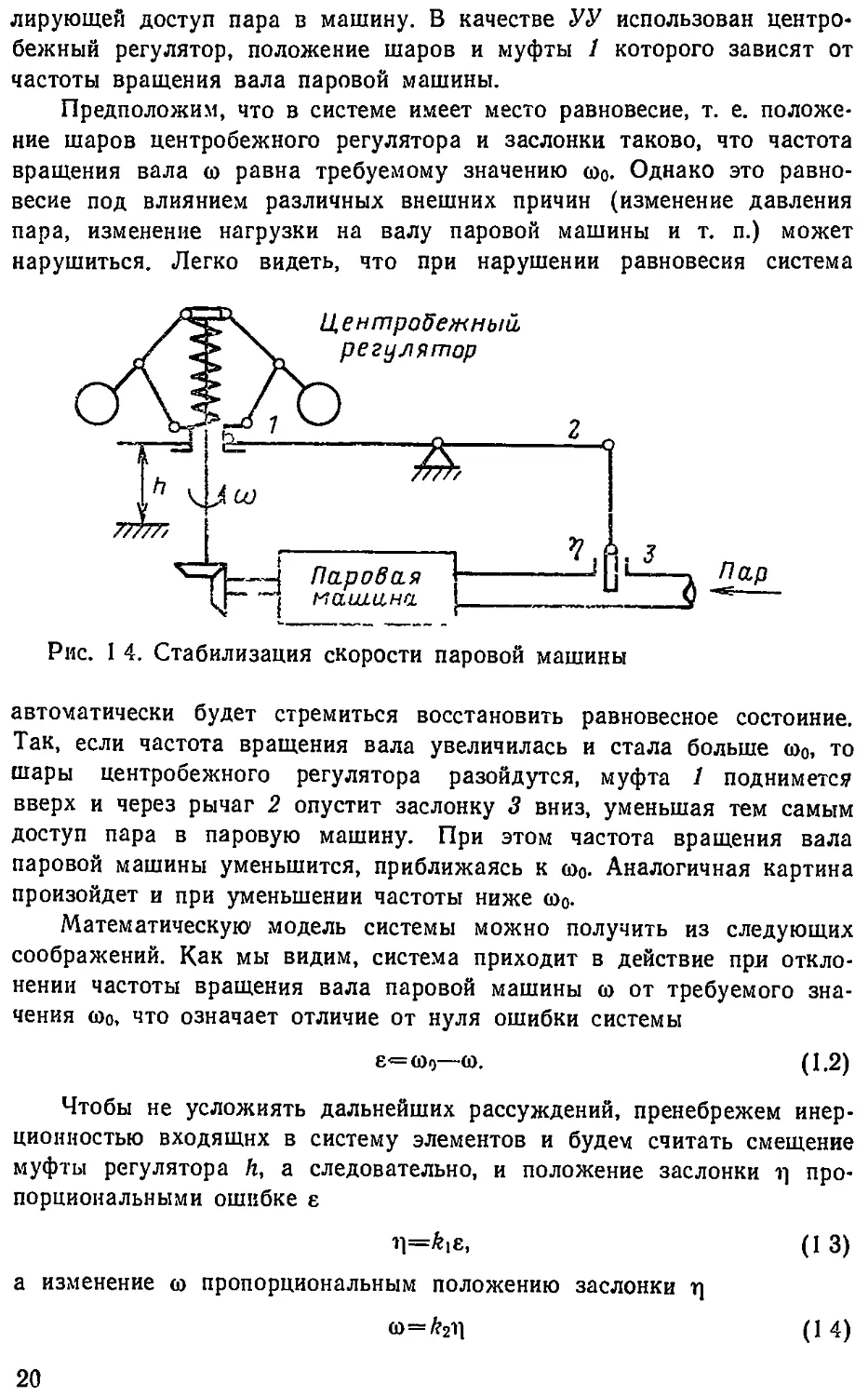
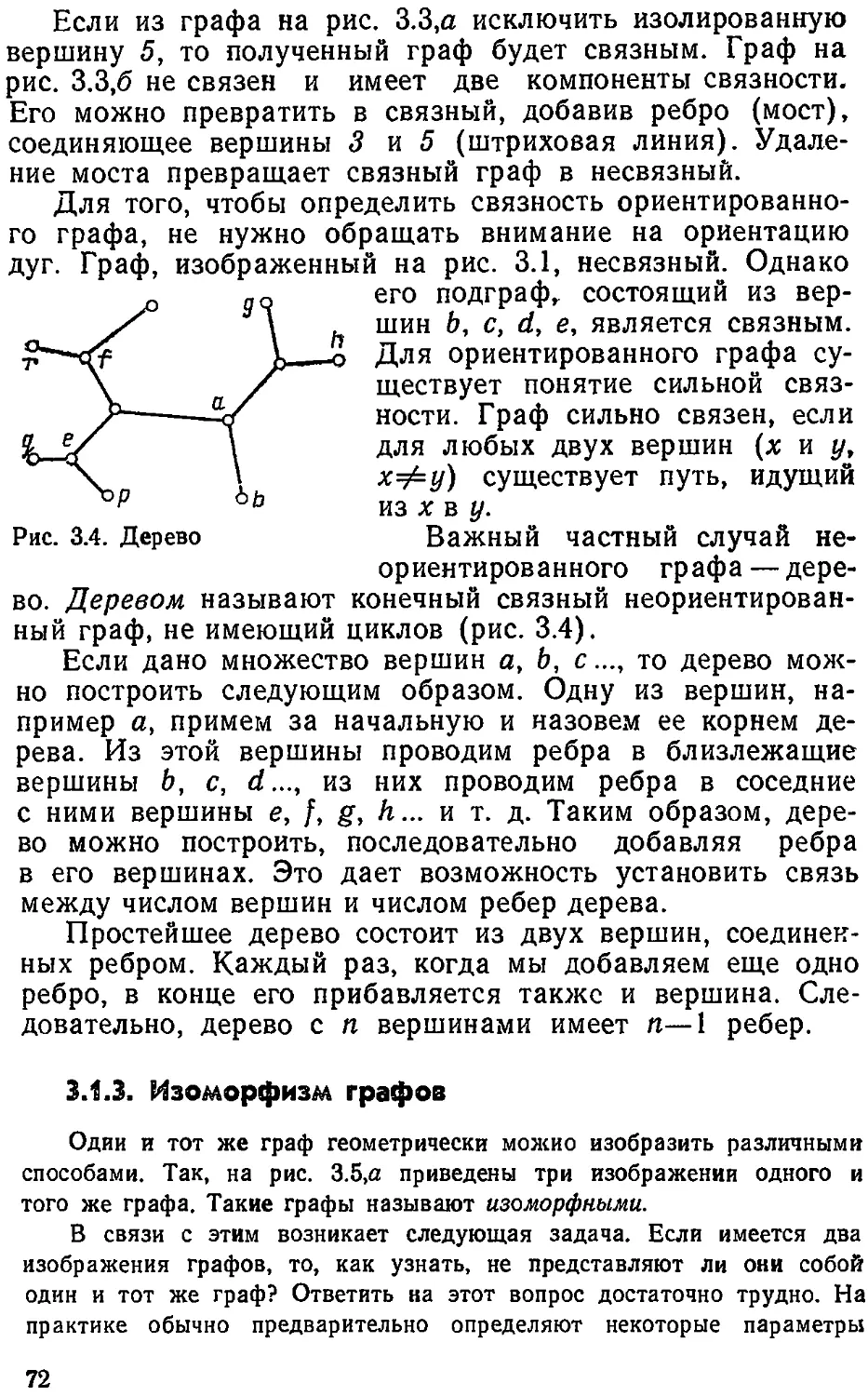
В качестве примера системы автоматического управления рассмот-
рим систему стабилизации скорости паровой машины, изображенной на
рис 1 4 Объектом управления здесь является паровая машина, часто-
та вращения вала которой изменяется положением заслонки 3, регу-
19
лирующей доступ пара в машину. В качестве УУ использован центро-
бежный регулятор, положение шаров и муфты 1 которого зависят от
частоты вращения вала паровой машины.
Предположим, что в системе имеет место равновесие, т. е. положе-
ние шаров центробежного регулятора и заслонки таково, что частота
вращения вала <о равна требуемому значению <оо- Однако это равно-
весие под влиянием различных внешних причин (изменение давления
пара, изменение нагрузки на валу паровой машины и т. п.) может
нарушиться. Легко видеть, что при нарушении равновесия система
Рис. 1 4. Стабилизация скорости паровой машины
автоматически будет стремиться восстановить равновесное состоиние.
Так, если частота вращения вала увеличилась и стала больше <о0, то
шары центробежного регулятора разойдутся, муфта 1 поднимете?
вверх и через рычаг 2 опустит заслонку 3 вниз, уменьшая тем самым
доступ пара в паровую машину. При этом частота вращения вала
паровой машины уменьшится, приближаясь к <о0. Аналогичная картина
произойдет и при уменьшении частоты ниже <о0-
Математическую модель системы можно получить из следующих
соображений. Как мы видим, система приходит в действие при откло-
нении частоты вращения вала паровой машины <о от требуемого зна-
чения <оо, что означает отличие от нуля ошибки системы
e-=(i),—со. (1.2)
Чтобы не усложнять дальнейших рассуждений, пренебрежем инер-
ционностью входящих в систему элементов и будем считать смещение
муфты регулятора h, а следовательно, и положение заслонки т| про-
порциональными ошибке е
il=^ie, (13)
а изменение <о пропорциональным положению заслонки г]
<о=М (14)
20
Полученная система уравнений представляет собой математическую
модель системы. Для ее наглядного представления часто используют
схемы, на которых элементы заменены на их математические описа-
ния и указаны связи между элементами. Схема рассматриваемой си-
стемы приведена на рис. 1 5.
Математическая модель позволяет заранее исследовать свойства
системы и наметить пути ее наилучшей реализации. Так, важнейшим
свойством системы стабилизации скорости является ее точность, опре-
деляемая значением ошибки е.
ностью, да к ним такие требова-
ния и не предъявлялись. Однако рис. 15. Схема системы стаби-
когда развитие промышленности лнзацин скорости
потребовало увеличения точности,
то конструкторы столкнулись с серьезными трудностями, не зная, как
решить эту задачу. На помощь пришла математическая модель, ко-
торая позволила связать ошибку с конструктивными параметрами си-
стемы Подставив (1.3) в (1.4), получим
a>=K\K2e=ke,
где k=K\K.2 — коэффициент усиления системы.
Подставляя <о в (1.2), находим е=<Оо—ke,, откуда
е=<Оо/(1-Ь^)-
(15)
Как видим, ошибка рассмотренной системы не может стать равной
нулю и при малых k будет значительна. С этим и столкнулись кон-
структоры первых стабилизаторов частоты вращения.
ходкого процесса прн увеличении
коэффициента усиления
Однако чрезмерное увеличение коэффициента усиления с целью
повышения точности системы приводит к другим нежелательным по-
следствиям, связанным с характером переходных процессов в системе.
На рис. 1.6 приведен характер приближения частоты вращения к зна-
чению <оо с течением времени при различных значениях коэффициента
усиления k: малом (/), большом (2) и очень большом (3). Как видим,
прн большом k процессы в системе приобретают колебательный харак-
тер и система становится неустойчивой. Это свойство также вытекает
из математической модели, если в ней учесть инерционность элементов.
21
Разрешение противоречия между требованием высокой точности и
устойчивости систем управления является предметом изучения научной
дисциплины «Теория автоматического управления».
Конечно системы, подобные рассмотренным в примере,
достаточно просты и для анализа их работы нет необходи-
мости привлекать методы кибернетики. Однако специалис-
ту по автоматике в своей практической деятельности при-
ходится сталкиваться с весьма сложными системами
управления, для анализа которых и предназначен рассмат-
риваемый в книге математический аппарат.
1.4. СЛОЖНЫЕ СИСТЕМЫ
Необычайные быстрые темпы развития науки и техни-
ки за последние десятилетия, сопровождающиеся резким
увеличением числа ученых и специалистов, быстротой и
многообразием появления новых научных идей, значитель-
ным сокращением сроков воплощения этих идей в конкрет-
ные технические устройства, системы и процессы, привели
не только к совершенствованию, но и к значительному
усложнению всех областей человеческой деятельности.
Промышленные предприятия, энергетические системы, си-
стемы связи, системы транспорта, системы противовоздуш-
ной обороны и другие становятся настолько сложными,
что для их описания пришлось ввести специальный термин
«сложные» или «большие» системы [8, 69].
Термин «большие» подчеркивает не только и не столь-
ко физические "размеры" систем, сколько разнообразие
компонентов, составляющих эти системы, функций, выпол-
няемых каждым из компонентов, связей между компонен-
тами и внешних условий, оказывающих влияние на работу
всех частей такой системы., В то же время большая систе-
ма представляет собой не просто собрание отдельных час-
тей, а некоторую целостность, определяемую наличием
у всей системы единого целевого назначения. Так, совре-
менное крупное промышленное предприятие включает
в себя целый ряд производств и объединяет в единое це-
лое сами эти производства, склады, транспорт, органы
снабжения, контроля и управления, образующие в сово-
купности большую систему.
Обеспечить слаженную работу всех частей большой
системы невозможно на основе использования старых ме-
тодов управления. Такие системы требуют коренного из-
менения привычных форм и методов работы. В основе-
22
управления большими системами лежит автоматизация,
использующая самым широким образом новейшие дости-
жения науки и техники и, в первую очередь, достижения
кибернетики и электронно-вычислительную технику.
На современном этапе развития основная роль в авто-
матизации крупных промышленных предприятий отводит-
ся автоматизированным системам управления (АСУ).
Создание АСУ означает, что с помощью средств автома-
тики и вычислительной техники предстоит автоматизиро-
вать, по существу, все виды производственной деятельно-
сти. Основным^направлениями автоматизации являются:
автоматизация управления технологическими процессами
в самых различных отраслях (АСУТП); автоматизация
оперативного управления; создание гибких автоматизиро-
ванных производств (ГАП); автоматизация администра-
тивно-организационной деятельности (АСУП); автоматиза-
ция систем массового обслуживания; автоматизация про-
ёктн“о~конструкторских работ (САПР); автоматизация
научных исследований (АСНИ).
Задачи к гл. 1
Рис. 1.7. Системы с последо-
вательными связями (а) и
иерархической структурой (б)
1.1. Система состоит из семи элементов, каждый из которых свя-
зан со всеми другими связями простейшего вида, имеющими только
два состояния: «связь есть» и «связи нет» Каково возможное число
состояний такой системы? Если нам
нужно путем эксперимента выделить
все состояния, обладающие свойст-
вом Р, и на исследование одного со-
стояния требуется 1 с, то какое время
потребуется на исследование все.г
возможных состояний?
1.2. Насколько уменьшится чис-
ло возможных состояний системы
в задаче 1.1, если имеются только
постедосательные направленные свя-
зи (рис. 1 7,а) или система
имеет иерархическую структуру
(рис. 1.7,6)? Приведите примеры систем, имеющих структуры обоих
типов.
1.3. Полином (1.1), служащий для представления числа в системе
счисления с основанием R, может быть записан в форме
={[(... d3) R + d2] R + dJtf + do, (16)
23
что равносильно последовательности формул
A/=W1/?-|-do>JVl = №/?+</., Л^2==Л^з/?-|-£/2 ...
Обосновать с помощью этих формул следующее правило перевода
числа 395 из десятичной формы в восьмеричную:
395 8 = 49 остаток 3 или коро ie 395
49.8 = 6 остаток 1 49 3
6 8 = 0 остаток 6, 6 1
О 6 ,
что дает восьмеричное число 613.
Как сформулировать правило для перевода числа из десятичной
формы в двоичную?
1.4. Запишите в двоичной, восьмеричной и шестнацатеричной си-
стемах счисления следующие числа (даны в десятичной системе счис-
лении) :
27, 467, 519, 1 263.
Примечание. Для цифр от 10 до 15 шестнадцатеричной систе-
мы счисления использовать буквы латинского алфавита a, b, с, d, е, f.
1.5. Числа задачи 1.4 запишите в десятично-двоичной и в восьме-
рично-двоичной системах счисления. Сколько двоичных разрядов при-
шлось использовать для записи одной восьмеричной цифры? Какая из
этих двух систем записи чисел более экономична с точки зрения числа
используемых двоичных цифр?
1.6. Имеют ли следующие системы управления уличным движением
цепь обратной связи: 1) с помощью светофора, зажигающего поочеред-
но па заранее обусловленное время красный, желтый и зеленый свет?
2) с помощью регулировщика?
Глава 2
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ МНОЖЕСТВ
2.1. КОНЕЧНЫЕ И БЕСКОНЕЧНЫЕ МНОЖЕСТВА
2.1.1. Основные определения
Понятие множества является фундаментальным неопре-
деляемым понятием. Интуитивно под множеством будем
понимать совокупность определенных вполне различаемых
объектов, рассматриваемых как единое целое.
24
Можно говорить о множестве стульев в комнате, людей,
живущих в г. Рязани, студентов в группе, о множестве
натуральных чисел, букв в алфавите, состояний системы
и т. п. При этом о множестве можно вести речь только
тогда, когда элементы множества различимы между собой.
Например, нельзя говорить о множестве капель в стакане
воды, так как невозможно четко и ясно указать каждую
отдельную каплю.
Отдельные объекты, из которых состоит множество,
называют элементами множества. Так, число 3 —элемент
множества натуральных чисел, а буква б —элемент мно-
жества букв русского алфавита.
Общим обозначением множества служит пара фигур-
ных скобок { }, внутри которых перечисляются элементы
множества. Для обозначения конкретных множеств исполь-
зуют различные прописные буквы A, S, X... или пропис-
ные буквы с индексами Ль А2. Для обозначения элементов
множества в общем виде используют различные строчные
буквы a, s, х... или строчные буквы с индексами а2...
Для указания того, что некоторый элемент а является
элементом множества S, используется символ е принад-
лежности множеству. Запись aeS означает, что элемент
а принадлежит множеству S, а запись x^S означает, что
элемент х не принадлежит множеству S. Записью хь х2,...
...,rneS пользуются в качестве сокращения для записи
Xi^S, x2<=S,..., xn^S.
Множества бывают конечными и бесконечными. Мно-
жество называют конечным, если число его элементов ко-
нечно, т. е. если существует натуральное число N, являю-
щееся числом элементов множества. Множество называют
бесконечным, если оно содержит бесконечное число эле-
ментов.
Для того, чтобы оперировать с конкретными множест-
вами, нужно уметь их задавать. Существуют два способа
задания множеств: перечисление и описание. Задание мно-
жества способом перечисления соответствует перечислению
всех элементов, составляющих множество. Так, множество
отличников группы можно задать, перечислив студентов,
которые учатся на отлично, например {Иванов, Петров,
Сидоров}. Для сокращения записи X={xlt х2,...,хп}
иногда пишут Х={хг}}п или вводят множество индексов
/={1, 2,...,/г} и пишут X={xI}, te/. Такой способ удобен
при рассмотрении конечных множеств, содержащих не-
большое число элементов, но иногда он может применяться
25
и для задания бесконечных множеств, например {2, 4, 6,
8...}. Естественно, что такая запись применима, если
вполне ясно, что понимается под многоточием.
Описательный способ задания множества состоит в том,
что указывается характерное свойство, которым обладают
все элементы множества. Так, если М — множество сту-
дентов группы, то множество А отличников этой группы
запишется в виде
A = {x*=M\x— отличник группы},
что читается следующим образом: множество А состоит
из элементов х множества М, обладающих тем свойством,
что х является отличником группы.
В тех случаях, когда не вызывает сомнений, из какого
множества берутся элементы х, указание о принадлежно-
сти х множеству М можно не делать. При этом множест-
во А запишется в виде
Л = {х|х— отличник группы}.
Приведем несколько примеров задания множеств мето-
дом описания:
(х|х — четное} — множество четных чисел;
{х|х2—1=0} — множество {+1, —1}.
Пусть С — множество целых чисел. Тогда {хеС|0<
<х=С7} есть множество {1, 2, 3, 4, 5, 6, 7}.
Важным понятием теории множеств является понятие
пустого множества. Пустым множеством называют мно-
жество, не содержащее ни одного элемента. Пустое мно-
жество обозначается 0, например:
{хеС|х2-х+1=О}=0.
Понятие пустого множества играет очень важную роль
при задании множеств с помощью описания. Так, без по-
нятия пустого множества мы не могли бы говорить о мно-
жестве отличников группы или о множестве вещественных
корней квадратного уравнения, не убедившись предвари-
тельно, есть ли вообще в данной группе отличники или
имеет ли данное уравнение вещественные корни. Введение
пустого множества позволяет совершенно спокойно опери-
ровать с множеством отличников группы, не заботясь
о том, есть или нет в рассматриваемой группе отличники.
26
Пустое множество будем условно относить к конечным
множествам.
Рассмотрим теперь вопрос о равенстве множеств. Два
множества_н.аз_ываются равными, если они состоят из од-
них и тех же элементов, т. е. представляют собой одно и
то же множество. Множества X и У не равны (Х^=У),
если либо в множестве X есть элементы, не принадлежа-
щие У, либо в множество У есть элементы, не принадле-
жащие X. Символ равенства множеств обладает свойст-
вами:
Х=Х — рефлексивность;
если Х=У, то У=Х — симметричность;
если Х=У и У=7, то X=Z — транзитивность.
Из определения равенства множеств вытекает, что по-
рядок элементов в множестве несуществен. Так, например,
множества {3, 4, 5, 6} и {4, 5, 6, 3} представляют собой
одно и то же множество.
Из определения множества следует, что в нем не долж-
но быть неразличимых элементов. Поэтому в множестве
не может быть одинаковых элементов. Запись {2, 2, 3, 5}
следует рассматривать как некорректную и заменить ее на
{2, 3, 5}. Так, множество простых делителей числа 60 рав-
но {2, 3, 5}.
2.1.2. Понятие подмножестве
Множество X является подмножеством множества У,
если любой элемент множества X принадлежит и множе-
ству У. Пусть У — множество студентов группы, а X —
множество отличников той же группы. Так как каждый
отличник группы является в то же время студентом этой
группы, то множество X является подмножеством множе-
ства У.
Многие определения теории множеств удобно давать
в виде математических выражений, содержащих некоторые
логические символы. Для определения подмножества ис-
пользуем два таких символа.
V — символ, называемый квантором и означающий лю-
бой, каков бы ни был, «для всех»;
—символ следствия (импликации), означающий
«влечет за собой».
Определение подмножества, которое может быть сфор-
мулировано в виде: для любого х утверждение «х принад-
27
лежит X» влечет за собой утверждение «х принадлежит
У», запишется так:
¥х[хе=Х->хе=У]. (2.1)
Более краткой записью выражения «X является под-
множеством У» будет запись
Xs У, (2.2)
что читается как «У содержит X». Используемый здесь
символ s означает включение. Если желают подчеркнуть,
что У содержит и другие элементы, кроме элементов из X,
то используют символ строгого включения
Хс=У. (2.3)
Связь между символами с: и S дается выражением
X<=Y+±X<=Y и ХУ=У. ; ' (2.4)
Здесь использован знак означающий эквивалентность
(в смысле «то же самое, что»).
Отметим некоторые свойства подмножества, вытекаю-
щие из его определения:
XsX (рефлексивность);
[XsУ и ysZ]-->XsZ (транзитивность).
Несколько труднее видеть, что для любого множест-
ва М
0<=М. (2.5)
Действительно, пустое множество 0 не содержит эле-
ментов.^Следовательно, добавляя к М пустое множество,
мы фактически ничего не добавляем. Поэтому всегда мож-
но считать, что любое множество М содержит в себе пус-
тое множество в качестве подмножества.
2.1.3. Взаимно однозначное соответствие между
множествами
Иногда бывает необходимо сопоставлять друг с другом
элементы некоторых множеств. Рассмотрим, например,
два множества: стадо из четырех овец и рощу из четырех
деревьев. Эти множества находятся между собой в таком
отношении, в каком ни одно из них не находится с кучей
из трех камней или с рощей из семи деревьев. Их можно
28
попарно сопоставить друг с другом, привязав овец к де-
ревьям, так что каждая овца и каждое дерево будут в точ-
ности принадлежать одной и той же паре. Такое попарное
соответствие между элементами двух множеств называется
взаимно однозначным соответствием.
Пусть X и У два конечных множества: т- и /г-элемент-
ные. Между ними можно установить взаимно однозначное
соответствие только в том случае, если т=п. Сколько же
существует таких взаимно однозначных соответствий для
двух n-элементных множеств X и У? Первый элемент
множества X может быть сопоставлен с любым из п эле-
ментов множества У. Для каждого такого сопоставления
второй элемент множества X может быть сопоставлен
с любым из оставшихся п—1 элементов множества У и
т. д. После того, как такое сопоставление проведено для
п—1 элементов множества X, последний элемент этого
множества будет сопоставляться с единственным остав-
шимся элементом множества У. Таким образом, общее
число взаимно однозначных соответствий для п-элементных
множеств будет
п(п—1) ... 1 = п\ ।
Задача. Определить число й-элементных подмножеств
n-элементного множества М.
Приведем множество М во взаимно однозначное соот-
ветствие с множеством натуральных чисел
Число таких соответствий равно п!. Беря первые k элемен-
тов каждого соответствия, получим п\ интересующих нас
подмножеств множества М. Однако среди них будут и
одинаковые, которые нужно учесть только один раз.
Пусть первые k элементов некоторого соответствия об-
разуют множество М/. То же самое множество обра-
зуют первые k элементов во всех соответствиях, отличаю-
щихся от данного или порядком первых k элементов, т. е.
k\ соответствий, или порядком последних п—k элементов,
т. е. (п—k) \ соответствий. Следовательно, общее число со-
ответствий, образующих й-элементное подмножество Mk',
равно й! (п—й)!. Такое же число соответствий из общего
числа п\ соответствий будет образовывать любое другое
й-элементное подмножество множества М. Поэтому общее
число й-элементных подмножеств множества М будет
п\______q к = ! п\
k\(n—k)\ ~ п \ k )’
т. е. равно числу сочетаний из п элементов по й.
29
Теперь не представляет труда определить общее число
L всевозможных подмножеств n-элементного множества М.
Это число
’ L = V С/ = 2П.
А=0
При этом числа Crt°=l и Спп—1 определяют пустое
множество 0 и само множество М. Множества 0 и М на-
зывают несобственными подмножествами множества М.
Все остальные подмножества называют собственными под-
множествами множества М
2.1.4. Счетные и несчетные множества
Если множества являются бесконечными, то установление между
ними взаимно однозначного соответствия наталкивается на трудности,
связанные с необходимостью оперировать с бесконечно большим чис-
лом элементов множества За основу для сопоставления бесконечных
множеств принято брать натуральный ряд чисел N:
1,2......п ...
Если бесконечное множество оказывается возможным привести во
взаимно однозначное соответствие с натуральным рядом чисел, то та-
кое множество называют счетным. Следует отметить, что не все бес-
конечные множества являются счетными. Если бесконечное множество
невозможно привести во взаимно однозначное
соответствие с натуральным рядом чисел, то
его называют несчетным.
В качестве примера бесконечного множе-
ства рассмотрим множество равносторонних
треугольников, в которых вершинами каждого
треугольника являются середины сторон уже
построенного треугольника (рис. 2.1). Это
бесконечное множество равносторонних тре-
угольников можно привести во взаимно одно-
значное соответствие с натуральным рядом
Рис. 2.1. Бесконечное
множество равносто-
ронних треугольников
чисел, расположив их в порядке уменьшения
длин сторон, т. е. в виде последовательности Т\. Тг, ..., Тп ... Следова-
тельно, рассмотренное бесконечное множество равносторонних треуголь-
ников является счетным. Однако существует бесконечное множество дру-
гих равносторонних треугольников, не входящих в рассмотренное мно-
жество Вопрос о том, является ли счетным множество всех равносто-
ронних треугольников или всех треугольников вообще, требует допол-
нительного исследования.
30
Приведем несколько примеров счетных множеств.
1. Множество квадратов целых чисел 1, 4, 9, пг ... представ-
ляет собой лишь подмножество множества натуральных чисел N. Одна-
ко множество является счетным, так как приводится во взаимно одно-
значные соответствия с натуральным рядом путем приписывания
каждому элементу номера того числа натурального ряда, квадратом
которого он является.
2 Счетным является множество С всех целых чисел — положи-
тельных и отрицательных, хотя натуральный ряд представляет собой
лишь подмножество этого множества. Это можно установить, рассмот-
рев взаимно однозначное соответствие
N: 1 2 3 4 5 6 7 ...
С: 0 1 —1 2 —2 3 —3 ...,
из которого следует, что
( п/2 при четных и,
С” 1 —(и —1)/2 при нечетных п.
3. Еще более удивителен тот факт, что счетным оказывается мно-
жество всех рациональных чисел, т. е. чисел, которые могут быть
представлены в виде дроби r=qjp, где q и р— любые целые числа.
Для того, чтобы убедиться в этом, представим все множество рацио-
нальных чисел в виде следующей таблицы, в которую, естественно,
заносим несократимые дроби:
Обход^ таблицу по направлению стрелок, приходим к последова-
тельности
11 2 3 2 11 2 3 4
1, 2,—, —, —, 3, 4, —, —, —, —, —, —, —. .,
2 3’3 2 5 4 5 7 4 3
позволяющей занумеровать все эти числа.
Из приведенных примеров видно одно из замечательных свойств
бесконечных множеств — возможность приведения во взаимно одно-
значное соответствие бесконечного множества с его бесконечным же
31
подмножеством, которое не имеет места в случае конечных множеств.
Существование несчетных множеств следует из теоремы, доказан-
ной немецким математиком Г. Кантором в 1874 г.
Теорема 2.1. Множество всех действительных чисел интервала 0<
<х<1 несчетно.
Заметим, что любое число рассматриваемого интервала представ-
ляет собой конечную или
Рнс. 2.2. Взаимно одно-
значное соответствие между
интервалами (0, 1] н (а, 6]
бесконечную десятичную дробь вида
О, .. и может быть представ-
лено точкой отрезка вещественной осн.
Следовательно, теорема утверждает, что
множество точек отрезка (0, 1] не-
счетно.
Доказательство. Для доказа-
тельства предположим, что последова-
тельность xi, Х2, Хз, Х4 . представляет
собой бесконечный перечень действи-
тельных чисел, принадлежащих этому
интервалу. Вопрос состоит в том, может
или не может подобный перечень содер-
жать все числа этого интервала, т е.
нельзя ли найти число, которое принад-
лежит этому интервалу, но конечно не входит в указанный пере-
чень чисел. Для того, чтобы найти такое число, запишем все входящие
в перечень десятичные дроби одну под другой.
О, Л77 Л72 a.J3 • • •
О, агз ••°
О, a.3i а-32 'азз аз^ • • ®
о, а4 7 ^2 ан3 • •
©се*
Образуем диагональную дробь, указанную стрелками, н заменим
в ней каждую из последовательных цифр апп на отличную от нее
цифру а'пп так, чтобы при этом не получилась конечная дробь. Полу-
ченная дробь 0, а'па'ца'зза'ц ... представляет собой действительное
число, принадлежащее нашему интервалу, ио не входящее в рассматри-
ваемый перечень. Действительно, эта дробь отличается от первой из
данных дробей своей первой цифрой после запятой, от второй — своей
второй цифрой после запятой, от третьей — третьей цифрой после за-
пятой и т. д.
Необычные свойства несчетных множеств проявляются в том, что
32
рассмотренный интервал (0, 1] ^ожет быть приведен во взаимно одно-
значное соответствие с любым другим интервалом (а, 6]. Такое взанм
ио однозначное соответствие можно осуществить с помощью централь-
ной проекции (рнс. 2.2). Таким образом, несчетным является множе-
ство всех действительных чисел любого интервала (а, 6].
2.1.5. Верхняя и нижняя границы множества
Имея дело с множеством вещественных чисел, можно
сравнивать элементы этого множества по их значению и,
в частности, находить наибольший и наименьший элемен-
ты множества. Для конечных множеств, заданных пере-
числением, эта задача не представляет труда. Так, для
множества Т={4, 3, 5, 6} имеем тахТ=6, ттТ=3. Од-
нако если множество задано описательным способом, на-
пример указано лишь правило вычисления числовых зна-
чений его элементов, то задача определения наибольшего
и наименьшего элементов становится весьма троной. Не-
сколько более легкой задачей является нахождение лишь
области, внутри которой лежат все элементы множества.
При решении этой задачи очень полезными являются по-
нятия верхней и нижней границ множества.
Пусть S — множество вещественных чисел. Верхней
границей S является число С такое, что для любого x^S
имеет место х^С. Чисел, которые могут рассматриваться
в качестве верхней границы множества, может быть беско'
нечно много, а может и не быть вообще. Так в множестве
m<S<M любое С^М является верхней границей. Мно-
жество всех целых чисел не имеет верхней границы.
Точной верхней границей или супремумом множества S,
обозначаемой supS, называют верхнюю границу, которая
не превосходит любую другую верхнюю границу. В при-
веденном выше примере supS=M. Множество может
иметь только одну точную верхнюю границу, так как если
Ci и С2— две такие границы, то С^С2 и C2^.Ci и, сле-
довательно, Ci—C2.
Нижней границей множества S является число с такое,
что для любого xeS имеет место х^с. Точной нижней
границей или инфинумом множества S, обозначаемой
inf S, называют нижнюю границу, не меньшую любой
другой нижней границы. В приводимом примере inf S=m.
Теорема 2.2. (теорема о верхней и нижней границах
подмножества). Если В^А, то
inf B>inf Д; sup Вsup А. (2.6)
3-804 ’' - . . 33
Доказательство. Обозначим через Ь' элемент мно-
жества В, имеющий наименьшее значение, т. е. Ь'<=В и
6'=inf В. Но В^А, т. е. 6'еА. Пусть а' — элемент мно-
жества А, имеющий наименьшее значение, т. е. а'^А и
a'=infA. При этом если Ь'—а', то b'=infA, если Ь'=£а',
то 6'><z'=infA. Таким образом, 6'^inf А или infB^
>inf А.
Вторая часть теоремы доказывается аналогично.
2.2. ОПЕРАЦИИ НАД МНОЖЕСТВАМИ
2.2.1. Предварительные замечания
Над множествами можно производить действия, кото-
рые во многом напоминают действия сложения и умноже-
ния в элементарной алгебре. Чтобы лучше разобраться
в действиях над множествами, необходимо вспомнить за-
коны, существующие в элементарной алгебре.
Пусть а и b — некоторые числа, а-{-Ь — их сумма и
ab — их произведение. Сумма и произведение чисел обла-
дают следующими свойствами, называемыми законами
алгебры:
1. a+6=Z>+a; ab—ba—коммутативный или перемес-
тительный закон;
2. (a+6)+c=a+(Z>+c); (ab)c=a(bc)—ассоциатив-
ный или сочетательный закон;
3. (а-Н>) c=<zc+6c — дистрибутивный или распредели-
тельный закон.
Заметим, что в ассоциативном и коммутативном зако-
нах можно заменить действие сложения умножением,
а действие умножения сложением. При этом получим дру-
гой закон, который будет так же справедлив, как и пер-
вый. Однако в дистрибутивном законе подобной симмет-
рии нет. Если в этом законе заменить сложение умноже-
нием, а умножение сложением, то придем к абсурду:
(а6)+с=(а-|-с) (6+с).
Спрашивается, всегда ли это так? Не существует ли
алгебры, в которой дистрибутивный закон был бы так же
симметричен относительно сложения и умножения, как
коммутативный и ассоциативный законы? Оказывается, су-
ществует алгебра, а именно алгебра множеств, в которой
все три закона симметричны относительно действий сложе-
ния и умножения.
34
Сходство между действиями сложения и умножения
проявляется также в существовании двух замечательных
чисел (0 и 1) таких, что прибавление первого и умножение
на второе не меняют ни одного числа:
й+0=а, а- 1—а.
Заметим, что второе соотношение получается из перво-
го заменой (+) на (•) и 0 на 1.
Однако и здесь сходство между действиями сложения и
умножения не простирается особенно далеко. Так, число О
играет несколько особую роль по сравнению со всеми дру-
гими числами, в том числе и единицей. Эта особая роль
числа 0 вытекает из соотношения а-0=0. Если мы в этом
выражении заменим (•) на (+) и 0 на 1, то приходим
к соотношению а-|-1=1, которое почти никогда не будет
верным.
Как мы увидим далее, сходство между нулем и едини-
цей в алгебре множеств будет значительно большим, чем
в обычной алгебре.
После этих предварительных замечаний можно присту-
пить к рассмотрению операций над множествами.
2.2.2. Объединение множеств
Объединением множеств X и У называют множество,
состоящее из всех тех и только тех элементов, которые
принадлежат хотя бы одному из множеств X, У, т. е. при-
надлежат множеству X или множеству У. Объединение X
н У обозначается через Х11У- Формальное определение
ХиУ={х|хеЛ или хеУ). (2.7)
Объединение множеств иногда называют суммой мно-
жеств и обозначают Х-|-У. Однако свойства объединения
множеств несколько отличаются от свойств суммы при
обычном арифметическом понимании, поэтому этим терми-
ном мы пользоваться не будем. /
Пример 2.1. Если Х={1, 2, 3, 4, 5} и У={2( 4, 6, 7}, то X(J7=
= {1, 2, 3, 4, 5, 6, 7}.
Пример 2.2. Если X— множество отличников в группе, У—мно-
жество студентов, проживающих в общежитии, то Х[)У — множество
студентов, которые или учатся на отлично, нли проживают в обще-
житии.
з. (1^910
д. у Пример 2.3. Рассмотрим два круга, при-
веденных на рис. 2 3. Если X — множество
точек левого круга, У — множество точек
правого круга, то X(JK представляет собой
заштрихованную область, ограниченную обо-
ими кругами.
Рис. 2.3. Объединение Понятие объединения можно рас-
множеств пространить и на большее число мно-
жеств. Обозначим через 2Я={Х1, ...
..., Хп} совокупность п множеств Хь ..., Хп, называемую
иногда системой множеств. Объединение этих множеств
U Xt= U Л’ = Л1и-..и^« (2.8)
<=> Л'еЯЛ
представляет собой множество, состоящее из всех тех и
только тех элементов, которые принадлежат хотя бы одно-
му из множеств системы 2Л.
Для объединения множеств справедливы коммутатив-
ный и ассоциативный законы
%Uy=W; (2.9)
(Xunuz=xu(w==xunjz, (2.10)
справедливость которых вытекает из того, что левая и
правая части равенств состоят из одних и тех же элемен-
тов. Далее,
Х[)0=Х. (2.11)
Это также очевидное соотношение, так как пустое мно-
жество не содержит элементов, а значит, X и Х[)0 состоят
из одних и тех же элементов. Из (2.11) видно, что пустое
множество 0 играет роль нуля в алгебре множеств. Здесь
имеет место аналогия с выражением й+0=а в обычной
алгебре.
2.2.3. Пересечение множеств
Пересечением множеств X и У называют множество,
состоящее из всех тех и только тех элементов, которые
принадлежат как множеству X, так и множеству У. Пере-
сечение множеств X и У обозначается через Xf)^- Фор-
мальное определение
ХПУ--{х|х^Х и хеУ}. (2.12)
36
Пересечение множеств иногда называют произведени-
ем множеств и обозначают XY. Однако свойства пересече-
ния множеств несколько отличаются от свойств произве-
дения в обычном арифметическом понимании, поэтому
этим термином мы пользоваться не будем.
Пример 2.4. Для множеств X и У в примере 2 1 ХРУ={2, 4}.
Пример 2.5. Для множеств X и Y в примере 2 2 ХрУ — множество
отличников группы, проживающих в общежитии.
Пример 2.6. Рассмотрим два круга, приведенных на рис. 2.4,а. Если
X—множество точек левого круга, У—множество точек правого кру-
га, то ХРУ представляет собой заштрихованную область, являющуюся
общей частью обоих кругов.
Рис. 2.4. Пересечение множеств (а)
и непересекающиеся множества (б)
®6О
б)
Операция пересечения позволяет установить ряд соот-
ношений между двумя множествами.
Множества X и У называют непересекающимися, если
они не имеют общих элементов, т. е. если
X(]Y—0. (2.13)
Пример 2.7. Непересекающимися множествами являются:
1) множества {1, 2, 3} и {4, 5, 6};
2) множество отличников и множество неуспевающих студентов
в группе;
3) множества точек кругов X и У на рис. 2.4,6,-
Говорят, что множества X и У находятся в общем по-
ложении, если выполняются три условия: существует эле-
мент множества X, не принадлежащий У; существует эле-
мент множества У, не принадлежащий X; существует эле-
мент, принадлежащий как X, так и У.
Укажем одно отличие алгебры множеств от алгебры
чисел. Если а и b — два числа, то между ними могут быть
три соотношения или три возможности:
а<Ь, а=Ь, Ь<а. (2.14)
Для множеств X и У, однако, может не выполняться ни
одно из соотношений:
ХсУ, Х=У- УсХ. (2.15)’
37
Так, если X — множество отличников, У—множество
студентов, проживающих в общежитии, то три ранее при-
веденных соотношения будут означать: Хед У—каждый
отличник обязательно проживает в общежитии; Х—У—в
общежитии проживают все отличники и только они; Уст
сХ — все студенты, проживающие в общежитии, являют-
ся отличниками.
Очевидно, что эти соотношения не исчерпывают всех
возможностей. На_ самом деле, как вытекает из предыду-
щих определений, между множествами X и У может быть
одно из пяти отношений:
Х=У; ХсУ; У<=Х; Х[\У=0,
X и У находятся в общем положении.
Понятие пересечения можно распространить и на боль-
шее, чем два, число множеств. Рассмотрим систему мно-
жеств ®1={Х1,..., Хп}. Пересечение этих множеств записы-
вается в виде
п X = (2.16)
хеал <=>
и представляет собой множество, элементы которого при-
надлежат каждому из множеств системы Ш1.
Нетрудно видеть, что пересечение множеств обладает
коммутативным свойством
Х()У=УПХ (2.17)
и ассоциативным
(^ПГ)П^ = А'П( W) = W- (2.18)
Заметим также, что имеет место соотношение
Х[\0=0, (2.19)
аналогичное соотношению а-0=0 в обычной алгебре. Со-
отношение (2.19) совместно с соотношением (2.11) пока-
зывает, что пустое множество играет роль нуля в алгебре
множеств.
2.2.4. Разность множеств
Данная операция в отличие от операций объединения
и пересечения определяется только для двух множеств.
Разностью множеств X и У называют множество, состоя-
38
щее из всех тех и только тех элемен-
тов, которые принадлежат X и не при-
надлежат У. Разность множеств X и
У обозначается через Х\У. Таким
образом,
Y={x\x(=X и x&Y}. (2.20) D п
11 у- > \ / Рис. 2.5. Разность
Пример 2.8. Для множеств X и У множеств
примера2.1 Х\У={1, 3, 5}, У\Х={6, 7}.
Если X и У—множества из примера 2.2, то X \ У — множество отлич-
ников, не проживающих в общежитии. Для множеств X и У примера
2 3 Х\ У — заштрихованная фигура на рнс. 2.5.
. 2.2.5. Универсальное множество
Как мы видели, роль нуля в алгебре множеств играет
пустое множество. Спрашивается, не существует ли мно-
жество /, которое будет играть роль единицы, т. е. удо-
влетворять условию
XQ/=X, (2.21)
аналогичному условию а- 1—а в обычной алгебре.
Соотношение (2.21) означает, что пересечение или «об-
щая часть» множества / и множества X для любого мно-
жества X совпадает с самим этим множеством. Но это
возможно лишь в том случае, если множество / содержит
все элементы, из которых может состоять множество X,
так что любое множество X полностью содержится в мно-
жестве /. Множество /, удовлетворяющее этому условию,
называют полным или универсальным.
Исходя из сказанного, можно дать следующее опреде-
ление универсального множества. Если в некотором рас-
смотрении участвуют только подмножества' некоторого
фиксированного множества /, то это самое большое мно-
жество / называют универсальным множеством.
Следует отметить, что в различных конкретных случа-
ях роль универсального множества могут играть различ-
ные множества. Так, при рассмотрении множеств студен-
тов в группе (отличники; студенты, получающие стипен-
дию; студенты, проживающие в общежитии и т. п.) роль
универсального множества играет множество студентов
в группе.
Универсальное множество удобно изображать графиче-
ски в виде множества точек прямоугольника. Отдельные
39
области внутри этого прямоугольника будут означать раз-
личные подмножества универсального множества. Изобра-
жение множества в виде областей в прямоугольнике,
представляющем универсальное множество, называют ди-
аграммой Эйлера — Венна.
Универсальное множество обладает интересным свой-
ством, которое не имеет аналогии в обычной алгебре,
а именно для любого множества X справедливо соотно-
шение
ХШ=1. (2.22)
Действительно, объединение X(J/ представляет собой
множество, в которое входят как все элементы множест-
ва X, так и все элементы множества /. Но множество /
уже включает в себя все элементы множества X, так что
XII/ будет состоять из тех же элементов, что и /, т. е.
представляет собой само универсальное множество I.
2.2.6. Дополнение множества
Множество X, определяемое из соотношения
Х=1\Х, (2.23)
называют дополнением множества X (до универсального
множества /). На рис. 2.6 множество X представляет со-
бой незаштрихованную область. Формальное определение
X={x| хе/ и х^Х}.
Рис. 2.6. Дополнение
множества
Пример 2.9. Если /={1, 2, 3, 4, 5, 6, 7} и Х={3, 5, 7}, то х =
= {1.2, 4, 6).
Из (2.23) следует, что X и X не имеют общих элемен-
тов, так что
ХПХ=0. (2 24)
Кроме того, не имеется элементов I, которые не при-
надлежали бы ни X, ни X, так как те элементы, которые
не принадлежат X, принадлежат X. Следовательно,
X(JX=/. (2.25)
40
^зсиммец)ии_фр.рмул (2.24) и _(2.25) относительно X
и X следует не только то, что X является дополнением X,
но и что X является дополнением X. Но дополнение X
есть X. Таким образом,
Х=Х.
(2.26)
С помощью операции дополнения можно в удобном
виде представить разность множеств
Х\У={х|хе=Х и x<£Y} = {x\x(=X и хе?},
Х\У=ДО-
(2.27)
2.2.7. Разбиение множества
Одной из наиболее часто встречающихся операций
над множествами является операция разбиения множест-
ва на систему подмножеств. Так, система курсов данного
факультета является разбиением множества студентов
факультета; система групп данного курса является разби-
ением множества студентов курса. Если N— множество
натуральных чисел, а До и Д1 — множества четных и не-
четных чисел, то система {До, 41} будет разбиением мно-
жества N. Множество натуральных чисел может быть
разбито иначе: на множество чисел, делящихся на 3 без
остатка, с остатком 1 и с остатком 2. Продукция предпри-
ятия разбивается на систему множеств, состоящих из про-
дукции первого сорта, второго сорта и брака. Подобные
примеры можно было бы продолжать бесконечно.
Для того, чтобы дать понятию разбиения строгое опре-
деление, рассмотрим некоторое множество М и систему
множеств Э1={Х1, ...,ХП}. Систему множеств ЭД называют
разбиением множества Л4,'ёсли удовлетворяются следую-
щие условия:
1) любое множество X из ЭД является подмножеством
множества М:
УХеЭД[Х<=М]; (2.28)
2) любые два множества X и У из ЭД являются непере-
секающимися:
VX, УеЭД[ХУ=У->ХПУ=0]; (2.29)
41
3£ объединение всех множеств, входящих в разбиение,
дает множество М:
U X = М.
(2.30)
К понятию разбиения мы вернемся при рассмотрении
отношения эквивалентности, с которым оно очень тесно
связано.
2.2.8. Тождества алгебры множеств
С помощью операций объединения, пересечения и до-
полнения из множеств можно составлять различные алге-
браические выражения. Обозначим через 91 (X, У, Z) не-
которое алгебраическое выражение, составленное из мно-
жеств X, У и Z и представляющее собой некоторое
множество. Пусть S(X, У, Z) —другое алгебраическое вы-
ражение, составленное из тех же множеств. Если оба ал-
гебраических выражения представляют собой одно и то
же множество, то их можно приравнять друг к другу, по-
лучая алгебраическое тождество вида
9((Х, У, Z)=93(X, У, Z). (2.31)
Такие тождества бывают очень полезны при преобра-
зованиях алгебраических выражений над множествами, и
некоторые из них мы рассмотрим в настоящем разделе.
1) На рис. 2.7,а приведены диаграммы Эйлера — Вен-
на для выражений (Х1|У)П2 и (Xf]Z)U(УП^). Из этих ди-
аграмм видно, что оба выражения определяют одно и то
же множество, так что в алгебре множеств имеет место
тождество _
\(ХиУ)П2==(ХП2)и(УП2Ц (2 32)
аналогичное дистрибутивному закону (a+b)c=ac+bc
в обычной алгебре.
2. В обычной алгебре мы не можем заменить в дистри-
бутивном законе действие сложения умножением, а дей-
ствие умножения сложением, так как это приводит к аб-
сурдному выражению (ab) 4-с=(а-|-с) (6+с]). Иначе об-
стоит дело в алгебре множеств.
На рис. 2.7,6 приведены диаграммы Эйлера — Венна
для алгебраических выражений (ХПУ)К^ и (Х1)Х)П(УиХ).
Оба эти выражения дают одно и то же множество, так что
42
имеет место тождество
Ч_ХПУ)и2=(ВДП(ад. (2.33)
3. Легко убедиться, что если YsX, то
' ХПУ=У,ХдУ=Х., (2.34)
Действительно, все элементы множества Y являются
в то же время и элементами множества X. Значит, пере-
сечение этих множеств, т. е. общая часть множеств X и Y,
а.)
В)
Рис. 2.7. Геометрическая иллюстрации тождеств (XJ Г) ()•£ = (XflZ)J
U(W) (а) и (ХЛУ)и2=(Хи2)П(Уи2) (6)
совпадает с У. В объединение множеств X и У множество
У не внесет ни одного элемента, который уже не входил
бы в него, будучи элементом множества X. Следователь-
но, XU У совпадает с X.
4. Полагая в (2.34) Y—X и учитывая, что ХеХ, на-
ходим
Xf]X=X, X|JX=X. (2.35)
Установление тождеств алгебры множеств с помощью
диаграммы Эйлера — Венна в ряде случаев оказывается
неудобным. Имеется более общий способ установления
тождественности двух алгебраических выражений.
Пусть, как и прежде, через Я(Х, У, Z) и Э(Х, У, Z)
обозначены два алгебраических выражения, получивших-
43
ся путем применения операций объединения, пересечения
и дополнения к множествам X, Y и Z. Для того чтобы до-
казать, что 91=83, достаточно показать, что SteSS и что
В свою очередь, чтобы показать, что 91е8Э, нужно
убедиться, что из хеЯ следует xeS. Аналогично, чтобы
показать, что 8Э^&, нужно убедиться, что из хеЭЗ следует
хеИ. Воспользуемся этим методом, чтобы доказать еще
несколько тождеств.
5. Докажем тождество
(2.36)
Предположим, что x^X[]Y, ъ е. что х^ХОУ- Это зна-
чит, что хфХ и х^У, т. е. хеЛ и хеУ. Следовательно,
хеХ()Р. Предположим теперь, что yeXf|F, т. е. у<=Х и
уеУ. Это значит, что уфХ и y^Y, т. е. что y<£X\}Y. Сле-
довательно, г/еХОУ-
6. Тождество
j ХПУ=Х1|У (2.37)
докажем, приведя обе его части к одинаковому виду. Вы-
полняя операцию дополнения над обеими частями (2.37),
получим ХПУ=Х1|У. Левая часть этого выражения дает
ХПУ- То же самое получим, преобразовывая правую часть
по правилу (2.36).
В литературе тождества (2.36) и (2.37) обычно назы-
ваются тождествами де-Моргана.
2.3. УПОРЯДОЧЕНИЕ ЭЛЕМЕНТОВ И ПРЯМОЕ
ПРОИЗВЕДЕНИЕ МНОЖЕСТВ
2.3.1. Упорядоченное множество у
Наряду с понятием множества как совокупности эле-
ментов важным понятием является понятие упорядочен-
ного множества или кортежа. Кортежам называют после-
довательность элементов, т. е. совокупность элементов,
в которой каждый элемент занимает определенное место.
Сами элементы при этом называют компонентами корте-
жа (первая компонента, вторая компонента и т. д.). При-
меры кортежей: множество людей, стоящих в очереди;
множество слов в фразе; числа, выражающие долготу и
широту точки на местности и т. п. Во всех этих множест-
44
вах место каждого элемента является вполне определен-
ным и не может быть произвольно изменено.
В технических задачах эта определенность часто явля-
ется просто предметом договоренности. Так, только дого-
воренностью можно объяснить, почему долготу ставят на
первое место, а широту на второе. Состояние кибернети-
ческой системы часто описывают множеством параметров,
принимающих числовые значения. При этом состояние
системы; — просто некоторое множество чисел. Чтобы не
оговаривать каждый раз, какое число что означает, уста-
навливают заранее, какой параметр считать первым, ка-
кой вторым и т. д., т. е. совокупность параметров пред-
ставляют в виде упорядоченного множества. Так, если
обозначить через h высоту самолета, а через v — его ско-
рость, то кортеж x—(h,v) будет описывать состояние са-
молета.
Число элементов кортежа называют его длиной. Для
обозначения кортежа используем круглые скобки. Так,
множество
а=(а\, а2,...,ап) (2.38)
является кортежем длины п с элементами а\,..., ап. Кор-
тежи длиной 2 называют парами или упорядоченными па-
рами, кортежи длиной 3 — тройками, 4 — четверками
и т. д В общем случае кортежи длиной п называют п-ка-
ми. Частным случаем кортежа является кортеж (а) дли-
ной 1 и пустой кортеж длиной 0, обозначаемый ( ) или
Л. В отличие от обычного множества в кортеже могут
быть и одинаковые элементы: два одинаковых слова
в фразе, одинаковые числовые значения долготы и широ-
ты точки на местности и т. п.
В дальнейшем будем рассматривать упорядоченные
множества, элементами которых являются вещественные
числа. Такие упорядоченные множества называют точка-
ми пространства или векторами. Так, кортеж (flb а2) мо-
жет рассматриваться как точка на плоскости или вектор,
проведенный из начала координат в данную точку
(рис. 2.8,а). Компоненты «1 и а2 будут проекциями векто-
ра на оси 1 и 2
Пр1(аь a2)=ai; Пр2(а1, а2)=а2.
Кортеж (Ль а2, а3) может рассматриваться как точка
в трехмерном пространстве или как трехмерный вектор,
проведенный из начала координат в эту точку (рис. 2.8,6).
45
Проекции вектора на оси координат
Прг(дь а2, a3)=ai, i=i, 2, 3.
Однако в данном случае можно говорить о проекции
кортежа сразу на две оси, например 1 и 2, т. е. на коорди-
натную плоскость. Нетрудно видеть, что эта проекция
представляет собой двухэлементный кортеж
Пр12(Л1, а2, a3) = (ai, а2).
2)
аг
------^Са7,а2)
I
^(а„аг,аа)
I
1
Рис. 2.8. Проекции двух- и трехэлементиого
кортежа
Обобщая эти понятия, будем рассматривать упорядо-
ченное га-элементное множество вещественных чисел (fli,...
..., ап) как точку в воображаемом га-мерном пространстве,
называемом иногда гиперпространством, или п-мерным
вектором. При этом компоненты «-элементного кортежа а
будем рассматривать как проекции этого кортежа на со-
ответствующие оси
Пр(а=а,-, i=l,га. (2.39)
Используемая здесь и далее запись t=l,ra означает пе-
речисление т=1,..., га.
Если i, j, ..., Z —номера осей, причем 1 <Сг</< •••
то проекция кортежа а на оси I, j,..., I будет
Пр,-.,-.....ia = {at, as......... at).
(2.40)
2.3.2. Прямое произведение множеств
Прямым произведением множеств X и У называют
множество, обозначаемое Х%У и состоящее из всех тех
и только тех упорядоченных пар, первая компонента ко-
торых принадлежит множеству X, а вторая — множест-
ву У. Таким образом, элементами прямого произведения
46
являются двухэлементные кортежи вида (х, у). Формаль-
ное определение
ХХУ={(х, У) \х^Х, yt=Y}. (2.41)
Пример 2.10. Пусть Х={1, 2}, У={1, 3, 4}. Тогда ХХУ={(1. 1),
(1, 3), (1, 4), (2, 1), (2, 3), (2, 4)}. Геометрическое представление
этого множества приведено на рис. 2.9,а.
Пример 2.11. Пусть X и У—отрезки вещественной оси. Прямое
произведение XX У изобразится заштрихованным прямоугольником
(рис. 2.9,6). Из этого рисунка следует, что свойства прямого произве-
Р.ис. 2.9. Геометрическая иллюстрация прямого произведения множеств
деиия отличаются от свойств обычного произведения в арифметиче-
ском смысле. В частности, прямое произведение изменяется при изме-
нении поридка сомножителей, т. е.
ХХУ=#УХХ. (2.42)
Операция прямого произведения легко распространя-
ется и на большее число множеств. Прямым произведени-
ем множеств Xi, Х2,...,ХГ называют множество, обозначае-
мое Х1ХХ2Х - ХХГ и состоящее из всех тех и только тех
кортежей длины г, первая компонента которых принадле-
жит Xi, вторая — Х2 и т. д.
Частным случаем операции прямого произведения яв-
ляется понятие степеней множества. Пусть М—произ-
вольное множество. Назовем s-й степенью множества М
и обозначим через Ms прямое'произведение s одинаковых
множеств, равных М:
MS = MXMX-XM. (2.43)
Это определение пригодно для s=2, 3... Его можно
расширить на любое целое неотрицательное s, если специ-
47
альными определениями положить
М'=М, М°={А}. (2.44)
Если R— множество вещественных чисел, то /?2=/?Х/?
представляет собой вещественную плоскость, а /?3==/?Х
XRXR— трехмерное вещественное пространство.
2.3.3. Проекция множества
Операция проектирования множества тесно связана
с операцией проектирования кортежа и мож;ет применять-
ся лишь к таким множествам, элементами которых явля-
ются кортежи одинаковой длины.
Пусть М — множество, состоящее из кортежей дли-
ной s. Тогда проекцией множества М будем называть мно-
жество проекций кортежей из М.
Пример 2.12. Пусть М= {(1, 2, 3, 4, 5), (2, 1, 3, 5, 5), (3, 3, 3, 3, 3),
(3, 2, 3, 4, 3)}. Тогда Пр2М={2, 1, 3}; Пр2,4Л4= {(2, 4), (1, 5), (3, 3)}.
Легко проверить, что если M=XXY, то
Пр1М=Х; Пр2М=У, (2.45)
а если QS-ХХУ, то
npiQeX; Пр2(Э<=У. (2.46)
2.4. СООТВЕТСТВИЯ
2.4.1. Определение соответствия
Рассмотрим два множества: X и У. Элементы этих
двух множеств могут каким-либо образом сопоставляться
друг с другом, образуя пары (х, у). Если способ такого
сопоставления определен, т. е. для каждого элемента
х<=Х указан элемент уеУ, с которым сопоставляется
элемент х, то говорят, что между множествами X и У
установлено соответствие [9, 10]. При этом совершенно
необязательно, чтобы в сопоставлении участвовали все
элементы множеств X и У.
Для того чтобы задать соответствие, необходимо ука-
зать: множество X, элементы которого сопоставляются
с элементами другого множества; множество У, с элемен-
тами которого сопоставляются элементы первого множе-
ства; множество QsXxy, определяющее закон, в соот-
ветствии с которым осуществляется соответствие, т. е.
48
перечисляющее все пары (х, у), участвующие в сопостав-
лении.
Таким образом, соответствие, обозначаемое q, пред-
ставляет собой тройку множеств
q=(X, У, Q), (2.47)
в которой QeXXT. В этом выражении первую компонен-
ту X называют областью отправления соответствия, вто-
прибытия соответствия,
Рис. 2.10. Геометрическое пред-
ставление прямого, (а) и об-
ратного (б) соответствий
рую компоненту У—областью
третью компоненту Q — гра-
фиком соответствия. Термин
«график» будет более по-
дробно разъяснен при рас-
смотрении .частного вида со-
ответствия, называемого функ-
цией.
Кроме рассмотренных мно-
жеств X, У и Q, с каждым
соответствием неразрывно
связаны еще два множества:
множество ripiQ, называемое
областью определения соот-
ветствия, в которое входят элементы множества X, участ-
вующие в сопоставлении, и множество Пр2<2, называемое
областью значений соответствия, в которое входят элемен-
ты множества У, участвующие в сопоставлении.
Если (х, y)^Q, то говорят, что элемент у соответству-
ет элементу х. Геометрически это удобно изображать
стрелкой, направленной от х к у.
Пример 2.13. Пусть Х= {1, 2}, У== {3, 5), так что ХХУ={(1. 3),
(1, 5), (2, 3), (2, 5)}. Это множество дает иозможиость получить
16 различных соответствий. Приведем некоторые из них:
Q,= {(i, 3)}; nPlQt = {l}; ПргО^З};
<?2={(1. 3), (1, 5)}; nPlQ2={l}; Пр2<Э2={3, 5}=У.
Пример 2.14. На предприятии имеются три автомашины: две гру-
зовые а и р, работающие в две смены, и автобус у, используемый ред-
ко. Машина р находится в ремонте. В штате имеются три шофера:
а, Ь, с, из которых с находится в отпуске. Распределение шоферов по
машинам представляет собой соответствие. Одним из возможных со-
ответствий будет следующее:
?=({а, Ь, с), {а, р, у), {(а, а), (а, у), (Ь, а)}).
4-804
49
Геометрически это соответствие изображено на рис. 2.10,а. В нем
элемент а соответствует элементам а и Ь, а элемент у —элементу а.
Соответствие q определено на а и Ь, но не определено на с, следова-
тельно, областью определения соответствия является множество {а, &}.
Областью значений соответствия является множество {а, у}.
2.4.2. Обратное соответствие
Для каждого соответствия q=(X, У, Q), Qs-ХХУ су-
ществует обратное соответствие, которое получается, если
данное соответствие рассматривать в' обратном направле-
нии, т. е. определять элементы х^Х, с которыми сопостав-
ляются элементы y^Y. Соответствие, обратное соответ-
ствию q, будем обозначать
q~'=(Y, X, Q-1), (2.48)
где Q-’еУХХ.
Пример 2.15. Обратным соответствием для примера 2.14 будет за-
крепление автомашин за шоферами ({а, 0, у}, {а, &, с), {(а, а), (а, &),
(у, а)}), что геометрически показано на рис. 2.10,6.
Из приведенного примера видно, что геометрическое
представление обратного соответствия получается путем
изменения направления стрелок в геометрическом пред-
ставлении прямого соответствия.' Отсюда следует, что об-
ратным соответствием обратного соответствия будет пря-
мое соответствие
(q~')~'=q. (2.49)
2.4.3. Композиция соответствий
Композицией соответствий называют последовательное
применение двух соответствий.
Композиция соответствий есть операция с тремя мно-
жествами X, Y и Z, на которых определены два соответ-
ствия:
q = (X, У, Q), (?СХХУ; |
р = (У. Z, Р), Рагхх, )
(2.50)
причем область значений первого соответствия совпадает
с областью определения второго соответствия:
Пр2<2=Пр!Л (2.51)
50
Первое соответствие определяет для любого x^npiQ
некоторый, возможно и не один, элемент y^Y. Согласно
определению операции композиции соответствий теперь
нужно для y^Y, найти zeZ, воспользовавшись вторым
соответствием. Таким образом, композиция соответ-
ствий сопоставляет с каждым элементом х из области оп-
ределения первого соответствия npiQ один или несколько
элементов z из области значений второго соответствия
Пр2Р.
Композицию соответствий q и р будем обозначать
q(p), а график композиции соответствий — через QOP.
При этом композиция соответствий (2.50) запишется
в виде
q(p) = (X, Z, QOP), QOP^XXZ. (2.52)
Пример 2.16. Если <? —соответствие, определяющее распределение
шоферов по автомашинам, р — соответствие, определяющее распреде-
ление автомашин по маршрутам, то соответствие q(p) есть соответ-
ствие, определяющее распределение шоферов по маршрутам.
Естественно, что операцию композиции можно распро-
странить и на большее, чем два, число соответствий.
2.5. ОТОБРАЖЕНИЯ И ФУНКЦИИ
2.5.1. Отображения и их свойства
Пусть X и Y —некоторые множества и ГеХХК при-
чем Пр1Г=Х. Тройка множеств (X, Y, Г) определяет не-
которое соответствие, обладающее, однако, тем свойством,
что его область определения ПрД совпадает с областью
отправления, т. е. X, и, следовательно, это соответствие
определено всюду на X. Другими словами, для каждого
х^Х существует y^Y, так что (х, у)^Г. Такое всюду оп-
ределенное соответствие называется отображением X в Y
и записывается как
Г: X-+Y. (2.53)
Под словом «отображение» часто понимают однознач-
ное отображение. Однако мы не будем придерживаться
этого правила и будем считать, что каждому элементу
хеХ отображение Г ставит в соответствие некоторое под-
множество
Гх<=У,
(2.54)
Ряс. 2.11. Геометри-
ческое представление
отображения
называемое образом элемента х. За-
кон, в соответствии с которым осуще-
ствляется соответствие, определяется
множеством Г.
Пример 2.17. Если в примере 2.14 исклю-
чить из рассмотрения шофера с, то получим
отображение Г:Х->У, в котором Х={а, &}—
множество шоферов; У={а, 0, у} —множе-
ство автомашин; Г={(а, а), (а, у), (Ь, а)}—
распределение шоферов по автомашинам.
Геометрическое представление этого отобра-
жения дано на рис. 2.11.
Обратимся теперь к рассмотрению некоторых свойств
отображения. Пусть AczX. Для любого х^А образом х
будет множество Гх=У. Совокупность всех элементов У,
являющихся образами Гх для всех х^А, назовем обра-
зом множества А и будем обозначать ГЛ. Согласно этому
определению
ГЛ= (J Гх. (2.55)
хел
Если Ai и Аг — подмножества X, то
Г(Д1иД2)=ГЛ1иГД2. (2.56)
Однако соотношение
Г(Л1ПЛ2)=ГЛ1ПГЛ2 (2.57)
справедливо только в том случае, если отображение
Г: X-+-Y является однозначным. В общем же случае
Г(Л1ПД2)еГЛ1ПГЛ2. (2.58)
Полученные соотношения легко обобщаются и на боль-
шее число подмножеств At. Так, если Ai,..., Ап—подмно-
жества X, то
Г(У1Л‘)==У1ГЛ'; (2-59>
г (п (2-60)
Поскольку отображение является частным случаем со-
ответствия, для отображения имеют место введенные при
рассмотрении соответствий понятия обратного отображе-
ния и композиции отображений.
52
2.5.2. Отображения, заданные на одном множестве
Важным частным случаем отображения является слу-
чай, когда множества X и Y совпадают. При этом отобра-
жение Г: Х-+Х будет представлять собой отображение
множества X самого в себя и будет определяться парой
(X, Г), (2.61)
где ГеХ2. Подробным изучением таких отображений за-
нимается теория графов. Коснемся лишь некоторых опе-
раций над подобными отображениями.
Пусть Г и Д — отображения множества X в X. Компо-
зицией этих отображений назовем отображение ГД, кото-
рое в соответствии с правилом, приведенным в § 2.4, опре-
деляется так
(ГД)х=Г(Дх). (2.62)
В частном случае, если Д=Г, получаем отображения
Г2х=Г(Гх); (2.63)
Г3х=Г(Г2х) и т. д. (2.64)
Таким образом, в общем случае для любого s^2
Рх=Г(Р-'х). (2.65)
Специальным определением введем соотношение
Г°х=х. (2.66)
Это дает возможность распространить соотношение
(2.65) и на отрицательные s. Действительно, согласно
(2.65)
Г°х=Г(Г-1х)=ГГ-,х=х. (2.67)
Это означает, что Г-1х представляет собой обратное
отображение. Тогда
Г~2х=Г-1(Г_1х) (2.68)
и т. д.
Пример 2.18. Пусть X — множество людей. Для каждого человека
хеХ обозначим через Гх множество его детей. Тогда Рх — множе-
ство внуков х; Г3х—множество правнуков х; Г-1х — множество ро-
дителей х и т. д.
Изображая людей точками и рисуя стрелки, идущие из х в Гх,
получаем родословное или генеалогическое дерево (рис. 2.12).
Пример 2.19. Рассмотрим шахматную игру. Обозначим через х не-
которое положение (расположение фигур на доске), которое может
создаться в процессе игры, через X множество всевозможных поло-
53
жений. Тогда Гх для любого хеХ будет означать множество положе-
ний, которые можно получить из х, делая один ход при соблюдении
правил игры. При этом Гх=0, если х—матовое или патовое поло-
жение; Г3х—множество положений, которые можно получить нз х
тремя ходами; Г-1х—множество положений, из которых данное поло-
жение может быть получено за один ход.
Для отображений, заданных на одном множестве, ча-
сто используют некоторые другие названия, которые у нас
встретятся в дальнейшем.
Гх
Рис. 2.12. Генеалогическое дерево
Так, если элементы х^Х представляют собой состоя-
ния динамической системы, то отображение Гх будем рас-
сматривать как множество состояний, в которые система
может перейти из данного состояния. В этом случае удо-
бен термин «преобразование состояния динамической си-
стемы». Для обозначения некоторых специальных видов
отображений, заданных на одном и том же множестве,
применяют также термин «отношение».
2.5.3. Функция
Рассмотрим некоторое отображение
f: X-+Y.
(2.69)
Это отображение называют функцией, если оно одно-
значно, т. е. если для любых пар (xiyi)^f и (x2y2)^f из
х2=Х1 следует y2=yi.
На рис. 2.il3,a приведен пример отображения, явля-
ющегося функцией. Отображение на рис. 2.13,6 функцией
не является.
Из определения отображения и из приведенных ранее
примеров следует, что элементами множеств X и Y мо-
гут быть объекты любой природы. Однако в задачах ки-
бернетики большой интерес представляют отображения,
54
которые являются однозначными и множество значений
которых представляет собой множество вещественных чи-
сел /?. Однозначное отображение f, определяемое (2.69),
называют функцией с вещественными значениями, если
Yc=R.
Понятие функции является чрезвычайно широким, и
изучению отдельных классов функций посвящены многие
математические дисциплины (алгебра, тригонометрия
Рис. 2.13. Иллюстрация к понятию функции
и т. п.). Мы рассмотрим только некоторые общие наибо-
лее фундаментальные свойства функции, не касаясь
свойств конкретных классов.
Пример 2.20. Из одного города в другой можно проехать по же-
лезной дороге (ж.д.), автобусом (авт.) или самолетом (сам.). Стои-
мость билета будет соответственно 7, 9 и 12 руб. Стоимость билета
можно представить как функцию от вида транспорта. Для этого рас-
смотрим множества Х={ж.д., авт., сам.}; У={7, 9, 12}
Функция f: получаемая из условий примера, может быть
записана в виде множества /={(ж.д., 7), (авт., 9), (сам., 12)}.
Значение у в любой из пар (х, y)^f называют функ-
цией от данного х и записывают в виде y=f(x). Такая
запись позволяет вести следующее формальное определе-
ние функции:
f={(x, y)<=XXY\y=f(x)}. (2.70)
Таким образом, символ f используют при определении
функции в двух смыслах:
f является множеством, элементами которого будут па-
ры (х, у), участвующие в соответствии;
55
f(x) является обозначением для y^Y, соответствую-
щего данному хеХ.
Формальное определение функции в виде соотношения
(2.70) позволяет установить способы задания функции.
1. Перечисление всех пар (х, у), составляющих мно-
жество f, как это было сделано в примере 2.20. Такой
способ задания функции применим, если X является ко-
нечным множеством. Для большей наглядности пары
(х, У) удобно располагать в виде таблицы.
2. Во многих случаях как X, так и Y представляют
собой множества вещественных или комплексных чисел.
В таких случаях очень часто под f (х) понимается форму-
ла, т. е. выражение, содержащее перечень математических
операций (сложение, вычитание, деление, логарифмиро-
вание и т. п.), которые нужно произвести над х&Х, что-
бы получить у.
Пример 2.21. Пусть X=Y=R и f={(x, t/)e/?2|i/=x2}. Тогда
f(x)-A
Иногда для разных подмножеств множества X функ-
ции приходится пользоваться различными формулами.
Пусть Ль Ап — попарно непересекающиеся подмноже-
ства X. Обозначим через А(х), i=l, п формулу, опреде-
ляющую у при х^А;. Тогда функция
{f,(x) при х(ЕА'.;
...................... (2.71)
fn(x) при х£Ап.
Так, функцию y=f(х)=| х | можно задать в виде
{х при х^О;
—х при х<0.
3. Если X и У — множества вещественных чисел, то
элементы (х, y)^f можно изобразить в виде точек на
плоскости R2. Полная совокупность таких точек будет
представлять собой график функции f(x).
Если в выражении (2.69) X=U%V, то приходим
к функции от двух переменных и и v, обозначаемой че-
рез f(u, v), где u^U и v^V. Формальное определение
функции двух вещественных переменных будет следую-
щим:
/=((«, v, y)}^UXVxY\y=f(u, v)}. (2.72)
56
Аналогично определяют функции от трех и большего
числа переменных.
Свяжем с функцией еще одно понятие, называемое су-
жением функции. Пусть f: X-+-Y — произвольная функция
и А — произвольное множество. Сужением функции f на
множество А называют функцию fA, содержащую все те
и только те пары (х, y)^f, в которых х^А, а значит,
(х, yj&A'XY. Следовательно,
/л=/ПИХП- (2.73)
Операцию сужения функции часто используют для таб-
личного задания функций с бесконечной областью опре-
деления X. В качестве множества А берут обычно выбор-
ку равноотносящих значений х множества X. Получаемое
при этом сужение fA функции f уже легко представить
в виде таблицы. По этому принципу построены таблицы
логарифмов, тригонометрических функций и некоторые
другие.
2.5.4. Обратная функция
Понятие обратной функции применимо для такого ото-
бражения f: X-+Y, которое, во-первых, является одно-
значным, т. е. для любых (xi, yi)^f и (х2, ytj^f из х2 =
=Х] следует y2 = t/i, и, во-вторых, является взаимноодно-
значным, т. е. из x2=^Xi следует у^у*.. При выполнении
этих условий отображение f: X-+Y является одно-
значным, т. е. определяет функцию y=f(x). Обратное
Отображение f~l: Y-+X также является однозначным и
определяет функцию x=f~'(y), называемую обратной по
отношению к функции у=[(х).
Рис. 2.14. Иллюстрация к понятию обратной функции
57
На рис. 2.14,а приведен пример функции, имеющей об-
ратную функцию. Функция на рис. 2.14,6 обратной функ-
ции не имеет, однако ее отдельные ветви, обозначенные
жирной и тонкой линиями, имеют обратную функцию.
При аналитическом задании функции f принято аргу-
мент как прямой, так и обратной функции обозначать од-
ной и той же буквой, например х. Поэтому для нахожде-
ния обратной функции следует уравнение y=f(x) раз-
решить относительно х и поменять обозначения, заменив
х на у и у на х. При этом обратная функция запишется
в виде y=f~'(x).
2.5.5. Функция времени
В основе понятия функции времени лежит множество
Те/?' с элементами t, называемое множеством моментов
времени. Время обладает той характерной особенностью,
что имеет направление. Это означает, что если 6, /2е
<^Т и /]</2, то момент t\ предшествует моменту t2. Дру-
гими словами, Т — упорядоченное множество.
Функция времени определяет отображение f множест-
ва моментов времени Т на множество вещественных чи-
сел R:
f: T-+R. (2.74)
Элементами f будут пары (/, х), обозначаемые также
через х(0, где l^T, x^R. Каждая такая пара определяет
значение функции в момент t и называется событием или
мгновенным значением функции. Полная совокупность
пар (t, х), т. е. значений x(t) для всех и представ-
ляет собой функцию времени. Дальнейшее уточнение
функции времени связано с уточнением ее области опре-
деления, т. е. вида множества Т.
Если T=R, т. е. t может принимать любое веществен-
ное значение от —оо до -|-оо, то функцию x(t) называют
функцией с непрерывным временем, например синусои-
дальная функция времени x(t) =А sin (со^+ф), описыва-
ющая напряжение в сети переменного тока.
Однако нас обычно не интересуют весьма удаленные
моменты времени как в прошлом, так и в будущем. По-
этому производят сужение x(t) на ограниченный интер-
вал ti<_t^l2, который обычно считают полузакрытым и
обозначают (fb /2]. Полузакрытые интервалы времени
удобны тем, что допускают последовательное сочленение
58
друг с другом. Так, если
интервал (Л, £2] разбить
моментом t' на два интерва-
ла: (Л, Л] и (Л, f2], то не
будет сомнений, к какому
интервалу отнести t'.
Сужение функции x(t),
заданной на интервале
—оо</< + оо, на интервал
функции x(t) и обозначают
нию
Та; о 1 л* tg)
Рис. 2.15. Единичный скачок и им-
пульсная функция
(Z1, /2] называют отрезком
Итак, по определе-
6) = {x(t) f2]}. (2.75)
Для осуществлении операции сужения часто используют специаль-
ную функцию времени, называемую единичной функцией или единич-
ным скачком:
приведенную на рис. 2.15,а. Так, напряжение, подаваемое на вход при-
бора, подключаемого к сети в момент (=Х, будет
и(/) = 1 (/—X)x(t) = 1 (/-X)A sin (<о/-|-<р).
Другой широко используемой функцией времени является импульс-
ная функция 6(/—X), определяемая соотношениями:
(2.77)
( оо при t = X;
Х + е
J с(/ —X)d/ = 1, е>0. (2.78)
Функцию 6(/—X) можно рассматривать как предельный случай при-
веденного на рис. 2.15, б прямоугольного импульса шириной Д/ и высо-
той 1 /Д/, появляющегося в момент /=Х при Д/->0.
Другой полезной аппроксимацией импульсной функции может слу-
жить гауссовская функция (см. § 5.3)
которая обращается в импульсную функцию б(() при <т->0.
59
Импульсная функция позволяет выделять мгновенные значения
функции х(/) для фиксированных моментов времени. Так, если tt<X<
<t2, то
(t— \)dt = x(k) J 8(t—\)dt = x(\). (2.79).
Если множество T представляет собой множество нату-
ральных чисел
-2, -1, 0, 1, 2, п
то говорят о функции с дискретным временем. В этом
случае элементы множества Т обозначают через п, так
что пара (п, х), обозначаемая также х[п] или хп, опре-
деляет значение функции в момент п. На рис. 2.16 при-
веден пример функции с дискретным временем.
2.5.6. Понятие функционала
Говоря об отображении f:X-*-Y как о функции с ве-
щественными значениями, мы не накладывали на харак-
тер элементов множества X каких-либо особых ограниче-
ний. В простейших задачах множество X, как и множе-
ство У, представляет собой множество вещественных
чисел. Каждая пара (х, y)^f ставит в соответствие одно-
му вещественному числу х другое вещественное число у.
Однако важным для практики является случай, когда
множество X представляет собой множество функций,
а множество У — множество вещественных чисел. Этот
случай приводит к понятию функционала, подробное рас-
смотрение которого удобно провести на примере.
Представим себе некоторую линию y=f(x), соединя-
ющую фиксированные точки А и В, как показано на
рис. 2.17, по которой скатывается свободно движущийся
шарик. Обозначим через t время, которое шарик затра-
ffr)
Рнс. 2.16. Функция с ди-
скретным временем
Рис. 2.17. Линия наискорейшего
спуска
тит на перемещение из точки А в точку В. Это время
зависит от характера линии АВ, т. е. от вида функции
f(x). Если обозначить через F(x) множество различных
функций, изображающих линию АВ, через Т множество
вещественных чисел t, определяющих время движения
шарика, то зависимость времени движения от вида функ-
ции может быть записана как отображение
J:F(x)->T. (2.80)
Элементами множества J будут пары (/(х), t), в ко-
торых f(x)^F(x), a t^T. В этом случае говорят, что
вещественное число teT представляет собой функционал
J от функции f(x)eF(x), записывают это в виде
t=J [/(%)]. (2.81)
В задачах управления функционалы используются как
критерии качества управления. Так, в рассмотренном при-
мере время перемещения шарика из точки А в точку В
можно трактовать как критерий «качества» выбранной
функции f(x). При этом говорят об оптимальном управ-
лении как о таком, при котором соответствующий крите-
рий качества обращается в минимум. С этой точки зрения
определение «оптимального» вида функции f(x) сводится
к выполнению условия
minJ[f(x)], (2.82)
I&
при котором время t будет минимальным. В математике
подобная линия наискорейшего спуска получила название
брахистохроны.
2.5.7. Понятие оператора
Оператором L называется отображение
L:X-*-Y, (2.83)
в котором множества X и У являются множествами функ-
ций с элементами x(t) и y(i), так что элементами мно-
жества L будут пары (x(t), y(t)). В этом случае гово-
рят, что оператор L преобразует функцию x(t) в функ-
цию
у(0=1[х(0]. (2.84)
Примером оператора служит оператор дифференциро-
вания р, ставящий в соответствие функции f(x) другую
61
*(t) ,-ГТ~] y(t) >
Рис. 2.18. Представление управляемой системы в виде оператора
функцию f'(x) = df(x)/dx, что может быть записано
в виде
f' (x)=P[f(x) ].
В задачах управления роль оператора часто выполняет
сама управляемая система, преобразующая по некоторому
закону L входной сигнал х(/) в выходной сигнал y(t),
как это показано на рис. 2.18.
2.6. ОТНОШЕНИЯ
2.6.1. Свойства отношений
Как уже указывалось, термин «отношение» использу-
ют для обозначения некоторых видов отображений, за-
данных на одном и том же множестве. В связи с этим
удобно вести специальную символику.
Пусть отображение (X, Г) является отношением. Рас-
смотрим элемент t/еГх. Будем говорить, что элемент у
находится в отношении Г к элементу х, и запишем это
в виде
уГх. (2.85)
Так символ Г в примере 2.18 означает отношение «быть
детьми данного человека».
Примечание. Используя для отображения, заданного на одном
множестве, соотношение (2.61), получаем, что отношение есть пара
множеств (Л, Г), в которой ГеХ2. Поскольку элементами множества
X2 являются упорядоченные пары, то можно сказать, что отношение
есть множество упорядоченных пар. Так как каждая пара связывает
между собой только два элемента множества X2, то такое отношение
называют бинарным.
Можно ввести более общее понятие отношения, называя отноше-
нием пару множества (X, Г), где Г=Х". Элементами множества Хп
являются упорядоченные n-ки, что позволяет назвать данное отноше-
ние n-арным. В частности, множество упорядоченных троек может быть
названо тернарным отношением? В дальнейшем, не оговаривая этого
62
особо, под термином «отношение» будем иметь в виду бинарное отно-
шение.
Отношения делятся на различные виды в зависимости
от того, обладают или не обладают они некоторыми свой-
ствами. Рассмотрим шесть основных свойств отношений.
При описании этих свойств будем считать, что х, у и г —
любые элементы из множества X.
Рефлексивность: хГх истинно; антирефлексивность:
хГх ложно; симметричность: хГу-^уГх-, антисимметрич-
ность: хГу и уГх->х=у, несимметричность: если хГу ис-
тинно, то уГх ложно; транзитивность: хГу и уГг-^хГг.
Воспользовавшись описанными свойствами, рассмотрим
некоторые важные виды отношений.
2.6.2. Отношение эквивалентности
Некоторые элементы множества можно рассматривать
как эквивалентные в том случае, когда любой из этих эле-
ментов при некотором рассмотрении может быть заменен
другим. В этом случае говорят, что данные элементы на-
ходятся в отношении эквивалентности. Примерами отно-
шений эквивалентности являются: отношение «быть на
одном курсе» на множестве студентов факультета; отно-
шение «иметь одинаковый остаток при делении на 3» на
множестве натуральных чисел; отношение параллельности
на множестве прямых плоскости; отношение подобия на
множестве треугольников и т. п.
Для того чтобы дать четкую формулировку отноше-
ния эквивалентности, будем считать, что термин «отно-
шение эквивалентности» применяется только в случае, ес-
ли выполняются следующие три условия:
каждый элемент эквивалентен самому себе;
высказывание, что два элемента являются эквивалент-
ными, не требует уточнения, какой из элементов рассмат-
ривается первым и какой? вторым;
два элемента, эквивалентные третьему, эквивалентны
между собой.
Примем для обозначения эквивалентности символ = .
Тогда общее определение эквивалентности получим, запи-
сав три вышеприведенных условия в виде следующих со-
отношений:
х=х (рефлексивность);
х=у-+у==х (симметричность);
х=у и t/=z->№z (транзитивность).
63
Таким образом, отношение Г называется отношением
эквивалентности, если оно рефлексивно, симметрично и
транзитивно.
Отношение эквивалентности находится в тесной связи
с разбиением множества, рассмотренным в § 2.2. Пусть
X — множество, на котором определено отношение экви-
валентности. Например, X — множество студентов курса,
а отношением эквивалентности является отношение «быть
в одной группе». Подмножество элементов, эквивалентных
некоторому элементу хеХ, будем называть классом эк-
вивалентности. Так, группа, в которой учится студент
Иванов, будет классом эквивалентности, эквивалентным
студенту Иванову.
Пусть J — некоторое множество индексов. Обозначим
через {Л/еХ|/е7} множество классов эквивалентности
для множества X. Очевидно, что все элементы одного
класса эквивалентности эквивалентны между собой (свой-
ство транзитивности) и всякий элемент хеХ может на-
ходиться в одном и только в одном классе. Но в таком
случае X является объединением непересекающихся мно-
жеств A/t так что полная система классов {^sXI/e/}
является разбиением множества X. Таким образом, каж-
дому отношению эквивалентности на множестве X соот-
ветствует некоторое разбиение множества на классы А,.
Отношение эквивалентности на множестве X и разбие-
ние этого множества на классы называют сопряженными,
если для любых х и у из X отношение х=у выполняется
тогда и только тогда, когда х и у принадлежат к одному
и тому же классу Д;, этого разбиения. Более четкому уясне-
нию связи отношения эквивалентности с разбиением мно-
жества поможет сравнение примеров данного раздела
с примерами из § 2.2.
В качестве общего символа отношения эквивалентно-
сти используют знак ss (иногда ^). Однако для отдель-
ных частных отношений эквивалентности применяют дру-
гие знаки: = —для обозначения равенства, || — парал-
лельности, — логической эквивалентности.
2.6.3. Отношение порядка
Часто приходится сталкиваться с отношениями, кото-
рые определяют некоторый порядок расположения элемен-
тов множества. Так, мы отличаем понятия «раньше» и
«позже» в случаях, когда элементами множества явля-
64
ются состояния динамической системы. Мы отличаем по-
нятия «больше» и «меньше» и пользуемся при этом сим-
волами > или С, если элементы множества являются
числами. Мы отличаем понятия множества и подмноже-
ства, пользуясь символами s или сг.
Во всех этих случаях можно расположить элементы
множества X или группы элементов в некотором порядке.
или, другими словами, ввести отношение порядка на мно-
жестве X.
Различают отношение нестрогого порядка, для которо-
го используется символ и отношение строгого поряд-
ка, для которого используется символ С. Опишем эти от-
ношения путем перечисления свойств, которыми они об-
ладают.
Отношением нестрогого порядка называют отношение,
обладающее следующими тремя свойствами:
х^.х истинно (рефлексивность);
х^у и ys^.x-+x=y (антисимметричность);
х^у и y-^zr+x^z (транзитивность).
Отношением строгого порядка называют отношение,
обладающее следующими тремя свойствами:
x<Zx ложно (антирефлексивность);
x<Zy и у<х взаимоисключаются (несимметричность);
х<.у и y<z-^xCz (транзитивность).
Множество X называют упорядоченным, если любые
два элемента (х и у) этого множества являются сравни-
мыми, т. е.
х<у или х=у или у<х.
2.6.4. Отношение доминирования
В тех случаях, когда X означает множество людей
или группу людей, приходится сталкиваться с отноше-
нием, которое является отношением доминирования. Мы
будем говорить, что х доминирует над у, и писать х^у,
если х в чем-то превосходит у. Так, х может быть спортс-
меном или командой, победившей спортсмена или коман-
ду у, или лицом, пользующимся авторитетом у лица у,
или свойством, которое мы предпочитаем свойству у.
Мы будем говорить, что между элементами множест-
ва X имеет место отношение доминирования, если эти
элементы обладают следующими двумя свойствами:
никакой индивидуум не может доминировать над са-
мим собой, т. е. ложно (антирефлексивность);
в каждой паре индивидуумов в точности один инди-
5-804 65
видуум доминирует над другим, т. е. х^у и у~>х взаи-
моисключаются (несимметричность).
В отношении доминирования свойство транзитивности
не имеет места. Действительно, если в соревнованиях
команда х победила команду у, а команда у победила
команду z, то отсюда еще не следует, что команда х обя-
зательно победит команду г.
Задачи к гл. 2
2.1. Что представляет собой множество У|\|Х из примера 2.1?
2.2. Обозначьте штриховкой множество У|\|х нз примера 2.3.
2.3. Пусть 7? — множество вещественных чисел и
Х={хе=Я|0<х<1}, Y={y<=R\0^y^Sl.}.
Что представляют собой множества ХиУ, Х(]У, X \ У?
2.4. Начертите фигуры, изображающие множества
Л={(х, В={(х,
Какие фигуры изображают множества ЛОВ, Л(]В,
2.5. Воспользовавшись соотношением (2.34), доказать тождества
Х{]0=0; Xl)0=X; /ПХ=Х; RJX=I.
2.6. Изобразить на вещественной плоскости R?=RxR множества
ХХУ и УхХ из задачи 2.3.
2.7. Изобразить геометрически множества Лх/? и RXA, где Л =
= [2, 3].
2.8. Что представляет собой пересечение множества всех прямо-
угольников с множеством всех ромбов?
2.9. Для множества М={(х, (х—2)2_|_^2=1} найти ПрМ4 в
Пр2М.
2.10. Пусть /={хь хг, х3} — универсальное множество, а Х=
~{xi, хг}, У={х2, х3}, Z={x3) — его подмножества. Определить пере-
числением следующие множества: ХХХ-, ZxZ; ХХУ; УХХ; ХХУЦУХ
XX; ХХУОУХХ.
2.11. Пусть X, У, Z — подмножества множества R2, равные Х=
= {(х, у) |х>0}, У={(х, у) |г/>0}, Z={(x, у) |хЦ-г/Эг1}. Представить
геометрически множества X; У; Z; ХОУ; Х1)У; Х(]У; Х(]У; Xf]Z; XQZ;
ХПУПХ; ХПУП2.
2.12. Чему равно множество ХХУ> если X и У — подмножества R1,
причем Х={(х, у) |2х—[-£/= 1}, У={(х, £f) |х—£г=0}?
2.13. В примере 2.13 выписать все 16 соответствий. Определить для
каждого из них npiQ и ПргО.
2.14. Для функции f примера 2 21 найти обратную функцию f-’.
2.15. Пусть f и g — функции на множестве R2, равные
= {(х, У)\У=х21> S=Uy, z)|z=sini/}. Найти композицию этих функций.
66
Глава 3
ОСНОВЫ ТЕОРИИ ГРАФОВ
3.1. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ ТЕОРИИ ГРАФОВ
3.1.1. Теоретико-множественное определение графа
Наглядное представление о графе можно получить,
если представить себе некоторое множество точек пло-
скости X, называемых вершинами, и множество направ-
ленных отрезков U, соединяющих все или некоторые из
вершин и называемых дугами [И, 12]. Математически
граф G можно определить как пару множеств X и U:
G=(X, U). (3.1)
На рис. 3.1 изображен граф, вершинами которого яв-
ляются точки а, Ь, с, d, е, g, h, а дугами — отрезки (а, а),
(с, b), (с, d), (с, е), (d, с), (d, d), (е, d), (g, h). Приме-
рами графов являются отношения отцовства и мате-
ринства на множестве людей (см. рис. 2.14), карта дорог
на местности, схема соединений электрических приборов,
отношения превосходства одних участников турнира над
другими и т п.
Иногда бывает удобно дать графу другое определение.
Можно считать, что множество направленных дуг U, со-
единяющих элементы множества
X, отображает это множество
само в себя Поэтому можно
считать граф заданным, если
дано множество его вершин X и
способ отображения Г множества
X в X. Таким образом, граф G
есть пара (X, Г), состоящая из
множества X и отображения Г,
заданного на этом множестве:
G=(X, Г).
Рнс. 3.1. Общий вид графа
(3-2)
Так, для графа, изображенного на рис. 3.1, отображе-
ние определяется следующим образом:
Га=а; Г&=0; Гс= {&; d; е}; Vd= {d, с};
Te=d; rg=h-, Г/г=0.
6?
Нетрудно видеть, что данное определение графа пол-
ностью совпадает с определением отношения на множе-
стве.
Введем некоторые понятия и определения, служащие
для описания различных видов графов.
Подграфом GA графа G—(X, Г) называется граф, в ко-
торый входит лишь часть вершин графа G, образующих
множество А, вместе с дугами, соединяющими эти верши-
ны, например, очерченная пунктиром область на рис. 3.1.
Математический подграф
Ga=(A, Гл),
(3.3)
(3.4)
где
Ас=Х, Гдх=(Гх)(р4.
Частичным графом бд по отношению к графу G =
= (Х, Г) называется граф, содержащий только часть дуг
графа G, т. е. определяемый условием
Сд=(Х, А), (3.5)
где
Ах<=Гх. (3.6)
Так, на рис. 3.1 граф, образованный жирными дугами,
является частичным графом.
Пример 3.1. Пусть G=(X, Г) — карта шоссейных дорог Советско-
го Союза. Тогда карта шоссейных дорог Тамбовской области пред-
ставляет собой подграф, а карта главных дорог Советского Союза —
частичный граф.
Другими важными понятиями являются понятия пути
и контура. Ранее было дано определение дуги как направ-
ленного отрезка, соединяющего две вершины. Дуга, соеди-
няющая вершины а и b и направленная от а к Ь, обозна-
чается и—(а, Ь).
Путем в графе G называют такую последовательность
дуг ц=(«ь ..., ик), в которой конец каждой предыдущей
дуги совпадает с началом следующей. Путь ц, последо-
вательными вершинами которого являются вершины а,
Ь, ..., т, обозначается через ц—(я, Ь, ..., т).
Длиной пути ц=(мь ..., «Л) называют число Z(p) =
= k, равное числу дуг, составляющих путь ц. Иногда
каждой дуге приписывают некоторое число Z(«t), назы-
ваемое длиной дуги. Тогда длина пути определяется как
сумма длин дуг, составляющих путь
f(l*) = 2 z(w)-
«eg
(3.7)
68
г
Рис. 3.2. Граф без петель
Путь, в котором никакая дуга не встречается дважды,
называется простым. Путь, в котором никакая вершина
не встречается дважды, называется элементарным.
Контур — это конечный путь р.= (xi, ..., х*), у которого
начальная вершина Xi совпадает с конечной Xk. При этом
контур называется элементарным, если все его вершины
различны (за исключением начальной и конечной, которые
совпадают). Контур единичной длины, образованный ду-
гой вида (а, а), называется пет-
лей. Так, на рис. 3 1 (е, d, с, Ь)—
путь, (с, е, d, с) — контур,
(d, d) — петля.
Иногда удобно представлять
графы в виде некоторых матриц,
в частности в виде матриц смеж-
ности и инциденций. Предвари-
тельно дадим два определения.
Вершины х и у являются
смежными, если они различны и
если существует дуга, идущая из
х в у.
Дугу и называют инцидентной
ходит в эту вершину или исходит из нее.
Обозначим через хь ..., хп вершины графа, а через
Ui, ..., um его дуги. Введем числа:
11, если имеется дуга, соединяющая вершину i с верши-
ной /;
О, если такой дуги нет.
вершине х, если она за-
Квадратная матрица R=[r,/] порядка называет-
ся матрицей смежности графа.
Введем числа:
1+ 1, если «у исходит из хс,
— 1, если Uj заходит в xt;
О, если Uj не инцидентна xt.
Матрица S=[s„] порядка пХпг называется матрицей
инциденций для дуг графа.
Матрицы_инциденций в описанном виде применимы
только к графам без петель. В случае наличия в графе пе-
тель эту матрицу следует расчленить на две полуматрицы:
положительную и отрицательную.
63
На рис. 3.2 приведен граф без петель, для которого
матрицы смежности и инциденций имеют вид:
3.1.2. Неориентированные графы
Иногда граф рассматривают без учета ориентации дуг,
тогда его называют неориентированным графом. Для не-
ориентированного графа понятие «дуга», «путь» и «кон-
тур» заменяются понятиями «ребро», «цепь», «цикл». Реб-
ро — это отрезок, соединяющий две вершины. Цепь — по-
следовательность ребер. Цикл —цепь, у которой началь-
ная и конечная вершины совпадают.
На рис. 3.3,а приведен пример неориентированного гра-
фа, у которого вершины обозначены цифрами, а ребра —
буквами латинского алфавита.
Описать неориентированный граф G можно путем за-
дания пары множеств (X, U), где X — множество вершин;
U — множество ребер. Однако более удобным является
описание неориентированного графа с помощью матрицы
смежности или инциденций, которые строятся аналогично
соответствующим матрицам для ориентированных графов
с той разницей, что не делается различия между заходя-
щей в вершину и исходящей из нее дугами. При этом вер-
шины х и у называют смежными, если существует соеди-
Рис. 3.3. Неориентированные графы
7Р
няющее их ребро, а само это ребро называется инцидент-
ным вершинам хну. Для графа рис. 3.3,а матрицы
смежности и инциденций имеют вид:
Матрица смежности
/=12345
Матрица иицидеиций
1 [~ 0 110 0“
U
abed
2| 10100
31 1 1 0 1 0
4100100
5 L 0 О О О О
1Г 1 0 1 0
2 110 0
X =3 0 111
110 0
0 111
0 0 0 1
0 0 0 0
5
Приведем еще несколько определений, служащих для
характеристики неориентированных графов.
Степенью вершины х, обозначаемой deg(x) или dx,
называют число ребер, инцидентных вершине х. Так, для
графа на рис. 3.3,а имеем: di = 2, d2=2, rf3=3, d4=l, d$ —
= 0. Если dx—l, то вершину х называют тупиковой (вер-
шина 4); если dx—0, то вершину называют изолированной
(вершина 5).
Теорема 3.1. Пусть G — неориентированный граф с п
вершинами и m ребрами и d/ —степень /-Й вершины.
Тогда
2 di =2tn-
Доказательство теоремы следует из того, что каждое
ребро добавляет единицу к степени каждой из двух вер-
шин, которые оно соединяет, т. е. добавляет 2 к сумме
степеней уже имеющихся вершин.
Следствие. В каждом графе число вершин нечетной
степени четно.
Для неориентированного графа понятия «подграф» и
«частичный граф» аналогичны соответствующим поня-
тиям для ориентированного графа.
С понятием неорйентированного графа связана важная
характеристика, называемая связностью графа. Говорят,
что граф связен, если любые две его вершины можно со-
единить цепью. Если граф G не связен, то его можно раз-
бить на такие подграфы Gt, что все вершины в каждом
подграфе связны, а вершины из различных подграфов не
связны. Такие подграфы G, называют компонентами связ-
ности графа G.
Если из графа на рис. 3.3,а исключить изолированную
вершину 5, то полученный граф будет связным. Граф на
рис. 3.3,6 не связен и имеет две компоненты связности.
Его можно превратить в связный, добавив ребро (мост),
соединяющее вершины 3 и 5 (штриховая линия). Удале-
ние моста превращает связный граф в несвязный.
Для того, чтобы определить связность ориентированно-
го графа, не нужно обращать внимание на ориентацию
дуг. Граф, изображенный на рис. 3.1, несвязный. Однако
его подграф, состоящий из вер-
\ шин Ь, с, d, е, является связным.
£—к —п Для ориентированного графа су-
\ / ществует понятие сильной связ-
----4/ ности. Граф сильно связен, если
\ Для любых двух вершин (х и у,
х. 1 х=£у) существует путь, идущий
ИЗ X в у.
Рис. 3.4. Дерево Важный частный случай не-
ориентированного графа — дере-
во. Деревом называют конечный связный неориентирован-
ный граф, не имеющий циклов (рис. 3.4).
Если дано множество вершин а, Ь, с..., то дерево мож-
но построить следующим образом. Одну из вершин, на-
пример а, примем за начальную и назовем ее корнем де-
рева. Из этой вершины проводим ребра в близлежащие
вершины Ь, с, d..., из них проводим ребра в соседние
с ними вершины е, f, g, h... и т. д. Таким образом, дере-
во можно построить, последовательно добавляя ребра
в его вершинах. Это дает возможность установить связь
между числом вершин и числом ребер дерева.
Простейшее дерево состоит из двух вершин, соединен-
ных ребром. Каждый раз, когда мы добавляем еще одно
ребро, в конце его прибавляется также и вершина. Сле-
довательно, дерево с п вершинами имеет п— 1 ребер.
3.1.3. Изоморфизм графов
Одни и тот же граф геометрически можно изобразить различными
способами. Так, на рис. 3.5,а приведены три изображении одного и
того же графа. Такие графы называют изоморфными.
В связи с этим возникает следующая задача. Если имеется два
изображения графов, то, как узнать, не представляют ли они собой
один и тот же граф? Ответить на этот вопрос достаточно трудно. На
практике обычно предварительно определяют некоторые параметры
72
Рис. 3.5. Изоморфные (а) и неизоморфные (б) графы
обоих графов. Такими параметрами могут быть число вершин, число
ребер, число компонент связности, последовательность степеней вершин
в убывающем порядке.
Если какие-то из этих параметров у двух графов различны, то эти
графы различны. Однако если все параметры у двух графов совпали,
то это не гарантирует, что графы изоморфны. Так, на рис. 3.5,6 при-
ведены два графа, у которых все параметры совпадают, и тем не ме-
нее они различны.
3.1.4. Отношение порядка и отношение
эквивалентности на графе
Как мы видели, граф дает удобное геометрическое
представление отношений на множестве, поэтому теория
графов и теория отношений на множестве взаимно допол-
няют друг друга.
Будем считать, что на графе С=(ХГ) введено отно-
шение порядка, если для любых двух вершин (х и у), удов-
летворяющих условию х^у, существует путь из х в у.
В этом случае говорят, что вершина х предшествует вер-
шине у или что вершина у следует за вершиной х.
Покажем, что данное определение отражает на гра-
фе все свойства отношения порядка.
Рефлексивность. Условие
Xi~Zx истинно
(3-8)
73
означает эквивалентность вершины самой себе, т. е. усло-
вие х=х. Однако при желании это условие можно рас-
сматривать как наличие пути из х в х, т. е. как петлю
в вершине х (рис. 3.6,а).
Транзитивность. Условие
х^у, y^z-+x^z (3.9)
означает, что вершины х, у, z последовательно встреча-
ются на одном и том же пути (рис. 3.6,6).
Рис. 3.6. Иллюстрация свойств отношения порядка
Антисимметричность. Покажем справедливость
условия
х^у, у^х-+х=у. (3.10)
Левая часть этого выражения говорит о том, что су-
ществует путь из х в у, а также существует путь из у
в х. Но это означает, что в графе имеется контур, на ко-
тором лежат вершины х и у (рис. 3.6,в).
Из правой части условия (3.10) вытекает, что верши-
ны, лежащие на одном и том же контуре, являются экви-
валентными. Будем рассматривать этот вывод как опре-
деление эквивалентности на графе и покажем, что такое оп-
ределение удовлетворяет всем трем условиям отношения
эквивалентности. Условия рефлексивности х^==х и сим-
метрии х^=у-+у==гх являются очевидными и вытекают из
данного выше определения эквивалентности. Условие
транзитивности х=у, y==z-^-x==z также является оче-
видным, так как говорит о том, что если в графе имеется
контур с вершинами х и у, а также контур с вершинами
у и z, то имеется и контур, на котором лежат вершины
х и z (рис. 3.6,в).
Таким образом, отношение порядка совместно с отно-
шением эквивалентности определяет некоторый граф.
На графе может быть также введено отношение стро-
гого порядка. В этом случае для любых двух вершин (х и
74
у), удовлетворяющих условно х<.у, существует путь,
идущий из х в у. Условие транзитивности x<y<z->x<2
означает, как и в предыдущем случае, что вершины х, у
и z встречаются последовательно на одном и том же
пути. Условие антирефлексивности (х<х ложно) говорит
об отсутствии петель на графе, а условие несимметрии
(х<1/, у<х взаимоисключаются) говорит об отсутствии
контуров.
Таким образом, отношение строгого порядка опреде-
ляет граф без контуров.
3.1.5. Характеристики графов
Решение многих технических задач методами теории
графов сводится к определению тех или иных характе-
ристик графов. Хотя технические приложения теории гра-
фов рассматривать в настоящей книге невозможно, зна-
комство с важнейшими характеристиками графов может
оказаться полезным при изучении других дисциплин.
Цикломат ическое число. Пусть G — неориен-
тированный граф, имеющий п вершин, m ребер и г ком-
понент связности. Цикломатическим числом графа G на-
зывают число
v(G) —пг—п+г.
Это (число имеет интересный физический смысл: оно
равно наибольшему числу независимых циклов в графе.
При расчете электрических цепей цикломатическим чис-
лом можно пользоваться для определения числа незави-
симых контуров.
Хроматическое число. Пусть р — натураль-
ное число. Граф G называют р-хроматическим, если его
вершины можно раскрасить р различными цветами так,
чтобы никакие две смежные вершины не были раскраше-
ны одинаково. Наименьшее число р, при котором граф
является р-хроматическим, называют хроматическим чис-
лом графа и обозначают y(G).
Если y(G)=2, то граф называют бихроматическим.
Необходимым и достаточным условием того, чтобы граф
был бихроматическим, является отсутствие в нем циклов
нечетной длины. Хроматическое число играет важную
роль при решении задачи наиболее экономичного исполь-
зования ячеек памяти при программировании. Однако его
определение, за исключением случая бихроматического
75
графа, представляет собой довольно трудную задачу, тре-
бующую нередко применения электронных вычислительных
машин.
Множество внутренней устойчивости.
Множество SsX графа G—(X, Г) называют внутренне
устойчивым, если никакие две вершины из S не смежны,
т. е. для любого x^S имеет место ГхП5=0.
Множество внутренней устойчивости, содержащее наи-
большее -число элементов, называют наибольшим внут-
ренне устойчивым множеством, а число элементов этого
множества —числом внутренней устойчивости графа G.
Наибольшее внутреннее устойчивое множество играет
важную роль в теории связи.
Множество внешней устойчивости. Мно-
жество Т<=Х графа G=(X, Г) называют внешне устой-
чивым, если любая вершина, не принадлежащая Т, со-
единена дугами с вершинами из Т, т. е. для любого х<£Т
имеет место Гх(~]Т=^0.
Множество внешней устойчивости, содержащее наи-
меньшее число элементов, называют наименьшим внешне
устойчивым множеством, а число элементов этого множе-
ства — числом внешней устойчивости графа G.
3.2. ЗАДАЧА О КРАТЧАЙШЕМ ПУТИ
3.2.1. Постановка задачи
В практических приложениях имеет большое значение
задача о нахождении кратчайшего пути между двумя вер-
шинами связного неориентированного графа. К такой за-
даче сводятся многие задачи выбора наиболее экономич-
ного (с точки зрения расстояния или времени или стои-
мости) маршрута на имеющейся карте дорог, многие зада-
чи выбора наиболее экономичного способа перевода
динамической системы из одного состояния в другое
и т. п. В математике разработан ряд методов для реше-
ния подобных задач. Однако весьма часто методы, осно-
ванные на использовании графов, оказываются наименее
трудоемкими.
Задача о кратчайшем пути на графе в общем виде мо-
жет быть сформулирована следующим образом. Дан
неориентированный граф G~(X, U). Каждому ребру это-
го графа приписано некоторое число /(и)^0, называемое
длиной ребра. В частных случаях /(м) может быть рас-
76
стоянием между вершинами, соединяемыми ребром и,
временем или стоимостью проезда по этому ребру и т. п.
При этом любая цепь ц будет характеризоваться длиной,
определяемой соотношением (3.7).
Требуется для произвольных вершин а и b графа 6
найти путь Цаб, причем такой, чтобы его полная длина
была наименьшей.
Прежде чем найти общий метод решения этой задачи,
рассмотрим правило для решения задачи частного вида,
когда длина каждого ребра равна единице.
3.2.2. Нахождение кратчайшего пути в графе
с ребрами единичной длины
Иногда приходится иметь дело с графами, ребра кото-
рых имеют одинаковую длину, принимаемую за единицу.
Вершины такого графа обычно представляют собой со-
стояния некоторой системы, в которой с некоторой точки
зрения все переходы, делаемые за один шаг, эквивалент-
ны. Приведем пример задачи, которая сводится к_рас-
смотрению графа с ребрами единичной длины. Данная
задача может служить иллюстрацией способов построения
графов для различных конкретных случаев.
Пример 3.2. (задача о ханойской башне). Доска имеет три колыш-
ка. На первый нанизаны т дисков, диаметр которых убывает снизу
вверх. Ставится задача: перекладывая диски по одному, расположить
их в том же порядке на третьем колышке, используя в качестве проме-
жуточного второй колышек и соблюдая условие, чтобы ни при како?4
шаге больший диск не мог оказаться выше меньшего ни на одном из
колышков В качестве добавочного условия можно потребовать найти
решение, требующее наименьшего числа шагов.
Пронумеруем диски в порядке убывания их диаметров: т,
т— 1, ..., 1. Обозначим через X, У и Z множества дисков, надетых
соответственно на первый, второй и третий колышки на любом из ша-
гов При этом достаточно указать только множества X и Z, так как
множество У получается как дополнение множества X и Z до полного
числа дисков Элементом множества X или Z может быть одна из сле-
дующих комбинаций дисков: 0, 1, 2, 21, 3, 31, 32, 321, 4, 41, 42, 421,
43, 431, 432, 4321 ... Эти комбинации можно изобразить условными
точками на осях X и Z, как показано на рис. 3 7, так что любое рас-
положение дисков будет изображаться некоторой точкой на плоскости
(X, Z). Соединяя эти точки линиями, указывающими возможные на
каждом шаге перемещения дисков, получаем неориентированный граф,
77
иа котором можно найти путь, в том числе и кратчайший, для перехо-
да из начальной точки графа в конечную.
Построение графа можно произвести путем перехода от т дисков
к т-1-1. При т—1 возможные состояния будут представляться множе-
ством {(1,0), (0, 0), (0, 1)}, которому соответствует граф на рис. 3.7,а
с указанным на нем кратчайшим переходом из начального состояния
(1, 0) в конечное (0, 1).
Рис. 3.7. Графы переходов в задаче о ханойской башне
Для получения общего правила предположим, что уже построен
граф для случая т дисков, который назовем m-графом Нетрудно убе-
диться, что такой граф будет иметь вид треугольника, изображенного
на рис 3.8,а, хотя внутренние связи в нем нам пока неизвестны. Каков
при этом будет граф для т-(-1 дисков?
Заметим, что диск с номером zn-f-1 может занимать на любом из
колышков только нижнее положение. При этом остальные т дисков
могут перемещаться как угодно в соответствии с m-графом без изме-
нения положения (zn-f-l)-ro диска. Следовательно, граф для отф-1
диска (рис. 3 8,6) будет состоять из трех m-графов, обозначенных
цифрами (в кружочках) /, 2 и 3, означающими номер колышка, па
котором находится (т-|-1)-й диск. Остается выяснить только переходы
от одного /n-графа к другому, соответствующие перемещению (т-]-1)-го
диска.
Диск (тф-1)-й может быть переложен только на свободный колы-
шек, а это возможно лишь в том случае, когда на одном из колышков
расположены все т меньших дисков. В соответствии с этим иа
рис. 3 8,6 показаны возможные переходы (щ-|-1)-го диска, обозначен*
78
ные цифрами 1, 2 и 3, означающими номер колышка, на котором на-
ходится т меньших дисков.
Диаграмма, показанная на рис. 3.8,6, дает общий принцип пере-
хода от m-графа к (иг-|-1) -графу. На рис. 3.7,6 и в приведены графы
переходов для двух и трех дисков.
Перейдем к задаче нахождения в графе кратчайшего
пути, соединяющего начальную вершину с конечной. По-
скольку рассмотренные графы сравнительно просты, та
кратчайший путь нетрудно найти просто путем перебора
Переход от от-графа к (m+l)-графу
возможных путей. Однако для сложных графов должен
быть найден систематический метод.
Общее правило для нахождения кратчайшего пути в
графе состоит в том, чтобы каждой вершине х, приписать
индекс X/, равный длине кратчайшего пути из данной вер-
шины в конечную. Приписывание индексов вершинам в
случае графа с ребрами единичной длины производится
в следующем порядке:
I) конечной вершине х0 приписывается индекс 0;
2) всем вершинам, из которых идет ребро в конечную
вершину, приписывается индекс I;
3) всем вершинам, еще не имеющим индексов, из ко-
торых идет ребро в вершину с индексом К, приписывается
индекс А.,+ 1. Этот процесс продолжается до тех пор,
пока не будет помечена начальная вершина. По оконча-
нии разметки индекс у начальной вершины будет равен
79
длине кратчайшего пути. Сам кратчайший путь найдем,
если будем двигаться из начальной вершины в направ-
лении убывания индексов.
Пример разметки индексов и определения кратчай-
шего пути показан на рис. 3.7,в для т=3.
Отметим, что описанный способ определения кратчай-
шего пути является частным случаем нахождения опти-
мального решения по методу динамического программи-
рования. Поэтому после изучения динамического програм-
мирования полезно вернуться к рассмотренному примеру.
3.2.3. Нахождение кратчайшего пути в графе
с ребрами произвольной длины
Задача приписывания вершинам графа числовых ин-
дексов усложняется, если ребра графа имеют произволь-
ную длину. Усложнение вызвано тем, что в сложном гра-
фе путь, проходящий через наименьшее число вершин,
нередко имеет большую длину, чем некоторые обходные
пути. Так, в графе (рис. 3.9), изображающем карту до-
рог, прямой путь из вершины, отмеченной звездочкой, в
конечную вершину имеет длину 7=12, тогда как обходной
путь через вершину, отмеченную треугольником, имеет
длину 7=10.
Процесс приписывания индексов для такого вида гра-
фов заключается в следующем [11, 13].
1. Каждая вершина xL помечается индексом X;. Пер-
воначально конечной вершине хо приписывается индекс
ло—0. Для остальных вершин предварительно полагаем
Л,=оо (i=^0).
2. Ищем такую дугу (xt, х;), для которой —Xt>
>1(х1, X,), и заменяем индекс К, индексом Х'/=Х,+
+/(%,, х/)<Х/. Продолжаем этот процесс замены индек-
сов до тех пор, пока остается хотя бы одна дуга, для
которой можно уменьшить
Отметим два свойства, которыми будут обладать при-
писанные вершинам индексы.
1. Пусть (хй, xs)—произвольное ребро. Для него обя-
зательно выполняется условие Xs—2ife^/(xfe, xs), так как
если бы оно не выполнялось, индекс нужно было бы
уменьшить.
2. Пусть хр — произвольная вершина. При рассмотрен-
ном процессе приписывания индексов индекс хр монотон-
но уменьшается. Пусть xq— последняя вершина, послу-
жившая для его уменьшения. Тогда X,p=?i9+/(x<7, хр).
80
Рис. 3.9. Карта дорог
Следовательно, для произвольной вершины хр с индексом
кр найдется вершина xq, соединенная ребром с хр, такая,
что хр).
Эти свойства позволяют сформулировать следующее
правило для нахождения кратчайшего пути.
Пусть хп = а — начальная вершина с индексом Я„. Ищем
вершину xPl такую, что — ZPl = /(xP1, хп). Далее Ищем
вершину хРг такую, что — ЛРг = 1(хРг, хР1) и т. д., до
тех пор, пока не дойдем до конечной вершины xpk+1 —
— Ь. Путь p0 = (x;i, xPl,..., хР/), х0), длина которого равна
Я,„, является кратчайшим.
Для доказательства рассмотрим произвольный путь из а
в b\ p. = (x„, Xki. Xks, ха). Его длина будет /(р). Соглас.
но правилу расстановки индексов будут выполняться сле-
дующие неравенства:
xa2);I
(311)
6-804
81
Складывая почленно эти неравенства, находим, что
для любого пути [л имеет место
In—0^/(ц). (3.12)
Так как для пути ц0 выполняется условие кп=1(у.о),
то путь цо является кратчайшим.
Метод нахождения кратчайшего пути проиллюстри-
рован на примере карты дорог, представленной в виде
графа на рис. 3.9. Цифры у ребер указывают время про-
езда по каждой из дорог. Индексы вершин дают время
проезда от данной вершины до конечной’.
3.2.4. Построение графа наименьшей длины
Большое практическое значение имеет следующая за-
дача, которую можно сформулировать в виде задачи о
проведении дорог Имеется несколько городов а, Ь, с ..
которые нужно соединить между собой сетью дорог. Для
каждой пары городов (х, у) известна стоимость 1(х, у)
строительства соединяющей их дороги. Задача состоит в
том, чтобы построить самую дешевую из возможных се-
тей дорог. Вместо сети дорог можно рассматривать сеть
линий электропередачи, сеть нефтепроводов и т. п. Назы-
вая в графе, изображающем сеть дорог, величину 1(х, у)
длиной ребра (х, у), приходим к задаче о построении
графа наименьшей длины. Поэтому далее в качестве стои-
мости дорог примем длину ребер графа.
Если имеются всего три вершины (а, Ь, с), то доста-
точно построить одну из соединяющих цепей abc, acb, Ьас,
причем если Ьс— самое длинное ребро, то именно его и
надо исключить, построив цепь Ьас.
Граф наименьшей длины всегда является деревом, так
как если бы он содержал цикл, можно было бы удалить
одно из ребер этого цикла и вершины все еще остались
бы соединенными. Следовательно, для соединения п вер-
шин нужно построить п—1 ребро.
Покажем, что граф наименьшей длины можно по-
строить, пользуясь следующим правилом [12]. Прежде
всего соединяем две вершины с наиболее коротким реб-
ром ui. На каждом из следующих шагов добавляем са-
мое короткое из ребер и„ при присоединении которого к
уже имеющимся ребрам не образуется никакого цикла.
Если имеется несколько ребер одинаковой длины, то вы-
бираем любое из них. Каждое дерево Q, построенное та-
82
ким образом, будем называть экономическим деревом. Его
длина равна сумме длин отдельных ребер.
/(Q)=/(«,)+ (3.13)
в том порядке, в котором
Рис. 3.10 К построению дерева
наименьшей длины
Покажем, что никакое другое дерево, соединяющее те
же вершины, не может иметь длину, меньшую длины
экономического дерева Q. Пусть Р — дерево наименьшей
длины, соединяющее рассматриваемые вершины, a Q —
любое экономическое дерево. Предположим, что ребра
Ui, U2, .... un-i занумерован - - - - - -
они присоединялись при по-
строении Q, т. е. удовлетво-
ряют условию l(uk)^
^/(uft+i). Если дерево Р не
совпадает с Q, то Q имеет
по меньшей мере одно ребро,
не принадлежащее Р. Пусть
и,= (а, Ь) — первое такое
ребро и пусть L(a, b)—цепь
графа Р, соединяющая вер-
шины а и Ь, как, например, на рис 3.10. Если ребро ut до-
бавить к Р, то получим цикл, а так как Q не имеет циклов,
то в этот цикл должно входить по крайней мере одно реб-
ро, не принадлежащее Q. Пусть это будет u't. Удалив
его, получим дерево Р' с тем же числом вершин, что и Р,
длина которого
Z(P')=Z(P)+Z(«e)—Z(«'O- (3.14)
Так как граф Р имеет наименьшую длину, то
Z(«z)^Z(«'e). (3.15)
Но и, было ребром наименьшей длины, при добавле-
нии которого к ребрам Ui, иг, ..ис—\ не получается цик-
лов. Так как при добавлении u't к этим ребрам также не
получается никакого цикла, то
/(«,)=/(«',) (3.16)
и, следовательно, Р' имеет, так же как и Р, наименьшую
длину. Но Р' имеет с экономическим деревом Q на одно
общее ребро больше, чем Р. Повторяя эту операцию не-
сколько раз, получаем дерево наименьшей длины, совпа-
дающее с Q. Следовательно, Q —дерево наименьшей
длины.
83
3.3. ТРАНСПОРТНЫЕ СЕТИ
3.3.1. Основные понятия
Транспортной сетью называют конечный граф без пе-
тель, у которого:
1) существует одна и только одна такая вершина x<j,
что Г~1хо=0 (эту вершину называют входом сети)-,
2) существует одна и только одна такая вершина z
что Vz—0 (эту вершину называют выходом сети);
3) каждой дуге графа и отнесено целое число с (и),
называемое пропускной способностью дуги и.
С понятием транспортной сети тесно связано понятие
потока. Пусть х — произвольная вершина. Обозначим че-
рез и~х множество дуг, заходящих в х, а через U+x —
множество дуг, выходящих из х. Потоком по транспортной
сети называют функцию <р(«), удовлетворяющую усло-
виям
0^<p(u)^c(u), ue=U; (3.17)
2 ?(«)- 2 <Р(«) = 0, х=/=хй,x^z. (3.18)
U&J7 u&Uv
Функцию <р(ц) можно рассматривать как количество
вещества, протекающего (в единицу времени) по дуге
и—(х, у) от х к у. Согласно условию (3.17) это количе-
ство вещества не может превышать пропускной способ-
ности дуги с (и). Согласно условию (3.18) в каждой вер-
шине х, отличной от входа хо и выхода г, количество при-
текающего вещества равно количеству вытекающего. Сле-
довательно, вещество не может накапливаться ни в одной
вершине транспортной сети, за исключением входа и вы-
хода. А это означает, что поток, выходящий из входной
вершины хо, в точности равен потоку, входящему в вы-
ходную вершину z:
2 ?(«) = 2 <р(и)=<рг. (3.19)
ueUx, и<=и~
Величину <р(г) называют величиной потока транспорт-
ной сети.
На рис. 3.11 приведен пример транспортной сети. Циф-
ры в разрывах дуг означают пропускную способность дуги.
Стрелки указывают направление потоков, а цифры около
стрелок — величину потока. К анализу транспортных сетей
84
Рис. 3 11 Распределение потоков
в транспортной сети
сводятся многие задачи,
возникающие при плани-
ровании поставок, рас-
пределении товаров между
потребителями и т. п.
Для исследования рас-
пределения потока по
транспортной сети удобно
ввести понятие разреза
транспортной сети. Пусть
А<пХ — некоторое множе-
ство, удовлетворяющее ус-
ловиям
х0^А, г^А. (3.20)
Через U~A и через U+A
обозначим соответственно
Множество дуг, заходящих
в А и выходящих из А. Полную совокупность дуг UA —
— U~A{jU+A назовем разрезом транспортной сети. Пример
разреза приведен на рис. 3.11,а.
Поскольку каждая частица вещества, двигающаяся ог
л'о к г, обязательно пройдет по какой-либо дуге разреза,
то общий поток через разрез будет равен значению потока
тра'нспортной сети; для любого разреза А имеет место
соотношение
<рг= 2 <р(ы) — S ?(»)•
оес/т и^и+
(3.21)
Назовем пропускной способностью разреза А сумму
пропускных способностей дуг, заходящих в этот разрез.
с (И) — 2 с(«)-
(3.22)
Поскольку для любой дуги имеет место cp(w)^c(u)r
то из (3.21) и (3.22) вытекает
<рг^с(Д).
(3.23)
85
3.3.2. Задача о наибольшем потоке
Задача о наибольшем потоке в транспортной сети
формулируется следующим образом. При заданной кон-
фигурации транспортной сети и известной пропускной
способности дуг найти наибольшее значение потока, ко-
торый может пропустить транспортная сеть, а также рас-
пределение этого потока по дугам транспортной сети.
Лемма. Если для некоторого значения потока транс-
портной сети <рг и некоторого разреза V (рис. 3.11,в)
имеет место фг=с(1/), то поток фг является наибольшим,
а разрез V имеет наименьшую пропускную способность.
Доказательство. Как было показано, значение
потока фг для любого разреза А должно удовлетворять
соотношению (3.23). Обозначим через V разрез с мини-
мальной пропускной способностью
c(V) = min с (А). (3.24)
Так как значение потока ф? одно и то же для любого
разреза транспортной сети, то увеличение значения пото-
ка фг возможно лишь до тех пор, пока он не достигнет
значения c(V). Следовательно, значение потока
фг=с(К) (3.25)
и определяет наибольший поток транспортной сети.
Однако данная лемма не дает еще практически при-
годного способа определения наибольшего потока. Для
формулировки такого метода введем несколько вспомога-
тельных определений.
Дугу и назовем насыщенной, когда ф(и)=с(и). Поток
фг называют полным, если каждый путь из Хо в г содер-
жит по крайней мере одну насыщенную дугу.
Полный поток для данной транспортной сети не яв-
ляется строго определенной величиной и зависит от на-
правления потоков в отдельных дугах. Так, на рис. 3.11/t
и в даны два различных распределения потока по одной
и той же транспортной сети. Насыщенные дуги показаны
жирными линиями. В обоих случаях потоки являются поч-
ными, хотя значения их различны.
Алгоритм для нахождения наибольшего потока, пред-
ложенный Фордом и Фалкерсоном [13], состоит в посте-
пенном увеличении потока фг до тех пор, пока он не ста-
нет наибольшим. При этом предполагается, что пропуск-
86
ные способности дуг с (и) представляют собой целые чис-
ла, так что потоки по дугам также будут выражаться це-
лыми числами. Нахождение наибольшего потока произво-
дится в два этапа.
1. Нахождение полного потока. Пусть
Ф(и) — некоторое распределение потока по дугам транс-
портной сети. Ищем путь ц из х0 в г, все дуги которою
не насыщены, и полагаем:
Л).|’м+1 "₽»“£« (3.26)
' <р(ц) при и ^|Л.
При ЭТОМ ПОТОК фг ИЗМеНИТСЯ ДО величины ф'г=фг4-
+ 1>фг. Таким путем производим постепенное увеличение
Фг до тех пор, пока он не станет полным.
Пример 3.3. Найдем полный поток на транспортной сети
(рис. 3.11,а). Последовательно рассматриваем следующие пути, отме-
чая насыщенные дуги жирными линиями
Hi=(x<>, Xi, х3, z), <p((i|) = 1 — насыщается дуга (х0, *i),
р.!= (хох'г, х4, х3, г), <р(ц2) = 1 — насыщаются дуги (х4, х3) и (х3, z);
j.t3=(x0, х2, х4, г), для насыщения этого пути можно взять <р(р3) =
= 2 — насыщается дуга (х2, х4).
Легко видеть, что больше нет путей из х0 в z, содержащих нена-
сыщенные дуги Следовательно, полный поток
фг = ф (Ц1НФ (Ц2)+<Р (Цз) =4.
2. Нахождение наибольшего потока. Пусть
Фг—полный поток, ф(х, у)—поток в дуге ц=(х, у), на-
правленный от вершины х к вершине у. Процесс увели-
чения фг состоит в разметке вершин графа индексами,
указывающими путь, на котором возможно увеличение по-
тока. Предварительно все вершины графа должны быть
перенумерованы.
Помечаем х0 индексом 0. Если х, — уже помеченная
вершина, то помечаем индексом +t все непомеченные вер-
шины, в которые идут ненасыщенные дуги из х„ т. е. вер-
шины у, для которых
(х„ y)t=U и ф(х„ z/)<c(x„ у}, (3.21)
и индексом — I все непомеченные вершины, из которых
идут дуги в вершину х„ т. е. вершины у, для которых
(у, xt)e=U и <р(у, х,)>0. (3.28)
87
Если в результате этого процесса окажется помечен
ной вершина z, то между вершинами х0 и z найдется цепь
[л, все вершины которой различны и (с точностью до зна-
ка) помечены номерами предыдущих вершин. Поток во
всех ребрах этой цепи увеличиваем на единицу в направ-
лении от х0 к z, т. е. полагаем:
<p'(u)=<p(u), если
ф'(ц)=ф(«) + !> если мер.
и при движении от х0 к z дуга и проходит в направлении
ее ориентации;
ф'(и)=ф(и) —1, если иец
и при движении от х0 к z дуга и проходит в направлении,
противоположном ее ориентации.
В результате этого процесса получим новый поток по
сети ф'г=фг+1, т. е. поток возрастает. Далее этот про-
цесс повторяем.
Если некоторый поток фг° невозможно увеличить опи-
санным методом, т. е. если окажется невозможным поме
тить вершину z, то фг° является наибольшим потоком сети
Действительно, пусть V — множество непомеченных вер-
шин, включающих, конечно, и вершину z. Следовательно,
V есть разрез, причем такой, который не имеет выходя-
щих дуг (в противном случае некоторые вершины этого
разреза были бы помечены отрицательными индексами),
а все входящие дуги насыщены:
Uv =UV; Uv = 0; *1 (3.29)
<р (и) = С ('/) ДЛЯ U е Uy. J
При этом
?/ = S <р(и)— 3 ?(“)= 3 с(«) —0 = c(V). (3.30)
u£LUy uf—Uy
Согласно доказанной ранее лемме фг° есть наибольший
поток, а V — разрез с наименьшей пропускной способ-
ностью.
Пример 3.4. Разметка индексов вершин транспортной сети приве-
дена на рис. 3.11,а. Вершина z оказалась помеченной индексом -|-4.
Убывающая последовательность индексов -J-4, —3, -1-2. -|-0 определяет
88
цепь ц=(хо. х2, х3, х4, z), поток в которой от х0 к г следует увеличить
на единицу. Это приводит к распределению потока, показанному на
рис. 3.11,6. Повторяя процесс разметки индексов на этом рисунке, на-
ходим цепь g=(xo, х2, Х|, х3, х4, z), поток в которой также должен
быть увеличен на единицу. Результирующее распределение потока по-
казано на рис. 3.11,в. При разметке индексов на этом рисунке остают-
ся непомеченными вершины х4 и г.
Следовательно, полученное распределение потока обеспечивает наи-
больший поток фг° в рассмотренной транспортной сети, а множество
V={x4, г} определяет разрез с наименьшей пропускной способностью.
Определив пропускную способность разреза V, найдем значение потока
ф?=С(Х2, Х4)-|-С(Хз, х4)-|-с(хз, г) = 3-|-1-J-2 = 6.
Увеличить наибольший поток транспортной сети можно путем по-
вышения пропускной способности какой-либо из дуг, заходящих в раз-
рез V.
3.3.3. Транспортная задача
Наряду с задачей отыскания наибольшего потока прак-
тическое значение имеет задача наиболее экономичного
распределения потока по дугам транспортной сети, полу-
чившая название транспортной. Поскольку транспортная
сеть во многих случаях представляет собой схему органи-
зации перевозок каких-либо грузов, то решение транс-
портной задачи позволяет определить рациональный план
перевозок, т. е. такое распределение маршрутов, которое
обеспечивает, например, минимальную стоимость перево-
зок или доставку грузов к потребителю в кратчайшее
время. Первая задача получила название транспортной
задачи по критерию стоимости, а вторая — транспортной
задачи по критерию времени.
Для удобства дальнейшего изложения обозначим: с,,—
— с(х„ х,) — пропускная способность дуги (х„ х;); tZ,/=
=d(x„ X,) — стоимость прохождения единицы потока по
дуге (х„ х,).
Транспортную задачу по критерию стоимости в тер-
минах теории графов можно сформулировать следующим
образом.
Даны транспортная сеть с наибольшим потоком <рг°
и поток фг^фг0, который должен быть пропущен по этой
транспортной сети. Требуется найти такое распределение
89
потока фг по дугам транспортной сети, которое обеспе-
чивает минимальную стоимость прохождения потока. При
этом для каждой дуги должно выполняться соотношение
ф(х£, х,)^с£/, а стоимость прохождения потока ф(х£, х,)
по дуге (Xi, xt) равна с(,/ф(х£, х;).
Для решения этой задачи будем рассматривать вели-
чины dtI как длины соответствующих дуг. В этом случае
стоимость прохождения потока ф по какому-либо пути р
от xq до z будет равна произведению длины этого пути
на значение потока ф и задача минимизации стоимости
прохождения потока сведется к решению рассмотренной
ранее задачи нахождения кратчайшего пути в графе от
х0 до z. Если нет ограничений на пропускную способность
дуг, то кратчайшим путем является тот, который обеспе-
чивает минимальную стоимость прохождения потока.
При наличии ограничений на пропускную способность
дуг задача решается в несколько этапов путем нахожде-
ния частичных потоков на каждом этапе. Общий путь ре-
шения задачи состоит в следующем.
В графе Gi=(X, Г), изображающем транспортную
сеть с длинами дуг d„=/(x£, х,), ищется кратчайший
путь pi от хо до z Пусть Ci — пропускная способность
пути ць По этому пути пропускается поток
(Т„ если (3 3[)
(с,,, если <рг>б\.
Если фг=СС1, то задача решена и путь щ является
наиболее экономичным для потока фг.
Если фг>С1, то поток ф! рассматриваем как частич-
ный и переходим к графу Gi, который получается из гра-
фа Gi путем замены пропускных способностей дуг с,, на
с',, из соотношения
с'ч = Iе'/для (3.32)
{Сч для
При этом дуги, у которых с'о=0, исключают из рас-
смотрения Поток, распределение которого ищется в гра-
фе G2, принимаем равным
ф'г = фг—ф1. (3.33)
Теперь возникает первоначальная задача отыскания
наиболее экономичного распределения потока ф'г, но уже
90
Рис. 3.12. Схема дорог
по отношению к графу G2. Ее решение дает путь ц2 с про-
пускной способностью с2, через который пропускается ча-
стичный поток
если (3.34)
(с£, если <рг' >-с2.
Если (p'zs^cz, то задача решена и наиболее экономич-
ным распределением потоков в графе Gi будет прохож-
дение потока <pi по пути ц; и потока ф2 по пути ц2.
Если ф'2>с2, то следует
перейти к новому графу G3 и
найти новый частичный по-
ток фз- Этот процесс повто-
ряется до тех пор, пока сум-
ма частичных потоков не до-
стигнет значения ф2. Эти ча-
стичные потоки, пропущенные
по графу Gi, и дают наиболее
экономичное распределение
потока ф2.
Для иллюстрации описан-
ного метода рассмотрим наи-
более часто встречающийся вариант транспортной задачи
по критерию стоимости.
Однородный груз имеется на станциях Xi, ..., хт в ко-
личествах ait ..., ат. Его требуется доставить на станции
t/i....уг в количествах bit ..., br. Предполагается, что
общее количество требуемого груза равно имеющимся за-
пасам:
<3-35)
Ь=1 7=1
Стоимость перевозки единицы груза со станции х< на
станцию у, равна dt/. Требуется найти наиболее эконо-
мичные маршруты перевозки грузов. Исходные данные
удобно записывать в виде табл. 3.1.
Транспортная сеть, соответствующая этой задаче,
строится следующим образом. Вход х0 соединяется с каж-
дой из вершин х, дугой с пропускной способностью
с(х0, х,)—а,. Каждая из вершин у, соединяется с выхо-
дом z дугой с пропускной способностью c(yi, z)=b} Стои-
мость прохождения потока по дугам (х0, хг) и (yh z) счи-
тается равной нулю. Наконец, каждая вершина х, соеди-
91
няется с каждой вершиной у; дугой с бесконечной про-
пускной способностью, стоимость прохождения единицы
потока по которой равна d(/. Далее к этой транспортной
сети применяют рассмотренный метод.
Пример 3.5. Найти наиболее экономичные маршруты для транс
портной задачи, заданной в табл. 3.2. Эта таблица соответствует пока-
занной на рис. 3.12 схеме дорог, связывающих заводы, изготовляющие
Таблица 3.1
Стоимость прохождения единицы потока dtj для следующих b, - *
bi \ 1 ”r
dtl dir
а„, dim. &тг
Таблица 3.2
a. Стоимость прохождения единицы потока d,. для значения bf
5 10 20 15
10 8 3 5 2
15 4 1 • 6 7
25 1 9 4 3
строительные детали, с потребителями этих деталей (стройками). Транс-
портная сеть, соответствующая данным табл. 3 2, приведена на
рис. 3.13,а
Применяя описанный выше метод, находим частичные потоки и
маршруты, перечисленные ниже в порядке их получения
к ........... 1 2 3 4 5 6
Маршрут
(Х[, У,) • . . * (х3, уд (х2, Уд (х,, Уд (х3, Уд (х3, Уд (Х2, Уд
Частичный по-
ТОК’«6 . . . . 5 10 10 5 15 5 50
dh . . . . 1 12 3 46 -
Стоимость пе-
ревозки diftk 5 10 20 15 60 30 140
Соответствующий план перевозок приведен также на схеме дорог.
92
Рис. 3 13. Решение транспортной задачи по критерию стоимости (а)
и по критерию времени (б)
Нетрудно видеть, что в общем случае стоимость пере-
возки грузов по транспортной сети рассмотренного вида
определяется выражением
S S у?>- (3-36)
Следовательно, разобранный метод решения транс-
портной задачи дает по существу способ нахождения
величин частичных потоков <р(х1( tji), минимизирующих
указанную сумму. Рассмотренный способ решения не яв-
ляется единственным. С подобными задачами мы встре-
тимся в разделе, посвященном линейному программирова-
нию, где будут приведены другие методы решения анало-
гичных задач.
Решение транспортной задачи по критерию времени
разберем на примере транспортной сети, заданной табл. 3.2,
в которой величины d,/ будем теперь трактовать как вре-
мя, потребное на перевозку груза из пункта xt в пункт у/
93
и обозначать далее через t4. С подобными задачами мож-
но столкнуться при транспортировке скоропортящихся
продуктов, при доставке средств помощи в районы сти-
хийных бедствий, при вывозке зерна нового урожая в
заготовительные пункты и т. п. Во всех этих задачах
стоит требование доставки всех грузов в пункты назна-
чения за возможно более короткий промежуток времени.
Рассмотрим общий путь решения этой задачи. Пред-
положим, что каким-либо методом найдено некоторое рас-
пределение потока <р2 в графе G, изображающем рассмат-
риваемую транспортную сеть. ' Выделим из графа G
частичный граф G', в который включим только дуги, уча-
ствующие в передаче потока <р2. Пусть р —некоторый
путь, ведущий из х0 в z, — время прохождения потока
по этому пути. Очевидно, что время, необходимое на пе-
ревозку всех грузов из в z, будет определяться путем,
имеющим наибольшую продолжительность прохождения
потока, так как перевозка грузов по остальным путям
закончится раньше. Следовательно, время, требуемое на
перевозку всех грузов,
Т = шах (3.37)
peG'
Решение транспортной задачи по критерию времени
сводится, таким образом, к тому, чтобы выделить из гра-
фа G такой частичный граф G', который был бы спосо-
бен пропустить весь поток <р2 и в котором длительность
наиболее продолжительного пути была бы минимальной
по сравнению со всеми другими подобными графами. При
этом решение, найденное по описанному ранее критерию
стоимости, минимизирующее величину, определяемую вы-
ражением (3.36), может и не быть наилучшим с точки
зрения критерия времени.
Решение поставленной задачи сводится к последова-
тельному улучшению графа G' путем удаления из него
наиболее продолжительных путей и введения более ко-
ротких, но неиспользованных ранее и соответствующего
перераспределения потока <р2.,
Обратимся к рассматриваемому примеру. В качестве первого при-
ближения к наилучшему решению примем решение, полученное на осно-
ве критерия стоимости. Распределение потоков для этого случая пока-
зано на рис. 3 13,а Из рисунка видно, что время прохождения потока
по наиболее продолжительному маршруту (№, у3) равно шести. Одна-
94
ко оказались неиспользованными менее продолжительные маршруты
(xi, уг), (%2, yi), (хь у3). Поэтому возможно, что использование
какого-либо из этих маршрутов позволит исключить маршрут (хг, у3).
Построим частичный граф G', в который включим только дуги
графа G, имеющие /,/<6, и в котором распределение потока осталось
тем же, что и в графе G. Граф G' показан на рис. 3.13,6, где для
удобства вершины у, обозначены через хт+/=х3+/. Поток <р'2 через
этот граф равен 45 ед„ т. е. меньше, чем первоначальный поток <₽г=
=50 ед. Этот поток является полным, так как в графе G' все пути
из х0 в z содержат насыщенные дуги. Однако возможно, что он не
является наибольшим.
Таблица 3.3
Маршрут Частичный поток Время прохождения потока
(Х2, У г) 10 1
(Хр У») 10 2
(х3, у4) 5 3
(х2, Уз) (х3. Уз) 5 4
20 4
- <рг=50 <тах=4
Если наибольший поток в графе G' равен <р2, то найдется распре-
деление этого потока, при котором наиболее продолжительный путь
будет иметь время /g<6. Следовательно, дальнейшее решение задачи
сводится к определению наибольшего потока в графе G'.
На рис. 3.13,6 произведена разметка вершин графа G' в соответ-
ствии с правилом § 3 3. Разметка вершин указывает на существование
пути (Хо, хг, Xt, Хз, хв, г), на котором поток в направлении от х0 к г
может быть увеличен на 5 ед. Этот добавочный поток показан стрел-
ками. Как видим, наибольший поток в графе G' равен <р2=50 ед. и
наиболее продолжительный маршрут имеет время 4 ед. Дальнейшего
уменьшения времени прохождения потока добиться невозможно, так
как к вершине хв не идут маршруты со временем, меньшим 4 ед.
Окончательное распределение частичных потоков по маршрутам,
дающее решение транспортной задачи по критерию' времени, приведено
в табл 3.3.
95
ЭЛЕМЕНТЫ ЛИНЕЙНОЙ АЛГЕБРЫ
И ВЫПУКЛЫЕ МНОЖЕСТВА
4.1. МЕТРИЧЕСКИЕ ПРОСТРАНСТВА И РАССТОЯНИЯ
4.1.1. Понятие о расстоянии
Проведенное в гл. 2 рассмотрение множеств как со-
вокупностей некоторых объектов имеет ограниченное при-
менение, так как в природе все материальные объекты
находятся во взаимной связи и взаимодействии. Поэтому
понятие множества необходимо увязать с установлением
тех или иных соотношений между его элементами.
Говорят, что множество имеет структуру, если между
элементами множества установлены определенные соотно-
шения или над ними определены некоторые операции.
Множество, наделенное структурой, называется простран-
ством.
Н
Рис. 4.1. Иллюстрация
аксиомы треугольника
Рис. 4.2. Определение расстояния в городе, разде-
ленном на кварталы
Изучение пространств начнем с пространств, называе-
мых метрическими, для определения которых необходимо
ввести понятие расстояния между элементами множества
[14].
С понятием расстояния человек сталкивается повсе-
дневно, связывая это понятие с пространственным раз-
мещением предметов и понимая под расстоянием меру
удаленности предметов друг от друга. Обычно расстояние
d(M, N) между точками М и N измеряется длиной от-
резка, соединяющего эти точки (рис. 4.1). Однако такое
96
определение расстояния часто оказывается недостаточным.
Так, даже в обиходе расстояние между двумя городами
определяется не однозначно (расстояние по железной до-
роге, расстояние по водному пути и т. п.). В городе, раз-
деленном на кварталы, как показано на рис. 4.2, измерять
расстояние отрезком прямой, соединяющей точки М и N,
не имеет смысла, так как двигаться можно только по
улицам.
а) х б) х б) х
Рис. 4.3. Различные случаи близости двух функций
С другой стороны, слово «удаленность» часто не свя-
зывают с пространством в обычном понимании. Так, бли-
зость двух клеточек на шахматной доске можно оценить
числом ходов, которые нужно сделать, чтобы перевести
шахматную фигуру с одной клеточки на другую. При
этом две соседние клеточки близки для короля, но далеки
для коня и являются бесконечно далекими, если из одной
в другую нужно перевести слона.
/_В математике часто стоит задача замены одной функ-
ийи^у—f (х), которая почему-либо неудобна для рассмот-
рения, другой функцией y=g(x). Такая замена возможна,
если функция g(x) близка к функции f(x) (рис. 4.3,а).
При этом следует договориться, как понимать близость
друг к другу двух функций. Если за условие близости
принять ограничиваемые функциями площади, то во всех
трех случаях функции близки друг к другу. Если бли-
зость оценивать по максимальному отклонению значений
у в этих функциях, то в случае на рис. 4.3, б функции уже
нельзя считать близкими, а если учитывать еще и харак-
тер функции, например кроме близости значений самих
функций потребовать близости производных, то функции не
будут близкими и в случае на рис. 4.3,в.
Из приведенных примеров видно, что должно сущест-
вовать некоторое общее определение расстояния как меры
7-804 97
удаленности ^объектов, а следовательно, и пространства,
в котором эти объекты существуют, причем в различных
конкретных ситуациях эти понятия могут иметь разное
содержание. Поскольку совокупности различных объек-
тов представляют собой множества, то понятия простран-
ства и расстояния должны быть связаны с понятием мно-
жества.
4.1.2. Определение метрического пространства
Пусть X — произвольное множество. Понятие расстоя-
ния между элементами из X получается путем обобщения
фундаментальных свойств, которые можно интуитивно
ожидать от понятия расстояния и которые легко могут
быть поняты из рассмотрения рис. 4.1.
Свяжем с каждой парой элементов из X некоторое
вещественное неотрицательное число d^Q. Это число на-
зывают расстоянием или метрикой в X, если для любых
х, у, z^X оно удовлетворяет следующим трем свойствам:
1) d(x, у)=0 тогда и только тогда, когда х=у (аксио-
ма идентичности);
2) d(x, y)—d(y, х) (аксиома симметрии);
3) для любой тройки х, у, z^X имеет место d(x, у)^
^d(x, z)-\-d(z, у) (аксиома треугольника).
Метрическим пространством называют пару (X, d),
т. е^ множество X с определенной на нем метрикой d.
Элементы множества X называют точками метрического
пространства (X, d).
Из данного определения следует, что множество X
только тогда превращается в метрическое пространство,
когда в него введена соответствующая метрика d(x, у).
Если в одном и том же множестве X ввести различные
метрики, то получатся и различные пространства. Так,
пространства, изображенные на рис. 4.1 и 4.2, имеют в
качестве элементов множества точки плоскости, но обла-
дают разными метриками.
4.1.3. Примеры метрических пространств
Пусть х, у—-любые элементы из множества R вещест-
венных чисел. Множество R можно превратить в метри-
ческое пространство, если расстояние между х и у опре-
делить из выражения
d(x, у) = \х-у\. (4.1)
98
Именно по этой формуле находят расстояние между
точками вещественной оси, которая является простейшим
примером метрического пространства.
Когда мы видели в § 2.3, упорядоченные п-элементные
множества удобно рассматривать как точки воображае-
мого «-мерного пространства Rn. Можно расширить пред-
ставление о таком пространстве, введя понятие расстоя-
ния между отдельными точками, т. е. рассматривая это
пространство как метрическое. Обозначим через х —
= (хь ..., х„), y=(yt, ..., уп) отдельные точки пространства
Rn. Пространство Rn можно превратить в метрическое не-
сколькими различными способами.
Наиболее часто расстояние между точкам и х и у опре-
деляют по формуле
йг(х, у)=* 2 |хг-«Л |г
(4.2)
В случае п=2, 3 это определение совпадает с обыч-
ным геометрическим понятием расстояния. Свойства 1, 2
и 3 для этого расстояния очевидны из рассмотрения
рис. 4.1.
Метрику d2(x, у) называют евклидовой, а .простран-
ство Rn с такой метрикой — евклидовым и обознача*
ют Еп.
Для множества Rn расстояние может быть определено
и другими способами, например:
^(х,у) = ^ |х( — yt\
(4-3)
или
dco(x, t/)=max(|xi—t/i|, ..., |х„—р„|). (4.4)
Легко видеть, что метрики d2, di, dx являются част-
ными случаями метрики
dp(x, у) =<>2 К- (4.5)
и получаются соответственно при р=2, р=1 и р—оо.
Свойства 1 и 2 для метрик (4.3) и (4.4) очевидны. Для
доказательства свойства 3 введем в рассмотрение еще
одну точку z=(zx.... zn)e/?rt. Для расстояния rfi(x, у)
имеем:
< (х, у) = 2 1 V, - Zi+z- — yt I <
<2 (1Хг ~z‘\ + \z‘-yt\)=d(x. z) + d1(z, у).
i=i
Для расстояния doo(x, у) свойство 3 проверяется сле-
дующим образом. Предположим, что |х*—z/*|—самая
большая из соответствующих разностей точек х и у.
Тогда /
da>{x, y) = \xk-yk\ = \xk-zk+zk-yk\<
< | — Zk I + I zk — yk |.
Очевидно, что
}хк — zj<max(|x1-z„|.... |xn - zn |) = dx(x, z);
— I<max(|2,-^1.!-. Izn-M=d°o(z, У)-
Следовательно,
d<x>(x, y)<d^(x, z)+^oo(z, y).
Рассмотрим множество всевозможных функций време-
ни, непрерывных на интервале a^t^b. Пусть x(t) и
y(t) —две такие функции. Расстояние между ними
d(x, у) — max \x(t) — y(t)\ (4.6)
a^t^b
удовлетворяет всем свойствам метрики. Пространство
с такой метрикой С[а> 6).
4.2. ИСПОЛЬЗОВАНИЕ МЕТРИЧЕСКИХ ПРОСТРАНСТВ
В НЕКОТОРЫХ ЗАДАЧАХ КИБЕРНЕТИКИ
4.2.1. Пространство сообщений
Как мы видели во введении, сообщения передаются по каналам
связи с помощью некоторого алфавита И, состоящего из конечного чис-
ла символов. Сообщения представляют собой различные последователь-
ности символов алфавита. Число символов в сообщении называют
длиной сообщения.
100
Рассмотрим случай, когда с помощью алфавита 81т, состоящего из
т символов, передаются сообщения длиной п. Сюда можно отнести
и более короткие сообщения, если дополнять их до длины п некото-
рым определенным символом, например нулем при использовании дво-
ичного алфавита. Множество всех таких сообщений можно рассматри-
вать как метрическое пространство, если ввести понятие расстояния
между сообщениями.
Назовем расстоянием d(x, у) между двумя сообщениями х и у
число позиций, в которых у сообщений х и у стоят разные символы.
Полученное при этом метрическое пространство обозначим Е(п, Slm) и
назовем пространством сообщений.
Пример 4.1. Пусть SI m— русский алфавит; п=7, х= (картина);
у= (корзина). Не совпадают вторая и четвертая буквы. Следовательно,
d(x, у) = 2.
Пример 4.2. Пусть 81=Э12={0, 1} —двоичный алфавит; п=10; х=
=0100111010; «/=0010110010. Не совпадают 2, 3 и 7-й знаки. Следова-
тельно, d(x, у)=3.
Приведенное определение расстояния d(x, у) в пространстве сооб-
щений удовлетворяет всем свойствам расстояния. Аксиома идентично-
сти и аксиома симметрии являются очевидными. Убедимся, что выпол-
няется и аксиома треругольника.
Рассмотрим сообщении х, у и z длиной п. Обозначим через хк, ун
и Zk символы у этих сообщений k-й позиции. Естественно, что если
хк=Уи и «/4=zft, то xk=zk, т. е. если в какой-либо позиции совпадают
символы у сообщений х и у и у сообщений у и z, тогда в этой пози-
ции совпадают символы и у сообщений х и z. Следовательно, у сооб-
щений х и z несовпадающие символы могут быть только на тех ме-
стах, где не совпадают символы, а также у сообщений х и у, или
у сообщений у и z. Но это значит, что общее число несовпадающих
символов у сообщений х и z не может превосходить суммы чисел не-
совпадающих символов у сообщений х и у и у сообщений у и z.
Для простоты и наглядности ограничимся рассмотрением только
двоичного алфавита 81=812= {0, 1). Это можно сделать, не уменьшая
общности рассуждений, так как сообщения, представляемые символа-
ми одного алфавита, можно всегда перекодировать в сообщения, пред-
ставляемые символами другого алфавита. Рассмотрим, например, алфа-
вит Э1т, содержащий m символов. Сопоставим каждому символу поряд-
ковый номер от 0 до m—1. Если теперь заменить в сообщении символы
алфавита Э1т их порядковыми номерами в двоичной системе счисления,
то получим представление сообщения в двоичном алфавите.
Совокупность символов двоичного алфавита, принятую для обо-
значения того или иного сообщения, будем называть двоичным кодом
или кодом сообщения.
101
4.2.2. Понятие о помехоустойчивых кодах
В процессе передачи по каналу связи возможно искажение пере-
даваемого сообщения. При двоичном алфавите искажение состоит
в том, что в принятом сообщении некоторые единицы окажутся заме-
ненными нулями, а некоторые нули — единицами. Возникает вопрос,
нельзя ли построить коды, которые позволяют обнаруживать, что
в процессе передачи произошло искажение, или даже восстанавливать
значения искаженных разрядов. Коды, обладающие этими свойствами,
называют помехоустойчивыми.
Рассмотрим случай, когда в процессе передачи сообщения не мо-
жет произойти искажения более чем в k разрядах. В пространстве со-
общений Е(п, Я2) выделим подмножество Н*=Е(п, Ш2), обладающее
тем свойством, что для любых х, уеНь имеет место:
d(x, y)>k. (4.7)
Множество Н* назовем множеством осмысленных слов. Здесь тер-
мин «слово» является синонимом термина «сообщение». Тогда любое
есть бессмысленное слово Предположим, что при передаче сло-
ва хеН» оно исказилось и превратилось в слово х'. Так как по усло-
вию могло произойти не более k искажений, то d(x, x')^k и
т. е. х' — бессмысленное слово. Таким образом, прием бессмысленного
слова означает, что в процессе передачи произошло искажение. Коды,
удовлетворяющие условию (4.7), называют кодами с обнаружением
ошибки.
Пример 4.3. Из множества Е(ЗИ2) выделим следующее множество
осмысленных слов, удовлетворяющих условию d(x, у)=2:
Я,= {000, 101, ОН, ПО}.
Искажение любого разряда в этих словах превращает их в бес-
смысленные, т. е. позволяет обнаруживать однократную ошибку.
Множество Я,, образующее код с обнаружением однократной
ошибки в словах длиной п, можно получить следующим образом. Рас-
смотрим множество Е(п—1, И2), т. е. множество слов длиной п—1.
Множество Я] получим, добавляя к этому множеству еще один раз-
ряд, значение которого выбираем таким, чтобы общее число единиц
в словах х<=Нг было четным.
Пример 4.4. Для п=4 имеем:
£(3, И2)={000, 001, 010, 100, 011, 101, ПО, 111}.
При этом
Я,= {0000, ООП, 0101, 1001, ОНО, 1010, 1100, 1111}.
Обнаруживать искаженное слово удобно с помощью операции сло-
жения по модулю 2 согласно правилам
0®0=0; Оф 1=1; 1ф0=1; 1ф 1=0. (4.8)
102
Так, в слове x=at, а2.... ап величина р = а1фа2 ©... фа„
-будет нулем или единицей в зависимости от того, четное или нечетное
число символов слова имеют значение единицы.
Заметим, что получившийся в примере 4.4 четырехразрядный код
•с обнаружением ошибки дает возможность составить 24=16 различных
слов, хотя в качестве осмысленных слов, т. е. подлежащих передаче по
каналу связи, используется только 8. Коды, у которых количество
осмысленных слов меньше общего числа возможных слов, получили
название кодов с избыточностью Наличие избыточности — необходимое
условие построения помехоустойчивых кодов.
Можно построить такие коды, которые позволяют исправить допу-
щенные ошибки. Полагаем опять, что в процессе передачи могут под-
вергнуться искажению не более k разрядов кода. Множество осмыс-
ленных слов Н4=Е(п, St2) выбираем из условия
d(x, y)>2k (4.9)
для любых х, уеНк-
Рассмотрим любые два сло^а х, уе=Нь. Пусть в результате иска-
жения х превратилось в х'. Поскольку d(x, y)>2k; d(x, x')<k, то из
аксиомы треугольника получаем
d(x', y)>k. (4.10)
Таким образом, расстояние от ошибочного слова х' до слова х,
подвергшегося искажению, меньше, чем до любого другого осмыслен-
ного слова. Находя ближайшее к х' осмысленное слово, мы тем самым
восстановим правильное сообщение х. Коды, удовлетворяющие условию
(4.10), называют кодами с исправлением ошибок. Вопросы практиче-
ской реализации кодов с исправлением ошибки достаточно сложны и
рассматриваются в специальной литературе [15].
4.2.3. Сглаживание ошибок в экспериментальных данных
При исследовании работы различных технических систем часто бы-
вает необходимо знать, как меняется некоторая физическая величина
у(1) с течением времени. С этой целью ставится эксперимент и в мо-
менты Zj, ..., tn измеряют значения yi=y(ti), ..., yn = y(Jn). После-
довательность дискретных значений физической величины У=(«/ь ...
Уп) будем рассматривать как точку в п-мериом пространстве.
Однако на практике условия эксперимента бывают далеко не
идеальны и результаты измерений оказываются в значительной степени
искаженными. Поэтому измеренные значения физической величины
Xi, ..., хп будут отличаться от истинных значений, как это показано
иа рис 4.4. Возникает вопрос, как нанлучшим образом по неточным
103
измеренным значениям х,; i=l, ,.п установить истинный характер
зависимости у(Z)?
Обозначим Х=(х........хп) точку n-мерного пространства, коорди-
натами которой будут результаты измерений. Очевидно, что если Х=
= У, т. е. расстояние d(X, У) между точками X и У равно нулю, то
измерения произведены без ошибок и последовательность (хь ..., хп)
дает истинный характер изменения физической величины. Если же
X=/=-Y, то о степени искажения можно судить по расстоянию d(X, У).
Обычно общий характер зависимости y(t) бывает известен с точ-
ностью до нескольких числовых параме-
трое, значения которых и должны быть
установлены по результатам эксперимен-
та. В этом случае задача сводится к то-
му, чтобы выбрать неизвестные парамет-
ры зависимости y(t) такими, при кото-
рых расстояние d(X, У) или, что час-
то бывает удобней, квадрат этого рас-
стояния d2(X, У) обращается в ми-
нимум.
Оставляя рассмотрение общего ре-
шения подобного вида задач до
Рис. 4.4. Неточные измере-
ния физической величины
гл. 10, ограничимся обсуждением лишь простейшего случая, когда при
проведении эксперимента величина y(t) остается неизменной, н обо-
значим через с истинное, хотя и неизвестное, значение y(t), так что
У=(с, .... с). Воспользовавшись метрикой (4.2), определяющей евкли-
дово расстояние dz(X, У), для квадрата этого расстояния получаем
d22(X, У) =2 (Xi-су.
(4.Н)
Приравнивая нулю производную от этого выражения по с:
(d/dc) [s (xf-c)»j = -22 (xf—с)=0,
находим
n
-tS'- ,,12>
Величину с, вычисленную no (4.12), называют средним арифмети-
ческим значений Х|, ..., хп, а использованный метод получения этой
формулы называется методом наименьших квадратов.
При ином определении расстояния получают другие формулы для
определения среднего. Для удобства будем считать, что величины
Xi, • , хп расположены в порядке возрастания их значений. Предла-
104
гаем читателям самостоятельно убедиться, что при определении рас-
стояния по (4.3) среднее значение, называемое медианой, находится из
соотношения
пРи нечетном п;
(любое от x„/2-i Д° хл/2+ 1 ПРИ четном п.
Иногда для конкретности при четном п полагают
с=0,5 ('Сп/г-r|-xn/2+i). (4.14)
Если расстояние определяется по (4.4), то формула для среднего
имеет вид
с=(х,+хп)/2. , (4.15)
4.2.4. Задача распознавания образов
Раздел кибернетики, занимающийся распознаванием образов, ста-
вит своей целью промоделировать одно из важнейших свойств чело-
веческого мозга — свойство распознавания предметов, явлений и ситуа-
ций, позволяющее человеку легко .ариентироваться в сложной окру-
жающей обстановке [16, 17].
Основными понятиями теории распознавания являются понятия
класса и образа. Отдельные предметы или явления реальной действи-
тельности отличаются друг от друга по своим свойствам. В то же
время у отдельных предметов и явлений есть и общие свойства, позво-
ляющие сгруппировать предметы в некоторые множества или классы.
Так, различные виды автомобилем объединяют в класс автомобилей.
Классы могут быть различной степени общности в зависимости от
свойств, которые им приписывают. Так, класс автомобилей является
элементом более обширного класса средств транспорта. Таким обра-
зом, классом называют множество предметов или явлений, объединен-
ных некоторыми общими свойствами.
В каждой конкретной ситуации приходится иметь дело с конечным
набором классов, выраженных конечным множеством
W={A, В, С.......Р}. (4.16)
Каждый класс включает в себя множество объектов, число кото-
рых может быть сколь угодно велико и свойства которых весьма раз-
нообразны. Однако практически оказывается возможным учитывать
лишь ограниченное и часто очень небольшое число различных свойств.
Назовем совокупность конечного числа свойств объекта изображением
или образом объекта и будем представлять образ в виде «-мерного
вектора х=(х....., хп), компоненты которого количественно характе-
ризуют свойства образа. Примером образа может служить телевизион-
ный сигнал фотографии, разделенной на п независимых ячеек. Сово-
105
купность яркостей свечения яечеек формирует точку в n-мерном про-
странстве, которая является образом фотографии.
Можно ожидать (конечно, при условии, что выбранная совокуп-
ность признаков достаточно полно характеризует свойства объектов),
что совокупность точек, соответствующих разным изображениям одно-
го и того же класса, будет занимать в пространстве образов некоторую
Рис. 4.5. Разделение пространства образов на классы
Задачу распознавания образов можно считать в принципе решен-
ной, если в пространстве образов проведены поверхности, разделяющие
это пространство на области, точки которых принадлежат к образам
разных классов Одним из возможных методов решения этой задачи
является предварительное изучение свойств отдельных образцов объек-
тов каждого класса.
Предположим, что имеется всего два класса объектов (-4 и В).
Обозначим через Ао и Во множества предварительно изучаемых образ-
цов из этих классов. Изображения этих образцов в пространстве обра-
зов могут иметь вид, показанный для двумерного случая на рис. 4.5,а,
где точки, соответствующие образцам из Ло, обозначены кружками,
а из Во — треугольниками.
Пусть х — образ исследуемого нового объекта. За меру близости
этого образа к классам А и В примем величины S(x, Л) и S(x, В),
представляющие собой, например, средние квадраты расстояния от точ-
ки х до точек, соответствующих отдельным образцам классов А н В.
Так, если Ло={аь .... ат} и Во= .......... bt}, то по (4 12) для сред-
него значения получим
S(x, Л) = (1/т)2^ (х, а{у,
S(x, В) -(1/Z)2 cfi(x, Ь}).
(4.17)
106
Поверхностью, разделяющей образы обоих классов в пространстве
образов, будет такая поверхность С, точки которой удовлетворяют
условию
S(x, A)=S(x, В). (4.18)
Как видно из рис. 4.5,а, в некоторых случаях поверхность С будет
такова, что возможно ошибочное отнесение образа к чужому классу.
Критерием качества распознавания может служить относительное число
неправильно распознаваемых образов.
Пример 4.5. Из классов А и В взято по одному образцу ateA и
tieB, выражающих в двумерном пространстве образов наиболее ха-
рактерные свойства этих классов. Провести линию, разделяющую про-
странство образов на две области, соответствующие классам А и В.
Будем определять расстояние по (4.2) длиной отрезка, соединяю-
щего две точки в пространстве образов. Согласно (4.18) разделяющей
линией будет такая, все точки которой удалены на одинаковое рас-
стояние от точек а( и &ь Эта линия будет перпендикуляром, восста-
новленным из середины отрезка, соединяющего точки at и bt
(рис. 4.5,6).
<3
4.3. ЛИНЕЙНЫЕ ПРОСТРАНСТВА
4.3.1. Определение линейного пространства
В начале главы пространство было определено как
множество, наделенное определенной структурой. Были
рассмотрены метрические пространства, структура кото-
рых определялась тем, что каждой паре элементов припи-
сывалось вещественное число, удовлетворяющее опреде-
ленным свойствам и называемое метрикой. Однако вве-
дение метрики далеко не исчерпывает всех структурных
свойств различных пространств. В частности, если множе-
ство X состоит из вещественных или комплексных чисел,
то к важным структурным свойствам относится возмож-
ность получения одних элементов множества из других
путем сложения этих элементов или умножения элемента
на скаляр. Множества, обладающие этими свойствами, от-
носятся к классу линейных пространств. Линейные про-
странства должны удовлетворять следующим условиям:
1) каждой паре элементов х, у^Х однозначно опреде-
лен третий элемент zeX, называемый их суммой и обо-
значаемый х-j-z/, причем
х-\-у=у-{-х (коммутативность);
x-j- (z/4-v) = (х+у) (ассоциативность);
в X существует такой элемент 0, что х-}-0=х для всех
хеХ (существование нуля);
107
для каждого х^Х существует такой элемент — х, что
х+( —х)=0 (существование противоположного элемента);
2) для любого числа а и любого элемента хеХ опре-
делен элемент ах<=Х, причем
(а-Ьр)х=<хх+рх; а(х+у)=ах+ау.
Условия 1 и 2 называют условиями аддитивности и
однородности линейного пространства.
Множества, элементы которых допускают выполнение
операций сложения и умножения на скаляр, весьма раз-
нообразны. Рассмотрим несколько примеров подобных
множеств:
4 множество вещественных чисел R с обычным опреде-
лением операций сложения и умножения;
множество векторов, т. е. направленных отрезков на
плоскости или в пространстве;
множество всех функций С|а, Ь] непрерывных на за-
данном сегменте [а, Ь], если для любых x(t), y(t) е
£Ci0, ы под x(t)+y(t) понимать сумму значений х(1)
и y(t), взятых при одних и тех же значениях t, а под
ах (0 понимать новую функцию, получаемую из x(t) ум-
ножением всех ее значений на а. Нулевой функцией бу-
дет функция х(0=0, тождественно равная нулю на всем
интервале [а, Ь];
\ множество всех многочленов степени, не превышающей
натурального числа п.
Однако в дальнейшем сосредоточим свое внимание на
линейных пространствах, элементами которых являются
упорядоченные последовательности п вещественных чисел,
их в соответствии со сказанным в § 2.3 будем называть
векторами.
Отметим, что,под понятие вектора можно подвести и
, функцию х(0, если рассматривать ее как множество зна-
чений х(0 при различных t, а также многочлен, который
может быть задан множеством коэффициентов при раз-
личных степенях переменной. Поэтому термин «вектор»
часто используют для' обозначения элементов произволь-
ного линейного пространства.
4.3.2. Действия над векторами
До сих пор, говоря о множествах, мы считали, что
элементами множеств могут быть элементы любой при-
роды. В настоящей главе сосредоточим внимание на мно-
108
жествах, элементами которых являются векторы, т. е. упо-
рядоченные последовательности из п чисел х(1), ..х<п),
которые условно могут быть записаны в виде вектор-
, столбца или в виде вектор-строки:
_х(«) _
х<п>) = (х<г))1п.
Сами числа, составляющие вектор, называются компо-
нентами. вектора.
Если один из этих векторов обозначить буквой х, то
для другого будем использовать обозначение хт и назы-
вать транспонированным вектором х. Таким образом,
операция транспонирования вектора представляет собой
переход от вектор-столбца к вектор-строке и наоборот.
В настоящей главе придется иметь дело в основном с век-
тор-столбцами, поэтому ниже, если не оговорено против-
ное, всякий вектор считаем вектор-столбцом и обознача-
ем как
х—[дс<0]1«== (х<0 .... х(ч))т. (4.19)
Число п компонент вектора называется его размерностью.
Сами компоненты могут быть вещественными или комп-
лексными числами, однако в дальнейшем ограничимся рас-
смотрением лишь векторов с вещественными компонентами
(вещественных векторов). Вектор размерности единица
представляет собой просто вещественное число, т. е. ска-
ляр.
Свойства рассматриваемых упорядоченных последова-
тельностей чисел являются обобщением свойств векторов,
рассматриваемых в элементарной алгебре.
Векторы х и у называются равными, если равны их
компоненты:
х=у, если = i=l, п. (4.20)
Суммой х-]-у векторов х и у называют вектор, компо-
ненты которого являются суммой компонент слагае-
мых:
(4.21)
109
Очевидно, что
х+у—у+х;
x+(y+z) = (x+y)+z.
(4.22)
(4.23)
Разность векторов х—у представляет собой вектор z
такой, что y+z=x.
Умножение вектора х на скаляр а дает вектор, ком-
поненты которого получаются из компонент вектора х
умножением их на а:
“Х(1) “ ~ах(1)“|
ах = ха = а
(4.24)
В дальнейшем вектор х будем называть точкой линей-
ного пространства.
4.3.3. Линейная зависимость и независимость векторов
Пусть X — линейное пространство. Рассмотрим некото-
рое множество точек этого пространства Xi, ..., х«. Точ-
ки Xi, ..., х„ называют линейно зависимыми; если сущест-
вуют числа си, ..., ал, не все тождественно равные нулю,
то имеет место равенство
Й0х1“Ь ... -|-(Хлхл-----0. I
(4-25)
Часто бывает удобно другое определение линейной за-
висимости. Векторы Xi, ..., хп являются линейно зависи-
мыми, если один из них может быть представлен в виде
линейной комбинации остальных. Так, если an:#0 и вы-
полняется условие линейной зависимости, то, принимая
a/=—at/an, получаем
хп—c/iXi-j- ... -J-aSi-iX/i-b
(4.26)
Пример 4.6. В пространстве упорядоченных n-ок вещественных
чисел линейно независимыми являются векторы
“ 0 -
" 0 "
0
х„ =
ПО
В пространстве непрерывных функций при фиксированном N ли-
нейно независимыми являются функции
fi(/) = l, f2(0=t, .... f»(t)
4.3.4. Линейное подпространство
Как следует из определения линейного пространства
X, для любых точек хь х2е% и любых чисел а и |3 ве-
личина aXi+pxa будет также элементом линейного про-
странства X.
Рассмотрим произвольное конечное множество точек
S={xi, xm} линейного пространства X. Покажем, что
множество
L(S) = 2azxf (4.27)
при всевозможных а, также представляет собой линей-
ное пространство, являющееся подмножеством линейного
пространства X и называемое линейным подпростран-
ством.
Доказательство. 1). Покажем, что L(S) есть
подмножество X. Это следует из определения линейного
пространства. Каждое слагаемое в сумме (4.27) есть эле-
мент линейного пространства X. При сложении же эле-
ментов линейного пространства опять получаем элементы
линейного пространства X.
2) Докажем, что L(S) — линейное пространство. Для
этого достаточно показать, что для любых х', x"eL(S)
имеет место ax'+px"eL(S).
Возьмем произвольные совокупности чисел а/ и а/\
i=l, ш. Тогда точки
X' = 2 а/хг'. Х”= 2 а/'хг
принадлежат £(S). Рассмотрим точку
х = ах' + рх" = а а/хг + Р 2 а‘"х‘ =
<=1 i=i
т т
= S (аа/ + Ра/,)Х1 = 2 aixz.
где a1=aaI'-|-pai".
Ill
Как видим, х определяется формулой (4.27), а значит,
принадлежит L(S). Таким образом, L(S) — линейное про-
странство.
Поскольку соотношение (4.27) однозначно связывает
с множеством S линейное пространство L(S), то говорят,
что линейное пространство L(S) определяется множест-
вом S.
4.3.5. Размерность линейного пространства
Если элементы множества S, определяющие линейное
пространство L(S), являются линейно зависимыми, то не-
которые из этих элементов можно представить как линейные
комбинации других элементов. Удаление этих эле-
ментов из множества S не повлияет на определение ли-
нейного пространства L(S). Следовательно, если из мно-
жества S выделить подмножество S„={xb ..., х„), элемен-
ты которого являются линейно независимыми, то опреде-
ляемое множеством Sn линейное пространство L(Sn)
совпадает с линейным простраством L(S). Поэтому число
линейно независимых элементов в множестве S, т. е. число
п, называют размерностью линейного пространства L(S).
При этом само линейное пространство L(S) называют
п-мерным.
4.4. ЕВКЛИДОВЫ ПРОСТРАНСТВА
4.4.1. Линейное нормированное пространство
Линейное пространство получает законченное описа-
ние лишь тогда, когда свойства аддитивности и однород-
ности дополнены возможностью измерения значений са-
мих элементов. Так, мы не можем сравнивать векторы,
если заранее не договоримся, что понимать под значе-
нием (длиной) вектора. Введение в линейное простран-
ство численных оценок отдельных элементов приводит
к понятию линейного нормированного пространства, на-
зываемого иногда банаховым пространством.
Линейное пространство называют нормированным ли-
нейным пространством, если для каждого хеХ сущест-
вует неотрицательное число ||х||, называемое нормой х,
которое удовлетворяет следующим условиям:
||х||=0 тогда и только тогда, когда х=0;
llax|| = |aj -||х||;
112
Нх+УIKI|x|| + llyll (неравенство треугольника).
Нетрудно установить, что величина ||х—у|| обладает
всеми свойствами расстояния d(x, у) в метрическом про-
странстве. Действительно, ||х—у||=0, если х—у=0, т. е.
если х=у. Учитывая, что у—х=—(х—у), находим
1|у-х|| = |-1|-||х-у|| = ||х-у||;
II х - у || = ||(х - z) + (z-у)||<|| х - z|| + ||z- у||-
Следовательно, нормированное линейное пространст-
во является метрическим пространством с метрикой
d.(x, у) = ||х—у||. (4.28)
Все рассмотренные ранее метрические пространства,
дополненные свойствами аддитивности и однородности, пре-
вращаются в нормированные линейные пространства. Для
этих пространств используют специальные обозначе-
ния:
1) пространство С2<п) или Еп — евклидово пространст-
во—с нормой
/л ) 1/2
Цх|1= <3 или?||;Х|| = |х| при>= 1; (4.29)
2) пространство с нормой
н>11 = 3IM (4.30)
3) пространство С(л) с нормой
||x||=max{|xi|, ..., |хл|); (4.31)
4) пространство С[а,ь] непрерывных функций, опреде-
ленных на промежутке [а, &], с нормой
||f|| = max|f(0|. (4.32)
4. 4.± Скалярное произведение векторов
Как уже указывалось, линейное пространство называ-
ют евклидовым, если норму вектора х= (х(1>, ..., х<п>)т,
определяющую его длину, находят из соотношения (4.29).
Такое определение нормы оказывается тесно связанным
8—804 ИЗ
с понятием скалярного произведения векторов. Пусть
[Хг 1 Г Уг 1
I И у = I &
х3 J I Уз J
— два вектора в трехмерном пространстве. Скалярным про-
изведением этих векторов называют скалярную величину
хту=утх=х1г/1+х2г/2+х3г/з. (4.33)
При этом легко видеть, что корень квадратный из ска-
лярного произведения вектора х на самого себя дает нор-
му этого вектора
(хтх)>/2== (х12+х22+хз2)1/2 = Цх||. (4.34)
Таким образом, понятия нормы вектора и скалярного
произведения векторов тесно связаны между собой, поэто-
му представляется важным обобщить понятие скалярного
произведения */2 на произвольное линейное пространство.
Определение. Пусть X — линейное пространство. Гово-
рят, что на пространстве X определено скалярное произ-
ведение, если каждой паре векторов х, уеХ соответствует
действительное число хту, обладающее следующими свой-
ствами:
II) хту=утх (коммутативность);
2) xT(y+z)=xTy+xTz (дистрибутивность);
3) Лхту=Л(хту), Л — действительное число;
4) хтх^0, причем хтх=0, только если х=0.
Линейное пространство, в котором определено скаляр-
ное произведение, называют евклидовым пространством.
Приведем примеры скалярных произведений в различ-
ных линейных пространствах.
1. Если векторами являются упорядоченные последо-
вательности вещественных чисел с обычным определением
операций сложения векторов и умножения вектора на ска-
ляр, то скалярное произведение векторов
определится формулой
п
хту = 2 Х(,)У(£) = Утх-
(4.35)
114
Это позволяет вычислить правило вычисления скаляр-
ного произведения
Скалярное произведение получаем, перемножая соот-
ветствующие элементы строки и столбца при движении
в направлении стрелок и суммируя полученные резуль-
таты.
2. Если в качестве векторов пространства X рассмат-
ривать непрерывные функции, заданные на интервале
[а, &], то скалярное произведение таких функций опреде-
ляется как
(4.36)
Легко убедиться, что соотношения (4.35) и (4.36) удов-
летворяют всем свойствам скалярного произведения.
Нормой или длиной вектора х в евклидовом простран-
стве называют число
||х|| = |х| = (хтх)1/2. (4.37)
Покажем, чю laitoe определение удовлетворяет всем
условиям нормы. Первые два условия вытекают из само-
го определения скалярного произведения. Для доказа-
тельства третьего условия (неравенство треугольника)
рассмотрим предварительно одно важное неравенство ев-
клидовых пространств, называемое неравенством Коши и
выражающееся соотношением
(хту)2<(хтх)(уту) (4.38)
или
хту<|х|-|у|. (4.39)
Рассмотрим квадрат длины вектора х+Х,у для дока-
зательства неравенства Коши (х+Лу)т (х-|-Лу) =хтх +
+ 2Л (хту) + Л2 (уту)^О. Обозначая а = xTx>0; b =
= хту; с=уту^О, запишем это соотношение в виде а+
+2Лд+Л2с^0.
Дополняя выражение а-|-2Л&=а(1-|-2Л&/а) до полно-
го квадрата, получаем
а (1 +М/а) 2+ (с—&2/а) V >0,
115
откуда следует справедливость соотношения Ь2^ас, т. е.
справедливость неравенства (4.38).
Используя в качестве скалярного произведения выра-
жения (4.35) и (4.36), приходим к следующим важным
неравенствам, являющимся частными случаями неравен-
ства Коши:
(з у* Y (4-40)
г f (о g (о ( j г (t) (j / (о dA. (4.4i)
Для получения неравенства треугольника рассмотрим вы-
ражение
(х + у)т (х +у) = хтх + 2 (хту) 4- уту.
Так как в силу неравенства Коши 2(xTy)<2(xTx)I/2 X
Х(УТУ)1/2. то
(х+у)т(х + у)<хтх + 2(хтх)1/2 (уту)1/а +
+ утУ = 1(хтх)1/2 + (уту)1/212
или
|х + у|<|х|+|у|. (4.42)
4.4.3. Угол между векторами. Ортогональные векторы
Неравенство Коши имеет простую геометрическую ин-
терпретацию для двумерного' пространства. Пусть х =
= (*1, х2) и у= (t/i, Уг) — два вектора на плоскости. Вы-
берем систему координат так, чтобы ось абсцисс совпада-
ла с направлением вектора х, так что Xi=|x[, х2=0
(рис. 4.6). Обозначим через а угол между векторами
х, у. При этом
xTy=X!i/i+x2t/2= |х| • I у I cos а. (4.43)
Так как cosas^l, то отсюда очевидно неравенство
Коши.
116
При |х| = 1 данное соотноше-
ние определяет величину |y|cosa,
являющуюся проекцией вектора у
на направление вектора х. уг
Поскольку неравенство Коши
доказано для произвольного п-мер-
ного евклидова пространства, то
можно считать, что в любом евкли-
СС
Ут
довом пространстве справедливо
соотношение (4.43), а угол между Рис. 4.6. К определению
векторами х и у определяется вы- скалярного произведения
ражением
a = arccos ——— (4.44)
и при [x| = l скалярное произведение хту определяет
проекцию вектора у на направление вектора х.
Векторы х и у называют ортогональными, если угол
между ними равен л/2, т. е. если
хту=0. (4.45)
Поскольку соотношением (4.36) понятие скалярного
произведения распространено на непрерывные функции,то
можно говорить и об ортогональных функциях. Функции
f(0 ” g(l) называют ортогональными, если для них вы-
полняется соотношение
(4.46)
4.5. МАТРИЦЫ И ЛИНЕЙНЫЕ ПРЕОБРАЗОВАНИЯ
4.5.1. Понятие матрицы
Матрицей А размером тХ« или просто (тХ«)-мат-
рицей называют таблицу, содержащую m строк и п столб-
цов, элементами которой являются вещественные или
комплексные числа
Если т = п, то матрицу называют квадратной.
117
При m=l матрица превращается в вектор-строку
(о,, ап),
а при п=1 — в вектор-столбец
~ °i ~
_а,п_
которые, таким образом, являются частными случаями
матриц.
Матрицы А=[а(/] и В=[&„] равны (А=В) в том и
только в том случае, если имеют один и тот же размер и
ац=Ьц для всех i, /.
С матрицами можно производить операции, которые
вытекают из правил линейных преобразований.
4.5.2. Линейное преобразование
Преобразованием линейного n-мерного пространства X
называют оператор А, отображающий это пространство
в m-мерное линейное пространство Y:
А : X-^Y. (4.47)
Таким образом, преобразование А ставит в соответ-
ствие каждому вектору х пространства X вектор
у=Ах (4.48)
пространства Y. В частном случае может быть Y=X.
При этом преобразование А ставит в соответствие каж-
дому вектору х пространства X вектор Ах того же самого
пространства.
Преобразование А называют линейным, если выпол-
няются условия:
A(xi+x2)=Axi+Ax2, .A (to) =V1x. (4.49)
Условия (4.49) будут выполняться, если между компо-
нентами х(1> и t/(£> векторов х и у имеется линейная зави-
симость вида
yth = 2 а^" i = TTm, (4.50)
где atl — произвольные числа.
118
Совокупность чисел ач, i=l, m; j—l, п образует мат-
рицу
А= .........
L^ni * * * ^mnJ
(4.51)
которую называют матрицей линейного преобразования.
Из (4.50) следует, что линейное преобразование полно-
стью определяется его матрицей'А.
'Сравнивая (4.50) с (4.35), видим, что t/<e> представля-
ет собой скалярное произведение i-й строки матрицы А на
вектор-столбец х:
Ув} =(ап,..., а£п)
1, т. (4.52)
.xi”)
При этом полную совокупность соотношений (4.52)
можно записать в виде одного векторного матричного со-
отношения у=Ах, на основании которого определяют пра-
вило умножения матрицы на вектор и которое в развер-
нутой форме имеет вид:
(4.53)
• -Отп _ _х(П)_
Сопоставляя (4.53) с (4.52), видим, что произведение
матрицы А на вектор-столбец х возможно только в том
случае, когда число столбцов матрицы А равно числу эле-
ментов в векторе-столбце х и определяет вектор-столбец
у, i-й элемент которого равен скалярному произведению
t-й строки матрицы А на вектор-столбец х.
Среди линейных преобразований линейного простран-
ства X особую роль играют два:
нулевое преобразование, ставящее в соответствие каж-
дому вектору х нулевой вектор О:
Ох=о; (4.54)
единичное преобразование, ставящее в соответствие
каждому вектору х тот же самый вектор-
1х=х. (4.55)
119
4.5.3. Операции над матрицами
Умножение матрицы на число. Пусть А —
матрица линейного преобразования Ах, а — число. Рас-
смотрим линейное преобразование, которое каждому век-
тору х ставит в соответствие вектор иАх. Если линейное
преобразование Ах описывается матрицей А=[я,-7], то
линейное преобразование а(Ах) будет описываться мат-
рицей
аА=[ая1;]. (4.56)
Таким образом, при умножении матрицы А на число
а все ее элементы умножаются на это число.
Сумма матриц. Пусть у=Ах и v=Bx — два ли-
нейных преобразования с матрицами А=[ач] и В=
=[ЬЧ] размером тХ«. Рассмотрим новое линейное пре-
образование, ставящее в соответствие каждому вектору
хеА' вектор у Ц-ve У:
y_|-v=Ax+Bx=(A+B)x. (4.57)
Преобразование (А-(-В)х называют суммой линейных
преобразований Ах п Вх. Для нахождения матрицы АЦ-
+ В это преобразование представим в виде соотношения
(4.50):
«/(‘) +и(£) = 2 + 2 ^л(;) = 2
.=1 /=1 /=1
или
А + В = [aj +[6е/1 = + bt,]. (4.58)
При сложении двух матриц одинакового размера по-
лучается новая матрица того же размера, элементы ко-
торой равны сумме элементов складываемых матриц.
Из этого определения следует, что
А+В = В+А. (4.59)
Произведение матриц. Пусть X, У и Z —линей-
ные пространства размерностью т, г, п и пусть у =
= Вх и z=Ay — линейные преобразования пространства
X в пространство У и пространства У в пространство Z,
где В=[6/г;] и A = [aIfe] — матрицы размером тХг и
и гХп соответственно. Произведением преобразований Ау
и Вх называют новое линейное преобразование Cz, со-
стоящее в последовательном выполнении сначала преобра-
120
зования у=Вх, затем преобразования z = Ау. Другими
словами, для любого хеА' имеем:
z=Cx=A (Вх)=АВх. (4.60)
Матрицу С=АВ размером т%,п называют произведе-
нием матриц А и В.
Для нахождения правила умножения матриц предста-
вим (4.60) в ином виде. Линейные преобразования у=
= Вх и z=Ay могут быть записаны в виде соотношения
(4.50} как
= 3 Ми>’ & = 1 > г;
/=1
2(Z) = S alky<-k\ i=T,~n.
Подставляя во второ^ соотношение значение из
первого соотношения, получаем
г п I г \ ______
2(/)=3 = 2 2 a«A/k(/). » = i. n. (4.6i)
4=1 /=1 /=1 \A=1 '
С другой стороны, преобразование z=Cx можно за-
писать в виде
z(<)= S i=17n, (4.62)
/=i
где через ctl обозначены элементы матрицы С.
Сравнивая (4.61) с (4.62), находим правило получе-
ния элементов матрицы С=АВ:
= S А/, i = Т~п, j = 1, т. (4.63)
Согласно (4.63) элемент с,, матрицы С представляет
собой скалярное произведение i-й строки матрицы А на
/-й столбец матрицы В, так что произведение матриц АВ
символически может быть представлено в виде
Г «и • • • «и 1Г I
L аП1 • • • anr J [б;1 • • • brm J 1
(4.64)
121
Отметим, что для возможности выполнения операции
умножения матрицы должны быть согласованы между со-
бой в том отношении, что число столбцов матрицы А
должно быть равно числу строк матрицы В. Из сущест-
вования произведения АВ совсем не следует существова-
ние произведения ВА. Более того, если даже ВА сущест-
вует, то в общем случае
АВ^ВА. (4.65)
Равенство в этом соотношении может иметь место
только для квадратных матриц. При этом две квадратные
матрицы называют коммутирующими, если АВ=ВА.
Для произведения матриц остаются в силе следующие
алгебраические законы:
(А+В)С=АС+ВС; (4.66)
С(А+В)=СА+СВ; (4.67)
(АВ)С=А(ВС). (4.68)
4.5.4. Транспонированная матрица
Пусть А=[аг^] — матрица размером тХ«- Матрица
Ат= [а',;] размером nXm, строки которой являются
столбцами матрицы А, а столбцы — строками матрицы А,
называется транспонированной матрицей А. Элементы
а'у матрицы Ат определяют по элементам а^ матрицы А
из соотношения
a'i/=a;i. (4.69)
Легко убедиться, что для транспонированных матриц
справедливы соотношения:
(А+В)Т=АТ+ВТ; (АВ)Т=ВТАТ. (4.70)
Понятие транспонированной матрицы приводит к од-
ному важному соотношению теории матриц. Пусть А —
квадратная матрица размером п\т, с помощью которой
в n-мерном линейном пространстве задано линейное пре-
образование у=Ах. Рассмотрим в этом же пространстве
вектор z, который с помощью матрицы Ат может быть
преобразован в вектор v—ATz. Найдем скалярные произ-
ведения
yTz=(Ax)Tz и xTv=xTATz. (4.71)
122
Принимая во внимание (4.70) и учитывая, что век-
тор х является частным случаем матрицы, находим
(Ax)Tz=xTATz. (4.72)
Другими словами, когда речь идет о скалярном произ-
ведении, то преобразование вектора х матрицей А экви-
валентно преобразованию вектора z матрицей Ат.
4.6. КВАДРАТНЫЕ МАТРИЦЫ
4.6.1. Особенности квадратных матриц. Нулевая
и единичная матрицы
До сих пор мы рассматривали линейные преобразова-
ния, отображающие линейное пространство X в некоторое
другое линейное пространство Y и описываемые прямо-
угольными матрицами. Теперь выясним некоторые доба-
вочные свойства линейны^ преобразований, определенных
на одном и том же пространстве X, т. е. преобразующих
X в X. Такие преобразования описываются квадратными
матрицами, которые имеют чрезвычайно важное значение
для многих технических приложений.
И (учение прямоугольных матриц наталкивается на оп-
ределенные трудности, связанные с тем, что две такие
м.прпцы одного п чого же размера нельзя перемножать.
Более того, при умножении матрицы размером тХг на
матрицу размером гХ« получается матрица, размер ко-
торой тУ^п отличается от размера каждой из перемно-
женных матриц.
Эти трудности отсутствуют при рассмотрении квадрат-
ных матриц. Матрицы А и В одного размера т можно пе-
ремножать в любом порядке, получая произведения АВ
или ВА, которые хотя в общем случае и не равны друг
другу, но имеют тот же размер т, что и перемноженные
матрицы.
Можно умножить квадратную матрицу саму на себя,
получая АА=А2. Можно продолжить этот процесс и опре-
делить А71 для целых положительных п. Полагая В=АП
можно определить В1/"=А и найти, таким образом, Аг
для “любого положительного рационального показателя г.
Если не требовать равенства АВ=ВА, то над квадратны-
ми матрицами можно производить действия, аналогичные
123
действиям над скалярами, например:
(А+В) 2=А2+ (АВ+ВА) +В2;
(А+В) (А—В) =А2—В2+ (ВА—АВ).
Особую роль среди квадратных матриц играют нуле-
вая и единичная, соответствующие нулевому (4.54) и еди-
ничному (4.55) преобразованиям линейного простран-
ства X.
Нулевой матрицей О размером пг называют квадрат-
ную матрицу, все элементы которой равны нулю.
Единичной матрицей I размером m называют квадрат-
ную матрицу, у которой элементы главной диагонали
равны единице, а остальные элементы — нулю.
Нулевая и единичная матрицы обладают следующими
свойствами:
А+О=А; ОА=АО=О; 1А=А1=А. (4.73)
Для квадратных матриц справедливы многие выраже-
ния,' встречающиеся в обычной алгебре, например:
(I + A)n = 1 + /гА + п(”^1} А» + ... + Ап. (4.74)
Иногда приходится иметь дело с неалгебраическими
функциями от А. Так, в теории дифференциальных урав-
нений важную роль играет матричная экспонента
е'А = 1 + ^А+ Аг+ ... (4.75)
4.6.2. Определитель квадратной матрицы
Определителем квадратной матрицы А=[сгг/] называ-
ют определитель, составленный из элементов ац этой мат-
рицы и обозначаемый det А.
Определитель det А обладает следующими свойствами
[19]:
1) при умножении на 1 любого столбца матрицы А оп-
ределитель det А умножается на X;
2) перемена местами двух соседних столбцов меняет
знак det А на противоположный;
3) " если любые два столбца матрицы А равны между
собой, то det А—0;
124
4) добавление к любому столбцу матрицы А любого
другого столбца, умноженного на произвольный скаляр-
ный множитель, оставляет det А неизменным;
5) если столбцы матрицы А линейно зависимы, то
det А=0.
Свойства 1—4 являются обычными свойствами любых
определителей. Поэтому остановимся на доказательстве
только свойства 5.
Доказательство. Представим матрицу А в виде
вектора А=(А1,..., Ат), где через А' = (а1;,..., ат}), j=l,m
обозначены столбцы матрицы А. При этом определитель
detk—D (Д',..., А.т).
Если столбцы А/ матрицы А_____линейно зависимы, то
можно найти такие числа а/, /=1,т, не все из которых
равны нулю, когда
2«/А^=р. (4.76)
Пусть а^О. Разрешая (4.76) относительно А* и обо-
значая ц,=—а;/ак, получаем:
А*= Жал
Теперь определитель
det А = D(...A& ...) = D Л.. ^(...А'...).
\ i^k J i^k
Определители, стоящие под знаком суммы, содержат
на месте столбца А* столбцы A', j^=k. Это зна-
чит, что каждый из них содержит по два одинаковых
столбца и в соответствии со свойством 3 равен нулю. Та-
ким образом, detA=O, если столбцы матрицы А линейно
зависимы.
4.6.3. Обратная матрица и решение систем
линейных уравнений
Пусть у=Ах —линейное преобразование с квадратной
матрицей А= [«г/], при котором произвольный вектор х
пространства X преобразуется в вектор у того же прост-
ранства. Обратным преобразованием называют преобра-
125
зование х=А~1у, при котором вектор у преобразуется в
первоначальный вектор х. Матрицу А~’ этого преобразо-
вания называют обратной по отношению к матрице А.
Обратную матрицу удобно трактовать в терминах ре-
шения систем линейных уравнений. Пусть дана система п
линейных уравнений с п неизвестными (хь..., хп):
2 a^Xj = у;, i = i, п, (4.77)
матричная запись которой имеет вид
Ах=у. (4.78)
По определению обратной матрицы решение этой си-
стемы уравнений в векторно-матричной форме будет
х=А~'у. (4.79)
Для нахождения элементов обратной матрицы А-1 за-
пишем решение системы уравнений (4.77) в явном виде.
Это решение может быть найдено по формулам Крамера
[19] и записано как
Х/ = Т S л,'у‘: z = 11 п' (4,80)
где A=detA — определитель матрицы А; —алгебраи-
ческое дополнение элемента аг, в определителе Д.
Таким образом, элементами матрицы А-1 являются ве-
личины Дг//Д.
Система уравнений (4.78) называется определенной и
имеет единственное решение, если detA^O. Матрицу А,
для которой выполнено это условие, называют невырож-
денной. Только в том случае, когда матрица А невырож-
денная, для нее существует обратная матрица А-1, для
вычисления которой удобно ввести следующие обозначе-
ния: Аг/ — алгебраическое дополнение элемента аг1 в оп-
ределителе матрицы А; [Аг;] — матрица с элементами Аг;.
Тогда
A-‘ = -i-[AJT. (4.81)
det А '
Заметим, что соотношение (4.79) можно было бы по-
лучить из (4.78) чисто формальным путем, умножая обе
части выражения (4.78) на матрицу А"1:
А->Ах=А-*у. (4.82)
126
Сравнивая (4.82) с (4.79), получаем соотношение свя-
зывающее прямую и обратную матрицы:
А'А=1. (4.83)
Соотношение (4.81) используют для вычисления об-
ратной матрицы, особенно для матриц небольшого разме-
ра. Однако с увеличением размера матрицы сложность
выкладок резко возрастает, поэтому разработаны более
эффективные вычислительные процедуры (алгоритм Гаус-
са, цепной алгоритм и др. [18]). Кроме того, алгоритм
обращения матриц входит в математическое обеспечение
большинства современных Э£М.
[8 6]
Пример 4.7. Пусть А = I Г тогда det А = 8-5—4-6 = 16. При
этом
a-i=-L[ 5 -4Г=—[ 5
16 [-6 8J 16 [-4
-61 Г 0.3125 —0,375
в] [—0,25 0,5 !
Если А и В — квадратные матрицы, то матрицу, об-
ратную произведению этих матриц, можно вычислить по
правилу
(АВ)-1 = В~1А~1.
Чтобы доказать это, умножим В-'А"1 на АВ, тогда
В~1А~1АВ=В~1 (А ’А) В=1.
С обратной матрицей тесно связано понятие ранга
матрицы. Ранг определяется с помощью миноров матри-
цы, причем минором порядка р произвольной матрицы А
размером тХ« называют определитель произвольной
рХр подматрицы А.
Рангом матрицы называют максимальный порядок от-
личных от нуля миноров этой матрицы. Если г —ранг пря-
моугольной матрицы А размером тХ«, то r^min(m, п).
Квадратная матрица размером «Хм является невы-
рожденной только тогда, когда ее ранг равен ее размеру,
и, следовательно, только в этом случае она имеет обрат-
ную матрицу.
4.6.4. Инвариантное подпространство. Собственные
векторы и собственные значения матриц
Пусть X — n-мерное линейное пространство и у=Ах—
линейное преобразование на пространстве X. Пусть XiczX
является некоторым подпространством X, обладающим,
127
Рис. 4.7. Одномерное
инвариантное подпро-
странство
однако, тем свойством, что если xeA'i, то и у=АхеХь
Подпространство Xi, обладающее подобным свойством,
называют инвариантным относительно линейного преоб-
разования у=Ах.
Особенно интересны одномерные инвариантные прост-
ранства, представляющие собой прямые в пространст-
ве X, проходящие через начало координат.
Если х —произвольная точка пространства X и а —
вещественная переменная, меняющаяся от —оо до +оо,
то ах будет представлять собой одно-
мерное подпространство X, проходя-
щее через х (при а=1) и через на-
чало координат (при а=0), как пока-
зано на рис. 4.7 для и—2. Такое одно-
мерное подпространство будем обозна-
чать R\.
Предположим, что среди беско-
нечного множества одномерных про-
странств 7?1 найдутся такие, которые
будут инвариантны относительно пре-
образования у==Ах, т. е. для любого
xe/?i имеет место у=Ахе/?ь Обо-
значим через X отношение у к х, которое при этом будет
просто вещественным числом, т. е. можем записать у=Хх.
Таким образом, если 7?i — инвариантное подпространство,
то для xe/?i имеет место равенство
Ах=Хх. (4.84)
Вектор х=/=0, удовлетворяющий соотношению (4.84),
называют собственным вектором матрицы А, а число X —
собственным значением (характеристическим числом)
матрицы А.
Для определения характеристических чисел матрицы
перепишем соотношение (4.84) в ином виде, введя тож-
дественное преобразование х=1х. При этом получаем
(А—М)х=0. (4.85)
Соотношение (4.85) представляет собой систему ли-
нейных однородных уравнений, которая может быть запи-
сана в явном виде как
(ап — Л)х1 + а12х2+ ... + ад, = 0; |
л2Л + (б?22— 2)х2 + ... + а2пхп = 0; I <4 8б)
4" *•* + (&ПП ^»)
128
Допустим, задались численным значением X и нас ин-
тересует вопрос, имеет ли система (4.86) нетривиальное
(отличное от нуля) решение, т. е. существуют ли такие
отличные от нуля значения х\,...,хп, которые обращают
уравнен-ия (4.86) в тождества.
Рассмотрим вначале случай двух переменных, для ко-
торого система (4.86) запишется в виде
(а„-2)х1+я1гХ2 = 0; | (4 87)
а21х( + (я22 — 2) х2 = 0. J
Полагая xi, х2#=0, из первого уравнения находим
Х2=—(flu—%>Xi/fli2.
Тогда второе уравнение дает
[я21—(я22—X) (я,,—Х)/Я12]Х1=0.
При Х15^0 это выражение имеет смысл, только если
(я„ -2) (я22 - 2) - я12я21 = I ~ 2 I = О,
I «21 «22 — I
т. е. если det .(А—XI) =0. Это условие является необходи-
мым и достаточным того, чтобы система (4.87) имела ре-
шение. Если это условие выполнено, то (4 87) дают воз-
можность определить лишь отношение переменных
x'i/x2=—Я12/ (ян—X) =—(я22—X) /я21, (4.88)
т. е. сами переменные определяются лишь с точностью до
постоянного множителя.
Аналогично обстоит дело и в общем случае системы
(4.85), которая имеет нетривиальное решение только в
том случае, если выполняется условие
det (А—XI) =0 (4.89)
При этом сами переменные, т. е. вектор х, определя-
ются с точностью до постоянного множителя.
Соотношение (4.89) называют характеристическим
уравнением матрицы А, представляющим собой алгебраи-
ческое уравнение n-й степени относительно X. Действи-
тельно, раскрывая определитель и группируя члены с оди-
наковыми степенями X, левую часть уравнения (4.89)
можно представить в виде многочлена по степеням X:
det (A-XI) —q (X) =9о+91Х+ ... +9rlXn.
9-804
129
Легко заметить, что здесь ?0=detA, ?„=(—1)л. Таким
образом, для нахождения собственных значений матрицы
А получаем уравнение n-й степени относительно А,:
?о+?Д+ ... +9nV=0. (4.90)
Это уравнение имеет п корней, среди которых могут
быть и одинаковые, являющиеся собственными значения-
ми матрицы А. Конечно, не все собственные значения
обязательно будут действительными, но так как А —дей-
ствительная матрица, то комплексные корни встречаются
сопряженными парами.
Подставив любое собственное значение А,,- в исходную
систему уравнений (4.85), получим уравнение
(А—М)х=0,
которое имеет нетривиальное решение, так как det (А—
—А,г1)=0. Это решение дает вектор хг, определяемый
с точностью до скалярного множителя. Этот вектор и на-
зывается собственным вектором матрицы А.
Так как А,г может быть комплексным числом, то хг мо-
жет содержать комплексные компоненты. Однако посколь-
ку комплексные корни встречаются сопряженными пара-
ми, то комплексные собственные векторы также будут
встречаться сопряженными парами.
Согласно (4.84) собственные векторы хг и соответст-
вующие им собственные значения А,, связаны соотноше-
ниями: ___
Ахг=М\ i=l, п, (4.91)
которые могут быть записаны в более компактной форме:
AV=VA, (4.92)
где V — квадратная матрица, составленная из собствен-
ных векторов матрицы А; А — диагональная матрица,
у которой по главной диагонали расположены числа А,,,
а все остальные элементы равны нулю:
V = (№
ГЛ, 0 ... О
Л = I о л2 • • • о
1_о’ o' ' Лп_
(4.93)
(4.94)
130
4.6.5. Диагонализация матриц
Вид квадратной матрицы А линейного преобразования
у=Ах может быть изменен без изменения характеристи-
ческого уравнения этой матрицы путем использования
преобразования подобия.
Пусть А — квадратная матрица; С — произвольная не-
вырожденная квадратная матрица. Преобразованием по-
добия называют преобразование
В=С-1АС. (4.95)
Получаемая в результате преобразования подобия
матрица В удовлетворяет тому же характеристическому
уравнению, что и матрица А, а следовательно, имеет те
же самые собственные значения. Действительно, легко
видеть, что
С"1 (А — XI)С - С‘АС - ХС"‘1С = С-АС — ХС"‘С1 = В—XI.
Учитывая легко доказываемое свойство определителей
матриц det AB=det Adet В, получаем
det (В — XI) - det [С~‘ (А — XI) С] = det С1 det (А — XI) det С.
Т;п» иль матрица С невырожденная, то из det (В—XI) =0
г.пса.уг ।. 'I ।<। del (Л XI) 0.
Hprnbp.lloil.llllli- ||1>/1<)(|ИЯ 11О111ОЛЯС1 приводить некото-
рые пилы квадратных матриц к диагональной форме, яв-
ляющейся наиболее удобным видом матрицы. Возмож-
ность диагонализации квадратной матрицы базируется на
следующей теореме о линейной независимости собствен-
ных векторов матрицы.
Теорема 4.1. Если собственные значения матрицы А
размером п занумерованы так, что первые k из них Xi,...
..., X* различны, то соответствующие собственные векторы
х1..xk линейно независимы.
Доказательство. Теорема доказывается по ин-
дукции. Для k=l утверждение очевидно. Предположим,
что утверждение справедливо для k—1 векторов, т. е. что
собственные векторы х1,..., х*-1 линейно независимы. До-
кажем, что оно справедливо и для всех k векторов.
Предположим противное, т. е. что векторы х1,..., х* ли-
нейно зависимы, так что имеет место
а,х* + а2х2 + ... + аАх* = 0,
131
причем не все а,- равны нулю. Будем считать, что aj=#O.
Проведем над этим выражением линейное преобразова-
ние, определяемое матрицей А. Получим
A (aix'+a2x2+ ... +akxk) =0
или
ajA.1x4-a2A.2X2-}-... +aj.Aj.xA=0.
Умножая предыдущее соотношение на А* и вычитая из
данного, находим
«1 (А-1—A*)x4-a2(A2—А*)х2+ ...
... +afe_j(Afe-i—Afe)xft-1=0.
Так как собственные значения Аь..., Aj. различны, то
имеет место равенство ai=a2=... =a*_i=0, что противо-
речит предположению о линейной независимости векторов
х1,..., х*-1.
Из доказанной теоремы следует, что если все собствен-
ные значения матрицы А различны, то все п ее собствен-
ных векторов будут линейно независимыми. В этом слу-
чае матрица допускает приведение к диагональной форме.
Рассмотрим матрицу V, определяемую (4.93), столбцы
которой являются собственными векторами матрицы А
и которая связана с матрицей А соотношением (4.92). Ес-
ли все собственные значения матрицы А различны, то ее
собственные векторы линейно независимы. Из свойства 5
определителей матриц (см. § 4.5, п. «б») следует, что
в этом случае матрица V невырожденная и существует
обратная V-1. Умножая обе части (4.92) на V-1, получаем:
V-'AV=V-'VA или V-'AV=A. (4.96)
Как видим, диагонализирующей матрицей является
матрица V, составленная из собственных векторов матри-
цы А.
4.7. СИММЕТРИЧЕСКИЕ МАТРИЦЫ
И КВАДРАТИЧНЫЕ ФОРМЫ
4.7.1. Собственные векторы и собственные значения
вещественных симметрических матриц
Вещественную квадратную матрицу А называют сим-
метрической, если ее элементы удовлетворяют соотноше-
нию oi; = Oj, для всех I, j. Это означает, что симметриче-
ская матрица не меняется при транспонировании, так что
АТ=А.
132
«12 I 0
Симметрические матрицы обладают двумя особыми
свойствами, которые играют важную роль во многих тех-
нических приложениях:-
собственные значения вещественной симметрической
матрицы вещественны-,
собственные векторы, соответствующие различным
собственным значениям вещественной симметрической
матрицы, ортогональны.
Справедливость этих свойств проверим для матрицы
размером 2X2. Собственные значения этой матрицы на-
ходят из уравнения
det(A —Х1) = | а”~1
I «12
или
Л* — («11 + «22) Я + апа22 - а*2 0.
Отсюда
2 = 0,5 [оп + а22 ± у (оп + о22)2 — 4(аиа22 - а?12) ].
Поскольку величина
(«11 4" «гг) 4 (йий22 — (аи <222)2 4" ^«12
неотрицательная, то М и Л2 являются всегда веществен-
ными числами.
Обозначим
— собственные векторы матрицы А, соответствующие раз-
личным собственным значениям V и Л2. Как мы видели
ранее, компоненты векторов удовлетворяют соотноше-
ниям:
xi'/x2'=—ai2/(an—A,i)=—(а22—A,i)/ai2;
Xi2/x22=—О1г/ (ап—Л,2) =—(а2г—А,2) /ai2-
Из этих соотношений можно составить следующее отно-
шение:
xi’xi2/ (хг’хг2) = (022—А,1)/(ац—М
или
x2Ix22= (ai i—Х2) xi ’Xi2/ (а22—ХО •
133
Найдем скалярное произведение собственных векторов.
(х’рх2:
(x')TX2=Xi'Xi2+x2lX22—
=Х1*Л'12 [1+ (ап—А,2)/(й22—А,1)] =
=XilXi2[an+a22—(A-i+ta) ]/ («22—М-
Но A,i+ta=«i 1+«12, так что (х*)тх2=0, т. е. векторы
х1 и х2 ортогональны.
Доказанные свойства вещественной симметрической
матрицы легко обобщаются на случай матрицы А любого
порядка. Из этих свойств следует, что если в веществен-
ной симметрической матрице A ki=/=^h то
(хг)тх'=0, /+=г, (4.97}
т. е. собственные векторы хг‘ и х1 ортогональны.
Принимая во внимание, что собственные векторы оп-
ределены с точностью до постоянного множителя, этот по-
стоянный множитель для любого собственного вектора х{
можно выбрать так, чтобы
(x{)Txf=l, i=\7n. (4 98)
Собственные векторы, удовлетворяющие этому усло-
вию, называют нормированными.
4.7.2. Диагонализация симметрических матриц
Рассмотрим вектор V, столбцы которого представляют
собой собственные векторы симметрической матрицы А.
Матрица VT, получающаяся путем транспонирования мат-
рицы V, представляет собой матрицу, строками которой
будут собственные векторы матрицы А.
Элемент (г, /) матрицы VT V будет равен скалярному
произведению г-й строки матрицы VT на /-Й столбец мат-
рицы V, т. е. величине (хг)т х>. Принимая во внимание со-
отношения (4.97) и (4.98), видим, что VTV=I, так что
VT=V-‘. (4.99)
Следовательно, диагонализация симметрической мат-
рицы производится согласно соотношению
VTAV=A. (4.100)
Этот вывод справедлив лишь для случая, когда все
собственные значения матрицы А различны.
134
4.7.3. Квадратичные формы
Пусть х=(х<|), ...,х<п>)т— вектор в n-мерном линейном
пространстве с вещественными компонентами. Выраже-
ние вида
Q(x) = 33ae;x(l)x(') (4.101)
называют квадратичной формой. В этом выражении без
ограничения общности можем считать ач=а,г. Если это
не так, то, производя преобразование
= (ач + alt)xW> =
= 0,5 (ati + а/г) + 0,5 (ог/ + о/г) х^'^х^,
можно привести квадратичную форму к виду, когда это
условие выполняется. Поэтому числа а,, можно рассмат-
ривать как элементы квадратной матрицы А, которая яв-
ляется вещественной и симметрической.
Квадратичную форму удобно записывать в векторно-
матричных обозначениях. Для этого перепишем выраже-
ние (4.101) в виде
Q(x) = 2^Sa4A-'') = 2«(t’)z(l) = xTz- (4.102)
где z(') = 2ач%(/)’ г == /г
являются компонентами вектора z, связанного с векто-
ром х линейным преобразованием:
z—Ах. (4.103)
Таким образом, квадратичная форма Q(x) может быть
записана в виде
Q(x)=xTAx. (4.104)
Квадратичную форму Q(x) и матрицу А называют
положительно определенными, если выполняется условие
Q(x)>0. При выполнении условия Q(x) <0 говорят об
отрицательно определенной квадратичной форме Q(x) и
матрице А. Для нахождения условий положительной (от-
рицательной) определенности матрицы А введем в рас-
смотрение линейное преобразование x=Vy, где V — невы-
135
рожденная матрица. Тогда
Q (х) - хтА х = утVTAVy = Q (у),
причем матрицей квадратичной формы Q(y) является?
VTAV. Возьмем в качестве V диагонализирующую матри-
цу. Тогда VTAV=A, так что
Q (х) = Q (у) = уТДу = 2 я£- [r/(‘’>]2. (4.105)
Как видим, необходимым и достаточным условием по-
ложительной (отрицательной) определенности матрицы А
является положительность (отрицательность) всех ее соб-
ственных значений Л,-.
4.7.4. Использование квадратичных форм
при отыскании экстремумов функций многих
переменных
Применение квадратичных форм проиллюстрируем на
примере задачи отыскания экстремумов функций, имею-
щей важное значение при решении многих технических
вопросов [36].
Пусть ц=(и1,...,ил)т —многомерная переменная,
f(u) =f(ui,..., ип) — функция от и, определенная в области
i=l,n и допускающая разложение в сходящий-
ся ряд Тейлора в каждой точке с=(сь..., сп)т внутри этой
области. Это разложение имеет вид
f <u)=f(c) + 2-57а“'+ tESs5;4‘'-4"' + <4-106>
дс(дс/ duidttj |“г=ср uj=cj*
Как известно, экстремумы подобных функций могут
достигаться внутри области определения только в стаци-
онарных точках, т. е. в точках, в которых производные
df/dut, 1=1, п обращаются в нуль. Пусть и=£ —стацио-
136
яарная точка. Тогда df/dct—Q, 1=1, п и разложение функ-
ций f(u) в ряд Тейлора в окрестности точки и=с прини-
мает вид
- (4.107)
11 1 I
Введем обозначения:
х,=Дм,=м,—ct;
1 <32f
1 1 2 dc[dct-
Тогда ряд (4.107) запишется в виде
f(u)=f(c)+Q(X) + ...,
где
I I
(4.108)
(4.109)
(4.110)
(4.1П)
представляет собой квадратичную форму хтАх с вещест-
венной симметрической матрицей А. ___
Учитывая, что при и=с х,=0, 1=1, п, из (4.110) видим,
•по в ст.ппюпарпой точке и=с имеет место относительный
минимум, гели Q(x)X), и огпоситсльпый максимум, если
Q(x) 0, 1. е. (Дх)^-О В случае, если Q(x) вблизи ста-
ционарной точки может принимать как положительные,
так и отрицательные значения, имеет место стационарная
точка более сложного характера, требующая дальнейшего
специального исследования.
Таким образом, мы видим, что выяснение характера
стационарной точки функции многих переменных требует
выяснения того, является ли положительно (отрицатель-
но) определенной матрица А квадратичной формы Q(x).
4.7.5. Векторные производные
При нахождении стационарных точек функций многих
переменных f(xi,...,xn) вычисляют производные вида
df(xl,...,xn)/dxli, k=l,...,n. (4.112)
Если совокупность переменных хь.. .,хп представить
в виде вектора х=(хь..., хп)т, то совокупность производ-
ных (4.112) можно также представить в виде некоторого
137
вектора
аг(х)_рШ...*«)Ж1
(4.113)
который называют векторной производной функции f(x).
В дальнейшем нам придется иметь дело с такими ска-
лярными функциями многих переменных, как скалярное
произведение векторов атх=хта и квадратичная форма
Q(x)=xTAx. Обратившись к определениям этих функций
(4.35) и (4.101) и вычисляя компоненты (4.113) соответ-
ствующих векторных производных, приходим к следую-
щим соотношениям, определяющим векторные производ-
ные от скалярного произведения и от квадратичной
формы:
д(атх)/дх = д(хта)/дх = а; (4.114)
д(хтАх)/дх = 2Ах. (4.115)
4.8. ВЫПУКЛЫЕ МНОЖЕСТВА
4.8.1. Понятие гиперсферы
В многомерном пространстве /?я можно рассматривать
геометрические образы, аналогичные геометрическим фи-
гурам и телам в двух- и трехмерном пространстве. Важ-
нейшими из них являются гиперсфера, гиперплоскость и
прямая.
Гиперсферой называют замкнутую поверхность, все
точки которой удалены на одинаковое расстояние г от не-
которой фиксированной точки а, т. е. удвлетворяют урав-
нению
d(x, а)=г.
(4.116)
Множество точек, удовлетворяющих условию d(x, а) <
<г и являющихся внутренними точками гиперсферы, на-
зывают открытым шаром. Множество точек, удовлетворя-
ющих условию d(x, a)sCr, замкнутым шаром.
Пример 4.8. В пространстве Л2 уравнение гиперсферы можно за-
писать в виде d2(x, а)=г2. Если расстояние определять по (4 2), то
гиперсфера превращается в окружность (х№—2-|-(х<2>—а'2>)2 = г2.
138
4.8.2. Ограниченные и конечные множества
Множество X называют ограниченным, если ограничено
расстояние между любыми двумя точками этого множест-
ва, т: е. если существует такое число М, что для любых хь
х2еХ имеет место d(xi, х2)^Л1.
Можно показать, что необходимым и достаточным ус-
ловием ограниченности множества X является нахождение
его в некоторой гиперсфере, т. е. существование точки а
и числа г таких, что для всего хеХ имеет место d(x, а)=С
Множество X называют конечным,...если .оно содержит
конечное число точек. Конечное множество всегда ограни-
чено.
4.8.3. Открытые и замкнутые множества
Разделение множеств на открытые и замкнутые тесно
связано с понятием окрестности точки множества. Окрест-
ностью точки х в пространстве Rn называют крытый шар
радиусом е с центром в х. Окрестность точки обозначают
Ое(х).
Точку х называют внутренней, точкой множества X, ес-
ли существует окрестность Ог(х), все точки которой при-
ц;1Длеж;| I X.
Точку х ii,i.ii.iii;iu> । .•pttnii'iiioii. точкой множества X, -если
люб.1я ее окрестность Ос(х) содержит.как дочки, принад-
лежащие X, так и точки, не принадлежащие X. Множе-
ство всех граничных точек образует границу множества X.
Множество X называют открытым, если в.се его точки
внутренние. Множество X называют замкнутым, если на-
ряду с внутренними оно содержит и
точки
Для пояснения введенных понятии рас-
смотрим в двумерном пространстве (и, v)
множество X, заданное неравенством
u2+o2cr2.
Это множество представляет собой круг
радиусом г с центром в начале координат, как
показано на рис. 4.8.
Для любой точки x=(u, v) этого множе-
ства можно записать либо
(1)
все свои граничные
Рнс. 4 8. Внутренняя
(/) и граничная (2)
точки множества
139
либо
U2_|_„2=r2- (2)
В первом случае можно найти такую окрестность Ое(х) точки х=
= (и, v), что неравенство будет выполняться для любой точки этой
окрестности, тогда х — внутренняя точка множества.
Если же точка х=(ы, о) удовлетворяет равенству (2), то в любой
окрестности Ое(х) существуют такие точки xi=(«i, «О и х2=(«2, «г),
что «i24-z;i2<r2, a U22-j-V22>r2, т. е. точки, как принадлежащие X, так и
непринадлежащие X. В этом случае х — граничная точка. Само урав-
нение (2) определяет границу исходного множества.
Поскольку исходное множество X задано с помощью нестрогого
неравенства (^), то граница является частью множества X. Следова-
тельно, множество X замкнуто. Если для задания множества X
использовать строгое неравенство «2-f-a2<r2, то граница уже не будет
принадлежать X. Получим открытое множество.
4.8.4. Гиперплоскости и полупространства
Гиперплоскостями в линейном пространстве Rn размер-
ностью п называют линейные подпространства размерно-
стью /г—1. Так, в трехмерном пространстве R3 гиперплос-
костями являются плоскости, а в двумерном пространст-
ве /?2 —прямые.
Уравнение гиперплоскости L(S) можно получить, зада-
вая в линейном пространстве Rn множество S, содержащее
п—1 линейно независимых точек хь ..., хп_ь В соответ-
ствии с (4 27) любая точка гиперплоскости
х=(х<‘)....x("))T<=L(S)
запиЩется в виде
Х = П£\Х/ (4.117)
/=1
или в координатной форме
х(‘) = 2 ауХ/О, i =ТГп7 (4.118)
i=i
Уравнение (4.117) неудобно для описания гиперплос-
кости, так как в него входят произвольно выбранные точ-
ки X],...,xn_i. С другой стороны, можно показать, что эти
140
точки определяют вектор p=(pi....рп) такой, что урав-
нение
2ЛХ/,)=О (4.119)
i=i
представляет собой уравнение L(S). Подставляя коорди-
наты х<‘> из (4.118) в (4.119), получаем
п п—1 л—1 п
Е Pi^ aixi(i}= s а> S = °- ,
1=1 j=l j=l i=l
Поскольку а/ могут принимать любые вещественные
значения, то равенство нулю будет иметь место только,
если
%р.Х,^О, j,="TT (4.120)
i=i
Система однородных уравнений (4.120) позволяет
с точностью до постоянного множителя определить ком-
поненты вектора р, что и подтверждает справедливость
(4.119) в качестве уравнения гиперплоскости.
Левая часть уравнения (4.119) представляет собой ска-
лярное произведение векторов р и х в линейном простран-
riiu* Но ному уравнение гиперплоскости L(S) обычно
I.'UIIK 1.111.110 I н пп/к*
рх=0. (4.121)
Данное уравнение определяет гиперплоскость, проходя-
щую через начало координат перпендикулярно вектору р.
Более общее уравнение гиперплоскости получим, если
сместим начало координат в произвольную точку х0, что
соответствует замене в (4.121) х на х—х0. Производя та-
кую замену и обозначая рхо=с, получаем уравнение
рх=с, (4.122)
представляющее собой общее уравнение гиперплоскости,,
ортогональной вектору р.
Наряду с гиперплоскостью L, определяемой уравнением
(4.122), в линейном пространстве имеются множества
точек, определяемых условиями:
L+={x|px>c}; L"={x|px<c}. (4.123)
Эти два множества называют открытыми полупрост-
ранствами, определяемыми гиперплоскостью L.
141
4.8.5. Прямая и отрезок. Средневзвешенное
по элементам множества
Согласно (4.84) уравнение
х=Хх! (4.124)
при фиксированном х( и переменном X представляет собой
одномерное линейное пространство, т. е. прямую, прохо-
дящую через начало координат и точку хь
Уравнение прямой, проходящей через фиксированные
точки Xi и х2, получим из (4.124), сместив начало коорди-
нат в точку х2, т. е. заменив х и Х] на х—х2 и х(—х2:
х—x2=X(xi—х2),
что удобней записывать в виде
х=ЛХ1+(1-Л)х2. (4.125)
Значения х=Х! и х=х2 получаются соответственно при
Х=1 и Х=0.
Уравнение отрезка, соединяющего точки Х] и х2, полу-
чим из (4.125), ограничив изменение к пределами Os^Xs^l.
Если обозначить Л.=Л.г, 1—к—%2, то уравнение отрезка
запишется в виде
X=A.]Xi-[-^2^2, ^2О, Я,1+?12=1. (4.126)
Величину х, определяемую из (4.126), называют сред-
невзвешенным по элементам X! и х2 с весами Aj и Х2. Это
название имеет простой физический смысл. Если в точках
Х| и х2 поместить грузы с весами %! и Х2, то точка х опре-
делит центр тяжести системы.
Понятие средневзешенного можно распространить и на
большее число точек. Будем называть средневзвешенным
по элементам хь...,хт величину х, определяемую соотно-
шением
х = 2 2‘х‘- 3 = L (4-127)
Точку х, найденную по (4.124), называют выпуклой
комбинацией точек xi. Это частный случай линейной ком-
бинации, получаемый по (4.127) без ограничений на ве-
личины X,.
142
4.8.6. Выпуклые множества
Пусть S — некоторое подмножество линейного прост-
ранства R". Множество S называют выпуклым, если отре-
зок, соединяющий любые две точки этого множества, це-
ликом принадлежит этому множеству. Другими словами,
S — выпуклое множество, если для любых хь x2eS и лю-
бого справедливо
ХХ1+(1—X)x2eS.
Il.i рис. 4.9 приведены примеры выпуклых (а —г) и
пспыпуклых (д — з) множеств на плоскости. Примерами
выпуклых множеств в многомерном, пространстве служат
все линейное пространство Rn, любое его линейное подпро-
странство (прямая, гиперплоскость), полупространство,
выпуклые многогранники, которыми являются выпуклые
множества, все границы которых линейны (прямые, гипер-
плоскости).
Гиперсфера не является выпуклым множеством. Одна-
ко открытый шар и замкнутый шар являются выпуклыми
множествами.
Теорема 4.2. Пересечение выпуклых множеств есть вы-
пуклое множество.
Доказательство. Пусть р и q — произвольные точ-
ки, принадлежащие пересечению выпуклых множеств X и
У. Соединяющий их отрезок будет принадлежать как мно-
жеству X, так и множеству У, а значит, и их пересечению.
143
4.8.7. Выпуклая оболочка конечного множества
Пусть Л={а1.......ат} — конечное множество точек
в пространстве Rn. Конечное множество не является вы-
пуклым. Однако точки конечного множества А могут быть
элементами каких-либо выпуклых множеств, например Si,
S2 и т. п. В этом случае А является подмножеством пере-
сечения выпуклых множеств 51П52П • • •
Выпуклой оболочкой множества А называют пересече-
ние всех выпуклых множеств, подмножествами которых
является А. В частности, если A<=Si и X<=S2, то
со ^)<=Sif|S2.
Из данного определения следует, что выпуклая оболоч-
ка со (Л) является наименьшим выпуклым множеством,
содержащим А. Действительно, если бы нашлось выпуклое
множество S такое, что Л<=5 и Ssco(X), то имело бы
место co0)sSf|co(X), т. е. co(X)sS. Отсюда следует,
что £=со(Л).
Теорема 4.3. Выпуклая оболочка конечного множества
А есть множество средневзвешенных по элементам мно-
жества А.
Пусть Л={аь ..., ат)—конечное множество и Xt-, i=
= 1,п— вещественные числа такие, что
2^=1- (4.128)
i
Величину
X = (4.129)
называют средневзвешенным по элементам множества А.
Множество S, элементами которого являются величины х,
определенные по (4.129) при всевозможных А,,- в пределах
ограничений (4.128), представляет собой множество сред-
невзвешенных по элементам множества А. Требуется до-
казать, что
5=со(Л).
(4.130)
Доказательство. Для того, чтобы множество S
было выпуклой оболочкой множества А, оно должно быть,
144
во-первых, выпуклым и, во-вторых, наименьшим выпуклым
множеством, содержащим множество А. Докажем, что оба
эти условия выполняются.
1. Возьмем две произвольные системы весов %,- и V,
определяющих две точки
х=21,аг и х'«^Д/аг
i i
из множества S. Выберем произвольную точку х" отрезка,
соединяющего х и х':
х” = 2х + (1 -2)х' =Slui + (I -1)1/1а£ = ^1£''а£,
i i
г де i,£" — Л2; —|— (1 — 2) Л/.
Величина К" неотрицательна, так как представляет
собой средневзвешенное двух неотрицательных чисел Хд- и
К/. Кроме того,
S2/' = 2S2Z + (1 -1)2V=1.
Таким обра «>м, х" есп. средневзвешенное по элементам
множссша А, 1. е. х"( .5. Следовательно, S — выпуклое
множество.
2. Пусть Т — произвольное выпуклое множество, содер-
жащее А. Покажем, что оно содержит и S.
По условию все элементы ад содержатся в Т. Далее
элемент
Х2=^1Н1/(7ч+^г) +^2аг/ (^-1+^2)
есть средневзвешенное аь а2еТ, так что х2<=Т. Точно так
же получаем, что
Хз= (Л-1 -J-%2) х2/ (Тч+^г+^з) +
+^заз/ (М-Ь^г+^з) =
=^iai/(^i+^г+^з) +^2аг/ (Тч+^г+^з) +
+^заз/ (Тч+^г+^з)
есть средневзвешенное х2, аз^Т, так что ХзеТ. Продолжая
рассмотрение этой последовательности точек, находим,
10—804 145
что точка
Х1+--
*i +
также принадлежит множеству Т. Таким образом, любое
xeS принадлежит и Т, т. е. S<=T. Но Т — произвольное
выпуклое множество, содержащее А. Следовательно, S —
наименьшее выпуклое множество, содержащее А.
Понятие выпуклой оболочки легко распространяется на
произвольное множество. ^Если X — произвольное множест-
во точек из R" (не обязательно выпуклое), то выпуклой
оболочкой со(Х) множества X называют наименьшее вы-
пуклое множество, содержащее X.
4.8.8. Разделительная и опорная гиперплоскости
Обоснование ряда результатов линейного программиро-
вания и теории игр основано на использовании понятий
разделительной и опорной гиперплоскостей.
Пусть S и Т — выпуклые непересекающиеся множества.
В теории выпуклых множеств доказывается существова-
ние гиперплоскости Lp, называемой разделительной, такой,
что множества S и Т лежат в разных полупространствах,
определяемых этой гиперплоскостью.
Если S — выпуклое множество, то доказывается суще-
ствование гиперплоскости Lo, называемой опорной гипер-
плоскостью, такой, что S лежит в одном из определяемых
ею полупространств и по крайней мере одна точка из S
будет принадлежать самой гиперплоскости. На рис. 4.10
приведена иллюстрация понятий разделительной и опор-
ной гиперплоскостей.
Для описания некоторых видов выпуклых множеств
используют понятие крайних точек. Точку х* называют
крайней точкой выпуклого множества S, если ни для каких
X], x2eS она не может быть представлена в виде
х*=Лх1+(1—%)х2, 0<Х<1. (4.131)
В этом определении X не может принимать значений
0 и 1. Это означает, что крайняя точка не может лежать
внутри отрезка, соединяющего любые две точки выпуклого
множества, а может быть лишь концевой точкой этого от-
резка.
146
Рис. 4.10. Разделительная (а)
опорная (б) гиперплоскости
Очевидно, что крайняя точка должна быть граничной
точкой множества. Но не все граничные точки являются
крайними. В выпуклом многоугольнике на рис. 4.9,6 точки
А и В крайние, а С нет. При искривленной границе, как,
например, на рис. 4.9,а, любая граничная точка С является
крайней. На понятии крайних точек основано определение
выпуклого многогранника. Выпуклым многогранником на-
зывают выпуклое множество, имеющее конечное число
крайних точек, являющихся вершинами многогранника.
Приведем без доказа-
тельства некоторые тео-
ремы, касающиеся край-
них точек.
Теорема 4.4.. Каждая
опорная гиперплоскость
выпуклого множества S
содержит его крайнюю
точку.
Теорема. 4.5. Выпук-
лое множество S является
его крайних точек.
Из теоремы 4.5 следует, что если S — выпуклый много-
гранник, то любая его точка является средневзвешенным
•< in:i его вершин. Сопоставляя данное утверждение
м< nriini M ki.iiivk.hoiT оболочки конечного множества
. 11/IIIM к KI.IIK |/|.у, 'IIO выпуклой оболочкой конечного
i-iii.i ,1 является выпуклый многогранник, вершина-
орого являются точки множества А.
Задачи к гл. 4
4.1. В трехмерном пространстве даны точки х=(1, 0, 2), у=(3,
4, 0), z=(l, 2, 3). Для этих точек проверить аксиому треугольника
п пространствах С2(3), С^31, С<3>.
4.2. На плоскости (х, у) нарисовать окружность с центром в 0 и
радиусом 1 в пространствах С2<3>, Ci<3>, О3).
4.3. Доказать, что открытый шар в пространстве /?<") является вы-
пуклым множеством.
4.4. Какие из множеств [О, 3], [5, 7], [О, 3]U[5, 7] в простран-
стве вещественных чисел R выпуклы, а какие нет?
множеством средневзвешенных
мной
МП 1\<
10*
Глава 5
ЭЛЕМЕНТЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
И МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
5.1. ПОНЯТИЕ ВЕРОЯТНОСТИ
5.1.1. События и пространство исходов эксперимента
В основе теории вероятностей лежит понятие события,
которое связано с проведением некоторого эксперимента.
Под событием понимается всякий факт, который в резуль-
тате эксперимента может произойти или не произойти.
Предположим, что при данной совокупности условий
результатами эксперимента может быть конечное число
исходов Zi,..., zm, полную совокупность которых обозна-
чим через
Z={zlt...,zm}. (5.1)
Множество Z будем называть пространством исходов
эксперимента, а элементы z<=Z— элементарными события-
ми в пространстве Z.
Однако практически наибольший интерес представляют
не сами элементарные события, а некоторые их совокуп-
ности, являющиеся подмножествами множества Z. Будем
называть событием в пространстве исходов эксперимента
Z любое подмножество S множества Z:
S^Z. (5.2)
Когда мы говорим, что происходит событие S, то под-
разумеваем, что исходом эксперимента является элемен-
тарное событие z, содержащееся в S.
Для любых событий S! и S2> принадлежащих простран-
ству исходов эксперимента Z, имеют место следующие
определения.
Объединением Si(JS2 событий Si и S2 называют собы-
тие, состоящее в осуществлении хотя бы одного из собы-
тий Si и S2.
Совмещением Sif|52 событий Si и S2 называют событие,
состоящее в осуществлении и Si, и S2. События Si и S2
называют несовместными, если осуществление одного из
них исключает возможность осуществления другого, т. е.
если Sif|S2=0.
148
Рис. 5.1. Пространство исходов экспери-
мента при бросании двух игральных ко-
стей
Дополнением S события S на-
зывают событие, состоящее в не-
осуществлении события S.
Достоверное событие состоит
в осуществлении хотя бы одного из
событий пространства Z.
Невозможным событием является пустое множество 0,
состоящее в том, что не осуществляется ни одно из собы-
тий пространства Z.
Пример 5.1. Эксперимент состоит в бросании двух игральных ко-
стей, на каждой из которых может выпасть от одного до шести очков.
Введем в рассмотрение множество 7={1, 2, .... 6}. Исход эксперимен-
ia будет упорядоченной парой z=(i, k), где i, k^J, причем i — резуль-
тат бросания первой кости; k — результат бросания второй кости. Исхо-
ды эксперимента удобно изображать точками на плоскости (Г, £), как
показано на рис. 5.1. Как видим, пространство исходов эксперимента
будет состоять из 36 точек: Z = {(1, 1), (1, 2), ..., (6, 6)}. События
Лесь могут быть весьма разнообразными. Обозначим через S, событие,
...тошнее и юм, что выпадает-/ очков. Тогда S2={(1, 1)}; S7=
(d. '). (". b). (Ч. 1). (4, 3), (5, 2), (6, 1)}; Зц={(6, 5), (5. 6)};
Понятие вероятности
В теории вероятностей каждый исход эксперимента
<=Z рассматривается как случайный. Это означает, что
.аранее неизвестно, какой из исходов будет иметь место
при проведении эксперимента. Однако ясно, что, во-первых,
н результате каждого испытания обязательно должен
иметь место какой-то исход zeZ и, во-вторых, в резуль-
тате одного испытания не может быть двух исходов.
Интуитивно под вероятностью исхода понимают чис-
ленную меру, которая характеризует объективную воз-
можность данного исхода эксперимента. Это означает, что
каждому из элементов zeZ приписывается некоторый вес
р, т. е. положительное вещественное число, на которое
наложены некоторые ограничения, а именно:
1) р тем больше, чем больше уверенность в том, что
будет иметь место именно данный исход эксперимента
zeZ;
149
2) сумма весов р для всех возможных исходов экспери-
мента должна быть равна единице.
Приписывание какому-либо элементу zeZ веса р—0
означает, что данный исход эксперимента невозможен,
т. е. представляет собой невозможное событие. Если како-
му-то элементу zeZ приписан вес р=1, то данный исход
представляет собой достоверное событие. Действительно,
в силу второго ограничения всем остальным элементам
множества Z должны быть приписаны веса р—0, т. е. со-
бытия, соответствующие этим элементам, являются невоз-
можными. Но так как какой-то исход эксперимента обя-
зательно должен иметь место, то это будет именно тот,
которому приписан вес р=1.
Совокупность весов, приписываемых отдельным элемен-
там множества Z, представляет собой некоторое множест-
во Р с элементами р, а сам процесс приписывания весов
представляет собой отображение множества Z на множе-
ство Р, т. е. определяет вероятности р^Р как функции
исхода эксперимента zeZ, что может быть записано в ви-
де p=p(z).
Согласно сформулированным выше ограничениям вели-
чины p(z) представляют собой вещественные числа, удов-
летворяющие условиям
p(z)>0; 2р(2) = 1' (5.3)
Совокупность весов p(z) для всех zeZ называют рас-
пределением вероятностей на пространстве исходов экспе-
римента Z, а каждый вес р^Р, приписываемый элемен-
тарному исходу zeZ, называют вероятностью данного
исхода.
Если множество Z элементарных событий представляет
собой множество значений некоторой (не обязательно чис-
ленной) переменной z, то эту переменную называют слу-
чайной величиной. В этом случае совокупность весов p(z)
будет представлять собой распределение вероятностей
случайной величины.
5.1.3. Вероятность события
События S мы определили как некоторое подмножество
множества исходов эксперимента Z. Следовательно, собы-
тие представляет собой множество, состоящее из части
150
элементов множества Z. При этом под вероятностью со-
бытия S, обозначаемой через Ps или P(S), понимают сум-
му весов составляющих это событие элементов:
P(S) — Ps= 3 Р(4 М
zeS
Частными случаями этой формулы являются:
1) S не содержит ни одного элемента из Z, т. е. явля-
ется пустым множеством; согласно (5.4) вероятность пус-
того множества равна нулю;
2) S совпадает с Z, т. е. содержит всевозможные исхо-
ды эксперимента. Так как не может быть исхода экспери-
мента, не входящего в Z, то все пространство Z можно
рассматривать как универсальное множество и приписать
ему вес р=1. Это вполне согласуется с формулой (5.4),
которая с учетом (5.3) дает:
Pz=-%p(z)=l. (5-5)
zez
5.1.4. Способы приписывания вероятностей исходам
эксперимента
Нмеск я ряд способоп приписывания весов отдельным
ЭЛСМ1ЧГ1.1М . пространства Z. Какой из способов применить
в том или ином случае, зависит от характера проводимого
эксперимента и от той информации, которой мы при этом
располагаем. Рассмотрим основные способы.
1. Определение вероятности через часто-
ту. Рассмотрим эксперимент с пространством исходов
Z={zi,...,zm}, который мы можем повторять многократно
в одних и тех же условиях. Предположим, что было про-
ведено N испытаний, при которых интересующий нас исход
zeZ произошел Nz раз. Относительное число случаев, при
которых данный исход z имел место, т. е.
q(z)=Nz/N, (5.6)
называют частотой исхода z. Нетрудно убедиться, что час-
тоты q(z) всевозможных исходов zeZ удовлетворяют ус-
ловиям (5.3).
При небольшом числе экспериментов частота носит
в значительной мере случайный характер. Так, при 10 бро-
саниях монеты «герб» может выпасть 2 раза, а при дру-
151
гих 10 бросаниях он может выпасть, например, 8 раз. Од-
нако практика показывает, что при увеличении числа
экспериментов частота отдельных исходов в значительной
мере теряет свой случайный характер и имеет тенденцию
приближаться с незначительными колебаниями к некото-
рому среднему значению, которое и может рассматривать-
ся как вероятность события. Однако это приближение
частоты к вероятности при увеличении числа эксперимен-
тов отличается от стремления к пределу в математическом
смысле.
Так, не является невозможным, что при 10-кратном
бросании монеты «герб» выпадает все 10 раз. Поскольку
результат каждого бросания монеты не зависит от резуль-
татов предыдущих бросаний, то нет ничего невозможного
и в том, что «герб» выпадет 1000 раз при 1000-кратном
бросании монеты. Однако вероятность такого события
столь мала, что его можно считать практически неосуще-
ствимым.
Вообще при увеличении числа опытов частота прибли-
жается к вероятности в том смысле, что вероятность
сколько-нибудь значительных отклонений частоты от ве-
роятности становится пренебрежимо малой. Следователь-
но, если имеется возможность многократно повторять экс-
перимент в одинаковых условиях, то частоты отдельных
исходов q(z) могут быть приняты за вероятности этих ис-
ходов. Вопрос о том, какое число экспериментов считать
достаточным при определении вероятности через частоту
и какова степень достоверности полученных при этом ре-
зультатов, будет более подробно рассмотрен в главах, по-
священных методам математической статистики.
Однако трудности, связанные с многократным повто-
рением эксперимента в реальных условиях, заставляют
использовать другие методы определения вероятности.
Принцип равных возможностей. Этот прин-
цип применяют, когда нет оснований отдать предпочтение
какому-либо одному исходу эксперимента перед другими.
В этом случае следует считать, что имеются равные воз-
можности для любого исхода эксперимента, и всем им
приписать одинаковые вероятности. Если при этом прост-
ранство исходов эксперимента Z состоит из т элементов,
а событие S содержит г элементов из Z, то вероятность
этого события
P(S)=r/m. (5.7)
152
Так, вероятность того, что из хорошо перемешанной
колоды в 52 карты будет вынут один из королей, рав-
на 1/13.
Априорные вероятности. Априорные вероят-
ности определяют на основании сбора статистических дан-
ных об интересующем нас событии или явлении за дли-
тельный промежуток времени.
Обычно в различных областях науки, техники и обще-
ственной жизни производится сбор статистических сведе-
ний о тех или иных событиях или явлениях, которые от-
носятся к разряду случайных, т. е. закономерности кото-
рых не поддаются строгому математическому описанию и
появление которых не может быть с достоверностью пред-
сказано. Изучение того, насколько часто данное событие
происходило в прошлом, позволяет определить вероят-
ность этого события и, следовательно, предсказать с опре-
деленной степенью достоверности появление этого собы-
тия в будущем.
Апостериорные вероятности. Априорные ве-
роятности дают достоверное описание явления лишь в том
случае, когда условия, при которых происходило явление
в прошлом, сохраняются и в настоящее время. Однако так
бывает далеко не всегда. Поэтому важное значение имеет
уio'iik'iiik' иенетвительных условий, имеющих место в на-
iirnii.iiii mo’khi npi-мепн, 'iio может быть сделано путем
и।»>ш• ’н-п11.1 । ik'iiи.i.ni.iii) inK'.r.iiijieniioi’o эксперимента. Ве-
рня ।ikk-rn, определяемые как на основе прошлых стати-
eiii'iecKiix данных, так и на основании специально постав-
ленного эксперимента, называют апостериорными вероят-
ностями.
Пример 5.2. По статистическим данным за длительный период
в июле в средней полосе 80 % дней солнечных (событие S|) н 20 %
дождливых (событие S2). Поэтому априорные вероятности того, что
12 июля будет солнце или дождь, P(S,)=0,8 и Р($2)=0,2. Однако
в отдельные годы могут быть значительные отклонения от этих сред-
них цифр. Уточнение состояния погоды на 12 июля по данным прогноза
па текущий месяц может рассматриваться как проведение эксперимен-
та (см. пример 5 5).
5.1.5. Вычисление вероятностей сложных событий
Пусть Si и 5г — некоторые события в пространстве ис-
ходов эксперимента Z с известными вероятностями Р(3|)
и Р(3?). Сложное событие может представлять собой, на-
153
пример, объединение, пересечение, дополнение простых
событий. Для упрощения вычислений вероятностей слож-
ных событий рассмотрим некоторые соотношения, связы-
вающие вероятность сложного события с вероятностями
составляющих его простых событий.
1. Если SiflS2=0, то согласно (5.4)
mUS2)= 3 ^(*)= 2 />(*)+ 2 Р& =
zeSxUSz zest ге52
= P(S1) + P(S8). (5.8)
Выражение (5.8) допускает обобщение. Пусть Si,...
..., Sz — несовместные события, т. е. такие, для которых
Sif|5,=0 при £=/=/• При этом
2^(s«)- (5-9)
2. Из условий X{JX=Z, Х[}Х=0 находим Р (XU-X) =
=Р(Х)4-Р(Л') = 1, откуда
Р(Х) = 1— Р(Х). (5.10)
3. Пусть Y^X. Рассмотрим множества У и Х\У, удо-
влетворяющие условиям УП (X \ У) =0, УК {X \ У) =Х.
Следовательно, Р (X) =Р [ Уи (X \ У) ] =Р (У) +Р (X \ У).
Поскольку Р(Х\У)^0, то
Р(Х)>Р(У); Р(Х\У)=Р(Х)—Р(У). (5.11)
4. Для произвольных X и У рассмотрим подмножество
В=У\(Х(]У), удовлетворяющее условиям:
х[\в=0, хив=хиу,
поэтому
Р (ХиУ) =Р (ХЦВ) =Р (X) +Р (В) =
=Р(Х)+Р[У\(ХПУ)]. (5.12)
Но ХПУ^У, так что согласно (5.11) Р[У\ (ХГ|У)] =
=Р(У)—Р(ХПУ). поэтому
Р(Д)У)=Р(Х)4-Р(У)-Р(ХЛП. (5.13)
Пример 5.3. Из колоды в 52 карты выбирается наугад одна. Како-
ва вероятность, что эта карта будет: 1) червонной масти или король
треф? 2) червонной масти или один из королей?
154
Обозначим: X—множество червей; У—множество королей; V —
король треф, так что Р(Х) = 1/4, Р(У)=1/13, P(V) = l/52.
1. Вычисляем P(X(JV). Поскольку P(X(")V)=0, то
Р (X(J V) =Р (X) +Р (V) = 1 /44-1 /52 =7/26.
2. Вычисляем P(XUK). Так как Х[\Уф0, то Р(ХиУ)=Р(Х)+’
4-Р(У)—Р(ХЛТ). Но XQУ— король червей, т. е. Р/ХПГ) = 1/52. Сле-
довательно,
Р(ХиГ) = 1/44-1/13-1/52=4/13.
5.2. УСЛОВНЫЕ ВЕРОЯТНОСТИ
5.2.1. Понятие условной вероятности
Рассмотрим некоторое событие Т в пространстве ис-
ходов эксперимента Z. По определению вероятность это-
го события
^(Г)= 3 P(z). (5.14)
гет
Предположим нам известно, что произошло некоторое
другое событие S. Спрашивается, каким образом знание
|<>к>, что произошло событие S, повлияет на вероятность
riiiii.ii ни /4’
Верой...си. события Т при условии, что произошло
другое событие S, называют условной вероятностью собы-
тия Т и обозначают PS(T) или P(T\S). Вероятность Р(Т)
называют безусловной вероятностью события Т. Перед
нами стоит задача найти соотношение, связывающее эти
две вероятности.
Упростим задачу. Будем считать, что множество Т со-
стоит только из одного элемента zeZ. При определении
безусловной вероятности p(z) исходим из того, что может
произойти любое zeZ. Если производится достаточно
большое число экспериментов, то
число экспериментов с данным zgZ Nz
общее число экспериментов М
Если налагается условие, что произошло событие S,
то тем самым должны быть исключены все те исходы экс-
перимента, при которых событие S не происходит. Значит,
при определении p(z|S) нужно заменить N на Ns — число
экспериментов, в которых произошло событие S, и Nz на
(5.15)
155
Nz,s — число экспериментов, в которых произошло как
данное г, так и событие S. Но в рассматриваемом случае
(г, 5) = гПЗ = (2'e“"2SLS’ (5.16)
(0, если z^S.
Поэтому N{z S) = Таким образом,
P(z\S) = Nzf}sINs. (5.17)
Поделив числитель и знаменатель этого выражения на
общее число экспериментов N, получим
p(2|S)=p(znS)/P(S). (5.18)
Рассмотрим теперь случай, когда Т — произвольное
подмножество Z. Учитывая, что вероятность события рав-
на сумме вероятностей элементов, составляющих это со-
бытие, находим
P(T\S)= SrP(z\S) = ^p(znS)/P(S). (5.19)
Рассмотрим сумму, стоящую в числителе этого выра-
жения. В нее входят только слагаемые для г^Т. Но в ней
можно не учитывать слагаемых для zf£S, так как при
этом p(zf]S)==O. Следовательно, эта сумма состоит из сла-
гаемых, для которых выполняются условия z^T и z^S.
Значит, суммирование можно вести по zeTf|S. Но при
z^S имеем p(zf)S)=p(z). Поэтому
2/W) = S р(2) = Р(ГПЗ). (5.20)
2GT 2ЕТП5
С учетом этого
P(7’\S)=P(7’nS)/P(S), (5.21)
что часто записывают в виде
P(T(]S)=P(T\S)P(S). (5.22)
Иногда встречаются случаи, когда наше знание того,
что произошло событие S, не влияет на вероятность собы-
тия Т. Другими словами, вероятность события Т не зави-
сит от того, произошло или не произошло событие S, так
что
P(T\S)=P(T). (5.23)
156
В этом случае говорят, что события Т и S являются
независимыми .и для них имеет место соотношение
P(7’f]S)=P(T)P(S), (5.24)
которое часто называют формулой умножения вероятно-
стей.
Пример 5.4. Монету бросают три раза. Пусть Т — событие, состои-
щее в том, что все три раза монета выпадает одной и той же сторо-
ной; S — событие, состоящее в том, что «герб» выпадает не более
одного раза. Являются лн события Т и S независимыми?
Из восьми возможных исходов эксперимента событию Т соответ-
ствуют два исхода, событию S — четыре, а событию Tf|S — одни. По-
этому Р(Т)=1/4, P(S) = l/2, P(TnS)=l/8. Сопоставляя эти данные
с условием (5.24), видим, что события Т и S независимы.
5.2.2. Формула полной вероятности
Пусть некоторое событие Т происходит вместе с одним
из несовместных событий St,..., Si, т. е. событий, удовлет-
воряющих условию Sif]S/=0 при Тогда
т=т n'(Sx и Ss u-u st)=(Т п з.) и (ГП^и-и^П^).
Поскольку события S, несовместны, то несовместны и
со(>|.гн|ц 7'(]Х, ('..11сдо||;1тольпо, согласно (5.9)
Р(Т)=Ер(тп5г)
<=|
или с учетом (5.22)
Р(Т)= (T\Si) р(&). <5-25)
z=i
Выражение (5.25) получило название формулы полной
вероятности.
5.2.3. Определение апостериорных вероятностей.
Формула Байеса
Пусть имеется множество возможных несовместных со-
бытий Si...Si и из прошлого опыта известны их априор-
ные вероятности Р(5г). Эти вероятности кажутся недоста-
157
точно надежными, поэтому для их уточнения проводим
эксперимент.
Пусть событие Т явилось исходом эксперимента. Из-
вестны (опять из прошлого опыта) условные вероятности
Р(Т\5г) события Т при каждом из несовместных событий
Si, i=l,..., I. Посмотрим, как изменится представление
о вероятностях событий Si,..., Si после получения резуль-
тата эксперимента Т. Эти вероятности обозначаются
P(Si\T), 1=1,..., I и называются апостериорными вероят-
ностями событий Si,...,Si.
Для вычисления апостериорных вероятностей восполь-
зуемся формулой (5.22), которую запишем в виде
Р=P(T\St)P(Si)=P (Si \ Т)Р(Т).
Отсюда
Р (St \ Т) =Р (Т \Si)P(Si)/P (Т). (5.26)
Входящую в (5.26) безусловную вероятность Р(Т) со-
бытия Т находим по формуле полной вероятности (5.25)
Р(Т) = SPiTXSiyPiSfr (5.27)
С учетом (5.27) формула (5.26), получившая название
формулы Байеса, запишется в виде
PJ<Sl\T)=P(T\Si)P(Sl} j 2Р(Т\ St)P(St). (5.28)
Пример 5.5. Прогноз погоды на 12 июля в примере 5.2 показал
«солнце» (событие Ti). Этот прогноз может быть ошибочным с услов-
ными верятиостями Р|Si) =0,9 и P(Tt|S2)=0,3. Апостериорные ве-
рятности событий Si н S2 будут: P(S|TI)=0,9-0,8/(0,9-0,8+0,3-0,2) =
= 0,923; P(S|Ti) =0,0769.
5.3. НЕПРЕРЫВНЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
И ИХ РАСПРЕДЕЛЕНИЯ
5.3.1. Понятие непрерывной случайной величины
До сих пор мы предполагали, что пространство исхо-
дов эксперимента Z представляет собой конечное множе-
ство. Однако во многих случаях исходом эксперимента z
158
может быть любое значение в некотором диапазоне
При этом z является непрерывной случайной ве-
личиной, Пространством исходов эксперимента которой
будет весь диапазон ее возможных значений:
Z={z|a<z<5}, (5.29)
содержащий бесконечное множество точек.
Непрерывными случайными величинами будут, напри-
мер, высоты деревьев в лесу или их диаметры, сила тока
или напряжение в электрической сети, температура возду-
ха в различное время суток,. В этих случаях уже нельзя
говорить о вероятности отдельного исхода, так как при
бесконечно большом числе возможных исходов вес каж-
дого исхода р=0. Поэтому распределение вероятностей
для непрерывной случайной величины определяется ина-
че, чем в дискретном случае. При этом используют два ви-
да распределения, называемых функцией распределения
вероятностей и плотностью вероятности.
5.3.2. Функция распределения вероятностей
Пусть Z— пространство исходов эксперимента одно-
мерной случайной величины, принимающей вещественнее
Mitii'H uinr, Д множество всех вещественных чисел, эле-
мсн। i.i и।ни|к»г1> обозначим через к. Функция распределе-
1'||( Г5.2. Функция распределения ве- -
риитностей для непрерывной случай-
ной величины „
ния вероятностей F(jc\ определяет вероятность того, что
значения случайной величины z не превзойдут данного х:
F(x)=P(—oo<z<x). (5.30)
Общий характер функции F(x) можно представить,
базируясь на некоторых ее свойствах:
1) поскольку при х2>Х1 интервал [—до, х2] лежит це-
ликом внутри интервала [—оо, xf], то. согласно (5.30)
F(x2)^F(xi). Следовательно; F(x) —неубывающая функ-
ция;
159
2) F(—oo)=0, так как исход эксперимента Ze(—оо,
х] становится невозможным событием при х-э—оо;
3) F( + oo) = l, так как исход эксперимента ze—(оо,
х] становится достоверным событием при х->-г<».
Общий вид функции, удовлетворяющий поставленным
свойствам, приведен на рис. 5.2.
5.3.3. Плотность вероятности
Зная функцию распределения вероятностей, можно
подсчитать вероятность того, что значение случайной ве-
личины будет лежать внутри малого интервала от х до
х-|-Ах. Согласно (5.30) эта вероятность
F (х-|-Ах) —F (х) =
= (F(x+Ax)—F(x))Ax/Ax. (5.31)
Первый сомножитель правой части этого выражения
представляет собой значение вероятности, приходящееся
на единицу длины участка Ах. Если предел этого отноше-
ния при Ах->0 существует, что обычно выполняется для
большинства непрерывных случайных величин, то его
обозначают через w(x) и называют функцией плотности
вероятности или просто плотностью вероятности. Таким
образом,
w (х) = lim [(F (х + Ах) — F (х))/Дх] — dF (x)/dx, (5.32)
так что
F(x+Ax)—F(x)=tw(x)Ax. (5.33)
На рис. 5.3 приведен общий характер графика функ-
ции w(x).
Выясним некоторые свойства функции w(x). Пусть а
и b — произвольные точки вещественной оси, причем Ь~>
>д.Найдем смысл интеграла §w(X)dx. Заменяя чи-
сто формально w(x)dx на dF(x), получаем
b F(b)
§w{x)dx = J dF(х) = F(b) — F(а). (5.34)
a F(a)
160
Однако согласно (5.30) это выражение дает вероят-
ность того, что случайная величина z принимает значение,
лежащее внутри интервала (я, &). Таким образом,
ь
P(a<z<b) = § w(x)dv. (5.35)
Из (5.35) как частный случай следует соотношение
+00
w(x)dx — 1,
(5.36)
о
Рис. 5.3. Функция плотности ве-
роятности
Me М х
Рис. 5.4. Взаимное расположение
моды и медианы
1ИЖ.1 плвающее, что площадь, ограниченная кривой плот-
|||и in iK'pdHTnocTii «у(х) и осью абсцисс, всегда равна еди-
I'.i |||.ы i iiik- (.'• 13) пи П1ОЛЖЧ пыра.чпть связь между
функциями /•(») и ।) и интегральной форме. Сравни-
it. г,i (5.30) п (5.35), находим
F(x)-=f w(B)^. (5.37)
Для более полного описания формы кривой плотности
псроятности используют две характерные величины, назы-
п.чемые модой и медианой.
Модой М случайной величины называют такое значе-
ние х, при котором oi(x)=max.
Медианой Me случайной величины называют такое
х=Ме, для которого P(z<_Me) — Р{г>Мё), т. е. для
которого левая и правая площади под кривой плотности
вероятности одинаковы.
На рис. 5.4 приведено взаимное расположение моды и
медианы для несимметричного относительно своего мак-
симума графика кривой плотности вероятности.
11—804
161
Понятия функции распределения вероятностей и плот-
ности вероятности легко распространяются и на случай
многомерной случайной величины (случайного вектора)
[20, 22]. Отложив рассмотрение этих вопросов до § 5.5,
разберем некоторые законы распределения непрерывных
случайных величин.
5.3.4. Равномерное распределение вероятностей
Если случайная величина с одинаковой вероятностью
может принимать любые значения в пределах участка ве-
щественной оси от а до р и не может принимать значений
вне этого участка, т. е. имеет плотность вероятности
“ХТ* <М8>
(0, z<a, z>0,
то ее называют равномерно распределенной в интервале
[«> ₽]•
Равномерное распределение удобно охарактеризовать
параметрами v=(a+p)/2 и ш—13—а, называемыми сред-
ним значением и размахом распределения, и обозначить
через R(y, и). Плотность распределения вероятностей
w(z) легко выразить через параметры распределения
X(v, <о) в виде
„и- (5.39)
’ [0, z<v—<о/2, Z>v + <»I2.
Пример 5.6. При округлении числа до целых значений погрешности
могут с одинаковой вероятностью принимать значения от —0,5 до
-|-0,5, т. е. подчиняются распределению 2?(0, 1).
Пример 5.7. При отсчете по шкале с ценой деления б погрешности
отсчета будут случайными величинами с распределением 2?(0, б).
Пример 5.8. Если движение троллейбуса происходит с интервалом
10 мин, то время ожидания для пассажира, не знакомого с расписа-
нием, будет случайной величиной с распределением R(5, 10).
5.3.5. Гауссовское (нормальное] распределение
вероятностей
Наиболее важным законом распределения случайной
величины является нормальный или гауссовский закон
распределения. Этот закон наиболее часто встречается на
162
практике и является предельным законом, к которому
приближается ряд других законов распределения при
весьма часто встречающихся типовых условиях.
Нормальный закон характеризуется функцией плотно-
сти вероятности вида
для —оо<г<4-оо.
в(2,= ч7й
e-(z-v)V23"-
(5.40)
о, в
°,5
о,4
0,3
oY.
^0,-L
<з=г,о
-Z -1 о
Рис. 5 5. График w(x) для нормального распределения
Нормальное распределение определяется параметра-
ми v п о2, называемыми математическим ожиданием и
ihn пе/н псп, и и дальнейшем будет обозначаться N(y, о2).
II.i [нн- !> приведен график функции (5.40) для -v=l,0
и нескольких значений о. Легко видеть, что при о->-0 нор-
мальный закон распределения вероятностей w(z) превра-
щается в импульсную функцию 6(z—v) (см. § 2.5).
Весьма важной задачей теории вероятностей является
определение вероятности того, что случайная величина
попадает на заданный интервал вещественной оси (а, Ь).
В случае нормального распределения
(5.41)
Это выражение принимает более удобный вид, если
произвести замену переменной, обозначив (z—v)/o=t.
При этом (И=йг/а и
(Ь—v)/cr
P(a<z<b)=-^=- j е~р/2^.
(5.42)
(a—v>/cr
И*
163
Однако интеграл вида J е р/2сИ через элементар-
ные функции не выражается. Поэтому для вычисления
(5.42) пользуются таблицами (см. [21]) специальной
функции
ф(х)==тк J (5-43)
называемой интегралом вероятностей. С учетом (5.43) ве-
роятность попадания случайной величины на интервал
(а, Ь)
P(a<z<b)=®( (b-v) /о)—Ф ((а-v) /о). (5.44)
При вычислениях по формуле (5.44) полезно помнить
следующее: \
Ф(0)=1/2; Ф(+оо)=1; Ф(—х) = 1—Ф(х). (5.45)
5.4. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СЛУЧАЙНЫХ
ВЕЛИЧИН
5.4.1. Понятие о числовых характеристиках
Функция распределения или плотность вероятностей
являются наиболее полными характеристиками случай-
ных величин. Однако во многих задачах оказывается
трудно или даже невозможно полностью описать функцию
распределения вероятностей.
В то же время для решения многих задач достаточно
знать лишь некоторые параметры, характеризующие слу-
чайную величину с той или иной точки зрения. Наиболее
распространенными числовыми параметрами, получивши-
ми название числовых характеристик или моментов слу-
чайных величин, являются математическое ожидание и
дисперсия или среднеквадратичное отклонение. Их легко
определяют из экспериментальных данных, они позволяют
в общих чертах судить о характере случайной величины.
5.4.2. Математическое ожидание случайной величины
Во многих задачах случайная величина, рассматривае-
мая как возможный исход некоторого эксперимента, вы-
ражается вещественным числом. Примерами случайных
164
величин, принимающих численное значение, могут слу-
жить: ток, потребляемый жильцами дома; напряжение
в сети в данный момент времени; температура воздуха
в данное время суток; число космических частиц, достига-
ющих земной поверхности за единицу времени; число оч-
ков, выбитых данным стрелком па мишени; число покупа-
телей в магазине в данный момент времени и т. п.
Для всех этих случаев важной числовой характеристи-
кой случайной величины является ее математическое
ожидание.
Предположим, что элементы пространства исходов экс-
перимента Z—{z\,..., zm} допускают численную оценку.
Если при N испытаниях исход z\ произошел г\ раз,..., ис-
ход zm произошел гт раз, так что п+... +rm=N, то сред-
нее значение случайной величины z будет
zcp = (zfi +... + zmrm)/N 2 z, (rt/N), (5.46)
/=1
где rt/N=qi — частота исхода Zf.
Если число экспериментов N будем увеличивать, то от-
ношение Гг/N будет приближаться к вероятности pi исхо-
да гг. Заменяя в (5.46) r-t/N на вероятность pt, получаем
формулу для определения математического ожидания
случайной величины z, обозначаемого через E(z) или z.
Опуская индексы при переменных, находим
E(z)-=z-= 2 zp(z).
(5-47)
Как видим, отличие математического ожидания слу-
чайной величины от ее среднего значения носит тот же ха-
рактер, что и отличие вероятности от частоты.
Выражение (5.47) может служить для определения ма-
тематического ожидания в случае, когда пространство ис-
ходов эксперимента Z является конечным множеством.
Если же z — непрерывная случайная величина с плотно-
стью распределения вероятностей w(z), то под p(z)
в (5.47) можно понимать вероятность того, что значение
случайной величины лежит в пределах от z до z+Az, т. е.
положить p(z)=sy(z) Az. Переходя к пределу при Az->0
и заменяя соответственно Az на dz, а сумму на интеграл,
165
получаем
_ +о°
Е (z) = z = j zw (z) dz. (5.48)
Отметим некоторые свойства математического ожида-
ния, важные для дальнейшего использования.
I. Математическое ожидание неслучайной величины
равно самой величине. Пусть с — неслучайная, т. е. по-
стоянная, величина. При этом с можно рассматривать как
результат эксперимента, при котором пространство исхо-
дов Z состоит только из одного элемента с, так что р(с) =
=1. По (5.47) находим
Е(с)=ср(с)=с. (5.49)
2. Постоянный множитель можно выносить за знак ма-
тематического ожидания
E(cz) = czpz = c 2 zp(z)=cE(z). (5.50)
z&Z z£Z
Пример 5.9. Математическое ожидание равномерно распределенной
случайной величины
J xiv (х) dx = \/{b—a) y%dx = (& + a)/2.
5.4.3. Математическое ожидание функции
от случайной величины
На практике часто встречаются задачи, в которых слу-
чайная величина не выражается числом. Так, выпускае-
мая заводом продукция делится на годную и бракован-
ную. При бросании монеты исходом эксперимента может
быть «герб» или «решка». Вынутая наугад из колоды кар-
та характеризуется наименованием и мастью. Принятый
радиолокационный сигнал несет информацию о наличии
или отсутствии цели и т. п. Во всех этих примерах случай-
ные величины имеют не количественное, а только качест-
венное различие. Однако обычно оказывается возможнььм
введение количественной оценки и для случайных вели-
чин, имеющих лишь качественное различие.
Случайную величину рассматриваем как результат не-
которого эксперимента, который или ставится искусствен-
166
но, или является результатом естественного процесса. При
этом следует помнить, что любой эксперимент требует оп-
ределенных затрат и ставится не ради удовлетворения на-
шего любопытства, а ради достижения определенной це-
ли. Тот или иной исход эксперимента является желатель-
ным или нежелательным в зависимости от того, насколько
достигается поставленная цель. Достижение поставленной
цели можно рассматривать как выигрыш или выгоду,
а недостижение—как проигрыш или убыток. И выгоду и
убыток можно выразить числами, представляющими на-
пример какие-то суммы денег в рублях.
Таким образом, каждому исходу эксперимента zeZ
можно поставить в соответствие некоторую численную
оценку, т. е. осуществить отображение f пространства ис-
ходов эксперимента Z на множество вещественных чи-
сел R:
f-.Z^R. (5.51)
Это отображение дает вещественную функцию f(z),
определенную на Z, с которой мы можем оперировать как
со случайной величиной и, в частности, определять ее ма-
тематическое ожидание.
Пусть f(z)—некоторая численная функция, опреде-
ленная па множестве Z. Это означает, что элементам zi,...
.. ,zm множества Z соответствуют значения функции
f(zt), Вероятности этих значений будут те же, что
п вероятности случайных величин zb..., zm. Таким обра-
зом, p(z) представляет собой распределение вероятностей
как для случайной величины z, так и для функции от слу-
чайной величины f(z). Следовательно, математическое
ожидание функции от случайной величины может быть
найдено по формулам для математического ожидания слу-
чайной величины путем замены z на f(z):
для дискретной случайной величины
Д[/(г)] = Й7)= S (5.52)
г&
для непрерывной случайной величины
+00
£[f(z)l -=Ш = 7 f(z)w(z)dz. (5.53)
167
Пример 5.10. Вероятность того, чго выпущенный заводом прибор
окажется бракованным, равна р. Какова средняя прибыль, приходя-
щаяся на одни прибор, если а — себестоимость, Ь — цена прибора?
Обозначая среднюю прибыль через Q и применяя (5.52), находим
Q= (6-a) (i_p)_ap=6(i_p)_a.
Во многих задачах математическое ожидание рассматривается как
средний выигрыш при большом числе экспериментов. В этом случае
считается, что эксперимент проводить целесообразно, если 7(z):»0.
Другая интерпретация математического ожидания относится
к пари. Предположим, что некоторое событие может произойти с ве-
роятностью р. Заключение пари предполагает, что один из его участ-
ников согласен заплатить сумму 6, если событие не произойдет, при
условии, что другой участник заплатит ему сумму а, если событие
произойдет. Таким образом, первый участник получает сумму а с ве-
роятностью р и выплачивает сумму 6 с вероятностью 1— р. Его сред-
ний выигрыш
Q=ap— 6(1—р).
Пари считается справедливым, если средний выигрыш будет равен
нулю, т. е. при условии
а/6=(1—р)/р.
Теорема 5.1 (теорема о среднем значении). Заменяя
в (5.52) под знаком суммы f(z) на его минимальное зна-
чение min f(z), получаем соотношение
777)>minf(z) 2 Р (2) = nun f(z),
г
выражающее собой теорему о среднем значении.
5.4.4. Моменты. Дисперсия. Среднеквадратичное
отклонение
Важнейшими числовыми характеристиками случайной
величины являются ее моменты, которые делятся на на-
чальные и центральные.
Начальный момент порядка s случайной величины z
для дискретной случайной величины
as(2)=S2W); (5.54)
168
для непрерывной случайной величины
+00
as(z)= J zsw(z)dz. (5.55)
Нетрудно видеть, что математическое ожидание E(z) —
=z представляет собой начальный момент первого по-
рядка ai(z). Начальный момент второго порядка — сред-
нее значение квадрата случайной величины
a2(z)= ==z2. (5.56)
, Очень часто в качестве случайной величины использу-
ют центрированную случайную величину z=z—z, пред-
ставляющую собой разность между случайной величиной
г и ее математическим ожиданием z. Если вместо г
в (5.54) и (5.55) представить z, то получим выражение
для центральных, моментов порядка s.
Легко убедиться, что центральный момент первого по-
рядка, т. е. математическое ожидание центрированной
случайной величины, равен нулю:
о +со — 4 00 —+°° — —
E(z) (г -~z)w(z)dz — J zw(z)dz — z§ w{z)dz—z-z—Q.
Важнейшей числовой характеристикой случайной вели-
чины служит центральный момент второго порядка, на-
зываемый дисперсией случайной величины г, обозначае-
мый D(z) или ог2 и определяемый для дискретной слу-
чайной величины
^(z) = az2 = S(z-z)2p(z); (5.57)
для непрерывной случайной величины
+00
D (г) — ога = j (г — z)2 w (z) dz. (5.58)
Сопоставляя (5.57) и (5.58) с (5.52) и (5.53), видим, что
дисперсию можно рассматривать как математическое ожи-
дание квадрата центрированной случайной величины
o22=E[(z-z)2]. (5.59)
169
Дисперсия характеризует отклонения отдельных зна-
чений случайной величины от математического ожидания,
т. е. является характеристикой рассеивания случайной ве-
личины. Чем меньше дисперсия, тем более тесно концент-
рируются отдельные значения случайной величины вблизи
математического ожидания.
Дисперсия оказывается в ряде случаев неудобной для
практического использования, так как имеет размерность
квадрата случайной величины. Поэтому в качестве ха-
рактеристики рассеивания случайной величины часто при-
меняют корень квадратный из дисперсии, получивший на-
звание среднеквадратичного отклонения и обозначаемый
а или о2:
(5.60)
Отметим основные свойства дисперсии:
1) дисперсия неслучайной величины равна нулю:
Д(с)=£[(с—с)2]=£(0)=0; (5.61)
2) неслучайную величину можно выносить за знак дис-
персии, возводя ее в квадрат:
D (cz) =Е [ (cz—cz)2] = c2D (z). (5.62)'
Некоторые другие свойства дисперсии будут рассмот-
рены позднее.
Пример 5.11. Дисперсия равномерно распределенной случайной ве-
личины
+ оо ь
°2г = J (г—i)2M(z)dz=l/(ft—л) J (г —(*+e)/2)»dz =
= (*—а)2/12.
5.5. ДВУМЕРНЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
5.5.1. Понятие двумерной случайной величины
Часто в качестве результата эксперимента нас интере-
сует не одна, а несколько случайных величин, например
х и у. Так, при вынимании карты из колоды могут инте-
ресовать ее масть х и ценность (число очков) у\ при вы-
боре деревьев в лесу для строительства — высота дерева
х и его диаметр у, при проверке конденсаторов на исправ-
ность — емкость х и пробивное напряжение у.
170
Во всех этих примерах имеют дело с двумя множества-
ми случайных величин: X={xi..... хп) и Y={y\, ..., у™}-
Однако эти множества не являются независимыми, они
определенным образом связаны между собой, а именно:
исходом одного эксперимента z являются две случайные
величины хеХ и y<^Y, так что z= (х, у). Таким обра-
зом, множество исходов эксперимента Z является прямым
произведением множеств X и Y:
Z=X*Y. (5.63)
Рассмотрим события и их вероятности, которые могут интересовать
при рассмотрении двумерных случайных величин. Вводимые понятия
будем иллюстрировать на примере коробки с карандашами, имеющими
два признака: цвет хеХ={К, С} в твердость #еУ={Т, М}. В коробке
имеется восемь карандашей со следующими значениями признаков:
кккккссс
тттммтмм.
Результатом эксперимента будет случайный выбор одного каранда-
ша, и нам хотелось бы, чтобы он обладал признаками х=К, у—М.. При
этом можно рассматривать следующие вероятности, значения которых
в нашем примере легко находят по принципу равных возможностей:
1) р(х)=р(К)=5/8 — вероятность того, что вынут красный каран-
даш (твердость карандаша не интересует);
2) р(у) =р(М)=1/2 — вероятность того, что будет вынут мягкий
карандаш (цвет карандаша не интересует). Вероятности р(х) и р(у)
являются безусловными вероятностями признаков х и у и дают рас-
пределения вероятностей на множествах X и Y, удовлетворяющих усло-
виям (5.3);
3) р(х, !/)=р(К. М) = 1/4—вероятность того, что случайно вы-
бранный карандаш окажется красным и мягким (таких карандашей
два). Это совместное распределение вероятностей двух признаков х
и у, заданное на пространстве Z=XX.Y с элементами z=(x, у) и удов-
летворяющее условиям:
Р(х, Ю>0; Р(х, у) = 1; (5.64)
х, И
4) р(х/у) = (К/М) = 1/2 — условная вероятность, в которой условие
у—М означает, что выбор производится только из мягких карандашей,
а твердые исключены из рассмотренвя.
Для того, чтобы увязать все разобранные вероятности
между собой, обозначим через xi некоторый исход хеХ,
171
а через yi некоторый исход y^Y и рассмотрим два собы-
тия в пространстве: Z=X'XY: Ti—{(xi, yi), ..., (хг, ут)} и
S/={(xi, у{). (х„, у,)}.
Сббытие Ti состоит в том, что произошел данный ис-
ход х(еХ и любое y^Y. Так как при любом эксперименте
какое-то y^Y всегда имеет место, то событие Л состоит
в том, что произошел исход х(-. Таким образом, Tt—xi.
Аналогично S/—yf. Нетрудно также видеть, что T,nS/ =
= (х/, у/). По (5.21) находим
p(xt\y,)=;p(xi, У/)/(Р(Уг)- (5.65)
Поскольку Xt может быть любым хеХ, a yf может
быть любым y^Y, то, опуская индексы, получаем для
любых хеХ и y^Y-.
Р(х\у)=р(х, у)/р(у), (5.66)
что можно записать в виде
Р(х, у)—р(х\у)р(у). (5.67)'
Если вероятность исхода х не зависит от того, какой
исход у имел место, то исходы х и у являются независи-
мыми. Для независимых исходов справедливо соотноше-
ние
р[х\у)=р(х), (5.68)
поэтому (5.67) принимает вид
Р{х, у)=р(х)р{у). (5.69)
Заметим далее, что при рассмотрении двумерной ве-
личины нам безразлично, какую из величин х или у при-
нять за первую и какую за вторую. Меняя в (5.67) ме-
стами х и у, получаем
Р{х, у)=р(у\х)р(х). (5.70)
Сравнивая (5.67) и (5.70), находим
Р(х, у)=р{х)р(у\х)=р(у)р(х\у). (5.71)
5.5.2. Распределение вероятностей для непрерывных
двумерных случайных величин
Выражения (5.66) —(5.71) позволяют определять со-
отношения между вероятностями различных событий для
двумерных случайных величин с конечными множествами
172
исходов эксперимента. Однако на практике часто прихо-
дится иметь дело с непрерывными случайными величинами
X и Y, для описания которых по аналогии с одномерным
случаем следует ввести понятие двумерной функции рас-
пределения вероятности и двумерной функции плотно-
сти вероятности.
Функция распределения вероятности, обозначаемая
в данном случае через F(x, у), определяет вероятность
того, что значение случайной величины X не превзойдет
данного х, а значение случайной величины Y не превзой-
дет данного у, т. е.
F(x, у) = Р (—со<Х^х, -<*><Y^y). (5.72)
Функция F(x, у) является однозначной, вещественной
и неотрицательной функцией от х и у, обладающей сле-
дующими свойствами:
1) F(x, у)— неубывающая функция от х и у,
2) F(—оо, y)=F(x, —оо)=0;
3) F(+oo, +оо) = 1.
Обозначим через F\(x) и F2(y) функции распределе-
ния вероятности каждой из компонент двумерной случай-
ной величины (X, Y). Эти одномерные функции распреде-
ления вероятности легко получить из двумерной функции
распределения вероятности F(x, у), если, исследуя рас-
пределение вероятностей одной из компонент, допустить,
что другая компонента может принимать любое значение
в пределах от —оо до 4~°°- Тогда
Fi(x)=F(x, 4-оо), F2(y)=F(4-oo, у). (5.73)
Наряду с двумерной функцией распределения вероят-
ности F(x, у) можно ввести по аналогии с одномерным
случаем двумерную плотность вероятности w(x, у), оп-
ределяемую как
w(x, y)=d2F(x, у)/(дхду). (5.74}
Величина w(x, y)dxdy определяет вероятность того, что
первая компонента X двумерной величины (X, У) будет
лежать в диапазоне от х до x-j-dx, а вторая компонента
У — в диапазоне от у до y-\-dy, т. е.
w(x, y)dxdy=P (x-^.X^x-\-dx, y^Y<^y-\-dy).
(5.75)
Вероятность того, что в двумерной случайной величи-
не (X, У) величина X лежит в пределах от а до Ь, а ве-
173
личина Y в пределах от с до d, будет
P(a<X<b, c<Y<d)=- J jay(x, y)dxdy. (5.76)
Выражение (5.76) позволяет найти связь между функ-
циями w(x, у) и F(x, у) в интегральной форме. Сравни-
вая (5.72) с (5.76), находим
« у
F(x, у)= $ J w (5, ц)с£ dy. (5.77)
Выражение (5.77) дает возможность получить одно-
мерные функции распределения вероятности для отдель-
ных компонент двумерной случайной величины (X, У).
Полагая г/=4-оо, получаем
X +00
Fl(x) = F(x, 4-оо)= J J «)(£, T))#di].
—00—00
Но одномерная функция распределения вероятности Fi(x)
связана с одномерной плотностью вероятности w(x) со-
отношением (5.37):
fiW= J wAtydt.
Сравнивая два последние соотношения, находим
+оо
w1 (х) = j w(x, y)dy\ (5.78)
+оо
w2 (у) = У w(x, y)dx. (5.79)
Зависимости Wi(x) и w2(y), определяющие^распреде-
ление вероятностей отдельных компонент случайной вели-
чины (X, У), не полностью характеризуют эту величину
и должны быть дополнены условными законами распре-
деления sy(x|z/) или w(i/|x), определяющими плотности
вероятностей одной случайной величины при фиксирован-
ном значении другой случайной величины.
1Т4
Рис. 5.6. Выделение эле-
мента Rd в двумерном про-
странстве
Для установления связи меж-
ду двумерной (совместной) плот-
ностью вероятности ш(х, у) и
условными распределениями
w(x\y) nw(y\(x введем в рас-
смотрение вещественную пло-
скость ЯХЯ, точки которой обо-
значим (X, У). Рассмотрим ве-
роятность попадания точки
(X, У) в элементарный прямо-
угольник Rd со сторонами dx и
dy, прилегающей к точке (х, у),
как показано на рис. 5.6.
Обозначим через S и Т события, состоящие в том, что
точка (X, У) попадает в полосу от х до x-\-dx и в полосу
от у до y-\-dy. Попадание точки в прямоугольник Rd со-
ответствует пересечению этих событий, тогда согласно
(5.22) и (5.75) вероятность
w(x, y)dxdy=P(S(}T) = P(T\S)P(S).
Учитывая, что P(S)=wt(x)dx, a P(T\S)=w(y\ x)dy,
получаем
ау(х, у) dxdy—w (у[х) dywi(x)dx
или
w(x, y)=w(y[x)wi(x). (5.80)
Выражению (5.80) можно придать другой вид, если
зафиксировать не X, а У:
ау(х, y) = w(x\y)w2(y). (5.81)
Эти соотношения могут быть использованы для на-
хождения условных плотностей вероятности:
w(x\y) = w(x, y)/w2(y)\ ay(z/|x) =
= ау(х, y)/ayifx). (5.82)‘
5.5.3. Математические ожидания для двумерной
случайной величины
Полученные выражения для плотностей вероятности
позволяют распространить понятие математического ожи-
дания на случай двумерной случайной величины (х, у).
Так, по (5.48) математические ожидания компонент дву-
175
мерной случайной величины х и у будут
+00 +00
х = J xw1(.x)dx; "у — J yw2(y)dy. (5.83)
Если f (х, у) — функция двумерной случайной величи-
ны, то ее математическое ожидание
)(х, у) = J J f(x, y)w(x, y)dxdy. (5.84)
Важное значение имеют условные математические
ожидания Е(х\у) и Е(у|х), которые можно найти по
условным плотностям вероятности йУ(х|у) и а>(у|х):
Е{х | у)= J xw(x | y)dx-, Е(у | х)= J yw(y\x)dy. (5.85)
С помощью двумерной плотности вероятности w(x, у)
легко доказать важное свойство математического ожида-
ния, состоящее в том, что математическое ожидание суммы
случайных величин равно сумме математических ожида-
ний этих величин. Будем рассматривать х+у как функ-
цию от двумерной случайной величины (х, у). По фор-
муле (5.84) для математического ожидания функций дву-
мерной случайной величины находим:
Е{х-\-у) = J J (х4-у)ю(х, y)dxdy =
+00 +00 +00 +00
= J X J а)(х, y)dydx-\- j у J w(x, y)dxdy =
= J xw^x)dx-\- J yWt(y)dy = E(x) + E{y).
5.5.4. Регрессия и корреляция
Когда приходится иметь дело с несколькими случай-
ными величинами, например с двумя, математическое ожи-
дание и дисперсия могут характеризовать каждую из этих
величин в отдельности. Однако в подобных случаях очень
важно знать влияние одной величины на другую, т. е. учи-
176
тывать характер взаимосвязи между случайными величи-
нами. Регрессия и корреляция как раз и служат для ко-
личественного выражения этой взаимосвязи.
Пусть х и у — две случайные величины. Для конкрет-
ности будем предполагать, что х представляет собой вы-
соту, а у — диаметр деревьев на участке леса. Каждому
дереву соответствует точка на плоскости (х, у), полная
совокупность деревьев изображена множеством точек, по-
казанных на рис. 5.7,а. В рассматриваемом случае вели-
чины х=£(х) и у=Е(у) дают математические ожидания
Рис. 5.7. Линия регрессии у(х) для зависимых (а) и независимых (б)
случайных величин
высоты и диаметра деревьев, а ох2 и характеризуют
рассеивание высоты л диаметра относительно их матема-
тических ожиданий.
Наряду с рассмотрением математических ожиданий вы-
соты и диаметра значительный интерес представляет изу-
чение изменения диаметра в зависимости от высоты. Од-
нако для деревьев, имеющих одну и ту же высоту х, диа-
метр у является случайной величиной. Поэтому можно
говорить лишь о зависимости математического ожидания
диаметра у от высоты х, т. е. определять величину
у(х), являющуюся условным математическим ожиданием
адх).
Определяя у(х) при различных х, можем построить
линию, графически выражающую эту зависимость и на-
зываемую линией регрессии у по х. Аналогично получаем
зависимость х(у)=Е(х\у), называемую регрессией х
по у.
Ограничимся рассмотрением регрессии для наиболее
простого и наиболее часто встречающегося на практике
случая линейной регрессии, когда линия регрессии пред-
ставляет собой прямую линию, уравнение которой может
быть записано в виде
у(х)=а-{-Ь(х—х)
(5.86)
177
12-804
Коэффициенты а и b выберем так, чтобы получить
наибольшую концентрацию точек (х, у) вблизи прямой
у(х), что может быть обеспечено применением метода
наименьших квадратов, как это уже было сделано
в § 4.2.
Зафиксируем некоторое х и обозначим е(х) =
=у—у(х)—у—а—Ь(х—х) отклонение ординаты экспери-
ментальной точки у от линии регрессии у(х). Метод наи-
меньших квадратов требует, чтобы было минимальным
математическое ожидание квадратов всех таких откло-
/=E[e2(x)]=min. (5.87)
Приравнивая нулю производные от / по а и Ь, полу-
чаем два уравнения для определения этих коэффициен-
тов:
— = Е Г—1 = 2Е [е — I = 0;
да I да J [ да ]
— = 2£[е—1 = 0.
db [ db ] L дЬ ]
Учитывая, что де (х)/да = — 1,
дг (х)/дЬ = — (х — х), находим
Е\у — a — b(x — х)] = 0; Е {[у — а —Ь(х—~х)](х— х)} =0.
Из первого уравнения находим
Е(у)—а—ЬЕ(х—х)—0 или а—Е(у)=у. (5.88)
Второе уравнение дает
£[ (У~У) (х—х)]—ЬЕ[ (х—х)2]=0, (5.89)
где £[(х—х)2]=ох2 — дисперсия величины х.
Назовем ковариацией между у и х величину
cov(i/, х)=Е[(у—у) (х—х)]. (5.90)
Тогда уравнение для определения b примет вид
con {у, х) — &ох2=0,
откуда
&=cov(i/, х)/оЛ (5.91)
Таким образом, уравнение линии регрессии (5.86) мо-
жет быть записано в виде
У (х) =£+cov (у, х) (х—х)/о,2. (5.92)
178
Ковариация cov (у, х) может служить мерой взаимной
связи между случайными величинами у и х. Однако по-
скольку мы ограничились рассмотрением случая, когда
линия регрессии представляет собой прямую, то и кова-
риация будет характеризовать не всякую взаимную связь,
а только линейную, т. е. стремление одной случайной ве-
личины возрастать или убывать в среднем по линейному
закону при возрастании или убывании другой случайной
величины. Для более наглядного представления зависи-
мости ковариации от характера связи между случайными
величинами полезно разобрать крайние случаи.
1. cov (у, х)—0. Это означает, что 6=0, у(х)=а и ли-
ния регрессии горизонтальна (рис. 5.7,6). В эксперимен-
тальных точках значения у группируются вокруг значе-
ния а независимо от значения х. Следовательно, в данном
случае у и х являются независимыми величинами.
2. Связь между у и х будет наиболее тесной, если
эти величины связаны линейной функциональной зави-
симостью. При этом все экспериментальные точки будут
лежать на линии регрессии, так что у—у(х). Заменяя
у(х) на у, уравнение регрессии перепишем в виде
i/-£=[cov(i/, х)/ох2] (х-х).
Дисперсия
Оу*=Е[(у-у)2] = [cov2(у, х)МЕ[ (х-х)2] =
= cov2(i/, х)/оД
откуда
cov (у, х) =охоу. (5.93)
Как видим, в зависимости от степени связи между ве-
личинами у и х ковариация cov (у, х) может меняться от
О ДО ОхО у.
Оценивать тесноту связи между случайными величина-
ми у и х с помощью ковариации несколько неудобно, так
как cov (г/, х) зависит от дисперсий самих случайных ве-
личин. Лучше использовать коэффициент корреляции
ryx=cov(y, х)/(охоу), (5.94)
который может меняться в пределах от нуля для незави-
симых случайных величин до единицы, если случайные
величины связаны линейной функциональной зависимо-
стью.
С помощью понятия ковариации получают простые со-
отношения для математического ожидания произведения
12* * 179
и дисперсии суммы двух случайных величин. Предлагаем
читателю самому проверить, что для этих случаев имеют
место соотношения:
ху±=ху+соч (х, у); (5.95)
D(x+f/)=D(x)+D(i/)+2cov(x, у). (5.96)
Когда случайные величины х и у независимы, то
ху=ху;
D (х-\-у) =D (x)-\-D (у).
(5.97)
(5.98)
5.6. МНОГОМЕРНОЕ ГАУССОВСКОЕ РАСПРЕДЕЛЕНИЕ
ВЕРОЯТНОСТЕЙ
5.6.1. Вектор математических ожиданий
и ковариационная матрица
Если имеется не две, а большее число случайных вели-
чин, например Xi...хп, то резко возрастает и число чис-
ловых параметров, характеризующих эти величины. Кроме
п первых моментов, определяющих математические ожида-
ния случайных величин xt—E(xt), i=l, ..., п, необходимо
определять еще п2 вторых центральных моментов, пред-
ставляющих собой дисперсии каждой случайной величины
и ковариации между каждой парой случайных величин.
В связи с этим становится очень важным вопрос о способе
компактной записи всех этих числовых характеристик.
Всю совокупность случайных величин хь ..хп удобно
представить в виде случайного вектор-столбца
= (X,,..., хл)т.
(5.99)
Тогда совокупность математических ожиданий компо-
нент этого вектора запишем в виде вектора математических
ожиданий
[xt 1 _ _
j = (Xj,..., хл)т. (5.100)
%п J
180
Совокупность вторых центральных моментов, представ-
ляющих собой дисперсии
<?Х~Е [(хг-х,)2], i=l, ..., п (5.1011
и ковариации
cov (xt, х,)=Е [(х,—Xi) (х,—X,)],
' (5.102)
i, J=1..«. Mi,
удобно записать в виде ковариационной матрицы
?ХХ=Е [х-х) (х-х)т]. (5.103)
Диагональные члены этой матрицы представляют собой
дисперсии о2х f, а остальные члены—ковариации cov (xj,x3).
Поскольку cov (х,-, x,)=cov (х/, X/), то ковариационная
матрица является симметрической.
Пример 5.12. Пусть х = ^ U | —двумерный случайный вектор. Тогда
вектор математических ожиданий
х = Е (х) = : ~й = Е(и)‘, v = E(y),
а ковариационная матрица
= 1^(и—й, о—й)
= £ [(“—“)* (и— й)(о — й) l_[°u2 cov (и, о) 1
L(o-й) (и —и) (о—й)* ]~[cov(o,» Г
Если имеется два случайных вектора x=(xi....хп),т и
y=(yi, •• •>_Уп)т, то наряду с векторами математических
ожиданий х=Е(х)_и у=£(у) и ковариационными_ матри-
цами Рхх=£ [(х—х) (х—х)т] и Pyv=£ [(у—у) (у—у)’] сле-
дует рассматривать и взаимные ковариационные матрицы
Pxy=E[(x-x)(y-f)T] (5.104)
и
Рох=^[(У-У)(х-х)т], (5.105)
причем Ртху=Рух.
181
5.6.2. Гауссовское распределение вероятностей
случайного вектора
В § 5.3 отмечалось, что гауссовский закон распределе-
ния занимает особое место среди других законов распреде-
ления. Эта особая роль нормального закона распределения
сохраняется и для многомерных случайных величин, пред-
ставляемых случайными векторами. Причин этому несколь-
ко:
1) очень многие встречающиеся на практике физические
явления подчиняются этому закону;
2) закон является предельным для многих других зако-
нов распределения;
3) закон имеет сравнительно простое математическое
описание, так как полностью определяется только первым
и вторым моментами, т. е. вектором математических ожи-
даний и ковариационной матрицей. Другие законы распре-
деления требуют использования моментов более высокого
порядка;
4) линейные преобразования случайных векторов с нор-
мальным законом распределения приводят к новым случай-
ным векторам, также подчиняющимся нормальному закону
распределения. Другими словами, если х и у — случайные
векторы с нормальными законами распределения, а А и
В — матрицы, то случайный вектор z=Ax-f-By также бу-
дет иметь нормальное распределение, причем его матема-
тическое ожидание и ковариационная матрица легко опре-
деляются.
Пример 5.13. Пусть х —случайный n-вектор, А —матрица разме-
ром гХ« и z= Ах — случайный r-вектор. Математическое ожидание
вектора z будет
z=£(Ax) =А£'(х)=Ах,
а его ковариационная матрица
Р„=£[ (z—z) (z-~г) Ч =£[А(х-х) (х-х)*АЧ =АР„АТ.
Случайный n-вектор х называют распределенным по га-
уссовскому закону, если его плотность вероятности w(x) —
= w (xi, ..., хп) определяется выражением
wW= i/<2.)»ip;~ ехр[-т(х -х)’₽“(х -*’]• <5Л06>
где | Рхх 1 =det Рхх — определитель ковариационной матри-
цы РХХ.
182
В частном случае, если х — скаляр, то п—1, (х—х)т=
= (х—х), РЛЖ=о2, |Рхзс|=о2, p-ixx=l/o2 и выражение
(5.106) превращается в (5.40) для нормального закона рас-
пределения одномерной случайной величины.
5.6.3. Нормальное распределение вероятностей
двух случайных векторов
Пусть
— случайные г- и fc-векторы, причем r~\~k—n. Обозначим
через х = [ u j= («1,..., ur, vk)r случайный n-вектор
с компонентами и и v. В этом случае (5.106) дает совме-
стное распределение a>(x)=a>(u, v) векторов и и v. Входя-
щие в (5.106) математическое ожидание и ковариационная
матрица соответственно будут
х=Е(х)=Е|“ = “1, u = E(u), v = E(v); (5.107)
где Puu и Pi>„ — ковариационные матрицы векторов и и v;
Риг, и РОи = Р£о — взаимные ковариационные матрицы.
Обратную матрицу Р-1хж представим в виде
где А и С — симметрические матрицы размером гхг и
kxk-, В — прямоугольная матрица размером г><&. Из усло-
вия РХТР- 1хх=1 определяют матрицы
С учетом введенных обозначений совместное нормаль-
ное распределение двух случайных векторов и и v запи-
шется в виде
ж(и'v)~ у
(5Л|1>
5.6.4. Условное нормальное распределение
вероятностей
Для двух случайных векторов и и v по аналогии с дву-
мерными случайными величинами, представленными в
§ 5.5, можно рассмотреть условную плотность вероятности
w(u|v), которая с учетом соотношения (5.82) определится
как
a>(u|v) = a>(u, v)/w(v). (5.112)
Учитывая, что
”’lv) = v<v-’>’₽” <v
и используя (5.111), находим
w(u ) v) = у-.....1 - х
у (2к)г I р«1 / |PW 1
хехр[-4-(:з)7‘ с_»;,)(::”)]
Проведя ряд матричных преобразований, это выраже-
ние более компактно можно записать в виде
'«и(и I v) = * .exp[---^(u —m)TQ-1(u-ni)1, (5.113)
И 1 Ч I L 2 J
где
m=E(u[v)=u+Pu«P-1«i)(v—v) (5.114)
— условное математическое ожидание;
, Q=Pu I D=PuU Pu«P-1®«P®U (5.115)
— условная ковариационная матрица.
184
5.7. СЛУЧАЙНЫЕ ПРОЦЕССЫ С ДИСКРЕТНЫМ
ВРЕМЕНЕМ
5.7.1. Понятие о случайных процессах с дискретным
временем
Предположим, что некоторая система, находящаяся под
влиянием совокупности внешних условий, может менять
случайным образом свое состояние в дискретные моменты
времени, условно обозначаемые 0, 1 .... интервалы между
которыми называют шагами. При этом в результате п-го
шага система примет состояние хп, которое мы можем рас-
сматривать как исход некоторого эксперимента и которое,
следовательно, будет элементом множества допустимых для
этого шага исходов:
Z„={zn0, zni, .... znLn}.
Множество Zo считаем состоящим из одного элемента
г°о, представляющего собой начальное состояние системы.
Последовательность принимаемых системой состояний х0,
Xi ... называют случайным процессом с дискретным вре-
менем.
Случайный процесс будет задан, если на каждом шаге
,задано распределение вероятностей на пространстве исхо-
дов, определяющее состояния, в которые может перейти си-
стема в результате следующего шага. Это распределение
вероятностей в общем случае зависит от состояний, прини-
маемых на .всех предыдущих шагах, и для любого п опре-
деляется набором условных вероятностей
p(Xn+i=z*n+1|*o..Хп), А=0, 1, .... Ln, (5.116)
причем
%p(xn+l =zn+' I x„)= 1. (5.117)
k=0
Случайный процесс будет продолжаться до бесконечно-
сти, если искусственно не оборвать его на каком-либо шаге.
Практически нам всегда приходится обрывать процесс по-
сле определенного конечного числа шагов, т. е. иметь дело
с конечными или многошаговыми процессами. Однако бес-
конечные процессы являются полезными аппроксимациями
более реальных конечных процессов, тем более что они не-
редко оказываются проще с аналитической точки зрения.
185
Случайный процесс, в который мы не -можем вмешивать-
ся, а следовательно, и влиять на распределение вероятно-
стей (5.116), называют неуправляемым.
В зависимости от вида распределения вероятностей
(5.116) случайные процессы делятся на ряд типов, наибо-
лее распространенными из которых являются процессы
с независимыми значениями, процессы независимых испы-
таний и марковские цепи.
Конечный случайный процесс называется процессом
с независимыми значениями, если распределение вероятно-
стей на пространстве исходов при каждом шаге не зависит
от результатов предыдущих шагов:
p(xn=znft|xo, ..., Xn-i)==p(xn==znh)- (5.118)
Это распределение вероятностей удобно обозначить про-
сто через рп (z), где z^Zn, п—0, 1 ...
Важное свойство процесса с независимыми значениями
заключается в том, что любая последовательность состоя-
ний х0, Xi, ..., хп может рассматриваться как совокупность
независимых исходов эксперимента. Следовательно, веро-
ятность появления такой последовательности будет равна
произведению вероятностей исходов, входящих в эту после-
довательность, что может быть записано в виде
р(х0, хь ..., хп)=р0(х0)р1(х1) ...рп(Хп), (5.119)
x,sZ„ i=0, 1.....п.
Важным частным случаем процессов с независимыми
значениями являются процессы независимых испытаний.
Процесс независимых испытаний есть процесс с независи-
мыми значениями, у которого пространство исходов экспе-
римента Z={z0, zi, ..., zL} и распределение вероятностей
на этом пространстве одно и то же на каждом шаге, т. е.
pn{z)=pm(z)=p(z) (5.120)
при любом zeZ и любых тип. Другими словами, процесс
независимых испытаний представляет собой многократное
повторение одного и того же эксперимента в одних и тех
же условиях.
Как и в случае процессов с независимыми значениями,
вероятность получения конкретной последовательности ис-
ходов эксперимента х0, хь ..., хп в процессе независимых
испытаний равна произведению вероятностей отдельных ис-
ходов.
186
Случайный процесс называют марковской цепью,
если пространство состояний Z={z0, zb ..zL} является
одним и тем же для каждого шага, а распределение веро-
ятностей исходов на каждом шаге зависит только от исхо-
дов предшествующего шага, так что
р(xn+i = z|ха, .... Xn)=p(Xn+l=z[xn). (5.121)
Удобно ввести обозначения для вероятностей вида
(5.121). Предположим, что на n-м шаге система находилась
в состоянии z,eZ. Тогда распределение вероятностей
(5.121) определит вероятность того, что на (п+1)-м шаге
система окажется в состоянии z}<=Z. В общем случае эта
вероятность зависит от номера шага и может быть обозна-
чена через р1;(п). Таким образом, вероятности
p./(n)=p(xri+i=z/|xn=z,), (5.122)
удовлетворяющие условиям
A/(«)>0, = (5-123)
/=о
являются вероятностями перехода на n-м шаге из состоя-
ния zx в состояние z}.
В том случае, когда вероятности перехода ро(л) зави-
сят от номера шага п, марковскую цепь называют неста-
ционарной. Однако в различных приложениях играют боль-
шую роль марковские цепи, в которых вероятности перехо-
да остаются одними и теми же для любого шага и могут
быть обозначены просто через рг].
5.7.2. Процесс независимых испытаний с двумя
исходами. Биномиальное распределение вероятностей
Рассмотрим более подробно случай, когда в процессе
независимых испытаний в результате каждого эксперимен-
та может произойти или не произойти некоторое событие S.
Один исход назовем успехом эксперимента и обозначим
его 1, другой неудачей — 0.
Обозначим через р вероятность успеха в одном отдель-
ном эксперименте, а через q=\—р — вероятность неудачи.
Зададимся вопросом, какова вероятность w(r, п, р) того,
что при п экспериментах будет иметь место г успехов.
Наступлению г успехов при п экспериментах будет со-
ответствовать последовательность п исходов, состоящая из
г единиц и п—г нулей. Так как результаты отдельных успе-
187
0,300
0,268
0,Z03
,088
I 0,027 0,001 0,000
, 0,006 0,000 o,ooa
0 1 2 3 4-06 7 8 Э 10 Г
Рис. 5.8. Биномиальное распределение
хов независимы, то вероятность этой последовательности,
равная произведению вероятностей отдельных исходов,
определится выражением
prqn~r. (5.124)
Общее число различных последовательностей из п
элементов, содержащих г единиц, равно числу сочетаний
из п элементов по г, т. е.
<5125>
Так как все эти последовательности несовместимы (если
появилась одна из них, то появление любой другой уже
исключено), то вероятность появления какой-либо одной
из них
w(r, П, p)^(JL\prqn-^ (5.126)
Легко проверить, что при этом суммарная вероятность
наступления любого числа событий от 0 до п равна еди-
нице.
Распределение вероятностей, определяемое формулой
(5.126), называют биномиальным распределением. Для на-
глядного представления характера биномиального распре-
деления на рис. 5.8 приведен график зависимости ординат
этого распределения от числа г для п—Ю и p=Vs> т. е.
график распределения w(r, 10, Vs).
Очень часто бывает необходимо определить значение г,
при котором биномиальное распределение достигает макси-
мума. Вычислим предварительно отношение двух соседних
188
ординат биномиального распределения
w(r, п, р)
w(r — 1, ri, р)
(п — г+\)р
rq
(5.127)
Это отношение будет не меньше единицы, если
^(п-|-1)р. Следовательно, функция w(r, п, р) достигает
максимума при
r=ent (и+1)р, (5.128)
где через entx обозначена целая часть числа х.
Числовыми характеристиками биномиального распреде-
ления служат математическое ожидание и дисперсия соот-
ветственно
vr=np; a2i=npq. (5.129)
5.7.3. Распределение Пуассона
Значения w(r, п, р) очень плохо поддаются вычисле-
нию при больших п. Однако существуют приближенные
методы, которые значительно облегчают вычисление этих
вероятностей. Одним из таких методов является замена би-
номиального распределения на распределение Пуассона.
Пусть w(r, п, р) — биномиальное распределение. Легко
убедиться, что предел этого распределения при п->-оо и р-+-
—>-0 при условии пр=а—const, так что р=а!п, будет
lima; (г, п, а/п)=аге_о/г! (5.130)
Распределение вида (5.130) обозначают через w(r, а)
и называют распределением Пуассона. Таким образом,
w (г, a) =are-o/rl (5.131)
Характерной особенностью распределения Пуассона яв-
ляется то, что математическое ожидание и дисперсия этого
распределения одинаковы и равны а.
Распределение Пуассона является хорошим приближе-
нием к биномиальному распределению при малых р. Так,
при ps^O.Ol можно заменить вычисление биномиального
распределения вычислением распределения Пуассона, на-
чиная с п=10.
Хотя мы пришли к распределению Пуассона как к пре-
дельному случаю биномиального распределения, оно явля-
189
ется распределением самостоятельного класса случайных
процессов, называемого классом редких случайных явлений.
Рассмотрим последовательность событий S, следующих
друг за другом через случайные промежутки времени. Чис-
ло таких событий, происходящих на интервале длительно-
стью т, будет случайной величиной с математическим ожи-
данием Хт, где X — среднее число событий за единицу вре-
мени. Поставим задачу определить вероятность того, что на
интервале т произойдет ровно г событий.
События S будем считать редкими в том смысле, что
интервал т можно разбить на малые интервалы длитель-
ностью Дт, в каждом из которых может произойти не более
одного события S. Общее число таких интервалов га—т/Дт,
а вероятность того, что событие произойдет в одном из ин-
тервалов Дт, будет р—\х/п, так чтогар=Хт. Поскольку мож-
но считать, что событие S в каждом из интервалов Дт про-
исходит независимо от того, произошло оно или нет в дру-
гих интервалах, то приходим к процессу независимых испы-
таний с плотностью вероятности w(r, п, р), где гар=Хт.
Однако предположение, что на интервале Дт может про-
изойти не более одного события S, будет оправдано только
в том случае, если длительность этого интервала очень ма-
ла, т. е. в пределе при Дт—>0. Так как при этом га—>оо и /?->-
—>-0, причем пр—\х=const, то процесс редких явлений под-
чиняется закону Пуассона с плотностью вероятности
w(r, kx)—(Kx)rerKx/r\ (5.132)
5.7.4. Экспоненциальное распределение.
Понятие о надежности
Во многих задачах представляет интерес распределе-
ние вероятности для интервалов времени между случайны-
ми событиями в процессе независимых испытаний. Из
(5.132) при г=0 и г=1 получаем: е~Кх — вероятность того,
что на интервале длительностью т не произойдет ни одного
события; 7,те-Хг — вероятность того, что на интервале дли-
тельностью х произойдет только одно событие.
Вероятность того, что на интервале длительностью х
произойдет более одного события, равна
l-(e-" + ».e-") = l-j[l-Z< + -^--,..]-
(5.133)
190
Как видим из выражения (5.133), вероятность пропор-
циональна величине (Хт)2, это означает, что при малых Хт
мы можем пренебречь вероятностью наступления на интер-
вале длительностью т двух и более событий. При этом ве-
роятность наступления на интервале длительностью т одно-
го события
Г(Л, т) =1—е-^, т>0. (5.134)
По существу выражение (5.134) определяет вероятность
того, что время, за которое произойдет одно событие, не
превысит т. Плотность этой вероятности, представляющую
собой вероятность того, что событие произойдет в момент т,
получим, продифференцировав (5.134)) пот:
w(K, т)=Хе~Хг, т>0. (5.135)
Зная плотность вероятности для т, легко определить
среднее время, за которое не происходит ни одного собы-
тия:
тСр = J тда (Ял) dx = 1 /I. (5.136)
Выражения (5.135) и (5.136) определяют экспоненци-
альное распределение, играющее важную роль в теории на-
дежности [24].
Предположим, что некоторое устройство состоит из большого чис-
ла отдельных элементов, каждый из которых может с течением време-
ни выйти из строя. Выход элемента из строя называют отказом эле-
мента. В большинстве случаев отказы отдельных элементов происходят
независимо друг от друга, и их последовательность можно рассматри-
вать как процесс независимых событий, в котором Л. — интенсивность
отказов определяет число отказов в единицу времени, величина 1/Л.
согласно (5.136) определяет среднее время безотказной работы.
Для характеристики надежности аппаратуры обычно используют
величину /г(т), называемую опасностью отказа и выражающую плот-
ность вероятности отказа в момент № при условии, что до этого мо-
мента отказы ие происходили
Определим предварительно величину й(т)Дт, дающую вероятность
того, что отказ произойдет в интервале Дт при условии, что перед этим
отказов не было в течение времени т По формуле условной вероят-
ности
й(т)Дт = и>(Х, т)Дт/[1-Г(Х, т)], (5.137)
откуда
ft(T)=te»(X, T)/[1-F(X, т)]. (5.138)
191
Для экспоненциального распределения имеем
й(т)=Л,е-^/е-Лг=Л, (5.139)
т. е. функция опасности есть постоянная, равная интенсивности от-
казов.
Опыт эксплуатации радиоэлектронной аппаратуры показывает, что
график функции й(т) имеет вид кривой, изображенной иа рис. 5.9.
Начальный участок этой кривой характеризуется повышенной интен-
сивностью отказов, объясняемой наличием в отдельных элементах
скрытых дефектов, которые выивляются в начальный период работы.
При больших т интенсивность отказов тоже возрастает, что связано
со старением элементов, выражающимся и ухудшении свойств элемен-
тов после длительной эксплуатации. По-
2
Рис. 5.9. Типичный вид
распределения времени
до отказа
стояиная интенсивность отказов, а значит,
и экспоненциальное распределение имеют ме-
сто лишь на среднем участке графики й(т).
Одиако от повышенной интенсивности
отказов в начальный период можно изба-
виться, подвергая аппаратуру предвари-
тельной тренировке перед началом эксплуа-
тации. С другой стороны, непрерывное воз-
растание требований к качеству аппарату-
ры, являющееся следствием технического
прогресса, приводит к тому, что качество аппаратуры со време-
нем перестает удовлетворять новым повышенным требованиям. Проис-
ходит моральный износ аппаратуры, который обычно наступает
раньше, чем наступает заметное старение отдельных элементов. Это
дает основания во многих случаях считать зависимость й(т) постоян-
ной и равной Л на всем периоде эксплуатации аппаратуры, т. е. поль-
зоваться при оценке надежности экспоненциальным законом распре-
деления.
5.7.5. Марковские цепи
Пусть Z={zu .... zL} — пространство исходов экспери-
мента или пространство состояний некоторой системы, оди-
наковое для каждого шага случайного процесса. В таких
случаях удобно обозначать состояния системы просто ин-
дексами при z, поднимая под / состояние z^eZ. При этом
пространство состояний будет изображаться множеством
индексов /={1, .с., L}.
Обозначим через Лп=(яп(1), .... лп(Ь)) распределение
вероятностей на множестве / для л-го шага. При этом лп(})
определяет вероятность того, что на n-м шаге система ока-
жется в состоянии /. Как уже указывалось, случайный про-
цесс является однородной марковской цепью, если вероят-
192
ности перехода системы pi, из состояния i в состояние /
зависят только от состояния i на предыдущем шаге и оди-
наковы для любого шага.
Вероятности перехода можно представить двумя раз-
личными способами. Первый способ состоит в записи веро-
ятностей перехода в виде таблицы, называемой матрицей
переходов и обозначаемой через Р. Для L—3 матрица име-
ет вид
ГЛх
Р= А.
LAi
А.
Ргг
Р,2
А»1
Аз I
Аз-*
(5.140)
Условие (5.123), которому обязательно должны удов-
летворять вероятности переходов, означает, что сумма эле-
ментов любой строки в матрице переходов обязательно
должна быть равна единице.
Второй способ представления вероятностей перехода со-
стоит в построении диаграммы перехода. Пример для си-
стемы с тремя состояниями приведен на рис. 5.10,а. Диа-
грамма переходов представляет собой граф, вершины ко-
торого соответствуют состояниям системы, а направленные
дуги указывают возможные переходы от одного состояния
к другому. Вероятности переходов отмечаются числами,
приписываемыми каждой дуге. В соответствии с условием
(5.123) сумма вероятностей для дуг, выходящих из любой
вершины графа, должна равняться единице.
К марковским цепям могут быть сведены многие про-
цессы в различных областях науки и техники. В социологии
марковские цепи помогают изучать проблемы изменения
социальной или профессиональной структуры населения,
проблемы миграции населения и т. п. В биологии с помо-
рие. 5.10. Диаграммы переходов для марковской цепи
13-804
193
щью марковских цепей изучают характер развития отдель-
ных видов животных и растений. В физике марковские це-
пи применяют для изучения диффузии газов. В технике
с помощью марковских цепей описывают некоторые про-
цессы передачи сообщений, ряд технологических процес-
сов, процессы контроля работоспособности и поиска неис-
правностей в сложных технических системах и т. п.
При изучении марковских цепей прежде всего необхо-
димо выяснить, как будет изменяться распределение веро-
ятностей состояний лп, когда система делает один шаг.
Обозначим через Т событие, состоящее в том, что на (п-|-
4-1)-м шаге система окажется в состоянии /.
В соответствии с принятыми обозначениями вероятность
этого события Р(Т) =л(’)п+1. Обозначим через Si событие,
состоящее в том, что на п-м шаге система находится в со-
стоянии i, так что P(Si)=n(t)n. При этом ptj будет пред-
ставлять собой вероятность того, что система на (п4~1)-м
шаге окажется в состоянии /, если на n-м шаге она была
в состоянии i, т. е. pi/=p(7’|Si). По формуле полной веро-
ятности (5.25) находим
4Р, = 24°Рф / = (5.141)
t=I
Формула (5.141) позволяет последовательно шаг за ша-
гом определять изменение распределения вероятностей си-
стемы, если известно начальное распределение вероятно-
стей.
Пример 5.14. Завод выпускает телевизоры определенной марки.
В зависимости от того, находит ли данный тип телевизора спрос у
населения, завод может в конце каждого года находиться в двух
состояниях: 1—спрос есть, 2 —спроса нет. С течением времени спрос
изменяется, так что имеется вероятность 4/5, что к концу года завод
останется в состоянии 1. С другой стороны, если завод оказался в со-
стоянии 2, то принимают меры к изменению и улучшению выпускаемой
модеЛ|и, так что с вероятностью 3/5 к концу следующего года завод
перейдет в состояние 1.
В данном примере развитие производства представляется марков-
ской цепью с матрицей переходов
Диаграмма переходов приведена на рис. 5.10,6.
194
Пример 5.15. Пусть завод из примера 5.14 н начальный момент
времени находится в состоянии 1, т. е. начальное распределение веро-
ятностей имеет вид л0'=(1, 0). Используя (5.141) и матрицу перехо-
дов, находим для первого шага
Я1(Ч=n0(i)P11+ло<2)Р21 = 1 • 4/5+0 • 3/5=0,8;
^,(21=110(1^2+110(2)^22= 1.1/54-0-2/5=0,2;
для второго шага
л2<Ч=0,76; л2<2>=0,24.
Продолжая эти вычисления, получаем последовательное изменевие
распределения вероятностей (табл. 5.1) при начальном состоянии
(1, 0). Из этой таблицы видно, что при возрнстаиии п значение лп<1)
приближается к 0,75, а лп<2) — к 0,25.
Таблица 5.1
п Начальное состояние я0=(1, 0)
0 1 3 3 4 5
1 0,8 0,76 0,752 0,7504 0,75008
<2’ 0 0.2 0,24 0,248 0,2495 0,24992
п Начальное состояние л0=(0, 1)
0 1 2 3 4 5
ч1) 0 0,6 0,72 0,744 0,7488 0,74976
<2) 1 0,4 0,28 0,256 0,2512 0,25024
В таблице приведено распределение вероятностей на последова-
тельных шагах при начальном состоянии л0=(0, 1). В этом случае
при возрастании п значения «,,(*> и лп(2) приближаются к тем же зна-
чениям 0,75 и 0,25, что и при начальном распределении Ло= (1, 0). Как
видим, в данной марковской цепи после большого числа шагов веро-
ятности переходов становятся независимыми от начального состояния
системы.
Если в марковской цепи существует предельное распре-
деление вероятностей, соответствующее «—>оо и не завися-
щее от начального состояния системы, то это распределе-
ние вероятностей определяет предельный или установив-
шийся режим системы. В этом случае систему называют
статически устойчивой, а марковский процесс в такой си-
стеме — эргодическим.
Обозначим через л=(л(1), ..ль) установившееся рас-
пределение вероятностей эргодической марковской цепи.
Компоненты л(з) этого распределения можно найти из урав-
нений (5.141), которые при п->оо принимают вид
z(o= j=l,..., L. (5.142)
1=1
Однако не все L уравнений (5.142) являются линейно
независимыми, так как вероятности л(з’> связаны между со-
бой соотношением
= (5.143)
l=i
поэтому для определения L неизвестных компонент рас-
пределения вероятностей л достаточно взять любые L— 1
уравнений (5.142) и решать их совместно с уравнением
(5.143).
Пример 5.16. Для матрицы переходов в примере 5.14 первое из
уравнений (5 142) имеет вид
л<1>=л<1>р1,4-л(г>р21=
=4л(‘)/5+ЗлР)/5.
Уравнение (5.143) дает n<*>-|-nP)=l. Решая совместно эти урав-
нения, находим л<‘>=0,75; л<2> = 0,25.
Переход эргодического марковского процесса от началь-
ного состояния к установившемуся режиму называют пере-
ходным процессом. Переходный процесс описывается после-
довательностью распределений вероятностей лп для п=1,
2 ... и при заданном начальном распределении вероятно-
стей ло может быть получен путем последовательного при-
менения формулы (5.141), как это было сделано в примере
(5.15). Однако можно поступить иначе.
Введем в рассмотрение величины р^г}, определяющие
вероятность перехода системы из состояния i в состояние j
за I шагов:
р[р=р(х„+г=/I x„ = i); « = 0,1... (5.144)
196
Вероятности pltj дают возможность определить распре-
деление вероятностей Л( по распределению ло по формуле,
аналогичной (5.141):
= (5.145)
1=1
Для установления связи вероятностей перехода рЮц
с вероятностями р,/ положим /=/1 + /2 и будем рассма-
тривать переход системы из состояния л0 в состояние щ
в два этапа: переход из (Состояния л0 в состояние itZ1.
а затем переход из состояния в состояние it(=it(1+z1.
При этом
(б-146)
где
(5.147)
i=i
Подставляя значение it* в (5.146), получаем
«Р- 2W 2’5" УрЧ,"р&- (5.148)
4=1 1=1 (=1 4=1
Сравнивая (5.148) и (5.145), находим
^*+z’> = 2р1/М^ (5.149)
4=1
Для последовательного вычисления вероятностей пере-
хода р(р, удобно в (5.149) положить /(=/—1, /2=
= 1. При этом получаем
Pi?~ %Р?Г"Ры- (5-150)
4=1
Полагая последовательно 1—1, 2 ... и учитывая, что по
определению вероятностей перехода pi3
• ) "Но: (5л51)
197
получаем
Р{ч= Р.г Р<4 = 'Zp.kPk,-- ('
А = |
Выражение (5.150) может быть обобщено па случг
однородной марковской цепи, в которой вероятности
хода зависят от номера шага. В этом случае под веро
стью рч(п, nJ при ге<П| будем понимать вероятность
что на шаге п} система окажется в состоянии /, есл!
шаге п она находилась в состоянии I:
ри(п, nj=p(xn,=j\xn=i), n<tii. (Е
При этом по аналогии с( 5.145) имеем
4? ~ ptj(n, nJ, и(
С другой стороны, рассматривая некоторое п',
летворяющее условию ге<п'<«|, можем nW)n, прсдст.
в виде
Pkit'1’’ nJ = '£Pill(n'> 'U ri
k-i k=\ i-1
= S71»’ nJ. (
f=l ft=l
Сравнивая (5.154) с (5.155), находим
L
P4(fi, "i)= n’)pltlJi’, nJ (
*=i
при любых n<n'<iii. Соотношение (5.156) называют
пением Чэпмена — Колмогорова.
5.7.6. Гауссовские марковские процессы
Среди различных видов случайных процессов мг
ские процессы играют важнейшую роль примерно и
же причинам, по которым нормальный закон распре
ния выделяется из всех других законов распределена
причины состоят в том, что марковские процессы паи
198
часто встречаются на практике и имеют сравнительно про-
стое математическое описание. Рассмотренные выше мар-
ковские цепи представляют собой лишь частный случай
марковских процессов. Для рассмотрения других видов
марковских процессов необходимо дать более общие опре-
деления.
Пусть х(/) — скалярный или векторный случайный про-
цесс, т. е. функция времени, значения которой для любого
момента t представляют собой случайные векторы. Рас-
смотрим последовательность дискретных моментов времени
t0<ti< ... <tm<tm+i- Обозначим через х(- значение х(/) в
момент ti, 1=0, ..., Процесс x(t) называют марков-
ским, если условная плотность вероятности для х(/) удов-
летворяет условиям
w (хт+| | хт, ..., x0)=a?(xm+I|xm). (5.157)
Из соотношения (5.157) видно, что если момент времени
1т считать настоящим, а моменты tm*i, .... to прошлыми, то
вероятностный закон, описывающий поведение процесса
в будущем, т. е. в момент tm+i, зависит только от текущего
состояния процесса хт и не зависит от его поведения
в прошлом, т. е. от его предыстории. Это свойство называ-
ют марковостью.
Другой способ описания марковского процесса состоит
в определении совместной плотности вероятности
а?(хт, ..., Хо). Воспользовавшись соотношением (5.81),
представим совместную плотность вероятности в виде
ш(Х1П, ..., Хо) = W (х,п| Хт-1, ..., Xo)w(Xm-I, •••, Хо) =
=ш(хт|х,п-1)ау(хт-1, ..., Хо).
Преобразуя аналогичным образом io(xm-i, ..., х0), по-
лучаем
w (х„.... Хо) = W (Xrn| Xm-i) W (Xm_, | X,rt-2) X
ХЬУ'(Хт_2, ..., Хо).
Продолжая этот процесс и далее, находим
ау(хга, .... x0)=-uy(xm|xm_I)ay(xm-i|xm-2)...
... w (х, | Хо) w (Хо). (5.158)
Если для любых t Ti т при t>r определена условная
плотность вероятности а)[х(£) |х(т)], то все сомножители
правой части (5.158) известны, за исключением w(x0).
Следовательно, совместная плотность вероятности w(xm,...
199
..., Xq) марковского процесса, а значит, и сам марковский
процесс полностью определяются начальной плотностью
вероятности w(x0) и плотностью вероятности переходов
W (X* | ХЛ-1) .
Марковский процесс называют гауссовским марков-
ским процессом, если плотности вероятностей для а>(х0) =
=а>[х(/о)] и w(nk\*k-1) являются гауссовскими и опре-
деляются соответствующими математическими ожидания-
ми и ковариационными матрицами:
Хо=£(х0); Ро=Е[(хо—х0) (х0—х0)т];
Xfe |fe-i=£ (XftlXft-i);_₽*)*-!=£[ (х*—xA/ft-i) (Xft—
(5.159)
5.7.7. Примеры гауссовских марковских процессов
Пример 5.17. Пусть u(t), ОО — скалярный процесс, описываемый
дифференциальным уравнением й(/)=0, причем и(0) — гауссовская
случайная величина. Интегрируя уравнение процесса, получаем и(1) =
=c=const. Следовательно, u(t) представляет собой просто постоян-
ный сигнал, совпадающий с и(0) дли любого 00 (рис. 5.11,а). Таким
образом, значение процесса u(t) для любого 00 полностью опреде-
ляется начальной плотностью распределения вероятностей, а значит,
процесс является марковским.
Пример 5.18. Пусть u(/), t^O — скалярный процесс, описываемый
дифференциальным уравнением й(Г)=О, причем и(0) и й(0) имеют
совместное гауссовское распределение вероятностей. Интегрируя диф-
ференциальное уравнение, находим
й(/) =u(0)=const;
и(/)=и(0)+/й(0).
Вид сигнала изображен на рис. 5.11,6.
a.) t ° б) 1
Рис. 5.11. Постоянный сигнал со случайным начальным значением (а)
и лииейио меняющийся сигнал (б)
200
Введем в рассмотрение вектор
х(о = Ги(<)1 = [«(0) + <“(0)'1.
L «(0) J
Поскольку и(0) и й(0) имеют совместное гауссовское распреде-
ление, то х (0 — гауссовский двумерный вектор. Следовательно, про-
цесс х(0 — гауссовский.
Для доказательства марковости процесса возьмем два произволь-
ных момента времени <2>0>О. При этом
p(0) + ^(°)l х р(0)+4М0)1
L «(0) I L «(о J
Учитывая, что й(0)=й(/1) и что «(0)+<2й(0) =и(0)+0й(О) +
+ (/2—/1)ц(О)=и(0) + (0—0)й(0), находим
l«(0) + (<а + G.) «(*х)‘
L й(/Т
Следовательно, х(0) можно полностью определить, зная x(G).
Это означает, что процесс х(0 является марковским.
Аналогичным образом можно показать, что, если скалярный про-
(A+D
цесс и(0, ОО задан дифференциальным уравнением и(1)—0, причем
(A+D
u(0), ii(0).. и(0) имеют совместное гауссовское распределение ве-
роятностей, то векторный процесс
является гауссовским марковским процессом.
Пример 5.19. Белый гауссовский шум (белая гауссовская последо-
вательность) .
Процессы, происходящие в системах автоматики -и телемеханики,
содержат в своем составе помеху sf/t), которую часто представляют
в виде белого гауссовского шума. Рассмотрим последовательность
дискретных моментов времени 0, /2..... tn и обозначим через si, з2,...,
sn значения помехи в эти моменты времени. Помеху sn называют бе-
лым гауссовским шумом (белой гауссовской последовательностью),
если значения sn распределены по нормальному закону с нулевым
201
математическим ожиданием и дисперсией о2 и не коррелирован меж-
ду собой:
£(sn)=sn=0; E(s2„) =
= о2; E(s;s/)=0 для /#=i.
(5.160)
Как видим, значение помехи в любой момент времени не зависит
от предыдущих значений помехи и является нормально распределен-
ной случайной величиной. Таким образом, гауссовский белый шум
представляет собой гауссовский марковский процесс.
Пример 5.20. Коррелированный гауссовский шум. Коррелирован-
ный гауссовский шум gn с нулевым математическим ожиданием
E(gn)=g..=0, дисперсией £[g2n] =g2n=a .и ковариацией «i/=E[gig/] =
<=a<pli-H, представляет собой последовательность, определяе-
мую соотношением
gn=<pgn_I+Sn, л=1, 2....
(5.161)
причем go —случайная величина, распределенная по нормальному за-
кону с нулевым математическим ожиданием E[gol—1о=0 н дисперсией
E[g2o]=a, a sn— белый гауссовский шум с дисперсией a2=a(l—ср2),
некоррелированный с g0.
То, что соотношение (5.161) определяет гауссовский марковский
процесс, видно из самого соотношения и из определения величин
go и sn. Приведенные значения величин gn, g2n и Цц легко проверить
путем рассмотрения нескольких первых членов последовательности
gn. Так, имеем для п=1
11-?1о + *1; = ?lo + Si = 0; gi2 = E[?2g20 + 2?g0s1+s12] = a<p2 +
+ о2 —а; /?01 = «ю = Е Но (?lo + Si) ] = a?;
для n = 2
g2=<pgl + s2; l2 = 0; "g22 — E [<p2gi2 + 2<pg1s2 + s22] = a<p2a2 = a;
«12 = «21 = E [gi (?gi + S2) ] = ат; «02 = «20 = E [go (?11 + S2) ] =
— ¥«01 = a?2
и T. Д.
Очень часто приходится иметь дело с совокупностью нескольких
последовательных значений помехи, например gb..., gi. В этом случае
удобно ввести в рассмотрение вектор помехи
11 "I
162 5)
Liz J
202
я охарактеризовать его вектором математических ожиданий v, пред-
ставляющим собой нулевой вектор, и ковариационной матрицей Rv=
— £[vvT], имеющей вид
Если <р=0, то gn = sn, т. е. коррелированная помеха превращается
в белый гауссовский шум с дисперсией а=а2. Ковариационная матрица
белого гауссовского шума имеет вид
(5.164)
5.8. ЭЛЕМЕНТЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
5.8.1. Предмет математической статистики
Развитие науки и техники требует все более и более
глубокого проникновения в сущность явлений природы.
Однако сами явления природы предстают перед нами в ви-
де огромного числа разнообразных фактов и наблюдений,
которые, в свою очередь, являются результатом действия
множества факторов, часть из которых лежит в основе
рассматриваемого явления, а другие являются второсте-
пенными, несущественными и нередко просто затемняют
сущность явления. Нужны большие знания и умение для
того, чтобы исключить всю второстепенную информацию и
выявить основные и существенные сведения, содержащие-
ся в наблюдениях.
Методы математической статистики дают возможность
представить множество результатов наблюдения в ком-
пактном, удобном для обозрения виде. Они позволяют вы-
делить существенную информацию из множества наблю-
дений, представив ее в виде небольшого числа сводных
показателей. Если оказывается, что имеющихся данных
недостаточно для понимания сути явления и требуется
проведение добавочного эксперимента, то методы матема-
203
тической статистики позволяют ответить ^на вопрос, как
такой эксперимент поставить, чтобы в максимальной сте-
пени облегчить работу исследователя как по постановке
эксперимента, так и по последующей обработке экспери-
ментальных данных.
Из сказанного следует, что математическая статистика
представляет собой науку о методах обработки большого
числа экспериментальных данных с целью получения из
них правильных выводов. i
В данном разделе невозможно охватить все задачи, ре-
шаемые методами математической статистики, которым
посвящен ряд учебников и монографий |22—25]. Поэтому
мы ограничимся рассмотрением лишь наиболее распрост-
раненных методов решения статистических задач. Разви-
тие некоторых из этих методов, проведенное с позиций
теории принятия решений, будет дано в гл. 110.
5.8.2. Понятие случайной выборки
Пусть х — одномерная случайная величина с функ-
цией распределения вероятностей F(x). Рассмотрим
n-мерную случайную величину
(х(», .... *(»)), (5.165)
отдельные компоненты которой являются независимыми
случайными величинами с одинаковыми функциями рас-
пределения вероятностей F(x). Функция распределения
вероятностей такой многомерной величины определится
как произведение функций распределения вероятностей ее
компонент
nW’)- (5.166)
Случайные величины х(,) удобно рассматривать как
результаты некоторого эксперимента. При этом многомер-
ная случайная величина (5.165) может рассматриваться
или как результат последовательного проведения п неза-
висимых экспериментов на одной и той же эксперимен-
тальной установке или как результат проведения п одно-
временных экспериментов на п однотипных эксперимен-
тальных установках.
Поскольку всегда имеется возможность, хотя бы тео-
ретическая, проводить неограниченное число эксперимен-
204
тов, то можно говорить о бесконечном наборе случайных
чисел х“> с функцией распределения вероятностей F(x).
Такой бесконечный набор называют бесконечной совокуп-
ностью с функцией распределения вероятностей F(x).
Каждый конкретный результат эксперимента, а следо-
вательно, каждое х(<'> из конечного выбора (5.165) может
рассматриваться как выбор одного из чисел бесконечной
совокупности. Весь набор (5.165) представляет собой по-
следовательность п таких выборов и называется случай-
ной выборкой.
5.8.3. Предельные теоремы теории вероятностей
В математической статистике большой интерес пред-
ставляет изучение изменения свойств случайной выборки
при увеличении ее объема и, в частности, предельных со-
отношений, которые получаются при п->оо. Здесь фунда-
ментальную роль играют неравенство Чебышева и выте-
кающие из него закон больших чисел и центральная пре-
дельная теорема.
Если х —случайная величина с математическим ожи-
данием v и дисперсией о2, то справедливо следующее не-
равенство, называемое неравенством Чебышева:
P(|x-v>Xo)<lA2. (5.167)
Чтобы доказать это неравенство, разобьем веществен-
ную ось на три интервала:
/=(— оо, V—Хо]; 7'=(v—Ко, v-|-Xo);
4-оо).
Дисперсию величины х запишем в виде
= j (x — v)2w(x)dx==^(x — v)2w(x)dx~l-
-f- j (х — v)2w(x)dx-{- j (x — v)2 w (x) dx.
Отбрасывая в выражении для о2 слагаемое, соответ-
ствующее интервалу Г, получаем
о2 > J(x-v)2w(x)dx-\- J (х — v)2w(x)dx.
205.
Поскольку в интервале / имеем х—v^—Z.O, а в ин-
тервале Г имеем х—v^Z,o, неравенство только усилится,
если в обоих интегралах заменить (х—v)2 на Vo2. Таким
образом,
о2^Х2о2 [Р (х ^v-Z.o) +Р (x^v+Z-o) ] =
=Vo2P(|x-v|>Xo).
что эквивалентно неравенству (5.167).
Неравенство (5.167) определяет вероятность того, что
значение x—v выйдет за пределы интервала (—Z,o, +Z,o).
Однако можно определить вероятность того, что значение
х—v не выйдет за пределы указанного интервала. Эта ве-
роятность
Р(|х—v| <Z,o)=l— Р(|х—v|^Z,o);
с учетом неравенства (5.167)
Р( |х-v| <Z,o)>l- 1/V. (5.168)
Если обозначить Z,o через е, то это неравенство при-
мет вид
P(|x-v|<e)^l-o2/e?. (5.169)
Обратимся к рассмотрению случайной выборки (хь...
...,х„) объема п. Обозначим черезх среднее арифметиче-
ское этой выборки:
х = (1//г) З*;- (5.170)
i=l
С целью упрощения подобного рода записей далее ис-
пользуем символ S или Sn для обозначения суммирования
по всем выборочным данным. При этом соотношение
(5.170) запишется в виде
x=S(x)/n=S„/n. (5.171)
Дисперсия величины х согласно (5.62) и (5.98) будет
D(x) = = -L S ID(x)] А (5.172)
Заменяя в (5.169) х на х и соответственно о2 на о2/п,
получаем
Р{ I Sn/n-v | <е}>1-б2/(«е2)_ (5.173)
206
где v — математическое ожидание х, являющееся средним
значением для бесконечной совокупности, из которой взя-
та выборка.
Из выражения (5.173) видно, что при п->оо и при лю-
бом е>0
Р{ | S,Jn — v | <s}-> 1, (5.174)
что и выражает собой закон больших чисел. Из этого за-
кона следует, что при больших п с вероятностью, сколь
угодно близкой к единице, среднее арифметическое со-
впадает с математическим ожиданием v=£(x) вели-
чины х.
Приведем без доказательства одно из важнейших пре-
дельных соотношений теории вероятностей, получившего
название центральная предельная теорема. Пусть (хь...
..., хп) — последовательность случайных величин, имеющих
в общем случае различные функции распределения веро-
ятностей Fi(x), ..., Fn(x), математические ожидания vb...
...,vn и дисперсии oi2, ..., оп2. Обозначим:
x^-SW; v = — S(v); s2 = —S(o2). (5.175)
n n n
Центральная предельная теорема утверждает, что если
случайные величины хь ..., хп являются независимыми и
имеют конечные дисперсии одного порядка, то при боль-
шом числе слагаемых закон распределения среднего ариф-
метического х приближается к нормальному с математи-
ческим ожиданием v и дисперсией s2/n. Замечая, что
в этом случае величина
t = (X - v)lslVn (5.176)
будет иметь нулевое математическое ожидание и единич-
ную дисперсию, на основании центральной предельной
теоремы можно утверждать, что при п->оо будет выпол-
няться соотношение
f (5.177)
\ slvn J |/2п
С задачами, когда исследуемая случайная величина яв-
ляется суммой большого числа независимых случайных
величин, приходится сталкиваться весьма часто. Напри-
мер, ошибка сложного прибора является результатом сум-
207
марного действия разнообразных внешних условий и оши-
бок в отдельных элементах этого прибора. При этом
большие по своему влиянию ошибки легко исключаются.
Так, если в электрической схеме произошел обрыв, то его
легко обнаружить и устранить. Однако причины малых
по значению ошибок обнаружить трудно. Следовательно,
отдельные слагаемые суммарной ошибки можно считать
равномерно малыми и на основании центральной предель-
ной теоремы утверждать, что суммарная ошибка будет
иметь распределение, близкое к нормальному.
5.8.4. Критерии статистических оценок
Одной из задач математической статистики является
определение неизвестных параметров распределения бес-
конечной совокупности по известной конечной выборке.
При этом речь может идти об определении или самой
функции распределения F(x), или отдельных параметров
функции распределения, таких как математическое ожи-
дание, дисперсия, наименьшее или наибольшее значение
случайной величины и т. п.
Поскольку элементы конечной выборки являются слу-
чайными величинами, то случайным будет и значение па-
раметра, определенное с помощью этой выборки. В част-
ности, если мы имеем несколько выборок одного и того же
объема из одной и той же бесконечной совокупности, то
каждая из них даст свое значение интересующего нас па-
раметра. Поэтому по конечной выборке не можем точно
судить о значении параметра, а можем лишь более или
менее точно оценить этот параметр. Численные значения
отдельных параметров, определенные из конечной выбор-
ки, называют оценками параметров бесконечной совокуп-
ности.
В общем случае из одной и той же выборки можно
получить различные оценки. Пусть, например, имеется вы-
борка {хь х2, ..., Хп}, причем х(^х2^ ... «Схл, и мы хотим
найти оценку математического ожидания. Можно рассмот-
реть несколько различных оценок:
медиана — среднее всех наблюдений
о [ х(„+1)/2 при нечетном «;
х- 1 , , ч (5.178)
— (хл/2-1+x»/2+i) при четном п;
208
полусумма наименьшего и наибольшего значений
х — 0,5 (х, (5.179)
среднее арифметическое всех наблюдений
x = (5.180)
Какая же из этих оценок является наиболее предпоч-
тительной? На этот вопрос можно ответить, если ввести
некоторые критерии, которым должна удовлетворять оцен-
ка. Рассмотрим важнейшие из критериев.
Несмещенность. Оценка не должна содержать си-
стематической ошибки, преувеличивающей или преумень-
шающей значение параметра для всех выборок. Это озна-
чает, что математическое ожидание оценки должно совпа-
дать с действительным значением параметра. Если дей-
ствительное значение параметра обозначить через а, а его
оценку через а, то требование несмещенности запишется
в виде
Е(а\=а. (5.181)
Состоятельность. Оценка а должна приближать-
ся к значению параметра а по мере увеличения объема
выборки. Ввиду того, что оценка o' является случайной
величиной, об этом приближении можно говорить лишь
в вероятностном смысле. Так, если обозначить через 'ап
оценку а, полученную при выборке объема п, то для со-
стоятельной оценки должно выполняться соотношение
Р[ 1«„ —а |<а]—>1 (5.182)
при п->оо и любом е>0.
Эффективность. Из всех несмещенных и состоя-
тельных оценок следует предпочесть такую, которая ока-
зывается наиболее близкой к оцениваемому параметру,
т. е. при которой большие отклонения при использовании
различных выборок встречались бы как можно реже.
Оценки, удовлетворяющие этому требованию, называются
эффективными. Математически требование эффективности
означает требование минимальной дисперсии оценки
D(a)=min. (5.183)
14-804
209
5.8.5. Несмещенные оценки математического ожидания
и дисперсии
Пусть (xi.... хя)—выборка из совокупности с мате-
матическим ожиданием v и дисперсией о2. Обозначим че-
рез х оценку для математического ожидания, а через s2
оценку для дисперсии.
За оценку величины v обычно берут среднее арифмети-
ческое значение выборки
х = ± ^х/==-1-5(х), (5.184)
называемое выборочным, средним. Как следует из закона
больших чисел, такая оценка является состоятельной, т. е.
приближается к v при п->оо.
Поскольку выборочное среднее х представляет собой
сумму случайных величин, то оно само будет случайной
величиной. Поэтому можно говорить о законе распреде-
ления выборочного среднего, его математическом ожида-
нии и дисперсии.
Математическое ожидание выборочного среднего
E(x) = -^-£[S(x)] = -i-Sl£Wl = v (5.185)
совпадает со значением v, что говорит о несмещенности
оценки (5.184). Дисперсия выборочного среднего согласно
(5.172) равна а2/п.-
Если выборка взята из совокупности с нормальным
распределением, то х как сумма нормально распределен-
ных случайных величин будет иметь нормальное распре-
деление, которое с учетом (5.185) и (5J172) имеет вид
w(x)=N(v, о2/п). (5.186)
Во многих случаях вместо х бывает удобно рассматри-
вать величину
= (х— ч)1<з1У п =(х— у)1У<?[п, (5.187)
имеющую нулевое математическое ожидание и единичную
дисперсию, плотность вероятности которой будет равна
JV(O, 1).
Если выборка взята из совокупности, имеющей распре-
деление, отличное от нормального, то закон распределения
210
выборочного среднего также будет отличаться от нормаль-
ного, однако на основании центральной предельной тео-
ремы можно считать, что при больших объемах выборки
этот закон будет близок к закону N (v, о2/п).
Для нахождения несмещенной оценки дисперсии s2
найдем математическое ожидание величины S(x—x)2. За-
писывая эту величину в виде
•S (х — х)а = S [(х — v) — (х — v)]s = 3 (х — V)2—
— 2 (х — v) S (х — v) + п (х — v)2
и беря математическое ожидание от каждого слагаемого,
получаем
E[S((x-x)2] = («-l)o2 (5.188)
или
£[S(x-x)2/(n-^]=o2. (5J189)
Из (5.189) следует, что несмещенной оценкой диспер-
сии может служить оценка вида
s2 = —i-yS(x —х)а. (5.190)
Для определения закона распределения оценки дис-
персии рассмотрим предварительно один важный закон
распределения. Если г/, — независимые случайные величи-
ны, подчиняющиеся нормальному распределению Af(0,1),
то случайная величина
%а = 2Х (5.191)
г = 1
подчиняется распределению %2 (хи-квадрат) с п степеня-
ми свободы. При этом число степеней свободы опреде-
ляется числом независимых случайных величин в сумме
(5.191). Для распределения х2 составлены подробные таб-
лицы, в которых приводятся для различных п значения
вероятности р(х2>%<?2). где х?2 — какое-либо положитель-
ное число.
Ниже приведен пример такой таблицы, в которой зна-
чения х?2 удовлетворяют условию р(х2>Х<72)=0>95 для п
от 1 до 30:
14*
211
п........................ 1 2 3 4 5 6 7
X,8.................... 0,004 0,103 0,352 0,71 1,14 1,63 2,17
п........................-8 9 Ю п 12 13 и
X,8.................... 2,73 3,32 3,94 4,6 5,2 5,9 6,6
п....................... 15 16 17 18 19 20 21
Х?8 ................... 7,3 8,0 8,7 9,4 10,1 10,9 11,6
п....................... 22 23 24 25 26 27 28
Х98....................12,3 13,1 13,8 14,6 15,4 16,2 16,9
п......................29 30
X,8....................17,7 18,5
Более подробные таблицы х?2 распределения можно най-
ти в [23].
Нетрудно видеть, что если под yt понимать величину
(х,—х)/а, удовлетворяющую наложенным на yt усло-
виям, то
x‘ = b/‘ = (n-W (5.192)
будет определять закон распределения для s2.
5.8.6. Нахождение оценок по методу максимального
правдоподобия
Многие задачи математической статистики сводятся
к тому, чтобы оценить некоторый параметр а в распреде-
лении, вид которого известен. По принципу максималь-
ного правдоподобия за оценку параметра а принимают
такое значение, которое представляется наиболее вероят-
ным на основании опытных данных.
Имеем выборку (xi, ..., хп) из совокупности с плотно-
стью распределения вероятности оу(х, а), зависящей от
параметра а. Многомерную плотность вероятностей для
этой выборки
L — П а)(хг, а) (5.193)
г=1
называют функцией правдоподобия. Согласно принципу
максимального правдоподобия за оценку параметра а
принимают значение а, при котором функция правдоподо-
бия L или, что то же самое, логарифм этой функции
InL достигает максимума. Значение а можно найти из
212
уравнения правдоподобия
dlnL dlntp(xf, «) = q ,5 194^
да. ~ да ’ 7
1=1
которое легко приводим к виду
S" ____!___^(xt,aj ~ 0 (5.195)
W (Х[, а) да
Для случая, когда выборка взята из совокупности с нормальным
распределением W(v, а2), определяемым (5.40), уравнения правдопо-
добия для определения параметров v и о имеют вид
3 (Х{ - v) = 0; 3 [ 1 - (х£ - v)2/a2] =0. (5.196)
i=l i=l
Из первого уравнения находим оценку для v:
£>>=«• <5i97>
которая совпадает с полученной ранее несмещенной и состоятельной
оценкой (5.184). Второе уравнение правдоподобия с учетом (5.197)
дает оценку для о2:
п
i2=vE(X£_'?)2’ (5,198)
i=i
которая, однако, не является несмещенной, поэтому на практике поль-
зуются обычно несмещенной оценкой (5.190).
Получение максимально правдоподобной оценки для экспоненци-
альиого распределения рассмотрим на примере.
Пример 5.21. Для определения среднего срока службы выпускае-
мой заводом аппаратуры было испытано п образцов аппаратуры в те-
чение t часов. За время испытания т образцов проработали без от-
казов в течение всего времени t, а п—т образцов отказали в моменты
Хь..., Tn-m- Какова наиболее правдоподобная оценка среднего вре-
мени безотказной работы?
Предполагая, что время, за которое происходит отказ аппаратуры,
подчиняется экспоненциальному закону (5.135), так что величина
о|(Л, t)=Xe_ta представляет собой вероятность выхода аппаратуры
213
в момент т, а величина е~М — вероятность исправной работы в тече-
ние времени t, получаем функцию правдоподобия
п—т
I=(e-W)'n [J Ш(А|Ч). (5.199)
1=1
Уравнение (5 194) прн этом дает
3 (1А-т()=0, (5.200)
откуда
(п—т \ I
mt + S х<) / (п — т). (5.201)
Аналогичным образом можно показать, что наиболее правдопо-
добная оценка ворон iпости события для процесса независимых испы-
таний при биномиальном распределении
Р=х/л, (5.202)
где п — число испытании: х — число успехов.
Если случайный процесс подчиняется распределению Пуассона
и в выборке за п интервалов содержится г событий, то п:пиболее
правдоподобной оценкой среднего числа событий в одном интервале
служит величина
й^г/п. (5.203)
5.8.7. Оценка параметров по методу
доверительных интервалов
В предыдущих разделах были рассмотрены методы, да-
ющие оценку параметра в виде некоторого числа, т. е. не-
которой точки вещественной оси. Такие оценки получили
название точечных. Поскольку выборка является случай-
ной, то во многих случаях, особенно при малых объемах
выборки, такая оценка может оказаться весьма далекой
от действительного значения параметра.
Значительно большую информацию может дать ука-
зание интервала, в котором с вероятностью, близкой к еди-
нице, находится значение оцениваемого параметра. Так,
если значение у близко к единице, то интервал (ai, а2),
в котором с вероятностью у находится значение неизве-
стного параметра а
Р(а1<а<а2)=у, (5.204)
214
называют ЮОу-процентным доверительным интервалом.
На практике часто ограничиваются рассмотрением 95%-
ного доверительного интервала, полагая у=0,95. Если най-
дена точечная оценка параметра а и известна плотность
вероятности для этой оценки, то границы доверительного
интервала получают из соотношения
У w (a) da. — у. (5.205)
В ряде случаев вместо нахождения двустороннего до-
верительного интервала (а>, аз) требуется найти только
нижнюю а/ или только верхнюю аз' границу для рас-
сматриваемого параметра а. Интервалы, определяемые
соотношением
/’(а><Х1/) =? и Р(а<а2')=Т> (5.206)
называют односторонними ЮОу-процентными доверитель-
ными интервалами. Границы а/ и аз' этих интервалов оп-
ределяют из выражений
+оо +«,'
^w(a)da = y и J w(a)da = y. (5.207)
Предположим, чго выборка объема п взята из сово-
купности с нормальным распределением Af(v, а2) с неиз-
всст11ым v и известной дисперсией о2, так что 1 =
= ]//г(х—v)/o будет иметь распределение Af(O, 1). Введем
также обозначение у=1— q. В этом случае 100(1—«^-про-
центный доверительный интервал определится соотноше-
нием
/>(-^<V«(x-v)/o< + Q= \ — q (5.208)
или
Р (х — v < х + tqo/Vn) = 1 — q. (5.209)
Учитывая соотношение (5.44), это выражение можно
записать в виде
1 _q=Q(tq) -ф (_/,) =2Ф (tq), (5.210),
что приводит к следующему соотношению для определе-
ния tq.
Ф(/?) =0,5(1—<?). (5.211)’
215
Для односторонних доверительных интервалов (tqf,
Ч-оо) и (—оо, tq') соотношение (5.210) запишем в виде
1 -q=® (tqf) -ф (-оо) =0,54-Ф (</). (5.212)
Для определения граничных значений односторонних
доверительных интервалов при этом получаем соотноше-
ние
Ф(//) =0,5(1 —2q). (5.213)
Как видим, граничные значения 100(1— q)-процентно-
го одностороннего доверительного интервала равны гра-
ничным значениям 100(1—2q)-процентного двустороннего
доверительного интервала.
Полагая </=0,05 и воспользовавшись таблицами инте-
грала вероятностей, из соотношений (5 211) и (5.213) на-
ходим следующие границы двусторонних и односторонних
доверительных интервалов:
/?=1,96; </=1,64.
(5.214)
Таким образом, вычисленное по выборке объема п из
совокупности с нормальным распределением и известной
дисперсией о2 выборочное среднее х дает возможность
с вероятностью 0,95 утверждать, что математическое ожи-
дание совокупности будет лежать в интервале
х= l,96o/J/7z< v<x + 1,96о/]//г, (5.215)
или что
v > х — 1,64о/]/й, (5.216)
или что
v<x+1,64о//й. (5.217)
Полученные значения tq могут быть использованы и
для нахождения доверительных интервалов при биноми-
альном распределении w(x, п, р), поскольку биномиаль-
ное распределение при больших п приближается к нор-
мальному с математическим ожиданием v—np и диспер-
сией o2=npq. Полагая <=(х— np)!Vnpq, приходим
к выводу, что если при п независимых испытаниях собы-
тие S произошло х раз, то с вероятностью 0,95 можно
утверждать, что математическое ожидание пр будет ле-
216
жать в следующих пределах:
1,96]/'лр^</гр< х+1,96]/я^, (5.218)
или что
пр>х — Xfi^Vnpq, ' (5.21 У)
или что
пр < х + 1,64 Vnpq, (5.220)
причем значение Vnpq подсчитывается по наиболее прав-
доподобному значению р=ф=х/п как
V~npq = Vx(n — х)/п. (5.221)
Пример 5.22. Из выпускаемой заводом продукции было случайным
образом отобрано и испытано 100 изделий, среди которых 37 оказа-
лись второго сорта. Что можно сказать о проценте изделий, выпускае-
мых вторым сортом?
В данном случае п = 100, х = 37, Vnpq — 4,94. При этом 1,96 X
Х/йр9 = 9,5. так что
х— l,96|/np<7 = 27,5; х + 1,96|/ лр^ = 46,5.
Таким образом, имеется 5 шансов из 100, что ошибемся, делая
одно из следующих утверждений относительно числа изделий, выпус-
каемых вторым сортом составляет: 1) между 27,5 и 46,5% общего
числа изделий; 2) не менее 29% общего числа изделий; 3) не более
45% общего числа изделий.
Доверительные интервалы весьма часто приходится
использовать для определения оценки v при нормальном
распределении, когда дисперсия о2 неизвестна. В этом
случае вместо о2 применяют оценку дисперсии s2. Однако
при этом величина
t = (x — v)lVs^n (5.222)
в отличие от (5.187) уже не будет распределена по нор-
мальному закону. В действительности величина t, опреде-
ляемая (5.222), подчиняется закону распределения Стью-
дента, которому можно дать следующее определение.
Пусть « — случайная величина, имеющая нормальное
распределение Af(O, 1); и —случайная величина, имеющая
^-распределение. Если и и v независимы, то случайная
величина
t = и iV^/k = и VklVb (5.223)
217
определяет распределение Стьюдента, в котором величину
k называют числом степеней свободы.
Если теперь определить величины
и=(х — ^/]/"^/п; v=(n—l)s*/c?, (5.224)
то согласно (5.187) и (5.192) они будут удовлетворять
условиям, определяющим распределение Стьюдента, а зна-
чение t, найденное согласно (5.223), совпадает с значе-
нием, даваемым (5.222) при k=n— 1. Таким образом,
Таблиц а"] 5.2
k
ч 1 2 | 3 4 Б 6 7 8 9 10 | 12
0,05 12,71 4,30 3,18 2,78 2,57 2,45 2,36 2,31 2,62 2,23 2,18
0,10 6,31 2.92 | 2,35 2.13 2,01 1,94 1,89 1,86 1,83 П1 1.81 | 1,78 оодолжсние
ч k
14 п> 1м 20 22 24 26 28 30 | 00
0.05 2,15 2.12 2,10 2,09 2,07 2,06 2,(6 2,05 2,04 1,96
0,1(1 1,76 1,75 1,73 1,72 1,72 1,71 1.71 1,70 1,70 | 1,64
случайная величина t, описываемая выражением (5.222),
будет распределена по закону Стьюдента со степенями
свободы k=n— 1.
Обозначим через границы двустороннего 100(il— q)-
процентного доверительного интервала для распределения
Стьюдента с k степенями свободы. Имеются подробные
таблицы (например, [23]) для определения tqk при раз-
личных q для /г от 1 до 30. При &>30 значения tqk прак-
тически совпадают с значениями tq, получаемыми для
нормального распределения. Примером такой таблицы яв-
ляется табл. 5.2, дающая значения tqh для <7=0,05
и 0,1.
Границы односторонних доверительных интервалов
t'qk могут быть найдены по значениям tqk из соотноше-
ния
t'qk=t2qk. (5.225)
218
Пример 5.23. Для уменьшения влияния помех в канале связи каж-
дый результат измерения некоторого параметра v передается с борта
ракеты на наземную измерительную станцию трижды. Результаты из-
мерений: Х| = 3,2; х2=2,9; х3=3,1. Определить двусторонний 95%-ный
доверительный интервал для параметра v, считая искажения в каж-
дом передаваемом значении независимыми друг от друга и распреде-
ленными по нормальному закону.
По измеренным данным находим
n=3; x=S(x)/n= 3,067; s2=S(x-x)2/(n— 1) =0,0234.
По табл. 5.2 для ^=0,05 и k=n—1=2 получаем /,4=4,30, так что
t.tnS/Vn = 0,377.
Следовательно, с вероятностью 0,95 имеем 2,69<v<3,44.
5.8.8. Проверка статистических гипотез.
Понятие о критерии согласия
Пусть Z — пространство исходов эксперимента с эле-
ментами zeZ. Для определения вероятности p(z) неко-
торого исхода z проводим п экспериментов. Если при
этом исход z произошел пг раз, то вероятность этого ис-
хода оцениваем по отношению пг/п. Однако в действи-
тельности отношение пг/п дает не вероятность p(z) ис-
хода z, а его частоту q(z), которая может значительно
отличаться от вероятности, особенно при не очень боль-
шом числе экспериментов. Возникает вопрос, насколько
можно судить о распределении вероятностей исходов
p(z), если известны частоты этих исходов q(z). Однако
такая постановка задачи является не совсем корректной
Действительно, если в результате эксперимента полу-
чен ряд чисел, выражающих частоты отдельных исходов
эксперимента q(z), то для того, чтобы заменить их на
другие числа [вероятности р (г) ], нужны какие-то осно-
вания. Что же может явиться основанием для замены од-
них чисел другими?
Пусть при 10-кратном бросании монеты «герб» выпал
7 раз. Частота выпадения «герба» в данном эксперименте
равна 0,7. Есть ли у нас основания заменить это значе-
ние и принять за вероятность выпадения «герба» некото-
рое другое число?
Если о монете ничего не известно, в частности, не зна-
ем, симметрична она или нет, то у нас нет и оснований
изменить полученное из эксперимента значение частоты.
Однако задачу можно поставить иначе. Знаем, что если
219
монета симметрична, то вероятность выпадения «герба»
равна 0,5. Хотим проверить, симметрична ли монета, и
с этой целью бросаем ее 10 раз. При этом «герб» выпа-
дает 7 раз. Спрашивается, есть ли у нас основания ут-
верждать, что монета симметрична?
Сформулированная таким образом задача носит назва-
ние задачи на проверку гипотезы. Подобные задачи воз-
никают, когда имеются основания построить некоторую
гипотезу (например, монета симметрична) о характере
распределения или значении параметров распределения
случайной величины. Целью эксперимента является под-
тверждение или опровержение выдвинутой гипотезы. Ме-
тоды статистической проверки гипотез позволяют ответить
на вопросы: 1) обладает ли новый образец прибора луч-
шими качествами по сравнению с существующими? 2) бу-
дет ли система обладать надежностью не ниже заданной?
3) будет ли новый способ лечения эффективнее существу-
ющих? и т. п.
Для того чтобы иметь основания принять или отверг-
нуть рассматриваемую гипотезу, необходимо выработать
некоторый критерий, который называют критерием согла-
сия проверяемой гипотезы с результатами эксперимента.
Предположим, что значение некоторого параметра а
равно ао, и проверим это на основании эксперимента.
В результате эксперимента находим опенку этого пара-
метра а, которая, являясь случайной величиной, вообще
говоря, не совпадает со значением а0. Однако отклонение
Да=а—а0 оценки а от истинного значения ао не должно
быть велико и, следовательно, если это отклонение ока-
залось большим, его нельзя объяснить случайными при-
чинами и следует считать, что гипотеза о том, что зна-
чение параметра равно ао, не подтверждается и должна
быть отклонена. Таким образом, выбор критерия согла-
сия — это задание критического значения отклонения
Дакр, выбранного так, чтобы вероятность превышения
этого значения была очень малой. За критическое откло-
нение может быть принята граница 100(1— q)-процентно-
го доверительного интервала. При этом имеется вероят-
ность q того, что наблюдаемое отклонение превысит кри-
тическое, а значит, будет необоснованно отклонена
правильная гипотеза. Величину q, называемую уровнем
статистической значимости, следует выбирать в зависи-
мости от тех последствий, к которым может привести от-
220
клонение правильной гипотезы. Практически в большин-
стве случаев считают 7=0,05, принимая тем самым за
критерий согласия 95%-ный доверительный интервал. Од-
нако в тех случаях, когда последствия некорректного от-
клонения гипотезы могут быть тяжелыми, принимают 7=
=0,01, а иногда и меньше.
Следует отметить, что хотя данный метод позволяет
с большой уверенностью отклонять ложные гипотезы, он
не может служить доказательством справедливости гипо-
тезы. Поэтому при попадании гипотетического значения а0
в пределы доверительного интервала принимаем гипотезу
не как истинную, а как согласующуюся с результатами
эксперимента. Для суждения об истинности гипотезы не-
обходимо проводить специальные исследования.
5.8.9. Оценка влияния некоторого фактора на характер
случайной величины
Часто встречается задача, в которой требуется отве-
тить на вопрос: влияет или не влияет некоторый фактор А
на характер случайной величины у. К такому типу отно-
сятся задачи по оценке эффективности нового способа ле-
чения, влияния нового способа обработки почвы на уро-
жай, уменьшения процента брака при изменении в тех-
нологии и т. п.
Для ответа на поставленный вопрос проводят п экспе-
риментов, в каждом из которых определяют значения у/
и у" при отсутствии и при наличии действия фактора А,
также разность х,=у/—у".
Предположим, что случайная величина у имеет нор-
мальное распределение V(v, о2) с известной дисперсией
о2, ожидаем, что действие фактора А сводится только
к изменению математического ожидания V. Если действие
фактора А несущественно, то математические ожидания
случайных величин у' и у" будут одинаковы и величина
х=у'—у" имеет нормальное распределение <N (0, ах2) с ну-
левым математическим ожиданием и дисперсией ах2 =
= 2а2. Таким образом, ответ на поставленный вопрос
сводится к проверке гипотезы о том, что математическое
ожидание величины х=у'—у" равно нулю.
В результате п экспериментов находится выборочное
среднее
x = -^S(x)=-J-S(y’ -у"), (5.226)
221
которое при справедливости сформулированной гипоте-
зы будет иметь нормальное распределение с нулевым ма-
тематическим ожиданием и дисперсией Используя
95%-ный доверительный интервал, можем утверждать,
что гипотеза о несущественности влияния фактора А не
противоречит экспериментальным данным, если выполня-
ется соотношение
| к | < ЬЭб]/-<зхг/п или | х:У<зх/п | < 1,96. (5.227)
Однако во многих случаях дисперсия о2 бывает неиз-
вестна и ее приходится заменять на ее оценку sx2, вы-
численную на основе тех же экспериментальных данных
по формуле (5.190)_.___
Величина х: Узх/п является случайной, подчиняющей-
ся распределению Стьюдента с п—(1 степенью свободы.
Поэтому гипотеза о несущественности влияния фактора Л
принимается в том случае, если выполняется соотноше-
ние
I « : V^Tn I <tq- (5.228)
где tq — граница 95%-ного доверительного интервала рас-
пределения Стьюдента с п—1 степенью свободы, опреде-
ляемая по табл. 5.2.
5.8.10. Проверка гипотезы о дисперсиях.
Понятие о /•’-распределении
Часто приходится сталкиваться с задачей проверки
равенства дисперсий в двух независимых выборках:
(xi, .... xnt) и (t/i, выборочные дисперсии которых
Si2 и s22 определяют по (5.190) со степенями свободы ki=
=«1—1 и й2 = п2—1- Для проверки того, взяты эти вы.
борки из одной и той же совокупности с дисперсией аг
или из разных совокупностей с дисперсиями Oi2 и о22,
необходимо проверить гипотезу о равенстве дисперсий сч2
и о22-
Гипотезу о равенстве дисперсий проверяют с помощью
F-критерия, для чего вычисляют
F=st2/s22, (5.229)
где предполагается, что Si2>s22 и принимается гипотеза
о том, что выборки взяты из различных совокупностей,
если значения величины F превосходят некоторое крити-
222
ческое значение Fq. При этом критическим значением Fq
при данных степенях свободы ki и k2 будет такое, что
P(F>Fq) =7/100. Как видим, значения Fq являются
верхним 7%-ным пределом F-распределения. В [23] при-
ведены подробные таблицы F-распределения для 7=5%
и 7=1% при степенях свободы kt от 1 до 500 и k2 от 1
до 1000.
5.9. РЕГРЕССИОННЫЙ АНАЛИЗ И ПЛАНИРОВАНИЕ
ЭКСПЕРИМЕНТА
5.9.1. Задача регрессионного анализа
Рассмотрим следующую задачу. Имеется k перемен-
ных Xi, ..., Xk и зависящая от них величина у. Сами пе-
ременные, вообще говоря, могут и не быть случайными,
и при желании можем задавать их значения по своему
усмотрению. Однако на величину у влияют и другие, не
поддающиеся точному контролю и наблюдению факторы,
благодаря чему величина у носит случайный характер.
Нас интересуют методы экспериментального определения
влияния переменных Xi xh на величину у [26].
Пример 5.24. Задачи подобного типа обычно связаны с анализом
условий протекания производственных и технологических процессов.
Примером может служить процесс получения аммиака путем выделе-
ния его из отходящих газов при коксовании угля. Отходящие газы,
содержащие азот N2, водород Н2 и углекислый газ СОг, должны
быть очищены от углекислого газа. Затем получение аммиака про-
исходит по схеме:
3H2+N2=2NH3.
Процесс очистки газа происходит путем пропускания отходящих
газов через слой движущейся воды, поглощающей СО2. Под величиной
у будем понимать качество очистки, характеризующееся процентным
содержанием СОг в очищенном газе. На качество очистки влияет
прежде всего температура отходящих газов и расход воды, которые
можно принять за переменные Xi и х2. Однако на качество очистки
влияет и множество случайных факторов, начиная с качества угля
и кончая температурой окружающего воздуха.
Будем считать Xi, ..., х*, которые принято называть
факторами, входными величинами некоторого технологи-
ческого процесса, а у будем рассматривать как выходную
величину (результат) этого процесса, что схематически
223
Входы • гический > Выход
хк процесс
Рис. 5.12. Структурная схема
технологического процесса
может быть изображено схе-
мой, показанной на рис. 5.12.
Величина у будет состоять
из детерминированной состав-
ляющей f(xi, ..., Xk), обуслов-
ленной влиянием и изменени-
ем факторов Xi, ..., хл, и со-
ставляющей g, обусловленной действием случайных фак-
торов
y=f(Xl, ..., xft)-H. (5.230)
Составляющую g будем считать случайной величиной,
имеющей нормальное распределение с нулевым математи-
ческим ожиданием. В этом случае детерминированная со-
ставляющая f(xi, ..., Xk) будет представлять собой услов-
ное математическое ожидание значения у при данных
значениях факторов Xi, ..., Ха, т. е.
f(xi, ..., хк) = E(y\Xi, ..., Xk)=y(x.. хк)=у(х).
(5.231)
Здесь x=(xi, ..., xft)T представляет собой вектор зна-
чений входных переменных, который может рассматри-
ваться как точка в й-мерном пространстве переменных
Xi, ..., Xk, называемом далее факторным пространством.
Цель дальнейшего рассмотрения — определение подан-
ным эксперимента вида зависимости (5.231), которая пред-
ставляет собой некоторую поверхность в факторном про-
странстве, называемую поверхностью отклика.
Для дальнейшего анализа удобно функцию f(xt...... xfe)
вблизи рабочей точки разложить в ряд Тейлора. Ограни-
чиваясь конечным числом членов разложения, приходим
к представлению функции отклика полиномом конечной
степени
У(х) = Ро + 2 Р/Х. + 2 Р^х2, + 3 pZ/xtx, + ... (5.232)
Это выражение можно представить в более компактном
виде, введя фиктивную переменную х0= 1, и заменив про-
изведение двух и большего числа переменных на новые
переменные Ха+....... Ха' по правилу
xi2=xa+i; х22=ха+2, ..., ха2=х2а; x,x2=X2a+i; xix3=x2a+2 ...
224
Общее число переменных при этом будет равно: k'=
=Ckk+a, где k — первоначальное число переменных; d —
степень полинома, представляющего собой функцию //(х).
С учетом вновь введенных обозначений уравнение по-
верхности отклика принимает вид
z/(x) = + ... + + pA+1rft+1 + ...
- + Ма' = 2 (5.233)
i=0
В дальнейшем индекс (') будем опускать, считая, что
поверхность отклика задается уравнением вида (5.233)
с k переменными.
Уравнение вида (5.233) получило название уравнения
регрессии, и входящие в него коэффициенты 0£ называют
коэффициентами регрессии. Задача регрессионного ана-
лиза состоит в экспериментальном определении коэффи-
циентов регрессии путем наблюдения за характером изме-
нения входных переменных Xi, ..., Хь и выходной перемен-
ной у. Этой цели могут служить методы пассивного или
активного эксперимента.
Пассивный эксперимент основан на регистрации конт-
ролируемых параметров в процессе нормальной работы
объекта без внесения каких-либо преднамеренных возму-
щений. Активный эксперимент основан на использовании
искусственных возмущений, вводимых в объект по зара-
нее спланированной программе. Каждый из этих способов
имеет свои достоинства и недостатки.
При активном эксперименте введение искусственных
возмущений позволяет целенаправленно и быстро вскры-
вать нужные зависимости между параметрами, нащупы-
вать области оптимального режима работы. Однако вве-
дение искусственных возмущений может привести к на-
рушению нормального хода технологического процесса.
При пассивном эксперименте вмешательства в ход про-
изводственного процесса не происходит и эксперимента-
тор просто ожидает естественного проявления интересу-
ющих его закономерностей, что значительно удлиняет
время эксперимента. При этом математическое описание
получается лишь для области, близкой к рабочей точке
объекта, которая может значительно отличаться от опти-
мального режима.
15—804
225
При ограниченном числе экспериментов невозможно
осуществить точное определение коэффициентов регрессии
р, и приходится ограничиваться определением оценокf£=
=bt этих коэффициентов. При этом вместо (5.233) полу-
чается уравнение регрессии вида
? = (5.234)
1=0
определяющее не математическое ожидание у(х), а оцен-
ку математического ожидания у(х).
5.9.2. Определение коэффициентов регрессии
по данным пассивного эксперимента
Уравнение (5.234) имеет &Н-1 неизвестных коэффи-
циентов регрессии. Для их определения проводят серию
экспериментов, в каждом из которых измеряют все ве-
личины на входах и выходе исследуемого объекта. Общее
число экспериментов п должно быть не меньше числа не-
известных коэффициентов регрессии.
Рассмотрим эксперимент с номером I. Обозначим че-
рез х/'\ i=0, k и t)i значения х,- и у в этом эксперимен-
те. При этом оценка
(5.235)
1=0
определяемая по уравнению (5.234), будет отличаться от
действительного измеренного значения yi. Разность между
измеренным значением yi и его оценкой называется не-
вязкой
yt-yi = У1 — ^ 1 = Т7п. (5.236)
1=0
При этом
yt =yt + SZ = S biXll) + ez, I =~n. (5.237)
i=0
В отличие от величины g в уравнении (5.230), кото-
рая носит чисто случайный характер, невязка е/ из выра-
226
жения (5.236) зависит от принятых значений коэффи-
циентов регрессии bt. Это позволяет использовать для
определения значений bt метод наименьших квадратов,
согласно последнему наилучшими оценками bi будут та-
кие, которые обращают в минимум сумму квадратов не-
вязок:
Q = 2 е/а = m!n-
(5.238)
Чтобы не усложнять дальнейшие выкладки, определе-
ние коэффициентов регрессии удобно провести в матрич-
ной форме.
Обозначим через В=(&о, blt ..., Ьа)т вектор-столбец
неизвестных коэффициентов регрессии, а через Y=
= (t/i, ..., уп)т вектор-столбец результатов измерения ве-
личины у. Результаты наблюдения за переменными
xh ..., ха зададим в виде матрицы результатов экспери-
мента
Через Е= (ei, ..., еп)т обозначим вектор-столбец невя-
зок.
В этих обозначениях (5.237) запишем в виде одного
матричного уравнения
Y=BX-|-E. (5.240}
Отсюда для вектора невязок
E=Y—ХВ. (5.241)
В матричной форме сумма квадратов невязок
Q=2 ez2 = E’E = (Y— XB)T(Y — ХВ). (5.242)
/=1
Раскрывая скобки, находим
Q=YTY-YTX В- BTXTY+
+ВТХТХВ. (5.243)
Легко заметить, что третье слагаемое этого выраже-
ния равно транспонированному второму слагаемому.
15*
227
А поскольку Q — скаляр,, а значит, и слагаемые выраже-
ния (5.243) также скаляры, которые при транспонирова-
нии не изменяются, то второе и третье слагаемые можно
объединить, записав выражение для Q в виде
q=YtY—2BTXTY-]-BTXTXB. (5.244)
Уравнение для определения В подучим, взяв вектор-
ную производную от Q по В и приравняв ее нулю. Вос-
пользовавшись правилом вычисления векторных произ-
водных (см. § 4.7), находим
dQ/dK=-2XTY-|-2XTXB=0. (5.245)
Отсюда
B=(XTX)-1XTY. (5.246)
Все вычисления, связанные с преобразованием матриц
в соответствии с (5.246), производятся на ЭВМ. Однако
в простейших случаях можно получить аналитические вы-
ражения.
Пример 5.25. Рассмотрим объект с одномерным входом
Xi=x, уравнение регрессии для которого имеет вид
В данном случае
y = b0 + btx.
В =
При этом
№'Х =
п
/
2x(')3(x(Z,)a
I
Здесь чертой обозначены средние значения соответствующих величин,
определяемые по (5.184).
228
Учитывая, что
(ХТХ)-»= Г *2
1 ’ n (х2 — х2) j х" 1 J
для вектора В из (5.246), почучаем
так что
х2 —№
х2у — х ху
—ху + ху .
Ьй=(х2у —хху)/(х2—х2), Ь1 = (ху-ху)/(х2-х2).
Поскольку определение оценок коэффициентов регрес-
сии bo, bi.. bk производится по искаженным помехами
экспериментальным данным, то для получения точных
оценок число экспериментов п должно значительно пре-
восходить число &-|-1 оцениваемых коэффициентов ре-
грессии. Разность между числом наблюдений и числом не-
известных параметров, оцениваемых на основании этих
наблюдений, называют числом степеней свободы экспери-
мента. При регрессионном анализе это число п'=
= n-(k+l).
Другим источником ошибок может явиться несоответ-
ствие между принятой степенью полинома d, описываю-
щего поверхность отклика, и действительным характером
этой поверхности. В этом случае говорят о неадекватности
представления результатов эксперимента полиномом дан-
ной степени.
О правильности выбора степени полинома можно су-
дить на основании F-критерия. Для этого вычисляют сум-
му Sr2 квадратов отклонений экспериментальных значе-
ний у, от найденных по уравнению регрессии (5.234)
(у.-y.?. (5.247)
i=i
Разделив эту сумму на число степеней свободы экс-
перимента n'=n-(k-\-\), определяют дисперсию sR2, ха-
рактеризующую рассеяние экспериментальных точек от-
носительно уравнения регрессии:
sR2=SR2/n'. (5.248)
229
Кроме того, вычисляют дисперсию sy2, характеризую-
щую ошибку эксперимента:
(5,249>
где у — выборочное среднее всех результатов эксперимен-
та; п—1—число степеней свободы при определении дис-
персии Sy2.
Далее находят F-отношение:
F=sR2/sy2 (5.250)
и проверяют гипотезу об адекватности представления ре-
зультатов полиномом заданной степени d путем сопостав-
ления вычисленного значения F со значением F?, найден-
ным из таблиц F-распределения при заданных степенях
свободы п' и п—1.
5.9.3. Понятие о планировании эксперимента
Планирование эксперимента, ставящее своей целью
обеспечить наиболее эффективное исследование свойств
объекта управления, лежит в основе проведения активного
эксперимента. Преимущества, которые может дать плани-
рование эксперимента, проиллюстрируем на простом при-
мере [27].
Пример 5.26. С помощью пружинных весов требуется определить
массу трех предметов: А, В, С. Обозначим через X неизвестную массу
чашки весов.
Обычный способ, использующий четыре взвешивания, — сначала
взвешивают чашку, а затем по очереди каждый из предметов, пред-
ставлен в виде табл. 5.3, где знаками «+» и «—» обозначено наличие
или отсутствие соответствующего груза на весах. Подобную таблицу
будем называть матрицей планирования эксперимента.
При данном способе взвешивания массу каждого предмета опреде-
ляют по двум взвешиваниям: взвешивание груза вместе с чашкой и
взвешивание чашки. Так, масса предмета А будет Ра=Уг—Уо. Обозна-
чим через о2 дисперсию ошибки одного взвешивания Тогда дисперсия
ошибки в определении массы Ра будет 02 = a2 f + <s2o — 2а2.
Другой способ определения массы тех же предметов с помощью
четырех взвешиваний (усовершенствованный способ взвешивания) пред-
ставлен второй матрицей планирования. Здесь в первых трех опытах
230
последовательно взвешивают предметы А, В, С, в последнем опыте
все три предмета взвешивают вместе. Легко видеть, что масса, на-
пример, предмета А будет определяться как
/>л=0,5(«/2+У4—У\—Уз)
с дисперсией ошибки о2л=4о2/4=о2.
Как видим, при втором способе взвешивания дисперсии ошибки
в два раза меньше, чем при первом, т. е. второй план эксперимента
лучше, чем первый. Объясняется это тем, что в первом способе массу
предмета определяют только по двум опытам, а во втором — по всем
четырем, что обеспечивает лучшую компенсацию ошибок отдельных
взвешиваний.
Таблица 5.3
Возникает вопрос: каким же образом находить наибо-
лее эффективный план эксперимента? Ответ на этот во-
прос дает теория планирования эксперимента [28, 29].
В частности, в регрессионном анализе эффективными ме-
тодами являются полный факторный эксперимент и дроб-
ные реплики от него.
5.9.4. Полный факторный эксперимент
Допустим, что мы имеем дело с независимыми вход-
ными переменными объекта управления (двумя фактора-
ми) xi и хч и каждую из них варьируем на двух уровнях,
условно обозначаемых +1 и -1 или короче «+» и «—».
Например, если за факторы принята температура xi (1120
и 80°C) и давление хг (3 и 2 МПа), то опыт, в котором
231
температура была 120 °C, а давление 2 МПа, будем ус-
ловно обозначать (+, —).
Предположим, что нас интересует уравнение регрес-
сии, в котором отражено влияние на величину у не толь-
ко факторов Xi и х2, но и их взаимодействия, отражае-
мого произведением х,х2. Уравнение регрессии запишем
в виде
y=boXo+biXi-\-b2x2-\-bi2XiX2, (5.251)
где, как и раньше, х0=1.
Таблица 5.4
ХО X. | . У Кодовое обозначение
+ + + + 1 + 1 ++1 1 + 11 + У1 Уз Уз У* (О а b ab
Легко видеть, что возможные комбинации двух факто-
ров Xi, х2, варьируемые на двух уровнях +1 и —1, будут
исчерпаны, если мы поставим четыре опыта, указанные
в табл. 5.4. В эту таблицу введем столбец х0, значение
которого всегда равно +1, столбец с произведением XiX2,
столбец, в котором фиксируются результаты измерения
выходной величины у, и столбец с кодовыми обозначения-
ми опытов, который будет объяснен позднее. Значения Xi
и х2, устанавливаемые в отдельных опытах, и представ-
ляют собой план эксперимента.
Данный эксперимент называют полным факторным
экспериментом, поскольку в нем полностью использованы
все возможные сочетания уровней обоих факторов. Дан-
ному способу планирования присвоено условное обозначе-
ние 22 —два уровня планирования для двух факторов.
Если производится планирование на пг уровнях для п
факторов, то полный факторный эксперимент, т. е. экс-
перимент, исчерпывающий все возможные сочетания фак-
торов, обозначается тп. Мы в дальнейшем ограничимся
лишь рассмотрением случая т = 2, т. е. планированием
вида 2”.
Для отдельных опытов в факторном эксперименте ис-
пользуют специальные кодовые обозначения. В этих обо-
232
значениях указывается, какие из факторов в данном опы-
те принимают значения верхнего уровня, т. е. «+». Для
обозначения верхних уровней факторов xt и х2 исполь-
зуют буквы а и b латинского алфавита. Если рассматри-
вают большее число факторов, например х3, х4..., то для
обозначения их верхних уровней необходимы последую-
щие буквы латинского алвафита с, d... Опыт, в котором
все факторы находятся на нижнем уровне, обознача-
ют (1). С помощью этих обозначений легко написать мат-
рицу планирования просто в виде строки
(1), a, b, ab
вместо того, чтобы выписывать ее в явном виде.
Обратимся теперь к задаче о взвешивании. Легко ви-
деть, что табл. 5.3 имеет в точности тот же вид, что мат-
рица планирования 22. Следовательно, эффективное взве-
шивание явилось результатом использования матрицы пла-
нирования факторного эксперимента 22.
Остановимся на применении результатов факторного
эксперимента. В рассмотренном случае число опытов (че-
тыре) равно в точности числу неизвестных коэффициен-
тов регрессии и, следовательно, по результатам полного
факторного эксперимента можно определить все коэффи-
циенты регрессии. Однако при этом не остается степеней
свободы для проверки гипотезы об адекватности пред-
ставления объекта выбранной моделью.
Однако если есть основания предполагать, что эф-
фект взаимодействия переменных, выражаемый членом
612X1X2, незначителен, то можно положить 612 = 0 и за-
писать уравнение регрессии в виде
^=&oXo+&iXi+&2x2. (5.252)
Теперь из четырех опытов нужно определить только
коэффициенты b0, bi, Ь2 и остается одна степень свободы
для проверки гипотезы адекватности.
Перейдем к рассмотрению случая трех переменных хь
х2, х3, варьируемых на двух уровнях и, следовательно,
описываемых матрицей 23. Чтобы исчерпать все возмож-
ные комбинации, нужно поставить восемь опытов, приве-
денных в табл. 5.5, где учтены также эффекты взаимодей-
ствия XiX2, Х1Х3, Х2Х3, XiX2X3.
Вместо того, чтобы выписывать всю эту матрицу, мож-
но просто записать ее кодовое обозначение:
(1), a, b, ab с, ас, be, abc.
233
Заметим, что матрица планирования 23 получается из
матрицы планирования 22, повторенной дважды при зна-
чениях Хз соответственно на нижнем «—» и на верхнем
«-]-» уровнях. Если нужно включить четвертый фактор,
то аналогичным образом повторяют матрицу планирова-
ния для трех факторов при значениях четвертого факто-
ра на нижнем и верхнем уровнях.
Эксперимент, проведенный по матрице планирования
23, дает возможность определить восемь коэффициентов
регрессии: b0, bi, b2, b3, bt2, bl3, b23, При этом, прав-
адекватности. Однако во многих случаях эффектами пар-
ных и тройного взаимодействий пренебрегают и ограничи-
ваются линейным приближением уравнения регрессии
0=boXo-\-biXi-{-b2X2-{-b3*-3- (5.253)
При этом для проверки гипотезы адекватности остают-
ся четыре степени свободы.
Для выяснения других свойств рассмотренных матриц
планирования введем новые переменные для обозначения
парных и тройных взаимодействий, как показано в табл. 5.4
и 5.5. При этом нетрудно видеть, что значения x((Z) (зна-
чение i-й переменной в эксперименте I) обладают следу-
ющими свойствами:
V = 0, i --- 1,
/=1
2 хРхР=0, 1,/ = бД, /У=/;
(5.254)
(5.255)
234
2 (хР) 2 = n, t = 0, k. (5.256)
z=i
Последние два уравнения означают, что матрица пла-
нирования Х=[х,<г’], определяемая согласно (5.239), яв-
ляется ортогональной, т. е. удовлетворяющей условию
ХтХ=п1, (ХТХ) -' = !/«. (5.257)
В этом случае согласно (5.246) вектор коэффициентов
регрессии
В—P-XTY, (5.258)
что в развернутом виде дает
= = (5.259)
5.9.5. Понятие дробных реплик
Рассмотрим теперь более полно случай, когда прене-
брегают эффектами парных, тройных и больших взаимо-
действий, т. е. ограничиваются моделями линейного при-
ближения. В случае трех переменных моделью линейного
приближения является уравнение (5.253), содержащее
четыре неизвестных коэффициента регрессии, в то время
как полный факторный эксперимент содержит восемь опы-
тов. Поэтому имеется четыре, степени свободы для провер-
ки гипотезы адекватности.
Поскольку при линейной модели число неизвестных ко-
эффициентов регрессии n=k+l, а число опытов в полном
факторном эксперименте М=2\ то превышение числа опы-
тов над числом неизвестных резко возрастает с увеличе-
нием k. Так, при k=G имеем М=64, п—7 и число степеней
свободы /V—п=57. Очевидно, что в этих случаях можно
значительно уменьшить число опытов. Однако возникает
вопрос, какие из M=2ft опытов следует оставить, чтобы
сохранить высокую эффективность эксперимента? Ответ на
этот вопрос дает понятие дробных реплик.
Обратимся опять к задаче с тремя переменными, в ко-
торой линейные эффекты выражаются четырьмя коэффи-
циентами регрессии: Ьо, Ь\, Ь2, Ь3. Для их определения не-
235
обходимо всего четыре опыта. Что же должны быть за
опыты?
Четыре опыта можно получить, поставив полный фак-
торный эксперимент только для двух переменных, напри-
мер xi и х2, т. е. использовав планирование 22. Но посколь-
ку в каждом опыте нужно задавать еще и уровни третьего
фактора х3, то их можно найти, связав х3 cxi и х2 некото-
рым соотношением, например положив х3=х1х2. При этом
получится матрица планирования для трех факторов, пол-
ностью совпадающая с матрицей планирования 22, описы-
ваемой табл. 5.4, в которой, однако же, столбец xix2 выра-
жает уровни третьего фактора. Легко также видеть, что
эта таблица представляет собой половину табл. 5.5. Пла-
нирование эксперимента по такой матрице называют пла-
нированием типа 23-1. В этом случае планирование про-
водится для трех переменных, но в его основе лежит пол-
ный факторный эксперимент для 3—1=2 переменных.
Особенностью табл. 5.4 являтся также то, что значения,
каждой из переменных получаются как произведение зна-
чений двух других переменных
xi=x2x3; x2=xix3; x3=xix2.
Это означает невозможность, например, отличить эф-
фект xi от эффекта х2х3, т .е. что найденный коэффициент
регрессии bt будет служить совместной оценкой для Pi и
р23, что записывается в виде b\-^Pi+p23. Аналогично &2->
-^Рг+Р1з, Ьз^Рз+Р12- Оценка величин pJ2, р23, Pi3 нас не
интересует, однако если эти величины отличаются от нуля,
они скажутся на точности оценки коэффициентов рь р2, р3.
Планирование 23~‘ можно было бы осуществить иначе,
а именно спланировать полный факторный эксперимент 22
для двух переменных хь х2 и положить х3=—xix2. При
таком планировании линейные и парные эффекты будут
связаны соотношениями:
xi=—х2х3; х2=—XiX3; х3=—Х]Х2.
Коэффициенты регрессии Ь\, Ь2, &з будут в этом случае
служить оценками величин Pi—р23, р2— Р1з, Рз—Р12-
Два рассмотренных способа планирования вида 23-1
в совокупности дают полный факторный эксперимент 23.
Поэтому эти способы планирования можно рассматривать
как разбиение полного факторного эксперимента на две
половины, называемые полу репликами. Рассмотрим неко-
торые принципы, лежащие в основе такого разбиения.
236
Если бы было не три, а, скажем, пять переменных, то
для определения линейных эффектов потребовалось бы
определить шесть коэффициентов регрессии, а число опы-
тов в полном факторном эксперименте равнялось бы25=32.
Полуреплика будет содержать 25~' = 16 опытов, что также
слишком много. Очевидно, в этом случае можно ограни-
читься одной четвертью полного факторного эксперимента,
т. е. использовать так называемую четвертьреплику, обоз-
начаемую 25-2. Аналогично вводится понятие и более мел-
ких дробных реплик, обозначаемых в общем случае как
2*-z
Рассмотрим три принципа, лежащих в основе построе-
ния дробных реплик.
1. Поскольку наиболее эффективным видом экспери-
мента является полный факторный эксперимент, то в ос-
нову построения дробной реплики 2k~l положен полный
факторный эксперимент с k—I переменными хь.. .,x*_/.
2. Для определения того, какие значения в каждом из
опытов придавать оставшимся I переменным xk-i+i,..., xkt
эти переменные выражаются через основные с помощью
некоторых соотношений, называемых генерирующими соот-
ношениями. Выбор того или иного генерирующего соотно-
шения полностью определяет план эксперимента.
Для планирования 23-1 мы могли использовать одно из генери-
рующих соотношений: х3=Х|Х2, х3=—х,х2.
При планировании 24-1 полный факторный эксперимент строится
для переменных хь х2, х3. Число генерирующих соотношений, выра-
жающих х4 через хь х2, х3, здесь уже значительно больше: х4=Х|Х2,
X4=X[X3, Х4=Х|Х2Х3, х4=—х,х2 н т. д.
При планировании 25~2 генерирующие соотношения выражают пе-
ременные х4 и х5 через хь х2, х3. Возможные генерирующие соот-
ношения
х4=х,х2, х5=х,х3;
х4=х,х2, х5=х1х2х3;
Х4=Х1Х3, Х5=Х2Х3 и т. д.
3. При выборе наиболее предпочтительного генерирую-
щего соотношения следует исходить из того, что при ис-
пользовании дробных реплик мы получаем не коэффици-
енты регрессии в чистом виде, а лишь оценки для некото-
рых совместных эффектов, как было показано в примере
планирования 23-'. План эксперимента должен быть таким,
чтобы в него входили лишь те совместные эффекты, кото-
237
рые в наименьшей мере влияют на определяемые коэффи-
циенты регрессии. Чтобы выбрать наиболее подходящий
план эксперимента, необходимо уметь легко и быстро на-
ходить совместные эффекты для различных планов экспе-
римента.
Для быстрой оценки совместных эффектов используют
определяющие контрасты. Определяющим контрастом на-
зывают соотношение между переменными, которое во всех
опытах дает элементы первого столбца, т. е. 4-1.
Способ нахождения определяющих контрастов и их применения
рассмотрим для примера планирования 23-1. Обозначим вектор-столбец
элементов первого столбца через /=(1,..., 1)т.. В качестве генери-
рующего соотношения возьмем х3=Х[Х2 Умножая обе части на х3 и
учитывая, что х23=1, получаем определяющий контраст I=xtx2x3.
Умножая это соотношение последовательно на х(, х2 и х3, полу-
чаем совместные эффекты xt=x2x3; x2=XiX3; x3=xtx2, которые были
найдены ранее другим путем.
В качестве другого примера рассмотрим планирование 25-2. Основ-
ные переменные xt, х2, х3 В качестве генерирующих соотношений
возьмем х4=Х[Х2, х5=х1х2х3. Умножая эти соотношения на х4 и х5, по-
лучаем определяющие контрасты /=х1х2х4, /=х!х2х3х5. Если эти опре-
деляющие контрасты попарно перемножить, то получим третье соот-
ношение, дающее также элементы первого столбца: /=х3х4х5.
Чтобы полностью определить все совместные эффекты, введем
обобщающий определяющий контраст
1 - Х[Х2Х4 = х1х2х3х5=х3х4х5.
Для получения совместных эффектов при определении коэффици-
ента регрессии bt умножим на xt все члены полученного выражения:
х1=х2х4=х2х3х3=х1х3х4х5, что означает
b I--->- р I + р244“p23S + р 134S.
Обычно совместные эффекты от трех и четырех взаимодействий
весьма малы, поэтому можно считать, что bt—*ф1+р24.
Аналогично находим совместные эффекты и при определении дру-
гих коэффициентов регрессии.
Задачи к гл. 5
5 1. Что представляют собой события S[ и Su в примере 5.1?
5.2. Показать, что если пространство исходов эксперимента со-
держат п элементов, то в этом пространстве имеется 2” различных
событий.
5.3. На склад предприятия поступают предохранители с двух за-
водов в отношении 1 :3. Первый завод дает 10, а второй 20% брака.
538
Воспользовавшись формулой полной вероятности, определить вероят-
ность того, что случайно взятый со склада предохранитель окажется
бракованным.
5.4. Построить график функции распределения вероятностей для
числа очков, выпадающих при бросании двух игральных костей, из
примера 5.1.
5.5. Определить вероятность того, что в примере 5.8 время ожи-
дания пассажира не превысит 3 мин.
5.6 Для того, чтобы узнать, сколько рыб в озере, отлавливают
1000 рыб, метят их и выпускают обратно в озеро. При каком числе
рыб в озере будет наибольшей вероятность встретить среди вновь пой-
манных 150 рыб 10 меченых?
Глава 6
СТРУКТУРА
И МАТЕМАТИЧЕСКОЕ ОПИСАНИЕ ЗАДАЧ
ОПТИМАЛЬНОГО УПРАВЛЕНИЯ
6.1. ОСНОВНЫЕ ЧЕРТЫ ПРОЦЕССА УПРАВЛЕНИЯ
6.1.1. Понятие об управлении
Повсюду в окружающем нас мире (природе, технике,
человеческом обществе) протекают различные процессы,
характер которых зависит от множества сопутствующих
им условий и факторов. Изменяя условия протекания про-
цессов, человек может влиять на их характер, изменять их,
приспосабливать к своим целям. Это вмешательство в ес-
тественный ход процесса, изменение естественного хода
процесса и представляет собой сущность управления. Та-
ким образом, можно сказать, что управление представляет
собой такую организацию того или иного процесса, кото-
рая обеспечивает достижение определенных целей [30, 36J.
Для лучшего понимания существа процесса управления рассмотрим
пример собаки, преследующей зайца. Для того чтобы настичь зайца,
собака должна определенным образом организовать свои действия,
управлять ими. Следовательно, процесс преследования является про-
цессом управления.
Началу преследования должно предшествовать появление зайца,
т. е. создание такой ситуации, при которой возникает определенная
цель, достижение которой является или необходимым, или желатель-
23»
ным. Однако, прежде чем начать преследование, собака должна оце-
нить сложившуюся ситуацию « сопоставить ее со своими желаниями и
возможностями. Оценка ситуации завершается принятием решения о том,
следует пытаться догнать зайца или нет (заяц может оказаться да-
леко н погоня бесполезна, собака может быть утомлена и т. п.). Толь-
ко после того, как принято решение о преследовании, собака присту-
пает к организации своего движения, ставя при этом цель догнать
зайца за кратчайшее время или при наименьшей затрате сил.
В этом примере можно отчетливо различить четыре
этапа, характерные для любого процесса управления: по-
явление цели, оценка ситуации, принятие решения и ис-
полнение принятого решения. Однако этап появления цели
предшествует началу процесса управления и его исключим
из рассмотрения. Учитывая также, что при управлении
сложными процессами оценка ситуации производится на
основе собранной и соответствующим образом обработан-
ной информации, приходим к следующим трем этапам
процесса управления:
1) сбор и обработка информации с целью оценки сло-
жившейся ситуации;
2) принятые решения о наиболее целесообразных дей-
ствиях;
3) исполнение принятого решения.
Иногда бывает необходим еще четвертый этап: конт-
роль исполнения решения.
Различные виды задач управления отличаются друг от
друга способом и последовательностью выполнения этих
операций.
6.1.2. Виды задач управления
Имеется много задач, в которых механизмы сбора ин-
формации и исполнения принятого решения отработаны
настолько четко, что над ними можно совершенно не за-
думываться при осуществлении процесса управления.
В таких задачах все рассмотрение процесса управления
сводится, по существу, к рассмотрению 'только второго
этапа. Подобные задачи называют одноэтапными или од-
ношаговыми задачами принятия решения.
Однако такой подход в большинстве случаев является
идеализацией и упрощением реального процесса управле-
ния. В действительности все этапы процесса управления
находятся в тесной взаимосвязи и этап принятия решения
требует более или менее детального рассмотрения возмож-
240
них способов реализации принятого решения. Так, для
принятия решения об отказе от преследования зайца нуж-
но убедиться, что преследование бесполезно, а для этого
нужно хотя бы грубо проанализировать возможные спосо-
бы преследования.
Иногда в подобных случаях процесс управления разби-
вают на несколько последовательных шагов, причем реше-
ние, принимаемое на каком-либо шаге, зависит от резуль-
татов выполнения решения предыдущего шага. Такие
процессы называют многошаговыми процессами принятия
решения. Примером может служить процесс управления
ракетой при запуске ее с Земли на Луну. Здесь можно
выделить следующие шаги: вывод ракеты на околоземную
орбиту, организация движения ракеты в направлении Лу-
ны, перевод ракеты на окололунную орбиту, прилунение.
В данном примере отдельные шаги многошагового про-
цесса управления получились вполне естественно. Однако
во многих случаях разбиение сложного процесса управле-
ния на шаги с четким выделением всех этапов управления
на каждом шаге оказывается весьма трудной задачей. Так,
в процессе преследования зайца приходится иметь дело
с непрерывно меняющейся ситуацией, вызванной стремле-
нием зайца уйти от преследования. Собака должна непре-
рывно оценивать эту ситуацию и принимать все новые и
новые решения, сообразуясь с изменяющейся ситуацией и
не ожидая окончательных результатов выполнения преды-
дущих решений. В подобных задачах сталкиваемся
с непрерывными динамическими процессами управления.
Из рассмотренного видно, насколько сложными и раз-
нообразными могут быть задачи управления. Однако в зна-
чительной степени недооценим трудность решения этих
задач, если не учтем того обстоятельства, что процессы
управления протекают, как правило, в сложной окружаю-
щей обстановке. На протекание процессов управления ока-
зывают влияние разнообразные внешние факторы, сово-
купность которых часто называют состоянием природы.
Для того чтобы принять правильное решение о тех или
иных действиях, нужно оценить результаты этих действий,
а для этого необходимо знать характер ситуации, в кото-
рой эти действия предпринимаются.
Однако типичным для задач управления является слу-
чай, когда имеющаяся информация бывает или недоста-
точна для точной оценки ситуации, или искажена посто-
ронними факторами. Тем не менее недостаточность инфор-
16-804 241
мации не снимает задачи принятия решения. Особенность
задач управления именно в том и состоит, что решение
должно быть обязательно принято независимо от того,
в состоянии ли мы точно оценить результаты, к которым
приведет принятое решение.
Таким образом, в процессе управления возникает важ-
ная задача принятия решения в условиях, когда информа-
ция о сложившейся ситуации пли недостаточна, или иска-
жена. Данная задача получила название задачи- принятия
решения в условиях неопределенности.
6.1.3. Понятие об исследовании операций
Отметим еще одни специфический класс задач управления, кото-
рые связаны с деятельностью крупных промышленных предприятий и
могут быть названы задачами организационно-управленческого харак-
тера [31, 32].
До промышленной революции руководство мелким предприятием
мог осуществлять всего одни человек, который делал закупки, плани-
ровал и направлял работу, сбывал продукцию, нанимал и увольнял
рабочих. При небольших размерах предприятия он мог принимать орга-
низационные решения, не прибегая к каким-либо научным методам и
базируясь на своих знаниях, опыте, интуиции. Если некоторые из при-
нятых решений были! не наилучшимн, то они или не приводили к
большому ущербу, или могли быть быстро исправлены.
Укрупнение промышленнх предприятий сделало невозможным осу-
ществление административных функций одним человеком. Появились
руководители производственных отделов, отделов сбыта, финансовых
отделов, отделов кадров и др. Усиливающаяся механизация и автомати-
зация производства привела к дальнейшему расчленению административ-
ных функций. Так, производственные отделы оказались разделенными на
более мелкие группы, занимающиеся вопросами эксплуатации и ремон-
та, контроля качества, планирования, снабжения, хранения готовой
продукции и т. п.
Каждое отдельное специализированное подразделение крупной
организации выполняет определенную часть общей работы, руковод-
ствуясь общими целями предприятия. Однако у каждого специализи-
рованного подразделения возникают и свои собственные цели. Все эти
цели не всегда согласуются, а иногда приходят в противоречие друг
с другом.
В качестве примера можно рассмотреть проблему обеспечения
предприятия запасами. Отдельное подразделение может быть заинте-
ресовано в значительном увеличении запасов на складе для обеспе-
чения бесперебойного выпуска своей продукции. Но при ограниченном
242
объеме складских помещений это приводит к снижению запасов для
других подразделений. В результате возникает задача организационно-
управленческого типа — выработка такой стратегии в отношении за-
пасов, которая была бы наиболее благоприятна для всего предприя-
тия в целом.
При решении подобного рода организациоино-управлеических за-
дач необходимо очень тонкое понимание целей отдельных подразделе-
ний и такое их согласование, чтобы они не приходили в противоречие
ни друг с другом, ни с общими целями всего предприятия. Если при
этом учесть, что принятие не иаилучших решений в условиях крупного
предприятия может принести немалый ущерб, то становится ясно, что
при решении организационно-управленческих задач оказывается недо-
пустимым базироваться только на личном опыте и здравом смысле.
Необходимы научные методы.
Разработкой научных методов решения организационно-управленче-
ских задач занимается научная дисциплина, получившая название
исследование операций. Под операцией понимается некоторое органи-
зационное мероприятие, проведение которого преследует определенную
четко сформулированную цель, например регламентацию хранимых на
складе запасов. Должны быть заданы условия, характеризующие об-
становку проведения мероприятия, в частности потребности в запасах
и ограничения на складские помещения в рассмотренном примере.
Целью исследования операций является нахождение и научное обосно-
вание таких способов проведения мероприятия, которые в некотором
смысле являются наиболее выгодными.
Специфическая особенность задач организационно-управленческого
типа состоит в том, что последствия того или иного способа их ре-
шения могут существенно отразиться иа работе всего предприятия.
Поэтому принятие окончательного решения всегда относится к ком-
петенции ответственного лица, администратора, наделенного соответ-
ствующими правами, и выходит за рамки исследования операций.
Исследование операций преследует лишь цель дать в руки администра-
тору обоснованные рекомендации по принятию решения.
Таким образом, исследование операций представлиет собой на-
учное направление, целью которого являются разработка методов
анализа целенаправленных действий (операций) и объективная срав-
нительная оценка возможных решений Хотя исследование операций
представляет собой самостоятельное научное направление, при реше-
нии отдельных задач оно широко применяет методы кибернетики.
6.2. ОПТИМИЗАЦИЯ ПРОЦЕССА УПРАВЛЕНИЯ
6.2.1. Критерий качества управления
Задачу управления будем в дальнейшем рассматривать
как математическую. Однако в отличие от многих других
математических задач она имеет ту особенность, что до-
пускает не одно, а множество различных решений [33].
Это связано с тем, что в задачах управления имеется, как
правило, много способов организации какого-либо процес-
са, которые приводят к достижению поставленной цели.
Так, в процессе погони за зайцем собака может по-разно-
му организовать характер своего движения, при запуске
ракеты на Луну можно выбирать различные траектории
для полета ракеты и т. п. Поэтому задачу управления
можно было бы ставить как задачу нахождения хотя бы
одного из возможных способов достижения поставленной
цели. Однако такая постановка вопроса обычно бывает
недостаточна.
Если имеется множество решений какой-либо задачи,
то следует вести речь о выборе такого решения, которое
с какой-либо точки зрения является наилучшим. Можно
привести много примеров подобных задач. Так, имеется
много способов для склеивания коробки из листа картона
заданных размеров. Решением этой задачи следует считать
получение коробки максимальной вместимости. Из одного
города в другой можно приехать, пользуясь различными
видами транспорта: воздушным, водным, автобусным, ав-
томобильным. Решением задачи будет выбор наиболее
выгодного вида транспорта с точки зрения времени проез-
да, стоимости, удобств и т. п. Аналогичное положение име-
ет место в задачах управления.
В тех случаях, когда цель управления может быть до-
стигнута несколькими различными способами, на способ
управления можно наложить добавочные требования, сте-
пень выполнения которых может служить основанием для
выбора способа управления.
Во многих случаях реализация процесса управления
требует затрат каких-либо ресурсов: времени, материалов,
топлива, электроэнергии. Следовательно, при выборе спо-
соба управления следует говорить не только о том, дости-
гается ли поставленная цель, но и о том, какие ресурсы при-
дется затратить для ее достижения. В этом случае задача
управления состоит в том, чтобы из множества решений,
244
обеспечивающих достижение цели, выбрать одно, которое
требует наименьшей затраты ресурсов.
В других случаях основанием для выбора способа управ-
ления могут служить иные требования, налагаемые на
систему управления: стоимость обслуживания, надежность,
степень близости получаемого состояния системы к тре-
буемому, степень достоверности знаний о состоянии при-
роды и т. п.
Математическое выражение, дающее количественную
оценку степени выполнения наложенных на способ управ-
ления требований, называют критерием качества управле-
ния. Наиболее предпочтительным или оптимальным спо-
собом управления будет такой, при котором критерий
качества управления достигает минимального (максималь-
ного) значения. При выборе, например, режима полета за
критерий качества управления можно принять или выра-
жение для количества топлива, расходуемого на единицу
пути, или путь, проходимый за счет единицы топлива. Наи-
более экономичному, т. е. оптимальному, режиму будет
соответствовать минимальное (максимальное) значение
критерия качества управления.
Приведенное определение оптимального управления
будем рассматривать как предварительное. Более строгое
определение будет дано после рассмотрения ограничений,
налагаемых на процесс управления.
6.2.2. Ограничения, накладываемые на процесс
управления
Задачу нахождения оптимального управления или
управления вообще следует считать несуществующей, если
на характер движения системы не наложено никаких огра-
ничений. Так, проблемы погони за зайцем вообще не су-
ществовало бы, если бы собака могла мгновенно преодо-
леть расстояние, отделяющее ее от зайца. Следовательно,
при решении задачи управления нельзя не считаться с тем
обстоятельством, что движение любой системы всегда под-
вержено различного рода ограничениям.
Для более ясного представления о встречающихся ог-
раничениях рассмотрим конкретный пример управления
автомобилем. Осуществляя процесс управления, водитель
должен считаться с тем, что автомобиль имеет ограничен-
ную мощность двигателя, а значит, может вести лишь
245
ограниченный груз с ограниченной предельной скоростью.
Благодаря инерционности скорость автомобиля и направ-
ление движения могут изменяться лишь с ограниченным
ускорением. Это означает невозможность мгновенной оста-
новки или мгновенного изменения направления движения
в случае возникновения непредвиденной опасной ситуации
и в свою очередь ограничивает скорость движения. При
выборе маршрута водитель вынужден считаться с ограни-
ченным запасом горючего в баке и необходимостью попол-
нения этого запаса в пути и т. п.
В общем случае имеются два вида ограничений иа вы-
бор способа управления [30]. Ограничениями первого вида
являются сами законы природы, в соответствии с которы-
ми происходит движение управляемой системы. При мате-
матической формулировке задачи управления эти ограни-
чения представляются обычно алгебраическими, диффе-
ренциальными или разностными уравнениями связи. Вто-
рой вид ограничений вызван ограниченностью ресурсов,
используемых при управлении, или иных величин, которые
в силу физических особенностей той или иной системы не
могут или не должны превосходить некоторых пределов.
Математически ограничения этого вида выражаются обыч-
но в виде систем алгебраических уравнений или нера-
венств, связывающих переменные, описывающие состоя-
ние системы.
6.2.3. Постановка задачи оптимального управления
Задачу управления можно считать сформулированной
математически, если: сформулирована цель управления,
выраженная через критерий качества управления; опреде-
лены ограничения первого вида, представляющие собой
системы дифференциальных или разностных уравнений,
сковывающих возможные способы движения системы;
определены ограничения второго вида, представляющие
собой систему алгебраических уравнений или неравенств,
выражающих ограниченность ресурсов или иных величин,
используемых при управлении.
Способ управления, который удовлетворяет всем по-
ставленным ограничениям и обращает в минимум (макси-
мум) критерий качества управления, называют оптималь-
ным управлением.
246
6.3. МАТЕМАТИЧЕСКОЕ ОПИСАНИЕ ОБЪЕКТА
УПРАВЛЕНИЯ
6.3.1. Производственно-экономические модели
Математические модели, позволяющие вести анализ н планирова-
ние производственной деятельности отдельных предприятий, отраслей
промышленности и всего народного хозяйства в целом, называют
производственно-экономическими моделями.
Производственный процесс можно рассматривать как многополюс-
ную систему, имеющую разнообразные входы, которые можно разбить
на следующие группы: X — технологические входы, представляющие
собой предметы труда (сырье, материалы, полуфабрикаты и т. п.);
R — средства труда (станки и прочее оборудование, служащее для
обработки предметов труда); L —живой труд, т. е. люди, участвую-
щие в производстве.
Выходом V производственного процесса является выпуск готовой
продукции.
Зависимость выхода от входов называют производственной функ-
цией и в общем виде
V=F(X, L, R). (6.1)
Вид этой зависимости может быть весьма разнообразным и зави-
сит от конкретных целей исследования. Ограничимся рассмотрением
простейшего вида этой зависимости, называемой линейной производ-
ственной функцией, при которой выход модели линейно зависит от
входов. Следует иметь в виду, что в любом реальном производствен-
ном процессе каждая группа входов, так же как и выход, будут пред-
ставлять собой многокомпонентные, т. е. векторные, величины
Введем в рассмотрение коэффициенты
alj = yi/vi< blj = li/vl\ hij = rllvj, (6.2)
определяющие размер затрат i-ro ресурса X, L или R иа производ-
ство единицы /-го продукта. Совокупности этих коэффициентов удобно
представить в виде следующих матриц: А= [а,;] — материальных за-
трат; В =[/>,/]—трудовых затрат; Н= [Л,;] —производственных мощ-
ностей.
Прн этом линейная производственная функция запишется в виде
трех матричных соотношений.
X=AV; L=BV; R=HV. (6.3)
247
Однако в этой модели не учтена цель производства, которой яв-
ляется удовлетворение потребностей, т. е. потребление. Цель плани-
рования производственной деятельности — достижение определенного
баланса между производством и потреблением, что выражается в со-
ставлении балансовых уравнений, описывающих многопродуктовые
модели производства. Такие модели могут быть статическими, когда
производственный процесс предполагается неизменным на протяжении
длительного времени, или динамическими, предполагающими непре-
рывный рост и усовершенствование производства. Коснемся кратко
обоих этих типов моделей
Статическая многопродуктовая модель. Рассмотрим случай, когда
имеется и производств, выпускающих п видов продукции . ., vn
Каждый вид продукции v, расходуется на потребление с интенсивно-
стью w, и на производство как данного, так и других видов продук-
ции с интенсивностью х„ что может быть записано в виде балансово-
го уравнения
vt=wt-\-xi, i=l,.. , п (6.4)
При линейной модели расход х// продукции вида i в /-м произ-
водстве будет пропорционален выпуску /-й продукции, так что
п п
*<7 = 2 «<Л7. i = », -, «•
/=1 /=1
В соответствии с этим совокупность балансовых уравнений для
всех п производств
VI —2 aHvi = i = 1.........«• (6.5)
/=1
Эти уравнения можно записать более компактно, если ввести в
рассмотрение вектор потребления w=(ttii,.... wn)T и матрицу коэф-
фициентов
1——«и ... —aw
С = ““«21 1- «22 •• -«2» (6 6)
_ —«Л1 —«712 ••• > —«ПЛ.
При этом систему уравнений (6.5) запишем в виде одного матрич-
ного уравнения
CV=W. (6.7)
Разрешая (6.7) относительно вектора V, можем найти интенсив-
ности выпуска продукции, обеспечивающие заданное потребление
V=C-‘W, (6.8)
248
или, обозначая через ач элементы обратной матрицы С"1, в развер-
нутом виде
VI = 2 “0-7, I = 1....П. (6.9)
/=1
Для обеспечения выпуска продукции с интенсивностями, определяе-
мыми соотношениями (6.9), необходимы затраты средств производства
в количествах
ь^' r=2 ^=2 hi°i- <6-10*
i=1 1=1 1=1 (=1
Поскольку, однако, конечной целью производства является потреб-
ление, то величины L и R удобно выражать не через интенсивности
производства выпускаемой продукции о/, а через интенсивности по-
требления w:, введя коэффициенты полной трудоемкости и фондоемко-
сти соответственно:
h.j=Rjlwi. (6.11)
Связь между коэффициентами bi, hi и Б;, Я/ легко установить, под-
ставив в (6.10) значения Vi из (6.9). При этом получаем
L = 2 ^2 “«/^/=2 bjWj, (6.12)
i=i /=1 /=1
где
*/=2“^- (613)
Аналогично
В реальных ситуациях не всегда удается удовлетворить соотноше-
ниям (6.12) и (6.14), поскольку трудовые ресурсы и ресурсы обору-
дования бывают ограниченными. Если ресурсы рабочей силы ограни-
чены величиной £0. а ресурсы оборудования — величиной Ro, то соот-
ношения (6.12) и (614) должны быть заменены неравенствами
2 № < £0; 2 [hwi<R^ (6-15)
249
причем на v, и ни, накладываются ограничения неотрицательности этих
величин
i=l,..., п. (6.16)
Будем также считать, что выпускаемые виды продукции являются
полностью взаимозаменяемыми, и обозначим через р, цену или обще-
ственную полезность i-ro продукта При этом можно сформулировать
задачу оптимального планирования производства, поставив в качестве
цели нахождение таких интенсивностей выпуска продукции, при кото
ром общая ценность выпускаемой продукции
п
f(^i....wn)=^plWl (6-17)
будет максимальна Эта задача решается методами линейного програм-
мирования.
Динамическая многопродуктовая модель. Статические модели не
отражают важнейшего фактора общественного производства, его не-
прерывного развития и усовершенствования. Модели, учитывающие
развитие производства, называют динамическими моделями.
Внутренними силами, обусловливающими развитие производства,
являются капитальные вложения. Последние создаются за счет про-
изведенного продукта V и образуют его накапливаемую часть — фонд
накопления. Остальная часть продукта составляет фонд потребления
Фонд накопления условно разбивают на две части. Первая чвсть
Нп составляет производственные фонды, расходуемые на увеличение и
усовершенствование средств производства. Вторая часть /7И направ-
лена на повышение информационного потенциала общественного про-
изводства, куда входят капитальные затраты на развитие науки и
образования.
Воздействие капитальных затрат происходит всегда с запаздыва-
нием относительно момента их вложения. Капитальные затраты на рас-
ширение производственных фондов HR реализуются, как правило,
с меньшим запаздыванием, но имеют и меньшую отдачу. Затраты на
развитие науки н образование реализуются с большим запаздыванием,
но в корне меняют характер производства и обеспечивают его непре-
рывное совершенствование
В дальнейшем с целью упрощения будем рассматривать единый
фонд накопления Н и считать, что эффект от капиталовложений реа-
лизуется без запаздывания Обозначим через gift) интенсивность про-
дукта, идущего в фонд накопления в i-м производстве. Уравнение ба-
ланса для i-го производства запишем в виде
и, (0=ю, (/)+*, (/)+£,(/). (6.18)
250
Согласно| (6.18) производственный продукт vt расходуется на по-
требление с интенсивностью Wt, иа воспроизводство с интенсивностью
xt и на увеличение производственных фондов с интенсивностью gi.
Обозначая через Xi, интенсивность расходования продукта i на воспро-
изводство продукта /, а через gn интенсивность расходования продук-
та i на капитальные вложения в производство продукта /, получаем
п п п
Х1 = 3 xl/ = 3 a4vl’ Si = 3 Sir (6-19)
/=1 /=1 /=1
Для того, чтобы увязать расход продукта на увеличение про-
изводственных фондов с ростом выпуска продукции, необходимо слить
воедино два процесса: процесс образования производственного фонда
Hi, и процесс его расходования. Рассмотрим приращение производ-
ственного фонда за малый интервал dt. Это приращение про-
порционально интенсивности накопления gi/(t) и интервалу dt:
dHtitt^cugt^dt. (6.20)
Расходование производственных фондов идет на усовершенствова-
ние используемого оборудования Ru(t) =hijvl, поэтому
dHti(t)=dRti(t)=hudvi(t). (6.21)
Сопоставляя (6.20) и (6.21), находим cugu(t)dt=ht/dv/(/), откуда
&1/(/)=М«/(0/Л. (6-22)
где kiF=hiilc,i — коэффициент удельных капиталовложений, называе-
мый также коэффициентом капиталоемкости.
С учетом (6.19) и (6.22) уравнения баланса (618) запишем
в виде
п п
VI (0-3 a4v! (О “3 k4dvi Wdt = “7(0. i = 1. «• (6.23)
/=1 /=1
Решить полученную систему уравнений чрезвычайно трудно в си-
лу очень большого числа входящих в это уравнение неизвестных. До-
бавочные трудности вызывает необходимость учета ограничений (6.15)
на трудовые ресурсы и ресурсы оборудования, а также условия (6.16)
неотрицательности переменных. Останавливаться на методах решения
данной системы уравнений не будем [35].
6.3.2. Структура объекта управления
Рассмотренные в предыдущем параграфе производст-
венно-экономические модели позволяют решать многие за-
дачи планирования производства. Однако планирование
251
является лишь одним из этапов процесса управления. Дру-
гой этап — реализация составленного плана, представляю-
щая собой процессы управления конкретными технологи-
ческими и производственными объектами. Для решения
этой задачи нужно иметь более детальное описание кон-
кретных объектов управления (ОУ), выражаемое соответ-
ствующими математическими моделями.
Ту физическую систему, процессами в которой управ-
ляем, будем называть объектом управления. Объекты
управления могут быть весьма разнообразны и иметь са-
мую различную физическую природу: технические устрой-
ства (автомобиль, самолет, ракета, токарный станок и
т. п.); производственные предприятия (отдел, цех, завод,
отрасль промышленности); экономические системы (эко-
номика предприятия, экономика отрасли промышленности,
экономика государства); биологические системы; социаль-
ные системы и т. д.
То обстоятельство, что закономерности, которым под-
чиняются процессы управления, являются общими для объ-
ектов управления любой физической природы, позволяет
рассмотреть общую структуру и дать общее математиче-
ское описание процесса управления.
Обозначим через х переменную, определяющую состоя-
ние ОУ. Иногда она является одномерной или скалярной
величиной. Это могут быть угол поворота вала двигателя,
скорость самолета или ракеты, давление пара в котле
паровой машины, количество предметов на складе, число
самолетов, базирующихся на аэродроме, и т. п.
Однако в большинстве случаев для описания ОУ тре-
буется не одна, а несколько переменных х(1),.. ,,х(п). При
описании механических систем величины х(£) представляют
собой координаты или скорости движущихся частей; элек-
трических систем — ток или напряжение; в экономике про-
изводственные мощности или ресурсы отдельных отраслей
промышленности; в биологической системе величины x(Z)
могут характеризовать концентрацию химических веществ
или лекарств в различных органах.
В этих случаях состояние объекта будет описываться
многомерной переменной х=(х(1), ..., х(,1)), которая далее
будет рассматриваться как точка в пространстве Rn. Пе-
ременную х будем называть переменной или вектором со-
стояния объекта управления. Величины х(<), а значит, и
вектор х, как правило, не могут принимать любые значе-
ния. Множество допустимых значений переменной х обо°-
252
начают через X и называют допустимым множеством или
пространством решений, подчеркивая тем самым, что вы-
бор некоторого хе^ представляет собой возможное реше-
ние задачи управления.
Если величины х(г) принимают конечное множество зна-
чений, то допустимое множество X также будет конечным
и имеет вид -V={x,......xw}, где xft=(x*<1>, ...,х*<л>)т, k=
=A,N.
Если величины х(,) могут изменяться непрерывно, т. е.
принимают бесконечное множество значений, то допусти-
мое множество X будет бесконечным множеством. Однако
и в этом случае значения обычно не могут быть каки-
ми угодно. На них накладываются ограничения, которые,
как уже отмечалось, обычно имеют вид алгебраических
уравнений или неравенств:
\<bh
f{ (tf1), ..., x<n>) = bh i = 1, m, (6.24)
1>6Z.
В каждом из ограничений (6.24) сохраняется только
один из знаков = или однако разные ограничения
могут иметь и разные знаки. Величины тип между собой
не связаны, так что т может быть больше, меньше или
равно п. В частности, т может быть равно нулю, так что
не исключается случай, когда ограничения (6.24) отсутст-
вуют. Часто некоторые или все переменные х(,) удовлет-
воряют условию неотрицательности
Условие неотрицательности переменных оказывается
весьма удобным при численном решении уравнений, опи-
сывающих процесс управления. Кроме того, во многих
задачах, например экономических, величины х(<) не могут
быть отрицательными по своему физическому смыслу
(затраты, выпуск продукции, объемы перевозимых товаров,
размещенные различным образом суммы денег и т. п.).
Однако и задачи, в которых переменные могут быть про-
извольного знака, т. е. удовлетворяют ограничениям вида
i=\,n,
где а,— произвольные числа, легко преобразуются в за-
дачи с неотрицательными переменными путем введения
новых переменных —at.
253
Состояние ОУ не только зависит от переменной х, ко-
торую будем далее считать доступной измерению и конт-
ролю, но и от множества неконтролируемых или не пол-
ностью контролируемых факторов, определяемых совокуп-
ностью внешних условий, в которых находится объект
управления. Такими факторами могут быть состав сырья,
случайные возмущения внешней среды, вибрации и т. п.
В технике подобные факторы называют возмущениями.
Летчик, например, может регулировать режим самолета
путем изменения высоты и скорости полета, которые явля-
ются в данном случае контролируемыми параметрами.
Однако на расход топлива в значительной степени влияют
внешние атмосферные условия, которые летчик может
лишь частично принимать во внимание, но на которые не
может активно воздействовать и даже точно их предви-
деть.
Полную совокупность неконтролируемых внешних фак-
торов, оказывающих влияние на процесс управления, бу-
дем 'называть состоянием природы и обозначать через Ф.
Во многих случаях путем некоторой идеализации реаль-
ных явлений удается свести все бесчисленное многообра-
зие внешних условий к конечному числу возможных состо-
яний природы .......©l.t. е. ввести в рассмотрение конечное
множество 0= {&!,...,&/.}, называемое пространст-
вом состояний природы. Элементы й, множества 0 в об-
щем случае являются______многомерными величинами
= (&,(!)...i=l, L.
Невозможность полного контроля всех внешних факто-
ров приводит к тому, что вместо точного знания состояния
природы О во многих случаях приходится ограничиваться
лишь знанием вероятностей £(&) различных состояний
природы ФеО. Вероятности £(&), полученные тем пли
иным путем для всех *&е0 до начала решения задачи
управления, будем называть априорными вероятностями
состояний природы. Естественно, что априорные вероятно-
сти £(&), представляющие собой распределение вероятно-
стей на пространстве 0, должны удовлетворять условиям
(5.3).
В ряде случаев состояние природы & необходимо рас-
сматривать как непрерывную случайную величину, для
которой пространство состояний природы 0 представляет
собой бесконечное множество. В таких случаях распреде-
ление вероятностей £(&) превращается в плотность веро-
ятности.
254
Для описания целенаправленного воздействия на ОУ
введем переменную и, которую будем называть управляю-
щим воздействием или просто управлением. Таким обра-
зом, слово «управление» будет в дальнейшем использо-
ваться в двух смыслах: 1) управление как организацион-
ная деятельность, направленная на достижение
определенных целей; 2) управление в смысле управляю-
щего воздействия, т. е. некоторой физической величины,
изменение которой производится по нашему желанию и
которая воздействует на характер процессов в ОУ, изменяя
их в нужном направлении.
Конкретный смысл, в котором используется слово
«управление» в различных случаях, бывает ясен из кон-
текста.
При управлении сложными объектами обычно прихо-
дится использовать несколько управляющих воздействий
и(1),..., и(г), так что управление и представляет собой в об-
щем случае многомерную величину и=(и(1), ..., u(r) )т. Так,
летчик может менять режим полета, применяя управление
и, состоящее из воздействия на количество расходуемого
топлива (и(1)) и руль высоты (ы<2>).
Управляющие воздействия и<‘> в реальных системах не
могут быть взяты какими угодно, а подвержены различ-
ного рода ограничениям. Обозначим через U множество
всех значений управления и, которые удовлетворяют по-
ставленным ограничениям. При этом любое u^U будет
допустимым управлением. В дальнейшем часто встречают-
ся задачи, в которых множество допустимых управлений U
является конечным множеством
и={щ, (6.25)
Судить о том, насколько примененное управление и
обеспечивает достижение поставленных целей, можно по
значениям переменных состояния х. Однако во многих
случаях это оказывается неудобным, так как цели управ-
ления могут выражаться через переменные состояния до-
статочно сложным образом. Поэтому наряду с переменны-
ми состояния х удобно ввести в рассмотрение выходные
переменные q, выражающие цели управления в явном
виде.
Иногда в качестве выходной переменной может быть
использована какая-либо из переменных состояния. Но
в общем случае это не так. Например, при управлении
режимом полета с целью минимизации расхода топлива на
255
Рис. 6.1. Структура объекта
управления
заданном маршруте за выход-
ную переменную удобно взять
путь, пройденный за счет еди-
ницы топлива, тогда как пере-
менными состояниями будут
скорость и высота самоле-
та. Выходными переменными
могут быть не только физи-
ческие величины, но и экономические показатели, напри-
мер КПД и т. п. В частности, критерий качества управле-
ния также может быть выходной переменной.
Выходная переменная q зависит в первую очередь от
состояния объекта управления х. Однако на нее могут
оказывать влияние используемое управление и и внешние
неконтролируемые факторы &. Следовательно, уравнение
для выходной переменной в общем случае имеет вид
q=q(n, и, •&). (6.26)
Взаимодействие всех рассмотренных выше переменных
можно наглядно представить в виде структуры объекта
управления (рис. 6.1).
6.3.3. Уравнения движения объекта управления
Под действием сигналов управления и объект управле-
ния изменяет свое состояние. Характер происходящих при
этом процессов определяется скоростью изменения пере-
менной состояния объекта x=dx/d/, которая представляет
собой многомерную величину
х=(х(»,...,х<л))т, (6.27)
где х(<), i=l, п — скорости изменения компонент многомер-
ной переменной X.
Для динамических систем, в которых физические про-
цессы протекают непрерывно во времени, скорости х(‘>
в какой-либо момент времени зависят от состояния ОУ
в тот же момент времени, которое в свою очередь опреде-
ляется значениями переменной состояния х, состоянием
природы & и используемым управлением и. Эту зависи-
мость можно записать в виде системы обыкновенных диф-
ференциальных уравнений
х(‘)=^(х, u, fl), x«>(0)=c„ i=\7n, (6.28)
где с„ i=l,п характеризуют начальное состояние ОУ.
256
Иногда бывает удобно использовать векторные обозна-
чения и заменить систему (6.28) одним уравнением
x=g(x, и, &), х(0)=с, (6.29)
где c=(ci,..., с„)т; g=(gi,gn)r — векторная функция.
Выходные переменные q обычно бывают связаны с пе-
ременными состояния алгебраическими уравнениями
7=Дх). (6.30)
Если рассматривается статический режим, то х=0 и
модель ОУ принимает вид
g (х, и, ^)=0. (6.31)
Введение переменной в качестве аргумента в уравне-
ние (6.29) в ряде случаев оказывается неудобным, так как
на протяжении одного процесса управления состояние при-
роды часто остается неизменным. Однако для разных про-
цессов управления состояние природы может быть раз-
личным, что проявляется в изменении вида уравнения дви-
жения. Эту зависимость вида уравнения от состояния при-
роды удобнее отмечать просто индексом •& при функции g
и записывать уравнение (6.29) как
x=ge(u, х), х(0)=с. (6.32)
Если состояние природы не меняется на протяжении
всех рассматриваемых процессов управления, то индекс О
можно не указывать.
6.3.4. Линейные модели динамических систем
Поскольку входящие в уравнение (6.28) переменные
х(/), и(/) и &(<) являются многомерными, т. е. векторны-
ми величинами, то уравнение (6.28) является векторным,
а следовательно, достаточно сложным. Положение усугуб-
ляется, если g — нелинейная функция. Поскольку методы
решения подобных векторных дифференциальных уравне-
ний хорошо разработаны лишь для линейных систем, огра-
ничимся рассмотрением только линейных динамических
моделей ОУ, предполагая, что если функция g нелинейна,
то ее можно линеаризовать.
Для линейной функции g дифференциальное уравнение
(6.28) можно представить в векторной форме
х(0 =F(0 х (0 + G (/) и (/) +Г(/Н(0 • (6.33)
17—804 257
Здесь F((), G(t), Г(0 — матрицы преобразования, элемен-
ты которых в общем случае могут быть функциями време-
ни. Если ОУ является стационарным, т. е. не меняет своих
•свойств с течением времени, то матрицы F, G, Г будут по-
стоянными.
Для наблюдения за поведением ОУ установлены дат-
чики, дающие численную оценку всех или некоторых из
переменных состояния. Выходные сигналы датчиков мож-
но описать матричным уравнением
z(/)=Hx(0+v(/), (6.34)
Рис. 6.2. Структура линейной динамической системы
где z(/)—вектор измерения; Н — матрица, связывающая
вектор состояния с вектором измерения; v(t) —вектор
ошибок наблюдения, которые часто называют помехой.
Структура линейной непрерывной системы приведена
на рис. 6.2.
Пример 6.1. Управление самолетом по углу рыскания.
Предположим, что осевая линия самолета под действием порывов
ветра отклонилась от заданного направления у иа угол 0 (рис. 6.3).
Возвращение самолета на заданный курс осуществляется с помощью
руля, отклонение которого равно <р. Предполагается, что относительно
осн, проходящей через центр тяжести ЦТ, самолет имеет момент
инерции Л Восстанавливающая сила руля пропорциональна <р, вязким
трением о воздух пренебрегаем.
Уравнение движения запишем по второму закону Ньютона
je=-k<p(0+m(0.
где k<p(0 — восстанавливающая сила; m(t) — момент, вызванный по-
рывами ветра. Разделив это уравнение на I и обозначив 6=—k/J,
/I, а также принимая <р(0 за управляющее воздействие
и(0, получаем 0 = 6и(0-j-'&f/).
258
Вводя в рассмотрение переменные состояния Xi=0, x2=0=xi, при-
ходим к двум дифференциальным уравнениям первого порядка
xi=x2; x2=bu(t) +•&(/),
которые в векторной форме запишем так
приходим к векторному дифференциальному уравнению вида (6.33):
x=Fx(/) + G«(/)+r'&(/).
Считая, что на борту самолета есть приборы, измеряющие откло-
нение по углу рысканья 0=х и скорость его изменения 0=х2, и обо-
значая показания приборов Z] и z2, а ошибки измерения £2, полу-
чаем уравнения измерений
Z| = Х1 + £|, Z2 = X2 + b>
которые перепишем в виде одного векторного уравнения (6.34):
z=Hx+v,
Пример 6.2. Уравнение двигателя постоянного тока с управлением
по цепи якоря (рис. 6.4).
Обозначим: Й — скорость якоря; I — момент инерции вращающих-
ся частей; Мс — момент сопротивления; MBp=kiR — момент вращения;
СО — момент вязкого трения. Уравнение движения вала двигателя за-
пишем по второму закону Ньютона
JQ = kin—Сй—Мс.
17*
259
По второму закону Кирхгофа определим силу тока в цепи якоря:
u=inRn+Lndia/dt+ea, ея=£ей
или
Lndin/dt=—keQ—1’я/?я4~и.
Введя обозначение 0=й, эти уравнении приведем к виду
J0=-C0+fciH-Mc;
Lndinldt=—ke9—</?я?я+и.
Рис. 6.4. Двигатель постоянного тока о управлением по цепи якоря
Разделив первое уравнение на J, а второе на La и обозначив ft =
=—C/J; 72=й//; О=-ЛГс//; f3=—f4=—R„/Ln; a=l/L„, по-
лучим
0=ft0+fiin +Ф; dia/dt=f3Q-[-fiin +au.
Введем в рассмотрение переменные состояния *t = 0, x2=ff=xi,
х3=«я> запишем полученные уравнения н виде трех дифференциальных
уравнений первого порядка
xt=x2; x2=fIx2+f2x3+'O'; x3=f3x24-f4x3+<i«.
Эта система может быть записана в виде одного некторного уравнения
(6.33):
x=Fx-}-GM+r0,
где
,=гпг_р UU-Ш, r-i;i
L 1 Lo f3 fd L a J L 0 J
Для наблюдения за работой двигателя используем амперметр А
в цепи якоря и датчик угла 0 на выходном валу. Обозначая показания
измерительных приборов zIt z2, а ошибки измерения g2, результаты
измерений запишем в виде
Zt=Xt~j-|b 2г=Хз-|-?2
или
z=Hx-pv,
260
где
6.3.5. Дискретные линейные системы
При использовании ЭВМ управление процессами обыч-
но производится в дискретные равноотстоящие моменты вре-
мени tn=nT0, где То — период квантования по времени,
принимаемый далее за единицу. Заменяя в (6.33) х(0,
и(/) и -6(0 на х„, и„ и &„, a x.(t)=dx(t)/dt на Дх,г/7’о=
=Дх„=Хп+1—х„, запишем это дифференциальное уравне-
ние в виде разностного уравнения
х„+1=Ф [n] Xn+G [n] u„4-r [п] &„, (6.35)
где
ф[и] = 1+Р[п]. (6.36)
Уравнение измерений (6.34) при этом примет вид
z„=Hxn+v„. (6.37)
6.4. КЛАССИФИКАЦИЯ ЗАДАЧ ОПТИМАЛЬНОГО
УПРАВЛЕНИЯ
6.4.1. Одношаговые задачи принятия решения
В одношаговых задачах обычно не рассматриваются
методы реализации принятого решения, т. е. определяется
не величина и характер управляющего воздействия и,
а непосредственно значение переменной состояния систе-
мы х, которое обеспечивает наилучшее достижение цели
управления.
Одношаговая задача принятия решения считается за-
данной, если заданы пространство состояний природы 0
с распределением вероятностей £(&) для всех -&е0, про-
странство решений X и критерий качества принятого ре-
шения, который для этого случая будем называть целевой
функцией. В литературе вместо термина «целевая функ-
ция» применяют также название «функция выигрыша» или
«функция потерь». Целевую функцию, выражающую в яв-
ном виде цели управления, можно рассматривать как вы-
ходную величину ОУ и обозначить через q. Целевую функ-
цию, являющуюся скалярной величиной, зависящей от
состояния природы 6 и от состояния объекта управления х,
261
по аналогии с (6.26) можно записать в виде
q=q(x, Ф). (6 38)
Как видим, одношаговая задача принятия решений
представляет собой тройку
а=(х, е, 7),
(6.39)
где q — скалярная функция, определенная на прямом про-
изведении множеств XX©.
Решение эюй задачи состоит в нахождении такого х'е
еХ, которое обращает в минимум функцию q, т. е. удов-
летворяет условию
хЛ={хе/|7(х, Ф)=пнп}. (6.40)
Заметим, что если стоит задача не минимизации, а мак-
симизации функции q, то она не приведет ни к каким
добавочным трудностям, так как если при х=хг функция
7(х, Ф) достигает максимума, то при том же самом х функ-
ция —<?(х, Ф) будет достигать минимума.
Существует ряд методов решения одношаговой задачи
принятия решения. Применимость того или иного метода
зависит от способа задания множества допустимых реше-
ний X, от имеющейся информации о состоянии природы и
от вида целевой функции q. Дадим краткую характеристи-
ку основных из этих методов.
Задачу называют детерминированной, если нет не-
определенности в отношении состояния природы. В детер-
минированных задачах пространство состояний природы 0
состоит всего из одного элемента Фо, вероятность которого
равна единице. В этом случае целевая функция будет за-
висеть только от состояния ОУ
9=7(х)=7(х(»..х<«>). (6.41)
Одношаговую детерминированную задачу называют
классической задачей оптимизации [39], если в ней имеют
место ограничения вида (6.24), причем среди этих ограни-
чений нет неравенств, нет условий неотрицательности или
дискретности переменных, т<п и функции f,-(x(1),.. .,л-<п))
и 7(х) непрерывны и имеют частные производные по край-
ней мере второго порядка. В этом случае задача формули-
руется следующим образом. Даны ограничения вида
/,(х<‘>...x<n>)=0, t=l,т, т<п.
(6.42)
262
Найти значения х(1),.. .,х<п>, удовлетворяющие уравне-
ниям (6.42) и обращающие в минимум функцию <?(х(1\...
...,х<«>).
За последние годы повысился интерес к методам реше-
ния одношаговой задачи, получившим название математи-
ческого программирования. Эти методы дают возможность
найти значения переменных х(1),..., х(п), удовлетворяющих
ограничениям типа (6.24) как в виде равенств, так и в ви-
де 'неравенств и обращающих в минимум целевую функ-
цию ?(х). На переменные обычно накладывают добавоч-
ные условия неотрицательности их значений. Следует от-
метить, что математическое программирование представ-
ляет собой не аналитическую, а алгоритмическую форму
решения задачи, т. е. дает не формулу, выражающую
окончательный результат, а указывает лишь вычислитель-
ную процедуру, которая приводит к решению задачи. По-
этому методы математического npoi раммирования стано-
вятся эффективными главным образом при использовании
цифровых вычислительных машин.
Простейшим случаем задачи математического програм-
мирования является задача линейного программирования.
Она соответствует случаю, когда левые части ограничений
(6.24) и целевая функция (6.41) представляют собой ли-
нейные функции от х(1),..., х(п). В задаче линейного про-
граммирования требуется найти неотрицательные значения
переменных х'1',..., х<п>, которые обращают в минимум це-
левую функцию
<7(х<’), ..., х(п>) = 2сух(')
(6.43)
и удовлетворяют системе ограничений
<bt, i = 1, тп.
(6.44)
Любую задачу математического программирования, от-
личающуюся от сформулированной, называют задачей не-
линейного программирования. В задачах нелинейного про-
граммирования или целевая функция (6.41), или левые
части ограничений (6.24), или то и другое являются нели-
нейными функциями от х<1>,.. .,х(">. Однако к задаче не-
линейного программирования относится и такая, в которой
целевая функция и ограничения имеют вид (6.43) и (6.44),
но предполагается, например целочисленность переменных.
263
Эта последняя задача получила название задачи целочис-
ленного программирования.
Одношаговую задачу принятия решений называют
стохастической, если пространство состояний природы О
состоит более чем из одного элемента, так что известным
является не действительное состояние природы &, а рас-
пределение вероятностей В('й') на пространстве 0.
Стохастические задачи, требующие нахождения значе-
ний переменных, удовлетворяющих ограничениям (6.24) и
обращающих в минимум целевую функцию (6.38), назы-
вают задачами стохастического программирования. Одна-
ко во многих случаях путем несколько иного определения
целевой функции задачи стохастического программирова-
ния могут быть сведены к задачам линейного или нели-
нейного программирования. Действительно, так как
состояние природы & является случайной величиной с рас-
пределением вероятностей £('&) на пространстве 0, то и
значение q(x, &) при данном х=(х<1>,..., х(п))т также бу-
дет случайной величиной с тем же распределением вероят-
ностей !(&) на пространстве 0. Поэтому в данном случае
за целевую функцию целесообразно принять математиче-
ское ожидание функции q(x, &) на пространстве 0.
Таким образом, для случайных процессов согласно
(5.52) целевая функция
<Мх) = Sw? (*.*)• (6-45)
8ge
Поскольку qi (х) является детерминированной функци-
ей от х, то задача нахождения переменных х(1),..., х<">,
удовлетворяющих ограничениям (6.24) и обращающих
в минимум целевую функцию (6.45), может быть решена
методами линейного или нелинейного программирования.
Важным случаем одношаговой стохастической задачи
принятия решения является случай, когда величины х„
i==17n могут принимать лишь конечное множество значе-
ний. Методами решения таких задач занимается раздел
математики, получивший название теория статистических
решений.
В настоящее время большое внимание уделяется зада-
чам, в которых решение принимается не одним лицом,
а несколькими (например, двумя), причем интересы этих
лиц противоположны. Примером может служить задача
преследования, в которой расстояние между преследова-
телем и преследуемым зависит от решений и действий
264
обоих этих лиц. При этом преследователь заинтересован
в том, чтобы предельно сократить это расстояние, а пре-
следуемый в том, чтобы сделать его по возможности наи-
большим. Подобные задачи получили название конфликт-
ных ситуаций, а методы их решения рассматриваются
в теории игр. Лица, принимающие решения, называют
игроками.
Поскольку в конфликтной ситуации решения каждым
из игроков принимаются независимо от решений, прини-
маемых другим игроком, при математическом описании
конфликтной ситуации пространство решений следует рас-
сматривать как прямое произведение двух множеств XXУ,
где X={xi,...,Лп) —пространство решений первого игро-
ка; Y={yi,...,ym} —пространство решений второго иг-
рока.
Элементы пространства решений XX/ будут представ-
лять собой пары вида (х, у), хеХ, уеУ, т. е. будут опре-
деляться решениями, принимаемыми как первым, так и
вторым игроком. Для простоты считаем, что неопределен-
ность в состоянии природы отсутствует. Тогда целевая
функция
<7=<7(х, у) (6.46)
зависит только от элементов пространства XX У.
Противоположность интересов игроков состоит в том,
что первый игрок, делающий выбор из множества X, стре-
мится своим выборохм минимизировать целевую функцию,
в то время как второй игрок, делающий выбор из множе-
ства У, стремится ее максимизировать. Таким образом,
сущность конфликтной ситуации состоит в том, что каж-
дый игрок должен принять наилучшее со своей точки зре-
ния решение, помня, что его противник сделает то же са-
мое.
6.4.2. Динамические задачи оптимизации управления
Среди разнообразных задач кибернетики значительное
место занимают задачи, в которых ОУ находится в состоя-
нии непрерывного движения и изменения под воздействи-
ем различных внешних и внутренних факторов. Задачи
управления такими объектами относятся к классу динами-
ческих задач управления.
Объект называют управляемым, если среди действую-
щих на него разнообразных факторов имеются такие, рас-
265
поражаясь которыми можно изменять характер его движе-
ния. Как уже указывалось, такие целенаправленные
воздействия называют управлениями и обозначают u(f).
Характер движения ОУ определяется системой диффе-
ренциальных уравнений (6.28), которую удобно сокращен-
но записывать в векторной форме в виде одного диффе-
ренциального уравнения (6.32). Управление u(i) входит
в уравнение (6.32), так что это уравнение определяет не
просто конкретное движение объекта, а лишь его техни-
ческие возможности, которые могут быть реализованы пу-
тем использования того или иного управления из прост-
ранства допустимых управлений U.
Оценить, насколько при том или ином способе управ-
ления достигаются поставленные цели, можно, как и рань-
ше, путем введения целевой функции типа (6.26), которую
в данном случае удобно записать в виде
9=7s[x(0, u(/)l. (6.47)
Так, если «(/)—мгновенный расход топлива, a x(t) —
мгновенная скорость самолета, то с точки зрения расхода
топлива качество управления в любой момент времени
может быть охарактеризовано величиной q(t)=u(t)/x(t)
(мгновенный расход топлива на единицу пути), которая,
естественно, будет зависеть от состояния природы •&, т. е.
совокупности внешних факторов, определяющих условия
полета.
Целевая функция вида (6.47) используется редко, так
как она дает оценку лишь мгновенных значений управляе-
мого процесса, тогда как в большинстве задач бывает
необходимо оценить процессы в ОУ на протяжении всего
времени управления от 0 до Т.
Во многих случаях целевую функцию удается подо-
брать так, что оценку процесса в ОУ можно произвести
путем интегрирования целевой функции за все время
управления, т. е. за критерий качества управления принять
функционал
J(u) = pe[x(/),u(/)l^. (6.48)
о
Так, если целевая функция имеет физический смысл
потерь, то выражение (6.48) определяет суммарные потери
за весь процесс управления.
266
Иногда в качестве цели управления удается задать
желаемый ход процесса z(t). При этом в качестве целе-
вой функции можно взять квадрат или абсолютное значе-
ние отклонения процесса x(t) от желаемого:
7=[x(t)—z(t)]2, 7=|х(0—z(/) |. (6.49)
В этих случаях критерий качества управления (6.48)
будет определять полную квадратичную или абсолютную
ошибку.
В динамических задачах управления наряду с ограни-
чениями вида (6.25), определяющими пространство допус-
тимых управлений U, приходится иметь дело с интеграль-
ными ограничениями вида
j//a[x,(Q, К = const. (6.50)
о
Часто, например, приходится сталкиваться с необходи-
мостью ограничения пределов изменения мгновенного зна-
чения некоторого параметра а(х, и) в процессе управле-
ния Обозначим через а0 то значение параметра а, превы-
шение которого является нежелательным. Если подынте-
гральную функцию 77 (х, и), называемую в данном случае
функцией штрафа, определить из соотношения
Я(Х,») = | 0 при а(х.
Цл(х, и) — л0]2 при а’(х, и) >а0,
то интегральное ограничение (6.50) будет выражать тре-
бование, чтобы мгновенное значение параметра а могло
превышать а0 лишь кратковременно и на незначительную
величину. Это условие будет выполняться тем жестче, чем
меньше К. Так, при К=0 ограничение (6 50) вообще не
будет допускать превышения а над а0.
Ограничения вида (6 50) возникают также тогда, ког-
да приходится иметь дело с ограниченными ресурсами:
может быть ограничено находящееся в распоряжении ко-
личество энергии, топлива, если речь идет о траекториях,
и т. п.
Приведенные соотношения позволяют дать следующее
определение оптимального управления в динамических
системах. Оптимальным называют управление и* (7), вы-
бираемое из пространства допустимых управлений U, та-
кое, которое для объекта, описываемого дифференциаль-
267
ным уравнением (6.32), минимизирует критерий качества
(6.48) при заданных ограничениях на используемые ре-
сурсы (6.50).
Динамические задачи управления, как и одношаговые,
могут быть детерминированными, если пространство со-
стояний природы 0 состоит только из одного элемента 0=
='&о, и стохастическими, если пространство состояний
природы 0 содержит более одного элемента и задано ап-
риорное распределение вероятностей g(8’) на пространст-
во 0.
Среди стохастических задач важное место занимают
задачи адаптивного управления, которое используют в тех
случаях, когда априорных данных о состоянии природы
недостаточно для осуществления эффективного управле-
ния или когда отсутствует достаточно точное математиче-
ское описание самого ОУ. Адаптивное управление имеет
целью уточнить данные о состоянии природы или свойства
ОУ непосредственно в процессе управления объектом пу-
тем опробования различных способов управления и по-
иска того из них, который в данных конкретных условиях
оказывается наиболее эффективным [34].
6.4.3. Управление конечным состоянием
В ряде случаев характер движения объекта в процессе
управления не представляет существенного интереса, а
важным является только состояние, которое примет объ-
ект в момент окончания процесса управления. Примерами
подобных задач могут служить слепая посадка самолета,
предъявляющая жесткие требования к скорости и положе-
нию самолета в момент касания земли, Доставка груза
к заданному сроку в заданный пункт назначения, дости-
жение к концу года заданной производительности труда
и т. п. Такие задачи называют задачами управления ко-
нечным состоянием.
Обозначим через х(Т) состояние объекта в конечный
момент времени. Тогда целевая функция
q=q»[\(T)]. (6.52)
Поскольку х(Т) зависит от характера примененного
управления и(0, то и значение q также будет зависеть от
примененного управления. Поэтому задачу выбора опти-
мального управления можно сформулировать для этого
случая следующим образом: из пространства допустимых
268
управлений U выбрать такое управление и*(/), которое
для объекта, описываемого дифференциальным уравнени-
ем (6.32), минимизирует целевую функцию (6.52) при ог-
раничениях (6.50) на используемые ресурсы.
6.5. МНОГОШАГОВЫЕ ПРОЦЕССЫ УПРАВЛЕНИЯ
6.5.1. Поведение динамической системы как функция
начального состояния
Нахождение оптимального управления в динамических
системах во многих случаях существенно облегчается, ес-
ли процесс управления удается разбить естественным или
искусственным путем на отдельные шаги или этапы. Для
того чтобы вести рассмотрение в общем виде, будем счи-
тать, что состояние объекта описывается многомерной пе-
ременной х=(х<1>,..., х<п>)т.
Предполагая, что процесс является неуправляемым и
неопределенность в состоянии природы отсутствует, диф-
ференциальное уравнение, определяющее движение объ-
екта по аналогии с (6.32), запишем в виде
x=g(x), х(0)=с. (6.53)
Решение этого уравнения зависит от времени х=х(/).
Однако важно и то, что решение уравнения (6.53) зависит
от начального состояния с. Поэтому выберем такую фор-
му записи, которая показывает явную зависимость реше-
ния х как от времени, так и начального состояния:
х=х(с, £)=х[х(0), ф (6.54)
Такая форма записи позволяет рассматривать состоя-
ние системы в произвольный момент времени t как некото-
рое преобразование начального состояния х(0)=с на ин-
тервале t.
Рассмотрим движение объекта на интервале от 0 до /2,
который промежуточной точкой разобьем на два интер-
вала длительностью Л и т=/2—Л (рис. 6.5,а). Рассмотрим
начальное состояние х(0)=с; состояние х(с, t\) в проме-
жуточный момент Л; состояние х(с, /2) в конечный мо-
мент t2.
К описанию последнего состояния можно подойти двоя-
ким образом. Это состояние можно рассматривать или как
269
Рис. 6.5. Разбиение интервала на два шага (а) и на п шагов (б)
преобразование начального состояния х(0)=с на интер-
вале /2=Л-Н
х(с, /2)=х(с, 6+т), (6.55)
или как преобразование состояния х(с, 6) на интервале т
х (с, /2)=х[х(с, 6),т]. (6.56)
Так как оба выражения описывают одно и то же состо-
яние, то, приравнивая их, получаем соотношение
х(с, Л+т)=х[х(с, 6),т]. (6.57)
6.5.2. Представление динамического процесса
в виде последовательности преобразований
Предположим, что динамический процесс х(с, t) на ин-
тервале от 0 до t' может быть естественным или искусст-
венным образом представлен как многошаговый, и найдем
подходящий способ описания такого процесса. Для того
чтобы получить многошаговый процесс, интервал от 0 до..
t' следует разбить на п последовательных шагов, длитель-
ности которых примем равными ti, т2, ...,тп (рис. 6.5,6).
Обозначим через tk (k=0,..., п) моменты окончания 6-го
тага так, что /*+i=6.-H*+i. а через xfe — состояние объек-
та в момент tk:
х*=х(с, tk). (6.58)
Рассмотрим состояние
хл+1=х(с, Zfe+i)=x(c, 6гН*+1). (6.59)
Это выражение в соответствии с (6.57) и (6.58) можно
представить в виде
Х*+1=Х[Х(С, tk), Тй+1] =Х (Хй, Тй+1). (6.60)
270
Соотношение (6.60) представляет состояние объекта
xft+i как результат преобразования состояния хк на (&+
4-1)-м шаге.
Введем в рассмотрение оператор Т, который будет оз-
начать преобразование состояния процесса за один шаг:
T(xk)=x(xk, Tfc+i), k=0 п-1. (6.61)
Тогда соотношение (6.60) запишем в виде
xk+l=T(xk). (6.62)
Полагая k—0, !,...,«—1, можем описать весь динами-
ческий процесс в виде последовательности преобразо-
ваний
Хо=С, Х1=Т(хо)....х„=7’(х„_1). (6.63)
6.5.3. Многошаговый процесс управления
Динамический процесс, описываемый преобразованием.
(6.62), является неуправляемым. Для получения управля-
емого многошагового процесса необходимо иметь возмож-
ность на каждом шаге осуществлять не одно преобразова-
ние T'(Xfe), а одно из множества преобразований Ti(xk),...
..., Tr(xk).
Удобно считать, что конкретный вид преобразования
будет зависеть от параметра и*, который на /г-м шаге мо-
жет принимать одно из множества значений Uk- Пара-
метр и* будем называть управлением, а множество Un —
пространством допустимых управлений на k-м шаге. Пре-
образование, осуществляемое на k-м шаге, теперь можно
записать в виде
xfe+i=7'(xft, uft), iik^Uk. (6.64)
Если в соотношении (6.64) положить последовательно
k=0, 1,...,п—1 и учесть начальное состояние х0, то полу-
чим описание всего управляемого многошагового про-
цесса:
х*+1=7'(хд., и*),
k=0, 1; Xo=x(O)=c. (6.65)
Соотношение (6.65), называемое разностным уравне-
нием объекта управления, аналогично дифференциально-
му уравнению (6.32), дающему описание непрерывного ди-
намического процесса.
271
Пример 6.3. Предположим, что переменная состояния является дву-
мерной величиной х=(хО>, х<2)), которая может принимать значении,
определяемые геометрически узлами сетки, изображенной на рис. 6.6,а.
От одного узла сетки можно переходить к другому, используя на каж-
дом шаге одно из двух возможных управлений: и*=0 — движение по
горизонтали и ик=1—движение по вертикали. Следовательно, про-
странство допустимых управлений одинаково для любого шага и будет
а*={0, 1}, k=0, 1, .. , я—1.
Рис. 6 6. Многошаговый процесс с двумерной перемен-
ной
Рассмотрим одну из клеток данной сетки, показанную на
рис. 6.6,6, в нижнем левом узле которой система оказалась после
fc-го шага, так что x*=(ai, bi). Значение X4+i = T(x*, ик) зависит от
примененного управления. Можно записать следующие соотношения:
T[(ai, hi), 0]=(a2, 6l)=x,*+i; T[(ai, 6,), 1] = (Я1. b2)=x",^
Конкретную траекторию движения системы можно описать, указав
начальное состояние х0 и последовательность примененных управлений.
Так, отмеченная жирной линией траектория (рис. 6.6,а) получается
при использовании управлении и= (01101001) и при начальных усло-
виях x0=(a, Р).
6.5.4. Критерий качества управления
при многошаговом процессе
Считаем, что качество управления определяется зна-
чением целевой функции q, численное значение которой
можно рассматривать как потери, которые несем при том
или ином управлении. Потери за один шаг будут зависеть
от состояния процесса в начале шага и примененного на
этом шаге управления, т. е.
qk=q(x.k, uft), Uk^Uk. (6.66)
272
За критерий качества управления можно принять пол-
ные потери за все п шагов процесса и представить крите-
рий качества управления n-шагового процесса в виде
/„(u) = S (6.67)
k=0
Здесь через и обозначена последовательность управле-
ния, т. е. упорядоченное множество вида
U = (Uo, . . Un_ i) т, Uoe U о, Un-iS U n-l. (6.68)
Если рассматривается многошаговый процесс управле-
ния конечным значением, то потери будут зависеть лишь
от состояния ОУ в конце процесса, которое в свою очередь
зависит от начального состояния и примененных на каж-
дом шаге управлений:
q=q(xn)=q(x0, и), (6.69)
где и определяется соотношением (6.68). Скалярную ве-
личину, определяемую выражением (6.69), называем це-
левой функцией многошагового процесса управления.
Задача нахождения оптимального управления при мно-
гошаговом процессе может быть сформулирована следу-
ющим образом. Для динамической системы, процесс в ко-
торой описывается разностным уравнением (6.65), найти
такую последовательность управлений Uo, Ui,...,ия-ь удо-
влетворяющих ограничениям вида Uk^Uk, 6=0, 1 п— 1,
которая обращает в минимум критерий качества управле-
ния (6.67) или целевую функцию (6.69).
Поскольку многошаговые процессы управления явля-
ются частным случаем динамических процессов управле-
ния, то среди них могут встретиться все те виды задач,
которые рассматривались в динамических задачах управ-
ления. Так, если пространство состояний природы 0 со-
стоит из одного элемента •бо, то многошаговую задачу уп-
равления называют детерминированной. В противном
случае ее относят к классу стохастических задач.
Отметим, что не всегда ту или иную задачу можно од-
нозначно отнести к классу многошаговых или одношаго-
вых задач. Так, если в многошаговой задаче последова-
тельность значений переменной, принимаемую на отдель-
ных шагах, рассматривать как одну многомерную пере-
менную, то многошаговая задача превращается в одноша-
говую.
18—804 " 273
6.6. ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ОПТИМИЗАЦИИ
6.6.1. Общая постановка задачи оптимизации
В общей задаче оптимизации требуется найти вектор
х=(х<‘>), ...,х<л’)т из допустимой области X, который обра-
щает в минимум целевую функцию q(x), т. е. такой вектор
х*еХ, для которого выполняется условие
для всех хе! (6.70)
Если такой вектор х* существует, то он определяет
слабый глобальный (абсолютный) минимум q*(x) в до-
пустимой области X. Этот минимум называют слабым, так
как он удовлетворяет нестрогому (слабому) неравенству,
глобальным или абсолютным, потому что неравенство
справедливо для любого х^Х. Минимум при х=х:: назы-
вают сильным, если имеет место <?(х*) <д(х) для х^х*.
Если поменять знаки неравенств, получим слабый и силь-
ный максимум. Однако максимум q(x) дает минимум —
q(x), поэтому в дальнейшем рассматриваем только задачу
минимизации.
Существование слабого глобального минимума допу-
скает неединственность оптимальной точки, так как лю-
бой х, удовлетворяющий условию q(x)=q(x*), также яв-
ляется оптимальной точкой. Сильный глобальный мини-
мум всегда единствен.
Хотя цель задачи оптимизации —получение глобально-
го минимума целевой функции, при ее решении важное
значение имеет понятие локального или относительного
минимума.
Минимум в точке х=х* называют локальным (относи-
тельным), если найдется такая окрестность Ое(х*) точки
х*, что для всех xeQe(x*) имеет место q(x'‘)^q(x).
Если функция q(x) дифференцируема, то задача отыс-
кания локальных минимумов сводится к нахождению ста-
ционарных точек, в которых обращаются в нуль частные
производные функции q(x):
dq(x)/dx^=0, i=\,n. (6.71)
Следует отметить, что (6.71) является лишь необходи-
мым, но не достаточным условием существования относи-
тельного минимума. Стационарная точка может быть и
точкой относительного максимума, и седловой точкой, в ко-
274
торой не достигается ни относительный минимум, ни отно-
сительный максимум. Как было показано в § 4.7, доста-
точным условием существования в стационарной точке от-
носительного минимума является положительная опреде-
ленность квадратичной формы (4.111).
Отметим также, что хотя абсолютный минимум явля-
ется в то же время и относительным, но относительный
минимум не обязательно будет абсолютным. Более того,
на допустимом множестве X функция q(x.) может иметь
не один, а несколько относительных минимумов. В то же
время большинство известных методов оптимизации по-
зволяет находить лишь точки относительного минимума.
При этом возникает очень сложная задача нахождения
того из относительных минимумов, который является аб-
солютным.
6.6.2. Ограничения на допустимое множество
Наиболее типичный способ определения допустимого
множества X — введение ограничений на переменные ти-
па (6.24), а также требование неотрицательности всех или
некоторых переменных. Если ограничений несколько, то
допустимое множество решений задачи оптимизации явля-
ется пересечением всех множеств, определяемых ограни-
чениями.
На рис. 6.7,а для двумерной переменной х=(ы, о) за-
даны два ограничения:
ы24-о2^г2; uv~^c.
Первое ограничение определяет круг радиусом г с цент-
ром вначале координат, второе — область, отделенную от
начала координат двумя ветвями гиперболы. В этом слу-
чае допустимое множество определяется незаштрихован-
ными областями в первом и третьем квадрантах. Если на-
ложено требование неотрицательности переменных и,
0, то остается только область в первом квадранте. На
рис. 6.7,6 показана допустимая область, определяемая ус-
ловиями
ц24-о2^г2, и^О, и>0.
При некоторых видах ограничений допустимое множе-
ство может оказаться пустым. Так, если уменьшить ради-
ус круга на рис. 6 7,а, то не окажется точек, находящихся
внутри круга и в области, определяемой ветвями гипербо-
18*
275
лы. Ограничения называют несовместными, если опреде-
ляемое ими допустимое множество пусто.
Многие из рассмотренных далее методов оптимизации
применимы только в том случае, если допустимое множе-
ство является выпуклым. Допустимые множества, приве-
денные на рис. 6.7, с учетом неотрицательности перемен-
ных выпуклы. Однако если в ограничении, описываемом
окружностью для рис. 6.7,6, поменять знак неравенства на
обратный, то допустимое множество превратится в поло-
жительный квадрант
без четверти круга
с центром в начале
координат и уже не
будет выпуклым.
Задача оптими-
зации, вообще гово-
ря, не всегда имеет
решение. Так, зада-
ча max (н+о) при
ограничении и^и
Рис. 6.7. Допустимые множества
не имеет решения, поскольку для любого u+v можно найти
другие и и v, дающие большее значение суммы. Тем не ме-
нее можно выделить широкий класс задач, для которых
существование оптимума гарантирует следующая тео-
рема.
Теорема Вейерштрасса. Непрерывная функция, опре-
деленная на непустом замкнутом ограниченном множест-
ве, достигает минимума (максимума) по крайней мере
в одной из точек этого множества.
Поэтому замкнутость допустимого множества являет-
ся важным условием большинства задач оптимизации.
Для обеспечения замкнутости все ограничения на до-
пустимое множество типа неравенств задаются как не-
строгие: или При этом знаки <, > определяют
внутренние, а знаки = граничные точки допустимого мно-
жества. Отметим, что теорема Вейерштрасса дает доста-
точные условия оптимума. Однако задачи, в которых ус-
ловия теоремы не выполняются, также могут иметь ре-
шения.
6.6.3. Выпуклые и вогнутые функции
Как уже отмечалось, большинство известных методов
решения задачи оптимизации сводится к исследованию ха-
276
рактера функции <?(х) в окрестности рассматриваемого
значения х, т. е. к выяснению того, не является ли точка х
точкой относительного минимума (максимума). При этом
задача чрезвычайно усложняется, если целевая функция
7(х) может иметь в допустимой области значений X не
один, а несколько максимумов или минимумов. Поэтому
значительный интерес представляют такие задачи, в ко-
торых целевая функция имеет всего один максимум или
минимум и в которых, следовательно, относительный ми-
нимум является в то же время абсолютным. Для выявле-
ния классов таких задач фундаментальную роль играют
понятия выпуклости и вогнутости функций.
Пусть f(x) — некоторая функция, заданная на выпук-
лом множестве X- хь х2— две произвольные точки из X,
а х=^Х!-|-(1—Z,)x2; — произвольная точка отрез-
ка, соединяющего Xi и х2. Рассмотрим также отрезок z—
=А/(Х1)4-(1—K)f(x2), соединяющий значения f(X[) и
Нх2) функции f(x).
Функцию f(x) называют выпуклой, если она целиком
лежит ниже (не выше) отрезка, соединяющего две ее про-
извольные точки, т. е. если прн любых xi и х2 и при лю-
бом значения функции в точке х будут не боль-
ше значений z отрезка, соединяющего f(xi) и f(x2):
+ (1-Х)х2] ^V(xi) + (1-W(x2)- (6.72)
Функцию называют вогнутой, если она целиком лежит
выше (не ниже) отрезка, соединяющего две ее произволь-
ные точки, т. е. если
f [Хх,+ (1 —А.)х2] >Kf (xi) + (1-Мf (х2). (6.73)
На рис. 6.8 приведены примеры выпуклых (а) и вогну-
тых (б) функций одной переменной, а также случаи (в),
когда функция не является ни выпуклой, ни вогнутой.
Если в соотношениях (6 72) и (6 73) заменить знаки
нестрогих неравенств на знаки строгих неравенств
<, >, то приходим к определению строго выпуклой и
строго вогнутой функций.
Теорема 6.1. Сумма выпуклых (вогнутых) функций есть
выпуклая (вогнутая) функция.
Доказательство. Рассмотрим функцию f(x) =
=Sfi(x), где f,(x) — выпуклые функции на выпуклом мно-
277
жестве X. Возьмем любые хь х2еХ и любое
Тогда
f [Ях, + (1 - Я)хг] = 3 [, [Лх, + (1 - Я) хг] < S (Я/, (х,) +
+ (1 - Л) Л (XS)] = я2 Мх,) + (1 - Я) S f, (хг) =
= Я/(х1) + (1-Я)/(х2),
т. е.'выполняется условие выпуклости функции f(x). Для
вогнутых функций теорема доказывается аналогично.
Рис. 6 8. Примеры видов функций
Рассмотрим некоторые важные виды выпуклых и во-
гнутых функций.
Линейная функция z=ax является выпуклой (и вогну-
той) на всем пространстве У?(п), так как для любых Xi и
х2 и любого X
а[Ах,+ (1—X)x2]=XaxI+ (l~?t)ax2.
Однако линейная функция не является ни строго вы-
пуклой, ни строго вогнутой.
Положительно (не отрицательно) определенная квад-
ратичная форма z=xTAx является выпуклой функцией на
всем пространстве RW. Действительно, для любых хь
х2&?(л> и х—Axj+(1—Я)х2 имеем
VAx= [Axi + (1—X)х2] ТА {Axs-j-
+ (1—А) х2] = [х2+А (xi—х2) ]1А [х2+
4-Z, (х!—Х2) ] =Х2ТАХ24-2А, (х 1—Х2 ) тДх2+
+ Х2(Х1— X2)tA(Xj— х2).
Так как по предположению хтАх;>0 и 0^7.^ 1, то
?.хтАх^№хтАх. Следовательно,
xtAx^x2tAx2+2Z,(xi—х2)тАх2+
+ 7,(х1—х2)т(х!—х2)=х2тАх2 +
+Z,(xi—х2)тАх2 + А,(х,—х2)тАхь
Учитывая, что для вещественной симметричной матри-
цы А
Х1тАх2= (xitAx2) т—x2tAtXi=x2tAxi,
получаем
xTAxs^xiTAx+ (1—Z,)x2tAx2.
Это и означает, что функция хтАх выпукла.
Аналогично доказывается, что отрицательно (не поло-
жительно) определенная квадратичная форма является
вогнутой функцией на всем Rn.
Сумма линейной функции и квадратичной формы
ах-(-хтАх выпукла, если квадратичная форма положитель-
но определенная, п вогнута, если квадратичная форма от-
рицательно определенная. Этот вывод является следстви-
ем теоремы 6 1.
6.6.4. Свойства выпуклых (вогнутых) функций
Приведем без доказательства некоторые свойства вы-
пуклых функций, являющиеся важными для решения за-
дачи НЛП и проиллюстрированные примерами рис. 6.9.
Минимумы
максимумы выпуклых функций
minf(x)=
maxf(x)
Пусть f(x) — выпуклая функция, заданная на замкну-
том выпуклом множестве X. Тогда: 1) любой относитель-
ный минимум Дх) на X является абсолютным (глобаль-
ным) минимумом f(x) на X; 2) не может быть двух и бо-
лее различных относительных минимумов; 3) если абсо-
лютный минимум достигается в двух различных точках,
то он достигается в бесконечном множестве точек; 4) гло-
бальный максимум f(x) достигается в одной или более
крайних точках множества X.
Аналогичными свойствами по отношению к максиму-
мам функции f(x) обладают вогнутые функции.
6.6.5. Классическая задача оптимизации
Как уже отмечалось, классическая задача оптимизации
состоит в нахождении минимума целевой функции <?(х),
где х=(х<!),..., x<n>)T— точка в пространстве при нали-
чии ограничении типа равенств
A(x)=0, i=i7m, т<п. (6.74)
Если ограничения (6.74) имеют место, то минимум
функции <?(х) называют условным минимумом. Если огра-
ничения (6.74) отсутствуют, то говорят о безусловном ми-
нимуме, нахождение которого сводится к определению и
исследованию стационарных точек функции <?(х)
Классический способ решения данной задачи состоит
в том, что уравнения (6.74) используются для исключения
из рассмотрения т. переменных. При этом целевая функ-
ция приводится к виду
q(x™..., х<«>) =q} (yW.у^-т)), (6.75)
где через ут,..., обозначены неисключенные пере-
менные. Задача состоит теперь в нахождении значений
у(1),..., у<п~т\ которые обращают в минимум функцию q\
и на которые не наложено никаких ограничений, т. е. сво-
дится к задаче на безустовный экстремум.
Пример 6.4. На рис 6 10 дана геометрическая интерпретация дан-
ной задачи для двумерной переменной x=(u, v)T с одним ограниче-
нием f(x) = и2—v-1-l = 0 и с целевой функцией <?(х)=(и—1)24-Л На
рисунке изображены ограничение f(x)=O и линии уровня <?(x)=const.
Оптимальное решение х' получаем в точке касания кривых f(x)=O и
<?(x)=const
280
Для получения аналитическо-
го решения из уравнения f(x)=O
находим а=/«2+1. Подс1авляя
его в <?(х), получаем q(x) =
= (и— l)2+(u2+ I)2. Дифференци-
руя это выражение по и, прихо-
дим к уравнению 2п3 + 3и—1=0,
которое имеет единственный ве-
щественный корень и* =0,313.
При этом v* —1,098, q(x*)~
Рис. 6.10. Геометрическая интер-
претация задачи на условный
экстремум
= 1,678.
Заметим, что при отсутствии
ограничения f(x)=O минимум це-
левой функции q(x) достигается
в точке х=(1, 0) и равен нулю.
Таким образом, ограничение
приводит к увеличению значения целевой функции, т. е. к ухудшению
качества оптимума.
Если уравнения (6.74) имеют сложный вид, то исклю-
чение с их помощью т переменных из функции q(x) пред-
ставляет значительные трудности. В связи с этим большое
практическое значение получил метод сведения задачи на
условный экстремум к задаче на безусловный экстремум,
основанный на использовании функции Лагранжа.
6.6.6. Функция Лагранжа
Введем в рассмотрение вектор Х=(Х],..., Х,п) и иссле-
дуем свойства функции
£(х,Х) = <7(х)+3 М.(х). (6.76)
Функцию Л(х, X) называют функцией Лагранжа, а ве-
личины X, — множителями Лагранжа. Как видим, функ-
ция L(x, X) является функцией п-\-т переменных х^, ...
X,,...,Xm.
Рассмотрим стационарные точки функции L(x, X), ко-
торые получим, приравняв нулю частные производные по
Ху, /=1, т и по х(,), i=l,п:
dL(x, X) /dk,=f, (х) =0, /= 1, т; , (6.77)
дЦх, X)/dx<!'>=0, i=17n. (6.78)
281
Заметим, что уравнения (6.77) совпадают с ограниче-
ниями (6.74) и, как следует из (6.76), при их выполнении
имеет место Л(х, A.)=<?(x). Поэтому, если в стационарной
точке (х*, V) функция Л(х, Л.) достигает минимума, то
х* обеспечивает и минимум функции <?(х) при выполне-
нии ограничений (6.74), т. е. дает решение задачи.
Как видим, задача на условный минимум целевой
функции q(x) при наличии ограничений типа равенств
сводится к задаче определения стационарных точек функ-
ции Лагранжа Л(х, X).
Для примера 6 4 функция Лагранжа L(x, X) = (и— !)5-р2-|-Х(и2—
—Н 1).
Дифференцируя эту функцию по и, v и К, получаем три урав-
нения:
«(l-f-X) —1=0; 2ц—Х=0, и2—о-]-1=0,
решая которые находим и', и* и X
Глава 7
ЛИНЕЙНОЕ
И НЕЛИНЕЙНОЕ ПРОГРАММИРОВАНИЕ
7.1. ПОСТАНОВКА ЗАДАЧИ ЛИНЕЙНОГО
ПРОГРАММИРОВАНИЯ
7.1.?. Ссковиые определения
Как указывалось в гл. 6, термин «линейное программи-
рование» связывается с исследованием и решением следу-
ющей задачи [43—45].
Дана система т линейно независимых уравнений с не-
известными .Г|,..., хп, называемая системой ограничений
задачи линейного программирования:
(7-1)
где не уменьшая общности, можно считать i=l,m.
Характерной особенностью данной задачи является то,
что число уравнений меньше числа неизвестных, т. е.
262
m<Zn. Требуется найти неотрицательные значения пере-
менных (xi^O, которые удовлетворяют уравне-
ниям (7.1) и обращают в минимум целевую функцию
<7—C|A'i+ ... +спхп, (7 2)
называемую линейной формой.
Более компактно задачи линейного программирования
могут быть записаны в матричной форме как
<?(х) = сх = min; |
Ах = b (Ь > 0), х > О, J
где А —матрица размером т.ухп\ Ь —m-мерный вектор;
х и с —n-мерные векторы.
Сделаем несколько пояснений по поводу этой задачи.
Система уравнений (7.1) для случая, когда число уравне-
ний равно числу неизвестных (т=п), рассматривается в
обычной алгебре. Если при этом определитель системы не
равен нулю, то система имеет одно-единственное решение,
для нахождения которого имеются хорошо разработан-
ные приемы (см. § 4.6). Если же число уравнений меньше
числа неизвестных (m<n), то система уравнений (7.1)
имеет бесчисленное множество решений, т. е. имеется бе”
численное множество наборов переменных хг, i=l,n, ко-
торые удовлетворяют уравнениям (7.1). Каждый набор
переменных хг, удовлетворяющий системе уравне-
ний (7.1), будем называть решением.
Однако на переменные хг наложено добавочное огра-
ничение, состоящее в том, что эти переменные должны
быть неотрицательны (хг:>0). В общем случае имеется
бесчисленное множество решений, удовлетворяющих это-
му добавочному условию. Любое решение системы (7.1)
с неотрицательными значениями переменных будем назы-
вать допустимым решением. Таким образом, суть задачи
линейного программирования состоит в том, чтобы из
множества допустимых решений выбрать одно, а именно
такое, которое обращает в минимум линейную форму
(72).
Иногда в задаче линейного программирования все или
некоторые из уравнений вида (7.1) имеют вид неравенств.
Так, вместо уравнения амХ14-... -j-alnxn=bj в систему
(7.1) может входить неравенство вида
а,1Х1+...+а,яхя<&,- или a,iXi4- ... +a}nxn^bI.
283
Однако такие неравенства легко превратить в уравне-
ния, введя добавочную переменную хп+/^0 так, чтобы
в зависимости от знака неравенства имело место одно из
двух выражений
••• +й;мХп + Л'м+/ = 6/;
Й/1Х1+ ... -j-cijnxn xn+l=bt.
Такое изменение приводит просто к увеличению числа
переменных, что не меняет существа задачи.
Иногда стоит задача не минимизации линейной формы
(7.2), а ее максимизации. Эта задача сводится к предыду-
щей путем перемены знака у выражения для q. Посколь-
ку в дальнейшем будут встречаться задачи обоих типов,
то условимся значение целевой функции обозначать через
q, если требуется ее минимизировать, и через q', если она
должна быть максимизирована
Прежде чем искать решение уравнений (7.1), удовле-
творяющее наложенным требованиям х;^0, i=l,n, q—
=min, попробуем найти какое-либо решение уравнений
(7.1). Поскольку число переменных п в этой системе боль-
ше числа уравнений т, то одно из возможных решений
можно найти, если п—т каких-либо переменных поло-
жить равными нулю. Полученную при этом систему т
уравнений с т неизвестными можно решать обычными ме-
тодами алгебры. Правда, для того чтобы система т. урав-
нений с т неизвестными имела решение, необходимо, что-
бы определитель, составленный из коэффициентов при не-
известных, не обращался в нуль. Если это условие не
выполняется, то можно приравнять нулю другие п—т пе-
ременных Полученное при этом решение называют базис-
ным. Можем ввести теперь некоторую терминологию, ши-
роко употребляемую в задачах линейного программиро-
вания
Базисом называют любой набор т переменных таких,
что определитель, составленный пз коэффициентов, при
этих переменных не равен нулю Эти т переменных назы-
вают базисными (по отношению к данному базису). Ос-
тальные н—т переменных называются небазисными или
свободными. В каждой конкретной системе уравнений
(7.1) может существовать несколько различных базисов
с различными базисными переменными
Если положить все свободные переменные равными ну-
лю и решить полученную систему т уравнений с т неиз-
284
вестными, то получим базисное решение. Однако среди
различных базисных решений будут такие, которые дают
отрицательные значения некоторых переменных. Эти ба-
зисные решения противоречат условию задачи и являют-
ся недопустимыми.
Допустимым базисным решением является такое ба-
зисное решение, которое одновременно допустимо, т. е. ко-
торое дает неотрицательные значения базисных перемен-
ных. Допустимые базисные решения являются наиболее
простыми из допустимых решений системы (7.1). Однако
на решение задачи накладывается добавочное условие:
линейная форма (7.2) должна при найденном решении
принимать минимальное значение. Решение задачи при
этом добавочном условии усложняется, однако понятие
допустимого базисного решения играет очень важную роль
и при нахождении полного решения задачи.
7.1.2. Примеры задач линейного программирования
Линейное программирование возникло в связи с рассмотрением во-
просов о нахождении наивыгодиейших вариантов при решении различ-
ных планово-производственных задач. В этих задачах имеются боль-
шая свобода изменения различных параметров и ряд ограничивающих
условий. Требуется найти такие значения параметров, которые с неко-
торой точки зрения были бы наилучшими. К таким задачам относятся
Таблица 7.1
Виды ресурсов Расход ресурсов на единицу продукции Запасы ресурсов
Г. 1 7*8
St «И «12 «13 bl
$2 «21 «22 «23 Ьг
$3 «31 «32 «33 ь3
S4 «41 «42 «43 &4
Доход от реализа- ции единицы про- дукции «1 С2 с3 -
задачи нахождения наиболее рационального способа использования
сырья и материалов, определения наивыгоднейших производственных
режимов, повышения эффективности работы транспорта и т. п.
Существо задач линейного программирования поясним на ряде при-
меров
285
Пример 7.1 (задача об использовании ресурсов). Для осуществле-
ния I различных технологических процессов Г,....Ti заводу требуетсн
т видов ресурсов Si, ..., S,„ (сырье, топливо, материалы, инструмент
и т. п.). Запасы ресурсов каждого вида ограничены и равны bi; ...
..., bm. Известен расход ресурсов на единицу продукции по каждому
технологическому процессу. Требуется определить, в каком количестве
выпускать продукцию каждого вида, чтобы доход от реализации этой
продукции был максимальным.
Обозначим ац — расход ресурсов вида S, на единицу продукции
вида Tj\ С/ — доход от реализации единицы продукции вида Т,. Все
имеющиеся данные представим в виде табл. 7.1, положив для конкрет-
ности /=3, ш=4
Обозначим через X/ количество единиц выпускаемой продукции
вида Г/. Ограничениями в этой задаче являются требования, чтобы
расход ресурсов вида Si на выпуск всех видов продукции не превышал
имеющихся запасов
X aijUj^bi, i= 1, /п. (7.4)
Эти ограничении легко превратить в уравнения, введя переменные
Xi+/^0, означающие неиспользованные ресурсы вида S,-. При этом вме-
сто (7.4) получим
i
Т +xl+l=bl, t = l. in. (7.5)
/=1
Доход от реализации выпущенной продукции
<?' = 2 cixi- <7-6)
/=1
Оптимальным планом выпуска продукции будет такое неотрица-
тельное решение системы уравнений (7.5), при котором целевая функ-
ция (7.6) будет максимальна.
Пример 7.2 (задача о распределении выпуска продукции по пред-
приятиям). План отрасли предусматривает за время Т выпуск следую-
щих видов продукции:
Ai в количестве N\ штук;
А2 в количестве N2 штук;
At в количестве Nt штук.
Эти виды продукции могут выпускаться на г однородных пред-
приятиях 77ь ..., Пг. Предполагаем, что ни одно предприятие не мо-
286
жет одновременно выпускать несколько видов продукции. Кроме того,
задано: ац — количество продукции At, выпускаемой на предприятии
/7, в единицу времени; bt, — стоимость единицы продукции вида А/,
выпущенной на предприятии Л/, хц —время работы предприятия Л/
по выпуску продукции А,.
Требуется найти такие значения х,„ при которых стоимость вы-
пускаемой продукции будет минимальной.
Ограничения. 1) время работы каждого предприятия не должно
превышать Т
Е xh<T, (7-7)
1=1
2) количество выпускаемой продукции должно соответствовать но-
менклатуре
S ailXij = Nh ,=177- (7.8)
Целевая функция будет представлять собой общую стоимость вы-
пущенной продукции. Если принять во внимание, что величина а^Ь^Хц
представляет собой стоимость части продукции At, выпускаемой пред-
приятием П,, то общая стоимость выпускаемой продукции
<? = Е|Е аИьЦХЦ- (7-9)
Согласно условиям задачи эта величина должна быть минимизиро-
вана при выполнении ограничений (7.7) и (7.8).
Пример 7.3 (транспортная задача). В пунктах Р,, ..., Р( имеется
однородный груз в количествах ... at Его необходимо перевезти
в пункты Qi, .... Qr в количестве blt ..., br, так, чтобы общая стои-
мость перевозок была минимальна. При этом предполагается, что ко-
личество требуемого груза равно имеющимся запасам:
У a, = >j bj. (7. 10)
Обозначим xtl — количество груза, перевозимого из пункта Р,
в пункт Q,, с,, — стоимость перевозки единицы этого груза
Ограничения: 1) количество груза, отправляемою из пункта Р, на
все пункты назначения, должно быть равно имеющимся запасам at.
Е хц = а{, 1=1, /; (7.11)
287
2) количество груза, прибиваемого в Q, со всех пунктов отправ-
ления, должно равняться потребности 6;:
2 х0- = 6/, /=~ (7.12)
i=i
Целевая функция определяет полную стоимость перевозки всех
грузов.
<7 = 2 2 q/o- (7.13)
/=1 f=l
Формулировка задачи остается прежней, если количество имеюще-
гося груза превышает потребности. При этом вводится фиктивная стан-
ция назначения Qr+i, на которую отправляется излишек груза 6г+1 со
стоимостью перевозок а.г+^О, 1=1,1.
Пример 7.4 (задача о выборе оптимального варианта аппаратуры).
Требуется спроектировать специализироваииое цифровое вычислитель-
ное устройство, которое должно выполнять последовательно г матема-
тических операций и в соответствии с этим состоит из г последова-
тельных блоков. Имеется I различных вариантов выполнения каждого
блока: на электронных лампах, полупроводниковых элементах, феррит-
транзисторных элементах, 'микромодулях и т. п. Заданы ограничения
в отношении максимальной стоимости (Л), габаритов (У) и макси-
мального времени производства операций (Z). Требуется выбрать ва-
риант, наиболее выгодный с точки зрения поставленных требований.
Обозначим через х„ у, и z< соответственно стоимость, габариты и
время производства операции для i-ro блока. Тогда имеющиеся огра-
ничения могут быть записаны в виде
2 хг<Х; 2?г<г. (7.14)
Величины у, и г, зависят от варианта выполнения блока, а зна-
чит, являются элементами следующих множеств:
{хи,..., хц}-, У1^ {уи, — , уц}‘, 2(е{2[ъ ..., гп}, (7.15)
где x,f, у,,, z,i — величины, означающие соответственно стоимость, га-
бариты и время производства операции для i-ro блока при j-м ва-
рианте его исполнения.
Если ci, С2, с3—коэффициенты, характеризующие относительную
ценность уменьшения стоимости, габаритов и времени производства
операций, то условие оптимального варианта аппаратуры запишем
288
в виде
Q= CiE *1 + ^2 ^ + сз2 г* = min‘ (7J6)
Особенностью данной задачи, отличающей ее от первоначально
сформулированной задачи линейного программирования, является то,
что хотя ограничения (7.14) и целевая функция (7.16) являются ли-
нейными, переменные х„ yh г, могут принимать не любые неотрица-
тельные значения, а лишь значения из конечных множеств (7.15). По-
этому обычные методы линейного программирования к данной задаче
неприменимы, и ее следует решать методами целочисленного (дискрет-
ного) программирования.
1.1.3. Геометрическая интерпретация задачи
линейного программирования
Для того чтобы получить более полное представление
о задаче линейного программирования, дадим геометриче-
скую интерпретацию следующей задачи. Имеется система
уравнений:
2х3 кг х3 — 2; I
Xj — 2х2 + = 2;
xi “Ь хг + хь = 5 '
(7-17)
и целевая функция
q=x2—хь (7.18)
Требуется найти неотрицательные значения перемен-
ных, удовлетворяющих уравнениям (7.17) и обращающих
в минимум целевую функцию (7.18). Удобней будет дать
правила решения задачи линейного программирования для
случая максимизации целевой функции, что легко сделать,
взяв в качестве целевой функции выражение
?=xi—х2. (7.19)
В данном примере число уравнений т=3, а число
неизвестных п=5, так что имеется базисных переменных
т—3 и свободных переменных п—т—2. То, что свобод-
ных переменных только две, дает возможность проиллю-
стрировать решение задачи геометрически в двумерном
пространстве, т. е. на плоскости.
19-804
289
Систему трех уравнений (7.17) можно разрешить от-
носительно трех переменных, например Л'з, х4 и х5, выра-
зив их через Xi и х2- При этом получим
= 2 + 2л, - х?; ]
= 2 —х,+2г2; 1 (7.20)
х5 = 5 — х, — х2. '
По условию задачи линейного программирования пе-
ременные могут принимать только неотрицательные зна-
чения, т. е. областью допустимых значений переменных
будет область, определяемая условиями
Xi^sO, i=l,5. (7.21)
Каждое из неравенств (7.21) определяет некоторую
полуплоскость на плоскости (хь х2). Так, неравенство
*1^0 определяет верхнюю полуплоскость, неравенство
x3JSsO — полуплоскость, лежащую по одну сторону от пря-
мой 2-]-2х1—х2=0, а именно ту, которая содержит начало
координат, что легко проверяется подстановкой в первое
из неравенств (7 20) координат точки (0, 0). Область, со-
ответствующая х3<0, является запрещенной, и ее удобно
отметить штриховкой, как показано на рис. 7.1.
Подобные построения для всех хг приведены на
рис. 7 2. На рисунке прямые, соответствующие условию
хг=0, i=lн-5, отмечены цифрой (I). Запрещенные обла-
сти, соответствующие хг<0, отмечены штриховкой. Допу-
стимой областью значений переменных Xi и х2 является за-
темненная область, представляющая собой многоугольник
Oabcd Важно отметить, что многоугольник допустимых
решений является замкнутым и выпуклым, так как пред-
ставляет собой пересечение выпуклых областей, опреде-
ляемых УСЛОВИЯМИ Хг^О.
Проведенное построение позволяет дать геометриче-
скую интерпретацию базисному решению. Так как каж-
дая прямая на рис. 7 2 соответствует обращению в нуль
одной из переменных, то в точках пересечения двух пря-
мых будут обращаться в нуль две, т. е. п—т переменных.
Но п—т есть число свободных переменных, обращение
которых в нуль соответствует базисному решению Таким
образом, точки пересечения прямых x,==0, t=14-5 опре-
деляют базисные решения задачи линейного программи-
рования.
290
Среди базисных решений имеются такие, которые не
принадлежат области допустимых решений. Это недопу-
стимые базисные решения. Области допустимых решений
принадлежат только те точки пересечения прямых х=0,
которые являются вершинами многоугольника допусти-
мых решений. Следовательно, вершины многоугольника
допустимых решений соответствуют допустимым базис-
ным решениям.
Рис 7 1 Полуплос-
кость
Рис. 7.2 Многоугольник допу-
стимых решении
Рассмотрим теперь условие обращения в максимум це-
левой функции (7.19). Геометрически при любом q' выра-
жение (7.19) определяет прямую, проведенную под углом
45° к оси абсцисс, причем увеличению q' соответствует
перемещение прямой в направлении стрелки, показанной
на рис. 7.2. Эта прямая будет совместна с допустимым ре-
шением задачи только в том случае, если она имеет об-
щие точки с областью допустимых решений. Максималь-
ное значение q' получится при крайнем положении пря-
мой, когда она обращается в опорную прямую к области
допустимых решений (пунктир на рис. 7.2). Однако опор-
ная прямая к выпуклому многоугольнику обязательно
проходит хотя бы через одну из его вершин, которые, как
мы видели, соответствуют допустимым базисным реше-
ниям.
Таким образом, приходим к очень важному выводу, что
решение задачи линейного программирования, обращаю-
щее в максимум целевую функцию q', обязательно лежит
среди допустимых базисных решений.
291
Этот вывод легко обобщается на случай произвольных
тип, когда п—т>2. Здесь уравнения (7.20) определя-
ют гиперплоскости в (п—т) -мерном пространстве, а ус-
ловия (7.21) — полупространства, ограниченные гипер-
плоскостями. При этом допустимое множество будет пред-
ставлять собой замкнутый выпуклый многогранник. Мно-
жество замкнуто, так как условия (7.21) заданы в виде
нестрогих неравенств, выпукло, так как является пересе-
чением выпуклых множеств (полупространств).
Целевая функция (7.2) линейна, поэтому ее можно
считать как вогнутой, так и выпуклой. Следовательно, оп-
тимум в задаче линейного программирования всегда един-
ственный, а значит, и глобальный. Функция q(x) не име-
ет стационарных точек. Следовательно, оптимум достига-
ется на границе допустимого множества.
Среди граничных точек допустимого множества суще-
ствуют крайние точки, являющиеся пересечением отдель-
ных граней, т. е. представляющие собой базисные реше-
ния. Особенность крайних точек в том, что они не могут
быть представлены в виде выпуклой комбинации других
точек множества (см. § 4.8.3).
Допустим, что максимум сх достигается в граничной
точке х, которая не является крайней. Представим эту
точку в виде выпуклой комбинации минимального числа
крайних точек, так чтобы в это представление не входили
крайние точки с нулевыми весами. Пусть это будут точки
Xt,...,xTO. Тогда х =2Ja)txz, где w£->0, При
этом
сх = с = Ste>,-(cx,).
Пусть в точке х* значение сх* будет наибольшим из
всех крайних точек. Обозначим это значение через и.
Правая часть выражения для сх не уменьшится, если все
схг заменить на v. Следовательно,
сх^и.
Если сх<и, то оптимальной точкой является не х,
а х*. Случай же сх=и может быть только тогда, когда оп-
тимум достигается во всех рассмотренных крайних точках.
Таким образом, оптимум в задаче линейного програм-
мирования достигается либо в одной крайней точке, либо
292
на множестве крайних точек, а значит, и на любой вы-
пуклой комбинации этих точек. Это означает, что решение
задачи линейного программирования обязательно лежит
среди допустимых базисных решений.
Полученный вывод позволяет наметить пути решения
задачи линейного программирования. Поскольку решение
должно находиться среди допустимых базисных решений,
число которых конечно, то можно найти все допустимые
базисные решения и для каждого из них вычислить значе-
ние q'. Окончательным решением явится то из найденных
решений, для которого значение q' будет максимально.
Такой путь решения задачи хотя и возможен, но весь-
ма трудоемок, так как число допустимых базисных реше-
ний может быть весьма большим. Однако существуют ра-
циональные способы последовательного перебора базис-
ных решений, которые позволяют рассматривать не все
допустимые базисные решения, а их минимальное число.
Одним из наиболее распространенных методов такого пе-
ребора является так называемый симплекс-метод, который
будет рассмотрен в следующем параграфе.
7.2. РЕШЕНИЕ ЗАДАЧИ ЛИНЕЙНОГО
ПРОГРАММИРОВАНИЯ
7.2.1. Алгебра симплекс-метода
Существо симплекс-метода состоит в следующем.
Прежде всего находим какое-либо допустимое базисное
решение. Его можно найти, приняв какие-либо п—т пе-
ременных за свободные, приравняв их нулю и решив си-
стему уравнений (7.1). Если при этом некоторые из базис-
ных переменных окажутся отрицательными, то нужно вы-
брать другие свободные переменные, т. е. перейти к ново-
му базису.
После того как найдено допустимое базисное решение,
проверяем, не достигнут ли уже максимум целевой функ-
ции q'. Если нет, то ищем новое допустимое базисное ре-
шение, но не любое, а такое, которое увеличивает значе-
ние целевой функции q'. Затем процедуру повторяем. Дан-
ный метод довольно быстро приводит к цели, так как по-
зволяет исключить из рассмотрения большое число базис-
ных решений, заведомо не обращающих в максимум це-
левую функцию.
293
Разберем этот метод более подробно на рассмотрен-
ном ранее примере.
Обратимся к системе уравнений (7.17), для которой требуется
найти неотрицательное решение, обращающее в максимум целевую
функцию (7.19). Поскольку п—т=2, то в качестве свободных можно
взять любые две переменные, например х, и х2. Положив пх равными
нулю, из (7.17) находим базисное решение Xi=x2 = 0, х3=2, х, = 2,
xs=5, которое является допустимым и при котором q'—X\— х2=0
Проверить, достигнут ли при найденном решении максимум целе-
вой функции, чможно путем поиска нового базисного решения, при ко-
тором целевая функция будет больше Для перехода к новому допу-
стимому базисному решению одну из свободных переменных Xj или х2
следует сделать базисной. При этом она будет отличной от нуля, т е.
возрастает. Следовательно, если какая-либо из свободных переменных
входит в выражение для целевой функции со знаком «-(-», т е при
ее увеличении целевая функция увеличивается, то максимум целевой
функции не достигнут и данную переменную следует превратиib в ба-
зисную, сделав ее отличной от нуля.
Однако при возрастании свободной переменной некоторые нз ба-
зисных переменных начнут уменьшайся. Так как отрицательные зна-
чения переменных недопустимы, в качестве новой свободной перемен-
ной следует взять ту из базисных, которая раньше других обратится
в нуль.
В рассматриваемом примере в выражение для целевой функции
(7.19) со знаком «-]-» входит свободная переменная Х|. Значит, макси-
мум целевой функции не достигнут и переменную Xj следует сделать
базисной Для определения новой свободной переменной выразим ба-
зисные переменные х3, х4, xs через свободные, приведя уравнения
(7 17) к виду (7.20). Из этих уравнений видим, что при х2=0 увели-
чение Х| не приводит к уменьшению х3, но уменьшает х4 и х5, так что
при xi = 2 получаем х4=0, х5 = 3>0 Таким образом, переменную х4
следует сделать свободной, что приводит к новому базису хь х3, х3.
Для продолжения решения разрешим систему (7 17) относительно
новых переменных, приведя ее к виду
•'1 = 2 + 2-'"г — '"41 ]
у3 == 6 + Зх2 — 2х4; | (7.22)
х5 = 3—Зх2Ч-х4. )
Целевую функцию также выразим через новые свободные перемен-
ные х2 и х4-
q' = 2-\-x2— х4. (7.23)
Повторяя проведенные ранее рассуждения, приходим к выводу, что
максимум целевой функции не достигнут и следует свободную перемен-
294
ную х2 перевести в базисную, а базисную переменную х5—в свобод-
ную Новый базис образуют при этом переменные хь х2, х3
Разрешая уравнение (7.17) относительно новых базисных перемен-
ных, получаем
xl = 4- х4/3 —2/g/3; }
*2= 1+*<1/3-х6/3, J> . (7.24)
х3 = 9 —х4—х6. J
Целевая функция при этом принимает вид
<f=3-2x4/3-x5/3. (7 25)
Из (7 25) видим, что при увеличении свободных переменных х4
и х5 значение q' уменьшается. Следовательно, при данном базисе до-
стигается максимум целевой функции q' и решением рассмотренной
задачи будет следующий набор переменных: х4=х5 = 0, х,=4, х2=1,
х3=9
При этом q'=—q = 3.
Рассмотренный метод решения задачи линейного про-
граммирования обладает тем недостатком, что связан
с громоздкими преобразованиями системы линейных урав-
нений из одной формы в другую. Значительного упроще-
ния преобразований можно добиться, если представить
уравнения в виде таблиц, содержащих коэффициенты при
переменных. Переход от одной системы уравнений к дру-
гой при этом сводится к пересчету коэффициентов в таб-
лицах, что осуществляется по чисто формальным прави-
лам, хорошо приспособленным к тому же для решения на
ЭВМ.
7.2.2. Табличный метод нахождения оптимального
решения
При пользовании табличным методом удобно ввести
специальную форму записи для уравнения (7.1) и целевой
функции (7.2) Обозначим через хг', 1=1, иг базисные пе-
ременные, а через х", j=l,n—т свободные переменные
Выразив целевую функцию и базисные переменные через
свободные, сформулируем задачу линейного программи-
рования в следующем виде максимизировать
q’= — аоа — 2
(7.26)
295
при условиях
x/-=aZo— 2 ачх”’ J‘ = 1 • т> х/'^о. (7.27)
£ = 1
При такой форме записи задача может быть представ-
лена следующей матрицей коэффициентов при пере-
менных:
I — Xi ... — Хп-т
а00 а01 ... at(,|_n!)
яюап • •
(7.28)
По виду коэффициентов матрицы (7.28) легко судить,
является ли найденное базисное решение допустимым, и
если оно допустимо, то будет ли оптимальным. Действи-
тельно, замечая, что столбец коэффициентов а10, г=#0
представляет собой базисное решение, соответствующее
базису х/,..., хт', а строка коэффициентов а0/, /У=0 пред-
ставляет собой взятые с обратным знаком коэффициенты
при свободных переменных в выражении для q', приходим
к выводу, что базисное решение, соответствующее базису
Xi',..., хт', допустимо, если аг0^0, £=#0. Если, кроме того,
ао/^0, /=#0, то это базисное решение является и опти-
мальным. Очевидно также, что при оптимальном базис-
ном решении коэффициент а00 дает значение q'—qM3K<:=
Начнем решение задачи с нахождения какого-либо до-
пустимого базисного решения, которой в общем случае не
является оптимальным. Это базисное решение представим
таблицей коэффициентов, составленной по типу матрицы
(7.28). Конечно, при этом нет необходимости переимено-
вывать переменные. Под коэффициентом а,, следует по-
нимать коэффициент, стоящий па пересечении строки с ба-
зисной переменной хг и столбца со свободной переменной
X,. Для перехода к лучшему базисному решению необхо-
димо преобразовать матрицу коэффициентов. Способ та-
кого преобразования сформулируем в виде системы правил,
которые проиллюстрируем на примере задачи, решенной
в предыдущем параграфе. Не будем давать строгое обо-
снование этим правилам. Отметим только, что они в точ-
ности соответствуют тем преобразованиям системы урав-
296
нений, которые осуществлялись в предыдущем примере и
могут быть легко проверены путем сопоставления соот-
ветствующих преобразований.
Пусть задача линейного программирования дана в ви-
де системы уравнений (7.17) и целевой функции (7.19),
которую надо максимизировать. Принимая и %2 за сво-
бодные переменные, приведем эту систему уравнений и це-
левую функцию к виду (7.26) и (7.27):
9' = 0 — (— х1 + х:>;
= 2 —'-2^ + ад
х4 — 2 — (х2 —42х2);
х6 = 5 - (х, + х2).
ЛАатрицу коэффициентов представим в виде табл. 7.2,а,
в верхнем левом углу клеток запишем коэффициенты ац
уравнений (7.29).
Проверим, не найдено ли оптимальное решение, усло-
вием которого является а0/^0, /У=0. Поскольку aOi (ко-
эффициент при —Xi в выражении для q') отрицателен, то
оптимальное решение не найдено и переменную х( следует
сделать базисной. Выделим жирными линиями столбец,
297
соответствующий переменной хь Если отрицательными
окажутся коэффициенты а0; при нескольких свободных
переменных, то в базисную можно переводить любую из
них.
Определим теперь, какую же из базисных переменных
следует сделать свободной. Очевидно, ту, которая быстрее
обратится в пуль при увеличении хь Это будет та базис-
ная переменная хг, для которой коэффициент в отмеченном
столбце a,i>0 и отношение al0/an наименьшее. Такой пе-
ременной является базисная переменная х4 с а40—2 и
а4! = 1. Строку, соответствующую базисной переменной
х4, также выделим жирными линиями.
Коэффициент a4i, стоящий в левом верхнем углу клет-
ки на пересечении выделенных строки и столбца, назовем
генеральным коэффициентом (взят в рамку). Обозначим
через X величину, обратную генеральному коэффициенту.
В нашем случае X=l/a4i = 1.
Теперь следует заполнить нижние углы каждой клетки.
Это делаем по следующим правилам: 1) в клетку на пе-
ресечении отмеченных строки и столбца записываем Х=
= 1/а4г, 2) в клетках выделенной строки записываем
верхние коэффициенты, умноженные на X (верхние коэф-
фициенты, за исключением генерального, выделены жир-
ным шрифтом); 3) в клетках выделенного столбца запи-
сываем верхние коэффициенты, умноженные на —X (ниж-
ние коэффициенты, за исключением клетки с генераль-
ным, выделены жирным шрифтом); 4) в остальных клет-
ках записываем произведение выделенных жирным шриф-
том коэффициентов, на пересечении которых стоит данная
клетка
Затем переходим к заполнению табл. 7.2,6, которая от-
личается от табл. 7.2,а тем, что отмеченная свободная пе-
ременная xi стала базисной, а отмеченная базисная пере-
менная ха стала свободной. Верхние левые углы клеток
табл 7 2,6 заполняются по следующим правилам: 1) стро-
ку п столбец, соответствующие новым свободной и базис-
ной переменным, заполняем нижними коэффициентами
выделенной строки и столбца табл. 7 2,а; 2) в остальные
клетки записываем суммы коэффициентов, стоящих в со-
ответствующих клетках табл 7.2,а.
Заполненная таким образом табл. 7.2,6 соответствует
матрице коэффициентов (7.28) при новом базисе xi, х3, х5.
Далее вся процедура повторяется.
Поскольку в табл 7.2,6 коэффициент а02<0, то опти
298
мальное решение не найдено. Следовательно, нужно со-
гласно приведенным правилам заполнить нижние левые
углы табл. 7.2,6 и перейти к новой табл. 7.2,в, соответст-
вующей базису хь х2, х3. В таблице коэффициенты а0/,
=#0 положительны, и она дает оптимальное решение зада-
чи, которое находим по столбцу свободных членов:
Xt=4; х2=1; Хз=9; х4=Х5=0; <7/макс==—<?мнн=3; 9»’ии=
= —3
7.2.3. Получение начального допустимого базисного
решения
В задачах с большим числом уравнений и неизвестных
значительные трудности представляет получение началь-
ного допустимого базисного решения Опишем один из
возможных способов решения этой задачи [38]. ,
Общий вид системы уравнений, имеющей допустимое
базисное решение хг',...,хт', получим из (7.27), перепи-
сав его в виде
*/+ s = а,о, а10 >0, t = 1, т. (7.30)
Особенность этой системы уравнений в том, что каж-
дая переменная хг', принятая за базисную, входит только
в одно из уравнений с коэффициентом +1 (или с любым
положительным коэффициентом, так как обе части урав-
нения можно разделить на этот коэффициент). Если такие
переменные найдутся в каждом из уравнений системы
(7 1), то онп и составят первоначальный допустимый ба-
зис. В рассмотренном примере системы (7 17) такими пе-
ременными оказались хз, х4, xg.
Если в некоторых уравнениях таких переменных нет,
то прибегаем к искусственному приему. Выписываем по
порядку те уравнения с переменными, которые можно при-
нять за базисные. Обозначим их х/, .. , х/, s<_m. В осталь-
ные т—s уравнений вводим искусственные базисные пе-
ременные х\, k=s+l,..., т, налагая на них условие х-.^
^0. Тогда система уравнений принимает вид
х' + 3 ачх<" = а‘»' l = !’s; |
г_: ________ [ <7-31)
Ч’ +2 ак!х," =°Чо> k = «+ !. "*•
299
Для того чтобы полученная система совпала с исход-
ной, в окончательном решении искусственные переменные
должны отсутствовать, т. е. обратиться в нуль. Для этого
их вводят в выражение для q' с достаточно большими от-
рицательными коэффициентами.
7.2.4. Двойственная задача линейного
программирования
Вернемся к задаче распределения ресурсов, рассмот-
ренной в примере 7.1, и зададимся вопросом, какова с точ-
ки зрения предприятия ценность имеющихся в его распо-
ряжении ресурсов. При решении этого вопроса будем
иметь в виду, что ресурсы, которые предприятие не может
полностью использовать, имеют для него очень низкую
ценность в том смысле, что предприятие не согласно нести
даже небольшие расходы на увеличение запасов этих ре-
сурсов. Так, дорогое оборудование, не участвующее в тех-
нологическом процессе, составляет для предприятия нуле-
вую ценность. Наибольшую ценность, очевидно, будут
иметь те ресурсы, которые в наибольшей степени ограни-
чивают выпуск продукции, а следовательно, и доход пред-
приятия и на увеличение запасов которых предприятие со-
гласно понести значительные расходы.
Поэтому можно считать, что каждый вид ресурса обла-
дает некоторой «теневой ценой» [38], определяющей цен-
ность данного ресурса для предприятия с точки зрения до-
хода от реализации выпускаемой продукции и зависящей
от наличного запаса этого ресурса и потребности в нем
для выпуска продукции.
Если предприятие по каким-либо причинам ограничи-
вается одним технологическим процессом, требующим
больших затрат некоторого ресурса, запасы которого ог-
раничены, то теневая цена этого ресурса будет велика.
Однако установленные в соответствии с этим технологиче-
ским процессом теневые цены не будут наилучшими, так
как введение других технологических процессов позволит
более рационально использовать все запасы ресурсов.
Следовательно, существуют оптимальные теневые цены,
которые соответствуют максимальному доходу предприя-
тия, т. е. оптимальному распределению ресурсов. В связи
с этим в экономической литературе оптимальные теневые
цены называют объективно обусловленными или опти-
мальными оценками. Как видим, определение оптималь-
300
них теневых цен оказывается тесно связанным с задачей
оптимального распределения ресурсов, т. е. с задачей ли-
нейного программирования, описываемой системой урав-
нений (7.5) и целевой функцией (7.6). Однако для опре-
деления оптимальных теневых цен можно составить са-
мостоятельную задачу линейного программирования.
Обозначим через иг теневую цену единицы ресурса S,.
Величины Ui должны быть такими, чтобы теневая цена
ресурсов, используемых в любом технологическом процес-
се, не была меньше получаемого дохода. Воспользовав-
шись обозначениями примера 7.1 и данными табл. 7.1, за-
пишем это условие в виде
2 ct, i = Tj. (7.32)
Если ввести переменные ит+1^0, представляющие со-
бой превышение теневой цены единицы продукции над до-
ходами от ее реализации, то система неравенств (7.32)
превращается в систему уравнений
2 ] = —/ (7.33),
z=i
Оптимальными теневыми ценами будем считать такие,
которые минимизируют общую стоимость ресурсов, т. е.
величину
^ = 2^- <7-34)
i=i
Система ограничений (7.32) совместно с целевой,
функцией (7.34) представляет собой новую задачу линей-
ного программирования, получившую название двойст-
венной задачи по отношению к задаче в примере 7.1, ко-
торую называют прямой или основной задачей линейного
программирования.
Нетрудно заметить, что прямая и двойственная задача
оказываются тесно связанными между собой. Эта связь
проявляется в следующем: если прямая задача является
задачей максимизации целевой функции, то двойственная
задача — минимизации; коэффициенты целевой функции
в прямой задаче являются свободными членами в ограни-
чениях двойственной задачи; свободные члены из ограни-
301
чений прямой задачи становятся коэффициентами целевой
функции в двойственной задаче; коэффициенты при пере-
менных в ограничениях двойственной задачи представля-
ют собой столбцы таблицы коэффициентов прямой задачи;
знаки неравенств в ограничениях меняются на противопо-
ложные.
Существует тесная связь между решениями прямой и
двойственной задач линейного программирования. Для
установления этой связи запишем уравнения прямой и
двойственной задач в иной форме.
Примем в прямой задаче переменные хь..., х; за сво-
бодные и сформулируем ее в следующем виде: максими-
зировать
<7'=°-2 (-<?,)*, (7.35)
/=!
при условиях
к1+1 — bi — 2 i' = 1, т. (7.36)
Этой задаче соответствует матрица вида
q' ГО -с. ... -се '
Kl + 1 I а11 ••• а11
xi+m\_b,n ат ат1
(7.37)
В двойственной задаче примем за свободные перемен-
ные «1,..., ит и сформулируем ее в следующем виде: мини-
мизировать
q^ = Q + ^biUt ’ (7.38)
при условиях
(7.39)
302
Этой задаче соответствует матрица вида
1 иг ... ит
q* Г 0 bt ... bm ~
ит+1 ~~с1 аи ••• аип
(7.40)
um+l \_~~clail ••• aml -
Как видим, столбцы матрицы (7.40) являются строка-
ми матрицы (7.37). Следовательно, и прямую, и двойст-
венную задачу можем описать одной и той же матрицей
(7.37), в которой, однако, должно быть установлено сле-
дующее соответствие между прямыми и двойственными
переменными:
(7.41)
Следует отметить, что любое преобразование матрицы
(7.37) по рассмотренным ранее правилам приведет к но-
вой матрице, которая также будет описывать как прямую,
так и двойственную задачу. Следовательно, и матрица са-
мого общего вида (7.28) может служить для описания
как прямой, так и двойственной задачи линейного про-
граммирования. Если при этом элементы первого столбца
(за исключением, может быть, »оо) положительны, то
матрица соответствует допустимому базисному решению
прямой задачи. Если положительны элементы первой
строки (за исключением, быть может, аОо), то матрица
соответствует допустимому решению двойственной задачи.
Если же в матрице (7.28) положительны элементы как
первого сторбца, так и верхней строки (за исключением,
быть может, <хоо), то матрица соответствует оптимально-
му решению как прямой, так и двойственной задачи. При
этом коэффициент а00 дает значение целевой функции, ко-
торое при оптимальном решении совпадает как для пря-
мой, так и для двойственной задачи:
х <?/макс—<7*МИН- (7.42)
Пример 7.5. Задача на распределение ресурсов задана табл 7.3.
В добавочных графах этой таблицы приведено решение прямой и
двойственной задач линейного программирования, т. е. указан опти-
мальный план распределения ресурсов, остатки ресурсов при оптималь-
ном плане и теневые цены. Из таблицы видно, что ресурсы вида Зь
303
присутствующие в избытке, имеют пулевую цену. Наивысшую цену
имеют ресурсы Зг, которые требуются для всех технологических про-
цессов и запасы которых невелики.
Отметим в заключение, что теневые цены могут в ряде
случаев играть важную роль как инструмент управления.
Так, на крупном предприятии или в отрасли промышлен-
ности, где многие решения принимаются самостоятельно
Таблица 7.3
Риды ресурсов Расход ресурсов на единицу продукции Запасы ресур- сов Остатки ресурсов при опти- мальном плане Теневые
г. 1 Г, Т8
S. 2 । 1 25 5,5 0
Sa 1 1 1 14 3,0
«3 0 4 2 19 0 0,5
$4 3 0 1 24 0 1,0
Доход от реализации еди- ницы продукции 6 5 5 - - -
Оптимальный план 5,5 1,0 7,5 —- — —
отделами и производственными группами, бывает затруд-
нительно информировать каждый отдел о решениях, при-
нимаемых другими отделами. В этом случае теневые цены
могут служить каждому отделу хорошим ориентиром для
лринятия решений, близких к оптимальным с точки зре-
ния интересов всего предприятия в целом.
7.2.5. Понятие о целочисленном программировании
Во многих задачах линейного программирования пере-
менные являются неделимыми на части величинами. Так,
предприятие не может выпустить 7,5 самолета, 4,8 турби-
ны и т. п. В таких задачах к условиям (7.1) и (7.2) до-
бавляем требование, чтобы переменные х,- выражались це-
лыми числами или, как в примере 7.4, были элементами
конечного множества. Геометрически это означает, что до-
пустимыми решениями будет не вся область допустимых
решений, определяемая ограничениями (7.1), а лишь от-
дельные дискретные точки этой области, как показано на
рис. 7 3.
304
Рис 7 3. Множество допустимых решений в
задаче целочисленного программирования
Можно, конечно, попытаться ре-
шить подобную задачу, не считаясь
с условием целочисленности, и найти
решение, определяемое точкой 1, аза-
тем округлить это решение до бли-
жайших целых чисел, получив, таким
образом, в качестве целочисленного
решения точку 2. Однако при этом может получиться ре-
шение, далекое от оптимального. Так, оптимальным цело-
численным решением будет служить точка 3.
Существует ряд методов решения задачи целочислен-
ного программирования, из которых наиболее распростра-
ненным является метод Гомори. Не останавливаясь на вы-
числительной стороне метода Гомори, с которой можно
познакомиться в [5, 41], укажем лишь общую идею этого
метода.
Метод Гомори основан на применении симплекс-мето-
да, с помощью которого ищется оптимальное решение, не
учитывающее целочисленности или дискретности перемен-
ных. Если это решение оказалось нецелочисленным, то
вводится добавочное ограничение, геометрически пред-
ставляющее собой прямую ab (рис. 7.3), а в общем случае
гиперплоскость, которая отсекает часть области допусти-
мых решений вместе с полученным оптимальным решени-
ем, не содержащую ни одной целочисленной допустимой
точки. При этом добавочном ограничении найденное опти-
мальное решение окажется вне новой области допустимых
решений, т. е. будет недопустимым, поэтому задача реша-
ется снова симплекс-методом и находится оптимальное
решение уже для новой области допустимых решений. Ес-
ли это новое решение опять не является целочисленным,
то процедуру повторяют.
За последнее время для решения задачи целочислен-
ного программирования успешно применяют комбинатор-
ные методы, среди которых важнейшим является метод
ветвей и границ [41].
20-804
305
7.3. НЕЛИНЕЙНОЕ ПРОГРАММИРОВАНИЕ
7.3.1. Постановка задачи
В задаче нелинейного программирования (НЛП) тре-
буется найти значение многомерной переменной x=(v<‘\...
..., х(")), минимизирующее целевую функцию <?(х) при ус-
ловиях, когда на переменную х наложены ограничения ти-
па неравенств
A(x)^0, {1AZ)
а переменные х(/>, т. е. компоненты вектора х, неотрица-
тельны:
х0)>0. (7.44)
Иногда в формулировке задачи ограничения (7.43)
имеют противоположные знаки неравенств. Учитывая, од-
нако, что если Д(х)^0, то — f((x)^O, всегда можно све-
сти задачу к неравенствам одного знака Если некоторые
ограничения входят в задачу со знаком равенства, напри-
мер ф(х)=0, то их можно представить в виде пары нера-
венств ф(х)^0, —ф(х)^0, сохранив тем самым типовую
формулировку задачи.
7.3.2. Метод штрафных функций
Как отмечалось в § 6.6, задача на условный экстремум
с ограничениями типа равенств может быть сведена к за-
даче на безусловный экстремум видоизменением целевой
функции путем введения множителей Лагранжа. Анало-
гично этому задача минимизации целевой функции <?(х)
с ограничениями типа неравенств (7.43) может быть све-
дена к задаче на безусловный экстремум видоизменением
целевой функции путем добавления к ней специально по-
добранных функций штрафа [36].
Общая идея метода штрафных функций состоит в по-
строении последовательности новых целевых функций
Qft(x)=?(x)4-rA(p(x), k=l, 2...,
где ф(х)—функция штрафа, принимающая по возможно-
сти малые (желательно нулевые) значения внутри допу-
стимой области и возрастающая по мере удаления за пре-
делы допустимой области, a rA, k=l, 2... — последователь-
306
ность возрастающих положительных чисел — параметров
штрафа.
Наиболее распространенным видом функции штрафа
при ограничениях вида (7.43) является выражение
<Р(х) = 2 (Л+ (х))2,
где Л+(х)—«срезка» функции А(х), равная нулю, если
f,(x)^O, и равная /г(х), если /\(x)>0, т. е.
f + (x)=max[0, А(х)]
Алгоритм решения задачи с использованием штрафных
функций состоит в следующем: а) выбираем произволь-
ное начальное приближение х0 и монотонно возрастаю-
щую последовательность чисел irft->oo; б) при &=1, 2 ...,
начиная с xft_i, решаем задачу безусловной минимизации
по х функции Qft(x), в результате чего находим очередное
приближение xft к решению исходной задачи.
Вопросы сходимости данного алгоритма, а также при-
менение других видов функций штрафа подробно рассмот-
рены в [36].
Пример 7.6. Пусть « — скаляр и q(x) =х2—4(х— 1), как показано
на рис. 7.4. Найти х\ при котором g(x)=min при ограничении х—1^0.
На рис. 7.4 допустимая область отмечена штриховкой. Из рис. 7.4
легко видеть, что решением задачи будет х*=1
Модифицированная целевая функция
Qk (х) = х2—4 (х-1) 4-r* (max (0, х-1))2.
Производная
_ (2х— 4, если х< 1;
6 Х (2х—4-}-2rft(x—1), еслих>1.
Легко видеть, что производная Q\(x) обращается в нуль в един-
ственной точке xft=(2+rft)/(l+r)i), лежащей вне допустимой области
х<1. Однако при />->00 величина xk неограниченно приближается
к оптимальной точке х*=1.
При многомерной переменной х с более сложными ви-
дами ограничений, чем в примере 7.6, нахождение началь-
ного приближения и оптимальных решений для модифици-
рованных целевых функций QA(x) наталкивается на целый
ряд трудностей. Поэтому при решении задач оптимизации
20’ 307
Рис. 7.4. Целевая q(x) и модифициро-
ванная целевая Q*(x) функции
очень важно иметь необходимые
условия, которым должна удов-
летворять точка, оптимизирую-
щая целевую функцию и удовле-
творяющая всем ограничениям.
Хотя такие условия обычно не
являются достаточными, но их
знание существенно облегчает
поиск оптимального решения.
В классической задаче оптимизации без ограничений
на переменные необходимыми условиями оптимума явля-
лись условия (6.71), определяющие стационарные точки
целевой функции ?(х). В задаче НЛП аналогичными усло-
виями являются условия Куна—Таккера. Однако прежде
чем их сформулировать, рассмотрим более простой вариант
задачи НЛП.
7.3.3. Ограничения типа равенств и неотрицательность
переменных --
Простейшей задачей НЛП является задача минимиза-
ции <?(х) с ограничениями типа равенств
fj(x)=O, /=1, т (7.45)
и с требованием неотрицательности переменных х(‘>, I—
= 1, п, что в векторной форме может быть записано в виде
х>0. (7.46)
Данную задачу можно рассматривать как расширение
рассмотренной в § 6.6 задачи на условный минимум на
случай неотрицательности переменных и для ее анализа
использовать уже знакомый математический аппарат, а
именно функцию Лагранжа А(х, %), определенную соотно-
шением (6.76).
Поскольку в рассматриваемой задаче имеют место
ограничения типа равенств, то остаются справедливыми и
соотношения (6.77), из которых вытекает, что в точке х
оптимального решения выполняется соотношение
А(х, Х)=д(х). (7.47)
308
Поэтому рассмотрение особенностей функции Лагран-
жа в окрестности точки оптимального решения можно за-
менить исследованием целевой функции <?(х).
Пусть х — точка, соответствующая оптимальному реше-
нию. Она может быть или внутренней, или граничной точ-
кой допустимой области х^О, т. е. каждая из ее компо-
нент, например х<‘) , будет удовлетворять либо условию
х(!>>0, либо условию х(‘>=0.
Если х(‘> находится не на границе допустимой области,
т. е. х({)>0, то отклонения от точки х возможны как в
сторону увеличения, так и в сторону уменьшения х(‘\ Но
поскольку х — оптимальная точка, то должно быть
<3<7(х)/<3x^=0.
Если х(‘> лежит на границе допустимой области, т. е.
х<г>=0, то отклонения от оптимальной точки возможны
только в сторону увеличения х(‘> и при этом <?(х) должна
увеличиваться, так что д<?(х)/дх<г>>0.
Обобщая эти случаи с учетом соотношения (7.47) и до-
бавляя к ним соотношение (6.78), необходимые условия
того, что точка х является решением рассмотренной зада-
чи оптимизации, можем записать в виде
dL(x, Л) |=0, если х<-1 > >0;
дх(,) |>0, если х<г) = 0, z = !,/?;
<ЗЛ(х, Л)/(ЗЛ;=О, /=ТГш.
(7.49)
7.3.4. Условия Куна — Танкера
Сформулируем теперь необходимые условия того, что
в точке х достигается оптимальное решение задачи НЛП,
т. е. минимизируется <?(х) при ограничениях (7.43) и
(7.44). Предварительно упростим задачу, заменив каждое
ограничение типа неравенств (7.43) на ограничение типа
равенств путем введения добавочных неотрицательных пе-
ременных Zj. При этом ограничения
^(х)+з5=0, z5>0, х<0^>0,
(7.50)
причем
| > 0, если /ДхХО;
( =0, если /Дх) =0.
(7.51)
309
Как видим, данная задача свелась к уже рассмотренной
задаче с ограничениями типа равенств, с п-\-т перемен-
ными Zj, j=l, т, i—l, nw с функцией Лагранжа, име-
ющей вид
L(z, х, Л) = <7(х) + 2 (7.52)
/=1
Условия, которым должны удовлетворять значения z,
и x(i) в точке оптимального решения, будут выражаться со-
отношениями (7.48) и (7.49) применительно к функции
Цг, х, Л).
Условие (7.48), примененное к переменной z„ дает:
М(гдЛ>) !=0' еслиг.>0; (7.53)
дг> I > о, если z; = 0.
Это соотношение вводит ограничения на множители Лаг-
ранжа Из него следует, что в функцию L(z, х, X) огра-
ничения типа неравенств входить не будут, так как для
них Xj=O, а ограничения типа равенств, соответствующие
Zj=O, будут входить с Xj>0. Поэтому функция Лагранжа
L(z, х, Л) фактически совпадает с функцией Лагранжа
L(x, X), определяемой соотношением (6.76). При этом ус-
ловие оптимальности (7.48) применительно к переменным
сохраняет свой вид.
Принимая также во внимание, что <5А(х, Л)/<5Л1=/:/(х),
и учитывая ограничения на вытекающие из (7.53),
окончательные условия, которым должна удовлетворять
точка х, являющаяся решением общей задачи НЛП, запи-
шем в виде
9L (х, X) Г >0, если %('’) = 0; 54
дх(‘) I = 0, если a*<z’>0, i = 17«;
dL (*• х) ( <0, если 2; = 0, 55
axz [ — 0, е ели Z, >0, j — 1, т.
Условия (7.54) и (7.55) называют условиями Куна—
Танкера.
Условия Куна—Таккера иногда записывают иначе. Вве-
дем обозначения
<5А(х, Л)/дл"=рг;
дЦи, Х)/дК3= — q,. (7.56)
310
Тогда соотношения (7.54) и (7.55) перепишем
'> S& О, pt 5s 0, = 0, i = 1, п\ I ,7
1, > О, 5s О, Я;?; = 0, 7=1, т.1
Другая интерпретация условий Куна—Таккера связана
с понятием седловой точки функции Лагранжа L(x, Я).
Седловой точкой функции L(x, X) называют такую точку,
в которой функция Л(х, Л) достигает минимума по х и мак-
симума по X, т. е. точку (х0, Хо), удовлетворяющую услови-
ям
Цх0, X) ^Л(х0, Хо) Хо). (7.58)
Условия, которым должна удовлетворять седловая точ-
ка функции L(x, X), совпадают с условиями Куна—Такке-
ра. Поэтому решение задачи НЛП можем рассматривать
как задачу нахождения седловых точек функции Лагран-
жа.
Следует отметить, что в общем случае условия Куна—
Таккера являются лишь необходимыми условиями сущест-
вования решения задачи НЛП. Для того чтобы они были
и достаточными, нужно, чтобы целевая функция имела
единственный оптимум в допустимой области, который в
этом случае будет и глобальным. Для выполнения этого
условия целевая функция должна быть выпуклой, а систе-
ма ограничений должна быть такой, чтобы допустимая об-
ласть решений представляла собой замкнутое выпуклое
множество. Кроме того, целевая функция q(x) и функции
f,(x), определяющие ограничения задачи, должны быть не-
прерывно-дифференцируемы.
Если необходимые и достаточные условия существова-
ния решения задачи НЛП выполняются, то могут быть
найдены эффективные вычислительные методы решения
задачи НЛП, с одним из которых мы познакомимся в сле-
дующем параграфе.
7.3.5. Квадратичное программирование
Задачей квадратичного программирования называют
задачу НЛП, в которой минимизируется сумма линейной
и квадратичной форм при ограничениях типа линейных
неравенств и неотрицательности переменных. В матричной
311
форме эта задача имеет вид
q(x) = cx+xTDx=min,
ZxsCb, х>0. (7.59)
Предполагается, что задача имеет т ограничений и п
переменных, так что матрица А имеет размеры mXn; D —
размеры «Хп; Ь — m-мерный вектор; х и с —и-мерные
векторы. В развернутой форме эти соотношения имеют вид
<7(х)=+22^(1)*(Ъ = min;
^alkx<k' — bj <0, j = 1, m; x(') > 0, (7.60)
Ограничимся рассмотрением случая, когда квадратич-
ная форма является положительно определенной, а значит,
выпуклой. Линейная форма также выпуклая функция. По-
этому целевая функция будет выпуклой. В этом случае не-
обходимые условия Куна—Таккера будут и достаточными
условиями существования единственного оптимума.
Для записи условий Куна—Таккера введем в рассмот-
рение функцию Лагранжа. В соответствии с (6.76) и
(7.60) получаем
L (X, Я) = 2 с,х^> + 2 2 d.tkx^x^ + 2Я/ ^2 Ь,^
(7.61)
Производные от А(х, Я) по и Л,- в соответствии
с обозначениями (7.56) запишутся в виде
сд 4-22<v^(ft) 4-2г/а/‘«= ТГ«; ]
k I ____ (7.62)
Ь,— j = l, m. |
Условия Куна—Таккера требуют найти решение этих
уравнений при удовлетворении требований (7.57), которые
удобно записать в виде
Л,<7,=0;
р,>0;
<7,^0, 7=1, п, j—l, tn. (7.63)
312
Система (7.62) содержит п-\-т уравнений с 2(«+т)
переменными х^\ р„ qi, из которых п-\-т являются сво-
бодными и равны нулю. Остальные переменные образуют
при этом допустимое базисное решение, если выполняются
условия (7.63).
Если число переменных в задаче невелико, то можно
попытаться «угадать» допустимое базисное решение, по-
ложив произвольно п-\-т переменных свободными, и при-
равняв их нулю и решив систему (7.62), найти значения
базисных переменных. Однако при этом нет никакой га-
рантии, что полученные значения переменных будут удов-
летворять условиям (7.63). Поэтому попытки «угадать»
допустимое базисное решение приходится проводить мно-
гократно.
Если допустимое базисное решение найдено, то его
улучшение, т. е. переход к новому лучшему базису, про-
изводят на основании симплекс-метода, аналогичного рас-
смотренному в задаче линейного программирования. От-
личие здесь заключается в том, что при выборе новой ба-
зисной переменной необходимо проверять выполнение
условий х(г')р1=0, которые означают, что если в
базисе имеется х(г) или то в него не может быть вве-
дено рг и qi соответственно.
При большом числе переменных метод «угадывания»
допустимого базисного решения становится чрезвычайно
трудоемким. В этом случае можно использовать эффектив-
ные систематические методы получения допустимого ба-
зисного решения, изложенные в [39, 47].
Если в формулировке задачи квадратичного програм-
мирования (7.59) линейные ограничения заданы в виде
равенств Ах=Ь, то условия Куна—Таккера запишутся в
виде соотношений (7.48), (7.49). Условие (7.49) означает,
что в соотношениях (7.62) и (7.63) должно быть принято
qj—Q, j=l, т. Это значительно упрощает решение зада-
чи, так как применение симплекс-метода потребует про-
верки только условия X^pi=Q.
7.4. ИТЕРАТИВНЫЕ МЕТОДЫ ПОИСКА ОПТИМУМА
7.4.1. Постановка задачи
Ограниченные возможности симплексного метода, за-
ключенные в задачах со сложными видами ограничений
и произвольным видом целевой функции, привели к широ-
313
кому использованию итеративных методов поиска опти-
мального решения, в основе которых лежат понятия гра-
диента целевой функции <?(х).
Градиентом функции <?(х), обозначаемым grad<?(x)
или V<?(x), называют вектор, величина которого определя-
ет скорость изменения функции <?(х), а направление сов-
падает с направлением наибольшего возрастания этой фун-
кции. Вектор — V<7(x), указывающий направление наиболь-
шего убывания функции <?(х), называют антиградиентом
функции q(x). Пусть х= (хС1>, .... х(п))т. Тогда градиент
функции <?(х) будет представлять собой вектор-столбец
вида
V<7(x) = (d<7(x)/dx(1), ...
... , dq(x)/d^)\ (7.64)
Условие того, что точка х является стационарной точкой
функции <?(х), с помощью градиента запишется в виде
V</(x)=0. (7.65)
Для обоснования итерационных алгоритмов оптимиза-
ции разложим функцию <?(х) в ряд Тейлора в окрестности
точки оптимума х*, которую считаем стационарной. Вос-
пользовавшись соотношением (4.107), получим
7(х) = q(x*) + 4" £ М^/г,^(/)- (7-66)
k I
где Дх=х*—х —отклонение от точки оптимума;
Беря производные q(x) по х(1'>, i = l, п, находим состав-
ляющие градиента функции <?(х) в рассматриваемой точ-
ке х:
dq(x)]dx(l} = —2ай[Дх(*>, t = 1. и- (7.68)
k
Для градиента функции q(x) при этом получаем выра-
жение
V9(x) =—АЛх=—А(х*—х), (7.69)
где А —квадратная симметричная матрица размером
пХп с элементами ah], определяемыми соотношением
314
(7.67). Разрешая систему уравнений (7.69) относительно
х*, получаем
х“=х—A->V<7(x). (7.70)
Если бы разложение (7.66) было точным представле-
нием <?(х) и существовали бы простые методы определения
матрицы А, то значение х* можно было бы найти непо-
средственно по (7.70). В большинстве практических задач
эти условия обычно не выполняются.
Однако если заменить неизвестную матрицу А-1 на
матрицу Г с элементами уь,, то можно надеяться, что ве-
личина х—rV<?(x) при соответствующем выборе коэффици-
ентов уЛз дает значение, более близкое к оптимальному,
чем х. При этом открывается возможность многошаговой
процедуры поиска решения.
Обозначим через хп значение х на n-м шаге и будем
считать, что элементы матрицы Г можно выбирать на раз-
ных шагах по-разному. Тогда в соответствии с (7.70) мно-
гошаговую процедуру поиска оптимума функции <?(х) за-
пишем в виде
хи+1=хп—Гп?<7(хи). (7.71)
Для того чтобы последовательность значений хп при-
водила к оптимальному решению, коэффициенты матрицы
Гп должны удовлетворять определенным условиям, назы-
ваемым условиями сходимо-
сти. При этом различные спо-
собы выбора Ги приводят к
различным поисковым алго-
ритмам оптимизации.
Иногда алгоритм оптими-
зации записывают в виде
xn+i =х„4-Дхп, (7.72)
где вектор поправок
Дхп =—rnV<7(xn). (7.73)
На рис. 7.5 представлена
схема алгоритма поиска по
выражениям (7.72) и (7.73).
Иллюстрацию рассматри-
ваемых далее методов поиска
| Начало поиска
Н ВычислениеI
vqU) I
Прекра-’
щение
поиска
Достигнут ли
оптимум?
yq(x)=Q
Нет
(Определение
матрицы Г
I Вычисление век-1
тора поправок Дх
Рис. 7.5. Схема алгоритма поиска
оптимума
Определение
новой точки х
315
экстремума будем производить для целевой функции <у(х),
где х= (х(1\ х(2)). Если стоит задача минимизации, то це-
левая функция может быть изображена в виде некоторой
поверхности, имеющей вид котловины, изображенной на
рис. 7.6,а, называемой поверхностью отклика. На рис.
7.6,6 профиль этой котловины изображен на плоскости
Рис 7.6. Поверхность отклика (а) и ее изображение в виде линий
уровня (б)
(х<>), х<2)) в виде линий равных значений q, представляю-
щих собой сечения котловины горизонтальными плоскос-
тями. Около каждой такой линии ставится соответствую-
щее ей значение q.
7.4.2. Градиентный метод
Наглядную интерпретацию задачи поиска оптимума
можно получить, если представить себе человека, стояще-
го на склоне котловины, заросшей густым лесом. Человек
должен опуститься на дно котловины, но не имеет возмож-
ности осмотреть котловину целиком, а может вести обзор
лишь весьма ограниченного участка вблизи места своего
расположения. В этих условиях наиболее естественным на-
правлением движения является направление в сторону на-
ибольшей крутизны спуска, т. е. в направлении, противо-
положном направлению градиента функции <у(х). Получа-
емая прн этом стратегия, называемая градиентным мето-
дом, будет представлять собой последовательность шагов,
каждый из которых содержит две операции:
1) определение направления наибольшей крутизны
спуска, т. е. направления антиградиента функции <у(х);
2) перемещение в выбранном направлении на заданное
расстояние.
316
Характер траектории при градиентном методе приведен
на рис. 7.6,6. Ее особенность состоит в том, что каждый
шаг происходит в направлении, перпендикулярном линии
постоянного уровня.
Математически стратегия градиентного метода получа-
ется, если перемещение на каждом шаге вдоль каж-
дой из осей будет пропорционально составляющей гради-
ента dq/dx^ в направлении этой оси:
Дх(г>=—-уд<?(х)1=1, п. (7.74)
Это означает, что в выражении (7.73) матрица Ги бу-
дет диагональной с элементами у на главной диагонали
Гп=у1. (7.75)
При этом поправка на n-м шаге может быть представ-
лена в виде
Axn==—yIV<?(xn) ==—у V<?(xn). (7.76)
Стратегия, выражаемая соотношением (7.76), определя-
ет движение с переменным шагом, так как значение шага
зависит от значения градиента V<?(x). Поскольку значение
градиента уменьшается на пологих склонах и вблизи оп-
тимума, то на некоторых участках шаги будут мелкими,
что удлиняет время поиска.
От этого недостатка можно избавиться, если использо-
вать градиентную стратегию с постоянным шагом, значе-
ние которого равно у. В этом случае поправка на каждом
шаге
Vxn = -yD(xn) (7.77)
получается из (7.76) заменой вектора градиента V<?(x) на
вектор направления градиента
D(x)=V7(x)/|V7(x)|, (7.78)
где
|V?(x) | = [(^/6х<’))2+ ...
... +(dq/dxW)2]1'2 (7.79)
— модуль градиента <?(х).
Градиентный метод обладает и рядом других недо-
статков. Для того чтобы двигаться все время в направле-
нии градиента, шаги должны быть не очень большими, по-
317
этому их будет много. Но
поскольку на каждом шаге
необходимо заново опреде-
лять направление градиен-
та, на что требуется значи-
тельное время, процесс при-
ближения к оптимуму будет
медленным.
Добавочные трудности
возникают, если точка оп-
тимума х0 лежит в овраге
или на длинном узком греб-
не, как показано на рис.
7.7. В этом случае гради-
ентный метод может вы-
звать прыжки через овраг, так что траектория хотя и до-
стигнет точки оптимума, но ценой многих неэффективных
шагов. От этих недостатков свободны некоторые другие
методы.
7.4.3. Метод наискорейшего спуска (подъема)
В отличие от градиентного метода, в котором градиент
определяют на каждом шаге, в методе наискорейшего спус-
ка градиент находят только в начальной точке и движение
Рис. 7.8. Характер траектории '(а) и схема алгоритма (б) по методу
наискорейшего спуска
318
в найденном направлении продолжается одинаковыми ша-
гами до тех пор, пока уменьшаются значения функции
<?(х). Если на каком-то шаге <?(х) возросло, то движение
в данном направлении прекращается, последний шаг сни-
мается полностью или наполовину и вычисляется новый
градиент функции <?(х), а значит, и новое направление
движения. На рис. 7.8,а показан характер траектории при
использовании метода наискорейшего спуска, а на рис.
7.8,6 приведена схема алгоритма этого метода.
Преимущество метода наискорейшего спуска —- его про-
стота, так как на большинстве шагов измеряются только
значения функции <?(х), а не вычисляются все элементы
вектора градиента. Однако шаг не должен быть большим,
чтобы не пропустить оптимум на данном направлении, сле-
довательно, общее число шагов будет значительным.
7.4.4. Алгоритм Ньютона
В тех случаях, когда поверхность отклика достаточно
хорошо описывается уравнением второго порядка, резкое
уменьшение числа шагов можно получить, если восполь-
зоваться алгоритмом Ньютона. При этом представление
<?(х) в виде (7.66) будет достаточно точным при значи-
тельном удалении от точки оптимума и в качестве матри-
цы Гп можно взять непосредственно матрицу А. Однако
элементы ак] матрицы А, вычисляемые в точке оптимума,
заранее неизвестны. Тем не менее при достаточно хорошей
поверхности отклика вторые производные функции <?(х)
d2q(x) /дх^дхМ, k, ! = Г~п, (7.80)
вычисленные в произвольной точке х=хп, будут близки
к элементам ahl матрицы А. Обозначая через [V2<?(xn)]
матрицу вторых производных <?(х) в точке хи и используя
ее в качестве матрицы Ги, получаем вектор поправок для
алгоритма Ньютона:
Ax„=-[V29(x„)]->V9(x„). (7.81)
Если разложение (7.66) является точным представле-
нием функции <7(х), то точка оптимума достигается за
один шаг.
7.4.5. Учет ограничений и многоэкстремальиые задачи
Ограничения в задачах НЛП приводят к тому, что в
рассматриваемом пространстве появляются гиперповерх-
ности, отделяющие допустимую зону от запретной. Это
319
создает трудности в применении методов, в которых дви-
жение к точке оптимума происходит в направлении гради-
ента, так как это направление может вести в запретную
зону (рис. 7.9). Однако для достижения точки оптимума
совсем не обязательно двигаться в направлении градиента,
можно двигаться в любом направлении, вдоль которого
значение функции q(x) убывает. Поэтому если на пути
движения встретилась граница допустимой зоны, то далее
следует двигаться вдоль этой границы, осуществляя на ней
г»
Рис. 7.9. Движение вдоль границы допустимой области
Рис 7 10 Ложный оптимум на
границе допустимой области
поиск оптимума одним из рассмотренных на рис. 7.9 мето-
дов. После определения точки оптимума на границе допу-
стимой зоны следует вновь определить направление гради-
ента. Может оказаться, что это направление укажет путь
внутрь допустимой области.
Движение вдоль границы допустимой области можно
осуществить и без изменения алгоритма поиска, если пре-
образовать функцию <?(х) таким образом, чтобы в запрет-
ной зоне значения q(x) резко возрастали. Тогда граница
допустимой области будет иметь вид дна оврага, и если
используемый алгоритм дает возможность двигаться
вдоль оврага, то он приведет к движению вдоль границы
в нужном направлении.
В задачах с ограничениями возникает и другая труд-
ность, состоящая в том, что движение вдоль границы при-
водит лишь к локальному минимуму. Пример подобного
случая для одномерной задачи с ограничением
приведен на рис. 7.10. Если начальная точка взята правее
точки с, то любой из рассмотренных методов приведет к
значению х=Ь, где q(x) достигает лишь относительного
минимума. Абсолютный же минимум получается при х—а,
и его можно достичь, лишь начав движение из точек, ле-
320
Рис. 7.11. Двухэкстремальная
целевая функция
жащих левее точки с.
Подобные задачи полу-
чили название многоэкс-
'^Ложный
опта ‘гум
тремальных. /// ) /
Многоэкстремальны е /'///~\ ] /
задачи не обязательно I / > (QJJ/ /
связаны с наличием огра- / I (
ничений. Ложные опти-
I 4 х—У У оптимум
мумы могут быть связа- \ у
ны со сложным видом це- 4---------_________________
левой функции ?(х), как
это показано на рис. 7.11.
Поскольку все рассмотренные методы относятся к клас-
су локальных методов, при которых направление и значе-
ние следующего шага определяются путем изучения огра-
ниченного участка поверхности q(x) вблизи точки, являю-
щейся результатом предыдущего шага, то возможность
получения глобального оптимума целиком зависит от удач-
ного выбора начальной точки. В этих условиях целесооб-
разным оказывается многократный поиск экстремума из
различных начальных точек. Опишем один из алгоритмов,
реализующих этот способ.
Случайным образом выбираем x=xi и из этой точки
ведем поиск локального оптимума q\=q(y.\*). Значения
Xi* и q\ запоминаем. Затем случайным образом выбираем
новое значение х=х2 и отыскиваем соответствующий ло-
кальный оптимум ^2=<7(х2*). Если q2<q\, то q\ и Xi* за-
бываем и храним в памяти q2 и х2*. Если же <?2>?i, то
считаем выбор точки х2 неудачным и забываем результаты
поиска. Затем снова производим случайный выбор точки
х и поиск локального оптимума и т. д. Найденное в конце
каждого этапа значение </(х*) запоминаем, если оно луч-
ше хранящегося в памяти.
Описанная процедура является монотонной, запомина-
емые значения функции не могут возрастать. Поскольку
на каждом этапе начальная точка выбирается случайно,
то можно ожидать, что по истечении достаточно большого
числа этапов удается побывать во всех локальных экстре-
мумах и выбрать из них наилучший.
Однако практически время поиска всегда ограничено,
поэтому результат поиска считается хорошим, если не-
21-804 321
сколько последних попыток не привели к уменьшению
функции q(x).
Более подробное изложение различных методов поиска
экстремума можно найти в [48, 49].
Задачи к гл. 7
7.1. Превратить неравенства (7 7) в уравнения. Каков физический
смысл добавляемых при этом переменных?
7.2. Определить с помощью снмплекс-метода оптимальный план
распределения ресурсов по данным примера 7.5, приняв на начальном
этапе за свободные переменные хь х2, х3.
7.3 Решить симплекс-методом двойственную задачу по данным
примера 7.5, приняв на начальном этапе за свободные переменные иь
и2. «5, Сравнить матрицу, соответствующую оптимальному решению,
с соответствующей матрицей в задаче 7.2
Глава 8
ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
8.1. ОПТИМАЛЬНОЕ УПРАВЛЕНИЕ
КАК ВАРИАЦИОННАЯ ЗАДАЧА
8.1.1. Математическая формулировка задачи
оптимального управления
Характерной тенденцией в построении современных сис-
тем автоматического управления является стремление по-
лучать системы, которые в некотором смысле являются на-
илучшпмн. При управлении технологическими процессами
это стремление выражается в том, чтобы получать макси-
мальное количество продукции высокого качества при ог-
раниченном использовании ресурсов (сырья, энергии и
т. и.). В системах управления кораблями, самолетами, ра-
кетами стремятся минимизировать время, по истечении ко-
торого объект выходит в заданную точку или на заданную
траекторию при ограничении угла отклонения рулей, коли-
чества расходуемого топлива и т. п. В следящих и стаби-
лизирующих системах представляет интерес достижение
максимальной точности при наличии всевозможных огра-
ничений, накладываемых на координаты регулируемого
объекта, исполнительные элементы и регулятор. Во всех
этих примерах задачи управления сводятся к нахождению
322
наилучшего в определенном смысле слова процесса из мно-
жества возможных процессов, т. е. относятся к классу ди-
намических задач управления.
Как было показано в гл. 6, математическая формули-
ровка динамических задач оптимального управления сво-
дится к следующему. Имеется объект управления (ОУ),
состояние которого характеризуется многомерной пере-
менной х— (х<‘>, ..., х<Л'>). Характер процессов в ОУ можно
изменять, используя то или иное управление и из простран-
ства допустимых управлений U. В общем случае управле-
ние u^U может быть также многомерной величиной и =
= («<'), , ц(Ю).
Характер движения ОУ описывается системой диффе-
ренциальных уравнений
x=g(x, и), х(0)=с. (8.1)
За критерий качества управления принимают интеграль-
ную оценку вида
Л(«) = (8.2)
имеющую физический смысл потерь, где Т — время проте-
кания процесса управления; Qi[x(f), и(0] =Ч\ (О —мгно-
венные потери в момент t при состоянии системы x(t) и
управлении и(0.
Добавочными могут быть ограничения, накладываемые
на количество ресурсов или пределы изменения некоторых
параметров, выражающиеся математически соотношением
т
J//ix(0, (8.3)
вытекающим из (6.50).
Как было установлено в гл. 6, оптимальным называют
такое управление и из множества допустимых управлений
U, при котором для объекта, описываемого дифференци-
альным управнением (8.1), при заданных ограничениях на
используемые ресурсы (8.3) критерий качества управле-
ния (8.2) принимает минимальное (максимальное) значе-
ние.
Сформулированная подобным образом задача опти-
мального управления относится к классу вариационных
задач, решением которых занимается раздел математики,
21»
323
получивший название вариационного исчисления. Величи-
на Zi(u), определяемая соотношением (8.2), получила на-
звание функционала (см. § 2.5). В отличие от функции,
например, f(x), численные значения которой задаются на
множестве значений аргумента х, численные значения фун-
кционала Zi(u) задаются на множестве всевозможных
управлений u(t). Задача нахождения оптимального управ-
ления сводится к тому, чтобы из множества допустимых
управлений U выбрать такое, при котором функционал
Л(ц) принимает минимальное численное значение.
Обычно задачи, требующие минимизации функционала
вида (8.2), подчиненного дифференциальному соотношению
(8.1), при наличии интегрального ограничения (8.3) заме-
няются минимизацией нового функционала
J (и) = QJx, u)dt + I f H (x. u)dt, (8.4)
о 6
подчиненного только дифференциальному соотношению
(8.1). Параметр А в функционале (8.4), получивший назва-
ние множителя Лагранжа, в задачах оптимизации управле-
ния играет роль «цены» ограниченных ресурсов. Его зна-
чение находится из граничных условий вариационной зада-
чи.
Возможность упрощения вариационной задачи с интег-
ральными ограничениями посредством введения множите-
лей Лагранжа вытекает из следующей теоремы.
Теорема 8.1. Если u(t)—оптимальное управление, при
котором функционал (8.4) достигает абсолютного мини-
мума и выполняется ограничение (8.3), тогда при u(t) до-
стигается абсолютный минимум функционала (8.2), под-
чиненного ограничению (8.3).
Доказательство следует от противного. Пусть
v (t) —другое управление, отличное от u(t), причем такое,
что
jQJx, v)dt < jQ^x, и) di (8.5)
о о
и выполнено условие
\jH(x,v)dt = K. (8.6)
О
324
Тогда
т т т
f Q, (х, -j) dt + Л f И (х, □) dt= [ Q, (х, □) dt + IK <
о оо
< J Q, (х, и) dt + м = J Q, (х, и) dt + Л f Н (х, и) dt, (8,7)
О 0 0
что противоречит предположению, что u(t) обращает (8.4)
в минимум.
Применение методов вариационного исчисления к зада-
че нахождения оптимального управления не получило рас-
пространения в связи с целым рядом возникающих при
этом трудностей. Поэтому мы не будем оста-
навливаться на методах решения вариационной задачи,
отсылая интересующихся этим вопросом к [50]. Отметим
лишь некоторые моменты, важные для дальнейшего изло-
жения.
Важнейшим понятием вариационного исчисления явля-
ется понятие вариации функции, которое при исследовании
функционалов играет такую же роль, как дифференциал
при исследовании функций.
Пусть f(x) —функция, непрерывная на интервале [а,
&]. Рассмотрим внутреннюю точку х этого интервала и не-
которое форсированное значение дифференциала аргумен-
та функции &x=dx. Разность
f (х+Дх) — f (х) —df (х) =f' (х) Дх (8.8)
называют дифференциалом функции f(x) в точке х. Как
известно, условие df(x)—O является необходимым усло-
вием минимума функции f(x) в точке х.
Для получения аналогии с вариационным исчислением
удобно дифференциал df(x) определить несколько иначе.
Рассмотрим значение функции /(х+еДх). При фиксирован-
ных х и Дх оно будет функцией от е. Дифференцируя эту
функцию по е и полагая е=0, получаем
К* + е&х} I е=о = Г W = 4 (х). (8.9)
Рассмотрим аналогичные понятия вариационного ис-
числения. Пусть u(t) и Ui(t)—два используемых управле-
ния. Разность
б«(/) =«,(/)— u(t) (8.10)
325
называют вариацией функции u(t), а разность
6Z(u)=/(u+6u)— J(w) (8.11)
называют вариацией функционала.
Вариацию функционала можно определить иначе. Для
этого рассмотрим при фиксированных u(t) и ftu(t) функци-
онал
Z(u+e6«)=<p(e), (8.12)
являющийся функцией е. Предположим: функционал опре-
делен для различных е; это означает, что возможны раз-
личные управления u(t)+e6u(t) вблизи фиксированного
управления u(t), т. е. что u(t) является внутренней точкой
пространства допустимых управлений U. При этом вари-
ацию функционала можно определить по аналогии с диф-
ференциалом функции, даваемым соотношением (8.9), как
SJ(«)=-^J(»+eSU)| е=0. (8.13)
Если u(t) является оптимальным управлением, то фун-
кция <р(е) будет достигать минимума при е=0. В этом
случае
Ml =A/(u+sS«)| =0, (8.14)
де |в=0 де |£=0
т. е. 6/(ы)=0. Итак, оптимальным управлением будет та-
кое, при котором вариация функционала обращается в
нуль.
В вариационном исчислении условие 6J(w)=0 исполь-
зуется для получения дифференциального уравнения Эйле-
ра, среди множества решений которого и определяется
затем управление u(t), обращающее в минимум функцио-
нал (8.4).
8.1.2. Трудности, связанные с решением
вариационной задачи
При отыскании оптимального управления вариацион-
ными методами приходится сталкиваться с трудностями,
ряд которых носит принципиальный характер:
1. Вариационные методы дают возможность находить
только относительные максимумы и минимумы функцио-
нала Ци), тогда как интерес представляет нахождение
абсолютного максимума или минимума.
326
2. Уравнения Эйлера для многих технических задач
оказываются нелинейными, что часто не дает возможности
получить решение вариационной задачи в явном виде
3. На значения управлющих сигналов обычно бывают
наложены ограничения, делающие невозможным поиск
оптимального управления вариационными методами.
Поскольку последнее обстоятельство имело решающее
значение для развития новых идей в области оптимально-
го управления, остановимся на нем более подробно.
Обычными ограничениями,
накладываемыми на сигналы уп- ____________
равления, являются ограничения ' ]
вида J \ /
(8.15)
означающие необходимость огра- ~/71
ничения ПО величине сигналов, рис 81 Характерный вид
подводимых к органам управле- оптимального управляюще-
ния. Так, ограниченными явля- го сигнала
ются предельное напряжение,
подводимое к якорю электродвигателя, предельный угол
поворота руля самолета, предельная температура в каме-
ре сгорания реактивного двигателя и т. п. При этом полу-
чение оптимальных процессов требует, как правило, под-
держания сигналов управления на предельных значениях,
что соответствует наиболее быстрому и эффективному про-
теканию процессов в объекте управления. Типичный для
этих случаев характер изменения управления u(t) при
оптимальном процессе приведен на рис. 8.1.
Однако предельные значения управления u(t) лежат
на границах области допустимых управлений U и, следо-
вательно, не являются внутренними точками этой области,
для которых только и применимы вариационные методы.
Правда, от ограничений вида (8.15) можно избавиться
путем введения новых переменных vt, связанных с пере-
менными соотношением «t = MIsinaI. При этом значения
будут соответствовать переменным ц,-= ±л/2,
являющимся внутренними точками области новых допу-
стимых управлений. Однако такая замена переменных
обычно приводит к значительному усложнению получае-
мых уравнений.
Трудности, состоящие на пути решения задачи оптими-
зации управления, привели к интенсивному изучению про-
блемы оптимальности рядом ученых в Советском Союзе
327
и в США. Советские математики Л. С. Понтрягин и его
ученики В. Г. Болтянский, Р. В. Гамкрелидзе, Е. Ф. Ми-
щенко создали теорию оптимального управления, в основе
которой лежит сформулированный Л. С. Понтрягиным
принцип максимума. Этот принцип позволил поставить
теорию оптимального управления на строгую математи-
ческую основу и открыл широкие возможности для ее
практического применения в области автоматических си-
стем управления. Однако в данной книге нет возможности
развивать общую теорию оптимального управления, ос-
нованную на принципе максимума. Ограничимся в этом
отношении ссылками на литературу [5, 36, 51—53].
Иной подход к вычислению оптимальных процессов на-
зывают динамическим программированием [54—56]. Ме-
тод динамического программирования дает в руки инже-
нера эффективную вычислительную процедуру решения
задачи оптимизации управления, хорошо приспособленную
к использованию ЭВМ. Этот метод рассмотрим более под-
робно.
8.2. МЕТОД ДИНАМИЧЕСКОГО ПРОГРАММИРОВАНИЯ
8.2.1. Дискретная форма вариационной задачи
Преодолевают рассмотренные трудности решения вари-
ационной задачи с помощью эффективных вычислитель-
ных методов, одним из которых является метод динами-
ческого программирования. Этот метод дает возможность
находить оптимальное управление в многошаговых зада-
чах. Однако его применяют и для решения вариационных
задач, если их представить в дискретной форме.
Воспользовавшись теоремой 8.1, сформулируем вариа-
ционную задачу в следующем виде: для объекта, описы-
ваемого дифференциальным управлением (8.1), найти уп-
равление u(t) из области допустимых уравнений U, кото-
рое минимизирует функционал
J(u) = ^Q[x(t), u(t)]dt, (8.16)
где
Q(x, u) = QI(x, и)+КН(х, и). (8.17)
Дискретную форму записи задачи получим, если выбор
управления u(t) будем производить только в дискретные
328
моменты i—kf>, k=0, 1, n—1, где Ь—Т/п. При этом
вместо функции x(t) и u(t) будем рассматривать после-
довательности
*й = *(0 I t=ki’ uk = u(t) | t=kl.
Заменяя производную x—dx/dt в уравнении (8.1) на от-
ношение приращений (xft+i—хй)/6, вместо дифференциаль-
ного уравнения (8.1) получаем уравнение в конечных раз-
ностях:
(xh+i—xh)/6=g(xk, uh). (8.18)
Обычно это уравнение записывают в более удобной фор-
ме, разрешая его относительно xft+i:
xft+i=Xfc+g(xft, цй)б;
k—0, 1, ..., п—1, Хо—с. (8.19)
При этом интеграл (8.16) заменится суммой
/„(«) = 2 Q(xk, uk)8, (8.20)
*=о
где под и понимается последовательность используемых
управлений
«=(«о..... Un-i). (8.21)
Теперь задача заключается в выборе таких управлений
«о, «I, Ип-ь которые обеспечивают минимальное значе-
ние суммы (8.20).
Во многих задачах управления целесообразно считать
6=1. В частности, это удобно делать в тех случаях, когда
процесс естественным образом разбивается на отдельные
шаги, причем в пределах каждого шага управление u(t)
остается неизменным. При этом приходим к многошагово-
му процессу управления, рассмотренному в гл. 6, в кото-
ром хй и wh означают состояние объекта и применяемое
управление в начале каждого шага. Обозначая в этом
случае
Xk+g(xh, uh)=T(xh, uk), (8.22)
уравнение (8.19) запишем в виде
хй+1 = 7’(хй, Uk)', k=0, 1, ..., n—1; Хо—с, (8.23)
совпадающем с выражением (6.65), которое определяет
преобразование состояния объекта за один шаг в много-
329
шаговом процессе управления. Сумма (8.20) при 6=1
принимает вид
4(«)=2Q(xs.«t). (8-24)
л=о
совпадающий с выражением (6.67) для критерия качества
в многошаговом процессе управления.
Метод динамического программирования далее будем
рассматривать применительно к соотношениям (8.23) и
(8.24), т. е. к многошаговому процессу управления. Однако
установленная нами связь математических формулировок
дискретной формы вариационной задачи и многошагового
процесса управления позволяет распространить полученные
результаты и иа решение вариационных задач.
8.2.2. Рекуррентное соотношение метода
динамического программирования
Оптимизация управления n-шагового процесса состоит
в том, чтобы найти такую последовательность управлений
Uo, ui,...,un~i, при которой критерий качества /п(и) при-
нимает минимальное значение. Это минимальное значение
критерия качества управления n-шагового процесса будет
зависеть только от начального состояния ,\'О и его можно
обозначать
/,г(х0) = min min ... min [Q(x0, »0) + Q(xx, ux) +•••
“0 «1 »n_x
...+Q(xn^,u,,_,)]. (8.25)
Заметим, что первое слагаемое этого выражения Q(x0,
ио) зависит только от управления и0, тогда как остальные
слагаемые зависят как от м0, так и от управлений на дру-
гих шагах. Так, Q(%i, щ) зависит от и\ и от м0, так как
х1=7’(х0, ио). Аналогично обстоит дело и с остальными
слагаемыми. Поэтому выражение (8.25) можно записать
в виде
)„(х0) = min [Q(x0, M0) + min...
«О «1
... min [Q(x1, Mx)4-... ч-Q(x„_!, u„_,)]}. (8.26)
un—1
Заметим, что выражениие
min... min [Q(x,, nj-j-... + Q(x„_x, un_x)] (8.27)
"> “n-l
330
представляет собой минимальное значение критерия каче-
ства управления (п—1)-шагового процесса, имеющего на-
чальное состояние %]. В соответствии с определением
(8.25) эту величину обозначить через fn-i(xi). Таким об-
разом, получаем
M*0) = min[Q(x0, (х,)]. (8 28)
«о
Эти рассуждения можно повторить, если рассмотреть
(и—1)-шаговый процесс, начинающийся с начального со-
стояния хь Минимальное значение критерия качества
управления для этого случая
/п-i (*,) = min [Q (хп i/J +7„_г(х2)]. (8.29)
Продолжая эти рассуждения, запишем аналогичное вы-
ражение для (п—I) -шагового процесса, начинающегося
с состояния хг.
L_,(xz) = min [Q(xz, и2)+/„_(/ + 1)(xz+l)]. (8.30)
"i
Уравнение (8.30), называемое часто уравнением Велл-
мана, представляет собой рекуррентное соотношение, по-
зволяющее последовательно определять оптимальное
управление на каждом шаге управляемого процесса.
Сама идея оптимизации управления на каждом шаге
отдельно, если трудно оптимизировать сразу весь процесс
в целом, не является оригинальной и широко используется
на практике. Однако при этом часто не принимают во вни-
мание, что оптимизация каждого шага еше не означает
оптимизацию всего процесса в целом. Так, жертва фигуры
в шахматной партии никогда не бывает выгодна с точки
зрения отдельного хода, но может быть выгодна с точки
зрения всей партии. Расход средств на амортизацию мо-
жет быть невыгоден с точки зрения конъюнктуры на от-
дельный момент, но он выгоден с точки зрения работы
предприятия за длительный период.
Особенностью метода динамического программирования
является то, что оно совмещает простоту решения задачи
оптимизации управления на отдельном шаге с дальновид-
ностью, заключающейся в учете самых отдаленных по-
следствий этого шага.
В методе динамического программирования выбор
управления на отдельном шаге производится не с точки
зрения интересов данного шага, выражающихся в миними-
331
зации потерь на данном шаге, т. е. величины Q(xi, щ),
а с точки зрения интересов всего процесса в целом, выра-
жающихся в минимизации суммарных потерь Q(xt, иг) +
+fn_(i+I)(xz+1) на всех последующих шагах. Отсюда следу-
ет основное свойство оптимального процесса, заключаю-
щееся в том, что каковы, бы ни были начальное состояние
и начальное управление, последующие управления должны
быть оптимальными относительно состояния, являющегося
результатом применения первого управления.
Из основного свойства оптимального управления следу-
ет, что оптимизация управления для произвольной стадии
многошагового процесса заключается в выборе только по-
следующих управлений. Поэтому бывает удобно учитывать
не те шаги, которые были уже пройдены, а те, которые
осталось проделать, для того чтобы привести процесс в ко-
нечное состояние. С этой точки зрения уравнение (8.30}
удобно записать в иной форме.
В выражении (8.30) величина п—I означает число ша-
гов до конца процесса. Обозначим эту величину через k.
При этом величины xi=xn-k и ui=un-k будем обозначать
просто через х и и. Они будут означать состояние объекта
и примененное управление за k шагов до конца процесса.
Последующее состояние, т. е. то, к которому объект пере-
ходит из состояния х при применении управления и, обоз-
начим через х'. Это будет xn_((+i) в прежних обозначениях.
При этом уравнение (8.23) запишем в виде
х'=Т(х, и), (8.31)
а рекуррентное соотношение (8.30) примет вид
/ft(x) = min[Q(x, «) + /,<-! (*')]• (8.32)
8.2.3. Вычислительные аспекты динамического
программирования
Динамическое программирование является численным
методом решения задачи оптимизации управления и по-
этому связано с довольно громоздкими вычислениями. Но
не будем придавать особого значения этому обстоятельст-
ву, предполагая, что соответствующие вычисления произ-
водятся на ЭВМ.
Оптимальное управление на произвольном /г-м шаге, от-
считываемом от момента окончания процесса, определяют
на основании соотношений (8.31) и (8.32), которые для
332
удобства проведения численных расчетов можно записать
в несколько иной форме. Обозначим через Fk(x, и) крите-
рий качества управления ^-шагового процесса при опти-
мальном управлении на последних k— 1 шагах и произ-
вольном управлении на начальном шаге. Тогда соотноше-
ние (8.32) может быть записано в виде
Fk (х, и) =Q (х, и) (х'); (8.33)
Мх) = шу»(х,и) (8.34}
где х' определяется из (8.31).
Переменные х и и могут или принимать конечные мно-
жества значений, или изменяться непрерывно в некоторых
диапазонах. В последнем случае проведем дискретизацию
этих переменных, выделив из них конечные множества по
возможности равноотстоящих значений. Следовательно,
в обоих случаях переменные х и и могут рассматриваться
как элементы конечных множеств Х={х<1>,...,х('”>} и U—
= {и(1), ..., и<г)}. Значение >Q(x, и) удобно вычислить зара-
нее и задать в виде таблицы на прямом произведении мно-
жеств X%U. Эта таблица должна храниться в памяти
ЭВМ.
Таблицу 8.1 заполняют по ходу вычислений по форму-
лам (8.33) и (8.34). В первых двух столбцах таблицы пе-
речислены всевозможные комбинации х^Х и u^U. В по-
следних столбцах таблицы для каждого хеХ записываем
минимальное значение Fk(x, и), т. е. определяем fk(x) и
оптимальное управление и*.
Подобные расчеты необходимо проводить для каждого
шага многошагового процесса. При этом следует учесть,
что для определения fft(x) необходимо предварительно
иметь таблицу для fk-i(x), так как с ее помощью находят
значения fk_i(x') при заполнении табл. 8.1. Следовательно,
значения fk-i(x) должны быть вычислены раньше, чем
значения fk(x). Отсюда следует, что вычисление функций
fk(x) нужно начинать с последнего шага многошагового
процесса. Замечая при этом, что fo(x)=O, за начальный
этап расчета следует взять k—1, для которого
Fi(x, m)=Q(x, и); fi(x)=min Q(x, и). (8.35)
Далее расчет проводят обычным путем для k=2, 3, ...
..., п.
ззэ
1 x’= T (x, u) Q (x, u)
ul1) T(x(4, m(*)) \ Qtxl1),/,•(>))
х(1) Utr) T(xM, u(r)) Qfxl1), «('))
M(1) T (x(3), mC1)) Q(x(3), u(*))
xm u(r) T (x(3>, u(r)) 0(х(2), м(г))
x(3)
Таб лица 8.1
Fk (X, U) и'
fk-! [Т(хт, ц(1))] fk-i [Т (xt1), иС))] Fk(xm, а(*)) Fk (хт, тг), fk (хт) a+i
fk-i Г (Л(«),«(П)] fk-i [Г (хт, «(')] Fk (хт, ит) Fk(xm, ит) fk (хт) а/
После того как проведены расчеты и составлены таб-
лицы для fk(x) и и* при k=\,...,n, можно приступить
к поиску оптимального управления для всего процесса при
данных начальных условиях х0. По таблице для fn(x) на-
ходим ио*, соответствующее заданному х0, и подсчитываем
х1=7'(хо, ио*). Далее по таблице для fn-i(x) находим Ui*,
соответствующее найденному Хь и подсчитываем х2=
=7’(xi, И1*) и т. д. В результате получаем оптимальное
управление и*— (uo*, Ui*,..
Если и является непрерыв-
ной величиной, то Fk(x{i\ и)
будет непрерывной функцией
от и Однако табл. 8.1 дает
лишь дискретные значения
Fft(x(‘), и(/)), /==1» •• , г этой
функции. При этом минималь-
ное значение Fk(xM, и) может
получиться при промежуточ-
ных значениях и. В этом
случае величины и* и fk(x^)
следует определять, восполь-
зовавшись интерполяционны-
ми формулами. Применение
интерполяционных формул не-
обходимо также для нахож-
Рис. 8.2. Траектория в задаче
набора высоты
дения оптимального управления ик* в тех случаях, когда
значения Xk=T(xk-i, uk-\) будут лежать между значения-
ми х, входящими в табл. 8.1.
Пример 8.1 (задача о наборе высоты). Самолет летит со скоростью
t»o на высоте h0. Нужно изменить его скорость до о, и высоту до hi
так, чтобы расход горючего на это изменение был минимальным.
Процесс изменения v и h будем изображать на плоскости (о, й).
Произведем дискретизацию переменных, разбив диапазоны изменения
v и h на четыре интервала каждый. При этом дискретные состояния
ОУ будут представляться узлами сетки, изображенной на рис. 8.2. Счи-
таем, что в каждом узле сетки возможно применение только двух
управлений: ut=0— изменение только скорости v; u,= 1 — изменение
только высоты Л.
Таким образом, множеством допустимых управлений будет множе-
ство U— {0, 1).
На рис. 8.2 изображена одна из возможных траекторий, соответ-
ствующая управлению «=(01011001). Для того чтобы оценить эту
траекторию, нужно знать расход топлива на каждом шаге Это и бу-
дет целевой функцией Q(x, «), значения которой зададим в виде
335
условных чисел (на рис. 8.2 отмечен каждый из возможных перехо-
дов). Для траектории, изображенной на рис. 8.2, суммарный расход
топлива, представляющий собой значения критерия эффективности
управления, будет 4-|-4-]-7-]-5-|-7-|-8-|-9-]-8 = 52.
Для того, чтобы представить рассматриваемый процесс как много-
шаговый, введем подходящий способ описания состояний ОУ. Дискрет-
ные значения и отметим числами от 0 до 4, начиная с конечного зна-
чения. Так же поступим в отношении h Тогда ху будет означать со-
стояние при v = i и h=i, из которого до конца процесса остается
сделать i-]-j шагов.
Таблица 8.2
* X' Q (х, и) Л W
*10 0 *00 9 9 0
*01 0 Xqq 8~ 8 1
Обозначим через Хк множество состояний, из которых процесс за-
канчивается за k шагов. В это множество войдут все те x,h для кото-
рых i+j — k. Полагая А=0, 1, 2...... получаем Х0=*оо; Xi = {xI0, xoi);
Хг= {хго. *п. *02} и т. д.
Теперь можно приступить к решению задачи. При k = 1 имеем Х1 =
= {*io. *01}; Fi(*. «)=<?(*, «): fi(*) =m>n/?i(*, и).
и
Эти соотношения используем для составления табл. 8.2 —• расчета
оптимального управления на последнем шаге, построенной по типу
табл. 8 1.
При А-=2 имеем Х2={х2е, хп, х02}; Fz(x, u)-=Q(x, и)4-Д(х'); f2(*) =
— minFgOc, u).
и
Эти соотношения используем для составления табл. 8.3 —• расчет
оптимального управления на предпоследнем шаге. Аналогичные расче-
ты проводятся прн k — 3, 4 ... (см. табл. 8 4, расчет оптимального
управления за три шага до конца и т. д.).
В рассматриваемом примере данные, содержащиеся в табл. 8.2—
8.4, можно изображать непосредственно на плоскости (о, ft), указывая
значения fk(x) в виде числа в соответствующем узле сетки, а и” —
стрелкой в направлении следующего узла, как показано на рис. 8.3.
После того, как значения f*(x) и и* определены для всех узлов сетки,
336
иаходпм оптимальную траекторию, двигаясь от начального узла в на-
правлении стрелок. Оптимальным управлением будет и*= (11000110),
которому соответствует f„(u*)=37.
Рассмотренный пример хорошо иллюстрирует достоин-
ства метода динамического программирования. Этот метод,
во-первых, снимает проблему абсолютного и относитель-
Таблица 83
X' Q(X. «) fi(X') F~.(x. и) f3(*> "*»
*20 0 1 *10 9 9 18 18 0
*11 0 1 *01 *10 9 7 8 9 17 16 16 1
*02 0 1 *01 6 7 14 14 Табл и на 8.4
* | Q(x, и) N(X') F«(x. «1 fs(-v) «•*
*30 0 1 *20 ! 6 18 24 24 0
*21 0 1 *11 8 8 16 18 24 26 24 0
*12 0 1 *02 9 6 14 16 23 22 22 1
*03 0 1 *02 3 14 17 17 1
ного минимума, так как из самой процедуры вычислений
ясно, что находится всегда абсолютный минимум. Во-вто-
рых, ограничения вида явившиеся серьезным
препятствием для применения вариационных методов,
только облегчают процесс вычислений по методу динами-
ческого программирования, так как сужают область до-
пустимых управлений U. Наконец, метод динамического
программирования несравненно упрощает поиск оптималь-
22—804
ем огромное число
Рис. 8.3. Оптимальная тра-
ектория в задаче набора
высоты
ного решения по сравнению с методом простого перебо-
ра вариантов. Это можно проиллюстрировать расче-
том.
Если на каждом шаге возможны г различных управле-
ний, то при прямом переборе каждое из этих управлений
должно рассматриваться в сочетании со всеми возможны-
ми управлениями на всех остальных шагах, что при п-ша-
говом процессе дает гп вариантов. Даже для весьма
скромной многошаговой задачи при г=10 и п= 10 получа-
фиантов.
В методе динамического про-
граммирования при выборе уп-
равления на каком-либо шаге
для состояния х рассматривают
не все возможные продолжения,
а только те, которые соответст-
вуют оптимальным продолжени-
ям из состояния х'—Т{х, и).
Это позволяет исключить из рас-
смотрения огромное число не
представляющих интереса вари-
антов. Так, если на каждом шаге
возможно пг состояний и для
каждого состояния г управлений,
то общее число подлежащих рас-
смотрению вариантов будет гпгп
или г2п, если считать, что г—пг, т. е. что имеется управле-
ние, переводящее каждое состояние в любое новое. При
г= 10 и п= 10 это дает всего 103 вариантов.
Однако, несмотря на большие достоинства, метод дина-
мического программирования имеет и свои неудобства. Эти
неудобства заключаются в том, что для нахождения опти-
мального управления при некотором начальном состоянии
объекта приходится идти от конца процесса к началу,
определяя на каждом шаге оптимальные управления для
всех возможных на этом шаге состояний объекта, причем
до самого последнего момента остается неизвестным, ка-
ково же будет оптимальное управление для заданного на-
чального состояния. При этом в конце концов оказывается,
что большая часть вычислительной работы проделана на-
прасно, так как результаты определения оптимального
управления для состояний, не лежащих на оптимальной
траектории, не используются. В этом отношении имеет
преимущества принцип максимума, который открывает
338
путь для построения одной отдельно взятой оптимальной
траектории.
Отметим, что хотя метод динамического программиро-
вания был рассмотрен как метод оптимизации динамиче-
ских задач, т. е. процессов, развивающихся во времени и
описываемых тройкой (х, и, t), его можно применять и для
статических задач оптимизации, если роль параметра t
будет выполнять некоторый другой параметр, допускаю-
щий разбиение задачи оптимизации на последовательность
этапов. Так, метод нахождения кратчайшего пути в графе,
рассмотренный в § 3.2, представляет собой модификацию
метода динамического программирования для статической
задачи оптимизации. Другие примеры подобного вида мож-
но найти в [5].
8.2.4. Управление конечным состоянием
Как указывалось в гл. 6, в ряде задач характер движе-
ния объекта в процессе управления интереса не представ-
ляет, а существенным является только состояние хп, в ко-
торое переходит объект по окончании процесса управле-
ния. При этом критерием качества управления будет слу-
жить значение целевой функции в конце процесса управ-
ления
q=q{xn). (8.36)
Обозначим, как и раньше, через х и и состояние объ-
екта и примененное управление за k шагов до конца про-
цесса, а через х'=Т(х, и) — последующее состояние, т. е.
состояние за k—1 шагов до конца процесса. Состояние хп,
а значит, и целевая функция q(xn) определяются как на-
чальным значением х, так и всеми последующими управ-
лениями.
Для получения рекуррентного соотношения, определяю-
щего оптимальное управление, обозначим через Fft(x, и)
значение целевой функции q(xn) за k шагов до конца про-
цесса при начальном состоянии х, произвольном управле-
нии и на начальном шаге и оптимальном управлении на
остальных k— 1 шагах, а через Д.(х) значение 7(хп) при
оптимальном управлении на всех k шагах до конца про-
цесса, так что
fk (х) = min Fk (х, и). (8.37)
22*
339
Значение Fk(x, и) можно получить из следующих со-
ображений. Под действием произвольного управления и
объект управления на начальном шаге переводится из со-
стояния х в состояние х'=Т(х, и). Чтобы получить q(xn) =
—Fk{x, и), необходимо на остальных k— 1 шагах применять
оптимальное управление, что дает p(xn)=f*-i(x,) =
=ffe-i[7’(x, «)]. Это и будет значением Fft(x, и). Таким
образом,
Fk(x, u)=fk-i[T(x, «)]. (8.38J
Подставляя значения Fk(x, и) в (8.37), находим
fk (х) = min [Т (г, «)]. (8.39)
Формула (8.39) по своей структуре полностью анало-
гична (8.32). Применяя к ней уже описанную методику
вычислений и учитывая, что
fo(x)=q(x), (8.40)
можно определить оптимальное управление для любого
начального состояния многошагового процесса.
8.2.5. Рекуррентное соотношение
для марковских процессов
Применение метода динамического программирования
для оптимизации случайных процессов рассмотрим для
случая, когда случайный процесс является управляемой
марковской цепью.
Как было показано в § 5.7, марковская цепь может
быть задана в виде матрицы вероятностей переходов Р==
= порядка LXL. Для того чтобы марковская цепь
была управляемой, должна иметься возможность изменять
вероятности переходов рц путем вмешательства извне.
Предположим, что имеется возможность вести марковский
процесс N различными способами, причем k-му способу
соответствует матрица вероятностей переходов Pk—[piiw],
£=1JV7 Каждый способ ведения марковского процесса
будем называть стратегией.
Считаем, что имеем возможность оценить каждый спо-
соб осуществления процесса путем задания матрицы по-
терь или, что в данном случае удобнее, матрицы доходов
=[/-,/*)]. Величины i, j=l, L; k=l, N выражают
доход за один шаг при переходе процесса из состояния i
в состояние j в случае использования k-Oi стратегии.
340
Пример 8.2. Завод по изготовлению телевизоров из примера 5.14,
находясь в состоянии 1, может увеличить спрос путем организации
рекламы, но это требует добавочных затрат и уменьшает доход. Если
завод находится в состоянии 2, то он может ускорить переход в со-
стояние 1 путем увеличения затрат на исследования. При этом стра-
тегия 1 состоит в том, чтобы не нести затрат иа рекламу и исследова-
ния, а стратегия 2 состоит в том, чтобы нести эти затраты. Матрицы
вероятностей переходов н матрицы доходов для этих стратегий могут
быть следующими:
р _ Р’5 0,5 1. r — Г9 31- Р =Г°’8 °’2]. R -Г4 41
1 [0,4 0,6]’ [3 —7J’ 2 [о,7 0,3 J’ Ка [1 —19]"
Поставим задачу найти метод выбора стратегии, обес-
печивающей получение максимального дохода за п шагов
управляемого марковского процесса.
Обозначим через /{(п) максимальный доход за п шагов,
начавшихся из состояния I. Предположим, что из состоя-
ния i сделан один шаг в состояние / с доходом п/Ч а ос-
тальные п—1 переходов сделаны оптимальным образом.
Полный доход за п шагов при этом будет n/ft)+/7(n—1).
Однако в действительности первый переход вида (i, /)’
совершается с вероятностью pz/fe>. Поскольку первый пере-
ход случаен, то следует учесть возможность перехода во
всевозможные состояния /е{1,...,N}. Поэтому ожидаемый
доход
N N
РДп, k)~ Зр‘«>[6|)+//(«-1)]=#>+ (8-41)
где
(8-42)
— доход за один шаг из состояния i при стратегии k.
В выражение (8.41) входит стратегия k, применяемая
на начальном шаге, соответствующим выбором которой
можем обеспечить максимальный ожидаемый доход
что приводит к рекуррентному соотношению для выбора
стратегии k на первом шаге n-шагового процесса:
Ji («) = max 2 ('г — 1) (8-43)
341
Расчет по формуле (8.43) удобно проводить табличным
методом, аналогичным рассмотренному в предыдущих па-
раграфах. Приведем соответствующие таблицы (табл. 8.5 и
8.6) для задачи из примера 8.2 для п=1 и п=2. Таблицы
для п>2 составляются по типу таблицы для п—2.
Таблица 8.6
Задачи к гл. 8
8.1. Продолжите решение примера 8.1 и вычислите всю оптималь-
ную траекторию.
8 2. Рассматривая сетку на рис. 8.3 как граф, найдите оптималь-
ную траекторию, воспользовавшись методами нахождения кратчайшего
пути в графе из § 3.2. Сравните это решение с решением методом ди-
намического программирования.
8.3 Найдите оптимальное управление для следующего трехшаго-
вого процесса управления скалярной величиной х. В начале процесса х
может быть любым целым числом —от —10 до -|-10. На отдельных
шагах осуществляют преобразования вида х'=Т(х, м)=х-]-и, причем
допустимые значения и определяются множествами:
{—1, 0, -|-1} на первом шаге; {—4, 0, -|-4} на втором шаге,
{—9, 0, -|-9} на третьем шаге.
312
Цель процесса — довести за три шага величину х до заданного
значения, которое принято равным нулю. Потери оцениваются квадра-
том отклонения х от 0 в конце процесса, т. е. величиной д(х)=>
= (х— 0)2=х2.
Глава 9
ТЕОРИЯ ИГР
9.1. ПРЕДМЕТ ТЕОРИИ ИГР
9.1.1. Игра как модель конфликтной ситуации
Теория игр представляет собой интенсивно развиваю-
щуюся математическую дисциплину, предметом исследова-
ния которой являются методы принятия решения в кон-
фликтных ситуациях [42, 57, 58]. Ситуация называется
конфликтной, если в ней сталкиваются интересы несколь-
ких (обычно двух) лиц, преследующих противоположные
цели. Каждая из сторон может проводить ряд мероприя-
тий для достижения своих целей, причем успех одной сто-
роны означает неудачу другой.
Авторы первого фундаментального трактата по тео-
рии игр Дж. фон Нейман и О. Моргенштерн [59] ориенти-
ровались на анализ конфликтных ситуаций в вопросах
экономики, когда при наличии свободной конкуренции
в роли борющихся сторон выступают торговые фирмы, про-
мышленные предприятия и т. п. Однако конфликтные си-
туации встречаются и во многих других областях. К кон-
фликтным ситуациям относятся почти все ситуации, воз-
никающие при планировании военных операций, выборе
системы оружия, охране объектов от нападения, преследо-
вании и перехвате цели и т. п. Интересными примерами
конфликтных ситуаций являются спортивные состязания,
арбитражные споры, аукционы, выборы в парламент при
наличии нескольких кандидатов на одно место.
Приведенные примеры показывают большое разнообра-
зие встречающихся на практике конфликтных ситуаций.
Обычно эти ситуации трудны для непосредственного ана-
лиза вследствие множества второстепенных факторов. Для
того чтобы сделать возможным математический анализ
конфликтной ситуации, ее необходимо упростить, учтя
только основные факторы. Упрощенную формализованную
343
модель конфликтной ситуации называют игрой, а конфлик-
тующие стороны — игроками. Ограничимся рассмотрением
игр, в которых имеются только две конфликтующие сторо-
ны. Прежде чем дать формальное определение игры, необ-
ходимо разъяснить используемую терминологию, которая
в основном совпадает с терминологией, встречающейся
в различных развлекательных и азартных играх (шахма-
ты, шашки, карточные игры и т. п.).
Следует различать понятие игры и понятие индивиду-
альной партии этой игры. Игра представляет собой сово-
купность правил, описывающих поведение игроков. Каж-
дый случай разыгрывания игры некоторым конкретным
образом от начала и до конца представляет собой партию
игры. Элементами игры являются ходы. Правила игры
предусматривают, какова должна быть последовательность
ходов, и указывают характер каждого хода.
Ходы бывают личные и случайные. Личный ход пред-
ставляет собой выбор игроком одного из заданного мно-
жества вариантов. Например, каждый ход в шахматах
является личным ходом, причем первый ход — выбор из
20 вариантов. Решение, принятое игроком при личном хо-
де, называют выбором.
Случайный ход также представляет собой выбор одного
из множества вариантов, но здесь вариант выбирается не
игроком, а некоторым механизмом случайного выбора.
Примерами случайных ходов может служить сдача карт
или бросание монеты. Выбор, осуществляемый при слу-
чайном ходе, называют исходом этого хода.
По отношению к ходам правила имеют следующую
структуру. Для первого хода правила указывают, будет
это личный или случайный ход. Если это личный ход, то
правила перечисляют имеющиеся варианты и указывают,
какой игрок должен делать выбор. Если это случайный
ход, то правила перечисляют имеющиеся варианты и обу-
словливают вероятности их выбора.
Для каждого следующего хода правила указывают
в зависимости от выборов и исходов предыдущих ходов:
будет это личный или случайный ход. Если это случайный
ход, то правила перечисляют имеющиеся варианты и обу-
словливают вероятности их выбора. Если это личный ход,
то правила указывают, какой игрок делает выбор, и пере-
числяют возможные варианты.
Наконец, правила определяют в зависимости от выбо-
ров и исходов следующих друг за другом ходов (т. е.
344
в зависимости от хода игры), когда игра должна закон-
читься и каков выигрыш или проигрыш каждого из игро-
ков.
9.1.2. Понятие стратегии
Представим себе, что хотим сыграть шахматную пар-
тию белыми, но лично присутствовать при игре не можем.
У нас есть заместитель, который должен провести партию
и выполнять все наши указания. Но сам он не умеет
играть в шахматы и не способен принимать самостоятель-
ные решения. Чтобы заместитель мог провести всю партию
до конца, ему должны быть даны такие указания, которые
предусматривали бы любые возможные положения на дос-
ке и для каждого положения определяли бы тот ход, ко-
торый должен быть сделан. Полная система таких указа-
ний и представляет собой стратегию.
Так, стратегия белых должна указывать первый ход,
затем для каждого возможного ответа черных следующий
ход белых и т. д. Конечно, составление полной стратегии
при игре в шахматы является огромной, практически не-
выполнимой работой. Например, игрок белыми, присутст-
вующий лично, должен принять два решения, чтобы сде-
лать два первых хода. Играя же через заместителя, он
должен приготовить 21 решение для тех же двух ходов
(одно решение —первый ход и 20 решений — ответы на
20 возможных первых ходов черных). Тем не менее во
многих более простых задачах понятие стратегии является
весьма полезным.
Таким образом, стратегия игрока представляет собой
однозначное описание его выбора в каждой возможной
ситуации, при которой он должен сделать личный ход.
Если игра состоит только из личных ходов, то исход
игры определен, если каждый из игроков выбрал свою
стратегию. Однако если в игре имеются случайные ходы,
то игра будет носить вероятностный характер и выбор стра-
тегий игроков еще не определит окончательно исход
игры.
9.1.3. Формальное описание игры двух лиц
Обозначим через X и У множества или пространства
всевозможных стратегий, которыми могут пользоваться
участники игры, называемые далее первым и вторым игро-
345
ками соответственно. Величины х^Х и y^Y будут озна-
чать конкретные стратегии первого и второго игроков.
Для того чтобы ввести в рассмотрение случайные ходы,
удобно считать, что в игре принимает участие третий иг-
рок, который и делает случайные ходы, пользуясь для
этого соответствующим механизмом случайного выбора.
Обозначим через Н пространство стратегий этого игрока.
Любая стратегия h^H третьего игрока, представляющая
собой конкретную последовательность всех случайных хо-
дов в партии, будет происходить с некоторой вероятностью
p(/i), которую легко подсчитать, зная вероятности каждо-
го случайного хода в этой последовательности. Легко ви-
деть, что p(h) представляет собой распределение вероят-
ностей на пространстве Н, т. е. удовлетворяет условиям
р(/г)>0, 2/>(й)=1. (9.1)
h^H
Обозначим через g некоторый вариант игры, т. е. одну
возможную партию. Этот вариант будет определен, если
выбраны стратегии игроков х и у и стратегия случайных
ходов h. Следовательно, конкретная партия g представля-
ет собой тройку величин х, у и h:
g=(x, у, h). (9.2)
Результатом партии является выигрыш или проигрыш
каждого из игроков. Для удобства выигрыши и проигрыши
будем оценивать каким-либо числом, например суммой
денег в рублях.
Рассмотрим одну из конкретных партий g(x, у, h) и
обозначим через Lx(x, у, h) и Ly(x, у, h) проигрыши или
потери первого и второго игроков соответственно. При этом
выигрыши рассматриваем как отрицательные проигрыши.
Общая сумма проигрышей обоих игроков равна
Д(*. у, h)+Ly(x, у, h). (9.3)
В дальнейшем ограничимся рассмотрением только так
называемых игр с нулевой суммой, т. е. таких игр, в ко-
торых общая сумма проигрыша (9.3) равна нулю. В таких
играх проигрыш одного игрока равен выигрышу другого.
При рассмотрении игр с нулевой суммой нет необходи-
мости отдельно учитывать проигрыши или выигрыши обоих
игроков, а можно ограничиться рассмотрением только про-
346
игрыша второго игрока (выигрыша первого):
Ly(x, у, h)=—Lx(x, у, h)=L(x, у, h). (9.4)’
Поскольку стратегия h является случайной, то при
выбранных стратегиях х и у потери Л(х, у, h) будут слу-
чайной величиной с распределением вероятностей p(/i) на
пространстве Н. Поэтому оценить выбранные стратегии х
и у можно лишь путем усреднения потерь L(x, у, h) по
всему пространству Н, т. е. введя понятие средних потерь
L(x, у), определяемых согласно (5.52) из соотношения
Ь(х, f/)= 3 У’ h)p(h). (9.5)
ле/-/
Игра будет определена, если перечислены все возмож-
ные стратегии игроков, т. е. заданы пространства X и Y,
и для любых хеХ и y^Y определены потери L(x, у). Та-
ким образом, приходим к следующему формальному опре-
делению игры.
Игра G определяется тройкой
G=(X, У, L), (9.6)
где X и У—некоторые пространства; Л —ограниченная
числовая функция, определенная на прямом произведении
XX У.
Точки хеХ и y^Y называют стратегиями первого и
второго игроков, а функцию L называют функцией потерь.
Игры, в которых каждый игрок имеет конечное число
стратегий (конечные игры), удобно задавать в виде мат-
рицы потерь. Пусть G=(X, У, L) — конечная игра, в кото-
рой X={xi,...,xm} и Y={yi,.. ,,уп}. Тогда матрица поряд-
ка пг\п
Г - Яш 1
Q=[Qj= ............ , (9-7)
L Qmi ••• Ятп J
в которой qij=L(xh у,), называют матрицей игры G.
Для того чтобы описание игры было законченным, не-
обходимо указать цели, которыми руководствуются игро-
ки при выборе своих стратегий. Эти цели достаточно прос-
ты. Первый игрок стремится обеспечить себе наибольший
выигрыш, т. е. максимизировать функцию L(x, у), второй
игрок стремится сделать свой проигрыш наименьшим, т. е.
минимизировать функцию L(x, у). Таким образом, цели
347
игроков прямо противоположны. Специфической трудно-
стью при этом является то, что ни один из игроков не кон-
тролирует полностью значение Цх, у), так как первый
игрок распоряжается только значением х, а второй —
только значением у. Преодоление этой трудности, т. е.
определение наиболее рационального способа ведения иг-
ры каждым из игроков, и представляет собой существо
теории игр.
Необходимо подчеркнуть, что приведенные рассуждения
справедливы только для игры двух лиц с нулевой суммой.
Если число игроков больше двух, то возникает совершенно
иная ситуация, особенность которой в том, что некоторые
из игроков могут объединять свои действия, образуя коа-
лиции с договорным распределением выигрыша между
участниками коалиции. Участники коалиции могут более
полно оценить свои возможности и проводить согласован-
ные действия, обеспечивая себе тем самым большую вели-
чину выигрыша.
Другим вариантом игры является игра с ненулевой сум-
мой. В такой игре выигрыши одних игроков могут полу-
читься не только за счет проигрышей других, но и за счет
каких-либо платежей, поступающих извне. Эти платежи
рассматривают как проигрыши некоторого добавочного
фиктивного игрока, что позволяет свести игру п лиц с не-
нулевой суммой к игре 1 лиц с нулевой суммой.
Однако теория игр с п участниками для п>2 является
довольно сложной и недостаточно разработанной, поэтому
мы ограничимся рассмотрением только игры двух лиц с ну-
левой суммой.
Пример 9.1. Для пояснения введенных понятий рассмотрим сле-
дующую игру, состоящую из четырех ходов.
Первый ход (личный): первый игрок выбирает одно из двух целых
чисел (1, 2).
Второй ход (случайный): бросают монету и, если выпадает «герб»
(и только в этом случае), второму игроку сообщают о выборе перво-
го игрока.
Третий ход (личный): второй игрок выбирает одно из двух целых
чисел (3, 4).
Четвертый ход (случайный): выбирается случайным образом с ве-
роятностями 0,4; 0,2; 0,4 одно из трех целых чисел (1, 2, 3).
Результаты игры: числа, выбранные в первом, третьем и четвертом
ходах, складывают и второй игрок полученную сумму выплачивает
первому игроку, если она четная, и первый игрок второму игроку, если
она нечетная.
348
При предварительном анализе игру удобно представить в виде де-
рева, на котором положения, возникающие в процессе игры, изобра-
жаются вершинами, а ходы — ветвями, соединяющими одну вершину
с другой. Дерево рассматриваемой игры приведено иа рис. 9.1. Верши-
ны, соответствующие личным ходам первого и второго игроков, обозна-
чены соответственно Z и II. Вершины, соответствующие случайным хо-
дам, обозначены' 0. Конечные вершины, определяющие отдельные ва-
рианты игры, помечены цифрами, означающими проигрыши второго
игрока.
Рис. 9.1. Дерево игры
В разных вершинах, соответствующих личным ходам, игрок обла-
дает определенным видом информации о предыдущих ходах. Если
в нескольких вершинах игроку доступна одна и та же информация, то
эти вершины удобно объединить. Путем такого объединения получают-
ся группы вершин S{, называемые классами информации. В рассмат-
риваемом примере имеется четыре класса информации, содержание ко-
торых следующее:
Si —ходов еще не было, первый игрок должен сделать первый
ход; S2 — первый игрок выбрал 1; S3 — первый игрок выбрал 2; S<—
неизвестно, что выбрал первый игрок.
Прн попадании иа вершину, находящуюся в классе S«, второй
игрок не имеет информации о выборе первого игрока. Такую игру на-
зывают игрой с неполной информацией. Если в класс информации вхо-
дит только одна вершина, то игрок, попадающий на эту вершину, пол-
ностью осведомлен о всех предыдущих ходах (эту информацию ои
может получить, например, проследив по дереву игры путь до данной
вершины), т. е. имеет полную информацию об игре. Игры, в которых
349
каждый класс информации содержит только одну вершину, называют
играми с полной информацией (шахматы, шашки, домино и т. п.).
Рассмотрим пространства стратегий игроков Пространство страте-
гий первого игрока, состоящее всего из двух элементов, которым со-
ответствует выбор 1 или 2, приведено ниже:
(1) I (2)
Стратегия второго игрока должна указывать его ход при любом воз-
можном варианте игры. Вариант же игры определяется классом инфор-
мации игрока. Для второго игрока имеется три класса информации:
Таблица 9.1
h Р(Л) £(х,. yi.h) L(xt, у,. Л) р (Л)
(Г, 1) 0,2 +5 +1,0
(Г, 2) 0,1 —6 <-0,6
(Г, 3) 0,2 +7 +1.4
(Р, 1) 0,2 +5 +1,0
(Р, 2) 0,1 —0,6
(Р, 3) 0,2 +7 + 1,4
Si, S3 и S-i. Следовательно, стратегия второго игрока состоит в указа-
нии, какое из двух чисел (3 или 4) он выбирает в каждом классе
информации. Так, стратегия (4, 3, 3) означает, что второй игрок выби-
рает 4 в классе информации S2 и 3 в классах информации S3 и S4.
Пространство стратегий второго игрока приведено ниже:
| У* | У> | | Рз | Уч | »7 j Уг
(333) | (334) | (343) | (344) | (433) | (434) | (443) | (444)
Случайные стратегии h состоят из двух ходов: второй ход—выбор
Г или Р с вероятностями 0,5; 0,5 и четвертый ход—выбор числа 1, 2
или 3 с вероятностями 0,4, 0,2, 0,4. Вероятность каждой стратегии
равна произведению вероятностей исходов обоих ходов. Пространство
случайных стратегий Н и распределение вероятностей р(й) даны ниже:
Л | (Г, 1) | (Г, 2) | (Г, 3) | (Р, I) | (Р, 2) | (Р, 3)
р (й) I 0,2 I 0,1 I 0,2 I 0,2 I 0,1 I 0,2
350
Для составления матрицы потерь следует определить потери сщ=
=L(xt, у/), которые в соответствии с (9.5) будут:
<lli= 3 у1’ АИА)>
h<=H
причем величины L(x(, yt, h) представляют собой цифры, которыми по-
мечены конечные вершины дерева игры.
Подсчет значений величин qtt удобно производить табличным спо-
собом по аналогии с табл. 9.1, построенной для определения <щ = 3,6.
9.1.4. Верхняя и нижняя цены игры
Для того чтобы понять принципы, которые лежат в
основе выбора каждым игроком своей стратегии, рас-
смотрим игру с матрицей, представленной табл. 9.2.
Предположим, что первый игрок выбирает стратегию
Xk. Выигрыш L(x/i, у) будет зависеть от стратегии, ко-
торую выберет второй игрок. Например, при стратегии
Xi выигрыши первого игрока могут быть 7, 2, 5, 1. Может
ли первый игрок рассчитывать на наибольший выигрышу
равный 7? Да, если он предположит, что второй игрок
выбирает стратегию уь Однако второй игрок может вы-
брать любую другую стратегию, в том числе и у^. А то-
Таблица 9.2
У1 У* Ул Ui Л(х)
7 2 5 3 2 2 3 2 5 3 1 4 4 6 2 3* 1
в (У) 7 3* 5 6
гда выигрыш первого игрока будет равен 1. Но уже мень-
ше 1 он быть не может ни при какой стратегии второго
игрока. Поэтому 1, являющаяся наименьшим элементом
множества L(xi, у) = {7, 2, 5, 1}, представляет собой га-
рантированный выигрыш первого игрока при страте-
гии Хь
Обобщая приведенные рассуждения, видим, что если
первый игрок применяет стратегию хк, то он обеспечи-
351
вает для себя гарантированный выигрыш A(xft), равный
наименьшему элементу множества L(xk, у):
A(xk) = minL(xb у). (9.8)
у
В теории игр предполагается, что игроки действуют
достаточно осторожно, избегая необоснованного риска.
В этом случае первый игрок должен выбирать такую
стратегию х^Х, которая соответствует максимальному из
чисел А(х). Обозначая гарантированный выигрыш пер-
вого игрока через а и называя его нижней ценой игры,
получаем
а = max А (х) = max min L (х, у). (9.9)
х X у
Значения А(х), соответствующие игре с матрицей вида
табл. 9.2, приведены в крайнем правом столбце. Значение
а отмечено в этом столбце звездочкой.
Аналогичные рассуждения можно провести в отноше-
нии второго игрока. Однако в матрице игры указаны его
проигрыши, которые он стремится сделать минималь-
ными. Рассмотрим стратегию уь. Эта стратегия может
принести ему проигрыш, не больший чем
В(уЛ) = тпахА(х, ук). (9.10)
Для того чтобы обеспечить себе наименьшую величи-
ну проигрыша, второй игрок должен применять такую
стратегию у^У, которая соответствует минимальному из
чисел В (у). Обозначая значение проигрыша, которым мо-
жет ограничиться второй игрок, через р и называя его
верхней ценой игры, получаем
P = minB(y) = minmaxL(x, у). (9.11)
у ух
Значения В (у) для игры с матрицей вида табл. 9.2
приведены в нижней строке таблицы. Значение р отме-
чено- в этой строке звездочкой.
Теорема 9.1. Если G=(X, У, L) — игра, то для любого
х<^Х и уеУ имеет место:
A(x)^L(x, у)^В(у) и а<р.
352
Доказательство. По определению
А(х) = minL(x, у)<Ь(х,’у);
у
В (у) = max L (х, y)>L(x, у).
(9.12)
(9.13)
Следовательно,
Л(х)^Л(х,у)^В(у). (9.14)
Так как это соотношение справедливо при любых хе
еА' и y^Y, то, выбирая в качестве х то значение, при
котором Л(х)=а, а в качестве у то значение, при котором
В(у)=Р, получаем
а^р. (9.15)
Как видим, нижняя цена игры, т. е. тот выигрыш, ко-
торый может обеспечить себе первый игрок, не превы-
шает верхней цены игры, т. е. того проигрыша, которым
может ограничиться второй игрок.
9.2. ЦЕНЫ И ОПТИМАЛЬНЫЕ СТРАТЕГИИ ИГР
9.2.1. Игра с седловой точкой
Простейшим частным случаем игры является случай,
когда а=р. Обозначим эту величну через с. Именно к
этому случаю относится игра с матрицей, заданной
табл. 9.2, где а=р=3.
В данном случае никакой способ игры не может га-
рантировать первому игроку выигрыш, больший чем р,
так как именно величиной р второй игрок может огра-
ничить свой проигрыш. С другой стороны, никакой спо-
соб игры не может гарантировать второму игроку про-
игрыш, меныпий чем а, так как первый игрок может га-
рантировать себе выигрыш а. Следовательно, если а=
=Р=с, то никакая стратегия ни одного из игроков не
может гарантировать ему лучшего результата, чем с.
В то же время каждый игрок может гарантировать себе
результат с. Другими словами, ни первый, ни второй игрок
не имеет лучшей стратегии, чем та, которая обеспечивает
им с. В этом случае с называют ценой игры, а стратегии
игроков, обеспечивающие результат с, — оптимальными
стратегиями.
23-604
353
Клетку матрицы, определяющую величину с, называют
седловой точкой, так как значение с является максиму-
мом столбца и минимумом строки, на пересечении ко-
торых стоит эта величина. Поэтому игру, имеющую цену,
называют игрой с седловой точкой.
Игру с седловой точкой называют справедливой, если
с=0. Если с=/=0, то игра будет несправедливой. Для того
чтобы сделать ее справедливой, первый игрок должен
уплатить второму игроку величину с перед началом каж-
дой новой партии.
9.2.2. Чистые и смешанные стратегии
Если игра не имеет седловой точки, то возникают за-
труднения в определении цены игры и оптимальных стра-
тегий игроков. Рассмотрим, например, игру, матрица ко-
торой дается табл. 9.3. В этой игре а=4 и р=5. Сле-
довательно, первый игрок может гарантировать себе вы-
игрыш, равный 4, а второй может ограничить свой про-
игрыш 5. Область между £ и а является как бы ничей-
ной, и каждый игрок может попытаться улучшить свой
результат за счет этой области. Каковы же должны
быть в этом случае оптимальные стратегии игроков?
Таблица 9.3
У\ Уг Л (А.)
3 6 3
х2 5 4 4*
В (у) б4- 6
Если каждый из игроков применяет отмеченную звез-
дочкой стратегию (хг и yi), то выигрыш первого игрока
и проигрыш второго будут равны 5. Это невыгодно вто-
рому игроку, так как первый выигрывает больше, чем
он может себе гарантировать. Однако если второй игрок
каким-либо образом раскроет замысел первого о наме-
рении использовать стратегию х2, то он может применить
стратегию у2 и уменьшить выигрыш первого до 4. Прав-
да, если первый игрок раскроет замысел второго при-
менить стратегию у2, то, используя стратегию Xi, он уве-
354
личит свой выигрыш до 6. Таким образом, возникает си-
туация, когда каждый игрок должен хранить в секрете
ту стратегию, которую он собирается использовать. Од-
нако, как это сделать? Ведь если партия играется много-
кратно и второй игрок применяет все время стратегию уг,
то первый игрок скоро разгадает замысел второго и,
применив стратегию х\, будет иметь добавочный выигрыш.
Очевидно, что второй игрок должен менять стратегию
в каждой новой партии, но делать это он должен так,
чтобы первый не догадался, какую стратегию применит
он в каждом случае.
Секретность можно сохранить, если каждый раз вы-
бирать стратегию случайным образом, используя для это-
го какой-либо механизм случайного выбора. Например,
второй игрок может бросить монету и применить стра-
тегию yi, если выпадет «герб», и у2, если выпадет «решка».
Такой способ действия лишает противника всякой воз-
можности узнать наперед о действиях другой стороны.
Для механизма случайного выбора выигрыши и про-
игрыши игроков будут случайными величинами. Резуль-
тат игры в этом случае можно оценить средней величи-
ной проигрыша второго игрока. Так, если в игре с мат-
рицей вида табл. 9.3 второй игрок использует стратегию
yi и у2 случайным образом с вероятностями 0,5; 0,5, то
при стратегии первого игрока xi среднее значение его
проигрыша будет
£^==^.0,5+912-0,5=3-0,5+6-0,5=4,5,
а при стратегии первого игрока х\
^-cp=?2i • 0,5+^22 • 0,5=5 • 0,5+4 • 0,5=4,5.
Следовательно, второй игрок может ограничить свой
средний проигрыш значением 4,5 независимо от страте-
гии, применяемой первым игроком.
Таким образом, в ряде случаев оказывается целесо-
образным не намечать заранее стратегию, а выбирать
ту или иную случайным образом, основанным на ис-
пользовании какого-либо механизма случайного выбора.
Стратегию, основанную на случайном выборе, будем на-
зывать смешанной стратегией в отличие от рассмотрен-
ных ранее намеченных стратегий, которые теперь будем
называть чистыми стратегиями.
Дадим более строгое определение чистых и смешанных
стратегий.
23* 355
Пусть G=(X, У, L)—игра. Пространства X={xi, ...
..., хт} и У={г/1, ..., уп}, содержащие перечни всех воз-
можных стратегий игроков, называют пространствами чи-
стых стратегий, а элементы этих пространств хеХ и y^Y
являются чистыми стратегиями игроков.
Для получения смешанной стратегии игрок должен
использовать некоторый механизм случайного выбора
(бросание монеты, бросание игральной кости и т. п.),
имеющий число исходов, равное числу чистых стратегий
игрока.
Обозначим через £(1>, ..., £(т) вероятности отдельных
исходов механизма случайного выбора первого игрока,
а через т](,\ ..., т](п> вероятности отдельных исходов ме-
ханизма случайного выбора второго игрока. Если каж-
дому исходу i механизма случайного выбора первого
игрока назначается чистая стратегия xt этого игрока, а
каждому j механизма случайного выбора второго игро-
ка— чистая стратегия у/ этого игрока, то упорядоченные
множества £=(£(1), ..., |(т)) и т]=(т]<1), ..., т](п)). элемен-
ты которых удовлетворяют условию нормировки (5.3),
будут представлять собой распределение вероятностей
Цх) и т](у) на пространствах X и У. Эти распределения
вероятностей полностью определяют характер игры, их
называют смешанными стратегиями первого и второго
игроков.
В общем случае каждый игрок может располагать не
одним, а несколькими механизмами случайного выбора,
отличающимися различными распределениями вероятно-
стей на пространствах X и У, например: gi = (gi(1)...,
Ь=(Ь(1>, .... Ь(т>) .... Л1= (П1(1)> ••• Л1(и)). т]2=(П2(1), ...
..., т]2(и)) ... При этом множества
V Е={&, Ь •••} И Я={т|1, Т]2 • ••} (9.16)
будут представлять собой пространства смешанных стра-
тегий первого и второго игроков.
9.2.3. Функция потерь при использовании
смешанных стратегий
Рассмотрим игру G=(X, У, L), в которой X={xi, ...
..хт} и У={г/1.......уп} являются пространствами чи-
стых стратегий игроков, a L(x, у) представляет собой
потери второго игрока, определенные для чистых стра-
356
тегий х^Х и уеУ. В дальнейшем функцию L(x, у) будем
называть функцией потерь.
Предположим теперь, что игроки применяют смешан-
ные стратегии. Это означает, что заданы множества Е=
= {Вь £2 • • •} и ЛГ={'П1> Лг •••}> элементы которых пред-
ставляют собой смешанные стратегии игроков, т. е. раз-
личные распределения вероятностей g(x) и т](у) на про-
странствах X и Y. Характер игры будет определен, если
каждый игрок выбрал свою смешанную стратегию gef
и т]^Н. Следовательно, при использовании смешанных
стратегий в определение игры вместо множеств X и У
должны войти множества Е и И.
При использовании смешанных стратегий изменится и
значение проигрыша второго игрока, т. е. функция по-
терь. Поскольку игра приобретает случайный характер,
то случайными будут значения выигрышей и проигрышей
игроков. Поэтому теперь можно вести речь лишь о сред-
нем значении выигрыша X или проигрыша У, которое
определится функцией потерь L(x, у), так и распреде-
лениями вероятностей g(x) и т)(1/) и может быть найдена
по формуле для среднего значения функции двух пере-
менных как
Ц*. Ч)= у)Цх)щ(у). (9.17)
х.у
Функция потерь L(g, т]) должна войти в определение
игры при смешанных стратегиях.
Таким образом, при использовании смешанных стра-
тегий вместо игры G=(X, У, L) получаем новую игру
r=(f, Н, L), которую называют усреднением игры G.
В этой игре функцию потерь L(g, т]) определяют по (9.17)
как среднее от L(x,y) при заданных распределениях ве-
роятностей g(x) и Т] (1/) •
Все вышесказанное можно суммировать в виде сле-
дующих определений.
Пусть G=(X, У, L) — игра. Пусть Е и Н определя-
ют различные распределения вероятностей g и т) на про-
странствах X и У, a L (g, т]) представляет собой среднее
значение функции потерь. Тогда игру
Г=(Е, Н, L) (9.18)
называют усреднением игры G.
357
Пусть Г=(Е, Н, L) —усреднение игры G=(X, У, L).
Тогда точки х^Х и y^Y называют чистыми стратегиями
в игре G, а точки ^Е и т\<^Н — смешанными стратегиями
в игре G.
Отметим, что чистые стратегии можно рассматривать
как частный случай смешанных. Действительно, смешан-
ная стратегия, определяемая распределением вероятно-
стей
( 1 при х = xk,
l-(x) = L , (9.19)
V ’ (0 При Х#=Х.(, ' ’
совпадает с чистой стратегией хЛ, а смешанная стратегия,
определяемая распределением вероятностей
( 1 при ц = и-
т](у)= „ , (9.20)
(0 при y-£yh z
совпадает с чистой стратегией у,.
9.2.4. Верхняя и нижняя цены игры при использовании
смешанных стратегий
Пусть G=(X, У, L)—игра, Г= (Е, Н, L)—усредне-
ние игры.
Предположим, что первый игрок применяет смешан-
ную стратегию ^Е. Этого игрока интересует, каков бу-
дет его гарантированный выигрыш, т. е. та наименьшая
сумма выигрыша, которую он может наверняка себе
обеспечить, даже если второй игрок применяет свою нап-
лучшую смешанную стратегию т). При этом не исклю-
чается случай использования вторым игроком какой-либо
из чистых стратегий.
Обозначим гарантированное значение выигрыша пер-
вого игрока при стратегии £ через Дг(£). Очевидно, что
это есть нижняя граница функции выигрыша L(g, т]) при
данном £ и различных т\^Н, т. е.
А-(5)— mini (5, ij). (9 21)
ч
Далее первого игрока будет интересовать выбор из
всех возможных стратегий такой, при которой его
гарантированный выигрыш будет максимальным, т. е. бу-
дет интересовать верхняя граница функции Лг(£), обо-
358
значаемая через аг и называемая нижней ценой игры
при смешанных стратегиях игроков:
аг = max Дг(£) = maxminL(£, ц). (9.22)
Стратегию, для которой выполняется условие (9.22),
называют максиминной стратегией первого игрока и обо-
значают go.
Предположим теперь, что второй игрок выбрал ка-
кую-либо смешанную стратегию х\^Н. Этого игрока ин-
тересует, каков будет его наибольший проигрыш при наи-
лучшей стратегии geB первого игрока, т. е. верхняя
граница функции L(g, т)) при заданном т) и различных
gef, обозначаемая
Вг (>]) = max L (?, т)). (9.23)
Второго игрока будет интересовать выбор такой стра-
тегии и\^Н, при которой проигрыш будет минимальным,
т. е нижняя граница функции Вг(т]), обозначаемая че-
рез В и называемая верхней ценой игры при смешан-
ных стратегиях игроков:
Рг = min Вг (>]) = min max L (£, ij). (9.24)
ч ч
Стратегию, для которой выполняется условие (9.24),
называют минимаксной стратегией второго игрока и обо-
значают Т]о-
Для удобства дальнейших рассуждений введем сле-
дующие обозначения для нижней и верхней цен игры
G=(X, У, L) при использовании чистых стратегий:
Ав (х) = min(х, у) — гарантированный выигрыш первого
у
игрока при стратегии х^Х\
аа = max До (х)— нижняя цена игры G при чистых стра-
тегиях игроков;
Во (у) = maxL(x, у) — наибольший проигрыш второго иг-
рока при стратегии у^У;
Ра = min Ва (у) —верхняя цена игры G при чистых стра-
у
тегиях игроков.
359
Целесообразность использования смешанных страте-
гий вытекает из следующей теоремы.
Теорема 9.2. Если имеется игра G—(X, У, L), а Г=
— (Е, Н, L) есть усреднение игры G, то
а) Лг (?) = rnin L (5, у); б) аа < аг;
в) Brh) = maxL(x, tj); г) > рг; Д) ^9’25^
В п. «а» содержится утверждение, что при выборе
первым игроком любой смешанной стратегии значение
его гарантированного выигрыша равно значению гаран-
тированного выигрыша при использовании вторым игро-
ком только чистых стратегий. Согласно п. «б» нижняя
цена игры при смешанных стратегиях первого игрока не
меньше нижней цены игры при чистых стратегиях, т. е.
что существует смешанная стратегия, которая во всяком
случае не хуже оптимальной чистой стратегии. Пункты
«в» и «г» содержат аналогичные утверждения в отно-
шении второго игрока. Пункт «д» означает, что нижняя
цена игры аг при использовании смешанных стратегий
не превосходит верхней цены игры, т. е. при использо-
вании наилучших смешанных стратегий гарантированный
выигрыш первого игрока не превзойдет обеспеченного
проигрыша второго игрока.
Доказательство, а) Так как чистые стратегии
уеУ являются частным случаем смешанных г\^Н, то
у) входит как частный случай в я), т. е. являет-
ся подмножеством L(g, я)- На основании теоремы о ниж-
ней границе подмножества (см. § 2.1) имеем
minL(E, у) mini (5, Т1) = ЛГ(?). (9.26)
у ч
Далее L(g, я) можно рассматривать как среднее от
у), взятое по всем у с распределением вероятностей
Я (у). На основании теоремы о среднем значении (см.
§ 5.4) получаем
minL(B, y)<L(?, я). (9.27)
У
Соотношение (9.27) справедливо при любом i\^H, в
том числе и при яо, для которого £(!-, т)0) = minL(!-, tj.)
360
Таким образом,
min L (В, у) < min L ($, tj) = Аг(Н). (9.28)
у ч
Сравнивая (9.26) и (9.28), убеждаемся в справедли-
вости п. «а».
б) Сравнивая Ao (х) = minL(x, у) с величиной Аг(£), ко-
у
торую на основании п. «а» можно определять, как и Ag(x),
только при чистых стратегиях у второго игрока, и учи-
тывая, что чистая стратегия х есть частный случай сме-
шанной стратегии £(х), видим, что Ag(x) есть подмно-
жество Аг(£)• На основании теоремы о верхней границе
подмножества имеем
max Ag (х) <max Аг (?),
что и доказывает п. «б».
Пункты «в» и «г» доказываются аналогично.
д) По определению имеем
AH5)=minL(£, T))<L(^, т));
ч
Вг(ч) = тах£(5, т))>^(?, il)-
%
Следовательно,
Ar(g)^L(g, п)^Вг(п).
Это справедливо для любых g и я> т- е- для такого
g, при котором Аг(^)=аг, и для такого я. ПРИ котором
£?г (я) =Рг, что и доказывает п. «д».
Следствие. Сопоставляя пп. «б», «г» и «д», на-
ходим
ао^аг^рг^рс. (9.29)
Из (9.29) следует, что если игра G имеет цену, т. е.
aG=PG=c (как мы видели, это имеет место для игр с
седловой точкой), то аг=|?г=с, т. е. игра Г также имеет
цену. Поэтому оптимальная стратегия в игре G является
оптимальной и в игре Г. В этом случае игру Г вообще
не следует рассматривать, а оптимальные стратегии игро-
ков можно находить методом, описанным для игр с сед-
ловой точкой.
361
иднако игра Г была введена с целью анализа таких
игр, у которых aG<Pc- Возникает вопрос, не окажется
ли для большого класса игр, что в этом случае аг =
— рг = сг и величину сг можно рассматривать как цену
игры Г. В дальнейшем покажем, что это действительно
имеет место, так что применение смешанных стратегий
позволяет найти цену игры и оптимальные стратегии
игроков и в этом случае. При этом будем исходить из
следующего определения оптимальной стратегии.
Пусть имеется игра G=(X, У, L), а Г—(Е, Н, L) есть
усреднение игры G. Если игра Г имеет цену сг = «г = рг,
то говорят, что игра G имеет цену сг и любую опти-
мальную стратегию в игре Г, т. е. стратегию, обеспечи-
вающую гарантированные значения выигрыша первого
игрока и проигрыша второго, равные сг, называют опти-
мальной стратегией в игре G. Нетрудно видеть, что если
аг=Рг = сг, то максиминпая и минимаксная стратегии
игроков ^о(х) и т]о(*/) будут оптимальными стратегиями.
Теорема о том, что всякая конечная игра имеет цену
и у каждого из игроков имеются оптимальные стратегии,
является основной теоремой теории игр (будет доказана
в следующем параграфе).
9.3. ОСНОВНАЯ ТЕОРЕМА ТЕОРИИ ИГР
9.3.1. S-игра
Играм, в которых у первого игрока конечное число чис-
тых стратегий, можно дать полезную геометрическую ин-
терпретацию. Пусть дана игра G=(X, У, L) с матрицей
Q=[<7ij], определяемой выражением (9.7). Свяжем с каж-
дым y^Y точку С в m-мерном пространстве, координатами
которой являются потери второго игрока при всевозмож-
ных чистых стратегиях первого игрока:
С=[А(хь у), ..., L(xm, z/)]. (9.30)
Учитывая, что L{xh yj)=qt} и придавая у всевозможные
значения, получаем п точек
С[=(^11, . . ., qml)t • •-J Cn=(^In, .... <]mn) > (9.31)
имеющих в качестве своих координат потери, заданные со-
ответствующими столбцами матрицы игры. Игра, заданная
множеством точек
{Сь .... Сп}, (9.32)
362
получила название S-игры. Играют в нее следующим обра-
зом.
Второй игрок выбирает одну из точек Ct множества
(9.32), например Сз. Независимо от выбора второго игрока
первый выбирает координату точки Съ например вторую.
При этом потери второго игрока будут равны значению вто-
рой координаты точки Сз, т. е. q23-
Таблица 9.4
У1 У* Уг У< Уъ
х2 0 2 3 0 2
Как видим, 5-игра эквивалентна обычной игре, по край-
ней мере при использовании чистых стратегий, так как вы-
бор точки из множества (9.32) эквивалентен выбору стра-
тегии t/еУ, а выбор координаты этой точки эквивалентен
выбору стратегии xsX.
Если число стратегий первого игрока равно двум, то S-
игра имеет наглядное геометрическое изображение, так как
точки множества (9.32) будут в этом случае точками пло-
скости.
Пример 9.2. Рассмотрим игру с матрицей, определяемой табл 9.4.
Эквивалентная S-игра содержит пять точек: ^=(1, 0), С2=(2, 3),С3=
= (—1, 1), С4=(0, —1), С5= (1, 2). Геометрическое изображение этой
игры приведено на рис. 9.2
Обозначим через S'1 выпуклую оболочку конечного мно-
жества точек {С,, ..., Сп} и докажем теорему, из которой
следует, что S-игра эквивалентна обычной игре при исполь-
зовании не только чистых, но и смешанных стратегий.
Теорема 9.3. Любая смешанная стратегия второго игро-
ка может быть представлена точкой, принадлежащей вы-
пуклой оболочке S*, и наоборот, любая точка SeS" может
рассматриваться как некоторая смешанная стратегия вто-
рого игрока.
Доказательство. Рассмотрим смешанные стратегии
игроков £=(£(1), ..., 1(т)) и т1= (я(1), • •., т|(п))- При исполь-
зовании данных смешанных стратегий потери второго игро-
ка
Ь(5, = (9.33)
I к i к k
363
где
(9.34)
Обозначим через 5 точку в /n-мерном пространстве с ко-
ординатами SC*), S<m>, где согласно (9.34)
.................................. (9.35)
Учитывая, что (qit, ..., qmt)=Cj, выражения (9.35) мо-
жем записать в виде одного векторного соотношения
S = Cit)(*> + С„7)(П> = (9.36)
i
Принимая во внимание, что величины rf‘> удовлетворя-
ют соотношениям (5.3), видим, что S есть не что иное, как
средневзвешенное точек Ci, ..., Сп с весами q(1>........q(n>,
'h =L-(xz,y^
Рис. 9.2. Геометрическое представление
S-игры
а следовательно, S есть некоторая точка, принадлежащая
выпуклой оболочке 5*. Таким образом, каждой стратегии
^(qU), .q(n)) второго игрока будет соответствовать не-
которая точка, принадлежащая выпуклой оболочке 5", и
задание этой точки равносильно заданию смешанной стра-
тегии второго игрока.
Справедливо и обратное. Поскольку любая точка S,
принадлежащая выпуклой оболочке 5*, может быть пред-
ставлена как средневзвешенное точек С\, ..., Сп, опреде-
ляющих выпуклую оболочку S*, т. е. представлена в виде
выражения (9.36), то для каждой точки S&S* найдутся
такие веса rf1), ..., т](п), задание которых определит сме-
шанную стратегию второго игрока.
364
Следствие. Поскольку смешанная стратегия первого
игрока остается в S-игре той же самой, что и в обычной
игре, из доказанной теоремы следует, что S-игра полностью
эквивалентна обычной игре, т. е. любая игра может быть
представлена в виде эквивалентной S-игры.
В дальнейшем S-игру будем обозначать Гь Для пере-
хода от игры Г—(Е, Н, L) к S-игре вместо пространства
смешанных стратегий второго игрока Н={яь Па •••} необ-
ходимо использовать пространство S-стратегий, т. е. вы-
пуклую оболочку S*. Если обозначить потери второго иг-
рока в S-игре через Lit то S-игра зависит от Е, S* и Lit
причем потери Li должны быть найдены на прямом произ-
ведении ExS*. Таким образом, выражение
Г1=(Е, S*, Li) (9.37}
определяет S-игру. На основании (9.33) функция потерь
•$) = 2$(i)S(,) = SS, (9.38)
где через gS обозначено скалярное произведение векторов
g= (g(D, . . g(m>) и S= ($(1), .. „ S(m)) .
9.3.2. Нижняя и верхняя цены игры в S-игре
Если первый игрок применяет в S-игре смешанную
стратегию ^Е, то значение его гарантированного выигры-
ша
Л, (?) = mjnLj (?, S) = mjnBS. (9.39)
Обозначим через §o=(go(1), ...» go(m)) такую стратегию
первого игрока, при которой Лг, (?) достигает максимума.
Значение Ar(g) будет равно нижней цене игры аг,, которая
в силу эквивалентности S-игры с обычной игрой совпадает
с аг. Следовательно,
а = Иг, (?0) = тах Л, (?) = max min $S. (9.40)
t 5 s
Стратегию go, удовлетворяющую соотношению (9.40),
называют максиминной стратегией первого игрока.
Предположим теперь, что второй игрок применяет неко-
торую стратегию S&S*. При этом значение проигрыша
Вг, (S) = max£1(?, S) = max?S. (9-41)
365
Обозначим через So=(So(1), ..So(m)) такую точку вы-
пуклой оболочки S*, которая обращает в минимум величи-
ну Вг, (S). Значение ВГ1 (50) будет равно верхней цене игры
рГ1, которая в силу эквивалентности S-игры с обычной
игрой совпадает с |3Г| Итак,
рг = Вг, (В ) = min Вг, (S) = min max ?S. (9.42)
з st
Стратегию So, удовлетворяющую соотношению (9.42),
называют минимаксной стратегией второго игрока
Выражения для Вг, (S) и ]3Г можно представить в бо-
лее удобном виде, если воспользоваться следующей теоре-
мой.
Теорема 9.4. Если S — произвольная точка т-мерного
пространства и £=(£(1), ..., g(m>) — многомерная перемен-
ная, компоненты которой удовлетворяют условию (5.3), то
имеет место соотношение
maxES = max(S<1),..., S<"!)). (9.43)
Доказательство. Пусть S<h>=max (В(‘), ..., S<m))_
Рассмотрим частное значение g, соответствующее случаю
1 пои i — k;
О при i=£k.
(9.44)
В этом случае £S=S<h). Таким образом, SO является
частным значением скалярного произведения gS, а значит,
подмножеством множества значений £S, получающихся при
всевозможных значениях На основании теоремы о верх-
ней границе подмножества находим
S<0 = max (SO,..., S<'">)<max5S. (9.45)
С другой стороны, заменяя в выражении для gS значе-
ния SO, ..S<m> на максимальное значение SO, получаем
?S= Sr'S'<S(fe>Seo = S(fe>. (9.46)
Это выражение справедливо при любом £, удовлетво-
ряющем соотношению (5.3), в том числе и при таком, когда
gS обращается в максимум. Сопоставляя (9.45) и (9.46),
приходим к соотношению (9.43).
366
Воспользовавшись доказанной теоремой, выражение для
Вг, (S) представим в виде
Вг, (S) = max ^S = max (SO,..., S(m)). (9.47)
Из выражения (9.47) выведем два следствия.
Следствие 1. Из условияВг^ ВГ1 (S) получаем
pr<max(S(1),..., S(m>). (9.48)
Любая точка SeS* имеет по крайней мере одну коор-
динату, не меньшую (т. е. большую или равную) Вг .
Следствие 2. Полагая S=Stf=(S0(l), ..., S0(m)), полу-
чаем
рг = ВГ1 (So) =max(S(’>. S^J). (9-49)
Верхняя цена игры Вг равна максимальной из коорди-
нат точки So, определяющей минимаксную стратегию вто-
рого игрока.
9.3.3. Теорема о минимаксе
Возможность нахождения каждым игроком своей наи-
лучшей стратегии основывается на следующей теореме, ко-
торая может рассматриваться как доказательство сущест-
вования решения для конечных игр.
Теорема 9.5. Всякая конечная игра имеет цену, и
у каждого игрока существует по меньшей мере одна опти-
мальная стратегия.
Исходные предпосылки. Пусть G=(X, Y, L) —
конечная игра, а Г=(В, Н, L)—усреднение этой игры.
При доказательстве теоремы удобно вести рассуждения в
терминах S-игры, поэтому через Г1=(£, S*, L\) обозначим
эквивалентную S-игру.
Нижняя и верхняя цены игры будут равны соответст-
венно аг и рг независимо от того, рассматривают игру Г
или эквивалентную S-игру Г,, причем, как было показано
ранее, «г<Рг-
Для того, чтобы доказать теорему, достаточно показать,
что рг< «г, так как из сравнения с предыдущим неравен-
ством будет следовать аг =р г, т. е. что игра имеет цену.
Для доказательства же этого неравенства достаточно
найти такую смешанную стратегию go первого игрока, при
367
которой для всех SeS* имеет место
₽г^о5, SeS*.
Действительно, если (9.50) имеет место, то
(9.50)
8г < min ?0S = Л (%) = «г.
s
ЦЫ)
Рис. 9.3. Область Т
для двумерного про-
странства
Таким образом, доказательство теоремы будет сводить-
ся к доказательству неравенства (9.50).
Доказательство. Рассмотрим множество Т, состоя-
щее из всех точек £=(/(1), ..., /(т)) таких, что /<г)< рг при
i=0, 1, ..., ш. На рис. 9.3 показана
область Т для двумерного простран-
ства, которая в данном случае имеет
вид прямоугольного клина с вершиной,
лежащей на прямой, проведенной из
начала координат под углом 45° коси
абсцисс. Выясним некоторые свойства
множества Т.
Множество Т является выпуклым.
Рассмотрим произвольные точки Л и
t2 этого множества. Уравнение отрез-
ка, соединяющего эти две точки, будет
иметь вид
t = W\tl+Wzt2, W\, w2^0, Wi+w2=l.
Проектируя это уравнение на i-ю ось и учитывая теоре-
му 9.4, получаем
&>) <рг. (9.51)
Следовательно, любая точка рассматриваемого отрезка
принадлежит Т и множество Т выпуклое.
Множество Т не пересекается с множеством 5*. Это
следует из того, что любая точка множества S* имеет по
крайней мере одну координату, большую или равную рг
(см. следствие 1 теоремы 9.4), а значит, Т и S* не имеют
общих точек.
Поскольку Т и S* — выпуклые непересекающиеся об-
ласти, то существует разделяющая их гиперплоскость та-
кая, что множество Т и S* окажутся в разных полупрост-
ранствах, определяемых этой гиперплоскостью. Следова-
тельно, существует такое а=(а(‘>, ..., а(т>) и число с, что
уравнение
ах=с (9.52)
368
будет уравнением разделяющей гиперплоскости, причем
aS^c для SeS*; at^.c для teT. (9.53)
Покажем, что i=l, ..., т. Пусть бг=(б1(,), ...
..., 6j(7n>) — точка, у которой i-я координата равна 1, а ос-
тальные равны малой величине е>0. Рассмотрим точку
So&S*. Поскольку ее максимальная координата равна рг
(см. следствие 2 теоремы 9.4), то точка So—6ieT. Следо-
вательно,
(Sq—6j).
Отсюда следует, что
a6i=a(1>6((1>+ ...
Если 8->0, то >0 при k=£i и При этом по-
следнее условие дает
i=l, ...,/и. (9.54)
Введем обозначение
Ча = а(9.55)
Очевидно, что EjoeE, так как
Кроме того, введем обозначение
(9.56)
Поделим неравенства (9.53) на ^я<‘>. С учетом (9.55) и
(9.56) получим
?0S>v для S£S*;|
Для t^T. I (9’57)
Рассмотрим точку t0 с координатами /о(<)=рг—е, е>0,
i=l, ..., т. Очевидно, что t0^T. На основании второго не-
равенства из (9.57) получаем
Mo<v. (9.58)
24—804 369
Пусть £—>0, так что /о(!)->рг. Тогда
Mo = S - Pr S #’ = Рг. (9.59)
I i
Сравнивая (9.58) и (9.59), находим
(9.60)
При этом первое из неравенств (9.57) дает
goS^v^pr, (9.61)
что и доказывает неравенство (9.50).
Таким образом, у=аг=Рг является ценой игры, a go
и So представляют собой оптимальные смешанные страте-
гии игроков.
9.3.4. Геометрическая иллюстрация принципа
минимакса
Покажем, что точка So, определяющая минимаксную
стратегию второго игрока, является граничной точкой обла-
сти S*, причем такой, в которой область Т касается обла-
сти S*.
Как мы видели, S0=(S0(1>, ..., Sp(m)) eS*, причем
max (So(1), ..., S0(’n))= Рг- С другой стороны, /=(/<*>, ...
..., /(т))е7’, если /г< рг. i=l, tn.
Рассмотрим точку 5'о=(5о(1)—е, ..., S0(m)—е), где е>0.
Очевидно, что max (Sp*1)—-е, ..., Sp<m>—е) < рг, так что
50<г)—e<pr,i=l, tn. Следовательно, S'q<=T. Но limS0' =
е-»0
= soes*.
Отсюда следуют два вывода: 1) So — граничная точка
области S*; 2) Sp — точка, в которой область Т касается
области S*.
Эти свойства позволяют легко найти геометрически ми-
нимаксную стратегию So для случая, когда первый игрок
имеет две чистые стратегии, т. е. когда эквивалентная S-
игра изображается множеством точек плоскости. Для по-
строения области Т, касательной к области S*, удобно про-
вести вспомогательную прямую из начала координат под
углом 45° к оси абсцисс, на которой лежит вершина пря-
моугольного клина, образующего область Т.
370
шнинакса.
Рис 9.4. Геометрическое определение минимаксной стратегии
На рис. 9.4 приведены различные случаи взаимного рас-
положения областей S* и Т и отмечены точки, определяю-
щие минимаксную стратегию So второго игрока.
9.4. РЕШЕНИЕ ИГР
9.4.1. Доминирующие и полезные стратегии
Смешанные стратегии игроков представляют собой
смесь чистых стратегий х<=Х и уеУ, которые берутся в со-
ответствии с распределением вероятностей £ (х) и т] (у). Од-
нако во многих случаях применение некоторых из чистых
стратегий явно нецелесообразно и при определении опти-
мальной смешанной стратегии их просто не следует учиты-
вать. Будем называть те из чистых стратегий, которые вхо-
дят в состав оптимальной смешанной стратегии, полезными
стратегиями игрока. Для облегчения выделения полезных
стратегий введем понятие доминирующих стратегий.
Рассмотрим две стратегии yt и ур второго игрока. Пусть
первый игрок применяет стратегию хг. Потери второго иг-
рока будут соответственно qa и qtp. Может оказаться, что
при любом i
qii^qtp, i=l, m, (9.62)
т. е. в матрице игры потери в столбце I не превосходят со-
ответствующих потерь в столбце р. Это означает, что вто-
рому игроку ни при каких условиях невыгодно применять
стратегию уР, так как ее применение дает большие потери,
чем при стратегии yi. Поэтому стратегия ур должна быть
отброшена, т. е. вычеркнута из матрицы игры. Стратегию
yi, удовлетворяющую условию (9.62), называют доминиру-
ющей по отношению к стратегии ур.
Доминирующие стратегии второго игрока имеют нагляд-
ную геометрическую иллюстрацию при переходе к эквива-
24* 371
лентной S-игре на плоскости. В этом случае т=2 и усло-
вие (9.62) перепишем в виде
?2(^a?2p- (9.63)
На рис. 9.5 приведены два случая расположения точек
Ct и Ср, соответствующие чистым стратегиям yi и ур второ-
го игрока. Легко видеть, что на рис. 9.5,а стратегия Сг до-
минирует над стратегий Ср, а на рис. 9.5,6 ни одна из стра-
тегий не является доминирующей. Для того чтобы страте-
гия yi доминировала над стратегией ур, точка Ci должна
лежать левее и ниже точки Ср.
в-) Чп 5) q1t q1pL(xf,y)
i—1» я,
Рис. 9.5. Определение доминирования в S-игре
Аналогичным образом определяют доминирующие стра-
тегии первого игрока. Мы говорим, что стратегия xi доми-
нирует над стратегией хр, если выигрыш первого игрока
при стратегии Xi больше выигрышей при стратегии хР при
любой стратегии уеУ:
(9.64)
т. е. если в матрице игры потери в строке xi больше соот-
ветствующих потерь строки хр.
Пример 9.3. На рис. 9.6 S-игра задана на плоскости точками
Ci—Св. Как видно из рисунка, над точкой С5 доминирует Сь а над
точкой С4 доминируют Сь С2 я Св. Отбрасывая точки С5 и С4, прихо-
дим к S-игре, определяемой точками Сь С2, С3, Св, среди которых нет
доминирующих.
Удаление из матрицы игры тех стратегий, над которыми
доминируют другие стратегии, значительно упрощает игру,
а следовательно, и поиск оптимальной стратегии. Предпо-
ложим теперь, что в рассматриваемой игре ни одна страте-
гия не доминирует над другой. Спрашивается, все ли стра-
тегии в этом случае являются полезными, т. е. использу*
ются для получения оптимальной смешанной стратегии.
372
Обратимся к игре, приведенной на рис. 9.6. После удаления точек
С4 и С5, над которыми доминируют другие точки, пришли к игре, изо-
бражаемой точками Ci, С2, С3, Св. Построив область Т, видим, что
точка So, определяющая стратегию второго игрока, лежит на прямой,
соединяющей точки С| и С2, и может быть представлена как средне-
взвешенное этих точек. Таким образом, оптимальная смешанная стра-
тегия второго игрока представляет собой смесь чистых стратегий ух
и 1/2, которые в энном случае и являются полезными. Стратегии у3 и
у6 полезными не являются, и их использование нерационально.
Общее число полезных стратегий каждого из игроков
можно определить, исходя из того, что выпуклая оболочка
S* конечного множества {Сь ..., Сп} является выпуклым
многогранником в m-мерном пространстве. Точка So, явля-
ющаяся граничной для выпуклого многогранника S*, будет
принадлежать обязательно к одной из его граней, верши-
ны которой и будут соответствовать полезным стратегиям
второго игрока. Учитывая, что число вершин любой грани
выпуклого многогранника S* не может превышать общего
числа его вершин, т. е. числа п, и не может превышать мер-
ности пространства, в котором существует выпуклый много-
гранник, т. е. числа ш, приходим к выводу, что число стра-
тегий второго игрока не превышает наименьшего из чисел
тип. Поскольку понятия первого и второго игроков услов-
ны, аналогичный вывод справедлив и для первого игрока.
Таким образом, в игре с матрицей размером тХп чис-
ло полезных стратегий каждого из игроков не превышает
наименьшего из чисел тип.
Теорема 9.6. Если один из игроков придерживается сво-
ей оптимальной смешанной стратегии, то выигрыш игроков
остается неизменным и равным цене игры v независимо от
того, какую смешанную (или чистую) стратегию применя-
ет другой игрок, если только он не выходит за пределы сво-
их полезных стратегий.
Доказательство. Пусть v — цена игры; £0=
= (|о(1>, £о(т)) — оптимальная смешанная стратегия пер-
373
вого игрока. Если первый игрок применяет свою оптималь-
ную стратегию £0, то его выигрыш не может быть меньше v.
Предположим, что второй игрок имеет k полезных стра-
тегий, обозначенных у\, .... yh. Если первый игрок исполь-
зует свою оптимальную стратегию |0, а второй игрок —
полезную стратегию у, (i=l, k), то выигрыш первого игро-
ка vt будет не меньше v:
v.>v, i=l^k. (9.65)
Рассмотрим теперь оптимальную смешанную стратегию
второго игрока т]0. Она задается вероятностями т]о<г>, с ко-
торыми применяются чистые полезные стратегии. Сущест-
венно, что ие может быть т]0о>=0 при i=l, k, так как в этом
случае /-я стратегия не входила бы в оптимальную сме-
шанную стратегию второго игрока, т. е. не была бы полез-
ной.
Найдем средний выигрыш первого игрока, если второй
игрок применяет свою оптимальную смешанную стратегию
Использование вторым игроком оптимальной смешанной
стратегии т]0 означает, что первый игрок будет получать вы-
игрыши vi, ..., v/i, соответствующие чистым стратегиям
yi, . ., yh, с вероятностями т]о(1), ..., т]о(/1). Средний выигрыш
первого игрока
^ср = V.TJ'1»-}- ... + (9.66)
;=i
Заменяя vt на v и учитывая (9.65), получаем
k
Lcv<v = v. (9.67)
Но средний выигрыш при оптимальных стратегиях игро-
ков и есть цена игры v, т. е.
£cp=v. (9.68)
С другой стороны, соотношение (9.66) может перейти
в (9.68), только если выполняется условие
Vf=v, i= 1, k, (9.69)
что и доказывает теорему.
Таким образом, средний выигрыш первого игрока, если
он применяет свою оптимальную смешанную стратегию, бу-
дет один и тот же при использовании вторым игроком лю-
374
бой из полезных стратегий, а значит, и любой смешанной
стратегии, состоящей из полезных стратегий.
Следует, конечно, помнить, что всегда наиболее выгод-
ными являются оптимальные смешанные стратегии. Полез-
ные, хотя и не оптимальные, стратегии не приносят ущерба
только в том случае, когда противник придерживается оп-
тимальной стратегии. Использование же оптимальной стра-
тегии всегда обеспечивает выигрыш, равный цене игры.
Теперь остается выяснить, как же находить полезные и
оптимальные стратегии игроков, т. е. рассмотреть вопрос
о нахождении решения игры.
9.4.2. Нахождение оптимальных стратегий
Рассмотрим игру G=(X, У, L) с матрицей размером
тХп. Будем считать, что в игре G отсутствует седловая
точка (в противном случае решение легко находится по
правилу, установленному в § 9.2) и удалены те стратегии,
над которыми имеется доминирование.
Обозначим через £о=(&)(1), , |о(т)) оптимальную сме-
шанную стратегию первого игрока. Некоторые g0(i> могут
быть равны нулю. Это означает, что соответствующая стра-
тегия х. не является полезной. Перед нами стоит задача
найти значения go(i> для t=l, tn.
Предположим, что второй игрок использует стратегию
yh. Если это полезная стратегия, то выигрыш первого игро-
ка будет равен v, если же эта стратегия не является полез-
ной, то выигрыш первого игрока может быть и больше v.
Следовательно, в общем случае
L (go, Ун) = go<’>?u+ • • • (9 70)
Такие выражения могут быть составлены для каждой
чистой стратегии второго игрока, т. е. для fe=l, п. Кроме
того, известно, что
^о(г)^0, £о(1)+ ••• +so(m)—1-
(9.71)
Будем считать v>0. Это выполняется всегда, когда все
элементы матрицы игры qtk положительны. Если же среди
элементов qth имеются отрицательные, то их можно сделать
положительными, прибавив ко всем элементам матрицы
игры некоторое число v'>0. При этом цена игры увеличит-
ся на величину v'.
375
Разделим уравнения (9.70) и (9.72) на v, обозначив
Ы^=Рг. (9.72)
Очевидно, что р,^0. Неравенства (9.70) при k=l, п
запишутся при этом в виде
+ I
.............................. (9.73)
Р1Ч1П + • • • + РтЯтп > 1, •
а соотношение (9.7!) примет вид
pH-...+pw=l/v. (9.74)
В линейные неравенства (9.73) входят неизвестные ве-
личины pi, ..., рт, определяющие смешанную стратегию
первого игрока. Нахождение оптимальной смешанной стра-
тегии требует такого решения системы (9.73), при котором
значение v становится максимальным, а следовательно,
линейная форма (9 74) принимает минимальное значение.
Но это — обычная задача линейного программирования.
Для удобства в выражениях (9.73) следует перейти от
неравенств к равенствам, вычтя из правых частей положи-
тельные добавочные неизвестные zt, что дает систему урав-
нений
Р1Р1г+ . . . +pmgml—2г=1, 1= 1~Гп. (9.75)
В тех уравнениях (9.75), которые соответствуют полез-
ным стратегиям второго игрока, в результате решения по-
лучим zt=0. Таким образом, решая систему (9.75) при ус-
ловии минимизации линейной формы (9.74), находим сме-
шанную стратегию первого игрока, цепу игры v и полезные
стратегии второго игрока yt, ..., ун-
Для определения оптимальной смешанной стратегии
второго игрока т]О=(т|о(|), ..., T]0(ft)), содержащей k неизве-
стных т]о(|>, • • -, tjo''0, необходимо составить k уравнений.
Одно из них
т|оП)+ ... +tio('°=1- (9-76)
Остальные /г—1 уравнений получим, составив выраже-
ния для средних потерь при оптимальной смешанной стра-
тегии второго игрока и при любых к— 1 полезных страте-
гиях первого игрока. Так, для полезной стратегии xt будем
иметь уравнение
т1о(1)Ф1+ ••• +r|otft>?i/i=v. (9.77)
376
Составив k— 1 уравнений вида (9.77) и добавив к ним
уравнение (9.76), получим k уравнений, решая которые
легко найти значения т]о(1), ..., определяющие опти-
мальную смешанную стратегию т]о второго игрока.
Пример 9.4. Найти решение игры с матрицей, заданной левой поло-
виной табл. 9.5 Прежде всего убеждаемся, что в игре отсутствует сед-
ловая точка н ии одна из стратегий не доминирует над другими. Для
Таблица 9.5
Ул \У» Уг Уъ
Х1 2 —3 4 7 2 9
—3 4 —5 4 9 0
хэ 4 -5 6 9 0 И
того, чтобы не иметь дела с отрицательными элементами матрицы игры,
добавляем к каждому элементу матрицы число 5, тогда все элементы
матрицы принимают вид, показанный в правой половине табл. 9 5.
Уравнения (9 75) запишем в виде
7₽1-|-2р2-|-9рз—Zi = 1;
2pi-|-9p2—Z2= 1;
9р1+Прз—зз=1.
Решение этих уравнений должно удовлетворять условию миниму’
ма линейной формы (9.74)
Р1-ЬР2+РЗ = П11П.
Решая полученную задачу линейного программирования, находим!
Zi=22=23= 0; pi=0,05; р2=0,1; р3=0,05.
Как видим, все три стратегии (yt, у2 н г/з) являются полезными.
Из выражения (9.74) находим
*=1/(Р.+Р2+Рз)=5;
при этом
go(,)=5p,=O,25; у2)=5р2=0,5; £0<3>=5р3=0,25.
Для нахождения оптимальной смешанной стратегии второго игро-
ка составим одно уравнение вида (9.76)
т)о“>Н-По<2Ч-По(3) = I
и два уравнения вида (9.77) для полезных стратегий первого игрока
х2 и х3:
2т1о<*>-Ь9по<2>=5; 9по‘”4-111]о(3)=5.
377
Решая совместно три полученных уравнения, находим
110(»=т)о(3)=о,25; т]о(г’=О,5.
Вспоминая, что ко всем элементам матрицы игры было прибавле-
но число 5, находим цену игры v—5=0.
9.4,3. Геометрическая иллюстрация принципа
минимакса в игре 2Хп
В игре 2Хп смешанная стратегия первого игрока пред-
ставляет собой упорядоченную пару g=(g, 1—g). Если вто-
рой игрок применяет стратегию yi„ то средний выигрыш
первого игрока
М£> Уь) =??!/»+ (1—g) ?2/i=?2/t~H (?lfe-?2ft), (9.78)
т. е. линейно зависит от g, как показано на рис. 9.7.
Таблица 9.6
Д1 д« д3
7S | 4 | 2 | I
Определение оптимальной стратегии g0 рассмотрим на
примере игры с матрицей, заданной табл. 9.6 На рис. 9.8
цифрами /, 2 и 3 обозначены линии выигрыша для страте-
гий у\, у2 и уз соответственно. Гарантированный выигрыш
первого игрока при любом t, будет определяться нижней
границей приведенного графика, отмеченной жирной лини-
ей. Согласно принципу минимакса оптимальной стратегией
go будет такая, при которой гарантированный выигрыш ма-
ксимален. Эта стратегия определится точкой М — пересе-
чение линий выигрыша при стратегиях yt и у2, которые,
таким образом, и будут полезными стратегиями второго
игрока.
Оптимальную смешанную стратегию go можно найти
из условия равенства среднего выигрыша первого игрока
при полезных стратегиях yi и у2 второго игрока
?о+4(1- &>) = 3g0+2(l—• go),
что дает g0=l/2. Таким образом, g0=(l/2, 1/2). Цену игры
теперь получим как средний выигрыш первого игрока при
стратегии go и любой из полезных стратегий, например z/i,
378
второго игрока
v=£o-H (1 —So) =2,5.
Оптимальная смешанная стратегия второго игрока т]0=
= (т]о(1)> 1—т|о(1)> 0) ПРИ известной цене игры v найдется из
выражения средних потерь второго игрока при любой из
полезных стратегий первого игрока. Например, при страте-
гии Xi получаем
т|о(1)+3(1- т|о(1))=2,5,
что дает т]о(1)=1/4. Итак, т]0= (1/4, 3/4, 0).
Рис. 9 7. Линия выигры-
ша при стратегии ук
Рис. 9.8. Минимаксная страте-
гия в игре 2 Хт
Задачи к гл. 9
9.1. Вычислите матрицу потерь для игры в примере 9.1.
9.2. Для следующей игры определите матрицу потерь, предвари-
тельно нарисовав дерево игры.
Бросают симметричную монету, и если выпадает «герб», первый
игрок выбирает одно нз чисел 1, 6, если выпадает «решка», выбирает
одно число (2 или 7). Затем второй игрок выбирает одно из чисел 3, 9.
Выбранные игроками числа складываются и дают сумму S. Потом
бросают жребий с вероятностью «герба» 0, 8. Если при этом бросании
выпадает «герб», второй игрок платит первому S руб., если выпадает
«решка», то первый игрок платит второму S руб. Первому игроку
известен исход первого случайного хода Второму игроку ничего не
известно о предыдущих ходах
9.3. Удобным механизмом случайного выбора является положение
секундной стрелки на циферблате в случайный момент времени. Опи-
шите использование этого механизма случайного выбора для получе-
ния следующих распределений вероятностей: (3/5, 2/5), (1/6, 2/3, 1/6),
(1/5, 2/5, 2/5).
9.4. Опишите действия игроков в одной партии игры, матрица ко-
торой задана табл. 9.3, при использовании первым игроком чистой
стратегии хг, а вторым игроком — смешанной стратегии т]= (0,5; 0,5).
379
Глава 10
ТЕОРИЯ СТАТИСТИЧЕСКИХ РЕШЕНИИ
(СТАТИСТИЧЕСКИЕ ИГРЫ)
10.1. СТРУКТУРА СТАТИСТИЧЕСКИХ ИГР
10.1.1. Стратегические и статистические игры
Специфическим видом игр, имеющих большое значение
при анализе различных практических ситуаций, являются
статистические игры. Они имеют ряд существенных отличий
от того вида игр, которые рассматривались до сих пор и
которые могут быть названы стратегическими играми.
В основе теории стратегических игр лежит предполо-
жение, что интересы двух игроков противоположны. Каж-
дый из игроков стремится так выбрать свою стратегию, что-
бы получить для себя наибольшую выгоду и свести до ми-
нимума выгоду противника. В таких играх каждый игрок
действует активно и стремится по возможности использо-
вать оптимальную стратегию.
Однако во многих практических ситуациях приходится
сталкиваться со случаями, когда один из игроков оказы-
вается нейтральным, т. с. таким, который не стремится из-
влечь для себя максимальной выгоды и, следовательно, не
стремится обратить в свою пользу ошибки, совершаемые
противником. К таким играм относят игры, в которых в ка-
честве одного из игроков выступает природа. Здесь в поня-
тие «природа» мы вкладываем всю совокупность внешних
обстоятельств, в которых приходится принимать решение.
Природу нельзя рассматривать как разумного против-
ника, который мог бы использовать ошибки, совершаемые
человеком. Другими словами, природа не имеет злого умыс-
ла по отношению к человеку. Она просто развивается и
действует в соответствии со своими законами и во власти
человека обратить эти законы себе на пользу. Если бы че-
ювек совершенно точно знал законы природы, он мог бы
их использовать с максимальной для себя выгодой. Однако
во многих случаях человек или не знает закона природы,
или знает его недостаточно полно.
Неизбежной платой за попытку получить решение в ус-
ловиях неполной информации о законе природы является
возможность принятия ошибочных решений. При этом прак-
тически ситуации бывают таковы, что отказаться вообще
380
от принятия какого-либо решения бывает невозможно. К то-
му же решение отказаться от принятия решения также
есть решение, и оно может иметь столь же нежелательные
последствия, как и другие решения. Единственный выход
из создавшейся ситуации — выработка человеком такой
стратегии в отношении принятия решений, которая хотя и
не исключает возможность принятия неправильных реше-
ний, но сводит к минимуму связанные с этим нежелатель-
ные последствия.
Правда, у человека есть еще возможность изучать про-
тивника, т. е. природу, посредством проведения эксперимен-
та. Теоретически путем проведения неограниченного экспе-
римента можем сделать свои знания о природе сколь угодно
полными и действовать уже в условиях полной опреде-
ленности. Однако этому мешают два обстоятельства: 1) на
проведение эксперимента требуется время, тогда как реше-
ние во многих случаях нужно принять быстро; 2) экспери-
мент требует затраты средств, т. е. может стоить дорого —
дороже того выигрыша, который дают добавочные знания,
полученные в результате эксперимента.
Поэтому важной задачей человека в игре против «при-
роды» является принятие решения о том, нужно ли прово-
дить эксперимент, а если нужно, то какой, когда его закон-
чить и какие действия предпринять после окончания экспе-
римента.
Игры, в которых один противник — природа, а дру-
гой — человек, получили название статистических игр,
а теорию таких игр называют теорией статических решений
[57, 60, 61]. Человека, который участвует в игре против
природы, будем в дальнейшем называть статистиком.
fl 0.1.2. Пространство стратегий природы
Под стратегией природы будем понимать полную сово-
купность внешних условий, в которых приходится прини-
мать решение. Эту совокупность внешних условий назовем
состоянием природы -6. В общем случае существует некото-
рое множество возможных состояний природы 0= {&!, ...
..., 'fl’m}, которое, как условились в гл. 6, будем называть
пространством состояний природы, а элементы Ф; этого про-
странства — чистыми стратегиями природы.
Если бы было известно заранее, какую из своих чистых
стратегий применяет природа в каждом конкретном слу-
чае, то с уверенностью принимали бы решение на основа-
381
нии полного знания состояния природы. Однако обычно
бывает известен только перечень чистых стратегий приро-
ды. Кроме того, из прошлого опыта бывает известно, как
часто природа применяет ту или иную из своих чистых стра-
тегий, т. е. бывает известно априорное распределение ве-
роятностей £(0-) на пространстве состояний природы 0. Это
априорное распределение вероятностей £(&) называют сме-
шанной стратегией природы.
10.1.3. Пространство стратегий статистика
и функция потерь
Задача статистика состоит в том, чтобы принять какое-
либо решение или выполнить какое-либо действие из сово-
купности решений или действий. Обозначим возможные
действия статистика через alt ..., ai. Каждое из этих дей-
ствий есть чистая стратегия статистика. Множество /1=
= {«!, ..., ai} является пространством чистых стратегий
статистика.
Статистик должен уметь оценить каждое из своих дей-
ствий. Для этого он допускает, что, совершая действие а,
может потерпеть убыток £(&, а), зависящий как от выпол-
няемого действия а, так и от неизвестного;состояния при-
роды •&. Функция £(•&, а), называемая функцией потерь,
должна быть заранее определена для всех возможных ком-
бинаций а^А и О-&0, т. е. должна быть задана на прямом
произведении множеств 0ХЛ. Ее можно задавать или ана-
литически, или по аналогии с (9.7) матрицей потерь вида
f?n - Ча I
(Ю-О
4ml ••• 4ml J
где а3). Знание функции потерь позволяет стати-
стику предпринять действия, которые являются наилучши-
ми в условиях имеющейся у него информации о состоянии
природы.
Статистику бывает обычно известна смешанная страте-
гия природы, т. е. априорное распределение вероятностей
£(&) на пространстве состояний природы 0. Знание апри-
орного распределения вероятностей позволяет определить
средние потери, которые несет статистик, выполняя то или
382
иное действие:
L (!•, а) = Ее [L (», а)] = 3 L (&, а) ? (&). (10.2)
Наилучшим для статистика действием будет байесов-
ское действие а*, при котором потери будут минимальны,
т. е.
= дх) = minL’(£, а). (10.3)
а=А
Статистик не обязательно должен ограничиваться ис-
пользованием только одной чистой стратегии. Он может
применять смесь чистых стратегий в соответствии с неко-
торым вероятностным законом распределения. В этом слу-
чае будем говорить о смешанной стратегии статистика. Для
смешанной стратегии статистик должен задаться распреде-
лением вероятности т](а) = (т](1), ..., -п<тп))> определяющим
вероятности, с которыми и будет использовать свои чистые
стратегии at, ..., am. В общем случае статистик распола-
гает некоторым набором смешанных стратегий Н =
— {tn(а), Я'' (а)}> называемым пространством смешан-
ных стратегий статистика.
Если статистик применяет смешанную стратегию т] (а),
а природа — смешанную стратегию £(&), то средние поте-
ри статистика
7)) = адм», а)] = ££(&, a) W) -n(fl). (10.4)
S,a
В этом случае задача статистика состоит в том, чтобы
выбрать такую стратегию r]*(a)eH, при которой его сред-
ние потери L(g, т]*) будут минимальны, т. е.
L(?, 7j*)= min (5, т)). (10.5)
is//
В рассмотренных случаях решалась сравнительно про-
стая статистическая задача — определение наилучшей
стратегии статистика только на основании имеющейся ап-
риорной информации о состояниях природы. Здесь стати-
стик не делает попытки уточнить свои знания о действи-
тельном состоянии природы путем проведения эксперимен-
та. Поэтому данный тип статистической игры может быть
назван статистической игрой без эксперимента.
383
10.1.4. Примеры статистических игр
Для лучшего понимания структуры статистических игр и методов
их решения приведем несколько примеров, на которых в дальнейшем
будем иллюстрировать основные положения теории статистических ре-
шений.
Пример 10.1 (задача о замене оборудования). Установленное
на предприятии сложное н дорогое оборудование после k лет работы
может оказаться в одном из трех состояний: й, — оборудование вполне
работоспособно и требует лишь небольшого текущего ремонта, <h> —
некоторые детали значительно износились и требуют серьезного ремон-
та или замены; Оз — основные детали износились настолько, что даль-
нейшая эксплуатация оборудования невозможна.
Прошлый опыт эксплуатации аналогичного оборудования показы-
вает, что в 20 % случаев оно может находиться в состоянии О,,
в 50 % — в состоянии и в 30 % — в состоянии •в'з.
Для предприятия возможны три различных способа действия. at —
оставить оборудование в работе еще на год, проведя незначительный
ремонт своими силами; а2 — провести капитальный ремонт оборудова-
ния с вызовом специальной бригады ремонтников; а3 — заменить обо-
рудование новым.
Таблица 10.1
£(» о)______________
| I °°
Задача о замене оборудования
Задача о технологической линии
»а
2
Потери, которые несет предприятие при различных способах дей-
ствия, приведены в табл. 10.1. В потери входят стоимость ремонта или
замены оборудования, а также убытки, связанные с ухудшением ка-
чества продукции и с простоями, вызванными неисправным оборудо-
ванием. В этой же таблице приведены априорные вероятности различ-
ных состояний природы, т. е. смешанная стратегия природы gfO).
384
Для заданной смешанной стратегии £(0) средние потери при раз-
личных способах действия
L(£, Д1)=2Л(а’ Л1)£(В) = Ь0,2 + 5.0,5+7-0,3=4,8; а2) =
а
= 3,4; £(£, а3) =3,9.
Пример 10.2 (задача о технологической линии). На технологиче-
скую линию может поступать сырье с малым и с большим Ф2 коли-
чеством примесей. Известно, что в среднем поступает 60 % сырья пер-
вого вида и 40 % сырья второго вида. Для использования различных
видов сырья предусмотрены три режима работы технологической ли-
нии: at, a2 и аз Априорные вероятности состояний природы и потери,
отражающие качество выпускаемой продукции и расходы сырья в зави-
симости от качества сырья и режима работы технологической линии,
приведены в табл. 10.1.
Средние потери, соответствующие заданным априорным вероятно-
стям при различных режимах работы:
£(g, at) =2,0; a2) = 1,8; Щ, a3)=2,6.
Байесовским действием будет установление режима работы а2.
10.2. СТАТИСТИЧЕСКИЕ ИГРЫ БЕЗ ЭКСПЕРИМЕНТА
10.2.1. Представление статистической игры
без эксперимента в виде S-игры
Статистическая игра может быть представлена в виде
эквивалентной S-игры совершенно таким же образом, как
это делалось в стратегических играх. Для этого с каждой
из чистых стратегий а„ j=l; I связываем точку С; =
= (?ij, ... , qmj) в m-мерном пространстве, координатами
которой будут потери статистика L(<h, а}) =qij при раз-
личных состояниях природы •&;, t=l, т. Так, в задаче о
технологической линии чистым стратегиям статистика
а2 и йз будут соответствовать точки плоскости С] = (0, 5);
С2=(1, 3) и С3= (3, 2), как показано на рис. 10.1. Вы-
пуклая оболочка S* множества точек {Сь С2, С3} дает об-
ласть всех возможных стратегий статистика, как чистых,
так и смешанных.
Рассмотрим несколько принципов, которыми может ру-
ководствоваться статистик при выборе своей стратегии.
При этом среди статистиков не существует единого мнения
о том, какой из принципов является наилучшим в статис-
25—804 385
О 7 2 7 4
Это возможно при
гий, аналогичного
Рис. 10.1. Представление задачи о техноло-
гической линии в виде S-игры
тических играх. Другими словами, не
существует универсального правила,
позволяющего выбрать, определенный
образ действия независимо от сло-
жившейся ситуации. Хотя могут иметь-
ся разногласия относительно того, что
нужно делать в данной ситуации,
можно прийти к полному согласию от-
носительно того, что не нужно делать,
введении понятия допустимых страте-
понятию доминирующих стратегий в
стратегических играх.
10.2.2. Допустимые стратегии в статистических играх
Предположим, что рассматриваем смешанную страте-
гию статистика г) (а). Могут встретиться два случая.
I. Нельзя найти ни одной стратегии, лучшей чем г](а)
Это означает, что не существует такой стратегии ц'а, для
которой
/.(&, п')=^Ш, П) (10.6)
при всех хотя для некоторых -0- соотношение (10.6)
будет справедливо. В этом случае стратегию т](а) можно
назвать допустимой, но она может и не быть предпочти-
тельной, так как могут быть и другие стратегии, которые
также имеют право на внимание.
2. Существует стратегия ^'(а), лучшая чем т](а). Это
означает, что соотношение (10.6) для стратегии if (а) бу-
дет справедливо при всех ^е0. В этом случае стратегию
q (а) нужно исключить из рассмотрения в пользу стратегии
т)'(а)> т. е. считать ее недопустимой.
Допустимые стратегии удобно рассматривать в терми-
нах S-игры. Поскольку в S-игре стратегия статистика опре-
деляется точкой S выпуклой оболочки S1, а потери при
различных бе© определяются координатами этой точки,
то стратегия, определяемая точкой S, будет допустимой,
если не существует другой точки S'<=S*, у которой все ко-
ординаты будут меньше сответствующих координат точ-
ки S.
386
Метод нахождения допустимых стратегий разберем для
случая, когда пространство состояний природы состоит из
элементов О, и Фг. На рис. 10.2 показана выпуклая область
S*, соответствующая этому случаю.
Рассмотрим стратегию, определяемую точкой Sb распо-
ложенной внутри области 5*. Эта стратегия не является
допустимой, так как все точки, лежащие на отрезке OSt
внутри S*. определяют лучшие стратегии, чем Наилуч-
шей из них является стратегия S, принадлежащая нижней
левой границе области S*. Поэтому все внутренние точки
можно исключить в пользу точек, принадлежащих нижней
левой границе области S*, отмеченной
на рисунке жирной линией.
Однако смещение точки вдоль этой
границы не дает каких-либо преиму-
ществ, так как при этом уменьшаются
потери, соответствующие одному со-
стоянию природы, но увеличиваются
потери, соответствующие другому со- о а.)
стоянию природы. Поэтому точки, при- Допусти-
надлежащие нижней левой границе мые’ стратеГиИ в S-
области S*, и определяют допустимые игре
стратегии статистика.
Пример 10.3. В задаче о технологической линии (см. рис. 10 1)
левая нижняя граница области S* состоит из отрезков С]С2 и С2С3,
каждый из которых определяется смесью чистых стратегий at, ai и аг,
аз. Пусть тогда уравнение для отрезка CiC2 запишем в век-
торной форме следующим образом:
S=a)Ci+(l— w)C2.
(Ю.7)
Это уравнение определяет смешанную стратегию i](a)=(u), 1 —
—w, 0). Проецируя уравнение отрезка CtC2 на оси координат, полу-
чаем
п) =0-10-1-1 •(!—а»)=1—w; L(&2, л)=5’10-|-
-|-3’(1—10) =3-|-2t0.
(10.8)
Аналогично для уравнения отрезка С2С3, определяющего смешан-
ную стратегию т](а) = (0, w, 1—w), запишем
ЦО,, т1)=3—2t0; t])=2-|-w. (10.9)
25*
387
10.2.3. Принципы выбора стратегий
в статистических играх
Принципом выбора называют правило, позволяющее
определить наилучшую смешанную стратегию статистика.
В различных случаях статистик может пользоваться раз-
личными принципами выбора своей стратегии.
Одним из возможных принципов выбора стратегии мо-
жет быть принцип минимакса, который успешно приме-
няют в стратегических играх, когда игра ведется против
0 а) ' ш
Рис. 10.3. Определение оптимальной стратегии по принципу минимакса
разумного противника, желающего причинить нам наи-
больший ущерб. Однако в ряде случаев целесообразно ис-
пользовать этот принцип и в статистических играх.
Согласно принципу минимакса статистик выбирает та-
кую смешанную стратегию т)(а), при которой средние по-
тери L(t)', t]) будут минимальны при наихудшем для него
состоянии природы О. Наихудшим случаем будет такое
когда величина Ц®, т]) принимает максимальное
значение. Эту величину статистик и должен минимизиро-
вать, т. е. выбирать стратегию (а), которая обеспечива-
ет условно
L({), »)*) - inininax/.(0, tq). (10.10)
ч ц
Пример 10.4. Найдем минимаксную оратсгию статистика н задаче
о технологической линии Так как решение должно лежать в классе
допустимых стратегий, то достаточно ограничиться рассмотрением стра-
тегий, определяемых соотношениями (10.8) н (10.9) и соответствующих
отрезкам CiC2 и С2Сз выпуклой оболочки S* на рис. 10.1. В соответ-
ствии с этими соотношениями и отрезками на рис. 10.3 построены гра-
фики Ц®, т]) в функции or w для &=О| и •в'='в'2. Значения
maxL(0, •*)) отмечены жирными линиями. Как видно из рис. 10.3,а, б,
&
минимум этой величины на отрезке CtC2 достигается при w=0 и ра-
388
вен 3, а на отрезке С2С3 определяется условием пересечения двух
прямых
3—2и>=2-|-t0,
т. е. достигается при 10=1/3, и равен 7/3<3. Таким образом, принцип
минимакса дает точку на отрезке С2С3, соответствующую 10=1/3, т. е.
определяет оптимальную смешанную стратегию тт1'=(О, 1/3, 2/3), при
которой потери статистика будут не больше 7/3 при любой стратегии
природы.
Иногда целесообразно выбирать стратегию, исходя не
из полных потерь £(&, а), а из дополнительных L' (&, а),
определяемых из соотношений:
L' (&, «) = £(&, a)— minL(&, а). (10.11)
Величина min/.(&, а) для каждого состояния природы
определяет те минимальные потери, которые статистик не-
сет обязательно даже при своем наилучшем действии, т. е.
это необходимые потери. Можно считать, что необходимые
потери тем или инь^м образом компенсируются (например,
путем установления соответствующих цен на выпускаемую
продукцию) и, следовательно, могут не учитываться при
выборе стратегии. В этом случае выбор стратегии может
быть осуществлен по принципу минимакса дополнительных
потерь.
Пример 10.5. Найденные из соотношения (1011) дополнительные
потерн L'(i\ а) в задаче о технологической линии сведены в табл. 10.2.
Применяя к данным этой таблицы принцип минимакса, в качестве
он in малыюй стратегии получаем чистую стратегию at с потерями 1.
Таблица 10.2
а L’(&. а)
д, 1 Of а3
о 1 3
"2 з 1 1 0
Минимаксные принципы, исходящие из предположения,
что природа действует наихудшим для статистика обра-
зом, являются оправданными в стратегических играх, но
в статистических играх они выражают точку зрения очень
осторожного человека, старающегося получить доступное
и не гоняющегося за несбыточным, чтобы не потерпеть
случайно большого ущерба. Недостатком минимаксных
389
принципов следует считать также то, что они не учиты-
вают априорной информации о состояниях природы и тем
самым ограничивают тот выигрыш, который эта информа-
ция может дать.
Поэтому минимаксные принципы можно рекомендовать
в тех случаях, когда отсутствует априорная информация о
состояниях природы или есть основания сомневаться в до-
стоверности этой информации.
Другим принципом выбора стратегии, учитывающим
априорное распределение вероятностей £(f)j, является
байесовский принцип. Согласно байесовскому принципу
смешанную стратегию статистика rj(a) оценивают путем
усреднения потерь L($, tj) по всем возможным состояниям
природы с учетом априорного распределения вероят-
ностен l('O’), т. е. по величине
Ш т))=2Ш, т))1;(&) (10.12)
&
Наилучшей стратегией т](а) при этом будет такая, ко-
торая дает минимум величины L(|, rj). Эту наилучшую
стратегию называют байесовской стратегией.
Байесовский принцип, естественно, можно применять
как к полным, так и к дополнительным потерям. Однако
в дальнейших примерах ограничимся применением байе-
совского принципа только к полным потерям.
Пример 10.6. В задаче о технологической линии при 1;(г>|)==0,6 и
Е,(-0-2) =0,4 для допустимых стратегий, определяемых отрезком CiC2,
имеем
т)) = (1— w) -0,6+(3+2ffi>)-0,4= 1,8+2,010,
так что minZ.(g, т])= 1,8 при ю=0, это соответствует смешанной стра-
тегии т]= (0, 1, 0);
определяемых отрезком СгС3
L(g, т)) =2,6-0,8®,
так 4TorninL(g, v)j =1,8 при w = 1, это соответствует той же самой
смешанной стратегии т]= (0, 1, 0). Таким образом, байесовской страте-
гией является чистая стратегия а2.
Следует отметить, что полученный результат не случаен. Далее мы
покажем, что байесовский принцип всегда дает в качестве наилучшей
стратегии одну из чистых стратегий статистика. При этом байесовское
действие а* будет определяться условием (10 3).
390
10.2.4. Геометрическая трактовка байесовских стратегий
Рассмотрим статистическую S-игру для двух состояний
природы От и Оу определяемую выпуклой областью S* на
плоскости (х, у), приведенную на рис. 10.4, где
х=£(0т, т]); у=Ь($2, т]).
(10.13)
Как знаем, допустимые стратегии лежат на нижней ле-
во!! границе области S*. Рассмотрим одну из допустимых
стратегий So. Построим вспомогательное множество R, со-
держащее все точки, лежащие ниже
и левее точки So. Очевидно, что S*
и R — выпуклые множества и ни
одна ючка из S* не принадлежит
R, в юм числе и точка So.
Построим прямую, разделяющую
множества S'1 и R. Эта прямая
должна проходить через So, т. е.
является опорной прямой для мно-
жества S1' в точке So и опорной
прямой для множества R Следова-
Рнс. 10.4. Построение
опорной линии к выпук-
лому множеству
тельно. эта прямая должна иметь
слрнцаюльпый наклон или оыге вертикальной (горизон-
тальной), ее уравнение можно записать в виде
y=—kx+c, £>0. (10.14)
Разделив обе части этого уравнения на £-|-1, приведем
его к виду
где
ах+Ьу=с',
(10.15)
a=k/(k+l); b=l/(fe + l); c' = c/(k + l). (10.16)
Замечая, что а^О, b^0, a-j-b= 1, можем положить
a=w, b = l—w и рассматривать ш и 1—w как априорные
вероятности состояний природы -fh и 0у
ay = U^i)> 1—ау=^(-02). (10.17)
Уравнение опорной прямой в этом случае может быть
записано в виде
wx+(l—w)y=c' (10.18)
или
ЦЪ, 11)£(<М+М<>2, п)1(^)=с'. (10.19)
Как видим, с' определяет средние потери L(|, tj) при
391
априорных вероятностях состояний природы и
ICfb) = 1—и». Нетрудно заметить также, что значение с'
для точки So является минимальным из всех возможных
значений L(j, rj), так как увеличение с' до с">с' означа-
ет, что прямая пройдет выше и будет проходить через
точки множества S*, не являющиеся допустимыми, а
уменьшение с' невозможно, так как прямая опустится вниз
и не будет иметь с S’ общих точек. Таким образом, с' оп-
ределяет стратегию
L(g, т]) при данном
т], дающую минимум средних потерь
распределении £(()) = (w, 1—да), т. е.
определяет для данного априорного
распределения вероятностей байесов-
скую стратегию.
Поскольку So является произволь-
ной точкой на границе допустимых
стратегий, то для любой точки этой
границы можно найти такие да и 1—да,
для которых эта точка будет опреде-
лять байесовскую стратегию. Отсюда
следует, что каждая допустимая стра-
тегия является байесовской для не-
Рис 10 5. Геометри-
ческое определение
байесовской страте-
гии
которых априорных вероятностей w и 1—да.
Предположим теперь, что заданы априорные вероят-
ности состояний природы да и 1—да и требуется на выпук-
лой оболочке S* найти точку, определяющую байесовскую
стратегию для этого случая. Построим на плоскости (х, у)
прямую
дах+(1—да)у=с. (10.20)
При произвольном с эта прямая будет параллельна
опорной прямой в точке, соответствующей байесовской
стратегии. Для удобства построения положим с=да(1—да)
и запишем уравнение (10.20) в виде
х/(1—да)+у/да=1 (10.21)
— уравнение прямой в отрезках. Прямая, соответствующая
уравнению (10.21), построена на рис. 10.5. Теперь уже лег-
ко построить опорную прямую, соответствующую заданным
значениям да и 1—да, кторая определит на выпуклой обо-
лочке S* точку, соответствующую байесовской стратегии
статистика.
Поскольку внешней границей выпуклой оболочки явля-
ется многоугольник с вершинами, соответствующими чис-
тым стратегиям статистика, то опорная прямая обязатель-
392
но проходит хотя бы через одну из вершин. Следовательно,
для заданных априорных вероятностей w и 1—w всегда
существует хотя бы одна байесовская стратегия, являюща-
яся чистой стратегией. Это обстоятельство чрезвычайно
упрощает решение статистических игр, так как позволяет
при поиске байесовского решения ограничиться рассмотре-
нием только конечного числа чистых допустимых стратегий
вместо рассмотрения бесконечного множества смешанных
стратегий. Это устраивает также многих скептически на-
строенных статистиков, возражающих против использова-
ния смешанных стратегий на том основании, что при этом
требуется применять механизм случайного выбора, кото-
рый к существу задачи отношения не имеет.
Все сделанные выводы остаются справедливыми и для
случая, когда имеется больше двух состояний природы.
Однако при этом рассмотрение на плоскости уже невоз-
можно, что затрудняет геометрическую иллюстрацию этих
случаев.
10.3. СТАТИСТИЧЕСКИЕ ИГРЫ С ПРОВЕДЕНИЕМ
ЕДИНИЧНОГО ЭКСПЕРИМЕНТА
10.3.1. Постановка задачи
Как уже отмечалось, особенностью статистической игры
является возможность для статистика углублять и уточнять
свои знания относительно состояния природы путем поста-
новки эксперимента. Если бы была возможность неограни-
ченного экспериментирования, статистик мог бы получить
полную информацию о состоянии природы и действовать
в условиях полной определенности. Однако постановка экс-
перимента всегда связана с затратой средств и времени,
потери от которых могут оказаться значительнее того вы-
игрыша, который могут дать результаты эксперимента.
Возможность проведения эксперимента чрезвычайно
расширяет класс стратегий статистика. Прежде всего ста-
тистик должен принять решение о том, проводить или не
проводить эксперимент. Он должен далее решить, каков
должен быть этот эксперимент, сколько следует провести
отдельных испытаний, прежде чем считать эксперимент за-
конченным, и какие предпринять действия при тех или иных
исходах эксперимента.
Попытаемся дать ответы на некоторые из этих вопросов
в последующих параграфах. В данном же параграфе со-
393
средоточим свое внимание на статистических играх с еди-
ничным экспериментом.
Пока не будем включать в класс стратегии статистика
принятие решения о проведении эксперимента, считая, что
уже приняли решение о проведении единичного экспери-
мента. При этом под единичным экспериментом будем по-
нимать такой, объем и порядок проведения которого зара-
нее определены. Так, если нужно проверить, является ли
данная момента симметричной, го можно провести единич-
ный эксперимент, состоящий в n-кратном бросании моне-
ты. Исходом эксперимента при /г=5 может быть последо-
вательность ГРГГР. Всего существует 2п таких последо-
вательностей, т. е. в данном случае пространство исходов
эксперимента состоит из 2п элементов. Аналогично при
проверке оружия под единичным экспериментом понимают
эксперимент, при котором делается п выстрелов. Для
оценки влияния какого-либо специального вида пищи на
животное может быть произведен единичный эксперимент,
состоящий в измерении в течение нескольких месяцев еже-
дневного прибавления в весе у п животных, и т. п. Хотя в
этих примерах эксперимент состоит из ряда подыспытаний,
мы его называем единичным, так как число подыспытаний
и характер каждого подыспытания заранее определены.
10.3.2. Пространство выборок
Обозначим через Z пространство исходов эксперимента.
Элементы этого пространства, т. е. отдельные исходы экс-
перимента, будут zb ..., zv.
Отдельные исходы эксперимента zeZ оказываются свя-
занными с состоянием природы Фе0. Эта связь состоит в
том, что для каждого состояния природы имеется оп-
ределенная вероятность p(z|Oj того, что исходом экспе-
римента будет данное zeZ. Величины р(z|Ф) представля-
ют собой условное распределение вероятностей на про-
странстве Z при данном & и удовлетворяют соотношениям:
|&)>0; р(г|&) = 1. (10.22)
Совокупность трех элементов: пространства исходов
эксперимента Z, пространства состояний природы 0 и рас-
пределения вероятностей р(z| ф) на пространстве Z при
заданном Фе©— называют пространством выборок
3=(Z, 0, р). (10.23)
394
Пространство выборок удобно задавать в виде таблицы,
содержащей распределение p(z|fl) на прямом произведе-
нии множеств 0XZ.
Пример 10.7. В задаче о замене оборудования эксперимент может
состоять в проведении проверочных испытаний оборудования силами
предприятия. При этом недостаточная квалификация персонала и отсут-
ствие необходимой измерительной аппаратуры приводят к тому, что
результаты испытаний лишь приближенно отражают состояние обору-
дования. Предположим, что эксперимент может иметь четыре исхода:
Zi — оборудование исправно; 22 — требуется текущий ремонт, г3 —тре-
буется замена изношенных деталей; г4 — оборудование непригодно
к дальнейшей эксплуатации.
Таблица 10.3
* Р (г 1&) г. | г3 | г3 |
Задача о замене оборудования
«1 1 ’/2 1 1/2 I 0 1 0
«2 0 1/2 1/2 0
1 о 0 1 1/3 2/3
Задача о технической линии
«1 1 0,60 I 0,25 I 0,15 I -
1 0,20 | 0,30 1 0,50 1 —
Вероятности каждого из этих исходов при различных состояниях
природы приведены в табл. 10.3, представляющей собой пространство
выборок для данной задачи.
Пример 10.8. В задаче о технологической линии эксперимент мо-
жет состоять в грубом предварительном анализе содержания примесей
(точный лабораторный анализ невозможен, так как требует затраты
значительного времени, а значит, простоя оборудования). Результаты
эксперимента. z\ — примесей не обнаружено; z2— примеси в неболь-
шом количестве; г3 — примесей много. Пространство выборок при этом
приведено в табл. 10.3.
i 0.3.3. Решающая функция
В задаче без эксперимента статистик должен был при-
нять решение из пространства решений А, основываясь на
априорной информации £(()) о состояниях природы. В за-
заче с экспериментом статистик принимает решение в за-
395
висимости от исхода эксперимента zeZ. Чтобы формали-
зовать эту задачу, можно заранее проанализировать все-
возможные исходы эксперимента и составить правило d,
определяющее, какое решение а^А следует принять при
каждом из возможных исходов эксперимента zeZ. Это
правило будет представлять собой отображение простран-
ства исходов эксперимента Z на пространство решений А
d:Z-+A, (10.24)
что может быть записано в виде
d(z)=a. (10.25)
Правило d(z), определяющее решение аеА, которое
должен принять статистик при любом исходе эксперимента
zeZ, называют решающей функцией.
Поясним понятие решающей функции на следующем примере. Пред-
положим, что пространство решений состоит из трех элементов А=
={ai, яз, as), а пространство исходов эксперимента — из пяти элемен-
тов Z={zi, 22, z3, z4, Z5}. Решающую функцию d(Z()=flZ можно задать
в виде множества пар индексов (ij), определяющих решение «/ при
исходе эксперимента zi Решающей функцией будет, например, множе-
ство {(1,1), (2,1), (3,2), (4,2), (5,3)}, означающее, что при исходных zt
и za принимается решение яь при исходах z3 и z4— решение а3, а при
исходе zs — решение аз Конечно, данная решающая функция не явля-
ется единственно возможной. Можно было бы рассматривать также
решающие функции вида {(1,1), (2,2), (3,2), (4,3), (5,3)} или {(1,3),
(2.1), (3,2), (4,3), (5,2)} и т. п. В связи с этим удобно вести простран-
ство D, содержащее полный перечень возможных решающих функций,
и назвать его пространством решающих функций.
Рассмотренная выше решающая функция разбивает
множество Z на непересекающиеся подмножества Sai, а
именно
S0, = K, z2}, Sfl2 = {z3, z4}, Sfl, = {z5}. (10.26)
В терминах теории множеств можно сказать, что любую
решающую функцию d^D можно рассматривать как раз-
биение пространства исходов эксперимента Z на непересе-
кающиеся подмножества Sa такие, что
\ = {z | d(z) = а}, а^А. (10.27)
В частности, если пространство решений А состоит
только из элементов и а2 (двухальтернативная задача),
то решающая функция d(z) разбивает пространство Z на
396
пространство 3, называемое критической областью, и его
дополнение C(S)=S, определяемые из условия
(а., если г^З;
d(2)=U2, если г£С(3). ( 0,28)
Понятие решающей функции позволяет более четко
сформулировать задачу статистика. Эта задача состоит
в том, чтобы из пространства решающих функций D вы-
брать такую решающую функцию d(z), которая позволит
принимать наиболее выгодные решения. Однако для этого
необходимо уметь оценивать различные решающие функ-
ции, что может быть сделано при помощи функции риска.
10.3.4. Функция риска
Если статистик остановил свой выбор на некоторой ре-
шающей функции d(z), то тем самым он определил для
каждого исхода эксперимента zeZ решение a=d(z), ко-
торому при данном Фей будут соответствовать потери
L(«,fl)=L[«,d(z)]=£z(#,d). (10.29)
Однако при заданном & исход эксперимента z будет
случайной величиной, определяемой распределением веро-
ятностей p(z|d) на пространстве Z. Следовательно, с той
же вероятностью р (z | д) будут иметь место и потери
Lz{&, d) при данном z, которые, таким образом, будут так-
же случайными.
Поскольку для оценки решающей функции d(z) при
данном состоянии природы д необходимо учитывать все-
возможные исходы эксперимента, то необходимо вести речь
о средних потерях, определяемых на всем пространстве ис-
ходов эксперимента Z. Эти средние потери называют фун-
кцией риска
Р(&, d) = Ez[Lz(b, d)]=£Lz(&, d)p(z | &). (10.30)
г
Каждому состоянию природы де© и каждой решаю-
щей функции d^D будет соответствовать свое значение
средних потерь, т. е. функции риска p(d, d), которая, та-
ким образом, определяется на прямом произведении мно-
жеств 0Х'£> совершенно аналогично тому, как функция
потерь L(d, а) в игре без эксперимента определялась на
397
Рис. 10.6. Функция риска и задаче о
технологической линии
прямом произведении множеств
0ХА. Из этого следует, что про-
странство решающих функций D
и функция риска р (О, d) в игре
с единичным экспериментом иг-
рают ту же роль, что простран-
ство решений А и функция по-
терь в игре без эксперимента.
Отсюда вытекают и аналогичные
методы решения этих двух за-
дач.
В играх с единичным экс-
периментом статистик может
использовать и смешанные стратегии. Для этого он должен
иметь механизм случайного выбора, задающий распределе-
ние вероятностей tj (с?) на пространстве D. Функция риска
при применении смешанной стратегии т] (с?), обозначаемая
в этом случае р(Ф, tj), получится путем усреднения
р(0, d) по всем чистым стратегиям, входящим в данную
смешанную стратегию. Таким образом,
Р(&, 7J) = [Р(Э-, </)]=3p(&, d)Tj(d) (Ю.31)
d
или с учетом (10.30)
Р (&, tj) = 2 L. (&, d) p(z | ft) tj (d) (10.32)
z.d
Естественно, что при поиске наилучшеп стратегии в иг-
ре с единичным экспериментом статистик должен исходить
только из допустимых стратегий, которые определяются
точно так же, как и в игре без эксперимента.
Пример 10.9. Определим функцию риска в задаче о технологиче-
ской линии. Для удобства расчетов потери статистика Ц-ti, а) и ве-
Таблица 10.4
398
роятности исходов эксперимента р(г|О), даваемые табл. 10.1 и 10.3,
сведем в одну таблицу (табл. 10.4).
Поскольку пространство исходов экспериментов состоит из трех
элементов, то решающая функция
d(z) = (a(, a,, ak)=dilit, (10.33)
где at, at и a* — решения, которые должен принять статистик прн
исходах эксперимента zb г2 и z3 соответственно. Так, решающая функ-
ция di22 означает, что при исходах эксперимента zi, z2 и г3 статистик
принимает решения alt а2, а3.
Значения функции риска, подсчитанные по (10 30) для каждой ре-
шающей функции, приведены в виде отдельных точек на диаграмме
рис. 10.6. Получение координат этих точек рассмотрим на примере вы-
числения р(О, d|22)- Согласно (10 30) имеем
Р(В, di22) = '-г, («,’ d122) Р (?!/») + Z-Z2(». d1S2) P (га I ®) + X
X P (z310) = L (&, 01) p (гг | 0) + L (0, a2)p(z2"| 0) +1. (0, as) p (z3 f 9).
Полагая и S=02, получаем p (0ъ dl22)=0,4; p (S2, d122)=3,4.
10.3.5. Принципы выбора стратегии в играх
с единичным экспериментом
Поскольку введение функции риска сводит игру с еди-
ничным экспериментом к форме, аналогичной игре без
эксперимента, то все принципы выбора стратегии в игре
без эксперимента остаются справедливыми и для данного
случая с той разницей, что вместо минимизации средних
потерь теперь статистик должен минимизировать средний
риск.
Принцип минимакса состоит в том, чтобы выбрать стра-
тегию т) (d), при которой средний риск р (О, т]) при наихуд-
шем для статистики состоянии природы был бы минима-
лен, т. е. выбор минимаксной стратегии т>* производится из
условия
р(&, if) = minmaxp (ft, т]). (10.34)
ч а
Если при определении среднего риска р (<Ь, т)) исходить
не из полных, а из дополнительных потерь £'(&, а), то
формула (10.34) будет определять принцип минимакса до-
полнительных потерь.
Для применения байесовского принципа введем поня-
тие ожидаемого риска, под которым понимаем средний
риск с учетом всех возможных состояний природы и
априорного распределения вероятностей на пространстве
399
€). Так как для байесовского принципа статистик может
ограничиться использованием только чистых стратегий, то
ожидаемый риск
pM=Sp(&. <*)!;(&). (Ю.35)
Байесовский принцип требует применения такой реша-
ющей функции d*, при которой ожидаемый риск, называе-
мый в этом случае байесовским., будет минимальным:
pir(5) = pff,d>-) = mjn(B,d). (10.36)
Пример JO.JO. Определим минимаксную н байесовскую стратегии
в задаче о технологической линии с проведением единичного экспери-
мента. На рис. 10.6 эта задача представлена в виде S-игры. Из прове-
денного геометрического построения легко установить, что минимаксная
стратегия определяется точкой So с координатами (30/14, 30/14) и со-
ответствует применению чистых стратегий d2» и d333 с вероятностями
10/14 и 4/14. Байесовской стратегией будет стратегия dm
10.4. ИСПОЛЬЗОВАНИЕ АПОСТЕРИОРНЫХ
ВЕРОЯТНОСТЕЙ
10.4.1. Определение числа стратегий в играх
с проведением эксперимента
Из рассмотренных в предыдущих параграфах примеров
видно, что проведение эксперимента в статических играх
приводит к значительному увеличению числа чистых стра-
тегий статистика. Так, в задаче о технологической линии
при учете результатов эксперимента число чистых страте-
гий возросло с 3 до 27. И если бы эту игру нам не удалось
представить в виде S-игры на плоскости, то возникли бы
серьезные трудности при ее анализе.
Обозначим через N общее число чистых стратегий
статистика в игре с единичным экспериментом. Это число
нетрудно подсчитать. Предположим, что в игре без экспе-
риментов у статистика имеется / возможных решений
а,, .. , at, а число возможных исходов эксперимента рав-
но V.
При v=l получаем игру с заранее известным исходом
эксперимента, что равносильно игре без эксперимента, при
которой N=l.
400
При v = 2 стратегия статистика может быть записана
в виде d — (ai„ а1а), где величинами ait и а/, могут быть
любые а£=А. Следовательно, может быть I различных зна-
чений ait, каждому из которых может соответствовать I
различных значений Л/а, так что N = /!.
При v = 3 стратегия статистика й = (аг„ ага, я,,). Сово-
купность решений ait и а/, может принимать F значений,
каждому из которых может соответствовать I значений ait,
так что N=l3.
Продолжая аналогичные рассуждения, приходим к вы-
воду, что при произвольных I и v общее число чистых стра-
тегий статистиков равно N=lv. При больших I и v число
чистых стратегий статистика может оказаться столь зна-
чительным, что возникнут серьезные затруднения, связан-
ные с их анализом.
В подобных случаях можно добиться значительного
упрощения при нахождении байесовских стратегий, если
вместо априорного распределения вероятностей использо-
вать апостериорное распределение, вычисленное на основе
результатов проведенного эксперимента. При этом число
чистых стратегий статистика в задаче с экспериментом
останется тем же самым, что и в задаче без эксперимента.
10.4.2. Апостериорное распределение вероятностей
Априорное распределение вероятностей |(О), получае-
мое на основе статистических данных и прошлого опыта,
дает полезную информацию о том, насколько часто то или
иное состояние природы встречается вообще, безотноси-
тельно к тем конкретным условиям, в которых статистику
приходится принимать решение. Целью эксперимента, про-
водимого статистиком, является получение добавочной ин-
формации о действительном состоянии природы.
Предположим, что пространством исходов эксперимента
является множество Z=(zb ... . zv). При этом исход кон-
кретного эксперимента будет случайным и потому также
не дает возможности точно судить о действительном состо-
янии природы. Однако неопределенность относительно со-
стояния природы значительно уменьшается, если экспери-
мент поставлен правильно.
Это изменение неопределенности относительно состоя-
ния природы состоит в том, что в результате эксперимента
26-804 401
вместо априорного распределения gfOj получается новое
распределение вероятностей ^(fl-|z), которое называют
апостериорным, распределением вероятностей на простран-
стве 0 при данном конкретном исходе эксперимента
zeZ.
Апостериорное распределение вероятностей gffljz) мо-
жет быть найдено по формуле Байеса (5.26), которую в
применении к нашему случаю запишем в виде
(10.37)
где p(z |0) —условная вероятность исхода эксперимента
z при данном состоянии природы •йе©, определенная на
основе статистических данных;
Р(^)=2р(г| &)?(&) (10.38)
— безусловная вероятность исхода эксперимента z, най-
денная по формуле полной вероятности (5.25).
С учетом (10.38) перепишем выражение апостериорного
распределения вероятностей в виде
Ц& | z) = p(? | &)Е (&)/£ р(г I &)Е(&). (10.39)
Пример 10.11. Определим апостериорное распределение вероятно-
стей в задаче о технологической линии. Расчеты по формуле (10.39)
производим табличным методом. Процесс расчета приведен в табл. 10.5.
Исходными данными для расчета служит априорное распределение ве-
роятностей £(<)), взятое из табл. 10 1, и условное распределение ве-
роятностей p(zlfl’) — из табл. 10.3.
Найденное значение апостериорных вероятностей показывает, что
при исходах эксперимента гх или z3 неопределенность относительно со-
стояний природы значительно уменьшается. Однако при исходе экспери-
мента гг неопределенность становится даже большей, чем до постанов-
ки эксперимента.
1 а б л и ц а 10.5
/>(г 1 U0I г)
г. г2 | г3 г, | г. гз 1 | г. г,
«3 0,6 0,4 0,60 0,20 0,25 0,15 0,30 0,50 0,36 0,08 0,15 0,12 0,09 0,20 0,818 0,182 0,555 0,445 0,310 0,690
0,44 0,27 0,29 - - -
402
10.4.3. Принцип максимального правдоподобия
Знание апостериорных вероятностей позволяет оцени-
вать состояние природы, используя принцип максимального
правдоподобия. Согласно этому принципу за оценку состо-
яния природы принимают то состояние, которое представ-
ляется наиболее вероятным на основании опытных данных.
Пример 10.12. Дадим оценку состояния природы О’ в задаче о тех-
нологическом процессе при исходе эксперимента zt. Согласно табл. 10.5
anociериорные вероятности состояний природы О] и От прн исходе
эксперимента Z| будут
=0,818; K^lz,) =0,182.
Поскольку max[g(<h|zi)> 6№21Zi)] фg(Oi |Z\), то согласно принципу
максимального правдоподобия ’6=Oi.
Принцип максимального правдоподобия часто применяют для вы-
бора решения в двухальтернативной задаче. В этой задаче простран-
ство состояний природы 0={О’ь От} состоит из двух элементов с апри-
орным распределением вероятностей §('&)=(?, 1—£). Пространство ре-
шений статистика также состоит из двух элементов A={alt аг}, где
at — решение о том, что природа находится в состоянии аг — в со-
стоянии От- Известны также условия распределения вероятностей исхо-
дов эксперимента p(z |'0j для и для О=О2. Требуется по резуль-
татам исхода экспервмента zeZ принять решение ое{О|, а2}.
Пример 10.13. Задача о радиолокационной станции (РЛС). Сигнал
иа экране РЛС может появиться или при наличии цели в зоне РЛС,
или в результате действия различных помех. Следовательно, могут
иметь место два состояния природы: От — цель есть, От — цели нет. По
наблюдениям за экраном можно принять два решения; at — цель есть,
а2 — цели нет. При этом могут быть допущены ошибки двух видов:
ail От —ошибка первого рода, называемая иногда «ложной тревогой»;
а2|О| —ошибка второго рода, называемая иногда «пропуском цели».
Для принятия решения в двухальтернативной задаче часто исполь-
зуют отношение правдоподобия, определяемое соотношением
A(z)=g(O,|z)/g('&2|z). (10.40)
Говорят, что имеет место проверка по отношению правдоподобия,
если задано число k такое, что решение принимают согласно одному
из следующих правил:
решение аь если Л(г)>й;
решение а2, если Л(г) <k;
решение at или а2, если Л(г)=А
Значение k выбирают в зависимости от последствий, к которым
может привести ошибочное решение Так, в задаче о РЛС ошибка
26* 403
типа «ложная тревога» может иметь значительно большие последствия,
чем ошибка типа «пропуск цели». Решение а, следует принимать толь-
ко в том случае, если существует уверенность, что цель действительно
есть, т. е. если выполняется условие g (чЭ-, | г) ;§>§ (тЭ-21 г). Это означает,
что в данном случае следует брать А^>1.
10.4.4. Определение байесовского решения
на основе использования апостериорных вероятностей
Как видели в начале настоящей главы, основная труд-
ность решения задачи с проведением эксперимента состоя-
ла в резком увеличении числа стратегий при увеличении
числа возможных исходов эксперимента. Однако в дейст-
вительности совсем нет необходимости рассматривать все-
возможные исходы эксперимента. Если в результате про-
ведения эксперимента получен какой-то конкретный исход
zeZ, то для этого исхода и следует решать задачу.
Это можно сделать, подсчитав при данном исходе экс-
перимента z апостериорное распределение вероятностей
^(O'|z) на пространстве состояний природы 0. При этом
будут известны пространство состояний природы 0, прост-
ранство решений А и распределение вероятностей на про-
странстве состояний природы £(Ф|г), в котором учтен ре-
зультат эксперимента. Но эта задача отличается от зада-
чи без эксперимента только тем, что здесь используется
апостериорное распределение вероятностей £(-0 |z) вместо
априорного распределения £(&)• Следовательно, и методы
решения этой задачи аналогичны тем, которые применя-
лись в задаче без эксперимента.
При применении апостериорных вероятностей £(-0|.г)
в качестве чистых стратегий статистика используются
элементы пространства решений А — {аь ..., at}. При этом
каждому действию аеЛ будут соответствовать потерн
статистика, определяемые по аналогии с (10.2):
L(?z, а) = (Г(б, а)] = а)Щ | г), (10.41)
йли с учетом (10.39)
Йг I a) = S L'&> | &)!(&). (10.42)
Байесовский принцип сводится к тому, чтобы выбрать
такое действие а*^А, при котором величина потерь, оп-
404
ределяемых согласно (10.42), будем минимальна:
R*&) = R(lz, a*)=min(!=z, а). (10.43)
10.4.5. Двухальтернативная задача
Проиллюстрируем изложенные принципы на примере
решения двухальтернативной задачи с априорным распре-
делением вероятностей £(&) = (£> 1—£)• При правильных
решениях потери считаем равными нулю. Ошибка первого
рода (<7z|'0’i) дает потери w, а ошибка второго рода
(oil^h1) —потери, равные единице. При этом матрица по-
черк имеет вид табл. 10 6.
Таблица 10.6
&2
Рассмотрим решающую функцию d(z), которая соглас-
но (1028) делит пространство исходов эксперимента Z на
области S и C(S) такие, что принимался решение «ь если
:eS, п решение а2, если zeC(S). Поскольку S и C(S)
должны быть компактными, то решение задачи сводится
к тому, чтобы найти границу, разбивающую множество Z
на кепересекающиеся подмножества S и C(S). Элементы
£(=Z, составляющие эту границу, обозначим г0. На
рис. 10.7 показан вид границы zq для одномерного (а) и
двумерного (б) случаев.
Для нахождения уравнения, определяющего границу
г0, напишем выражения для средних потерь при данных z
и решениях сц и а2. Учитывая (10.42) и данные табл 10.6,
получаем
£(Вг, й1) = р(г | &г)(1 —С) 2p(z | &)!•(&); (Ю.44)
a2) = wp(z | &,)ч I (10.45)
I a
405
Граница z0 соответствует равенству средних потерь при
решениях он и а2, что дает
(l-£)p(~o|fl2)=t®p(zo|'O1) (Ю.46)
или
Р<Л I *г)Ж I ^'=^(1— С) = с(С, w). (10.47)
Как видим, каждому значению £ будет соответство-
вать своя граница z0, а следовательно, и соответствующие
области St п C(Ss). При этом величиной £ будут опреде-
ляться и вероятности ошибочных решений а(£) и Р(^), яв-
»)
Рис. 10.7. Разбиение пространства исходов эксперимента в двухаль-
тернативпой задаче
ляющиеся вероятностями того, что при -0’=-0ч точка z по-
падет в область CS& и будет принято решение о2 и при
0-=-02 точка г попадет в область S? и будет принято ре-
шение й|. Эги вероятности определяются соотношениями:
а(С) =- /-W,) = 2 Р(г|8.); (10-48)
zeC(Sc)
Р(С)=-/Дй1|&г)= 2 Р(г|«-)- (10.49)
zesc
Для определения характера зависимости вероятности
ошибочных решений от I; определим значения а(£) и Р(£)
для крайних значений £=0 п £=1.
Элементы zeZ, входящие в множество S, определяют-
ся условием L(£,z, а2) или
p(z|fM/p(2|fli)<^/(l-(10.50)
При t=0 условие (10.50) дает
p(z|^2)/p(z|0,)=0,
что возможно только в том случае, если 5^—0, C(St)=z.
При этом из (10.48) и (10.49) находим а(0)=1, Р(0)=0.
406
При£=1 условие (10.50) дает
p(z|02)
что определяет область S^=z, C(S^)=0, так что а(1)=0,
р(1) = 1.
Таким образом, при изменении £ от 0 до 1 а(£) меня-
ется от 1 до 0, а Р(£) —от 0 до 1.
Рис 10.8. Кривая байесовского рис-
ка в двухальтернативной задаче
Для того чтобы определить средние потери при всевоз-
можных значениях t, найдем байесовский риск р+(?) для
рассмотренной решающей функции d(z). Используя вы-
ражение (10.30) для решающей функции р(0, d) и усред-
няя эту функцию по всем состояниям природы, находим:
p^)=4wa(£) + (l- S)P(S). (Ю.51)
График зависимости р* (£), построенный по этой фор-
муле с учетом найденного характера изменения а(£) и
Р(£), приведен на рис. 10.8. Из этого графика видно, что
p*'(t;) обращается в нуль при £=0 и при £=1 и достигает
максимума при некотором ^=^о- Значение с0 определяет
напхудшую для статистика стратегию природы, прн кото-
рой он, применяя байесовский принцип, имеет потери
Р*.(£о).
На практике часто встречаются случаи, когда предва-
рительных статистических данных недостаточно для того,
чтобы точно определить априорную вероятность L Поэто-
му представляет интерес найти значение байесовского рис-
ка для случая, когда статистик исходит из некоторого
значения априорной вероятности £' и в соответствии
с этим получает значения Sga(£') и Р(£'), тогда как дей-
ствительное значение £ будет иным. В этом случае байе-
совский риск определяется выражением
р(£, n=^a(£') + (l-S)m, (10-52)
которое является линейным относительно £ и определяет
касательную к кривой у=р*(£) в точке £=£'• Из рис. 10.8
407
видно, что потери, определяемые функцией р(£, t,'), будут
больше, чем для функции р*(£), если так что не-
точное знание априорного распределения вероятностей
приводит к увеличению потерь. Более того, если £ значи-
тельно отличаются от £', то потери, определяемые функци-
ей р(£, £')» могут превысить значение р*(£о), соответству-
ющее максимальному значению байесовских потерь. Однако
если исходить из наиболее неблагоприятного распре-
деления вероятностей, соответствующего значению £0, то
функция 0=р(£;, и0) будет постоянна и при любом £ опре-
деляет потери, равные р*(£о). Этот случай соответствует
применению минимаксной стратегии.
Таким образом, применение байесовского принципа це-
лесообразно лишь в тех случаях, когда априорное распре-
деление вероятностей £(()) известно достаточно точно. Ес-
ли же априорное распределение вероятностей ^(б) неиз-
вестно или известно не точно, то более выгодным может
оказап.ся минимаксный принцип
10.5. СТАТИСТИЧЕСКИЕ ИГРЫ
С ПОСЛЕДОВАТЕЛЬНЫМИ ВЫБОРКАМИ
10.5.1. Предварительные замечания
При рассмотрении статистической игры с единичным
эксперимент ом отмечалось, что единичный эксперимент
необязательно состоит нз одиого-едипс гневного испыта-
ния. Он может состоять и из последовательности испыта-
ний, по объем и порядок этих испытаний должны быть
определены заранее. Так, если заранее установлено, что
решение принимается после того, как проведено N после-
довательных испытаний, ю вся эта последовательное>ь
испытаний рассматривается как единичный эксперимент,
исходом которого будет многомерная величина z=(£i, ...
...,Zjv), где Zi i=\,N— исход i-ro испытания. В связи
с этим игру с единичным экспериментом часто называют
игрой с заданным объемом выборки, понимая под объемом
выборки число последовательно проведенных эксперимен-
тов.
В играх с заданным объемом выборки статистик может
использовать только те стратегии, которые определяют ха-
рактер его действий после полного окончания всей после-
довательности испытаний. Однако для статистика открыт
408
и другой путь. Так, вместо проведения всех N испытаний
он может после каждого последовательного испытания ре-
шать, прекратить ли испытание и выбрать какое-то реше-
ние из А на основании уже имеющейся информации или
провести следующее испытание. Это расширяет класс
возможных стратегий статистика, так как к выбору реше-
ния из множества А добавляется еще выбор решения о
том, прекратить или продолжить эксперимент. Подобные
игры называют играми с последовательной выборкой. При
этом, если задано предельное допустимое число испыта-
ний, после проведения которых решение из А должно-
быть обязательно принято, игру называют игрой с усечен-
ной последовательной выборкой. Только такими играми
мы и ограничим дальнейшее изложение, отсылая интере-
сующихся более детальным рассмотрением вопроса к [57,.
62, 63]. Отдельные последовательные результаты экспе-
римента будем называть наблюдениями.
Если бы эксперимент ничего не стоил, то расширение
класса стратегий путем введения последовательных выбо-
рок не имело бы смысла, так как статистик ничего бы не
терял, а мог только выиграть, проведя все N наблюдений.
Однако во многих случаях эксперимент дорог и требует
затраты времени. При этом статистик может получить зна-
чительный выигрыш, если на каждой стадии эксперимента
сопоставляет стоимость продолжения эксперимента с ожи
даемым выигрышем от получения добавочной информации.
Рассмотрим способ описания игры с усеченными по-
следовательными выборками. Обозначим через Zz множе-
ство исходов i-ro испытания. Тогда полное пространства
исходов эксперимента Z при проведении всех N испыта-
ний можно представить в виде
Z=Z{X...XZN. (10.53)
В игре с последовательными выборками допускаем
принятие решения на основе проведения не всех N наблю-
дений ..., Zff, а только j первых из них: zb..., г,. В связи
с этим множество Z можно разбить на непересекагощиеся
подмножества So, Si,...,Sn такие, что если zeS,-, то реше-
ние принимают на основании проведения j первых наблю-
дений.
Множество S=(So, Si,...,Sn) называют планом после-
довательной выборки. Множество Z можно разбить на не-
пересекающиеся подмножества S/ несколькими различны-
ми способами. Каждый из этих способов определит свой
409
план последовательной выборки. Множество всевозмож-
ных планов последовательной выборки обозначим 6 и на-
зовем полным классом последовательных выборок.
Для возможности принятия решения должна быть за-
дана решающая функция d(z), определяющая для каж-
дой последовательности наблюдений решение из А. Ре-
шающую функцию d(z), как и в игре с единичным экспе-
риментом, статистик выбирает из пространства решаю-
щих функций D, в которое входят всевозможные решаю-
щие функции.
Стратегия статистика в игре с последовательными вы-
борками состоит, во-первых, в выборе плана последова-
тельной выборки SeS, указывающего, когда должен быть
закончен эксперимент, и, во-вторых, в выборе решающей
функции cteZ), указывающей, какое решение должно быть
принято по окончании эксперимента. Таким образом, па-
ра (S, d) определяет стратегию статистика. Учитывая, что
пара (S, d) является элементом прямого произведения
6XZ), приходим к выводу, что 6XD является пространст-
вом чистых стратегий статистика.
Общее число стратегий в играх с последовательными
выборками получается значительно большим, чем в играх
с единичным экспериментом, что вызывает значительные
трудности при составлении полного перечня стратегий
статистика и выборе паилучшей из них. Эту работу мож-
но значительно упростить, если на каждой стадии экспе-
римента вычислять апостериорное распределение вероят-
ностей, используя для этого всю накопленную к данному
моменту информацию. По мере проведения последова-
тельных наблюдений неопределенность относительно дей-
ствительного состояния природы будет при этом умень-
шаться, так что открывается возможность выработат
критерий для определения момента окончания эксперн
мента и принятия решения из множества А.
1Э.5.2. Использование апостериорного распределения
вероятностей для определения последовательных
байесовских правил
Будем рассматривать только такие статистические иг-
ры, в которых результаты отдельных подыспытаний гь...
..., zn являются независимыми случайными величинами.
Обозначим через q{z, ]&) распределение вероятностей на
пространстве Z, при данном состоянии природы &. Стои-
410
мость отдельного подыспытания считаем постоянной и рав-
ной с—1.
В качестве основы для описания плана последователь-
ных выборок примем распределение вероятностен £(&)
на пространстве состояний природы 0, причем под рас-
пределением £(Ф) будем понимать не только априорное
распределение вероятностей до начала эксперимента, но
и апостериорное распределение вероятностей после прове-
дения нескольких подыспытаний. В дальнейшем будем
обозначать через £о('&) априорное распределение вероят-
ностей, а через £,(&)—апостериорное распределение ве-
роятностей после проведения j подыспытаний.
Распределение вероятностей £,(&) будет содержать в
себе всю информацию о состоянии природы &, которая
имелась до проведения эксперимента, а также была полу-
чена в результате проведения первых j наблюдений. По-
этому распределение £,(&) может рассматриваться как
априорное перед (/+1)-м наблюдением. Следовательно,
распределение выражается через £/(&) с помощью
формулы для апостериорного распределения вероятно-
стей. Рассмотрим переход от априорного распределения
вероятностей £,(&) к апостериорному +1(й) как некото-
рое преобразование Т распределения ^(0). Тогда соглас-
но (10.39) апостериорное распределение вероятностей
Л,.(&) = ^+1(&) = ^(&)<7(^+1 I ») | &)• (Ю.54)
Принцип получения плана последовательной выборки
на основе использования апостериорного распределения
вероятностен рассмотрим на примере двухальтернативной
задачи, в которой 0={й1, $2} и A — {ai, а2}.
Обозначим через (£, 1—£) апостериорное распределе-
ние вероятностей на пространстве 0 после проведения не-
скольких подыспытаний. Пространство Е смешанных
стратегий природы в этой задаче определяется областью
возможных значений £, т е. интервалом [0, 1] веществен-
ной оси.
Может оказаться, что £=1. В этом случае можно при-
нять только решение а\. Если £=0, то обязательно прини-
маем решение а2. Но если окажется £=0,5, то невозможно
отдать предпочтение ни одному решению и следует про-
должить эксперимент для того, чтобы уточнить действи-
тельное состояние природы.
411
Здесь были рассмотрены крайние случаи распределе-
ния вероятностей £($). В общем же случае можно задать-
ся значениями б и у (0^б^1, O^y^l, б^у) такими,
что:
если £ лежит в диапазоне [б, 1], то принимаем реше-
ние аг,
если £ лежит в диапазоне [0, у), то принимаем реше-
ние а2;
если £ лежит в диапазоне (у, б), то принимаем реше-
ние о проведении следующего подыспытания.
Решение
о продолжении
1 Решение а; эксперимента
О Д(а,) ff
Решение а,
-------------
Д(а,) 1 ;
Рис. 10.9. Правило принятия решения в двухальтерпативной задаче
Диапазоны A(ai) = [б, 1] и Д(а2) = [0, у] называют
областями остановки. На рис. 10.9 сформулированное пра-
вило принятия решения изображено графически.
Области остановки можно определить и для случая,
когда число состояний природы больше двух. Правда,
в этом случае пространство смешанных стратегий приро-
ды Е будет иметь более сложный вид. Так, в случае трех
состояний природы оно имеет вид равностороннего тре-
угольника с высотой, равной единице (см. рис. 10.15).
В общем случае областью остановки А (а) в простран-
стве Е называют такое подмножество пространства Е
Л(а)<=Е, (10.55)
что если после некоторого подыспытания окажется ^('О)е
еА(а), то эксперимент прекращают и принимают реше-
ние а.
Поскольку каждое подыспытание имеет стоимость, то
будет небезразлично, попадет ли £(&) в область А(а) до
проведения эксперимента или после нескольких подыспы-
таний. Это означает, что с каждым новым подыспытанием
будут изменяться значения как £('0,)> так и области А (а).
При этом на каждой стадии эксперимента представляют
интерес не те подыспытания, которые уже были проведе-
ны и результаты которых уже использованы, а те, которые
еще осталось провести до полного окончания эксперимен-
та. В соответствии с этим области остановки на той ста-
412
дии эксперимента, когда проведено ] подыспытаний из N,
будем обозначать Aw-, (а).
Если пространство решений состоит из т элементов
аь.... ат, то на каждой стадии эксперимента должно быть
определено т областей А (а), соответствующих каждому
аеД. Эти области должны быть выпуклыми и непересе-
кающимися [57].
10.5.3. Правило последовательных выборок
Предположим, что в пространстве Е выделено т об-
ластей А (а) на каждой стадии эксперимента. Тогда пра-
вило последовательных выборок будет состоять в следую-
щем.
Первоначально известно априорное распределение ве-
роятностей g0('&). Если go (•О’) eAwfaj) при каком-либо I,
то принимаем решение ai без проведения эксперимента.
Если go (О’) ^Aw (а,) ни при каком i, то проводят первое
подыспытание и вычисляют апостериорное распределение
вероятностей si (О’). Затем рассматривают области
Aw-Да). Если g1(O)eAw_1(ai) при каком-либо i, то экспе-
римент прекращают и принимают решение а,. Если
gi(O’)^Aw-i(ai) ни при каком I, то проводят следующее
подыспытание и т. д.
Вообще, если эксперимент не был прекращен при пер-
вых j—1 наблюдениях, то проводят дополнительное на-
блюдение и вычисляют gy(O’). Если gJfljeAw^a) при ка-
ком-либо I, то эксперимент заканчивают и принимают ре-
шение аг. Если выбор не был произведен после (N—1)-го
наблюдения, то после N-vo наблюдения производят окон-
чательный выбор. Для выполнения этого условия области
До(«г) выбирают так, чтобы
UA0(at-)=E. (10.56)
Как видим, задача описания последовательных байе-
совских правил сводится к задаче определения областей
АЛ-_1(а) в пространстве Е для всех а^А и для всех j от 0
до УУ.
10.5.4. Функция риска при оптимальном
последовательном правиле
Функция риска при последовательных выборках долж-
на определять на каждой стадии эксперимента (напри-
мер, после j подыспытаний) минимальные средние потери,
413
которые будет нести статистик, принимая наилучшее ре-
шение из числа возможных, включая решение о том, что
эксперимент должен быть продолжен. Поскольку приня-
тие решения основывается на знании апостериорного рас-
пределения вероятностей g/(fl), то от этого распределения
вероятностей будет зависеть и функция риска. Функцию
риска, получающуюся после проведения j подыспытаний,
будем обозначать p*(g,).
Выражения, определяющие функцию риска, будем ис-
кать последовательно, начиная с последней стадии экспе-
римента. Предположим, что проведены все N подыспыта-
ний и найдено апостериорное распределение вероятностей
gw (fl). Средние потери, которые при этом несет статистик,
принимая решение а^А, будут
L (^, а) - L (ft, а) (ft). (10.57)
6
Минимальное значение этих потерь, соответствующее
байесовскому решению а*, определится выражением
/?*(^) = L(^, a‘) = min(^, а). (10.58)
Поскольку никакого лучшего решения, чем а*, принять
невозможно, то величина /?*(gw) на этой стадии экспери-
мента совпадает с функцией риска
рЧЫ=ЛЧЫ. (10.59)
Рассмотрим теперь произвольную стадию эксперимен-
та и найдем минимальные средние потери, которые стати-
стик будет нести после того, как он провел j подыспыта-
ний (/=0, 1,...,N—1). При этом статистик располагает
распределением вероятностей g/(fl).
В данном случае статистик может поступить следую-
щим образом.
1. Статистик может прекратить эксперимент и принять
решение аеД. При этом минимальные средние потери
/?»(£,) = min LG/, а) = min 2^(3-. л) МН О0-60)
2. Статистик может принять решение проводить (/+1)-е
подыспытание. При этом он будет нести, во-первых, поте-
ри, равные стоимости испытания, которые приняли за
414
единицу, и, во-вторых, потери, которые он несет после при-
нятия наилучшего решения по результатам (/+1)-го на-
блюдения, т. е. р*(£/+1).
Однако статистику неизвестно распределение вероятно-
стей (-0) - Он знает только распределение !/('&),
а §/+1('&) может определить лишь по (10.54) как П-ДФ).
При этом значение 7'^(0’) может быть найдено для кон-
кретных значений zl+i^.Zl+i и йе0, которые статистик
пока не знает, поэтому он должен вести речь не о кон-
кретном значении функции риска р*(£/+1), а лишь о сред-
нем £[р* (Th)], причем усреднение должно быть прове-
дено по всем возможным значениям z/+ieZ/+1 с распреде-
лением вероятностей (г/+11 тЕ)*) и по всем Фе©
с распределением вероятностей
ТО1 = SpWWIW (10-61)
Таким образом, при решении о продолжении экспери-
мента минимальные потери статистика
1+£[рЧ^/)].
(10.62)
Функция риска после проведения / подыспытаний оп-
ределится минимумом средних потерь при рассмотрении
как прекращения, так и продолжения эксперимента. Сле-
довательно,
Р*(М = min {/?*(&,)- 1 + Е [р*(Д,.)]}. (10.63)
Выражение (10.63) можно записать более компактно,
не употребляя индекса /, обозначающего номер подыспы-
тания. Будем рассматривать стадию эксперимента, когда
до полного окончания эксперимента осталось k подыс-
пытаний. Обозначим через £(&) апостериорное распреде-
ление вероятностей на этой стадии, а через —
= 7’£(0) апостериорное распределение вероятностей пос-
ле проведения еще одного подыспытания. Функцию риска
на стадии, когда до конца эксперимента осталось k под-
ыспытаний, обозначим через р*‘(£). Тогда выражения
(10.59) и (’10 63) запишутся в виде
р0*(Ю = ^(5); (Ю.64)
р;(1;) = пнп{/т Ц-Я^-ЛЛ;)]}. (10.65)
415
Обозначим через V пространство исходов следующего
подыспытапия, элементы которого будем обозначать v.
При этих обозначениях получим
(10.66)
е [р;_, (Л)] = £ [Л (&л q (v । &) е w; (i o.67)
О
W) = i-(&)<7(a|&)l^)q(u\^).
(10.68)
Формулы (10.64) и (10.65) могут быть использованы
для определения областей остановки. Однако сравнитель-
но простые результаты получают лишь для двухальтерна-
тивной задачи, рассмотрением которой в дальнейшем и
ограничимся.
10.5.5. Определение областей остановки
для двухальтернативной задачи при усеченной
последовательной выборке
Рассмотрим случай двухальтернативной задачи с функ-
цией потерь, заданной матрицей
Q =
[°
L <?21
<712 I
о J
(10.69)
и с распределением вероятностей на пространстве состоя-
ния природы ^(0) = (^, 1—£)• Обозначим через A*(O|) и
Ай(й2) области остановки, соответствующие решениям
и а2, когда до окончания эксперимента осталось провести
k наблюдений. Эти области определяются значениями5=
—f>!{ и t,=yk, уь^би такими, что
Aft(ai) = [6ft^^l]; А*(я2) = (Ю.70)
Определение областей остановки сводится к нахожде-
нию значений ук и б* при fe=0, 1, N. Это можно сделать,
воспользовавшись полученными выражениями для функ-
ции риска.
416
Начнем определение граничных точек областей оста-
новки с k=0. Выражая £(&) через £, из (10.64) и (10.66)
получаем
p0*U)=/?=4£)=min[(l-;)<72i, ^12]. (Ю.7.1)
Согласно (9.56) Ao(ai) и До(аг) должны быть непе-
ресекающимися вещественными множествами, объедине-
ние которых дает замкнутый отрезок [0, 1]. Следова-
тельно, эти области должны отделяться друг от друга
точкой £=уо=бо, которую найдем из условия
(l-O<Z2i=^i2. (10.72)
Выражение (10.72) является условием равенства ми-
нимальных средних потерь при принятии решений а, и аг.
Из (10.72) находим
yo=6o=^2l/(?12 + ?21) . (10.73)
При произвольном £=/=0 функция риска имеет вид
рг (О -min {7?* (£), 1+Е [pV. (Т£) ]}. (10.74)
Условия получения граничных значений £ для мно-
жеств A*(ai) и Дл(а2) будут условиями равенства ми-
нимальных средних потерь при принятии решения а\ или
а2 и при принятии решения о продолжении эксперимен-
та, что выражается соотношением
/?*(£)=l+E[pVi(7£)]. 010.75)
Замечая, что в (10.71) для 7?*(^) величина £<721 яв-
ляется монотонно возрастающей функцией £, обращаю-
щейся в нуль при £=0, а (1—£) <712 — монотонно убываю-
щей функцией £, обращающейся в нуль при £=1, и за-
меняя в граничных точках £ на у* для области Д*(а2) и
на б* для области Дй(аг), условие (10.75) можем запи-
сать в виде
7й<721 = Ц-Е[р*й-1(Ттй)]; (10.76)
(1-6ft)<7i2=H-E[p\-i (Гбй)]. (10.77)'
Эти условия геометрически иллюстрируются рис. 110.10.
Полученные соотношения показывают, что задача опре-
деления у* и б*, а также функции риска р** (£) сводятся
к вычислению величины E[p*ft_I(7’^)]. Формула (10.67)
27—804 417
дает общее выражение для этой величины при произ-
вольном 0. Для двухальтернативной задачи это выраже-
ние принимает вид
£[р;_.га =5Sp;- । »*)+
+ (1 - Q [Т(1 — C)J q (v I &2), (10.78)
где
7X = fy(» | I <M + (1 -0<7(« I M; (Ю.79)
7’(1-5) = (1-С)7(у I (10.80)
У=Чг.
P*(S)
<1 У=(^)?12
° йк <Рг) £ PMa-i) 1 С
Рис. 10.10. Определение областей остановки в двухальтериативиой
задаче
При &=1 функция ро*'(С;), определяемая выражением
(10.71), является очень простой функцией от £, так что
величина £[р0*(7^)] может быть определена из (10.78)
непосредственно. Зная £[р0* (77;) ], можно вычислить
из (10.74) pi*(^) и, следовательно, определить £[pi* (7?)]
из (10.78), а отсюда рг’Ч?) из (10.74) и т. д. Хотя подоб-
ный процесс нахождения рй*(^) требует больших вычис-
лений, при этом не приходится производить никаких бо-
лее сложных операций, чем отыскание математических
ожиданий.
10.6. ОЦЕНИВАНИЕ ПАРАМЕТРОВ И ФИЛЬТРАЦИЯ
10.6.1. Задача оценки параметров
Одной из задач общей теории статистических решений,
имеющей большие практические приложения, является
задача оценки векторов состояния и параметров систем
418
[64—66], которую можно сформулировать следующим об-
разом. Предположим, что хотим оценить значение ска-
лярного или векторного параметра х, недоступного непо-
средственному измерению. Вместо параметра х измеряем
другой параметр z, зависящий от х. Задача оценивания
состоит в ответе на вопрос: что можно сказать об х,
зная z?
Будем считать, что вектор х содержит I компонент,
т. е. представляет собой /-вектор, a z является т-векто-
ром. Обозначим через х некоторый /-вектор, который при-
нимаем за оценку вектора х. Вектор j? можно выбирать
по-разному. Для того, чтобы судить, какой из возможных
векторов х лучше всего подходит для оценки вектора х,
необходимо иметь критерий J качества оценки х.
За основу для построения критерия можно взять ошиб-
ку оценки х=х—х и ввести в рассмотрение некоторую
неотрицательную функцию этой ошибки g(x), которую по
аналогии с (10.1) можно назвать функцией потерь. При
этом, как было сделано в (10.4'1), за критерий качества
оценки х можно взять математическое ожидание функции
потерь g(x) при данном наблюдении z:
; = ад£(х)] = Jg(x)a>(x | z)dx, (10.81)
X
где да (х | z) — условная плотность вероятности вектора х.
Следуя байесовскому принципу, в качестве оптималь-
ной оценки должны взять такой вектор х, который обра-
щает в минимум критерий J, т. е. удовлетворяет условию
dJ/dx = f [dg(x)ldx] да(х | z)dx = 0. (10.82)
X
Естественно, что оптимальная оценка х зависит от вы-
бранного вида функции потерь. Наиболее употребитель-
ными являются квадратичная функция потерь
g(x) =хтх= (х—х)т(х—х) (10.83)
и модульная
g(x)=||J||=(“x^)^. (10.84)
27*
419
Рассмотрим только квадратичную функцию потерь, для
которой в соответствии с (4.115) находим
dg (х) / дх——2 (х—х),
так что согласно (10.82) оптимальная оценка удовлетво-
ряет соотношению
J(x—х)су(х | i)dx =0
или
х Jw(x | z)dx = j xw(x | z)dx.
Учитывая, что интеграл в левой части обращается
в единицу, а правая часть представляет собой условное
математическое ожидание вектора х, находим
x=£(x|z). (10.85)
Если векторы х и z имеют нормальное распределение
с математическими ожиданиями £(х)=х, £(z)==z и кова-
риационными матрицами Рхх=£[(х—х) (х—х)т], Рлг =
= £[(z—z) (z—z)T], Р*г=£[(х—x) (z—z)T], то оптималь-
ная оценка в соответствии с (10.85) определится соотно-
шением (5.114) и будет
Х = х+РлгРгг_1(2—z). (10.86)
При этом соотношение (5.'115) даст ковариационную
матрицу оценки
Q = £ [(х — х) (х — £)т] = Р.„ - Рл; Р^' Ргл. (10.87
Пример 10.14. Измеряется скалярная величина х, которая может
с одинаковой вероятностью лежать в пределах от 1 до 11 и на кото-
рую наложена нормально распределенная помеха s с нулевым мате-
матическим ожиданием и дисперсией os2=l. Результат измерения г=
= x-f-s оказался равным 8. Какова оценка для х?
Для х математическое ожидание и дисперсия (см примеры 5.9
и 5.11) будут: х=(114-1)/2=6, a?=(li —1)2/12=8,3. Чтобы можно
было применить рассмотренную методику, заменим равномерный за-
кон распределения вероятностей для х нормальным с тем же мате-
матическим ожиданием и дисперсией Поскольку х и г — скаляры,
причем г=х, то ковариационные матрицы, входящие в (10.86) и
420
810.87), превратятся в дисперсии и ковариации:
P<Z= Е[(х — x)(z —z)] = E[(x—х)(х—x + s)] = o?;
Ргг = Е [ (z-~)2] = Е [(х - Г+ s)2J = ах2 + а?.
Согласно (10.86) оптимальная оценка
x=x4-a?(z—z) /(.оЛН?) =64-8,3 (8-6)/9,3=7,78.
Согласно (10.87) дисперсия этой оценки
<2=а?—а//(ог?4-а?)=а?а?/(а?+а?) =8,3-1/9,3=0,89.
Заметим, что если положить ах2=оо, что означает отсутствие
априорных данных об х, то оптимальная оценка Л=з=8 с дисперсией
Q=a/=1. Это означает, что учет априорных данных позволяет полу-
чить оценку с меньшей дисперсией, т. е. более точную.
10.6.2. Оценки метода наименьших квадратов
Рассмотренный выше байесовский подход к задаче
оценки требует полного описания вероятностных свойств
оцениваемого параметра, что иногда сделать бывает за-
труднительно. В этих случаях целесообразно получать
оценки по методу наименьших квадратов, который тре-
бует значительно меньшей априорной информации.
Применение метода наименьших квадратов (МНК)
рассмотрим для случая, когда вектор наблюдения z свя-
зан с оценкой параметров х линейной моделью
z=Hx4-v, (10.88)
причем вектор помехи v считаем некоррелированным с па-
раметром х и имеющем ковариационную матрицу Rv =
=E[vvT], выражаемую, например, соотношением (5.163).
Пусть х — некоторая оценка параметра х. Величину
e=z—Нх^чазывают вектором невязки [64, 65]. Его вели-
чина зависит от выбора оценки"х. По методу наименьших
квадратов оптимальной оценкой х будет такая, которая
обращает в минимум взвешенный квадрат вектора невя-
зок е с весовой матрицей Rv-‘, т. е. минимизирует квад-
ратичную форму
J = -L8’R,-l8= ~(z — Hx)TRr*(z — Нх). (10.89)
421
Дифференцируя J по х и приравнивая производную
нулю, находим d//Jx=HTRv-’ (z— Нх)=0, откуда
(10.90)
Если помеха не коррелирована (белый шум), то в со-
ответствии с (5.164) ковариационную матрицу помехи
в (10.89) считают единичной матрицей I и оценку х оп-
ределяют по формуле
x=(HTH)-1HTz. (10.91)
Пример 10.15. В электрической цепи, приведенной на рис. 10.11,
силу гока и напряжение измеряют неточными приборами, показания
которых составляют Ai = l А, Аг=2 А, У=20 В. Все три резистора
имеют сопротивление R=5 Ом. Считая, что ошибки измерения имеют
одинаковую дисперсию и не коррелированы между собой, необходимо
найти оценки токов Ц и i2.
Показания измерительных приборов связаны с токами й и i2 сле-
дующей системой уравнений, составленных иа основе первого и второ-
го законов Кирхгофа:
Zj=At=j|-|-£i=l; z2=A2=»]-|-»24-|2=2; Zs= V/R=ii4-2i2-{~l;3=4.
Эта система уравнений может быть записана в векторной фор-
ме как
где
-[гНД-1; ]-lib -It
422
Поскольку значения помехи не коррелированы между собой, то
оценку наименьших квадратов найдем по (10.91), в которой
Соотношение (10.91) при этом дает
-=_1_Г 5 -31 Г 7 1 1_Г 5 1
Х 6 [-3 3J'L Ю )“ 6 [ 9 ]‘
Итак и=5/6=0,833 А; f2=9/6=l,5 А.
10.6.3. Анализ точности оценки метода
наименьших квадратов
Анализ точности оценки метода наименьших квадратов
(МНК) сводится к определению математического ожида-
ния Е(х), вектора оценки х'иее ковариационной матрицы
Q = E[(x—х) (х—х)т]. Для удобства запишем x=Kz, где
К= (HTRv“IH)-IHTRv-1, и введем в рассмотрение вектор
ошибки х=х—х. Принимая во внимание модель процесса
наблюдения (10.83), получаем
х=х—Kz=x—K(Hx-f-v).
Но поскольку КН= (HTRV-1H)-1HTRV-1H=I, то х=
=—Kv. Следовательно,
Е (х) =—KE (v) =0,
что говорит о несмещенности оценки х, т. е. о том, что
Е(£)=Е(х).
Ковариационная матрица оценки х будет
Q=E (\v) = KE (wT) Кт= KRVKT= (HTRV-1H)_1X
X HTRV-1RV[(HTRV_IH)-1HTRV-1]T.
Учитывая, что RV_‘RV=I, а также, что (HTRV~’Н)—1 и
Rv~‘ — симметрические матрицы, которые при транспони-
423
ровании не изменяются,получаем
Q = (Н^Г’Н)-1 HT(HTRr1)T(HTR71H)-1 -
= (HTR-1H) 1 НТГ’НОГВ/НГ*
или
Q = (HTR?IH)-1. (10.92)
Если помеха не коррелирована и в каждом измерении
имеет одну и ту же дисперсию о2, то Rv— E(vvT) = <j2I.
В этом случае ковариационная матрица оценки х будет
Q о^Н’Н)-1. (10.93)
10.6.4. Применение метода наименьших квадратов
для оценки параметров нелинейных объектов
Пусть х=(х...... х;)т —вектор оцениваемых парамет-
ров, a z,=fi (xi, ..., xz)-H,=f, (x)+g„ i=ll, ..., /г —совокуп-
ность наблюдаемых сигналов. Если f>(xi, ..., хп)—нели-
нейная функция оцениваемых параметров, то функционал
метода наименьших квадратов
S(W)h-И*..---. *«)Г
становится настолько сложным, что система уравнений
dJ/dx.—Q, г = 1, ..., л в большинстве случаев ие поддает-
ся решению аналитическими методами. Однако если
удастся_каким-либо путем найти хотя бы грубое прибли-
жение х= (xi, ..., xt) к требуемому решению (грубая
оценка), то открывается возможность использования ите-
рационной процедуры уточнения решения.
Положив х=х-{-Дх, где х —найденная каким-либо об-
разом грубая оценка вектора параметров х. Разлагая
Л(х) в ряд Тейлора в окрестности точки х и ограничи-
ваясь линейными членами разложения, получаем
fi (х) = f, (X 4- Дх) = fi (х)+f,' (х) Дх,
где f/(x) = ^-| ..
дх |х=х
Совокупность наблюдений z,; 1=1, п при этом запи-
424
шем в виде
zt=A(x)+f'£(x)Ax+a,
или, вводя обозначение 6z£=z(—frjx), 6z,=f,'(x)Ax-f-,
ti.
Полученная система уравнений является линейной от-
носительно вектора поправок Ах и допускает решение
методом наименьших квадратов. В векторной форме эта
система уравнений примет вид
AZ = HAx-j-v,
где
ГМ П/ОО] [6,-1
AZ = • I; Н= ; * = :
|_М U„'(x)J LU
Оценка вектора поправок Ах= (H'RV-1H)-|HTRV-1AZ,
а уточненное значение вектора оценок х=х-}-Ах.
Теперь можно принять х за новую грубую оценку х и
повторить всю процедуру, получив еще более точную оцен-
ку, и т. д. Критерием окончания процесса итераций может
Служить условие Ах=0.
е 0.6.5. Постановка задачи фильтрации
В отличие от задачи оценки параметров, имеющих фик-
сированные, хотя и неизвестные, значения, в задаче фильт-
рации требуется оценивать процессы, т. е. находить теку-
щие оценки изменяющегося во времени скалярного или
векторного сигнала u(t), искаженного помехой и в силу
этого недоступного непосредственному наблюдению. При
этом термин фильтрация используется обычно лишь при
получении оценки текущего значения сигнала u(i). Если
же требуется получить оценки будущих или прошлых зна-
чений сигнала, то соответствующую задачу называют за-
дачей прогноза или задачей интерполяции [66—68].
Конкретный вид алгоритмов, используемых для реше-
ния задачи фильтрации, зависит от статистических свойств
сигнала и помехи. Рассмотрим случай, когда сигнал пред-
ставляет собой медленно меняющуюся функцию времени,
а помеха — случайный процесс типа белого шума.
425
Рис. 10.13. Виды полиномиальных сигналов при разных г
Оценить текущие значения сигнала можно или на ос-
нове байесовского принципа, или по методу наименьших
квадратов, на последнем методе и остановимся. Пусть по-
лезный сигнал представляет собой медленно меняющийся
скалярный процесс и(1), допускающий на конечном ин-
тервале наблюдения представление в виде ряда Тейлора
с конечным числом г-j-l членов разложения. Такой сиг-
нал представлен на рис. 10.12, а его разложение в ряд
Тейлора относительно текущего момента времени t имеет
вид
и (t- .) = и(0- то(0 + и(0 + ... + «(0- (Ю-94)
Соотношение (10.94) описывает полиномиальную мо-
дель сигнала и при r=0, 1, 2... —соответственно посто-
янный сигнал, линейно меняющийся сигнал и т. д., виды
которых приведены на рис. 10.13. Считаем также, что
помеха в дискретные отсчеты времени может быть пред-
ставлена в виде белого шума (см. пример 5.19) с нуле-
вым математическим ожиданием и дисперсией о2.
10.6.6. Фильтрация по методу наименьших квадратов
Найдем производные от полезного сигнала, продиффе-
ренцировав выражение (110.92) г раз по т:
ч= и(/) — то(/) + ... + (~^ч(0;
426
Реализация алгоритмов фильтрации осуществляется
с помощью ЭВМ, которые оперируют с дискретными от-
счетами сигнала ип. Переход к дискретной форме осуще-
ствляется путем введения квантованного времени /rt =
—пТ0, л = 0, 1, 2,... и т(=1’Г0, i=0, 1, 2..., где Го —период
квантования, принимаемый за единицу измерения време-
ни. Дискретную модель сигнала можно представить сле-
дующей системой разностных уравнений:
и„_; = un—iun + ;
( __ пг— 1(г)
i<n-i = un—iun+... + ;
или в векторной форме
х«_,=Ф;х„, (10.95)
— вектор состояния сигнала и матрица преобразования.
Текущую оценку хя хотим получить, используя I по-
следних наблюдений за сигналом, включая и текущее на-
блюдение. Результаты этих наблюдений
i=0, 1.... 1-1. (10.97)
Для более удобной записи совокупности наблюдений
(10.97) введем в рассмотрение вектор
Ь, = (1. -‘-Т...... <10м»
представляющий собой первую строку матрицы Ф(. Учи-
тывая, что h0=(l 0 ... 0), для вектора h, получаем соот-
ношение
Ь(=Ь0Ф/. (10.99)
427
Первую компоненту un-i вектора Хп_г с помощью век-
торов h0 и h, можно представить в следующем виде:
и„_, = hox„_(=h001x,t=h(x„. (10.100)
Результаты наблюдений ('10.97) при этом запишутся
в виде:
2n-t=h,Xn+s„_„ i=0, 1, .... I— 1 (10.101)
пли
z,= hz_]X,t + s„ _(/_!>; j
= h/.jXn+ «„_(,_s); I (10.102)
z„ = hox„ + s„. '
Эти l результатов наблюдении могут быть представлены
в виде одного вектора наблюдения
Уравнение (10.103) имеет тот же вид, что и (10.88).
Учитывая, что v,(,z представляет собой вектор некоррели-
рованной помехи, оптимальную оценку наименьших квад-
ратов найдем по выражению (110.91), которое удобно за-
писать в виде двух соотношений:
Pz=HzTHz; (ЮЛ 04)
£=Pz->HzTZ„,z. (10.105)
Соотношения (10.104) и (10.105) легко реализуются
па ЭВМ непосредственно в матричном виде. Для этого
необходимо ввести в память машины матрицу коэффи-
циентов Hz и полную совокупность наблюдений Zn,z. При
этом оценка £, получается по конечному числу наблюде-
ний, хранящихся в памяти машины. Цифровые фильтры,
работающие по соотношениям (10.104) и (10.105), полу-
чили название фильтров с конечной памятью.
Данные фильтры позволяют получать текущие оценки
хп при изменяющемся п. При этом для каждого п в па-
428
мяти машины должно храниться I последних наблюдений
за процессом. Таким образом, совокупность хранящихся
в памяти ЭВМ наблюдений будет изменяться вместе с из-
менением п. На каждом новом такте к совокупности Z„j
добавляется одно новое наблюдение zrt+l и отбрасывается
самое раннее zn-(i-o- Подобный процесс получения теку-
щих оценок получил название скользящего окна.
При текущей фильтрации принимается z,t_( = 0, если
n^i. Поскольку процесс наблюдения начинается с л=!1,
то при п=1, 2, I— 1 в совокупность Zn,i не будет вхо-
дить полное число наблюдений, а следовательно, не мо-
жет быть получена оценка х„. Поэтому первые 1—1 на-
блюдений будут представлять собой переходный процесс
цифрового фильтра.
Иногда стоит задача получения вектора оценок не в мо-
мент наблюдения и, а в момент п-[-т, являющийся буду-
щим при т>0, или прошлым при т<0 по отношению
к настоящему моменту п. При этом оценка Хп+т будет
прогнозом вектора оценок хп на т тактов вперед или ин-
терполяцией вектора оценок х„ на т тактов назад. Имея
вектор оценок х„ и используя соотношение (10.95), полу-
чаем значение вектора оценок
10.6.7. Представление векторе оценок с помощью
весовых коэффициентов
Иногда бывает целесообразным применять для полу-
чения оценок хп вектор весовых коэффициентов
Л (Л и)]
к(/, от)= • • • •
\kr (I, т) J
(10.107)
с помощью которого оценка состояния сигнала выражает-
ся соотношением
Хп — 3 т)2п—т
(10.108)
429
или в развернутом виде
«1 = 2 j = г. (10.109)
Для приведения ^выражения (10.105) к виду (10.108) ра-
скроем произведение
k-U-o 1
HTZ„., = (h7-i.... ho) : =2
L Zn J «=0
таким образом, согласно (10.105)
x„ = PF* (10.110)
Сравнивая это выражение с (10.108), видим, что
к(/, /п)=Р/-1Ьтт. (10.111)
Так, при г=0 [случай постоянного сигнала u(Z)=const] на-
ходим hm=l, Н(=(1.... 1)т, P/=Z, P;-’=l/Z. Следовательно,
k(Z. m)=A0(Z, m) = l/Z.
Согласно (10.109) получаем
^ = (1//) 2 (10.112)
т=0
Предлагаем читателю самому проверить, что в случае линейно
меняющегося сигнала (г=1) оценки ип и ип находятся по формулам
ип = 2 Ао(/> т)г«-„г; 2 k^1' т)гп-ш, (Ю.113)
где
Ao(Z. m)=2(2Z—1—3m)/[/(Z-]-l)]; kx(l, т) =
=6(/-l-2m)/[(/-l)/(Z+l)]. (10.114)
Прогноз оценок осуществляется при этом по соотношению
(10.106):
£i+m = “n + tniln, Un^m — Un. (10.115)
430
Пример 10.16. Пусть г=1 н 1=5. Оценки, получаемые по (10.114),
принимают вид
(1 /5) (3zn-}-2zn-t-[-zn-2-zn_^; йп = (1 /10) (2гп-{-гп^-
—Zn-з—2z„_4).
Для обеспечения надлежащего качества работы цифровых фильт-
рон необходимо согласовывать такие параметры фильтра, как период
квантования, степень г полинома, представляющего собой полезный
сигнал, и величина интервала наблюдения Т = 1Т0, определяющего число
наблюдений I, хранящихся в памяти фильтра, с параметрами реальных
сигналов я помех. Со всеми этими вопросами, носящими весьма спе-
циальный характер, можно познакомиться в [67].
10.6.8. Фильтры с растущей памятью
Рассмотренные фильтры с конечной памятью обладают
рядом существенных недостатков, ограничивающих их
практическое использование. Эти недостатки вытекают из
соотношения (10.1108) и заключаются в следующем.
1. Фильтры с конечной памятью сложны в реализа-
ции:
а) требуют хранения в памяти I последних результа-
тов наблюдений, причем при текущей фильтрации эта со-
вокупность наблюдений обновляется по мере поступления
новых наблюдений;
б) в памяти фильтра должны храниться I весовых ко-
эффициентов к(/, tn), пг=0 I—1, которые должны быть
заранее вычислены;
в) после каждого наблюдения необходимо заново про-
изводить полный расчет по всей совокупности хранящихся
в памяти наблюдений.
Таким образом, для осуществления текущей фильтра-
ции нужны большой объем памяти ЭВМ. и большое быст-
родействие процессора, которое могло бы обеспечить про-
ведение всех необходимых вычислений в интервале между
двумя соседними наблюдениями.
2. Вычисление вектора оценок х„ можно начинать толь-
ко с момента, когда в памяти ЭВМ накоплены результаты
I первых наблюдений, поэтому данные фильтры обладают
большой длительностью переходного процесса, что не
всегда допустимо, так как информацию о процессе жела-
тельно получить как можно раньше.
Рассмотрим некоторые пути устранения этих недостат-
ков и прежде всего второго из них, что достигается пере-
431
ходом от фильтров с конечной памятью к фильтрам с ра-
стущей памятью.
В цифровом фильтре с растущей памятью число дис-
кретных значений наблюдаемого сигнала I, по которым
производится определение х„, должно совпадать с номе-
ром п текущего наблюдения. Поэтому вектор оценок хп
для фильтра с растущей памятью получится из соотно-
шения (10.108) для фплыра с конечной памятью путем
замены I на п:
х„ = S k(«, (10.116)
ш=0
Данное соотношение позволяет получать текущие оцен-
ки х„, начиная с «=г+1, т. е. начиная с числа наблюде-
ний, равного числу компонент вектора х„. В частности,
при г=0 такой фильтр будет иметь нулевую длительность
переходного процесса. С ростом п улучшаются сглажива-
ющие свойства фильтра, т. е. повышается точность оце-
нок.
Однако непосредственная реализация фильтра по фор-
муле (10.116) нерациональна, так как требует сложной
процедуры вычисления коэффициентов к (п, т), т—
=0, . , п— 1, которые будут меняться с каждым новым
наблюдением, а также необходимости хранить в памяти
фильтра непрерывно нарастающее с ростом п число на-
блюдений Поэтому фильтры с растущей памятью необ-
ходимо реализовывать как рекуррентные.
Предположим, что к моменту п уже получена оценка
хп_|, содержащая всю информацию о предшествующих
наблюдениях гь ..., zn-t. Оценку х„ получаем после оче-
редного zn наблюдения. Спрашивается, нельзя ли полу-
чить эту оценку, не используя непосредственно результа-
ты наблюдений гь ..., zn-\, а применяя лишь информацию
об этих наблюдениях, заключенную в оценке x^-i? Такая
процедура возможна и получила название рекуррентной
фильтрации. В общих чертах эта процедура состоит в сле-
дующем.
1. Прогнозируют оценку х„_! на один шаг и по соот-
ношению ('10.106) определяют прогнозируемую или апри-
орную оценку
"хя==Ф—iX«—1. (10.117)
432
2. По результатам текущего наблюдения гп эту апри-
орную оценку превращают в истинную, т. е. апостериор-
ную хп.
Эту процедуру повторяют на каждом шаге, начиная
с n=r-j-2. Начальным условием для данной процедуры
служит оценка £+i, получаемая по формулам фильтра
с конечной памятью (10.108) при n=r-j-l.
Для получения алгоритма рекуррентной фильтрации
рассмотрим наблюдение с номером k
Zft = nfe-|-sfe==l1oXfe-]-.Sft.
Учитывая, что через х„ можно выразить xft=x„_(rt_ft) =
=Ф«-йХ„, получаем
Zfe=ho®n-feXn4-Sn==:hn_iXn-]-Sfe.
Полагая, k=\, 2,.. .,п—1,п, найдем описание полной
совокупности наблюдений на п первых тактах:
IZ1 = bn—iXn 4- $1
^ = Ь"Г^.+/2. . • (10.118)
__________1 = Мп + Srt-t
гп — Ьохп + sn
Рассмотрим первые п— 1 наблюдений. Введем в рас-
смотрение векторы
и запишем эти наблюдения в векторной форме
Zn— I = Нл—iXn-bVri—1.
Решение этой системы уравнений дает априорную оцен-
ку хя, поскольку наблюдение гп в совокупность результа-
тов наблюдений не входит, По соотношению (10.91) нахо-
дим
х„ = Р„ Л H^Zn-,; H„_b (10.119)
Полная совокупность п наблюдений Z„=H„Xn+vn. Ее
решение, дающее уже апостериорную оценку хп, по соот-
ношению (10.91) представим в виде
x„ = P7'fc Р„=<Н„. (10.120)
28—804
433
Теперь нам нужно выразить апостериорную оценку х„ че-
рез априорную х„. Для этого запишем векторы
Подставив эти соотношения в (10.120), получим
x„ = P7*(HU, hS)
При этом
х„ — Х„ = х„ - Р71 Р„х„ =р?1(н;_1 Z„_; + hT02„— Рх„).
Из (10.119) находим H„_i Z„_, = Р„_,хп, так что
х„-х„ = Р71 [hT^„-(Pn-Р„_.) х„]. (10.121)
Учитывая, что
Р„ = НХ = (Hj_i, hS) +h5h0 =
= Pn-1 + hX,
получаем
P„ — P„_, = hjho.
Из (10.121) находим интересующее нас соотношение,
связывающее х« с хя:
x„-=x,l + P7lhS(?„ —h^). (10.122)
Фильтр с растущей памятью, определимый соотношени-
ем (10.122), является частным случаем алгоритма фильт-
рации, известного под названием фильтра Калмана [66,
68). Структура этого фильтра и выполняемые им операции
наглядно представлены в виде схемы, изображенной на
рис. 10.14. На рисунке двойными линиями обозначены свя-
зи, по которым информация передается в векторной форме.
При практическом использовании алгоритма (10.122)
необходимо помнить, что входящая в него априорная оцен-
ка_х« определяется по соотношению (10.117), а величина
hox« представляет собой первую компоненту йп вектора хп.
434
Рис. 10.14. Структура фильтра Калмана
Приведем конкретный внд алгоритмон фильтра с растущей па-
мятью для постоянного (г=0) и линейно меняющегося (г=1) сигна-
лов соответственно:
г = 0: ?; = «п_1+(гп—« = 2, 3...
при начальных условиях = zt;
r = 1: «п = ^+2(2п-1)(гп—«„)/[«(«+ 1)]}
«я = йп + 6(гп — йп)/[п(п+ 1)1
при начальных условиях u^ = z2, «4 = г2—zp где
йп = wn-i + «n-й ih = Un-i, п = 3, 4, 5...
10,6.9. Экспоненциальные фильтры
Для выяснения одной важной особенности фильтров
с растущей памятью обратимся к более детальному рас-
смотрению структуры выражения (10.122). В этом выра-
жении вектор оценок состояния сигнала &п получается
в виде суммы вектора прогнозируемых оценок хп и кор-
ректирующего члена 2п—йп, взятого с весовыми коэффи-
циентами, определяемыми компонентами вектора Pn~lhoT.
При малых п, когда точность прогноза невелика, поправки,
вносимые корректирующим членом по результатам по-
следнего наблюдения гп, будут значительными, так как
компоненты вектора весовых коэффициентов при
этом существенно отличаются от нуля. Однако с ростом п
эти весовые коэффициенты уменьшаются, стремясь к нулю
при п->оо, в чем легко убедиться из рассмотрения приво-
димых выше примеров фильтров с растущей памятью. Это
обстоятельство отражает тот факт, что с ростом п, т. е.
с увеличением интервала наблюдения за сигналом, проис-
28* 435
ходит более эффективное сглаживание помехи, а следова-
тельно, повышается точность прогнозируемой оценки 'х«.
Однако повышение точности прогноза с ростом п будет
иметь место только в том случае, если реальный сигнал
имеет тот же вид, что и принятая при прогнозе модель сиг-
нала.
Прогнозируемая оценка хп получается по соотношению
(10.117) при полиномиальной модели сигнала (10.92). В то
же время реальные сигналы могут быть представлены по-
линомиальной моделью лишь на ограниченных интервалах
времени. Поэтому с ростом п увеличивается отличие ре-
ального сигнала от полиномиальной модели и ухудшается
точность прогноза.
Исправить это положение можно путем повышения веса
текущего наблюдения гп при больших п, что позволит
скорректировать неточность прогнозируемой оценки хп по
реальному сигналу гп. Это можно сделать, наложив за-
прет на чрезмерное уменьшение веса Ptr'ho1 с увеличени-
ем Л. Для этого зададимся некоторым числом наблюдений
/, при котором прогноз оценки хп при реальном сигнале
осуществляется еще достаточно точно, и будем использо-
вать для получения текущей оценки хп фильтр с расту-
щей памятью (10.122) только при п^Л. Тогда вес Pn-'hf
будет постепенно уменьшаться, достигнув значения PrlHov
при п—1.
Начиная с момента п=1, наложим запрет на дальней-
шее уменьшение веса Ря-1Лот, сохранив его на уровне
Рг,Лот- Тем самым будет достигнут компромисс между
приемлемой точностью прогноза и коррекцией ошибки
прогноза по реальному сигналу. Получающийся при этом
алгоритм фильтрации для ri^l принимает вид
t„=xn+Pr4i04zn-iin). (10.123)
Фильтры, реализующие алгоритм (10.123), называют
экспоненциальными фильтрами.
Наиболее широко применяют такие фильтры для получения теку-
щих оценок сигналов, допускающих на интервалах конечной длитель-
ности 1Т0 аппроксимацию полиномов пулевой (г=0) или первой (г=1)
степени.
При г=0 экспоненциальный фильтр, получивший название а-фильт-
ра нли «экспоненциального сглаживания», описывается выражением
йп=йп-1-|-а(гя-Йп_,); а=1Д (10.124)
436
. При г=1 оценки, даваемые экспоненциальным фильтром, называе-
мым а- или Р-фильтром, получаются из соотношений
йп = йп-|-<Х(2п—Un)! Йп = Йп-|-Р(2п—Йп), (10.125)
где йя=й„_1-р„-1; a=2(2Z—1)/[Z(Z_pi)]; p=6/Z(Z_pi).
Задачи к гл. 10
10.1. По данным табл. 10.2 найтн стратегию, основанную иа прин-
ципе минимакса дополнительных потерь в задаче о технологической
линии.
10 2. Воспользовавшись геометрическим построением из рис. 10.6,
произвести необходимые вычисления для определения минимаксной и
байесовской стратегий в задаче о техноло-
гической лнняи с единичным экспериментом,
10.3. По каналу связи передается сиг-
нал и, на который наложена помеха з
с гауссовским законом распределения
N(0, о2), так что на приемной стороне
измеряется величина г=и+з. Сигнал и
может принимать два значения: и — 0 —
сигнала нет (fy) и и=«о=const — сигнал
есть (б'г). Приемное устройство имеет по-
рог za и выдает решение о том, что передан
сигнал iiq, если z>za. Определить порог zo,
пользуясь методами решения двухальтерна-
тивной задачи, положив £=0,25 и w =
W)
(0,1,0) (0,0,1)
Рис IO I5 Пространст-
во смешанных стратегий
для случая трех состоя-
ний природы
10.4. Показать, что в случае трех состояний природы 0={<Ь,
^2.^3} всевозможные смешанные стратегии статистики £(0) = (£i, £2. £з)
образуют пространство смешанных стратегий, имеющее вид треугольни-
ка с высотой, равной единице, как показано на рис. 10.15.
ЗАДАЧИ ТЕОРИИ РАСПИСАНИЙ
И МАССОВОГО ОБСЛУЖИВАНИЯ
11.1. ПРЕДМЕТ ТЕОРИИ РАСПИСАНИЙ
11.1.1. Общие сведения
Важное практическое значение имеет целая группа за-
дач, связанных с выполнением комплекса работ, называе-
мых «операциями», «заявками», «требованиями» и т, п.,
437
при наличии ограничений на порядок их выполнения, дли-
тельность каждой работы, выделяемые ресурсы и т. п.
С такими задачами приходится сталкиваться при решении
вопросов календарного планирования и оперативного
управления как в производстве, так и при обслуживании
населения [73].
Задачи подобного рода весьма разнообразны, и их ис-
следование в зависимости от характерных признаков про-
водится в рамках различных научных дисциплин. В теории
сетевого планирования основное внимание уделяется опре-
делению порядка выполнения сложных разработок, вклю-
чающих в себя большое число взаимосвязанных работ,
требующих многочисленных исполнителей и значительных
материальных затрат. В теории упорядочения рассматри-
ваются вопросы установления порядка выполнения боль-
шого комплекса однородных работ с помощью одного или
нескольких специализированных устройств, машин, прибо-
ров. В теории массового обслуживания разбираются зада-
чи назначения приоритетов в обслуживании поступающих
заявок некоторыми устройствами, приборами и т. п. Одна-
ко определенное сходство формальных моделей всех этих
видов задач позволяет сосредоточить их в одной главе.
11.1.2. Постановка задачи теории расписаний
Целенаправленную деятельность можно рассматривать
как некоторый протекающий во времени процесс, заклю-
чающийся в реализации (выполнении) определенной сово-
купности работ
S={Pi.....PJ, (11.1),
называемой также программой.
Выполнение программы стеснено целым рядом ограни-
чений и условий, которые обычно удается разбить на две
группы [37].
Ограничения а. Эти ограничения описывают взаимную
зависимость выполнения работ. Каждой работе Pi^S мож-
но поставить в соответствие некоторое множество /7(<=5
непосредственно предшествующих работ, без выполнения
которых нельзя начинать выполнение работы Р{, а также
ряд работ, не входящих в множество S, которые могут
рассматриваться как внешние факторы, необходимые для
выполнения работы Pt. Так, возведение стен строящегося
здания возможно начать лишь после того, как сделан фун-
488
дамент (работа из множества S), а также при наличии
кирпича и раствора, изготовление и транспортировка ко-
торых могут и не входить в данный перечень работ.
Для описания некоторых других условий, входящих
в ограничения а, удобно ход выполнения работ рассмат-
ривать в дискретном времени, приняв некоторую величину
за единичный интервал времени. Этот интервал можно
назвать «условный день», «условный год» и т. п. Однако нам
будет удобно называть его шагом.
Некоторые работы могут быть выполнены целиком за
один шаг, другие — за несколько шагов. В ограничение а
должно входить условие допустимости или недопустимости
прерывания работ.
Пусть I — номер рассматриваемого шага (?=1, 2,...).
Обозначим через yt(t) долю работы выполняемую на
шаге с номером t, которую назовем единичной (дневной,
годовой и т. п.) порцией работы Р,. Через S(i) обозначим
перечень работ, выполняемых на шаге с номером t.
Пусть работа Р, состоит из т единичных порций yt и
прерывание этой работы недопустимо. Условие недопусти-
мости прерывания работы заключается в том, что если эта
работа начинается на шаге с номером t, то единичные пор-
ции yt должны входить в перечни работ S(j), S(?4-l),,..
...,S(t+m—1).
Ограничения р. Они связаны с ограниченным объемом
ресурса, который может быть выделен на выполнение про-
граммы S.
Обозначим через Q(t) вектор ресурса, который может
быть выделен на выполнение работ на шаге с номером I.
Компонентами вектора Q(?) могут быть величины Qi —
сырье, материалы, Q2— оборудование, Q3 —рабочая сила и
т. п. Обозначим также через q [«/,(<)] количество ресурса,
которое необходимо затратить для выполнения работы
yt(t}. В этих обозначениях ограничение р запишется в виде
^=1. 2,.., М, (Н.2)
где М — общее число шагов.
В задачу часто вводится предположение, что единич-
ная порция работы yt(t) либо выполняется полностью, ес-
ли для нее выделен весь необходимый ресурс, либо не вы-
полняется совсем, если ресурс выделен не полностью.
Более общая, однако, и более сложная задача получается
439
тогда, когда доля выполненной работы зависит от коли-
чества выделенного ресурса.
Задача на составление расписания сводится к тому,
чтобы для каждого шага I назвать перечень работ S(Z) =
= {Р7,,...»PrJ, которые должны выполняться в течение
этого шага, а также долю yt(t) каждой нз этих работ
с учетом всех ограничении, накладываемых на порядок
выполнения работ и на выделяемые ресурсы.
Если число работ велико, то число вариантов расписа-
ния может быть огромным. Выбор конкретного варианта
расписания связан с понятием директивного срока. Если
перечень работ и ресурс на их выполнение уже заданы,
ю наплучшим (оптимальным) вариантом расписания сле-
дует считать такой, при котором срок выполнения всего
перечня будет минимальным. Этот срок и принято назы-
вать директивным.
11.1.3. Виды задач на составление расписаний
Пусть имеется сложная программа работ S={Pi,...
Ps}> в которой действуют как ограничения а, опреде-
ляющие очередность выполнения отдельных работ, так и
ограничения р на выделяемые ресурсы. На практике обыч-
но бывает так, что ограничения а связывают между собой
не все работы, а действуют лишь внутри некоторых неза-
висимых групп работ. Сами же такие группы между собой
жесткими ограничениями не связаны.
В таких случаях программу работ S можно предста-
вить в виде некоторого разбиения S»={7?i..Rm}, элемен-
ты которого /?е2В представляют собой некоторые само-
стоятельные подпрограммы, обладающие тем свойством,
что между ними отсутствуют жесткие ограничения очеред-
ности, так что каждая подпрограмма может выпол-
няться почти независимо от выполнения других подпро-
грамм. Однако внутри каждой подпрограммы ..
...,Р,Г} порядок выполнения работ подчинен жестким
ограничениям а.
Таким образом, задачу на составление расписания
можно разбить на две самостоятельные задачи.
Особенности задач первого типа состоят в том, что
жесткие ограничения а в таких задачах в значительной
степени предопределяют порядок выполнения отдельных
работ и число возможных вариантов расписания здесь не
440
очень велико. Однако варианты всегда возможны и среди
них могут найтись такие, при которых окажется мини-
мальным время выполнения подпрограммы, наиболее ра-
циональное распределение ресурсов и т. п. Для решения
задач этого типа широкое применение получили методы
сетевого планирования и управления (СПУ).
В задачах второго типа ограничения на очередность
выполнения отдельных работ незначительны. Однако это
не означает, что порядок выполнения работ здесь безраз-
личен. От порядка выполнения работ зависит распределе-
ние ресурса по шагам. На переход от одной работы к дру-
гой тратится время, может потребоваться переквалифика-
ция персонала, переналадка дли замена оборудования и
т. п. Поэтому и здесь стоит задача составления такого
расписания работ, которое в определенном смысле было
бы наилучшим.
Однако отсутствие ограничений в задачах этого типа
приводит к необходимости рассматривать очень большое
число различных комбинаций порядка выполнения работ и
давать оценку каждой комбинации. Такие задачи получи-
ли название комбинаторных задач на составление распи-
сания или задач упорядочения.
11.2. СЕТЕВОЕ ПЛАНИРОВАНИЕ И УПРАВЛЕНИЕ
11.2.1. Понятие сетевого графика. Составление
перечня работ
Сетевые методы широко применяют для рационального планирова-
ния крупных разработок, включающих в себя выполнение целого ком-
плекса взаимосвязанных работ, например сооружение строительных
объектов, разработка новых технических систем и изделий, проведение
крупных ремонтов и реконструкций, изготовление и сборка крупных
изделий (самолетов, судов, космических кораблей) и т. п. Эти методы
основаны на наглядном представлении выполняемого комплекса работ
в виде ориентированного графа, дуги которого изображают выполняе-
мые работы, а вершины — события, представляющие собой завершение
отдельных работ. Последовательность дуг в таком графе определяет
порядок, в котором выполняются работы.
На рис. 11.1 приведен образец сетевого графика, на котором пока-
заны работы, необходимые для изготовления некоторого прибора. Се-
тевой график дает наглядное представление о порядке выполнения ра-
бот, что дает возможность наиболее рационально распорядиться имею-
щимися трудовыми и материальными ресурсами.
441
Первый шаг в построении сетевого графика состоит в расчленении
всего комплекса на отдельные работы или операции. Каждая работа
связана с затратами времени, а значит, имеет свое начало и конец.
Моменты начала и окончания работы должны легко определяться. Ра*
боты, ие имеющие строго определенного начала и конца, ие должны
входить в перечень и подлежат дальнейшему уточнению.
Подготовка Подготовка
Отгрузка
Рис. 11.1. Сетевой график изготовления прибора
Перечень работ обычно составляют лица, компетентные в данном
конкретном проекте (эксперты). Однако даже компетентный эксперт
никогда не гарантирован от ошибок, основные из которых заключают*
ся в том, что некоторые работы могут оказаться пропущенными. Поэто-
му перечень работ должен обязательно согласоваться с непосредствен-
ными исполнителями, которые могут легко заметить пропущенные ра-
боты и другие недостатки перечня работ.
Таблица 11.1
Вид работы Л.п ительность. Средства, тыс. руб. Интенсив- ность. чел/мес Непосредственно предшествующие работы
] 2,0 3 —
В 4 13,0 13 Л, С, D
С 1 5,0 20
D 1 5,0 20 —
Е 2 2,0 4
<1 12,0 16 D, Е
Л 4 5,0 5 F
/У 1 1,0 4 С
/ 5 4,0 3 в, G, N
к 2 1,0 2 С
L 2 3,0 6 Н
м 2 1,0 2 н
м 4 0,5 1 A, D
р 2 5,0 10 р
Q 6 15,0 10
R. 3 5,0 7 Q
442
Одновременно с составлением перечня работ определяются ограни-
чительные условия на их выполнение: длительность каждой работы,
средства иа ее выполнение, интенсивность, а также перечень непосред-
ственно предшествующих работ, выполнение которых является необхо-
двмым для начала данной работы. Все эти данные заносят в таблицу,
(см. например, табл. 11.1), содержащую 16 видов работ.
11.2.2. Упорядочение (ранжировка) работ
Порядок работ, представленный в табл. 11.1, иосит до некоторой
степени случайный характер. Из таблицы не ясно, какие работы
являются важными, а следовательно, ие видно, иа каких работах
нужно сосредоточить основное внимание при выполнении всего ком-
плекса.
Для устранения этого недостатка отдельным работам удобно при-
писывать вес, отражающий степень важности этих работ и в значитель-
ной степени предопределяющий порядок, в котором должны выпол-
няться работы. Приписыванве весов представляет собой упорядочение
или ранжировку работ.
Таблица И 2
Работа и ограничения Вес работы Работа и огра, ннчения Вес работы
А<В, N 24-2+2=6 1— 1
В<1 1+1=2 к- 1
С<В, н, к 3+2+4+1=10 L — 1
D<B, F, N 3+2+5+2=12 М — 1
E<F 1+5=6 N<I 1+1=2
F<G, Р 2+2+1=5 Р- 1
О<1 1+1=2 1+1=2
H<L, М 2+1+1=4 R- 1
Известно много способов упорядочения работ. Рассмотрим лишь
один из возможных [72]. Каждой работе приписываем вес, равный
сумме числа непосредственно следующих за ней работ и вес этих ра-
бот. Ковечным работам, т. е. таким, за которыми не следуют другие
работы, приписываем относительный вес, соответствующий важности
этих работ. Будем считать все конечные работы одинаково важными
и всем нм припишем вес, равный единице.
Приписывание веса сводим в табл. 11.2. Слева перечвсляем все
работы н около каждой из них указываем непосредственно следующие
за вей. Эти работы находим, просматривая последний столбец
табл. 11.1.
Так, из второй строки видим, что работе В непосредственно пред-
шествуют работы А, С, D, что можно записать в виде А<В, С<В,
443
D<B. Значит, работа В являетси непосредственно следующей за рабо-
тами А, С и D, что и отмечаем в соответствующих строках табл. 11.2.
Вес подсчитываем, просматривая левый столбец табл. 11.2 снизу
вверх. Такой просмотр приходится проводить несколько раз. Вначале
приписываем вес конечным работам R, Р, М, L, К, I. При каждом сле-
дующем просмотре подсчитываем вес тех работ, для которых уже
известен вес непосредственно следующих за ними работ.
Таблица П.З
Номер работы ИснТв“' Дли- “А “А 4 4' в^ме- Раннее начало работы Р
• D 20 1 В, N, Р ] 2 1 0
20 1 В, н, к ] 5 4 0
Е 4 2 —* р 2 2 0 0
А 8 1 В, N 1 5 4 0
р 16 3 D, Е G, Р 5 5 0 2
и 4 1 L, М 2 12 10 1
Q 10 6 — К 6 11 5 0
N 1 4 A, D f 5 9 4 1
G 5 4 р f 9 9 0 5
В 13 4 А, С, D I 5 9 4 ]
R 7 3 Q 9 14 5 6
р 10 2 F 7 14 7 5
м 2 2 Н 4 14 10 2
L 6 2 Н 4 14 10 2
К 2 2 С 3 14 11 1
I 3 5 В, G, N 14 14 0 9
Примечание. ч-длительность работы; ш"-н«™сродс™еиио предше-
с гвующие и следующие работы; —наиболее ранний и поздний сроки окота-
Упорядоченное множество работ получим, перенося работы из
табл. 11.2 в табл. 11.3 в порядке убывания их веса. Для работ с оди-
наковым весом порядок можно выбрать произвольно. Одновременно
в табл. 11.3 заносим данные об интенсивности работ, их длительности
г, множестве <о' и &>" непосредственно предшествующих и непосредст-
венно следующих работ, а также данные для определения сроков нача-
ла, окончания и резервов времени для каждой работы. На определении
последних величин остановимся особо.
11.2.3. Определение резервов времени
Начало некоторых работ можно варьировать в пределах, называе-
мых резервами времени, не нарушая требуемой последовательности ра-
бот и обшегб срока окончания всего комплекса работ. Обозначим через
414
т* длительность работы с номером k, а через Vк и /"*—наиболее ран-
ний и поздний сроки ее окончания. Тогда резерв времени для работы к
&tk=l"к—1’к. '(11.3) '
Задача, таким образом, сводится к определению моментов /'* и
для каждой из работ.
Определение моментов 1'к. Рассмотрим работу т. е. одну из
работ, непосредственно предшествующих работе k. Если /'* —момент
окончания работы k, то момент ее начала будет i'k—тк. Поскольку
работа k не может начаться, пока не закончены все непосредственно
предшествующие работы, то должно выполняться условие
t'k—i<=a>'k. (11.4)
Знак равенства в этом соотношении определяет наиболее ранний
срок окончания работы
<й'=* max (// -Нй)- (11.5)
iEw*'
Как видим, для определения /'* необходимо знать значения t'i для
всех непосредственно предшествующих работ. Поэтому определение
t’k следует начинать с работ, которые не имеют предшествующих, т. е.
стоят в основном в начале списка, и для которых наиболее ранние
сроки окончания будут равны длительности работ.
Наибольший из моментов t'k определяет время завершения всего
комплекса работ
Т — max (11,6)
В рассматриваемом примере 7=14 мес.
Определение моментов t"k. Рассмотрим работу /ею"#, т. е. одну из
работ, непосредственно следующих за работой к. Если /"у —наиболее
поздний срок ее окончания, то наиболее поздний срок ее начала будет
Поскольку работа j не может начаться, пока не закончена
работа k, то должно иметь место
Г/, (11,7)
откуда следует, что
/*" = min (//' — ту). (11,8)
Поскольку для определения t"k необходимо знать моменты окон-
чания непосредственно следующих работ, то рассмотрение следует на-
чинать с работ, за которыми ие следуют никакие другие работы, т. е,
с работ 1, К, L, М, Р, R. Для этих работ за наиболее поздний срок
окончания принимается время Т окончания всего комплекса.
445
После определения моментов и t"k для каждой из работ опре-
деляются резервы времени по соотношению (11.3).
Заполненная табл. 11.3 дает большую информацию о характере
комплекса работ и может оказать существенную помощь руководителю
работ в организации его выполнения. Из нее, в частности, следует:
1) общий срок Т выполнения комплекса работ равен 14 мес. Это
так называемый директивный срок-,
2) работы Е, F, G, I имеют нулевые резервы времени и называют-
ся критическими работами. Любая задержка в выполнении критических
работ удлинит срок выполнения всего комплекса, н правильной орга-
низации этих работ необходимо уделять максимальное внимание;
3) весьма малый резерв времени у работы D (1 мес.). Эту работу
надо также взять под особый контроль;
4) остальные работы имеют значительные резервы времени и руко-
водитель может уделять им меньше внимания
Таким образом, таблица дает возможность руководителю не рас-
пыляться по многим работам, а сосредоточить свое внимание на тех,
от своевременного выполнения которых в наибольшей степени вависит
выполнение всего комплекса. Одиако представление хода выполнения
работ в виде таблицы неудобно и не наглядно. Гораздо удобнее пред-
ставлять работы графически в виде сетевого графика.
11,2.4. Построение сетевого графика
На сетевом графике каждая
графа, т. е. стрелки, содержащей
события, соответствующие началу
на рис. 11.2,а.
работа изображается в виде дуги
две вершины, представляющие собой
и окончанию работы, как показано
Рис. 11 2 Примеры изображения
работ и событий (а), объедине-
ния работ (б) и расчленения ра-
бот (&)
Событие обозначаем кружком с крестиком наверху, в котором ука-
зываем момент наступления данного события. Работы (стрелки) обо-
значаем буквами латинского алфавита, а вершины — цифрами. При этом
каждая работа может быть обозначена или буквой, например А, или
цифрами, например (/, 2). Первое обозначение удобней при ручных,
а второе при машинных расчетах.
В тех случаях, когда несколько работ оканчивается одним и тем
же событием, имеем дело с объединением работ. Если с одного и того
446
же события начинается несколько работ, то это называют расчлене-
нием работы. Объединение и расчленение работ легко обнаружить по
перечню ограничений. На рис. 11.2 приведены примеры объединения и
расчленения работ.
Последовательность работ на сетевом графике должна отражать
все ограничения, приведенные в табл. 11.3. Пусть, например L<K,
М<К, т, е. <o'*={L, М} и l. Тогда началом работы К должно
служить событие I, представляющее собой окончание работы L с более
поздним сроком окончания ft, как показано иа рис. 11.3,0. Поскольку
Рис. 11.3. Введение фиктивной работы, означающей резерв времени
(а), и для различения работ (б) и (в)
работа М заканчивается раньше, чем работа L, то моменту ее оконча-
ния соответствует другое событие 2. Для обеспечения на сетевом гра-
фике условия M<L необходимо события 2 и 1 соединить пунктирной
стрелкой, обозначающей фиктивную работу (2, /), которая на самом
деле не выполняется и означает просто резерв времени. Таким обра-
зом, на сетевом графике приходится вводить ряд фиктивных работ.
Фиктивные работы могут не только означать резервы времени, но
и служить для разделения некоторых работ, неразличимых прв цифро-
вом обозначении. Так, на рис. 11.3,6 работы А и В начинаются и за-
канчиваются одинаковыми событиями 1 и 2 и в цифровом обозначении
не отличаются, что затрудняет машинные расчеты. В данном случае
приходится вводить фиктивную вершину 3 и фиктивную работу (3, 2),
имеющую нулевую продолжительность (рис. 11.3,в).
Введение фиктивных работ и событий требует большого внимания
и осторожности. Необходимо проверять, чтобы фиктивные работы не
нарушали ограничений на очередность работ и не вносили новых огра-
ничений, не имеющихся в исходной таблице, а также чтобы не было
ненужных и лишних фиктивных работ, которые лишь усложнят расче-
ты. Типичные примеры неправильного и правильного введения фиктив-
ных работ приведены в табл. 11.4.
Случай Введение излишних ограничений
Ограничения А<С ВСЕ G<D, Е ACD, Е В.<Е, F CCF
Неправильно В £4 Лишнее ог BCD Л •рагнчение А<?
Правильно 1 л
Таблица 11.4
Излишние фиктивные работы
А<С А<С
B<D В<С, D, Е
C<D С<Е
А с е
х \ СГ ф е*
fl Л/
Л
Фиктивная работа не Ограничение В<Е
н жна отражено 2 раза
С Е
А С V
Сетевой график, построенный по данным табл. П.з, в которой
каждая работа k начинается в наиболее ранний срок приведен на
рис. 11.4. На этом графике двойными стрелками отмечены работы, ие
имеющие резервов времени. Последовательность двойных стрелок обра-
зует критический путь, определяющий длительность выполнения всего
комплекса.
Рис 11.4. Первоначальный сетевой график
Построенный по вышеизложенным правилам сетевой график может
быть по ряду причин не совсем удовлетворительным. В ием может ока-
заться неудачное распределение ресурсов по этапам или слишком боль-
шим срок выполнения всего комплекса работ, или какие-либо другие
недостатки. Эти недостатки можно уменьшить, проводя оптимизацию
сетевого графика. Рассмотрим некоторые из применяемых при этом
методов.
11.2.5. Коррекция распределения ресурсов
Если начинать все работы в наиболее ранние возможные сроки,
то распределение ресурсов по месяцам (интенсивность работ в рас-
сматриваемом случае), приведенное на рис. 11.5,а, получается очень
неравномерным и уже в первом месяце достигает 62 чел., тогда как во
втором месяце потребуется всего 32 чел.
29—804 449
Рис. 11.5. Распределение ресурсов
Рис. 11 6. Скорректированный сетевой график
450
Распределение ресурсов можно сделать более равномерным, сме-
стив начало некоторых работ, имеющих значительные резервы времени.
Процедура смещения начала работ представляет собой коррекцию
сетевого графика. На рис. 11.6 приведен скорректированный сетевой
график, распределение ресурсов для которого показано иа рис. 11.5Д
11.2.6. Оптимизация срока выполнения
комплекса работ
Может оказаться, что время Т выполнения комплекса работ чрез-
вычайно велико и стоит задача сократить его до величины Т'<Т. Для
этого необходимо сократить длительности некоторых работ.
Пусть — первоначально запланированная длительность t-й рабо-
ты. Если в эту работу вложить сумму xt дополнительных средств, то
длительность этой работы изменится. Если вкладываемые средства не
очень велики и ограничены, например значениями с<, то новую дли-
тельность работы т'< можно считать линейно зависящей от Xi, т. е. по-
ложить
т',=т,(1-М.). .(Н.9)
где Ь/ — известные для каждой работы коэффициенты.
Теперь стоит задача найти дополнительные вложения xt в каждую
из работ, чтобы уложить весь комплекс работ в заданный срок Т'. При
этом следует добиваться такого распределения добавочных средств по
работам, при котором требуемое сокращение длительности всего ком-
плекса работ достигается при минимальной общей сумме добавочных
вложений. Эта задача может быть решена методами линейного про-
граммирования.
Обозначим через v( момент начала i-й работы, а через 6 момент
ее окончания. Для рассмотренного комплекса работ ограничения на
последовательность выполнении работ приводят к следующей системе
неравенств:
v.-X), i=A...R-, Ill.lO).
Vr>v0, ve; V/(>vc и t. д. (1111)
Условие зависимости длительности работ от вложенных средств
дает
/<=VrH<(l—МО. ..........R, (11.12)
Ограничения на средства, вкладываемые в отдельные работы,
имеют вид
i=A.....R.
,(Н 13)
451
29*
Условие окончания всего комплекса работ в заданный срок озна-
чает, что ви одна из конечных работ не должна иметь срок окончания
больший, чем Т':
i=I, К, L, М, Р, R. (11,14)
При выполнении всех этих условий нужно найти такое распреде-
ление добавочных вложений xt по работам, при котором обтай сумма
вложений
Д = (11-15)
будет минимальна.
Эта задача является типичной задачей линейного программирова-
ния, в которой неизвестными являются добавочные вложения и
сроки начала каждой работы vi. Но так как число самих неизвестных
и налагаемых на них ограничений велико, решение этой задачи может
представлять значительные трудности.
Задачу можно значительно упростить, если учесть, что общее время
выполнения комплекса определяется длительностью работ, лежащих на
критическом пути. Отсюда следует, что если есть основание считать,
что критический путь при новом времени выполнения комплекса оста-
нется тем же самым, то все рассмотрение нужно проводить лишь для
работ Е, F, G, 1, лежащих на критическом пути.
11.2.7 . Вероятностные методы сетевого планирования
Рассмотренные методы построения сетевого графика исходят из
того, что заранее точно известны длительности т( каждой работы. На
самом деле длительности работ зависят от множества различных фак-
торов и фактически являются случайными величинами. Неучет этого
обстоятельства может привести к значительным ошибкам в определе-
нии общего срока выполнения комплекса.
Оценка времени выполнения каждой работы производится экспер-
тами, т. е. людьми, хорошо знающими все особенности технологии и
организации проведения данной работы. При использовании вероят-
ностных методов от эксперта требуется выдача трех видов оценок
времени выполнения каждой работы:
оптимистическая оценка ah указывающая время выполнения рабо-
ты при наиболее благоприятно сложившихся условиях;
пессимистическая оценка bt, дающая время выполнения работы при
наиболее неблагоприятно сложившихся условиях;
наиболее вероятная продолжительность работы пи, имеющая место
при существующих условиях.
При этом предполагают, что время выполнения работы является
случайной величиной, подчиняющейся закону 0-распределения [69].
452
На основании оценол at, bt, т1 определяют ожидаемое время вы-
полнения работы
^=(агН^4-Ь0/6 .(11.16),
п дисперсию ожидаемой оценки
а<2= [(&,—а<)/6]2. (11.17)
Все дальнейшие расчеты ведутси так же, как н ранее, только вме-
сто заданной длительности каждой работы используют ожидаемое вре-
мя ее выполнении. По проведенной ранее методике определяют ожи-
даемые наиболее ранний н наиболее поздний сроки выполнения каждой
работы н ожидаемые резервы времени.
Рис. 11.7, Определение вероятности
выполнения комплекса работ в за-
данный срок Та
Отличне заключается в том, что одновременно с определением
ожидаемых сроков окончания работ подсчитывают дисперсии этих
сроков. При подсчете дисперсий пользуются обычным правилом: дис-
персия суммы случайных величин равна сумме дисперсий слагаемых.
Таким образом, если ожидаемый срок окончания i-й работы
то дисперсия этого срока
Знание дисперсий позволяет оценить вероятность выполнения той
нлн иной работы или всего комплекса работ в заданный срок. Пред-
положим, что запланированное времи выполнении работ равно Та. Рас-
чет сетевого графика показал, что ожидаемое время выполнения ком-
плекса работ равно Т с дисперсией атг. Достаточно справедливым бу-
дет предположение, что действительное время выполнении комплекса Т
будет случайной величиной, имеющей нормальный закон распределе-
нии со средним значением Т и дисперсией аг2, как показано на
рис. 11.7.
Вероятность того, что действительное времи выполнения комплек-
са работ Т не превзойдет запланированного Та, определится заштри-
хованной площадью под кривой плотности вероятности. Математически
эта вероятность может быть найдена в соответствии о (5,44) из соот-
ношения
Р(Т^Та)=Ф[(Та-Т)/ог], (11.18)
где Ф(х) — интеграл вероитностей.
Более подробное изложение методов сетевого планирования и
управления можно найтн в [31, 69, 75, 76].
453
11.3. КОМБИНАТОРНЫЕ ЗАДАЧИ НА СОСТАВЛЕНИЕ
РАСПИСАНИЯ
11.3.1. Понятие о комбинаторных задачах
Существо комбинаторных задач проиллюстрируем на
примере определения оптимальной последовательности об-
работки деталей.
Пусть имеется два станка, например токарный и фре-
зерный, и п различных деталей, каждая из которых долж-
на быть последовательно обработана на каждом из этих
станков. Требуется определить, в какой последовательно-
сти нужно обрабатывать эти детали.
Данная задача имеет характерные признаки задач на
составление расписания с ограничениями а, на последова-
тельность операций (сначала токарная обработка, а затем
фрезерование) и с ограничениями р на используемые ре-
сурсы (имеются только один токарный и один фрезерный
станки). Однако данные ограничения не являются чрезвы-
чайно жесткими и допускают большую свободу выбора
вариантов обработки деталей. Начать обработку можно
с любой нз п деталей, потом можно обрабатывать любую
из оставшихся п—1 деталей и т. д. Общее число вариантов
n(n-l) ...1=п!
Однако, может быть, все эти варианты равноценны, так
что нет и никакой проблемы? Оказывается, что это не так.
От выбора порядка обработки деталей зависят простои
оборудования (фрезерный станок уже освободился, а то-
карная обработка очередной детали не закончена) и пере-
рывы в обработке деталей (закончена токарная обработка
очередной детали, но фрезерный станок еще занят).
Очевидно, из всех возможных вариантов обработки
следует выбрать такой, который позволит закончить обра-
ботку всей партии деталей за кратчайшее время. Поэтому
данная задача является задачей оптимизации. Однако ее
решение чрезвычайно затруднено наличием огромного чис-
ла вариантов обработки, что и заставляет отнести данную
задачу к задачам комбинаторного типа. Ее решение при-
ведем позднее. Рассмотрим задачу с более простыми вида-
ми ограничений, на примере которой и познакомимся
с некоторыми методами решения задач подобного типа.
11.3.2. Задача коммивояжера
Рассмотрим более простой вариант задачи об определе-
нии оптимальной последовательности обработки деталей.
454
Предположим, что п различных деталей, занумерованных
от 1 до п, надо обработать на одном станке. При переходе
от обработки детали i к детали k требуется время dtk на
переналадку станка, различное при различных I и k. Зна-
чения dik заданы в табл. 11.5. Требуется определить такой
порядок обработки деталей, при котором общее время на
обработку будет минимальным. Поскольку возможно п ва-
риантов обработки первой детали, п—1 — второй и т. д., то
Таблице 11.5
общее число вариантов обработки будет равно п! Следо-
вательно, эта задача относится к задачам комбинаторно-
го типа.
Поскольку время, затрачиваемое непосредственно на
обработку всех деталей, будет одним и тем же при любом
порядке обработки, то минимизация общего времени об-
работки сводится к минимизации времени на переналадку
станков. Данные для решения этой задачи содержатся
в табл. 11.5.
В математике задача подобного вида получила назва-
ние задачи коммивояжера. Коммивояжер (агент, реклами-
рующий товар своей фирмы) должен посетить п— 1 других
городов и вернуться к исходному пункту. Известны рас-
стояния между городами d,A, заданные в виде уже рас-
смотренной табл. 11.5. Требуется установить, в каком по-
рядке коммивояжер должен посещать города, чтобы общее
пройденное расстояние было минимальным.
Если несколько изменить формулировку задачи и не
требовать возвращения к исходному пункту, то получим
незамкнутую задачу коммивояжера. Если же не задан и
начальный пункт, то получаем полную аналогию с задачей
о выборе оптимальной последовательности обработки де-
талей. Впрочем, эти последние задачи^без труда сводятся
к первоначальной, как будет показано далее.
455
If. 3.3. Представление задачи коммивояжера
в виде графа
Очень наглядно задачу коммивояжера можно пред-
ставить в виде графа G=(X, U), вершины которого соот-
ветствуют городам, а дуги —дорогам, соединяющим горо-
да между собой. Каждой дуге, соединяющей города i, k,
приписывается число dik, называемое длиной дуги и равное
расстоянию между городами i и k. Если из каждого горо-
да имеется непосредственный путь в любой другой город
без захода в промежуточные города, то каждые две вер-
шины графа будут соединены дугами в обоих направле-
ниях. Получающийся при этом граф оказывается полным.
На практике полные графы встречаются редко. Если
граф не полный, то его можно считать полным, мысленно
восстановив недостающие дуги и приписав им длину d==
—со. В таблице расстояний соответствующие клетки удоб-
но оставлять незаполненными.
Элементарный путь в графе, проходящий через все вер-
шины, называют гамильтоновым путем. Замкнутый эле-
ментарный путь, т. е. элементарный контур, проходящий
через все вершины графа, называют гамильтоновым кон-
туром. Эти названия связаны с задачей Гамильтона, кото-
рая будет рассмотрена позднее. Как видим, задача ком-
мивояжера сводится к нахождению кратчайшего гамильто-
нова контура или кратчайшего гамильтонова пути.
В дальнейшем основным видом задачи коммивояжера
будем считать замкнутый вариант, когда задана вершина,
в которой начинается и заканчивается маршрут коммивоя-
жера. Однако незамкнутые варианты легко приводятся
к замкнутым.
Пусть дан граф G—(X, U) и дана начальная точка
Хо&Х, но не указана конечная точка. Заменим длины всех
дуг, заканчивающихся в х0, нулями. Тогда любой гамиль-
тонов контур будет содержать дугу нулевой длины, закан-
чивающуюся в х0. Если найти кратчайший контур и ис-
ключить из него дугу нулевой длины, оканчивающуюся
в х0, то получим кратчайший гамильтонов путь.
Если не указаны ни начальная, ни конечная вершины
графа, то вводим фиктивную вершину z, которая соединя-
ется дугами нулевой длины со всеми вершинами графа
в обоих направлениях. Эту вершину принимаем за началь-
ную и находим кратчайший гамильтонов контур. Исключив
456
из него дугу нулевой длины, выходящую из 2, и дугу нуле-
вой длины, заходящую в г, получим кратчайший гамиль-
тонов путь.
11.4. ПРИМЕРЫ ЗАДАЧ, СВОДЯЩИХСЯ К ЗАДАЧЕ
КОММИВОЯЖЕРА
11.4.1. Задача Гамильтона
На рис. 11.8 изображен додекаэдр, т. е. правильный многоугольник
с 12 пятиугольными гранями и 20 вершинами. Требуется, двигаясь по
ребрам додекаэдра, обойти все вершины, заходя в каждую из них
только один раз, и вернуться в исходную
вершину. Каждый такой путь, если он су-
ществует, называют гамильтоновым циклом
или гамильтоновым контуром.
Для того, чтобы свести эту задачу
к задаче коммивояжера, будем считать, что
расстояние «Л/ между двумя вершинами
равно единице, если вершины соединены
ребром, и равно бесконечности в противо-
положном случае. По этим данным можно
16 15
Рис. 11.8. Додекаэдр
составить таблицу взаимных расстояний
между вершинами по типу табл. 11.5 и далее решать получившуюся
задачу коммивояжера.
11.4.2. Транспортные задачи
Имеется огромное число задач, связанных с объездом ряда пунк-
тов и возвращением в исходный пункт: развозка почты, продуктов пи-
тания и т. п. Аналогичный характер носят задачи соединения отдель-
ных пунктов линиями электроснабжения, водопровода, газоснабжении
и т. п.
11.4.3. Оптимизация программирования для ЭВМ
При сложных вычислениях на ЭВМ приходится выполнять различ-
ные операции, осуществляемые подпрограммами .... Вп. Заранее
производится предварительное программирование, при котором уста-
навливается определенный порядок выполнения операций. Однако при
решении конкретных задач эти операции приходится выполнять в ином
порядке. К
В подобных случаях программирование сводится к введению
команд условного перехода, нарушающих естественный ход выполне-
457
ния программы, так что за операцией В< будет следовать не операция
B<+t, н некоторая другая операция Bs, как показано на рис. 11.9.
Каждая команда условного перехода требует затраты дополни-
тельного времени и усложняет как программирование, так и работу
ЭВМ.. Поэтому целесообразно так составить предварительную програм-
му, чтобы при решении заданного набора задач использовать мини-
мальное количество команд условного перехода.
Bj ... В^.,.Вп
Рис. 11.9. Введение команд ус-
ловного перехода
Пусть имеется набор из N задач, предназначенных для решения
на ЭВМ в данных конкретных условиях. Обозначим через рь вероят-
ность (частоту) решения й-й задачи, введем числа
( 1, если в й-н задаче за операцией В( следует операции By;
Ч ( 0 в противном случае.
(11.19)
При этом величина
N
i, j=~rn (П.20)
k=i
будет численно выражать математическое ожидание того, что в рас-
смотренных условиях за операцией В/ будет следовать операция В/.
Величину (1ц можно условно принять за расстояние между операциями
В{ и Bf, а сами операции рассматривать как вершины графа. Тогда
оптимизация программы, минимизирующая среднее число команд
условного перехода, сведется к нахождению кратчайшего гамильтонова
пути в полученном графе. В соответствии с последовательностью опе-
раций па этом пути н следует осуществлять предварительное програм-
мирование.
11.4.4. Определение оптимальной последовательности
обработки деталей на двух станквх
Вернемся к задаче об обработке деталей па двух станках. Обозна-
чим через at н bit время обработки ft-й детали на первом и втором
станках соответственно. Требуется найти такую последовательность
обработки деталей, прн которой общее время обработки всех деталей
будет наименьшим.
Отметим, прежде всего, особенности работы каждого из станков.
Первый станок может начать обрабатывать следующую деталь сразу
458
же после окончания обработки предыдущей, и простоев у него не бу-
дет. Второй станок может начать обработку очередной детали только
в том случае, когда 1) закончилась обработка этой детали на первом
станке; 2) закончилась обработка предыдущей детали на втором
стайке.
Рассмотрим простейший случай обработки двух деталей. Если сна-
чала обрабатывается первая деталь, то момент окончания ее обработки
на первом станке будет Моменты ai-|-bi и соответствуют
окончанию обработки первой детали иа втором станке и второй детали
на первом станке. Вторую деталь на втором станке можно начать
обрабатывать тогда, когда обе эти операции закончены, т. е. в момент
max (ai-|-bi, ai-f-aj) =ai-|-tnax (П2, bt). Обработка обеих деталей закон-
чится bi момент
f=ai-|-max (а2, b|)4-b2. (11.21)
Аналогично, если сначала обрабатывается вторая деталь, то мо-
мент окончания обработки обеих деталей
Г=а2-|-тах («|, 1>2)-H>i. (11.22)
Обработку выгодней начинать с первой детали при т. е.
если
fli-|-max (о2, b|)-j-i>2<a2-|-max (аь b2)-H»i. .(11.23)
Легко видеть справедливость соотношений
ai+&2=max (аь &2)-|-min (ai, b2); ar-J-b^max (а2, bt)-|-min (а2, bt),
с учетом которых (11.23) запишем в виде
min (аь &2)Cmin (а2, Ь,). (11.24)
Это и есть условие, когда обработку выгодней начинать с первой
детали.
Рассмотрение случая п деталей более сложно, но можно показать,
что из деталей i и j раньше нужно начинать обработку детали i, если
выполняется условие
min (alt b/)<min (ah bt). (11.25)
Если теперь поставить в соответствие каждой детали вершину гра-
фа и считать, что расстояние dt/ между вершинами i и / равно еди-
нице, когда выполняется условие (11.25), и равно бесконечности в про-
тивном случае, то приходим к матрице расстояний, определяющей со-
ответствующую задачу коммивояжера. Кратчайший гамильтонов путь,
определяемый этой матрицей, и дает оптимальную последовательность
обработки деталей.
459
, 11.5. МЕТОДЫ РЕШЕНИЯ ЗАДАЧИ КОММИВОЯЖЕРА
11.5.1. Применение метода Монте-Карло
Методами Монте-Карло называют любую статистиче-
скую процедуру, включающую в себя приемы статистиче-
ской выборки. Не останавливаясь на общих идеях метода
Монте-Карло, рассмотрим его применение к решению зада-
чи коммивояжера.
Вершину I принимают за начальную и закладывают
в урну жетоны с номерами от 2 до п. Тщательно переме-
шав жетоны, вытаскивают их по одному и записывают
номера, например /2,....t„, При этом получают гамильто-
нов контур 1, 4г.....tn, 1. Подсчитывают длину этого кон-
тура и запоминают ее. После этого процедуру повторяют,
и если новый маршрут окажется хуже, его тотчас забы-
вают, а если лучше, то забывают предыдущий, а новый
запоминают. Проводя такую процедуру многократно, мож-
но с высокой степенью вероятности рассчитывать на то,
что удастся найти если и не иаилучший, то достаточно хо-
роший маршрут.
Для проведения таких испытаний обычно используют
ЭВМ, снабженные датчиками случайных чисел, что позво-
ляет за короткое время просмотреть значительное число
маршрутов.
11.5.2. Сведение к задаче целочисленного
линейного программирования
В графе G=(X, U), соответствующем задаче коммивоя-
жера, рассмотрим некоторый гамильтонов контур 1, 12,...
...,irl, 1. Совокупность дуг, входящих в гамильтонов кон-
тур, можно описать в виде матрицы
[Уп ••• Z/inl
(U.26)
Ут ••• У/ш]
в которой
11, если дуга (t, /) входит в рассматриваемый
контур; (11.27)
О в противоположном случае.
Так как каждая вершина встречается в гамильтоновом
контуре один и только один раз, то в каждую вершину
460
обязательно входит и из каждой вершины обязательно
выходит одна и только одна дуга. Это означает, что в мат-
рице (11,26) в каждой строке и в каждом столбце должна
стоять одна и только одна единица, что математически
запишется в виде
2^ = 1- (Н.28)
.=1 /=1
С учетом (11.28) условие, чтобы все уч были равны О
или 1, можно заменить требованием, чтобы все уч были
неотрицательными целыми числами:
Уч 0, ij = ТГп; (11.29)
ent = уч, (11.30)
где ent [yf/] означает операцию взятия целой части чис-
ла у,
Как видим, любой гамильтонов контур может быть опи-
сан матрицей (11.26), элементы которой уч удовлетворяют
соотношениям (11.28) — (11.30). Длина гамильтонова кон-
тура равна сумме длин составляющих его дуг:
<1L31)
Нахождение гамильтонова контура минимальной дли-
ны сводится, таким образом, к нахождению значений пере-
менных у,j, удовлетворяющих линейным уравнени-
ям и неравенствам (11.28) и (11.29), условию целочислен-
ности (11.30) и обращающих в минимум линейную форму
(11.31), т. е. к решению задачи целочисленного линейного
программирования.
Следует, однако, учесть, что условия (11.28) —(11.30)',
означающие, что в каждую вершину входит и из каждой
вершины выходит только одна дуга, не обязательно опре-
деляют гамильтонов контур. Этим условиям будет отвечать
и контур, проходящий не через все вершины, если в остав-
шихся вершинах образуются петли. Это соответствует об-
ращению в единицу некоторых элементов матрицы (11.26),
стоящих на главной диагонали, и может быть исключено
наложением на уч добавочных ограничений вида
Уч—0 при i=j, (11.32)
461
Рис. 11.10. Образование двух
несвязных контуров
Возможны также случаи,
когда получается не один га-
мильтонов контур, а два или
более замкнутых контура,
каждый из которых охватыва-
ет только часть вершин, как
показано, например, на рис.
11.10 для п=1. Если получи-
лось именно такое решение, то
вводят добавочное ограничение
вида
У12 + У23 + У з 7+у 71 3,
запрещающее, возникновение контура (/, 2, 3, 7, /), и ре-
шают задачу заново совместно с этим ограничением.
11.5.3. Метод ветвей и границ
Пусть U — множество вариантов решения некоторой за-
дачи. Если эти варианты перенумеровать от 1 до т, то под
U можно понимать множество номеров вариантов решения,
т. е. положить 1/={1,...,т}.
Обозначим через qi значение некоторого параметра,
характеризующего качество решения в t-м варианте. Оп-
тимальным решением будет такое, которое дает мини-
мальное значение
q* = min qt (11.33)
i&J
критерию качества, являющееся точной нижней границей
для множества {<?i,....qm}.
Введем понятие оценки снизу для множества U, под
которым будем понимать такое значение q—Q, которое
удовлетворяет соотношению
<?<<?='• или Q^q\ (11.34)
Если в соотношении (11.34) стоит знак нестрогого
неравенства то оценку Q будем называть достижи-
мой.
Метод ветвей и границ состоит в последовательном
улучшения оценки и приближении ее к значению q*.
Предположим, что имеем возможность получить оценку
снизу как для всего множества U, так и для его различных
462
подмножеств.
Разобьем множество U на два подмножества А и В
с точными нижними границами критерия качества qA* и
qn*, связанными с q* очевидным соотношением
9*=min(^*, qB*). (11.35)'
Поскольку в множествах Л и В присутствует меньшее
число элементов, чем в множестве U, то имеется возмож-
ность получить оценки $А, qe, более близкие к значениям
qA*, qe*, чем в первоначальном множестве U, что означает,
что оценка min(^, qB) будет более близка к q*, чем оцен-
ка
Рис. 11.11. Построение
дерева разбиений
Рис. 11.12. Дерево разбвенвй
в задаче коммивояжера
Имеется также большая вероятность того, что опти-
мальный вариант, т. е. вариант с наименьшим значением
q=q*', окажется в том из подмножеств Л и В, которое
имеет меньшую оценку снизу. Эта вероятность будет тем
больше, чем- больше отличаются друг от друга оценки $А
и $в, поэтому разбивать множества U на подмножества А
и В желательно так, чтобы оценки снизу для этих под-
множеств отличались возможно больше.
Если оказалось, что qB<Z^A, то есть основания подо-
зревать, что оптимальный вариант входит в множество В
и это множество надо исследовать детальней. Для этого
разбиваем его в свою очередь на два подмножества С и D
так, чтобы оценки <?с и различались возможно больше.
Если оказалось, что £jo<Z()c, то подобному же разбиению
подвергаем множество D и т. д. до тех пор, пока не при-
дем к подмножеству, состоящему всего из одного элемен-
463
та со значением параметра q=qo. Всю процедуру разбие-
ния удобно представить в виде дерева разбиений, приве-
денного на рис. 11.11.
Однако найденный элемент со значением q=qQ может
лишь подозреваться как оптимальный. Необходимо про-
верить, нет ли среди нерассмотренных множеств А, С и
т. д. элемента со значением q<Zqo- При этом множества,
у которых q>qo, могут не рассматриваться, поскольку
элемента с q<qo в них быть не может.
Разбиение вышеуказанных множеств или приведет
к элементу с q<Zqo, тогда этот элемент и должен быть
принят за оптимальный, или приведет к оценкам снизу
tj>q0. В этом случае элемент со значением параметра qo
и будет искомым вариантом решения задачи.
If.5.4. Применение метода ветвей и границ
к решению задачи коммивояжера
Считаем, что задача коммивояжера задана в виде матрицы рас-
стояний по типу табл. 11 5. Для конкретности зададимся численными
значениями расстояний, приводимыми в числителе табл. 11 6,а.
- Таблица 11.6
а) б) в)
1 / 1 I J
1 2 3 4 1 5 2 3 4 5 2 31 4
1 X 7/5 7/4 2/0 4/2 2/- 1 5/3 4/2 X 2/0 2 X 0 0
2 6/5 X 2/0 4/3 1/0 1/- 2 X о/о. 3/0 0/0 3 0 X 5
3 6/5 1/0 X 9/8 2/1 1/- з 0/0 X 8/5 1/1 5 0 0 X
4 2/0 3/1 8'5 X 5/3 2/- 5 0/0 0/0 4/1 X
5 6/5 1/0 2/0 5/4 х 1/-
Для получения оценки снизу длин множества всех гамильтоновых
контуров воспользуемся гем, что в каждый гамильтонов контур входит
только по одному элементу из каждой строки и из каждого столбца
матрицы расстояний. Поэтому если элементы любой строки или любого
столбца уменьшить на какое-либо число, то на это же число умеиь-
464
шатси длины всех гамильтоновых контуров. На этом свойстве основан
метод приведения матрицы расстояний.
Приведение матрицы может производиться по строкам и столбцам.
Приведение матрицы расстояний по строкам заключается в том, что из
элементов каждой строки t вычитают наименьший элемент этой строки,
обозначаемый hi. При этом длины всех гамильтоновых контуров умень-
шатся на сумму вычтенных из каждой строки чисел, т. е. на величину
2 hf оставаясь в то же время неотрицательными. Поэтому величина
I 1
равная в рассматриваемом примере 7, дает некоторую оценку
снизу длин всех гамильтоновых контуров. Полученная оценка может
быть улучшена путем повторного приведения матрицы расстояний по
столбцам. При этом из значений элементов каждого столбца j приве-
денных по строкам матрицы расстояний вычитается наименьший эле-
мент этого столбца, обозначаемый gj. Сумма вычтенных при этом чи-
сел Sfij — •• Уточненная оценка снизу длин гамильтоновых кон-
туров
? = S hi + 2 9/ = 7 + 1 = 8.
I i
Получаемая после приведения матрица расстояний (значения в зна-
менателе) дана в виде табл. 11.6,а.
Метод приведения матрицы расстояний будем применять и далее
дли получения оценок снизу различных подмножеств множества га-
мильтоновых контуров.
Рассмотрим теперь способ разбиения множества гамильтоновых
контуров на подмножества. Возьмем некоторую дугу (1, /). К первому
подмножеству отнесем все гамильтоновы контуры, в которые эта дуга
входит. Обозначим это множество [(i, /)]. Ко второму множеству
отнесем все гамильтоновы контуры, в которые дуга (i, /) не входит.
Это множество обозначим [(t, /)].
Таблицу расстояний для множества [(Г, /)] легко получить, если
учесть, что включение дуги (i, j) в гамильтонов контур исключает воз-
можность включения других дуг, стоящих в t-строке или /-м столбце.
Следовательно, таблица расстояний для множества [(i, /)] получается
из первоначальной таблицы вычеркиванием t-й строки и /-го столбца.
Для того чтобы получить таблицу расстояний для множества
[(;, /], следует в первоначальной таблице запретить движение по дуге
(i, /), положив ее длину равной бесконечности. Этот запрет движения
по дуге (i, /) будем отмечать крестом в соответствующей клетке пер-
воначальной таблицы.
30—804 465
Теперь возникает вопрос: какую дугу положить в основу разбие-
ния множества маршрутов на подмножества? Заметим, прежде всего,
что по количеству элементов множества [(1, /)] н [(i, j)] не одинако-
вы. Общее число гамильтоновых контуров в задаче с п городами рййно
(я—1)1. Если зафиксировали дугу (i, /), т. е. выбрали две вершины,
то имеется п—2 способов выбрать третью, п—3 способов —• четвертую
и т. д. Следовательно, имеется (п—2)1 гамильтоновых контуров, вклю-
чающих дугу (i, /), а значит, (n—1) I— (п—2) 1=(п—2) (п—2) I гамиль-
тоновых контуров, не включающих дугу (t, /). Поэтому при п>2 мно-
жество [(/, /)] будет содержать большее число элементов, чем мно-
жество [(t, /)]. А поскольку множество с меньшим числом элементов
исследовать проще, то в качестве дуги (i, /) следует брать такую, при
которой множество [(/, /)] имеет меньшую оценку, чем множество
[(/, /)]. Из множества дуг, удовлетворяющих этому условию, следует
отдать предпочтение той, которая дает наибольшую разницу в оценках
для множеств [(I, /)] и [(i~jj].
Если в качестве дуги (i, /) взять такую, у которой в приведенной
таблице dtJ=£Q, то для группы [(i, /)] оценка снизу возрастает иа dtj,
поскольку заранее известно, что эта дуга войдет во все гамильтоновы
контуры. Она может еще возрасти, если таблица при вычеркивании
i-й строки и /-го столбца будет допускать дальнейшее приведение. В то
же время при замене элемента dt,i на бесконечность таблица расстоя-
ний останется приведенной, т. е. оценка снизу для [(/, /)] не возрастет.
Следовательно, меньшее значение оценки снизу будет для множества
[(г, /)], что нежелательно. Поэтому в качестве дуги (i, j) надо брать
такую, у которой в приведенной таблице расстоянвй величина «Л,/=0.
Но таких дуг несколько. Какую же из них выбрать? Очевидно, ту,
для которой увеличение оценки для множества [ (t, /)] будет наиболь-
шим, так как при этом получится наибольшая разница в оценках для
множеств [(/, /)] и [ (i, /)].
Обозначим увеличение оценки множества [(i, j)] через A(i, j).
Значение этой величины получаем путем сложения наименьших чисел
в »-й строке и j-м столбце.
Обратимся вновь к рассматриваемому примеру. Для табл. 11.6,а
(знаменатель) значения Д(г, /') следующие:
Д(1, 4) =2-|-3=5; Д(2, 3) =0;
Д(2,5)=1; Д(3,2) = 1; Д(4,1)=6;
Д(5, 2)=0; Д(5,3)=0.
Наибольшее увеличение оценки для группы [(i, /)] получается для
дуги (4, 1). Исключая четвертую строку и первый столбец из приве-
466
денной матрицы, приходим к табл. 11.6,6 (числитель), представляющий
собой таблицу расстояний для множества [(4, 1)].
При получении подобных матриц нужно строго следить за. тем,
чтобы не могло получиться контуров, не являющихся гамильтоновыми.
Поскольку дуга [(4, 1)] уже введена в намечаемый гамвльтоиов кон-
тур, то нужно наложить запрет на дугу [(1, 4)], отметив клеточку
[(1, 4)] крестом, так как дуга [(1, 4)] совместно с дугой [(4, I)]
образует контур. В табл. 11.6,6 (знаменатель) дана приведенная таб-
лица расстояний с увеличением оценки Д$=2-}-3=5.
Для табл. 11.6,6 (знаменатель) значении A(i, /) следующие:
Д(1,5)=2; Д(2,3)=0; Д(2,4)=1;
Д(2,5) =0; Д(3,2) = 1; Д(5,2)=0;
Д(5,3)=0.
Наибольшее увеличение оценки для группы [(£, /)] получается для
дуги [(1, 5)], которую также вводим в намечаемый гамильтонов кон-
тур, получая цепочку [(4, 1, 5)]. Исключая первую строку н питый
столбец из матрицы табл. 11.6,6 (знаменатель), приходим к табл. 11.6,о
для множества [(4, 1) (1, 5)], в которой необходимо наложить запрет
на дугу [(5, 4)], образующую контур с участком [(4, 1, 5)]. Получен-
ная таблица является приведенной. Поэтому дли нее сразу же находим
значения A(i, /):
Д(2,3)=0; Д(2,4) =5; Д(3,2)=5;
Д(5,2)=0; Д(5,3)=0.
Как видим, наибольшие значения A(t, /) получились равными для
дуг (2, 4) и (3, 2). Поэтому обе эти дуги можно отнести к намечаемо-
му гамильтонову контуру, получая, таким образом1, последовательность
дуг [(3, 2)], [(2, 4)], [(4, 1)], [(1, 5)], для замыкании которой не
хватает лишь дуги [(5, 3)]. Добавляя эту дугу, получаем предпола-
гаемый оптимальный гамильтонов контур [(3, 2, 4, 1, 5, 3)] длиной 13.
Анализируй нерассмотренные ранее подмножества [(4, 1)], [(4, 1),
(1. 5)j, [(4,’ 1), (1, 5), (2, 4)], убеждаемся, что их оценки снизу боль-
ше, чем 13, так что эти подмножества не могут содержать гамильто-
новы контуры короче найденного. Следовательно, дальнейшая проверка
не нужна н полученный гамильтонов контур является оптимальным.
На рис. 11.12 приведено дерево разбиений, строящееся по ходу
решения задачи.
Более подробные сведения о методах решения комбинаторных за-
дач содержатся в [73, 77, 78],
30*
467
11.6. ЗАДАЧИ МАССОВОГО ОБСЛУЖИВАНИЯ
11.6.1. Основные понятия. Терминология
Задачи массового обслуживания возникают в тех слу-
чаях, когда требования на выполняемые работы поступа-
ют в случайные моменты времени, а выполнение этих ра-
бот, называемое обслуживанием, осуществляется одним
или несколькими обслуживающими устройствами (прибо-
рами). Длительность выполнения отдельных требований
Дослуживающие устройства
Рис H.I3 Модель системы массового обслуживания
предполагается случайной. На рис. 11.13 приведена общая
модель системы массового обслуживания с тремя обслужи-
вающими приборами.
Устройство, способное в любой момент времени обслу-
живать лишь одно требование, называют каналом обслу-
живапия. При наличии нескольких каналов, способных
одновременно обслужить ряд требований, говорят о мно-
гоканальной системе. Все каналы или часть их могут вы-
полнять один и тот же или разные виды обслужива-
ния.
Характерной особенностью задач массового обслужива-
ния является возникновение несоответствия между скоро-
стью поступления требований и скоростью обслуживания,
в результате чего или оказываются простаивающими об-
служивающие приборы или образуется очередь на обслу-
живание. С подобными' ситуациями приходится сталки-
ваться постоянно: люди стоят в очередях у касс и прилав-
ков, подлежащее ремонту оборудование скапливается
в ожидании ремонтных бригад, самолеты ждут, когда ос-
вободится взлетная полоса. Принципиальный интерес
представляют следующие характеристики системы массо-
вого обслуживания: 1) длина очереди в различные момен-
468
ты времени; 2) общая продолжительность нахождения
требования в системе обслуживания (ожидание в очереди
и самообслуживание) ; 3) доля времени, в течение которого
обслуживающие приборы были незаняты.
Для получения математической модели системы массо-
вого обслуживания необходимо иметь: 1) описание входя-
щего потока требований; 2) описание способа, каким
выполняется обслуживание; 3) описание дисциплины оче-
реди, т. е. указание того, каким образом требования по-
ступают из очереди иа обслуживание: живая очередь
(первым пришел— первым обслужен), обслуживание по
степени срочности, по какой-то шкале приоритетов и т. п.
При исследовании систем массового обслуживания вхо-
дящий поток требований обычно считают пуассоновским
(см. § 5.7), характеризующимся интенсивностью I. Это
означает, что требования поступают в случайные моменты
времени, причем вероятность появления одного требования
в интервале от t до Я-Д^ равна 1Д< и не зависит от t,
а вероятность появления в этом интервале двух и более
требований пренебрежимо мала. Такие предположения яв-
ляются достаточно обоснованными для многих практиче-
ских случаев.
Длительности обслуживания отдельных требований
предполагаем случайными с экспоненциальным законом
распределения и средним временем обслуживания 1/ц, где
ц—интенсивность обслуживания. Это означает, что веро-
ятность окончания обслуживания очередного требования
в интервале от t до t-j-kt не зависит от t и равна цДЛ Та-
кое распределение вероятностей обслуживания не всегда
хорошо отражает работу реальных приборов обслужива-
ния, и основным мотивом в пользу его применения явля-
ется упрощение математической стороны исследования.
Будем также предполагать, что обслуживание произ-
водится в порядке поступления требований.
11.6.2. Дифференциальные уравнения системы
массового обслуживания
Обозначим через S£ состояние системы массового об-
служивания, означающее наличие очереди из I требований
(7=0, !....,), а через р, (f) вероятность того, что система
находится в состоянии S, в момент t. Найдем изменение
этой вероятности ДрДО за малый интервал Д7, непосред-
ственно следующий за моментом t. Обозначим также через
469
%, и ц/ интенсивность потока требований и интенсивность
обслуживания системой в состоянии S,, считая, что в об-
щем случае эти интенсивности зависят от длины очереди.
Рассмотрим большое число М идентичных систем массо-
вого обслуживания, из них будут в момент t
находиться в состоянии Sz_t; pt(t)N — B состоянии S,;
р,+1(/)М— в состоянии Sl+i. Рассмотрим изменение коли-
чества систем Др,(ОМ находящихся в состоянии S„ за ин-
тервал времени от t до /4-ДЛ
Поскольку при пуассоновском потоке требований и экс-
поненциальном обслуживании за малое время Д/ пи на
одну из систем не может поступить более одного требова-
ния и ни одна из систем не может закончить обслуживание
более одного требования, то состояние каждой из систем
не может измениться более чем па единицу. Поскольку
вероятности поступления нового требования и окончания
обслуживания очередного требования в интервале Д/ рав-
ны ХД/ и цД/ соо1ветственно, то за время Д/ па X/ &tpi(t)N
систем, находящихся в состоянии St, поступят новые тре-
бования, переводя их в состояние S,.H, и у,Д/р, (/)AZ систем
закончат обслуживание очередного требования в перейдут
в состояние S/_(. Кроме того, М-|Дф,-1 (t)N, систем, нахо-
дящихся в состоянии 5,-ь перейдут в состояние S,-, полу-
чив добавочное требование, и р(+|Д/р1+1 (t)N систем, нахо-
дящихся в состоянии S,+i, перейдут в состояние S„ закон-
чив обслуживание очередного требования. Изменение за
время Д/ общего числа систем &p,(t)N, находящихся в со-
стоянии S,,
Др,(/)^=-М(р/(П^—
—ц,Д/р, (П ЛН- М-i Д 1 (О ЛН-
+р, HMpl+l(t)N.
Поделив это уравнение на Д/ и перейдя к пределу при
Д/->0, получим
dpl(t)/dt=-(ki+lil)pl(i) +
-\-^i-ipi-\ (0 +ц<+1Рж (0 • О1-36)
Это уравнение неприменимо при i=0, так как в этом
случае требования не могут покидать систему и теряет
смысл вероятность p,-i(0- Поэтому данный случай следу-
ет рассмотреть особо. Поскольку при i=0 система мо-
жет изменить состояние So на Sj только за счет поступ-
470
ления нового требования, а состояние Si на So —за счет
окончания обслуживания единственного требования, то
dp0 (О /Л=—ХоРо (О + Ц1Р1 (0 • (11 -37)
Уравнения (11.36), (11.37) обычно называют уравне-
ниями «размножения и гибели», имея в виду использова-
ние этих уравнений для изучения изменения численности
популяции в биологии. В задачах массового обслуживания
эти уравнения позволяют при заданных начальных услови-
ях и известных интенсивностях и ц{ определить измене-
ние характера обслуживания во времени. Однако решение
их для практически важных случаев связано с чрезвычай-
но большими трудностями.
Обычно значительный интерес представляет не пере-
ходный процесс, а стацион-арное состояние системы обслу-
живания, называемое также статистическим равновесием.
В этом состоянии вероятности p,(t) не меняются со вре-
менем, так что можно положить dpi(t}/dt=Q и записать
уравнения системы массового обслуживания в виде
КРа = Р-1А; 1 j „
Р. + Hz) Pt ~ M-lPi-1 + Hi+iPi+v < = 1 • 2... j
Полагая во втором уравнении i=l, 2... и вычитая из
каждого уравнения предыдущее, приходим к следующей
системе уравнений для стационарного режима:
ЪР0 = Н1А; |
V.1=WV. I (11.39)
^iPi = Hz+iPi+i- I
Решение этой системы уравнений имеет вид
A- (!•«>>
Hl Н1Н2.Н1Нг---Н1
Естественно, что найденный стационарный режим мо-
жет реально существовать, только если
= (П.41)
1=0
Рассмотрим применение соотношений (11.40)', (11.41)'
для описания некоторых часто встречающихся видов си-
стем массового обслуживания.
471
Hf.4.3» Система массового обслуживвнмя с отказами
Рассмотрим систему массового обслуживания с п оди-
наковыми каналами, на вход которой поступает поток
требований с интенсивностью X. Если в момент поступле-
ния очередного требования в системе имеется свободный
канал, то требование попадает на обслуживание, если сво-
бодного канала нет, то оно покидает систему обслужива-
ния. Такая ситуация возникает в тех случаях, когда тре-
бования не могут образовывать очереди, как, например,
в телефонии, где просто подается сигнал занятости, в ре-
монтных мастерских на вокзалах, где нет времени на
ожидание в очереди, и т. и.
В подобных системах обслуживания под длиной оче-
реди i будем понимать число занятых каналов обслужи-
вания, так чго интенсивность поступающих па обслужива-
ние требований
j Л, если //;
(О, если г>/г.
(11.42)
Обозначим через ц интенсивность обслуживания од-
ним каналом. Интенсивность обслуживания при i работаю-
щих каналах
И1==/н, t==i7^ (11.43)
Вероятность одновременной работы i каналов находим
по формулам (11.40)
pi=A'po/«!p.'<=p’po/t!, (11.44)
где параметр
р=л/м (11.45)
представляет собой приведенную интенсивность потока.
Вероятность простоя всех каналов ро находится из со-
отношения (11.41):
/Л, =- 1 / (1 + Р -I- -^Р2 -1- - + Р j. (11 -46)
Работу рассматриваемой системы обычно характеризу-
ют вероятностью отказа рП1К и средним числом занятых
каналов k. Отказ от обслуживания происходит тогда, ког-
да все каналы заняты. Вероятность этого
Ротк=Рп=ряРо/п1. (11-47)
472
Иногда вместо вероятности отказа пользуются'поняти-
ем пропускной способности системы, определяемой как
С=(1-Ротк)?1. (11.48)
Среднее число занятых каналов
= Л Зр7(« —Ob (П.49)
/=! /=|
Пример 11.1. Имеется система массового обслуживания с отказа-
ми при р=Х/р=2.
Если используется три канала, то
Ро = 1 [ ( 1 + Р + ₽® + -у =0,16
Вероятность отказа
ротк=р«=р3ро/6=0,21.
Среднее число занятых каналов
й=Ро(р+р24-Р3/2) = 1,58.
Если использовать только два канала, то
ротк=р2 = 0,4; £=1,2.
41.6.4. Одноканальная система обслуживания
с ожиданием
В рассматриваемом случае имеется один канал’Обслу-
живания, на который поступает поток требований с интен-
сивностью X. Интенсивность обслуживания равна р. Выра-
жение для вероятностей р/ получим из (11.40), положив
Х,=Х; р,=р и введя параметр р=Х/р:
p/=pip0, f=l, 2... (11.50)
Значение р0 найдем из соотношения (11.41), которое
в рассматриваемом случае примет вид:
ро (1+р+р2+р3+ ...) = 1
и имеет смысл только при р<1. Используя формулу сум-
мы бесконечно убывающей геометрической прогрессии, по-
лучаем
ро=1-р. (11.51)
С учетом (11.51) выражения для р,- принимают вид
р,= (1-р)р‘, i=0, 1, 2... (11.52)
473
Основными характеристиками в системе являются сред-
няя длина очереди и среднее время ожидания обслужива-
ния. Среднее число требований, находящихся в системе об-
служивания,
(Р14-2р2+Зрз4- ...) = ( 1-р) X
Х(р+2р2+3р3+...).
Учитывая, что [70]
р+2р24-3р3+... =р/(1—р)2,
находим
й=р/(1_р)\ (11.53)
Можно определить среднее число заявок £s, проходя-
щих обслуживание. Поскольку число заявок, находящихся
на обслуживании, равно нулю, если канал свободен, и еди-
нице во всех остальных случаях, то
йд=О-ро+1 (pi+Pz-i- ...) = 1—Ро=р. (11.54)
Разность между Б и дает среднюю длину очереди
£'=£-^=р/(1-р)-р=Р2/(1-р). (11.55)
Учитывая, что среднее время обслуживания одной за-
явки равно 1/р, получаем среднее время ожидания обслу-
живания
/ож=/г/р. (11.56)’
11.6.5. Многоканальная система обслуживания
с ожиданием
Если в системе обслуживания имеется п каналов, на
которые поступает поток требований с интенсивностью К,
а интенсивность обслуживания по одному каналу равна ц,
то
Z,=X, t=0, 1, 2...; (11.57)
при
Яр. при
(11.58)
Как увидим далее, система сохраняет работоспособ-
ность, если р=Х/и<«- В этом случае
р‘-"‘59>
474
_______________________ ==
Pi RX2nX...X«HX("H)z-n Ра
Ро =
(11.60)
Ро> Г
п! n(z~n)
При найденных значениях рг соотношение (11.41)
мает вид
nt
прини-
Ро
(п-1)!
Учитывая, Что
1 —₽/п
получаем
Ро
(п-
(11.61)
Основные параметры системы обслуживания легко нахо-
дят с помощью рассмотренной ранее методики [74]: '
?=___________________________________(11.62)
tnn!(l— р/л)» Г» (п—1)!(п—р)»^° ' ’
As = p; (11.63)
Jf=£'+p; (11.64)
fo»=Wn). (И-65)
Разобранные примеры определения основных характе-
ристик систем массового обслуживания, конечно, не могут
охватить всего многообразия встречающихся на практике
случаев и имеют целью показать лишь общий подход
к анализу подобных систем. Более детально различные
виды систем массового обслуживания описаны в [31, 32,
71, 74, 79].
475
11.6.6. Статистическое моделирование систем
.массового обслуживания
Аналитические методы могут применяться лишь для сравнительно
простых систем массового обслуживания. Поэтому при анализе реаль-
ных систем, особенно в случаях, когда характер входящего потока тре-
бований ,и времени обслуживания подчиняется иным законам распре-
деления, чем рассмотренные, приходится прибегать к статистическому
моделированию процесса массового обслуживания.
В основе статистического моделирования лежит имитация процес-
са массового обслуживания, при которой моменты поступления требо-
ваний и длительности обслуживания получают по таблицам случайных
чисел или от специальных датчиков случайных чисел с помощью ЭВМ.
Наиболее просто реализуются на ЭВМ алгоритмы для получения
последовательности случайных чисел уп, п=1, 2, .... имеющих равно-
мерное распределение вероятностей в интервале от 0 до 1. Такие числа
получаются обычно путем использования рекуррентных формул
у„«Ф(у„-1). и=1, 2 ... (11.60)
при заданном начальном значении у0. Ограничимся рассмотрением лишь
одного из алгоритмов подобного вида, называемою методом сравнений,
в соответствии с которым случайные числа у„ получаются по соотно-
шению
Vn=gYn-i—ent (gyn-т), n=l, 2 .... (11.67)
где g — целое число, много большее единицы; ent (gyn-i)—целая
часть числа gyn-г, Yo задано.
Алгоритм вида (11.67) дает не чисто случайные, а так называемые
псевдослучайные числа Особенностью этого алгоршма является то,
что при реализации на ЭВМ он всегда порождает периодические по-
следовательности. Действительно, поскольку числа в ЭВМ представ-
ляюгся с конечным числом разрядов, общее число чисел, заключенных
между нулем и единицей, будет конечным. Эго означает, что рано или
поздно какое-либо значение у/. совпадает с одним из предыдущих зна-
чений Yi. Тотда в силу (11.67) j
Ylt/=Y<ii при 1=1, 2 ... (1168)
Пусть /. — наименьшее число, удовлетворяющее (11.68). Тогда L
называется длиной отрезка апериодичности, a p=L—l —длиной перио-
да. Естественно, что при моделировании можно использовать не более
чем L чисел последовательности (11.67). Поэтому после выбора чисел
g и у0 следует экспериментально определить длину отрезка апериодич-
ности, а также проверить, насколько близок закон распределения полу-
чающейся псевдослучайной последовательности к требуемому равномер-
ному закону распределения. Методы осуществлении таких проверок
описаны в [80].
476
О X'X+dx х
Рис. 11.14. Получение слу-
чайной выборки с заданной
функцией распределения
Для осуществления статистического
моделировании необходимо иметь вы-
борки случайных чисел с различными
законами распределения, которые мож-
но получить путем функционального
преобразования выборки чисел у с рав-
номерным законом распределения. Рас-
смотрим некоторые способы решения
этой задачи.
Поставим задачу получить алгоритм
выработки на ЭВМ последовательности
случайных чисел х>, хг, ..хп • • > имею-
щих заданную плотность вероятности
w(x) или функцию распределения вероятности F(x), связанную с w(x)
соотношением (5.37).
Положим F(x)—y и построим зависимость y=F(x), как показано
на рис. 11.14. При изменении х от —оо до -|-оо значение у меняется
от 0 до 1. Будем теперь считать у случайной величиной, равномерно
распределенной от 0 до 1, т. е. имеющей плотность вероятности р(у) = 1
при O^j/^1, и найдем вероятность того, что F(x) лежит в пределах
от у до y±dy:
P(y^F(x)<y-\-dy)=p(y)dy=dy = dF (x)=w(x)dx. (11 69)
Если y=F(x) равномерно распределена от 0 до 1, то х имеет плот-
ность вероятности w(x)=dF(x) /dx. Поэтому при моделированив слу-
чайного процесса х с заданной функцией распределения вероятностей
Г(х) надо в качестве у брать случайные числа у от датчика случайных
чисел с равномерным распределением вероятностей от 0 до 1, т. е. по-
ложить v=E(x), и отсюда f
x^F~'(y), , ’ (11.70)
1де Г-1(у) — обратная функция.
Данный метод получения выборки х с заданной функцией распре-
деления Fix) получил название метода обратной функции.
Пример 11.2. В задачах теории надежности и при исследовании
работы систем массового обслуживания широко используются случай-
ные величины х, подчиненные экспоненциальному распределению
с плотностью вероятности а/(х)=Л. ехр (—Лх) и с функцией распреде-
ления вероятностей
Г(х)= Jw(g)d(g)=l-e-4
—ОО
Полагая F(jc)=Y, находим откуда
х=—(1/Х) 1п(1-у).
(11.71)
(11.72)
477
Поскольку у имеет равномерное распределение вероятностей от О
до 1, то 1—у будет иметь такое же распределение вероятностей, Поэто-
му можно заменить 1—у иа у и тогда
х=—(1/Л.) 1пу. (11.73)
Пример 11.3. На систему массового обслуживания поступает ре-
гулярный поток требований с интервалами 2 мин. Время обслуживания
носит экспоненциальный характер с интенсивностью Х=0,5.
Рис. II 16. Схема программы имитации процесса массового обслужи-
вания
Имитация работы системы осуществлялась на ЭВМ по программе,
схема которой приведена на рис. 11.15. На схеме для требования с но-
мером I обозначено: — момент поступления требования; 1/ — момент
начала обслуживания; vt — время ожидания; Тт—время обслуживания;
t," — момент окончания обслуживания
Выборка у( нз равномерного распределения получена по соотноше-
нию (11.67) при £=3125 и уо=О, 1 2345678 9. Время обслужи-
вания Xi найдено для этой выборки по (11.72). Результаты моделиро-
вания сведены в табл. 11.7.
Метод обратной функции не ивлиетси единственно возможным ме-
тодом получения случайной выборки с заданным законом распределе-
ния. Разработан ряд других методов, которые во многих случаях ока-
478
Таблица 117
Номер требова- Момент поступле- ния требо- вания Время ожидания Момент начала обслужи- вания ii Выборка из равно- мерного распреде- ления обслужи- Моиевт окончания обслужи- вания Q
1 2 0 2 0,8025 3,244 5,244
2 4 1,244 5,244 0,7037 2,433 7,677
3 6 1,668 7,677 0,2207 0,499 8,175
4 8 0,175 8,175 0,5542 1,615 9,791
5 10 0 10 0.9202 5,057 15,057
6 12 3,057 15,057 0,7572 2,831 17,889
7 14 3,889 17,889 0,3044 0,726 18,615
8 16 2,615 18,615 0,2424 0,555 19,170
9 18 1,710 19,170 0,6465 2,080 21,250
10 20 1,250 21,250 0,5021 1,395 22,645
зываются более удобными [80, 81]. Приведем соотношения, позволяю-
щие получать на ЭВМ последовательности статистически независимых
случайных чисел с нормальным законом распределения.
Пусть Yi н Уг —два числа из последовательности с равномерным
распределением вероятностей в диапазоне от 0 до 1. Тогда последова-
тельности
2- = У—2 In Yt cos 2лу2; = |/—2 In Yi sin 2луа
(11.74)
будут независимыми последовательностями нормально распределенных
случайных чисел с нулевым математическим ожиданием и единичной
дисперсией, а последовательности
x=og+v; i/=<n)+v
(И75)
будут иметь нормальное распределение с математическим ожиданием
v и двсперсней о2.
СПИСОК ЛИТЕРАТУРЫ
1. Винер Н. Кибернетика М • Советское радио, 1968.
2. Управление. Информация. Интеллект/ Под ред. А. И. Берга,
В. В. Бирюкова, Е. С. Геллера, Г. Н. Поварова. М.. Мысль, 1976
3. Бир С. Кибернетика н управление производством. М.: Физмат-
|нз, 1960.
(959* Эшби У’ Р’ Ввсдапис в кибернетику. М.: Изд-во иностр, лит,,
5. Кузин Л. Т. Основы кибернетики. Т. 1. Математические основы
кибернетики. М.: Энергия, 1973.
6. Кузин Л. Т. Основы кибернетики. Т. 2. Основы кибернетических
моделей М.: Энергия, 1979.
7. Коршунов 10. М. Математические основы кибернетики. М.:
Энергия, 1972.
8. Гуд Г. X., Макол Р. Э Системотехника. Введение в проектиро-
вание больших систем. М.: Советское радио, 1962.
9. Шиханович Ю. А. Введение в современную математику. М.:
Наука, 1965.
10. Кузнецов О. П, Адельсои-Вельский Г, М. Дискретная матема-
тика для инженера. М.. Энергия, 1980.
11. Берж К- Теория графов п се применение. М’ Изд во иностр,
лит., 1962.
12. Оре О Теория графов. М. Наука, 1968
13. Форд Л Р., Фалкерсон Д Р. Потоки в сетях. М.: Мир, 1966.
14. Колмогоров А. Н, Фомин С. В Элементы теории функций и
функционального анализа М.: Наука, 1968.
15. Харкевич А. А Борьба с помехами. М : Наука, 1965.
16. Вопросы статистической теории распознавания/ 10. Л. Бара-
баш, Б. В. Барский н др М Советское радио, 1967.
17. Ту Дж., Гонсалес Р. Принципы распознавания образов. М:
Мир, 1978.
18. Гильберт А. Как работать с матрицами. М.: Статистика, 1981.
19. Бронштейн И. Н., Семендяев К- А. Справочник ио математике.
М • Наука, 1964.
20. Вептцель Е. С. Теория вероятностен. М,- Паука, 1964.
21. Янке Е., Эмде Ф, Леш Ф. Специальные функции. М.: Наука,
1968
22. Уилкс С. Математическая статистика М: Наука, 1967.
23. Смирнов В. Н„ Дунин-Барковский И. В Курс теории вероят-
ностей и математической статистики. М.- Наука, 1965.
24. Гисдеико Б. В., Беляев 10. К, Соловьев А. Д. Математические
методы в теории надежности. М.: Наука, 1965
25. Лемаи Э. Проверка статистических гипотез М • Наука, 1964.
26. Налимов В. В., Чернова Н. А. Статистические методы плани-
рования экстремальных экспериментов. М : Наука, 1965.
480
27. Налимов В. В. Теория эксперимента. М.: Наука, 1971.
28. Финни Д. Введение в теорию планирования эксперимента. М.:
Наука, 1970.
29. Вознесенский В. А. Статистические методы планирования экепе-
римента в технико-экономических исследованиях. М.: Финансы и ста-
тистика, 1981.
30. Основы автоматического управления/ Под ред. В. С. Пугачева.
М.: Физматгиз, 1963.
31. Вентцель Е. С. Исследование операций. М: Советское радио,
1972.
32. Чермен У., Акоф Р„ Ариов Л. Введение в исследование опе-
рации. М : Наука, 1968.
33. Болтянский В. Г. Математика и оптимальное управление. М:
Знание, 1968.
34. Цыпкин Я. 3. Адаптация и обучение в автоматических систе-
мах. М.: Наука, 1968.
35. Кобринский Н. Е., Маймииас Н Е„ Смирнов А. Д. Экономи-
ческая кибернетика. М.. Экономика, 1982.
36. Моисеев Н Н, Иванилов Ю. П., Столярова Е. М. Методы
оптимизации. М.: Наука, 1978. i
37. Моисеев Н. Н. Математические задачи системного анализа. ,М.:
Наука, 1981.
38. Карр Ч., Хоув Ч. Количественные методы принятия решений
в управлении и экономике. М.: Мир, 1966.
39. Хедли Д. Нелинейное и динамическое программирование. М:
Мир, 1967.
40. Краснощеков П С. Математические модели исследования опе-
раций. М.: Знание, 1984.
41. Корбут А. А., Финкельштейн Ю. Ю. Дискретное программиро-
вание. М.: Наука, 1969.
42. Дюбин Г. Н., Суздаль В. Г. Введение в прикладную теорию
игр. М.: Наука, 1984. (
43. Карпелевич Ф. И , Садовский Л. Е. Элементы линейной алгеб- >
ры и линейного программирования. М.: Физматгиз, 1963.
44. Юдин Д. Б., Гольштейн Е. Г, Задачи и методы линейного
программирования. М.: Советское радио, 1964.
45. Данциг Д. Линейное программирование, его применения и обоб-
щения. М.: Прогресс, 1966.
46. Математика и кибернетика в экономике. Словарь-справочник.
М.: Экономика, 1975.
47. Юдин Д. Б. Математические методы управления в условиях
неполной информации. М : Советское радио, 1974.
48. Уайлд Д. Дж Методы поиска экстремума. М.: Наука, 1967.
49. Первозваиский А. А. Поиск. М.: Наука, 1970
50. Эльсгольц Л. Э. Вариационное исчисление. М: Наука, 1958.
51. Понтрягин Л. С., Болтянский Р. В., Гамкрелидзе Р. В., Ми-
щенко Е. Ф. Математическая теория оптимальных процессов. М.: Нау-
ка, 1983.
52. Болтянский В. Г. Математические методы оптимального управ-
ления. М.: Наука, 1969.
53. Розоноэр Л. И. Принцип максимума Л. С. Понтрягина в тео-
рии оптимальных систем// Автоматика и телемеханика, 1959, № 10—12.
Т. 20. С. 1320—1334, 1441 — 1458, 1561—1578.
54. Веллман Р. Динамическое программирование. М.: Изд-во
иностр, лит., 1960.
31-804 481
55. Беллман Р. Процессы регулирования с адаптацией. М.: Нау-
ка, 1964.
56. Вентцель Е. С. Элементы динамического программирования.
М.: Наука, 1964.
57. Блекуэлл Д„ Гиршик М. А. Теория игр и статистических ре-
шений. М- Изд-во иностр, лит, 1958.
58. Мак-Кииси Д. Введение в теорию игр. М.: Фнзматгнз, 1960.
59. Нейман Д„ Моргенштерн О. Теория игр и экономическое по-
ведение. М.: Наука, 1970.
60. Чернов Г„ Мозес Л. Элементарная теория статистических ре-
шений. М: Советское радио, 1962.
61. Миддлтон Д. Введение в статистическую теорию связи, Т. I.
М.: Советское радио, 1961.
62. Вальд А. Последовательный анализ. М.: Физматгиэ, 1960.
63. Башаринов А. Е, Флейшман Б. С. Методы статистического
последовательного анализа н их приложения. М.: Советское радио,
1962
М Сейдж Э., Меле Дж. Теория оценивания и ее применение в
связи н управлении М- Связь, 1976.
65. Спнди К., Браун Р, Гудвин Дж. Теория управления. М.: Мир,
1973.
66. Медич Дж Статистически оптимальные оценки в управление.
М: Энергия, 1973.
67. Коршунов 10. М, Бобиков А. И Цифровые сглаживающие и
преобразующие системы М • Энергия, 1969.
68. Брайсон А., Хо Ю-Ши Прикладная теория оптимального управ-
ления Оптимизация, опенка и управление. М: Мир, 1972.
69. Справочник по системотехнике/ Под рсд. Р. Макола. М.: Со-
ветское радио, 1970.
70 Рыжик И. М, Градштсйи И. С. Таблицы интегралов, сумм,
рядов в произведений М —Л.: Гостсхиздат, 1951.
71. Риордан Дж. Вероятностные системы обслуживания. М.: Связь,
1966.
72. Моисеев Н Н. Численные методы в теории оптимальных си-
стем. М- Наука, 1971.
73. Таиаев В. С., Шкурба В. В. Введение в теорию расписаний. М.:
Наука, 1975.
74 Акоф Р, Саснсни М. Основы исследования операций. М.: Мир,
1971.
75. Бигель Дж. Управление производством. М.: Мир, 1973.
76 Риггс Дж. Производственные системы. М.: Прогресс, 1972.
77. Бурков В. Н., Ловецкий С. Е. Комбинаторика и развитие тех-
ники. М: Знание, 1968.
78. Мудров В. И. Задача о коммивояжере. М • Знание, 1969.
79. Розенберг В. Я., Прохоров А. И. Что такое теория массового
обслуживания. М.: Советское радио, 1962.
80 Соболь И. М Численные методы Монте-Карло. М.: Наука, 1973.
81. Полляк Ю Г. Вероятностное моделирование на электронных
вычислительных машинах. М.: Советское радио, 1971,
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Алгоритм 19
Алфавит 15, 100
— двоичный 16
Анализ регрессионный 225
Антирефлективность 63
Антисимметричность 63
Байеса формула 158
Базис 284
Брахистохрона 61
Вариация 325
Вектор 45, 108
— математических ожиданий 180
— матрицы собственный 128
Векторные производные 137
Вектор транспонированный 109
Векторы ортогональные 117
Вероятность 149
— апостериорная 153, 158, 402
— априорная 153
— условная (безусловная) 155
Внутренняя точка множества 139
Возмущение 254
Выборка случайная 205, 478
Выборочное среднее 210
Гауссовский марковский процесс
Генерирующее соотношение 237
Гиперплоскость 140
Гиперплоскость опорная 146
— разделительная 146
Гиперсфера 138
Градиент 314
Граница множества 33, 139
Граф 67
— биохроматический 75
— наименьшей длины 82
— неориентированный 70
— полный 456
— частичный 68
31*
График сетевой 441, 446
— соответствия 49
— функции 56
Графы изоморфные 72
Действие байесовское 383
Дерево 72
— игры 349
Диаграмма переходов 193
— Эйлера—Венна 40
Дисперсия 169
Длина пути 68
Дополнение множества 40
— события 149
Дуга 67
— насыщенная 86
Зависимость линейная 110
Задача вариационная 323
— двухальтернативная 397, 403,
405, 416
— детерминированная 262, 268
Задача коммивояжера 454
— линейного программирования
263, 282
------- двойственная 300
— иа составление расписания 440
— одношаговая 240, 261
— оптимизация классическая 262,
280
— оценивания 418
— стохастическая 264, 268
— транспортная 89, 287
Задачи комбинаторные 441, 454
Закон больших чисел 207
Значение матрицы собственное 130
Значимость статистическая 220
Игра 344
— с нулевой суммой 346
— с полной (неполной) инфор-
мацией 349
483
Игра справедливая 354
— с седловой точкой 354
— статистическая 380, 384
— — без эксперимента 385
— — с единичным эксперимен-
том 393
---с последовательными выбор-
ками 409
Интеграл вероятностей 164
Интенсивность отказов 191
Интервал доверительный 215
Инцидентность 69
Капал обслуживания 468
— - связи 14
Кибернетика 9
Класс 105
— информации 349
Ковариация 178
Кодирование 15
Коды помехоустойчивые 102
Комбинация выпуклая 142
- - линейная 142
Композиция соответствий 50, 53
Компоненты вектора 109
— связности 71
Контраст определяющий 238
Контур 69
— гамильтонов 456
Кортеж 45
Коши неравенство 115
Коэффициент корреляции 179
Коэффициент регрессии 225
Критерий 19
— качества управления 61, 245,
273
— сО1ла<ия 220
Линия pei рсссии 177
Марковская цепь 192
Марковский процесс 199, 340
Математическое ожидание 165,
167, 176
Матрица 117
— единичная 124
— игры 347
— инциденций 69
— квадратная 117, 123
Матрица ковариационная 181
— коммутирующая 122
— невырожденная 126
— пулевая 124
— обратная 126
Матрица переходов 193 >
— потерь 382
— симметрическая 132
— смежности 69
— транспонярованиая 122
Медиана 105, 161
Метод ветвей и границ 462
— Гомори 305
— максимального правдоподобия
212
— Монте-Карло 460
— наименьших квадратов 104,
178, 227
Метрика 98
Механизм случайного выбора 344,
356
Минимум глобальный (абсолют-
ный) 274
— локальный (относительный)
274
— слабый (сильный) 274
Многогранник выпуклый 147
Множества в общем положен)»)
37
— счетные (несчетные) 30
Множество 24
— бесконечное 25, 30
— внутренней (внешней) устойчи-
вости 76
— выпуклое 143
— замкнутое 139
— конечное 25, 139
— ограниченное 139
Множество открытое 139
— - пустое 26
• — универсальное 39
— упорядоченное 44, 65
Множитель Лагранжа 281
Мода 161
Модель 19
Моменты случайной величины 168
Надежное) ь 191
Невязка 226
Неравенства Чебышева 205
Несимметричность 63
Норма 112
— вектора 115
Область определения (значений)
соответствия 49
— остановки 412
Оболочка выпуклая 144
Образ 52, 105
484
Образец 106
Обратная связь 19
Объединение множеств 35
— событий 148
Объект управления 252
Ограничения на процесс управ-
ления 246, 327
Окрестность 139
Оператор 61, 271
Определитель квадратной матри-
цы 124
Ортогональные векторы (функ-
ции) 117
Отказ 191
Отклонение среднеквадратичное
170
Отношение 62
— доминирования 65
— порядка 64, 73
— правдоподобия 403
— строгого порядка 65
— эквивалентности 63, 74
Отображение 51
Отрезок 142
Оценка 208
— байесовская 419
— наименьших квадратов 421
— несмещенная 209
— состоятельная 209
— точечная 214
— эффективная 209
Пари 168
Переменная выходная 255
— состояния 252
Переменные базисные (свобод-
ные) 284
Пересечение множеств 36
Петля 69
План последовательной выборки
409
Планирование сетевое 441
— эксперимента 230
Плотность вероятности 160
--- условная 175
Поверхность отклика 224
Подграф 68
Подмножество 27
Подпространство инвариантное
128
— линейное 111
Полный факторный эксперимент
232
Полупространство 141
Поток 84
— наибольший 86
— полный 86
Преобразование 271, 411
— единичное 119
— линейное 118
— нулевое 119
— обратное 125
— подобия 131
Принцип байесовский 390, 399,
419
— максимального правдоподобия
212, 403
— максимума 328
— минимакса 388, 399
— равных возможностей 152
Программа 438
Программирование динамическое
328, 331
— линейное 263, 282
— квадратичное 311
— математическое 263
— нелинейное 263, 306
— целочисленное 264, 304
Проекция кортежа 45
— множества 48
Произведение множеств прямое
46
Производственная функция 247
Пространство 96
— банахово 112
Пространство выборок 394
— евклидово 99, 114
— исходов эксперимента 148
— линейное 107
--- нормированное 112
— метрическое 98
— решений 253, 261
— сообщений 101
— состояний природы 254, 381
— факторное 224
Процесс гауссовский марковский
200
— многошаговый 185, 241, 271,
329
— независимых испытаний 186
— случайный 185
— с независимыми значениями
186
— эргодический 196
Прямая 142
— связь 18
Путь 68
—гамильтонов 456
485
Путь кратчайший 76, 80
— критический 449
Работа критическая 446
— фиктивная 447
Равенство множеств 27
Равновесие статистическое 471
Разбиение множества 41
Разность множеств 38
Разрез транспортной сети 85
Ранг матрицы 127
Распределение вероятностей 150,
159
---- апостериорное 402
---- биномиальное 188
— — нормальное 163
----Пуассона 189
---- равномерное 162
---- совместное 173
----Стьюдента 218
---- условное 394
---- X2 211
---- экспоненциальное 191
Расстояние 96
Ребро 70
Регрессия 177
Резервы времени 444
Рефлективность 63
Решение базисное 285
Риск ожидаемый 399
Связность графа 71
Сеть транспортная 84
Сигнал 14
Симметричность 63
Симплекс-метод 293
Система кибернетическая 11
— множеств 36
— счисления 16
Ситуация конфликтная 265, 343
Скалярное произведение векторов
113
Скачок единичный 59
Сложение по модулю 2, 102
Случайная величина 150
---- двумерная 173
----непрерывная 158
•--- центрированная 169
Событие 148
События независимые 157
— несовместные 148
Сообщение 14, 100
Соответствие 48
— взаимно-однозначиое 28
Соответствие обратное 50
Состояние природы 241, 254
Среднее арифметическое 104
Срок директивный 440, 446
Статистик 381
Статистика математическая 203
Стационарные точки функции 136,
274
Степень вершины графа 71
— множества 47
Стратегия 345
— байесовская 390
— доминирующая 371
— допустимая 386
— минимаксная 359, 365, 388
— оптимальная 362
— полезная 371
— смешанная 355, 383
— чистая 355, 382
Структура 96
Сужение функции 57
Тождества де-Моргана 44
Точка множества крайняя 146
— стационарная 136, 274
Транзитивность 63
Упорядочение работ 443
Управление 12, 18, 239, 255
— адаптивное 268
— допустимое 255
— конечным состоянием 268
— оптимальное 246, 268, 332
Уравнение матрицы характеристи-
ческое 129
— регрессии 225
Уравнения размножения и гибели
Факторы 223
Фильтрация 425
Фильтр Калмана 434
— с конечной памятью 428 ,
— с растущей памятью 431
— экспоненциальный 435
Форма квадратичная 135
---положительно (отрицатель-
но) определенная 135
— линейная 283
Функционал 60, 324
Функция 54
— выпуклая 277
— импульсная 59
— Лагранжа 281
486
Функция обратная 57
— потерь 347, 357, 382
— правдоподобия 212
Функция распределении вероятно»
стей 159
— решающая 396
— риска 397, 413
— с дискретным временем 60
— с непрерывным временем 58
— целевая 261, 266, 273
— штрафа 267, 306
Ход личный (случайный) 344
Цена игры 352, 362
— теневая 300
Центральная предельная теорема
Цепь 70
— марковская 187, 192
Цикл 70
Частота 151
Числа матрицы характеристиче-
ские 128
Число внутренней (внешней) ус-
тойчивости 76
— степеней свободы эксперимента
229
— хроматическое 75
— циклическое 75
Шар 138
Эксперимент 381. 394
— активный 225, 230
— единичный 394
— пассивный 225
Экспоненциальное сглаживание
436
ОГЛАВЛЕНИЕ
Предисловие.................................................
Указатель обозначений ................................
Глава 1. Введение...........................................
1.1. Предмет кибернетики ... .............
1.2. Передача и кодирование информации
1.3. Понятие об управляемой системе..............
1.4. Сложные системы.............................
Задачи к гл. I ... .........................................
Г л а и а 2. Основные понятия теории множест в..............
2,1. Конечные и бесконечные множества..................
2.1.1. Основные определения...................
2.1.2. Понятие подмножества...................
2.1.3. Взаимно однозначное соответствие между мно-
жествами ...........................................
2.1.4. Счетные н несчетные множества................
2.1.5. Верхняя и нижняя границы множества . . . .
2.2. Операции иад множествами....................
2.2.1. Предварительные замечания..............
2.2.2. Объединение множеств...............
2.2.3. Пересечение множеств...................
2.2.4. Разность множеств..................
2 2.5. Универсальное множество ... . .
2.2.6. Дополнение множества ... ...
2.2.7. Разбиение множества..........................
2.2.8. Тождества алгебры множеств ...
2.3. Упорядочение элементов и прямое произведение множеств
2 3.1. Упорядоченное множество.........................
2.3.2. Прямое произведение множеств.................
2.3.3. Проекция множества .................
2.4. Соответствия......................................
2.4.1. Определение соответствия.....................
2.4 2. Обратное соответствие .......................
2 4 3. Композиция соответствий......................
2.5. Отображения и функции........................ ...
2 5 1. Отображения и их свойства....................
2 5 2. Отображения, заданные иа одном множестве
2 5 3. Функция......................................
2 5 4 Обратная функция..............................
2 5 5. Функция времени..............................
2 5 6. Понятие функционала..........................
2 5 7. Понятие оператора............................
18
22
23
24
24
24
28
30
33
31
34
35
36
38
39
40
41
42
44
44
46
48
48
48
50
50
51
61
53
64
57
58
60
61
488
2,6, Отношения.........................................
2.6.1. Свойства отношений . . ................
2 6.2. Отношение эквивалентности ... ...
2.6.3. Отношение порядка . ....................
2.6.4. Отношение доминирования . . ....
Задачи к гл. 2.............................................
Глава 3. Основы теории графов..............................
3.1. Основные определения теории графов................
3.1.1. Теоретико-множественное определение графа .
• 3.1 2. Неориентированные графы......................
3 1 3. Изоморфизм графов...........................
3 1.4. Отношение порядка и отношение эквивалентности
на графе...........................................
3.1.5. Характеристики графов
3.2 Задача о кратчайшем пути
3.2.1. Постановка задачи...........................
3.2.2. Нахождение кратчайшего пути в графе с ребрами
единичной длины ...................................
3.2 3 Нахождение кратчайшего пути в графе с ребрамв
произвольной длины ................................
3,2 4. Построение графа наименьшей длины . . . .
3.3 . Транспортные сети...............................
3 3.1. Основные понятия............................
3 3 2. Задача о наибольшем потоке..................
3 3.3. Транспортная задача.........................
62
62
63
64
65
67
67
67
70
72
73
75
76
76
80
82
84
84
86
Глава 4. Элементы линейной алгебры и выпуклые множества 96
4 1. Метрические пространства и расстояния . . .96
4.1 1. Понятие о расстоянии .... ... 96
4 1 2. Определение метрического пространства ... 98
4 1 3. Примеры метрических пространств..................98
4.2 Использование метрических пространств в некоторых
задачах кибернетики ................................. 100
4.2.1. Пространство сообщений................100
42.2. Понятие о помехоустойчивых кодах .... 102
4 2.3. Сглаживание ошибок в экспериментальных данных 103
4.2.4. Задача распознавания образов...........Ю5
4 3 Линейные пространства.......................107
4 3.1. Определение линейного пространства .... 107
4 3 2. Действия над векторами................108
4.3.3 Линейная зависимость и независимость векторов НО
4 34 Линейное подпространство . . .... Ill
4.3.5 Размерность линейного пространства .... 112
4 4 Евклидовы пространства......................1)2
4.4.1. Линейное нормированное пространство ... 112
4 4 2. Скалярное произведение векторов..............113
4.4.3. Угол между векторами Ортогональные векторы 116
4.5 Матрицы н линейные преобразования......................117
4.5.1. Понятие матрицы.................................117
4.5 2. Линейное преобразование..................... . 118
4 5.3 Операции над матрицами...........................120
4.5.4. Транспонированная матрица ......................122
4.6 . Квадратные матрицы.................................123
489
4.6.1. Особенности квадратных матриц. Нулевая и еди-
ничная матрицы.........................................123
4.6 2. Определитель квадратной матрицы ..... 124
4.6.3. Обратная матрица и решение систем линейных
уравнений..............................................125
4.6.4. Инвариантное подпространство. Собственные век-
торы н собственные значения матриц.....................127
4.6 5 Диагонализация матриц...........................131
, 4 7. Симметрические матрицы и квадратичные формы . . 132
4 7.1. Собственные векторы и собственные значения ве-
щественных симметрических матриц.......................132
4.7 2 Диагонализация симметрических матриц ... 134
4.7 3. Квадратичные формы..............................135
4.7.4. Использование квадратичных форм при отыскании
экстремумов функций многих переменных .... 136
4.7.5. Векторные производные...........................137
4 8. Выпуклые множества..................................138
4 8.1. Понятие гиперсферы..............................138
4.8 2. Ограниченные и конечные множества , . . . 139
4.8.3. Открытые и замкнутые множества.............119
4 8.4. Гиперплоскости и полупространства .... НО
4 8 5. Прямая и отрезок. Средневзвешенное по элемен-
там множества..........................................142
4 8 6. Выпуклые множества..............................143
4.8 7 Выпуклая оболочка конечного множества ... [44
4 8 8. Разделительная и опорная гиперплоскости ... 146
Задачи к гл. 4............................................... 147
Глава 5. Элементы теории вероятностей и математической
статистики................................................148
5 1. Понятие вероятности............................148
5.1 1. События и пространство исходов эксперимента 148
5.12 Понятие вероятности..........................149
5 1 3. Вероятность события........................150
5 1.4. Способы приписывания вероятностен исходам
эксперимента . . 151
5.1.5. Вычисление вероятностей сложных событий . . 153
5 2. Условные вероятности . . ................155
5 2 1 Понятие условной вероятности.....................155
5 22 Формула полной вероятности........................157
5 23 Определение апостериорных вероятностей. Форму-
ла Байеса............................................ 157
5.3. Непрерывные случайные величины и их распределения 158
5 3 1 Понятие непрерывной случайной величины ... 158
5 3.2 Функция распределения вероятностей . . . Iv9
5.3.3 Плотность вероятности.......................160
5.3.4. Равномерное распределение вероятностей ... 162
5.3.5. Гауссовское (нормальное) распределение вероят-
ностей ................................................162
5 4. Числовые характеристики случайных величин ... 164
5 4.1. Понятие о числовых характеристиках .... 164
5.4 2. Математическое ожидание случайной величины 164
5.4 3 Математическое ожидание функции от случайной
величины , . 166
490
5.4.4. Моменты. Дисперсия. Среднеквадратичное откло-
нение ........................................ , , 168
5.5. Двумерные случайные величины . ...... 170
5.5.1. Понятие двумерной случайной величины ... 170
5.5.2. Распределение вероятностей для непрерывных дву-
мерных случайных величин ............................. 172
5.5 3. Математические ожидания для двумерной случай-
ной величины...........................................175
5.5.4. Регрессия и корреляция.........................176
5.6. Многомерное гауссовское распределение вероятностей 180
5.6.1. Вектор математических ожиданий и ковариацион-
ная матрица............................................180
5.6.2. Гауссовское распределение вероятностей случайно-
го вектора.............................................182
5 6 3. Нормальное распределение вероятностей двух
случайных векторов.....................................183
56.4. Условное нормальное распределение вероятностей 184
5.7. Случайные процессы с дискретным временем .... 185
5.7.1. Понятие о случайных процессах с дискретным вре-
менем .................................................185
5.7.2. Процесс независимых испытаний с двумя исхода-
ми Биномиальное распределение вероятностей . . . 187
5.7.3. Распределение Пуассона......................< 189
5.7.4. Экспоненциальное распределение. Понятие о на-
дежности ..............................................*90
5.7.5 Марковские цепи..................................
5.7.6. Гауссовские марковские процессы................19°
5.7.7. Примеры гауссовских марковских процессов . 200
5.8. Элементы математической статистики...................203
5.8.1. Предмет математической статистики .... 203
5 8.2. Понятие случайной выборки .... . . 204
5 8.3. Предельные теоремы теории вероятностей . . 205
5 8 4. Критерии статистических оценок..................208
5 8 5. Несмещенные оценки математического ожидания
и дисперсии ...........................................210
5.8 6. Нахождение оценок по методу максимального
правдоподобия ...................... , .... 212
5 8 7. Оценка параметров по методу доверительных
интервалов.............................................214
5.8.8. Проверка статистических гипотез. Понятие о кри-
терии согласия.........................................219
5 8 9. Оценка влияния некоторого фактора на характер
случайной величины.....................................221
5 8.10. Проверка гипотезы о дисперсиях. Понятие о F-
распределепии . . .................................222
5.9. Регрессионный анализ и планирование эксперимента
591. Задача регрессионного анализа.....................223
59.2 Определение коэффициентов регрессии по данным
пассивного эксперимента................................226
5.9 3. Понятие о планировании эксперимента .... 230
5.9 4. Полный факторный эксперимент....................231
59.5. Понятие дробных реплик...........................235
Задачи и гл. 5................................................238
491
.П Я R Я 6,.. Структура и . математическое описание задач оцти-
мального управления 239
6.1. Основные черты процесса управления 239
6.1.1. Понятие об управлении 239
6 1.2. Виды задач управления 240
6.1.3. Понятие об исследовании операций Оптимизация процесса управления 242
6.2 244
6 2.1. Критерий качества управления .... 244
6 2 2. Ограничения, накладываемые на процесс управ- ления 245
6 2 3. Постановка задачи оптимального управления . 246
63 Математическое описание объекта управления . 247
6 3 1. Производственно-экономические модели 247
6 3.2. Структура объекта управления 251
6.3 3. Уравнения движения объекта управления . 256
6.3 4 Линейные модели динамических систем .... 257
6.3 5. Дискретные линейные системы ...... 261
64 Классификация задач оптимального управления . 261
6 4 1. Одпошаговые задачи принятия решения 261
6 4 2. Динамические задачи оптимизации управления 265
6.4.3. Управление конечным состоянием 268
6.5. Многошаговые процессы управления . . ... 6.5.1. Поведение динамической системы как функция на- 269
чального состояния 269
6 5 2. Представление динамического процесса в виде последовательности преобразований 6 5.3. Многошаговый процесс управления 6 5.4. Критерий качества управления при многошаговом 270 271 272
процессе
6.6 Основные понятия теории оптимизации 274
6 6.1. Общая постановка задачи оптимизации . 274
6.6.2. Ограничения на допустимое множество 275
6.6.3. Выпуклые и вогнутые функции 276
6.6.4. Свойства выпуклых (вогнутых) функций . 279
6.6.5. Классическая задача оптимизации 280
6 6 6. Функция Лагранжа 281
Глава 7 Линейное и нелинейное программирование
282
7 I Постановка задачи линейного программирования
7 1.1. Основные определения........................
7 12. Примеры задач линейного про!раммирования .
71.3. Геометрическая интерпретация задачи линейного
программирования...................................
7.2 Решение задачи линейного программирования .
7 2 1. Алгебра симплекс-метода.....................
7.2.2. Табличный метод нахождения оптимального ре-
шения .............................................
7 2.3 Получение начального допустимого базисного ре-
шения .............................................
72 4 Двойственная задача линейного программирования
7 2 5. Понятие о целочисленном программировании .
73. Нелинейное программирование ... . . . .
7.3.1. Постановка задачи...........................
7 3.2. Метод штрафных функций...................
492
7.3.3. Ограничения типа равенств и неотрицательность
переменных.......................................... 308
73.4. Условия Куна—Таккера.........................309
7.3.5. Квадратичное программирование . . ... . 311
- 7.4. Итеративные методы поиска оптимума.................313
7.4.1. Постановка задачи..........................313
7.4.2. Градиентный метод..........................316
7.4.3. Метод наискорейшего спуска (подъема) . . . 318
7.4 4. Алгоритм Ньютона........................... 319
7.4 5. Учет ограничений и многоэкстремальные задачи
Задачи к гл. 7..............................................319
Глава 8. Динамическое программирование . , „ „ , , 322
8.1. Оптимальное управление как вариационная задача .
8.1.1. Математическая формулировка задачи оптималь-
ного управления ..................................
8.1.2. Трудности, связанные с решением вариационной
задачи ...........................................
8.2. Метод динамического программирования............
8.2.1. Дискретная форма вариационной задачи ,
8.2.2. Рекуррентное соотношение метода динамического
программирования..................................
8 2.3. Вычислительные аспекты динамического програм-
мирования .............................„
8.2.4. Управление конечным состоянием.............
8.2.5. Рекуррентное соотношение для марковских про-
цессов .... .... ...
Задачи к гл. 8 . . . ................. .
322
322
326
328
328
330
332
339
310
342
Глава 9. Теория игр..........................................343
91. Предмет теории игр ..................................343
9 1.1. Игра как модель конфликтной ситуации . . 343
9.1.2. Понятие стратегии............. ... 345
9 1.3. Формальное описание игры двух лиц . . 345
9.1.4. Верхняя и нижняя цены игры . . ... 351
9.2. Цены и оптимальные стратегии игр...................353
9 2 1. Игра с седловой точкой..................... . 353
9 2.2. Чистые и смешанные стратегии ... . 354
9.2.3. Функция потерь при использовании смешанных
стратегий............................................356
9.2.4. Верхняя и нижняя цены игры при использовании
смешанных стратегий..................................358
9.3. Основная теорема теории игр........................362
9.3 1. 3-игра........................................362
9.3.2. Нижняя и верхняя цены игры в 3-игре . . 362
9.3 3. Теорема о минимаксе...........................367
9 3.4. Геометрическая иллюстрация принципа минимакса 370
9.4. Решение игр . . 371
9.4.1. Доминирующие и полезные стратегии .... 371
9 4 2 Нахождение оптимальных стратегий .... 375
9.4.3 Геометрическая иллюстрация принципа минимакса
в игре 2Хп.........................................
Задачи к гл. 9...............................................379
’493
Глава 10. Теория статистических решений (статистические игры)
ij 5=8 88 Ш88 88 88 88» 888 8
10.1. Структура статистических игр................. ,
10.1.1. Стратегические и статистические игры .
10.1.2. Пространство стратегий природы.............
10.1.3. Пространство стратегий статистика и функция
потерь.......................................
10.1.4. Примеры статистических игр . .....
10 2. Статистические игры без эксперимента................
10.2.1. Представление статистической игры без экспери-
мента в виде 3-игры.................................
10 2.2. Допустимые стратегии в статистических играх
10 2.3. Принципы выбора стратегий в статистических
играх ..............................................
102 4. Геометрическая трактовка байесовских стратегий
10 3. Статистические игры с проведением единичного экспе-
римента ..................................................
10 3 1. Постановка задачи..........................
10.3 2. Пространство выборок.......................
10.3.3. Решающая функция...........................
10.3.4. Функция риска..............................
10.3 5. Принципы выбора стратегии в играх с единич-
ным экспериментом ..................................
10 4. Использование апостериорных вероятностей
10.4.1. Определение числа стратегий в играх с прове-
дением эксперимента...............................
10 4.2. Апостериорное распределение вероятностей . ,
10 4.3. Принцип максимального правдоподобия .
10.4.4. Определение байесовского решения на основе
использования апостериорных вероятностей ....
10 4.5 Двухальтернативиая задача.....................4С5
10 5. Статистические игры с последовательными выборками 4С8
10 5.1 Предварительные замечания.....................408
105.2. Использование апостериорного распределения
вероятностей для определения последовательных байе-
совских правил.......................................410
10.5 3. Правило последовательных выборок .... 413
10.5.4. Функция риска при оптимальном последователь-
ном правиле..........................................413
10 5.5. Определение областей остановки для двухаль-
терпативной задачи при усеченной последовательной
выборке..............................................416
10 6. Оценивание параметров и фильтрация....................418
10.6.1. Задача оценки параметров.....................418
10 6 2 Оценки метода наименьших квадратов ... 421
10 6.3. Анализ точности оценки метода наименьших
квадратов . . . .......... 423
10.6.4 Применение метода наименьших квадратов для
оценки параметров нелинейных объектов .... 424
10 6 5. Постановка задачи фильтрации.................425
10.6 6. Фильтрация по методу наименьших квадратов 426
10 6.7. Представление вектора оценок е помощью весо-
вых коэффициентов....................................429
10 6.8. Фильтры с растущей памятью...................431
10.6.9. Экспоненциальные фильтры . , , .... 435
494
Задачи к гл. 10 . . ................................437
Глава 11. Задачи теории расписаний и массового обслуживания 437
11.1. Предмет теории расписаний.......................
11.1.1. Общие сведения............................
11.1.2. Постановка задачи теории расписаний .
11.1.3. Виды задач на составление расписаний .
11.2. Сетевое планирование и управление...............
11.2.1. Понятие сетевого графика. Составление перечня
работ . . ................................
11.2.2. Упорядочение (ранжировка) работ .
11.2.3. Определение резервов времени...............
11.2.4. Построение сетевого графика...............
11 .2 5. Коррекция распределения ресурсов ....
1 Г.2 6. Оптимизация срока выполнения комплекса работ
11 .2.7. Вероятностные методы сетевого планирования
11.3. Комбинаторные задачи на составление расписания .
11.3.1. Понятие о комбинаторных задачах ....
11.3.2. Задача коммивояжера.......................
11.3.3. Представление задачи коммивояжера в виде
графа..............................................
11.4. Примеры задач, сводящихся к задаче коммивояжера
11.4.1 Задача Гамильтона..........................
11.4.2. Транспортные задачи........................
11.4 3. Оптимизация программирования для ЭВМ .
11.4.4 Определение оптимальной последовательности
обработки деталей на двух стайках .................
11.5. Методы решения задачи коммивояжера...............
11.5 1. Применение метода Монте-Карло . , . .
11.5.2. Сведение к задаче целочисленного линейного
программирования...................................
11.5.3. Метод ветвей и границ......................
11.5.4. Применение метода ветвей и границ к решению
задачи коммивояжера . . ....................
11.6. Задачи массового обслуживания....................
11.6.1. Основные понятия. Терминология
11.6.2. Дифференциальные уравнения системы массово-
го обслуживания....................................
11.6.3. Система массового обслуживания с отказами
11.6.4. Однокаиальная система обслуживания с ожи-
данием ............................................
11 6.5 Многоканальная система обслуживания с ожи-
данием ...........................................
116 6 Статистическое моделирование систем массового
обслуживания ............................
Список литературы .... .........................
Предметный указатель.......................................
437
437
438
440
441
441
443
444
446
449
451
452
454
454
454
456
457
457
457
457
458
460
460
460
462
464
468
468
469
472
473
474
476
480
483
УЧЕБНОЕ ПОСОБИЕ
Юрий Михайлоиич Коршунов
МАТЕМАТИЧЕСКИЕ ОСНОВЫ КИБЕРНЕТИКИ
Редактор издательства В. И. Петухова
Художественный редактор Т. А. Дворецкова
Технический редактор Г. В. Преображенская
Корректор Г. А. Полонская
ИБ № 1692
Сдано в набор 25.09.8S Подписано в печать 27.11 86 Т-22998
Формат 84X108'/s, Бумага типографская № 2 Гарнитура литературная
Печать высокая Усл. печ. л. 26,04 Усл. кр.-отт. 26,04 Уч.-изд. л. 27,75
Тираж 21 000 эка. Заказ 804 Цена 1 р. 20 к.
Энергоатомнздат. 113114, Москва, М-114, Шлюзовая наб, 10
Набрано в ордена Октябрьской Революции и ордена Трудового Крас,
кого Знамени МПО «Первая Образцовая типография имени А. А. Жда-
нова» Союзполнграфпрома при Государственном комитете СССР ш*
делам издательств, полиграфии и книжной торговли. 113054, Мосюш,
Валовая, 28
Отпечатано во Владимирской типографии Союзполнграфпрома при I -
сударственном комитете СССР по делам издательств, полиграфии п
книжной торговли 600000, г. Владимир, Октябрьский проспект, д /